
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.1k
25.4k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 582
39.1k
| num_tokens
int64 271
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_26333
|
rasdani/github-patches
|
git_diff
|
cal-itp__benefits-333
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Create VerifierSessionRequired middleware that expects a verifier to exist in session
## Background
Once the session tracks the selected verifier in #321, we can make use of that infrastructure to put guards on certain view functions that require a verifier to be selected. The first step is to create a new middleware class that enforces the requirement.
This is similar to how the [`AgencySessionRequired`](https://github.com/cal-itp/benefits/blob/dev/benefits/core/middleware.py#L20) and [`EligibileSessionRequired`](https://github.com/cal-itp/benefits/blob/dev/benefits/core/middleware.py#L68) middleware are used.
## Tasks
- [x] Create a new middleware class like `VerifierSessionRequired` inheriting from `MiddlewareMixin`, see the other `*SessionRequired` as examples
- [x] In `process_request()`, check `session.verifier()` for the request.
- If `None`, raise an error to stop the request
- Otherwise return `None` to allow the request to continue
- [x] Apply this middleware to the following views to enforce that a verifier is needed:
- [x] [`eligibility:index`](https://github.com/cal-itp/benefits/blob/dev/benefits/eligibility/views.py#L16)
- [x] [`eligibility:confirm`](https://github.com/cal-itp/benefits/blob/dev/benefits/eligibility/views.py#L46)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `benefits/core/middleware.py`
Content:
```
1 """
2 The core application: middleware definitions for request/response cycle.
3 """
4 import logging
5 import time
6
7 from django.http import HttpResponse, HttpResponseBadRequest
8 from django.template import loader
9 from django.utils.decorators import decorator_from_middleware
10 from django.utils.deprecation import MiddlewareMixin
11 from django.views import i18n
12
13 from benefits.settings import RATE_LIMIT, RATE_LIMIT_METHODS, RATE_LIMIT_PERIOD, DEBUG
14 from . import analytics, session, viewmodels
15
16
17 logger = logging.getLogger(__name__)
18
19
20 class AgencySessionRequired(MiddlewareMixin):
21 """Middleware raises an exception for sessions lacking an agency configuration."""
22
23 def process_request(self, request):
24 if session.active_agency(request):
25 logger.debug("Session configured with agency")
26 return None
27 else:
28 raise AttributeError("Session not configured with agency")
29
30
31 class RateLimit(MiddlewareMixin):
32 """Middleware checks settings and session to ensure rate limit is respected."""
33
34 def process_request(self, request):
35 if any((RATE_LIMIT < 1, len(RATE_LIMIT_METHODS) < 1, RATE_LIMIT_PERIOD < 1)):
36 logger.debug("RATE_LIMIT, RATE_LIMIT_METHODS, or RATE_LIMIT_PERIOD are not configured")
37 return None
38
39 if request.method in RATE_LIMIT_METHODS:
40 session.increment_rate_limit_counter(request)
41 else:
42 # bail early if the request method doesn't match
43 return None
44
45 counter = session.rate_limit_counter(request)
46 reset_time = session.rate_limit_time(request)
47 now = int(time.time())
48
49 if counter > RATE_LIMIT:
50 if reset_time > now:
51 logger.warn("Rate limit exceeded")
52 home = viewmodels.Button.home(request)
53 page = viewmodels.ErrorPage.error(
54 title="Rate limit error",
55 content_title="Rate limit error",
56 paragraphs=["You have reached the rate limit. Please try again."],
57 button=home,
58 )
59 t = loader.get_template("400.html")
60 return HttpResponseBadRequest(t.render(page.context_dict()))
61 else:
62 # enough time has passed, reset the rate limit
63 session.reset_rate_limit(request)
64
65 return None
66
67
68 class EligibleSessionRequired(MiddlewareMixin):
69 """Middleware raises an exception for sessions lacking confirmed eligibility."""
70
71 def process_request(self, request):
72 if session.eligible(request):
73 logger.debug("Session has confirmed eligibility")
74 return None
75 else:
76 raise AttributeError("Session has no confirmed eligibility")
77
78
79 class DebugSession(MiddlewareMixin):
80 """Middleware to configure debug context in the request session."""
81
82 def process_request(self, request):
83 session.update(request, debug=DEBUG)
84 return None
85
86
87 class Healthcheck:
88 """Middleware intercepts and accepts /healthcheck requests."""
89
90 def __init__(self, get_response):
91 self.get_response = get_response
92
93 def __call__(self, request):
94 if request.path == "/healthcheck":
95 return HttpResponse("Healthy", content_type="text/plain")
96 return self.get_response(request)
97
98
99 class ViewedPageEvent(MiddlewareMixin):
100 """Middleware sends an analytics event for page views."""
101
102 def process_response(self, request, response):
103 event = analytics.ViewedPageEvent(request)
104 try:
105 analytics.send_event(event)
106 except Exception:
107 logger.warning(f"Failed to send event: {event}")
108 finally:
109 return response
110
111
112 pageview_decorator = decorator_from_middleware(ViewedPageEvent)
113
114
115 class ChangedLanguageEvent(MiddlewareMixin):
116 """Middleware hooks into django.views.i18n.set_language to send an analytics event."""
117
118 def process_view(self, request, view_func, view_args, view_kwargs):
119 if view_func == i18n.set_language:
120 new_lang = request.POST["language"]
121 event = analytics.ChangedLanguageEvent(request, new_lang)
122 analytics.send_event(event)
123 return None
124
```
Path: `benefits/eligibility/views.py`
Content:
```
1 """
2 The eligibility application: view definitions for the eligibility verification flow.
3 """
4 from django.contrib import messages
5 from django.shortcuts import redirect
6 from django.urls import reverse
7 from django.utils.decorators import decorator_from_middleware
8 from django.utils.translation import pgettext, gettext as _
9
10 from benefits.core import middleware, recaptcha, session, viewmodels
11 from benefits.core.views import PageTemplateResponse, _index_image
12 from . import analytics, api, forms
13
14
15 @decorator_from_middleware(middleware.AgencySessionRequired)
16 def index(request):
17 """View handler for the eligibility verification getting started screen."""
18
19 session.update(request, eligibility_types=[], origin=reverse("eligibility:index"))
20
21 page = viewmodels.Page(
22 title=_("eligibility.pages.index.title"),
23 content_title=_("eligibility.pages.index.content_title"),
24 media=[
25 viewmodels.MediaItem(
26 icon=viewmodels.Icon("idcardcheck", pgettext("image alt text", "core.icons.idcardcheck")),
27 heading=_("eligibility.pages.index.items[0].title"),
28 details=_("eligibility.pages.index.items[0].text"),
29 ),
30 viewmodels.MediaItem(
31 icon=viewmodels.Icon("bankcardcheck", pgettext("image alt text", "core.icons.bankcardcheck")),
32 heading=_("eligibility.pages.index.items[1].title"),
33 details=_("eligibility.pages.index.items[1].text"),
34 ),
35 ],
36 paragraphs=[_("eligibility.pages.index.p[0]")],
37 image=_index_image(),
38 button=viewmodels.Button.primary(text=_("eligibility.pages.index.button"), url=reverse("eligibility:confirm")),
39 )
40
41 return PageTemplateResponse(request, page)
42
43
44 @decorator_from_middleware(middleware.AgencySessionRequired)
45 @decorator_from_middleware(middleware.RateLimit)
46 def confirm(request):
47 """View handler for the eligibility verification form."""
48
49 page = viewmodels.Page(
50 title=_("eligibility.pages.confirm.title"),
51 content_title=_("eligibility.pages.confirm.content_title"),
52 paragraphs=[_("eligibility.pages.confirm.p[0]")],
53 form=forms.EligibilityVerificationForm(auto_id=True, label_suffix=""),
54 classes="text-lg-center",
55 )
56
57 if request.method == "POST":
58 analytics.started_eligibility(request)
59
60 form = forms.EligibilityVerificationForm(request.POST)
61 response = _verify(request, form)
62
63 if response is None:
64 # form was not valid, allow for correction/resubmission
65 analytics.returned_error(request, form.errors)
66 page.forms = [form]
67 response = PageTemplateResponse(request, page)
68 elif session.eligible(request):
69 eligibility = session.eligibility(request)
70 response = verified(request, [eligibility.name])
71 else:
72 response = PageTemplateResponse(request, page)
73
74 return response
75
76
77 def _verify(request, form):
78 """Helper calls the eligibility verification API with user input."""
79
80 if not form.is_valid():
81 if recaptcha.has_error(form):
82 messages.error(request, "Recaptcha failed. Please try again.")
83 return None
84
85 sub, name = form.cleaned_data.get("sub"), form.cleaned_data.get("name")
86
87 agency = session.agency(request)
88 verifier = session.verifier(request)
89 client = api.Client(agency, verifier)
90
91 response = client.verify(sub, name)
92
93 if response.error and any(response.error):
94 form.add_api_errors(response.error)
95 return None
96 elif any(response.eligibility):
97 return verified(request, response.eligibility)
98 else:
99 return unverified(request)
100
101
102 @decorator_from_middleware(middleware.AgencySessionRequired)
103 def verified(request, verified_types):
104 """View handler for the verified eligibility page."""
105
106 analytics.returned_success(request)
107
108 enrollment_index = reverse("enrollment:index")
109 session.update(request, eligibility_types=verified_types, origin=enrollment_index)
110
111 return redirect(enrollment_index)
112
113
114 @decorator_from_middleware(middleware.AgencySessionRequired)
115 def unverified(request):
116 """View handler for the unverified eligibility page."""
117
118 analytics.returned_fail(request)
119
120 # tel: link to agency phone number
121 agency = session.agency(request)
122 buttons = viewmodels.Button.agency_contact_links(agency)
123
124 page = viewmodels.Page(
125 title=_("eligibility.pages.unverified.title"),
126 content_title=_("eligibility.pages.unverified.content_title"),
127 icon=viewmodels.Icon("idcardquestion", pgettext("image alt text", "core.icons.idcardquestion")),
128 paragraphs=[_("eligibility.pages.unverified.p[0]"), _("eligibility.pages.unverified.p[1]")],
129 buttons=buttons,
130 classes="text-lg-center",
131 )
132
133 return PageTemplateResponse(request, page)
134
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/benefits/core/middleware.py b/benefits/core/middleware.py
--- a/benefits/core/middleware.py
+++ b/benefits/core/middleware.py
@@ -96,6 +96,17 @@
return self.get_response(request)
+class VerifierSessionRequired(MiddlewareMixin):
+ """Middleware raises an exception for sessions lacking an eligibility verifier configuration."""
+
+ def process_request(self, request):
+ if session.verifier(request):
+ logger.debug("Session configured with eligibility verifier")
+ return None
+ else:
+ raise AttributeError("Session not configured with eligibility verifier")
+
+
class ViewedPageEvent(MiddlewareMixin):
"""Middleware sends an analytics event for page views."""
diff --git a/benefits/eligibility/views.py b/benefits/eligibility/views.py
--- a/benefits/eligibility/views.py
+++ b/benefits/eligibility/views.py
@@ -13,6 +13,7 @@
@decorator_from_middleware(middleware.AgencySessionRequired)
+@decorator_from_middleware(middleware.VerifierSessionRequired)
def index(request):
"""View handler for the eligibility verification getting started screen."""
@@ -43,6 +44,7 @@
@decorator_from_middleware(middleware.AgencySessionRequired)
@decorator_from_middleware(middleware.RateLimit)
+@decorator_from_middleware(middleware.VerifierSessionRequired)
def confirm(request):
"""View handler for the eligibility verification form."""
|
{"golden_diff": "diff --git a/benefits/core/middleware.py b/benefits/core/middleware.py\n--- a/benefits/core/middleware.py\n+++ b/benefits/core/middleware.py\n@@ -96,6 +96,17 @@\n return self.get_response(request)\n \n \n+class VerifierSessionRequired(MiddlewareMixin):\n+ \"\"\"Middleware raises an exception for sessions lacking an eligibility verifier configuration.\"\"\"\n+\n+ def process_request(self, request):\n+ if session.verifier(request):\n+ logger.debug(\"Session configured with eligibility verifier\")\n+ return None\n+ else:\n+ raise AttributeError(\"Session not configured with eligibility verifier\")\n+\n+\n class ViewedPageEvent(MiddlewareMixin):\n \"\"\"Middleware sends an analytics event for page views.\"\"\"\n \ndiff --git a/benefits/eligibility/views.py b/benefits/eligibility/views.py\n--- a/benefits/eligibility/views.py\n+++ b/benefits/eligibility/views.py\n@@ -13,6 +13,7 @@\n \n \n @decorator_from_middleware(middleware.AgencySessionRequired)\n+@decorator_from_middleware(middleware.VerifierSessionRequired)\n def index(request):\n \"\"\"View handler for the eligibility verification getting started screen.\"\"\"\n \n@@ -43,6 +44,7 @@\n \n @decorator_from_middleware(middleware.AgencySessionRequired)\n @decorator_from_middleware(middleware.RateLimit)\n+@decorator_from_middleware(middleware.VerifierSessionRequired)\n def confirm(request):\n \"\"\"View handler for the eligibility verification form.\"\"\"\n", "issue": "Create VerifierSessionRequired middleware that expects a verifier to exist in session\n## Background\r\n\r\nOnce the session tracks the selected verifier in #321, we can make use of that infrastructure to put guards on certain view functions that require a verifier to be selected. The first step is to create a new middleware class that enforces the requirement.\r\n\r\nThis is similar to how the [`AgencySessionRequired`](https://github.com/cal-itp/benefits/blob/dev/benefits/core/middleware.py#L20) and [`EligibileSessionRequired`](https://github.com/cal-itp/benefits/blob/dev/benefits/core/middleware.py#L68) middleware are used.\r\n\r\n## Tasks\r\n\r\n- [x] Create a new middleware class like `VerifierSessionRequired` inheriting from `MiddlewareMixin`, see the other `*SessionRequired` as examples\r\n- [x] In `process_request()`, check `session.verifier()` for the request.\r\n - If `None`, raise an error to stop the request\r\n - Otherwise return `None` to allow the request to continue\r\n- [x] Apply this middleware to the following views to enforce that a verifier is needed:\r\n - [x] [`eligibility:index`](https://github.com/cal-itp/benefits/blob/dev/benefits/eligibility/views.py#L16)\r\n - [x] [`eligibility:confirm`](https://github.com/cal-itp/benefits/blob/dev/benefits/eligibility/views.py#L46)\r\n\n", "before_files": [{"content": "\"\"\"\nThe core application: middleware definitions for request/response cycle.\n\"\"\"\nimport logging\nimport time\n\nfrom django.http import HttpResponse, HttpResponseBadRequest\nfrom django.template import loader\nfrom django.utils.decorators import decorator_from_middleware\nfrom django.utils.deprecation import MiddlewareMixin\nfrom django.views import i18n\n\nfrom benefits.settings import RATE_LIMIT, RATE_LIMIT_METHODS, RATE_LIMIT_PERIOD, DEBUG\nfrom . import analytics, session, viewmodels\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass AgencySessionRequired(MiddlewareMixin):\n \"\"\"Middleware raises an exception for sessions lacking an agency configuration.\"\"\"\n\n def process_request(self, request):\n if session.active_agency(request):\n logger.debug(\"Session configured with agency\")\n return None\n else:\n raise AttributeError(\"Session not configured with agency\")\n\n\nclass RateLimit(MiddlewareMixin):\n \"\"\"Middleware checks settings and session to ensure rate limit is respected.\"\"\"\n\n def process_request(self, request):\n if any((RATE_LIMIT < 1, len(RATE_LIMIT_METHODS) < 1, RATE_LIMIT_PERIOD < 1)):\n logger.debug(\"RATE_LIMIT, RATE_LIMIT_METHODS, or RATE_LIMIT_PERIOD are not configured\")\n return None\n\n if request.method in RATE_LIMIT_METHODS:\n session.increment_rate_limit_counter(request)\n else:\n # bail early if the request method doesn't match\n return None\n\n counter = session.rate_limit_counter(request)\n reset_time = session.rate_limit_time(request)\n now = int(time.time())\n\n if counter > RATE_LIMIT:\n if reset_time > now:\n logger.warn(\"Rate limit exceeded\")\n home = viewmodels.Button.home(request)\n page = viewmodels.ErrorPage.error(\n title=\"Rate limit error\",\n content_title=\"Rate limit error\",\n paragraphs=[\"You have reached the rate limit. Please try again.\"],\n button=home,\n )\n t = loader.get_template(\"400.html\")\n return HttpResponseBadRequest(t.render(page.context_dict()))\n else:\n # enough time has passed, reset the rate limit\n session.reset_rate_limit(request)\n\n return None\n\n\nclass EligibleSessionRequired(MiddlewareMixin):\n \"\"\"Middleware raises an exception for sessions lacking confirmed eligibility.\"\"\"\n\n def process_request(self, request):\n if session.eligible(request):\n logger.debug(\"Session has confirmed eligibility\")\n return None\n else:\n raise AttributeError(\"Session has no confirmed eligibility\")\n\n\nclass DebugSession(MiddlewareMixin):\n \"\"\"Middleware to configure debug context in the request session.\"\"\"\n\n def process_request(self, request):\n session.update(request, debug=DEBUG)\n return None\n\n\nclass Healthcheck:\n \"\"\"Middleware intercepts and accepts /healthcheck requests.\"\"\"\n\n def __init__(self, get_response):\n self.get_response = get_response\n\n def __call__(self, request):\n if request.path == \"/healthcheck\":\n return HttpResponse(\"Healthy\", content_type=\"text/plain\")\n return self.get_response(request)\n\n\nclass ViewedPageEvent(MiddlewareMixin):\n \"\"\"Middleware sends an analytics event for page views.\"\"\"\n\n def process_response(self, request, response):\n event = analytics.ViewedPageEvent(request)\n try:\n analytics.send_event(event)\n except Exception:\n logger.warning(f\"Failed to send event: {event}\")\n finally:\n return response\n\n\npageview_decorator = decorator_from_middleware(ViewedPageEvent)\n\n\nclass ChangedLanguageEvent(MiddlewareMixin):\n \"\"\"Middleware hooks into django.views.i18n.set_language to send an analytics event.\"\"\"\n\n def process_view(self, request, view_func, view_args, view_kwargs):\n if view_func == i18n.set_language:\n new_lang = request.POST[\"language\"]\n event = analytics.ChangedLanguageEvent(request, new_lang)\n analytics.send_event(event)\n return None\n", "path": "benefits/core/middleware.py"}, {"content": "\"\"\"\nThe eligibility application: view definitions for the eligibility verification flow.\n\"\"\"\nfrom django.contrib import messages\nfrom django.shortcuts import redirect\nfrom django.urls import reverse\nfrom django.utils.decorators import decorator_from_middleware\nfrom django.utils.translation import pgettext, gettext as _\n\nfrom benefits.core import middleware, recaptcha, session, viewmodels\nfrom benefits.core.views import PageTemplateResponse, _index_image\nfrom . import analytics, api, forms\n\n\n@decorator_from_middleware(middleware.AgencySessionRequired)\ndef index(request):\n \"\"\"View handler for the eligibility verification getting started screen.\"\"\"\n\n session.update(request, eligibility_types=[], origin=reverse(\"eligibility:index\"))\n\n page = viewmodels.Page(\n title=_(\"eligibility.pages.index.title\"),\n content_title=_(\"eligibility.pages.index.content_title\"),\n media=[\n viewmodels.MediaItem(\n icon=viewmodels.Icon(\"idcardcheck\", pgettext(\"image alt text\", \"core.icons.idcardcheck\")),\n heading=_(\"eligibility.pages.index.items[0].title\"),\n details=_(\"eligibility.pages.index.items[0].text\"),\n ),\n viewmodels.MediaItem(\n icon=viewmodels.Icon(\"bankcardcheck\", pgettext(\"image alt text\", \"core.icons.bankcardcheck\")),\n heading=_(\"eligibility.pages.index.items[1].title\"),\n details=_(\"eligibility.pages.index.items[1].text\"),\n ),\n ],\n paragraphs=[_(\"eligibility.pages.index.p[0]\")],\n image=_index_image(),\n button=viewmodels.Button.primary(text=_(\"eligibility.pages.index.button\"), url=reverse(\"eligibility:confirm\")),\n )\n\n return PageTemplateResponse(request, page)\n\n\n@decorator_from_middleware(middleware.AgencySessionRequired)\n@decorator_from_middleware(middleware.RateLimit)\ndef confirm(request):\n \"\"\"View handler for the eligibility verification form.\"\"\"\n\n page = viewmodels.Page(\n title=_(\"eligibility.pages.confirm.title\"),\n content_title=_(\"eligibility.pages.confirm.content_title\"),\n paragraphs=[_(\"eligibility.pages.confirm.p[0]\")],\n form=forms.EligibilityVerificationForm(auto_id=True, label_suffix=\"\"),\n classes=\"text-lg-center\",\n )\n\n if request.method == \"POST\":\n analytics.started_eligibility(request)\n\n form = forms.EligibilityVerificationForm(request.POST)\n response = _verify(request, form)\n\n if response is None:\n # form was not valid, allow for correction/resubmission\n analytics.returned_error(request, form.errors)\n page.forms = [form]\n response = PageTemplateResponse(request, page)\n elif session.eligible(request):\n eligibility = session.eligibility(request)\n response = verified(request, [eligibility.name])\n else:\n response = PageTemplateResponse(request, page)\n\n return response\n\n\ndef _verify(request, form):\n \"\"\"Helper calls the eligibility verification API with user input.\"\"\"\n\n if not form.is_valid():\n if recaptcha.has_error(form):\n messages.error(request, \"Recaptcha failed. Please try again.\")\n return None\n\n sub, name = form.cleaned_data.get(\"sub\"), form.cleaned_data.get(\"name\")\n\n agency = session.agency(request)\n verifier = session.verifier(request)\n client = api.Client(agency, verifier)\n\n response = client.verify(sub, name)\n\n if response.error and any(response.error):\n form.add_api_errors(response.error)\n return None\n elif any(response.eligibility):\n return verified(request, response.eligibility)\n else:\n return unverified(request)\n\n\n@decorator_from_middleware(middleware.AgencySessionRequired)\ndef verified(request, verified_types):\n \"\"\"View handler for the verified eligibility page.\"\"\"\n\n analytics.returned_success(request)\n\n enrollment_index = reverse(\"enrollment:index\")\n session.update(request, eligibility_types=verified_types, origin=enrollment_index)\n\n return redirect(enrollment_index)\n\n\n@decorator_from_middleware(middleware.AgencySessionRequired)\ndef unverified(request):\n \"\"\"View handler for the unverified eligibility page.\"\"\"\n\n analytics.returned_fail(request)\n\n # tel: link to agency phone number\n agency = session.agency(request)\n buttons = viewmodels.Button.agency_contact_links(agency)\n\n page = viewmodels.Page(\n title=_(\"eligibility.pages.unverified.title\"),\n content_title=_(\"eligibility.pages.unverified.content_title\"),\n icon=viewmodels.Icon(\"idcardquestion\", pgettext(\"image alt text\", \"core.icons.idcardquestion\")),\n paragraphs=[_(\"eligibility.pages.unverified.p[0]\"), _(\"eligibility.pages.unverified.p[1]\")],\n buttons=buttons,\n classes=\"text-lg-center\",\n )\n\n return PageTemplateResponse(request, page)\n", "path": "benefits/eligibility/views.py"}], "after_files": [{"content": "\"\"\"\nThe core application: middleware definitions for request/response cycle.\n\"\"\"\nimport logging\nimport time\n\nfrom django.http import HttpResponse, HttpResponseBadRequest\nfrom django.template import loader\nfrom django.utils.decorators import decorator_from_middleware\nfrom django.utils.deprecation import MiddlewareMixin\nfrom django.views import i18n\n\nfrom benefits.settings import RATE_LIMIT, RATE_LIMIT_METHODS, RATE_LIMIT_PERIOD, DEBUG\nfrom . import analytics, session, viewmodels\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass AgencySessionRequired(MiddlewareMixin):\n \"\"\"Middleware raises an exception for sessions lacking an agency configuration.\"\"\"\n\n def process_request(self, request):\n if session.active_agency(request):\n logger.debug(\"Session configured with agency\")\n return None\n else:\n raise AttributeError(\"Session not configured with agency\")\n\n\nclass RateLimit(MiddlewareMixin):\n \"\"\"Middleware checks settings and session to ensure rate limit is respected.\"\"\"\n\n def process_request(self, request):\n if any((RATE_LIMIT < 1, len(RATE_LIMIT_METHODS) < 1, RATE_LIMIT_PERIOD < 1)):\n logger.debug(\"RATE_LIMIT, RATE_LIMIT_METHODS, or RATE_LIMIT_PERIOD are not configured\")\n return None\n\n if request.method in RATE_LIMIT_METHODS:\n session.increment_rate_limit_counter(request)\n else:\n # bail early if the request method doesn't match\n return None\n\n counter = session.rate_limit_counter(request)\n reset_time = session.rate_limit_time(request)\n now = int(time.time())\n\n if counter > RATE_LIMIT:\n if reset_time > now:\n logger.warn(\"Rate limit exceeded\")\n home = viewmodels.Button.home(request)\n page = viewmodels.ErrorPage.error(\n title=\"Rate limit error\",\n content_title=\"Rate limit error\",\n paragraphs=[\"You have reached the rate limit. Please try again.\"],\n button=home,\n )\n t = loader.get_template(\"400.html\")\n return HttpResponseBadRequest(t.render(page.context_dict()))\n else:\n # enough time has passed, reset the rate limit\n session.reset_rate_limit(request)\n\n return None\n\n\nclass EligibleSessionRequired(MiddlewareMixin):\n \"\"\"Middleware raises an exception for sessions lacking confirmed eligibility.\"\"\"\n\n def process_request(self, request):\n if session.eligible(request):\n logger.debug(\"Session has confirmed eligibility\")\n return None\n else:\n raise AttributeError(\"Session has no confirmed eligibility\")\n\n\nclass DebugSession(MiddlewareMixin):\n \"\"\"Middleware to configure debug context in the request session.\"\"\"\n\n def process_request(self, request):\n session.update(request, debug=DEBUG)\n return None\n\n\nclass Healthcheck:\n \"\"\"Middleware intercepts and accepts /healthcheck requests.\"\"\"\n\n def __init__(self, get_response):\n self.get_response = get_response\n\n def __call__(self, request):\n if request.path == \"/healthcheck\":\n return HttpResponse(\"Healthy\", content_type=\"text/plain\")\n return self.get_response(request)\n\n\nclass VerifierSessionRequired(MiddlewareMixin):\n \"\"\"Middleware raises an exception for sessions lacking an eligibility verifier configuration.\"\"\"\n\n def process_request(self, request):\n if session.verifier(request):\n logger.debug(\"Session configured with eligibility verifier\")\n return None\n else:\n raise AttributeError(\"Session not configured with eligibility verifier\")\n\n\nclass ViewedPageEvent(MiddlewareMixin):\n \"\"\"Middleware sends an analytics event for page views.\"\"\"\n\n def process_response(self, request, response):\n event = analytics.ViewedPageEvent(request)\n try:\n analytics.send_event(event)\n except Exception:\n logger.warning(f\"Failed to send event: {event}\")\n finally:\n return response\n\n\npageview_decorator = decorator_from_middleware(ViewedPageEvent)\n\n\nclass ChangedLanguageEvent(MiddlewareMixin):\n \"\"\"Middleware hooks into django.views.i18n.set_language to send an analytics event.\"\"\"\n\n def process_view(self, request, view_func, view_args, view_kwargs):\n if view_func == i18n.set_language:\n new_lang = request.POST[\"language\"]\n event = analytics.ChangedLanguageEvent(request, new_lang)\n analytics.send_event(event)\n return None\n", "path": "benefits/core/middleware.py"}, {"content": "\"\"\"\nThe eligibility application: view definitions for the eligibility verification flow.\n\"\"\"\nfrom django.contrib import messages\nfrom django.shortcuts import redirect\nfrom django.urls import reverse\nfrom django.utils.decorators import decorator_from_middleware\nfrom django.utils.translation import pgettext, gettext as _\n\nfrom benefits.core import middleware, recaptcha, session, viewmodels\nfrom benefits.core.views import PageTemplateResponse, _index_image\nfrom . import analytics, api, forms\n\n\n@decorator_from_middleware(middleware.AgencySessionRequired)\n@decorator_from_middleware(middleware.VerifierSessionRequired)\ndef index(request):\n \"\"\"View handler for the eligibility verification getting started screen.\"\"\"\n\n session.update(request, eligibility_types=[], origin=reverse(\"eligibility:index\"))\n\n page = viewmodels.Page(\n title=_(\"eligibility.pages.index.title\"),\n content_title=_(\"eligibility.pages.index.content_title\"),\n media=[\n viewmodels.MediaItem(\n icon=viewmodels.Icon(\"idcardcheck\", pgettext(\"image alt text\", \"core.icons.idcardcheck\")),\n heading=_(\"eligibility.pages.index.items[0].title\"),\n details=_(\"eligibility.pages.index.items[0].text\"),\n ),\n viewmodels.MediaItem(\n icon=viewmodels.Icon(\"bankcardcheck\", pgettext(\"image alt text\", \"core.icons.bankcardcheck\")),\n heading=_(\"eligibility.pages.index.items[1].title\"),\n details=_(\"eligibility.pages.index.items[1].text\"),\n ),\n ],\n paragraphs=[_(\"eligibility.pages.index.p[0]\")],\n image=_index_image(),\n button=viewmodels.Button.primary(text=_(\"eligibility.pages.index.button\"), url=reverse(\"eligibility:confirm\")),\n )\n\n return PageTemplateResponse(request, page)\n\n\n@decorator_from_middleware(middleware.AgencySessionRequired)\n@decorator_from_middleware(middleware.RateLimit)\n@decorator_from_middleware(middleware.VerifierSessionRequired)\ndef confirm(request):\n \"\"\"View handler for the eligibility verification form.\"\"\"\n\n page = viewmodels.Page(\n title=_(\"eligibility.pages.confirm.title\"),\n content_title=_(\"eligibility.pages.confirm.content_title\"),\n paragraphs=[_(\"eligibility.pages.confirm.p[0]\")],\n form=forms.EligibilityVerificationForm(auto_id=True, label_suffix=\"\"),\n classes=\"text-lg-center\",\n )\n\n if request.method == \"POST\":\n analytics.started_eligibility(request)\n\n form = forms.EligibilityVerificationForm(request.POST)\n response = _verify(request, form)\n\n if response is None:\n # form was not valid, allow for correction/resubmission\n analytics.returned_error(request, form.errors)\n page.forms = [form]\n response = PageTemplateResponse(request, page)\n elif session.eligible(request):\n eligibility = session.eligibility(request)\n response = verified(request, [eligibility.name])\n else:\n response = PageTemplateResponse(request, page)\n\n return response\n\n\ndef _verify(request, form):\n \"\"\"Helper calls the eligibility verification API with user input.\"\"\"\n\n if not form.is_valid():\n if recaptcha.has_error(form):\n messages.error(request, \"Recaptcha failed. Please try again.\")\n return None\n\n sub, name = form.cleaned_data.get(\"sub\"), form.cleaned_data.get(\"name\")\n\n agency = session.agency(request)\n verifier = session.verifier(request)\n client = api.Client(agency, verifier)\n\n response = client.verify(sub, name)\n\n if response.error and any(response.error):\n form.add_api_errors(response.error)\n return None\n elif any(response.eligibility):\n return verified(request, response.eligibility)\n else:\n return unverified(request)\n\n\n@decorator_from_middleware(middleware.AgencySessionRequired)\ndef verified(request, verified_types):\n \"\"\"View handler for the verified eligibility page.\"\"\"\n\n analytics.returned_success(request)\n\n enrollment_index = reverse(\"enrollment:index\")\n session.update(request, eligibility_types=verified_types, origin=enrollment_index)\n\n return redirect(enrollment_index)\n\n\n@decorator_from_middleware(middleware.AgencySessionRequired)\ndef unverified(request):\n \"\"\"View handler for the unverified eligibility page.\"\"\"\n\n analytics.returned_fail(request)\n\n # tel: link to agency phone number\n agency = session.agency(request)\n buttons = viewmodels.Button.agency_contact_links(agency)\n\n page = viewmodels.Page(\n title=_(\"eligibility.pages.unverified.title\"),\n content_title=_(\"eligibility.pages.unverified.content_title\"),\n icon=viewmodels.Icon(\"idcardquestion\", pgettext(\"image alt text\", \"core.icons.idcardquestion\")),\n paragraphs=[_(\"eligibility.pages.unverified.p[0]\"), _(\"eligibility.pages.unverified.p[1]\")],\n buttons=buttons,\n classes=\"text-lg-center\",\n )\n\n return PageTemplateResponse(request, page)\n", "path": "benefits/eligibility/views.py"}]}
| 2,954 | 326 |
gh_patches_debug_26135
|
rasdani/github-patches
|
git_diff
|
liqd__a4-meinberlin-4364
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
B-Plan API: tile picture not transferred from Imperia to mB; bplan not published
**URL:** see below
**user:** bplan initiator via imperia API
**expected behaviour:** the tile picture entered via Imperia is shown on mB, the plan is published and not only saved as draft
**behaviour:** sometimes the picture is not shown, sometimes the plan does not get automatically published
**important screensize:**
**device & browser:**
**Comment/Question:** it does not happen always but sometimes with different districts involved. Prio set as high as we need to find a solution but not release right away as there is a workaround.
list of bplans that recently had problems (as far as I can read from mails as I wasn't always included directly into the support):
https://mein.berlin.de/django-admin/meinberlin_bplan/bplan/1535 (May 2022, not published)
https://mein.berlin.de/django-admin/meinberlin_bplan/bplan/1488/change/ (March 22, not published)
https://mein.berlin.de/django-admin/meinberlin_bplan/bplan/1476/change/ (March 22, picture not transferred)
https://mein.berlin.de/django-admin/meinberlin_bplan/bplan/1502/change/ (April 22, not published, picture not transferred)
https://mein.berlin.de/django-admin/meinberlin_bplan/bplan/1449/change/ (Feb 22, picture not transferred)
Regarding 1449, we have already been in contact with BO, they write the following:
beim übermitteln der Daten aus dem Imperia-System bekommen wir ein
"HTTP/2 400"
Wäre schön wenn wir bei diesen 400 immer auch gleich eine Error-Meldung mit bekommen könnten, das ist aber immer nur ein schwarzes Loch.
Folgender POST-Request schlägt fehl
{"name":"Bebauungsplan XIV-3-1 (\u201eNeuk\u00f6llnische Allee \/ Schmalenbachstra\u00dfe\u201c)","url":"https:\/\/[www.berlin.de](http://www.berlin.de/)\/ba-neukoelln\/politik-und-verwaltung\/aemter\/stadtentwicklungsamt\/stadtplanung\/bebauungsplaene\/bebauungsplan-fuer-meinberlin\/bebauungsplan.1176597.php","office_worker_email":"[[email protected]](mailto:[email protected])","start_date":"2022-02-21 00:00","end_date":"2022-03-11 23:59","description":"Sicherung und Stabilisierung eines Gewerbegebietes durch den Ausschluss unerw\u00fcnschter Einzelnutzungen.","identifier":"XIV-3-1","is_draft":"False","image_url":"https:\/\/[www.berlin.de](http://www.berlin.de/)\/imgscaler\/r9Iz3AbUfqVDjoWe7B-GLwXcCWHjBVGlMLWfoeyqvwc\/meinberlin\/L3N5czExLXByb2QvYmEtbmV1a29lbGxuL3BvbGl0aWstdW5kLXZlcndhbHR1bmcvYWVtdGVyL3N0YWR0ZW50d2lja2x1bmdzYW10L3N0YWR0cGxhbnVuZy9iZWJhdXVuZ3NwbGFlbmUvYmViYXV1bmdzcGxhbi1mdWVyLW1laW5iZXJsaW4vdW50ZXJsYWdlbi9rYXJ0ZW4tdW5kLXBsYWVuZS91cGxvYWRfXzgzZWIwZjA4OGNjZmEwMTUxNjk0YTcyODQzZWJjYjA1X3hpdi0zLTFfMTAwMDB1ZWJlcnNpY2h0LmpwZw.jpg","image_copyright":"Bezirksamt Neuk\u00f6lln von Berlin"}
Wahrscheinlich ist es die "image_url"
Mit "\\" sind es 408 Zeichen
Ohne "\\" sind es 402 Zeichen
In der API-Beschreibung auf https://github.com/liqd/a4-meinberlin/blob/main/docs/bplan_api.md ist keine Pfad-Längenbeschränkung dokumentiert.
Die Bildgröße ist korrekt.
https://www.berlin.de/imgscaler/r9Iz3AbUfqVDjoWe7B-GLwXcCWHjBVGlMLWfoeyqvwc/meinberlin/L3N5czExLXByb2QvYmEtbmV1a29lbGxuL3BvbGl0aWstdW5kLXZlcndhbHR1bmcvYWVtdGVyL3N0YWR0ZW50d2lja2x1bmdzYW10L3N0YWR0cGxhbnVuZy9iZWJhdXVuZ3NwbGFlbmUvYmViYXV1bmdzcGxhbi1mdWVyLW1laW5iZXJsaW4vdW50ZXJsYWdlbi9rYXJ0ZW4tdW5kLXBsYWVuZS91cGxvYWRfXzgzZWIwZjA4OGNjZmEwMTUxNjk0YTcyODQzZWJjYjA1X3hpdi0zLTFfMTAwMDB1ZWJlcnNpY2h0LmpwZw.jpg
Bildgröße: 800x600 (ist Y als die Minimalgröße 500x300)
Bildgröße <10MB ist a cuh erfüllt: 124332 Bytes
Bitte überprüfen, ob es an image_url liegt
und bitte das das Feld bis 512 Zeichen Länge erlauben
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `meinberlin/apps/bplan/serializers.py`
Content:
```
1 import datetime
2 import imghdr
3 import posixpath
4 import tempfile
5 from urllib.parse import urlparse
6
7 import requests
8 from django.apps import apps
9 from django.conf import settings
10 from django.contrib.sites.models import Site
11 from django.core.exceptions import ValidationError
12 from django.core.files.images import ImageFile
13 from django.urls import reverse
14 from django.utils import timezone
15 from django.utils.translation import gettext as _
16 from rest_framework import serializers
17
18 from adhocracy4.dashboard import components
19 from adhocracy4.dashboard import signals as a4dashboard_signals
20 from adhocracy4.images.validators import validate_image
21 from adhocracy4.modules import models as module_models
22 from adhocracy4.phases import models as phase_models
23 from adhocracy4.projects import models as project_models
24
25 from .models import Bplan
26 from .phases import StatementPhase
27
28 BPLAN_EMBED = '<iframe height="500" style="width: 100%; min-height: 300px; ' \
29 'max-height: 100vh" src="{}" frameborder="0"></iframe>'
30 DOWNLOAD_IMAGE_SIZE_LIMIT_BYTES = 10 * 1024 * 1024
31
32
33 class BplanSerializer(serializers.ModelSerializer):
34 id = serializers.IntegerField(required=False)
35
36 # make write_only for consistency reasons
37 start_date = serializers.DateTimeField(write_only=True)
38 end_date = serializers.DateTimeField(write_only=True)
39 image_url = serializers.URLField(
40 required=False,
41 write_only=True,
42 max_length=(project_models.Project._meta.
43 get_field('tile_image').max_length))
44 image_copyright = serializers.CharField(
45 required=False,
46 write_only=True,
47 source='tile_image_copyright',
48 allow_blank=True,
49 max_length=(project_models.Project._meta.
50 get_field('tile_image_copyright').max_length))
51 embed_code = serializers.SerializerMethodField()
52
53 class Meta:
54 model = Bplan
55 fields = (
56 'id', 'name', 'identifier', 'description', 'url',
57 'office_worker_email', 'is_draft', 'start_date', 'end_date',
58 'image_url', 'image_copyright', 'embed_code'
59 )
60 extra_kwargs = {
61 # write_only for consistency reasons
62 'is_draft': {'default': False, 'write_only': True},
63 'name': {'write_only': True},
64 'description': {'write_only': True},
65 'url': {'write_only': True},
66 'office_worker_email': {'write_only': True},
67 'identifier': {'write_only': True}
68 }
69
70 def create(self, validated_data):
71 orga_pk = self._context.get('organisation_pk', None)
72 orga_model = apps.get_model(settings.A4_ORGANISATIONS_MODEL)
73 orga = orga_model.objects.get(pk=orga_pk)
74 validated_data['organisation'] = orga
75
76 start_date = validated_data['start_date']
77 end_date = validated_data['end_date']
78
79 image_url = validated_data.pop('image_url', None)
80 if image_url:
81 validated_data['tile_image'] = \
82 self._download_image_from_url(image_url)
83
84 bplan = super().create(validated_data)
85 self._create_module_and_phase(bplan, start_date, end_date)
86 self._send_project_created_signal(bplan)
87 return bplan
88
89 def _create_module_and_phase(self, bplan, start_date, end_date):
90 module = module_models.Module.objects.create(
91 name=bplan.slug + '_module',
92 weight=1,
93 project=bplan,
94 )
95
96 phase_content = StatementPhase()
97 phase_models.Phase.objects.create(
98 name=_('Bplan statement phase'),
99 description=_('Bplan statement phase'),
100 type=phase_content.identifier,
101 module=module,
102 start_date=start_date,
103 end_date=end_date
104 )
105
106 def update(self, instance, validated_data):
107 start_date = validated_data.get('start_date', None)
108 end_date = validated_data.get('end_date', None)
109 if start_date or end_date:
110 self._update_phase(instance, start_date, end_date)
111 if end_date and end_date > timezone.localtime(timezone.now()):
112 instance.is_archived = False
113
114 image_url = validated_data.pop('image_url', None)
115 if image_url:
116 validated_data['tile_image'] = \
117 self._download_image_from_url(image_url)
118
119 instance = super().update(instance, validated_data)
120
121 self._send_component_updated_signal(instance)
122 return instance
123
124 def _update_phase(self, bplan, start_date, end_date):
125 module = module_models.Module.objects.get(project=bplan)
126 phase = phase_models.Phase.objects.get(module=module)
127 if start_date:
128 phase.start_date = start_date
129 if end_date:
130 phase.end_date = end_date
131 phase.save()
132
133 def get_embed_code(self, bplan):
134 url = self._get_absolute_url(bplan)
135 embed = BPLAN_EMBED.format(url)
136 return embed
137
138 def _get_absolute_url(self, bplan):
139 site_url = Site.objects.get_current().domain
140 embed_url = reverse('embed-project', kwargs={'slug': bplan.slug, })
141 url = 'https://{}{}'.format(site_url, embed_url)
142 return url
143
144 def _download_image_from_url(self, url):
145 parsed_url = urlparse(url)
146 file_name = None
147 try:
148 r = requests.get(url, stream=True, timeout=10)
149 downloaded_bytes = 0
150 with tempfile.TemporaryFile() as f:
151 for chunk in r.iter_content(chunk_size=1024):
152 downloaded_bytes += len(chunk)
153 if downloaded_bytes > DOWNLOAD_IMAGE_SIZE_LIMIT_BYTES:
154 raise serializers.ValidationError(
155 'Image too large to download {}'.format(url))
156 if chunk:
157 f.write(chunk)
158 file_name = self._generate_image_filename(parsed_url.path, f)
159 self._image_storage.save(file_name, f)
160 except Exception:
161 if file_name:
162 self._image_storage.delete(file_name)
163 raise serializers.ValidationError(
164 'Failed to download image {}'.format(url))
165
166 try:
167 self._validate_image(file_name)
168 except ValidationError as e:
169 self._image_storage.delete(file_name)
170 raise serializers.ValidationError(e)
171
172 return file_name
173
174 def _validate_image(self, file_name):
175 image_file = self._image_storage.open(file_name, 'rb')
176 image = ImageFile(image_file, file_name)
177 config = settings.IMAGE_ALIASES.get('*', {})
178 config.update(settings.IMAGE_ALIASES['tileimage'])
179 validate_image(image, **config)
180
181 @property
182 def _image_storage(self):
183 return project_models.Project._meta.get_field('tile_image').storage
184
185 @property
186 def _image_upload_to(self):
187 return project_models.Project._meta.get_field('tile_image').upload_to
188
189 def _generate_image_filename(self, url_path, file):
190 if callable(self._image_upload_to):
191 raise Exception('Callable upload_to fields are not supported')
192
193 root_path, extension = posixpath.splitext(url_path)
194 if file:
195 # Workaround: imghdr expects the files position on 0
196 file.seek(0)
197 extension = imghdr.what(file) or 'jpeg'
198
199 basename = posixpath.basename(root_path)
200 if not basename:
201 basename = 'bplan'
202
203 dirname = datetime.datetime.now().strftime(self._image_upload_to)
204 filename = posixpath.join(dirname, basename + '.' + extension)
205
206 return self._image_storage.get_available_name(filename)
207
208 def _send_project_created_signal(self, bplan):
209 a4dashboard_signals.project_created.send(
210 sender=self.__class__,
211 project=bplan,
212 user=self.context['request'].user
213 )
214
215 def _send_component_updated_signal(self, bplan):
216 component = components.projects['bplan']
217 a4dashboard_signals.project_component_updated.send(
218 sender=self.__class__,
219 project=bplan,
220 component=component,
221 user=self.context['request'].user
222 )
223
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/meinberlin/apps/bplan/serializers.py b/meinberlin/apps/bplan/serializers.py
--- a/meinberlin/apps/bplan/serializers.py
+++ b/meinberlin/apps/bplan/serializers.py
@@ -39,15 +39,15 @@
image_url = serializers.URLField(
required=False,
write_only=True,
- max_length=(project_models.Project._meta.
- get_field('tile_image').max_length))
+ )
image_copyright = serializers.CharField(
required=False,
write_only=True,
source='tile_image_copyright',
allow_blank=True,
max_length=(project_models.Project._meta.
- get_field('tile_image_copyright').max_length))
+ get_field('tile_image_copyright').max_length),
+ )
embed_code = serializers.SerializerMethodField()
class Meta:
@@ -196,9 +196,7 @@
file.seek(0)
extension = imghdr.what(file) or 'jpeg'
- basename = posixpath.basename(root_path)
- if not basename:
- basename = 'bplan'
+ basename = 'bplan_%s' % (timezone.now().strftime('%Y%m%dT%H%M%S'))
dirname = datetime.datetime.now().strftime(self._image_upload_to)
filename = posixpath.join(dirname, basename + '.' + extension)
|
{"golden_diff": "diff --git a/meinberlin/apps/bplan/serializers.py b/meinberlin/apps/bplan/serializers.py\n--- a/meinberlin/apps/bplan/serializers.py\n+++ b/meinberlin/apps/bplan/serializers.py\n@@ -39,15 +39,15 @@\n image_url = serializers.URLField(\n required=False,\n write_only=True,\n- max_length=(project_models.Project._meta.\n- get_field('tile_image').max_length))\n+ )\n image_copyright = serializers.CharField(\n required=False,\n write_only=True,\n source='tile_image_copyright',\n allow_blank=True,\n max_length=(project_models.Project._meta.\n- get_field('tile_image_copyright').max_length))\n+ get_field('tile_image_copyright').max_length),\n+ )\n embed_code = serializers.SerializerMethodField()\n \n class Meta:\n@@ -196,9 +196,7 @@\n file.seek(0)\n extension = imghdr.what(file) or 'jpeg'\n \n- basename = posixpath.basename(root_path)\n- if not basename:\n- basename = 'bplan'\n+ basename = 'bplan_%s' % (timezone.now().strftime('%Y%m%dT%H%M%S'))\n \n dirname = datetime.datetime.now().strftime(self._image_upload_to)\n filename = posixpath.join(dirname, basename + '.' + extension)\n", "issue": "B-Plan API: tile picture not transferred from Imperia to mB; bplan not published\n**URL:** see below\r\n**user:** bplan initiator via imperia API\r\n**expected behaviour:** the tile picture entered via Imperia is shown on mB, the plan is published and not only saved as draft\r\n**behaviour:** sometimes the picture is not shown, sometimes the plan does not get automatically published\r\n**important screensize:**\r\n**device & browser:** \r\n**Comment/Question:** it does not happen always but sometimes with different districts involved. Prio set as high as we need to find a solution but not release right away as there is a workaround.\r\n\r\nlist of bplans that recently had problems (as far as I can read from mails as I wasn't always included directly into the support):\r\nhttps://mein.berlin.de/django-admin/meinberlin_bplan/bplan/1535 (May 2022, not published)\r\nhttps://mein.berlin.de/django-admin/meinberlin_bplan/bplan/1488/change/ (March 22, not published)\r\nhttps://mein.berlin.de/django-admin/meinberlin_bplan/bplan/1476/change/ (March 22, picture not transferred)\r\nhttps://mein.berlin.de/django-admin/meinberlin_bplan/bplan/1502/change/ (April 22, not published, picture not transferred)\r\nhttps://mein.berlin.de/django-admin/meinberlin_bplan/bplan/1449/change/ (Feb 22, picture not transferred)\r\n\r\n\r\nRegarding 1449, we have already been in contact with BO, they write the following: \r\n\r\nbeim \u00fcbermitteln der Daten aus dem Imperia-System bekommen wir ein\r\n \"HTTP/2 400\"\r\n\r\nW\u00e4re sch\u00f6n wenn wir bei diesen 400 immer auch gleich eine Error-Meldung mit bekommen k\u00f6nnten, das ist aber immer nur ein schwarzes Loch.\r\n\r\nFolgender POST-Request schl\u00e4gt fehl\r\n\r\n{\"name\":\"Bebauungsplan XIV-3-1 (\\u201eNeuk\\u00f6llnische Allee \\/ Schmalenbachstra\\u00dfe\\u201c)\",\"url\":\"https:\\/\\/[www.berlin.de](http://www.berlin.de/)\\/ba-neukoelln\\/politik-und-verwaltung\\/aemter\\/stadtentwicklungsamt\\/stadtplanung\\/bebauungsplaene\\/bebauungsplan-fuer-meinberlin\\/bebauungsplan.1176597.php\",\"office_worker_email\":\"[[email protected]](mailto:[email protected])\",\"start_date\":\"2022-02-21 00:00\",\"end_date\":\"2022-03-11 23:59\",\"description\":\"Sicherung und Stabilisierung eines Gewerbegebietes durch den Ausschluss unerw\\u00fcnschter Einzelnutzungen.\",\"identifier\":\"XIV-3-1\",\"is_draft\":\"False\",\"image_url\":\"https:\\/\\/[www.berlin.de](http://www.berlin.de/)\\/imgscaler\\/r9Iz3AbUfqVDjoWe7B-GLwXcCWHjBVGlMLWfoeyqvwc\\/meinberlin\\/L3N5czExLXByb2QvYmEtbmV1a29lbGxuL3BvbGl0aWstdW5kLXZlcndhbHR1bmcvYWVtdGVyL3N0YWR0ZW50d2lja2x1bmdzYW10L3N0YWR0cGxhbnVuZy9iZWJhdXVuZ3NwbGFlbmUvYmViYXV1bmdzcGxhbi1mdWVyLW1laW5iZXJsaW4vdW50ZXJsYWdlbi9rYXJ0ZW4tdW5kLXBsYWVuZS91cGxvYWRfXzgzZWIwZjA4OGNjZmEwMTUxNjk0YTcyODQzZWJjYjA1X3hpdi0zLTFfMTAwMDB1ZWJlcnNpY2h0LmpwZw.jpg\",\"image_copyright\":\"Bezirksamt Neuk\\u00f6lln von Berlin\"}\r\n\r\n\r\nWahrscheinlich ist es die \"image_url\"\r\nMit \"\\\\\" sind es 408 Zeichen\r\nOhne \"\\\\\" sind es 402 Zeichen\r\n\r\nIn der API-Beschreibung auf https://github.com/liqd/a4-meinberlin/blob/main/docs/bplan_api.md ist keine Pfad-L\u00e4ngenbeschr\u00e4nkung dokumentiert.\r\nDie Bildgr\u00f6\u00dfe ist korrekt.\r\n\r\nhttps://www.berlin.de/imgscaler/r9Iz3AbUfqVDjoWe7B-GLwXcCWHjBVGlMLWfoeyqvwc/meinberlin/L3N5czExLXByb2QvYmEtbmV1a29lbGxuL3BvbGl0aWstdW5kLXZlcndhbHR1bmcvYWVtdGVyL3N0YWR0ZW50d2lja2x1bmdzYW10L3N0YWR0cGxhbnVuZy9iZWJhdXVuZ3NwbGFlbmUvYmViYXV1bmdzcGxhbi1mdWVyLW1laW5iZXJsaW4vdW50ZXJsYWdlbi9rYXJ0ZW4tdW5kLXBsYWVuZS91cGxvYWRfXzgzZWIwZjA4OGNjZmEwMTUxNjk0YTcyODQzZWJjYjA1X3hpdi0zLTFfMTAwMDB1ZWJlcnNpY2h0LmpwZw.jpg\r\nBildgr\u00f6\u00dfe: 800x600 (ist Y als die Minimalgr\u00f6\u00dfe 500x300)\r\nBildgr\u00f6\u00dfe <10MB ist a cuh erf\u00fcllt: 124332 Bytes\r\n\r\n\r\nBitte \u00fcberpr\u00fcfen, ob es an image_url liegt\r\nund bitte das das Feld bis 512 Zeichen L\u00e4nge erlauben\n", "before_files": [{"content": "import datetime\nimport imghdr\nimport posixpath\nimport tempfile\nfrom urllib.parse import urlparse\n\nimport requests\nfrom django.apps import apps\nfrom django.conf import settings\nfrom django.contrib.sites.models import Site\nfrom django.core.exceptions import ValidationError\nfrom django.core.files.images import ImageFile\nfrom django.urls import reverse\nfrom django.utils import timezone\nfrom django.utils.translation import gettext as _\nfrom rest_framework import serializers\n\nfrom adhocracy4.dashboard import components\nfrom adhocracy4.dashboard import signals as a4dashboard_signals\nfrom adhocracy4.images.validators import validate_image\nfrom adhocracy4.modules import models as module_models\nfrom adhocracy4.phases import models as phase_models\nfrom adhocracy4.projects import models as project_models\n\nfrom .models import Bplan\nfrom .phases import StatementPhase\n\nBPLAN_EMBED = '<iframe height=\"500\" style=\"width: 100%; min-height: 300px; ' \\\n 'max-height: 100vh\" src=\"{}\" frameborder=\"0\"></iframe>'\nDOWNLOAD_IMAGE_SIZE_LIMIT_BYTES = 10 * 1024 * 1024\n\n\nclass BplanSerializer(serializers.ModelSerializer):\n id = serializers.IntegerField(required=False)\n\n # make write_only for consistency reasons\n start_date = serializers.DateTimeField(write_only=True)\n end_date = serializers.DateTimeField(write_only=True)\n image_url = serializers.URLField(\n required=False,\n write_only=True,\n max_length=(project_models.Project._meta.\n get_field('tile_image').max_length))\n image_copyright = serializers.CharField(\n required=False,\n write_only=True,\n source='tile_image_copyright',\n allow_blank=True,\n max_length=(project_models.Project._meta.\n get_field('tile_image_copyright').max_length))\n embed_code = serializers.SerializerMethodField()\n\n class Meta:\n model = Bplan\n fields = (\n 'id', 'name', 'identifier', 'description', 'url',\n 'office_worker_email', 'is_draft', 'start_date', 'end_date',\n 'image_url', 'image_copyright', 'embed_code'\n )\n extra_kwargs = {\n # write_only for consistency reasons\n 'is_draft': {'default': False, 'write_only': True},\n 'name': {'write_only': True},\n 'description': {'write_only': True},\n 'url': {'write_only': True},\n 'office_worker_email': {'write_only': True},\n 'identifier': {'write_only': True}\n }\n\n def create(self, validated_data):\n orga_pk = self._context.get('organisation_pk', None)\n orga_model = apps.get_model(settings.A4_ORGANISATIONS_MODEL)\n orga = orga_model.objects.get(pk=orga_pk)\n validated_data['organisation'] = orga\n\n start_date = validated_data['start_date']\n end_date = validated_data['end_date']\n\n image_url = validated_data.pop('image_url', None)\n if image_url:\n validated_data['tile_image'] = \\\n self._download_image_from_url(image_url)\n\n bplan = super().create(validated_data)\n self._create_module_and_phase(bplan, start_date, end_date)\n self._send_project_created_signal(bplan)\n return bplan\n\n def _create_module_and_phase(self, bplan, start_date, end_date):\n module = module_models.Module.objects.create(\n name=bplan.slug + '_module',\n weight=1,\n project=bplan,\n )\n\n phase_content = StatementPhase()\n phase_models.Phase.objects.create(\n name=_('Bplan statement phase'),\n description=_('Bplan statement phase'),\n type=phase_content.identifier,\n module=module,\n start_date=start_date,\n end_date=end_date\n )\n\n def update(self, instance, validated_data):\n start_date = validated_data.get('start_date', None)\n end_date = validated_data.get('end_date', None)\n if start_date or end_date:\n self._update_phase(instance, start_date, end_date)\n if end_date and end_date > timezone.localtime(timezone.now()):\n instance.is_archived = False\n\n image_url = validated_data.pop('image_url', None)\n if image_url:\n validated_data['tile_image'] = \\\n self._download_image_from_url(image_url)\n\n instance = super().update(instance, validated_data)\n\n self._send_component_updated_signal(instance)\n return instance\n\n def _update_phase(self, bplan, start_date, end_date):\n module = module_models.Module.objects.get(project=bplan)\n phase = phase_models.Phase.objects.get(module=module)\n if start_date:\n phase.start_date = start_date\n if end_date:\n phase.end_date = end_date\n phase.save()\n\n def get_embed_code(self, bplan):\n url = self._get_absolute_url(bplan)\n embed = BPLAN_EMBED.format(url)\n return embed\n\n def _get_absolute_url(self, bplan):\n site_url = Site.objects.get_current().domain\n embed_url = reverse('embed-project', kwargs={'slug': bplan.slug, })\n url = 'https://{}{}'.format(site_url, embed_url)\n return url\n\n def _download_image_from_url(self, url):\n parsed_url = urlparse(url)\n file_name = None\n try:\n r = requests.get(url, stream=True, timeout=10)\n downloaded_bytes = 0\n with tempfile.TemporaryFile() as f:\n for chunk in r.iter_content(chunk_size=1024):\n downloaded_bytes += len(chunk)\n if downloaded_bytes > DOWNLOAD_IMAGE_SIZE_LIMIT_BYTES:\n raise serializers.ValidationError(\n 'Image too large to download {}'.format(url))\n if chunk:\n f.write(chunk)\n file_name = self._generate_image_filename(parsed_url.path, f)\n self._image_storage.save(file_name, f)\n except Exception:\n if file_name:\n self._image_storage.delete(file_name)\n raise serializers.ValidationError(\n 'Failed to download image {}'.format(url))\n\n try:\n self._validate_image(file_name)\n except ValidationError as e:\n self._image_storage.delete(file_name)\n raise serializers.ValidationError(e)\n\n return file_name\n\n def _validate_image(self, file_name):\n image_file = self._image_storage.open(file_name, 'rb')\n image = ImageFile(image_file, file_name)\n config = settings.IMAGE_ALIASES.get('*', {})\n config.update(settings.IMAGE_ALIASES['tileimage'])\n validate_image(image, **config)\n\n @property\n def _image_storage(self):\n return project_models.Project._meta.get_field('tile_image').storage\n\n @property\n def _image_upload_to(self):\n return project_models.Project._meta.get_field('tile_image').upload_to\n\n def _generate_image_filename(self, url_path, file):\n if callable(self._image_upload_to):\n raise Exception('Callable upload_to fields are not supported')\n\n root_path, extension = posixpath.splitext(url_path)\n if file:\n # Workaround: imghdr expects the files position on 0\n file.seek(0)\n extension = imghdr.what(file) or 'jpeg'\n\n basename = posixpath.basename(root_path)\n if not basename:\n basename = 'bplan'\n\n dirname = datetime.datetime.now().strftime(self._image_upload_to)\n filename = posixpath.join(dirname, basename + '.' + extension)\n\n return self._image_storage.get_available_name(filename)\n\n def _send_project_created_signal(self, bplan):\n a4dashboard_signals.project_created.send(\n sender=self.__class__,\n project=bplan,\n user=self.context['request'].user\n )\n\n def _send_component_updated_signal(self, bplan):\n component = components.projects['bplan']\n a4dashboard_signals.project_component_updated.send(\n sender=self.__class__,\n project=bplan,\n component=component,\n user=self.context['request'].user\n )\n", "path": "meinberlin/apps/bplan/serializers.py"}], "after_files": [{"content": "import datetime\nimport imghdr\nimport posixpath\nimport tempfile\nfrom urllib.parse import urlparse\n\nimport requests\nfrom django.apps import apps\nfrom django.conf import settings\nfrom django.contrib.sites.models import Site\nfrom django.core.exceptions import ValidationError\nfrom django.core.files.images import ImageFile\nfrom django.urls import reverse\nfrom django.utils import timezone\nfrom django.utils.translation import gettext as _\nfrom rest_framework import serializers\n\nfrom adhocracy4.dashboard import components\nfrom adhocracy4.dashboard import signals as a4dashboard_signals\nfrom adhocracy4.images.validators import validate_image\nfrom adhocracy4.modules import models as module_models\nfrom adhocracy4.phases import models as phase_models\nfrom adhocracy4.projects import models as project_models\n\nfrom .models import Bplan\nfrom .phases import StatementPhase\n\nBPLAN_EMBED = '<iframe height=\"500\" style=\"width: 100%; min-height: 300px; ' \\\n 'max-height: 100vh\" src=\"{}\" frameborder=\"0\"></iframe>'\nDOWNLOAD_IMAGE_SIZE_LIMIT_BYTES = 10 * 1024 * 1024\n\n\nclass BplanSerializer(serializers.ModelSerializer):\n id = serializers.IntegerField(required=False)\n\n # make write_only for consistency reasons\n start_date = serializers.DateTimeField(write_only=True)\n end_date = serializers.DateTimeField(write_only=True)\n image_url = serializers.URLField(\n required=False,\n write_only=True,\n )\n image_copyright = serializers.CharField(\n required=False,\n write_only=True,\n source='tile_image_copyright',\n allow_blank=True,\n max_length=(project_models.Project._meta.\n get_field('tile_image_copyright').max_length),\n )\n embed_code = serializers.SerializerMethodField()\n\n class Meta:\n model = Bplan\n fields = (\n 'id', 'name', 'identifier', 'description', 'url',\n 'office_worker_email', 'is_draft', 'start_date', 'end_date',\n 'image_url', 'image_copyright', 'embed_code'\n )\n extra_kwargs = {\n # write_only for consistency reasons\n 'is_draft': {'default': False, 'write_only': True},\n 'name': {'write_only': True},\n 'description': {'write_only': True},\n 'url': {'write_only': True},\n 'office_worker_email': {'write_only': True},\n 'identifier': {'write_only': True}\n }\n\n def create(self, validated_data):\n orga_pk = self._context.get('organisation_pk', None)\n orga_model = apps.get_model(settings.A4_ORGANISATIONS_MODEL)\n orga = orga_model.objects.get(pk=orga_pk)\n validated_data['organisation'] = orga\n\n start_date = validated_data['start_date']\n end_date = validated_data['end_date']\n\n image_url = validated_data.pop('image_url', None)\n if image_url:\n validated_data['tile_image'] = \\\n self._download_image_from_url(image_url)\n\n bplan = super().create(validated_data)\n self._create_module_and_phase(bplan, start_date, end_date)\n self._send_project_created_signal(bplan)\n return bplan\n\n def _create_module_and_phase(self, bplan, start_date, end_date):\n module = module_models.Module.objects.create(\n name=bplan.slug + '_module',\n weight=1,\n project=bplan,\n )\n\n phase_content = StatementPhase()\n phase_models.Phase.objects.create(\n name=_('Bplan statement phase'),\n description=_('Bplan statement phase'),\n type=phase_content.identifier,\n module=module,\n start_date=start_date,\n end_date=end_date\n )\n\n def update(self, instance, validated_data):\n start_date = validated_data.get('start_date', None)\n end_date = validated_data.get('end_date', None)\n if start_date or end_date:\n self._update_phase(instance, start_date, end_date)\n if end_date and end_date > timezone.localtime(timezone.now()):\n instance.is_archived = False\n\n image_url = validated_data.pop('image_url', None)\n if image_url:\n validated_data['tile_image'] = \\\n self._download_image_from_url(image_url)\n\n instance = super().update(instance, validated_data)\n\n self._send_component_updated_signal(instance)\n return instance\n\n def _update_phase(self, bplan, start_date, end_date):\n module = module_models.Module.objects.get(project=bplan)\n phase = phase_models.Phase.objects.get(module=module)\n if start_date:\n phase.start_date = start_date\n if end_date:\n phase.end_date = end_date\n phase.save()\n\n def get_embed_code(self, bplan):\n url = self._get_absolute_url(bplan)\n embed = BPLAN_EMBED.format(url)\n return embed\n\n def _get_absolute_url(self, bplan):\n site_url = Site.objects.get_current().domain\n embed_url = reverse('embed-project', kwargs={'slug': bplan.slug, })\n url = 'https://{}{}'.format(site_url, embed_url)\n return url\n\n def _download_image_from_url(self, url):\n parsed_url = urlparse(url)\n file_name = None\n try:\n r = requests.get(url, stream=True, timeout=10)\n downloaded_bytes = 0\n with tempfile.TemporaryFile() as f:\n for chunk in r.iter_content(chunk_size=1024):\n downloaded_bytes += len(chunk)\n if downloaded_bytes > DOWNLOAD_IMAGE_SIZE_LIMIT_BYTES:\n raise serializers.ValidationError(\n 'Image too large to download {}'.format(url))\n if chunk:\n f.write(chunk)\n file_name = self._generate_image_filename(parsed_url.path, f)\n self._image_storage.save(file_name, f)\n except Exception:\n if file_name:\n self._image_storage.delete(file_name)\n raise serializers.ValidationError(\n 'Failed to download image {}'.format(url))\n\n try:\n self._validate_image(file_name)\n except ValidationError as e:\n self._image_storage.delete(file_name)\n raise serializers.ValidationError(e)\n\n return file_name\n\n def _validate_image(self, file_name):\n image_file = self._image_storage.open(file_name, 'rb')\n image = ImageFile(image_file, file_name)\n config = settings.IMAGE_ALIASES.get('*', {})\n config.update(settings.IMAGE_ALIASES['tileimage'])\n validate_image(image, **config)\n\n @property\n def _image_storage(self):\n return project_models.Project._meta.get_field('tile_image').storage\n\n @property\n def _image_upload_to(self):\n return project_models.Project._meta.get_field('tile_image').upload_to\n\n def _generate_image_filename(self, url_path, file):\n if callable(self._image_upload_to):\n raise Exception('Callable upload_to fields are not supported')\n\n root_path, extension = posixpath.splitext(url_path)\n if file:\n # Workaround: imghdr expects the files position on 0\n file.seek(0)\n extension = imghdr.what(file) or 'jpeg'\n\n basename = 'bplan_%s' % (timezone.now().strftime('%Y%m%dT%H%M%S'))\n\n dirname = datetime.datetime.now().strftime(self._image_upload_to)\n filename = posixpath.join(dirname, basename + '.' + extension)\n\n return self._image_storage.get_available_name(filename)\n\n def _send_project_created_signal(self, bplan):\n a4dashboard_signals.project_created.send(\n sender=self.__class__,\n project=bplan,\n user=self.context['request'].user\n )\n\n def _send_component_updated_signal(self, bplan):\n component = components.projects['bplan']\n a4dashboard_signals.project_component_updated.send(\n sender=self.__class__,\n project=bplan,\n component=component,\n user=self.context['request'].user\n )\n", "path": "meinberlin/apps/bplan/serializers.py"}]}
| 4,024 | 307 |
gh_patches_debug_27898
|
rasdani/github-patches
|
git_diff
|
pypa__pip-4046
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
pip freeze --requirement doesn't accept inline comments
- Pip version: 8.1.2
- Python version: 2.7.11
- Operating System: Mac OS X
### Description:
pip freeze --requirement doesn't accept inline comments
### What I've run:
```
pip freeze -r requirements.txt
```
Output:
```
Invalid requirement: 'alembic==0.8.6 # MIT license'
Traceback (most recent call last):
File ".../site-packages/pip/req/req_install.py", line 78, in __init__
req = Requirement(req)
File ".../site-packages/pip/_vendor/packaging/requirements.py", line 96, in __init__
requirement_string[e.loc:e.loc + 8]))
InvalidRequirement: Invalid requirement, parse error at "'# MIT li'"
```
requirements.txt:
```
alembic==0.8.6 # MIT license
Babel==2.3.4 # BSD license
```
`pip install -r` works for this requirements.txt file.
Documentation states:
> Whitespace followed by a # causes the # and the remainder of the line to be treated as a comment.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pip/operations/freeze.py`
Content:
```
1 from __future__ import absolute_import
2
3 import logging
4 import re
5
6 import pip
7 from pip.req import InstallRequirement
8 from pip.utils import get_installed_distributions
9 from pip._vendor import pkg_resources
10 from pip._vendor.packaging.utils import canonicalize_name
11 from pip._vendor.pkg_resources import RequirementParseError
12
13
14 logger = logging.getLogger(__name__)
15
16
17 def freeze(
18 requirement=None,
19 find_links=None, local_only=None, user_only=None, skip_regex=None,
20 default_vcs=None,
21 isolated=False,
22 wheel_cache=None,
23 skip=()):
24 find_links = find_links or []
25 skip_match = None
26
27 if skip_regex:
28 skip_match = re.compile(skip_regex).search
29
30 dependency_links = []
31
32 for dist in pkg_resources.working_set:
33 if dist.has_metadata('dependency_links.txt'):
34 dependency_links.extend(
35 dist.get_metadata_lines('dependency_links.txt')
36 )
37 for link in find_links:
38 if '#egg=' in link:
39 dependency_links.append(link)
40 for link in find_links:
41 yield '-f %s' % link
42 installations = {}
43 for dist in get_installed_distributions(local_only=local_only,
44 skip=(),
45 user_only=user_only):
46 try:
47 req = pip.FrozenRequirement.from_dist(
48 dist,
49 dependency_links
50 )
51 except RequirementParseError:
52 logger.warning(
53 "Could not parse requirement: %s",
54 dist.project_name
55 )
56 continue
57 installations[req.name] = req
58
59 if requirement:
60 # the options that don't get turned into an InstallRequirement
61 # should only be emitted once, even if the same option is in multiple
62 # requirements files, so we need to keep track of what has been emitted
63 # so that we don't emit it again if it's seen again
64 emitted_options = set()
65 for req_file_path in requirement:
66 with open(req_file_path) as req_file:
67 for line in req_file:
68 if (not line.strip() or
69 line.strip().startswith('#') or
70 (skip_match and skip_match(line)) or
71 line.startswith((
72 '-r', '--requirement',
73 '-Z', '--always-unzip',
74 '-f', '--find-links',
75 '-i', '--index-url',
76 '--pre',
77 '--trusted-host',
78 '--process-dependency-links',
79 '--extra-index-url'))):
80 line = line.rstrip()
81 if line not in emitted_options:
82 emitted_options.add(line)
83 yield line
84 continue
85
86 if line.startswith('-e') or line.startswith('--editable'):
87 if line.startswith('-e'):
88 line = line[2:].strip()
89 else:
90 line = line[len('--editable'):].strip().lstrip('=')
91 line_req = InstallRequirement.from_editable(
92 line,
93 default_vcs=default_vcs,
94 isolated=isolated,
95 wheel_cache=wheel_cache,
96 )
97 else:
98 line_req = InstallRequirement.from_line(
99 line,
100 isolated=isolated,
101 wheel_cache=wheel_cache,
102 )
103
104 if not line_req.name:
105 logger.info(
106 "Skipping line in requirement file [%s] because "
107 "it's not clear what it would install: %s",
108 req_file_path, line.strip(),
109 )
110 logger.info(
111 " (add #egg=PackageName to the URL to avoid"
112 " this warning)"
113 )
114 elif line_req.name not in installations:
115 logger.warning(
116 "Requirement file [%s] contains %s, but that "
117 "package is not installed",
118 req_file_path, line.strip(),
119 )
120 else:
121 yield str(installations[line_req.name]).rstrip()
122 del installations[line_req.name]
123
124 yield(
125 '## The following requirements were added by '
126 'pip freeze:'
127 )
128 for installation in sorted(
129 installations.values(), key=lambda x: x.name.lower()):
130 if canonicalize_name(installation.name) not in skip:
131 yield str(installation).rstrip()
132
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pip/operations/freeze.py b/pip/operations/freeze.py
--- a/pip/operations/freeze.py
+++ b/pip/operations/freeze.py
@@ -5,6 +5,7 @@
import pip
from pip.req import InstallRequirement
+from pip.req.req_file import COMMENT_RE
from pip.utils import get_installed_distributions
from pip._vendor import pkg_resources
from pip._vendor.packaging.utils import canonicalize_name
@@ -96,7 +97,7 @@
)
else:
line_req = InstallRequirement.from_line(
- line,
+ COMMENT_RE.sub('', line).strip(),
isolated=isolated,
wheel_cache=wheel_cache,
)
@@ -115,7 +116,7 @@
logger.warning(
"Requirement file [%s] contains %s, but that "
"package is not installed",
- req_file_path, line.strip(),
+ req_file_path, COMMENT_RE.sub('', line).strip(),
)
else:
yield str(installations[line_req.name]).rstrip()
|
{"golden_diff": "diff --git a/pip/operations/freeze.py b/pip/operations/freeze.py\n--- a/pip/operations/freeze.py\n+++ b/pip/operations/freeze.py\n@@ -5,6 +5,7 @@\n \n import pip\n from pip.req import InstallRequirement\n+from pip.req.req_file import COMMENT_RE\n from pip.utils import get_installed_distributions\n from pip._vendor import pkg_resources\n from pip._vendor.packaging.utils import canonicalize_name\n@@ -96,7 +97,7 @@\n )\n else:\n line_req = InstallRequirement.from_line(\n- line,\n+ COMMENT_RE.sub('', line).strip(),\n isolated=isolated,\n wheel_cache=wheel_cache,\n )\n@@ -115,7 +116,7 @@\n logger.warning(\n \"Requirement file [%s] contains %s, but that \"\n \"package is not installed\",\n- req_file_path, line.strip(),\n+ req_file_path, COMMENT_RE.sub('', line).strip(),\n )\n else:\n yield str(installations[line_req.name]).rstrip()\n", "issue": "pip freeze --requirement doesn't accept inline comments\n- Pip version: 8.1.2\n- Python version: 2.7.11\n- Operating System: Mac OS X\n### Description:\n\npip freeze --requirement doesn't accept inline comments\n### What I've run:\n\n```\npip freeze -r requirements.txt\n```\n\nOutput:\n\n```\nInvalid requirement: 'alembic==0.8.6 # MIT license'\nTraceback (most recent call last):\n File \".../site-packages/pip/req/req_install.py\", line 78, in __init__\n req = Requirement(req)\n File \".../site-packages/pip/_vendor/packaging/requirements.py\", line 96, in __init__\n requirement_string[e.loc:e.loc + 8]))\nInvalidRequirement: Invalid requirement, parse error at \"'# MIT li'\"\n```\n\nrequirements.txt:\n\n```\nalembic==0.8.6 # MIT license\nBabel==2.3.4 # BSD license\n```\n\n`pip install -r` works for this requirements.txt file.\n\nDocumentation states:\n\n> Whitespace followed by a # causes the # and the remainder of the line to be treated as a comment.\n\n", "before_files": [{"content": "from __future__ import absolute_import\n\nimport logging\nimport re\n\nimport pip\nfrom pip.req import InstallRequirement\nfrom pip.utils import get_installed_distributions\nfrom pip._vendor import pkg_resources\nfrom pip._vendor.packaging.utils import canonicalize_name\nfrom pip._vendor.pkg_resources import RequirementParseError\n\n\nlogger = logging.getLogger(__name__)\n\n\ndef freeze(\n requirement=None,\n find_links=None, local_only=None, user_only=None, skip_regex=None,\n default_vcs=None,\n isolated=False,\n wheel_cache=None,\n skip=()):\n find_links = find_links or []\n skip_match = None\n\n if skip_regex:\n skip_match = re.compile(skip_regex).search\n\n dependency_links = []\n\n for dist in pkg_resources.working_set:\n if dist.has_metadata('dependency_links.txt'):\n dependency_links.extend(\n dist.get_metadata_lines('dependency_links.txt')\n )\n for link in find_links:\n if '#egg=' in link:\n dependency_links.append(link)\n for link in find_links:\n yield '-f %s' % link\n installations = {}\n for dist in get_installed_distributions(local_only=local_only,\n skip=(),\n user_only=user_only):\n try:\n req = pip.FrozenRequirement.from_dist(\n dist,\n dependency_links\n )\n except RequirementParseError:\n logger.warning(\n \"Could not parse requirement: %s\",\n dist.project_name\n )\n continue\n installations[req.name] = req\n\n if requirement:\n # the options that don't get turned into an InstallRequirement\n # should only be emitted once, even if the same option is in multiple\n # requirements files, so we need to keep track of what has been emitted\n # so that we don't emit it again if it's seen again\n emitted_options = set()\n for req_file_path in requirement:\n with open(req_file_path) as req_file:\n for line in req_file:\n if (not line.strip() or\n line.strip().startswith('#') or\n (skip_match and skip_match(line)) or\n line.startswith((\n '-r', '--requirement',\n '-Z', '--always-unzip',\n '-f', '--find-links',\n '-i', '--index-url',\n '--pre',\n '--trusted-host',\n '--process-dependency-links',\n '--extra-index-url'))):\n line = line.rstrip()\n if line not in emitted_options:\n emitted_options.add(line)\n yield line\n continue\n\n if line.startswith('-e') or line.startswith('--editable'):\n if line.startswith('-e'):\n line = line[2:].strip()\n else:\n line = line[len('--editable'):].strip().lstrip('=')\n line_req = InstallRequirement.from_editable(\n line,\n default_vcs=default_vcs,\n isolated=isolated,\n wheel_cache=wheel_cache,\n )\n else:\n line_req = InstallRequirement.from_line(\n line,\n isolated=isolated,\n wheel_cache=wheel_cache,\n )\n\n if not line_req.name:\n logger.info(\n \"Skipping line in requirement file [%s] because \"\n \"it's not clear what it would install: %s\",\n req_file_path, line.strip(),\n )\n logger.info(\n \" (add #egg=PackageName to the URL to avoid\"\n \" this warning)\"\n )\n elif line_req.name not in installations:\n logger.warning(\n \"Requirement file [%s] contains %s, but that \"\n \"package is not installed\",\n req_file_path, line.strip(),\n )\n else:\n yield str(installations[line_req.name]).rstrip()\n del installations[line_req.name]\n\n yield(\n '## The following requirements were added by '\n 'pip freeze:'\n )\n for installation in sorted(\n installations.values(), key=lambda x: x.name.lower()):\n if canonicalize_name(installation.name) not in skip:\n yield str(installation).rstrip()\n", "path": "pip/operations/freeze.py"}], "after_files": [{"content": "from __future__ import absolute_import\n\nimport logging\nimport re\n\nimport pip\nfrom pip.req import InstallRequirement\nfrom pip.req.req_file import COMMENT_RE\nfrom pip.utils import get_installed_distributions\nfrom pip._vendor import pkg_resources\nfrom pip._vendor.packaging.utils import canonicalize_name\nfrom pip._vendor.pkg_resources import RequirementParseError\n\n\nlogger = logging.getLogger(__name__)\n\n\ndef freeze(\n requirement=None,\n find_links=None, local_only=None, user_only=None, skip_regex=None,\n default_vcs=None,\n isolated=False,\n wheel_cache=None,\n skip=()):\n find_links = find_links or []\n skip_match = None\n\n if skip_regex:\n skip_match = re.compile(skip_regex).search\n\n dependency_links = []\n\n for dist in pkg_resources.working_set:\n if dist.has_metadata('dependency_links.txt'):\n dependency_links.extend(\n dist.get_metadata_lines('dependency_links.txt')\n )\n for link in find_links:\n if '#egg=' in link:\n dependency_links.append(link)\n for link in find_links:\n yield '-f %s' % link\n installations = {}\n for dist in get_installed_distributions(local_only=local_only,\n skip=(),\n user_only=user_only):\n try:\n req = pip.FrozenRequirement.from_dist(\n dist,\n dependency_links\n )\n except RequirementParseError:\n logger.warning(\n \"Could not parse requirement: %s\",\n dist.project_name\n )\n continue\n installations[req.name] = req\n\n if requirement:\n # the options that don't get turned into an InstallRequirement\n # should only be emitted once, even if the same option is in multiple\n # requirements files, so we need to keep track of what has been emitted\n # so that we don't emit it again if it's seen again\n emitted_options = set()\n for req_file_path in requirement:\n with open(req_file_path) as req_file:\n for line in req_file:\n if (not line.strip() or\n line.strip().startswith('#') or\n (skip_match and skip_match(line)) or\n line.startswith((\n '-r', '--requirement',\n '-Z', '--always-unzip',\n '-f', '--find-links',\n '-i', '--index-url',\n '--pre',\n '--trusted-host',\n '--process-dependency-links',\n '--extra-index-url'))):\n line = line.rstrip()\n if line not in emitted_options:\n emitted_options.add(line)\n yield line\n continue\n\n if line.startswith('-e') or line.startswith('--editable'):\n if line.startswith('-e'):\n line = line[2:].strip()\n else:\n line = line[len('--editable'):].strip().lstrip('=')\n line_req = InstallRequirement.from_editable(\n line,\n default_vcs=default_vcs,\n isolated=isolated,\n wheel_cache=wheel_cache,\n )\n else:\n line_req = InstallRequirement.from_line(\n COMMENT_RE.sub('', line).strip(),\n isolated=isolated,\n wheel_cache=wheel_cache,\n )\n\n if not line_req.name:\n logger.info(\n \"Skipping line in requirement file [%s] because \"\n \"it's not clear what it would install: %s\",\n req_file_path, line.strip(),\n )\n logger.info(\n \" (add #egg=PackageName to the URL to avoid\"\n \" this warning)\"\n )\n elif line_req.name not in installations:\n logger.warning(\n \"Requirement file [%s] contains %s, but that \"\n \"package is not installed\",\n req_file_path, COMMENT_RE.sub('', line).strip(),\n )\n else:\n yield str(installations[line_req.name]).rstrip()\n del installations[line_req.name]\n\n yield(\n '## The following requirements were added by '\n 'pip freeze:'\n )\n for installation in sorted(\n installations.values(), key=lambda x: x.name.lower()):\n if canonicalize_name(installation.name) not in skip:\n yield str(installation).rstrip()\n", "path": "pip/operations/freeze.py"}]}
| 1,662 | 234 |
gh_patches_debug_33248
|
rasdani/github-patches
|
git_diff
|
WeblateOrg__weblate-9101
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Checking "Needs editing" on a translated entry trigger "Has been translated" warning
**Describe the bug**
After an entry has been already translated (even if it's already marked as "Need editing"), if the translation is modified and the user adds (or keeps) the "Need editing" checked, it will trigger the warning "Has been translated".
I think it shouldn't trigger that warning at least, the message is misleading and in any case the report already marks the entry that needs editing as red.
**To Reproduce the bug**
1. Go to an entry for a component (.po in my case)
2. Translate for the first time the entry and click Save.
3. Go to that entry again, click on "Needs editing" and then Save.
4. The warning will appear.
**Expected behavior**
This specific warning shouldn't show every time a translation is made and Needs editing is there. It's not a warning and the user is already marking as needing some action.
**Additional context**
See also #2935
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `weblate/checks/consistency.py`
Content:
```
1 # Copyright © Michal Čihař <[email protected]>
2 #
3 # SPDX-License-Identifier: GPL-3.0-or-later
4
5 from functools import reduce
6
7 from django.db.models import Count, Prefetch, Q
8 from django.utils.translation import gettext_lazy as _
9
10 from weblate.checks.base import TargetCheck
11 from weblate.utils.state import STATE_TRANSLATED
12
13
14 class PluralsCheck(TargetCheck):
15 """Check for incomplete plural forms."""
16
17 check_id = "plurals"
18 name = _("Missing plurals")
19 description = _("Some plural forms are untranslated")
20
21 def should_skip(self, unit):
22 if unit.translation.component.is_multivalue:
23 return True
24 return super().should_skip(unit)
25
26 def check_target_unit(self, sources, targets, unit):
27 # Is this plural?
28 if len(sources) == 1:
29 return False
30 # Is at least something translated?
31 if targets == len(targets) * [""]:
32 return False
33 # Check for empty translation
34 return "" in targets
35
36 def check_single(self, source, target, unit):
37 """We don't check target strings here."""
38 return False
39
40
41 class SamePluralsCheck(TargetCheck):
42 """Check for same plural forms."""
43
44 check_id = "same-plurals"
45 name = _("Same plurals")
46 description = _("Some plural forms are translated in the same way")
47
48 def check_target_unit(self, sources, targets, unit):
49 # Is this plural?
50 if len(sources) == 1 or len(targets) == 1:
51 return False
52 if not targets[0]:
53 return False
54 return len(set(targets)) == 1
55
56 def check_single(self, source, target, unit):
57 """We don't check target strings here."""
58 return False
59
60
61 class ConsistencyCheck(TargetCheck):
62 """Check for inconsistent translations."""
63
64 check_id = "inconsistent"
65 name = _("Inconsistent")
66 description = _(
67 "This string has more than one translation in this project "
68 "or is untranslated in some components."
69 )
70 ignore_untranslated = False
71 propagates = True
72 batch_project_wide = True
73 skip_suggestions = True
74
75 def check_target_unit(self, sources, targets, unit):
76 component = unit.translation.component
77 if not component.allow_translation_propagation:
78 return False
79
80 # Use last result if checks are batched
81 if component.batch_checks:
82 return self.handle_batch(unit, component)
83
84 for other in unit.same_source_units:
85 if unit.target == other.target:
86 continue
87 if unit.translated or other.translated:
88 return True
89 return False
90
91 def check_single(self, source, target, unit):
92 """We don't check target strings here."""
93 return False
94
95 def check_component(self, component):
96 from weblate.trans.models import Unit
97
98 units = Unit.objects.filter(
99 translation__component__project=component.project,
100 translation__component__allow_translation_propagation=True,
101 )
102
103 # List strings with different targets
104 # Limit this to 100 strings, otherwise the resulting query is way too complex
105 matches = (
106 units.values("id_hash", "translation__language", "translation__plural")
107 .annotate(Count("target", distinct=True))
108 .filter(target__count__gt=1)
109 .order_by("id_hash")[:100]
110 )
111
112 if not matches:
113 return []
114
115 return (
116 units.filter(
117 reduce(
118 lambda x, y: x
119 | (
120 Q(id_hash=y["id_hash"])
121 & Q(translation__language=y["translation__language"])
122 & Q(translation__plural=y["translation__plural"])
123 ),
124 matches,
125 Q(),
126 )
127 )
128 .prefetch()
129 .prefetch_bulk()
130 )
131
132
133 class TranslatedCheck(TargetCheck):
134 """Check for inconsistent translations."""
135
136 check_id = "translated"
137 name = _("Has been translated")
138 description = _("This string has been translated in the past")
139 ignore_untranslated = False
140 skip_suggestions = True
141
142 def get_description(self, check_obj):
143 unit = check_obj.unit
144 target = self.check_target_unit(unit.source, unit.target, unit)
145 if not target:
146 return super().get_description(check_obj)
147 return _('Previous translation was "%s".') % target
148
149 def check_target_unit(self, sources, targets, unit):
150 if unit.translated:
151 return False
152
153 component = unit.translation.component
154
155 if component.batch_checks:
156 return self.handle_batch(unit, component)
157
158 from weblate.trans.models import Change
159
160 changes = unit.change_set.filter(action__in=Change.ACTIONS_CONTENT).order()
161
162 for action, target in changes.values_list("action", "target"):
163 if action == Change.ACTION_SOURCE_CHANGE:
164 break
165 if target and target != unit.target:
166 return target
167
168 return False
169
170 def check_single(self, source, target, unit):
171 """We don't check target strings here."""
172 return False
173
174 def get_fixup(self, unit):
175 target = self.check_target_unit(unit.source, unit.target, unit)
176 if not target:
177 return None
178 return [(".*", target, "u")]
179
180 def check_component(self, component):
181 from weblate.trans.models import Change, Unit
182
183 units = (
184 Unit.objects.filter(
185 translation__component=component,
186 change__action__in=Change.ACTIONS_CONTENT,
187 state__lt=STATE_TRANSLATED,
188 )
189 .prefetch_related(
190 Prefetch(
191 "change_set",
192 queryset=Change.objects.filter(
193 action__in=Change.ACTIONS_CONTENT,
194 ).order(),
195 to_attr="recent_consistency_changes",
196 )
197 )
198 .prefetch()
199 .prefetch_bulk()
200 )
201
202 for unit in units:
203 for change in unit.recent_consistency_changes:
204 if change.action == Change.ACTION_SOURCE_CHANGE:
205 break
206 if change.target:
207 yield unit
208
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/weblate/checks/consistency.py b/weblate/checks/consistency.py
--- a/weblate/checks/consistency.py
+++ b/weblate/checks/consistency.py
@@ -146,6 +146,23 @@
return super().get_description(check_obj)
return _('Previous translation was "%s".') % target
+ def should_skip_change(self, change, unit):
+ from weblate.trans.models import Change
+
+ # Skip automatic translation entries adding needs editing string
+ return (
+ change.action == Change.ACTION_AUTO
+ and change.details.get("state", STATE_TRANSLATED) < STATE_TRANSLATED
+ )
+
+ @staticmethod
+ def should_break_changes(change):
+ from weblate.trans.models import Change
+
+ # Stop changes processin on source string change or on
+ # intentional marking as needing edit
+ return change.action in (Change.ACTION_SOURCE_CHANGE, Change.ACTION_MARKED_EDIT)
+
def check_target_unit(self, sources, targets, unit):
if unit.translated:
return False
@@ -159,11 +176,13 @@
changes = unit.change_set.filter(action__in=Change.ACTIONS_CONTENT).order()
- for action, target in changes.values_list("action", "target"):
- if action == Change.ACTION_SOURCE_CHANGE:
+ for change in changes:
+ if self.should_break_changes(change):
break
- if target and target != unit.target:
- return target
+ if self.should_skip_change(change, unit):
+ continue
+ if change.target and change.target != unit.target:
+ return change.target
return False
@@ -201,7 +220,9 @@
for unit in units:
for change in unit.recent_consistency_changes:
- if change.action == Change.ACTION_SOURCE_CHANGE:
+ if self.should_break_changes(change):
break
+ if self.should_skip_change(change, unit):
+ continue
if change.target:
yield unit
|
{"golden_diff": "diff --git a/weblate/checks/consistency.py b/weblate/checks/consistency.py\n--- a/weblate/checks/consistency.py\n+++ b/weblate/checks/consistency.py\n@@ -146,6 +146,23 @@\n return super().get_description(check_obj)\n return _('Previous translation was \"%s\".') % target\n \n+ def should_skip_change(self, change, unit):\n+ from weblate.trans.models import Change\n+\n+ # Skip automatic translation entries adding needs editing string\n+ return (\n+ change.action == Change.ACTION_AUTO\n+ and change.details.get(\"state\", STATE_TRANSLATED) < STATE_TRANSLATED\n+ )\n+\n+ @staticmethod\n+ def should_break_changes(change):\n+ from weblate.trans.models import Change\n+\n+ # Stop changes processin on source string change or on\n+ # intentional marking as needing edit\n+ return change.action in (Change.ACTION_SOURCE_CHANGE, Change.ACTION_MARKED_EDIT)\n+\n def check_target_unit(self, sources, targets, unit):\n if unit.translated:\n return False\n@@ -159,11 +176,13 @@\n \n changes = unit.change_set.filter(action__in=Change.ACTIONS_CONTENT).order()\n \n- for action, target in changes.values_list(\"action\", \"target\"):\n- if action == Change.ACTION_SOURCE_CHANGE:\n+ for change in changes:\n+ if self.should_break_changes(change):\n break\n- if target and target != unit.target:\n- return target\n+ if self.should_skip_change(change, unit):\n+ continue\n+ if change.target and change.target != unit.target:\n+ return change.target\n \n return False\n \n@@ -201,7 +220,9 @@\n \n for unit in units:\n for change in unit.recent_consistency_changes:\n- if change.action == Change.ACTION_SOURCE_CHANGE:\n+ if self.should_break_changes(change):\n break\n+ if self.should_skip_change(change, unit):\n+ continue\n if change.target:\n yield unit\n", "issue": "Checking \"Needs editing\" on a translated entry trigger \"Has been translated\" warning \n**Describe the bug**\r\n\r\nAfter an entry has been already translated (even if it's already marked as \"Need editing\"), if the translation is modified and the user adds (or keeps) the \"Need editing\" checked, it will trigger the warning \"Has been translated\".\r\n\r\nI think it shouldn't trigger that warning at least, the message is misleading and in any case the report already marks the entry that needs editing as red.\r\n\r\n**To Reproduce the bug**\r\n\r\n1. Go to an entry for a component (.po in my case)\r\n2. Translate for the first time the entry and click Save.\r\n3. Go to that entry again, click on \"Needs editing\" and then Save.\r\n4. The warning will appear.\r\n\r\n**Expected behavior**\r\n\r\nThis specific warning shouldn't show every time a translation is made and Needs editing is there. It's not a warning and the user is already marking as needing some action.\r\n\r\n**Additional context**\r\n\r\nSee also #2935\r\n\n", "before_files": [{"content": "# Copyright \u00a9 Michal \u010ciha\u0159 <[email protected]>\n#\n# SPDX-License-Identifier: GPL-3.0-or-later\n\nfrom functools import reduce\n\nfrom django.db.models import Count, Prefetch, Q\nfrom django.utils.translation import gettext_lazy as _\n\nfrom weblate.checks.base import TargetCheck\nfrom weblate.utils.state import STATE_TRANSLATED\n\n\nclass PluralsCheck(TargetCheck):\n \"\"\"Check for incomplete plural forms.\"\"\"\n\n check_id = \"plurals\"\n name = _(\"Missing plurals\")\n description = _(\"Some plural forms are untranslated\")\n\n def should_skip(self, unit):\n if unit.translation.component.is_multivalue:\n return True\n return super().should_skip(unit)\n\n def check_target_unit(self, sources, targets, unit):\n # Is this plural?\n if len(sources) == 1:\n return False\n # Is at least something translated?\n if targets == len(targets) * [\"\"]:\n return False\n # Check for empty translation\n return \"\" in targets\n\n def check_single(self, source, target, unit):\n \"\"\"We don't check target strings here.\"\"\"\n return False\n\n\nclass SamePluralsCheck(TargetCheck):\n \"\"\"Check for same plural forms.\"\"\"\n\n check_id = \"same-plurals\"\n name = _(\"Same plurals\")\n description = _(\"Some plural forms are translated in the same way\")\n\n def check_target_unit(self, sources, targets, unit):\n # Is this plural?\n if len(sources) == 1 or len(targets) == 1:\n return False\n if not targets[0]:\n return False\n return len(set(targets)) == 1\n\n def check_single(self, source, target, unit):\n \"\"\"We don't check target strings here.\"\"\"\n return False\n\n\nclass ConsistencyCheck(TargetCheck):\n \"\"\"Check for inconsistent translations.\"\"\"\n\n check_id = \"inconsistent\"\n name = _(\"Inconsistent\")\n description = _(\n \"This string has more than one translation in this project \"\n \"or is untranslated in some components.\"\n )\n ignore_untranslated = False\n propagates = True\n batch_project_wide = True\n skip_suggestions = True\n\n def check_target_unit(self, sources, targets, unit):\n component = unit.translation.component\n if not component.allow_translation_propagation:\n return False\n\n # Use last result if checks are batched\n if component.batch_checks:\n return self.handle_batch(unit, component)\n\n for other in unit.same_source_units:\n if unit.target == other.target:\n continue\n if unit.translated or other.translated:\n return True\n return False\n\n def check_single(self, source, target, unit):\n \"\"\"We don't check target strings here.\"\"\"\n return False\n\n def check_component(self, component):\n from weblate.trans.models import Unit\n\n units = Unit.objects.filter(\n translation__component__project=component.project,\n translation__component__allow_translation_propagation=True,\n )\n\n # List strings with different targets\n # Limit this to 100 strings, otherwise the resulting query is way too complex\n matches = (\n units.values(\"id_hash\", \"translation__language\", \"translation__plural\")\n .annotate(Count(\"target\", distinct=True))\n .filter(target__count__gt=1)\n .order_by(\"id_hash\")[:100]\n )\n\n if not matches:\n return []\n\n return (\n units.filter(\n reduce(\n lambda x, y: x\n | (\n Q(id_hash=y[\"id_hash\"])\n & Q(translation__language=y[\"translation__language\"])\n & Q(translation__plural=y[\"translation__plural\"])\n ),\n matches,\n Q(),\n )\n )\n .prefetch()\n .prefetch_bulk()\n )\n\n\nclass TranslatedCheck(TargetCheck):\n \"\"\"Check for inconsistent translations.\"\"\"\n\n check_id = \"translated\"\n name = _(\"Has been translated\")\n description = _(\"This string has been translated in the past\")\n ignore_untranslated = False\n skip_suggestions = True\n\n def get_description(self, check_obj):\n unit = check_obj.unit\n target = self.check_target_unit(unit.source, unit.target, unit)\n if not target:\n return super().get_description(check_obj)\n return _('Previous translation was \"%s\".') % target\n\n def check_target_unit(self, sources, targets, unit):\n if unit.translated:\n return False\n\n component = unit.translation.component\n\n if component.batch_checks:\n return self.handle_batch(unit, component)\n\n from weblate.trans.models import Change\n\n changes = unit.change_set.filter(action__in=Change.ACTIONS_CONTENT).order()\n\n for action, target in changes.values_list(\"action\", \"target\"):\n if action == Change.ACTION_SOURCE_CHANGE:\n break\n if target and target != unit.target:\n return target\n\n return False\n\n def check_single(self, source, target, unit):\n \"\"\"We don't check target strings here.\"\"\"\n return False\n\n def get_fixup(self, unit):\n target = self.check_target_unit(unit.source, unit.target, unit)\n if not target:\n return None\n return [(\".*\", target, \"u\")]\n\n def check_component(self, component):\n from weblate.trans.models import Change, Unit\n\n units = (\n Unit.objects.filter(\n translation__component=component,\n change__action__in=Change.ACTIONS_CONTENT,\n state__lt=STATE_TRANSLATED,\n )\n .prefetch_related(\n Prefetch(\n \"change_set\",\n queryset=Change.objects.filter(\n action__in=Change.ACTIONS_CONTENT,\n ).order(),\n to_attr=\"recent_consistency_changes\",\n )\n )\n .prefetch()\n .prefetch_bulk()\n )\n\n for unit in units:\n for change in unit.recent_consistency_changes:\n if change.action == Change.ACTION_SOURCE_CHANGE:\n break\n if change.target:\n yield unit\n", "path": "weblate/checks/consistency.py"}], "after_files": [{"content": "# Copyright \u00a9 Michal \u010ciha\u0159 <[email protected]>\n#\n# SPDX-License-Identifier: GPL-3.0-or-later\n\nfrom functools import reduce\n\nfrom django.db.models import Count, Prefetch, Q\nfrom django.utils.translation import gettext_lazy as _\n\nfrom weblate.checks.base import TargetCheck\nfrom weblate.utils.state import STATE_TRANSLATED\n\n\nclass PluralsCheck(TargetCheck):\n \"\"\"Check for incomplete plural forms.\"\"\"\n\n check_id = \"plurals\"\n name = _(\"Missing plurals\")\n description = _(\"Some plural forms are untranslated\")\n\n def should_skip(self, unit):\n if unit.translation.component.is_multivalue:\n return True\n return super().should_skip(unit)\n\n def check_target_unit(self, sources, targets, unit):\n # Is this plural?\n if len(sources) == 1:\n return False\n # Is at least something translated?\n if targets == len(targets) * [\"\"]:\n return False\n # Check for empty translation\n return \"\" in targets\n\n def check_single(self, source, target, unit):\n \"\"\"We don't check target strings here.\"\"\"\n return False\n\n\nclass SamePluralsCheck(TargetCheck):\n \"\"\"Check for same plural forms.\"\"\"\n\n check_id = \"same-plurals\"\n name = _(\"Same plurals\")\n description = _(\"Some plural forms are translated in the same way\")\n\n def check_target_unit(self, sources, targets, unit):\n # Is this plural?\n if len(sources) == 1 or len(targets) == 1:\n return False\n if not targets[0]:\n return False\n return len(set(targets)) == 1\n\n def check_single(self, source, target, unit):\n \"\"\"We don't check target strings here.\"\"\"\n return False\n\n\nclass ConsistencyCheck(TargetCheck):\n \"\"\"Check for inconsistent translations.\"\"\"\n\n check_id = \"inconsistent\"\n name = _(\"Inconsistent\")\n description = _(\n \"This string has more than one translation in this project \"\n \"or is untranslated in some components.\"\n )\n ignore_untranslated = False\n propagates = True\n batch_project_wide = True\n skip_suggestions = True\n\n def check_target_unit(self, sources, targets, unit):\n component = unit.translation.component\n if not component.allow_translation_propagation:\n return False\n\n # Use last result if checks are batched\n if component.batch_checks:\n return self.handle_batch(unit, component)\n\n for other in unit.same_source_units:\n if unit.target == other.target:\n continue\n if unit.translated or other.translated:\n return True\n return False\n\n def check_single(self, source, target, unit):\n \"\"\"We don't check target strings here.\"\"\"\n return False\n\n def check_component(self, component):\n from weblate.trans.models import Unit\n\n units = Unit.objects.filter(\n translation__component__project=component.project,\n translation__component__allow_translation_propagation=True,\n )\n\n # List strings with different targets\n # Limit this to 100 strings, otherwise the resulting query is way too complex\n matches = (\n units.values(\"id_hash\", \"translation__language\", \"translation__plural\")\n .annotate(Count(\"target\", distinct=True))\n .filter(target__count__gt=1)\n .order_by(\"id_hash\")[:100]\n )\n\n if not matches:\n return []\n\n return (\n units.filter(\n reduce(\n lambda x, y: x\n | (\n Q(id_hash=y[\"id_hash\"])\n & Q(translation__language=y[\"translation__language\"])\n & Q(translation__plural=y[\"translation__plural\"])\n ),\n matches,\n Q(),\n )\n )\n .prefetch()\n .prefetch_bulk()\n )\n\n\nclass TranslatedCheck(TargetCheck):\n \"\"\"Check for inconsistent translations.\"\"\"\n\n check_id = \"translated\"\n name = _(\"Has been translated\")\n description = _(\"This string has been translated in the past\")\n ignore_untranslated = False\n skip_suggestions = True\n\n def get_description(self, check_obj):\n unit = check_obj.unit\n target = self.check_target_unit(unit.source, unit.target, unit)\n if not target:\n return super().get_description(check_obj)\n return _('Previous translation was \"%s\".') % target\n\n def should_skip_change(self, change, unit):\n from weblate.trans.models import Change\n\n # Skip automatic translation entries adding needs editing string\n return (\n change.action == Change.ACTION_AUTO\n and change.details.get(\"state\", STATE_TRANSLATED) < STATE_TRANSLATED\n )\n\n @staticmethod\n def should_break_changes(change):\n from weblate.trans.models import Change\n\n # Stop changes processin on source string change or on\n # intentional marking as needing edit\n return change.action in (Change.ACTION_SOURCE_CHANGE, Change.ACTION_MARKED_EDIT)\n\n def check_target_unit(self, sources, targets, unit):\n if unit.translated:\n return False\n\n component = unit.translation.component\n\n if component.batch_checks:\n return self.handle_batch(unit, component)\n\n from weblate.trans.models import Change\n\n changes = unit.change_set.filter(action__in=Change.ACTIONS_CONTENT).order()\n\n for change in changes:\n if self.should_break_changes(change):\n break\n if self.should_skip_change(change, unit):\n continue\n if change.target and change.target != unit.target:\n return change.target\n\n return False\n\n def check_single(self, source, target, unit):\n \"\"\"We don't check target strings here.\"\"\"\n return False\n\n def get_fixup(self, unit):\n target = self.check_target_unit(unit.source, unit.target, unit)\n if not target:\n return None\n return [(\".*\", target, \"u\")]\n\n def check_component(self, component):\n from weblate.trans.models import Change, Unit\n\n units = (\n Unit.objects.filter(\n translation__component=component,\n change__action__in=Change.ACTIONS_CONTENT,\n state__lt=STATE_TRANSLATED,\n )\n .prefetch_related(\n Prefetch(\n \"change_set\",\n queryset=Change.objects.filter(\n action__in=Change.ACTIONS_CONTENT,\n ).order(),\n to_attr=\"recent_consistency_changes\",\n )\n )\n .prefetch()\n .prefetch_bulk()\n )\n\n for unit in units:\n for change in unit.recent_consistency_changes:\n if self.should_break_changes(change):\n break\n if self.should_skip_change(change, unit):\n continue\n if change.target:\n yield unit\n", "path": "weblate/checks/consistency.py"}]}
| 2,317 | 458 |
gh_patches_debug_16982
|
rasdani/github-patches
|
git_diff
|
crytic__slither-51
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Handle multiple files
Would be nice to run batch analyses
```bash
$ slither contracts/*.sol
usage: slither.py contract.sol [flag]
slither: error: unrecognized arguments: contracts/B.sol contracts/C.sol ...
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `slither/__main__.py`
Content:
```
1 #!/usr/bin/env python3
2
3 import argparse
4 import glob
5 import json
6 import logging
7 import os
8 import sys
9 import traceback
10
11 from pkg_resources import iter_entry_points
12
13 from slither.detectors.abstract_detector import (AbstractDetector,
14 DetectorClassification,
15 classification_txt)
16 from slither.printers.abstract_printer import AbstractPrinter
17 from slither.slither import Slither
18
19 logging.basicConfig()
20 logger = logging.getLogger("Slither")
21
22 def output_to_markdown(detector_classes):
23 """
24 Pretty print of the detectors to README.md
25 """
26 detectors_list = []
27 for detector in detector_classes:
28 argument = detector.ARGUMENT
29 # dont show the backdoor example
30 if argument == 'backdoor':
31 continue
32 help_info = detector.HELP
33 impact = detector.IMPACT
34 confidence = classification_txt[detector.CONFIDENCE]
35 detectors_list.append((argument, help_info, impact, confidence))
36
37 # Sort by impact, confidence, and name
38 detectors_list = sorted(detectors_list, key=lambda element: (element[2], element[3], element[0]))
39 idx = 1
40 for (argument, help_info, impact, confidence) in detectors_list:
41 print('{} | `{}` | {} | {} | {}'.format(idx,
42 argument,
43 help_info,
44 classification_txt[impact],
45 confidence))
46 idx = idx +1
47
48 def process(filename, args, detector_classes, printer_classes):
49 """
50 The core high-level code for running Slither static analysis.
51
52 Returns:
53 list(result), int: Result list and number of contracts analyzed
54 """
55 slither = Slither(filename, args.solc, args.disable_solc_warnings, args.solc_args)
56
57 for detector_cls in detector_classes:
58 slither.register_detector(detector_cls)
59
60 for printer_cls in printer_classes:
61 slither.register_printer(printer_cls)
62
63 analyzed_contracts_count = len(slither.contracts)
64
65 results = []
66
67 if printer_classes:
68 slither.run_printers() # Currently printers does not return results
69
70 elif detector_classes:
71 detector_results = slither.run_detectors()
72 detector_results = [x for x in detector_results if x] # remove empty results
73 detector_results = [item for sublist in detector_results for item in sublist] # flatten
74
75 results.extend(detector_results)
76
77 return results, analyzed_contracts_count
78
79
80 def output_json(results, filename):
81 with open(filename, 'w') as f:
82 json.dump(results, f)
83
84
85 def exit(results):
86 if not results:
87 sys.exit(0)
88 sys.exit(len(results))
89
90
91 def main():
92 """
93 NOTE: This contains just a few detectors and printers that we made public.
94 """
95 from slither.detectors.examples.backdoor import Backdoor
96 from slither.detectors.variables.uninitialized_state_variables import UninitializedStateVarsDetection
97 from slither.detectors.attributes.constant_pragma import ConstantPragma
98 from slither.detectors.attributes.old_solc import OldSolc
99 from slither.detectors.attributes.locked_ether import LockedEther
100 from slither.detectors.functions.arbitrary_send import ArbitrarySend
101 from slither.detectors.functions.suicidal import Suicidal
102 from slither.detectors.reentrancy.reentrancy import Reentrancy
103 from slither.detectors.variables.uninitialized_storage_variables import UninitializedStorageVars
104 from slither.detectors.variables.unused_state_variables import UnusedStateVars
105 from slither.detectors.variables.possible_const_state_variables import ConstCandidateStateVars
106 from slither.detectors.statements.tx_origin import TxOrigin
107 from slither.detectors.statements.assembly import Assembly
108 from slither.detectors.operations.low_level_calls import LowLevelCalls
109 from slither.detectors.naming_convention.naming_convention import NamingConvention
110
111 detectors = [Backdoor,
112 UninitializedStateVarsDetection,
113 ConstantPragma,
114 OldSolc,
115 Reentrancy,
116 UninitializedStorageVars,
117 LockedEther,
118 ArbitrarySend,
119 Suicidal,
120 UnusedStateVars,
121 TxOrigin,
122 Assembly,
123 LowLevelCalls,
124 NamingConvention,
125 ConstCandidateStateVars]
126
127 from slither.printers.summary.function import FunctionSummary
128 from slither.printers.summary.contract import ContractSummary
129 from slither.printers.inheritance.inheritance import PrinterInheritance
130 from slither.printers.inheritance.inheritance_graph import PrinterInheritanceGraph
131 from slither.printers.functions.authorization import PrinterWrittenVariablesAndAuthorization
132 from slither.printers.summary.slithir import PrinterSlithIR
133
134 printers = [FunctionSummary,
135 ContractSummary,
136 PrinterInheritance,
137 PrinterInheritanceGraph,
138 PrinterWrittenVariablesAndAuthorization,
139 PrinterSlithIR]
140
141 # Handle plugins!
142 for entry_point in iter_entry_points(group='slither_analyzer.plugin', name=None):
143 make_plugin = entry_point.load()
144
145 plugin_detectors, plugin_printers = make_plugin()
146
147 if not all(issubclass(d, AbstractDetector) for d in plugin_detectors):
148 raise Exception('Error when loading plugin %s, %r is not a detector' % (entry_point, d))
149
150 if not all(issubclass(p, AbstractPrinter) for p in plugin_printers):
151 raise Exception('Error when loading plugin %s, %r is not a printer' % (entry_point, p))
152
153 # We convert those to lists in case someone returns a tuple
154 detectors += list(plugin_detectors)
155 printers += list(plugin_printers)
156
157 main_impl(all_detector_classes=detectors, all_printer_classes=printers)
158
159
160 def main_impl(all_detector_classes, all_printer_classes):
161 """
162 :param all_detector_classes: A list of all detectors that can be included/excluded.
163 :param all_printer_classes: A list of all printers that can be included.
164 """
165 args = parse_args(all_detector_classes, all_printer_classes)
166
167 if args.markdown:
168 output_to_markdown(all_detector_classes)
169 return
170
171 detector_classes = choose_detectors(args, all_detector_classes)
172 printer_classes = choose_printers(args, all_printer_classes)
173
174 default_log = logging.INFO if not args.debug else logging.DEBUG
175
176 for (l_name, l_level) in [('Slither', default_log),
177 ('Contract', default_log),
178 ('Function', default_log),
179 ('Node', default_log),
180 ('Parsing', default_log),
181 ('Detectors', default_log),
182 ('FunctionSolc', default_log),
183 ('ExpressionParsing', default_log),
184 ('TypeParsing', default_log),
185 ('Printers', default_log)]:
186 l = logging.getLogger(l_name)
187 l.setLevel(l_level)
188
189 try:
190 filename = args.filename
191
192 if os.path.isfile(filename):
193 (results, number_contracts) = process(filename, args, detector_classes, printer_classes)
194
195 elif os.path.isdir(filename):
196 extension = "*.sol" if not args.solc_ast else "*.json"
197 filenames = glob.glob(os.path.join(filename, extension))
198 number_contracts = 0
199 results = []
200 for filename in filenames:
201 (results_tmp, number_contracts_tmp) = process(filename, args, detector_classes, printer_classes)
202 number_contracts += number_contracts_tmp
203 results += results_tmp
204 # if args.json:
205 # output_json(results, args.json)
206 # exit(results)
207
208 else:
209 raise Exception("Unrecognised file/dir path: '#{filename}'".format(filename=filename))
210
211 if args.json:
212 output_json(results, args.json)
213 # Dont print the number of result for printers
214 if printer_classes:
215 logger.info('%s analyzed (%d contracts)', filename, number_contracts)
216 else:
217 logger.info('%s analyzed (%d contracts), %d result(s) found', filename, number_contracts, len(results))
218 exit(results)
219
220 except Exception:
221 logging.error('Error in %s' % args.filename)
222 logging.error(traceback.format_exc())
223 sys.exit(-1)
224
225
226 def parse_args(detector_classes, printer_classes):
227 parser = argparse.ArgumentParser(description='Slither',
228 usage="slither.py contract.sol [flag]",
229 formatter_class=lambda prog: argparse.HelpFormatter(prog, max_help_position=35))
230
231 parser.add_argument('filename',
232 help='contract.sol file')
233
234 parser.add_argument('--solc',
235 help='solc path',
236 action='store',
237 default='solc')
238
239 parser.add_argument('--solc-args',
240 help='Add custom solc arguments. Example: --solc-args "--allow-path /tmp --evm-version byzantium".',
241 action='store',
242 default=None)
243
244 parser.add_argument('--disable-solc-warnings',
245 help='Disable solc warnings',
246 action='store_true',
247 default=False)
248
249 parser.add_argument('--solc-ast',
250 help='Provide the ast solc file',
251 action='store_true',
252 default=False)
253
254 parser.add_argument('--json',
255 help='Export results as JSON',
256 action='store',
257 default=None)
258
259 parser.add_argument('--exclude-informational',
260 help='Exclude informational impact analyses',
261 action='store_true',
262 default=False)
263
264 parser.add_argument('--exclude-low',
265 help='Exclude low impact analyses',
266 action='store_true',
267 default=False)
268
269 parser.add_argument('--exclude-medium',
270 help='Exclude medium impact analyses',
271 action='store_true',
272 default=False)
273
274 parser.add_argument('--exclude-high',
275 help='Exclude high impact analyses',
276 action='store_true',
277 default=False)
278
279 for detector_cls in detector_classes:
280 detector_arg = '--detect-{}'.format(detector_cls.ARGUMENT)
281 detector_help = '{}'.format(detector_cls.HELP)
282 parser.add_argument(detector_arg,
283 help=detector_help,
284 action="append_const",
285 dest="detectors_to_run",
286 const=detector_cls.ARGUMENT)
287
288 # Second loop so that the --exclude are shown after all the detectors
289 for detector_cls in detector_classes:
290 exclude_detector_arg = '--exclude-{}'.format(detector_cls.ARGUMENT)
291 exclude_detector_help = 'Exclude {} detector'.format(detector_cls.ARGUMENT)
292 parser.add_argument(exclude_detector_arg,
293 help=exclude_detector_help,
294 action="append_const",
295 dest="detectors_to_exclude",
296 const=detector_cls.ARGUMENT)
297
298 for printer_cls in printer_classes:
299 printer_arg = '--printer-{}'.format(printer_cls.ARGUMENT)
300 printer_help = 'Print {}'.format(printer_cls.HELP)
301 parser.add_argument(printer_arg,
302 help=printer_help,
303 action="append_const",
304 dest="printers_to_run",
305 const=printer_cls.ARGUMENT)
306
307 # debugger command
308 parser.add_argument('--debug',
309 help=argparse.SUPPRESS,
310 action="store_true",
311 default=False)
312
313 parser.add_argument('--markdown',
314 help=argparse.SUPPRESS,
315 action="store_true",
316 default=False)
317
318 return parser.parse_args()
319
320
321 def choose_detectors(args, all_detector_classes):
322 # If detectors are specified, run only these ones
323 if args.detectors_to_run:
324 return [d for d in all_detector_classes if d.ARGUMENT in args.detectors_to_run]
325
326 detectors_to_run = all_detector_classes
327
328 if args.exclude_informational:
329 detectors_to_run = [d for d in detectors_to_run if
330 d.IMPACT != DetectorClassification.INFORMATIONAL]
331 if args.exclude_low:
332 detectors_to_run = [d for d in detectors_to_run if
333 d.IMPACT != DetectorClassification.LOW]
334 if args.exclude_medium:
335 detectors_to_run = [d for d in detectors_to_run if
336 d.IMPACT != DetectorClassification.MEDIUM]
337 if args.exclude_high:
338 detectors_to_run = [d for d in detectors_to_run if
339 d.IMPACT != DetectorClassification.HIGH]
340 if args.detectors_to_exclude:
341 detectors_to_run = [d for d in detectors_to_run if
342 d.ARGUMENT not in args.detectors_to_exclude]
343 return detectors_to_run
344
345
346 def choose_printers(args, all_printer_classes):
347 # by default, dont run any printer
348 printers_to_run = []
349 if args.printers_to_run:
350 printers_to_run = [p for p in all_printer_classes if
351 p.ARGUMENT in args.printers_to_run]
352 return printers_to_run
353
354
355 if __name__ == '__main__':
356 main()
357
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/slither/__main__.py b/slither/__main__.py
--- a/slither/__main__.py
+++ b/slither/__main__.py
@@ -184,12 +184,16 @@
try:
filename = args.filename
+ globbed_filenames = glob.glob(filename, recursive=True)
+
if os.path.isfile(filename):
(results, number_contracts) = process(filename, args, detector_classes, printer_classes)
- elif os.path.isdir(filename):
+ elif os.path.isdir(filename) or len(globbed_filenames) > 0:
extension = "*.sol" if not args.solc_ast else "*.json"
filenames = glob.glob(os.path.join(filename, extension))
+ if len(filenames) == 0:
+ filenames = globbed_filenames
number_contracts = 0
results = []
for filename in filenames:
|
{"golden_diff": "diff --git a/slither/__main__.py b/slither/__main__.py\n--- a/slither/__main__.py\n+++ b/slither/__main__.py\n@@ -184,12 +184,16 @@\n try:\n filename = args.filename\n \n+ globbed_filenames = glob.glob(filename, recursive=True)\n+\n if os.path.isfile(filename):\n (results, number_contracts) = process(filename, args, detector_classes, printer_classes)\n \n- elif os.path.isdir(filename):\n+ elif os.path.isdir(filename) or len(globbed_filenames) > 0:\n extension = \"*.sol\" if not args.solc_ast else \"*.json\"\n filenames = glob.glob(os.path.join(filename, extension))\n+ if len(filenames) == 0:\n+ filenames = globbed_filenames\n number_contracts = 0\n results = []\n for filename in filenames:\n", "issue": "Handle multiple files\nWould be nice to run batch analyses\r\n\r\n```bash\r\n$ slither contracts/*.sol\r\nusage: slither.py contract.sol [flag]\r\nslither: error: unrecognized arguments: contracts/B.sol contracts/C.sol ...\r\n```\n", "before_files": [{"content": "#!/usr/bin/env python3\n\nimport argparse\nimport glob\nimport json\nimport logging\nimport os\nimport sys\nimport traceback\n\nfrom pkg_resources import iter_entry_points\n\nfrom slither.detectors.abstract_detector import (AbstractDetector,\n DetectorClassification,\n classification_txt)\nfrom slither.printers.abstract_printer import AbstractPrinter\nfrom slither.slither import Slither\n\nlogging.basicConfig()\nlogger = logging.getLogger(\"Slither\")\n\ndef output_to_markdown(detector_classes):\n \"\"\"\n Pretty print of the detectors to README.md\n \"\"\"\n detectors_list = []\n for detector in detector_classes:\n argument = detector.ARGUMENT\n # dont show the backdoor example\n if argument == 'backdoor':\n continue\n help_info = detector.HELP\n impact = detector.IMPACT\n confidence = classification_txt[detector.CONFIDENCE]\n detectors_list.append((argument, help_info, impact, confidence))\n\n # Sort by impact, confidence, and name\n detectors_list = sorted(detectors_list, key=lambda element: (element[2], element[3], element[0]))\n idx = 1\n for (argument, help_info, impact, confidence) in detectors_list:\n print('{} | `{}` | {} | {} | {}'.format(idx,\n argument,\n help_info,\n classification_txt[impact],\n confidence))\n idx = idx +1\n\ndef process(filename, args, detector_classes, printer_classes):\n \"\"\"\n The core high-level code for running Slither static analysis.\n\n Returns:\n list(result), int: Result list and number of contracts analyzed\n \"\"\"\n slither = Slither(filename, args.solc, args.disable_solc_warnings, args.solc_args)\n\n for detector_cls in detector_classes:\n slither.register_detector(detector_cls)\n\n for printer_cls in printer_classes:\n slither.register_printer(printer_cls)\n\n analyzed_contracts_count = len(slither.contracts)\n\n results = []\n\n if printer_classes:\n slither.run_printers() # Currently printers does not return results\n\n elif detector_classes:\n detector_results = slither.run_detectors()\n detector_results = [x for x in detector_results if x] # remove empty results\n detector_results = [item for sublist in detector_results for item in sublist] # flatten\n\n results.extend(detector_results)\n\n return results, analyzed_contracts_count\n\n\ndef output_json(results, filename):\n with open(filename, 'w') as f:\n json.dump(results, f)\n\n\ndef exit(results):\n if not results:\n sys.exit(0)\n sys.exit(len(results))\n\n\ndef main():\n \"\"\"\n NOTE: This contains just a few detectors and printers that we made public.\n \"\"\"\n from slither.detectors.examples.backdoor import Backdoor\n from slither.detectors.variables.uninitialized_state_variables import UninitializedStateVarsDetection\n from slither.detectors.attributes.constant_pragma import ConstantPragma\n from slither.detectors.attributes.old_solc import OldSolc\n from slither.detectors.attributes.locked_ether import LockedEther\n from slither.detectors.functions.arbitrary_send import ArbitrarySend\n from slither.detectors.functions.suicidal import Suicidal\n from slither.detectors.reentrancy.reentrancy import Reentrancy\n from slither.detectors.variables.uninitialized_storage_variables import UninitializedStorageVars\n from slither.detectors.variables.unused_state_variables import UnusedStateVars\n from slither.detectors.variables.possible_const_state_variables import ConstCandidateStateVars\n from slither.detectors.statements.tx_origin import TxOrigin\n from slither.detectors.statements.assembly import Assembly\n from slither.detectors.operations.low_level_calls import LowLevelCalls\n from slither.detectors.naming_convention.naming_convention import NamingConvention\n\n detectors = [Backdoor,\n UninitializedStateVarsDetection,\n ConstantPragma,\n OldSolc,\n Reentrancy,\n UninitializedStorageVars,\n LockedEther,\n ArbitrarySend,\n Suicidal,\n UnusedStateVars,\n TxOrigin,\n Assembly,\n LowLevelCalls,\n NamingConvention,\n ConstCandidateStateVars]\n\n from slither.printers.summary.function import FunctionSummary\n from slither.printers.summary.contract import ContractSummary\n from slither.printers.inheritance.inheritance import PrinterInheritance\n from slither.printers.inheritance.inheritance_graph import PrinterInheritanceGraph\n from slither.printers.functions.authorization import PrinterWrittenVariablesAndAuthorization\n from slither.printers.summary.slithir import PrinterSlithIR\n\n printers = [FunctionSummary,\n ContractSummary,\n PrinterInheritance,\n PrinterInheritanceGraph,\n PrinterWrittenVariablesAndAuthorization,\n PrinterSlithIR]\n\n # Handle plugins!\n for entry_point in iter_entry_points(group='slither_analyzer.plugin', name=None):\n make_plugin = entry_point.load()\n\n plugin_detectors, plugin_printers = make_plugin()\n\n if not all(issubclass(d, AbstractDetector) for d in plugin_detectors):\n raise Exception('Error when loading plugin %s, %r is not a detector' % (entry_point, d))\n\n if not all(issubclass(p, AbstractPrinter) for p in plugin_printers):\n raise Exception('Error when loading plugin %s, %r is not a printer' % (entry_point, p))\n\n # We convert those to lists in case someone returns a tuple\n detectors += list(plugin_detectors)\n printers += list(plugin_printers)\n\n main_impl(all_detector_classes=detectors, all_printer_classes=printers)\n\n\ndef main_impl(all_detector_classes, all_printer_classes):\n \"\"\"\n :param all_detector_classes: A list of all detectors that can be included/excluded.\n :param all_printer_classes: A list of all printers that can be included.\n \"\"\"\n args = parse_args(all_detector_classes, all_printer_classes)\n\n if args.markdown:\n output_to_markdown(all_detector_classes)\n return\n\n detector_classes = choose_detectors(args, all_detector_classes)\n printer_classes = choose_printers(args, all_printer_classes)\n\n default_log = logging.INFO if not args.debug else logging.DEBUG\n\n for (l_name, l_level) in [('Slither', default_log),\n ('Contract', default_log),\n ('Function', default_log),\n ('Node', default_log),\n ('Parsing', default_log),\n ('Detectors', default_log),\n ('FunctionSolc', default_log),\n ('ExpressionParsing', default_log),\n ('TypeParsing', default_log),\n ('Printers', default_log)]:\n l = logging.getLogger(l_name)\n l.setLevel(l_level)\n\n try:\n filename = args.filename\n\n if os.path.isfile(filename):\n (results, number_contracts) = process(filename, args, detector_classes, printer_classes)\n\n elif os.path.isdir(filename):\n extension = \"*.sol\" if not args.solc_ast else \"*.json\"\n filenames = glob.glob(os.path.join(filename, extension))\n number_contracts = 0\n results = []\n for filename in filenames:\n (results_tmp, number_contracts_tmp) = process(filename, args, detector_classes, printer_classes)\n number_contracts += number_contracts_tmp\n results += results_tmp\n # if args.json:\n # output_json(results, args.json)\n # exit(results)\n\n else:\n raise Exception(\"Unrecognised file/dir path: '#{filename}'\".format(filename=filename))\n\n if args.json:\n output_json(results, args.json)\n # Dont print the number of result for printers\n if printer_classes:\n logger.info('%s analyzed (%d contracts)', filename, number_contracts)\n else:\n logger.info('%s analyzed (%d contracts), %d result(s) found', filename, number_contracts, len(results))\n exit(results)\n\n except Exception:\n logging.error('Error in %s' % args.filename)\n logging.error(traceback.format_exc())\n sys.exit(-1)\n\n\ndef parse_args(detector_classes, printer_classes):\n parser = argparse.ArgumentParser(description='Slither',\n usage=\"slither.py contract.sol [flag]\",\n formatter_class=lambda prog: argparse.HelpFormatter(prog, max_help_position=35))\n\n parser.add_argument('filename',\n help='contract.sol file')\n\n parser.add_argument('--solc',\n help='solc path',\n action='store',\n default='solc')\n\n parser.add_argument('--solc-args',\n help='Add custom solc arguments. Example: --solc-args \"--allow-path /tmp --evm-version byzantium\".',\n action='store',\n default=None)\n\n parser.add_argument('--disable-solc-warnings',\n help='Disable solc warnings',\n action='store_true',\n default=False)\n\n parser.add_argument('--solc-ast',\n help='Provide the ast solc file',\n action='store_true',\n default=False)\n\n parser.add_argument('--json',\n help='Export results as JSON',\n action='store',\n default=None)\n\n parser.add_argument('--exclude-informational',\n help='Exclude informational impact analyses',\n action='store_true',\n default=False)\n\n parser.add_argument('--exclude-low',\n help='Exclude low impact analyses',\n action='store_true',\n default=False)\n\n parser.add_argument('--exclude-medium',\n help='Exclude medium impact analyses',\n action='store_true',\n default=False)\n\n parser.add_argument('--exclude-high',\n help='Exclude high impact analyses',\n action='store_true',\n default=False)\n\n for detector_cls in detector_classes:\n detector_arg = '--detect-{}'.format(detector_cls.ARGUMENT)\n detector_help = '{}'.format(detector_cls.HELP)\n parser.add_argument(detector_arg,\n help=detector_help,\n action=\"append_const\",\n dest=\"detectors_to_run\",\n const=detector_cls.ARGUMENT)\n\n # Second loop so that the --exclude are shown after all the detectors\n for detector_cls in detector_classes:\n exclude_detector_arg = '--exclude-{}'.format(detector_cls.ARGUMENT)\n exclude_detector_help = 'Exclude {} detector'.format(detector_cls.ARGUMENT)\n parser.add_argument(exclude_detector_arg,\n help=exclude_detector_help,\n action=\"append_const\",\n dest=\"detectors_to_exclude\",\n const=detector_cls.ARGUMENT)\n\n for printer_cls in printer_classes:\n printer_arg = '--printer-{}'.format(printer_cls.ARGUMENT)\n printer_help = 'Print {}'.format(printer_cls.HELP)\n parser.add_argument(printer_arg,\n help=printer_help,\n action=\"append_const\",\n dest=\"printers_to_run\",\n const=printer_cls.ARGUMENT)\n\n # debugger command\n parser.add_argument('--debug',\n help=argparse.SUPPRESS,\n action=\"store_true\",\n default=False)\n\n parser.add_argument('--markdown',\n help=argparse.SUPPRESS,\n action=\"store_true\",\n default=False)\n\n return parser.parse_args()\n\n\ndef choose_detectors(args, all_detector_classes):\n # If detectors are specified, run only these ones\n if args.detectors_to_run:\n return [d for d in all_detector_classes if d.ARGUMENT in args.detectors_to_run]\n\n detectors_to_run = all_detector_classes\n\n if args.exclude_informational:\n detectors_to_run = [d for d in detectors_to_run if\n d.IMPACT != DetectorClassification.INFORMATIONAL]\n if args.exclude_low:\n detectors_to_run = [d for d in detectors_to_run if\n d.IMPACT != DetectorClassification.LOW]\n if args.exclude_medium:\n detectors_to_run = [d for d in detectors_to_run if\n d.IMPACT != DetectorClassification.MEDIUM]\n if args.exclude_high:\n detectors_to_run = [d for d in detectors_to_run if\n d.IMPACT != DetectorClassification.HIGH]\n if args.detectors_to_exclude:\n detectors_to_run = [d for d in detectors_to_run if\n d.ARGUMENT not in args.detectors_to_exclude]\n return detectors_to_run\n\n\ndef choose_printers(args, all_printer_classes):\n # by default, dont run any printer\n printers_to_run = []\n if args.printers_to_run:\n printers_to_run = [p for p in all_printer_classes if\n p.ARGUMENT in args.printers_to_run]\n return printers_to_run\n\n\nif __name__ == '__main__':\n main()\n", "path": "slither/__main__.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n\nimport argparse\nimport glob\nimport json\nimport logging\nimport os\nimport sys\nimport traceback\n\nfrom pkg_resources import iter_entry_points\n\nfrom slither.detectors.abstract_detector import (AbstractDetector,\n DetectorClassification,\n classification_txt)\nfrom slither.printers.abstract_printer import AbstractPrinter\nfrom slither.slither import Slither\n\nlogging.basicConfig()\nlogger = logging.getLogger(\"Slither\")\n\ndef output_to_markdown(detector_classes):\n \"\"\"\n Pretty print of the detectors to README.md\n \"\"\"\n detectors_list = []\n for detector in detector_classes:\n argument = detector.ARGUMENT\n # dont show the backdoor example\n if argument == 'backdoor':\n continue\n help_info = detector.HELP\n impact = detector.IMPACT\n confidence = classification_txt[detector.CONFIDENCE]\n detectors_list.append((argument, help_info, impact, confidence))\n\n # Sort by impact and name\n detectors_list = sorted(detectors_list, key=lambda element: (element[2], element[0]))\n for (argument, help_info, impact, confidence) in detectors_list:\n print('`--detect-{}`| Detect {} | {} | {}'.format(argument,\n help_info,\n classification_txt[impact],\n confidence))\n\ndef process(filename, args, detector_classes, printer_classes):\n \"\"\"\n The core high-level code for running Slither static analysis.\n\n Returns:\n list(result), int: Result list and number of contracts analyzed\n \"\"\"\n slither = Slither(filename, args.solc, args.disable_solc_warnings, args.solc_args)\n\n for detector_cls in detector_classes:\n slither.register_detector(detector_cls)\n\n for printer_cls in printer_classes:\n slither.register_printer(printer_cls)\n\n analyzed_contracts_count = len(slither.contracts)\n\n results = []\n\n if printer_classes:\n slither.run_printers() # Currently printers does not return results\n\n elif detector_classes:\n detector_results = slither.run_detectors()\n detector_results = [x for x in detector_results if x] # remove empty results\n detector_results = [item for sublist in detector_results for item in sublist] # flatten\n\n results.extend(detector_results)\n\n return results, analyzed_contracts_count\n\n\ndef output_json(results, filename):\n with open(filename, 'w') as f:\n json.dump(results, f)\n\n\ndef exit(results):\n if not results:\n sys.exit(0)\n sys.exit(len(results))\n\n\ndef main():\n \"\"\"\n NOTE: This contains just a few detectors and printers that we made public.\n \"\"\"\n from slither.detectors.examples.backdoor import Backdoor\n from slither.detectors.variables.uninitialized_state_variables import UninitializedStateVarsDetection\n from slither.detectors.attributes.constant_pragma import ConstantPragma\n from slither.detectors.attributes.old_solc import OldSolc\n from slither.detectors.attributes.locked_ether import LockedEther\n from slither.detectors.functions.arbitrary_send import ArbitrarySend\n from slither.detectors.functions.suicidal import Suicidal\n from slither.detectors.reentrancy.reentrancy import Reentrancy\n from slither.detectors.variables.uninitialized_storage_variables import UninitializedStorageVars\n from slither.detectors.variables.unused_state_variables import UnusedStateVars\n from slither.detectors.statements.tx_origin import TxOrigin\n from slither.detectors.statements.assembly import Assembly\n from slither.detectors.operations.low_level_calls import LowLevelCalls\n from slither.detectors.naming_convention.naming_convention import NamingConvention\n\n detectors = [Backdoor,\n UninitializedStateVarsDetection,\n ConstantPragma,\n OldSolc,\n Reentrancy,\n UninitializedStorageVars,\n LockedEther,\n ArbitrarySend,\n Suicidal,\n UnusedStateVars,\n TxOrigin,\n Assembly,\n LowLevelCalls,\n NamingConvention]\n\n from slither.printers.summary.function import FunctionSummary\n from slither.printers.summary.contract import ContractSummary\n from slither.printers.inheritance.inheritance import PrinterInheritance\n from slither.printers.inheritance.inheritance_graph import PrinterInheritanceGraph\n from slither.printers.functions.authorization import PrinterWrittenVariablesAndAuthorization\n from slither.printers.summary.slithir import PrinterSlithIR\n\n printers = [FunctionSummary,\n ContractSummary,\n PrinterInheritance,\n PrinterInheritanceGraph,\n PrinterWrittenVariablesAndAuthorization,\n PrinterSlithIR]\n\n # Handle plugins!\n for entry_point in iter_entry_points(group='slither_analyzer.plugin', name=None):\n make_plugin = entry_point.load()\n\n plugin_detectors, plugin_printers = make_plugin()\n\n if not all(issubclass(d, AbstractDetector) for d in plugin_detectors):\n raise Exception('Error when loading plugin %s, %r is not a detector' % (entry_point, d))\n\n if not all(issubclass(p, AbstractPrinter) for p in plugin_printers):\n raise Exception('Error when loading plugin %s, %r is not a printer' % (entry_point, p))\n\n # We convert those to lists in case someone returns a tuple\n detectors += list(plugin_detectors)\n printers += list(plugin_printers)\n\n main_impl(all_detector_classes=detectors, all_printer_classes=printers)\n\n\ndef main_impl(all_detector_classes, all_printer_classes):\n \"\"\"\n :param all_detector_classes: A list of all detectors that can be included/excluded.\n :param all_printer_classes: A list of all printers that can be included.\n \"\"\"\n args = parse_args(all_detector_classes, all_printer_classes)\n\n if args.markdown:\n output_to_markdown(all_detector_classes)\n return\n\n detector_classes = choose_detectors(args, all_detector_classes)\n printer_classes = choose_printers(args, all_printer_classes)\n\n default_log = logging.INFO if not args.debug else logging.DEBUG\n\n for (l_name, l_level) in [('Slither', default_log),\n ('Contract', default_log),\n ('Function', default_log),\n ('Node', default_log),\n ('Parsing', default_log),\n ('Detectors', default_log),\n ('FunctionSolc', default_log),\n ('ExpressionParsing', default_log),\n ('TypeParsing', default_log),\n ('Printers', default_log)]:\n l = logging.getLogger(l_name)\n l.setLevel(l_level)\n\n try:\n filename = args.filename\n\n globbed_filenames = glob.glob(filename, recursive=True)\n\n if os.path.isfile(filename):\n (results, number_contracts) = process(filename, args, detector_classes, printer_classes)\n\n elif os.path.isdir(filename) or len(globbed_filenames) > 0:\n extension = \"*.sol\" if not args.solc_ast else \"*.json\"\n filenames = glob.glob(os.path.join(filename, extension))\n if len(filenames) == 0:\n filenames = globbed_filenames\n number_contracts = 0\n results = []\n for filename in filenames:\n (results_tmp, number_contracts_tmp) = process(filename, args, detector_classes, printer_classes)\n number_contracts += number_contracts_tmp\n results += results_tmp\n # if args.json:\n # output_json(results, args.json)\n # exit(results)\n\n else:\n raise Exception(\"Unrecognised file/dir path: '#{filename}'\".format(filename=filename))\n\n if args.json:\n output_json(results, args.json)\n # Dont print the number of result for printers\n if printer_classes:\n logger.info('%s analyzed (%d contracts)', filename, number_contracts)\n else:\n logger.info('%s analyzed (%d contracts), %d result(s) found', filename, number_contracts, len(results))\n exit(results)\n\n except Exception:\n logging.error('Error in %s' % args.filename)\n logging.error(traceback.format_exc())\n sys.exit(-1)\n\n\ndef parse_args(detector_classes, printer_classes):\n parser = argparse.ArgumentParser(description='Slither',\n usage=\"slither.py contract.sol [flag]\",\n formatter_class=lambda prog: argparse.HelpFormatter(prog, max_help_position=35))\n\n parser.add_argument('filename',\n help='contract.sol file')\n\n parser.add_argument('--solc',\n help='solc path',\n action='store',\n default='solc')\n\n parser.add_argument('--solc-args',\n help='Add custom solc arguments. Example: --solc-args \"--allow-path /tmp --evm-version byzantium\".',\n action='store',\n default=None)\n\n parser.add_argument('--disable-solc-warnings',\n help='Disable solc warnings',\n action='store_true',\n default=False)\n\n parser.add_argument('--solc-ast',\n help='Provide the ast solc file',\n action='store_true',\n default=False)\n\n parser.add_argument('--json',\n help='Export results as JSON',\n action='store',\n default=None)\n\n parser.add_argument('--exclude-informational',\n help='Exclude informational impact analyses',\n action='store_true',\n default=False)\n\n parser.add_argument('--exclude-low',\n help='Exclude low impact analyses',\n action='store_true',\n default=False)\n\n parser.add_argument('--exclude-medium',\n help='Exclude medium impact analyses',\n action='store_true',\n default=False)\n\n parser.add_argument('--exclude-high',\n help='Exclude high impact analyses',\n action='store_true',\n default=False)\n\n for detector_cls in detector_classes:\n detector_arg = '--detect-{}'.format(detector_cls.ARGUMENT)\n detector_help = 'Detection of {}'.format(detector_cls.HELP)\n parser.add_argument(detector_arg,\n help=detector_help,\n action=\"append_const\",\n dest=\"detectors_to_run\",\n const=detector_cls.ARGUMENT)\n\n # Second loop so that the --exclude are shown after all the detectors\n for detector_cls in detector_classes:\n exclude_detector_arg = '--exclude-{}'.format(detector_cls.ARGUMENT)\n exclude_detector_help = 'Exclude {} detector'.format(detector_cls.ARGUMENT)\n parser.add_argument(exclude_detector_arg,\n help=exclude_detector_help,\n action=\"append_const\",\n dest=\"detectors_to_exclude\",\n const=detector_cls.ARGUMENT)\n\n for printer_cls in printer_classes:\n printer_arg = '--printer-{}'.format(printer_cls.ARGUMENT)\n printer_help = 'Print {}'.format(printer_cls.HELP)\n parser.add_argument(printer_arg,\n help=printer_help,\n action=\"append_const\",\n dest=\"printers_to_run\",\n const=printer_cls.ARGUMENT)\n\n # debugger command\n parser.add_argument('--debug',\n help=argparse.SUPPRESS,\n action=\"store_true\",\n default=False)\n\n parser.add_argument('--markdown',\n help=argparse.SUPPRESS,\n action=\"store_true\",\n default=False)\n\n return parser.parse_args()\n\n\ndef choose_detectors(args, all_detector_classes):\n # If detectors are specified, run only these ones\n if args.detectors_to_run:\n return [d for d in all_detector_classes if d.ARGUMENT in args.detectors_to_run]\n\n detectors_to_run = all_detector_classes\n\n if args.exclude_informational:\n detectors_to_run = [d for d in detectors_to_run if\n d.IMPACT != DetectorClassification.INFORMATIONAL]\n if args.exclude_low:\n detectors_to_run = [d for d in detectors_to_run if\n d.IMPACT != DetectorClassification.LOW]\n if args.exclude_medium:\n detectors_to_run = [d for d in detectors_to_run if\n d.IMPACT != DetectorClassification.MEDIUM]\n if args.exclude_high:\n detectors_to_run = [d for d in detectors_to_run if\n d.IMPACT != DetectorClassification.HIGH]\n if args.detectors_to_exclude:\n detectors_to_run = [d for d in detectors_to_run if\n d.ARGUMENT not in args.detectors_to_exclude]\n return detectors_to_run\n\n\ndef choose_printers(args, all_printer_classes):\n # by default, dont run any printer\n printers_to_run = []\n if args.printers_to_run:\n printers_to_run = [p for p in all_printer_classes if\n p.ARGUMENT in args.printers_to_run]\n return printers_to_run\n\n\nif __name__ == '__main__':\n main()\n", "path": "slither/__main__.py"}]}
| 3,973 | 195 |
gh_patches_debug_13353
|
rasdani/github-patches
|
git_diff
|
python__peps-2981
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Superseded-By And Replaces link is bugged
See for example https://peps.python.org/pep-0509/.
The link to PEP 699 in the header points to a link relative to the the same document (which does not exist), instead of a link to another PEP.
Similarly, the `Replaces` link is bugged too https://peps.python.org/pep-0699/
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pep_sphinx_extensions/pep_processor/transforms/pep_headers.py`
Content:
```
1 from pathlib import Path
2 import re
3
4 from docutils import nodes
5 from docutils import transforms
6 from sphinx import errors
7
8 from pep_sphinx_extensions.pep_processor.transforms import pep_zero
9 from pep_sphinx_extensions.pep_processor.transforms.pep_zero import _mask_email
10 from pep_sphinx_extensions.pep_zero_generator.constants import (
11 SPECIAL_STATUSES,
12 STATUS_ACCEPTED,
13 STATUS_ACTIVE,
14 STATUS_DEFERRED,
15 STATUS_DRAFT,
16 STATUS_FINAL,
17 STATUS_PROVISIONAL,
18 STATUS_REJECTED,
19 STATUS_SUPERSEDED,
20 STATUS_WITHDRAWN,
21 TYPE_INFO,
22 TYPE_PROCESS,
23 TYPE_STANDARDS,
24 )
25
26 ABBREVIATED_STATUSES = {
27 STATUS_DRAFT: "Proposal under active discussion and revision",
28 STATUS_DEFERRED: "Inactive draft that may be taken up again at a later time",
29 STATUS_ACCEPTED: "Normative proposal accepted for implementation",
30 STATUS_ACTIVE: "Currently valid informational guidance, or an in-use process",
31 STATUS_FINAL: "Accepted and implementation complete, or no longer active",
32 STATUS_WITHDRAWN: "Removed from consideration by sponsor or authors",
33 STATUS_REJECTED: "Formally declined and will not be accepted",
34 STATUS_SUPERSEDED: "Replaced by another succeeding PEP",
35 STATUS_PROVISIONAL: "Provisionally accepted but additional feedback needed",
36 }
37
38 ABBREVIATED_TYPES = {
39 TYPE_STANDARDS: "Normative PEP with a new feature for Python, implementation "
40 "change for CPython or interoperability standard for the ecosystem",
41 TYPE_INFO: "Non-normative PEP containing background, guidelines or other "
42 "information relevant to the Python ecosystem",
43 TYPE_PROCESS: "Normative PEP describing or proposing a change to a Python "
44 "community process, workflow or governance",
45 }
46
47 class PEPParsingError(errors.SphinxError):
48 pass
49
50
51 # PEPHeaders is identical to docutils.transforms.peps.Headers excepting bdfl-delegate, sponsor & superseeded-by
52 class PEPHeaders(transforms.Transform):
53 """Process fields in a PEP's initial RFC-2822 header."""
54
55 # Run before pep_processor.transforms.pep_title.PEPTitle
56 default_priority = 330
57
58 def apply(self) -> None:
59 if not Path(self.document["source"]).match("pep-*"):
60 return # not a PEP file, exit early
61
62 if not len(self.document):
63 raise PEPParsingError("Document tree is empty.")
64
65 header = self.document[0]
66 if not isinstance(header, nodes.field_list) or "rfc2822" not in header["classes"]:
67 raise PEPParsingError("Document does not begin with an RFC-2822 header; it is not a PEP.")
68
69 # PEP number should be the first field
70 pep_field = header[0]
71 if pep_field[0].astext().lower() != "pep":
72 raise PEPParsingError("Document does not contain an RFC-2822 'PEP' header!")
73
74 # Extract PEP number
75 value = pep_field[1].astext()
76 try:
77 pep_num = int(value)
78 except ValueError:
79 raise PEPParsingError(f"'PEP' header must contain an integer. '{value}' is invalid!")
80
81 # Special processing for PEP 0.
82 if pep_num == 0:
83 pending = nodes.pending(pep_zero.PEPZero)
84 self.document.insert(1, pending)
85 self.document.note_pending(pending)
86
87 # If there are less than two headers in the preamble, or if Title is absent
88 if len(header) < 2 or header[1][0].astext().lower() != "title":
89 raise PEPParsingError("No title!")
90
91 fields_to_remove = []
92 for field in header:
93 name = field[0].astext().lower()
94 body = field[1]
95 if len(body) == 0:
96 # body is empty
97 continue
98 elif len(body) > 1:
99 msg = f"PEP header field body contains multiple elements:\n{field.pformat(level=1)}"
100 raise PEPParsingError(msg)
101 elif not isinstance(body[0], nodes.paragraph): # len(body) == 1
102 msg = f"PEP header field body may only contain a single paragraph:\n{field.pformat(level=1)}"
103 raise PEPParsingError(msg)
104
105 para = body[0]
106 if name in {"author", "bdfl-delegate", "pep-delegate", "sponsor"}:
107 # mask emails
108 for node in para:
109 if not isinstance(node, nodes.reference):
110 continue
111 node.replace_self(_mask_email(node))
112 elif name in {"discussions-to", "resolution", "post-history"}:
113 # Prettify mailing list and Discourse links
114 for node in para:
115 if (not isinstance(node, nodes.reference)
116 or not node["refuri"]):
117 continue
118 # Have known mailto links link to their main list pages
119 if node["refuri"].lower().startswith("mailto:"):
120 node["refuri"] = _generate_list_url(node["refuri"])
121 parts = node["refuri"].lower().split("/")
122 if len(parts) <= 2 or parts[2] not in LINK_PRETTIFIERS:
123 continue
124 pretty_title = _make_link_pretty(str(node["refuri"]))
125 if name == "post-history":
126 node["reftitle"] = pretty_title
127 else:
128 node[0] = nodes.Text(pretty_title)
129 elif name in {"replaces", "superseded-by", "requires"}:
130 # replace PEP numbers with normalised list of links to PEPs
131 new_body = []
132 for pep_str in re.split(r",?\s+", body.astext()):
133 target = self.document.settings.pep_url.format(int(pep_str))
134 new_body += [nodes.reference("", pep_str, refuri=target), nodes.Text(", ")]
135 para[:] = new_body[:-1] # drop trailing space
136 elif name == "topic":
137 new_body = []
138 for topic_name in body.astext().split(","):
139 if topic_name:
140 target = f"topic/{topic_name.lower().strip()}"
141 if self.document.settings.builder == "html":
142 target = f"{target}.html"
143 else:
144 target = f"../{target}/"
145 new_body += [
146 nodes.reference("", topic_name, refuri=target),
147 nodes.Text(", "),
148 ]
149 if new_body:
150 para[:] = new_body[:-1] # Drop trailing space/comma
151 elif name == "status":
152 para[:] = [
153 nodes.abbreviation(
154 body.astext(),
155 body.astext(),
156 explanation=_abbreviate_status(body.astext()),
157 )
158 ]
159 elif name == "type":
160 para[:] = [
161 nodes.abbreviation(
162 body.astext(),
163 body.astext(),
164 explanation=_abbreviate_type(body.astext()),
165 )
166 ]
167 elif name in {"last-modified", "content-type", "version"}:
168 # Mark unneeded fields
169 fields_to_remove.append(field)
170
171 # Remove any trailing commas and whitespace in the headers
172 if para and isinstance(para[-1], nodes.Text):
173 last_node = para[-1]
174 if last_node.astext().strip() == ",":
175 last_node.parent.remove(last_node)
176 else:
177 para[-1] = last_node.rstrip().rstrip(",")
178
179 # Remove unneeded fields
180 for field in fields_to_remove:
181 field.parent.remove(field)
182
183
184 def _generate_list_url(mailto: str) -> str:
185 list_name_domain = mailto.lower().removeprefix("mailto:").strip()
186 list_name = list_name_domain.split("@")[0]
187
188 if list_name_domain.endswith("@googlegroups.com"):
189 return f"https://groups.google.com/g/{list_name}"
190
191 if not list_name_domain.endswith("@python.org"):
192 return mailto
193
194 # Active lists not yet on Mailman3; this URL will redirect if/when they are
195 if list_name in {"csv", "db-sig", "doc-sig", "python-list", "web-sig"}:
196 return f"https://mail.python.org/mailman/listinfo/{list_name}"
197 # Retired lists that are closed for posting, so only the archive matters
198 if list_name in {"import-sig", "python-3000"}:
199 return f"https://mail.python.org/pipermail/{list_name}/"
200 # The remaining lists (and any new ones) are all on Mailman3/Hyperkitty
201 return f"https://mail.python.org/archives/list/{list_name}@python.org/"
202
203
204 def _process_list_url(parts: list[str]) -> tuple[str, str]:
205 item_type = "list"
206
207 # HyperKitty (Mailman3) archive structure is
208 # https://mail.python.org/archives/list/<list_name>/thread/<id>
209 if "archives" in parts:
210 list_name = (
211 parts[parts.index("archives") + 2].removesuffix("@python.org"))
212 if len(parts) > 6 and parts[6] in {"message", "thread"}:
213 item_type = parts[6]
214
215 # Mailman3 list info structure is
216 # https://mail.python.org/mailman3/lists/<list_name>.python.org/
217 elif "mailman3" in parts:
218 list_name = (
219 parts[parts.index("mailman3") + 2].removesuffix(".python.org"))
220
221 # Pipermail (Mailman) archive structure is
222 # https://mail.python.org/pipermail/<list_name>/<month>-<year>/<id>
223 elif "pipermail" in parts:
224 list_name = parts[parts.index("pipermail") + 1]
225 item_type = "message" if len(parts) > 6 else "list"
226
227 # Mailman listinfo structure is
228 # https://mail.python.org/mailman/listinfo/<list_name>
229 elif "listinfo" in parts:
230 list_name = parts[parts.index("listinfo") + 1]
231
232 # Not a link to a mailing list, message or thread
233 else:
234 raise ValueError(
235 f"{'/'.join(parts)} not a link to a list, message or thread")
236
237 return list_name, item_type
238
239
240 def _process_discourse_url(parts: list[str]) -> tuple[str, str]:
241 item_name = "discourse"
242
243 if len(parts) < 5 or ("t" not in parts and "c" not in parts):
244 raise ValueError(
245 f"{'/'.join(parts)} not a link to a Discourse thread or category")
246
247 first_subpart = parts[4]
248 has_title = not first_subpart.isnumeric()
249
250 if "t" in parts:
251 item_type = "post" if len(parts) > (5 + has_title) else "thread"
252 elif "c" in parts:
253 item_type = "category"
254 if has_title:
255 item_name = f"{first_subpart.replace('-', ' ')} {item_name}"
256
257 return item_name, item_type
258
259
260 # Domains supported for pretty URL parsing
261 LINK_PRETTIFIERS = {
262 "mail.python.org": _process_list_url,
263 "discuss.python.org": _process_discourse_url,
264 }
265
266
267 def _process_pretty_url(url: str) -> tuple[str, str]:
268 parts = url.lower().strip().strip("/").split("/")
269 try:
270 item_name, item_type = LINK_PRETTIFIERS[parts[2]](parts)
271 except KeyError as error:
272 raise ValueError(
273 f"{url} not a link to a recognized domain to prettify") from error
274 item_name = item_name.title().replace("Sig", "SIG").replace("Pep", "PEP")
275 return item_name, item_type
276
277
278 def _make_link_pretty(url: str) -> str:
279 item_name, item_type = _process_pretty_url(url)
280 return f"{item_name} {item_type}"
281
282
283 def _abbreviate_status(status: str) -> str:
284 if status in SPECIAL_STATUSES:
285 status = SPECIAL_STATUSES[status]
286
287 try:
288 return ABBREVIATED_STATUSES[status]
289 except KeyError:
290 raise PEPParsingError(f"Unknown status: {status}")
291
292
293 def _abbreviate_type(type_: str) -> str:
294 try:
295 return ABBREVIATED_TYPES[type_]
296 except KeyError:
297 raise PEPParsingError(f"Unknown type: {type_}")
298
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pep_sphinx_extensions/pep_processor/transforms/pep_headers.py b/pep_sphinx_extensions/pep_processor/transforms/pep_headers.py
--- a/pep_sphinx_extensions/pep_processor/transforms/pep_headers.py
+++ b/pep_sphinx_extensions/pep_processor/transforms/pep_headers.py
@@ -131,6 +131,8 @@
new_body = []
for pep_str in re.split(r",?\s+", body.astext()):
target = self.document.settings.pep_url.format(int(pep_str))
+ if self.document.settings.builder == "dirhtml":
+ target = f"../{target}"
new_body += [nodes.reference("", pep_str, refuri=target), nodes.Text(", ")]
para[:] = new_body[:-1] # drop trailing space
elif name == "topic":
|
{"golden_diff": "diff --git a/pep_sphinx_extensions/pep_processor/transforms/pep_headers.py b/pep_sphinx_extensions/pep_processor/transforms/pep_headers.py\n--- a/pep_sphinx_extensions/pep_processor/transforms/pep_headers.py\n+++ b/pep_sphinx_extensions/pep_processor/transforms/pep_headers.py\n@@ -131,6 +131,8 @@\n new_body = []\n for pep_str in re.split(r\",?\\s+\", body.astext()):\n target = self.document.settings.pep_url.format(int(pep_str))\n+ if self.document.settings.builder == \"dirhtml\":\n+ target = f\"../{target}\"\n new_body += [nodes.reference(\"\", pep_str, refuri=target), nodes.Text(\", \")]\n para[:] = new_body[:-1] # drop trailing space\n elif name == \"topic\":\n", "issue": "Superseded-By And Replaces link is bugged\nSee for example https://peps.python.org/pep-0509/.\r\n\r\nThe link to PEP 699 in the header points to a link relative to the the same document (which does not exist), instead of a link to another PEP.\r\n\r\nSimilarly, the `Replaces` link is bugged too https://peps.python.org/pep-0699/\n", "before_files": [{"content": "from pathlib import Path\nimport re\n\nfrom docutils import nodes\nfrom docutils import transforms\nfrom sphinx import errors\n\nfrom pep_sphinx_extensions.pep_processor.transforms import pep_zero\nfrom pep_sphinx_extensions.pep_processor.transforms.pep_zero import _mask_email\nfrom pep_sphinx_extensions.pep_zero_generator.constants import (\n SPECIAL_STATUSES,\n STATUS_ACCEPTED,\n STATUS_ACTIVE,\n STATUS_DEFERRED,\n STATUS_DRAFT,\n STATUS_FINAL,\n STATUS_PROVISIONAL,\n STATUS_REJECTED,\n STATUS_SUPERSEDED,\n STATUS_WITHDRAWN,\n TYPE_INFO,\n TYPE_PROCESS,\n TYPE_STANDARDS,\n)\n\nABBREVIATED_STATUSES = {\n STATUS_DRAFT: \"Proposal under active discussion and revision\",\n STATUS_DEFERRED: \"Inactive draft that may be taken up again at a later time\",\n STATUS_ACCEPTED: \"Normative proposal accepted for implementation\",\n STATUS_ACTIVE: \"Currently valid informational guidance, or an in-use process\",\n STATUS_FINAL: \"Accepted and implementation complete, or no longer active\",\n STATUS_WITHDRAWN: \"Removed from consideration by sponsor or authors\",\n STATUS_REJECTED: \"Formally declined and will not be accepted\",\n STATUS_SUPERSEDED: \"Replaced by another succeeding PEP\",\n STATUS_PROVISIONAL: \"Provisionally accepted but additional feedback needed\",\n}\n\nABBREVIATED_TYPES = {\n TYPE_STANDARDS: \"Normative PEP with a new feature for Python, implementation \"\n \"change for CPython or interoperability standard for the ecosystem\",\n TYPE_INFO: \"Non-normative PEP containing background, guidelines or other \"\n \"information relevant to the Python ecosystem\",\n TYPE_PROCESS: \"Normative PEP describing or proposing a change to a Python \"\n \"community process, workflow or governance\",\n}\n\nclass PEPParsingError(errors.SphinxError):\n pass\n\n\n# PEPHeaders is identical to docutils.transforms.peps.Headers excepting bdfl-delegate, sponsor & superseeded-by\nclass PEPHeaders(transforms.Transform):\n \"\"\"Process fields in a PEP's initial RFC-2822 header.\"\"\"\n\n # Run before pep_processor.transforms.pep_title.PEPTitle\n default_priority = 330\n\n def apply(self) -> None:\n if not Path(self.document[\"source\"]).match(\"pep-*\"):\n return # not a PEP file, exit early\n\n if not len(self.document):\n raise PEPParsingError(\"Document tree is empty.\")\n\n header = self.document[0]\n if not isinstance(header, nodes.field_list) or \"rfc2822\" not in header[\"classes\"]:\n raise PEPParsingError(\"Document does not begin with an RFC-2822 header; it is not a PEP.\")\n\n # PEP number should be the first field\n pep_field = header[0]\n if pep_field[0].astext().lower() != \"pep\":\n raise PEPParsingError(\"Document does not contain an RFC-2822 'PEP' header!\")\n\n # Extract PEP number\n value = pep_field[1].astext()\n try:\n pep_num = int(value)\n except ValueError:\n raise PEPParsingError(f\"'PEP' header must contain an integer. '{value}' is invalid!\")\n\n # Special processing for PEP 0.\n if pep_num == 0:\n pending = nodes.pending(pep_zero.PEPZero)\n self.document.insert(1, pending)\n self.document.note_pending(pending)\n\n # If there are less than two headers in the preamble, or if Title is absent\n if len(header) < 2 or header[1][0].astext().lower() != \"title\":\n raise PEPParsingError(\"No title!\")\n\n fields_to_remove = []\n for field in header:\n name = field[0].astext().lower()\n body = field[1]\n if len(body) == 0:\n # body is empty\n continue\n elif len(body) > 1:\n msg = f\"PEP header field body contains multiple elements:\\n{field.pformat(level=1)}\"\n raise PEPParsingError(msg)\n elif not isinstance(body[0], nodes.paragraph): # len(body) == 1\n msg = f\"PEP header field body may only contain a single paragraph:\\n{field.pformat(level=1)}\"\n raise PEPParsingError(msg)\n\n para = body[0]\n if name in {\"author\", \"bdfl-delegate\", \"pep-delegate\", \"sponsor\"}:\n # mask emails\n for node in para:\n if not isinstance(node, nodes.reference):\n continue\n node.replace_self(_mask_email(node))\n elif name in {\"discussions-to\", \"resolution\", \"post-history\"}:\n # Prettify mailing list and Discourse links\n for node in para:\n if (not isinstance(node, nodes.reference)\n or not node[\"refuri\"]):\n continue\n # Have known mailto links link to their main list pages\n if node[\"refuri\"].lower().startswith(\"mailto:\"):\n node[\"refuri\"] = _generate_list_url(node[\"refuri\"])\n parts = node[\"refuri\"].lower().split(\"/\")\n if len(parts) <= 2 or parts[2] not in LINK_PRETTIFIERS:\n continue\n pretty_title = _make_link_pretty(str(node[\"refuri\"]))\n if name == \"post-history\":\n node[\"reftitle\"] = pretty_title\n else:\n node[0] = nodes.Text(pretty_title)\n elif name in {\"replaces\", \"superseded-by\", \"requires\"}:\n # replace PEP numbers with normalised list of links to PEPs\n new_body = []\n for pep_str in re.split(r\",?\\s+\", body.astext()):\n target = self.document.settings.pep_url.format(int(pep_str))\n new_body += [nodes.reference(\"\", pep_str, refuri=target), nodes.Text(\", \")]\n para[:] = new_body[:-1] # drop trailing space\n elif name == \"topic\":\n new_body = []\n for topic_name in body.astext().split(\",\"):\n if topic_name:\n target = f\"topic/{topic_name.lower().strip()}\"\n if self.document.settings.builder == \"html\":\n target = f\"{target}.html\"\n else:\n target = f\"../{target}/\"\n new_body += [\n nodes.reference(\"\", topic_name, refuri=target),\n nodes.Text(\", \"),\n ]\n if new_body:\n para[:] = new_body[:-1] # Drop trailing space/comma\n elif name == \"status\":\n para[:] = [\n nodes.abbreviation(\n body.astext(),\n body.astext(),\n explanation=_abbreviate_status(body.astext()),\n )\n ]\n elif name == \"type\":\n para[:] = [\n nodes.abbreviation(\n body.astext(),\n body.astext(),\n explanation=_abbreviate_type(body.astext()),\n )\n ]\n elif name in {\"last-modified\", \"content-type\", \"version\"}:\n # Mark unneeded fields\n fields_to_remove.append(field)\n\n # Remove any trailing commas and whitespace in the headers\n if para and isinstance(para[-1], nodes.Text):\n last_node = para[-1]\n if last_node.astext().strip() == \",\":\n last_node.parent.remove(last_node)\n else:\n para[-1] = last_node.rstrip().rstrip(\",\")\n\n # Remove unneeded fields\n for field in fields_to_remove:\n field.parent.remove(field)\n\n\ndef _generate_list_url(mailto: str) -> str:\n list_name_domain = mailto.lower().removeprefix(\"mailto:\").strip()\n list_name = list_name_domain.split(\"@\")[0]\n\n if list_name_domain.endswith(\"@googlegroups.com\"):\n return f\"https://groups.google.com/g/{list_name}\"\n\n if not list_name_domain.endswith(\"@python.org\"):\n return mailto\n\n # Active lists not yet on Mailman3; this URL will redirect if/when they are\n if list_name in {\"csv\", \"db-sig\", \"doc-sig\", \"python-list\", \"web-sig\"}:\n return f\"https://mail.python.org/mailman/listinfo/{list_name}\"\n # Retired lists that are closed for posting, so only the archive matters\n if list_name in {\"import-sig\", \"python-3000\"}:\n return f\"https://mail.python.org/pipermail/{list_name}/\"\n # The remaining lists (and any new ones) are all on Mailman3/Hyperkitty\n return f\"https://mail.python.org/archives/list/{list_name}@python.org/\"\n\n\ndef _process_list_url(parts: list[str]) -> tuple[str, str]:\n item_type = \"list\"\n\n # HyperKitty (Mailman3) archive structure is\n # https://mail.python.org/archives/list/<list_name>/thread/<id>\n if \"archives\" in parts:\n list_name = (\n parts[parts.index(\"archives\") + 2].removesuffix(\"@python.org\"))\n if len(parts) > 6 and parts[6] in {\"message\", \"thread\"}:\n item_type = parts[6]\n\n # Mailman3 list info structure is\n # https://mail.python.org/mailman3/lists/<list_name>.python.org/\n elif \"mailman3\" in parts:\n list_name = (\n parts[parts.index(\"mailman3\") + 2].removesuffix(\".python.org\"))\n\n # Pipermail (Mailman) archive structure is\n # https://mail.python.org/pipermail/<list_name>/<month>-<year>/<id>\n elif \"pipermail\" in parts:\n list_name = parts[parts.index(\"pipermail\") + 1]\n item_type = \"message\" if len(parts) > 6 else \"list\"\n\n # Mailman listinfo structure is\n # https://mail.python.org/mailman/listinfo/<list_name>\n elif \"listinfo\" in parts:\n list_name = parts[parts.index(\"listinfo\") + 1]\n\n # Not a link to a mailing list, message or thread\n else:\n raise ValueError(\n f\"{'/'.join(parts)} not a link to a list, message or thread\")\n\n return list_name, item_type\n\n\ndef _process_discourse_url(parts: list[str]) -> tuple[str, str]:\n item_name = \"discourse\"\n\n if len(parts) < 5 or (\"t\" not in parts and \"c\" not in parts):\n raise ValueError(\n f\"{'/'.join(parts)} not a link to a Discourse thread or category\")\n\n first_subpart = parts[4]\n has_title = not first_subpart.isnumeric()\n\n if \"t\" in parts:\n item_type = \"post\" if len(parts) > (5 + has_title) else \"thread\"\n elif \"c\" in parts:\n item_type = \"category\"\n if has_title:\n item_name = f\"{first_subpart.replace('-', ' ')} {item_name}\"\n\n return item_name, item_type\n\n\n# Domains supported for pretty URL parsing\nLINK_PRETTIFIERS = {\n \"mail.python.org\": _process_list_url,\n \"discuss.python.org\": _process_discourse_url,\n}\n\n\ndef _process_pretty_url(url: str) -> tuple[str, str]:\n parts = url.lower().strip().strip(\"/\").split(\"/\")\n try:\n item_name, item_type = LINK_PRETTIFIERS[parts[2]](parts)\n except KeyError as error:\n raise ValueError(\n f\"{url} not a link to a recognized domain to prettify\") from error\n item_name = item_name.title().replace(\"Sig\", \"SIG\").replace(\"Pep\", \"PEP\")\n return item_name, item_type\n\n\ndef _make_link_pretty(url: str) -> str:\n item_name, item_type = _process_pretty_url(url)\n return f\"{item_name} {item_type}\"\n\n\ndef _abbreviate_status(status: str) -> str:\n if status in SPECIAL_STATUSES:\n status = SPECIAL_STATUSES[status]\n\n try:\n return ABBREVIATED_STATUSES[status]\n except KeyError:\n raise PEPParsingError(f\"Unknown status: {status}\")\n\n\ndef _abbreviate_type(type_: str) -> str:\n try:\n return ABBREVIATED_TYPES[type_]\n except KeyError:\n raise PEPParsingError(f\"Unknown type: {type_}\")\n", "path": "pep_sphinx_extensions/pep_processor/transforms/pep_headers.py"}], "after_files": [{"content": "from pathlib import Path\nimport re\n\nfrom docutils import nodes\nfrom docutils import transforms\nfrom sphinx import errors\n\nfrom pep_sphinx_extensions.pep_processor.transforms import pep_zero\nfrom pep_sphinx_extensions.pep_processor.transforms.pep_zero import _mask_email\nfrom pep_sphinx_extensions.pep_zero_generator.constants import (\n SPECIAL_STATUSES,\n STATUS_ACCEPTED,\n STATUS_ACTIVE,\n STATUS_DEFERRED,\n STATUS_DRAFT,\n STATUS_FINAL,\n STATUS_PROVISIONAL,\n STATUS_REJECTED,\n STATUS_SUPERSEDED,\n STATUS_WITHDRAWN,\n TYPE_INFO,\n TYPE_PROCESS,\n TYPE_STANDARDS,\n)\n\nABBREVIATED_STATUSES = {\n STATUS_DRAFT: \"Proposal under active discussion and revision\",\n STATUS_DEFERRED: \"Inactive draft that may be taken up again at a later time\",\n STATUS_ACCEPTED: \"Normative proposal accepted for implementation\",\n STATUS_ACTIVE: \"Currently valid informational guidance, or an in-use process\",\n STATUS_FINAL: \"Accepted and implementation complete, or no longer active\",\n STATUS_WITHDRAWN: \"Removed from consideration by sponsor or authors\",\n STATUS_REJECTED: \"Formally declined and will not be accepted\",\n STATUS_SUPERSEDED: \"Replaced by another succeeding PEP\",\n STATUS_PROVISIONAL: \"Provisionally accepted but additional feedback needed\",\n}\n\nABBREVIATED_TYPES = {\n TYPE_STANDARDS: \"Normative PEP with a new feature for Python, implementation \"\n \"change for CPython or interoperability standard for the ecosystem\",\n TYPE_INFO: \"Non-normative PEP containing background, guidelines or other \"\n \"information relevant to the Python ecosystem\",\n TYPE_PROCESS: \"Normative PEP describing or proposing a change to a Python \"\n \"community process, workflow or governance\",\n}\n\nclass PEPParsingError(errors.SphinxError):\n pass\n\n\n# PEPHeaders is identical to docutils.transforms.peps.Headers excepting bdfl-delegate, sponsor & superseeded-by\nclass PEPHeaders(transforms.Transform):\n \"\"\"Process fields in a PEP's initial RFC-2822 header.\"\"\"\n\n # Run before pep_processor.transforms.pep_title.PEPTitle\n default_priority = 330\n\n def apply(self) -> None:\n if not Path(self.document[\"source\"]).match(\"pep-*\"):\n return # not a PEP file, exit early\n\n if not len(self.document):\n raise PEPParsingError(\"Document tree is empty.\")\n\n header = self.document[0]\n if not isinstance(header, nodes.field_list) or \"rfc2822\" not in header[\"classes\"]:\n raise PEPParsingError(\"Document does not begin with an RFC-2822 header; it is not a PEP.\")\n\n # PEP number should be the first field\n pep_field = header[0]\n if pep_field[0].astext().lower() != \"pep\":\n raise PEPParsingError(\"Document does not contain an RFC-2822 'PEP' header!\")\n\n # Extract PEP number\n value = pep_field[1].astext()\n try:\n pep_num = int(value)\n except ValueError:\n raise PEPParsingError(f\"'PEP' header must contain an integer. '{value}' is invalid!\")\n\n # Special processing for PEP 0.\n if pep_num == 0:\n pending = nodes.pending(pep_zero.PEPZero)\n self.document.insert(1, pending)\n self.document.note_pending(pending)\n\n # If there are less than two headers in the preamble, or if Title is absent\n if len(header) < 2 or header[1][0].astext().lower() != \"title\":\n raise PEPParsingError(\"No title!\")\n\n fields_to_remove = []\n for field in header:\n name = field[0].astext().lower()\n body = field[1]\n if len(body) == 0:\n # body is empty\n continue\n elif len(body) > 1:\n msg = f\"PEP header field body contains multiple elements:\\n{field.pformat(level=1)}\"\n raise PEPParsingError(msg)\n elif not isinstance(body[0], nodes.paragraph): # len(body) == 1\n msg = f\"PEP header field body may only contain a single paragraph:\\n{field.pformat(level=1)}\"\n raise PEPParsingError(msg)\n\n para = body[0]\n if name in {\"author\", \"bdfl-delegate\", \"pep-delegate\", \"sponsor\"}:\n # mask emails\n for node in para:\n if not isinstance(node, nodes.reference):\n continue\n node.replace_self(_mask_email(node))\n elif name in {\"discussions-to\", \"resolution\", \"post-history\"}:\n # Prettify mailing list and Discourse links\n for node in para:\n if (not isinstance(node, nodes.reference)\n or not node[\"refuri\"]):\n continue\n # Have known mailto links link to their main list pages\n if node[\"refuri\"].lower().startswith(\"mailto:\"):\n node[\"refuri\"] = _generate_list_url(node[\"refuri\"])\n parts = node[\"refuri\"].lower().split(\"/\")\n if len(parts) <= 2 or parts[2] not in LINK_PRETTIFIERS:\n continue\n pretty_title = _make_link_pretty(str(node[\"refuri\"]))\n if name == \"post-history\":\n node[\"reftitle\"] = pretty_title\n else:\n node[0] = nodes.Text(pretty_title)\n elif name in {\"replaces\", \"superseded-by\", \"requires\"}:\n # replace PEP numbers with normalised list of links to PEPs\n new_body = []\n for pep_str in re.split(r\",?\\s+\", body.astext()):\n target = self.document.settings.pep_url.format(int(pep_str))\n if self.document.settings.builder == \"dirhtml\":\n target = f\"../{target}\"\n new_body += [nodes.reference(\"\", pep_str, refuri=target), nodes.Text(\", \")]\n para[:] = new_body[:-1] # drop trailing space\n elif name == \"topic\":\n new_body = []\n for topic_name in body.astext().split(\",\"):\n if topic_name:\n target = f\"topic/{topic_name.lower().strip()}\"\n if self.document.settings.builder == \"html\":\n target = f\"{target}.html\"\n else:\n target = f\"../{target}/\"\n new_body += [\n nodes.reference(\"\", topic_name, refuri=target),\n nodes.Text(\", \"),\n ]\n if new_body:\n para[:] = new_body[:-1] # Drop trailing space/comma\n elif name == \"status\":\n para[:] = [\n nodes.abbreviation(\n body.astext(),\n body.astext(),\n explanation=_abbreviate_status(body.astext()),\n )\n ]\n elif name == \"type\":\n para[:] = [\n nodes.abbreviation(\n body.astext(),\n body.astext(),\n explanation=_abbreviate_type(body.astext()),\n )\n ]\n elif name in {\"last-modified\", \"content-type\", \"version\"}:\n # Mark unneeded fields\n fields_to_remove.append(field)\n\n # Remove any trailing commas and whitespace in the headers\n if para and isinstance(para[-1], nodes.Text):\n last_node = para[-1]\n if last_node.astext().strip() == \",\":\n last_node.parent.remove(last_node)\n else:\n para[-1] = last_node.rstrip().rstrip(\",\")\n\n # Remove unneeded fields\n for field in fields_to_remove:\n field.parent.remove(field)\n\n\ndef _generate_list_url(mailto: str) -> str:\n list_name_domain = mailto.lower().removeprefix(\"mailto:\").strip()\n list_name = list_name_domain.split(\"@\")[0]\n\n if list_name_domain.endswith(\"@googlegroups.com\"):\n return f\"https://groups.google.com/g/{list_name}\"\n\n if not list_name_domain.endswith(\"@python.org\"):\n return mailto\n\n # Active lists not yet on Mailman3; this URL will redirect if/when they are\n if list_name in {\"csv\", \"db-sig\", \"doc-sig\", \"python-list\", \"web-sig\"}:\n return f\"https://mail.python.org/mailman/listinfo/{list_name}\"\n # Retired lists that are closed for posting, so only the archive matters\n if list_name in {\"import-sig\", \"python-3000\"}:\n return f\"https://mail.python.org/pipermail/{list_name}/\"\n # The remaining lists (and any new ones) are all on Mailman3/Hyperkitty\n return f\"https://mail.python.org/archives/list/{list_name}@python.org/\"\n\n\ndef _process_list_url(parts: list[str]) -> tuple[str, str]:\n item_type = \"list\"\n\n # HyperKitty (Mailman3) archive structure is\n # https://mail.python.org/archives/list/<list_name>/thread/<id>\n if \"archives\" in parts:\n list_name = (\n parts[parts.index(\"archives\") + 2].removesuffix(\"@python.org\"))\n if len(parts) > 6 and parts[6] in {\"message\", \"thread\"}:\n item_type = parts[6]\n\n # Mailman3 list info structure is\n # https://mail.python.org/mailman3/lists/<list_name>.python.org/\n elif \"mailman3\" in parts:\n list_name = (\n parts[parts.index(\"mailman3\") + 2].removesuffix(\".python.org\"))\n\n # Pipermail (Mailman) archive structure is\n # https://mail.python.org/pipermail/<list_name>/<month>-<year>/<id>\n elif \"pipermail\" in parts:\n list_name = parts[parts.index(\"pipermail\") + 1]\n item_type = \"message\" if len(parts) > 6 else \"list\"\n\n # Mailman listinfo structure is\n # https://mail.python.org/mailman/listinfo/<list_name>\n elif \"listinfo\" in parts:\n list_name = parts[parts.index(\"listinfo\") + 1]\n\n # Not a link to a mailing list, message or thread\n else:\n raise ValueError(\n f\"{'/'.join(parts)} not a link to a list, message or thread\")\n\n return list_name, item_type\n\n\ndef _process_discourse_url(parts: list[str]) -> tuple[str, str]:\n item_name = \"discourse\"\n\n if len(parts) < 5 or (\"t\" not in parts and \"c\" not in parts):\n raise ValueError(\n f\"{'/'.join(parts)} not a link to a Discourse thread or category\")\n\n first_subpart = parts[4]\n has_title = not first_subpart.isnumeric()\n\n if \"t\" in parts:\n item_type = \"post\" if len(parts) > (5 + has_title) else \"thread\"\n elif \"c\" in parts:\n item_type = \"category\"\n if has_title:\n item_name = f\"{first_subpart.replace('-', ' ')} {item_name}\"\n\n return item_name, item_type\n\n\n# Domains supported for pretty URL parsing\nLINK_PRETTIFIERS = {\n \"mail.python.org\": _process_list_url,\n \"discuss.python.org\": _process_discourse_url,\n}\n\n\ndef _process_pretty_url(url: str) -> tuple[str, str]:\n parts = url.lower().strip().strip(\"/\").split(\"/\")\n try:\n item_name, item_type = LINK_PRETTIFIERS[parts[2]](parts)\n except KeyError as error:\n raise ValueError(\n f\"{url} not a link to a recognized domain to prettify\") from error\n item_name = item_name.title().replace(\"Sig\", \"SIG\").replace(\"Pep\", \"PEP\")\n return item_name, item_type\n\n\ndef _make_link_pretty(url: str) -> str:\n item_name, item_type = _process_pretty_url(url)\n return f\"{item_name} {item_type}\"\n\n\ndef _abbreviate_status(status: str) -> str:\n if status in SPECIAL_STATUSES:\n status = SPECIAL_STATUSES[status]\n\n try:\n return ABBREVIATED_STATUSES[status]\n except KeyError:\n raise PEPParsingError(f\"Unknown status: {status}\")\n\n\ndef _abbreviate_type(type_: str) -> str:\n try:\n return ABBREVIATED_TYPES[type_]\n except KeyError:\n raise PEPParsingError(f\"Unknown type: {type_}\")\n", "path": "pep_sphinx_extensions/pep_processor/transforms/pep_headers.py"}]}
| 3,883 | 194 |
gh_patches_debug_21087
|
rasdani/github-patches
|
git_diff
|
python-discord__bot-195
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Cog load with duplicate command reporting wrong error
**Originally posted by Scragly:**
In the `cogs` extension module, there's a `try: except ClientException`. The reason for the error is hardcoded, assuming that it raises only when a setup function does not exist.
[Click here to view the relevant code.](https://gitlab.com/python-discord/projects/bot/blob/184b6d51e44915319e09b1bdf24ee26541391350/bot/cogs/cogs.py#L80-83)
Unfortunately, the same exception will also raise down the stack in `bot.add_cog` when a command within the cog has a name that's already existing in commands, conflicting and raising the exception.
To avoid incorrect errors being reported/logged, and to prevent confusion during debugging, it might be best to simply remove the `except ClientException` block and let it fall down into the catchall `except Exception as e` block which prints the exception details as given.
Feel free to comment better suggestions, of course.
This will be something for after the migration over to GitHub, hence why it's an Issue, rather than a quick MR.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bot/cogs/cogs.py`
Content:
```
1 import logging
2 import os
3
4 from discord import ClientException, Colour, Embed
5 from discord.ext.commands import Bot, Context, group
6
7 from bot.constants import (
8 Emojis, Roles, URLs,
9 )
10 from bot.decorators import with_role
11 from bot.pagination import LinePaginator
12
13 log = logging.getLogger(__name__)
14
15 KEEP_LOADED = ["bot.cogs.cogs", "bot.cogs.modlog"]
16
17
18 class Cogs:
19 """
20 Cog management commands
21 """
22
23 def __init__(self, bot: Bot):
24 self.bot = bot
25 self.cogs = {}
26
27 # Load up the cog names
28 log.info("Initializing cog names...")
29 for filename in os.listdir("bot/cogs"):
30 if filename.endswith(".py") and "_" not in filename:
31 if os.path.isfile(f"bot/cogs/{filename}"):
32 cog = filename[:-3]
33
34 self.cogs[cog] = f"bot.cogs.{cog}"
35
36 # Allow reverse lookups by reversing the pairs
37 self.cogs.update({v: k for k, v in self.cogs.items()})
38
39 @group(name='cogs', aliases=('c',), invoke_without_command=True)
40 @with_role(Roles.moderator, Roles.admin, Roles.owner, Roles.devops)
41 async def cogs_group(self, ctx: Context):
42 """Load, unload, reload, and list active cogs."""
43
44 await ctx.invoke(self.bot.get_command("help"), "cogs")
45
46 @cogs_group.command(name='load', aliases=('l',))
47 @with_role(Roles.moderator, Roles.admin, Roles.owner, Roles.devops)
48 async def load_command(self, ctx: Context, cog: str):
49 """
50 Load up an unloaded cog, given the module containing it
51
52 You can specify the cog name for any cogs that are placed directly within `!cogs`, or specify the
53 entire module directly.
54 """
55
56 cog = cog.lower()
57
58 embed = Embed()
59 embed.colour = Colour.red()
60
61 embed.set_author(
62 name="Python Bot (Cogs)",
63 url=URLs.gitlab_bot_repo,
64 icon_url=URLs.bot_avatar
65 )
66
67 if cog in self.cogs:
68 full_cog = self.cogs[cog]
69 elif "." in cog:
70 full_cog = cog
71 else:
72 full_cog = None
73 log.warning(f"{ctx.author} requested we load the '{cog}' cog, but that cog doesn't exist.")
74 embed.description = f"Unknown cog: {cog}"
75
76 if full_cog:
77 if full_cog not in self.bot.extensions:
78 try:
79 self.bot.load_extension(full_cog)
80 except ClientException:
81 log.error(f"{ctx.author} requested we load the '{cog}' cog, "
82 "but that cog doesn't have a 'setup()' function.")
83 embed.description = f"Invalid cog: {cog}\n\nCog does not have a `setup()` function"
84 except ImportError:
85 log.error(f"{ctx.author} requested we load the '{cog}' cog, "
86 f"but the cog module {full_cog} could not be found!")
87 embed.description = f"Invalid cog: {cog}\n\nCould not find cog module {full_cog}"
88 except Exception as e:
89 log.error(f"{ctx.author} requested we load the '{cog}' cog, "
90 "but the loading failed with the following error: \n"
91 f"{e}")
92 embed.description = f"Failed to load cog: {cog}\n\n```{e}```"
93 else:
94 log.debug(f"{ctx.author} requested we load the '{cog}' cog. Cog loaded!")
95 embed.description = f"Cog loaded: {cog}"
96 embed.colour = Colour.green()
97 else:
98 log.warning(f"{ctx.author} requested we load the '{cog}' cog, but the cog was already loaded!")
99 embed.description = f"Cog {cog} is already loaded"
100
101 await ctx.send(embed=embed)
102
103 @cogs_group.command(name='unload', aliases=('ul',))
104 @with_role(Roles.moderator, Roles.admin, Roles.owner, Roles.devops)
105 async def unload_command(self, ctx: Context, cog: str):
106 """
107 Unload an already-loaded cog, given the module containing it
108
109 You can specify the cog name for any cogs that are placed directly within `!cogs`, or specify the
110 entire module directly.
111 """
112
113 cog = cog.lower()
114
115 embed = Embed()
116 embed.colour = Colour.red()
117
118 embed.set_author(
119 name="Python Bot (Cogs)",
120 url=URLs.gitlab_bot_repo,
121 icon_url=URLs.bot_avatar
122 )
123
124 if cog in self.cogs:
125 full_cog = self.cogs[cog]
126 elif "." in cog:
127 full_cog = cog
128 else:
129 full_cog = None
130 log.warning(f"{ctx.author} requested we unload the '{cog}' cog, but that cog doesn't exist.")
131 embed.description = f"Unknown cog: {cog}"
132
133 if full_cog:
134 if full_cog in KEEP_LOADED:
135 log.warning(f"{ctx.author} requested we unload `{full_cog}`, that sneaky pete. We said no.")
136 embed.description = f"You may not unload `{full_cog}`!"
137 elif full_cog in self.bot.extensions:
138 try:
139 self.bot.unload_extension(full_cog)
140 except Exception as e:
141 log.error(f"{ctx.author} requested we unload the '{cog}' cog, "
142 "but the unloading failed with the following error: \n"
143 f"{e}")
144 embed.description = f"Failed to unload cog: {cog}\n\n```{e}```"
145 else:
146 log.debug(f"{ctx.author} requested we unload the '{cog}' cog. Cog unloaded!")
147 embed.description = f"Cog unloaded: {cog}"
148 embed.colour = Colour.green()
149 else:
150 log.warning(f"{ctx.author} requested we unload the '{cog}' cog, but the cog wasn't loaded!")
151 embed.description = f"Cog {cog} is not loaded"
152
153 await ctx.send(embed=embed)
154
155 @cogs_group.command(name='reload', aliases=('r',))
156 @with_role(Roles.moderator, Roles.admin, Roles.owner, Roles.devops)
157 async def reload_command(self, ctx: Context, cog: str):
158 """
159 Reload an unloaded cog, given the module containing it
160
161 You can specify the cog name for any cogs that are placed directly within `!cogs`, or specify the
162 entire module directly.
163
164 If you specify "*" as the cog, every cog currently loaded will be unloaded, and then every cog present in the
165 bot/cogs directory will be loaded.
166 """
167
168 cog = cog.lower()
169
170 embed = Embed()
171 embed.colour = Colour.red()
172
173 embed.set_author(
174 name="Python Bot (Cogs)",
175 url=URLs.gitlab_bot_repo,
176 icon_url=URLs.bot_avatar
177 )
178
179 if cog == "*":
180 full_cog = cog
181 elif cog in self.cogs:
182 full_cog = self.cogs[cog]
183 elif "." in cog:
184 full_cog = cog
185 else:
186 full_cog = None
187 log.warning(f"{ctx.author} requested we reload the '{cog}' cog, but that cog doesn't exist.")
188 embed.description = f"Unknown cog: {cog}"
189
190 if full_cog:
191 if full_cog == "*":
192 all_cogs = [
193 f"bot.cogs.{fn[:-3]}" for fn in os.listdir("bot/cogs")
194 if os.path.isfile(f"bot/cogs/{fn}") and fn.endswith(".py") and "_" not in fn
195 ]
196
197 failed_unloads = {}
198 failed_loads = {}
199
200 unloaded = 0
201 loaded = 0
202
203 for loaded_cog in self.bot.extensions.copy().keys():
204 try:
205 self.bot.unload_extension(loaded_cog)
206 except Exception as e:
207 failed_unloads[loaded_cog] = str(e)
208 else:
209 unloaded += 1
210
211 for unloaded_cog in all_cogs:
212 try:
213 self.bot.load_extension(unloaded_cog)
214 except Exception as e:
215 failed_loads[unloaded_cog] = str(e)
216 else:
217 loaded += 1
218
219 lines = [
220 "**All cogs reloaded**",
221 f"**Unloaded**: {unloaded} / **Loaded**: {loaded}"
222 ]
223
224 if failed_unloads:
225 lines.append("\n**Unload failures**")
226
227 for cog, error in failed_unloads:
228 lines.append(f"`{cog}` {Emojis.white_chevron} `{error}`")
229
230 if failed_loads:
231 lines.append("\n**Load failures**")
232
233 for cog, error in failed_loads:
234 lines.append(f"`{cog}` {Emojis.white_chevron} `{error}`")
235
236 log.debug(f"{ctx.author} requested we reload all cogs. Here are the results: \n"
237 f"{lines}")
238
239 return await LinePaginator.paginate(lines, ctx, embed, empty=False)
240
241 elif full_cog in self.bot.extensions:
242 try:
243 self.bot.unload_extension(full_cog)
244 self.bot.load_extension(full_cog)
245 except Exception as e:
246 log.error(f"{ctx.author} requested we reload the '{cog}' cog, "
247 "but the unloading failed with the following error: \n"
248 f"{e}")
249 embed.description = f"Failed to reload cog: {cog}\n\n```{e}```"
250 else:
251 log.debug(f"{ctx.author} requested we reload the '{cog}' cog. Cog reloaded!")
252 embed.description = f"Cog reload: {cog}"
253 embed.colour = Colour.green()
254 else:
255 log.warning(f"{ctx.author} requested we reload the '{cog}' cog, but the cog wasn't loaded!")
256 embed.description = f"Cog {cog} is not loaded"
257
258 await ctx.send(embed=embed)
259
260 @cogs_group.command(name='list', aliases=('all',))
261 @with_role(Roles.moderator, Roles.admin, Roles.owner, Roles.devops)
262 async def list_command(self, ctx: Context):
263 """
264 Get a list of all cogs, including their loaded status.
265
266 A red double-chevron indicates that the cog is unloaded. Green indicates that the cog is currently loaded.
267 """
268
269 embed = Embed()
270 lines = []
271 cogs = {}
272
273 embed.colour = Colour.blurple()
274 embed.set_author(
275 name="Python Bot (Cogs)",
276 url=URLs.gitlab_bot_repo,
277 icon_url=URLs.bot_avatar
278 )
279
280 for key, _value in self.cogs.items():
281 if "." not in key:
282 continue
283
284 if key in self.bot.extensions:
285 cogs[key] = True
286 else:
287 cogs[key] = False
288
289 for key in self.bot.extensions.keys():
290 if key not in self.cogs:
291 cogs[key] = True
292
293 for cog, loaded in sorted(cogs.items(), key=lambda x: x[0]):
294 if cog in self.cogs:
295 cog = self.cogs[cog]
296
297 if loaded:
298 chevron = Emojis.green_chevron
299 else:
300 chevron = Emojis.red_chevron
301
302 lines.append(f"{chevron} {cog}")
303
304 log.debug(f"{ctx.author} requested a list of all cogs. Returning a paginated list.")
305 await LinePaginator.paginate(lines, ctx, embed, max_size=300, empty=False)
306
307
308 def setup(bot):
309 bot.add_cog(Cogs(bot))
310 log.info("Cog loaded: Cogs")
311
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/bot/cogs/cogs.py b/bot/cogs/cogs.py
--- a/bot/cogs/cogs.py
+++ b/bot/cogs/cogs.py
@@ -1,7 +1,7 @@
import logging
import os
-from discord import ClientException, Colour, Embed
+from discord import Colour, Embed
from discord.ext.commands import Bot, Context, group
from bot.constants import (
@@ -77,10 +77,6 @@
if full_cog not in self.bot.extensions:
try:
self.bot.load_extension(full_cog)
- except ClientException:
- log.error(f"{ctx.author} requested we load the '{cog}' cog, "
- "but that cog doesn't have a 'setup()' function.")
- embed.description = f"Invalid cog: {cog}\n\nCog does not have a `setup()` function"
except ImportError:
log.error(f"{ctx.author} requested we load the '{cog}' cog, "
f"but the cog module {full_cog} could not be found!")
|
{"golden_diff": "diff --git a/bot/cogs/cogs.py b/bot/cogs/cogs.py\n--- a/bot/cogs/cogs.py\n+++ b/bot/cogs/cogs.py\n@@ -1,7 +1,7 @@\n import logging\n import os\n \n-from discord import ClientException, Colour, Embed\n+from discord import Colour, Embed\n from discord.ext.commands import Bot, Context, group\n \n from bot.constants import (\n@@ -77,10 +77,6 @@\n if full_cog not in self.bot.extensions:\n try:\n self.bot.load_extension(full_cog)\n- except ClientException:\n- log.error(f\"{ctx.author} requested we load the '{cog}' cog, \"\n- \"but that cog doesn't have a 'setup()' function.\")\n- embed.description = f\"Invalid cog: {cog}\\n\\nCog does not have a `setup()` function\"\n except ImportError:\n log.error(f\"{ctx.author} requested we load the '{cog}' cog, \"\n f\"but the cog module {full_cog} could not be found!\")\n", "issue": "Cog load with duplicate command reporting wrong error\n**Originally posted by Scragly:**\n\nIn the `cogs` extension module, there's a `try: except ClientException`. The reason for the error is hardcoded, assuming that it raises only when a setup function does not exist.\n\n[Click here to view the relevant code.](https://gitlab.com/python-discord/projects/bot/blob/184b6d51e44915319e09b1bdf24ee26541391350/bot/cogs/cogs.py#L80-83)\n\nUnfortunately, the same exception will also raise down the stack in `bot.add_cog` when a command within the cog has a name that's already existing in commands, conflicting and raising the exception.\n\nTo avoid incorrect errors being reported/logged, and to prevent confusion during debugging, it might be best to simply remove the `except ClientException` block and let it fall down into the catchall `except Exception as e` block which prints the exception details as given.\n\nFeel free to comment better suggestions, of course. \n\nThis will be something for after the migration over to GitHub, hence why it's an Issue, rather than a quick MR.\n", "before_files": [{"content": "import logging\nimport os\n\nfrom discord import ClientException, Colour, Embed\nfrom discord.ext.commands import Bot, Context, group\n\nfrom bot.constants import (\n Emojis, Roles, URLs,\n)\nfrom bot.decorators import with_role\nfrom bot.pagination import LinePaginator\n\nlog = logging.getLogger(__name__)\n\nKEEP_LOADED = [\"bot.cogs.cogs\", \"bot.cogs.modlog\"]\n\n\nclass Cogs:\n \"\"\"\n Cog management commands\n \"\"\"\n\n def __init__(self, bot: Bot):\n self.bot = bot\n self.cogs = {}\n\n # Load up the cog names\n log.info(\"Initializing cog names...\")\n for filename in os.listdir(\"bot/cogs\"):\n if filename.endswith(\".py\") and \"_\" not in filename:\n if os.path.isfile(f\"bot/cogs/{filename}\"):\n cog = filename[:-3]\n\n self.cogs[cog] = f\"bot.cogs.{cog}\"\n\n # Allow reverse lookups by reversing the pairs\n self.cogs.update({v: k for k, v in self.cogs.items()})\n\n @group(name='cogs', aliases=('c',), invoke_without_command=True)\n @with_role(Roles.moderator, Roles.admin, Roles.owner, Roles.devops)\n async def cogs_group(self, ctx: Context):\n \"\"\"Load, unload, reload, and list active cogs.\"\"\"\n\n await ctx.invoke(self.bot.get_command(\"help\"), \"cogs\")\n\n @cogs_group.command(name='load', aliases=('l',))\n @with_role(Roles.moderator, Roles.admin, Roles.owner, Roles.devops)\n async def load_command(self, ctx: Context, cog: str):\n \"\"\"\n Load up an unloaded cog, given the module containing it\n\n You can specify the cog name for any cogs that are placed directly within `!cogs`, or specify the\n entire module directly.\n \"\"\"\n\n cog = cog.lower()\n\n embed = Embed()\n embed.colour = Colour.red()\n\n embed.set_author(\n name=\"Python Bot (Cogs)\",\n url=URLs.gitlab_bot_repo,\n icon_url=URLs.bot_avatar\n )\n\n if cog in self.cogs:\n full_cog = self.cogs[cog]\n elif \".\" in cog:\n full_cog = cog\n else:\n full_cog = None\n log.warning(f\"{ctx.author} requested we load the '{cog}' cog, but that cog doesn't exist.\")\n embed.description = f\"Unknown cog: {cog}\"\n\n if full_cog:\n if full_cog not in self.bot.extensions:\n try:\n self.bot.load_extension(full_cog)\n except ClientException:\n log.error(f\"{ctx.author} requested we load the '{cog}' cog, \"\n \"but that cog doesn't have a 'setup()' function.\")\n embed.description = f\"Invalid cog: {cog}\\n\\nCog does not have a `setup()` function\"\n except ImportError:\n log.error(f\"{ctx.author} requested we load the '{cog}' cog, \"\n f\"but the cog module {full_cog} could not be found!\")\n embed.description = f\"Invalid cog: {cog}\\n\\nCould not find cog module {full_cog}\"\n except Exception as e:\n log.error(f\"{ctx.author} requested we load the '{cog}' cog, \"\n \"but the loading failed with the following error: \\n\"\n f\"{e}\")\n embed.description = f\"Failed to load cog: {cog}\\n\\n```{e}```\"\n else:\n log.debug(f\"{ctx.author} requested we load the '{cog}' cog. Cog loaded!\")\n embed.description = f\"Cog loaded: {cog}\"\n embed.colour = Colour.green()\n else:\n log.warning(f\"{ctx.author} requested we load the '{cog}' cog, but the cog was already loaded!\")\n embed.description = f\"Cog {cog} is already loaded\"\n\n await ctx.send(embed=embed)\n\n @cogs_group.command(name='unload', aliases=('ul',))\n @with_role(Roles.moderator, Roles.admin, Roles.owner, Roles.devops)\n async def unload_command(self, ctx: Context, cog: str):\n \"\"\"\n Unload an already-loaded cog, given the module containing it\n\n You can specify the cog name for any cogs that are placed directly within `!cogs`, or specify the\n entire module directly.\n \"\"\"\n\n cog = cog.lower()\n\n embed = Embed()\n embed.colour = Colour.red()\n\n embed.set_author(\n name=\"Python Bot (Cogs)\",\n url=URLs.gitlab_bot_repo,\n icon_url=URLs.bot_avatar\n )\n\n if cog in self.cogs:\n full_cog = self.cogs[cog]\n elif \".\" in cog:\n full_cog = cog\n else:\n full_cog = None\n log.warning(f\"{ctx.author} requested we unload the '{cog}' cog, but that cog doesn't exist.\")\n embed.description = f\"Unknown cog: {cog}\"\n\n if full_cog:\n if full_cog in KEEP_LOADED:\n log.warning(f\"{ctx.author} requested we unload `{full_cog}`, that sneaky pete. We said no.\")\n embed.description = f\"You may not unload `{full_cog}`!\"\n elif full_cog in self.bot.extensions:\n try:\n self.bot.unload_extension(full_cog)\n except Exception as e:\n log.error(f\"{ctx.author} requested we unload the '{cog}' cog, \"\n \"but the unloading failed with the following error: \\n\"\n f\"{e}\")\n embed.description = f\"Failed to unload cog: {cog}\\n\\n```{e}```\"\n else:\n log.debug(f\"{ctx.author} requested we unload the '{cog}' cog. Cog unloaded!\")\n embed.description = f\"Cog unloaded: {cog}\"\n embed.colour = Colour.green()\n else:\n log.warning(f\"{ctx.author} requested we unload the '{cog}' cog, but the cog wasn't loaded!\")\n embed.description = f\"Cog {cog} is not loaded\"\n\n await ctx.send(embed=embed)\n\n @cogs_group.command(name='reload', aliases=('r',))\n @with_role(Roles.moderator, Roles.admin, Roles.owner, Roles.devops)\n async def reload_command(self, ctx: Context, cog: str):\n \"\"\"\n Reload an unloaded cog, given the module containing it\n\n You can specify the cog name for any cogs that are placed directly within `!cogs`, or specify the\n entire module directly.\n\n If you specify \"*\" as the cog, every cog currently loaded will be unloaded, and then every cog present in the\n bot/cogs directory will be loaded.\n \"\"\"\n\n cog = cog.lower()\n\n embed = Embed()\n embed.colour = Colour.red()\n\n embed.set_author(\n name=\"Python Bot (Cogs)\",\n url=URLs.gitlab_bot_repo,\n icon_url=URLs.bot_avatar\n )\n\n if cog == \"*\":\n full_cog = cog\n elif cog in self.cogs:\n full_cog = self.cogs[cog]\n elif \".\" in cog:\n full_cog = cog\n else:\n full_cog = None\n log.warning(f\"{ctx.author} requested we reload the '{cog}' cog, but that cog doesn't exist.\")\n embed.description = f\"Unknown cog: {cog}\"\n\n if full_cog:\n if full_cog == \"*\":\n all_cogs = [\n f\"bot.cogs.{fn[:-3]}\" for fn in os.listdir(\"bot/cogs\")\n if os.path.isfile(f\"bot/cogs/{fn}\") and fn.endswith(\".py\") and \"_\" not in fn\n ]\n\n failed_unloads = {}\n failed_loads = {}\n\n unloaded = 0\n loaded = 0\n\n for loaded_cog in self.bot.extensions.copy().keys():\n try:\n self.bot.unload_extension(loaded_cog)\n except Exception as e:\n failed_unloads[loaded_cog] = str(e)\n else:\n unloaded += 1\n\n for unloaded_cog in all_cogs:\n try:\n self.bot.load_extension(unloaded_cog)\n except Exception as e:\n failed_loads[unloaded_cog] = str(e)\n else:\n loaded += 1\n\n lines = [\n \"**All cogs reloaded**\",\n f\"**Unloaded**: {unloaded} / **Loaded**: {loaded}\"\n ]\n\n if failed_unloads:\n lines.append(\"\\n**Unload failures**\")\n\n for cog, error in failed_unloads:\n lines.append(f\"`{cog}` {Emojis.white_chevron} `{error}`\")\n\n if failed_loads:\n lines.append(\"\\n**Load failures**\")\n\n for cog, error in failed_loads:\n lines.append(f\"`{cog}` {Emojis.white_chevron} `{error}`\")\n\n log.debug(f\"{ctx.author} requested we reload all cogs. Here are the results: \\n\"\n f\"{lines}\")\n\n return await LinePaginator.paginate(lines, ctx, embed, empty=False)\n\n elif full_cog in self.bot.extensions:\n try:\n self.bot.unload_extension(full_cog)\n self.bot.load_extension(full_cog)\n except Exception as e:\n log.error(f\"{ctx.author} requested we reload the '{cog}' cog, \"\n \"but the unloading failed with the following error: \\n\"\n f\"{e}\")\n embed.description = f\"Failed to reload cog: {cog}\\n\\n```{e}```\"\n else:\n log.debug(f\"{ctx.author} requested we reload the '{cog}' cog. Cog reloaded!\")\n embed.description = f\"Cog reload: {cog}\"\n embed.colour = Colour.green()\n else:\n log.warning(f\"{ctx.author} requested we reload the '{cog}' cog, but the cog wasn't loaded!\")\n embed.description = f\"Cog {cog} is not loaded\"\n\n await ctx.send(embed=embed)\n\n @cogs_group.command(name='list', aliases=('all',))\n @with_role(Roles.moderator, Roles.admin, Roles.owner, Roles.devops)\n async def list_command(self, ctx: Context):\n \"\"\"\n Get a list of all cogs, including their loaded status.\n\n A red double-chevron indicates that the cog is unloaded. Green indicates that the cog is currently loaded.\n \"\"\"\n\n embed = Embed()\n lines = []\n cogs = {}\n\n embed.colour = Colour.blurple()\n embed.set_author(\n name=\"Python Bot (Cogs)\",\n url=URLs.gitlab_bot_repo,\n icon_url=URLs.bot_avatar\n )\n\n for key, _value in self.cogs.items():\n if \".\" not in key:\n continue\n\n if key in self.bot.extensions:\n cogs[key] = True\n else:\n cogs[key] = False\n\n for key in self.bot.extensions.keys():\n if key not in self.cogs:\n cogs[key] = True\n\n for cog, loaded in sorted(cogs.items(), key=lambda x: x[0]):\n if cog in self.cogs:\n cog = self.cogs[cog]\n\n if loaded:\n chevron = Emojis.green_chevron\n else:\n chevron = Emojis.red_chevron\n\n lines.append(f\"{chevron} {cog}\")\n\n log.debug(f\"{ctx.author} requested a list of all cogs. Returning a paginated list.\")\n await LinePaginator.paginate(lines, ctx, embed, max_size=300, empty=False)\n\n\ndef setup(bot):\n bot.add_cog(Cogs(bot))\n log.info(\"Cog loaded: Cogs\")\n", "path": "bot/cogs/cogs.py"}], "after_files": [{"content": "import logging\nimport os\n\nfrom discord import Colour, Embed\nfrom discord.ext.commands import Bot, Context, group\n\nfrom bot.constants import (\n Emojis, Roles, URLs,\n)\nfrom bot.decorators import with_role\nfrom bot.pagination import LinePaginator\n\nlog = logging.getLogger(__name__)\n\nKEEP_LOADED = [\"bot.cogs.cogs\", \"bot.cogs.modlog\"]\n\n\nclass Cogs:\n \"\"\"\n Cog management commands\n \"\"\"\n\n def __init__(self, bot: Bot):\n self.bot = bot\n self.cogs = {}\n\n # Load up the cog names\n log.info(\"Initializing cog names...\")\n for filename in os.listdir(\"bot/cogs\"):\n if filename.endswith(\".py\") and \"_\" not in filename:\n if os.path.isfile(f\"bot/cogs/{filename}\"):\n cog = filename[:-3]\n\n self.cogs[cog] = f\"bot.cogs.{cog}\"\n\n # Allow reverse lookups by reversing the pairs\n self.cogs.update({v: k for k, v in self.cogs.items()})\n\n @group(name='cogs', aliases=('c',), invoke_without_command=True)\n @with_role(Roles.moderator, Roles.admin, Roles.owner, Roles.devops)\n async def cogs_group(self, ctx: Context):\n \"\"\"Load, unload, reload, and list active cogs.\"\"\"\n\n await ctx.invoke(self.bot.get_command(\"help\"), \"cogs\")\n\n @cogs_group.command(name='load', aliases=('l',))\n @with_role(Roles.moderator, Roles.admin, Roles.owner, Roles.devops)\n async def load_command(self, ctx: Context, cog: str):\n \"\"\"\n Load up an unloaded cog, given the module containing it\n\n You can specify the cog name for any cogs that are placed directly within `!cogs`, or specify the\n entire module directly.\n \"\"\"\n\n cog = cog.lower()\n\n embed = Embed()\n embed.colour = Colour.red()\n\n embed.set_author(\n name=\"Python Bot (Cogs)\",\n url=URLs.gitlab_bot_repo,\n icon_url=URLs.bot_avatar\n )\n\n if cog in self.cogs:\n full_cog = self.cogs[cog]\n elif \".\" in cog:\n full_cog = cog\n else:\n full_cog = None\n log.warning(f\"{ctx.author} requested we load the '{cog}' cog, but that cog doesn't exist.\")\n embed.description = f\"Unknown cog: {cog}\"\n\n if full_cog:\n if full_cog not in self.bot.extensions:\n try:\n self.bot.load_extension(full_cog)\n except ImportError:\n log.error(f\"{ctx.author} requested we load the '{cog}' cog, \"\n f\"but the cog module {full_cog} could not be found!\")\n embed.description = f\"Invalid cog: {cog}\\n\\nCould not find cog module {full_cog}\"\n except Exception as e:\n log.error(f\"{ctx.author} requested we load the '{cog}' cog, \"\n \"but the loading failed with the following error: \\n\"\n f\"{e}\")\n embed.description = f\"Failed to load cog: {cog}\\n\\n```{e}```\"\n else:\n log.debug(f\"{ctx.author} requested we load the '{cog}' cog. Cog loaded!\")\n embed.description = f\"Cog loaded: {cog}\"\n embed.colour = Colour.green()\n else:\n log.warning(f\"{ctx.author} requested we load the '{cog}' cog, but the cog was already loaded!\")\n embed.description = f\"Cog {cog} is already loaded\"\n\n await ctx.send(embed=embed)\n\n @cogs_group.command(name='unload', aliases=('ul',))\n @with_role(Roles.moderator, Roles.admin, Roles.owner, Roles.devops)\n async def unload_command(self, ctx: Context, cog: str):\n \"\"\"\n Unload an already-loaded cog, given the module containing it\n\n You can specify the cog name for any cogs that are placed directly within `!cogs`, or specify the\n entire module directly.\n \"\"\"\n\n cog = cog.lower()\n\n embed = Embed()\n embed.colour = Colour.red()\n\n embed.set_author(\n name=\"Python Bot (Cogs)\",\n url=URLs.gitlab_bot_repo,\n icon_url=URLs.bot_avatar\n )\n\n if cog in self.cogs:\n full_cog = self.cogs[cog]\n elif \".\" in cog:\n full_cog = cog\n else:\n full_cog = None\n log.warning(f\"{ctx.author} requested we unload the '{cog}' cog, but that cog doesn't exist.\")\n embed.description = f\"Unknown cog: {cog}\"\n\n if full_cog:\n if full_cog in KEEP_LOADED:\n log.warning(f\"{ctx.author} requested we unload `{full_cog}`, that sneaky pete. We said no.\")\n embed.description = f\"You may not unload `{full_cog}`!\"\n elif full_cog in self.bot.extensions:\n try:\n self.bot.unload_extension(full_cog)\n except Exception as e:\n log.error(f\"{ctx.author} requested we unload the '{cog}' cog, \"\n \"but the unloading failed with the following error: \\n\"\n f\"{e}\")\n embed.description = f\"Failed to unload cog: {cog}\\n\\n```{e}```\"\n else:\n log.debug(f\"{ctx.author} requested we unload the '{cog}' cog. Cog unloaded!\")\n embed.description = f\"Cog unloaded: {cog}\"\n embed.colour = Colour.green()\n else:\n log.warning(f\"{ctx.author} requested we unload the '{cog}' cog, but the cog wasn't loaded!\")\n embed.description = f\"Cog {cog} is not loaded\"\n\n await ctx.send(embed=embed)\n\n @cogs_group.command(name='reload', aliases=('r',))\n @with_role(Roles.moderator, Roles.admin, Roles.owner, Roles.devops)\n async def reload_command(self, ctx: Context, cog: str):\n \"\"\"\n Reload an unloaded cog, given the module containing it\n\n You can specify the cog name for any cogs that are placed directly within `!cogs`, or specify the\n entire module directly.\n\n If you specify \"*\" as the cog, every cog currently loaded will be unloaded, and then every cog present in the\n bot/cogs directory will be loaded.\n \"\"\"\n\n cog = cog.lower()\n\n embed = Embed()\n embed.colour = Colour.red()\n\n embed.set_author(\n name=\"Python Bot (Cogs)\",\n url=URLs.gitlab_bot_repo,\n icon_url=URLs.bot_avatar\n )\n\n if cog == \"*\":\n full_cog = cog\n elif cog in self.cogs:\n full_cog = self.cogs[cog]\n elif \".\" in cog:\n full_cog = cog\n else:\n full_cog = None\n log.warning(f\"{ctx.author} requested we reload the '{cog}' cog, but that cog doesn't exist.\")\n embed.description = f\"Unknown cog: {cog}\"\n\n if full_cog:\n if full_cog == \"*\":\n all_cogs = [\n f\"bot.cogs.{fn[:-3]}\" for fn in os.listdir(\"bot/cogs\")\n if os.path.isfile(f\"bot/cogs/{fn}\") and fn.endswith(\".py\") and \"_\" not in fn\n ]\n\n failed_unloads = {}\n failed_loads = {}\n\n unloaded = 0\n loaded = 0\n\n for loaded_cog in self.bot.extensions.copy().keys():\n try:\n self.bot.unload_extension(loaded_cog)\n except Exception as e:\n failed_unloads[loaded_cog] = str(e)\n else:\n unloaded += 1\n\n for unloaded_cog in all_cogs:\n try:\n self.bot.load_extension(unloaded_cog)\n except Exception as e:\n failed_loads[unloaded_cog] = str(e)\n else:\n loaded += 1\n\n lines = [\n \"**All cogs reloaded**\",\n f\"**Unloaded**: {unloaded} / **Loaded**: {loaded}\"\n ]\n\n if failed_unloads:\n lines.append(\"\\n**Unload failures**\")\n\n for cog, error in failed_unloads:\n lines.append(f\"`{cog}` {Emojis.white_chevron} `{error}`\")\n\n if failed_loads:\n lines.append(\"\\n**Load failures**\")\n\n for cog, error in failed_loads:\n lines.append(f\"`{cog}` {Emojis.white_chevron} `{error}`\")\n\n log.debug(f\"{ctx.author} requested we reload all cogs. Here are the results: \\n\"\n f\"{lines}\")\n\n return await LinePaginator.paginate(lines, ctx, embed, empty=False)\n\n elif full_cog in self.bot.extensions:\n try:\n self.bot.unload_extension(full_cog)\n self.bot.load_extension(full_cog)\n except Exception as e:\n log.error(f\"{ctx.author} requested we reload the '{cog}' cog, \"\n \"but the unloading failed with the following error: \\n\"\n f\"{e}\")\n embed.description = f\"Failed to reload cog: {cog}\\n\\n```{e}```\"\n else:\n log.debug(f\"{ctx.author} requested we reload the '{cog}' cog. Cog reloaded!\")\n embed.description = f\"Cog reload: {cog}\"\n embed.colour = Colour.green()\n else:\n log.warning(f\"{ctx.author} requested we reload the '{cog}' cog, but the cog wasn't loaded!\")\n embed.description = f\"Cog {cog} is not loaded\"\n\n await ctx.send(embed=embed)\n\n @cogs_group.command(name='list', aliases=('all',))\n @with_role(Roles.moderator, Roles.admin, Roles.owner, Roles.devops)\n async def list_command(self, ctx: Context):\n \"\"\"\n Get a list of all cogs, including their loaded status.\n\n A red double-chevron indicates that the cog is unloaded. Green indicates that the cog is currently loaded.\n \"\"\"\n\n embed = Embed()\n lines = []\n cogs = {}\n\n embed.colour = Colour.blurple()\n embed.set_author(\n name=\"Python Bot (Cogs)\",\n url=URLs.gitlab_bot_repo,\n icon_url=URLs.bot_avatar\n )\n\n for key, _value in self.cogs.items():\n if \".\" not in key:\n continue\n\n if key in self.bot.extensions:\n cogs[key] = True\n else:\n cogs[key] = False\n\n for key in self.bot.extensions.keys():\n if key not in self.cogs:\n cogs[key] = True\n\n for cog, loaded in sorted(cogs.items(), key=lambda x: x[0]):\n if cog in self.cogs:\n cog = self.cogs[cog]\n\n if loaded:\n chevron = Emojis.green_chevron\n else:\n chevron = Emojis.red_chevron\n\n lines.append(f\"{chevron} {cog}\")\n\n log.debug(f\"{ctx.author} requested a list of all cogs. Returning a paginated list.\")\n await LinePaginator.paginate(lines, ctx, embed, max_size=300, empty=False)\n\n\ndef setup(bot):\n bot.add_cog(Cogs(bot))\n log.info(\"Cog loaded: Cogs\")\n", "path": "bot/cogs/cogs.py"}]}
| 3,941 | 233 |
gh_patches_debug_15122
|
rasdani/github-patches
|
git_diff
|
fedora-infra__bodhi-537
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
epel5 needs more createrepo_c compatibility for security plugin
From: https://bugzilla.redhat.com/show_bug.cgi?id=1256336
The rhel5 yum security plugin is unable to deal with the updateinfo being .bz2. It wants it to be .gz apparently.
Not sure if this is something we need to change in createrepo_c, or in bodhi2 when it injects the security info in.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bodhi/metadata.py`
Content:
```
1 # This program is free software; you can redistribute it and/or modify
2 # it under the terms of the GNU General Public License as published by
3 # the Free Software Foundation; either version 2 of the License, or
4 # (at your option) any later version.
5 #
6 # This program is distributed in the hope that it will be useful,
7 # but WITHOUT ANY WARRANTY; without even the implied warranty of
8 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
9 # GNU General Public License for more details.
10 #
11 # You should have received a copy of the GNU General Public License along
12 # with this program; if not, write to the Free Software Foundation, Inc.,
13 # 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
14
15 __version__ = '2.0'
16
17 import os
18 import logging
19 import shutil
20 import tempfile
21
22 from urlgrabber.grabber import urlgrab
23 from kitchen.text.converters import to_bytes
24
25 import createrepo_c as cr
26
27 from bodhi.config import config
28 from bodhi.models import Build, UpdateStatus, UpdateRequest, UpdateSuggestion
29 from bodhi.buildsys import get_session
30
31 log = logging.getLogger(__name__)
32
33
34 class ExtendedMetadata(object):
35 """This class represents the updateinfo.xml yum metadata.
36
37 It is generated during push time by the bodhi masher based on koji tags
38 and is injected into the yum repodata using the `modifyrepo_c` tool,
39 which is included in the `createrepo_c` package.
40
41 """
42 def __init__(self, release, request, db, path):
43 self.repo = path
44 log.debug('repo = %r' % self.repo)
45 self.request = request
46 if request is UpdateRequest.stable:
47 self.tag = release.stable_tag
48 else:
49 self.tag = release.testing_tag
50 self.repo_path = os.path.join(self.repo, self.tag)
51
52 self.db = db
53 self.updates = set()
54 self.builds = {}
55 self.missing_ids = []
56 self._from = config.get('bodhi_email')
57 self.koji = get_session()
58 self._fetch_updates()
59
60 self.uinfo = cr.UpdateInfo()
61
62 self.hash_type = cr.SHA256
63 self.comp_type = cr.XZ
64
65 if release.id_prefix == u'FEDORA-EPEL':
66 # yum on py2.4 doesn't support sha256 (#1080373)
67 if 'el5' in self.repo or '5E' in self.repo:
68 self.hash_type = cr.SHA1
69
70 # FIXME: I'm not sure which versions of RHEL support xz metadata
71 # compression, so use the lowest common denominator for now.
72 self.comp_type = cr.BZ2
73
74 # Load from the cache if it exists
75 self.cached_repodata = os.path.join(self.repo, '..', self.tag +
76 '.repocache', 'repodata/')
77 if os.path.isdir(self.cached_repodata):
78 self._load_cached_updateinfo()
79 else:
80 log.debug("Generating new updateinfo.xml")
81 self.uinfo = cr.UpdateInfo()
82 for update in self.updates:
83 if update.alias:
84 self.add_update(update)
85 else:
86 self.missing_ids.append(update.title)
87
88 if self.missing_ids:
89 log.error("%d updates with missing ID!" % len(self.missing_ids))
90 log.error(self.missing_ids)
91
92 def _load_cached_updateinfo(self):
93 """
94 Load the cached updateinfo.xml from '../{tag}.repocache/repodata'
95 """
96 seen_ids = set()
97 from_cache = set()
98 existing_ids = set()
99
100 # Parse the updateinfo out of the repomd
101 updateinfo = None
102 repomd_xml = os.path.join(self.cached_repodata, 'repomd.xml')
103 repomd = cr.Repomd()
104 cr.xml_parse_repomd(repomd_xml, repomd)
105 for record in repomd.records:
106 if record.type == 'updateinfo':
107 updateinfo = os.path.join(os.path.dirname(
108 os.path.dirname(self.cached_repodata)),
109 record.location_href)
110 break
111
112 assert updateinfo, 'Unable to find updateinfo'
113
114 # Load the metadata with createrepo_c
115 log.info('Loading cached updateinfo: %s', updateinfo)
116 uinfo = cr.UpdateInfo(updateinfo)
117
118 # Determine which updates are present in the cache
119 for update in uinfo.updates:
120 existing_ids.add(update.id)
121
122 # Generate metadata for any new builds
123 for update in self.updates:
124 seen_ids.add(update.alias)
125 if not update.alias:
126 self.missing_ids.append(update.title)
127 continue
128 if update.alias in existing_ids:
129 notice = None
130 for value in uinfo.updates:
131 if value.title == update.title:
132 notice = value
133 break
134 if not notice:
135 log.warn('%s ID in cache but notice cannot be found', update.title)
136 self.add_update(update)
137 continue
138 if notice.updated_date:
139 if notice.updated_date < update.date_modified:
140 log.debug('Update modified, generating new notice: %s' % update.title)
141 self.add_update(update)
142 else:
143 log.debug('Loading updated %s from cache' % update.title)
144 from_cache.add(update.alias)
145 elif update.date_modified:
146 log.debug('Update modified, generating new notice: %s' % update.title)
147 self.add_update(update)
148 else:
149 log.debug('Loading %s from cache' % update.title)
150 from_cache.add(update.alias)
151 else:
152 log.debug('Adding new update notice: %s' % update.title)
153 self.add_update(update)
154
155 # Add all relevant notices from the cache to this document
156 for notice in uinfo.updates:
157 if notice.id in from_cache:
158 log.debug('Keeping existing notice: %s', notice.title)
159 self.uinfo.append(notice)
160 else:
161 # Keep all security notices in the stable repo
162 if self.request is not UpdateRequest.testing:
163 if notice.type == 'security':
164 if notice.id not in seen_ids:
165 log.debug('Keeping existing security notice: %s',
166 notice.title)
167 self.uinfo.append(notice)
168 else:
169 log.debug('%s already added?', notice.title)
170 else:
171 log.debug('Purging cached stable notice %s', notice.title)
172 else:
173 log.debug('Purging cached testing update %s', notice.title)
174
175 def _fetch_updates(self):
176 """Based on our given koji tag, populate a list of Update objects"""
177 log.debug("Fetching builds tagged with '%s'" % self.tag)
178 kojiBuilds = self.koji.listTagged(self.tag, latest=True)
179 nonexistent = []
180 log.debug("%d builds found" % len(kojiBuilds))
181 for build in kojiBuilds:
182 self.builds[build['nvr']] = build
183 build_obj = self.db.query(Build).filter_by(nvr=unicode(build['nvr'])).first()
184 if build_obj:
185 self.updates.add(build_obj.update)
186 else:
187 nonexistent.append(build['nvr'])
188 if nonexistent:
189 log.warning("Couldn't find the following koji builds tagged as "
190 "%s in bodhi: %s" % (self.tag, nonexistent))
191
192 def add_update(self, update):
193 """Generate the extended metadata for a given update"""
194 rec = cr.UpdateRecord()
195 rec.version = __version__
196 rec.fromstr = config.get('bodhi_email')
197 rec.status = update.status.value
198 rec.type = update.type.value
199 rec.id = to_bytes(update.alias)
200 rec.title = to_bytes(update.title)
201 rec.summary = to_bytes('%s %s update' % (update.get_title(),
202 update.type.value))
203 rec.description = to_bytes(update.notes)
204 rec.release = to_bytes(update.release.long_name)
205 rec.rights = config.get('updateinfo_rights')
206
207 if update.date_pushed:
208 rec.issued_date = update.date_pushed
209 if update.date_modified:
210 rec.updated_date = update.date_modified
211
212 col = cr.UpdateCollection()
213 col.name = to_bytes(update.release.long_name)
214 col.shortname = to_bytes(update.release.name)
215
216 for build in update.builds:
217 try:
218 kojiBuild = self.builds[build.nvr]
219 except:
220 kojiBuild = self.koji.getBuild(build.nvr)
221
222 rpms = self.koji.listBuildRPMs(kojiBuild['id'])
223 for rpm in rpms:
224 pkg = cr.UpdateCollectionPackage()
225 pkg.name = rpm['name']
226 pkg.version = rpm['version']
227 pkg.release = rpm['release']
228 if rpm['epoch'] is not None:
229 pkg.epoch = str(rpm['epoch'])
230 else:
231 pkg.epoch = '0'
232 pkg.arch = rpm['arch']
233
234 # TODO: how do we handle UpdateSuggestion.logout, etc?
235 pkg.reboot_suggested = update.suggest is UpdateSuggestion.reboot
236
237 filename = '%s.%s.rpm' % (rpm['nvr'], rpm['arch'])
238 pkg.filename = filename
239
240 # Build the URL
241 if rpm['arch'] == 'src':
242 arch = 'SRPMS'
243 elif rpm['arch'] in ('noarch', 'i686'):
244 arch = 'i386'
245 else:
246 arch = rpm['arch']
247
248 pkg.src = os.path.join(config.get('file_url'), update.status is
249 UpdateStatus.testing and 'testing' or '',
250 str(update.release.version), arch, filename[0], filename)
251
252 col.append(pkg)
253
254 rec.append_collection(col)
255
256 # Create references for each bug
257 for bug in update.bugs:
258 ref = cr.UpdateReference()
259 ref.type = 'bugzilla'
260 ref.id = to_bytes(bug.bug_id)
261 ref.href = to_bytes(bug.url)
262 ref.title = to_bytes(bug.title)
263 rec.append_reference(ref)
264
265 # Create references for each CVE
266 for cve in update.cves:
267 ref = cr.UpdateReference()
268 ref.type = 'cve'
269 ref.id = to_bytes(cve.cve_id)
270 ref.href = to_bytes(cve.url)
271 rec.append_reference(ref)
272
273 self.uinfo.append(rec)
274
275 def insert_updateinfo(self):
276 fd, name = tempfile.mkstemp()
277 os.write(fd, self.uinfo.xml_dump())
278 os.close(fd)
279 self.modifyrepo(name)
280 os.unlink(name)
281
282 def modifyrepo(self, filename):
283 """Inject a file into the repodata for each architecture"""
284 for arch in os.listdir(self.repo_path):
285 repodata = os.path.join(self.repo_path, arch, 'repodata')
286 log.info('Inserting %s into %s', filename, repodata)
287 uinfo_xml = os.path.join(repodata, 'updateinfo.xml')
288 shutil.copyfile(filename, uinfo_xml)
289 repomd_xml = os.path.join(repodata, 'repomd.xml')
290 repomd = cr.Repomd(repomd_xml)
291 uinfo_rec = cr.RepomdRecord('updateinfo', uinfo_xml)
292 uinfo_rec_comp = uinfo_rec.compress_and_fill(self.hash_type, self.comp_type)
293 uinfo_rec_comp.rename_file()
294 uinfo_rec_comp.type = 'updateinfo'
295 repomd.set_record(uinfo_rec_comp)
296 with file(repomd_xml, 'w') as repomd_file:
297 repomd_file.write(repomd.xml_dump())
298 os.unlink(uinfo_xml)
299
300 def insert_pkgtags(self):
301 """Download and inject the pkgtags sqlite from fedora-tagger"""
302 if config.get('pkgtags_url'):
303 try:
304 tags_url = config.get('pkgtags_url')
305 tempdir = tempfile.mkdtemp('bodhi')
306 local_tags = os.path.join(tempdir, 'pkgtags.sqlite')
307 log.info('Downloading %s' % tags_url)
308 urlgrab(tags_url, filename=local_tags)
309 self.modifyrepo(local_tags)
310 except:
311 log.exception("There was a problem injecting pkgtags")
312 finally:
313 shutil.rmtree(tempdir)
314
315 def cache_repodata(self):
316 arch = os.listdir(self.repo_path)[0] # Take the first arch
317 repodata = os.path.join(self.repo_path, arch, 'repodata')
318 if not os.path.isdir(repodata):
319 log.warning('Cannot find repodata to cache: %s' % repodata)
320 return
321 cache = self.cached_repodata
322 if os.path.isdir(cache):
323 shutil.rmtree(cache)
324 shutil.copytree(repodata, cache)
325 log.info('%s cached to %s' % (repodata, cache))
326
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/bodhi/metadata.py b/bodhi/metadata.py
--- a/bodhi/metadata.py
+++ b/bodhi/metadata.py
@@ -66,10 +66,11 @@
# yum on py2.4 doesn't support sha256 (#1080373)
if 'el5' in self.repo or '5E' in self.repo:
self.hash_type = cr.SHA1
-
- # FIXME: I'm not sure which versions of RHEL support xz metadata
- # compression, so use the lowest common denominator for now.
- self.comp_type = cr.BZ2
+ self.comp_type = cr.GZ
+ else:
+ # FIXME: I'm not sure which versions of RHEL support xz metadata
+ # compression, so use the lowest common denominator for now.
+ self.comp_type = cr.BZ2
# Load from the cache if it exists
self.cached_repodata = os.path.join(self.repo, '..', self.tag +
|
{"golden_diff": "diff --git a/bodhi/metadata.py b/bodhi/metadata.py\n--- a/bodhi/metadata.py\n+++ b/bodhi/metadata.py\n@@ -66,10 +66,11 @@\n # yum on py2.4 doesn't support sha256 (#1080373)\n if 'el5' in self.repo or '5E' in self.repo:\n self.hash_type = cr.SHA1\n-\n- # FIXME: I'm not sure which versions of RHEL support xz metadata\n- # compression, so use the lowest common denominator for now.\n- self.comp_type = cr.BZ2\n+ self.comp_type = cr.GZ\n+ else:\n+ # FIXME: I'm not sure which versions of RHEL support xz metadata\n+ # compression, so use the lowest common denominator for now.\n+ self.comp_type = cr.BZ2\n \n # Load from the cache if it exists\n self.cached_repodata = os.path.join(self.repo, '..', self.tag +\n", "issue": "epel5 needs more createrepo_c compatibility for security plugin\nFrom: https://bugzilla.redhat.com/show_bug.cgi?id=1256336\n\nThe rhel5 yum security plugin is unable to deal with the updateinfo being .bz2. It wants it to be .gz apparently. \n\nNot sure if this is something we need to change in createrepo_c, or in bodhi2 when it injects the security info in.\n\n", "before_files": [{"content": "# This program is free software; you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation; either version 2 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License along\n# with this program; if not, write to the Free Software Foundation, Inc.,\n# 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n\n__version__ = '2.0'\n\nimport os\nimport logging\nimport shutil\nimport tempfile\n\nfrom urlgrabber.grabber import urlgrab\nfrom kitchen.text.converters import to_bytes\n\nimport createrepo_c as cr\n\nfrom bodhi.config import config\nfrom bodhi.models import Build, UpdateStatus, UpdateRequest, UpdateSuggestion\nfrom bodhi.buildsys import get_session\n\nlog = logging.getLogger(__name__)\n\n\nclass ExtendedMetadata(object):\n \"\"\"This class represents the updateinfo.xml yum metadata.\n\n It is generated during push time by the bodhi masher based on koji tags\n and is injected into the yum repodata using the `modifyrepo_c` tool,\n which is included in the `createrepo_c` package.\n\n \"\"\"\n def __init__(self, release, request, db, path):\n self.repo = path\n log.debug('repo = %r' % self.repo)\n self.request = request\n if request is UpdateRequest.stable:\n self.tag = release.stable_tag\n else:\n self.tag = release.testing_tag\n self.repo_path = os.path.join(self.repo, self.tag)\n\n self.db = db\n self.updates = set()\n self.builds = {}\n self.missing_ids = []\n self._from = config.get('bodhi_email')\n self.koji = get_session()\n self._fetch_updates()\n\n self.uinfo = cr.UpdateInfo()\n\n self.hash_type = cr.SHA256\n self.comp_type = cr.XZ\n\n if release.id_prefix == u'FEDORA-EPEL':\n # yum on py2.4 doesn't support sha256 (#1080373)\n if 'el5' in self.repo or '5E' in self.repo:\n self.hash_type = cr.SHA1\n\n # FIXME: I'm not sure which versions of RHEL support xz metadata\n # compression, so use the lowest common denominator for now.\n self.comp_type = cr.BZ2\n\n # Load from the cache if it exists\n self.cached_repodata = os.path.join(self.repo, '..', self.tag +\n '.repocache', 'repodata/')\n if os.path.isdir(self.cached_repodata):\n self._load_cached_updateinfo()\n else:\n log.debug(\"Generating new updateinfo.xml\")\n self.uinfo = cr.UpdateInfo()\n for update in self.updates:\n if update.alias:\n self.add_update(update)\n else:\n self.missing_ids.append(update.title)\n\n if self.missing_ids:\n log.error(\"%d updates with missing ID!\" % len(self.missing_ids))\n log.error(self.missing_ids)\n\n def _load_cached_updateinfo(self):\n \"\"\"\n Load the cached updateinfo.xml from '../{tag}.repocache/repodata'\n \"\"\"\n seen_ids = set()\n from_cache = set()\n existing_ids = set()\n\n # Parse the updateinfo out of the repomd\n updateinfo = None\n repomd_xml = os.path.join(self.cached_repodata, 'repomd.xml')\n repomd = cr.Repomd()\n cr.xml_parse_repomd(repomd_xml, repomd)\n for record in repomd.records:\n if record.type == 'updateinfo':\n updateinfo = os.path.join(os.path.dirname(\n os.path.dirname(self.cached_repodata)),\n record.location_href)\n break\n\n assert updateinfo, 'Unable to find updateinfo'\n\n # Load the metadata with createrepo_c\n log.info('Loading cached updateinfo: %s', updateinfo)\n uinfo = cr.UpdateInfo(updateinfo)\n\n # Determine which updates are present in the cache\n for update in uinfo.updates:\n existing_ids.add(update.id)\n\n # Generate metadata for any new builds\n for update in self.updates:\n seen_ids.add(update.alias)\n if not update.alias:\n self.missing_ids.append(update.title)\n continue\n if update.alias in existing_ids:\n notice = None\n for value in uinfo.updates:\n if value.title == update.title:\n notice = value\n break\n if not notice:\n log.warn('%s ID in cache but notice cannot be found', update.title)\n self.add_update(update)\n continue\n if notice.updated_date:\n if notice.updated_date < update.date_modified:\n log.debug('Update modified, generating new notice: %s' % update.title)\n self.add_update(update)\n else:\n log.debug('Loading updated %s from cache' % update.title)\n from_cache.add(update.alias)\n elif update.date_modified:\n log.debug('Update modified, generating new notice: %s' % update.title)\n self.add_update(update)\n else:\n log.debug('Loading %s from cache' % update.title)\n from_cache.add(update.alias)\n else:\n log.debug('Adding new update notice: %s' % update.title)\n self.add_update(update)\n\n # Add all relevant notices from the cache to this document\n for notice in uinfo.updates:\n if notice.id in from_cache:\n log.debug('Keeping existing notice: %s', notice.title)\n self.uinfo.append(notice)\n else:\n # Keep all security notices in the stable repo\n if self.request is not UpdateRequest.testing:\n if notice.type == 'security':\n if notice.id not in seen_ids:\n log.debug('Keeping existing security notice: %s',\n notice.title)\n self.uinfo.append(notice)\n else:\n log.debug('%s already added?', notice.title)\n else:\n log.debug('Purging cached stable notice %s', notice.title)\n else:\n log.debug('Purging cached testing update %s', notice.title)\n\n def _fetch_updates(self):\n \"\"\"Based on our given koji tag, populate a list of Update objects\"\"\"\n log.debug(\"Fetching builds tagged with '%s'\" % self.tag)\n kojiBuilds = self.koji.listTagged(self.tag, latest=True)\n nonexistent = []\n log.debug(\"%d builds found\" % len(kojiBuilds))\n for build in kojiBuilds:\n self.builds[build['nvr']] = build\n build_obj = self.db.query(Build).filter_by(nvr=unicode(build['nvr'])).first()\n if build_obj:\n self.updates.add(build_obj.update)\n else:\n nonexistent.append(build['nvr'])\n if nonexistent:\n log.warning(\"Couldn't find the following koji builds tagged as \"\n \"%s in bodhi: %s\" % (self.tag, nonexistent))\n\n def add_update(self, update):\n \"\"\"Generate the extended metadata for a given update\"\"\"\n rec = cr.UpdateRecord()\n rec.version = __version__\n rec.fromstr = config.get('bodhi_email')\n rec.status = update.status.value\n rec.type = update.type.value\n rec.id = to_bytes(update.alias)\n rec.title = to_bytes(update.title)\n rec.summary = to_bytes('%s %s update' % (update.get_title(),\n update.type.value))\n rec.description = to_bytes(update.notes)\n rec.release = to_bytes(update.release.long_name)\n rec.rights = config.get('updateinfo_rights')\n\n if update.date_pushed:\n rec.issued_date = update.date_pushed\n if update.date_modified:\n rec.updated_date = update.date_modified\n\n col = cr.UpdateCollection()\n col.name = to_bytes(update.release.long_name)\n col.shortname = to_bytes(update.release.name)\n\n for build in update.builds:\n try:\n kojiBuild = self.builds[build.nvr]\n except:\n kojiBuild = self.koji.getBuild(build.nvr)\n\n rpms = self.koji.listBuildRPMs(kojiBuild['id'])\n for rpm in rpms:\n pkg = cr.UpdateCollectionPackage()\n pkg.name = rpm['name']\n pkg.version = rpm['version']\n pkg.release = rpm['release']\n if rpm['epoch'] is not None:\n pkg.epoch = str(rpm['epoch'])\n else:\n pkg.epoch = '0'\n pkg.arch = rpm['arch']\n\n # TODO: how do we handle UpdateSuggestion.logout, etc?\n pkg.reboot_suggested = update.suggest is UpdateSuggestion.reboot\n\n filename = '%s.%s.rpm' % (rpm['nvr'], rpm['arch'])\n pkg.filename = filename\n\n # Build the URL\n if rpm['arch'] == 'src':\n arch = 'SRPMS'\n elif rpm['arch'] in ('noarch', 'i686'):\n arch = 'i386'\n else:\n arch = rpm['arch']\n\n pkg.src = os.path.join(config.get('file_url'), update.status is\n UpdateStatus.testing and 'testing' or '',\n str(update.release.version), arch, filename[0], filename)\n\n col.append(pkg)\n\n rec.append_collection(col)\n\n # Create references for each bug\n for bug in update.bugs:\n ref = cr.UpdateReference()\n ref.type = 'bugzilla'\n ref.id = to_bytes(bug.bug_id)\n ref.href = to_bytes(bug.url)\n ref.title = to_bytes(bug.title)\n rec.append_reference(ref)\n\n # Create references for each CVE\n for cve in update.cves:\n ref = cr.UpdateReference()\n ref.type = 'cve'\n ref.id = to_bytes(cve.cve_id)\n ref.href = to_bytes(cve.url)\n rec.append_reference(ref)\n\n self.uinfo.append(rec)\n\n def insert_updateinfo(self):\n fd, name = tempfile.mkstemp()\n os.write(fd, self.uinfo.xml_dump())\n os.close(fd)\n self.modifyrepo(name)\n os.unlink(name)\n\n def modifyrepo(self, filename):\n \"\"\"Inject a file into the repodata for each architecture\"\"\"\n for arch in os.listdir(self.repo_path):\n repodata = os.path.join(self.repo_path, arch, 'repodata')\n log.info('Inserting %s into %s', filename, repodata)\n uinfo_xml = os.path.join(repodata, 'updateinfo.xml')\n shutil.copyfile(filename, uinfo_xml)\n repomd_xml = os.path.join(repodata, 'repomd.xml')\n repomd = cr.Repomd(repomd_xml)\n uinfo_rec = cr.RepomdRecord('updateinfo', uinfo_xml)\n uinfo_rec_comp = uinfo_rec.compress_and_fill(self.hash_type, self.comp_type)\n uinfo_rec_comp.rename_file()\n uinfo_rec_comp.type = 'updateinfo'\n repomd.set_record(uinfo_rec_comp)\n with file(repomd_xml, 'w') as repomd_file:\n repomd_file.write(repomd.xml_dump())\n os.unlink(uinfo_xml)\n\n def insert_pkgtags(self):\n \"\"\"Download and inject the pkgtags sqlite from fedora-tagger\"\"\"\n if config.get('pkgtags_url'):\n try:\n tags_url = config.get('pkgtags_url')\n tempdir = tempfile.mkdtemp('bodhi')\n local_tags = os.path.join(tempdir, 'pkgtags.sqlite')\n log.info('Downloading %s' % tags_url)\n urlgrab(tags_url, filename=local_tags)\n self.modifyrepo(local_tags)\n except:\n log.exception(\"There was a problem injecting pkgtags\")\n finally:\n shutil.rmtree(tempdir)\n\n def cache_repodata(self):\n arch = os.listdir(self.repo_path)[0] # Take the first arch\n repodata = os.path.join(self.repo_path, arch, 'repodata')\n if not os.path.isdir(repodata):\n log.warning('Cannot find repodata to cache: %s' % repodata)\n return\n cache = self.cached_repodata\n if os.path.isdir(cache):\n shutil.rmtree(cache)\n shutil.copytree(repodata, cache)\n log.info('%s cached to %s' % (repodata, cache))\n", "path": "bodhi/metadata.py"}], "after_files": [{"content": "# This program is free software; you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation; either version 2 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License along\n# with this program; if not, write to the Free Software Foundation, Inc.,\n# 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n\n__version__ = '2.0'\n\nimport os\nimport logging\nimport shutil\nimport tempfile\n\nfrom urlgrabber.grabber import urlgrab\nfrom kitchen.text.converters import to_bytes\n\nimport createrepo_c as cr\n\nfrom bodhi.config import config\nfrom bodhi.models import Build, UpdateStatus, UpdateRequest, UpdateSuggestion\nfrom bodhi.buildsys import get_session\n\nlog = logging.getLogger(__name__)\n\n\nclass ExtendedMetadata(object):\n \"\"\"This class represents the updateinfo.xml yum metadata.\n\n It is generated during push time by the bodhi masher based on koji tags\n and is injected into the yum repodata using the `modifyrepo_c` tool,\n which is included in the `createrepo_c` package.\n\n \"\"\"\n def __init__(self, release, request, db, path):\n self.repo = path\n log.debug('repo = %r' % self.repo)\n self.request = request\n if request is UpdateRequest.stable:\n self.tag = release.stable_tag\n else:\n self.tag = release.testing_tag\n self.repo_path = os.path.join(self.repo, self.tag)\n\n self.db = db\n self.updates = set()\n self.builds = {}\n self.missing_ids = []\n self._from = config.get('bodhi_email')\n self.koji = get_session()\n self._fetch_updates()\n\n self.uinfo = cr.UpdateInfo()\n\n self.hash_type = cr.SHA256\n self.comp_type = cr.XZ\n\n if release.id_prefix == u'FEDORA-EPEL':\n # yum on py2.4 doesn't support sha256 (#1080373)\n if 'el5' in self.repo or '5E' in self.repo:\n self.hash_type = cr.SHA1\n self.comp_type = cr.GZ\n else:\n # FIXME: I'm not sure which versions of RHEL support xz metadata\n # compression, so use the lowest common denominator for now.\n self.comp_type = cr.BZ2\n\n # Load from the cache if it exists\n self.cached_repodata = os.path.join(self.repo, '..', self.tag +\n '.repocache', 'repodata/')\n if os.path.isdir(self.cached_repodata):\n self._load_cached_updateinfo()\n else:\n log.debug(\"Generating new updateinfo.xml\")\n self.uinfo = cr.UpdateInfo()\n for update in self.updates:\n if update.alias:\n self.add_update(update)\n else:\n self.missing_ids.append(update.title)\n\n if self.missing_ids:\n log.error(\"%d updates with missing ID!\" % len(self.missing_ids))\n log.error(self.missing_ids)\n\n def _load_cached_updateinfo(self):\n \"\"\"\n Load the cached updateinfo.xml from '../{tag}.repocache/repodata'\n \"\"\"\n seen_ids = set()\n from_cache = set()\n existing_ids = set()\n\n # Parse the updateinfo out of the repomd\n updateinfo = None\n repomd_xml = os.path.join(self.cached_repodata, 'repomd.xml')\n repomd = cr.Repomd()\n cr.xml_parse_repomd(repomd_xml, repomd)\n for record in repomd.records:\n if record.type == 'updateinfo':\n updateinfo = os.path.join(os.path.dirname(\n os.path.dirname(self.cached_repodata)),\n record.location_href)\n break\n\n assert updateinfo, 'Unable to find updateinfo'\n\n # Load the metadata with createrepo_c\n log.info('Loading cached updateinfo: %s', updateinfo)\n uinfo = cr.UpdateInfo(updateinfo)\n\n # Determine which updates are present in the cache\n for update in uinfo.updates:\n existing_ids.add(update.id)\n\n # Generate metadata for any new builds\n for update in self.updates:\n seen_ids.add(update.alias)\n if not update.alias:\n self.missing_ids.append(update.title)\n continue\n if update.alias in existing_ids:\n notice = None\n for value in uinfo.updates:\n if value.title == update.title:\n notice = value\n break\n if not notice:\n log.warn('%s ID in cache but notice cannot be found', update.title)\n self.add_update(update)\n continue\n if notice.updated_date:\n if notice.updated_date < update.date_modified:\n log.debug('Update modified, generating new notice: %s' % update.title)\n self.add_update(update)\n else:\n log.debug('Loading updated %s from cache' % update.title)\n from_cache.add(update.alias)\n elif update.date_modified:\n log.debug('Update modified, generating new notice: %s' % update.title)\n self.add_update(update)\n else:\n log.debug('Loading %s from cache' % update.title)\n from_cache.add(update.alias)\n else:\n log.debug('Adding new update notice: %s' % update.title)\n self.add_update(update)\n\n # Add all relevant notices from the cache to this document\n for notice in uinfo.updates:\n if notice.id in from_cache:\n log.debug('Keeping existing notice: %s', notice.title)\n self.uinfo.append(notice)\n else:\n # Keep all security notices in the stable repo\n if self.request is not UpdateRequest.testing:\n if notice.type == 'security':\n if notice.id not in seen_ids:\n log.debug('Keeping existing security notice: %s',\n notice.title)\n self.uinfo.append(notice)\n else:\n log.debug('%s already added?', notice.title)\n else:\n log.debug('Purging cached stable notice %s', notice.title)\n else:\n log.debug('Purging cached testing update %s', notice.title)\n\n def _fetch_updates(self):\n \"\"\"Based on our given koji tag, populate a list of Update objects\"\"\"\n log.debug(\"Fetching builds tagged with '%s'\" % self.tag)\n kojiBuilds = self.koji.listTagged(self.tag, latest=True)\n nonexistent = []\n log.debug(\"%d builds found\" % len(kojiBuilds))\n for build in kojiBuilds:\n self.builds[build['nvr']] = build\n build_obj = self.db.query(Build).filter_by(nvr=unicode(build['nvr'])).first()\n if build_obj:\n self.updates.add(build_obj.update)\n else:\n nonexistent.append(build['nvr'])\n if nonexistent:\n log.warning(\"Couldn't find the following koji builds tagged as \"\n \"%s in bodhi: %s\" % (self.tag, nonexistent))\n\n def add_update(self, update):\n \"\"\"Generate the extended metadata for a given update\"\"\"\n rec = cr.UpdateRecord()\n rec.version = __version__\n rec.fromstr = config.get('bodhi_email')\n rec.status = update.status.value\n rec.type = update.type.value\n rec.id = to_bytes(update.alias)\n rec.title = to_bytes(update.title)\n rec.summary = to_bytes('%s %s update' % (update.get_title(),\n update.type.value))\n rec.description = to_bytes(update.notes)\n rec.release = to_bytes(update.release.long_name)\n rec.rights = config.get('updateinfo_rights')\n\n if update.date_pushed:\n rec.issued_date = update.date_pushed\n if update.date_modified:\n rec.updated_date = update.date_modified\n\n col = cr.UpdateCollection()\n col.name = to_bytes(update.release.long_name)\n col.shortname = to_bytes(update.release.name)\n\n for build in update.builds:\n try:\n kojiBuild = self.builds[build.nvr]\n except:\n kojiBuild = self.koji.getBuild(build.nvr)\n\n rpms = self.koji.listBuildRPMs(kojiBuild['id'])\n for rpm in rpms:\n pkg = cr.UpdateCollectionPackage()\n pkg.name = rpm['name']\n pkg.version = rpm['version']\n pkg.release = rpm['release']\n if rpm['epoch'] is not None:\n pkg.epoch = str(rpm['epoch'])\n else:\n pkg.epoch = '0'\n pkg.arch = rpm['arch']\n\n # TODO: how do we handle UpdateSuggestion.logout, etc?\n pkg.reboot_suggested = update.suggest is UpdateSuggestion.reboot\n\n filename = '%s.%s.rpm' % (rpm['nvr'], rpm['arch'])\n pkg.filename = filename\n\n # Build the URL\n if rpm['arch'] == 'src':\n arch = 'SRPMS'\n elif rpm['arch'] in ('noarch', 'i686'):\n arch = 'i386'\n else:\n arch = rpm['arch']\n\n pkg.src = os.path.join(config.get('file_url'), update.status is\n UpdateStatus.testing and 'testing' or '',\n str(update.release.version), arch, filename[0], filename)\n\n col.append(pkg)\n\n rec.append_collection(col)\n\n # Create references for each bug\n for bug in update.bugs:\n ref = cr.UpdateReference()\n ref.type = 'bugzilla'\n ref.id = to_bytes(bug.bug_id)\n ref.href = to_bytes(bug.url)\n ref.title = to_bytes(bug.title)\n rec.append_reference(ref)\n\n # Create references for each CVE\n for cve in update.cves:\n ref = cr.UpdateReference()\n ref.type = 'cve'\n ref.id = to_bytes(cve.cve_id)\n ref.href = to_bytes(cve.url)\n rec.append_reference(ref)\n\n self.uinfo.append(rec)\n\n def insert_updateinfo(self):\n fd, name = tempfile.mkstemp()\n os.write(fd, self.uinfo.xml_dump())\n os.close(fd)\n self.modifyrepo(name)\n os.unlink(name)\n\n def modifyrepo(self, filename):\n \"\"\"Inject a file into the repodata for each architecture\"\"\"\n for arch in os.listdir(self.repo_path):\n repodata = os.path.join(self.repo_path, arch, 'repodata')\n log.info('Inserting %s into %s', filename, repodata)\n uinfo_xml = os.path.join(repodata, 'updateinfo.xml')\n shutil.copyfile(filename, uinfo_xml)\n repomd_xml = os.path.join(repodata, 'repomd.xml')\n repomd = cr.Repomd(repomd_xml)\n uinfo_rec = cr.RepomdRecord('updateinfo', uinfo_xml)\n uinfo_rec_comp = uinfo_rec.compress_and_fill(self.hash_type, self.comp_type)\n uinfo_rec_comp.rename_file()\n uinfo_rec_comp.type = 'updateinfo'\n repomd.set_record(uinfo_rec_comp)\n with file(repomd_xml, 'w') as repomd_file:\n repomd_file.write(repomd.xml_dump())\n os.unlink(uinfo_xml)\n\n def insert_pkgtags(self):\n \"\"\"Download and inject the pkgtags sqlite from fedora-tagger\"\"\"\n if config.get('pkgtags_url'):\n try:\n tags_url = config.get('pkgtags_url')\n tempdir = tempfile.mkdtemp('bodhi')\n local_tags = os.path.join(tempdir, 'pkgtags.sqlite')\n log.info('Downloading %s' % tags_url)\n urlgrab(tags_url, filename=local_tags)\n self.modifyrepo(local_tags)\n except:\n log.exception(\"There was a problem injecting pkgtags\")\n finally:\n shutil.rmtree(tempdir)\n\n def cache_repodata(self):\n arch = os.listdir(self.repo_path)[0] # Take the first arch\n repodata = os.path.join(self.repo_path, arch, 'repodata')\n if not os.path.isdir(repodata):\n log.warning('Cannot find repodata to cache: %s' % repodata)\n return\n cache = self.cached_repodata\n if os.path.isdir(cache):\n shutil.rmtree(cache)\n shutil.copytree(repodata, cache)\n log.info('%s cached to %s' % (repodata, cache))\n", "path": "bodhi/metadata.py"}]}
| 4,012 | 232 |
gh_patches_debug_12666
|
rasdani/github-patches
|
git_diff
|
openshift__openshift-ansible-3887
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[healthchecks] the package_version check always checks for master/node packages regardless of host group
#### Description
When running `playbooks/byo/openshift-preflight/check.yml`, the `package_version` check reports failures on hosts that can't access the `atomic-openshift-{master,node}` packages even when this is expected, e.g. on etcd or lb hosts.
##### Version
```
openshift-ansible-3.5.3-1-521-g3125e72
```
##### Steps To Reproduce
1. Have a cluster with `[etcd]`, `[lb]` and/or additional "auxiliary" host groups
2. Run the `playbooks/byo/openshift-preflight/check.yml` playbook
##### Expected Results
Hosts would not report a failure when they have access to the packages they need.
##### Observed Results
Hosts that don't have access to `atomic-openshift-{master,node}` packages in their configured repos are reported as failed, even when the hosts don't need these packages.
Describe what is actually happening.
```
$ ansible-playbook playbooks/byo/openshift-preflight/check.yml
[...]
Failure summary:
1. Host: etcd2.example.com
Play: run OpenShift health checks
Task: openshift_health_check
Message: One or more checks failed
Details: {'package_availability': {'_ansible_parsed': True,
u'changed': False,
u'invocation': {u'module_args': {u'packages': []}}},
'package_update': {'_ansible_parsed': True,
u'changed': False,
u'invocation': {u'module_args': {u'packages': []}}},
'package_version': {'_ansible_parsed': True,
u'failed': True,
u'invocation': {u'module_args': {u'prefix': u'atomic-openshift',
u'version': u'v3.4'}},
u'msg': u'Not all of the required packages are available at requested version 3.4:\n atomic-openshift\n atomic-openshift-master\n atomic-openshift-node\nPlease check your subscriptions and enabled repositories.'}}
```
##### Additional Information
The inventory file used here has:
```
[OSEv3:children]
masters
nodes
etcd
lb
dns
# [...]
[etcd]
etcd2.example.com
# [...]
[lb]
lb.example.com
```
the hosts in *etcd*, *lb* and *dns* groups all fail the check.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `roles/openshift_health_checker/openshift_checks/package_version.py`
Content:
```
1 # pylint: disable=missing-docstring
2 from openshift_checks import OpenShiftCheck, get_var
3 from openshift_checks.mixins import NotContainerizedMixin
4
5
6 class PackageVersion(NotContainerizedMixin, OpenShiftCheck):
7 """Check that available RPM packages match the required versions."""
8
9 name = "package_version"
10 tags = ["preflight"]
11
12 def run(self, tmp, task_vars):
13 rpm_prefix = get_var(task_vars, "openshift", "common", "service_type")
14 openshift_release = get_var(task_vars, "openshift_release")
15
16 args = {
17 "prefix": rpm_prefix,
18 "version": openshift_release,
19 }
20 return self.execute_module("aos_version", args, tmp, task_vars)
21
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/roles/openshift_health_checker/openshift_checks/package_version.py b/roles/openshift_health_checker/openshift_checks/package_version.py
--- a/roles/openshift_health_checker/openshift_checks/package_version.py
+++ b/roles/openshift_health_checker/openshift_checks/package_version.py
@@ -9,6 +9,13 @@
name = "package_version"
tags = ["preflight"]
+ @classmethod
+ def is_active(cls, task_vars):
+ """Skip hosts that do not have package requirements."""
+ group_names = get_var(task_vars, "group_names", default=[])
+ master_or_node = 'masters' in group_names or 'nodes' in group_names
+ return super(PackageVersion, cls).is_active(task_vars) and master_or_node
+
def run(self, tmp, task_vars):
rpm_prefix = get_var(task_vars, "openshift", "common", "service_type")
openshift_release = get_var(task_vars, "openshift_release")
|
{"golden_diff": "diff --git a/roles/openshift_health_checker/openshift_checks/package_version.py b/roles/openshift_health_checker/openshift_checks/package_version.py\n--- a/roles/openshift_health_checker/openshift_checks/package_version.py\n+++ b/roles/openshift_health_checker/openshift_checks/package_version.py\n@@ -9,6 +9,13 @@\n name = \"package_version\"\n tags = [\"preflight\"]\n \n+ @classmethod\n+ def is_active(cls, task_vars):\n+ \"\"\"Skip hosts that do not have package requirements.\"\"\"\n+ group_names = get_var(task_vars, \"group_names\", default=[])\n+ master_or_node = 'masters' in group_names or 'nodes' in group_names\n+ return super(PackageVersion, cls).is_active(task_vars) and master_or_node\n+\n def run(self, tmp, task_vars):\n rpm_prefix = get_var(task_vars, \"openshift\", \"common\", \"service_type\")\n openshift_release = get_var(task_vars, \"openshift_release\")\n", "issue": "[healthchecks] the package_version check always checks for master/node packages regardless of host group\n#### Description\r\n\r\nWhen running `playbooks/byo/openshift-preflight/check.yml`, the `package_version` check reports failures on hosts that can't access the `atomic-openshift-{master,node}` packages even when this is expected, e.g. on etcd or lb hosts.\r\n\r\n\r\n##### Version\r\n\r\n```\r\nopenshift-ansible-3.5.3-1-521-g3125e72\r\n```\r\n\r\n##### Steps To Reproduce\r\n1. Have a cluster with `[etcd]`, `[lb]` and/or additional \"auxiliary\" host groups\r\n2. Run the `playbooks/byo/openshift-preflight/check.yml` playbook\r\n\r\n\r\n##### Expected Results\r\nHosts would not report a failure when they have access to the packages they need.\r\n\r\n##### Observed Results\r\nHosts that don't have access to `atomic-openshift-{master,node}` packages in their configured repos are reported as failed, even when the hosts don't need these packages.\r\nDescribe what is actually happening.\r\n\r\n```\r\n$ ansible-playbook playbooks/byo/openshift-preflight/check.yml\r\n[...]\r\nFailure summary:\r\n\r\n 1. Host: etcd2.example.com\r\n Play: run OpenShift health checks\r\n Task: openshift_health_check\r\n Message: One or more checks failed\r\n Details: {'package_availability': {'_ansible_parsed': True,\r\n u'changed': False,\r\n u'invocation': {u'module_args': {u'packages': []}}},\r\n 'package_update': {'_ansible_parsed': True,\r\n u'changed': False,\r\n u'invocation': {u'module_args': {u'packages': []}}},\r\n 'package_version': {'_ansible_parsed': True,\r\n u'failed': True,\r\n u'invocation': {u'module_args': {u'prefix': u'atomic-openshift',\r\n u'version': u'v3.4'}},\r\n u'msg': u'Not all of the required packages are available at requested version 3.4:\\n atomic-openshift\\n atomic-openshift-master\\n atomic-openshift-node\\nPlease check your subscriptions and enabled repositories.'}}\r\n```\r\n\r\n##### Additional Information\r\n\r\nThe inventory file used here has:\r\n\r\n```\r\n[OSEv3:children]\r\nmasters\r\nnodes\r\netcd\r\nlb\r\ndns\r\n\r\n# [...]\r\n\r\n[etcd]\r\netcd2.example.com\r\n# [...]\r\n\r\n[lb]\r\nlb.example.com\r\n```\r\n\r\nthe hosts in *etcd*, *lb* and *dns* groups all fail the check.\r\n\r\n\r\n\n", "before_files": [{"content": "# pylint: disable=missing-docstring\nfrom openshift_checks import OpenShiftCheck, get_var\nfrom openshift_checks.mixins import NotContainerizedMixin\n\n\nclass PackageVersion(NotContainerizedMixin, OpenShiftCheck):\n \"\"\"Check that available RPM packages match the required versions.\"\"\"\n\n name = \"package_version\"\n tags = [\"preflight\"]\n\n def run(self, tmp, task_vars):\n rpm_prefix = get_var(task_vars, \"openshift\", \"common\", \"service_type\")\n openshift_release = get_var(task_vars, \"openshift_release\")\n\n args = {\n \"prefix\": rpm_prefix,\n \"version\": openshift_release,\n }\n return self.execute_module(\"aos_version\", args, tmp, task_vars)\n", "path": "roles/openshift_health_checker/openshift_checks/package_version.py"}], "after_files": [{"content": "# pylint: disable=missing-docstring\nfrom openshift_checks import OpenShiftCheck, get_var\nfrom openshift_checks.mixins import NotContainerizedMixin\n\n\nclass PackageVersion(NotContainerizedMixin, OpenShiftCheck):\n \"\"\"Check that available RPM packages match the required versions.\"\"\"\n\n name = \"package_version\"\n tags = [\"preflight\"]\n\n @classmethod\n def is_active(cls, task_vars):\n \"\"\"Skip hosts that do not have package requirements.\"\"\"\n group_names = get_var(task_vars, \"group_names\", default=[])\n master_or_node = 'masters' in group_names or 'nodes' in group_names\n return super(PackageVersion, cls).is_active(task_vars) and master_or_node\n\n def run(self, tmp, task_vars):\n rpm_prefix = get_var(task_vars, \"openshift\", \"common\", \"service_type\")\n openshift_release = get_var(task_vars, \"openshift_release\")\n\n args = {\n \"prefix\": rpm_prefix,\n \"version\": openshift_release,\n }\n return self.execute_module(\"aos_version\", args, tmp, task_vars)\n", "path": "roles/openshift_health_checker/openshift_checks/package_version.py"}]}
| 1,031 | 224 |
gh_patches_debug_28149
|
rasdani/github-patches
|
git_diff
|
pypi__warehouse-1407
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Remove unused classifiers from filter list
We currently show all trove classifiers in the search filter panel, despite the fact that some are not applied to any projects in the DB.
It would be better to only show those classifiers that are actually applied to projects, so we avoid filtering by a classifier and returning an empty result.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `warehouse/views.py`
Content:
```
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13 import collections
14
15 from pyramid.httpexceptions import (
16 HTTPException, HTTPSeeOther, HTTPMovedPermanently, HTTPNotFound,
17 HTTPBadRequest,
18 )
19 from pyramid.view import (
20 notfound_view_config, forbidden_view_config, view_config,
21 )
22 from elasticsearch_dsl import Q
23 from sqlalchemy import func
24 from sqlalchemy.orm import aliased, joinedload
25
26 from warehouse.accounts import REDIRECT_FIELD_NAME
27 from warehouse.accounts.models import User
28 from warehouse.cache.origin import origin_cache
29 from warehouse.cache.http import cache_control
30 from warehouse.classifiers.models import Classifier
31 from warehouse.packaging.models import Project, Release, File
32 from warehouse.utils.row_counter import RowCount
33 from warehouse.utils.paginate import ElasticsearchPage, paginate_url_factory
34
35
36 SEARCH_FIELDS = [
37 "author", "author_email", "description", "download_url", "home_page",
38 "keywords", "license", "maintainer", "maintainer_email", "normalized_name",
39 "platform", "summary",
40 ]
41 SEARCH_BOOSTS = {
42 "normalized_name": 10,
43 "description": 5,
44 "keywords": 5,
45 "summary": 5,
46 }
47 SEARCH_FILTER_ORDER = (
48 "Programming Language",
49 "License",
50 "Framework",
51 "Topic",
52 "Intended Audience",
53 "Environment",
54 "Operating System",
55 "Natural Language",
56 "Development Status",
57 )
58
59
60 @view_config(context=HTTPException)
61 @notfound_view_config(append_slash=HTTPMovedPermanently)
62 def httpexception_view(exc, request):
63 return exc
64
65
66 @forbidden_view_config()
67 def forbidden(exc, request):
68 # If the forbidden error is because the user isn't logged in, then we'll
69 # redirect them to the log in page.
70 if request.authenticated_userid is None:
71 url = request.route_url(
72 "accounts.login",
73 _query={REDIRECT_FIELD_NAME: request.path_qs},
74 )
75 return HTTPSeeOther(url)
76
77 # If we've reached here, then the user is logged in and they are genuinely
78 # not allowed to access this page.
79 # TODO: Style the forbidden page.
80 return exc
81
82
83 @view_config(
84 route_name="robots.txt",
85 renderer="robots.txt",
86 decorator=[
87 cache_control(1 * 24 * 60 * 60), # 1 day
88 origin_cache(
89 1 * 24 * 60 * 60, # 1 day
90 stale_while_revalidate=6 * 60 * 60, # 6 hours
91 stale_if_error=1 * 24 * 60 * 60, # 1 day
92 ),
93 ],
94 )
95 def robotstxt(request):
96 request.response.content_type = "text/plain"
97 return {}
98
99
100 @view_config(
101 route_name="index",
102 renderer="index.html",
103 decorator=[
104 origin_cache(
105 1 * 60 * 60, # 1 hour
106 stale_while_revalidate=10 * 60, # 10 minutes
107 stale_if_error=1 * 24 * 60 * 60, # 1 day
108 keys=["all-projects"],
109 ),
110 ]
111 )
112 def index(request):
113 project_names = [
114 r[0] for r in (
115 request.db.query(File.name)
116 .group_by(File.name)
117 .order_by(func.sum(File.downloads).desc())
118 .limit(5)
119 .all())
120 ]
121 release_a = aliased(
122 Release,
123 request.db.query(Release)
124 .distinct(Release.name)
125 .filter(Release.name.in_(project_names))
126 .order_by(Release.name, Release._pypi_ordering.desc())
127 .subquery(),
128 )
129 top_projects = (
130 request.db.query(release_a)
131 .options(joinedload(release_a.project))
132 .order_by(func.array_idx(project_names, release_a.name))
133 .all()
134 )
135
136 latest_releases = (
137 request.db.query(Release)
138 .options(joinedload(Release.project))
139 .order_by(Release.created.desc())
140 .limit(5)
141 .all()
142 )
143
144 counts = dict(
145 request.db.query(RowCount.table_name, RowCount.count)
146 .filter(
147 RowCount.table_name.in_([
148 Project.__tablename__,
149 Release.__tablename__,
150 File.__tablename__,
151 User.__tablename__,
152 ]))
153 .all()
154 )
155
156 return {
157 "latest_releases": latest_releases,
158 "top_projects": top_projects,
159 "num_projects": counts.get(Project.__tablename__, 0),
160 "num_releases": counts.get(Release.__tablename__, 0),
161 "num_files": counts.get(File.__tablename__, 0),
162 "num_users": counts.get(User.__tablename__, 0),
163 }
164
165
166 @view_config(
167 route_name="search",
168 renderer="search/results.html",
169 decorator=[
170 origin_cache(
171 1 * 60 * 60, # 1 hour
172 stale_while_revalidate=10 * 60, # 10 minutes
173 stale_if_error=1 * 24 * 60 * 60, # 1 day
174 keys=["all-projects"],
175 )
176 ],
177 )
178 def search(request):
179
180 q = request.params.get("q", '')
181
182 if q:
183 should = []
184 for field in SEARCH_FIELDS:
185 kw = {"query": q}
186 if field in SEARCH_BOOSTS:
187 kw["boost"] = SEARCH_BOOSTS[field]
188 should.append(Q("match", **{field: kw}))
189
190 # Add a prefix query if ``q`` is longer than one character.
191 if len(q) > 1:
192 should.append(Q('prefix', normalized_name=q))
193
194 query = request.es.query("dis_max", queries=should)
195 query = query.suggest("name_suggestion", q, term={"field": "name"})
196 else:
197 query = request.es.query()
198
199 if request.params.get("o"):
200 query = query.sort(request.params["o"])
201
202 if request.params.getall("c"):
203 query = query.filter("terms", classifiers=request.params.getall("c"))
204
205 try:
206 page_num = int(request.params.get("page", 1))
207 except ValueError:
208 raise HTTPBadRequest("'page' must be an integer.")
209
210 page = ElasticsearchPage(
211 query,
212 page=page_num,
213 url_maker=paginate_url_factory(request),
214 )
215
216 if page.page_count and page_num > page.page_count:
217 return HTTPNotFound()
218
219 available_filters = collections.defaultdict(list)
220
221 for cls in request.db.query(Classifier).order_by(Classifier.classifier):
222 first, *_ = cls.classifier.split(' :: ')
223 available_filters[first].append(cls.classifier)
224
225 def filter_key(item):
226 try:
227 return 0, SEARCH_FILTER_ORDER.index(item[0]), item[0]
228 except ValueError:
229 return 1, 0, item[0]
230
231 return {
232 "page": page,
233 "term": q,
234 "order": request.params.get("o", ''),
235 "available_filters": sorted(available_filters.items(), key=filter_key),
236 "applied_filters": request.params.getall("c"),
237 }
238
239
240 @view_config(
241 route_name="includes.current-user-indicator",
242 renderer="includes/current-user-indicator.html",
243 uses_session=True,
244 )
245 def current_user_indicator(request):
246 return {}
247
248
249 @view_config(route_name="health", renderer="string")
250 def health(request):
251 # This will ensure that we can access the database and run queries against
252 # it without doing anything that will take a lock or block other queries.
253 request.db.execute("SELECT 1")
254
255 # Nothing will actually check this, but it's a little nicer to have
256 # something to return besides an empty body.
257 return "OK"
258
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/warehouse/views.py b/warehouse/views.py
--- a/warehouse/views.py
+++ b/warehouse/views.py
@@ -22,13 +22,16 @@
from elasticsearch_dsl import Q
from sqlalchemy import func
from sqlalchemy.orm import aliased, joinedload
+from sqlalchemy.sql import exists
from warehouse.accounts import REDIRECT_FIELD_NAME
from warehouse.accounts.models import User
from warehouse.cache.origin import origin_cache
from warehouse.cache.http import cache_control
from warehouse.classifiers.models import Classifier
-from warehouse.packaging.models import Project, Release, File
+from warehouse.packaging.models import (
+ Project, Release, File, release_classifiers,
+)
from warehouse.utils.row_counter import RowCount
from warehouse.utils.paginate import ElasticsearchPage, paginate_url_factory
@@ -218,7 +221,17 @@
available_filters = collections.defaultdict(list)
- for cls in request.db.query(Classifier).order_by(Classifier.classifier):
+ classifiers_q = (
+ request.db.query(Classifier)
+ .with_entities(Classifier.classifier)
+ .filter(
+ exists([release_classifiers.c.trove_id])
+ .where(release_classifiers.c.trove_id == Classifier.id)
+ )
+ .order_by(Classifier.classifier)
+ )
+
+ for cls in classifiers_q:
first, *_ = cls.classifier.split(' :: ')
available_filters[first].append(cls.classifier)
|
{"golden_diff": "diff --git a/warehouse/views.py b/warehouse/views.py\n--- a/warehouse/views.py\n+++ b/warehouse/views.py\n@@ -22,13 +22,16 @@\n from elasticsearch_dsl import Q\n from sqlalchemy import func\n from sqlalchemy.orm import aliased, joinedload\n+from sqlalchemy.sql import exists\n \n from warehouse.accounts import REDIRECT_FIELD_NAME\n from warehouse.accounts.models import User\n from warehouse.cache.origin import origin_cache\n from warehouse.cache.http import cache_control\n from warehouse.classifiers.models import Classifier\n-from warehouse.packaging.models import Project, Release, File\n+from warehouse.packaging.models import (\n+ Project, Release, File, release_classifiers,\n+)\n from warehouse.utils.row_counter import RowCount\n from warehouse.utils.paginate import ElasticsearchPage, paginate_url_factory\n \n@@ -218,7 +221,17 @@\n \n available_filters = collections.defaultdict(list)\n \n- for cls in request.db.query(Classifier).order_by(Classifier.classifier):\n+ classifiers_q = (\n+ request.db.query(Classifier)\n+ .with_entities(Classifier.classifier)\n+ .filter(\n+ exists([release_classifiers.c.trove_id])\n+ .where(release_classifiers.c.trove_id == Classifier.id)\n+ )\n+ .order_by(Classifier.classifier)\n+ )\n+\n+ for cls in classifiers_q:\n first, *_ = cls.classifier.split(' :: ')\n available_filters[first].append(cls.classifier)\n", "issue": "Remove unused classifiers from filter list\nWe currently show all trove classifiers in the search filter panel, despite the fact that some are not applied to any projects in the DB.\n\nIt would be better to only show those classifiers that are actually applied to projects, so we avoid filtering by a classifier and returning an empty result.\n\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport collections\n\nfrom pyramid.httpexceptions import (\n HTTPException, HTTPSeeOther, HTTPMovedPermanently, HTTPNotFound,\n HTTPBadRequest,\n)\nfrom pyramid.view import (\n notfound_view_config, forbidden_view_config, view_config,\n)\nfrom elasticsearch_dsl import Q\nfrom sqlalchemy import func\nfrom sqlalchemy.orm import aliased, joinedload\n\nfrom warehouse.accounts import REDIRECT_FIELD_NAME\nfrom warehouse.accounts.models import User\nfrom warehouse.cache.origin import origin_cache\nfrom warehouse.cache.http import cache_control\nfrom warehouse.classifiers.models import Classifier\nfrom warehouse.packaging.models import Project, Release, File\nfrom warehouse.utils.row_counter import RowCount\nfrom warehouse.utils.paginate import ElasticsearchPage, paginate_url_factory\n\n\nSEARCH_FIELDS = [\n \"author\", \"author_email\", \"description\", \"download_url\", \"home_page\",\n \"keywords\", \"license\", \"maintainer\", \"maintainer_email\", \"normalized_name\",\n \"platform\", \"summary\",\n]\nSEARCH_BOOSTS = {\n \"normalized_name\": 10,\n \"description\": 5,\n \"keywords\": 5,\n \"summary\": 5,\n}\nSEARCH_FILTER_ORDER = (\n \"Programming Language\",\n \"License\",\n \"Framework\",\n \"Topic\",\n \"Intended Audience\",\n \"Environment\",\n \"Operating System\",\n \"Natural Language\",\n \"Development Status\",\n)\n\n\n@view_config(context=HTTPException)\n@notfound_view_config(append_slash=HTTPMovedPermanently)\ndef httpexception_view(exc, request):\n return exc\n\n\n@forbidden_view_config()\ndef forbidden(exc, request):\n # If the forbidden error is because the user isn't logged in, then we'll\n # redirect them to the log in page.\n if request.authenticated_userid is None:\n url = request.route_url(\n \"accounts.login\",\n _query={REDIRECT_FIELD_NAME: request.path_qs},\n )\n return HTTPSeeOther(url)\n\n # If we've reached here, then the user is logged in and they are genuinely\n # not allowed to access this page.\n # TODO: Style the forbidden page.\n return exc\n\n\n@view_config(\n route_name=\"robots.txt\",\n renderer=\"robots.txt\",\n decorator=[\n cache_control(1 * 24 * 60 * 60), # 1 day\n origin_cache(\n 1 * 24 * 60 * 60, # 1 day\n stale_while_revalidate=6 * 60 * 60, # 6 hours\n stale_if_error=1 * 24 * 60 * 60, # 1 day\n ),\n ],\n)\ndef robotstxt(request):\n request.response.content_type = \"text/plain\"\n return {}\n\n\n@view_config(\n route_name=\"index\",\n renderer=\"index.html\",\n decorator=[\n origin_cache(\n 1 * 60 * 60, # 1 hour\n stale_while_revalidate=10 * 60, # 10 minutes\n stale_if_error=1 * 24 * 60 * 60, # 1 day\n keys=[\"all-projects\"],\n ),\n ]\n)\ndef index(request):\n project_names = [\n r[0] for r in (\n request.db.query(File.name)\n .group_by(File.name)\n .order_by(func.sum(File.downloads).desc())\n .limit(5)\n .all())\n ]\n release_a = aliased(\n Release,\n request.db.query(Release)\n .distinct(Release.name)\n .filter(Release.name.in_(project_names))\n .order_by(Release.name, Release._pypi_ordering.desc())\n .subquery(),\n )\n top_projects = (\n request.db.query(release_a)\n .options(joinedload(release_a.project))\n .order_by(func.array_idx(project_names, release_a.name))\n .all()\n )\n\n latest_releases = (\n request.db.query(Release)\n .options(joinedload(Release.project))\n .order_by(Release.created.desc())\n .limit(5)\n .all()\n )\n\n counts = dict(\n request.db.query(RowCount.table_name, RowCount.count)\n .filter(\n RowCount.table_name.in_([\n Project.__tablename__,\n Release.__tablename__,\n File.__tablename__,\n User.__tablename__,\n ]))\n .all()\n )\n\n return {\n \"latest_releases\": latest_releases,\n \"top_projects\": top_projects,\n \"num_projects\": counts.get(Project.__tablename__, 0),\n \"num_releases\": counts.get(Release.__tablename__, 0),\n \"num_files\": counts.get(File.__tablename__, 0),\n \"num_users\": counts.get(User.__tablename__, 0),\n }\n\n\n@view_config(\n route_name=\"search\",\n renderer=\"search/results.html\",\n decorator=[\n origin_cache(\n 1 * 60 * 60, # 1 hour\n stale_while_revalidate=10 * 60, # 10 minutes\n stale_if_error=1 * 24 * 60 * 60, # 1 day\n keys=[\"all-projects\"],\n )\n ],\n)\ndef search(request):\n\n q = request.params.get(\"q\", '')\n\n if q:\n should = []\n for field in SEARCH_FIELDS:\n kw = {\"query\": q}\n if field in SEARCH_BOOSTS:\n kw[\"boost\"] = SEARCH_BOOSTS[field]\n should.append(Q(\"match\", **{field: kw}))\n\n # Add a prefix query if ``q`` is longer than one character.\n if len(q) > 1:\n should.append(Q('prefix', normalized_name=q))\n\n query = request.es.query(\"dis_max\", queries=should)\n query = query.suggest(\"name_suggestion\", q, term={\"field\": \"name\"})\n else:\n query = request.es.query()\n\n if request.params.get(\"o\"):\n query = query.sort(request.params[\"o\"])\n\n if request.params.getall(\"c\"):\n query = query.filter(\"terms\", classifiers=request.params.getall(\"c\"))\n\n try:\n page_num = int(request.params.get(\"page\", 1))\n except ValueError:\n raise HTTPBadRequest(\"'page' must be an integer.\")\n\n page = ElasticsearchPage(\n query,\n page=page_num,\n url_maker=paginate_url_factory(request),\n )\n\n if page.page_count and page_num > page.page_count:\n return HTTPNotFound()\n\n available_filters = collections.defaultdict(list)\n\n for cls in request.db.query(Classifier).order_by(Classifier.classifier):\n first, *_ = cls.classifier.split(' :: ')\n available_filters[first].append(cls.classifier)\n\n def filter_key(item):\n try:\n return 0, SEARCH_FILTER_ORDER.index(item[0]), item[0]\n except ValueError:\n return 1, 0, item[0]\n\n return {\n \"page\": page,\n \"term\": q,\n \"order\": request.params.get(\"o\", ''),\n \"available_filters\": sorted(available_filters.items(), key=filter_key),\n \"applied_filters\": request.params.getall(\"c\"),\n }\n\n\n@view_config(\n route_name=\"includes.current-user-indicator\",\n renderer=\"includes/current-user-indicator.html\",\n uses_session=True,\n)\ndef current_user_indicator(request):\n return {}\n\n\n@view_config(route_name=\"health\", renderer=\"string\")\ndef health(request):\n # This will ensure that we can access the database and run queries against\n # it without doing anything that will take a lock or block other queries.\n request.db.execute(\"SELECT 1\")\n\n # Nothing will actually check this, but it's a little nicer to have\n # something to return besides an empty body.\n return \"OK\"\n", "path": "warehouse/views.py"}], "after_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport collections\n\nfrom pyramid.httpexceptions import (\n HTTPException, HTTPSeeOther, HTTPMovedPermanently, HTTPNotFound,\n HTTPBadRequest,\n)\nfrom pyramid.view import (\n notfound_view_config, forbidden_view_config, view_config,\n)\nfrom elasticsearch_dsl import Q\nfrom sqlalchemy import func\nfrom sqlalchemy.orm import aliased, joinedload\nfrom sqlalchemy.sql import exists\n\nfrom warehouse.accounts import REDIRECT_FIELD_NAME\nfrom warehouse.accounts.models import User\nfrom warehouse.cache.origin import origin_cache\nfrom warehouse.cache.http import cache_control\nfrom warehouse.classifiers.models import Classifier\nfrom warehouse.packaging.models import (\n Project, Release, File, release_classifiers,\n)\nfrom warehouse.utils.row_counter import RowCount\nfrom warehouse.utils.paginate import ElasticsearchPage, paginate_url_factory\n\n\nSEARCH_FIELDS = [\n \"author\", \"author_email\", \"description\", \"download_url\", \"home_page\",\n \"keywords\", \"license\", \"maintainer\", \"maintainer_email\", \"normalized_name\",\n \"platform\", \"summary\",\n]\nSEARCH_BOOSTS = {\n \"normalized_name\": 10,\n \"description\": 5,\n \"keywords\": 5,\n \"summary\": 5,\n}\nSEARCH_FILTER_ORDER = (\n \"Programming Language\",\n \"License\",\n \"Framework\",\n \"Topic\",\n \"Intended Audience\",\n \"Environment\",\n \"Operating System\",\n \"Natural Language\",\n \"Development Status\",\n)\n\n\n@view_config(context=HTTPException)\n@notfound_view_config(append_slash=HTTPMovedPermanently)\ndef httpexception_view(exc, request):\n return exc\n\n\n@forbidden_view_config()\ndef forbidden(exc, request):\n # If the forbidden error is because the user isn't logged in, then we'll\n # redirect them to the log in page.\n if request.authenticated_userid is None:\n url = request.route_url(\n \"accounts.login\",\n _query={REDIRECT_FIELD_NAME: request.path_qs},\n )\n return HTTPSeeOther(url)\n\n # If we've reached here, then the user is logged in and they are genuinely\n # not allowed to access this page.\n # TODO: Style the forbidden page.\n return exc\n\n\n@view_config(\n route_name=\"robots.txt\",\n renderer=\"robots.txt\",\n decorator=[\n cache_control(1 * 24 * 60 * 60), # 1 day\n origin_cache(\n 1 * 24 * 60 * 60, # 1 day\n stale_while_revalidate=6 * 60 * 60, # 6 hours\n stale_if_error=1 * 24 * 60 * 60, # 1 day\n ),\n ],\n)\ndef robotstxt(request):\n request.response.content_type = \"text/plain\"\n return {}\n\n\n@view_config(\n route_name=\"index\",\n renderer=\"index.html\",\n decorator=[\n origin_cache(\n 1 * 60 * 60, # 1 hour\n stale_while_revalidate=10 * 60, # 10 minutes\n stale_if_error=1 * 24 * 60 * 60, # 1 day\n keys=[\"all-projects\"],\n ),\n ]\n)\ndef index(request):\n project_names = [\n r[0] for r in (\n request.db.query(File.name)\n .group_by(File.name)\n .order_by(func.sum(File.downloads).desc())\n .limit(5)\n .all())\n ]\n release_a = aliased(\n Release,\n request.db.query(Release)\n .distinct(Release.name)\n .filter(Release.name.in_(project_names))\n .order_by(Release.name, Release._pypi_ordering.desc())\n .subquery(),\n )\n top_projects = (\n request.db.query(release_a)\n .options(joinedload(release_a.project))\n .order_by(func.array_idx(project_names, release_a.name))\n .all()\n )\n\n latest_releases = (\n request.db.query(Release)\n .options(joinedload(Release.project))\n .order_by(Release.created.desc())\n .limit(5)\n .all()\n )\n\n counts = dict(\n request.db.query(RowCount.table_name, RowCount.count)\n .filter(\n RowCount.table_name.in_([\n Project.__tablename__,\n Release.__tablename__,\n File.__tablename__,\n User.__tablename__,\n ]))\n .all()\n )\n\n return {\n \"latest_releases\": latest_releases,\n \"top_projects\": top_projects,\n \"num_projects\": counts.get(Project.__tablename__, 0),\n \"num_releases\": counts.get(Release.__tablename__, 0),\n \"num_files\": counts.get(File.__tablename__, 0),\n \"num_users\": counts.get(User.__tablename__, 0),\n }\n\n\n@view_config(\n route_name=\"search\",\n renderer=\"search/results.html\",\n decorator=[\n origin_cache(\n 1 * 60 * 60, # 1 hour\n stale_while_revalidate=10 * 60, # 10 minutes\n stale_if_error=1 * 24 * 60 * 60, # 1 day\n keys=[\"all-projects\"],\n )\n ],\n)\ndef search(request):\n\n q = request.params.get(\"q\", '')\n\n if q:\n should = []\n for field in SEARCH_FIELDS:\n kw = {\"query\": q}\n if field in SEARCH_BOOSTS:\n kw[\"boost\"] = SEARCH_BOOSTS[field]\n should.append(Q(\"match\", **{field: kw}))\n\n # Add a prefix query if ``q`` is longer than one character.\n if len(q) > 1:\n should.append(Q('prefix', normalized_name=q))\n\n query = request.es.query(\"dis_max\", queries=should)\n query = query.suggest(\"name_suggestion\", q, term={\"field\": \"name\"})\n else:\n query = request.es.query()\n\n if request.params.get(\"o\"):\n query = query.sort(request.params[\"o\"])\n\n if request.params.getall(\"c\"):\n query = query.filter(\"terms\", classifiers=request.params.getall(\"c\"))\n\n try:\n page_num = int(request.params.get(\"page\", 1))\n except ValueError:\n raise HTTPBadRequest(\"'page' must be an integer.\")\n\n page = ElasticsearchPage(\n query,\n page=page_num,\n url_maker=paginate_url_factory(request),\n )\n\n if page.page_count and page_num > page.page_count:\n return HTTPNotFound()\n\n available_filters = collections.defaultdict(list)\n\n classifiers_q = (\n request.db.query(Classifier)\n .with_entities(Classifier.classifier)\n .filter(\n exists([release_classifiers.c.trove_id])\n .where(release_classifiers.c.trove_id == Classifier.id)\n )\n .order_by(Classifier.classifier)\n )\n\n for cls in classifiers_q:\n first, *_ = cls.classifier.split(' :: ')\n available_filters[first].append(cls.classifier)\n\n def filter_key(item):\n try:\n return 0, SEARCH_FILTER_ORDER.index(item[0]), item[0]\n except ValueError:\n return 1, 0, item[0]\n\n return {\n \"page\": page,\n \"term\": q,\n \"order\": request.params.get(\"o\", ''),\n \"available_filters\": sorted(available_filters.items(), key=filter_key),\n \"applied_filters\": request.params.getall(\"c\"),\n }\n\n\n@view_config(\n route_name=\"includes.current-user-indicator\",\n renderer=\"includes/current-user-indicator.html\",\n uses_session=True,\n)\ndef current_user_indicator(request):\n return {}\n\n\n@view_config(route_name=\"health\", renderer=\"string\")\ndef health(request):\n # This will ensure that we can access the database and run queries against\n # it without doing anything that will take a lock or block other queries.\n request.db.execute(\"SELECT 1\")\n\n # Nothing will actually check this, but it's a little nicer to have\n # something to return besides an empty body.\n return \"OK\"\n", "path": "warehouse/views.py"}]}
| 2,814 | 316 |
gh_patches_debug_30542
|
rasdani/github-patches
|
git_diff
|
internetarchive__openlibrary-7202
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
partner_batch_imports.py should not import books published in a future year
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
Per the [Open-Mic topics](https://docs.google.com/document/d/1LEbzsLZ1F9_YIQOoZzO7GoZnG1z-rudhZ9HNtsameTc/edit#heading=h.swvutwwydubf) for the Open Library Community call on 2022-11-29, we should not import partner data for books purporting to be published in a future year, as this is resulting in bad records of books that may never exist.
### Describe the problem that you'd like solved
<!-- A clear and concise description of what you want to happen. -->
When importing books, `partner_batch_imports.py` does not currently check if the `publish_date` is in a future year when importing. It should. E.g. if an import is attempted in the year 2022, it should not import a book purported to be published in 2023.
### Proposal & Constraints
<!-- What is the proposed solution / implementation? Is there a precedent of this approach succeeding elsewhere? -->
The proposed solution is to add a check to `batch_import()` in `partner_batch_imports.py` to ensure a book isn't purported to be published in a future year.
<!-- Which suggestions or requirements should be considered for how feature needs to appear or be implemented? -->
### Additional context
<!-- Add any other context or screenshots about the feature request here. -->
I will submit a PR to address this.
### Stakeholders
<!-- @ tag stakeholders of this bug -->
@mekarpeles, @cdrini
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `scripts/partner_batch_imports.py`
Content:
```
1 """
2 Process partner bibliographic csv data into importable json book
3 records and then batch submit into the ImportBot
4 `import_item` table (http://openlibrary.org/admin/imports)
5 which queues items to be imported via the
6 Open Library JSON import API: https://openlibrary.org/api/import
7
8 To Run:
9
10 PYTHONPATH=. python ./scripts/partner_batch_imports.py /olsystem/etc/openlibrary.yml
11 """
12
13 import datetime
14 import logging
15 import os
16 import re
17
18 import requests
19
20 from infogami import config # noqa: F401
21 from openlibrary.config import load_config
22 from openlibrary.core.imports import Batch
23 from scripts.solr_builder.solr_builder.fn_to_cli import FnToCLI
24
25 logger = logging.getLogger("openlibrary.importer.bwb")
26
27 EXCLUDED_AUTHORS = {
28 x.casefold()
29 for x in (
30 "1570 publishing",
31 "bahija",
32 "bruna murino",
33 "creative elegant edition",
34 "delsee notebooks",
35 "grace garcia",
36 "holo",
37 "jeryx publishing",
38 "mado",
39 "mazzo",
40 "mikemix",
41 "mitch allison",
42 "pickleball publishing",
43 "pizzelle passion",
44 "punny cuaderno",
45 "razal koraya",
46 "t. d. publishing",
47 "tobias publishing",
48 )
49 }
50
51 EXCLUDED_INDEPENDENTLY_PUBLISHED_TITLES = {
52 x.casefold()
53 for x in (
54 # Noisy classic re-prints
55 'annotated',
56 'annoté',
57 'classic',
58 'classics',
59 'illustarted', # Some books have typos in their titles!
60 'illustrated',
61 'Illustrée',
62 'original',
63 'summary',
64 'version',
65 # Not a book
66 'calendar',
67 'diary',
68 'journal',
69 'logbook',
70 'notebook',
71 'notizbuch',
72 'planner',
73 'sketchbook',
74 )
75 }
76
77 SCHEMA_URL = (
78 "https://raw.githubusercontent.com/internetarchive"
79 "/openlibrary-client/master/olclient/schemata/import.schema.json"
80 )
81
82
83 class Biblio:
84
85 ACTIVE_FIELDS = [
86 'title',
87 'isbn_13',
88 'publish_date',
89 'publishers',
90 'weight',
91 'authors',
92 'lc_classifications',
93 'pagination',
94 'languages',
95 'subjects',
96 'source_records',
97 ]
98 INACTIVE_FIELDS = [
99 "copyright",
100 "issn",
101 "doi",
102 "lccn",
103 "dewey",
104 "length",
105 "width",
106 "height",
107 ]
108 REQUIRED_FIELDS = requests.get(SCHEMA_URL).json()['required']
109
110 NONBOOK = """A2 AA AB AJ AVI AZ BK BM C3 CD CE CF CR CRM CRW CX D3 DA DD DF DI DL
111 DO DR DRM DRW DS DV EC FC FI FM FR FZ GB GC GM GR H3 H5 L3 L5 LP MAC MC MF MG MH ML
112 MS MSX MZ N64 NGA NGB NGC NGE NT OR OS PC PP PRP PS PSC PY QU RE RV SA SD SG SH SK
113 SL SMD SN SO SO1 SO2 SR SU TA TB TR TS TY UX V35 V8 VC VD VE VF VK VM VN VO VP VS
114 VU VY VZ WA WC WI WL WM WP WT WX XL XZ ZF ZZ""".split()
115
116 def __init__(self, data):
117 self.isbn = data[124]
118 self.source_id = f'bwb:{self.isbn}'
119 self.isbn_13 = [self.isbn]
120 self.title = data[10]
121 self.primary_format = data[6]
122 self.publish_date = data[20][:4] # YYYY, YYYYMMDD
123 self.publishers = [data[135]]
124 self.weight = data[39]
125 self.authors = self.contributors(data)
126 self.lc_classifications = [data[147]] if data[147] else []
127 self.pagination = data[36]
128 self.languages = [data[37].lower()]
129 self.source_records = [self.source_id]
130 self.subjects = [
131 s.capitalize().replace('_', ', ')
132 for s in data[91:100]
133 # + data[101:120]
134 # + data[153:158]
135 if s
136 ]
137
138 # Inactive fields
139 self.copyright = data[19]
140 self.issn = data[54]
141 self.doi = data[145]
142 self.lccn = data[146]
143 self.dewey = data[49]
144 # physical_dimensions
145 # e.g. "5.4 x 4.7 x 0.2 inches"
146 self.length, self.width, self.height = data[40:43]
147
148 # Assert importable
149 for field in self.REQUIRED_FIELDS + ['isbn_13']:
150 assert getattr(self, field), field
151 assert (
152 self.primary_format not in self.NONBOOK
153 ), f"{self.primary_format} is NONBOOK"
154
155 @staticmethod
156 def contributors(data):
157 def make_author(name, _, typ):
158 author = {'name': name}
159 if typ == 'X':
160 # set corporate contributor
161 author['entity_type'] = 'org'
162 # TODO: sort out contributor types
163 # AU = author
164 # ED = editor
165 return author
166
167 contributors = (
168 (data[21 + i * 3], data[22 + i * 3], data[23 + i * 3]) for i in range(5)
169 )
170
171 # form list of author dicts
172 authors = [make_author(*c) for c in contributors if c[0]]
173 return authors
174
175 def json(self):
176 return {
177 field: getattr(self, field)
178 for field in self.ACTIVE_FIELDS
179 if getattr(self, field)
180 }
181
182
183 def load_state(path, logfile):
184 """Retrieves starting point from logfile, if log exists
185
186 Takes as input a path which expands to an ordered candidate list
187 of bettworldbks* filenames to process, the location of the
188 logfile, and determines which of those files are remaining, as
189 well as what our offset is in that file.
190
191 e.g. if we request path containing f1, f2, f3 and our log
192 says f2,100 then we start our processing at f2 at the 100th line.
193
194 This assumes the script is being called w/ e.g.:
195 /1/var/tmp/imports/2021-08/Bibliographic/*/
196 """
197 filenames = sorted(
198 os.path.join(path, f) for f in os.listdir(path) if f.startswith("bettworldbks")
199 )
200 try:
201 with open(logfile) as fin:
202 active_fname, offset = next(fin).strip().split(',')
203 unfinished_filenames = filenames[filenames.index(active_fname) :]
204 return unfinished_filenames, int(offset)
205 except (ValueError, OSError):
206 return filenames, 0
207
208
209 def update_state(logfile, fname, line_num=0):
210 """Records the last file we began processing and the current line"""
211 with open(logfile, 'w') as fout:
212 fout.write(f'{fname},{line_num}\n')
213
214
215 def csv_to_ol_json_item(line):
216 """converts a line to a book item"""
217 try:
218 data = line.decode().strip().split('|')
219 except UnicodeDecodeError:
220 data = line.decode('ISO-8859-1').strip().split('|')
221
222 b = Biblio(data)
223 return {'ia_id': b.source_id, 'data': b.json()}
224
225
226 def is_low_quality_book(book_item) -> bool:
227 """
228 Check if a book item is of low quality which means that 1) one of its authors
229 (regardless of case) is in the set of excluded authors.
230 """
231 authors = {a['name'].casefold() for a in book_item.get('authors') or []}
232 if authors & EXCLUDED_AUTHORS: # Leverage Python set intersection for speed.
233 return True
234
235 # A recent independently published book with excluded key words in its title
236 # (regardless of case) is also considered a low quality book.
237 title_words = set(re.split(r'\W+', book_item["title"].casefold()))
238 publishers = {p.casefold() for p in book_item.get('publishers') or []}
239 publish_year = int(book_item.get("publish_date", "0")[:4]) # YYYY
240 return bool(
241 "independently published" in publishers
242 and publish_year >= 2018
243 and title_words & EXCLUDED_INDEPENDENTLY_PUBLISHED_TITLES
244 )
245
246
247 def batch_import(path, batch, batch_size=5000):
248 logfile = os.path.join(path, 'import.log')
249 filenames, offset = load_state(path, logfile)
250
251 for fname in filenames:
252 book_items = []
253 with open(fname, 'rb') as f:
254 logger.info(f"Processing: {fname} from line {offset}")
255 for line_num, line in enumerate(f):
256
257 # skip over already processed records
258 if offset:
259 if offset > line_num:
260 continue
261 offset = 0
262
263 try:
264 book_item = csv_to_ol_json_item(line)
265 if not is_low_quality_book(book_item["data"]):
266 book_items.append(book_item)
267 except (AssertionError, IndexError) as e:
268 logger.info(f"Error: {e} from {line}")
269
270 # If we have enough items, submit a batch
271 if not ((line_num + 1) % batch_size):
272 batch.add_items(book_items)
273 update_state(logfile, fname, line_num)
274 book_items = [] # clear added items
275
276 # Add any remaining book_items to batch
277 if book_items:
278 batch.add_items(book_items)
279 update_state(logfile, fname, line_num)
280
281
282 def main(ol_config: str, batch_path: str):
283 load_config(ol_config)
284
285 # Partner data is offset ~15 days from start of month
286 date = datetime.date.today() - datetime.timedelta(days=15)
287 batch_name = "%s-%04d%02d" % ('bwb', date.year, date.month)
288 batch = Batch.find(batch_name) or Batch.new(batch_name)
289 batch_import(batch_path, batch)
290
291
292 if __name__ == '__main__':
293 FnToCLI(main).run()
294
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/scripts/partner_batch_imports.py b/scripts/partner_batch_imports.py
--- a/scripts/partner_batch_imports.py
+++ b/scripts/partner_batch_imports.py
@@ -10,10 +10,12 @@
PYTHONPATH=. python ./scripts/partner_batch_imports.py /olsystem/etc/openlibrary.yml
"""
+from collections.abc import Mapping
import datetime
import logging
import os
import re
+from typing import TypedDict, cast
import requests
@@ -244,6 +246,18 @@
)
+def is_published_in_future_year(book_item: Mapping[str, str | list]) -> bool:
+ """
+ Prevent import of books with a publication after the current year.
+
+ Some import sources have publication dates in a future year, and the likelihood
+ is high that this is bad data. So we don't want to import these.
+ """
+ publish_year = int(cast(str, book_item.get("publish_date", "0")[:4])) # YYYY
+ this_year = datetime.datetime.now().year
+ return publish_year > this_year
+
+
def batch_import(path, batch, batch_size=5000):
logfile = os.path.join(path, 'import.log')
filenames, offset = load_state(path, logfile)
@@ -262,7 +276,12 @@
try:
book_item = csv_to_ol_json_item(line)
- if not is_low_quality_book(book_item["data"]):
+ if not any(
+ [
+ is_low_quality_book(book_item["data"]),
+ is_published_in_future_year(book_item["data"]),
+ ]
+ ):
book_items.append(book_item)
except (AssertionError, IndexError) as e:
logger.info(f"Error: {e} from {line}")
|
{"golden_diff": "diff --git a/scripts/partner_batch_imports.py b/scripts/partner_batch_imports.py\n--- a/scripts/partner_batch_imports.py\n+++ b/scripts/partner_batch_imports.py\n@@ -10,10 +10,12 @@\n PYTHONPATH=. python ./scripts/partner_batch_imports.py /olsystem/etc/openlibrary.yml\n \"\"\"\n \n+from collections.abc import Mapping\n import datetime\n import logging\n import os\n import re\n+from typing import TypedDict, cast\n \n import requests\n \n@@ -244,6 +246,18 @@\n )\n \n \n+def is_published_in_future_year(book_item: Mapping[str, str | list]) -> bool:\n+ \"\"\"\n+ Prevent import of books with a publication after the current year.\n+\n+ Some import sources have publication dates in a future year, and the likelihood\n+ is high that this is bad data. So we don't want to import these.\n+ \"\"\"\n+ publish_year = int(cast(str, book_item.get(\"publish_date\", \"0\")[:4])) # YYYY\n+ this_year = datetime.datetime.now().year\n+ return publish_year > this_year\n+\n+\n def batch_import(path, batch, batch_size=5000):\n logfile = os.path.join(path, 'import.log')\n filenames, offset = load_state(path, logfile)\n@@ -262,7 +276,12 @@\n \n try:\n book_item = csv_to_ol_json_item(line)\n- if not is_low_quality_book(book_item[\"data\"]):\n+ if not any(\n+ [\n+ is_low_quality_book(book_item[\"data\"]),\n+ is_published_in_future_year(book_item[\"data\"]),\n+ ]\n+ ):\n book_items.append(book_item)\n except (AssertionError, IndexError) as e:\n logger.info(f\"Error: {e} from {line}\")\n", "issue": "partner_batch_imports.py should not import books published in a future year\n<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->\r\nPer the [Open-Mic topics](https://docs.google.com/document/d/1LEbzsLZ1F9_YIQOoZzO7GoZnG1z-rudhZ9HNtsameTc/edit#heading=h.swvutwwydubf) for the Open Library Community call on 2022-11-29, we should not import partner data for books purporting to be published in a future year, as this is resulting in bad records of books that may never exist.\r\n\r\n### Describe the problem that you'd like solved\r\n<!-- A clear and concise description of what you want to happen. -->\r\nWhen importing books, `partner_batch_imports.py` does not currently check if the `publish_date` is in a future year when importing. It should. E.g. if an import is attempted in the year 2022, it should not import a book purported to be published in 2023.\r\n\r\n### Proposal & Constraints\r\n<!-- What is the proposed solution / implementation? Is there a precedent of this approach succeeding elsewhere? -->\r\nThe proposed solution is to add a check to `batch_import()` in `partner_batch_imports.py` to ensure a book isn't purported to be published in a future year.\r\n\r\n<!-- Which suggestions or requirements should be considered for how feature needs to appear or be implemented? -->\r\n\r\n### Additional context\r\n<!-- Add any other context or screenshots about the feature request here. -->\r\nI will submit a PR to address this.\r\n\r\n### Stakeholders\r\n<!-- @ tag stakeholders of this bug -->\r\n@mekarpeles, @cdrini \r\n\r\n\r\n\n", "before_files": [{"content": "\"\"\"\nProcess partner bibliographic csv data into importable json book\nrecords and then batch submit into the ImportBot\n`import_item` table (http://openlibrary.org/admin/imports)\nwhich queues items to be imported via the\nOpen Library JSON import API: https://openlibrary.org/api/import\n\nTo Run:\n\nPYTHONPATH=. python ./scripts/partner_batch_imports.py /olsystem/etc/openlibrary.yml\n\"\"\"\n\nimport datetime\nimport logging\nimport os\nimport re\n\nimport requests\n\nfrom infogami import config # noqa: F401\nfrom openlibrary.config import load_config\nfrom openlibrary.core.imports import Batch\nfrom scripts.solr_builder.solr_builder.fn_to_cli import FnToCLI\n\nlogger = logging.getLogger(\"openlibrary.importer.bwb\")\n\nEXCLUDED_AUTHORS = {\n x.casefold()\n for x in (\n \"1570 publishing\",\n \"bahija\",\n \"bruna murino\",\n \"creative elegant edition\",\n \"delsee notebooks\",\n \"grace garcia\",\n \"holo\",\n \"jeryx publishing\",\n \"mado\",\n \"mazzo\",\n \"mikemix\",\n \"mitch allison\",\n \"pickleball publishing\",\n \"pizzelle passion\",\n \"punny cuaderno\",\n \"razal koraya\",\n \"t. d. publishing\",\n \"tobias publishing\",\n )\n}\n\nEXCLUDED_INDEPENDENTLY_PUBLISHED_TITLES = {\n x.casefold()\n for x in (\n # Noisy classic re-prints\n 'annotated',\n 'annot\u00e9',\n 'classic',\n 'classics',\n 'illustarted', # Some books have typos in their titles!\n 'illustrated',\n 'Illustr\u00e9e',\n 'original',\n 'summary',\n 'version',\n # Not a book\n 'calendar',\n 'diary',\n 'journal',\n 'logbook',\n 'notebook',\n 'notizbuch',\n 'planner',\n 'sketchbook',\n )\n}\n\nSCHEMA_URL = (\n \"https://raw.githubusercontent.com/internetarchive\"\n \"/openlibrary-client/master/olclient/schemata/import.schema.json\"\n)\n\n\nclass Biblio:\n\n ACTIVE_FIELDS = [\n 'title',\n 'isbn_13',\n 'publish_date',\n 'publishers',\n 'weight',\n 'authors',\n 'lc_classifications',\n 'pagination',\n 'languages',\n 'subjects',\n 'source_records',\n ]\n INACTIVE_FIELDS = [\n \"copyright\",\n \"issn\",\n \"doi\",\n \"lccn\",\n \"dewey\",\n \"length\",\n \"width\",\n \"height\",\n ]\n REQUIRED_FIELDS = requests.get(SCHEMA_URL).json()['required']\n\n NONBOOK = \"\"\"A2 AA AB AJ AVI AZ BK BM C3 CD CE CF CR CRM CRW CX D3 DA DD DF DI DL\n DO DR DRM DRW DS DV EC FC FI FM FR FZ GB GC GM GR H3 H5 L3 L5 LP MAC MC MF MG MH ML\n MS MSX MZ N64 NGA NGB NGC NGE NT OR OS PC PP PRP PS PSC PY QU RE RV SA SD SG SH SK\n SL SMD SN SO SO1 SO2 SR SU TA TB TR TS TY UX V35 V8 VC VD VE VF VK VM VN VO VP VS\n VU VY VZ WA WC WI WL WM WP WT WX XL XZ ZF ZZ\"\"\".split()\n\n def __init__(self, data):\n self.isbn = data[124]\n self.source_id = f'bwb:{self.isbn}'\n self.isbn_13 = [self.isbn]\n self.title = data[10]\n self.primary_format = data[6]\n self.publish_date = data[20][:4] # YYYY, YYYYMMDD\n self.publishers = [data[135]]\n self.weight = data[39]\n self.authors = self.contributors(data)\n self.lc_classifications = [data[147]] if data[147] else []\n self.pagination = data[36]\n self.languages = [data[37].lower()]\n self.source_records = [self.source_id]\n self.subjects = [\n s.capitalize().replace('_', ', ')\n for s in data[91:100]\n # + data[101:120]\n # + data[153:158]\n if s\n ]\n\n # Inactive fields\n self.copyright = data[19]\n self.issn = data[54]\n self.doi = data[145]\n self.lccn = data[146]\n self.dewey = data[49]\n # physical_dimensions\n # e.g. \"5.4 x 4.7 x 0.2 inches\"\n self.length, self.width, self.height = data[40:43]\n\n # Assert importable\n for field in self.REQUIRED_FIELDS + ['isbn_13']:\n assert getattr(self, field), field\n assert (\n self.primary_format not in self.NONBOOK\n ), f\"{self.primary_format} is NONBOOK\"\n\n @staticmethod\n def contributors(data):\n def make_author(name, _, typ):\n author = {'name': name}\n if typ == 'X':\n # set corporate contributor\n author['entity_type'] = 'org'\n # TODO: sort out contributor types\n # AU = author\n # ED = editor\n return author\n\n contributors = (\n (data[21 + i * 3], data[22 + i * 3], data[23 + i * 3]) for i in range(5)\n )\n\n # form list of author dicts\n authors = [make_author(*c) for c in contributors if c[0]]\n return authors\n\n def json(self):\n return {\n field: getattr(self, field)\n for field in self.ACTIVE_FIELDS\n if getattr(self, field)\n }\n\n\ndef load_state(path, logfile):\n \"\"\"Retrieves starting point from logfile, if log exists\n\n Takes as input a path which expands to an ordered candidate list\n of bettworldbks* filenames to process, the location of the\n logfile, and determines which of those files are remaining, as\n well as what our offset is in that file.\n\n e.g. if we request path containing f1, f2, f3 and our log\n says f2,100 then we start our processing at f2 at the 100th line.\n\n This assumes the script is being called w/ e.g.:\n /1/var/tmp/imports/2021-08/Bibliographic/*/\n \"\"\"\n filenames = sorted(\n os.path.join(path, f) for f in os.listdir(path) if f.startswith(\"bettworldbks\")\n )\n try:\n with open(logfile) as fin:\n active_fname, offset = next(fin).strip().split(',')\n unfinished_filenames = filenames[filenames.index(active_fname) :]\n return unfinished_filenames, int(offset)\n except (ValueError, OSError):\n return filenames, 0\n\n\ndef update_state(logfile, fname, line_num=0):\n \"\"\"Records the last file we began processing and the current line\"\"\"\n with open(logfile, 'w') as fout:\n fout.write(f'{fname},{line_num}\\n')\n\n\ndef csv_to_ol_json_item(line):\n \"\"\"converts a line to a book item\"\"\"\n try:\n data = line.decode().strip().split('|')\n except UnicodeDecodeError:\n data = line.decode('ISO-8859-1').strip().split('|')\n\n b = Biblio(data)\n return {'ia_id': b.source_id, 'data': b.json()}\n\n\ndef is_low_quality_book(book_item) -> bool:\n \"\"\"\n Check if a book item is of low quality which means that 1) one of its authors\n (regardless of case) is in the set of excluded authors.\n \"\"\"\n authors = {a['name'].casefold() for a in book_item.get('authors') or []}\n if authors & EXCLUDED_AUTHORS: # Leverage Python set intersection for speed.\n return True\n\n # A recent independently published book with excluded key words in its title\n # (regardless of case) is also considered a low quality book.\n title_words = set(re.split(r'\\W+', book_item[\"title\"].casefold()))\n publishers = {p.casefold() for p in book_item.get('publishers') or []}\n publish_year = int(book_item.get(\"publish_date\", \"0\")[:4]) # YYYY\n return bool(\n \"independently published\" in publishers\n and publish_year >= 2018\n and title_words & EXCLUDED_INDEPENDENTLY_PUBLISHED_TITLES\n )\n\n\ndef batch_import(path, batch, batch_size=5000):\n logfile = os.path.join(path, 'import.log')\n filenames, offset = load_state(path, logfile)\n\n for fname in filenames:\n book_items = []\n with open(fname, 'rb') as f:\n logger.info(f\"Processing: {fname} from line {offset}\")\n for line_num, line in enumerate(f):\n\n # skip over already processed records\n if offset:\n if offset > line_num:\n continue\n offset = 0\n\n try:\n book_item = csv_to_ol_json_item(line)\n if not is_low_quality_book(book_item[\"data\"]):\n book_items.append(book_item)\n except (AssertionError, IndexError) as e:\n logger.info(f\"Error: {e} from {line}\")\n\n # If we have enough items, submit a batch\n if not ((line_num + 1) % batch_size):\n batch.add_items(book_items)\n update_state(logfile, fname, line_num)\n book_items = [] # clear added items\n\n # Add any remaining book_items to batch\n if book_items:\n batch.add_items(book_items)\n update_state(logfile, fname, line_num)\n\n\ndef main(ol_config: str, batch_path: str):\n load_config(ol_config)\n\n # Partner data is offset ~15 days from start of month\n date = datetime.date.today() - datetime.timedelta(days=15)\n batch_name = \"%s-%04d%02d\" % ('bwb', date.year, date.month)\n batch = Batch.find(batch_name) or Batch.new(batch_name)\n batch_import(batch_path, batch)\n\n\nif __name__ == '__main__':\n FnToCLI(main).run()\n", "path": "scripts/partner_batch_imports.py"}], "after_files": [{"content": "\"\"\"\nProcess partner bibliographic csv data into importable json book\nrecords and then batch submit into the ImportBot\n`import_item` table (http://openlibrary.org/admin/imports)\nwhich queues items to be imported via the\nOpen Library JSON import API: https://openlibrary.org/api/import\n\nTo Run:\n\nPYTHONPATH=. python ./scripts/partner_batch_imports.py /olsystem/etc/openlibrary.yml\n\"\"\"\n\nfrom collections.abc import Mapping\nimport datetime\nimport logging\nimport os\nimport re\nfrom typing import TypedDict, cast\n\nimport requests\n\nfrom infogami import config # noqa: F401\nfrom openlibrary.config import load_config\nfrom openlibrary.core.imports import Batch\nfrom scripts.solr_builder.solr_builder.fn_to_cli import FnToCLI\n\nlogger = logging.getLogger(\"openlibrary.importer.bwb\")\n\nEXCLUDED_AUTHORS = {\n x.casefold()\n for x in (\n \"1570 publishing\",\n \"bahija\",\n \"bruna murino\",\n \"creative elegant edition\",\n \"delsee notebooks\",\n \"grace garcia\",\n \"holo\",\n \"jeryx publishing\",\n \"mado\",\n \"mazzo\",\n \"mikemix\",\n \"mitch allison\",\n \"pickleball publishing\",\n \"pizzelle passion\",\n \"punny cuaderno\",\n \"razal koraya\",\n \"t. d. publishing\",\n \"tobias publishing\",\n )\n}\n\nEXCLUDED_INDEPENDENTLY_PUBLISHED_TITLES = {\n x.casefold()\n for x in (\n # Noisy classic re-prints\n 'annotated',\n 'annot\u00e9',\n 'classic',\n 'classics',\n 'illustarted', # Some books have typos in their titles!\n 'illustrated',\n 'Illustr\u00e9e',\n 'original',\n 'summary',\n 'version',\n # Not a book\n 'calendar',\n 'diary',\n 'journal',\n 'logbook',\n 'notebook',\n 'notizbuch',\n 'planner',\n 'sketchbook',\n )\n}\n\nSCHEMA_URL = (\n \"https://raw.githubusercontent.com/internetarchive\"\n \"/openlibrary-client/master/olclient/schemata/import.schema.json\"\n)\n\n\nclass Biblio:\n\n ACTIVE_FIELDS = [\n 'title',\n 'isbn_13',\n 'publish_date',\n 'publishers',\n 'weight',\n 'authors',\n 'lc_classifications',\n 'pagination',\n 'languages',\n 'subjects',\n 'source_records',\n ]\n INACTIVE_FIELDS = [\n \"copyright\",\n \"issn\",\n \"doi\",\n \"lccn\",\n \"dewey\",\n \"length\",\n \"width\",\n \"height\",\n ]\n REQUIRED_FIELDS = requests.get(SCHEMA_URL).json()['required']\n\n NONBOOK = \"\"\"A2 AA AB AJ AVI AZ BK BM C3 CD CE CF CR CRM CRW CX D3 DA DD DF DI DL\n DO DR DRM DRW DS DV EC FC FI FM FR FZ GB GC GM GR H3 H5 L3 L5 LP MAC MC MF MG MH ML\n MS MSX MZ N64 NGA NGB NGC NGE NT OR OS PC PP PRP PS PSC PY QU RE RV SA SD SG SH SK\n SL SMD SN SO SO1 SO2 SR SU TA TB TR TS TY UX V35 V8 VC VD VE VF VK VM VN VO VP VS\n VU VY VZ WA WC WI WL WM WP WT WX XL XZ ZF ZZ\"\"\".split()\n\n def __init__(self, data):\n self.isbn = data[124]\n self.source_id = f'bwb:{self.isbn}'\n self.isbn_13 = [self.isbn]\n self.title = data[10]\n self.primary_format = data[6]\n self.publish_date = data[20][:4] # YYYY, YYYYMMDD\n self.publishers = [data[135]]\n self.weight = data[39]\n self.authors = self.contributors(data)\n self.lc_classifications = [data[147]] if data[147] else []\n self.pagination = data[36]\n self.languages = [data[37].lower()]\n self.source_records = [self.source_id]\n self.subjects = [\n s.capitalize().replace('_', ', ')\n for s in data[91:100]\n # + data[101:120]\n # + data[153:158]\n if s\n ]\n\n # Inactive fields\n self.copyright = data[19]\n self.issn = data[54]\n self.doi = data[145]\n self.lccn = data[146]\n self.dewey = data[49]\n # physical_dimensions\n # e.g. \"5.4 x 4.7 x 0.2 inches\"\n self.length, self.width, self.height = data[40:43]\n\n # Assert importable\n for field in self.REQUIRED_FIELDS + ['isbn_13']:\n assert getattr(self, field), field\n assert (\n self.primary_format not in self.NONBOOK\n ), f\"{self.primary_format} is NONBOOK\"\n\n @staticmethod\n def contributors(data):\n def make_author(name, _, typ):\n author = {'name': name}\n if typ == 'X':\n # set corporate contributor\n author['entity_type'] = 'org'\n # TODO: sort out contributor types\n # AU = author\n # ED = editor\n return author\n\n contributors = (\n (data[21 + i * 3], data[22 + i * 3], data[23 + i * 3]) for i in range(5)\n )\n\n # form list of author dicts\n authors = [make_author(*c) for c in contributors if c[0]]\n return authors\n\n def json(self):\n return {\n field: getattr(self, field)\n for field in self.ACTIVE_FIELDS\n if getattr(self, field)\n }\n\n\ndef load_state(path, logfile):\n \"\"\"Retrieves starting point from logfile, if log exists\n\n Takes as input a path which expands to an ordered candidate list\n of bettworldbks* filenames to process, the location of the\n logfile, and determines which of those files are remaining, as\n well as what our offset is in that file.\n\n e.g. if we request path containing f1, f2, f3 and our log\n says f2,100 then we start our processing at f2 at the 100th line.\n\n This assumes the script is being called w/ e.g.:\n /1/var/tmp/imports/2021-08/Bibliographic/*/\n \"\"\"\n filenames = sorted(\n os.path.join(path, f) for f in os.listdir(path) if f.startswith(\"bettworldbks\")\n )\n try:\n with open(logfile) as fin:\n active_fname, offset = next(fin).strip().split(',')\n unfinished_filenames = filenames[filenames.index(active_fname) :]\n return unfinished_filenames, int(offset)\n except (ValueError, OSError):\n return filenames, 0\n\n\ndef update_state(logfile, fname, line_num=0):\n \"\"\"Records the last file we began processing and the current line\"\"\"\n with open(logfile, 'w') as fout:\n fout.write(f'{fname},{line_num}\\n')\n\n\ndef csv_to_ol_json_item(line):\n \"\"\"converts a line to a book item\"\"\"\n try:\n data = line.decode().strip().split('|')\n except UnicodeDecodeError:\n data = line.decode('ISO-8859-1').strip().split('|')\n\n b = Biblio(data)\n return {'ia_id': b.source_id, 'data': b.json()}\n\n\ndef is_low_quality_book(book_item) -> bool:\n \"\"\"\n Check if a book item is of low quality which means that 1) one of its authors\n (regardless of case) is in the set of excluded authors.\n \"\"\"\n authors = {a['name'].casefold() for a in book_item.get('authors') or []}\n if authors & EXCLUDED_AUTHORS: # Leverage Python set intersection for speed.\n return True\n\n # A recent independently published book with excluded key words in its title\n # (regardless of case) is also considered a low quality book.\n title_words = set(re.split(r'\\W+', book_item[\"title\"].casefold()))\n publishers = {p.casefold() for p in book_item.get('publishers') or []}\n publish_year = int(book_item.get(\"publish_date\", \"0\")[:4]) # YYYY\n return bool(\n \"independently published\" in publishers\n and publish_year >= 2018\n and title_words & EXCLUDED_INDEPENDENTLY_PUBLISHED_TITLES\n )\n\n\ndef is_published_in_future_year(book_item: Mapping[str, str | list]) -> bool:\n \"\"\"\n Prevent import of books with a publication after the current year.\n\n Some import sources have publication dates in a future year, and the likelihood\n is high that this is bad data. So we don't want to import these.\n \"\"\"\n publish_year = int(cast(str, book_item.get(\"publish_date\", \"0\")[:4])) # YYYY\n this_year = datetime.datetime.now().year\n return publish_year > this_year\n\n\ndef batch_import(path, batch, batch_size=5000):\n logfile = os.path.join(path, 'import.log')\n filenames, offset = load_state(path, logfile)\n\n for fname in filenames:\n book_items = []\n with open(fname, 'rb') as f:\n logger.info(f\"Processing: {fname} from line {offset}\")\n for line_num, line in enumerate(f):\n\n # skip over already processed records\n if offset:\n if offset > line_num:\n continue\n offset = 0\n\n try:\n book_item = csv_to_ol_json_item(line)\n if not any(\n [\n is_low_quality_book(book_item[\"data\"]),\n is_published_in_future_year(book_item[\"data\"]),\n ]\n ):\n book_items.append(book_item)\n except (AssertionError, IndexError) as e:\n logger.info(f\"Error: {e} from {line}\")\n\n # If we have enough items, submit a batch\n if not ((line_num + 1) % batch_size):\n batch.add_items(book_items)\n update_state(logfile, fname, line_num)\n book_items = [] # clear added items\n\n # Add any remaining book_items to batch\n if book_items:\n batch.add_items(book_items)\n update_state(logfile, fname, line_num)\n\n\ndef main(ol_config: str, batch_path: str):\n load_config(ol_config)\n\n # Partner data is offset ~15 days from start of month\n date = datetime.date.today() - datetime.timedelta(days=15)\n batch_name = \"%s-%04d%02d\" % ('bwb', date.year, date.month)\n batch = Batch.find(batch_name) or Batch.new(batch_name)\n batch_import(batch_path, batch)\n\n\nif __name__ == '__main__':\n FnToCLI(main).run()\n", "path": "scripts/partner_batch_imports.py"}]}
| 3,775 | 405 |
gh_patches_debug_20166
|
rasdani/github-patches
|
git_diff
|
marshmallow-code__webargs-680
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
typing issue with __version_info__ += __parsed_version__.pre
mypy issue:
```
__version_info__ += __parsed_version__.pre
```
```
src/webargs/__init__.py:14: error: Unsupported operand types for + ("Tuple[int, ...]" and "Tuple[str, int]")
```
Not sure what the problem is. I'm tempted to just add a `# type: ignore`. Any better idea, anyone?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/webargs/__init__.py`
Content:
```
1 from packaging.version import Version
2 from marshmallow.utils import missing
3
4 # Make marshmallow's validation functions importable from webargs
5 from marshmallow import validate
6
7 from webargs.core import ValidationError
8 from webargs import fields
9
10 __version__ = "8.0.1"
11 __parsed_version__ = Version(__version__)
12 __version_info__ = __parsed_version__.release
13 if __parsed_version__.pre:
14 __version_info__ += __parsed_version__.pre
15 __all__ = ("ValidationError", "fields", "missing", "validate")
16
```
Path: `setup.py`
Content:
```
1 import re
2 from setuptools import setup, find_packages
3
4 FRAMEWORKS = [
5 "Flask>=0.12.5",
6 "Django>=2.2.0",
7 "bottle>=0.12.13",
8 "tornado>=4.5.2",
9 "pyramid>=1.9.1",
10 "falcon>=2.0.0",
11 "aiohttp>=3.0.8",
12 ]
13 EXTRAS_REQUIRE = {
14 "frameworks": FRAMEWORKS,
15 "tests": [
16 "pytest",
17 "webtest==3.0.0",
18 "webtest-aiohttp==2.0.0",
19 "pytest-aiohttp>=0.3.0",
20 ]
21 + FRAMEWORKS,
22 "lint": [
23 "mypy==0.910",
24 "flake8==4.0.1",
25 "flake8-bugbear==21.11.29",
26 "pre-commit~=2.4",
27 ],
28 "docs": [
29 "Sphinx==4.3.2",
30 "sphinx-issues==2.0.0",
31 "furo==2022.1.2",
32 ]
33 + FRAMEWORKS,
34 }
35 EXTRAS_REQUIRE["dev"] = EXTRAS_REQUIRE["tests"] + EXTRAS_REQUIRE["lint"] + ["tox"]
36
37
38 def find_version(fname):
39 """Attempts to find the version number in the file names fname.
40 Raises RuntimeError if not found.
41 """
42 version = ""
43 with open(fname) as fp:
44 reg = re.compile(r'__version__ = [\'"]([^\'"]*)[\'"]')
45 for line in fp:
46 m = reg.match(line)
47 if m:
48 version = m.group(1)
49 break
50 if not version:
51 raise RuntimeError("Cannot find version information")
52 return version
53
54
55 def read(fname):
56 with open(fname) as fp:
57 content = fp.read()
58 return content
59
60
61 setup(
62 name="webargs",
63 version=find_version("src/webargs/__init__.py"),
64 description=(
65 "Declarative parsing and validation of HTTP request objects, "
66 "with built-in support for popular web frameworks, including "
67 "Flask, Django, Bottle, Tornado, Pyramid, Falcon, and aiohttp."
68 ),
69 long_description=read("README.rst"),
70 author="Steven Loria",
71 author_email="[email protected]",
72 url="https://github.com/marshmallow-code/webargs",
73 packages=find_packages("src"),
74 package_dir={"": "src"},
75 package_data={"webargs": ["py.typed"]},
76 install_requires=["marshmallow>=3.0.0", "packaging"],
77 extras_require=EXTRAS_REQUIRE,
78 license="MIT",
79 zip_safe=False,
80 keywords=(
81 "webargs",
82 "http",
83 "flask",
84 "django",
85 "bottle",
86 "tornado",
87 "aiohttp",
88 "request",
89 "arguments",
90 "validation",
91 "parameters",
92 "rest",
93 "api",
94 "marshmallow",
95 ),
96 python_requires=">=3.7",
97 classifiers=[
98 "Development Status :: 5 - Production/Stable",
99 "Intended Audience :: Developers",
100 "License :: OSI Approved :: MIT License",
101 "Natural Language :: English",
102 "Programming Language :: Python :: 3",
103 "Programming Language :: Python :: 3.7",
104 "Programming Language :: Python :: 3.8",
105 "Programming Language :: Python :: 3.9",
106 "Programming Language :: Python :: 3.10",
107 "Programming Language :: Python :: 3 :: Only",
108 "Topic :: Internet :: WWW/HTTP :: Dynamic Content",
109 "Topic :: Internet :: WWW/HTTP :: WSGI :: Application",
110 ],
111 test_suite="tests",
112 project_urls={
113 "Changelog": "https://webargs.readthedocs.io/en/latest/changelog.html",
114 "Issues": "https://github.com/marshmallow-code/webargs/issues",
115 "Funding": "https://opencollective.com/marshmallow",
116 "Tidelift": "https://tidelift.com/subscription/pkg/pypi-webargs?utm_source=pypi-marshmallow&utm_medium=pypi", # noqa
117 },
118 )
119
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -20,7 +20,7 @@
]
+ FRAMEWORKS,
"lint": [
- "mypy==0.910",
+ "mypy==0.930",
"flake8==4.0.1",
"flake8-bugbear==21.11.29",
"pre-commit~=2.4",
diff --git a/src/webargs/__init__.py b/src/webargs/__init__.py
--- a/src/webargs/__init__.py
+++ b/src/webargs/__init__.py
@@ -1,3 +1,5 @@
+from __future__ import annotations
+
from packaging.version import Version
from marshmallow.utils import missing
@@ -9,7 +11,9 @@
__version__ = "8.0.1"
__parsed_version__ = Version(__version__)
-__version_info__ = __parsed_version__.release
+__version_info__: tuple[int, int, int] | tuple[
+ int, int, int, str, int
+] = __parsed_version__.release # type: ignore[assignment]
if __parsed_version__.pre:
- __version_info__ += __parsed_version__.pre
+ __version_info__ += __parsed_version__.pre # type: ignore[assignment]
__all__ = ("ValidationError", "fields", "missing", "validate")
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -20,7 +20,7 @@\n ]\n + FRAMEWORKS,\n \"lint\": [\n- \"mypy==0.910\",\n+ \"mypy==0.930\",\n \"flake8==4.0.1\",\n \"flake8-bugbear==21.11.29\",\n \"pre-commit~=2.4\",\ndiff --git a/src/webargs/__init__.py b/src/webargs/__init__.py\n--- a/src/webargs/__init__.py\n+++ b/src/webargs/__init__.py\n@@ -1,3 +1,5 @@\n+from __future__ import annotations\n+\n from packaging.version import Version\n from marshmallow.utils import missing\n \n@@ -9,7 +11,9 @@\n \n __version__ = \"8.0.1\"\n __parsed_version__ = Version(__version__)\n-__version_info__ = __parsed_version__.release\n+__version_info__: tuple[int, int, int] | tuple[\n+ int, int, int, str, int\n+] = __parsed_version__.release # type: ignore[assignment]\n if __parsed_version__.pre:\n- __version_info__ += __parsed_version__.pre\n+ __version_info__ += __parsed_version__.pre # type: ignore[assignment]\n __all__ = (\"ValidationError\", \"fields\", \"missing\", \"validate\")\n", "issue": "typing issue with __version_info__ += __parsed_version__.pre\nmypy issue:\r\n\r\n```\r\n __version_info__ += __parsed_version__.pre\r\n```\r\n\r\n```\r\nsrc/webargs/__init__.py:14: error: Unsupported operand types for + (\"Tuple[int, ...]\" and \"Tuple[str, int]\")\r\n```\r\n\r\nNot sure what the problem is. I'm tempted to just add a `# type: ignore`. Any better idea, anyone?\n", "before_files": [{"content": "from packaging.version import Version\nfrom marshmallow.utils import missing\n\n# Make marshmallow's validation functions importable from webargs\nfrom marshmallow import validate\n\nfrom webargs.core import ValidationError\nfrom webargs import fields\n\n__version__ = \"8.0.1\"\n__parsed_version__ = Version(__version__)\n__version_info__ = __parsed_version__.release\nif __parsed_version__.pre:\n __version_info__ += __parsed_version__.pre\n__all__ = (\"ValidationError\", \"fields\", \"missing\", \"validate\")\n", "path": "src/webargs/__init__.py"}, {"content": "import re\nfrom setuptools import setup, find_packages\n\nFRAMEWORKS = [\n \"Flask>=0.12.5\",\n \"Django>=2.2.0\",\n \"bottle>=0.12.13\",\n \"tornado>=4.5.2\",\n \"pyramid>=1.9.1\",\n \"falcon>=2.0.0\",\n \"aiohttp>=3.0.8\",\n]\nEXTRAS_REQUIRE = {\n \"frameworks\": FRAMEWORKS,\n \"tests\": [\n \"pytest\",\n \"webtest==3.0.0\",\n \"webtest-aiohttp==2.0.0\",\n \"pytest-aiohttp>=0.3.0\",\n ]\n + FRAMEWORKS,\n \"lint\": [\n \"mypy==0.910\",\n \"flake8==4.0.1\",\n \"flake8-bugbear==21.11.29\",\n \"pre-commit~=2.4\",\n ],\n \"docs\": [\n \"Sphinx==4.3.2\",\n \"sphinx-issues==2.0.0\",\n \"furo==2022.1.2\",\n ]\n + FRAMEWORKS,\n}\nEXTRAS_REQUIRE[\"dev\"] = EXTRAS_REQUIRE[\"tests\"] + EXTRAS_REQUIRE[\"lint\"] + [\"tox\"]\n\n\ndef find_version(fname):\n \"\"\"Attempts to find the version number in the file names fname.\n Raises RuntimeError if not found.\n \"\"\"\n version = \"\"\n with open(fname) as fp:\n reg = re.compile(r'__version__ = [\\'\"]([^\\'\"]*)[\\'\"]')\n for line in fp:\n m = reg.match(line)\n if m:\n version = m.group(1)\n break\n if not version:\n raise RuntimeError(\"Cannot find version information\")\n return version\n\n\ndef read(fname):\n with open(fname) as fp:\n content = fp.read()\n return content\n\n\nsetup(\n name=\"webargs\",\n version=find_version(\"src/webargs/__init__.py\"),\n description=(\n \"Declarative parsing and validation of HTTP request objects, \"\n \"with built-in support for popular web frameworks, including \"\n \"Flask, Django, Bottle, Tornado, Pyramid, Falcon, and aiohttp.\"\n ),\n long_description=read(\"README.rst\"),\n author=\"Steven Loria\",\n author_email=\"[email protected]\",\n url=\"https://github.com/marshmallow-code/webargs\",\n packages=find_packages(\"src\"),\n package_dir={\"\": \"src\"},\n package_data={\"webargs\": [\"py.typed\"]},\n install_requires=[\"marshmallow>=3.0.0\", \"packaging\"],\n extras_require=EXTRAS_REQUIRE,\n license=\"MIT\",\n zip_safe=False,\n keywords=(\n \"webargs\",\n \"http\",\n \"flask\",\n \"django\",\n \"bottle\",\n \"tornado\",\n \"aiohttp\",\n \"request\",\n \"arguments\",\n \"validation\",\n \"parameters\",\n \"rest\",\n \"api\",\n \"marshmallow\",\n ),\n python_requires=\">=3.7\",\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: MIT License\",\n \"Natural Language :: English\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Programming Language :: Python :: 3 :: Only\",\n \"Topic :: Internet :: WWW/HTTP :: Dynamic Content\",\n \"Topic :: Internet :: WWW/HTTP :: WSGI :: Application\",\n ],\n test_suite=\"tests\",\n project_urls={\n \"Changelog\": \"https://webargs.readthedocs.io/en/latest/changelog.html\",\n \"Issues\": \"https://github.com/marshmallow-code/webargs/issues\",\n \"Funding\": \"https://opencollective.com/marshmallow\",\n \"Tidelift\": \"https://tidelift.com/subscription/pkg/pypi-webargs?utm_source=pypi-marshmallow&utm_medium=pypi\", # noqa\n },\n)\n", "path": "setup.py"}], "after_files": [{"content": "from __future__ import annotations\n\nfrom packaging.version import Version\nfrom marshmallow.utils import missing\n\n# Make marshmallow's validation functions importable from webargs\nfrom marshmallow import validate\n\nfrom webargs.core import ValidationError\nfrom webargs import fields\n\n__version__ = \"8.0.1\"\n__parsed_version__ = Version(__version__)\n__version_info__: tuple[int, int, int] | tuple[\n int, int, int, str, int\n] = __parsed_version__.release # type: ignore[assignment]\nif __parsed_version__.pre:\n __version_info__ += __parsed_version__.pre # type: ignore[assignment]\n__all__ = (\"ValidationError\", \"fields\", \"missing\", \"validate\")\n", "path": "src/webargs/__init__.py"}, {"content": "import re\nfrom setuptools import setup, find_packages\n\nFRAMEWORKS = [\n \"Flask>=0.12.5\",\n \"Django>=2.2.0\",\n \"bottle>=0.12.13\",\n \"tornado>=4.5.2\",\n \"pyramid>=1.9.1\",\n \"falcon>=2.0.0\",\n \"aiohttp>=3.0.8\",\n]\nEXTRAS_REQUIRE = {\n \"frameworks\": FRAMEWORKS,\n \"tests\": [\n \"pytest\",\n \"webtest==3.0.0\",\n \"webtest-aiohttp==2.0.0\",\n \"pytest-aiohttp>=0.3.0\",\n ]\n + FRAMEWORKS,\n \"lint\": [\n \"mypy==0.930\",\n \"flake8==4.0.1\",\n \"flake8-bugbear==21.11.29\",\n \"pre-commit~=2.4\",\n ],\n \"docs\": [\n \"Sphinx==4.3.2\",\n \"sphinx-issues==2.0.0\",\n \"furo==2022.1.2\",\n ]\n + FRAMEWORKS,\n}\nEXTRAS_REQUIRE[\"dev\"] = EXTRAS_REQUIRE[\"tests\"] + EXTRAS_REQUIRE[\"lint\"] + [\"tox\"]\n\n\ndef find_version(fname):\n \"\"\"Attempts to find the version number in the file names fname.\n Raises RuntimeError if not found.\n \"\"\"\n version = \"\"\n with open(fname) as fp:\n reg = re.compile(r'__version__ = [\\'\"]([^\\'\"]*)[\\'\"]')\n for line in fp:\n m = reg.match(line)\n if m:\n version = m.group(1)\n break\n if not version:\n raise RuntimeError(\"Cannot find version information\")\n return version\n\n\ndef read(fname):\n with open(fname) as fp:\n content = fp.read()\n return content\n\n\nsetup(\n name=\"webargs\",\n version=find_version(\"src/webargs/__init__.py\"),\n description=(\n \"Declarative parsing and validation of HTTP request objects, \"\n \"with built-in support for popular web frameworks, including \"\n \"Flask, Django, Bottle, Tornado, Pyramid, Falcon, and aiohttp.\"\n ),\n long_description=read(\"README.rst\"),\n author=\"Steven Loria\",\n author_email=\"[email protected]\",\n url=\"https://github.com/marshmallow-code/webargs\",\n packages=find_packages(\"src\"),\n package_dir={\"\": \"src\"},\n package_data={\"webargs\": [\"py.typed\"]},\n install_requires=[\"marshmallow>=3.0.0\", \"packaging\"],\n extras_require=EXTRAS_REQUIRE,\n license=\"MIT\",\n zip_safe=False,\n keywords=(\n \"webargs\",\n \"http\",\n \"flask\",\n \"django\",\n \"bottle\",\n \"tornado\",\n \"aiohttp\",\n \"request\",\n \"arguments\",\n \"validation\",\n \"parameters\",\n \"rest\",\n \"api\",\n \"marshmallow\",\n ),\n python_requires=\">=3.7\",\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: MIT License\",\n \"Natural Language :: English\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Programming Language :: Python :: 3 :: Only\",\n \"Topic :: Internet :: WWW/HTTP :: Dynamic Content\",\n \"Topic :: Internet :: WWW/HTTP :: WSGI :: Application\",\n ],\n test_suite=\"tests\",\n project_urls={\n \"Changelog\": \"https://webargs.readthedocs.io/en/latest/changelog.html\",\n \"Issues\": \"https://github.com/marshmallow-code/webargs/issues\",\n \"Funding\": \"https://opencollective.com/marshmallow\",\n \"Tidelift\": \"https://tidelift.com/subscription/pkg/pypi-webargs?utm_source=pypi-marshmallow&utm_medium=pypi\", # noqa\n },\n)\n", "path": "setup.py"}]}
| 1,699 | 320 |
gh_patches_debug_50867
|
rasdani/github-patches
|
git_diff
|
spyder-ide__spyder-8896
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
spyder 3.3.3 icon theme Spyder 3 problem with PyQt 5.12
## Problem Description
After updating to Spyder 3.3.3 (on Linux, with Python 3.6.7 64-bit | | Qt 5.12.1 | PyQt5 5.12 ) spyder icon theme "Spyder 3" stopped working (because of coming with this version PyQt upgrade probably) . Only the "Spyder 2" icon theme is working.
Below the look of Spyder3 icon theme

After reverting to PyQt 5.9.2 the icon set Spyder3 is working again.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 #
3 # Copyright © Spyder Project Contributors
4 # Licensed under the terms of the MIT License
5 # (see spyder/__init__.py for details)
6
7 """
8 Spyder
9 ======
10
11 The Scientific Python Development Environment
12
13 Spyder is a powerful scientific environment written in Python, for Python,
14 and designed by and for scientists, engineers and data analysts.
15
16 It features a unique combination of the advanced editing, analysis, debugging
17 and profiling functionality of a comprehensive development tool with the data
18 exploration, interactive execution, deep inspection and beautiful visualization
19 capabilities of a scientific package.
20 """
21
22 from __future__ import print_function
23
24 import os
25 import os.path as osp
26 import subprocess
27 import sys
28 import shutil
29
30 from distutils.core import setup
31 from distutils.command.install_data import install_data
32
33
34 #==============================================================================
35 # Check for Python 3
36 #==============================================================================
37 PY3 = sys.version_info[0] == 3
38
39
40 #==============================================================================
41 # Minimal Python version sanity check
42 # Taken from the notebook setup.py -- Modified BSD License
43 #==============================================================================
44 v = sys.version_info
45 if v[:2] < (2, 7) or (v[0] >= 3 and v[:2] < (3, 4)):
46 error = "ERROR: Spyder requires Python version 2.7 or 3.4 and above."
47 print(error, file=sys.stderr)
48 sys.exit(1)
49
50
51 #==============================================================================
52 # Constants
53 #==============================================================================
54 NAME = 'spyder'
55 LIBNAME = 'spyder'
56 from spyder import __version__, __website_url__ #analysis:ignore
57
58
59 #==============================================================================
60 # Auxiliary functions
61 #==============================================================================
62 def get_package_data(name, extlist):
63 """Return data files for package *name* with extensions in *extlist*"""
64 flist = []
65 # Workaround to replace os.path.relpath (not available until Python 2.6):
66 offset = len(name)+len(os.pathsep)
67 for dirpath, _dirnames, filenames in os.walk(name):
68 for fname in filenames:
69 if not fname.startswith('.') and osp.splitext(fname)[1] in extlist:
70 flist.append(osp.join(dirpath, fname)[offset:])
71 return flist
72
73
74 def get_subpackages(name):
75 """Return subpackages of package *name*"""
76 splist = []
77 for dirpath, _dirnames, _filenames in os.walk(name):
78 if osp.isfile(osp.join(dirpath, '__init__.py')):
79 splist.append(".".join(dirpath.split(os.sep)))
80 return splist
81
82
83 def get_data_files():
84 """Return data_files in a platform dependent manner"""
85 if sys.platform.startswith('linux'):
86 if PY3:
87 data_files = [('share/applications', ['scripts/spyder3.desktop']),
88 ('share/icons', ['img_src/spyder3.png']),
89 ('share/metainfo', ['scripts/spyder3.appdata.xml'])]
90 else:
91 data_files = [('share/applications', ['scripts/spyder.desktop']),
92 ('share/icons', ['img_src/spyder.png'])]
93 elif os.name == 'nt':
94 data_files = [('scripts', ['img_src/spyder.ico',
95 'img_src/spyder_reset.ico'])]
96 else:
97 data_files = []
98 return data_files
99
100
101 def get_packages():
102 """Return package list"""
103 packages = (
104 get_subpackages(LIBNAME)
105 + get_subpackages('spyder_breakpoints')
106 + get_subpackages('spyder_profiler')
107 + get_subpackages('spyder_pylint')
108 + get_subpackages('spyder_io_dcm')
109 + get_subpackages('spyder_io_hdf5')
110 )
111 return packages
112
113
114 #==============================================================================
115 # Make Linux detect Spyder desktop file
116 #==============================================================================
117 class MyInstallData(install_data):
118 def run(self):
119 install_data.run(self)
120 if sys.platform.startswith('linux'):
121 try:
122 subprocess.call(['update-desktop-database'])
123 except:
124 print("ERROR: unable to update desktop database",
125 file=sys.stderr)
126 CMDCLASS = {'install_data': MyInstallData}
127
128
129 #==============================================================================
130 # Main scripts
131 #==============================================================================
132 # NOTE: the '[...]_win_post_install.py' script is installed even on non-Windows
133 # platforms due to a bug in pip installation process (see Issue 1158)
134 SCRIPTS = ['%s_win_post_install.py' % NAME]
135 if PY3 and sys.platform.startswith('linux'):
136 SCRIPTS.append('spyder3')
137 else:
138 SCRIPTS.append('spyder')
139
140
141 #==============================================================================
142 # Files added to the package
143 #==============================================================================
144 EXTLIST = ['.mo', '.svg', '.png', '.css', '.html', '.js', '.chm', '.ini',
145 '.txt', '.rst', '.qss', '.ttf', '.json', '.c', '.cpp', '.java',
146 '.md', '.R', '.csv', '.pyx', '.ipynb', '.xml']
147 if os.name == 'nt':
148 SCRIPTS += ['spyder.bat']
149 EXTLIST += ['.ico']
150
151
152 #==============================================================================
153 # Setup arguments
154 #==============================================================================
155 setup_args = dict(
156 name=NAME,
157 version=__version__,
158 description='The Scientific Python Development Environment',
159 long_description=(
160 """Spyder is a powerful scientific environment written in Python, for Python,
161 and designed by and for scientists, engineers and data analysts.
162 It features a unique combination of the advanced editing, analysis, debugging
163 and profiling functionality of a comprehensive development tool with the data
164 exploration, interactive execution, deep inspection and beautiful visualization
165 capabilities of a scientific package.\n
166 Furthermore, Spyder offers built-in integration with many popular
167 scientific packages, including NumPy, SciPy, Pandas, IPython, QtConsole,
168 Matplotlib, SymPy, and more.\n
169 Beyond its many built-in features, Spyder's abilities can be extended even
170 further via first- and third-party plugins.\n
171 Spyder can also be used as a PyQt5 extension library, allowing you to build
172 upon its functionality and embed its components, such as the interactive
173 console or advanced editor, in your own software.
174 """),
175 download_url=__website_url__ + "#fh5co-download",
176 author="The Spyder Project Contributors",
177 author_email="[email protected]",
178 url=__website_url__,
179 license='MIT',
180 keywords='PyQt5 editor console widgets IDE science data analysis IPython',
181 platforms=["Windows", "Linux", "Mac OS-X"],
182 packages=get_packages(),
183 package_data={LIBNAME: get_package_data(LIBNAME, EXTLIST),
184 'spyder_breakpoints': get_package_data('spyder_breakpoints',
185 EXTLIST),
186 'spyder_profiler': get_package_data('spyder_profiler',
187 EXTLIST),
188 'spyder_pylint': get_package_data('spyder_pylint',
189 EXTLIST),
190 'spyder_io_dcm': get_package_data('spyder_io_dcm',
191 EXTLIST),
192 'spyder_io_hdf5': get_package_data('spyder_io_hdf5',
193 EXTLIST),
194 },
195 scripts=[osp.join('scripts', fname) for fname in SCRIPTS],
196 data_files=get_data_files(),
197 classifiers=['License :: OSI Approved :: MIT License',
198 'Operating System :: MacOS',
199 'Operating System :: Microsoft :: Windows',
200 'Operating System :: POSIX :: Linux',
201 'Programming Language :: Python :: 2',
202 'Programming Language :: Python :: 2.7',
203 'Programming Language :: Python :: 3',
204 'Programming Language :: Python :: 3.4',
205 'Programming Language :: Python :: 3.5',
206 'Programming Language :: Python :: 3.6',
207 'Programming Language :: Python :: 3.7',
208 'Development Status :: 5 - Production/Stable',
209 'Intended Audience :: Education',
210 'Intended Audience :: Science/Research',
211 'Intended Audience :: Developers',
212 'Topic :: Scientific/Engineering',
213 'Topic :: Software Development :: Widget Sets'],
214 cmdclass=CMDCLASS)
215
216
217 #==============================================================================
218 # Setuptools deps
219 #==============================================================================
220 if any(arg == 'bdist_wheel' for arg in sys.argv):
221 import setuptools # analysis:ignore
222
223 install_requires = [
224 'cloudpickle',
225 'rope>=0.10.5',
226 'jedi>=0.9.0',
227 'pyflakes',
228 'pygments>=2.0',
229 'qtconsole>=4.2.0',
230 'nbconvert',
231 'sphinx',
232 'pycodestyle',
233 'pylint',
234 'psutil',
235 'qtawesome>=0.4.1',
236 'qtpy>=1.5.0',
237 'pickleshare',
238 'pyzmq',
239 'chardet>=2.0.0',
240 'numpydoc',
241 'spyder-kernels>=0.4.2,<1.0',
242 # Don't require keyring for Python 2 and Linux
243 # because it depends on system packages
244 'keyring;sys_platform!="linux2"',
245 # Packages for pyqt5 are only available in
246 # Python 3
247 'pyqt5<5.13;python_version>="3"',
248 # pyqt5 5.12 split WebEngine into the
249 # pyqtwebengine module
250 'pyqtwebengine<5.13'
251 ]
252
253 extras_require = {
254 'test:python_version == "2.7"': ['mock'],
255 'test': ['pytest<4.1',
256 'pytest-qt',
257 'pytest-mock',
258 'pytest-cov',
259 'pytest-xvfb',
260 'mock',
261 'flaky',
262 'pandas',
263 'scipy',
264 'sympy',
265 'pillow',
266 'matplotlib',
267 'cython'],
268 }
269
270 if 'setuptools' in sys.modules:
271 setup_args['install_requires'] = install_requires
272 setup_args['extras_require'] = extras_require
273
274 setup_args['entry_points'] = {
275 'gui_scripts': [
276 '{} = spyder.app.start:main'.format(
277 'spyder3' if PY3 else 'spyder')
278 ]
279 }
280
281 setup_args.pop('scripts', None)
282
283
284 #==============================================================================
285 # Main setup
286 #==============================================================================
287 setup(**setup_args)
288
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -232,7 +232,7 @@
'pycodestyle',
'pylint',
'psutil',
- 'qtawesome>=0.4.1',
+ 'qtawesome>=0.5.7',
'qtpy>=1.5.0',
'pickleshare',
'pyzmq',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -232,7 +232,7 @@\n 'pycodestyle',\n 'pylint',\n 'psutil',\n- 'qtawesome>=0.4.1',\n+ 'qtawesome>=0.5.7',\n 'qtpy>=1.5.0',\n 'pickleshare',\n 'pyzmq',\n", "issue": "spyder 3.3.3 icon theme Spyder 3 problem with PyQt 5.12\n## Problem Description\r\nAfter updating to Spyder 3.3.3 (on Linux, with Python 3.6.7 64-bit | | Qt 5.12.1 | PyQt5 5.12 ) spyder icon theme \"Spyder 3\" stopped working (because of coming with this version PyQt upgrade probably) . Only the \"Spyder 2\" icon theme is working.\r\nBelow the look of Spyder3 icon theme\r\n\r\n\r\nAfter reverting to PyQt 5.9.2 the icon set Spyder3 is working again.\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Copyright \u00a9 Spyder Project Contributors\n# Licensed under the terms of the MIT License\n# (see spyder/__init__.py for details)\n\n\"\"\"\nSpyder\n======\n\nThe Scientific Python Development Environment\n\nSpyder is a powerful scientific environment written in Python, for Python,\nand designed by and for scientists, engineers and data analysts.\n\nIt features a unique combination of the advanced editing, analysis, debugging\nand profiling functionality of a comprehensive development tool with the data\nexploration, interactive execution, deep inspection and beautiful visualization\ncapabilities of a scientific package.\n\"\"\"\n\nfrom __future__ import print_function\n\nimport os\nimport os.path as osp\nimport subprocess\nimport sys\nimport shutil\n\nfrom distutils.core import setup\nfrom distutils.command.install_data import install_data\n\n\n#==============================================================================\n# Check for Python 3\n#==============================================================================\nPY3 = sys.version_info[0] == 3\n\n\n#==============================================================================\n# Minimal Python version sanity check\n# Taken from the notebook setup.py -- Modified BSD License\n#==============================================================================\nv = sys.version_info\nif v[:2] < (2, 7) or (v[0] >= 3 and v[:2] < (3, 4)):\n error = \"ERROR: Spyder requires Python version 2.7 or 3.4 and above.\"\n print(error, file=sys.stderr)\n sys.exit(1)\n\n\n#==============================================================================\n# Constants\n#==============================================================================\nNAME = 'spyder'\nLIBNAME = 'spyder'\nfrom spyder import __version__, __website_url__ #analysis:ignore\n\n\n#==============================================================================\n# Auxiliary functions\n#==============================================================================\ndef get_package_data(name, extlist):\n \"\"\"Return data files for package *name* with extensions in *extlist*\"\"\"\n flist = []\n # Workaround to replace os.path.relpath (not available until Python 2.6):\n offset = len(name)+len(os.pathsep)\n for dirpath, _dirnames, filenames in os.walk(name):\n for fname in filenames:\n if not fname.startswith('.') and osp.splitext(fname)[1] in extlist:\n flist.append(osp.join(dirpath, fname)[offset:])\n return flist\n\n\ndef get_subpackages(name):\n \"\"\"Return subpackages of package *name*\"\"\"\n splist = []\n for dirpath, _dirnames, _filenames in os.walk(name):\n if osp.isfile(osp.join(dirpath, '__init__.py')):\n splist.append(\".\".join(dirpath.split(os.sep)))\n return splist\n\n\ndef get_data_files():\n \"\"\"Return data_files in a platform dependent manner\"\"\"\n if sys.platform.startswith('linux'):\n if PY3:\n data_files = [('share/applications', ['scripts/spyder3.desktop']),\n ('share/icons', ['img_src/spyder3.png']),\n ('share/metainfo', ['scripts/spyder3.appdata.xml'])]\n else:\n data_files = [('share/applications', ['scripts/spyder.desktop']),\n ('share/icons', ['img_src/spyder.png'])]\n elif os.name == 'nt':\n data_files = [('scripts', ['img_src/spyder.ico',\n 'img_src/spyder_reset.ico'])]\n else:\n data_files = []\n return data_files\n\n\ndef get_packages():\n \"\"\"Return package list\"\"\"\n packages = (\n get_subpackages(LIBNAME)\n + get_subpackages('spyder_breakpoints')\n + get_subpackages('spyder_profiler')\n + get_subpackages('spyder_pylint')\n + get_subpackages('spyder_io_dcm')\n + get_subpackages('spyder_io_hdf5')\n )\n return packages\n\n\n#==============================================================================\n# Make Linux detect Spyder desktop file\n#==============================================================================\nclass MyInstallData(install_data):\n def run(self):\n install_data.run(self)\n if sys.platform.startswith('linux'):\n try:\n subprocess.call(['update-desktop-database'])\n except:\n print(\"ERROR: unable to update desktop database\",\n file=sys.stderr)\nCMDCLASS = {'install_data': MyInstallData}\n\n\n#==============================================================================\n# Main scripts\n#==============================================================================\n# NOTE: the '[...]_win_post_install.py' script is installed even on non-Windows\n# platforms due to a bug in pip installation process (see Issue 1158)\nSCRIPTS = ['%s_win_post_install.py' % NAME]\nif PY3 and sys.platform.startswith('linux'):\n SCRIPTS.append('spyder3')\nelse:\n SCRIPTS.append('spyder')\n\n\n#==============================================================================\n# Files added to the package\n#==============================================================================\nEXTLIST = ['.mo', '.svg', '.png', '.css', '.html', '.js', '.chm', '.ini',\n '.txt', '.rst', '.qss', '.ttf', '.json', '.c', '.cpp', '.java',\n '.md', '.R', '.csv', '.pyx', '.ipynb', '.xml']\nif os.name == 'nt':\n SCRIPTS += ['spyder.bat']\n EXTLIST += ['.ico']\n\n\n#==============================================================================\n# Setup arguments\n#==============================================================================\nsetup_args = dict(\n name=NAME,\n version=__version__,\n description='The Scientific Python Development Environment',\n long_description=(\n\"\"\"Spyder is a powerful scientific environment written in Python, for Python,\nand designed by and for scientists, engineers and data analysts.\nIt features a unique combination of the advanced editing, analysis, debugging\nand profiling functionality of a comprehensive development tool with the data\nexploration, interactive execution, deep inspection and beautiful visualization\ncapabilities of a scientific package.\\n\nFurthermore, Spyder offers built-in integration with many popular\nscientific packages, including NumPy, SciPy, Pandas, IPython, QtConsole,\nMatplotlib, SymPy, and more.\\n\nBeyond its many built-in features, Spyder's abilities can be extended even\nfurther via first- and third-party plugins.\\n\nSpyder can also be used as a PyQt5 extension library, allowing you to build\nupon its functionality and embed its components, such as the interactive\nconsole or advanced editor, in your own software.\n\"\"\"),\n download_url=__website_url__ + \"#fh5co-download\",\n author=\"The Spyder Project Contributors\",\n author_email=\"[email protected]\",\n url=__website_url__,\n license='MIT',\n keywords='PyQt5 editor console widgets IDE science data analysis IPython',\n platforms=[\"Windows\", \"Linux\", \"Mac OS-X\"],\n packages=get_packages(),\n package_data={LIBNAME: get_package_data(LIBNAME, EXTLIST),\n 'spyder_breakpoints': get_package_data('spyder_breakpoints',\n EXTLIST),\n 'spyder_profiler': get_package_data('spyder_profiler',\n EXTLIST),\n 'spyder_pylint': get_package_data('spyder_pylint',\n EXTLIST),\n 'spyder_io_dcm': get_package_data('spyder_io_dcm',\n EXTLIST),\n 'spyder_io_hdf5': get_package_data('spyder_io_hdf5',\n EXTLIST),\n },\n scripts=[osp.join('scripts', fname) for fname in SCRIPTS],\n data_files=get_data_files(),\n classifiers=['License :: OSI Approved :: MIT License',\n 'Operating System :: MacOS',\n 'Operating System :: Microsoft :: Windows',\n 'Operating System :: POSIX :: Linux',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Education',\n 'Intended Audience :: Science/Research',\n 'Intended Audience :: Developers',\n 'Topic :: Scientific/Engineering',\n 'Topic :: Software Development :: Widget Sets'],\n cmdclass=CMDCLASS)\n\n\n#==============================================================================\n# Setuptools deps\n#==============================================================================\nif any(arg == 'bdist_wheel' for arg in sys.argv):\n import setuptools # analysis:ignore\n\ninstall_requires = [\n 'cloudpickle',\n 'rope>=0.10.5',\n 'jedi>=0.9.0',\n 'pyflakes',\n 'pygments>=2.0',\n 'qtconsole>=4.2.0',\n 'nbconvert',\n 'sphinx',\n 'pycodestyle',\n 'pylint',\n 'psutil',\n 'qtawesome>=0.4.1',\n 'qtpy>=1.5.0',\n 'pickleshare',\n 'pyzmq',\n 'chardet>=2.0.0',\n 'numpydoc',\n 'spyder-kernels>=0.4.2,<1.0',\n # Don't require keyring for Python 2 and Linux\n # because it depends on system packages\n 'keyring;sys_platform!=\"linux2\"',\n # Packages for pyqt5 are only available in\n # Python 3\n 'pyqt5<5.13;python_version>=\"3\"',\n # pyqt5 5.12 split WebEngine into the\n # pyqtwebengine module\n 'pyqtwebengine<5.13'\n]\n\nextras_require = {\n 'test:python_version == \"2.7\"': ['mock'],\n 'test': ['pytest<4.1',\n 'pytest-qt',\n 'pytest-mock',\n 'pytest-cov',\n 'pytest-xvfb',\n 'mock',\n 'flaky',\n 'pandas',\n 'scipy',\n 'sympy',\n 'pillow',\n 'matplotlib',\n 'cython'],\n}\n\nif 'setuptools' in sys.modules:\n setup_args['install_requires'] = install_requires\n setup_args['extras_require'] = extras_require\n\n setup_args['entry_points'] = {\n 'gui_scripts': [\n '{} = spyder.app.start:main'.format(\n 'spyder3' if PY3 else 'spyder')\n ]\n }\n\n setup_args.pop('scripts', None)\n\n\n#==============================================================================\n# Main setup\n#==============================================================================\nsetup(**setup_args)\n", "path": "setup.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Copyright \u00a9 Spyder Project Contributors\n# Licensed under the terms of the MIT License\n# (see spyder/__init__.py for details)\n\n\"\"\"\nSpyder\n======\n\nThe Scientific Python Development Environment\n\nSpyder is a powerful scientific environment written in Python, for Python,\nand designed by and for scientists, engineers and data analysts.\n\nIt features a unique combination of the advanced editing, analysis, debugging\nand profiling functionality of a comprehensive development tool with the data\nexploration, interactive execution, deep inspection and beautiful visualization\ncapabilities of a scientific package.\n\"\"\"\n\nfrom __future__ import print_function\n\nimport os\nimport os.path as osp\nimport subprocess\nimport sys\nimport shutil\n\nfrom distutils.core import setup\nfrom distutils.command.install_data import install_data\n\n\n#==============================================================================\n# Check for Python 3\n#==============================================================================\nPY3 = sys.version_info[0] == 3\n\n\n#==============================================================================\n# Minimal Python version sanity check\n# Taken from the notebook setup.py -- Modified BSD License\n#==============================================================================\nv = sys.version_info\nif v[:2] < (2, 7) or (v[0] >= 3 and v[:2] < (3, 4)):\n error = \"ERROR: Spyder requires Python version 2.7 or 3.4 and above.\"\n print(error, file=sys.stderr)\n sys.exit(1)\n\n\n#==============================================================================\n# Constants\n#==============================================================================\nNAME = 'spyder'\nLIBNAME = 'spyder'\nfrom spyder import __version__, __website_url__ #analysis:ignore\n\n\n#==============================================================================\n# Auxiliary functions\n#==============================================================================\ndef get_package_data(name, extlist):\n \"\"\"Return data files for package *name* with extensions in *extlist*\"\"\"\n flist = []\n # Workaround to replace os.path.relpath (not available until Python 2.6):\n offset = len(name)+len(os.pathsep)\n for dirpath, _dirnames, filenames in os.walk(name):\n for fname in filenames:\n if not fname.startswith('.') and osp.splitext(fname)[1] in extlist:\n flist.append(osp.join(dirpath, fname)[offset:])\n return flist\n\n\ndef get_subpackages(name):\n \"\"\"Return subpackages of package *name*\"\"\"\n splist = []\n for dirpath, _dirnames, _filenames in os.walk(name):\n if osp.isfile(osp.join(dirpath, '__init__.py')):\n splist.append(\".\".join(dirpath.split(os.sep)))\n return splist\n\n\ndef get_data_files():\n \"\"\"Return data_files in a platform dependent manner\"\"\"\n if sys.platform.startswith('linux'):\n if PY3:\n data_files = [('share/applications', ['scripts/spyder3.desktop']),\n ('share/icons', ['img_src/spyder3.png']),\n ('share/metainfo', ['scripts/spyder3.appdata.xml'])]\n else:\n data_files = [('share/applications', ['scripts/spyder.desktop']),\n ('share/icons', ['img_src/spyder.png'])]\n elif os.name == 'nt':\n data_files = [('scripts', ['img_src/spyder.ico',\n 'img_src/spyder_reset.ico'])]\n else:\n data_files = []\n return data_files\n\n\ndef get_packages():\n \"\"\"Return package list\"\"\"\n packages = (\n get_subpackages(LIBNAME)\n + get_subpackages('spyder_breakpoints')\n + get_subpackages('spyder_profiler')\n + get_subpackages('spyder_pylint')\n + get_subpackages('spyder_io_dcm')\n + get_subpackages('spyder_io_hdf5')\n )\n return packages\n\n\n#==============================================================================\n# Make Linux detect Spyder desktop file\n#==============================================================================\nclass MyInstallData(install_data):\n def run(self):\n install_data.run(self)\n if sys.platform.startswith('linux'):\n try:\n subprocess.call(['update-desktop-database'])\n except:\n print(\"ERROR: unable to update desktop database\",\n file=sys.stderr)\nCMDCLASS = {'install_data': MyInstallData}\n\n\n#==============================================================================\n# Main scripts\n#==============================================================================\n# NOTE: the '[...]_win_post_install.py' script is installed even on non-Windows\n# platforms due to a bug in pip installation process (see Issue 1158)\nSCRIPTS = ['%s_win_post_install.py' % NAME]\nif PY3 and sys.platform.startswith('linux'):\n SCRIPTS.append('spyder3')\nelse:\n SCRIPTS.append('spyder')\n\n\n#==============================================================================\n# Files added to the package\n#==============================================================================\nEXTLIST = ['.mo', '.svg', '.png', '.css', '.html', '.js', '.chm', '.ini',\n '.txt', '.rst', '.qss', '.ttf', '.json', '.c', '.cpp', '.java',\n '.md', '.R', '.csv', '.pyx', '.ipynb', '.xml']\nif os.name == 'nt':\n SCRIPTS += ['spyder.bat']\n EXTLIST += ['.ico']\n\n\n#==============================================================================\n# Setup arguments\n#==============================================================================\nsetup_args = dict(\n name=NAME,\n version=__version__,\n description='The Scientific Python Development Environment',\n long_description=(\n\"\"\"Spyder is a powerful scientific environment written in Python, for Python,\nand designed by and for scientists, engineers and data analysts.\nIt features a unique combination of the advanced editing, analysis, debugging\nand profiling functionality of a comprehensive development tool with the data\nexploration, interactive execution, deep inspection and beautiful visualization\ncapabilities of a scientific package.\\n\nFurthermore, Spyder offers built-in integration with many popular\nscientific packages, including NumPy, SciPy, Pandas, IPython, QtConsole,\nMatplotlib, SymPy, and more.\\n\nBeyond its many built-in features, Spyder's abilities can be extended even\nfurther via first- and third-party plugins.\\n\nSpyder can also be used as a PyQt5 extension library, allowing you to build\nupon its functionality and embed its components, such as the interactive\nconsole or advanced editor, in your own software.\n\"\"\"),\n download_url=__website_url__ + \"#fh5co-download\",\n author=\"The Spyder Project Contributors\",\n author_email=\"[email protected]\",\n url=__website_url__,\n license='MIT',\n keywords='PyQt5 editor console widgets IDE science data analysis IPython',\n platforms=[\"Windows\", \"Linux\", \"Mac OS-X\"],\n packages=get_packages(),\n package_data={LIBNAME: get_package_data(LIBNAME, EXTLIST),\n 'spyder_breakpoints': get_package_data('spyder_breakpoints',\n EXTLIST),\n 'spyder_profiler': get_package_data('spyder_profiler',\n EXTLIST),\n 'spyder_pylint': get_package_data('spyder_pylint',\n EXTLIST),\n 'spyder_io_dcm': get_package_data('spyder_io_dcm',\n EXTLIST),\n 'spyder_io_hdf5': get_package_data('spyder_io_hdf5',\n EXTLIST),\n },\n scripts=[osp.join('scripts', fname) for fname in SCRIPTS],\n data_files=get_data_files(),\n classifiers=['License :: OSI Approved :: MIT License',\n 'Operating System :: MacOS',\n 'Operating System :: Microsoft :: Windows',\n 'Operating System :: POSIX :: Linux',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Education',\n 'Intended Audience :: Science/Research',\n 'Intended Audience :: Developers',\n 'Topic :: Scientific/Engineering',\n 'Topic :: Software Development :: Widget Sets'],\n cmdclass=CMDCLASS)\n\n\n#==============================================================================\n# Setuptools deps\n#==============================================================================\nif any(arg == 'bdist_wheel' for arg in sys.argv):\n import setuptools # analysis:ignore\n\ninstall_requires = [\n 'cloudpickle',\n 'rope>=0.10.5',\n 'jedi>=0.9.0',\n 'pyflakes',\n 'pygments>=2.0',\n 'qtconsole>=4.2.0',\n 'nbconvert',\n 'sphinx',\n 'pycodestyle',\n 'pylint',\n 'psutil',\n 'qtawesome>=0.5.7',\n 'qtpy>=1.5.0',\n 'pickleshare',\n 'pyzmq',\n 'chardet>=2.0.0',\n 'numpydoc',\n 'spyder-kernels>=0.4.2,<1.0',\n # Don't require keyring for Python 2 and Linux\n # because it depends on system packages\n 'keyring;sys_platform!=\"linux2\"',\n # Packages for pyqt5 are only available in\n # Python 3\n 'pyqt5<5.13;python_version>=\"3\"',\n # pyqt5 5.12 split WebEngine into the\n # pyqtwebengine module\n 'pyqtwebengine<5.13'\n]\n\nextras_require = {\n 'test:python_version == \"2.7\"': ['mock'],\n 'test': ['pytest<4.1',\n 'pytest-qt',\n 'pytest-mock',\n 'pytest-cov',\n 'pytest-xvfb',\n 'mock',\n 'flaky',\n 'pandas',\n 'scipy',\n 'sympy',\n 'pillow',\n 'matplotlib',\n 'cython'],\n}\n\nif 'setuptools' in sys.modules:\n setup_args['install_requires'] = install_requires\n setup_args['extras_require'] = extras_require\n\n setup_args['entry_points'] = {\n 'gui_scripts': [\n '{} = spyder.app.start:main'.format(\n 'spyder3' if PY3 else 'spyder')\n ]\n }\n\n setup_args.pop('scripts', None)\n\n\n#==============================================================================\n# Main setup\n#==============================================================================\nsetup(**setup_args)\n", "path": "setup.py"}]}
| 3,472 | 98 |
gh_patches_debug_11347
|
rasdani/github-patches
|
git_diff
|
plotly__dash-999
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[BUG] + in version string breaks fingerprint system
**Describe your context**
- replace the result of `pip list | grep dash` below
```
dash 1.5.1
dash-core-components 1.4.0
dash-daq 0.2.2
dash-html-components 1.0.1
dash-renderer 1.2.0
dash-table 4.5.0
```
**Describe the bug**
When going from `dash==1.4` to `dash==1.5`, we experienced a breaking change in the custom Dash components we use.
It took some hours to debug, but the reason was found to be related to the new "fingerprint" system in Dash. In our project, we use the [setuptools_scm](https://github.com/pypa/setuptools_scm) package (by the Python Packaging Authority) in order to have a versioning system that automatically is linked to the git repo tags. This makes continuous deployment to e.g. Pypi easy and robust wrt. keeping versions consistent.
I.e. instead of
```python
__version__ = package['version']
```
in the component package, we use something like
```
__version__ = get_distribution(__name__).version
```
This worked until `dash==1.5`, then it broke on non-release-versions due to automatic tags of the type
`1.0.0.dev5+af4304c.d20191103`, where the tag includes a `+`. See [the default tag formats](https://github.com/pypa/setuptools_scm#default-versioning-scheme).
Changing the line above to
```
__version__ = get_distribution(__name__).version.replace("+", ".")
```
is one workaround that gets the third party components to also work on `dash==1.5`
**Expected behavior**
`setuptools_scm` provided versions to work also in `dash>=1.5`.
**Suggested solution**
Change [this line](https://github.com/plotly/dash/blob/40b5357f262ac207f94ac980e6cb928d94df65b7/dash/fingerprint.py#L12) in Dash's `build_fingerprint` to also replace `+` with `_`?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `dash/fingerprint.py`
Content:
```
1 import re
2
3 cache_regex = re.compile(r"^v[\w-]+m[0-9a-fA-F]+$")
4
5
6 def build_fingerprint(path, version, hash_value):
7 path_parts = path.split("/")
8 filename, extension = path_parts[-1].split(".", 1)
9
10 return "{}.v{}m{}.{}".format(
11 "/".join(path_parts[:-1] + [filename]),
12 str(version).replace(".", "_"),
13 hash_value,
14 extension,
15 )
16
17
18 def check_fingerprint(path):
19 path_parts = path.split("/")
20 name_parts = path_parts[-1].split(".")
21
22 # Check if the resource has a fingerprint
23 if len(name_parts) > 2 and cache_regex.match(name_parts[1]):
24 original_name = ".".join([name_parts[0]] + name_parts[2:])
25 return "/".join(path_parts[:-1] + [original_name]), True
26
27 return path, False
28
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/dash/fingerprint.py b/dash/fingerprint.py
--- a/dash/fingerprint.py
+++ b/dash/fingerprint.py
@@ -1,7 +1,7 @@
import re
cache_regex = re.compile(r"^v[\w-]+m[0-9a-fA-F]+$")
-
+version_clean = re.compile(r"[^\w-]")
def build_fingerprint(path, version, hash_value):
path_parts = path.split("/")
@@ -9,7 +9,7 @@
return "{}.v{}m{}.{}".format(
"/".join(path_parts[:-1] + [filename]),
- str(version).replace(".", "_"),
+ re.sub(version_clean, "_", str(version)),
hash_value,
extension,
)
|
{"golden_diff": "diff --git a/dash/fingerprint.py b/dash/fingerprint.py\n--- a/dash/fingerprint.py\n+++ b/dash/fingerprint.py\n@@ -1,7 +1,7 @@\n import re\n \n cache_regex = re.compile(r\"^v[\\w-]+m[0-9a-fA-F]+$\")\n-\n+version_clean = re.compile(r\"[^\\w-]\")\n \n def build_fingerprint(path, version, hash_value):\n path_parts = path.split(\"/\")\n@@ -9,7 +9,7 @@\n \n return \"{}.v{}m{}.{}\".format(\n \"/\".join(path_parts[:-1] + [filename]),\n- str(version).replace(\".\", \"_\"),\n+ re.sub(version_clean, \"_\", str(version)),\n hash_value,\n extension,\n )\n", "issue": "[BUG] + in version string breaks fingerprint system\n**Describe your context**\r\n- replace the result of `pip list | grep dash` below\r\n```\r\ndash 1.5.1 \r\ndash-core-components 1.4.0 \r\ndash-daq 0.2.2 \r\ndash-html-components 1.0.1 \r\ndash-renderer 1.2.0 \r\ndash-table 4.5.0 \r\n```\r\n\r\n**Describe the bug**\r\n\r\nWhen going from `dash==1.4` to `dash==1.5`, we experienced a breaking change in the custom Dash components we use.\r\n\r\nIt took some hours to debug, but the reason was found to be related to the new \"fingerprint\" system in Dash. In our project, we use the [setuptools_scm](https://github.com/pypa/setuptools_scm) package (by the Python Packaging Authority) in order to have a versioning system that automatically is linked to the git repo tags. This makes continuous deployment to e.g. Pypi easy and robust wrt. keeping versions consistent.\r\n\r\nI.e. instead of\r\n```python\r\n__version__ = package['version']\r\n```\r\nin the component package, we use something like\r\n```\r\n__version__ = get_distribution(__name__).version\r\n```\r\nThis worked until `dash==1.5`, then it broke on non-release-versions due to automatic tags of the type\r\n`1.0.0.dev5+af4304c.d20191103`, where the tag includes a `+`. See [the default tag formats](https://github.com/pypa/setuptools_scm#default-versioning-scheme).\r\n\r\nChanging the line above to\r\n```\r\n__version__ = get_distribution(__name__).version.replace(\"+\", \".\")\r\n```\r\nis one workaround that gets the third party components to also work on `dash==1.5`\r\n\r\n**Expected behavior**\r\n\r\n`setuptools_scm` provided versions to work also in `dash>=1.5`.\r\n\r\n**Suggested solution**\r\n\r\nChange [this line](https://github.com/plotly/dash/blob/40b5357f262ac207f94ac980e6cb928d94df65b7/dash/fingerprint.py#L12) in Dash's `build_fingerprint` to also replace `+` with `_`?\n", "before_files": [{"content": "import re\n\ncache_regex = re.compile(r\"^v[\\w-]+m[0-9a-fA-F]+$\")\n\n\ndef build_fingerprint(path, version, hash_value):\n path_parts = path.split(\"/\")\n filename, extension = path_parts[-1].split(\".\", 1)\n\n return \"{}.v{}m{}.{}\".format(\n \"/\".join(path_parts[:-1] + [filename]),\n str(version).replace(\".\", \"_\"),\n hash_value,\n extension,\n )\n\n\ndef check_fingerprint(path):\n path_parts = path.split(\"/\")\n name_parts = path_parts[-1].split(\".\")\n\n # Check if the resource has a fingerprint\n if len(name_parts) > 2 and cache_regex.match(name_parts[1]):\n original_name = \".\".join([name_parts[0]] + name_parts[2:])\n return \"/\".join(path_parts[:-1] + [original_name]), True\n\n return path, False\n", "path": "dash/fingerprint.py"}], "after_files": [{"content": "import re\n\ncache_regex = re.compile(r\"^v[\\w-]+m[0-9a-fA-F]+$\")\nversion_clean = re.compile(r\"[^\\w-]\")\n\ndef build_fingerprint(path, version, hash_value):\n path_parts = path.split(\"/\")\n filename, extension = path_parts[-1].split(\".\", 1)\n\n return \"{}.v{}m{}.{}\".format(\n \"/\".join(path_parts[:-1] + [filename]),\n re.sub(version_clean, \"_\", str(version)),\n hash_value,\n extension,\n )\n\n\ndef check_fingerprint(path):\n path_parts = path.split(\"/\")\n name_parts = path_parts[-1].split(\".\")\n\n # Check if the resource has a fingerprint\n if len(name_parts) > 2 and cache_regex.match(name_parts[1]):\n original_name = \".\".join([name_parts[0]] + name_parts[2:])\n return \"/\".join(path_parts[:-1] + [original_name]), True\n\n return path, False\n", "path": "dash/fingerprint.py"}]}
| 1,031 | 165 |
gh_patches_debug_175
|
rasdani/github-patches
|
git_diff
|
open-mmlab__mmengine-684
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
config/utils.py haven't mmyolo

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mmengine/config/utils.py`
Content:
```
1 # Copyright (c) OpenMMLab. All rights reserved.
2 import ast
3 import os.path as osp
4 import re
5 import warnings
6 from typing import Tuple
7
8 from mmengine.fileio import load
9 from mmengine.utils import check_file_exist
10
11 PKG2PROJECT = {
12 'mmcls': 'mmcls',
13 'mmdet': 'mmdet',
14 'mmdet3d': 'mmdet3d',
15 'mmseg': 'mmsegmentation',
16 'mmaction2': 'mmaction2',
17 'mmtrack': 'mmtrack',
18 'mmpose': 'mmpose',
19 'mmedit': 'mmedit',
20 'mmocr': 'mmocr',
21 'mmgen': 'mmgen',
22 'mmfewshot': 'mmfewshot',
23 'mmrazor': 'mmrazor',
24 'mmflow': 'mmflow',
25 'mmhuman3d': 'mmhuman3d',
26 'mmrotate': 'mmrotate',
27 'mmselfsup': 'mmselfsup',
28 }
29
30
31 def _get_cfg_metainfo(package_path: str, cfg_path: str) -> dict:
32 """Get target meta information from all 'metafile.yml' defined in `mode-
33 index.yml` of external package.
34
35 Args:
36 package_path (str): Path of external package.
37 cfg_path (str): Name of experiment config.
38
39 Returns:
40 dict: Meta information of target experiment.
41 """
42 meta_index_path = osp.join(package_path, '.mim', 'model-index.yml')
43 meta_index = load(meta_index_path)
44 cfg_dict = dict()
45 for meta_path in meta_index['Import']:
46 meta_path = osp.join(package_path, '.mim', meta_path)
47 cfg_meta = load(meta_path)
48 for model_cfg in cfg_meta['Models']:
49 if 'Config' not in model_cfg:
50 warnings.warn(f'There is not `Config` define in {model_cfg}')
51 continue
52 cfg_name = model_cfg['Config'].partition('/')[-1]
53 # Some config could have multiple weights, we only pick the
54 # first one.
55 if cfg_name in cfg_dict:
56 continue
57 cfg_dict[cfg_name] = model_cfg
58 if cfg_path not in cfg_dict:
59 raise ValueError(f'Expected configs: {cfg_dict.keys()}, but got '
60 f'{cfg_path}')
61 return cfg_dict[cfg_path]
62
63
64 def _get_external_cfg_path(package_path: str, cfg_file: str) -> str:
65 """Get config path of external package.
66
67 Args:
68 package_path (str): Path of external package.
69 cfg_file (str): Name of experiment config.
70
71 Returns:
72 str: Absolute config path from external package.
73 """
74 cfg_file = cfg_file.split('.')[0]
75 model_cfg = _get_cfg_metainfo(package_path, cfg_file)
76 cfg_path = osp.join(package_path, model_cfg['Config'])
77 check_file_exist(cfg_path)
78 return cfg_path
79
80
81 def _get_external_cfg_base_path(package_path: str, cfg_name: str) -> str:
82 """Get base config path of external package.
83
84 Args:
85 package_path (str): Path of external package.
86 cfg_name (str): External relative config path with 'package::'.
87
88 Returns:
89 str: Absolute config path from external package.
90 """
91 cfg_path = osp.join(package_path, '.mim', 'configs', cfg_name)
92 check_file_exist(cfg_path)
93 return cfg_path
94
95
96 def _get_package_and_cfg_path(cfg_path: str) -> Tuple[str, str]:
97 """Get package name and relative config path.
98
99 Args:
100 cfg_path (str): External relative config path with 'package::'.
101
102 Returns:
103 Tuple[str, str]: Package name and config path.
104 """
105 if re.match(r'\w*::\w*/\w*', cfg_path) is None:
106 raise ValueError(
107 '`_get_package_and_cfg_path` is used for get external package, '
108 'please specify the package name and relative config path, just '
109 'like `mmdet::faster_rcnn/faster-rcnn_r50_fpn_1x_coco.py`')
110 package_cfg = cfg_path.split('::')
111 if len(package_cfg) > 2:
112 raise ValueError('`::` should only be used to separate package and '
113 'config name, but found multiple `::` in '
114 f'{cfg_path}')
115 package, cfg_path = package_cfg
116 assert package in PKG2PROJECT, 'mmengine does not support to load ' \
117 f'{package} config.'
118 package = PKG2PROJECT[package]
119 return package, cfg_path
120
121
122 class RemoveAssignFromAST(ast.NodeTransformer):
123 """Remove Assign node if the target's name match the key.
124
125 Args:
126 key (str): The target name of the Assign node.
127 """
128
129 def __init__(self, key):
130 self.key = key
131
132 def visit_Assign(self, node):
133 if (isinstance(node.targets[0], ast.Name)
134 and node.targets[0].id == self.key):
135 return None
136 else:
137 return node
138
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mmengine/config/utils.py b/mmengine/config/utils.py
--- a/mmengine/config/utils.py
+++ b/mmengine/config/utils.py
@@ -25,6 +25,7 @@
'mmhuman3d': 'mmhuman3d',
'mmrotate': 'mmrotate',
'mmselfsup': 'mmselfsup',
+ 'mmyolo': 'mmyolo',
}
|
{"golden_diff": "diff --git a/mmengine/config/utils.py b/mmengine/config/utils.py\n--- a/mmengine/config/utils.py\n+++ b/mmengine/config/utils.py\n@@ -25,6 +25,7 @@\n 'mmhuman3d': 'mmhuman3d',\n 'mmrotate': 'mmrotate',\n 'mmselfsup': 'mmselfsup',\n+ 'mmyolo': 'mmyolo',\n }\n", "issue": "config/utils.py haven't mmyolo\n\r\n\n", "before_files": [{"content": "# Copyright (c) OpenMMLab. All rights reserved.\nimport ast\nimport os.path as osp\nimport re\nimport warnings\nfrom typing import Tuple\n\nfrom mmengine.fileio import load\nfrom mmengine.utils import check_file_exist\n\nPKG2PROJECT = {\n 'mmcls': 'mmcls',\n 'mmdet': 'mmdet',\n 'mmdet3d': 'mmdet3d',\n 'mmseg': 'mmsegmentation',\n 'mmaction2': 'mmaction2',\n 'mmtrack': 'mmtrack',\n 'mmpose': 'mmpose',\n 'mmedit': 'mmedit',\n 'mmocr': 'mmocr',\n 'mmgen': 'mmgen',\n 'mmfewshot': 'mmfewshot',\n 'mmrazor': 'mmrazor',\n 'mmflow': 'mmflow',\n 'mmhuman3d': 'mmhuman3d',\n 'mmrotate': 'mmrotate',\n 'mmselfsup': 'mmselfsup',\n}\n\n\ndef _get_cfg_metainfo(package_path: str, cfg_path: str) -> dict:\n \"\"\"Get target meta information from all 'metafile.yml' defined in `mode-\n index.yml` of external package.\n\n Args:\n package_path (str): Path of external package.\n cfg_path (str): Name of experiment config.\n\n Returns:\n dict: Meta information of target experiment.\n \"\"\"\n meta_index_path = osp.join(package_path, '.mim', 'model-index.yml')\n meta_index = load(meta_index_path)\n cfg_dict = dict()\n for meta_path in meta_index['Import']:\n meta_path = osp.join(package_path, '.mim', meta_path)\n cfg_meta = load(meta_path)\n for model_cfg in cfg_meta['Models']:\n if 'Config' not in model_cfg:\n warnings.warn(f'There is not `Config` define in {model_cfg}')\n continue\n cfg_name = model_cfg['Config'].partition('/')[-1]\n # Some config could have multiple weights, we only pick the\n # first one.\n if cfg_name in cfg_dict:\n continue\n cfg_dict[cfg_name] = model_cfg\n if cfg_path not in cfg_dict:\n raise ValueError(f'Expected configs: {cfg_dict.keys()}, but got '\n f'{cfg_path}')\n return cfg_dict[cfg_path]\n\n\ndef _get_external_cfg_path(package_path: str, cfg_file: str) -> str:\n \"\"\"Get config path of external package.\n\n Args:\n package_path (str): Path of external package.\n cfg_file (str): Name of experiment config.\n\n Returns:\n str: Absolute config path from external package.\n \"\"\"\n cfg_file = cfg_file.split('.')[0]\n model_cfg = _get_cfg_metainfo(package_path, cfg_file)\n cfg_path = osp.join(package_path, model_cfg['Config'])\n check_file_exist(cfg_path)\n return cfg_path\n\n\ndef _get_external_cfg_base_path(package_path: str, cfg_name: str) -> str:\n \"\"\"Get base config path of external package.\n\n Args:\n package_path (str): Path of external package.\n cfg_name (str): External relative config path with 'package::'.\n\n Returns:\n str: Absolute config path from external package.\n \"\"\"\n cfg_path = osp.join(package_path, '.mim', 'configs', cfg_name)\n check_file_exist(cfg_path)\n return cfg_path\n\n\ndef _get_package_and_cfg_path(cfg_path: str) -> Tuple[str, str]:\n \"\"\"Get package name and relative config path.\n\n Args:\n cfg_path (str): External relative config path with 'package::'.\n\n Returns:\n Tuple[str, str]: Package name and config path.\n \"\"\"\n if re.match(r'\\w*::\\w*/\\w*', cfg_path) is None:\n raise ValueError(\n '`_get_package_and_cfg_path` is used for get external package, '\n 'please specify the package name and relative config path, just '\n 'like `mmdet::faster_rcnn/faster-rcnn_r50_fpn_1x_coco.py`')\n package_cfg = cfg_path.split('::')\n if len(package_cfg) > 2:\n raise ValueError('`::` should only be used to separate package and '\n 'config name, but found multiple `::` in '\n f'{cfg_path}')\n package, cfg_path = package_cfg\n assert package in PKG2PROJECT, 'mmengine does not support to load ' \\\n f'{package} config.'\n package = PKG2PROJECT[package]\n return package, cfg_path\n\n\nclass RemoveAssignFromAST(ast.NodeTransformer):\n \"\"\"Remove Assign node if the target's name match the key.\n\n Args:\n key (str): The target name of the Assign node.\n \"\"\"\n\n def __init__(self, key):\n self.key = key\n\n def visit_Assign(self, node):\n if (isinstance(node.targets[0], ast.Name)\n and node.targets[0].id == self.key):\n return None\n else:\n return node\n", "path": "mmengine/config/utils.py"}], "after_files": [{"content": "# Copyright (c) OpenMMLab. All rights reserved.\nimport ast\nimport os.path as osp\nimport re\nimport warnings\nfrom typing import Tuple\n\nfrom mmengine.fileio import load\nfrom mmengine.utils import check_file_exist\n\nPKG2PROJECT = {\n 'mmcls': 'mmcls',\n 'mmdet': 'mmdet',\n 'mmdet3d': 'mmdet3d',\n 'mmseg': 'mmsegmentation',\n 'mmaction2': 'mmaction2',\n 'mmtrack': 'mmtrack',\n 'mmpose': 'mmpose',\n 'mmedit': 'mmedit',\n 'mmocr': 'mmocr',\n 'mmgen': 'mmgen',\n 'mmfewshot': 'mmfewshot',\n 'mmrazor': 'mmrazor',\n 'mmflow': 'mmflow',\n 'mmhuman3d': 'mmhuman3d',\n 'mmrotate': 'mmrotate',\n 'mmselfsup': 'mmselfsup',\n 'mmyolo': 'mmyolo',\n}\n\n\ndef _get_cfg_metainfo(package_path: str, cfg_path: str) -> dict:\n \"\"\"Get target meta information from all 'metafile.yml' defined in `mode-\n index.yml` of external package.\n\n Args:\n package_path (str): Path of external package.\n cfg_path (str): Name of experiment config.\n\n Returns:\n dict: Meta information of target experiment.\n \"\"\"\n meta_index_path = osp.join(package_path, '.mim', 'model-index.yml')\n meta_index = load(meta_index_path)\n cfg_dict = dict()\n for meta_path in meta_index['Import']:\n meta_path = osp.join(package_path, '.mim', meta_path)\n cfg_meta = load(meta_path)\n for model_cfg in cfg_meta['Models']:\n if 'Config' not in model_cfg:\n warnings.warn(f'There is not `Config` define in {model_cfg}')\n continue\n cfg_name = model_cfg['Config'].partition('/')[-1]\n # Some config could have multiple weights, we only pick the\n # first one.\n if cfg_name in cfg_dict:\n continue\n cfg_dict[cfg_name] = model_cfg\n if cfg_path not in cfg_dict:\n raise ValueError(f'Expected configs: {cfg_dict.keys()}, but got '\n f'{cfg_path}')\n return cfg_dict[cfg_path]\n\n\ndef _get_external_cfg_path(package_path: str, cfg_file: str) -> str:\n \"\"\"Get config path of external package.\n\n Args:\n package_path (str): Path of external package.\n cfg_file (str): Name of experiment config.\n\n Returns:\n str: Absolute config path from external package.\n \"\"\"\n cfg_file = cfg_file.split('.')[0]\n model_cfg = _get_cfg_metainfo(package_path, cfg_file)\n cfg_path = osp.join(package_path, model_cfg['Config'])\n check_file_exist(cfg_path)\n return cfg_path\n\n\ndef _get_external_cfg_base_path(package_path: str, cfg_name: str) -> str:\n \"\"\"Get base config path of external package.\n\n Args:\n package_path (str): Path of external package.\n cfg_name (str): External relative config path with 'package::'.\n\n Returns:\n str: Absolute config path from external package.\n \"\"\"\n cfg_path = osp.join(package_path, '.mim', 'configs', cfg_name)\n check_file_exist(cfg_path)\n return cfg_path\n\n\ndef _get_package_and_cfg_path(cfg_path: str) -> Tuple[str, str]:\n \"\"\"Get package name and relative config path.\n\n Args:\n cfg_path (str): External relative config path with 'package::'.\n\n Returns:\n Tuple[str, str]: Package name and config path.\n \"\"\"\n if re.match(r'\\w*::\\w*/\\w*', cfg_path) is None:\n raise ValueError(\n '`_get_package_and_cfg_path` is used for get external package, '\n 'please specify the package name and relative config path, just '\n 'like `mmdet::faster_rcnn/faster-rcnn_r50_fpn_1x_coco.py`')\n package_cfg = cfg_path.split('::')\n if len(package_cfg) > 2:\n raise ValueError('`::` should only be used to separate package and '\n 'config name, but found multiple `::` in '\n f'{cfg_path}')\n package, cfg_path = package_cfg\n assert package in PKG2PROJECT, 'mmengine does not support to load ' \\\n f'{package} config.'\n package = PKG2PROJECT[package]\n return package, cfg_path\n\n\nclass RemoveAssignFromAST(ast.NodeTransformer):\n \"\"\"Remove Assign node if the target's name match the key.\n\n Args:\n key (str): The target name of the Assign node.\n \"\"\"\n\n def __init__(self, key):\n self.key = key\n\n def visit_Assign(self, node):\n if (isinstance(node.targets[0], ast.Name)\n and node.targets[0].id == self.key):\n return None\n else:\n return node\n", "path": "mmengine/config/utils.py"}]}
| 1,777 | 90 |
gh_patches_debug_18337
|
rasdani/github-patches
|
git_diff
|
microsoft__botbuilder-python-1220
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Complete the aiohttp ApplicationInsights implementation
See also #673
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `libraries/botbuilder-applicationinsights/botbuilder/applicationinsights/application_insights_telemetry_client.py`
Content:
```
1 # Copyright (c) Microsoft Corporation. All rights reserved.
2 # Licensed under the MIT License.
3 """Application Insights Telemetry Client for Bots."""
4
5 import traceback
6 from typing import Dict, Callable
7
8 from applicationinsights import TelemetryClient # pylint: disable=no-name-in-module
9 from botbuilder.core.bot_telemetry_client import (
10 BotTelemetryClient,
11 Severity,
12 TelemetryDataPointType,
13 )
14
15 from .bot_telemetry_processor import BotTelemetryProcessor
16
17
18 def bot_telemetry_processor(data, context) -> bool:
19 """Bot Telemetry Processor as a method for backward compatibility. Refer to
20 callable object :class:`BotTelemetryProcessor` for details.
21
22 :param data: Data from Application Insights
23 :type data: telemetry item
24 :param context: Context from Application Insights
25 :type context: context object
26 :return: determines if the event is passed to the server (False = Filtered).
27 :rtype: bool
28 """
29 processor = BotTelemetryProcessor()
30 return processor(data, context)
31
32
33 class ApplicationInsightsTelemetryClient(BotTelemetryClient):
34 """Application Insights Telemetry Client."""
35
36 def __init__(
37 self,
38 instrumentation_key: str,
39 telemetry_client: TelemetryClient = None,
40 telemetry_processor: Callable[[object, object], bool] = None,
41 ):
42 self._instrumentation_key = instrumentation_key
43 self._client = (
44 telemetry_client
45 if telemetry_client is not None
46 else TelemetryClient(self._instrumentation_key)
47 )
48 # Telemetry Processor
49 processor = (
50 telemetry_processor
51 if telemetry_processor is not None
52 else bot_telemetry_processor
53 )
54 self._client.add_telemetry_processor(processor)
55
56 def track_pageview(
57 self,
58 name: str,
59 url: str,
60 duration: int = 0,
61 properties: Dict[str, object] = None,
62 measurements: Dict[str, object] = None,
63 ) -> None:
64 """
65 Send information about the page viewed in the application (a web page for instance).
66 :param name: the name of the page that was viewed.
67 :param url: the URL of the page that was viewed.
68 :param duration: the duration of the page view in milliseconds. (defaults to: 0)
69 :param properties: the set of custom properties the client wants attached to this data item.
70 (defaults to: None)
71 :param measurements: the set of custom measurements the client wants to attach to this data item.
72 (defaults to: None)
73 """
74 self._client.track_pageview(name, url, duration, properties, measurements)
75
76 def track_exception(
77 self,
78 exception_type: type = None,
79 value: Exception = None,
80 trace: traceback = None,
81 properties: Dict[str, object] = None,
82 measurements: Dict[str, object] = None,
83 ) -> None:
84 """
85 Send information about a single exception that occurred in the application.
86 :param exception_type: the type of the exception that was thrown.
87 :param value: the exception that the client wants to send.
88 :param trace: the traceback information as returned by :func:`sys.exc_info`.
89 :param properties: the set of custom properties the client wants attached to this data item.
90 (defaults to: None)
91 :param measurements: the set of custom measurements the client wants to attach to this data item.
92 (defaults to: None)
93 """
94 self._client.track_exception(
95 exception_type, value, trace, properties, measurements
96 )
97
98 def track_event(
99 self,
100 name: str,
101 properties: Dict[str, object] = None,
102 measurements: Dict[str, object] = None,
103 ) -> None:
104 """
105 Send information about a single event that has occurred in the context of the application.
106 :param name: the data to associate to this event.
107 :param properties: the set of custom properties the client wants attached to this data item.
108 (defaults to: None)
109 :param measurements: the set of custom measurements the client wants to attach to this data item.
110 (defaults to: None)
111 """
112 self._client.track_event(name, properties=properties, measurements=measurements)
113
114 def track_metric(
115 self,
116 name: str,
117 value: float,
118 tel_type: TelemetryDataPointType = None,
119 count: int = None,
120 min_val: float = None,
121 max_val: float = None,
122 std_dev: float = None,
123 properties: Dict[str, object] = None,
124 ) -> NotImplemented:
125 """
126 Send information about a single metric data point that was captured for the application.
127 :param name: The name of the metric that was captured.
128 :param value: The value of the metric that was captured.
129 :param tel_type: The type of the metric. (defaults to: TelemetryDataPointType.aggregation`)
130 :param count: the number of metrics that were aggregated into this data point. (defaults to: None)
131 :param min_val: the minimum of all metrics collected that were aggregated into this data point.
132 (defaults to: None)
133 :param max_val: the maximum of all metrics collected that were aggregated into this data point.
134 (defaults to: None)
135 :param std_dev: the standard deviation of all metrics collected that were aggregated into this data point.
136 (defaults to: None)
137 :param properties: the set of custom properties the client wants attached to this data item.
138 (defaults to: None)
139 """
140 self._client.track_metric(
141 name, value, tel_type, count, min_val, max_val, std_dev, properties
142 )
143
144 def track_trace(
145 self, name: str, properties: Dict[str, object] = None, severity: Severity = None
146 ):
147 """
148 Sends a single trace statement.
149 :param name: the trace statement.
150 :param properties: the set of custom properties the client wants attached to this data item. (defaults to: None)
151 :param severity: the severity level of this trace, one of DEBUG, INFO, WARNING, ERROR, CRITICAL
152 """
153 self._client.track_trace(name, properties, severity)
154
155 def track_request(
156 self,
157 name: str,
158 url: str,
159 success: bool,
160 start_time: str = None,
161 duration: int = None,
162 response_code: str = None,
163 http_method: str = None,
164 properties: Dict[str, object] = None,
165 measurements: Dict[str, object] = None,
166 request_id: str = None,
167 ):
168 """
169 Sends a single request that was captured for the application.
170 :param name: The name for this request. All requests with the same name will be grouped together.
171 :param url: The actual URL for this request (to show in individual request instances).
172 :param success: True if the request ended in success, False otherwise.
173 :param start_time: the start time of the request. The value should look the same as the one returned by
174 :func:`datetime.isoformat`. (defaults to: None)
175 :param duration: the number of milliseconds that this request lasted. (defaults to: None)
176 :param response_code: the response code that this request returned. (defaults to: None)
177 :param http_method: the HTTP method that triggered this request. (defaults to: None)
178 :param properties: the set of custom properties the client wants attached to this data item.
179 (defaults to: None)
180 :param measurements: the set of custom measurements the client wants to attach to this data item.
181 (defaults to: None)
182 :param request_id: the id for this request. If None, a new uuid will be generated. (defaults to: None)
183 """
184 self._client.track_request(
185 name,
186 url,
187 success,
188 start_time,
189 duration,
190 response_code,
191 http_method,
192 properties,
193 measurements,
194 request_id,
195 )
196
197 def track_dependency(
198 self,
199 name: str,
200 data: str,
201 type_name: str = None,
202 target: str = None,
203 duration: int = None,
204 success: bool = None,
205 result_code: str = None,
206 properties: Dict[str, object] = None,
207 measurements: Dict[str, object] = None,
208 dependency_id: str = None,
209 ):
210 """
211 Sends a single dependency telemetry that was captured for the application.
212 :param name: the name of the command initiated with this dependency call. Low cardinality value.
213 Examples are stored procedure name and URL path template.
214 :param data: the command initiated by this dependency call.
215 Examples are SQL statement and HTTP URL with all query parameters.
216 :param type_name: the dependency type name. Low cardinality value for logical grouping of dependencies and
217 interpretation of other fields like commandName and resultCode. Examples are SQL, Azure table, and HTTP.
218 (default to: None)
219 :param target: the target site of a dependency call. Examples are server name, host address.
220 (default to: None)
221 :param duration: the number of milliseconds that this dependency call lasted.
222 (defaults to: None)
223 :param success: true if the dependency call ended in success, false otherwise.
224 (defaults to: None)
225 :param result_code: the result code of a dependency call. Examples are SQL error code and HTTP status code.
226 (defaults to: None)
227 :param properties: the set of custom properties the client wants attached to this data item. (defaults to: None)
228 :param measurements: the set of custom measurements the client wants to attach to this data item.
229 (defaults to: None)
230 :param id: the id for this dependency call. If None, a new uuid will be generated. (defaults to: None)
231 """
232 self._client.track_dependency(
233 name,
234 data,
235 type_name,
236 target,
237 duration,
238 success,
239 result_code,
240 properties,
241 measurements,
242 dependency_id,
243 )
244
245 def flush(self):
246 """Flushes data in the queue. Data in the queue will be sent either immediately irrespective of what sender is
247 being used.
248 """
249 self._client.flush()
250
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/libraries/botbuilder-applicationinsights/botbuilder/applicationinsights/application_insights_telemetry_client.py b/libraries/botbuilder-applicationinsights/botbuilder/applicationinsights/application_insights_telemetry_client.py
--- a/libraries/botbuilder-applicationinsights/botbuilder/applicationinsights/application_insights_telemetry_client.py
+++ b/libraries/botbuilder-applicationinsights/botbuilder/applicationinsights/application_insights_telemetry_client.py
@@ -38,13 +38,18 @@
instrumentation_key: str,
telemetry_client: TelemetryClient = None,
telemetry_processor: Callable[[object, object], bool] = None,
+ client_queue_size: int = None,
):
self._instrumentation_key = instrumentation_key
+
self._client = (
telemetry_client
if telemetry_client is not None
else TelemetryClient(self._instrumentation_key)
)
+ if client_queue_size:
+ self._client.channel.queue.max_queue_length = client_queue_size
+
# Telemetry Processor
processor = (
telemetry_processor
|
{"golden_diff": "diff --git a/libraries/botbuilder-applicationinsights/botbuilder/applicationinsights/application_insights_telemetry_client.py b/libraries/botbuilder-applicationinsights/botbuilder/applicationinsights/application_insights_telemetry_client.py\n--- a/libraries/botbuilder-applicationinsights/botbuilder/applicationinsights/application_insights_telemetry_client.py\n+++ b/libraries/botbuilder-applicationinsights/botbuilder/applicationinsights/application_insights_telemetry_client.py\n@@ -38,13 +38,18 @@\n instrumentation_key: str,\n telemetry_client: TelemetryClient = None,\n telemetry_processor: Callable[[object, object], bool] = None,\n+ client_queue_size: int = None,\n ):\n self._instrumentation_key = instrumentation_key\n+\n self._client = (\n telemetry_client\n if telemetry_client is not None\n else TelemetryClient(self._instrumentation_key)\n )\n+ if client_queue_size:\n+ self._client.channel.queue.max_queue_length = client_queue_size\n+\n # Telemetry Processor\n processor = (\n telemetry_processor\n", "issue": "Complete the aiohttp ApplicationInsights implementation\nSee also #673 \n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License.\n\"\"\"Application Insights Telemetry Client for Bots.\"\"\"\n\nimport traceback\nfrom typing import Dict, Callable\n\nfrom applicationinsights import TelemetryClient # pylint: disable=no-name-in-module\nfrom botbuilder.core.bot_telemetry_client import (\n BotTelemetryClient,\n Severity,\n TelemetryDataPointType,\n)\n\nfrom .bot_telemetry_processor import BotTelemetryProcessor\n\n\ndef bot_telemetry_processor(data, context) -> bool:\n \"\"\"Bot Telemetry Processor as a method for backward compatibility. Refer to\n callable object :class:`BotTelemetryProcessor` for details.\n\n :param data: Data from Application Insights\n :type data: telemetry item\n :param context: Context from Application Insights\n :type context: context object\n :return: determines if the event is passed to the server (False = Filtered).\n :rtype: bool\n \"\"\"\n processor = BotTelemetryProcessor()\n return processor(data, context)\n\n\nclass ApplicationInsightsTelemetryClient(BotTelemetryClient):\n \"\"\"Application Insights Telemetry Client.\"\"\"\n\n def __init__(\n self,\n instrumentation_key: str,\n telemetry_client: TelemetryClient = None,\n telemetry_processor: Callable[[object, object], bool] = None,\n ):\n self._instrumentation_key = instrumentation_key\n self._client = (\n telemetry_client\n if telemetry_client is not None\n else TelemetryClient(self._instrumentation_key)\n )\n # Telemetry Processor\n processor = (\n telemetry_processor\n if telemetry_processor is not None\n else bot_telemetry_processor\n )\n self._client.add_telemetry_processor(processor)\n\n def track_pageview(\n self,\n name: str,\n url: str,\n duration: int = 0,\n properties: Dict[str, object] = None,\n measurements: Dict[str, object] = None,\n ) -> None:\n \"\"\"\n Send information about the page viewed in the application (a web page for instance).\n :param name: the name of the page that was viewed.\n :param url: the URL of the page that was viewed.\n :param duration: the duration of the page view in milliseconds. (defaults to: 0)\n :param properties: the set of custom properties the client wants attached to this data item.\n (defaults to: None)\n :param measurements: the set of custom measurements the client wants to attach to this data item.\n (defaults to: None)\n \"\"\"\n self._client.track_pageview(name, url, duration, properties, measurements)\n\n def track_exception(\n self,\n exception_type: type = None,\n value: Exception = None,\n trace: traceback = None,\n properties: Dict[str, object] = None,\n measurements: Dict[str, object] = None,\n ) -> None:\n \"\"\"\n Send information about a single exception that occurred in the application.\n :param exception_type: the type of the exception that was thrown.\n :param value: the exception that the client wants to send.\n :param trace: the traceback information as returned by :func:`sys.exc_info`.\n :param properties: the set of custom properties the client wants attached to this data item.\n (defaults to: None)\n :param measurements: the set of custom measurements the client wants to attach to this data item.\n (defaults to: None)\n \"\"\"\n self._client.track_exception(\n exception_type, value, trace, properties, measurements\n )\n\n def track_event(\n self,\n name: str,\n properties: Dict[str, object] = None,\n measurements: Dict[str, object] = None,\n ) -> None:\n \"\"\"\n Send information about a single event that has occurred in the context of the application.\n :param name: the data to associate to this event.\n :param properties: the set of custom properties the client wants attached to this data item.\n (defaults to: None)\n :param measurements: the set of custom measurements the client wants to attach to this data item.\n (defaults to: None)\n \"\"\"\n self._client.track_event(name, properties=properties, measurements=measurements)\n\n def track_metric(\n self,\n name: str,\n value: float,\n tel_type: TelemetryDataPointType = None,\n count: int = None,\n min_val: float = None,\n max_val: float = None,\n std_dev: float = None,\n properties: Dict[str, object] = None,\n ) -> NotImplemented:\n \"\"\"\n Send information about a single metric data point that was captured for the application.\n :param name: The name of the metric that was captured.\n :param value: The value of the metric that was captured.\n :param tel_type: The type of the metric. (defaults to: TelemetryDataPointType.aggregation`)\n :param count: the number of metrics that were aggregated into this data point. (defaults to: None)\n :param min_val: the minimum of all metrics collected that were aggregated into this data point.\n (defaults to: None)\n :param max_val: the maximum of all metrics collected that were aggregated into this data point.\n (defaults to: None)\n :param std_dev: the standard deviation of all metrics collected that were aggregated into this data point.\n (defaults to: None)\n :param properties: the set of custom properties the client wants attached to this data item.\n (defaults to: None)\n \"\"\"\n self._client.track_metric(\n name, value, tel_type, count, min_val, max_val, std_dev, properties\n )\n\n def track_trace(\n self, name: str, properties: Dict[str, object] = None, severity: Severity = None\n ):\n \"\"\"\n Sends a single trace statement.\n :param name: the trace statement.\n :param properties: the set of custom properties the client wants attached to this data item. (defaults to: None)\n :param severity: the severity level of this trace, one of DEBUG, INFO, WARNING, ERROR, CRITICAL\n \"\"\"\n self._client.track_trace(name, properties, severity)\n\n def track_request(\n self,\n name: str,\n url: str,\n success: bool,\n start_time: str = None,\n duration: int = None,\n response_code: str = None,\n http_method: str = None,\n properties: Dict[str, object] = None,\n measurements: Dict[str, object] = None,\n request_id: str = None,\n ):\n \"\"\"\n Sends a single request that was captured for the application.\n :param name: The name for this request. All requests with the same name will be grouped together.\n :param url: The actual URL for this request (to show in individual request instances).\n :param success: True if the request ended in success, False otherwise.\n :param start_time: the start time of the request. The value should look the same as the one returned by\n :func:`datetime.isoformat`. (defaults to: None)\n :param duration: the number of milliseconds that this request lasted. (defaults to: None)\n :param response_code: the response code that this request returned. (defaults to: None)\n :param http_method: the HTTP method that triggered this request. (defaults to: None)\n :param properties: the set of custom properties the client wants attached to this data item.\n (defaults to: None)\n :param measurements: the set of custom measurements the client wants to attach to this data item.\n (defaults to: None)\n :param request_id: the id for this request. If None, a new uuid will be generated. (defaults to: None)\n \"\"\"\n self._client.track_request(\n name,\n url,\n success,\n start_time,\n duration,\n response_code,\n http_method,\n properties,\n measurements,\n request_id,\n )\n\n def track_dependency(\n self,\n name: str,\n data: str,\n type_name: str = None,\n target: str = None,\n duration: int = None,\n success: bool = None,\n result_code: str = None,\n properties: Dict[str, object] = None,\n measurements: Dict[str, object] = None,\n dependency_id: str = None,\n ):\n \"\"\"\n Sends a single dependency telemetry that was captured for the application.\n :param name: the name of the command initiated with this dependency call. Low cardinality value.\n Examples are stored procedure name and URL path template.\n :param data: the command initiated by this dependency call.\n Examples are SQL statement and HTTP URL with all query parameters.\n :param type_name: the dependency type name. Low cardinality value for logical grouping of dependencies and\n interpretation of other fields like commandName and resultCode. Examples are SQL, Azure table, and HTTP.\n (default to: None)\n :param target: the target site of a dependency call. Examples are server name, host address.\n (default to: None)\n :param duration: the number of milliseconds that this dependency call lasted.\n (defaults to: None)\n :param success: true if the dependency call ended in success, false otherwise.\n (defaults to: None)\n :param result_code: the result code of a dependency call. Examples are SQL error code and HTTP status code.\n (defaults to: None)\n :param properties: the set of custom properties the client wants attached to this data item. (defaults to: None)\n :param measurements: the set of custom measurements the client wants to attach to this data item.\n (defaults to: None)\n :param id: the id for this dependency call. If None, a new uuid will be generated. (defaults to: None)\n \"\"\"\n self._client.track_dependency(\n name,\n data,\n type_name,\n target,\n duration,\n success,\n result_code,\n properties,\n measurements,\n dependency_id,\n )\n\n def flush(self):\n \"\"\"Flushes data in the queue. Data in the queue will be sent either immediately irrespective of what sender is\n being used.\n \"\"\"\n self._client.flush()\n", "path": "libraries/botbuilder-applicationinsights/botbuilder/applicationinsights/application_insights_telemetry_client.py"}], "after_files": [{"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License.\n\"\"\"Application Insights Telemetry Client for Bots.\"\"\"\n\nimport traceback\nfrom typing import Dict, Callable\n\nfrom applicationinsights import TelemetryClient # pylint: disable=no-name-in-module\nfrom botbuilder.core.bot_telemetry_client import (\n BotTelemetryClient,\n Severity,\n TelemetryDataPointType,\n)\n\nfrom .bot_telemetry_processor import BotTelemetryProcessor\n\n\ndef bot_telemetry_processor(data, context) -> bool:\n \"\"\"Bot Telemetry Processor as a method for backward compatibility. Refer to\n callable object :class:`BotTelemetryProcessor` for details.\n\n :param data: Data from Application Insights\n :type data: telemetry item\n :param context: Context from Application Insights\n :type context: context object\n :return: determines if the event is passed to the server (False = Filtered).\n :rtype: bool\n \"\"\"\n processor = BotTelemetryProcessor()\n return processor(data, context)\n\n\nclass ApplicationInsightsTelemetryClient(BotTelemetryClient):\n \"\"\"Application Insights Telemetry Client.\"\"\"\n\n def __init__(\n self,\n instrumentation_key: str,\n telemetry_client: TelemetryClient = None,\n telemetry_processor: Callable[[object, object], bool] = None,\n client_queue_size: int = None,\n ):\n self._instrumentation_key = instrumentation_key\n\n self._client = (\n telemetry_client\n if telemetry_client is not None\n else TelemetryClient(self._instrumentation_key)\n )\n if client_queue_size:\n self._client.channel.queue.max_queue_length = client_queue_size\n\n # Telemetry Processor\n processor = (\n telemetry_processor\n if telemetry_processor is not None\n else bot_telemetry_processor\n )\n self._client.add_telemetry_processor(processor)\n\n def track_pageview(\n self,\n name: str,\n url: str,\n duration: int = 0,\n properties: Dict[str, object] = None,\n measurements: Dict[str, object] = None,\n ) -> None:\n \"\"\"\n Send information about the page viewed in the application (a web page for instance).\n :param name: the name of the page that was viewed.\n :param url: the URL of the page that was viewed.\n :param duration: the duration of the page view in milliseconds. (defaults to: 0)\n :param properties: the set of custom properties the client wants attached to this data item.\n (defaults to: None)\n :param measurements: the set of custom measurements the client wants to attach to this data item.\n (defaults to: None)\n \"\"\"\n self._client.track_pageview(name, url, duration, properties, measurements)\n\n def track_exception(\n self,\n exception_type: type = None,\n value: Exception = None,\n trace: traceback = None,\n properties: Dict[str, object] = None,\n measurements: Dict[str, object] = None,\n ) -> None:\n \"\"\"\n Send information about a single exception that occurred in the application.\n :param exception_type: the type of the exception that was thrown.\n :param value: the exception that the client wants to send.\n :param trace: the traceback information as returned by :func:`sys.exc_info`.\n :param properties: the set of custom properties the client wants attached to this data item.\n (defaults to: None)\n :param measurements: the set of custom measurements the client wants to attach to this data item.\n (defaults to: None)\n \"\"\"\n self._client.track_exception(\n exception_type, value, trace, properties, measurements\n )\n\n def track_event(\n self,\n name: str,\n properties: Dict[str, object] = None,\n measurements: Dict[str, object] = None,\n ) -> None:\n \"\"\"\n Send information about a single event that has occurred in the context of the application.\n :param name: the data to associate to this event.\n :param properties: the set of custom properties the client wants attached to this data item.\n (defaults to: None)\n :param measurements: the set of custom measurements the client wants to attach to this data item.\n (defaults to: None)\n \"\"\"\n self._client.track_event(name, properties=properties, measurements=measurements)\n\n def track_metric(\n self,\n name: str,\n value: float,\n tel_type: TelemetryDataPointType = None,\n count: int = None,\n min_val: float = None,\n max_val: float = None,\n std_dev: float = None,\n properties: Dict[str, object] = None,\n ) -> NotImplemented:\n \"\"\"\n Send information about a single metric data point that was captured for the application.\n :param name: The name of the metric that was captured.\n :param value: The value of the metric that was captured.\n :param tel_type: The type of the metric. (defaults to: TelemetryDataPointType.aggregation`)\n :param count: the number of metrics that were aggregated into this data point. (defaults to: None)\n :param min_val: the minimum of all metrics collected that were aggregated into this data point.\n (defaults to: None)\n :param max_val: the maximum of all metrics collected that were aggregated into this data point.\n (defaults to: None)\n :param std_dev: the standard deviation of all metrics collected that were aggregated into this data point.\n (defaults to: None)\n :param properties: the set of custom properties the client wants attached to this data item.\n (defaults to: None)\n \"\"\"\n self._client.track_metric(\n name, value, tel_type, count, min_val, max_val, std_dev, properties\n )\n\n def track_trace(\n self, name: str, properties: Dict[str, object] = None, severity: Severity = None\n ):\n \"\"\"\n Sends a single trace statement.\n :param name: the trace statement.\n :param properties: the set of custom properties the client wants attached to this data item. (defaults to: None)\n :param severity: the severity level of this trace, one of DEBUG, INFO, WARNING, ERROR, CRITICAL\n \"\"\"\n self._client.track_trace(name, properties, severity)\n\n def track_request(\n self,\n name: str,\n url: str,\n success: bool,\n start_time: str = None,\n duration: int = None,\n response_code: str = None,\n http_method: str = None,\n properties: Dict[str, object] = None,\n measurements: Dict[str, object] = None,\n request_id: str = None,\n ):\n \"\"\"\n Sends a single request that was captured for the application.\n :param name: The name for this request. All requests with the same name will be grouped together.\n :param url: The actual URL for this request (to show in individual request instances).\n :param success: True if the request ended in success, False otherwise.\n :param start_time: the start time of the request. The value should look the same as the one returned by\n :func:`datetime.isoformat`. (defaults to: None)\n :param duration: the number of milliseconds that this request lasted. (defaults to: None)\n :param response_code: the response code that this request returned. (defaults to: None)\n :param http_method: the HTTP method that triggered this request. (defaults to: None)\n :param properties: the set of custom properties the client wants attached to this data item.\n (defaults to: None)\n :param measurements: the set of custom measurements the client wants to attach to this data item.\n (defaults to: None)\n :param request_id: the id for this request. If None, a new uuid will be generated. (defaults to: None)\n \"\"\"\n self._client.track_request(\n name,\n url,\n success,\n start_time,\n duration,\n response_code,\n http_method,\n properties,\n measurements,\n request_id,\n )\n\n def track_dependency(\n self,\n name: str,\n data: str,\n type_name: str = None,\n target: str = None,\n duration: int = None,\n success: bool = None,\n result_code: str = None,\n properties: Dict[str, object] = None,\n measurements: Dict[str, object] = None,\n dependency_id: str = None,\n ):\n \"\"\"\n Sends a single dependency telemetry that was captured for the application.\n :param name: the name of the command initiated with this dependency call. Low cardinality value.\n Examples are stored procedure name and URL path template.\n :param data: the command initiated by this dependency call.\n Examples are SQL statement and HTTP URL with all query parameters.\n :param type_name: the dependency type name. Low cardinality value for logical grouping of dependencies and\n interpretation of other fields like commandName and resultCode. Examples are SQL, Azure table, and HTTP.\n (default to: None)\n :param target: the target site of a dependency call. Examples are server name, host address.\n (default to: None)\n :param duration: the number of milliseconds that this dependency call lasted.\n (defaults to: None)\n :param success: true if the dependency call ended in success, false otherwise.\n (defaults to: None)\n :param result_code: the result code of a dependency call. Examples are SQL error code and HTTP status code.\n (defaults to: None)\n :param properties: the set of custom properties the client wants attached to this data item. (defaults to: None)\n :param measurements: the set of custom measurements the client wants to attach to this data item.\n (defaults to: None)\n :param id: the id for this dependency call. If None, a new uuid will be generated. (defaults to: None)\n \"\"\"\n self._client.track_dependency(\n name,\n data,\n type_name,\n target,\n duration,\n success,\n result_code,\n properties,\n measurements,\n dependency_id,\n )\n\n def flush(self):\n \"\"\"Flushes data in the queue. Data in the queue will be sent either immediately irrespective of what sender is\n being used.\n \"\"\"\n self._client.flush()\n", "path": "libraries/botbuilder-applicationinsights/botbuilder/applicationinsights/application_insights_telemetry_client.py"}]}
| 3,133 | 236 |
gh_patches_debug_22464
|
rasdani/github-patches
|
git_diff
|
pulp__pulpcore-5371
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Task cleanup must not delete content nor artifacts
Deleting content or artifacts outside of orphan cleanup is breaking the rules.
And no, we cannot get away with that.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pulpcore/tasking/_util.py`
Content:
```
1 import asyncio
2 import importlib
3 import logging
4 import os
5 import resource
6 import signal
7 import sys
8 import threading
9 import time
10 from gettext import gettext as _
11
12 from django.conf import settings
13 from django.db import connection, transaction
14 from django.db.models import Q
15 from django.utils import timezone
16 from django_guid import set_guid
17 from django_guid.utils import generate_guid
18 from pulpcore.app.models import Task, TaskSchedule
19 from pulpcore.app.role_util import get_users_with_perms
20 from pulpcore.app.util import set_current_user, set_domain, configure_analytics, configure_cleanup
21 from pulpcore.constants import TASK_FINAL_STATES, TASK_STATES, VAR_TMP_PULP
22 from pulpcore.exceptions import AdvisoryLockError
23 from pulpcore.tasking.tasks import dispatch, execute_task
24
25 _logger = logging.getLogger(__name__)
26
27
28 class PGAdvisoryLock:
29 """
30 A context manager that will hold a postgres advisory lock non-blocking.
31
32 The locks can be chosen from a lock group to avoid collisions. They will never collide with the
33 locks used for tasks.
34 """
35
36 def __init__(self, lock, lock_group=0):
37 self.lock_group = lock_group
38 self.lock = lock
39
40 def __enter__(self):
41 with connection.cursor() as cursor:
42 cursor.execute("SELECT pg_try_advisory_lock(%s, %s)", [self.lock_group, self.lock])
43 acquired = cursor.fetchone()[0]
44 if not acquired:
45 raise AdvisoryLockError("Could not acquire lock.")
46 return self
47
48 def __exit__(self, exc_type, exc_value, traceback):
49 with connection.cursor() as cursor:
50 cursor.execute("SELECT pg_advisory_unlock(%s, %s)", [self.lock_group, self.lock])
51 released = cursor.fetchone()[0]
52 if not released:
53 raise RuntimeError("Lock not held.")
54
55
56 def startup_hook():
57 configure_analytics()
58 configure_cleanup()
59
60
61 def delete_incomplete_resources(task):
62 """
63 Delete all incomplete created-resources on a canceled task.
64
65 Args:
66 task (Task): A task.
67 """
68 if task.state != TASK_STATES.CANCELING:
69 raise RuntimeError(_("Task must be canceling."))
70 for model in (r.content_object for r in task.created_resources.all()):
71 try:
72 if model.complete:
73 continue
74 except AttributeError:
75 continue
76 try:
77 with transaction.atomic():
78 model.delete()
79 except Exception as error:
80 _logger.error(_("Delete created resource, failed: {}").format(str(error)))
81
82
83 def write_memory_usage(path):
84 _logger.info("Writing task memory data to {}".format(path))
85
86 with open(path, "w") as file:
87 file.write("# Seconds\tMemory in MB\n")
88 seconds = 0
89 while True:
90 current_mb_in_use = resource.getrusage(resource.RUSAGE_SELF).ru_maxrss / 1024
91 file.write(f"{seconds}\t{current_mb_in_use:.2f}\n")
92 file.flush()
93 time.sleep(5)
94 seconds += 5
95
96
97 def child_signal_handler(sig, frame):
98 _logger.debug("Signal %s recieved by %s.", sig, os.getpid())
99 # Reset signal handlers to default
100 # If you kill the process a second time it's not graceful anymore.
101 signal.signal(signal.SIGINT, signal.SIG_DFL)
102 signal.signal(signal.SIGTERM, signal.SIG_DFL)
103 signal.signal(signal.SIGHUP, signal.SIG_DFL)
104 signal.signal(signal.SIGUSR1, signal.SIG_DFL)
105
106 if sig == signal.SIGUSR1:
107 sys.exit()
108
109
110 def perform_task(task_pk, task_working_dir_rel_path):
111 """Setup the environment to handle a task and execute it.
112 This must be called as a subprocess, while the parent holds the advisory lock of the task."""
113 signal.signal(signal.SIGINT, child_signal_handler)
114 signal.signal(signal.SIGTERM, child_signal_handler)
115 signal.signal(signal.SIGHUP, child_signal_handler)
116 signal.signal(signal.SIGUSR1, child_signal_handler)
117 if settings.TASK_DIAGNOSTICS:
118 diagnostics_dir = VAR_TMP_PULP / str(task_pk)
119 diagnostics_dir.mkdir(parents=True, exist_ok=True)
120 mem_diagnostics_path = diagnostics_dir / "memory.datum"
121 # It would be better to have this recording happen in the parent process instead of here
122 # https://github.com/pulp/pulpcore/issues/2337
123 mem_diagnostics_thread = threading.Thread(
124 target=write_memory_usage, args=(mem_diagnostics_path,), daemon=True
125 )
126 mem_diagnostics_thread.start()
127 # All processes need to create their own postgres connection
128 connection.connection = None
129 task = Task.objects.select_related("pulp_domain").get(pk=task_pk)
130 user = get_users_with_perms(task, with_group_users=False).first()
131 # Isolate from the parent asyncio.
132 asyncio.set_event_loop(asyncio.new_event_loop())
133 # Set current contexts
134 set_guid(task.logging_cid)
135 set_current_user(user)
136 set_domain(task.pulp_domain)
137 os.chdir(task_working_dir_rel_path)
138
139 # set up profiling
140 if settings.TASK_DIAGNOSTICS and importlib.util.find_spec("pyinstrument") is not None:
141 from pyinstrument import Profiler
142
143 with Profiler() as profiler:
144 execute_task(task)
145
146 profile_file = diagnostics_dir / "pyinstrument.html"
147 _logger.info("Writing task profile data to {}".format(profile_file))
148 with open(profile_file, "w+") as f:
149 f.write(profiler.output_html())
150 else:
151 execute_task(task)
152
153
154 def dispatch_scheduled_tasks():
155 # Warning, dispatch_scheduled_tasks is not race condition free!
156 now = timezone.now()
157 # Dispatch all tasks old enough and not still running
158 for task_schedule in TaskSchedule.objects.filter(next_dispatch__lte=now).filter(
159 Q(last_task=None) | Q(last_task__state__in=TASK_FINAL_STATES)
160 ):
161 try:
162 if task_schedule.dispatch_interval is None:
163 # This was a timed one shot task schedule
164 task_schedule.next_dispatch = None
165 else:
166 # This is a recurring task schedule
167 while task_schedule.next_dispatch < now:
168 # Do not schedule in the past
169 task_schedule.next_dispatch += task_schedule.dispatch_interval
170 set_guid(generate_guid())
171 with transaction.atomic():
172 task_schedule.last_task = dispatch(
173 task_schedule.task_name,
174 )
175 task_schedule.save(update_fields=["next_dispatch", "last_task"])
176
177 _logger.info(
178 "Dispatched scheduled task {task_name} as task id {task_id}".format(
179 task_name=task_schedule.task_name, task_id=task_schedule.last_task.pk
180 )
181 )
182 except Exception as e:
183 _logger.warning(
184 "Dispatching scheduled task {task_name} failed. {error}".format(
185 task_name=task_schedule.task_name, error=str(e)
186 )
187 )
188
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pulpcore/tasking/_util.py b/pulpcore/tasking/_util.py
--- a/pulpcore/tasking/_util.py
+++ b/pulpcore/tasking/_util.py
@@ -15,7 +15,7 @@
from django.utils import timezone
from django_guid import set_guid
from django_guid.utils import generate_guid
-from pulpcore.app.models import Task, TaskSchedule
+from pulpcore.app.models import Artifact, Content, Task, TaskSchedule
from pulpcore.app.role_util import get_users_with_perms
from pulpcore.app.util import set_current_user, set_domain, configure_analytics, configure_cleanup
from pulpcore.constants import TASK_FINAL_STATES, TASK_STATES, VAR_TMP_PULP
@@ -68,6 +68,8 @@
if task.state != TASK_STATES.CANCELING:
raise RuntimeError(_("Task must be canceling."))
for model in (r.content_object for r in task.created_resources.all()):
+ if isinstance(model, (Artifact, Content)):
+ continue
try:
if model.complete:
continue
|
{"golden_diff": "diff --git a/pulpcore/tasking/_util.py b/pulpcore/tasking/_util.py\n--- a/pulpcore/tasking/_util.py\n+++ b/pulpcore/tasking/_util.py\n@@ -15,7 +15,7 @@\n from django.utils import timezone\n from django_guid import set_guid\n from django_guid.utils import generate_guid\n-from pulpcore.app.models import Task, TaskSchedule\n+from pulpcore.app.models import Artifact, Content, Task, TaskSchedule\n from pulpcore.app.role_util import get_users_with_perms\n from pulpcore.app.util import set_current_user, set_domain, configure_analytics, configure_cleanup\n from pulpcore.constants import TASK_FINAL_STATES, TASK_STATES, VAR_TMP_PULP\n@@ -68,6 +68,8 @@\n if task.state != TASK_STATES.CANCELING:\n raise RuntimeError(_(\"Task must be canceling.\"))\n for model in (r.content_object for r in task.created_resources.all()):\n+ if isinstance(model, (Artifact, Content)):\n+ continue\n try:\n if model.complete:\n continue\n", "issue": "Task cleanup must not delete content nor artifacts\nDeleting content or artifacts outside of orphan cleanup is breaking the rules.\r\nAnd no, we cannot get away with that.\r\n\n", "before_files": [{"content": "import asyncio\nimport importlib\nimport logging\nimport os\nimport resource\nimport signal\nimport sys\nimport threading\nimport time\nfrom gettext import gettext as _\n\nfrom django.conf import settings\nfrom django.db import connection, transaction\nfrom django.db.models import Q\nfrom django.utils import timezone\nfrom django_guid import set_guid\nfrom django_guid.utils import generate_guid\nfrom pulpcore.app.models import Task, TaskSchedule\nfrom pulpcore.app.role_util import get_users_with_perms\nfrom pulpcore.app.util import set_current_user, set_domain, configure_analytics, configure_cleanup\nfrom pulpcore.constants import TASK_FINAL_STATES, TASK_STATES, VAR_TMP_PULP\nfrom pulpcore.exceptions import AdvisoryLockError\nfrom pulpcore.tasking.tasks import dispatch, execute_task\n\n_logger = logging.getLogger(__name__)\n\n\nclass PGAdvisoryLock:\n \"\"\"\n A context manager that will hold a postgres advisory lock non-blocking.\n\n The locks can be chosen from a lock group to avoid collisions. They will never collide with the\n locks used for tasks.\n \"\"\"\n\n def __init__(self, lock, lock_group=0):\n self.lock_group = lock_group\n self.lock = lock\n\n def __enter__(self):\n with connection.cursor() as cursor:\n cursor.execute(\"SELECT pg_try_advisory_lock(%s, %s)\", [self.lock_group, self.lock])\n acquired = cursor.fetchone()[0]\n if not acquired:\n raise AdvisoryLockError(\"Could not acquire lock.\")\n return self\n\n def __exit__(self, exc_type, exc_value, traceback):\n with connection.cursor() as cursor:\n cursor.execute(\"SELECT pg_advisory_unlock(%s, %s)\", [self.lock_group, self.lock])\n released = cursor.fetchone()[0]\n if not released:\n raise RuntimeError(\"Lock not held.\")\n\n\ndef startup_hook():\n configure_analytics()\n configure_cleanup()\n\n\ndef delete_incomplete_resources(task):\n \"\"\"\n Delete all incomplete created-resources on a canceled task.\n\n Args:\n task (Task): A task.\n \"\"\"\n if task.state != TASK_STATES.CANCELING:\n raise RuntimeError(_(\"Task must be canceling.\"))\n for model in (r.content_object for r in task.created_resources.all()):\n try:\n if model.complete:\n continue\n except AttributeError:\n continue\n try:\n with transaction.atomic():\n model.delete()\n except Exception as error:\n _logger.error(_(\"Delete created resource, failed: {}\").format(str(error)))\n\n\ndef write_memory_usage(path):\n _logger.info(\"Writing task memory data to {}\".format(path))\n\n with open(path, \"w\") as file:\n file.write(\"# Seconds\\tMemory in MB\\n\")\n seconds = 0\n while True:\n current_mb_in_use = resource.getrusage(resource.RUSAGE_SELF).ru_maxrss / 1024\n file.write(f\"{seconds}\\t{current_mb_in_use:.2f}\\n\")\n file.flush()\n time.sleep(5)\n seconds += 5\n\n\ndef child_signal_handler(sig, frame):\n _logger.debug(\"Signal %s recieved by %s.\", sig, os.getpid())\n # Reset signal handlers to default\n # If you kill the process a second time it's not graceful anymore.\n signal.signal(signal.SIGINT, signal.SIG_DFL)\n signal.signal(signal.SIGTERM, signal.SIG_DFL)\n signal.signal(signal.SIGHUP, signal.SIG_DFL)\n signal.signal(signal.SIGUSR1, signal.SIG_DFL)\n\n if sig == signal.SIGUSR1:\n sys.exit()\n\n\ndef perform_task(task_pk, task_working_dir_rel_path):\n \"\"\"Setup the environment to handle a task and execute it.\n This must be called as a subprocess, while the parent holds the advisory lock of the task.\"\"\"\n signal.signal(signal.SIGINT, child_signal_handler)\n signal.signal(signal.SIGTERM, child_signal_handler)\n signal.signal(signal.SIGHUP, child_signal_handler)\n signal.signal(signal.SIGUSR1, child_signal_handler)\n if settings.TASK_DIAGNOSTICS:\n diagnostics_dir = VAR_TMP_PULP / str(task_pk)\n diagnostics_dir.mkdir(parents=True, exist_ok=True)\n mem_diagnostics_path = diagnostics_dir / \"memory.datum\"\n # It would be better to have this recording happen in the parent process instead of here\n # https://github.com/pulp/pulpcore/issues/2337\n mem_diagnostics_thread = threading.Thread(\n target=write_memory_usage, args=(mem_diagnostics_path,), daemon=True\n )\n mem_diagnostics_thread.start()\n # All processes need to create their own postgres connection\n connection.connection = None\n task = Task.objects.select_related(\"pulp_domain\").get(pk=task_pk)\n user = get_users_with_perms(task, with_group_users=False).first()\n # Isolate from the parent asyncio.\n asyncio.set_event_loop(asyncio.new_event_loop())\n # Set current contexts\n set_guid(task.logging_cid)\n set_current_user(user)\n set_domain(task.pulp_domain)\n os.chdir(task_working_dir_rel_path)\n\n # set up profiling\n if settings.TASK_DIAGNOSTICS and importlib.util.find_spec(\"pyinstrument\") is not None:\n from pyinstrument import Profiler\n\n with Profiler() as profiler:\n execute_task(task)\n\n profile_file = diagnostics_dir / \"pyinstrument.html\"\n _logger.info(\"Writing task profile data to {}\".format(profile_file))\n with open(profile_file, \"w+\") as f:\n f.write(profiler.output_html())\n else:\n execute_task(task)\n\n\ndef dispatch_scheduled_tasks():\n # Warning, dispatch_scheduled_tasks is not race condition free!\n now = timezone.now()\n # Dispatch all tasks old enough and not still running\n for task_schedule in TaskSchedule.objects.filter(next_dispatch__lte=now).filter(\n Q(last_task=None) | Q(last_task__state__in=TASK_FINAL_STATES)\n ):\n try:\n if task_schedule.dispatch_interval is None:\n # This was a timed one shot task schedule\n task_schedule.next_dispatch = None\n else:\n # This is a recurring task schedule\n while task_schedule.next_dispatch < now:\n # Do not schedule in the past\n task_schedule.next_dispatch += task_schedule.dispatch_interval\n set_guid(generate_guid())\n with transaction.atomic():\n task_schedule.last_task = dispatch(\n task_schedule.task_name,\n )\n task_schedule.save(update_fields=[\"next_dispatch\", \"last_task\"])\n\n _logger.info(\n \"Dispatched scheduled task {task_name} as task id {task_id}\".format(\n task_name=task_schedule.task_name, task_id=task_schedule.last_task.pk\n )\n )\n except Exception as e:\n _logger.warning(\n \"Dispatching scheduled task {task_name} failed. {error}\".format(\n task_name=task_schedule.task_name, error=str(e)\n )\n )\n", "path": "pulpcore/tasking/_util.py"}], "after_files": [{"content": "import asyncio\nimport importlib\nimport logging\nimport os\nimport resource\nimport signal\nimport sys\nimport threading\nimport time\nfrom gettext import gettext as _\n\nfrom django.conf import settings\nfrom django.db import connection, transaction\nfrom django.db.models import Q\nfrom django.utils import timezone\nfrom django_guid import set_guid\nfrom django_guid.utils import generate_guid\nfrom pulpcore.app.models import Artifact, Content, Task, TaskSchedule\nfrom pulpcore.app.role_util import get_users_with_perms\nfrom pulpcore.app.util import set_current_user, set_domain, configure_analytics, configure_cleanup\nfrom pulpcore.constants import TASK_FINAL_STATES, TASK_STATES, VAR_TMP_PULP\nfrom pulpcore.exceptions import AdvisoryLockError\nfrom pulpcore.tasking.tasks import dispatch, execute_task\n\n_logger = logging.getLogger(__name__)\n\n\nclass PGAdvisoryLock:\n \"\"\"\n A context manager that will hold a postgres advisory lock non-blocking.\n\n The locks can be chosen from a lock group to avoid collisions. They will never collide with the\n locks used for tasks.\n \"\"\"\n\n def __init__(self, lock, lock_group=0):\n self.lock_group = lock_group\n self.lock = lock\n\n def __enter__(self):\n with connection.cursor() as cursor:\n cursor.execute(\"SELECT pg_try_advisory_lock(%s, %s)\", [self.lock_group, self.lock])\n acquired = cursor.fetchone()[0]\n if not acquired:\n raise AdvisoryLockError(\"Could not acquire lock.\")\n return self\n\n def __exit__(self, exc_type, exc_value, traceback):\n with connection.cursor() as cursor:\n cursor.execute(\"SELECT pg_advisory_unlock(%s, %s)\", [self.lock_group, self.lock])\n released = cursor.fetchone()[0]\n if not released:\n raise RuntimeError(\"Lock not held.\")\n\n\ndef startup_hook():\n configure_analytics()\n configure_cleanup()\n\n\ndef delete_incomplete_resources(task):\n \"\"\"\n Delete all incomplete created-resources on a canceled task.\n\n Args:\n task (Task): A task.\n \"\"\"\n if task.state != TASK_STATES.CANCELING:\n raise RuntimeError(_(\"Task must be canceling.\"))\n for model in (r.content_object for r in task.created_resources.all()):\n if isinstance(model, (Artifact, Content)):\n continue\n try:\n if model.complete:\n continue\n except AttributeError:\n continue\n try:\n with transaction.atomic():\n model.delete()\n except Exception as error:\n _logger.error(_(\"Delete created resource, failed: {}\").format(str(error)))\n\n\ndef write_memory_usage(path):\n _logger.info(\"Writing task memory data to {}\".format(path))\n\n with open(path, \"w\") as file:\n file.write(\"# Seconds\\tMemory in MB\\n\")\n seconds = 0\n while True:\n current_mb_in_use = resource.getrusage(resource.RUSAGE_SELF).ru_maxrss / 1024\n file.write(f\"{seconds}\\t{current_mb_in_use:.2f}\\n\")\n file.flush()\n time.sleep(5)\n seconds += 5\n\n\ndef child_signal_handler(sig, frame):\n _logger.debug(\"Signal %s recieved by %s.\", sig, os.getpid())\n # Reset signal handlers to default\n # If you kill the process a second time it's not graceful anymore.\n signal.signal(signal.SIGINT, signal.SIG_DFL)\n signal.signal(signal.SIGTERM, signal.SIG_DFL)\n signal.signal(signal.SIGHUP, signal.SIG_DFL)\n signal.signal(signal.SIGUSR1, signal.SIG_DFL)\n\n if sig == signal.SIGUSR1:\n sys.exit()\n\n\ndef perform_task(task_pk, task_working_dir_rel_path):\n \"\"\"Setup the environment to handle a task and execute it.\n This must be called as a subprocess, while the parent holds the advisory lock of the task.\"\"\"\n signal.signal(signal.SIGINT, child_signal_handler)\n signal.signal(signal.SIGTERM, child_signal_handler)\n signal.signal(signal.SIGHUP, child_signal_handler)\n signal.signal(signal.SIGUSR1, child_signal_handler)\n if settings.TASK_DIAGNOSTICS:\n diagnostics_dir = VAR_TMP_PULP / str(task_pk)\n diagnostics_dir.mkdir(parents=True, exist_ok=True)\n mem_diagnostics_path = diagnostics_dir / \"memory.datum\"\n # It would be better to have this recording happen in the parent process instead of here\n # https://github.com/pulp/pulpcore/issues/2337\n mem_diagnostics_thread = threading.Thread(\n target=write_memory_usage, args=(mem_diagnostics_path,), daemon=True\n )\n mem_diagnostics_thread.start()\n # All processes need to create their own postgres connection\n connection.connection = None\n task = Task.objects.select_related(\"pulp_domain\").get(pk=task_pk)\n user = get_users_with_perms(task, with_group_users=False).first()\n # Isolate from the parent asyncio.\n asyncio.set_event_loop(asyncio.new_event_loop())\n # Set current contexts\n set_guid(task.logging_cid)\n set_current_user(user)\n set_domain(task.pulp_domain)\n os.chdir(task_working_dir_rel_path)\n\n # set up profiling\n if settings.TASK_DIAGNOSTICS and importlib.util.find_spec(\"pyinstrument\") is not None:\n from pyinstrument import Profiler\n\n with Profiler() as profiler:\n execute_task(task)\n\n profile_file = diagnostics_dir / \"pyinstrument.html\"\n _logger.info(\"Writing task profile data to {}\".format(profile_file))\n with open(profile_file, \"w+\") as f:\n f.write(profiler.output_html())\n else:\n execute_task(task)\n\n\ndef dispatch_scheduled_tasks():\n # Warning, dispatch_scheduled_tasks is not race condition free!\n now = timezone.now()\n # Dispatch all tasks old enough and not still running\n for task_schedule in TaskSchedule.objects.filter(next_dispatch__lte=now).filter(\n Q(last_task=None) | Q(last_task__state__in=TASK_FINAL_STATES)\n ):\n try:\n if task_schedule.dispatch_interval is None:\n # This was a timed one shot task schedule\n task_schedule.next_dispatch = None\n else:\n # This is a recurring task schedule\n while task_schedule.next_dispatch < now:\n # Do not schedule in the past\n task_schedule.next_dispatch += task_schedule.dispatch_interval\n set_guid(generate_guid())\n with transaction.atomic():\n task_schedule.last_task = dispatch(\n task_schedule.task_name,\n )\n task_schedule.save(update_fields=[\"next_dispatch\", \"last_task\"])\n\n _logger.info(\n \"Dispatched scheduled task {task_name} as task id {task_id}\".format(\n task_name=task_schedule.task_name, task_id=task_schedule.last_task.pk\n )\n )\n except Exception as e:\n _logger.warning(\n \"Dispatching scheduled task {task_name} failed. {error}\".format(\n task_name=task_schedule.task_name, error=str(e)\n )\n )\n", "path": "pulpcore/tasking/_util.py"}]}
| 2,232 | 230 |
gh_patches_debug_1507
|
rasdani/github-patches
|
git_diff
|
keras-team__autokeras-1285
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
How use multiple gpu?
### Feature Description
I want to use a single machine with multiple gpu for training, but it seems to have no actual effect### Code Example
```python
with strategy.scope():
```
### Reason
Speed up the calculation of toxins
### Solution
<!---
Please tell us how to implement the feature,
if you have one in mind.
-->
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `autokeras/graph.py`
Content:
```
1 # Copyright 2020 The AutoKeras Authors.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import kerastuner
16 import tensorflow as tf
17 from tensorflow.python.util import nest
18
19 from autokeras import blocks as blocks_module
20 from autokeras import nodes as nodes_module
21 from autokeras.engine import head as head_module
22 from autokeras.engine import serializable
23 from autokeras.utils import utils
24
25
26 def feature_encoding_input(block):
27 """Fetch the column_types and column_names.
28
29 The values are fetched for FeatureEncoding from StructuredDataInput.
30 """
31 if not isinstance(block.inputs[0], nodes_module.StructuredDataInput):
32 raise TypeError(
33 "CategoricalToNumerical can only be used with StructuredDataInput."
34 )
35 block.column_types = block.inputs[0].column_types
36 block.column_names = block.inputs[0].column_names
37
38
39 # Compile the graph.
40 COMPILE_FUNCTIONS = {
41 blocks_module.StructuredDataBlock: [feature_encoding_input],
42 blocks_module.CategoricalToNumerical: [feature_encoding_input],
43 }
44
45
46 def load_graph(filepath, custom_objects=None):
47 if custom_objects is None:
48 custom_objects = {}
49 with tf.keras.utils.custom_object_scope(custom_objects):
50 return Graph.from_config(utils.load_json(filepath))
51
52
53 class Graph(kerastuner.HyperModel, serializable.Serializable):
54 """A graph consists of connected Blocks, or Heads.
55
56 # Arguments
57 inputs: A list of input node(s) for the Graph.
58 outputs: A list of output node(s) for the Graph.
59 override_hps: A list of HyperParameters. The predefined HyperParameters that
60 will override the space of the Hyperparameters defined in the Hypermodels
61 with the same names.
62 """
63
64 def __init__(self, inputs=None, outputs=None, override_hps=None):
65 super().__init__()
66 self.inputs = nest.flatten(inputs)
67 self.outputs = nest.flatten(outputs)
68 self._node_to_id = {}
69 self._nodes = []
70 self.blocks = []
71 self._block_to_id = {}
72 if inputs and outputs:
73 self._build_network()
74 self.override_hps = override_hps or []
75
76 def compile(self):
77 """Share the information between blocks."""
78 for block in self.blocks:
79 for func in COMPILE_FUNCTIONS.get(block.__class__, []):
80 func(block)
81
82 def _register_hps(self, hp):
83 """Register the override HyperParameters for current HyperParameters."""
84 for single_hp in self.override_hps:
85 name = single_hp.name
86 if name not in hp.values:
87 hp._register(single_hp)
88 hp.values[name] = single_hp.default
89
90 def _build_network(self):
91 self._node_to_id = {}
92
93 # Recursively find all the interested nodes.
94 for input_node in self.inputs:
95 self._search_network(input_node, self.outputs, set(), set())
96 self._nodes = sorted(
97 list(self._node_to_id.keys()), key=lambda x: self._node_to_id[x]
98 )
99
100 for node in self.inputs + self.outputs:
101 if node not in self._node_to_id:
102 raise ValueError("Inputs and outputs not connected.")
103
104 # Find the blocks.
105 blocks = []
106 for input_node in self._nodes:
107 for block in input_node.out_blocks:
108 if (
109 any(
110 [
111 output_node in self._node_to_id
112 for output_node in block.outputs
113 ]
114 )
115 and block not in blocks
116 ):
117 blocks.append(block)
118
119 # Check if all the inputs of the blocks are set as inputs.
120 for block in blocks:
121 for input_node in block.inputs:
122 if input_node not in self._node_to_id:
123 raise ValueError(
124 "A required input is missing for HyperModel "
125 "{name}.".format(name=block.name)
126 )
127
128 # Calculate the in degree of all the nodes
129 in_degree = [0] * len(self._nodes)
130 for node_id, node in enumerate(self._nodes):
131 in_degree[node_id] = len(
132 [block for block in node.in_blocks if block in blocks]
133 )
134
135 # Add the blocks in topological order.
136 self.blocks = []
137 self._block_to_id = {}
138 while len(blocks) != 0:
139 new_added = []
140
141 # Collect blocks with in degree 0.
142 for block in blocks:
143 if any([in_degree[self._node_to_id[node]] for node in block.inputs]):
144 continue
145 new_added.append(block)
146
147 # Remove the collected blocks from blocks.
148 for block in new_added:
149 blocks.remove(block)
150
151 for block in new_added:
152 # Add the collected blocks to the Graph.
153 self._add_block(block)
154
155 # Decrease the in degree of the output nodes.
156 for output_node in block.outputs:
157 output_node_id = self._node_to_id[output_node]
158 in_degree[output_node_id] -= 1
159
160 def _search_network(self, input_node, outputs, in_stack_nodes, visited_nodes):
161 visited_nodes.add(input_node)
162 in_stack_nodes.add(input_node)
163
164 outputs_reached = False
165 if input_node in outputs:
166 outputs_reached = True
167
168 for block in input_node.out_blocks:
169 for output_node in block.outputs:
170 if output_node in in_stack_nodes:
171 raise ValueError("The network has a cycle.")
172 if output_node not in visited_nodes:
173 self._search_network(
174 output_node, outputs, in_stack_nodes, visited_nodes
175 )
176 if output_node in self._node_to_id.keys():
177 outputs_reached = True
178
179 if outputs_reached:
180 self._add_node(input_node)
181
182 in_stack_nodes.remove(input_node)
183
184 def _add_block(self, block):
185 if block not in self.blocks:
186 block_id = len(self.blocks)
187 self._block_to_id[block] = block_id
188 self.blocks.append(block)
189
190 def _add_node(self, input_node):
191 if input_node not in self._node_to_id:
192 self._node_to_id[input_node] = len(self._node_to_id)
193
194 def get_config(self):
195 blocks = [blocks_module.serialize(block) for block in self.blocks]
196 nodes = {
197 str(self._node_to_id[node]): nodes_module.serialize(node)
198 for node in self.inputs
199 }
200 override_hps = [
201 kerastuner.engine.hyperparameters.serialize(hp)
202 for hp in self.override_hps
203 ]
204 block_inputs = {
205 str(block_id): [self._node_to_id[node] for node in block.inputs]
206 for block_id, block in enumerate(self.blocks)
207 }
208 block_outputs = {
209 str(block_id): [self._node_to_id[node] for node in block.outputs]
210 for block_id, block in enumerate(self.blocks)
211 }
212
213 outputs = [self._node_to_id[node] for node in self.outputs]
214
215 return {
216 "override_hps": override_hps, # List [serialized].
217 "blocks": blocks, # Dict {id: serialized}.
218 "nodes": nodes, # Dict {id: serialized}.
219 "outputs": outputs, # List of node_ids.
220 "block_inputs": block_inputs, # Dict {id: List of node_ids}.
221 "block_outputs": block_outputs, # Dict {id: List of node_ids}.
222 }
223
224 @classmethod
225 def from_config(cls, config):
226 blocks = [blocks_module.deserialize(block) for block in config["blocks"]]
227 nodes = {
228 int(node_id): nodes_module.deserialize(node)
229 for node_id, node in config["nodes"].items()
230 }
231 override_hps = [
232 kerastuner.engine.hyperparameters.deserialize(config)
233 for config in config["override_hps"]
234 ]
235
236 inputs = [nodes[node_id] for node_id in nodes]
237 for block_id, block in enumerate(blocks):
238 input_nodes = [
239 nodes[node_id] for node_id in config["block_inputs"][str(block_id)]
240 ]
241 output_nodes = nest.flatten(block(input_nodes))
242 for output_node, node_id in zip(
243 output_nodes, config["block_outputs"][str(block_id)]
244 ):
245 nodes[node_id] = output_node
246
247 outputs = [nodes[node_id] for node_id in config["outputs"]]
248 return cls(inputs=inputs, outputs=outputs, override_hps=override_hps)
249
250 def build(self, hp):
251 """Build the HyperModel into a Keras Model."""
252 tf.keras.backend.clear_session()
253 self._register_hps(hp)
254 self.compile()
255 real_nodes = {}
256 for input_node in self.inputs:
257 node_id = self._node_to_id[input_node]
258 real_nodes[node_id] = input_node.build()
259 for block in self.blocks:
260 temp_inputs = [
261 real_nodes[self._node_to_id[input_node]]
262 for input_node in block.inputs
263 ]
264 outputs = block.build(hp, inputs=temp_inputs)
265 outputs = nest.flatten(outputs)
266 for output_node, real_output_node in zip(block.outputs, outputs):
267 real_nodes[self._node_to_id[output_node]] = real_output_node
268 model = tf.keras.Model(
269 [real_nodes[self._node_to_id[input_node]] for input_node in self.inputs],
270 [
271 real_nodes[self._node_to_id[output_node]]
272 for output_node in self.outputs
273 ],
274 )
275
276 return self._compile_keras_model(hp, model)
277
278 def _get_metrics(self):
279 metrics = {}
280 for output_node in self.outputs:
281 block = output_node.in_blocks[0]
282 if isinstance(block, head_module.Head):
283 metrics[block.name] = block.metrics
284 return metrics
285
286 def _get_loss(self):
287 loss = {}
288 for output_node in self.outputs:
289 block = output_node.in_blocks[0]
290 if isinstance(block, head_module.Head):
291 loss[block.name] = block.loss
292 return loss
293
294 def _compile_keras_model(self, hp, model):
295 # Specify hyperparameters from compile(...)
296 optimizer_name = hp.Choice(
297 "optimizer", ["adam", "adadelta", "sgd"], default="adam"
298 )
299 learning_rate = hp.Choice(
300 "learning_rate", [1e-1, 1e-2, 1e-3, 1e-4, 1e-5], default=1e-3
301 )
302
303 if optimizer_name == "adam":
304 optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
305 elif optimizer_name == "adadelta":
306 optimizer = tf.keras.optimizers.Adadelta(learning_rate=learning_rate)
307 elif optimizer_name == "sgd":
308 optimizer = tf.keras.optimizers.SGD(learning_rate=learning_rate)
309
310 model.compile(
311 optimizer=optimizer, metrics=self._get_metrics(), loss=self._get_loss()
312 )
313
314 return model
315
316 def save(self, filepath):
317 utils.save_json(filepath, self.get_config())
318
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/autokeras/graph.py b/autokeras/graph.py
--- a/autokeras/graph.py
+++ b/autokeras/graph.py
@@ -249,7 +249,6 @@
def build(self, hp):
"""Build the HyperModel into a Keras Model."""
- tf.keras.backend.clear_session()
self._register_hps(hp)
self.compile()
real_nodes = {}
|
{"golden_diff": "diff --git a/autokeras/graph.py b/autokeras/graph.py\n--- a/autokeras/graph.py\n+++ b/autokeras/graph.py\n@@ -249,7 +249,6 @@\n \n def build(self, hp):\n \"\"\"Build the HyperModel into a Keras Model.\"\"\"\n- tf.keras.backend.clear_session()\n self._register_hps(hp)\n self.compile()\n real_nodes = {}\n", "issue": "How use multiple gpu?\n### Feature Description\r\nI want to use a single machine with multiple gpu for training, but it seems to have no actual effect### Code Example\r\n\r\n```python\r\nwith strategy.scope():\r\n```\r\n\r\n### Reason\r\nSpeed up the calculation of toxins\r\n\r\n### Solution\r\n<!---\r\nPlease tell us how to implement the feature,\r\nif you have one in mind.\r\n-->\r\n\n", "before_files": [{"content": "# Copyright 2020 The AutoKeras Authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport kerastuner\nimport tensorflow as tf\nfrom tensorflow.python.util import nest\n\nfrom autokeras import blocks as blocks_module\nfrom autokeras import nodes as nodes_module\nfrom autokeras.engine import head as head_module\nfrom autokeras.engine import serializable\nfrom autokeras.utils import utils\n\n\ndef feature_encoding_input(block):\n \"\"\"Fetch the column_types and column_names.\n\n The values are fetched for FeatureEncoding from StructuredDataInput.\n \"\"\"\n if not isinstance(block.inputs[0], nodes_module.StructuredDataInput):\n raise TypeError(\n \"CategoricalToNumerical can only be used with StructuredDataInput.\"\n )\n block.column_types = block.inputs[0].column_types\n block.column_names = block.inputs[0].column_names\n\n\n# Compile the graph.\nCOMPILE_FUNCTIONS = {\n blocks_module.StructuredDataBlock: [feature_encoding_input],\n blocks_module.CategoricalToNumerical: [feature_encoding_input],\n}\n\n\ndef load_graph(filepath, custom_objects=None):\n if custom_objects is None:\n custom_objects = {}\n with tf.keras.utils.custom_object_scope(custom_objects):\n return Graph.from_config(utils.load_json(filepath))\n\n\nclass Graph(kerastuner.HyperModel, serializable.Serializable):\n \"\"\"A graph consists of connected Blocks, or Heads.\n\n # Arguments\n inputs: A list of input node(s) for the Graph.\n outputs: A list of output node(s) for the Graph.\n override_hps: A list of HyperParameters. The predefined HyperParameters that\n will override the space of the Hyperparameters defined in the Hypermodels\n with the same names.\n \"\"\"\n\n def __init__(self, inputs=None, outputs=None, override_hps=None):\n super().__init__()\n self.inputs = nest.flatten(inputs)\n self.outputs = nest.flatten(outputs)\n self._node_to_id = {}\n self._nodes = []\n self.blocks = []\n self._block_to_id = {}\n if inputs and outputs:\n self._build_network()\n self.override_hps = override_hps or []\n\n def compile(self):\n \"\"\"Share the information between blocks.\"\"\"\n for block in self.blocks:\n for func in COMPILE_FUNCTIONS.get(block.__class__, []):\n func(block)\n\n def _register_hps(self, hp):\n \"\"\"Register the override HyperParameters for current HyperParameters.\"\"\"\n for single_hp in self.override_hps:\n name = single_hp.name\n if name not in hp.values:\n hp._register(single_hp)\n hp.values[name] = single_hp.default\n\n def _build_network(self):\n self._node_to_id = {}\n\n # Recursively find all the interested nodes.\n for input_node in self.inputs:\n self._search_network(input_node, self.outputs, set(), set())\n self._nodes = sorted(\n list(self._node_to_id.keys()), key=lambda x: self._node_to_id[x]\n )\n\n for node in self.inputs + self.outputs:\n if node not in self._node_to_id:\n raise ValueError(\"Inputs and outputs not connected.\")\n\n # Find the blocks.\n blocks = []\n for input_node in self._nodes:\n for block in input_node.out_blocks:\n if (\n any(\n [\n output_node in self._node_to_id\n for output_node in block.outputs\n ]\n )\n and block not in blocks\n ):\n blocks.append(block)\n\n # Check if all the inputs of the blocks are set as inputs.\n for block in blocks:\n for input_node in block.inputs:\n if input_node not in self._node_to_id:\n raise ValueError(\n \"A required input is missing for HyperModel \"\n \"{name}.\".format(name=block.name)\n )\n\n # Calculate the in degree of all the nodes\n in_degree = [0] * len(self._nodes)\n for node_id, node in enumerate(self._nodes):\n in_degree[node_id] = len(\n [block for block in node.in_blocks if block in blocks]\n )\n\n # Add the blocks in topological order.\n self.blocks = []\n self._block_to_id = {}\n while len(blocks) != 0:\n new_added = []\n\n # Collect blocks with in degree 0.\n for block in blocks:\n if any([in_degree[self._node_to_id[node]] for node in block.inputs]):\n continue\n new_added.append(block)\n\n # Remove the collected blocks from blocks.\n for block in new_added:\n blocks.remove(block)\n\n for block in new_added:\n # Add the collected blocks to the Graph.\n self._add_block(block)\n\n # Decrease the in degree of the output nodes.\n for output_node in block.outputs:\n output_node_id = self._node_to_id[output_node]\n in_degree[output_node_id] -= 1\n\n def _search_network(self, input_node, outputs, in_stack_nodes, visited_nodes):\n visited_nodes.add(input_node)\n in_stack_nodes.add(input_node)\n\n outputs_reached = False\n if input_node in outputs:\n outputs_reached = True\n\n for block in input_node.out_blocks:\n for output_node in block.outputs:\n if output_node in in_stack_nodes:\n raise ValueError(\"The network has a cycle.\")\n if output_node not in visited_nodes:\n self._search_network(\n output_node, outputs, in_stack_nodes, visited_nodes\n )\n if output_node in self._node_to_id.keys():\n outputs_reached = True\n\n if outputs_reached:\n self._add_node(input_node)\n\n in_stack_nodes.remove(input_node)\n\n def _add_block(self, block):\n if block not in self.blocks:\n block_id = len(self.blocks)\n self._block_to_id[block] = block_id\n self.blocks.append(block)\n\n def _add_node(self, input_node):\n if input_node not in self._node_to_id:\n self._node_to_id[input_node] = len(self._node_to_id)\n\n def get_config(self):\n blocks = [blocks_module.serialize(block) for block in self.blocks]\n nodes = {\n str(self._node_to_id[node]): nodes_module.serialize(node)\n for node in self.inputs\n }\n override_hps = [\n kerastuner.engine.hyperparameters.serialize(hp)\n for hp in self.override_hps\n ]\n block_inputs = {\n str(block_id): [self._node_to_id[node] for node in block.inputs]\n for block_id, block in enumerate(self.blocks)\n }\n block_outputs = {\n str(block_id): [self._node_to_id[node] for node in block.outputs]\n for block_id, block in enumerate(self.blocks)\n }\n\n outputs = [self._node_to_id[node] for node in self.outputs]\n\n return {\n \"override_hps\": override_hps, # List [serialized].\n \"blocks\": blocks, # Dict {id: serialized}.\n \"nodes\": nodes, # Dict {id: serialized}.\n \"outputs\": outputs, # List of node_ids.\n \"block_inputs\": block_inputs, # Dict {id: List of node_ids}.\n \"block_outputs\": block_outputs, # Dict {id: List of node_ids}.\n }\n\n @classmethod\n def from_config(cls, config):\n blocks = [blocks_module.deserialize(block) for block in config[\"blocks\"]]\n nodes = {\n int(node_id): nodes_module.deserialize(node)\n for node_id, node in config[\"nodes\"].items()\n }\n override_hps = [\n kerastuner.engine.hyperparameters.deserialize(config)\n for config in config[\"override_hps\"]\n ]\n\n inputs = [nodes[node_id] for node_id in nodes]\n for block_id, block in enumerate(blocks):\n input_nodes = [\n nodes[node_id] for node_id in config[\"block_inputs\"][str(block_id)]\n ]\n output_nodes = nest.flatten(block(input_nodes))\n for output_node, node_id in zip(\n output_nodes, config[\"block_outputs\"][str(block_id)]\n ):\n nodes[node_id] = output_node\n\n outputs = [nodes[node_id] for node_id in config[\"outputs\"]]\n return cls(inputs=inputs, outputs=outputs, override_hps=override_hps)\n\n def build(self, hp):\n \"\"\"Build the HyperModel into a Keras Model.\"\"\"\n tf.keras.backend.clear_session()\n self._register_hps(hp)\n self.compile()\n real_nodes = {}\n for input_node in self.inputs:\n node_id = self._node_to_id[input_node]\n real_nodes[node_id] = input_node.build()\n for block in self.blocks:\n temp_inputs = [\n real_nodes[self._node_to_id[input_node]]\n for input_node in block.inputs\n ]\n outputs = block.build(hp, inputs=temp_inputs)\n outputs = nest.flatten(outputs)\n for output_node, real_output_node in zip(block.outputs, outputs):\n real_nodes[self._node_to_id[output_node]] = real_output_node\n model = tf.keras.Model(\n [real_nodes[self._node_to_id[input_node]] for input_node in self.inputs],\n [\n real_nodes[self._node_to_id[output_node]]\n for output_node in self.outputs\n ],\n )\n\n return self._compile_keras_model(hp, model)\n\n def _get_metrics(self):\n metrics = {}\n for output_node in self.outputs:\n block = output_node.in_blocks[0]\n if isinstance(block, head_module.Head):\n metrics[block.name] = block.metrics\n return metrics\n\n def _get_loss(self):\n loss = {}\n for output_node in self.outputs:\n block = output_node.in_blocks[0]\n if isinstance(block, head_module.Head):\n loss[block.name] = block.loss\n return loss\n\n def _compile_keras_model(self, hp, model):\n # Specify hyperparameters from compile(...)\n optimizer_name = hp.Choice(\n \"optimizer\", [\"adam\", \"adadelta\", \"sgd\"], default=\"adam\"\n )\n learning_rate = hp.Choice(\n \"learning_rate\", [1e-1, 1e-2, 1e-3, 1e-4, 1e-5], default=1e-3\n )\n\n if optimizer_name == \"adam\":\n optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)\n elif optimizer_name == \"adadelta\":\n optimizer = tf.keras.optimizers.Adadelta(learning_rate=learning_rate)\n elif optimizer_name == \"sgd\":\n optimizer = tf.keras.optimizers.SGD(learning_rate=learning_rate)\n\n model.compile(\n optimizer=optimizer, metrics=self._get_metrics(), loss=self._get_loss()\n )\n\n return model\n\n def save(self, filepath):\n utils.save_json(filepath, self.get_config())\n", "path": "autokeras/graph.py"}], "after_files": [{"content": "# Copyright 2020 The AutoKeras Authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport kerastuner\nimport tensorflow as tf\nfrom tensorflow.python.util import nest\n\nfrom autokeras import blocks as blocks_module\nfrom autokeras import nodes as nodes_module\nfrom autokeras.engine import head as head_module\nfrom autokeras.engine import serializable\nfrom autokeras.utils import utils\n\n\ndef feature_encoding_input(block):\n \"\"\"Fetch the column_types and column_names.\n\n The values are fetched for FeatureEncoding from StructuredDataInput.\n \"\"\"\n if not isinstance(block.inputs[0], nodes_module.StructuredDataInput):\n raise TypeError(\n \"CategoricalToNumerical can only be used with StructuredDataInput.\"\n )\n block.column_types = block.inputs[0].column_types\n block.column_names = block.inputs[0].column_names\n\n\n# Compile the graph.\nCOMPILE_FUNCTIONS = {\n blocks_module.StructuredDataBlock: [feature_encoding_input],\n blocks_module.CategoricalToNumerical: [feature_encoding_input],\n}\n\n\ndef load_graph(filepath, custom_objects=None):\n if custom_objects is None:\n custom_objects = {}\n with tf.keras.utils.custom_object_scope(custom_objects):\n return Graph.from_config(utils.load_json(filepath))\n\n\nclass Graph(kerastuner.HyperModel, serializable.Serializable):\n \"\"\"A graph consists of connected Blocks, or Heads.\n\n # Arguments\n inputs: A list of input node(s) for the Graph.\n outputs: A list of output node(s) for the Graph.\n override_hps: A list of HyperParameters. The predefined HyperParameters that\n will override the space of the Hyperparameters defined in the Hypermodels\n with the same names.\n \"\"\"\n\n def __init__(self, inputs=None, outputs=None, override_hps=None):\n super().__init__()\n self.inputs = nest.flatten(inputs)\n self.outputs = nest.flatten(outputs)\n self._node_to_id = {}\n self._nodes = []\n self.blocks = []\n self._block_to_id = {}\n if inputs and outputs:\n self._build_network()\n self.override_hps = override_hps or []\n\n def compile(self):\n \"\"\"Share the information between blocks.\"\"\"\n for block in self.blocks:\n for func in COMPILE_FUNCTIONS.get(block.__class__, []):\n func(block)\n\n def _register_hps(self, hp):\n \"\"\"Register the override HyperParameters for current HyperParameters.\"\"\"\n for single_hp in self.override_hps:\n name = single_hp.name\n if name not in hp.values:\n hp._register(single_hp)\n hp.values[name] = single_hp.default\n\n def _build_network(self):\n self._node_to_id = {}\n\n # Recursively find all the interested nodes.\n for input_node in self.inputs:\n self._search_network(input_node, self.outputs, set(), set())\n self._nodes = sorted(\n list(self._node_to_id.keys()), key=lambda x: self._node_to_id[x]\n )\n\n for node in self.inputs + self.outputs:\n if node not in self._node_to_id:\n raise ValueError(\"Inputs and outputs not connected.\")\n\n # Find the blocks.\n blocks = []\n for input_node in self._nodes:\n for block in input_node.out_blocks:\n if (\n any(\n [\n output_node in self._node_to_id\n for output_node in block.outputs\n ]\n )\n and block not in blocks\n ):\n blocks.append(block)\n\n # Check if all the inputs of the blocks are set as inputs.\n for block in blocks:\n for input_node in block.inputs:\n if input_node not in self._node_to_id:\n raise ValueError(\n \"A required input is missing for HyperModel \"\n \"{name}.\".format(name=block.name)\n )\n\n # Calculate the in degree of all the nodes\n in_degree = [0] * len(self._nodes)\n for node_id, node in enumerate(self._nodes):\n in_degree[node_id] = len(\n [block for block in node.in_blocks if block in blocks]\n )\n\n # Add the blocks in topological order.\n self.blocks = []\n self._block_to_id = {}\n while len(blocks) != 0:\n new_added = []\n\n # Collect blocks with in degree 0.\n for block in blocks:\n if any([in_degree[self._node_to_id[node]] for node in block.inputs]):\n continue\n new_added.append(block)\n\n # Remove the collected blocks from blocks.\n for block in new_added:\n blocks.remove(block)\n\n for block in new_added:\n # Add the collected blocks to the Graph.\n self._add_block(block)\n\n # Decrease the in degree of the output nodes.\n for output_node in block.outputs:\n output_node_id = self._node_to_id[output_node]\n in_degree[output_node_id] -= 1\n\n def _search_network(self, input_node, outputs, in_stack_nodes, visited_nodes):\n visited_nodes.add(input_node)\n in_stack_nodes.add(input_node)\n\n outputs_reached = False\n if input_node in outputs:\n outputs_reached = True\n\n for block in input_node.out_blocks:\n for output_node in block.outputs:\n if output_node in in_stack_nodes:\n raise ValueError(\"The network has a cycle.\")\n if output_node not in visited_nodes:\n self._search_network(\n output_node, outputs, in_stack_nodes, visited_nodes\n )\n if output_node in self._node_to_id.keys():\n outputs_reached = True\n\n if outputs_reached:\n self._add_node(input_node)\n\n in_stack_nodes.remove(input_node)\n\n def _add_block(self, block):\n if block not in self.blocks:\n block_id = len(self.blocks)\n self._block_to_id[block] = block_id\n self.blocks.append(block)\n\n def _add_node(self, input_node):\n if input_node not in self._node_to_id:\n self._node_to_id[input_node] = len(self._node_to_id)\n\n def get_config(self):\n blocks = [blocks_module.serialize(block) for block in self.blocks]\n nodes = {\n str(self._node_to_id[node]): nodes_module.serialize(node)\n for node in self.inputs\n }\n override_hps = [\n kerastuner.engine.hyperparameters.serialize(hp)\n for hp in self.override_hps\n ]\n block_inputs = {\n str(block_id): [self._node_to_id[node] for node in block.inputs]\n for block_id, block in enumerate(self.blocks)\n }\n block_outputs = {\n str(block_id): [self._node_to_id[node] for node in block.outputs]\n for block_id, block in enumerate(self.blocks)\n }\n\n outputs = [self._node_to_id[node] for node in self.outputs]\n\n return {\n \"override_hps\": override_hps, # List [serialized].\n \"blocks\": blocks, # Dict {id: serialized}.\n \"nodes\": nodes, # Dict {id: serialized}.\n \"outputs\": outputs, # List of node_ids.\n \"block_inputs\": block_inputs, # Dict {id: List of node_ids}.\n \"block_outputs\": block_outputs, # Dict {id: List of node_ids}.\n }\n\n @classmethod\n def from_config(cls, config):\n blocks = [blocks_module.deserialize(block) for block in config[\"blocks\"]]\n nodes = {\n int(node_id): nodes_module.deserialize(node)\n for node_id, node in config[\"nodes\"].items()\n }\n override_hps = [\n kerastuner.engine.hyperparameters.deserialize(config)\n for config in config[\"override_hps\"]\n ]\n\n inputs = [nodes[node_id] for node_id in nodes]\n for block_id, block in enumerate(blocks):\n input_nodes = [\n nodes[node_id] for node_id in config[\"block_inputs\"][str(block_id)]\n ]\n output_nodes = nest.flatten(block(input_nodes))\n for output_node, node_id in zip(\n output_nodes, config[\"block_outputs\"][str(block_id)]\n ):\n nodes[node_id] = output_node\n\n outputs = [nodes[node_id] for node_id in config[\"outputs\"]]\n return cls(inputs=inputs, outputs=outputs, override_hps=override_hps)\n\n def build(self, hp):\n \"\"\"Build the HyperModel into a Keras Model.\"\"\"\n self._register_hps(hp)\n self.compile()\n real_nodes = {}\n for input_node in self.inputs:\n node_id = self._node_to_id[input_node]\n real_nodes[node_id] = input_node.build()\n for block in self.blocks:\n temp_inputs = [\n real_nodes[self._node_to_id[input_node]]\n for input_node in block.inputs\n ]\n outputs = block.build(hp, inputs=temp_inputs)\n outputs = nest.flatten(outputs)\n for output_node, real_output_node in zip(block.outputs, outputs):\n real_nodes[self._node_to_id[output_node]] = real_output_node\n model = tf.keras.Model(\n [real_nodes[self._node_to_id[input_node]] for input_node in self.inputs],\n [\n real_nodes[self._node_to_id[output_node]]\n for output_node in self.outputs\n ],\n )\n\n return self._compile_keras_model(hp, model)\n\n def _get_metrics(self):\n metrics = {}\n for output_node in self.outputs:\n block = output_node.in_blocks[0]\n if isinstance(block, head_module.Head):\n metrics[block.name] = block.metrics\n return metrics\n\n def _get_loss(self):\n loss = {}\n for output_node in self.outputs:\n block = output_node.in_blocks[0]\n if isinstance(block, head_module.Head):\n loss[block.name] = block.loss\n return loss\n\n def _compile_keras_model(self, hp, model):\n # Specify hyperparameters from compile(...)\n optimizer_name = hp.Choice(\n \"optimizer\", [\"adam\", \"adadelta\", \"sgd\"], default=\"adam\"\n )\n learning_rate = hp.Choice(\n \"learning_rate\", [1e-1, 1e-2, 1e-3, 1e-4, 1e-5], default=1e-3\n )\n\n if optimizer_name == \"adam\":\n optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)\n elif optimizer_name == \"adadelta\":\n optimizer = tf.keras.optimizers.Adadelta(learning_rate=learning_rate)\n elif optimizer_name == \"sgd\":\n optimizer = tf.keras.optimizers.SGD(learning_rate=learning_rate)\n\n model.compile(\n optimizer=optimizer, metrics=self._get_metrics(), loss=self._get_loss()\n )\n\n return model\n\n def save(self, filepath):\n utils.save_json(filepath, self.get_config())\n", "path": "autokeras/graph.py"}]}
| 3,650 | 96 |
gh_patches_debug_58655
|
rasdani/github-patches
|
git_diff
|
Anselmoo__spectrafit-715
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Feature]: Add python 3.11 support
### Is there an existing issue for this?
- [X] I have searched the existing issues
### Current Missing Feature
Add python 3.11 support
### Possible Solution
_No response_
### Anything else?
_No response_
### Code of Conduct
- [X] I agree to follow this project's Code of Conduct
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `spectrafit/__init__.py`
Content:
```
1 """SpectraFit, fast command line tool for fitting data."""
2 __version__ = "0.16.6"
3
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/spectrafit/__init__.py b/spectrafit/__init__.py
--- a/spectrafit/__init__.py
+++ b/spectrafit/__init__.py
@@ -1,2 +1,2 @@
"""SpectraFit, fast command line tool for fitting data."""
-__version__ = "0.16.6"
+__version__ = "0.16.7"
|
{"golden_diff": "diff --git a/spectrafit/__init__.py b/spectrafit/__init__.py\n--- a/spectrafit/__init__.py\n+++ b/spectrafit/__init__.py\n@@ -1,2 +1,2 @@\n \"\"\"SpectraFit, fast command line tool for fitting data.\"\"\"\n-__version__ = \"0.16.6\"\n+__version__ = \"0.16.7\"\n", "issue": "[Feature]: Add python 3.11 support\n### Is there an existing issue for this?\n\n- [X] I have searched the existing issues\n\n### Current Missing Feature\n\nAdd python 3.11 support\n\n### Possible Solution\n\n_No response_\n\n### Anything else?\n\n_No response_\n\n### Code of Conduct\n\n- [X] I agree to follow this project's Code of Conduct\n", "before_files": [{"content": "\"\"\"SpectraFit, fast command line tool for fitting data.\"\"\"\n__version__ = \"0.16.6\"\n", "path": "spectrafit/__init__.py"}], "after_files": [{"content": "\"\"\"SpectraFit, fast command line tool for fitting data.\"\"\"\n__version__ = \"0.16.7\"\n", "path": "spectrafit/__init__.py"}]}
| 370 | 94 |
gh_patches_debug_2025
|
rasdani/github-patches
|
git_diff
|
pre-commit__pre-commit-2836
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Alternative to stashing files for testing
Are there any plans to implement alternatives to stashing the worktree?
Ideally this would be hook/scriptable, like some 'prepare-worktree' and 'restore-worktree' options (which default to the current stash behavior) but can also yield some new directory where the tests are run. The rationale here is that my editor reverts files changed on disk and I'd like to add notes to source files while the commit is in progress.
In my own pre-commit hooks I use something like:
git archive "$(git write-tree)" --prefix="$test_dir/" | tar xf -
To create a pristine source tree (actually, I also prime it with `cp -rl` with build artifacts from the previous build to speed up incremental builds). 'git-worktree' and other tools could be used as well...
Eventually I have the idea to run some (more expensive) pre-commit checks in the background while one types the commit message. Then in the commit-msg hook wait for the background results and abort the commit there. This should reduce the turn around times significantly.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pre_commit/languages/swift.py`
Content:
```
1 from __future__ import annotations
2
3 import contextlib
4 import os
5 from typing import Generator
6 from typing import Sequence
7
8 from pre_commit import lang_base
9 from pre_commit.envcontext import envcontext
10 from pre_commit.envcontext import PatchesT
11 from pre_commit.envcontext import Var
12 from pre_commit.prefix import Prefix
13 from pre_commit.util import cmd_output_b
14
15 BUILD_DIR = '.build'
16 BUILD_CONFIG = 'release'
17
18 ENVIRONMENT_DIR = 'swift_env'
19 get_default_version = lang_base.basic_get_default_version
20 health_check = lang_base.basic_health_check
21 run_hook = lang_base.basic_run_hook
22
23
24 def get_env_patch(venv: str) -> PatchesT: # pragma: win32 no cover
25 bin_path = os.path.join(venv, BUILD_DIR, BUILD_CONFIG)
26 return (('PATH', (bin_path, os.pathsep, Var('PATH'))),)
27
28
29 @contextlib.contextmanager # pragma: win32 no cover
30 def in_env(prefix: Prefix, version: str) -> Generator[None, None, None]:
31 envdir = lang_base.environment_dir(prefix, ENVIRONMENT_DIR, version)
32 with envcontext(get_env_patch(envdir)):
33 yield
34
35
36 def install_environment(
37 prefix: Prefix, version: str, additional_dependencies: Sequence[str],
38 ) -> None: # pragma: win32 no cover
39 lang_base.assert_version_default('swift', version)
40 lang_base.assert_no_additional_deps('swift', additional_dependencies)
41 envdir = lang_base.environment_dir(prefix, ENVIRONMENT_DIR, version)
42
43 # Build the swift package
44 os.mkdir(envdir)
45 cmd_output_b(
46 'swift', 'build',
47 '-C', prefix.prefix_dir,
48 '-c', BUILD_CONFIG,
49 '--build-path', os.path.join(envdir, BUILD_DIR),
50 )
51
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pre_commit/languages/swift.py b/pre_commit/languages/swift.py
--- a/pre_commit/languages/swift.py
+++ b/pre_commit/languages/swift.py
@@ -44,7 +44,7 @@
os.mkdir(envdir)
cmd_output_b(
'swift', 'build',
- '-C', prefix.prefix_dir,
+ '--package-path', prefix.prefix_dir,
'-c', BUILD_CONFIG,
'--build-path', os.path.join(envdir, BUILD_DIR),
)
|
{"golden_diff": "diff --git a/pre_commit/languages/swift.py b/pre_commit/languages/swift.py\n--- a/pre_commit/languages/swift.py\n+++ b/pre_commit/languages/swift.py\n@@ -44,7 +44,7 @@\n os.mkdir(envdir)\n cmd_output_b(\n 'swift', 'build',\n- '-C', prefix.prefix_dir,\n+ '--package-path', prefix.prefix_dir,\n '-c', BUILD_CONFIG,\n '--build-path', os.path.join(envdir, BUILD_DIR),\n )\n", "issue": "Alternative to stashing files for testing\nAre there any plans to implement alternatives to stashing the worktree?\r\n\r\nIdeally this would be hook/scriptable, like some 'prepare-worktree' and 'restore-worktree' options (which default to the current stash behavior) but can also yield some new directory where the tests are run. The rationale here is that my editor reverts files changed on disk and I'd like to add notes to source files while the commit is in progress.\r\n\r\nIn my own pre-commit hooks I use something like:\r\n\r\n git archive \"$(git write-tree)\" --prefix=\"$test_dir/\" | tar xf -\r\n\r\nTo create a pristine source tree (actually, I also prime it with `cp -rl` with build artifacts from the previous build to speed up incremental builds). 'git-worktree' and other tools could be used as well...\r\n\r\nEventually I have the idea to run some (more expensive) pre-commit checks in the background while one types the commit message. Then in the commit-msg hook wait for the background results and abort the commit there. This should reduce the turn around times significantly.\r\n\r\n\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nimport contextlib\nimport os\nfrom typing import Generator\nfrom typing import Sequence\n\nfrom pre_commit import lang_base\nfrom pre_commit.envcontext import envcontext\nfrom pre_commit.envcontext import PatchesT\nfrom pre_commit.envcontext import Var\nfrom pre_commit.prefix import Prefix\nfrom pre_commit.util import cmd_output_b\n\nBUILD_DIR = '.build'\nBUILD_CONFIG = 'release'\n\nENVIRONMENT_DIR = 'swift_env'\nget_default_version = lang_base.basic_get_default_version\nhealth_check = lang_base.basic_health_check\nrun_hook = lang_base.basic_run_hook\n\n\ndef get_env_patch(venv: str) -> PatchesT: # pragma: win32 no cover\n bin_path = os.path.join(venv, BUILD_DIR, BUILD_CONFIG)\n return (('PATH', (bin_path, os.pathsep, Var('PATH'))),)\n\n\[email protected] # pragma: win32 no cover\ndef in_env(prefix: Prefix, version: str) -> Generator[None, None, None]:\n envdir = lang_base.environment_dir(prefix, ENVIRONMENT_DIR, version)\n with envcontext(get_env_patch(envdir)):\n yield\n\n\ndef install_environment(\n prefix: Prefix, version: str, additional_dependencies: Sequence[str],\n) -> None: # pragma: win32 no cover\n lang_base.assert_version_default('swift', version)\n lang_base.assert_no_additional_deps('swift', additional_dependencies)\n envdir = lang_base.environment_dir(prefix, ENVIRONMENT_DIR, version)\n\n # Build the swift package\n os.mkdir(envdir)\n cmd_output_b(\n 'swift', 'build',\n '-C', prefix.prefix_dir,\n '-c', BUILD_CONFIG,\n '--build-path', os.path.join(envdir, BUILD_DIR),\n )\n", "path": "pre_commit/languages/swift.py"}], "after_files": [{"content": "from __future__ import annotations\n\nimport contextlib\nimport os\nfrom typing import Generator\nfrom typing import Sequence\n\nfrom pre_commit import lang_base\nfrom pre_commit.envcontext import envcontext\nfrom pre_commit.envcontext import PatchesT\nfrom pre_commit.envcontext import Var\nfrom pre_commit.prefix import Prefix\nfrom pre_commit.util import cmd_output_b\n\nBUILD_DIR = '.build'\nBUILD_CONFIG = 'release'\n\nENVIRONMENT_DIR = 'swift_env'\nget_default_version = lang_base.basic_get_default_version\nhealth_check = lang_base.basic_health_check\nrun_hook = lang_base.basic_run_hook\n\n\ndef get_env_patch(venv: str) -> PatchesT: # pragma: win32 no cover\n bin_path = os.path.join(venv, BUILD_DIR, BUILD_CONFIG)\n return (('PATH', (bin_path, os.pathsep, Var('PATH'))),)\n\n\[email protected] # pragma: win32 no cover\ndef in_env(prefix: Prefix, version: str) -> Generator[None, None, None]:\n envdir = lang_base.environment_dir(prefix, ENVIRONMENT_DIR, version)\n with envcontext(get_env_patch(envdir)):\n yield\n\n\ndef install_environment(\n prefix: Prefix, version: str, additional_dependencies: Sequence[str],\n) -> None: # pragma: win32 no cover\n lang_base.assert_version_default('swift', version)\n lang_base.assert_no_additional_deps('swift', additional_dependencies)\n envdir = lang_base.environment_dir(prefix, ENVIRONMENT_DIR, version)\n\n # Build the swift package\n os.mkdir(envdir)\n cmd_output_b(\n 'swift', 'build',\n '--package-path', prefix.prefix_dir,\n '-c', BUILD_CONFIG,\n '--build-path', os.path.join(envdir, BUILD_DIR),\n )\n", "path": "pre_commit/languages/swift.py"}]}
| 972 | 112 |
gh_patches_debug_16451
|
rasdani/github-patches
|
git_diff
|
getredash__redash-602
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
API keys should be supported in the HTTP headers
Currently it seems that all API calls must include the `api_key` in the query string. Ideally the HTTP headers could also be used (e.g. `Authorization: Key XXXX` or `X-Api-Key`) so that Web server logs don't log the API key in the clear.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `redash/authentication.py`
Content:
```
1 import hashlib
2 import hmac
3 import time
4 import logging
5
6 from flask.ext.login import LoginManager
7 from flask.ext.login import user_logged_in
8
9 from redash import models, settings, google_oauth, saml_auth
10 from redash.tasks import record_event
11
12 login_manager = LoginManager()
13 logger = logging.getLogger('authentication')
14
15
16 def sign(key, path, expires):
17 if not key:
18 return None
19
20 h = hmac.new(str(key), msg=path, digestmod=hashlib.sha1)
21 h.update(str(expires))
22
23 return h.hexdigest()
24
25
26 @login_manager.user_loader
27 def load_user(user_id):
28 return models.User.get_by_id(user_id)
29
30
31 def hmac_load_user_from_request(request):
32 signature = request.args.get('signature')
33 expires = float(request.args.get('expires') or 0)
34 query_id = request.view_args.get('query_id', None)
35 user_id = request.args.get('user_id', None)
36
37 # TODO: 3600 should be a setting
38 if signature and time.time() < expires <= time.time() + 3600:
39 if user_id:
40 user = models.User.get_by_id(user_id)
41 calculated_signature = sign(user.api_key, request.path, expires)
42
43 if user.api_key and signature == calculated_signature:
44 return user
45
46 if query_id:
47 query = models.Query.get(models.Query.id == query_id)
48 calculated_signature = sign(query.api_key, request.path, expires)
49
50 if query.api_key and signature == calculated_signature:
51 return models.ApiUser(query.api_key)
52
53 return None
54
55 def get_user_from_api_key(api_key, query_id):
56 if not api_key:
57 return None
58
59 user = None
60 try:
61 user = models.User.get_by_api_key(api_key)
62 except models.User.DoesNotExist:
63 if query_id:
64 query = models.Query.get_by_id(query_id)
65 if query and query.api_key == api_key:
66 user = models.ApiUser(api_key)
67
68 return user
69
70 def api_key_load_user_from_request(request):
71 api_key = request.args.get('api_key', None)
72 query_id = request.view_args.get('query_id', None)
73
74 user = get_user_from_api_key(api_key, query_id)
75 return user
76
77
78 def log_user_logged_in(app, user):
79 event = {
80 'user_id': user.id,
81 'action': 'login',
82 'object_type': 'redash',
83 'timestamp': int(time.time()),
84 }
85
86 record_event.delay(event)
87
88
89 def setup_authentication(app):
90 login_manager.init_app(app)
91 login_manager.anonymous_user = models.AnonymousUser
92 login_manager.login_view = 'login'
93 app.secret_key = settings.COOKIE_SECRET
94 app.register_blueprint(google_oauth.blueprint)
95 app.register_blueprint(saml_auth.blueprint)
96
97 user_logged_in.connect(log_user_logged_in)
98
99 if settings.AUTH_TYPE == 'hmac':
100 login_manager.request_loader(hmac_load_user_from_request)
101 elif settings.AUTH_TYPE == 'api_key':
102 login_manager.request_loader(api_key_load_user_from_request)
103 else:
104 logger.warning("Unknown authentication type ({}). Using default (HMAC).".format(settings.AUTH_TYPE))
105 login_manager.request_loader(hmac_load_user_from_request)
106
107
108
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/redash/authentication.py b/redash/authentication.py
--- a/redash/authentication.py
+++ b/redash/authentication.py
@@ -52,6 +52,7 @@
return None
+
def get_user_from_api_key(api_key, query_id):
if not api_key:
return None
@@ -67,8 +68,19 @@
return user
-def api_key_load_user_from_request(request):
+
+def get_api_key_from_request(request):
api_key = request.args.get('api_key', None)
+
+ if api_key is None and request.headers.get('Authorization'):
+ auth_header = request.headers.get('Authorization')
+ api_key = auth_header.replace('Key ', '', 1)
+
+ return api_key
+
+
+def api_key_load_user_from_request(request):
+ api_key = get_api_key_from_request(request)
query_id = request.view_args.get('query_id', None)
user = get_user_from_api_key(api_key, query_id)
|
{"golden_diff": "diff --git a/redash/authentication.py b/redash/authentication.py\n--- a/redash/authentication.py\n+++ b/redash/authentication.py\n@@ -52,6 +52,7 @@\n \n return None\n \n+\n def get_user_from_api_key(api_key, query_id):\n if not api_key:\n return None\n@@ -67,8 +68,19 @@\n \n return user\n \n-def api_key_load_user_from_request(request):\n+\n+def get_api_key_from_request(request):\n api_key = request.args.get('api_key', None)\n+\n+ if api_key is None and request.headers.get('Authorization'):\n+ auth_header = request.headers.get('Authorization')\n+ api_key = auth_header.replace('Key ', '', 1)\n+\n+ return api_key\n+\n+\n+def api_key_load_user_from_request(request):\n+ api_key = get_api_key_from_request(request)\n query_id = request.view_args.get('query_id', None)\n \n user = get_user_from_api_key(api_key, query_id)\n", "issue": "API keys should be supported in the HTTP headers\nCurrently it seems that all API calls must include the `api_key` in the query string. Ideally the HTTP headers could also be used (e.g. `Authorization: Key XXXX` or `X-Api-Key`) so that Web server logs don't log the API key in the clear.\n\n", "before_files": [{"content": "import hashlib\nimport hmac\nimport time\nimport logging\n\nfrom flask.ext.login import LoginManager\nfrom flask.ext.login import user_logged_in\n\nfrom redash import models, settings, google_oauth, saml_auth\nfrom redash.tasks import record_event\n\nlogin_manager = LoginManager()\nlogger = logging.getLogger('authentication')\n\n\ndef sign(key, path, expires):\n if not key:\n return None\n\n h = hmac.new(str(key), msg=path, digestmod=hashlib.sha1)\n h.update(str(expires))\n\n return h.hexdigest()\n\n\n@login_manager.user_loader\ndef load_user(user_id):\n return models.User.get_by_id(user_id)\n\n\ndef hmac_load_user_from_request(request):\n signature = request.args.get('signature')\n expires = float(request.args.get('expires') or 0)\n query_id = request.view_args.get('query_id', None)\n user_id = request.args.get('user_id', None)\n\n # TODO: 3600 should be a setting\n if signature and time.time() < expires <= time.time() + 3600:\n if user_id:\n user = models.User.get_by_id(user_id)\n calculated_signature = sign(user.api_key, request.path, expires)\n\n if user.api_key and signature == calculated_signature:\n return user\n\n if query_id:\n query = models.Query.get(models.Query.id == query_id)\n calculated_signature = sign(query.api_key, request.path, expires)\n\n if query.api_key and signature == calculated_signature:\n return models.ApiUser(query.api_key)\n\n return None\n\ndef get_user_from_api_key(api_key, query_id):\n if not api_key:\n return None\n\n user = None\n try:\n user = models.User.get_by_api_key(api_key)\n except models.User.DoesNotExist:\n if query_id:\n query = models.Query.get_by_id(query_id)\n if query and query.api_key == api_key:\n user = models.ApiUser(api_key)\n\n return user\n\ndef api_key_load_user_from_request(request):\n api_key = request.args.get('api_key', None)\n query_id = request.view_args.get('query_id', None)\n\n user = get_user_from_api_key(api_key, query_id)\n return user\n\n\ndef log_user_logged_in(app, user):\n event = {\n 'user_id': user.id,\n 'action': 'login',\n 'object_type': 'redash',\n 'timestamp': int(time.time()),\n }\n\n record_event.delay(event)\n\n\ndef setup_authentication(app):\n login_manager.init_app(app)\n login_manager.anonymous_user = models.AnonymousUser\n login_manager.login_view = 'login'\n app.secret_key = settings.COOKIE_SECRET\n app.register_blueprint(google_oauth.blueprint)\n app.register_blueprint(saml_auth.blueprint)\n\n user_logged_in.connect(log_user_logged_in)\n\n if settings.AUTH_TYPE == 'hmac':\n login_manager.request_loader(hmac_load_user_from_request)\n elif settings.AUTH_TYPE == 'api_key':\n login_manager.request_loader(api_key_load_user_from_request)\n else:\n logger.warning(\"Unknown authentication type ({}). Using default (HMAC).\".format(settings.AUTH_TYPE))\n login_manager.request_loader(hmac_load_user_from_request)\n\n\n", "path": "redash/authentication.py"}], "after_files": [{"content": "import hashlib\nimport hmac\nimport time\nimport logging\n\nfrom flask.ext.login import LoginManager\nfrom flask.ext.login import user_logged_in\n\nfrom redash import models, settings, google_oauth, saml_auth\nfrom redash.tasks import record_event\n\nlogin_manager = LoginManager()\nlogger = logging.getLogger('authentication')\n\n\ndef sign(key, path, expires):\n if not key:\n return None\n\n h = hmac.new(str(key), msg=path, digestmod=hashlib.sha1)\n h.update(str(expires))\n\n return h.hexdigest()\n\n\n@login_manager.user_loader\ndef load_user(user_id):\n return models.User.get_by_id(user_id)\n\n\ndef hmac_load_user_from_request(request):\n signature = request.args.get('signature')\n expires = float(request.args.get('expires') or 0)\n query_id = request.view_args.get('query_id', None)\n user_id = request.args.get('user_id', None)\n\n # TODO: 3600 should be a setting\n if signature and time.time() < expires <= time.time() + 3600:\n if user_id:\n user = models.User.get_by_id(user_id)\n calculated_signature = sign(user.api_key, request.path, expires)\n\n if user.api_key and signature == calculated_signature:\n return user\n\n if query_id:\n query = models.Query.get(models.Query.id == query_id)\n calculated_signature = sign(query.api_key, request.path, expires)\n\n if query.api_key and signature == calculated_signature:\n return models.ApiUser(query.api_key)\n\n return None\n\n\ndef get_user_from_api_key(api_key, query_id):\n if not api_key:\n return None\n\n user = None\n try:\n user = models.User.get_by_api_key(api_key)\n except models.User.DoesNotExist:\n if query_id:\n query = models.Query.get_by_id(query_id)\n if query and query.api_key == api_key:\n user = models.ApiUser(api_key)\n\n return user\n\n\ndef get_api_key_from_request(request):\n api_key = request.args.get('api_key', None)\n\n if api_key is None and request.headers.get('Authorization'):\n auth_header = request.headers.get('Authorization')\n api_key = auth_header.replace('Key ', '', 1)\n\n return api_key\n\n\ndef api_key_load_user_from_request(request):\n api_key = get_api_key_from_request(request)\n query_id = request.view_args.get('query_id', None)\n\n user = get_user_from_api_key(api_key, query_id)\n return user\n\n\ndef log_user_logged_in(app, user):\n event = {\n 'user_id': user.id,\n 'action': 'login',\n 'object_type': 'redash',\n 'timestamp': int(time.time()),\n }\n\n record_event.delay(event)\n\n\ndef setup_authentication(app):\n login_manager.init_app(app)\n login_manager.anonymous_user = models.AnonymousUser\n login_manager.login_view = 'login'\n app.secret_key = settings.COOKIE_SECRET\n app.register_blueprint(google_oauth.blueprint)\n app.register_blueprint(saml_auth.blueprint)\n\n user_logged_in.connect(log_user_logged_in)\n\n if settings.AUTH_TYPE == 'hmac':\n login_manager.request_loader(hmac_load_user_from_request)\n elif settings.AUTH_TYPE == 'api_key':\n login_manager.request_loader(api_key_load_user_from_request)\n else:\n logger.warning(\"Unknown authentication type ({}). Using default (HMAC).\".format(settings.AUTH_TYPE))\n login_manager.request_loader(hmac_load_user_from_request)\n\n\n", "path": "redash/authentication.py"}]}
| 1,253 | 219 |
gh_patches_debug_2463
|
rasdani/github-patches
|
git_diff
|
kedro-org__kedro-1977
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
pickle.PickleDataSet docstring examples are incorrect
## Description
Kind of a small issue but the "advanced" example in the [pickle.PickleDataSet API docs](https://kedro.readthedocs.io/en/stable/kedro.extras.datasets.pickle.PickleDataSet.html) is wrong.
`compression` is not a valid [`joblib.dump`](https://joblib.readthedocs.io/en/latest/generated/joblib.dump.html) parameter (it should simply be `compress`) and [`joblib.load`](https://joblib.readthedocs.io/en/latest/generated/joblib.load.html) does not require a `compression` kwarg at all since it can automagically discover the correct compression algorithm used.
## Context
Even if it's a trivial issue I stumbled upon it and I hope to fix it so that future users will not have to go the joblib docs to find the problem.
## Possible Alternatives
I'a m working on a trivial fix, I'm going to open a PR as soon as possible.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kedro/extras/datasets/pickle/pickle_dataset.py`
Content:
```
1 """``PickleDataSet`` loads/saves data from/to a Pickle file using an underlying
2 filesystem (e.g.: local, S3, GCS). The underlying functionality is supported by
3 the specified backend library passed in (defaults to the ``pickle`` library), so it
4 supports all allowed options for loading and saving pickle files.
5 """
6 import importlib
7 from copy import deepcopy
8 from pathlib import PurePosixPath
9 from typing import Any, Dict
10
11 import fsspec
12
13 from kedro.io.core import (
14 AbstractVersionedDataSet,
15 DataSetError,
16 Version,
17 get_filepath_str,
18 get_protocol_and_path,
19 )
20
21
22 class PickleDataSet(AbstractVersionedDataSet[Any, Any]):
23 """``PickleDataSet`` loads/saves data from/to a Pickle file using an underlying
24 filesystem (e.g.: local, S3, GCS). The underlying functionality is supported by
25 the specified backend library passed in (defaults to the ``pickle`` library), so it
26 supports all allowed options for loading and saving pickle files.
27
28 Example adding a catalog entry with
29 `YAML API <https://kedro.readthedocs.io/en/stable/data/\
30 data_catalog.html#use-the-data-catalog-with-the-yaml-api>`_:
31
32 .. code-block:: yaml
33
34 >>> test_model: # simple example without compression
35 >>> type: pickle.PickleDataSet
36 >>> filepath: data/07_model_output/test_model.pkl
37 >>> backend: pickle
38 >>>
39 >>> final_model: # example with load and save args
40 >>> type: pickle.PickleDataSet
41 >>> filepath: s3://your_bucket/final_model.pkl.lz4
42 >>> backend: joblib
43 >>> credentials: s3_credentials
44 >>> save_args:
45 >>> compression: lz4
46 >>> load_args:
47 >>> compression: lz4
48
49 Example using Python API:
50 ::
51
52 >>> from kedro.extras.datasets.pickle import PickleDataSet
53 >>> import pandas as pd
54 >>>
55 >>> data = pd.DataFrame({'col1': [1, 2], 'col2': [4, 5],
56 >>> 'col3': [5, 6]})
57 >>>
58 >>> # data_set = PickleDataSet(filepath="gcs://bucket/test.pkl")
59 >>> data_set = PickleDataSet(filepath="test.pkl", backend="pickle")
60 >>> data_set.save(data)
61 >>> reloaded = data_set.load()
62 >>> assert data.equals(reloaded)
63 >>>
64 >>> # Add "compress_pickle[lz4]" to requirements.txt
65 >>> data_set = PickleDataSet(filepath="test.pickle.lz4",
66 >>> backend="compress_pickle",
67 >>> load_args={"compression":"lz4"},
68 >>> save_args={"compression":"lz4"})
69 >>> data_set.save(data)
70 >>> reloaded = data_set.load()
71 >>> assert data.equals(reloaded)
72 """
73
74 DEFAULT_LOAD_ARGS = {} # type: Dict[str, Any]
75 DEFAULT_SAVE_ARGS = {} # type: Dict[str, Any]
76
77 # pylint: disable=too-many-arguments,too-many-locals
78 def __init__(
79 self,
80 filepath: str,
81 backend: str = "pickle",
82 load_args: Dict[str, Any] = None,
83 save_args: Dict[str, Any] = None,
84 version: Version = None,
85 credentials: Dict[str, Any] = None,
86 fs_args: Dict[str, Any] = None,
87 ) -> None:
88 """Creates a new instance of ``PickleDataSet`` pointing to a concrete Pickle
89 file on a specific filesystem. ``PickleDataSet`` supports custom backends to
90 serialise/deserialise objects.
91
92 Example backends that are compatible (non-exhaustive):
93 * `pickle`
94 * `joblib`
95 * `dill`
96 * `compress_pickle`
97
98 Example backends that are incompatible:
99 * `torch`
100
101 Args:
102 filepath: Filepath in POSIX format to a Pickle file prefixed with a protocol like
103 `s3://`. If prefix is not provided, `file` protocol (local filesystem) will be used.
104 The prefix should be any protocol supported by ``fsspec``.
105 Note: `http(s)` doesn't support versioning.
106 backend: Backend to use, must be an import path to a module which satisfies the
107 ``pickle`` interface. That is, contains a `load` and `dump` function.
108 Defaults to 'pickle'.
109 load_args: Pickle options for loading pickle files.
110 You can pass in arguments that the backend load function specified accepts, e.g:
111 pickle.load: https://docs.python.org/3/library/pickle.html#pickle.load
112 joblib.load: https://joblib.readthedocs.io/en/latest/generated/joblib.load.html
113 dill.load: https://dill.readthedocs.io/en/latest/dill.html#dill._dill.load
114 compress_pickle.load:
115 https://lucianopaz.github.io/compress_pickle/html/api/compress_pickle.html#compress_pickle.compress_pickle.load
116 All defaults are preserved.
117 save_args: Pickle options for saving pickle files.
118 You can pass in arguments that the backend dump function specified accepts, e.g:
119 pickle.dump: https://docs.python.org/3/library/pickle.html#pickle.dump
120 joblib.dump: https://joblib.readthedocs.io/en/latest/generated/joblib.dump.html
121 dill.dump: https://dill.readthedocs.io/en/latest/dill.html#dill._dill.dump
122 compress_pickle.dump:
123 https://lucianopaz.github.io/compress_pickle/html/api/compress_pickle.html#compress_pickle.compress_pickle.dump
124 All defaults are preserved.
125 version: If specified, should be an instance of
126 ``kedro.io.core.Version``. If its ``load`` attribute is
127 None, the latest version will be loaded. If its ``save``
128 attribute is None, save version will be autogenerated.
129 credentials: Credentials required to get access to the underlying filesystem.
130 E.g. for ``GCSFileSystem`` it should look like `{"token": None}`.
131 fs_args: Extra arguments to pass into underlying filesystem class constructor
132 (e.g. `{"project": "my-project"}` for ``GCSFileSystem``), as well as
133 to pass to the filesystem's `open` method through nested keys
134 `open_args_load` and `open_args_save`.
135 Here you can find all available arguments for `open`:
136 https://filesystem-spec.readthedocs.io/en/latest/api.html#fsspec.spec.AbstractFileSystem.open
137 All defaults are preserved, except `mode`, which is set to `wb` when saving.
138
139 Raises:
140 ValueError: If ``backend`` does not satisfy the `pickle` interface.
141 ImportError: If the ``backend`` module could not be imported.
142 """
143 # We do not store `imported_backend` as an attribute to be used in `load`/`save`
144 # as this would mean the dataset cannot be deepcopied (module objects cannot be
145 # pickled). The import here is purely to raise any errors as early as possible.
146 # Repeated imports in the `load` and `save` methods should not be a significant
147 # performance hit as Python caches imports.
148 try:
149 imported_backend = importlib.import_module(backend)
150 except ImportError as exc:
151 raise ImportError(
152 f"Selected backend '{backend}' could not be imported. "
153 "Make sure it is installed and importable."
154 ) from exc
155
156 if not (
157 hasattr(imported_backend, "load") and hasattr(imported_backend, "dump")
158 ):
159 raise ValueError(
160 f"Selected backend '{backend}' should satisfy the pickle interface. "
161 "Missing one of 'load' and 'dump' on the backend."
162 )
163
164 _fs_args = deepcopy(fs_args) or {}
165 _fs_open_args_load = _fs_args.pop("open_args_load", {})
166 _fs_open_args_save = _fs_args.pop("open_args_save", {})
167 _credentials = deepcopy(credentials) or {}
168
169 protocol, path = get_protocol_and_path(filepath, version)
170 if protocol == "file":
171 _fs_args.setdefault("auto_mkdir", True)
172
173 self._protocol = protocol
174 self._fs = fsspec.filesystem(self._protocol, **_credentials, **_fs_args)
175
176 super().__init__(
177 filepath=PurePosixPath(path),
178 version=version,
179 exists_function=self._fs.exists,
180 glob_function=self._fs.glob,
181 )
182
183 self._backend = backend
184
185 # Handle default load and save arguments
186 self._load_args = deepcopy(self.DEFAULT_LOAD_ARGS)
187 if load_args is not None:
188 self._load_args.update(load_args)
189 self._save_args = deepcopy(self.DEFAULT_SAVE_ARGS)
190 if save_args is not None:
191 self._save_args.update(save_args)
192
193 _fs_open_args_save.setdefault("mode", "wb")
194 self._fs_open_args_load = _fs_open_args_load
195 self._fs_open_args_save = _fs_open_args_save
196
197 def _describe(self) -> Dict[str, Any]:
198 return dict(
199 filepath=self._filepath,
200 backend=self._backend,
201 protocol=self._protocol,
202 load_args=self._load_args,
203 save_args=self._save_args,
204 version=self._version,
205 )
206
207 def _load(self) -> Any:
208 load_path = get_filepath_str(self._get_load_path(), self._protocol)
209
210 with self._fs.open(load_path, **self._fs_open_args_load) as fs_file:
211 imported_backend = importlib.import_module(self._backend)
212 return imported_backend.load(fs_file, **self._load_args) # type: ignore
213
214 def _save(self, data: Any) -> None:
215 save_path = get_filepath_str(self._get_save_path(), self._protocol)
216
217 with self._fs.open(save_path, **self._fs_open_args_save) as fs_file:
218 try:
219 imported_backend = importlib.import_module(self._backend)
220 imported_backend.dump(data, fs_file, **self._save_args) # type: ignore
221 except Exception as exc:
222 raise DataSetError(
223 f"{data.__class__} was not serialised due to: {exc}"
224 ) from exc
225
226 self._invalidate_cache()
227
228 def _exists(self) -> bool:
229 try:
230 load_path = get_filepath_str(self._get_load_path(), self._protocol)
231 except DataSetError:
232 return False
233
234 return self._fs.exists(load_path)
235
236 def _release(self) -> None:
237 super()._release()
238 self._invalidate_cache()
239
240 def _invalidate_cache(self) -> None:
241 """Invalidate underlying filesystem caches."""
242 filepath = get_filepath_str(self._filepath, self._protocol)
243 self._fs.invalidate_cache(filepath)
244
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kedro/extras/datasets/pickle/pickle_dataset.py b/kedro/extras/datasets/pickle/pickle_dataset.py
--- a/kedro/extras/datasets/pickle/pickle_dataset.py
+++ b/kedro/extras/datasets/pickle/pickle_dataset.py
@@ -42,9 +42,7 @@
>>> backend: joblib
>>> credentials: s3_credentials
>>> save_args:
- >>> compression: lz4
- >>> load_args:
- >>> compression: lz4
+ >>> compress: lz4
Example using Python API:
::
|
{"golden_diff": "diff --git a/kedro/extras/datasets/pickle/pickle_dataset.py b/kedro/extras/datasets/pickle/pickle_dataset.py\n--- a/kedro/extras/datasets/pickle/pickle_dataset.py\n+++ b/kedro/extras/datasets/pickle/pickle_dataset.py\n@@ -42,9 +42,7 @@\n >>> backend: joblib\n >>> credentials: s3_credentials\n >>> save_args:\n- >>> compression: lz4\n- >>> load_args:\n- >>> compression: lz4\n+ >>> compress: lz4\n \n Example using Python API:\n ::\n", "issue": "pickle.PickleDataSet docstring examples are incorrect\n## Description\r\nKind of a small issue but the \"advanced\" example in the [pickle.PickleDataSet API docs](https://kedro.readthedocs.io/en/stable/kedro.extras.datasets.pickle.PickleDataSet.html) is wrong.\r\n`compression` is not a valid [`joblib.dump`](https://joblib.readthedocs.io/en/latest/generated/joblib.dump.html) parameter (it should simply be `compress`) and [`joblib.load`](https://joblib.readthedocs.io/en/latest/generated/joblib.load.html) does not require a `compression` kwarg at all since it can automagically discover the correct compression algorithm used.\r\n\r\n\r\n## Context\r\nEven if it's a trivial issue I stumbled upon it and I hope to fix it so that future users will not have to go the joblib docs to find the problem.\r\n\r\n\r\n## Possible Alternatives\r\nI'a m working on a trivial fix, I'm going to open a PR as soon as possible.\r\n\n", "before_files": [{"content": "\"\"\"``PickleDataSet`` loads/saves data from/to a Pickle file using an underlying\nfilesystem (e.g.: local, S3, GCS). The underlying functionality is supported by\nthe specified backend library passed in (defaults to the ``pickle`` library), so it\nsupports all allowed options for loading and saving pickle files.\n\"\"\"\nimport importlib\nfrom copy import deepcopy\nfrom pathlib import PurePosixPath\nfrom typing import Any, Dict\n\nimport fsspec\n\nfrom kedro.io.core import (\n AbstractVersionedDataSet,\n DataSetError,\n Version,\n get_filepath_str,\n get_protocol_and_path,\n)\n\n\nclass PickleDataSet(AbstractVersionedDataSet[Any, Any]):\n \"\"\"``PickleDataSet`` loads/saves data from/to a Pickle file using an underlying\n filesystem (e.g.: local, S3, GCS). The underlying functionality is supported by\n the specified backend library passed in (defaults to the ``pickle`` library), so it\n supports all allowed options for loading and saving pickle files.\n\n Example adding a catalog entry with\n `YAML API <https://kedro.readthedocs.io/en/stable/data/\\\n data_catalog.html#use-the-data-catalog-with-the-yaml-api>`_:\n\n .. code-block:: yaml\n\n >>> test_model: # simple example without compression\n >>> type: pickle.PickleDataSet\n >>> filepath: data/07_model_output/test_model.pkl\n >>> backend: pickle\n >>>\n >>> final_model: # example with load and save args\n >>> type: pickle.PickleDataSet\n >>> filepath: s3://your_bucket/final_model.pkl.lz4\n >>> backend: joblib\n >>> credentials: s3_credentials\n >>> save_args:\n >>> compression: lz4\n >>> load_args:\n >>> compression: lz4\n\n Example using Python API:\n ::\n\n >>> from kedro.extras.datasets.pickle import PickleDataSet\n >>> import pandas as pd\n >>>\n >>> data = pd.DataFrame({'col1': [1, 2], 'col2': [4, 5],\n >>> 'col3': [5, 6]})\n >>>\n >>> # data_set = PickleDataSet(filepath=\"gcs://bucket/test.pkl\")\n >>> data_set = PickleDataSet(filepath=\"test.pkl\", backend=\"pickle\")\n >>> data_set.save(data)\n >>> reloaded = data_set.load()\n >>> assert data.equals(reloaded)\n >>>\n >>> # Add \"compress_pickle[lz4]\" to requirements.txt\n >>> data_set = PickleDataSet(filepath=\"test.pickle.lz4\",\n >>> backend=\"compress_pickle\",\n >>> load_args={\"compression\":\"lz4\"},\n >>> save_args={\"compression\":\"lz4\"})\n >>> data_set.save(data)\n >>> reloaded = data_set.load()\n >>> assert data.equals(reloaded)\n \"\"\"\n\n DEFAULT_LOAD_ARGS = {} # type: Dict[str, Any]\n DEFAULT_SAVE_ARGS = {} # type: Dict[str, Any]\n\n # pylint: disable=too-many-arguments,too-many-locals\n def __init__(\n self,\n filepath: str,\n backend: str = \"pickle\",\n load_args: Dict[str, Any] = None,\n save_args: Dict[str, Any] = None,\n version: Version = None,\n credentials: Dict[str, Any] = None,\n fs_args: Dict[str, Any] = None,\n ) -> None:\n \"\"\"Creates a new instance of ``PickleDataSet`` pointing to a concrete Pickle\n file on a specific filesystem. ``PickleDataSet`` supports custom backends to\n serialise/deserialise objects.\n\n Example backends that are compatible (non-exhaustive):\n * `pickle`\n * `joblib`\n * `dill`\n * `compress_pickle`\n\n Example backends that are incompatible:\n * `torch`\n\n Args:\n filepath: Filepath in POSIX format to a Pickle file prefixed with a protocol like\n `s3://`. If prefix is not provided, `file` protocol (local filesystem) will be used.\n The prefix should be any protocol supported by ``fsspec``.\n Note: `http(s)` doesn't support versioning.\n backend: Backend to use, must be an import path to a module which satisfies the\n ``pickle`` interface. That is, contains a `load` and `dump` function.\n Defaults to 'pickle'.\n load_args: Pickle options for loading pickle files.\n You can pass in arguments that the backend load function specified accepts, e.g:\n pickle.load: https://docs.python.org/3/library/pickle.html#pickle.load\n joblib.load: https://joblib.readthedocs.io/en/latest/generated/joblib.load.html\n dill.load: https://dill.readthedocs.io/en/latest/dill.html#dill._dill.load\n compress_pickle.load:\n https://lucianopaz.github.io/compress_pickle/html/api/compress_pickle.html#compress_pickle.compress_pickle.load\n All defaults are preserved.\n save_args: Pickle options for saving pickle files.\n You can pass in arguments that the backend dump function specified accepts, e.g:\n pickle.dump: https://docs.python.org/3/library/pickle.html#pickle.dump\n joblib.dump: https://joblib.readthedocs.io/en/latest/generated/joblib.dump.html\n dill.dump: https://dill.readthedocs.io/en/latest/dill.html#dill._dill.dump\n compress_pickle.dump:\n https://lucianopaz.github.io/compress_pickle/html/api/compress_pickle.html#compress_pickle.compress_pickle.dump\n All defaults are preserved.\n version: If specified, should be an instance of\n ``kedro.io.core.Version``. If its ``load`` attribute is\n None, the latest version will be loaded. If its ``save``\n attribute is None, save version will be autogenerated.\n credentials: Credentials required to get access to the underlying filesystem.\n E.g. for ``GCSFileSystem`` it should look like `{\"token\": None}`.\n fs_args: Extra arguments to pass into underlying filesystem class constructor\n (e.g. `{\"project\": \"my-project\"}` for ``GCSFileSystem``), as well as\n to pass to the filesystem's `open` method through nested keys\n `open_args_load` and `open_args_save`.\n Here you can find all available arguments for `open`:\n https://filesystem-spec.readthedocs.io/en/latest/api.html#fsspec.spec.AbstractFileSystem.open\n All defaults are preserved, except `mode`, which is set to `wb` when saving.\n\n Raises:\n ValueError: If ``backend`` does not satisfy the `pickle` interface.\n ImportError: If the ``backend`` module could not be imported.\n \"\"\"\n # We do not store `imported_backend` as an attribute to be used in `load`/`save`\n # as this would mean the dataset cannot be deepcopied (module objects cannot be\n # pickled). The import here is purely to raise any errors as early as possible.\n # Repeated imports in the `load` and `save` methods should not be a significant\n # performance hit as Python caches imports.\n try:\n imported_backend = importlib.import_module(backend)\n except ImportError as exc:\n raise ImportError(\n f\"Selected backend '{backend}' could not be imported. \"\n \"Make sure it is installed and importable.\"\n ) from exc\n\n if not (\n hasattr(imported_backend, \"load\") and hasattr(imported_backend, \"dump\")\n ):\n raise ValueError(\n f\"Selected backend '{backend}' should satisfy the pickle interface. \"\n \"Missing one of 'load' and 'dump' on the backend.\"\n )\n\n _fs_args = deepcopy(fs_args) or {}\n _fs_open_args_load = _fs_args.pop(\"open_args_load\", {})\n _fs_open_args_save = _fs_args.pop(\"open_args_save\", {})\n _credentials = deepcopy(credentials) or {}\n\n protocol, path = get_protocol_and_path(filepath, version)\n if protocol == \"file\":\n _fs_args.setdefault(\"auto_mkdir\", True)\n\n self._protocol = protocol\n self._fs = fsspec.filesystem(self._protocol, **_credentials, **_fs_args)\n\n super().__init__(\n filepath=PurePosixPath(path),\n version=version,\n exists_function=self._fs.exists,\n glob_function=self._fs.glob,\n )\n\n self._backend = backend\n\n # Handle default load and save arguments\n self._load_args = deepcopy(self.DEFAULT_LOAD_ARGS)\n if load_args is not None:\n self._load_args.update(load_args)\n self._save_args = deepcopy(self.DEFAULT_SAVE_ARGS)\n if save_args is not None:\n self._save_args.update(save_args)\n\n _fs_open_args_save.setdefault(\"mode\", \"wb\")\n self._fs_open_args_load = _fs_open_args_load\n self._fs_open_args_save = _fs_open_args_save\n\n def _describe(self) -> Dict[str, Any]:\n return dict(\n filepath=self._filepath,\n backend=self._backend,\n protocol=self._protocol,\n load_args=self._load_args,\n save_args=self._save_args,\n version=self._version,\n )\n\n def _load(self) -> Any:\n load_path = get_filepath_str(self._get_load_path(), self._protocol)\n\n with self._fs.open(load_path, **self._fs_open_args_load) as fs_file:\n imported_backend = importlib.import_module(self._backend)\n return imported_backend.load(fs_file, **self._load_args) # type: ignore\n\n def _save(self, data: Any) -> None:\n save_path = get_filepath_str(self._get_save_path(), self._protocol)\n\n with self._fs.open(save_path, **self._fs_open_args_save) as fs_file:\n try:\n imported_backend = importlib.import_module(self._backend)\n imported_backend.dump(data, fs_file, **self._save_args) # type: ignore\n except Exception as exc:\n raise DataSetError(\n f\"{data.__class__} was not serialised due to: {exc}\"\n ) from exc\n\n self._invalidate_cache()\n\n def _exists(self) -> bool:\n try:\n load_path = get_filepath_str(self._get_load_path(), self._protocol)\n except DataSetError:\n return False\n\n return self._fs.exists(load_path)\n\n def _release(self) -> None:\n super()._release()\n self._invalidate_cache()\n\n def _invalidate_cache(self) -> None:\n \"\"\"Invalidate underlying filesystem caches.\"\"\"\n filepath = get_filepath_str(self._filepath, self._protocol)\n self._fs.invalidate_cache(filepath)\n", "path": "kedro/extras/datasets/pickle/pickle_dataset.py"}], "after_files": [{"content": "\"\"\"``PickleDataSet`` loads/saves data from/to a Pickle file using an underlying\nfilesystem (e.g.: local, S3, GCS). The underlying functionality is supported by\nthe specified backend library passed in (defaults to the ``pickle`` library), so it\nsupports all allowed options for loading and saving pickle files.\n\"\"\"\nimport importlib\nfrom copy import deepcopy\nfrom pathlib import PurePosixPath\nfrom typing import Any, Dict\n\nimport fsspec\n\nfrom kedro.io.core import (\n AbstractVersionedDataSet,\n DataSetError,\n Version,\n get_filepath_str,\n get_protocol_and_path,\n)\n\n\nclass PickleDataSet(AbstractVersionedDataSet[Any, Any]):\n \"\"\"``PickleDataSet`` loads/saves data from/to a Pickle file using an underlying\n filesystem (e.g.: local, S3, GCS). The underlying functionality is supported by\n the specified backend library passed in (defaults to the ``pickle`` library), so it\n supports all allowed options for loading and saving pickle files.\n\n Example adding a catalog entry with\n `YAML API <https://kedro.readthedocs.io/en/stable/data/\\\n data_catalog.html#use-the-data-catalog-with-the-yaml-api>`_:\n\n .. code-block:: yaml\n\n >>> test_model: # simple example without compression\n >>> type: pickle.PickleDataSet\n >>> filepath: data/07_model_output/test_model.pkl\n >>> backend: pickle\n >>>\n >>> final_model: # example with load and save args\n >>> type: pickle.PickleDataSet\n >>> filepath: s3://your_bucket/final_model.pkl.lz4\n >>> backend: joblib\n >>> credentials: s3_credentials\n >>> save_args:\n >>> compress: lz4\n\n Example using Python API:\n ::\n\n >>> from kedro.extras.datasets.pickle import PickleDataSet\n >>> import pandas as pd\n >>>\n >>> data = pd.DataFrame({'col1': [1, 2], 'col2': [4, 5],\n >>> 'col3': [5, 6]})\n >>>\n >>> # data_set = PickleDataSet(filepath=\"gcs://bucket/test.pkl\")\n >>> data_set = PickleDataSet(filepath=\"test.pkl\", backend=\"pickle\")\n >>> data_set.save(data)\n >>> reloaded = data_set.load()\n >>> assert data.equals(reloaded)\n >>>\n >>> # Add \"compress_pickle[lz4]\" to requirements.txt\n >>> data_set = PickleDataSet(filepath=\"test.pickle.lz4\",\n >>> backend=\"compress_pickle\",\n >>> load_args={\"compression\":\"lz4\"},\n >>> save_args={\"compression\":\"lz4\"})\n >>> data_set.save(data)\n >>> reloaded = data_set.load()\n >>> assert data.equals(reloaded)\n \"\"\"\n\n DEFAULT_LOAD_ARGS = {} # type: Dict[str, Any]\n DEFAULT_SAVE_ARGS = {} # type: Dict[str, Any]\n\n # pylint: disable=too-many-arguments,too-many-locals\n def __init__(\n self,\n filepath: str,\n backend: str = \"pickle\",\n load_args: Dict[str, Any] = None,\n save_args: Dict[str, Any] = None,\n version: Version = None,\n credentials: Dict[str, Any] = None,\n fs_args: Dict[str, Any] = None,\n ) -> None:\n \"\"\"Creates a new instance of ``PickleDataSet`` pointing to a concrete Pickle\n file on a specific filesystem. ``PickleDataSet`` supports custom backends to\n serialise/deserialise objects.\n\n Example backends that are compatible (non-exhaustive):\n * `pickle`\n * `joblib`\n * `dill`\n * `compress_pickle`\n\n Example backends that are incompatible:\n * `torch`\n\n Args:\n filepath: Filepath in POSIX format to a Pickle file prefixed with a protocol like\n `s3://`. If prefix is not provided, `file` protocol (local filesystem) will be used.\n The prefix should be any protocol supported by ``fsspec``.\n Note: `http(s)` doesn't support versioning.\n backend: Backend to use, must be an import path to a module which satisfies the\n ``pickle`` interface. That is, contains a `load` and `dump` function.\n Defaults to 'pickle'.\n load_args: Pickle options for loading pickle files.\n You can pass in arguments that the backend load function specified accepts, e.g:\n pickle.load: https://docs.python.org/3/library/pickle.html#pickle.load\n joblib.load: https://joblib.readthedocs.io/en/latest/generated/joblib.load.html\n dill.load: https://dill.readthedocs.io/en/latest/dill.html#dill._dill.load\n compress_pickle.load:\n https://lucianopaz.github.io/compress_pickle/html/api/compress_pickle.html#compress_pickle.compress_pickle.load\n All defaults are preserved.\n save_args: Pickle options for saving pickle files.\n You can pass in arguments that the backend dump function specified accepts, e.g:\n pickle.dump: https://docs.python.org/3/library/pickle.html#pickle.dump\n joblib.dump: https://joblib.readthedocs.io/en/latest/generated/joblib.dump.html\n dill.dump: https://dill.readthedocs.io/en/latest/dill.html#dill._dill.dump\n compress_pickle.dump:\n https://lucianopaz.github.io/compress_pickle/html/api/compress_pickle.html#compress_pickle.compress_pickle.dump\n All defaults are preserved.\n version: If specified, should be an instance of\n ``kedro.io.core.Version``. If its ``load`` attribute is\n None, the latest version will be loaded. If its ``save``\n attribute is None, save version will be autogenerated.\n credentials: Credentials required to get access to the underlying filesystem.\n E.g. for ``GCSFileSystem`` it should look like `{\"token\": None}`.\n fs_args: Extra arguments to pass into underlying filesystem class constructor\n (e.g. `{\"project\": \"my-project\"}` for ``GCSFileSystem``), as well as\n to pass to the filesystem's `open` method through nested keys\n `open_args_load` and `open_args_save`.\n Here you can find all available arguments for `open`:\n https://filesystem-spec.readthedocs.io/en/latest/api.html#fsspec.spec.AbstractFileSystem.open\n All defaults are preserved, except `mode`, which is set to `wb` when saving.\n\n Raises:\n ValueError: If ``backend`` does not satisfy the `pickle` interface.\n ImportError: If the ``backend`` module could not be imported.\n \"\"\"\n # We do not store `imported_backend` as an attribute to be used in `load`/`save`\n # as this would mean the dataset cannot be deepcopied (module objects cannot be\n # pickled). The import here is purely to raise any errors as early as possible.\n # Repeated imports in the `load` and `save` methods should not be a significant\n # performance hit as Python caches imports.\n try:\n imported_backend = importlib.import_module(backend)\n except ImportError as exc:\n raise ImportError(\n f\"Selected backend '{backend}' could not be imported. \"\n \"Make sure it is installed and importable.\"\n ) from exc\n\n if not (\n hasattr(imported_backend, \"load\") and hasattr(imported_backend, \"dump\")\n ):\n raise ValueError(\n f\"Selected backend '{backend}' should satisfy the pickle interface. \"\n \"Missing one of 'load' and 'dump' on the backend.\"\n )\n\n _fs_args = deepcopy(fs_args) or {}\n _fs_open_args_load = _fs_args.pop(\"open_args_load\", {})\n _fs_open_args_save = _fs_args.pop(\"open_args_save\", {})\n _credentials = deepcopy(credentials) or {}\n\n protocol, path = get_protocol_and_path(filepath, version)\n if protocol == \"file\":\n _fs_args.setdefault(\"auto_mkdir\", True)\n\n self._protocol = protocol\n self._fs = fsspec.filesystem(self._protocol, **_credentials, **_fs_args)\n\n super().__init__(\n filepath=PurePosixPath(path),\n version=version,\n exists_function=self._fs.exists,\n glob_function=self._fs.glob,\n )\n\n self._backend = backend\n\n # Handle default load and save arguments\n self._load_args = deepcopy(self.DEFAULT_LOAD_ARGS)\n if load_args is not None:\n self._load_args.update(load_args)\n self._save_args = deepcopy(self.DEFAULT_SAVE_ARGS)\n if save_args is not None:\n self._save_args.update(save_args)\n\n _fs_open_args_save.setdefault(\"mode\", \"wb\")\n self._fs_open_args_load = _fs_open_args_load\n self._fs_open_args_save = _fs_open_args_save\n\n def _describe(self) -> Dict[str, Any]:\n return dict(\n filepath=self._filepath,\n backend=self._backend,\n protocol=self._protocol,\n load_args=self._load_args,\n save_args=self._save_args,\n version=self._version,\n )\n\n def _load(self) -> Any:\n load_path = get_filepath_str(self._get_load_path(), self._protocol)\n\n with self._fs.open(load_path, **self._fs_open_args_load) as fs_file:\n imported_backend = importlib.import_module(self._backend)\n return imported_backend.load(fs_file, **self._load_args) # type: ignore\n\n def _save(self, data: Any) -> None:\n save_path = get_filepath_str(self._get_save_path(), self._protocol)\n\n with self._fs.open(save_path, **self._fs_open_args_save) as fs_file:\n try:\n imported_backend = importlib.import_module(self._backend)\n imported_backend.dump(data, fs_file, **self._save_args) # type: ignore\n except Exception as exc:\n raise DataSetError(\n f\"{data.__class__} was not serialised due to: {exc}\"\n ) from exc\n\n self._invalidate_cache()\n\n def _exists(self) -> bool:\n try:\n load_path = get_filepath_str(self._get_load_path(), self._protocol)\n except DataSetError:\n return False\n\n return self._fs.exists(load_path)\n\n def _release(self) -> None:\n super()._release()\n self._invalidate_cache()\n\n def _invalidate_cache(self) -> None:\n \"\"\"Invalidate underlying filesystem caches.\"\"\"\n filepath = get_filepath_str(self._filepath, self._protocol)\n self._fs.invalidate_cache(filepath)\n", "path": "kedro/extras/datasets/pickle/pickle_dataset.py"}]}
| 3,454 | 141 |
gh_patches_debug_42802
|
rasdani/github-patches
|
git_diff
|
mampfes__hacs_waste_collection_schedule-1318
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
missing file or path in source: aha_region_de.py
Hi,
I recently installed Version 1.42.0 using HACS and cant get it to run.
Changed the adress to one of the test-adresses, but same issue.
That home directory '/home/silas/tmp/test.html' seems like debug file for some server-responds. But thats not going to work :)
Any ideas?
Thanks for your help!
configuration.yaml
```
waste_collection_schedule:
sources:
- name: aha_region_de
args:
gemeinde: "Hannover"
strasse: "Voltastr. / Vahrenwald"
hnr: "25"
zusatz: ""
```
```
Logger: waste_collection_schedule.source_shell
Source: custom_components/waste_collection_schedule/waste_collection_schedule/source_shell.py:136
Integration: waste_collection_schedule (documentation)
First occurred: 20:08:22 (2 occurrences)
Last logged: 20:09:05
fetch failed for source Zweckverband Abfallwirtschaft Region Hannover: Traceback (most recent call last): File "/config/custom_components/waste_collection_schedule/waste_collection_schedule/source_shell.py", line 134, in fetch entries = self._source.fetch() ^^^^^^^^^^^^^^^^^^^^ File "/config/custom_components/waste_collection_schedule/waste_collection_schedule/source/aha_region_de.py", line 85, in fetch with open("/home/silas/tmp/test.html", "w") as f: ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ FileNotFoundError: [Errno 2] No such file or directory: '/home/silas/tmp/test.html'`
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `custom_components/waste_collection_schedule/waste_collection_schedule/source/aha_region_de.py`
Content:
```
1 from waste_collection_schedule import Collection # type: ignore[attr-defined]
2 from waste_collection_schedule.service.ICS import ICS
3
4 import requests
5 from bs4 import BeautifulSoup
6
7 TITLE = "Zweckverband Abfallwirtschaft Region Hannover"
8 DESCRIPTION = "Source for Zweckverband Abfallwirtschaft Region Hannover."
9 URL = "https://www.aha-region.de/"
10 TEST_CASES = {
11 "Neustadt a. Rbge., Am Rotdorn / Nöpke, 1 ": {
12 "gemeinde": "Neustadt a. Rbge.",
13 "strasse": "Am Rotdorn / Nöpke",
14 "hnr": 1,
15 },
16 "Isernhagen, Am Lohner Hof / Isernhagen Fb, 10": {
17 "gemeinde": "Isernhagen",
18 "strasse": "Am Lohner Hof / Isernhagen Fb",
19 "hnr": "10",
20 },
21 "Hannover, Voltastr. / Vahrenwald, 25": {
22 "gemeinde": "Hannover",
23 "strasse": "Voltastr. / Vahrenwald",
24 "hnr": "25",
25 },
26 "Hannover, Melanchthonstr., 10A": {
27 "gemeinde": "Hannover",
28 "strasse": "Melanchthonstr.",
29 "hnr": "10",
30 "zusatz": "A",
31 }
32 }
33
34 ICON_MAP = {
35 "Restabfall": "mdi:trash-can",
36 "Glass": "mdi:bottle-soda",
37 "Bioabfall": "mdi:leaf",
38 "Papier": "mdi:package-variant",
39 "Leichtverpackungen": "mdi:recycle",
40 }
41
42 API_URL = "https://www.aha-region.de/abholtermine/abfuhrkalender"
43
44 class Source:
45 def __init__(self, gemeinde: str, strasse: str, hnr: str | int, zusatz: str | int = ""):
46 self._gemeinde: str = gemeinde
47 self._strasse: str = strasse
48 self._hnr: str = str(hnr)
49 self._zusatz: str = str(zusatz)
50 self._ics = ICS()
51
52 def fetch(self):
53 # find strassen_id
54 r = requests.get(API_URL, params={"gemeinde": self._gemeinde, "von": "A", "bis": "["})
55 r.raise_for_status()
56
57 strassen_id = None
58 selects = BeautifulSoup(r.text, "html.parser").find("select", {"id": "strasse"}).find_all("option")
59 for select in selects:
60 if select.text.lower().replace(" ", "") == self._strasse.lower().replace(" ", ""):
61 strassen_id = select["value"]
62 break
63
64 if not strassen_id:
65 raise Exception("Street not found for gemeinde: " + self._gemeinde + " and strasse: " + self._strasse)
66
67 # request overview page
68 args = {
69 "gemeinde": self._gemeinde,
70 "jsaus": "",
71 "strasse": strassen_id,
72 "hausnr": self._hnr,
73 "hausnraddon": self._zusatz,
74 "anzeigen": "Suchen",
75 }
76
77 r = requests.post(API_URL, data=args)
78 r.raise_for_status()
79
80 soup = BeautifulSoup(r.text, "html.parser")
81 # find all ICAL download buttons
82 download_buttons = soup.find_all("button", {"name": "ical_apple"})
83
84 if not download_buttons:
85 with open("/home/silas/tmp/test.html", "w") as f:
86 f.write(r.text)
87 raise Exception("Invalid response from server, check you configuration if it is correct.")
88
89 entries = []
90
91 for button in download_buttons:
92 # get form data and request ICAL file for every waste type
93 args = {}
94 args["ical_apple"] = button["value"]
95 form = button.parent
96 for input in form.find_all("input"):
97 args[input["name"]] = input["value"]
98
99 r = requests.post(API_URL, data=args)
100 r.encoding = "utf-8"
101
102 dates = self._ics.convert(r.text)
103
104 for d in dates:
105 bin_type = d[1].replace("Abfuhr", "").strip()
106 entries.append(Collection(d[0], bin_type, ICON_MAP.get(bin_type)))
107
108 return entries
109
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/custom_components/waste_collection_schedule/waste_collection_schedule/source/aha_region_de.py b/custom_components/waste_collection_schedule/waste_collection_schedule/source/aha_region_de.py
--- a/custom_components/waste_collection_schedule/waste_collection_schedule/source/aha_region_de.py
+++ b/custom_components/waste_collection_schedule/waste_collection_schedule/source/aha_region_de.py
@@ -1,8 +1,7 @@
-from waste_collection_schedule import Collection # type: ignore[attr-defined]
-from waste_collection_schedule.service.ICS import ICS
-
import requests
from bs4 import BeautifulSoup
+from waste_collection_schedule import Collection # type: ignore[attr-defined]
+from waste_collection_schedule.service.ICS import ICS
TITLE = "Zweckverband Abfallwirtschaft Region Hannover"
DESCRIPTION = "Source for Zweckverband Abfallwirtschaft Region Hannover."
@@ -14,9 +13,9 @@
"hnr": 1,
},
"Isernhagen, Am Lohner Hof / Isernhagen Fb, 10": {
- "gemeinde": "Isernhagen",
- "strasse": "Am Lohner Hof / Isernhagen Fb",
- "hnr": "10",
+ "gemeinde": "Isernhagen",
+ "strasse": "Am Lohner Hof / Isernhagen Fb",
+ "hnr": "10",
},
"Hannover, Voltastr. / Vahrenwald, 25": {
"gemeinde": "Hannover",
@@ -28,7 +27,7 @@
"strasse": "Melanchthonstr.",
"hnr": "10",
"zusatz": "A",
- }
+ },
}
ICON_MAP = {
@@ -41,8 +40,11 @@
API_URL = "https://www.aha-region.de/abholtermine/abfuhrkalender"
+
class Source:
- def __init__(self, gemeinde: str, strasse: str, hnr: str | int, zusatz: str | int = ""):
+ def __init__(
+ self, gemeinde: str, strasse: str, hnr: str | int, zusatz: str | int = ""
+ ):
self._gemeinde: str = gemeinde
self._strasse: str = strasse
self._hnr: str = str(hnr)
@@ -51,18 +53,31 @@
def fetch(self):
# find strassen_id
- r = requests.get(API_URL, params={"gemeinde": self._gemeinde, "von": "A", "bis": "["})
+ r = requests.get(
+ API_URL, params={"gemeinde": self._gemeinde, "von": "A", "bis": "["}
+ )
r.raise_for_status()
strassen_id = None
- selects = BeautifulSoup(r.text, "html.parser").find("select", {"id": "strasse"}).find_all("option")
+ selects = (
+ BeautifulSoup(r.text, "html.parser")
+ .find("select", {"id": "strasse"})
+ .find_all("option")
+ )
for select in selects:
- if select.text.lower().replace(" ", "") == self._strasse.lower().replace(" ", ""):
+ if select.text.lower().replace(" ", "") == self._strasse.lower().replace(
+ " ", ""
+ ):
strassen_id = select["value"]
break
if not strassen_id:
- raise Exception("Street not found for gemeinde: " + self._gemeinde + " and strasse: " + self._strasse)
+ raise Exception(
+ "Street not found for gemeinde: "
+ + self._gemeinde
+ + " and strasse: "
+ + self._strasse
+ )
# request overview page
args = {
@@ -82,9 +97,9 @@
download_buttons = soup.find_all("button", {"name": "ical_apple"})
if not download_buttons:
- with open("/home/silas/tmp/test.html", "w") as f:
- f.write(r.text)
- raise Exception("Invalid response from server, check you configuration if it is correct.")
+ raise Exception(
+ "Invalid response from server, check you configuration if it is correct."
+ )
entries = []
|
{"golden_diff": "diff --git a/custom_components/waste_collection_schedule/waste_collection_schedule/source/aha_region_de.py b/custom_components/waste_collection_schedule/waste_collection_schedule/source/aha_region_de.py\n--- a/custom_components/waste_collection_schedule/waste_collection_schedule/source/aha_region_de.py\n+++ b/custom_components/waste_collection_schedule/waste_collection_schedule/source/aha_region_de.py\n@@ -1,8 +1,7 @@\n-from waste_collection_schedule import Collection # type: ignore[attr-defined]\n-from waste_collection_schedule.service.ICS import ICS\n-\n import requests\n from bs4 import BeautifulSoup\n+from waste_collection_schedule import Collection # type: ignore[attr-defined]\n+from waste_collection_schedule.service.ICS import ICS\n \n TITLE = \"Zweckverband Abfallwirtschaft Region Hannover\"\n DESCRIPTION = \"Source for Zweckverband Abfallwirtschaft Region Hannover.\"\n@@ -14,9 +13,9 @@\n \"hnr\": 1,\n },\n \"Isernhagen, Am Lohner Hof / Isernhagen Fb, 10\": {\n- \"gemeinde\": \"Isernhagen\",\n- \"strasse\": \"Am Lohner Hof / Isernhagen Fb\",\n- \"hnr\": \"10\",\n+ \"gemeinde\": \"Isernhagen\",\n+ \"strasse\": \"Am Lohner Hof / Isernhagen Fb\",\n+ \"hnr\": \"10\",\n },\n \"Hannover, Voltastr. / Vahrenwald, 25\": {\n \"gemeinde\": \"Hannover\",\n@@ -28,7 +27,7 @@\n \"strasse\": \"Melanchthonstr.\",\n \"hnr\": \"10\",\n \"zusatz\": \"A\",\n- }\n+ },\n }\n \n ICON_MAP = {\n@@ -41,8 +40,11 @@\n \n API_URL = \"https://www.aha-region.de/abholtermine/abfuhrkalender\"\n \n+\n class Source:\n- def __init__(self, gemeinde: str, strasse: str, hnr: str | int, zusatz: str | int = \"\"):\n+ def __init__(\n+ self, gemeinde: str, strasse: str, hnr: str | int, zusatz: str | int = \"\"\n+ ):\n self._gemeinde: str = gemeinde\n self._strasse: str = strasse\n self._hnr: str = str(hnr)\n@@ -51,18 +53,31 @@\n \n def fetch(self):\n # find strassen_id\n- r = requests.get(API_URL, params={\"gemeinde\": self._gemeinde, \"von\": \"A\", \"bis\": \"[\"})\n+ r = requests.get(\n+ API_URL, params={\"gemeinde\": self._gemeinde, \"von\": \"A\", \"bis\": \"[\"}\n+ )\n r.raise_for_status()\n \n strassen_id = None\n- selects = BeautifulSoup(r.text, \"html.parser\").find(\"select\", {\"id\": \"strasse\"}).find_all(\"option\")\n+ selects = (\n+ BeautifulSoup(r.text, \"html.parser\")\n+ .find(\"select\", {\"id\": \"strasse\"})\n+ .find_all(\"option\")\n+ )\n for select in selects:\n- if select.text.lower().replace(\" \", \"\") == self._strasse.lower().replace(\" \", \"\"):\n+ if select.text.lower().replace(\" \", \"\") == self._strasse.lower().replace(\n+ \" \", \"\"\n+ ):\n strassen_id = select[\"value\"]\n break\n \n if not strassen_id:\n- raise Exception(\"Street not found for gemeinde: \" + self._gemeinde + \" and strasse: \" + self._strasse)\n+ raise Exception(\n+ \"Street not found for gemeinde: \"\n+ + self._gemeinde\n+ + \" and strasse: \"\n+ + self._strasse\n+ )\n \n # request overview page\n args = {\n@@ -82,9 +97,9 @@\n download_buttons = soup.find_all(\"button\", {\"name\": \"ical_apple\"})\n \n if not download_buttons:\n- with open(\"/home/silas/tmp/test.html\", \"w\") as f:\n- f.write(r.text)\n- raise Exception(\"Invalid response from server, check you configuration if it is correct.\")\n+ raise Exception(\n+ \"Invalid response from server, check you configuration if it is correct.\"\n+ )\n \n entries = []\n", "issue": "missing file or path in source: aha_region_de.py\nHi,\r\nI recently installed Version 1.42.0 using HACS and cant get it to run.\r\nChanged the adress to one of the test-adresses, but same issue.\r\n\r\nThat home directory '/home/silas/tmp/test.html' seems like debug file for some server-responds. But thats not going to work :)\r\n\r\nAny ideas?\r\n\r\nThanks for your help!\r\n\r\nconfiguration.yaml\r\n```\r\nwaste_collection_schedule:\r\n sources:\r\n - name: aha_region_de\r\n args:\r\n gemeinde: \"Hannover\"\r\n strasse: \"Voltastr. / Vahrenwald\"\r\n hnr: \"25\"\r\n zusatz: \"\"\r\n```\r\n\r\n```\r\nLogger: waste_collection_schedule.source_shell\r\nSource: custom_components/waste_collection_schedule/waste_collection_schedule/source_shell.py:136\r\nIntegration: waste_collection_schedule (documentation)\r\nFirst occurred: 20:08:22 (2 occurrences)\r\nLast logged: 20:09:05\r\n\r\nfetch failed for source Zweckverband Abfallwirtschaft Region Hannover: Traceback (most recent call last): File \"/config/custom_components/waste_collection_schedule/waste_collection_schedule/source_shell.py\", line 134, in fetch entries = self._source.fetch() ^^^^^^^^^^^^^^^^^^^^ File \"/config/custom_components/waste_collection_schedule/waste_collection_schedule/source/aha_region_de.py\", line 85, in fetch with open(\"/home/silas/tmp/test.html\", \"w\") as f: ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ FileNotFoundError: [Errno 2] No such file or directory: '/home/silas/tmp/test.html'`\r\n```\n", "before_files": [{"content": "from waste_collection_schedule import Collection # type: ignore[attr-defined]\nfrom waste_collection_schedule.service.ICS import ICS\n\nimport requests\nfrom bs4 import BeautifulSoup\n\nTITLE = \"Zweckverband Abfallwirtschaft Region Hannover\"\nDESCRIPTION = \"Source for Zweckverband Abfallwirtschaft Region Hannover.\"\nURL = \"https://www.aha-region.de/\"\nTEST_CASES = {\n \"Neustadt a. Rbge., Am Rotdorn / N\u00f6pke, 1 \": {\n \"gemeinde\": \"Neustadt a. Rbge.\",\n \"strasse\": \"Am Rotdorn / N\u00f6pke\",\n \"hnr\": 1,\n },\n \"Isernhagen, Am Lohner Hof / Isernhagen Fb, 10\": {\n \"gemeinde\": \"Isernhagen\",\n \"strasse\": \"Am Lohner Hof / Isernhagen Fb\",\n \"hnr\": \"10\",\n },\n \"Hannover, Voltastr. / Vahrenwald, 25\": {\n \"gemeinde\": \"Hannover\",\n \"strasse\": \"Voltastr. / Vahrenwald\",\n \"hnr\": \"25\",\n },\n \"Hannover, Melanchthonstr., 10A\": {\n \"gemeinde\": \"Hannover\",\n \"strasse\": \"Melanchthonstr.\",\n \"hnr\": \"10\",\n \"zusatz\": \"A\",\n }\n}\n\nICON_MAP = {\n \"Restabfall\": \"mdi:trash-can\",\n \"Glass\": \"mdi:bottle-soda\",\n \"Bioabfall\": \"mdi:leaf\",\n \"Papier\": \"mdi:package-variant\",\n \"Leichtverpackungen\": \"mdi:recycle\",\n}\n\nAPI_URL = \"https://www.aha-region.de/abholtermine/abfuhrkalender\"\n\nclass Source:\n def __init__(self, gemeinde: str, strasse: str, hnr: str | int, zusatz: str | int = \"\"):\n self._gemeinde: str = gemeinde\n self._strasse: str = strasse\n self._hnr: str = str(hnr)\n self._zusatz: str = str(zusatz)\n self._ics = ICS()\n\n def fetch(self):\n # find strassen_id\n r = requests.get(API_URL, params={\"gemeinde\": self._gemeinde, \"von\": \"A\", \"bis\": \"[\"})\n r.raise_for_status()\n\n strassen_id = None\n selects = BeautifulSoup(r.text, \"html.parser\").find(\"select\", {\"id\": \"strasse\"}).find_all(\"option\")\n for select in selects:\n if select.text.lower().replace(\" \", \"\") == self._strasse.lower().replace(\" \", \"\"):\n strassen_id = select[\"value\"]\n break\n\n if not strassen_id:\n raise Exception(\"Street not found for gemeinde: \" + self._gemeinde + \" and strasse: \" + self._strasse)\n\n # request overview page\n args = {\n \"gemeinde\": self._gemeinde,\n \"jsaus\": \"\",\n \"strasse\": strassen_id,\n \"hausnr\": self._hnr,\n \"hausnraddon\": self._zusatz,\n \"anzeigen\": \"Suchen\",\n }\n\n r = requests.post(API_URL, data=args)\n r.raise_for_status()\n\n soup = BeautifulSoup(r.text, \"html.parser\")\n # find all ICAL download buttons\n download_buttons = soup.find_all(\"button\", {\"name\": \"ical_apple\"})\n\n if not download_buttons:\n with open(\"/home/silas/tmp/test.html\", \"w\") as f:\n f.write(r.text)\n raise Exception(\"Invalid response from server, check you configuration if it is correct.\")\n\n entries = []\n\n for button in download_buttons:\n # get form data and request ICAL file for every waste type\n args = {}\n args[\"ical_apple\"] = button[\"value\"]\n form = button.parent\n for input in form.find_all(\"input\"):\n args[input[\"name\"]] = input[\"value\"]\n\n r = requests.post(API_URL, data=args)\n r.encoding = \"utf-8\"\n\n dates = self._ics.convert(r.text)\n\n for d in dates:\n bin_type = d[1].replace(\"Abfuhr\", \"\").strip()\n entries.append(Collection(d[0], bin_type, ICON_MAP.get(bin_type)))\n\n return entries\n", "path": "custom_components/waste_collection_schedule/waste_collection_schedule/source/aha_region_de.py"}], "after_files": [{"content": "import requests\nfrom bs4 import BeautifulSoup\nfrom waste_collection_schedule import Collection # type: ignore[attr-defined]\nfrom waste_collection_schedule.service.ICS import ICS\n\nTITLE = \"Zweckverband Abfallwirtschaft Region Hannover\"\nDESCRIPTION = \"Source for Zweckverband Abfallwirtschaft Region Hannover.\"\nURL = \"https://www.aha-region.de/\"\nTEST_CASES = {\n \"Neustadt a. Rbge., Am Rotdorn / N\u00f6pke, 1 \": {\n \"gemeinde\": \"Neustadt a. Rbge.\",\n \"strasse\": \"Am Rotdorn / N\u00f6pke\",\n \"hnr\": 1,\n },\n \"Isernhagen, Am Lohner Hof / Isernhagen Fb, 10\": {\n \"gemeinde\": \"Isernhagen\",\n \"strasse\": \"Am Lohner Hof / Isernhagen Fb\",\n \"hnr\": \"10\",\n },\n \"Hannover, Voltastr. / Vahrenwald, 25\": {\n \"gemeinde\": \"Hannover\",\n \"strasse\": \"Voltastr. / Vahrenwald\",\n \"hnr\": \"25\",\n },\n \"Hannover, Melanchthonstr., 10A\": {\n \"gemeinde\": \"Hannover\",\n \"strasse\": \"Melanchthonstr.\",\n \"hnr\": \"10\",\n \"zusatz\": \"A\",\n },\n}\n\nICON_MAP = {\n \"Restabfall\": \"mdi:trash-can\",\n \"Glass\": \"mdi:bottle-soda\",\n \"Bioabfall\": \"mdi:leaf\",\n \"Papier\": \"mdi:package-variant\",\n \"Leichtverpackungen\": \"mdi:recycle\",\n}\n\nAPI_URL = \"https://www.aha-region.de/abholtermine/abfuhrkalender\"\n\n\nclass Source:\n def __init__(\n self, gemeinde: str, strasse: str, hnr: str | int, zusatz: str | int = \"\"\n ):\n self._gemeinde: str = gemeinde\n self._strasse: str = strasse\n self._hnr: str = str(hnr)\n self._zusatz: str = str(zusatz)\n self._ics = ICS()\n\n def fetch(self):\n # find strassen_id\n r = requests.get(\n API_URL, params={\"gemeinde\": self._gemeinde, \"von\": \"A\", \"bis\": \"[\"}\n )\n r.raise_for_status()\n\n strassen_id = None\n selects = (\n BeautifulSoup(r.text, \"html.parser\")\n .find(\"select\", {\"id\": \"strasse\"})\n .find_all(\"option\")\n )\n for select in selects:\n if select.text.lower().replace(\" \", \"\") == self._strasse.lower().replace(\n \" \", \"\"\n ):\n strassen_id = select[\"value\"]\n break\n\n if not strassen_id:\n raise Exception(\n \"Street not found for gemeinde: \"\n + self._gemeinde\n + \" and strasse: \"\n + self._strasse\n )\n\n # request overview page\n args = {\n \"gemeinde\": self._gemeinde,\n \"jsaus\": \"\",\n \"strasse\": strassen_id,\n \"hausnr\": self._hnr,\n \"hausnraddon\": self._zusatz,\n \"anzeigen\": \"Suchen\",\n }\n\n r = requests.post(API_URL, data=args)\n r.raise_for_status()\n\n soup = BeautifulSoup(r.text, \"html.parser\")\n # find all ICAL download buttons\n download_buttons = soup.find_all(\"button\", {\"name\": \"ical_apple\"})\n\n if not download_buttons:\n raise Exception(\n \"Invalid response from server, check you configuration if it is correct.\"\n )\n\n entries = []\n\n for button in download_buttons:\n # get form data and request ICAL file for every waste type\n args = {}\n args[\"ical_apple\"] = button[\"value\"]\n form = button.parent\n for input in form.find_all(\"input\"):\n args[input[\"name\"]] = input[\"value\"]\n\n r = requests.post(API_URL, data=args)\n r.encoding = \"utf-8\"\n\n dates = self._ics.convert(r.text)\n\n for d in dates:\n bin_type = d[1].replace(\"Abfuhr\", \"\").strip()\n entries.append(Collection(d[0], bin_type, ICON_MAP.get(bin_type)))\n\n return entries\n", "path": "custom_components/waste_collection_schedule/waste_collection_schedule/source/aha_region_de.py"}]}
| 1,855 | 993 |
gh_patches_debug_4484
|
rasdani/github-patches
|
git_diff
|
python-telegram-bot__python-telegram-bot-953
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
pre_checkout_query does not store bot.
### Steps to reproduce
- On a PreChecoutQueryHandler, get the PreCheckoutQuery object update.pre_checkout_query
- Try to answer it, bot has not been set:
File "/home/folarte/sexychat/nor File "/home/folarte/sexychat/normalstate.py", line 998, in on_pcoq
pcoq.answer(ok=True)
File "/home/folarte/venv-sxc/local/lib/python3.6/site-packages/telegram/payment/precheckoutquery.py", line 115, in answer
return self.bot.answer_pre_checkout_query(self.id, *args, **kwargs)
AttributeError: 'NoneType' object has no attribute 'answer_pre_checkout_query'
malstate.py", line 998, in on_pcoq
pcoq.answer(ok=True)
File "/home/folarte/venv-sxc/local/lib/python3.6/site-packages/telegram/payment/precheckoutquery.py", line 115, in answer
return self.bot.answer_pre_checkout_query(self.id, *args, **kwargs)
AttributeError: 'NoneType' object has no attribute 'answer_pre_checkout_query'
### Expected behaviour
pcoq.bot should contain the bot object.
### Actual behaviour
bot object is not set. Thi is due to the de_json function being:
@classmethod
def de_json(cls, data, bot):
if not data:
return None
data = super(PreCheckoutQuery, cls).de_json(data, bot)
data['from_user'] = User.de_json(data.pop('from'), bot)
data['order_info'] = OrderInfo.de_json(data.get('order_info'), bot)
return cls(**data)
When the last call should pass the bot to the constructor, as done in the callbackquery object:
return cls(bot=bot, **data)
When editing the line to these, it works fine.
Do not know GIT, can try to do it, but it is a trivial fix, probably a typo.
### Configuration
Amazon Linux, aws instance.
$ python -m telegram
python-telegram-bot 9.0.0
certifi 2017.11.05
future 0.16.0
Python 3.6.2 (default, Nov 2 2017, 19:34:31) [GCC 4.8.5 20150623 (Red Hat 4.8.5-11)]
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `telegram/payment/precheckoutquery.py`
Content:
```
1 #!/usr/bin/env python
2 #
3 # A library that provides a Python interface to the Telegram Bot API
4 # Copyright (C) 2015-2017
5 # Leandro Toledo de Souza <[email protected]>
6 #
7 # This program is free software: you can redistribute it and/or modify
8 # it under the terms of the GNU Lesser Public License as published by
9 # the Free Software Foundation, either version 3 of the License, or
10 # (at your option) any later version.
11 #
12 # This program is distributed in the hope that it will be useful,
13 # but WITHOUT ANY WARRANTY; without even the implied warranty of
14 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
15 # GNU Lesser Public License for more details.
16 #
17 # You should have received a copy of the GNU Lesser Public License
18 # along with this program. If not, see [http://www.gnu.org/licenses/].
19 """This module contains an object that represents a Telegram PreCheckoutQuery."""
20
21 from telegram import TelegramObject, User, OrderInfo
22
23
24 class PreCheckoutQuery(TelegramObject):
25 """This object contains information about an incoming pre-checkout query.
26
27 Note:
28 * In Python `from` is a reserved word, use `from_user` instead.
29
30 Attributes:
31 id (:obj:`str`): Unique query identifier.
32 from_user (:class:`telegram.User`): User who sent the query.
33 currency (:obj:`str`): Three-letter ISO 4217 currency code.
34 total_amount (:obj:`int`): Total price in the smallest units of the currency.
35 invoice_payload (:obj:`str`): Bot specified invoice payload.
36 shipping_option_id (:obj:`str`): Optional. Identifier of the shipping option chosen by the
37 user.
38 order_info (:class:`telegram.OrderInfo`): Optional. Order info provided by the user.
39 bot (:class:`telegram.Bot`): Optional. The Bot to use for instance methods.
40
41 Args:
42 id (:obj:`str`): Unique query identifier.
43 from_user (:class:`telegram.User`): User who sent the query.
44 currency (:obj:`str`): Three-letter ISO 4217 currency code
45 total_amount (:obj:`int`): Total price in the smallest units of the currency (integer, not
46 float/double). For example, for a price of US$ 1.45 pass amount = 145. See the exp
47 parameter in currencies.json, it shows the number of digits past the decimal point for
48 each currency (2 for the majority of currencies).
49 invoice_payload (:obj:`str`): Bot specified invoice payload.
50 shipping_option_id (:obj:`str`, optional): Identifier of the shipping option chosen by the
51 user.
52 order_info (:class:`telegram.OrderInfo`, optional): Order info provided by the user.
53 bot (:class:`telegram.Bot`, optional): The Bot to use for instance methods.
54 **kwargs (:obj:`dict`): Arbitrary keyword arguments.
55
56 """
57
58 def __init__(self,
59 id,
60 from_user,
61 currency,
62 total_amount,
63 invoice_payload,
64 shipping_option_id=None,
65 order_info=None,
66 bot=None,
67 **kwargs):
68 self.id = id
69 self.from_user = from_user
70 self.currency = currency
71 self.total_amount = total_amount
72 self.invoice_payload = invoice_payload
73 self.shipping_option_id = shipping_option_id
74 self.order_info = order_info
75
76 self.bot = bot
77
78 self._id_attrs = (self.id,)
79
80 @classmethod
81 def de_json(cls, data, bot):
82 if not data:
83 return None
84
85 data = super(PreCheckoutQuery, cls).de_json(data, bot)
86
87 data['from_user'] = User.de_json(data.pop('from'), bot)
88 data['order_info'] = OrderInfo.de_json(data.get('order_info'), bot)
89
90 return cls(**data)
91
92 def to_dict(self):
93 data = super(PreCheckoutQuery, self).to_dict()
94
95 data['from'] = data.pop('from_user', None)
96
97 return data
98
99 def answer(self, *args, **kwargs):
100 """Shortcut for::
101
102 bot.answer_pre_checkout_query(update.pre_checkout_query.id, *args, **kwargs)
103
104 Args:
105 ok (:obj:`bool`): Specify True if everything is alright (goods are available, etc.) and
106 the bot is ready to proceed with the order. Use False if there are any problems.
107 error_message (:obj:`str`, optional): Required if ok is False. Error message in human
108 readable form that explains the reason for failure to proceed with the checkout
109 (e.g. "Sorry, somebody just bought the last of our amazing black T-shirts while you
110 were busy filling out your payment details. Please choose a different color or
111 garment!"). Telegram will display this message to the user.
112 **kwargs (:obj:`dict`): Arbitrary keyword arguments.
113
114 """
115 return self.bot.answer_pre_checkout_query(self.id, *args, **kwargs)
116
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/telegram/payment/precheckoutquery.py b/telegram/payment/precheckoutquery.py
--- a/telegram/payment/precheckoutquery.py
+++ b/telegram/payment/precheckoutquery.py
@@ -87,7 +87,7 @@
data['from_user'] = User.de_json(data.pop('from'), bot)
data['order_info'] = OrderInfo.de_json(data.get('order_info'), bot)
- return cls(**data)
+ return cls(bot=bot, **data)
def to_dict(self):
data = super(PreCheckoutQuery, self).to_dict()
|
{"golden_diff": "diff --git a/telegram/payment/precheckoutquery.py b/telegram/payment/precheckoutquery.py\n--- a/telegram/payment/precheckoutquery.py\n+++ b/telegram/payment/precheckoutquery.py\n@@ -87,7 +87,7 @@\n data['from_user'] = User.de_json(data.pop('from'), bot)\n data['order_info'] = OrderInfo.de_json(data.get('order_info'), bot)\n \n- return cls(**data)\n+ return cls(bot=bot, **data)\n \n def to_dict(self):\n data = super(PreCheckoutQuery, self).to_dict()\n", "issue": "pre_checkout_query does not store bot.\n\r\n### Steps to reproduce\r\n- On a PreChecoutQueryHandler, get the PreCheckoutQuery object update.pre_checkout_query\r\n\r\n- Try to answer it, bot has not been set:\r\n\r\n File \"/home/folarte/sexychat/nor File \"/home/folarte/sexychat/normalstate.py\", line 998, in on_pcoq\r\n pcoq.answer(ok=True)\r\n File \"/home/folarte/venv-sxc/local/lib/python3.6/site-packages/telegram/payment/precheckoutquery.py\", line 115, in answer\r\n return self.bot.answer_pre_checkout_query(self.id, *args, **kwargs)\r\nAttributeError: 'NoneType' object has no attribute 'answer_pre_checkout_query'\r\nmalstate.py\", line 998, in on_pcoq\r\n pcoq.answer(ok=True)\r\n File \"/home/folarte/venv-sxc/local/lib/python3.6/site-packages/telegram/payment/precheckoutquery.py\", line 115, in answer\r\n return self.bot.answer_pre_checkout_query(self.id, *args, **kwargs)\r\nAttributeError: 'NoneType' object has no attribute 'answer_pre_checkout_query'\r\n\r\n### Expected behaviour\r\n\r\npcoq.bot should contain the bot object.\r\n\r\n### Actual behaviour\r\n\r\nbot object is not set. Thi is due to the de_json function being:\r\n\r\n @classmethod\r\n def de_json(cls, data, bot):\r\n if not data:\r\n return None\r\n\r\n data = super(PreCheckoutQuery, cls).de_json(data, bot)\r\n\r\n data['from_user'] = User.de_json(data.pop('from'), bot)\r\n\tdata['order_info'] = OrderInfo.de_json(data.get('order_info'), bot)\r\n\r\n return cls(**data)\r\n\r\nWhen the last call should pass the bot to the constructor, as done in the callbackquery object:\r\n\r\n return cls(bot=bot, **data)\r\n\r\nWhen editing the line to these, it works fine.\r\n\r\nDo not know GIT, can try to do it, but it is a trivial fix, probably a typo.\r\n\r\n### Configuration\r\n\r\nAmazon Linux, aws instance.\r\n\r\n$ python -m telegram\r\npython-telegram-bot 9.0.0\r\ncertifi 2017.11.05\r\nfuture 0.16.0\r\nPython 3.6.2 (default, Nov 2 2017, 19:34:31) [GCC 4.8.5 20150623 (Red Hat 4.8.5-11)]\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\n#\n# A library that provides a Python interface to the Telegram Bot API\n# Copyright (C) 2015-2017\n# Leandro Toledo de Souza <[email protected]>\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU Lesser Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU Lesser Public License for more details.\n#\n# You should have received a copy of the GNU Lesser Public License\n# along with this program. If not, see [http://www.gnu.org/licenses/].\n\"\"\"This module contains an object that represents a Telegram PreCheckoutQuery.\"\"\"\n\nfrom telegram import TelegramObject, User, OrderInfo\n\n\nclass PreCheckoutQuery(TelegramObject):\n \"\"\"This object contains information about an incoming pre-checkout query.\n\n Note:\n * In Python `from` is a reserved word, use `from_user` instead.\n\n Attributes:\n id (:obj:`str`): Unique query identifier.\n from_user (:class:`telegram.User`): User who sent the query.\n currency (:obj:`str`): Three-letter ISO 4217 currency code.\n total_amount (:obj:`int`): Total price in the smallest units of the currency.\n invoice_payload (:obj:`str`): Bot specified invoice payload.\n shipping_option_id (:obj:`str`): Optional. Identifier of the shipping option chosen by the\n user.\n order_info (:class:`telegram.OrderInfo`): Optional. Order info provided by the user.\n bot (:class:`telegram.Bot`): Optional. The Bot to use for instance methods.\n\n Args:\n id (:obj:`str`): Unique query identifier.\n from_user (:class:`telegram.User`): User who sent the query.\n currency (:obj:`str`): Three-letter ISO 4217 currency code\n total_amount (:obj:`int`): Total price in the smallest units of the currency (integer, not\n float/double). For example, for a price of US$ 1.45 pass amount = 145. See the exp\n parameter in currencies.json, it shows the number of digits past the decimal point for\n each currency (2 for the majority of currencies).\n invoice_payload (:obj:`str`): Bot specified invoice payload.\n shipping_option_id (:obj:`str`, optional): Identifier of the shipping option chosen by the\n user.\n order_info (:class:`telegram.OrderInfo`, optional): Order info provided by the user.\n bot (:class:`telegram.Bot`, optional): The Bot to use for instance methods.\n **kwargs (:obj:`dict`): Arbitrary keyword arguments.\n\n \"\"\"\n\n def __init__(self,\n id,\n from_user,\n currency,\n total_amount,\n invoice_payload,\n shipping_option_id=None,\n order_info=None,\n bot=None,\n **kwargs):\n self.id = id\n self.from_user = from_user\n self.currency = currency\n self.total_amount = total_amount\n self.invoice_payload = invoice_payload\n self.shipping_option_id = shipping_option_id\n self.order_info = order_info\n\n self.bot = bot\n\n self._id_attrs = (self.id,)\n\n @classmethod\n def de_json(cls, data, bot):\n if not data:\n return None\n\n data = super(PreCheckoutQuery, cls).de_json(data, bot)\n\n data['from_user'] = User.de_json(data.pop('from'), bot)\n data['order_info'] = OrderInfo.de_json(data.get('order_info'), bot)\n\n return cls(**data)\n\n def to_dict(self):\n data = super(PreCheckoutQuery, self).to_dict()\n\n data['from'] = data.pop('from_user', None)\n\n return data\n\n def answer(self, *args, **kwargs):\n \"\"\"Shortcut for::\n\n bot.answer_pre_checkout_query(update.pre_checkout_query.id, *args, **kwargs)\n\n Args:\n ok (:obj:`bool`): Specify True if everything is alright (goods are available, etc.) and\n the bot is ready to proceed with the order. Use False if there are any problems.\n error_message (:obj:`str`, optional): Required if ok is False. Error message in human\n readable form that explains the reason for failure to proceed with the checkout\n (e.g. \"Sorry, somebody just bought the last of our amazing black T-shirts while you\n were busy filling out your payment details. Please choose a different color or\n garment!\"). Telegram will display this message to the user.\n **kwargs (:obj:`dict`): Arbitrary keyword arguments.\n\n \"\"\"\n return self.bot.answer_pre_checkout_query(self.id, *args, **kwargs)\n", "path": "telegram/payment/precheckoutquery.py"}], "after_files": [{"content": "#!/usr/bin/env python\n#\n# A library that provides a Python interface to the Telegram Bot API\n# Copyright (C) 2015-2017\n# Leandro Toledo de Souza <[email protected]>\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU Lesser Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU Lesser Public License for more details.\n#\n# You should have received a copy of the GNU Lesser Public License\n# along with this program. If not, see [http://www.gnu.org/licenses/].\n\"\"\"This module contains an object that represents a Telegram PreCheckoutQuery.\"\"\"\n\nfrom telegram import TelegramObject, User, OrderInfo\n\n\nclass PreCheckoutQuery(TelegramObject):\n \"\"\"This object contains information about an incoming pre-checkout query.\n\n Note:\n * In Python `from` is a reserved word, use `from_user` instead.\n\n Attributes:\n id (:obj:`str`): Unique query identifier.\n from_user (:class:`telegram.User`): User who sent the query.\n currency (:obj:`str`): Three-letter ISO 4217 currency code.\n total_amount (:obj:`int`): Total price in the smallest units of the currency.\n invoice_payload (:obj:`str`): Bot specified invoice payload.\n shipping_option_id (:obj:`str`): Optional. Identifier of the shipping option chosen by the\n user.\n order_info (:class:`telegram.OrderInfo`): Optional. Order info provided by the user.\n bot (:class:`telegram.Bot`): Optional. The Bot to use for instance methods.\n\n Args:\n id (:obj:`str`): Unique query identifier.\n from_user (:class:`telegram.User`): User who sent the query.\n currency (:obj:`str`): Three-letter ISO 4217 currency code\n total_amount (:obj:`int`): Total price in the smallest units of the currency (integer, not\n float/double). For example, for a price of US$ 1.45 pass amount = 145. See the exp\n parameter in currencies.json, it shows the number of digits past the decimal point for\n each currency (2 for the majority of currencies).\n invoice_payload (:obj:`str`): Bot specified invoice payload.\n shipping_option_id (:obj:`str`, optional): Identifier of the shipping option chosen by the\n user.\n order_info (:class:`telegram.OrderInfo`, optional): Order info provided by the user.\n bot (:class:`telegram.Bot`, optional): The Bot to use for instance methods.\n **kwargs (:obj:`dict`): Arbitrary keyword arguments.\n\n \"\"\"\n\n def __init__(self,\n id,\n from_user,\n currency,\n total_amount,\n invoice_payload,\n shipping_option_id=None,\n order_info=None,\n bot=None,\n **kwargs):\n self.id = id\n self.from_user = from_user\n self.currency = currency\n self.total_amount = total_amount\n self.invoice_payload = invoice_payload\n self.shipping_option_id = shipping_option_id\n self.order_info = order_info\n\n self.bot = bot\n\n self._id_attrs = (self.id,)\n\n @classmethod\n def de_json(cls, data, bot):\n if not data:\n return None\n\n data = super(PreCheckoutQuery, cls).de_json(data, bot)\n\n data['from_user'] = User.de_json(data.pop('from'), bot)\n data['order_info'] = OrderInfo.de_json(data.get('order_info'), bot)\n\n return cls(bot=bot, **data)\n\n def to_dict(self):\n data = super(PreCheckoutQuery, self).to_dict()\n\n data['from'] = data.pop('from_user', None)\n\n return data\n\n def answer(self, *args, **kwargs):\n \"\"\"Shortcut for::\n\n bot.answer_pre_checkout_query(update.pre_checkout_query.id, *args, **kwargs)\n\n Args:\n ok (:obj:`bool`): Specify True if everything is alright (goods are available, etc.) and\n the bot is ready to proceed with the order. Use False if there are any problems.\n error_message (:obj:`str`, optional): Required if ok is False. Error message in human\n readable form that explains the reason for failure to proceed with the checkout\n (e.g. \"Sorry, somebody just bought the last of our amazing black T-shirts while you\n were busy filling out your payment details. Please choose a different color or\n garment!\"). Telegram will display this message to the user.\n **kwargs (:obj:`dict`): Arbitrary keyword arguments.\n\n \"\"\"\n return self.bot.answer_pre_checkout_query(self.id, *args, **kwargs)\n", "path": "telegram/payment/precheckoutquery.py"}]}
| 2,138 | 128 |
gh_patches_debug_30794
|
rasdani/github-patches
|
git_diff
|
chainer__chainer-6991
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Support ChainerX in F.GetItem backward
`GetItemGrad` does not suport it yet.
Related: #5944
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `chainer/functions/array/get_item.py`
Content:
```
1 import numpy
2
3 import chainer
4 from chainer import backend
5 from chainer import function_node
6 from chainer import utils
7 from chainer.utils import type_check
8 from chainer import variable
9 import chainerx
10
11
12 _numpy_supports_0d_bool_index = \
13 numpy.lib.NumpyVersion(numpy.__version__) >= '1.13.0'
14
15
16 class GetItem(function_node.FunctionNode):
17
18 """Function that slices array and extract elements."""
19
20 def __init__(self, slices):
21 if isinstance(slices, list):
22 if all([isinstance(s, int) for s in slices]):
23 slices = slices,
24 slices = tuple(slices)
25 elif not isinstance(slices, tuple):
26 slices = slices,
27
28 if chainer.is_debug():
29 n_ellipses = 0
30 for s in slices:
31 if s is Ellipsis:
32 n_ellipses += 1
33 if n_ellipses > 1:
34 raise ValueError('Only one Ellipsis is allowed')
35
36 self.slices = slices
37
38 def check_type_forward(self, in_types):
39 type_check._argname(in_types, ('x',))
40
41 def forward(self, xs):
42 slices = tuple([
43 backend.from_chx(s) if isinstance(s, chainerx.ndarray) else s
44 for s in self.slices])
45 return utils.force_array(xs[0][slices]),
46
47 def backward(self, indexes, gy):
48 return GetItemGrad(
49 self.slices, self.inputs[0].shape).apply(gy)
50
51
52 class GetItemGrad(function_node.FunctionNode):
53
54 def __init__(self, slices, in_shape):
55 self.slices = slices
56 self._in_shape = in_shape
57
58 def forward(self, inputs):
59 gy, = inputs
60 xp = backend.get_array_module(*inputs)
61 gx = xp.zeros(self._in_shape, gy.dtype)
62 if xp is numpy:
63 try:
64 numpy.add.at(gx, self.slices, gy)
65 except IndexError:
66 done = False
67 # In numpy<1.13, 0-dim boolean index is not supported in
68 # numpy.add.at and it's supported for 0-dim arr in
69 # arr.__getitem__.
70 if not _numpy_supports_0d_bool_index and len(self.slices) == 1:
71 idx = numpy.asanyarray(self.slices[0])
72 if idx.dtype == numpy.dtype(bool):
73 # Convert the array and the mask to 1-dim.
74 # numpy.add.at with them is supported in older numpy.
75 numpy.add.at(gx[None], idx[None], gy)
76 done = True
77
78 if not done:
79 msg = '''
80 GetItem does not support backward for this slices. The slices argument is not
81 supported by numpy.add.at, while it is supported by numpy.ndarray.__getitem__.
82
83 Please report this error to the issue tracker with the stack trace,
84 the information of your environment, and your script:
85 https://github.com/chainer/chainer/issues/new.
86 '''
87 raise IndexError(msg)
88 else:
89 gx.scatter_add(self.slices, inputs[0])
90 return gx,
91
92 def backward(self, indexes, ggx):
93 return GetItem(self.slices).apply(ggx)
94
95
96 def get_item(x, slices):
97 """Extract elements from array with specified shape, axes and offsets.
98
99 Args:
100 x (:class:`~chainer.Variable` or :ref:`ndarray`):
101 A variable to be sliced.
102 slices (int, slice, Ellipsis, None, integer array-like, boolean\
103 array-like or tuple of them):
104 An object to specify the selection of elements.
105
106 Returns:
107 A :class:`~chainer.Variable` object which contains sliced array of
108 ``x``.
109
110 .. note::
111
112 It only supports types that are supported by CUDA's atomicAdd when
113 an integer array is included in ``slices``.
114 The supported types are ``numpy.float32``, ``numpy.int32``,
115 ``numpy.uint32``, ``numpy.uint64`` and ``numpy.ulonglong``.
116
117 .. note::
118
119 It does not support ``slices`` that contains multiple boolean arrays.
120
121 .. note::
122
123 See NumPy documentation for details of `indexing
124 <https://docs.scipy.org/doc/numpy/reference/arrays.indexing.html>`_.
125
126 .. admonition:: Example
127
128 >>> x = np.arange(12).reshape((2, 2, 3))
129 >>> x
130 array([[[ 0, 1, 2],
131 [ 3, 4, 5]],
132 <BLANKLINE>
133 [[ 6, 7, 8],
134 [ 9, 10, 11]]])
135 >>> F.get_item(x, 0)
136 variable([[0, 1, 2],
137 [3, 4, 5]])
138 >>> F.get_item(x, (0, 0, slice(0, 2, 1))) # equals x[0, 0, 0:2:1]
139 variable([0, 1])
140 >>> F.get_item(x, (Ellipsis, 2)) # equals x[..., 2]
141 variable([[ 2, 5],
142 [ 8, 11]])
143 >>> F.get_item(x, (1, np.newaxis, 1, 0)) # equals x[1, None, 1, 0]
144 variable([9])
145
146 """
147 return GetItem(slices).apply((x,))[0]
148
149
150 def install_variable_get_item():
151 variable.Variable.__getitem__ = get_item
152
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/chainer/functions/array/get_item.py b/chainer/functions/array/get_item.py
--- a/chainer/functions/array/get_item.py
+++ b/chainer/functions/array/get_item.py
@@ -56,19 +56,23 @@
self._in_shape = in_shape
def forward(self, inputs):
+ slices = tuple([
+ backend.from_chx(s) if isinstance(s, chainerx.ndarray) else s
+ for s in self.slices])
+
gy, = inputs
xp = backend.get_array_module(*inputs)
gx = xp.zeros(self._in_shape, gy.dtype)
if xp is numpy:
try:
- numpy.add.at(gx, self.slices, gy)
+ numpy.add.at(gx, slices, gy)
except IndexError:
done = False
# In numpy<1.13, 0-dim boolean index is not supported in
# numpy.add.at and it's supported for 0-dim arr in
# arr.__getitem__.
- if not _numpy_supports_0d_bool_index and len(self.slices) == 1:
- idx = numpy.asanyarray(self.slices[0])
+ if not _numpy_supports_0d_bool_index and len(slices) == 1:
+ idx = numpy.asanyarray(slices[0])
if idx.dtype == numpy.dtype(bool):
# Convert the array and the mask to 1-dim.
# numpy.add.at with them is supported in older numpy.
@@ -86,7 +90,7 @@
'''
raise IndexError(msg)
else:
- gx.scatter_add(self.slices, inputs[0])
+ gx.scatter_add(slices, inputs[0])
return gx,
def backward(self, indexes, ggx):
|
{"golden_diff": "diff --git a/chainer/functions/array/get_item.py b/chainer/functions/array/get_item.py\n--- a/chainer/functions/array/get_item.py\n+++ b/chainer/functions/array/get_item.py\n@@ -56,19 +56,23 @@\n self._in_shape = in_shape\n \n def forward(self, inputs):\n+ slices = tuple([\n+ backend.from_chx(s) if isinstance(s, chainerx.ndarray) else s\n+ for s in self.slices])\n+\n gy, = inputs\n xp = backend.get_array_module(*inputs)\n gx = xp.zeros(self._in_shape, gy.dtype)\n if xp is numpy:\n try:\n- numpy.add.at(gx, self.slices, gy)\n+ numpy.add.at(gx, slices, gy)\n except IndexError:\n done = False\n # In numpy<1.13, 0-dim boolean index is not supported in\n # numpy.add.at and it's supported for 0-dim arr in\n # arr.__getitem__.\n- if not _numpy_supports_0d_bool_index and len(self.slices) == 1:\n- idx = numpy.asanyarray(self.slices[0])\n+ if not _numpy_supports_0d_bool_index and len(slices) == 1:\n+ idx = numpy.asanyarray(slices[0])\n if idx.dtype == numpy.dtype(bool):\n # Convert the array and the mask to 1-dim.\n # numpy.add.at with them is supported in older numpy.\n@@ -86,7 +90,7 @@\n '''\n raise IndexError(msg)\n else:\n- gx.scatter_add(self.slices, inputs[0])\n+ gx.scatter_add(slices, inputs[0])\n return gx,\n \n def backward(self, indexes, ggx):\n", "issue": "Support ChainerX in F.GetItem backward\n`GetItemGrad` does not suport it yet.\r\n\r\nRelated: #5944\n", "before_files": [{"content": "import numpy\n\nimport chainer\nfrom chainer import backend\nfrom chainer import function_node\nfrom chainer import utils\nfrom chainer.utils import type_check\nfrom chainer import variable\nimport chainerx\n\n\n_numpy_supports_0d_bool_index = \\\n numpy.lib.NumpyVersion(numpy.__version__) >= '1.13.0'\n\n\nclass GetItem(function_node.FunctionNode):\n\n \"\"\"Function that slices array and extract elements.\"\"\"\n\n def __init__(self, slices):\n if isinstance(slices, list):\n if all([isinstance(s, int) for s in slices]):\n slices = slices,\n slices = tuple(slices)\n elif not isinstance(slices, tuple):\n slices = slices,\n\n if chainer.is_debug():\n n_ellipses = 0\n for s in slices:\n if s is Ellipsis:\n n_ellipses += 1\n if n_ellipses > 1:\n raise ValueError('Only one Ellipsis is allowed')\n\n self.slices = slices\n\n def check_type_forward(self, in_types):\n type_check._argname(in_types, ('x',))\n\n def forward(self, xs):\n slices = tuple([\n backend.from_chx(s) if isinstance(s, chainerx.ndarray) else s\n for s in self.slices])\n return utils.force_array(xs[0][slices]),\n\n def backward(self, indexes, gy):\n return GetItemGrad(\n self.slices, self.inputs[0].shape).apply(gy)\n\n\nclass GetItemGrad(function_node.FunctionNode):\n\n def __init__(self, slices, in_shape):\n self.slices = slices\n self._in_shape = in_shape\n\n def forward(self, inputs):\n gy, = inputs\n xp = backend.get_array_module(*inputs)\n gx = xp.zeros(self._in_shape, gy.dtype)\n if xp is numpy:\n try:\n numpy.add.at(gx, self.slices, gy)\n except IndexError:\n done = False\n # In numpy<1.13, 0-dim boolean index is not supported in\n # numpy.add.at and it's supported for 0-dim arr in\n # arr.__getitem__.\n if not _numpy_supports_0d_bool_index and len(self.slices) == 1:\n idx = numpy.asanyarray(self.slices[0])\n if idx.dtype == numpy.dtype(bool):\n # Convert the array and the mask to 1-dim.\n # numpy.add.at with them is supported in older numpy.\n numpy.add.at(gx[None], idx[None], gy)\n done = True\n\n if not done:\n msg = '''\nGetItem does not support backward for this slices. The slices argument is not\nsupported by numpy.add.at, while it is supported by numpy.ndarray.__getitem__.\n\nPlease report this error to the issue tracker with the stack trace,\nthe information of your environment, and your script:\nhttps://github.com/chainer/chainer/issues/new.\n'''\n raise IndexError(msg)\n else:\n gx.scatter_add(self.slices, inputs[0])\n return gx,\n\n def backward(self, indexes, ggx):\n return GetItem(self.slices).apply(ggx)\n\n\ndef get_item(x, slices):\n \"\"\"Extract elements from array with specified shape, axes and offsets.\n\n Args:\n x (:class:`~chainer.Variable` or :ref:`ndarray`):\n A variable to be sliced.\n slices (int, slice, Ellipsis, None, integer array-like, boolean\\\n array-like or tuple of them):\n An object to specify the selection of elements.\n\n Returns:\n A :class:`~chainer.Variable` object which contains sliced array of\n ``x``.\n\n .. note::\n\n It only supports types that are supported by CUDA's atomicAdd when\n an integer array is included in ``slices``.\n The supported types are ``numpy.float32``, ``numpy.int32``,\n ``numpy.uint32``, ``numpy.uint64`` and ``numpy.ulonglong``.\n\n .. note::\n\n It does not support ``slices`` that contains multiple boolean arrays.\n\n .. note::\n\n See NumPy documentation for details of `indexing\n <https://docs.scipy.org/doc/numpy/reference/arrays.indexing.html>`_.\n\n .. admonition:: Example\n\n >>> x = np.arange(12).reshape((2, 2, 3))\n >>> x\n array([[[ 0, 1, 2],\n [ 3, 4, 5]],\n <BLANKLINE>\n [[ 6, 7, 8],\n [ 9, 10, 11]]])\n >>> F.get_item(x, 0)\n variable([[0, 1, 2],\n [3, 4, 5]])\n >>> F.get_item(x, (0, 0, slice(0, 2, 1))) # equals x[0, 0, 0:2:1]\n variable([0, 1])\n >>> F.get_item(x, (Ellipsis, 2)) # equals x[..., 2]\n variable([[ 2, 5],\n [ 8, 11]])\n >>> F.get_item(x, (1, np.newaxis, 1, 0)) # equals x[1, None, 1, 0]\n variable([9])\n\n \"\"\"\n return GetItem(slices).apply((x,))[0]\n\n\ndef install_variable_get_item():\n variable.Variable.__getitem__ = get_item\n", "path": "chainer/functions/array/get_item.py"}], "after_files": [{"content": "import numpy\n\nimport chainer\nfrom chainer import backend\nfrom chainer import function_node\nfrom chainer import utils\nfrom chainer.utils import type_check\nfrom chainer import variable\nimport chainerx\n\n\n_numpy_supports_0d_bool_index = \\\n numpy.lib.NumpyVersion(numpy.__version__) >= '1.13.0'\n\n\nclass GetItem(function_node.FunctionNode):\n\n \"\"\"Function that slices array and extract elements.\"\"\"\n\n def __init__(self, slices):\n if isinstance(slices, list):\n if all([isinstance(s, int) for s in slices]):\n slices = slices,\n slices = tuple(slices)\n elif not isinstance(slices, tuple):\n slices = slices,\n\n if chainer.is_debug():\n n_ellipses = 0\n for s in slices:\n if s is Ellipsis:\n n_ellipses += 1\n if n_ellipses > 1:\n raise ValueError('Only one Ellipsis is allowed')\n\n self.slices = slices\n\n def check_type_forward(self, in_types):\n type_check._argname(in_types, ('x',))\n\n def forward(self, xs):\n slices = tuple([\n backend.from_chx(s) if isinstance(s, chainerx.ndarray) else s\n for s in self.slices])\n return utils.force_array(xs[0][slices]),\n\n def backward(self, indexes, gy):\n return GetItemGrad(\n self.slices, self.inputs[0].shape).apply(gy)\n\n\nclass GetItemGrad(function_node.FunctionNode):\n\n def __init__(self, slices, in_shape):\n self.slices = slices\n self._in_shape = in_shape\n\n def forward(self, inputs):\n slices = tuple([\n backend.from_chx(s) if isinstance(s, chainerx.ndarray) else s\n for s in self.slices])\n\n gy, = inputs\n xp = backend.get_array_module(*inputs)\n gx = xp.zeros(self._in_shape, gy.dtype)\n if xp is numpy:\n try:\n numpy.add.at(gx, slices, gy)\n except IndexError:\n done = False\n # In numpy<1.13, 0-dim boolean index is not supported in\n # numpy.add.at and it's supported for 0-dim arr in\n # arr.__getitem__.\n if not _numpy_supports_0d_bool_index and len(slices) == 1:\n idx = numpy.asanyarray(slices[0])\n if idx.dtype == numpy.dtype(bool):\n # Convert the array and the mask to 1-dim.\n # numpy.add.at with them is supported in older numpy.\n numpy.add.at(gx[None], idx[None], gy)\n done = True\n\n if not done:\n msg = '''\nGetItem does not support backward for this slices. The slices argument is not\nsupported by numpy.add.at, while it is supported by numpy.ndarray.__getitem__.\n\nPlease report this error to the issue tracker with the stack trace,\nthe information of your environment, and your script:\nhttps://github.com/chainer/chainer/issues/new.\n'''\n raise IndexError(msg)\n else:\n gx.scatter_add(slices, inputs[0])\n return gx,\n\n def backward(self, indexes, ggx):\n return GetItem(self.slices).apply(ggx)\n\n\ndef get_item(x, slices):\n \"\"\"Extract elements from array with specified shape, axes and offsets.\n\n Args:\n x (:class:`~chainer.Variable` or :ref:`ndarray`):\n A variable to be sliced.\n slices (int, slice, Ellipsis, None, integer array-like, boolean\\\n array-like or tuple of them):\n An object to specify the selection of elements.\n\n Returns:\n A :class:`~chainer.Variable` object which contains sliced array of\n ``x``.\n\n .. note::\n\n It only supports types that are supported by CUDA's atomicAdd when\n an integer array is included in ``slices``.\n The supported types are ``numpy.float32``, ``numpy.int32``,\n ``numpy.uint32``, ``numpy.uint64`` and ``numpy.ulonglong``.\n\n .. note::\n\n It does not support ``slices`` that contains multiple boolean arrays.\n\n .. note::\n\n See NumPy documentation for details of `indexing\n <https://docs.scipy.org/doc/numpy/reference/arrays.indexing.html>`_.\n\n .. admonition:: Example\n\n >>> x = np.arange(12).reshape((2, 2, 3))\n >>> x\n array([[[ 0, 1, 2],\n [ 3, 4, 5]],\n <BLANKLINE>\n [[ 6, 7, 8],\n [ 9, 10, 11]]])\n >>> F.get_item(x, 0)\n variable([[0, 1, 2],\n [3, 4, 5]])\n >>> F.get_item(x, (0, 0, slice(0, 2, 1))) # equals x[0, 0, 0:2:1]\n variable([0, 1])\n >>> F.get_item(x, (Ellipsis, 2)) # equals x[..., 2]\n variable([[ 2, 5],\n [ 8, 11]])\n >>> F.get_item(x, (1, np.newaxis, 1, 0)) # equals x[1, None, 1, 0]\n variable([9])\n\n \"\"\"\n return GetItem(slices).apply((x,))[0]\n\n\ndef install_variable_get_item():\n variable.Variable.__getitem__ = get_item\n", "path": "chainer/functions/array/get_item.py"}]}
| 1,876 | 393 |
gh_patches_debug_12838
|
rasdani/github-patches
|
git_diff
|
aws__aws-cli-429
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
VIMPAGER error
I realize that it is a bit of an aside, but it would be great to support alternative pagers.
```
~ $ echo $MANPAGER
/bin/sh -c "col -bx | vim -c 'set ft=man' -"
~ $ python --version 1
Python 2.7.5
~ $ pip --version
pip 1.4.1 from /Users/carl/.virtualenv/lib/python2.7/site-packages (python 2.7)
~ $ aws --version
aws-cli/1.1.0 Python/2.7.5 Darwin/12.5.0
~ $ aws help
-bx: -c: line 0: unexpected EOF while looking for matching `"'
-bx: -c: line 1: syntax error: unexpected end of file
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `awscli/help.py`
Content:
```
1 # Copyright 2012-2013 Amazon.com, Inc. or its affiliates. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License"). You
4 # may not use this file except in compliance with the License. A copy of
5 # the License is located at
6 #
7 # http://aws.amazon.com/apache2.0/
8 #
9 # or in the "license" file accompanying this file. This file is
10 # distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF
11 # ANY KIND, either express or implied. See the License for the specific
12 # language governing permissions and limitations under the License.
13 import sys
14 import logging
15 import os
16 import platform
17 from subprocess import Popen, PIPE
18
19 from docutils.core import publish_string
20 from docutils.writers import manpage
21 import bcdoc
22 from bcdoc.clidocs import ReSTDocument
23 from bcdoc.clidocs import ProviderDocumentEventHandler
24 from bcdoc.clidocs import ServiceDocumentEventHandler
25 from bcdoc.clidocs import OperationDocumentEventHandler
26 import bcdoc.clidocevents
27 from bcdoc.textwriter import TextWriter
28
29 from awscli.argprocess import ParamShorthand
30
31
32 LOG = logging.getLogger('awscli.help')
33
34
35 class ExecutableNotFoundError(Exception):
36 def __init__(self, executable_name):
37 super(ExecutableNotFoundError, self).__init__(
38 'Could not find executable named "%s"' % executable_name)
39
40
41 def get_renderer():
42 """
43 Return the appropriate HelpRenderer implementation for the
44 current platform.
45 """
46 if platform.system() == 'Windows':
47 return WindowsHelpRenderer()
48 else:
49 return PosixHelpRenderer()
50
51
52 class HelpRenderer(object):
53 """
54 Interface for a help renderer.
55
56 The renderer is responsible for displaying the help content on
57 a particular platform.
58 """
59
60 def render(self, contents):
61 """
62 Each implementation of HelpRenderer must implement this
63 render method.
64 """
65 pass
66
67
68 class PosixHelpRenderer(HelpRenderer):
69 """
70 Render help content on a Posix-like system. This includes
71 Linux and MacOS X.
72 """
73
74 PAGER = 'less -R'
75
76 def get_pager_cmdline(self):
77 pager = self.PAGER
78 if 'MANPAGER' in os.environ:
79 pager = os.environ['MANPAGER']
80 elif 'PAGER' in os.environ:
81 pager = os.environ['PAGER']
82 return pager.split()
83
84 def render(self, contents):
85 man_contents = publish_string(contents, writer=manpage.Writer())
86 if not self._exists_on_path('groff'):
87 raise ExecutableNotFoundError('groff')
88 cmdline = ['groff', '-man', '-T', 'ascii']
89 LOG.debug("Running command: %s", cmdline)
90 p3 = self._popen(cmdline, stdin=PIPE, stdout=PIPE)
91 groff_output = p3.communicate(input=man_contents)[0]
92 cmdline = self.get_pager_cmdline()
93 LOG.debug("Running command: %s", cmdline)
94 p4 = self._popen(cmdline, stdin=PIPE)
95 p4.communicate(input=groff_output)
96 sys.exit(1)
97
98 def _get_rst2man_name(self):
99 if self._exists_on_path('rst2man.py'):
100 return 'rst2man.py'
101 elif self._exists_on_path('rst2man'):
102 # Some distros like ubuntu will rename rst2man.py to rst2man
103 # if you install their version (i.e. "apt-get install
104 # python-docutils"). Though they could technically rename
105 # this to anything we'll support it renamed to 'rst2man' by
106 # explicitly checking for this case ourself.
107 return 'rst2man'
108 else:
109 # Give them the original name as set from docutils.
110 raise ExecutableNotFoundError('rst2man.py')
111
112 def _exists_on_path(self, name):
113 # Since we're only dealing with POSIX systems, we can
114 # ignore things like PATHEXT.
115 return any([os.path.exists(os.path.join(p, name))
116 for p in os.environ.get('PATH', []).split(os.pathsep)])
117
118 def _popen(self, *args, **kwargs):
119 return Popen(*args, **kwargs)
120
121
122 class WindowsHelpRenderer(HelpRenderer):
123 """
124 Render help content on a Windows platform.
125 """
126
127 def render(self, contents):
128 text_output = publish_string(contents,
129 writer=TextWriter())
130 sys.stdout.write(text_output.decode('utf-8'))
131 sys.exit(1)
132
133
134 class RawRenderer(HelpRenderer):
135 """
136 Render help as the raw ReST document.
137 """
138
139 def render(self, contents):
140 sys.stdout.write(contents)
141 sys.exit(1)
142
143
144 class HelpCommand(object):
145 """
146 HelpCommand Interface
147 ---------------------
148 A HelpCommand object acts as the interface between objects in the
149 CLI (e.g. Providers, Services, Operations, etc.) and the documentation
150 system (bcdoc).
151
152 A HelpCommand object wraps the object from the CLI space and provides
153 a consistent interface to critical information needed by the
154 documentation pipeline such as the object's name, description, etc.
155
156 The HelpCommand object is passed to the component of the
157 documentation pipeline that fires documentation events. It is
158 then passed on to each document event handler that has registered
159 for the events.
160
161 All HelpCommand objects contain the following attributes:
162
163 + ``session`` - A ``botocore`` ``Session`` object.
164 + ``obj`` - The object that is being documented.
165 + ``command_table`` - A dict mapping command names to
166 callable objects.
167 + ``arg_table`` - A dict mapping argument names to callable objects.
168 + ``doc`` - A ``Document`` object that is used to collect the
169 generated documentation.
170
171 In addition, please note the `properties` defined below which are
172 required to allow the object to be used in the document pipeline.
173
174 Implementations of HelpCommand are provided here for Provider,
175 Service and Operation objects. Other implementations for other
176 types of objects might be needed for customization in plugins.
177 As long as the implementations conform to this basic interface
178 it should be possible to pass them to the documentation system
179 and generate interactive and static help files.
180 """
181
182 EventHandlerClass = None
183 """
184 Each subclass should define this class variable to point to the
185 EventHandler class used by this HelpCommand.
186 """
187
188 def __init__(self, session, obj, command_table, arg_table):
189 self.session = session
190 self.obj = obj
191 self.command_table = command_table
192 self.arg_table = arg_table
193 self.renderer = get_renderer()
194 self.doc = ReSTDocument(target='man')
195
196 @property
197 def event_class(self):
198 """
199 Return the ``event_class`` for this object.
200
201 The ``event_class`` is used by the documentation pipeline
202 when generating documentation events. For the event below::
203
204 doc-title.<event_class>.<name>
205
206 The document pipeline would use this property to determine
207 the ``event_class`` value.
208 """
209 pass
210
211 @property
212 def name(self):
213 """
214 Return the name of the wrapped object.
215
216 This would be called by the document pipeline to determine
217 the ``name`` to be inserted into the event, as shown above.
218 """
219 pass
220
221 def __call__(self, args, parsed_globals):
222 # Create an event handler for a Provider Document
223 instance = self.EventHandlerClass(self)
224 # Now generate all of the events for a Provider document.
225 # We pass ourselves along so that we can, in turn, get passed
226 # to all event handlers.
227 bcdoc.clidocevents.generate_events(self.session, self)
228 self.renderer.render(self.doc.getvalue())
229 instance.unregister()
230
231
232 class ProviderHelpCommand(HelpCommand):
233 """Implements top level help command.
234
235 This is what is called when ``aws help`` is run.
236
237 """
238 EventHandlerClass = ProviderDocumentEventHandler
239
240 def __init__(self, session, command_table, arg_table,
241 description, synopsis, usage):
242 HelpCommand.__init__(self, session, session.provider,
243 command_table, arg_table)
244 self.description = description
245 self.synopsis = synopsis
246 self.help_usage = usage
247
248 @property
249 def event_class(self):
250 return 'Provider'
251
252 @property
253 def name(self):
254 return self.obj.name
255
256
257 class ServiceHelpCommand(HelpCommand):
258 """Implements service level help.
259
260 This is the object invoked whenever a service command
261 help is implemented, e.g. ``aws ec2 help``.
262
263 """
264
265 EventHandlerClass = ServiceDocumentEventHandler
266
267 def __init__(self, session, obj, command_table, arg_table, name,
268 event_class):
269 super(ServiceHelpCommand, self).__init__(session, obj, command_table,
270 arg_table)
271 self._name = name
272 self._event_class = event_class
273
274 @property
275 def event_class(self):
276 return self._event_class
277
278 @property
279 def name(self):
280 return self._name
281
282
283 class OperationHelpCommand(HelpCommand):
284 """Implements operation level help.
285
286 This is the object invoked whenever help for a service is requested,
287 e.g. ``aws ec2 describe-instances help``.
288
289 """
290 EventHandlerClass = OperationDocumentEventHandler
291
292 def __init__(self, session, service, operation, arg_table, name,
293 event_class):
294 HelpCommand.__init__(self, session, operation, None, arg_table)
295 self.service = service
296 self.param_shorthand = ParamShorthand()
297 self._name = name
298 self._event_class = event_class
299
300 @property
301 def event_class(self):
302 return self._event_class
303
304 @property
305 def name(self):
306 return self._name
307
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/awscli/help.py b/awscli/help.py
--- a/awscli/help.py
+++ b/awscli/help.py
@@ -14,6 +14,7 @@
import logging
import os
import platform
+import shlex
from subprocess import Popen, PIPE
from docutils.core import publish_string
@@ -79,7 +80,7 @@
pager = os.environ['MANPAGER']
elif 'PAGER' in os.environ:
pager = os.environ['PAGER']
- return pager.split()
+ return shlex.split(pager)
def render(self, contents):
man_contents = publish_string(contents, writer=manpage.Writer())
|
{"golden_diff": "diff --git a/awscli/help.py b/awscli/help.py\n--- a/awscli/help.py\n+++ b/awscli/help.py\n@@ -14,6 +14,7 @@\n import logging\n import os\n import platform\n+import shlex\n from subprocess import Popen, PIPE\n \n from docutils.core import publish_string\n@@ -79,7 +80,7 @@\n pager = os.environ['MANPAGER']\n elif 'PAGER' in os.environ:\n pager = os.environ['PAGER']\n- return pager.split()\n+ return shlex.split(pager)\n \n def render(self, contents):\n man_contents = publish_string(contents, writer=manpage.Writer())\n", "issue": "VIMPAGER error\nI realize that it is a bit of an aside, but it would be great to support alternative pagers.\n\n```\n~ $ echo $MANPAGER\n/bin/sh -c \"col -bx | vim -c 'set ft=man' -\"\n~ $ python --version 1\nPython 2.7.5\n~ $ pip --version\npip 1.4.1 from /Users/carl/.virtualenv/lib/python2.7/site-packages (python 2.7)\n~ $ aws --version\naws-cli/1.1.0 Python/2.7.5 Darwin/12.5.0\n~ $ aws help\n-bx: -c: line 0: unexpected EOF while looking for matching `\"'\n-bx: -c: line 1: syntax error: unexpected end of file\n```\n\n", "before_files": [{"content": "# Copyright 2012-2013 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\"). You\n# may not use this file except in compliance with the License. A copy of\n# the License is located at\n#\n# http://aws.amazon.com/apache2.0/\n#\n# or in the \"license\" file accompanying this file. This file is\n# distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF\n# ANY KIND, either express or implied. See the License for the specific\n# language governing permissions and limitations under the License.\nimport sys\nimport logging\nimport os\nimport platform\nfrom subprocess import Popen, PIPE\n\nfrom docutils.core import publish_string\nfrom docutils.writers import manpage\nimport bcdoc\nfrom bcdoc.clidocs import ReSTDocument\nfrom bcdoc.clidocs import ProviderDocumentEventHandler\nfrom bcdoc.clidocs import ServiceDocumentEventHandler\nfrom bcdoc.clidocs import OperationDocumentEventHandler\nimport bcdoc.clidocevents\nfrom bcdoc.textwriter import TextWriter\n\nfrom awscli.argprocess import ParamShorthand\n\n\nLOG = logging.getLogger('awscli.help')\n\n\nclass ExecutableNotFoundError(Exception):\n def __init__(self, executable_name):\n super(ExecutableNotFoundError, self).__init__(\n 'Could not find executable named \"%s\"' % executable_name)\n\n\ndef get_renderer():\n \"\"\"\n Return the appropriate HelpRenderer implementation for the\n current platform.\n \"\"\"\n if platform.system() == 'Windows':\n return WindowsHelpRenderer()\n else:\n return PosixHelpRenderer()\n\n\nclass HelpRenderer(object):\n \"\"\"\n Interface for a help renderer.\n\n The renderer is responsible for displaying the help content on\n a particular platform.\n \"\"\"\n\n def render(self, contents):\n \"\"\"\n Each implementation of HelpRenderer must implement this\n render method.\n \"\"\"\n pass\n\n\nclass PosixHelpRenderer(HelpRenderer):\n \"\"\"\n Render help content on a Posix-like system. This includes\n Linux and MacOS X.\n \"\"\"\n\n PAGER = 'less -R'\n\n def get_pager_cmdline(self):\n pager = self.PAGER\n if 'MANPAGER' in os.environ:\n pager = os.environ['MANPAGER']\n elif 'PAGER' in os.environ:\n pager = os.environ['PAGER']\n return pager.split()\n\n def render(self, contents):\n man_contents = publish_string(contents, writer=manpage.Writer())\n if not self._exists_on_path('groff'):\n raise ExecutableNotFoundError('groff')\n cmdline = ['groff', '-man', '-T', 'ascii']\n LOG.debug(\"Running command: %s\", cmdline)\n p3 = self._popen(cmdline, stdin=PIPE, stdout=PIPE)\n groff_output = p3.communicate(input=man_contents)[0]\n cmdline = self.get_pager_cmdline()\n LOG.debug(\"Running command: %s\", cmdline)\n p4 = self._popen(cmdline, stdin=PIPE)\n p4.communicate(input=groff_output)\n sys.exit(1)\n\n def _get_rst2man_name(self):\n if self._exists_on_path('rst2man.py'):\n return 'rst2man.py'\n elif self._exists_on_path('rst2man'):\n # Some distros like ubuntu will rename rst2man.py to rst2man\n # if you install their version (i.e. \"apt-get install\n # python-docutils\"). Though they could technically rename\n # this to anything we'll support it renamed to 'rst2man' by\n # explicitly checking for this case ourself.\n return 'rst2man'\n else:\n # Give them the original name as set from docutils.\n raise ExecutableNotFoundError('rst2man.py')\n\n def _exists_on_path(self, name):\n # Since we're only dealing with POSIX systems, we can\n # ignore things like PATHEXT.\n return any([os.path.exists(os.path.join(p, name))\n for p in os.environ.get('PATH', []).split(os.pathsep)])\n\n def _popen(self, *args, **kwargs):\n return Popen(*args, **kwargs)\n\n\nclass WindowsHelpRenderer(HelpRenderer):\n \"\"\"\n Render help content on a Windows platform.\n \"\"\"\n\n def render(self, contents):\n text_output = publish_string(contents,\n writer=TextWriter())\n sys.stdout.write(text_output.decode('utf-8'))\n sys.exit(1)\n\n\nclass RawRenderer(HelpRenderer):\n \"\"\"\n Render help as the raw ReST document.\n \"\"\"\n\n def render(self, contents):\n sys.stdout.write(contents)\n sys.exit(1)\n\n\nclass HelpCommand(object):\n \"\"\"\n HelpCommand Interface\n ---------------------\n A HelpCommand object acts as the interface between objects in the\n CLI (e.g. Providers, Services, Operations, etc.) and the documentation\n system (bcdoc).\n\n A HelpCommand object wraps the object from the CLI space and provides\n a consistent interface to critical information needed by the\n documentation pipeline such as the object's name, description, etc.\n\n The HelpCommand object is passed to the component of the\n documentation pipeline that fires documentation events. It is\n then passed on to each document event handler that has registered\n for the events.\n\n All HelpCommand objects contain the following attributes:\n\n + ``session`` - A ``botocore`` ``Session`` object.\n + ``obj`` - The object that is being documented.\n + ``command_table`` - A dict mapping command names to\n callable objects.\n + ``arg_table`` - A dict mapping argument names to callable objects.\n + ``doc`` - A ``Document`` object that is used to collect the\n generated documentation.\n\n In addition, please note the `properties` defined below which are\n required to allow the object to be used in the document pipeline.\n\n Implementations of HelpCommand are provided here for Provider,\n Service and Operation objects. Other implementations for other\n types of objects might be needed for customization in plugins.\n As long as the implementations conform to this basic interface\n it should be possible to pass them to the documentation system\n and generate interactive and static help files.\n \"\"\"\n\n EventHandlerClass = None\n \"\"\"\n Each subclass should define this class variable to point to the\n EventHandler class used by this HelpCommand.\n \"\"\"\n\n def __init__(self, session, obj, command_table, arg_table):\n self.session = session\n self.obj = obj\n self.command_table = command_table\n self.arg_table = arg_table\n self.renderer = get_renderer()\n self.doc = ReSTDocument(target='man')\n\n @property\n def event_class(self):\n \"\"\"\n Return the ``event_class`` for this object.\n\n The ``event_class`` is used by the documentation pipeline\n when generating documentation events. For the event below::\n\n doc-title.<event_class>.<name>\n\n The document pipeline would use this property to determine\n the ``event_class`` value.\n \"\"\"\n pass\n\n @property\n def name(self):\n \"\"\"\n Return the name of the wrapped object.\n\n This would be called by the document pipeline to determine\n the ``name`` to be inserted into the event, as shown above.\n \"\"\"\n pass\n\n def __call__(self, args, parsed_globals):\n # Create an event handler for a Provider Document\n instance = self.EventHandlerClass(self)\n # Now generate all of the events for a Provider document.\n # We pass ourselves along so that we can, in turn, get passed\n # to all event handlers.\n bcdoc.clidocevents.generate_events(self.session, self)\n self.renderer.render(self.doc.getvalue())\n instance.unregister()\n\n\nclass ProviderHelpCommand(HelpCommand):\n \"\"\"Implements top level help command.\n\n This is what is called when ``aws help`` is run.\n\n \"\"\"\n EventHandlerClass = ProviderDocumentEventHandler\n\n def __init__(self, session, command_table, arg_table,\n description, synopsis, usage):\n HelpCommand.__init__(self, session, session.provider,\n command_table, arg_table)\n self.description = description\n self.synopsis = synopsis\n self.help_usage = usage\n\n @property\n def event_class(self):\n return 'Provider'\n\n @property\n def name(self):\n return self.obj.name\n\n\nclass ServiceHelpCommand(HelpCommand):\n \"\"\"Implements service level help.\n\n This is the object invoked whenever a service command\n help is implemented, e.g. ``aws ec2 help``.\n\n \"\"\"\n\n EventHandlerClass = ServiceDocumentEventHandler\n\n def __init__(self, session, obj, command_table, arg_table, name,\n event_class):\n super(ServiceHelpCommand, self).__init__(session, obj, command_table,\n arg_table)\n self._name = name\n self._event_class = event_class\n\n @property\n def event_class(self):\n return self._event_class\n\n @property\n def name(self):\n return self._name\n\n\nclass OperationHelpCommand(HelpCommand):\n \"\"\"Implements operation level help.\n\n This is the object invoked whenever help for a service is requested,\n e.g. ``aws ec2 describe-instances help``.\n\n \"\"\"\n EventHandlerClass = OperationDocumentEventHandler\n\n def __init__(self, session, service, operation, arg_table, name,\n event_class):\n HelpCommand.__init__(self, session, operation, None, arg_table)\n self.service = service\n self.param_shorthand = ParamShorthand()\n self._name = name\n self._event_class = event_class\n\n @property\n def event_class(self):\n return self._event_class\n\n @property\n def name(self):\n return self._name\n", "path": "awscli/help.py"}], "after_files": [{"content": "# Copyright 2012-2013 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\"). You\n# may not use this file except in compliance with the License. A copy of\n# the License is located at\n#\n# http://aws.amazon.com/apache2.0/\n#\n# or in the \"license\" file accompanying this file. This file is\n# distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF\n# ANY KIND, either express or implied. See the License for the specific\n# language governing permissions and limitations under the License.\nimport sys\nimport logging\nimport os\nimport platform\nimport shlex\nfrom subprocess import Popen, PIPE\n\nfrom docutils.core import publish_string\nfrom docutils.writers import manpage\nimport bcdoc\nfrom bcdoc.clidocs import ReSTDocument\nfrom bcdoc.clidocs import ProviderDocumentEventHandler\nfrom bcdoc.clidocs import ServiceDocumentEventHandler\nfrom bcdoc.clidocs import OperationDocumentEventHandler\nimport bcdoc.clidocevents\nfrom bcdoc.textwriter import TextWriter\n\nfrom awscli.argprocess import ParamShorthand\n\n\nLOG = logging.getLogger('awscli.help')\n\n\nclass ExecutableNotFoundError(Exception):\n def __init__(self, executable_name):\n super(ExecutableNotFoundError, self).__init__(\n 'Could not find executable named \"%s\"' % executable_name)\n\n\ndef get_renderer():\n \"\"\"\n Return the appropriate HelpRenderer implementation for the\n current platform.\n \"\"\"\n if platform.system() == 'Windows':\n return WindowsHelpRenderer()\n else:\n return PosixHelpRenderer()\n\n\nclass HelpRenderer(object):\n \"\"\"\n Interface for a help renderer.\n\n The renderer is responsible for displaying the help content on\n a particular platform.\n \"\"\"\n\n def render(self, contents):\n \"\"\"\n Each implementation of HelpRenderer must implement this\n render method.\n \"\"\"\n pass\n\n\nclass PosixHelpRenderer(HelpRenderer):\n \"\"\"\n Render help content on a Posix-like system. This includes\n Linux and MacOS X.\n \"\"\"\n\n PAGER = 'less -R'\n\n def get_pager_cmdline(self):\n pager = self.PAGER\n if 'MANPAGER' in os.environ:\n pager = os.environ['MANPAGER']\n elif 'PAGER' in os.environ:\n pager = os.environ['PAGER']\n return shlex.split(pager)\n\n def render(self, contents):\n man_contents = publish_string(contents, writer=manpage.Writer())\n if not self._exists_on_path('groff'):\n raise ExecutableNotFoundError('groff')\n cmdline = ['groff', '-man', '-T', 'ascii']\n LOG.debug(\"Running command: %s\", cmdline)\n p3 = self._popen(cmdline, stdin=PIPE, stdout=PIPE)\n groff_output = p3.communicate(input=man_contents)[0]\n cmdline = self.get_pager_cmdline()\n LOG.debug(\"Running command: %s\", cmdline)\n p4 = self._popen(cmdline, stdin=PIPE)\n p4.communicate(input=groff_output)\n sys.exit(1)\n\n def _get_rst2man_name(self):\n if self._exists_on_path('rst2man.py'):\n return 'rst2man.py'\n elif self._exists_on_path('rst2man'):\n # Some distros like ubuntu will rename rst2man.py to rst2man\n # if you install their version (i.e. \"apt-get install\n # python-docutils\"). Though they could technically rename\n # this to anything we'll support it renamed to 'rst2man' by\n # explicitly checking for this case ourself.\n return 'rst2man'\n else:\n # Give them the original name as set from docutils.\n raise ExecutableNotFoundError('rst2man.py')\n\n def _exists_on_path(self, name):\n # Since we're only dealing with POSIX systems, we can\n # ignore things like PATHEXT.\n return any([os.path.exists(os.path.join(p, name))\n for p in os.environ.get('PATH', []).split(os.pathsep)])\n\n def _popen(self, *args, **kwargs):\n return Popen(*args, **kwargs)\n\n\nclass WindowsHelpRenderer(HelpRenderer):\n \"\"\"\n Render help content on a Windows platform.\n \"\"\"\n\n def render(self, contents):\n text_output = publish_string(contents,\n writer=TextWriter())\n sys.stdout.write(text_output.decode('utf-8'))\n sys.exit(1)\n\n\nclass RawRenderer(HelpRenderer):\n \"\"\"\n Render help as the raw ReST document.\n \"\"\"\n\n def render(self, contents):\n sys.stdout.write(contents)\n sys.exit(1)\n\n\nclass HelpCommand(object):\n \"\"\"\n HelpCommand Interface\n ---------------------\n A HelpCommand object acts as the interface between objects in the\n CLI (e.g. Providers, Services, Operations, etc.) and the documentation\n system (bcdoc).\n\n A HelpCommand object wraps the object from the CLI space and provides\n a consistent interface to critical information needed by the\n documentation pipeline such as the object's name, description, etc.\n\n The HelpCommand object is passed to the component of the\n documentation pipeline that fires documentation events. It is\n then passed on to each document event handler that has registered\n for the events.\n\n All HelpCommand objects contain the following attributes:\n\n + ``session`` - A ``botocore`` ``Session`` object.\n + ``obj`` - The object that is being documented.\n + ``command_table`` - A dict mapping command names to\n callable objects.\n + ``arg_table`` - A dict mapping argument names to callable objects.\n + ``doc`` - A ``Document`` object that is used to collect the\n generated documentation.\n\n In addition, please note the `properties` defined below which are\n required to allow the object to be used in the document pipeline.\n\n Implementations of HelpCommand are provided here for Provider,\n Service and Operation objects. Other implementations for other\n types of objects might be needed for customization in plugins.\n As long as the implementations conform to this basic interface\n it should be possible to pass them to the documentation system\n and generate interactive and static help files.\n \"\"\"\n\n EventHandlerClass = None\n \"\"\"\n Each subclass should define this class variable to point to the\n EventHandler class used by this HelpCommand.\n \"\"\"\n\n def __init__(self, session, obj, command_table, arg_table):\n self.session = session\n self.obj = obj\n self.command_table = command_table\n self.arg_table = arg_table\n self.renderer = get_renderer()\n self.doc = ReSTDocument(target='man')\n\n @property\n def event_class(self):\n \"\"\"\n Return the ``event_class`` for this object.\n\n The ``event_class`` is used by the documentation pipeline\n when generating documentation events. For the event below::\n\n doc-title.<event_class>.<name>\n\n The document pipeline would use this property to determine\n the ``event_class`` value.\n \"\"\"\n pass\n\n @property\n def name(self):\n \"\"\"\n Return the name of the wrapped object.\n\n This would be called by the document pipeline to determine\n the ``name`` to be inserted into the event, as shown above.\n \"\"\"\n pass\n\n def __call__(self, args, parsed_globals):\n # Create an event handler for a Provider Document\n instance = self.EventHandlerClass(self)\n # Now generate all of the events for a Provider document.\n # We pass ourselves along so that we can, in turn, get passed\n # to all event handlers.\n bcdoc.clidocevents.generate_events(self.session, self)\n self.renderer.render(self.doc.getvalue())\n instance.unregister()\n\n\nclass ProviderHelpCommand(HelpCommand):\n \"\"\"Implements top level help command.\n\n This is what is called when ``aws help`` is run.\n\n \"\"\"\n EventHandlerClass = ProviderDocumentEventHandler\n\n def __init__(self, session, command_table, arg_table,\n description, synopsis, usage):\n HelpCommand.__init__(self, session, session.provider,\n command_table, arg_table)\n self.description = description\n self.synopsis = synopsis\n self.help_usage = usage\n\n @property\n def event_class(self):\n return 'Provider'\n\n @property\n def name(self):\n return self.obj.name\n\n\nclass ServiceHelpCommand(HelpCommand):\n \"\"\"Implements service level help.\n\n This is the object invoked whenever a service command\n help is implemented, e.g. ``aws ec2 help``.\n\n \"\"\"\n\n EventHandlerClass = ServiceDocumentEventHandler\n\n def __init__(self, session, obj, command_table, arg_table, name,\n event_class):\n super(ServiceHelpCommand, self).__init__(session, obj, command_table,\n arg_table)\n self._name = name\n self._event_class = event_class\n\n @property\n def event_class(self):\n return self._event_class\n\n @property\n def name(self):\n return self._name\n\n\nclass OperationHelpCommand(HelpCommand):\n \"\"\"Implements operation level help.\n\n This is the object invoked whenever help for a service is requested,\n e.g. ``aws ec2 describe-instances help``.\n\n \"\"\"\n EventHandlerClass = OperationDocumentEventHandler\n\n def __init__(self, session, service, operation, arg_table, name,\n event_class):\n HelpCommand.__init__(self, session, operation, None, arg_table)\n self.service = service\n self.param_shorthand = ParamShorthand()\n self._name = name\n self._event_class = event_class\n\n @property\n def event_class(self):\n return self._event_class\n\n @property\n def name(self):\n return self._name\n", "path": "awscli/help.py"}]}
| 3,429 | 148 |
gh_patches_debug_41523
|
rasdani/github-patches
|
git_diff
|
pypa__pip-6879
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Don't use file locking to protect selfcheck state file
**What's the problem this feature will solve?**
There are several issues around file locking that have been filed over the years, specifically related to:
1. Underlying OS/filesystem does not support hardlinks as used by the file lock (#2993, #5322, #6761)
2. Lingering lock files and/or lock files in an inconsistent state can cause pip to hang when attempting to acquire the lock (some of #3532, #5034)
3. lockfile uses hostname when creating its unique name, which can result in invalid paths when hostname includes a `/` (#6938)
**Describe the solution you'd like**
1. Write a selfcheck state file per-prefix, to remove the need to read and then write the file within a lock
2. Write the file atomically (write to a separate tmp file and then move into place) to avoid partial writes if the process is killed
This will satisfy the linked issues and help us progress on #4766 to remove lockfile entirely.
**Alternative Solutions**
1. Switch to `MkdirLockFile` as currently used in the HTTP cache - the downside of this approach is that it is not backwards-compatible, so we would need to use a separate file to track the information for modern pip versions. If we would need to use a separate file anyway, we might as well go one step further to progress #4766.
**Additional context**
* PR #6855 - writes per-prefix selfcheck state files
* PR #6879 - removes file locking
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/pip/_internal/utils/outdated.py`
Content:
```
1 from __future__ import absolute_import
2
3 import datetime
4 import hashlib
5 import json
6 import logging
7 import os.path
8 import sys
9
10 from pip._vendor import lockfile, pkg_resources
11 from pip._vendor.packaging import version as packaging_version
12 from pip._vendor.six import ensure_binary
13
14 from pip._internal.cli.cmdoptions import make_search_scope
15 from pip._internal.index import PackageFinder
16 from pip._internal.models.selection_prefs import SelectionPreferences
17 from pip._internal.utils.compat import WINDOWS
18 from pip._internal.utils.filesystem import check_path_owner
19 from pip._internal.utils.misc import ensure_dir, get_installed_version
20 from pip._internal.utils.packaging import get_installer
21 from pip._internal.utils.typing import MYPY_CHECK_RUNNING
22
23 if MYPY_CHECK_RUNNING:
24 import optparse
25 from typing import Any, Dict, Text, Union
26 from pip._internal.download import PipSession
27
28
29 SELFCHECK_DATE_FMT = "%Y-%m-%dT%H:%M:%SZ"
30
31
32 logger = logging.getLogger(__name__)
33
34
35 def _get_statefile_name(key):
36 # type: (Union[str, Text]) -> str
37 key_bytes = ensure_binary(key)
38 name = hashlib.sha224(key_bytes).hexdigest()
39 return name
40
41
42 class SelfCheckState(object):
43 def __init__(self, cache_dir):
44 # type: (str) -> None
45 self.state = {} # type: Dict[str, Any]
46 self.statefile_path = None
47
48 # Try to load the existing state
49 if cache_dir:
50 self.statefile_path = os.path.join(
51 cache_dir, "selfcheck", _get_statefile_name(self.key)
52 )
53 try:
54 with open(self.statefile_path) as statefile:
55 self.state = json.load(statefile)
56 except (IOError, ValueError, KeyError):
57 # Explicitly suppressing exceptions, since we don't want to
58 # error out if the cache file is invalid.
59 pass
60
61 @property
62 def key(self):
63 return sys.prefix
64
65 def save(self, pypi_version, current_time):
66 # type: (str, datetime.datetime) -> None
67 # If we do not have a path to cache in, don't bother saving.
68 if not self.statefile_path:
69 return
70
71 # Check to make sure that we own the directory
72 if not check_path_owner(os.path.dirname(self.statefile_path)):
73 return
74
75 # Now that we've ensured the directory is owned by this user, we'll go
76 # ahead and make sure that all our directories are created.
77 ensure_dir(os.path.dirname(self.statefile_path))
78
79 state = {
80 # Include the key so it's easy to tell which pip wrote the
81 # file.
82 "key": self.key,
83 "last_check": current_time.strftime(SELFCHECK_DATE_FMT),
84 "pypi_version": pypi_version,
85 }
86
87 text = json.dumps(state, sort_keys=True, separators=(",", ":"))
88
89 # Attempt to write out our version check file
90 with lockfile.LockFile(self.statefile_path):
91 # Since we have a prefix-specific state file, we can just
92 # overwrite whatever is there, no need to check.
93 with open(self.statefile_path, "w") as statefile:
94 statefile.write(text)
95
96
97 def was_installed_by_pip(pkg):
98 # type: (str) -> bool
99 """Checks whether pkg was installed by pip
100
101 This is used not to display the upgrade message when pip is in fact
102 installed by system package manager, such as dnf on Fedora.
103 """
104 try:
105 dist = pkg_resources.get_distribution(pkg)
106 return "pip" == get_installer(dist)
107 except pkg_resources.DistributionNotFound:
108 return False
109
110
111 def pip_version_check(session, options):
112 # type: (PipSession, optparse.Values) -> None
113 """Check for an update for pip.
114
115 Limit the frequency of checks to once per week. State is stored either in
116 the active virtualenv or in the user's USER_CACHE_DIR keyed off the prefix
117 of the pip script path.
118 """
119 installed_version = get_installed_version("pip")
120 if not installed_version:
121 return
122
123 pip_version = packaging_version.parse(installed_version)
124 pypi_version = None
125
126 try:
127 state = SelfCheckState(cache_dir=options.cache_dir)
128
129 current_time = datetime.datetime.utcnow()
130 # Determine if we need to refresh the state
131 if "last_check" in state.state and "pypi_version" in state.state:
132 last_check = datetime.datetime.strptime(
133 state.state["last_check"],
134 SELFCHECK_DATE_FMT
135 )
136 if (current_time - last_check).total_seconds() < 7 * 24 * 60 * 60:
137 pypi_version = state.state["pypi_version"]
138
139 # Refresh the version if we need to or just see if we need to warn
140 if pypi_version is None:
141 # Lets use PackageFinder to see what the latest pip version is
142 search_scope = make_search_scope(options, suppress_no_index=True)
143
144 # Pass allow_yanked=False so we don't suggest upgrading to a
145 # yanked version.
146 selection_prefs = SelectionPreferences(
147 allow_yanked=False,
148 allow_all_prereleases=False, # Explicitly set to False
149 )
150
151 finder = PackageFinder.create(
152 search_scope=search_scope,
153 selection_prefs=selection_prefs,
154 session=session,
155 )
156 best_candidate = finder.find_best_candidate("pip").best_candidate
157 if best_candidate is None:
158 return
159 pypi_version = str(best_candidate.version)
160
161 # save that we've performed a check
162 state.save(pypi_version, current_time)
163
164 remote_version = packaging_version.parse(pypi_version)
165
166 local_version_is_older = (
167 pip_version < remote_version and
168 pip_version.base_version != remote_version.base_version and
169 was_installed_by_pip('pip')
170 )
171
172 # Determine if our pypi_version is older
173 if not local_version_is_older:
174 return
175
176 # Advise "python -m pip" on Windows to avoid issues
177 # with overwriting pip.exe.
178 if WINDOWS:
179 pip_cmd = "python -m pip"
180 else:
181 pip_cmd = "pip"
182 logger.warning(
183 "You are using pip version %s, however version %s is "
184 "available.\nYou should consider upgrading via the "
185 "'%s install --upgrade pip' command.",
186 pip_version, pypi_version, pip_cmd
187 )
188 except Exception:
189 logger.debug(
190 "There was an error checking the latest version of pip",
191 exc_info=True,
192 )
193
```
Path: `src/pip/_internal/utils/filesystem.py`
Content:
```
1 import os
2 import os.path
3 import shutil
4 import stat
5
6 from pip._internal.utils.compat import get_path_uid
7
8
9 def check_path_owner(path):
10 # type: (str) -> bool
11 # If we don't have a way to check the effective uid of this process, then
12 # we'll just assume that we own the directory.
13 if not hasattr(os, "geteuid"):
14 return True
15
16 previous = None
17 while path != previous:
18 if os.path.lexists(path):
19 # Check if path is writable by current user.
20 if os.geteuid() == 0:
21 # Special handling for root user in order to handle properly
22 # cases where users use sudo without -H flag.
23 try:
24 path_uid = get_path_uid(path)
25 except OSError:
26 return False
27 return path_uid == 0
28 else:
29 return os.access(path, os.W_OK)
30 else:
31 previous, path = path, os.path.dirname(path)
32 return False # assume we don't own the path
33
34
35 def copy2_fixed(src, dest):
36 # type: (str, str) -> None
37 """Wrap shutil.copy2() but map errors copying socket files to
38 SpecialFileError as expected.
39
40 See also https://bugs.python.org/issue37700.
41 """
42 try:
43 shutil.copy2(src, dest)
44 except (OSError, IOError):
45 for f in [src, dest]:
46 try:
47 is_socket_file = is_socket(f)
48 except OSError:
49 # An error has already occurred. Another error here is not
50 # a problem and we can ignore it.
51 pass
52 else:
53 if is_socket_file:
54 raise shutil.SpecialFileError("`%s` is a socket" % f)
55
56 raise
57
58
59 def is_socket(path):
60 # type: (str) -> bool
61 return stat.S_ISSOCK(os.lstat(path).st_mode)
62
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/pip/_internal/utils/filesystem.py b/src/pip/_internal/utils/filesystem.py
--- a/src/pip/_internal/utils/filesystem.py
+++ b/src/pip/_internal/utils/filesystem.py
@@ -2,8 +2,26 @@
import os.path
import shutil
import stat
+from contextlib import contextmanager
+from tempfile import NamedTemporaryFile
+
+# NOTE: retrying is not annotated in typeshed as on 2017-07-17, which is
+# why we ignore the type on this import.
+from pip._vendor.retrying import retry # type: ignore
+from pip._vendor.six import PY2
from pip._internal.utils.compat import get_path_uid
+from pip._internal.utils.misc import cast
+from pip._internal.utils.typing import MYPY_CHECK_RUNNING
+
+if MYPY_CHECK_RUNNING:
+ from typing import BinaryIO, Iterator
+
+ class NamedTemporaryFileResult(BinaryIO):
+ @property
+ def file(self):
+ # type: () -> BinaryIO
+ pass
def check_path_owner(path):
@@ -59,3 +77,39 @@
def is_socket(path):
# type: (str) -> bool
return stat.S_ISSOCK(os.lstat(path).st_mode)
+
+
+@contextmanager
+def adjacent_tmp_file(path):
+ # type: (str) -> Iterator[NamedTemporaryFileResult]
+ """Given a path to a file, open a temp file next to it securely and ensure
+ it is written to disk after the context reaches its end.
+ """
+ with NamedTemporaryFile(
+ delete=False,
+ dir=os.path.dirname(path),
+ prefix=os.path.basename(path),
+ suffix='.tmp',
+ ) as f:
+ result = cast('NamedTemporaryFileResult', f)
+ try:
+ yield result
+ finally:
+ result.file.flush()
+ os.fsync(result.file.fileno())
+
+
+_replace_retry = retry(stop_max_delay=1000, wait_fixed=250)
+
+if PY2:
+ @_replace_retry
+ def replace(src, dest):
+ # type: (str, str) -> None
+ try:
+ os.rename(src, dest)
+ except OSError:
+ os.remove(dest)
+ os.rename(src, dest)
+
+else:
+ replace = _replace_retry(os.replace)
diff --git a/src/pip/_internal/utils/outdated.py b/src/pip/_internal/utils/outdated.py
--- a/src/pip/_internal/utils/outdated.py
+++ b/src/pip/_internal/utils/outdated.py
@@ -7,7 +7,7 @@
import os.path
import sys
-from pip._vendor import lockfile, pkg_resources
+from pip._vendor import pkg_resources
from pip._vendor.packaging import version as packaging_version
from pip._vendor.six import ensure_binary
@@ -15,7 +15,11 @@
from pip._internal.index import PackageFinder
from pip._internal.models.selection_prefs import SelectionPreferences
from pip._internal.utils.compat import WINDOWS
-from pip._internal.utils.filesystem import check_path_owner
+from pip._internal.utils.filesystem import (
+ adjacent_tmp_file,
+ check_path_owner,
+ replace,
+)
from pip._internal.utils.misc import ensure_dir, get_installed_version
from pip._internal.utils.packaging import get_installer
from pip._internal.utils.typing import MYPY_CHECK_RUNNING
@@ -86,12 +90,16 @@
text = json.dumps(state, sort_keys=True, separators=(",", ":"))
- # Attempt to write out our version check file
- with lockfile.LockFile(self.statefile_path):
+ with adjacent_tmp_file(self.statefile_path) as f:
+ f.write(ensure_binary(text))
+
+ try:
# Since we have a prefix-specific state file, we can just
# overwrite whatever is there, no need to check.
- with open(self.statefile_path, "w") as statefile:
- statefile.write(text)
+ replace(f.name, self.statefile_path)
+ except OSError:
+ # Best effort.
+ pass
def was_installed_by_pip(pkg):
|
{"golden_diff": "diff --git a/src/pip/_internal/utils/filesystem.py b/src/pip/_internal/utils/filesystem.py\n--- a/src/pip/_internal/utils/filesystem.py\n+++ b/src/pip/_internal/utils/filesystem.py\n@@ -2,8 +2,26 @@\n import os.path\n import shutil\n import stat\n+from contextlib import contextmanager\n+from tempfile import NamedTemporaryFile\n+\n+# NOTE: retrying is not annotated in typeshed as on 2017-07-17, which is\n+# why we ignore the type on this import.\n+from pip._vendor.retrying import retry # type: ignore\n+from pip._vendor.six import PY2\n \n from pip._internal.utils.compat import get_path_uid\n+from pip._internal.utils.misc import cast\n+from pip._internal.utils.typing import MYPY_CHECK_RUNNING\n+\n+if MYPY_CHECK_RUNNING:\n+ from typing import BinaryIO, Iterator\n+\n+ class NamedTemporaryFileResult(BinaryIO):\n+ @property\n+ def file(self):\n+ # type: () -> BinaryIO\n+ pass\n \n \n def check_path_owner(path):\n@@ -59,3 +77,39 @@\n def is_socket(path):\n # type: (str) -> bool\n return stat.S_ISSOCK(os.lstat(path).st_mode)\n+\n+\n+@contextmanager\n+def adjacent_tmp_file(path):\n+ # type: (str) -> Iterator[NamedTemporaryFileResult]\n+ \"\"\"Given a path to a file, open a temp file next to it securely and ensure\n+ it is written to disk after the context reaches its end.\n+ \"\"\"\n+ with NamedTemporaryFile(\n+ delete=False,\n+ dir=os.path.dirname(path),\n+ prefix=os.path.basename(path),\n+ suffix='.tmp',\n+ ) as f:\n+ result = cast('NamedTemporaryFileResult', f)\n+ try:\n+ yield result\n+ finally:\n+ result.file.flush()\n+ os.fsync(result.file.fileno())\n+\n+\n+_replace_retry = retry(stop_max_delay=1000, wait_fixed=250)\n+\n+if PY2:\n+ @_replace_retry\n+ def replace(src, dest):\n+ # type: (str, str) -> None\n+ try:\n+ os.rename(src, dest)\n+ except OSError:\n+ os.remove(dest)\n+ os.rename(src, dest)\n+\n+else:\n+ replace = _replace_retry(os.replace)\ndiff --git a/src/pip/_internal/utils/outdated.py b/src/pip/_internal/utils/outdated.py\n--- a/src/pip/_internal/utils/outdated.py\n+++ b/src/pip/_internal/utils/outdated.py\n@@ -7,7 +7,7 @@\n import os.path\n import sys\n \n-from pip._vendor import lockfile, pkg_resources\n+from pip._vendor import pkg_resources\n from pip._vendor.packaging import version as packaging_version\n from pip._vendor.six import ensure_binary\n \n@@ -15,7 +15,11 @@\n from pip._internal.index import PackageFinder\n from pip._internal.models.selection_prefs import SelectionPreferences\n from pip._internal.utils.compat import WINDOWS\n-from pip._internal.utils.filesystem import check_path_owner\n+from pip._internal.utils.filesystem import (\n+ adjacent_tmp_file,\n+ check_path_owner,\n+ replace,\n+)\n from pip._internal.utils.misc import ensure_dir, get_installed_version\n from pip._internal.utils.packaging import get_installer\n from pip._internal.utils.typing import MYPY_CHECK_RUNNING\n@@ -86,12 +90,16 @@\n \n text = json.dumps(state, sort_keys=True, separators=(\",\", \":\"))\n \n- # Attempt to write out our version check file\n- with lockfile.LockFile(self.statefile_path):\n+ with adjacent_tmp_file(self.statefile_path) as f:\n+ f.write(ensure_binary(text))\n+\n+ try:\n # Since we have a prefix-specific state file, we can just\n # overwrite whatever is there, no need to check.\n- with open(self.statefile_path, \"w\") as statefile:\n- statefile.write(text)\n+ replace(f.name, self.statefile_path)\n+ except OSError:\n+ # Best effort.\n+ pass\n \n \n def was_installed_by_pip(pkg):\n", "issue": "Don't use file locking to protect selfcheck state file\n**What's the problem this feature will solve?**\r\n\r\nThere are several issues around file locking that have been filed over the years, specifically related to:\r\n\r\n1. Underlying OS/filesystem does not support hardlinks as used by the file lock (#2993, #5322, #6761)\r\n2. Lingering lock files and/or lock files in an inconsistent state can cause pip to hang when attempting to acquire the lock (some of #3532, #5034)\r\n3. lockfile uses hostname when creating its unique name, which can result in invalid paths when hostname includes a `/` (#6938)\r\n\r\n**Describe the solution you'd like**\r\n\r\n1. Write a selfcheck state file per-prefix, to remove the need to read and then write the file within a lock\r\n2. Write the file atomically (write to a separate tmp file and then move into place) to avoid partial writes if the process is killed\r\n\r\nThis will satisfy the linked issues and help us progress on #4766 to remove lockfile entirely.\r\n\r\n**Alternative Solutions**\r\n\r\n1. Switch to `MkdirLockFile` as currently used in the HTTP cache - the downside of this approach is that it is not backwards-compatible, so we would need to use a separate file to track the information for modern pip versions. If we would need to use a separate file anyway, we might as well go one step further to progress #4766.\r\n\r\n**Additional context**\r\n\r\n* PR #6855 - writes per-prefix selfcheck state files\r\n* PR #6879 - removes file locking\n", "before_files": [{"content": "from __future__ import absolute_import\n\nimport datetime\nimport hashlib\nimport json\nimport logging\nimport os.path\nimport sys\n\nfrom pip._vendor import lockfile, pkg_resources\nfrom pip._vendor.packaging import version as packaging_version\nfrom pip._vendor.six import ensure_binary\n\nfrom pip._internal.cli.cmdoptions import make_search_scope\nfrom pip._internal.index import PackageFinder\nfrom pip._internal.models.selection_prefs import SelectionPreferences\nfrom pip._internal.utils.compat import WINDOWS\nfrom pip._internal.utils.filesystem import check_path_owner\nfrom pip._internal.utils.misc import ensure_dir, get_installed_version\nfrom pip._internal.utils.packaging import get_installer\nfrom pip._internal.utils.typing import MYPY_CHECK_RUNNING\n\nif MYPY_CHECK_RUNNING:\n import optparse\n from typing import Any, Dict, Text, Union\n from pip._internal.download import PipSession\n\n\nSELFCHECK_DATE_FMT = \"%Y-%m-%dT%H:%M:%SZ\"\n\n\nlogger = logging.getLogger(__name__)\n\n\ndef _get_statefile_name(key):\n # type: (Union[str, Text]) -> str\n key_bytes = ensure_binary(key)\n name = hashlib.sha224(key_bytes).hexdigest()\n return name\n\n\nclass SelfCheckState(object):\n def __init__(self, cache_dir):\n # type: (str) -> None\n self.state = {} # type: Dict[str, Any]\n self.statefile_path = None\n\n # Try to load the existing state\n if cache_dir:\n self.statefile_path = os.path.join(\n cache_dir, \"selfcheck\", _get_statefile_name(self.key)\n )\n try:\n with open(self.statefile_path) as statefile:\n self.state = json.load(statefile)\n except (IOError, ValueError, KeyError):\n # Explicitly suppressing exceptions, since we don't want to\n # error out if the cache file is invalid.\n pass\n\n @property\n def key(self):\n return sys.prefix\n\n def save(self, pypi_version, current_time):\n # type: (str, datetime.datetime) -> None\n # If we do not have a path to cache in, don't bother saving.\n if not self.statefile_path:\n return\n\n # Check to make sure that we own the directory\n if not check_path_owner(os.path.dirname(self.statefile_path)):\n return\n\n # Now that we've ensured the directory is owned by this user, we'll go\n # ahead and make sure that all our directories are created.\n ensure_dir(os.path.dirname(self.statefile_path))\n\n state = {\n # Include the key so it's easy to tell which pip wrote the\n # file.\n \"key\": self.key,\n \"last_check\": current_time.strftime(SELFCHECK_DATE_FMT),\n \"pypi_version\": pypi_version,\n }\n\n text = json.dumps(state, sort_keys=True, separators=(\",\", \":\"))\n\n # Attempt to write out our version check file\n with lockfile.LockFile(self.statefile_path):\n # Since we have a prefix-specific state file, we can just\n # overwrite whatever is there, no need to check.\n with open(self.statefile_path, \"w\") as statefile:\n statefile.write(text)\n\n\ndef was_installed_by_pip(pkg):\n # type: (str) -> bool\n \"\"\"Checks whether pkg was installed by pip\n\n This is used not to display the upgrade message when pip is in fact\n installed by system package manager, such as dnf on Fedora.\n \"\"\"\n try:\n dist = pkg_resources.get_distribution(pkg)\n return \"pip\" == get_installer(dist)\n except pkg_resources.DistributionNotFound:\n return False\n\n\ndef pip_version_check(session, options):\n # type: (PipSession, optparse.Values) -> None\n \"\"\"Check for an update for pip.\n\n Limit the frequency of checks to once per week. State is stored either in\n the active virtualenv or in the user's USER_CACHE_DIR keyed off the prefix\n of the pip script path.\n \"\"\"\n installed_version = get_installed_version(\"pip\")\n if not installed_version:\n return\n\n pip_version = packaging_version.parse(installed_version)\n pypi_version = None\n\n try:\n state = SelfCheckState(cache_dir=options.cache_dir)\n\n current_time = datetime.datetime.utcnow()\n # Determine if we need to refresh the state\n if \"last_check\" in state.state and \"pypi_version\" in state.state:\n last_check = datetime.datetime.strptime(\n state.state[\"last_check\"],\n SELFCHECK_DATE_FMT\n )\n if (current_time - last_check).total_seconds() < 7 * 24 * 60 * 60:\n pypi_version = state.state[\"pypi_version\"]\n\n # Refresh the version if we need to or just see if we need to warn\n if pypi_version is None:\n # Lets use PackageFinder to see what the latest pip version is\n search_scope = make_search_scope(options, suppress_no_index=True)\n\n # Pass allow_yanked=False so we don't suggest upgrading to a\n # yanked version.\n selection_prefs = SelectionPreferences(\n allow_yanked=False,\n allow_all_prereleases=False, # Explicitly set to False\n )\n\n finder = PackageFinder.create(\n search_scope=search_scope,\n selection_prefs=selection_prefs,\n session=session,\n )\n best_candidate = finder.find_best_candidate(\"pip\").best_candidate\n if best_candidate is None:\n return\n pypi_version = str(best_candidate.version)\n\n # save that we've performed a check\n state.save(pypi_version, current_time)\n\n remote_version = packaging_version.parse(pypi_version)\n\n local_version_is_older = (\n pip_version < remote_version and\n pip_version.base_version != remote_version.base_version and\n was_installed_by_pip('pip')\n )\n\n # Determine if our pypi_version is older\n if not local_version_is_older:\n return\n\n # Advise \"python -m pip\" on Windows to avoid issues\n # with overwriting pip.exe.\n if WINDOWS:\n pip_cmd = \"python -m pip\"\n else:\n pip_cmd = \"pip\"\n logger.warning(\n \"You are using pip version %s, however version %s is \"\n \"available.\\nYou should consider upgrading via the \"\n \"'%s install --upgrade pip' command.\",\n pip_version, pypi_version, pip_cmd\n )\n except Exception:\n logger.debug(\n \"There was an error checking the latest version of pip\",\n exc_info=True,\n )\n", "path": "src/pip/_internal/utils/outdated.py"}, {"content": "import os\nimport os.path\nimport shutil\nimport stat\n\nfrom pip._internal.utils.compat import get_path_uid\n\n\ndef check_path_owner(path):\n # type: (str) -> bool\n # If we don't have a way to check the effective uid of this process, then\n # we'll just assume that we own the directory.\n if not hasattr(os, \"geteuid\"):\n return True\n\n previous = None\n while path != previous:\n if os.path.lexists(path):\n # Check if path is writable by current user.\n if os.geteuid() == 0:\n # Special handling for root user in order to handle properly\n # cases where users use sudo without -H flag.\n try:\n path_uid = get_path_uid(path)\n except OSError:\n return False\n return path_uid == 0\n else:\n return os.access(path, os.W_OK)\n else:\n previous, path = path, os.path.dirname(path)\n return False # assume we don't own the path\n\n\ndef copy2_fixed(src, dest):\n # type: (str, str) -> None\n \"\"\"Wrap shutil.copy2() but map errors copying socket files to\n SpecialFileError as expected.\n\n See also https://bugs.python.org/issue37700.\n \"\"\"\n try:\n shutil.copy2(src, dest)\n except (OSError, IOError):\n for f in [src, dest]:\n try:\n is_socket_file = is_socket(f)\n except OSError:\n # An error has already occurred. Another error here is not\n # a problem and we can ignore it.\n pass\n else:\n if is_socket_file:\n raise shutil.SpecialFileError(\"`%s` is a socket\" % f)\n\n raise\n\n\ndef is_socket(path):\n # type: (str) -> bool\n return stat.S_ISSOCK(os.lstat(path).st_mode)\n", "path": "src/pip/_internal/utils/filesystem.py"}], "after_files": [{"content": "from __future__ import absolute_import\n\nimport datetime\nimport hashlib\nimport json\nimport logging\nimport os.path\nimport sys\n\nfrom pip._vendor import pkg_resources\nfrom pip._vendor.packaging import version as packaging_version\nfrom pip._vendor.six import ensure_binary\n\nfrom pip._internal.cli.cmdoptions import make_search_scope\nfrom pip._internal.index import PackageFinder\nfrom pip._internal.models.selection_prefs import SelectionPreferences\nfrom pip._internal.utils.compat import WINDOWS\nfrom pip._internal.utils.filesystem import (\n adjacent_tmp_file,\n check_path_owner,\n replace,\n)\nfrom pip._internal.utils.misc import ensure_dir, get_installed_version\nfrom pip._internal.utils.packaging import get_installer\nfrom pip._internal.utils.typing import MYPY_CHECK_RUNNING\n\nif MYPY_CHECK_RUNNING:\n import optparse\n from typing import Any, Dict, Text, Union\n from pip._internal.download import PipSession\n\n\nSELFCHECK_DATE_FMT = \"%Y-%m-%dT%H:%M:%SZ\"\n\n\nlogger = logging.getLogger(__name__)\n\n\ndef _get_statefile_name(key):\n # type: (Union[str, Text]) -> str\n key_bytes = ensure_binary(key)\n name = hashlib.sha224(key_bytes).hexdigest()\n return name\n\n\nclass SelfCheckState(object):\n def __init__(self, cache_dir):\n # type: (str) -> None\n self.state = {} # type: Dict[str, Any]\n self.statefile_path = None\n\n # Try to load the existing state\n if cache_dir:\n self.statefile_path = os.path.join(\n cache_dir, \"selfcheck\", _get_statefile_name(self.key)\n )\n try:\n with open(self.statefile_path) as statefile:\n self.state = json.load(statefile)\n except (IOError, ValueError, KeyError):\n # Explicitly suppressing exceptions, since we don't want to\n # error out if the cache file is invalid.\n pass\n\n @property\n def key(self):\n return sys.prefix\n\n def save(self, pypi_version, current_time):\n # type: (str, datetime.datetime) -> None\n # If we do not have a path to cache in, don't bother saving.\n if not self.statefile_path:\n return\n\n # Check to make sure that we own the directory\n if not check_path_owner(os.path.dirname(self.statefile_path)):\n return\n\n # Now that we've ensured the directory is owned by this user, we'll go\n # ahead and make sure that all our directories are created.\n ensure_dir(os.path.dirname(self.statefile_path))\n\n state = {\n # Include the key so it's easy to tell which pip wrote the\n # file.\n \"key\": self.key,\n \"last_check\": current_time.strftime(SELFCHECK_DATE_FMT),\n \"pypi_version\": pypi_version,\n }\n\n text = json.dumps(state, sort_keys=True, separators=(\",\", \":\"))\n\n with adjacent_tmp_file(self.statefile_path) as f:\n f.write(ensure_binary(text))\n\n try:\n # Since we have a prefix-specific state file, we can just\n # overwrite whatever is there, no need to check.\n replace(f.name, self.statefile_path)\n except OSError:\n # Best effort.\n pass\n\n\ndef was_installed_by_pip(pkg):\n # type: (str) -> bool\n \"\"\"Checks whether pkg was installed by pip\n\n This is used not to display the upgrade message when pip is in fact\n installed by system package manager, such as dnf on Fedora.\n \"\"\"\n try:\n dist = pkg_resources.get_distribution(pkg)\n return \"pip\" == get_installer(dist)\n except pkg_resources.DistributionNotFound:\n return False\n\n\ndef pip_version_check(session, options):\n # type: (PipSession, optparse.Values) -> None\n \"\"\"Check for an update for pip.\n\n Limit the frequency of checks to once per week. State is stored either in\n the active virtualenv or in the user's USER_CACHE_DIR keyed off the prefix\n of the pip script path.\n \"\"\"\n installed_version = get_installed_version(\"pip\")\n if not installed_version:\n return\n\n pip_version = packaging_version.parse(installed_version)\n pypi_version = None\n\n try:\n state = SelfCheckState(cache_dir=options.cache_dir)\n\n current_time = datetime.datetime.utcnow()\n # Determine if we need to refresh the state\n if \"last_check\" in state.state and \"pypi_version\" in state.state:\n last_check = datetime.datetime.strptime(\n state.state[\"last_check\"],\n SELFCHECK_DATE_FMT\n )\n if (current_time - last_check).total_seconds() < 7 * 24 * 60 * 60:\n pypi_version = state.state[\"pypi_version\"]\n\n # Refresh the version if we need to or just see if we need to warn\n if pypi_version is None:\n # Lets use PackageFinder to see what the latest pip version is\n search_scope = make_search_scope(options, suppress_no_index=True)\n\n # Pass allow_yanked=False so we don't suggest upgrading to a\n # yanked version.\n selection_prefs = SelectionPreferences(\n allow_yanked=False,\n allow_all_prereleases=False, # Explicitly set to False\n )\n\n finder = PackageFinder.create(\n search_scope=search_scope,\n selection_prefs=selection_prefs,\n session=session,\n )\n best_candidate = finder.find_best_candidate(\"pip\").best_candidate\n if best_candidate is None:\n return\n pypi_version = str(best_candidate.version)\n\n # save that we've performed a check\n state.save(pypi_version, current_time)\n\n remote_version = packaging_version.parse(pypi_version)\n\n local_version_is_older = (\n pip_version < remote_version and\n pip_version.base_version != remote_version.base_version and\n was_installed_by_pip('pip')\n )\n\n # Determine if our pypi_version is older\n if not local_version_is_older:\n return\n\n # Advise \"python -m pip\" on Windows to avoid issues\n # with overwriting pip.exe.\n if WINDOWS:\n pip_cmd = \"python -m pip\"\n else:\n pip_cmd = \"pip\"\n logger.warning(\n \"You are using pip version %s, however version %s is \"\n \"available.\\nYou should consider upgrading via the \"\n \"'%s install --upgrade pip' command.\",\n pip_version, pypi_version, pip_cmd\n )\n except Exception:\n logger.debug(\n \"There was an error checking the latest version of pip\",\n exc_info=True,\n )\n", "path": "src/pip/_internal/utils/outdated.py"}, {"content": "import os\nimport os.path\nimport shutil\nimport stat\nfrom contextlib import contextmanager\nfrom tempfile import NamedTemporaryFile\n\n# NOTE: retrying is not annotated in typeshed as on 2017-07-17, which is\n# why we ignore the type on this import.\nfrom pip._vendor.retrying import retry # type: ignore\nfrom pip._vendor.six import PY2\n\nfrom pip._internal.utils.compat import get_path_uid\nfrom pip._internal.utils.misc import cast\nfrom pip._internal.utils.typing import MYPY_CHECK_RUNNING\n\nif MYPY_CHECK_RUNNING:\n from typing import BinaryIO, Iterator\n\n class NamedTemporaryFileResult(BinaryIO):\n @property\n def file(self):\n # type: () -> BinaryIO\n pass\n\n\ndef check_path_owner(path):\n # type: (str) -> bool\n # If we don't have a way to check the effective uid of this process, then\n # we'll just assume that we own the directory.\n if not hasattr(os, \"geteuid\"):\n return True\n\n previous = None\n while path != previous:\n if os.path.lexists(path):\n # Check if path is writable by current user.\n if os.geteuid() == 0:\n # Special handling for root user in order to handle properly\n # cases where users use sudo without -H flag.\n try:\n path_uid = get_path_uid(path)\n except OSError:\n return False\n return path_uid == 0\n else:\n return os.access(path, os.W_OK)\n else:\n previous, path = path, os.path.dirname(path)\n return False # assume we don't own the path\n\n\ndef copy2_fixed(src, dest):\n # type: (str, str) -> None\n \"\"\"Wrap shutil.copy2() but map errors copying socket files to\n SpecialFileError as expected.\n\n See also https://bugs.python.org/issue37700.\n \"\"\"\n try:\n shutil.copy2(src, dest)\n except (OSError, IOError):\n for f in [src, dest]:\n try:\n is_socket_file = is_socket(f)\n except OSError:\n # An error has already occurred. Another error here is not\n # a problem and we can ignore it.\n pass\n else:\n if is_socket_file:\n raise shutil.SpecialFileError(\"`%s` is a socket\" % f)\n\n raise\n\n\ndef is_socket(path):\n # type: (str) -> bool\n return stat.S_ISSOCK(os.lstat(path).st_mode)\n\n\n@contextmanager\ndef adjacent_tmp_file(path):\n # type: (str) -> Iterator[NamedTemporaryFileResult]\n \"\"\"Given a path to a file, open a temp file next to it securely and ensure\n it is written to disk after the context reaches its end.\n \"\"\"\n with NamedTemporaryFile(\n delete=False,\n dir=os.path.dirname(path),\n prefix=os.path.basename(path),\n suffix='.tmp',\n ) as f:\n result = cast('NamedTemporaryFileResult', f)\n try:\n yield result\n finally:\n result.file.flush()\n os.fsync(result.file.fileno())\n\n\n_replace_retry = retry(stop_max_delay=1000, wait_fixed=250)\n\nif PY2:\n @_replace_retry\n def replace(src, dest):\n # type: (str, str) -> None\n try:\n os.rename(src, dest)\n except OSError:\n os.remove(dest)\n os.rename(src, dest)\n\nelse:\n replace = _replace_retry(os.replace)\n", "path": "src/pip/_internal/utils/filesystem.py"}]}
| 3,090 | 940 |
gh_patches_debug_2701
|
rasdani/github-patches
|
git_diff
|
sunpy__sunpy-3835
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Plot titles and x-labels overlapping in example
The plot titles and labels overlap in the 3rd image of https://docs.sunpy.org/en/latest/generated/gallery/acquiring_data/2011_06_07_sampledata_overview.html#sphx-glr-generated-gallery-acquiring-data-2011-06-07-sampledata-overview-py (see below). I'm guessing the tight-layout just needs tweaking.

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/acquiring_data/2011_06_07_sampledata_overview.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 """
3 ========================
4 Sample data set overview
5 ========================
6
7 An overview of the coordinated sample data set.
8 """
9 import matplotlib.pyplot as plt
10 import astropy.units as u
11
12 import sunpy.map
13 import sunpy.timeseries
14 import sunpy.data.sample as sample_data
15
16 ###############################################################################
17 # On 2011 June 7, various solar instruments observed a spectacular solar
18 # eruption from NOAA AR 11226. The event included an M2.5 flare, a
19 # filament eruption, a coronal mass ejection, and a global coronal EUV wave (IAU standard:
20 # SOL2011-06-07T06:24:00L045C112). This event was spectacular because it
21 # features the ejection of a large amount of prominence material, much of which
22 # failed to escape and fell back to the solar surface.
23 # This event received some press coverage (e.g. `National Geographics
24 # <https://news.nationalgeographic.com/news/2011/06/110608-solar-flare-sun-science-space/>`_,
25 # `Discover Magazine <http://blogs.discovermagazine.com/badastronomy/2011/06/07/the-sun-lets-loose-a-huge-explosion/>`_)
26 # and the literature contains a number of a papers about it (e.g. `Li et al.
27 # <https://iopscience.iop.org/article/10.1088/0004-637X/746/1/13/meta>`_,
28 # `Inglis et al. <https://iopscience.iop.org/article/10.1088/0004-637X/777/1/30/meta>`_)
29
30 ###############################################################################
31 # The following image of the flare is now fairly iconic.
32 aia_cutout03_map = sunpy.map.Map(sample_data.AIA_193_CUTOUT03_IMAGE)
33 fig = plt.figure()
34 ax = fig.add_subplot(111, projection=aia_cutout03_map)
35 aia_cutout03_map.plot()
36 plt.show()
37
38 ###############################################################################
39 # Let's take a look at the GOES XRS data.
40 goes = sunpy.timeseries.TimeSeries(sample_data.GOES_XRS_TIMESERIES)
41 fig = plt.figure()
42 goes.plot()
43 plt.show()
44
45 ###############################################################################
46 # Next let's investigate the AIA full disk images that are available. Please
47 # note that these images are not at the full AIA resolution.
48
49 aia_131_map = sunpy.map.Map(sample_data.AIA_131_IMAGE)
50 aia_171_map = sunpy.map.Map(sample_data.AIA_171_IMAGE)
51 aia_211_map = sunpy.map.Map(sample_data.AIA_211_IMAGE)
52 aia_335_map = sunpy.map.Map(sample_data.AIA_335_IMAGE)
53 aia_094_map = sunpy.map.Map(sample_data.AIA_094_IMAGE)
54 aia_1600_map = sunpy.map.Map(sample_data.AIA_1600_IMAGE)
55
56 fig = plt.figure(figsize=(6, 28))
57 ax = fig.add_subplot(611, projection=aia_131_map)
58 aia_131_map.plot(clip_interval=(0.5, 99.9)*u.percent)
59 aia_131_map.draw_grid()
60
61 ax = fig.add_subplot(612, projection=aia_171_map)
62 aia_171_map.plot(clip_interval=(0.5, 99.9)*u.percent)
63 aia_171_map.draw_grid()
64
65 ax = fig.add_subplot(613, projection=aia_211_map)
66 aia_211_map.plot(clip_interval=(0.5, 99.9)*u.percent)
67 aia_211_map.draw_grid()
68
69 ax = fig.add_subplot(614, projection=aia_335_map)
70 aia_335_map.plot(clip_interval=(0.5, 99.9)*u.percent)
71 aia_335_map.draw_grid()
72
73 ax = fig.add_subplot(615, projection=aia_094_map)
74 aia_094_map.plot(clip_interval=(0.5, 99.9)*u.percent)
75 aia_094_map.draw_grid()
76
77 ax = fig.add_subplot(616, projection=aia_1600_map)
78 aia_1600_map.plot(clip_interval=(0.5, 99.9)*u.percent)
79 aia_1600_map.draw_grid()
80
81 fig.tight_layout(pad=6.50)
82 plt.show()
83
84 ###############################################################################
85 # We also provide a series of AIA cutouts so that you can get a sense of the
86 # dynamics of the in-falling material.
87 aia_cutout01_map = sunpy.map.Map(sample_data.AIA_193_CUTOUT01_IMAGE)
88 aia_cutout02_map = sunpy.map.Map(sample_data.AIA_193_CUTOUT02_IMAGE)
89 aia_cutout03_map = sunpy.map.Map(sample_data.AIA_193_CUTOUT03_IMAGE)
90 aia_cutout04_map = sunpy.map.Map(sample_data.AIA_193_CUTOUT04_IMAGE)
91 aia_cutout05_map = sunpy.map.Map(sample_data.AIA_193_CUTOUT05_IMAGE)
92
93 fig = plt.figure(figsize=(6, 28))
94 ax = fig.add_subplot(511, projection=aia_cutout01_map)
95 aia_cutout01_map.plot()
96
97 ax = fig.add_subplot(512, projection=aia_cutout02_map)
98 aia_cutout02_map.plot()
99
100 ax = fig.add_subplot(513, projection=aia_cutout03_map)
101 aia_cutout03_map.plot()
102
103 ax = fig.add_subplot(514, projection=aia_cutout04_map)
104 aia_cutout04_map.plot()
105
106 ax = fig.add_subplot(515, projection=aia_cutout05_map)
107 aia_cutout05_map.plot()
108
109 fig.tight_layout(pad=5.50)
110 plt.show()
111
112 ###############################################################################
113 # There are a number of other data sources available as well, such as SWAP.
114 swap_map = sunpy.map.Map(sample_data.SWAP_LEVEL1_IMAGE)
115 fig = plt.figure()
116 swap_map.plot()
117 plt.show()
118
119 ###############################################################################
120 # And also RHESSI.
121 rhessi_map = sunpy.map.Map(sample_data.RHESSI_IMAGE)
122 fig = plt.figure()
123 rhessi_map.plot()
124 plt.show()
125
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/acquiring_data/2011_06_07_sampledata_overview.py b/examples/acquiring_data/2011_06_07_sampledata_overview.py
--- a/examples/acquiring_data/2011_06_07_sampledata_overview.py
+++ b/examples/acquiring_data/2011_06_07_sampledata_overview.py
@@ -78,7 +78,7 @@
aia_1600_map.plot(clip_interval=(0.5, 99.9)*u.percent)
aia_1600_map.draw_grid()
-fig.tight_layout(pad=6.50)
+fig.tight_layout(pad=8.50)
plt.show()
###############################################################################
|
{"golden_diff": "diff --git a/examples/acquiring_data/2011_06_07_sampledata_overview.py b/examples/acquiring_data/2011_06_07_sampledata_overview.py\n--- a/examples/acquiring_data/2011_06_07_sampledata_overview.py\n+++ b/examples/acquiring_data/2011_06_07_sampledata_overview.py\n@@ -78,7 +78,7 @@\n aia_1600_map.plot(clip_interval=(0.5, 99.9)*u.percent)\n aia_1600_map.draw_grid()\n \n-fig.tight_layout(pad=6.50)\n+fig.tight_layout(pad=8.50)\n plt.show()\n \n ###############################################################################\n", "issue": "Plot titles and x-labels overlapping in example\nThe plot titles and labels overlap in the 3rd image of https://docs.sunpy.org/en/latest/generated/gallery/acquiring_data/2011_06_07_sampledata_overview.html#sphx-glr-generated-gallery-acquiring-data-2011-06-07-sampledata-overview-py (see below). I'm guessing the tight-layout just needs tweaking.\r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\n========================\nSample data set overview\n========================\n\nAn overview of the coordinated sample data set.\n\"\"\"\nimport matplotlib.pyplot as plt\nimport astropy.units as u\n\nimport sunpy.map\nimport sunpy.timeseries\nimport sunpy.data.sample as sample_data\n\n###############################################################################\n# On 2011 June 7, various solar instruments observed a spectacular solar\n# eruption from NOAA AR 11226. The event included an M2.5 flare, a\n# filament eruption, a coronal mass ejection, and a global coronal EUV wave (IAU standard:\n# SOL2011-06-07T06:24:00L045C112). This event was spectacular because it\n# features the ejection of a large amount of prominence material, much of which\n# failed to escape and fell back to the solar surface.\n# This event received some press coverage (e.g. `National Geographics\n# <https://news.nationalgeographic.com/news/2011/06/110608-solar-flare-sun-science-space/>`_,\n# `Discover Magazine <http://blogs.discovermagazine.com/badastronomy/2011/06/07/the-sun-lets-loose-a-huge-explosion/>`_)\n# and the literature contains a number of a papers about it (e.g. `Li et al.\n# <https://iopscience.iop.org/article/10.1088/0004-637X/746/1/13/meta>`_,\n# `Inglis et al. <https://iopscience.iop.org/article/10.1088/0004-637X/777/1/30/meta>`_)\n\n###############################################################################\n# The following image of the flare is now fairly iconic.\naia_cutout03_map = sunpy.map.Map(sample_data.AIA_193_CUTOUT03_IMAGE)\nfig = plt.figure()\nax = fig.add_subplot(111, projection=aia_cutout03_map)\naia_cutout03_map.plot()\nplt.show()\n\n###############################################################################\n# Let's take a look at the GOES XRS data.\ngoes = sunpy.timeseries.TimeSeries(sample_data.GOES_XRS_TIMESERIES)\nfig = plt.figure()\ngoes.plot()\nplt.show()\n\n###############################################################################\n# Next let's investigate the AIA full disk images that are available. Please\n# note that these images are not at the full AIA resolution.\n\naia_131_map = sunpy.map.Map(sample_data.AIA_131_IMAGE)\naia_171_map = sunpy.map.Map(sample_data.AIA_171_IMAGE)\naia_211_map = sunpy.map.Map(sample_data.AIA_211_IMAGE)\naia_335_map = sunpy.map.Map(sample_data.AIA_335_IMAGE)\naia_094_map = sunpy.map.Map(sample_data.AIA_094_IMAGE)\naia_1600_map = sunpy.map.Map(sample_data.AIA_1600_IMAGE)\n\nfig = plt.figure(figsize=(6, 28))\nax = fig.add_subplot(611, projection=aia_131_map)\naia_131_map.plot(clip_interval=(0.5, 99.9)*u.percent)\naia_131_map.draw_grid()\n\nax = fig.add_subplot(612, projection=aia_171_map)\naia_171_map.plot(clip_interval=(0.5, 99.9)*u.percent)\naia_171_map.draw_grid()\n\nax = fig.add_subplot(613, projection=aia_211_map)\naia_211_map.plot(clip_interval=(0.5, 99.9)*u.percent)\naia_211_map.draw_grid()\n\nax = fig.add_subplot(614, projection=aia_335_map)\naia_335_map.plot(clip_interval=(0.5, 99.9)*u.percent)\naia_335_map.draw_grid()\n\nax = fig.add_subplot(615, projection=aia_094_map)\naia_094_map.plot(clip_interval=(0.5, 99.9)*u.percent)\naia_094_map.draw_grid()\n\nax = fig.add_subplot(616, projection=aia_1600_map)\naia_1600_map.plot(clip_interval=(0.5, 99.9)*u.percent)\naia_1600_map.draw_grid()\n\nfig.tight_layout(pad=6.50)\nplt.show()\n\n###############################################################################\n# We also provide a series of AIA cutouts so that you can get a sense of the\n# dynamics of the in-falling material.\naia_cutout01_map = sunpy.map.Map(sample_data.AIA_193_CUTOUT01_IMAGE)\naia_cutout02_map = sunpy.map.Map(sample_data.AIA_193_CUTOUT02_IMAGE)\naia_cutout03_map = sunpy.map.Map(sample_data.AIA_193_CUTOUT03_IMAGE)\naia_cutout04_map = sunpy.map.Map(sample_data.AIA_193_CUTOUT04_IMAGE)\naia_cutout05_map = sunpy.map.Map(sample_data.AIA_193_CUTOUT05_IMAGE)\n\nfig = plt.figure(figsize=(6, 28))\nax = fig.add_subplot(511, projection=aia_cutout01_map)\naia_cutout01_map.plot()\n\nax = fig.add_subplot(512, projection=aia_cutout02_map)\naia_cutout02_map.plot()\n\nax = fig.add_subplot(513, projection=aia_cutout03_map)\naia_cutout03_map.plot()\n\nax = fig.add_subplot(514, projection=aia_cutout04_map)\naia_cutout04_map.plot()\n\nax = fig.add_subplot(515, projection=aia_cutout05_map)\naia_cutout05_map.plot()\n\nfig.tight_layout(pad=5.50)\nplt.show()\n\n###############################################################################\n# There are a number of other data sources available as well, such as SWAP.\nswap_map = sunpy.map.Map(sample_data.SWAP_LEVEL1_IMAGE)\nfig = plt.figure()\nswap_map.plot()\nplt.show()\n\n###############################################################################\n# And also RHESSI.\nrhessi_map = sunpy.map.Map(sample_data.RHESSI_IMAGE)\nfig = plt.figure()\nrhessi_map.plot()\nplt.show()\n", "path": "examples/acquiring_data/2011_06_07_sampledata_overview.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\n========================\nSample data set overview\n========================\n\nAn overview of the coordinated sample data set.\n\"\"\"\nimport matplotlib.pyplot as plt\nimport astropy.units as u\n\nimport sunpy.map\nimport sunpy.timeseries\nimport sunpy.data.sample as sample_data\n\n###############################################################################\n# On 2011 June 7, various solar instruments observed a spectacular solar\n# eruption from NOAA AR 11226. The event included an M2.5 flare, a\n# filament eruption, a coronal mass ejection, and a global coronal EUV wave (IAU standard:\n# SOL2011-06-07T06:24:00L045C112). This event was spectacular because it\n# features the ejection of a large amount of prominence material, much of which\n# failed to escape and fell back to the solar surface.\n# This event received some press coverage (e.g. `National Geographics\n# <https://news.nationalgeographic.com/news/2011/06/110608-solar-flare-sun-science-space/>`_,\n# `Discover Magazine <http://blogs.discovermagazine.com/badastronomy/2011/06/07/the-sun-lets-loose-a-huge-explosion/>`_)\n# and the literature contains a number of a papers about it (e.g. `Li et al.\n# <https://iopscience.iop.org/article/10.1088/0004-637X/746/1/13/meta>`_,\n# `Inglis et al. <https://iopscience.iop.org/article/10.1088/0004-637X/777/1/30/meta>`_)\n\n###############################################################################\n# The following image of the flare is now fairly iconic.\naia_cutout03_map = sunpy.map.Map(sample_data.AIA_193_CUTOUT03_IMAGE)\nfig = plt.figure()\nax = fig.add_subplot(111, projection=aia_cutout03_map)\naia_cutout03_map.plot()\nplt.show()\n\n###############################################################################\n# Let's take a look at the GOES XRS data.\ngoes = sunpy.timeseries.TimeSeries(sample_data.GOES_XRS_TIMESERIES)\nfig = plt.figure()\ngoes.plot()\nplt.show()\n\n###############################################################################\n# Next let's investigate the AIA full disk images that are available. Please\n# note that these images are not at the full AIA resolution.\n\naia_131_map = sunpy.map.Map(sample_data.AIA_131_IMAGE)\naia_171_map = sunpy.map.Map(sample_data.AIA_171_IMAGE)\naia_211_map = sunpy.map.Map(sample_data.AIA_211_IMAGE)\naia_335_map = sunpy.map.Map(sample_data.AIA_335_IMAGE)\naia_094_map = sunpy.map.Map(sample_data.AIA_094_IMAGE)\naia_1600_map = sunpy.map.Map(sample_data.AIA_1600_IMAGE)\n\nfig = plt.figure(figsize=(6, 28))\nax = fig.add_subplot(611, projection=aia_131_map)\naia_131_map.plot(clip_interval=(0.5, 99.9)*u.percent)\naia_131_map.draw_grid()\n\nax = fig.add_subplot(612, projection=aia_171_map)\naia_171_map.plot(clip_interval=(0.5, 99.9)*u.percent)\naia_171_map.draw_grid()\n\nax = fig.add_subplot(613, projection=aia_211_map)\naia_211_map.plot(clip_interval=(0.5, 99.9)*u.percent)\naia_211_map.draw_grid()\n\nax = fig.add_subplot(614, projection=aia_335_map)\naia_335_map.plot(clip_interval=(0.5, 99.9)*u.percent)\naia_335_map.draw_grid()\n\nax = fig.add_subplot(615, projection=aia_094_map)\naia_094_map.plot(clip_interval=(0.5, 99.9)*u.percent)\naia_094_map.draw_grid()\n\nax = fig.add_subplot(616, projection=aia_1600_map)\naia_1600_map.plot(clip_interval=(0.5, 99.9)*u.percent)\naia_1600_map.draw_grid()\n\nfig.tight_layout(pad=8.50)\nplt.show()\n\n###############################################################################\n# We also provide a series of AIA cutouts so that you can get a sense of the\n# dynamics of the in-falling material.\naia_cutout01_map = sunpy.map.Map(sample_data.AIA_193_CUTOUT01_IMAGE)\naia_cutout02_map = sunpy.map.Map(sample_data.AIA_193_CUTOUT02_IMAGE)\naia_cutout03_map = sunpy.map.Map(sample_data.AIA_193_CUTOUT03_IMAGE)\naia_cutout04_map = sunpy.map.Map(sample_data.AIA_193_CUTOUT04_IMAGE)\naia_cutout05_map = sunpy.map.Map(sample_data.AIA_193_CUTOUT05_IMAGE)\n\nfig = plt.figure(figsize=(6, 28))\nax = fig.add_subplot(511, projection=aia_cutout01_map)\naia_cutout01_map.plot()\n\nax = fig.add_subplot(512, projection=aia_cutout02_map)\naia_cutout02_map.plot()\n\nax = fig.add_subplot(513, projection=aia_cutout03_map)\naia_cutout03_map.plot()\n\nax = fig.add_subplot(514, projection=aia_cutout04_map)\naia_cutout04_map.plot()\n\nax = fig.add_subplot(515, projection=aia_cutout05_map)\naia_cutout05_map.plot()\n\nfig.tight_layout(pad=5.50)\nplt.show()\n\n###############################################################################\n# There are a number of other data sources available as well, such as SWAP.\nswap_map = sunpy.map.Map(sample_data.SWAP_LEVEL1_IMAGE)\nfig = plt.figure()\nswap_map.plot()\nplt.show()\n\n###############################################################################\n# And also RHESSI.\nrhessi_map = sunpy.map.Map(sample_data.RHESSI_IMAGE)\nfig = plt.figure()\nrhessi_map.plot()\nplt.show()\n", "path": "examples/acquiring_data/2011_06_07_sampledata_overview.py"}]}
| 2,208 | 170 |
gh_patches_debug_26918
|
rasdani/github-patches
|
git_diff
|
Kinto__kinto-1567
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
OpenID state length is too long for the PostgreSQL cache backend
Those two lines are not compatible together:
- https://github.com/Kinto/kinto/blob/c6cc7bba094aed6897d0157dc78b1731ac12c8db/kinto/core/cache/postgresql/schema.sql#L7
- https://github.com/Kinto/kinto/blob/c6cc7bba094aed6897d0157dc78b1731ac12c8db/kinto/plugins/openid/views.py#L97
OpenID state length is too long for the PostgreSQL cache backend
Those two lines are not compatible together:
- https://github.com/Kinto/kinto/blob/c6cc7bba094aed6897d0157dc78b1731ac12c8db/kinto/core/cache/postgresql/schema.sql#L7
- https://github.com/Kinto/kinto/blob/c6cc7bba094aed6897d0157dc78b1731ac12c8db/kinto/plugins/openid/views.py#L97
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kinto/plugins/openid/views.py`
Content:
```
1 import urllib.parse
2
3 import colander
4 import requests
5 from pyramid import httpexceptions
6
7 from cornice.validators import colander_validator
8 from kinto.core import Service
9 from kinto.core.errors import raise_invalid, ERRORS
10 from kinto.core.utils import random_bytes_hex
11 from kinto.core.resource.schema import ErrorResponseSchema
12 from kinto.core.schema import URL
13
14 from .utils import fetch_openid_config
15
16
17 DEFAULT_STATE_TTL_SECONDS = 3600
18
19
20 class RedirectHeadersSchema(colander.MappingSchema):
21 """Redirect response headers."""
22 location = colander.SchemaNode(colander.String(), name='Location')
23
24
25 class RedirectResponseSchema(colander.MappingSchema):
26 """Redirect response schema."""
27 headers = RedirectHeadersSchema()
28
29
30 response_schemas = {
31 '307': RedirectResponseSchema(description='Successful redirection.'),
32 '400': ErrorResponseSchema(description='The request is invalid.'),
33 }
34
35
36 def provider_validator(request, **kwargs):
37 """
38 This validator verifies that the validator in URL (eg. /openid/auth0/login)
39 is a configured OpenIDConnect policy.
40 """
41 provider = request.matchdict['provider']
42 used = request.registry.settings.get('multiauth.policy.%s.use' % provider, '')
43 if not used.endswith('OpenIDConnectPolicy'):
44 request.errors.add('path', 'provider', 'Unknow provider %r' % provider)
45
46
47 class LoginQuerystringSchema(colander.MappingSchema):
48 """
49 Querystring schema for the login endpoint.
50 """
51 callback = URL()
52 scope = colander.SchemaNode(colander.String())
53
54
55 class LoginSchema(colander.MappingSchema):
56 querystring = LoginQuerystringSchema()
57
58
59 login = Service(name='openid_login',
60 path='/openid/{provider}/login',
61 description='Initiate the OAuth2 login')
62
63
64 @login.get(schema=LoginSchema(),
65 validators=(colander_validator, provider_validator),
66 response_schemas=response_schemas)
67 def get_login(request):
68 """Initiates to login dance for the specified scopes and callback URI
69 using appropriate redirections."""
70
71 # Settings.
72 provider = request.matchdict['provider']
73 settings_prefix = 'multiauth.policy.%s.' % provider
74 issuer = request.registry.settings[settings_prefix + 'issuer']
75 client_id = request.registry.settings[settings_prefix + 'client_id']
76 userid_field = request.registry.settings.get(settings_prefix + 'userid_field')
77 state_ttl = int(request.registry.settings.get(settings_prefix + 'state_ttl_seconds',
78 DEFAULT_STATE_TTL_SECONDS))
79
80 # Read OpenID configuration (cached by issuer)
81 oid_config = fetch_openid_config(issuer)
82 auth_endpoint = oid_config['authorization_endpoint']
83
84 scope = request.GET['scope']
85 callback = request.GET['callback']
86
87 # Check that email scope is requested if userid field is configured as email.
88 if userid_field == 'email' and 'email' not in scope:
89 error_details = {
90 'name': 'scope',
91 'description': "Provider %s requires 'email' scope" % provider,
92 }
93 raise_invalid(request, **error_details)
94
95 # Generate a random string as state.
96 # And save it until code is traded.
97 state = random_bytes_hex(256)
98 request.registry.cache.set('openid:state:' + state, callback, ttl=state_ttl)
99
100 # Redirect the client to the Identity Provider that will eventually redirect
101 # to the OpenID token endpoint.
102 token_uri = request.route_url('openid_token', provider=provider) + '?'
103 params = dict(client_id=client_id, response_type='code', scope=scope,
104 redirect_uri=token_uri, state=state)
105 redirect = '{}?{}'.format(auth_endpoint, urllib.parse.urlencode(params))
106 raise httpexceptions.HTTPTemporaryRedirect(redirect)
107
108
109 class TokenQuerystringSchema(colander.MappingSchema):
110 """
111 Querystring schema for the token endpoint.
112 """
113 code = colander.SchemaNode(colander.String())
114 state = colander.SchemaNode(colander.String())
115
116
117 class TokenSchema(colander.MappingSchema):
118 querystring = TokenQuerystringSchema()
119
120
121 token = Service(name='openid_token',
122 path='/openid/{provider}/token',
123 description='')
124
125
126 @token.get(schema=TokenSchema(),
127 validators=(colander_validator, provider_validator))
128 def get_token(request):
129 """Trades the specified code and state against access and ID tokens.
130 The client is redirected to the original ``callback`` URI with the
131 result in querystring."""
132
133 # Settings.
134 provider = request.matchdict['provider']
135 settings_prefix = 'multiauth.policy.%s.' % provider
136 issuer = request.registry.settings[settings_prefix + 'issuer']
137 client_id = request.registry.settings[settings_prefix + 'client_id']
138 client_secret = request.registry.settings[settings_prefix + 'client_secret']
139
140 # Read OpenID configuration (cached by issuer)
141 oid_config = fetch_openid_config(issuer)
142 token_endpoint = oid_config['token_endpoint']
143
144 code = request.GET['code']
145 state = request.GET['state']
146
147 # State can be used only once.
148 callback = request.registry.cache.delete('openid:state:' + state)
149 if callback is None:
150 error_details = {
151 'name': 'state',
152 'description': 'Invalid state',
153 'errno': ERRORS.INVALID_AUTH_TOKEN.value,
154 }
155 raise_invalid(request, **error_details)
156
157 # Trade the code for tokens on the Identity Provider.
158 # Google Identity requires to specify again redirect_uri.
159 redirect_uri = request.route_url('openid_token', provider=provider) + '?'
160 data = {
161 'code': code,
162 'client_id': client_id,
163 'client_secret': client_secret,
164 'redirect_uri': redirect_uri,
165 'grant_type': 'authorization_code',
166 }
167 resp = requests.post(token_endpoint, data=data)
168
169 # The IdP response is forwarded to the client in the querystring/location hash.
170 # (eg. callback=`http://localhost:3000/#tokens=`)
171 redirect = callback + urllib.parse.quote(resp.text)
172 raise httpexceptions.HTTPTemporaryRedirect(redirect)
173
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kinto/plugins/openid/views.py b/kinto/plugins/openid/views.py
--- a/kinto/plugins/openid/views.py
+++ b/kinto/plugins/openid/views.py
@@ -15,6 +15,7 @@
DEFAULT_STATE_TTL_SECONDS = 3600
+DEFAULT_STATE_LENGTH = 32
class RedirectHeadersSchema(colander.MappingSchema):
@@ -76,6 +77,8 @@
userid_field = request.registry.settings.get(settings_prefix + 'userid_field')
state_ttl = int(request.registry.settings.get(settings_prefix + 'state_ttl_seconds',
DEFAULT_STATE_TTL_SECONDS))
+ state_length = int(request.registry.settings.get(settings_prefix + 'state_length',
+ DEFAULT_STATE_LENGTH))
# Read OpenID configuration (cached by issuer)
oid_config = fetch_openid_config(issuer)
@@ -94,7 +97,7 @@
# Generate a random string as state.
# And save it until code is traded.
- state = random_bytes_hex(256)
+ state = random_bytes_hex(state_length)
request.registry.cache.set('openid:state:' + state, callback, ttl=state_ttl)
# Redirect the client to the Identity Provider that will eventually redirect
|
{"golden_diff": "diff --git a/kinto/plugins/openid/views.py b/kinto/plugins/openid/views.py\n--- a/kinto/plugins/openid/views.py\n+++ b/kinto/plugins/openid/views.py\n@@ -15,6 +15,7 @@\n \n \n DEFAULT_STATE_TTL_SECONDS = 3600\n+DEFAULT_STATE_LENGTH = 32\n \n \n class RedirectHeadersSchema(colander.MappingSchema):\n@@ -76,6 +77,8 @@\n userid_field = request.registry.settings.get(settings_prefix + 'userid_field')\n state_ttl = int(request.registry.settings.get(settings_prefix + 'state_ttl_seconds',\n DEFAULT_STATE_TTL_SECONDS))\n+ state_length = int(request.registry.settings.get(settings_prefix + 'state_length',\n+ DEFAULT_STATE_LENGTH))\n \n # Read OpenID configuration (cached by issuer)\n oid_config = fetch_openid_config(issuer)\n@@ -94,7 +97,7 @@\n \n # Generate a random string as state.\n # And save it until code is traded.\n- state = random_bytes_hex(256)\n+ state = random_bytes_hex(state_length)\n request.registry.cache.set('openid:state:' + state, callback, ttl=state_ttl)\n \n # Redirect the client to the Identity Provider that will eventually redirect\n", "issue": "OpenID state length is too long for the PostgreSQL cache backend\nThose two lines are not compatible together:\r\n\r\n- https://github.com/Kinto/kinto/blob/c6cc7bba094aed6897d0157dc78b1731ac12c8db/kinto/core/cache/postgresql/schema.sql#L7\r\n- https://github.com/Kinto/kinto/blob/c6cc7bba094aed6897d0157dc78b1731ac12c8db/kinto/plugins/openid/views.py#L97\nOpenID state length is too long for the PostgreSQL cache backend\nThose two lines are not compatible together:\r\n\r\n- https://github.com/Kinto/kinto/blob/c6cc7bba094aed6897d0157dc78b1731ac12c8db/kinto/core/cache/postgresql/schema.sql#L7\r\n- https://github.com/Kinto/kinto/blob/c6cc7bba094aed6897d0157dc78b1731ac12c8db/kinto/plugins/openid/views.py#L97\n", "before_files": [{"content": "import urllib.parse\n\nimport colander\nimport requests\nfrom pyramid import httpexceptions\n\nfrom cornice.validators import colander_validator\nfrom kinto.core import Service\nfrom kinto.core.errors import raise_invalid, ERRORS\nfrom kinto.core.utils import random_bytes_hex\nfrom kinto.core.resource.schema import ErrorResponseSchema\nfrom kinto.core.schema import URL\n\nfrom .utils import fetch_openid_config\n\n\nDEFAULT_STATE_TTL_SECONDS = 3600\n\n\nclass RedirectHeadersSchema(colander.MappingSchema):\n \"\"\"Redirect response headers.\"\"\"\n location = colander.SchemaNode(colander.String(), name='Location')\n\n\nclass RedirectResponseSchema(colander.MappingSchema):\n \"\"\"Redirect response schema.\"\"\"\n headers = RedirectHeadersSchema()\n\n\nresponse_schemas = {\n '307': RedirectResponseSchema(description='Successful redirection.'),\n '400': ErrorResponseSchema(description='The request is invalid.'),\n}\n\n\ndef provider_validator(request, **kwargs):\n \"\"\"\n This validator verifies that the validator in URL (eg. /openid/auth0/login)\n is a configured OpenIDConnect policy.\n \"\"\"\n provider = request.matchdict['provider']\n used = request.registry.settings.get('multiauth.policy.%s.use' % provider, '')\n if not used.endswith('OpenIDConnectPolicy'):\n request.errors.add('path', 'provider', 'Unknow provider %r' % provider)\n\n\nclass LoginQuerystringSchema(colander.MappingSchema):\n \"\"\"\n Querystring schema for the login endpoint.\n \"\"\"\n callback = URL()\n scope = colander.SchemaNode(colander.String())\n\n\nclass LoginSchema(colander.MappingSchema):\n querystring = LoginQuerystringSchema()\n\n\nlogin = Service(name='openid_login',\n path='/openid/{provider}/login',\n description='Initiate the OAuth2 login')\n\n\[email protected](schema=LoginSchema(),\n validators=(colander_validator, provider_validator),\n response_schemas=response_schemas)\ndef get_login(request):\n \"\"\"Initiates to login dance for the specified scopes and callback URI\n using appropriate redirections.\"\"\"\n\n # Settings.\n provider = request.matchdict['provider']\n settings_prefix = 'multiauth.policy.%s.' % provider\n issuer = request.registry.settings[settings_prefix + 'issuer']\n client_id = request.registry.settings[settings_prefix + 'client_id']\n userid_field = request.registry.settings.get(settings_prefix + 'userid_field')\n state_ttl = int(request.registry.settings.get(settings_prefix + 'state_ttl_seconds',\n DEFAULT_STATE_TTL_SECONDS))\n\n # Read OpenID configuration (cached by issuer)\n oid_config = fetch_openid_config(issuer)\n auth_endpoint = oid_config['authorization_endpoint']\n\n scope = request.GET['scope']\n callback = request.GET['callback']\n\n # Check that email scope is requested if userid field is configured as email.\n if userid_field == 'email' and 'email' not in scope:\n error_details = {\n 'name': 'scope',\n 'description': \"Provider %s requires 'email' scope\" % provider,\n }\n raise_invalid(request, **error_details)\n\n # Generate a random string as state.\n # And save it until code is traded.\n state = random_bytes_hex(256)\n request.registry.cache.set('openid:state:' + state, callback, ttl=state_ttl)\n\n # Redirect the client to the Identity Provider that will eventually redirect\n # to the OpenID token endpoint.\n token_uri = request.route_url('openid_token', provider=provider) + '?'\n params = dict(client_id=client_id, response_type='code', scope=scope,\n redirect_uri=token_uri, state=state)\n redirect = '{}?{}'.format(auth_endpoint, urllib.parse.urlencode(params))\n raise httpexceptions.HTTPTemporaryRedirect(redirect)\n\n\nclass TokenQuerystringSchema(colander.MappingSchema):\n \"\"\"\n Querystring schema for the token endpoint.\n \"\"\"\n code = colander.SchemaNode(colander.String())\n state = colander.SchemaNode(colander.String())\n\n\nclass TokenSchema(colander.MappingSchema):\n querystring = TokenQuerystringSchema()\n\n\ntoken = Service(name='openid_token',\n path='/openid/{provider}/token',\n description='')\n\n\[email protected](schema=TokenSchema(),\n validators=(colander_validator, provider_validator))\ndef get_token(request):\n \"\"\"Trades the specified code and state against access and ID tokens.\n The client is redirected to the original ``callback`` URI with the\n result in querystring.\"\"\"\n\n # Settings.\n provider = request.matchdict['provider']\n settings_prefix = 'multiauth.policy.%s.' % provider\n issuer = request.registry.settings[settings_prefix + 'issuer']\n client_id = request.registry.settings[settings_prefix + 'client_id']\n client_secret = request.registry.settings[settings_prefix + 'client_secret']\n\n # Read OpenID configuration (cached by issuer)\n oid_config = fetch_openid_config(issuer)\n token_endpoint = oid_config['token_endpoint']\n\n code = request.GET['code']\n state = request.GET['state']\n\n # State can be used only once.\n callback = request.registry.cache.delete('openid:state:' + state)\n if callback is None:\n error_details = {\n 'name': 'state',\n 'description': 'Invalid state',\n 'errno': ERRORS.INVALID_AUTH_TOKEN.value,\n }\n raise_invalid(request, **error_details)\n\n # Trade the code for tokens on the Identity Provider.\n # Google Identity requires to specify again redirect_uri.\n redirect_uri = request.route_url('openid_token', provider=provider) + '?'\n data = {\n 'code': code,\n 'client_id': client_id,\n 'client_secret': client_secret,\n 'redirect_uri': redirect_uri,\n 'grant_type': 'authorization_code',\n }\n resp = requests.post(token_endpoint, data=data)\n\n # The IdP response is forwarded to the client in the querystring/location hash.\n # (eg. callback=`http://localhost:3000/#tokens=`)\n redirect = callback + urllib.parse.quote(resp.text)\n raise httpexceptions.HTTPTemporaryRedirect(redirect)\n", "path": "kinto/plugins/openid/views.py"}], "after_files": [{"content": "import urllib.parse\n\nimport colander\nimport requests\nfrom pyramid import httpexceptions\n\nfrom cornice.validators import colander_validator\nfrom kinto.core import Service\nfrom kinto.core.errors import raise_invalid, ERRORS\nfrom kinto.core.utils import random_bytes_hex\nfrom kinto.core.resource.schema import ErrorResponseSchema\nfrom kinto.core.schema import URL\n\nfrom .utils import fetch_openid_config\n\n\nDEFAULT_STATE_TTL_SECONDS = 3600\nDEFAULT_STATE_LENGTH = 32\n\n\nclass RedirectHeadersSchema(colander.MappingSchema):\n \"\"\"Redirect response headers.\"\"\"\n location = colander.SchemaNode(colander.String(), name='Location')\n\n\nclass RedirectResponseSchema(colander.MappingSchema):\n \"\"\"Redirect response schema.\"\"\"\n headers = RedirectHeadersSchema()\n\n\nresponse_schemas = {\n '307': RedirectResponseSchema(description='Successful redirection.'),\n '400': ErrorResponseSchema(description='The request is invalid.'),\n}\n\n\ndef provider_validator(request, **kwargs):\n \"\"\"\n This validator verifies that the validator in URL (eg. /openid/auth0/login)\n is a configured OpenIDConnect policy.\n \"\"\"\n provider = request.matchdict['provider']\n used = request.registry.settings.get('multiauth.policy.%s.use' % provider, '')\n if not used.endswith('OpenIDConnectPolicy'):\n request.errors.add('path', 'provider', 'Unknow provider %r' % provider)\n\n\nclass LoginQuerystringSchema(colander.MappingSchema):\n \"\"\"\n Querystring schema for the login endpoint.\n \"\"\"\n callback = URL()\n scope = colander.SchemaNode(colander.String())\n\n\nclass LoginSchema(colander.MappingSchema):\n querystring = LoginQuerystringSchema()\n\n\nlogin = Service(name='openid_login',\n path='/openid/{provider}/login',\n description='Initiate the OAuth2 login')\n\n\[email protected](schema=LoginSchema(),\n validators=(colander_validator, provider_validator),\n response_schemas=response_schemas)\ndef get_login(request):\n \"\"\"Initiates to login dance for the specified scopes and callback URI\n using appropriate redirections.\"\"\"\n\n # Settings.\n provider = request.matchdict['provider']\n settings_prefix = 'multiauth.policy.%s.' % provider\n issuer = request.registry.settings[settings_prefix + 'issuer']\n client_id = request.registry.settings[settings_prefix + 'client_id']\n userid_field = request.registry.settings.get(settings_prefix + 'userid_field')\n state_ttl = int(request.registry.settings.get(settings_prefix + 'state_ttl_seconds',\n DEFAULT_STATE_TTL_SECONDS))\n state_length = int(request.registry.settings.get(settings_prefix + 'state_length',\n DEFAULT_STATE_LENGTH))\n\n # Read OpenID configuration (cached by issuer)\n oid_config = fetch_openid_config(issuer)\n auth_endpoint = oid_config['authorization_endpoint']\n\n scope = request.GET['scope']\n callback = request.GET['callback']\n\n # Check that email scope is requested if userid field is configured as email.\n if userid_field == 'email' and 'email' not in scope:\n error_details = {\n 'name': 'scope',\n 'description': \"Provider %s requires 'email' scope\" % provider,\n }\n raise_invalid(request, **error_details)\n\n # Generate a random string as state.\n # And save it until code is traded.\n state = random_bytes_hex(state_length)\n request.registry.cache.set('openid:state:' + state, callback, ttl=state_ttl)\n\n # Redirect the client to the Identity Provider that will eventually redirect\n # to the OpenID token endpoint.\n token_uri = request.route_url('openid_token', provider=provider) + '?'\n params = dict(client_id=client_id, response_type='code', scope=scope,\n redirect_uri=token_uri, state=state)\n redirect = '{}?{}'.format(auth_endpoint, urllib.parse.urlencode(params))\n raise httpexceptions.HTTPTemporaryRedirect(redirect)\n\n\nclass TokenQuerystringSchema(colander.MappingSchema):\n \"\"\"\n Querystring schema for the token endpoint.\n \"\"\"\n code = colander.SchemaNode(colander.String())\n state = colander.SchemaNode(colander.String())\n\n\nclass TokenSchema(colander.MappingSchema):\n querystring = TokenQuerystringSchema()\n\n\ntoken = Service(name='openid_token',\n path='/openid/{provider}/token',\n description='')\n\n\[email protected](schema=TokenSchema(),\n validators=(colander_validator, provider_validator))\ndef get_token(request):\n \"\"\"Trades the specified code and state against access and ID tokens.\n The client is redirected to the original ``callback`` URI with the\n result in querystring.\"\"\"\n\n # Settings.\n provider = request.matchdict['provider']\n settings_prefix = 'multiauth.policy.%s.' % provider\n issuer = request.registry.settings[settings_prefix + 'issuer']\n client_id = request.registry.settings[settings_prefix + 'client_id']\n client_secret = request.registry.settings[settings_prefix + 'client_secret']\n\n # Read OpenID configuration (cached by issuer)\n oid_config = fetch_openid_config(issuer)\n token_endpoint = oid_config['token_endpoint']\n\n code = request.GET['code']\n state = request.GET['state']\n\n # State can be used only once.\n callback = request.registry.cache.delete('openid:state:' + state)\n if callback is None:\n error_details = {\n 'name': 'state',\n 'description': 'Invalid state',\n 'errno': ERRORS.INVALID_AUTH_TOKEN.value,\n }\n raise_invalid(request, **error_details)\n\n # Trade the code for tokens on the Identity Provider.\n # Google Identity requires to specify again redirect_uri.\n redirect_uri = request.route_url('openid_token', provider=provider) + '?'\n data = {\n 'code': code,\n 'client_id': client_id,\n 'client_secret': client_secret,\n 'redirect_uri': redirect_uri,\n 'grant_type': 'authorization_code',\n }\n resp = requests.post(token_endpoint, data=data)\n\n # The IdP response is forwarded to the client in the querystring/location hash.\n # (eg. callback=`http://localhost:3000/#tokens=`)\n redirect = callback + urllib.parse.quote(resp.text)\n raise httpexceptions.HTTPTemporaryRedirect(redirect)\n", "path": "kinto/plugins/openid/views.py"}]}
| 2,245 | 270 |
gh_patches_debug_2814
|
rasdani/github-patches
|
git_diff
|
dotkom__onlineweb4-496
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Make offline archive look more like event archive
Same as #481. This is mainly about the filtering section.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `apps/api/v0/article.py`
Content:
```
1 #-*- coding: utf-8 -*-
2 from copy import copy
3
4 from django.conf import settings
5 from django.template.defaultfilters import slugify
6 from django.utils import timezone
7
8 from filebrowser.base import FileObject
9 from filebrowser.settings import VERSIONS
10 from tastypie import fields
11 from tastypie.resources import ModelResource
12
13 from apps.api.v0.authentication import UserResource
14 from apps.article.models import Article, ArticleTag, Tag
15
16
17
18
19 class ArticleResource(ModelResource):
20 author = fields.ToOneField(UserResource, 'created_by')
21
22 def alter_list_data_to_serialize(self, request, data):
23 # Renames list data 'object' to 'articles'.
24 if isinstance(data, dict):
25 data['articles'] = copy(data['objects'])
26 del(data['objects'])
27 return data
28
29 # Making multiple images for the article
30 def dehydrate(self, bundle):
31
32 # Setting slug-field
33 bundle.data['slug'] = slugify(bundle.data['heading'])
34
35 # If image is set
36 if bundle.data['image']:
37 # Parse to FileObject used by Filebrowser
38 temp_image = FileObject(bundle.data['image'])
39
40 # Itterate the different versions (by key)
41 for ver in VERSIONS.keys():
42 # Check if the key start with article_ (if it does, we want to crop to that size)
43 if ver.startswith('article_'):
44 # Adding the new image to the object
45 bundle.data['image_'+ver] = temp_image.version_generate(ver).url
46
47 # Unset the image-field
48 del(bundle.data['image'])
49
50 # Returning washed object
51 return bundle
52
53 def get_object_list(self, request):
54 # Getting the GET-params
55 if 'tag' in request.GET:
56 request_tag = request.GET['tag']
57 else:
58 request_tag = None
59
60 if 'year' in request.GET:
61 request_year = request.GET['year']
62 else:
63 request_year = None
64
65 if 'month' in request.GET:
66 request_month = request.GET['month']
67 else:
68 request_month = None
69
70 # Check filtering here
71 if (request_year is not None):
72 if (request_month is not None):
73 # Filtering on both year and month
74 queryset = Article.objects.filter(published_date__year=request_year, published_date__month=request_month, published_date__lte=timezone.now()).order_by('-published_date')
75 else:
76 # Filtering on only year
77 queryset = Article.objects.filter(published_date__year=request_year, published_date__lte=timezone.now()).order_by('-published_date')
78 else:
79 # Not filtering on year, check if filtering on slug (tag) or return default query
80 if (request_tag is not None):
81 # Filtering on slug
82 slug_query = Tag.objects.filter(slug = request_tag)
83 slug_connect = ArticleTag.objects.filter(tag = slug_query).values('article_id')
84 queryset = Article.objects.filter(id__in = slug_connect, published_date__lte=timezone.now()).order_by('-published_date')
85 else:
86 # No filtering at all, return default query
87 queryset = Article.objects.filter(published_date__lte=timezone.now()).order_by('-published_date')
88 return queryset
89
90 class Meta:
91 API_LIMIT_PER_PAGE = 9
92 queryset = Article.objects.filter(published_date__lte=timezone.now())
93 resource_name = 'article/all'
94 ordering = ['-published_date']
95 include_absolute_url = True
96 filtering = {
97 'featured' : ('exact',),
98 'published_date' : ('gte',),
99 }
100
101 class ArticleLatestResource(ModelResource):
102 author = fields.ToOneField(UserResource, 'created_by')
103
104 class Meta:
105 queryset = Article.objects.filter(published_date__lte=timezone.now())
106
107 resource_name = 'article/latest'
108 filtering = {
109 'featured': ('exact',)
110 }
111 ordering = ['-published_date']
112 max_limit = 25
113 def alter_list_data_to_serialize(self, request, data):
114 # Renames list data 'object' to 'articles'.
115 if isinstance(data, dict):
116 data['articles'] = copy(data['objects'])
117 del(data['objects'])
118 return data
119 def dehydrate(self, bundle):
120 bundle.data['slug'] = slugify(bundle.data['heading'])
121 return bundle
122
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/apps/api/v0/article.py b/apps/api/v0/article.py
--- a/apps/api/v0/article.py
+++ b/apps/api/v0/article.py
@@ -17,7 +17,7 @@
class ArticleResource(ModelResource):
- author = fields.ToOneField(UserResource, 'created_by')
+ author = fields.ToOneField(UserResource, 'created_by', full=True)
def alter_list_data_to_serialize(self, request, data):
# Renames list data 'object' to 'articles'.
|
{"golden_diff": "diff --git a/apps/api/v0/article.py b/apps/api/v0/article.py\n--- a/apps/api/v0/article.py\n+++ b/apps/api/v0/article.py\n@@ -17,7 +17,7 @@\n \n \n class ArticleResource(ModelResource):\n- author = fields.ToOneField(UserResource, 'created_by')\n+ author = fields.ToOneField(UserResource, 'created_by', full=True)\n \n def alter_list_data_to_serialize(self, request, data):\n # Renames list data 'object' to 'articles'.\n", "issue": "Make offline archive look more like event archive\nSame as #481. This is mainly about the filtering section.\n\n", "before_files": [{"content": "#-*- coding: utf-8 -*-\nfrom copy import copy\n\nfrom django.conf import settings\nfrom django.template.defaultfilters import slugify\nfrom django.utils import timezone\n\nfrom filebrowser.base import FileObject\nfrom filebrowser.settings import VERSIONS\nfrom tastypie import fields\nfrom tastypie.resources import ModelResource\n\nfrom apps.api.v0.authentication import UserResource\nfrom apps.article.models import Article, ArticleTag, Tag\n\n\n\n\nclass ArticleResource(ModelResource):\n author = fields.ToOneField(UserResource, 'created_by')\n \n def alter_list_data_to_serialize(self, request, data):\n # Renames list data 'object' to 'articles'.\n if isinstance(data, dict):\n data['articles'] = copy(data['objects'])\n del(data['objects'])\n return data\n \n # Making multiple images for the article\n def dehydrate(self, bundle):\n \n # Setting slug-field\n bundle.data['slug'] = slugify(bundle.data['heading'])\n \n # If image is set\n if bundle.data['image']:\n # Parse to FileObject used by Filebrowser\n temp_image = FileObject(bundle.data['image'])\n \n # Itterate the different versions (by key)\n for ver in VERSIONS.keys():\n # Check if the key start with article_ (if it does, we want to crop to that size)\n if ver.startswith('article_'):\n # Adding the new image to the object\n bundle.data['image_'+ver] = temp_image.version_generate(ver).url\n \n # Unset the image-field\n del(bundle.data['image'])\n \n # Returning washed object\n return bundle\n \n def get_object_list(self, request):\n # Getting the GET-params\n if 'tag' in request.GET:\n request_tag = request.GET['tag']\n else:\n request_tag = None\n \n if 'year' in request.GET:\n request_year = request.GET['year']\n else:\n request_year = None\n \n if 'month' in request.GET:\n request_month = request.GET['month']\n else:\n request_month = None\n \n # Check filtering here\n if (request_year is not None):\n if (request_month is not None):\n # Filtering on both year and month\n queryset = Article.objects.filter(published_date__year=request_year, published_date__month=request_month, published_date__lte=timezone.now()).order_by('-published_date')\n else:\n # Filtering on only year\n queryset = Article.objects.filter(published_date__year=request_year, published_date__lte=timezone.now()).order_by('-published_date')\n else:\n # Not filtering on year, check if filtering on slug (tag) or return default query\n if (request_tag is not None):\n # Filtering on slug\n slug_query = Tag.objects.filter(slug = request_tag)\n slug_connect = ArticleTag.objects.filter(tag = slug_query).values('article_id')\n queryset = Article.objects.filter(id__in = slug_connect, published_date__lte=timezone.now()).order_by('-published_date')\n else:\n # No filtering at all, return default query\n queryset = Article.objects.filter(published_date__lte=timezone.now()).order_by('-published_date')\n return queryset\n \n class Meta: \n API_LIMIT_PER_PAGE = 9\n queryset = Article.objects.filter(published_date__lte=timezone.now())\n resource_name = 'article/all'\n ordering = ['-published_date']\n include_absolute_url = True\n filtering = {\n 'featured' : ('exact',),\n 'published_date' : ('gte',),\n }\n\nclass ArticleLatestResource(ModelResource):\n author = fields.ToOneField(UserResource, 'created_by')\n \n class Meta:\n queryset = Article.objects.filter(published_date__lte=timezone.now())\n \n resource_name = 'article/latest'\n filtering = {\n 'featured': ('exact',)\n }\n ordering = ['-published_date']\n max_limit = 25\n def alter_list_data_to_serialize(self, request, data):\n # Renames list data 'object' to 'articles'.\n if isinstance(data, dict): \n data['articles'] = copy(data['objects'])\n del(data['objects'])\n return data\n def dehydrate(self, bundle):\n bundle.data['slug'] = slugify(bundle.data['heading'])\n return bundle\n", "path": "apps/api/v0/article.py"}], "after_files": [{"content": "#-*- coding: utf-8 -*-\nfrom copy import copy\n\nfrom django.conf import settings\nfrom django.template.defaultfilters import slugify\nfrom django.utils import timezone\n\nfrom filebrowser.base import FileObject\nfrom filebrowser.settings import VERSIONS\nfrom tastypie import fields\nfrom tastypie.resources import ModelResource\n\nfrom apps.api.v0.authentication import UserResource\nfrom apps.article.models import Article, ArticleTag, Tag\n\n\n\n\nclass ArticleResource(ModelResource):\n author = fields.ToOneField(UserResource, 'created_by', full=True)\n \n def alter_list_data_to_serialize(self, request, data):\n # Renames list data 'object' to 'articles'.\n if isinstance(data, dict):\n data['articles'] = copy(data['objects'])\n del(data['objects'])\n return data\n \n # Making multiple images for the article\n def dehydrate(self, bundle):\n \n # Setting slug-field\n bundle.data['slug'] = slugify(bundle.data['heading'])\n \n # If image is set\n if bundle.data['image']:\n # Parse to FileObject used by Filebrowser\n temp_image = FileObject(bundle.data['image'])\n \n # Itterate the different versions (by key)\n for ver in VERSIONS.keys():\n # Check if the key start with article_ (if it does, we want to crop to that size)\n if ver.startswith('article_'):\n # Adding the new image to the object\n bundle.data['image_'+ver] = temp_image.version_generate(ver).url\n \n # Unset the image-field\n del(bundle.data['image'])\n \n # Returning washed object\n return bundle\n \n def get_object_list(self, request):\n # Getting the GET-params\n if 'tag' in request.GET:\n request_tag = request.GET['tag']\n else:\n request_tag = None\n \n if 'year' in request.GET:\n request_year = request.GET['year']\n else:\n request_year = None\n \n if 'month' in request.GET:\n request_month = request.GET['month']\n else:\n request_month = None\n \n # Check filtering here\n if (request_year is not None):\n if (request_month is not None):\n # Filtering on both year and month\n queryset = Article.objects.filter(published_date__year=request_year, published_date__month=request_month, published_date__lte=timezone.now()).order_by('-published_date')\n else:\n # Filtering on only year\n queryset = Article.objects.filter(published_date__year=request_year, published_date__lte=timezone.now()).order_by('-published_date')\n else:\n # Not filtering on year, check if filtering on slug (tag) or return default query\n if (request_tag is not None):\n # Filtering on slug\n slug_query = Tag.objects.filter(slug = request_tag)\n slug_connect = ArticleTag.objects.filter(tag = slug_query).values('article_id')\n queryset = Article.objects.filter(id__in = slug_connect, published_date__lte=timezone.now()).order_by('-published_date')\n else:\n # No filtering at all, return default query\n queryset = Article.objects.filter(published_date__lte=timezone.now()).order_by('-published_date')\n return queryset\n \n class Meta: \n API_LIMIT_PER_PAGE = 9\n queryset = Article.objects.filter(published_date__lte=timezone.now())\n resource_name = 'article/all'\n ordering = ['-published_date']\n include_absolute_url = True\n filtering = {\n 'featured' : ('exact',),\n 'published_date' : ('gte',),\n }\n\nclass ArticleLatestResource(ModelResource):\n author = fields.ToOneField(UserResource, 'created_by')\n \n class Meta:\n queryset = Article.objects.filter(published_date__lte=timezone.now())\n \n resource_name = 'article/latest'\n filtering = {\n 'featured': ('exact',)\n }\n ordering = ['-published_date']\n max_limit = 25\n def alter_list_data_to_serialize(self, request, data):\n # Renames list data 'object' to 'articles'.\n if isinstance(data, dict): \n data['articles'] = copy(data['objects'])\n del(data['objects'])\n return data\n def dehydrate(self, bundle):\n bundle.data['slug'] = slugify(bundle.data['heading'])\n return bundle\n", "path": "apps/api/v0/article.py"}]}
| 1,473 | 115 |
gh_patches_debug_18808
|
rasdani/github-patches
|
git_diff
|
ipython__ipython-13433
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Improvement of `core.magic_arguments` example
Currently, there is only a [very raw example](https://ipython.readthedocs.io/en/stable/api/generated/IPython.core.magic_arguments.html?highlight=%40magic_arguments.argumen#module-IPython.core.magic_arguments
) of using `magic_arguments` with custom cell magic.
Therefore, I have the idea to add a second, more fleshed out example that might help people to easier understand and use cell magic arguments:
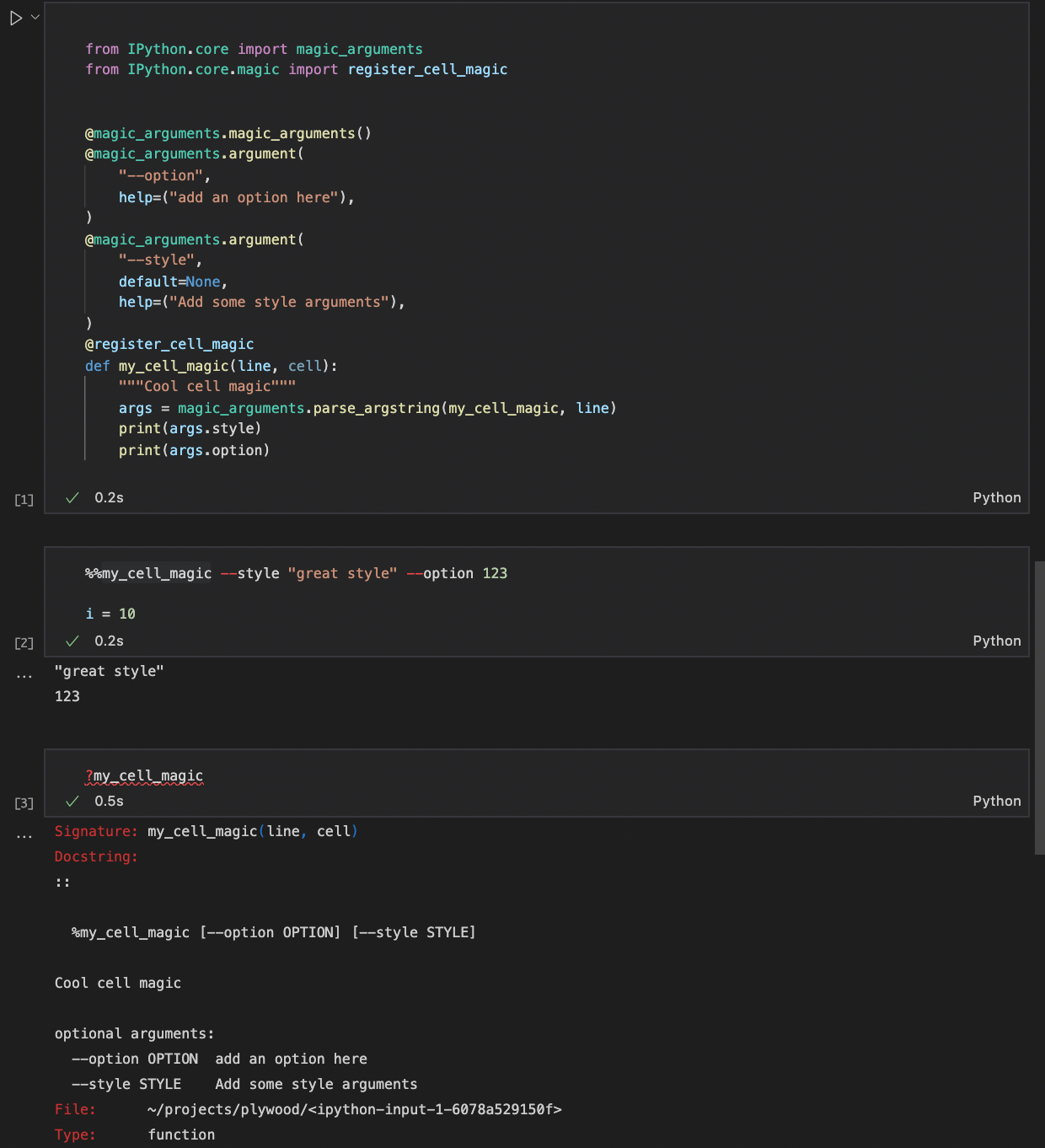
Here is the code:
```py
from IPython.core import magic_arguments
from IPython.core.magic import register_cell_magic
@magic_arguments.magic_arguments()
@magic_arguments.argument(
"--option",
help=("Add an option here"),
)
@magic_arguments.argument(
"--style",
default=None,
help=("Add some style arguments"),
)
@register_cell_magic
def my_cell_magic(line, cell):
"""Cool cell magic"""
args = magic_arguments.parse_argstring(my_cell_magic, line)
print(args.style)
print(args.option)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `IPython/core/magic_arguments.py`
Content:
```
1 ''' A decorator-based method of constructing IPython magics with `argparse`
2 option handling.
3
4 New magic functions can be defined like so::
5
6 from IPython.core.magic_arguments import (argument, magic_arguments,
7 parse_argstring)
8
9 @magic_arguments()
10 @argument('-o', '--option', help='An optional argument.')
11 @argument('arg', type=int, help='An integer positional argument.')
12 def magic_cool(self, arg):
13 """ A really cool magic command.
14
15 """
16 args = parse_argstring(magic_cool, arg)
17 ...
18
19 The `@magic_arguments` decorator marks the function as having argparse arguments.
20 The `@argument` decorator adds an argument using the same syntax as argparse's
21 `add_argument()` method. More sophisticated uses may also require the
22 `@argument_group` or `@kwds` decorator to customize the formatting and the
23 parsing.
24
25 Help text for the magic is automatically generated from the docstring and the
26 arguments::
27
28 In[1]: %cool?
29 %cool [-o OPTION] arg
30
31 A really cool magic command.
32
33 positional arguments:
34 arg An integer positional argument.
35
36 optional arguments:
37 -o OPTION, --option OPTION
38 An optional argument.
39
40 Inheritance diagram:
41
42 .. inheritance-diagram:: IPython.core.magic_arguments
43 :parts: 3
44
45 '''
46 #-----------------------------------------------------------------------------
47 # Copyright (C) 2010-2011, IPython Development Team.
48 #
49 # Distributed under the terms of the Modified BSD License.
50 #
51 # The full license is in the file COPYING.txt, distributed with this software.
52 #-----------------------------------------------------------------------------
53 import argparse
54 import re
55
56 # Our own imports
57 from IPython.core.error import UsageError
58 from IPython.utils.decorators import undoc
59 from IPython.utils.process import arg_split
60 from IPython.utils.text import dedent
61
62 NAME_RE = re.compile(r"[a-zA-Z][a-zA-Z0-9_-]*$")
63
64 @undoc
65 class MagicHelpFormatter(argparse.RawDescriptionHelpFormatter):
66 """A HelpFormatter with a couple of changes to meet our needs.
67 """
68 # Modified to dedent text.
69 def _fill_text(self, text, width, indent):
70 return argparse.RawDescriptionHelpFormatter._fill_text(self, dedent(text), width, indent)
71
72 # Modified to wrap argument placeholders in <> where necessary.
73 def _format_action_invocation(self, action):
74 if not action.option_strings:
75 metavar, = self._metavar_formatter(action, action.dest)(1)
76 return metavar
77
78 else:
79 parts = []
80
81 # if the Optional doesn't take a value, format is:
82 # -s, --long
83 if action.nargs == 0:
84 parts.extend(action.option_strings)
85
86 # if the Optional takes a value, format is:
87 # -s ARGS, --long ARGS
88 else:
89 default = action.dest.upper()
90 args_string = self._format_args(action, default)
91 # IPYTHON MODIFICATION: If args_string is not a plain name, wrap
92 # it in <> so it's valid RST.
93 if not NAME_RE.match(args_string):
94 args_string = "<%s>" % args_string
95 for option_string in action.option_strings:
96 parts.append('%s %s' % (option_string, args_string))
97
98 return ', '.join(parts)
99
100 # Override the default prefix ('usage') to our % magic escape,
101 # in a code block.
102 def add_usage(self, usage, actions, groups, prefix="::\n\n %"):
103 super(MagicHelpFormatter, self).add_usage(usage, actions, groups, prefix)
104
105 class MagicArgumentParser(argparse.ArgumentParser):
106 """ An ArgumentParser tweaked for use by IPython magics.
107 """
108 def __init__(self,
109 prog=None,
110 usage=None,
111 description=None,
112 epilog=None,
113 parents=None,
114 formatter_class=MagicHelpFormatter,
115 prefix_chars='-',
116 argument_default=None,
117 conflict_handler='error',
118 add_help=False):
119 if parents is None:
120 parents = []
121 super(MagicArgumentParser, self).__init__(prog=prog, usage=usage,
122 description=description, epilog=epilog,
123 parents=parents, formatter_class=formatter_class,
124 prefix_chars=prefix_chars, argument_default=argument_default,
125 conflict_handler=conflict_handler, add_help=add_help)
126
127 def error(self, message):
128 """ Raise a catchable error instead of exiting.
129 """
130 raise UsageError(message)
131
132 def parse_argstring(self, argstring):
133 """ Split a string into an argument list and parse that argument list.
134 """
135 argv = arg_split(argstring)
136 return self.parse_args(argv)
137
138
139 def construct_parser(magic_func):
140 """ Construct an argument parser using the function decorations.
141 """
142 kwds = getattr(magic_func, 'argcmd_kwds', {})
143 if 'description' not in kwds:
144 kwds['description'] = getattr(magic_func, '__doc__', None)
145 arg_name = real_name(magic_func)
146 parser = MagicArgumentParser(arg_name, **kwds)
147 # Reverse the list of decorators in order to apply them in the
148 # order in which they appear in the source.
149 group = None
150 for deco in magic_func.decorators[::-1]:
151 result = deco.add_to_parser(parser, group)
152 if result is not None:
153 group = result
154
155 # Replace the magic function's docstring with the full help text.
156 magic_func.__doc__ = parser.format_help()
157
158 return parser
159
160
161 def parse_argstring(magic_func, argstring):
162 """ Parse the string of arguments for the given magic function.
163 """
164 return magic_func.parser.parse_argstring(argstring)
165
166
167 def real_name(magic_func):
168 """ Find the real name of the magic.
169 """
170 magic_name = magic_func.__name__
171 if magic_name.startswith('magic_'):
172 magic_name = magic_name[len('magic_'):]
173 return getattr(magic_func, 'argcmd_name', magic_name)
174
175
176 class ArgDecorator(object):
177 """ Base class for decorators to add ArgumentParser information to a method.
178 """
179
180 def __call__(self, func):
181 if not getattr(func, 'has_arguments', False):
182 func.has_arguments = True
183 func.decorators = []
184 func.decorators.append(self)
185 return func
186
187 def add_to_parser(self, parser, group):
188 """ Add this object's information to the parser, if necessary.
189 """
190 pass
191
192
193 class magic_arguments(ArgDecorator):
194 """ Mark the magic as having argparse arguments and possibly adjust the
195 name.
196 """
197
198 def __init__(self, name=None):
199 self.name = name
200
201 def __call__(self, func):
202 if not getattr(func, 'has_arguments', False):
203 func.has_arguments = True
204 func.decorators = []
205 if self.name is not None:
206 func.argcmd_name = self.name
207 # This should be the first decorator in the list of decorators, thus the
208 # last to execute. Build the parser.
209 func.parser = construct_parser(func)
210 return func
211
212
213 class ArgMethodWrapper(ArgDecorator):
214
215 """
216 Base class to define a wrapper for ArgumentParser method.
217
218 Child class must define either `_method_name` or `add_to_parser`.
219
220 """
221
222 _method_name = None
223
224 def __init__(self, *args, **kwds):
225 self.args = args
226 self.kwds = kwds
227
228 def add_to_parser(self, parser, group):
229 """ Add this object's information to the parser.
230 """
231 if group is not None:
232 parser = group
233 getattr(parser, self._method_name)(*self.args, **self.kwds)
234 return None
235
236
237 class argument(ArgMethodWrapper):
238 """ Store arguments and keywords to pass to add_argument().
239
240 Instances also serve to decorate command methods.
241 """
242 _method_name = 'add_argument'
243
244
245 class defaults(ArgMethodWrapper):
246 """ Store arguments and keywords to pass to set_defaults().
247
248 Instances also serve to decorate command methods.
249 """
250 _method_name = 'set_defaults'
251
252
253 class argument_group(ArgMethodWrapper):
254 """ Store arguments and keywords to pass to add_argument_group().
255
256 Instances also serve to decorate command methods.
257 """
258
259 def add_to_parser(self, parser, group):
260 """ Add this object's information to the parser.
261 """
262 return parser.add_argument_group(*self.args, **self.kwds)
263
264
265 class kwds(ArgDecorator):
266 """ Provide other keywords to the sub-parser constructor.
267 """
268 def __init__(self, **kwds):
269 self.kwds = kwds
270
271 def __call__(self, func):
272 func = super(kwds, self).__call__(func)
273 func.argcmd_kwds = self.kwds
274 return func
275
276
277 __all__ = ['magic_arguments', 'argument', 'argument_group', 'kwds',
278 'parse_argstring']
279
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/IPython/core/magic_arguments.py b/IPython/core/magic_arguments.py
--- a/IPython/core/magic_arguments.py
+++ b/IPython/core/magic_arguments.py
@@ -37,6 +37,38 @@
-o OPTION, --option OPTION
An optional argument.
+Here is an elaborated example that uses default parameters in `argument` and calls the `args` in the cell magic::
+
+ from IPython.core.magic import register_cell_magic
+ from IPython.core.magic_arguments import (argument, magic_arguments,
+ parse_argstring)
+
+
+ @magic_arguments()
+ @argument(
+ "--option",
+ "-o",
+ help=("Add an option here"),
+ )
+ @argument(
+ "--style",
+ "-s",
+ default="foo",
+ help=("Add some style arguments"),
+ )
+ @register_cell_magic
+ def my_cell_magic(line, cell):
+ args = parse_argstring(my_cell_magic, line)
+ print(f"{args.option=}")
+ print(f"{args.style=}")
+ print(f"{cell=}")
+
+In a jupyter notebook, this cell magic can be executed like this::
+
+ %%my_cell_magic -o Hello
+ print("bar")
+ i = 42
+
Inheritance diagram:
.. inheritance-diagram:: IPython.core.magic_arguments
|
{"golden_diff": "diff --git a/IPython/core/magic_arguments.py b/IPython/core/magic_arguments.py\n--- a/IPython/core/magic_arguments.py\n+++ b/IPython/core/magic_arguments.py\n@@ -37,6 +37,38 @@\n -o OPTION, --option OPTION\n An optional argument.\n \n+Here is an elaborated example that uses default parameters in `argument` and calls the `args` in the cell magic::\n+\n+ from IPython.core.magic import register_cell_magic\n+ from IPython.core.magic_arguments import (argument, magic_arguments,\n+ parse_argstring)\n+\n+\n+ @magic_arguments()\n+ @argument(\n+ \"--option\",\n+ \"-o\",\n+ help=(\"Add an option here\"),\n+ )\n+ @argument(\n+ \"--style\",\n+ \"-s\",\n+ default=\"foo\",\n+ help=(\"Add some style arguments\"),\n+ )\n+ @register_cell_magic\n+ def my_cell_magic(line, cell):\n+ args = parse_argstring(my_cell_magic, line)\n+ print(f\"{args.option=}\")\n+ print(f\"{args.style=}\")\n+ print(f\"{cell=}\")\n+\n+In a jupyter notebook, this cell magic can be executed like this::\n+\n+ %%my_cell_magic -o Hello\n+ print(\"bar\")\n+ i = 42\n+\n Inheritance diagram:\n \n .. inheritance-diagram:: IPython.core.magic_arguments\n", "issue": "Improvement of `core.magic_arguments` example\nCurrently, there is only a [very raw example](https://ipython.readthedocs.io/en/stable/api/generated/IPython.core.magic_arguments.html?highlight=%40magic_arguments.argumen#module-IPython.core.magic_arguments\r\n) of using `magic_arguments` with custom cell magic.\r\nTherefore, I have the idea to add a second, more fleshed out example that might help people to easier understand and use cell magic arguments: \r\n\r\nHere is the code:\r\n```py\r\nfrom IPython.core import magic_arguments\r\nfrom IPython.core.magic import register_cell_magic\r\n\r\n\r\n@magic_arguments.magic_arguments()\r\n@magic_arguments.argument(\r\n \"--option\",\r\n help=(\"Add an option here\"),\r\n)\r\n@magic_arguments.argument(\r\n \"--style\",\r\n default=None,\r\n help=(\"Add some style arguments\"),\r\n)\r\n@register_cell_magic\r\ndef my_cell_magic(line, cell):\r\n \"\"\"Cool cell magic\"\"\"\r\n args = magic_arguments.parse_argstring(my_cell_magic, line)\r\n print(args.style)\r\n print(args.option)\r\n```\n", "before_files": [{"content": "''' A decorator-based method of constructing IPython magics with `argparse`\noption handling.\n\nNew magic functions can be defined like so::\n\n from IPython.core.magic_arguments import (argument, magic_arguments,\n parse_argstring)\n\n @magic_arguments()\n @argument('-o', '--option', help='An optional argument.')\n @argument('arg', type=int, help='An integer positional argument.')\n def magic_cool(self, arg):\n \"\"\" A really cool magic command.\n\n \"\"\"\n args = parse_argstring(magic_cool, arg)\n ...\n\nThe `@magic_arguments` decorator marks the function as having argparse arguments.\nThe `@argument` decorator adds an argument using the same syntax as argparse's\n`add_argument()` method. More sophisticated uses may also require the\n`@argument_group` or `@kwds` decorator to customize the formatting and the\nparsing.\n\nHelp text for the magic is automatically generated from the docstring and the\narguments::\n\n In[1]: %cool?\n %cool [-o OPTION] arg\n \n A really cool magic command.\n \n positional arguments:\n arg An integer positional argument.\n \n optional arguments:\n -o OPTION, --option OPTION\n An optional argument.\n\nInheritance diagram:\n\n.. inheritance-diagram:: IPython.core.magic_arguments\n :parts: 3\n\n'''\n#-----------------------------------------------------------------------------\n# Copyright (C) 2010-2011, IPython Development Team.\n#\n# Distributed under the terms of the Modified BSD License.\n#\n# The full license is in the file COPYING.txt, distributed with this software.\n#-----------------------------------------------------------------------------\nimport argparse\nimport re\n\n# Our own imports\nfrom IPython.core.error import UsageError\nfrom IPython.utils.decorators import undoc\nfrom IPython.utils.process import arg_split\nfrom IPython.utils.text import dedent\n\nNAME_RE = re.compile(r\"[a-zA-Z][a-zA-Z0-9_-]*$\")\n\n@undoc\nclass MagicHelpFormatter(argparse.RawDescriptionHelpFormatter):\n \"\"\"A HelpFormatter with a couple of changes to meet our needs.\n \"\"\"\n # Modified to dedent text.\n def _fill_text(self, text, width, indent):\n return argparse.RawDescriptionHelpFormatter._fill_text(self, dedent(text), width, indent)\n\n # Modified to wrap argument placeholders in <> where necessary.\n def _format_action_invocation(self, action):\n if not action.option_strings:\n metavar, = self._metavar_formatter(action, action.dest)(1)\n return metavar\n\n else:\n parts = []\n\n # if the Optional doesn't take a value, format is:\n # -s, --long\n if action.nargs == 0:\n parts.extend(action.option_strings)\n\n # if the Optional takes a value, format is:\n # -s ARGS, --long ARGS\n else:\n default = action.dest.upper()\n args_string = self._format_args(action, default)\n # IPYTHON MODIFICATION: If args_string is not a plain name, wrap\n # it in <> so it's valid RST.\n if not NAME_RE.match(args_string):\n args_string = \"<%s>\" % args_string\n for option_string in action.option_strings:\n parts.append('%s %s' % (option_string, args_string))\n\n return ', '.join(parts)\n\n # Override the default prefix ('usage') to our % magic escape,\n # in a code block.\n def add_usage(self, usage, actions, groups, prefix=\"::\\n\\n %\"):\n super(MagicHelpFormatter, self).add_usage(usage, actions, groups, prefix)\n\nclass MagicArgumentParser(argparse.ArgumentParser):\n \"\"\" An ArgumentParser tweaked for use by IPython magics.\n \"\"\"\n def __init__(self,\n prog=None,\n usage=None,\n description=None,\n epilog=None,\n parents=None,\n formatter_class=MagicHelpFormatter,\n prefix_chars='-',\n argument_default=None,\n conflict_handler='error',\n add_help=False):\n if parents is None:\n parents = []\n super(MagicArgumentParser, self).__init__(prog=prog, usage=usage,\n description=description, epilog=epilog,\n parents=parents, formatter_class=formatter_class,\n prefix_chars=prefix_chars, argument_default=argument_default,\n conflict_handler=conflict_handler, add_help=add_help)\n\n def error(self, message):\n \"\"\" Raise a catchable error instead of exiting.\n \"\"\"\n raise UsageError(message)\n\n def parse_argstring(self, argstring):\n \"\"\" Split a string into an argument list and parse that argument list.\n \"\"\"\n argv = arg_split(argstring)\n return self.parse_args(argv)\n\n\ndef construct_parser(magic_func):\n \"\"\" Construct an argument parser using the function decorations.\n \"\"\"\n kwds = getattr(magic_func, 'argcmd_kwds', {})\n if 'description' not in kwds:\n kwds['description'] = getattr(magic_func, '__doc__', None)\n arg_name = real_name(magic_func)\n parser = MagicArgumentParser(arg_name, **kwds)\n # Reverse the list of decorators in order to apply them in the\n # order in which they appear in the source.\n group = None\n for deco in magic_func.decorators[::-1]:\n result = deco.add_to_parser(parser, group)\n if result is not None:\n group = result\n\n # Replace the magic function's docstring with the full help text.\n magic_func.__doc__ = parser.format_help()\n\n return parser\n\n\ndef parse_argstring(magic_func, argstring):\n \"\"\" Parse the string of arguments for the given magic function.\n \"\"\"\n return magic_func.parser.parse_argstring(argstring)\n\n\ndef real_name(magic_func):\n \"\"\" Find the real name of the magic.\n \"\"\"\n magic_name = magic_func.__name__\n if magic_name.startswith('magic_'):\n magic_name = magic_name[len('magic_'):]\n return getattr(magic_func, 'argcmd_name', magic_name)\n\n\nclass ArgDecorator(object):\n \"\"\" Base class for decorators to add ArgumentParser information to a method.\n \"\"\"\n\n def __call__(self, func):\n if not getattr(func, 'has_arguments', False):\n func.has_arguments = True\n func.decorators = []\n func.decorators.append(self)\n return func\n\n def add_to_parser(self, parser, group):\n \"\"\" Add this object's information to the parser, if necessary.\n \"\"\"\n pass\n\n\nclass magic_arguments(ArgDecorator):\n \"\"\" Mark the magic as having argparse arguments and possibly adjust the\n name.\n \"\"\"\n\n def __init__(self, name=None):\n self.name = name\n\n def __call__(self, func):\n if not getattr(func, 'has_arguments', False):\n func.has_arguments = True\n func.decorators = []\n if self.name is not None:\n func.argcmd_name = self.name\n # This should be the first decorator in the list of decorators, thus the\n # last to execute. Build the parser.\n func.parser = construct_parser(func)\n return func\n\n\nclass ArgMethodWrapper(ArgDecorator):\n\n \"\"\"\n Base class to define a wrapper for ArgumentParser method.\n\n Child class must define either `_method_name` or `add_to_parser`.\n\n \"\"\"\n\n _method_name = None\n\n def __init__(self, *args, **kwds):\n self.args = args\n self.kwds = kwds\n\n def add_to_parser(self, parser, group):\n \"\"\" Add this object's information to the parser.\n \"\"\"\n if group is not None:\n parser = group\n getattr(parser, self._method_name)(*self.args, **self.kwds)\n return None\n\n\nclass argument(ArgMethodWrapper):\n \"\"\" Store arguments and keywords to pass to add_argument().\n\n Instances also serve to decorate command methods.\n \"\"\"\n _method_name = 'add_argument'\n\n\nclass defaults(ArgMethodWrapper):\n \"\"\" Store arguments and keywords to pass to set_defaults().\n\n Instances also serve to decorate command methods.\n \"\"\"\n _method_name = 'set_defaults'\n\n\nclass argument_group(ArgMethodWrapper):\n \"\"\" Store arguments and keywords to pass to add_argument_group().\n\n Instances also serve to decorate command methods.\n \"\"\"\n\n def add_to_parser(self, parser, group):\n \"\"\" Add this object's information to the parser.\n \"\"\"\n return parser.add_argument_group(*self.args, **self.kwds)\n\n\nclass kwds(ArgDecorator):\n \"\"\" Provide other keywords to the sub-parser constructor.\n \"\"\"\n def __init__(self, **kwds):\n self.kwds = kwds\n\n def __call__(self, func):\n func = super(kwds, self).__call__(func)\n func.argcmd_kwds = self.kwds\n return func\n\n\n__all__ = ['magic_arguments', 'argument', 'argument_group', 'kwds',\n 'parse_argstring']\n", "path": "IPython/core/magic_arguments.py"}], "after_files": [{"content": "''' A decorator-based method of constructing IPython magics with `argparse`\noption handling.\n\nNew magic functions can be defined like so::\n\n from IPython.core.magic_arguments import (argument, magic_arguments,\n parse_argstring)\n\n @magic_arguments()\n @argument('-o', '--option', help='An optional argument.')\n @argument('arg', type=int, help='An integer positional argument.')\n def magic_cool(self, arg):\n \"\"\" A really cool magic command.\n\n \"\"\"\n args = parse_argstring(magic_cool, arg)\n ...\n\nThe `@magic_arguments` decorator marks the function as having argparse arguments.\nThe `@argument` decorator adds an argument using the same syntax as argparse's\n`add_argument()` method. More sophisticated uses may also require the\n`@argument_group` or `@kwds` decorator to customize the formatting and the\nparsing.\n\nHelp text for the magic is automatically generated from the docstring and the\narguments::\n\n In[1]: %cool?\n %cool [-o OPTION] arg\n \n A really cool magic command.\n \n positional arguments:\n arg An integer positional argument.\n \n optional arguments:\n -o OPTION, --option OPTION\n An optional argument.\n\nHere is an elaborated example that uses default parameters in `argument` and calls the `args` in the cell magic::\n\n from IPython.core.magic import register_cell_magic\n from IPython.core.magic_arguments import (argument, magic_arguments,\n parse_argstring)\n\n\n @magic_arguments()\n @argument(\n \"--option\",\n \"-o\",\n help=(\"Add an option here\"),\n )\n @argument(\n \"--style\",\n \"-s\",\n default=\"foo\",\n help=(\"Add some style arguments\"),\n )\n @register_cell_magic\n def my_cell_magic(line, cell):\n args = parse_argstring(my_cell_magic, line)\n print(f\"{args.option=}\")\n print(f\"{args.style=}\")\n print(f\"{cell=}\")\n\nIn a jupyter notebook, this cell magic can be executed like this::\n\n %%my_cell_magic -o Hello\n print(\"bar\")\n i = 42\n\nInheritance diagram:\n\n.. inheritance-diagram:: IPython.core.magic_arguments\n :parts: 3\n\n'''\n#-----------------------------------------------------------------------------\n# Copyright (C) 2010-2011, IPython Development Team.\n#\n# Distributed under the terms of the Modified BSD License.\n#\n# The full license is in the file COPYING.txt, distributed with this software.\n#-----------------------------------------------------------------------------\nimport argparse\nimport re\n\n# Our own imports\nfrom IPython.core.error import UsageError\nfrom IPython.utils.decorators import undoc\nfrom IPython.utils.process import arg_split\nfrom IPython.utils.text import dedent\n\nNAME_RE = re.compile(r\"[a-zA-Z][a-zA-Z0-9_-]*$\")\n\n@undoc\nclass MagicHelpFormatter(argparse.RawDescriptionHelpFormatter):\n \"\"\"A HelpFormatter with a couple of changes to meet our needs.\n \"\"\"\n # Modified to dedent text.\n def _fill_text(self, text, width, indent):\n return argparse.RawDescriptionHelpFormatter._fill_text(self, dedent(text), width, indent)\n\n # Modified to wrap argument placeholders in <> where necessary.\n def _format_action_invocation(self, action):\n if not action.option_strings:\n metavar, = self._metavar_formatter(action, action.dest)(1)\n return metavar\n\n else:\n parts = []\n\n # if the Optional doesn't take a value, format is:\n # -s, --long\n if action.nargs == 0:\n parts.extend(action.option_strings)\n\n # if the Optional takes a value, format is:\n # -s ARGS, --long ARGS\n else:\n default = action.dest.upper()\n args_string = self._format_args(action, default)\n # IPYTHON MODIFICATION: If args_string is not a plain name, wrap\n # it in <> so it's valid RST.\n if not NAME_RE.match(args_string):\n args_string = \"<%s>\" % args_string\n for option_string in action.option_strings:\n parts.append('%s %s' % (option_string, args_string))\n\n return ', '.join(parts)\n\n # Override the default prefix ('usage') to our % magic escape,\n # in a code block.\n def add_usage(self, usage, actions, groups, prefix=\"::\\n\\n %\"):\n super(MagicHelpFormatter, self).add_usage(usage, actions, groups, prefix)\n\nclass MagicArgumentParser(argparse.ArgumentParser):\n \"\"\" An ArgumentParser tweaked for use by IPython magics.\n \"\"\"\n def __init__(self,\n prog=None,\n usage=None,\n description=None,\n epilog=None,\n parents=None,\n formatter_class=MagicHelpFormatter,\n prefix_chars='-',\n argument_default=None,\n conflict_handler='error',\n add_help=False):\n if parents is None:\n parents = []\n super(MagicArgumentParser, self).__init__(prog=prog, usage=usage,\n description=description, epilog=epilog,\n parents=parents, formatter_class=formatter_class,\n prefix_chars=prefix_chars, argument_default=argument_default,\n conflict_handler=conflict_handler, add_help=add_help)\n\n def error(self, message):\n \"\"\" Raise a catchable error instead of exiting.\n \"\"\"\n raise UsageError(message)\n\n def parse_argstring(self, argstring):\n \"\"\" Split a string into an argument list and parse that argument list.\n \"\"\"\n argv = arg_split(argstring)\n return self.parse_args(argv)\n\n\ndef construct_parser(magic_func):\n \"\"\" Construct an argument parser using the function decorations.\n \"\"\"\n kwds = getattr(magic_func, 'argcmd_kwds', {})\n if 'description' not in kwds:\n kwds['description'] = getattr(magic_func, '__doc__', None)\n arg_name = real_name(magic_func)\n parser = MagicArgumentParser(arg_name, **kwds)\n # Reverse the list of decorators in order to apply them in the\n # order in which they appear in the source.\n group = None\n for deco in magic_func.decorators[::-1]:\n result = deco.add_to_parser(parser, group)\n if result is not None:\n group = result\n\n # Replace the magic function's docstring with the full help text.\n magic_func.__doc__ = parser.format_help()\n\n return parser\n\n\ndef parse_argstring(magic_func, argstring):\n \"\"\" Parse the string of arguments for the given magic function.\n \"\"\"\n return magic_func.parser.parse_argstring(argstring)\n\n\ndef real_name(magic_func):\n \"\"\" Find the real name of the magic.\n \"\"\"\n magic_name = magic_func.__name__\n if magic_name.startswith('magic_'):\n magic_name = magic_name[len('magic_'):]\n return getattr(magic_func, 'argcmd_name', magic_name)\n\n\nclass ArgDecorator(object):\n \"\"\" Base class for decorators to add ArgumentParser information to a method.\n \"\"\"\n\n def __call__(self, func):\n if not getattr(func, 'has_arguments', False):\n func.has_arguments = True\n func.decorators = []\n func.decorators.append(self)\n return func\n\n def add_to_parser(self, parser, group):\n \"\"\" Add this object's information to the parser, if necessary.\n \"\"\"\n pass\n\n\nclass magic_arguments(ArgDecorator):\n \"\"\" Mark the magic as having argparse arguments and possibly adjust the\n name.\n \"\"\"\n\n def __init__(self, name=None):\n self.name = name\n\n def __call__(self, func):\n if not getattr(func, 'has_arguments', False):\n func.has_arguments = True\n func.decorators = []\n if self.name is not None:\n func.argcmd_name = self.name\n # This should be the first decorator in the list of decorators, thus the\n # last to execute. Build the parser.\n func.parser = construct_parser(func)\n return func\n\n\nclass ArgMethodWrapper(ArgDecorator):\n\n \"\"\"\n Base class to define a wrapper for ArgumentParser method.\n\n Child class must define either `_method_name` or `add_to_parser`.\n\n \"\"\"\n\n _method_name = None\n\n def __init__(self, *args, **kwds):\n self.args = args\n self.kwds = kwds\n\n def add_to_parser(self, parser, group):\n \"\"\" Add this object's information to the parser.\n \"\"\"\n if group is not None:\n parser = group\n getattr(parser, self._method_name)(*self.args, **self.kwds)\n return None\n\n\nclass argument(ArgMethodWrapper):\n \"\"\" Store arguments and keywords to pass to add_argument().\n\n Instances also serve to decorate command methods.\n \"\"\"\n _method_name = 'add_argument'\n\n\nclass defaults(ArgMethodWrapper):\n \"\"\" Store arguments and keywords to pass to set_defaults().\n\n Instances also serve to decorate command methods.\n \"\"\"\n _method_name = 'set_defaults'\n\n\nclass argument_group(ArgMethodWrapper):\n \"\"\" Store arguments and keywords to pass to add_argument_group().\n\n Instances also serve to decorate command methods.\n \"\"\"\n\n def add_to_parser(self, parser, group):\n \"\"\" Add this object's information to the parser.\n \"\"\"\n return parser.add_argument_group(*self.args, **self.kwds)\n\n\nclass kwds(ArgDecorator):\n \"\"\" Provide other keywords to the sub-parser constructor.\n \"\"\"\n def __init__(self, **kwds):\n self.kwds = kwds\n\n def __call__(self, func):\n func = super(kwds, self).__call__(func)\n func.argcmd_kwds = self.kwds\n return func\n\n\n__all__ = ['magic_arguments', 'argument', 'argument_group', 'kwds',\n 'parse_argstring']\n", "path": "IPython/core/magic_arguments.py"}]}
| 3,209 | 311 |
gh_patches_debug_14108
|
rasdani/github-patches
|
git_diff
|
wright-group__WrightTools-726
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Group is not defined in collection
https://github.com/wright-group/WrightTools/blob/ca056aa600f341501a99d2ea4d11f7d74047bc26/WrightTools/_open.py#L48
Statement will cause an attribute error. Not tested currently
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `WrightTools/_open.py`
Content:
```
1 """Generic open method for wt5 files."""
2
3
4 # --- import -------------------------------------------------------------------------------------
5
6
7 import posixpath
8
9 import h5py
10
11 from . import collection as wt_collection
12 from . import data as wt_data
13
14
15 # --- define -------------------------------------------------------------------------------------
16
17
18 __all__ = ["open"]
19
20
21 # --- functions ----------------------------------------------------------------------------------
22
23
24 def open(filepath, edit_local=False):
25 """Open any wt5 file, returning the top-level object (data or collection).
26
27 Parameters
28 ----------
29 filepath : string
30 Path to file.
31 edit_local : boolean (optional)
32 If True, the file itself will be opened for editing. Otherwise, a
33 copy will be created. Default is False.
34
35 Returns
36 -------
37 WrightTools Collection or Data
38 Root-level object in file.
39 """
40 f = h5py.File(filepath)
41 class_name = f[posixpath.sep].attrs["class"]
42 name = f[posixpath.sep].attrs["name"]
43 if class_name == "Data":
44 return wt_data.Data(filepath=filepath, name=name, edit_local=edit_local)
45 elif class_name == "Collection":
46 return wt_collection.Collection(filepath=filepath, name=name, edit_local=edit_local)
47 else:
48 return wt_collection.Group(filepath=filepath, name=name, edit_local=edit_local)
49
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/WrightTools/_open.py b/WrightTools/_open.py
--- a/WrightTools/_open.py
+++ b/WrightTools/_open.py
@@ -10,6 +10,7 @@
from . import collection as wt_collection
from . import data as wt_data
+from . import _group as wt_group
# --- define -------------------------------------------------------------------------------------
@@ -45,4 +46,4 @@
elif class_name == "Collection":
return wt_collection.Collection(filepath=filepath, name=name, edit_local=edit_local)
else:
- return wt_collection.Group(filepath=filepath, name=name, edit_local=edit_local)
+ return wt_group.Group(filepath=filepath, name=name, edit_local=edit_local)
|
{"golden_diff": "diff --git a/WrightTools/_open.py b/WrightTools/_open.py\n--- a/WrightTools/_open.py\n+++ b/WrightTools/_open.py\n@@ -10,6 +10,7 @@\n \n from . import collection as wt_collection\n from . import data as wt_data\n+from . import _group as wt_group\n \n \n # --- define -------------------------------------------------------------------------------------\n@@ -45,4 +46,4 @@\n elif class_name == \"Collection\":\n return wt_collection.Collection(filepath=filepath, name=name, edit_local=edit_local)\n else:\n- return wt_collection.Group(filepath=filepath, name=name, edit_local=edit_local)\n+ return wt_group.Group(filepath=filepath, name=name, edit_local=edit_local)\n", "issue": "Group is not defined in collection\nhttps://github.com/wright-group/WrightTools/blob/ca056aa600f341501a99d2ea4d11f7d74047bc26/WrightTools/_open.py#L48\r\n\r\nStatement will cause an attribute error. Not tested currently\n", "before_files": [{"content": "\"\"\"Generic open method for wt5 files.\"\"\"\n\n\n# --- import -------------------------------------------------------------------------------------\n\n\nimport posixpath\n\nimport h5py\n\nfrom . import collection as wt_collection\nfrom . import data as wt_data\n\n\n# --- define -------------------------------------------------------------------------------------\n\n\n__all__ = [\"open\"]\n\n\n# --- functions ----------------------------------------------------------------------------------\n\n\ndef open(filepath, edit_local=False):\n \"\"\"Open any wt5 file, returning the top-level object (data or collection).\n\n Parameters\n ----------\n filepath : string\n Path to file.\n edit_local : boolean (optional)\n If True, the file itself will be opened for editing. Otherwise, a\n copy will be created. Default is False.\n\n Returns\n -------\n WrightTools Collection or Data\n Root-level object in file.\n \"\"\"\n f = h5py.File(filepath)\n class_name = f[posixpath.sep].attrs[\"class\"]\n name = f[posixpath.sep].attrs[\"name\"]\n if class_name == \"Data\":\n return wt_data.Data(filepath=filepath, name=name, edit_local=edit_local)\n elif class_name == \"Collection\":\n return wt_collection.Collection(filepath=filepath, name=name, edit_local=edit_local)\n else:\n return wt_collection.Group(filepath=filepath, name=name, edit_local=edit_local)\n", "path": "WrightTools/_open.py"}], "after_files": [{"content": "\"\"\"Generic open method for wt5 files.\"\"\"\n\n\n# --- import -------------------------------------------------------------------------------------\n\n\nimport posixpath\n\nimport h5py\n\nfrom . import collection as wt_collection\nfrom . import data as wt_data\nfrom . import _group as wt_group\n\n\n# --- define -------------------------------------------------------------------------------------\n\n\n__all__ = [\"open\"]\n\n\n# --- functions ----------------------------------------------------------------------------------\n\n\ndef open(filepath, edit_local=False):\n \"\"\"Open any wt5 file, returning the top-level object (data or collection).\n\n Parameters\n ----------\n filepath : string\n Path to file.\n edit_local : boolean (optional)\n If True, the file itself will be opened for editing. Otherwise, a\n copy will be created. Default is False.\n\n Returns\n -------\n WrightTools Collection or Data\n Root-level object in file.\n \"\"\"\n f = h5py.File(filepath)\n class_name = f[posixpath.sep].attrs[\"class\"]\n name = f[posixpath.sep].attrs[\"name\"]\n if class_name == \"Data\":\n return wt_data.Data(filepath=filepath, name=name, edit_local=edit_local)\n elif class_name == \"Collection\":\n return wt_collection.Collection(filepath=filepath, name=name, edit_local=edit_local)\n else:\n return wt_group.Group(filepath=filepath, name=name, edit_local=edit_local)\n", "path": "WrightTools/_open.py"}]}
| 703 | 160 |
gh_patches_debug_14577
|
rasdani/github-patches
|
git_diff
|
urllib3__urllib3-2289
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Deprecate NTLMConnectionPool in 1.26.x
As was mentioned in https://github.com/urllib3/urllib3/pull/2278#issuecomment-864414599 and https://github.com/urllib3/urllib3/pull/2278#issuecomment-864450016 we're moving to remove `NTLMConnectionPool` and the `urllib3.contrib.nltmpool` module from urllib3 in v2.0 if we don't find a new maintainer for the module (perhaps as a third-party package ie `urllib3-ntlmpool`?)
- The module is not covered by our test suite.
- It is not clear even which pypi package is needed for it.
- It has fallen into disrepair (e.g. timeout/ssl/other options not being respected).
- According to Wikipedia, "Since 2010, Microsoft no longer recommends NTLM in applications"
- Seems like it's not used often, if at all.
In the `1.26.x` branch we should unconditionally raise a `DeprecationWarning` when the module is imported. Should link to this issue with a call to action to comment in the issue if they are a user. This should help us better discover who (if any) our users are here so we can better make a decision.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/urllib3/contrib/ntlmpool.py`
Content:
```
1 """
2 NTLM authenticating pool, contributed by erikcederstran
3
4 Issue #10, see: http://code.google.com/p/urllib3/issues/detail?id=10
5 """
6 from __future__ import absolute_import
7
8 from logging import getLogger
9
10 from ntlm import ntlm
11
12 from .. import HTTPSConnectionPool
13 from ..packages.six.moves.http_client import HTTPSConnection
14
15 log = getLogger(__name__)
16
17
18 class NTLMConnectionPool(HTTPSConnectionPool):
19 """
20 Implements an NTLM authentication version of an urllib3 connection pool
21 """
22
23 scheme = "https"
24
25 def __init__(self, user, pw, authurl, *args, **kwargs):
26 """
27 authurl is a random URL on the server that is protected by NTLM.
28 user is the Windows user, probably in the DOMAIN\\username format.
29 pw is the password for the user.
30 """
31 super(NTLMConnectionPool, self).__init__(*args, **kwargs)
32 self.authurl = authurl
33 self.rawuser = user
34 user_parts = user.split("\\", 1)
35 self.domain = user_parts[0].upper()
36 self.user = user_parts[1]
37 self.pw = pw
38
39 def _new_conn(self):
40 # Performs the NTLM handshake that secures the connection. The socket
41 # must be kept open while requests are performed.
42 self.num_connections += 1
43 log.debug(
44 "Starting NTLM HTTPS connection no. %d: https://%s%s",
45 self.num_connections,
46 self.host,
47 self.authurl,
48 )
49
50 headers = {"Connection": "Keep-Alive"}
51 req_header = "Authorization"
52 resp_header = "www-authenticate"
53
54 conn = HTTPSConnection(host=self.host, port=self.port)
55
56 # Send negotiation message
57 headers[req_header] = "NTLM %s" % ntlm.create_NTLM_NEGOTIATE_MESSAGE(
58 self.rawuser
59 )
60 log.debug("Request headers: %s", headers)
61 conn.request("GET", self.authurl, None, headers)
62 res = conn.getresponse()
63 reshdr = dict(res.getheaders())
64 log.debug("Response status: %s %s", res.status, res.reason)
65 log.debug("Response headers: %s", reshdr)
66 log.debug("Response data: %s [...]", res.read(100))
67
68 # Remove the reference to the socket, so that it can not be closed by
69 # the response object (we want to keep the socket open)
70 res.fp = None
71
72 # Server should respond with a challenge message
73 auth_header_values = reshdr[resp_header].split(", ")
74 auth_header_value = None
75 for s in auth_header_values:
76 if s[:5] == "NTLM ":
77 auth_header_value = s[5:]
78 if auth_header_value is None:
79 raise Exception(
80 "Unexpected %s response header: %s" % (resp_header, reshdr[resp_header])
81 )
82
83 # Send authentication message
84 ServerChallenge, NegotiateFlags = ntlm.parse_NTLM_CHALLENGE_MESSAGE(
85 auth_header_value
86 )
87 auth_msg = ntlm.create_NTLM_AUTHENTICATE_MESSAGE(
88 ServerChallenge, self.user, self.domain, self.pw, NegotiateFlags
89 )
90 headers[req_header] = "NTLM %s" % auth_msg
91 log.debug("Request headers: %s", headers)
92 conn.request("GET", self.authurl, None, headers)
93 res = conn.getresponse()
94 log.debug("Response status: %s %s", res.status, res.reason)
95 log.debug("Response headers: %s", dict(res.getheaders()))
96 log.debug("Response data: %s [...]", res.read()[:100])
97 if res.status != 200:
98 if res.status == 401:
99 raise Exception("Server rejected request: wrong username or password")
100 raise Exception("Wrong server response: %s %s" % (res.status, res.reason))
101
102 res.fp = None
103 log.debug("Connection established")
104 return conn
105
106 def urlopen(
107 self,
108 method,
109 url,
110 body=None,
111 headers=None,
112 retries=3,
113 redirect=True,
114 assert_same_host=True,
115 ):
116 if headers is None:
117 headers = {}
118 headers["Connection"] = "Keep-Alive"
119 return super(NTLMConnectionPool, self).urlopen(
120 method, url, body, headers, retries, redirect, assert_same_host
121 )
122
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/urllib3/contrib/ntlmpool.py b/src/urllib3/contrib/ntlmpool.py
--- a/src/urllib3/contrib/ntlmpool.py
+++ b/src/urllib3/contrib/ntlmpool.py
@@ -5,6 +5,7 @@
"""
from __future__ import absolute_import
+import warnings
from logging import getLogger
from ntlm import ntlm
@@ -12,6 +13,14 @@
from .. import HTTPSConnectionPool
from ..packages.six.moves.http_client import HTTPSConnection
+warnings.warn(
+ "The 'urllib3.contrib.ntlmpool' module is deprecated and will be removed "
+ "in urllib3 v2.0 release, urllib3 is not able to support it properly due "
+ "to reasons listed in issue: https://github.com/urllib3/urllib3/issues/2282. "
+ "If you are a user of this module please comment in the mentioned issue.",
+ DeprecationWarning,
+)
+
log = getLogger(__name__)
|
{"golden_diff": "diff --git a/src/urllib3/contrib/ntlmpool.py b/src/urllib3/contrib/ntlmpool.py\n--- a/src/urllib3/contrib/ntlmpool.py\n+++ b/src/urllib3/contrib/ntlmpool.py\n@@ -5,6 +5,7 @@\n \"\"\"\n from __future__ import absolute_import\n \n+import warnings\n from logging import getLogger\n \n from ntlm import ntlm\n@@ -12,6 +13,14 @@\n from .. import HTTPSConnectionPool\n from ..packages.six.moves.http_client import HTTPSConnection\n \n+warnings.warn(\n+ \"The 'urllib3.contrib.ntlmpool' module is deprecated and will be removed \"\n+ \"in urllib3 v2.0 release, urllib3 is not able to support it properly due \"\n+ \"to reasons listed in issue: https://github.com/urllib3/urllib3/issues/2282. \"\n+ \"If you are a user of this module please comment in the mentioned issue.\",\n+ DeprecationWarning,\n+)\n+\n log = getLogger(__name__)\n", "issue": "Deprecate NTLMConnectionPool in 1.26.x\nAs was mentioned in https://github.com/urllib3/urllib3/pull/2278#issuecomment-864414599 and https://github.com/urllib3/urllib3/pull/2278#issuecomment-864450016 we're moving to remove `NTLMConnectionPool` and the `urllib3.contrib.nltmpool` module from urllib3 in v2.0 if we don't find a new maintainer for the module (perhaps as a third-party package ie `urllib3-ntlmpool`?)\r\n\r\n- The module is not covered by our test suite.\r\n- It is not clear even which pypi package is needed for it.\r\n- It has fallen into disrepair (e.g. timeout/ssl/other options not being respected).\r\n- According to Wikipedia, \"Since 2010, Microsoft no longer recommends NTLM in applications\"\r\n- Seems like it's not used often, if at all.\r\n\r\nIn the `1.26.x` branch we should unconditionally raise a `DeprecationWarning` when the module is imported. Should link to this issue with a call to action to comment in the issue if they are a user. This should help us better discover who (if any) our users are here so we can better make a decision.\n", "before_files": [{"content": "\"\"\"\nNTLM authenticating pool, contributed by erikcederstran\n\nIssue #10, see: http://code.google.com/p/urllib3/issues/detail?id=10\n\"\"\"\nfrom __future__ import absolute_import\n\nfrom logging import getLogger\n\nfrom ntlm import ntlm\n\nfrom .. import HTTPSConnectionPool\nfrom ..packages.six.moves.http_client import HTTPSConnection\n\nlog = getLogger(__name__)\n\n\nclass NTLMConnectionPool(HTTPSConnectionPool):\n \"\"\"\n Implements an NTLM authentication version of an urllib3 connection pool\n \"\"\"\n\n scheme = \"https\"\n\n def __init__(self, user, pw, authurl, *args, **kwargs):\n \"\"\"\n authurl is a random URL on the server that is protected by NTLM.\n user is the Windows user, probably in the DOMAIN\\\\username format.\n pw is the password for the user.\n \"\"\"\n super(NTLMConnectionPool, self).__init__(*args, **kwargs)\n self.authurl = authurl\n self.rawuser = user\n user_parts = user.split(\"\\\\\", 1)\n self.domain = user_parts[0].upper()\n self.user = user_parts[1]\n self.pw = pw\n\n def _new_conn(self):\n # Performs the NTLM handshake that secures the connection. The socket\n # must be kept open while requests are performed.\n self.num_connections += 1\n log.debug(\n \"Starting NTLM HTTPS connection no. %d: https://%s%s\",\n self.num_connections,\n self.host,\n self.authurl,\n )\n\n headers = {\"Connection\": \"Keep-Alive\"}\n req_header = \"Authorization\"\n resp_header = \"www-authenticate\"\n\n conn = HTTPSConnection(host=self.host, port=self.port)\n\n # Send negotiation message\n headers[req_header] = \"NTLM %s\" % ntlm.create_NTLM_NEGOTIATE_MESSAGE(\n self.rawuser\n )\n log.debug(\"Request headers: %s\", headers)\n conn.request(\"GET\", self.authurl, None, headers)\n res = conn.getresponse()\n reshdr = dict(res.getheaders())\n log.debug(\"Response status: %s %s\", res.status, res.reason)\n log.debug(\"Response headers: %s\", reshdr)\n log.debug(\"Response data: %s [...]\", res.read(100))\n\n # Remove the reference to the socket, so that it can not be closed by\n # the response object (we want to keep the socket open)\n res.fp = None\n\n # Server should respond with a challenge message\n auth_header_values = reshdr[resp_header].split(\", \")\n auth_header_value = None\n for s in auth_header_values:\n if s[:5] == \"NTLM \":\n auth_header_value = s[5:]\n if auth_header_value is None:\n raise Exception(\n \"Unexpected %s response header: %s\" % (resp_header, reshdr[resp_header])\n )\n\n # Send authentication message\n ServerChallenge, NegotiateFlags = ntlm.parse_NTLM_CHALLENGE_MESSAGE(\n auth_header_value\n )\n auth_msg = ntlm.create_NTLM_AUTHENTICATE_MESSAGE(\n ServerChallenge, self.user, self.domain, self.pw, NegotiateFlags\n )\n headers[req_header] = \"NTLM %s\" % auth_msg\n log.debug(\"Request headers: %s\", headers)\n conn.request(\"GET\", self.authurl, None, headers)\n res = conn.getresponse()\n log.debug(\"Response status: %s %s\", res.status, res.reason)\n log.debug(\"Response headers: %s\", dict(res.getheaders()))\n log.debug(\"Response data: %s [...]\", res.read()[:100])\n if res.status != 200:\n if res.status == 401:\n raise Exception(\"Server rejected request: wrong username or password\")\n raise Exception(\"Wrong server response: %s %s\" % (res.status, res.reason))\n\n res.fp = None\n log.debug(\"Connection established\")\n return conn\n\n def urlopen(\n self,\n method,\n url,\n body=None,\n headers=None,\n retries=3,\n redirect=True,\n assert_same_host=True,\n ):\n if headers is None:\n headers = {}\n headers[\"Connection\"] = \"Keep-Alive\"\n return super(NTLMConnectionPool, self).urlopen(\n method, url, body, headers, retries, redirect, assert_same_host\n )\n", "path": "src/urllib3/contrib/ntlmpool.py"}], "after_files": [{"content": "\"\"\"\nNTLM authenticating pool, contributed by erikcederstran\n\nIssue #10, see: http://code.google.com/p/urllib3/issues/detail?id=10\n\"\"\"\nfrom __future__ import absolute_import\n\nimport warnings\nfrom logging import getLogger\n\nfrom ntlm import ntlm\n\nfrom .. import HTTPSConnectionPool\nfrom ..packages.six.moves.http_client import HTTPSConnection\n\nwarnings.warn(\n \"The 'urllib3.contrib.ntlmpool' module is deprecated and will be removed \"\n \"in urllib3 v2.0 release, urllib3 is not able to support it properly due \"\n \"to reasons listed in issue: https://github.com/urllib3/urllib3/issues/2282. \"\n \"If you are a user of this module please comment in the mentioned issue.\",\n DeprecationWarning,\n)\n\nlog = getLogger(__name__)\n\n\nclass NTLMConnectionPool(HTTPSConnectionPool):\n \"\"\"\n Implements an NTLM authentication version of an urllib3 connection pool\n \"\"\"\n\n scheme = \"https\"\n\n def __init__(self, user, pw, authurl, *args, **kwargs):\n \"\"\"\n authurl is a random URL on the server that is protected by NTLM.\n user is the Windows user, probably in the DOMAIN\\\\username format.\n pw is the password for the user.\n \"\"\"\n super(NTLMConnectionPool, self).__init__(*args, **kwargs)\n self.authurl = authurl\n self.rawuser = user\n user_parts = user.split(\"\\\\\", 1)\n self.domain = user_parts[0].upper()\n self.user = user_parts[1]\n self.pw = pw\n\n def _new_conn(self):\n # Performs the NTLM handshake that secures the connection. The socket\n # must be kept open while requests are performed.\n self.num_connections += 1\n log.debug(\n \"Starting NTLM HTTPS connection no. %d: https://%s%s\",\n self.num_connections,\n self.host,\n self.authurl,\n )\n\n headers = {\"Connection\": \"Keep-Alive\"}\n req_header = \"Authorization\"\n resp_header = \"www-authenticate\"\n\n conn = HTTPSConnection(host=self.host, port=self.port)\n\n # Send negotiation message\n headers[req_header] = \"NTLM %s\" % ntlm.create_NTLM_NEGOTIATE_MESSAGE(\n self.rawuser\n )\n log.debug(\"Request headers: %s\", headers)\n conn.request(\"GET\", self.authurl, None, headers)\n res = conn.getresponse()\n reshdr = dict(res.getheaders())\n log.debug(\"Response status: %s %s\", res.status, res.reason)\n log.debug(\"Response headers: %s\", reshdr)\n log.debug(\"Response data: %s [...]\", res.read(100))\n\n # Remove the reference to the socket, so that it can not be closed by\n # the response object (we want to keep the socket open)\n res.fp = None\n\n # Server should respond with a challenge message\n auth_header_values = reshdr[resp_header].split(\", \")\n auth_header_value = None\n for s in auth_header_values:\n if s[:5] == \"NTLM \":\n auth_header_value = s[5:]\n if auth_header_value is None:\n raise Exception(\n \"Unexpected %s response header: %s\" % (resp_header, reshdr[resp_header])\n )\n\n # Send authentication message\n ServerChallenge, NegotiateFlags = ntlm.parse_NTLM_CHALLENGE_MESSAGE(\n auth_header_value\n )\n auth_msg = ntlm.create_NTLM_AUTHENTICATE_MESSAGE(\n ServerChallenge, self.user, self.domain, self.pw, NegotiateFlags\n )\n headers[req_header] = \"NTLM %s\" % auth_msg\n log.debug(\"Request headers: %s\", headers)\n conn.request(\"GET\", self.authurl, None, headers)\n res = conn.getresponse()\n log.debug(\"Response status: %s %s\", res.status, res.reason)\n log.debug(\"Response headers: %s\", dict(res.getheaders()))\n log.debug(\"Response data: %s [...]\", res.read()[:100])\n if res.status != 200:\n if res.status == 401:\n raise Exception(\"Server rejected request: wrong username or password\")\n raise Exception(\"Wrong server response: %s %s\" % (res.status, res.reason))\n\n res.fp = None\n log.debug(\"Connection established\")\n return conn\n\n def urlopen(\n self,\n method,\n url,\n body=None,\n headers=None,\n retries=3,\n redirect=True,\n assert_same_host=True,\n ):\n if headers is None:\n headers = {}\n headers[\"Connection\"] = \"Keep-Alive\"\n return super(NTLMConnectionPool, self).urlopen(\n method, url, body, headers, retries, redirect, assert_same_host\n )\n", "path": "src/urllib3/contrib/ntlmpool.py"}]}
| 1,816 | 241 |
gh_patches_debug_17014
|
rasdani/github-patches
|
git_diff
|
pymedusa__Medusa-5472
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
IndexError sending to uTorrent
**Describe the bug**
Sending an magnet link to uTorret goes into error
**To Reproduce**
Steps to reproduce the behavior:
1. Just add an existing episode to the wanted category and click go
**Expected behavior**
An download into uTorrent
**Medusa (please complete the following information):**
- OS: Windows 10
- Branch: master
- Commit: 4614efc77151ded92ef458a09dec39f8bd5acfc6
**Logs:**
<details>
```
2018-09-10 10:48:55 DEBUG SEARCHQUEUE-BACKLOG-80379 :: [4614efc] uTorrent: Exception raised when sending torrent Rarbg @ magnet:?xt=urn:btih:04a442a9f4ec4f968897faa4bce27f6b2d6f9083&dn=The.Big.Bang.Theory.S11E24.The.Bow.Tie.Asymmetry.720p.AMZN.WEBRip.DDP5.1.x264-NTb%5Brartv%5D&tr=http%3A%2F%2Ftracker.trackerfix.com%3A80%2Fannounce&tr=udp%3A%2F%2F9.rarbg.me%3A2710&tr=udp%3A%2F%2F9.rarbg.to%3A2710&tr=udp%3A%2F%2Fopen.demonii.com%3A1337%2Fannounce&tr=udp://tracker.coppersurfer.tk:6969/announce&tr=udp://tracker.leechers-paradise.org:6969/announce&tr=udp://tracker.zer0day.to:1337/announce&tr=udp://tracker.opentrackr.org:1337/announce&tr=http://tracker.opentrackr.org:1337/announce&tr=udp://p4p.arenabg.com:1337/announce&tr=http://p4p.arenabg.com:1337/announce&tr=udp://explodie.org:6969/announce&tr=udp://9.rarbg.com:2710/announce&tr=http://explodie.org:6969/announce&tr=http://tracker.dler.org:6969/announce&tr=udp://public.popcorn-tracker.org:6969/announce&tr=udp://tracker.internetwarriors.net:1337/announce&tr=udp://ipv4.tracker.harry.lu:80/announce&tr=http://ipv4.tracker.harry.lu:80/announce&tr=udp://mgtracker.org:2710/announce&tr=http://mgtracker.org:6969/announce&tr=udp://tracker.mg64.net:6969/announce&tr=http://tracker.mg64.net:6881/announce&tr=http://torrentsmd.com:8080/announce
Extra Info:
Episodes:
u'The Big Bang Theory' - u'S11E24' - u'The Bow Tie Asymmetry'
location: u''
description: u'When Amy\u2019s parents and Sheldon\u2019s family arrive for the wedding, everybody is focused on making sure all goes according to plan \u2013 everyone except the bride and groom.'
subtitles: u''
subtitles_searchcount: 0
subtitles_lastsearch: u'0001-01-01 00:00:00'
airdate: 736824 (datetime.date(2018, 5, 10))
hasnfo: False
hastbn: False
status: 3
quality: 64
Quality: 720p WEB-DL
Name: The.Big.Bang.Theory.S11E24.The.Bow.Tie.Asymmetry.720p.AMZN.WEBRip.DDP5.1.x264-NTb[rartv]
Size: 770147134
Release Group: NTb
. Error: list index out of range
2018-09-10 10:48:55 ERROR SEARCHQUEUE-BACKLOG-80379 :: [4614efc] uTorrent: Failed Sending Torrent
Traceback (most recent call last):
File "C:\medusa\medusa\clients\torrent\generic.py", line 261, in send_torrent
r_code = self._add_torrent_uri(result)
File "C:\medusa\medusa\clients\torrent\utorrent_client.py", line 92, in _add_torrent_uri
torrent_subfolder = get_torrent_subfolder(result)
File "C:\medusa\medusa\clients\torrent\utorrent_client.py", line 27, in get_torrent_subfolder
root_location = root_dirs[int(root_dirs[0]) + 1]
IndexError: list index out of range
```
</details>
**Additional context**
Add any other context about the problem here.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `medusa/clients/torrent/utorrent_client.py`
Content:
```
1 # coding=utf-8
2
3 """uTorrent Client."""
4
5 from __future__ import unicode_literals
6
7 import logging
8 import os
9 import re
10 from collections import OrderedDict
11
12 from medusa import app
13 from medusa.clients.torrent.generic import GenericClient
14 from medusa.logger.adapters.style import BraceAdapter
15
16 from requests.compat import urljoin
17 from requests.exceptions import RequestException
18
19 log = BraceAdapter(logging.getLogger(__name__))
20 log.logger.addHandler(logging.NullHandler())
21
22
23 def get_torrent_subfolder(result):
24 """Retrieve the series destination-subfolder required for uTorrent WebUI 'start' action."""
25 # Get the subfolder name the user has assigned to that series
26 root_dirs = app.ROOT_DIRS
27 root_location = root_dirs[int(root_dirs[0]) + 1]
28 torrent_path = result.series.raw_location
29
30 if not root_location == torrent_path:
31 # Subfolder is under root, but possibly not directly under
32 if torrent_path.startswith(root_location):
33 torrent_subfolder = torrent_path.replace(root_location, '')
34 # Subfolder is NOT under root, use it too (WebUI limitation)
35 else:
36 torrent_subfolder = os.path.basename(torrent_path)
37 # Use the series name if there is no subfolder defined
38 else:
39 torrent_subfolder = result.series.name
40
41 log.debug('Show {name}: torrent download destination folder is: {path} (sub-folder: {sub})',
42 {'name': result.series.name, 'path': torrent_path, 'sub': torrent_subfolder})
43
44 return torrent_subfolder
45
46
47 class UTorrentAPI(GenericClient):
48 """uTorrent API class."""
49
50 def __init__(self, host=None, username=None, password=None):
51 """Constructor.
52
53 :param host:
54 :type host: string
55 :param username:
56 :type username: string
57 :param password:
58 :type password: string
59 """
60 super(UTorrentAPI, self).__init__('uTorrent', host, username, password)
61 self.url = urljoin(self.host, 'gui/')
62
63 def _request(self, method='get', params=None, data=None, files=None, cookies=None):
64 if cookies:
65 log.debug('{name}: Received unused argument: cookies={value!r}',
66 {'name': self.name, 'value': cookies})
67
68 # "token" must be the first parameter: https://goo.gl/qTxf9x
69 ordered_params = OrderedDict({
70 'token': self.auth,
71 })
72 ordered_params.update(params)
73
74 return super(UTorrentAPI, self)._request(method=method, params=ordered_params, data=data, files=files)
75
76 def _get_auth(self):
77 try:
78 self.response = self.session.get(urljoin(self.url, 'token.html'), verify=False)
79 except RequestException as error:
80 log.warning('Unable to authenticate with uTorrent client: {0!r}', error)
81 return None
82
83 if not self.response.status_code == 404:
84 self.auth = re.findall('<div.*?>(.*?)</', self.response.text)[0]
85 return self.auth
86
87 return None
88
89 def _add_torrent_uri(self, result):
90 """Send an 'add-url' download request to uTorrent when search provider is using a magnet link."""
91 # Set proper subfolder as download destination for uTorrent torrent
92 torrent_subfolder = get_torrent_subfolder(result)
93
94 return self._request(params={
95 'action': 'add-url',
96 # limit the param length to 1024 chars (uTorrent bug)
97 's': result.url[:1024],
98 'path': torrent_subfolder,
99 })
100
101 def _add_torrent_file(self, result):
102 """Send an 'add-file' download request to uTorrent when the search provider is using a .torrent file."""
103 # Set proper subfolder as download destination for uTorrent torrent
104 torrent_subfolder = get_torrent_subfolder(result)
105
106 return self._request(
107 method='post',
108 params={
109 'action': 'add-file',
110 'path': torrent_subfolder,
111 },
112 files={
113 'torrent_file': (
114 '{name}.torrent'.format(name=result.name),
115 result.content,
116 ),
117 }
118 )
119
120 def _set_torrent_label(self, result):
121 """Send a 'setprop' request to uTorrent to set a label for the torrent, optionally - the show name."""
122 torrent_new_label = result.series.name
123
124 if result.series.is_anime and app.TORRENT_LABEL_ANIME:
125 label = app.TORRENT_LABEL_ANIME
126 else:
127 label = app.TORRENT_LABEL
128
129 label = label.replace('%N', torrent_new_label)
130
131 log.debug('Torrent label is now set to {path}', {'path': label})
132
133 return self._request(
134 params={
135 'action': 'setprops',
136 'hash': result.hash,
137 's': 'label',
138 'v': label,
139 }
140 )
141
142 def _set_torrent_ratio(self, result):
143 ratio = result.ratio or None
144
145 if ratio:
146 if self._request(params={
147 'action': 'setprops',
148 'hash': result.hash,
149 's': 'seed_override',
150 'v': '1',
151 }):
152 return self._request(params={
153 'action': 'setprops',
154 'hash': result.hash,
155 's': 'seed_ratio',
156 'v': float(ratio) * 10,
157 })
158 else:
159 return False
160
161 return True
162
163 def _set_torrent_seed_time(self, result):
164 # Allow 0 - as unlimitted, and "-1" - that is used to disable
165 if float(app.TORRENT_SEED_TIME) >= 0:
166 if self._request(params={
167 'action': 'setprops',
168 'hash': result.hash,
169 's': 'seed_override',
170 'v': '1',
171 }):
172 return self._request(params={
173 'action': 'setprops',
174 'hash': result.hash,
175 's': 'seed_time',
176 'v': 3600 * float(app.TORRENT_SEED_TIME),
177 })
178 else:
179 return False
180 else:
181 return True
182
183 def _set_torrent_priority(self, result):
184 return True if result.priority != 1 else self._request(params={
185 'action': 'queuetop',
186 'hash': result.hash,
187 })
188
189 def _set_torrent_pause(self, result):
190 return self._request(params={
191 # "stop" torrent, can always be resumed!
192 'action': 'stop' if app.TORRENT_PAUSED else 'start',
193 'hash': result.hash,
194 })
195
196 def remove_torrent(self, info_hash):
197 """Remove torrent from client using given info_hash.
198
199 :param info_hash:
200 :type info_hash: string
201 :return
202 :rtype: bool
203 """
204 return self._request(params={
205 'action': 'removedatatorrent',
206 'hash': info_hash,
207 })
208
209
210 api = UTorrentAPI
211
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/medusa/clients/torrent/utorrent_client.py b/medusa/clients/torrent/utorrent_client.py
--- a/medusa/clients/torrent/utorrent_client.py
+++ b/medusa/clients/torrent/utorrent_client.py
@@ -24,10 +24,11 @@
"""Retrieve the series destination-subfolder required for uTorrent WebUI 'start' action."""
# Get the subfolder name the user has assigned to that series
root_dirs = app.ROOT_DIRS
- root_location = root_dirs[int(root_dirs[0]) + 1]
+ if root_dirs:
+ root_location = root_dirs[int(root_dirs[0]) + 1]
torrent_path = result.series.raw_location
- if not root_location == torrent_path:
+ if root_dirs and root_location != torrent_path:
# Subfolder is under root, but possibly not directly under
if torrent_path.startswith(root_location):
torrent_subfolder = torrent_path.replace(root_location, '')
|
{"golden_diff": "diff --git a/medusa/clients/torrent/utorrent_client.py b/medusa/clients/torrent/utorrent_client.py\n--- a/medusa/clients/torrent/utorrent_client.py\n+++ b/medusa/clients/torrent/utorrent_client.py\n@@ -24,10 +24,11 @@\n \"\"\"Retrieve the series destination-subfolder required for uTorrent WebUI 'start' action.\"\"\"\n # Get the subfolder name the user has assigned to that series\n root_dirs = app.ROOT_DIRS\n- root_location = root_dirs[int(root_dirs[0]) + 1]\n+ if root_dirs:\n+ root_location = root_dirs[int(root_dirs[0]) + 1]\n torrent_path = result.series.raw_location\n \n- if not root_location == torrent_path:\n+ if root_dirs and root_location != torrent_path:\n # Subfolder is under root, but possibly not directly under\n if torrent_path.startswith(root_location):\n torrent_subfolder = torrent_path.replace(root_location, '')\n", "issue": "IndexError sending to uTorrent\n**Describe the bug**\r\nSending an magnet link to uTorret goes into error\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Just add an existing episode to the wanted category and click go\r\n\r\n**Expected behavior**\r\nAn download into uTorrent\r\n\r\n**Medusa (please complete the following information):**\r\n - OS: Windows 10\r\n - Branch: master\r\n - Commit: 4614efc77151ded92ef458a09dec39f8bd5acfc6 \r\n\r\n**Logs:**\r\n<details>\r\n\r\n```\r\n2018-09-10 10:48:55 DEBUG SEARCHQUEUE-BACKLOG-80379 :: [4614efc] uTorrent: Exception raised when sending torrent Rarbg @ magnet:?xt=urn:btih:04a442a9f4ec4f968897faa4bce27f6b2d6f9083&dn=The.Big.Bang.Theory.S11E24.The.Bow.Tie.Asymmetry.720p.AMZN.WEBRip.DDP5.1.x264-NTb%5Brartv%5D&tr=http%3A%2F%2Ftracker.trackerfix.com%3A80%2Fannounce&tr=udp%3A%2F%2F9.rarbg.me%3A2710&tr=udp%3A%2F%2F9.rarbg.to%3A2710&tr=udp%3A%2F%2Fopen.demonii.com%3A1337%2Fannounce&tr=udp://tracker.coppersurfer.tk:6969/announce&tr=udp://tracker.leechers-paradise.org:6969/announce&tr=udp://tracker.zer0day.to:1337/announce&tr=udp://tracker.opentrackr.org:1337/announce&tr=http://tracker.opentrackr.org:1337/announce&tr=udp://p4p.arenabg.com:1337/announce&tr=http://p4p.arenabg.com:1337/announce&tr=udp://explodie.org:6969/announce&tr=udp://9.rarbg.com:2710/announce&tr=http://explodie.org:6969/announce&tr=http://tracker.dler.org:6969/announce&tr=udp://public.popcorn-tracker.org:6969/announce&tr=udp://tracker.internetwarriors.net:1337/announce&tr=udp://ipv4.tracker.harry.lu:80/announce&tr=http://ipv4.tracker.harry.lu:80/announce&tr=udp://mgtracker.org:2710/announce&tr=http://mgtracker.org:6969/announce&tr=udp://tracker.mg64.net:6969/announce&tr=http://tracker.mg64.net:6881/announce&tr=http://torrentsmd.com:8080/announce\r\nExtra Info:\r\nEpisodes:\r\n u'The Big Bang Theory' - u'S11E24' - u'The Bow Tie Asymmetry'\r\nlocation: u''\r\ndescription: u'When Amy\\u2019s parents and Sheldon\\u2019s family arrive for the wedding, everybody is focused on making sure all goes according to plan \\u2013 everyone except the bride and groom.'\r\nsubtitles: u''\r\nsubtitles_searchcount: 0\r\nsubtitles_lastsearch: u'0001-01-01 00:00:00'\r\nairdate: 736824 (datetime.date(2018, 5, 10))\r\nhasnfo: False\r\nhastbn: False\r\nstatus: 3\r\nquality: 64\r\nQuality: 720p WEB-DL\r\nName: The.Big.Bang.Theory.S11E24.The.Bow.Tie.Asymmetry.720p.AMZN.WEBRip.DDP5.1.x264-NTb[rartv]\r\nSize: 770147134\r\nRelease Group: NTb\r\n. Error: list index out of range\r\n2018-09-10 10:48:55 ERROR SEARCHQUEUE-BACKLOG-80379 :: [4614efc] uTorrent: Failed Sending Torrent\r\nTraceback (most recent call last):\r\n File \"C:\\medusa\\medusa\\clients\\torrent\\generic.py\", line 261, in send_torrent\r\n r_code = self._add_torrent_uri(result)\r\n File \"C:\\medusa\\medusa\\clients\\torrent\\utorrent_client.py\", line 92, in _add_torrent_uri\r\n torrent_subfolder = get_torrent_subfolder(result)\r\n File \"C:\\medusa\\medusa\\clients\\torrent\\utorrent_client.py\", line 27, in get_torrent_subfolder\r\n root_location = root_dirs[int(root_dirs[0]) + 1]\r\nIndexError: list index out of range\r\n```\r\n</details>\r\n\r\n**Additional context**\r\nAdd any other context about the problem here.\r\n\n", "before_files": [{"content": "# coding=utf-8\n\n\"\"\"uTorrent Client.\"\"\"\n\nfrom __future__ import unicode_literals\n\nimport logging\nimport os\nimport re\nfrom collections import OrderedDict\n\nfrom medusa import app\nfrom medusa.clients.torrent.generic import GenericClient\nfrom medusa.logger.adapters.style import BraceAdapter\n\nfrom requests.compat import urljoin\nfrom requests.exceptions import RequestException\n\nlog = BraceAdapter(logging.getLogger(__name__))\nlog.logger.addHandler(logging.NullHandler())\n\n\ndef get_torrent_subfolder(result):\n \"\"\"Retrieve the series destination-subfolder required for uTorrent WebUI 'start' action.\"\"\"\n # Get the subfolder name the user has assigned to that series\n root_dirs = app.ROOT_DIRS\n root_location = root_dirs[int(root_dirs[0]) + 1]\n torrent_path = result.series.raw_location\n\n if not root_location == torrent_path:\n # Subfolder is under root, but possibly not directly under\n if torrent_path.startswith(root_location):\n torrent_subfolder = torrent_path.replace(root_location, '')\n # Subfolder is NOT under root, use it too (WebUI limitation)\n else:\n torrent_subfolder = os.path.basename(torrent_path)\n # Use the series name if there is no subfolder defined\n else:\n torrent_subfolder = result.series.name\n\n log.debug('Show {name}: torrent download destination folder is: {path} (sub-folder: {sub})',\n {'name': result.series.name, 'path': torrent_path, 'sub': torrent_subfolder})\n\n return torrent_subfolder\n\n\nclass UTorrentAPI(GenericClient):\n \"\"\"uTorrent API class.\"\"\"\n\n def __init__(self, host=None, username=None, password=None):\n \"\"\"Constructor.\n\n :param host:\n :type host: string\n :param username:\n :type username: string\n :param password:\n :type password: string\n \"\"\"\n super(UTorrentAPI, self).__init__('uTorrent', host, username, password)\n self.url = urljoin(self.host, 'gui/')\n\n def _request(self, method='get', params=None, data=None, files=None, cookies=None):\n if cookies:\n log.debug('{name}: Received unused argument: cookies={value!r}',\n {'name': self.name, 'value': cookies})\n\n # \"token\" must be the first parameter: https://goo.gl/qTxf9x\n ordered_params = OrderedDict({\n 'token': self.auth,\n })\n ordered_params.update(params)\n\n return super(UTorrentAPI, self)._request(method=method, params=ordered_params, data=data, files=files)\n\n def _get_auth(self):\n try:\n self.response = self.session.get(urljoin(self.url, 'token.html'), verify=False)\n except RequestException as error:\n log.warning('Unable to authenticate with uTorrent client: {0!r}', error)\n return None\n\n if not self.response.status_code == 404:\n self.auth = re.findall('<div.*?>(.*?)</', self.response.text)[0]\n return self.auth\n\n return None\n\n def _add_torrent_uri(self, result):\n \"\"\"Send an 'add-url' download request to uTorrent when search provider is using a magnet link.\"\"\"\n # Set proper subfolder as download destination for uTorrent torrent\n torrent_subfolder = get_torrent_subfolder(result)\n\n return self._request(params={\n 'action': 'add-url',\n # limit the param length to 1024 chars (uTorrent bug)\n 's': result.url[:1024],\n 'path': torrent_subfolder,\n })\n\n def _add_torrent_file(self, result):\n \"\"\"Send an 'add-file' download request to uTorrent when the search provider is using a .torrent file.\"\"\"\n # Set proper subfolder as download destination for uTorrent torrent\n torrent_subfolder = get_torrent_subfolder(result)\n\n return self._request(\n method='post',\n params={\n 'action': 'add-file',\n 'path': torrent_subfolder,\n },\n files={\n 'torrent_file': (\n '{name}.torrent'.format(name=result.name),\n result.content,\n ),\n }\n )\n\n def _set_torrent_label(self, result):\n \"\"\"Send a 'setprop' request to uTorrent to set a label for the torrent, optionally - the show name.\"\"\"\n torrent_new_label = result.series.name\n\n if result.series.is_anime and app.TORRENT_LABEL_ANIME:\n label = app.TORRENT_LABEL_ANIME\n else:\n label = app.TORRENT_LABEL\n\n label = label.replace('%N', torrent_new_label)\n\n log.debug('Torrent label is now set to {path}', {'path': label})\n\n return self._request(\n params={\n 'action': 'setprops',\n 'hash': result.hash,\n 's': 'label',\n 'v': label,\n }\n )\n\n def _set_torrent_ratio(self, result):\n ratio = result.ratio or None\n\n if ratio:\n if self._request(params={\n 'action': 'setprops',\n 'hash': result.hash,\n 's': 'seed_override',\n 'v': '1',\n }):\n return self._request(params={\n 'action': 'setprops',\n 'hash': result.hash,\n 's': 'seed_ratio',\n 'v': float(ratio) * 10,\n })\n else:\n return False\n\n return True\n\n def _set_torrent_seed_time(self, result):\n # Allow 0 - as unlimitted, and \"-1\" - that is used to disable\n if float(app.TORRENT_SEED_TIME) >= 0:\n if self._request(params={\n 'action': 'setprops',\n 'hash': result.hash,\n 's': 'seed_override',\n 'v': '1',\n }):\n return self._request(params={\n 'action': 'setprops',\n 'hash': result.hash,\n 's': 'seed_time',\n 'v': 3600 * float(app.TORRENT_SEED_TIME),\n })\n else:\n return False\n else:\n return True\n\n def _set_torrent_priority(self, result):\n return True if result.priority != 1 else self._request(params={\n 'action': 'queuetop',\n 'hash': result.hash,\n })\n\n def _set_torrent_pause(self, result):\n return self._request(params={\n # \"stop\" torrent, can always be resumed!\n 'action': 'stop' if app.TORRENT_PAUSED else 'start',\n 'hash': result.hash,\n })\n\n def remove_torrent(self, info_hash):\n \"\"\"Remove torrent from client using given info_hash.\n\n :param info_hash:\n :type info_hash: string\n :return\n :rtype: bool\n \"\"\"\n return self._request(params={\n 'action': 'removedatatorrent',\n 'hash': info_hash,\n })\n\n\napi = UTorrentAPI\n", "path": "medusa/clients/torrent/utorrent_client.py"}], "after_files": [{"content": "# coding=utf-8\n\n\"\"\"uTorrent Client.\"\"\"\n\nfrom __future__ import unicode_literals\n\nimport logging\nimport os\nimport re\nfrom collections import OrderedDict\n\nfrom medusa import app\nfrom medusa.clients.torrent.generic import GenericClient\nfrom medusa.logger.adapters.style import BraceAdapter\n\nfrom requests.compat import urljoin\nfrom requests.exceptions import RequestException\n\nlog = BraceAdapter(logging.getLogger(__name__))\nlog.logger.addHandler(logging.NullHandler())\n\n\ndef get_torrent_subfolder(result):\n \"\"\"Retrieve the series destination-subfolder required for uTorrent WebUI 'start' action.\"\"\"\n # Get the subfolder name the user has assigned to that series\n root_dirs = app.ROOT_DIRS\n if root_dirs:\n root_location = root_dirs[int(root_dirs[0]) + 1]\n torrent_path = result.series.raw_location\n\n if root_dirs and root_location != torrent_path:\n # Subfolder is under root, but possibly not directly under\n if torrent_path.startswith(root_location):\n torrent_subfolder = torrent_path.replace(root_location, '')\n # Subfolder is NOT under root, use it too (WebUI limitation)\n else:\n torrent_subfolder = os.path.basename(torrent_path)\n # Use the series name if there is no subfolder defined\n else:\n torrent_subfolder = result.series.name\n\n log.debug('Show {name}: torrent download destination folder is: {path} (sub-folder: {sub})',\n {'name': result.series.name, 'path': torrent_path, 'sub': torrent_subfolder})\n\n return torrent_subfolder\n\n\nclass UTorrentAPI(GenericClient):\n \"\"\"uTorrent API class.\"\"\"\n\n def __init__(self, host=None, username=None, password=None):\n \"\"\"Constructor.\n\n :param host:\n :type host: string\n :param username:\n :type username: string\n :param password:\n :type password: string\n \"\"\"\n super(UTorrentAPI, self).__init__('uTorrent', host, username, password)\n self.url = urljoin(self.host, 'gui/')\n\n def _request(self, method='get', params=None, data=None, files=None, cookies=None):\n if cookies:\n log.debug('{name}: Received unused argument: cookies={value!r}',\n {'name': self.name, 'value': cookies})\n\n # \"token\" must be the first parameter: https://goo.gl/qTxf9x\n ordered_params = OrderedDict({\n 'token': self.auth,\n })\n ordered_params.update(params)\n\n return super(UTorrentAPI, self)._request(method=method, params=ordered_params, data=data, files=files)\n\n def _get_auth(self):\n try:\n self.response = self.session.get(urljoin(self.url, 'token.html'), verify=False)\n except RequestException as error:\n log.warning('Unable to authenticate with uTorrent client: {0!r}', error)\n return None\n\n if not self.response.status_code == 404:\n self.auth = re.findall('<div.*?>(.*?)</', self.response.text)[0]\n return self.auth\n\n return None\n\n def _add_torrent_uri(self, result):\n \"\"\"Send an 'add-url' download request to uTorrent when search provider is using a magnet link.\"\"\"\n # Set proper subfolder as download destination for uTorrent torrent\n torrent_subfolder = get_torrent_subfolder(result)\n\n return self._request(params={\n 'action': 'add-url',\n # limit the param length to 1024 chars (uTorrent bug)\n 's': result.url[:1024],\n 'path': torrent_subfolder,\n })\n\n def _add_torrent_file(self, result):\n \"\"\"Send an 'add-file' download request to uTorrent when the search provider is using a .torrent file.\"\"\"\n # Set proper subfolder as download destination for uTorrent torrent\n torrent_subfolder = get_torrent_subfolder(result)\n\n return self._request(\n method='post',\n params={\n 'action': 'add-file',\n 'path': torrent_subfolder,\n },\n files={\n 'torrent_file': (\n '{name}.torrent'.format(name=result.name),\n result.content,\n ),\n }\n )\n\n def _set_torrent_label(self, result):\n \"\"\"Send a 'setprop' request to uTorrent to set a label for the torrent, optionally - the show name.\"\"\"\n torrent_new_label = result.series.name\n\n if result.series.is_anime and app.TORRENT_LABEL_ANIME:\n label = app.TORRENT_LABEL_ANIME\n else:\n label = app.TORRENT_LABEL\n\n label = label.replace('%N', torrent_new_label)\n\n log.debug('Torrent label is now set to {path}', {'path': label})\n\n return self._request(\n params={\n 'action': 'setprops',\n 'hash': result.hash,\n 's': 'label',\n 'v': label,\n }\n )\n\n def _set_torrent_ratio(self, result):\n ratio = result.ratio or None\n\n if ratio:\n if self._request(params={\n 'action': 'setprops',\n 'hash': result.hash,\n 's': 'seed_override',\n 'v': '1',\n }):\n return self._request(params={\n 'action': 'setprops',\n 'hash': result.hash,\n 's': 'seed_ratio',\n 'v': float(ratio) * 10,\n })\n else:\n return False\n\n return True\n\n def _set_torrent_seed_time(self, result):\n # Allow 0 - as unlimitted, and \"-1\" - that is used to disable\n if float(app.TORRENT_SEED_TIME) >= 0:\n if self._request(params={\n 'action': 'setprops',\n 'hash': result.hash,\n 's': 'seed_override',\n 'v': '1',\n }):\n return self._request(params={\n 'action': 'setprops',\n 'hash': result.hash,\n 's': 'seed_time',\n 'v': 3600 * float(app.TORRENT_SEED_TIME),\n })\n else:\n return False\n else:\n return True\n\n def _set_torrent_priority(self, result):\n return True if result.priority != 1 else self._request(params={\n 'action': 'queuetop',\n 'hash': result.hash,\n })\n\n def _set_torrent_pause(self, result):\n return self._request(params={\n # \"stop\" torrent, can always be resumed!\n 'action': 'stop' if app.TORRENT_PAUSED else 'start',\n 'hash': result.hash,\n })\n\n def remove_torrent(self, info_hash):\n \"\"\"Remove torrent from client using given info_hash.\n\n :param info_hash:\n :type info_hash: string\n :return\n :rtype: bool\n \"\"\"\n return self._request(params={\n 'action': 'removedatatorrent',\n 'hash': info_hash,\n })\n\n\napi = UTorrentAPI\n", "path": "medusa/clients/torrent/utorrent_client.py"}]}
| 3,543 | 222 |
gh_patches_debug_16553
|
rasdani/github-patches
|
git_diff
|
internetarchive__openlibrary-8214
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
DOCKER: git rev-parse --short HEAD --` returns a non-zero exit status 128. web container won't load
### Evidence / Screenshot (if possible)

### Steps to Reproduce
1. Follow the instructions from openlibrary/docker/README.md to build a new docker setup
2. Run docker compose up
* Actual:
The errors shown on the screen capture are thrown, and the _web_ container fails to get up.
* Expected:
_web_ container successfully brought up
### Proposal & Constraints
The issue seems to be on the `get_software_version()` function called on `openlibrary/plugins/openlibrary/status.py`, when `git rev-parse --short HEAD --` returns a non-zero exit status 128.
I put the function call between quotation marks as a test, so that "Software version" becomes a hardcoded string, and after that everything seems to load and work just fine.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `openlibrary/utils/__init__.py`
Content:
```
1 """Generic utilities"""
2
3 from enum import Enum
4 import re
5 from subprocess import run
6 from typing import TypeVar, Literal, Optional
7 from collections.abc import Iterable, Callable
8
9 to_drop = set(''';/?:@&=+$,<>#%"{}|\\^[]`\n\r''')
10
11
12 def str_to_key(s: str) -> str:
13 """
14 >>> str_to_key("?H$e##l{o}[0] -world!")
15 'helo0_-world!'
16 >>> str_to_key("".join(to_drop))
17 ''
18 >>> str_to_key("")
19 ''
20 """
21 return ''.join(c if c != ' ' else '_' for c in s.lower() if c not in to_drop)
22
23
24 def finddict(dicts, **filters):
25 """Find a dictionary that matches given filter conditions.
26
27 >>> dicts = [{"x": 1, "y": 2}, {"x": 3, "y": 4}]
28 >>> sorted(finddict(dicts, x=1).items())
29 [('x', 1), ('y', 2)]
30 """
31 for d in dicts:
32 if all(d.get(k) == v for k, v in filters.items()):
33 return d
34
35
36 T = TypeVar('T')
37
38
39 def uniq(values: Iterable[T], key=None) -> list[T]:
40 """Returns the unique entries from the given values in the original order.
41
42 The value of the optional `key` parameter should be a function that takes
43 a single argument and returns a key to test the uniqueness.
44 TODO: Moved this to core/utils.py
45
46 >>> uniq("abcbcddefefg")
47 ['a', 'b', 'c', 'd', 'e', 'f', 'g']
48 >>> uniq("011223344556677889")
49 ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
50 """
51 key = key or (lambda x: x)
52 s = set()
53 result = []
54 for v in values:
55 k = key(v)
56 if k not in s:
57 s.add(k)
58 result.append(v)
59 return result
60
61
62 def take_best(
63 items: list[T],
64 optimization: Literal["min", "max"],
65 scoring_fn: Callable[[T], float],
66 ) -> list[T]:
67 """
68 >>> take_best([], 'min', lambda x: x)
69 []
70 >>> take_best([3, 2, 1], 'min', lambda x: x)
71 [1]
72 >>> take_best([3, 4, 5], 'max', lambda x: x)
73 [5]
74 >>> take_best([4, 1, -1, -1], 'min', lambda x: x)
75 [-1, -1]
76 """
77 best_score = float("-inf") if optimization == "max" else float("inf")
78 besties = []
79 for item in items:
80 score = scoring_fn(item)
81 if (optimization == "max" and score > best_score) or (
82 optimization == "min" and score < best_score
83 ):
84 best_score = score
85 besties = [item]
86 elif score == best_score:
87 besties.append(item)
88 else:
89 continue
90 return besties
91
92
93 def multisort_best(
94 items: list[T], specs: list[tuple[Literal["min", "max"], Callable[[T], float]]]
95 ) -> Optional[T]:
96 """
97 Takes the best item, taking into account the multisorts
98
99 >>> multisort_best([], [])
100
101 >>> multisort_best([3,4,5], [('max', lambda x: x)])
102 5
103
104 >>> multisort_best([
105 ... {'provider': 'ia', 'size': 4},
106 ... {'provider': 'ia', 'size': 12},
107 ... {'provider': None, 'size': 42},
108 ... ], [
109 ... ('min', lambda x: 0 if x['provider'] == 'ia' else 1),
110 ... ('max', lambda x: x['size']),
111 ... ])
112 {'provider': 'ia', 'size': 12}
113 """
114 if not items:
115 return None
116 pool = items
117 for optimization, fn in specs:
118 # Shrink the pool down each time
119 pool = take_best(pool, optimization, fn)
120 return pool[0]
121
122
123 def dicthash(d):
124 """Dictionaries are not hashable. This function converts dictionary into nested
125 tuples, so that it can hashed.
126 """
127 if isinstance(d, dict):
128 return tuple((k, dicthash(d[k])) for k in sorted(d))
129 elif isinstance(d, list):
130 return tuple(dicthash(v) for v in d)
131 else:
132 return d
133
134
135 olid_re = re.compile(r'OL\d+[A-Z]', re.IGNORECASE)
136
137
138 def find_olid_in_string(s: str, olid_suffix: str | None = None) -> str | None:
139 """
140 >>> find_olid_in_string("ol123w")
141 'OL123W'
142 >>> find_olid_in_string("/authors/OL123A/DAVIE_BOWIE")
143 'OL123A'
144 >>> find_olid_in_string("/authors/OL123A/DAVIE_BOWIE", "W")
145 >>> find_olid_in_string("some random string")
146 """
147 found = re.search(olid_re, s)
148 if not found:
149 return None
150 olid = found.group(0).upper()
151
152 if olid_suffix and not olid.endswith(olid_suffix):
153 return None
154
155 return olid
156
157
158 def olid_to_key(olid: str) -> str:
159 """
160 >>> olid_to_key('OL123W')
161 '/works/OL123W'
162 >>> olid_to_key('OL123A')
163 '/authors/OL123A'
164 >>> olid_to_key('OL123M')
165 '/books/OL123M'
166 >>> olid_to_key("OL123L")
167 '/lists/OL123L'
168 """
169 typ = {
170 'A': 'authors',
171 'W': 'works',
172 'M': 'books',
173 'L': 'lists',
174 }[olid[-1]]
175 if not typ:
176 raise ValueError(f"Invalid olid: {olid}")
177 return f"/{typ}/{olid}"
178
179
180 def extract_numeric_id_from_olid(olid):
181 """
182 >>> extract_numeric_id_from_olid("OL123W")
183 '123'
184 >>> extract_numeric_id_from_olid("/authors/OL123A")
185 '123'
186 """
187 if '/' in olid:
188 olid = olid.split('/')[-1]
189 if olid.lower().startswith('ol'):
190 olid = olid[2:]
191 if not is_number(olid[-1].lower()):
192 olid = olid[:-1]
193 return olid
194
195
196 def is_number(s):
197 """
198 >>> all(is_number(n) for n in (1234, "1234", -1234, "-1234", 123.4, -123.4))
199 True
200 >>> not any(is_number(n) for n in ("123.4", "-123.4", "123a", "--1234"))
201 True
202 """
203 try:
204 int(s)
205 return True
206 except ValueError:
207 return False
208
209
210 def get_software_version() -> str:
211 """
212 assert get_software_version() # Should never return a falsy value
213 """
214 cmd = "git rev-parse --short HEAD --".split()
215 return run(cmd, capture_output=True, text=True, check=True).stdout.strip()
216
217
218 # See https://docs.python.org/3/library/enum.html#orderedenum
219 class OrderedEnum(Enum):
220 def __ge__(self, other):
221 if self.__class__ is other.__class__:
222 return self.value >= other.value
223 return NotImplemented
224
225 def __gt__(self, other):
226 if self.__class__ is other.__class__:
227 return self.value > other.value
228 return NotImplemented
229
230 def __le__(self, other):
231 if self.__class__ is other.__class__:
232 return self.value <= other.value
233 return NotImplemented
234
235 def __lt__(self, other):
236 if self.__class__ is other.__class__:
237 return self.value < other.value
238 return NotImplemented
239
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/openlibrary/utils/__init__.py b/openlibrary/utils/__init__.py
--- a/openlibrary/utils/__init__.py
+++ b/openlibrary/utils/__init__.py
@@ -2,7 +2,7 @@
from enum import Enum
import re
-from subprocess import run
+from subprocess import CalledProcessError, run
from typing import TypeVar, Literal, Optional
from collections.abc import Iterable, Callable
@@ -212,7 +212,10 @@
assert get_software_version() # Should never return a falsy value
"""
cmd = "git rev-parse --short HEAD --".split()
- return run(cmd, capture_output=True, text=True, check=True).stdout.strip()
+ try:
+ return run(cmd, capture_output=True, text=True, check=True).stdout.strip()
+ except CalledProcessError:
+ return "unknown"
# See https://docs.python.org/3/library/enum.html#orderedenum
|
{"golden_diff": "diff --git a/openlibrary/utils/__init__.py b/openlibrary/utils/__init__.py\n--- a/openlibrary/utils/__init__.py\n+++ b/openlibrary/utils/__init__.py\n@@ -2,7 +2,7 @@\n \n from enum import Enum\n import re\n-from subprocess import run\n+from subprocess import CalledProcessError, run\n from typing import TypeVar, Literal, Optional\n from collections.abc import Iterable, Callable\n \n@@ -212,7 +212,10 @@\n assert get_software_version() # Should never return a falsy value\n \"\"\"\n cmd = \"git rev-parse --short HEAD --\".split()\n- return run(cmd, capture_output=True, text=True, check=True).stdout.strip()\n+ try:\n+ return run(cmd, capture_output=True, text=True, check=True).stdout.strip()\n+ except CalledProcessError:\n+ return \"unknown\"\n \n \n # See https://docs.python.org/3/library/enum.html#orderedenum\n", "issue": "DOCKER: git rev-parse --short HEAD --` returns a non-zero exit status 128. web container won't load\n### Evidence / Screenshot (if possible)\r\n\r\n\r\n### Steps to Reproduce\r\n\r\n1. Follow the instructions from openlibrary/docker/README.md to build a new docker setup\r\n2. Run docker compose up\r\n\r\n* Actual:\r\nThe errors shown on the screen capture are thrown, and the _web_ container fails to get up.\r\n* Expected:\r\n_web_ container successfully brought up\r\n\r\n### Proposal & Constraints\r\nThe issue seems to be on the `get_software_version()` function called on `openlibrary/plugins/openlibrary/status.py`, when `git rev-parse --short HEAD --` returns a non-zero exit status 128.\r\n\r\nI put the function call between quotation marks as a test, so that \"Software version\" becomes a hardcoded string, and after that everything seems to load and work just fine.\r\n\r\n\n", "before_files": [{"content": "\"\"\"Generic utilities\"\"\"\n\nfrom enum import Enum\nimport re\nfrom subprocess import run\nfrom typing import TypeVar, Literal, Optional\nfrom collections.abc import Iterable, Callable\n\nto_drop = set(''';/?:@&=+$,<>#%\"{}|\\\\^[]`\\n\\r''')\n\n\ndef str_to_key(s: str) -> str:\n \"\"\"\n >>> str_to_key(\"?H$e##l{o}[0] -world!\")\n 'helo0_-world!'\n >>> str_to_key(\"\".join(to_drop))\n ''\n >>> str_to_key(\"\")\n ''\n \"\"\"\n return ''.join(c if c != ' ' else '_' for c in s.lower() if c not in to_drop)\n\n\ndef finddict(dicts, **filters):\n \"\"\"Find a dictionary that matches given filter conditions.\n\n >>> dicts = [{\"x\": 1, \"y\": 2}, {\"x\": 3, \"y\": 4}]\n >>> sorted(finddict(dicts, x=1).items())\n [('x', 1), ('y', 2)]\n \"\"\"\n for d in dicts:\n if all(d.get(k) == v for k, v in filters.items()):\n return d\n\n\nT = TypeVar('T')\n\n\ndef uniq(values: Iterable[T], key=None) -> list[T]:\n \"\"\"Returns the unique entries from the given values in the original order.\n\n The value of the optional `key` parameter should be a function that takes\n a single argument and returns a key to test the uniqueness.\n TODO: Moved this to core/utils.py\n\n >>> uniq(\"abcbcddefefg\")\n ['a', 'b', 'c', 'd', 'e', 'f', 'g']\n >>> uniq(\"011223344556677889\")\n ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']\n \"\"\"\n key = key or (lambda x: x)\n s = set()\n result = []\n for v in values:\n k = key(v)\n if k not in s:\n s.add(k)\n result.append(v)\n return result\n\n\ndef take_best(\n items: list[T],\n optimization: Literal[\"min\", \"max\"],\n scoring_fn: Callable[[T], float],\n) -> list[T]:\n \"\"\"\n >>> take_best([], 'min', lambda x: x)\n []\n >>> take_best([3, 2, 1], 'min', lambda x: x)\n [1]\n >>> take_best([3, 4, 5], 'max', lambda x: x)\n [5]\n >>> take_best([4, 1, -1, -1], 'min', lambda x: x)\n [-1, -1]\n \"\"\"\n best_score = float(\"-inf\") if optimization == \"max\" else float(\"inf\")\n besties = []\n for item in items:\n score = scoring_fn(item)\n if (optimization == \"max\" and score > best_score) or (\n optimization == \"min\" and score < best_score\n ):\n best_score = score\n besties = [item]\n elif score == best_score:\n besties.append(item)\n else:\n continue\n return besties\n\n\ndef multisort_best(\n items: list[T], specs: list[tuple[Literal[\"min\", \"max\"], Callable[[T], float]]]\n) -> Optional[T]:\n \"\"\"\n Takes the best item, taking into account the multisorts\n\n >>> multisort_best([], [])\n\n >>> multisort_best([3,4,5], [('max', lambda x: x)])\n 5\n\n >>> multisort_best([\n ... {'provider': 'ia', 'size': 4},\n ... {'provider': 'ia', 'size': 12},\n ... {'provider': None, 'size': 42},\n ... ], [\n ... ('min', lambda x: 0 if x['provider'] == 'ia' else 1),\n ... ('max', lambda x: x['size']),\n ... ])\n {'provider': 'ia', 'size': 12}\n \"\"\"\n if not items:\n return None\n pool = items\n for optimization, fn in specs:\n # Shrink the pool down each time\n pool = take_best(pool, optimization, fn)\n return pool[0]\n\n\ndef dicthash(d):\n \"\"\"Dictionaries are not hashable. This function converts dictionary into nested\n tuples, so that it can hashed.\n \"\"\"\n if isinstance(d, dict):\n return tuple((k, dicthash(d[k])) for k in sorted(d))\n elif isinstance(d, list):\n return tuple(dicthash(v) for v in d)\n else:\n return d\n\n\nolid_re = re.compile(r'OL\\d+[A-Z]', re.IGNORECASE)\n\n\ndef find_olid_in_string(s: str, olid_suffix: str | None = None) -> str | None:\n \"\"\"\n >>> find_olid_in_string(\"ol123w\")\n 'OL123W'\n >>> find_olid_in_string(\"/authors/OL123A/DAVIE_BOWIE\")\n 'OL123A'\n >>> find_olid_in_string(\"/authors/OL123A/DAVIE_BOWIE\", \"W\")\n >>> find_olid_in_string(\"some random string\")\n \"\"\"\n found = re.search(olid_re, s)\n if not found:\n return None\n olid = found.group(0).upper()\n\n if olid_suffix and not olid.endswith(olid_suffix):\n return None\n\n return olid\n\n\ndef olid_to_key(olid: str) -> str:\n \"\"\"\n >>> olid_to_key('OL123W')\n '/works/OL123W'\n >>> olid_to_key('OL123A')\n '/authors/OL123A'\n >>> olid_to_key('OL123M')\n '/books/OL123M'\n >>> olid_to_key(\"OL123L\")\n '/lists/OL123L'\n \"\"\"\n typ = {\n 'A': 'authors',\n 'W': 'works',\n 'M': 'books',\n 'L': 'lists',\n }[olid[-1]]\n if not typ:\n raise ValueError(f\"Invalid olid: {olid}\")\n return f\"/{typ}/{olid}\"\n\n\ndef extract_numeric_id_from_olid(olid):\n \"\"\"\n >>> extract_numeric_id_from_olid(\"OL123W\")\n '123'\n >>> extract_numeric_id_from_olid(\"/authors/OL123A\")\n '123'\n \"\"\"\n if '/' in olid:\n olid = olid.split('/')[-1]\n if olid.lower().startswith('ol'):\n olid = olid[2:]\n if not is_number(olid[-1].lower()):\n olid = olid[:-1]\n return olid\n\n\ndef is_number(s):\n \"\"\"\n >>> all(is_number(n) for n in (1234, \"1234\", -1234, \"-1234\", 123.4, -123.4))\n True\n >>> not any(is_number(n) for n in (\"123.4\", \"-123.4\", \"123a\", \"--1234\"))\n True\n \"\"\"\n try:\n int(s)\n return True\n except ValueError:\n return False\n\n\ndef get_software_version() -> str:\n \"\"\"\n assert get_software_version() # Should never return a falsy value\n \"\"\"\n cmd = \"git rev-parse --short HEAD --\".split()\n return run(cmd, capture_output=True, text=True, check=True).stdout.strip()\n\n\n# See https://docs.python.org/3/library/enum.html#orderedenum\nclass OrderedEnum(Enum):\n def __ge__(self, other):\n if self.__class__ is other.__class__:\n return self.value >= other.value\n return NotImplemented\n\n def __gt__(self, other):\n if self.__class__ is other.__class__:\n return self.value > other.value\n return NotImplemented\n\n def __le__(self, other):\n if self.__class__ is other.__class__:\n return self.value <= other.value\n return NotImplemented\n\n def __lt__(self, other):\n if self.__class__ is other.__class__:\n return self.value < other.value\n return NotImplemented\n", "path": "openlibrary/utils/__init__.py"}], "after_files": [{"content": "\"\"\"Generic utilities\"\"\"\n\nfrom enum import Enum\nimport re\nfrom subprocess import CalledProcessError, run\nfrom typing import TypeVar, Literal, Optional\nfrom collections.abc import Iterable, Callable\n\nto_drop = set(''';/?:@&=+$,<>#%\"{}|\\\\^[]`\\n\\r''')\n\n\ndef str_to_key(s: str) -> str:\n \"\"\"\n >>> str_to_key(\"?H$e##l{o}[0] -world!\")\n 'helo0_-world!'\n >>> str_to_key(\"\".join(to_drop))\n ''\n >>> str_to_key(\"\")\n ''\n \"\"\"\n return ''.join(c if c != ' ' else '_' for c in s.lower() if c not in to_drop)\n\n\ndef finddict(dicts, **filters):\n \"\"\"Find a dictionary that matches given filter conditions.\n\n >>> dicts = [{\"x\": 1, \"y\": 2}, {\"x\": 3, \"y\": 4}]\n >>> sorted(finddict(dicts, x=1).items())\n [('x', 1), ('y', 2)]\n \"\"\"\n for d in dicts:\n if all(d.get(k) == v for k, v in filters.items()):\n return d\n\n\nT = TypeVar('T')\n\n\ndef uniq(values: Iterable[T], key=None) -> list[T]:\n \"\"\"Returns the unique entries from the given values in the original order.\n\n The value of the optional `key` parameter should be a function that takes\n a single argument and returns a key to test the uniqueness.\n TODO: Moved this to core/utils.py\n\n >>> uniq(\"abcbcddefefg\")\n ['a', 'b', 'c', 'd', 'e', 'f', 'g']\n >>> uniq(\"011223344556677889\")\n ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']\n \"\"\"\n key = key or (lambda x: x)\n s = set()\n result = []\n for v in values:\n k = key(v)\n if k not in s:\n s.add(k)\n result.append(v)\n return result\n\n\ndef take_best(\n items: list[T],\n optimization: Literal[\"min\", \"max\"],\n scoring_fn: Callable[[T], float],\n) -> list[T]:\n \"\"\"\n >>> take_best([], 'min', lambda x: x)\n []\n >>> take_best([3, 2, 1], 'min', lambda x: x)\n [1]\n >>> take_best([3, 4, 5], 'max', lambda x: x)\n [5]\n >>> take_best([4, 1, -1, -1], 'min', lambda x: x)\n [-1, -1]\n \"\"\"\n best_score = float(\"-inf\") if optimization == \"max\" else float(\"inf\")\n besties = []\n for item in items:\n score = scoring_fn(item)\n if (optimization == \"max\" and score > best_score) or (\n optimization == \"min\" and score < best_score\n ):\n best_score = score\n besties = [item]\n elif score == best_score:\n besties.append(item)\n else:\n continue\n return besties\n\n\ndef multisort_best(\n items: list[T], specs: list[tuple[Literal[\"min\", \"max\"], Callable[[T], float]]]\n) -> Optional[T]:\n \"\"\"\n Takes the best item, taking into account the multisorts\n\n >>> multisort_best([], [])\n\n >>> multisort_best([3,4,5], [('max', lambda x: x)])\n 5\n\n >>> multisort_best([\n ... {'provider': 'ia', 'size': 4},\n ... {'provider': 'ia', 'size': 12},\n ... {'provider': None, 'size': 42},\n ... ], [\n ... ('min', lambda x: 0 if x['provider'] == 'ia' else 1),\n ... ('max', lambda x: x['size']),\n ... ])\n {'provider': 'ia', 'size': 12}\n \"\"\"\n if not items:\n return None\n pool = items\n for optimization, fn in specs:\n # Shrink the pool down each time\n pool = take_best(pool, optimization, fn)\n return pool[0]\n\n\ndef dicthash(d):\n \"\"\"Dictionaries are not hashable. This function converts dictionary into nested\n tuples, so that it can hashed.\n \"\"\"\n if isinstance(d, dict):\n return tuple((k, dicthash(d[k])) for k in sorted(d))\n elif isinstance(d, list):\n return tuple(dicthash(v) for v in d)\n else:\n return d\n\n\nolid_re = re.compile(r'OL\\d+[A-Z]', re.IGNORECASE)\n\n\ndef find_olid_in_string(s: str, olid_suffix: str | None = None) -> str | None:\n \"\"\"\n >>> find_olid_in_string(\"ol123w\")\n 'OL123W'\n >>> find_olid_in_string(\"/authors/OL123A/DAVIE_BOWIE\")\n 'OL123A'\n >>> find_olid_in_string(\"/authors/OL123A/DAVIE_BOWIE\", \"W\")\n >>> find_olid_in_string(\"some random string\")\n \"\"\"\n found = re.search(olid_re, s)\n if not found:\n return None\n olid = found.group(0).upper()\n\n if olid_suffix and not olid.endswith(olid_suffix):\n return None\n\n return olid\n\n\ndef olid_to_key(olid: str) -> str:\n \"\"\"\n >>> olid_to_key('OL123W')\n '/works/OL123W'\n >>> olid_to_key('OL123A')\n '/authors/OL123A'\n >>> olid_to_key('OL123M')\n '/books/OL123M'\n >>> olid_to_key(\"OL123L\")\n '/lists/OL123L'\n \"\"\"\n typ = {\n 'A': 'authors',\n 'W': 'works',\n 'M': 'books',\n 'L': 'lists',\n }[olid[-1]]\n if not typ:\n raise ValueError(f\"Invalid olid: {olid}\")\n return f\"/{typ}/{olid}\"\n\n\ndef extract_numeric_id_from_olid(olid):\n \"\"\"\n >>> extract_numeric_id_from_olid(\"OL123W\")\n '123'\n >>> extract_numeric_id_from_olid(\"/authors/OL123A\")\n '123'\n \"\"\"\n if '/' in olid:\n olid = olid.split('/')[-1]\n if olid.lower().startswith('ol'):\n olid = olid[2:]\n if not is_number(olid[-1].lower()):\n olid = olid[:-1]\n return olid\n\n\ndef is_number(s):\n \"\"\"\n >>> all(is_number(n) for n in (1234, \"1234\", -1234, \"-1234\", 123.4, -123.4))\n True\n >>> not any(is_number(n) for n in (\"123.4\", \"-123.4\", \"123a\", \"--1234\"))\n True\n \"\"\"\n try:\n int(s)\n return True\n except ValueError:\n return False\n\n\ndef get_software_version() -> str:\n \"\"\"\n assert get_software_version() # Should never return a falsy value\n \"\"\"\n cmd = \"git rev-parse --short HEAD --\".split()\n try:\n return run(cmd, capture_output=True, text=True, check=True).stdout.strip()\n except CalledProcessError:\n return \"unknown\"\n\n\n# See https://docs.python.org/3/library/enum.html#orderedenum\nclass OrderedEnum(Enum):\n def __ge__(self, other):\n if self.__class__ is other.__class__:\n return self.value >= other.value\n return NotImplemented\n\n def __gt__(self, other):\n if self.__class__ is other.__class__:\n return self.value > other.value\n return NotImplemented\n\n def __le__(self, other):\n if self.__class__ is other.__class__:\n return self.value <= other.value\n return NotImplemented\n\n def __lt__(self, other):\n if self.__class__ is other.__class__:\n return self.value < other.value\n return NotImplemented\n", "path": "openlibrary/utils/__init__.py"}]}
| 3,018 | 214 |
gh_patches_debug_61109
|
rasdani/github-patches
|
git_diff
|
pre-commit__pre-commit-1709
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
running `pre-commit autoupdate` fails because tip of HEAD is missing hook
Hello 👋
I'm setting up `pre-commit` on a project and came across an issue when adding hook `destroyed-symlinks`. The error message suggested running `pre-commit autoupdate`. I ran that and saw that it cannot update because the tip of HEAD is missing that hook. I'm not sure what that means so posting here.
```console
$ echo ' - id: destroyed-symlinks' >> .pre-commit-config.yaml
$ git add -p !$
git add -p .pre-commit-config.yaml
diff --git a/.pre-commit-config.yaml b/.pre-commit-config.yaml
index bfde4717..949f3ffc 100644
--- a/.pre-commit-config.yaml
+++ b/.pre-commit-config.yaml
@@ -21,3 +21,4 @@ repos:
- id: check-vcs-permalinks
- id: check-xml
- id: debug-statements
+ - id: destroyed-symlinks
(1/1) Stage this hunk [y,n,q,a,d,e,?]? y
$ git commit -m 'new hook destroyed-symlinks'
[ERROR] `destroyed-symlinks` is not present in repository https://github.com/pre-commit/pre-commit-hooks. Typo? Perhaps it is introduced in a newer version? Often `pre-commit autoupdate` fixes this.
$ git status
On branch pre-commit
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
modified: .pre-commit-config.yaml
Untracked files:
(use "git add <file>..." to include in what will be committed)
tests/__init__.py
$ pre-commit autoupdate
Updating https://github.com/pre-commit/pre-commit-hooks ... [INFO] Initializing environment for https://github.com/pre-commit/pre-commit-hooks.
Cannot update because the tip of HEAD is missing these hooks:
destroyed-symlinks
$ git checkout .
Updated 0 paths from the index
$ pre-commit autoupdate
Updating https://github.com/pre-commit/pre-commit-hooks ... Cannot update because the tip of HEAD is missing these hooks:
destroyed-symlinks
$ pre-commit --version
pre-commit 2.9.0
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pre_commit/commands/autoupdate.py`
Content:
```
1 import os.path
2 import re
3 from typing import Any
4 from typing import Dict
5 from typing import List
6 from typing import NamedTuple
7 from typing import Optional
8 from typing import Sequence
9 from typing import Tuple
10
11 import pre_commit.constants as C
12 from pre_commit import git
13 from pre_commit import output
14 from pre_commit.clientlib import InvalidManifestError
15 from pre_commit.clientlib import load_config
16 from pre_commit.clientlib import load_manifest
17 from pre_commit.clientlib import LOCAL
18 from pre_commit.clientlib import META
19 from pre_commit.commands.migrate_config import migrate_config
20 from pre_commit.store import Store
21 from pre_commit.util import CalledProcessError
22 from pre_commit.util import cmd_output
23 from pre_commit.util import cmd_output_b
24 from pre_commit.util import tmpdir
25 from pre_commit.util import yaml_dump
26 from pre_commit.util import yaml_load
27
28
29 class RevInfo(NamedTuple):
30 repo: str
31 rev: str
32 frozen: Optional[str]
33
34 @classmethod
35 def from_config(cls, config: Dict[str, Any]) -> 'RevInfo':
36 return cls(config['repo'], config['rev'], None)
37
38 def update(self, tags_only: bool, freeze: bool) -> 'RevInfo':
39 if tags_only:
40 tag_cmd = ('git', 'describe', 'FETCH_HEAD', '--tags', '--abbrev=0')
41 else:
42 tag_cmd = ('git', 'describe', 'FETCH_HEAD', '--tags', '--exact')
43
44 with tmpdir() as tmp:
45 git.init_repo(tmp, self.repo)
46 cmd_output_b('git', 'fetch', 'origin', 'HEAD', '--tags', cwd=tmp)
47
48 try:
49 rev = cmd_output(*tag_cmd, cwd=tmp)[1].strip()
50 except CalledProcessError:
51 cmd = ('git', 'rev-parse', 'FETCH_HEAD')
52 rev = cmd_output(*cmd, cwd=tmp)[1].strip()
53
54 frozen = None
55 if freeze:
56 exact = cmd_output('git', 'rev-parse', rev, cwd=tmp)[1].strip()
57 if exact != rev:
58 rev, frozen = exact, rev
59 return self._replace(rev=rev, frozen=frozen)
60
61
62 class RepositoryCannotBeUpdatedError(RuntimeError):
63 pass
64
65
66 def _check_hooks_still_exist_at_rev(
67 repo_config: Dict[str, Any],
68 info: RevInfo,
69 store: Store,
70 ) -> None:
71 try:
72 path = store.clone(repo_config['repo'], info.rev)
73 manifest = load_manifest(os.path.join(path, C.MANIFEST_FILE))
74 except InvalidManifestError as e:
75 raise RepositoryCannotBeUpdatedError(str(e))
76
77 # See if any of our hooks were deleted with the new commits
78 hooks = {hook['id'] for hook in repo_config['hooks']}
79 hooks_missing = hooks - {hook['id'] for hook in manifest}
80 if hooks_missing:
81 raise RepositoryCannotBeUpdatedError(
82 f'Cannot update because the tip of HEAD is missing these hooks:\n'
83 f'{", ".join(sorted(hooks_missing))}',
84 )
85
86
87 REV_LINE_RE = re.compile(r'^(\s+)rev:(\s*)([\'"]?)([^\s#]+)(.*)(\r?\n)$')
88
89
90 def _original_lines(
91 path: str,
92 rev_infos: List[Optional[RevInfo]],
93 retry: bool = False,
94 ) -> Tuple[List[str], List[int]]:
95 """detect `rev:` lines or reformat the file"""
96 with open(path, newline='') as f:
97 original = f.read()
98
99 lines = original.splitlines(True)
100 idxs = [i for i, line in enumerate(lines) if REV_LINE_RE.match(line)]
101 if len(idxs) == len(rev_infos):
102 return lines, idxs
103 elif retry:
104 raise AssertionError('could not find rev lines')
105 else:
106 with open(path, 'w') as f:
107 f.write(yaml_dump(yaml_load(original)))
108 return _original_lines(path, rev_infos, retry=True)
109
110
111 def _write_new_config(path: str, rev_infos: List[Optional[RevInfo]]) -> None:
112 lines, idxs = _original_lines(path, rev_infos)
113
114 for idx, rev_info in zip(idxs, rev_infos):
115 if rev_info is None:
116 continue
117 match = REV_LINE_RE.match(lines[idx])
118 assert match is not None
119 new_rev_s = yaml_dump({'rev': rev_info.rev}, default_style=match[3])
120 new_rev = new_rev_s.split(':', 1)[1].strip()
121 if rev_info.frozen is not None:
122 comment = f' # frozen: {rev_info.frozen}'
123 elif match[5].strip().startswith('# frozen:'):
124 comment = ''
125 else:
126 comment = match[5]
127 lines[idx] = f'{match[1]}rev:{match[2]}{new_rev}{comment}{match[6]}'
128
129 with open(path, 'w', newline='') as f:
130 f.write(''.join(lines))
131
132
133 def autoupdate(
134 config_file: str,
135 store: Store,
136 tags_only: bool,
137 freeze: bool,
138 repos: Sequence[str] = (),
139 ) -> int:
140 """Auto-update the pre-commit config to the latest versions of repos."""
141 migrate_config(config_file, quiet=True)
142 retv = 0
143 rev_infos: List[Optional[RevInfo]] = []
144 changed = False
145
146 config = load_config(config_file)
147 for repo_config in config['repos']:
148 if repo_config['repo'] in {LOCAL, META}:
149 continue
150
151 info = RevInfo.from_config(repo_config)
152 if repos and info.repo not in repos:
153 rev_infos.append(None)
154 continue
155
156 output.write(f'Updating {info.repo} ... ')
157 new_info = info.update(tags_only=tags_only, freeze=freeze)
158 try:
159 _check_hooks_still_exist_at_rev(repo_config, new_info, store)
160 except RepositoryCannotBeUpdatedError as error:
161 output.write_line(error.args[0])
162 rev_infos.append(None)
163 retv = 1
164 continue
165
166 if new_info.rev != info.rev:
167 changed = True
168 if new_info.frozen:
169 updated_to = f'{new_info.frozen} (frozen)'
170 else:
171 updated_to = new_info.rev
172 msg = f'updating {info.rev} -> {updated_to}.'
173 output.write_line(msg)
174 rev_infos.append(new_info)
175 else:
176 output.write_line('already up to date.')
177 rev_infos.append(None)
178
179 if changed:
180 _write_new_config(config_file, rev_infos)
181
182 return retv
183
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pre_commit/commands/autoupdate.py b/pre_commit/commands/autoupdate.py
--- a/pre_commit/commands/autoupdate.py
+++ b/pre_commit/commands/autoupdate.py
@@ -79,8 +79,8 @@
hooks_missing = hooks - {hook['id'] for hook in manifest}
if hooks_missing:
raise RepositoryCannotBeUpdatedError(
- f'Cannot update because the tip of HEAD is missing these hooks:\n'
- f'{", ".join(sorted(hooks_missing))}',
+ f'Cannot update because the update target is missing these '
+ f'hooks:\n{", ".join(sorted(hooks_missing))}',
)
|
{"golden_diff": "diff --git a/pre_commit/commands/autoupdate.py b/pre_commit/commands/autoupdate.py\n--- a/pre_commit/commands/autoupdate.py\n+++ b/pre_commit/commands/autoupdate.py\n@@ -79,8 +79,8 @@\n hooks_missing = hooks - {hook['id'] for hook in manifest}\n if hooks_missing:\n raise RepositoryCannotBeUpdatedError(\n- f'Cannot update because the tip of HEAD is missing these hooks:\\n'\n- f'{\", \".join(sorted(hooks_missing))}',\n+ f'Cannot update because the update target is missing these '\n+ f'hooks:\\n{\", \".join(sorted(hooks_missing))}',\n )\n", "issue": "running `pre-commit autoupdate` fails because tip of HEAD is missing hook\nHello \ud83d\udc4b \r\nI'm setting up `pre-commit` on a project and came across an issue when adding hook `destroyed-symlinks`. The error message suggested running `pre-commit autoupdate`. I ran that and saw that it cannot update because the tip of HEAD is missing that hook. I'm not sure what that means so posting here.\r\n\r\n```console\r\n$ echo ' - id: destroyed-symlinks' >> .pre-commit-config.yaml\r\n$ git add -p !$\r\ngit add -p .pre-commit-config.yaml\r\ndiff --git a/.pre-commit-config.yaml b/.pre-commit-config.yaml\r\nindex bfde4717..949f3ffc 100644\r\n--- a/.pre-commit-config.yaml\r\n+++ b/.pre-commit-config.yaml\r\n@@ -21,3 +21,4 @@ repos:\r\n - id: check-vcs-permalinks\r\n - id: check-xml\r\n - id: debug-statements\r\n+ - id: destroyed-symlinks\r\n(1/1) Stage this hunk [y,n,q,a,d,e,?]? y\r\n\r\n$ git commit -m 'new hook destroyed-symlinks'\r\n[ERROR] `destroyed-symlinks` is not present in repository https://github.com/pre-commit/pre-commit-hooks. Typo? Perhaps it is introduced in a newer version? Often `pre-commit autoupdate` fixes this.\r\n$ git status\r\nOn branch pre-commit\r\nChanges to be committed:\r\n (use \"git restore --staged <file>...\" to unstage)\r\n modified: .pre-commit-config.yaml\r\n\r\nUntracked files:\r\n (use \"git add <file>...\" to include in what will be committed)\r\n tests/__init__.py\r\n\r\n$ pre-commit autoupdate\r\nUpdating https://github.com/pre-commit/pre-commit-hooks ... [INFO] Initializing environment for https://github.com/pre-commit/pre-commit-hooks.\r\nCannot update because the tip of HEAD is missing these hooks:\r\ndestroyed-symlinks\r\n$ git checkout .\r\nUpdated 0 paths from the index\r\n$ pre-commit autoupdate\r\nUpdating https://github.com/pre-commit/pre-commit-hooks ... Cannot update because the tip of HEAD is missing these hooks:\r\ndestroyed-symlinks\r\n$ pre-commit --version\r\npre-commit 2.9.0\r\n```\n", "before_files": [{"content": "import os.path\nimport re\nfrom typing import Any\nfrom typing import Dict\nfrom typing import List\nfrom typing import NamedTuple\nfrom typing import Optional\nfrom typing import Sequence\nfrom typing import Tuple\n\nimport pre_commit.constants as C\nfrom pre_commit import git\nfrom pre_commit import output\nfrom pre_commit.clientlib import InvalidManifestError\nfrom pre_commit.clientlib import load_config\nfrom pre_commit.clientlib import load_manifest\nfrom pre_commit.clientlib import LOCAL\nfrom pre_commit.clientlib import META\nfrom pre_commit.commands.migrate_config import migrate_config\nfrom pre_commit.store import Store\nfrom pre_commit.util import CalledProcessError\nfrom pre_commit.util import cmd_output\nfrom pre_commit.util import cmd_output_b\nfrom pre_commit.util import tmpdir\nfrom pre_commit.util import yaml_dump\nfrom pre_commit.util import yaml_load\n\n\nclass RevInfo(NamedTuple):\n repo: str\n rev: str\n frozen: Optional[str]\n\n @classmethod\n def from_config(cls, config: Dict[str, Any]) -> 'RevInfo':\n return cls(config['repo'], config['rev'], None)\n\n def update(self, tags_only: bool, freeze: bool) -> 'RevInfo':\n if tags_only:\n tag_cmd = ('git', 'describe', 'FETCH_HEAD', '--tags', '--abbrev=0')\n else:\n tag_cmd = ('git', 'describe', 'FETCH_HEAD', '--tags', '--exact')\n\n with tmpdir() as tmp:\n git.init_repo(tmp, self.repo)\n cmd_output_b('git', 'fetch', 'origin', 'HEAD', '--tags', cwd=tmp)\n\n try:\n rev = cmd_output(*tag_cmd, cwd=tmp)[1].strip()\n except CalledProcessError:\n cmd = ('git', 'rev-parse', 'FETCH_HEAD')\n rev = cmd_output(*cmd, cwd=tmp)[1].strip()\n\n frozen = None\n if freeze:\n exact = cmd_output('git', 'rev-parse', rev, cwd=tmp)[1].strip()\n if exact != rev:\n rev, frozen = exact, rev\n return self._replace(rev=rev, frozen=frozen)\n\n\nclass RepositoryCannotBeUpdatedError(RuntimeError):\n pass\n\n\ndef _check_hooks_still_exist_at_rev(\n repo_config: Dict[str, Any],\n info: RevInfo,\n store: Store,\n) -> None:\n try:\n path = store.clone(repo_config['repo'], info.rev)\n manifest = load_manifest(os.path.join(path, C.MANIFEST_FILE))\n except InvalidManifestError as e:\n raise RepositoryCannotBeUpdatedError(str(e))\n\n # See if any of our hooks were deleted with the new commits\n hooks = {hook['id'] for hook in repo_config['hooks']}\n hooks_missing = hooks - {hook['id'] for hook in manifest}\n if hooks_missing:\n raise RepositoryCannotBeUpdatedError(\n f'Cannot update because the tip of HEAD is missing these hooks:\\n'\n f'{\", \".join(sorted(hooks_missing))}',\n )\n\n\nREV_LINE_RE = re.compile(r'^(\\s+)rev:(\\s*)([\\'\"]?)([^\\s#]+)(.*)(\\r?\\n)$')\n\n\ndef _original_lines(\n path: str,\n rev_infos: List[Optional[RevInfo]],\n retry: bool = False,\n) -> Tuple[List[str], List[int]]:\n \"\"\"detect `rev:` lines or reformat the file\"\"\"\n with open(path, newline='') as f:\n original = f.read()\n\n lines = original.splitlines(True)\n idxs = [i for i, line in enumerate(lines) if REV_LINE_RE.match(line)]\n if len(idxs) == len(rev_infos):\n return lines, idxs\n elif retry:\n raise AssertionError('could not find rev lines')\n else:\n with open(path, 'w') as f:\n f.write(yaml_dump(yaml_load(original)))\n return _original_lines(path, rev_infos, retry=True)\n\n\ndef _write_new_config(path: str, rev_infos: List[Optional[RevInfo]]) -> None:\n lines, idxs = _original_lines(path, rev_infos)\n\n for idx, rev_info in zip(idxs, rev_infos):\n if rev_info is None:\n continue\n match = REV_LINE_RE.match(lines[idx])\n assert match is not None\n new_rev_s = yaml_dump({'rev': rev_info.rev}, default_style=match[3])\n new_rev = new_rev_s.split(':', 1)[1].strip()\n if rev_info.frozen is not None:\n comment = f' # frozen: {rev_info.frozen}'\n elif match[5].strip().startswith('# frozen:'):\n comment = ''\n else:\n comment = match[5]\n lines[idx] = f'{match[1]}rev:{match[2]}{new_rev}{comment}{match[6]}'\n\n with open(path, 'w', newline='') as f:\n f.write(''.join(lines))\n\n\ndef autoupdate(\n config_file: str,\n store: Store,\n tags_only: bool,\n freeze: bool,\n repos: Sequence[str] = (),\n) -> int:\n \"\"\"Auto-update the pre-commit config to the latest versions of repos.\"\"\"\n migrate_config(config_file, quiet=True)\n retv = 0\n rev_infos: List[Optional[RevInfo]] = []\n changed = False\n\n config = load_config(config_file)\n for repo_config in config['repos']:\n if repo_config['repo'] in {LOCAL, META}:\n continue\n\n info = RevInfo.from_config(repo_config)\n if repos and info.repo not in repos:\n rev_infos.append(None)\n continue\n\n output.write(f'Updating {info.repo} ... ')\n new_info = info.update(tags_only=tags_only, freeze=freeze)\n try:\n _check_hooks_still_exist_at_rev(repo_config, new_info, store)\n except RepositoryCannotBeUpdatedError as error:\n output.write_line(error.args[0])\n rev_infos.append(None)\n retv = 1\n continue\n\n if new_info.rev != info.rev:\n changed = True\n if new_info.frozen:\n updated_to = f'{new_info.frozen} (frozen)'\n else:\n updated_to = new_info.rev\n msg = f'updating {info.rev} -> {updated_to}.'\n output.write_line(msg)\n rev_infos.append(new_info)\n else:\n output.write_line('already up to date.')\n rev_infos.append(None)\n\n if changed:\n _write_new_config(config_file, rev_infos)\n\n return retv\n", "path": "pre_commit/commands/autoupdate.py"}], "after_files": [{"content": "import os.path\nimport re\nfrom typing import Any\nfrom typing import Dict\nfrom typing import List\nfrom typing import NamedTuple\nfrom typing import Optional\nfrom typing import Sequence\nfrom typing import Tuple\n\nimport pre_commit.constants as C\nfrom pre_commit import git\nfrom pre_commit import output\nfrom pre_commit.clientlib import InvalidManifestError\nfrom pre_commit.clientlib import load_config\nfrom pre_commit.clientlib import load_manifest\nfrom pre_commit.clientlib import LOCAL\nfrom pre_commit.clientlib import META\nfrom pre_commit.commands.migrate_config import migrate_config\nfrom pre_commit.store import Store\nfrom pre_commit.util import CalledProcessError\nfrom pre_commit.util import cmd_output\nfrom pre_commit.util import cmd_output_b\nfrom pre_commit.util import tmpdir\nfrom pre_commit.util import yaml_dump\nfrom pre_commit.util import yaml_load\n\n\nclass RevInfo(NamedTuple):\n repo: str\n rev: str\n frozen: Optional[str]\n\n @classmethod\n def from_config(cls, config: Dict[str, Any]) -> 'RevInfo':\n return cls(config['repo'], config['rev'], None)\n\n def update(self, tags_only: bool, freeze: bool) -> 'RevInfo':\n if tags_only:\n tag_cmd = ('git', 'describe', 'FETCH_HEAD', '--tags', '--abbrev=0')\n else:\n tag_cmd = ('git', 'describe', 'FETCH_HEAD', '--tags', '--exact')\n\n with tmpdir() as tmp:\n git.init_repo(tmp, self.repo)\n cmd_output_b('git', 'fetch', 'origin', 'HEAD', '--tags', cwd=tmp)\n\n try:\n rev = cmd_output(*tag_cmd, cwd=tmp)[1].strip()\n except CalledProcessError:\n cmd = ('git', 'rev-parse', 'FETCH_HEAD')\n rev = cmd_output(*cmd, cwd=tmp)[1].strip()\n\n frozen = None\n if freeze:\n exact = cmd_output('git', 'rev-parse', rev, cwd=tmp)[1].strip()\n if exact != rev:\n rev, frozen = exact, rev\n return self._replace(rev=rev, frozen=frozen)\n\n\nclass RepositoryCannotBeUpdatedError(RuntimeError):\n pass\n\n\ndef _check_hooks_still_exist_at_rev(\n repo_config: Dict[str, Any],\n info: RevInfo,\n store: Store,\n) -> None:\n try:\n path = store.clone(repo_config['repo'], info.rev)\n manifest = load_manifest(os.path.join(path, C.MANIFEST_FILE))\n except InvalidManifestError as e:\n raise RepositoryCannotBeUpdatedError(str(e))\n\n # See if any of our hooks were deleted with the new commits\n hooks = {hook['id'] for hook in repo_config['hooks']}\n hooks_missing = hooks - {hook['id'] for hook in manifest}\n if hooks_missing:\n raise RepositoryCannotBeUpdatedError(\n f'Cannot update because the update target is missing these '\n f'hooks:\\n{\", \".join(sorted(hooks_missing))}',\n )\n\n\nREV_LINE_RE = re.compile(r'^(\\s+)rev:(\\s*)([\\'\"]?)([^\\s#]+)(.*)(\\r?\\n)$')\n\n\ndef _original_lines(\n path: str,\n rev_infos: List[Optional[RevInfo]],\n retry: bool = False,\n) -> Tuple[List[str], List[int]]:\n \"\"\"detect `rev:` lines or reformat the file\"\"\"\n with open(path, newline='') as f:\n original = f.read()\n\n lines = original.splitlines(True)\n idxs = [i for i, line in enumerate(lines) if REV_LINE_RE.match(line)]\n if len(idxs) == len(rev_infos):\n return lines, idxs\n elif retry:\n raise AssertionError('could not find rev lines')\n else:\n with open(path, 'w') as f:\n f.write(yaml_dump(yaml_load(original)))\n return _original_lines(path, rev_infos, retry=True)\n\n\ndef _write_new_config(path: str, rev_infos: List[Optional[RevInfo]]) -> None:\n lines, idxs = _original_lines(path, rev_infos)\n\n for idx, rev_info in zip(idxs, rev_infos):\n if rev_info is None:\n continue\n match = REV_LINE_RE.match(lines[idx])\n assert match is not None\n new_rev_s = yaml_dump({'rev': rev_info.rev}, default_style=match[3])\n new_rev = new_rev_s.split(':', 1)[1].strip()\n if rev_info.frozen is not None:\n comment = f' # frozen: {rev_info.frozen}'\n elif match[5].strip().startswith('# frozen:'):\n comment = ''\n else:\n comment = match[5]\n lines[idx] = f'{match[1]}rev:{match[2]}{new_rev}{comment}{match[6]}'\n\n with open(path, 'w', newline='') as f:\n f.write(''.join(lines))\n\n\ndef autoupdate(\n config_file: str,\n store: Store,\n tags_only: bool,\n freeze: bool,\n repos: Sequence[str] = (),\n) -> int:\n \"\"\"Auto-update the pre-commit config to the latest versions of repos.\"\"\"\n migrate_config(config_file, quiet=True)\n retv = 0\n rev_infos: List[Optional[RevInfo]] = []\n changed = False\n\n config = load_config(config_file)\n for repo_config in config['repos']:\n if repo_config['repo'] in {LOCAL, META}:\n continue\n\n info = RevInfo.from_config(repo_config)\n if repos and info.repo not in repos:\n rev_infos.append(None)\n continue\n\n output.write(f'Updating {info.repo} ... ')\n new_info = info.update(tags_only=tags_only, freeze=freeze)\n try:\n _check_hooks_still_exist_at_rev(repo_config, new_info, store)\n except RepositoryCannotBeUpdatedError as error:\n output.write_line(error.args[0])\n rev_infos.append(None)\n retv = 1\n continue\n\n if new_info.rev != info.rev:\n changed = True\n if new_info.frozen:\n updated_to = f'{new_info.frozen} (frozen)'\n else:\n updated_to = new_info.rev\n msg = f'updating {info.rev} -> {updated_to}.'\n output.write_line(msg)\n rev_infos.append(new_info)\n else:\n output.write_line('already up to date.')\n rev_infos.append(None)\n\n if changed:\n _write_new_config(config_file, rev_infos)\n\n return retv\n", "path": "pre_commit/commands/autoupdate.py"}]}
| 2,655 | 153 |
gh_patches_debug_10228
|
rasdani/github-patches
|
git_diff
|
fedora-infra__bodhi-1520
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
alembic/versions/9241378c92ab_convert_the_builds_table_to_be_.py uses server default
The ```alembic/versions/9241378c92ab_convert_the_builds_table_to_be_.py``` migration uses a server default, which is not allowed by BDR:
```
[bowlofeggs@bodhi-backend01 ~][STG]$ sudo /usr/bin/alembic -c /etc/bodhi/alembic.ini upgrade head
INFO [alembic.runtime.migration] Context impl PostgresqlImpl.
INFO [alembic.runtime.migration] Will assume transactional DDL.
INFO [alembic.runtime.migration] Running upgrade 12d3e8695f90 -> 9241378c92ab, Convert the builds table to be polymorphic.
Traceback (most recent call last):
File "/usr/bin/alembic", line 12, in <module>
sys.exit(load_entry_point('alembic', 'console_scripts', 'alembic')())
File "/usr/lib/python2.7/site-packages/alembic/config.py", line 479, in main
CommandLine(prog=prog).main(argv=argv)
File "/usr/lib/python2.7/site-packages/alembic/config.py", line 473, in main
self.run_cmd(cfg, options)
File "/usr/lib/python2.7/site-packages/alembic/config.py", line 456, in run_cmd
**dict((k, getattr(options, k)) for k in kwarg)
File "/usr/lib/python2.7/site-packages/alembic/command.py", line 174, in upgrade
script.run_env()
File "/usr/lib/python2.7/site-packages/alembic/script/base.py", line 397, in run_env
util.load_python_file(self.dir, 'env.py')
File "/usr/lib/python2.7/site-packages/alembic/util/pyfiles.py", line 93, in load_python_file
module = load_module_py(module_id, path)
File "/usr/lib/python2.7/site-packages/alembic/util/compat.py", line 79, in load_module_py
mod = imp.load_source(module_id, path, fp)
File "/usr/share/bodhi/alembic/env.py", line 83, in <module>
run_migrations_online()
File "/usr/share/bodhi/alembic/env.py", line 76, in run_migrations_online
context.run_migrations()
File "<string>", line 8, in run_migrations
File "/usr/lib/python2.7/site-packages/alembic/runtime/environment.py", line 797, in run_migrations
self.get_context().run_migrations(**kw)
File "/usr/lib/python2.7/site-packages/alembic/runtime/migration.py", line 312, in run_migrations
step.migration_fn(**kw)
File "/usr/share/bodhi/alembic/versions/9241378c92ab_convert_the_builds_table_to_be_.py", line 19, in upgrade
op.add_column('builds', sa.Column('type', sa.Integer(), nullable=False, server_default=u'1'))
File "<string>", line 8, in add_column
File "<string>", line 3, in add_column
File "/usr/lib/python2.7/site-packages/alembic/operations/ops.py", line 1535, in add_column
return operations.invoke(op)
File "/usr/lib/python2.7/site-packages/alembic/operations/base.py", line 318, in invoke
return fn(self, operation)
File "/usr/lib/python2.7/site-packages/alembic/operations/toimpl.py", line 123, in add_column
schema=schema
File "/usr/lib/python2.7/site-packages/alembic/ddl/impl.py", line 172, in add_column
self._exec(base.AddColumn(table_name, column, schema=schema))
File "/usr/lib/python2.7/site-packages/alembic/ddl/impl.py", line 118, in _exec
return conn.execute(construct, *multiparams, **params)
File "/usr/lib64/python2.7/site-packages/sqlalchemy/engine/base.py", line 914, in execute
return meth(self, multiparams, params)
File "/usr/lib64/python2.7/site-packages/sqlalchemy/sql/ddl.py", line 68, in _execute_on_connection
return connection._execute_ddl(self, multiparams, params)
File "/usr/lib64/python2.7/site-packages/sqlalchemy/engine/base.py", line 968, in _execute_ddl
compiled
File "/usr/lib64/python2.7/site-packages/sqlalchemy/engine/base.py", line 1146, in _execute_context
context)
File "/usr/lib64/python2.7/site-packages/sqlalchemy/engine/base.py", line 1341, in _handle_dbapi_exception
exc_info
File "/usr/lib64/python2.7/site-packages/sqlalchemy/util/compat.py", line 203, in raise_from_cause
reraise(type(exception), exception, tb=exc_tb, cause=cause)
File "/usr/lib64/python2.7/site-packages/sqlalchemy/engine/base.py", line 1139, in _execute_context
context)
File "/usr/lib64/python2.7/site-packages/sqlalchemy/engine/default.py", line 450, in do_execute
cursor.execute(statement, parameters)
sqlalchemy.exc.NotSupportedError: (psycopg2.NotSupportedError) ALTER TABLE ... ADD COLUMN ... DEFAULT may only affect UNLOGGED or TEMPORARY tables when BDR is active; builds is a regular table
[SQL: "ALTER TABLE builds ADD COLUMN type INTEGER DEFAULT '1' NOT NULL"]
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `alembic/versions/9241378c92ab_convert_the_builds_table_to_be_.py`
Content:
```
1 """Convert the builds table to be polymorphic.
2
3 Revision ID: 9241378c92ab
4 Revises: 12d3e8695f90
5 Create Date: 2017-04-06 20:37:24.766366
6 """
7 from alembic import op
8 import sqlalchemy as sa
9
10
11 # revision identifiers, used by Alembic.
12 revision = '9241378c92ab'
13 down_revision = '12d3e8695f90'
14
15
16 def upgrade():
17 """Add the type column to the builds table."""
18 # The default of ``1`` is the RPM Build type.
19 op.add_column('builds', sa.Column('type', sa.Integer(), nullable=False, server_default=u'1'))
20 op.alter_column('builds', 'type', server_default=None)
21
22
23 def downgrade():
24 """Remove the type column from the builds table."""
25 op.drop_column('builds', 'type')
26
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/alembic/versions/9241378c92ab_convert_the_builds_table_to_be_.py b/alembic/versions/9241378c92ab_convert_the_builds_table_to_be_.py
--- a/alembic/versions/9241378c92ab_convert_the_builds_table_to_be_.py
+++ b/alembic/versions/9241378c92ab_convert_the_builds_table_to_be_.py
@@ -15,9 +15,11 @@
def upgrade():
"""Add the type column to the builds table."""
- # The default of ``1`` is the RPM Build type.
- op.add_column('builds', sa.Column('type', sa.Integer(), nullable=False, server_default=u'1'))
- op.alter_column('builds', 'type', server_default=None)
+ builds = sa.sql.table('builds', sa.sql.column('type', sa.Integer()))
+ op.add_column('builds', sa.Column('type', sa.Integer(), nullable=True))
+ # The type 1 is the RPM Build type.
+ op.execute(builds.update().values({'type': 1}))
+ op.alter_column('builds', 'type', nullable=False)
def downgrade():
|
{"golden_diff": "diff --git a/alembic/versions/9241378c92ab_convert_the_builds_table_to_be_.py b/alembic/versions/9241378c92ab_convert_the_builds_table_to_be_.py\n--- a/alembic/versions/9241378c92ab_convert_the_builds_table_to_be_.py\n+++ b/alembic/versions/9241378c92ab_convert_the_builds_table_to_be_.py\n@@ -15,9 +15,11 @@\n \n def upgrade():\n \"\"\"Add the type column to the builds table.\"\"\"\n- # The default of ``1`` is the RPM Build type.\n- op.add_column('builds', sa.Column('type', sa.Integer(), nullable=False, server_default=u'1'))\n- op.alter_column('builds', 'type', server_default=None)\n+ builds = sa.sql.table('builds', sa.sql.column('type', sa.Integer()))\n+ op.add_column('builds', sa.Column('type', sa.Integer(), nullable=True))\n+ # The type 1 is the RPM Build type.\n+ op.execute(builds.update().values({'type': 1}))\n+ op.alter_column('builds', 'type', nullable=False)\n \n \n def downgrade():\n", "issue": "alembic/versions/9241378c92ab_convert_the_builds_table_to_be_.py uses server default\nThe ```alembic/versions/9241378c92ab_convert_the_builds_table_to_be_.py``` migration uses a server default, which is not allowed by BDR:\r\n\r\n```\r\n[bowlofeggs@bodhi-backend01 ~][STG]$ sudo /usr/bin/alembic -c /etc/bodhi/alembic.ini upgrade head\r\nINFO [alembic.runtime.migration] Context impl PostgresqlImpl.\r\nINFO [alembic.runtime.migration] Will assume transactional DDL.\r\nINFO [alembic.runtime.migration] Running upgrade 12d3e8695f90 -> 9241378c92ab, Convert the builds table to be polymorphic.\r\nTraceback (most recent call last):\r\n File \"/usr/bin/alembic\", line 12, in <module>\r\n sys.exit(load_entry_point('alembic', 'console_scripts', 'alembic')())\r\n File \"/usr/lib/python2.7/site-packages/alembic/config.py\", line 479, in main\r\n CommandLine(prog=prog).main(argv=argv)\r\n File \"/usr/lib/python2.7/site-packages/alembic/config.py\", line 473, in main\r\n self.run_cmd(cfg, options)\r\n File \"/usr/lib/python2.7/site-packages/alembic/config.py\", line 456, in run_cmd\r\n **dict((k, getattr(options, k)) for k in kwarg)\r\n File \"/usr/lib/python2.7/site-packages/alembic/command.py\", line 174, in upgrade\r\n script.run_env()\r\n File \"/usr/lib/python2.7/site-packages/alembic/script/base.py\", line 397, in run_env\r\n util.load_python_file(self.dir, 'env.py')\r\n File \"/usr/lib/python2.7/site-packages/alembic/util/pyfiles.py\", line 93, in load_python_file\r\n module = load_module_py(module_id, path)\r\n File \"/usr/lib/python2.7/site-packages/alembic/util/compat.py\", line 79, in load_module_py\r\n mod = imp.load_source(module_id, path, fp)\r\n File \"/usr/share/bodhi/alembic/env.py\", line 83, in <module>\r\n run_migrations_online()\r\n File \"/usr/share/bodhi/alembic/env.py\", line 76, in run_migrations_online\r\n context.run_migrations()\r\n File \"<string>\", line 8, in run_migrations\r\n File \"/usr/lib/python2.7/site-packages/alembic/runtime/environment.py\", line 797, in run_migrations\r\n self.get_context().run_migrations(**kw)\r\n File \"/usr/lib/python2.7/site-packages/alembic/runtime/migration.py\", line 312, in run_migrations\r\n step.migration_fn(**kw)\r\n File \"/usr/share/bodhi/alembic/versions/9241378c92ab_convert_the_builds_table_to_be_.py\", line 19, in upgrade\r\n op.add_column('builds', sa.Column('type', sa.Integer(), nullable=False, server_default=u'1'))\r\n File \"<string>\", line 8, in add_column\r\n File \"<string>\", line 3, in add_column\r\n File \"/usr/lib/python2.7/site-packages/alembic/operations/ops.py\", line 1535, in add_column\r\n return operations.invoke(op)\r\n File \"/usr/lib/python2.7/site-packages/alembic/operations/base.py\", line 318, in invoke\r\n return fn(self, operation)\r\n File \"/usr/lib/python2.7/site-packages/alembic/operations/toimpl.py\", line 123, in add_column\r\n schema=schema\r\n File \"/usr/lib/python2.7/site-packages/alembic/ddl/impl.py\", line 172, in add_column\r\n self._exec(base.AddColumn(table_name, column, schema=schema))\r\n File \"/usr/lib/python2.7/site-packages/alembic/ddl/impl.py\", line 118, in _exec\r\n return conn.execute(construct, *multiparams, **params)\r\n File \"/usr/lib64/python2.7/site-packages/sqlalchemy/engine/base.py\", line 914, in execute\r\n return meth(self, multiparams, params)\r\n File \"/usr/lib64/python2.7/site-packages/sqlalchemy/sql/ddl.py\", line 68, in _execute_on_connection\r\n return connection._execute_ddl(self, multiparams, params)\r\n File \"/usr/lib64/python2.7/site-packages/sqlalchemy/engine/base.py\", line 968, in _execute_ddl\r\n compiled\r\n File \"/usr/lib64/python2.7/site-packages/sqlalchemy/engine/base.py\", line 1146, in _execute_context\r\n context)\r\n File \"/usr/lib64/python2.7/site-packages/sqlalchemy/engine/base.py\", line 1341, in _handle_dbapi_exception\r\n exc_info\r\n File \"/usr/lib64/python2.7/site-packages/sqlalchemy/util/compat.py\", line 203, in raise_from_cause\r\n reraise(type(exception), exception, tb=exc_tb, cause=cause)\r\n File \"/usr/lib64/python2.7/site-packages/sqlalchemy/engine/base.py\", line 1139, in _execute_context\r\n context)\r\n File \"/usr/lib64/python2.7/site-packages/sqlalchemy/engine/default.py\", line 450, in do_execute\r\n cursor.execute(statement, parameters)\r\nsqlalchemy.exc.NotSupportedError: (psycopg2.NotSupportedError) ALTER TABLE ... ADD COLUMN ... DEFAULT may only affect UNLOGGED or TEMPORARY tables when BDR is active; builds is a regular table\r\n [SQL: \"ALTER TABLE builds ADD COLUMN type INTEGER DEFAULT '1' NOT NULL\"]\r\n```\n", "before_files": [{"content": "\"\"\"Convert the builds table to be polymorphic.\n\nRevision ID: 9241378c92ab\nRevises: 12d3e8695f90\nCreate Date: 2017-04-06 20:37:24.766366\n\"\"\"\nfrom alembic import op\nimport sqlalchemy as sa\n\n\n# revision identifiers, used by Alembic.\nrevision = '9241378c92ab'\ndown_revision = '12d3e8695f90'\n\n\ndef upgrade():\n \"\"\"Add the type column to the builds table.\"\"\"\n # The default of ``1`` is the RPM Build type.\n op.add_column('builds', sa.Column('type', sa.Integer(), nullable=False, server_default=u'1'))\n op.alter_column('builds', 'type', server_default=None)\n\n\ndef downgrade():\n \"\"\"Remove the type column from the builds table.\"\"\"\n op.drop_column('builds', 'type')\n", "path": "alembic/versions/9241378c92ab_convert_the_builds_table_to_be_.py"}], "after_files": [{"content": "\"\"\"Convert the builds table to be polymorphic.\n\nRevision ID: 9241378c92ab\nRevises: 12d3e8695f90\nCreate Date: 2017-04-06 20:37:24.766366\n\"\"\"\nfrom alembic import op\nimport sqlalchemy as sa\n\n\n# revision identifiers, used by Alembic.\nrevision = '9241378c92ab'\ndown_revision = '12d3e8695f90'\n\n\ndef upgrade():\n \"\"\"Add the type column to the builds table.\"\"\"\n builds = sa.sql.table('builds', sa.sql.column('type', sa.Integer()))\n op.add_column('builds', sa.Column('type', sa.Integer(), nullable=True))\n # The type 1 is the RPM Build type.\n op.execute(builds.update().values({'type': 1}))\n op.alter_column('builds', 'type', nullable=False)\n\n\ndef downgrade():\n \"\"\"Remove the type column from the builds table.\"\"\"\n op.drop_column('builds', 'type')\n", "path": "alembic/versions/9241378c92ab_convert_the_builds_table_to_be_.py"}]}
| 1,902 | 294 |
gh_patches_debug_5168
|
rasdani/github-patches
|
git_diff
|
ivy-llc__ivy-13695
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
poisson
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ivy/functional/frontends/jax/random.py`
Content:
```
1 # local
2 import ivy
3 from ivy.func_wrapper import with_unsupported_dtypes
4 from ivy.functional.frontends.jax.func_wrapper import (
5 to_ivy_arrays_and_back,
6 handle_jax_dtype,
7 )
8
9
10 @to_ivy_arrays_and_back
11 def PRNGKey(seed):
12 return ivy.array([0, seed % 4294967295 - (seed // 4294967295)], dtype=ivy.int64)
13
14
15 @handle_jax_dtype
16 @to_ivy_arrays_and_back
17 def uniform(key, shape=(), dtype=None, minval=0.0, maxval=1.0):
18 return ivy.random_uniform(
19 low=minval, high=maxval, shape=shape, dtype=dtype, seed=ivy.to_scalar(key[1])
20 )
21
22
23 @handle_jax_dtype
24 @to_ivy_arrays_and_back
25 def normal(key, shape=(), dtype=None):
26 return ivy.random_normal(shape=shape, dtype=dtype, seed=ivy.to_scalar(key[1]))
27
28
29 def _get_seed(key):
30 key1, key2 = int(key[0]), int(key[1])
31 return ivy.to_scalar(int("".join(map(str, [key1, key2]))))
32
33
34 @handle_jax_dtype
35 @to_ivy_arrays_and_back
36 @with_unsupported_dtypes(
37 {
38 "0.3.14 and below": (
39 "float16",
40 "bfloat16",
41 )
42 },
43 "jax",
44 )
45 def beta(key, a, b, shape=None, dtype=None):
46 seed = _get_seed(key)
47 return ivy.beta(a, b, shape=shape, dtype=dtype, seed=seed)
48
49
50 @handle_jax_dtype
51 @to_ivy_arrays_and_back
52 @with_unsupported_dtypes(
53 {
54 "0.3.14 and below": (
55 "float16",
56 "bfloat16",
57 )
58 },
59 "jax",
60 )
61 def dirichlet(key, alpha, shape=None, dtype="float32"):
62 seed = _get_seed(key)
63 alpha = ivy.astype(alpha, dtype)
64 return ivy.dirichlet(alpha, size=shape, dtype=dtype, seed=seed)
65
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ivy/functional/frontends/jax/random.py b/ivy/functional/frontends/jax/random.py
--- a/ivy/functional/frontends/jax/random.py
+++ b/ivy/functional/frontends/jax/random.py
@@ -62,3 +62,14 @@
seed = _get_seed(key)
alpha = ivy.astype(alpha, dtype)
return ivy.dirichlet(alpha, size=shape, dtype=dtype, seed=seed)
+
+
+@handle_jax_dtype
+@to_ivy_arrays_and_back
+@with_unsupported_dtypes(
+ {"0.3.14 and below": ("unsigned", "int8", "int16")},
+ "jax",
+)
+def poisson(key, lam, shape=None, dtype=None):
+ seed = _get_seed(key)
+ return ivy.poisson(lam, shape=shape, dtype=dtype, seed=seed)
|
{"golden_diff": "diff --git a/ivy/functional/frontends/jax/random.py b/ivy/functional/frontends/jax/random.py\n--- a/ivy/functional/frontends/jax/random.py\n+++ b/ivy/functional/frontends/jax/random.py\n@@ -62,3 +62,14 @@\n seed = _get_seed(key)\n alpha = ivy.astype(alpha, dtype)\n return ivy.dirichlet(alpha, size=shape, dtype=dtype, seed=seed)\n+\n+\n+@handle_jax_dtype\n+@to_ivy_arrays_and_back\n+@with_unsupported_dtypes(\n+ {\"0.3.14 and below\": (\"unsigned\", \"int8\", \"int16\")},\n+ \"jax\",\n+)\n+def poisson(key, lam, shape=None, dtype=None):\n+ seed = _get_seed(key)\n+ return ivy.poisson(lam, shape=shape, dtype=dtype, seed=seed)\n", "issue": "poisson\n\n", "before_files": [{"content": "# local\nimport ivy\nfrom ivy.func_wrapper import with_unsupported_dtypes\nfrom ivy.functional.frontends.jax.func_wrapper import (\n to_ivy_arrays_and_back,\n handle_jax_dtype,\n)\n\n\n@to_ivy_arrays_and_back\ndef PRNGKey(seed):\n return ivy.array([0, seed % 4294967295 - (seed // 4294967295)], dtype=ivy.int64)\n\n\n@handle_jax_dtype\n@to_ivy_arrays_and_back\ndef uniform(key, shape=(), dtype=None, minval=0.0, maxval=1.0):\n return ivy.random_uniform(\n low=minval, high=maxval, shape=shape, dtype=dtype, seed=ivy.to_scalar(key[1])\n )\n\n\n@handle_jax_dtype\n@to_ivy_arrays_and_back\ndef normal(key, shape=(), dtype=None):\n return ivy.random_normal(shape=shape, dtype=dtype, seed=ivy.to_scalar(key[1]))\n\n\ndef _get_seed(key):\n key1, key2 = int(key[0]), int(key[1])\n return ivy.to_scalar(int(\"\".join(map(str, [key1, key2]))))\n\n\n@handle_jax_dtype\n@to_ivy_arrays_and_back\n@with_unsupported_dtypes(\n {\n \"0.3.14 and below\": (\n \"float16\",\n \"bfloat16\",\n )\n },\n \"jax\",\n)\ndef beta(key, a, b, shape=None, dtype=None):\n seed = _get_seed(key)\n return ivy.beta(a, b, shape=shape, dtype=dtype, seed=seed)\n\n\n@handle_jax_dtype\n@to_ivy_arrays_and_back\n@with_unsupported_dtypes(\n {\n \"0.3.14 and below\": (\n \"float16\",\n \"bfloat16\",\n )\n },\n \"jax\",\n)\ndef dirichlet(key, alpha, shape=None, dtype=\"float32\"):\n seed = _get_seed(key)\n alpha = ivy.astype(alpha, dtype)\n return ivy.dirichlet(alpha, size=shape, dtype=dtype, seed=seed)\n", "path": "ivy/functional/frontends/jax/random.py"}], "after_files": [{"content": "# local\nimport ivy\nfrom ivy.func_wrapper import with_unsupported_dtypes\nfrom ivy.functional.frontends.jax.func_wrapper import (\n to_ivy_arrays_and_back,\n handle_jax_dtype,\n)\n\n\n@to_ivy_arrays_and_back\ndef PRNGKey(seed):\n return ivy.array([0, seed % 4294967295 - (seed // 4294967295)], dtype=ivy.int64)\n\n\n@handle_jax_dtype\n@to_ivy_arrays_and_back\ndef uniform(key, shape=(), dtype=None, minval=0.0, maxval=1.0):\n return ivy.random_uniform(\n low=minval, high=maxval, shape=shape, dtype=dtype, seed=ivy.to_scalar(key[1])\n )\n\n\n@handle_jax_dtype\n@to_ivy_arrays_and_back\ndef normal(key, shape=(), dtype=None):\n return ivy.random_normal(shape=shape, dtype=dtype, seed=ivy.to_scalar(key[1]))\n\n\ndef _get_seed(key):\n key1, key2 = int(key[0]), int(key[1])\n return ivy.to_scalar(int(\"\".join(map(str, [key1, key2]))))\n\n\n@handle_jax_dtype\n@to_ivy_arrays_and_back\n@with_unsupported_dtypes(\n {\n \"0.3.14 and below\": (\n \"float16\",\n \"bfloat16\",\n )\n },\n \"jax\",\n)\ndef beta(key, a, b, shape=None, dtype=None):\n seed = _get_seed(key)\n return ivy.beta(a, b, shape=shape, dtype=dtype, seed=seed)\n\n\n@handle_jax_dtype\n@to_ivy_arrays_and_back\n@with_unsupported_dtypes(\n {\n \"0.3.14 and below\": (\n \"float16\",\n \"bfloat16\",\n )\n },\n \"jax\",\n)\ndef dirichlet(key, alpha, shape=None, dtype=\"float32\"):\n seed = _get_seed(key)\n alpha = ivy.astype(alpha, dtype)\n return ivy.dirichlet(alpha, size=shape, dtype=dtype, seed=seed)\n\n\n@handle_jax_dtype\n@to_ivy_arrays_and_back\n@with_unsupported_dtypes(\n {\"0.3.14 and below\": (\"unsigned\", \"int8\", \"int16\")},\n \"jax\",\n)\ndef poisson(key, lam, shape=None, dtype=None):\n seed = _get_seed(key)\n return ivy.poisson(lam, shape=shape, dtype=dtype, seed=seed)\n", "path": "ivy/functional/frontends/jax/random.py"}]}
| 880 | 207 |
gh_patches_debug_42998
|
rasdani/github-patches
|
git_diff
|
wagtail__wagtail-10983
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
SnippetBulkAction not respecting models definition
<!--
Found a bug? Please fill out the sections below. 👍
-->
### Issue Summary
I'm registering a bulk action for a snippet model and declared the bulk action as specific for a model with class variable `models`, but the bulk action is being showed on all snippet models and not only the one I've declared.
### Steps to Reproduce
1. Declare on `wagtail_hooks.py` the snippet:
```python
class PeriodicTaskSnippetViewSet(SnippetViewSet):
model = PeriodicTask
icon = "tasks"
menu_order = 100
list_display = ("name", "enabled", "scheduler", "interval", "start_time", "last_run_at", "one_off")
list_filter = ["enabled", "one_off", "task", "start_time", "last_run_at"]
search_fields = ["name"]
```
1. Also declare the bulk action:
```python
@hooks.register("register_bulk_action")
class EnableTaskBulkAction(SnippetBulkAction):
models = [PeriodicTask]
display_name = _("Enable")
aria_label = _("Enable selected tasks")
action_type = "enable"
template_name = "core/wagtailadmin/bulk_action_enable_tasks.html"
@classmethod
def execute_action(cls, objects, **kwargs):
for obj in objects:
obj.enabled = True
obj.save()
rows_updated = len(objects)
return rows_updated, rows_updated
```
Any other relevant information. For example, why do you consider this a bug and what did you expect to happen instead?
The documentation (https://docs.wagtail.org/en/stable/extending/custom_bulk_actions.html#adding-bulk-actions-to-the-snippets-listing) says how to limit action to specific models on snippets, but that's not happening.
After checking the code, I think that because `get_models` is being overwritten on `SnippetBulkAction` which ignores if `models` is already defined by the user or not.
- I have confirmed that this issue can be reproduced as described on a fresh Wagtail project: yes
### Technical details
- Python version: 3.11.5
- Django version: 4.2.5
- Wagtail version: 5.1.2.
- Browser version: Chrome 117.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `wagtail/snippets/bulk_actions/snippet_bulk_action.py`
Content:
```
1 from wagtail.admin.admin_url_finder import AdminURLFinder
2 from wagtail.admin.views.bulk_action import BulkAction
3 from wagtail.snippets.models import get_snippet_models
4
5
6 class SnippetBulkAction(BulkAction):
7 @classmethod
8 def get_models(cls):
9 # We used to set `models = get_snippet_models()` directly on the class,
10 # but this is problematic because it means that the list of models is
11 # evaluated at import time.
12
13 # Bulk actions are normally registered in wagtail_hooks.py, but snippets
14 # can also be registered in wagtail_hooks.py. Evaluating
15 # get_snippet_models() at import time could result in either a circular
16 # import or an incomplete list of models.
17
18 # Update the models list with the latest registered snippets in case
19 # there is user code that still accesses cls.models instead of calling
20 # this get_models() method.
21 cls.models = get_snippet_models()
22 return cls.models
23
24 def object_context(self, snippet):
25 return {
26 "item": snippet,
27 "edit_url": AdminURLFinder(self.request.user).get_edit_url(snippet),
28 }
29
30 def get_context_data(self, **kwargs):
31 kwargs.update(
32 {
33 "model_opts": self.model._meta,
34 "header_icon": self.model.snippet_viewset.icon,
35 }
36 )
37 return super().get_context_data(**kwargs)
38
39 def get_execution_context(self):
40 return {**super().get_execution_context(), "self": self}
41
```
Path: `wagtail/admin/views/bulk_action/registry.py`
Content:
```
1 from wagtail import hooks
2 from wagtail.admin.views.bulk_action import BulkAction
3
4
5 class BulkActionRegistry:
6 def __init__(self):
7 self.actions = {} # {app_name: {model_name: {action_name: action_class]}}
8 self.has_scanned_for_bulk_actions = False
9
10 def _scan_for_bulk_actions(self):
11 if not self.has_scanned_for_bulk_actions:
12 for action_class in hooks.get_hooks("register_bulk_action"):
13 if not issubclass(action_class, BulkAction):
14 raise Exception(
15 "{} is not a subclass of {}".format(
16 action_class.__name__, BulkAction.__name__
17 )
18 )
19 for model in action_class.get_models():
20 self.actions.setdefault(model._meta.app_label, {})
21 self.actions[model._meta.app_label].setdefault(
22 model._meta.model_name, {}
23 )
24 self.actions[model._meta.app_label][model._meta.model_name][
25 action_class.action_type
26 ] = action_class
27 self.has_scanned_for_bulk_actions = True
28
29 def get_bulk_actions_for_model(self, app_label, model_name):
30 self._scan_for_bulk_actions()
31 return self.actions.get(app_label, {}).get(model_name, {}).values()
32
33 def get_bulk_action_class(self, app_label, model_name, action_type):
34 self._scan_for_bulk_actions()
35 return (
36 self.actions.get(app_label, {}).get(model_name, {}).get(action_type, None)
37 )
38
39
40 bulk_action_registry = BulkActionRegistry()
41
```
Path: `wagtail/admin/views/bulk_action/base_bulk_action.py`
Content:
```
1 from abc import ABC, abstractmethod
2
3 from django import forms
4 from django.db import transaction
5 from django.shortcuts import get_list_or_404, redirect
6 from django.views.generic import FormView
7
8 from wagtail import hooks
9 from wagtail.admin import messages
10 from wagtail.admin.utils import get_valid_next_url_from_request
11
12
13 class BulkAction(ABC, FormView):
14 @property
15 @abstractmethod
16 def display_name(self):
17 pass
18
19 @property
20 @abstractmethod
21 def action_type(self):
22 pass
23
24 @property
25 @abstractmethod
26 def aria_label(self):
27 pass
28
29 extras = {}
30 action_priority = 100
31 models = []
32 classes = set()
33
34 form_class = forms.Form
35 cleaned_form = None
36
37 def __init__(self, request, model):
38 self.request = request
39 next_url = get_valid_next_url_from_request(request)
40 if not next_url:
41 next_url = request.path
42 self.next_url = next_url
43 self.num_parent_objects = self.num_child_objects = 0
44 if model in self.get_models():
45 self.model = model
46 else:
47 raise Exception(
48 "model {} is not among the specified list of models".format(
49 model.__class__.__name__
50 )
51 )
52
53 @classmethod
54 def get_models(cls):
55 return cls.models
56
57 @classmethod
58 def get_queryset(cls, model, object_ids):
59 return get_list_or_404(model, pk__in=object_ids)
60
61 def check_perm(self, obj):
62 return True
63
64 @classmethod
65 def execute_action(cls, objects, **kwargs):
66 raise NotImplementedError("execute_action needs to be implemented")
67
68 def get_success_message(self, num_parent_objects, num_child_objects):
69 pass
70
71 def object_context(self, obj):
72 return {"item": obj}
73
74 @classmethod
75 def get_default_model(cls):
76 models = cls.get_models()
77 if len(models) == 1:
78 return models[0]
79 raise Exception(
80 "Cannot get default model if number of models is greater than 1"
81 )
82
83 def __run_before_hooks(self, action_type, request, objects):
84 for hook in hooks.get_hooks("before_bulk_action"):
85 result = hook(request, action_type, objects, self)
86 if hasattr(result, "status_code"):
87 return result
88
89 def __run_after_hooks(self, action_type, request, objects):
90 for hook in hooks.get_hooks("after_bulk_action"):
91 result = hook(request, action_type, objects, self)
92 if hasattr(result, "status_code"):
93 return result
94
95 def get_all_objects_in_listing_query(self, parent_id):
96 return self.model.objects.all().values_list("pk", flat=True)
97
98 def get_actionable_objects(self):
99 objects = []
100 items_with_no_access = []
101 object_ids = self.request.GET.getlist("id")
102 if "all" in object_ids:
103 object_ids = self.get_all_objects_in_listing_query(
104 self.request.GET.get("childOf")
105 )
106
107 for obj in self.get_queryset(self.model, object_ids):
108 if not self.check_perm(obj):
109 items_with_no_access.append(obj)
110 else:
111 objects.append(obj)
112 return objects, {"items_with_no_access": items_with_no_access}
113
114 def get_context_data(self, **kwargs):
115 items, items_with_no_access = self.get_actionable_objects()
116 _items = []
117 for item in items:
118 _items.append(self.object_context(item))
119 return {
120 **super().get_context_data(**kwargs),
121 "items": _items,
122 **items_with_no_access,
123 "next": self.next_url,
124 "submit_url": self.request.path + "?" + self.request.META["QUERY_STRING"],
125 }
126
127 def prepare_action(self, objects, objects_without_access):
128 return
129
130 def get_execution_context(self):
131 return {}
132
133 def form_valid(self, form):
134 request = self.request
135 self.cleaned_form = form
136 objects, objects_without_access = self.get_actionable_objects()
137 self.actionable_objects = objects
138 resp = self.prepare_action(objects, objects_without_access)
139 if hasattr(resp, "status_code"):
140 return resp
141 with transaction.atomic():
142 before_hook_result = self.__run_before_hooks(
143 self.action_type, request, objects
144 )
145 if before_hook_result is not None:
146 return before_hook_result
147 num_parent_objects, num_child_objects = self.execute_action(
148 objects, **self.get_execution_context()
149 )
150 after_hook_result = self.__run_after_hooks(
151 self.action_type, request, objects
152 )
153 if after_hook_result is not None:
154 return after_hook_result
155 success_message = self.get_success_message(
156 num_parent_objects, num_child_objects
157 )
158 if success_message is not None:
159 messages.success(request, success_message)
160 return redirect(self.next_url)
161
162 def form_invalid(self, form):
163 return super().form_invalid(form)
164
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/wagtail/admin/views/bulk_action/base_bulk_action.py b/wagtail/admin/views/bulk_action/base_bulk_action.py
--- a/wagtail/admin/views/bulk_action/base_bulk_action.py
+++ b/wagtail/admin/views/bulk_action/base_bulk_action.py
@@ -3,6 +3,7 @@
from django import forms
from django.db import transaction
from django.shortcuts import get_list_or_404, redirect
+from django.utils.functional import classproperty
from django.views.generic import FormView
from wagtail import hooks
@@ -28,7 +29,6 @@
extras = {}
action_priority = 100
- models = []
classes = set()
form_class = forms.Form
@@ -41,7 +41,7 @@
next_url = request.path
self.next_url = next_url
self.num_parent_objects = self.num_child_objects = 0
- if model in self.get_models():
+ if model in self.models:
self.model = model
else:
raise Exception(
@@ -50,9 +50,9 @@
)
)
- @classmethod
- def get_models(cls):
- return cls.models
+ @classproperty
+ def models(cls):
+ return []
@classmethod
def get_queryset(cls, model, object_ids):
@@ -73,7 +73,7 @@
@classmethod
def get_default_model(cls):
- models = cls.get_models()
+ models = cls.models
if len(models) == 1:
return models[0]
raise Exception(
diff --git a/wagtail/admin/views/bulk_action/registry.py b/wagtail/admin/views/bulk_action/registry.py
--- a/wagtail/admin/views/bulk_action/registry.py
+++ b/wagtail/admin/views/bulk_action/registry.py
@@ -16,7 +16,7 @@
action_class.__name__, BulkAction.__name__
)
)
- for model in action_class.get_models():
+ for model in action_class.models:
self.actions.setdefault(model._meta.app_label, {})
self.actions[model._meta.app_label].setdefault(
model._meta.model_name, {}
diff --git a/wagtail/snippets/bulk_actions/snippet_bulk_action.py b/wagtail/snippets/bulk_actions/snippet_bulk_action.py
--- a/wagtail/snippets/bulk_actions/snippet_bulk_action.py
+++ b/wagtail/snippets/bulk_actions/snippet_bulk_action.py
@@ -1,11 +1,13 @@
+from django.utils.functional import classproperty
+
from wagtail.admin.admin_url_finder import AdminURLFinder
from wagtail.admin.views.bulk_action import BulkAction
from wagtail.snippets.models import get_snippet_models
class SnippetBulkAction(BulkAction):
- @classmethod
- def get_models(cls):
+ @classproperty
+ def models(cls):
# We used to set `models = get_snippet_models()` directly on the class,
# but this is problematic because it means that the list of models is
# evaluated at import time.
@@ -14,12 +16,7 @@
# can also be registered in wagtail_hooks.py. Evaluating
# get_snippet_models() at import time could result in either a circular
# import or an incomplete list of models.
-
- # Update the models list with the latest registered snippets in case
- # there is user code that still accesses cls.models instead of calling
- # this get_models() method.
- cls.models = get_snippet_models()
- return cls.models
+ return get_snippet_models()
def object_context(self, snippet):
return {
|
{"golden_diff": "diff --git a/wagtail/admin/views/bulk_action/base_bulk_action.py b/wagtail/admin/views/bulk_action/base_bulk_action.py\n--- a/wagtail/admin/views/bulk_action/base_bulk_action.py\n+++ b/wagtail/admin/views/bulk_action/base_bulk_action.py\n@@ -3,6 +3,7 @@\n from django import forms\n from django.db import transaction\n from django.shortcuts import get_list_or_404, redirect\n+from django.utils.functional import classproperty\n from django.views.generic import FormView\n \n from wagtail import hooks\n@@ -28,7 +29,6 @@\n \n extras = {}\n action_priority = 100\n- models = []\n classes = set()\n \n form_class = forms.Form\n@@ -41,7 +41,7 @@\n next_url = request.path\n self.next_url = next_url\n self.num_parent_objects = self.num_child_objects = 0\n- if model in self.get_models():\n+ if model in self.models:\n self.model = model\n else:\n raise Exception(\n@@ -50,9 +50,9 @@\n )\n )\n \n- @classmethod\n- def get_models(cls):\n- return cls.models\n+ @classproperty\n+ def models(cls):\n+ return []\n \n @classmethod\n def get_queryset(cls, model, object_ids):\n@@ -73,7 +73,7 @@\n \n @classmethod\n def get_default_model(cls):\n- models = cls.get_models()\n+ models = cls.models\n if len(models) == 1:\n return models[0]\n raise Exception(\ndiff --git a/wagtail/admin/views/bulk_action/registry.py b/wagtail/admin/views/bulk_action/registry.py\n--- a/wagtail/admin/views/bulk_action/registry.py\n+++ b/wagtail/admin/views/bulk_action/registry.py\n@@ -16,7 +16,7 @@\n action_class.__name__, BulkAction.__name__\n )\n )\n- for model in action_class.get_models():\n+ for model in action_class.models:\n self.actions.setdefault(model._meta.app_label, {})\n self.actions[model._meta.app_label].setdefault(\n model._meta.model_name, {}\ndiff --git a/wagtail/snippets/bulk_actions/snippet_bulk_action.py b/wagtail/snippets/bulk_actions/snippet_bulk_action.py\n--- a/wagtail/snippets/bulk_actions/snippet_bulk_action.py\n+++ b/wagtail/snippets/bulk_actions/snippet_bulk_action.py\n@@ -1,11 +1,13 @@\n+from django.utils.functional import classproperty\n+\n from wagtail.admin.admin_url_finder import AdminURLFinder\n from wagtail.admin.views.bulk_action import BulkAction\n from wagtail.snippets.models import get_snippet_models\n \n \n class SnippetBulkAction(BulkAction):\n- @classmethod\n- def get_models(cls):\n+ @classproperty\n+ def models(cls):\n # We used to set `models = get_snippet_models()` directly on the class,\n # but this is problematic because it means that the list of models is\n # evaluated at import time.\n@@ -14,12 +16,7 @@\n # can also be registered in wagtail_hooks.py. Evaluating\n # get_snippet_models() at import time could result in either a circular\n # import or an incomplete list of models.\n-\n- # Update the models list with the latest registered snippets in case\n- # there is user code that still accesses cls.models instead of calling\n- # this get_models() method.\n- cls.models = get_snippet_models()\n- return cls.models\n+ return get_snippet_models()\n \n def object_context(self, snippet):\n return {\n", "issue": "SnippetBulkAction not respecting models definition\n<!--\r\nFound a bug? Please fill out the sections below. \ud83d\udc4d\r\n-->\r\n\r\n### Issue Summary\r\n\r\nI'm registering a bulk action for a snippet model and declared the bulk action as specific for a model with class variable `models`, but the bulk action is being showed on all snippet models and not only the one I've declared.\r\n\r\n### Steps to Reproduce\r\n\r\n1. Declare on `wagtail_hooks.py` the snippet:\r\n ```python\r\n class PeriodicTaskSnippetViewSet(SnippetViewSet):\r\n model = PeriodicTask\r\n icon = \"tasks\"\r\n menu_order = 100\r\n list_display = (\"name\", \"enabled\", \"scheduler\", \"interval\", \"start_time\", \"last_run_at\", \"one_off\")\r\n list_filter = [\"enabled\", \"one_off\", \"task\", \"start_time\", \"last_run_at\"]\r\n search_fields = [\"name\"]\r\n ```\r\n1. Also declare the bulk action:\r\n ```python\r\n @hooks.register(\"register_bulk_action\")\r\n class EnableTaskBulkAction(SnippetBulkAction):\r\n models = [PeriodicTask]\r\n display_name = _(\"Enable\")\r\n aria_label = _(\"Enable selected tasks\")\r\n action_type = \"enable\"\r\n template_name = \"core/wagtailadmin/bulk_action_enable_tasks.html\"\r\n\r\n @classmethod\r\n def execute_action(cls, objects, **kwargs):\r\n for obj in objects:\r\n obj.enabled = True\r\n obj.save()\r\n rows_updated = len(objects)\r\n return rows_updated, rows_updated\r\n ```\r\n\r\nAny other relevant information. For example, why do you consider this a bug and what did you expect to happen instead?\r\n\r\nThe documentation (https://docs.wagtail.org/en/stable/extending/custom_bulk_actions.html#adding-bulk-actions-to-the-snippets-listing) says how to limit action to specific models on snippets, but that's not happening.\r\n\r\nAfter checking the code, I think that because `get_models` is being overwritten on `SnippetBulkAction` which ignores if `models` is already defined by the user or not. \r\n\r\n- I have confirmed that this issue can be reproduced as described on a fresh Wagtail project: yes \r\n\r\n### Technical details\r\n\r\n- Python version: 3.11.5\r\n- Django version: 4.2.5\r\n- Wagtail version: 5.1.2.\r\n- Browser version: Chrome 117.\r\n\n", "before_files": [{"content": "from wagtail.admin.admin_url_finder import AdminURLFinder\nfrom wagtail.admin.views.bulk_action import BulkAction\nfrom wagtail.snippets.models import get_snippet_models\n\n\nclass SnippetBulkAction(BulkAction):\n @classmethod\n def get_models(cls):\n # We used to set `models = get_snippet_models()` directly on the class,\n # but this is problematic because it means that the list of models is\n # evaluated at import time.\n\n # Bulk actions are normally registered in wagtail_hooks.py, but snippets\n # can also be registered in wagtail_hooks.py. Evaluating\n # get_snippet_models() at import time could result in either a circular\n # import or an incomplete list of models.\n\n # Update the models list with the latest registered snippets in case\n # there is user code that still accesses cls.models instead of calling\n # this get_models() method.\n cls.models = get_snippet_models()\n return cls.models\n\n def object_context(self, snippet):\n return {\n \"item\": snippet,\n \"edit_url\": AdminURLFinder(self.request.user).get_edit_url(snippet),\n }\n\n def get_context_data(self, **kwargs):\n kwargs.update(\n {\n \"model_opts\": self.model._meta,\n \"header_icon\": self.model.snippet_viewset.icon,\n }\n )\n return super().get_context_data(**kwargs)\n\n def get_execution_context(self):\n return {**super().get_execution_context(), \"self\": self}\n", "path": "wagtail/snippets/bulk_actions/snippet_bulk_action.py"}, {"content": "from wagtail import hooks\nfrom wagtail.admin.views.bulk_action import BulkAction\n\n\nclass BulkActionRegistry:\n def __init__(self):\n self.actions = {} # {app_name: {model_name: {action_name: action_class]}}\n self.has_scanned_for_bulk_actions = False\n\n def _scan_for_bulk_actions(self):\n if not self.has_scanned_for_bulk_actions:\n for action_class in hooks.get_hooks(\"register_bulk_action\"):\n if not issubclass(action_class, BulkAction):\n raise Exception(\n \"{} is not a subclass of {}\".format(\n action_class.__name__, BulkAction.__name__\n )\n )\n for model in action_class.get_models():\n self.actions.setdefault(model._meta.app_label, {})\n self.actions[model._meta.app_label].setdefault(\n model._meta.model_name, {}\n )\n self.actions[model._meta.app_label][model._meta.model_name][\n action_class.action_type\n ] = action_class\n self.has_scanned_for_bulk_actions = True\n\n def get_bulk_actions_for_model(self, app_label, model_name):\n self._scan_for_bulk_actions()\n return self.actions.get(app_label, {}).get(model_name, {}).values()\n\n def get_bulk_action_class(self, app_label, model_name, action_type):\n self._scan_for_bulk_actions()\n return (\n self.actions.get(app_label, {}).get(model_name, {}).get(action_type, None)\n )\n\n\nbulk_action_registry = BulkActionRegistry()\n", "path": "wagtail/admin/views/bulk_action/registry.py"}, {"content": "from abc import ABC, abstractmethod\n\nfrom django import forms\nfrom django.db import transaction\nfrom django.shortcuts import get_list_or_404, redirect\nfrom django.views.generic import FormView\n\nfrom wagtail import hooks\nfrom wagtail.admin import messages\nfrom wagtail.admin.utils import get_valid_next_url_from_request\n\n\nclass BulkAction(ABC, FormView):\n @property\n @abstractmethod\n def display_name(self):\n pass\n\n @property\n @abstractmethod\n def action_type(self):\n pass\n\n @property\n @abstractmethod\n def aria_label(self):\n pass\n\n extras = {}\n action_priority = 100\n models = []\n classes = set()\n\n form_class = forms.Form\n cleaned_form = None\n\n def __init__(self, request, model):\n self.request = request\n next_url = get_valid_next_url_from_request(request)\n if not next_url:\n next_url = request.path\n self.next_url = next_url\n self.num_parent_objects = self.num_child_objects = 0\n if model in self.get_models():\n self.model = model\n else:\n raise Exception(\n \"model {} is not among the specified list of models\".format(\n model.__class__.__name__\n )\n )\n\n @classmethod\n def get_models(cls):\n return cls.models\n\n @classmethod\n def get_queryset(cls, model, object_ids):\n return get_list_or_404(model, pk__in=object_ids)\n\n def check_perm(self, obj):\n return True\n\n @classmethod\n def execute_action(cls, objects, **kwargs):\n raise NotImplementedError(\"execute_action needs to be implemented\")\n\n def get_success_message(self, num_parent_objects, num_child_objects):\n pass\n\n def object_context(self, obj):\n return {\"item\": obj}\n\n @classmethod\n def get_default_model(cls):\n models = cls.get_models()\n if len(models) == 1:\n return models[0]\n raise Exception(\n \"Cannot get default model if number of models is greater than 1\"\n )\n\n def __run_before_hooks(self, action_type, request, objects):\n for hook in hooks.get_hooks(\"before_bulk_action\"):\n result = hook(request, action_type, objects, self)\n if hasattr(result, \"status_code\"):\n return result\n\n def __run_after_hooks(self, action_type, request, objects):\n for hook in hooks.get_hooks(\"after_bulk_action\"):\n result = hook(request, action_type, objects, self)\n if hasattr(result, \"status_code\"):\n return result\n\n def get_all_objects_in_listing_query(self, parent_id):\n return self.model.objects.all().values_list(\"pk\", flat=True)\n\n def get_actionable_objects(self):\n objects = []\n items_with_no_access = []\n object_ids = self.request.GET.getlist(\"id\")\n if \"all\" in object_ids:\n object_ids = self.get_all_objects_in_listing_query(\n self.request.GET.get(\"childOf\")\n )\n\n for obj in self.get_queryset(self.model, object_ids):\n if not self.check_perm(obj):\n items_with_no_access.append(obj)\n else:\n objects.append(obj)\n return objects, {\"items_with_no_access\": items_with_no_access}\n\n def get_context_data(self, **kwargs):\n items, items_with_no_access = self.get_actionable_objects()\n _items = []\n for item in items:\n _items.append(self.object_context(item))\n return {\n **super().get_context_data(**kwargs),\n \"items\": _items,\n **items_with_no_access,\n \"next\": self.next_url,\n \"submit_url\": self.request.path + \"?\" + self.request.META[\"QUERY_STRING\"],\n }\n\n def prepare_action(self, objects, objects_without_access):\n return\n\n def get_execution_context(self):\n return {}\n\n def form_valid(self, form):\n request = self.request\n self.cleaned_form = form\n objects, objects_without_access = self.get_actionable_objects()\n self.actionable_objects = objects\n resp = self.prepare_action(objects, objects_without_access)\n if hasattr(resp, \"status_code\"):\n return resp\n with transaction.atomic():\n before_hook_result = self.__run_before_hooks(\n self.action_type, request, objects\n )\n if before_hook_result is not None:\n return before_hook_result\n num_parent_objects, num_child_objects = self.execute_action(\n objects, **self.get_execution_context()\n )\n after_hook_result = self.__run_after_hooks(\n self.action_type, request, objects\n )\n if after_hook_result is not None:\n return after_hook_result\n success_message = self.get_success_message(\n num_parent_objects, num_child_objects\n )\n if success_message is not None:\n messages.success(request, success_message)\n return redirect(self.next_url)\n\n def form_invalid(self, form):\n return super().form_invalid(form)\n", "path": "wagtail/admin/views/bulk_action/base_bulk_action.py"}], "after_files": [{"content": "from django.utils.functional import classproperty\n\nfrom wagtail.admin.admin_url_finder import AdminURLFinder\nfrom wagtail.admin.views.bulk_action import BulkAction\nfrom wagtail.snippets.models import get_snippet_models\n\n\nclass SnippetBulkAction(BulkAction):\n @classproperty\n def models(cls):\n # We used to set `models = get_snippet_models()` directly on the class,\n # but this is problematic because it means that the list of models is\n # evaluated at import time.\n\n # Bulk actions are normally registered in wagtail_hooks.py, but snippets\n # can also be registered in wagtail_hooks.py. Evaluating\n # get_snippet_models() at import time could result in either a circular\n # import or an incomplete list of models.\n return get_snippet_models()\n\n def object_context(self, snippet):\n return {\n \"item\": snippet,\n \"edit_url\": AdminURLFinder(self.request.user).get_edit_url(snippet),\n }\n\n def get_context_data(self, **kwargs):\n kwargs.update(\n {\n \"model_opts\": self.model._meta,\n \"header_icon\": self.model.snippet_viewset.icon,\n }\n )\n return super().get_context_data(**kwargs)\n\n def get_execution_context(self):\n return {**super().get_execution_context(), \"self\": self}\n", "path": "wagtail/snippets/bulk_actions/snippet_bulk_action.py"}, {"content": "from wagtail import hooks\nfrom wagtail.admin.views.bulk_action import BulkAction\n\n\nclass BulkActionRegistry:\n def __init__(self):\n self.actions = {} # {app_name: {model_name: {action_name: action_class]}}\n self.has_scanned_for_bulk_actions = False\n\n def _scan_for_bulk_actions(self):\n if not self.has_scanned_for_bulk_actions:\n for action_class in hooks.get_hooks(\"register_bulk_action\"):\n if not issubclass(action_class, BulkAction):\n raise Exception(\n \"{} is not a subclass of {}\".format(\n action_class.__name__, BulkAction.__name__\n )\n )\n for model in action_class.models:\n self.actions.setdefault(model._meta.app_label, {})\n self.actions[model._meta.app_label].setdefault(\n model._meta.model_name, {}\n )\n self.actions[model._meta.app_label][model._meta.model_name][\n action_class.action_type\n ] = action_class\n self.has_scanned_for_bulk_actions = True\n\n def get_bulk_actions_for_model(self, app_label, model_name):\n self._scan_for_bulk_actions()\n return self.actions.get(app_label, {}).get(model_name, {}).values()\n\n def get_bulk_action_class(self, app_label, model_name, action_type):\n self._scan_for_bulk_actions()\n return (\n self.actions.get(app_label, {}).get(model_name, {}).get(action_type, None)\n )\n\n\nbulk_action_registry = BulkActionRegistry()\n", "path": "wagtail/admin/views/bulk_action/registry.py"}, {"content": "from abc import ABC, abstractmethod\n\nfrom django import forms\nfrom django.db import transaction\nfrom django.shortcuts import get_list_or_404, redirect\nfrom django.utils.functional import classproperty\nfrom django.views.generic import FormView\n\nfrom wagtail import hooks\nfrom wagtail.admin import messages\nfrom wagtail.admin.utils import get_valid_next_url_from_request\n\n\nclass BulkAction(ABC, FormView):\n @property\n @abstractmethod\n def display_name(self):\n pass\n\n @property\n @abstractmethod\n def action_type(self):\n pass\n\n @property\n @abstractmethod\n def aria_label(self):\n pass\n\n extras = {}\n action_priority = 100\n classes = set()\n\n form_class = forms.Form\n cleaned_form = None\n\n def __init__(self, request, model):\n self.request = request\n next_url = get_valid_next_url_from_request(request)\n if not next_url:\n next_url = request.path\n self.next_url = next_url\n self.num_parent_objects = self.num_child_objects = 0\n if model in self.models:\n self.model = model\n else:\n raise Exception(\n \"model {} is not among the specified list of models\".format(\n model.__class__.__name__\n )\n )\n\n @classproperty\n def models(cls):\n return []\n\n @classmethod\n def get_queryset(cls, model, object_ids):\n return get_list_or_404(model, pk__in=object_ids)\n\n def check_perm(self, obj):\n return True\n\n @classmethod\n def execute_action(cls, objects, **kwargs):\n raise NotImplementedError(\"execute_action needs to be implemented\")\n\n def get_success_message(self, num_parent_objects, num_child_objects):\n pass\n\n def object_context(self, obj):\n return {\"item\": obj}\n\n @classmethod\n def get_default_model(cls):\n models = cls.models\n if len(models) == 1:\n return models[0]\n raise Exception(\n \"Cannot get default model if number of models is greater than 1\"\n )\n\n def __run_before_hooks(self, action_type, request, objects):\n for hook in hooks.get_hooks(\"before_bulk_action\"):\n result = hook(request, action_type, objects, self)\n if hasattr(result, \"status_code\"):\n return result\n\n def __run_after_hooks(self, action_type, request, objects):\n for hook in hooks.get_hooks(\"after_bulk_action\"):\n result = hook(request, action_type, objects, self)\n if hasattr(result, \"status_code\"):\n return result\n\n def get_all_objects_in_listing_query(self, parent_id):\n return self.model.objects.all().values_list(\"pk\", flat=True)\n\n def get_actionable_objects(self):\n objects = []\n items_with_no_access = []\n object_ids = self.request.GET.getlist(\"id\")\n if \"all\" in object_ids:\n object_ids = self.get_all_objects_in_listing_query(\n self.request.GET.get(\"childOf\")\n )\n\n for obj in self.get_queryset(self.model, object_ids):\n if not self.check_perm(obj):\n items_with_no_access.append(obj)\n else:\n objects.append(obj)\n return objects, {\"items_with_no_access\": items_with_no_access}\n\n def get_context_data(self, **kwargs):\n items, items_with_no_access = self.get_actionable_objects()\n _items = []\n for item in items:\n _items.append(self.object_context(item))\n return {\n **super().get_context_data(**kwargs),\n \"items\": _items,\n **items_with_no_access,\n \"next\": self.next_url,\n \"submit_url\": self.request.path + \"?\" + self.request.META[\"QUERY_STRING\"],\n }\n\n def prepare_action(self, objects, objects_without_access):\n return\n\n def get_execution_context(self):\n return {}\n\n def form_valid(self, form):\n request = self.request\n self.cleaned_form = form\n objects, objects_without_access = self.get_actionable_objects()\n self.actionable_objects = objects\n resp = self.prepare_action(objects, objects_without_access)\n if hasattr(resp, \"status_code\"):\n return resp\n with transaction.atomic():\n before_hook_result = self.__run_before_hooks(\n self.action_type, request, objects\n )\n if before_hook_result is not None:\n return before_hook_result\n num_parent_objects, num_child_objects = self.execute_action(\n objects, **self.get_execution_context()\n )\n after_hook_result = self.__run_after_hooks(\n self.action_type, request, objects\n )\n if after_hook_result is not None:\n return after_hook_result\n success_message = self.get_success_message(\n num_parent_objects, num_child_objects\n )\n if success_message is not None:\n messages.success(request, success_message)\n return redirect(self.next_url)\n\n def form_invalid(self, form):\n return super().form_invalid(form)\n", "path": "wagtail/admin/views/bulk_action/base_bulk_action.py"}]}
| 3,076 | 820 |
gh_patches_debug_40806
|
rasdani/github-patches
|
git_diff
|
hpcaitech__ColossalAI-5652
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[tensor] fix some unittests
[tensor] fix some unittests
[tensor] fix some unittests
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `colossalai/shardformer/policies/gptj.py`
Content:
```
1 import warnings
2 from functools import partial
3 from typing import Callable, Dict, List
4
5 from torch import Tensor, nn
6
7 import colossalai.shardformer.layer as col_nn
8
9 from ..modeling.gptj import (
10 GPTJPipelineForwards,
11 get_gptj_flash_attention_forward,
12 gptj_model_forward_for_flash_attention,
13 )
14 from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
15
16 __all__ = [
17 "GPTJPolicy",
18 "GPTJModelPolicy",
19 "GPTJForCausalLMPolicy",
20 "GPTJForSequenceClassificationPolicy",
21 "GPTJForQuestionAnsweringPolicy",
22 "FlaxGPTJPolicy",
23 "FlaxGPTJForCausalLMPolicy",
24 ]
25
26
27 class GPTJPolicy(Policy):
28 def config_sanity_check(self):
29 pass
30
31 def preprocess(self):
32 self.tie_weight = self.tie_weight_check()
33 self.origin_attn_implement = self.model.config._attn_implementation
34 return self.model
35
36 def module_policy(self):
37 from transformers.models.gptj.modeling_gptj import GPTJAttention, GPTJBlock, GPTJModel
38
39 ATTN_IMPLEMENTATION = {
40 "eager": GPTJAttention,
41 }
42
43 policy = {}
44
45 attn_cls = ATTN_IMPLEMENTATION[self.origin_attn_implement]
46
47 embedding_cls = None
48 if self.shard_config.enable_tensor_parallelism:
49 embedding_cls = col_nn.VocabParallelEmbedding1D
50 else:
51 if self.tie_weight:
52 embedding_cls = col_nn.PaddingEmbedding
53
54 if self.shard_config.enable_sequence_parallelism:
55 self.shard_config.enable_sequence_parallelism = False
56 warnings.warn("GPTJ doesn't support sequence parallelism now, will ignore the sequence parallelism flag.")
57 use_sequence_parallel = self.shard_config.enable_sequence_parallelism
58
59 overlap = self.shard_config.enable_sequence_overlap
60 if self.shard_config.enable_tensor_parallelism:
61 policy[GPTJModel] = ModulePolicyDescription(
62 sub_module_replacement=[
63 SubModuleReplacementDescription(
64 suffix="drop",
65 target_module=col_nn.DropoutForParallelInput,
66 ),
67 ]
68 )
69
70 policy[GPTJBlock] = ModulePolicyDescription(
71 attribute_replacement={
72 "attn.embed_dim": self.model.config.hidden_size // self.shard_config.tensor_parallel_size,
73 "attn.num_attention_heads": self.model.config.num_attention_heads
74 // self.shard_config.tensor_parallel_size,
75 },
76 sub_module_replacement=[
77 SubModuleReplacementDescription(
78 suffix="attn.k_proj",
79 target_module=col_nn.Linear1D_Col,
80 kwargs={
81 "seq_parallel": use_sequence_parallel,
82 "overlap": overlap,
83 },
84 ),
85 SubModuleReplacementDescription(
86 suffix="attn.q_proj",
87 target_module=col_nn.Linear1D_Col,
88 kwargs={
89 "seq_parallel": use_sequence_parallel,
90 "overlap": overlap,
91 },
92 ),
93 SubModuleReplacementDescription(
94 suffix="attn.v_proj",
95 target_module=col_nn.Linear1D_Col,
96 kwargs={
97 "seq_parallel": use_sequence_parallel,
98 "overlap": overlap,
99 },
100 ),
101 SubModuleReplacementDescription(
102 suffix="attn.out_proj",
103 target_module=col_nn.Linear1D_Row,
104 kwargs={"seq_parallel": use_sequence_parallel},
105 ),
106 SubModuleReplacementDescription(
107 suffix="mlp.fc_in",
108 target_module=col_nn.Linear1D_Col,
109 kwargs={"seq_parallel": use_sequence_parallel},
110 ),
111 SubModuleReplacementDescription(
112 suffix="mlp.fc_out",
113 target_module=col_nn.Linear1D_Row,
114 kwargs={"seq_parallel": use_sequence_parallel},
115 ),
116 SubModuleReplacementDescription(
117 suffix="attn.attn_dropout",
118 target_module=col_nn.DropoutForParallelInput,
119 ),
120 SubModuleReplacementDescription(
121 suffix="attn.resid_dropout",
122 target_module=col_nn.DropoutForParallelInput,
123 ),
124 SubModuleReplacementDescription(
125 suffix="mlp.dropout",
126 target_module=col_nn.DropoutForParallelInput,
127 ),
128 ],
129 )
130
131 if embedding_cls is not None:
132 self.append_or_create_submodule_replacement(
133 description=SubModuleReplacementDescription(
134 suffix="wte",
135 target_module=embedding_cls,
136 kwargs={"make_vocab_size_divisible_by": self.shard_config.make_vocab_size_divisible_by},
137 ),
138 policy=policy,
139 target_key=GPTJModel,
140 )
141
142 # optimization configuration
143 if self.shard_config.enable_fused_normalization:
144 self.append_or_create_submodule_replacement(
145 description=SubModuleReplacementDescription(
146 suffix="ln_f",
147 target_module=col_nn.FusedLayerNorm,
148 ),
149 policy=policy,
150 target_key=GPTJModel,
151 )
152
153 self.append_or_create_submodule_replacement(
154 description=[
155 SubModuleReplacementDescription(
156 suffix="ln_1",
157 target_module=col_nn.FusedLayerNorm,
158 )
159 ],
160 policy=policy,
161 target_key=GPTJBlock,
162 )
163
164 if self.shard_config.enable_flash_attention:
165 self.append_or_create_method_replacement(
166 description={
167 "forward": get_gptj_flash_attention_forward(),
168 },
169 policy=policy,
170 target_key=attn_cls,
171 )
172 if not self.shard_config.pipeline_stage_manager:
173 self.append_or_create_method_replacement(
174 description={"forward": gptj_model_forward_for_flash_attention(self.shard_config)},
175 policy=policy,
176 target_key=GPTJModel,
177 )
178
179 return policy
180
181 def postprocess(self):
182 return self.model
183
184 def get_held_layers(self) -> List[nn.Module]:
185 """Get pipeline layers for current stage."""
186 assert self.pipeline_stage_manager is not None
187
188 if self.model.__class__.__name__ == "GPTJModel":
189 module = self.model
190 else:
191 module = self.model.transformer
192 stage_manager = self.pipeline_stage_manager
193
194 held_layers = []
195 layers_per_stage = stage_manager.distribute_layers(len(module.h))
196 if stage_manager.is_first_stage():
197 held_layers.append(module.wte)
198 held_layers.append(module.drop)
199 start_idx, end_idx = stage_manager.get_stage_index(layers_per_stage)
200 held_layers.extend(module.h[start_idx:end_idx])
201 if stage_manager.is_last_stage():
202 held_layers.append(module.ln_f)
203 return held_layers
204
205 def set_pipeline_forward(self, model_cls: nn.Module, new_forward: Callable, policy: Dict) -> None:
206 """If under pipeline parallel setting, replacing the original forward method of huggingface
207 to customized forward method, and add this changing to policy."""
208 if not self.pipeline_stage_manager:
209 raise ValueError("set_pipeline_forward method can only be called when pipeline parallel is enabled.")
210 stage_manager = self.pipeline_stage_manager
211 if self.model.__class__.__name__ == "GPTJModel":
212 module = self.model
213 else:
214 module = self.model.transformer
215
216 layers_per_stage = stage_manager.distribute_layers(len(module.h))
217 stage_index = stage_manager.get_stage_index(layers_per_stage)
218 method_replacement = {
219 "forward": partial(
220 new_forward,
221 stage_manager=stage_manager,
222 stage_index=stage_index,
223 shard_config=self.shard_config,
224 )
225 }
226 self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=model_cls)
227
228
229 # GPTJModel
230 class GPTJModelPolicy(GPTJPolicy):
231 def __init__(self) -> None:
232 super().__init__()
233
234 def module_policy(self):
235 from transformers.models.gptj.modeling_gptj import GPTJModel
236
237 policy = super().module_policy()
238
239 if self.pipeline_stage_manager is not None:
240 self.set_pipeline_forward(
241 model_cls=GPTJModel,
242 new_forward=GPTJPipelineForwards.gptj_model_forward,
243 policy=policy,
244 )
245 return policy
246
247 def get_held_layers(self) -> List[nn.Module]:
248 return super().get_held_layers()
249
250 def get_shared_params(self) -> List[Dict[int, Tensor]]:
251 """No shared params in GPT2Model."""
252 return []
253
254
255 # GPTJForCausalLM
256 class GPTJForCausalLMPolicy(GPTJPolicy):
257 def __init__(self) -> None:
258 super().__init__()
259
260 def module_policy(self):
261 from transformers.models.gptj.modeling_gptj import GPTJForCausalLM
262
263 policy = super().module_policy()
264
265 if self.shard_config.enable_tensor_parallelism:
266 addon_module = {
267 GPTJForCausalLM: ModulePolicyDescription(
268 sub_module_replacement=[
269 SubModuleReplacementDescription(
270 suffix="lm_head",
271 target_module=col_nn.VocabParallelLMHead1D,
272 kwargs={
273 "gather_output": True,
274 "make_vocab_size_divisible_by": self.shard_config.make_vocab_size_divisible_by,
275 },
276 )
277 ]
278 )
279 }
280 else:
281 addon_module = {
282 GPTJForCausalLM: ModulePolicyDescription(
283 sub_module_replacement=[
284 SubModuleReplacementDescription(
285 suffix="lm_head",
286 target_module=col_nn.PaddingLMHead,
287 kwargs={"make_vocab_size_divisible_by": self.shard_config.make_vocab_size_divisible_by},
288 )
289 ]
290 )
291 }
292 policy.update(addon_module)
293
294 if self.pipeline_stage_manager is not None:
295 self.set_pipeline_forward(
296 model_cls=GPTJForCausalLM,
297 new_forward=GPTJPipelineForwards.gptj_causallm_model_forward,
298 policy=policy,
299 )
300 return policy
301
302 def get_held_layers(self) -> List[nn.Module]:
303 held_layers = super().get_held_layers()
304 if self.pipeline_stage_manager.is_last_stage():
305 held_layers.append(self.model.lm_head)
306 return held_layers
307
308 def get_shared_params(self) -> List[Dict[int, Tensor]]:
309 """The weights of wte and lm_head are shared."""
310 module = self.model
311 stage_manager = self.pipeline_stage_manager
312 if stage_manager is not None:
313 if stage_manager.num_stages > 1 and id(module.transformer.wte.weight) == id(module.lm_head.weight):
314 first_stage, last_stage = 0, stage_manager.num_stages - 1
315 return [
316 {
317 first_stage: module.transformer.wte.weight,
318 last_stage: module.lm_head.weight,
319 }
320 ]
321 return []
322
323
324 # GPTJForSequenceClassification
325 class GPTJForSequenceClassificationPolicy(GPTJPolicy):
326 def __init__(self) -> None:
327 super().__init__()
328
329 def module_policy(self):
330 from transformers.models.gptj.modeling_gptj import GPTJForSequenceClassification
331
332 policy = super().module_policy()
333
334 if self.pipeline_stage_manager is not None:
335 self.set_pipeline_forward(
336 model_cls=GPTJForSequenceClassification,
337 new_forward=GPTJPipelineForwards.gptj_for_sequence_classification_forward,
338 policy=policy,
339 )
340 return policy
341
342 def get_held_layers(self) -> List[nn.Module]:
343 held_layers = super().get_held_layers()
344 if self.pipeline_stage_manager.is_last_stage():
345 held_layers.append(self.model.score)
346 return held_layers
347
348 def get_shared_params(self) -> List[Dict[int, Tensor]]:
349 """No shared params in GPTJForSequenceClassification."""
350 return []
351
352
353 # GPTJForQuestionAnswering
354 class GPTJForQuestionAnsweringPolicy(GPTJPolicy):
355 def __init__(self) -> None:
356 super().__init__()
357
358 def module_policy(self):
359 from transformers.models.gptj.modeling_gptj import GPTJForQuestionAnswering
360
361 policy = super().module_policy()
362
363 if self.pipeline_stage_manager is not None:
364 self.set_pipeline_forward(
365 model_cls=GPTJForQuestionAnswering,
366 new_forward=GPTJPipelineForwards.gptj_for_question_answering_forward,
367 policy=policy,
368 )
369 return policy
370
371 def get_held_layers(self) -> List[nn.Module]:
372 held_layers = super().get_held_layers()
373 if self.pipeline_stage_manager.is_last_stage():
374 held_layers.append(self.model.qa_outputs)
375 return held_layers
376
377 def get_shared_params(self) -> List[Dict[int, Tensor]]:
378 """No shared params in GPT2ForQuestionAnswering."""
379 return []
380
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/colossalai/shardformer/policies/gptj.py b/colossalai/shardformer/policies/gptj.py
--- a/colossalai/shardformer/policies/gptj.py
+++ b/colossalai/shardformer/policies/gptj.py
@@ -54,7 +54,6 @@
if self.shard_config.enable_sequence_parallelism:
self.shard_config.enable_sequence_parallelism = False
warnings.warn("GPTJ doesn't support sequence parallelism now, will ignore the sequence parallelism flag.")
- use_sequence_parallel = self.shard_config.enable_sequence_parallelism
overlap = self.shard_config.enable_sequence_overlap
if self.shard_config.enable_tensor_parallelism:
@@ -78,7 +77,6 @@
suffix="attn.k_proj",
target_module=col_nn.Linear1D_Col,
kwargs={
- "seq_parallel": use_sequence_parallel,
"overlap": overlap,
},
),
@@ -86,7 +84,6 @@
suffix="attn.q_proj",
target_module=col_nn.Linear1D_Col,
kwargs={
- "seq_parallel": use_sequence_parallel,
"overlap": overlap,
},
),
@@ -94,24 +91,20 @@
suffix="attn.v_proj",
target_module=col_nn.Linear1D_Col,
kwargs={
- "seq_parallel": use_sequence_parallel,
"overlap": overlap,
},
),
SubModuleReplacementDescription(
suffix="attn.out_proj",
target_module=col_nn.Linear1D_Row,
- kwargs={"seq_parallel": use_sequence_parallel},
),
SubModuleReplacementDescription(
suffix="mlp.fc_in",
target_module=col_nn.Linear1D_Col,
- kwargs={"seq_parallel": use_sequence_parallel},
),
SubModuleReplacementDescription(
suffix="mlp.fc_out",
target_module=col_nn.Linear1D_Row,
- kwargs={"seq_parallel": use_sequence_parallel},
),
SubModuleReplacementDescription(
suffix="attn.attn_dropout",
|
{"golden_diff": "diff --git a/colossalai/shardformer/policies/gptj.py b/colossalai/shardformer/policies/gptj.py\n--- a/colossalai/shardformer/policies/gptj.py\n+++ b/colossalai/shardformer/policies/gptj.py\n@@ -54,7 +54,6 @@\n if self.shard_config.enable_sequence_parallelism:\n self.shard_config.enable_sequence_parallelism = False\n warnings.warn(\"GPTJ doesn't support sequence parallelism now, will ignore the sequence parallelism flag.\")\n- use_sequence_parallel = self.shard_config.enable_sequence_parallelism\n \n overlap = self.shard_config.enable_sequence_overlap\n if self.shard_config.enable_tensor_parallelism:\n@@ -78,7 +77,6 @@\n suffix=\"attn.k_proj\",\n target_module=col_nn.Linear1D_Col,\n kwargs={\n- \"seq_parallel\": use_sequence_parallel,\n \"overlap\": overlap,\n },\n ),\n@@ -86,7 +84,6 @@\n suffix=\"attn.q_proj\",\n target_module=col_nn.Linear1D_Col,\n kwargs={\n- \"seq_parallel\": use_sequence_parallel,\n \"overlap\": overlap,\n },\n ),\n@@ -94,24 +91,20 @@\n suffix=\"attn.v_proj\",\n target_module=col_nn.Linear1D_Col,\n kwargs={\n- \"seq_parallel\": use_sequence_parallel,\n \"overlap\": overlap,\n },\n ),\n SubModuleReplacementDescription(\n suffix=\"attn.out_proj\",\n target_module=col_nn.Linear1D_Row,\n- kwargs={\"seq_parallel\": use_sequence_parallel},\n ),\n SubModuleReplacementDescription(\n suffix=\"mlp.fc_in\",\n target_module=col_nn.Linear1D_Col,\n- kwargs={\"seq_parallel\": use_sequence_parallel},\n ),\n SubModuleReplacementDescription(\n suffix=\"mlp.fc_out\",\n target_module=col_nn.Linear1D_Row,\n- kwargs={\"seq_parallel\": use_sequence_parallel},\n ),\n SubModuleReplacementDescription(\n suffix=\"attn.attn_dropout\",\n", "issue": "[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n", "before_files": [{"content": "import warnings\nfrom functools import partial\nfrom typing import Callable, Dict, List\n\nfrom torch import Tensor, nn\n\nimport colossalai.shardformer.layer as col_nn\n\nfrom ..modeling.gptj import (\n GPTJPipelineForwards,\n get_gptj_flash_attention_forward,\n gptj_model_forward_for_flash_attention,\n)\nfrom .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription\n\n__all__ = [\n \"GPTJPolicy\",\n \"GPTJModelPolicy\",\n \"GPTJForCausalLMPolicy\",\n \"GPTJForSequenceClassificationPolicy\",\n \"GPTJForQuestionAnsweringPolicy\",\n \"FlaxGPTJPolicy\",\n \"FlaxGPTJForCausalLMPolicy\",\n]\n\n\nclass GPTJPolicy(Policy):\n def config_sanity_check(self):\n pass\n\n def preprocess(self):\n self.tie_weight = self.tie_weight_check()\n self.origin_attn_implement = self.model.config._attn_implementation\n return self.model\n\n def module_policy(self):\n from transformers.models.gptj.modeling_gptj import GPTJAttention, GPTJBlock, GPTJModel\n\n ATTN_IMPLEMENTATION = {\n \"eager\": GPTJAttention,\n }\n\n policy = {}\n\n attn_cls = ATTN_IMPLEMENTATION[self.origin_attn_implement]\n\n embedding_cls = None\n if self.shard_config.enable_tensor_parallelism:\n embedding_cls = col_nn.VocabParallelEmbedding1D\n else:\n if self.tie_weight:\n embedding_cls = col_nn.PaddingEmbedding\n\n if self.shard_config.enable_sequence_parallelism:\n self.shard_config.enable_sequence_parallelism = False\n warnings.warn(\"GPTJ doesn't support sequence parallelism now, will ignore the sequence parallelism flag.\")\n use_sequence_parallel = self.shard_config.enable_sequence_parallelism\n\n overlap = self.shard_config.enable_sequence_overlap\n if self.shard_config.enable_tensor_parallelism:\n policy[GPTJModel] = ModulePolicyDescription(\n sub_module_replacement=[\n SubModuleReplacementDescription(\n suffix=\"drop\",\n target_module=col_nn.DropoutForParallelInput,\n ),\n ]\n )\n\n policy[GPTJBlock] = ModulePolicyDescription(\n attribute_replacement={\n \"attn.embed_dim\": self.model.config.hidden_size // self.shard_config.tensor_parallel_size,\n \"attn.num_attention_heads\": self.model.config.num_attention_heads\n // self.shard_config.tensor_parallel_size,\n },\n sub_module_replacement=[\n SubModuleReplacementDescription(\n suffix=\"attn.k_proj\",\n target_module=col_nn.Linear1D_Col,\n kwargs={\n \"seq_parallel\": use_sequence_parallel,\n \"overlap\": overlap,\n },\n ),\n SubModuleReplacementDescription(\n suffix=\"attn.q_proj\",\n target_module=col_nn.Linear1D_Col,\n kwargs={\n \"seq_parallel\": use_sequence_parallel,\n \"overlap\": overlap,\n },\n ),\n SubModuleReplacementDescription(\n suffix=\"attn.v_proj\",\n target_module=col_nn.Linear1D_Col,\n kwargs={\n \"seq_parallel\": use_sequence_parallel,\n \"overlap\": overlap,\n },\n ),\n SubModuleReplacementDescription(\n suffix=\"attn.out_proj\",\n target_module=col_nn.Linear1D_Row,\n kwargs={\"seq_parallel\": use_sequence_parallel},\n ),\n SubModuleReplacementDescription(\n suffix=\"mlp.fc_in\",\n target_module=col_nn.Linear1D_Col,\n kwargs={\"seq_parallel\": use_sequence_parallel},\n ),\n SubModuleReplacementDescription(\n suffix=\"mlp.fc_out\",\n target_module=col_nn.Linear1D_Row,\n kwargs={\"seq_parallel\": use_sequence_parallel},\n ),\n SubModuleReplacementDescription(\n suffix=\"attn.attn_dropout\",\n target_module=col_nn.DropoutForParallelInput,\n ),\n SubModuleReplacementDescription(\n suffix=\"attn.resid_dropout\",\n target_module=col_nn.DropoutForParallelInput,\n ),\n SubModuleReplacementDescription(\n suffix=\"mlp.dropout\",\n target_module=col_nn.DropoutForParallelInput,\n ),\n ],\n )\n\n if embedding_cls is not None:\n self.append_or_create_submodule_replacement(\n description=SubModuleReplacementDescription(\n suffix=\"wte\",\n target_module=embedding_cls,\n kwargs={\"make_vocab_size_divisible_by\": self.shard_config.make_vocab_size_divisible_by},\n ),\n policy=policy,\n target_key=GPTJModel,\n )\n\n # optimization configuration\n if self.shard_config.enable_fused_normalization:\n self.append_or_create_submodule_replacement(\n description=SubModuleReplacementDescription(\n suffix=\"ln_f\",\n target_module=col_nn.FusedLayerNorm,\n ),\n policy=policy,\n target_key=GPTJModel,\n )\n\n self.append_or_create_submodule_replacement(\n description=[\n SubModuleReplacementDescription(\n suffix=\"ln_1\",\n target_module=col_nn.FusedLayerNorm,\n )\n ],\n policy=policy,\n target_key=GPTJBlock,\n )\n\n if self.shard_config.enable_flash_attention:\n self.append_or_create_method_replacement(\n description={\n \"forward\": get_gptj_flash_attention_forward(),\n },\n policy=policy,\n target_key=attn_cls,\n )\n if not self.shard_config.pipeline_stage_manager:\n self.append_or_create_method_replacement(\n description={\"forward\": gptj_model_forward_for_flash_attention(self.shard_config)},\n policy=policy,\n target_key=GPTJModel,\n )\n\n return policy\n\n def postprocess(self):\n return self.model\n\n def get_held_layers(self) -> List[nn.Module]:\n \"\"\"Get pipeline layers for current stage.\"\"\"\n assert self.pipeline_stage_manager is not None\n\n if self.model.__class__.__name__ == \"GPTJModel\":\n module = self.model\n else:\n module = self.model.transformer\n stage_manager = self.pipeline_stage_manager\n\n held_layers = []\n layers_per_stage = stage_manager.distribute_layers(len(module.h))\n if stage_manager.is_first_stage():\n held_layers.append(module.wte)\n held_layers.append(module.drop)\n start_idx, end_idx = stage_manager.get_stage_index(layers_per_stage)\n held_layers.extend(module.h[start_idx:end_idx])\n if stage_manager.is_last_stage():\n held_layers.append(module.ln_f)\n return held_layers\n\n def set_pipeline_forward(self, model_cls: nn.Module, new_forward: Callable, policy: Dict) -> None:\n \"\"\"If under pipeline parallel setting, replacing the original forward method of huggingface\n to customized forward method, and add this changing to policy.\"\"\"\n if not self.pipeline_stage_manager:\n raise ValueError(\"set_pipeline_forward method can only be called when pipeline parallel is enabled.\")\n stage_manager = self.pipeline_stage_manager\n if self.model.__class__.__name__ == \"GPTJModel\":\n module = self.model\n else:\n module = self.model.transformer\n\n layers_per_stage = stage_manager.distribute_layers(len(module.h))\n stage_index = stage_manager.get_stage_index(layers_per_stage)\n method_replacement = {\n \"forward\": partial(\n new_forward,\n stage_manager=stage_manager,\n stage_index=stage_index,\n shard_config=self.shard_config,\n )\n }\n self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=model_cls)\n\n\n# GPTJModel\nclass GPTJModelPolicy(GPTJPolicy):\n def __init__(self) -> None:\n super().__init__()\n\n def module_policy(self):\n from transformers.models.gptj.modeling_gptj import GPTJModel\n\n policy = super().module_policy()\n\n if self.pipeline_stage_manager is not None:\n self.set_pipeline_forward(\n model_cls=GPTJModel,\n new_forward=GPTJPipelineForwards.gptj_model_forward,\n policy=policy,\n )\n return policy\n\n def get_held_layers(self) -> List[nn.Module]:\n return super().get_held_layers()\n\n def get_shared_params(self) -> List[Dict[int, Tensor]]:\n \"\"\"No shared params in GPT2Model.\"\"\"\n return []\n\n\n# GPTJForCausalLM\nclass GPTJForCausalLMPolicy(GPTJPolicy):\n def __init__(self) -> None:\n super().__init__()\n\n def module_policy(self):\n from transformers.models.gptj.modeling_gptj import GPTJForCausalLM\n\n policy = super().module_policy()\n\n if self.shard_config.enable_tensor_parallelism:\n addon_module = {\n GPTJForCausalLM: ModulePolicyDescription(\n sub_module_replacement=[\n SubModuleReplacementDescription(\n suffix=\"lm_head\",\n target_module=col_nn.VocabParallelLMHead1D,\n kwargs={\n \"gather_output\": True,\n \"make_vocab_size_divisible_by\": self.shard_config.make_vocab_size_divisible_by,\n },\n )\n ]\n )\n }\n else:\n addon_module = {\n GPTJForCausalLM: ModulePolicyDescription(\n sub_module_replacement=[\n SubModuleReplacementDescription(\n suffix=\"lm_head\",\n target_module=col_nn.PaddingLMHead,\n kwargs={\"make_vocab_size_divisible_by\": self.shard_config.make_vocab_size_divisible_by},\n )\n ]\n )\n }\n policy.update(addon_module)\n\n if self.pipeline_stage_manager is not None:\n self.set_pipeline_forward(\n model_cls=GPTJForCausalLM,\n new_forward=GPTJPipelineForwards.gptj_causallm_model_forward,\n policy=policy,\n )\n return policy\n\n def get_held_layers(self) -> List[nn.Module]:\n held_layers = super().get_held_layers()\n if self.pipeline_stage_manager.is_last_stage():\n held_layers.append(self.model.lm_head)\n return held_layers\n\n def get_shared_params(self) -> List[Dict[int, Tensor]]:\n \"\"\"The weights of wte and lm_head are shared.\"\"\"\n module = self.model\n stage_manager = self.pipeline_stage_manager\n if stage_manager is not None:\n if stage_manager.num_stages > 1 and id(module.transformer.wte.weight) == id(module.lm_head.weight):\n first_stage, last_stage = 0, stage_manager.num_stages - 1\n return [\n {\n first_stage: module.transformer.wte.weight,\n last_stage: module.lm_head.weight,\n }\n ]\n return []\n\n\n# GPTJForSequenceClassification\nclass GPTJForSequenceClassificationPolicy(GPTJPolicy):\n def __init__(self) -> None:\n super().__init__()\n\n def module_policy(self):\n from transformers.models.gptj.modeling_gptj import GPTJForSequenceClassification\n\n policy = super().module_policy()\n\n if self.pipeline_stage_manager is not None:\n self.set_pipeline_forward(\n model_cls=GPTJForSequenceClassification,\n new_forward=GPTJPipelineForwards.gptj_for_sequence_classification_forward,\n policy=policy,\n )\n return policy\n\n def get_held_layers(self) -> List[nn.Module]:\n held_layers = super().get_held_layers()\n if self.pipeline_stage_manager.is_last_stage():\n held_layers.append(self.model.score)\n return held_layers\n\n def get_shared_params(self) -> List[Dict[int, Tensor]]:\n \"\"\"No shared params in GPTJForSequenceClassification.\"\"\"\n return []\n\n\n# GPTJForQuestionAnswering\nclass GPTJForQuestionAnsweringPolicy(GPTJPolicy):\n def __init__(self) -> None:\n super().__init__()\n\n def module_policy(self):\n from transformers.models.gptj.modeling_gptj import GPTJForQuestionAnswering\n\n policy = super().module_policy()\n\n if self.pipeline_stage_manager is not None:\n self.set_pipeline_forward(\n model_cls=GPTJForQuestionAnswering,\n new_forward=GPTJPipelineForwards.gptj_for_question_answering_forward,\n policy=policy,\n )\n return policy\n\n def get_held_layers(self) -> List[nn.Module]:\n held_layers = super().get_held_layers()\n if self.pipeline_stage_manager.is_last_stage():\n held_layers.append(self.model.qa_outputs)\n return held_layers\n\n def get_shared_params(self) -> List[Dict[int, Tensor]]:\n \"\"\"No shared params in GPT2ForQuestionAnswering.\"\"\"\n return []\n", "path": "colossalai/shardformer/policies/gptj.py"}], "after_files": [{"content": "import warnings\nfrom functools import partial\nfrom typing import Callable, Dict, List\n\nfrom torch import Tensor, nn\n\nimport colossalai.shardformer.layer as col_nn\n\nfrom ..modeling.gptj import (\n GPTJPipelineForwards,\n get_gptj_flash_attention_forward,\n gptj_model_forward_for_flash_attention,\n)\nfrom .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription\n\n__all__ = [\n \"GPTJPolicy\",\n \"GPTJModelPolicy\",\n \"GPTJForCausalLMPolicy\",\n \"GPTJForSequenceClassificationPolicy\",\n \"GPTJForQuestionAnsweringPolicy\",\n \"FlaxGPTJPolicy\",\n \"FlaxGPTJForCausalLMPolicy\",\n]\n\n\nclass GPTJPolicy(Policy):\n def config_sanity_check(self):\n pass\n\n def preprocess(self):\n self.tie_weight = self.tie_weight_check()\n self.origin_attn_implement = self.model.config._attn_implementation\n return self.model\n\n def module_policy(self):\n from transformers.models.gptj.modeling_gptj import GPTJAttention, GPTJBlock, GPTJModel\n\n ATTN_IMPLEMENTATION = {\n \"eager\": GPTJAttention,\n }\n\n policy = {}\n\n attn_cls = ATTN_IMPLEMENTATION[self.origin_attn_implement]\n\n embedding_cls = None\n if self.shard_config.enable_tensor_parallelism:\n embedding_cls = col_nn.VocabParallelEmbedding1D\n else:\n if self.tie_weight:\n embedding_cls = col_nn.PaddingEmbedding\n\n if self.shard_config.enable_sequence_parallelism:\n self.shard_config.enable_sequence_parallelism = False\n warnings.warn(\"GPTJ doesn't support sequence parallelism now, will ignore the sequence parallelism flag.\")\n\n overlap = self.shard_config.enable_sequence_overlap\n if self.shard_config.enable_tensor_parallelism:\n policy[GPTJModel] = ModulePolicyDescription(\n sub_module_replacement=[\n SubModuleReplacementDescription(\n suffix=\"drop\",\n target_module=col_nn.DropoutForParallelInput,\n ),\n ]\n )\n\n policy[GPTJBlock] = ModulePolicyDescription(\n attribute_replacement={\n \"attn.embed_dim\": self.model.config.hidden_size // self.shard_config.tensor_parallel_size,\n \"attn.num_attention_heads\": self.model.config.num_attention_heads\n // self.shard_config.tensor_parallel_size,\n },\n sub_module_replacement=[\n SubModuleReplacementDescription(\n suffix=\"attn.k_proj\",\n target_module=col_nn.Linear1D_Col,\n kwargs={\n \"overlap\": overlap,\n },\n ),\n SubModuleReplacementDescription(\n suffix=\"attn.q_proj\",\n target_module=col_nn.Linear1D_Col,\n kwargs={\n \"overlap\": overlap,\n },\n ),\n SubModuleReplacementDescription(\n suffix=\"attn.v_proj\",\n target_module=col_nn.Linear1D_Col,\n kwargs={\n \"overlap\": overlap,\n },\n ),\n SubModuleReplacementDescription(\n suffix=\"attn.out_proj\",\n target_module=col_nn.Linear1D_Row,\n ),\n SubModuleReplacementDescription(\n suffix=\"mlp.fc_in\",\n target_module=col_nn.Linear1D_Col,\n ),\n SubModuleReplacementDescription(\n suffix=\"mlp.fc_out\",\n target_module=col_nn.Linear1D_Row,\n ),\n SubModuleReplacementDescription(\n suffix=\"attn.attn_dropout\",\n target_module=col_nn.DropoutForParallelInput,\n ),\n SubModuleReplacementDescription(\n suffix=\"attn.resid_dropout\",\n target_module=col_nn.DropoutForParallelInput,\n ),\n SubModuleReplacementDescription(\n suffix=\"mlp.dropout\",\n target_module=col_nn.DropoutForParallelInput,\n ),\n ],\n )\n\n if embedding_cls is not None:\n self.append_or_create_submodule_replacement(\n description=SubModuleReplacementDescription(\n suffix=\"wte\",\n target_module=embedding_cls,\n kwargs={\"make_vocab_size_divisible_by\": self.shard_config.make_vocab_size_divisible_by},\n ),\n policy=policy,\n target_key=GPTJModel,\n )\n\n # optimization configuration\n if self.shard_config.enable_fused_normalization:\n self.append_or_create_submodule_replacement(\n description=SubModuleReplacementDescription(\n suffix=\"ln_f\",\n target_module=col_nn.FusedLayerNorm,\n ),\n policy=policy,\n target_key=GPTJModel,\n )\n\n self.append_or_create_submodule_replacement(\n description=[\n SubModuleReplacementDescription(\n suffix=\"ln_1\",\n target_module=col_nn.FusedLayerNorm,\n )\n ],\n policy=policy,\n target_key=GPTJBlock,\n )\n\n if self.shard_config.enable_flash_attention:\n self.append_or_create_method_replacement(\n description={\n \"forward\": get_gptj_flash_attention_forward(),\n },\n policy=policy,\n target_key=attn_cls,\n )\n if not self.shard_config.pipeline_stage_manager:\n self.append_or_create_method_replacement(\n description={\"forward\": gptj_model_forward_for_flash_attention(self.shard_config)},\n policy=policy,\n target_key=GPTJModel,\n )\n\n return policy\n\n def postprocess(self):\n return self.model\n\n def get_held_layers(self) -> List[nn.Module]:\n \"\"\"Get pipeline layers for current stage.\"\"\"\n assert self.pipeline_stage_manager is not None\n\n if self.model.__class__.__name__ == \"GPTJModel\":\n module = self.model\n else:\n module = self.model.transformer\n stage_manager = self.pipeline_stage_manager\n\n held_layers = []\n layers_per_stage = stage_manager.distribute_layers(len(module.h))\n if stage_manager.is_first_stage():\n held_layers.append(module.wte)\n held_layers.append(module.drop)\n start_idx, end_idx = stage_manager.get_stage_index(layers_per_stage)\n held_layers.extend(module.h[start_idx:end_idx])\n if stage_manager.is_last_stage():\n held_layers.append(module.ln_f)\n return held_layers\n\n def set_pipeline_forward(self, model_cls: nn.Module, new_forward: Callable, policy: Dict) -> None:\n \"\"\"If under pipeline parallel setting, replacing the original forward method of huggingface\n to customized forward method, and add this changing to policy.\"\"\"\n if not self.pipeline_stage_manager:\n raise ValueError(\"set_pipeline_forward method can only be called when pipeline parallel is enabled.\")\n stage_manager = self.pipeline_stage_manager\n if self.model.__class__.__name__ == \"GPTJModel\":\n module = self.model\n else:\n module = self.model.transformer\n\n layers_per_stage = stage_manager.distribute_layers(len(module.h))\n stage_index = stage_manager.get_stage_index(layers_per_stage)\n method_replacement = {\n \"forward\": partial(\n new_forward,\n stage_manager=stage_manager,\n stage_index=stage_index,\n shard_config=self.shard_config,\n )\n }\n self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=model_cls)\n\n\n# GPTJModel\nclass GPTJModelPolicy(GPTJPolicy):\n def __init__(self) -> None:\n super().__init__()\n\n def module_policy(self):\n from transformers.models.gptj.modeling_gptj import GPTJModel\n\n policy = super().module_policy()\n\n if self.pipeline_stage_manager is not None:\n self.set_pipeline_forward(\n model_cls=GPTJModel,\n new_forward=GPTJPipelineForwards.gptj_model_forward,\n policy=policy,\n )\n return policy\n\n def get_held_layers(self) -> List[nn.Module]:\n return super().get_held_layers()\n\n def get_shared_params(self) -> List[Dict[int, Tensor]]:\n \"\"\"No shared params in GPT2Model.\"\"\"\n return []\n\n\n# GPTJForCausalLM\nclass GPTJForCausalLMPolicy(GPTJPolicy):\n def __init__(self) -> None:\n super().__init__()\n\n def module_policy(self):\n from transformers.models.gptj.modeling_gptj import GPTJForCausalLM\n\n policy = super().module_policy()\n\n if self.shard_config.enable_tensor_parallelism:\n addon_module = {\n GPTJForCausalLM: ModulePolicyDescription(\n sub_module_replacement=[\n SubModuleReplacementDescription(\n suffix=\"lm_head\",\n target_module=col_nn.VocabParallelLMHead1D,\n kwargs={\n \"gather_output\": True,\n \"make_vocab_size_divisible_by\": self.shard_config.make_vocab_size_divisible_by,\n },\n )\n ]\n )\n }\n else:\n addon_module = {\n GPTJForCausalLM: ModulePolicyDescription(\n sub_module_replacement=[\n SubModuleReplacementDescription(\n suffix=\"lm_head\",\n target_module=col_nn.PaddingLMHead,\n kwargs={\"make_vocab_size_divisible_by\": self.shard_config.make_vocab_size_divisible_by},\n )\n ]\n )\n }\n policy.update(addon_module)\n\n if self.pipeline_stage_manager is not None:\n self.set_pipeline_forward(\n model_cls=GPTJForCausalLM,\n new_forward=GPTJPipelineForwards.gptj_causallm_model_forward,\n policy=policy,\n )\n return policy\n\n def get_held_layers(self) -> List[nn.Module]:\n held_layers = super().get_held_layers()\n if self.pipeline_stage_manager.is_last_stage():\n held_layers.append(self.model.lm_head)\n return held_layers\n\n def get_shared_params(self) -> List[Dict[int, Tensor]]:\n \"\"\"The weights of wte and lm_head are shared.\"\"\"\n module = self.model\n stage_manager = self.pipeline_stage_manager\n if stage_manager is not None:\n if stage_manager.num_stages > 1 and id(module.transformer.wte.weight) == id(module.lm_head.weight):\n first_stage, last_stage = 0, stage_manager.num_stages - 1\n return [\n {\n first_stage: module.transformer.wte.weight,\n last_stage: module.lm_head.weight,\n }\n ]\n return []\n\n\n# GPTJForSequenceClassification\nclass GPTJForSequenceClassificationPolicy(GPTJPolicy):\n def __init__(self) -> None:\n super().__init__()\n\n def module_policy(self):\n from transformers.models.gptj.modeling_gptj import GPTJForSequenceClassification\n\n policy = super().module_policy()\n\n if self.pipeline_stage_manager is not None:\n self.set_pipeline_forward(\n model_cls=GPTJForSequenceClassification,\n new_forward=GPTJPipelineForwards.gptj_for_sequence_classification_forward,\n policy=policy,\n )\n return policy\n\n def get_held_layers(self) -> List[nn.Module]:\n held_layers = super().get_held_layers()\n if self.pipeline_stage_manager.is_last_stage():\n held_layers.append(self.model.score)\n return held_layers\n\n def get_shared_params(self) -> List[Dict[int, Tensor]]:\n \"\"\"No shared params in GPTJForSequenceClassification.\"\"\"\n return []\n\n\n# GPTJForQuestionAnswering\nclass GPTJForQuestionAnsweringPolicy(GPTJPolicy):\n def __init__(self) -> None:\n super().__init__()\n\n def module_policy(self):\n from transformers.models.gptj.modeling_gptj import GPTJForQuestionAnswering\n\n policy = super().module_policy()\n\n if self.pipeline_stage_manager is not None:\n self.set_pipeline_forward(\n model_cls=GPTJForQuestionAnswering,\n new_forward=GPTJPipelineForwards.gptj_for_question_answering_forward,\n policy=policy,\n )\n return policy\n\n def get_held_layers(self) -> List[nn.Module]:\n held_layers = super().get_held_layers()\n if self.pipeline_stage_manager.is_last_stage():\n held_layers.append(self.model.qa_outputs)\n return held_layers\n\n def get_shared_params(self) -> List[Dict[int, Tensor]]:\n \"\"\"No shared params in GPT2ForQuestionAnswering.\"\"\"\n return []\n", "path": "colossalai/shardformer/policies/gptj.py"}]}
| 4,042 | 456 |
gh_patches_debug_41621
|
rasdani/github-patches
|
git_diff
|
watchdogpolska__feder-328
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Eksport w CSV EmailLog
Wprowadziliśmy w ```feder.letters.logs``` statystyki dostarczania wiadomości. Należy wprowadzić zestawienie wszystkich danych z EmailLog dla danego monitoringu, aby można było zrobić statystykę czy coś.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `feder/letters/logs/views.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 from __future__ import unicode_literals
3
4 from braces.views import SelectRelatedMixin, PrefetchRelatedMixin
5 from cached_property import cached_property
6 from django.shortcuts import get_object_or_404
7 from django.views.generic import DetailView, ListView
8
9 from feder.cases.models import Case
10 from feder.letters.logs.models import EmailLog
11 from feder.main.mixins import AttrPermissionRequiredMixin
12 from feder.monitorings.models import Monitoring
13
14
15 class ListMonitoringMixin(AttrPermissionRequiredMixin, SelectRelatedMixin):
16 select_related = ['case']
17 paginate_by = 100
18 model = EmailLog
19 permission_attribute = 'case__monitoring'
20 permission_required = 'monitorings.view_log'
21
22 def get_permission_object(self):
23 return self.monitoring
24
25 def get_queryset(self):
26 return super(ListMonitoringMixin, self).get_queryset().filter(case__monitoring=self.monitoring).with_logrecord_count()
27
28 def get_context_data(self, **kwargs):
29 kwargs['monitoring'] = self.monitoring
30 return super(ListMonitoringMixin, self).get_context_data(**kwargs)
31
32
33 class EmailLogMonitoringListView(ListMonitoringMixin, ListView):
34 template_name_suffix = '_list_for_monitoring'
35 permission_required = 'monitorings.view_log'
36
37 @cached_property
38 def monitoring(self):
39 return get_object_or_404(Monitoring, pk=self.kwargs['monitoring_pk'])
40
41
42 class EmailLogCaseListView(ListMonitoringMixin, ListView):
43 template_name_suffix = '_list_for_case'
44
45 @cached_property
46 def case(self):
47 return get_object_or_404(Case.objects.select_related('monitoring'),
48 pk=self.kwargs['case_pk'])
49
50 @cached_property
51 def monitoring(self):
52 return self.case.monitoring
53
54 def get_context_data(self, **kwargs):
55 kwargs['case'] = self.case
56 return super(EmailLogCaseListView, self).get_context_data(**kwargs)
57
58 def get_queryset(self):
59 return super(ListMonitoringMixin, self).get_queryset().filter(case=self.case)
60
61
62 class EmailLogDetailView(AttrPermissionRequiredMixin, PrefetchRelatedMixin,
63 SelectRelatedMixin, DetailView):
64 model = EmailLog
65 select_related = ['case__monitoring']
66 prefetch_related = ['logrecord_set']
67 permission_attribute = 'case__monitoring'
68 permission_required = 'monitorings.view_log'
69
```
Path: `feder/letters/logs/urls.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 from __future__ import unicode_literals
3
4 from django.conf.urls import url
5 from django.utils.translation import ugettext_lazy as _
6
7 from . import views
8
9 urlpatterns = [
10 url(_(r'^case-(?P<case_pk>[\d-]+)$'), views.EmailLogCaseListView.as_view(),
11 name="list"),
12 url(_(r'^monitoring-(?P<monitoring_pk>[\d-]+)$'), views.EmailLogMonitoringListView.as_view(),
13 name="list"),
14 url(_(r'^log-(?P<pk>[\d-]+)$'), views.EmailLogDetailView.as_view(),
15 name="detail"),
16 ]
17
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/feder/letters/logs/urls.py b/feder/letters/logs/urls.py
--- a/feder/letters/logs/urls.py
+++ b/feder/letters/logs/urls.py
@@ -11,6 +11,8 @@
name="list"),
url(_(r'^monitoring-(?P<monitoring_pk>[\d-]+)$'), views.EmailLogMonitoringListView.as_view(),
name="list"),
+ url(_(r'^monitoring-(?P<monitoring_pk>[\d-]+)/export$'), views.EmailLogMonitoringCsvView.as_view(),
+ name="export"),
url(_(r'^log-(?P<pk>[\d-]+)$'), views.EmailLogDetailView.as_view(),
name="detail"),
]
diff --git a/feder/letters/logs/views.py b/feder/letters/logs/views.py
--- a/feder/letters/logs/views.py
+++ b/feder/letters/logs/views.py
@@ -1,8 +1,12 @@
# -*- coding: utf-8 -*-
from __future__ import unicode_literals
+from django.utils import timezone
+import unicodecsv as csv
+
from braces.views import SelectRelatedMixin, PrefetchRelatedMixin
from cached_property import cached_property
+from django.http import HttpResponse
from django.shortcuts import get_object_or_404
from django.views.generic import DetailView, ListView
@@ -10,7 +14,7 @@
from feder.letters.logs.models import EmailLog
from feder.main.mixins import AttrPermissionRequiredMixin
from feder.monitorings.models import Monitoring
-
+from django.views.generic.list import ListView
class ListMonitoringMixin(AttrPermissionRequiredMixin, SelectRelatedMixin):
select_related = ['case']
@@ -39,6 +43,61 @@
return get_object_or_404(Monitoring, pk=self.kwargs['monitoring_pk'])
+class EmailLogMonitoringCsvView(ListMonitoringMixin, ListView):
+ permission_required = 'monitorings.view_log'
+
+ select_related = ['case', 'case__institution']
+
+ @cached_property
+ def monitoring(self):
+ return get_object_or_404(Monitoring, pk=self.kwargs['monitoring_pk'])
+
+ def get(self, *args, **kwargs):
+ response = self._get_csv_response()
+ self._write_rows(response, self.get_queryset())
+ return response
+
+ @staticmethod
+ def _get_base_model_field_names(queryset):
+ opts = queryset.model._meta
+ return [field.name for field in opts.fields if field.related_model is None]
+
+ def _get_csv_response(self):
+ csv_response = HttpResponse(content_type='text/csv')
+ current_time = timezone.now()
+ filename = 'email_log_{0}-{1}-{2}.csv'.format(self.monitoring.id,
+ current_time.strftime('%Y_%m_%d-%H_%M_%S'),
+ current_time.tzname()
+ )
+ csv_response['Content-Disposition'] = "attachment;filename={0}".format(filename)
+ return csv_response
+
+ def _write_rows(self, response, queryset):
+ writer = csv.writer(response)
+
+ # automatically add all fields from base table/model
+ base_field_names = self._get_base_model_field_names(queryset)
+
+ # print header row
+ writer.writerow(base_field_names +
+ [
+ 'case id',
+ 'case email',
+ 'institution',
+ 'institution id',
+ 'monitoring id']
+ )
+
+ for obj in queryset:
+ writer.writerow(
+ [getattr(obj, field) for field in base_field_names] + [
+ obj.case.id,
+ obj.case.email,
+ obj.case.institution.name,
+ obj.case.institution_id,
+ obj.case.monitoring_id,
+ ])
+
class EmailLogCaseListView(ListMonitoringMixin, ListView):
template_name_suffix = '_list_for_case'
|
{"golden_diff": "diff --git a/feder/letters/logs/urls.py b/feder/letters/logs/urls.py\n--- a/feder/letters/logs/urls.py\n+++ b/feder/letters/logs/urls.py\n@@ -11,6 +11,8 @@\n name=\"list\"),\n url(_(r'^monitoring-(?P<monitoring_pk>[\\d-]+)$'), views.EmailLogMonitoringListView.as_view(),\n name=\"list\"),\n+ url(_(r'^monitoring-(?P<monitoring_pk>[\\d-]+)/export$'), views.EmailLogMonitoringCsvView.as_view(),\n+ name=\"export\"),\n url(_(r'^log-(?P<pk>[\\d-]+)$'), views.EmailLogDetailView.as_view(),\n name=\"detail\"),\n ]\ndiff --git a/feder/letters/logs/views.py b/feder/letters/logs/views.py\n--- a/feder/letters/logs/views.py\n+++ b/feder/letters/logs/views.py\n@@ -1,8 +1,12 @@\n # -*- coding: utf-8 -*-\n from __future__ import unicode_literals\n \n+from django.utils import timezone\n+import unicodecsv as csv\n+\n from braces.views import SelectRelatedMixin, PrefetchRelatedMixin\n from cached_property import cached_property\n+from django.http import HttpResponse\n from django.shortcuts import get_object_or_404\n from django.views.generic import DetailView, ListView\n \n@@ -10,7 +14,7 @@\n from feder.letters.logs.models import EmailLog\n from feder.main.mixins import AttrPermissionRequiredMixin\n from feder.monitorings.models import Monitoring\n-\n+from django.views.generic.list import ListView\n \n class ListMonitoringMixin(AttrPermissionRequiredMixin, SelectRelatedMixin):\n select_related = ['case']\n@@ -39,6 +43,61 @@\n return get_object_or_404(Monitoring, pk=self.kwargs['monitoring_pk'])\n \n \n+class EmailLogMonitoringCsvView(ListMonitoringMixin, ListView):\n+ permission_required = 'monitorings.view_log'\n+\n+ select_related = ['case', 'case__institution']\n+\n+ @cached_property\n+ def monitoring(self):\n+ return get_object_or_404(Monitoring, pk=self.kwargs['monitoring_pk'])\n+\n+ def get(self, *args, **kwargs):\n+ response = self._get_csv_response()\n+ self._write_rows(response, self.get_queryset())\n+ return response\n+\n+ @staticmethod\n+ def _get_base_model_field_names(queryset):\n+ opts = queryset.model._meta\n+ return [field.name for field in opts.fields if field.related_model is None]\n+\n+ def _get_csv_response(self):\n+ csv_response = HttpResponse(content_type='text/csv')\n+ current_time = timezone.now()\n+ filename = 'email_log_{0}-{1}-{2}.csv'.format(self.monitoring.id,\n+ current_time.strftime('%Y_%m_%d-%H_%M_%S'),\n+ current_time.tzname()\n+ )\n+ csv_response['Content-Disposition'] = \"attachment;filename={0}\".format(filename)\n+ return csv_response\n+\n+ def _write_rows(self, response, queryset):\n+ writer = csv.writer(response)\n+\n+ # automatically add all fields from base table/model\n+ base_field_names = self._get_base_model_field_names(queryset)\n+\n+ # print header row\n+ writer.writerow(base_field_names +\n+ [\n+ 'case id',\n+ 'case email',\n+ 'institution',\n+ 'institution id',\n+ 'monitoring id']\n+ )\n+\n+ for obj in queryset:\n+ writer.writerow(\n+ [getattr(obj, field) for field in base_field_names] + [\n+ obj.case.id,\n+ obj.case.email,\n+ obj.case.institution.name,\n+ obj.case.institution_id,\n+ obj.case.monitoring_id,\n+ ])\n+\n class EmailLogCaseListView(ListMonitoringMixin, ListView):\n template_name_suffix = '_list_for_case'\n", "issue": "Eksport w CSV EmailLog \nWprowadzili\u015bmy w ```feder.letters.logs``` statystyki dostarczania wiadomo\u015bci. Nale\u017cy wprowadzi\u0107 zestawienie wszystkich danych z EmailLog dla danego monitoringu, aby mo\u017cna by\u0142o zrobi\u0107 statystyk\u0119 czy co\u015b.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals\n\nfrom braces.views import SelectRelatedMixin, PrefetchRelatedMixin\nfrom cached_property import cached_property\nfrom django.shortcuts import get_object_or_404\nfrom django.views.generic import DetailView, ListView\n\nfrom feder.cases.models import Case\nfrom feder.letters.logs.models import EmailLog\nfrom feder.main.mixins import AttrPermissionRequiredMixin\nfrom feder.monitorings.models import Monitoring\n\n\nclass ListMonitoringMixin(AttrPermissionRequiredMixin, SelectRelatedMixin):\n select_related = ['case']\n paginate_by = 100\n model = EmailLog\n permission_attribute = 'case__monitoring'\n permission_required = 'monitorings.view_log'\n\n def get_permission_object(self):\n return self.monitoring\n\n def get_queryset(self):\n return super(ListMonitoringMixin, self).get_queryset().filter(case__monitoring=self.monitoring).with_logrecord_count()\n\n def get_context_data(self, **kwargs):\n kwargs['monitoring'] = self.monitoring\n return super(ListMonitoringMixin, self).get_context_data(**kwargs)\n\n\nclass EmailLogMonitoringListView(ListMonitoringMixin, ListView):\n template_name_suffix = '_list_for_monitoring'\n permission_required = 'monitorings.view_log'\n\n @cached_property\n def monitoring(self):\n return get_object_or_404(Monitoring, pk=self.kwargs['monitoring_pk'])\n\n\nclass EmailLogCaseListView(ListMonitoringMixin, ListView):\n template_name_suffix = '_list_for_case'\n\n @cached_property\n def case(self):\n return get_object_or_404(Case.objects.select_related('monitoring'),\n pk=self.kwargs['case_pk'])\n\n @cached_property\n def monitoring(self):\n return self.case.monitoring\n\n def get_context_data(self, **kwargs):\n kwargs['case'] = self.case\n return super(EmailLogCaseListView, self).get_context_data(**kwargs)\n\n def get_queryset(self):\n return super(ListMonitoringMixin, self).get_queryset().filter(case=self.case)\n\n\nclass EmailLogDetailView(AttrPermissionRequiredMixin, PrefetchRelatedMixin,\n SelectRelatedMixin, DetailView):\n model = EmailLog\n select_related = ['case__monitoring']\n prefetch_related = ['logrecord_set']\n permission_attribute = 'case__monitoring'\n permission_required = 'monitorings.view_log'\n", "path": "feder/letters/logs/views.py"}, {"content": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals\n\nfrom django.conf.urls import url\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom . import views\n\nurlpatterns = [\n url(_(r'^case-(?P<case_pk>[\\d-]+)$'), views.EmailLogCaseListView.as_view(),\n name=\"list\"),\n url(_(r'^monitoring-(?P<monitoring_pk>[\\d-]+)$'), views.EmailLogMonitoringListView.as_view(),\n name=\"list\"),\n url(_(r'^log-(?P<pk>[\\d-]+)$'), views.EmailLogDetailView.as_view(),\n name=\"detail\"),\n]\n", "path": "feder/letters/logs/urls.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals\n\nfrom django.utils import timezone\nimport unicodecsv as csv\n\nfrom braces.views import SelectRelatedMixin, PrefetchRelatedMixin\nfrom cached_property import cached_property\nfrom django.http import HttpResponse\nfrom django.shortcuts import get_object_or_404\nfrom django.views.generic import DetailView, ListView\n\nfrom feder.cases.models import Case\nfrom feder.letters.logs.models import EmailLog\nfrom feder.main.mixins import AttrPermissionRequiredMixin\nfrom feder.monitorings.models import Monitoring\nfrom django.views.generic.list import ListView\n\nclass ListMonitoringMixin(AttrPermissionRequiredMixin, SelectRelatedMixin):\n select_related = ['case']\n paginate_by = 100\n model = EmailLog\n permission_attribute = 'case__monitoring'\n permission_required = 'monitorings.view_log'\n\n def get_permission_object(self):\n return self.monitoring\n\n def get_queryset(self):\n return super(ListMonitoringMixin, self).get_queryset().filter(case__monitoring=self.monitoring).with_logrecord_count()\n\n def get_context_data(self, **kwargs):\n kwargs['monitoring'] = self.monitoring\n return super(ListMonitoringMixin, self).get_context_data(**kwargs)\n\n\nclass EmailLogMonitoringListView(ListMonitoringMixin, ListView):\n template_name_suffix = '_list_for_monitoring'\n permission_required = 'monitorings.view_log'\n\n @cached_property\n def monitoring(self):\n return get_object_or_404(Monitoring, pk=self.kwargs['monitoring_pk'])\n\n\nclass EmailLogMonitoringCsvView(ListMonitoringMixin, ListView):\n permission_required = 'monitorings.view_log'\n\n select_related = ['case', 'case__institution']\n\n @cached_property\n def monitoring(self):\n return get_object_or_404(Monitoring, pk=self.kwargs['monitoring_pk'])\n\n def get(self, *args, **kwargs):\n response = self._get_csv_response()\n self._write_rows(response, self.get_queryset())\n return response\n\n @staticmethod\n def _get_base_model_field_names(queryset):\n opts = queryset.model._meta\n return [field.name for field in opts.fields if field.related_model is None]\n\n def _get_csv_response(self):\n csv_response = HttpResponse(content_type='text/csv')\n current_time = timezone.now()\n filename = 'email_log_{0}-{1}-{2}.csv'.format(self.monitoring.id,\n current_time.strftime('%Y_%m_%d-%H_%M_%S'),\n current_time.tzname()\n )\n csv_response['Content-Disposition'] = \"attachment;filename={0}\".format(filename)\n return csv_response\n\n def _write_rows(self, response, queryset):\n writer = csv.writer(response)\n\n # automatically add all fields from base table/model\n base_field_names = self._get_base_model_field_names(queryset)\n\n # print header row\n writer.writerow(base_field_names +\n [\n 'case id',\n 'case email',\n 'institution',\n 'institution id',\n 'monitoring id']\n )\n\n for obj in queryset:\n writer.writerow(\n [getattr(obj, field) for field in base_field_names] + [\n obj.case.id,\n obj.case.email,\n obj.case.institution.name,\n obj.case.institution_id,\n obj.case.monitoring_id,\n ])\n\nclass EmailLogCaseListView(ListMonitoringMixin, ListView):\n template_name_suffix = '_list_for_case'\n\n @cached_property\n def case(self):\n return get_object_or_404(Case.objects.select_related('monitoring'),\n pk=self.kwargs['case_pk'])\n\n @cached_property\n def monitoring(self):\n return self.case.monitoring\n\n def get_context_data(self, **kwargs):\n kwargs['case'] = self.case\n return super(EmailLogCaseListView, self).get_context_data(**kwargs)\n\n def get_queryset(self):\n return super(ListMonitoringMixin, self).get_queryset().filter(case=self.case)\n\n\nclass EmailLogDetailView(AttrPermissionRequiredMixin, PrefetchRelatedMixin,\n SelectRelatedMixin, DetailView):\n model = EmailLog\n select_related = ['case__monitoring']\n prefetch_related = ['logrecord_set']\n permission_attribute = 'case__monitoring'\n permission_required = 'monitorings.view_log'\n", "path": "feder/letters/logs/views.py"}, {"content": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals\n\nfrom django.conf.urls import url\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom . import views\n\nurlpatterns = [\n url(_(r'^case-(?P<case_pk>[\\d-]+)$'), views.EmailLogCaseListView.as_view(),\n name=\"list\"),\n url(_(r'^monitoring-(?P<monitoring_pk>[\\d-]+)$'), views.EmailLogMonitoringListView.as_view(),\n name=\"list\"),\n url(_(r'^monitoring-(?P<monitoring_pk>[\\d-]+)/export$'), views.EmailLogMonitoringCsvView.as_view(),\n name=\"export\"),\n url(_(r'^log-(?P<pk>[\\d-]+)$'), views.EmailLogDetailView.as_view(),\n name=\"detail\"),\n]\n", "path": "feder/letters/logs/urls.py"}]}
| 1,156 | 860 |
gh_patches_debug_32913
|
rasdani/github-patches
|
git_diff
|
translate__pootle-3588
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
REGEXP not present in PostgreSQL
Postgres [fails on Travis tests](https://travis-ci.org/dwaynebailey/pootle/jobs/50400894#L2516) because of the use of [NOT REGEXP](http://dev.mysql.com/doc/refman/5.1/en/regexp.html#operator_not-regexp)
The equivalent in Postgres is to use [POSIX Regular Expressions](http://www.postgresql.org/docs/9.3/static/functions-matching.html#FUNCTIONS-POSIX-REGEXP)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pootle/core/decorators.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 #
4 # Copyright 2013 Zuza Software Foundation
5 # Copyright 2013-2015 Evernote Corporation
6 #
7 # This file is part of Pootle.
8 #
9 # Pootle is free software; you can redistribute it and/or modify
10 # it under the terms of the GNU General Public License as published by
11 # the Free Software Foundation; either version 2 of the License, or
12 # (at your option) any later version.
13 #
14 # This program is distributed in the hope that it will be useful,
15 # but WITHOUT ANY WARRANTY; without even the implied warranty of
16 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
17 # GNU General Public License for more details.
18 #
19 # You should have received a copy of the GNU General Public License
20 # along with this program; if not, see <http://www.gnu.org/licenses/>.
21
22 from functools import wraps
23
24 from django.contrib.auth import get_user_model
25 from django.core.exceptions import PermissionDenied
26 from django.core.urlresolvers import reverse
27 from django.http import Http404
28 from django.shortcuts import get_object_or_404, redirect
29 from django.utils.translation import ugettext as _
30
31 from pootle_app.models.directory import Directory
32 from pootle_app.models.permissions import (check_permission,
33 get_matching_permissions)
34 from pootle_language.models import Language
35 from pootle_project.models import Project, ProjectSet, ProjectResource
36 from pootle_store.models import Store
37 from pootle_translationproject.models import TranslationProject
38
39 from .exceptions import Http400
40 from .url_helpers import split_pootle_path
41
42
43 CLS2ATTR = {
44 'TranslationProject': 'translation_project',
45 'Project': 'project',
46 'Language': 'language',
47 }
48
49
50 def get_path_obj(func):
51 @wraps(func)
52 def wrapped(request, *args, **kwargs):
53 if request.is_ajax():
54 pootle_path = request.GET.get('path', None)
55 if pootle_path is None:
56 raise Http400(_('Arguments missing.'))
57
58 language_code, project_code, dir_path, filename = \
59 split_pootle_path(pootle_path)
60 kwargs['dir_path'] = dir_path
61 kwargs['filename'] = filename
62 else:
63 language_code = kwargs.pop('language_code', None)
64 project_code = kwargs.pop('project_code', None)
65
66 if language_code and project_code:
67 try:
68 path_obj = TranslationProject.objects.enabled().get(
69 language__code=language_code,
70 project__code=project_code,
71 )
72 except TranslationProject.DoesNotExist:
73 path_obj = None
74
75 if path_obj is None and not request.is_ajax():
76 # Explicit selection via the UI: redirect either to
77 # ``/language_code/`` or ``/projects/project_code/``
78 user_choice = request.COOKIES.get('user-choice', None)
79 if user_choice and user_choice in ('language', 'project',):
80 url = {
81 'language': reverse('pootle-language-overview',
82 args=[language_code]),
83 'project': reverse('pootle-project-overview',
84 args=[project_code, '', '']),
85 }
86 response = redirect(url[user_choice])
87 response.delete_cookie('user-choice')
88
89 return response
90
91 raise Http404
92 elif language_code:
93 user_projects = Project.accessible_by_user(request.user)
94 language = get_object_or_404(Language, code=language_code)
95 children = language.children \
96 .filter(project__code__in=user_projects)
97 language.set_children(children)
98 path_obj = language
99 elif project_code:
100 try:
101 path_obj = Project.objects.get_for_user(project_code,
102 request.user)
103 except Project.DoesNotExist:
104 raise Http404
105 else: # No arguments: all user-accessible projects
106 user_projects = Project.accessible_by_user(request.user)
107 user_projects = Project.objects.for_user(request.user) \
108 .filter(code__in=user_projects)
109
110 path_obj = ProjectSet(user_projects)
111
112 request.ctx_obj = path_obj
113 request.ctx_path = path_obj.pootle_path
114 request.resource_obj = path_obj
115 request.pootle_path = path_obj.pootle_path
116
117 return func(request, path_obj, *args, **kwargs)
118
119 return wrapped
120
121
122 def set_resource(request, path_obj, dir_path, filename):
123 """Loads :cls:`pootle_app.models.Directory` and
124 :cls:`pootle_store.models.Store` models and populates the
125 request object.
126
127 :param path_obj: A path-like object object.
128 :param dir_path: Path relative to the root of `path_obj`.
129 :param filename: Optional filename.
130 """
131 obj_directory = getattr(path_obj, 'directory', path_obj)
132 ctx_path = obj_directory.pootle_path
133 resource_path = dir_path
134 pootle_path = ctx_path + dir_path
135
136 directory = None
137 store = None
138
139 is_404 = False
140
141 if filename:
142 pootle_path = pootle_path + filename
143 resource_path = resource_path + filename
144
145 try:
146 store = Store.objects.select_related(
147 'translation_project',
148 'parent',
149 ).get(pootle_path=pootle_path)
150 directory = store.parent
151 except Store.DoesNotExist:
152 is_404 = True
153
154 if directory is None and not is_404:
155 if dir_path:
156 try:
157 directory = Directory.objects.get(pootle_path=pootle_path)
158 except Directory.DoesNotExist:
159 is_404 = True
160 else:
161 directory = obj_directory
162
163 if is_404: # Try parent directory
164 language_code, project_code, dp, fn = split_pootle_path(pootle_path)
165 if not filename:
166 dir_path = dir_path[:dir_path[:-1].rfind('/') + 1]
167
168 url = reverse('pootle-tp-overview',
169 args=[language_code, project_code, dir_path])
170 request.redirect_url = url
171
172 raise Http404
173
174 request.store = store
175 request.directory = directory
176 request.pootle_path = pootle_path
177
178 request.resource_obj = store or (directory if dir_path else path_obj)
179 request.resource_path = resource_path
180 request.ctx_obj = path_obj or request.resource_obj
181 request.ctx_path = ctx_path
182
183
184 def set_project_resource(request, path_obj, dir_path, filename):
185 """Loads :cls:`pootle_app.models.Directory` and
186 :cls:`pootle_store.models.Store` models and populates the
187 request object.
188
189 This is the same as `set_resource` but operates at the project level
190 across all languages.
191
192 :param path_obj: A :cls:`pootle_project.models.Project` object.
193 :param dir_path: Path relative to the root of `path_obj`.
194 :param filename: Optional filename.
195 """
196 query_ctx_path = ''.join(['/%/', path_obj.code, '/'])
197 query_pootle_path = query_ctx_path + dir_path
198
199 obj_directory = getattr(path_obj, 'directory', path_obj)
200 ctx_path = obj_directory.pootle_path
201 resource_path = dir_path
202 pootle_path = ctx_path + dir_path
203
204 # List of disabled TP paths
205 disabled_tps = TranslationProject.objects.disabled().filter(
206 project__code=path_obj.code,
207 ).values_list('pootle_path', flat=True)
208 disabled_tps = list(disabled_tps)
209 disabled_tps.append('/templates/')
210 disabled_tps_regex = '^%s' % u'|'.join(disabled_tps)
211
212 if filename:
213 query_pootle_path = query_pootle_path + filename
214 pootle_path = pootle_path + filename
215 resource_path = resource_path + filename
216
217 resources = Store.objects.extra(
218 where=[
219 'pootle_store_store.pootle_path LIKE %s',
220 'pootle_store_store.pootle_path NOT REGEXP %s',
221 ], params=[query_pootle_path, disabled_tps_regex]
222 ).select_related('translation_project__language')
223 else:
224 resources = Directory.objects.extra(
225 where=[
226 'pootle_app_directory.pootle_path LIKE %s',
227 'pootle_app_directory.pootle_path NOT REGEXP %s',
228 ], params=[query_pootle_path, disabled_tps_regex]
229 ).select_related('parent')
230
231 if not resources.exists():
232 raise Http404
233
234 request.store = None
235 request.directory = None
236 request.pootle_path = pootle_path
237
238 request.resource_obj = ProjectResource(resources, pootle_path)
239 request.resource_path = resource_path
240 request.ctx_obj = path_obj or request.resource_obj
241 request.ctx_path = ctx_path
242
243
244 def get_resource(func):
245 @wraps(func)
246 def wrapped(request, path_obj, dir_path, filename):
247 """Gets resources associated to the current context."""
248 try:
249 directory = getattr(path_obj, 'directory', path_obj)
250 if directory.is_project() and (dir_path or filename):
251 set_project_resource(request, path_obj, dir_path, filename)
252 else:
253 set_resource(request, path_obj, dir_path, filename)
254 except Http404:
255 if not request.is_ajax():
256 user_choice = request.COOKIES.get('user-choice', None)
257 url = None
258
259 if hasattr(request, 'redirect_url'):
260 url = request.redirect_url
261 elif user_choice in ('language', 'resource',):
262 project = (path_obj if isinstance(path_obj, Project)
263 else path_obj.project)
264 url = reverse('pootle-project-overview',
265 args=[project.code, dir_path, filename])
266
267 if url is not None:
268 response = redirect(url)
269
270 if user_choice in ('language', 'resource',):
271 # XXX: should we rather delete this in a single place?
272 response.delete_cookie('user-choice')
273
274 return response
275
276 raise Http404
277
278 return func(request, path_obj, dir_path, filename)
279
280 return wrapped
281
282
283 def permission_required(permission_code):
284 """Checks for `permission_code` in the current context.
285
286 To retrieve the proper context, the `get_path_obj` decorator must be
287 used along with this decorator.
288 """
289 def wrapped(func):
290 @wraps(func)
291 def _wrapped(request, *args, **kwargs):
292 path_obj = args[0]
293 directory = getattr(path_obj, 'directory', path_obj)
294
295 # HACKISH: some old code relies on
296 # `request.translation_project`, `request.language` etc.
297 # being set, so we need to set that too.
298 attr_name = CLS2ATTR.get(path_obj.__class__.__name__,
299 'path_obj')
300 setattr(request, attr_name, path_obj)
301
302 User = get_user_model()
303 request.profile = User.get(request.user)
304 request.permissions = get_matching_permissions(request.profile,
305 directory)
306
307 if not permission_code:
308 return func(request, *args, **kwargs)
309
310 if not check_permission(permission_code, request):
311 raise PermissionDenied(
312 _("Insufficient rights to access this page."),
313 )
314
315 return func(request, *args, **kwargs)
316 return _wrapped
317 return wrapped
318
319
320 def admin_required(func):
321 @wraps(func)
322 def wrapped(request, *args, **kwargs):
323 if not request.user.is_superuser:
324 raise PermissionDenied(
325 _("You do not have rights to administer Pootle.")
326 )
327 return func(request, *args, **kwargs)
328
329 return wrapped
330
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pootle/core/decorators.py b/pootle/core/decorators.py
--- a/pootle/core/decorators.py
+++ b/pootle/core/decorators.py
@@ -24,6 +24,7 @@
from django.contrib.auth import get_user_model
from django.core.exceptions import PermissionDenied
from django.core.urlresolvers import reverse
+from django.db import connection
from django.http import Http404
from django.shortcuts import get_object_or_404, redirect
from django.utils.translation import ugettext as _
@@ -208,6 +209,9 @@
disabled_tps = list(disabled_tps)
disabled_tps.append('/templates/')
disabled_tps_regex = '^%s' % u'|'.join(disabled_tps)
+ sql_not_regex = 'NOT REGEXP'
+ if connection.vendor == 'postgresql':
+ sql_not_regex = '!~'
if filename:
query_pootle_path = query_pootle_path + filename
@@ -217,14 +221,14 @@
resources = Store.objects.extra(
where=[
'pootle_store_store.pootle_path LIKE %s',
- 'pootle_store_store.pootle_path NOT REGEXP %s',
+ 'pootle_store_store.pootle_path ' + sql_not_regex + ' %s',
], params=[query_pootle_path, disabled_tps_regex]
).select_related('translation_project__language')
else:
resources = Directory.objects.extra(
where=[
'pootle_app_directory.pootle_path LIKE %s',
- 'pootle_app_directory.pootle_path NOT REGEXP %s',
+ 'pootle_app_directory.pootle_path ' + sql_not_regex + ' %s',
], params=[query_pootle_path, disabled_tps_regex]
).select_related('parent')
|
{"golden_diff": "diff --git a/pootle/core/decorators.py b/pootle/core/decorators.py\n--- a/pootle/core/decorators.py\n+++ b/pootle/core/decorators.py\n@@ -24,6 +24,7 @@\n from django.contrib.auth import get_user_model\n from django.core.exceptions import PermissionDenied\n from django.core.urlresolvers import reverse\n+from django.db import connection\n from django.http import Http404\n from django.shortcuts import get_object_or_404, redirect\n from django.utils.translation import ugettext as _\n@@ -208,6 +209,9 @@\n disabled_tps = list(disabled_tps)\n disabled_tps.append('/templates/')\n disabled_tps_regex = '^%s' % u'|'.join(disabled_tps)\n+ sql_not_regex = 'NOT REGEXP'\n+ if connection.vendor == 'postgresql':\n+ sql_not_regex = '!~'\n \n if filename:\n query_pootle_path = query_pootle_path + filename\n@@ -217,14 +221,14 @@\n resources = Store.objects.extra(\n where=[\n 'pootle_store_store.pootle_path LIKE %s',\n- 'pootle_store_store.pootle_path NOT REGEXP %s',\n+ 'pootle_store_store.pootle_path ' + sql_not_regex + ' %s',\n ], params=[query_pootle_path, disabled_tps_regex]\n ).select_related('translation_project__language')\n else:\n resources = Directory.objects.extra(\n where=[\n 'pootle_app_directory.pootle_path LIKE %s',\n- 'pootle_app_directory.pootle_path NOT REGEXP %s',\n+ 'pootle_app_directory.pootle_path ' + sql_not_regex + ' %s',\n ], params=[query_pootle_path, disabled_tps_regex]\n ).select_related('parent')\n", "issue": "REGEXP not present in PostgreSQL\nPostgres [fails on Travis tests](https://travis-ci.org/dwaynebailey/pootle/jobs/50400894#L2516) because of the use of [NOT REGEXP](http://dev.mysql.com/doc/refman/5.1/en/regexp.html#operator_not-regexp)\n\nThe equivalent in Postgres is to use [POSIX Regular Expressions](http://www.postgresql.org/docs/9.3/static/functions-matching.html#FUNCTIONS-POSIX-REGEXP)\n\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n#\n# Copyright 2013 Zuza Software Foundation\n# Copyright 2013-2015 Evernote Corporation\n#\n# This file is part of Pootle.\n#\n# Pootle is free software; you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation; either version 2 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this program; if not, see <http://www.gnu.org/licenses/>.\n\nfrom functools import wraps\n\nfrom django.contrib.auth import get_user_model\nfrom django.core.exceptions import PermissionDenied\nfrom django.core.urlresolvers import reverse\nfrom django.http import Http404\nfrom django.shortcuts import get_object_or_404, redirect\nfrom django.utils.translation import ugettext as _\n\nfrom pootle_app.models.directory import Directory\nfrom pootle_app.models.permissions import (check_permission,\n get_matching_permissions)\nfrom pootle_language.models import Language\nfrom pootle_project.models import Project, ProjectSet, ProjectResource\nfrom pootle_store.models import Store\nfrom pootle_translationproject.models import TranslationProject\n\nfrom .exceptions import Http400\nfrom .url_helpers import split_pootle_path\n\n\nCLS2ATTR = {\n 'TranslationProject': 'translation_project',\n 'Project': 'project',\n 'Language': 'language',\n}\n\n\ndef get_path_obj(func):\n @wraps(func)\n def wrapped(request, *args, **kwargs):\n if request.is_ajax():\n pootle_path = request.GET.get('path', None)\n if pootle_path is None:\n raise Http400(_('Arguments missing.'))\n\n language_code, project_code, dir_path, filename = \\\n split_pootle_path(pootle_path)\n kwargs['dir_path'] = dir_path\n kwargs['filename'] = filename\n else:\n language_code = kwargs.pop('language_code', None)\n project_code = kwargs.pop('project_code', None)\n\n if language_code and project_code:\n try:\n path_obj = TranslationProject.objects.enabled().get(\n language__code=language_code,\n project__code=project_code,\n )\n except TranslationProject.DoesNotExist:\n path_obj = None\n\n if path_obj is None and not request.is_ajax():\n # Explicit selection via the UI: redirect either to\n # ``/language_code/`` or ``/projects/project_code/``\n user_choice = request.COOKIES.get('user-choice', None)\n if user_choice and user_choice in ('language', 'project',):\n url = {\n 'language': reverse('pootle-language-overview',\n args=[language_code]),\n 'project': reverse('pootle-project-overview',\n args=[project_code, '', '']),\n }\n response = redirect(url[user_choice])\n response.delete_cookie('user-choice')\n\n return response\n\n raise Http404\n elif language_code:\n user_projects = Project.accessible_by_user(request.user)\n language = get_object_or_404(Language, code=language_code)\n children = language.children \\\n .filter(project__code__in=user_projects)\n language.set_children(children)\n path_obj = language\n elif project_code:\n try:\n path_obj = Project.objects.get_for_user(project_code,\n request.user)\n except Project.DoesNotExist:\n raise Http404\n else: # No arguments: all user-accessible projects\n user_projects = Project.accessible_by_user(request.user)\n user_projects = Project.objects.for_user(request.user) \\\n .filter(code__in=user_projects)\n\n path_obj = ProjectSet(user_projects)\n\n request.ctx_obj = path_obj\n request.ctx_path = path_obj.pootle_path\n request.resource_obj = path_obj\n request.pootle_path = path_obj.pootle_path\n\n return func(request, path_obj, *args, **kwargs)\n\n return wrapped\n\n\ndef set_resource(request, path_obj, dir_path, filename):\n \"\"\"Loads :cls:`pootle_app.models.Directory` and\n :cls:`pootle_store.models.Store` models and populates the\n request object.\n\n :param path_obj: A path-like object object.\n :param dir_path: Path relative to the root of `path_obj`.\n :param filename: Optional filename.\n \"\"\"\n obj_directory = getattr(path_obj, 'directory', path_obj)\n ctx_path = obj_directory.pootle_path\n resource_path = dir_path\n pootle_path = ctx_path + dir_path\n\n directory = None\n store = None\n\n is_404 = False\n\n if filename:\n pootle_path = pootle_path + filename\n resource_path = resource_path + filename\n\n try:\n store = Store.objects.select_related(\n 'translation_project',\n 'parent',\n ).get(pootle_path=pootle_path)\n directory = store.parent\n except Store.DoesNotExist:\n is_404 = True\n\n if directory is None and not is_404:\n if dir_path:\n try:\n directory = Directory.objects.get(pootle_path=pootle_path)\n except Directory.DoesNotExist:\n is_404 = True\n else:\n directory = obj_directory\n\n if is_404: # Try parent directory\n language_code, project_code, dp, fn = split_pootle_path(pootle_path)\n if not filename:\n dir_path = dir_path[:dir_path[:-1].rfind('/') + 1]\n\n url = reverse('pootle-tp-overview',\n args=[language_code, project_code, dir_path])\n request.redirect_url = url\n\n raise Http404\n\n request.store = store\n request.directory = directory\n request.pootle_path = pootle_path\n\n request.resource_obj = store or (directory if dir_path else path_obj)\n request.resource_path = resource_path\n request.ctx_obj = path_obj or request.resource_obj\n request.ctx_path = ctx_path\n\n\ndef set_project_resource(request, path_obj, dir_path, filename):\n \"\"\"Loads :cls:`pootle_app.models.Directory` and\n :cls:`pootle_store.models.Store` models and populates the\n request object.\n\n This is the same as `set_resource` but operates at the project level\n across all languages.\n\n :param path_obj: A :cls:`pootle_project.models.Project` object.\n :param dir_path: Path relative to the root of `path_obj`.\n :param filename: Optional filename.\n \"\"\"\n query_ctx_path = ''.join(['/%/', path_obj.code, '/'])\n query_pootle_path = query_ctx_path + dir_path\n\n obj_directory = getattr(path_obj, 'directory', path_obj)\n ctx_path = obj_directory.pootle_path\n resource_path = dir_path\n pootle_path = ctx_path + dir_path\n\n # List of disabled TP paths\n disabled_tps = TranslationProject.objects.disabled().filter(\n project__code=path_obj.code,\n ).values_list('pootle_path', flat=True)\n disabled_tps = list(disabled_tps)\n disabled_tps.append('/templates/')\n disabled_tps_regex = '^%s' % u'|'.join(disabled_tps)\n\n if filename:\n query_pootle_path = query_pootle_path + filename\n pootle_path = pootle_path + filename\n resource_path = resource_path + filename\n\n resources = Store.objects.extra(\n where=[\n 'pootle_store_store.pootle_path LIKE %s',\n 'pootle_store_store.pootle_path NOT REGEXP %s',\n ], params=[query_pootle_path, disabled_tps_regex]\n ).select_related('translation_project__language')\n else:\n resources = Directory.objects.extra(\n where=[\n 'pootle_app_directory.pootle_path LIKE %s',\n 'pootle_app_directory.pootle_path NOT REGEXP %s',\n ], params=[query_pootle_path, disabled_tps_regex]\n ).select_related('parent')\n\n if not resources.exists():\n raise Http404\n\n request.store = None\n request.directory = None\n request.pootle_path = pootle_path\n\n request.resource_obj = ProjectResource(resources, pootle_path)\n request.resource_path = resource_path\n request.ctx_obj = path_obj or request.resource_obj\n request.ctx_path = ctx_path\n\n\ndef get_resource(func):\n @wraps(func)\n def wrapped(request, path_obj, dir_path, filename):\n \"\"\"Gets resources associated to the current context.\"\"\"\n try:\n directory = getattr(path_obj, 'directory', path_obj)\n if directory.is_project() and (dir_path or filename):\n set_project_resource(request, path_obj, dir_path, filename)\n else:\n set_resource(request, path_obj, dir_path, filename)\n except Http404:\n if not request.is_ajax():\n user_choice = request.COOKIES.get('user-choice', None)\n url = None\n\n if hasattr(request, 'redirect_url'):\n url = request.redirect_url\n elif user_choice in ('language', 'resource',):\n project = (path_obj if isinstance(path_obj, Project)\n else path_obj.project)\n url = reverse('pootle-project-overview',\n args=[project.code, dir_path, filename])\n\n if url is not None:\n response = redirect(url)\n\n if user_choice in ('language', 'resource',):\n # XXX: should we rather delete this in a single place?\n response.delete_cookie('user-choice')\n\n return response\n\n raise Http404\n\n return func(request, path_obj, dir_path, filename)\n\n return wrapped\n\n\ndef permission_required(permission_code):\n \"\"\"Checks for `permission_code` in the current context.\n\n To retrieve the proper context, the `get_path_obj` decorator must be\n used along with this decorator.\n \"\"\"\n def wrapped(func):\n @wraps(func)\n def _wrapped(request, *args, **kwargs):\n path_obj = args[0]\n directory = getattr(path_obj, 'directory', path_obj)\n\n # HACKISH: some old code relies on\n # `request.translation_project`, `request.language` etc.\n # being set, so we need to set that too.\n attr_name = CLS2ATTR.get(path_obj.__class__.__name__,\n 'path_obj')\n setattr(request, attr_name, path_obj)\n\n User = get_user_model()\n request.profile = User.get(request.user)\n request.permissions = get_matching_permissions(request.profile,\n directory)\n\n if not permission_code:\n return func(request, *args, **kwargs)\n\n if not check_permission(permission_code, request):\n raise PermissionDenied(\n _(\"Insufficient rights to access this page.\"),\n )\n\n return func(request, *args, **kwargs)\n return _wrapped\n return wrapped\n\n\ndef admin_required(func):\n @wraps(func)\n def wrapped(request, *args, **kwargs):\n if not request.user.is_superuser:\n raise PermissionDenied(\n _(\"You do not have rights to administer Pootle.\")\n )\n return func(request, *args, **kwargs)\n\n return wrapped\n", "path": "pootle/core/decorators.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n#\n# Copyright 2013 Zuza Software Foundation\n# Copyright 2013-2015 Evernote Corporation\n#\n# This file is part of Pootle.\n#\n# Pootle is free software; you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation; either version 2 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this program; if not, see <http://www.gnu.org/licenses/>.\n\nfrom functools import wraps\n\nfrom django.contrib.auth import get_user_model\nfrom django.core.exceptions import PermissionDenied\nfrom django.core.urlresolvers import reverse\nfrom django.db import connection\nfrom django.http import Http404\nfrom django.shortcuts import get_object_or_404, redirect\nfrom django.utils.translation import ugettext as _\n\nfrom pootle_app.models.directory import Directory\nfrom pootle_app.models.permissions import (check_permission,\n get_matching_permissions)\nfrom pootle_language.models import Language\nfrom pootle_project.models import Project, ProjectSet, ProjectResource\nfrom pootle_store.models import Store\nfrom pootle_translationproject.models import TranslationProject\n\nfrom .exceptions import Http400\nfrom .url_helpers import split_pootle_path\n\n\nCLS2ATTR = {\n 'TranslationProject': 'translation_project',\n 'Project': 'project',\n 'Language': 'language',\n}\n\n\ndef get_path_obj(func):\n @wraps(func)\n def wrapped(request, *args, **kwargs):\n if request.is_ajax():\n pootle_path = request.GET.get('path', None)\n if pootle_path is None:\n raise Http400(_('Arguments missing.'))\n\n language_code, project_code, dir_path, filename = \\\n split_pootle_path(pootle_path)\n kwargs['dir_path'] = dir_path\n kwargs['filename'] = filename\n else:\n language_code = kwargs.pop('language_code', None)\n project_code = kwargs.pop('project_code', None)\n\n if language_code and project_code:\n try:\n path_obj = TranslationProject.objects.enabled().get(\n language__code=language_code,\n project__code=project_code,\n )\n except TranslationProject.DoesNotExist:\n path_obj = None\n\n if path_obj is None and not request.is_ajax():\n # Explicit selection via the UI: redirect either to\n # ``/language_code/`` or ``/projects/project_code/``\n user_choice = request.COOKIES.get('user-choice', None)\n if user_choice and user_choice in ('language', 'project',):\n url = {\n 'language': reverse('pootle-language-overview',\n args=[language_code]),\n 'project': reverse('pootle-project-overview',\n args=[project_code, '', '']),\n }\n response = redirect(url[user_choice])\n response.delete_cookie('user-choice')\n\n return response\n\n raise Http404\n elif language_code:\n user_projects = Project.accessible_by_user(request.user)\n language = get_object_or_404(Language, code=language_code)\n children = language.children \\\n .filter(project__code__in=user_projects)\n language.set_children(children)\n path_obj = language\n elif project_code:\n try:\n path_obj = Project.objects.get_for_user(project_code,\n request.user)\n except Project.DoesNotExist:\n raise Http404\n else: # No arguments: all user-accessible projects\n user_projects = Project.accessible_by_user(request.user)\n user_projects = Project.objects.for_user(request.user) \\\n .filter(code__in=user_projects)\n\n path_obj = ProjectSet(user_projects)\n\n request.ctx_obj = path_obj\n request.ctx_path = path_obj.pootle_path\n request.resource_obj = path_obj\n request.pootle_path = path_obj.pootle_path\n\n return func(request, path_obj, *args, **kwargs)\n\n return wrapped\n\n\ndef set_resource(request, path_obj, dir_path, filename):\n \"\"\"Loads :cls:`pootle_app.models.Directory` and\n :cls:`pootle_store.models.Store` models and populates the\n request object.\n\n :param path_obj: A path-like object object.\n :param dir_path: Path relative to the root of `path_obj`.\n :param filename: Optional filename.\n \"\"\"\n obj_directory = getattr(path_obj, 'directory', path_obj)\n ctx_path = obj_directory.pootle_path\n resource_path = dir_path\n pootle_path = ctx_path + dir_path\n\n directory = None\n store = None\n\n is_404 = False\n\n if filename:\n pootle_path = pootle_path + filename\n resource_path = resource_path + filename\n\n try:\n store = Store.objects.select_related(\n 'translation_project',\n 'parent',\n ).get(pootle_path=pootle_path)\n directory = store.parent\n except Store.DoesNotExist:\n is_404 = True\n\n if directory is None and not is_404:\n if dir_path:\n try:\n directory = Directory.objects.get(pootle_path=pootle_path)\n except Directory.DoesNotExist:\n is_404 = True\n else:\n directory = obj_directory\n\n if is_404: # Try parent directory\n language_code, project_code, dp, fn = split_pootle_path(pootle_path)\n if not filename:\n dir_path = dir_path[:dir_path[:-1].rfind('/') + 1]\n\n url = reverse('pootle-tp-overview',\n args=[language_code, project_code, dir_path])\n request.redirect_url = url\n\n raise Http404\n\n request.store = store\n request.directory = directory\n request.pootle_path = pootle_path\n\n request.resource_obj = store or (directory if dir_path else path_obj)\n request.resource_path = resource_path\n request.ctx_obj = path_obj or request.resource_obj\n request.ctx_path = ctx_path\n\n\ndef set_project_resource(request, path_obj, dir_path, filename):\n \"\"\"Loads :cls:`pootle_app.models.Directory` and\n :cls:`pootle_store.models.Store` models and populates the\n request object.\n\n This is the same as `set_resource` but operates at the project level\n across all languages.\n\n :param path_obj: A :cls:`pootle_project.models.Project` object.\n :param dir_path: Path relative to the root of `path_obj`.\n :param filename: Optional filename.\n \"\"\"\n query_ctx_path = ''.join(['/%/', path_obj.code, '/'])\n query_pootle_path = query_ctx_path + dir_path\n\n obj_directory = getattr(path_obj, 'directory', path_obj)\n ctx_path = obj_directory.pootle_path\n resource_path = dir_path\n pootle_path = ctx_path + dir_path\n\n # List of disabled TP paths\n disabled_tps = TranslationProject.objects.disabled().filter(\n project__code=path_obj.code,\n ).values_list('pootle_path', flat=True)\n disabled_tps = list(disabled_tps)\n disabled_tps.append('/templates/')\n disabled_tps_regex = '^%s' % u'|'.join(disabled_tps)\n sql_not_regex = 'NOT REGEXP'\n if connection.vendor == 'postgresql':\n sql_not_regex = '!~'\n\n if filename:\n query_pootle_path = query_pootle_path + filename\n pootle_path = pootle_path + filename\n resource_path = resource_path + filename\n\n resources = Store.objects.extra(\n where=[\n 'pootle_store_store.pootle_path LIKE %s',\n 'pootle_store_store.pootle_path ' + sql_not_regex + ' %s',\n ], params=[query_pootle_path, disabled_tps_regex]\n ).select_related('translation_project__language')\n else:\n resources = Directory.objects.extra(\n where=[\n 'pootle_app_directory.pootle_path LIKE %s',\n 'pootle_app_directory.pootle_path ' + sql_not_regex + ' %s',\n ], params=[query_pootle_path, disabled_tps_regex]\n ).select_related('parent')\n\n if not resources.exists():\n raise Http404\n\n request.store = None\n request.directory = None\n request.pootle_path = pootle_path\n\n request.resource_obj = ProjectResource(resources, pootle_path)\n request.resource_path = resource_path\n request.ctx_obj = path_obj or request.resource_obj\n request.ctx_path = ctx_path\n\n\ndef get_resource(func):\n @wraps(func)\n def wrapped(request, path_obj, dir_path, filename):\n \"\"\"Gets resources associated to the current context.\"\"\"\n try:\n directory = getattr(path_obj, 'directory', path_obj)\n if directory.is_project() and (dir_path or filename):\n set_project_resource(request, path_obj, dir_path, filename)\n else:\n set_resource(request, path_obj, dir_path, filename)\n except Http404:\n if not request.is_ajax():\n user_choice = request.COOKIES.get('user-choice', None)\n url = None\n\n if hasattr(request, 'redirect_url'):\n url = request.redirect_url\n elif user_choice in ('language', 'resource',):\n project = (path_obj if isinstance(path_obj, Project)\n else path_obj.project)\n url = reverse('pootle-project-overview',\n args=[project.code, dir_path, filename])\n\n if url is not None:\n response = redirect(url)\n\n if user_choice in ('language', 'resource',):\n # XXX: should we rather delete this in a single place?\n response.delete_cookie('user-choice')\n\n return response\n\n raise Http404\n\n return func(request, path_obj, dir_path, filename)\n\n return wrapped\n\n\ndef permission_required(permission_code):\n \"\"\"Checks for `permission_code` in the current context.\n\n To retrieve the proper context, the `get_path_obj` decorator must be\n used along with this decorator.\n \"\"\"\n def wrapped(func):\n @wraps(func)\n def _wrapped(request, *args, **kwargs):\n path_obj = args[0]\n directory = getattr(path_obj, 'directory', path_obj)\n\n # HACKISH: some old code relies on\n # `request.translation_project`, `request.language` etc.\n # being set, so we need to set that too.\n attr_name = CLS2ATTR.get(path_obj.__class__.__name__,\n 'path_obj')\n setattr(request, attr_name, path_obj)\n\n User = get_user_model()\n request.profile = User.get(request.user)\n request.permissions = get_matching_permissions(request.profile,\n directory)\n\n if not permission_code:\n return func(request, *args, **kwargs)\n\n if not check_permission(permission_code, request):\n raise PermissionDenied(\n _(\"Insufficient rights to access this page.\"),\n )\n\n return func(request, *args, **kwargs)\n return _wrapped\n return wrapped\n\n\ndef admin_required(func):\n @wraps(func)\n def wrapped(request, *args, **kwargs):\n if not request.user.is_superuser:\n raise PermissionDenied(\n _(\"You do not have rights to administer Pootle.\")\n )\n return func(request, *args, **kwargs)\n\n return wrapped\n", "path": "pootle/core/decorators.py"}]}
| 3,811 | 419 |
gh_patches_debug_34199
|
rasdani/github-patches
|
git_diff
|
pre-commit__pre-commit-1251
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
pip install crashes can easily confuse newbies
those that are not familiar with the usual annoying messaging that pip presents can get pretty easily confused by the output that happens when `pip` fails to install
here's an example:
```console
$ pre-commit run flake8 --all-files
[INFO] Initializing environment for https://gitlab.com/pycqa/flake8:flake8-walrus.
[INFO] Installing environment for https://gitlab.com/pycqa/flake8.
[INFO] Once installed this environment will be reused.
[INFO] This may take a few minutes...
An unexpected error has occurred: CalledProcessError: Command: ('/home/asottile/.cache/pre-commit/repoi6ij0tyu/py_env-python3/bin/python', '/home/asottile/.cache/pre-commit/repoi6ij0tyu/py_env-python3/bin/pip', 'install', '.', 'flake8-walrus')
Return code: 1
Expected return code: 0
Output:
Processing /home/asottile/.cache/pre-commit/repoi6ij0tyu
Collecting flake8-walrus
Errors:
ERROR: Could not find a version that satisfies the requirement flake8-walrus (from versions: none)
ERROR: No matching distribution found for flake8-walrus
WARNING: You are using pip version 19.2.3, however version 19.3.1 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.
Check the log at /home/asottile/.cache/pre-commit/pre-commit.log
```
this ~admittedly is a bit garbled for a number of reasons:
- pip's error message here isn't great (it _could_ say something about `python_requires` or that there are versions available for other versions) **(the actual error is that the python is python3.6 and the plugin requires python3.8)**
- pip is out of date (when is it not? but admittedly who cares) -- **this is what a lot of people try and fix** -- unfortunately there's not really anything to fix here, the version of `pip` is from inside the virtualenv and doesn't really matter all that much
- `pre-commit` is currently splitting the output from stdout and stderr making it harder to read what's going on
I can't really fix the first one, and the second one I could silence but it doesn't quite feel like the right thing to do (and admittedly knowing the pip version is sometimes useful when debugging). The third however I can pretty easily fix!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pre_commit/util.py`
Content:
```
1 from __future__ import unicode_literals
2
3 import contextlib
4 import errno
5 import os.path
6 import shutil
7 import stat
8 import subprocess
9 import sys
10 import tempfile
11
12 import six
13
14 from pre_commit import five
15 from pre_commit import parse_shebang
16
17 if sys.version_info >= (3, 7): # pragma: no cover (PY37+)
18 from importlib.resources import open_binary
19 from importlib.resources import read_text
20 else: # pragma: no cover (<PY37)
21 from importlib_resources import open_binary
22 from importlib_resources import read_text
23
24
25 def mkdirp(path):
26 try:
27 os.makedirs(path)
28 except OSError:
29 if not os.path.exists(path):
30 raise
31
32
33 @contextlib.contextmanager
34 def clean_path_on_failure(path):
35 """Cleans up the directory on an exceptional failure."""
36 try:
37 yield
38 except BaseException:
39 if os.path.exists(path):
40 rmtree(path)
41 raise
42
43
44 @contextlib.contextmanager
45 def noop_context():
46 yield
47
48
49 @contextlib.contextmanager
50 def tmpdir():
51 """Contextmanager to create a temporary directory. It will be cleaned up
52 afterwards.
53 """
54 tempdir = tempfile.mkdtemp()
55 try:
56 yield tempdir
57 finally:
58 rmtree(tempdir)
59
60
61 def resource_bytesio(filename):
62 return open_binary('pre_commit.resources', filename)
63
64
65 def resource_text(filename):
66 return read_text('pre_commit.resources', filename)
67
68
69 def make_executable(filename):
70 original_mode = os.stat(filename).st_mode
71 os.chmod(
72 filename, original_mode | stat.S_IXUSR | stat.S_IXGRP | stat.S_IXOTH,
73 )
74
75
76 class CalledProcessError(RuntimeError):
77 def __init__(self, returncode, cmd, expected_returncode, output=None):
78 super(CalledProcessError, self).__init__(
79 returncode, cmd, expected_returncode, output,
80 )
81 self.returncode = returncode
82 self.cmd = cmd
83 self.expected_returncode = expected_returncode
84 self.output = output
85
86 def to_bytes(self):
87 output = []
88 for maybe_text in self.output:
89 if maybe_text:
90 output.append(
91 b'\n ' +
92 five.to_bytes(maybe_text).replace(b'\n', b'\n '),
93 )
94 else:
95 output.append(b'(none)')
96
97 return b''.join((
98 five.to_bytes(
99 'Command: {!r}\n'
100 'Return code: {}\n'
101 'Expected return code: {}\n'.format(
102 self.cmd, self.returncode, self.expected_returncode,
103 ),
104 ),
105 b'Output: ', output[0], b'\n',
106 b'Errors: ', output[1],
107 ))
108
109 def to_text(self):
110 return self.to_bytes().decode('UTF-8')
111
112 if six.PY2: # pragma: no cover (py2)
113 __str__ = to_bytes
114 __unicode__ = to_text
115 else: # pragma: no cover (py3)
116 __bytes__ = to_bytes
117 __str__ = to_text
118
119
120 def _cmd_kwargs(*cmd, **kwargs):
121 # py2/py3 on windows are more strict about the types here
122 cmd = tuple(five.n(arg) for arg in cmd)
123 kwargs['env'] = {
124 five.n(key): five.n(value)
125 for key, value in kwargs.pop('env', {}).items()
126 } or None
127 for arg in ('stdin', 'stdout', 'stderr'):
128 kwargs.setdefault(arg, subprocess.PIPE)
129 return cmd, kwargs
130
131
132 def cmd_output_b(*cmd, **kwargs):
133 retcode = kwargs.pop('retcode', 0)
134 cmd, kwargs = _cmd_kwargs(*cmd, **kwargs)
135
136 try:
137 cmd = parse_shebang.normalize_cmd(cmd)
138 except parse_shebang.ExecutableNotFoundError as e:
139 returncode, stdout_b, stderr_b = e.to_output()
140 else:
141 proc = subprocess.Popen(cmd, **kwargs)
142 stdout_b, stderr_b = proc.communicate()
143 returncode = proc.returncode
144
145 if retcode is not None and retcode != returncode:
146 raise CalledProcessError(
147 returncode, cmd, retcode, output=(stdout_b, stderr_b),
148 )
149
150 return returncode, stdout_b, stderr_b
151
152
153 def cmd_output(*cmd, **kwargs):
154 returncode, stdout_b, stderr_b = cmd_output_b(*cmd, **kwargs)
155 stdout = stdout_b.decode('UTF-8') if stdout_b is not None else None
156 stderr = stderr_b.decode('UTF-8') if stderr_b is not None else None
157 return returncode, stdout, stderr
158
159
160 if os.name != 'nt': # pragma: windows no cover
161 from os import openpty
162 import termios
163
164 class Pty(object):
165 def __init__(self):
166 self.r = self.w = None
167
168 def __enter__(self):
169 self.r, self.w = openpty()
170
171 # tty flags normally change \n to \r\n
172 attrs = termios.tcgetattr(self.r)
173 attrs[1] &= ~(termios.ONLCR | termios.OPOST)
174 termios.tcsetattr(self.r, termios.TCSANOW, attrs)
175
176 return self
177
178 def close_w(self):
179 if self.w is not None:
180 os.close(self.w)
181 self.w = None
182
183 def close_r(self):
184 assert self.r is not None
185 os.close(self.r)
186 self.r = None
187
188 def __exit__(self, exc_type, exc_value, traceback):
189 self.close_w()
190 self.close_r()
191
192 def cmd_output_p(*cmd, **kwargs):
193 assert kwargs.pop('retcode') is None
194 assert kwargs['stderr'] == subprocess.STDOUT, kwargs['stderr']
195 cmd, kwargs = _cmd_kwargs(*cmd, **kwargs)
196
197 try:
198 cmd = parse_shebang.normalize_cmd(cmd)
199 except parse_shebang.ExecutableNotFoundError as e:
200 return e.to_output()
201
202 with open(os.devnull) as devnull, Pty() as pty:
203 kwargs.update({'stdin': devnull, 'stdout': pty.w, 'stderr': pty.w})
204 proc = subprocess.Popen(cmd, **kwargs)
205 pty.close_w()
206
207 buf = b''
208 while True:
209 try:
210 bts = os.read(pty.r, 4096)
211 except OSError as e:
212 if e.errno == errno.EIO:
213 bts = b''
214 else:
215 raise
216 else:
217 buf += bts
218 if not bts:
219 break
220
221 return proc.wait(), buf, None
222 else: # pragma: no cover
223 cmd_output_p = cmd_output_b
224
225
226 def rmtree(path):
227 """On windows, rmtree fails for readonly dirs."""
228 def handle_remove_readonly(func, path, exc):
229 excvalue = exc[1]
230 if (
231 func in (os.rmdir, os.remove, os.unlink) and
232 excvalue.errno == errno.EACCES
233 ):
234 for p in (path, os.path.dirname(path)):
235 os.chmod(p, os.stat(p).st_mode | stat.S_IWUSR)
236 func(path)
237 else:
238 raise
239 shutil.rmtree(path, ignore_errors=False, onerror=handle_remove_readonly)
240
241
242 def parse_version(s):
243 """poor man's version comparison"""
244 return tuple(int(p) for p in s.split('.'))
245
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pre_commit/util.py b/pre_commit/util.py
--- a/pre_commit/util.py
+++ b/pre_commit/util.py
@@ -74,36 +74,31 @@
class CalledProcessError(RuntimeError):
- def __init__(self, returncode, cmd, expected_returncode, output=None):
+ def __init__(self, returncode, cmd, expected_returncode, stdout, stderr):
super(CalledProcessError, self).__init__(
- returncode, cmd, expected_returncode, output,
+ returncode, cmd, expected_returncode, stdout, stderr,
)
self.returncode = returncode
self.cmd = cmd
self.expected_returncode = expected_returncode
- self.output = output
+ self.stdout = stdout
+ self.stderr = stderr
def to_bytes(self):
- output = []
- for maybe_text in self.output:
- if maybe_text:
- output.append(
- b'\n ' +
- five.to_bytes(maybe_text).replace(b'\n', b'\n '),
- )
+ def _indent_or_none(part):
+ if part:
+ return b'\n ' + part.replace(b'\n', b'\n ')
else:
- output.append(b'(none)')
+ return b' (none)'
return b''.join((
- five.to_bytes(
- 'Command: {!r}\n'
- 'Return code: {}\n'
- 'Expected return code: {}\n'.format(
- self.cmd, self.returncode, self.expected_returncode,
- ),
- ),
- b'Output: ', output[0], b'\n',
- b'Errors: ', output[1],
+ 'command: {!r}\n'
+ 'return code: {}\n'
+ 'expected return code: {}\n'.format(
+ self.cmd, self.returncode, self.expected_returncode,
+ ).encode('UTF-8'),
+ b'stdout:', _indent_or_none(self.stdout), b'\n',
+ b'stderr:', _indent_or_none(self.stderr),
))
def to_text(self):
@@ -143,9 +138,7 @@
returncode = proc.returncode
if retcode is not None and retcode != returncode:
- raise CalledProcessError(
- returncode, cmd, retcode, output=(stdout_b, stderr_b),
- )
+ raise CalledProcessError(returncode, cmd, retcode, stdout_b, stderr_b)
return returncode, stdout_b, stderr_b
|
{"golden_diff": "diff --git a/pre_commit/util.py b/pre_commit/util.py\n--- a/pre_commit/util.py\n+++ b/pre_commit/util.py\n@@ -74,36 +74,31 @@\n \n \n class CalledProcessError(RuntimeError):\n- def __init__(self, returncode, cmd, expected_returncode, output=None):\n+ def __init__(self, returncode, cmd, expected_returncode, stdout, stderr):\n super(CalledProcessError, self).__init__(\n- returncode, cmd, expected_returncode, output,\n+ returncode, cmd, expected_returncode, stdout, stderr,\n )\n self.returncode = returncode\n self.cmd = cmd\n self.expected_returncode = expected_returncode\n- self.output = output\n+ self.stdout = stdout\n+ self.stderr = stderr\n \n def to_bytes(self):\n- output = []\n- for maybe_text in self.output:\n- if maybe_text:\n- output.append(\n- b'\\n ' +\n- five.to_bytes(maybe_text).replace(b'\\n', b'\\n '),\n- )\n+ def _indent_or_none(part):\n+ if part:\n+ return b'\\n ' + part.replace(b'\\n', b'\\n ')\n else:\n- output.append(b'(none)')\n+ return b' (none)'\n \n return b''.join((\n- five.to_bytes(\n- 'Command: {!r}\\n'\n- 'Return code: {}\\n'\n- 'Expected return code: {}\\n'.format(\n- self.cmd, self.returncode, self.expected_returncode,\n- ),\n- ),\n- b'Output: ', output[0], b'\\n',\n- b'Errors: ', output[1],\n+ 'command: {!r}\\n'\n+ 'return code: {}\\n'\n+ 'expected return code: {}\\n'.format(\n+ self.cmd, self.returncode, self.expected_returncode,\n+ ).encode('UTF-8'),\n+ b'stdout:', _indent_or_none(self.stdout), b'\\n',\n+ b'stderr:', _indent_or_none(self.stderr),\n ))\n \n def to_text(self):\n@@ -143,9 +138,7 @@\n returncode = proc.returncode\n \n if retcode is not None and retcode != returncode:\n- raise CalledProcessError(\n- returncode, cmd, retcode, output=(stdout_b, stderr_b),\n- )\n+ raise CalledProcessError(returncode, cmd, retcode, stdout_b, stderr_b)\n \n return returncode, stdout_b, stderr_b\n", "issue": "pip install crashes can easily confuse newbies\nthose that are not familiar with the usual annoying messaging that pip presents can get pretty easily confused by the output that happens when `pip` fails to install\r\n\r\nhere's an example:\r\n\r\n```console\r\n$ pre-commit run flake8 --all-files\r\n[INFO] Initializing environment for https://gitlab.com/pycqa/flake8:flake8-walrus.\r\n[INFO] Installing environment for https://gitlab.com/pycqa/flake8.\r\n[INFO] Once installed this environment will be reused.\r\n[INFO] This may take a few minutes...\r\nAn unexpected error has occurred: CalledProcessError: Command: ('/home/asottile/.cache/pre-commit/repoi6ij0tyu/py_env-python3/bin/python', '/home/asottile/.cache/pre-commit/repoi6ij0tyu/py_env-python3/bin/pip', 'install', '.', 'flake8-walrus')\r\nReturn code: 1\r\nExpected return code: 0\r\nOutput: \r\n Processing /home/asottile/.cache/pre-commit/repoi6ij0tyu\r\n Collecting flake8-walrus\r\n \r\nErrors: \r\n ERROR: Could not find a version that satisfies the requirement flake8-walrus (from versions: none)\r\n ERROR: No matching distribution found for flake8-walrus\r\n WARNING: You are using pip version 19.2.3, however version 19.3.1 is available.\r\n You should consider upgrading via the 'pip install --upgrade pip' command.\r\n \r\nCheck the log at /home/asottile/.cache/pre-commit/pre-commit.log\r\n```\r\n\r\nthis ~admittedly is a bit garbled for a number of reasons:\r\n- pip's error message here isn't great (it _could_ say something about `python_requires` or that there are versions available for other versions) **(the actual error is that the python is python3.6 and the plugin requires python3.8)**\r\n- pip is out of date (when is it not? but admittedly who cares) -- **this is what a lot of people try and fix** -- unfortunately there's not really anything to fix here, the version of `pip` is from inside the virtualenv and doesn't really matter all that much\r\n- `pre-commit` is currently splitting the output from stdout and stderr making it harder to read what's going on\r\n\r\nI can't really fix the first one, and the second one I could silence but it doesn't quite feel like the right thing to do (and admittedly knowing the pip version is sometimes useful when debugging). The third however I can pretty easily fix!\n", "before_files": [{"content": "from __future__ import unicode_literals\n\nimport contextlib\nimport errno\nimport os.path\nimport shutil\nimport stat\nimport subprocess\nimport sys\nimport tempfile\n\nimport six\n\nfrom pre_commit import five\nfrom pre_commit import parse_shebang\n\nif sys.version_info >= (3, 7): # pragma: no cover (PY37+)\n from importlib.resources import open_binary\n from importlib.resources import read_text\nelse: # pragma: no cover (<PY37)\n from importlib_resources import open_binary\n from importlib_resources import read_text\n\n\ndef mkdirp(path):\n try:\n os.makedirs(path)\n except OSError:\n if not os.path.exists(path):\n raise\n\n\[email protected]\ndef clean_path_on_failure(path):\n \"\"\"Cleans up the directory on an exceptional failure.\"\"\"\n try:\n yield\n except BaseException:\n if os.path.exists(path):\n rmtree(path)\n raise\n\n\[email protected]\ndef noop_context():\n yield\n\n\[email protected]\ndef tmpdir():\n \"\"\"Contextmanager to create a temporary directory. It will be cleaned up\n afterwards.\n \"\"\"\n tempdir = tempfile.mkdtemp()\n try:\n yield tempdir\n finally:\n rmtree(tempdir)\n\n\ndef resource_bytesio(filename):\n return open_binary('pre_commit.resources', filename)\n\n\ndef resource_text(filename):\n return read_text('pre_commit.resources', filename)\n\n\ndef make_executable(filename):\n original_mode = os.stat(filename).st_mode\n os.chmod(\n filename, original_mode | stat.S_IXUSR | stat.S_IXGRP | stat.S_IXOTH,\n )\n\n\nclass CalledProcessError(RuntimeError):\n def __init__(self, returncode, cmd, expected_returncode, output=None):\n super(CalledProcessError, self).__init__(\n returncode, cmd, expected_returncode, output,\n )\n self.returncode = returncode\n self.cmd = cmd\n self.expected_returncode = expected_returncode\n self.output = output\n\n def to_bytes(self):\n output = []\n for maybe_text in self.output:\n if maybe_text:\n output.append(\n b'\\n ' +\n five.to_bytes(maybe_text).replace(b'\\n', b'\\n '),\n )\n else:\n output.append(b'(none)')\n\n return b''.join((\n five.to_bytes(\n 'Command: {!r}\\n'\n 'Return code: {}\\n'\n 'Expected return code: {}\\n'.format(\n self.cmd, self.returncode, self.expected_returncode,\n ),\n ),\n b'Output: ', output[0], b'\\n',\n b'Errors: ', output[1],\n ))\n\n def to_text(self):\n return self.to_bytes().decode('UTF-8')\n\n if six.PY2: # pragma: no cover (py2)\n __str__ = to_bytes\n __unicode__ = to_text\n else: # pragma: no cover (py3)\n __bytes__ = to_bytes\n __str__ = to_text\n\n\ndef _cmd_kwargs(*cmd, **kwargs):\n # py2/py3 on windows are more strict about the types here\n cmd = tuple(five.n(arg) for arg in cmd)\n kwargs['env'] = {\n five.n(key): five.n(value)\n for key, value in kwargs.pop('env', {}).items()\n } or None\n for arg in ('stdin', 'stdout', 'stderr'):\n kwargs.setdefault(arg, subprocess.PIPE)\n return cmd, kwargs\n\n\ndef cmd_output_b(*cmd, **kwargs):\n retcode = kwargs.pop('retcode', 0)\n cmd, kwargs = _cmd_kwargs(*cmd, **kwargs)\n\n try:\n cmd = parse_shebang.normalize_cmd(cmd)\n except parse_shebang.ExecutableNotFoundError as e:\n returncode, stdout_b, stderr_b = e.to_output()\n else:\n proc = subprocess.Popen(cmd, **kwargs)\n stdout_b, stderr_b = proc.communicate()\n returncode = proc.returncode\n\n if retcode is not None and retcode != returncode:\n raise CalledProcessError(\n returncode, cmd, retcode, output=(stdout_b, stderr_b),\n )\n\n return returncode, stdout_b, stderr_b\n\n\ndef cmd_output(*cmd, **kwargs):\n returncode, stdout_b, stderr_b = cmd_output_b(*cmd, **kwargs)\n stdout = stdout_b.decode('UTF-8') if stdout_b is not None else None\n stderr = stderr_b.decode('UTF-8') if stderr_b is not None else None\n return returncode, stdout, stderr\n\n\nif os.name != 'nt': # pragma: windows no cover\n from os import openpty\n import termios\n\n class Pty(object):\n def __init__(self):\n self.r = self.w = None\n\n def __enter__(self):\n self.r, self.w = openpty()\n\n # tty flags normally change \\n to \\r\\n\n attrs = termios.tcgetattr(self.r)\n attrs[1] &= ~(termios.ONLCR | termios.OPOST)\n termios.tcsetattr(self.r, termios.TCSANOW, attrs)\n\n return self\n\n def close_w(self):\n if self.w is not None:\n os.close(self.w)\n self.w = None\n\n def close_r(self):\n assert self.r is not None\n os.close(self.r)\n self.r = None\n\n def __exit__(self, exc_type, exc_value, traceback):\n self.close_w()\n self.close_r()\n\n def cmd_output_p(*cmd, **kwargs):\n assert kwargs.pop('retcode') is None\n assert kwargs['stderr'] == subprocess.STDOUT, kwargs['stderr']\n cmd, kwargs = _cmd_kwargs(*cmd, **kwargs)\n\n try:\n cmd = parse_shebang.normalize_cmd(cmd)\n except parse_shebang.ExecutableNotFoundError as e:\n return e.to_output()\n\n with open(os.devnull) as devnull, Pty() as pty:\n kwargs.update({'stdin': devnull, 'stdout': pty.w, 'stderr': pty.w})\n proc = subprocess.Popen(cmd, **kwargs)\n pty.close_w()\n\n buf = b''\n while True:\n try:\n bts = os.read(pty.r, 4096)\n except OSError as e:\n if e.errno == errno.EIO:\n bts = b''\n else:\n raise\n else:\n buf += bts\n if not bts:\n break\n\n return proc.wait(), buf, None\nelse: # pragma: no cover\n cmd_output_p = cmd_output_b\n\n\ndef rmtree(path):\n \"\"\"On windows, rmtree fails for readonly dirs.\"\"\"\n def handle_remove_readonly(func, path, exc):\n excvalue = exc[1]\n if (\n func in (os.rmdir, os.remove, os.unlink) and\n excvalue.errno == errno.EACCES\n ):\n for p in (path, os.path.dirname(path)):\n os.chmod(p, os.stat(p).st_mode | stat.S_IWUSR)\n func(path)\n else:\n raise\n shutil.rmtree(path, ignore_errors=False, onerror=handle_remove_readonly)\n\n\ndef parse_version(s):\n \"\"\"poor man's version comparison\"\"\"\n return tuple(int(p) for p in s.split('.'))\n", "path": "pre_commit/util.py"}], "after_files": [{"content": "from __future__ import unicode_literals\n\nimport contextlib\nimport errno\nimport os.path\nimport shutil\nimport stat\nimport subprocess\nimport sys\nimport tempfile\n\nimport six\n\nfrom pre_commit import five\nfrom pre_commit import parse_shebang\n\nif sys.version_info >= (3, 7): # pragma: no cover (PY37+)\n from importlib.resources import open_binary\n from importlib.resources import read_text\nelse: # pragma: no cover (<PY37)\n from importlib_resources import open_binary\n from importlib_resources import read_text\n\n\ndef mkdirp(path):\n try:\n os.makedirs(path)\n except OSError:\n if not os.path.exists(path):\n raise\n\n\[email protected]\ndef clean_path_on_failure(path):\n \"\"\"Cleans up the directory on an exceptional failure.\"\"\"\n try:\n yield\n except BaseException:\n if os.path.exists(path):\n rmtree(path)\n raise\n\n\[email protected]\ndef noop_context():\n yield\n\n\[email protected]\ndef tmpdir():\n \"\"\"Contextmanager to create a temporary directory. It will be cleaned up\n afterwards.\n \"\"\"\n tempdir = tempfile.mkdtemp()\n try:\n yield tempdir\n finally:\n rmtree(tempdir)\n\n\ndef resource_bytesio(filename):\n return open_binary('pre_commit.resources', filename)\n\n\ndef resource_text(filename):\n return read_text('pre_commit.resources', filename)\n\n\ndef make_executable(filename):\n original_mode = os.stat(filename).st_mode\n os.chmod(\n filename, original_mode | stat.S_IXUSR | stat.S_IXGRP | stat.S_IXOTH,\n )\n\n\nclass CalledProcessError(RuntimeError):\n def __init__(self, returncode, cmd, expected_returncode, stdout, stderr):\n super(CalledProcessError, self).__init__(\n returncode, cmd, expected_returncode, stdout, stderr,\n )\n self.returncode = returncode\n self.cmd = cmd\n self.expected_returncode = expected_returncode\n self.stdout = stdout\n self.stderr = stderr\n\n def to_bytes(self):\n def _indent_or_none(part):\n if part:\n return b'\\n ' + part.replace(b'\\n', b'\\n ')\n else:\n return b' (none)'\n\n return b''.join((\n 'command: {!r}\\n'\n 'return code: {}\\n'\n 'expected return code: {}\\n'.format(\n self.cmd, self.returncode, self.expected_returncode,\n ).encode('UTF-8'),\n b'stdout:', _indent_or_none(self.stdout), b'\\n',\n b'stderr:', _indent_or_none(self.stderr),\n ))\n\n def to_text(self):\n return self.to_bytes().decode('UTF-8')\n\n if six.PY2: # pragma: no cover (py2)\n __str__ = to_bytes\n __unicode__ = to_text\n else: # pragma: no cover (py3)\n __bytes__ = to_bytes\n __str__ = to_text\n\n\ndef _cmd_kwargs(*cmd, **kwargs):\n # py2/py3 on windows are more strict about the types here\n cmd = tuple(five.n(arg) for arg in cmd)\n kwargs['env'] = {\n five.n(key): five.n(value)\n for key, value in kwargs.pop('env', {}).items()\n } or None\n for arg in ('stdin', 'stdout', 'stderr'):\n kwargs.setdefault(arg, subprocess.PIPE)\n return cmd, kwargs\n\n\ndef cmd_output_b(*cmd, **kwargs):\n retcode = kwargs.pop('retcode', 0)\n cmd, kwargs = _cmd_kwargs(*cmd, **kwargs)\n\n try:\n cmd = parse_shebang.normalize_cmd(cmd)\n except parse_shebang.ExecutableNotFoundError as e:\n returncode, stdout_b, stderr_b = e.to_output()\n else:\n proc = subprocess.Popen(cmd, **kwargs)\n stdout_b, stderr_b = proc.communicate()\n returncode = proc.returncode\n\n if retcode is not None and retcode != returncode:\n raise CalledProcessError(returncode, cmd, retcode, stdout_b, stderr_b)\n\n return returncode, stdout_b, stderr_b\n\n\ndef cmd_output(*cmd, **kwargs):\n returncode, stdout_b, stderr_b = cmd_output_b(*cmd, **kwargs)\n stdout = stdout_b.decode('UTF-8') if stdout_b is not None else None\n stderr = stderr_b.decode('UTF-8') if stderr_b is not None else None\n return returncode, stdout, stderr\n\n\nif os.name != 'nt': # pragma: windows no cover\n from os import openpty\n import termios\n\n class Pty(object):\n def __init__(self):\n self.r = self.w = None\n\n def __enter__(self):\n self.r, self.w = openpty()\n\n # tty flags normally change \\n to \\r\\n\n attrs = termios.tcgetattr(self.r)\n attrs[1] &= ~(termios.ONLCR | termios.OPOST)\n termios.tcsetattr(self.r, termios.TCSANOW, attrs)\n\n return self\n\n def close_w(self):\n if self.w is not None:\n os.close(self.w)\n self.w = None\n\n def close_r(self):\n assert self.r is not None\n os.close(self.r)\n self.r = None\n\n def __exit__(self, exc_type, exc_value, traceback):\n self.close_w()\n self.close_r()\n\n def cmd_output_p(*cmd, **kwargs):\n assert kwargs.pop('retcode') is None\n assert kwargs['stderr'] == subprocess.STDOUT, kwargs['stderr']\n cmd, kwargs = _cmd_kwargs(*cmd, **kwargs)\n\n try:\n cmd = parse_shebang.normalize_cmd(cmd)\n except parse_shebang.ExecutableNotFoundError as e:\n return e.to_output()\n\n with open(os.devnull) as devnull, Pty() as pty:\n kwargs.update({'stdin': devnull, 'stdout': pty.w, 'stderr': pty.w})\n proc = subprocess.Popen(cmd, **kwargs)\n pty.close_w()\n\n buf = b''\n while True:\n try:\n bts = os.read(pty.r, 4096)\n except OSError as e:\n if e.errno == errno.EIO:\n bts = b''\n else:\n raise\n else:\n buf += bts\n if not bts:\n break\n\n return proc.wait(), buf, None\nelse: # pragma: no cover\n cmd_output_p = cmd_output_b\n\n\ndef rmtree(path):\n \"\"\"On windows, rmtree fails for readonly dirs.\"\"\"\n def handle_remove_readonly(func, path, exc):\n excvalue = exc[1]\n if (\n func in (os.rmdir, os.remove, os.unlink) and\n excvalue.errno == errno.EACCES\n ):\n for p in (path, os.path.dirname(path)):\n os.chmod(p, os.stat(p).st_mode | stat.S_IWUSR)\n func(path)\n else:\n raise\n shutil.rmtree(path, ignore_errors=False, onerror=handle_remove_readonly)\n\n\ndef parse_version(s):\n \"\"\"poor man's version comparison\"\"\"\n return tuple(int(p) for p in s.split('.'))\n", "path": "pre_commit/util.py"}]}
| 3,087 | 573 |
gh_patches_debug_14332
|
rasdani/github-patches
|
git_diff
|
scikit-hep__pyhf-638
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Automate deployment to PyPI
# Description
According to @lukasheinrich, the current workflow for deploying to PyPI is:
```
git checkout master
git pull
bumpversion patch
git commit
git push origin master --tags
```
This is a bit annoyingly manual and ideally should be done automatically.
Luckily, there is an [official PyPA GitHub action](https://discuss.python.org/t/official-github-action-for-publishing-to-pypi/1061) to do this:
https://github.com/pypa/gh-action-pypi-publish
However, we need GitHub actions for pyhf, so we have to wait.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 from setuptools import setup, find_packages
2 from os import path
3 import sys
4
5 this_directory = path.abspath(path.dirname(__file__))
6 if sys.version_info.major < 3:
7 from io import open
8 with open(path.join(this_directory, 'README.md'), encoding='utf-8') as readme_md:
9 long_description = readme_md.read()
10
11 extras_require = {
12 'tensorflow': ['tensorflow~=1.15', 'tensorflow-probability~=0.8', 'numpy~=1.16',],
13 'torch': ['torch~=1.2'],
14 'xmlio': ['uproot'],
15 'minuit': ['iminuit'],
16 'develop': [
17 'pyflakes',
18 'pytest~=3.5',
19 'pytest-cov>=2.5.1',
20 'pytest-mock',
21 'pytest-benchmark[histogram]',
22 'pytest-console-scripts',
23 'pydocstyle',
24 'coverage>=4.0', # coveralls
25 'matplotlib',
26 'jupyter',
27 'nbdime',
28 'uproot~=3.3',
29 'papermill~=1.0',
30 'nteract-scrapbook~=0.2',
31 'graphviz',
32 'bumpversion',
33 'sphinx',
34 'sphinxcontrib-bibtex',
35 'sphinxcontrib-napoleon',
36 'sphinx_rtd_theme',
37 'nbsphinx',
38 'sphinx-issues',
39 'm2r',
40 'jsonpatch',
41 'ipython',
42 'pre-commit',
43 'black;python_version>="3.6"', # Black is Python3 only
44 'twine',
45 'check-manifest',
46 ],
47 }
48 extras_require['complete'] = sorted(set(sum(extras_require.values(), [])))
49
50
51 def _is_test_pypi():
52 """
53 Determine if the Travis CI environment has TESTPYPI_UPLOAD defined and
54 set to true (c.f. .travis.yml)
55
56 The use_scm_version kwarg accepts a callable for the local_scheme
57 configuration parameter with argument "version". This can be replaced
58 with a lambda as the desired version structure is {next_version}.dev{distance}
59 c.f. https://github.com/pypa/setuptools_scm/#importing-in-setuppy
60
61 As the scm versioning is only desired for TestPyPI, for depolyment to PyPI the version
62 controlled through bumpversion is used.
63 """
64 from os import getenv
65
66 return (
67 {'local_scheme': lambda version: ''}
68 if getenv('TESTPYPI_UPLOAD') == 'true'
69 else False
70 )
71
72
73 setup(
74 name='pyhf',
75 version='0.2.0',
76 description='(partial) pure python histfactory implementation',
77 long_description=long_description,
78 long_description_content_type='text/markdown',
79 url='https://github.com/diana-hep/pyhf',
80 author='Lukas Heinrich, Matthew Feickert, Giordon Stark',
81 author_email='[email protected], [email protected], [email protected]',
82 license='Apache',
83 keywords='physics fitting numpy scipy tensorflow pytorch',
84 classifiers=[
85 "Programming Language :: Python :: 2",
86 "Programming Language :: Python :: 2.7",
87 "Programming Language :: Python :: 3",
88 "Programming Language :: Python :: 3.6",
89 "Programming Language :: Python :: 3.7",
90 ],
91 package_dir={'': 'src'},
92 packages=find_packages(where='src'),
93 include_package_data=True,
94 python_requires=">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*, !=3.5.*",
95 install_requires=[
96 'scipy', # requires numpy, which is required by pyhf and tensorflow
97 'click>=6.0', # for console scripts,
98 'tqdm', # for readxml
99 'six', # for modifiers
100 'jsonschema>=v3.0.0a2', # for utils, alpha-release for draft 6
101 'jsonpatch',
102 'pyyaml', # for parsing CLI equal-delimited options
103 ],
104 extras_require=extras_require,
105 entry_points={'console_scripts': ['pyhf=pyhf.commandline:pyhf']},
106 dependency_links=[],
107 use_scm_version=_is_test_pypi(),
108 )
109
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -50,8 +50,8 @@
def _is_test_pypi():
"""
- Determine if the Travis CI environment has TESTPYPI_UPLOAD defined and
- set to true (c.f. .travis.yml)
+ Determine if the CI environment has IS_TESTPYPI defined and
+ set to true (c.f. .github/workflows/publish-package.yml)
The use_scm_version kwarg accepts a callable for the local_scheme
configuration parameter with argument "version". This can be replaced
@@ -65,7 +65,7 @@
return (
{'local_scheme': lambda version: ''}
- if getenv('TESTPYPI_UPLOAD') == 'true'
+ if getenv('IS_TESTPYPI') == 'true'
else False
)
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -50,8 +50,8 @@\n \n def _is_test_pypi():\n \"\"\"\n- Determine if the Travis CI environment has TESTPYPI_UPLOAD defined and\n- set to true (c.f. .travis.yml)\n+ Determine if the CI environment has IS_TESTPYPI defined and\n+ set to true (c.f. .github/workflows/publish-package.yml)\n \n The use_scm_version kwarg accepts a callable for the local_scheme\n configuration parameter with argument \"version\". This can be replaced\n@@ -65,7 +65,7 @@\n \n return (\n {'local_scheme': lambda version: ''}\n- if getenv('TESTPYPI_UPLOAD') == 'true'\n+ if getenv('IS_TESTPYPI') == 'true'\n else False\n )\n", "issue": "Automate deployment to PyPI\n# Description\r\n\r\nAccording to @lukasheinrich, the current workflow for deploying to PyPI is:\r\n\r\n```\r\ngit checkout master\r\ngit pull\r\nbumpversion patch\r\ngit commit\r\ngit push origin master --tags\r\n```\r\n\r\nThis is a bit annoyingly manual and ideally should be done automatically.\r\n\r\nLuckily, there is an [official PyPA GitHub action](https://discuss.python.org/t/official-github-action-for-publishing-to-pypi/1061) to do this:\r\n\r\nhttps://github.com/pypa/gh-action-pypi-publish\r\n\r\nHowever, we need GitHub actions for pyhf, so we have to wait.\n", "before_files": [{"content": "from setuptools import setup, find_packages\nfrom os import path\nimport sys\n\nthis_directory = path.abspath(path.dirname(__file__))\nif sys.version_info.major < 3:\n from io import open\nwith open(path.join(this_directory, 'README.md'), encoding='utf-8') as readme_md:\n long_description = readme_md.read()\n\nextras_require = {\n 'tensorflow': ['tensorflow~=1.15', 'tensorflow-probability~=0.8', 'numpy~=1.16',],\n 'torch': ['torch~=1.2'],\n 'xmlio': ['uproot'],\n 'minuit': ['iminuit'],\n 'develop': [\n 'pyflakes',\n 'pytest~=3.5',\n 'pytest-cov>=2.5.1',\n 'pytest-mock',\n 'pytest-benchmark[histogram]',\n 'pytest-console-scripts',\n 'pydocstyle',\n 'coverage>=4.0', # coveralls\n 'matplotlib',\n 'jupyter',\n 'nbdime',\n 'uproot~=3.3',\n 'papermill~=1.0',\n 'nteract-scrapbook~=0.2',\n 'graphviz',\n 'bumpversion',\n 'sphinx',\n 'sphinxcontrib-bibtex',\n 'sphinxcontrib-napoleon',\n 'sphinx_rtd_theme',\n 'nbsphinx',\n 'sphinx-issues',\n 'm2r',\n 'jsonpatch',\n 'ipython',\n 'pre-commit',\n 'black;python_version>=\"3.6\"', # Black is Python3 only\n 'twine',\n 'check-manifest',\n ],\n}\nextras_require['complete'] = sorted(set(sum(extras_require.values(), [])))\n\n\ndef _is_test_pypi():\n \"\"\"\n Determine if the Travis CI environment has TESTPYPI_UPLOAD defined and\n set to true (c.f. .travis.yml)\n\n The use_scm_version kwarg accepts a callable for the local_scheme\n configuration parameter with argument \"version\". This can be replaced\n with a lambda as the desired version structure is {next_version}.dev{distance}\n c.f. https://github.com/pypa/setuptools_scm/#importing-in-setuppy\n\n As the scm versioning is only desired for TestPyPI, for depolyment to PyPI the version\n controlled through bumpversion is used.\n \"\"\"\n from os import getenv\n\n return (\n {'local_scheme': lambda version: ''}\n if getenv('TESTPYPI_UPLOAD') == 'true'\n else False\n )\n\n\nsetup(\n name='pyhf',\n version='0.2.0',\n description='(partial) pure python histfactory implementation',\n long_description=long_description,\n long_description_content_type='text/markdown',\n url='https://github.com/diana-hep/pyhf',\n author='Lukas Heinrich, Matthew Feickert, Giordon Stark',\n author_email='[email protected], [email protected], [email protected]',\n license='Apache',\n keywords='physics fitting numpy scipy tensorflow pytorch',\n classifiers=[\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n ],\n package_dir={'': 'src'},\n packages=find_packages(where='src'),\n include_package_data=True,\n python_requires=\">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*, !=3.5.*\",\n install_requires=[\n 'scipy', # requires numpy, which is required by pyhf and tensorflow\n 'click>=6.0', # for console scripts,\n 'tqdm', # for readxml\n 'six', # for modifiers\n 'jsonschema>=v3.0.0a2', # for utils, alpha-release for draft 6\n 'jsonpatch',\n 'pyyaml', # for parsing CLI equal-delimited options\n ],\n extras_require=extras_require,\n entry_points={'console_scripts': ['pyhf=pyhf.commandline:pyhf']},\n dependency_links=[],\n use_scm_version=_is_test_pypi(),\n)\n", "path": "setup.py"}], "after_files": [{"content": "from setuptools import setup, find_packages\nfrom os import path\nimport sys\n\nthis_directory = path.abspath(path.dirname(__file__))\nif sys.version_info.major < 3:\n from io import open\nwith open(path.join(this_directory, 'README.md'), encoding='utf-8') as readme_md:\n long_description = readme_md.read()\n\nextras_require = {\n 'tensorflow': ['tensorflow~=1.15', 'tensorflow-probability~=0.8', 'numpy~=1.16',],\n 'torch': ['torch~=1.2'],\n 'xmlio': ['uproot'],\n 'minuit': ['iminuit'],\n 'develop': [\n 'pyflakes',\n 'pytest~=3.5',\n 'pytest-cov>=2.5.1',\n 'pytest-mock',\n 'pytest-benchmark[histogram]',\n 'pytest-console-scripts',\n 'pydocstyle',\n 'coverage>=4.0', # coveralls\n 'matplotlib',\n 'jupyter',\n 'nbdime',\n 'uproot~=3.3',\n 'papermill~=1.0',\n 'nteract-scrapbook~=0.2',\n 'graphviz',\n 'bumpversion',\n 'sphinx',\n 'sphinxcontrib-bibtex',\n 'sphinxcontrib-napoleon',\n 'sphinx_rtd_theme',\n 'nbsphinx',\n 'sphinx-issues',\n 'm2r',\n 'jsonpatch',\n 'ipython',\n 'pre-commit',\n 'black;python_version>=\"3.6\"', # Black is Python3 only\n 'twine',\n 'check-manifest',\n ],\n}\nextras_require['complete'] = sorted(set(sum(extras_require.values(), [])))\n\n\ndef _is_test_pypi():\n \"\"\"\n Determine if the CI environment has IS_TESTPYPI defined and\n set to true (c.f. .github/workflows/publish-package.yml)\n\n The use_scm_version kwarg accepts a callable for the local_scheme\n configuration parameter with argument \"version\". This can be replaced\n with a lambda as the desired version structure is {next_version}.dev{distance}\n c.f. https://github.com/pypa/setuptools_scm/#importing-in-setuppy\n\n As the scm versioning is only desired for TestPyPI, for depolyment to PyPI the version\n controlled through bumpversion is used.\n \"\"\"\n from os import getenv\n\n return (\n {'local_scheme': lambda version: ''}\n if getenv('IS_TESTPYPI') == 'true'\n else False\n )\n\n\nsetup(\n name='pyhf',\n version='0.2.0',\n description='(partial) pure python histfactory implementation',\n long_description=long_description,\n long_description_content_type='text/markdown',\n url='https://github.com/diana-hep/pyhf',\n author='Lukas Heinrich, Matthew Feickert, Giordon Stark',\n author_email='[email protected], [email protected], [email protected]',\n license='Apache',\n keywords='physics fitting numpy scipy tensorflow pytorch',\n classifiers=[\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n ],\n package_dir={'': 'src'},\n packages=find_packages(where='src'),\n include_package_data=True,\n python_requires=\">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*, !=3.5.*\",\n install_requires=[\n 'scipy', # requires numpy, which is required by pyhf and tensorflow\n 'click>=6.0', # for console scripts,\n 'tqdm', # for readxml\n 'six', # for modifiers\n 'jsonschema>=v3.0.0a2', # for utils, alpha-release for draft 6\n 'jsonpatch',\n 'pyyaml', # for parsing CLI equal-delimited options\n ],\n extras_require=extras_require,\n entry_points={'console_scripts': ['pyhf=pyhf.commandline:pyhf']},\n dependency_links=[],\n use_scm_version=_is_test_pypi(),\n)\n", "path": "setup.py"}]}
| 1,573 | 194 |
gh_patches_debug_59597
|
rasdani/github-patches
|
git_diff
|
googleapis__python-bigquery-587
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
loosen opentelemetry dependencies
See Spanner PR: https://github.com/googleapis/python-spanner/pull/298
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # Copyright 2018 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import io
16 import os
17
18 import setuptools
19
20
21 # Package metadata.
22
23 name = "google-cloud-bigquery"
24 description = "Google BigQuery API client library"
25
26 # Should be one of:
27 # 'Development Status :: 3 - Alpha'
28 # 'Development Status :: 4 - Beta'
29 # 'Development Status :: 5 - Production/Stable'
30 release_status = "Development Status :: 5 - Production/Stable"
31 dependencies = [
32 "google-api-core[grpc] >= 1.23.0, < 2.0.0dev",
33 "proto-plus >= 1.10.0",
34 "google-cloud-core >= 1.4.1, < 2.0dev",
35 "google-resumable-media >= 0.6.0, < 2.0dev",
36 "packaging >= 14.3",
37 "protobuf >= 3.12.0",
38 "requests >= 2.18.0, < 3.0.0dev",
39 ]
40 extras = {
41 "bqstorage": [
42 "google-cloud-bigquery-storage >= 2.0.0, <3.0.0dev",
43 # Due to an issue in pip's dependency resolver, the `grpc` extra is not
44 # installed, even though `google-cloud-bigquery-storage` specifies it
45 # as `google-api-core[grpc]`. We thus need to explicitly specify it here.
46 # See: https://github.com/googleapis/python-bigquery/issues/83 The
47 # grpc.Channel.close() method isn't added until 1.32.0.
48 # https://github.com/grpc/grpc/pull/15254
49 "grpcio >= 1.32.0, < 2.0dev",
50 "pyarrow >= 1.0.0, < 4.0dev",
51 ],
52 "pandas": ["pandas>=0.23.0", "pyarrow >= 1.0.0, < 4.0dev"],
53 "bignumeric_type": ["pyarrow >= 3.0.0, < 4.0dev"],
54 "tqdm": ["tqdm >= 4.7.4, <5.0.0dev"],
55 "opentelemetry": [
56 "opentelemetry-api==0.11b0",
57 "opentelemetry-sdk==0.11b0",
58 "opentelemetry-instrumentation==0.11b0",
59 ],
60 }
61
62 all_extras = []
63
64 for extra in extras:
65 # Exclude this extra from all to avoid overly strict dependencies on core
66 # libraries such as pyarrow.
67 # https://github.com/googleapis/python-bigquery/issues/563
68 if extra in {"bignumeric_type"}:
69 continue
70 all_extras.extend(extras[extra])
71
72 extras["all"] = all_extras
73
74 # Setup boilerplate below this line.
75
76 package_root = os.path.abspath(os.path.dirname(__file__))
77
78 readme_filename = os.path.join(package_root, "README.rst")
79 with io.open(readme_filename, encoding="utf-8") as readme_file:
80 readme = readme_file.read()
81
82 version = {}
83 with open(os.path.join(package_root, "google/cloud/bigquery/version.py")) as fp:
84 exec(fp.read(), version)
85 version = version["__version__"]
86
87 # Only include packages under the 'google' namespace. Do not include tests,
88 # benchmarks, etc.
89 packages = [
90 package
91 for package in setuptools.PEP420PackageFinder.find()
92 if package.startswith("google")
93 ]
94
95 # Determine which namespaces are needed.
96 namespaces = ["google"]
97 if "google.cloud" in packages:
98 namespaces.append("google.cloud")
99
100
101 setuptools.setup(
102 name=name,
103 version=version,
104 description=description,
105 long_description=readme,
106 author="Google LLC",
107 author_email="[email protected]",
108 license="Apache 2.0",
109 url="https://github.com/googleapis/python-bigquery",
110 classifiers=[
111 release_status,
112 "Intended Audience :: Developers",
113 "License :: OSI Approved :: Apache Software License",
114 "Programming Language :: Python",
115 "Programming Language :: Python :: 3",
116 "Programming Language :: Python :: 3.6",
117 "Programming Language :: Python :: 3.7",
118 "Programming Language :: Python :: 3.8",
119 "Programming Language :: Python :: 3.9",
120 "Operating System :: OS Independent",
121 "Topic :: Internet",
122 ],
123 platforms="Posix; MacOS X; Windows",
124 packages=packages,
125 namespace_packages=namespaces,
126 install_requires=dependencies,
127 extras_require=extras,
128 python_requires=">=3.6, <3.10",
129 include_package_data=True,
130 zip_safe=False,
131 )
132
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -53,9 +53,9 @@
"bignumeric_type": ["pyarrow >= 3.0.0, < 4.0dev"],
"tqdm": ["tqdm >= 4.7.4, <5.0.0dev"],
"opentelemetry": [
- "opentelemetry-api==0.11b0",
- "opentelemetry-sdk==0.11b0",
- "opentelemetry-instrumentation==0.11b0",
+ "opentelemetry-api >= 0.11b0",
+ "opentelemetry-sdk >= 0.11b0",
+ "opentelemetry-instrumentation >= 0.11b0",
],
}
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -53,9 +53,9 @@\n \"bignumeric_type\": [\"pyarrow >= 3.0.0, < 4.0dev\"],\n \"tqdm\": [\"tqdm >= 4.7.4, <5.0.0dev\"],\n \"opentelemetry\": [\n- \"opentelemetry-api==0.11b0\",\n- \"opentelemetry-sdk==0.11b0\",\n- \"opentelemetry-instrumentation==0.11b0\",\n+ \"opentelemetry-api >= 0.11b0\",\n+ \"opentelemetry-sdk >= 0.11b0\",\n+ \"opentelemetry-instrumentation >= 0.11b0\",\n ],\n }\n", "issue": "loosen opentelemetry dependencies\nSee Spanner PR: https://github.com/googleapis/python-spanner/pull/298\n", "before_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport io\nimport os\n\nimport setuptools\n\n\n# Package metadata.\n\nname = \"google-cloud-bigquery\"\ndescription = \"Google BigQuery API client library\"\n\n# Should be one of:\n# 'Development Status :: 3 - Alpha'\n# 'Development Status :: 4 - Beta'\n# 'Development Status :: 5 - Production/Stable'\nrelease_status = \"Development Status :: 5 - Production/Stable\"\ndependencies = [\n \"google-api-core[grpc] >= 1.23.0, < 2.0.0dev\",\n \"proto-plus >= 1.10.0\",\n \"google-cloud-core >= 1.4.1, < 2.0dev\",\n \"google-resumable-media >= 0.6.0, < 2.0dev\",\n \"packaging >= 14.3\",\n \"protobuf >= 3.12.0\",\n \"requests >= 2.18.0, < 3.0.0dev\",\n]\nextras = {\n \"bqstorage\": [\n \"google-cloud-bigquery-storage >= 2.0.0, <3.0.0dev\",\n # Due to an issue in pip's dependency resolver, the `grpc` extra is not\n # installed, even though `google-cloud-bigquery-storage` specifies it\n # as `google-api-core[grpc]`. We thus need to explicitly specify it here.\n # See: https://github.com/googleapis/python-bigquery/issues/83 The\n # grpc.Channel.close() method isn't added until 1.32.0.\n # https://github.com/grpc/grpc/pull/15254\n \"grpcio >= 1.32.0, < 2.0dev\",\n \"pyarrow >= 1.0.0, < 4.0dev\",\n ],\n \"pandas\": [\"pandas>=0.23.0\", \"pyarrow >= 1.0.0, < 4.0dev\"],\n \"bignumeric_type\": [\"pyarrow >= 3.0.0, < 4.0dev\"],\n \"tqdm\": [\"tqdm >= 4.7.4, <5.0.0dev\"],\n \"opentelemetry\": [\n \"opentelemetry-api==0.11b0\",\n \"opentelemetry-sdk==0.11b0\",\n \"opentelemetry-instrumentation==0.11b0\",\n ],\n}\n\nall_extras = []\n\nfor extra in extras:\n # Exclude this extra from all to avoid overly strict dependencies on core\n # libraries such as pyarrow.\n # https://github.com/googleapis/python-bigquery/issues/563\n if extra in {\"bignumeric_type\"}:\n continue\n all_extras.extend(extras[extra])\n\nextras[\"all\"] = all_extras\n\n# Setup boilerplate below this line.\n\npackage_root = os.path.abspath(os.path.dirname(__file__))\n\nreadme_filename = os.path.join(package_root, \"README.rst\")\nwith io.open(readme_filename, encoding=\"utf-8\") as readme_file:\n readme = readme_file.read()\n\nversion = {}\nwith open(os.path.join(package_root, \"google/cloud/bigquery/version.py\")) as fp:\n exec(fp.read(), version)\nversion = version[\"__version__\"]\n\n# Only include packages under the 'google' namespace. Do not include tests,\n# benchmarks, etc.\npackages = [\n package\n for package in setuptools.PEP420PackageFinder.find()\n if package.startswith(\"google\")\n]\n\n# Determine which namespaces are needed.\nnamespaces = [\"google\"]\nif \"google.cloud\" in packages:\n namespaces.append(\"google.cloud\")\n\n\nsetuptools.setup(\n name=name,\n version=version,\n description=description,\n long_description=readme,\n author=\"Google LLC\",\n author_email=\"[email protected]\",\n license=\"Apache 2.0\",\n url=\"https://github.com/googleapis/python-bigquery\",\n classifiers=[\n release_status,\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Operating System :: OS Independent\",\n \"Topic :: Internet\",\n ],\n platforms=\"Posix; MacOS X; Windows\",\n packages=packages,\n namespace_packages=namespaces,\n install_requires=dependencies,\n extras_require=extras,\n python_requires=\">=3.6, <3.10\",\n include_package_data=True,\n zip_safe=False,\n)\n", "path": "setup.py"}], "after_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport io\nimport os\n\nimport setuptools\n\n\n# Package metadata.\n\nname = \"google-cloud-bigquery\"\ndescription = \"Google BigQuery API client library\"\n\n# Should be one of:\n# 'Development Status :: 3 - Alpha'\n# 'Development Status :: 4 - Beta'\n# 'Development Status :: 5 - Production/Stable'\nrelease_status = \"Development Status :: 5 - Production/Stable\"\ndependencies = [\n \"google-api-core[grpc] >= 1.23.0, < 2.0.0dev\",\n \"proto-plus >= 1.10.0\",\n \"google-cloud-core >= 1.4.1, < 2.0dev\",\n \"google-resumable-media >= 0.6.0, < 2.0dev\",\n \"packaging >= 14.3\",\n \"protobuf >= 3.12.0\",\n \"requests >= 2.18.0, < 3.0.0dev\",\n]\nextras = {\n \"bqstorage\": [\n \"google-cloud-bigquery-storage >= 2.0.0, <3.0.0dev\",\n # Due to an issue in pip's dependency resolver, the `grpc` extra is not\n # installed, even though `google-cloud-bigquery-storage` specifies it\n # as `google-api-core[grpc]`. We thus need to explicitly specify it here.\n # See: https://github.com/googleapis/python-bigquery/issues/83 The\n # grpc.Channel.close() method isn't added until 1.32.0.\n # https://github.com/grpc/grpc/pull/15254\n \"grpcio >= 1.32.0, < 2.0dev\",\n \"pyarrow >= 1.0.0, < 4.0dev\",\n ],\n \"pandas\": [\"pandas>=0.23.0\", \"pyarrow >= 1.0.0, < 4.0dev\"],\n \"bignumeric_type\": [\"pyarrow >= 3.0.0, < 4.0dev\"],\n \"tqdm\": [\"tqdm >= 4.7.4, <5.0.0dev\"],\n \"opentelemetry\": [\n \"opentelemetry-api >= 0.11b0\",\n \"opentelemetry-sdk >= 0.11b0\",\n \"opentelemetry-instrumentation >= 0.11b0\",\n ],\n}\n\nall_extras = []\n\nfor extra in extras:\n # Exclude this extra from all to avoid overly strict dependencies on core\n # libraries such as pyarrow.\n # https://github.com/googleapis/python-bigquery/issues/563\n if extra in {\"bignumeric_type\"}:\n continue\n all_extras.extend(extras[extra])\n\nextras[\"all\"] = all_extras\n\n# Setup boilerplate below this line.\n\npackage_root = os.path.abspath(os.path.dirname(__file__))\n\nreadme_filename = os.path.join(package_root, \"README.rst\")\nwith io.open(readme_filename, encoding=\"utf-8\") as readme_file:\n readme = readme_file.read()\n\nversion = {}\nwith open(os.path.join(package_root, \"google/cloud/bigquery/version.py\")) as fp:\n exec(fp.read(), version)\nversion = version[\"__version__\"]\n\n# Only include packages under the 'google' namespace. Do not include tests,\n# benchmarks, etc.\npackages = [\n package\n for package in setuptools.PEP420PackageFinder.find()\n if package.startswith(\"google\")\n]\n\n# Determine which namespaces are needed.\nnamespaces = [\"google\"]\nif \"google.cloud\" in packages:\n namespaces.append(\"google.cloud\")\n\n\nsetuptools.setup(\n name=name,\n version=version,\n description=description,\n long_description=readme,\n author=\"Google LLC\",\n author_email=\"[email protected]\",\n license=\"Apache 2.0\",\n url=\"https://github.com/googleapis/python-bigquery\",\n classifiers=[\n release_status,\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Operating System :: OS Independent\",\n \"Topic :: Internet\",\n ],\n platforms=\"Posix; MacOS X; Windows\",\n packages=packages,\n namespace_packages=namespaces,\n install_requires=dependencies,\n extras_require=extras,\n python_requires=\">=3.6, <3.10\",\n include_package_data=True,\n zip_safe=False,\n)\n", "path": "setup.py"}]}
| 1,740 | 190 |
gh_patches_debug_14536
|
rasdani/github-patches
|
git_diff
|
mozmeao__snippets-service-864
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Filter by release channel on ASRSnippets raises an error
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `snippets/base/admin/filters.py`
Content:
```
1 from datetime import datetime, timedelta
2
3 from django.contrib import admin
4 from django.utils.encoding import force_text
5
6
7 class ModifiedFilter(admin.SimpleListFilter):
8 title = 'Last modified'
9 parameter_name = 'last_modified'
10
11 def lookups(self, request, model_admin):
12 return (
13 ('24', '24 hours'),
14 ('168', '7 days'),
15 ('336', '14 days'),
16 ('720', '30 days'),
17 ('all', 'All'),
18 )
19
20 def queryset(self, request, queryset):
21 value = self.value()
22 if not value or value == 'all':
23 return queryset
24
25 when = datetime.utcnow() - timedelta(hours=int(value))
26 return queryset.exclude(modified__lt=when)
27
28 def choices(self, cl):
29 for lookup, title in self.lookup_choices:
30 yield {
31 'selected': self.value() == force_text(lookup),
32 'query_string': cl.get_query_string({
33 self.parameter_name: lookup,
34 }, []),
35 'display': title,
36 }
37
38
39 class ChannelFilter(admin.SimpleListFilter):
40 title = 'Channel'
41 parameter_name = 'channel'
42
43 def lookups(self, request, model_admin):
44 return (
45 ('on_release', 'Release'),
46 ('on_esr', 'ESR'),
47 ('on_beta', 'Beta'),
48 ('on_aurora', 'Dev (Aurora)'),
49 ('on_nightly', 'Nightly'),
50 )
51
52 def queryset(self, request, queryset):
53 if self.value() is None:
54 return queryset
55
56 return queryset.filter(**{self.value(): True})
57
58
59 class ActivityStreamFilter(admin.SimpleListFilter):
60 title = 'Activity Stream'
61 parameter_name = 'is_activity_stream'
62
63 def lookups(self, request, model_admin):
64 return (
65 ('yes', 'Yes'),
66 ('no', 'No'),
67 )
68
69 def queryset(self, request, queryset):
70 if self.value() is None:
71 return queryset
72 elif self.value() == 'yes':
73 return queryset.filter(on_startpage_5=True)
74 elif self.value() == 'no':
75 return queryset.exclude(on_startpage_5=True)
76
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/snippets/base/admin/filters.py b/snippets/base/admin/filters.py
--- a/snippets/base/admin/filters.py
+++ b/snippets/base/admin/filters.py
@@ -3,6 +3,8 @@
from django.contrib import admin
from django.utils.encoding import force_text
+from snippets.base.managers import SnippetQuerySet
+
class ModifiedFilter(admin.SimpleListFilter):
title = 'Last modified'
@@ -53,7 +55,9 @@
if self.value() is None:
return queryset
- return queryset.filter(**{self.value(): True})
+ if isinstance(queryset, SnippetQuerySet):
+ return queryset.filter(**{self.value(): True})
+ return queryset.filter(**{f'target__{self.value()}': True})
class ActivityStreamFilter(admin.SimpleListFilter):
|
{"golden_diff": "diff --git a/snippets/base/admin/filters.py b/snippets/base/admin/filters.py\n--- a/snippets/base/admin/filters.py\n+++ b/snippets/base/admin/filters.py\n@@ -3,6 +3,8 @@\n from django.contrib import admin\n from django.utils.encoding import force_text\n \n+from snippets.base.managers import SnippetQuerySet\n+\n \n class ModifiedFilter(admin.SimpleListFilter):\n title = 'Last modified'\n@@ -53,7 +55,9 @@\n if self.value() is None:\n return queryset\n \n- return queryset.filter(**{self.value(): True})\n+ if isinstance(queryset, SnippetQuerySet):\n+ return queryset.filter(**{self.value(): True})\n+ return queryset.filter(**{f'target__{self.value()}': True})\n \n \n class ActivityStreamFilter(admin.SimpleListFilter):\n", "issue": "Filter by release channel on ASRSnippets raises an error\n\n", "before_files": [{"content": "from datetime import datetime, timedelta\n\nfrom django.contrib import admin\nfrom django.utils.encoding import force_text\n\n\nclass ModifiedFilter(admin.SimpleListFilter):\n title = 'Last modified'\n parameter_name = 'last_modified'\n\n def lookups(self, request, model_admin):\n return (\n ('24', '24 hours'),\n ('168', '7 days'),\n ('336', '14 days'),\n ('720', '30 days'),\n ('all', 'All'),\n )\n\n def queryset(self, request, queryset):\n value = self.value()\n if not value or value == 'all':\n return queryset\n\n when = datetime.utcnow() - timedelta(hours=int(value))\n return queryset.exclude(modified__lt=when)\n\n def choices(self, cl):\n for lookup, title in self.lookup_choices:\n yield {\n 'selected': self.value() == force_text(lookup),\n 'query_string': cl.get_query_string({\n self.parameter_name: lookup,\n }, []),\n 'display': title,\n }\n\n\nclass ChannelFilter(admin.SimpleListFilter):\n title = 'Channel'\n parameter_name = 'channel'\n\n def lookups(self, request, model_admin):\n return (\n ('on_release', 'Release'),\n ('on_esr', 'ESR'),\n ('on_beta', 'Beta'),\n ('on_aurora', 'Dev (Aurora)'),\n ('on_nightly', 'Nightly'),\n )\n\n def queryset(self, request, queryset):\n if self.value() is None:\n return queryset\n\n return queryset.filter(**{self.value(): True})\n\n\nclass ActivityStreamFilter(admin.SimpleListFilter):\n title = 'Activity Stream'\n parameter_name = 'is_activity_stream'\n\n def lookups(self, request, model_admin):\n return (\n ('yes', 'Yes'),\n ('no', 'No'),\n )\n\n def queryset(self, request, queryset):\n if self.value() is None:\n return queryset\n elif self.value() == 'yes':\n return queryset.filter(on_startpage_5=True)\n elif self.value() == 'no':\n return queryset.exclude(on_startpage_5=True)\n", "path": "snippets/base/admin/filters.py"}], "after_files": [{"content": "from datetime import datetime, timedelta\n\nfrom django.contrib import admin\nfrom django.utils.encoding import force_text\n\nfrom snippets.base.managers import SnippetQuerySet\n\n\nclass ModifiedFilter(admin.SimpleListFilter):\n title = 'Last modified'\n parameter_name = 'last_modified'\n\n def lookups(self, request, model_admin):\n return (\n ('24', '24 hours'),\n ('168', '7 days'),\n ('336', '14 days'),\n ('720', '30 days'),\n ('all', 'All'),\n )\n\n def queryset(self, request, queryset):\n value = self.value()\n if not value or value == 'all':\n return queryset\n\n when = datetime.utcnow() - timedelta(hours=int(value))\n return queryset.exclude(modified__lt=when)\n\n def choices(self, cl):\n for lookup, title in self.lookup_choices:\n yield {\n 'selected': self.value() == force_text(lookup),\n 'query_string': cl.get_query_string({\n self.parameter_name: lookup,\n }, []),\n 'display': title,\n }\n\n\nclass ChannelFilter(admin.SimpleListFilter):\n title = 'Channel'\n parameter_name = 'channel'\n\n def lookups(self, request, model_admin):\n return (\n ('on_release', 'Release'),\n ('on_esr', 'ESR'),\n ('on_beta', 'Beta'),\n ('on_aurora', 'Dev (Aurora)'),\n ('on_nightly', 'Nightly'),\n )\n\n def queryset(self, request, queryset):\n if self.value() is None:\n return queryset\n\n if isinstance(queryset, SnippetQuerySet):\n return queryset.filter(**{self.value(): True})\n return queryset.filter(**{f'target__{self.value()}': True})\n\n\nclass ActivityStreamFilter(admin.SimpleListFilter):\n title = 'Activity Stream'\n parameter_name = 'is_activity_stream'\n\n def lookups(self, request, model_admin):\n return (\n ('yes', 'Yes'),\n ('no', 'No'),\n )\n\n def queryset(self, request, queryset):\n if self.value() is None:\n return queryset\n elif self.value() == 'yes':\n return queryset.filter(on_startpage_5=True)\n elif self.value() == 'no':\n return queryset.exclude(on_startpage_5=True)\n", "path": "snippets/base/admin/filters.py"}]}
| 890 | 181 |
gh_patches_debug_21120
|
rasdani/github-patches
|
git_diff
|
chainer__chainer-242
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add type check to NonparameterizedLinear function
Related to #123
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `chainer/functions/nonparameterized_linear.py`
Content:
```
1 from chainer import cuda
2 from chainer import function
3 from chainer.functions import linear as linear_module
4
5
6 class NonparameterizedLinear(function.Function):
7
8 """Nonparameterized linear class.
9
10 .. seealso:: :class:`Linear`
11
12 """
13
14 def forward(self, x):
15 W = x[1]
16 b = None
17 if len(x) == 3:
18 b = x[2]
19 out_size, in_size = W.shape
20 func = linear_module.Linear(
21 in_size, out_size, initialW=W, initial_bias=b)
22 self.func = func
23 if any(isinstance(i, cuda.GPUArray) for i in x):
24 func.to_gpu()
25 return func.forward(x[:1])
26
27 def backward(self, x, gy):
28 func = self.func
29 func.zero_grads()
30 gx = func.backward(x[:1], gy)
31 if func.gb is None:
32 return (gx[0], func.gW)
33 return (gx[0], func.gW, func.gb)
34
35
36 def linear(x, W, b=None, stride=1, pad=0, use_cudnn=True):
37 """Nonparameterized linear function.
38
39 Args:
40 x (~chainer.Variable): Input variable.
41 W (~chainer.Variable): Weight variable.
42 b (~chainer.Variable): Bias variable.
43
44 Returns:
45 ~chainer.Variable: Output variable.
46
47 .. seealso:: :class:`Linear`
48
49 """
50
51 return NonparameterizedLinear()(x, W, b)
52
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/chainer/functions/nonparameterized_linear.py b/chainer/functions/nonparameterized_linear.py
--- a/chainer/functions/nonparameterized_linear.py
+++ b/chainer/functions/nonparameterized_linear.py
@@ -1,6 +1,9 @@
+import numpy
+
from chainer import cuda
from chainer import function
from chainer.functions import linear as linear_module
+from chainer.utils import type_check
class NonparameterizedLinear(function.Function):
@@ -11,6 +14,29 @@
"""
+ def check_type_forward(self, in_types):
+ type_check.expect(
+ 2 <= in_types.size(),
+ in_types.size() <= 3,
+ )
+ x_type = in_types[0]
+ w_type = in_types[1]
+
+ prod = type_check.Variable(numpy.prod, 'prod')
+ type_check.expect(
+ x_type.dtype == numpy.float32,
+ w_type.dtype == numpy.float32,
+ x_type.ndim >= 2,
+ w_type.ndim == 2,
+ prod(x_type.shape[1:]) == w_type.shape[1],
+ )
+ if in_types.size().eval() == 3:
+ b_type = in_types[2]
+ type_check.expect(
+ b_type.ndim == 1,
+ b_type.shape[0] == w_type.shape[0],
+ )
+
def forward(self, x):
W = x[1]
b = None
|
{"golden_diff": "diff --git a/chainer/functions/nonparameterized_linear.py b/chainer/functions/nonparameterized_linear.py\n--- a/chainer/functions/nonparameterized_linear.py\n+++ b/chainer/functions/nonparameterized_linear.py\n@@ -1,6 +1,9 @@\n+import numpy\n+\n from chainer import cuda\n from chainer import function\n from chainer.functions import linear as linear_module\n+from chainer.utils import type_check\n \n \n class NonparameterizedLinear(function.Function):\n@@ -11,6 +14,29 @@\n \n \"\"\"\n \n+ def check_type_forward(self, in_types):\n+ type_check.expect(\n+ 2 <= in_types.size(),\n+ in_types.size() <= 3,\n+ )\n+ x_type = in_types[0]\n+ w_type = in_types[1]\n+\n+ prod = type_check.Variable(numpy.prod, 'prod')\n+ type_check.expect(\n+ x_type.dtype == numpy.float32,\n+ w_type.dtype == numpy.float32,\n+ x_type.ndim >= 2,\n+ w_type.ndim == 2,\n+ prod(x_type.shape[1:]) == w_type.shape[1],\n+ )\n+ if in_types.size().eval() == 3:\n+ b_type = in_types[2]\n+ type_check.expect(\n+ b_type.ndim == 1,\n+ b_type.shape[0] == w_type.shape[0],\n+ )\n+\n def forward(self, x):\n W = x[1]\n b = None\n", "issue": "Add type check to NonparameterizedLinear function\nRelated to #123\n\n", "before_files": [{"content": "from chainer import cuda\nfrom chainer import function\nfrom chainer.functions import linear as linear_module\n\n\nclass NonparameterizedLinear(function.Function):\n\n \"\"\"Nonparameterized linear class.\n\n .. seealso:: :class:`Linear`\n\n \"\"\"\n\n def forward(self, x):\n W = x[1]\n b = None\n if len(x) == 3:\n b = x[2]\n out_size, in_size = W.shape\n func = linear_module.Linear(\n in_size, out_size, initialW=W, initial_bias=b)\n self.func = func\n if any(isinstance(i, cuda.GPUArray) for i in x):\n func.to_gpu()\n return func.forward(x[:1])\n\n def backward(self, x, gy):\n func = self.func\n func.zero_grads()\n gx = func.backward(x[:1], gy)\n if func.gb is None:\n return (gx[0], func.gW)\n return (gx[0], func.gW, func.gb)\n\n\ndef linear(x, W, b=None, stride=1, pad=0, use_cudnn=True):\n \"\"\"Nonparameterized linear function.\n\n Args:\n x (~chainer.Variable): Input variable.\n W (~chainer.Variable): Weight variable.\n b (~chainer.Variable): Bias variable.\n\n Returns:\n ~chainer.Variable: Output variable.\n\n .. seealso:: :class:`Linear`\n\n \"\"\"\n\n return NonparameterizedLinear()(x, W, b)\n", "path": "chainer/functions/nonparameterized_linear.py"}], "after_files": [{"content": "import numpy\n\nfrom chainer import cuda\nfrom chainer import function\nfrom chainer.functions import linear as linear_module\nfrom chainer.utils import type_check\n\n\nclass NonparameterizedLinear(function.Function):\n\n \"\"\"Nonparameterized linear class.\n\n .. seealso:: :class:`Linear`\n\n \"\"\"\n\n def check_type_forward(self, in_types):\n type_check.expect(\n 2 <= in_types.size(),\n in_types.size() <= 3,\n )\n x_type = in_types[0]\n w_type = in_types[1]\n\n prod = type_check.Variable(numpy.prod, 'prod')\n type_check.expect(\n x_type.dtype == numpy.float32,\n w_type.dtype == numpy.float32,\n x_type.ndim >= 2,\n w_type.ndim == 2,\n prod(x_type.shape[1:]) == w_type.shape[1],\n )\n if in_types.size().eval() == 3:\n b_type = in_types[2]\n type_check.expect(\n b_type.ndim == 1,\n b_type.shape[0] == w_type.shape[0],\n )\n\n def forward(self, x):\n W = x[1]\n b = None\n if len(x) == 3:\n b = x[2]\n out_size, in_size = W.shape\n func = linear_module.Linear(\n in_size, out_size, initialW=W, initial_bias=b)\n self.func = func\n if any(isinstance(i, cuda.GPUArray) for i in x):\n func.to_gpu()\n return func.forward(x[:1])\n\n def backward(self, x, gy):\n func = self.func\n func.zero_grads()\n gx = func.backward(x[:1], gy)\n if func.gb is None:\n return (gx[0], func.gW)\n return (gx[0], func.gW, func.gb)\n\n\ndef linear(x, W, b=None, stride=1, pad=0, use_cudnn=True):\n \"\"\"Nonparameterized linear function.\n\n Args:\n x (~chainer.Variable): Input variable.\n W (~chainer.Variable): Weight variable.\n b (~chainer.Variable): Bias variable.\n\n Returns:\n ~chainer.Variable: Output variable.\n\n .. seealso:: :class:`Linear`\n\n \"\"\"\n\n return NonparameterizedLinear()(x, W, b)\n", "path": "chainer/functions/nonparameterized_linear.py"}]}
| 705 | 330 |
gh_patches_debug_21472
|
rasdani/github-patches
|
git_diff
|
liqd__a4-meinberlin-2877
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
bplan template dates saved but not shown in Dashboard
URL: https://mein.berlin.de/dashboard/projects/erweiterung-mauerpark-bebauungsplan-3-64-im-bezirk/bplan/
user: initiator
expected behaviour: date and time that I have entered are still shown after saving form
behaviour: dates are no longer shown after saving, no error message, I can still publish the project and date is shown correctly on project tile
device & browser: Desktop, mac, chrome Version 76.0.3809.132 (Offizieller Build) (64-Bit)
Importance: relevant bug, fix before next release
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `meinberlin/apps/bplan/serializers.py`
Content:
```
1 import datetime
2 import imghdr
3 import posixpath
4 import tempfile
5 from urllib.parse import urlparse
6
7 import requests
8 from django.apps import apps
9 from django.conf import settings
10 from django.contrib.sites.models import Site
11 from django.core.exceptions import ValidationError
12 from django.core.files.images import ImageFile
13 from django.urls import reverse
14 from django.utils import timezone
15 from django.utils.translation import ugettext as _
16 from rest_framework import serializers
17
18 from adhocracy4.dashboard import components
19 from adhocracy4.dashboard import signals as a4dashboard_signals
20 from adhocracy4.images.validators import validate_image
21 from adhocracy4.modules import models as module_models
22 from adhocracy4.phases import models as phase_models
23 from adhocracy4.projects import models as project_models
24
25 from .models import Bplan
26 from .phases import StatementPhase
27
28 BPLAN_EMBED = '<iframe height="500" style="width: 100%; min-height: 300px; ' \
29 'max-height: 100vh" src="{}" frameborder="0"></iframe>'
30 DOWNLOAD_IMAGE_SIZE_LIMIT_BYTES = 10 * 1024 * 1024
31
32
33 class BplanSerializer(serializers.ModelSerializer):
34 id = serializers.IntegerField(required=False)
35
36 # make write_only for consistency reasons
37 start_date = serializers.DateTimeField(write_only=True)
38 end_date = serializers.DateTimeField(write_only=True)
39 image_url = serializers.URLField(required=False, write_only=True)
40 image_copyright = serializers.CharField(required=False, write_only=True,
41 source='tile_image_copyright',
42 allow_blank=True,
43 max_length=120)
44 embed_code = serializers.SerializerMethodField()
45
46 class Meta:
47 model = Bplan
48 fields = (
49 'id', 'name', 'identifier', 'description', 'url',
50 'office_worker_email', 'is_draft', 'start_date', 'end_date',
51 'image_url', 'image_copyright', 'embed_code'
52 )
53 extra_kwargs = {
54 # write_only for consistency reasons
55 'is_draft': {'default': False, 'write_only': True},
56 'name': {'write_only': True},
57 'description': {'write_only': True},
58 'url': {'write_only': True},
59 'office_worker_email': {'write_only': True},
60 'identifier': {'write_only': True}
61 }
62
63 def create(self, validated_data):
64 orga_pk = self._context.get('organisation_pk', None)
65 orga_model = apps.get_model(settings.A4_ORGANISATIONS_MODEL)
66 orga = orga_model.objects.get(pk=orga_pk)
67 validated_data['organisation'] = orga
68
69 start_date = validated_data.pop('start_date')
70 end_date = validated_data.pop('end_date')
71
72 image_url = validated_data.pop('image_url', None)
73 if image_url:
74 validated_data['tile_image'] = \
75 self._download_image_from_url(image_url)
76
77 bplan = super().create(validated_data)
78 self._create_module_and_phase(bplan, start_date, end_date)
79 self._send_project_created_signal(bplan)
80 return bplan
81
82 def _create_module_and_phase(self, bplan, start_date, end_date):
83 module = module_models.Module.objects.create(
84 name=bplan.slug + '_module',
85 weight=1,
86 project=bplan,
87 )
88
89 phase_content = StatementPhase()
90 phase_models.Phase.objects.create(
91 name=_('Bplan statement phase'),
92 description=_('Bplan statement phase'),
93 type=phase_content.identifier,
94 module=module,
95 start_date=start_date,
96 end_date=end_date
97 )
98
99 def update(self, instance, validated_data):
100 start_date = validated_data.pop('start_date', None)
101 end_date = validated_data.pop('end_date', None)
102 if start_date or end_date:
103 self._update_phase(instance, start_date, end_date)
104 if end_date and end_date > timezone.localtime(timezone.now()):
105 instance.is_archived = False
106
107 image_url = validated_data.pop('image_url', None)
108 if image_url:
109 validated_data['tile_image'] = \
110 self._download_image_from_url(image_url)
111
112 instance = super().update(instance, validated_data)
113
114 self._send_component_updated_signal(instance)
115 return instance
116
117 def _update_phase(self, bplan, start_date, end_date):
118 module = module_models.Module.objects.get(project=bplan)
119 phase = phase_models.Phase.objects.get(module=module)
120 if start_date:
121 phase.start_date = start_date
122 if end_date:
123 phase.end_date = end_date
124 phase.save()
125
126 def get_embed_code(self, bplan):
127 url = self._get_absolute_url(bplan)
128 embed = BPLAN_EMBED.format(url)
129 return embed
130
131 def _get_absolute_url(self, bplan):
132 site_url = Site.objects.get_current().domain
133 embed_url = reverse('embed-project', kwargs={'slug': bplan.slug, })
134 url = 'https://{}{}'.format(site_url, embed_url)
135 return url
136
137 def _download_image_from_url(self, url):
138 parsed_url = urlparse(url)
139 file_name = None
140 try:
141 r = requests.get(url, stream=True, timeout=10)
142 downloaded_bytes = 0
143 with tempfile.TemporaryFile() as f:
144 for chunk in r.iter_content(chunk_size=1024):
145 downloaded_bytes += len(chunk)
146 if downloaded_bytes > DOWNLOAD_IMAGE_SIZE_LIMIT_BYTES:
147 raise serializers.ValidationError(
148 'Image too large to download {}'.format(url))
149 if chunk:
150 f.write(chunk)
151 file_name = self._generate_image_filename(parsed_url.path, f)
152 self._image_storage.save(file_name, f)
153 except Exception:
154 if file_name:
155 self._image_storage.delete(file_name)
156 raise serializers.ValidationError(
157 'Failed to download image {}'.format(url))
158
159 try:
160 self._validate_image(file_name)
161 except ValidationError as e:
162 self._image_storage.delete(file_name)
163 raise serializers.ValidationError(e)
164
165 return file_name
166
167 def _validate_image(self, file_name):
168 image_file = self._image_storage.open(file_name, 'rb')
169 image = ImageFile(image_file, file_name)
170 config = settings.IMAGE_ALIASES.get('*', {})
171 config.update(settings.IMAGE_ALIASES['tileimage'])
172 validate_image(image, **config)
173
174 @property
175 def _image_storage(self):
176 return project_models.Project._meta.get_field('tile_image').storage
177
178 @property
179 def _image_upload_to(self):
180 return project_models.Project._meta.get_field('tile_image').upload_to
181
182 def _generate_image_filename(self, url_path, file):
183 if callable(self._image_upload_to):
184 raise Exception('Callable upload_to fields are not supported')
185
186 root_path, extension = posixpath.splitext(url_path)
187 if file:
188 # Workaround: imghdr expects the files position on 0
189 file.seek(0)
190 extension = imghdr.what(file) or 'jpeg'
191
192 basename = posixpath.basename(root_path)
193 if not basename:
194 basename = 'bplan'
195
196 dirname = datetime.datetime.now().strftime(self._image_upload_to)
197 filename = posixpath.join(dirname, basename + '.' + extension)
198
199 return self._image_storage.get_available_name(filename)
200
201 def _send_project_created_signal(self, bplan):
202 a4dashboard_signals.project_created.send(
203 sender=self.__class__,
204 project=bplan,
205 user=self.context['request'].user
206 )
207
208 def _send_component_updated_signal(self, bplan):
209 component = components.projects['bplan']
210 a4dashboard_signals.project_component_updated.send(
211 sender=self.__class__,
212 project=bplan,
213 component=component,
214 user=self.context['request'].user
215 )
216
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/meinberlin/apps/bplan/serializers.py b/meinberlin/apps/bplan/serializers.py
--- a/meinberlin/apps/bplan/serializers.py
+++ b/meinberlin/apps/bplan/serializers.py
@@ -66,8 +66,8 @@
orga = orga_model.objects.get(pk=orga_pk)
validated_data['organisation'] = orga
- start_date = validated_data.pop('start_date')
- end_date = validated_data.pop('end_date')
+ start_date = validated_data['start_date']
+ end_date = validated_data['end_date']
image_url = validated_data.pop('image_url', None)
if image_url:
@@ -97,8 +97,8 @@
)
def update(self, instance, validated_data):
- start_date = validated_data.pop('start_date', None)
- end_date = validated_data.pop('end_date', None)
+ start_date = validated_data.get('start_date', None)
+ end_date = validated_data.get('end_date', None)
if start_date or end_date:
self._update_phase(instance, start_date, end_date)
if end_date and end_date > timezone.localtime(timezone.now()):
|
{"golden_diff": "diff --git a/meinberlin/apps/bplan/serializers.py b/meinberlin/apps/bplan/serializers.py\n--- a/meinberlin/apps/bplan/serializers.py\n+++ b/meinberlin/apps/bplan/serializers.py\n@@ -66,8 +66,8 @@\n orga = orga_model.objects.get(pk=orga_pk)\n validated_data['organisation'] = orga\n \n- start_date = validated_data.pop('start_date')\n- end_date = validated_data.pop('end_date')\n+ start_date = validated_data['start_date']\n+ end_date = validated_data['end_date']\n \n image_url = validated_data.pop('image_url', None)\n if image_url:\n@@ -97,8 +97,8 @@\n )\n \n def update(self, instance, validated_data):\n- start_date = validated_data.pop('start_date', None)\n- end_date = validated_data.pop('end_date', None)\n+ start_date = validated_data.get('start_date', None)\n+ end_date = validated_data.get('end_date', None)\n if start_date or end_date:\n self._update_phase(instance, start_date, end_date)\n if end_date and end_date > timezone.localtime(timezone.now()):\n", "issue": "bplan template dates saved but not shown in Dashboard\nURL: https://mein.berlin.de/dashboard/projects/erweiterung-mauerpark-bebauungsplan-3-64-im-bezirk/bplan/\r\nuser: initiator\r\nexpected behaviour: date and time that I have entered are still shown after saving form\r\nbehaviour: dates are no longer shown after saving, no error message, I can still publish the project and date is shown correctly on project tile\r\ndevice & browser: Desktop, mac, chrome Version 76.0.3809.132 (Offizieller Build) (64-Bit)\r\nImportance: relevant bug, fix before next release\n", "before_files": [{"content": "import datetime\nimport imghdr\nimport posixpath\nimport tempfile\nfrom urllib.parse import urlparse\n\nimport requests\nfrom django.apps import apps\nfrom django.conf import settings\nfrom django.contrib.sites.models import Site\nfrom django.core.exceptions import ValidationError\nfrom django.core.files.images import ImageFile\nfrom django.urls import reverse\nfrom django.utils import timezone\nfrom django.utils.translation import ugettext as _\nfrom rest_framework import serializers\n\nfrom adhocracy4.dashboard import components\nfrom adhocracy4.dashboard import signals as a4dashboard_signals\nfrom adhocracy4.images.validators import validate_image\nfrom adhocracy4.modules import models as module_models\nfrom adhocracy4.phases import models as phase_models\nfrom adhocracy4.projects import models as project_models\n\nfrom .models import Bplan\nfrom .phases import StatementPhase\n\nBPLAN_EMBED = '<iframe height=\"500\" style=\"width: 100%; min-height: 300px; ' \\\n 'max-height: 100vh\" src=\"{}\" frameborder=\"0\"></iframe>'\nDOWNLOAD_IMAGE_SIZE_LIMIT_BYTES = 10 * 1024 * 1024\n\n\nclass BplanSerializer(serializers.ModelSerializer):\n id = serializers.IntegerField(required=False)\n\n # make write_only for consistency reasons\n start_date = serializers.DateTimeField(write_only=True)\n end_date = serializers.DateTimeField(write_only=True)\n image_url = serializers.URLField(required=False, write_only=True)\n image_copyright = serializers.CharField(required=False, write_only=True,\n source='tile_image_copyright',\n allow_blank=True,\n max_length=120)\n embed_code = serializers.SerializerMethodField()\n\n class Meta:\n model = Bplan\n fields = (\n 'id', 'name', 'identifier', 'description', 'url',\n 'office_worker_email', 'is_draft', 'start_date', 'end_date',\n 'image_url', 'image_copyright', 'embed_code'\n )\n extra_kwargs = {\n # write_only for consistency reasons\n 'is_draft': {'default': False, 'write_only': True},\n 'name': {'write_only': True},\n 'description': {'write_only': True},\n 'url': {'write_only': True},\n 'office_worker_email': {'write_only': True},\n 'identifier': {'write_only': True}\n }\n\n def create(self, validated_data):\n orga_pk = self._context.get('organisation_pk', None)\n orga_model = apps.get_model(settings.A4_ORGANISATIONS_MODEL)\n orga = orga_model.objects.get(pk=orga_pk)\n validated_data['organisation'] = orga\n\n start_date = validated_data.pop('start_date')\n end_date = validated_data.pop('end_date')\n\n image_url = validated_data.pop('image_url', None)\n if image_url:\n validated_data['tile_image'] = \\\n self._download_image_from_url(image_url)\n\n bplan = super().create(validated_data)\n self._create_module_and_phase(bplan, start_date, end_date)\n self._send_project_created_signal(bplan)\n return bplan\n\n def _create_module_and_phase(self, bplan, start_date, end_date):\n module = module_models.Module.objects.create(\n name=bplan.slug + '_module',\n weight=1,\n project=bplan,\n )\n\n phase_content = StatementPhase()\n phase_models.Phase.objects.create(\n name=_('Bplan statement phase'),\n description=_('Bplan statement phase'),\n type=phase_content.identifier,\n module=module,\n start_date=start_date,\n end_date=end_date\n )\n\n def update(self, instance, validated_data):\n start_date = validated_data.pop('start_date', None)\n end_date = validated_data.pop('end_date', None)\n if start_date or end_date:\n self._update_phase(instance, start_date, end_date)\n if end_date and end_date > timezone.localtime(timezone.now()):\n instance.is_archived = False\n\n image_url = validated_data.pop('image_url', None)\n if image_url:\n validated_data['tile_image'] = \\\n self._download_image_from_url(image_url)\n\n instance = super().update(instance, validated_data)\n\n self._send_component_updated_signal(instance)\n return instance\n\n def _update_phase(self, bplan, start_date, end_date):\n module = module_models.Module.objects.get(project=bplan)\n phase = phase_models.Phase.objects.get(module=module)\n if start_date:\n phase.start_date = start_date\n if end_date:\n phase.end_date = end_date\n phase.save()\n\n def get_embed_code(self, bplan):\n url = self._get_absolute_url(bplan)\n embed = BPLAN_EMBED.format(url)\n return embed\n\n def _get_absolute_url(self, bplan):\n site_url = Site.objects.get_current().domain\n embed_url = reverse('embed-project', kwargs={'slug': bplan.slug, })\n url = 'https://{}{}'.format(site_url, embed_url)\n return url\n\n def _download_image_from_url(self, url):\n parsed_url = urlparse(url)\n file_name = None\n try:\n r = requests.get(url, stream=True, timeout=10)\n downloaded_bytes = 0\n with tempfile.TemporaryFile() as f:\n for chunk in r.iter_content(chunk_size=1024):\n downloaded_bytes += len(chunk)\n if downloaded_bytes > DOWNLOAD_IMAGE_SIZE_LIMIT_BYTES:\n raise serializers.ValidationError(\n 'Image too large to download {}'.format(url))\n if chunk:\n f.write(chunk)\n file_name = self._generate_image_filename(parsed_url.path, f)\n self._image_storage.save(file_name, f)\n except Exception:\n if file_name:\n self._image_storage.delete(file_name)\n raise serializers.ValidationError(\n 'Failed to download image {}'.format(url))\n\n try:\n self._validate_image(file_name)\n except ValidationError as e:\n self._image_storage.delete(file_name)\n raise serializers.ValidationError(e)\n\n return file_name\n\n def _validate_image(self, file_name):\n image_file = self._image_storage.open(file_name, 'rb')\n image = ImageFile(image_file, file_name)\n config = settings.IMAGE_ALIASES.get('*', {})\n config.update(settings.IMAGE_ALIASES['tileimage'])\n validate_image(image, **config)\n\n @property\n def _image_storage(self):\n return project_models.Project._meta.get_field('tile_image').storage\n\n @property\n def _image_upload_to(self):\n return project_models.Project._meta.get_field('tile_image').upload_to\n\n def _generate_image_filename(self, url_path, file):\n if callable(self._image_upload_to):\n raise Exception('Callable upload_to fields are not supported')\n\n root_path, extension = posixpath.splitext(url_path)\n if file:\n # Workaround: imghdr expects the files position on 0\n file.seek(0)\n extension = imghdr.what(file) or 'jpeg'\n\n basename = posixpath.basename(root_path)\n if not basename:\n basename = 'bplan'\n\n dirname = datetime.datetime.now().strftime(self._image_upload_to)\n filename = posixpath.join(dirname, basename + '.' + extension)\n\n return self._image_storage.get_available_name(filename)\n\n def _send_project_created_signal(self, bplan):\n a4dashboard_signals.project_created.send(\n sender=self.__class__,\n project=bplan,\n user=self.context['request'].user\n )\n\n def _send_component_updated_signal(self, bplan):\n component = components.projects['bplan']\n a4dashboard_signals.project_component_updated.send(\n sender=self.__class__,\n project=bplan,\n component=component,\n user=self.context['request'].user\n )\n", "path": "meinberlin/apps/bplan/serializers.py"}], "after_files": [{"content": "import datetime\nimport imghdr\nimport posixpath\nimport tempfile\nfrom urllib.parse import urlparse\n\nimport requests\nfrom django.apps import apps\nfrom django.conf import settings\nfrom django.contrib.sites.models import Site\nfrom django.core.exceptions import ValidationError\nfrom django.core.files.images import ImageFile\nfrom django.urls import reverse\nfrom django.utils import timezone\nfrom django.utils.translation import ugettext as _\nfrom rest_framework import serializers\n\nfrom adhocracy4.dashboard import components\nfrom adhocracy4.dashboard import signals as a4dashboard_signals\nfrom adhocracy4.images.validators import validate_image\nfrom adhocracy4.modules import models as module_models\nfrom adhocracy4.phases import models as phase_models\nfrom adhocracy4.projects import models as project_models\n\nfrom .models import Bplan\nfrom .phases import StatementPhase\n\nBPLAN_EMBED = '<iframe height=\"500\" style=\"width: 100%; min-height: 300px; ' \\\n 'max-height: 100vh\" src=\"{}\" frameborder=\"0\"></iframe>'\nDOWNLOAD_IMAGE_SIZE_LIMIT_BYTES = 10 * 1024 * 1024\n\n\nclass BplanSerializer(serializers.ModelSerializer):\n id = serializers.IntegerField(required=False)\n\n # make write_only for consistency reasons\n start_date = serializers.DateTimeField(write_only=True)\n end_date = serializers.DateTimeField(write_only=True)\n image_url = serializers.URLField(required=False, write_only=True)\n image_copyright = serializers.CharField(required=False, write_only=True,\n source='tile_image_copyright',\n allow_blank=True,\n max_length=120)\n embed_code = serializers.SerializerMethodField()\n\n class Meta:\n model = Bplan\n fields = (\n 'id', 'name', 'identifier', 'description', 'url',\n 'office_worker_email', 'is_draft', 'start_date', 'end_date',\n 'image_url', 'image_copyright', 'embed_code'\n )\n extra_kwargs = {\n # write_only for consistency reasons\n 'is_draft': {'default': False, 'write_only': True},\n 'name': {'write_only': True},\n 'description': {'write_only': True},\n 'url': {'write_only': True},\n 'office_worker_email': {'write_only': True},\n 'identifier': {'write_only': True}\n }\n\n def create(self, validated_data):\n orga_pk = self._context.get('organisation_pk', None)\n orga_model = apps.get_model(settings.A4_ORGANISATIONS_MODEL)\n orga = orga_model.objects.get(pk=orga_pk)\n validated_data['organisation'] = orga\n\n start_date = validated_data['start_date']\n end_date = validated_data['end_date']\n\n image_url = validated_data.pop('image_url', None)\n if image_url:\n validated_data['tile_image'] = \\\n self._download_image_from_url(image_url)\n\n bplan = super().create(validated_data)\n self._create_module_and_phase(bplan, start_date, end_date)\n self._send_project_created_signal(bplan)\n return bplan\n\n def _create_module_and_phase(self, bplan, start_date, end_date):\n module = module_models.Module.objects.create(\n name=bplan.slug + '_module',\n weight=1,\n project=bplan,\n )\n\n phase_content = StatementPhase()\n phase_models.Phase.objects.create(\n name=_('Bplan statement phase'),\n description=_('Bplan statement phase'),\n type=phase_content.identifier,\n module=module,\n start_date=start_date,\n end_date=end_date\n )\n\n def update(self, instance, validated_data):\n start_date = validated_data.get('start_date', None)\n end_date = validated_data.get('end_date', None)\n if start_date or end_date:\n self._update_phase(instance, start_date, end_date)\n if end_date and end_date > timezone.localtime(timezone.now()):\n instance.is_archived = False\n\n image_url = validated_data.pop('image_url', None)\n if image_url:\n validated_data['tile_image'] = \\\n self._download_image_from_url(image_url)\n\n instance = super().update(instance, validated_data)\n\n self._send_component_updated_signal(instance)\n return instance\n\n def _update_phase(self, bplan, start_date, end_date):\n module = module_models.Module.objects.get(project=bplan)\n phase = phase_models.Phase.objects.get(module=module)\n if start_date:\n phase.start_date = start_date\n if end_date:\n phase.end_date = end_date\n phase.save()\n\n def get_embed_code(self, bplan):\n url = self._get_absolute_url(bplan)\n embed = BPLAN_EMBED.format(url)\n return embed\n\n def _get_absolute_url(self, bplan):\n site_url = Site.objects.get_current().domain\n embed_url = reverse('embed-project', kwargs={'slug': bplan.slug, })\n url = 'https://{}{}'.format(site_url, embed_url)\n return url\n\n def _download_image_from_url(self, url):\n parsed_url = urlparse(url)\n file_name = None\n try:\n r = requests.get(url, stream=True, timeout=10)\n downloaded_bytes = 0\n with tempfile.TemporaryFile() as f:\n for chunk in r.iter_content(chunk_size=1024):\n downloaded_bytes += len(chunk)\n if downloaded_bytes > DOWNLOAD_IMAGE_SIZE_LIMIT_BYTES:\n raise serializers.ValidationError(\n 'Image too large to download {}'.format(url))\n if chunk:\n f.write(chunk)\n file_name = self._generate_image_filename(parsed_url.path, f)\n self._image_storage.save(file_name, f)\n except Exception:\n if file_name:\n self._image_storage.delete(file_name)\n raise serializers.ValidationError(\n 'Failed to download image {}'.format(url))\n\n try:\n self._validate_image(file_name)\n except ValidationError as e:\n self._image_storage.delete(file_name)\n raise serializers.ValidationError(e)\n\n return file_name\n\n def _validate_image(self, file_name):\n image_file = self._image_storage.open(file_name, 'rb')\n image = ImageFile(image_file, file_name)\n config = settings.IMAGE_ALIASES.get('*', {})\n config.update(settings.IMAGE_ALIASES['tileimage'])\n validate_image(image, **config)\n\n @property\n def _image_storage(self):\n return project_models.Project._meta.get_field('tile_image').storage\n\n @property\n def _image_upload_to(self):\n return project_models.Project._meta.get_field('tile_image').upload_to\n\n def _generate_image_filename(self, url_path, file):\n if callable(self._image_upload_to):\n raise Exception('Callable upload_to fields are not supported')\n\n root_path, extension = posixpath.splitext(url_path)\n if file:\n # Workaround: imghdr expects the files position on 0\n file.seek(0)\n extension = imghdr.what(file) or 'jpeg'\n\n basename = posixpath.basename(root_path)\n if not basename:\n basename = 'bplan'\n\n dirname = datetime.datetime.now().strftime(self._image_upload_to)\n filename = posixpath.join(dirname, basename + '.' + extension)\n\n return self._image_storage.get_available_name(filename)\n\n def _send_project_created_signal(self, bplan):\n a4dashboard_signals.project_created.send(\n sender=self.__class__,\n project=bplan,\n user=self.context['request'].user\n )\n\n def _send_component_updated_signal(self, bplan):\n component = components.projects['bplan']\n a4dashboard_signals.project_component_updated.send(\n sender=self.__class__,\n project=bplan,\n component=component,\n user=self.context['request'].user\n )\n", "path": "meinberlin/apps/bplan/serializers.py"}]}
| 2,643 | 274 |
gh_patches_debug_63158
|
rasdani/github-patches
|
git_diff
|
dotkom__onlineweb4-2101
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Users should be able to edit expired 'careeropportunity' from Dashboard
## What kind of an issue is this?
- Feature request
## What is the expected behaviour?
You should be able to click to edit from the list of expired careeropportunities in the Dashboard.
## Other information
This was requested by one of our users on email.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `apps/careeropportunity/dashboard/views.py`
Content:
```
1 # -*- encoding: utf-8 -*-
2 import logging
3
4 from django.contrib import messages
5 from django.contrib.auth.decorators import login_required
6 from django.core.exceptions import PermissionDenied
7 from django.shortcuts import get_object_or_404, redirect, render
8 from django.utils import timezone
9 from guardian.decorators import permission_required
10
11 from apps.careeropportunity.forms import AddCareerOpportunityForm
12 from apps.careeropportunity.models import CareerOpportunity
13 from apps.dashboard.tools import get_base_context, has_access
14
15
16 @login_required
17 @permission_required('careeropportunity.view_careeropportunity', return_403=True)
18 def index(request):
19
20 if not has_access(request):
21 raise PermissionDenied
22
23 context = get_base_context(request)
24
25 # "cops" is short for "careeropportunities" which is a fucking long word
26 # "cop" is short for "careeropportunity" which also is a fucking long word
27 cops = CareerOpportunity.objects.all()
28 context['cops'] = cops.filter(end__gte=timezone.now()).order_by('end')
29 context['archive'] = cops.filter(end__lte=timezone.now()).order_by('-id')
30
31 return render(request, 'careeropportunity/dashboard/index.html', context)
32
33
34 @login_required
35 @permission_required('careeropportunity.change_careeropportunity', return_403=True)
36 def detail(request, opportunity_id=None):
37 logger = logging.getLogger(__name__)
38 logger.debug('Editing careeropportunity with id: %s' % (opportunity_id))
39
40 if not has_access(request):
41 raise PermissionDenied
42
43 context = get_base_context(request)
44 cop = None
45 if opportunity_id:
46 cop = get_object_or_404(CareerOpportunity, pk=opportunity_id)
47 context['cop'] = cop
48 context['form'] = AddCareerOpportunityForm(instance=cop)
49 else:
50 context['form'] = AddCareerOpportunityForm()
51
52 if request.method == 'POST':
53 if cop:
54 form = AddCareerOpportunityForm(data=request.POST, instance=cop)
55 else:
56 form = AddCareerOpportunityForm(data=request.POST)
57
58 if form.is_valid():
59 form.save()
60 messages.success(request, 'La til ny karrieremulighet')
61 return redirect(index)
62 else:
63 context['form'] = form
64 messages.error(request,
65 'Skjemaet ble ikke korrekt utfylt. Se etter markerte felter for å se hva som gikk galt.')
66
67 return render(request, 'careeropportunity/dashboard/detail.html', context)
68
69
70 @login_required
71 @permission_required('careeropportunity.change_careeropportunity', return_403=True)
72 def delete(request, opportunity_id=None):
73 logger = logging.getLogger(__name__)
74 logger.debug('Deleting careeropportunitywith id: %s' % (opportunity_id))
75 if not has_access(request):
76 raise PermissionDenied
77
78 cop = get_object_or_404(CareerOpportunity, pk=opportunity_id)
79 cop.delete()
80 messages.success(request, 'Slettet karrieremuligheten')
81 return redirect(index)
82
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/apps/careeropportunity/dashboard/views.py b/apps/careeropportunity/dashboard/views.py
--- a/apps/careeropportunity/dashboard/views.py
+++ b/apps/careeropportunity/dashboard/views.py
@@ -27,7 +27,7 @@
cops = CareerOpportunity.objects.all()
context['cops'] = cops.filter(end__gte=timezone.now()).order_by('end')
context['archive'] = cops.filter(end__lte=timezone.now()).order_by('-id')
-
+ context['all'] = cops
return render(request, 'careeropportunity/dashboard/index.html', context)
|
{"golden_diff": "diff --git a/apps/careeropportunity/dashboard/views.py b/apps/careeropportunity/dashboard/views.py\n--- a/apps/careeropportunity/dashboard/views.py\n+++ b/apps/careeropportunity/dashboard/views.py\n@@ -27,7 +27,7 @@\n cops = CareerOpportunity.objects.all()\n context['cops'] = cops.filter(end__gte=timezone.now()).order_by('end')\n context['archive'] = cops.filter(end__lte=timezone.now()).order_by('-id')\n-\n+ context['all'] = cops\n return render(request, 'careeropportunity/dashboard/index.html', context)\n", "issue": "Users should be able to edit expired 'careeropportunity' from Dashboard\n## What kind of an issue is this?\r\n- Feature request\r\n\r\n## What is the expected behaviour?\r\n\r\nYou should be able to click to edit from the list of expired careeropportunities in the Dashboard.\r\n\r\n## Other information\r\n\r\nThis was requested by one of our users on email.\r\n\n", "before_files": [{"content": "# -*- encoding: utf-8 -*-\nimport logging\n\nfrom django.contrib import messages\nfrom django.contrib.auth.decorators import login_required\nfrom django.core.exceptions import PermissionDenied\nfrom django.shortcuts import get_object_or_404, redirect, render\nfrom django.utils import timezone\nfrom guardian.decorators import permission_required\n\nfrom apps.careeropportunity.forms import AddCareerOpportunityForm\nfrom apps.careeropportunity.models import CareerOpportunity\nfrom apps.dashboard.tools import get_base_context, has_access\n\n\n@login_required\n@permission_required('careeropportunity.view_careeropportunity', return_403=True)\ndef index(request):\n\n if not has_access(request):\n raise PermissionDenied\n\n context = get_base_context(request)\n\n # \"cops\" is short for \"careeropportunities\" which is a fucking long word\n # \"cop\" is short for \"careeropportunity\" which also is a fucking long word\n cops = CareerOpportunity.objects.all()\n context['cops'] = cops.filter(end__gte=timezone.now()).order_by('end')\n context['archive'] = cops.filter(end__lte=timezone.now()).order_by('-id')\n\n return render(request, 'careeropportunity/dashboard/index.html', context)\n\n\n@login_required\n@permission_required('careeropportunity.change_careeropportunity', return_403=True)\ndef detail(request, opportunity_id=None):\n logger = logging.getLogger(__name__)\n logger.debug('Editing careeropportunity with id: %s' % (opportunity_id))\n\n if not has_access(request):\n raise PermissionDenied\n\n context = get_base_context(request)\n cop = None\n if opportunity_id:\n cop = get_object_or_404(CareerOpportunity, pk=opportunity_id)\n context['cop'] = cop\n context['form'] = AddCareerOpportunityForm(instance=cop)\n else:\n context['form'] = AddCareerOpportunityForm()\n\n if request.method == 'POST':\n if cop:\n form = AddCareerOpportunityForm(data=request.POST, instance=cop)\n else:\n form = AddCareerOpportunityForm(data=request.POST)\n\n if form.is_valid():\n form.save()\n messages.success(request, 'La til ny karrieremulighet')\n return redirect(index)\n else:\n context['form'] = form\n messages.error(request,\n 'Skjemaet ble ikke korrekt utfylt. Se etter markerte felter for \u00e5 se hva som gikk galt.')\n\n return render(request, 'careeropportunity/dashboard/detail.html', context)\n\n\n@login_required\n@permission_required('careeropportunity.change_careeropportunity', return_403=True)\ndef delete(request, opportunity_id=None):\n logger = logging.getLogger(__name__)\n logger.debug('Deleting careeropportunitywith id: %s' % (opportunity_id))\n if not has_access(request):\n raise PermissionDenied\n\n cop = get_object_or_404(CareerOpportunity, pk=opportunity_id)\n cop.delete()\n messages.success(request, 'Slettet karrieremuligheten')\n return redirect(index)\n", "path": "apps/careeropportunity/dashboard/views.py"}], "after_files": [{"content": "# -*- encoding: utf-8 -*-\nimport logging\n\nfrom django.contrib import messages\nfrom django.contrib.auth.decorators import login_required\nfrom django.core.exceptions import PermissionDenied\nfrom django.shortcuts import get_object_or_404, redirect, render\nfrom django.utils import timezone\nfrom guardian.decorators import permission_required\n\nfrom apps.careeropportunity.forms import AddCareerOpportunityForm\nfrom apps.careeropportunity.models import CareerOpportunity\nfrom apps.dashboard.tools import get_base_context, has_access\n\n\n@login_required\n@permission_required('careeropportunity.view_careeropportunity', return_403=True)\ndef index(request):\n\n if not has_access(request):\n raise PermissionDenied\n\n context = get_base_context(request)\n\n # \"cops\" is short for \"careeropportunities\" which is a fucking long word\n # \"cop\" is short for \"careeropportunity\" which also is a fucking long word\n cops = CareerOpportunity.objects.all()\n context['cops'] = cops.filter(end__gte=timezone.now()).order_by('end')\n context['archive'] = cops.filter(end__lte=timezone.now()).order_by('-id')\n context['all'] = cops\n return render(request, 'careeropportunity/dashboard/index.html', context)\n\n\n@login_required\n@permission_required('careeropportunity.change_careeropportunity', return_403=True)\ndef detail(request, opportunity_id=None):\n logger = logging.getLogger(__name__)\n logger.debug('Editing careeropportunity with id: %s' % (opportunity_id))\n\n if not has_access(request):\n raise PermissionDenied\n\n context = get_base_context(request)\n cop = None\n if opportunity_id:\n cop = get_object_or_404(CareerOpportunity, pk=opportunity_id)\n context['cop'] = cop\n context['form'] = AddCareerOpportunityForm(instance=cop)\n else:\n context['form'] = AddCareerOpportunityForm()\n\n if request.method == 'POST':\n if cop:\n form = AddCareerOpportunityForm(data=request.POST, instance=cop)\n else:\n form = AddCareerOpportunityForm(data=request.POST)\n\n if form.is_valid():\n form.save()\n messages.success(request, 'La til ny karrieremulighet')\n return redirect(index)\n else:\n context['form'] = form\n messages.error(request,\n 'Skjemaet ble ikke korrekt utfylt. Se etter markerte felter for \u00e5 se hva som gikk galt.')\n\n return render(request, 'careeropportunity/dashboard/detail.html', context)\n\n\n@login_required\n@permission_required('careeropportunity.change_careeropportunity', return_403=True)\ndef delete(request, opportunity_id=None):\n logger = logging.getLogger(__name__)\n logger.debug('Deleting careeropportunitywith id: %s' % (opportunity_id))\n if not has_access(request):\n raise PermissionDenied\n\n cop = get_object_or_404(CareerOpportunity, pk=opportunity_id)\n cop.delete()\n messages.success(request, 'Slettet karrieremuligheten')\n return redirect(index)\n", "path": "apps/careeropportunity/dashboard/views.py"}]}
| 1,174 | 135 |
gh_patches_debug_12009
|
rasdani/github-patches
|
git_diff
|
Netflix__lemur-111
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Duplicate Plugins Listed
Plugins are duplicated in the authority dropdown.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lemur/plugins/views.py`
Content:
```
1 """
2 .. module: lemur.plugins.views
3 :platform: Unix
4 :synopsis: This module contains all of the accounts view code.
5 :copyright: (c) 2015 by Netflix Inc., see AUTHORS for more
6 :license: Apache, see LICENSE for more details.
7 .. moduleauthor:: Kevin Glisson <[email protected]>
8 """
9 from flask import Blueprint
10 from flask.ext.restful import Api, reqparse, fields
11 from lemur.auth.service import AuthenticatedResource
12
13 from lemur.common.utils import marshal_items
14
15 from lemur.plugins.base import plugins
16
17 mod = Blueprint('plugins', __name__)
18 api = Api(mod)
19
20
21 FIELDS = {
22 'title': fields.String,
23 'pluginOptions': fields.Raw(attribute='options'),
24 'description': fields.String,
25 'version': fields.String,
26 'author': fields.String,
27 'authorUrl': fields.String,
28 'type': fields.String,
29 'slug': fields.String,
30 }
31
32
33 class PluginsList(AuthenticatedResource):
34 """ Defines the 'plugins' endpoint """
35 def __init__(self):
36 self.reqparse = reqparse.RequestParser()
37 super(PluginsList, self).__init__()
38
39 @marshal_items(FIELDS)
40 def get(self):
41 """
42 .. http:get:: /plugins
43
44 The current plugin list
45
46 **Example request**:
47
48 .. sourcecode:: http
49
50 GET /plugins HTTP/1.1
51 Host: example.com
52 Accept: application/json, text/javascript
53
54 **Example response**:
55
56 .. sourcecode:: http
57
58 HTTP/1.1 200 OK
59 Vary: Accept
60 Content-Type: text/javascript
61
62 {
63 "items": [
64 {
65 "id": 2,
66 "accountNumber": 222222222,
67 "label": "account2",
68 "description": "this is a thing"
69 },
70 {
71 "id": 1,
72 "accountNumber": 11111111111,
73 "label": "account1",
74 "description": "this is a thing"
75 },
76 ]
77 "total": 2
78 }
79
80 :reqheader Authorization: OAuth token to authenticate
81 :statuscode 200: no error
82 """
83 self.reqparse.add_argument('type', type=str, location='args')
84 args = self.reqparse.parse_args()
85
86 if args['type']:
87 return list(plugins.all(plugin_type=args['type']))
88
89 return plugins.all()
90
91
92 class Plugins(AuthenticatedResource):
93 """ Defines the the 'plugins' endpoint """
94 def __init__(self):
95 super(Plugins, self).__init__()
96
97 @marshal_items(FIELDS)
98 def get(self, name):
99 """
100 .. http:get:: /plugins/<name>
101
102 The current plugin list
103
104 **Example request**:
105
106 .. sourcecode:: http
107
108 GET /plugins HTTP/1.1
109 Host: example.com
110 Accept: application/json, text/javascript
111
112 **Example response**:
113
114 .. sourcecode:: http
115
116 HTTP/1.1 200 OK
117 Vary: Accept
118 Content-Type: text/javascript
119
120 {
121 "accountNumber": 222222222,
122 "label": "account2",
123 "description": "this is a thing"
124 }
125
126 :reqheader Authorization: OAuth token to authenticate
127 :statuscode 200: no error
128 """
129 return plugins.get(name)
130
131
132 api.add_resource(PluginsList, '/plugins', endpoint='plugins')
133 api.add_resource(Plugins, '/plugins/<name>', endpoint='pluginName')
134
```
Path: `lemur/common/managers.py`
Content:
```
1 """
2 .. module: lemur.common.managers
3 :platform: Unix
4 :copyright: (c) 2015 by Netflix Inc., see AUTHORS for more
5 :license: Apache, see LICENSE for more details.
6
7 .. moduleauthor:: Kevin Glisson <[email protected]>
8 """
9 from flask import current_app
10
11
12 # inspired by https://github.com/getsentry/sentry
13 class InstanceManager(object):
14 def __init__(self, class_list=None, instances=True):
15 if class_list is None:
16 class_list = []
17 self.instances = instances
18 self.update(class_list)
19
20 def get_class_list(self):
21 return self.class_list
22
23 def add(self, class_path):
24 self.cache = None
25 self.class_list.append(class_path)
26
27 def remove(self, class_path):
28 self.cache = None
29 self.class_list.remove(class_path)
30
31 def update(self, class_list):
32 """
33 Updates the class list and wipes the cache.
34 """
35 self.cache = None
36 self.class_list = class_list
37
38 def all(self):
39 """
40 Returns a list of cached instances.
41 """
42 class_list = list(self.get_class_list())
43 if not class_list:
44 self.cache = []
45 return []
46
47 if self.cache is not None:
48 return self.cache
49
50 results = []
51 for cls_path in class_list:
52 module_name, class_name = cls_path.rsplit('.', 1)
53 try:
54 module = __import__(module_name, {}, {}, class_name)
55 cls = getattr(module, class_name)
56 if self.instances:
57 results.append(cls())
58 else:
59 results.append(cls)
60 except Exception:
61 current_app.logger.exception('Unable to import %s', cls_path)
62 continue
63 self.cache = results
64
65 return results
66
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lemur/common/managers.py b/lemur/common/managers.py
--- a/lemur/common/managers.py
+++ b/lemur/common/managers.py
@@ -22,7 +22,8 @@
def add(self, class_path):
self.cache = None
- self.class_list.append(class_path)
+ if class_path not in self.class_list:
+ self.class_list.append(class_path)
def remove(self, class_path):
self.cache = None
diff --git a/lemur/plugins/views.py b/lemur/plugins/views.py
--- a/lemur/plugins/views.py
+++ b/lemur/plugins/views.py
@@ -86,7 +86,7 @@
if args['type']:
return list(plugins.all(plugin_type=args['type']))
- return plugins.all()
+ return list(plugins.all())
class Plugins(AuthenticatedResource):
|
{"golden_diff": "diff --git a/lemur/common/managers.py b/lemur/common/managers.py\n--- a/lemur/common/managers.py\n+++ b/lemur/common/managers.py\n@@ -22,7 +22,8 @@\n \n def add(self, class_path):\n self.cache = None\n- self.class_list.append(class_path)\n+ if class_path not in self.class_list:\n+ self.class_list.append(class_path)\n \n def remove(self, class_path):\n self.cache = None\ndiff --git a/lemur/plugins/views.py b/lemur/plugins/views.py\n--- a/lemur/plugins/views.py\n+++ b/lemur/plugins/views.py\n@@ -86,7 +86,7 @@\n if args['type']:\n return list(plugins.all(plugin_type=args['type']))\n \n- return plugins.all()\n+ return list(plugins.all())\n \n \n class Plugins(AuthenticatedResource):\n", "issue": "Duplicate Plugins Listed\nPlugins are duplicated in the authority dropdown.\n\n", "before_files": [{"content": "\"\"\"\n.. module: lemur.plugins.views\n :platform: Unix\n :synopsis: This module contains all of the accounts view code.\n :copyright: (c) 2015 by Netflix Inc., see AUTHORS for more\n :license: Apache, see LICENSE for more details.\n.. moduleauthor:: Kevin Glisson <[email protected]>\n\"\"\"\nfrom flask import Blueprint\nfrom flask.ext.restful import Api, reqparse, fields\nfrom lemur.auth.service import AuthenticatedResource\n\nfrom lemur.common.utils import marshal_items\n\nfrom lemur.plugins.base import plugins\n\nmod = Blueprint('plugins', __name__)\napi = Api(mod)\n\n\nFIELDS = {\n 'title': fields.String,\n 'pluginOptions': fields.Raw(attribute='options'),\n 'description': fields.String,\n 'version': fields.String,\n 'author': fields.String,\n 'authorUrl': fields.String,\n 'type': fields.String,\n 'slug': fields.String,\n}\n\n\nclass PluginsList(AuthenticatedResource):\n \"\"\" Defines the 'plugins' endpoint \"\"\"\n def __init__(self):\n self.reqparse = reqparse.RequestParser()\n super(PluginsList, self).__init__()\n\n @marshal_items(FIELDS)\n def get(self):\n \"\"\"\n .. http:get:: /plugins\n\n The current plugin list\n\n **Example request**:\n\n .. sourcecode:: http\n\n GET /plugins HTTP/1.1\n Host: example.com\n Accept: application/json, text/javascript\n\n **Example response**:\n\n .. sourcecode:: http\n\n HTTP/1.1 200 OK\n Vary: Accept\n Content-Type: text/javascript\n\n {\n \"items\": [\n {\n \"id\": 2,\n \"accountNumber\": 222222222,\n \"label\": \"account2\",\n \"description\": \"this is a thing\"\n },\n {\n \"id\": 1,\n \"accountNumber\": 11111111111,\n \"label\": \"account1\",\n \"description\": \"this is a thing\"\n },\n ]\n \"total\": 2\n }\n\n :reqheader Authorization: OAuth token to authenticate\n :statuscode 200: no error\n \"\"\"\n self.reqparse.add_argument('type', type=str, location='args')\n args = self.reqparse.parse_args()\n\n if args['type']:\n return list(plugins.all(plugin_type=args['type']))\n\n return plugins.all()\n\n\nclass Plugins(AuthenticatedResource):\n \"\"\" Defines the the 'plugins' endpoint \"\"\"\n def __init__(self):\n super(Plugins, self).__init__()\n\n @marshal_items(FIELDS)\n def get(self, name):\n \"\"\"\n .. http:get:: /plugins/<name>\n\n The current plugin list\n\n **Example request**:\n\n .. sourcecode:: http\n\n GET /plugins HTTP/1.1\n Host: example.com\n Accept: application/json, text/javascript\n\n **Example response**:\n\n .. sourcecode:: http\n\n HTTP/1.1 200 OK\n Vary: Accept\n Content-Type: text/javascript\n\n {\n \"accountNumber\": 222222222,\n \"label\": \"account2\",\n \"description\": \"this is a thing\"\n }\n\n :reqheader Authorization: OAuth token to authenticate\n :statuscode 200: no error\n \"\"\"\n return plugins.get(name)\n\n\napi.add_resource(PluginsList, '/plugins', endpoint='plugins')\napi.add_resource(Plugins, '/plugins/<name>', endpoint='pluginName')\n", "path": "lemur/plugins/views.py"}, {"content": "\"\"\"\n.. module: lemur.common.managers\n :platform: Unix\n :copyright: (c) 2015 by Netflix Inc., see AUTHORS for more\n :license: Apache, see LICENSE for more details.\n\n.. moduleauthor:: Kevin Glisson <[email protected]>\n\"\"\"\nfrom flask import current_app\n\n\n# inspired by https://github.com/getsentry/sentry\nclass InstanceManager(object):\n def __init__(self, class_list=None, instances=True):\n if class_list is None:\n class_list = []\n self.instances = instances\n self.update(class_list)\n\n def get_class_list(self):\n return self.class_list\n\n def add(self, class_path):\n self.cache = None\n self.class_list.append(class_path)\n\n def remove(self, class_path):\n self.cache = None\n self.class_list.remove(class_path)\n\n def update(self, class_list):\n \"\"\"\n Updates the class list and wipes the cache.\n \"\"\"\n self.cache = None\n self.class_list = class_list\n\n def all(self):\n \"\"\"\n Returns a list of cached instances.\n \"\"\"\n class_list = list(self.get_class_list())\n if not class_list:\n self.cache = []\n return []\n\n if self.cache is not None:\n return self.cache\n\n results = []\n for cls_path in class_list:\n module_name, class_name = cls_path.rsplit('.', 1)\n try:\n module = __import__(module_name, {}, {}, class_name)\n cls = getattr(module, class_name)\n if self.instances:\n results.append(cls())\n else:\n results.append(cls)\n except Exception:\n current_app.logger.exception('Unable to import %s', cls_path)\n continue\n self.cache = results\n\n return results\n", "path": "lemur/common/managers.py"}], "after_files": [{"content": "\"\"\"\n.. module: lemur.plugins.views\n :platform: Unix\n :synopsis: This module contains all of the accounts view code.\n :copyright: (c) 2015 by Netflix Inc., see AUTHORS for more\n :license: Apache, see LICENSE for more details.\n.. moduleauthor:: Kevin Glisson <[email protected]>\n\"\"\"\nfrom flask import Blueprint\nfrom flask.ext.restful import Api, reqparse, fields\nfrom lemur.auth.service import AuthenticatedResource\n\nfrom lemur.common.utils import marshal_items\n\nfrom lemur.plugins.base import plugins\n\nmod = Blueprint('plugins', __name__)\napi = Api(mod)\n\n\nFIELDS = {\n 'title': fields.String,\n 'pluginOptions': fields.Raw(attribute='options'),\n 'description': fields.String,\n 'version': fields.String,\n 'author': fields.String,\n 'authorUrl': fields.String,\n 'type': fields.String,\n 'slug': fields.String,\n}\n\n\nclass PluginsList(AuthenticatedResource):\n \"\"\" Defines the 'plugins' endpoint \"\"\"\n def __init__(self):\n self.reqparse = reqparse.RequestParser()\n super(PluginsList, self).__init__()\n\n @marshal_items(FIELDS)\n def get(self):\n \"\"\"\n .. http:get:: /plugins\n\n The current plugin list\n\n **Example request**:\n\n .. sourcecode:: http\n\n GET /plugins HTTP/1.1\n Host: example.com\n Accept: application/json, text/javascript\n\n **Example response**:\n\n .. sourcecode:: http\n\n HTTP/1.1 200 OK\n Vary: Accept\n Content-Type: text/javascript\n\n {\n \"items\": [\n {\n \"id\": 2,\n \"accountNumber\": 222222222,\n \"label\": \"account2\",\n \"description\": \"this is a thing\"\n },\n {\n \"id\": 1,\n \"accountNumber\": 11111111111,\n \"label\": \"account1\",\n \"description\": \"this is a thing\"\n },\n ]\n \"total\": 2\n }\n\n :reqheader Authorization: OAuth token to authenticate\n :statuscode 200: no error\n \"\"\"\n self.reqparse.add_argument('type', type=str, location='args')\n args = self.reqparse.parse_args()\n\n if args['type']:\n return list(plugins.all(plugin_type=args['type']))\n\n return list(plugins.all())\n\n\nclass Plugins(AuthenticatedResource):\n \"\"\" Defines the the 'plugins' endpoint \"\"\"\n def __init__(self):\n super(Plugins, self).__init__()\n\n @marshal_items(FIELDS)\n def get(self, name):\n \"\"\"\n .. http:get:: /plugins/<name>\n\n The current plugin list\n\n **Example request**:\n\n .. sourcecode:: http\n\n GET /plugins HTTP/1.1\n Host: example.com\n Accept: application/json, text/javascript\n\n **Example response**:\n\n .. sourcecode:: http\n\n HTTP/1.1 200 OK\n Vary: Accept\n Content-Type: text/javascript\n\n {\n \"accountNumber\": 222222222,\n \"label\": \"account2\",\n \"description\": \"this is a thing\"\n }\n\n :reqheader Authorization: OAuth token to authenticate\n :statuscode 200: no error\n \"\"\"\n return plugins.get(name)\n\n\napi.add_resource(PluginsList, '/plugins', endpoint='plugins')\napi.add_resource(Plugins, '/plugins/<name>', endpoint='pluginName')\n", "path": "lemur/plugins/views.py"}, {"content": "\"\"\"\n.. module: lemur.common.managers\n :platform: Unix\n :copyright: (c) 2015 by Netflix Inc., see AUTHORS for more\n :license: Apache, see LICENSE for more details.\n\n.. moduleauthor:: Kevin Glisson <[email protected]>\n\"\"\"\nfrom flask import current_app\n\n\n# inspired by https://github.com/getsentry/sentry\nclass InstanceManager(object):\n def __init__(self, class_list=None, instances=True):\n if class_list is None:\n class_list = []\n self.instances = instances\n self.update(class_list)\n\n def get_class_list(self):\n return self.class_list\n\n def add(self, class_path):\n self.cache = None\n if class_path not in self.class_list:\n self.class_list.append(class_path)\n\n def remove(self, class_path):\n self.cache = None\n self.class_list.remove(class_path)\n\n def update(self, class_list):\n \"\"\"\n Updates the class list and wipes the cache.\n \"\"\"\n self.cache = None\n self.class_list = class_list\n\n def all(self):\n \"\"\"\n Returns a list of cached instances.\n \"\"\"\n class_list = list(self.get_class_list())\n if not class_list:\n self.cache = []\n return []\n\n if self.cache is not None:\n return self.cache\n\n results = []\n for cls_path in class_list:\n module_name, class_name = cls_path.rsplit('.', 1)\n try:\n module = __import__(module_name, {}, {}, class_name)\n cls = getattr(module, class_name)\n if self.instances:\n results.append(cls())\n else:\n results.append(cls)\n except Exception:\n current_app.logger.exception('Unable to import %s', cls_path)\n continue\n self.cache = results\n\n return results\n", "path": "lemur/common/managers.py"}]}
| 1,901 | 199 |
gh_patches_debug_12142
|
rasdani/github-patches
|
git_diff
|
safe-global__safe-config-service-90
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Use different namespace and endpoint name for `/safe-apps`
The endpoint `/api/v1/safe-apps` is currently under the `v1` namespace and `safe-apps` endpoint name.
To align it better with the future endpoints the following should be changed:
- the namespace changes from `v1` to `safe-apps`
- the endpoint name changes from `safe-apps` to `list`
This results in a reverse url resolution with `safe-apps:list` instead of `v1:safe-apps`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/config/urls.py`
Content:
```
1 from django.contrib import admin
2 from django.http import HttpResponse
3 from django.urls import include, path, re_path
4 from drf_yasg.views import get_schema_view
5 from rest_framework import permissions
6
7 schema_view = get_schema_view(
8 validators=["flex", "ssv"],
9 public=True,
10 permission_classes=(permissions.AllowAny,),
11 )
12
13 urlpatterns = [
14 path("api/v1/", include("safe_apps.urls", namespace="v1")),
15 path("api/v1/", include("chains.urls", namespace="chains")),
16 path("admin/", admin.site.urls),
17 path("check/", lambda request: HttpResponse("Ok"), name="check"),
18 re_path(
19 r"^swagger(?P<format>\.json|\.yaml)$",
20 schema_view.without_ui(cache_timeout=0),
21 name="schema-json",
22 ),
23 re_path(
24 r"^$",
25 schema_view.with_ui("swagger", cache_timeout=0),
26 name="schema-swagger-ui",
27 ),
28 ]
29
```
Path: `src/safe_apps/urls.py`
Content:
```
1 from django.urls import path
2
3 from .views import SafeAppsListView
4
5 app_name = "apps"
6
7 urlpatterns = [
8 path("safe-apps/", SafeAppsListView.as_view(), name="safe-apps"),
9 ]
10
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/config/urls.py b/src/config/urls.py
--- a/src/config/urls.py
+++ b/src/config/urls.py
@@ -11,7 +11,7 @@
)
urlpatterns = [
- path("api/v1/", include("safe_apps.urls", namespace="v1")),
+ path("api/v1/", include("safe_apps.urls", namespace="safe-apps")),
path("api/v1/", include("chains.urls", namespace="chains")),
path("admin/", admin.site.urls),
path("check/", lambda request: HttpResponse("Ok"), name="check"),
diff --git a/src/safe_apps/urls.py b/src/safe_apps/urls.py
--- a/src/safe_apps/urls.py
+++ b/src/safe_apps/urls.py
@@ -5,5 +5,5 @@
app_name = "apps"
urlpatterns = [
- path("safe-apps/", SafeAppsListView.as_view(), name="safe-apps"),
+ path("safe-apps/", SafeAppsListView.as_view(), name="list"),
]
|
{"golden_diff": "diff --git a/src/config/urls.py b/src/config/urls.py\n--- a/src/config/urls.py\n+++ b/src/config/urls.py\n@@ -11,7 +11,7 @@\n )\n \n urlpatterns = [\n- path(\"api/v1/\", include(\"safe_apps.urls\", namespace=\"v1\")),\n+ path(\"api/v1/\", include(\"safe_apps.urls\", namespace=\"safe-apps\")),\n path(\"api/v1/\", include(\"chains.urls\", namespace=\"chains\")),\n path(\"admin/\", admin.site.urls),\n path(\"check/\", lambda request: HttpResponse(\"Ok\"), name=\"check\"),\ndiff --git a/src/safe_apps/urls.py b/src/safe_apps/urls.py\n--- a/src/safe_apps/urls.py\n+++ b/src/safe_apps/urls.py\n@@ -5,5 +5,5 @@\n app_name = \"apps\"\n \n urlpatterns = [\n- path(\"safe-apps/\", SafeAppsListView.as_view(), name=\"safe-apps\"),\n+ path(\"safe-apps/\", SafeAppsListView.as_view(), name=\"list\"),\n ]\n", "issue": "Use different namespace and endpoint name for `/safe-apps`\nThe endpoint `/api/v1/safe-apps` is currently under the `v1` namespace and `safe-apps` endpoint name.\r\n\r\nTo align it better with the future endpoints the following should be changed:\r\n\r\n- the namespace changes from `v1` to `safe-apps`\r\n- the endpoint name changes from `safe-apps` to `list`\r\n\r\nThis results in a reverse url resolution with `safe-apps:list` instead of `v1:safe-apps`\n", "before_files": [{"content": "from django.contrib import admin\nfrom django.http import HttpResponse\nfrom django.urls import include, path, re_path\nfrom drf_yasg.views import get_schema_view\nfrom rest_framework import permissions\n\nschema_view = get_schema_view(\n validators=[\"flex\", \"ssv\"],\n public=True,\n permission_classes=(permissions.AllowAny,),\n)\n\nurlpatterns = [\n path(\"api/v1/\", include(\"safe_apps.urls\", namespace=\"v1\")),\n path(\"api/v1/\", include(\"chains.urls\", namespace=\"chains\")),\n path(\"admin/\", admin.site.urls),\n path(\"check/\", lambda request: HttpResponse(\"Ok\"), name=\"check\"),\n re_path(\n r\"^swagger(?P<format>\\.json|\\.yaml)$\",\n schema_view.without_ui(cache_timeout=0),\n name=\"schema-json\",\n ),\n re_path(\n r\"^$\",\n schema_view.with_ui(\"swagger\", cache_timeout=0),\n name=\"schema-swagger-ui\",\n ),\n]\n", "path": "src/config/urls.py"}, {"content": "from django.urls import path\n\nfrom .views import SafeAppsListView\n\napp_name = \"apps\"\n\nurlpatterns = [\n path(\"safe-apps/\", SafeAppsListView.as_view(), name=\"safe-apps\"),\n]\n", "path": "src/safe_apps/urls.py"}], "after_files": [{"content": "from django.contrib import admin\nfrom django.http import HttpResponse\nfrom django.urls import include, path, re_path\nfrom drf_yasg.views import get_schema_view\nfrom rest_framework import permissions\n\nschema_view = get_schema_view(\n validators=[\"flex\", \"ssv\"],\n public=True,\n permission_classes=(permissions.AllowAny,),\n)\n\nurlpatterns = [\n path(\"api/v1/\", include(\"safe_apps.urls\", namespace=\"safe-apps\")),\n path(\"api/v1/\", include(\"chains.urls\", namespace=\"chains\")),\n path(\"admin/\", admin.site.urls),\n path(\"check/\", lambda request: HttpResponse(\"Ok\"), name=\"check\"),\n re_path(\n r\"^swagger(?P<format>\\.json|\\.yaml)$\",\n schema_view.without_ui(cache_timeout=0),\n name=\"schema-json\",\n ),\n re_path(\n r\"^$\",\n schema_view.with_ui(\"swagger\", cache_timeout=0),\n name=\"schema-swagger-ui\",\n ),\n]\n", "path": "src/config/urls.py"}, {"content": "from django.urls import path\n\nfrom .views import SafeAppsListView\n\napp_name = \"apps\"\n\nurlpatterns = [\n path(\"safe-apps/\", SafeAppsListView.as_view(), name=\"list\"),\n]\n", "path": "src/safe_apps/urls.py"}]}
| 699 | 228 |
gh_patches_debug_61113
|
rasdani/github-patches
|
git_diff
|
pre-commit__pre-commit-1022
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Good old 'utf-8' codec error on Windows
Howdy,
I'm unable to run `tox -re linting` on pytest anymore. I'm getting this error:
```
λ tox -re linting
linting recreate: c:\pytest\.tox\linting
linting installdeps: pre-commit>=1.11.0
linting installed: aspy.yaml==1.2.0,cfgv==1.6.0,identify==1.4.2,importlib-metadata==0.9,nodeenv==1.3.3,pre-commit==1.16.0,pytest==3.6.0,PyYAML==5.1,six==1.12.0,toml==0.10.0,virtualenv==16.5.0,zipp==0.4.0
linting run-test-pre: PYTHONHASHSEED='335'
linting run-test: commands[0] | pre-commit run --all-files --show-diff-on-failure
An unexpected error has occurred: UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe3 in position 282: invalid continuation byte
Check the log at C:\Users\Bruno/.cache\pre-commit\pre-commit.log
ERROR: InvocationError for command 'c:\pytest\.tox\linting\Scripts\pre-commit.EXE' run --all-files --show-diff-on-failure (exited with code 1)
```
Here's the contents of the log file:
```
An unexpected error has occurred: UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe3 in position 282: invalid continuation byte
Traceback (most recent call last):
File "c:\pytest\.tox\linting\lib\site-packages\pre_commit\error_handler.py", line 46, in error_handler
yield
File "c:\pytest\.tox\linting\lib\site-packages\pre_commit\main.py", line 294, in main
return run(args.config, store, args)
File "c:\pytest\.tox\linting\lib\site-packages\pre_commit\commands\run.py", line 285, in run
install_hook_envs(hooks, store)
File "c:\pytest\.tox\linting\lib\site-packages\pre_commit\repository.py", line 210, in install_hook_envs
if not _need_installed():
File "c:\pytest\.tox\linting\lib\site-packages\pre_commit\repository.py", line 205, in _need_installed
if hook.install_key not in seen and not hook.installed():
File "c:\pytest\.tox\linting\lib\site-packages\pre_commit\repository.py", line 75, in installed
lang.healthy(self.prefix, self.language_version)
File "c:\pytest\.tox\linting\lib\site-packages\pre_commit\languages\python.py", line 139, in healthy
retcode, _, _ = cmd_output(
File "c:\pytest\.tox\linting\lib\site-packages\pre_commit\util.py", line 149, in cmd_output
stderr = stderr.decode(encoding)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe3 in position 282: invalid continuation byte
```
I've seen #835, #330 and #245, so I've tried to cleanup the pre-commit cache and updating `pip` and `virtualenv`, both on my system and in the virtualenv I have for pytest:
```
(.env37) λ pip install -U virtualenv
Requirement already up-to-date: virtualenv in .\.env37\lib\site-packages (16.5.0)
(.env37) λ py -3.7 -m pip install -U virtualenv
Requirement already up-to-date: virtualenv in c:\users\bruno\appdata\local\programs\python\python37\lib\site-packages (16.5.0)
(.env37) λ .tox\linting\Scripts\pip install virtualenv -U
Requirement already up-to-date: virtualenv in .\.tox\linting\lib\site-packages (16.5.0)
```
Same for `pre-commit`:
```
(.env37) λ .tox\linting\Scripts\pip list
Package Version
------------------ -------
aspy.yaml 1.2.0
cfgv 1.6.0
identify 1.4.2
importlib-metadata 0.9
nodeenv 1.3.3
pip 19.1.1
pre-commit 1.16.0
PyYAML 5.1
setuptools 41.0.1
six 1.12.0
toml 0.10.0
virtualenv 16.5.0
wheel 0.33.1
zipp 0.4.0
(.env37) λ pip list
Package Version Location
------------------ ---------------------- -------------
aspy.yaml 1.2.0
atomicwrites 1.3.0
attrs 19.1.0
cfgv 1.6.0
colorama 0.4.1
filelock 3.0.10
identify 1.4.2
importlib-metadata 0.9
more-itertools 7.0.0
nodeenv 1.3.3
pip 19.1.1
pluggy 0.9.0
pre-commit 1.16.0
py 1.8.0
pytest 4.4.2.dev43+g8605ed2a1 c:\pytest\src
PyYAML 5.1
setuptools 39.0.1
six 1.12.0
toml 0.10.0
tox 3.9.0
virtualenv 16.5.0
zipp 0.4.0
```
Any hints @asottile? 🤔
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pre_commit/languages/python.py`
Content:
```
1 from __future__ import unicode_literals
2
3 import contextlib
4 import os
5 import sys
6
7 import pre_commit.constants as C
8 from pre_commit.envcontext import envcontext
9 from pre_commit.envcontext import UNSET
10 from pre_commit.envcontext import Var
11 from pre_commit.languages import helpers
12 from pre_commit.parse_shebang import find_executable
13 from pre_commit.util import CalledProcessError
14 from pre_commit.util import clean_path_on_failure
15 from pre_commit.util import cmd_output
16
17
18 ENVIRONMENT_DIR = 'py_env'
19
20
21 def bin_dir(venv):
22 """On windows there's a different directory for the virtualenv"""
23 bin_part = 'Scripts' if os.name == 'nt' else 'bin'
24 return os.path.join(venv, bin_part)
25
26
27 def get_env_patch(venv):
28 return (
29 ('PYTHONHOME', UNSET),
30 ('VIRTUAL_ENV', venv),
31 ('PATH', (bin_dir(venv), os.pathsep, Var('PATH'))),
32 )
33
34
35 def _find_by_py_launcher(version): # pragma: no cover (windows only)
36 if version.startswith('python'):
37 try:
38 return cmd_output(
39 'py', '-{}'.format(version[len('python'):]),
40 '-c', 'import sys; print(sys.executable)',
41 )[1].strip()
42 except CalledProcessError:
43 pass
44
45
46 def _get_default_version(): # pragma: no cover (platform dependent)
47 def _norm(path):
48 _, exe = os.path.split(path.lower())
49 exe, _, _ = exe.partition('.exe')
50 if find_executable(exe) and exe not in {'python', 'pythonw'}:
51 return exe
52
53 # First attempt from `sys.executable` (or the realpath)
54 # On linux, I see these common sys.executables:
55 #
56 # system `python`: /usr/bin/python -> python2.7
57 # system `python2`: /usr/bin/python2 -> python2.7
58 # virtualenv v: v/bin/python (will not return from this loop)
59 # virtualenv v -ppython2: v/bin/python -> python2
60 # virtualenv v -ppython2.7: v/bin/python -> python2.7
61 # virtualenv v -ppypy: v/bin/python -> v/bin/pypy
62 for path in {sys.executable, os.path.realpath(sys.executable)}:
63 exe = _norm(path)
64 if exe:
65 return exe
66
67 # Next try the `pythonX.X` executable
68 exe = 'python{}.{}'.format(*sys.version_info)
69 if find_executable(exe):
70 return exe
71
72 if _find_by_py_launcher(exe):
73 return exe
74
75 # Give a best-effort try for windows
76 if os.path.exists(r'C:\{}\python.exe'.format(exe.replace('.', ''))):
77 return exe
78
79 # We tried!
80 return C.DEFAULT
81
82
83 def get_default_version():
84 # TODO: when dropping python2, use `functools.lru_cache(maxsize=1)`
85 try:
86 return get_default_version.cached_version
87 except AttributeError:
88 get_default_version.cached_version = _get_default_version()
89 return get_default_version()
90
91
92 def _sys_executable_matches(version):
93 if version == 'python':
94 return True
95 elif not version.startswith('python'):
96 return False
97
98 try:
99 info = tuple(int(p) for p in version[len('python'):].split('.'))
100 except ValueError:
101 return False
102
103 return sys.version_info[:len(info)] == info
104
105
106 def norm_version(version):
107 if os.name == 'nt': # pragma: no cover (windows)
108 # first see if our current executable is appropriate
109 if _sys_executable_matches(version):
110 return sys.executable
111
112 version_exec = _find_by_py_launcher(version)
113 if version_exec:
114 return version_exec
115
116 # Try looking up by name
117 version_exec = find_executable(version)
118 if version_exec and version_exec != version:
119 return version_exec
120
121 # If it is in the form pythonx.x search in the default
122 # place on windows
123 if version.startswith('python'):
124 return r'C:\{}\python.exe'.format(version.replace('.', ''))
125
126 # Otherwise assume it is a path
127 return os.path.expanduser(version)
128
129
130 def py_interface(_dir, _make_venv):
131 @contextlib.contextmanager
132 def in_env(prefix, language_version):
133 envdir = prefix.path(helpers.environment_dir(_dir, language_version))
134 with envcontext(get_env_patch(envdir)):
135 yield
136
137 def healthy(prefix, language_version):
138 with in_env(prefix, language_version):
139 retcode, _, _ = cmd_output(
140 'python', '-c',
141 'import ctypes, datetime, io, os, ssl, weakref',
142 retcode=None,
143 )
144 return retcode == 0
145
146 def run_hook(hook, file_args):
147 with in_env(hook.prefix, hook.language_version):
148 return helpers.run_xargs(hook, helpers.to_cmd(hook), file_args)
149
150 def install_environment(prefix, version, additional_dependencies):
151 additional_dependencies = tuple(additional_dependencies)
152 directory = helpers.environment_dir(_dir, version)
153
154 env_dir = prefix.path(directory)
155 with clean_path_on_failure(env_dir):
156 if version != C.DEFAULT:
157 python = norm_version(version)
158 else:
159 python = os.path.realpath(sys.executable)
160 _make_venv(env_dir, python)
161 with in_env(prefix, version):
162 helpers.run_setup_cmd(
163 prefix, ('pip', 'install', '.') + additional_dependencies,
164 )
165
166 return in_env, healthy, run_hook, install_environment
167
168
169 def make_venv(envdir, python):
170 env = dict(os.environ, VIRTUALENV_NO_DOWNLOAD='1')
171 cmd = (sys.executable, '-mvirtualenv', envdir, '-p', python)
172 cmd_output(*cmd, env=env, cwd='/')
173
174
175 _interface = py_interface(ENVIRONMENT_DIR, make_venv)
176 in_env, healthy, run_hook, install_environment = _interface
177
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pre_commit/languages/python.py b/pre_commit/languages/python.py
--- a/pre_commit/languages/python.py
+++ b/pre_commit/languages/python.py
@@ -140,6 +140,7 @@
'python', '-c',
'import ctypes, datetime, io, os, ssl, weakref',
retcode=None,
+ encoding=None,
)
return retcode == 0
|
{"golden_diff": "diff --git a/pre_commit/languages/python.py b/pre_commit/languages/python.py\n--- a/pre_commit/languages/python.py\n+++ b/pre_commit/languages/python.py\n@@ -140,6 +140,7 @@\n 'python', '-c',\n 'import ctypes, datetime, io, os, ssl, weakref',\n retcode=None,\n+ encoding=None,\n )\n return retcode == 0\n", "issue": "Good old 'utf-8' codec error on Windows\nHowdy,\r\n\r\nI'm unable to run `tox -re linting` on pytest anymore. I'm getting this error:\r\n\r\n```\r\n\u03bb tox -re linting\r\nlinting recreate: c:\\pytest\\.tox\\linting\r\nlinting installdeps: pre-commit>=1.11.0\r\nlinting installed: aspy.yaml==1.2.0,cfgv==1.6.0,identify==1.4.2,importlib-metadata==0.9,nodeenv==1.3.3,pre-commit==1.16.0,pytest==3.6.0,PyYAML==5.1,six==1.12.0,toml==0.10.0,virtualenv==16.5.0,zipp==0.4.0\r\nlinting run-test-pre: PYTHONHASHSEED='335'\r\nlinting run-test: commands[0] | pre-commit run --all-files --show-diff-on-failure\r\nAn unexpected error has occurred: UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe3 in position 282: invalid continuation byte\r\nCheck the log at C:\\Users\\Bruno/.cache\\pre-commit\\pre-commit.log\r\nERROR: InvocationError for command 'c:\\pytest\\.tox\\linting\\Scripts\\pre-commit.EXE' run --all-files --show-diff-on-failure (exited with code 1)\r\n```\r\n\r\nHere's the contents of the log file:\r\n\r\n```\r\nAn unexpected error has occurred: UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe3 in position 282: invalid continuation byte\r\nTraceback (most recent call last):\r\n File \"c:\\pytest\\.tox\\linting\\lib\\site-packages\\pre_commit\\error_handler.py\", line 46, in error_handler\r\n yield\r\n File \"c:\\pytest\\.tox\\linting\\lib\\site-packages\\pre_commit\\main.py\", line 294, in main\r\n return run(args.config, store, args)\r\n File \"c:\\pytest\\.tox\\linting\\lib\\site-packages\\pre_commit\\commands\\run.py\", line 285, in run\r\n install_hook_envs(hooks, store)\r\n File \"c:\\pytest\\.tox\\linting\\lib\\site-packages\\pre_commit\\repository.py\", line 210, in install_hook_envs\r\n if not _need_installed():\r\n File \"c:\\pytest\\.tox\\linting\\lib\\site-packages\\pre_commit\\repository.py\", line 205, in _need_installed\r\n if hook.install_key not in seen and not hook.installed():\r\n File \"c:\\pytest\\.tox\\linting\\lib\\site-packages\\pre_commit\\repository.py\", line 75, in installed\r\n lang.healthy(self.prefix, self.language_version)\r\n File \"c:\\pytest\\.tox\\linting\\lib\\site-packages\\pre_commit\\languages\\python.py\", line 139, in healthy\r\n retcode, _, _ = cmd_output(\r\n File \"c:\\pytest\\.tox\\linting\\lib\\site-packages\\pre_commit\\util.py\", line 149, in cmd_output\r\n stderr = stderr.decode(encoding)\r\nUnicodeDecodeError: 'utf-8' codec can't decode byte 0xe3 in position 282: invalid continuation byte\r\n```\r\n\r\nI've seen #835, #330 and #245, so I've tried to cleanup the pre-commit cache and updating `pip` and `virtualenv`, both on my system and in the virtualenv I have for pytest:\r\n\r\n```\r\n(.env37) \u03bb pip install -U virtualenv\r\nRequirement already up-to-date: virtualenv in .\\.env37\\lib\\site-packages (16.5.0)\r\n\r\n(.env37) \u03bb py -3.7 -m pip install -U virtualenv\r\nRequirement already up-to-date: virtualenv in c:\\users\\bruno\\appdata\\local\\programs\\python\\python37\\lib\\site-packages (16.5.0)\r\n\r\n(.env37) \u03bb .tox\\linting\\Scripts\\pip install virtualenv -U\r\nRequirement already up-to-date: virtualenv in .\\.tox\\linting\\lib\\site-packages (16.5.0)\r\n```\r\n\r\nSame for `pre-commit`:\r\n\r\n```\r\n(.env37) \u03bb .tox\\linting\\Scripts\\pip list\r\nPackage Version\r\n------------------ -------\r\naspy.yaml 1.2.0\r\ncfgv 1.6.0\r\nidentify 1.4.2\r\nimportlib-metadata 0.9\r\nnodeenv 1.3.3\r\npip 19.1.1\r\npre-commit 1.16.0\r\nPyYAML 5.1\r\nsetuptools 41.0.1\r\nsix 1.12.0\r\ntoml 0.10.0\r\nvirtualenv 16.5.0\r\nwheel 0.33.1\r\nzipp 0.4.0\r\n\r\n(.env37) \u03bb pip list\r\nPackage Version Location\r\n------------------ ---------------------- -------------\r\naspy.yaml 1.2.0\r\natomicwrites 1.3.0\r\nattrs 19.1.0\r\ncfgv 1.6.0\r\ncolorama 0.4.1\r\nfilelock 3.0.10\r\nidentify 1.4.2\r\nimportlib-metadata 0.9\r\nmore-itertools 7.0.0\r\nnodeenv 1.3.3\r\npip 19.1.1\r\npluggy 0.9.0\r\npre-commit 1.16.0\r\npy 1.8.0\r\npytest 4.4.2.dev43+g8605ed2a1 c:\\pytest\\src\r\nPyYAML 5.1\r\nsetuptools 39.0.1\r\nsix 1.12.0\r\ntoml 0.10.0\r\ntox 3.9.0\r\nvirtualenv 16.5.0\r\nzipp 0.4.0\r\n```\r\n\r\nAny hints @asottile? \ud83e\udd14 \n", "before_files": [{"content": "from __future__ import unicode_literals\n\nimport contextlib\nimport os\nimport sys\n\nimport pre_commit.constants as C\nfrom pre_commit.envcontext import envcontext\nfrom pre_commit.envcontext import UNSET\nfrom pre_commit.envcontext import Var\nfrom pre_commit.languages import helpers\nfrom pre_commit.parse_shebang import find_executable\nfrom pre_commit.util import CalledProcessError\nfrom pre_commit.util import clean_path_on_failure\nfrom pre_commit.util import cmd_output\n\n\nENVIRONMENT_DIR = 'py_env'\n\n\ndef bin_dir(venv):\n \"\"\"On windows there's a different directory for the virtualenv\"\"\"\n bin_part = 'Scripts' if os.name == 'nt' else 'bin'\n return os.path.join(venv, bin_part)\n\n\ndef get_env_patch(venv):\n return (\n ('PYTHONHOME', UNSET),\n ('VIRTUAL_ENV', venv),\n ('PATH', (bin_dir(venv), os.pathsep, Var('PATH'))),\n )\n\n\ndef _find_by_py_launcher(version): # pragma: no cover (windows only)\n if version.startswith('python'):\n try:\n return cmd_output(\n 'py', '-{}'.format(version[len('python'):]),\n '-c', 'import sys; print(sys.executable)',\n )[1].strip()\n except CalledProcessError:\n pass\n\n\ndef _get_default_version(): # pragma: no cover (platform dependent)\n def _norm(path):\n _, exe = os.path.split(path.lower())\n exe, _, _ = exe.partition('.exe')\n if find_executable(exe) and exe not in {'python', 'pythonw'}:\n return exe\n\n # First attempt from `sys.executable` (or the realpath)\n # On linux, I see these common sys.executables:\n #\n # system `python`: /usr/bin/python -> python2.7\n # system `python2`: /usr/bin/python2 -> python2.7\n # virtualenv v: v/bin/python (will not return from this loop)\n # virtualenv v -ppython2: v/bin/python -> python2\n # virtualenv v -ppython2.7: v/bin/python -> python2.7\n # virtualenv v -ppypy: v/bin/python -> v/bin/pypy\n for path in {sys.executable, os.path.realpath(sys.executable)}:\n exe = _norm(path)\n if exe:\n return exe\n\n # Next try the `pythonX.X` executable\n exe = 'python{}.{}'.format(*sys.version_info)\n if find_executable(exe):\n return exe\n\n if _find_by_py_launcher(exe):\n return exe\n\n # Give a best-effort try for windows\n if os.path.exists(r'C:\\{}\\python.exe'.format(exe.replace('.', ''))):\n return exe\n\n # We tried!\n return C.DEFAULT\n\n\ndef get_default_version():\n # TODO: when dropping python2, use `functools.lru_cache(maxsize=1)`\n try:\n return get_default_version.cached_version\n except AttributeError:\n get_default_version.cached_version = _get_default_version()\n return get_default_version()\n\n\ndef _sys_executable_matches(version):\n if version == 'python':\n return True\n elif not version.startswith('python'):\n return False\n\n try:\n info = tuple(int(p) for p in version[len('python'):].split('.'))\n except ValueError:\n return False\n\n return sys.version_info[:len(info)] == info\n\n\ndef norm_version(version):\n if os.name == 'nt': # pragma: no cover (windows)\n # first see if our current executable is appropriate\n if _sys_executable_matches(version):\n return sys.executable\n\n version_exec = _find_by_py_launcher(version)\n if version_exec:\n return version_exec\n\n # Try looking up by name\n version_exec = find_executable(version)\n if version_exec and version_exec != version:\n return version_exec\n\n # If it is in the form pythonx.x search in the default\n # place on windows\n if version.startswith('python'):\n return r'C:\\{}\\python.exe'.format(version.replace('.', ''))\n\n # Otherwise assume it is a path\n return os.path.expanduser(version)\n\n\ndef py_interface(_dir, _make_venv):\n @contextlib.contextmanager\n def in_env(prefix, language_version):\n envdir = prefix.path(helpers.environment_dir(_dir, language_version))\n with envcontext(get_env_patch(envdir)):\n yield\n\n def healthy(prefix, language_version):\n with in_env(prefix, language_version):\n retcode, _, _ = cmd_output(\n 'python', '-c',\n 'import ctypes, datetime, io, os, ssl, weakref',\n retcode=None,\n )\n return retcode == 0\n\n def run_hook(hook, file_args):\n with in_env(hook.prefix, hook.language_version):\n return helpers.run_xargs(hook, helpers.to_cmd(hook), file_args)\n\n def install_environment(prefix, version, additional_dependencies):\n additional_dependencies = tuple(additional_dependencies)\n directory = helpers.environment_dir(_dir, version)\n\n env_dir = prefix.path(directory)\n with clean_path_on_failure(env_dir):\n if version != C.DEFAULT:\n python = norm_version(version)\n else:\n python = os.path.realpath(sys.executable)\n _make_venv(env_dir, python)\n with in_env(prefix, version):\n helpers.run_setup_cmd(\n prefix, ('pip', 'install', '.') + additional_dependencies,\n )\n\n return in_env, healthy, run_hook, install_environment\n\n\ndef make_venv(envdir, python):\n env = dict(os.environ, VIRTUALENV_NO_DOWNLOAD='1')\n cmd = (sys.executable, '-mvirtualenv', envdir, '-p', python)\n cmd_output(*cmd, env=env, cwd='/')\n\n\n_interface = py_interface(ENVIRONMENT_DIR, make_venv)\nin_env, healthy, run_hook, install_environment = _interface\n", "path": "pre_commit/languages/python.py"}], "after_files": [{"content": "from __future__ import unicode_literals\n\nimport contextlib\nimport os\nimport sys\n\nimport pre_commit.constants as C\nfrom pre_commit.envcontext import envcontext\nfrom pre_commit.envcontext import UNSET\nfrom pre_commit.envcontext import Var\nfrom pre_commit.languages import helpers\nfrom pre_commit.parse_shebang import find_executable\nfrom pre_commit.util import CalledProcessError\nfrom pre_commit.util import clean_path_on_failure\nfrom pre_commit.util import cmd_output\n\n\nENVIRONMENT_DIR = 'py_env'\n\n\ndef bin_dir(venv):\n \"\"\"On windows there's a different directory for the virtualenv\"\"\"\n bin_part = 'Scripts' if os.name == 'nt' else 'bin'\n return os.path.join(venv, bin_part)\n\n\ndef get_env_patch(venv):\n return (\n ('PYTHONHOME', UNSET),\n ('VIRTUAL_ENV', venv),\n ('PATH', (bin_dir(venv), os.pathsep, Var('PATH'))),\n )\n\n\ndef _find_by_py_launcher(version): # pragma: no cover (windows only)\n if version.startswith('python'):\n try:\n return cmd_output(\n 'py', '-{}'.format(version[len('python'):]),\n '-c', 'import sys; print(sys.executable)',\n )[1].strip()\n except CalledProcessError:\n pass\n\n\ndef _get_default_version(): # pragma: no cover (platform dependent)\n def _norm(path):\n _, exe = os.path.split(path.lower())\n exe, _, _ = exe.partition('.exe')\n if find_executable(exe) and exe not in {'python', 'pythonw'}:\n return exe\n\n # First attempt from `sys.executable` (or the realpath)\n # On linux, I see these common sys.executables:\n #\n # system `python`: /usr/bin/python -> python2.7\n # system `python2`: /usr/bin/python2 -> python2.7\n # virtualenv v: v/bin/python (will not return from this loop)\n # virtualenv v -ppython2: v/bin/python -> python2\n # virtualenv v -ppython2.7: v/bin/python -> python2.7\n # virtualenv v -ppypy: v/bin/python -> v/bin/pypy\n for path in {sys.executable, os.path.realpath(sys.executable)}:\n exe = _norm(path)\n if exe:\n return exe\n\n # Next try the `pythonX.X` executable\n exe = 'python{}.{}'.format(*sys.version_info)\n if find_executable(exe):\n return exe\n\n if _find_by_py_launcher(exe):\n return exe\n\n # Give a best-effort try for windows\n if os.path.exists(r'C:\\{}\\python.exe'.format(exe.replace('.', ''))):\n return exe\n\n # We tried!\n return C.DEFAULT\n\n\ndef get_default_version():\n # TODO: when dropping python2, use `functools.lru_cache(maxsize=1)`\n try:\n return get_default_version.cached_version\n except AttributeError:\n get_default_version.cached_version = _get_default_version()\n return get_default_version()\n\n\ndef _sys_executable_matches(version):\n if version == 'python':\n return True\n elif not version.startswith('python'):\n return False\n\n try:\n info = tuple(int(p) for p in version[len('python'):].split('.'))\n except ValueError:\n return False\n\n return sys.version_info[:len(info)] == info\n\n\ndef norm_version(version):\n if os.name == 'nt': # pragma: no cover (windows)\n # first see if our current executable is appropriate\n if _sys_executable_matches(version):\n return sys.executable\n\n version_exec = _find_by_py_launcher(version)\n if version_exec:\n return version_exec\n\n # Try looking up by name\n version_exec = find_executable(version)\n if version_exec and version_exec != version:\n return version_exec\n\n # If it is in the form pythonx.x search in the default\n # place on windows\n if version.startswith('python'):\n return r'C:\\{}\\python.exe'.format(version.replace('.', ''))\n\n # Otherwise assume it is a path\n return os.path.expanduser(version)\n\n\ndef py_interface(_dir, _make_venv):\n @contextlib.contextmanager\n def in_env(prefix, language_version):\n envdir = prefix.path(helpers.environment_dir(_dir, language_version))\n with envcontext(get_env_patch(envdir)):\n yield\n\n def healthy(prefix, language_version):\n with in_env(prefix, language_version):\n retcode, _, _ = cmd_output(\n 'python', '-c',\n 'import ctypes, datetime, io, os, ssl, weakref',\n retcode=None,\n encoding=None,\n )\n return retcode == 0\n\n def run_hook(hook, file_args):\n with in_env(hook.prefix, hook.language_version):\n return helpers.run_xargs(hook, helpers.to_cmd(hook), file_args)\n\n def install_environment(prefix, version, additional_dependencies):\n additional_dependencies = tuple(additional_dependencies)\n directory = helpers.environment_dir(_dir, version)\n\n env_dir = prefix.path(directory)\n with clean_path_on_failure(env_dir):\n if version != C.DEFAULT:\n python = norm_version(version)\n else:\n python = os.path.realpath(sys.executable)\n _make_venv(env_dir, python)\n with in_env(prefix, version):\n helpers.run_setup_cmd(\n prefix, ('pip', 'install', '.') + additional_dependencies,\n )\n\n return in_env, healthy, run_hook, install_environment\n\n\ndef make_venv(envdir, python):\n env = dict(os.environ, VIRTUALENV_NO_DOWNLOAD='1')\n cmd = (sys.executable, '-mvirtualenv', envdir, '-p', python)\n cmd_output(*cmd, env=env, cwd='/')\n\n\n_interface = py_interface(ENVIRONMENT_DIR, make_venv)\nin_env, healthy, run_hook, install_environment = _interface\n", "path": "pre_commit/languages/python.py"}]}
| 3,425 | 93 |
gh_patches_debug_41061
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-3019
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[bug] BTV plugin needs updating
## Bug Report
- [x] This is a bug report and I have read the contribution guidelines.
### Description
The location of the BTV livestream has moved to https://btvplus.bg/live/
**Edit**: Livestreaming no longer requires a user to login, so that can be removed from the plugin info page.
### Expected / Actual behavior
Streamlink should be able to handle the link.
### Reproduction steps / Explicit stream URLs to test
1. streamlink https://btvplus.bg/live/ best
2. error: No plugin can handle URL: https://btvplus.bg/live/
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/streamlink/plugins/btv.py`
Content:
```
1 from __future__ import print_function
2 import re
3
4 from streamlink import PluginError
5 from streamlink.plugin import Plugin
6 from streamlink.plugin.api import validate
7 from streamlink.stream import HLSStream
8 from streamlink.utils import parse_json
9 from streamlink.plugin import PluginArgument, PluginArguments
10
11
12 class BTV(Plugin):
13 arguments = PluginArguments(
14 PluginArgument(
15 "username",
16 metavar="USERNAME",
17 requires=["password"],
18 help="""
19 A BTV username required to access any stream.
20 """
21 ),
22 PluginArgument(
23 "password",
24 sensitive=True,
25 metavar="PASSWORD",
26 help="""
27 A BTV account password to use with --btv-username.
28 """
29 )
30 )
31 url_re = re.compile(r"https?://(?:www\.)?btv\.bg/live/?")
32
33 api_url = "http://www.btv.bg/lbin/global/player_config.php"
34 check_login_url = "http://www.btv.bg/lbin/userRegistration/check_user_login.php"
35 login_url = "https://www.btv.bg/bin/registration2/login.php?action=login&settings=0"
36
37 media_id_re = re.compile(r"media_id=(\d+)")
38 src_re = re.compile(r"src: \"(http.*?)\"")
39 api_schema = validate.Schema(
40 validate.all(
41 {"status": "ok", "config": validate.text},
42 validate.get("config"),
43 validate.all(
44 validate.transform(src_re.search),
45 validate.any(
46 None,
47 validate.get(1),
48 validate.url()
49 )
50 )
51 )
52 )
53
54 @classmethod
55 def can_handle_url(cls, url):
56 return cls.url_re.match(url) is not None
57
58 def login(self, username, password):
59 res = self.session.http.post(self.login_url, data={"username": username, "password": password})
60 if "success_logged_in" in res.text:
61 return True
62 else:
63 return False
64
65 def get_hls_url(self, media_id):
66 res = self.session.http.get(self.api_url, params=dict(media_id=media_id))
67 try:
68 return parse_json(res.text, schema=self.api_schema)
69 except PluginError:
70 return
71
72 def _get_streams(self):
73 if not self.options.get("username") or not self.options.get("password"):
74 self.logger.error("BTV requires registration, set the username and password"
75 " with --btv-username and --btv-password")
76 elif self.login(self.options.get("username"), self.options.get("password")):
77 res = self.session.http.get(self.url)
78 media_match = self.media_id_re.search(res.text)
79 media_id = media_match and media_match.group(1)
80 if media_id:
81 self.logger.debug("Found media id: {0}", media_id)
82 stream_url = self.get_hls_url(media_id)
83 if stream_url:
84 return HLSStream.parse_variant_playlist(self.session, stream_url)
85 else:
86 self.logger.error("Login failed, a valid username and password is required")
87
88
89 __plugin__ = BTV
90
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/streamlink/plugins/btv.py b/src/streamlink/plugins/btv.py
--- a/src/streamlink/plugins/btv.py
+++ b/src/streamlink/plugins/btv.py
@@ -1,38 +1,30 @@
-from __future__ import print_function
+import argparse
+import logging
import re
-from streamlink import PluginError
-from streamlink.plugin import Plugin
+from streamlink.plugin import Plugin, PluginArguments, PluginArgument
from streamlink.plugin.api import validate
from streamlink.stream import HLSStream
from streamlink.utils import parse_json
-from streamlink.plugin import PluginArgument, PluginArguments
+
+log = logging.getLogger(__name__)
class BTV(Plugin):
arguments = PluginArguments(
PluginArgument(
"username",
- metavar="USERNAME",
- requires=["password"],
- help="""
- A BTV username required to access any stream.
- """
+ help=argparse.SUPPRESS
),
PluginArgument(
"password",
sensitive=True,
- metavar="PASSWORD",
- help="""
- A BTV account password to use with --btv-username.
- """
+ help=argparse.SUPPRESS
)
)
- url_re = re.compile(r"https?://(?:www\.)?btv\.bg/live/?")
- api_url = "http://www.btv.bg/lbin/global/player_config.php"
- check_login_url = "http://www.btv.bg/lbin/userRegistration/check_user_login.php"
- login_url = "https://www.btv.bg/bin/registration2/login.php?action=login&settings=0"
+ url_re = re.compile(r"https?://(?:www\.)?btvplus\.bg/live/?")
+ api_url = "https://btvplus.bg/lbin/v3/btvplus/player_config.php"
media_id_re = re.compile(r"media_id=(\d+)")
src_re = re.compile(r"src: \"(http.*?)\"")
@@ -55,35 +47,19 @@
def can_handle_url(cls, url):
return cls.url_re.match(url) is not None
- def login(self, username, password):
- res = self.session.http.post(self.login_url, data={"username": username, "password": password})
- if "success_logged_in" in res.text:
- return True
- else:
- return False
-
def get_hls_url(self, media_id):
res = self.session.http.get(self.api_url, params=dict(media_id=media_id))
- try:
- return parse_json(res.text, schema=self.api_schema)
- except PluginError:
- return
+ return parse_json(res.text, schema=self.api_schema)
def _get_streams(self):
- if not self.options.get("username") or not self.options.get("password"):
- self.logger.error("BTV requires registration, set the username and password"
- " with --btv-username and --btv-password")
- elif self.login(self.options.get("username"), self.options.get("password")):
- res = self.session.http.get(self.url)
- media_match = self.media_id_re.search(res.text)
- media_id = media_match and media_match.group(1)
- if media_id:
- self.logger.debug("Found media id: {0}", media_id)
- stream_url = self.get_hls_url(media_id)
- if stream_url:
- return HLSStream.parse_variant_playlist(self.session, stream_url)
- else:
- self.logger.error("Login failed, a valid username and password is required")
+ res = self.session.http.get(self.url)
+ media_match = self.media_id_re.search(res.text)
+ media_id = media_match and media_match.group(1)
+ if media_id:
+ log.debug("Found media id: {0}", media_id)
+ stream_url = self.get_hls_url(media_id)
+ if stream_url:
+ return HLSStream.parse_variant_playlist(self.session, stream_url)
__plugin__ = BTV
|
{"golden_diff": "diff --git a/src/streamlink/plugins/btv.py b/src/streamlink/plugins/btv.py\n--- a/src/streamlink/plugins/btv.py\n+++ b/src/streamlink/plugins/btv.py\n@@ -1,38 +1,30 @@\n-from __future__ import print_function\n+import argparse\n+import logging\n import re\n \n-from streamlink import PluginError\n-from streamlink.plugin import Plugin\n+from streamlink.plugin import Plugin, PluginArguments, PluginArgument\n from streamlink.plugin.api import validate\n from streamlink.stream import HLSStream\n from streamlink.utils import parse_json\n-from streamlink.plugin import PluginArgument, PluginArguments\n+\n+log = logging.getLogger(__name__)\n \n \n class BTV(Plugin):\n arguments = PluginArguments(\n PluginArgument(\n \"username\",\n- metavar=\"USERNAME\",\n- requires=[\"password\"],\n- help=\"\"\"\n- A BTV username required to access any stream.\n- \"\"\"\n+ help=argparse.SUPPRESS\n ),\n PluginArgument(\n \"password\",\n sensitive=True,\n- metavar=\"PASSWORD\",\n- help=\"\"\"\n- A BTV account password to use with --btv-username.\n- \"\"\"\n+ help=argparse.SUPPRESS\n )\n )\n- url_re = re.compile(r\"https?://(?:www\\.)?btv\\.bg/live/?\")\n \n- api_url = \"http://www.btv.bg/lbin/global/player_config.php\"\n- check_login_url = \"http://www.btv.bg/lbin/userRegistration/check_user_login.php\"\n- login_url = \"https://www.btv.bg/bin/registration2/login.php?action=login&settings=0\"\n+ url_re = re.compile(r\"https?://(?:www\\.)?btvplus\\.bg/live/?\")\n+ api_url = \"https://btvplus.bg/lbin/v3/btvplus/player_config.php\"\n \n media_id_re = re.compile(r\"media_id=(\\d+)\")\n src_re = re.compile(r\"src: \\\"(http.*?)\\\"\")\n@@ -55,35 +47,19 @@\n def can_handle_url(cls, url):\n return cls.url_re.match(url) is not None\n \n- def login(self, username, password):\n- res = self.session.http.post(self.login_url, data={\"username\": username, \"password\": password})\n- if \"success_logged_in\" in res.text:\n- return True\n- else:\n- return False\n-\n def get_hls_url(self, media_id):\n res = self.session.http.get(self.api_url, params=dict(media_id=media_id))\n- try:\n- return parse_json(res.text, schema=self.api_schema)\n- except PluginError:\n- return\n+ return parse_json(res.text, schema=self.api_schema)\n \n def _get_streams(self):\n- if not self.options.get(\"username\") or not self.options.get(\"password\"):\n- self.logger.error(\"BTV requires registration, set the username and password\"\n- \" with --btv-username and --btv-password\")\n- elif self.login(self.options.get(\"username\"), self.options.get(\"password\")):\n- res = self.session.http.get(self.url)\n- media_match = self.media_id_re.search(res.text)\n- media_id = media_match and media_match.group(1)\n- if media_id:\n- self.logger.debug(\"Found media id: {0}\", media_id)\n- stream_url = self.get_hls_url(media_id)\n- if stream_url:\n- return HLSStream.parse_variant_playlist(self.session, stream_url)\n- else:\n- self.logger.error(\"Login failed, a valid username and password is required\")\n+ res = self.session.http.get(self.url)\n+ media_match = self.media_id_re.search(res.text)\n+ media_id = media_match and media_match.group(1)\n+ if media_id:\n+ log.debug(\"Found media id: {0}\", media_id)\n+ stream_url = self.get_hls_url(media_id)\n+ if stream_url:\n+ return HLSStream.parse_variant_playlist(self.session, stream_url)\n \n \n __plugin__ = BTV\n", "issue": "[bug] BTV plugin needs updating\n## Bug Report\r\n- [x] This is a bug report and I have read the contribution guidelines.\r\n\r\n\r\n### Description\r\nThe location of the BTV livestream has moved to https://btvplus.bg/live/\r\n**Edit**: Livestreaming no longer requires a user to login, so that can be removed from the plugin info page.\r\n\r\n\r\n### Expected / Actual behavior\r\nStreamlink should be able to handle the link.\r\n\r\n\r\n### Reproduction steps / Explicit stream URLs to test\r\n1. streamlink https://btvplus.bg/live/ best \r\n2. error: No plugin can handle URL: https://btvplus.bg/live/\n", "before_files": [{"content": "from __future__ import print_function\nimport re\n\nfrom streamlink import PluginError\nfrom streamlink.plugin import Plugin\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream import HLSStream\nfrom streamlink.utils import parse_json\nfrom streamlink.plugin import PluginArgument, PluginArguments\n\n\nclass BTV(Plugin):\n arguments = PluginArguments(\n PluginArgument(\n \"username\",\n metavar=\"USERNAME\",\n requires=[\"password\"],\n help=\"\"\"\n A BTV username required to access any stream.\n \"\"\"\n ),\n PluginArgument(\n \"password\",\n sensitive=True,\n metavar=\"PASSWORD\",\n help=\"\"\"\n A BTV account password to use with --btv-username.\n \"\"\"\n )\n )\n url_re = re.compile(r\"https?://(?:www\\.)?btv\\.bg/live/?\")\n\n api_url = \"http://www.btv.bg/lbin/global/player_config.php\"\n check_login_url = \"http://www.btv.bg/lbin/userRegistration/check_user_login.php\"\n login_url = \"https://www.btv.bg/bin/registration2/login.php?action=login&settings=0\"\n\n media_id_re = re.compile(r\"media_id=(\\d+)\")\n src_re = re.compile(r\"src: \\\"(http.*?)\\\"\")\n api_schema = validate.Schema(\n validate.all(\n {\"status\": \"ok\", \"config\": validate.text},\n validate.get(\"config\"),\n validate.all(\n validate.transform(src_re.search),\n validate.any(\n None,\n validate.get(1),\n validate.url()\n )\n )\n )\n )\n\n @classmethod\n def can_handle_url(cls, url):\n return cls.url_re.match(url) is not None\n\n def login(self, username, password):\n res = self.session.http.post(self.login_url, data={\"username\": username, \"password\": password})\n if \"success_logged_in\" in res.text:\n return True\n else:\n return False\n\n def get_hls_url(self, media_id):\n res = self.session.http.get(self.api_url, params=dict(media_id=media_id))\n try:\n return parse_json(res.text, schema=self.api_schema)\n except PluginError:\n return\n\n def _get_streams(self):\n if not self.options.get(\"username\") or not self.options.get(\"password\"):\n self.logger.error(\"BTV requires registration, set the username and password\"\n \" with --btv-username and --btv-password\")\n elif self.login(self.options.get(\"username\"), self.options.get(\"password\")):\n res = self.session.http.get(self.url)\n media_match = self.media_id_re.search(res.text)\n media_id = media_match and media_match.group(1)\n if media_id:\n self.logger.debug(\"Found media id: {0}\", media_id)\n stream_url = self.get_hls_url(media_id)\n if stream_url:\n return HLSStream.parse_variant_playlist(self.session, stream_url)\n else:\n self.logger.error(\"Login failed, a valid username and password is required\")\n\n\n__plugin__ = BTV\n", "path": "src/streamlink/plugins/btv.py"}], "after_files": [{"content": "import argparse\nimport logging\nimport re\n\nfrom streamlink.plugin import Plugin, PluginArguments, PluginArgument\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream import HLSStream\nfrom streamlink.utils import parse_json\n\nlog = logging.getLogger(__name__)\n\n\nclass BTV(Plugin):\n arguments = PluginArguments(\n PluginArgument(\n \"username\",\n help=argparse.SUPPRESS\n ),\n PluginArgument(\n \"password\",\n sensitive=True,\n help=argparse.SUPPRESS\n )\n )\n\n url_re = re.compile(r\"https?://(?:www\\.)?btvplus\\.bg/live/?\")\n api_url = \"https://btvplus.bg/lbin/v3/btvplus/player_config.php\"\n\n media_id_re = re.compile(r\"media_id=(\\d+)\")\n src_re = re.compile(r\"src: \\\"(http.*?)\\\"\")\n api_schema = validate.Schema(\n validate.all(\n {\"status\": \"ok\", \"config\": validate.text},\n validate.get(\"config\"),\n validate.all(\n validate.transform(src_re.search),\n validate.any(\n None,\n validate.get(1),\n validate.url()\n )\n )\n )\n )\n\n @classmethod\n def can_handle_url(cls, url):\n return cls.url_re.match(url) is not None\n\n def get_hls_url(self, media_id):\n res = self.session.http.get(self.api_url, params=dict(media_id=media_id))\n return parse_json(res.text, schema=self.api_schema)\n\n def _get_streams(self):\n res = self.session.http.get(self.url)\n media_match = self.media_id_re.search(res.text)\n media_id = media_match and media_match.group(1)\n if media_id:\n log.debug(\"Found media id: {0}\", media_id)\n stream_url = self.get_hls_url(media_id)\n if stream_url:\n return HLSStream.parse_variant_playlist(self.session, stream_url)\n\n\n__plugin__ = BTV\n", "path": "src/streamlink/plugins/btv.py"}]}
| 1,231 | 890 |
gh_patches_debug_10309
|
rasdani/github-patches
|
git_diff
|
akvo__akvo-rsr-5209
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Fallback to value in "Report Admin > Pending Approval" list view
# Current situation
Some updates look like they have no value and others do.
The reason is that some have descriptions and others don't.
**Examples:**
With description
Without description
# Improvement
Fallback to the actual value when no description has been provided.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `akvo/rest/serializers/indicator_period_data.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # Akvo RSR is covered by the GNU Affero General Public License.
4 # See more details in the license.txt file located at the root folder of the Akvo RSR module.
5 # For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.
6 import json
7
8 from rest_framework import serializers
9 from django.db.models import Sum
10 from django.contrib.admin.models import LogEntry, CHANGE, DELETION
11 from django.contrib.contenttypes.models import ContentType
12
13 from akvo.rest.serializers.disaggregation import DisaggregationSerializer, DisaggregationReadOnlySerializer
14 from akvo.rest.serializers.rsr_serializer import BaseRSRSerializer
15 from akvo.rest.serializers.user import UserDetailsSerializer, UserRawSerializer
16 from akvo.rsr.models import (
17 IndicatorPeriod, IndicatorPeriodData, IndicatorPeriodDataComment, IndicatorPeriodDataFile, IndicatorPeriodDataPhoto,
18 IndicatorDimensionValue, Disaggregation
19 )
20 from akvo.utils import ensure_decimal
21
22
23 class IndicatorPeriodDataCommentSerializer(BaseRSRSerializer):
24
25 user_details = UserDetailsSerializer(read_only=True, source='user')
26
27 class Meta:
28 model = IndicatorPeriodDataComment
29 fields = '__all__'
30 read_only_fields = ['user']
31
32
33 class IndicatorPeriodDataCommentNestedSerializer(BaseRSRSerializer):
34 id = serializers.IntegerField(required=False)
35
36 class Meta:
37 model = IndicatorPeriodDataComment
38 fields = '__all__'
39 read_only_fields = ('id', 'data', 'user')
40
41
42 class IndicatorPeriodDataFileSerializer(BaseRSRSerializer):
43 class Meta:
44 model = IndicatorPeriodDataFile
45 fields = '__all__'
46
47
48 class IndicatorPeriodDataPhotoSerializer(BaseRSRSerializer):
49 class Meta:
50 model = IndicatorPeriodDataPhoto
51 fields = '__all__'
52
53
54 class IndicatorPeriodDataSerializer(BaseRSRSerializer):
55
56 user_details = UserDetailsSerializer(read_only=True, source='user')
57 approver_details = UserDetailsSerializer(read_only=True, source='approved_by')
58 status_display = serializers.ReadOnlyField()
59 photo_url = serializers.ReadOnlyField()
60 file_url = serializers.ReadOnlyField()
61
62 class Meta:
63 model = IndicatorPeriodData
64 fields = '__all__'
65 read_only_fields = ['user']
66
67
68 class IndicatorPeriodDataLiteSerializer(BaseRSRSerializer):
69
70 user_details = UserRawSerializer(required=False, source='user')
71 status_display = serializers.ReadOnlyField()
72 photo_url = serializers.ReadOnlyField()
73 file_url = serializers.ReadOnlyField()
74 disaggregations = DisaggregationReadOnlySerializer(many=True, required=False)
75 value = serializers.SerializerMethodField()
76 file_set = IndicatorPeriodDataFileSerializer(many=True, read_only=True, source='indicatorperioddatafile_set')
77 photo_set = IndicatorPeriodDataPhotoSerializer(many=True, read_only=True, source='indicatorperioddataphoto_set')
78 comments = IndicatorPeriodDataCommentSerializer(read_only=True, many=True, required=False)
79
80 def get_value(self, obj):
81 return ensure_decimal(obj.value)
82
83 class Meta:
84 model = IndicatorPeriodData
85 fields = (
86 'id', 'user_details', 'status', 'status_display', 'update_method', 'value', 'numerator', 'denominator', 'text',
87 'disaggregations', 'narrative', 'photo_url', 'file_url', 'created_at', 'last_modified_at',
88 'file_set', 'photo_set', 'review_note', 'comments',
89 )
90
91
92 class IndicatorPeriodDataFrameworkSerializer(BaseRSRSerializer):
93
94 period = serializers.PrimaryKeyRelatedField(queryset=IndicatorPeriod.objects.all())
95 comments = IndicatorPeriodDataCommentNestedSerializer(many=True, required=False)
96 disaggregations = DisaggregationSerializer(many=True, required=False)
97 user_details = UserDetailsSerializer(read_only=True, source='user')
98 approver_details = UserDetailsSerializer(read_only=True, source='approved_by')
99 status_display = serializers.ReadOnlyField()
100 photo_url = serializers.ReadOnlyField()
101 file_url = serializers.ReadOnlyField()
102 period_can_add_update = serializers.ReadOnlyField(source='period.can_save_update')
103 files = serializers.ListField(child=serializers.FileField(), required=False, write_only=True)
104 photos = serializers.ListField(child=serializers.FileField(), required=False, write_only=True)
105 file_set = IndicatorPeriodDataFileSerializer(many=True, read_only=True, source='indicatorperioddatafile_set')
106 photo_set = IndicatorPeriodDataPhotoSerializer(many=True, read_only=True, source='indicatorperioddataphoto_set')
107 audit_trail = serializers.SerializerMethodField()
108
109 class Meta:
110 model = IndicatorPeriodData
111 fields = '__all__'
112 read_only_fields = ['user']
113
114 def get_audit_trail(self, obj):
115 entries = LogEntry.objects.filter(
116 content_type=ContentType.objects.get_for_model(IndicatorPeriodData),
117 object_id=obj.id,
118 change_message__contains='"audit_trail": true'
119 )
120 return [
121 {
122 'user': {'id': entry.user.id, 'email': entry.user.email, 'first_name': entry.user.first_name, 'last_name': entry.user.last_name},
123 'action_time': entry.action_time,
124 'action_flag': 'CHANGE' if entry.action_flag == CHANGE else 'DELETION' if entry.action_flag == DELETION else 'ADDITION',
125 'data': json.loads(entry.change_message)['data'],
126 }
127 for entry in entries
128 ]
129
130 def create(self, validated_data):
131 self._validate_disaggregations(
132 self._disaggregations_data,
133 value=ensure_decimal(validated_data.get('value', 0)),
134 numerator=ensure_decimal(validated_data.get('numerator', None)),
135 denominator=ensure_decimal(validated_data.get('denominator', None))
136 )
137 """Over-ridden to handle nested writes."""
138 files = validated_data.pop('files', [])
139 photos = validated_data.pop('photos', [])
140 comments = validated_data.pop('comments', [])
141 update = super(IndicatorPeriodDataFrameworkSerializer, self).create(validated_data)
142 for disaggregation in self._disaggregations_data:
143 disaggregation['update'] = update.id
144 if 'type_id' in disaggregation and 'dimension_value' not in disaggregation:
145 disaggregation['dimension_value'] = disaggregation['type_id']
146 serializer = DisaggregationSerializer(data=disaggregation)
147 serializer.is_valid(raise_exception=True)
148 serializer.create(serializer.validated_data)
149 for file in files:
150 IndicatorPeriodDataFile.objects.create(update=update, file=file)
151 for photo in photos:
152 IndicatorPeriodDataPhoto.objects.create(update=update, photo=photo)
153 for comment in comments:
154 IndicatorPeriodDataComment.objects.create(data=update, user=update.user, comment=comment['comment'])
155
156 return update
157
158 def update(self, instance, validated_data):
159 self._validate_disaggregations(
160 self._disaggregations_data,
161 value=ensure_decimal(validated_data.get('value', instance.value)),
162 numerator=ensure_decimal(validated_data.get('numerator', instance.numerator)),
163 denominator=ensure_decimal(validated_data.get('denominator', instance.denominator)),
164 update=instance
165 )
166 """Over-ridden to handle nested updates."""
167 files = validated_data.pop('files', [])
168 photos = validated_data.pop('photos', [])
169 comments = validated_data.pop('comments', [])
170 super(IndicatorPeriodDataFrameworkSerializer, self).update(instance, validated_data)
171 for disaggregation in self._disaggregations_data:
172 disaggregation['update'] = instance.id
173 serializer = DisaggregationSerializer(data=disaggregation)
174 serializer.is_valid(raise_exception=True)
175 disaggregation_instance, _ = instance.disaggregations.get_or_create(
176 update=instance,
177 dimension_value=serializer.validated_data['dimension_value'],
178 )
179 serializer.update(disaggregation_instance, serializer.validated_data)
180 for file in files:
181 IndicatorPeriodDataFile.objects.create(update=instance, file=file)
182 for photo in photos:
183 IndicatorPeriodDataPhoto.objects.create(update=instance, photo=photo)
184 for comment in comments:
185 comment_id = int(comment.get('id', 0))
186 comment_txt = str(comment.get('comment', ''))
187 if not comment_id:
188 IndicatorPeriodDataComment.objects.create(data=instance, user=instance.user, comment=comment['comment'])
189 else:
190 comment_obj = IndicatorPeriodDataComment.objects.get(id=comment_id)
191 if not comment_txt:
192 comment_obj.delete()
193 else:
194 comment_obj.comment = comment_txt
195 comment_obj.save()
196
197 return instance._meta.model.objects.select_related(
198 'period',
199 'user',
200 'approved_by',
201 ).prefetch_related(
202 'comments',
203 'disaggregations',
204 ).get(id=instance.id)
205
206 def _validate_disaggregations(self, disaggregations, value, numerator=None, denominator=None, update=None):
207 adjustments = {}
208 for disaggregation in disaggregations:
209 type_id = disaggregation.get('type_id', disaggregation.get('dimension_value', None))
210 if type_id is None:
211 continue
212 if denominator is not None:
213 disaggregation_denominator = ensure_decimal(disaggregation.get('denominator', 0))
214 if disaggregation_denominator > denominator:
215 raise serializers.ValidationError("disaggregations denominator should not exceed update denominator")
216 category = IndicatorDimensionValue.objects.get(pk=type_id).name
217 if category.id not in adjustments:
218 adjustments[category.id] = {'values': 0, 'numerators': 0, 'type_ids': []}
219 adjustments[category.id]['values'] += ensure_decimal(disaggregation.get('value', 0))
220 adjustments[category.id]['numerators'] += ensure_decimal(disaggregation.get('numerator', 0))
221 adjustments[category.id]['type_ids'].append(type_id)
222 for key, adjustment in adjustments.items():
223 unmodifieds = Disaggregation.objects.filter(update=update, dimension_value__name=key)\
224 .exclude(dimension_value__in=adjustment['type_ids'])\
225 .aggregate(values=Sum('value'))
226 total = adjustment['values'] + ensure_decimal(unmodifieds['values'])
227 if numerator is not None and adjustment['numerators'] > numerator:
228 raise serializers.ValidationError("The disaggregation numerator should not exceed update numerator")
229 if total > value:
230 raise serializers.ValidationError("The accumulated disaggregations value should not exceed update value")
231
232 def is_valid(self, raise_exception=False):
233 # HACK to allow nested posting...
234 self._disaggregations_data = self.initial_data.pop('disaggregations', [])
235 super(IndicatorPeriodDataFrameworkSerializer, self).is_valid(raise_exception=raise_exception)
236
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/akvo/rest/serializers/indicator_period_data.py b/akvo/rest/serializers/indicator_period_data.py
--- a/akvo/rest/serializers/indicator_period_data.py
+++ b/akvo/rest/serializers/indicator_period_data.py
@@ -84,7 +84,7 @@
model = IndicatorPeriodData
fields = (
'id', 'user_details', 'status', 'status_display', 'update_method', 'value', 'numerator', 'denominator', 'text',
- 'disaggregations', 'narrative', 'photo_url', 'file_url', 'created_at', 'last_modified_at',
+ 'disaggregations', 'narrative', 'score_indices', 'photo_url', 'file_url', 'created_at', 'last_modified_at',
'file_set', 'photo_set', 'review_note', 'comments',
)
|
{"golden_diff": "diff --git a/akvo/rest/serializers/indicator_period_data.py b/akvo/rest/serializers/indicator_period_data.py\n--- a/akvo/rest/serializers/indicator_period_data.py\n+++ b/akvo/rest/serializers/indicator_period_data.py\n@@ -84,7 +84,7 @@\n model = IndicatorPeriodData\n fields = (\n 'id', 'user_details', 'status', 'status_display', 'update_method', 'value', 'numerator', 'denominator', 'text',\n- 'disaggregations', 'narrative', 'photo_url', 'file_url', 'created_at', 'last_modified_at',\n+ 'disaggregations', 'narrative', 'score_indices', 'photo_url', 'file_url', 'created_at', 'last_modified_at',\n 'file_set', 'photo_set', 'review_note', 'comments',\n )\n", "issue": "Fallback to value in \"Report Admin > Pending Approval\" list view\n# Current situation\n\nSome updates look like they have no value and others do.\n\n\n\nThe reason is that some have descriptions and others don't.\n\n**Examples:**\n\nWith description\n\n\nWithout description\n\n\n# Improvement\n\nFallback to the actual value when no description has been provided.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Akvo RSR is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\nimport json\n\nfrom rest_framework import serializers\nfrom django.db.models import Sum\nfrom django.contrib.admin.models import LogEntry, CHANGE, DELETION\nfrom django.contrib.contenttypes.models import ContentType\n\nfrom akvo.rest.serializers.disaggregation import DisaggregationSerializer, DisaggregationReadOnlySerializer\nfrom akvo.rest.serializers.rsr_serializer import BaseRSRSerializer\nfrom akvo.rest.serializers.user import UserDetailsSerializer, UserRawSerializer\nfrom akvo.rsr.models import (\n IndicatorPeriod, IndicatorPeriodData, IndicatorPeriodDataComment, IndicatorPeriodDataFile, IndicatorPeriodDataPhoto,\n IndicatorDimensionValue, Disaggregation\n)\nfrom akvo.utils import ensure_decimal\n\n\nclass IndicatorPeriodDataCommentSerializer(BaseRSRSerializer):\n\n user_details = UserDetailsSerializer(read_only=True, source='user')\n\n class Meta:\n model = IndicatorPeriodDataComment\n fields = '__all__'\n read_only_fields = ['user']\n\n\nclass IndicatorPeriodDataCommentNestedSerializer(BaseRSRSerializer):\n id = serializers.IntegerField(required=False)\n\n class Meta:\n model = IndicatorPeriodDataComment\n fields = '__all__'\n read_only_fields = ('id', 'data', 'user')\n\n\nclass IndicatorPeriodDataFileSerializer(BaseRSRSerializer):\n class Meta:\n model = IndicatorPeriodDataFile\n fields = '__all__'\n\n\nclass IndicatorPeriodDataPhotoSerializer(BaseRSRSerializer):\n class Meta:\n model = IndicatorPeriodDataPhoto\n fields = '__all__'\n\n\nclass IndicatorPeriodDataSerializer(BaseRSRSerializer):\n\n user_details = UserDetailsSerializer(read_only=True, source='user')\n approver_details = UserDetailsSerializer(read_only=True, source='approved_by')\n status_display = serializers.ReadOnlyField()\n photo_url = serializers.ReadOnlyField()\n file_url = serializers.ReadOnlyField()\n\n class Meta:\n model = IndicatorPeriodData\n fields = '__all__'\n read_only_fields = ['user']\n\n\nclass IndicatorPeriodDataLiteSerializer(BaseRSRSerializer):\n\n user_details = UserRawSerializer(required=False, source='user')\n status_display = serializers.ReadOnlyField()\n photo_url = serializers.ReadOnlyField()\n file_url = serializers.ReadOnlyField()\n disaggregations = DisaggregationReadOnlySerializer(many=True, required=False)\n value = serializers.SerializerMethodField()\n file_set = IndicatorPeriodDataFileSerializer(many=True, read_only=True, source='indicatorperioddatafile_set')\n photo_set = IndicatorPeriodDataPhotoSerializer(many=True, read_only=True, source='indicatorperioddataphoto_set')\n comments = IndicatorPeriodDataCommentSerializer(read_only=True, many=True, required=False)\n\n def get_value(self, obj):\n return ensure_decimal(obj.value)\n\n class Meta:\n model = IndicatorPeriodData\n fields = (\n 'id', 'user_details', 'status', 'status_display', 'update_method', 'value', 'numerator', 'denominator', 'text',\n 'disaggregations', 'narrative', 'photo_url', 'file_url', 'created_at', 'last_modified_at',\n 'file_set', 'photo_set', 'review_note', 'comments',\n )\n\n\nclass IndicatorPeriodDataFrameworkSerializer(BaseRSRSerializer):\n\n period = serializers.PrimaryKeyRelatedField(queryset=IndicatorPeriod.objects.all())\n comments = IndicatorPeriodDataCommentNestedSerializer(many=True, required=False)\n disaggregations = DisaggregationSerializer(many=True, required=False)\n user_details = UserDetailsSerializer(read_only=True, source='user')\n approver_details = UserDetailsSerializer(read_only=True, source='approved_by')\n status_display = serializers.ReadOnlyField()\n photo_url = serializers.ReadOnlyField()\n file_url = serializers.ReadOnlyField()\n period_can_add_update = serializers.ReadOnlyField(source='period.can_save_update')\n files = serializers.ListField(child=serializers.FileField(), required=False, write_only=True)\n photos = serializers.ListField(child=serializers.FileField(), required=False, write_only=True)\n file_set = IndicatorPeriodDataFileSerializer(many=True, read_only=True, source='indicatorperioddatafile_set')\n photo_set = IndicatorPeriodDataPhotoSerializer(many=True, read_only=True, source='indicatorperioddataphoto_set')\n audit_trail = serializers.SerializerMethodField()\n\n class Meta:\n model = IndicatorPeriodData\n fields = '__all__'\n read_only_fields = ['user']\n\n def get_audit_trail(self, obj):\n entries = LogEntry.objects.filter(\n content_type=ContentType.objects.get_for_model(IndicatorPeriodData),\n object_id=obj.id,\n change_message__contains='\"audit_trail\": true'\n )\n return [\n {\n 'user': {'id': entry.user.id, 'email': entry.user.email, 'first_name': entry.user.first_name, 'last_name': entry.user.last_name},\n 'action_time': entry.action_time,\n 'action_flag': 'CHANGE' if entry.action_flag == CHANGE else 'DELETION' if entry.action_flag == DELETION else 'ADDITION',\n 'data': json.loads(entry.change_message)['data'],\n }\n for entry in entries\n ]\n\n def create(self, validated_data):\n self._validate_disaggregations(\n self._disaggregations_data,\n value=ensure_decimal(validated_data.get('value', 0)),\n numerator=ensure_decimal(validated_data.get('numerator', None)),\n denominator=ensure_decimal(validated_data.get('denominator', None))\n )\n \"\"\"Over-ridden to handle nested writes.\"\"\"\n files = validated_data.pop('files', [])\n photos = validated_data.pop('photos', [])\n comments = validated_data.pop('comments', [])\n update = super(IndicatorPeriodDataFrameworkSerializer, self).create(validated_data)\n for disaggregation in self._disaggregations_data:\n disaggregation['update'] = update.id\n if 'type_id' in disaggregation and 'dimension_value' not in disaggregation:\n disaggregation['dimension_value'] = disaggregation['type_id']\n serializer = DisaggregationSerializer(data=disaggregation)\n serializer.is_valid(raise_exception=True)\n serializer.create(serializer.validated_data)\n for file in files:\n IndicatorPeriodDataFile.objects.create(update=update, file=file)\n for photo in photos:\n IndicatorPeriodDataPhoto.objects.create(update=update, photo=photo)\n for comment in comments:\n IndicatorPeriodDataComment.objects.create(data=update, user=update.user, comment=comment['comment'])\n\n return update\n\n def update(self, instance, validated_data):\n self._validate_disaggregations(\n self._disaggregations_data,\n value=ensure_decimal(validated_data.get('value', instance.value)),\n numerator=ensure_decimal(validated_data.get('numerator', instance.numerator)),\n denominator=ensure_decimal(validated_data.get('denominator', instance.denominator)),\n update=instance\n )\n \"\"\"Over-ridden to handle nested updates.\"\"\"\n files = validated_data.pop('files', [])\n photos = validated_data.pop('photos', [])\n comments = validated_data.pop('comments', [])\n super(IndicatorPeriodDataFrameworkSerializer, self).update(instance, validated_data)\n for disaggregation in self._disaggregations_data:\n disaggregation['update'] = instance.id\n serializer = DisaggregationSerializer(data=disaggregation)\n serializer.is_valid(raise_exception=True)\n disaggregation_instance, _ = instance.disaggregations.get_or_create(\n update=instance,\n dimension_value=serializer.validated_data['dimension_value'],\n )\n serializer.update(disaggregation_instance, serializer.validated_data)\n for file in files:\n IndicatorPeriodDataFile.objects.create(update=instance, file=file)\n for photo in photos:\n IndicatorPeriodDataPhoto.objects.create(update=instance, photo=photo)\n for comment in comments:\n comment_id = int(comment.get('id', 0))\n comment_txt = str(comment.get('comment', ''))\n if not comment_id:\n IndicatorPeriodDataComment.objects.create(data=instance, user=instance.user, comment=comment['comment'])\n else:\n comment_obj = IndicatorPeriodDataComment.objects.get(id=comment_id)\n if not comment_txt:\n comment_obj.delete()\n else:\n comment_obj.comment = comment_txt\n comment_obj.save()\n\n return instance._meta.model.objects.select_related(\n 'period',\n 'user',\n 'approved_by',\n ).prefetch_related(\n 'comments',\n 'disaggregations',\n ).get(id=instance.id)\n\n def _validate_disaggregations(self, disaggregations, value, numerator=None, denominator=None, update=None):\n adjustments = {}\n for disaggregation in disaggregations:\n type_id = disaggregation.get('type_id', disaggregation.get('dimension_value', None))\n if type_id is None:\n continue\n if denominator is not None:\n disaggregation_denominator = ensure_decimal(disaggregation.get('denominator', 0))\n if disaggregation_denominator > denominator:\n raise serializers.ValidationError(\"disaggregations denominator should not exceed update denominator\")\n category = IndicatorDimensionValue.objects.get(pk=type_id).name\n if category.id not in adjustments:\n adjustments[category.id] = {'values': 0, 'numerators': 0, 'type_ids': []}\n adjustments[category.id]['values'] += ensure_decimal(disaggregation.get('value', 0))\n adjustments[category.id]['numerators'] += ensure_decimal(disaggregation.get('numerator', 0))\n adjustments[category.id]['type_ids'].append(type_id)\n for key, adjustment in adjustments.items():\n unmodifieds = Disaggregation.objects.filter(update=update, dimension_value__name=key)\\\n .exclude(dimension_value__in=adjustment['type_ids'])\\\n .aggregate(values=Sum('value'))\n total = adjustment['values'] + ensure_decimal(unmodifieds['values'])\n if numerator is not None and adjustment['numerators'] > numerator:\n raise serializers.ValidationError(\"The disaggregation numerator should not exceed update numerator\")\n if total > value:\n raise serializers.ValidationError(\"The accumulated disaggregations value should not exceed update value\")\n\n def is_valid(self, raise_exception=False):\n # HACK to allow nested posting...\n self._disaggregations_data = self.initial_data.pop('disaggregations', [])\n super(IndicatorPeriodDataFrameworkSerializer, self).is_valid(raise_exception=raise_exception)\n", "path": "akvo/rest/serializers/indicator_period_data.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Akvo RSR is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\nimport json\n\nfrom rest_framework import serializers\nfrom django.db.models import Sum\nfrom django.contrib.admin.models import LogEntry, CHANGE, DELETION\nfrom django.contrib.contenttypes.models import ContentType\n\nfrom akvo.rest.serializers.disaggregation import DisaggregationSerializer, DisaggregationReadOnlySerializer\nfrom akvo.rest.serializers.rsr_serializer import BaseRSRSerializer\nfrom akvo.rest.serializers.user import UserDetailsSerializer, UserRawSerializer\nfrom akvo.rsr.models import (\n IndicatorPeriod, IndicatorPeriodData, IndicatorPeriodDataComment, IndicatorPeriodDataFile, IndicatorPeriodDataPhoto,\n IndicatorDimensionValue, Disaggregation\n)\nfrom akvo.utils import ensure_decimal\n\n\nclass IndicatorPeriodDataCommentSerializer(BaseRSRSerializer):\n\n user_details = UserDetailsSerializer(read_only=True, source='user')\n\n class Meta:\n model = IndicatorPeriodDataComment\n fields = '__all__'\n read_only_fields = ['user']\n\n\nclass IndicatorPeriodDataCommentNestedSerializer(BaseRSRSerializer):\n id = serializers.IntegerField(required=False)\n\n class Meta:\n model = IndicatorPeriodDataComment\n fields = '__all__'\n read_only_fields = ('id', 'data', 'user')\n\n\nclass IndicatorPeriodDataFileSerializer(BaseRSRSerializer):\n class Meta:\n model = IndicatorPeriodDataFile\n fields = '__all__'\n\n\nclass IndicatorPeriodDataPhotoSerializer(BaseRSRSerializer):\n class Meta:\n model = IndicatorPeriodDataPhoto\n fields = '__all__'\n\n\nclass IndicatorPeriodDataSerializer(BaseRSRSerializer):\n\n user_details = UserDetailsSerializer(read_only=True, source='user')\n approver_details = UserDetailsSerializer(read_only=True, source='approved_by')\n status_display = serializers.ReadOnlyField()\n photo_url = serializers.ReadOnlyField()\n file_url = serializers.ReadOnlyField()\n\n class Meta:\n model = IndicatorPeriodData\n fields = '__all__'\n read_only_fields = ['user']\n\n\nclass IndicatorPeriodDataLiteSerializer(BaseRSRSerializer):\n\n user_details = UserRawSerializer(required=False, source='user')\n status_display = serializers.ReadOnlyField()\n photo_url = serializers.ReadOnlyField()\n file_url = serializers.ReadOnlyField()\n disaggregations = DisaggregationReadOnlySerializer(many=True, required=False)\n value = serializers.SerializerMethodField()\n file_set = IndicatorPeriodDataFileSerializer(many=True, read_only=True, source='indicatorperioddatafile_set')\n photo_set = IndicatorPeriodDataPhotoSerializer(many=True, read_only=True, source='indicatorperioddataphoto_set')\n comments = IndicatorPeriodDataCommentSerializer(read_only=True, many=True, required=False)\n\n def get_value(self, obj):\n return ensure_decimal(obj.value)\n\n class Meta:\n model = IndicatorPeriodData\n fields = (\n 'id', 'user_details', 'status', 'status_display', 'update_method', 'value', 'numerator', 'denominator', 'text',\n 'disaggregations', 'narrative', 'score_indices', 'photo_url', 'file_url', 'created_at', 'last_modified_at',\n 'file_set', 'photo_set', 'review_note', 'comments',\n )\n\n\nclass IndicatorPeriodDataFrameworkSerializer(BaseRSRSerializer):\n\n period = serializers.PrimaryKeyRelatedField(queryset=IndicatorPeriod.objects.all())\n comments = IndicatorPeriodDataCommentNestedSerializer(many=True, required=False)\n disaggregations = DisaggregationSerializer(many=True, required=False)\n user_details = UserDetailsSerializer(read_only=True, source='user')\n approver_details = UserDetailsSerializer(read_only=True, source='approved_by')\n status_display = serializers.ReadOnlyField()\n photo_url = serializers.ReadOnlyField()\n file_url = serializers.ReadOnlyField()\n period_can_add_update = serializers.ReadOnlyField(source='period.can_save_update')\n files = serializers.ListField(child=serializers.FileField(), required=False, write_only=True)\n photos = serializers.ListField(child=serializers.FileField(), required=False, write_only=True)\n file_set = IndicatorPeriodDataFileSerializer(many=True, read_only=True, source='indicatorperioddatafile_set')\n photo_set = IndicatorPeriodDataPhotoSerializer(many=True, read_only=True, source='indicatorperioddataphoto_set')\n audit_trail = serializers.SerializerMethodField()\n\n class Meta:\n model = IndicatorPeriodData\n fields = '__all__'\n read_only_fields = ['user']\n\n def get_audit_trail(self, obj):\n entries = LogEntry.objects.filter(\n content_type=ContentType.objects.get_for_model(IndicatorPeriodData),\n object_id=obj.id,\n change_message__contains='\"audit_trail\": true'\n )\n return [\n {\n 'user': {'id': entry.user.id, 'email': entry.user.email, 'first_name': entry.user.first_name, 'last_name': entry.user.last_name},\n 'action_time': entry.action_time,\n 'action_flag': 'CHANGE' if entry.action_flag == CHANGE else 'DELETION' if entry.action_flag == DELETION else 'ADDITION',\n 'data': json.loads(entry.change_message)['data'],\n }\n for entry in entries\n ]\n\n def create(self, validated_data):\n self._validate_disaggregations(\n self._disaggregations_data,\n value=ensure_decimal(validated_data.get('value', 0)),\n numerator=ensure_decimal(validated_data.get('numerator', None)),\n denominator=ensure_decimal(validated_data.get('denominator', None))\n )\n \"\"\"Over-ridden to handle nested writes.\"\"\"\n files = validated_data.pop('files', [])\n photos = validated_data.pop('photos', [])\n comments = validated_data.pop('comments', [])\n update = super(IndicatorPeriodDataFrameworkSerializer, self).create(validated_data)\n for disaggregation in self._disaggregations_data:\n disaggregation['update'] = update.id\n if 'type_id' in disaggregation and 'dimension_value' not in disaggregation:\n disaggregation['dimension_value'] = disaggregation['type_id']\n serializer = DisaggregationSerializer(data=disaggregation)\n serializer.is_valid(raise_exception=True)\n serializer.create(serializer.validated_data)\n for file in files:\n IndicatorPeriodDataFile.objects.create(update=update, file=file)\n for photo in photos:\n IndicatorPeriodDataPhoto.objects.create(update=update, photo=photo)\n for comment in comments:\n IndicatorPeriodDataComment.objects.create(data=update, user=update.user, comment=comment['comment'])\n\n return update\n\n def update(self, instance, validated_data):\n self._validate_disaggregations(\n self._disaggregations_data,\n value=ensure_decimal(validated_data.get('value', instance.value)),\n numerator=ensure_decimal(validated_data.get('numerator', instance.numerator)),\n denominator=ensure_decimal(validated_data.get('denominator', instance.denominator)),\n update=instance\n )\n \"\"\"Over-ridden to handle nested updates.\"\"\"\n files = validated_data.pop('files', [])\n photos = validated_data.pop('photos', [])\n comments = validated_data.pop('comments', [])\n super(IndicatorPeriodDataFrameworkSerializer, self).update(instance, validated_data)\n for disaggregation in self._disaggregations_data:\n disaggregation['update'] = instance.id\n serializer = DisaggregationSerializer(data=disaggregation)\n serializer.is_valid(raise_exception=True)\n disaggregation_instance, _ = instance.disaggregations.get_or_create(\n update=instance,\n dimension_value=serializer.validated_data['dimension_value'],\n )\n serializer.update(disaggregation_instance, serializer.validated_data)\n for file in files:\n IndicatorPeriodDataFile.objects.create(update=instance, file=file)\n for photo in photos:\n IndicatorPeriodDataPhoto.objects.create(update=instance, photo=photo)\n for comment in comments:\n comment_id = int(comment.get('id', 0))\n comment_txt = str(comment.get('comment', ''))\n if not comment_id:\n IndicatorPeriodDataComment.objects.create(data=instance, user=instance.user, comment=comment['comment'])\n else:\n comment_obj = IndicatorPeriodDataComment.objects.get(id=comment_id)\n if not comment_txt:\n comment_obj.delete()\n else:\n comment_obj.comment = comment_txt\n comment_obj.save()\n\n return instance._meta.model.objects.select_related(\n 'period',\n 'user',\n 'approved_by',\n ).prefetch_related(\n 'comments',\n 'disaggregations',\n ).get(id=instance.id)\n\n def _validate_disaggregations(self, disaggregations, value, numerator=None, denominator=None, update=None):\n adjustments = {}\n for disaggregation in disaggregations:\n type_id = disaggregation.get('type_id', disaggregation.get('dimension_value', None))\n if type_id is None:\n continue\n if denominator is not None:\n disaggregation_denominator = ensure_decimal(disaggregation.get('denominator', 0))\n if disaggregation_denominator > denominator:\n raise serializers.ValidationError(\"disaggregations denominator should not exceed update denominator\")\n category = IndicatorDimensionValue.objects.get(pk=type_id).name\n if category.id not in adjustments:\n adjustments[category.id] = {'values': 0, 'numerators': 0, 'type_ids': []}\n adjustments[category.id]['values'] += ensure_decimal(disaggregation.get('value', 0))\n adjustments[category.id]['numerators'] += ensure_decimal(disaggregation.get('numerator', 0))\n adjustments[category.id]['type_ids'].append(type_id)\n for key, adjustment in adjustments.items():\n unmodifieds = Disaggregation.objects.filter(update=update, dimension_value__name=key)\\\n .exclude(dimension_value__in=adjustment['type_ids'])\\\n .aggregate(values=Sum('value'))\n total = adjustment['values'] + ensure_decimal(unmodifieds['values'])\n if numerator is not None and adjustment['numerators'] > numerator:\n raise serializers.ValidationError(\"The disaggregation numerator should not exceed update numerator\")\n if total > value:\n raise serializers.ValidationError(\"The accumulated disaggregations value should not exceed update value\")\n\n def is_valid(self, raise_exception=False):\n # HACK to allow nested posting...\n self._disaggregations_data = self.initial_data.pop('disaggregations', [])\n super(IndicatorPeriodDataFrameworkSerializer, self).is_valid(raise_exception=raise_exception)\n", "path": "akvo/rest/serializers/indicator_period_data.py"}]}
| 3,400 | 198 |
gh_patches_debug_27700
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-5742
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
plugins.atresplayer: Error -3 while decompressing data: incorrect header check
### Checklist
- [X] This is a [plugin issue](https://streamlink.github.io/plugins.html) and not [a different kind of issue](https://github.com/streamlink/streamlink/issues/new/choose)
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)
- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)
### Streamlink version
streamlink 6.4.2
### Description
Possible change in link decoding.
### Debug log
```text
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.11.6
[cli][debug] OpenSSL: OpenSSL 3.0.11 19 Sep 2023
[cli][debug] Streamlink: 6.4.2
[cli][debug] Dependencies:
[cli][debug] certifi: 2023.11.17
[cli][debug] isodate: 0.6.1
[cli][debug] lxml: 4.9.3
[cli][debug] pycountry: 22.3.5
[cli][debug] pycryptodome: 3.19.0
[cli][debug] PySocks: 1.7.1
[cli][debug] requests: 2.31.0
[cli][debug] trio: 0.23.1
[cli][debug] trio-websocket: 0.11.1
[cli][debug] typing-extensions: 4.8.0
[cli][debug] urllib3: 2.1.0
[cli][debug] websocket-client: 1.6.4
[cli][debug] Arguments:
[cli][debug] url=https://www.atresplayer.com/directos/antena3/
[cli][debug] stream=['best']
[cli][debug] --loglevel=debug
[cli][debug] --ffmpeg-ffmpeg=C:\Program Files\Streamlink\ffmpeg\ffmpeg.exe
[cli][info] Found matching plugin atresplayer for URL https://www.atresplayer.com/directos/antena3/
[plugins.atresplayer][debug] Player API URL: https://api.atresplayer.com/player/v1/live/5a6a165a7ed1a834493ebf6a
[plugins.atresplayer][debug] Stream source: https://directo.atresmedia.com/49aa0979c14a4113668984aa8f6f7a43dd3a624a_1701338572/antena3/master.m3u8 (application/vnd.apple.mpegurl)
[utils.l10n][debug] Language code: es_ES
error: Unable to open URL: https://directo.atresmedia.com/49aa0979c14a4113668984aa8f6f7a43dd3a624a_1701338572/antena3/master.m3u8 (('Received response with content-encoding: gzip, but failed to decode it.', error('Error -3 while decompressing data: incorrect header check')))
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/streamlink/plugins/atresplayer.py`
Content:
```
1 """
2 $description Spanish live TV channels from Atresmedia Television, including Antena 3 and laSexta.
3 $url atresplayer.com
4 $type live
5 $region Spain
6 """
7
8 import logging
9 import re
10
11 from streamlink.plugin import Plugin, pluginmatcher
12 from streamlink.plugin.api import validate
13 from streamlink.stream.dash import DASHStream
14 from streamlink.stream.hls import HLSStream
15 from streamlink.utils.url import update_scheme
16
17
18 log = logging.getLogger(__name__)
19
20
21 @pluginmatcher(re.compile(
22 r"https?://(?:www\.)?atresplayer\.com/directos/.+",
23 ))
24 class AtresPlayer(Plugin):
25 _channels_api_url = "https://api.atresplayer.com/client/v1/info/channels"
26 _player_api_url = "https://api.atresplayer.com/player/v1/live/{channel_id}"
27
28 def __init__(self, *args, **kwargs):
29 super().__init__(*args, **kwargs)
30 self.url = update_scheme("https://", f"{self.url.rstrip('/')}/")
31
32 def _get_streams(self):
33 channel_path = f"/{self.url.split('/')[-2]}/"
34 channel_data = self.session.http.get(self._channels_api_url, schema=validate.Schema(
35 validate.parse_json(),
36 [{
37 "id": str,
38 "link": {"url": str},
39 }],
40 validate.filter(lambda item: item["link"]["url"] == channel_path),
41 ))
42 if not channel_data:
43 return
44 channel_id = channel_data[0]["id"]
45
46 player_api_url = self._player_api_url.format(channel_id=channel_id)
47 log.debug(f"Player API URL: {player_api_url}")
48
49 sources = self.session.http.get(player_api_url, acceptable_status=(200, 403), schema=validate.Schema(
50 validate.parse_json(),
51 validate.any(
52 {
53 "error": str,
54 "error_description": str,
55 },
56 {
57 "sources": [
58 validate.all(
59 {
60 "src": validate.url(),
61 validate.optional("type"): str,
62 },
63 validate.union_get("type", "src"),
64 ),
65 ],
66 },
67 ),
68 ))
69 if "error" in sources:
70 log.error(f"Player API error: {sources['error']} - {sources['error_description']}")
71 return
72
73 for streamtype, streamsrc in sources.get("sources"):
74 log.debug(f"Stream source: {streamsrc} ({streamtype or 'n/a'})")
75
76 if streamtype == "application/vnd.apple.mpegurl":
77 streams = HLSStream.parse_variant_playlist(self.session, streamsrc)
78 if not streams:
79 yield "live", HLSStream(self.session, streamsrc)
80 else:
81 yield from streams.items()
82 elif streamtype == "application/dash+xml":
83 yield from DASHStream.parse_manifest(self.session, streamsrc).items()
84
85
86 __plugin__ = AtresPlayer
87
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/streamlink/plugins/atresplayer.py b/src/streamlink/plugins/atresplayer.py
--- a/src/streamlink/plugins/atresplayer.py
+++ b/src/streamlink/plugins/atresplayer.py
@@ -23,7 +23,7 @@
))
class AtresPlayer(Plugin):
_channels_api_url = "https://api.atresplayer.com/client/v1/info/channels"
- _player_api_url = "https://api.atresplayer.com/player/v1/live/{channel_id}"
+ _player_api_url = "https://api.atresplayer.com/player/v1/live/{channel_id}?NODRM=true"
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
@@ -54,7 +54,7 @@
"error_description": str,
},
{
- "sources": [
+ "sourcesLive": [
validate.all(
{
"src": validate.url(),
@@ -70,7 +70,7 @@
log.error(f"Player API error: {sources['error']} - {sources['error_description']}")
return
- for streamtype, streamsrc in sources.get("sources"):
+ for streamtype, streamsrc in sources.get("sourcesLive"):
log.debug(f"Stream source: {streamsrc} ({streamtype or 'n/a'})")
if streamtype == "application/vnd.apple.mpegurl":
|
{"golden_diff": "diff --git a/src/streamlink/plugins/atresplayer.py b/src/streamlink/plugins/atresplayer.py\n--- a/src/streamlink/plugins/atresplayer.py\n+++ b/src/streamlink/plugins/atresplayer.py\n@@ -23,7 +23,7 @@\n ))\n class AtresPlayer(Plugin):\n _channels_api_url = \"https://api.atresplayer.com/client/v1/info/channels\"\n- _player_api_url = \"https://api.atresplayer.com/player/v1/live/{channel_id}\"\n+ _player_api_url = \"https://api.atresplayer.com/player/v1/live/{channel_id}?NODRM=true\"\n \n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n@@ -54,7 +54,7 @@\n \"error_description\": str,\n },\n {\n- \"sources\": [\n+ \"sourcesLive\": [\n validate.all(\n {\n \"src\": validate.url(),\n@@ -70,7 +70,7 @@\n log.error(f\"Player API error: {sources['error']} - {sources['error_description']}\")\n return\n \n- for streamtype, streamsrc in sources.get(\"sources\"):\n+ for streamtype, streamsrc in sources.get(\"sourcesLive\"):\n log.debug(f\"Stream source: {streamsrc} ({streamtype or 'n/a'})\")\n \n if streamtype == \"application/vnd.apple.mpegurl\":\n", "issue": "plugins.atresplayer: Error -3 while decompressing data: incorrect header check\n### Checklist\n\n- [X] This is a [plugin issue](https://streamlink.github.io/plugins.html) and not [a different kind of issue](https://github.com/streamlink/streamlink/issues/new/choose)\n- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)\n- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)\n- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)\n\n### Streamlink version\n\nstreamlink 6.4.2\n\n### Description\n\nPossible change in link decoding.\n\n### Debug log\n\n```text\n[cli][debug] OS: Windows 10\r\n[cli][debug] Python: 3.11.6\r\n[cli][debug] OpenSSL: OpenSSL 3.0.11 19 Sep 2023\r\n[cli][debug] Streamlink: 6.4.2\r\n[cli][debug] Dependencies:\r\n[cli][debug] certifi: 2023.11.17\r\n[cli][debug] isodate: 0.6.1\r\n[cli][debug] lxml: 4.9.3\r\n[cli][debug] pycountry: 22.3.5\r\n[cli][debug] pycryptodome: 3.19.0\r\n[cli][debug] PySocks: 1.7.1\r\n[cli][debug] requests: 2.31.0\r\n[cli][debug] trio: 0.23.1\r\n[cli][debug] trio-websocket: 0.11.1\r\n[cli][debug] typing-extensions: 4.8.0\r\n[cli][debug] urllib3: 2.1.0\r\n[cli][debug] websocket-client: 1.6.4\r\n[cli][debug] Arguments:\r\n[cli][debug] url=https://www.atresplayer.com/directos/antena3/\r\n[cli][debug] stream=['best']\r\n[cli][debug] --loglevel=debug\r\n[cli][debug] --ffmpeg-ffmpeg=C:\\Program Files\\Streamlink\\ffmpeg\\ffmpeg.exe\r\n[cli][info] Found matching plugin atresplayer for URL https://www.atresplayer.com/directos/antena3/\r\n[plugins.atresplayer][debug] Player API URL: https://api.atresplayer.com/player/v1/live/5a6a165a7ed1a834493ebf6a\r\n[plugins.atresplayer][debug] Stream source: https://directo.atresmedia.com/49aa0979c14a4113668984aa8f6f7a43dd3a624a_1701338572/antena3/master.m3u8 (application/vnd.apple.mpegurl)\r\n[utils.l10n][debug] Language code: es_ES\r\nerror: Unable to open URL: https://directo.atresmedia.com/49aa0979c14a4113668984aa8f6f7a43dd3a624a_1701338572/antena3/master.m3u8 (('Received response with content-encoding: gzip, but failed to decode it.', error('Error -3 while decompressing data: incorrect header check')))\n```\n\n", "before_files": [{"content": "\"\"\"\n$description Spanish live TV channels from Atresmedia Television, including Antena 3 and laSexta.\n$url atresplayer.com\n$type live\n$region Spain\n\"\"\"\n\nimport logging\nimport re\n\nfrom streamlink.plugin import Plugin, pluginmatcher\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream.dash import DASHStream\nfrom streamlink.stream.hls import HLSStream\nfrom streamlink.utils.url import update_scheme\n\n\nlog = logging.getLogger(__name__)\n\n\n@pluginmatcher(re.compile(\n r\"https?://(?:www\\.)?atresplayer\\.com/directos/.+\",\n))\nclass AtresPlayer(Plugin):\n _channels_api_url = \"https://api.atresplayer.com/client/v1/info/channels\"\n _player_api_url = \"https://api.atresplayer.com/player/v1/live/{channel_id}\"\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.url = update_scheme(\"https://\", f\"{self.url.rstrip('/')}/\")\n\n def _get_streams(self):\n channel_path = f\"/{self.url.split('/')[-2]}/\"\n channel_data = self.session.http.get(self._channels_api_url, schema=validate.Schema(\n validate.parse_json(),\n [{\n \"id\": str,\n \"link\": {\"url\": str},\n }],\n validate.filter(lambda item: item[\"link\"][\"url\"] == channel_path),\n ))\n if not channel_data:\n return\n channel_id = channel_data[0][\"id\"]\n\n player_api_url = self._player_api_url.format(channel_id=channel_id)\n log.debug(f\"Player API URL: {player_api_url}\")\n\n sources = self.session.http.get(player_api_url, acceptable_status=(200, 403), schema=validate.Schema(\n validate.parse_json(),\n validate.any(\n {\n \"error\": str,\n \"error_description\": str,\n },\n {\n \"sources\": [\n validate.all(\n {\n \"src\": validate.url(),\n validate.optional(\"type\"): str,\n },\n validate.union_get(\"type\", \"src\"),\n ),\n ],\n },\n ),\n ))\n if \"error\" in sources:\n log.error(f\"Player API error: {sources['error']} - {sources['error_description']}\")\n return\n\n for streamtype, streamsrc in sources.get(\"sources\"):\n log.debug(f\"Stream source: {streamsrc} ({streamtype or 'n/a'})\")\n\n if streamtype == \"application/vnd.apple.mpegurl\":\n streams = HLSStream.parse_variant_playlist(self.session, streamsrc)\n if not streams:\n yield \"live\", HLSStream(self.session, streamsrc)\n else:\n yield from streams.items()\n elif streamtype == \"application/dash+xml\":\n yield from DASHStream.parse_manifest(self.session, streamsrc).items()\n\n\n__plugin__ = AtresPlayer\n", "path": "src/streamlink/plugins/atresplayer.py"}], "after_files": [{"content": "\"\"\"\n$description Spanish live TV channels from Atresmedia Television, including Antena 3 and laSexta.\n$url atresplayer.com\n$type live\n$region Spain\n\"\"\"\n\nimport logging\nimport re\n\nfrom streamlink.plugin import Plugin, pluginmatcher\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream.dash import DASHStream\nfrom streamlink.stream.hls import HLSStream\nfrom streamlink.utils.url import update_scheme\n\n\nlog = logging.getLogger(__name__)\n\n\n@pluginmatcher(re.compile(\n r\"https?://(?:www\\.)?atresplayer\\.com/directos/.+\",\n))\nclass AtresPlayer(Plugin):\n _channels_api_url = \"https://api.atresplayer.com/client/v1/info/channels\"\n _player_api_url = \"https://api.atresplayer.com/player/v1/live/{channel_id}?NODRM=true\"\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.url = update_scheme(\"https://\", f\"{self.url.rstrip('/')}/\")\n\n def _get_streams(self):\n channel_path = f\"/{self.url.split('/')[-2]}/\"\n channel_data = self.session.http.get(self._channels_api_url, schema=validate.Schema(\n validate.parse_json(),\n [{\n \"id\": str,\n \"link\": {\"url\": str},\n }],\n validate.filter(lambda item: item[\"link\"][\"url\"] == channel_path),\n ))\n if not channel_data:\n return\n channel_id = channel_data[0][\"id\"]\n\n player_api_url = self._player_api_url.format(channel_id=channel_id)\n log.debug(f\"Player API URL: {player_api_url}\")\n\n sources = self.session.http.get(player_api_url, acceptable_status=(200, 403), schema=validate.Schema(\n validate.parse_json(),\n validate.any(\n {\n \"error\": str,\n \"error_description\": str,\n },\n {\n \"sourcesLive\": [\n validate.all(\n {\n \"src\": validate.url(),\n validate.optional(\"type\"): str,\n },\n validate.union_get(\"type\", \"src\"),\n ),\n ],\n },\n ),\n ))\n if \"error\" in sources:\n log.error(f\"Player API error: {sources['error']} - {sources['error_description']}\")\n return\n\n for streamtype, streamsrc in sources.get(\"sourcesLive\"):\n log.debug(f\"Stream source: {streamsrc} ({streamtype or 'n/a'})\")\n\n if streamtype == \"application/vnd.apple.mpegurl\":\n streams = HLSStream.parse_variant_playlist(self.session, streamsrc)\n if not streams:\n yield \"live\", HLSStream(self.session, streamsrc)\n else:\n yield from streams.items()\n elif streamtype == \"application/dash+xml\":\n yield from DASHStream.parse_manifest(self.session, streamsrc).items()\n\n\n__plugin__ = AtresPlayer\n", "path": "src/streamlink/plugins/atresplayer.py"}]}
| 1,898 | 310 |
gh_patches_debug_17070
|
rasdani/github-patches
|
git_diff
|
xonsh__xonsh-341
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
xonsh dies if the prompt raises an exception
If a function in the prompt raises an exception, it kills xonsh. I would expect the error to be displayed, but not kill the shell.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `xonsh/base_shell.py`
Content:
```
1 """The base class for xonsh shell"""
2 import os
3 import sys
4 import builtins
5 import traceback
6
7 from xonsh.execer import Execer
8 from xonsh.tools import XonshError, escape_windows_title_string
9 from xonsh.tools import ON_WINDOWS
10 from xonsh.completer import Completer
11 from xonsh.environ import multiline_prompt, format_prompt
12
13
14 class BaseShell(object):
15 """The xonsh shell."""
16
17 def __init__(self, execer, ctx, **kwargs):
18 super().__init__(**kwargs)
19 self.execer = execer
20 self.ctx = ctx
21 self.completer = Completer()
22 self.buffer = []
23 self.need_more_lines = False
24 self.mlprompt = None
25
26 def emptyline(self):
27 """Called when an empty line has been entered."""
28 self.need_more_lines = False
29 self.default('')
30
31 def precmd(self, line):
32 """Called just before execution of line."""
33 return line if self.need_more_lines else line.lstrip()
34
35 def default(self, line):
36 """Implements code execution."""
37 line = line if line.endswith('\n') else line + '\n'
38 code = self.push(line)
39 if code is None:
40 return
41 try:
42 self.execer.exec(code, mode='single', glbs=self.ctx) # no locals
43 except XonshError as e:
44 print(e.args[0], file=sys.stderr)
45 except:
46 _print_exception()
47 if builtins.__xonsh_exit__:
48 return True
49
50 def push(self, line):
51 """Pushes a line onto the buffer and compiles the code in a way that
52 enables multiline input.
53 """
54 code = None
55 self.buffer.append(line)
56 if self.need_more_lines:
57 return code
58 src = ''.join(self.buffer)
59 try:
60 code = self.execer.compile(src,
61 mode='single',
62 glbs=None,
63 locs=self.ctx)
64 self.reset_buffer()
65 except SyntaxError:
66 if line == '\n':
67 self.reset_buffer()
68 _print_exception()
69 return None
70 self.need_more_lines = True
71 except:
72 self.reset_buffer()
73 _print_exception()
74 return None
75 return code
76
77 def reset_buffer(self):
78 """Resets the line buffer."""
79 self.buffer.clear()
80 self.need_more_lines = False
81 self.mlprompt = None
82
83 def settitle(self):
84 """Sets terminal title."""
85 env = builtins.__xonsh_env__
86 term = env.get('TERM', None)
87 if term is None or term == 'linux':
88 return
89 if 'TITLE' in env:
90 t = env['TITLE']
91 else:
92 return
93 t = format_prompt(t)
94 if ON_WINDOWS and 'ANSICON' not in env:
95 t = escape_windows_title_string(t)
96 os.system('title {}'.format(t))
97 else:
98 sys.stdout.write("\x1b]2;{0}\x07".format(t))
99
100 @property
101 def prompt(self):
102 """Obtains the current prompt string."""
103 if self.need_more_lines:
104 if self.mlprompt is None:
105 self.mlprompt = multiline_prompt()
106 return self.mlprompt
107 env = builtins.__xonsh_env__
108 if 'PROMPT' in env:
109 p = env['PROMPT']
110 p = format_prompt(p)
111 else:
112 p = "set '$PROMPT = ...' $ "
113 self.settitle()
114 return p
115
116 def _print_exception():
117 """Print exceptions with/without traceback."""
118 if not 'XONSH_SHOW_TRACEBACK' in builtins.__xonsh_env__:
119 sys.stderr.write('xonsh: For full traceback set: '
120 '$XONSH_SHOW_TRACEBACK=True\n')
121 if builtins.__xonsh_env__.get('XONSH_SHOW_TRACEBACK', False):
122 traceback.print_exc()
123 else:
124 exc_type, exc_value, exc_traceback = sys.exc_info()
125 exception_only = traceback.format_exception_only(exc_type, exc_value)
126 sys.stderr.write(''.join(exception_only))
127
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/xonsh/base_shell.py b/xonsh/base_shell.py
--- a/xonsh/base_shell.py
+++ b/xonsh/base_shell.py
@@ -102,12 +102,19 @@
"""Obtains the current prompt string."""
if self.need_more_lines:
if self.mlprompt is None:
- self.mlprompt = multiline_prompt()
+ try:
+ self.mlprompt = multiline_prompt()
+ except Exception:
+ _print_exception()
+ self.mlprompt = '<multiline prompt error> '
return self.mlprompt
env = builtins.__xonsh_env__
if 'PROMPT' in env:
p = env['PROMPT']
- p = format_prompt(p)
+ try:
+ p = format_prompt(p)
+ except Exception:
+ _print_exception()
else:
p = "set '$PROMPT = ...' $ "
self.settitle()
|
{"golden_diff": "diff --git a/xonsh/base_shell.py b/xonsh/base_shell.py\n--- a/xonsh/base_shell.py\n+++ b/xonsh/base_shell.py\n@@ -102,12 +102,19 @@\n \"\"\"Obtains the current prompt string.\"\"\"\n if self.need_more_lines:\n if self.mlprompt is None:\n- self.mlprompt = multiline_prompt()\n+ try:\n+ self.mlprompt = multiline_prompt()\n+ except Exception:\n+ _print_exception()\n+ self.mlprompt = '<multiline prompt error> '\n return self.mlprompt\n env = builtins.__xonsh_env__\n if 'PROMPT' in env:\n p = env['PROMPT']\n- p = format_prompt(p)\n+ try:\n+ p = format_prompt(p)\n+ except Exception:\n+ _print_exception()\n else:\n p = \"set '$PROMPT = ...' $ \"\n self.settitle()\n", "issue": "xonsh dies if the prompt raises an exception\nIf a function in the prompt raises an exception, it kills xonsh. I would expect the error to be displayed, but not kill the shell. \n\n", "before_files": [{"content": "\"\"\"The base class for xonsh shell\"\"\"\nimport os\nimport sys\nimport builtins\nimport traceback\n\nfrom xonsh.execer import Execer\nfrom xonsh.tools import XonshError, escape_windows_title_string\nfrom xonsh.tools import ON_WINDOWS\nfrom xonsh.completer import Completer\nfrom xonsh.environ import multiline_prompt, format_prompt\n\n\nclass BaseShell(object):\n \"\"\"The xonsh shell.\"\"\"\n\n def __init__(self, execer, ctx, **kwargs):\n super().__init__(**kwargs)\n self.execer = execer\n self.ctx = ctx\n self.completer = Completer()\n self.buffer = []\n self.need_more_lines = False\n self.mlprompt = None\n\n def emptyline(self):\n \"\"\"Called when an empty line has been entered.\"\"\"\n self.need_more_lines = False\n self.default('')\n\n def precmd(self, line):\n \"\"\"Called just before execution of line.\"\"\"\n return line if self.need_more_lines else line.lstrip()\n\n def default(self, line):\n \"\"\"Implements code execution.\"\"\"\n line = line if line.endswith('\\n') else line + '\\n'\n code = self.push(line)\n if code is None:\n return\n try:\n self.execer.exec(code, mode='single', glbs=self.ctx) # no locals\n except XonshError as e:\n print(e.args[0], file=sys.stderr)\n except:\n _print_exception()\n if builtins.__xonsh_exit__:\n return True\n\n def push(self, line):\n \"\"\"Pushes a line onto the buffer and compiles the code in a way that\n enables multiline input.\n \"\"\"\n code = None\n self.buffer.append(line)\n if self.need_more_lines:\n return code\n src = ''.join(self.buffer)\n try:\n code = self.execer.compile(src,\n mode='single',\n glbs=None,\n locs=self.ctx)\n self.reset_buffer()\n except SyntaxError:\n if line == '\\n':\n self.reset_buffer()\n _print_exception()\n return None\n self.need_more_lines = True\n except:\n self.reset_buffer()\n _print_exception()\n return None\n return code\n\n def reset_buffer(self):\n \"\"\"Resets the line buffer.\"\"\"\n self.buffer.clear()\n self.need_more_lines = False\n self.mlprompt = None\n\n def settitle(self):\n \"\"\"Sets terminal title.\"\"\"\n env = builtins.__xonsh_env__\n term = env.get('TERM', None)\n if term is None or term == 'linux':\n return\n if 'TITLE' in env:\n t = env['TITLE']\n else:\n return\n t = format_prompt(t)\n if ON_WINDOWS and 'ANSICON' not in env:\n t = escape_windows_title_string(t)\n os.system('title {}'.format(t))\n else:\n sys.stdout.write(\"\\x1b]2;{0}\\x07\".format(t))\n\n @property\n def prompt(self):\n \"\"\"Obtains the current prompt string.\"\"\"\n if self.need_more_lines:\n if self.mlprompt is None:\n self.mlprompt = multiline_prompt()\n return self.mlprompt\n env = builtins.__xonsh_env__\n if 'PROMPT' in env:\n p = env['PROMPT']\n p = format_prompt(p)\n else:\n p = \"set '$PROMPT = ...' $ \"\n self.settitle()\n return p\n \ndef _print_exception():\n \"\"\"Print exceptions with/without traceback.\"\"\"\n if not 'XONSH_SHOW_TRACEBACK' in builtins.__xonsh_env__:\n sys.stderr.write('xonsh: For full traceback set: '\n '$XONSH_SHOW_TRACEBACK=True\\n')\n if builtins.__xonsh_env__.get('XONSH_SHOW_TRACEBACK', False):\n traceback.print_exc()\n else:\n exc_type, exc_value, exc_traceback = sys.exc_info()\n exception_only = traceback.format_exception_only(exc_type, exc_value)\n sys.stderr.write(''.join(exception_only))\n", "path": "xonsh/base_shell.py"}], "after_files": [{"content": "\"\"\"The base class for xonsh shell\"\"\"\nimport os\nimport sys\nimport builtins\nimport traceback\n\nfrom xonsh.execer import Execer\nfrom xonsh.tools import XonshError, escape_windows_title_string\nfrom xonsh.tools import ON_WINDOWS\nfrom xonsh.completer import Completer\nfrom xonsh.environ import multiline_prompt, format_prompt\n\n\nclass BaseShell(object):\n \"\"\"The xonsh shell.\"\"\"\n\n def __init__(self, execer, ctx, **kwargs):\n super().__init__(**kwargs)\n self.execer = execer\n self.ctx = ctx\n self.completer = Completer()\n self.buffer = []\n self.need_more_lines = False\n self.mlprompt = None\n\n def emptyline(self):\n \"\"\"Called when an empty line has been entered.\"\"\"\n self.need_more_lines = False\n self.default('')\n\n def precmd(self, line):\n \"\"\"Called just before execution of line.\"\"\"\n return line if self.need_more_lines else line.lstrip()\n\n def default(self, line):\n \"\"\"Implements code execution.\"\"\"\n line = line if line.endswith('\\n') else line + '\\n'\n code = self.push(line)\n if code is None:\n return\n try:\n self.execer.exec(code, mode='single', glbs=self.ctx) # no locals\n except XonshError as e:\n print(e.args[0], file=sys.stderr)\n except:\n _print_exception()\n if builtins.__xonsh_exit__:\n return True\n\n def push(self, line):\n \"\"\"Pushes a line onto the buffer and compiles the code in a way that\n enables multiline input.\n \"\"\"\n code = None\n self.buffer.append(line)\n if self.need_more_lines:\n return code\n src = ''.join(self.buffer)\n try:\n code = self.execer.compile(src,\n mode='single',\n glbs=None,\n locs=self.ctx)\n self.reset_buffer()\n except SyntaxError:\n if line == '\\n':\n self.reset_buffer()\n _print_exception()\n return None\n self.need_more_lines = True\n except:\n self.reset_buffer()\n _print_exception()\n return None\n return code\n\n def reset_buffer(self):\n \"\"\"Resets the line buffer.\"\"\"\n self.buffer.clear()\n self.need_more_lines = False\n self.mlprompt = None\n\n def settitle(self):\n \"\"\"Sets terminal title.\"\"\"\n env = builtins.__xonsh_env__\n term = env.get('TERM', None)\n if term is None or term == 'linux':\n return\n if 'TITLE' in env:\n t = env['TITLE']\n else:\n return\n t = format_prompt(t)\n if ON_WINDOWS and 'ANSICON' not in env:\n t = escape_windows_title_string(t)\n os.system('title {}'.format(t))\n else:\n sys.stdout.write(\"\\x1b]2;{0}\\x07\".format(t))\n\n @property\n def prompt(self):\n \"\"\"Obtains the current prompt string.\"\"\"\n if self.need_more_lines:\n if self.mlprompt is None:\n try:\n self.mlprompt = multiline_prompt()\n except Exception:\n _print_exception()\n self.mlprompt = '<multiline prompt error> '\n return self.mlprompt\n env = builtins.__xonsh_env__\n if 'PROMPT' in env:\n p = env['PROMPT']\n try:\n p = format_prompt(p)\n except Exception:\n _print_exception()\n else:\n p = \"set '$PROMPT = ...' $ \"\n self.settitle()\n return p\n \ndef _print_exception():\n \"\"\"Print exceptions with/without traceback.\"\"\"\n if not 'XONSH_SHOW_TRACEBACK' in builtins.__xonsh_env__:\n sys.stderr.write('xonsh: For full traceback set: '\n '$XONSH_SHOW_TRACEBACK=True\\n')\n if builtins.__xonsh_env__.get('XONSH_SHOW_TRACEBACK', False):\n traceback.print_exc()\n else:\n exc_type, exc_value, exc_traceback = sys.exc_info()\n exception_only = traceback.format_exception_only(exc_type, exc_value)\n sys.stderr.write(''.join(exception_only))\n", "path": "xonsh/base_shell.py"}]}
| 1,480 | 217 |
gh_patches_debug_31644
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-16451
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[bug] cmake_lib template adds find_package to all requirements in test_package
### Describe the bug
Environment: everyone
OS: everyone
The `cmake_lib` template of `conan new` command does generate not invalid CMake code, but redundant.
On `test_package/CMakeLists.txt` it generates `find_package` directives of every dependency passed as `-d requires` parameter and it should only generate the `find_package` of the main package, delegating the finding of transitive dependencies to the original package.
### How to reproduce it
```sh
$ conan new cmake_lib -d name=sdk -d version=1.0 -d requires="lib_a/1.0" -d requires="lib_b/1.0"
```
```
File saved: CMakeLists.txt
File saved: conanfile.py
File saved: include/sdk.h
File saved: src/sdk.cpp
File saved: test_package/CMakeLists.txt
File saved: test_package/conanfile.py
File saved: test_package/src/example.cpp
```
```sh
$ cat test_package/CMakeLists.txt
```
```
cmake_minimum_required(VERSION 3.15)
project(PackageTest CXX)
find_package(sdk CONFIG REQUIRED)
find_package(lib_a CONFIG REQUIRED) # This find_packages are incorrect.
find_package(lib_b CONFIG REQUIRED) # Conan should delegate on sdk generator to find their transitive dependencies
add_executable(example src/example.cpp)
target_link_libraries(example sdk::sdk)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conan/internal/api/new/cmake_lib.py`
Content:
```
1 conanfile_sources_v2 = '''from conan import ConanFile
2 from conan.tools.cmake import CMakeToolchain, CMake, cmake_layout, CMakeDeps
3
4
5 class {{package_name}}Recipe(ConanFile):
6 name = "{{name}}"
7 version = "{{version}}"
8 package_type = "library"
9
10 # Optional metadata
11 license = "<Put the package license here>"
12 author = "<Put your name here> <And your email here>"
13 url = "<Package recipe repository url here, for issues about the package>"
14 description = "<Description of {{ name }} package here>"
15 topics = ("<Put some tag here>", "<here>", "<and here>")
16
17 # Binary configuration
18 settings = "os", "compiler", "build_type", "arch"
19 options = {"shared": [True, False], "fPIC": [True, False]}
20 default_options = {"shared": False, "fPIC": True}
21
22 # Sources are located in the same place as this recipe, copy them to the recipe
23 exports_sources = "CMakeLists.txt", "src/*", "include/*"
24
25 def config_options(self):
26 if self.settings.os == "Windows":
27 self.options.rm_safe("fPIC")
28
29 def configure(self):
30 if self.options.shared:
31 self.options.rm_safe("fPIC")
32
33 def layout(self):
34 cmake_layout(self)
35
36 def generate(self):
37 deps = CMakeDeps(self)
38 deps.generate()
39 tc = CMakeToolchain(self)
40 tc.generate()
41
42 def build(self):
43 cmake = CMake(self)
44 cmake.configure()
45 cmake.build()
46
47 def package(self):
48 cmake = CMake(self)
49 cmake.install()
50
51 def package_info(self):
52 self.cpp_info.libs = ["{{name}}"]
53
54 {% if requires is defined -%}
55 def requirements(self):
56 {% for require in requires -%}
57 self.requires("{{ require }}")
58 {% endfor %}
59 {%- endif %}
60
61 {% if tool_requires is defined -%}
62 def build_requirements(self):
63 {% for require in tool_requires -%}
64 self.tool_requires("{{ require }}")
65 {% endfor %}
66 {%- endif %}
67
68 '''
69
70 cmake_v2 = """cmake_minimum_required(VERSION 3.15)
71 project({{name}} CXX)
72
73 {% if requires is defined -%}
74 {% for require in requires -%}
75 find_package({{as_name(require)}} CONFIG REQUIRED)
76 {% endfor %}
77 {%- endif %}
78
79
80 add_library({{name}} src/{{name}}.cpp)
81 target_include_directories({{name}} PUBLIC include)
82
83 {% if requires is defined -%}
84 {% for require in requires -%}
85 target_link_libraries({{name}} PRIVATE {{as_name(require)}}::{{as_name(require)}})
86 {% endfor %}
87 {%- endif %}
88
89 set_target_properties({{name}} PROPERTIES PUBLIC_HEADER "include/{{name}}.h")
90 install(TARGETS {{name}})
91 """
92
93 source_h = """#pragma once
94
95 #include <vector>
96 #include <string>
97
98 {% set define_name = package_name.upper() %}
99 #ifdef _WIN32
100 #define {{define_name}}_EXPORT __declspec(dllexport)
101 #else
102 #define {{define_name}}_EXPORT
103 #endif
104
105 {{define_name}}_EXPORT void {{package_name}}();
106 {{define_name}}_EXPORT void {{package_name}}_print_vector(const std::vector<std::string> &strings);
107 """
108
109 source_cpp = r"""#include <iostream>
110 #include "{{name}}.h"
111 {% if requires is defined -%}
112 {% for require in requires -%}
113 #include "{{ as_name(require) }}.h"
114 {% endfor %}
115 {%- endif %}
116
117
118 void {{package_name}}(){
119 {% if requires is defined -%}
120 {% for require in requires -%}
121 {{ as_name(require) }}();
122 {% endfor %}
123 {%- endif %}
124
125 #ifdef NDEBUG
126 std::cout << "{{name}}/{{version}}: Hello World Release!\n";
127 #else
128 std::cout << "{{name}}/{{version}}: Hello World Debug!\n";
129 #endif
130
131 // ARCHITECTURES
132 #ifdef _M_X64
133 std::cout << " {{name}}/{{version}}: _M_X64 defined\n";
134 #endif
135
136 #ifdef _M_IX86
137 std::cout << " {{name}}/{{version}}: _M_IX86 defined\n";
138 #endif
139
140 #ifdef _M_ARM64
141 std::cout << " {{name}}/{{version}}: _M_ARM64 defined\n";
142 #endif
143
144 #if __i386__
145 std::cout << " {{name}}/{{version}}: __i386__ defined\n";
146 #endif
147
148 #if __x86_64__
149 std::cout << " {{name}}/{{version}}: __x86_64__ defined\n";
150 #endif
151
152 #if __aarch64__
153 std::cout << " {{name}}/{{version}}: __aarch64__ defined\n";
154 #endif
155
156 // Libstdc++
157 #if defined _GLIBCXX_USE_CXX11_ABI
158 std::cout << " {{name}}/{{version}}: _GLIBCXX_USE_CXX11_ABI "<< _GLIBCXX_USE_CXX11_ABI << "\n";
159 #endif
160
161 // MSVC runtime
162 #if defined(_DEBUG)
163 #if defined(_MT) && defined(_DLL)
164 std::cout << " {{name}}/{{version}}: MSVC runtime: MultiThreadedDebugDLL\n";
165 #elif defined(_MT)
166 std::cout << " {{name}}/{{version}}: MSVC runtime: MultiThreadedDebug\n";
167 #endif
168 #else
169 #if defined(_MT) && defined(_DLL)
170 std::cout << " {{name}}/{{version}}: MSVC runtime: MultiThreadedDLL\n";
171 #elif defined(_MT)
172 std::cout << " {{name}}/{{version}}: MSVC runtime: MultiThreaded\n";
173 #endif
174 #endif
175
176 // COMPILER VERSIONS
177 #if _MSC_VER
178 std::cout << " {{name}}/{{version}}: _MSC_VER" << _MSC_VER<< "\n";
179 #endif
180
181 #if _MSVC_LANG
182 std::cout << " {{name}}/{{version}}: _MSVC_LANG" << _MSVC_LANG<< "\n";
183 #endif
184
185 #if __cplusplus
186 std::cout << " {{name}}/{{version}}: __cplusplus" << __cplusplus<< "\n";
187 #endif
188
189 #if __INTEL_COMPILER
190 std::cout << " {{name}}/{{version}}: __INTEL_COMPILER" << __INTEL_COMPILER<< "\n";
191 #endif
192
193 #if __GNUC__
194 std::cout << " {{name}}/{{version}}: __GNUC__" << __GNUC__<< "\n";
195 #endif
196
197 #if __GNUC_MINOR__
198 std::cout << " {{name}}/{{version}}: __GNUC_MINOR__" << __GNUC_MINOR__<< "\n";
199 #endif
200
201 #if __clang_major__
202 std::cout << " {{name}}/{{version}}: __clang_major__" << __clang_major__<< "\n";
203 #endif
204
205 #if __clang_minor__
206 std::cout << " {{name}}/{{version}}: __clang_minor__" << __clang_minor__<< "\n";
207 #endif
208
209 #if __apple_build_version__
210 std::cout << " {{name}}/{{version}}: __apple_build_version__" << __apple_build_version__<< "\n";
211 #endif
212
213 // SUBSYSTEMS
214
215 #if __MSYS__
216 std::cout << " {{name}}/{{version}}: __MSYS__" << __MSYS__<< "\n";
217 #endif
218
219 #if __MINGW32__
220 std::cout << " {{name}}/{{version}}: __MINGW32__" << __MINGW32__<< "\n";
221 #endif
222
223 #if __MINGW64__
224 std::cout << " {{name}}/{{version}}: __MINGW64__" << __MINGW64__<< "\n";
225 #endif
226
227 #if __CYGWIN__
228 std::cout << " {{name}}/{{version}}: __CYGWIN__" << __CYGWIN__<< "\n";
229 #endif
230 }
231
232 void {{package_name}}_print_vector(const std::vector<std::string> &strings) {
233 for(std::vector<std::string>::const_iterator it = strings.begin(); it != strings.end(); ++it) {
234 std::cout << "{{package_name}}/{{version}} " << *it << std::endl;
235 }
236 }
237 """
238
239
240 test_conanfile_v2 = """import os
241
242 from conan import ConanFile
243 from conan.tools.cmake import CMake, cmake_layout
244 from conan.tools.build import can_run
245
246
247 class {{package_name}}TestConan(ConanFile):
248 settings = "os", "compiler", "build_type", "arch"
249 generators = "CMakeDeps", "CMakeToolchain"
250
251 def requirements(self):
252 self.requires(self.tested_reference_str)
253
254 def build(self):
255 cmake = CMake(self)
256 cmake.configure()
257 cmake.build()
258
259 def layout(self):
260 cmake_layout(self)
261
262 def test(self):
263 if can_run(self):
264 cmd = os.path.join(self.cpp.build.bindir, "example")
265 self.run(cmd, env="conanrun")
266 """
267
268 test_cmake_v2 = """cmake_minimum_required(VERSION 3.15)
269 project(PackageTest CXX)
270
271 find_package({{name}} CONFIG REQUIRED)
272
273 {% if requires is defined -%}
274 {% for require in requires -%}
275 find_package({{as_name(require)}} CONFIG REQUIRED)
276 {% endfor %}
277 {%- endif %}
278
279 add_executable(example src/example.cpp)
280 target_link_libraries(example {{name}}::{{name}})
281 """
282
283
284 test_main = """#include "{{name}}.h"
285 #include <vector>
286 #include <string>
287
288 int main() {
289 {{package_name}}();
290
291 std::vector<std::string> vec;
292 vec.push_back("test_package");
293
294 {{package_name}}_print_vector(vec);
295 }
296 """
297
298 cmake_lib_files = {"conanfile.py": conanfile_sources_v2,
299 "src/{{name}}.cpp": source_cpp,
300 "include/{{name}}.h": source_h,
301 "CMakeLists.txt": cmake_v2,
302 "test_package/conanfile.py": test_conanfile_v2,
303 "test_package/src/example.cpp": test_main,
304 "test_package/CMakeLists.txt": test_cmake_v2}
305
```
Path: `conans/__init__.py`
Content:
```
1 CHECKSUM_DEPLOY = "checksum_deploy" # Only when v2
2 REVISIONS = "revisions" # Only when enabled in config, not by default look at server_launcher.py
3 OAUTH_TOKEN = "oauth_token"
4
5 __version__ = '2.4.1'
6
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/conan/internal/api/new/cmake_lib.py b/conan/internal/api/new/cmake_lib.py
--- a/conan/internal/api/new/cmake_lib.py
+++ b/conan/internal/api/new/cmake_lib.py
@@ -32,7 +32,18 @@
def layout(self):
cmake_layout(self)
-
+ {% if requires is defined %}
+ def requirements(self):
+ {% for require in requires -%}
+ self.requires("{{ require }}")
+ {% endfor %}
+ {%- endif %}
+ {%- if tool_requires is defined %}
+ def build_requirements(self):
+ {% for require in tool_requires -%}
+ self.tool_requires("{{ require }}")
+ {% endfor %}
+ {%- endif %}
def generate(self):
deps = CMakeDeps(self)
deps.generate()
@@ -51,20 +62,6 @@
def package_info(self):
self.cpp_info.libs = ["{{name}}"]
- {% if requires is defined -%}
- def requirements(self):
- {% for require in requires -%}
- self.requires("{{ require }}")
- {% endfor %}
- {%- endif %}
-
- {% if tool_requires is defined -%}
- def build_requirements(self):
- {% for require in tool_requires -%}
- self.tool_requires("{{ require }}")
- {% endfor %}
- {%- endif %}
-
'''
cmake_v2 = """cmake_minimum_required(VERSION 3.15)
@@ -270,12 +267,6 @@
find_package({{name}} CONFIG REQUIRED)
-{% if requires is defined -%}
-{% for require in requires -%}
-find_package({{as_name(require)}} CONFIG REQUIRED)
-{% endfor %}
-{%- endif %}
-
add_executable(example src/example.cpp)
target_link_libraries(example {{name}}::{{name}})
"""
diff --git a/conans/__init__.py b/conans/__init__.py
--- a/conans/__init__.py
+++ b/conans/__init__.py
@@ -2,4 +2,4 @@
REVISIONS = "revisions" # Only when enabled in config, not by default look at server_launcher.py
OAUTH_TOKEN = "oauth_token"
-__version__ = '2.4.0'
+__version__ = '2.4.1'
|
{"golden_diff": "diff --git a/conan/internal/api/new/cmake_lib.py b/conan/internal/api/new/cmake_lib.py\n--- a/conan/internal/api/new/cmake_lib.py\n+++ b/conan/internal/api/new/cmake_lib.py\n@@ -32,7 +32,18 @@\n \n def layout(self):\n cmake_layout(self)\n-\n+ {% if requires is defined %}\n+ def requirements(self):\n+ {% for require in requires -%}\n+ self.requires(\"{{ require }}\")\n+ {% endfor %}\n+ {%- endif %}\n+ {%- if tool_requires is defined %}\n+ def build_requirements(self):\n+ {% for require in tool_requires -%}\n+ self.tool_requires(\"{{ require }}\")\n+ {% endfor %}\n+ {%- endif %}\n def generate(self):\n deps = CMakeDeps(self)\n deps.generate()\n@@ -51,20 +62,6 @@\n def package_info(self):\n self.cpp_info.libs = [\"{{name}}\"]\n \n- {% if requires is defined -%}\n- def requirements(self):\n- {% for require in requires -%}\n- self.requires(\"{{ require }}\")\n- {% endfor %}\n- {%- endif %}\n-\n- {% if tool_requires is defined -%}\n- def build_requirements(self):\n- {% for require in tool_requires -%}\n- self.tool_requires(\"{{ require }}\")\n- {% endfor %}\n- {%- endif %}\n-\n '''\n \n cmake_v2 = \"\"\"cmake_minimum_required(VERSION 3.15)\n@@ -270,12 +267,6 @@\n \n find_package({{name}} CONFIG REQUIRED)\n \n-{% if requires is defined -%}\n-{% for require in requires -%}\n-find_package({{as_name(require)}} CONFIG REQUIRED)\n-{% endfor %}\n-{%- endif %}\n-\n add_executable(example src/example.cpp)\n target_link_libraries(example {{name}}::{{name}})\n \"\"\"\ndiff --git a/conans/__init__.py b/conans/__init__.py\n--- a/conans/__init__.py\n+++ b/conans/__init__.py\n@@ -2,4 +2,4 @@\n REVISIONS = \"revisions\" # Only when enabled in config, not by default look at server_launcher.py\n OAUTH_TOKEN = \"oauth_token\"\n \n-__version__ = '2.4.0'\n+__version__ = '2.4.1'\n", "issue": "[bug] cmake_lib template adds find_package to all requirements in test_package\n### Describe the bug\n\nEnvironment: everyone\r\nOS: everyone\r\n\r\nThe `cmake_lib` template of `conan new` command does generate not invalid CMake code, but redundant. \r\nOn `test_package/CMakeLists.txt` it generates `find_package` directives of every dependency passed as `-d requires` parameter and it should only generate the `find_package` of the main package, delegating the finding of transitive dependencies to the original package.\r\n\n\n### How to reproduce it\n\n```sh\r\n$ conan new cmake_lib -d name=sdk -d version=1.0 -d requires=\"lib_a/1.0\" -d requires=\"lib_b/1.0\"\r\n```\r\n\r\n```\r\nFile saved: CMakeLists.txt\r\nFile saved: conanfile.py\r\nFile saved: include/sdk.h\r\nFile saved: src/sdk.cpp\r\nFile saved: test_package/CMakeLists.txt\r\nFile saved: test_package/conanfile.py\r\nFile saved: test_package/src/example.cpp\r\n```\r\n\r\n```sh\r\n$ cat test_package/CMakeLists.txt\r\n```\r\n```\r\ncmake_minimum_required(VERSION 3.15)\r\nproject(PackageTest CXX)\r\n\r\nfind_package(sdk CONFIG REQUIRED)\r\n\r\nfind_package(lib_a CONFIG REQUIRED) # This find_packages are incorrect. \r\nfind_package(lib_b CONFIG REQUIRED) # Conan should delegate on sdk generator to find their transitive dependencies\r\n\r\n\r\nadd_executable(example src/example.cpp)\r\ntarget_link_libraries(example sdk::sdk)\r\n```\n", "before_files": [{"content": "conanfile_sources_v2 = '''from conan import ConanFile\nfrom conan.tools.cmake import CMakeToolchain, CMake, cmake_layout, CMakeDeps\n\n\nclass {{package_name}}Recipe(ConanFile):\n name = \"{{name}}\"\n version = \"{{version}}\"\n package_type = \"library\"\n\n # Optional metadata\n license = \"<Put the package license here>\"\n author = \"<Put your name here> <And your email here>\"\n url = \"<Package recipe repository url here, for issues about the package>\"\n description = \"<Description of {{ name }} package here>\"\n topics = (\"<Put some tag here>\", \"<here>\", \"<and here>\")\n\n # Binary configuration\n settings = \"os\", \"compiler\", \"build_type\", \"arch\"\n options = {\"shared\": [True, False], \"fPIC\": [True, False]}\n default_options = {\"shared\": False, \"fPIC\": True}\n\n # Sources are located in the same place as this recipe, copy them to the recipe\n exports_sources = \"CMakeLists.txt\", \"src/*\", \"include/*\"\n\n def config_options(self):\n if self.settings.os == \"Windows\":\n self.options.rm_safe(\"fPIC\")\n\n def configure(self):\n if self.options.shared:\n self.options.rm_safe(\"fPIC\")\n\n def layout(self):\n cmake_layout(self)\n\n def generate(self):\n deps = CMakeDeps(self)\n deps.generate()\n tc = CMakeToolchain(self)\n tc.generate()\n\n def build(self):\n cmake = CMake(self)\n cmake.configure()\n cmake.build()\n\n def package(self):\n cmake = CMake(self)\n cmake.install()\n\n def package_info(self):\n self.cpp_info.libs = [\"{{name}}\"]\n\n {% if requires is defined -%}\n def requirements(self):\n {% for require in requires -%}\n self.requires(\"{{ require }}\")\n {% endfor %}\n {%- endif %}\n\n {% if tool_requires is defined -%}\n def build_requirements(self):\n {% for require in tool_requires -%}\n self.tool_requires(\"{{ require }}\")\n {% endfor %}\n {%- endif %}\n\n'''\n\ncmake_v2 = \"\"\"cmake_minimum_required(VERSION 3.15)\nproject({{name}} CXX)\n\n{% if requires is defined -%}\n{% for require in requires -%}\nfind_package({{as_name(require)}} CONFIG REQUIRED)\n{% endfor %}\n{%- endif %}\n\n\nadd_library({{name}} src/{{name}}.cpp)\ntarget_include_directories({{name}} PUBLIC include)\n\n{% if requires is defined -%}\n{% for require in requires -%}\ntarget_link_libraries({{name}} PRIVATE {{as_name(require)}}::{{as_name(require)}})\n{% endfor %}\n{%- endif %}\n\nset_target_properties({{name}} PROPERTIES PUBLIC_HEADER \"include/{{name}}.h\")\ninstall(TARGETS {{name}})\n\"\"\"\n\nsource_h = \"\"\"#pragma once\n\n#include <vector>\n#include <string>\n\n{% set define_name = package_name.upper() %}\n#ifdef _WIN32\n #define {{define_name}}_EXPORT __declspec(dllexport)\n#else\n #define {{define_name}}_EXPORT\n#endif\n\n{{define_name}}_EXPORT void {{package_name}}();\n{{define_name}}_EXPORT void {{package_name}}_print_vector(const std::vector<std::string> &strings);\n\"\"\"\n\nsource_cpp = r\"\"\"#include <iostream>\n#include \"{{name}}.h\"\n{% if requires is defined -%}\n{% for require in requires -%}\n#include \"{{ as_name(require) }}.h\"\n{% endfor %}\n{%- endif %}\n\n\nvoid {{package_name}}(){\n {% if requires is defined -%}\n {% for require in requires -%}\n {{ as_name(require) }}();\n {% endfor %}\n {%- endif %}\n\n #ifdef NDEBUG\n std::cout << \"{{name}}/{{version}}: Hello World Release!\\n\";\n #else\n std::cout << \"{{name}}/{{version}}: Hello World Debug!\\n\";\n #endif\n\n // ARCHITECTURES\n #ifdef _M_X64\n std::cout << \" {{name}}/{{version}}: _M_X64 defined\\n\";\n #endif\n\n #ifdef _M_IX86\n std::cout << \" {{name}}/{{version}}: _M_IX86 defined\\n\";\n #endif\n\n #ifdef _M_ARM64\n std::cout << \" {{name}}/{{version}}: _M_ARM64 defined\\n\";\n #endif\n\n #if __i386__\n std::cout << \" {{name}}/{{version}}: __i386__ defined\\n\";\n #endif\n\n #if __x86_64__\n std::cout << \" {{name}}/{{version}}: __x86_64__ defined\\n\";\n #endif\n\n #if __aarch64__\n std::cout << \" {{name}}/{{version}}: __aarch64__ defined\\n\";\n #endif\n\n // Libstdc++\n #if defined _GLIBCXX_USE_CXX11_ABI\n std::cout << \" {{name}}/{{version}}: _GLIBCXX_USE_CXX11_ABI \"<< _GLIBCXX_USE_CXX11_ABI << \"\\n\";\n #endif\n\n // MSVC runtime\n #if defined(_DEBUG)\n #if defined(_MT) && defined(_DLL)\n std::cout << \" {{name}}/{{version}}: MSVC runtime: MultiThreadedDebugDLL\\n\";\n #elif defined(_MT)\n std::cout << \" {{name}}/{{version}}: MSVC runtime: MultiThreadedDebug\\n\";\n #endif\n #else\n #if defined(_MT) && defined(_DLL)\n std::cout << \" {{name}}/{{version}}: MSVC runtime: MultiThreadedDLL\\n\";\n #elif defined(_MT)\n std::cout << \" {{name}}/{{version}}: MSVC runtime: MultiThreaded\\n\";\n #endif\n #endif\n\n // COMPILER VERSIONS\n #if _MSC_VER\n std::cout << \" {{name}}/{{version}}: _MSC_VER\" << _MSC_VER<< \"\\n\";\n #endif\n\n #if _MSVC_LANG\n std::cout << \" {{name}}/{{version}}: _MSVC_LANG\" << _MSVC_LANG<< \"\\n\";\n #endif\n\n #if __cplusplus\n std::cout << \" {{name}}/{{version}}: __cplusplus\" << __cplusplus<< \"\\n\";\n #endif\n\n #if __INTEL_COMPILER\n std::cout << \" {{name}}/{{version}}: __INTEL_COMPILER\" << __INTEL_COMPILER<< \"\\n\";\n #endif\n\n #if __GNUC__\n std::cout << \" {{name}}/{{version}}: __GNUC__\" << __GNUC__<< \"\\n\";\n #endif\n\n #if __GNUC_MINOR__\n std::cout << \" {{name}}/{{version}}: __GNUC_MINOR__\" << __GNUC_MINOR__<< \"\\n\";\n #endif\n\n #if __clang_major__\n std::cout << \" {{name}}/{{version}}: __clang_major__\" << __clang_major__<< \"\\n\";\n #endif\n\n #if __clang_minor__\n std::cout << \" {{name}}/{{version}}: __clang_minor__\" << __clang_minor__<< \"\\n\";\n #endif\n\n #if __apple_build_version__\n std::cout << \" {{name}}/{{version}}: __apple_build_version__\" << __apple_build_version__<< \"\\n\";\n #endif\n\n // SUBSYSTEMS\n\n #if __MSYS__\n std::cout << \" {{name}}/{{version}}: __MSYS__\" << __MSYS__<< \"\\n\";\n #endif\n\n #if __MINGW32__\n std::cout << \" {{name}}/{{version}}: __MINGW32__\" << __MINGW32__<< \"\\n\";\n #endif\n\n #if __MINGW64__\n std::cout << \" {{name}}/{{version}}: __MINGW64__\" << __MINGW64__<< \"\\n\";\n #endif\n\n #if __CYGWIN__\n std::cout << \" {{name}}/{{version}}: __CYGWIN__\" << __CYGWIN__<< \"\\n\";\n #endif\n}\n\nvoid {{package_name}}_print_vector(const std::vector<std::string> &strings) {\n for(std::vector<std::string>::const_iterator it = strings.begin(); it != strings.end(); ++it) {\n std::cout << \"{{package_name}}/{{version}} \" << *it << std::endl;\n }\n}\n\"\"\"\n\n\ntest_conanfile_v2 = \"\"\"import os\n\nfrom conan import ConanFile\nfrom conan.tools.cmake import CMake, cmake_layout\nfrom conan.tools.build import can_run\n\n\nclass {{package_name}}TestConan(ConanFile):\n settings = \"os\", \"compiler\", \"build_type\", \"arch\"\n generators = \"CMakeDeps\", \"CMakeToolchain\"\n\n def requirements(self):\n self.requires(self.tested_reference_str)\n\n def build(self):\n cmake = CMake(self)\n cmake.configure()\n cmake.build()\n\n def layout(self):\n cmake_layout(self)\n\n def test(self):\n if can_run(self):\n cmd = os.path.join(self.cpp.build.bindir, \"example\")\n self.run(cmd, env=\"conanrun\")\n\"\"\"\n\ntest_cmake_v2 = \"\"\"cmake_minimum_required(VERSION 3.15)\nproject(PackageTest CXX)\n\nfind_package({{name}} CONFIG REQUIRED)\n\n{% if requires is defined -%}\n{% for require in requires -%}\nfind_package({{as_name(require)}} CONFIG REQUIRED)\n{% endfor %}\n{%- endif %}\n\nadd_executable(example src/example.cpp)\ntarget_link_libraries(example {{name}}::{{name}})\n\"\"\"\n\n\ntest_main = \"\"\"#include \"{{name}}.h\"\n#include <vector>\n#include <string>\n\nint main() {\n {{package_name}}();\n\n std::vector<std::string> vec;\n vec.push_back(\"test_package\");\n\n {{package_name}}_print_vector(vec);\n}\n\"\"\"\n\ncmake_lib_files = {\"conanfile.py\": conanfile_sources_v2,\n \"src/{{name}}.cpp\": source_cpp,\n \"include/{{name}}.h\": source_h,\n \"CMakeLists.txt\": cmake_v2,\n \"test_package/conanfile.py\": test_conanfile_v2,\n \"test_package/src/example.cpp\": test_main,\n \"test_package/CMakeLists.txt\": test_cmake_v2}\n", "path": "conan/internal/api/new/cmake_lib.py"}, {"content": "CHECKSUM_DEPLOY = \"checksum_deploy\" # Only when v2\nREVISIONS = \"revisions\" # Only when enabled in config, not by default look at server_launcher.py\nOAUTH_TOKEN = \"oauth_token\"\n\n__version__ = '2.4.1'\n", "path": "conans/__init__.py"}], "after_files": [{"content": "conanfile_sources_v2 = '''from conan import ConanFile\nfrom conan.tools.cmake import CMakeToolchain, CMake, cmake_layout, CMakeDeps\n\n\nclass {{package_name}}Recipe(ConanFile):\n name = \"{{name}}\"\n version = \"{{version}}\"\n package_type = \"library\"\n\n # Optional metadata\n license = \"<Put the package license here>\"\n author = \"<Put your name here> <And your email here>\"\n url = \"<Package recipe repository url here, for issues about the package>\"\n description = \"<Description of {{ name }} package here>\"\n topics = (\"<Put some tag here>\", \"<here>\", \"<and here>\")\n\n # Binary configuration\n settings = \"os\", \"compiler\", \"build_type\", \"arch\"\n options = {\"shared\": [True, False], \"fPIC\": [True, False]}\n default_options = {\"shared\": False, \"fPIC\": True}\n\n # Sources are located in the same place as this recipe, copy them to the recipe\n exports_sources = \"CMakeLists.txt\", \"src/*\", \"include/*\"\n\n def config_options(self):\n if self.settings.os == \"Windows\":\n self.options.rm_safe(\"fPIC\")\n\n def configure(self):\n if self.options.shared:\n self.options.rm_safe(\"fPIC\")\n\n def layout(self):\n cmake_layout(self)\n {% if requires is defined %}\n def requirements(self):\n {% for require in requires -%}\n self.requires(\"{{ require }}\")\n {% endfor %}\n {%- endif %}\n {%- if tool_requires is defined %}\n def build_requirements(self):\n {% for require in tool_requires -%}\n self.tool_requires(\"{{ require }}\")\n {% endfor %}\n {%- endif %}\n def generate(self):\n deps = CMakeDeps(self)\n deps.generate()\n tc = CMakeToolchain(self)\n tc.generate()\n\n def build(self):\n cmake = CMake(self)\n cmake.configure()\n cmake.build()\n\n def package(self):\n cmake = CMake(self)\n cmake.install()\n\n def package_info(self):\n self.cpp_info.libs = [\"{{name}}\"]\n\n'''\n\ncmake_v2 = \"\"\"cmake_minimum_required(VERSION 3.15)\nproject({{name}} CXX)\n\n{% if requires is defined -%}\n{% for require in requires -%}\nfind_package({{as_name(require)}} CONFIG REQUIRED)\n{% endfor %}\n{%- endif %}\n\n\nadd_library({{name}} src/{{name}}.cpp)\ntarget_include_directories({{name}} PUBLIC include)\n\n{% if requires is defined -%}\n{% for require in requires -%}\ntarget_link_libraries({{name}} PRIVATE {{as_name(require)}}::{{as_name(require)}})\n{% endfor %}\n{%- endif %}\n\nset_target_properties({{name}} PROPERTIES PUBLIC_HEADER \"include/{{name}}.h\")\ninstall(TARGETS {{name}})\n\"\"\"\n\nsource_h = \"\"\"#pragma once\n\n#include <vector>\n#include <string>\n\n{% set define_name = package_name.upper() %}\n#ifdef _WIN32\n #define {{define_name}}_EXPORT __declspec(dllexport)\n#else\n #define {{define_name}}_EXPORT\n#endif\n\n{{define_name}}_EXPORT void {{package_name}}();\n{{define_name}}_EXPORT void {{package_name}}_print_vector(const std::vector<std::string> &strings);\n\"\"\"\n\nsource_cpp = r\"\"\"#include <iostream>\n#include \"{{name}}.h\"\n{% if requires is defined -%}\n{% for require in requires -%}\n#include \"{{ as_name(require) }}.h\"\n{% endfor %}\n{%- endif %}\n\n\nvoid {{package_name}}(){\n {% if requires is defined -%}\n {% for require in requires -%}\n {{ as_name(require) }}();\n {% endfor %}\n {%- endif %}\n\n #ifdef NDEBUG\n std::cout << \"{{name}}/{{version}}: Hello World Release!\\n\";\n #else\n std::cout << \"{{name}}/{{version}}: Hello World Debug!\\n\";\n #endif\n\n // ARCHITECTURES\n #ifdef _M_X64\n std::cout << \" {{name}}/{{version}}: _M_X64 defined\\n\";\n #endif\n\n #ifdef _M_IX86\n std::cout << \" {{name}}/{{version}}: _M_IX86 defined\\n\";\n #endif\n\n #ifdef _M_ARM64\n std::cout << \" {{name}}/{{version}}: _M_ARM64 defined\\n\";\n #endif\n\n #if __i386__\n std::cout << \" {{name}}/{{version}}: __i386__ defined\\n\";\n #endif\n\n #if __x86_64__\n std::cout << \" {{name}}/{{version}}: __x86_64__ defined\\n\";\n #endif\n\n #if __aarch64__\n std::cout << \" {{name}}/{{version}}: __aarch64__ defined\\n\";\n #endif\n\n // Libstdc++\n #if defined _GLIBCXX_USE_CXX11_ABI\n std::cout << \" {{name}}/{{version}}: _GLIBCXX_USE_CXX11_ABI \"<< _GLIBCXX_USE_CXX11_ABI << \"\\n\";\n #endif\n\n // MSVC runtime\n #if defined(_DEBUG)\n #if defined(_MT) && defined(_DLL)\n std::cout << \" {{name}}/{{version}}: MSVC runtime: MultiThreadedDebugDLL\\n\";\n #elif defined(_MT)\n std::cout << \" {{name}}/{{version}}: MSVC runtime: MultiThreadedDebug\\n\";\n #endif\n #else\n #if defined(_MT) && defined(_DLL)\n std::cout << \" {{name}}/{{version}}: MSVC runtime: MultiThreadedDLL\\n\";\n #elif defined(_MT)\n std::cout << \" {{name}}/{{version}}: MSVC runtime: MultiThreaded\\n\";\n #endif\n #endif\n\n // COMPILER VERSIONS\n #if _MSC_VER\n std::cout << \" {{name}}/{{version}}: _MSC_VER\" << _MSC_VER<< \"\\n\";\n #endif\n\n #if _MSVC_LANG\n std::cout << \" {{name}}/{{version}}: _MSVC_LANG\" << _MSVC_LANG<< \"\\n\";\n #endif\n\n #if __cplusplus\n std::cout << \" {{name}}/{{version}}: __cplusplus\" << __cplusplus<< \"\\n\";\n #endif\n\n #if __INTEL_COMPILER\n std::cout << \" {{name}}/{{version}}: __INTEL_COMPILER\" << __INTEL_COMPILER<< \"\\n\";\n #endif\n\n #if __GNUC__\n std::cout << \" {{name}}/{{version}}: __GNUC__\" << __GNUC__<< \"\\n\";\n #endif\n\n #if __GNUC_MINOR__\n std::cout << \" {{name}}/{{version}}: __GNUC_MINOR__\" << __GNUC_MINOR__<< \"\\n\";\n #endif\n\n #if __clang_major__\n std::cout << \" {{name}}/{{version}}: __clang_major__\" << __clang_major__<< \"\\n\";\n #endif\n\n #if __clang_minor__\n std::cout << \" {{name}}/{{version}}: __clang_minor__\" << __clang_minor__<< \"\\n\";\n #endif\n\n #if __apple_build_version__\n std::cout << \" {{name}}/{{version}}: __apple_build_version__\" << __apple_build_version__<< \"\\n\";\n #endif\n\n // SUBSYSTEMS\n\n #if __MSYS__\n std::cout << \" {{name}}/{{version}}: __MSYS__\" << __MSYS__<< \"\\n\";\n #endif\n\n #if __MINGW32__\n std::cout << \" {{name}}/{{version}}: __MINGW32__\" << __MINGW32__<< \"\\n\";\n #endif\n\n #if __MINGW64__\n std::cout << \" {{name}}/{{version}}: __MINGW64__\" << __MINGW64__<< \"\\n\";\n #endif\n\n #if __CYGWIN__\n std::cout << \" {{name}}/{{version}}: __CYGWIN__\" << __CYGWIN__<< \"\\n\";\n #endif\n}\n\nvoid {{package_name}}_print_vector(const std::vector<std::string> &strings) {\n for(std::vector<std::string>::const_iterator it = strings.begin(); it != strings.end(); ++it) {\n std::cout << \"{{package_name}}/{{version}} \" << *it << std::endl;\n }\n}\n\"\"\"\n\n\ntest_conanfile_v2 = \"\"\"import os\n\nfrom conan import ConanFile\nfrom conan.tools.cmake import CMake, cmake_layout\nfrom conan.tools.build import can_run\n\n\nclass {{package_name}}TestConan(ConanFile):\n settings = \"os\", \"compiler\", \"build_type\", \"arch\"\n generators = \"CMakeDeps\", \"CMakeToolchain\"\n\n def requirements(self):\n self.requires(self.tested_reference_str)\n\n def build(self):\n cmake = CMake(self)\n cmake.configure()\n cmake.build()\n\n def layout(self):\n cmake_layout(self)\n\n def test(self):\n if can_run(self):\n cmd = os.path.join(self.cpp.build.bindir, \"example\")\n self.run(cmd, env=\"conanrun\")\n\"\"\"\n\ntest_cmake_v2 = \"\"\"cmake_minimum_required(VERSION 3.15)\nproject(PackageTest CXX)\n\nfind_package({{name}} CONFIG REQUIRED)\n\nadd_executable(example src/example.cpp)\ntarget_link_libraries(example {{name}}::{{name}})\n\"\"\"\n\n\ntest_main = \"\"\"#include \"{{name}}.h\"\n#include <vector>\n#include <string>\n\nint main() {\n {{package_name}}();\n\n std::vector<std::string> vec;\n vec.push_back(\"test_package\");\n\n {{package_name}}_print_vector(vec);\n}\n\"\"\"\n\ncmake_lib_files = {\"conanfile.py\": conanfile_sources_v2,\n \"src/{{name}}.cpp\": source_cpp,\n \"include/{{name}}.h\": source_h,\n \"CMakeLists.txt\": cmake_v2,\n \"test_package/conanfile.py\": test_conanfile_v2,\n \"test_package/src/example.cpp\": test_main,\n \"test_package/CMakeLists.txt\": test_cmake_v2}\n", "path": "conan/internal/api/new/cmake_lib.py"}, {"content": "CHECKSUM_DEPLOY = \"checksum_deploy\" # Only when v2\nREVISIONS = \"revisions\" # Only when enabled in config, not by default look at server_launcher.py\nOAUTH_TOKEN = \"oauth_token\"\n\n__version__ = '2.4.1'\n", "path": "conans/__init__.py"}]}
| 3,879 | 526 |
gh_patches_debug_36944
|
rasdani/github-patches
|
git_diff
|
paperless-ngx__paperless-ngx-903
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[BUG] Password reset after docker container restarted
*Copy from old repository*: https://github.com/jonaswinkler/paperless-ng/issues/1511
**Describe the bug**
I deployed Paperless-NG in TrueNAS via the TrueCharts integration. TrueCharts uses the official docker container and passes environment variables to configure the superuser.
I changed the admin password in the Django admin interface. However, after redeploying the application (for example due to an update) the password gets overridden by the initial password passed via environment variable.
**To Reproduce**
Steps to reproduce the behavior:
1. Deploy Paperless with credentials admin//secret
2. Open Paperless
3. Navigate to admin interface
4. Change password to "mysupersecretpassword"
5. Restart/update the docker container
6. Navigate to Paperless and try to login with admin/mysupersecretpassword
7. You can't login.
**Expected behavior**
The admin password should not be overridden by the initial password.
**Relevant information**
- Version
- Installation method: **docker**
- Any configuration changes you made in `docker-compose.yml`, `docker-compose.env` or `paperless.conf`. -
I think this is related to the admin user password reset when the docker container is started:
docker-entrypoint.sh calls docker-prepare.sh calls the manage_superuser mgmt command and there the password is updated:
https://github.com/jonaswinkler/paperless-ng/blob/master/src/documents/management/commands/manage_superuser.py#L29
Am I missing something?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/documents/management/commands/manage_superuser.py`
Content:
```
1 import logging
2 import os
3
4 from django.contrib.auth.models import User
5 from django.core.management.base import BaseCommand
6
7
8 logger = logging.getLogger("paperless.management.superuser")
9
10
11 class Command(BaseCommand):
12
13 help = """
14 Creates a Django superuser based on env variables.
15 """.replace(
16 " ",
17 "",
18 )
19
20 def handle(self, *args, **options):
21
22 username = os.getenv("PAPERLESS_ADMIN_USER")
23 if not username:
24 return
25
26 mail = os.getenv("PAPERLESS_ADMIN_MAIL", "root@localhost")
27 password = os.getenv("PAPERLESS_ADMIN_PASSWORD")
28
29 # Check if user exists already, leave as is if it does
30 if User.objects.filter(username=username).exists():
31 user: User = User.objects.get_by_natural_key(username)
32 user.set_password(password)
33 user.save()
34 self.stdout.write(f"Changed password of user {username}.")
35 elif password:
36 # Create superuser based on env variables
37 User.objects.create_superuser(username, mail, password)
38 self.stdout.write(f'Created superuser "{username}" with provided password.')
39 else:
40 self.stdout.write(f'Did not create superuser "{username}".')
41 self.stdout.write(
42 'Make sure you specified "PAPERLESS_ADMIN_PASSWORD" in your '
43 '"docker-compose.env" file.',
44 )
45
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/documents/management/commands/manage_superuser.py b/src/documents/management/commands/manage_superuser.py
--- a/src/documents/management/commands/manage_superuser.py
+++ b/src/documents/management/commands/manage_superuser.py
@@ -11,7 +11,14 @@
class Command(BaseCommand):
help = """
- Creates a Django superuser based on env variables.
+ Creates a Django superuser:
+ User named: admin
+ Email: root@localhost
+ with password based on env variable.
+ No superuser will be created, when:
+ - The username is taken already exists
+ - A superuser already exists
+ - PAPERLESS_ADMIN_PASSWORD is not set
""".replace(
" ",
"",
@@ -19,26 +26,41 @@
def handle(self, *args, **options):
- username = os.getenv("PAPERLESS_ADMIN_USER")
- if not username:
- return
-
+ username = os.getenv("PAPERLESS_ADMIN_USER", "admin")
mail = os.getenv("PAPERLESS_ADMIN_MAIL", "root@localhost")
password = os.getenv("PAPERLESS_ADMIN_PASSWORD")
- # Check if user exists already, leave as is if it does
+ # Check if there's already a user called admin
if User.objects.filter(username=username).exists():
- user: User = User.objects.get_by_natural_key(username)
- user.set_password(password)
- user.save()
- self.stdout.write(f"Changed password of user {username}.")
- elif password:
- # Create superuser based on env variables
- User.objects.create_superuser(username, mail, password)
- self.stdout.write(f'Created superuser "{username}" with provided password.')
+ self.stdout.write(
+ self.style.NOTICE(
+ f"Did not create superuser, a user {username} already exists",
+ ),
+ )
+ return
+
+ # Check if any superuseruser
+ # exists already, leave as is if it does
+ if User.objects.filter(is_superuser=True).count() > 0:
+ self.stdout.write(
+ self.style.NOTICE(
+ "Did not create superuser, the DB already contains superusers",
+ ),
+ )
+ return
+
+ if password is None:
+ self.stdout.write(
+ self.style.ERROR(
+ "Please check if PAPERLESS_ADMIN_PASSWORD has been"
+ " set in the environment",
+ ),
+ )
else:
- self.stdout.write(f'Did not create superuser "{username}".')
+ # Create superuser with password based on env variable
+ User.objects.create_superuser(username, mail, password)
self.stdout.write(
- 'Make sure you specified "PAPERLESS_ADMIN_PASSWORD" in your '
- '"docker-compose.env" file.',
+ self.style.SUCCESS(
+ f'Created superuser "{username}" with provided password.',
+ ),
)
|
{"golden_diff": "diff --git a/src/documents/management/commands/manage_superuser.py b/src/documents/management/commands/manage_superuser.py\n--- a/src/documents/management/commands/manage_superuser.py\n+++ b/src/documents/management/commands/manage_superuser.py\n@@ -11,7 +11,14 @@\n class Command(BaseCommand):\n \n help = \"\"\"\n- Creates a Django superuser based on env variables.\n+ Creates a Django superuser:\n+ User named: admin\n+ Email: root@localhost\n+ with password based on env variable.\n+ No superuser will be created, when:\n+ - The username is taken already exists\n+ - A superuser already exists\n+ - PAPERLESS_ADMIN_PASSWORD is not set\n \"\"\".replace(\n \" \",\n \"\",\n@@ -19,26 +26,41 @@\n \n def handle(self, *args, **options):\n \n- username = os.getenv(\"PAPERLESS_ADMIN_USER\")\n- if not username:\n- return\n-\n+ username = os.getenv(\"PAPERLESS_ADMIN_USER\", \"admin\")\n mail = os.getenv(\"PAPERLESS_ADMIN_MAIL\", \"root@localhost\")\n password = os.getenv(\"PAPERLESS_ADMIN_PASSWORD\")\n \n- # Check if user exists already, leave as is if it does\n+ # Check if there's already a user called admin\n if User.objects.filter(username=username).exists():\n- user: User = User.objects.get_by_natural_key(username)\n- user.set_password(password)\n- user.save()\n- self.stdout.write(f\"Changed password of user {username}.\")\n- elif password:\n- # Create superuser based on env variables\n- User.objects.create_superuser(username, mail, password)\n- self.stdout.write(f'Created superuser \"{username}\" with provided password.')\n+ self.stdout.write(\n+ self.style.NOTICE(\n+ f\"Did not create superuser, a user {username} already exists\",\n+ ),\n+ )\n+ return\n+\n+ # Check if any superuseruser\n+ # exists already, leave as is if it does\n+ if User.objects.filter(is_superuser=True).count() > 0:\n+ self.stdout.write(\n+ self.style.NOTICE(\n+ \"Did not create superuser, the DB already contains superusers\",\n+ ),\n+ )\n+ return\n+\n+ if password is None:\n+ self.stdout.write(\n+ self.style.ERROR(\n+ \"Please check if PAPERLESS_ADMIN_PASSWORD has been\"\n+ \" set in the environment\",\n+ ),\n+ )\n else:\n- self.stdout.write(f'Did not create superuser \"{username}\".')\n+ # Create superuser with password based on env variable\n+ User.objects.create_superuser(username, mail, password)\n self.stdout.write(\n- 'Make sure you specified \"PAPERLESS_ADMIN_PASSWORD\" in your '\n- '\"docker-compose.env\" file.',\n+ self.style.SUCCESS(\n+ f'Created superuser \"{username}\" with provided password.',\n+ ),\n )\n", "issue": "[BUG] Password reset after docker container restarted\n*Copy from old repository*: https://github.com/jonaswinkler/paperless-ng/issues/1511\r\n\r\n**Describe the bug**\r\nI deployed Paperless-NG in TrueNAS via the TrueCharts integration. TrueCharts uses the official docker container and passes environment variables to configure the superuser.\r\n\r\nI changed the admin password in the Django admin interface. However, after redeploying the application (for example due to an update) the password gets overridden by the initial password passed via environment variable.\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Deploy Paperless with credentials admin//secret\r\n2. Open Paperless\r\n3. Navigate to admin interface\r\n4. Change password to \"mysupersecretpassword\"\r\n5. Restart/update the docker container\r\n6. Navigate to Paperless and try to login with admin/mysupersecretpassword\r\n7. You can't login.\r\n\r\n**Expected behavior**\r\nThe admin password should not be overridden by the initial password.\r\n\r\n**Relevant information**\r\n - Version \r\n - Installation method: **docker**\r\n - Any configuration changes you made in `docker-compose.yml`, `docker-compose.env` or `paperless.conf`. -\r\n\r\nI think this is related to the admin user password reset when the docker container is started:\r\ndocker-entrypoint.sh calls docker-prepare.sh calls the manage_superuser mgmt command and there the password is updated:\r\nhttps://github.com/jonaswinkler/paperless-ng/blob/master/src/documents/management/commands/manage_superuser.py#L29\r\n\r\nAm I missing something?\n", "before_files": [{"content": "import logging\nimport os\n\nfrom django.contrib.auth.models import User\nfrom django.core.management.base import BaseCommand\n\n\nlogger = logging.getLogger(\"paperless.management.superuser\")\n\n\nclass Command(BaseCommand):\n\n help = \"\"\"\n Creates a Django superuser based on env variables.\n \"\"\".replace(\n \" \",\n \"\",\n )\n\n def handle(self, *args, **options):\n\n username = os.getenv(\"PAPERLESS_ADMIN_USER\")\n if not username:\n return\n\n mail = os.getenv(\"PAPERLESS_ADMIN_MAIL\", \"root@localhost\")\n password = os.getenv(\"PAPERLESS_ADMIN_PASSWORD\")\n\n # Check if user exists already, leave as is if it does\n if User.objects.filter(username=username).exists():\n user: User = User.objects.get_by_natural_key(username)\n user.set_password(password)\n user.save()\n self.stdout.write(f\"Changed password of user {username}.\")\n elif password:\n # Create superuser based on env variables\n User.objects.create_superuser(username, mail, password)\n self.stdout.write(f'Created superuser \"{username}\" with provided password.')\n else:\n self.stdout.write(f'Did not create superuser \"{username}\".')\n self.stdout.write(\n 'Make sure you specified \"PAPERLESS_ADMIN_PASSWORD\" in your '\n '\"docker-compose.env\" file.',\n )\n", "path": "src/documents/management/commands/manage_superuser.py"}], "after_files": [{"content": "import logging\nimport os\n\nfrom django.contrib.auth.models import User\nfrom django.core.management.base import BaseCommand\n\n\nlogger = logging.getLogger(\"paperless.management.superuser\")\n\n\nclass Command(BaseCommand):\n\n help = \"\"\"\n Creates a Django superuser:\n User named: admin\n Email: root@localhost\n with password based on env variable.\n No superuser will be created, when:\n - The username is taken already exists\n - A superuser already exists\n - PAPERLESS_ADMIN_PASSWORD is not set\n \"\"\".replace(\n \" \",\n \"\",\n )\n\n def handle(self, *args, **options):\n\n username = os.getenv(\"PAPERLESS_ADMIN_USER\", \"admin\")\n mail = os.getenv(\"PAPERLESS_ADMIN_MAIL\", \"root@localhost\")\n password = os.getenv(\"PAPERLESS_ADMIN_PASSWORD\")\n\n # Check if there's already a user called admin\n if User.objects.filter(username=username).exists():\n self.stdout.write(\n self.style.NOTICE(\n f\"Did not create superuser, a user {username} already exists\",\n ),\n )\n return\n\n # Check if any superuseruser\n # exists already, leave as is if it does\n if User.objects.filter(is_superuser=True).count() > 0:\n self.stdout.write(\n self.style.NOTICE(\n \"Did not create superuser, the DB already contains superusers\",\n ),\n )\n return\n\n if password is None:\n self.stdout.write(\n self.style.ERROR(\n \"Please check if PAPERLESS_ADMIN_PASSWORD has been\"\n \" set in the environment\",\n ),\n )\n else:\n # Create superuser with password based on env variable\n User.objects.create_superuser(username, mail, password)\n self.stdout.write(\n self.style.SUCCESS(\n f'Created superuser \"{username}\" with provided password.',\n ),\n )\n", "path": "src/documents/management/commands/manage_superuser.py"}]}
| 960 | 658 |
gh_patches_debug_1384
|
rasdani/github-patches
|
git_diff
|
huggingface__text-generation-inference-1182
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Update Docker to torch 2.1?
### Feature request
H100s have trouble with gptq quants due to not having latest pytorch, can in the next TGI Docker we update torch to this, or have one special for this for use on h100s?
### Motivation
Cant get tgi + gptq quant to work on h100s
### Your contribution
Sorry I dont have any contribution ^_^
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `integration-tests/conftest.py`
Content:
```
1 import sys
2 import subprocess
3 import contextlib
4 import pytest
5 import asyncio
6 import os
7 import docker
8 import json
9 import math
10 import time
11 import random
12
13 from docker.errors import NotFound
14 from typing import Optional, List, Dict
15 from syrupy.extensions.json import JSONSnapshotExtension
16 from aiohttp import ClientConnectorError, ClientOSError, ServerDisconnectedError
17
18 from text_generation import AsyncClient
19 from text_generation.types import Response, Details, InputToken, Token, BestOfSequence
20
21 DOCKER_IMAGE = os.getenv("DOCKER_IMAGE", None)
22 HUGGING_FACE_HUB_TOKEN = os.getenv("HUGGING_FACE_HUB_TOKEN", None)
23 DOCKER_VOLUME = os.getenv("DOCKER_VOLUME", "/data")
24
25
26 class ResponseComparator(JSONSnapshotExtension):
27 def serialize(
28 self,
29 data,
30 *,
31 exclude=None,
32 matcher=None,
33 ):
34 if isinstance(data, List):
35 data = [d.dict() for d in data]
36
37 data = self._filter(
38 data=data, depth=0, path=(), exclude=exclude, matcher=matcher
39 )
40 return json.dumps(data, indent=2, ensure_ascii=False, sort_keys=False) + "\n"
41
42 def matches(
43 self,
44 *,
45 serialized_data,
46 snapshot_data,
47 ) -> bool:
48 def convert_data(data):
49 data = json.loads(data)
50
51 if isinstance(data, Dict):
52 return Response(**data)
53 if isinstance(data, List):
54 return [Response(**d) for d in data]
55 raise NotImplementedError
56
57 def eq_token(token: Token, other: Token) -> bool:
58 return (
59 token.id == other.id
60 and token.text == other.text
61 and math.isclose(token.logprob, other.logprob, rel_tol=0.2)
62 and token.special == other.special
63 )
64
65 def eq_prefill_token(prefill_token: InputToken, other: InputToken) -> bool:
66 try:
67 return (
68 prefill_token.id == other.id
69 and prefill_token.text == other.text
70 and (
71 math.isclose(prefill_token.logprob, other.logprob, rel_tol=0.2)
72 if prefill_token.logprob is not None
73 else prefill_token.logprob == other.logprob
74 )
75 )
76 except TypeError:
77 return False
78
79 def eq_best_of(details: BestOfSequence, other: BestOfSequence) -> bool:
80 return (
81 details.finish_reason == other.finish_reason
82 and details.generated_tokens == other.generated_tokens
83 and details.seed == other.seed
84 and len(details.prefill) == len(other.prefill)
85 and all(
86 [
87 eq_prefill_token(d, o)
88 for d, o in zip(details.prefill, other.prefill)
89 ]
90 )
91 and len(details.tokens) == len(other.tokens)
92 and all([eq_token(d, o) for d, o in zip(details.tokens, other.tokens)])
93 )
94
95 def eq_details(details: Details, other: Details) -> bool:
96 return (
97 details.finish_reason == other.finish_reason
98 and details.generated_tokens == other.generated_tokens
99 and details.seed == other.seed
100 and len(details.prefill) == len(other.prefill)
101 and all(
102 [
103 eq_prefill_token(d, o)
104 for d, o in zip(details.prefill, other.prefill)
105 ]
106 )
107 and len(details.tokens) == len(other.tokens)
108 and all([eq_token(d, o) for d, o in zip(details.tokens, other.tokens)])
109 and (
110 len(details.best_of_sequences)
111 if details.best_of_sequences is not None
112 else 0
113 )
114 == (
115 len(other.best_of_sequences)
116 if other.best_of_sequences is not None
117 else 0
118 )
119 and (
120 all(
121 [
122 eq_best_of(d, o)
123 for d, o in zip(
124 details.best_of_sequences, other.best_of_sequences
125 )
126 ]
127 )
128 if details.best_of_sequences is not None
129 else details.best_of_sequences == other.best_of_sequences
130 )
131 )
132
133 def eq_response(response: Response, other: Response) -> bool:
134 return response.generated_text == other.generated_text and eq_details(
135 response.details, other.details
136 )
137
138 serialized_data = convert_data(serialized_data)
139 snapshot_data = convert_data(snapshot_data)
140
141 if not isinstance(serialized_data, List):
142 serialized_data = [serialized_data]
143 if not isinstance(snapshot_data, List):
144 snapshot_data = [snapshot_data]
145
146 return len(snapshot_data) == len(serialized_data) and all(
147 [eq_response(r, o) for r, o in zip(serialized_data, snapshot_data)]
148 )
149
150
151 class LauncherHandle:
152 def __init__(self, port: int):
153 self.client = AsyncClient(f"http://localhost:{port}")
154
155 def _inner_health(self):
156 raise NotImplementedError
157
158 async def health(self, timeout: int = 60):
159 assert timeout > 0
160 for _ in range(timeout):
161 if not self._inner_health():
162 raise RuntimeError("Launcher crashed")
163
164 try:
165 await self.client.generate("test")
166 return
167 except (ClientConnectorError, ClientOSError, ServerDisconnectedError) as e:
168 time.sleep(1)
169 raise RuntimeError("Health check failed")
170
171
172 class ContainerLauncherHandle(LauncherHandle):
173 def __init__(self, docker_client, container_name, port: int):
174 super(ContainerLauncherHandle, self).__init__(port)
175 self.docker_client = docker_client
176 self.container_name = container_name
177
178 def _inner_health(self) -> bool:
179 container = self.docker_client.containers.get(self.container_name)
180 return container.status in ["running", "created"]
181
182
183 class ProcessLauncherHandle(LauncherHandle):
184 def __init__(self, process, port: int):
185 super(ProcessLauncherHandle, self).__init__(port)
186 self.process = process
187
188 def _inner_health(self) -> bool:
189 return self.process.poll() is None
190
191
192 @pytest.fixture
193 def response_snapshot(snapshot):
194 return snapshot.use_extension(ResponseComparator)
195
196
197 @pytest.fixture(scope="module")
198 def event_loop():
199 loop = asyncio.get_event_loop()
200 yield loop
201 loop.close()
202
203
204 @pytest.fixture(scope="module")
205 def launcher(event_loop):
206 @contextlib.contextmanager
207 def local_launcher(
208 model_id: str,
209 num_shard: Optional[int] = None,
210 quantize: Optional[str] = None,
211 trust_remote_code: bool = False,
212 use_flash_attention: bool = True,
213 ):
214 port = random.randint(8000, 10_000)
215 master_port = random.randint(10_000, 20_000)
216
217 shard_uds_path = (
218 f"/tmp/tgi-tests-{model_id.split('/')[-1]}-{num_shard}-{quantize}-server"
219 )
220
221 args = [
222 "text-generation-launcher",
223 "--model-id",
224 model_id,
225 "--port",
226 str(port),
227 "--master-port",
228 str(master_port),
229 "--shard-uds-path",
230 shard_uds_path,
231 ]
232
233 env = os.environ
234
235 if num_shard is not None:
236 args.extend(["--num-shard", str(num_shard)])
237 if quantize is not None:
238 args.append("--quantize")
239 args.append(quantize)
240 if trust_remote_code:
241 args.append("--trust-remote-code")
242
243 env["LOG_LEVEL"] = "info,text_generation_router=debug"
244
245 if not use_flash_attention:
246 env["USE_FLASH_ATTENTION"] = "false"
247
248 with subprocess.Popen(
249 args, stdout=subprocess.PIPE, stderr=subprocess.PIPE, env=env
250 ) as process:
251 yield ProcessLauncherHandle(process, port)
252
253 process.terminate()
254 process.wait(60)
255
256 launcher_output = process.stdout.read().decode("utf-8")
257 print(launcher_output, file=sys.stderr)
258
259 process.stdout.close()
260 process.stderr.close()
261
262 if not use_flash_attention:
263 del env["USE_FLASH_ATTENTION"]
264
265 @contextlib.contextmanager
266 def docker_launcher(
267 model_id: str,
268 num_shard: Optional[int] = None,
269 quantize: Optional[str] = None,
270 trust_remote_code: bool = False,
271 use_flash_attention: bool = True,
272 ):
273 port = random.randint(8000, 10_000)
274
275 args = ["--model-id", model_id, "--env"]
276
277 if num_shard is not None:
278 args.extend(["--num-shard", str(num_shard)])
279 if quantize is not None:
280 args.append("--quantize")
281 args.append(quantize)
282 if trust_remote_code:
283 args.append("--trust-remote-code")
284
285 client = docker.from_env()
286
287 container_name = f"tgi-tests-{model_id.split('/')[-1]}-{num_shard}-{quantize}"
288
289 try:
290 container = client.containers.get(container_name)
291 container.stop()
292 container.wait()
293 except NotFound:
294 pass
295
296 gpu_count = num_shard if num_shard is not None else 1
297
298 env = {"LOG_LEVEL": "info,text_generation_router=debug"}
299 if not use_flash_attention:
300 env["USE_FLASH_ATTENTION"] = "false"
301
302 if HUGGING_FACE_HUB_TOKEN is not None:
303 env["HUGGING_FACE_HUB_TOKEN"] = HUGGING_FACE_HUB_TOKEN
304
305 volumes = []
306 if DOCKER_VOLUME:
307 volumes = [f"{DOCKER_VOLUME}:/data"]
308
309 container = client.containers.run(
310 DOCKER_IMAGE,
311 command=args,
312 name=container_name,
313 environment=env,
314 auto_remove=False,
315 detach=True,
316 device_requests=[
317 docker.types.DeviceRequest(count=gpu_count, capabilities=[["gpu"]])
318 ],
319 volumes=volumes,
320 ports={"80/tcp": port},
321 )
322
323 yield ContainerLauncherHandle(client, container.name, port)
324
325 if not use_flash_attention:
326 del env["USE_FLASH_ATTENTION"]
327
328 try:
329 container.stop()
330 container.wait()
331 except NotFound:
332 pass
333
334 container_output = container.logs().decode("utf-8")
335 print(container_output, file=sys.stderr)
336
337 container.remove()
338
339 if DOCKER_IMAGE is not None:
340 return docker_launcher
341 return local_launcher
342
343
344 @pytest.fixture(scope="module")
345 def generate_load():
346 async def generate_load_inner(
347 client: AsyncClient, prompt: str, max_new_tokens: int, n: int
348 ) -> List[Response]:
349 futures = [
350 client.generate(
351 prompt, max_new_tokens=max_new_tokens, decoder_input_details=True
352 )
353 for _ in range(n)
354 ]
355
356 return await asyncio.gather(*futures)
357
358 return generate_load_inner
359
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/integration-tests/conftest.py b/integration-tests/conftest.py
--- a/integration-tests/conftest.py
+++ b/integration-tests/conftest.py
@@ -318,6 +318,7 @@
],
volumes=volumes,
ports={"80/tcp": port},
+ shm_size="1G"
)
yield ContainerLauncherHandle(client, container.name, port)
|
{"golden_diff": "diff --git a/integration-tests/conftest.py b/integration-tests/conftest.py\n--- a/integration-tests/conftest.py\n+++ b/integration-tests/conftest.py\n@@ -318,6 +318,7 @@\n ],\n volumes=volumes,\n ports={\"80/tcp\": port},\n+ shm_size=\"1G\"\n )\n \n yield ContainerLauncherHandle(client, container.name, port)\n", "issue": "Update Docker to torch 2.1?\n### Feature request\n\nH100s have trouble with gptq quants due to not having latest pytorch, can in the next TGI Docker we update torch to this, or have one special for this for use on h100s? \n\n### Motivation\n\nCant get tgi + gptq quant to work on h100s\n\n### Your contribution\n\nSorry I dont have any contribution ^_^ \n", "before_files": [{"content": "import sys\nimport subprocess\nimport contextlib\nimport pytest\nimport asyncio\nimport os\nimport docker\nimport json\nimport math\nimport time\nimport random\n\nfrom docker.errors import NotFound\nfrom typing import Optional, List, Dict\nfrom syrupy.extensions.json import JSONSnapshotExtension\nfrom aiohttp import ClientConnectorError, ClientOSError, ServerDisconnectedError\n\nfrom text_generation import AsyncClient\nfrom text_generation.types import Response, Details, InputToken, Token, BestOfSequence\n\nDOCKER_IMAGE = os.getenv(\"DOCKER_IMAGE\", None)\nHUGGING_FACE_HUB_TOKEN = os.getenv(\"HUGGING_FACE_HUB_TOKEN\", None)\nDOCKER_VOLUME = os.getenv(\"DOCKER_VOLUME\", \"/data\")\n\n\nclass ResponseComparator(JSONSnapshotExtension):\n def serialize(\n self,\n data,\n *,\n exclude=None,\n matcher=None,\n ):\n if isinstance(data, List):\n data = [d.dict() for d in data]\n\n data = self._filter(\n data=data, depth=0, path=(), exclude=exclude, matcher=matcher\n )\n return json.dumps(data, indent=2, ensure_ascii=False, sort_keys=False) + \"\\n\"\n\n def matches(\n self,\n *,\n serialized_data,\n snapshot_data,\n ) -> bool:\n def convert_data(data):\n data = json.loads(data)\n\n if isinstance(data, Dict):\n return Response(**data)\n if isinstance(data, List):\n return [Response(**d) for d in data]\n raise NotImplementedError\n\n def eq_token(token: Token, other: Token) -> bool:\n return (\n token.id == other.id\n and token.text == other.text\n and math.isclose(token.logprob, other.logprob, rel_tol=0.2)\n and token.special == other.special\n )\n\n def eq_prefill_token(prefill_token: InputToken, other: InputToken) -> bool:\n try:\n return (\n prefill_token.id == other.id\n and prefill_token.text == other.text\n and (\n math.isclose(prefill_token.logprob, other.logprob, rel_tol=0.2)\n if prefill_token.logprob is not None\n else prefill_token.logprob == other.logprob\n )\n )\n except TypeError:\n return False\n\n def eq_best_of(details: BestOfSequence, other: BestOfSequence) -> bool:\n return (\n details.finish_reason == other.finish_reason\n and details.generated_tokens == other.generated_tokens\n and details.seed == other.seed\n and len(details.prefill) == len(other.prefill)\n and all(\n [\n eq_prefill_token(d, o)\n for d, o in zip(details.prefill, other.prefill)\n ]\n )\n and len(details.tokens) == len(other.tokens)\n and all([eq_token(d, o) for d, o in zip(details.tokens, other.tokens)])\n )\n\n def eq_details(details: Details, other: Details) -> bool:\n return (\n details.finish_reason == other.finish_reason\n and details.generated_tokens == other.generated_tokens\n and details.seed == other.seed\n and len(details.prefill) == len(other.prefill)\n and all(\n [\n eq_prefill_token(d, o)\n for d, o in zip(details.prefill, other.prefill)\n ]\n )\n and len(details.tokens) == len(other.tokens)\n and all([eq_token(d, o) for d, o in zip(details.tokens, other.tokens)])\n and (\n len(details.best_of_sequences)\n if details.best_of_sequences is not None\n else 0\n )\n == (\n len(other.best_of_sequences)\n if other.best_of_sequences is not None\n else 0\n )\n and (\n all(\n [\n eq_best_of(d, o)\n for d, o in zip(\n details.best_of_sequences, other.best_of_sequences\n )\n ]\n )\n if details.best_of_sequences is not None\n else details.best_of_sequences == other.best_of_sequences\n )\n )\n\n def eq_response(response: Response, other: Response) -> bool:\n return response.generated_text == other.generated_text and eq_details(\n response.details, other.details\n )\n\n serialized_data = convert_data(serialized_data)\n snapshot_data = convert_data(snapshot_data)\n\n if not isinstance(serialized_data, List):\n serialized_data = [serialized_data]\n if not isinstance(snapshot_data, List):\n snapshot_data = [snapshot_data]\n\n return len(snapshot_data) == len(serialized_data) and all(\n [eq_response(r, o) for r, o in zip(serialized_data, snapshot_data)]\n )\n\n\nclass LauncherHandle:\n def __init__(self, port: int):\n self.client = AsyncClient(f\"http://localhost:{port}\")\n\n def _inner_health(self):\n raise NotImplementedError\n\n async def health(self, timeout: int = 60):\n assert timeout > 0\n for _ in range(timeout):\n if not self._inner_health():\n raise RuntimeError(\"Launcher crashed\")\n\n try:\n await self.client.generate(\"test\")\n return\n except (ClientConnectorError, ClientOSError, ServerDisconnectedError) as e:\n time.sleep(1)\n raise RuntimeError(\"Health check failed\")\n\n\nclass ContainerLauncherHandle(LauncherHandle):\n def __init__(self, docker_client, container_name, port: int):\n super(ContainerLauncherHandle, self).__init__(port)\n self.docker_client = docker_client\n self.container_name = container_name\n\n def _inner_health(self) -> bool:\n container = self.docker_client.containers.get(self.container_name)\n return container.status in [\"running\", \"created\"]\n\n\nclass ProcessLauncherHandle(LauncherHandle):\n def __init__(self, process, port: int):\n super(ProcessLauncherHandle, self).__init__(port)\n self.process = process\n\n def _inner_health(self) -> bool:\n return self.process.poll() is None\n\n\[email protected]\ndef response_snapshot(snapshot):\n return snapshot.use_extension(ResponseComparator)\n\n\[email protected](scope=\"module\")\ndef event_loop():\n loop = asyncio.get_event_loop()\n yield loop\n loop.close()\n\n\[email protected](scope=\"module\")\ndef launcher(event_loop):\n @contextlib.contextmanager\n def local_launcher(\n model_id: str,\n num_shard: Optional[int] = None,\n quantize: Optional[str] = None,\n trust_remote_code: bool = False,\n use_flash_attention: bool = True,\n ):\n port = random.randint(8000, 10_000)\n master_port = random.randint(10_000, 20_000)\n\n shard_uds_path = (\n f\"/tmp/tgi-tests-{model_id.split('/')[-1]}-{num_shard}-{quantize}-server\"\n )\n\n args = [\n \"text-generation-launcher\",\n \"--model-id\",\n model_id,\n \"--port\",\n str(port),\n \"--master-port\",\n str(master_port),\n \"--shard-uds-path\",\n shard_uds_path,\n ]\n\n env = os.environ\n\n if num_shard is not None:\n args.extend([\"--num-shard\", str(num_shard)])\n if quantize is not None:\n args.append(\"--quantize\")\n args.append(quantize)\n if trust_remote_code:\n args.append(\"--trust-remote-code\")\n\n env[\"LOG_LEVEL\"] = \"info,text_generation_router=debug\"\n\n if not use_flash_attention:\n env[\"USE_FLASH_ATTENTION\"] = \"false\"\n\n with subprocess.Popen(\n args, stdout=subprocess.PIPE, stderr=subprocess.PIPE, env=env\n ) as process:\n yield ProcessLauncherHandle(process, port)\n\n process.terminate()\n process.wait(60)\n\n launcher_output = process.stdout.read().decode(\"utf-8\")\n print(launcher_output, file=sys.stderr)\n\n process.stdout.close()\n process.stderr.close()\n\n if not use_flash_attention:\n del env[\"USE_FLASH_ATTENTION\"]\n\n @contextlib.contextmanager\n def docker_launcher(\n model_id: str,\n num_shard: Optional[int] = None,\n quantize: Optional[str] = None,\n trust_remote_code: bool = False,\n use_flash_attention: bool = True,\n ):\n port = random.randint(8000, 10_000)\n\n args = [\"--model-id\", model_id, \"--env\"]\n\n if num_shard is not None:\n args.extend([\"--num-shard\", str(num_shard)])\n if quantize is not None:\n args.append(\"--quantize\")\n args.append(quantize)\n if trust_remote_code:\n args.append(\"--trust-remote-code\")\n\n client = docker.from_env()\n\n container_name = f\"tgi-tests-{model_id.split('/')[-1]}-{num_shard}-{quantize}\"\n\n try:\n container = client.containers.get(container_name)\n container.stop()\n container.wait()\n except NotFound:\n pass\n\n gpu_count = num_shard if num_shard is not None else 1\n\n env = {\"LOG_LEVEL\": \"info,text_generation_router=debug\"}\n if not use_flash_attention:\n env[\"USE_FLASH_ATTENTION\"] = \"false\"\n\n if HUGGING_FACE_HUB_TOKEN is not None:\n env[\"HUGGING_FACE_HUB_TOKEN\"] = HUGGING_FACE_HUB_TOKEN\n\n volumes = []\n if DOCKER_VOLUME:\n volumes = [f\"{DOCKER_VOLUME}:/data\"]\n\n container = client.containers.run(\n DOCKER_IMAGE,\n command=args,\n name=container_name,\n environment=env,\n auto_remove=False,\n detach=True,\n device_requests=[\n docker.types.DeviceRequest(count=gpu_count, capabilities=[[\"gpu\"]])\n ],\n volumes=volumes,\n ports={\"80/tcp\": port},\n )\n\n yield ContainerLauncherHandle(client, container.name, port)\n\n if not use_flash_attention:\n del env[\"USE_FLASH_ATTENTION\"]\n\n try:\n container.stop()\n container.wait()\n except NotFound:\n pass\n\n container_output = container.logs().decode(\"utf-8\")\n print(container_output, file=sys.stderr)\n\n container.remove()\n\n if DOCKER_IMAGE is not None:\n return docker_launcher\n return local_launcher\n\n\[email protected](scope=\"module\")\ndef generate_load():\n async def generate_load_inner(\n client: AsyncClient, prompt: str, max_new_tokens: int, n: int\n ) -> List[Response]:\n futures = [\n client.generate(\n prompt, max_new_tokens=max_new_tokens, decoder_input_details=True\n )\n for _ in range(n)\n ]\n\n return await asyncio.gather(*futures)\n\n return generate_load_inner\n", "path": "integration-tests/conftest.py"}], "after_files": [{"content": "import sys\nimport subprocess\nimport contextlib\nimport pytest\nimport asyncio\nimport os\nimport docker\nimport json\nimport math\nimport time\nimport random\n\nfrom docker.errors import NotFound\nfrom typing import Optional, List, Dict\nfrom syrupy.extensions.json import JSONSnapshotExtension\nfrom aiohttp import ClientConnectorError, ClientOSError, ServerDisconnectedError\n\nfrom text_generation import AsyncClient\nfrom text_generation.types import Response, Details, InputToken, Token, BestOfSequence\n\nDOCKER_IMAGE = os.getenv(\"DOCKER_IMAGE\", None)\nHUGGING_FACE_HUB_TOKEN = os.getenv(\"HUGGING_FACE_HUB_TOKEN\", None)\nDOCKER_VOLUME = os.getenv(\"DOCKER_VOLUME\", \"/data\")\n\n\nclass ResponseComparator(JSONSnapshotExtension):\n def serialize(\n self,\n data,\n *,\n exclude=None,\n matcher=None,\n ):\n if isinstance(data, List):\n data = [d.dict() for d in data]\n\n data = self._filter(\n data=data, depth=0, path=(), exclude=exclude, matcher=matcher\n )\n return json.dumps(data, indent=2, ensure_ascii=False, sort_keys=False) + \"\\n\"\n\n def matches(\n self,\n *,\n serialized_data,\n snapshot_data,\n ) -> bool:\n def convert_data(data):\n data = json.loads(data)\n\n if isinstance(data, Dict):\n return Response(**data)\n if isinstance(data, List):\n return [Response(**d) for d in data]\n raise NotImplementedError\n\n def eq_token(token: Token, other: Token) -> bool:\n return (\n token.id == other.id\n and token.text == other.text\n and math.isclose(token.logprob, other.logprob, rel_tol=0.2)\n and token.special == other.special\n )\n\n def eq_prefill_token(prefill_token: InputToken, other: InputToken) -> bool:\n try:\n return (\n prefill_token.id == other.id\n and prefill_token.text == other.text\n and (\n math.isclose(prefill_token.logprob, other.logprob, rel_tol=0.2)\n if prefill_token.logprob is not None\n else prefill_token.logprob == other.logprob\n )\n )\n except TypeError:\n return False\n\n def eq_best_of(details: BestOfSequence, other: BestOfSequence) -> bool:\n return (\n details.finish_reason == other.finish_reason\n and details.generated_tokens == other.generated_tokens\n and details.seed == other.seed\n and len(details.prefill) == len(other.prefill)\n and all(\n [\n eq_prefill_token(d, o)\n for d, o in zip(details.prefill, other.prefill)\n ]\n )\n and len(details.tokens) == len(other.tokens)\n and all([eq_token(d, o) for d, o in zip(details.tokens, other.tokens)])\n )\n\n def eq_details(details: Details, other: Details) -> bool:\n return (\n details.finish_reason == other.finish_reason\n and details.generated_tokens == other.generated_tokens\n and details.seed == other.seed\n and len(details.prefill) == len(other.prefill)\n and all(\n [\n eq_prefill_token(d, o)\n for d, o in zip(details.prefill, other.prefill)\n ]\n )\n and len(details.tokens) == len(other.tokens)\n and all([eq_token(d, o) for d, o in zip(details.tokens, other.tokens)])\n and (\n len(details.best_of_sequences)\n if details.best_of_sequences is not None\n else 0\n )\n == (\n len(other.best_of_sequences)\n if other.best_of_sequences is not None\n else 0\n )\n and (\n all(\n [\n eq_best_of(d, o)\n for d, o in zip(\n details.best_of_sequences, other.best_of_sequences\n )\n ]\n )\n if details.best_of_sequences is not None\n else details.best_of_sequences == other.best_of_sequences\n )\n )\n\n def eq_response(response: Response, other: Response) -> bool:\n return response.generated_text == other.generated_text and eq_details(\n response.details, other.details\n )\n\n serialized_data = convert_data(serialized_data)\n snapshot_data = convert_data(snapshot_data)\n\n if not isinstance(serialized_data, List):\n serialized_data = [serialized_data]\n if not isinstance(snapshot_data, List):\n snapshot_data = [snapshot_data]\n\n return len(snapshot_data) == len(serialized_data) and all(\n [eq_response(r, o) for r, o in zip(serialized_data, snapshot_data)]\n )\n\n\nclass LauncherHandle:\n def __init__(self, port: int):\n self.client = AsyncClient(f\"http://localhost:{port}\")\n\n def _inner_health(self):\n raise NotImplementedError\n\n async def health(self, timeout: int = 60):\n assert timeout > 0\n for _ in range(timeout):\n if not self._inner_health():\n raise RuntimeError(\"Launcher crashed\")\n\n try:\n await self.client.generate(\"test\")\n return\n except (ClientConnectorError, ClientOSError, ServerDisconnectedError) as e:\n time.sleep(1)\n raise RuntimeError(\"Health check failed\")\n\n\nclass ContainerLauncherHandle(LauncherHandle):\n def __init__(self, docker_client, container_name, port: int):\n super(ContainerLauncherHandle, self).__init__(port)\n self.docker_client = docker_client\n self.container_name = container_name\n\n def _inner_health(self) -> bool:\n container = self.docker_client.containers.get(self.container_name)\n return container.status in [\"running\", \"created\"]\n\n\nclass ProcessLauncherHandle(LauncherHandle):\n def __init__(self, process, port: int):\n super(ProcessLauncherHandle, self).__init__(port)\n self.process = process\n\n def _inner_health(self) -> bool:\n return self.process.poll() is None\n\n\[email protected]\ndef response_snapshot(snapshot):\n return snapshot.use_extension(ResponseComparator)\n\n\[email protected](scope=\"module\")\ndef event_loop():\n loop = asyncio.get_event_loop()\n yield loop\n loop.close()\n\n\[email protected](scope=\"module\")\ndef launcher(event_loop):\n @contextlib.contextmanager\n def local_launcher(\n model_id: str,\n num_shard: Optional[int] = None,\n quantize: Optional[str] = None,\n trust_remote_code: bool = False,\n use_flash_attention: bool = True,\n ):\n port = random.randint(8000, 10_000)\n master_port = random.randint(10_000, 20_000)\n\n shard_uds_path = (\n f\"/tmp/tgi-tests-{model_id.split('/')[-1]}-{num_shard}-{quantize}-server\"\n )\n\n args = [\n \"text-generation-launcher\",\n \"--model-id\",\n model_id,\n \"--port\",\n str(port),\n \"--master-port\",\n str(master_port),\n \"--shard-uds-path\",\n shard_uds_path,\n ]\n\n env = os.environ\n\n if num_shard is not None:\n args.extend([\"--num-shard\", str(num_shard)])\n if quantize is not None:\n args.append(\"--quantize\")\n args.append(quantize)\n if trust_remote_code:\n args.append(\"--trust-remote-code\")\n\n env[\"LOG_LEVEL\"] = \"info,text_generation_router=debug\"\n\n if not use_flash_attention:\n env[\"USE_FLASH_ATTENTION\"] = \"false\"\n\n with subprocess.Popen(\n args, stdout=subprocess.PIPE, stderr=subprocess.PIPE, env=env\n ) as process:\n yield ProcessLauncherHandle(process, port)\n\n process.terminate()\n process.wait(60)\n\n launcher_output = process.stdout.read().decode(\"utf-8\")\n print(launcher_output, file=sys.stderr)\n\n process.stdout.close()\n process.stderr.close()\n\n if not use_flash_attention:\n del env[\"USE_FLASH_ATTENTION\"]\n\n @contextlib.contextmanager\n def docker_launcher(\n model_id: str,\n num_shard: Optional[int] = None,\n quantize: Optional[str] = None,\n trust_remote_code: bool = False,\n use_flash_attention: bool = True,\n ):\n port = random.randint(8000, 10_000)\n\n args = [\"--model-id\", model_id, \"--env\"]\n\n if num_shard is not None:\n args.extend([\"--num-shard\", str(num_shard)])\n if quantize is not None:\n args.append(\"--quantize\")\n args.append(quantize)\n if trust_remote_code:\n args.append(\"--trust-remote-code\")\n\n client = docker.from_env()\n\n container_name = f\"tgi-tests-{model_id.split('/')[-1]}-{num_shard}-{quantize}\"\n\n try:\n container = client.containers.get(container_name)\n container.stop()\n container.wait()\n except NotFound:\n pass\n\n gpu_count = num_shard if num_shard is not None else 1\n\n env = {\"LOG_LEVEL\": \"info,text_generation_router=debug\"}\n if not use_flash_attention:\n env[\"USE_FLASH_ATTENTION\"] = \"false\"\n\n if HUGGING_FACE_HUB_TOKEN is not None:\n env[\"HUGGING_FACE_HUB_TOKEN\"] = HUGGING_FACE_HUB_TOKEN\n\n volumes = []\n if DOCKER_VOLUME:\n volumes = [f\"{DOCKER_VOLUME}:/data\"]\n\n container = client.containers.run(\n DOCKER_IMAGE,\n command=args,\n name=container_name,\n environment=env,\n auto_remove=False,\n detach=True,\n device_requests=[\n docker.types.DeviceRequest(count=gpu_count, capabilities=[[\"gpu\"]])\n ],\n volumes=volumes,\n ports={\"80/tcp\": port},\n shm_size=\"1G\"\n )\n\n yield ContainerLauncherHandle(client, container.name, port)\n\n if not use_flash_attention:\n del env[\"USE_FLASH_ATTENTION\"]\n\n try:\n container.stop()\n container.wait()\n except NotFound:\n pass\n\n container_output = container.logs().decode(\"utf-8\")\n print(container_output, file=sys.stderr)\n\n container.remove()\n\n if DOCKER_IMAGE is not None:\n return docker_launcher\n return local_launcher\n\n\[email protected](scope=\"module\")\ndef generate_load():\n async def generate_load_inner(\n client: AsyncClient, prompt: str, max_new_tokens: int, n: int\n ) -> List[Response]:\n futures = [\n client.generate(\n prompt, max_new_tokens=max_new_tokens, decoder_input_details=True\n )\n for _ in range(n)\n ]\n\n return await asyncio.gather(*futures)\n\n return generate_load_inner\n", "path": "integration-tests/conftest.py"}]}
| 3,676 | 93 |
gh_patches_debug_9140
|
rasdani/github-patches
|
git_diff
|
Lightning-AI__torchmetrics-1155
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
notation typo in Cosine Similarity docs
## 📚 Documentation
There is a typo in the notation for the [pairwise_cosine_similarity](https://torchmetrics.readthedocs.io/en/stable/pairwise/cosine_similarity.html)

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/torchmetrics/functional/pairwise/cosine.py`
Content:
```
1 # Copyright The PyTorch Lightning team.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 from typing import Optional
15
16 import torch
17 from torch import Tensor
18 from typing_extensions import Literal
19
20 from torchmetrics.functional.pairwise.helpers import _check_input, _reduce_distance_matrix
21 from torchmetrics.utilities.compute import _safe_matmul
22
23
24 def _pairwise_cosine_similarity_update(
25 x: Tensor, y: Optional[Tensor] = None, zero_diagonal: Optional[bool] = None
26 ) -> Tensor:
27 """Calculates the pairwise cosine similarity matrix.
28
29 Args:
30 x: tensor of shape ``[N,d]``
31 y: tensor of shape ``[M,d]``
32 zero_diagonal: determines if the diagonal of the distance matrix should be set to zero
33 """
34 x, y, zero_diagonal = _check_input(x, y, zero_diagonal)
35
36 norm = torch.norm(x, p=2, dim=1)
37 x /= norm.unsqueeze(1)
38 norm = torch.norm(y, p=2, dim=1)
39 y /= norm.unsqueeze(1)
40
41 distance = _safe_matmul(x, y)
42 if zero_diagonal:
43 distance.fill_diagonal_(0)
44 return distance
45
46
47 def pairwise_cosine_similarity(
48 x: Tensor,
49 y: Optional[Tensor] = None,
50 reduction: Literal["mean", "sum", "none", None] = None,
51 zero_diagonal: Optional[bool] = None,
52 ) -> Tensor:
53 r"""Calculates pairwise cosine similarity:
54
55 .. math::
56 s_{cos}(x,y) = \frac{<x,y>}{||x|| \cdot ||y||}
57 = \frac{\sum_{d=1}^D x_d \cdot y_d }{\sqrt{\sum_{d=1}^D x_i^2} \cdot \sqrt{\sum_{d=1}^D x_i^2}}
58
59 If both :math:`x` and :math:`y` are passed in, the calculation will be performed pairwise
60 between the rows of :math:`x` and :math:`y`.
61 If only :math:`x` is passed in, the calculation will be performed between the rows of :math:`x`.
62
63 Args:
64 x: Tensor with shape ``[N, d]``
65 y: Tensor with shape ``[M, d]``, optional
66 reduction: reduction to apply along the last dimension. Choose between `'mean'`, `'sum'`
67 (applied along column dimension) or `'none'`, `None` for no reduction
68 zero_diagonal: if the diagonal of the distance matrix should be set to 0. If only :math:`x` is given
69 this defaults to ``True`` else if :math:`y` is also given it defaults to ``False``
70
71 Returns:
72 A ``[N,N]`` matrix of distances if only ``x`` is given, else a ``[N,M]`` matrix
73
74 Example:
75 >>> import torch
76 >>> from torchmetrics.functional import pairwise_cosine_similarity
77 >>> x = torch.tensor([[2, 3], [3, 5], [5, 8]], dtype=torch.float32)
78 >>> y = torch.tensor([[1, 0], [2, 1]], dtype=torch.float32)
79 >>> pairwise_cosine_similarity(x, y)
80 tensor([[0.5547, 0.8682],
81 [0.5145, 0.8437],
82 [0.5300, 0.8533]])
83 >>> pairwise_cosine_similarity(x)
84 tensor([[0.0000, 0.9989, 0.9996],
85 [0.9989, 0.0000, 0.9998],
86 [0.9996, 0.9998, 0.0000]])
87
88 """
89 distance = _pairwise_cosine_similarity_update(x, y, zero_diagonal)
90 return _reduce_distance_matrix(distance, reduction)
91
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/torchmetrics/functional/pairwise/cosine.py b/src/torchmetrics/functional/pairwise/cosine.py
--- a/src/torchmetrics/functional/pairwise/cosine.py
+++ b/src/torchmetrics/functional/pairwise/cosine.py
@@ -54,7 +54,7 @@
.. math::
s_{cos}(x,y) = \frac{<x,y>}{||x|| \cdot ||y||}
- = \frac{\sum_{d=1}^D x_d \cdot y_d }{\sqrt{\sum_{d=1}^D x_i^2} \cdot \sqrt{\sum_{d=1}^D x_i^2}}
+ = \frac{\sum_{d=1}^D x_d \cdot y_d }{\sqrt{\sum_{d=1}^D x_i^2} \cdot \sqrt{\sum_{d=1}^D y_i^2}}
If both :math:`x` and :math:`y` are passed in, the calculation will be performed pairwise
between the rows of :math:`x` and :math:`y`.
|
{"golden_diff": "diff --git a/src/torchmetrics/functional/pairwise/cosine.py b/src/torchmetrics/functional/pairwise/cosine.py\n--- a/src/torchmetrics/functional/pairwise/cosine.py\n+++ b/src/torchmetrics/functional/pairwise/cosine.py\n@@ -54,7 +54,7 @@\n \n .. math::\n s_{cos}(x,y) = \\frac{<x,y>}{||x|| \\cdot ||y||}\n- = \\frac{\\sum_{d=1}^D x_d \\cdot y_d }{\\sqrt{\\sum_{d=1}^D x_i^2} \\cdot \\sqrt{\\sum_{d=1}^D x_i^2}}\n+ = \\frac{\\sum_{d=1}^D x_d \\cdot y_d }{\\sqrt{\\sum_{d=1}^D x_i^2} \\cdot \\sqrt{\\sum_{d=1}^D y_i^2}}\n \n If both :math:`x` and :math:`y` are passed in, the calculation will be performed pairwise\n between the rows of :math:`x` and :math:`y`.\n", "issue": "notation typo in Cosine Similarity docs \n## \ud83d\udcda Documentation\r\n\r\nThere is a typo in the notation for the [pairwise_cosine_similarity](https://torchmetrics.readthedocs.io/en/stable/pairwise/cosine_similarity.html)\r\n\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom typing import Optional\n\nimport torch\nfrom torch import Tensor\nfrom typing_extensions import Literal\n\nfrom torchmetrics.functional.pairwise.helpers import _check_input, _reduce_distance_matrix\nfrom torchmetrics.utilities.compute import _safe_matmul\n\n\ndef _pairwise_cosine_similarity_update(\n x: Tensor, y: Optional[Tensor] = None, zero_diagonal: Optional[bool] = None\n) -> Tensor:\n \"\"\"Calculates the pairwise cosine similarity matrix.\n\n Args:\n x: tensor of shape ``[N,d]``\n y: tensor of shape ``[M,d]``\n zero_diagonal: determines if the diagonal of the distance matrix should be set to zero\n \"\"\"\n x, y, zero_diagonal = _check_input(x, y, zero_diagonal)\n\n norm = torch.norm(x, p=2, dim=1)\n x /= norm.unsqueeze(1)\n norm = torch.norm(y, p=2, dim=1)\n y /= norm.unsqueeze(1)\n\n distance = _safe_matmul(x, y)\n if zero_diagonal:\n distance.fill_diagonal_(0)\n return distance\n\n\ndef pairwise_cosine_similarity(\n x: Tensor,\n y: Optional[Tensor] = None,\n reduction: Literal[\"mean\", \"sum\", \"none\", None] = None,\n zero_diagonal: Optional[bool] = None,\n) -> Tensor:\n r\"\"\"Calculates pairwise cosine similarity:\n\n .. math::\n s_{cos}(x,y) = \\frac{<x,y>}{||x|| \\cdot ||y||}\n = \\frac{\\sum_{d=1}^D x_d \\cdot y_d }{\\sqrt{\\sum_{d=1}^D x_i^2} \\cdot \\sqrt{\\sum_{d=1}^D x_i^2}}\n\n If both :math:`x` and :math:`y` are passed in, the calculation will be performed pairwise\n between the rows of :math:`x` and :math:`y`.\n If only :math:`x` is passed in, the calculation will be performed between the rows of :math:`x`.\n\n Args:\n x: Tensor with shape ``[N, d]``\n y: Tensor with shape ``[M, d]``, optional\n reduction: reduction to apply along the last dimension. Choose between `'mean'`, `'sum'`\n (applied along column dimension) or `'none'`, `None` for no reduction\n zero_diagonal: if the diagonal of the distance matrix should be set to 0. If only :math:`x` is given\n this defaults to ``True`` else if :math:`y` is also given it defaults to ``False``\n\n Returns:\n A ``[N,N]`` matrix of distances if only ``x`` is given, else a ``[N,M]`` matrix\n\n Example:\n >>> import torch\n >>> from torchmetrics.functional import pairwise_cosine_similarity\n >>> x = torch.tensor([[2, 3], [3, 5], [5, 8]], dtype=torch.float32)\n >>> y = torch.tensor([[1, 0], [2, 1]], dtype=torch.float32)\n >>> pairwise_cosine_similarity(x, y)\n tensor([[0.5547, 0.8682],\n [0.5145, 0.8437],\n [0.5300, 0.8533]])\n >>> pairwise_cosine_similarity(x)\n tensor([[0.0000, 0.9989, 0.9996],\n [0.9989, 0.0000, 0.9998],\n [0.9996, 0.9998, 0.0000]])\n\n \"\"\"\n distance = _pairwise_cosine_similarity_update(x, y, zero_diagonal)\n return _reduce_distance_matrix(distance, reduction)\n", "path": "src/torchmetrics/functional/pairwise/cosine.py"}], "after_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom typing import Optional\n\nimport torch\nfrom torch import Tensor\nfrom typing_extensions import Literal\n\nfrom torchmetrics.functional.pairwise.helpers import _check_input, _reduce_distance_matrix\nfrom torchmetrics.utilities.compute import _safe_matmul\n\n\ndef _pairwise_cosine_similarity_update(\n x: Tensor, y: Optional[Tensor] = None, zero_diagonal: Optional[bool] = None\n) -> Tensor:\n \"\"\"Calculates the pairwise cosine similarity matrix.\n\n Args:\n x: tensor of shape ``[N,d]``\n y: tensor of shape ``[M,d]``\n zero_diagonal: determines if the diagonal of the distance matrix should be set to zero\n \"\"\"\n x, y, zero_diagonal = _check_input(x, y, zero_diagonal)\n\n norm = torch.norm(x, p=2, dim=1)\n x /= norm.unsqueeze(1)\n norm = torch.norm(y, p=2, dim=1)\n y /= norm.unsqueeze(1)\n\n distance = _safe_matmul(x, y)\n if zero_diagonal:\n distance.fill_diagonal_(0)\n return distance\n\n\ndef pairwise_cosine_similarity(\n x: Tensor,\n y: Optional[Tensor] = None,\n reduction: Literal[\"mean\", \"sum\", \"none\", None] = None,\n zero_diagonal: Optional[bool] = None,\n) -> Tensor:\n r\"\"\"Calculates pairwise cosine similarity:\n\n .. math::\n s_{cos}(x,y) = \\frac{<x,y>}{||x|| \\cdot ||y||}\n = \\frac{\\sum_{d=1}^D x_d \\cdot y_d }{\\sqrt{\\sum_{d=1}^D x_i^2} \\cdot \\sqrt{\\sum_{d=1}^D y_i^2}}\n\n If both :math:`x` and :math:`y` are passed in, the calculation will be performed pairwise\n between the rows of :math:`x` and :math:`y`.\n If only :math:`x` is passed in, the calculation will be performed between the rows of :math:`x`.\n\n Args:\n x: Tensor with shape ``[N, d]``\n y: Tensor with shape ``[M, d]``, optional\n reduction: reduction to apply along the last dimension. Choose between `'mean'`, `'sum'`\n (applied along column dimension) or `'none'`, `None` for no reduction\n zero_diagonal: if the diagonal of the distance matrix should be set to 0. If only :math:`x` is given\n this defaults to ``True`` else if :math:`y` is also given it defaults to ``False``\n\n Returns:\n A ``[N,N]`` matrix of distances if only ``x`` is given, else a ``[N,M]`` matrix\n\n Example:\n >>> import torch\n >>> from torchmetrics.functional import pairwise_cosine_similarity\n >>> x = torch.tensor([[2, 3], [3, 5], [5, 8]], dtype=torch.float32)\n >>> y = torch.tensor([[1, 0], [2, 1]], dtype=torch.float32)\n >>> pairwise_cosine_similarity(x, y)\n tensor([[0.5547, 0.8682],\n [0.5145, 0.8437],\n [0.5300, 0.8533]])\n >>> pairwise_cosine_similarity(x)\n tensor([[0.0000, 0.9989, 0.9996],\n [0.9989, 0.0000, 0.9998],\n [0.9996, 0.9998, 0.0000]])\n\n \"\"\"\n distance = _pairwise_cosine_similarity_update(x, y, zero_diagonal)\n return _reduce_distance_matrix(distance, reduction)\n", "path": "src/torchmetrics/functional/pairwise/cosine.py"}]}
| 1,564 | 259 |
gh_patches_debug_16473
|
rasdani/github-patches
|
git_diff
|
streamlit__streamlit-2115
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
When "streamlit run" file doesn't exit and has no extension, error printout is weird
1. Create a Python file and call it `example` (without .py)
2. `streamlit run example`
Here's what you get:
<img width="400px" src="https://user-images.githubusercontent.com/690814/95294472-307bcb00-082a-11eb-86b0-37c2a1335988.png" />
**This error message is not a valid sentence: "Streamlit requires raw Python (.py) files, not ."**
What's happening is that the code is trying to write the file extension in the error message, but in this case the file has no extension.
We should instead say something like "Streamlit requires raw Python (.py) files, and the provided file has no extension."
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lib/streamlit/cli.py`
Content:
```
1 # Copyright 2018-2020 Streamlit Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """This is a script which is run when the Streamlit package is executed."""
16
17 from streamlit import config as _config
18
19 import os
20 import re
21 from typing import Optional
22
23 import click
24
25 import streamlit
26 from streamlit.credentials import Credentials, check_credentials
27 from streamlit import version
28 import streamlit.bootstrap as bootstrap
29 from streamlit.case_converters import to_snake_case
30
31 ACCEPTED_FILE_EXTENSIONS = ("py", "py3")
32
33 LOG_LEVELS = ("error", "warning", "info", "debug")
34
35 NEW_VERSION_TEXT = """
36 %(new_version)s
37
38 See what's new at https://discuss.streamlit.io/c/announcements
39
40 Enter the following command to upgrade:
41 %(prompt)s %(command)s
42 """ % {
43 "new_version": click.style(
44 "A new version of Streamlit is available.", fg="blue", bold=True
45 ),
46 "prompt": click.style("$", fg="blue"),
47 "command": click.style("pip install streamlit --upgrade", bold=True),
48 }
49
50
51 def _convert_config_option_to_click_option(config_option):
52 """Composes given config option options as options for click lib."""
53 option = "--{}".format(config_option.key)
54 param = config_option.key.replace(".", "_")
55 description = config_option.description
56 if config_option.deprecated:
57 description += "\n {} - {}".format(
58 config_option.deprecation_text, config_option.expiration_date
59 )
60 envvar = "STREAMLIT_{}".format(to_snake_case(param).upper())
61
62 return {
63 "param": param,
64 "description": description,
65 "type": config_option.type,
66 "option": option,
67 "envvar": envvar,
68 }
69
70
71 def configurator_options(func):
72 """Decorator that adds config param keys to click dynamically."""
73 for _, value in reversed(_config._config_options.items()):
74 parsed_parameter = _convert_config_option_to_click_option(value)
75 config_option = click.option(
76 parsed_parameter["option"],
77 parsed_parameter["param"],
78 help=parsed_parameter["description"],
79 type=parsed_parameter["type"],
80 show_envvar=True,
81 envvar=parsed_parameter["envvar"],
82 )
83 func = config_option(func)
84 return func
85
86
87 def _apply_config_options_from_cli(kwargs):
88 """The "streamlit run" command supports passing Streamlit's config options
89 as flags.
90
91 This function reads through all config flags, massage them, and
92 pass them to _set_config() overriding default values and values set via
93 config.toml file
94
95 """
96 # Parse config files first before setting CLI args.
97 # Prevents CLI args from being overwritten
98 if not _config._config_file_has_been_parsed:
99 _config.parse_config_file()
100
101 for config_option in kwargs:
102 if kwargs[config_option] is not None:
103 config_option_def_key = config_option.replace("_", ".")
104 _config._set_option(
105 config_option_def_key,
106 kwargs[config_option],
107 "command-line argument or environment variable",
108 )
109
110 _config._on_config_parsed.send()
111
112
113 # Fetch remote file at url_path to script_path
114 def _download_remote(script_path, url_path):
115 import requests
116
117 with open(script_path, "wb") as fp:
118 try:
119 resp = requests.get(url_path)
120 resp.raise_for_status()
121 fp.write(resp.content)
122 except requests.exceptions.RequestException as e:
123 raise click.BadParameter(("Unable to fetch {}.\n{}".format(url_path, e)))
124
125
126 @click.group(context_settings={"auto_envvar_prefix": "STREAMLIT"})
127 @click.option("--log_level", show_default=True, type=click.Choice(LOG_LEVELS))
128 @click.version_option(prog_name="Streamlit")
129 @click.pass_context
130 def main(ctx, log_level="info"):
131 """Try out a demo with:
132
133 $ streamlit hello
134
135 Or use the line below to run your own script:
136
137 $ streamlit run your_script.py
138 """
139
140 if log_level:
141 import streamlit.logger
142
143 streamlit.logger.set_log_level(log_level.upper())
144
145
146 @main.command("help")
147 @click.pass_context
148 def help(ctx):
149 """Print this help message."""
150 # Pretend user typed 'streamlit --help' instead of 'streamlit help'.
151 import sys
152
153 assert len(sys.argv) == 2 # This is always true, but let's assert anyway.
154 sys.argv[1] = "--help"
155 main()
156
157
158 @main.command("version")
159 @click.pass_context
160 def main_version(ctx):
161 """Print Streamlit's version number."""
162 # Pretend user typed 'streamlit --version' instead of 'streamlit version'
163 import sys
164
165 assert len(sys.argv) == 2 # This is always true, but let's assert anyway.
166 sys.argv[1] = "--version"
167 main()
168
169
170 @main.command("docs")
171 def main_docs():
172 """Show help in browser."""
173 print("Showing help page in browser...")
174 from streamlit import util
175
176 util.open_browser("https://docs.streamlit.io")
177
178
179 @main.command("hello")
180 @configurator_options
181 def main_hello(**kwargs):
182 """Runs the Hello World script."""
183 from streamlit.hello import hello
184
185 _apply_config_options_from_cli(kwargs)
186 filename = hello.__file__
187 _main_run(filename)
188
189
190 @main.command("run")
191 @configurator_options
192 @click.argument("target", required=True, envvar="STREAMLIT_RUN_TARGET")
193 @click.argument("args", nargs=-1)
194 def main_run(target, args=None, **kwargs):
195 """Run a Python script, piping stderr to Streamlit.
196
197 The script can be local or it can be an url. In the latter case, Streamlit
198 will download the script to a temporary file and runs this file.
199
200 """
201 from validators import url
202
203 _apply_config_options_from_cli(kwargs)
204
205 _, extension = os.path.splitext(target)
206 if extension[1:] not in ACCEPTED_FILE_EXTENSIONS:
207 raise click.BadArgumentUsage(
208 "Streamlit requires raw Python (.py) files, not %s.\nFor more information, please see https://docs.streamlit.io"
209 % extension
210 )
211
212 if url(target):
213 from streamlit.temporary_directory import TemporaryDirectory
214
215 with TemporaryDirectory() as temp_dir:
216 from urllib.parse import urlparse
217 from streamlit import url_util
218
219 path = urlparse(target).path
220 script_path = os.path.join(temp_dir, path.strip("/").rsplit("/", 1)[-1])
221 # if this is a GitHub/Gist blob url, convert to a raw URL first.
222 target = url_util.process_gitblob_url(target)
223 _download_remote(script_path, target)
224 _main_run(script_path, args)
225 else:
226 if not os.path.exists(target):
227 raise click.BadParameter("File does not exist: {}".format(target))
228 _main_run(target, args)
229
230
231 # Utility function to compute the command line as a string
232 def _get_command_line_as_string() -> Optional[str]:
233 import subprocess
234
235 parent = click.get_current_context().parent
236 if parent is None:
237 return None
238 cmd_line_as_list = [parent.command_path]
239 cmd_line_as_list.extend(click.get_os_args())
240 return subprocess.list2cmdline(cmd_line_as_list)
241
242
243 def _main_run(file, args=[]):
244 command_line = _get_command_line_as_string()
245
246 # Set a global flag indicating that we're "within" streamlit.
247 streamlit._is_running_with_streamlit = True
248
249 # Check credentials.
250 check_credentials()
251
252 # Notify if streamlit is out of date.
253 if version.should_show_new_version_notice():
254 click.echo(NEW_VERSION_TEXT)
255
256 bootstrap.run(file, command_line, args)
257
258
259 # SUBCOMMAND: cache
260
261
262 @main.group("cache")
263 def cache():
264 """Manage the Streamlit cache."""
265 pass
266
267
268 @cache.command("clear")
269 def cache_clear():
270 """Clear the Streamlit on-disk cache."""
271 import streamlit.caching
272
273 result = streamlit.caching.clear_cache()
274 cache_path = streamlit.caching.get_cache_path()
275 if result:
276 print("Cleared directory %s." % cache_path)
277 else:
278 print("Nothing to clear at %s." % cache_path)
279
280
281 # SUBCOMMAND: config
282
283
284 @main.group("config")
285 def config():
286 """Manage Streamlit's config settings."""
287 pass
288
289
290 @config.command("show")
291 @configurator_options
292 def config_show(**kwargs):
293 """Show all of Streamlit's config settings."""
294
295 _apply_config_options_from_cli(kwargs)
296
297 _config.show_config()
298
299
300 # SUBCOMMAND: activate
301
302
303 @main.group("activate", invoke_without_command=True)
304 @click.pass_context
305 def activate(ctx):
306 """Activate Streamlit by entering your email."""
307 if not ctx.invoked_subcommand:
308 Credentials.get_current().activate()
309
310
311 @activate.command("reset")
312 def activate_reset():
313 """Reset Activation Credentials."""
314 Credentials.get_current().reset()
315
316
317 if __name__ == "__main__":
318 main()
319
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lib/streamlit/cli.py b/lib/streamlit/cli.py
--- a/lib/streamlit/cli.py
+++ b/lib/streamlit/cli.py
@@ -204,10 +204,15 @@
_, extension = os.path.splitext(target)
if extension[1:] not in ACCEPTED_FILE_EXTENSIONS:
- raise click.BadArgumentUsage(
- "Streamlit requires raw Python (.py) files, not %s.\nFor more information, please see https://docs.streamlit.io"
- % extension
- )
+ if extension[1:] == "":
+ raise click.BadArgumentUsage(
+ "Streamlit requires raw Python (.py) files, but the provided file has no extension.\nFor more information, please see https://docs.streamlit.io"
+ )
+ else:
+ raise click.BadArgumentUsage(
+ "Streamlit requires raw Python (.py) files, not %s.\nFor more information, please see https://docs.streamlit.io"
+ % extension
+ )
if url(target):
from streamlit.temporary_directory import TemporaryDirectory
|
{"golden_diff": "diff --git a/lib/streamlit/cli.py b/lib/streamlit/cli.py\n--- a/lib/streamlit/cli.py\n+++ b/lib/streamlit/cli.py\n@@ -204,10 +204,15 @@\n \n _, extension = os.path.splitext(target)\n if extension[1:] not in ACCEPTED_FILE_EXTENSIONS:\n- raise click.BadArgumentUsage(\n- \"Streamlit requires raw Python (.py) files, not %s.\\nFor more information, please see https://docs.streamlit.io\"\n- % extension\n- )\n+ if extension[1:] == \"\":\n+ raise click.BadArgumentUsage(\n+ \"Streamlit requires raw Python (.py) files, but the provided file has no extension.\\nFor more information, please see https://docs.streamlit.io\"\n+ )\n+ else: \n+ raise click.BadArgumentUsage(\n+ \"Streamlit requires raw Python (.py) files, not %s.\\nFor more information, please see https://docs.streamlit.io\"\n+ % extension\n+ )\n \n if url(target):\n from streamlit.temporary_directory import TemporaryDirectory\n", "issue": "When \"streamlit run\" file doesn't exit and has no extension, error printout is weird\n1. Create a Python file and call it `example` (without .py)\r\n2. `streamlit run example`\r\n\r\nHere's what you get:\r\n<img width=\"400px\" src=\"https://user-images.githubusercontent.com/690814/95294472-307bcb00-082a-11eb-86b0-37c2a1335988.png\" />\r\n\r\n**This error message is not a valid sentence: \"Streamlit requires raw Python (.py) files, not .\"**\r\n\r\nWhat's happening is that the code is trying to write the file extension in the error message, but in this case the file has no extension.\r\n\r\nWe should instead say something like \"Streamlit requires raw Python (.py) files, and the provided file has no extension.\"\r\n\r\n\n", "before_files": [{"content": "# Copyright 2018-2020 Streamlit Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"This is a script which is run when the Streamlit package is executed.\"\"\"\n\nfrom streamlit import config as _config\n\nimport os\nimport re\nfrom typing import Optional\n\nimport click\n\nimport streamlit\nfrom streamlit.credentials import Credentials, check_credentials\nfrom streamlit import version\nimport streamlit.bootstrap as bootstrap\nfrom streamlit.case_converters import to_snake_case\n\nACCEPTED_FILE_EXTENSIONS = (\"py\", \"py3\")\n\nLOG_LEVELS = (\"error\", \"warning\", \"info\", \"debug\")\n\nNEW_VERSION_TEXT = \"\"\"\n %(new_version)s\n\n See what's new at https://discuss.streamlit.io/c/announcements\n\n Enter the following command to upgrade:\n %(prompt)s %(command)s\n\"\"\" % {\n \"new_version\": click.style(\n \"A new version of Streamlit is available.\", fg=\"blue\", bold=True\n ),\n \"prompt\": click.style(\"$\", fg=\"blue\"),\n \"command\": click.style(\"pip install streamlit --upgrade\", bold=True),\n}\n\n\ndef _convert_config_option_to_click_option(config_option):\n \"\"\"Composes given config option options as options for click lib.\"\"\"\n option = \"--{}\".format(config_option.key)\n param = config_option.key.replace(\".\", \"_\")\n description = config_option.description\n if config_option.deprecated:\n description += \"\\n {} - {}\".format(\n config_option.deprecation_text, config_option.expiration_date\n )\n envvar = \"STREAMLIT_{}\".format(to_snake_case(param).upper())\n\n return {\n \"param\": param,\n \"description\": description,\n \"type\": config_option.type,\n \"option\": option,\n \"envvar\": envvar,\n }\n\n\ndef configurator_options(func):\n \"\"\"Decorator that adds config param keys to click dynamically.\"\"\"\n for _, value in reversed(_config._config_options.items()):\n parsed_parameter = _convert_config_option_to_click_option(value)\n config_option = click.option(\n parsed_parameter[\"option\"],\n parsed_parameter[\"param\"],\n help=parsed_parameter[\"description\"],\n type=parsed_parameter[\"type\"],\n show_envvar=True,\n envvar=parsed_parameter[\"envvar\"],\n )\n func = config_option(func)\n return func\n\n\ndef _apply_config_options_from_cli(kwargs):\n \"\"\"The \"streamlit run\" command supports passing Streamlit's config options\n as flags.\n\n This function reads through all config flags, massage them, and\n pass them to _set_config() overriding default values and values set via\n config.toml file\n\n \"\"\"\n # Parse config files first before setting CLI args.\n # Prevents CLI args from being overwritten\n if not _config._config_file_has_been_parsed:\n _config.parse_config_file()\n\n for config_option in kwargs:\n if kwargs[config_option] is not None:\n config_option_def_key = config_option.replace(\"_\", \".\")\n _config._set_option(\n config_option_def_key,\n kwargs[config_option],\n \"command-line argument or environment variable\",\n )\n\n _config._on_config_parsed.send()\n\n\n# Fetch remote file at url_path to script_path\ndef _download_remote(script_path, url_path):\n import requests\n\n with open(script_path, \"wb\") as fp:\n try:\n resp = requests.get(url_path)\n resp.raise_for_status()\n fp.write(resp.content)\n except requests.exceptions.RequestException as e:\n raise click.BadParameter((\"Unable to fetch {}.\\n{}\".format(url_path, e)))\n\n\[email protected](context_settings={\"auto_envvar_prefix\": \"STREAMLIT\"})\[email protected](\"--log_level\", show_default=True, type=click.Choice(LOG_LEVELS))\[email protected]_option(prog_name=\"Streamlit\")\[email protected]_context\ndef main(ctx, log_level=\"info\"):\n \"\"\"Try out a demo with:\n\n $ streamlit hello\n\n Or use the line below to run your own script:\n\n $ streamlit run your_script.py\n \"\"\"\n\n if log_level:\n import streamlit.logger\n\n streamlit.logger.set_log_level(log_level.upper())\n\n\[email protected](\"help\")\[email protected]_context\ndef help(ctx):\n \"\"\"Print this help message.\"\"\"\n # Pretend user typed 'streamlit --help' instead of 'streamlit help'.\n import sys\n\n assert len(sys.argv) == 2 # This is always true, but let's assert anyway.\n sys.argv[1] = \"--help\"\n main()\n\n\[email protected](\"version\")\[email protected]_context\ndef main_version(ctx):\n \"\"\"Print Streamlit's version number.\"\"\"\n # Pretend user typed 'streamlit --version' instead of 'streamlit version'\n import sys\n\n assert len(sys.argv) == 2 # This is always true, but let's assert anyway.\n sys.argv[1] = \"--version\"\n main()\n\n\[email protected](\"docs\")\ndef main_docs():\n \"\"\"Show help in browser.\"\"\"\n print(\"Showing help page in browser...\")\n from streamlit import util\n\n util.open_browser(\"https://docs.streamlit.io\")\n\n\[email protected](\"hello\")\n@configurator_options\ndef main_hello(**kwargs):\n \"\"\"Runs the Hello World script.\"\"\"\n from streamlit.hello import hello\n\n _apply_config_options_from_cli(kwargs)\n filename = hello.__file__\n _main_run(filename)\n\n\[email protected](\"run\")\n@configurator_options\[email protected](\"target\", required=True, envvar=\"STREAMLIT_RUN_TARGET\")\[email protected](\"args\", nargs=-1)\ndef main_run(target, args=None, **kwargs):\n \"\"\"Run a Python script, piping stderr to Streamlit.\n\n The script can be local or it can be an url. In the latter case, Streamlit\n will download the script to a temporary file and runs this file.\n\n \"\"\"\n from validators import url\n\n _apply_config_options_from_cli(kwargs)\n\n _, extension = os.path.splitext(target)\n if extension[1:] not in ACCEPTED_FILE_EXTENSIONS:\n raise click.BadArgumentUsage(\n \"Streamlit requires raw Python (.py) files, not %s.\\nFor more information, please see https://docs.streamlit.io\"\n % extension\n )\n\n if url(target):\n from streamlit.temporary_directory import TemporaryDirectory\n\n with TemporaryDirectory() as temp_dir:\n from urllib.parse import urlparse\n from streamlit import url_util\n\n path = urlparse(target).path\n script_path = os.path.join(temp_dir, path.strip(\"/\").rsplit(\"/\", 1)[-1])\n # if this is a GitHub/Gist blob url, convert to a raw URL first.\n target = url_util.process_gitblob_url(target)\n _download_remote(script_path, target)\n _main_run(script_path, args)\n else:\n if not os.path.exists(target):\n raise click.BadParameter(\"File does not exist: {}\".format(target))\n _main_run(target, args)\n\n\n# Utility function to compute the command line as a string\ndef _get_command_line_as_string() -> Optional[str]:\n import subprocess\n\n parent = click.get_current_context().parent\n if parent is None:\n return None\n cmd_line_as_list = [parent.command_path]\n cmd_line_as_list.extend(click.get_os_args())\n return subprocess.list2cmdline(cmd_line_as_list)\n\n\ndef _main_run(file, args=[]):\n command_line = _get_command_line_as_string()\n\n # Set a global flag indicating that we're \"within\" streamlit.\n streamlit._is_running_with_streamlit = True\n\n # Check credentials.\n check_credentials()\n\n # Notify if streamlit is out of date.\n if version.should_show_new_version_notice():\n click.echo(NEW_VERSION_TEXT)\n\n bootstrap.run(file, command_line, args)\n\n\n# SUBCOMMAND: cache\n\n\[email protected](\"cache\")\ndef cache():\n \"\"\"Manage the Streamlit cache.\"\"\"\n pass\n\n\[email protected](\"clear\")\ndef cache_clear():\n \"\"\"Clear the Streamlit on-disk cache.\"\"\"\n import streamlit.caching\n\n result = streamlit.caching.clear_cache()\n cache_path = streamlit.caching.get_cache_path()\n if result:\n print(\"Cleared directory %s.\" % cache_path)\n else:\n print(\"Nothing to clear at %s.\" % cache_path)\n\n\n# SUBCOMMAND: config\n\n\[email protected](\"config\")\ndef config():\n \"\"\"Manage Streamlit's config settings.\"\"\"\n pass\n\n\[email protected](\"show\")\n@configurator_options\ndef config_show(**kwargs):\n \"\"\"Show all of Streamlit's config settings.\"\"\"\n\n _apply_config_options_from_cli(kwargs)\n\n _config.show_config()\n\n\n# SUBCOMMAND: activate\n\n\[email protected](\"activate\", invoke_without_command=True)\[email protected]_context\ndef activate(ctx):\n \"\"\"Activate Streamlit by entering your email.\"\"\"\n if not ctx.invoked_subcommand:\n Credentials.get_current().activate()\n\n\[email protected](\"reset\")\ndef activate_reset():\n \"\"\"Reset Activation Credentials.\"\"\"\n Credentials.get_current().reset()\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "lib/streamlit/cli.py"}], "after_files": [{"content": "# Copyright 2018-2020 Streamlit Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"This is a script which is run when the Streamlit package is executed.\"\"\"\n\nfrom streamlit import config as _config\n\nimport os\nimport re\nfrom typing import Optional\n\nimport click\n\nimport streamlit\nfrom streamlit.credentials import Credentials, check_credentials\nfrom streamlit import version\nimport streamlit.bootstrap as bootstrap\nfrom streamlit.case_converters import to_snake_case\n\nACCEPTED_FILE_EXTENSIONS = (\"py\", \"py3\")\n\nLOG_LEVELS = (\"error\", \"warning\", \"info\", \"debug\")\n\nNEW_VERSION_TEXT = \"\"\"\n %(new_version)s\n\n See what's new at https://discuss.streamlit.io/c/announcements\n\n Enter the following command to upgrade:\n %(prompt)s %(command)s\n\"\"\" % {\n \"new_version\": click.style(\n \"A new version of Streamlit is available.\", fg=\"blue\", bold=True\n ),\n \"prompt\": click.style(\"$\", fg=\"blue\"),\n \"command\": click.style(\"pip install streamlit --upgrade\", bold=True),\n}\n\n\ndef _convert_config_option_to_click_option(config_option):\n \"\"\"Composes given config option options as options for click lib.\"\"\"\n option = \"--{}\".format(config_option.key)\n param = config_option.key.replace(\".\", \"_\")\n description = config_option.description\n if config_option.deprecated:\n description += \"\\n {} - {}\".format(\n config_option.deprecation_text, config_option.expiration_date\n )\n envvar = \"STREAMLIT_{}\".format(to_snake_case(param).upper())\n\n return {\n \"param\": param,\n \"description\": description,\n \"type\": config_option.type,\n \"option\": option,\n \"envvar\": envvar,\n }\n\n\ndef configurator_options(func):\n \"\"\"Decorator that adds config param keys to click dynamically.\"\"\"\n for _, value in reversed(_config._config_options.items()):\n parsed_parameter = _convert_config_option_to_click_option(value)\n config_option = click.option(\n parsed_parameter[\"option\"],\n parsed_parameter[\"param\"],\n help=parsed_parameter[\"description\"],\n type=parsed_parameter[\"type\"],\n show_envvar=True,\n envvar=parsed_parameter[\"envvar\"],\n )\n func = config_option(func)\n return func\n\n\ndef _apply_config_options_from_cli(kwargs):\n \"\"\"The \"streamlit run\" command supports passing Streamlit's config options\n as flags.\n\n This function reads through all config flags, massage them, and\n pass them to _set_config() overriding default values and values set via\n config.toml file\n\n \"\"\"\n # Parse config files first before setting CLI args.\n # Prevents CLI args from being overwritten\n if not _config._config_file_has_been_parsed:\n _config.parse_config_file()\n\n for config_option in kwargs:\n if kwargs[config_option] is not None:\n config_option_def_key = config_option.replace(\"_\", \".\")\n _config._set_option(\n config_option_def_key,\n kwargs[config_option],\n \"command-line argument or environment variable\",\n )\n\n _config._on_config_parsed.send()\n\n\n# Fetch remote file at url_path to script_path\ndef _download_remote(script_path, url_path):\n import requests\n\n with open(script_path, \"wb\") as fp:\n try:\n resp = requests.get(url_path)\n resp.raise_for_status()\n fp.write(resp.content)\n except requests.exceptions.RequestException as e:\n raise click.BadParameter((\"Unable to fetch {}.\\n{}\".format(url_path, e)))\n\n\[email protected](context_settings={\"auto_envvar_prefix\": \"STREAMLIT\"})\[email protected](\"--log_level\", show_default=True, type=click.Choice(LOG_LEVELS))\[email protected]_option(prog_name=\"Streamlit\")\[email protected]_context\ndef main(ctx, log_level=\"info\"):\n \"\"\"Try out a demo with:\n\n $ streamlit hello\n\n Or use the line below to run your own script:\n\n $ streamlit run your_script.py\n \"\"\"\n\n if log_level:\n import streamlit.logger\n\n streamlit.logger.set_log_level(log_level.upper())\n\n\[email protected](\"help\")\[email protected]_context\ndef help(ctx):\n \"\"\"Print this help message.\"\"\"\n # Pretend user typed 'streamlit --help' instead of 'streamlit help'.\n import sys\n\n assert len(sys.argv) == 2 # This is always true, but let's assert anyway.\n sys.argv[1] = \"--help\"\n main()\n\n\[email protected](\"version\")\[email protected]_context\ndef main_version(ctx):\n \"\"\"Print Streamlit's version number.\"\"\"\n # Pretend user typed 'streamlit --version' instead of 'streamlit version'\n import sys\n\n assert len(sys.argv) == 2 # This is always true, but let's assert anyway.\n sys.argv[1] = \"--version\"\n main()\n\n\[email protected](\"docs\")\ndef main_docs():\n \"\"\"Show help in browser.\"\"\"\n print(\"Showing help page in browser...\")\n from streamlit import util\n\n util.open_browser(\"https://docs.streamlit.io\")\n\n\[email protected](\"hello\")\n@configurator_options\ndef main_hello(**kwargs):\n \"\"\"Runs the Hello World script.\"\"\"\n from streamlit.hello import hello\n\n _apply_config_options_from_cli(kwargs)\n filename = hello.__file__\n _main_run(filename)\n\n\[email protected](\"run\")\n@configurator_options\[email protected](\"target\", required=True, envvar=\"STREAMLIT_RUN_TARGET\")\[email protected](\"args\", nargs=-1)\ndef main_run(target, args=None, **kwargs):\n \"\"\"Run a Python script, piping stderr to Streamlit.\n\n The script can be local or it can be an url. In the latter case, Streamlit\n will download the script to a temporary file and runs this file.\n\n \"\"\"\n from validators import url\n\n _apply_config_options_from_cli(kwargs)\n\n _, extension = os.path.splitext(target)\n if extension[1:] not in ACCEPTED_FILE_EXTENSIONS:\n if extension[1:] == \"\":\n raise click.BadArgumentUsage(\n \"Streamlit requires raw Python (.py) files, but the provided file has no extension.\\nFor more information, please see https://docs.streamlit.io\"\n )\n else: \n raise click.BadArgumentUsage(\n \"Streamlit requires raw Python (.py) files, not %s.\\nFor more information, please see https://docs.streamlit.io\"\n % extension\n )\n\n if url(target):\n from streamlit.temporary_directory import TemporaryDirectory\n\n with TemporaryDirectory() as temp_dir:\n from urllib.parse import urlparse\n from streamlit import url_util\n\n path = urlparse(target).path\n script_path = os.path.join(temp_dir, path.strip(\"/\").rsplit(\"/\", 1)[-1])\n # if this is a GitHub/Gist blob url, convert to a raw URL first.\n target = url_util.process_gitblob_url(target)\n _download_remote(script_path, target)\n _main_run(script_path, args)\n else:\n if not os.path.exists(target):\n raise click.BadParameter(\"File does not exist: {}\".format(target))\n _main_run(target, args)\n\n\n# Utility function to compute the command line as a string\ndef _get_command_line_as_string() -> Optional[str]:\n import subprocess\n\n parent = click.get_current_context().parent\n if parent is None:\n return None\n cmd_line_as_list = [parent.command_path]\n cmd_line_as_list.extend(click.get_os_args())\n return subprocess.list2cmdline(cmd_line_as_list)\n\n\ndef _main_run(file, args=[]):\n command_line = _get_command_line_as_string()\n\n # Set a global flag indicating that we're \"within\" streamlit.\n streamlit._is_running_with_streamlit = True\n\n # Check credentials.\n check_credentials()\n\n # Notify if streamlit is out of date.\n if version.should_show_new_version_notice():\n click.echo(NEW_VERSION_TEXT)\n\n bootstrap.run(file, command_line, args)\n\n\n# SUBCOMMAND: cache\n\n\[email protected](\"cache\")\ndef cache():\n \"\"\"Manage the Streamlit cache.\"\"\"\n pass\n\n\[email protected](\"clear\")\ndef cache_clear():\n \"\"\"Clear the Streamlit on-disk cache.\"\"\"\n import streamlit.caching\n\n result = streamlit.caching.clear_cache()\n cache_path = streamlit.caching.get_cache_path()\n if result:\n print(\"Cleared directory %s.\" % cache_path)\n else:\n print(\"Nothing to clear at %s.\" % cache_path)\n\n\n# SUBCOMMAND: config\n\n\[email protected](\"config\")\ndef config():\n \"\"\"Manage Streamlit's config settings.\"\"\"\n pass\n\n\[email protected](\"show\")\n@configurator_options\ndef config_show(**kwargs):\n \"\"\"Show all of Streamlit's config settings.\"\"\"\n\n _apply_config_options_from_cli(kwargs)\n\n _config.show_config()\n\n\n# SUBCOMMAND: activate\n\n\[email protected](\"activate\", invoke_without_command=True)\[email protected]_context\ndef activate(ctx):\n \"\"\"Activate Streamlit by entering your email.\"\"\"\n if not ctx.invoked_subcommand:\n Credentials.get_current().activate()\n\n\[email protected](\"reset\")\ndef activate_reset():\n \"\"\"Reset Activation Credentials.\"\"\"\n Credentials.get_current().reset()\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "lib/streamlit/cli.py"}]}
| 3,420 | 242 |
gh_patches_debug_12586
|
rasdani/github-patches
|
git_diff
|
nerfstudio-project__nerfstudio-824
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Depth normalization inconsistent for packed vs. nonpacked samples
**Describe the bug**
When the raymarching samples are packed, the depth is calculated according to `sum_i w_i t_i`: https://github.com/nerfstudio-project/nerfstudio/blob/863fc77ab5f247ff3ce3c80f192173063529b036/nerfstudio/model_components/renderers.py#L236
When the raymarching samples are not packed, the depth is calculated with a normalization factor dividing by the total accumulation, `(sum_i w_i t_i) / (sum_i w_i)`: https://github.com/nerfstudio-project/nerfstudio/blob/863fc77ab5f247ff3ce3c80f192173063529b036/nerfstudio/model_components/renderers.py#L238
**To Reproduce**
N/A
**Expected behavior**
For consistency, the calculation for packed samples should also divide by the total accumulation.
**Screenshots**
N/A
**Additional context**
If this is desired, I can implement the change.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nerfstudio/model_components/renderers.py`
Content:
```
1 # Copyright 2022 The Nerfstudio Team. All rights reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """
16 Collection of renderers
17
18 Example:
19
20 .. code-block:: python
21
22 field_outputs = field(ray_sampler)
23 weights = ray_sampler.get_weights(field_outputs[FieldHeadNames.DENSITY])
24
25 rgb_renderer = RGBRenderer()
26 rgb = rgb_renderer(rgb=field_outputs[FieldHeadNames.RGB], weights=weights)
27
28 """
29 import math
30 from typing import Optional, Union
31
32 import nerfacc
33 import torch
34 from torch import nn
35 from torchtyping import TensorType
36 from typing_extensions import Literal
37
38 from nerfstudio.cameras.rays import RaySamples
39 from nerfstudio.utils.math import components_from_spherical_harmonics
40
41
42 class RGBRenderer(nn.Module):
43 """Standard volumetic rendering.
44
45 Args:
46 background_color: Background color as RGB. Uses random colors if None.
47 """
48
49 def __init__(self, background_color: Union[Literal["random", "last_sample"], TensorType[3]] = "random") -> None:
50 super().__init__()
51 self.background_color = background_color
52
53 @classmethod
54 def combine_rgb(
55 cls,
56 rgb: TensorType["bs":..., "num_samples", 3],
57 weights: TensorType["bs":..., "num_samples", 1],
58 background_color: Union[Literal["random", "last_sample"], TensorType[3]] = "random",
59 ray_indices: Optional[TensorType["num_samples"]] = None,
60 num_rays: Optional[int] = None,
61 ) -> TensorType["bs":..., 3]:
62 """Composite samples along ray and render color image
63
64 Args:
65 rgb: RGB for each sample
66 weights: Weights for each sample
67 background_color: Background color as RGB.
68 ray_indices: Ray index for each sample, used when samples are packed.
69 num_rays: Number of rays, used when samples are packed.
70
71 Returns:
72 Outputs rgb values.
73 """
74 if ray_indices is not None and num_rays is not None:
75 # Necessary for packed samples from volumetric ray sampler
76 if background_color == "last_sample":
77 raise NotImplementedError("Background color 'last_sample' not implemented for packed samples.")
78 comp_rgb = nerfacc.accumulate_along_rays(weights, ray_indices, rgb, num_rays)
79 accumulated_weight = nerfacc.accumulate_along_rays(weights, ray_indices, None, num_rays)
80 else:
81 comp_rgb = torch.sum(weights * rgb, dim=-2)
82 accumulated_weight = torch.sum(weights, dim=-2)
83
84 if background_color == "last_sample":
85 background_color = rgb[..., -1, :]
86 if background_color == "random":
87 background_color = torch.rand_like(comp_rgb).to(rgb.device)
88
89 assert isinstance(background_color, torch.Tensor)
90 comp_rgb = comp_rgb + background_color.to(weights.device) * (1.0 - accumulated_weight)
91
92 return comp_rgb
93
94 def forward(
95 self,
96 rgb: TensorType["bs":..., "num_samples", 3],
97 weights: TensorType["bs":..., "num_samples", 1],
98 ray_indices: Optional[TensorType["num_samples"]] = None,
99 num_rays: Optional[int] = None,
100 ) -> TensorType["bs":..., 3]:
101 """Composite samples along ray and render color image
102
103 Args:
104 rgb: RGB for each sample
105 weights: Weights for each sample
106 ray_indices: Ray index for each sample, used when samples are packed.
107 num_rays: Number of rays, used when samples are packed.
108
109 Returns:
110 Outputs of rgb values.
111 """
112
113 rgb = self.combine_rgb(
114 rgb, weights, background_color=self.background_color, ray_indices=ray_indices, num_rays=num_rays
115 )
116 if not self.training:
117 torch.clamp_(rgb, min=0.0, max=1.0)
118 return rgb
119
120
121 class SHRenderer(nn.Module):
122 """Render RGB value from spherical harmonics.
123
124 Args:
125 background_color: Background color as RGB. Uses random colors if None
126 activation: Output activation.
127 """
128
129 def __init__(
130 self,
131 background_color: Union[Literal["random", "last_sample"], TensorType[3]] = "random",
132 activation: Optional[nn.Module] = nn.Sigmoid(),
133 ) -> None:
134 super().__init__()
135 self.background_color = background_color
136 self.activation = activation
137
138 def forward(
139 self,
140 sh: TensorType[..., "num_samples", "coeffs"],
141 directions: TensorType[..., "num_samples", 3],
142 weights: TensorType[..., "num_samples", 1],
143 ) -> TensorType[..., 3]:
144 """Composite samples along ray and render color image
145
146 Args:
147 sh: Spherical hamonics coefficients for each sample
148 directions: Sample direction
149 weights: Weights for each sample
150
151 Returns:
152 Outputs of rgb values.
153 """
154
155 sh = sh.view(*sh.shape[:-1], 3, sh.shape[-1] // 3)
156
157 levels = int(math.sqrt(sh.shape[-1]))
158 components = components_from_spherical_harmonics(levels=levels, directions=directions)
159
160 rgb = sh * components[..., None, :] # [..., num_samples, 3, sh_components]
161 rgb = torch.sum(sh, dim=-1) + 0.5 # [..., num_samples, 3]
162
163 if self.activation is not None:
164 self.activation(rgb)
165
166 rgb = RGBRenderer.combine_rgb(rgb, weights, background_color=self.background_color)
167
168 return rgb
169
170
171 class AccumulationRenderer(nn.Module):
172 """Accumulated value along a ray."""
173
174 @classmethod
175 def forward(
176 cls,
177 weights: TensorType["bs":..., "num_samples", 1],
178 ray_indices: Optional[TensorType["num_samples"]] = None,
179 num_rays: Optional[int] = None,
180 ) -> TensorType["bs":..., 1]:
181 """Composite samples along ray and calculate accumulation.
182
183 Args:
184 weights: Weights for each sample
185 ray_indices: Ray index for each sample, used when samples are packed.
186 num_rays: Number of rays, used when samples are packed.
187
188 Returns:
189 Outputs of accumulated values.
190 """
191
192 if ray_indices is not None and num_rays is not None:
193 # Necessary for packed samples from volumetric ray sampler
194 accumulation = nerfacc.accumulate_along_rays(weights, ray_indices, None, num_rays)
195 else:
196 accumulation = torch.sum(weights, dim=-2)
197 return accumulation
198
199
200 class DepthRenderer(nn.Module):
201 """Calculate depth along ray.
202
203 Args:
204 method (str, optional): Depth calculation method.
205 """
206
207 def __init__(self, method: Literal["expected"] = "expected") -> None:
208 super().__init__()
209 self.method = method
210
211 def forward(
212 self,
213 weights: TensorType[..., "num_samples", 1],
214 ray_samples: RaySamples,
215 ray_indices: Optional[TensorType["num_samples"]] = None,
216 num_rays: Optional[int] = None,
217 ) -> TensorType[..., 1]:
218 """Composite samples along ray and calculate disparities.
219
220 Args:
221 weights: Weights for each sample.
222 ray_samples: Set of ray samples.
223 ray_indices: Ray index for each sample, used when samples are packed.
224 num_rays: Number of rays, used when samples are packed.
225
226 Returns:
227 Outputs of depth values.
228 """
229
230 if self.method == "expected":
231 eps = 1e-10
232 steps = (ray_samples.frustums.starts + ray_samples.frustums.ends) / 2
233
234 if ray_indices is not None and num_rays is not None:
235 # Necessary for packed samples from volumetric ray sampler
236 depth = nerfacc.accumulate_along_rays(weights, ray_indices, steps, num_rays)
237 else:
238 depth = torch.sum(weights * steps, dim=-2) / (torch.sum(weights, -2) + eps)
239
240 depth = torch.clip(depth, steps.min(), steps.max())
241
242 return depth
243
244 raise NotImplementedError(f"Method {self.method} not implemented")
245
246
247 class UncertaintyRenderer(nn.Module):
248 """Calculate uncertainty along the ray."""
249
250 @classmethod
251 def forward(
252 cls, betas: TensorType["bs":..., "num_samples", 1], weights: TensorType["bs":..., "num_samples", 1]
253 ) -> TensorType["bs":..., 1]:
254 """Calculate uncertainty along the ray.
255
256 Args:
257 betas: Uncertainty betas for each sample.
258 weights: Weights of each sample.
259
260 Returns:
261 Rendering of uncertainty.
262 """
263 uncertainty = torch.sum(weights * betas, dim=-2)
264 return uncertainty
265
266
267 class SemanticRenderer(nn.Module):
268 """Calculate semantics along the ray."""
269
270 @classmethod
271 def forward(
272 cls,
273 semantics: TensorType["bs":..., "num_samples", "num_classes"],
274 weights: TensorType["bs":..., "num_samples", 1],
275 ) -> TensorType["bs":..., "num_classes"]:
276 """_summary_"""
277 sem = torch.sum(weights * semantics, dim=-2)
278 return sem
279
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nerfstudio/model_components/renderers.py b/nerfstudio/model_components/renderers.py
--- a/nerfstudio/model_components/renderers.py
+++ b/nerfstudio/model_components/renderers.py
@@ -234,6 +234,8 @@
if ray_indices is not None and num_rays is not None:
# Necessary for packed samples from volumetric ray sampler
depth = nerfacc.accumulate_along_rays(weights, ray_indices, steps, num_rays)
+ accumulation = nerfacc.accumulate_along_rays(weights, ray_indices, None, num_rays)
+ depth = depth / (accumulation + eps)
else:
depth = torch.sum(weights * steps, dim=-2) / (torch.sum(weights, -2) + eps)
|
{"golden_diff": "diff --git a/nerfstudio/model_components/renderers.py b/nerfstudio/model_components/renderers.py\n--- a/nerfstudio/model_components/renderers.py\n+++ b/nerfstudio/model_components/renderers.py\n@@ -234,6 +234,8 @@\n if ray_indices is not None and num_rays is not None:\n # Necessary for packed samples from volumetric ray sampler\n depth = nerfacc.accumulate_along_rays(weights, ray_indices, steps, num_rays)\n+ accumulation = nerfacc.accumulate_along_rays(weights, ray_indices, None, num_rays)\n+ depth = depth / (accumulation + eps)\n else:\n depth = torch.sum(weights * steps, dim=-2) / (torch.sum(weights, -2) + eps)\n", "issue": "Depth normalization inconsistent for packed vs. nonpacked samples\n**Describe the bug**\r\nWhen the raymarching samples are packed, the depth is calculated according to `sum_i w_i t_i`: https://github.com/nerfstudio-project/nerfstudio/blob/863fc77ab5f247ff3ce3c80f192173063529b036/nerfstudio/model_components/renderers.py#L236\r\n\r\nWhen the raymarching samples are not packed, the depth is calculated with a normalization factor dividing by the total accumulation, `(sum_i w_i t_i) / (sum_i w_i)`: https://github.com/nerfstudio-project/nerfstudio/blob/863fc77ab5f247ff3ce3c80f192173063529b036/nerfstudio/model_components/renderers.py#L238\r\n\r\n**To Reproduce**\r\nN/A\r\n\r\n**Expected behavior**\r\nFor consistency, the calculation for packed samples should also divide by the total accumulation.\r\n\r\n**Screenshots**\r\nN/A\r\n\r\n**Additional context**\r\nIf this is desired, I can implement the change.\r\n\n", "before_files": [{"content": "# Copyright 2022 The Nerfstudio Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nCollection of renderers\n\nExample:\n\n.. code-block:: python\n\n field_outputs = field(ray_sampler)\n weights = ray_sampler.get_weights(field_outputs[FieldHeadNames.DENSITY])\n\n rgb_renderer = RGBRenderer()\n rgb = rgb_renderer(rgb=field_outputs[FieldHeadNames.RGB], weights=weights)\n\n\"\"\"\nimport math\nfrom typing import Optional, Union\n\nimport nerfacc\nimport torch\nfrom torch import nn\nfrom torchtyping import TensorType\nfrom typing_extensions import Literal\n\nfrom nerfstudio.cameras.rays import RaySamples\nfrom nerfstudio.utils.math import components_from_spherical_harmonics\n\n\nclass RGBRenderer(nn.Module):\n \"\"\"Standard volumetic rendering.\n\n Args:\n background_color: Background color as RGB. Uses random colors if None.\n \"\"\"\n\n def __init__(self, background_color: Union[Literal[\"random\", \"last_sample\"], TensorType[3]] = \"random\") -> None:\n super().__init__()\n self.background_color = background_color\n\n @classmethod\n def combine_rgb(\n cls,\n rgb: TensorType[\"bs\":..., \"num_samples\", 3],\n weights: TensorType[\"bs\":..., \"num_samples\", 1],\n background_color: Union[Literal[\"random\", \"last_sample\"], TensorType[3]] = \"random\",\n ray_indices: Optional[TensorType[\"num_samples\"]] = None,\n num_rays: Optional[int] = None,\n ) -> TensorType[\"bs\":..., 3]:\n \"\"\"Composite samples along ray and render color image\n\n Args:\n rgb: RGB for each sample\n weights: Weights for each sample\n background_color: Background color as RGB.\n ray_indices: Ray index for each sample, used when samples are packed.\n num_rays: Number of rays, used when samples are packed.\n\n Returns:\n Outputs rgb values.\n \"\"\"\n if ray_indices is not None and num_rays is not None:\n # Necessary for packed samples from volumetric ray sampler\n if background_color == \"last_sample\":\n raise NotImplementedError(\"Background color 'last_sample' not implemented for packed samples.\")\n comp_rgb = nerfacc.accumulate_along_rays(weights, ray_indices, rgb, num_rays)\n accumulated_weight = nerfacc.accumulate_along_rays(weights, ray_indices, None, num_rays)\n else:\n comp_rgb = torch.sum(weights * rgb, dim=-2)\n accumulated_weight = torch.sum(weights, dim=-2)\n\n if background_color == \"last_sample\":\n background_color = rgb[..., -1, :]\n if background_color == \"random\":\n background_color = torch.rand_like(comp_rgb).to(rgb.device)\n\n assert isinstance(background_color, torch.Tensor)\n comp_rgb = comp_rgb + background_color.to(weights.device) * (1.0 - accumulated_weight)\n\n return comp_rgb\n\n def forward(\n self,\n rgb: TensorType[\"bs\":..., \"num_samples\", 3],\n weights: TensorType[\"bs\":..., \"num_samples\", 1],\n ray_indices: Optional[TensorType[\"num_samples\"]] = None,\n num_rays: Optional[int] = None,\n ) -> TensorType[\"bs\":..., 3]:\n \"\"\"Composite samples along ray and render color image\n\n Args:\n rgb: RGB for each sample\n weights: Weights for each sample\n ray_indices: Ray index for each sample, used when samples are packed.\n num_rays: Number of rays, used when samples are packed.\n\n Returns:\n Outputs of rgb values.\n \"\"\"\n\n rgb = self.combine_rgb(\n rgb, weights, background_color=self.background_color, ray_indices=ray_indices, num_rays=num_rays\n )\n if not self.training:\n torch.clamp_(rgb, min=0.0, max=1.0)\n return rgb\n\n\nclass SHRenderer(nn.Module):\n \"\"\"Render RGB value from spherical harmonics.\n\n Args:\n background_color: Background color as RGB. Uses random colors if None\n activation: Output activation.\n \"\"\"\n\n def __init__(\n self,\n background_color: Union[Literal[\"random\", \"last_sample\"], TensorType[3]] = \"random\",\n activation: Optional[nn.Module] = nn.Sigmoid(),\n ) -> None:\n super().__init__()\n self.background_color = background_color\n self.activation = activation\n\n def forward(\n self,\n sh: TensorType[..., \"num_samples\", \"coeffs\"],\n directions: TensorType[..., \"num_samples\", 3],\n weights: TensorType[..., \"num_samples\", 1],\n ) -> TensorType[..., 3]:\n \"\"\"Composite samples along ray and render color image\n\n Args:\n sh: Spherical hamonics coefficients for each sample\n directions: Sample direction\n weights: Weights for each sample\n\n Returns:\n Outputs of rgb values.\n \"\"\"\n\n sh = sh.view(*sh.shape[:-1], 3, sh.shape[-1] // 3)\n\n levels = int(math.sqrt(sh.shape[-1]))\n components = components_from_spherical_harmonics(levels=levels, directions=directions)\n\n rgb = sh * components[..., None, :] # [..., num_samples, 3, sh_components]\n rgb = torch.sum(sh, dim=-1) + 0.5 # [..., num_samples, 3]\n\n if self.activation is not None:\n self.activation(rgb)\n\n rgb = RGBRenderer.combine_rgb(rgb, weights, background_color=self.background_color)\n\n return rgb\n\n\nclass AccumulationRenderer(nn.Module):\n \"\"\"Accumulated value along a ray.\"\"\"\n\n @classmethod\n def forward(\n cls,\n weights: TensorType[\"bs\":..., \"num_samples\", 1],\n ray_indices: Optional[TensorType[\"num_samples\"]] = None,\n num_rays: Optional[int] = None,\n ) -> TensorType[\"bs\":..., 1]:\n \"\"\"Composite samples along ray and calculate accumulation.\n\n Args:\n weights: Weights for each sample\n ray_indices: Ray index for each sample, used when samples are packed.\n num_rays: Number of rays, used when samples are packed.\n\n Returns:\n Outputs of accumulated values.\n \"\"\"\n\n if ray_indices is not None and num_rays is not None:\n # Necessary for packed samples from volumetric ray sampler\n accumulation = nerfacc.accumulate_along_rays(weights, ray_indices, None, num_rays)\n else:\n accumulation = torch.sum(weights, dim=-2)\n return accumulation\n\n\nclass DepthRenderer(nn.Module):\n \"\"\"Calculate depth along ray.\n\n Args:\n method (str, optional): Depth calculation method.\n \"\"\"\n\n def __init__(self, method: Literal[\"expected\"] = \"expected\") -> None:\n super().__init__()\n self.method = method\n\n def forward(\n self,\n weights: TensorType[..., \"num_samples\", 1],\n ray_samples: RaySamples,\n ray_indices: Optional[TensorType[\"num_samples\"]] = None,\n num_rays: Optional[int] = None,\n ) -> TensorType[..., 1]:\n \"\"\"Composite samples along ray and calculate disparities.\n\n Args:\n weights: Weights for each sample.\n ray_samples: Set of ray samples.\n ray_indices: Ray index for each sample, used when samples are packed.\n num_rays: Number of rays, used when samples are packed.\n\n Returns:\n Outputs of depth values.\n \"\"\"\n\n if self.method == \"expected\":\n eps = 1e-10\n steps = (ray_samples.frustums.starts + ray_samples.frustums.ends) / 2\n\n if ray_indices is not None and num_rays is not None:\n # Necessary for packed samples from volumetric ray sampler\n depth = nerfacc.accumulate_along_rays(weights, ray_indices, steps, num_rays)\n else:\n depth = torch.sum(weights * steps, dim=-2) / (torch.sum(weights, -2) + eps)\n\n depth = torch.clip(depth, steps.min(), steps.max())\n\n return depth\n\n raise NotImplementedError(f\"Method {self.method} not implemented\")\n\n\nclass UncertaintyRenderer(nn.Module):\n \"\"\"Calculate uncertainty along the ray.\"\"\"\n\n @classmethod\n def forward(\n cls, betas: TensorType[\"bs\":..., \"num_samples\", 1], weights: TensorType[\"bs\":..., \"num_samples\", 1]\n ) -> TensorType[\"bs\":..., 1]:\n \"\"\"Calculate uncertainty along the ray.\n\n Args:\n betas: Uncertainty betas for each sample.\n weights: Weights of each sample.\n\n Returns:\n Rendering of uncertainty.\n \"\"\"\n uncertainty = torch.sum(weights * betas, dim=-2)\n return uncertainty\n\n\nclass SemanticRenderer(nn.Module):\n \"\"\"Calculate semantics along the ray.\"\"\"\n\n @classmethod\n def forward(\n cls,\n semantics: TensorType[\"bs\":..., \"num_samples\", \"num_classes\"],\n weights: TensorType[\"bs\":..., \"num_samples\", 1],\n ) -> TensorType[\"bs\":..., \"num_classes\"]:\n \"\"\"_summary_\"\"\"\n sem = torch.sum(weights * semantics, dim=-2)\n return sem\n", "path": "nerfstudio/model_components/renderers.py"}], "after_files": [{"content": "# Copyright 2022 The Nerfstudio Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nCollection of renderers\n\nExample:\n\n.. code-block:: python\n\n field_outputs = field(ray_sampler)\n weights = ray_sampler.get_weights(field_outputs[FieldHeadNames.DENSITY])\n\n rgb_renderer = RGBRenderer()\n rgb = rgb_renderer(rgb=field_outputs[FieldHeadNames.RGB], weights=weights)\n\n\"\"\"\nimport math\nfrom typing import Optional, Union\n\nimport nerfacc\nimport torch\nfrom torch import nn\nfrom torchtyping import TensorType\nfrom typing_extensions import Literal\n\nfrom nerfstudio.cameras.rays import RaySamples\nfrom nerfstudio.utils.math import components_from_spherical_harmonics\n\n\nclass RGBRenderer(nn.Module):\n \"\"\"Standard volumetic rendering.\n\n Args:\n background_color: Background color as RGB. Uses random colors if None.\n \"\"\"\n\n def __init__(self, background_color: Union[Literal[\"random\", \"last_sample\"], TensorType[3]] = \"random\") -> None:\n super().__init__()\n self.background_color = background_color\n\n @classmethod\n def combine_rgb(\n cls,\n rgb: TensorType[\"bs\":..., \"num_samples\", 3],\n weights: TensorType[\"bs\":..., \"num_samples\", 1],\n background_color: Union[Literal[\"random\", \"last_sample\"], TensorType[3]] = \"random\",\n ray_indices: Optional[TensorType[\"num_samples\"]] = None,\n num_rays: Optional[int] = None,\n ) -> TensorType[\"bs\":..., 3]:\n \"\"\"Composite samples along ray and render color image\n\n Args:\n rgb: RGB for each sample\n weights: Weights for each sample\n background_color: Background color as RGB.\n ray_indices: Ray index for each sample, used when samples are packed.\n num_rays: Number of rays, used when samples are packed.\n\n Returns:\n Outputs rgb values.\n \"\"\"\n if ray_indices is not None and num_rays is not None:\n # Necessary for packed samples from volumetric ray sampler\n if background_color == \"last_sample\":\n raise NotImplementedError(\"Background color 'last_sample' not implemented for packed samples.\")\n comp_rgb = nerfacc.accumulate_along_rays(weights, ray_indices, rgb, num_rays)\n accumulated_weight = nerfacc.accumulate_along_rays(weights, ray_indices, None, num_rays)\n else:\n comp_rgb = torch.sum(weights * rgb, dim=-2)\n accumulated_weight = torch.sum(weights, dim=-2)\n\n if background_color == \"last_sample\":\n background_color = rgb[..., -1, :]\n if background_color == \"random\":\n background_color = torch.rand_like(comp_rgb).to(rgb.device)\n\n assert isinstance(background_color, torch.Tensor)\n comp_rgb = comp_rgb + background_color.to(weights.device) * (1.0 - accumulated_weight)\n\n return comp_rgb\n\n def forward(\n self,\n rgb: TensorType[\"bs\":..., \"num_samples\", 3],\n weights: TensorType[\"bs\":..., \"num_samples\", 1],\n ray_indices: Optional[TensorType[\"num_samples\"]] = None,\n num_rays: Optional[int] = None,\n ) -> TensorType[\"bs\":..., 3]:\n \"\"\"Composite samples along ray and render color image\n\n Args:\n rgb: RGB for each sample\n weights: Weights for each sample\n ray_indices: Ray index for each sample, used when samples are packed.\n num_rays: Number of rays, used when samples are packed.\n\n Returns:\n Outputs of rgb values.\n \"\"\"\n\n rgb = self.combine_rgb(\n rgb, weights, background_color=self.background_color, ray_indices=ray_indices, num_rays=num_rays\n )\n if not self.training:\n torch.clamp_(rgb, min=0.0, max=1.0)\n return rgb\n\n\nclass SHRenderer(nn.Module):\n \"\"\"Render RGB value from spherical harmonics.\n\n Args:\n background_color: Background color as RGB. Uses random colors if None\n activation: Output activation.\n \"\"\"\n\n def __init__(\n self,\n background_color: Union[Literal[\"random\", \"last_sample\"], TensorType[3]] = \"random\",\n activation: Optional[nn.Module] = nn.Sigmoid(),\n ) -> None:\n super().__init__()\n self.background_color = background_color\n self.activation = activation\n\n def forward(\n self,\n sh: TensorType[..., \"num_samples\", \"coeffs\"],\n directions: TensorType[..., \"num_samples\", 3],\n weights: TensorType[..., \"num_samples\", 1],\n ) -> TensorType[..., 3]:\n \"\"\"Composite samples along ray and render color image\n\n Args:\n sh: Spherical hamonics coefficients for each sample\n directions: Sample direction\n weights: Weights for each sample\n\n Returns:\n Outputs of rgb values.\n \"\"\"\n\n sh = sh.view(*sh.shape[:-1], 3, sh.shape[-1] // 3)\n\n levels = int(math.sqrt(sh.shape[-1]))\n components = components_from_spherical_harmonics(levels=levels, directions=directions)\n\n rgb = sh * components[..., None, :] # [..., num_samples, 3, sh_components]\n rgb = torch.sum(sh, dim=-1) + 0.5 # [..., num_samples, 3]\n\n if self.activation is not None:\n self.activation(rgb)\n\n rgb = RGBRenderer.combine_rgb(rgb, weights, background_color=self.background_color)\n\n return rgb\n\n\nclass AccumulationRenderer(nn.Module):\n \"\"\"Accumulated value along a ray.\"\"\"\n\n @classmethod\n def forward(\n cls,\n weights: TensorType[\"bs\":..., \"num_samples\", 1],\n ray_indices: Optional[TensorType[\"num_samples\"]] = None,\n num_rays: Optional[int] = None,\n ) -> TensorType[\"bs\":..., 1]:\n \"\"\"Composite samples along ray and calculate accumulation.\n\n Args:\n weights: Weights for each sample\n ray_indices: Ray index for each sample, used when samples are packed.\n num_rays: Number of rays, used when samples are packed.\n\n Returns:\n Outputs of accumulated values.\n \"\"\"\n\n if ray_indices is not None and num_rays is not None:\n # Necessary for packed samples from volumetric ray sampler\n accumulation = nerfacc.accumulate_along_rays(weights, ray_indices, None, num_rays)\n else:\n accumulation = torch.sum(weights, dim=-2)\n return accumulation\n\n\nclass DepthRenderer(nn.Module):\n \"\"\"Calculate depth along ray.\n\n Args:\n method (str, optional): Depth calculation method.\n \"\"\"\n\n def __init__(self, method: Literal[\"expected\"] = \"expected\") -> None:\n super().__init__()\n self.method = method\n\n def forward(\n self,\n weights: TensorType[..., \"num_samples\", 1],\n ray_samples: RaySamples,\n ray_indices: Optional[TensorType[\"num_samples\"]] = None,\n num_rays: Optional[int] = None,\n ) -> TensorType[..., 1]:\n \"\"\"Composite samples along ray and calculate disparities.\n\n Args:\n weights: Weights for each sample.\n ray_samples: Set of ray samples.\n ray_indices: Ray index for each sample, used when samples are packed.\n num_rays: Number of rays, used when samples are packed.\n\n Returns:\n Outputs of depth values.\n \"\"\"\n\n if self.method == \"expected\":\n eps = 1e-10\n steps = (ray_samples.frustums.starts + ray_samples.frustums.ends) / 2\n\n if ray_indices is not None and num_rays is not None:\n # Necessary for packed samples from volumetric ray sampler\n depth = nerfacc.accumulate_along_rays(weights, ray_indices, steps, num_rays)\n accumulation = nerfacc.accumulate_along_rays(weights, ray_indices, None, num_rays)\n depth = depth / (accumulation + eps)\n else:\n depth = torch.sum(weights * steps, dim=-2) / (torch.sum(weights, -2) + eps)\n\n depth = torch.clip(depth, steps.min(), steps.max())\n\n return depth\n\n raise NotImplementedError(f\"Method {self.method} not implemented\")\n\n\nclass UncertaintyRenderer(nn.Module):\n \"\"\"Calculate uncertainty along the ray.\"\"\"\n\n @classmethod\n def forward(\n cls, betas: TensorType[\"bs\":..., \"num_samples\", 1], weights: TensorType[\"bs\":..., \"num_samples\", 1]\n ) -> TensorType[\"bs\":..., 1]:\n \"\"\"Calculate uncertainty along the ray.\n\n Args:\n betas: Uncertainty betas for each sample.\n weights: Weights of each sample.\n\n Returns:\n Rendering of uncertainty.\n \"\"\"\n uncertainty = torch.sum(weights * betas, dim=-2)\n return uncertainty\n\n\nclass SemanticRenderer(nn.Module):\n \"\"\"Calculate semantics along the ray.\"\"\"\n\n @classmethod\n def forward(\n cls,\n semantics: TensorType[\"bs\":..., \"num_samples\", \"num_classes\"],\n weights: TensorType[\"bs\":..., \"num_samples\", 1],\n ) -> TensorType[\"bs\":..., \"num_classes\"]:\n \"\"\"_summary_\"\"\"\n sem = torch.sum(weights * semantics, dim=-2)\n return sem\n", "path": "nerfstudio/model_components/renderers.py"}]}
| 3,401 | 176 |
gh_patches_debug_27323
|
rasdani/github-patches
|
git_diff
|
mindsdb__lightwood-168
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Construct comperhensive test suite to evaluate predictions with missing column
We should have a test suite to evaluate prediction accuracy with missing column.
This should take the form of:
Given `M` columns and a Lightwood model trained with them to predict `y`, the accuracy for `y` when predicting with `M` columns (where `M` is a subset of `N`), should be about equal to or greater than that of a Gradient Boosting Regressor or Classifier trained with just the columns `M` to predict `y`.
The reason we are using a Gradient Booster to determine the benchmark accuracy is that it's safe to assume they are fairly generic (i.e. should get about the same accuracy as a well trained neural network) and fast&easy to train.
We can do this testing in two phases:
First, we can add this as a check to the generate-data tests in lightwood, which should be fairly easy.
Second, we can add these tests to mindsdb_examples, the helpers that are already present in there can help.
I'll be handling this but @torrmal feel free to review the methodology
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/examples/learn_to_classify.py`
Content:
```
1 import lightwood
2 import random
3 import pandas as pd
4 import numpy as np
5 from collections import Counter
6
7
8 random.seed(66)
9 n = 100
10 m = 500
11 train = True
12 nr_inputs = 10
13
14 #options = ['a','b','c','d','e','f','g','h','n','m']
15 options = ['a','b','c']
16
17 data_train = {}
18 data_test = {}
19
20 for data, nr_ele in [(data_train,n), (data_test,m)]:
21 for i in range(nr_inputs):
22 data[f'x_{i}'] = [random.choice(options) for _ in range(nr_ele)]
23
24 data['y'] = [Counter([data[f'x_{i}'][n] for i in range(nr_inputs)]).most_common(1)[0][0] for n in range(nr_ele)]
25
26 data_train = pd.DataFrame(data_train)
27 data_test = pd.DataFrame(data_test)
28
29 def iter_function(epoch, training_error, test_error, test_error_gradient, test_accuracy):
30 print(f'Epoch: {epoch}, Train Error: {training_error}, Test Error: {test_error}, Test Error Gradient: {test_error_gradient}, Test Accuracy: {test_accuracy}')
31
32 if train:
33 predictor = lightwood.Predictor(output=['y'])
34 predictor.learn(from_data=data_train, callback_on_iter=iter_function, eval_every_x_epochs=200)
35 predictor.save('/tmp/ltcrl.pkl')
36
37 predictor = lightwood.Predictor(load_from_path='/tmp/ltcrl.pkl')
38 print('Train accuracy: ', predictor.train_accuracy['y']['value'])
39 print('Test accuracy: ', predictor.calculate_accuracy(from_data=data_test)['y']['value'])
40
41 predictions = predictor.predict(when_data=data_test)
42 print(f'Confidence mean for all columns present ', np.mean(predictions['y']['selfaware_confidences']))
43
44 for i_drop in range(nr_inputs):
45 predictions = predictor.predict(when_data=data_test.drop(columns=[f'x_{i_drop}']))
46 print(f'Accuracy for x_{i_drop} missing: ', predictor.calculate_accuracy(from_data=data_test.drop(columns=[f'x_{i_drop}']))['y']['value'])
47 print(f'Confidence mean for x_{i_drop} missing: ', np.mean(predictions['y']['selfaware_confidences']))
48
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docs/examples/learn_to_classify.py b/docs/examples/learn_to_classify.py
--- a/docs/examples/learn_to_classify.py
+++ b/docs/examples/learn_to_classify.py
@@ -34,14 +34,18 @@
predictor.learn(from_data=data_train, callback_on_iter=iter_function, eval_every_x_epochs=200)
predictor.save('/tmp/ltcrl.pkl')
+
predictor = lightwood.Predictor(load_from_path='/tmp/ltcrl.pkl')
print('Train accuracy: ', predictor.train_accuracy['y']['value'])
print('Test accuracy: ', predictor.calculate_accuracy(from_data=data_test)['y']['value'])
-predictions = predictor.predict(when_data=data_test)
+print(f'Accuracy for all columns present: ', predictor.calculate_accuracy(from_data=data_test)['y']['value'])
+
+predictions = predictor.calculate_accuracy(from_data=data_test)
print(f'Confidence mean for all columns present ', np.mean(predictions['y']['selfaware_confidences']))
for i_drop in range(nr_inputs):
- predictions = predictor.predict(when_data=data_test.drop(columns=[f'x_{i_drop}']))
print(f'Accuracy for x_{i_drop} missing: ', predictor.calculate_accuracy(from_data=data_test.drop(columns=[f'x_{i_drop}']))['y']['value'])
+
+ predictions = predictor.calculate_accuracy(from_data=data_test.drop(columns=[f'x_{i_drop}']))
print(f'Confidence mean for x_{i_drop} missing: ', np.mean(predictions['y']['selfaware_confidences']))
|
{"golden_diff": "diff --git a/docs/examples/learn_to_classify.py b/docs/examples/learn_to_classify.py\n--- a/docs/examples/learn_to_classify.py\n+++ b/docs/examples/learn_to_classify.py\n@@ -34,14 +34,18 @@\n predictor.learn(from_data=data_train, callback_on_iter=iter_function, eval_every_x_epochs=200)\n predictor.save('/tmp/ltcrl.pkl')\n \n+\n predictor = lightwood.Predictor(load_from_path='/tmp/ltcrl.pkl')\n print('Train accuracy: ', predictor.train_accuracy['y']['value'])\n print('Test accuracy: ', predictor.calculate_accuracy(from_data=data_test)['y']['value'])\n \n-predictions = predictor.predict(when_data=data_test)\n+print(f'Accuracy for all columns present: ', predictor.calculate_accuracy(from_data=data_test)['y']['value'])\n+\n+predictions = predictor.calculate_accuracy(from_data=data_test)\n print(f'Confidence mean for all columns present ', np.mean(predictions['y']['selfaware_confidences']))\n \n for i_drop in range(nr_inputs):\n- predictions = predictor.predict(when_data=data_test.drop(columns=[f'x_{i_drop}']))\n print(f'Accuracy for x_{i_drop} missing: ', predictor.calculate_accuracy(from_data=data_test.drop(columns=[f'x_{i_drop}']))['y']['value'])\n+\n+ predictions = predictor.calculate_accuracy(from_data=data_test.drop(columns=[f'x_{i_drop}']))\n print(f'Confidence mean for x_{i_drop} missing: ', np.mean(predictions['y']['selfaware_confidences']))\n", "issue": "Construct comperhensive test suite to evaluate predictions with missing column\nWe should have a test suite to evaluate prediction accuracy with missing column.\r\n\r\nThis should take the form of:\r\n\r\nGiven `M` columns and a Lightwood model trained with them to predict `y`, the accuracy for `y` when predicting with `M` columns (where `M` is a subset of `N`), should be about equal to or greater than that of a Gradient Boosting Regressor or Classifier trained with just the columns `M` to predict `y`.\r\n\r\nThe reason we are using a Gradient Booster to determine the benchmark accuracy is that it's safe to assume they are fairly generic (i.e. should get about the same accuracy as a well trained neural network) and fast&easy to train.\r\n\r\nWe can do this testing in two phases:\r\n\r\nFirst, we can add this as a check to the generate-data tests in lightwood, which should be fairly easy.\r\n\r\nSecond, we can add these tests to mindsdb_examples, the helpers that are already present in there can help.\r\n\r\nI'll be handling this but @torrmal feel free to review the methodology\n", "before_files": [{"content": "import lightwood\nimport random\nimport pandas as pd\nimport numpy as np\nfrom collections import Counter\n\n\nrandom.seed(66)\nn = 100\nm = 500\ntrain = True\nnr_inputs = 10\n\n#options = ['a','b','c','d','e','f','g','h','n','m']\noptions = ['a','b','c']\n\ndata_train = {}\ndata_test = {}\n\nfor data, nr_ele in [(data_train,n), (data_test,m)]:\n for i in range(nr_inputs):\n data[f'x_{i}'] = [random.choice(options) for _ in range(nr_ele)]\n\n data['y'] = [Counter([data[f'x_{i}'][n] for i in range(nr_inputs)]).most_common(1)[0][0] for n in range(nr_ele)]\n\ndata_train = pd.DataFrame(data_train)\ndata_test = pd.DataFrame(data_test)\n\ndef iter_function(epoch, training_error, test_error, test_error_gradient, test_accuracy):\n print(f'Epoch: {epoch}, Train Error: {training_error}, Test Error: {test_error}, Test Error Gradient: {test_error_gradient}, Test Accuracy: {test_accuracy}')\n\nif train:\n predictor = lightwood.Predictor(output=['y'])\n predictor.learn(from_data=data_train, callback_on_iter=iter_function, eval_every_x_epochs=200)\n predictor.save('/tmp/ltcrl.pkl')\n\npredictor = lightwood.Predictor(load_from_path='/tmp/ltcrl.pkl')\nprint('Train accuracy: ', predictor.train_accuracy['y']['value'])\nprint('Test accuracy: ', predictor.calculate_accuracy(from_data=data_test)['y']['value'])\n\npredictions = predictor.predict(when_data=data_test)\nprint(f'Confidence mean for all columns present ', np.mean(predictions['y']['selfaware_confidences']))\n\nfor i_drop in range(nr_inputs):\n predictions = predictor.predict(when_data=data_test.drop(columns=[f'x_{i_drop}']))\n print(f'Accuracy for x_{i_drop} missing: ', predictor.calculate_accuracy(from_data=data_test.drop(columns=[f'x_{i_drop}']))['y']['value'])\n print(f'Confidence mean for x_{i_drop} missing: ', np.mean(predictions['y']['selfaware_confidences']))\n", "path": "docs/examples/learn_to_classify.py"}], "after_files": [{"content": "import lightwood\nimport random\nimport pandas as pd\nimport numpy as np\nfrom collections import Counter\n\n\nrandom.seed(66)\nn = 100\nm = 500\ntrain = True\nnr_inputs = 10\n\n#options = ['a','b','c','d','e','f','g','h','n','m']\noptions = ['a','b','c']\n\ndata_train = {}\ndata_test = {}\n\nfor data, nr_ele in [(data_train,n), (data_test,m)]:\n for i in range(nr_inputs):\n data[f'x_{i}'] = [random.choice(options) for _ in range(nr_ele)]\n\n data['y'] = [Counter([data[f'x_{i}'][n] for i in range(nr_inputs)]).most_common(1)[0][0] for n in range(nr_ele)]\n\ndata_train = pd.DataFrame(data_train)\ndata_test = pd.DataFrame(data_test)\n\ndef iter_function(epoch, training_error, test_error, test_error_gradient, test_accuracy):\n print(f'Epoch: {epoch}, Train Error: {training_error}, Test Error: {test_error}, Test Error Gradient: {test_error_gradient}, Test Accuracy: {test_accuracy}')\n\nif train:\n predictor = lightwood.Predictor(output=['y'])\n predictor.learn(from_data=data_train, callback_on_iter=iter_function, eval_every_x_epochs=200)\n predictor.save('/tmp/ltcrl.pkl')\n\n\npredictor = lightwood.Predictor(load_from_path='/tmp/ltcrl.pkl')\nprint('Train accuracy: ', predictor.train_accuracy['y']['value'])\nprint('Test accuracy: ', predictor.calculate_accuracy(from_data=data_test)['y']['value'])\n\nprint(f'Accuracy for all columns present: ', predictor.calculate_accuracy(from_data=data_test)['y']['value'])\n\npredictions = predictor.calculate_accuracy(from_data=data_test)\nprint(f'Confidence mean for all columns present ', np.mean(predictions['y']['selfaware_confidences']))\n\nfor i_drop in range(nr_inputs):\n print(f'Accuracy for x_{i_drop} missing: ', predictor.calculate_accuracy(from_data=data_test.drop(columns=[f'x_{i_drop}']))['y']['value'])\n\n predictions = predictor.calculate_accuracy(from_data=data_test.drop(columns=[f'x_{i_drop}']))\n print(f'Confidence mean for x_{i_drop} missing: ', np.mean(predictions['y']['selfaware_confidences']))\n", "path": "docs/examples/learn_to_classify.py"}]}
| 1,076 | 333 |
gh_patches_debug_35750
|
rasdani/github-patches
|
git_diff
|
chainer__chainer-1663
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Test N-dimensional convolution link for dtypes of FP16 and FP64
Follows #1279 and #1556.
Since #1295 is now merged to master, we can add test for dtypes of FP16 and FP64 to N-dimensional convolution **LINK**.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `chainer/links/connection/convolution_nd.py`
Content:
```
1 from chainer.functions.connection import convolution_nd
2 from chainer import initializers
3 from chainer import link
4 from chainer.utils import conv_nd
5
6
7 class ConvolutionND(link.Link):
8 """N-dimensional convolution layer.
9
10 This link wraps the :func:`~chainer.functions.convolution_nd` function and
11 holds the filter weight and bias vector as parameters.
12
13 Args:
14 ndim (int): Number of spatial dimensions.
15 in_channels (int): Number of channels of input arrays.
16 out_channels (int): Number of channels of output arrays.
17 ksize (int or tuple of ints): Size of filters (a.k.a. kernels).
18 ``ksize=k`` and ``ksize=(k, k, ..., k)`` are equivalent.
19 stride (int or tuple of ints): Stride of filter application.
20 ``stride=s`` and ``stride=(s, s, ..., s)`` are equivalent.
21 pad (int or tuple of ints): Spatial padding width for input arrays.
22 ``pad=p`` and ``pad=(p, p, ..., p)`` are equivalent.
23 initialW: Value used to initialize the filter weight. May be an
24 initializer instance or another value that
25 :func:`~chainer.init_weight` helper function can take. This link
26 uses :func:`~chainer.init_weight` to initialize the filter weight
27 and passes the value of ``initialW`` to it as it is.
28 initial_bias: Value used to initialize the bias vector. May be an
29 initializer instance or another value except ``None`` that
30 :func:`~chainer.init_weight` helper function can take. If ``None``
31 is given, this link does not use the bias vector. This link uses
32 :func:`~chainer.init_weight` to initialize the bias vector and
33 passes the value of ``initial_bias`` other than ``None`` to it as
34 it is.
35 use_cudnn (bool): If ``True``, then this link uses cuDNN if available.
36 See :func:`~chainer.functions.convolution_nd` for exact conditions
37 of cuDNN availability.
38 cover_all (bool): If ``True``, all spatial locations are convoluted
39 into some output pixels. It may make the output size larger.
40 ``cover_all`` needs to be ``False`` if you want to use cuDNN.
41
42 .. seealso::
43 See :func:`~chainer.functions.convolution_nd` for the definition of
44 N-dimensional convolution. See
45 :func:`~chainer.functions.convolution_2d` for the definition of
46 two-dimensional convolution.
47
48 Attributes:
49 W (~chainer.Variable): Weight parameter.
50 b (~chainer.Variable): Bias parameter. If ``initial_bias`` is ``None``,
51 set to ``None``.
52
53 """
54
55 def __init__(self, ndim, in_channels, out_channels, ksize, stride=1, pad=0,
56 initialW=None, initial_bias=None, use_cudnn=True,
57 cover_all=False):
58 ksize = conv_nd.as_tuple(ksize, ndim)
59 self.stride = stride
60 self.pad = pad
61 self.use_cudnn = use_cudnn
62 self.cover_all = cover_all
63
64 W_shape = (out_channels, in_channels) + ksize
65 super(ConvolutionND, self).__init__(W=W_shape)
66 initializers.init_weight(self.W.data, initialW)
67
68 if initial_bias is None:
69 self.b = None
70 else:
71 self.add_param('b', out_channels)
72 initializers.init_weight(self.b.data, initial_bias)
73
74 def __call__(self, x):
75 """Applies N-dimensional convolution layer.
76
77 Args:
78 x (~chainer.Variable): Input image.
79
80 Returns:
81 ~chainer.Variable: Output of convolution.
82
83 """
84 return convolution_nd.convolution_nd(
85 x, self.W, self.b, self.stride, self.pad,
86 use_cudnn=self.use_cudnn, cover_all=self.cover_all)
87
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/chainer/links/connection/convolution_nd.py b/chainer/links/connection/convolution_nd.py
--- a/chainer/links/connection/convolution_nd.py
+++ b/chainer/links/connection/convolution_nd.py
@@ -22,16 +22,11 @@
``pad=p`` and ``pad=(p, p, ..., p)`` are equivalent.
initialW: Value used to initialize the filter weight. May be an
initializer instance or another value that
- :func:`~chainer.init_weight` helper function can take. This link
- uses :func:`~chainer.init_weight` to initialize the filter weight
- and passes the value of ``initialW`` to it as it is.
+ :func:`~chainer.init_weight` helper function can take.
initial_bias: Value used to initialize the bias vector. May be an
initializer instance or another value except ``None`` that
:func:`~chainer.init_weight` helper function can take. If ``None``
- is given, this link does not use the bias vector. This link uses
- :func:`~chainer.init_weight` to initialize the bias vector and
- passes the value of ``initial_bias`` other than ``None`` to it as
- it is.
+ is given, this link does not use the bias vector.
use_cudnn (bool): If ``True``, then this link uses cuDNN if available.
See :func:`~chainer.functions.convolution_nd` for exact conditions
of cuDNN availability.
@@ -61,15 +56,17 @@
self.use_cudnn = use_cudnn
self.cover_all = cover_all
+ super(ConvolutionND, self).__init__()
+
W_shape = (out_channels, in_channels) + ksize
- super(ConvolutionND, self).__init__(W=W_shape)
- initializers.init_weight(self.W.data, initialW)
+ initialW = initializers._get_initializer(initialW)
+ self.add_param('W', W_shape, initializer=initialW)
if initial_bias is None:
self.b = None
else:
- self.add_param('b', out_channels)
- initializers.init_weight(self.b.data, initial_bias)
+ initial_bias = initializers._get_initializer(initial_bias)
+ self.add_param('b', out_channels, initializer=initial_bias)
def __call__(self, x):
"""Applies N-dimensional convolution layer.
|
{"golden_diff": "diff --git a/chainer/links/connection/convolution_nd.py b/chainer/links/connection/convolution_nd.py\n--- a/chainer/links/connection/convolution_nd.py\n+++ b/chainer/links/connection/convolution_nd.py\n@@ -22,16 +22,11 @@\n ``pad=p`` and ``pad=(p, p, ..., p)`` are equivalent.\n initialW: Value used to initialize the filter weight. May be an\n initializer instance or another value that\n- :func:`~chainer.init_weight` helper function can take. This link\n- uses :func:`~chainer.init_weight` to initialize the filter weight\n- and passes the value of ``initialW`` to it as it is.\n+ :func:`~chainer.init_weight` helper function can take.\n initial_bias: Value used to initialize the bias vector. May be an\n initializer instance or another value except ``None`` that\n :func:`~chainer.init_weight` helper function can take. If ``None``\n- is given, this link does not use the bias vector. This link uses\n- :func:`~chainer.init_weight` to initialize the bias vector and\n- passes the value of ``initial_bias`` other than ``None`` to it as\n- it is.\n+ is given, this link does not use the bias vector.\n use_cudnn (bool): If ``True``, then this link uses cuDNN if available.\n See :func:`~chainer.functions.convolution_nd` for exact conditions\n of cuDNN availability.\n@@ -61,15 +56,17 @@\n self.use_cudnn = use_cudnn\n self.cover_all = cover_all\n \n+ super(ConvolutionND, self).__init__()\n+\n W_shape = (out_channels, in_channels) + ksize\n- super(ConvolutionND, self).__init__(W=W_shape)\n- initializers.init_weight(self.W.data, initialW)\n+ initialW = initializers._get_initializer(initialW)\n+ self.add_param('W', W_shape, initializer=initialW)\n \n if initial_bias is None:\n self.b = None\n else:\n- self.add_param('b', out_channels)\n- initializers.init_weight(self.b.data, initial_bias)\n+ initial_bias = initializers._get_initializer(initial_bias)\n+ self.add_param('b', out_channels, initializer=initial_bias)\n \n def __call__(self, x):\n \"\"\"Applies N-dimensional convolution layer.\n", "issue": "Test N-dimensional convolution link for dtypes of FP16 and FP64\nFollows #1279 and #1556.\n\nSince #1295 is now merged to master, we can add test for dtypes of FP16 and FP64 to N-dimensional convolution **LINK**.\n\n", "before_files": [{"content": "from chainer.functions.connection import convolution_nd\nfrom chainer import initializers\nfrom chainer import link\nfrom chainer.utils import conv_nd\n\n\nclass ConvolutionND(link.Link):\n \"\"\"N-dimensional convolution layer.\n\n This link wraps the :func:`~chainer.functions.convolution_nd` function and\n holds the filter weight and bias vector as parameters.\n\n Args:\n ndim (int): Number of spatial dimensions.\n in_channels (int): Number of channels of input arrays.\n out_channels (int): Number of channels of output arrays.\n ksize (int or tuple of ints): Size of filters (a.k.a. kernels).\n ``ksize=k`` and ``ksize=(k, k, ..., k)`` are equivalent.\n stride (int or tuple of ints): Stride of filter application.\n ``stride=s`` and ``stride=(s, s, ..., s)`` are equivalent.\n pad (int or tuple of ints): Spatial padding width for input arrays.\n ``pad=p`` and ``pad=(p, p, ..., p)`` are equivalent.\n initialW: Value used to initialize the filter weight. May be an\n initializer instance or another value that\n :func:`~chainer.init_weight` helper function can take. This link\n uses :func:`~chainer.init_weight` to initialize the filter weight\n and passes the value of ``initialW`` to it as it is.\n initial_bias: Value used to initialize the bias vector. May be an\n initializer instance or another value except ``None`` that\n :func:`~chainer.init_weight` helper function can take. If ``None``\n is given, this link does not use the bias vector. This link uses\n :func:`~chainer.init_weight` to initialize the bias vector and\n passes the value of ``initial_bias`` other than ``None`` to it as\n it is.\n use_cudnn (bool): If ``True``, then this link uses cuDNN if available.\n See :func:`~chainer.functions.convolution_nd` for exact conditions\n of cuDNN availability.\n cover_all (bool): If ``True``, all spatial locations are convoluted\n into some output pixels. It may make the output size larger.\n ``cover_all`` needs to be ``False`` if you want to use cuDNN.\n\n .. seealso::\n See :func:`~chainer.functions.convolution_nd` for the definition of\n N-dimensional convolution. See\n :func:`~chainer.functions.convolution_2d` for the definition of\n two-dimensional convolution.\n\n Attributes:\n W (~chainer.Variable): Weight parameter.\n b (~chainer.Variable): Bias parameter. If ``initial_bias`` is ``None``,\n set to ``None``.\n\n \"\"\"\n\n def __init__(self, ndim, in_channels, out_channels, ksize, stride=1, pad=0,\n initialW=None, initial_bias=None, use_cudnn=True,\n cover_all=False):\n ksize = conv_nd.as_tuple(ksize, ndim)\n self.stride = stride\n self.pad = pad\n self.use_cudnn = use_cudnn\n self.cover_all = cover_all\n\n W_shape = (out_channels, in_channels) + ksize\n super(ConvolutionND, self).__init__(W=W_shape)\n initializers.init_weight(self.W.data, initialW)\n\n if initial_bias is None:\n self.b = None\n else:\n self.add_param('b', out_channels)\n initializers.init_weight(self.b.data, initial_bias)\n\n def __call__(self, x):\n \"\"\"Applies N-dimensional convolution layer.\n\n Args:\n x (~chainer.Variable): Input image.\n\n Returns:\n ~chainer.Variable: Output of convolution.\n\n \"\"\"\n return convolution_nd.convolution_nd(\n x, self.W, self.b, self.stride, self.pad,\n use_cudnn=self.use_cudnn, cover_all=self.cover_all)\n", "path": "chainer/links/connection/convolution_nd.py"}], "after_files": [{"content": "from chainer.functions.connection import convolution_nd\nfrom chainer import initializers\nfrom chainer import link\nfrom chainer.utils import conv_nd\n\n\nclass ConvolutionND(link.Link):\n \"\"\"N-dimensional convolution layer.\n\n This link wraps the :func:`~chainer.functions.convolution_nd` function and\n holds the filter weight and bias vector as parameters.\n\n Args:\n ndim (int): Number of spatial dimensions.\n in_channels (int): Number of channels of input arrays.\n out_channels (int): Number of channels of output arrays.\n ksize (int or tuple of ints): Size of filters (a.k.a. kernels).\n ``ksize=k`` and ``ksize=(k, k, ..., k)`` are equivalent.\n stride (int or tuple of ints): Stride of filter application.\n ``stride=s`` and ``stride=(s, s, ..., s)`` are equivalent.\n pad (int or tuple of ints): Spatial padding width for input arrays.\n ``pad=p`` and ``pad=(p, p, ..., p)`` are equivalent.\n initialW: Value used to initialize the filter weight. May be an\n initializer instance or another value that\n :func:`~chainer.init_weight` helper function can take.\n initial_bias: Value used to initialize the bias vector. May be an\n initializer instance or another value except ``None`` that\n :func:`~chainer.init_weight` helper function can take. If ``None``\n is given, this link does not use the bias vector.\n use_cudnn (bool): If ``True``, then this link uses cuDNN if available.\n See :func:`~chainer.functions.convolution_nd` for exact conditions\n of cuDNN availability.\n cover_all (bool): If ``True``, all spatial locations are convoluted\n into some output pixels. It may make the output size larger.\n ``cover_all`` needs to be ``False`` if you want to use cuDNN.\n\n .. seealso::\n See :func:`~chainer.functions.convolution_nd` for the definition of\n N-dimensional convolution. See\n :func:`~chainer.functions.convolution_2d` for the definition of\n two-dimensional convolution.\n\n Attributes:\n W (~chainer.Variable): Weight parameter.\n b (~chainer.Variable): Bias parameter. If ``initial_bias`` is ``None``,\n set to ``None``.\n\n \"\"\"\n\n def __init__(self, ndim, in_channels, out_channels, ksize, stride=1, pad=0,\n initialW=None, initial_bias=None, use_cudnn=True,\n cover_all=False):\n ksize = conv_nd.as_tuple(ksize, ndim)\n self.stride = stride\n self.pad = pad\n self.use_cudnn = use_cudnn\n self.cover_all = cover_all\n\n super(ConvolutionND, self).__init__()\n\n W_shape = (out_channels, in_channels) + ksize\n initialW = initializers._get_initializer(initialW)\n self.add_param('W', W_shape, initializer=initialW)\n\n if initial_bias is None:\n self.b = None\n else:\n initial_bias = initializers._get_initializer(initial_bias)\n self.add_param('b', out_channels, initializer=initial_bias)\n\n def __call__(self, x):\n \"\"\"Applies N-dimensional convolution layer.\n\n Args:\n x (~chainer.Variable): Input image.\n\n Returns:\n ~chainer.Variable: Output of convolution.\n\n \"\"\"\n return convolution_nd.convolution_nd(\n x, self.W, self.b, self.stride, self.pad,\n use_cudnn=self.use_cudnn, cover_all=self.cover_all)\n", "path": "chainer/links/connection/convolution_nd.py"}]}
| 1,358 | 548 |
gh_patches_debug_17963
|
rasdani/github-patches
|
git_diff
|
frappe__frappe-11391
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
SMTP: Exception Handling Resolution Order
In `frappe/frappe/email/smtp.py` In `SMTPServer.sess`:
` try:`
` ....`
` except `_socket.error` as e: `
` .... `
` except smtplib.SMTPAuthenticationError as e: `
` .... `
` except smtplib.SMTPException: `
` .... `
`
Where:
`_socket.error` is `OSError` Which is defined: `class OSError(Exception):`
`class SMTPException(OSError):`
`class SMTPResponseException(SMTPException):`
`class SMTPAuthenticationError(SMTPResponseException):`
From the python documentation:
> A class in an except clause is compatible with an exception if it is the same class or a base class thereof (but not the other way around — an except clause listing a derived class is not compatible with a base class).
So the way the except clauses are ordered now will always be handled by the `except` clause with `_socket.error` no matter what the error is.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `frappe/email/smtp.py`
Content:
```
1 # Copyright (c) 2015, Frappe Technologies Pvt. Ltd. and Contributors
2 # MIT License. See license.txt
3
4 from __future__ import unicode_literals
5 from six import reraise as raise_
6 import frappe
7 import smtplib
8 import email.utils
9 import _socket, sys
10 from frappe import _
11 from frappe.utils import cint, cstr, parse_addr
12
13 def send(email, append_to=None, retry=1):
14 """Deprecated: Send the message or add it to Outbox Email"""
15 def _send(retry):
16 try:
17 smtpserver = SMTPServer(append_to=append_to)
18
19 # validate is called in as_string
20 email_body = email.as_string()
21
22 smtpserver.sess.sendmail(email.sender, email.recipients + (email.cc or []), email_body)
23 except smtplib.SMTPSenderRefused:
24 frappe.throw(_("Invalid login or password"), title='Email Failed')
25 raise
26 except smtplib.SMTPRecipientsRefused:
27 frappe.msgprint(_("Invalid recipient address"), title='Email Failed')
28 raise
29 except (smtplib.SMTPServerDisconnected, smtplib.SMTPAuthenticationError):
30 if not retry:
31 raise
32 else:
33 retry = retry - 1
34 _send(retry)
35
36 _send(retry)
37
38 def get_outgoing_email_account(raise_exception_not_set=True, append_to=None, sender=None):
39 """Returns outgoing email account based on `append_to` or the default
40 outgoing account. If default outgoing account is not found, it will
41 try getting settings from `site_config.json`."""
42
43 sender_email_id = None
44 if sender:
45 sender_email_id = parse_addr(sender)[1]
46
47 if not getattr(frappe.local, "outgoing_email_account", None):
48 frappe.local.outgoing_email_account = {}
49
50 if not (frappe.local.outgoing_email_account.get(append_to)
51 or frappe.local.outgoing_email_account.get(sender_email_id)
52 or frappe.local.outgoing_email_account.get("default")):
53 email_account = None
54
55 if append_to:
56 # append_to is only valid when enable_incoming is checked
57
58 # in case of multiple Email Accounts with same append_to
59 # narrow it down based on email_id
60 email_account = _get_email_account({
61 "enable_outgoing": 1,
62 "enable_incoming": 1,
63 "append_to": append_to,
64 "email_id": sender_email_id
65 })
66
67 # else find the first Email Account with append_to
68 if not email_account:
69 email_account = _get_email_account({
70 "enable_outgoing": 1,
71 "enable_incoming": 1,
72 "append_to": append_to
73 })
74
75 if not email_account and sender_email_id:
76 # check if the sender has email account with enable_outgoing
77 email_account = _get_email_account({"enable_outgoing": 1, "email_id": sender_email_id})
78
79 if not email_account:
80 # sender don't have the outging email account
81 sender_email_id = None
82 email_account = get_default_outgoing_email_account(raise_exception_not_set=raise_exception_not_set)
83
84 if not email_account and raise_exception_not_set and cint(frappe.db.get_single_value('System Settings', 'setup_complete')):
85 frappe.throw(_("Please setup default Email Account from Setup > Email > Email Account"),
86 frappe.OutgoingEmailError)
87
88 if email_account:
89 if email_account.enable_outgoing and not getattr(email_account, 'from_site_config', False):
90 raise_exception = True
91 if email_account.smtp_server in ['localhost','127.0.0.1'] or email_account.no_smtp_authentication:
92 raise_exception = False
93 email_account.password = email_account.get_password(raise_exception=raise_exception)
94 email_account.default_sender = email.utils.formataddr((email_account.name, email_account.get("email_id")))
95
96 frappe.local.outgoing_email_account[append_to or sender_email_id or "default"] = email_account
97
98 return frappe.local.outgoing_email_account.get(append_to) \
99 or frappe.local.outgoing_email_account.get(sender_email_id) \
100 or frappe.local.outgoing_email_account.get("default")
101
102 def get_default_outgoing_email_account(raise_exception_not_set=True):
103 '''conf should be like:
104 {
105 "mail_server": "smtp.example.com",
106 "mail_port": 587,
107 "use_tls": 1,
108 "mail_login": "[email protected]",
109 "mail_password": "Super.Secret.Password",
110 "auto_email_id": "[email protected]",
111 "email_sender_name": "Example Notifications",
112 "always_use_account_email_id_as_sender": 0,
113 "always_use_account_name_as_sender_name": 0
114 }
115 '''
116 email_account = _get_email_account({"enable_outgoing": 1, "default_outgoing": 1})
117 if email_account:
118 email_account.password = email_account.get_password(raise_exception=False)
119
120 if not email_account and frappe.conf.get("mail_server"):
121 # from site_config.json
122 email_account = frappe.new_doc("Email Account")
123 email_account.update({
124 "smtp_server": frappe.conf.get("mail_server"),
125 "smtp_port": frappe.conf.get("mail_port"),
126
127 # legacy: use_ssl was used in site_config instead of use_tls, but meant the same thing
128 "use_tls": cint(frappe.conf.get("use_tls") or 0) or cint(frappe.conf.get("use_ssl") or 0),
129 "login_id": frappe.conf.get("mail_login"),
130 "email_id": frappe.conf.get("auto_email_id") or frappe.conf.get("mail_login") or '[email protected]',
131 "password": frappe.conf.get("mail_password"),
132 "always_use_account_email_id_as_sender": frappe.conf.get("always_use_account_email_id_as_sender", 0),
133 "always_use_account_name_as_sender_name": frappe.conf.get("always_use_account_name_as_sender_name", 0)
134 })
135 email_account.from_site_config = True
136 email_account.name = frappe.conf.get("email_sender_name") or "Frappe"
137
138 if not email_account and not raise_exception_not_set:
139 return None
140
141 if frappe.are_emails_muted():
142 # create a stub
143 email_account = frappe.new_doc("Email Account")
144 email_account.update({
145 "email_id": "[email protected]"
146 })
147
148 return email_account
149
150 def _get_email_account(filters):
151 name = frappe.db.get_value("Email Account", filters)
152 return frappe.get_doc("Email Account", name) if name else None
153
154 class SMTPServer:
155 def __init__(self, login=None, password=None, server=None, port=None, use_tls=None, append_to=None):
156 # get defaults from mail settings
157
158 self._sess = None
159 self.email_account = None
160 self.server = None
161 if server:
162 self.server = server
163 self.port = port
164 self.use_tls = cint(use_tls)
165 self.login = login
166 self.password = password
167
168 else:
169 self.setup_email_account(append_to)
170
171 def setup_email_account(self, append_to=None, sender=None):
172 self.email_account = get_outgoing_email_account(raise_exception_not_set=False, append_to=append_to, sender=sender)
173 if self.email_account:
174 self.server = self.email_account.smtp_server
175 self.login = (getattr(self.email_account, "login_id", None) or self.email_account.email_id)
176 if not self.email_account.no_smtp_authentication:
177 if self.email_account.ascii_encode_password:
178 self.password = frappe.safe_encode(self.email_account.password, 'ascii')
179 else:
180 self.password = self.email_account.password
181 else:
182 self.password = None
183 self.port = self.email_account.smtp_port
184 self.use_tls = self.email_account.use_tls
185 self.sender = self.email_account.email_id
186 self.always_use_account_email_id_as_sender = cint(self.email_account.get("always_use_account_email_id_as_sender"))
187 self.always_use_account_name_as_sender_name = cint(self.email_account.get("always_use_account_name_as_sender_name"))
188
189 @property
190 def sess(self):
191 """get session"""
192 if self._sess:
193 return self._sess
194
195 # check if email server specified
196 if not getattr(self, 'server'):
197 err_msg = _('Email Account not setup. Please create a new Email Account from Setup > Email > Email Account')
198 frappe.msgprint(err_msg)
199 raise frappe.OutgoingEmailError(err_msg)
200
201 try:
202 if self.use_tls and not self.port:
203 self.port = 587
204
205 self._sess = smtplib.SMTP(cstr(self.server or ""),
206 cint(self.port) or None)
207
208 if not self._sess:
209 err_msg = _('Could not connect to outgoing email server')
210 frappe.msgprint(err_msg)
211 raise frappe.OutgoingEmailError(err_msg)
212
213 if self.use_tls:
214 self._sess.ehlo()
215 self._sess.starttls()
216 self._sess.ehlo()
217
218 if self.login and self.password:
219 ret = self._sess.login(str(self.login or ""), str(self.password or ""))
220
221 # check if logged correctly
222 if ret[0]!=235:
223 frappe.msgprint(ret[1])
224 raise frappe.OutgoingEmailError(ret[1])
225
226 return self._sess
227
228 except _socket.error as e:
229 # Invalid mail server -- due to refusing connection
230 frappe.msgprint(_('Invalid Outgoing Mail Server or Port'))
231 traceback = sys.exc_info()[2]
232 raise_(frappe.ValidationError, e, traceback)
233
234 except smtplib.SMTPAuthenticationError as e:
235 frappe.msgprint(_("Invalid login or password"))
236 traceback = sys.exc_info()[2]
237 raise_(frappe.ValidationError, e, traceback)
238
239 except smtplib.SMTPException:
240 frappe.msgprint(_('Unable to send emails at this time'))
241 raise
242
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/frappe/email/smtp.py b/frappe/email/smtp.py
--- a/frappe/email/smtp.py
+++ b/frappe/email/smtp.py
@@ -225,12 +225,6 @@
return self._sess
- except _socket.error as e:
- # Invalid mail server -- due to refusing connection
- frappe.msgprint(_('Invalid Outgoing Mail Server or Port'))
- traceback = sys.exc_info()[2]
- raise_(frappe.ValidationError, e, traceback)
-
except smtplib.SMTPAuthenticationError as e:
frappe.msgprint(_("Invalid login or password"))
traceback = sys.exc_info()[2]
@@ -239,3 +233,9 @@
except smtplib.SMTPException:
frappe.msgprint(_('Unable to send emails at this time'))
raise
+
+ except _socket.error as e:
+ # Invalid mail server -- due to refusing connection
+ frappe.msgprint(_('Invalid Outgoing Mail Server or Port'))
+ traceback = sys.exc_info()[2]
+ raise_(frappe.ValidationError, e, traceback)
|
{"golden_diff": "diff --git a/frappe/email/smtp.py b/frappe/email/smtp.py\n--- a/frappe/email/smtp.py\n+++ b/frappe/email/smtp.py\n@@ -225,12 +225,6 @@\n \n \t\t\treturn self._sess\n \n-\t\texcept _socket.error as e:\n-\t\t\t# Invalid mail server -- due to refusing connection\n-\t\t\tfrappe.msgprint(_('Invalid Outgoing Mail Server or Port'))\n-\t\t\ttraceback = sys.exc_info()[2]\n-\t\t\traise_(frappe.ValidationError, e, traceback)\n-\n \t\texcept smtplib.SMTPAuthenticationError as e:\n \t\t\tfrappe.msgprint(_(\"Invalid login or password\"))\n \t\t\ttraceback = sys.exc_info()[2]\n@@ -239,3 +233,9 @@\n \t\texcept smtplib.SMTPException:\n \t\t\tfrappe.msgprint(_('Unable to send emails at this time'))\n \t\t\traise\n+\n+\t\texcept _socket.error as e:\n+\t\t\t# Invalid mail server -- due to refusing connection\n+\t\t\tfrappe.msgprint(_('Invalid Outgoing Mail Server or Port'))\n+\t\t\ttraceback = sys.exc_info()[2]\n+\t\t\traise_(frappe.ValidationError, e, traceback)\n", "issue": "SMTP: Exception Handling Resolution Order\nIn `frappe/frappe/email/smtp.py` In `SMTPServer.sess`:\r\n`\t\ttry:`\r\n`\t\t\t\t....`\r\n`\t\texcept `_socket.error` as e: `\r\n`\t\t\t.... `\r\n`\t\texcept smtplib.SMTPAuthenticationError as e: `\r\n`\t\t\t.... `\r\n`\t\texcept smtplib.SMTPException: `\r\n`\t\t\t.... `\r\n`\r\n\r\nWhere:\r\n`_socket.error` is `OSError` Which is defined: `class OSError(Exception):`\r\n`class SMTPException(OSError):`\r\n`class SMTPResponseException(SMTPException):`\r\n`class SMTPAuthenticationError(SMTPResponseException):`\r\n\r\nFrom the python documentation:\r\n\r\n> A class in an except clause is compatible with an exception if it is the same class or a base class thereof (but not the other way around \u2014 an except clause listing a derived class is not compatible with a base class).\r\n\r\nSo the way the except clauses are ordered now will always be handled by the `except` clause with `_socket.error` no matter what the error is.\n", "before_files": [{"content": "# Copyright (c) 2015, Frappe Technologies Pvt. Ltd. and Contributors\n# MIT License. See license.txt\n\nfrom __future__ import unicode_literals\nfrom six import reraise as raise_\nimport frappe\nimport smtplib\nimport email.utils\nimport _socket, sys\nfrom frappe import _\nfrom frappe.utils import cint, cstr, parse_addr\n\ndef send(email, append_to=None, retry=1):\n\t\"\"\"Deprecated: Send the message or add it to Outbox Email\"\"\"\n\tdef _send(retry):\n\t\ttry:\n\t\t\tsmtpserver = SMTPServer(append_to=append_to)\n\n\t\t\t# validate is called in as_string\n\t\t\temail_body = email.as_string()\n\n\t\t\tsmtpserver.sess.sendmail(email.sender, email.recipients + (email.cc or []), email_body)\n\t\texcept smtplib.SMTPSenderRefused:\n\t\t\tfrappe.throw(_(\"Invalid login or password\"), title='Email Failed')\n\t\t\traise\n\t\texcept smtplib.SMTPRecipientsRefused:\n\t\t\tfrappe.msgprint(_(\"Invalid recipient address\"), title='Email Failed')\n\t\t\traise\n\t\texcept (smtplib.SMTPServerDisconnected, smtplib.SMTPAuthenticationError):\n\t\t\tif not retry:\n\t\t\t\traise\n\t\t\telse:\n\t\t\t\tretry = retry - 1\n\t\t\t\t_send(retry)\n\n\t_send(retry)\n\ndef get_outgoing_email_account(raise_exception_not_set=True, append_to=None, sender=None):\n\t\"\"\"Returns outgoing email account based on `append_to` or the default\n\t\toutgoing account. If default outgoing account is not found, it will\n\t\ttry getting settings from `site_config.json`.\"\"\"\n\n\tsender_email_id = None\n\tif sender:\n\t\tsender_email_id = parse_addr(sender)[1]\n\n\tif not getattr(frappe.local, \"outgoing_email_account\", None):\n\t\tfrappe.local.outgoing_email_account = {}\n\n\tif not (frappe.local.outgoing_email_account.get(append_to)\n\t\tor frappe.local.outgoing_email_account.get(sender_email_id)\n\t\tor frappe.local.outgoing_email_account.get(\"default\")):\n\t\temail_account = None\n\n\t\tif append_to:\n\t\t\t# append_to is only valid when enable_incoming is checked\n\n\t\t\t# in case of multiple Email Accounts with same append_to\n\t\t\t# narrow it down based on email_id\n\t\t\temail_account = _get_email_account({\n\t\t\t\t\"enable_outgoing\": 1,\n\t\t\t\t\"enable_incoming\": 1,\n\t\t\t\t\"append_to\": append_to,\n\t\t\t\t\"email_id\": sender_email_id\n\t\t\t})\n\n\t\t\t# else find the first Email Account with append_to\n\t\t\tif not email_account:\n\t\t\t\temail_account = _get_email_account({\n\t\t\t\t\t\"enable_outgoing\": 1,\n\t\t\t\t\t\"enable_incoming\": 1,\n\t\t\t\t\t\"append_to\": append_to\n\t\t\t\t})\n\n\t\tif not email_account and sender_email_id:\n\t\t\t# check if the sender has email account with enable_outgoing\n\t\t\temail_account = _get_email_account({\"enable_outgoing\": 1, \"email_id\": sender_email_id})\n\n\t\tif not email_account:\n\t\t\t# sender don't have the outging email account\n\t\t\tsender_email_id = None\n\t\t\temail_account = get_default_outgoing_email_account(raise_exception_not_set=raise_exception_not_set)\n\n\t\tif not email_account and raise_exception_not_set and cint(frappe.db.get_single_value('System Settings', 'setup_complete')):\n\t\t\tfrappe.throw(_(\"Please setup default Email Account from Setup > Email > Email Account\"),\n\t\t\t\tfrappe.OutgoingEmailError)\n\n\t\tif email_account:\n\t\t\tif email_account.enable_outgoing and not getattr(email_account, 'from_site_config', False):\n\t\t\t\traise_exception = True\n\t\t\t\tif email_account.smtp_server in ['localhost','127.0.0.1'] or email_account.no_smtp_authentication:\n\t\t\t\t\traise_exception = False\n\t\t\t\temail_account.password = email_account.get_password(raise_exception=raise_exception)\n\t\t\temail_account.default_sender = email.utils.formataddr((email_account.name, email_account.get(\"email_id\")))\n\n\t\tfrappe.local.outgoing_email_account[append_to or sender_email_id or \"default\"] = email_account\n\n\treturn frappe.local.outgoing_email_account.get(append_to) \\\n\t\tor frappe.local.outgoing_email_account.get(sender_email_id) \\\n\t\tor frappe.local.outgoing_email_account.get(\"default\")\n\ndef get_default_outgoing_email_account(raise_exception_not_set=True):\n\t'''conf should be like:\n\t\t{\n\t\t \"mail_server\": \"smtp.example.com\",\n\t\t \"mail_port\": 587,\n\t\t \"use_tls\": 1,\n\t\t \"mail_login\": \"[email protected]\",\n\t\t \"mail_password\": \"Super.Secret.Password\",\n\t\t \"auto_email_id\": \"[email protected]\",\n\t\t \"email_sender_name\": \"Example Notifications\",\n\t\t \"always_use_account_email_id_as_sender\": 0,\n\t\t \"always_use_account_name_as_sender_name\": 0\n\t\t}\n\t'''\n\temail_account = _get_email_account({\"enable_outgoing\": 1, \"default_outgoing\": 1})\n\tif email_account:\n\t\temail_account.password = email_account.get_password(raise_exception=False)\n\n\tif not email_account and frappe.conf.get(\"mail_server\"):\n\t\t# from site_config.json\n\t\temail_account = frappe.new_doc(\"Email Account\")\n\t\temail_account.update({\n\t\t\t\"smtp_server\": frappe.conf.get(\"mail_server\"),\n\t\t\t\"smtp_port\": frappe.conf.get(\"mail_port\"),\n\n\t\t\t# legacy: use_ssl was used in site_config instead of use_tls, but meant the same thing\n\t\t\t\"use_tls\": cint(frappe.conf.get(\"use_tls\") or 0) or cint(frappe.conf.get(\"use_ssl\") or 0),\n\t\t\t\"login_id\": frappe.conf.get(\"mail_login\"),\n\t\t\t\"email_id\": frappe.conf.get(\"auto_email_id\") or frappe.conf.get(\"mail_login\") or '[email protected]',\n\t\t\t\"password\": frappe.conf.get(\"mail_password\"),\n\t\t\t\"always_use_account_email_id_as_sender\": frappe.conf.get(\"always_use_account_email_id_as_sender\", 0),\n\t\t\t\"always_use_account_name_as_sender_name\": frappe.conf.get(\"always_use_account_name_as_sender_name\", 0)\n\t\t})\n\t\temail_account.from_site_config = True\n\t\temail_account.name = frappe.conf.get(\"email_sender_name\") or \"Frappe\"\n\n\tif not email_account and not raise_exception_not_set:\n\t\treturn None\n\n\tif frappe.are_emails_muted():\n\t\t# create a stub\n\t\temail_account = frappe.new_doc(\"Email Account\")\n\t\temail_account.update({\n\t\t\t\"email_id\": \"[email protected]\"\n\t\t})\n\n\treturn email_account\n\ndef _get_email_account(filters):\n\tname = frappe.db.get_value(\"Email Account\", filters)\n\treturn frappe.get_doc(\"Email Account\", name) if name else None\n\nclass SMTPServer:\n\tdef __init__(self, login=None, password=None, server=None, port=None, use_tls=None, append_to=None):\n\t\t# get defaults from mail settings\n\n\t\tself._sess = None\n\t\tself.email_account = None\n\t\tself.server = None\n\t\tif server:\n\t\t\tself.server = server\n\t\t\tself.port = port\n\t\t\tself.use_tls = cint(use_tls)\n\t\t\tself.login = login\n\t\t\tself.password = password\n\n\t\telse:\n\t\t\tself.setup_email_account(append_to)\n\n\tdef setup_email_account(self, append_to=None, sender=None):\n\t\tself.email_account = get_outgoing_email_account(raise_exception_not_set=False, append_to=append_to, sender=sender)\n\t\tif self.email_account:\n\t\t\tself.server = self.email_account.smtp_server\n\t\t\tself.login = (getattr(self.email_account, \"login_id\", None) or self.email_account.email_id)\n\t\t\tif not self.email_account.no_smtp_authentication:\n\t\t\t\tif self.email_account.ascii_encode_password:\n\t\t\t\t\tself.password = frappe.safe_encode(self.email_account.password, 'ascii')\n\t\t\t\telse:\n\t\t\t\t\tself.password = self.email_account.password\n\t\t\telse:\n\t\t\t\tself.password = None\n\t\t\tself.port = self.email_account.smtp_port\n\t\t\tself.use_tls = self.email_account.use_tls\n\t\t\tself.sender = self.email_account.email_id\n\t\t\tself.always_use_account_email_id_as_sender = cint(self.email_account.get(\"always_use_account_email_id_as_sender\"))\n\t\t\tself.always_use_account_name_as_sender_name = cint(self.email_account.get(\"always_use_account_name_as_sender_name\"))\n\n\t@property\n\tdef sess(self):\n\t\t\"\"\"get session\"\"\"\n\t\tif self._sess:\n\t\t\treturn self._sess\n\n\t\t# check if email server specified\n\t\tif not getattr(self, 'server'):\n\t\t\terr_msg = _('Email Account not setup. Please create a new Email Account from Setup > Email > Email Account')\n\t\t\tfrappe.msgprint(err_msg)\n\t\t\traise frappe.OutgoingEmailError(err_msg)\n\n\t\ttry:\n\t\t\tif self.use_tls and not self.port:\n\t\t\t\tself.port = 587\n\n\t\t\tself._sess = smtplib.SMTP(cstr(self.server or \"\"),\n\t\t\t\tcint(self.port) or None)\n\n\t\t\tif not self._sess:\n\t\t\t\terr_msg = _('Could not connect to outgoing email server')\n\t\t\t\tfrappe.msgprint(err_msg)\n\t\t\t\traise frappe.OutgoingEmailError(err_msg)\n\n\t\t\tif self.use_tls:\n\t\t\t\tself._sess.ehlo()\n\t\t\t\tself._sess.starttls()\n\t\t\t\tself._sess.ehlo()\n\n\t\t\tif self.login and self.password:\n\t\t\t\tret = self._sess.login(str(self.login or \"\"), str(self.password or \"\"))\n\n\t\t\t\t# check if logged correctly\n\t\t\t\tif ret[0]!=235:\n\t\t\t\t\tfrappe.msgprint(ret[1])\n\t\t\t\t\traise frappe.OutgoingEmailError(ret[1])\n\n\t\t\treturn self._sess\n\n\t\texcept _socket.error as e:\n\t\t\t# Invalid mail server -- due to refusing connection\n\t\t\tfrappe.msgprint(_('Invalid Outgoing Mail Server or Port'))\n\t\t\ttraceback = sys.exc_info()[2]\n\t\t\traise_(frappe.ValidationError, e, traceback)\n\n\t\texcept smtplib.SMTPAuthenticationError as e:\n\t\t\tfrappe.msgprint(_(\"Invalid login or password\"))\n\t\t\ttraceback = sys.exc_info()[2]\n\t\t\traise_(frappe.ValidationError, e, traceback)\n\n\t\texcept smtplib.SMTPException:\n\t\t\tfrappe.msgprint(_('Unable to send emails at this time'))\n\t\t\traise\n", "path": "frappe/email/smtp.py"}], "after_files": [{"content": "# Copyright (c) 2015, Frappe Technologies Pvt. Ltd. and Contributors\n# MIT License. See license.txt\n\nfrom __future__ import unicode_literals\nfrom six import reraise as raise_\nimport frappe\nimport smtplib\nimport email.utils\nimport _socket, sys\nfrom frappe import _\nfrom frappe.utils import cint, cstr, parse_addr\n\ndef send(email, append_to=None, retry=1):\n\t\"\"\"Deprecated: Send the message or add it to Outbox Email\"\"\"\n\tdef _send(retry):\n\t\ttry:\n\t\t\tsmtpserver = SMTPServer(append_to=append_to)\n\n\t\t\t# validate is called in as_string\n\t\t\temail_body = email.as_string()\n\n\t\t\tsmtpserver.sess.sendmail(email.sender, email.recipients + (email.cc or []), email_body)\n\t\texcept smtplib.SMTPSenderRefused:\n\t\t\tfrappe.throw(_(\"Invalid login or password\"), title='Email Failed')\n\t\t\traise\n\t\texcept smtplib.SMTPRecipientsRefused:\n\t\t\tfrappe.msgprint(_(\"Invalid recipient address\"), title='Email Failed')\n\t\t\traise\n\t\texcept (smtplib.SMTPServerDisconnected, smtplib.SMTPAuthenticationError):\n\t\t\tif not retry:\n\t\t\t\traise\n\t\t\telse:\n\t\t\t\tretry = retry - 1\n\t\t\t\t_send(retry)\n\n\t_send(retry)\n\ndef get_outgoing_email_account(raise_exception_not_set=True, append_to=None, sender=None):\n\t\"\"\"Returns outgoing email account based on `append_to` or the default\n\t\toutgoing account. If default outgoing account is not found, it will\n\t\ttry getting settings from `site_config.json`.\"\"\"\n\n\tsender_email_id = None\n\tif sender:\n\t\tsender_email_id = parse_addr(sender)[1]\n\n\tif not getattr(frappe.local, \"outgoing_email_account\", None):\n\t\tfrappe.local.outgoing_email_account = {}\n\n\tif not (frappe.local.outgoing_email_account.get(append_to)\n\t\tor frappe.local.outgoing_email_account.get(sender_email_id)\n\t\tor frappe.local.outgoing_email_account.get(\"default\")):\n\t\temail_account = None\n\n\t\tif append_to:\n\t\t\t# append_to is only valid when enable_incoming is checked\n\n\t\t\t# in case of multiple Email Accounts with same append_to\n\t\t\t# narrow it down based on email_id\n\t\t\temail_account = _get_email_account({\n\t\t\t\t\"enable_outgoing\": 1,\n\t\t\t\t\"enable_incoming\": 1,\n\t\t\t\t\"append_to\": append_to,\n\t\t\t\t\"email_id\": sender_email_id\n\t\t\t})\n\n\t\t\t# else find the first Email Account with append_to\n\t\t\tif not email_account:\n\t\t\t\temail_account = _get_email_account({\n\t\t\t\t\t\"enable_outgoing\": 1,\n\t\t\t\t\t\"enable_incoming\": 1,\n\t\t\t\t\t\"append_to\": append_to\n\t\t\t\t})\n\n\t\tif not email_account and sender_email_id:\n\t\t\t# check if the sender has email account with enable_outgoing\n\t\t\temail_account = _get_email_account({\"enable_outgoing\": 1, \"email_id\": sender_email_id})\n\n\t\tif not email_account:\n\t\t\t# sender don't have the outging email account\n\t\t\tsender_email_id = None\n\t\t\temail_account = get_default_outgoing_email_account(raise_exception_not_set=raise_exception_not_set)\n\n\t\tif not email_account and raise_exception_not_set and cint(frappe.db.get_single_value('System Settings', 'setup_complete')):\n\t\t\tfrappe.throw(_(\"Please setup default Email Account from Setup > Email > Email Account\"),\n\t\t\t\tfrappe.OutgoingEmailError)\n\n\t\tif email_account:\n\t\t\tif email_account.enable_outgoing and not getattr(email_account, 'from_site_config', False):\n\t\t\t\traise_exception = True\n\t\t\t\tif email_account.smtp_server in ['localhost','127.0.0.1'] or email_account.no_smtp_authentication:\n\t\t\t\t\traise_exception = False\n\t\t\t\temail_account.password = email_account.get_password(raise_exception=raise_exception)\n\t\t\temail_account.default_sender = email.utils.formataddr((email_account.name, email_account.get(\"email_id\")))\n\n\t\tfrappe.local.outgoing_email_account[append_to or sender_email_id or \"default\"] = email_account\n\n\treturn frappe.local.outgoing_email_account.get(append_to) \\\n\t\tor frappe.local.outgoing_email_account.get(sender_email_id) \\\n\t\tor frappe.local.outgoing_email_account.get(\"default\")\n\ndef get_default_outgoing_email_account(raise_exception_not_set=True):\n\t'''conf should be like:\n\t\t{\n\t\t \"mail_server\": \"smtp.example.com\",\n\t\t \"mail_port\": 587,\n\t\t \"use_tls\": 1,\n\t\t \"mail_login\": \"[email protected]\",\n\t\t \"mail_password\": \"Super.Secret.Password\",\n\t\t \"auto_email_id\": \"[email protected]\",\n\t\t \"email_sender_name\": \"Example Notifications\",\n\t\t \"always_use_account_email_id_as_sender\": 0,\n\t\t \"always_use_account_name_as_sender_name\": 0\n\t\t}\n\t'''\n\temail_account = _get_email_account({\"enable_outgoing\": 1, \"default_outgoing\": 1})\n\tif email_account:\n\t\temail_account.password = email_account.get_password(raise_exception=False)\n\n\tif not email_account and frappe.conf.get(\"mail_server\"):\n\t\t# from site_config.json\n\t\temail_account = frappe.new_doc(\"Email Account\")\n\t\temail_account.update({\n\t\t\t\"smtp_server\": frappe.conf.get(\"mail_server\"),\n\t\t\t\"smtp_port\": frappe.conf.get(\"mail_port\"),\n\n\t\t\t# legacy: use_ssl was used in site_config instead of use_tls, but meant the same thing\n\t\t\t\"use_tls\": cint(frappe.conf.get(\"use_tls\") or 0) or cint(frappe.conf.get(\"use_ssl\") or 0),\n\t\t\t\"login_id\": frappe.conf.get(\"mail_login\"),\n\t\t\t\"email_id\": frappe.conf.get(\"auto_email_id\") or frappe.conf.get(\"mail_login\") or '[email protected]',\n\t\t\t\"password\": frappe.conf.get(\"mail_password\"),\n\t\t\t\"always_use_account_email_id_as_sender\": frappe.conf.get(\"always_use_account_email_id_as_sender\", 0),\n\t\t\t\"always_use_account_name_as_sender_name\": frappe.conf.get(\"always_use_account_name_as_sender_name\", 0)\n\t\t})\n\t\temail_account.from_site_config = True\n\t\temail_account.name = frappe.conf.get(\"email_sender_name\") or \"Frappe\"\n\n\tif not email_account and not raise_exception_not_set:\n\t\treturn None\n\n\tif frappe.are_emails_muted():\n\t\t# create a stub\n\t\temail_account = frappe.new_doc(\"Email Account\")\n\t\temail_account.update({\n\t\t\t\"email_id\": \"[email protected]\"\n\t\t})\n\n\treturn email_account\n\ndef _get_email_account(filters):\n\tname = frappe.db.get_value(\"Email Account\", filters)\n\treturn frappe.get_doc(\"Email Account\", name) if name else None\n\nclass SMTPServer:\n\tdef __init__(self, login=None, password=None, server=None, port=None, use_tls=None, append_to=None):\n\t\t# get defaults from mail settings\n\n\t\tself._sess = None\n\t\tself.email_account = None\n\t\tself.server = None\n\t\tif server:\n\t\t\tself.server = server\n\t\t\tself.port = port\n\t\t\tself.use_tls = cint(use_tls)\n\t\t\tself.login = login\n\t\t\tself.password = password\n\n\t\telse:\n\t\t\tself.setup_email_account(append_to)\n\n\tdef setup_email_account(self, append_to=None, sender=None):\n\t\tself.email_account = get_outgoing_email_account(raise_exception_not_set=False, append_to=append_to, sender=sender)\n\t\tif self.email_account:\n\t\t\tself.server = self.email_account.smtp_server\n\t\t\tself.login = (getattr(self.email_account, \"login_id\", None) or self.email_account.email_id)\n\t\t\tif not self.email_account.no_smtp_authentication:\n\t\t\t\tif self.email_account.ascii_encode_password:\n\t\t\t\t\tself.password = frappe.safe_encode(self.email_account.password, 'ascii')\n\t\t\t\telse:\n\t\t\t\t\tself.password = self.email_account.password\n\t\t\telse:\n\t\t\t\tself.password = None\n\t\t\tself.port = self.email_account.smtp_port\n\t\t\tself.use_tls = self.email_account.use_tls\n\t\t\tself.sender = self.email_account.email_id\n\t\t\tself.always_use_account_email_id_as_sender = cint(self.email_account.get(\"always_use_account_email_id_as_sender\"))\n\t\t\tself.always_use_account_name_as_sender_name = cint(self.email_account.get(\"always_use_account_name_as_sender_name\"))\n\n\t@property\n\tdef sess(self):\n\t\t\"\"\"get session\"\"\"\n\t\tif self._sess:\n\t\t\treturn self._sess\n\n\t\t# check if email server specified\n\t\tif not getattr(self, 'server'):\n\t\t\terr_msg = _('Email Account not setup. Please create a new Email Account from Setup > Email > Email Account')\n\t\t\tfrappe.msgprint(err_msg)\n\t\t\traise frappe.OutgoingEmailError(err_msg)\n\n\t\ttry:\n\t\t\tif self.use_tls and not self.port:\n\t\t\t\tself.port = 587\n\n\t\t\tself._sess = smtplib.SMTP(cstr(self.server or \"\"),\n\t\t\t\tcint(self.port) or None)\n\n\t\t\tif not self._sess:\n\t\t\t\terr_msg = _('Could not connect to outgoing email server')\n\t\t\t\tfrappe.msgprint(err_msg)\n\t\t\t\traise frappe.OutgoingEmailError(err_msg)\n\n\t\t\tif self.use_tls:\n\t\t\t\tself._sess.ehlo()\n\t\t\t\tself._sess.starttls()\n\t\t\t\tself._sess.ehlo()\n\n\t\t\tif self.login and self.password:\n\t\t\t\tret = self._sess.login(str(self.login or \"\"), str(self.password or \"\"))\n\n\t\t\t\t# check if logged correctly\n\t\t\t\tif ret[0]!=235:\n\t\t\t\t\tfrappe.msgprint(ret[1])\n\t\t\t\t\traise frappe.OutgoingEmailError(ret[1])\n\n\t\t\treturn self._sess\n\n\t\texcept smtplib.SMTPAuthenticationError as e:\n\t\t\tfrappe.msgprint(_(\"Invalid login or password\"))\n\t\t\ttraceback = sys.exc_info()[2]\n\t\t\traise_(frappe.ValidationError, e, traceback)\n\n\t\texcept smtplib.SMTPException:\n\t\t\tfrappe.msgprint(_('Unable to send emails at this time'))\n\t\t\traise\n\n\t\texcept _socket.error as e:\n\t\t\t# Invalid mail server -- due to refusing connection\n\t\t\tfrappe.msgprint(_('Invalid Outgoing Mail Server or Port'))\n\t\t\ttraceback = sys.exc_info()[2]\n\t\t\traise_(frappe.ValidationError, e, traceback)\n", "path": "frappe/email/smtp.py"}]}
| 3,359 | 255 |
gh_patches_debug_28984
|
rasdani/github-patches
|
git_diff
|
urllib3__urllib3-1318
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
IndexError when handle malformed http response
I use urllib3 receive a http response like this,
```
HTTP/1.1 200 OK
Content-Type: application/octet-stream
Content-Length: 89606
Content-Disposition: attachment; filename="MB-500Ap_2009-01-12.cfg"
Connection: close
Brickcom-50xA
OperationSetting.locale=auto
HostName.name=cam
ModuleInfo.DIDO_module=1
ModuleInfo.PIR_module=0
ModuleInfo.WLED=0
SensorFPSSetting.fps=0
ModuleInfo.AUTOIRIS_module=0
ModuleInfo.IRCUT_module=0
ModuleInfo.IRLED_module=0
ModuleInfo.lightsensor=0
ModuleInfo.EXPOSURE_module=0
ModuleInfo.MDNS_module=0
ModuleInfo.PTZ_module=1
ModuleInfo.MSN_module=0
ModuleInfo.WIFI_module=0
ModuleInfo.watchDog_module=0
ModuleInfo.sdcard_module=1
ModuleInfo.usbstorage_module=0
ModuleInfo.sambamount_module=0
ModuleInfo.QoS=0
ModuleInfo.shutter_speed=0
ModuleInfo.discovery_internet=1
ModuleInfo.POE_module=
ModuleInfo.audio_record=1
```
it throws a IndexError,I print the traceback,
```
req = http_get(url, auth=("admin", "admin"), timeout=timeout, verify=False)
File "C:\Python27\lib\site-packages\requests\api.py", line 72, in get
return request('get', url, params=params, **kwargs)
File "C:\Python27\lib\site-packages\requests\api.py", line 58, in request
return session.request(method=method, url=url, **kwargs)
File "C:\Python27\lib\site-packages\requests\sessions.py", line 508, in request
resp = self.send(prep, **send_kwargs)
File "C:\Python27\lib\site-packages\requests\sessions.py", line 618, in send
r = adapter.send(request, **kwargs)
File "C:\Python27\lib\site-packages\requests\adapters.py", line 440, in send
timeout=timeout
File "C:\Python27\lib\site-packages\urllib3\connectionpool.py", line 617, in urlopen
**response_kw)
File "C:\Python27\lib\site-packages\urllib3\response.py", line 456, in from_httplib
headers = HTTPHeaderDict.from_httplib(headers)
File "C:\Python27\lib\site-packages\urllib3\_collections.py", line 312, in from_httplib
key, value = headers[-1]
IndexError: list index out of range
```
how can I deal with this issue?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `urllib3/_collections.py`
Content:
```
1 from __future__ import absolute_import
2 from collections import Mapping, MutableMapping
3 try:
4 from threading import RLock
5 except ImportError: # Platform-specific: No threads available
6 class RLock:
7 def __enter__(self):
8 pass
9
10 def __exit__(self, exc_type, exc_value, traceback):
11 pass
12
13
14 try: # Python 2.7+
15 from collections import OrderedDict
16 except ImportError:
17 from .packages.ordered_dict import OrderedDict
18 from .packages.six import iterkeys, itervalues, PY3
19
20
21 __all__ = ['RecentlyUsedContainer', 'HTTPHeaderDict']
22
23
24 _Null = object()
25
26
27 class RecentlyUsedContainer(MutableMapping):
28 """
29 Provides a thread-safe dict-like container which maintains up to
30 ``maxsize`` keys while throwing away the least-recently-used keys beyond
31 ``maxsize``.
32
33 :param maxsize:
34 Maximum number of recent elements to retain.
35
36 :param dispose_func:
37 Every time an item is evicted from the container,
38 ``dispose_func(value)`` is called. Callback which will get called
39 """
40
41 ContainerCls = OrderedDict
42
43 def __init__(self, maxsize=10, dispose_func=None):
44 self._maxsize = maxsize
45 self.dispose_func = dispose_func
46
47 self._container = self.ContainerCls()
48 self.lock = RLock()
49
50 def __getitem__(self, key):
51 # Re-insert the item, moving it to the end of the eviction line.
52 with self.lock:
53 item = self._container.pop(key)
54 self._container[key] = item
55 return item
56
57 def __setitem__(self, key, value):
58 evicted_value = _Null
59 with self.lock:
60 # Possibly evict the existing value of 'key'
61 evicted_value = self._container.get(key, _Null)
62 self._container[key] = value
63
64 # If we didn't evict an existing value, we might have to evict the
65 # least recently used item from the beginning of the container.
66 if len(self._container) > self._maxsize:
67 _key, evicted_value = self._container.popitem(last=False)
68
69 if self.dispose_func and evicted_value is not _Null:
70 self.dispose_func(evicted_value)
71
72 def __delitem__(self, key):
73 with self.lock:
74 value = self._container.pop(key)
75
76 if self.dispose_func:
77 self.dispose_func(value)
78
79 def __len__(self):
80 with self.lock:
81 return len(self._container)
82
83 def __iter__(self):
84 raise NotImplementedError('Iteration over this class is unlikely to be threadsafe.')
85
86 def clear(self):
87 with self.lock:
88 # Copy pointers to all values, then wipe the mapping
89 values = list(itervalues(self._container))
90 self._container.clear()
91
92 if self.dispose_func:
93 for value in values:
94 self.dispose_func(value)
95
96 def keys(self):
97 with self.lock:
98 return list(iterkeys(self._container))
99
100
101 class HTTPHeaderDict(MutableMapping):
102 """
103 :param headers:
104 An iterable of field-value pairs. Must not contain multiple field names
105 when compared case-insensitively.
106
107 :param kwargs:
108 Additional field-value pairs to pass in to ``dict.update``.
109
110 A ``dict`` like container for storing HTTP Headers.
111
112 Field names are stored and compared case-insensitively in compliance with
113 RFC 7230. Iteration provides the first case-sensitive key seen for each
114 case-insensitive pair.
115
116 Using ``__setitem__`` syntax overwrites fields that compare equal
117 case-insensitively in order to maintain ``dict``'s api. For fields that
118 compare equal, instead create a new ``HTTPHeaderDict`` and use ``.add``
119 in a loop.
120
121 If multiple fields that are equal case-insensitively are passed to the
122 constructor or ``.update``, the behavior is undefined and some will be
123 lost.
124
125 >>> headers = HTTPHeaderDict()
126 >>> headers.add('Set-Cookie', 'foo=bar')
127 >>> headers.add('set-cookie', 'baz=quxx')
128 >>> headers['content-length'] = '7'
129 >>> headers['SET-cookie']
130 'foo=bar, baz=quxx'
131 >>> headers['Content-Length']
132 '7'
133 """
134
135 def __init__(self, headers=None, **kwargs):
136 super(HTTPHeaderDict, self).__init__()
137 self._container = OrderedDict()
138 if headers is not None:
139 if isinstance(headers, HTTPHeaderDict):
140 self._copy_from(headers)
141 else:
142 self.extend(headers)
143 if kwargs:
144 self.extend(kwargs)
145
146 def __setitem__(self, key, val):
147 self._container[key.lower()] = [key, val]
148 return self._container[key.lower()]
149
150 def __getitem__(self, key):
151 val = self._container[key.lower()]
152 return ', '.join(val[1:])
153
154 def __delitem__(self, key):
155 del self._container[key.lower()]
156
157 def __contains__(self, key):
158 return key.lower() in self._container
159
160 def __eq__(self, other):
161 if not isinstance(other, Mapping) and not hasattr(other, 'keys'):
162 return False
163 if not isinstance(other, type(self)):
164 other = type(self)(other)
165 return (dict((k.lower(), v) for k, v in self.itermerged()) ==
166 dict((k.lower(), v) for k, v in other.itermerged()))
167
168 def __ne__(self, other):
169 return not self.__eq__(other)
170
171 if not PY3: # Python 2
172 iterkeys = MutableMapping.iterkeys
173 itervalues = MutableMapping.itervalues
174
175 __marker = object()
176
177 def __len__(self):
178 return len(self._container)
179
180 def __iter__(self):
181 # Only provide the originally cased names
182 for vals in self._container.values():
183 yield vals[0]
184
185 def pop(self, key, default=__marker):
186 '''D.pop(k[,d]) -> v, remove specified key and return the corresponding value.
187 If key is not found, d is returned if given, otherwise KeyError is raised.
188 '''
189 # Using the MutableMapping function directly fails due to the private marker.
190 # Using ordinary dict.pop would expose the internal structures.
191 # So let's reinvent the wheel.
192 try:
193 value = self[key]
194 except KeyError:
195 if default is self.__marker:
196 raise
197 return default
198 else:
199 del self[key]
200 return value
201
202 def discard(self, key):
203 try:
204 del self[key]
205 except KeyError:
206 pass
207
208 def add(self, key, val):
209 """Adds a (name, value) pair, doesn't overwrite the value if it already
210 exists.
211
212 >>> headers = HTTPHeaderDict(foo='bar')
213 >>> headers.add('Foo', 'baz')
214 >>> headers['foo']
215 'bar, baz'
216 """
217 key_lower = key.lower()
218 new_vals = [key, val]
219 # Keep the common case aka no item present as fast as possible
220 vals = self._container.setdefault(key_lower, new_vals)
221 if new_vals is not vals:
222 vals.append(val)
223
224 def extend(self, *args, **kwargs):
225 """Generic import function for any type of header-like object.
226 Adapted version of MutableMapping.update in order to insert items
227 with self.add instead of self.__setitem__
228 """
229 if len(args) > 1:
230 raise TypeError("extend() takes at most 1 positional "
231 "arguments ({0} given)".format(len(args)))
232 other = args[0] if len(args) >= 1 else ()
233
234 if isinstance(other, HTTPHeaderDict):
235 for key, val in other.iteritems():
236 self.add(key, val)
237 elif isinstance(other, Mapping):
238 for key in other:
239 self.add(key, other[key])
240 elif hasattr(other, "keys"):
241 for key in other.keys():
242 self.add(key, other[key])
243 else:
244 for key, value in other:
245 self.add(key, value)
246
247 for key, value in kwargs.items():
248 self.add(key, value)
249
250 def getlist(self, key, default=__marker):
251 """Returns a list of all the values for the named field. Returns an
252 empty list if the key doesn't exist."""
253 try:
254 vals = self._container[key.lower()]
255 except KeyError:
256 if default is self.__marker:
257 return []
258 return default
259 else:
260 return vals[1:]
261
262 # Backwards compatibility for httplib
263 getheaders = getlist
264 getallmatchingheaders = getlist
265 iget = getlist
266
267 # Backwards compatibility for http.cookiejar
268 get_all = getlist
269
270 def __repr__(self):
271 return "%s(%s)" % (type(self).__name__, dict(self.itermerged()))
272
273 def _copy_from(self, other):
274 for key in other:
275 val = other.getlist(key)
276 if isinstance(val, list):
277 # Don't need to convert tuples
278 val = list(val)
279 self._container[key.lower()] = [key] + val
280
281 def copy(self):
282 clone = type(self)()
283 clone._copy_from(self)
284 return clone
285
286 def iteritems(self):
287 """Iterate over all header lines, including duplicate ones."""
288 for key in self:
289 vals = self._container[key.lower()]
290 for val in vals[1:]:
291 yield vals[0], val
292
293 def itermerged(self):
294 """Iterate over all headers, merging duplicate ones together."""
295 for key in self:
296 val = self._container[key.lower()]
297 yield val[0], ', '.join(val[1:])
298
299 def items(self):
300 return list(self.iteritems())
301
302 @classmethod
303 def from_httplib(cls, message): # Python 2
304 """Read headers from a Python 2 httplib message object."""
305 # python2.7 does not expose a proper API for exporting multiheaders
306 # efficiently. This function re-reads raw lines from the message
307 # object and extracts the multiheaders properly.
308 headers = []
309
310 for line in message.headers:
311 if line.startswith((' ', '\t')):
312 key, value = headers[-1]
313 headers[-1] = (key, value + '\r\n' + line.rstrip())
314 continue
315
316 key, value = line.split(':', 1)
317 headers.append((key, value.strip()))
318
319 return cls(headers)
320
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/urllib3/_collections.py b/urllib3/_collections.py
--- a/urllib3/_collections.py
+++ b/urllib3/_collections.py
@@ -15,6 +15,7 @@
from collections import OrderedDict
except ImportError:
from .packages.ordered_dict import OrderedDict
+from .exceptions import InvalidHeader
from .packages.six import iterkeys, itervalues, PY3
@@ -305,13 +306,22 @@
# python2.7 does not expose a proper API for exporting multiheaders
# efficiently. This function re-reads raw lines from the message
# object and extracts the multiheaders properly.
+ obs_fold_continued_leaders = (' ', '\t')
headers = []
for line in message.headers:
- if line.startswith((' ', '\t')):
- key, value = headers[-1]
- headers[-1] = (key, value + '\r\n' + line.rstrip())
- continue
+ if line.startswith(obs_fold_continued_leaders):
+ if not headers:
+ # We received a header line that starts with OWS as described
+ # in RFC-7230 S3.2.4. This indicates a multiline header, but
+ # there exists no previous header to which we can attach it.
+ raise InvalidHeader(
+ 'Header continuation with no previous header: %s' % line
+ )
+ else:
+ key, value = headers[-1]
+ headers[-1] = (key, value + ' ' + line.strip())
+ continue
key, value = line.split(':', 1)
headers.append((key, value.strip()))
|
{"golden_diff": "diff --git a/urllib3/_collections.py b/urllib3/_collections.py\n--- a/urllib3/_collections.py\n+++ b/urllib3/_collections.py\n@@ -15,6 +15,7 @@\n from collections import OrderedDict\n except ImportError:\n from .packages.ordered_dict import OrderedDict\n+from .exceptions import InvalidHeader\n from .packages.six import iterkeys, itervalues, PY3\n \n \n@@ -305,13 +306,22 @@\n # python2.7 does not expose a proper API for exporting multiheaders\n # efficiently. This function re-reads raw lines from the message\n # object and extracts the multiheaders properly.\n+ obs_fold_continued_leaders = (' ', '\\t')\n headers = []\n \n for line in message.headers:\n- if line.startswith((' ', '\\t')):\n- key, value = headers[-1]\n- headers[-1] = (key, value + '\\r\\n' + line.rstrip())\n- continue\n+ if line.startswith(obs_fold_continued_leaders):\n+ if not headers:\n+ # We received a header line that starts with OWS as described\n+ # in RFC-7230 S3.2.4. This indicates a multiline header, but\n+ # there exists no previous header to which we can attach it.\n+ raise InvalidHeader(\n+ 'Header continuation with no previous header: %s' % line\n+ )\n+ else:\n+ key, value = headers[-1]\n+ headers[-1] = (key, value + ' ' + line.strip())\n+ continue\n \n key, value = line.split(':', 1)\n headers.append((key, value.strip()))\n", "issue": "IndexError when handle malformed http response\nI use urllib3 receive a http response like this,\r\n```\r\nHTTP/1.1 200 OK\r\n\tContent-Type: application/octet-stream\r\n\tContent-Length: 89606\r\n\tContent-Disposition: attachment; filename=\"MB-500Ap_2009-01-12.cfg\"\r\n\tConnection: close\r\n\r\nBrickcom-50xA\r\nOperationSetting.locale=auto\r\nHostName.name=cam\r\nModuleInfo.DIDO_module=1\r\nModuleInfo.PIR_module=0\r\nModuleInfo.WLED=0\r\nSensorFPSSetting.fps=0\r\nModuleInfo.AUTOIRIS_module=0\r\nModuleInfo.IRCUT_module=0\r\nModuleInfo.IRLED_module=0\r\nModuleInfo.lightsensor=0\r\nModuleInfo.EXPOSURE_module=0\r\nModuleInfo.MDNS_module=0\r\nModuleInfo.PTZ_module=1\r\nModuleInfo.MSN_module=0\r\nModuleInfo.WIFI_module=0\r\nModuleInfo.watchDog_module=0\r\nModuleInfo.sdcard_module=1\r\nModuleInfo.usbstorage_module=0\r\nModuleInfo.sambamount_module=0\r\nModuleInfo.QoS=0\r\nModuleInfo.shutter_speed=0\r\nModuleInfo.discovery_internet=1\r\nModuleInfo.POE_module=\r\nModuleInfo.audio_record=1\r\n```\r\nit throws a IndexError,I print the traceback,\r\n```\r\n req = http_get(url, auth=(\"admin\", \"admin\"), timeout=timeout, verify=False)\r\n File \"C:\\Python27\\lib\\site-packages\\requests\\api.py\", line 72, in get\r\n return request('get', url, params=params, **kwargs)\r\n File \"C:\\Python27\\lib\\site-packages\\requests\\api.py\", line 58, in request\r\n return session.request(method=method, url=url, **kwargs)\r\n File \"C:\\Python27\\lib\\site-packages\\requests\\sessions.py\", line 508, in request\r\n resp = self.send(prep, **send_kwargs)\r\n File \"C:\\Python27\\lib\\site-packages\\requests\\sessions.py\", line 618, in send\r\n r = adapter.send(request, **kwargs)\r\n File \"C:\\Python27\\lib\\site-packages\\requests\\adapters.py\", line 440, in send\r\n timeout=timeout\r\n File \"C:\\Python27\\lib\\site-packages\\urllib3\\connectionpool.py\", line 617, in urlopen\r\n **response_kw)\r\n File \"C:\\Python27\\lib\\site-packages\\urllib3\\response.py\", line 456, in from_httplib\r\n headers = HTTPHeaderDict.from_httplib(headers)\r\n File \"C:\\Python27\\lib\\site-packages\\urllib3\\_collections.py\", line 312, in from_httplib\r\n key, value = headers[-1]\r\nIndexError: list index out of range\r\n```\r\nhow can I deal with this issue?\n", "before_files": [{"content": "from __future__ import absolute_import\nfrom collections import Mapping, MutableMapping\ntry:\n from threading import RLock\nexcept ImportError: # Platform-specific: No threads available\n class RLock:\n def __enter__(self):\n pass\n\n def __exit__(self, exc_type, exc_value, traceback):\n pass\n\n\ntry: # Python 2.7+\n from collections import OrderedDict\nexcept ImportError:\n from .packages.ordered_dict import OrderedDict\nfrom .packages.six import iterkeys, itervalues, PY3\n\n\n__all__ = ['RecentlyUsedContainer', 'HTTPHeaderDict']\n\n\n_Null = object()\n\n\nclass RecentlyUsedContainer(MutableMapping):\n \"\"\"\n Provides a thread-safe dict-like container which maintains up to\n ``maxsize`` keys while throwing away the least-recently-used keys beyond\n ``maxsize``.\n\n :param maxsize:\n Maximum number of recent elements to retain.\n\n :param dispose_func:\n Every time an item is evicted from the container,\n ``dispose_func(value)`` is called. Callback which will get called\n \"\"\"\n\n ContainerCls = OrderedDict\n\n def __init__(self, maxsize=10, dispose_func=None):\n self._maxsize = maxsize\n self.dispose_func = dispose_func\n\n self._container = self.ContainerCls()\n self.lock = RLock()\n\n def __getitem__(self, key):\n # Re-insert the item, moving it to the end of the eviction line.\n with self.lock:\n item = self._container.pop(key)\n self._container[key] = item\n return item\n\n def __setitem__(self, key, value):\n evicted_value = _Null\n with self.lock:\n # Possibly evict the existing value of 'key'\n evicted_value = self._container.get(key, _Null)\n self._container[key] = value\n\n # If we didn't evict an existing value, we might have to evict the\n # least recently used item from the beginning of the container.\n if len(self._container) > self._maxsize:\n _key, evicted_value = self._container.popitem(last=False)\n\n if self.dispose_func and evicted_value is not _Null:\n self.dispose_func(evicted_value)\n\n def __delitem__(self, key):\n with self.lock:\n value = self._container.pop(key)\n\n if self.dispose_func:\n self.dispose_func(value)\n\n def __len__(self):\n with self.lock:\n return len(self._container)\n\n def __iter__(self):\n raise NotImplementedError('Iteration over this class is unlikely to be threadsafe.')\n\n def clear(self):\n with self.lock:\n # Copy pointers to all values, then wipe the mapping\n values = list(itervalues(self._container))\n self._container.clear()\n\n if self.dispose_func:\n for value in values:\n self.dispose_func(value)\n\n def keys(self):\n with self.lock:\n return list(iterkeys(self._container))\n\n\nclass HTTPHeaderDict(MutableMapping):\n \"\"\"\n :param headers:\n An iterable of field-value pairs. Must not contain multiple field names\n when compared case-insensitively.\n\n :param kwargs:\n Additional field-value pairs to pass in to ``dict.update``.\n\n A ``dict`` like container for storing HTTP Headers.\n\n Field names are stored and compared case-insensitively in compliance with\n RFC 7230. Iteration provides the first case-sensitive key seen for each\n case-insensitive pair.\n\n Using ``__setitem__`` syntax overwrites fields that compare equal\n case-insensitively in order to maintain ``dict``'s api. For fields that\n compare equal, instead create a new ``HTTPHeaderDict`` and use ``.add``\n in a loop.\n\n If multiple fields that are equal case-insensitively are passed to the\n constructor or ``.update``, the behavior is undefined and some will be\n lost.\n\n >>> headers = HTTPHeaderDict()\n >>> headers.add('Set-Cookie', 'foo=bar')\n >>> headers.add('set-cookie', 'baz=quxx')\n >>> headers['content-length'] = '7'\n >>> headers['SET-cookie']\n 'foo=bar, baz=quxx'\n >>> headers['Content-Length']\n '7'\n \"\"\"\n\n def __init__(self, headers=None, **kwargs):\n super(HTTPHeaderDict, self).__init__()\n self._container = OrderedDict()\n if headers is not None:\n if isinstance(headers, HTTPHeaderDict):\n self._copy_from(headers)\n else:\n self.extend(headers)\n if kwargs:\n self.extend(kwargs)\n\n def __setitem__(self, key, val):\n self._container[key.lower()] = [key, val]\n return self._container[key.lower()]\n\n def __getitem__(self, key):\n val = self._container[key.lower()]\n return ', '.join(val[1:])\n\n def __delitem__(self, key):\n del self._container[key.lower()]\n\n def __contains__(self, key):\n return key.lower() in self._container\n\n def __eq__(self, other):\n if not isinstance(other, Mapping) and not hasattr(other, 'keys'):\n return False\n if not isinstance(other, type(self)):\n other = type(self)(other)\n return (dict((k.lower(), v) for k, v in self.itermerged()) ==\n dict((k.lower(), v) for k, v in other.itermerged()))\n\n def __ne__(self, other):\n return not self.__eq__(other)\n\n if not PY3: # Python 2\n iterkeys = MutableMapping.iterkeys\n itervalues = MutableMapping.itervalues\n\n __marker = object()\n\n def __len__(self):\n return len(self._container)\n\n def __iter__(self):\n # Only provide the originally cased names\n for vals in self._container.values():\n yield vals[0]\n\n def pop(self, key, default=__marker):\n '''D.pop(k[,d]) -> v, remove specified key and return the corresponding value.\n If key is not found, d is returned if given, otherwise KeyError is raised.\n '''\n # Using the MutableMapping function directly fails due to the private marker.\n # Using ordinary dict.pop would expose the internal structures.\n # So let's reinvent the wheel.\n try:\n value = self[key]\n except KeyError:\n if default is self.__marker:\n raise\n return default\n else:\n del self[key]\n return value\n\n def discard(self, key):\n try:\n del self[key]\n except KeyError:\n pass\n\n def add(self, key, val):\n \"\"\"Adds a (name, value) pair, doesn't overwrite the value if it already\n exists.\n\n >>> headers = HTTPHeaderDict(foo='bar')\n >>> headers.add('Foo', 'baz')\n >>> headers['foo']\n 'bar, baz'\n \"\"\"\n key_lower = key.lower()\n new_vals = [key, val]\n # Keep the common case aka no item present as fast as possible\n vals = self._container.setdefault(key_lower, new_vals)\n if new_vals is not vals:\n vals.append(val)\n\n def extend(self, *args, **kwargs):\n \"\"\"Generic import function for any type of header-like object.\n Adapted version of MutableMapping.update in order to insert items\n with self.add instead of self.__setitem__\n \"\"\"\n if len(args) > 1:\n raise TypeError(\"extend() takes at most 1 positional \"\n \"arguments ({0} given)\".format(len(args)))\n other = args[0] if len(args) >= 1 else ()\n\n if isinstance(other, HTTPHeaderDict):\n for key, val in other.iteritems():\n self.add(key, val)\n elif isinstance(other, Mapping):\n for key in other:\n self.add(key, other[key])\n elif hasattr(other, \"keys\"):\n for key in other.keys():\n self.add(key, other[key])\n else:\n for key, value in other:\n self.add(key, value)\n\n for key, value in kwargs.items():\n self.add(key, value)\n\n def getlist(self, key, default=__marker):\n \"\"\"Returns a list of all the values for the named field. Returns an\n empty list if the key doesn't exist.\"\"\"\n try:\n vals = self._container[key.lower()]\n except KeyError:\n if default is self.__marker:\n return []\n return default\n else:\n return vals[1:]\n\n # Backwards compatibility for httplib\n getheaders = getlist\n getallmatchingheaders = getlist\n iget = getlist\n\n # Backwards compatibility for http.cookiejar\n get_all = getlist\n\n def __repr__(self):\n return \"%s(%s)\" % (type(self).__name__, dict(self.itermerged()))\n\n def _copy_from(self, other):\n for key in other:\n val = other.getlist(key)\n if isinstance(val, list):\n # Don't need to convert tuples\n val = list(val)\n self._container[key.lower()] = [key] + val\n\n def copy(self):\n clone = type(self)()\n clone._copy_from(self)\n return clone\n\n def iteritems(self):\n \"\"\"Iterate over all header lines, including duplicate ones.\"\"\"\n for key in self:\n vals = self._container[key.lower()]\n for val in vals[1:]:\n yield vals[0], val\n\n def itermerged(self):\n \"\"\"Iterate over all headers, merging duplicate ones together.\"\"\"\n for key in self:\n val = self._container[key.lower()]\n yield val[0], ', '.join(val[1:])\n\n def items(self):\n return list(self.iteritems())\n\n @classmethod\n def from_httplib(cls, message): # Python 2\n \"\"\"Read headers from a Python 2 httplib message object.\"\"\"\n # python2.7 does not expose a proper API for exporting multiheaders\n # efficiently. This function re-reads raw lines from the message\n # object and extracts the multiheaders properly.\n headers = []\n\n for line in message.headers:\n if line.startswith((' ', '\\t')):\n key, value = headers[-1]\n headers[-1] = (key, value + '\\r\\n' + line.rstrip())\n continue\n\n key, value = line.split(':', 1)\n headers.append((key, value.strip()))\n\n return cls(headers)\n", "path": "urllib3/_collections.py"}], "after_files": [{"content": "from __future__ import absolute_import\nfrom collections import Mapping, MutableMapping\ntry:\n from threading import RLock\nexcept ImportError: # Platform-specific: No threads available\n class RLock:\n def __enter__(self):\n pass\n\n def __exit__(self, exc_type, exc_value, traceback):\n pass\n\n\ntry: # Python 2.7+\n from collections import OrderedDict\nexcept ImportError:\n from .packages.ordered_dict import OrderedDict\nfrom .exceptions import InvalidHeader\nfrom .packages.six import iterkeys, itervalues, PY3\n\n\n__all__ = ['RecentlyUsedContainer', 'HTTPHeaderDict']\n\n\n_Null = object()\n\n\nclass RecentlyUsedContainer(MutableMapping):\n \"\"\"\n Provides a thread-safe dict-like container which maintains up to\n ``maxsize`` keys while throwing away the least-recently-used keys beyond\n ``maxsize``.\n\n :param maxsize:\n Maximum number of recent elements to retain.\n\n :param dispose_func:\n Every time an item is evicted from the container,\n ``dispose_func(value)`` is called. Callback which will get called\n \"\"\"\n\n ContainerCls = OrderedDict\n\n def __init__(self, maxsize=10, dispose_func=None):\n self._maxsize = maxsize\n self.dispose_func = dispose_func\n\n self._container = self.ContainerCls()\n self.lock = RLock()\n\n def __getitem__(self, key):\n # Re-insert the item, moving it to the end of the eviction line.\n with self.lock:\n item = self._container.pop(key)\n self._container[key] = item\n return item\n\n def __setitem__(self, key, value):\n evicted_value = _Null\n with self.lock:\n # Possibly evict the existing value of 'key'\n evicted_value = self._container.get(key, _Null)\n self._container[key] = value\n\n # If we didn't evict an existing value, we might have to evict the\n # least recently used item from the beginning of the container.\n if len(self._container) > self._maxsize:\n _key, evicted_value = self._container.popitem(last=False)\n\n if self.dispose_func and evicted_value is not _Null:\n self.dispose_func(evicted_value)\n\n def __delitem__(self, key):\n with self.lock:\n value = self._container.pop(key)\n\n if self.dispose_func:\n self.dispose_func(value)\n\n def __len__(self):\n with self.lock:\n return len(self._container)\n\n def __iter__(self):\n raise NotImplementedError('Iteration over this class is unlikely to be threadsafe.')\n\n def clear(self):\n with self.lock:\n # Copy pointers to all values, then wipe the mapping\n values = list(itervalues(self._container))\n self._container.clear()\n\n if self.dispose_func:\n for value in values:\n self.dispose_func(value)\n\n def keys(self):\n with self.lock:\n return list(iterkeys(self._container))\n\n\nclass HTTPHeaderDict(MutableMapping):\n \"\"\"\n :param headers:\n An iterable of field-value pairs. Must not contain multiple field names\n when compared case-insensitively.\n\n :param kwargs:\n Additional field-value pairs to pass in to ``dict.update``.\n\n A ``dict`` like container for storing HTTP Headers.\n\n Field names are stored and compared case-insensitively in compliance with\n RFC 7230. Iteration provides the first case-sensitive key seen for each\n case-insensitive pair.\n\n Using ``__setitem__`` syntax overwrites fields that compare equal\n case-insensitively in order to maintain ``dict``'s api. For fields that\n compare equal, instead create a new ``HTTPHeaderDict`` and use ``.add``\n in a loop.\n\n If multiple fields that are equal case-insensitively are passed to the\n constructor or ``.update``, the behavior is undefined and some will be\n lost.\n\n >>> headers = HTTPHeaderDict()\n >>> headers.add('Set-Cookie', 'foo=bar')\n >>> headers.add('set-cookie', 'baz=quxx')\n >>> headers['content-length'] = '7'\n >>> headers['SET-cookie']\n 'foo=bar, baz=quxx'\n >>> headers['Content-Length']\n '7'\n \"\"\"\n\n def __init__(self, headers=None, **kwargs):\n super(HTTPHeaderDict, self).__init__()\n self._container = OrderedDict()\n if headers is not None:\n if isinstance(headers, HTTPHeaderDict):\n self._copy_from(headers)\n else:\n self.extend(headers)\n if kwargs:\n self.extend(kwargs)\n\n def __setitem__(self, key, val):\n self._container[key.lower()] = [key, val]\n return self._container[key.lower()]\n\n def __getitem__(self, key):\n val = self._container[key.lower()]\n return ', '.join(val[1:])\n\n def __delitem__(self, key):\n del self._container[key.lower()]\n\n def __contains__(self, key):\n return key.lower() in self._container\n\n def __eq__(self, other):\n if not isinstance(other, Mapping) and not hasattr(other, 'keys'):\n return False\n if not isinstance(other, type(self)):\n other = type(self)(other)\n return (dict((k.lower(), v) for k, v in self.itermerged()) ==\n dict((k.lower(), v) for k, v in other.itermerged()))\n\n def __ne__(self, other):\n return not self.__eq__(other)\n\n if not PY3: # Python 2\n iterkeys = MutableMapping.iterkeys\n itervalues = MutableMapping.itervalues\n\n __marker = object()\n\n def __len__(self):\n return len(self._container)\n\n def __iter__(self):\n # Only provide the originally cased names\n for vals in self._container.values():\n yield vals[0]\n\n def pop(self, key, default=__marker):\n '''D.pop(k[,d]) -> v, remove specified key and return the corresponding value.\n If key is not found, d is returned if given, otherwise KeyError is raised.\n '''\n # Using the MutableMapping function directly fails due to the private marker.\n # Using ordinary dict.pop would expose the internal structures.\n # So let's reinvent the wheel.\n try:\n value = self[key]\n except KeyError:\n if default is self.__marker:\n raise\n return default\n else:\n del self[key]\n return value\n\n def discard(self, key):\n try:\n del self[key]\n except KeyError:\n pass\n\n def add(self, key, val):\n \"\"\"Adds a (name, value) pair, doesn't overwrite the value if it already\n exists.\n\n >>> headers = HTTPHeaderDict(foo='bar')\n >>> headers.add('Foo', 'baz')\n >>> headers['foo']\n 'bar, baz'\n \"\"\"\n key_lower = key.lower()\n new_vals = [key, val]\n # Keep the common case aka no item present as fast as possible\n vals = self._container.setdefault(key_lower, new_vals)\n if new_vals is not vals:\n vals.append(val)\n\n def extend(self, *args, **kwargs):\n \"\"\"Generic import function for any type of header-like object.\n Adapted version of MutableMapping.update in order to insert items\n with self.add instead of self.__setitem__\n \"\"\"\n if len(args) > 1:\n raise TypeError(\"extend() takes at most 1 positional \"\n \"arguments ({0} given)\".format(len(args)))\n other = args[0] if len(args) >= 1 else ()\n\n if isinstance(other, HTTPHeaderDict):\n for key, val in other.iteritems():\n self.add(key, val)\n elif isinstance(other, Mapping):\n for key in other:\n self.add(key, other[key])\n elif hasattr(other, \"keys\"):\n for key in other.keys():\n self.add(key, other[key])\n else:\n for key, value in other:\n self.add(key, value)\n\n for key, value in kwargs.items():\n self.add(key, value)\n\n def getlist(self, key, default=__marker):\n \"\"\"Returns a list of all the values for the named field. Returns an\n empty list if the key doesn't exist.\"\"\"\n try:\n vals = self._container[key.lower()]\n except KeyError:\n if default is self.__marker:\n return []\n return default\n else:\n return vals[1:]\n\n # Backwards compatibility for httplib\n getheaders = getlist\n getallmatchingheaders = getlist\n iget = getlist\n\n # Backwards compatibility for http.cookiejar\n get_all = getlist\n\n def __repr__(self):\n return \"%s(%s)\" % (type(self).__name__, dict(self.itermerged()))\n\n def _copy_from(self, other):\n for key in other:\n val = other.getlist(key)\n if isinstance(val, list):\n # Don't need to convert tuples\n val = list(val)\n self._container[key.lower()] = [key] + val\n\n def copy(self):\n clone = type(self)()\n clone._copy_from(self)\n return clone\n\n def iteritems(self):\n \"\"\"Iterate over all header lines, including duplicate ones.\"\"\"\n for key in self:\n vals = self._container[key.lower()]\n for val in vals[1:]:\n yield vals[0], val\n\n def itermerged(self):\n \"\"\"Iterate over all headers, merging duplicate ones together.\"\"\"\n for key in self:\n val = self._container[key.lower()]\n yield val[0], ', '.join(val[1:])\n\n def items(self):\n return list(self.iteritems())\n\n @classmethod\n def from_httplib(cls, message): # Python 2\n \"\"\"Read headers from a Python 2 httplib message object.\"\"\"\n # python2.7 does not expose a proper API for exporting multiheaders\n # efficiently. This function re-reads raw lines from the message\n # object and extracts the multiheaders properly.\n obs_fold_continued_leaders = (' ', '\\t')\n headers = []\n\n for line in message.headers:\n if line.startswith(obs_fold_continued_leaders):\n if not headers:\n # We received a header line that starts with OWS as described\n # in RFC-7230 S3.2.4. This indicates a multiline header, but\n # there exists no previous header to which we can attach it.\n raise InvalidHeader(\n 'Header continuation with no previous header: %s' % line\n )\n else:\n key, value = headers[-1]\n headers[-1] = (key, value + ' ' + line.strip())\n continue\n\n key, value = line.split(':', 1)\n headers.append((key, value.strip()))\n\n return cls(headers)\n", "path": "urllib3/_collections.py"}]}
| 4,075 | 379 |
gh_patches_debug_22607
|
rasdani/github-patches
|
git_diff
|
Parsl__parsl-1314
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
RepresentationMixin breaks on classes with no default parameters
```
from parsl.utils import RepresentationMixin
class A(RepresentationMixin):
def __init__(self, q):
self.q = q
x = A(q=4)
print(x)
```
gives:
```
$ python b.py
Traceback (most recent call last):
File "b.py", line 10, in <module>
print(x)
File "/home/benc/parsl/src/parsl/parsl/utils.py", line 193, in __repr__
defaults = dict(zip(reversed(argspec.args), reversed(argspec.defaults)))
TypeError: 'NoneType' object is not reversible
```
Changing `__init__` to:
```
def __init__(self, q=3):
```
fixes this.
At a guess, argspec.defaults is None rather than an empty sequence in the breaking case.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `parsl/utils.py`
Content:
```
1 import inspect
2 import logging
3 import os
4 import shlex
5 import subprocess
6 import threading
7 import time
8 from contextlib import contextmanager
9 from functools import wraps
10
11 import parsl
12 from parsl.version import VERSION
13
14 logger = logging.getLogger(__name__)
15
16
17 def get_version():
18 version = parsl.__version__
19 work_tree = os.path.dirname(os.path.dirname(__file__))
20 git_dir = os.path.join(work_tree, '.git')
21 if os.path.exists(git_dir):
22 env = {'GIT_WORK_TREE': work_tree, 'GIT_DIR': git_dir}
23 try:
24 cmd = shlex.split('git rev-parse --short HEAD')
25 head = subprocess.check_output(cmd, env=env).strip().decode('utf-8')
26 diff = subprocess.check_output(shlex.split('git diff HEAD'), env=env)
27 status = 'dirty' if diff else 'clean'
28 version = '{v}-{head}-{status}'.format(v=VERSION, head=head, status=status)
29 except Exception:
30 pass
31
32 return version
33
34
35 def get_all_checkpoints(rundir="runinfo"):
36 """Finds the checkpoints from all last runs.
37
38 Note that checkpoints are incremental, and this helper will not find
39 previous checkpoints from earlier than the most recent run. It probably
40 should be made to do so.
41
42 Kwargs:
43 - rundir(str) : Path to the runinfo directory
44
45 Returns:
46 - a list suitable for the checkpointFiles parameter of DataFlowKernel
47 constructor
48
49 """
50
51 if(not os.path.isdir(rundir)):
52 return []
53
54 dirs = sorted(os.listdir(rundir))
55
56 checkpoints = []
57
58 for runid in dirs:
59
60 checkpoint = os.path.abspath('{}/{}/checkpoint'.format(rundir, runid))
61
62 if os.path.isdir(checkpoint):
63 checkpoints.append(checkpoint)
64
65 return checkpoints
66
67
68 def get_last_checkpoint(rundir="runinfo"):
69 """Find the checkpoint from the last run, if one exists.
70
71 Note that checkpoints are incremental, and this helper will not find
72 previous checkpoints from earlier than the most recent run. It probably
73 should be made to do so.
74
75 Kwargs:
76 - rundir(str) : Path to the runinfo directory
77
78 Returns:
79 - a list suitable for checkpointFiles parameter of DataFlowKernel
80 constructor, with 0 or 1 elements
81
82 """
83 if not os.path.isdir(rundir):
84 return []
85
86 dirs = sorted(os.listdir(rundir))
87
88 if len(dirs) == 0:
89 return []
90
91 last_runid = dirs[-1]
92 last_checkpoint = os.path.abspath('{}/{}/checkpoint'.format(rundir, last_runid))
93
94 if(not(os.path.isdir(last_checkpoint))):
95 return []
96
97 return [last_checkpoint]
98
99
100 def timeout(seconds=None):
101 def decorator(func, *args, **kwargs):
102 @wraps(func)
103 def wrapper(*args, **kwargs):
104 t = threading.Thread(target=func, args=args, kwargs=kwargs, name="Timeout-Decorator")
105 t.start()
106 result = t.join(seconds)
107 if t.is_alive():
108 raise RuntimeError('timed out in {}'.format(func))
109 return result
110 return wrapper
111 return decorator
112
113
114 @contextmanager
115 def wait_for_file(path, seconds=10):
116 for i in range(0, int(seconds * 100)):
117 time.sleep(seconds / 100.)
118 if os.path.exists(path):
119 break
120 yield
121
122
123 @contextmanager
124 def time_limited_open(path, mode, seconds=1):
125 with wait_for_file(path, seconds):
126 logger.debug("wait_for_file yielded")
127 f = open(path, mode)
128 yield f
129 f.close()
130
131
132 def wtime_to_minutes(time_string):
133 ''' wtime_to_minutes
134
135 Convert standard wallclock time string to minutes.
136
137 Args:
138 - Time_string in HH:MM:SS format
139
140 Returns:
141 (int) minutes
142
143 '''
144 hours, mins, seconds = time_string.split(':')
145 total_mins = int(hours) * 60 + int(mins)
146 if total_mins < 1:
147 logger.warning("Time string '{}' parsed to {} minutes, less than 1".format(time_string, total_mins))
148 return total_mins
149
150
151 class RepresentationMixin(object):
152 """A mixin class for adding a __repr__ method.
153
154 The __repr__ method will return a string equivalent to the code used to instantiate
155 the child class, with any defaults included explicitly. The __max_width__ class variable
156 controls the maximum width of the representation string. If this width is exceeded,
157 the representation string will be split up, with one argument or keyword argument per line.
158
159 Any arguments or keyword arguments in the constructor must be defined as attributes, or
160 an AttributeError will be raised.
161
162 Examples
163 --------
164 >>> from parsl.utils import RepresentationMixin
165 >>> class Foo(RepresentationMixin):
166 def __init__(self, first, second, third='three', fourth='fourth'):
167 self.first = first
168 self.second = second
169 self.third = third
170 self.fourth = fourth
171 >>> bar = Foo(1, 'two', fourth='baz')
172 >>> bar
173 Foo(1, 'two', third='three', fourth='baz')
174 """
175 __max_width__ = 80
176
177 def __repr__(self):
178 init = self.__init__
179
180 # This test looks for a single layer of wrapping performed by
181 # functools.update_wrapper, commonly used in decorators. This will
182 # allow RepresentationMixin to see through a single such decorator
183 # applied to the __init__ method of a class, and find the underlying
184 # arguments. It will not see through multiple layers of such
185 # decorators, or cope with other decorators which do not use
186 # functools.update_wrapper.
187
188 if hasattr(init, '__wrapped__'):
189 init = init.__wrapped__
190
191 argspec = inspect.getfullargspec(init)
192 if len(argspec.args) > 1:
193 defaults = dict(zip(reversed(argspec.args), reversed(argspec.defaults)))
194 else:
195 defaults = {}
196
197 for arg in argspec.args[1:]:
198 if not hasattr(self, arg):
199 template = 'class {} uses {} in the constructor, but does not define it as an attribute'
200 raise AttributeError(template.format(self.__class__.__name__, arg))
201
202 args = [getattr(self, a) for a in argspec.args[1:-len(defaults)]]
203 kwargs = {key: getattr(self, key) for key in defaults}
204
205 def assemble_multiline(args, kwargs):
206 def indent(text):
207 lines = text.splitlines()
208 if len(lines) <= 1:
209 return text
210 return "\n".join(" " + l for l in lines).strip()
211 args = ["\n {},".format(indent(repr(a))) for a in args]
212 kwargs = ["\n {}={}".format(k, indent(repr(v)))
213 for k, v in sorted(kwargs.items())]
214
215 info = "".join(args) + ", ".join(kwargs)
216 return self.__class__.__name__ + "({}\n)".format(info)
217
218 def assemble_line(args, kwargs):
219 kwargs = ['{}={}'.format(k, repr(v)) for k, v in sorted(kwargs.items())]
220
221 info = ", ".join([repr(a) for a in args] + kwargs)
222 return self.__class__.__name__ + "({})".format(info)
223
224 if len(assemble_line(args, kwargs)) <= self.__class__.__max_width__:
225 return assemble_line(args, kwargs)
226 else:
227 return assemble_multiline(args, kwargs)
228
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/parsl/utils.py b/parsl/utils.py
--- a/parsl/utils.py
+++ b/parsl/utils.py
@@ -189,7 +189,7 @@
init = init.__wrapped__
argspec = inspect.getfullargspec(init)
- if len(argspec.args) > 1:
+ if len(argspec.args) > 1 and argspec.defaults is not None:
defaults = dict(zip(reversed(argspec.args), reversed(argspec.defaults)))
else:
defaults = {}
@@ -199,7 +199,10 @@
template = 'class {} uses {} in the constructor, but does not define it as an attribute'
raise AttributeError(template.format(self.__class__.__name__, arg))
- args = [getattr(self, a) for a in argspec.args[1:-len(defaults)]]
+ if len(defaults) != 0:
+ args = [getattr(self, a) for a in argspec.args[1:-len(defaults)]]
+ else:
+ args = [getattr(self, a) for a in argspec.args[1:]]
kwargs = {key: getattr(self, key) for key in defaults}
def assemble_multiline(args, kwargs):
|
{"golden_diff": "diff --git a/parsl/utils.py b/parsl/utils.py\n--- a/parsl/utils.py\n+++ b/parsl/utils.py\n@@ -189,7 +189,7 @@\n init = init.__wrapped__\n \n argspec = inspect.getfullargspec(init)\n- if len(argspec.args) > 1:\n+ if len(argspec.args) > 1 and argspec.defaults is not None:\n defaults = dict(zip(reversed(argspec.args), reversed(argspec.defaults)))\n else:\n defaults = {}\n@@ -199,7 +199,10 @@\n template = 'class {} uses {} in the constructor, but does not define it as an attribute'\n raise AttributeError(template.format(self.__class__.__name__, arg))\n \n- args = [getattr(self, a) for a in argspec.args[1:-len(defaults)]]\n+ if len(defaults) != 0:\n+ args = [getattr(self, a) for a in argspec.args[1:-len(defaults)]]\n+ else:\n+ args = [getattr(self, a) for a in argspec.args[1:]]\n kwargs = {key: getattr(self, key) for key in defaults}\n \n def assemble_multiline(args, kwargs):\n", "issue": "RepresentationMixin breaks on classes with no default parameters\n```\r\nfrom parsl.utils import RepresentationMixin\r\n\r\nclass A(RepresentationMixin):\r\n\r\n def __init__(self, q):\r\n self.q = q\r\n\r\nx = A(q=4)\r\nprint(x)\r\n```\r\n\r\ngives:\r\n\r\n```\r\n$ python b.py \r\nTraceback (most recent call last):\r\n File \"b.py\", line 10, in <module>\r\n print(x)\r\n File \"/home/benc/parsl/src/parsl/parsl/utils.py\", line 193, in __repr__\r\n defaults = dict(zip(reversed(argspec.args), reversed(argspec.defaults)))\r\nTypeError: 'NoneType' object is not reversible\r\n```\r\n\r\nChanging `__init__` to:\r\n\r\n```\r\n def __init__(self, q=3):\r\n```\r\n\r\nfixes this.\r\n\r\nAt a guess, argspec.defaults is None rather than an empty sequence in the breaking case.\n", "before_files": [{"content": "import inspect\nimport logging\nimport os\nimport shlex\nimport subprocess\nimport threading\nimport time\nfrom contextlib import contextmanager\nfrom functools import wraps\n\nimport parsl\nfrom parsl.version import VERSION\n\nlogger = logging.getLogger(__name__)\n\n\ndef get_version():\n version = parsl.__version__\n work_tree = os.path.dirname(os.path.dirname(__file__))\n git_dir = os.path.join(work_tree, '.git')\n if os.path.exists(git_dir):\n env = {'GIT_WORK_TREE': work_tree, 'GIT_DIR': git_dir}\n try:\n cmd = shlex.split('git rev-parse --short HEAD')\n head = subprocess.check_output(cmd, env=env).strip().decode('utf-8')\n diff = subprocess.check_output(shlex.split('git diff HEAD'), env=env)\n status = 'dirty' if diff else 'clean'\n version = '{v}-{head}-{status}'.format(v=VERSION, head=head, status=status)\n except Exception:\n pass\n\n return version\n\n\ndef get_all_checkpoints(rundir=\"runinfo\"):\n \"\"\"Finds the checkpoints from all last runs.\n\n Note that checkpoints are incremental, and this helper will not find\n previous checkpoints from earlier than the most recent run. It probably\n should be made to do so.\n\n Kwargs:\n - rundir(str) : Path to the runinfo directory\n\n Returns:\n - a list suitable for the checkpointFiles parameter of DataFlowKernel\n constructor\n\n \"\"\"\n\n if(not os.path.isdir(rundir)):\n return []\n\n dirs = sorted(os.listdir(rundir))\n\n checkpoints = []\n\n for runid in dirs:\n\n checkpoint = os.path.abspath('{}/{}/checkpoint'.format(rundir, runid))\n\n if os.path.isdir(checkpoint):\n checkpoints.append(checkpoint)\n\n return checkpoints\n\n\ndef get_last_checkpoint(rundir=\"runinfo\"):\n \"\"\"Find the checkpoint from the last run, if one exists.\n\n Note that checkpoints are incremental, and this helper will not find\n previous checkpoints from earlier than the most recent run. It probably\n should be made to do so.\n\n Kwargs:\n - rundir(str) : Path to the runinfo directory\n\n Returns:\n - a list suitable for checkpointFiles parameter of DataFlowKernel\n constructor, with 0 or 1 elements\n\n \"\"\"\n if not os.path.isdir(rundir):\n return []\n\n dirs = sorted(os.listdir(rundir))\n\n if len(dirs) == 0:\n return []\n\n last_runid = dirs[-1]\n last_checkpoint = os.path.abspath('{}/{}/checkpoint'.format(rundir, last_runid))\n\n if(not(os.path.isdir(last_checkpoint))):\n return []\n\n return [last_checkpoint]\n\n\ndef timeout(seconds=None):\n def decorator(func, *args, **kwargs):\n @wraps(func)\n def wrapper(*args, **kwargs):\n t = threading.Thread(target=func, args=args, kwargs=kwargs, name=\"Timeout-Decorator\")\n t.start()\n result = t.join(seconds)\n if t.is_alive():\n raise RuntimeError('timed out in {}'.format(func))\n return result\n return wrapper\n return decorator\n\n\n@contextmanager\ndef wait_for_file(path, seconds=10):\n for i in range(0, int(seconds * 100)):\n time.sleep(seconds / 100.)\n if os.path.exists(path):\n break\n yield\n\n\n@contextmanager\ndef time_limited_open(path, mode, seconds=1):\n with wait_for_file(path, seconds):\n logger.debug(\"wait_for_file yielded\")\n f = open(path, mode)\n yield f\n f.close()\n\n\ndef wtime_to_minutes(time_string):\n ''' wtime_to_minutes\n\n Convert standard wallclock time string to minutes.\n\n Args:\n - Time_string in HH:MM:SS format\n\n Returns:\n (int) minutes\n\n '''\n hours, mins, seconds = time_string.split(':')\n total_mins = int(hours) * 60 + int(mins)\n if total_mins < 1:\n logger.warning(\"Time string '{}' parsed to {} minutes, less than 1\".format(time_string, total_mins))\n return total_mins\n\n\nclass RepresentationMixin(object):\n \"\"\"A mixin class for adding a __repr__ method.\n\n The __repr__ method will return a string equivalent to the code used to instantiate\n the child class, with any defaults included explicitly. The __max_width__ class variable\n controls the maximum width of the representation string. If this width is exceeded,\n the representation string will be split up, with one argument or keyword argument per line.\n\n Any arguments or keyword arguments in the constructor must be defined as attributes, or\n an AttributeError will be raised.\n\n Examples\n --------\n >>> from parsl.utils import RepresentationMixin\n >>> class Foo(RepresentationMixin):\n def __init__(self, first, second, third='three', fourth='fourth'):\n self.first = first\n self.second = second\n self.third = third\n self.fourth = fourth\n >>> bar = Foo(1, 'two', fourth='baz')\n >>> bar\n Foo(1, 'two', third='three', fourth='baz')\n \"\"\"\n __max_width__ = 80\n\n def __repr__(self):\n init = self.__init__\n\n # This test looks for a single layer of wrapping performed by\n # functools.update_wrapper, commonly used in decorators. This will\n # allow RepresentationMixin to see through a single such decorator\n # applied to the __init__ method of a class, and find the underlying\n # arguments. It will not see through multiple layers of such\n # decorators, or cope with other decorators which do not use\n # functools.update_wrapper.\n\n if hasattr(init, '__wrapped__'):\n init = init.__wrapped__\n\n argspec = inspect.getfullargspec(init)\n if len(argspec.args) > 1:\n defaults = dict(zip(reversed(argspec.args), reversed(argspec.defaults)))\n else:\n defaults = {}\n\n for arg in argspec.args[1:]:\n if not hasattr(self, arg):\n template = 'class {} uses {} in the constructor, but does not define it as an attribute'\n raise AttributeError(template.format(self.__class__.__name__, arg))\n\n args = [getattr(self, a) for a in argspec.args[1:-len(defaults)]]\n kwargs = {key: getattr(self, key) for key in defaults}\n\n def assemble_multiline(args, kwargs):\n def indent(text):\n lines = text.splitlines()\n if len(lines) <= 1:\n return text\n return \"\\n\".join(\" \" + l for l in lines).strip()\n args = [\"\\n {},\".format(indent(repr(a))) for a in args]\n kwargs = [\"\\n {}={}\".format(k, indent(repr(v)))\n for k, v in sorted(kwargs.items())]\n\n info = \"\".join(args) + \", \".join(kwargs)\n return self.__class__.__name__ + \"({}\\n)\".format(info)\n\n def assemble_line(args, kwargs):\n kwargs = ['{}={}'.format(k, repr(v)) for k, v in sorted(kwargs.items())]\n\n info = \", \".join([repr(a) for a in args] + kwargs)\n return self.__class__.__name__ + \"({})\".format(info)\n\n if len(assemble_line(args, kwargs)) <= self.__class__.__max_width__:\n return assemble_line(args, kwargs)\n else:\n return assemble_multiline(args, kwargs)\n", "path": "parsl/utils.py"}], "after_files": [{"content": "import inspect\nimport logging\nimport os\nimport shlex\nimport subprocess\nimport threading\nimport time\nfrom contextlib import contextmanager\nfrom functools import wraps\n\nimport parsl\nfrom parsl.version import VERSION\n\nlogger = logging.getLogger(__name__)\n\n\ndef get_version():\n version = parsl.__version__\n work_tree = os.path.dirname(os.path.dirname(__file__))\n git_dir = os.path.join(work_tree, '.git')\n if os.path.exists(git_dir):\n env = {'GIT_WORK_TREE': work_tree, 'GIT_DIR': git_dir}\n try:\n cmd = shlex.split('git rev-parse --short HEAD')\n head = subprocess.check_output(cmd, env=env).strip().decode('utf-8')\n diff = subprocess.check_output(shlex.split('git diff HEAD'), env=env)\n status = 'dirty' if diff else 'clean'\n version = '{v}-{head}-{status}'.format(v=VERSION, head=head, status=status)\n except Exception:\n pass\n\n return version\n\n\ndef get_all_checkpoints(rundir=\"runinfo\"):\n \"\"\"Finds the checkpoints from all last runs.\n\n Note that checkpoints are incremental, and this helper will not find\n previous checkpoints from earlier than the most recent run. It probably\n should be made to do so.\n\n Kwargs:\n - rundir(str) : Path to the runinfo directory\n\n Returns:\n - a list suitable for the checkpointFiles parameter of DataFlowKernel\n constructor\n\n \"\"\"\n\n if(not os.path.isdir(rundir)):\n return []\n\n dirs = sorted(os.listdir(rundir))\n\n checkpoints = []\n\n for runid in dirs:\n\n checkpoint = os.path.abspath('{}/{}/checkpoint'.format(rundir, runid))\n\n if os.path.isdir(checkpoint):\n checkpoints.append(checkpoint)\n\n return checkpoints\n\n\ndef get_last_checkpoint(rundir=\"runinfo\"):\n \"\"\"Find the checkpoint from the last run, if one exists.\n\n Note that checkpoints are incremental, and this helper will not find\n previous checkpoints from earlier than the most recent run. It probably\n should be made to do so.\n\n Kwargs:\n - rundir(str) : Path to the runinfo directory\n\n Returns:\n - a list suitable for checkpointFiles parameter of DataFlowKernel\n constructor, with 0 or 1 elements\n\n \"\"\"\n if not os.path.isdir(rundir):\n return []\n\n dirs = sorted(os.listdir(rundir))\n\n if len(dirs) == 0:\n return []\n\n last_runid = dirs[-1]\n last_checkpoint = os.path.abspath('{}/{}/checkpoint'.format(rundir, last_runid))\n\n if(not(os.path.isdir(last_checkpoint))):\n return []\n\n return [last_checkpoint]\n\n\ndef timeout(seconds=None):\n def decorator(func, *args, **kwargs):\n @wraps(func)\n def wrapper(*args, **kwargs):\n t = threading.Thread(target=func, args=args, kwargs=kwargs, name=\"Timeout-Decorator\")\n t.start()\n result = t.join(seconds)\n if t.is_alive():\n raise RuntimeError('timed out in {}'.format(func))\n return result\n return wrapper\n return decorator\n\n\n@contextmanager\ndef wait_for_file(path, seconds=10):\n for i in range(0, int(seconds * 100)):\n time.sleep(seconds / 100.)\n if os.path.exists(path):\n break\n yield\n\n\n@contextmanager\ndef time_limited_open(path, mode, seconds=1):\n with wait_for_file(path, seconds):\n logger.debug(\"wait_for_file yielded\")\n f = open(path, mode)\n yield f\n f.close()\n\n\ndef wtime_to_minutes(time_string):\n ''' wtime_to_minutes\n\n Convert standard wallclock time string to minutes.\n\n Args:\n - Time_string in HH:MM:SS format\n\n Returns:\n (int) minutes\n\n '''\n hours, mins, seconds = time_string.split(':')\n total_mins = int(hours) * 60 + int(mins)\n if total_mins < 1:\n logger.warning(\"Time string '{}' parsed to {} minutes, less than 1\".format(time_string, total_mins))\n return total_mins\n\n\nclass RepresentationMixin(object):\n \"\"\"A mixin class for adding a __repr__ method.\n\n The __repr__ method will return a string equivalent to the code used to instantiate\n the child class, with any defaults included explicitly. The __max_width__ class variable\n controls the maximum width of the representation string. If this width is exceeded,\n the representation string will be split up, with one argument or keyword argument per line.\n\n Any arguments or keyword arguments in the constructor must be defined as attributes, or\n an AttributeError will be raised.\n\n Examples\n --------\n >>> from parsl.utils import RepresentationMixin\n >>> class Foo(RepresentationMixin):\n def __init__(self, first, second, third='three', fourth='fourth'):\n self.first = first\n self.second = second\n self.third = third\n self.fourth = fourth\n >>> bar = Foo(1, 'two', fourth='baz')\n >>> bar\n Foo(1, 'two', third='three', fourth='baz')\n \"\"\"\n __max_width__ = 80\n\n def __repr__(self):\n init = self.__init__\n\n # This test looks for a single layer of wrapping performed by\n # functools.update_wrapper, commonly used in decorators. This will\n # allow RepresentationMixin to see through a single such decorator\n # applied to the __init__ method of a class, and find the underlying\n # arguments. It will not see through multiple layers of such\n # decorators, or cope with other decorators which do not use\n # functools.update_wrapper.\n\n if hasattr(init, '__wrapped__'):\n init = init.__wrapped__\n\n argspec = inspect.getfullargspec(init)\n if len(argspec.args) > 1 and argspec.defaults is not None:\n defaults = dict(zip(reversed(argspec.args), reversed(argspec.defaults)))\n else:\n defaults = {}\n\n for arg in argspec.args[1:]:\n if not hasattr(self, arg):\n template = 'class {} uses {} in the constructor, but does not define it as an attribute'\n raise AttributeError(template.format(self.__class__.__name__, arg))\n\n if len(defaults) != 0:\n args = [getattr(self, a) for a in argspec.args[1:-len(defaults)]]\n else:\n args = [getattr(self, a) for a in argspec.args[1:]]\n kwargs = {key: getattr(self, key) for key in defaults}\n\n def assemble_multiline(args, kwargs):\n def indent(text):\n lines = text.splitlines()\n if len(lines) <= 1:\n return text\n return \"\\n\".join(\" \" + l for l in lines).strip()\n args = [\"\\n {},\".format(indent(repr(a))) for a in args]\n kwargs = [\"\\n {}={}\".format(k, indent(repr(v)))\n for k, v in sorted(kwargs.items())]\n\n info = \"\".join(args) + \", \".join(kwargs)\n return self.__class__.__name__ + \"({}\\n)\".format(info)\n\n def assemble_line(args, kwargs):\n kwargs = ['{}={}'.format(k, repr(v)) for k, v in sorted(kwargs.items())]\n\n info = \", \".join([repr(a) for a in args] + kwargs)\n return self.__class__.__name__ + \"({})\".format(info)\n\n if len(assemble_line(args, kwargs)) <= self.__class__.__max_width__:\n return assemble_line(args, kwargs)\n else:\n return assemble_multiline(args, kwargs)\n", "path": "parsl/utils.py"}]}
| 2,709 | 278 |
gh_patches_debug_36694
|
rasdani/github-patches
|
git_diff
|
mabel-dev__opteryx-1443
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
🪲stats for distinct incorrect
### Thank you for taking the time to report a problem with Opteryx.
_To help us to respond to your request we ask that you try to provide the below detail about the bug._
**Describe the bug** _A clear and specific description of what the bug is. What the error, incorrect or unexpected behaviour was._
**Expected behaviour** _A clear and concise description of what you expected to happen._
**Sample Code/Statement** _If you can, please submit the SQL statement or Python code snippet, or a representative example using the sample datasets._
~~~sql
~~~
**Additional context** _Add any other context about the problem here, for example what you have done to try to diagnose or workaround the problem._
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `opteryx/operators/distinct_node.py`
Content:
```
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13 """
14 Distinct Node
15
16 This is a SQL Query Execution Plan Node.
17
18 This Node eliminates duplicate records.
19 """
20 import time
21 from typing import Generator
22
23 import pyarrow
24 import pyarrow.compute
25
26 from opteryx.models import QueryProperties
27 from opteryx.operators import BasePlanNode
28
29
30 class DistinctNode(BasePlanNode):
31 def __init__(self, properties: QueryProperties, **config):
32 super().__init__(properties=properties)
33 self._distinct_on = config.get("on")
34 if self._distinct_on:
35 self._distinct_on = [col.schema_column.identity for col in self._distinct_on]
36
37 @property
38 def config(self): # pragma: no cover
39 return ""
40
41 @property
42 def greedy(self): # pragma: no cover
43 return True
44
45 @property
46 def name(self): # pragma: no cover
47 return "Distinction"
48
49 def execute(self) -> Generator[pyarrow.Table, None, None]:
50
51 from opteryx.compiled.functions import HashSet
52 from opteryx.compiled.functions import distinct
53
54 # We create a HashSet outside the distinct call, this allows us to pass
55 # the hash to each run of the distinct which means we don't need to concat
56 # all of the tables together to return a result.
57 # The Cython distinct is about 8x faster on a 10 million row dataset with
58 # approx 85k distinct entries (4.8sec vs 0.8sec) and faster on a 177 record
59 # dataset with 7 distinct entries.
60 # Being able to run morsel-by-morsel means if we have a LIMIT clause, we can
61 # limit processing
62 hash_set = HashSet()
63
64 morsels = self._producers[0] # type:ignore
65
66 start = time.monotonic_ns()
67 for morsel in morsels.execute():
68 deduped, hash_set = distinct(
69 morsel, columns=self._distinct_on, seen_hashes=hash_set, return_seen_hashes=True
70 )
71 if deduped.num_rows > 0:
72 self.statistics.time_distincting += time.monotonic_ns() - start
73 yield deduped
74 start = time.monotonic_ns()
75
```
Path: `opteryx/__version__.py`
Content:
```
1 __build__ = 296
2
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """
16 Store the version here so:
17 1) we don't load dependencies by storing it in __init__.py
18 2) we can import it in setup.py for the same reason
19 """
20 from enum import Enum # isort: skip
21
22
23 class VersionStatus(Enum):
24 ALPHA = "alpha"
25 BETA = "beta"
26 RELEASE = "release"
27
28
29 _major = 0
30 _minor = 14
31 _revision = 0
32 _status = VersionStatus.ALPHA
33
34 __author__ = "@joocer"
35 __version__ = f"{_major}.{_minor}.{_revision}" + (
36 f"-{_status.value}.{__build__}" if _status != VersionStatus.RELEASE else ""
37 )
38
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/opteryx/__version__.py b/opteryx/__version__.py
--- a/opteryx/__version__.py
+++ b/opteryx/__version__.py
@@ -1,4 +1,4 @@
-__build__ = 296
+__build__ = 298
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
diff --git a/opteryx/operators/distinct_node.py b/opteryx/operators/distinct_node.py
--- a/opteryx/operators/distinct_node.py
+++ b/opteryx/operators/distinct_node.py
@@ -29,10 +29,13 @@
class DistinctNode(BasePlanNode):
def __init__(self, properties: QueryProperties, **config):
+ from opteryx.compiled.functions import HashSet
+
super().__init__(properties=properties)
self._distinct_on = config.get("on")
if self._distinct_on:
self._distinct_on = [col.schema_column.identity for col in self._distinct_on]
+ self.hash_set = HashSet()
@property
def config(self): # pragma: no cover
@@ -48,7 +51,6 @@
def execute(self) -> Generator[pyarrow.Table, None, None]:
- from opteryx.compiled.functions import HashSet
from opteryx.compiled.functions import distinct
# We create a HashSet outside the distinct call, this allows us to pass
@@ -59,16 +61,17 @@
# dataset with 7 distinct entries.
# Being able to run morsel-by-morsel means if we have a LIMIT clause, we can
# limit processing
- hash_set = HashSet()
morsels = self._producers[0] # type:ignore
- start = time.monotonic_ns()
for morsel in morsels.execute():
- deduped, hash_set = distinct(
- morsel, columns=self._distinct_on, seen_hashes=hash_set, return_seen_hashes=True
+ start = time.monotonic_ns()
+ deduped, self.hash_set = distinct(
+ morsel,
+ columns=self._distinct_on,
+ seen_hashes=self.hash_set,
+ return_seen_hashes=True,
)
+ self.statistics.time_distincting += time.monotonic_ns() - start
if deduped.num_rows > 0:
- self.statistics.time_distincting += time.monotonic_ns() - start
yield deduped
- start = time.monotonic_ns()
|
{"golden_diff": "diff --git a/opteryx/__version__.py b/opteryx/__version__.py\n--- a/opteryx/__version__.py\n+++ b/opteryx/__version__.py\n@@ -1,4 +1,4 @@\n-__build__ = 296\n+__build__ = 298\n \n # Licensed under the Apache License, Version 2.0 (the \"License\");\n # you may not use this file except in compliance with the License.\ndiff --git a/opteryx/operators/distinct_node.py b/opteryx/operators/distinct_node.py\n--- a/opteryx/operators/distinct_node.py\n+++ b/opteryx/operators/distinct_node.py\n@@ -29,10 +29,13 @@\n \n class DistinctNode(BasePlanNode):\n def __init__(self, properties: QueryProperties, **config):\n+ from opteryx.compiled.functions import HashSet\n+\n super().__init__(properties=properties)\n self._distinct_on = config.get(\"on\")\n if self._distinct_on:\n self._distinct_on = [col.schema_column.identity for col in self._distinct_on]\n+ self.hash_set = HashSet()\n \n @property\n def config(self): # pragma: no cover\n@@ -48,7 +51,6 @@\n \n def execute(self) -> Generator[pyarrow.Table, None, None]:\n \n- from opteryx.compiled.functions import HashSet\n from opteryx.compiled.functions import distinct\n \n # We create a HashSet outside the distinct call, this allows us to pass\n@@ -59,16 +61,17 @@\n # dataset with 7 distinct entries.\n # Being able to run morsel-by-morsel means if we have a LIMIT clause, we can\n # limit processing\n- hash_set = HashSet()\n \n morsels = self._producers[0] # type:ignore\n \n- start = time.monotonic_ns()\n for morsel in morsels.execute():\n- deduped, hash_set = distinct(\n- morsel, columns=self._distinct_on, seen_hashes=hash_set, return_seen_hashes=True\n+ start = time.monotonic_ns()\n+ deduped, self.hash_set = distinct(\n+ morsel,\n+ columns=self._distinct_on,\n+ seen_hashes=self.hash_set,\n+ return_seen_hashes=True,\n )\n+ self.statistics.time_distincting += time.monotonic_ns() - start\n if deduped.num_rows > 0:\n- self.statistics.time_distincting += time.monotonic_ns() - start\n yield deduped\n- start = time.monotonic_ns()\n", "issue": "\ud83e\udeb2stats for distinct incorrect\n### Thank you for taking the time to report a problem with Opteryx.\r\n_To help us to respond to your request we ask that you try to provide the below detail about the bug._\r\n\r\n**Describe the bug** _A clear and specific description of what the bug is. What the error, incorrect or unexpected behaviour was._\r\n\r\n\r\n**Expected behaviour** _A clear and concise description of what you expected to happen._\r\n\r\n\r\n**Sample Code/Statement** _If you can, please submit the SQL statement or Python code snippet, or a representative example using the sample datasets._\r\n\r\n~~~sql\r\n\r\n~~~\r\n\r\n**Additional context** _Add any other context about the problem here, for example what you have done to try to diagnose or workaround the problem._\r\n\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nDistinct Node\n\nThis is a SQL Query Execution Plan Node.\n\nThis Node eliminates duplicate records.\n\"\"\"\nimport time\nfrom typing import Generator\n\nimport pyarrow\nimport pyarrow.compute\n\nfrom opteryx.models import QueryProperties\nfrom opteryx.operators import BasePlanNode\n\n\nclass DistinctNode(BasePlanNode):\n def __init__(self, properties: QueryProperties, **config):\n super().__init__(properties=properties)\n self._distinct_on = config.get(\"on\")\n if self._distinct_on:\n self._distinct_on = [col.schema_column.identity for col in self._distinct_on]\n\n @property\n def config(self): # pragma: no cover\n return \"\"\n\n @property\n def greedy(self): # pragma: no cover\n return True\n\n @property\n def name(self): # pragma: no cover\n return \"Distinction\"\n\n def execute(self) -> Generator[pyarrow.Table, None, None]:\n\n from opteryx.compiled.functions import HashSet\n from opteryx.compiled.functions import distinct\n\n # We create a HashSet outside the distinct call, this allows us to pass\n # the hash to each run of the distinct which means we don't need to concat\n # all of the tables together to return a result.\n # The Cython distinct is about 8x faster on a 10 million row dataset with\n # approx 85k distinct entries (4.8sec vs 0.8sec) and faster on a 177 record\n # dataset with 7 distinct entries.\n # Being able to run morsel-by-morsel means if we have a LIMIT clause, we can\n # limit processing\n hash_set = HashSet()\n\n morsels = self._producers[0] # type:ignore\n\n start = time.monotonic_ns()\n for morsel in morsels.execute():\n deduped, hash_set = distinct(\n morsel, columns=self._distinct_on, seen_hashes=hash_set, return_seen_hashes=True\n )\n if deduped.num_rows > 0:\n self.statistics.time_distincting += time.monotonic_ns() - start\n yield deduped\n start = time.monotonic_ns()\n", "path": "opteryx/operators/distinct_node.py"}, {"content": "__build__ = 296\n\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nStore the version here so:\n1) we don't load dependencies by storing it in __init__.py\n2) we can import it in setup.py for the same reason\n\"\"\"\nfrom enum import Enum # isort: skip\n\n\nclass VersionStatus(Enum):\n ALPHA = \"alpha\"\n BETA = \"beta\"\n RELEASE = \"release\"\n\n\n_major = 0\n_minor = 14\n_revision = 0\n_status = VersionStatus.ALPHA\n\n__author__ = \"@joocer\"\n__version__ = f\"{_major}.{_minor}.{_revision}\" + (\n f\"-{_status.value}.{__build__}\" if _status != VersionStatus.RELEASE else \"\"\n)\n", "path": "opteryx/__version__.py"}], "after_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nDistinct Node\n\nThis is a SQL Query Execution Plan Node.\n\nThis Node eliminates duplicate records.\n\"\"\"\nimport time\nfrom typing import Generator\n\nimport pyarrow\nimport pyarrow.compute\n\nfrom opteryx.models import QueryProperties\nfrom opteryx.operators import BasePlanNode\n\n\nclass DistinctNode(BasePlanNode):\n def __init__(self, properties: QueryProperties, **config):\n from opteryx.compiled.functions import HashSet\n\n super().__init__(properties=properties)\n self._distinct_on = config.get(\"on\")\n if self._distinct_on:\n self._distinct_on = [col.schema_column.identity for col in self._distinct_on]\n self.hash_set = HashSet()\n\n @property\n def config(self): # pragma: no cover\n return \"\"\n\n @property\n def greedy(self): # pragma: no cover\n return True\n\n @property\n def name(self): # pragma: no cover\n return \"Distinction\"\n\n def execute(self) -> Generator[pyarrow.Table, None, None]:\n\n from opteryx.compiled.functions import distinct\n\n # We create a HashSet outside the distinct call, this allows us to pass\n # the hash to each run of the distinct which means we don't need to concat\n # all of the tables together to return a result.\n # The Cython distinct is about 8x faster on a 10 million row dataset with\n # approx 85k distinct entries (4.8sec vs 0.8sec) and faster on a 177 record\n # dataset with 7 distinct entries.\n # Being able to run morsel-by-morsel means if we have a LIMIT clause, we can\n # limit processing\n\n morsels = self._producers[0] # type:ignore\n\n for morsel in morsels.execute():\n start = time.monotonic_ns()\n deduped, self.hash_set = distinct(\n morsel,\n columns=self._distinct_on,\n seen_hashes=self.hash_set,\n return_seen_hashes=True,\n )\n self.statistics.time_distincting += time.monotonic_ns() - start\n if deduped.num_rows > 0:\n yield deduped\n", "path": "opteryx/operators/distinct_node.py"}, {"content": "__build__ = 298\n\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nStore the version here so:\n1) we don't load dependencies by storing it in __init__.py\n2) we can import it in setup.py for the same reason\n\"\"\"\nfrom enum import Enum # isort: skip\n\n\nclass VersionStatus(Enum):\n ALPHA = \"alpha\"\n BETA = \"beta\"\n RELEASE = \"release\"\n\n\n_major = 0\n_minor = 14\n_revision = 0\n_status = VersionStatus.ALPHA\n\n__author__ = \"@joocer\"\n__version__ = f\"{_major}.{_minor}.{_revision}\" + (\n f\"-{_status.value}.{__build__}\" if _status != VersionStatus.RELEASE else \"\"\n)\n", "path": "opteryx/__version__.py"}]}
| 1,555 | 586 |
gh_patches_debug_15665
|
rasdani/github-patches
|
git_diff
|
meltano__meltano-6562
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
bug: No way to dismiss image scan alerts
### Meltano Version
NA
### Python Version
NA
### Bug scope
Other
### Operating System
NA
### Description
Currently we use `.github/actions/docker-build-scan-push/check_sarif.py` to analyze the SARIF report created from running `grype` to scan our Docker images. It parses the SARIF JSON file itself to check if there are any issues detected with a severity above some threshold in the range [0.0, 10.0].
Before running this check, we upload the SARIF results to GitHub, which stores them for our repository using the "code scanning" feature. From there, we can review them, dismiss them, and create issues to address them. [An example can be found here](https://github.com/meltano/meltano/security/code-scanning?query=ref%3Arefs%2Fpull%2F6410%2Fmerge+tool%3AGrype).
Our `check_sarif.py` script does not consider whether we've dismissed the issue via GitHub's "code scanning" feature, so we have no way to deem a detected issue acceptable, and have the Docker publish workflow pass. To fix this we should replace `check_sarif.py` with some steps that use [the GitHub code scanning API](https://docs.github.com/en/rest/code-scanning#list-code-scanning-alerts-for-a-repository) to check if there are any issues above some set severity level *that haven't been dismissed*.
### Code
_No response_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `.github/actions/docker-build-scan-push/check_sarif.py`
Content:
```
1 """Check if the provided SARIF file has any violations at or above some severity level."""
2
3 from __future__ import annotations
4
5 import argparse
6 import json
7
8 DEFAULT_SEVERITY_CUTOFF = 4.0
9
10 parser = argparse.ArgumentParser()
11 parser.add_argument(
12 "sarif_path",
13 help="The path to the SARIF file to be checked.",
14 )
15 parser.add_argument(
16 "--severity-cutoff",
17 help="Violations with a severity >= this value result in an exit code of 1"
18 + " - must be a number in the range [0.0, 10.0].",
19 type=float,
20 default=DEFAULT_SEVERITY_CUTOFF,
21 )
22 args = parser.parse_args()
23
24 with open(args.sarif_path) as sarif_file:
25 sarif_data = json.load(sarif_file)
26
27 first_run = sarif_data["runs"][0]
28 triggered_rules = first_run["tool"]["driver"]["rules"]
29
30 exit( # noqa: WPS421
31 any(
32 float(rule["properties"]["security-severity"]) >= args.severity_cutoff
33 for rule in triggered_rules
34 )
35 )
36
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/.github/actions/docker-build-scan-push/check_sarif.py b/.github/actions/docker-build-scan-push/check_sarif.py
deleted file mode 100644
--- a/.github/actions/docker-build-scan-push/check_sarif.py
+++ /dev/null
@@ -1,35 +0,0 @@
-"""Check if the provided SARIF file has any violations at or above some severity level."""
-
-from __future__ import annotations
-
-import argparse
-import json
-
-DEFAULT_SEVERITY_CUTOFF = 4.0
-
-parser = argparse.ArgumentParser()
-parser.add_argument(
- "sarif_path",
- help="The path to the SARIF file to be checked.",
-)
-parser.add_argument(
- "--severity-cutoff",
- help="Violations with a severity >= this value result in an exit code of 1"
- + " - must be a number in the range [0.0, 10.0].",
- type=float,
- default=DEFAULT_SEVERITY_CUTOFF,
-)
-args = parser.parse_args()
-
-with open(args.sarif_path) as sarif_file:
- sarif_data = json.load(sarif_file)
-
-first_run = sarif_data["runs"][0]
-triggered_rules = first_run["tool"]["driver"]["rules"]
-
-exit( # noqa: WPS421
- any(
- float(rule["properties"]["security-severity"]) >= args.severity_cutoff
- for rule in triggered_rules
- )
-)
|
{"golden_diff": "diff --git a/.github/actions/docker-build-scan-push/check_sarif.py b/.github/actions/docker-build-scan-push/check_sarif.py\ndeleted file mode 100644\n--- a/.github/actions/docker-build-scan-push/check_sarif.py\n+++ /dev/null\n@@ -1,35 +0,0 @@\n-\"\"\"Check if the provided SARIF file has any violations at or above some severity level.\"\"\"\n-\n-from __future__ import annotations\n-\n-import argparse\n-import json\n-\n-DEFAULT_SEVERITY_CUTOFF = 4.0\n-\n-parser = argparse.ArgumentParser()\n-parser.add_argument(\n- \"sarif_path\",\n- help=\"The path to the SARIF file to be checked.\",\n-)\n-parser.add_argument(\n- \"--severity-cutoff\",\n- help=\"Violations with a severity >= this value result in an exit code of 1\"\n- + \" - must be a number in the range [0.0, 10.0].\",\n- type=float,\n- default=DEFAULT_SEVERITY_CUTOFF,\n-)\n-args = parser.parse_args()\n-\n-with open(args.sarif_path) as sarif_file:\n- sarif_data = json.load(sarif_file)\n-\n-first_run = sarif_data[\"runs\"][0]\n-triggered_rules = first_run[\"tool\"][\"driver\"][\"rules\"]\n-\n-exit( # noqa: WPS421\n- any(\n- float(rule[\"properties\"][\"security-severity\"]) >= args.severity_cutoff\n- for rule in triggered_rules\n- )\n-)\n", "issue": "bug: No way to dismiss image scan alerts\n### Meltano Version\n\nNA\n\n### Python Version\n\nNA\n\n### Bug scope\n\nOther\n\n### Operating System\n\nNA\n\n### Description\n\nCurrently we use `.github/actions/docker-build-scan-push/check_sarif.py` to analyze the SARIF report created from running `grype` to scan our Docker images. It parses the SARIF JSON file itself to check if there are any issues detected with a severity above some threshold in the range [0.0, 10.0].\r\n\r\nBefore running this check, we upload the SARIF results to GitHub, which stores them for our repository using the \"code scanning\" feature. From there, we can review them, dismiss them, and create issues to address them. [An example can be found here](https://github.com/meltano/meltano/security/code-scanning?query=ref%3Arefs%2Fpull%2F6410%2Fmerge+tool%3AGrype).\r\n\r\nOur `check_sarif.py` script does not consider whether we've dismissed the issue via GitHub's \"code scanning\" feature, so we have no way to deem a detected issue acceptable, and have the Docker publish workflow pass. To fix this we should replace `check_sarif.py` with some steps that use [the GitHub code scanning API](https://docs.github.com/en/rest/code-scanning#list-code-scanning-alerts-for-a-repository) to check if there are any issues above some set severity level *that haven't been dismissed*.\n\n### Code\n\n_No response_\n", "before_files": [{"content": "\"\"\"Check if the provided SARIF file has any violations at or above some severity level.\"\"\"\n\nfrom __future__ import annotations\n\nimport argparse\nimport json\n\nDEFAULT_SEVERITY_CUTOFF = 4.0\n\nparser = argparse.ArgumentParser()\nparser.add_argument(\n \"sarif_path\",\n help=\"The path to the SARIF file to be checked.\",\n)\nparser.add_argument(\n \"--severity-cutoff\",\n help=\"Violations with a severity >= this value result in an exit code of 1\"\n + \" - must be a number in the range [0.0, 10.0].\",\n type=float,\n default=DEFAULT_SEVERITY_CUTOFF,\n)\nargs = parser.parse_args()\n\nwith open(args.sarif_path) as sarif_file:\n sarif_data = json.load(sarif_file)\n\nfirst_run = sarif_data[\"runs\"][0]\ntriggered_rules = first_run[\"tool\"][\"driver\"][\"rules\"]\n\nexit( # noqa: WPS421\n any(\n float(rule[\"properties\"][\"security-severity\"]) >= args.severity_cutoff\n for rule in triggered_rules\n )\n)\n", "path": ".github/actions/docker-build-scan-push/check_sarif.py"}], "after_files": [{"content": null, "path": ".github/actions/docker-build-scan-push/check_sarif.py"}]}
| 906 | 340 |
gh_patches_debug_38163
|
rasdani/github-patches
|
git_diff
|
google__jax-736
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
namedtuple support in arguments to transformed functions
It would be great if `xla.abstractify` would also accept namedtuples. Loop state's can consist of quite a lot of values and organizing them in a namedtuple rather than a tuple would make things nicer.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `jax/tree_util.py`
Content:
```
1 # Copyright 2018 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Utilities for working with tree-like container data structures.
16
17 The code here is independent of JAX. The only dependence is on jax.util, which
18 itself has no JAX-specific code.
19
20 This module provides a small set of utility functions for working with tree-like
21 data structures, such as nested tuples, lists, and dicts. We call these
22 structures pytrees. They are trees in that they are defined recursively (any
23 non-pytree is a pytree, i.e. a leaf, and any pytree of pytrees is a pytree) and
24 can be operated on recursively (object identity equivalence is not preserved by
25 mapping operations, and the structures cannot contain reference cycles).
26
27 The set of Python types that are considered pytree nodes (e.g. that can be
28 mapped over, rather than treated as leaves) is extensible. There is a single
29 module-level registry of types, and class hierarchy is ignored. By registering a
30 new pytree node type, that type in effect becomes transparent to the utility
31 functions in this file.
32 """
33
34 from __future__ import absolute_import
35 from __future__ import division
36 from __future__ import print_function
37
38 from collections import namedtuple
39 import itertools as it
40 from six.moves import reduce
41
42 from .util import unzip2, concatenate, partial, safe_map
43
44 map = safe_map
45
46
47 def tree_map(f, tree):
48 """Map a function over a pytree to produce a new pytree.
49
50 Args:
51 f: function to be applied at each leaf.
52 tree: a pytree to be mapped over.
53
54 Returns:
55 A new pytree with the same structure as `tree` but with the value at each
56 leaf given by `f(x)` where `x` is the value at the corresponding leaf in
57 `tree`.
58 """
59 node_type = node_types.get(type(tree))
60 if node_type:
61 children, node_spec = node_type.to_iterable(tree)
62 new_children = [tree_map(f, child) for child in children]
63 return node_type.from_iterable(node_spec, new_children)
64 else:
65 return f(tree)
66
67 def tree_multimap(f, tree, *rest):
68 """Map a multi-input function over pytree args to produce a new pytree.
69
70 Args:
71 f: function that takes `1 + len(rest)` arguments, to be applied at the
72 corresponding leaves of the pytrees.
73 tree: a pytree to be mapped over, with each leaf providing the first
74 positional argument to `f`.
75 *rest: a tuple of pytrees, each with the same structure as `tree`.
76
77 Returns:
78 A new pytree with the same structure as `tree` but with the value at each
79 leaf given by `f(x, *xs)` where `x` is the value at the corresponding leaf
80 in `tree` and `xs` is the tuple of values at corresponding leaves in `rest`.
81 """
82 node_type = node_types.get(type(tree))
83 if node_type:
84 children, aux_data = node_type.to_iterable(tree)
85 all_children = [children]
86 for other_tree in rest:
87 other_node_type = node_types.get(type(other_tree))
88 if node_type != other_node_type:
89 raise TypeError('Mismatch: {} != {}'.format(other_node_type, node_type))
90 other_children, other_aux_data = node_type.to_iterable(other_tree)
91 if other_aux_data != aux_data:
92 raise TypeError('Mismatch: {} != {}'.format(other_aux_data, aux_data))
93 all_children.append(other_children)
94
95 new_children = [tree_multimap(f, *xs) for xs in zip(*all_children)]
96 return node_type.from_iterable(aux_data, new_children)
97 else:
98 return f(tree, *rest)
99
100
101 def tree_reduce(f, tree):
102 flat, _ = tree_flatten(tree)
103 return reduce(f, flat)
104
105
106 def tree_all(tree):
107 flat, _ = tree_flatten(tree)
108 return all(flat)
109
110
111 def process_pytree(process_node, tree):
112 return walk_pytree(process_node, lambda x: x, tree)
113
114
115 def walk_pytree(f_node, f_leaf, tree):
116 node_type = node_types.get(type(tree))
117 if node_type:
118 children, node_spec = node_type.to_iterable(tree)
119 proc_children, child_specs = unzip2([walk_pytree(f_node, f_leaf, child)
120 for child in children])
121 tree_def = PyTreeDef(node_type, node_spec, child_specs)
122 return f_node(proc_children), tree_def
123 else:
124 return f_leaf(tree), leaf
125
126
127 def build_tree(treedef, xs):
128 if treedef is leaf:
129 return xs
130 else:
131 # We use 'iter' for clearer error messages
132 children = map(build_tree, iter(treedef.children), iter(xs))
133 return treedef.node_type.from_iterable(treedef.node_data, children)
134
135
136 tree_flatten = partial(walk_pytree, concatenate, lambda x: [x])
137
138 def tree_unflatten(treedef, xs):
139 return _tree_unflatten(iter(xs), treedef)
140
141 def _tree_unflatten(xs, treedef):
142 if treedef is leaf:
143 return next(xs)
144 else:
145 children = map(partial(_tree_unflatten, xs), treedef.children)
146 return treedef.node_type.from_iterable(treedef.node_data, children)
147
148
149 def tree_transpose(outer_treedef, inner_treedef, pytree_to_transpose):
150 flat, treedef = tree_flatten(pytree_to_transpose)
151 expected_treedef = _nested_treedef(inner_treedef, outer_treedef)
152 if treedef != expected_treedef:
153 raise TypeError("Mismatch\n{}\n != \n{}".format(treedef, expected_treedef))
154
155 inner_size = _num_leaves(inner_treedef)
156 outer_size = _num_leaves(outer_treedef)
157 flat = iter(flat)
158 lol = [[next(flat) for _ in range(inner_size)] for __ in range(outer_size)]
159 transposed_lol = zip(*lol)
160 subtrees = map(partial(tree_unflatten, outer_treedef), transposed_lol)
161 return tree_unflatten(inner_treedef, subtrees)
162
163 def _num_leaves(treedef):
164 return 1 if treedef is leaf else sum(map(_num_leaves, treedef.children))
165
166 def _nested_treedef(inner, outer):
167 # just used in tree_transpose error checking
168 if outer is leaf:
169 return inner
170 else:
171 children = map(partial(_nested_treedef, inner), outer.children)
172 return PyTreeDef(outer.node_type, outer.node_data, tuple(children))
173
174
175 def tree_structure(tree):
176 _, spec = process_pytree(lambda _: None, tree)
177 return spec
178
179
180 class PyTreeDef(object):
181 def __init__(self, node_type, node_data, children):
182 self.node_type = node_type
183 self.node_data = node_data
184 self.children = children
185
186 def __repr__(self):
187 if self.node_data is None:
188 data_repr = ""
189 else:
190 data_repr = "[{}]".format(self.node_data)
191
192 return "PyTree({}{}, [{}])".format(self.node_type.name, data_repr,
193 ','.join(map(repr, self.children)))
194
195 def __hash__(self):
196 return hash((self.node_type, self.node_data, tuple(self.children)))
197
198 def __eq__(self, other):
199 if other is leaf:
200 return False
201 else:
202 return (self.node_type == other.node_type and
203 self.node_data == other.node_data and
204 self.children == other.children)
205
206 def __ne__(self, other):
207 return not self == other
208
209
210 class PyLeaf(object):
211 def __repr__(self):
212 return '*'
213
214 leaf = PyLeaf()
215
216 def dict_to_iterable(xs):
217 keys = tuple(sorted(xs.keys()))
218 return tuple(map(xs.get, keys)), keys
219
220 class NodeType(object):
221 def __init__(self, name, to_iterable, from_iterable):
222 self.name = name
223 self.to_iterable = to_iterable
224 self.from_iterable = from_iterable
225
226 def __repr__(self):
227 return self.name
228
229 node_types = {}
230
231 def register_pytree_node(py_type, to_iterable, from_iterable):
232 assert py_type not in node_types
233 node_types[py_type] = NodeType(str(py_type), to_iterable, from_iterable)
234
235 register_pytree_node(tuple, lambda xs: (xs, None), lambda _, xs: tuple(xs))
236 register_pytree_node(list, lambda xs: (tuple(xs), None), lambda _, xs: list(xs))
237 register_pytree_node(dict, dict_to_iterable, lambda keys, xs: dict(zip(keys, xs)))
238 register_pytree_node(type(None), lambda z: ((), None), lambda _, xs: None)
239
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/jax/tree_util.py b/jax/tree_util.py
--- a/jax/tree_util.py
+++ b/jax/tree_util.py
@@ -56,7 +56,7 @@
leaf given by `f(x)` where `x` is the value at the corresponding leaf in
`tree`.
"""
- node_type = node_types.get(type(tree))
+ node_type = _get_node_type(tree)
if node_type:
children, node_spec = node_type.to_iterable(tree)
new_children = [tree_map(f, child) for child in children]
@@ -79,12 +79,12 @@
leaf given by `f(x, *xs)` where `x` is the value at the corresponding leaf
in `tree` and `xs` is the tuple of values at corresponding leaves in `rest`.
"""
- node_type = node_types.get(type(tree))
+ node_type = _get_node_type(tree)
if node_type:
children, aux_data = node_type.to_iterable(tree)
all_children = [children]
for other_tree in rest:
- other_node_type = node_types.get(type(other_tree))
+ other_node_type = _get_node_type(other_tree)
if node_type != other_node_type:
raise TypeError('Mismatch: {} != {}'.format(other_node_type, node_type))
other_children, other_aux_data = node_type.to_iterable(other_tree)
@@ -113,7 +113,7 @@
def walk_pytree(f_node, f_leaf, tree):
- node_type = node_types.get(type(tree))
+ node_type = _get_node_type(tree)
if node_type:
children, node_spec = node_type.to_iterable(tree)
proc_children, child_specs = unzip2([walk_pytree(f_node, f_leaf, child)
@@ -236,3 +236,20 @@
register_pytree_node(list, lambda xs: (tuple(xs), None), lambda _, xs: list(xs))
register_pytree_node(dict, dict_to_iterable, lambda keys, xs: dict(zip(keys, xs)))
register_pytree_node(type(None), lambda z: ((), None), lambda _, xs: None)
+
+
+# To handle namedtuples, we can't just use the standard table of node_types
+# because every namedtuple creates its own type and thus would require its own
+# entry in the table. Instead we use a heuristic check on the type itself to
+# decide whether it's a namedtuple type, and if so treat it as a pytree node.
+def _get_node_type(maybe_tree):
+ t = type(maybe_tree)
+ return node_types.get(t) or _namedtuple_node(t)
+
+def _namedtuple_node(t):
+ if t.__bases__ == (tuple,) and hasattr(t, '_fields'):
+ return NamedtupleNode
+
+NamedtupleNode = NodeType('namedtuple',
+ lambda xs: (tuple(xs), type(xs)),
+ lambda t, xs: t(*xs))
|
{"golden_diff": "diff --git a/jax/tree_util.py b/jax/tree_util.py\n--- a/jax/tree_util.py\n+++ b/jax/tree_util.py\n@@ -56,7 +56,7 @@\n leaf given by `f(x)` where `x` is the value at the corresponding leaf in\n `tree`.\n \"\"\"\n- node_type = node_types.get(type(tree))\n+ node_type = _get_node_type(tree)\n if node_type:\n children, node_spec = node_type.to_iterable(tree)\n new_children = [tree_map(f, child) for child in children]\n@@ -79,12 +79,12 @@\n leaf given by `f(x, *xs)` where `x` is the value at the corresponding leaf\n in `tree` and `xs` is the tuple of values at corresponding leaves in `rest`.\n \"\"\"\n- node_type = node_types.get(type(tree))\n+ node_type = _get_node_type(tree)\n if node_type:\n children, aux_data = node_type.to_iterable(tree)\n all_children = [children]\n for other_tree in rest:\n- other_node_type = node_types.get(type(other_tree))\n+ other_node_type = _get_node_type(other_tree)\n if node_type != other_node_type:\n raise TypeError('Mismatch: {} != {}'.format(other_node_type, node_type))\n other_children, other_aux_data = node_type.to_iterable(other_tree)\n@@ -113,7 +113,7 @@\n \n \n def walk_pytree(f_node, f_leaf, tree):\n- node_type = node_types.get(type(tree))\n+ node_type = _get_node_type(tree)\n if node_type:\n children, node_spec = node_type.to_iterable(tree)\n proc_children, child_specs = unzip2([walk_pytree(f_node, f_leaf, child)\n@@ -236,3 +236,20 @@\n register_pytree_node(list, lambda xs: (tuple(xs), None), lambda _, xs: list(xs))\n register_pytree_node(dict, dict_to_iterable, lambda keys, xs: dict(zip(keys, xs)))\n register_pytree_node(type(None), lambda z: ((), None), lambda _, xs: None)\n+\n+\n+# To handle namedtuples, we can't just use the standard table of node_types\n+# because every namedtuple creates its own type and thus would require its own\n+# entry in the table. Instead we use a heuristic check on the type itself to\n+# decide whether it's a namedtuple type, and if so treat it as a pytree node.\n+def _get_node_type(maybe_tree):\n+ t = type(maybe_tree)\n+ return node_types.get(t) or _namedtuple_node(t)\n+\n+def _namedtuple_node(t):\n+ if t.__bases__ == (tuple,) and hasattr(t, '_fields'):\n+ return NamedtupleNode\n+\n+NamedtupleNode = NodeType('namedtuple',\n+ lambda xs: (tuple(xs), type(xs)),\n+ lambda t, xs: t(*xs))\n", "issue": "namedtuple support in arguments to transformed functions\nIt would be great if `xla.abstractify` would also accept namedtuples. Loop state's can consist of quite a lot of values and organizing them in a namedtuple rather than a tuple would make things nicer.\n", "before_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Utilities for working with tree-like container data structures.\n\nThe code here is independent of JAX. The only dependence is on jax.util, which\nitself has no JAX-specific code.\n\nThis module provides a small set of utility functions for working with tree-like\ndata structures, such as nested tuples, lists, and dicts. We call these\nstructures pytrees. They are trees in that they are defined recursively (any\nnon-pytree is a pytree, i.e. a leaf, and any pytree of pytrees is a pytree) and\ncan be operated on recursively (object identity equivalence is not preserved by\nmapping operations, and the structures cannot contain reference cycles).\n\nThe set of Python types that are considered pytree nodes (e.g. that can be\nmapped over, rather than treated as leaves) is extensible. There is a single\nmodule-level registry of types, and class hierarchy is ignored. By registering a\nnew pytree node type, that type in effect becomes transparent to the utility\nfunctions in this file.\n\"\"\"\n\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nfrom collections import namedtuple\nimport itertools as it\nfrom six.moves import reduce\n\nfrom .util import unzip2, concatenate, partial, safe_map\n\nmap = safe_map\n\n\ndef tree_map(f, tree):\n \"\"\"Map a function over a pytree to produce a new pytree.\n\n Args:\n f: function to be applied at each leaf.\n tree: a pytree to be mapped over.\n\n Returns:\n A new pytree with the same structure as `tree` but with the value at each\n leaf given by `f(x)` where `x` is the value at the corresponding leaf in\n `tree`.\n \"\"\"\n node_type = node_types.get(type(tree))\n if node_type:\n children, node_spec = node_type.to_iterable(tree)\n new_children = [tree_map(f, child) for child in children]\n return node_type.from_iterable(node_spec, new_children)\n else:\n return f(tree)\n\ndef tree_multimap(f, tree, *rest):\n \"\"\"Map a multi-input function over pytree args to produce a new pytree.\n\n Args:\n f: function that takes `1 + len(rest)` arguments, to be applied at the\n corresponding leaves of the pytrees.\n tree: a pytree to be mapped over, with each leaf providing the first\n positional argument to `f`.\n *rest: a tuple of pytrees, each with the same structure as `tree`.\n\n Returns:\n A new pytree with the same structure as `tree` but with the value at each\n leaf given by `f(x, *xs)` where `x` is the value at the corresponding leaf\n in `tree` and `xs` is the tuple of values at corresponding leaves in `rest`.\n \"\"\"\n node_type = node_types.get(type(tree))\n if node_type:\n children, aux_data = node_type.to_iterable(tree)\n all_children = [children]\n for other_tree in rest:\n other_node_type = node_types.get(type(other_tree))\n if node_type != other_node_type:\n raise TypeError('Mismatch: {} != {}'.format(other_node_type, node_type))\n other_children, other_aux_data = node_type.to_iterable(other_tree)\n if other_aux_data != aux_data:\n raise TypeError('Mismatch: {} != {}'.format(other_aux_data, aux_data))\n all_children.append(other_children)\n\n new_children = [tree_multimap(f, *xs) for xs in zip(*all_children)]\n return node_type.from_iterable(aux_data, new_children)\n else:\n return f(tree, *rest)\n\n\ndef tree_reduce(f, tree):\n flat, _ = tree_flatten(tree)\n return reduce(f, flat)\n\n\ndef tree_all(tree):\n flat, _ = tree_flatten(tree)\n return all(flat)\n\n\ndef process_pytree(process_node, tree):\n return walk_pytree(process_node, lambda x: x, tree)\n\n\ndef walk_pytree(f_node, f_leaf, tree):\n node_type = node_types.get(type(tree))\n if node_type:\n children, node_spec = node_type.to_iterable(tree)\n proc_children, child_specs = unzip2([walk_pytree(f_node, f_leaf, child)\n for child in children])\n tree_def = PyTreeDef(node_type, node_spec, child_specs)\n return f_node(proc_children), tree_def\n else:\n return f_leaf(tree), leaf\n\n\ndef build_tree(treedef, xs):\n if treedef is leaf:\n return xs\n else:\n # We use 'iter' for clearer error messages\n children = map(build_tree, iter(treedef.children), iter(xs))\n return treedef.node_type.from_iterable(treedef.node_data, children)\n\n\ntree_flatten = partial(walk_pytree, concatenate, lambda x: [x])\n\ndef tree_unflatten(treedef, xs):\n return _tree_unflatten(iter(xs), treedef)\n\ndef _tree_unflatten(xs, treedef):\n if treedef is leaf:\n return next(xs)\n else:\n children = map(partial(_tree_unflatten, xs), treedef.children)\n return treedef.node_type.from_iterable(treedef.node_data, children)\n\n\ndef tree_transpose(outer_treedef, inner_treedef, pytree_to_transpose):\n flat, treedef = tree_flatten(pytree_to_transpose)\n expected_treedef = _nested_treedef(inner_treedef, outer_treedef)\n if treedef != expected_treedef:\n raise TypeError(\"Mismatch\\n{}\\n != \\n{}\".format(treedef, expected_treedef))\n\n inner_size = _num_leaves(inner_treedef)\n outer_size = _num_leaves(outer_treedef)\n flat = iter(flat)\n lol = [[next(flat) for _ in range(inner_size)] for __ in range(outer_size)]\n transposed_lol = zip(*lol)\n subtrees = map(partial(tree_unflatten, outer_treedef), transposed_lol)\n return tree_unflatten(inner_treedef, subtrees)\n\ndef _num_leaves(treedef):\n return 1 if treedef is leaf else sum(map(_num_leaves, treedef.children))\n\ndef _nested_treedef(inner, outer):\n # just used in tree_transpose error checking\n if outer is leaf:\n return inner\n else:\n children = map(partial(_nested_treedef, inner), outer.children)\n return PyTreeDef(outer.node_type, outer.node_data, tuple(children))\n\n\ndef tree_structure(tree):\n _, spec = process_pytree(lambda _: None, tree)\n return spec\n\n\nclass PyTreeDef(object):\n def __init__(self, node_type, node_data, children):\n self.node_type = node_type\n self.node_data = node_data\n self.children = children\n\n def __repr__(self):\n if self.node_data is None:\n data_repr = \"\"\n else:\n data_repr = \"[{}]\".format(self.node_data)\n\n return \"PyTree({}{}, [{}])\".format(self.node_type.name, data_repr,\n ','.join(map(repr, self.children)))\n\n def __hash__(self):\n return hash((self.node_type, self.node_data, tuple(self.children)))\n\n def __eq__(self, other):\n if other is leaf:\n return False\n else:\n return (self.node_type == other.node_type and\n self.node_data == other.node_data and\n self.children == other.children)\n\n def __ne__(self, other):\n return not self == other\n\n\nclass PyLeaf(object):\n def __repr__(self):\n return '*'\n\nleaf = PyLeaf()\n\ndef dict_to_iterable(xs):\n keys = tuple(sorted(xs.keys()))\n return tuple(map(xs.get, keys)), keys\n\nclass NodeType(object):\n def __init__(self, name, to_iterable, from_iterable):\n self.name = name\n self.to_iterable = to_iterable\n self.from_iterable = from_iterable\n\n def __repr__(self):\n return self.name\n\nnode_types = {}\n\ndef register_pytree_node(py_type, to_iterable, from_iterable):\n assert py_type not in node_types\n node_types[py_type] = NodeType(str(py_type), to_iterable, from_iterable)\n\nregister_pytree_node(tuple, lambda xs: (xs, None), lambda _, xs: tuple(xs))\nregister_pytree_node(list, lambda xs: (tuple(xs), None), lambda _, xs: list(xs))\nregister_pytree_node(dict, dict_to_iterable, lambda keys, xs: dict(zip(keys, xs)))\nregister_pytree_node(type(None), lambda z: ((), None), lambda _, xs: None)\n", "path": "jax/tree_util.py"}], "after_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Utilities for working with tree-like container data structures.\n\nThe code here is independent of JAX. The only dependence is on jax.util, which\nitself has no JAX-specific code.\n\nThis module provides a small set of utility functions for working with tree-like\ndata structures, such as nested tuples, lists, and dicts. We call these\nstructures pytrees. They are trees in that they are defined recursively (any\nnon-pytree is a pytree, i.e. a leaf, and any pytree of pytrees is a pytree) and\ncan be operated on recursively (object identity equivalence is not preserved by\nmapping operations, and the structures cannot contain reference cycles).\n\nThe set of Python types that are considered pytree nodes (e.g. that can be\nmapped over, rather than treated as leaves) is extensible. There is a single\nmodule-level registry of types, and class hierarchy is ignored. By registering a\nnew pytree node type, that type in effect becomes transparent to the utility\nfunctions in this file.\n\"\"\"\n\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nfrom collections import namedtuple\nimport itertools as it\nfrom six.moves import reduce\n\nfrom .util import unzip2, concatenate, partial, safe_map\n\nmap = safe_map\n\n\ndef tree_map(f, tree):\n \"\"\"Map a function over a pytree to produce a new pytree.\n\n Args:\n f: function to be applied at each leaf.\n tree: a pytree to be mapped over.\n\n Returns:\n A new pytree with the same structure as `tree` but with the value at each\n leaf given by `f(x)` where `x` is the value at the corresponding leaf in\n `tree`.\n \"\"\"\n node_type = _get_node_type(tree)\n if node_type:\n children, node_spec = node_type.to_iterable(tree)\n new_children = [tree_map(f, child) for child in children]\n return node_type.from_iterable(node_spec, new_children)\n else:\n return f(tree)\n\ndef tree_multimap(f, tree, *rest):\n \"\"\"Map a multi-input function over pytree args to produce a new pytree.\n\n Args:\n f: function that takes `1 + len(rest)` arguments, to be applied at the\n corresponding leaves of the pytrees.\n tree: a pytree to be mapped over, with each leaf providing the first\n positional argument to `f`.\n *rest: a tuple of pytrees, each with the same structure as `tree`.\n\n Returns:\n A new pytree with the same structure as `tree` but with the value at each\n leaf given by `f(x, *xs)` where `x` is the value at the corresponding leaf\n in `tree` and `xs` is the tuple of values at corresponding leaves in `rest`.\n \"\"\"\n node_type = _get_node_type(tree)\n if node_type:\n children, aux_data = node_type.to_iterable(tree)\n all_children = [children]\n for other_tree in rest:\n other_node_type = _get_node_type(other_tree)\n if node_type != other_node_type:\n raise TypeError('Mismatch: {} != {}'.format(other_node_type, node_type))\n other_children, other_aux_data = node_type.to_iterable(other_tree)\n if other_aux_data != aux_data:\n raise TypeError('Mismatch: {} != {}'.format(other_aux_data, aux_data))\n all_children.append(other_children)\n\n new_children = [tree_multimap(f, *xs) for xs in zip(*all_children)]\n return node_type.from_iterable(aux_data, new_children)\n else:\n return f(tree, *rest)\n\n\ndef tree_reduce(f, tree):\n flat, _ = tree_flatten(tree)\n return reduce(f, flat)\n\n\ndef tree_all(tree):\n flat, _ = tree_flatten(tree)\n return all(flat)\n\n\ndef process_pytree(process_node, tree):\n return walk_pytree(process_node, lambda x: x, tree)\n\n\ndef walk_pytree(f_node, f_leaf, tree):\n node_type = _get_node_type(tree)\n if node_type:\n children, node_spec = node_type.to_iterable(tree)\n proc_children, child_specs = unzip2([walk_pytree(f_node, f_leaf, child)\n for child in children])\n tree_def = PyTreeDef(node_type, node_spec, child_specs)\n return f_node(proc_children), tree_def\n else:\n return f_leaf(tree), leaf\n\n\ndef build_tree(treedef, xs):\n if treedef is leaf:\n return xs\n else:\n # We use 'iter' for clearer error messages\n children = map(build_tree, iter(treedef.children), iter(xs))\n return treedef.node_type.from_iterable(treedef.node_data, children)\n\n\ntree_flatten = partial(walk_pytree, concatenate, lambda x: [x])\n\ndef tree_unflatten(treedef, xs):\n return _tree_unflatten(iter(xs), treedef)\n\ndef _tree_unflatten(xs, treedef):\n if treedef is leaf:\n return next(xs)\n else:\n children = map(partial(_tree_unflatten, xs), treedef.children)\n return treedef.node_type.from_iterable(treedef.node_data, children)\n\n\ndef tree_transpose(outer_treedef, inner_treedef, pytree_to_transpose):\n flat, treedef = tree_flatten(pytree_to_transpose)\n expected_treedef = _nested_treedef(inner_treedef, outer_treedef)\n if treedef != expected_treedef:\n raise TypeError(\"Mismatch\\n{}\\n != \\n{}\".format(treedef, expected_treedef))\n\n inner_size = _num_leaves(inner_treedef)\n outer_size = _num_leaves(outer_treedef)\n flat = iter(flat)\n lol = [[next(flat) for _ in range(inner_size)] for __ in range(outer_size)]\n transposed_lol = zip(*lol)\n subtrees = map(partial(tree_unflatten, outer_treedef), transposed_lol)\n return tree_unflatten(inner_treedef, subtrees)\n\ndef _num_leaves(treedef):\n return 1 if treedef is leaf else sum(map(_num_leaves, treedef.children))\n\ndef _nested_treedef(inner, outer):\n # just used in tree_transpose error checking\n if outer is leaf:\n return inner\n else:\n children = map(partial(_nested_treedef, inner), outer.children)\n return PyTreeDef(outer.node_type, outer.node_data, tuple(children))\n\n\ndef tree_structure(tree):\n _, spec = process_pytree(lambda _: None, tree)\n return spec\n\n\nclass PyTreeDef(object):\n def __init__(self, node_type, node_data, children):\n self.node_type = node_type\n self.node_data = node_data\n self.children = children\n\n def __repr__(self):\n if self.node_data is None:\n data_repr = \"\"\n else:\n data_repr = \"[{}]\".format(self.node_data)\n\n return \"PyTree({}{}, [{}])\".format(self.node_type.name, data_repr,\n ','.join(map(repr, self.children)))\n\n def __hash__(self):\n return hash((self.node_type, self.node_data, tuple(self.children)))\n\n def __eq__(self, other):\n if other is leaf:\n return False\n else:\n return (self.node_type == other.node_type and\n self.node_data == other.node_data and\n self.children == other.children)\n\n def __ne__(self, other):\n return not self == other\n\n\nclass PyLeaf(object):\n def __repr__(self):\n return '*'\n\nleaf = PyLeaf()\n\ndef dict_to_iterable(xs):\n keys = tuple(sorted(xs.keys()))\n return tuple(map(xs.get, keys)), keys\n\nclass NodeType(object):\n def __init__(self, name, to_iterable, from_iterable):\n self.name = name\n self.to_iterable = to_iterable\n self.from_iterable = from_iterable\n\n def __repr__(self):\n return self.name\n\nnode_types = {}\n\ndef register_pytree_node(py_type, to_iterable, from_iterable):\n assert py_type not in node_types\n node_types[py_type] = NodeType(str(py_type), to_iterable, from_iterable)\n\nregister_pytree_node(tuple, lambda xs: (xs, None), lambda _, xs: tuple(xs))\nregister_pytree_node(list, lambda xs: (tuple(xs), None), lambda _, xs: list(xs))\nregister_pytree_node(dict, dict_to_iterable, lambda keys, xs: dict(zip(keys, xs)))\nregister_pytree_node(type(None), lambda z: ((), None), lambda _, xs: None)\n\n\n# To handle namedtuples, we can't just use the standard table of node_types\n# because every namedtuple creates its own type and thus would require its own\n# entry in the table. Instead we use a heuristic check on the type itself to\n# decide whether it's a namedtuple type, and if so treat it as a pytree node.\ndef _get_node_type(maybe_tree):\n t = type(maybe_tree)\n return node_types.get(t) or _namedtuple_node(t)\n\ndef _namedtuple_node(t):\n if t.__bases__ == (tuple,) and hasattr(t, '_fields'):\n return NamedtupleNode\n\nNamedtupleNode = NodeType('namedtuple',\n lambda xs: (tuple(xs), type(xs)),\n lambda t, xs: t(*xs))\n", "path": "jax/tree_util.py"}]}
| 2,977 | 652 |
gh_patches_debug_4122
|
rasdani/github-patches
|
git_diff
|
mozilla__bugbug-3897
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Restrict the training set of the StepsToReproduce model only to defects
Given that STRs don't apply to enhancement or task.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bugbug/models/stepstoreproduce.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 # This Source Code Form is subject to the terms of the Mozilla Public
3 # License, v. 2.0. If a copy of the MPL was not distributed with this file,
4 # You can obtain one at http://mozilla.org/MPL/2.0/.
5
6 import logging
7
8 import xgboost
9 from imblearn.pipeline import Pipeline as ImblearnPipeline
10 from imblearn.under_sampling import RandomUnderSampler
11 from sklearn.compose import ColumnTransformer
12 from sklearn.feature_extraction import DictVectorizer
13 from sklearn.pipeline import Pipeline
14
15 from bugbug import bug_features, bugzilla, feature_cleanup, utils
16 from bugbug.model import BugModel
17
18 logging.basicConfig(level=logging.INFO)
19 logger = logging.getLogger(__name__)
20
21
22 class StepsToReproduceModel(BugModel):
23 def __init__(self, lemmatization=False):
24 BugModel.__init__(self, lemmatization)
25
26 feature_extractors = [
27 bug_features.HasRegressionRange(),
28 bug_features.Severity(),
29 bug_features.Keywords({"stepswanted"}),
30 bug_features.IsCoverityIssue(),
31 bug_features.HasCrashSignature(),
32 bug_features.HasURL(),
33 bug_features.HasW3CURL(),
34 bug_features.HasGithubURL(),
35 bug_features.Whiteboard(),
36 bug_features.Patches(),
37 bug_features.Landings(),
38 ]
39
40 cleanup_functions = [
41 feature_cleanup.fileref(),
42 feature_cleanup.url(),
43 feature_cleanup.synonyms(),
44 ]
45
46 self.extraction_pipeline = Pipeline(
47 [
48 (
49 "bug_extractor",
50 bug_features.BugExtractor(feature_extractors, cleanup_functions),
51 ),
52 ]
53 )
54
55 self.clf = ImblearnPipeline(
56 [
57 (
58 "union",
59 ColumnTransformer(
60 [
61 ("data", DictVectorizer(), "data"),
62 ("title", self.text_vectorizer(), "title"),
63 ("comments", self.text_vectorizer(), "comments"),
64 ]
65 ),
66 ),
67 ("sampler", RandomUnderSampler(random_state=0)),
68 (
69 "estimator",
70 xgboost.XGBClassifier(n_jobs=utils.get_physical_cpu_count()),
71 ),
72 ]
73 )
74
75 def get_labels(self):
76 classes = {}
77
78 for bug_data in bugzilla.get_bugs():
79 if "cf_has_str" in bug_data:
80 if bug_data["cf_has_str"] == "no":
81 classes[int(bug_data["id"])] = 0
82 elif bug_data["cf_has_str"] == "yes":
83 classes[int(bug_data["id"])] = 1
84 elif "stepswanted" in bug_data["keywords"]:
85 classes[int(bug_data["id"])] = 0
86 else:
87 for entry in bug_data["history"]:
88 for change in entry["changes"]:
89 if change["removed"].startswith("stepswanted"):
90 classes[int(bug_data["id"])] = 1
91
92 logger.info(
93 "%d bugs have no steps to reproduce",
94 sum(label == 0 for label in classes.values()),
95 )
96 logger.info(
97 "%d bugs have steps to reproduce",
98 sum(label == 1 for label in classes.values()),
99 )
100
101 return classes, [0, 1]
102
103 def overwrite_classes(self, bugs, classes, probabilities):
104 for i, bug in enumerate(bugs):
105 if "cf_has_str" in bug and bug["cf_has_str"] == "no":
106 classes[i] = 0 if not probabilities else [1.0, 0.0]
107 elif "cf_has_str" in bug and bug["cf_has_str"] == "yes":
108 classes[i] = 1 if not probabilities else [0.0, 1.0]
109 elif "stepswanted" in bug["keywords"]:
110 classes[i] = 0 if not probabilities else [1.0, 0.0]
111
112 return classes
113
114 def get_feature_names(self):
115 return self.clf.named_steps["union"].get_feature_names_out()
116
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/bugbug/models/stepstoreproduce.py b/bugbug/models/stepstoreproduce.py
--- a/bugbug/models/stepstoreproduce.py
+++ b/bugbug/models/stepstoreproduce.py
@@ -76,6 +76,8 @@
classes = {}
for bug_data in bugzilla.get_bugs():
+ if bug_data["type"] != "defect":
+ continue
if "cf_has_str" in bug_data:
if bug_data["cf_has_str"] == "no":
classes[int(bug_data["id"])] = 0
|
{"golden_diff": "diff --git a/bugbug/models/stepstoreproduce.py b/bugbug/models/stepstoreproduce.py\n--- a/bugbug/models/stepstoreproduce.py\n+++ b/bugbug/models/stepstoreproduce.py\n@@ -76,6 +76,8 @@\n classes = {}\n \n for bug_data in bugzilla.get_bugs():\n+ if bug_data[\"type\"] != \"defect\":\n+ continue\n if \"cf_has_str\" in bug_data:\n if bug_data[\"cf_has_str\"] == \"no\":\n classes[int(bug_data[\"id\"])] = 0\n", "issue": "Restrict the training set of the StepsToReproduce model only to defects\nGiven that STRs don't apply to enhancement or task.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# This Source Code Form is subject to the terms of the Mozilla Public\n# License, v. 2.0. If a copy of the MPL was not distributed with this file,\n# You can obtain one at http://mozilla.org/MPL/2.0/.\n\nimport logging\n\nimport xgboost\nfrom imblearn.pipeline import Pipeline as ImblearnPipeline\nfrom imblearn.under_sampling import RandomUnderSampler\nfrom sklearn.compose import ColumnTransformer\nfrom sklearn.feature_extraction import DictVectorizer\nfrom sklearn.pipeline import Pipeline\n\nfrom bugbug import bug_features, bugzilla, feature_cleanup, utils\nfrom bugbug.model import BugModel\n\nlogging.basicConfig(level=logging.INFO)\nlogger = logging.getLogger(__name__)\n\n\nclass StepsToReproduceModel(BugModel):\n def __init__(self, lemmatization=False):\n BugModel.__init__(self, lemmatization)\n\n feature_extractors = [\n bug_features.HasRegressionRange(),\n bug_features.Severity(),\n bug_features.Keywords({\"stepswanted\"}),\n bug_features.IsCoverityIssue(),\n bug_features.HasCrashSignature(),\n bug_features.HasURL(),\n bug_features.HasW3CURL(),\n bug_features.HasGithubURL(),\n bug_features.Whiteboard(),\n bug_features.Patches(),\n bug_features.Landings(),\n ]\n\n cleanup_functions = [\n feature_cleanup.fileref(),\n feature_cleanup.url(),\n feature_cleanup.synonyms(),\n ]\n\n self.extraction_pipeline = Pipeline(\n [\n (\n \"bug_extractor\",\n bug_features.BugExtractor(feature_extractors, cleanup_functions),\n ),\n ]\n )\n\n self.clf = ImblearnPipeline(\n [\n (\n \"union\",\n ColumnTransformer(\n [\n (\"data\", DictVectorizer(), \"data\"),\n (\"title\", self.text_vectorizer(), \"title\"),\n (\"comments\", self.text_vectorizer(), \"comments\"),\n ]\n ),\n ),\n (\"sampler\", RandomUnderSampler(random_state=0)),\n (\n \"estimator\",\n xgboost.XGBClassifier(n_jobs=utils.get_physical_cpu_count()),\n ),\n ]\n )\n\n def get_labels(self):\n classes = {}\n\n for bug_data in bugzilla.get_bugs():\n if \"cf_has_str\" in bug_data:\n if bug_data[\"cf_has_str\"] == \"no\":\n classes[int(bug_data[\"id\"])] = 0\n elif bug_data[\"cf_has_str\"] == \"yes\":\n classes[int(bug_data[\"id\"])] = 1\n elif \"stepswanted\" in bug_data[\"keywords\"]:\n classes[int(bug_data[\"id\"])] = 0\n else:\n for entry in bug_data[\"history\"]:\n for change in entry[\"changes\"]:\n if change[\"removed\"].startswith(\"stepswanted\"):\n classes[int(bug_data[\"id\"])] = 1\n\n logger.info(\n \"%d bugs have no steps to reproduce\",\n sum(label == 0 for label in classes.values()),\n )\n logger.info(\n \"%d bugs have steps to reproduce\",\n sum(label == 1 for label in classes.values()),\n )\n\n return classes, [0, 1]\n\n def overwrite_classes(self, bugs, classes, probabilities):\n for i, bug in enumerate(bugs):\n if \"cf_has_str\" in bug and bug[\"cf_has_str\"] == \"no\":\n classes[i] = 0 if not probabilities else [1.0, 0.0]\n elif \"cf_has_str\" in bug and bug[\"cf_has_str\"] == \"yes\":\n classes[i] = 1 if not probabilities else [0.0, 1.0]\n elif \"stepswanted\" in bug[\"keywords\"]:\n classes[i] = 0 if not probabilities else [1.0, 0.0]\n\n return classes\n\n def get_feature_names(self):\n return self.clf.named_steps[\"union\"].get_feature_names_out()\n", "path": "bugbug/models/stepstoreproduce.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n# This Source Code Form is subject to the terms of the Mozilla Public\n# License, v. 2.0. If a copy of the MPL was not distributed with this file,\n# You can obtain one at http://mozilla.org/MPL/2.0/.\n\nimport logging\n\nimport xgboost\nfrom imblearn.pipeline import Pipeline as ImblearnPipeline\nfrom imblearn.under_sampling import RandomUnderSampler\nfrom sklearn.compose import ColumnTransformer\nfrom sklearn.feature_extraction import DictVectorizer\nfrom sklearn.pipeline import Pipeline\n\nfrom bugbug import bug_features, bugzilla, feature_cleanup, utils\nfrom bugbug.model import BugModel\n\nlogging.basicConfig(level=logging.INFO)\nlogger = logging.getLogger(__name__)\n\n\nclass StepsToReproduceModel(BugModel):\n def __init__(self, lemmatization=False):\n BugModel.__init__(self, lemmatization)\n\n feature_extractors = [\n bug_features.HasRegressionRange(),\n bug_features.Severity(),\n bug_features.Keywords({\"stepswanted\"}),\n bug_features.IsCoverityIssue(),\n bug_features.HasCrashSignature(),\n bug_features.HasURL(),\n bug_features.HasW3CURL(),\n bug_features.HasGithubURL(),\n bug_features.Whiteboard(),\n bug_features.Patches(),\n bug_features.Landings(),\n ]\n\n cleanup_functions = [\n feature_cleanup.fileref(),\n feature_cleanup.url(),\n feature_cleanup.synonyms(),\n ]\n\n self.extraction_pipeline = Pipeline(\n [\n (\n \"bug_extractor\",\n bug_features.BugExtractor(feature_extractors, cleanup_functions),\n ),\n ]\n )\n\n self.clf = ImblearnPipeline(\n [\n (\n \"union\",\n ColumnTransformer(\n [\n (\"data\", DictVectorizer(), \"data\"),\n (\"title\", self.text_vectorizer(), \"title\"),\n (\"comments\", self.text_vectorizer(), \"comments\"),\n ]\n ),\n ),\n (\"sampler\", RandomUnderSampler(random_state=0)),\n (\n \"estimator\",\n xgboost.XGBClassifier(n_jobs=utils.get_physical_cpu_count()),\n ),\n ]\n )\n\n def get_labels(self):\n classes = {}\n\n for bug_data in bugzilla.get_bugs():\n if bug_data[\"type\"] != \"defect\":\n continue\n if \"cf_has_str\" in bug_data:\n if bug_data[\"cf_has_str\"] == \"no\":\n classes[int(bug_data[\"id\"])] = 0\n elif bug_data[\"cf_has_str\"] == \"yes\":\n classes[int(bug_data[\"id\"])] = 1\n elif \"stepswanted\" in bug_data[\"keywords\"]:\n classes[int(bug_data[\"id\"])] = 0\n else:\n for entry in bug_data[\"history\"]:\n for change in entry[\"changes\"]:\n if change[\"removed\"].startswith(\"stepswanted\"):\n classes[int(bug_data[\"id\"])] = 1\n\n logger.info(\n \"%d bugs have no steps to reproduce\",\n sum(label == 0 for label in classes.values()),\n )\n logger.info(\n \"%d bugs have steps to reproduce\",\n sum(label == 1 for label in classes.values()),\n )\n\n return classes, [0, 1]\n\n def overwrite_classes(self, bugs, classes, probabilities):\n for i, bug in enumerate(bugs):\n if \"cf_has_str\" in bug and bug[\"cf_has_str\"] == \"no\":\n classes[i] = 0 if not probabilities else [1.0, 0.0]\n elif \"cf_has_str\" in bug and bug[\"cf_has_str\"] == \"yes\":\n classes[i] = 1 if not probabilities else [0.0, 1.0]\n elif \"stepswanted\" in bug[\"keywords\"]:\n classes[i] = 0 if not probabilities else [1.0, 0.0]\n\n return classes\n\n def get_feature_names(self):\n return self.clf.named_steps[\"union\"].get_feature_names_out()\n", "path": "bugbug/models/stepstoreproduce.py"}]}
| 1,375 | 131 |
gh_patches_debug_10433
|
rasdani/github-patches
|
git_diff
|
scikit-image__scikit-image-1086
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
filter.threshold_isodata fails on 16-bit int images
The problem is the following line in threshholding.py:threshold_isodata():
```
binnums = np.arange(pmf.size, dtype=np.uint8)
```
Obviously the histogram bin numbers for images with more than 255 intensity levels don't get generated properly, leading to hilarity. Changing that to dtype=np.uint16 should do the trick for 8- and 16-bit images, and float images as long as the nbins parameter is < 2**16. (This wouldn't work for 32-bit integer images -- are these even supported though?)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `skimage/filter/thresholding.py`
Content:
```
1 __all__ = ['threshold_adaptive',
2 'threshold_otsu',
3 'threshold_yen',
4 'threshold_isodata']
5
6 import numpy as np
7 import scipy.ndimage
8 from skimage.exposure import histogram
9
10
11 def threshold_adaptive(image, block_size, method='gaussian', offset=0,
12 mode='reflect', param=None):
13 """Applies an adaptive threshold to an array.
14
15 Also known as local or dynamic thresholding where the threshold value is
16 the weighted mean for the local neighborhood of a pixel subtracted by a
17 constant. Alternatively the threshold can be determined dynamically by a a
18 given function using the 'generic' method.
19
20 Parameters
21 ----------
22 image : (N, M) ndarray
23 Input image.
24 block_size : int
25 Uneven size of pixel neighborhood which is used to calculate the
26 threshold value (e.g. 3, 5, 7, ..., 21, ...).
27 method : {'generic', 'gaussian', 'mean', 'median'}, optional
28 Method used to determine adaptive threshold for local neighbourhood in
29 weighted mean image.
30
31 * 'generic': use custom function (see `param` parameter)
32 * 'gaussian': apply gaussian filter (see `param` parameter for custom\
33 sigma value)
34 * 'mean': apply arithmetic mean filter
35 * 'median': apply median rank filter
36
37 By default the 'gaussian' method is used.
38 offset : float, optional
39 Constant subtracted from weighted mean of neighborhood to calculate
40 the local threshold value. Default offset is 0.
41 mode : {'reflect', 'constant', 'nearest', 'mirror', 'wrap'}, optional
42 The mode parameter determines how the array borders are handled, where
43 cval is the value when mode is equal to 'constant'.
44 Default is 'reflect'.
45 param : {int, function}, optional
46 Either specify sigma for 'gaussian' method or function object for
47 'generic' method. This functions takes the flat array of local
48 neighbourhood as a single argument and returns the calculated
49 threshold for the centre pixel.
50
51 Returns
52 -------
53 threshold : (N, M) ndarray
54 Thresholded binary image
55
56 References
57 ----------
58 .. [1] http://docs.opencv.org/modules/imgproc/doc/miscellaneous_transformations.html?highlight=threshold#adaptivethreshold
59
60 Examples
61 --------
62 >>> from skimage.data import camera
63 >>> image = camera()[:50, :50]
64 >>> binary_image1 = threshold_adaptive(image, 15, 'mean')
65 >>> func = lambda arr: arr.mean()
66 >>> binary_image2 = threshold_adaptive(image, 15, 'generic', param=func)
67 """
68 thresh_image = np.zeros(image.shape, 'double')
69 if method == 'generic':
70 scipy.ndimage.generic_filter(image, param, block_size,
71 output=thresh_image, mode=mode)
72 elif method == 'gaussian':
73 if param is None:
74 # automatically determine sigma which covers > 99% of distribution
75 sigma = (block_size - 1) / 6.0
76 else:
77 sigma = param
78 scipy.ndimage.gaussian_filter(image, sigma, output=thresh_image,
79 mode=mode)
80 elif method == 'mean':
81 mask = 1. / block_size * np.ones((block_size,))
82 # separation of filters to speedup convolution
83 scipy.ndimage.convolve1d(image, mask, axis=0, output=thresh_image,
84 mode=mode)
85 scipy.ndimage.convolve1d(thresh_image, mask, axis=1,
86 output=thresh_image, mode=mode)
87 elif method == 'median':
88 scipy.ndimage.median_filter(image, block_size, output=thresh_image,
89 mode=mode)
90
91 return image > (thresh_image - offset)
92
93
94 def threshold_otsu(image, nbins=256):
95 """Return threshold value based on Otsu's method.
96
97 Parameters
98 ----------
99 image : array
100 Input image.
101 nbins : int, optional
102 Number of bins used to calculate histogram. This value is ignored for
103 integer arrays.
104
105 Returns
106 -------
107 threshold : float
108 Upper threshold value. All pixels intensities that less or equal of
109 this value assumed as foreground.
110
111 References
112 ----------
113 .. [1] Wikipedia, http://en.wikipedia.org/wiki/Otsu's_Method
114
115 Examples
116 --------
117 >>> from skimage.data import camera
118 >>> image = camera()
119 >>> thresh = threshold_otsu(image)
120 >>> binary = image <= thresh
121 """
122 hist, bin_centers = histogram(image, nbins)
123 hist = hist.astype(float)
124
125 # class probabilities for all possible thresholds
126 weight1 = np.cumsum(hist)
127 weight2 = np.cumsum(hist[::-1])[::-1]
128 # class means for all possible thresholds
129 mean1 = np.cumsum(hist * bin_centers) / weight1
130 mean2 = (np.cumsum((hist * bin_centers)[::-1]) / weight2[::-1])[::-1]
131
132 # Clip ends to align class 1 and class 2 variables:
133 # The last value of `weight1`/`mean1` should pair with zero values in
134 # `weight2`/`mean2`, which do not exist.
135 variance12 = weight1[:-1] * weight2[1:] * (mean1[:-1] - mean2[1:]) ** 2
136
137 idx = np.argmax(variance12)
138 threshold = bin_centers[:-1][idx]
139 return threshold
140
141
142 def threshold_yen(image, nbins=256):
143 """Return threshold value based on Yen's method.
144
145 Parameters
146 ----------
147 image : array
148 Input image.
149 nbins : int, optional
150 Number of bins used to calculate histogram. This value is ignored for
151 integer arrays.
152
153 Returns
154 -------
155 threshold : float
156 Upper threshold value. All pixels intensities that less or equal of
157 this value assumed as foreground.
158
159 References
160 ----------
161 .. [1] Yen J.C., Chang F.J., and Chang S. (1995) "A New Criterion
162 for Automatic Multilevel Thresholding" IEEE Trans. on Image
163 Processing, 4(3): 370-378
164 .. [2] Sezgin M. and Sankur B. (2004) "Survey over Image Thresholding
165 Techniques and Quantitative Performance Evaluation" Journal of
166 Electronic Imaging, 13(1): 146-165,
167 http://www.busim.ee.boun.edu.tr/~sankur/SankurFolder/Threshold_survey.pdf
168 .. [3] ImageJ AutoThresholder code, http://fiji.sc/wiki/index.php/Auto_Threshold
169
170 Examples
171 --------
172 >>> from skimage.data import camera
173 >>> image = camera()
174 >>> thresh = threshold_yen(image)
175 >>> binary = image <= thresh
176 """
177 hist, bin_centers = histogram(image, nbins)
178 # On blank images (e.g. filled with 0) with int dtype, `histogram()`
179 # returns `bin_centers` containing only one value. Speed up with it.
180 if bin_centers.size == 1:
181 return bin_centers[0]
182
183 # Calculate probability mass function
184 pmf = hist.astype(np.float32) / hist.sum()
185 P1 = np.cumsum(pmf) # Cumulative normalized histogram
186 P1_sq = np.cumsum(pmf ** 2)
187 # Get cumsum calculated from end of squared array:
188 P2_sq = np.cumsum(pmf[::-1] ** 2)[::-1]
189 # P2_sq indexes is shifted +1. I assume, with P1[:-1] it's help avoid '-inf'
190 # in crit. ImageJ Yen implementation replaces those values by zero.
191 crit = np.log(((P1_sq[:-1] * P2_sq[1:]) ** -1) *
192 (P1[:-1] * (1.0 - P1[:-1])) ** 2)
193 return bin_centers[crit.argmax()]
194
195
196 def threshold_isodata(image, nbins=256):
197 """Return threshold value based on ISODATA method.
198
199 Histogram-based threshold, known as Ridler-Calvard method or intermeans.
200
201 Parameters
202 ----------
203 image : array
204 Input image.
205 nbins : int, optional
206 Number of bins used to calculate histogram. This value is ignored for
207 integer arrays.
208
209 Returns
210 -------
211 threshold : float or int, corresponding input array dtype.
212 Upper threshold value. All pixels intensities that less or equal of
213 this value assumed as background.
214
215 References
216 ----------
217 .. [1] Ridler, TW & Calvard, S (1978), "Picture thresholding using an
218 iterative selection method"
219 .. [2] IEEE Transactions on Systems, Man and Cybernetics 8: 630-632,
220 http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=4310039
221 .. [3] Sezgin M. and Sankur B. (2004) "Survey over Image Thresholding
222 Techniques and Quantitative Performance Evaluation" Journal of
223 Electronic Imaging, 13(1): 146-165,
224 http://www.busim.ee.boun.edu.tr/~sankur/SankurFolder/Threshold_survey.pdf
225 .. [4] ImageJ AutoThresholder code,
226 http://fiji.sc/wiki/index.php/Auto_Threshold
227
228 Examples
229 --------
230 >>> from skimage.data import coins
231 >>> image = coins()
232 >>> thresh = threshold_isodata(image)
233 >>> binary = image > thresh
234 """
235 hist, bin_centers = histogram(image, nbins)
236 # On blank images (e.g. filled with 0) with int dtype, `histogram()`
237 # returns `bin_centers` containing only one value. Speed up with it.
238 if bin_centers.size == 1:
239 return bin_centers[0]
240 # It is not necessary to calculate the probability mass function here,
241 # because the l and h fractions already include the normalization.
242 pmf = hist.astype(np.float32) # / hist.sum()
243 cpmfl = np.cumsum(pmf, dtype=np.float32)
244 cpmfh = np.cumsum(pmf[::-1], dtype=np.float32)[::-1]
245
246 binnums = np.arange(pmf.size, dtype=np.uint8)
247 # l and h contain average value of pixels in sum of bins, calculated
248 # from lower to higher and from higher to lower respectively.
249 l = np.ma.divide(np.cumsum(pmf * binnums, dtype=np.float32), cpmfl)
250 h = np.ma.divide(
251 np.cumsum((pmf[::-1] * binnums[::-1]), dtype=np.float32)[::-1],
252 cpmfh)
253
254 allmean = (l + h) / 2.0
255 threshold = bin_centers[np.nonzero(allmean.round() == binnums)[0][0]]
256 # This implementation returns threshold where
257 # `background <= threshold < foreground`.
258 return threshold
259
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/skimage/filter/thresholding.py b/skimage/filter/thresholding.py
--- a/skimage/filter/thresholding.py
+++ b/skimage/filter/thresholding.py
@@ -243,7 +243,7 @@
cpmfl = np.cumsum(pmf, dtype=np.float32)
cpmfh = np.cumsum(pmf[::-1], dtype=np.float32)[::-1]
- binnums = np.arange(pmf.size, dtype=np.uint8)
+ binnums = np.arange(pmf.size, dtype=np.min_scalar_type(nbins))
# l and h contain average value of pixels in sum of bins, calculated
# from lower to higher and from higher to lower respectively.
l = np.ma.divide(np.cumsum(pmf * binnums, dtype=np.float32), cpmfl)
|
{"golden_diff": "diff --git a/skimage/filter/thresholding.py b/skimage/filter/thresholding.py\n--- a/skimage/filter/thresholding.py\n+++ b/skimage/filter/thresholding.py\n@@ -243,7 +243,7 @@\n cpmfl = np.cumsum(pmf, dtype=np.float32)\n cpmfh = np.cumsum(pmf[::-1], dtype=np.float32)[::-1]\n \n- binnums = np.arange(pmf.size, dtype=np.uint8)\n+ binnums = np.arange(pmf.size, dtype=np.min_scalar_type(nbins))\n # l and h contain average value of pixels in sum of bins, calculated\n # from lower to higher and from higher to lower respectively.\n l = np.ma.divide(np.cumsum(pmf * binnums, dtype=np.float32), cpmfl)\n", "issue": "filter.threshold_isodata fails on 16-bit int images\nThe problem is the following line in threshholding.py:threshold_isodata():\n\n```\n binnums = np.arange(pmf.size, dtype=np.uint8)\n```\n\nObviously the histogram bin numbers for images with more than 255 intensity levels don't get generated properly, leading to hilarity. Changing that to dtype=np.uint16 should do the trick for 8- and 16-bit images, and float images as long as the nbins parameter is < 2**16. (This wouldn't work for 32-bit integer images -- are these even supported though?)\n\n", "before_files": [{"content": "__all__ = ['threshold_adaptive',\n 'threshold_otsu',\n 'threshold_yen',\n 'threshold_isodata']\n\nimport numpy as np\nimport scipy.ndimage\nfrom skimage.exposure import histogram\n\n\ndef threshold_adaptive(image, block_size, method='gaussian', offset=0,\n mode='reflect', param=None):\n \"\"\"Applies an adaptive threshold to an array.\n\n Also known as local or dynamic thresholding where the threshold value is\n the weighted mean for the local neighborhood of a pixel subtracted by a\n constant. Alternatively the threshold can be determined dynamically by a a\n given function using the 'generic' method.\n\n Parameters\n ----------\n image : (N, M) ndarray\n Input image.\n block_size : int\n Uneven size of pixel neighborhood which is used to calculate the\n threshold value (e.g. 3, 5, 7, ..., 21, ...).\n method : {'generic', 'gaussian', 'mean', 'median'}, optional\n Method used to determine adaptive threshold for local neighbourhood in\n weighted mean image.\n\n * 'generic': use custom function (see `param` parameter)\n * 'gaussian': apply gaussian filter (see `param` parameter for custom\\\n sigma value)\n * 'mean': apply arithmetic mean filter\n * 'median': apply median rank filter\n\n By default the 'gaussian' method is used.\n offset : float, optional\n Constant subtracted from weighted mean of neighborhood to calculate\n the local threshold value. Default offset is 0.\n mode : {'reflect', 'constant', 'nearest', 'mirror', 'wrap'}, optional\n The mode parameter determines how the array borders are handled, where\n cval is the value when mode is equal to 'constant'.\n Default is 'reflect'.\n param : {int, function}, optional\n Either specify sigma for 'gaussian' method or function object for\n 'generic' method. This functions takes the flat array of local\n neighbourhood as a single argument and returns the calculated\n threshold for the centre pixel.\n\n Returns\n -------\n threshold : (N, M) ndarray\n Thresholded binary image\n\n References\n ----------\n .. [1] http://docs.opencv.org/modules/imgproc/doc/miscellaneous_transformations.html?highlight=threshold#adaptivethreshold\n\n Examples\n --------\n >>> from skimage.data import camera\n >>> image = camera()[:50, :50]\n >>> binary_image1 = threshold_adaptive(image, 15, 'mean')\n >>> func = lambda arr: arr.mean()\n >>> binary_image2 = threshold_adaptive(image, 15, 'generic', param=func)\n \"\"\"\n thresh_image = np.zeros(image.shape, 'double')\n if method == 'generic':\n scipy.ndimage.generic_filter(image, param, block_size,\n output=thresh_image, mode=mode)\n elif method == 'gaussian':\n if param is None:\n # automatically determine sigma which covers > 99% of distribution\n sigma = (block_size - 1) / 6.0\n else:\n sigma = param\n scipy.ndimage.gaussian_filter(image, sigma, output=thresh_image,\n mode=mode)\n elif method == 'mean':\n mask = 1. / block_size * np.ones((block_size,))\n # separation of filters to speedup convolution\n scipy.ndimage.convolve1d(image, mask, axis=0, output=thresh_image,\n mode=mode)\n scipy.ndimage.convolve1d(thresh_image, mask, axis=1,\n output=thresh_image, mode=mode)\n elif method == 'median':\n scipy.ndimage.median_filter(image, block_size, output=thresh_image,\n mode=mode)\n\n return image > (thresh_image - offset)\n\n\ndef threshold_otsu(image, nbins=256):\n \"\"\"Return threshold value based on Otsu's method.\n\n Parameters\n ----------\n image : array\n Input image.\n nbins : int, optional\n Number of bins used to calculate histogram. This value is ignored for\n integer arrays.\n\n Returns\n -------\n threshold : float\n Upper threshold value. All pixels intensities that less or equal of\n this value assumed as foreground.\n\n References\n ----------\n .. [1] Wikipedia, http://en.wikipedia.org/wiki/Otsu's_Method\n\n Examples\n --------\n >>> from skimage.data import camera\n >>> image = camera()\n >>> thresh = threshold_otsu(image)\n >>> binary = image <= thresh\n \"\"\"\n hist, bin_centers = histogram(image, nbins)\n hist = hist.astype(float)\n\n # class probabilities for all possible thresholds\n weight1 = np.cumsum(hist)\n weight2 = np.cumsum(hist[::-1])[::-1]\n # class means for all possible thresholds\n mean1 = np.cumsum(hist * bin_centers) / weight1\n mean2 = (np.cumsum((hist * bin_centers)[::-1]) / weight2[::-1])[::-1]\n\n # Clip ends to align class 1 and class 2 variables:\n # The last value of `weight1`/`mean1` should pair with zero values in\n # `weight2`/`mean2`, which do not exist.\n variance12 = weight1[:-1] * weight2[1:] * (mean1[:-1] - mean2[1:]) ** 2\n\n idx = np.argmax(variance12)\n threshold = bin_centers[:-1][idx]\n return threshold\n\n\ndef threshold_yen(image, nbins=256):\n \"\"\"Return threshold value based on Yen's method.\n\n Parameters\n ----------\n image : array\n Input image.\n nbins : int, optional\n Number of bins used to calculate histogram. This value is ignored for\n integer arrays.\n\n Returns\n -------\n threshold : float\n Upper threshold value. All pixels intensities that less or equal of\n this value assumed as foreground.\n\n References\n ----------\n .. [1] Yen J.C., Chang F.J., and Chang S. (1995) \"A New Criterion\n for Automatic Multilevel Thresholding\" IEEE Trans. on Image\n Processing, 4(3): 370-378\n .. [2] Sezgin M. and Sankur B. (2004) \"Survey over Image Thresholding\n Techniques and Quantitative Performance Evaluation\" Journal of\n Electronic Imaging, 13(1): 146-165,\n http://www.busim.ee.boun.edu.tr/~sankur/SankurFolder/Threshold_survey.pdf\n .. [3] ImageJ AutoThresholder code, http://fiji.sc/wiki/index.php/Auto_Threshold\n\n Examples\n --------\n >>> from skimage.data import camera\n >>> image = camera()\n >>> thresh = threshold_yen(image)\n >>> binary = image <= thresh\n \"\"\"\n hist, bin_centers = histogram(image, nbins)\n # On blank images (e.g. filled with 0) with int dtype, `histogram()`\n # returns `bin_centers` containing only one value. Speed up with it.\n if bin_centers.size == 1:\n return bin_centers[0]\n\n # Calculate probability mass function\n pmf = hist.astype(np.float32) / hist.sum()\n P1 = np.cumsum(pmf) # Cumulative normalized histogram\n P1_sq = np.cumsum(pmf ** 2)\n # Get cumsum calculated from end of squared array:\n P2_sq = np.cumsum(pmf[::-1] ** 2)[::-1]\n # P2_sq indexes is shifted +1. I assume, with P1[:-1] it's help avoid '-inf'\n # in crit. ImageJ Yen implementation replaces those values by zero.\n crit = np.log(((P1_sq[:-1] * P2_sq[1:]) ** -1) *\n (P1[:-1] * (1.0 - P1[:-1])) ** 2)\n return bin_centers[crit.argmax()]\n\n\ndef threshold_isodata(image, nbins=256):\n \"\"\"Return threshold value based on ISODATA method.\n\n Histogram-based threshold, known as Ridler-Calvard method or intermeans.\n\n Parameters\n ----------\n image : array\n Input image.\n nbins : int, optional\n Number of bins used to calculate histogram. This value is ignored for\n integer arrays.\n\n Returns\n -------\n threshold : float or int, corresponding input array dtype.\n Upper threshold value. All pixels intensities that less or equal of\n this value assumed as background.\n\n References\n ----------\n .. [1] Ridler, TW & Calvard, S (1978), \"Picture thresholding using an\n iterative selection method\"\n .. [2] IEEE Transactions on Systems, Man and Cybernetics 8: 630-632,\n http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=4310039\n .. [3] Sezgin M. and Sankur B. (2004) \"Survey over Image Thresholding\n Techniques and Quantitative Performance Evaluation\" Journal of\n Electronic Imaging, 13(1): 146-165,\n http://www.busim.ee.boun.edu.tr/~sankur/SankurFolder/Threshold_survey.pdf\n .. [4] ImageJ AutoThresholder code,\n http://fiji.sc/wiki/index.php/Auto_Threshold\n\n Examples\n --------\n >>> from skimage.data import coins\n >>> image = coins()\n >>> thresh = threshold_isodata(image)\n >>> binary = image > thresh\n \"\"\"\n hist, bin_centers = histogram(image, nbins)\n # On blank images (e.g. filled with 0) with int dtype, `histogram()`\n # returns `bin_centers` containing only one value. Speed up with it.\n if bin_centers.size == 1:\n return bin_centers[0]\n # It is not necessary to calculate the probability mass function here,\n # because the l and h fractions already include the normalization.\n pmf = hist.astype(np.float32) # / hist.sum()\n cpmfl = np.cumsum(pmf, dtype=np.float32)\n cpmfh = np.cumsum(pmf[::-1], dtype=np.float32)[::-1]\n\n binnums = np.arange(pmf.size, dtype=np.uint8)\n # l and h contain average value of pixels in sum of bins, calculated\n # from lower to higher and from higher to lower respectively.\n l = np.ma.divide(np.cumsum(pmf * binnums, dtype=np.float32), cpmfl)\n h = np.ma.divide(\n np.cumsum((pmf[::-1] * binnums[::-1]), dtype=np.float32)[::-1],\n cpmfh)\n\n allmean = (l + h) / 2.0\n threshold = bin_centers[np.nonzero(allmean.round() == binnums)[0][0]]\n # This implementation returns threshold where\n # `background <= threshold < foreground`.\n return threshold\n", "path": "skimage/filter/thresholding.py"}], "after_files": [{"content": "__all__ = ['threshold_adaptive',\n 'threshold_otsu',\n 'threshold_yen',\n 'threshold_isodata']\n\nimport numpy as np\nimport scipy.ndimage\nfrom skimage.exposure import histogram\n\n\ndef threshold_adaptive(image, block_size, method='gaussian', offset=0,\n mode='reflect', param=None):\n \"\"\"Applies an adaptive threshold to an array.\n\n Also known as local or dynamic thresholding where the threshold value is\n the weighted mean for the local neighborhood of a pixel subtracted by a\n constant. Alternatively the threshold can be determined dynamically by a a\n given function using the 'generic' method.\n\n Parameters\n ----------\n image : (N, M) ndarray\n Input image.\n block_size : int\n Uneven size of pixel neighborhood which is used to calculate the\n threshold value (e.g. 3, 5, 7, ..., 21, ...).\n method : {'generic', 'gaussian', 'mean', 'median'}, optional\n Method used to determine adaptive threshold for local neighbourhood in\n weighted mean image.\n\n * 'generic': use custom function (see `param` parameter)\n * 'gaussian': apply gaussian filter (see `param` parameter for custom\\\n sigma value)\n * 'mean': apply arithmetic mean filter\n * 'median': apply median rank filter\n\n By default the 'gaussian' method is used.\n offset : float, optional\n Constant subtracted from weighted mean of neighborhood to calculate\n the local threshold value. Default offset is 0.\n mode : {'reflect', 'constant', 'nearest', 'mirror', 'wrap'}, optional\n The mode parameter determines how the array borders are handled, where\n cval is the value when mode is equal to 'constant'.\n Default is 'reflect'.\n param : {int, function}, optional\n Either specify sigma for 'gaussian' method or function object for\n 'generic' method. This functions takes the flat array of local\n neighbourhood as a single argument and returns the calculated\n threshold for the centre pixel.\n\n Returns\n -------\n threshold : (N, M) ndarray\n Thresholded binary image\n\n References\n ----------\n .. [1] http://docs.opencv.org/modules/imgproc/doc/miscellaneous_transformations.html?highlight=threshold#adaptivethreshold\n\n Examples\n --------\n >>> from skimage.data import camera\n >>> image = camera()[:50, :50]\n >>> binary_image1 = threshold_adaptive(image, 15, 'mean')\n >>> func = lambda arr: arr.mean()\n >>> binary_image2 = threshold_adaptive(image, 15, 'generic', param=func)\n \"\"\"\n thresh_image = np.zeros(image.shape, 'double')\n if method == 'generic':\n scipy.ndimage.generic_filter(image, param, block_size,\n output=thresh_image, mode=mode)\n elif method == 'gaussian':\n if param is None:\n # automatically determine sigma which covers > 99% of distribution\n sigma = (block_size - 1) / 6.0\n else:\n sigma = param\n scipy.ndimage.gaussian_filter(image, sigma, output=thresh_image,\n mode=mode)\n elif method == 'mean':\n mask = 1. / block_size * np.ones((block_size,))\n # separation of filters to speedup convolution\n scipy.ndimage.convolve1d(image, mask, axis=0, output=thresh_image,\n mode=mode)\n scipy.ndimage.convolve1d(thresh_image, mask, axis=1,\n output=thresh_image, mode=mode)\n elif method == 'median':\n scipy.ndimage.median_filter(image, block_size, output=thresh_image,\n mode=mode)\n\n return image > (thresh_image - offset)\n\n\ndef threshold_otsu(image, nbins=256):\n \"\"\"Return threshold value based on Otsu's method.\n\n Parameters\n ----------\n image : array\n Input image.\n nbins : int, optional\n Number of bins used to calculate histogram. This value is ignored for\n integer arrays.\n\n Returns\n -------\n threshold : float\n Upper threshold value. All pixels intensities that less or equal of\n this value assumed as foreground.\n\n References\n ----------\n .. [1] Wikipedia, http://en.wikipedia.org/wiki/Otsu's_Method\n\n Examples\n --------\n >>> from skimage.data import camera\n >>> image = camera()\n >>> thresh = threshold_otsu(image)\n >>> binary = image <= thresh\n \"\"\"\n hist, bin_centers = histogram(image, nbins)\n hist = hist.astype(float)\n\n # class probabilities for all possible thresholds\n weight1 = np.cumsum(hist)\n weight2 = np.cumsum(hist[::-1])[::-1]\n # class means for all possible thresholds\n mean1 = np.cumsum(hist * bin_centers) / weight1\n mean2 = (np.cumsum((hist * bin_centers)[::-1]) / weight2[::-1])[::-1]\n\n # Clip ends to align class 1 and class 2 variables:\n # The last value of `weight1`/`mean1` should pair with zero values in\n # `weight2`/`mean2`, which do not exist.\n variance12 = weight1[:-1] * weight2[1:] * (mean1[:-1] - mean2[1:]) ** 2\n\n idx = np.argmax(variance12)\n threshold = bin_centers[:-1][idx]\n return threshold\n\n\ndef threshold_yen(image, nbins=256):\n \"\"\"Return threshold value based on Yen's method.\n\n Parameters\n ----------\n image : array\n Input image.\n nbins : int, optional\n Number of bins used to calculate histogram. This value is ignored for\n integer arrays.\n\n Returns\n -------\n threshold : float\n Upper threshold value. All pixels intensities that less or equal of\n this value assumed as foreground.\n\n References\n ----------\n .. [1] Yen J.C., Chang F.J., and Chang S. (1995) \"A New Criterion\n for Automatic Multilevel Thresholding\" IEEE Trans. on Image\n Processing, 4(3): 370-378\n .. [2] Sezgin M. and Sankur B. (2004) \"Survey over Image Thresholding\n Techniques and Quantitative Performance Evaluation\" Journal of\n Electronic Imaging, 13(1): 146-165,\n http://www.busim.ee.boun.edu.tr/~sankur/SankurFolder/Threshold_survey.pdf\n .. [3] ImageJ AutoThresholder code, http://fiji.sc/wiki/index.php/Auto_Threshold\n\n Examples\n --------\n >>> from skimage.data import camera\n >>> image = camera()\n >>> thresh = threshold_yen(image)\n >>> binary = image <= thresh\n \"\"\"\n hist, bin_centers = histogram(image, nbins)\n # On blank images (e.g. filled with 0) with int dtype, `histogram()`\n # returns `bin_centers` containing only one value. Speed up with it.\n if bin_centers.size == 1:\n return bin_centers[0]\n\n # Calculate probability mass function\n pmf = hist.astype(np.float32) / hist.sum()\n P1 = np.cumsum(pmf) # Cumulative normalized histogram\n P1_sq = np.cumsum(pmf ** 2)\n # Get cumsum calculated from end of squared array:\n P2_sq = np.cumsum(pmf[::-1] ** 2)[::-1]\n # P2_sq indexes is shifted +1. I assume, with P1[:-1] it's help avoid '-inf'\n # in crit. ImageJ Yen implementation replaces those values by zero.\n crit = np.log(((P1_sq[:-1] * P2_sq[1:]) ** -1) *\n (P1[:-1] * (1.0 - P1[:-1])) ** 2)\n return bin_centers[crit.argmax()]\n\n\ndef threshold_isodata(image, nbins=256):\n \"\"\"Return threshold value based on ISODATA method.\n\n Histogram-based threshold, known as Ridler-Calvard method or intermeans.\n\n Parameters\n ----------\n image : array\n Input image.\n nbins : int, optional\n Number of bins used to calculate histogram. This value is ignored for\n integer arrays.\n\n Returns\n -------\n threshold : float or int, corresponding input array dtype.\n Upper threshold value. All pixels intensities that less or equal of\n this value assumed as background.\n\n References\n ----------\n .. [1] Ridler, TW & Calvard, S (1978), \"Picture thresholding using an\n iterative selection method\"\n .. [2] IEEE Transactions on Systems, Man and Cybernetics 8: 630-632,\n http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=4310039\n .. [3] Sezgin M. and Sankur B. (2004) \"Survey over Image Thresholding\n Techniques and Quantitative Performance Evaluation\" Journal of\n Electronic Imaging, 13(1): 146-165,\n http://www.busim.ee.boun.edu.tr/~sankur/SankurFolder/Threshold_survey.pdf\n .. [4] ImageJ AutoThresholder code,\n http://fiji.sc/wiki/index.php/Auto_Threshold\n\n Examples\n --------\n >>> from skimage.data import coins\n >>> image = coins()\n >>> thresh = threshold_isodata(image)\n >>> binary = image > thresh\n \"\"\"\n hist, bin_centers = histogram(image, nbins)\n # On blank images (e.g. filled with 0) with int dtype, `histogram()`\n # returns `bin_centers` containing only one value. Speed up with it.\n if bin_centers.size == 1:\n return bin_centers[0]\n # It is not necessary to calculate the probability mass function here,\n # because the l and h fractions already include the normalization.\n pmf = hist.astype(np.float32) # / hist.sum()\n cpmfl = np.cumsum(pmf, dtype=np.float32)\n cpmfh = np.cumsum(pmf[::-1], dtype=np.float32)[::-1]\n\n binnums = np.arange(pmf.size, dtype=np.min_scalar_type(nbins))\n # l and h contain average value of pixels in sum of bins, calculated\n # from lower to higher and from higher to lower respectively.\n l = np.ma.divide(np.cumsum(pmf * binnums, dtype=np.float32), cpmfl)\n h = np.ma.divide(\n np.cumsum((pmf[::-1] * binnums[::-1]), dtype=np.float32)[::-1],\n cpmfh)\n\n allmean = (l + h) / 2.0\n threshold = bin_centers[np.nonzero(allmean.round() == binnums)[0][0]]\n # This implementation returns threshold where\n # `background <= threshold < foreground`.\n return threshold\n", "path": "skimage/filter/thresholding.py"}]}
| 3,536 | 188 |
gh_patches_debug_5493
|
rasdani/github-patches
|
git_diff
|
scikit-hep__pyhf-1821
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Use of `del` for staterror in writexml necessary?
In PR #435 the use of `del` was added in
https://github.com/scikit-hep/pyhf/blob/e3d879f3e4982ac629bec7bf92d78b00025e52dc/src/pyhf/writexml.py#L186-L191
I assume because later on in the PR it mentions
https://github.com/scikit-hep/pyhf/blob/e3d879f3e4982ac629bec7bf92d78b00025e52dc/tests/test_export.py#L257-L259
However, if you remove that `del` statement
```
pytest -sx tests/test_export.py -k test_export_modifier
```
still passes.
Do we still need it? @kratsg have any thoughts here?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/pyhf/writexml.py`
Content:
```
1 import logging
2
3 from pathlib import Path
4 import shutil
5 import xml.etree.ElementTree as ET
6 import numpy as np
7
8 import uproot
9
10 from pyhf.mixins import _ChannelSummaryMixin
11 from pyhf.schema import path as schema_path
12
13 _ROOT_DATA_FILE = None
14
15 log = logging.getLogger(__name__)
16
17 __all__ = [
18 "build_channel",
19 "build_data",
20 "build_measurement",
21 "build_modifier",
22 "build_sample",
23 "indent",
24 ]
25
26
27 def __dir__():
28 return __all__
29
30
31 # 'spec' gets passed through all functions as NormFactor is a unique case of having
32 # parameter configurations stored at the modifier-definition-spec level. This means
33 # that build_modifier() needs access to the measurements. The call stack is:
34 #
35 # writexml
36 # ->build_channel
37 # ->build_sample
38 # ->build_modifier
39 #
40 # Therefore, 'spec' needs to be threaded through all these calls.
41
42
43 def _make_hist_name(channel, sample, modifier='', prefix='hist', suffix=''):
44 middle = '_'.join(filter(lambda x: x, [channel, sample, modifier]))
45 return f"{prefix}{middle}{suffix}"
46
47
48 def _export_root_histogram(hist_name, data):
49 if hist_name in _ROOT_DATA_FILE:
50 raise KeyError(f"Duplicate key {hist_name} being written.")
51 _ROOT_DATA_FILE[hist_name] = uproot.to_writable(
52 (np.asarray(data), np.arange(len(data) + 1))
53 )
54
55
56 # https://stackoverflow.com/a/4590052
57 def indent(elem, level=0):
58 i = "\n" + level * " "
59 if elem:
60 if not elem.text or not elem.text.strip():
61 elem.text = i + " "
62 if not elem.tail or not elem.tail.strip():
63 elem.tail = i
64 for subelem in elem:
65 indent(subelem, level + 1)
66 if not elem.tail or not elem.tail.strip():
67 elem.tail = i
68 else:
69 if level and (not elem.tail or not elem.tail.strip()):
70 elem.tail = i
71
72
73 def build_measurement(measurementspec, modifiertypes):
74 """
75 Build the XML measurement specification for a given measurement adhering to defs.json/#definitions/measurement.
76
77 Args:
78 measurementspec (:obj:`dict`): The measurements specification from a :class:`~pyhf.workspace.Workspace`.
79 modifiertypes (:obj:`dict`): A mapping from modifier name (:obj:`str`) to modifier type (:obj:`str`).
80
81 Returns:
82 :class:`xml.etree.cElementTree.Element`: The XML measurement specification.
83
84 """
85 # need to determine prefixes
86 prefixes = {
87 'normsys': 'alpha_',
88 'histosys': 'alpha_',
89 'shapesys': 'gamma_',
90 'staterror': 'gamma_',
91 }
92
93 config = measurementspec['config']
94 name = measurementspec['name']
95 poi = config['poi']
96
97 # we want to know which parameters are fixed (constant)
98 # and to additionally extract the luminosity information
99 fixed_params = []
100 lumi = 1.0
101 lumierr = 0.0
102 for parameter in config['parameters']:
103 if parameter.get('fixed', False):
104 pname = parameter['name']
105 if pname == 'lumi':
106 fixed_params.append('Lumi')
107 else:
108 prefix = prefixes.get(modifiertypes[pname], '')
109 fixed_params.append(f'{prefix}{pname}')
110 # we found luminosity, so handle it
111 if parameter['name'] == 'lumi':
112 lumi = parameter['auxdata'][0]
113 lumierr = parameter['sigmas'][0]
114
115 # define measurement
116 meas = ET.Element(
117 "Measurement",
118 Name=name,
119 Lumi=str(lumi),
120 LumiRelErr=str(lumierr),
121 ExportOnly=str(True),
122 )
123 poiel = ET.Element('POI')
124 poiel.text = poi
125 meas.append(poiel)
126
127 # add fixed parameters (constant)
128 if fixed_params:
129 se = ET.Element('ParamSetting', Const='True')
130 se.text = ' '.join(fixed_params)
131 meas.append(se)
132 return meas
133
134
135 def build_modifier(spec, modifierspec, channelname, samplename, sampledata):
136 if modifierspec['name'] == 'lumi':
137 return None
138 mod_map = {
139 'histosys': 'HistoSys',
140 'staterror': 'StatError',
141 'normsys': 'OverallSys',
142 'shapesys': 'ShapeSys',
143 'normfactor': 'NormFactor',
144 'shapefactor': 'ShapeFactor',
145 }
146
147 attrs = {'Name': modifierspec['name']}
148 if modifierspec['type'] == 'histosys':
149 attrs['HistoNameLow'] = _make_hist_name(
150 channelname, samplename, modifierspec['name'], suffix='Low'
151 )
152 attrs['HistoNameHigh'] = _make_hist_name(
153 channelname, samplename, modifierspec['name'], suffix='High'
154 )
155 _export_root_histogram(attrs['HistoNameLow'], modifierspec['data']['lo_data'])
156 _export_root_histogram(attrs['HistoNameHigh'], modifierspec['data']['hi_data'])
157 elif modifierspec['type'] == 'normsys':
158 attrs['High'] = str(modifierspec['data']['hi'])
159 attrs['Low'] = str(modifierspec['data']['lo'])
160 elif modifierspec['type'] == 'normfactor':
161 # NB: only look at first measurement for normfactor configs. In order
162 # to dump as HistFactory XML, this has to be the same for all
163 # measurements or it will not work correctly. Why?
164 #
165 # Unlike other modifiers, NormFactor has the unique circumstance of
166 # defining its parameter configurations at the modifier level inside
167 # the channel specification, instead of at the measurement level, like
168 # all of the other modifiers.
169 #
170 # However, since I strive for perfection, the "Const" attribute will
171 # never be set here, but at the per-measurement configuration instead
172 # like all other parameters. This is an acceptable compromise.
173 #
174 # Lastly, if a normfactor parameter configuration doesn't exist in the
175 # first measurement parameter configuration, then set defaults.
176 val = 1
177 low = 0
178 high = 10
179 for p in spec['measurements'][0]['config']['parameters']:
180 if p['name'] == modifierspec['name']:
181 val = p.get('inits', [val])[0]
182 low, high = p.get('bounds', [[low, high]])[0]
183 attrs['Val'] = str(val)
184 attrs['Low'] = str(low)
185 attrs['High'] = str(high)
186 elif modifierspec['type'] == 'staterror':
187 attrs['Activate'] = 'True'
188 attrs['HistoName'] = _make_hist_name(
189 channelname, samplename, modifierspec['name']
190 )
191 del attrs['Name']
192 # need to make this a relative uncertainty stored in ROOT file
193 _export_root_histogram(
194 attrs['HistoName'],
195 np.divide(
196 modifierspec['data'],
197 sampledata,
198 out=np.zeros_like(sampledata),
199 where=np.asarray(sampledata) != 0,
200 dtype='float',
201 ).tolist(),
202 )
203 elif modifierspec['type'] == 'shapesys':
204 attrs['ConstraintType'] = 'Poisson'
205 attrs['HistoName'] = _make_hist_name(
206 channelname, samplename, modifierspec['name']
207 )
208 # need to make this a relative uncertainty stored in ROOT file
209 _export_root_histogram(
210 attrs['HistoName'],
211 [
212 np.divide(
213 a, b, out=np.zeros_like(a), where=np.asarray(b) != 0, dtype='float'
214 )
215 for a, b in np.array(
216 (modifierspec['data'], sampledata), dtype="float"
217 ).T
218 ],
219 )
220 elif modifierspec['type'] == 'shapefactor':
221 pass
222 else:
223 log.warning(
224 f"Skipping modifier {modifierspec['name']}({modifierspec['type']}) for now"
225 )
226 return None
227
228 modifier = ET.Element(mod_map[modifierspec['type']], **attrs)
229 return modifier
230
231
232 def build_sample(spec, samplespec, channelname):
233 histname = _make_hist_name(channelname, samplespec['name'])
234 attrs = {
235 'Name': samplespec['name'],
236 'HistoName': histname,
237 'InputFile': _ROOT_DATA_FILE.file_path,
238 'NormalizeByTheory': 'False',
239 }
240 sample = ET.Element('Sample', **attrs)
241 for modspec in samplespec['modifiers']:
242 # if lumi modifier added for this sample, need to set NormalizeByTheory
243 if modspec['type'] == 'lumi':
244 sample.attrib.update({'NormalizeByTheory': 'True'})
245 modifier = build_modifier(
246 spec, modspec, channelname, samplespec['name'], samplespec['data']
247 )
248 if modifier is not None:
249 sample.append(modifier)
250 _export_root_histogram(histname, samplespec['data'])
251 return sample
252
253
254 def build_data(obsspec, channelname):
255 histname = _make_hist_name(channelname, 'data')
256 data = ET.Element('Data', HistoName=histname, InputFile=_ROOT_DATA_FILE.file_path)
257
258 observation = next((obs for obs in obsspec if obs['name'] == channelname), None)
259 _export_root_histogram(histname, observation['data'])
260 return data
261
262
263 def build_channel(spec, channelspec, obsspec):
264 channel = ET.Element(
265 'Channel', Name=channelspec['name'], InputFile=_ROOT_DATA_FILE.file_path
266 )
267 if obsspec:
268 data = build_data(obsspec, channelspec['name'])
269 channel.append(data)
270 for samplespec in channelspec['samples']:
271 channel.append(build_sample(spec, samplespec, channelspec['name']))
272 return channel
273
274
275 def writexml(spec, specdir, data_rootdir, resultprefix):
276 global _ROOT_DATA_FILE
277
278 shutil.copyfile(
279 schema_path.joinpath('HistFactorySchema.dtd'),
280 Path(specdir).parent.joinpath('HistFactorySchema.dtd'),
281 )
282 combination = ET.Element(
283 "Combination", OutputFilePrefix=str(Path(specdir).joinpath(resultprefix))
284 )
285
286 with uproot.recreate(Path(data_rootdir).joinpath('data.root')) as _ROOT_DATA_FILE:
287 for channelspec in spec['channels']:
288 channelfilename = str(
289 Path(specdir).joinpath(f'{resultprefix}_{channelspec["name"]}.xml')
290 )
291 with open(channelfilename, 'w') as channelfile:
292 channel = build_channel(spec, channelspec, spec.get('observations'))
293 indent(channel)
294 channelfile.write(
295 "<!DOCTYPE Channel SYSTEM '../HistFactorySchema.dtd'>\n\n"
296 )
297 channelfile.write(
298 ET.tostring(channel, encoding='utf-8').decode('utf-8')
299 )
300
301 inp = ET.Element("Input")
302 inp.text = channelfilename
303 combination.append(inp)
304
305 # need information about modifier types to get the right prefix in measurement
306 mixin = _ChannelSummaryMixin(channels=spec['channels'])
307
308 for measurement in spec['measurements']:
309 combination.append(build_measurement(measurement, dict(mixin.modifiers)))
310 indent(combination)
311 return b"<!DOCTYPE Combination SYSTEM 'HistFactorySchema.dtd'>\n\n" + ET.tostring(
312 combination, encoding='utf-8'
313 )
314
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/pyhf/writexml.py b/src/pyhf/writexml.py
--- a/src/pyhf/writexml.py
+++ b/src/pyhf/writexml.py
@@ -188,6 +188,7 @@
attrs['HistoName'] = _make_hist_name(
channelname, samplename, modifierspec['name']
)
+ # must be deleted, HiFa XML specification does not support 'Name'
del attrs['Name']
# need to make this a relative uncertainty stored in ROOT file
_export_root_histogram(
|
{"golden_diff": "diff --git a/src/pyhf/writexml.py b/src/pyhf/writexml.py\n--- a/src/pyhf/writexml.py\n+++ b/src/pyhf/writexml.py\n@@ -188,6 +188,7 @@\n attrs['HistoName'] = _make_hist_name(\n channelname, samplename, modifierspec['name']\n )\n+ # must be deleted, HiFa XML specification does not support 'Name'\n del attrs['Name']\n # need to make this a relative uncertainty stored in ROOT file\n _export_root_histogram(\n", "issue": "Use of `del` for staterror in writexml necessary?\nIn PR #435 the use of `del` was added in \r\n\r\nhttps://github.com/scikit-hep/pyhf/blob/e3d879f3e4982ac629bec7bf92d78b00025e52dc/src/pyhf/writexml.py#L186-L191\r\n\r\nI assume because later on in the PR it mentions\r\n\r\nhttps://github.com/scikit-hep/pyhf/blob/e3d879f3e4982ac629bec7bf92d78b00025e52dc/tests/test_export.py#L257-L259\r\n\r\nHowever, if you remove that `del` statement\r\n\r\n```\r\npytest -sx tests/test_export.py -k test_export_modifier\r\n```\r\n\r\nstill passes.\r\n\r\nDo we still need it? @kratsg have any thoughts here?\n", "before_files": [{"content": "import logging\n\nfrom pathlib import Path\nimport shutil\nimport xml.etree.ElementTree as ET\nimport numpy as np\n\nimport uproot\n\nfrom pyhf.mixins import _ChannelSummaryMixin\nfrom pyhf.schema import path as schema_path\n\n_ROOT_DATA_FILE = None\n\nlog = logging.getLogger(__name__)\n\n__all__ = [\n \"build_channel\",\n \"build_data\",\n \"build_measurement\",\n \"build_modifier\",\n \"build_sample\",\n \"indent\",\n]\n\n\ndef __dir__():\n return __all__\n\n\n# 'spec' gets passed through all functions as NormFactor is a unique case of having\n# parameter configurations stored at the modifier-definition-spec level. This means\n# that build_modifier() needs access to the measurements. The call stack is:\n#\n# writexml\n# ->build_channel\n# ->build_sample\n# ->build_modifier\n#\n# Therefore, 'spec' needs to be threaded through all these calls.\n\n\ndef _make_hist_name(channel, sample, modifier='', prefix='hist', suffix=''):\n middle = '_'.join(filter(lambda x: x, [channel, sample, modifier]))\n return f\"{prefix}{middle}{suffix}\"\n\n\ndef _export_root_histogram(hist_name, data):\n if hist_name in _ROOT_DATA_FILE:\n raise KeyError(f\"Duplicate key {hist_name} being written.\")\n _ROOT_DATA_FILE[hist_name] = uproot.to_writable(\n (np.asarray(data), np.arange(len(data) + 1))\n )\n\n\n# https://stackoverflow.com/a/4590052\ndef indent(elem, level=0):\n i = \"\\n\" + level * \" \"\n if elem:\n if not elem.text or not elem.text.strip():\n elem.text = i + \" \"\n if not elem.tail or not elem.tail.strip():\n elem.tail = i\n for subelem in elem:\n indent(subelem, level + 1)\n if not elem.tail or not elem.tail.strip():\n elem.tail = i\n else:\n if level and (not elem.tail or not elem.tail.strip()):\n elem.tail = i\n\n\ndef build_measurement(measurementspec, modifiertypes):\n \"\"\"\n Build the XML measurement specification for a given measurement adhering to defs.json/#definitions/measurement.\n\n Args:\n measurementspec (:obj:`dict`): The measurements specification from a :class:`~pyhf.workspace.Workspace`.\n modifiertypes (:obj:`dict`): A mapping from modifier name (:obj:`str`) to modifier type (:obj:`str`).\n\n Returns:\n :class:`xml.etree.cElementTree.Element`: The XML measurement specification.\n\n \"\"\"\n # need to determine prefixes\n prefixes = {\n 'normsys': 'alpha_',\n 'histosys': 'alpha_',\n 'shapesys': 'gamma_',\n 'staterror': 'gamma_',\n }\n\n config = measurementspec['config']\n name = measurementspec['name']\n poi = config['poi']\n\n # we want to know which parameters are fixed (constant)\n # and to additionally extract the luminosity information\n fixed_params = []\n lumi = 1.0\n lumierr = 0.0\n for parameter in config['parameters']:\n if parameter.get('fixed', False):\n pname = parameter['name']\n if pname == 'lumi':\n fixed_params.append('Lumi')\n else:\n prefix = prefixes.get(modifiertypes[pname], '')\n fixed_params.append(f'{prefix}{pname}')\n # we found luminosity, so handle it\n if parameter['name'] == 'lumi':\n lumi = parameter['auxdata'][0]\n lumierr = parameter['sigmas'][0]\n\n # define measurement\n meas = ET.Element(\n \"Measurement\",\n Name=name,\n Lumi=str(lumi),\n LumiRelErr=str(lumierr),\n ExportOnly=str(True),\n )\n poiel = ET.Element('POI')\n poiel.text = poi\n meas.append(poiel)\n\n # add fixed parameters (constant)\n if fixed_params:\n se = ET.Element('ParamSetting', Const='True')\n se.text = ' '.join(fixed_params)\n meas.append(se)\n return meas\n\n\ndef build_modifier(spec, modifierspec, channelname, samplename, sampledata):\n if modifierspec['name'] == 'lumi':\n return None\n mod_map = {\n 'histosys': 'HistoSys',\n 'staterror': 'StatError',\n 'normsys': 'OverallSys',\n 'shapesys': 'ShapeSys',\n 'normfactor': 'NormFactor',\n 'shapefactor': 'ShapeFactor',\n }\n\n attrs = {'Name': modifierspec['name']}\n if modifierspec['type'] == 'histosys':\n attrs['HistoNameLow'] = _make_hist_name(\n channelname, samplename, modifierspec['name'], suffix='Low'\n )\n attrs['HistoNameHigh'] = _make_hist_name(\n channelname, samplename, modifierspec['name'], suffix='High'\n )\n _export_root_histogram(attrs['HistoNameLow'], modifierspec['data']['lo_data'])\n _export_root_histogram(attrs['HistoNameHigh'], modifierspec['data']['hi_data'])\n elif modifierspec['type'] == 'normsys':\n attrs['High'] = str(modifierspec['data']['hi'])\n attrs['Low'] = str(modifierspec['data']['lo'])\n elif modifierspec['type'] == 'normfactor':\n # NB: only look at first measurement for normfactor configs. In order\n # to dump as HistFactory XML, this has to be the same for all\n # measurements or it will not work correctly. Why?\n #\n # Unlike other modifiers, NormFactor has the unique circumstance of\n # defining its parameter configurations at the modifier level inside\n # the channel specification, instead of at the measurement level, like\n # all of the other modifiers.\n #\n # However, since I strive for perfection, the \"Const\" attribute will\n # never be set here, but at the per-measurement configuration instead\n # like all other parameters. This is an acceptable compromise.\n #\n # Lastly, if a normfactor parameter configuration doesn't exist in the\n # first measurement parameter configuration, then set defaults.\n val = 1\n low = 0\n high = 10\n for p in spec['measurements'][0]['config']['parameters']:\n if p['name'] == modifierspec['name']:\n val = p.get('inits', [val])[0]\n low, high = p.get('bounds', [[low, high]])[0]\n attrs['Val'] = str(val)\n attrs['Low'] = str(low)\n attrs['High'] = str(high)\n elif modifierspec['type'] == 'staterror':\n attrs['Activate'] = 'True'\n attrs['HistoName'] = _make_hist_name(\n channelname, samplename, modifierspec['name']\n )\n del attrs['Name']\n # need to make this a relative uncertainty stored in ROOT file\n _export_root_histogram(\n attrs['HistoName'],\n np.divide(\n modifierspec['data'],\n sampledata,\n out=np.zeros_like(sampledata),\n where=np.asarray(sampledata) != 0,\n dtype='float',\n ).tolist(),\n )\n elif modifierspec['type'] == 'shapesys':\n attrs['ConstraintType'] = 'Poisson'\n attrs['HistoName'] = _make_hist_name(\n channelname, samplename, modifierspec['name']\n )\n # need to make this a relative uncertainty stored in ROOT file\n _export_root_histogram(\n attrs['HistoName'],\n [\n np.divide(\n a, b, out=np.zeros_like(a), where=np.asarray(b) != 0, dtype='float'\n )\n for a, b in np.array(\n (modifierspec['data'], sampledata), dtype=\"float\"\n ).T\n ],\n )\n elif modifierspec['type'] == 'shapefactor':\n pass\n else:\n log.warning(\n f\"Skipping modifier {modifierspec['name']}({modifierspec['type']}) for now\"\n )\n return None\n\n modifier = ET.Element(mod_map[modifierspec['type']], **attrs)\n return modifier\n\n\ndef build_sample(spec, samplespec, channelname):\n histname = _make_hist_name(channelname, samplespec['name'])\n attrs = {\n 'Name': samplespec['name'],\n 'HistoName': histname,\n 'InputFile': _ROOT_DATA_FILE.file_path,\n 'NormalizeByTheory': 'False',\n }\n sample = ET.Element('Sample', **attrs)\n for modspec in samplespec['modifiers']:\n # if lumi modifier added for this sample, need to set NormalizeByTheory\n if modspec['type'] == 'lumi':\n sample.attrib.update({'NormalizeByTheory': 'True'})\n modifier = build_modifier(\n spec, modspec, channelname, samplespec['name'], samplespec['data']\n )\n if modifier is not None:\n sample.append(modifier)\n _export_root_histogram(histname, samplespec['data'])\n return sample\n\n\ndef build_data(obsspec, channelname):\n histname = _make_hist_name(channelname, 'data')\n data = ET.Element('Data', HistoName=histname, InputFile=_ROOT_DATA_FILE.file_path)\n\n observation = next((obs for obs in obsspec if obs['name'] == channelname), None)\n _export_root_histogram(histname, observation['data'])\n return data\n\n\ndef build_channel(spec, channelspec, obsspec):\n channel = ET.Element(\n 'Channel', Name=channelspec['name'], InputFile=_ROOT_DATA_FILE.file_path\n )\n if obsspec:\n data = build_data(obsspec, channelspec['name'])\n channel.append(data)\n for samplespec in channelspec['samples']:\n channel.append(build_sample(spec, samplespec, channelspec['name']))\n return channel\n\n\ndef writexml(spec, specdir, data_rootdir, resultprefix):\n global _ROOT_DATA_FILE\n\n shutil.copyfile(\n schema_path.joinpath('HistFactorySchema.dtd'),\n Path(specdir).parent.joinpath('HistFactorySchema.dtd'),\n )\n combination = ET.Element(\n \"Combination\", OutputFilePrefix=str(Path(specdir).joinpath(resultprefix))\n )\n\n with uproot.recreate(Path(data_rootdir).joinpath('data.root')) as _ROOT_DATA_FILE:\n for channelspec in spec['channels']:\n channelfilename = str(\n Path(specdir).joinpath(f'{resultprefix}_{channelspec[\"name\"]}.xml')\n )\n with open(channelfilename, 'w') as channelfile:\n channel = build_channel(spec, channelspec, spec.get('observations'))\n indent(channel)\n channelfile.write(\n \"<!DOCTYPE Channel SYSTEM '../HistFactorySchema.dtd'>\\n\\n\"\n )\n channelfile.write(\n ET.tostring(channel, encoding='utf-8').decode('utf-8')\n )\n\n inp = ET.Element(\"Input\")\n inp.text = channelfilename\n combination.append(inp)\n\n # need information about modifier types to get the right prefix in measurement\n mixin = _ChannelSummaryMixin(channels=spec['channels'])\n\n for measurement in spec['measurements']:\n combination.append(build_measurement(measurement, dict(mixin.modifiers)))\n indent(combination)\n return b\"<!DOCTYPE Combination SYSTEM 'HistFactorySchema.dtd'>\\n\\n\" + ET.tostring(\n combination, encoding='utf-8'\n )\n", "path": "src/pyhf/writexml.py"}], "after_files": [{"content": "import logging\n\nfrom pathlib import Path\nimport shutil\nimport xml.etree.ElementTree as ET\nimport numpy as np\n\nimport uproot\n\nfrom pyhf.mixins import _ChannelSummaryMixin\nfrom pyhf.schema import path as schema_path\n\n_ROOT_DATA_FILE = None\n\nlog = logging.getLogger(__name__)\n\n__all__ = [\n \"build_channel\",\n \"build_data\",\n \"build_measurement\",\n \"build_modifier\",\n \"build_sample\",\n \"indent\",\n]\n\n\ndef __dir__():\n return __all__\n\n\n# 'spec' gets passed through all functions as NormFactor is a unique case of having\n# parameter configurations stored at the modifier-definition-spec level. This means\n# that build_modifier() needs access to the measurements. The call stack is:\n#\n# writexml\n# ->build_channel\n# ->build_sample\n# ->build_modifier\n#\n# Therefore, 'spec' needs to be threaded through all these calls.\n\n\ndef _make_hist_name(channel, sample, modifier='', prefix='hist', suffix=''):\n middle = '_'.join(filter(lambda x: x, [channel, sample, modifier]))\n return f\"{prefix}{middle}{suffix}\"\n\n\ndef _export_root_histogram(hist_name, data):\n if hist_name in _ROOT_DATA_FILE:\n raise KeyError(f\"Duplicate key {hist_name} being written.\")\n _ROOT_DATA_FILE[hist_name] = uproot.to_writable(\n (np.asarray(data), np.arange(len(data) + 1))\n )\n\n\n# https://stackoverflow.com/a/4590052\ndef indent(elem, level=0):\n i = \"\\n\" + level * \" \"\n if elem:\n if not elem.text or not elem.text.strip():\n elem.text = i + \" \"\n if not elem.tail or not elem.tail.strip():\n elem.tail = i\n for subelem in elem:\n indent(subelem, level + 1)\n if not elem.tail or not elem.tail.strip():\n elem.tail = i\n else:\n if level and (not elem.tail or not elem.tail.strip()):\n elem.tail = i\n\n\ndef build_measurement(measurementspec, modifiertypes):\n \"\"\"\n Build the XML measurement specification for a given measurement adhering to defs.json/#definitions/measurement.\n\n Args:\n measurementspec (:obj:`dict`): The measurements specification from a :class:`~pyhf.workspace.Workspace`.\n modifiertypes (:obj:`dict`): A mapping from modifier name (:obj:`str`) to modifier type (:obj:`str`).\n\n Returns:\n :class:`xml.etree.cElementTree.Element`: The XML measurement specification.\n\n \"\"\"\n # need to determine prefixes\n prefixes = {\n 'normsys': 'alpha_',\n 'histosys': 'alpha_',\n 'shapesys': 'gamma_',\n 'staterror': 'gamma_',\n }\n\n config = measurementspec['config']\n name = measurementspec['name']\n poi = config['poi']\n\n # we want to know which parameters are fixed (constant)\n # and to additionally extract the luminosity information\n fixed_params = []\n lumi = 1.0\n lumierr = 0.0\n for parameter in config['parameters']:\n if parameter.get('fixed', False):\n pname = parameter['name']\n if pname == 'lumi':\n fixed_params.append('Lumi')\n else:\n prefix = prefixes.get(modifiertypes[pname], '')\n fixed_params.append(f'{prefix}{pname}')\n # we found luminosity, so handle it\n if parameter['name'] == 'lumi':\n lumi = parameter['auxdata'][0]\n lumierr = parameter['sigmas'][0]\n\n # define measurement\n meas = ET.Element(\n \"Measurement\",\n Name=name,\n Lumi=str(lumi),\n LumiRelErr=str(lumierr),\n ExportOnly=str(True),\n )\n poiel = ET.Element('POI')\n poiel.text = poi\n meas.append(poiel)\n\n # add fixed parameters (constant)\n if fixed_params:\n se = ET.Element('ParamSetting', Const='True')\n se.text = ' '.join(fixed_params)\n meas.append(se)\n return meas\n\n\ndef build_modifier(spec, modifierspec, channelname, samplename, sampledata):\n if modifierspec['name'] == 'lumi':\n return None\n mod_map = {\n 'histosys': 'HistoSys',\n 'staterror': 'StatError',\n 'normsys': 'OverallSys',\n 'shapesys': 'ShapeSys',\n 'normfactor': 'NormFactor',\n 'shapefactor': 'ShapeFactor',\n }\n\n attrs = {'Name': modifierspec['name']}\n if modifierspec['type'] == 'histosys':\n attrs['HistoNameLow'] = _make_hist_name(\n channelname, samplename, modifierspec['name'], suffix='Low'\n )\n attrs['HistoNameHigh'] = _make_hist_name(\n channelname, samplename, modifierspec['name'], suffix='High'\n )\n _export_root_histogram(attrs['HistoNameLow'], modifierspec['data']['lo_data'])\n _export_root_histogram(attrs['HistoNameHigh'], modifierspec['data']['hi_data'])\n elif modifierspec['type'] == 'normsys':\n attrs['High'] = str(modifierspec['data']['hi'])\n attrs['Low'] = str(modifierspec['data']['lo'])\n elif modifierspec['type'] == 'normfactor':\n # NB: only look at first measurement for normfactor configs. In order\n # to dump as HistFactory XML, this has to be the same for all\n # measurements or it will not work correctly. Why?\n #\n # Unlike other modifiers, NormFactor has the unique circumstance of\n # defining its parameter configurations at the modifier level inside\n # the channel specification, instead of at the measurement level, like\n # all of the other modifiers.\n #\n # However, since I strive for perfection, the \"Const\" attribute will\n # never be set here, but at the per-measurement configuration instead\n # like all other parameters. This is an acceptable compromise.\n #\n # Lastly, if a normfactor parameter configuration doesn't exist in the\n # first measurement parameter configuration, then set defaults.\n val = 1\n low = 0\n high = 10\n for p in spec['measurements'][0]['config']['parameters']:\n if p['name'] == modifierspec['name']:\n val = p.get('inits', [val])[0]\n low, high = p.get('bounds', [[low, high]])[0]\n attrs['Val'] = str(val)\n attrs['Low'] = str(low)\n attrs['High'] = str(high)\n elif modifierspec['type'] == 'staterror':\n attrs['Activate'] = 'True'\n attrs['HistoName'] = _make_hist_name(\n channelname, samplename, modifierspec['name']\n )\n # must be deleted, HiFa XML specification does not support 'Name'\n del attrs['Name']\n # need to make this a relative uncertainty stored in ROOT file\n _export_root_histogram(\n attrs['HistoName'],\n np.divide(\n modifierspec['data'],\n sampledata,\n out=np.zeros_like(sampledata),\n where=np.asarray(sampledata) != 0,\n dtype='float',\n ).tolist(),\n )\n elif modifierspec['type'] == 'shapesys':\n attrs['ConstraintType'] = 'Poisson'\n attrs['HistoName'] = _make_hist_name(\n channelname, samplename, modifierspec['name']\n )\n # need to make this a relative uncertainty stored in ROOT file\n _export_root_histogram(\n attrs['HistoName'],\n [\n np.divide(\n a, b, out=np.zeros_like(a), where=np.asarray(b) != 0, dtype='float'\n )\n for a, b in np.array(\n (modifierspec['data'], sampledata), dtype=\"float\"\n ).T\n ],\n )\n elif modifierspec['type'] == 'shapefactor':\n pass\n else:\n log.warning(\n f\"Skipping modifier {modifierspec['name']}({modifierspec['type']}) for now\"\n )\n return None\n\n modifier = ET.Element(mod_map[modifierspec['type']], **attrs)\n return modifier\n\n\ndef build_sample(spec, samplespec, channelname):\n histname = _make_hist_name(channelname, samplespec['name'])\n attrs = {\n 'Name': samplespec['name'],\n 'HistoName': histname,\n 'InputFile': _ROOT_DATA_FILE.file_path,\n 'NormalizeByTheory': 'False',\n }\n sample = ET.Element('Sample', **attrs)\n for modspec in samplespec['modifiers']:\n # if lumi modifier added for this sample, need to set NormalizeByTheory\n if modspec['type'] == 'lumi':\n sample.attrib.update({'NormalizeByTheory': 'True'})\n modifier = build_modifier(\n spec, modspec, channelname, samplespec['name'], samplespec['data']\n )\n if modifier is not None:\n sample.append(modifier)\n _export_root_histogram(histname, samplespec['data'])\n return sample\n\n\ndef build_data(obsspec, channelname):\n histname = _make_hist_name(channelname, 'data')\n data = ET.Element('Data', HistoName=histname, InputFile=_ROOT_DATA_FILE.file_path)\n\n observation = next((obs for obs in obsspec if obs['name'] == channelname), None)\n _export_root_histogram(histname, observation['data'])\n return data\n\n\ndef build_channel(spec, channelspec, obsspec):\n channel = ET.Element(\n 'Channel', Name=channelspec['name'], InputFile=_ROOT_DATA_FILE.file_path\n )\n if obsspec:\n data = build_data(obsspec, channelspec['name'])\n channel.append(data)\n for samplespec in channelspec['samples']:\n channel.append(build_sample(spec, samplespec, channelspec['name']))\n return channel\n\n\ndef writexml(spec, specdir, data_rootdir, resultprefix):\n global _ROOT_DATA_FILE\n\n shutil.copyfile(\n schema_path.joinpath('HistFactorySchema.dtd'),\n Path(specdir).parent.joinpath('HistFactorySchema.dtd'),\n )\n combination = ET.Element(\n \"Combination\", OutputFilePrefix=str(Path(specdir).joinpath(resultprefix))\n )\n\n with uproot.recreate(Path(data_rootdir).joinpath('data.root')) as _ROOT_DATA_FILE:\n for channelspec in spec['channels']:\n channelfilename = str(\n Path(specdir).joinpath(f'{resultprefix}_{channelspec[\"name\"]}.xml')\n )\n with open(channelfilename, 'w') as channelfile:\n channel = build_channel(spec, channelspec, spec.get('observations'))\n indent(channel)\n channelfile.write(\n \"<!DOCTYPE Channel SYSTEM '../HistFactorySchema.dtd'>\\n\\n\"\n )\n channelfile.write(\n ET.tostring(channel, encoding='utf-8').decode('utf-8')\n )\n\n inp = ET.Element(\"Input\")\n inp.text = channelfilename\n combination.append(inp)\n\n # need information about modifier types to get the right prefix in measurement\n mixin = _ChannelSummaryMixin(channels=spec['channels'])\n\n for measurement in spec['measurements']:\n combination.append(build_measurement(measurement, dict(mixin.modifiers)))\n indent(combination)\n return b\"<!DOCTYPE Combination SYSTEM 'HistFactorySchema.dtd'>\\n\\n\" + ET.tostring(\n combination, encoding='utf-8'\n )\n", "path": "src/pyhf/writexml.py"}]}
| 3,872 | 129 |
gh_patches_debug_36958
|
rasdani/github-patches
|
git_diff
|
mitmproxy__mitmproxy-1655
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Handle `bytes` in request parameters
When POST data is encoded as UTF8, `har_dump.py` would bail with
```
TypeError: b'xxxxx' is not JSON serializable
```
(please excuse my poor python, feel free to reject and solve in some other canonical way)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/har_dump.py`
Content:
```
1 """
2 This inline script can be used to dump flows as HAR files.
3 """
4
5
6 import pprint
7 import json
8 import sys
9 import base64
10 import zlib
11
12 from datetime import datetime
13 import pytz
14
15 import mitmproxy
16
17 from mitmproxy import version
18 from mitmproxy.utils import strutils
19 from mitmproxy.net.http import cookies
20
21 HAR = {}
22
23 # A list of server seen till now is maintained so we can avoid
24 # using 'connect' time for entries that use an existing connection.
25 SERVERS_SEEN = set()
26
27
28 def start():
29 """
30 Called once on script startup before any other events.
31 """
32 if len(sys.argv) != 2:
33 raise ValueError(
34 'Usage: -s "har_dump.py filename" '
35 '(- will output to stdout, filenames ending with .zhar '
36 'will result in compressed har)'
37 )
38
39 HAR.update({
40 "log": {
41 "version": "1.2",
42 "creator": {
43 "name": "mitmproxy har_dump",
44 "version": "0.1",
45 "comment": "mitmproxy version %s" % version.MITMPROXY
46 },
47 "entries": []
48 }
49 })
50
51
52 def response(flow):
53 """
54 Called when a server response has been received.
55 """
56
57 # -1 indicates that these values do not apply to current request
58 ssl_time = -1
59 connect_time = -1
60
61 if flow.server_conn and flow.server_conn not in SERVERS_SEEN:
62 connect_time = (flow.server_conn.timestamp_tcp_setup -
63 flow.server_conn.timestamp_start)
64
65 if flow.server_conn.timestamp_ssl_setup is not None:
66 ssl_time = (flow.server_conn.timestamp_ssl_setup -
67 flow.server_conn.timestamp_tcp_setup)
68
69 SERVERS_SEEN.add(flow.server_conn)
70
71 # Calculate raw timings from timestamps. DNS timings can not be calculated
72 # for lack of a way to measure it. The same goes for HAR blocked.
73 # mitmproxy will open a server connection as soon as it receives the host
74 # and port from the client connection. So, the time spent waiting is actually
75 # spent waiting between request.timestamp_end and response.timestamp_start
76 # thus it correlates to HAR wait instead.
77 timings_raw = {
78 'send': flow.request.timestamp_end - flow.request.timestamp_start,
79 'receive': flow.response.timestamp_end - flow.response.timestamp_start,
80 'wait': flow.response.timestamp_start - flow.request.timestamp_end,
81 'connect': connect_time,
82 'ssl': ssl_time,
83 }
84
85 # HAR timings are integers in ms, so we re-encode the raw timings to that format.
86 timings = dict([(k, int(1000 * v)) for k, v in timings_raw.items()])
87
88 # full_time is the sum of all timings.
89 # Timings set to -1 will be ignored as per spec.
90 full_time = sum(v for v in timings.values() if v > -1)
91
92 started_date_time = format_datetime(datetime.utcfromtimestamp(flow.request.timestamp_start))
93
94 # Response body size and encoding
95 response_body_size = len(flow.response.raw_content)
96 response_body_decoded_size = len(flow.response.content)
97 response_body_compression = response_body_decoded_size - response_body_size
98
99 entry = {
100 "startedDateTime": started_date_time,
101 "time": full_time,
102 "request": {
103 "method": flow.request.method,
104 "url": flow.request.url,
105 "httpVersion": flow.request.http_version,
106 "cookies": format_request_cookies(flow.request.cookies.fields),
107 "headers": name_value(flow.request.headers),
108 "queryString": name_value(flow.request.query or {}),
109 "headersSize": len(str(flow.request.headers)),
110 "bodySize": len(flow.request.content),
111 },
112 "response": {
113 "status": flow.response.status_code,
114 "statusText": flow.response.reason,
115 "httpVersion": flow.response.http_version,
116 "cookies": format_response_cookies(flow.response.cookies.fields),
117 "headers": name_value(flow.response.headers),
118 "content": {
119 "size": response_body_size,
120 "compression": response_body_compression,
121 "mimeType": flow.response.headers.get('Content-Type', '')
122 },
123 "redirectURL": flow.response.headers.get('Location', ''),
124 "headersSize": len(str(flow.response.headers)),
125 "bodySize": response_body_size,
126 },
127 "cache": {},
128 "timings": timings,
129 }
130
131 # Store binay data as base64
132 if strutils.is_mostly_bin(flow.response.content):
133 b64 = base64.b64encode(flow.response.content)
134 entry["response"]["content"]["text"] = b64.decode('ascii')
135 entry["response"]["content"]["encoding"] = "base64"
136 else:
137 entry["response"]["content"]["text"] = flow.response.text
138
139 if flow.request.method in ["POST", "PUT", "PATCH"]:
140 entry["request"]["postData"] = {
141 "mimeType": flow.request.headers.get("Content-Type", "").split(";")[0],
142 "text": flow.request.content,
143 "params": name_value(flow.request.urlencoded_form)
144 }
145
146 if flow.server_conn:
147 entry["serverIPAddress"] = str(flow.server_conn.ip_address.address[0])
148
149 HAR["log"]["entries"].append(entry)
150
151
152 def done():
153 """
154 Called once on script shutdown, after any other events.
155 """
156 dump_file = sys.argv[1]
157
158 if dump_file == '-':
159 mitmproxy.ctx.log(pprint.pformat(HAR))
160 else:
161 json_dump = json.dumps(HAR, indent=2)
162
163 if dump_file.endswith('.zhar'):
164 json_dump = zlib.compress(json_dump, 9)
165
166 with open(dump_file, "w") as f:
167 f.write(json_dump)
168
169 mitmproxy.ctx.log("HAR dump finished (wrote %s bytes to file)" % len(json_dump))
170
171
172 def format_datetime(dt):
173 return dt.replace(tzinfo=pytz.timezone("UTC")).isoformat()
174
175
176 def format_cookies(cookie_list):
177 rv = []
178
179 for name, value, attrs in cookie_list:
180 cookie_har = {
181 "name": name,
182 "value": value,
183 }
184
185 # HAR only needs some attributes
186 for key in ["path", "domain", "comment"]:
187 if key in attrs:
188 cookie_har[key] = attrs[key]
189
190 # These keys need to be boolean!
191 for key in ["httpOnly", "secure"]:
192 cookie_har[key] = bool(key in attrs)
193
194 # Expiration time needs to be formatted
195 expire_ts = cookies.get_expiration_ts(attrs)
196 if expire_ts is not None:
197 cookie_har["expires"] = format_datetime(datetime.fromtimestamp(expire_ts))
198
199 rv.append(cookie_har)
200
201 return rv
202
203
204 def format_request_cookies(fields):
205 return format_cookies(cookies.group_cookies(fields))
206
207
208 def format_response_cookies(fields):
209 return format_cookies((c[0], c[1].value, c[1].attrs) for c in fields)
210
211
212 def name_value(obj):
213 """
214 Convert (key, value) pairs to HAR format.
215 """
216 return [{"name": k, "value": v} for k, v in obj.items()]
217
```
Path: `pathod/language/generators.py`
Content:
```
1 import string
2 import random
3 import mmap
4
5 import sys
6
7 DATATYPES = dict(
8 ascii_letters=string.ascii_letters.encode(),
9 ascii_lowercase=string.ascii_lowercase.encode(),
10 ascii_uppercase=string.ascii_uppercase.encode(),
11 digits=string.digits.encode(),
12 hexdigits=string.hexdigits.encode(),
13 octdigits=string.octdigits.encode(),
14 punctuation=string.punctuation.encode(),
15 whitespace=string.whitespace.encode(),
16 ascii=string.printable.encode(),
17 bytes=bytes(bytearray(range(256)))
18 )
19
20
21 class TransformGenerator:
22
23 """
24 Perform a byte-by-byte transform another generator - that is, for each
25 input byte, the transformation must produce one output byte.
26
27 gen: A generator to wrap
28 transform: A function (offset, data) -> transformed
29 """
30
31 def __init__(self, gen, transform):
32 self.gen = gen
33 self.transform = transform
34
35 def __len__(self):
36 return len(self.gen)
37
38 def __getitem__(self, x):
39 d = self.gen.__getitem__(x)
40 if isinstance(x, slice):
41 return self.transform(x.start, d)
42 return self.transform(x, d)
43
44 def __repr__(self):
45 return "'transform(%s)'" % self.gen
46
47
48 def rand_byte(chars):
49 """
50 Return a random character as byte from a charset.
51 """
52 # bytearray has consistent behaviour on both Python 2 and 3
53 # while bytes does not
54 return bytes([random.choice(chars)])
55
56
57 class RandomGenerator:
58
59 def __init__(self, dtype, length):
60 self.dtype = dtype
61 self.length = length
62
63 def __len__(self):
64 return self.length
65
66 def __getitem__(self, x):
67 chars = DATATYPES[self.dtype]
68 if isinstance(x, slice):
69 return b"".join(rand_byte(chars) for _ in range(*x.indices(min(self.length, sys.maxsize))))
70 return rand_byte(chars)
71
72 def __repr__(self):
73 return "%s random from %s" % (self.length, self.dtype)
74
75
76 class FileGenerator:
77
78 def __init__(self, path):
79 self.path = path
80 self.fp = open(path, "rb")
81 self.map = mmap.mmap(self.fp.fileno(), 0, access=mmap.ACCESS_READ)
82
83 def __len__(self):
84 return len(self.map)
85
86 def __getitem__(self, x):
87 if isinstance(x, slice):
88 return self.map.__getitem__(x)
89 # A slice of length 1 returns a byte object (not an integer)
90 return self.map.__getitem__(slice(x, x + 1 or self.map.size()))
91
92 def __repr__(self):
93 return "<%s" % self.path
94
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/har_dump.py b/examples/har_dump.py
--- a/examples/har_dump.py
+++ b/examples/har_dump.py
@@ -3,7 +3,6 @@
"""
-import pprint
import json
import sys
import base64
@@ -128,19 +127,22 @@
"timings": timings,
}
- # Store binay data as base64
+ # Store binary data as base64
if strutils.is_mostly_bin(flow.response.content):
- b64 = base64.b64encode(flow.response.content)
- entry["response"]["content"]["text"] = b64.decode('ascii')
+ entry["response"]["content"]["text"] = base64.b64encode(flow.response.content).decode()
entry["response"]["content"]["encoding"] = "base64"
else:
- entry["response"]["content"]["text"] = flow.response.text
+ entry["response"]["content"]["text"] = flow.response.get_text(strict=False)
if flow.request.method in ["POST", "PUT", "PATCH"]:
+ params = [
+ {"name": a.decode("utf8", "surrogateescape"), "value": b.decode("utf8", "surrogateescape")}
+ for a, b in flow.request.urlencoded_form.items(multi=True)
+ ]
entry["request"]["postData"] = {
"mimeType": flow.request.headers.get("Content-Type", "").split(";")[0],
- "text": flow.request.content,
- "params": name_value(flow.request.urlencoded_form)
+ "text": flow.request.get_text(strict=False),
+ "params": params
}
if flow.server_conn:
@@ -155,16 +157,17 @@
"""
dump_file = sys.argv[1]
+ json_dump = json.dumps(HAR, indent=2) # type: str
+
if dump_file == '-':
- mitmproxy.ctx.log(pprint.pformat(HAR))
+ mitmproxy.ctx.log(json_dump)
else:
- json_dump = json.dumps(HAR, indent=2)
-
+ raw = json_dump.encode() # type: bytes
if dump_file.endswith('.zhar'):
- json_dump = zlib.compress(json_dump, 9)
+ raw = zlib.compress(raw, 9)
- with open(dump_file, "w") as f:
- f.write(json_dump)
+ with open(dump_file, "wb") as f:
+ f.write(raw)
mitmproxy.ctx.log("HAR dump finished (wrote %s bytes to file)" % len(json_dump))
diff --git a/pathod/language/generators.py b/pathod/language/generators.py
--- a/pathod/language/generators.py
+++ b/pathod/language/generators.py
@@ -14,7 +14,7 @@
punctuation=string.punctuation.encode(),
whitespace=string.whitespace.encode(),
ascii=string.printable.encode(),
- bytes=bytes(bytearray(range(256)))
+ bytes=bytes(range(256))
)
|
{"golden_diff": "diff --git a/examples/har_dump.py b/examples/har_dump.py\n--- a/examples/har_dump.py\n+++ b/examples/har_dump.py\n@@ -3,7 +3,6 @@\n \"\"\"\n \n \n-import pprint\n import json\n import sys\n import base64\n@@ -128,19 +127,22 @@\n \"timings\": timings,\n }\n \n- # Store binay data as base64\n+ # Store binary data as base64\n if strutils.is_mostly_bin(flow.response.content):\n- b64 = base64.b64encode(flow.response.content)\n- entry[\"response\"][\"content\"][\"text\"] = b64.decode('ascii')\n+ entry[\"response\"][\"content\"][\"text\"] = base64.b64encode(flow.response.content).decode()\n entry[\"response\"][\"content\"][\"encoding\"] = \"base64\"\n else:\n- entry[\"response\"][\"content\"][\"text\"] = flow.response.text\n+ entry[\"response\"][\"content\"][\"text\"] = flow.response.get_text(strict=False)\n \n if flow.request.method in [\"POST\", \"PUT\", \"PATCH\"]:\n+ params = [\n+ {\"name\": a.decode(\"utf8\", \"surrogateescape\"), \"value\": b.decode(\"utf8\", \"surrogateescape\")}\n+ for a, b in flow.request.urlencoded_form.items(multi=True)\n+ ]\n entry[\"request\"][\"postData\"] = {\n \"mimeType\": flow.request.headers.get(\"Content-Type\", \"\").split(\";\")[0],\n- \"text\": flow.request.content,\n- \"params\": name_value(flow.request.urlencoded_form)\n+ \"text\": flow.request.get_text(strict=False),\n+ \"params\": params\n }\n \n if flow.server_conn:\n@@ -155,16 +157,17 @@\n \"\"\"\n dump_file = sys.argv[1]\n \n+ json_dump = json.dumps(HAR, indent=2) # type: str\n+\n if dump_file == '-':\n- mitmproxy.ctx.log(pprint.pformat(HAR))\n+ mitmproxy.ctx.log(json_dump)\n else:\n- json_dump = json.dumps(HAR, indent=2)\n-\n+ raw = json_dump.encode() # type: bytes\n if dump_file.endswith('.zhar'):\n- json_dump = zlib.compress(json_dump, 9)\n+ raw = zlib.compress(raw, 9)\n \n- with open(dump_file, \"w\") as f:\n- f.write(json_dump)\n+ with open(dump_file, \"wb\") as f:\n+ f.write(raw)\n \n mitmproxy.ctx.log(\"HAR dump finished (wrote %s bytes to file)\" % len(json_dump))\n \ndiff --git a/pathod/language/generators.py b/pathod/language/generators.py\n--- a/pathod/language/generators.py\n+++ b/pathod/language/generators.py\n@@ -14,7 +14,7 @@\n punctuation=string.punctuation.encode(),\n whitespace=string.whitespace.encode(),\n ascii=string.printable.encode(),\n- bytes=bytes(bytearray(range(256)))\n+ bytes=bytes(range(256))\n )\n", "issue": "Handle `bytes` in request parameters\nWhen POST data is encoded as UTF8, `har_dump.py` would bail with\n\n```\nTypeError: b'xxxxx' is not JSON serializable\n```\n\n(please excuse my poor python, feel free to reject and solve in some other canonical way)\n\n", "before_files": [{"content": "\"\"\"\nThis inline script can be used to dump flows as HAR files.\n\"\"\"\n\n\nimport pprint\nimport json\nimport sys\nimport base64\nimport zlib\n\nfrom datetime import datetime\nimport pytz\n\nimport mitmproxy\n\nfrom mitmproxy import version\nfrom mitmproxy.utils import strutils\nfrom mitmproxy.net.http import cookies\n\nHAR = {}\n\n# A list of server seen till now is maintained so we can avoid\n# using 'connect' time for entries that use an existing connection.\nSERVERS_SEEN = set()\n\n\ndef start():\n \"\"\"\n Called once on script startup before any other events.\n \"\"\"\n if len(sys.argv) != 2:\n raise ValueError(\n 'Usage: -s \"har_dump.py filename\" '\n '(- will output to stdout, filenames ending with .zhar '\n 'will result in compressed har)'\n )\n\n HAR.update({\n \"log\": {\n \"version\": \"1.2\",\n \"creator\": {\n \"name\": \"mitmproxy har_dump\",\n \"version\": \"0.1\",\n \"comment\": \"mitmproxy version %s\" % version.MITMPROXY\n },\n \"entries\": []\n }\n })\n\n\ndef response(flow):\n \"\"\"\n Called when a server response has been received.\n \"\"\"\n\n # -1 indicates that these values do not apply to current request\n ssl_time = -1\n connect_time = -1\n\n if flow.server_conn and flow.server_conn not in SERVERS_SEEN:\n connect_time = (flow.server_conn.timestamp_tcp_setup -\n flow.server_conn.timestamp_start)\n\n if flow.server_conn.timestamp_ssl_setup is not None:\n ssl_time = (flow.server_conn.timestamp_ssl_setup -\n flow.server_conn.timestamp_tcp_setup)\n\n SERVERS_SEEN.add(flow.server_conn)\n\n # Calculate raw timings from timestamps. DNS timings can not be calculated\n # for lack of a way to measure it. The same goes for HAR blocked.\n # mitmproxy will open a server connection as soon as it receives the host\n # and port from the client connection. So, the time spent waiting is actually\n # spent waiting between request.timestamp_end and response.timestamp_start\n # thus it correlates to HAR wait instead.\n timings_raw = {\n 'send': flow.request.timestamp_end - flow.request.timestamp_start,\n 'receive': flow.response.timestamp_end - flow.response.timestamp_start,\n 'wait': flow.response.timestamp_start - flow.request.timestamp_end,\n 'connect': connect_time,\n 'ssl': ssl_time,\n }\n\n # HAR timings are integers in ms, so we re-encode the raw timings to that format.\n timings = dict([(k, int(1000 * v)) for k, v in timings_raw.items()])\n\n # full_time is the sum of all timings.\n # Timings set to -1 will be ignored as per spec.\n full_time = sum(v for v in timings.values() if v > -1)\n\n started_date_time = format_datetime(datetime.utcfromtimestamp(flow.request.timestamp_start))\n\n # Response body size and encoding\n response_body_size = len(flow.response.raw_content)\n response_body_decoded_size = len(flow.response.content)\n response_body_compression = response_body_decoded_size - response_body_size\n\n entry = {\n \"startedDateTime\": started_date_time,\n \"time\": full_time,\n \"request\": {\n \"method\": flow.request.method,\n \"url\": flow.request.url,\n \"httpVersion\": flow.request.http_version,\n \"cookies\": format_request_cookies(flow.request.cookies.fields),\n \"headers\": name_value(flow.request.headers),\n \"queryString\": name_value(flow.request.query or {}),\n \"headersSize\": len(str(flow.request.headers)),\n \"bodySize\": len(flow.request.content),\n },\n \"response\": {\n \"status\": flow.response.status_code,\n \"statusText\": flow.response.reason,\n \"httpVersion\": flow.response.http_version,\n \"cookies\": format_response_cookies(flow.response.cookies.fields),\n \"headers\": name_value(flow.response.headers),\n \"content\": {\n \"size\": response_body_size,\n \"compression\": response_body_compression,\n \"mimeType\": flow.response.headers.get('Content-Type', '')\n },\n \"redirectURL\": flow.response.headers.get('Location', ''),\n \"headersSize\": len(str(flow.response.headers)),\n \"bodySize\": response_body_size,\n },\n \"cache\": {},\n \"timings\": timings,\n }\n\n # Store binay data as base64\n if strutils.is_mostly_bin(flow.response.content):\n b64 = base64.b64encode(flow.response.content)\n entry[\"response\"][\"content\"][\"text\"] = b64.decode('ascii')\n entry[\"response\"][\"content\"][\"encoding\"] = \"base64\"\n else:\n entry[\"response\"][\"content\"][\"text\"] = flow.response.text\n\n if flow.request.method in [\"POST\", \"PUT\", \"PATCH\"]:\n entry[\"request\"][\"postData\"] = {\n \"mimeType\": flow.request.headers.get(\"Content-Type\", \"\").split(\";\")[0],\n \"text\": flow.request.content,\n \"params\": name_value(flow.request.urlencoded_form)\n }\n\n if flow.server_conn:\n entry[\"serverIPAddress\"] = str(flow.server_conn.ip_address.address[0])\n\n HAR[\"log\"][\"entries\"].append(entry)\n\n\ndef done():\n \"\"\"\n Called once on script shutdown, after any other events.\n \"\"\"\n dump_file = sys.argv[1]\n\n if dump_file == '-':\n mitmproxy.ctx.log(pprint.pformat(HAR))\n else:\n json_dump = json.dumps(HAR, indent=2)\n\n if dump_file.endswith('.zhar'):\n json_dump = zlib.compress(json_dump, 9)\n\n with open(dump_file, \"w\") as f:\n f.write(json_dump)\n\n mitmproxy.ctx.log(\"HAR dump finished (wrote %s bytes to file)\" % len(json_dump))\n\n\ndef format_datetime(dt):\n return dt.replace(tzinfo=pytz.timezone(\"UTC\")).isoformat()\n\n\ndef format_cookies(cookie_list):\n rv = []\n\n for name, value, attrs in cookie_list:\n cookie_har = {\n \"name\": name,\n \"value\": value,\n }\n\n # HAR only needs some attributes\n for key in [\"path\", \"domain\", \"comment\"]:\n if key in attrs:\n cookie_har[key] = attrs[key]\n\n # These keys need to be boolean!\n for key in [\"httpOnly\", \"secure\"]:\n cookie_har[key] = bool(key in attrs)\n\n # Expiration time needs to be formatted\n expire_ts = cookies.get_expiration_ts(attrs)\n if expire_ts is not None:\n cookie_har[\"expires\"] = format_datetime(datetime.fromtimestamp(expire_ts))\n\n rv.append(cookie_har)\n\n return rv\n\n\ndef format_request_cookies(fields):\n return format_cookies(cookies.group_cookies(fields))\n\n\ndef format_response_cookies(fields):\n return format_cookies((c[0], c[1].value, c[1].attrs) for c in fields)\n\n\ndef name_value(obj):\n \"\"\"\n Convert (key, value) pairs to HAR format.\n \"\"\"\n return [{\"name\": k, \"value\": v} for k, v in obj.items()]\n", "path": "examples/har_dump.py"}, {"content": "import string\nimport random\nimport mmap\n\nimport sys\n\nDATATYPES = dict(\n ascii_letters=string.ascii_letters.encode(),\n ascii_lowercase=string.ascii_lowercase.encode(),\n ascii_uppercase=string.ascii_uppercase.encode(),\n digits=string.digits.encode(),\n hexdigits=string.hexdigits.encode(),\n octdigits=string.octdigits.encode(),\n punctuation=string.punctuation.encode(),\n whitespace=string.whitespace.encode(),\n ascii=string.printable.encode(),\n bytes=bytes(bytearray(range(256)))\n)\n\n\nclass TransformGenerator:\n\n \"\"\"\n Perform a byte-by-byte transform another generator - that is, for each\n input byte, the transformation must produce one output byte.\n\n gen: A generator to wrap\n transform: A function (offset, data) -> transformed\n \"\"\"\n\n def __init__(self, gen, transform):\n self.gen = gen\n self.transform = transform\n\n def __len__(self):\n return len(self.gen)\n\n def __getitem__(self, x):\n d = self.gen.__getitem__(x)\n if isinstance(x, slice):\n return self.transform(x.start, d)\n return self.transform(x, d)\n\n def __repr__(self):\n return \"'transform(%s)'\" % self.gen\n\n\ndef rand_byte(chars):\n \"\"\"\n Return a random character as byte from a charset.\n \"\"\"\n # bytearray has consistent behaviour on both Python 2 and 3\n # while bytes does not\n return bytes([random.choice(chars)])\n\n\nclass RandomGenerator:\n\n def __init__(self, dtype, length):\n self.dtype = dtype\n self.length = length\n\n def __len__(self):\n return self.length\n\n def __getitem__(self, x):\n chars = DATATYPES[self.dtype]\n if isinstance(x, slice):\n return b\"\".join(rand_byte(chars) for _ in range(*x.indices(min(self.length, sys.maxsize))))\n return rand_byte(chars)\n\n def __repr__(self):\n return \"%s random from %s\" % (self.length, self.dtype)\n\n\nclass FileGenerator:\n\n def __init__(self, path):\n self.path = path\n self.fp = open(path, \"rb\")\n self.map = mmap.mmap(self.fp.fileno(), 0, access=mmap.ACCESS_READ)\n\n def __len__(self):\n return len(self.map)\n\n def __getitem__(self, x):\n if isinstance(x, slice):\n return self.map.__getitem__(x)\n # A slice of length 1 returns a byte object (not an integer)\n return self.map.__getitem__(slice(x, x + 1 or self.map.size()))\n\n def __repr__(self):\n return \"<%s\" % self.path\n", "path": "pathod/language/generators.py"}], "after_files": [{"content": "\"\"\"\nThis inline script can be used to dump flows as HAR files.\n\"\"\"\n\n\nimport json\nimport sys\nimport base64\nimport zlib\n\nfrom datetime import datetime\nimport pytz\n\nimport mitmproxy\n\nfrom mitmproxy import version\nfrom mitmproxy.utils import strutils\nfrom mitmproxy.net.http import cookies\n\nHAR = {}\n\n# A list of server seen till now is maintained so we can avoid\n# using 'connect' time for entries that use an existing connection.\nSERVERS_SEEN = set()\n\n\ndef start():\n \"\"\"\n Called once on script startup before any other events.\n \"\"\"\n if len(sys.argv) != 2:\n raise ValueError(\n 'Usage: -s \"har_dump.py filename\" '\n '(- will output to stdout, filenames ending with .zhar '\n 'will result in compressed har)'\n )\n\n HAR.update({\n \"log\": {\n \"version\": \"1.2\",\n \"creator\": {\n \"name\": \"mitmproxy har_dump\",\n \"version\": \"0.1\",\n \"comment\": \"mitmproxy version %s\" % version.MITMPROXY\n },\n \"entries\": []\n }\n })\n\n\ndef response(flow):\n \"\"\"\n Called when a server response has been received.\n \"\"\"\n\n # -1 indicates that these values do not apply to current request\n ssl_time = -1\n connect_time = -1\n\n if flow.server_conn and flow.server_conn not in SERVERS_SEEN:\n connect_time = (flow.server_conn.timestamp_tcp_setup -\n flow.server_conn.timestamp_start)\n\n if flow.server_conn.timestamp_ssl_setup is not None:\n ssl_time = (flow.server_conn.timestamp_ssl_setup -\n flow.server_conn.timestamp_tcp_setup)\n\n SERVERS_SEEN.add(flow.server_conn)\n\n # Calculate raw timings from timestamps. DNS timings can not be calculated\n # for lack of a way to measure it. The same goes for HAR blocked.\n # mitmproxy will open a server connection as soon as it receives the host\n # and port from the client connection. So, the time spent waiting is actually\n # spent waiting between request.timestamp_end and response.timestamp_start\n # thus it correlates to HAR wait instead.\n timings_raw = {\n 'send': flow.request.timestamp_end - flow.request.timestamp_start,\n 'receive': flow.response.timestamp_end - flow.response.timestamp_start,\n 'wait': flow.response.timestamp_start - flow.request.timestamp_end,\n 'connect': connect_time,\n 'ssl': ssl_time,\n }\n\n # HAR timings are integers in ms, so we re-encode the raw timings to that format.\n timings = dict([(k, int(1000 * v)) for k, v in timings_raw.items()])\n\n # full_time is the sum of all timings.\n # Timings set to -1 will be ignored as per spec.\n full_time = sum(v for v in timings.values() if v > -1)\n\n started_date_time = format_datetime(datetime.utcfromtimestamp(flow.request.timestamp_start))\n\n # Response body size and encoding\n response_body_size = len(flow.response.raw_content)\n response_body_decoded_size = len(flow.response.content)\n response_body_compression = response_body_decoded_size - response_body_size\n\n entry = {\n \"startedDateTime\": started_date_time,\n \"time\": full_time,\n \"request\": {\n \"method\": flow.request.method,\n \"url\": flow.request.url,\n \"httpVersion\": flow.request.http_version,\n \"cookies\": format_request_cookies(flow.request.cookies.fields),\n \"headers\": name_value(flow.request.headers),\n \"queryString\": name_value(flow.request.query or {}),\n \"headersSize\": len(str(flow.request.headers)),\n \"bodySize\": len(flow.request.content),\n },\n \"response\": {\n \"status\": flow.response.status_code,\n \"statusText\": flow.response.reason,\n \"httpVersion\": flow.response.http_version,\n \"cookies\": format_response_cookies(flow.response.cookies.fields),\n \"headers\": name_value(flow.response.headers),\n \"content\": {\n \"size\": response_body_size,\n \"compression\": response_body_compression,\n \"mimeType\": flow.response.headers.get('Content-Type', '')\n },\n \"redirectURL\": flow.response.headers.get('Location', ''),\n \"headersSize\": len(str(flow.response.headers)),\n \"bodySize\": response_body_size,\n },\n \"cache\": {},\n \"timings\": timings,\n }\n\n # Store binary data as base64\n if strutils.is_mostly_bin(flow.response.content):\n entry[\"response\"][\"content\"][\"text\"] = base64.b64encode(flow.response.content).decode()\n entry[\"response\"][\"content\"][\"encoding\"] = \"base64\"\n else:\n entry[\"response\"][\"content\"][\"text\"] = flow.response.get_text(strict=False)\n\n if flow.request.method in [\"POST\", \"PUT\", \"PATCH\"]:\n params = [\n {\"name\": a.decode(\"utf8\", \"surrogateescape\"), \"value\": b.decode(\"utf8\", \"surrogateescape\")}\n for a, b in flow.request.urlencoded_form.items(multi=True)\n ]\n entry[\"request\"][\"postData\"] = {\n \"mimeType\": flow.request.headers.get(\"Content-Type\", \"\").split(\";\")[0],\n \"text\": flow.request.get_text(strict=False),\n \"params\": params\n }\n\n if flow.server_conn:\n entry[\"serverIPAddress\"] = str(flow.server_conn.ip_address.address[0])\n\n HAR[\"log\"][\"entries\"].append(entry)\n\n\ndef done():\n \"\"\"\n Called once on script shutdown, after any other events.\n \"\"\"\n dump_file = sys.argv[1]\n\n json_dump = json.dumps(HAR, indent=2) # type: str\n\n if dump_file == '-':\n mitmproxy.ctx.log(json_dump)\n else:\n raw = json_dump.encode() # type: bytes\n if dump_file.endswith('.zhar'):\n raw = zlib.compress(raw, 9)\n\n with open(dump_file, \"wb\") as f:\n f.write(raw)\n\n mitmproxy.ctx.log(\"HAR dump finished (wrote %s bytes to file)\" % len(json_dump))\n\n\ndef format_datetime(dt):\n return dt.replace(tzinfo=pytz.timezone(\"UTC\")).isoformat()\n\n\ndef format_cookies(cookie_list):\n rv = []\n\n for name, value, attrs in cookie_list:\n cookie_har = {\n \"name\": name,\n \"value\": value,\n }\n\n # HAR only needs some attributes\n for key in [\"path\", \"domain\", \"comment\"]:\n if key in attrs:\n cookie_har[key] = attrs[key]\n\n # These keys need to be boolean!\n for key in [\"httpOnly\", \"secure\"]:\n cookie_har[key] = bool(key in attrs)\n\n # Expiration time needs to be formatted\n expire_ts = cookies.get_expiration_ts(attrs)\n if expire_ts is not None:\n cookie_har[\"expires\"] = format_datetime(datetime.fromtimestamp(expire_ts))\n\n rv.append(cookie_har)\n\n return rv\n\n\ndef format_request_cookies(fields):\n return format_cookies(cookies.group_cookies(fields))\n\n\ndef format_response_cookies(fields):\n return format_cookies((c[0], c[1].value, c[1].attrs) for c in fields)\n\n\ndef name_value(obj):\n \"\"\"\n Convert (key, value) pairs to HAR format.\n \"\"\"\n return [{\"name\": k, \"value\": v} for k, v in obj.items()]\n", "path": "examples/har_dump.py"}, {"content": "import string\nimport random\nimport mmap\n\nimport sys\n\nDATATYPES = dict(\n ascii_letters=string.ascii_letters.encode(),\n ascii_lowercase=string.ascii_lowercase.encode(),\n ascii_uppercase=string.ascii_uppercase.encode(),\n digits=string.digits.encode(),\n hexdigits=string.hexdigits.encode(),\n octdigits=string.octdigits.encode(),\n punctuation=string.punctuation.encode(),\n whitespace=string.whitespace.encode(),\n ascii=string.printable.encode(),\n bytes=bytes(range(256))\n)\n\n\nclass TransformGenerator:\n\n \"\"\"\n Perform a byte-by-byte transform another generator - that is, for each\n input byte, the transformation must produce one output byte.\n\n gen: A generator to wrap\n transform: A function (offset, data) -> transformed\n \"\"\"\n\n def __init__(self, gen, transform):\n self.gen = gen\n self.transform = transform\n\n def __len__(self):\n return len(self.gen)\n\n def __getitem__(self, x):\n d = self.gen.__getitem__(x)\n if isinstance(x, slice):\n return self.transform(x.start, d)\n return self.transform(x, d)\n\n def __repr__(self):\n return \"'transform(%s)'\" % self.gen\n\n\ndef rand_byte(chars):\n \"\"\"\n Return a random character as byte from a charset.\n \"\"\"\n # bytearray has consistent behaviour on both Python 2 and 3\n # while bytes does not\n return bytes([random.choice(chars)])\n\n\nclass RandomGenerator:\n\n def __init__(self, dtype, length):\n self.dtype = dtype\n self.length = length\n\n def __len__(self):\n return self.length\n\n def __getitem__(self, x):\n chars = DATATYPES[self.dtype]\n if isinstance(x, slice):\n return b\"\".join(rand_byte(chars) for _ in range(*x.indices(min(self.length, sys.maxsize))))\n return rand_byte(chars)\n\n def __repr__(self):\n return \"%s random from %s\" % (self.length, self.dtype)\n\n\nclass FileGenerator:\n\n def __init__(self, path):\n self.path = path\n self.fp = open(path, \"rb\")\n self.map = mmap.mmap(self.fp.fileno(), 0, access=mmap.ACCESS_READ)\n\n def __len__(self):\n return len(self.map)\n\n def __getitem__(self, x):\n if isinstance(x, slice):\n return self.map.__getitem__(x)\n # A slice of length 1 returns a byte object (not an integer)\n return self.map.__getitem__(slice(x, x + 1 or self.map.size()))\n\n def __repr__(self):\n return \"<%s\" % self.path\n", "path": "pathod/language/generators.py"}]}
| 3,235 | 691 |
gh_patches_debug_20629
|
rasdani/github-patches
|
git_diff
|
pfnet__pytorch-pfn-extras-107
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[ONNX] Single input is not exported correctly
When exporting ONNX with single input, input tensor is split and input shape will be wrong.
https://github.com/pfnet/pytorch-pfn-extras/blob/2c5e1440f3137f48d651e705fddb7ea0251583d3/pytorch_pfn_extras/onnx/export_testcase.py#L177
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pytorch_pfn_extras/onnx/export_testcase.py`
Content:
```
1 import datetime
2 import io
3 import json
4 import os
5 import subprocess
6 import warnings
7
8 import onnx
9 import onnx.numpy_helper
10 import torch
11 import torch.autograd
12 from torch.onnx import OperatorExportTypes
13 from torch.onnx.symbolic_helper import _default_onnx_opset_version
14 from torch.onnx.utils import _export as torch_export
15
16 from pytorch_pfn_extras.onnx.annotate import init_annotate
17 from pytorch_pfn_extras.onnx.strip_large_tensor import \
18 LARGE_TENSOR_DATA_THRESHOLD
19 from pytorch_pfn_extras.onnx.strip_large_tensor import is_large_tensor
20 from pytorch_pfn_extras.onnx.strip_large_tensor import _strip_raw_data
21 from pytorch_pfn_extras.onnx.strip_large_tensor import \
22 _strip_large_initializer_raw_data
23
24
25 def _export_meta(model, out_dir, strip_large_tensor_data):
26 ret = {
27 'generated_at': datetime.datetime.now().isoformat(),
28 'output_directory': out_dir,
29 'exporter': 'torch-onnx-utils',
30 'strip_large_tensor_data': strip_large_tensor_data,
31 }
32 try:
33 git_status = subprocess.Popen(['git', 'status'],
34 stdout=subprocess.PIPE,
35 stderr=subprocess.PIPE)
36 git_status.communicate()
37
38 def strip_cmd(cmd):
39 return os.popen(cmd).read().strip()
40 if git_status.returncode == 0:
41 ret['git'] = {
42 'branch': strip_cmd('git rev-parse --abbrev-ref HEAD'),
43 'commit': strip_cmd('git rev-parse HEAD'),
44 'remote': strip_cmd('git ls-remote --get-url origin'),
45 'commit_date': strip_cmd('git show -s --format=%ci HEAD'),
46 }
47 except FileNotFoundError:
48 pass
49
50 return ret
51
52
53 def _export_util(model, args, f, **kwargs):
54 """Wrap operator type to export
55
56 Copied from torch.onnx.utils.export, to get output values.
57 """
58 aten = kwargs.get('aten', False)
59 export_raw_ir = kwargs.get('export_raw_ir', False)
60 operator_export_type = kwargs.get('operator_export_type', None)
61
62 if aten or export_raw_ir:
63 assert operator_export_type is None
64 assert aten ^ export_raw_ir
65 operator_export_type = OperatorExportTypes.ATEN if\
66 aten else OperatorExportTypes.RAW
67 elif operator_export_type is None:
68 if torch.onnx.PYTORCH_ONNX_CAFFE2_BUNDLE:
69 operator_export_type = OperatorExportTypes.ONNX_ATEN_FALLBACK
70 else:
71 operator_export_type = OperatorExportTypes.ONNX
72
73 return torch_export(model, args, f, _retain_param_name=True, **kwargs)
74
75
76 def _export(
77 model, args, strip_large_tensor_data=False,
78 large_tensor_threshold=LARGE_TENSOR_DATA_THRESHOLD, **kwargs):
79 model.zero_grad()
80 bytesio = io.BytesIO()
81 opset_ver = kwargs.get('opset_version', None)
82 if opset_ver is None:
83 opset_ver = _default_onnx_opset_version
84 strip_doc_string = kwargs.pop('strip_doc_string', True)
85 with init_annotate(model, opset_ver) as ann:
86 outs = _export_util(
87 model, args, bytesio, strip_doc_string=False, **kwargs)
88 onnx_graph = onnx.load(io.BytesIO(bytesio.getvalue()))
89 onnx_graph = ann.set_annotate(onnx_graph)
90 onnx_graph = ann.reorg_anchor(onnx_graph)
91 if strip_doc_string:
92 for node in onnx_graph.graph.node:
93 node.doc_string = b''
94 if strip_large_tensor_data:
95 _strip_large_initializer_raw_data(onnx_graph, large_tensor_threshold)
96
97 return onnx_graph, outs
98
99
100 def export(
101 model, args, f, return_output=False, strip_large_tensor_data=False,
102 large_tensor_threshold=LARGE_TENSOR_DATA_THRESHOLD, **kwargs):
103 """Export model into ONNX Graph.
104
105 Args:
106 f: A file-like object or a string file path to be written to this
107 file.
108 return_output (bool): If True, return output values come from the
109 model.
110 strip_large_tensor_data (bool): If True, this function will strip
111 data of large tensors to reduce ONNX file size for benchmarking
112 large_tensor_threshold (int): If number of elements of tensor is
113 larger than this value, the tensor is stripped when
114 *strip_large_tensor_data* is True
115 """
116 onnx_graph, outs = _export(
117 model, args, strip_large_tensor_data, large_tensor_threshold,
118 **kwargs)
119
120 if hasattr(f, 'write'):
121 f.write(onnx_graph.SerializeToString())
122 else:
123 assert isinstance(f, str)
124 warnings.warn(
125 'When export ONNX graph as file, "export_testcase" is '
126 'strongly recommended, please consider use it instead',
127 UserWarning)
128 with open(f, 'wb') as fp:
129 fp.write(onnx_graph.SerializeToString())
130
131 if return_output:
132 return outs
133
134
135 def export_testcase(
136 model, args, out_dir, *, output_grad=False, metadata=True,
137 model_overwrite=True, strip_large_tensor_data=False,
138 large_tensor_threshold=LARGE_TENSOR_DATA_THRESHOLD,
139 return_output=False, **kwargs):
140 """Export model and I/O tensors of the model in protobuf format.
141
142 Args:
143 output_grad (bool or Tensor): If True, this function will output
144 model's gradient with names 'gradient_%d.pb'. If set Tensor,
145 use it as gradient *input*. The gradient inputs are output as
146 'gradient_input_%d.pb' along with gradient.
147 metadata (bool): If True, output meta information taken from git log.
148 model_overwrite (bool): If False and model.onnx has already existed,
149 only export input/output data as another test dataset.
150 strip_large_tensor_data (bool): If True, this function will strip
151 data of large tensors to reduce ONNX file size for benchmarking
152 large_tensor_threshold (int): If number of elements of tensor is
153 larger than this value, the tensor is stripped when
154 *strip_large_tensor_data* is True
155 """
156
157 os.makedirs(out_dir, exist_ok=True)
158 input_names = kwargs.pop(
159 'input_names',
160 ['input_{}'.format(i) for i in range(len(args))])
161 assert len(input_names) == len(args)
162
163 onnx_graph, outs = _export(
164 model, args, strip_large_tensor_data, large_tensor_threshold,
165 input_names=input_names, **kwargs)
166
167 # Remove unused inputs
168 # - When keep_initializers_as_inputs=True, inputs contains initializers.
169 # So we have to filt initializers.
170 # - model.onnx is already issued, so we can modify args here.
171 initializer_names = [init.name for init in onnx_graph.graph.initializer]
172 used_input_index_list = []
173 for used_input in onnx_graph.graph.input:
174 if used_input.name not in initializer_names:
175 used_input_index_list.append(input_names.index(used_input.name))
176 input_names = [input_names[i] for i in used_input_index_list]
177 args = [args[i] for i in used_input_index_list]
178
179 output_path = os.path.join(out_dir, 'model.onnx')
180 is_on_memory = True
181 if model_overwrite or (not os.path.isfile(output_path)):
182 is_on_memory = False
183 with open(output_path, 'wb') as fp:
184 fp.write(onnx_graph.SerializeToString())
185
186 def write_to_pb(f, tensor, name=None):
187 array = tensor.detach().cpu().numpy()
188 with open(f, 'wb') as fp:
189 t = onnx.numpy_helper.from_array(array, name)
190 if (strip_large_tensor_data and
191 is_large_tensor(t, large_tensor_threshold)):
192 _strip_raw_data(t)
193 fp.write(t.SerializeToString())
194
195 if isinstance(args, torch.Tensor):
196 args = args,
197 if isinstance(outs, torch.Tensor):
198 outs = outs,
199 data_set_path = os.path.join(out_dir, 'test_data_set_0')
200 seq_id = 0
201 while is_on_memory and os.path.exists(data_set_path):
202 seq_id += 1
203 data_set_path = os.path.join(
204 out_dir, 'test_data_set_{:d}'.format(seq_id))
205 os.makedirs(data_set_path, exist_ok=True)
206 for i, (arg, name) in enumerate(zip(args, input_names)):
207 f = os.path.join(data_set_path, 'input_{}.pb'.format(i))
208 write_to_pb(f, arg, name)
209
210 output_names = kwargs.get('output_names')
211 if output_names is None:
212 if isinstance(outs, dict):
213 output_names = outs.keys()
214 else:
215 output_names = [None] * len(outs)
216 for i, name in enumerate(output_names):
217 if isinstance(outs, dict):
218 out = outs[name]
219 else:
220 out = outs[i]
221 if isinstance(out, (list, tuple)):
222 assert len(out) == 1, \
223 'Models returning nested lists/tuples are not supported yet'
224 out = out[0]
225 f = os.path.join(data_set_path, 'output_{}.pb'.format(i))
226 write_to_pb(f, out, name)
227
228 if output_grad is not False:
229 if isinstance(output_grad, bool):
230 output_grad = [torch.ones_like(outs[idx])
231 for idx in range(len(output_names))]
232 if isinstance(output_grad, torch.Tensor):
233 output_grad = [output_grad]
234 for idx in range(len(output_names)):
235 write_to_pb(
236 os.path.join(data_set_path, 'gradient_input_{}.pb'.format(
237 idx)), output_grad[idx],
238 output_names[idx])
239 if len(output_names) == len(outs):
240 torch.autograd.backward(outs, grad_tensors=output_grad)
241 else:
242 assert len(
243 output_names) == 1, 'Single output names is only supported'
244 outs[0].backward(output_grad[0])
245
246 for i, (name, param) in enumerate(model.named_parameters()):
247 f = os.path.join(data_set_path, 'gradient_{}.pb'.format(i))
248 # NOTE: name does not follow C identifier syntax rules,
249 # like "fc1.bias", not cleanse for now
250 if param.grad is None:
251 warnings.warn(
252 'Parameter `{}` does not have gradient value'.format(name))
253 else:
254 write_to_pb(f, param.grad, name)
255
256 if metadata:
257 with open(os.path.join(out_dir, 'meta.json'), 'w') as f:
258 json.dump(_export_meta(model, out_dir,
259 strip_large_tensor_data), f, indent=2)
260
261 if return_output:
262 return outs
263
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pytorch_pfn_extras/onnx/export_testcase.py b/pytorch_pfn_extras/onnx/export_testcase.py
--- a/pytorch_pfn_extras/onnx/export_testcase.py
+++ b/pytorch_pfn_extras/onnx/export_testcase.py
@@ -163,6 +163,10 @@
onnx_graph, outs = _export(
model, args, strip_large_tensor_data, large_tensor_threshold,
input_names=input_names, **kwargs)
+ if isinstance(args, torch.Tensor):
+ args = args,
+ if isinstance(outs, torch.Tensor):
+ outs = outs,
# Remove unused inputs
# - When keep_initializers_as_inputs=True, inputs contains initializers.
@@ -192,10 +196,6 @@
_strip_raw_data(t)
fp.write(t.SerializeToString())
- if isinstance(args, torch.Tensor):
- args = args,
- if isinstance(outs, torch.Tensor):
- outs = outs,
data_set_path = os.path.join(out_dir, 'test_data_set_0')
seq_id = 0
while is_on_memory and os.path.exists(data_set_path):
|
{"golden_diff": "diff --git a/pytorch_pfn_extras/onnx/export_testcase.py b/pytorch_pfn_extras/onnx/export_testcase.py\n--- a/pytorch_pfn_extras/onnx/export_testcase.py\n+++ b/pytorch_pfn_extras/onnx/export_testcase.py\n@@ -163,6 +163,10 @@\n onnx_graph, outs = _export(\n model, args, strip_large_tensor_data, large_tensor_threshold,\n input_names=input_names, **kwargs)\n+ if isinstance(args, torch.Tensor):\n+ args = args,\n+ if isinstance(outs, torch.Tensor):\n+ outs = outs,\n \n # Remove unused inputs\n # - When keep_initializers_as_inputs=True, inputs contains initializers.\n@@ -192,10 +196,6 @@\n _strip_raw_data(t)\n fp.write(t.SerializeToString())\n \n- if isinstance(args, torch.Tensor):\n- args = args,\n- if isinstance(outs, torch.Tensor):\n- outs = outs,\n data_set_path = os.path.join(out_dir, 'test_data_set_0')\n seq_id = 0\n while is_on_memory and os.path.exists(data_set_path):\n", "issue": "[ONNX] Single input is not exported correctly\nWhen exporting ONNX with single input, input tensor is split and input shape will be wrong.\r\n\r\nhttps://github.com/pfnet/pytorch-pfn-extras/blob/2c5e1440f3137f48d651e705fddb7ea0251583d3/pytorch_pfn_extras/onnx/export_testcase.py#L177\n", "before_files": [{"content": "import datetime\nimport io\nimport json\nimport os\nimport subprocess\nimport warnings\n\nimport onnx\nimport onnx.numpy_helper\nimport torch\nimport torch.autograd\nfrom torch.onnx import OperatorExportTypes\nfrom torch.onnx.symbolic_helper import _default_onnx_opset_version\nfrom torch.onnx.utils import _export as torch_export\n\nfrom pytorch_pfn_extras.onnx.annotate import init_annotate\nfrom pytorch_pfn_extras.onnx.strip_large_tensor import \\\n LARGE_TENSOR_DATA_THRESHOLD\nfrom pytorch_pfn_extras.onnx.strip_large_tensor import is_large_tensor\nfrom pytorch_pfn_extras.onnx.strip_large_tensor import _strip_raw_data\nfrom pytorch_pfn_extras.onnx.strip_large_tensor import \\\n _strip_large_initializer_raw_data\n\n\ndef _export_meta(model, out_dir, strip_large_tensor_data):\n ret = {\n 'generated_at': datetime.datetime.now().isoformat(),\n 'output_directory': out_dir,\n 'exporter': 'torch-onnx-utils',\n 'strip_large_tensor_data': strip_large_tensor_data,\n }\n try:\n git_status = subprocess.Popen(['git', 'status'],\n stdout=subprocess.PIPE,\n stderr=subprocess.PIPE)\n git_status.communicate()\n\n def strip_cmd(cmd):\n return os.popen(cmd).read().strip()\n if git_status.returncode == 0:\n ret['git'] = {\n 'branch': strip_cmd('git rev-parse --abbrev-ref HEAD'),\n 'commit': strip_cmd('git rev-parse HEAD'),\n 'remote': strip_cmd('git ls-remote --get-url origin'),\n 'commit_date': strip_cmd('git show -s --format=%ci HEAD'),\n }\n except FileNotFoundError:\n pass\n\n return ret\n\n\ndef _export_util(model, args, f, **kwargs):\n \"\"\"Wrap operator type to export\n\n Copied from torch.onnx.utils.export, to get output values.\n \"\"\"\n aten = kwargs.get('aten', False)\n export_raw_ir = kwargs.get('export_raw_ir', False)\n operator_export_type = kwargs.get('operator_export_type', None)\n\n if aten or export_raw_ir:\n assert operator_export_type is None\n assert aten ^ export_raw_ir\n operator_export_type = OperatorExportTypes.ATEN if\\\n aten else OperatorExportTypes.RAW\n elif operator_export_type is None:\n if torch.onnx.PYTORCH_ONNX_CAFFE2_BUNDLE:\n operator_export_type = OperatorExportTypes.ONNX_ATEN_FALLBACK\n else:\n operator_export_type = OperatorExportTypes.ONNX\n\n return torch_export(model, args, f, _retain_param_name=True, **kwargs)\n\n\ndef _export(\n model, args, strip_large_tensor_data=False,\n large_tensor_threshold=LARGE_TENSOR_DATA_THRESHOLD, **kwargs):\n model.zero_grad()\n bytesio = io.BytesIO()\n opset_ver = kwargs.get('opset_version', None)\n if opset_ver is None:\n opset_ver = _default_onnx_opset_version\n strip_doc_string = kwargs.pop('strip_doc_string', True)\n with init_annotate(model, opset_ver) as ann:\n outs = _export_util(\n model, args, bytesio, strip_doc_string=False, **kwargs)\n onnx_graph = onnx.load(io.BytesIO(bytesio.getvalue()))\n onnx_graph = ann.set_annotate(onnx_graph)\n onnx_graph = ann.reorg_anchor(onnx_graph)\n if strip_doc_string:\n for node in onnx_graph.graph.node:\n node.doc_string = b''\n if strip_large_tensor_data:\n _strip_large_initializer_raw_data(onnx_graph, large_tensor_threshold)\n\n return onnx_graph, outs\n\n\ndef export(\n model, args, f, return_output=False, strip_large_tensor_data=False,\n large_tensor_threshold=LARGE_TENSOR_DATA_THRESHOLD, **kwargs):\n \"\"\"Export model into ONNX Graph.\n\n Args:\n f: A file-like object or a string file path to be written to this\n file.\n return_output (bool): If True, return output values come from the\n model.\n strip_large_tensor_data (bool): If True, this function will strip\n data of large tensors to reduce ONNX file size for benchmarking\n large_tensor_threshold (int): If number of elements of tensor is\n larger than this value, the tensor is stripped when\n *strip_large_tensor_data* is True\n \"\"\"\n onnx_graph, outs = _export(\n model, args, strip_large_tensor_data, large_tensor_threshold,\n **kwargs)\n\n if hasattr(f, 'write'):\n f.write(onnx_graph.SerializeToString())\n else:\n assert isinstance(f, str)\n warnings.warn(\n 'When export ONNX graph as file, \"export_testcase\" is '\n 'strongly recommended, please consider use it instead',\n UserWarning)\n with open(f, 'wb') as fp:\n fp.write(onnx_graph.SerializeToString())\n\n if return_output:\n return outs\n\n\ndef export_testcase(\n model, args, out_dir, *, output_grad=False, metadata=True,\n model_overwrite=True, strip_large_tensor_data=False,\n large_tensor_threshold=LARGE_TENSOR_DATA_THRESHOLD,\n return_output=False, **kwargs):\n \"\"\"Export model and I/O tensors of the model in protobuf format.\n\n Args:\n output_grad (bool or Tensor): If True, this function will output\n model's gradient with names 'gradient_%d.pb'. If set Tensor,\n use it as gradient *input*. The gradient inputs are output as\n 'gradient_input_%d.pb' along with gradient.\n metadata (bool): If True, output meta information taken from git log.\n model_overwrite (bool): If False and model.onnx has already existed,\n only export input/output data as another test dataset.\n strip_large_tensor_data (bool): If True, this function will strip\n data of large tensors to reduce ONNX file size for benchmarking\n large_tensor_threshold (int): If number of elements of tensor is\n larger than this value, the tensor is stripped when\n *strip_large_tensor_data* is True\n \"\"\"\n\n os.makedirs(out_dir, exist_ok=True)\n input_names = kwargs.pop(\n 'input_names',\n ['input_{}'.format(i) for i in range(len(args))])\n assert len(input_names) == len(args)\n\n onnx_graph, outs = _export(\n model, args, strip_large_tensor_data, large_tensor_threshold,\n input_names=input_names, **kwargs)\n\n # Remove unused inputs\n # - When keep_initializers_as_inputs=True, inputs contains initializers.\n # So we have to filt initializers.\n # - model.onnx is already issued, so we can modify args here.\n initializer_names = [init.name for init in onnx_graph.graph.initializer]\n used_input_index_list = []\n for used_input in onnx_graph.graph.input:\n if used_input.name not in initializer_names:\n used_input_index_list.append(input_names.index(used_input.name))\n input_names = [input_names[i] for i in used_input_index_list]\n args = [args[i] for i in used_input_index_list]\n\n output_path = os.path.join(out_dir, 'model.onnx')\n is_on_memory = True\n if model_overwrite or (not os.path.isfile(output_path)):\n is_on_memory = False\n with open(output_path, 'wb') as fp:\n fp.write(onnx_graph.SerializeToString())\n\n def write_to_pb(f, tensor, name=None):\n array = tensor.detach().cpu().numpy()\n with open(f, 'wb') as fp:\n t = onnx.numpy_helper.from_array(array, name)\n if (strip_large_tensor_data and\n is_large_tensor(t, large_tensor_threshold)):\n _strip_raw_data(t)\n fp.write(t.SerializeToString())\n\n if isinstance(args, torch.Tensor):\n args = args,\n if isinstance(outs, torch.Tensor):\n outs = outs,\n data_set_path = os.path.join(out_dir, 'test_data_set_0')\n seq_id = 0\n while is_on_memory and os.path.exists(data_set_path):\n seq_id += 1\n data_set_path = os.path.join(\n out_dir, 'test_data_set_{:d}'.format(seq_id))\n os.makedirs(data_set_path, exist_ok=True)\n for i, (arg, name) in enumerate(zip(args, input_names)):\n f = os.path.join(data_set_path, 'input_{}.pb'.format(i))\n write_to_pb(f, arg, name)\n\n output_names = kwargs.get('output_names')\n if output_names is None:\n if isinstance(outs, dict):\n output_names = outs.keys()\n else:\n output_names = [None] * len(outs)\n for i, name in enumerate(output_names):\n if isinstance(outs, dict):\n out = outs[name]\n else:\n out = outs[i]\n if isinstance(out, (list, tuple)):\n assert len(out) == 1, \\\n 'Models returning nested lists/tuples are not supported yet'\n out = out[0]\n f = os.path.join(data_set_path, 'output_{}.pb'.format(i))\n write_to_pb(f, out, name)\n\n if output_grad is not False:\n if isinstance(output_grad, bool):\n output_grad = [torch.ones_like(outs[idx])\n for idx in range(len(output_names))]\n if isinstance(output_grad, torch.Tensor):\n output_grad = [output_grad]\n for idx in range(len(output_names)):\n write_to_pb(\n os.path.join(data_set_path, 'gradient_input_{}.pb'.format(\n idx)), output_grad[idx],\n output_names[idx])\n if len(output_names) == len(outs):\n torch.autograd.backward(outs, grad_tensors=output_grad)\n else:\n assert len(\n output_names) == 1, 'Single output names is only supported'\n outs[0].backward(output_grad[0])\n\n for i, (name, param) in enumerate(model.named_parameters()):\n f = os.path.join(data_set_path, 'gradient_{}.pb'.format(i))\n # NOTE: name does not follow C identifier syntax rules,\n # like \"fc1.bias\", not cleanse for now\n if param.grad is None:\n warnings.warn(\n 'Parameter `{}` does not have gradient value'.format(name))\n else:\n write_to_pb(f, param.grad, name)\n\n if metadata:\n with open(os.path.join(out_dir, 'meta.json'), 'w') as f:\n json.dump(_export_meta(model, out_dir,\n strip_large_tensor_data), f, indent=2)\n\n if return_output:\n return outs\n", "path": "pytorch_pfn_extras/onnx/export_testcase.py"}], "after_files": [{"content": "import datetime\nimport io\nimport json\nimport os\nimport subprocess\nimport warnings\n\nimport onnx\nimport onnx.numpy_helper\nimport torch\nimport torch.autograd\nfrom torch.onnx import OperatorExportTypes\nfrom torch.onnx.symbolic_helper import _default_onnx_opset_version\nfrom torch.onnx.utils import _export as torch_export\n\nfrom pytorch_pfn_extras.onnx.annotate import init_annotate\nfrom pytorch_pfn_extras.onnx.strip_large_tensor import \\\n LARGE_TENSOR_DATA_THRESHOLD\nfrom pytorch_pfn_extras.onnx.strip_large_tensor import is_large_tensor\nfrom pytorch_pfn_extras.onnx.strip_large_tensor import _strip_raw_data\nfrom pytorch_pfn_extras.onnx.strip_large_tensor import \\\n _strip_large_initializer_raw_data\n\n\ndef _export_meta(model, out_dir, strip_large_tensor_data):\n ret = {\n 'generated_at': datetime.datetime.now().isoformat(),\n 'output_directory': out_dir,\n 'exporter': 'torch-onnx-utils',\n 'strip_large_tensor_data': strip_large_tensor_data,\n }\n try:\n git_status = subprocess.Popen(['git', 'status'],\n stdout=subprocess.PIPE,\n stderr=subprocess.PIPE)\n git_status.communicate()\n\n def strip_cmd(cmd):\n return os.popen(cmd).read().strip()\n if git_status.returncode == 0:\n ret['git'] = {\n 'branch': strip_cmd('git rev-parse --abbrev-ref HEAD'),\n 'commit': strip_cmd('git rev-parse HEAD'),\n 'remote': strip_cmd('git ls-remote --get-url origin'),\n 'commit_date': strip_cmd('git show -s --format=%ci HEAD'),\n }\n except FileNotFoundError:\n pass\n\n return ret\n\n\ndef _export_util(model, args, f, **kwargs):\n \"\"\"Wrap operator type to export\n\n Copied from torch.onnx.utils.export, to get output values.\n \"\"\"\n aten = kwargs.get('aten', False)\n export_raw_ir = kwargs.get('export_raw_ir', False)\n operator_export_type = kwargs.get('operator_export_type', None)\n\n if aten or export_raw_ir:\n assert operator_export_type is None\n assert aten ^ export_raw_ir\n operator_export_type = OperatorExportTypes.ATEN if\\\n aten else OperatorExportTypes.RAW\n elif operator_export_type is None:\n if torch.onnx.PYTORCH_ONNX_CAFFE2_BUNDLE:\n operator_export_type = OperatorExportTypes.ONNX_ATEN_FALLBACK\n else:\n operator_export_type = OperatorExportTypes.ONNX\n\n return torch_export(model, args, f, _retain_param_name=True, **kwargs)\n\n\ndef _export(\n model, args, strip_large_tensor_data=False,\n large_tensor_threshold=LARGE_TENSOR_DATA_THRESHOLD, **kwargs):\n model.zero_grad()\n bytesio = io.BytesIO()\n opset_ver = kwargs.get('opset_version', None)\n if opset_ver is None:\n opset_ver = _default_onnx_opset_version\n strip_doc_string = kwargs.pop('strip_doc_string', True)\n with init_annotate(model, opset_ver) as ann:\n outs = _export_util(\n model, args, bytesio, strip_doc_string=False, **kwargs)\n onnx_graph = onnx.load(io.BytesIO(bytesio.getvalue()))\n onnx_graph = ann.set_annotate(onnx_graph)\n onnx_graph = ann.reorg_anchor(onnx_graph)\n if strip_doc_string:\n for node in onnx_graph.graph.node:\n node.doc_string = b''\n if strip_large_tensor_data:\n _strip_large_initializer_raw_data(onnx_graph, large_tensor_threshold)\n\n return onnx_graph, outs\n\n\ndef export(\n model, args, f, return_output=False, strip_large_tensor_data=False,\n large_tensor_threshold=LARGE_TENSOR_DATA_THRESHOLD, **kwargs):\n \"\"\"Export model into ONNX Graph.\n\n Args:\n f: A file-like object or a string file path to be written to this\n file.\n return_output (bool): If True, return output values come from the\n model.\n strip_large_tensor_data (bool): If True, this function will strip\n data of large tensors to reduce ONNX file size for benchmarking\n large_tensor_threshold (int): If number of elements of tensor is\n larger than this value, the tensor is stripped when\n *strip_large_tensor_data* is True\n \"\"\"\n onnx_graph, outs = _export(\n model, args, strip_large_tensor_data, large_tensor_threshold,\n **kwargs)\n\n if hasattr(f, 'write'):\n f.write(onnx_graph.SerializeToString())\n else:\n assert isinstance(f, str)\n warnings.warn(\n 'When export ONNX graph as file, \"export_testcase\" is '\n 'strongly recommended, please consider use it instead',\n UserWarning)\n with open(f, 'wb') as fp:\n fp.write(onnx_graph.SerializeToString())\n\n if return_output:\n return outs\n\n\ndef export_testcase(\n model, args, out_dir, *, output_grad=False, metadata=True,\n model_overwrite=True, strip_large_tensor_data=False,\n large_tensor_threshold=LARGE_TENSOR_DATA_THRESHOLD,\n return_output=False, **kwargs):\n \"\"\"Export model and I/O tensors of the model in protobuf format.\n\n Args:\n output_grad (bool or Tensor): If True, this function will output\n model's gradient with names 'gradient_%d.pb'. If set Tensor,\n use it as gradient *input*. The gradient inputs are output as\n 'gradient_input_%d.pb' along with gradient.\n metadata (bool): If True, output meta information taken from git log.\n model_overwrite (bool): If False and model.onnx has already existed,\n only export input/output data as another test dataset.\n strip_large_tensor_data (bool): If True, this function will strip\n data of large tensors to reduce ONNX file size for benchmarking\n large_tensor_threshold (int): If number of elements of tensor is\n larger than this value, the tensor is stripped when\n *strip_large_tensor_data* is True\n \"\"\"\n\n os.makedirs(out_dir, exist_ok=True)\n input_names = kwargs.pop(\n 'input_names',\n ['input_{}'.format(i) for i in range(len(args))])\n assert len(input_names) == len(args)\n\n onnx_graph, outs = _export(\n model, args, strip_large_tensor_data, large_tensor_threshold,\n input_names=input_names, **kwargs)\n if isinstance(args, torch.Tensor):\n args = args,\n if isinstance(outs, torch.Tensor):\n outs = outs,\n\n # Remove unused inputs\n # - When keep_initializers_as_inputs=True, inputs contains initializers.\n # So we have to filt initializers.\n # - model.onnx is already issued, so we can modify args here.\n initializer_names = [init.name for init in onnx_graph.graph.initializer]\n used_input_index_list = []\n for used_input in onnx_graph.graph.input:\n if used_input.name not in initializer_names:\n used_input_index_list.append(input_names.index(used_input.name))\n input_names = [input_names[i] for i in used_input_index_list]\n args = [args[i] for i in used_input_index_list]\n\n output_path = os.path.join(out_dir, 'model.onnx')\n is_on_memory = True\n if model_overwrite or (not os.path.isfile(output_path)):\n is_on_memory = False\n with open(output_path, 'wb') as fp:\n fp.write(onnx_graph.SerializeToString())\n\n def write_to_pb(f, tensor, name=None):\n array = tensor.detach().cpu().numpy()\n with open(f, 'wb') as fp:\n t = onnx.numpy_helper.from_array(array, name)\n if (strip_large_tensor_data and\n is_large_tensor(t, large_tensor_threshold)):\n _strip_raw_data(t)\n fp.write(t.SerializeToString())\n\n data_set_path = os.path.join(out_dir, 'test_data_set_0')\n seq_id = 0\n while is_on_memory and os.path.exists(data_set_path):\n seq_id += 1\n data_set_path = os.path.join(\n out_dir, 'test_data_set_{:d}'.format(seq_id))\n os.makedirs(data_set_path, exist_ok=True)\n for i, (arg, name) in enumerate(zip(args, input_names)):\n f = os.path.join(data_set_path, 'input_{}.pb'.format(i))\n write_to_pb(f, arg, name)\n\n output_names = kwargs.get('output_names')\n if output_names is None:\n if isinstance(outs, dict):\n output_names = outs.keys()\n else:\n output_names = [None] * len(outs)\n for i, name in enumerate(output_names):\n if isinstance(outs, dict):\n out = outs[name]\n else:\n out = outs[i]\n if isinstance(out, (list, tuple)):\n assert len(out) == 1, \\\n 'Models returning nested lists/tuples are not supported yet'\n out = out[0]\n f = os.path.join(data_set_path, 'output_{}.pb'.format(i))\n write_to_pb(f, out, name)\n\n if output_grad is not False:\n if isinstance(output_grad, bool):\n output_grad = [torch.ones_like(outs[idx])\n for idx in range(len(output_names))]\n if isinstance(output_grad, torch.Tensor):\n output_grad = [output_grad]\n for idx in range(len(output_names)):\n write_to_pb(\n os.path.join(data_set_path, 'gradient_input_{}.pb'.format(\n idx)), output_grad[idx],\n output_names[idx])\n if len(output_names) == len(outs):\n torch.autograd.backward(outs, grad_tensors=output_grad)\n else:\n assert len(\n output_names) == 1, 'Single output names is only supported'\n outs[0].backward(output_grad[0])\n\n for i, (name, param) in enumerate(model.named_parameters()):\n f = os.path.join(data_set_path, 'gradient_{}.pb'.format(i))\n # NOTE: name does not follow C identifier syntax rules,\n # like \"fc1.bias\", not cleanse for now\n if param.grad is None:\n warnings.warn(\n 'Parameter `{}` does not have gradient value'.format(name))\n else:\n write_to_pb(f, param.grad, name)\n\n if metadata:\n with open(os.path.join(out_dir, 'meta.json'), 'w') as f:\n json.dump(_export_meta(model, out_dir,\n strip_large_tensor_data), f, indent=2)\n\n if return_output:\n return outs\n", "path": "pytorch_pfn_extras/onnx/export_testcase.py"}]}
| 3,367 | 261 |
gh_patches_debug_28779
|
rasdani/github-patches
|
git_diff
|
PaddlePaddle__PaddleDetection-1960
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
当返回的roidbs为空时,卡在if isinstance(item, collections.Sequence) and len(item) == 0
def _load_batch(self):
batch = []
bs = 0
while bs != self._batch_size:
if self._pos >= self.size():
break
pos = self.indexes[self._pos]
sample = copy.deepcopy(self._roidbs[pos])
sample["curr_iter"] = self._curr_iter
self._pos += 1
if self._drop_empty and self._fields and 'gt_bbox' in sample:
if _has_empty(sample['gt_bbox']):
经自己测试 如果record有数据 但是roidbs里面bbox数据为[],会一直循环 跳不出去 望加个判断修复下
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ppdet/data/source/coco.py`
Content:
```
1 # Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import os
16 import numpy as np
17
18 from .dataset import DataSet
19 from ppdet.core.workspace import register, serializable
20
21 import logging
22 logger = logging.getLogger(__name__)
23
24
25 @register
26 @serializable
27 class COCODataSet(DataSet):
28 """
29 Load COCO records with annotations in json file 'anno_path'
30
31 Args:
32 dataset_dir (str): root directory for dataset.
33 image_dir (str): directory for images.
34 anno_path (str): json file path.
35 sample_num (int): number of samples to load, -1 means all.
36 with_background (bool): whether load background as a class.
37 if True, total class number will be 81. default True.
38 """
39
40 def __init__(self,
41 image_dir=None,
42 anno_path=None,
43 dataset_dir=None,
44 sample_num=-1,
45 with_background=True,
46 load_semantic=False):
47 super(COCODataSet, self).__init__(
48 image_dir=image_dir,
49 anno_path=anno_path,
50 dataset_dir=dataset_dir,
51 sample_num=sample_num,
52 with_background=with_background)
53 self.anno_path = anno_path
54 self.sample_num = sample_num
55 self.with_background = with_background
56 # `roidbs` is list of dict whose structure is:
57 # {
58 # 'im_file': im_fname, # image file name
59 # 'im_id': img_id, # image id
60 # 'h': im_h, # height of image
61 # 'w': im_w, # width
62 # 'is_crowd': is_crowd,
63 # 'gt_score': gt_score,
64 # 'gt_class': gt_class,
65 # 'gt_bbox': gt_bbox,
66 # 'gt_poly': gt_poly,
67 # }
68 self.roidbs = None
69 # a dict used to map category name to class id
70 self.cname2cid = None
71 self.load_image_only = False
72 self.load_semantic = load_semantic
73
74 def load_roidb_and_cname2cid(self):
75 anno_path = os.path.join(self.dataset_dir, self.anno_path)
76 image_dir = os.path.join(self.dataset_dir, self.image_dir)
77
78 assert anno_path.endswith('.json'), \
79 'invalid coco annotation file: ' + anno_path
80 from pycocotools.coco import COCO
81 coco = COCO(anno_path)
82 img_ids = coco.getImgIds()
83 cat_ids = coco.getCatIds()
84 records = []
85 ct = 0
86
87 # when with_background = True, mapping category to classid, like:
88 # background:0, first_class:1, second_class:2, ...
89 catid2clsid = dict({
90 catid: i + int(self.with_background)
91 for i, catid in enumerate(cat_ids)
92 })
93 cname2cid = dict({
94 coco.loadCats(catid)[0]['name']: clsid
95 for catid, clsid in catid2clsid.items()
96 })
97
98 if 'annotations' not in coco.dataset:
99 self.load_image_only = True
100 logger.warn('Annotation file: {} does not contains ground truth '
101 'and load image information only.'.format(anno_path))
102
103 for img_id in img_ids:
104 img_anno = coco.loadImgs(img_id)[0]
105 im_fname = img_anno['file_name']
106 im_w = float(img_anno['width'])
107 im_h = float(img_anno['height'])
108
109 im_path = os.path.join(image_dir,
110 im_fname) if image_dir else im_fname
111 if not os.path.exists(im_path):
112 logger.warn('Illegal image file: {}, and it will be '
113 'ignored'.format(im_path))
114 continue
115
116 if im_w < 0 or im_h < 0:
117 logger.warn('Illegal width: {} or height: {} in annotation, '
118 'and im_id: {} will be ignored'.format(im_w, im_h,
119 img_id))
120 continue
121
122 coco_rec = {
123 'im_file': im_path,
124 'im_id': np.array([img_id]),
125 'h': im_h,
126 'w': im_w,
127 }
128
129 if not self.load_image_only:
130 ins_anno_ids = coco.getAnnIds(imgIds=img_id, iscrowd=False)
131 instances = coco.loadAnns(ins_anno_ids)
132
133 bboxes = []
134 for inst in instances:
135 x, y, box_w, box_h = inst['bbox']
136 x1 = max(0, x)
137 y1 = max(0, y)
138 x2 = min(im_w - 1, x1 + max(0, box_w - 1))
139 y2 = min(im_h - 1, y1 + max(0, box_h - 1))
140 if x2 >= x1 and y2 >= y1:
141 inst['clean_bbox'] = [x1, y1, x2, y2]
142 bboxes.append(inst)
143 else:
144 logger.warn(
145 'Found an invalid bbox in annotations: im_id: {}, '
146 'x1: {}, y1: {}, x2: {}, y2: {}.'.format(
147 img_id, x1, y1, x2, y2))
148 num_bbox = len(bboxes)
149
150 gt_bbox = np.zeros((num_bbox, 4), dtype=np.float32)
151 gt_class = np.zeros((num_bbox, 1), dtype=np.int32)
152 gt_score = np.ones((num_bbox, 1), dtype=np.float32)
153 is_crowd = np.zeros((num_bbox, 1), dtype=np.int32)
154 difficult = np.zeros((num_bbox, 1), dtype=np.int32)
155 gt_poly = [None] * num_bbox
156
157 for i, box in enumerate(bboxes):
158 catid = box['category_id']
159 gt_class[i][0] = catid2clsid[catid]
160 gt_bbox[i, :] = box['clean_bbox']
161 is_crowd[i][0] = box['iscrowd']
162 if 'segmentation' in box:
163 gt_poly[i] = box['segmentation']
164
165 coco_rec.update({
166 'is_crowd': is_crowd,
167 'gt_class': gt_class,
168 'gt_bbox': gt_bbox,
169 'gt_score': gt_score,
170 'gt_poly': gt_poly,
171 })
172
173 if self.load_semantic:
174 seg_path = os.path.join(self.dataset_dir, 'stuffthingmaps',
175 'train2017', im_fname[:-3] + 'png')
176 coco_rec.update({'semantic': seg_path})
177
178 logger.debug('Load file: {}, im_id: {}, h: {}, w: {}.'.format(
179 im_path, img_id, im_h, im_w))
180 records.append(coco_rec)
181 ct += 1
182 if self.sample_num > 0 and ct >= self.sample_num:
183 break
184 assert len(records) > 0, 'not found any coco record in %s' % (anno_path)
185 logger.debug('{} samples in file {}'.format(ct, anno_path))
186 self.roidbs, self.cname2cid = records, cname2cid
187
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ppdet/data/source/coco.py b/ppdet/data/source/coco.py
--- a/ppdet/data/source/coco.py
+++ b/ppdet/data/source/coco.py
@@ -146,6 +146,8 @@
'x1: {}, y1: {}, x2: {}, y2: {}.'.format(
img_id, x1, y1, x2, y2))
num_bbox = len(bboxes)
+ if num_bbox <= 0:
+ continue
gt_bbox = np.zeros((num_bbox, 4), dtype=np.float32)
gt_class = np.zeros((num_bbox, 1), dtype=np.int32)
@@ -154,6 +156,7 @@
difficult = np.zeros((num_bbox, 1), dtype=np.int32)
gt_poly = [None] * num_bbox
+ has_segmentation = False
for i, box in enumerate(bboxes):
catid = box['category_id']
gt_class[i][0] = catid2clsid[catid]
@@ -161,6 +164,10 @@
is_crowd[i][0] = box['iscrowd']
if 'segmentation' in box:
gt_poly[i] = box['segmentation']
+ has_segmentation = True
+
+ if has_segmentation and not any(gt_poly):
+ continue
coco_rec.update({
'is_crowd': is_crowd,
|
{"golden_diff": "diff --git a/ppdet/data/source/coco.py b/ppdet/data/source/coco.py\n--- a/ppdet/data/source/coco.py\n+++ b/ppdet/data/source/coco.py\n@@ -146,6 +146,8 @@\n 'x1: {}, y1: {}, x2: {}, y2: {}.'.format(\n img_id, x1, y1, x2, y2))\n num_bbox = len(bboxes)\n+ if num_bbox <= 0:\n+ continue\n \n gt_bbox = np.zeros((num_bbox, 4), dtype=np.float32)\n gt_class = np.zeros((num_bbox, 1), dtype=np.int32)\n@@ -154,6 +156,7 @@\n difficult = np.zeros((num_bbox, 1), dtype=np.int32)\n gt_poly = [None] * num_bbox\n \n+ has_segmentation = False\n for i, box in enumerate(bboxes):\n catid = box['category_id']\n gt_class[i][0] = catid2clsid[catid]\n@@ -161,6 +164,10 @@\n is_crowd[i][0] = box['iscrowd']\n if 'segmentation' in box:\n gt_poly[i] = box['segmentation']\n+ has_segmentation = True\n+\n+ if has_segmentation and not any(gt_poly):\n+ continue\n \n coco_rec.update({\n 'is_crowd': is_crowd,\n", "issue": "\u5f53\u8fd4\u56de\u7684roidbs\u4e3a\u7a7a\u65f6\uff0c\u5361\u5728if isinstance(item, collections.Sequence) and len(item) == 0\n def _load_batch(self):\r\n batch = []\r\n bs = 0\r\n while bs != self._batch_size:\r\n if self._pos >= self.size():\r\n break\r\n pos = self.indexes[self._pos]\r\n sample = copy.deepcopy(self._roidbs[pos])\r\n sample[\"curr_iter\"] = self._curr_iter\r\n self._pos += 1\r\n\r\n if self._drop_empty and self._fields and 'gt_bbox' in sample:\r\n if _has_empty(sample['gt_bbox']):\r\n\r\n\u7ecf\u81ea\u5df1\u6d4b\u8bd5 \u5982\u679crecord\u6709\u6570\u636e \u4f46\u662froidbs\u91cc\u9762bbox\u6570\u636e\u4e3a[]\uff0c\u4f1a\u4e00\u76f4\u5faa\u73af \u8df3\u4e0d\u51fa\u53bb \u671b\u52a0\u4e2a\u5224\u65ad\u4fee\u590d\u4e0b\n", "before_files": [{"content": "# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\nimport numpy as np\n\nfrom .dataset import DataSet\nfrom ppdet.core.workspace import register, serializable\n\nimport logging\nlogger = logging.getLogger(__name__)\n\n\n@register\n@serializable\nclass COCODataSet(DataSet):\n \"\"\"\n Load COCO records with annotations in json file 'anno_path'\n\n Args:\n dataset_dir (str): root directory for dataset.\n image_dir (str): directory for images.\n anno_path (str): json file path.\n sample_num (int): number of samples to load, -1 means all.\n with_background (bool): whether load background as a class.\n if True, total class number will be 81. default True.\n \"\"\"\n\n def __init__(self,\n image_dir=None,\n anno_path=None,\n dataset_dir=None,\n sample_num=-1,\n with_background=True,\n load_semantic=False):\n super(COCODataSet, self).__init__(\n image_dir=image_dir,\n anno_path=anno_path,\n dataset_dir=dataset_dir,\n sample_num=sample_num,\n with_background=with_background)\n self.anno_path = anno_path\n self.sample_num = sample_num\n self.with_background = with_background\n # `roidbs` is list of dict whose structure is:\n # {\n # 'im_file': im_fname, # image file name\n # 'im_id': img_id, # image id\n # 'h': im_h, # height of image\n # 'w': im_w, # width\n # 'is_crowd': is_crowd,\n # 'gt_score': gt_score,\n # 'gt_class': gt_class,\n # 'gt_bbox': gt_bbox,\n # 'gt_poly': gt_poly,\n # }\n self.roidbs = None\n # a dict used to map category name to class id\n self.cname2cid = None\n self.load_image_only = False\n self.load_semantic = load_semantic\n\n def load_roidb_and_cname2cid(self):\n anno_path = os.path.join(self.dataset_dir, self.anno_path)\n image_dir = os.path.join(self.dataset_dir, self.image_dir)\n\n assert anno_path.endswith('.json'), \\\n 'invalid coco annotation file: ' + anno_path\n from pycocotools.coco import COCO\n coco = COCO(anno_path)\n img_ids = coco.getImgIds()\n cat_ids = coco.getCatIds()\n records = []\n ct = 0\n\n # when with_background = True, mapping category to classid, like:\n # background:0, first_class:1, second_class:2, ...\n catid2clsid = dict({\n catid: i + int(self.with_background)\n for i, catid in enumerate(cat_ids)\n })\n cname2cid = dict({\n coco.loadCats(catid)[0]['name']: clsid\n for catid, clsid in catid2clsid.items()\n })\n\n if 'annotations' not in coco.dataset:\n self.load_image_only = True\n logger.warn('Annotation file: {} does not contains ground truth '\n 'and load image information only.'.format(anno_path))\n\n for img_id in img_ids:\n img_anno = coco.loadImgs(img_id)[0]\n im_fname = img_anno['file_name']\n im_w = float(img_anno['width'])\n im_h = float(img_anno['height'])\n\n im_path = os.path.join(image_dir,\n im_fname) if image_dir else im_fname\n if not os.path.exists(im_path):\n logger.warn('Illegal image file: {}, and it will be '\n 'ignored'.format(im_path))\n continue\n\n if im_w < 0 or im_h < 0:\n logger.warn('Illegal width: {} or height: {} in annotation, '\n 'and im_id: {} will be ignored'.format(im_w, im_h,\n img_id))\n continue\n\n coco_rec = {\n 'im_file': im_path,\n 'im_id': np.array([img_id]),\n 'h': im_h,\n 'w': im_w,\n }\n\n if not self.load_image_only:\n ins_anno_ids = coco.getAnnIds(imgIds=img_id, iscrowd=False)\n instances = coco.loadAnns(ins_anno_ids)\n\n bboxes = []\n for inst in instances:\n x, y, box_w, box_h = inst['bbox']\n x1 = max(0, x)\n y1 = max(0, y)\n x2 = min(im_w - 1, x1 + max(0, box_w - 1))\n y2 = min(im_h - 1, y1 + max(0, box_h - 1))\n if x2 >= x1 and y2 >= y1:\n inst['clean_bbox'] = [x1, y1, x2, y2]\n bboxes.append(inst)\n else:\n logger.warn(\n 'Found an invalid bbox in annotations: im_id: {}, '\n 'x1: {}, y1: {}, x2: {}, y2: {}.'.format(\n img_id, x1, y1, x2, y2))\n num_bbox = len(bboxes)\n\n gt_bbox = np.zeros((num_bbox, 4), dtype=np.float32)\n gt_class = np.zeros((num_bbox, 1), dtype=np.int32)\n gt_score = np.ones((num_bbox, 1), dtype=np.float32)\n is_crowd = np.zeros((num_bbox, 1), dtype=np.int32)\n difficult = np.zeros((num_bbox, 1), dtype=np.int32)\n gt_poly = [None] * num_bbox\n\n for i, box in enumerate(bboxes):\n catid = box['category_id']\n gt_class[i][0] = catid2clsid[catid]\n gt_bbox[i, :] = box['clean_bbox']\n is_crowd[i][0] = box['iscrowd']\n if 'segmentation' in box:\n gt_poly[i] = box['segmentation']\n\n coco_rec.update({\n 'is_crowd': is_crowd,\n 'gt_class': gt_class,\n 'gt_bbox': gt_bbox,\n 'gt_score': gt_score,\n 'gt_poly': gt_poly,\n })\n\n if self.load_semantic:\n seg_path = os.path.join(self.dataset_dir, 'stuffthingmaps',\n 'train2017', im_fname[:-3] + 'png')\n coco_rec.update({'semantic': seg_path})\n\n logger.debug('Load file: {}, im_id: {}, h: {}, w: {}.'.format(\n im_path, img_id, im_h, im_w))\n records.append(coco_rec)\n ct += 1\n if self.sample_num > 0 and ct >= self.sample_num:\n break\n assert len(records) > 0, 'not found any coco record in %s' % (anno_path)\n logger.debug('{} samples in file {}'.format(ct, anno_path))\n self.roidbs, self.cname2cid = records, cname2cid\n", "path": "ppdet/data/source/coco.py"}], "after_files": [{"content": "# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\nimport numpy as np\n\nfrom .dataset import DataSet\nfrom ppdet.core.workspace import register, serializable\n\nimport logging\nlogger = logging.getLogger(__name__)\n\n\n@register\n@serializable\nclass COCODataSet(DataSet):\n \"\"\"\n Load COCO records with annotations in json file 'anno_path'\n\n Args:\n dataset_dir (str): root directory for dataset.\n image_dir (str): directory for images.\n anno_path (str): json file path.\n sample_num (int): number of samples to load, -1 means all.\n with_background (bool): whether load background as a class.\n if True, total class number will be 81. default True.\n \"\"\"\n\n def __init__(self,\n image_dir=None,\n anno_path=None,\n dataset_dir=None,\n sample_num=-1,\n with_background=True,\n load_semantic=False):\n super(COCODataSet, self).__init__(\n image_dir=image_dir,\n anno_path=anno_path,\n dataset_dir=dataset_dir,\n sample_num=sample_num,\n with_background=with_background)\n self.anno_path = anno_path\n self.sample_num = sample_num\n self.with_background = with_background\n # `roidbs` is list of dict whose structure is:\n # {\n # 'im_file': im_fname, # image file name\n # 'im_id': img_id, # image id\n # 'h': im_h, # height of image\n # 'w': im_w, # width\n # 'is_crowd': is_crowd,\n # 'gt_score': gt_score,\n # 'gt_class': gt_class,\n # 'gt_bbox': gt_bbox,\n # 'gt_poly': gt_poly,\n # }\n self.roidbs = None\n # a dict used to map category name to class id\n self.cname2cid = None\n self.load_image_only = False\n self.load_semantic = load_semantic\n\n def load_roidb_and_cname2cid(self):\n anno_path = os.path.join(self.dataset_dir, self.anno_path)\n image_dir = os.path.join(self.dataset_dir, self.image_dir)\n\n assert anno_path.endswith('.json'), \\\n 'invalid coco annotation file: ' + anno_path\n from pycocotools.coco import COCO\n coco = COCO(anno_path)\n img_ids = coco.getImgIds()\n cat_ids = coco.getCatIds()\n records = []\n ct = 0\n\n # when with_background = True, mapping category to classid, like:\n # background:0, first_class:1, second_class:2, ...\n catid2clsid = dict({\n catid: i + int(self.with_background)\n for i, catid in enumerate(cat_ids)\n })\n cname2cid = dict({\n coco.loadCats(catid)[0]['name']: clsid\n for catid, clsid in catid2clsid.items()\n })\n\n if 'annotations' not in coco.dataset:\n self.load_image_only = True\n logger.warn('Annotation file: {} does not contains ground truth '\n 'and load image information only.'.format(anno_path))\n\n for img_id in img_ids:\n img_anno = coco.loadImgs(img_id)[0]\n im_fname = img_anno['file_name']\n im_w = float(img_anno['width'])\n im_h = float(img_anno['height'])\n\n im_path = os.path.join(image_dir,\n im_fname) if image_dir else im_fname\n if not os.path.exists(im_path):\n logger.warn('Illegal image file: {}, and it will be '\n 'ignored'.format(im_path))\n continue\n\n if im_w < 0 or im_h < 0:\n logger.warn('Illegal width: {} or height: {} in annotation, '\n 'and im_id: {} will be ignored'.format(im_w, im_h,\n img_id))\n continue\n\n coco_rec = {\n 'im_file': im_path,\n 'im_id': np.array([img_id]),\n 'h': im_h,\n 'w': im_w,\n }\n\n if not self.load_image_only:\n ins_anno_ids = coco.getAnnIds(imgIds=img_id, iscrowd=False)\n instances = coco.loadAnns(ins_anno_ids)\n\n bboxes = []\n for inst in instances:\n x, y, box_w, box_h = inst['bbox']\n x1 = max(0, x)\n y1 = max(0, y)\n x2 = min(im_w - 1, x1 + max(0, box_w - 1))\n y2 = min(im_h - 1, y1 + max(0, box_h - 1))\n if x2 >= x1 and y2 >= y1:\n inst['clean_bbox'] = [x1, y1, x2, y2]\n bboxes.append(inst)\n else:\n logger.warn(\n 'Found an invalid bbox in annotations: im_id: {}, '\n 'x1: {}, y1: {}, x2: {}, y2: {}.'.format(\n img_id, x1, y1, x2, y2))\n num_bbox = len(bboxes)\n if num_bbox <= 0:\n continue\n\n gt_bbox = np.zeros((num_bbox, 4), dtype=np.float32)\n gt_class = np.zeros((num_bbox, 1), dtype=np.int32)\n gt_score = np.ones((num_bbox, 1), dtype=np.float32)\n is_crowd = np.zeros((num_bbox, 1), dtype=np.int32)\n difficult = np.zeros((num_bbox, 1), dtype=np.int32)\n gt_poly = [None] * num_bbox\n\n has_segmentation = False\n for i, box in enumerate(bboxes):\n catid = box['category_id']\n gt_class[i][0] = catid2clsid[catid]\n gt_bbox[i, :] = box['clean_bbox']\n is_crowd[i][0] = box['iscrowd']\n if 'segmentation' in box:\n gt_poly[i] = box['segmentation']\n has_segmentation = True\n\n if has_segmentation and not any(gt_poly):\n continue\n\n coco_rec.update({\n 'is_crowd': is_crowd,\n 'gt_class': gt_class,\n 'gt_bbox': gt_bbox,\n 'gt_score': gt_score,\n 'gt_poly': gt_poly,\n })\n\n if self.load_semantic:\n seg_path = os.path.join(self.dataset_dir, 'stuffthingmaps',\n 'train2017', im_fname[:-3] + 'png')\n coco_rec.update({'semantic': seg_path})\n\n logger.debug('Load file: {}, im_id: {}, h: {}, w: {}.'.format(\n im_path, img_id, im_h, im_w))\n records.append(coco_rec)\n ct += 1\n if self.sample_num > 0 and ct >= self.sample_num:\n break\n assert len(records) > 0, 'not found any coco record in %s' % (anno_path)\n logger.debug('{} samples in file {}'.format(ct, anno_path))\n self.roidbs, self.cname2cid = records, cname2cid\n", "path": "ppdet/data/source/coco.py"}]}
| 2,598 | 329 |
gh_patches_debug_58
|
rasdani/github-patches
|
git_diff
|
Anselmoo__spectrafit-701
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Bug]: ASCII Char in creating branch
### Is there an existing issue for this?
- [X] I have searched the existing issues
### Current Behavior
Is crashing
### Expected Behavior
Is realising a change in changeling
### Steps To Reproduce
_No response_
### ⚙️ Environment
```markdown
- OS:
- Python:
- spectrafit:
```
### Anything else?
_No response_
### Code of Conduct
- [X] I agree to follow this project's Code of Conduct
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `spectrafit/__init__.py`
Content:
```
1 """SpectraFit, fast command line tool for fitting data."""
2 __version__ = "1.0.0b1"
3
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/spectrafit/__init__.py b/spectrafit/__init__.py
--- a/spectrafit/__init__.py
+++ b/spectrafit/__init__.py
@@ -1,2 +1,2 @@
"""SpectraFit, fast command line tool for fitting data."""
-__version__ = "1.0.0b1"
+__version__ = "1.0.0b2"
|
{"golden_diff": "diff --git a/spectrafit/__init__.py b/spectrafit/__init__.py\n--- a/spectrafit/__init__.py\n+++ b/spectrafit/__init__.py\n@@ -1,2 +1,2 @@\n \"\"\"SpectraFit, fast command line tool for fitting data.\"\"\"\n-__version__ = \"1.0.0b1\"\n+__version__ = \"1.0.0b2\"\n", "issue": "[Bug]: ASCII Char in creating branch\n### Is there an existing issue for this?\n\n- [X] I have searched the existing issues\n\n### Current Behavior\n\nIs crashing\n\n### Expected Behavior\n\nIs realising a change in changeling\n\n### Steps To Reproduce\n\n_No response_\n\n### \u2699\ufe0f Environment\n\n```markdown\n- OS:\r\n- Python:\r\n- spectrafit:\n```\n\n\n### Anything else?\n\n_No response_\n\n### Code of Conduct\n\n- [X] I agree to follow this project's Code of Conduct\n", "before_files": [{"content": "\"\"\"SpectraFit, fast command line tool for fitting data.\"\"\"\n__version__ = \"1.0.0b1\"\n", "path": "spectrafit/__init__.py"}], "after_files": [{"content": "\"\"\"SpectraFit, fast command line tool for fitting data.\"\"\"\n__version__ = \"1.0.0b2\"\n", "path": "spectrafit/__init__.py"}]}
| 398 | 96 |
gh_patches_debug_35958
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-2644
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Spider advanceautoparts is broken
During the global build at 2021-05-21-20-28-08, spider **advanceautoparts** failed with **0 features** and **405 errors**.
Here's [the log](https://data.alltheplaces.xyz/runs/2021-05-21-20-28-08/logs/advanceautoparts.log) and [the output](https://data.alltheplaces.xyz/runs/2021-05-21-20-28-08/output/advanceautoparts.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-05-21-20-28-08/output/advanceautoparts.geojson))
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `locations/spiders/advanceautoparts.py`
Content:
```
1 import json
2 import re
3
4 import scrapy
5
6 from locations.hours import OpeningHours
7 from locations.items import GeojsonPointItem
8
9
10 class AdvanceautopartsSpider(scrapy.Spider):
11
12 name = "advanceautoparts"
13 item_attributes = {"brand": "Advance Auto Parts", "brand_wikidata": "Q4686051"}
14 allowed_domains = ["stores.advanceautoparts.com"]
15 start_urls = ("https://stores.advanceautoparts.com/sitemap.xml",)
16
17 def parse(self, response):
18 response.selector.remove_namespaces()
19 urls = response.xpath("//loc/text()").getall()
20 storeRe = re.compile(r"^https://stores.advanceautoparts.com/[^/]+/[^/]+/[^/]+$")
21 for url in urls:
22 if storeRe.fullmatch(url):
23 yield scrapy.Request(url, callback=self.parse_store)
24
25 def parse_hours(self, store_hours):
26 opening_hours = OpeningHours()
27
28 for weekday in store_hours:
29 day = weekday.get("day").title()
30 for interval in weekday.get("intervals", []):
31 open_time = str(interval.get("start"))
32 close_time = str(interval.get("end"))
33 opening_hours.add_range(
34 day=day[:2],
35 open_time=open_time,
36 close_time=close_time,
37 time_format="%H%M",
38 )
39
40 return opening_hours.as_opening_hours()
41
42 def parse_store(self, response):
43 name = response.xpath('//h1[@itemprop="name"]/text()').extract_first()
44
45 js = json.loads(response.xpath('//script[@class="js-map-config"]/text()').get())
46 ref = js["entities"][0]["profile"]["meta"]["id"]
47
48 hours = response.xpath(
49 '//div[@class="c-hours-details-wrapper js-hours-table"]/@data-days'
50 ).extract_first()
51 try:
52 opening_hours = self.parse_hours(json.loads(hours))
53 except ValueError:
54 opening_hours = None
55
56 properties = {
57 "addr_full": response.xpath(
58 'normalize-space(//meta[@itemprop="streetAddress"]/@content)'
59 ).extract_first(),
60 "phone": response.xpath(
61 'normalize-space(//div[@itemprop="telephone"]/text())'
62 ).extract_first(),
63 "city": response.xpath(
64 'normalize-space(//meta[@itemprop="addressLocality"]/@content)'
65 ).extract_first(),
66 "state": response.xpath(
67 'normalize-space(//abbr[@itemprop="addressRegion"]/text())'
68 ).extract_first(),
69 "postcode": response.xpath(
70 'normalize-space(//span[@itemprop="postalCode"]/text())'
71 ).extract_first(),
72 "ref": ref,
73 "website": response.url,
74 "lat": response.xpath(
75 'normalize-space(//meta[@itemprop="latitude"]/@content)'
76 ).extract_first(),
77 "lon": response.xpath(
78 'normalize-space(//meta[@itemprop="longitude"]/@content)'
79 ).extract_first(),
80 "name": name,
81 "opening_hours": opening_hours,
82 "extras": {"shop": "car_parts"},
83 }
84 yield GeojsonPointItem(**properties)
85
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/locations/spiders/advanceautoparts.py b/locations/spiders/advanceautoparts.py
--- a/locations/spiders/advanceautoparts.py
+++ b/locations/spiders/advanceautoparts.py
@@ -45,38 +45,22 @@
js = json.loads(response.xpath('//script[@class="js-map-config"]/text()').get())
ref = js["entities"][0]["profile"]["meta"]["id"]
- hours = response.xpath(
- '//div[@class="c-hours-details-wrapper js-hours-table"]/@data-days'
- ).extract_first()
+ hours = response.xpath('//div[@class="c-hours-details-wrapper js-hours-table"]/@data-days').extract_first()
try:
opening_hours = self.parse_hours(json.loads(hours))
except ValueError:
opening_hours = None
properties = {
- "addr_full": response.xpath(
- 'normalize-space(//meta[@itemprop="streetAddress"]/@content)'
- ).extract_first(),
- "phone": response.xpath(
- 'normalize-space(//div[@itemprop="telephone"]/text())'
- ).extract_first(),
- "city": response.xpath(
- 'normalize-space(//meta[@itemprop="addressLocality"]/@content)'
- ).extract_first(),
- "state": response.xpath(
- 'normalize-space(//abbr[@itemprop="addressRegion"]/text())'
- ).extract_first(),
- "postcode": response.xpath(
- 'normalize-space(//span[@itemprop="postalCode"]/text())'
- ).extract_first(),
+ "addr_full": response.xpath('normalize-space(//meta[@itemprop="streetAddress"]/@content)').extract_first(),
+ "phone": response.xpath('normalize-space(//div[@itemprop="telephone"]/text())').extract_first(),
+ "city": response.xpath('normalize-space(//meta[@itemprop="addressLocality"]/@content)').extract_first(),
+ "state": response.xpath('normalize-space(//abbr[@itemprop="addressRegion"]/text())').extract_first(),
+ "postcode": response.xpath('normalize-space(//span[@itemprop="postalCode"]/text())').extract_first(),
"ref": ref,
"website": response.url,
- "lat": response.xpath(
- 'normalize-space(//meta[@itemprop="latitude"]/@content)'
- ).extract_first(),
- "lon": response.xpath(
- 'normalize-space(//meta[@itemprop="longitude"]/@content)'
- ).extract_first(),
+ "lat": response.xpath('normalize-space(//meta[@itemprop="latitude"]/@content)').extract_first(),
+ "lon": response.xpath('normalize-space(//meta[@itemprop="longitude"]/@content)').extract_first(),
"name": name,
"opening_hours": opening_hours,
"extras": {"shop": "car_parts"},
|
{"golden_diff": "diff --git a/locations/spiders/advanceautoparts.py b/locations/spiders/advanceautoparts.py\n--- a/locations/spiders/advanceautoparts.py\n+++ b/locations/spiders/advanceautoparts.py\n@@ -45,38 +45,22 @@\n js = json.loads(response.xpath('//script[@class=\"js-map-config\"]/text()').get())\n ref = js[\"entities\"][0][\"profile\"][\"meta\"][\"id\"]\n \n- hours = response.xpath(\n- '//div[@class=\"c-hours-details-wrapper js-hours-table\"]/@data-days'\n- ).extract_first()\n+ hours = response.xpath('//div[@class=\"c-hours-details-wrapper js-hours-table\"]/@data-days').extract_first()\n try:\n opening_hours = self.parse_hours(json.loads(hours))\n except ValueError:\n opening_hours = None\n \n properties = {\n- \"addr_full\": response.xpath(\n- 'normalize-space(//meta[@itemprop=\"streetAddress\"]/@content)'\n- ).extract_first(),\n- \"phone\": response.xpath(\n- 'normalize-space(//div[@itemprop=\"telephone\"]/text())'\n- ).extract_first(),\n- \"city\": response.xpath(\n- 'normalize-space(//meta[@itemprop=\"addressLocality\"]/@content)'\n- ).extract_first(),\n- \"state\": response.xpath(\n- 'normalize-space(//abbr[@itemprop=\"addressRegion\"]/text())'\n- ).extract_first(),\n- \"postcode\": response.xpath(\n- 'normalize-space(//span[@itemprop=\"postalCode\"]/text())'\n- ).extract_first(),\n+ \"addr_full\": response.xpath('normalize-space(//meta[@itemprop=\"streetAddress\"]/@content)').extract_first(),\n+ \"phone\": response.xpath('normalize-space(//div[@itemprop=\"telephone\"]/text())').extract_first(),\n+ \"city\": response.xpath('normalize-space(//meta[@itemprop=\"addressLocality\"]/@content)').extract_first(),\n+ \"state\": response.xpath('normalize-space(//abbr[@itemprop=\"addressRegion\"]/text())').extract_first(),\n+ \"postcode\": response.xpath('normalize-space(//span[@itemprop=\"postalCode\"]/text())').extract_first(),\n \"ref\": ref,\n \"website\": response.url,\n- \"lat\": response.xpath(\n- 'normalize-space(//meta[@itemprop=\"latitude\"]/@content)'\n- ).extract_first(),\n- \"lon\": response.xpath(\n- 'normalize-space(//meta[@itemprop=\"longitude\"]/@content)'\n- ).extract_first(),\n+ \"lat\": response.xpath('normalize-space(//meta[@itemprop=\"latitude\"]/@content)').extract_first(),\n+ \"lon\": response.xpath('normalize-space(//meta[@itemprop=\"longitude\"]/@content)').extract_first(),\n \"name\": name,\n \"opening_hours\": opening_hours,\n \"extras\": {\"shop\": \"car_parts\"},\n", "issue": "Spider advanceautoparts is broken\nDuring the global build at 2021-05-21-20-28-08, spider **advanceautoparts** failed with **0 features** and **405 errors**.\n\nHere's [the log](https://data.alltheplaces.xyz/runs/2021-05-21-20-28-08/logs/advanceautoparts.log) and [the output](https://data.alltheplaces.xyz/runs/2021-05-21-20-28-08/output/advanceautoparts.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-05-21-20-28-08/output/advanceautoparts.geojson))\n", "before_files": [{"content": "import json\nimport re\n\nimport scrapy\n\nfrom locations.hours import OpeningHours\nfrom locations.items import GeojsonPointItem\n\n\nclass AdvanceautopartsSpider(scrapy.Spider):\n\n name = \"advanceautoparts\"\n item_attributes = {\"brand\": \"Advance Auto Parts\", \"brand_wikidata\": \"Q4686051\"}\n allowed_domains = [\"stores.advanceautoparts.com\"]\n start_urls = (\"https://stores.advanceautoparts.com/sitemap.xml\",)\n\n def parse(self, response):\n response.selector.remove_namespaces()\n urls = response.xpath(\"//loc/text()\").getall()\n storeRe = re.compile(r\"^https://stores.advanceautoparts.com/[^/]+/[^/]+/[^/]+$\")\n for url in urls:\n if storeRe.fullmatch(url):\n yield scrapy.Request(url, callback=self.parse_store)\n\n def parse_hours(self, store_hours):\n opening_hours = OpeningHours()\n\n for weekday in store_hours:\n day = weekday.get(\"day\").title()\n for interval in weekday.get(\"intervals\", []):\n open_time = str(interval.get(\"start\"))\n close_time = str(interval.get(\"end\"))\n opening_hours.add_range(\n day=day[:2],\n open_time=open_time,\n close_time=close_time,\n time_format=\"%H%M\",\n )\n\n return opening_hours.as_opening_hours()\n\n def parse_store(self, response):\n name = response.xpath('//h1[@itemprop=\"name\"]/text()').extract_first()\n\n js = json.loads(response.xpath('//script[@class=\"js-map-config\"]/text()').get())\n ref = js[\"entities\"][0][\"profile\"][\"meta\"][\"id\"]\n\n hours = response.xpath(\n '//div[@class=\"c-hours-details-wrapper js-hours-table\"]/@data-days'\n ).extract_first()\n try:\n opening_hours = self.parse_hours(json.loads(hours))\n except ValueError:\n opening_hours = None\n\n properties = {\n \"addr_full\": response.xpath(\n 'normalize-space(//meta[@itemprop=\"streetAddress\"]/@content)'\n ).extract_first(),\n \"phone\": response.xpath(\n 'normalize-space(//div[@itemprop=\"telephone\"]/text())'\n ).extract_first(),\n \"city\": response.xpath(\n 'normalize-space(//meta[@itemprop=\"addressLocality\"]/@content)'\n ).extract_first(),\n \"state\": response.xpath(\n 'normalize-space(//abbr[@itemprop=\"addressRegion\"]/text())'\n ).extract_first(),\n \"postcode\": response.xpath(\n 'normalize-space(//span[@itemprop=\"postalCode\"]/text())'\n ).extract_first(),\n \"ref\": ref,\n \"website\": response.url,\n \"lat\": response.xpath(\n 'normalize-space(//meta[@itemprop=\"latitude\"]/@content)'\n ).extract_first(),\n \"lon\": response.xpath(\n 'normalize-space(//meta[@itemprop=\"longitude\"]/@content)'\n ).extract_first(),\n \"name\": name,\n \"opening_hours\": opening_hours,\n \"extras\": {\"shop\": \"car_parts\"},\n }\n yield GeojsonPointItem(**properties)\n", "path": "locations/spiders/advanceautoparts.py"}], "after_files": [{"content": "import json\nimport re\n\nimport scrapy\n\nfrom locations.hours import OpeningHours\nfrom locations.items import GeojsonPointItem\n\n\nclass AdvanceautopartsSpider(scrapy.Spider):\n\n name = \"advanceautoparts\"\n item_attributes = {\"brand\": \"Advance Auto Parts\", \"brand_wikidata\": \"Q4686051\"}\n allowed_domains = [\"stores.advanceautoparts.com\"]\n start_urls = (\"https://stores.advanceautoparts.com/sitemap.xml\",)\n\n def parse(self, response):\n response.selector.remove_namespaces()\n urls = response.xpath(\"//loc/text()\").getall()\n storeRe = re.compile(r\"^https://stores.advanceautoparts.com/[^/]+/[^/]+/[^/]+$\")\n for url in urls:\n if storeRe.fullmatch(url):\n yield scrapy.Request(url, callback=self.parse_store)\n\n def parse_hours(self, store_hours):\n opening_hours = OpeningHours()\n\n for weekday in store_hours:\n day = weekday.get(\"day\").title()\n for interval in weekday.get(\"intervals\", []):\n open_time = str(interval.get(\"start\"))\n close_time = str(interval.get(\"end\"))\n opening_hours.add_range(\n day=day[:2],\n open_time=open_time,\n close_time=close_time,\n time_format=\"%H%M\",\n )\n\n return opening_hours.as_opening_hours()\n\n def parse_store(self, response):\n name = response.xpath('//h1[@itemprop=\"name\"]/text()').extract_first()\n\n js = json.loads(response.xpath('//script[@class=\"js-map-config\"]/text()').get())\n ref = js[\"entities\"][0][\"profile\"][\"meta\"][\"id\"]\n\n hours = response.xpath('//div[@class=\"c-hours-details-wrapper js-hours-table\"]/@data-days').extract_first()\n try:\n opening_hours = self.parse_hours(json.loads(hours))\n except ValueError:\n opening_hours = None\n\n properties = {\n \"addr_full\": response.xpath('normalize-space(//meta[@itemprop=\"streetAddress\"]/@content)').extract_first(),\n \"phone\": response.xpath('normalize-space(//div[@itemprop=\"telephone\"]/text())').extract_first(),\n \"city\": response.xpath('normalize-space(//meta[@itemprop=\"addressLocality\"]/@content)').extract_first(),\n \"state\": response.xpath('normalize-space(//abbr[@itemprop=\"addressRegion\"]/text())').extract_first(),\n \"postcode\": response.xpath('normalize-space(//span[@itemprop=\"postalCode\"]/text())').extract_first(),\n \"ref\": ref,\n \"website\": response.url,\n \"lat\": response.xpath('normalize-space(//meta[@itemprop=\"latitude\"]/@content)').extract_first(),\n \"lon\": response.xpath('normalize-space(//meta[@itemprop=\"longitude\"]/@content)').extract_first(),\n \"name\": name,\n \"opening_hours\": opening_hours,\n \"extras\": {\"shop\": \"car_parts\"},\n }\n yield GeojsonPointItem(**properties)\n", "path": "locations/spiders/advanceautoparts.py"}]}
| 1,286 | 627 |
gh_patches_debug_24842
|
rasdani/github-patches
|
git_diff
|
Kinto__kinto-667
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Relax record id validation
Do we really need to ensure that posted record ids match a uuid regex?
We can generate a uuid when a record without id is posted, and leave the usage of uuid in our official clients.
But is there any reason to use a different regex that collection and bucket names?
edit: The usecase is the Web sync extension chrome.storage.sync: since any key is accepted, it takes the md5 of the key to "generate" UUIDs. Instead we could let the client push any key as record id.
- Related #140
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kinto/views/records.py`
Content:
```
1 import copy
2
3 import jsonschema
4 from kinto.core import resource
5 from kinto.core.errors import raise_invalid
6 from jsonschema import exceptions as jsonschema_exceptions
7 from pyramid.security import Authenticated
8 from pyramid.settings import asbool
9
10 from kinto.views import object_exists_or_404
11
12
13 class RecordSchema(resource.ResourceSchema):
14 class Options:
15 preserve_unknown = True
16
17
18 _parent_path = '/buckets/{{bucket_id}}/collections/{{collection_id}}'
19
20
21 @resource.register(name='record',
22 collection_path=_parent_path + '/records',
23 record_path=_parent_path + '/records/{{id}}')
24 class Record(resource.ShareableResource):
25
26 mapping = RecordSchema()
27 schema_field = 'schema'
28
29 def __init__(self, *args, **kwargs):
30 super(Record, self).__init__(*args, **kwargs)
31
32 # Check if already fetched before (in batch).
33 collections = self.request.bound_data.setdefault('collections', {})
34 collection_uri = self.get_parent_id(self.request)
35 if collection_uri not in collections:
36 # Unknown yet, fetch from storage.
37 collection_parent_id = '/buckets/%s' % self.bucket_id
38 collection = object_exists_or_404(self.request,
39 collection_id='collection',
40 parent_id=collection_parent_id,
41 object_id=self.collection_id)
42 collections[collection_uri] = collection
43
44 self._collection = collections[collection_uri]
45
46 def get_parent_id(self, request):
47 self.bucket_id = request.matchdict['bucket_id']
48 self.collection_id = request.matchdict['collection_id']
49 return '/buckets/%s/collections/%s' % (self.bucket_id,
50 self.collection_id)
51
52 def is_known_field(self, field_name):
53 """Without schema, any field is considered as known."""
54 return True
55
56 def process_record(self, new, old=None):
57 """Validate records against collection schema, if any."""
58 new = super(Record, self).process_record(new, old)
59
60 schema = self._collection.get('schema')
61 settings = self.request.registry.settings
62 schema_validation = 'experimental_collection_schema_validation'
63 if not schema or not asbool(settings.get(schema_validation)):
64 return new
65
66 collection_timestamp = self._collection[self.model.modified_field]
67
68 try:
69 stripped = copy.deepcopy(new)
70 stripped.pop(self.model.id_field, None)
71 stripped.pop(self.model.modified_field, None)
72 stripped.pop(self.model.permissions_field, None)
73 stripped.pop(self.schema_field, None)
74 jsonschema.validate(stripped, schema)
75 except jsonschema_exceptions.ValidationError as e:
76 try:
77 field = e.path.pop() if e.path else e.validator_value.pop()
78 except AttributeError:
79 field = None
80 raise_invalid(self.request, name=field, description=e.message)
81
82 new[self.schema_field] = collection_timestamp
83 return new
84
85 def collection_get(self):
86 result = super(Record, self).collection_get()
87 self._handle_cache_expires(self.request.response)
88 return result
89
90 def get(self):
91 result = super(Record, self).get()
92 self._handle_cache_expires(self.request.response)
93 return result
94
95 def _handle_cache_expires(self, response):
96 """If the parent collection defines a ``cache_expires`` attribute,
97 then cache-control response headers are sent.
98
99 .. note::
100
101 Those headers are also sent if the
102 ``kinto.record_cache_expires_seconds`` setting is defined.
103 """
104 is_anonymous = Authenticated not in self.request.effective_principals
105 if not is_anonymous:
106 return
107
108 cache_expires = self._collection.get('cache_expires')
109 if cache_expires is None:
110 by_bucket = '%s_record_cache_expires_seconds' % (self.bucket_id)
111 by_collection = '%s_%s_record_cache_expires_seconds' % (
112 self.bucket_id, self.collection_id)
113 settings = self.request.registry.settings
114 cache_expires = settings.get(by_collection,
115 settings.get(by_bucket))
116
117 if cache_expires is not None:
118 response.cache_expires(seconds=int(cache_expires))
119
```
Path: `kinto/views/__init__.py`
Content:
```
1 import random
2 import string
3
4 from kinto.core.storage import generators, exceptions
5 from pyramid import httpexceptions
6
7
8 class NameGenerator(generators.Generator):
9 def __call__(self):
10 ascii_letters = ('abcdefghijklmopqrstuvwxyz'
11 'ABCDEFGHIJKLMOPQRSTUVWXYZ')
12 alphabet = ascii_letters + string.digits + '-_'
13 letters = [random.choice(ascii_letters + string.digits)]
14 letters += [random.choice(alphabet) for x in range(7)]
15 return ''.join(letters)
16
17
18 def object_exists_or_404(request, collection_id, object_id, parent_id=''):
19 storage = request.registry.storage
20 try:
21 return storage.get(collection_id=collection_id,
22 parent_id=parent_id,
23 object_id=object_id)
24 except exceptions.RecordNotFoundError:
25 # XXX: We gave up putting details about parent id here (See #53).
26 raise httpexceptions.HTTPNotFound()
27
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kinto/views/__init__.py b/kinto/views/__init__.py
--- a/kinto/views/__init__.py
+++ b/kinto/views/__init__.py
@@ -15,6 +15,12 @@
return ''.join(letters)
+class RelaxedUUID(generators.UUID4):
+ """A generator that generates UUIDs but accepts any string.
+ """
+ regexp = generators.Generator.regexp
+
+
def object_exists_or_404(request, collection_id, object_id, parent_id=''):
storage = request.registry.storage
try:
diff --git a/kinto/views/records.py b/kinto/views/records.py
--- a/kinto/views/records.py
+++ b/kinto/views/records.py
@@ -7,7 +7,7 @@
from pyramid.security import Authenticated
from pyramid.settings import asbool
-from kinto.views import object_exists_or_404
+from kinto.views import RelaxedUUID, object_exists_or_404
class RecordSchema(resource.ResourceSchema):
@@ -29,6 +29,8 @@
def __init__(self, *args, **kwargs):
super(Record, self).__init__(*args, **kwargs)
+ self.model.id_generator = RelaxedUUID()
+
# Check if already fetched before (in batch).
collections = self.request.bound_data.setdefault('collections', {})
collection_uri = self.get_parent_id(self.request)
|
{"golden_diff": "diff --git a/kinto/views/__init__.py b/kinto/views/__init__.py\n--- a/kinto/views/__init__.py\n+++ b/kinto/views/__init__.py\n@@ -15,6 +15,12 @@\n return ''.join(letters)\n \n \n+class RelaxedUUID(generators.UUID4):\n+ \"\"\"A generator that generates UUIDs but accepts any string.\n+ \"\"\"\n+ regexp = generators.Generator.regexp\n+\n+\n def object_exists_or_404(request, collection_id, object_id, parent_id=''):\n storage = request.registry.storage\n try:\ndiff --git a/kinto/views/records.py b/kinto/views/records.py\n--- a/kinto/views/records.py\n+++ b/kinto/views/records.py\n@@ -7,7 +7,7 @@\n from pyramid.security import Authenticated\n from pyramid.settings import asbool\n \n-from kinto.views import object_exists_or_404\n+from kinto.views import RelaxedUUID, object_exists_or_404\n \n \n class RecordSchema(resource.ResourceSchema):\n@@ -29,6 +29,8 @@\n def __init__(self, *args, **kwargs):\n super(Record, self).__init__(*args, **kwargs)\n \n+ self.model.id_generator = RelaxedUUID()\n+\n # Check if already fetched before (in batch).\n collections = self.request.bound_data.setdefault('collections', {})\n collection_uri = self.get_parent_id(self.request)\n", "issue": "Relax record id validation\nDo we really need to ensure that posted record ids match a uuid regex?\n\nWe can generate a uuid when a record without id is posted, and leave the usage of uuid in our official clients.\nBut is there any reason to use a different regex that collection and bucket names?\n\nedit: The usecase is the Web sync extension chrome.storage.sync: since any key is accepted, it takes the md5 of the key to \"generate\" UUIDs. Instead we could let the client push any key as record id.\n- Related #140 \n\n", "before_files": [{"content": "import copy\n\nimport jsonschema\nfrom kinto.core import resource\nfrom kinto.core.errors import raise_invalid\nfrom jsonschema import exceptions as jsonschema_exceptions\nfrom pyramid.security import Authenticated\nfrom pyramid.settings import asbool\n\nfrom kinto.views import object_exists_or_404\n\n\nclass RecordSchema(resource.ResourceSchema):\n class Options:\n preserve_unknown = True\n\n\n_parent_path = '/buckets/{{bucket_id}}/collections/{{collection_id}}'\n\n\[email protected](name='record',\n collection_path=_parent_path + '/records',\n record_path=_parent_path + '/records/{{id}}')\nclass Record(resource.ShareableResource):\n\n mapping = RecordSchema()\n schema_field = 'schema'\n\n def __init__(self, *args, **kwargs):\n super(Record, self).__init__(*args, **kwargs)\n\n # Check if already fetched before (in batch).\n collections = self.request.bound_data.setdefault('collections', {})\n collection_uri = self.get_parent_id(self.request)\n if collection_uri not in collections:\n # Unknown yet, fetch from storage.\n collection_parent_id = '/buckets/%s' % self.bucket_id\n collection = object_exists_or_404(self.request,\n collection_id='collection',\n parent_id=collection_parent_id,\n object_id=self.collection_id)\n collections[collection_uri] = collection\n\n self._collection = collections[collection_uri]\n\n def get_parent_id(self, request):\n self.bucket_id = request.matchdict['bucket_id']\n self.collection_id = request.matchdict['collection_id']\n return '/buckets/%s/collections/%s' % (self.bucket_id,\n self.collection_id)\n\n def is_known_field(self, field_name):\n \"\"\"Without schema, any field is considered as known.\"\"\"\n return True\n\n def process_record(self, new, old=None):\n \"\"\"Validate records against collection schema, if any.\"\"\"\n new = super(Record, self).process_record(new, old)\n\n schema = self._collection.get('schema')\n settings = self.request.registry.settings\n schema_validation = 'experimental_collection_schema_validation'\n if not schema or not asbool(settings.get(schema_validation)):\n return new\n\n collection_timestamp = self._collection[self.model.modified_field]\n\n try:\n stripped = copy.deepcopy(new)\n stripped.pop(self.model.id_field, None)\n stripped.pop(self.model.modified_field, None)\n stripped.pop(self.model.permissions_field, None)\n stripped.pop(self.schema_field, None)\n jsonschema.validate(stripped, schema)\n except jsonschema_exceptions.ValidationError as e:\n try:\n field = e.path.pop() if e.path else e.validator_value.pop()\n except AttributeError:\n field = None\n raise_invalid(self.request, name=field, description=e.message)\n\n new[self.schema_field] = collection_timestamp\n return new\n\n def collection_get(self):\n result = super(Record, self).collection_get()\n self._handle_cache_expires(self.request.response)\n return result\n\n def get(self):\n result = super(Record, self).get()\n self._handle_cache_expires(self.request.response)\n return result\n\n def _handle_cache_expires(self, response):\n \"\"\"If the parent collection defines a ``cache_expires`` attribute,\n then cache-control response headers are sent.\n\n .. note::\n\n Those headers are also sent if the\n ``kinto.record_cache_expires_seconds`` setting is defined.\n \"\"\"\n is_anonymous = Authenticated not in self.request.effective_principals\n if not is_anonymous:\n return\n\n cache_expires = self._collection.get('cache_expires')\n if cache_expires is None:\n by_bucket = '%s_record_cache_expires_seconds' % (self.bucket_id)\n by_collection = '%s_%s_record_cache_expires_seconds' % (\n self.bucket_id, self.collection_id)\n settings = self.request.registry.settings\n cache_expires = settings.get(by_collection,\n settings.get(by_bucket))\n\n if cache_expires is not None:\n response.cache_expires(seconds=int(cache_expires))\n", "path": "kinto/views/records.py"}, {"content": "import random\nimport string\n\nfrom kinto.core.storage import generators, exceptions\nfrom pyramid import httpexceptions\n\n\nclass NameGenerator(generators.Generator):\n def __call__(self):\n ascii_letters = ('abcdefghijklmopqrstuvwxyz'\n 'ABCDEFGHIJKLMOPQRSTUVWXYZ')\n alphabet = ascii_letters + string.digits + '-_'\n letters = [random.choice(ascii_letters + string.digits)]\n letters += [random.choice(alphabet) for x in range(7)]\n return ''.join(letters)\n\n\ndef object_exists_or_404(request, collection_id, object_id, parent_id=''):\n storage = request.registry.storage\n try:\n return storage.get(collection_id=collection_id,\n parent_id=parent_id,\n object_id=object_id)\n except exceptions.RecordNotFoundError:\n # XXX: We gave up putting details about parent id here (See #53).\n raise httpexceptions.HTTPNotFound()\n", "path": "kinto/views/__init__.py"}], "after_files": [{"content": "import copy\n\nimport jsonschema\nfrom kinto.core import resource\nfrom kinto.core.errors import raise_invalid\nfrom jsonschema import exceptions as jsonschema_exceptions\nfrom pyramid.security import Authenticated\nfrom pyramid.settings import asbool\n\nfrom kinto.views import RelaxedUUID, object_exists_or_404\n\n\nclass RecordSchema(resource.ResourceSchema):\n class Options:\n preserve_unknown = True\n\n\n_parent_path = '/buckets/{{bucket_id}}/collections/{{collection_id}}'\n\n\[email protected](name='record',\n collection_path=_parent_path + '/records',\n record_path=_parent_path + '/records/{{id}}')\nclass Record(resource.ShareableResource):\n\n mapping = RecordSchema()\n schema_field = 'schema'\n\n def __init__(self, *args, **kwargs):\n super(Record, self).__init__(*args, **kwargs)\n\n self.model.id_generator = RelaxedUUID()\n\n # Check if already fetched before (in batch).\n collections = self.request.bound_data.setdefault('collections', {})\n collection_uri = self.get_parent_id(self.request)\n if collection_uri not in collections:\n # Unknown yet, fetch from storage.\n collection_parent_id = '/buckets/%s' % self.bucket_id\n collection = object_exists_or_404(self.request,\n collection_id='collection',\n parent_id=collection_parent_id,\n object_id=self.collection_id)\n collections[collection_uri] = collection\n\n self._collection = collections[collection_uri]\n\n def get_parent_id(self, request):\n self.bucket_id = request.matchdict['bucket_id']\n self.collection_id = request.matchdict['collection_id']\n return '/buckets/%s/collections/%s' % (self.bucket_id,\n self.collection_id)\n\n def is_known_field(self, field_name):\n \"\"\"Without schema, any field is considered as known.\"\"\"\n return True\n\n def process_record(self, new, old=None):\n \"\"\"Validate records against collection schema, if any.\"\"\"\n new = super(Record, self).process_record(new, old)\n\n schema = self._collection.get('schema')\n settings = self.request.registry.settings\n schema_validation = 'experimental_collection_schema_validation'\n if not schema or not asbool(settings.get(schema_validation)):\n return new\n\n collection_timestamp = self._collection[self.model.modified_field]\n\n try:\n stripped = copy.deepcopy(new)\n stripped.pop(self.model.id_field, None)\n stripped.pop(self.model.modified_field, None)\n stripped.pop(self.model.permissions_field, None)\n stripped.pop(self.schema_field, None)\n jsonschema.validate(stripped, schema)\n except jsonschema_exceptions.ValidationError as e:\n try:\n field = e.path.pop() if e.path else e.validator_value.pop()\n except AttributeError:\n field = None\n raise_invalid(self.request, name=field, description=e.message)\n\n new[self.schema_field] = collection_timestamp\n return new\n\n def collection_get(self):\n result = super(Record, self).collection_get()\n self._handle_cache_expires(self.request.response)\n return result\n\n def get(self):\n result = super(Record, self).get()\n self._handle_cache_expires(self.request.response)\n return result\n\n def _handle_cache_expires(self, response):\n \"\"\"If the parent collection defines a ``cache_expires`` attribute,\n then cache-control response headers are sent.\n\n .. note::\n\n Those headers are also sent if the\n ``kinto.record_cache_expires_seconds`` setting is defined.\n \"\"\"\n is_anonymous = Authenticated not in self.request.effective_principals\n if not is_anonymous:\n return\n\n cache_expires = self._collection.get('cache_expires')\n if cache_expires is None:\n by_bucket = '%s_record_cache_expires_seconds' % (self.bucket_id)\n by_collection = '%s_%s_record_cache_expires_seconds' % (\n self.bucket_id, self.collection_id)\n settings = self.request.registry.settings\n cache_expires = settings.get(by_collection,\n settings.get(by_bucket))\n\n if cache_expires is not None:\n response.cache_expires(seconds=int(cache_expires))\n", "path": "kinto/views/records.py"}, {"content": "import random\nimport string\n\nfrom kinto.core.storage import generators, exceptions\nfrom pyramid import httpexceptions\n\n\nclass NameGenerator(generators.Generator):\n def __call__(self):\n ascii_letters = ('abcdefghijklmopqrstuvwxyz'\n 'ABCDEFGHIJKLMOPQRSTUVWXYZ')\n alphabet = ascii_letters + string.digits + '-_'\n letters = [random.choice(ascii_letters + string.digits)]\n letters += [random.choice(alphabet) for x in range(7)]\n return ''.join(letters)\n\n\nclass RelaxedUUID(generators.UUID4):\n \"\"\"A generator that generates UUIDs but accepts any string.\n \"\"\"\n regexp = generators.Generator.regexp\n\n\ndef object_exists_or_404(request, collection_id, object_id, parent_id=''):\n storage = request.registry.storage\n try:\n return storage.get(collection_id=collection_id,\n parent_id=parent_id,\n object_id=object_id)\n except exceptions.RecordNotFoundError:\n # XXX: We gave up putting details about parent id here (See #53).\n raise httpexceptions.HTTPNotFound()\n", "path": "kinto/views/__init__.py"}]}
| 1,764 | 316 |
gh_patches_debug_50905
|
rasdani/github-patches
|
git_diff
|
pymedusa__Medusa-6208
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[APP SUBMITTED]: TypeError: cannot use a string pattern on a bytes-like object
### INFO
**Python Version**: `3.7.2 (default, Jan 3 2019, 02:55:40) [GCC 8.2.0]`
**Operating System**: `Linux-4.9.35-v7+-armv7l-with-debian-buster-sid`
**Locale**: `UTF-8`
**Branch**: [develop](../tree/develop)
**Database**: `44.14`
**Commit**: pymedusa/Medusa@18bd87dded99e1ecfbeae7757e226ea5510e0f96
**Link to Log**: https://gist.github.com/4421b6f5dd716b24746e97ed3008b0c4
### ERROR
<pre>
2019-02-10 19:30:40 ERROR SNATCHQUEUE-SNATCH-526 :: [18bd87d] Snatch failed! For result: The.Office.(US).S03.1080p.WEB-DL.AAC2.0.AVC-TrollHD
Traceback (most recent call last):
File "/home/pi/Medusa/<a href="../blob/18bd87dded99e1ecfbeae7757e226ea5510e0f96/medusa/search/queue.py#L503">medusa/search/queue.py</a>", line 503, in run
self.success = snatch_episode(result)
File "/home/pi/Medusa/<a href="../blob/18bd87dded99e1ecfbeae7757e226ea5510e0f96/medusa/search/core.py#L132">medusa/search/core.py</a>", line 132, in snatch_episode
nzb_data = result.provider.download_nzb_for_post(result)
File "/home/pi/Medusa/<a href="../blob/18bd87dded99e1ecfbeae7757e226ea5510e0f96/medusa/providers/nzb/binsearch.py#L275">medusa/providers/nzb/binsearch.py</a>", line 275, in download_nzb_for_post
if not BinSearchProvider.nzb_check_segment.search(response.content):
TypeError: cannot use a string pattern on a bytes-like object
</pre>
---
_STAFF NOTIFIED_: @pymedusa/support @pymedusa/moderators
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `medusa/providers/nzb/binsearch.py`
Content:
```
1 # coding=utf-8
2
3 """Provider code for Binsearch provider."""
4
5 from __future__ import unicode_literals
6
7 import logging
8 import re
9 from builtins import zip
10 from os.path import join
11
12 from medusa import tv
13 from medusa.bs4_parser import BS4Parser
14 from medusa.helper.common import convert_size, sanitize_filename
15 from medusa.helpers import download_file
16 from medusa.logger.adapters.style import BraceAdapter
17 from medusa.providers.nzb.nzb_provider import NZBProvider
18
19 from requests.compat import urljoin
20
21 log = BraceAdapter(logging.getLogger(__name__))
22 log.logger.addHandler(logging.NullHandler())
23
24
25 class BinSearchProvider(NZBProvider):
26 """BinSearch Newznab provider."""
27
28 size_regex = re.compile(r'size: (\d+\.\d+\xa0\w{2}), parts', re.I)
29 title_regex = re.compile(r'\"([^\"]+)"', re.I)
30 title_reqex_clean = re.compile(r'^[ \d_]+ (.+)')
31 title_regex_rss = re.compile(r'- \"([^\"]+)"', re.I)
32 nzb_check_segment = re.compile(r'<segment bytes="[\d]+"')
33
34 def __init__(self):
35 """Initialize the class."""
36 super(BinSearchProvider, self).__init__('BinSearch')
37
38 # Credentials
39 self.public = True
40
41 # URLs
42 self.url = 'https://www.binsearch.info'
43 self.urls = {
44 'search': urljoin(self.url, 'index.php'),
45 'rss': urljoin(self.url, 'browse.php'),
46 }
47
48 # Proper Strings
49 self.proper_strings = ['PROPER', 'REPACK', 'REAL', 'RERIP']
50
51 # Miscellaneous Options
52
53 # Cache
54 self.cache = tv.Cache(self, min_time=10)
55
56 def search(self, search_strings, **kwargs):
57 """
58 Search a provider and parse the results.
59
60 :param search_strings: A dict with mode (key) and the search value (value)
61 :returns: A list of search results (structure)
62 """
63 results = []
64 search_params = {
65 'adv_age': '',
66 'xminsize': 20,
67 'max': 250,
68 }
69 groups = [1, 2]
70
71 for mode in search_strings:
72 log.debug('Search mode: {0}', mode)
73 # https://www.binsearch.info/browse.php?bg=alt.binaries.teevee&server=2
74 for search_string in search_strings[mode]:
75 search_params['q'] = search_string
76 for group in groups:
77 # Try both 'search in the most popular groups' & 'search in the other groups' modes
78 search_params['server'] = group
79 if mode != 'RSS':
80 log.debug('Search string: {search}', {'search': search_string})
81 search_url = self.urls['search']
82 else:
83 search_params = {
84 'bg': 'alt.binaries.teevee',
85 'server': 2,
86 'max': 50,
87 }
88 search_url = self.urls['rss']
89
90 response = self.session.get(search_url, params=search_params)
91 if not response or not response.text:
92 log.debug('No data returned from provider')
93 continue
94
95 results += self.parse(response.text, mode)
96
97 return results
98
99 def parse(self, data, mode):
100 """
101 Parse search results for items.
102
103 :param data: The raw response from a search
104 :param mode: The current mode used to search, e.g. RSS
105
106 :return: A list of items found
107 """
108 def process_column_header(td):
109 return td.get_text(strip=True).lower()
110
111 items = []
112
113 with BS4Parser(data, 'html5lib') as html:
114
115 # We need to store the post url, to be used with every result later on.
116 post_url = html.find('form', {'method': 'post'})['action']
117
118 table = html.find('table', class_='xMenuT')
119 rows = table('tr') if table else []
120 row_offset = 1
121 if not rows or not len(rows) - row_offset:
122 log.debug('Data returned from provider does not contain any torrents')
123 return items
124
125 headers = rows[0]('th')
126 # 0, 1, subject, poster, group, age
127 labels = [process_column_header(header) or idx
128 for idx, header in enumerate(headers)]
129
130 # Skip column headers
131 rows = rows[row_offset:]
132 for row in rows:
133 try:
134 col = dict(list(zip(labels, row('td'))))
135 nzb_id_input = col[0 if mode == 'RSS' else 1].find('input')
136 if not nzb_id_input:
137 continue
138 nzb_id = nzb_id_input['name']
139 # Try and get the the article subject from the weird binsearch format
140 title = self.clean_title(col['subject'].text, mode)
141
142 except AttributeError:
143 log.debug('Parsing rows, that may not always have useful info. Skipping to next.')
144 continue
145 if not all([title, nzb_id]):
146 continue
147
148 # Obtain the size from the 'description'
149 size_field = BinSearchProvider.size_regex.search(col['subject'].text)
150 if size_field:
151 size_field = size_field.group(1)
152 size = convert_size(size_field, sep='\xa0') or -1
153 size = int(size)
154
155 download_url = urljoin(self.url, '{post_url}|nzb_id={nzb_id}'.format(post_url=post_url, nzb_id=nzb_id))
156
157 # For future use
158 # detail_url = 'https://www.binsearch.info/?q={0}'.format(title)
159 human_time = True
160 date = col['age' if mode != 'RSS' else 'date'].get_text(strip=True).replace('-', ' ')
161 if mode == 'RSS':
162 human_time = False
163 pubdate_raw = date
164 pubdate = self.parse_pubdate(pubdate_raw, human_time=human_time)
165
166 item = {
167 'title': title,
168 'link': download_url,
169 'size': size,
170 'pubdate': pubdate,
171 }
172 if mode != 'RSS':
173 log.debug('Found result: {0}', title)
174
175 items.append(item)
176
177 return items
178
179 @staticmethod
180 def clean_title(title, mode):
181 """
182 Clean title field, using a series of regex.
183
184 RSS search requires different cleaning then the other searches.
185 When adding to this function, make sure you update the tests.
186 """
187 try:
188 if mode == 'RSS':
189 title = BinSearchProvider.title_regex_rss.search(title).group(1)
190 else:
191 title = BinSearchProvider.title_regex.search(title).group(1)
192 if BinSearchProvider.title_reqex_clean.search(title):
193 title = BinSearchProvider.title_reqex_clean.search(title).group(1)
194 for extension in ('.nfo', '.par2', '.rar', '.zip', '.nzb', '.part'):
195 # Strip extensions that aren't part of the file name
196 if title.endswith(extension):
197 title = title[:len(title) - len(extension)]
198 return title
199 except AttributeError:
200 return None
201
202 def download_result(self, result):
203 """
204 Download result from provider.
205
206 This is used when a blackhole is used for sending the nzb file to the nzb client.
207 For now the url and the post data is stored as one string in the db, using a pipe (|) to separate them.
208
209 :param result: A SearchResult object.
210 :return: The result of the nzb download (True/False).
211 """
212 if not self.login():
213 return False
214
215 result_name = sanitize_filename(result.name)
216 filename = join(self._get_storage_dir(), result_name + '.' + self.provider_type)
217
218 if result.url.startswith('http'):
219 self.session.headers.update({
220 'Referer': '/'.join(result.url.split('/')[:3]) + '/'
221 })
222
223 log.info('Downloading {result} from {provider} at {url}',
224 {'result': result.name, 'provider': self.name, 'url': result.url})
225
226 verify = False if self.public else None
227
228 url, data = result.url.split('|')
229
230 data = {
231 data.split('=')[1]: 'on',
232 'action': 'nzb',
233 }
234
235 if download_file(url, filename, method='POST', data=data, session=self.session,
236 headers=self.headers, verify=verify):
237
238 if self._verify_download(filename):
239 log.info('Saved {result} to {location}',
240 {'result': result.name, 'location': filename})
241 return True
242
243 return False
244
245 def download_nzb_for_post(self, result):
246 """
247 Download the nzb content, prior to sending it to the nzb download client.
248
249 :param result: Nzb SearchResult object.
250 :return: The content of the nzb file if successful else None.
251 """
252 if not self.login():
253 return False
254
255 # For now to separate the url and the post data, where splitting it with a pipe.
256 url, data = result.url.split('|')
257
258 data = {
259 data.split('=')[1]: 'on',
260 'action': 'nzb',
261 }
262
263 log.info('Downloading {result} from {provider} at {url} and data {data}',
264 {'result': result.name, 'provider': self.name, 'url': result.url, 'data': data})
265
266 verify = False if self.public else None
267
268 response = self.session.post(url, data=data, headers=self.session.headers,
269 verify=verify, hooks={}, allow_redirects=True)
270 if not response or not response.content:
271 log.warning('Failed to download the NZB from BinSearch')
272 return None
273
274 # Validate that the result has the content of a valid nzb.
275 if not BinSearchProvider.nzb_check_segment.search(response.content):
276 log.warning('Result returned from BinSearch was not a valid NZB')
277 return None
278
279 return response.content
280
281 def _get_size(self, item):
282 """
283 Get result size.
284
285 Overwrite this, as the default _get_size() from nzb_provider isn't working for us.
286 :param item:
287 :return: size in bytes or -1
288 """
289 return item.get('size', -1)
290
291
292 provider = BinSearchProvider()
293
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/medusa/providers/nzb/binsearch.py b/medusa/providers/nzb/binsearch.py
--- a/medusa/providers/nzb/binsearch.py
+++ b/medusa/providers/nzb/binsearch.py
@@ -272,7 +272,7 @@
return None
# Validate that the result has the content of a valid nzb.
- if not BinSearchProvider.nzb_check_segment.search(response.content):
+ if not BinSearchProvider.nzb_check_segment.search(response.text):
log.warning('Result returned from BinSearch was not a valid NZB')
return None
|
{"golden_diff": "diff --git a/medusa/providers/nzb/binsearch.py b/medusa/providers/nzb/binsearch.py\n--- a/medusa/providers/nzb/binsearch.py\n+++ b/medusa/providers/nzb/binsearch.py\n@@ -272,7 +272,7 @@\n return None\n \n # Validate that the result has the content of a valid nzb.\n- if not BinSearchProvider.nzb_check_segment.search(response.content):\n+ if not BinSearchProvider.nzb_check_segment.search(response.text):\n log.warning('Result returned from BinSearch was not a valid NZB')\n return None\n", "issue": "[APP SUBMITTED]: TypeError: cannot use a string pattern on a bytes-like object\n\n### INFO\n**Python Version**: `3.7.2 (default, Jan 3 2019, 02:55:40) [GCC 8.2.0]`\n**Operating System**: `Linux-4.9.35-v7+-armv7l-with-debian-buster-sid`\n**Locale**: `UTF-8`\n**Branch**: [develop](../tree/develop)\n**Database**: `44.14`\n**Commit**: pymedusa/Medusa@18bd87dded99e1ecfbeae7757e226ea5510e0f96\n**Link to Log**: https://gist.github.com/4421b6f5dd716b24746e97ed3008b0c4\n### ERROR\n<pre>\n2019-02-10 19:30:40 ERROR SNATCHQUEUE-SNATCH-526 :: [18bd87d] Snatch failed! For result: The.Office.(US).S03.1080p.WEB-DL.AAC2.0.AVC-TrollHD\nTraceback (most recent call last):\n File \"/home/pi/Medusa/<a href=\"../blob/18bd87dded99e1ecfbeae7757e226ea5510e0f96/medusa/search/queue.py#L503\">medusa/search/queue.py</a>\", line 503, in run\n self.success = snatch_episode(result)\n File \"/home/pi/Medusa/<a href=\"../blob/18bd87dded99e1ecfbeae7757e226ea5510e0f96/medusa/search/core.py#L132\">medusa/search/core.py</a>\", line 132, in snatch_episode\n nzb_data = result.provider.download_nzb_for_post(result)\n File \"/home/pi/Medusa/<a href=\"../blob/18bd87dded99e1ecfbeae7757e226ea5510e0f96/medusa/providers/nzb/binsearch.py#L275\">medusa/providers/nzb/binsearch.py</a>\", line 275, in download_nzb_for_post\n if not BinSearchProvider.nzb_check_segment.search(response.content):\nTypeError: cannot use a string pattern on a bytes-like object\n</pre>\n---\n_STAFF NOTIFIED_: @pymedusa/support @pymedusa/moderators\n\n", "before_files": [{"content": "# coding=utf-8\n\n\"\"\"Provider code for Binsearch provider.\"\"\"\n\nfrom __future__ import unicode_literals\n\nimport logging\nimport re\nfrom builtins import zip\nfrom os.path import join\n\nfrom medusa import tv\nfrom medusa.bs4_parser import BS4Parser\nfrom medusa.helper.common import convert_size, sanitize_filename\nfrom medusa.helpers import download_file\nfrom medusa.logger.adapters.style import BraceAdapter\nfrom medusa.providers.nzb.nzb_provider import NZBProvider\n\nfrom requests.compat import urljoin\n\nlog = BraceAdapter(logging.getLogger(__name__))\nlog.logger.addHandler(logging.NullHandler())\n\n\nclass BinSearchProvider(NZBProvider):\n \"\"\"BinSearch Newznab provider.\"\"\"\n\n size_regex = re.compile(r'size: (\\d+\\.\\d+\\xa0\\w{2}), parts', re.I)\n title_regex = re.compile(r'\\\"([^\\\"]+)\"', re.I)\n title_reqex_clean = re.compile(r'^[ \\d_]+ (.+)')\n title_regex_rss = re.compile(r'- \\\"([^\\\"]+)\"', re.I)\n nzb_check_segment = re.compile(r'<segment bytes=\"[\\d]+\"')\n\n def __init__(self):\n \"\"\"Initialize the class.\"\"\"\n super(BinSearchProvider, self).__init__('BinSearch')\n\n # Credentials\n self.public = True\n\n # URLs\n self.url = 'https://www.binsearch.info'\n self.urls = {\n 'search': urljoin(self.url, 'index.php'),\n 'rss': urljoin(self.url, 'browse.php'),\n }\n\n # Proper Strings\n self.proper_strings = ['PROPER', 'REPACK', 'REAL', 'RERIP']\n\n # Miscellaneous Options\n\n # Cache\n self.cache = tv.Cache(self, min_time=10)\n\n def search(self, search_strings, **kwargs):\n \"\"\"\n Search a provider and parse the results.\n\n :param search_strings: A dict with mode (key) and the search value (value)\n :returns: A list of search results (structure)\n \"\"\"\n results = []\n search_params = {\n 'adv_age': '',\n 'xminsize': 20,\n 'max': 250,\n }\n groups = [1, 2]\n\n for mode in search_strings:\n log.debug('Search mode: {0}', mode)\n # https://www.binsearch.info/browse.php?bg=alt.binaries.teevee&server=2\n for search_string in search_strings[mode]:\n search_params['q'] = search_string\n for group in groups:\n # Try both 'search in the most popular groups' & 'search in the other groups' modes\n search_params['server'] = group\n if mode != 'RSS':\n log.debug('Search string: {search}', {'search': search_string})\n search_url = self.urls['search']\n else:\n search_params = {\n 'bg': 'alt.binaries.teevee',\n 'server': 2,\n 'max': 50,\n }\n search_url = self.urls['rss']\n\n response = self.session.get(search_url, params=search_params)\n if not response or not response.text:\n log.debug('No data returned from provider')\n continue\n\n results += self.parse(response.text, mode)\n\n return results\n\n def parse(self, data, mode):\n \"\"\"\n Parse search results for items.\n\n :param data: The raw response from a search\n :param mode: The current mode used to search, e.g. RSS\n\n :return: A list of items found\n \"\"\"\n def process_column_header(td):\n return td.get_text(strip=True).lower()\n\n items = []\n\n with BS4Parser(data, 'html5lib') as html:\n\n # We need to store the post url, to be used with every result later on.\n post_url = html.find('form', {'method': 'post'})['action']\n\n table = html.find('table', class_='xMenuT')\n rows = table('tr') if table else []\n row_offset = 1\n if not rows or not len(rows) - row_offset:\n log.debug('Data returned from provider does not contain any torrents')\n return items\n\n headers = rows[0]('th')\n # 0, 1, subject, poster, group, age\n labels = [process_column_header(header) or idx\n for idx, header in enumerate(headers)]\n\n # Skip column headers\n rows = rows[row_offset:]\n for row in rows:\n try:\n col = dict(list(zip(labels, row('td'))))\n nzb_id_input = col[0 if mode == 'RSS' else 1].find('input')\n if not nzb_id_input:\n continue\n nzb_id = nzb_id_input['name']\n # Try and get the the article subject from the weird binsearch format\n title = self.clean_title(col['subject'].text, mode)\n\n except AttributeError:\n log.debug('Parsing rows, that may not always have useful info. Skipping to next.')\n continue\n if not all([title, nzb_id]):\n continue\n\n # Obtain the size from the 'description'\n size_field = BinSearchProvider.size_regex.search(col['subject'].text)\n if size_field:\n size_field = size_field.group(1)\n size = convert_size(size_field, sep='\\xa0') or -1\n size = int(size)\n\n download_url = urljoin(self.url, '{post_url}|nzb_id={nzb_id}'.format(post_url=post_url, nzb_id=nzb_id))\n\n # For future use\n # detail_url = 'https://www.binsearch.info/?q={0}'.format(title)\n human_time = True\n date = col['age' if mode != 'RSS' else 'date'].get_text(strip=True).replace('-', ' ')\n if mode == 'RSS':\n human_time = False\n pubdate_raw = date\n pubdate = self.parse_pubdate(pubdate_raw, human_time=human_time)\n\n item = {\n 'title': title,\n 'link': download_url,\n 'size': size,\n 'pubdate': pubdate,\n }\n if mode != 'RSS':\n log.debug('Found result: {0}', title)\n\n items.append(item)\n\n return items\n\n @staticmethod\n def clean_title(title, mode):\n \"\"\"\n Clean title field, using a series of regex.\n\n RSS search requires different cleaning then the other searches.\n When adding to this function, make sure you update the tests.\n \"\"\"\n try:\n if mode == 'RSS':\n title = BinSearchProvider.title_regex_rss.search(title).group(1)\n else:\n title = BinSearchProvider.title_regex.search(title).group(1)\n if BinSearchProvider.title_reqex_clean.search(title):\n title = BinSearchProvider.title_reqex_clean.search(title).group(1)\n for extension in ('.nfo', '.par2', '.rar', '.zip', '.nzb', '.part'):\n # Strip extensions that aren't part of the file name\n if title.endswith(extension):\n title = title[:len(title) - len(extension)]\n return title\n except AttributeError:\n return None\n\n def download_result(self, result):\n \"\"\"\n Download result from provider.\n\n This is used when a blackhole is used for sending the nzb file to the nzb client.\n For now the url and the post data is stored as one string in the db, using a pipe (|) to separate them.\n\n :param result: A SearchResult object.\n :return: The result of the nzb download (True/False).\n \"\"\"\n if not self.login():\n return False\n\n result_name = sanitize_filename(result.name)\n filename = join(self._get_storage_dir(), result_name + '.' + self.provider_type)\n\n if result.url.startswith('http'):\n self.session.headers.update({\n 'Referer': '/'.join(result.url.split('/')[:3]) + '/'\n })\n\n log.info('Downloading {result} from {provider} at {url}',\n {'result': result.name, 'provider': self.name, 'url': result.url})\n\n verify = False if self.public else None\n\n url, data = result.url.split('|')\n\n data = {\n data.split('=')[1]: 'on',\n 'action': 'nzb',\n }\n\n if download_file(url, filename, method='POST', data=data, session=self.session,\n headers=self.headers, verify=verify):\n\n if self._verify_download(filename):\n log.info('Saved {result} to {location}',\n {'result': result.name, 'location': filename})\n return True\n\n return False\n\n def download_nzb_for_post(self, result):\n \"\"\"\n Download the nzb content, prior to sending it to the nzb download client.\n\n :param result: Nzb SearchResult object.\n :return: The content of the nzb file if successful else None.\n \"\"\"\n if not self.login():\n return False\n\n # For now to separate the url and the post data, where splitting it with a pipe.\n url, data = result.url.split('|')\n\n data = {\n data.split('=')[1]: 'on',\n 'action': 'nzb',\n }\n\n log.info('Downloading {result} from {provider} at {url} and data {data}',\n {'result': result.name, 'provider': self.name, 'url': result.url, 'data': data})\n\n verify = False if self.public else None\n\n response = self.session.post(url, data=data, headers=self.session.headers,\n verify=verify, hooks={}, allow_redirects=True)\n if not response or not response.content:\n log.warning('Failed to download the NZB from BinSearch')\n return None\n\n # Validate that the result has the content of a valid nzb.\n if not BinSearchProvider.nzb_check_segment.search(response.content):\n log.warning('Result returned from BinSearch was not a valid NZB')\n return None\n\n return response.content\n\n def _get_size(self, item):\n \"\"\"\n Get result size.\n\n Overwrite this, as the default _get_size() from nzb_provider isn't working for us.\n :param item:\n :return: size in bytes or -1\n \"\"\"\n return item.get('size', -1)\n\n\nprovider = BinSearchProvider()\n", "path": "medusa/providers/nzb/binsearch.py"}], "after_files": [{"content": "# coding=utf-8\n\n\"\"\"Provider code for Binsearch provider.\"\"\"\n\nfrom __future__ import unicode_literals\n\nimport logging\nimport re\nfrom builtins import zip\nfrom os.path import join\n\nfrom medusa import tv\nfrom medusa.bs4_parser import BS4Parser\nfrom medusa.helper.common import convert_size, sanitize_filename\nfrom medusa.helpers import download_file\nfrom medusa.logger.adapters.style import BraceAdapter\nfrom medusa.providers.nzb.nzb_provider import NZBProvider\n\nfrom requests.compat import urljoin\n\nlog = BraceAdapter(logging.getLogger(__name__))\nlog.logger.addHandler(logging.NullHandler())\n\n\nclass BinSearchProvider(NZBProvider):\n \"\"\"BinSearch Newznab provider.\"\"\"\n\n size_regex = re.compile(r'size: (\\d+\\.\\d+\\xa0\\w{2}), parts', re.I)\n title_regex = re.compile(r'\\\"([^\\\"]+)\"', re.I)\n title_reqex_clean = re.compile(r'^[ \\d_]+ (.+)')\n title_regex_rss = re.compile(r'- \\\"([^\\\"]+)\"', re.I)\n nzb_check_segment = re.compile(r'<segment bytes=\"[\\d]+\"')\n\n def __init__(self):\n \"\"\"Initialize the class.\"\"\"\n super(BinSearchProvider, self).__init__('BinSearch')\n\n # Credentials\n self.public = True\n\n # URLs\n self.url = 'https://www.binsearch.info'\n self.urls = {\n 'search': urljoin(self.url, 'index.php'),\n 'rss': urljoin(self.url, 'browse.php'),\n }\n\n # Proper Strings\n self.proper_strings = ['PROPER', 'REPACK', 'REAL', 'RERIP']\n\n # Miscellaneous Options\n\n # Cache\n self.cache = tv.Cache(self, min_time=10)\n\n def search(self, search_strings, **kwargs):\n \"\"\"\n Search a provider and parse the results.\n\n :param search_strings: A dict with mode (key) and the search value (value)\n :returns: A list of search results (structure)\n \"\"\"\n results = []\n search_params = {\n 'adv_age': '',\n 'xminsize': 20,\n 'max': 250,\n }\n groups = [1, 2]\n\n for mode in search_strings:\n log.debug('Search mode: {0}', mode)\n # https://www.binsearch.info/browse.php?bg=alt.binaries.teevee&server=2\n for search_string in search_strings[mode]:\n search_params['q'] = search_string\n for group in groups:\n # Try both 'search in the most popular groups' & 'search in the other groups' modes\n search_params['server'] = group\n if mode != 'RSS':\n log.debug('Search string: {search}', {'search': search_string})\n search_url = self.urls['search']\n else:\n search_params = {\n 'bg': 'alt.binaries.teevee',\n 'server': 2,\n 'max': 50,\n }\n search_url = self.urls['rss']\n\n response = self.session.get(search_url, params=search_params)\n if not response or not response.text:\n log.debug('No data returned from provider')\n continue\n\n results += self.parse(response.text, mode)\n\n return results\n\n def parse(self, data, mode):\n \"\"\"\n Parse search results for items.\n\n :param data: The raw response from a search\n :param mode: The current mode used to search, e.g. RSS\n\n :return: A list of items found\n \"\"\"\n def process_column_header(td):\n return td.get_text(strip=True).lower()\n\n items = []\n\n with BS4Parser(data, 'html5lib') as html:\n\n # We need to store the post url, to be used with every result later on.\n post_url = html.find('form', {'method': 'post'})['action']\n\n table = html.find('table', class_='xMenuT')\n rows = table('tr') if table else []\n row_offset = 1\n if not rows or not len(rows) - row_offset:\n log.debug('Data returned from provider does not contain any torrents')\n return items\n\n headers = rows[0]('th')\n # 0, 1, subject, poster, group, age\n labels = [process_column_header(header) or idx\n for idx, header in enumerate(headers)]\n\n # Skip column headers\n rows = rows[row_offset:]\n for row in rows:\n try:\n col = dict(list(zip(labels, row('td'))))\n nzb_id_input = col[0 if mode == 'RSS' else 1].find('input')\n if not nzb_id_input:\n continue\n nzb_id = nzb_id_input['name']\n # Try and get the the article subject from the weird binsearch format\n title = self.clean_title(col['subject'].text, mode)\n\n except AttributeError:\n log.debug('Parsing rows, that may not always have useful info. Skipping to next.')\n continue\n if not all([title, nzb_id]):\n continue\n\n # Obtain the size from the 'description'\n size_field = BinSearchProvider.size_regex.search(col['subject'].text)\n if size_field:\n size_field = size_field.group(1)\n size = convert_size(size_field, sep='\\xa0') or -1\n size = int(size)\n\n download_url = urljoin(self.url, '{post_url}|nzb_id={nzb_id}'.format(post_url=post_url, nzb_id=nzb_id))\n\n # For future use\n # detail_url = 'https://www.binsearch.info/?q={0}'.format(title)\n human_time = True\n date = col['age' if mode != 'RSS' else 'date'].get_text(strip=True).replace('-', ' ')\n if mode == 'RSS':\n human_time = False\n pubdate_raw = date\n pubdate = self.parse_pubdate(pubdate_raw, human_time=human_time)\n\n item = {\n 'title': title,\n 'link': download_url,\n 'size': size,\n 'pubdate': pubdate,\n }\n if mode != 'RSS':\n log.debug('Found result: {0}', title)\n\n items.append(item)\n\n return items\n\n @staticmethod\n def clean_title(title, mode):\n \"\"\"\n Clean title field, using a series of regex.\n\n RSS search requires different cleaning then the other searches.\n When adding to this function, make sure you update the tests.\n \"\"\"\n try:\n if mode == 'RSS':\n title = BinSearchProvider.title_regex_rss.search(title).group(1)\n else:\n title = BinSearchProvider.title_regex.search(title).group(1)\n if BinSearchProvider.title_reqex_clean.search(title):\n title = BinSearchProvider.title_reqex_clean.search(title).group(1)\n for extension in ('.nfo', '.par2', '.rar', '.zip', '.nzb', '.part'):\n # Strip extensions that aren't part of the file name\n if title.endswith(extension):\n title = title[:len(title) - len(extension)]\n return title\n except AttributeError:\n return None\n\n def download_result(self, result):\n \"\"\"\n Download result from provider.\n\n This is used when a blackhole is used for sending the nzb file to the nzb client.\n For now the url and the post data is stored as one string in the db, using a pipe (|) to separate them.\n\n :param result: A SearchResult object.\n :return: The result of the nzb download (True/False).\n \"\"\"\n if not self.login():\n return False\n\n result_name = sanitize_filename(result.name)\n filename = join(self._get_storage_dir(), result_name + '.' + self.provider_type)\n\n if result.url.startswith('http'):\n self.session.headers.update({\n 'Referer': '/'.join(result.url.split('/')[:3]) + '/'\n })\n\n log.info('Downloading {result} from {provider} at {url}',\n {'result': result.name, 'provider': self.name, 'url': result.url})\n\n verify = False if self.public else None\n\n url, data = result.url.split('|')\n\n data = {\n data.split('=')[1]: 'on',\n 'action': 'nzb',\n }\n\n if download_file(url, filename, method='POST', data=data, session=self.session,\n headers=self.headers, verify=verify):\n\n if self._verify_download(filename):\n log.info('Saved {result} to {location}',\n {'result': result.name, 'location': filename})\n return True\n\n return False\n\n def download_nzb_for_post(self, result):\n \"\"\"\n Download the nzb content, prior to sending it to the nzb download client.\n\n :param result: Nzb SearchResult object.\n :return: The content of the nzb file if successful else None.\n \"\"\"\n if not self.login():\n return False\n\n # For now to separate the url and the post data, where splitting it with a pipe.\n url, data = result.url.split('|')\n\n data = {\n data.split('=')[1]: 'on',\n 'action': 'nzb',\n }\n\n log.info('Downloading {result} from {provider} at {url} and data {data}',\n {'result': result.name, 'provider': self.name, 'url': result.url, 'data': data})\n\n verify = False if self.public else None\n\n response = self.session.post(url, data=data, headers=self.session.headers,\n verify=verify, hooks={}, allow_redirects=True)\n if not response or not response.content:\n log.warning('Failed to download the NZB from BinSearch')\n return None\n\n # Validate that the result has the content of a valid nzb.\n if not BinSearchProvider.nzb_check_segment.search(response.text):\n log.warning('Result returned from BinSearch was not a valid NZB')\n return None\n\n return response.content\n\n def _get_size(self, item):\n \"\"\"\n Get result size.\n\n Overwrite this, as the default _get_size() from nzb_provider isn't working for us.\n :param item:\n :return: size in bytes or -1\n \"\"\"\n return item.get('size', -1)\n\n\nprovider = BinSearchProvider()\n", "path": "medusa/providers/nzb/binsearch.py"}]}
| 3,924 | 131 |
gh_patches_debug_27223
|
rasdani/github-patches
|
git_diff
|
mitmproxy__mitmproxy-5322
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
mailcap deprecated for Python 3.11 removed for Python 3.13
I've been following this Python dev mailing thread which proposed to deprecate `mailcap` from the standard library: https://mail.python.org/archives/list/[email protected]/thread/EB2BS4DBWSTBIOPQL5QTBSIOBORWSCMJ/
After a code search I noticed that you were the only library I recognized which used this module:
https://grep.app/search?q=import%20mailcap
https://github.com/mitmproxy/mitmproxy/blob/4f7f64c516341c586c9f8cb6593217ff3e359351/mitmproxy/tools/console/master.py#L2
Please be aware the Steering Council just accepted this deprecation proposal meaning the module will be deprecated for Python 3.11 removed for Python 3.13.
(I don't have any affiliation with this decision, I am just trying to proactively raise awareness)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mitmproxy/tools/console/master.py`
Content:
```
1 import asyncio
2 import mailcap
3 import mimetypes
4 import os
5 import os.path
6 import shlex
7 import shutil
8 import stat
9 import subprocess
10 import sys
11 import tempfile
12 import contextlib
13 import threading
14
15 from tornado.platform.asyncio import AddThreadSelectorEventLoop
16
17 import urwid
18
19 from mitmproxy import addons
20 from mitmproxy import master
21 from mitmproxy import log
22 from mitmproxy.addons import errorcheck, intercept
23 from mitmproxy.addons import eventstore
24 from mitmproxy.addons import readfile
25 from mitmproxy.addons import view
26 from mitmproxy.contrib.tornado import patch_tornado
27 from mitmproxy.tools.console import consoleaddons
28 from mitmproxy.tools.console import defaultkeys
29 from mitmproxy.tools.console import keymap
30 from mitmproxy.tools.console import palettes
31 from mitmproxy.tools.console import signals
32 from mitmproxy.tools.console import window
33
34
35 class ConsoleMaster(master.Master):
36 def __init__(self, opts):
37 super().__init__(opts)
38
39 self.view: view.View = view.View()
40 self.events = eventstore.EventStore()
41 self.events.sig_add.connect(self.sig_add_log)
42
43 self.stream_path = None
44 self.keymap = keymap.Keymap(self)
45 defaultkeys.map(self.keymap)
46 self.options.errored.connect(self.options_error)
47
48 self.view_stack = []
49
50 self.addons.add(*addons.default_addons())
51 self.addons.add(
52 intercept.Intercept(),
53 self.view,
54 self.events,
55 readfile.ReadFile(),
56 consoleaddons.ConsoleAddon(self),
57 keymap.KeymapConfig(),
58 errorcheck.ErrorCheck(log_to_stderr=True),
59 )
60
61 self.window = None
62
63 def __setattr__(self, name, value):
64 super().__setattr__(name, value)
65 signals.update_settings.send(self)
66
67 def options_error(self, opts, exc):
68 signals.status_message.send(message=str(exc), expire=1)
69
70 def prompt_for_exit(self):
71 signals.status_prompt_onekey.send(
72 self,
73 prompt="Quit",
74 keys=(
75 ("yes", "y"),
76 ("no", "n"),
77 ),
78 callback=self.quit,
79 )
80
81 def sig_add_log(self, event_store, entry: log.LogEntry):
82 if log.log_tier(self.options.console_eventlog_verbosity) < log.log_tier(
83 entry.level
84 ):
85 return
86 if entry.level in ("error", "warn", "alert"):
87 signals.status_message.send(
88 message=(
89 entry.level,
90 f"{entry.level.title()}: {str(entry.msg).lstrip()}",
91 ),
92 expire=5,
93 )
94
95 def sig_call_in(self, sender, seconds, callback, args=()):
96 def cb(*_):
97 return callback(*args)
98
99 self.loop.set_alarm_in(seconds, cb)
100
101 @contextlib.contextmanager
102 def uistopped(self):
103 self.loop.stop()
104 try:
105 yield
106 finally:
107 self.loop.start()
108 self.loop.screen_size = None
109 self.loop.draw_screen()
110
111 def get_editor(self) -> str:
112 # based upon https://github.com/pallets/click/blob/main/src/click/_termui_impl.py
113 if m := os.environ.get("MITMPROXY_EDITOR"):
114 return m
115 if m := os.environ.get("EDITOR"):
116 return m
117 for editor in "sensible-editor", "nano", "vim":
118 if shutil.which(editor):
119 return editor
120 if os.name == "nt":
121 return "notepad"
122 else:
123 return "vi"
124
125 def spawn_editor(self, data):
126 text = not isinstance(data, bytes)
127 fd, name = tempfile.mkstemp("", "mitmproxy", text=text)
128 with open(fd, "w" if text else "wb") as f:
129 f.write(data)
130 c = self.get_editor()
131 cmd = shlex.split(c)
132 cmd.append(name)
133 with self.uistopped():
134 try:
135 subprocess.call(cmd)
136 except:
137 signals.status_message.send(message="Can't start editor: %s" % c)
138 else:
139 with open(name, "r" if text else "rb") as f:
140 data = f.read()
141 os.unlink(name)
142 return data
143
144 def spawn_external_viewer(self, data, contenttype):
145 if contenttype:
146 contenttype = contenttype.split(";")[0]
147 ext = mimetypes.guess_extension(contenttype) or ""
148 else:
149 ext = ""
150 fd, name = tempfile.mkstemp(ext, "mproxy")
151 os.write(fd, data)
152 os.close(fd)
153
154 # read-only to remind the user that this is a view function
155 os.chmod(name, stat.S_IREAD)
156
157 cmd = None
158 shell = False
159
160 if contenttype:
161 c = mailcap.getcaps()
162 cmd, _ = mailcap.findmatch(c, contenttype, filename=name)
163 if cmd:
164 shell = True
165 if not cmd:
166 # hm which one should get priority?
167 c = (
168 os.environ.get("MITMPROXY_EDITOR")
169 or os.environ.get("PAGER")
170 or os.environ.get("EDITOR")
171 )
172 if not c:
173 c = "less"
174 cmd = shlex.split(c)
175 cmd.append(name)
176 with self.uistopped():
177 try:
178 subprocess.call(cmd, shell=shell)
179 except:
180 signals.status_message.send(
181 message="Can't start external viewer: %s" % " ".join(c)
182 )
183 # add a small delay before deletion so that the file is not removed before being loaded by the viewer
184 t = threading.Timer(1.0, os.unlink, args=[name])
185 t.start()
186
187 def set_palette(self, opts, updated):
188 self.ui.register_palette(
189 palettes.palettes[opts.console_palette].palette(
190 opts.console_palette_transparent
191 )
192 )
193 self.ui.clear()
194
195 def inject_key(self, key):
196 self.loop.process_input([key])
197
198 async def running(self) -> None:
199 if not sys.stdout.isatty():
200 print(
201 "Error: mitmproxy's console interface requires a tty. "
202 "Please run mitmproxy in an interactive shell environment.",
203 file=sys.stderr,
204 )
205 sys.exit(1)
206
207 if os.name != "nt" and "utf" not in urwid.detected_encoding.lower():
208 print(
209 f"mitmproxy expects a UTF-8 console environment, not {urwid.detected_encoding!r}. "
210 f"Set your LANG environment variable to something like en_US.UTF-8.",
211 file=sys.stderr,
212 )
213 # Experimental (04/2022): We just don't exit here and see if/how that affects users.
214 # sys.exit(1)
215 urwid.set_encoding("utf8")
216
217 signals.call_in.connect(self.sig_call_in)
218 self.ui = window.Screen()
219 self.ui.set_terminal_properties(256)
220 self.set_palette(self.options, None)
221 self.options.subscribe(
222 self.set_palette, ["console_palette", "console_palette_transparent"]
223 )
224
225 loop = asyncio.get_running_loop()
226 if isinstance(loop, getattr(asyncio, "ProactorEventLoop", tuple())):
227 patch_tornado()
228 # fix for https://bugs.python.org/issue37373
229 loop = AddThreadSelectorEventLoop(loop) # type: ignore
230 self.loop = urwid.MainLoop(
231 urwid.SolidFill("x"),
232 event_loop=urwid.AsyncioEventLoop(loop=loop),
233 screen=self.ui,
234 handle_mouse=self.options.console_mouse,
235 )
236 self.window = window.Window(self)
237 self.loop.widget = self.window
238 self.window.refresh()
239
240 self.loop.start()
241
242 await super().running()
243
244 async def done(self):
245 self.loop.stop()
246 await super().done()
247
248 def overlay(self, widget, **kwargs):
249 self.window.set_overlay(widget, **kwargs)
250
251 def switch_view(self, name):
252 self.window.push(name)
253
254 def quit(self, a):
255 if a != "n":
256 self.shutdown()
257
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mitmproxy/tools/console/master.py b/mitmproxy/tools/console/master.py
--- a/mitmproxy/tools/console/master.py
+++ b/mitmproxy/tools/console/master.py
@@ -1,5 +1,4 @@
import asyncio
-import mailcap
import mimetypes
import os
import os.path
@@ -154,28 +153,20 @@
# read-only to remind the user that this is a view function
os.chmod(name, stat.S_IREAD)
- cmd = None
- shell = False
+ # hm which one should get priority?
+ c = (
+ os.environ.get("MITMPROXY_EDITOR")
+ or os.environ.get("PAGER")
+ or os.environ.get("EDITOR")
+ )
+ if not c:
+ c = "less"
+ cmd = shlex.split(c)
+ cmd.append(name)
- if contenttype:
- c = mailcap.getcaps()
- cmd, _ = mailcap.findmatch(c, contenttype, filename=name)
- if cmd:
- shell = True
- if not cmd:
- # hm which one should get priority?
- c = (
- os.environ.get("MITMPROXY_EDITOR")
- or os.environ.get("PAGER")
- or os.environ.get("EDITOR")
- )
- if not c:
- c = "less"
- cmd = shlex.split(c)
- cmd.append(name)
with self.uistopped():
try:
- subprocess.call(cmd, shell=shell)
+ subprocess.call(cmd, shell=False)
except:
signals.status_message.send(
message="Can't start external viewer: %s" % " ".join(c)
|
{"golden_diff": "diff --git a/mitmproxy/tools/console/master.py b/mitmproxy/tools/console/master.py\n--- a/mitmproxy/tools/console/master.py\n+++ b/mitmproxy/tools/console/master.py\n@@ -1,5 +1,4 @@\n import asyncio\n-import mailcap\n import mimetypes\n import os\n import os.path\n@@ -154,28 +153,20 @@\n # read-only to remind the user that this is a view function\n os.chmod(name, stat.S_IREAD)\n \n- cmd = None\n- shell = False\n+ # hm which one should get priority?\n+ c = (\n+ os.environ.get(\"MITMPROXY_EDITOR\")\n+ or os.environ.get(\"PAGER\")\n+ or os.environ.get(\"EDITOR\")\n+ )\n+ if not c:\n+ c = \"less\"\n+ cmd = shlex.split(c)\n+ cmd.append(name)\n \n- if contenttype:\n- c = mailcap.getcaps()\n- cmd, _ = mailcap.findmatch(c, contenttype, filename=name)\n- if cmd:\n- shell = True\n- if not cmd:\n- # hm which one should get priority?\n- c = (\n- os.environ.get(\"MITMPROXY_EDITOR\")\n- or os.environ.get(\"PAGER\")\n- or os.environ.get(\"EDITOR\")\n- )\n- if not c:\n- c = \"less\"\n- cmd = shlex.split(c)\n- cmd.append(name)\n with self.uistopped():\n try:\n- subprocess.call(cmd, shell=shell)\n+ subprocess.call(cmd, shell=False)\n except:\n signals.status_message.send(\n message=\"Can't start external viewer: %s\" % \" \".join(c)\n", "issue": "mailcap deprecated for Python 3.11 removed for Python 3.13\nI've been following this Python dev mailing thread which proposed to deprecate `mailcap` from the standard library: https://mail.python.org/archives/list/[email protected]/thread/EB2BS4DBWSTBIOPQL5QTBSIOBORWSCMJ/\r\n\r\nAfter a code search I noticed that you were the only library I recognized which used this module: \r\nhttps://grep.app/search?q=import%20mailcap\r\nhttps://github.com/mitmproxy/mitmproxy/blob/4f7f64c516341c586c9f8cb6593217ff3e359351/mitmproxy/tools/console/master.py#L2\r\n\r\nPlease be aware the Steering Council just accepted this deprecation proposal meaning the module will be deprecated for Python 3.11 removed for Python 3.13.\r\n\r\n(I don't have any affiliation with this decision, I am just trying to proactively raise awareness)\n", "before_files": [{"content": "import asyncio\nimport mailcap\nimport mimetypes\nimport os\nimport os.path\nimport shlex\nimport shutil\nimport stat\nimport subprocess\nimport sys\nimport tempfile\nimport contextlib\nimport threading\n\nfrom tornado.platform.asyncio import AddThreadSelectorEventLoop\n\nimport urwid\n\nfrom mitmproxy import addons\nfrom mitmproxy import master\nfrom mitmproxy import log\nfrom mitmproxy.addons import errorcheck, intercept\nfrom mitmproxy.addons import eventstore\nfrom mitmproxy.addons import readfile\nfrom mitmproxy.addons import view\nfrom mitmproxy.contrib.tornado import patch_tornado\nfrom mitmproxy.tools.console import consoleaddons\nfrom mitmproxy.tools.console import defaultkeys\nfrom mitmproxy.tools.console import keymap\nfrom mitmproxy.tools.console import palettes\nfrom mitmproxy.tools.console import signals\nfrom mitmproxy.tools.console import window\n\n\nclass ConsoleMaster(master.Master):\n def __init__(self, opts):\n super().__init__(opts)\n\n self.view: view.View = view.View()\n self.events = eventstore.EventStore()\n self.events.sig_add.connect(self.sig_add_log)\n\n self.stream_path = None\n self.keymap = keymap.Keymap(self)\n defaultkeys.map(self.keymap)\n self.options.errored.connect(self.options_error)\n\n self.view_stack = []\n\n self.addons.add(*addons.default_addons())\n self.addons.add(\n intercept.Intercept(),\n self.view,\n self.events,\n readfile.ReadFile(),\n consoleaddons.ConsoleAddon(self),\n keymap.KeymapConfig(),\n errorcheck.ErrorCheck(log_to_stderr=True),\n )\n\n self.window = None\n\n def __setattr__(self, name, value):\n super().__setattr__(name, value)\n signals.update_settings.send(self)\n\n def options_error(self, opts, exc):\n signals.status_message.send(message=str(exc), expire=1)\n\n def prompt_for_exit(self):\n signals.status_prompt_onekey.send(\n self,\n prompt=\"Quit\",\n keys=(\n (\"yes\", \"y\"),\n (\"no\", \"n\"),\n ),\n callback=self.quit,\n )\n\n def sig_add_log(self, event_store, entry: log.LogEntry):\n if log.log_tier(self.options.console_eventlog_verbosity) < log.log_tier(\n entry.level\n ):\n return\n if entry.level in (\"error\", \"warn\", \"alert\"):\n signals.status_message.send(\n message=(\n entry.level,\n f\"{entry.level.title()}: {str(entry.msg).lstrip()}\",\n ),\n expire=5,\n )\n\n def sig_call_in(self, sender, seconds, callback, args=()):\n def cb(*_):\n return callback(*args)\n\n self.loop.set_alarm_in(seconds, cb)\n\n @contextlib.contextmanager\n def uistopped(self):\n self.loop.stop()\n try:\n yield\n finally:\n self.loop.start()\n self.loop.screen_size = None\n self.loop.draw_screen()\n\n def get_editor(self) -> str:\n # based upon https://github.com/pallets/click/blob/main/src/click/_termui_impl.py\n if m := os.environ.get(\"MITMPROXY_EDITOR\"):\n return m\n if m := os.environ.get(\"EDITOR\"):\n return m\n for editor in \"sensible-editor\", \"nano\", \"vim\":\n if shutil.which(editor):\n return editor\n if os.name == \"nt\":\n return \"notepad\"\n else:\n return \"vi\"\n\n def spawn_editor(self, data):\n text = not isinstance(data, bytes)\n fd, name = tempfile.mkstemp(\"\", \"mitmproxy\", text=text)\n with open(fd, \"w\" if text else \"wb\") as f:\n f.write(data)\n c = self.get_editor()\n cmd = shlex.split(c)\n cmd.append(name)\n with self.uistopped():\n try:\n subprocess.call(cmd)\n except:\n signals.status_message.send(message=\"Can't start editor: %s\" % c)\n else:\n with open(name, \"r\" if text else \"rb\") as f:\n data = f.read()\n os.unlink(name)\n return data\n\n def spawn_external_viewer(self, data, contenttype):\n if contenttype:\n contenttype = contenttype.split(\";\")[0]\n ext = mimetypes.guess_extension(contenttype) or \"\"\n else:\n ext = \"\"\n fd, name = tempfile.mkstemp(ext, \"mproxy\")\n os.write(fd, data)\n os.close(fd)\n\n # read-only to remind the user that this is a view function\n os.chmod(name, stat.S_IREAD)\n\n cmd = None\n shell = False\n\n if contenttype:\n c = mailcap.getcaps()\n cmd, _ = mailcap.findmatch(c, contenttype, filename=name)\n if cmd:\n shell = True\n if not cmd:\n # hm which one should get priority?\n c = (\n os.environ.get(\"MITMPROXY_EDITOR\")\n or os.environ.get(\"PAGER\")\n or os.environ.get(\"EDITOR\")\n )\n if not c:\n c = \"less\"\n cmd = shlex.split(c)\n cmd.append(name)\n with self.uistopped():\n try:\n subprocess.call(cmd, shell=shell)\n except:\n signals.status_message.send(\n message=\"Can't start external viewer: %s\" % \" \".join(c)\n )\n # add a small delay before deletion so that the file is not removed before being loaded by the viewer\n t = threading.Timer(1.0, os.unlink, args=[name])\n t.start()\n\n def set_palette(self, opts, updated):\n self.ui.register_palette(\n palettes.palettes[opts.console_palette].palette(\n opts.console_palette_transparent\n )\n )\n self.ui.clear()\n\n def inject_key(self, key):\n self.loop.process_input([key])\n\n async def running(self) -> None:\n if not sys.stdout.isatty():\n print(\n \"Error: mitmproxy's console interface requires a tty. \"\n \"Please run mitmproxy in an interactive shell environment.\",\n file=sys.stderr,\n )\n sys.exit(1)\n\n if os.name != \"nt\" and \"utf\" not in urwid.detected_encoding.lower():\n print(\n f\"mitmproxy expects a UTF-8 console environment, not {urwid.detected_encoding!r}. \"\n f\"Set your LANG environment variable to something like en_US.UTF-8.\",\n file=sys.stderr,\n )\n # Experimental (04/2022): We just don't exit here and see if/how that affects users.\n # sys.exit(1)\n urwid.set_encoding(\"utf8\")\n\n signals.call_in.connect(self.sig_call_in)\n self.ui = window.Screen()\n self.ui.set_terminal_properties(256)\n self.set_palette(self.options, None)\n self.options.subscribe(\n self.set_palette, [\"console_palette\", \"console_palette_transparent\"]\n )\n\n loop = asyncio.get_running_loop()\n if isinstance(loop, getattr(asyncio, \"ProactorEventLoop\", tuple())):\n patch_tornado()\n # fix for https://bugs.python.org/issue37373\n loop = AddThreadSelectorEventLoop(loop) # type: ignore\n self.loop = urwid.MainLoop(\n urwid.SolidFill(\"x\"),\n event_loop=urwid.AsyncioEventLoop(loop=loop),\n screen=self.ui,\n handle_mouse=self.options.console_mouse,\n )\n self.window = window.Window(self)\n self.loop.widget = self.window\n self.window.refresh()\n\n self.loop.start()\n\n await super().running()\n\n async def done(self):\n self.loop.stop()\n await super().done()\n\n def overlay(self, widget, **kwargs):\n self.window.set_overlay(widget, **kwargs)\n\n def switch_view(self, name):\n self.window.push(name)\n\n def quit(self, a):\n if a != \"n\":\n self.shutdown()\n", "path": "mitmproxy/tools/console/master.py"}], "after_files": [{"content": "import asyncio\nimport mimetypes\nimport os\nimport os.path\nimport shlex\nimport shutil\nimport stat\nimport subprocess\nimport sys\nimport tempfile\nimport contextlib\nimport threading\n\nfrom tornado.platform.asyncio import AddThreadSelectorEventLoop\n\nimport urwid\n\nfrom mitmproxy import addons\nfrom mitmproxy import master\nfrom mitmproxy import log\nfrom mitmproxy.addons import errorcheck, intercept\nfrom mitmproxy.addons import eventstore\nfrom mitmproxy.addons import readfile\nfrom mitmproxy.addons import view\nfrom mitmproxy.contrib.tornado import patch_tornado\nfrom mitmproxy.tools.console import consoleaddons\nfrom mitmproxy.tools.console import defaultkeys\nfrom mitmproxy.tools.console import keymap\nfrom mitmproxy.tools.console import palettes\nfrom mitmproxy.tools.console import signals\nfrom mitmproxy.tools.console import window\n\n\nclass ConsoleMaster(master.Master):\n def __init__(self, opts):\n super().__init__(opts)\n\n self.view: view.View = view.View()\n self.events = eventstore.EventStore()\n self.events.sig_add.connect(self.sig_add_log)\n\n self.stream_path = None\n self.keymap = keymap.Keymap(self)\n defaultkeys.map(self.keymap)\n self.options.errored.connect(self.options_error)\n\n self.view_stack = []\n\n self.addons.add(*addons.default_addons())\n self.addons.add(\n intercept.Intercept(),\n self.view,\n self.events,\n readfile.ReadFile(),\n consoleaddons.ConsoleAddon(self),\n keymap.KeymapConfig(),\n errorcheck.ErrorCheck(log_to_stderr=True),\n )\n\n self.window = None\n\n def __setattr__(self, name, value):\n super().__setattr__(name, value)\n signals.update_settings.send(self)\n\n def options_error(self, opts, exc):\n signals.status_message.send(message=str(exc), expire=1)\n\n def prompt_for_exit(self):\n signals.status_prompt_onekey.send(\n self,\n prompt=\"Quit\",\n keys=(\n (\"yes\", \"y\"),\n (\"no\", \"n\"),\n ),\n callback=self.quit,\n )\n\n def sig_add_log(self, event_store, entry: log.LogEntry):\n if log.log_tier(self.options.console_eventlog_verbosity) < log.log_tier(\n entry.level\n ):\n return\n if entry.level in (\"error\", \"warn\", \"alert\"):\n signals.status_message.send(\n message=(\n entry.level,\n f\"{entry.level.title()}: {str(entry.msg).lstrip()}\",\n ),\n expire=5,\n )\n\n def sig_call_in(self, sender, seconds, callback, args=()):\n def cb(*_):\n return callback(*args)\n\n self.loop.set_alarm_in(seconds, cb)\n\n @contextlib.contextmanager\n def uistopped(self):\n self.loop.stop()\n try:\n yield\n finally:\n self.loop.start()\n self.loop.screen_size = None\n self.loop.draw_screen()\n\n def get_editor(self) -> str:\n # based upon https://github.com/pallets/click/blob/main/src/click/_termui_impl.py\n if m := os.environ.get(\"MITMPROXY_EDITOR\"):\n return m\n if m := os.environ.get(\"EDITOR\"):\n return m\n for editor in \"sensible-editor\", \"nano\", \"vim\":\n if shutil.which(editor):\n return editor\n if os.name == \"nt\":\n return \"notepad\"\n else:\n return \"vi\"\n\n def spawn_editor(self, data):\n text = not isinstance(data, bytes)\n fd, name = tempfile.mkstemp(\"\", \"mitmproxy\", text=text)\n with open(fd, \"w\" if text else \"wb\") as f:\n f.write(data)\n c = self.get_editor()\n cmd = shlex.split(c)\n cmd.append(name)\n with self.uistopped():\n try:\n subprocess.call(cmd)\n except:\n signals.status_message.send(message=\"Can't start editor: %s\" % c)\n else:\n with open(name, \"r\" if text else \"rb\") as f:\n data = f.read()\n os.unlink(name)\n return data\n\n def spawn_external_viewer(self, data, contenttype):\n if contenttype:\n contenttype = contenttype.split(\";\")[0]\n ext = mimetypes.guess_extension(contenttype) or \"\"\n else:\n ext = \"\"\n fd, name = tempfile.mkstemp(ext, \"mproxy\")\n os.write(fd, data)\n os.close(fd)\n\n # read-only to remind the user that this is a view function\n os.chmod(name, stat.S_IREAD)\n\n # hm which one should get priority?\n c = (\n os.environ.get(\"MITMPROXY_EDITOR\")\n or os.environ.get(\"PAGER\")\n or os.environ.get(\"EDITOR\")\n )\n if not c:\n c = \"less\"\n cmd = shlex.split(c)\n cmd.append(name)\n\n with self.uistopped():\n try:\n subprocess.call(cmd, shell=False)\n except:\n signals.status_message.send(\n message=\"Can't start external viewer: %s\" % \" \".join(c)\n )\n # add a small delay before deletion so that the file is not removed before being loaded by the viewer\n t = threading.Timer(1.0, os.unlink, args=[name])\n t.start()\n\n def set_palette(self, opts, updated):\n self.ui.register_palette(\n palettes.palettes[opts.console_palette].palette(\n opts.console_palette_transparent\n )\n )\n self.ui.clear()\n\n def inject_key(self, key):\n self.loop.process_input([key])\n\n async def running(self) -> None:\n if not sys.stdout.isatty():\n print(\n \"Error: mitmproxy's console interface requires a tty. \"\n \"Please run mitmproxy in an interactive shell environment.\",\n file=sys.stderr,\n )\n sys.exit(1)\n\n if os.name != \"nt\" and \"utf\" not in urwid.detected_encoding.lower():\n print(\n f\"mitmproxy expects a UTF-8 console environment, not {urwid.detected_encoding!r}. \"\n f\"Set your LANG environment variable to something like en_US.UTF-8.\",\n file=sys.stderr,\n )\n # Experimental (04/2022): We just don't exit here and see if/how that affects users.\n # sys.exit(1)\n urwid.set_encoding(\"utf8\")\n\n signals.call_in.connect(self.sig_call_in)\n self.ui = window.Screen()\n self.ui.set_terminal_properties(256)\n self.set_palette(self.options, None)\n self.options.subscribe(\n self.set_palette, [\"console_palette\", \"console_palette_transparent\"]\n )\n\n loop = asyncio.get_running_loop()\n if isinstance(loop, getattr(asyncio, \"ProactorEventLoop\", tuple())):\n patch_tornado()\n # fix for https://bugs.python.org/issue37373\n loop = AddThreadSelectorEventLoop(loop) # type: ignore\n self.loop = urwid.MainLoop(\n urwid.SolidFill(\"x\"),\n event_loop=urwid.AsyncioEventLoop(loop=loop),\n screen=self.ui,\n handle_mouse=self.options.console_mouse,\n )\n self.window = window.Window(self)\n self.loop.widget = self.window\n self.window.refresh()\n\n self.loop.start()\n\n await super().running()\n\n async def done(self):\n self.loop.stop()\n await super().done()\n\n def overlay(self, widget, **kwargs):\n self.window.set_overlay(widget, **kwargs)\n\n def switch_view(self, name):\n self.window.push(name)\n\n def quit(self, a):\n if a != \"n\":\n self.shutdown()\n", "path": "mitmproxy/tools/console/master.py"}]}
| 2,900 | 385 |
gh_patches_debug_43674
|
rasdani/github-patches
|
git_diff
|
dotkom__onlineweb4-293
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Menu is missing link to admin page when user is logged in
Should only be visible when it's a privileged user with access to the panel
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `apps/authentication/forms.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 import datetime
4 import re
5
6 from django import forms
7 from django.contrib import auth
8 from django.utils.translation import ugettext as _
9
10 from apps.authentication.models import OnlineUser as User
11
12 class LoginForm(forms.Form):
13 username = forms.CharField(widget=forms.TextInput(), label=_("Brukernavn"), max_length=50)
14 password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_("Passord"))
15 user = None
16
17 def clean(self):
18 if self._errors:
19 return
20
21 user = auth.authenticate(username=self.cleaned_data['username'], password=self.cleaned_data['password'])
22
23 if user:
24 if user.is_active:
25 self.user = user
26 else:
27 self._errors['username'] = self.error_class([_("Din konto er ikke aktiv. Forsøk gjenoppretning av passord.")])
28 else:
29 self._errors['username'] = self.error_class([_("Kontoen eksisterer ikke, eller kombinasjonen av brukernavn og passord er feil.")])
30 return self.cleaned_data
31
32 def login(self, request):
33 try:
34 User.objects.get(username=request.POST['username'])
35 except:
36 return False
37 if self.is_valid():
38 auth.login(request, self.user)
39 request.session.set_expiry(0)
40 return True
41 return False
42
43 class RegisterForm(forms.Form):
44 username = forms.CharField(label=_("brukernavn"), max_length=20)
45 first_name = forms.CharField(label=_("fornavn"), max_length=50)
46 last_name = forms.CharField(label=_("etternavn"), max_length=50)
47 email = forms.EmailField(label=_("epost"), max_length=50)
48 password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_("passord"))
49 repeat_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_("gjenta passord"))
50 address = forms.CharField(label=_("adresse"), max_length=50)
51 zip_code = forms.CharField(label=_("postnummer"), max_length=4)
52 phone = forms.CharField(label=_("telefon"), max_length=20)
53
54 def clean(self):
55 super(RegisterForm, self).clean()
56 if self.is_valid():
57 cleaned_data = self.cleaned_data
58
59 # Check passwords
60 if cleaned_data['password'] != cleaned_data['repeat_password']:
61 self._errors['repeat_password'] = self.error_class([_("Passordene er ikke like.")])
62
63 # Check username
64 username = cleaned_data['username']
65 if User.objects.filter(username=username).count() > 0:
66 self._errors['username'] = self.error_class([_("Brukernavnet er allerede registrert.")])
67 if not re.match("^[a-zA-Z0-9_-]+$", username):
68 self._errors['username'] = self.error_class([_("Ditt brukernavn inneholdt ulovlige tegn. Lovlige tegn: a-Z 0-9 - _")])
69
70 # Check email
71 email = cleaned_data['email']
72 if User.objects.filter(email=email).count() > 0:
73 self._errors['email'] = self.error_class([_("Det fins allerede en bruker med denne epostadressen.")])
74
75 # ZIP code digits only
76 zip_code = cleaned_data['zip_code']
77 if len(zip_code) != 4 or not zip_code.isdigit():
78 self._errors['zip_code'] = self.error_class([_("Postnummer må bestå av fire siffer.")])
79
80 return cleaned_data
81
82 class RecoveryForm(forms.Form):
83 email = forms.EmailField(label="Email", max_length=50)
84
85 class ChangePasswordForm(forms.Form):
86 new_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_("nytt passord"))
87 repeat_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_("gjenta passord"))
88
89 def clean(self):
90 super(ChangePasswordForm, self).clean()
91 if self.is_valid():
92 cleaned_data = self.cleaned_data
93
94 # Check passwords
95 if cleaned_data['new_password'] != cleaned_data['repeat_password']:
96 self._errors['repeat_password'] = self.error_class([_("Passordene er ikke like.")])
97
98 return cleaned_data
99
100
101 class NewEmailForm(forms.Form):
102 new_email = forms.EmailField(_(u"ny epostadresse"))
103
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/apps/authentication/forms.py b/apps/authentication/forms.py
--- a/apps/authentication/forms.py
+++ b/apps/authentication/forms.py
@@ -11,7 +11,7 @@
class LoginForm(forms.Form):
username = forms.CharField(widget=forms.TextInput(), label=_("Brukernavn"), max_length=50)
- password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_("Passord"))
+ password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_(u"Passord"))
user = None
def clean(self):
@@ -24,9 +24,9 @@
if user.is_active:
self.user = user
else:
- self._errors['username'] = self.error_class([_("Din konto er ikke aktiv. Forsøk gjenoppretning av passord.")])
+ self._errors['username'] = self.error_class([_(u"Din konto er ikke aktiv. Forsøk gjenoppretning av passord.")])
else:
- self._errors['username'] = self.error_class([_("Kontoen eksisterer ikke, eller kombinasjonen av brukernavn og passord er feil.")])
+ self._errors['username'] = self.error_class([_(u"Kontoen eksisterer ikke, eller kombinasjonen av brukernavn og passord er feil.")])
return self.cleaned_data
def login(self, request):
@@ -58,24 +58,24 @@
# Check passwords
if cleaned_data['password'] != cleaned_data['repeat_password']:
- self._errors['repeat_password'] = self.error_class([_("Passordene er ikke like.")])
+ self._errors['repeat_password'] = self.error_class([_(u"Passordene er ikke like.")])
# Check username
username = cleaned_data['username']
if User.objects.filter(username=username).count() > 0:
- self._errors['username'] = self.error_class([_("Brukernavnet er allerede registrert.")])
+ self._errors['username'] = self.error_class([_(u"Brukernavnet er allerede registrert.")])
if not re.match("^[a-zA-Z0-9_-]+$", username):
- self._errors['username'] = self.error_class([_("Ditt brukernavn inneholdt ulovlige tegn. Lovlige tegn: a-Z 0-9 - _")])
+ self._errors['username'] = self.error_class([_(u"Ditt brukernavn inneholdt ulovlige tegn. Lovlige tegn: a-Z 0-9 - _")])
# Check email
email = cleaned_data['email']
if User.objects.filter(email=email).count() > 0:
- self._errors['email'] = self.error_class([_("Det fins allerede en bruker med denne epostadressen.")])
+ self._errors['email'] = self.error_class([_(u"Det fins allerede en bruker med denne epostadressen.")])
# ZIP code digits only
zip_code = cleaned_data['zip_code']
if len(zip_code) != 4 or not zip_code.isdigit():
- self._errors['zip_code'] = self.error_class([_("Postnummer må bestå av fire siffer.")])
+ self._errors['zip_code'] = self.error_class([_(u"Postnummer må bestå av fire siffer.")])
return cleaned_data
@@ -83,8 +83,8 @@
email = forms.EmailField(label="Email", max_length=50)
class ChangePasswordForm(forms.Form):
- new_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_("nytt passord"))
- repeat_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_("gjenta passord"))
+ new_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_(u"nytt passord"))
+ repeat_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_(u"gjenta passord"))
def clean(self):
super(ChangePasswordForm, self).clean()
@@ -93,7 +93,7 @@
# Check passwords
if cleaned_data['new_password'] != cleaned_data['repeat_password']:
- self._errors['repeat_password'] = self.error_class([_("Passordene er ikke like.")])
+ self._errors['repeat_password'] = self.error_class([_(u"Passordene er ikke like.")])
return cleaned_data
|
{"golden_diff": "diff --git a/apps/authentication/forms.py b/apps/authentication/forms.py\n--- a/apps/authentication/forms.py\n+++ b/apps/authentication/forms.py\n@@ -11,7 +11,7 @@\n \n class LoginForm(forms.Form):\n username = forms.CharField(widget=forms.TextInput(), label=_(\"Brukernavn\"), max_length=50)\n- password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_(\"Passord\"))\n+ password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_(u\"Passord\"))\n user = None\n \n def clean(self):\n@@ -24,9 +24,9 @@\n if user.is_active:\n self.user = user\n else:\n- self._errors['username'] = self.error_class([_(\"Din konto er ikke aktiv. Fors\u00f8k gjenoppretning av passord.\")])\n+ self._errors['username'] = self.error_class([_(u\"Din konto er ikke aktiv. Fors\u00f8k gjenoppretning av passord.\")])\n else:\n- self._errors['username'] = self.error_class([_(\"Kontoen eksisterer ikke, eller kombinasjonen av brukernavn og passord er feil.\")])\n+ self._errors['username'] = self.error_class([_(u\"Kontoen eksisterer ikke, eller kombinasjonen av brukernavn og passord er feil.\")])\n return self.cleaned_data\n \n def login(self, request):\n@@ -58,24 +58,24 @@\n \n # Check passwords\n if cleaned_data['password'] != cleaned_data['repeat_password']:\n- self._errors['repeat_password'] = self.error_class([_(\"Passordene er ikke like.\")])\n+ self._errors['repeat_password'] = self.error_class([_(u\"Passordene er ikke like.\")])\n \n # Check username\n username = cleaned_data['username']\n if User.objects.filter(username=username).count() > 0:\n- self._errors['username'] = self.error_class([_(\"Brukernavnet er allerede registrert.\")])\n+ self._errors['username'] = self.error_class([_(u\"Brukernavnet er allerede registrert.\")])\n if not re.match(\"^[a-zA-Z0-9_-]+$\", username):\n- self._errors['username'] = self.error_class([_(\"Ditt brukernavn inneholdt ulovlige tegn. Lovlige tegn: a-Z 0-9 - _\")])\n+ self._errors['username'] = self.error_class([_(u\"Ditt brukernavn inneholdt ulovlige tegn. Lovlige tegn: a-Z 0-9 - _\")])\n \n # Check email\n email = cleaned_data['email']\n if User.objects.filter(email=email).count() > 0:\n- self._errors['email'] = self.error_class([_(\"Det fins allerede en bruker med denne epostadressen.\")])\n+ self._errors['email'] = self.error_class([_(u\"Det fins allerede en bruker med denne epostadressen.\")])\n \n # ZIP code digits only\n zip_code = cleaned_data['zip_code']\n if len(zip_code) != 4 or not zip_code.isdigit():\n- self._errors['zip_code'] = self.error_class([_(\"Postnummer m\u00e5 best\u00e5 av fire siffer.\")])\n+ self._errors['zip_code'] = self.error_class([_(u\"Postnummer m\u00e5 best\u00e5 av fire siffer.\")])\n \n return cleaned_data \n \n@@ -83,8 +83,8 @@\n email = forms.EmailField(label=\"Email\", max_length=50)\n \n class ChangePasswordForm(forms.Form):\n- new_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_(\"nytt passord\"))\n- repeat_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_(\"gjenta passord\"))\n+ new_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_(u\"nytt passord\"))\n+ repeat_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_(u\"gjenta passord\"))\n \n def clean(self):\n super(ChangePasswordForm, self).clean()\n@@ -93,7 +93,7 @@\n \n # Check passwords\n if cleaned_data['new_password'] != cleaned_data['repeat_password']:\n- self._errors['repeat_password'] = self.error_class([_(\"Passordene er ikke like.\")])\n+ self._errors['repeat_password'] = self.error_class([_(u\"Passordene er ikke like.\")])\n \n return cleaned_data\n", "issue": "Menu is missing link to admin page when user is logged in\nShould only be visible when it's a privileged user with access to the panel \n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\nimport datetime\nimport re\n\nfrom django import forms\nfrom django.contrib import auth\nfrom django.utils.translation import ugettext as _\n\nfrom apps.authentication.models import OnlineUser as User\n\nclass LoginForm(forms.Form):\n username = forms.CharField(widget=forms.TextInput(), label=_(\"Brukernavn\"), max_length=50)\n password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_(\"Passord\"))\n user = None\n\n def clean(self):\n if self._errors:\n return\n \n user = auth.authenticate(username=self.cleaned_data['username'], password=self.cleaned_data['password'])\n\n if user:\n if user.is_active:\n self.user = user\n else:\n self._errors['username'] = self.error_class([_(\"Din konto er ikke aktiv. Fors\u00f8k gjenoppretning av passord.\")])\n else:\n self._errors['username'] = self.error_class([_(\"Kontoen eksisterer ikke, eller kombinasjonen av brukernavn og passord er feil.\")])\n return self.cleaned_data\n\n def login(self, request):\n try:\n User.objects.get(username=request.POST['username'])\n except:\n return False\n if self.is_valid():\n auth.login(request, self.user)\n request.session.set_expiry(0)\n return True\n return False\n\nclass RegisterForm(forms.Form):\n username = forms.CharField(label=_(\"brukernavn\"), max_length=20)\n first_name = forms.CharField(label=_(\"fornavn\"), max_length=50)\n last_name = forms.CharField(label=_(\"etternavn\"), max_length=50)\n email = forms.EmailField(label=_(\"epost\"), max_length=50)\n password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_(\"passord\"))\n repeat_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_(\"gjenta passord\"))\n address = forms.CharField(label=_(\"adresse\"), max_length=50)\n zip_code = forms.CharField(label=_(\"postnummer\"), max_length=4)\n phone = forms.CharField(label=_(\"telefon\"), max_length=20)\n \n def clean(self):\n super(RegisterForm, self).clean()\n if self.is_valid():\n cleaned_data = self.cleaned_data\n\n # Check passwords\n if cleaned_data['password'] != cleaned_data['repeat_password']:\n self._errors['repeat_password'] = self.error_class([_(\"Passordene er ikke like.\")])\n\n # Check username\n username = cleaned_data['username']\n if User.objects.filter(username=username).count() > 0:\n self._errors['username'] = self.error_class([_(\"Brukernavnet er allerede registrert.\")])\n if not re.match(\"^[a-zA-Z0-9_-]+$\", username):\n self._errors['username'] = self.error_class([_(\"Ditt brukernavn inneholdt ulovlige tegn. Lovlige tegn: a-Z 0-9 - _\")])\n\n # Check email\n email = cleaned_data['email']\n if User.objects.filter(email=email).count() > 0:\n self._errors['email'] = self.error_class([_(\"Det fins allerede en bruker med denne epostadressen.\")])\n\n # ZIP code digits only\n zip_code = cleaned_data['zip_code']\n if len(zip_code) != 4 or not zip_code.isdigit():\n self._errors['zip_code'] = self.error_class([_(\"Postnummer m\u00e5 best\u00e5 av fire siffer.\")])\n\n return cleaned_data \n\nclass RecoveryForm(forms.Form):\n email = forms.EmailField(label=\"Email\", max_length=50)\n\nclass ChangePasswordForm(forms.Form):\n new_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_(\"nytt passord\"))\n repeat_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_(\"gjenta passord\"))\n\n def clean(self):\n super(ChangePasswordForm, self).clean()\n if self.is_valid():\n cleaned_data = self.cleaned_data\n\n # Check passwords\n if cleaned_data['new_password'] != cleaned_data['repeat_password']:\n self._errors['repeat_password'] = self.error_class([_(\"Passordene er ikke like.\")])\n\n return cleaned_data\n\n\nclass NewEmailForm(forms.Form):\n new_email = forms.EmailField(_(u\"ny epostadresse\"))\n", "path": "apps/authentication/forms.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\nimport datetime\nimport re\n\nfrom django import forms\nfrom django.contrib import auth\nfrom django.utils.translation import ugettext as _\n\nfrom apps.authentication.models import OnlineUser as User\n\nclass LoginForm(forms.Form):\n username = forms.CharField(widget=forms.TextInput(), label=_(\"Brukernavn\"), max_length=50)\n password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_(u\"Passord\"))\n user = None\n\n def clean(self):\n if self._errors:\n return\n \n user = auth.authenticate(username=self.cleaned_data['username'], password=self.cleaned_data['password'])\n\n if user:\n if user.is_active:\n self.user = user\n else:\n self._errors['username'] = self.error_class([_(u\"Din konto er ikke aktiv. Fors\u00f8k gjenoppretning av passord.\")])\n else:\n self._errors['username'] = self.error_class([_(u\"Kontoen eksisterer ikke, eller kombinasjonen av brukernavn og passord er feil.\")])\n return self.cleaned_data\n\n def login(self, request):\n try:\n User.objects.get(username=request.POST['username'])\n except:\n return False\n if self.is_valid():\n auth.login(request, self.user)\n request.session.set_expiry(0)\n return True\n return False\n\nclass RegisterForm(forms.Form):\n username = forms.CharField(label=_(\"brukernavn\"), max_length=20)\n first_name = forms.CharField(label=_(\"fornavn\"), max_length=50)\n last_name = forms.CharField(label=_(\"etternavn\"), max_length=50)\n email = forms.EmailField(label=_(\"epost\"), max_length=50)\n password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_(\"passord\"))\n repeat_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_(\"gjenta passord\"))\n address = forms.CharField(label=_(\"adresse\"), max_length=50)\n zip_code = forms.CharField(label=_(\"postnummer\"), max_length=4)\n phone = forms.CharField(label=_(\"telefon\"), max_length=20)\n \n def clean(self):\n super(RegisterForm, self).clean()\n if self.is_valid():\n cleaned_data = self.cleaned_data\n\n # Check passwords\n if cleaned_data['password'] != cleaned_data['repeat_password']:\n self._errors['repeat_password'] = self.error_class([_(u\"Passordene er ikke like.\")])\n\n # Check username\n username = cleaned_data['username']\n if User.objects.filter(username=username).count() > 0:\n self._errors['username'] = self.error_class([_(u\"Brukernavnet er allerede registrert.\")])\n if not re.match(\"^[a-zA-Z0-9_-]+$\", username):\n self._errors['username'] = self.error_class([_(u\"Ditt brukernavn inneholdt ulovlige tegn. Lovlige tegn: a-Z 0-9 - _\")])\n\n # Check email\n email = cleaned_data['email']\n if User.objects.filter(email=email).count() > 0:\n self._errors['email'] = self.error_class([_(u\"Det fins allerede en bruker med denne epostadressen.\")])\n\n # ZIP code digits only\n zip_code = cleaned_data['zip_code']\n if len(zip_code) != 4 or not zip_code.isdigit():\n self._errors['zip_code'] = self.error_class([_(u\"Postnummer m\u00e5 best\u00e5 av fire siffer.\")])\n\n return cleaned_data \n\nclass RecoveryForm(forms.Form):\n email = forms.EmailField(label=\"Email\", max_length=50)\n\nclass ChangePasswordForm(forms.Form):\n new_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_(u\"nytt passord\"))\n repeat_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_(u\"gjenta passord\"))\n\n def clean(self):\n super(ChangePasswordForm, self).clean()\n if self.is_valid():\n cleaned_data = self.cleaned_data\n\n # Check passwords\n if cleaned_data['new_password'] != cleaned_data['repeat_password']:\n self._errors['repeat_password'] = self.error_class([_(u\"Passordene er ikke like.\")])\n\n return cleaned_data\n\n\nclass NewEmailForm(forms.Form):\n new_email = forms.EmailField(_(u\"ny epostadresse\"))\n", "path": "apps/authentication/forms.py"}]}
| 1,430 | 1,001 |
gh_patches_debug_17187
|
rasdani/github-patches
|
git_diff
|
DataDog__integrations-extras-320
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Filebeat instance cache is broken (which breaks increment metrics)
**Output of the [info page](https://docs.datadoghq.com/agent/faq/agent-commands/#agent-status-and-information)**
```text
====================
Collector (v 5.30.1)
====================
Status date: 2019-01-08 06:09:58 (10s ago)
Pid: 4468
Platform: Linux-3.13.0-163-generic-x86_64-with-Ubuntu-14.04-trusty
Python Version: 2.7.15, 64bit
Logs: <stderr>, /var/log/datadog/collector.log
<snip>
filebeat (custom)
-----------------
- instance #0 [OK]
- Collected 1 metric, 0 events & 0 service checks
<snip>
```
**Additional environment details (Operating System, Cloud provider, etc):**
Filebeat version 6.5.1
**Steps to reproduce the issue:**
1. Install and configure filebeat check with:
```yaml
init_config:
instances:
- registry_file_path: /var/lib/filebeat/registry
stats_endpoint: http://localhost:5066/stats
```
**Describe the results you received:**
Metrics in `GAUGE_METRIC_NAMES` are reported to Datadog, but none of the metrics in `INCREMENT_METRIC_NAMES` are.
**Describe the results you expected:**
All listed metrics in the above variables and present in `http://localhost:5066/stats` are reported.
**Additional information you deem important (e.g. issue happens only occasionally):**
The issue is here: https://github.com/DataDog/integrations-extras/blob/2eff6e2dd2b123214cd562b93a9b45753e27a959/filebeat/check.py#L211-L218
Line 213 checks for `instance_key` in `self.instance_cache`, but that key is never actually put in that dictionary. The only keys in that dictionary are `'config'` and `'profiler'`, added on lines 217 and 218.
The result of this is that the `FilebeatCheckInstanceConfig` and `FilebeatCheckHttpProfiler` are re-created every check, which means that the `_previous_increment_values` property on FilebeatCheckHttpProfiler is always empty, which means no increment metrics are ever reported.
This appears to have been introduced in #250.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `filebeat/check.py`
Content:
```
1 # (C) Datadog, Inc. 2010-2016
2 # All rights reserved
3 # Licensed under Simplified BSD License (see LICENSE)
4
5 # stdlib
6 import collections
7 import errno
8 import numbers
9 import os
10 import re
11 import sre_constants
12
13 # 3rd party
14 import requests
15 import simplejson
16
17 # project
18 from datadog_checks.checks import AgentCheck
19 from datadog_checks.utils.containers import hash_mutable
20
21
22 EVENT_TYPE = SOURCE_TYPE_NAME = 'filebeat'
23
24
25 class FilebeatCheckHttpProfiler(object):
26 '''
27 Filebeat's HTTP profiler gives a bunch of counter variables; their value holds little interest,
28 what we really want is the delta in between runs. This class is responsible for caching the
29 values from the previous run
30 '''
31
32 INCREMENT_METRIC_NAMES = [
33 'filebeat.harvester.closed',
34 'filebeat.harvester.files.truncated',
35 'filebeat.harvester.open_files',
36 'filebeat.harvester.skipped',
37 'filebeat.harvester.started',
38 'filebeat.prospector.log.files.renamed',
39 'filebeat.prospector.log.files.truncated',
40 'libbeat.config.module.running',
41 'libbeat.config.module.starts',
42 'libbeat.config.module.stops',
43 'libbeat.config.reloads',
44 'libbeat.es.call_count.PublishEvents',
45 'libbeat.es.publish.read_bytes',
46 'libbeat.es.publish.read_errors',
47 'libbeat.es.publish.write_bytes',
48 'libbeat.es.publish.write_errors',
49 'libbeat.es.published_and_acked_events',
50 'libbeat.es.published_but_not_acked_events',
51 'libbeat.kafka.call_count.PublishEvents',
52 'libbeat.kafka.published_and_acked_events',
53 'libbeat.kafka.published_but_not_acked_events',
54 'libbeat.logstash.call_count.PublishEvents',
55 'libbeat.logstash.publish.read_bytes',
56 'libbeat.logstash.publish.read_errors',
57 'libbeat.logstash.publish.write_bytes',
58 'libbeat.logstash.publish.write_errors',
59 'libbeat.logstash.published_and_acked_events',
60 'libbeat.logstash.published_but_not_acked_events',
61 'libbeat.output.events.dropped',
62 'libbeat.output.events.failed',
63 'libbeat.pipeline.events.dropped',
64 'libbeat.pipeline.events.failed',
65 'libbeat.publisher.messages_in_worker_queues',
66 'libbeat.publisher.published_events',
67 'libbeat.redis.publish.read_bytes',
68 'libbeat.redis.publish.read_errors',
69 'libbeat.redis.publish.write_bytes',
70 'libbeat.redis.publish.write_errors',
71 'publish.events',
72 'registrar.states.cleanup',
73 'registrar.states.current',
74 'registrar.states.update',
75 'registrar.writes'
76 ]
77
78 GAUGE_METRIC_NAMES = [
79 'filebeat.harvester.running'
80 ]
81
82 VARS_ROUTE = 'debug/vars'
83
84 def __init__(self, config):
85 self._config = config
86 self._previous_increment_values = {}
87 # regex matching ain't free, let's cache this
88 self._should_keep_metrics = {}
89
90 def gather_metrics(self):
91 response = self._make_request()
92
93 return {
94 'increment': self._gather_increment_metrics(response),
95 'gauge': self._gather_gauge_metrics(response)
96 }
97
98 def _make_request(self):
99
100 response = requests.get(self._config.stats_endpoint, timeout=self._config.timeout)
101 response.raise_for_status()
102
103 return self.flatten(response.json())
104
105 def _gather_increment_metrics(self, response):
106 new_values = {name: response[name] for name in self.INCREMENT_METRIC_NAMES
107 if self._should_keep_metric(name) and name in response}
108
109 deltas = self._compute_increment_deltas(new_values)
110
111 self._previous_increment_values = new_values
112
113 return deltas
114
115 def _compute_increment_deltas(self, new_values):
116 deltas = {}
117
118 for name, new_value in new_values.iteritems():
119 if name not in self._previous_increment_values \
120 or self._previous_increment_values[name] > new_value:
121 # either the agent or filebeat got restarted, we're not
122 # reporting anything this time around
123 return {}
124 deltas[name] = new_value - self._previous_increment_values[name]
125
126 return deltas
127
128 def _gather_gauge_metrics(self, response):
129 return {name: response[name] for name in self.GAUGE_METRIC_NAMES
130 if self._should_keep_metric(name) and name in response}
131
132 def _should_keep_metric(self, name):
133 if name not in self._should_keep_metrics:
134 self._should_keep_metrics[name] = self._config.should_keep_metric(name)
135 return self._should_keep_metrics[name]
136
137 def flatten(self, d, parent_key='', sep='.'):
138 items = []
139 for k, v in d.items():
140 new_key = parent_key + sep + k if parent_key else k
141 if isinstance(v, collections.MutableMapping):
142 items.extend(self.flatten(v, new_key, sep=sep).items())
143 else:
144 items.append((new_key, v))
145 return dict(items)
146
147
148 class FilebeatCheckInstanceConfig(object):
149
150 def __init__(self, instance):
151 self._registry_file_path = instance.get('registry_file_path')
152 if self._registry_file_path is None:
153 raise Exception('An absolute path to a filebeat registry path must be specified')
154
155 self._stats_endpoint = instance.get('stats_endpoint')
156
157 self._only_metrics = instance.get('only_metrics', [])
158 if not isinstance(self._only_metrics, list):
159 raise Exception("If given, filebeat's only_metrics must be a list of regexes, got %s" % (
160 self._only_metrics, ))
161
162 self._timeout = instance.get('timeout', 2)
163 if not isinstance(self._timeout, numbers.Real) or self._timeout <= 0:
164 raise Exception("If given, filebeats timeout must be a positive number, got %s" % (self._timeout, ))
165
166 @property
167 def registry_file_path(self):
168 return self._registry_file_path
169
170 @property
171 def stats_endpoint(self):
172 return self._stats_endpoint
173
174 @property
175 def timeout(self):
176 return self._timeout
177
178 def should_keep_metric(self, metric_name):
179
180 if not self._only_metrics:
181 return True
182
183 return any(re.search(regex, metric_name) for regex in self._compiled_regexes())
184
185 def _compiled_regexes(self):
186 try:
187 return self._only_metrics_regexes
188 except AttributeError:
189 self._only_metrics_regexes = self._compile_regexes()
190 return self._compiled_regexes()
191
192 def _compile_regexes(self):
193 compiled_regexes = []
194
195 for regex in self._only_metrics:
196 try:
197 compiled_regexes.append(re.compile(regex))
198 except sre_constants.error as ex:
199 raise Exception(
200 'Invalid only_metric regex for filebeat: "%s", error: %s' % (regex, ex))
201
202 return compiled_regexes
203
204
205 class FilebeatCheck(AgentCheck):
206
207 def __init__(self, *args, **kwargs):
208 AgentCheck.__init__(self, *args, **kwargs)
209 self.instance_cache = {}
210
211 def check(self, instance):
212 instance_key = hash_mutable(instance)
213 if instance_key in self.instance_cache:
214 config = self.instance_cache['config']
215 profiler = self.instance_cache['profiler']
216 else:
217 self.instance_cache['config'] = config = FilebeatCheckInstanceConfig(instance)
218 self.instance_cache['profiler'] = profiler = FilebeatCheckHttpProfiler(config)
219
220 self._process_registry(config)
221 self._gather_http_profiler_metrics(config, profiler)
222
223 def _process_registry(self, config):
224 registry_contents = self._parse_registry_file(config.registry_file_path)
225
226 if isinstance(registry_contents, dict):
227 # filebeat version < 5
228 registry_contents = registry_contents.values()
229
230 for item in registry_contents:
231 self._process_registry_item(item)
232
233 def _parse_registry_file(self, registry_file_path):
234 try:
235 with open(registry_file_path) as registry_file:
236 return simplejson.load(registry_file)
237 except IOError as ex:
238 self.log.error('Cannot read the registry log file at %s: %s' % (registry_file_path, ex))
239
240 if ex.errno == errno.EACCES:
241 self.log.error('You might be interesting in having a look at https://github.com/elastic/beats/pull/6455')
242
243 return []
244
245 def _process_registry_item(self, item):
246 source = item['source']
247 offset = item['offset']
248
249 try:
250 stats = os.stat(source)
251
252 if self._is_same_file(stats, item['FileStateOS']):
253 unprocessed_bytes = stats.st_size - offset
254
255 self.gauge('filebeat.registry.unprocessed_bytes', unprocessed_bytes,
256 tags=['source:{0}'.format(source)])
257 else:
258 self.log.debug("Filebeat source %s appears to have changed" % (source, ))
259 except OSError:
260 self.log.debug("Unable to get stats on filebeat source %s" % (source, ))
261
262 def _is_same_file(self, stats, file_state_os):
263 return stats.st_dev == file_state_os['device'] and stats.st_ino == file_state_os['inode']
264
265 def _gather_http_profiler_metrics(self, config, profiler):
266 try:
267 all_metrics = profiler.gather_metrics()
268 except StandardError as ex:
269 self.log.error('Error when fetching metrics from %s: %s' % (config.stats_endpoint, ex))
270 return
271
272 tags = ['stats_endpoint:{0}'.format(config.stats_endpoint)]
273
274 for action, metrics in all_metrics.iteritems():
275 method = getattr(self, action)
276
277 for name, value in metrics.iteritems():
278 method(name, value, tags)
279
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/filebeat/check.py b/filebeat/check.py
--- a/filebeat/check.py
+++ b/filebeat/check.py
@@ -211,11 +211,12 @@
def check(self, instance):
instance_key = hash_mutable(instance)
if instance_key in self.instance_cache:
- config = self.instance_cache['config']
- profiler = self.instance_cache['profiler']
+ config = self.instance_cache[instance_key]['config']
+ profiler = self.instance_cache[instance_key]['profiler']
else:
- self.instance_cache['config'] = config = FilebeatCheckInstanceConfig(instance)
- self.instance_cache['profiler'] = profiler = FilebeatCheckHttpProfiler(config)
+ config = FilebeatCheckInstanceConfig(instance)
+ profiler = FilebeatCheckHttpProfiler(config)
+ self.instance_cache[instance_key] = {'config': config, 'profiler': profiler}
self._process_registry(config)
self._gather_http_profiler_metrics(config, profiler)
|
{"golden_diff": "diff --git a/filebeat/check.py b/filebeat/check.py\n--- a/filebeat/check.py\n+++ b/filebeat/check.py\n@@ -211,11 +211,12 @@\n def check(self, instance):\n instance_key = hash_mutable(instance)\n if instance_key in self.instance_cache:\n- config = self.instance_cache['config']\n- profiler = self.instance_cache['profiler']\n+ config = self.instance_cache[instance_key]['config']\n+ profiler = self.instance_cache[instance_key]['profiler']\n else:\n- self.instance_cache['config'] = config = FilebeatCheckInstanceConfig(instance)\n- self.instance_cache['profiler'] = profiler = FilebeatCheckHttpProfiler(config)\n+ config = FilebeatCheckInstanceConfig(instance)\n+ profiler = FilebeatCheckHttpProfiler(config)\n+ self.instance_cache[instance_key] = {'config': config, 'profiler': profiler}\n \n self._process_registry(config)\n self._gather_http_profiler_metrics(config, profiler)\n", "issue": "Filebeat instance cache is broken (which breaks increment metrics)\n**Output of the [info page](https://docs.datadoghq.com/agent/faq/agent-commands/#agent-status-and-information)**\r\n\r\n```text\r\n====================\r\nCollector (v 5.30.1)\r\n====================\r\n\r\n Status date: 2019-01-08 06:09:58 (10s ago)\r\n Pid: 4468\r\n Platform: Linux-3.13.0-163-generic-x86_64-with-Ubuntu-14.04-trusty\r\n Python Version: 2.7.15, 64bit\r\n Logs: <stderr>, /var/log/datadog/collector.log\r\n<snip>\r\n filebeat (custom)\r\n -----------------\r\n - instance #0 [OK]\r\n - Collected 1 metric, 0 events & 0 service checks\r\n<snip>\r\n```\r\n\r\n**Additional environment details (Operating System, Cloud provider, etc):**\r\nFilebeat version 6.5.1\r\n\r\n**Steps to reproduce the issue:**\r\n1. Install and configure filebeat check with:\r\n```yaml\r\ninit_config:\r\n\r\ninstances:\r\n - registry_file_path: /var/lib/filebeat/registry\r\n stats_endpoint: http://localhost:5066/stats\r\n```\r\n\r\n**Describe the results you received:**\r\nMetrics in `GAUGE_METRIC_NAMES` are reported to Datadog, but none of the metrics in `INCREMENT_METRIC_NAMES` are.\r\n\r\n**Describe the results you expected:**\r\nAll listed metrics in the above variables and present in `http://localhost:5066/stats` are reported.\r\n\r\n**Additional information you deem important (e.g. issue happens only occasionally):**\r\nThe issue is here: https://github.com/DataDog/integrations-extras/blob/2eff6e2dd2b123214cd562b93a9b45753e27a959/filebeat/check.py#L211-L218\r\n\r\nLine 213 checks for `instance_key` in `self.instance_cache`, but that key is never actually put in that dictionary. The only keys in that dictionary are `'config'` and `'profiler'`, added on lines 217 and 218.\r\n\r\nThe result of this is that the `FilebeatCheckInstanceConfig` and `FilebeatCheckHttpProfiler` are re-created every check, which means that the `_previous_increment_values` property on FilebeatCheckHttpProfiler is always empty, which means no increment metrics are ever reported.\r\n\r\nThis appears to have been introduced in #250.\n", "before_files": [{"content": "# (C) Datadog, Inc. 2010-2016\n# All rights reserved\n# Licensed under Simplified BSD License (see LICENSE)\n\n# stdlib\nimport collections\nimport errno\nimport numbers\nimport os\nimport re\nimport sre_constants\n\n# 3rd party\nimport requests\nimport simplejson\n\n# project\nfrom datadog_checks.checks import AgentCheck\nfrom datadog_checks.utils.containers import hash_mutable\n\n\nEVENT_TYPE = SOURCE_TYPE_NAME = 'filebeat'\n\n\nclass FilebeatCheckHttpProfiler(object):\n '''\n Filebeat's HTTP profiler gives a bunch of counter variables; their value holds little interest,\n what we really want is the delta in between runs. This class is responsible for caching the\n values from the previous run\n '''\n\n INCREMENT_METRIC_NAMES = [\n 'filebeat.harvester.closed',\n 'filebeat.harvester.files.truncated',\n 'filebeat.harvester.open_files',\n 'filebeat.harvester.skipped',\n 'filebeat.harvester.started',\n 'filebeat.prospector.log.files.renamed',\n 'filebeat.prospector.log.files.truncated',\n 'libbeat.config.module.running',\n 'libbeat.config.module.starts',\n 'libbeat.config.module.stops',\n 'libbeat.config.reloads',\n 'libbeat.es.call_count.PublishEvents',\n 'libbeat.es.publish.read_bytes',\n 'libbeat.es.publish.read_errors',\n 'libbeat.es.publish.write_bytes',\n 'libbeat.es.publish.write_errors',\n 'libbeat.es.published_and_acked_events',\n 'libbeat.es.published_but_not_acked_events',\n 'libbeat.kafka.call_count.PublishEvents',\n 'libbeat.kafka.published_and_acked_events',\n 'libbeat.kafka.published_but_not_acked_events',\n 'libbeat.logstash.call_count.PublishEvents',\n 'libbeat.logstash.publish.read_bytes',\n 'libbeat.logstash.publish.read_errors',\n 'libbeat.logstash.publish.write_bytes',\n 'libbeat.logstash.publish.write_errors',\n 'libbeat.logstash.published_and_acked_events',\n 'libbeat.logstash.published_but_not_acked_events',\n 'libbeat.output.events.dropped',\n 'libbeat.output.events.failed',\n 'libbeat.pipeline.events.dropped',\n 'libbeat.pipeline.events.failed',\n 'libbeat.publisher.messages_in_worker_queues',\n 'libbeat.publisher.published_events',\n 'libbeat.redis.publish.read_bytes',\n 'libbeat.redis.publish.read_errors',\n 'libbeat.redis.publish.write_bytes',\n 'libbeat.redis.publish.write_errors',\n 'publish.events',\n 'registrar.states.cleanup',\n 'registrar.states.current',\n 'registrar.states.update',\n 'registrar.writes'\n ]\n\n GAUGE_METRIC_NAMES = [\n 'filebeat.harvester.running'\n ]\n\n VARS_ROUTE = 'debug/vars'\n\n def __init__(self, config):\n self._config = config\n self._previous_increment_values = {}\n # regex matching ain't free, let's cache this\n self._should_keep_metrics = {}\n\n def gather_metrics(self):\n response = self._make_request()\n\n return {\n 'increment': self._gather_increment_metrics(response),\n 'gauge': self._gather_gauge_metrics(response)\n }\n\n def _make_request(self):\n\n response = requests.get(self._config.stats_endpoint, timeout=self._config.timeout)\n response.raise_for_status()\n\n return self.flatten(response.json())\n\n def _gather_increment_metrics(self, response):\n new_values = {name: response[name] for name in self.INCREMENT_METRIC_NAMES\n if self._should_keep_metric(name) and name in response}\n\n deltas = self._compute_increment_deltas(new_values)\n\n self._previous_increment_values = new_values\n\n return deltas\n\n def _compute_increment_deltas(self, new_values):\n deltas = {}\n\n for name, new_value in new_values.iteritems():\n if name not in self._previous_increment_values \\\n or self._previous_increment_values[name] > new_value:\n # either the agent or filebeat got restarted, we're not\n # reporting anything this time around\n return {}\n deltas[name] = new_value - self._previous_increment_values[name]\n\n return deltas\n\n def _gather_gauge_metrics(self, response):\n return {name: response[name] for name in self.GAUGE_METRIC_NAMES\n if self._should_keep_metric(name) and name in response}\n\n def _should_keep_metric(self, name):\n if name not in self._should_keep_metrics:\n self._should_keep_metrics[name] = self._config.should_keep_metric(name)\n return self._should_keep_metrics[name]\n\n def flatten(self, d, parent_key='', sep='.'):\n items = []\n for k, v in d.items():\n new_key = parent_key + sep + k if parent_key else k\n if isinstance(v, collections.MutableMapping):\n items.extend(self.flatten(v, new_key, sep=sep).items())\n else:\n items.append((new_key, v))\n return dict(items)\n\n\nclass FilebeatCheckInstanceConfig(object):\n\n def __init__(self, instance):\n self._registry_file_path = instance.get('registry_file_path')\n if self._registry_file_path is None:\n raise Exception('An absolute path to a filebeat registry path must be specified')\n\n self._stats_endpoint = instance.get('stats_endpoint')\n\n self._only_metrics = instance.get('only_metrics', [])\n if not isinstance(self._only_metrics, list):\n raise Exception(\"If given, filebeat's only_metrics must be a list of regexes, got %s\" % (\n self._only_metrics, ))\n\n self._timeout = instance.get('timeout', 2)\n if not isinstance(self._timeout, numbers.Real) or self._timeout <= 0:\n raise Exception(\"If given, filebeats timeout must be a positive number, got %s\" % (self._timeout, ))\n\n @property\n def registry_file_path(self):\n return self._registry_file_path\n\n @property\n def stats_endpoint(self):\n return self._stats_endpoint\n\n @property\n def timeout(self):\n return self._timeout\n\n def should_keep_metric(self, metric_name):\n\n if not self._only_metrics:\n return True\n\n return any(re.search(regex, metric_name) for regex in self._compiled_regexes())\n\n def _compiled_regexes(self):\n try:\n return self._only_metrics_regexes\n except AttributeError:\n self._only_metrics_regexes = self._compile_regexes()\n return self._compiled_regexes()\n\n def _compile_regexes(self):\n compiled_regexes = []\n\n for regex in self._only_metrics:\n try:\n compiled_regexes.append(re.compile(regex))\n except sre_constants.error as ex:\n raise Exception(\n 'Invalid only_metric regex for filebeat: \"%s\", error: %s' % (regex, ex))\n\n return compiled_regexes\n\n\nclass FilebeatCheck(AgentCheck):\n\n def __init__(self, *args, **kwargs):\n AgentCheck.__init__(self, *args, **kwargs)\n self.instance_cache = {}\n\n def check(self, instance):\n instance_key = hash_mutable(instance)\n if instance_key in self.instance_cache:\n config = self.instance_cache['config']\n profiler = self.instance_cache['profiler']\n else:\n self.instance_cache['config'] = config = FilebeatCheckInstanceConfig(instance)\n self.instance_cache['profiler'] = profiler = FilebeatCheckHttpProfiler(config)\n\n self._process_registry(config)\n self._gather_http_profiler_metrics(config, profiler)\n\n def _process_registry(self, config):\n registry_contents = self._parse_registry_file(config.registry_file_path)\n\n if isinstance(registry_contents, dict):\n # filebeat version < 5\n registry_contents = registry_contents.values()\n\n for item in registry_contents:\n self._process_registry_item(item)\n\n def _parse_registry_file(self, registry_file_path):\n try:\n with open(registry_file_path) as registry_file:\n return simplejson.load(registry_file)\n except IOError as ex:\n self.log.error('Cannot read the registry log file at %s: %s' % (registry_file_path, ex))\n\n if ex.errno == errno.EACCES:\n self.log.error('You might be interesting in having a look at https://github.com/elastic/beats/pull/6455')\n\n return []\n\n def _process_registry_item(self, item):\n source = item['source']\n offset = item['offset']\n\n try:\n stats = os.stat(source)\n\n if self._is_same_file(stats, item['FileStateOS']):\n unprocessed_bytes = stats.st_size - offset\n\n self.gauge('filebeat.registry.unprocessed_bytes', unprocessed_bytes,\n tags=['source:{0}'.format(source)])\n else:\n self.log.debug(\"Filebeat source %s appears to have changed\" % (source, ))\n except OSError:\n self.log.debug(\"Unable to get stats on filebeat source %s\" % (source, ))\n\n def _is_same_file(self, stats, file_state_os):\n return stats.st_dev == file_state_os['device'] and stats.st_ino == file_state_os['inode']\n\n def _gather_http_profiler_metrics(self, config, profiler):\n try:\n all_metrics = profiler.gather_metrics()\n except StandardError as ex:\n self.log.error('Error when fetching metrics from %s: %s' % (config.stats_endpoint, ex))\n return\n\n tags = ['stats_endpoint:{0}'.format(config.stats_endpoint)]\n\n for action, metrics in all_metrics.iteritems():\n method = getattr(self, action)\n\n for name, value in metrics.iteritems():\n method(name, value, tags)\n", "path": "filebeat/check.py"}], "after_files": [{"content": "# (C) Datadog, Inc. 2010-2016\n# All rights reserved\n# Licensed under Simplified BSD License (see LICENSE)\n\n# stdlib\nimport collections\nimport errno\nimport numbers\nimport os\nimport re\nimport sre_constants\n\n# 3rd party\nimport requests\nimport simplejson\n\n# project\nfrom datadog_checks.checks import AgentCheck\nfrom datadog_checks.utils.containers import hash_mutable\n\n\nEVENT_TYPE = SOURCE_TYPE_NAME = 'filebeat'\n\n\nclass FilebeatCheckHttpProfiler(object):\n '''\n Filebeat's HTTP profiler gives a bunch of counter variables; their value holds little interest,\n what we really want is the delta in between runs. This class is responsible for caching the\n values from the previous run\n '''\n\n INCREMENT_METRIC_NAMES = [\n 'filebeat.harvester.closed',\n 'filebeat.harvester.files.truncated',\n 'filebeat.harvester.open_files',\n 'filebeat.harvester.skipped',\n 'filebeat.harvester.started',\n 'filebeat.prospector.log.files.renamed',\n 'filebeat.prospector.log.files.truncated',\n 'libbeat.config.module.running',\n 'libbeat.config.module.starts',\n 'libbeat.config.module.stops',\n 'libbeat.config.reloads',\n 'libbeat.es.call_count.PublishEvents',\n 'libbeat.es.publish.read_bytes',\n 'libbeat.es.publish.read_errors',\n 'libbeat.es.publish.write_bytes',\n 'libbeat.es.publish.write_errors',\n 'libbeat.es.published_and_acked_events',\n 'libbeat.es.published_but_not_acked_events',\n 'libbeat.kafka.call_count.PublishEvents',\n 'libbeat.kafka.published_and_acked_events',\n 'libbeat.kafka.published_but_not_acked_events',\n 'libbeat.logstash.call_count.PublishEvents',\n 'libbeat.logstash.publish.read_bytes',\n 'libbeat.logstash.publish.read_errors',\n 'libbeat.logstash.publish.write_bytes',\n 'libbeat.logstash.publish.write_errors',\n 'libbeat.logstash.published_and_acked_events',\n 'libbeat.logstash.published_but_not_acked_events',\n 'libbeat.output.events.dropped',\n 'libbeat.output.events.failed',\n 'libbeat.pipeline.events.dropped',\n 'libbeat.pipeline.events.failed',\n 'libbeat.publisher.messages_in_worker_queues',\n 'libbeat.publisher.published_events',\n 'libbeat.redis.publish.read_bytes',\n 'libbeat.redis.publish.read_errors',\n 'libbeat.redis.publish.write_bytes',\n 'libbeat.redis.publish.write_errors',\n 'publish.events',\n 'registrar.states.cleanup',\n 'registrar.states.current',\n 'registrar.states.update',\n 'registrar.writes'\n ]\n\n GAUGE_METRIC_NAMES = [\n 'filebeat.harvester.running'\n ]\n\n VARS_ROUTE = 'debug/vars'\n\n def __init__(self, config):\n self._config = config\n self._previous_increment_values = {}\n # regex matching ain't free, let's cache this\n self._should_keep_metrics = {}\n\n def gather_metrics(self):\n response = self._make_request()\n\n return {\n 'increment': self._gather_increment_metrics(response),\n 'gauge': self._gather_gauge_metrics(response)\n }\n\n def _make_request(self):\n\n response = requests.get(self._config.stats_endpoint, timeout=self._config.timeout)\n response.raise_for_status()\n\n return self.flatten(response.json())\n\n def _gather_increment_metrics(self, response):\n new_values = {name: response[name] for name in self.INCREMENT_METRIC_NAMES\n if self._should_keep_metric(name) and name in response}\n\n deltas = self._compute_increment_deltas(new_values)\n\n self._previous_increment_values = new_values\n\n return deltas\n\n def _compute_increment_deltas(self, new_values):\n deltas = {}\n\n for name, new_value in new_values.iteritems():\n if name not in self._previous_increment_values \\\n or self._previous_increment_values[name] > new_value:\n # either the agent or filebeat got restarted, we're not\n # reporting anything this time around\n return {}\n deltas[name] = new_value - self._previous_increment_values[name]\n\n return deltas\n\n def _gather_gauge_metrics(self, response):\n return {name: response[name] for name in self.GAUGE_METRIC_NAMES\n if self._should_keep_metric(name) and name in response}\n\n def _should_keep_metric(self, name):\n if name not in self._should_keep_metrics:\n self._should_keep_metrics[name] = self._config.should_keep_metric(name)\n return self._should_keep_metrics[name]\n\n def flatten(self, d, parent_key='', sep='.'):\n items = []\n for k, v in d.items():\n new_key = parent_key + sep + k if parent_key else k\n if isinstance(v, collections.MutableMapping):\n items.extend(self.flatten(v, new_key, sep=sep).items())\n else:\n items.append((new_key, v))\n return dict(items)\n\n\nclass FilebeatCheckInstanceConfig(object):\n\n def __init__(self, instance):\n self._registry_file_path = instance.get('registry_file_path')\n if self._registry_file_path is None:\n raise Exception('An absolute path to a filebeat registry path must be specified')\n\n self._stats_endpoint = instance.get('stats_endpoint')\n\n self._only_metrics = instance.get('only_metrics', [])\n if not isinstance(self._only_metrics, list):\n raise Exception(\"If given, filebeat's only_metrics must be a list of regexes, got %s\" % (\n self._only_metrics, ))\n\n self._timeout = instance.get('timeout', 2)\n if not isinstance(self._timeout, numbers.Real) or self._timeout <= 0:\n raise Exception(\"If given, filebeats timeout must be a positive number, got %s\" % (self._timeout, ))\n\n @property\n def registry_file_path(self):\n return self._registry_file_path\n\n @property\n def stats_endpoint(self):\n return self._stats_endpoint\n\n @property\n def timeout(self):\n return self._timeout\n\n def should_keep_metric(self, metric_name):\n\n if not self._only_metrics:\n return True\n\n return any(re.search(regex, metric_name) for regex in self._compiled_regexes())\n\n def _compiled_regexes(self):\n try:\n return self._only_metrics_regexes\n except AttributeError:\n self._only_metrics_regexes = self._compile_regexes()\n return self._compiled_regexes()\n\n def _compile_regexes(self):\n compiled_regexes = []\n\n for regex in self._only_metrics:\n try:\n compiled_regexes.append(re.compile(regex))\n except sre_constants.error as ex:\n raise Exception(\n 'Invalid only_metric regex for filebeat: \"%s\", error: %s' % (regex, ex))\n\n return compiled_regexes\n\n\nclass FilebeatCheck(AgentCheck):\n\n def __init__(self, *args, **kwargs):\n AgentCheck.__init__(self, *args, **kwargs)\n self.instance_cache = {}\n\n def check(self, instance):\n instance_key = hash_mutable(instance)\n if instance_key in self.instance_cache:\n config = self.instance_cache[instance_key]['config']\n profiler = self.instance_cache[instance_key]['profiler']\n else:\n config = FilebeatCheckInstanceConfig(instance)\n profiler = FilebeatCheckHttpProfiler(config)\n self.instance_cache[instance_key] = {'config': config, 'profiler': profiler}\n\n self._process_registry(config)\n self._gather_http_profiler_metrics(config, profiler)\n\n def _process_registry(self, config):\n registry_contents = self._parse_registry_file(config.registry_file_path)\n\n if isinstance(registry_contents, dict):\n # filebeat version < 5\n registry_contents = registry_contents.values()\n\n for item in registry_contents:\n self._process_registry_item(item)\n\n def _parse_registry_file(self, registry_file_path):\n try:\n with open(registry_file_path) as registry_file:\n return simplejson.load(registry_file)\n except IOError as ex:\n self.log.error('Cannot read the registry log file at %s: %s' % (registry_file_path, ex))\n\n if ex.errno == errno.EACCES:\n self.log.error('You might be interesting in having a look at https://github.com/elastic/beats/pull/6455')\n\n return []\n\n def _process_registry_item(self, item):\n source = item['source']\n offset = item['offset']\n\n try:\n stats = os.stat(source)\n\n if self._is_same_file(stats, item['FileStateOS']):\n unprocessed_bytes = stats.st_size - offset\n\n self.gauge('filebeat.registry.unprocessed_bytes', unprocessed_bytes,\n tags=['source:{0}'.format(source)])\n else:\n self.log.debug(\"Filebeat source %s appears to have changed\" % (source, ))\n except OSError:\n self.log.debug(\"Unable to get stats on filebeat source %s\" % (source, ))\n\n def _is_same_file(self, stats, file_state_os):\n return stats.st_dev == file_state_os['device'] and stats.st_ino == file_state_os['inode']\n\n def _gather_http_profiler_metrics(self, config, profiler):\n try:\n all_metrics = profiler.gather_metrics()\n except StandardError as ex:\n self.log.error('Error when fetching metrics from %s: %s' % (config.stats_endpoint, ex))\n return\n\n tags = ['stats_endpoint:{0}'.format(config.stats_endpoint)]\n\n for action, metrics in all_metrics.iteritems():\n method = getattr(self, action)\n\n for name, value in metrics.iteritems():\n method(name, value, tags)\n", "path": "filebeat/check.py"}]}
| 3,702 | 220 |
gh_patches_debug_465
|
rasdani/github-patches
|
git_diff
|
coala__coala-408
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
escaping stuff: scrutinizer issues
https://scrutinizer-ci.com/g/coala-analyzer/coala/inspections/8589a071-2905-40dd-a562-bfae3b8f40e5/issues/
need to fix after merging the escaping stuff
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `coalib/parsing/StringProcessing.py`
Content:
```
1 import re
2
3
4 def search_for(pattern, string, flags=0, max_match=0):
5 """
6 Searches for a given pattern in a string.
7
8 :param pattern: A regex pattern that defines what to match.
9 :param string: The string to search in.
10 :param flags: Additional flags to pass to the regex processor.
11 :param max_match: Defines the maximum number of matches to perform. If 0 or
12 less is provided, the number of splits is not limited.
13 :return: An iterator returning MatchObject's.
14 """
15 for elem in limit(re.finditer(pattern, string, flags), max_match):
16 yield elem
17
18
19 def limit(iterator, count):
20 """
21 A filter that removes all elements behind the set limit.
22
23 :param iterator: The iterator to be filtered.
24 :param count: The iterator limit. All elements at positions bigger than
25 this limit are trimmed off. Exclusion: 0 or numbers below
26 does not limit at all, means the passed iterator is
27 completely yielded.
28 """
29 if count <= 0: # Performance branch
30 for elem in iterator:
31 yield elem
32 else:
33 for elem in iterator:
34 yield elem
35 count -= 1
36 if count == 0:
37 break
38
39
40 def trim_empty_matches(iterator, groups=[0]):
41 """
42 A filter that removes empty match strings. It can only operate on iterators
43 whose elements are of type MatchObject.
44
45 :param iterator: The iterator to be filtered.
46 :param groups: An iteratable defining the groups to check for blankness.
47 Only results are not yielded if all groups of the match
48 are blank.
49 You can not only pass numbers but also strings, if your
50 MatchObject contains named groups.
51 """
52 for elem in iterator:
53 for group in groups:
54 if len(elem.group(group)) != 0:
55 yield elem
56
57 continue
58
59
60 def split(pattern,
61 string,
62 max_split=0,
63 remove_empty_matches=False):
64 """
65 Splits the given string by the specified pattern. The return character (\n)
66 is not a natural split pattern (if you don't specify it yourself).
67 This function ignores escape sequences.
68
69 :param pattern: A regex pattern that defines where to split.
70 :param string: The string to split by the defined pattern.
71 :param max_split: Defines the maximum number of splits. If 0 or
72 less is provided, the number of splits is not
73 limited.
74 :param remove_empty_matches: Defines whether empty entries should
75 be removed from the result.
76 :return: An iterator returning the split up strings.
77 """
78 # re.split() is not usable for this function. It has a bug when using too
79 # many capturing groups "()".
80
81 # Regex explanation:
82 # 1. (.*?) Match any char unlimited times, as few times as
83 # possible. Save the match in the first capturing
84 # group (match.group(1)).
85 # 2. (?:pattern) A non-capturing group that matches the
86 # split-pattern. Because the first group is lazy
87 # (matches as few times as possible) the next
88 # occurring split-sequence is matched.
89 regex = r"(.*?)(?:" + pattern + r")"
90
91 item = None
92 for item in re.finditer(regex, string, re.DOTALL):
93 if not remove_empty_matches or len(item.group(1)) != 0:
94 # Return the first matching group. The pattern from parameter can't
95 # change the group order.
96 yield item.group(1)
97
98 max_split -= 1
99 if 0 == max_split:
100 break # only reachable when max_split > 0
101
102 if item is None:
103 last_pos = 0
104 else:
105 last_pos = item.end()
106
107 # Append the rest of the string, since it's not in the result list (only
108 # matches are captured that have a leading separator).
109 if not remove_empty_matches or len(string) > last_pos:
110 yield string[last_pos:]
111
112
113 def unescaped_split(pattern,
114 string,
115 max_split=0,
116 remove_empty_matches=False):
117 """
118 Splits the given string by the specified pattern. The return character (\n)
119 is not a natural split pattern (if you don't specify it yourself).
120 This function handles escaped split-patterns (and so splits only patterns
121 that are unescaped).
122 CAUTION: Using the escaped character '\' in the pattern the function can
123 return strange results. The backslash can interfere with the
124 escaping regex-sequence used internally to split.
125
126 :param pattern: A regex pattern that defines where to split.
127 :param string: The string to split by the defined pattern.
128 :param max_split: Defines the maximum number of splits. If 0 or
129 less is provided, the number of splits is not
130 limited.
131 :param remove_empty_matches: Defines whether empty entries should
132 be removed from the result.
133 :return: An iterator returning the split up strings.
134 """
135 # Need to use re.search() since using splitting directly is not possible.
136 # We need to match the separator only if the number of escapes is even.
137 # The solution is to use look-behind-assertions, but these don't support a
138 # variable number of letters (means quantifiers are not usable there). So
139 # if we try to match the escape sequences too, they would be replaced,
140 # because they are consumed then by the regex. That's not wanted.
141
142 # Regex explanation:
143 # 1. (.*?) Match any char unlimited times, as few times as
144 # possible. Save the match in the first capturing
145 # group (match.group(1)).
146 # 2. (?<!\\)((?:\\\\)*) Unescaping sequence. Only matches backslashes if
147 # their count is even.
148 # 3. (?:pattern) A non-capturing group that matches the
149 # split-pattern. Because the first group is lazy
150 # (matches as few times as possible) the next
151 # occurring split-sequence is matched.
152 regex = r"(.*?)(?<!\\)((?:\\\\)*)(?:" + pattern + r")"
153
154 item = None
155 for item in re.finditer(regex, string, re.DOTALL):
156 concat_string = item.group(1)
157
158 if item.group(2) is not None:
159 # Escaped escapes were consumed from the second group, append them
160 # too.
161 concat_string += item.group(2)
162
163 if not remove_empty_matches or len(concat_string) != 0:
164 # Return the first matching group. The pattern from parameter can't
165 # change the group order.
166 yield concat_string
167
168 max_split -= 1
169 if max_split == 0:
170 break # only reachable when max_split > 0
171
172 if item is None:
173 last_pos = 0
174 else:
175 last_pos = item.end()
176
177 # Append the rest of the string, since it's not in the result list (only
178 # matches are captured that have a leading separator).
179 if not remove_empty_matches or len(string) > last_pos:
180 yield string[last_pos:]
181
182
183 def search_in_between(begin,
184 end,
185 string,
186 max_matches=0,
187 remove_empty_matches=False):
188 """
189 Searches for a string enclosed between a specified begin- and end-sequence.
190 Also enclosed \n are put into the result. Doesn't handle escape sequences.
191
192 :param begin: A regex pattern that defines where to start
193 matching.
194 :param end: A regex pattern that defines where to end
195 matching.
196 :param string: The string where to search in.
197 :param max_matches Defines the maximum number of matches. If 0 or
198 less is provided, the number of splits is not
199 limited.
200 :param remove_empty_matches: Defines whether empty entries should
201 be removed from the result.
202 :return: An iterator returning the matched strings.
203 """
204
205 # Compilation of the begin sequence is needed to get the number of
206 # capturing groups in it.
207 compiled_begin_pattern = re.compile(begin)
208
209 # Regex explanation:
210 # 1. (?:begin) A non-capturing group that matches the begin sequence.
211 # 2. (.*?) Match any char unlimited times, as few times as possible.
212 # Save the match in the first capturing group
213 # (match.group(1)).
214 # 3. (?:end) A non-capturing group that matches the end sequence.
215 # Because the previous group is lazy (matches as few times as
216 # possible) the next occurring end-sequence is matched.
217 regex = r"(?:" + begin + r")(.*?)(?:" + end + r")"
218
219 matches = re.finditer(regex, string, re.DOTALL)
220
221 if remove_empty_matches:
222 matches = trim_empty_matches(matches,
223 [compiled_begin_pattern.groups + 1])
224
225 matches = limit(matches, max_matches)
226
227 for elem in matches:
228 yield elem.group(compiled_begin_pattern.groups + 1)
229
230
231 def unescaped_search_in_between(begin,
232 end,
233 string,
234 max_matches=0,
235 remove_empty_matches=False):
236 """
237 Searches for a string enclosed between a specified begin- and end-sequence.
238 Also enclosed \n are put into the result.
239 Handles escaped begin- and end-sequences (and so only patterns that are
240 unescaped).
241 CAUTION: Using the escaped character '\' in the begin- or end-sequences
242 the function can return strange results. The backslash can
243 interfere with the escaping regex-sequence used internally to
244 match the enclosed string.
245
246 :param begin: The begin-sequence where to start matching.
247 Providing regexes (and not only fixed strings)
248 is allowed.
249 :param end: The end-sequence where to end matching.
250 Providing regexes (and not only fixed strings)
251 is allowed.
252 :param string: The string where to search in.
253 :param max_matches Defines the maximum number of matches. If 0 or
254 less is provided, the number of splits is not
255 limited.
256 :param remove_empty_matches: Defines whether empty entries should
257 be removed from the result.
258 :return: An iterator returning the matched strings.
259 """
260 # Compilation of the begin sequence is needed to get the number of
261 # capturing groups in it.
262 compiled_begin_pattern = re.compile(begin)
263
264 # Regex explanation:
265 # 1. (?<!\\)(?:\\\\)* Unescapes the following char. The first part of this
266 # regex is a look-behind assertion. Only match the
267 # following if no single backslash is before it.
268 # The second part matches all double backslashes.
269 # In fact this sequence matches all escapes that occur
270 # as a multiple of two, means the following statement
271 # is not escaped.
272 # 2. (?:begin) A non-capturing group that matches the begin
273 # 3. (.*?) sequence. Match any char unlimited times, as few
274 # times as possible. Save the match in the capturing
275 # group after all capturing groups that can appear in
276 # 'begin'.
277 # 4. (?<!\\)(?:\\\\)* Again the unescaping regex.
278 # 5. (?:end) A non-capturing group that matches the end sequence.
279 # Because the 3. group is lazy (matches as few times as
280 # possible) the next occurring end-sequence is matched.
281 regex = (r"(?<!\\)(?:\\\\)*(?:" + begin + r")(.*?)(?<!\\)((?:\\\\)*)(?:" +
282 end + r")")
283
284 matches = re.finditer(regex, string, re.DOTALL)
285
286 if remove_empty_matches:
287 matches = trim_empty_matches(matches,
288 [compiled_begin_pattern.groups + 1,
289 compiled_begin_pattern.groups + 2])
290
291 matches = limit(matches, max_matches)
292
293 for elem in matches:
294 yield (elem.group(compiled_begin_pattern.groups + 1) +
295 elem.group(compiled_begin_pattern.groups + 2))
296
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/coalib/parsing/StringProcessing.py b/coalib/parsing/StringProcessing.py
--- a/coalib/parsing/StringProcessing.py
+++ b/coalib/parsing/StringProcessing.py
@@ -53,7 +53,6 @@
for group in groups:
if len(elem.group(group)) != 0:
yield elem
-
continue
|
{"golden_diff": "diff --git a/coalib/parsing/StringProcessing.py b/coalib/parsing/StringProcessing.py\n--- a/coalib/parsing/StringProcessing.py\n+++ b/coalib/parsing/StringProcessing.py\n@@ -53,7 +53,6 @@\n for group in groups:\n if len(elem.group(group)) != 0:\n yield elem\n-\n continue\n", "issue": "escaping stuff: scrutinizer issues\nhttps://scrutinizer-ci.com/g/coala-analyzer/coala/inspections/8589a071-2905-40dd-a562-bfae3b8f40e5/issues/\n\nneed to fix after merging the escaping stuff\n\n", "before_files": [{"content": "import re\n\n\ndef search_for(pattern, string, flags=0, max_match=0):\n \"\"\"\n Searches for a given pattern in a string.\n\n :param pattern: A regex pattern that defines what to match.\n :param string: The string to search in.\n :param flags: Additional flags to pass to the regex processor.\n :param max_match: Defines the maximum number of matches to perform. If 0 or\n less is provided, the number of splits is not limited.\n :return: An iterator returning MatchObject's.\n \"\"\"\n for elem in limit(re.finditer(pattern, string, flags), max_match):\n yield elem\n\n\ndef limit(iterator, count):\n \"\"\"\n A filter that removes all elements behind the set limit.\n\n :param iterator: The iterator to be filtered.\n :param count: The iterator limit. All elements at positions bigger than\n this limit are trimmed off. Exclusion: 0 or numbers below\n does not limit at all, means the passed iterator is\n completely yielded.\n \"\"\"\n if count <= 0: # Performance branch\n for elem in iterator:\n yield elem\n else:\n for elem in iterator:\n yield elem\n count -= 1\n if count == 0:\n break\n\n\ndef trim_empty_matches(iterator, groups=[0]):\n \"\"\"\n A filter that removes empty match strings. It can only operate on iterators\n whose elements are of type MatchObject.\n\n :param iterator: The iterator to be filtered.\n :param groups: An iteratable defining the groups to check for blankness.\n Only results are not yielded if all groups of the match\n are blank.\n You can not only pass numbers but also strings, if your\n MatchObject contains named groups.\n \"\"\"\n for elem in iterator:\n for group in groups:\n if len(elem.group(group)) != 0:\n yield elem\n\n continue\n\n\ndef split(pattern,\n string,\n max_split=0,\n remove_empty_matches=False):\n \"\"\"\n Splits the given string by the specified pattern. The return character (\\n)\n is not a natural split pattern (if you don't specify it yourself).\n This function ignores escape sequences.\n\n :param pattern: A regex pattern that defines where to split.\n :param string: The string to split by the defined pattern.\n :param max_split: Defines the maximum number of splits. If 0 or\n less is provided, the number of splits is not\n limited.\n :param remove_empty_matches: Defines whether empty entries should\n be removed from the result.\n :return: An iterator returning the split up strings.\n \"\"\"\n # re.split() is not usable for this function. It has a bug when using too\n # many capturing groups \"()\".\n\n # Regex explanation:\n # 1. (.*?) Match any char unlimited times, as few times as\n # possible. Save the match in the first capturing\n # group (match.group(1)).\n # 2. (?:pattern) A non-capturing group that matches the\n # split-pattern. Because the first group is lazy\n # (matches as few times as possible) the next\n # occurring split-sequence is matched.\n regex = r\"(.*?)(?:\" + pattern + r\")\"\n\n item = None\n for item in re.finditer(regex, string, re.DOTALL):\n if not remove_empty_matches or len(item.group(1)) != 0:\n # Return the first matching group. The pattern from parameter can't\n # change the group order.\n yield item.group(1)\n\n max_split -= 1\n if 0 == max_split:\n break # only reachable when max_split > 0\n\n if item is None:\n last_pos = 0\n else:\n last_pos = item.end()\n\n # Append the rest of the string, since it's not in the result list (only\n # matches are captured that have a leading separator).\n if not remove_empty_matches or len(string) > last_pos:\n yield string[last_pos:]\n\n\ndef unescaped_split(pattern,\n string,\n max_split=0,\n remove_empty_matches=False):\n \"\"\"\n Splits the given string by the specified pattern. The return character (\\n)\n is not a natural split pattern (if you don't specify it yourself).\n This function handles escaped split-patterns (and so splits only patterns\n that are unescaped).\n CAUTION: Using the escaped character '\\' in the pattern the function can\n return strange results. The backslash can interfere with the\n escaping regex-sequence used internally to split.\n\n :param pattern: A regex pattern that defines where to split.\n :param string: The string to split by the defined pattern.\n :param max_split: Defines the maximum number of splits. If 0 or\n less is provided, the number of splits is not\n limited.\n :param remove_empty_matches: Defines whether empty entries should\n be removed from the result.\n :return: An iterator returning the split up strings.\n \"\"\"\n # Need to use re.search() since using splitting directly is not possible.\n # We need to match the separator only if the number of escapes is even.\n # The solution is to use look-behind-assertions, but these don't support a\n # variable number of letters (means quantifiers are not usable there). So\n # if we try to match the escape sequences too, they would be replaced,\n # because they are consumed then by the regex. That's not wanted.\n\n # Regex explanation:\n # 1. (.*?) Match any char unlimited times, as few times as\n # possible. Save the match in the first capturing\n # group (match.group(1)).\n # 2. (?<!\\\\)((?:\\\\\\\\)*) Unescaping sequence. Only matches backslashes if\n # their count is even.\n # 3. (?:pattern) A non-capturing group that matches the\n # split-pattern. Because the first group is lazy\n # (matches as few times as possible) the next\n # occurring split-sequence is matched.\n regex = r\"(.*?)(?<!\\\\)((?:\\\\\\\\)*)(?:\" + pattern + r\")\"\n\n item = None\n for item in re.finditer(regex, string, re.DOTALL):\n concat_string = item.group(1)\n\n if item.group(2) is not None:\n # Escaped escapes were consumed from the second group, append them\n # too.\n concat_string += item.group(2)\n\n if not remove_empty_matches or len(concat_string) != 0:\n # Return the first matching group. The pattern from parameter can't\n # change the group order.\n yield concat_string\n\n max_split -= 1\n if max_split == 0:\n break # only reachable when max_split > 0\n\n if item is None:\n last_pos = 0\n else:\n last_pos = item.end()\n\n # Append the rest of the string, since it's not in the result list (only\n # matches are captured that have a leading separator).\n if not remove_empty_matches or len(string) > last_pos:\n yield string[last_pos:]\n\n\ndef search_in_between(begin,\n end,\n string,\n max_matches=0,\n remove_empty_matches=False):\n \"\"\"\n Searches for a string enclosed between a specified begin- and end-sequence.\n Also enclosed \\n are put into the result. Doesn't handle escape sequences.\n\n :param begin: A regex pattern that defines where to start\n matching.\n :param end: A regex pattern that defines where to end\n matching.\n :param string: The string where to search in.\n :param max_matches Defines the maximum number of matches. If 0 or\n less is provided, the number of splits is not\n limited.\n :param remove_empty_matches: Defines whether empty entries should\n be removed from the result.\n :return: An iterator returning the matched strings.\n \"\"\"\n\n # Compilation of the begin sequence is needed to get the number of\n # capturing groups in it.\n compiled_begin_pattern = re.compile(begin)\n\n # Regex explanation:\n # 1. (?:begin) A non-capturing group that matches the begin sequence.\n # 2. (.*?) Match any char unlimited times, as few times as possible.\n # Save the match in the first capturing group\n # (match.group(1)).\n # 3. (?:end) A non-capturing group that matches the end sequence.\n # Because the previous group is lazy (matches as few times as\n # possible) the next occurring end-sequence is matched.\n regex = r\"(?:\" + begin + r\")(.*?)(?:\" + end + r\")\"\n\n matches = re.finditer(regex, string, re.DOTALL)\n\n if remove_empty_matches:\n matches = trim_empty_matches(matches,\n [compiled_begin_pattern.groups + 1])\n\n matches = limit(matches, max_matches)\n\n for elem in matches:\n yield elem.group(compiled_begin_pattern.groups + 1)\n\n\ndef unescaped_search_in_between(begin,\n end,\n string,\n max_matches=0,\n remove_empty_matches=False):\n \"\"\"\n Searches for a string enclosed between a specified begin- and end-sequence.\n Also enclosed \\n are put into the result.\n Handles escaped begin- and end-sequences (and so only patterns that are\n unescaped).\n CAUTION: Using the escaped character '\\' in the begin- or end-sequences\n the function can return strange results. The backslash can\n interfere with the escaping regex-sequence used internally to\n match the enclosed string.\n\n :param begin: The begin-sequence where to start matching.\n Providing regexes (and not only fixed strings)\n is allowed.\n :param end: The end-sequence where to end matching.\n Providing regexes (and not only fixed strings)\n is allowed.\n :param string: The string where to search in.\n :param max_matches Defines the maximum number of matches. If 0 or\n less is provided, the number of splits is not\n limited.\n :param remove_empty_matches: Defines whether empty entries should\n be removed from the result.\n :return: An iterator returning the matched strings.\n \"\"\"\n # Compilation of the begin sequence is needed to get the number of\n # capturing groups in it.\n compiled_begin_pattern = re.compile(begin)\n\n # Regex explanation:\n # 1. (?<!\\\\)(?:\\\\\\\\)* Unescapes the following char. The first part of this\n # regex is a look-behind assertion. Only match the\n # following if no single backslash is before it.\n # The second part matches all double backslashes.\n # In fact this sequence matches all escapes that occur\n # as a multiple of two, means the following statement\n # is not escaped.\n # 2. (?:begin) A non-capturing group that matches the begin\n # 3. (.*?) sequence. Match any char unlimited times, as few\n # times as possible. Save the match in the capturing\n # group after all capturing groups that can appear in\n # 'begin'.\n # 4. (?<!\\\\)(?:\\\\\\\\)* Again the unescaping regex.\n # 5. (?:end) A non-capturing group that matches the end sequence.\n # Because the 3. group is lazy (matches as few times as\n # possible) the next occurring end-sequence is matched.\n regex = (r\"(?<!\\\\)(?:\\\\\\\\)*(?:\" + begin + r\")(.*?)(?<!\\\\)((?:\\\\\\\\)*)(?:\" +\n end + r\")\")\n\n matches = re.finditer(regex, string, re.DOTALL)\n\n if remove_empty_matches:\n matches = trim_empty_matches(matches,\n [compiled_begin_pattern.groups + 1,\n compiled_begin_pattern.groups + 2])\n\n matches = limit(matches, max_matches)\n\n for elem in matches:\n yield (elem.group(compiled_begin_pattern.groups + 1) +\n elem.group(compiled_begin_pattern.groups + 2))\n", "path": "coalib/parsing/StringProcessing.py"}], "after_files": [{"content": "import re\n\n\ndef search_for(pattern, string, flags=0, max_match=0):\n \"\"\"\n Searches for a given pattern in a string.\n\n :param pattern: A regex pattern that defines what to match.\n :param string: The string to search in.\n :param flags: Additional flags to pass to the regex processor.\n :param max_match: Defines the maximum number of matches to perform. If 0 or\n less is provided, the number of splits is not limited.\n :return: An iterator returning MatchObject's.\n \"\"\"\n for elem in limit(re.finditer(pattern, string, flags), max_match):\n yield elem\n\n\ndef limit(iterator, count):\n \"\"\"\n A filter that removes all elements behind the set limit.\n\n :param iterator: The iterator to be filtered.\n :param count: The iterator limit. All elements at positions bigger than\n this limit are trimmed off. Exclusion: 0 or numbers below\n does not limit at all, means the passed iterator is\n completely yielded.\n \"\"\"\n if count <= 0: # Performance branch\n for elem in iterator:\n yield elem\n else:\n for elem in iterator:\n yield elem\n count -= 1\n if count == 0:\n break\n\n\ndef trim_empty_matches(iterator, groups=[0]):\n \"\"\"\n A filter that removes empty match strings. It can only operate on iterators\n whose elements are of type MatchObject.\n\n :param iterator: The iterator to be filtered.\n :param groups: An iteratable defining the groups to check for blankness.\n Only results are not yielded if all groups of the match\n are blank.\n You can not only pass numbers but also strings, if your\n MatchObject contains named groups.\n \"\"\"\n for elem in iterator:\n for group in groups:\n if len(elem.group(group)) != 0:\n yield elem\n continue\n\n\ndef split(pattern,\n string,\n max_split=0,\n remove_empty_matches=False):\n \"\"\"\n Splits the given string by the specified pattern. The return character (\\n)\n is not a natural split pattern (if you don't specify it yourself).\n This function ignores escape sequences.\n\n :param pattern: A regex pattern that defines where to split.\n :param string: The string to split by the defined pattern.\n :param max_split: Defines the maximum number of splits. If 0 or\n less is provided, the number of splits is not\n limited.\n :param remove_empty_matches: Defines whether empty entries should\n be removed from the result.\n :return: An iterator returning the split up strings.\n \"\"\"\n # re.split() is not usable for this function. It has a bug when using too\n # many capturing groups \"()\".\n\n # Regex explanation:\n # 1. (.*?) Match any char unlimited times, as few times as\n # possible. Save the match in the first capturing\n # group (match.group(1)).\n # 2. (?:pattern) A non-capturing group that matches the\n # split-pattern. Because the first group is lazy\n # (matches as few times as possible) the next\n # occurring split-sequence is matched.\n regex = r\"(.*?)(?:\" + pattern + r\")\"\n\n item = None\n for item in re.finditer(regex, string, re.DOTALL):\n if not remove_empty_matches or len(item.group(1)) != 0:\n # Return the first matching group. The pattern from parameter can't\n # change the group order.\n yield item.group(1)\n\n max_split -= 1\n if 0 == max_split:\n break # only reachable when max_split > 0\n\n if item is None:\n last_pos = 0\n else:\n last_pos = item.end()\n\n # Append the rest of the string, since it's not in the result list (only\n # matches are captured that have a leading separator).\n if not remove_empty_matches or len(string) > last_pos:\n yield string[last_pos:]\n\n\ndef unescaped_split(pattern,\n string,\n max_split=0,\n remove_empty_matches=False):\n \"\"\"\n Splits the given string by the specified pattern. The return character (\\n)\n is not a natural split pattern (if you don't specify it yourself).\n This function handles escaped split-patterns (and so splits only patterns\n that are unescaped).\n CAUTION: Using the escaped character '\\' in the pattern the function can\n return strange results. The backslash can interfere with the\n escaping regex-sequence used internally to split.\n\n :param pattern: A regex pattern that defines where to split.\n :param string: The string to split by the defined pattern.\n :param max_split: Defines the maximum number of splits. If 0 or\n less is provided, the number of splits is not\n limited.\n :param remove_empty_matches: Defines whether empty entries should\n be removed from the result.\n :return: An iterator returning the split up strings.\n \"\"\"\n # Need to use re.search() since using splitting directly is not possible.\n # We need to match the separator only if the number of escapes is even.\n # The solution is to use look-behind-assertions, but these don't support a\n # variable number of letters (means quantifiers are not usable there). So\n # if we try to match the escape sequences too, they would be replaced,\n # because they are consumed then by the regex. That's not wanted.\n\n # Regex explanation:\n # 1. (.*?) Match any char unlimited times, as few times as\n # possible. Save the match in the first capturing\n # group (match.group(1)).\n # 2. (?<!\\\\)((?:\\\\\\\\)*) Unescaping sequence. Only matches backslashes if\n # their count is even.\n # 3. (?:pattern) A non-capturing group that matches the\n # split-pattern. Because the first group is lazy\n # (matches as few times as possible) the next\n # occurring split-sequence is matched.\n regex = r\"(.*?)(?<!\\\\)((?:\\\\\\\\)*)(?:\" + pattern + r\")\"\n\n item = None\n for item in re.finditer(regex, string, re.DOTALL):\n concat_string = item.group(1)\n\n if item.group(2) is not None:\n # Escaped escapes were consumed from the second group, append them\n # too.\n concat_string += item.group(2)\n\n if not remove_empty_matches or len(concat_string) != 0:\n # Return the first matching group. The pattern from parameter can't\n # change the group order.\n yield concat_string\n\n max_split -= 1\n if max_split == 0:\n break # only reachable when max_split > 0\n\n if item is None:\n last_pos = 0\n else:\n last_pos = item.end()\n\n # Append the rest of the string, since it's not in the result list (only\n # matches are captured that have a leading separator).\n if not remove_empty_matches or len(string) > last_pos:\n yield string[last_pos:]\n\n\ndef search_in_between(begin,\n end,\n string,\n max_matches=0,\n remove_empty_matches=False):\n \"\"\"\n Searches for a string enclosed between a specified begin- and end-sequence.\n Also enclosed \\n are put into the result. Doesn't handle escape sequences.\n\n :param begin: A regex pattern that defines where to start\n matching.\n :param end: A regex pattern that defines where to end\n matching.\n :param string: The string where to search in.\n :param max_matches Defines the maximum number of matches. If 0 or\n less is provided, the number of splits is not\n limited.\n :param remove_empty_matches: Defines whether empty entries should\n be removed from the result.\n :return: An iterator returning the matched strings.\n \"\"\"\n\n # Compilation of the begin sequence is needed to get the number of\n # capturing groups in it.\n compiled_begin_pattern = re.compile(begin)\n\n # Regex explanation:\n # 1. (?:begin) A non-capturing group that matches the begin sequence.\n # 2. (.*?) Match any char unlimited times, as few times as possible.\n # Save the match in the first capturing group\n # (match.group(1)).\n # 3. (?:end) A non-capturing group that matches the end sequence.\n # Because the previous group is lazy (matches as few times as\n # possible) the next occurring end-sequence is matched.\n regex = r\"(?:\" + begin + r\")(.*?)(?:\" + end + r\")\"\n\n matches = re.finditer(regex, string, re.DOTALL)\n\n if remove_empty_matches:\n matches = trim_empty_matches(matches,\n [compiled_begin_pattern.groups + 1])\n\n matches = limit(matches, max_matches)\n\n for elem in matches:\n yield elem.group(compiled_begin_pattern.groups + 1)\n\n\ndef unescaped_search_in_between(begin,\n end,\n string,\n max_matches=0,\n remove_empty_matches=False):\n \"\"\"\n Searches for a string enclosed between a specified begin- and end-sequence.\n Also enclosed \\n are put into the result.\n Handles escaped begin- and end-sequences (and so only patterns that are\n unescaped).\n CAUTION: Using the escaped character '\\' in the begin- or end-sequences\n the function can return strange results. The backslash can\n interfere with the escaping regex-sequence used internally to\n match the enclosed string.\n\n :param begin: The begin-sequence where to start matching.\n Providing regexes (and not only fixed strings)\n is allowed.\n :param end: The end-sequence where to end matching.\n Providing regexes (and not only fixed strings)\n is allowed.\n :param string: The string where to search in.\n :param max_matches Defines the maximum number of matches. If 0 or\n less is provided, the number of splits is not\n limited.\n :param remove_empty_matches: Defines whether empty entries should\n be removed from the result.\n :return: An iterator returning the matched strings.\n \"\"\"\n # Compilation of the begin sequence is needed to get the number of\n # capturing groups in it.\n compiled_begin_pattern = re.compile(begin)\n\n # Regex explanation:\n # 1. (?<!\\\\)(?:\\\\\\\\)* Unescapes the following char. The first part of this\n # regex is a look-behind assertion. Only match the\n # following if no single backslash is before it.\n # The second part matches all double backslashes.\n # In fact this sequence matches all escapes that occur\n # as a multiple of two, means the following statement\n # is not escaped.\n # 2. (?:begin) A non-capturing group that matches the begin\n # 3. (.*?) sequence. Match any char unlimited times, as few\n # times as possible. Save the match in the capturing\n # group after all capturing groups that can appear in\n # 'begin'.\n # 4. (?<!\\\\)(?:\\\\\\\\)* Again the unescaping regex.\n # 5. (?:end) A non-capturing group that matches the end sequence.\n # Because the 3. group is lazy (matches as few times as\n # possible) the next occurring end-sequence is matched.\n regex = (r\"(?<!\\\\)(?:\\\\\\\\)*(?:\" + begin + r\")(.*?)(?<!\\\\)((?:\\\\\\\\)*)(?:\" +\n end + r\")\")\n\n matches = re.finditer(regex, string, re.DOTALL)\n\n if remove_empty_matches:\n matches = trim_empty_matches(matches,\n [compiled_begin_pattern.groups + 1,\n compiled_begin_pattern.groups + 2])\n\n matches = limit(matches, max_matches)\n\n for elem in matches:\n yield (elem.group(compiled_begin_pattern.groups + 1) +\n elem.group(compiled_begin_pattern.groups + 2))\n", "path": "coalib/parsing/StringProcessing.py"}]}
| 3,823 | 81 |
gh_patches_debug_23037
|
rasdani/github-patches
|
git_diff
|
e-valuation__EvaP-1221
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Contact modal broken in Firefox
The contact modal does not work in Firefox, because `event` is undefined. Chrome provides this in global scope, that's why it's working there (see https://stackoverflow.com/questions/18274383/ajax-post-working-in-chrome-but-not-in-firefox).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `evap/evaluation/views.py`
Content:
```
1 import logging
2
3 from django.conf import settings
4 from django.contrib import messages, auth
5 from django.contrib.auth.decorators import login_required
6 from django.core.mail import EmailMessage
7 from django.http import HttpResponse
8 from django.shortcuts import redirect, render
9 from django.utils.translation import ugettext as _
10 from django.views.decorators.http import require_POST
11 from django.views.decorators.debug import sensitive_post_parameters
12 from django.views.i18n import set_language
13
14 from evap.evaluation.forms import NewKeyForm, LoginUsernameForm
15 from evap.evaluation.models import UserProfile, FaqSection, EmailTemplate, Semester
16
17 logger = logging.getLogger(__name__)
18
19
20 @sensitive_post_parameters("password")
21 def index(request):
22 """Main entry page into EvaP providing all the login options available. The username/password
23 login is thought to be used for internal users, e.g. by connecting to a LDAP directory.
24 The login key mechanism is meant to be used to include external participants, e.g. visiting
25 students or visiting contributors.
26 """
27
28 # parse the form data into the respective form
29 submit_type = request.POST.get("submit_type", "no_submit")
30 new_key_form = NewKeyForm(request.POST if submit_type == "new_key" else None)
31 login_username_form = LoginUsernameForm(request, request.POST if submit_type == "login_username" else None)
32
33 # process form data
34 if request.method == 'POST':
35 if new_key_form.is_valid():
36 # user wants a new login key
37 profile = new_key_form.get_user()
38 profile.ensure_valid_login_key()
39 profile.save()
40
41 EmailTemplate.send_login_url_to_user(new_key_form.get_user())
42
43 messages.success(request, _("We sent you an email with a one-time login URL. Please check your inbox."))
44 return redirect('evaluation:index')
45 elif login_username_form.is_valid():
46 # user would like to login with username and password and passed password test
47 auth.login(request, login_username_form.get_user())
48
49 # clean up our test cookie
50 if request.session.test_cookie_worked():
51 request.session.delete_test_cookie()
52
53 # if not logged in by now, render form
54 if not request.user.is_authenticated:
55 # set test cookie to verify whether they work in the next step
56 request.session.set_test_cookie()
57
58 template_data = dict(new_key_form=new_key_form, login_username_form=login_username_form)
59 return render(request, "index.html", template_data)
60 else:
61 user, __ = UserProfile.objects.get_or_create(username=request.user.username)
62
63 # check for redirect variable
64 redirect_to = request.GET.get("next", None)
65 if redirect_to is not None:
66 return redirect(redirect_to)
67
68 # redirect user to appropriate start page
69 if request.user.is_reviewer:
70 return redirect('staff:semester_view', Semester.active_semester().id)
71 if request.user.is_staff:
72 return redirect('staff:index')
73 elif request.user.is_grade_publisher:
74 return redirect('grades:semester_view', Semester.active_semester().id)
75 elif user.is_student:
76 return redirect('student:index')
77 elif user.is_contributor_or_delegate:
78 return redirect('contributor:index')
79 else:
80 return redirect('results:index')
81
82
83 def faq(request):
84 return render(request, "faq.html", dict(sections=FaqSection.objects.all()))
85
86
87 def legal_notice(request):
88 return render(request, "legal_notice.html", dict())
89
90
91 @require_POST
92 @login_required
93 def contact(request):
94 message = request.POST.get("message")
95 title = request.POST.get("title")
96 subject = "[EvaP] Message from {}".format(request.user.username)
97
98 if message:
99 mail = EmailMessage(
100 subject=subject,
101 body="{}\n{} ({})\n\n{}".format(title, request.user.username, request.user.email, message),
102 to=[settings.CONTACT_EMAIL])
103 try:
104 mail.send()
105 logger.info('Sent contact email: \n{}\n'.format(mail.message()))
106 except Exception:
107 logger.exception('An exception occurred when sending the following contact email:\n{}\n'.format(mail.message()))
108 raise
109
110 return HttpResponse()
111
112
113 @require_POST
114 def set_lang(request):
115 if request.user.is_authenticated:
116 user = request.user
117 user.language = request.POST['language']
118 user.save()
119
120 return set_language(request)
121
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/evap/evaluation/views.py b/evap/evaluation/views.py
--- a/evap/evaluation/views.py
+++ b/evap/evaluation/views.py
@@ -4,7 +4,7 @@
from django.contrib import messages, auth
from django.contrib.auth.decorators import login_required
from django.core.mail import EmailMessage
-from django.http import HttpResponse
+from django.http import HttpResponse, HttpResponseBadRequest
from django.shortcuts import redirect, render
from django.utils.translation import ugettext as _
from django.views.decorators.http import require_POST
@@ -103,11 +103,12 @@
try:
mail.send()
logger.info('Sent contact email: \n{}\n'.format(mail.message()))
+ return HttpResponse()
except Exception:
logger.exception('An exception occurred when sending the following contact email:\n{}\n'.format(mail.message()))
raise
- return HttpResponse()
+ return HttpResponseBadRequest()
@require_POST
|
{"golden_diff": "diff --git a/evap/evaluation/views.py b/evap/evaluation/views.py\n--- a/evap/evaluation/views.py\n+++ b/evap/evaluation/views.py\n@@ -4,7 +4,7 @@\n from django.contrib import messages, auth\n from django.contrib.auth.decorators import login_required\n from django.core.mail import EmailMessage\n-from django.http import HttpResponse\n+from django.http import HttpResponse, HttpResponseBadRequest\n from django.shortcuts import redirect, render\n from django.utils.translation import ugettext as _\n from django.views.decorators.http import require_POST\n@@ -103,11 +103,12 @@\n try:\n mail.send()\n logger.info('Sent contact email: \\n{}\\n'.format(mail.message()))\n+ return HttpResponse()\n except Exception:\n logger.exception('An exception occurred when sending the following contact email:\\n{}\\n'.format(mail.message()))\n raise\n \n- return HttpResponse()\n+ return HttpResponseBadRequest()\n \n \n @require_POST\n", "issue": "Contact modal broken in Firefox\nThe contact modal does not work in Firefox, because `event` is undefined. Chrome provides this in global scope, that's why it's working there (see https://stackoverflow.com/questions/18274383/ajax-post-working-in-chrome-but-not-in-firefox).\n", "before_files": [{"content": "import logging\n\nfrom django.conf import settings\nfrom django.contrib import messages, auth\nfrom django.contrib.auth.decorators import login_required\nfrom django.core.mail import EmailMessage\nfrom django.http import HttpResponse\nfrom django.shortcuts import redirect, render\nfrom django.utils.translation import ugettext as _\nfrom django.views.decorators.http import require_POST\nfrom django.views.decorators.debug import sensitive_post_parameters\nfrom django.views.i18n import set_language\n\nfrom evap.evaluation.forms import NewKeyForm, LoginUsernameForm\nfrom evap.evaluation.models import UserProfile, FaqSection, EmailTemplate, Semester\n\nlogger = logging.getLogger(__name__)\n\n\n@sensitive_post_parameters(\"password\")\ndef index(request):\n \"\"\"Main entry page into EvaP providing all the login options available. The username/password\n login is thought to be used for internal users, e.g. by connecting to a LDAP directory.\n The login key mechanism is meant to be used to include external participants, e.g. visiting\n students or visiting contributors.\n \"\"\"\n\n # parse the form data into the respective form\n submit_type = request.POST.get(\"submit_type\", \"no_submit\")\n new_key_form = NewKeyForm(request.POST if submit_type == \"new_key\" else None)\n login_username_form = LoginUsernameForm(request, request.POST if submit_type == \"login_username\" else None)\n\n # process form data\n if request.method == 'POST':\n if new_key_form.is_valid():\n # user wants a new login key\n profile = new_key_form.get_user()\n profile.ensure_valid_login_key()\n profile.save()\n\n EmailTemplate.send_login_url_to_user(new_key_form.get_user())\n\n messages.success(request, _(\"We sent you an email with a one-time login URL. Please check your inbox.\"))\n return redirect('evaluation:index')\n elif login_username_form.is_valid():\n # user would like to login with username and password and passed password test\n auth.login(request, login_username_form.get_user())\n\n # clean up our test cookie\n if request.session.test_cookie_worked():\n request.session.delete_test_cookie()\n\n # if not logged in by now, render form\n if not request.user.is_authenticated:\n # set test cookie to verify whether they work in the next step\n request.session.set_test_cookie()\n\n template_data = dict(new_key_form=new_key_form, login_username_form=login_username_form)\n return render(request, \"index.html\", template_data)\n else:\n user, __ = UserProfile.objects.get_or_create(username=request.user.username)\n\n # check for redirect variable\n redirect_to = request.GET.get(\"next\", None)\n if redirect_to is not None:\n return redirect(redirect_to)\n\n # redirect user to appropriate start page\n if request.user.is_reviewer:\n return redirect('staff:semester_view', Semester.active_semester().id)\n if request.user.is_staff:\n return redirect('staff:index')\n elif request.user.is_grade_publisher:\n return redirect('grades:semester_view', Semester.active_semester().id)\n elif user.is_student:\n return redirect('student:index')\n elif user.is_contributor_or_delegate:\n return redirect('contributor:index')\n else:\n return redirect('results:index')\n\n\ndef faq(request):\n return render(request, \"faq.html\", dict(sections=FaqSection.objects.all()))\n\n\ndef legal_notice(request):\n return render(request, \"legal_notice.html\", dict())\n\n\n@require_POST\n@login_required\ndef contact(request):\n message = request.POST.get(\"message\")\n title = request.POST.get(\"title\")\n subject = \"[EvaP] Message from {}\".format(request.user.username)\n\n if message:\n mail = EmailMessage(\n subject=subject,\n body=\"{}\\n{} ({})\\n\\n{}\".format(title, request.user.username, request.user.email, message),\n to=[settings.CONTACT_EMAIL])\n try:\n mail.send()\n logger.info('Sent contact email: \\n{}\\n'.format(mail.message()))\n except Exception:\n logger.exception('An exception occurred when sending the following contact email:\\n{}\\n'.format(mail.message()))\n raise\n\n return HttpResponse()\n\n\n@require_POST\ndef set_lang(request):\n if request.user.is_authenticated:\n user = request.user\n user.language = request.POST['language']\n user.save()\n\n return set_language(request)\n", "path": "evap/evaluation/views.py"}], "after_files": [{"content": "import logging\n\nfrom django.conf import settings\nfrom django.contrib import messages, auth\nfrom django.contrib.auth.decorators import login_required\nfrom django.core.mail import EmailMessage\nfrom django.http import HttpResponse, HttpResponseBadRequest\nfrom django.shortcuts import redirect, render\nfrom django.utils.translation import ugettext as _\nfrom django.views.decorators.http import require_POST\nfrom django.views.decorators.debug import sensitive_post_parameters\nfrom django.views.i18n import set_language\n\nfrom evap.evaluation.forms import NewKeyForm, LoginUsernameForm\nfrom evap.evaluation.models import UserProfile, FaqSection, EmailTemplate, Semester\n\nlogger = logging.getLogger(__name__)\n\n\n@sensitive_post_parameters(\"password\")\ndef index(request):\n \"\"\"Main entry page into EvaP providing all the login options available. The username/password\n login is thought to be used for internal users, e.g. by connecting to a LDAP directory.\n The login key mechanism is meant to be used to include external participants, e.g. visiting\n students or visiting contributors.\n \"\"\"\n\n # parse the form data into the respective form\n submit_type = request.POST.get(\"submit_type\", \"no_submit\")\n new_key_form = NewKeyForm(request.POST if submit_type == \"new_key\" else None)\n login_username_form = LoginUsernameForm(request, request.POST if submit_type == \"login_username\" else None)\n\n # process form data\n if request.method == 'POST':\n if new_key_form.is_valid():\n # user wants a new login key\n profile = new_key_form.get_user()\n profile.ensure_valid_login_key()\n profile.save()\n\n EmailTemplate.send_login_url_to_user(new_key_form.get_user())\n\n messages.success(request, _(\"We sent you an email with a one-time login URL. Please check your inbox.\"))\n return redirect('evaluation:index')\n elif login_username_form.is_valid():\n # user would like to login with username and password and passed password test\n auth.login(request, login_username_form.get_user())\n\n # clean up our test cookie\n if request.session.test_cookie_worked():\n request.session.delete_test_cookie()\n\n # if not logged in by now, render form\n if not request.user.is_authenticated:\n # set test cookie to verify whether they work in the next step\n request.session.set_test_cookie()\n\n template_data = dict(new_key_form=new_key_form, login_username_form=login_username_form)\n return render(request, \"index.html\", template_data)\n else:\n user, __ = UserProfile.objects.get_or_create(username=request.user.username)\n\n # check for redirect variable\n redirect_to = request.GET.get(\"next\", None)\n if redirect_to is not None:\n return redirect(redirect_to)\n\n # redirect user to appropriate start page\n if request.user.is_reviewer:\n return redirect('staff:semester_view', Semester.active_semester().id)\n if request.user.is_staff:\n return redirect('staff:index')\n elif request.user.is_grade_publisher:\n return redirect('grades:semester_view', Semester.active_semester().id)\n elif user.is_student:\n return redirect('student:index')\n elif user.is_contributor_or_delegate:\n return redirect('contributor:index')\n else:\n return redirect('results:index')\n\n\ndef faq(request):\n return render(request, \"faq.html\", dict(sections=FaqSection.objects.all()))\n\n\ndef legal_notice(request):\n return render(request, \"legal_notice.html\", dict())\n\n\n@require_POST\n@login_required\ndef contact(request):\n message = request.POST.get(\"message\")\n title = request.POST.get(\"title\")\n subject = \"[EvaP] Message from {}\".format(request.user.username)\n\n if message:\n mail = EmailMessage(\n subject=subject,\n body=\"{}\\n{} ({})\\n\\n{}\".format(title, request.user.username, request.user.email, message),\n to=[settings.CONTACT_EMAIL])\n try:\n mail.send()\n logger.info('Sent contact email: \\n{}\\n'.format(mail.message()))\n return HttpResponse()\n except Exception:\n logger.exception('An exception occurred when sending the following contact email:\\n{}\\n'.format(mail.message()))\n raise\n\n return HttpResponseBadRequest()\n\n\n@require_POST\ndef set_lang(request):\n if request.user.is_authenticated:\n user = request.user\n user.language = request.POST['language']\n user.save()\n\n return set_language(request)\n", "path": "evap/evaluation/views.py"}]}
| 1,505 | 207 |
gh_patches_debug_33662
|
rasdani/github-patches
|
git_diff
|
aws-cloudformation__cfn-lint-2011
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Duplicate properties on a resource can cause unhandled exceptions
*cfn-lint version: (`cfn-lint --version`)*
0.48.3
*Description of issue.*
Duplicate properties can cause unhandled exceptions
Please provide as much information as possible:
* Template linting issues:
* Please provide a CloudFormation sample that generated the issue.
* If present, please add links to the (official) documentation for clarification.
* Validate if the issue still exists with the latest version of `cfn-lint` and/or the latest Spec files
e.g.
```yaml
PublicHttpsListener:
Type: 'AWS::ElasticLoadBalancingV2::Listener'
Properties:
LoadBalancerArn: !Ref PublicLoadBalancer
Port: 443
Protocol: HTTPS
Certificates: !Ref LoadBalancerCertificateArn
DefaultActions:
- Type: fixed-response
FixedResponseConfig:
StatusCode: 404
Port: 443
Protocol: HTTPS
```
results in:
```bash
Traceback (most recent call last):
File "/Users/nick.chadwick/Projects/msd/miniconda3/bin/cfn-lint", line 10, in <module>
sys.exit(main())
File "/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/__main__.py", line 28, in main
(template, rules, errors) = cfnlint.core.get_template_rules(filename, args)
File "/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/core.py", line 187, in get_template_rules
(template, errors) = cfnlint.decode.decode(filename)
File "/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/decode/__init__.py", line 28, in decode
template = cfn_yaml.load(filename)
File "/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/decode/cfn_yaml.py", line 237, in load
return loads(content, filename)
File "/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/decode/cfn_yaml.py", line 215, in loads
template = loader.get_single_data()
File "/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/yaml/constructor.py", line 51, in get_single_data
return self.construct_document(node)
File "/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/yaml/constructor.py", line 55, in construct_document
data = self.construct_object(node)
File "/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/yaml/constructor.py", line 100, in construct_object
data = constructor(self, node)
File "/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/decode/cfn_yaml.py", line 81, in construct_yaml_map
value = self.construct_object(value_node, False)
File "/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/yaml/constructor.py", line 100, in construct_object
data = constructor(self, node)
File "/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/decode/cfn_yaml.py", line 81, in construct_yaml_map
value = self.construct_object(value_node, False)
File "/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/yaml/constructor.py", line 100, in construct_object
data = constructor(self, node)
File "/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/decode/cfn_yaml.py", line 81, in construct_yaml_map
value = self.construct_object(value_node, False)
File "/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/yaml/constructor.py", line 100, in construct_object
data = constructor(self, node)
File "/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/decode/cfn_yaml.py", line 98, in construct_yaml_map
key, mapping[key].start_mark.line + 1),
AttributeError: 'int' object has no attribute 'start_mark'
```
* Feature request:
* Please provide argumentation about the missing feature. Context is key!
Cfn-lint uses the [CloudFormation Resource Specifications](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/cfn-resource-specification.html) as the base to do validation. These files are included as part of the application version. Please update to the latest version of `cfn-lint` or update the spec files manually (`cfn-lint -u`)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/cfnlint/decode/cfn_yaml.py`
Content:
```
1 """
2 Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
3 SPDX-License-Identifier: MIT-0
4 """
5 import fileinput
6 import logging
7 import sys
8 import six
9 from yaml.composer import Composer
10 from yaml.reader import Reader
11 from yaml.scanner import Scanner
12 from yaml.resolver import Resolver
13 from yaml import ScalarNode
14 from yaml import SequenceNode
15 from yaml import MappingNode
16 from yaml.constructor import SafeConstructor
17 from yaml.constructor import ConstructorError
18 import cfnlint
19 from cfnlint.decode.node import str_node, dict_node, list_node
20
21 try:
22 from yaml.cyaml import CParser as Parser # pylint: disable=ungrouped-imports
23 cyaml = True
24 except ImportError:
25 from yaml.parser import Parser # pylint: disable=ungrouped-imports
26 cyaml = False
27
28 UNCONVERTED_SUFFIXES = ['Ref', 'Condition']
29 FN_PREFIX = 'Fn::'
30
31 LOGGER = logging.getLogger(__name__)
32
33
34 class CfnParseError(ConstructorError):
35 """
36 Error thrown when the template contains Cfn Error
37 """
38
39 def __init__(self, filename, errors):
40
41 if isinstance(errors, cfnlint.rules.Match):
42 errors = [errors]
43
44 # Call the base class constructor with the parameters it needs
45 super(CfnParseError, self).__init__(errors[0].message)
46
47 # Now for your custom code...
48 self.filename = filename
49 self.matches = errors
50
51 def build_match(filename, message, line_number, column_number, key):
52 return cfnlint.rules.Match(
53 line_number + 1, column_number + 1, line_number + 1,
54 column_number + 1 + len(key), filename, cfnlint.rules.ParseError(), message=message)
55
56 class NodeConstructor(SafeConstructor):
57 """
58 Node Constructors for loading different types in Yaml
59 """
60
61 def __init__(self, filename):
62 # Call the base class constructor
63 super(NodeConstructor, self).__init__()
64
65 self.filename = filename
66
67 # To support lazy loading, the original constructors first yield
68 # an empty object, then fill them in when iterated. Due to
69 # laziness we omit this behaviour (and will only do "deep
70 # construction") by first exhausting iterators, then yielding
71 # copies.
72 def construct_yaml_map(self, node):
73
74 # Check for duplicate keys on the current level, this is not desirable
75 # because a dict does not support this. It overwrites it with the last
76 # occurance, which can give unexpected results
77 mapping = {}
78 self.flatten_mapping(node)
79 for key_node, value_node in node.value:
80 key = self.construct_object(key_node, False)
81 value = self.construct_object(value_node, False)
82
83 if key in mapping:
84 raise CfnParseError(
85 self.filename,
86 [
87 build_match(
88 filename=self.filename,
89 message='Duplicate resource found "{}" (line {})'.format(
90 key, key_node.start_mark.line + 1),
91 line_number=key_node.start_mark.line,
92 column_number=key_node.start_mark.column,
93 key=key
94 ),
95 build_match(
96 filename=self.filename,
97 message='Duplicate resource found "{}" (line {})'.format(
98 key, mapping[key].start_mark.line + 1),
99 line_number=mapping[key].start_mark.line,
100 column_number=mapping[key].start_mark.column,
101 key=key
102 )
103 ]
104 )
105 mapping[key] = value
106
107 obj, = SafeConstructor.construct_yaml_map(self, node)
108 return dict_node(obj, node.start_mark, node.end_mark)
109
110 def construct_yaml_str(self, node):
111 obj = SafeConstructor.construct_yaml_str(self, node)
112 assert isinstance(obj, (six.string_types))
113 return str_node(obj, node.start_mark, node.end_mark)
114
115 def construct_yaml_seq(self, node):
116 obj, = SafeConstructor.construct_yaml_seq(self, node)
117 assert isinstance(obj, list)
118 return list_node(obj, node.start_mark, node.end_mark)
119
120 def construct_yaml_null_error(self, node):
121 """Throw a null error"""
122 raise CfnParseError(
123 self.filename,
124 [
125 build_match(
126 filename=self.filename,
127 message='Null value at line {0} column {1}'.format(
128 node.start_mark.line + 1, node.start_mark.column + 1),
129 line_number=node.start_mark.line,
130 column_number=node.start_mark.column,
131 key=' ',
132 )
133 ]
134 )
135
136
137 NodeConstructor.add_constructor(
138 u'tag:yaml.org,2002:map',
139 NodeConstructor.construct_yaml_map)
140
141 NodeConstructor.add_constructor(
142 u'tag:yaml.org,2002:str',
143 NodeConstructor.construct_yaml_str)
144
145 NodeConstructor.add_constructor(
146 u'tag:yaml.org,2002:seq',
147 NodeConstructor.construct_yaml_seq)
148
149 NodeConstructor.add_constructor(
150 u'tag:yaml.org,2002:null',
151 NodeConstructor.construct_yaml_null_error)
152
153
154 class MarkedLoader(Reader, Scanner, Parser, Composer, NodeConstructor, Resolver):
155 """
156 Class for marked loading YAML
157 """
158 # pylint: disable=non-parent-init-called,super-init-not-called
159
160 def __init__(self, stream, filename):
161 Reader.__init__(self, stream)
162 Scanner.__init__(self)
163 if cyaml:
164 Parser.__init__(self, stream)
165 else:
166 Parser.__init__(self)
167 Composer.__init__(self)
168 SafeConstructor.__init__(self)
169 Resolver.__init__(self)
170 NodeConstructor.__init__(self, filename)
171
172
173 def multi_constructor(loader, tag_suffix, node):
174 """
175 Deal with !Ref style function format
176 """
177
178 if tag_suffix not in UNCONVERTED_SUFFIXES:
179 tag_suffix = '{}{}'.format(FN_PREFIX, tag_suffix)
180
181 constructor = None
182 if tag_suffix == 'Fn::GetAtt':
183 constructor = construct_getatt
184 elif isinstance(node, ScalarNode):
185 constructor = loader.construct_scalar
186 elif isinstance(node, SequenceNode):
187 constructor = loader.construct_sequence
188 elif isinstance(node, MappingNode):
189 constructor = loader.construct_mapping
190 else:
191 raise 'Bad tag: !{}'.format(tag_suffix)
192
193 return dict_node({tag_suffix: constructor(node)}, node.start_mark, node.end_mark)
194
195
196 def construct_getatt(node):
197 """
198 Reconstruct !GetAtt into a list
199 """
200
201 if isinstance(node.value, (six.string_types)):
202 return list_node(node.value.split('.', 1), node.start_mark, node.end_mark)
203 if isinstance(node.value, list):
204 return list_node([s.value for s in node.value], node.start_mark, node.end_mark)
205
206 raise ValueError('Unexpected node type: {}'.format(type(node.value)))
207
208
209 def loads(yaml_string, fname=None):
210 """
211 Load the given YAML string
212 """
213 loader = MarkedLoader(yaml_string, fname)
214 loader.add_multi_constructor('!', multi_constructor)
215 template = loader.get_single_data()
216 # Convert an empty file to an empty dict
217 if template is None:
218 template = {}
219
220 return template
221
222
223 def load(filename):
224 """
225 Load the given YAML file
226 """
227
228 content = ''
229
230 if not sys.stdin.isatty():
231 for line in fileinput.input(files=filename):
232 content = content + line
233 else:
234 with open(filename) as fp:
235 content = fp.read()
236
237 return loads(content, filename)
238
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/cfnlint/decode/cfn_yaml.py b/src/cfnlint/decode/cfn_yaml.py
--- a/src/cfnlint/decode/cfn_yaml.py
+++ b/src/cfnlint/decode/cfn_yaml.py
@@ -80,28 +80,29 @@
key = self.construct_object(key_node, False)
value = self.construct_object(value_node, False)
- if key in mapping:
- raise CfnParseError(
- self.filename,
- [
- build_match(
- filename=self.filename,
- message='Duplicate resource found "{}" (line {})'.format(
- key, key_node.start_mark.line + 1),
- line_number=key_node.start_mark.line,
- column_number=key_node.start_mark.column,
- key=key
- ),
- build_match(
- filename=self.filename,
- message='Duplicate resource found "{}" (line {})'.format(
- key, mapping[key].start_mark.line + 1),
- line_number=mapping[key].start_mark.line,
- column_number=mapping[key].start_mark.column,
- key=key
- )
- ]
- )
+ for key_dup in mapping:
+ if key_dup == key:
+ raise CfnParseError(
+ self.filename,
+ [
+ build_match(
+ filename=self.filename,
+ message='Duplicate resource found "{}" (line {})'.format(
+ key, key_dup.start_mark.line + 1),
+ line_number=key_dup.start_mark.line,
+ column_number=key_dup.start_mark.column,
+ key=key
+ ),
+ build_match(
+ filename=self.filename,
+ message='Duplicate resource found "{}" (line {})'.format(
+ key, key_node.start_mark.line + 1),
+ line_number=key_node.start_mark.line,
+ column_number=key_node.start_mark.column,
+ key=key
+ ),
+ ]
+ )
mapping[key] = value
obj, = SafeConstructor.construct_yaml_map(self, node)
|
{"golden_diff": "diff --git a/src/cfnlint/decode/cfn_yaml.py b/src/cfnlint/decode/cfn_yaml.py\n--- a/src/cfnlint/decode/cfn_yaml.py\n+++ b/src/cfnlint/decode/cfn_yaml.py\n@@ -80,28 +80,29 @@\n key = self.construct_object(key_node, False)\n value = self.construct_object(value_node, False)\n \n- if key in mapping:\n- raise CfnParseError(\n- self.filename,\n- [\n- build_match(\n- filename=self.filename,\n- message='Duplicate resource found \"{}\" (line {})'.format(\n- key, key_node.start_mark.line + 1),\n- line_number=key_node.start_mark.line,\n- column_number=key_node.start_mark.column,\n- key=key\n- ),\n- build_match(\n- filename=self.filename,\n- message='Duplicate resource found \"{}\" (line {})'.format(\n- key, mapping[key].start_mark.line + 1),\n- line_number=mapping[key].start_mark.line,\n- column_number=mapping[key].start_mark.column,\n- key=key\n- )\n- ]\n- )\n+ for key_dup in mapping:\n+ if key_dup == key:\n+ raise CfnParseError(\n+ self.filename,\n+ [\n+ build_match(\n+ filename=self.filename,\n+ message='Duplicate resource found \"{}\" (line {})'.format(\n+ key, key_dup.start_mark.line + 1),\n+ line_number=key_dup.start_mark.line,\n+ column_number=key_dup.start_mark.column,\n+ key=key\n+ ),\n+ build_match(\n+ filename=self.filename,\n+ message='Duplicate resource found \"{}\" (line {})'.format(\n+ key, key_node.start_mark.line + 1),\n+ line_number=key_node.start_mark.line,\n+ column_number=key_node.start_mark.column,\n+ key=key\n+ ),\n+ ]\n+ )\n mapping[key] = value\n \n obj, = SafeConstructor.construct_yaml_map(self, node)\n", "issue": "Duplicate properties on a resource can cause unhandled exceptions\n*cfn-lint version: (`cfn-lint --version`)*\r\n0.48.3\r\n\r\n*Description of issue.*\r\nDuplicate properties can cause unhandled exceptions\r\n\r\nPlease provide as much information as possible:\r\n* Template linting issues:\r\n * Please provide a CloudFormation sample that generated the issue.\r\n * If present, please add links to the (official) documentation for clarification.\r\n * Validate if the issue still exists with the latest version of `cfn-lint` and/or the latest Spec files\r\n\r\ne.g.\r\n```yaml\r\n PublicHttpsListener:\r\n Type: 'AWS::ElasticLoadBalancingV2::Listener'\r\n Properties:\r\n LoadBalancerArn: !Ref PublicLoadBalancer\r\n Port: 443\r\n Protocol: HTTPS\r\n Certificates: !Ref LoadBalancerCertificateArn\r\n DefaultActions:\r\n - Type: fixed-response\r\n FixedResponseConfig:\r\n StatusCode: 404\r\n Port: 443\r\n Protocol: HTTPS\r\n```\r\nresults in:\r\n```bash\r\nTraceback (most recent call last):\r\n File \"/Users/nick.chadwick/Projects/msd/miniconda3/bin/cfn-lint\", line 10, in <module>\r\n sys.exit(main())\r\n File \"/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/__main__.py\", line 28, in main\r\n (template, rules, errors) = cfnlint.core.get_template_rules(filename, args)\r\n File \"/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/core.py\", line 187, in get_template_rules\r\n (template, errors) = cfnlint.decode.decode(filename)\r\n File \"/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/decode/__init__.py\", line 28, in decode\r\n template = cfn_yaml.load(filename)\r\n File \"/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/decode/cfn_yaml.py\", line 237, in load\r\n return loads(content, filename)\r\n File \"/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/decode/cfn_yaml.py\", line 215, in loads\r\n template = loader.get_single_data()\r\n File \"/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/yaml/constructor.py\", line 51, in get_single_data\r\n return self.construct_document(node)\r\n File \"/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/yaml/constructor.py\", line 55, in construct_document\r\n data = self.construct_object(node)\r\n File \"/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/yaml/constructor.py\", line 100, in construct_object\r\n data = constructor(self, node)\r\n File \"/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/decode/cfn_yaml.py\", line 81, in construct_yaml_map\r\n value = self.construct_object(value_node, False)\r\n File \"/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/yaml/constructor.py\", line 100, in construct_object\r\n data = constructor(self, node)\r\n File \"/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/decode/cfn_yaml.py\", line 81, in construct_yaml_map\r\n value = self.construct_object(value_node, False)\r\n File \"/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/yaml/constructor.py\", line 100, in construct_object\r\n data = constructor(self, node)\r\n File \"/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/decode/cfn_yaml.py\", line 81, in construct_yaml_map\r\n value = self.construct_object(value_node, False)\r\n File \"/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/yaml/constructor.py\", line 100, in construct_object\r\n data = constructor(self, node)\r\n File \"/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/decode/cfn_yaml.py\", line 98, in construct_yaml_map\r\n key, mapping[key].start_mark.line + 1),\r\nAttributeError: 'int' object has no attribute 'start_mark'\r\n```\r\n* Feature request:\r\n * Please provide argumentation about the missing feature. Context is key!\r\n\r\n\r\nCfn-lint uses the [CloudFormation Resource Specifications](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/cfn-resource-specification.html) as the base to do validation. These files are included as part of the application version. Please update to the latest version of `cfn-lint` or update the spec files manually (`cfn-lint -u`)\r\n\n", "before_files": [{"content": "\"\"\"\nCopyright Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\nimport fileinput\nimport logging\nimport sys\nimport six\nfrom yaml.composer import Composer\nfrom yaml.reader import Reader\nfrom yaml.scanner import Scanner\nfrom yaml.resolver import Resolver\nfrom yaml import ScalarNode\nfrom yaml import SequenceNode\nfrom yaml import MappingNode\nfrom yaml.constructor import SafeConstructor\nfrom yaml.constructor import ConstructorError\nimport cfnlint\nfrom cfnlint.decode.node import str_node, dict_node, list_node\n\ntry:\n from yaml.cyaml import CParser as Parser # pylint: disable=ungrouped-imports\n cyaml = True\nexcept ImportError:\n from yaml.parser import Parser # pylint: disable=ungrouped-imports\n cyaml = False\n\nUNCONVERTED_SUFFIXES = ['Ref', 'Condition']\nFN_PREFIX = 'Fn::'\n\nLOGGER = logging.getLogger(__name__)\n\n\nclass CfnParseError(ConstructorError):\n \"\"\"\n Error thrown when the template contains Cfn Error\n \"\"\"\n\n def __init__(self, filename, errors):\n\n if isinstance(errors, cfnlint.rules.Match):\n errors = [errors]\n\n # Call the base class constructor with the parameters it needs\n super(CfnParseError, self).__init__(errors[0].message)\n\n # Now for your custom code...\n self.filename = filename\n self.matches = errors\n\ndef build_match(filename, message, line_number, column_number, key):\n return cfnlint.rules.Match(\n line_number + 1, column_number + 1, line_number + 1,\n column_number + 1 + len(key), filename, cfnlint.rules.ParseError(), message=message)\n\nclass NodeConstructor(SafeConstructor):\n \"\"\"\n Node Constructors for loading different types in Yaml\n \"\"\"\n\n def __init__(self, filename):\n # Call the base class constructor\n super(NodeConstructor, self).__init__()\n\n self.filename = filename\n\n # To support lazy loading, the original constructors first yield\n # an empty object, then fill them in when iterated. Due to\n # laziness we omit this behaviour (and will only do \"deep\n # construction\") by first exhausting iterators, then yielding\n # copies.\n def construct_yaml_map(self, node):\n\n # Check for duplicate keys on the current level, this is not desirable\n # because a dict does not support this. It overwrites it with the last\n # occurance, which can give unexpected results\n mapping = {}\n self.flatten_mapping(node)\n for key_node, value_node in node.value:\n key = self.construct_object(key_node, False)\n value = self.construct_object(value_node, False)\n\n if key in mapping:\n raise CfnParseError(\n self.filename,\n [\n build_match(\n filename=self.filename,\n message='Duplicate resource found \"{}\" (line {})'.format(\n key, key_node.start_mark.line + 1),\n line_number=key_node.start_mark.line,\n column_number=key_node.start_mark.column,\n key=key\n ),\n build_match(\n filename=self.filename,\n message='Duplicate resource found \"{}\" (line {})'.format(\n key, mapping[key].start_mark.line + 1),\n line_number=mapping[key].start_mark.line,\n column_number=mapping[key].start_mark.column,\n key=key\n )\n ]\n )\n mapping[key] = value\n\n obj, = SafeConstructor.construct_yaml_map(self, node)\n return dict_node(obj, node.start_mark, node.end_mark)\n\n def construct_yaml_str(self, node):\n obj = SafeConstructor.construct_yaml_str(self, node)\n assert isinstance(obj, (six.string_types))\n return str_node(obj, node.start_mark, node.end_mark)\n\n def construct_yaml_seq(self, node):\n obj, = SafeConstructor.construct_yaml_seq(self, node)\n assert isinstance(obj, list)\n return list_node(obj, node.start_mark, node.end_mark)\n\n def construct_yaml_null_error(self, node):\n \"\"\"Throw a null error\"\"\"\n raise CfnParseError(\n self.filename,\n [\n build_match(\n filename=self.filename,\n message='Null value at line {0} column {1}'.format(\n node.start_mark.line + 1, node.start_mark.column + 1),\n line_number=node.start_mark.line,\n column_number=node.start_mark.column,\n key=' ',\n )\n ]\n )\n\n\nNodeConstructor.add_constructor(\n u'tag:yaml.org,2002:map',\n NodeConstructor.construct_yaml_map)\n\nNodeConstructor.add_constructor(\n u'tag:yaml.org,2002:str',\n NodeConstructor.construct_yaml_str)\n\nNodeConstructor.add_constructor(\n u'tag:yaml.org,2002:seq',\n NodeConstructor.construct_yaml_seq)\n\nNodeConstructor.add_constructor(\n u'tag:yaml.org,2002:null',\n NodeConstructor.construct_yaml_null_error)\n\n\nclass MarkedLoader(Reader, Scanner, Parser, Composer, NodeConstructor, Resolver):\n \"\"\"\n Class for marked loading YAML\n \"\"\"\n # pylint: disable=non-parent-init-called,super-init-not-called\n\n def __init__(self, stream, filename):\n Reader.__init__(self, stream)\n Scanner.__init__(self)\n if cyaml:\n Parser.__init__(self, stream)\n else:\n Parser.__init__(self)\n Composer.__init__(self)\n SafeConstructor.__init__(self)\n Resolver.__init__(self)\n NodeConstructor.__init__(self, filename)\n\n\ndef multi_constructor(loader, tag_suffix, node):\n \"\"\"\n Deal with !Ref style function format\n \"\"\"\n\n if tag_suffix not in UNCONVERTED_SUFFIXES:\n tag_suffix = '{}{}'.format(FN_PREFIX, tag_suffix)\n\n constructor = None\n if tag_suffix == 'Fn::GetAtt':\n constructor = construct_getatt\n elif isinstance(node, ScalarNode):\n constructor = loader.construct_scalar\n elif isinstance(node, SequenceNode):\n constructor = loader.construct_sequence\n elif isinstance(node, MappingNode):\n constructor = loader.construct_mapping\n else:\n raise 'Bad tag: !{}'.format(tag_suffix)\n\n return dict_node({tag_suffix: constructor(node)}, node.start_mark, node.end_mark)\n\n\ndef construct_getatt(node):\n \"\"\"\n Reconstruct !GetAtt into a list\n \"\"\"\n\n if isinstance(node.value, (six.string_types)):\n return list_node(node.value.split('.', 1), node.start_mark, node.end_mark)\n if isinstance(node.value, list):\n return list_node([s.value for s in node.value], node.start_mark, node.end_mark)\n\n raise ValueError('Unexpected node type: {}'.format(type(node.value)))\n\n\ndef loads(yaml_string, fname=None):\n \"\"\"\n Load the given YAML string\n \"\"\"\n loader = MarkedLoader(yaml_string, fname)\n loader.add_multi_constructor('!', multi_constructor)\n template = loader.get_single_data()\n # Convert an empty file to an empty dict\n if template is None:\n template = {}\n\n return template\n\n\ndef load(filename):\n \"\"\"\n Load the given YAML file\n \"\"\"\n\n content = ''\n\n if not sys.stdin.isatty():\n for line in fileinput.input(files=filename):\n content = content + line\n else:\n with open(filename) as fp:\n content = fp.read()\n\n return loads(content, filename)\n", "path": "src/cfnlint/decode/cfn_yaml.py"}], "after_files": [{"content": "\"\"\"\nCopyright Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\nimport fileinput\nimport logging\nimport sys\nimport six\nfrom yaml.composer import Composer\nfrom yaml.reader import Reader\nfrom yaml.scanner import Scanner\nfrom yaml.resolver import Resolver\nfrom yaml import ScalarNode\nfrom yaml import SequenceNode\nfrom yaml import MappingNode\nfrom yaml.constructor import SafeConstructor\nfrom yaml.constructor import ConstructorError\nimport cfnlint\nfrom cfnlint.decode.node import str_node, dict_node, list_node\n\ntry:\n from yaml.cyaml import CParser as Parser # pylint: disable=ungrouped-imports\n cyaml = True\nexcept ImportError:\n from yaml.parser import Parser # pylint: disable=ungrouped-imports\n cyaml = False\n\nUNCONVERTED_SUFFIXES = ['Ref', 'Condition']\nFN_PREFIX = 'Fn::'\n\nLOGGER = logging.getLogger(__name__)\n\n\nclass CfnParseError(ConstructorError):\n \"\"\"\n Error thrown when the template contains Cfn Error\n \"\"\"\n\n def __init__(self, filename, errors):\n\n if isinstance(errors, cfnlint.rules.Match):\n errors = [errors]\n\n # Call the base class constructor with the parameters it needs\n super(CfnParseError, self).__init__(errors[0].message)\n\n # Now for your custom code...\n self.filename = filename\n self.matches = errors\n\ndef build_match(filename, message, line_number, column_number, key):\n return cfnlint.rules.Match(\n line_number + 1, column_number + 1, line_number + 1,\n column_number + 1 + len(key), filename, cfnlint.rules.ParseError(), message=message)\n\nclass NodeConstructor(SafeConstructor):\n \"\"\"\n Node Constructors for loading different types in Yaml\n \"\"\"\n\n def __init__(self, filename):\n # Call the base class constructor\n super(NodeConstructor, self).__init__()\n\n self.filename = filename\n\n # To support lazy loading, the original constructors first yield\n # an empty object, then fill them in when iterated. Due to\n # laziness we omit this behaviour (and will only do \"deep\n # construction\") by first exhausting iterators, then yielding\n # copies.\n def construct_yaml_map(self, node):\n\n # Check for duplicate keys on the current level, this is not desirable\n # because a dict does not support this. It overwrites it with the last\n # occurance, which can give unexpected results\n mapping = {}\n self.flatten_mapping(node)\n for key_node, value_node in node.value:\n key = self.construct_object(key_node, False)\n value = self.construct_object(value_node, False)\n\n for key_dup in mapping:\n if key_dup == key:\n raise CfnParseError(\n self.filename,\n [\n build_match(\n filename=self.filename,\n message='Duplicate resource found \"{}\" (line {})'.format(\n key, key_dup.start_mark.line + 1),\n line_number=key_dup.start_mark.line,\n column_number=key_dup.start_mark.column,\n key=key\n ),\n build_match(\n filename=self.filename,\n message='Duplicate resource found \"{}\" (line {})'.format(\n key, key_node.start_mark.line + 1),\n line_number=key_node.start_mark.line,\n column_number=key_node.start_mark.column,\n key=key\n ),\n ]\n )\n mapping[key] = value\n\n obj, = SafeConstructor.construct_yaml_map(self, node)\n return dict_node(obj, node.start_mark, node.end_mark)\n\n def construct_yaml_str(self, node):\n obj = SafeConstructor.construct_yaml_str(self, node)\n assert isinstance(obj, (six.string_types))\n return str_node(obj, node.start_mark, node.end_mark)\n\n def construct_yaml_seq(self, node):\n obj, = SafeConstructor.construct_yaml_seq(self, node)\n assert isinstance(obj, list)\n return list_node(obj, node.start_mark, node.end_mark)\n\n def construct_yaml_null_error(self, node):\n \"\"\"Throw a null error\"\"\"\n raise CfnParseError(\n self.filename,\n [\n build_match(\n filename=self.filename,\n message='Null value at line {0} column {1}'.format(\n node.start_mark.line + 1, node.start_mark.column + 1),\n line_number=node.start_mark.line,\n column_number=node.start_mark.column,\n key=' ',\n )\n ]\n )\n\n\nNodeConstructor.add_constructor(\n u'tag:yaml.org,2002:map',\n NodeConstructor.construct_yaml_map)\n\nNodeConstructor.add_constructor(\n u'tag:yaml.org,2002:str',\n NodeConstructor.construct_yaml_str)\n\nNodeConstructor.add_constructor(\n u'tag:yaml.org,2002:seq',\n NodeConstructor.construct_yaml_seq)\n\nNodeConstructor.add_constructor(\n u'tag:yaml.org,2002:null',\n NodeConstructor.construct_yaml_null_error)\n\n\nclass MarkedLoader(Reader, Scanner, Parser, Composer, NodeConstructor, Resolver):\n \"\"\"\n Class for marked loading YAML\n \"\"\"\n # pylint: disable=non-parent-init-called,super-init-not-called\n\n def __init__(self, stream, filename):\n Reader.__init__(self, stream)\n Scanner.__init__(self)\n if cyaml:\n Parser.__init__(self, stream)\n else:\n Parser.__init__(self)\n Composer.__init__(self)\n SafeConstructor.__init__(self)\n Resolver.__init__(self)\n NodeConstructor.__init__(self, filename)\n\n\ndef multi_constructor(loader, tag_suffix, node):\n \"\"\"\n Deal with !Ref style function format\n \"\"\"\n\n if tag_suffix not in UNCONVERTED_SUFFIXES:\n tag_suffix = '{}{}'.format(FN_PREFIX, tag_suffix)\n\n constructor = None\n if tag_suffix == 'Fn::GetAtt':\n constructor = construct_getatt\n elif isinstance(node, ScalarNode):\n constructor = loader.construct_scalar\n elif isinstance(node, SequenceNode):\n constructor = loader.construct_sequence\n elif isinstance(node, MappingNode):\n constructor = loader.construct_mapping\n else:\n raise 'Bad tag: !{}'.format(tag_suffix)\n\n return dict_node({tag_suffix: constructor(node)}, node.start_mark, node.end_mark)\n\n\ndef construct_getatt(node):\n \"\"\"\n Reconstruct !GetAtt into a list\n \"\"\"\n\n if isinstance(node.value, (six.string_types)):\n return list_node(node.value.split('.', 1), node.start_mark, node.end_mark)\n if isinstance(node.value, list):\n return list_node([s.value for s in node.value], node.start_mark, node.end_mark)\n\n raise ValueError('Unexpected node type: {}'.format(type(node.value)))\n\n\ndef loads(yaml_string, fname=None):\n \"\"\"\n Load the given YAML string\n \"\"\"\n loader = MarkedLoader(yaml_string, fname)\n loader.add_multi_constructor('!', multi_constructor)\n template = loader.get_single_data()\n # Convert an empty file to an empty dict\n if template is None:\n template = {}\n\n return template\n\n\ndef load(filename):\n \"\"\"\n Load the given YAML file\n \"\"\"\n\n content = ''\n\n if not sys.stdin.isatty():\n for line in fileinput.input(files=filename):\n content = content + line\n else:\n with open(filename) as fp:\n content = fp.read()\n\n return loads(content, filename)\n", "path": "src/cfnlint/decode/cfn_yaml.py"}]}
| 3,647 | 449 |
gh_patches_debug_12075
|
rasdani/github-patches
|
git_diff
|
urllib3__urllib3-3333
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Emscripten support emits an InsecureRequestWarning even when using HTTPS
This is a side-effect of us using JavaScript APIs instead of Python TLS and setting `is_verified` on the `EmscriptenHTTPConnection` so urllib3 is emitting an `InsecureRequestWarning` for every request, even ones that are using HTTPS.
* Set the proper value of `is_verified` depending on whether the request is HTTP or HTTPS.
* Add a test case that asserts that an `InsecureRequestWarning` is emitted for HTTP and isn't emitted for HTTPS.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/urllib3/contrib/emscripten/connection.py`
Content:
```
1 from __future__ import annotations
2
3 import os
4 import typing
5
6 # use http.client.HTTPException for consistency with non-emscripten
7 from http.client import HTTPException as HTTPException # noqa: F401
8 from http.client import ResponseNotReady
9
10 from ..._base_connection import _TYPE_BODY
11 from ...connection import HTTPConnection, ProxyConfig, port_by_scheme
12 from ...exceptions import TimeoutError
13 from ...response import BaseHTTPResponse
14 from ...util.connection import _TYPE_SOCKET_OPTIONS
15 from ...util.timeout import _DEFAULT_TIMEOUT, _TYPE_TIMEOUT
16 from ...util.url import Url
17 from .fetch import _RequestError, _TimeoutError, send_request, send_streaming_request
18 from .request import EmscriptenRequest
19 from .response import EmscriptenHttpResponseWrapper, EmscriptenResponse
20
21 if typing.TYPE_CHECKING:
22 from ..._base_connection import BaseHTTPConnection, BaseHTTPSConnection
23
24
25 class EmscriptenHTTPConnection:
26 default_port: typing.ClassVar[int] = port_by_scheme["http"]
27 default_socket_options: typing.ClassVar[_TYPE_SOCKET_OPTIONS]
28
29 timeout: None | (float)
30
31 host: str
32 port: int
33 blocksize: int
34 source_address: tuple[str, int] | None
35 socket_options: _TYPE_SOCKET_OPTIONS | None
36
37 proxy: Url | None
38 proxy_config: ProxyConfig | None
39
40 is_verified: bool = False
41 proxy_is_verified: bool | None = None
42
43 _response: EmscriptenResponse | None
44
45 def __init__(
46 self,
47 host: str,
48 port: int = 0,
49 *,
50 timeout: _TYPE_TIMEOUT = _DEFAULT_TIMEOUT,
51 source_address: tuple[str, int] | None = None,
52 blocksize: int = 8192,
53 socket_options: _TYPE_SOCKET_OPTIONS | None = None,
54 proxy: Url | None = None,
55 proxy_config: ProxyConfig | None = None,
56 ) -> None:
57 self.host = host
58 self.port = port
59 self.timeout = timeout if isinstance(timeout, float) else 0.0
60 self.scheme = "http"
61 self._closed = True
62 self._response = None
63 # ignore these things because we don't
64 # have control over that stuff
65 self.proxy = None
66 self.proxy_config = None
67 self.blocksize = blocksize
68 self.source_address = None
69 self.socket_options = None
70
71 def set_tunnel(
72 self,
73 host: str,
74 port: int | None = 0,
75 headers: typing.Mapping[str, str] | None = None,
76 scheme: str = "http",
77 ) -> None:
78 pass
79
80 def connect(self) -> None:
81 pass
82
83 def request(
84 self,
85 method: str,
86 url: str,
87 body: _TYPE_BODY | None = None,
88 headers: typing.Mapping[str, str] | None = None,
89 # We know *at least* botocore is depending on the order of the
90 # first 3 parameters so to be safe we only mark the later ones
91 # as keyword-only to ensure we have space to extend.
92 *,
93 chunked: bool = False,
94 preload_content: bool = True,
95 decode_content: bool = True,
96 enforce_content_length: bool = True,
97 ) -> None:
98 self._closed = False
99 if url.startswith("/"):
100 # no scheme / host / port included, make a full url
101 url = f"{self.scheme}://{self.host}:{self.port}" + url
102 request = EmscriptenRequest(
103 url=url,
104 method=method,
105 timeout=self.timeout if self.timeout else 0,
106 decode_content=decode_content,
107 )
108 request.set_body(body)
109 if headers:
110 for k, v in headers.items():
111 request.set_header(k, v)
112 self._response = None
113 try:
114 if not preload_content:
115 self._response = send_streaming_request(request)
116 if self._response is None:
117 self._response = send_request(request)
118 except _TimeoutError as e:
119 raise TimeoutError(e.message) from e
120 except _RequestError as e:
121 raise HTTPException(e.message) from e
122
123 def getresponse(self) -> BaseHTTPResponse:
124 if self._response is not None:
125 return EmscriptenHttpResponseWrapper(
126 internal_response=self._response,
127 url=self._response.request.url,
128 connection=self,
129 )
130 else:
131 raise ResponseNotReady()
132
133 def close(self) -> None:
134 self._closed = True
135 self._response = None
136
137 @property
138 def is_closed(self) -> bool:
139 """Whether the connection either is brand new or has been previously closed.
140 If this property is True then both ``is_connected`` and ``has_connected_to_proxy``
141 properties must be False.
142 """
143 return self._closed
144
145 @property
146 def is_connected(self) -> bool:
147 """Whether the connection is actively connected to any origin (proxy or target)"""
148 return True
149
150 @property
151 def has_connected_to_proxy(self) -> bool:
152 """Whether the connection has successfully connected to its proxy.
153 This returns False if no proxy is in use. Used to determine whether
154 errors are coming from the proxy layer or from tunnelling to the target origin.
155 """
156 return False
157
158
159 class EmscriptenHTTPSConnection(EmscriptenHTTPConnection):
160 default_port = port_by_scheme["https"]
161 # all this is basically ignored, as browser handles https
162 cert_reqs: int | str | None = None
163 ca_certs: str | None = None
164 ca_cert_dir: str | None = None
165 ca_cert_data: None | str | bytes = None
166 cert_file: str | None
167 key_file: str | None
168 key_password: str | None
169 ssl_context: typing.Any | None
170 ssl_version: int | str | None = None
171 ssl_minimum_version: int | None = None
172 ssl_maximum_version: int | None = None
173 assert_hostname: None | str | typing.Literal[False]
174 assert_fingerprint: str | None = None
175
176 def __init__(
177 self,
178 host: str,
179 port: int = 0,
180 *,
181 timeout: _TYPE_TIMEOUT = _DEFAULT_TIMEOUT,
182 source_address: tuple[str, int] | None = None,
183 blocksize: int = 16384,
184 socket_options: None
185 | _TYPE_SOCKET_OPTIONS = HTTPConnection.default_socket_options,
186 proxy: Url | None = None,
187 proxy_config: ProxyConfig | None = None,
188 cert_reqs: int | str | None = None,
189 assert_hostname: None | str | typing.Literal[False] = None,
190 assert_fingerprint: str | None = None,
191 server_hostname: str | None = None,
192 ssl_context: typing.Any | None = None,
193 ca_certs: str | None = None,
194 ca_cert_dir: str | None = None,
195 ca_cert_data: None | str | bytes = None,
196 ssl_minimum_version: int | None = None,
197 ssl_maximum_version: int | None = None,
198 ssl_version: int | str | None = None, # Deprecated
199 cert_file: str | None = None,
200 key_file: str | None = None,
201 key_password: str | None = None,
202 ) -> None:
203 super().__init__(
204 host,
205 port=port,
206 timeout=timeout,
207 source_address=source_address,
208 blocksize=blocksize,
209 socket_options=socket_options,
210 proxy=proxy,
211 proxy_config=proxy_config,
212 )
213 self.scheme = "https"
214
215 self.key_file = key_file
216 self.cert_file = cert_file
217 self.key_password = key_password
218 self.ssl_context = ssl_context
219 self.server_hostname = server_hostname
220 self.assert_hostname = assert_hostname
221 self.assert_fingerprint = assert_fingerprint
222 self.ssl_version = ssl_version
223 self.ssl_minimum_version = ssl_minimum_version
224 self.ssl_maximum_version = ssl_maximum_version
225 self.ca_certs = ca_certs and os.path.expanduser(ca_certs)
226 self.ca_cert_dir = ca_cert_dir and os.path.expanduser(ca_cert_dir)
227 self.ca_cert_data = ca_cert_data
228
229 self.cert_reqs = None
230
231 def set_cert(
232 self,
233 key_file: str | None = None,
234 cert_file: str | None = None,
235 cert_reqs: int | str | None = None,
236 key_password: str | None = None,
237 ca_certs: str | None = None,
238 assert_hostname: None | str | typing.Literal[False] = None,
239 assert_fingerprint: str | None = None,
240 ca_cert_dir: str | None = None,
241 ca_cert_data: None | str | bytes = None,
242 ) -> None:
243 pass
244
245
246 # verify that this class implements BaseHTTP(s) connection correctly
247 if typing.TYPE_CHECKING:
248 _supports_http_protocol: BaseHTTPConnection = EmscriptenHTTPConnection("", 0)
249 _supports_https_protocol: BaseHTTPSConnection = EmscriptenHTTPSConnection("", 0)
250
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/urllib3/contrib/emscripten/connection.py b/src/urllib3/contrib/emscripten/connection.py
--- a/src/urllib3/contrib/emscripten/connection.py
+++ b/src/urllib3/contrib/emscripten/connection.py
@@ -67,6 +67,7 @@
self.blocksize = blocksize
self.source_address = None
self.socket_options = None
+ self.is_verified = False
def set_tunnel(
self,
@@ -228,6 +229,10 @@
self.cert_reqs = None
+ # The browser will automatically verify all requests.
+ # We have no control over that setting.
+ self.is_verified = True
+
def set_cert(
self,
key_file: str | None = None,
|
{"golden_diff": "diff --git a/src/urllib3/contrib/emscripten/connection.py b/src/urllib3/contrib/emscripten/connection.py\n--- a/src/urllib3/contrib/emscripten/connection.py\n+++ b/src/urllib3/contrib/emscripten/connection.py\n@@ -67,6 +67,7 @@\n self.blocksize = blocksize\n self.source_address = None\n self.socket_options = None\n+ self.is_verified = False\n \n def set_tunnel(\n self,\n@@ -228,6 +229,10 @@\n \n self.cert_reqs = None\n \n+ # The browser will automatically verify all requests.\n+ # We have no control over that setting.\n+ self.is_verified = True\n+\n def set_cert(\n self,\n key_file: str | None = None,\n", "issue": "Emscripten support emits an InsecureRequestWarning even when using HTTPS\nThis is a side-effect of us using JavaScript APIs instead of Python TLS and setting `is_verified` on the `EmscriptenHTTPConnection` so urllib3 is emitting an `InsecureRequestWarning` for every request, even ones that are using HTTPS.\r\n\r\n* Set the proper value of `is_verified` depending on whether the request is HTTP or HTTPS.\r\n* Add a test case that asserts that an `InsecureRequestWarning` is emitted for HTTP and isn't emitted for HTTPS.\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nimport os\nimport typing\n\n# use http.client.HTTPException for consistency with non-emscripten\nfrom http.client import HTTPException as HTTPException # noqa: F401\nfrom http.client import ResponseNotReady\n\nfrom ..._base_connection import _TYPE_BODY\nfrom ...connection import HTTPConnection, ProxyConfig, port_by_scheme\nfrom ...exceptions import TimeoutError\nfrom ...response import BaseHTTPResponse\nfrom ...util.connection import _TYPE_SOCKET_OPTIONS\nfrom ...util.timeout import _DEFAULT_TIMEOUT, _TYPE_TIMEOUT\nfrom ...util.url import Url\nfrom .fetch import _RequestError, _TimeoutError, send_request, send_streaming_request\nfrom .request import EmscriptenRequest\nfrom .response import EmscriptenHttpResponseWrapper, EmscriptenResponse\n\nif typing.TYPE_CHECKING:\n from ..._base_connection import BaseHTTPConnection, BaseHTTPSConnection\n\n\nclass EmscriptenHTTPConnection:\n default_port: typing.ClassVar[int] = port_by_scheme[\"http\"]\n default_socket_options: typing.ClassVar[_TYPE_SOCKET_OPTIONS]\n\n timeout: None | (float)\n\n host: str\n port: int\n blocksize: int\n source_address: tuple[str, int] | None\n socket_options: _TYPE_SOCKET_OPTIONS | None\n\n proxy: Url | None\n proxy_config: ProxyConfig | None\n\n is_verified: bool = False\n proxy_is_verified: bool | None = None\n\n _response: EmscriptenResponse | None\n\n def __init__(\n self,\n host: str,\n port: int = 0,\n *,\n timeout: _TYPE_TIMEOUT = _DEFAULT_TIMEOUT,\n source_address: tuple[str, int] | None = None,\n blocksize: int = 8192,\n socket_options: _TYPE_SOCKET_OPTIONS | None = None,\n proxy: Url | None = None,\n proxy_config: ProxyConfig | None = None,\n ) -> None:\n self.host = host\n self.port = port\n self.timeout = timeout if isinstance(timeout, float) else 0.0\n self.scheme = \"http\"\n self._closed = True\n self._response = None\n # ignore these things because we don't\n # have control over that stuff\n self.proxy = None\n self.proxy_config = None\n self.blocksize = blocksize\n self.source_address = None\n self.socket_options = None\n\n def set_tunnel(\n self,\n host: str,\n port: int | None = 0,\n headers: typing.Mapping[str, str] | None = None,\n scheme: str = \"http\",\n ) -> None:\n pass\n\n def connect(self) -> None:\n pass\n\n def request(\n self,\n method: str,\n url: str,\n body: _TYPE_BODY | None = None,\n headers: typing.Mapping[str, str] | None = None,\n # We know *at least* botocore is depending on the order of the\n # first 3 parameters so to be safe we only mark the later ones\n # as keyword-only to ensure we have space to extend.\n *,\n chunked: bool = False,\n preload_content: bool = True,\n decode_content: bool = True,\n enforce_content_length: bool = True,\n ) -> None:\n self._closed = False\n if url.startswith(\"/\"):\n # no scheme / host / port included, make a full url\n url = f\"{self.scheme}://{self.host}:{self.port}\" + url\n request = EmscriptenRequest(\n url=url,\n method=method,\n timeout=self.timeout if self.timeout else 0,\n decode_content=decode_content,\n )\n request.set_body(body)\n if headers:\n for k, v in headers.items():\n request.set_header(k, v)\n self._response = None\n try:\n if not preload_content:\n self._response = send_streaming_request(request)\n if self._response is None:\n self._response = send_request(request)\n except _TimeoutError as e:\n raise TimeoutError(e.message) from e\n except _RequestError as e:\n raise HTTPException(e.message) from e\n\n def getresponse(self) -> BaseHTTPResponse:\n if self._response is not None:\n return EmscriptenHttpResponseWrapper(\n internal_response=self._response,\n url=self._response.request.url,\n connection=self,\n )\n else:\n raise ResponseNotReady()\n\n def close(self) -> None:\n self._closed = True\n self._response = None\n\n @property\n def is_closed(self) -> bool:\n \"\"\"Whether the connection either is brand new or has been previously closed.\n If this property is True then both ``is_connected`` and ``has_connected_to_proxy``\n properties must be False.\n \"\"\"\n return self._closed\n\n @property\n def is_connected(self) -> bool:\n \"\"\"Whether the connection is actively connected to any origin (proxy or target)\"\"\"\n return True\n\n @property\n def has_connected_to_proxy(self) -> bool:\n \"\"\"Whether the connection has successfully connected to its proxy.\n This returns False if no proxy is in use. Used to determine whether\n errors are coming from the proxy layer or from tunnelling to the target origin.\n \"\"\"\n return False\n\n\nclass EmscriptenHTTPSConnection(EmscriptenHTTPConnection):\n default_port = port_by_scheme[\"https\"]\n # all this is basically ignored, as browser handles https\n cert_reqs: int | str | None = None\n ca_certs: str | None = None\n ca_cert_dir: str | None = None\n ca_cert_data: None | str | bytes = None\n cert_file: str | None\n key_file: str | None\n key_password: str | None\n ssl_context: typing.Any | None\n ssl_version: int | str | None = None\n ssl_minimum_version: int | None = None\n ssl_maximum_version: int | None = None\n assert_hostname: None | str | typing.Literal[False]\n assert_fingerprint: str | None = None\n\n def __init__(\n self,\n host: str,\n port: int = 0,\n *,\n timeout: _TYPE_TIMEOUT = _DEFAULT_TIMEOUT,\n source_address: tuple[str, int] | None = None,\n blocksize: int = 16384,\n socket_options: None\n | _TYPE_SOCKET_OPTIONS = HTTPConnection.default_socket_options,\n proxy: Url | None = None,\n proxy_config: ProxyConfig | None = None,\n cert_reqs: int | str | None = None,\n assert_hostname: None | str | typing.Literal[False] = None,\n assert_fingerprint: str | None = None,\n server_hostname: str | None = None,\n ssl_context: typing.Any | None = None,\n ca_certs: str | None = None,\n ca_cert_dir: str | None = None,\n ca_cert_data: None | str | bytes = None,\n ssl_minimum_version: int | None = None,\n ssl_maximum_version: int | None = None,\n ssl_version: int | str | None = None, # Deprecated\n cert_file: str | None = None,\n key_file: str | None = None,\n key_password: str | None = None,\n ) -> None:\n super().__init__(\n host,\n port=port,\n timeout=timeout,\n source_address=source_address,\n blocksize=blocksize,\n socket_options=socket_options,\n proxy=proxy,\n proxy_config=proxy_config,\n )\n self.scheme = \"https\"\n\n self.key_file = key_file\n self.cert_file = cert_file\n self.key_password = key_password\n self.ssl_context = ssl_context\n self.server_hostname = server_hostname\n self.assert_hostname = assert_hostname\n self.assert_fingerprint = assert_fingerprint\n self.ssl_version = ssl_version\n self.ssl_minimum_version = ssl_minimum_version\n self.ssl_maximum_version = ssl_maximum_version\n self.ca_certs = ca_certs and os.path.expanduser(ca_certs)\n self.ca_cert_dir = ca_cert_dir and os.path.expanduser(ca_cert_dir)\n self.ca_cert_data = ca_cert_data\n\n self.cert_reqs = None\n\n def set_cert(\n self,\n key_file: str | None = None,\n cert_file: str | None = None,\n cert_reqs: int | str | None = None,\n key_password: str | None = None,\n ca_certs: str | None = None,\n assert_hostname: None | str | typing.Literal[False] = None,\n assert_fingerprint: str | None = None,\n ca_cert_dir: str | None = None,\n ca_cert_data: None | str | bytes = None,\n ) -> None:\n pass\n\n\n# verify that this class implements BaseHTTP(s) connection correctly\nif typing.TYPE_CHECKING:\n _supports_http_protocol: BaseHTTPConnection = EmscriptenHTTPConnection(\"\", 0)\n _supports_https_protocol: BaseHTTPSConnection = EmscriptenHTTPSConnection(\"\", 0)\n", "path": "src/urllib3/contrib/emscripten/connection.py"}], "after_files": [{"content": "from __future__ import annotations\n\nimport os\nimport typing\n\n# use http.client.HTTPException for consistency with non-emscripten\nfrom http.client import HTTPException as HTTPException # noqa: F401\nfrom http.client import ResponseNotReady\n\nfrom ..._base_connection import _TYPE_BODY\nfrom ...connection import HTTPConnection, ProxyConfig, port_by_scheme\nfrom ...exceptions import TimeoutError\nfrom ...response import BaseHTTPResponse\nfrom ...util.connection import _TYPE_SOCKET_OPTIONS\nfrom ...util.timeout import _DEFAULT_TIMEOUT, _TYPE_TIMEOUT\nfrom ...util.url import Url\nfrom .fetch import _RequestError, _TimeoutError, send_request, send_streaming_request\nfrom .request import EmscriptenRequest\nfrom .response import EmscriptenHttpResponseWrapper, EmscriptenResponse\n\nif typing.TYPE_CHECKING:\n from ..._base_connection import BaseHTTPConnection, BaseHTTPSConnection\n\n\nclass EmscriptenHTTPConnection:\n default_port: typing.ClassVar[int] = port_by_scheme[\"http\"]\n default_socket_options: typing.ClassVar[_TYPE_SOCKET_OPTIONS]\n\n timeout: None | (float)\n\n host: str\n port: int\n blocksize: int\n source_address: tuple[str, int] | None\n socket_options: _TYPE_SOCKET_OPTIONS | None\n\n proxy: Url | None\n proxy_config: ProxyConfig | None\n\n is_verified: bool = False\n proxy_is_verified: bool | None = None\n\n _response: EmscriptenResponse | None\n\n def __init__(\n self,\n host: str,\n port: int = 0,\n *,\n timeout: _TYPE_TIMEOUT = _DEFAULT_TIMEOUT,\n source_address: tuple[str, int] | None = None,\n blocksize: int = 8192,\n socket_options: _TYPE_SOCKET_OPTIONS | None = None,\n proxy: Url | None = None,\n proxy_config: ProxyConfig | None = None,\n ) -> None:\n self.host = host\n self.port = port\n self.timeout = timeout if isinstance(timeout, float) else 0.0\n self.scheme = \"http\"\n self._closed = True\n self._response = None\n # ignore these things because we don't\n # have control over that stuff\n self.proxy = None\n self.proxy_config = None\n self.blocksize = blocksize\n self.source_address = None\n self.socket_options = None\n self.is_verified = False\n\n def set_tunnel(\n self,\n host: str,\n port: int | None = 0,\n headers: typing.Mapping[str, str] | None = None,\n scheme: str = \"http\",\n ) -> None:\n pass\n\n def connect(self) -> None:\n pass\n\n def request(\n self,\n method: str,\n url: str,\n body: _TYPE_BODY | None = None,\n headers: typing.Mapping[str, str] | None = None,\n # We know *at least* botocore is depending on the order of the\n # first 3 parameters so to be safe we only mark the later ones\n # as keyword-only to ensure we have space to extend.\n *,\n chunked: bool = False,\n preload_content: bool = True,\n decode_content: bool = True,\n enforce_content_length: bool = True,\n ) -> None:\n self._closed = False\n if url.startswith(\"/\"):\n # no scheme / host / port included, make a full url\n url = f\"{self.scheme}://{self.host}:{self.port}\" + url\n request = EmscriptenRequest(\n url=url,\n method=method,\n timeout=self.timeout if self.timeout else 0,\n decode_content=decode_content,\n )\n request.set_body(body)\n if headers:\n for k, v in headers.items():\n request.set_header(k, v)\n self._response = None\n try:\n if not preload_content:\n self._response = send_streaming_request(request)\n if self._response is None:\n self._response = send_request(request)\n except _TimeoutError as e:\n raise TimeoutError(e.message) from e\n except _RequestError as e:\n raise HTTPException(e.message) from e\n\n def getresponse(self) -> BaseHTTPResponse:\n if self._response is not None:\n return EmscriptenHttpResponseWrapper(\n internal_response=self._response,\n url=self._response.request.url,\n connection=self,\n )\n else:\n raise ResponseNotReady()\n\n def close(self) -> None:\n self._closed = True\n self._response = None\n\n @property\n def is_closed(self) -> bool:\n \"\"\"Whether the connection either is brand new or has been previously closed.\n If this property is True then both ``is_connected`` and ``has_connected_to_proxy``\n properties must be False.\n \"\"\"\n return self._closed\n\n @property\n def is_connected(self) -> bool:\n \"\"\"Whether the connection is actively connected to any origin (proxy or target)\"\"\"\n return True\n\n @property\n def has_connected_to_proxy(self) -> bool:\n \"\"\"Whether the connection has successfully connected to its proxy.\n This returns False if no proxy is in use. Used to determine whether\n errors are coming from the proxy layer or from tunnelling to the target origin.\n \"\"\"\n return False\n\n\nclass EmscriptenHTTPSConnection(EmscriptenHTTPConnection):\n default_port = port_by_scheme[\"https\"]\n # all this is basically ignored, as browser handles https\n cert_reqs: int | str | None = None\n ca_certs: str | None = None\n ca_cert_dir: str | None = None\n ca_cert_data: None | str | bytes = None\n cert_file: str | None\n key_file: str | None\n key_password: str | None\n ssl_context: typing.Any | None\n ssl_version: int | str | None = None\n ssl_minimum_version: int | None = None\n ssl_maximum_version: int | None = None\n assert_hostname: None | str | typing.Literal[False]\n assert_fingerprint: str | None = None\n\n def __init__(\n self,\n host: str,\n port: int = 0,\n *,\n timeout: _TYPE_TIMEOUT = _DEFAULT_TIMEOUT,\n source_address: tuple[str, int] | None = None,\n blocksize: int = 16384,\n socket_options: None\n | _TYPE_SOCKET_OPTIONS = HTTPConnection.default_socket_options,\n proxy: Url | None = None,\n proxy_config: ProxyConfig | None = None,\n cert_reqs: int | str | None = None,\n assert_hostname: None | str | typing.Literal[False] = None,\n assert_fingerprint: str | None = None,\n server_hostname: str | None = None,\n ssl_context: typing.Any | None = None,\n ca_certs: str | None = None,\n ca_cert_dir: str | None = None,\n ca_cert_data: None | str | bytes = None,\n ssl_minimum_version: int | None = None,\n ssl_maximum_version: int | None = None,\n ssl_version: int | str | None = None, # Deprecated\n cert_file: str | None = None,\n key_file: str | None = None,\n key_password: str | None = None,\n ) -> None:\n super().__init__(\n host,\n port=port,\n timeout=timeout,\n source_address=source_address,\n blocksize=blocksize,\n socket_options=socket_options,\n proxy=proxy,\n proxy_config=proxy_config,\n )\n self.scheme = \"https\"\n\n self.key_file = key_file\n self.cert_file = cert_file\n self.key_password = key_password\n self.ssl_context = ssl_context\n self.server_hostname = server_hostname\n self.assert_hostname = assert_hostname\n self.assert_fingerprint = assert_fingerprint\n self.ssl_version = ssl_version\n self.ssl_minimum_version = ssl_minimum_version\n self.ssl_maximum_version = ssl_maximum_version\n self.ca_certs = ca_certs and os.path.expanduser(ca_certs)\n self.ca_cert_dir = ca_cert_dir and os.path.expanduser(ca_cert_dir)\n self.ca_cert_data = ca_cert_data\n\n self.cert_reqs = None\n\n # The browser will automatically verify all requests.\n # We have no control over that setting.\n self.is_verified = True\n\n def set_cert(\n self,\n key_file: str | None = None,\n cert_file: str | None = None,\n cert_reqs: int | str | None = None,\n key_password: str | None = None,\n ca_certs: str | None = None,\n assert_hostname: None | str | typing.Literal[False] = None,\n assert_fingerprint: str | None = None,\n ca_cert_dir: str | None = None,\n ca_cert_data: None | str | bytes = None,\n ) -> None:\n pass\n\n\n# verify that this class implements BaseHTTP(s) connection correctly\nif typing.TYPE_CHECKING:\n _supports_http_protocol: BaseHTTPConnection = EmscriptenHTTPConnection(\"\", 0)\n _supports_https_protocol: BaseHTTPSConnection = EmscriptenHTTPSConnection(\"\", 0)\n", "path": "src/urllib3/contrib/emscripten/connection.py"}]}
| 3,032 | 183 |
gh_patches_debug_10679
|
rasdani/github-patches
|
git_diff
|
Qiskit__qiskit-4870
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Executing a schedule with one instruction raises an error
<!-- ⚠️ If you do not respect this template, your issue will be closed -->
<!-- ⚠️ Make sure to browse the opened and closed issues -->
### Information
- **Qiskit Terra version**:
- **Python version**:
- **Operating system**:
### What is the current behavior?
If I make a schedule with only one instruction:
```
sched = pulse.Acquire(20, pulse.AcquireChannel(0), pulse.MemorySlot(0))
```
then when I `execute` it, it's type is `Instruction` and not `Schedule`, so `execute` wrongly sends it through the `transpiler`, thinking it's a `QuantumCircuit`. Since the transpiler is expecting a circuit, we end up with an attribute error as it tries to access `circuit.qubits`, which isn't a Schedule property.
### Steps to reproduce the problem
### What is the expected behavior?
### Suggested solutions
The easiest fix is to replace `isinstance(experiments, Schedule)` with `isinstance(experiments, (Schedule, pulse.Instruction)`, or perhaps more correctly: `isinstance(experiments, ScheduleComponent)`. Would have to add tests and make sure there aren't other consequences of taking an `Instruction` as input.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `qiskit/assembler/assemble_schedules.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # This code is part of Qiskit.
4 #
5 # (C) Copyright IBM 2017, 2019.
6 #
7 # This code is licensed under the Apache License, Version 2.0. You may
8 # obtain a copy of this license in the LICENSE.txt file in the root directory
9 # of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.
10 #
11 # Any modifications or derivative works of this code must retain this
12 # copyright notice, and modified files need to carry a notice indicating
13 # that they have been altered from the originals.
14
15 """Assemble function for converting a list of circuits into a qobj."""
16 from collections import defaultdict
17 from typing import Any, Dict, List, Tuple
18 import hashlib
19
20 from qiskit import qobj, pulse
21 from qiskit.assembler.run_config import RunConfig
22 from qiskit.exceptions import QiskitError
23 from qiskit.pulse import instructions, transforms, library
24 from qiskit.qobj import utils as qobj_utils, converters
25 from qiskit.qobj.converters.pulse_instruction import ParametricPulseShapes
26
27
28 def assemble_schedules(schedules: List[pulse.Schedule],
29 qobj_id: int,
30 qobj_header: qobj.QobjHeader,
31 run_config: RunConfig) -> qobj.PulseQobj:
32 """Assembles a list of schedules into a qobj that can be run on the backend.
33
34 Args:
35 schedules: Schedules to assemble.
36 qobj_id: Identifier for the generated qobj.
37 qobj_header: Header to pass to the results.
38 run_config: Configuration of the runtime environment.
39
40 Returns:
41 The Qobj to be run on the backends.
42
43 Raises:
44 QiskitError: when frequency settings are not supplied.
45 """
46 if not hasattr(run_config, 'qubit_lo_freq'):
47 raise QiskitError('qubit_lo_freq must be supplied.')
48 if not hasattr(run_config, 'meas_lo_freq'):
49 raise QiskitError('meas_lo_freq must be supplied.')
50
51 lo_converter = converters.LoConfigConverter(qobj.PulseQobjExperimentConfig,
52 **run_config.to_dict())
53 experiments, experiment_config = _assemble_experiments(schedules,
54 lo_converter,
55 run_config)
56 qobj_config = _assemble_config(lo_converter, experiment_config, run_config)
57
58 return qobj.PulseQobj(experiments=experiments,
59 qobj_id=qobj_id,
60 header=qobj_header,
61 config=qobj_config)
62
63
64 def _assemble_experiments(
65 schedules: List[pulse.Schedule],
66 lo_converter: converters.LoConfigConverter,
67 run_config: RunConfig
68 ) -> Tuple[List[qobj.PulseQobjExperiment], Dict[str, Any]]:
69 """Assembles a list of schedules into PulseQobjExperiments, and returns related metadata that
70 will be assembled into the Qobj configuration.
71
72 Args:
73 schedules: Schedules to assemble.
74 lo_converter: The configured frequency converter and validator.
75 run_config: Configuration of the runtime environment.
76
77 Returns:
78 The list of assembled experiments, and the dictionary of related experiment config.
79
80 Raises:
81 QiskitError: when frequency settings are not compatible with the experiments.
82 """
83 freq_configs = [lo_converter(lo_dict) for lo_dict in getattr(run_config, 'schedule_los', [])]
84
85 if len(schedules) > 1 and len(freq_configs) not in [0, 1, len(schedules)]:
86 raise QiskitError('Invalid frequency setting is specified. If the frequency is specified, '
87 'it should be configured the same for all schedules, configured for each '
88 'schedule, or a list of frequencies should be provided for a single '
89 'frequency sweep schedule.')
90
91 instruction_converter = getattr(run_config,
92 'instruction_converter',
93 converters.InstructionToQobjConverter)
94 instruction_converter = instruction_converter(qobj.PulseQobjInstruction,
95 **run_config.to_dict())
96 compressed_schedules = transforms.compress_pulses(schedules)
97
98 user_pulselib = {}
99 experiments = []
100 for idx, schedule in enumerate(compressed_schedules):
101 qobj_instructions, max_memory_slot = _assemble_instructions(
102 schedule,
103 instruction_converter,
104 run_config,
105 user_pulselib)
106
107 # TODO: add other experimental header items (see circuit assembler)
108 qobj_experiment_header = qobj.QobjExperimentHeader(
109 memory_slots=max_memory_slot + 1, # Memory slots are 0 indexed
110 name=schedule.name or 'Experiment-%d' % idx)
111
112 experiment = qobj.PulseQobjExperiment(
113 header=qobj_experiment_header,
114 instructions=qobj_instructions)
115 if freq_configs:
116 # This handles the cases where one frequency setting applies to all experiments and
117 # where each experiment has a different frequency
118 freq_idx = idx if len(freq_configs) != 1 else 0
119 experiment.config = freq_configs[freq_idx]
120
121 experiments.append(experiment)
122
123 # Frequency sweep
124 if freq_configs and len(experiments) == 1:
125 experiment = experiments[0]
126 experiments = []
127 for freq_config in freq_configs:
128 experiments.append(qobj.PulseQobjExperiment(
129 header=experiment.header,
130 instructions=experiment.instructions,
131 config=freq_config))
132
133 # Top level Qobj configuration
134 experiment_config = {
135 'pulse_library': [qobj.PulseLibraryItem(name=name, samples=samples)
136 for name, samples in user_pulselib.items()],
137 'memory_slots': max([exp.header.memory_slots for exp in experiments])
138 }
139
140 return experiments, experiment_config
141
142
143 def _assemble_instructions(
144 schedule: pulse.Schedule,
145 instruction_converter: converters.InstructionToQobjConverter,
146 run_config: RunConfig,
147 user_pulselib: Dict[str, List[complex]]
148 ) -> Tuple[List[qobj.PulseQobjInstruction], int]:
149 """Assembles the instructions in a schedule into a list of PulseQobjInstructions and returns
150 related metadata that will be assembled into the Qobj configuration. Lookup table for
151 pulses defined in all experiments are registered in ``user_pulselib``. This object should be
152 mutable python dictionary so that items are properly updated after each instruction assemble.
153 The dictionary is not returned to avoid redundancy.
154
155 Args:
156 schedule: Schedule to assemble.
157 instruction_converter: A converter instance which can convert PulseInstructions to
158 PulseQobjInstructions.
159 run_config: Configuration of the runtime environment.
160 user_pulselib: User pulse library from previous schedule.
161
162 Returns:
163 A list of converted instructions, the user pulse library dictionary (from pulse name to
164 pulse samples), and the maximum number of readout memory slots used by this Schedule.
165 """
166 max_memory_slot = 0
167 qobj_instructions = []
168
169 acquire_instruction_map = defaultdict(list)
170 for time, instruction in schedule.instructions:
171
172 if (isinstance(instruction, instructions.Play) and
173 isinstance(instruction.pulse, library.ParametricPulse)):
174 pulse_shape = ParametricPulseShapes(type(instruction.pulse)).name
175 if pulse_shape not in run_config.parametric_pulses:
176 instruction = instructions.Play(instruction.pulse.get_sample_pulse(),
177 instruction.channel,
178 name=instruction.name)
179
180 if (isinstance(instruction, instructions.Play) and
181 isinstance(instruction.pulse, library.Waveform)):
182 name = hashlib.sha256(instruction.pulse.samples).hexdigest()
183 instruction = instructions.Play(
184 library.Waveform(name=name, samples=instruction.pulse.samples),
185 channel=instruction.channel,
186 name=name)
187 user_pulselib[name] = instruction.pulse.samples
188
189 if isinstance(instruction, instructions.Acquire):
190 if instruction.mem_slot:
191 max_memory_slot = max(max_memory_slot, instruction.mem_slot.index)
192 # Acquires have a single AcquireChannel per inst, but we have to bundle them
193 # together into the Qobj as one instruction with many channels
194 acquire_instruction_map[(time, instruction.duration)].append(instruction)
195 continue
196
197 if isinstance(instruction, (instructions.Delay, instructions.Directive)):
198 # delay instructions are ignored as timing is explicit within qobj
199 continue
200
201 qobj_instructions.append(instruction_converter(time, instruction))
202
203 if acquire_instruction_map:
204 if hasattr(run_config, 'meas_map'):
205 _validate_meas_map(acquire_instruction_map, run_config.meas_map)
206 for (time, _), instrs in acquire_instruction_map.items():
207 qobj_instructions.append(
208 instruction_converter.convert_bundled_acquires(
209 time,
210 instrs
211 ),
212 )
213
214 return qobj_instructions, max_memory_slot
215
216
217 def _validate_meas_map(instruction_map: Dict[Tuple[int, instructions.Acquire],
218 List[instructions.Acquire]],
219 meas_map: List[List[int]]) -> None:
220 """Validate all qubits tied in ``meas_map`` are to be acquired.
221
222 Args:
223 instruction_map: A dictionary grouping Acquire instructions according to their start time
224 and duration.
225 meas_map: List of groups of qubits that must be acquired together.
226
227 Raises:
228 QiskitError: If the instructions do not satisfy the measurement map.
229 """
230 meas_map_sets = [set(m) for m in meas_map]
231
232 # Check each acquisition time individually
233 for _, instrs in instruction_map.items():
234 measured_qubits = set()
235 for inst in instrs:
236 measured_qubits.add(inst.channel.index)
237
238 for meas_set in meas_map_sets:
239 intersection = measured_qubits.intersection(meas_set)
240 if intersection and intersection != meas_set:
241 raise QiskitError('Qubits to be acquired: {0} do not satisfy required qubits '
242 'in measurement map: {1}'.format(measured_qubits, meas_set))
243
244
245 def _assemble_config(lo_converter: converters.LoConfigConverter,
246 experiment_config: Dict[str, Any],
247 run_config: RunConfig) -> qobj.PulseQobjConfig:
248 """Assembles the QobjConfiguration from experimental config and runtime config.
249
250 Args:
251 lo_converter: The configured frequency converter and validator.
252 experiment_config: Schedules to assemble.
253 run_config: Configuration of the runtime environment.
254
255 Returns:
256 The assembled PulseQobjConfig.
257 """
258 qobj_config = run_config.to_dict()
259 qobj_config.update(experiment_config)
260
261 # Run config not needed in qobj config
262 qobj_config.pop('meas_map', None)
263 qobj_config.pop('qubit_lo_range', None)
264 qobj_config.pop('meas_lo_range', None)
265
266 # convert enums to serialized values
267 meas_return = qobj_config.get('meas_return', 'avg')
268 if isinstance(meas_return, qobj_utils.MeasReturnType):
269 qobj_config['meas_return'] = meas_return.value
270
271 meas_level = qobj_config.get('meas_level', 2)
272 if isinstance(meas_level, qobj_utils.MeasLevel):
273 qobj_config['meas_level'] = meas_level.value
274
275 # convert lo frequencies to Hz
276 qobj_config['qubit_lo_freq'] = [freq / 1e9 for freq in qobj_config['qubit_lo_freq']]
277 qobj_config['meas_lo_freq'] = [freq / 1e9 for freq in qobj_config['meas_lo_freq']]
278
279 # frequency sweep config
280 schedule_los = qobj_config.pop('schedule_los', [])
281 if len(schedule_los) == 1:
282 lo_dict = schedule_los[0]
283 q_los = lo_converter.get_qubit_los(lo_dict)
284 # Hz -> GHz
285 if q_los:
286 qobj_config['qubit_lo_freq'] = [freq / 1e9 for freq in q_los]
287 m_los = lo_converter.get_meas_los(lo_dict)
288 if m_los:
289 qobj_config['meas_lo_freq'] = [freq / 1e9 for freq in m_los]
290
291 return qobj.PulseQobjConfig(**qobj_config)
292
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/qiskit/assembler/assemble_schedules.py b/qiskit/assembler/assemble_schedules.py
--- a/qiskit/assembler/assemble_schedules.py
+++ b/qiskit/assembler/assemble_schedules.py
@@ -93,6 +93,10 @@
converters.InstructionToQobjConverter)
instruction_converter = instruction_converter(qobj.PulseQobjInstruction,
**run_config.to_dict())
+
+ schedules = [
+ sched if isinstance(sched, pulse.Schedule) else pulse.Schedule(sched) for sched in schedules
+ ]
compressed_schedules = transforms.compress_pulses(schedules)
user_pulselib = {}
|
{"golden_diff": "diff --git a/qiskit/assembler/assemble_schedules.py b/qiskit/assembler/assemble_schedules.py\n--- a/qiskit/assembler/assemble_schedules.py\n+++ b/qiskit/assembler/assemble_schedules.py\n@@ -93,6 +93,10 @@\n converters.InstructionToQobjConverter)\n instruction_converter = instruction_converter(qobj.PulseQobjInstruction,\n **run_config.to_dict())\n+\n+ schedules = [\n+ sched if isinstance(sched, pulse.Schedule) else pulse.Schedule(sched) for sched in schedules\n+ ]\n compressed_schedules = transforms.compress_pulses(schedules)\n \n user_pulselib = {}\n", "issue": "Executing a schedule with one instruction raises an error\n<!-- \u26a0\ufe0f If you do not respect this template, your issue will be closed -->\r\n<!-- \u26a0\ufe0f Make sure to browse the opened and closed issues -->\r\n\r\n### Information\r\n\r\n- **Qiskit Terra version**:\r\n- **Python version**:\r\n- **Operating system**:\r\n\r\n### What is the current behavior?\r\n\r\nIf I make a schedule with only one instruction:\r\n```\r\nsched = pulse.Acquire(20, pulse.AcquireChannel(0), pulse.MemorySlot(0))\r\n```\r\nthen when I `execute` it, it's type is `Instruction` and not `Schedule`, so `execute` wrongly sends it through the `transpiler`, thinking it's a `QuantumCircuit`. Since the transpiler is expecting a circuit, we end up with an attribute error as it tries to access `circuit.qubits`, which isn't a Schedule property.\r\n\r\n\r\n### Steps to reproduce the problem\r\n\r\n\r\n\r\n### What is the expected behavior?\r\n\r\n\r\n\r\n### Suggested solutions\r\n\r\nThe easiest fix is to replace `isinstance(experiments, Schedule)` with `isinstance(experiments, (Schedule, pulse.Instruction)`, or perhaps more correctly: `isinstance(experiments, ScheduleComponent)`. Would have to add tests and make sure there aren't other consequences of taking an `Instruction` as input. \r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# This code is part of Qiskit.\n#\n# (C) Copyright IBM 2017, 2019.\n#\n# This code is licensed under the Apache License, Version 2.0. You may\n# obtain a copy of this license in the LICENSE.txt file in the root directory\n# of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.\n#\n# Any modifications or derivative works of this code must retain this\n# copyright notice, and modified files need to carry a notice indicating\n# that they have been altered from the originals.\n\n\"\"\"Assemble function for converting a list of circuits into a qobj.\"\"\"\nfrom collections import defaultdict\nfrom typing import Any, Dict, List, Tuple\nimport hashlib\n\nfrom qiskit import qobj, pulse\nfrom qiskit.assembler.run_config import RunConfig\nfrom qiskit.exceptions import QiskitError\nfrom qiskit.pulse import instructions, transforms, library\nfrom qiskit.qobj import utils as qobj_utils, converters\nfrom qiskit.qobj.converters.pulse_instruction import ParametricPulseShapes\n\n\ndef assemble_schedules(schedules: List[pulse.Schedule],\n qobj_id: int,\n qobj_header: qobj.QobjHeader,\n run_config: RunConfig) -> qobj.PulseQobj:\n \"\"\"Assembles a list of schedules into a qobj that can be run on the backend.\n\n Args:\n schedules: Schedules to assemble.\n qobj_id: Identifier for the generated qobj.\n qobj_header: Header to pass to the results.\n run_config: Configuration of the runtime environment.\n\n Returns:\n The Qobj to be run on the backends.\n\n Raises:\n QiskitError: when frequency settings are not supplied.\n \"\"\"\n if not hasattr(run_config, 'qubit_lo_freq'):\n raise QiskitError('qubit_lo_freq must be supplied.')\n if not hasattr(run_config, 'meas_lo_freq'):\n raise QiskitError('meas_lo_freq must be supplied.')\n\n lo_converter = converters.LoConfigConverter(qobj.PulseQobjExperimentConfig,\n **run_config.to_dict())\n experiments, experiment_config = _assemble_experiments(schedules,\n lo_converter,\n run_config)\n qobj_config = _assemble_config(lo_converter, experiment_config, run_config)\n\n return qobj.PulseQobj(experiments=experiments,\n qobj_id=qobj_id,\n header=qobj_header,\n config=qobj_config)\n\n\ndef _assemble_experiments(\n schedules: List[pulse.Schedule],\n lo_converter: converters.LoConfigConverter,\n run_config: RunConfig\n) -> Tuple[List[qobj.PulseQobjExperiment], Dict[str, Any]]:\n \"\"\"Assembles a list of schedules into PulseQobjExperiments, and returns related metadata that\n will be assembled into the Qobj configuration.\n\n Args:\n schedules: Schedules to assemble.\n lo_converter: The configured frequency converter and validator.\n run_config: Configuration of the runtime environment.\n\n Returns:\n The list of assembled experiments, and the dictionary of related experiment config.\n\n Raises:\n QiskitError: when frequency settings are not compatible with the experiments.\n \"\"\"\n freq_configs = [lo_converter(lo_dict) for lo_dict in getattr(run_config, 'schedule_los', [])]\n\n if len(schedules) > 1 and len(freq_configs) not in [0, 1, len(schedules)]:\n raise QiskitError('Invalid frequency setting is specified. If the frequency is specified, '\n 'it should be configured the same for all schedules, configured for each '\n 'schedule, or a list of frequencies should be provided for a single '\n 'frequency sweep schedule.')\n\n instruction_converter = getattr(run_config,\n 'instruction_converter',\n converters.InstructionToQobjConverter)\n instruction_converter = instruction_converter(qobj.PulseQobjInstruction,\n **run_config.to_dict())\n compressed_schedules = transforms.compress_pulses(schedules)\n\n user_pulselib = {}\n experiments = []\n for idx, schedule in enumerate(compressed_schedules):\n qobj_instructions, max_memory_slot = _assemble_instructions(\n schedule,\n instruction_converter,\n run_config,\n user_pulselib)\n\n # TODO: add other experimental header items (see circuit assembler)\n qobj_experiment_header = qobj.QobjExperimentHeader(\n memory_slots=max_memory_slot + 1, # Memory slots are 0 indexed\n name=schedule.name or 'Experiment-%d' % idx)\n\n experiment = qobj.PulseQobjExperiment(\n header=qobj_experiment_header,\n instructions=qobj_instructions)\n if freq_configs:\n # This handles the cases where one frequency setting applies to all experiments and\n # where each experiment has a different frequency\n freq_idx = idx if len(freq_configs) != 1 else 0\n experiment.config = freq_configs[freq_idx]\n\n experiments.append(experiment)\n\n # Frequency sweep\n if freq_configs and len(experiments) == 1:\n experiment = experiments[0]\n experiments = []\n for freq_config in freq_configs:\n experiments.append(qobj.PulseQobjExperiment(\n header=experiment.header,\n instructions=experiment.instructions,\n config=freq_config))\n\n # Top level Qobj configuration\n experiment_config = {\n 'pulse_library': [qobj.PulseLibraryItem(name=name, samples=samples)\n for name, samples in user_pulselib.items()],\n 'memory_slots': max([exp.header.memory_slots for exp in experiments])\n }\n\n return experiments, experiment_config\n\n\ndef _assemble_instructions(\n schedule: pulse.Schedule,\n instruction_converter: converters.InstructionToQobjConverter,\n run_config: RunConfig,\n user_pulselib: Dict[str, List[complex]]\n) -> Tuple[List[qobj.PulseQobjInstruction], int]:\n \"\"\"Assembles the instructions in a schedule into a list of PulseQobjInstructions and returns\n related metadata that will be assembled into the Qobj configuration. Lookup table for\n pulses defined in all experiments are registered in ``user_pulselib``. This object should be\n mutable python dictionary so that items are properly updated after each instruction assemble.\n The dictionary is not returned to avoid redundancy.\n\n Args:\n schedule: Schedule to assemble.\n instruction_converter: A converter instance which can convert PulseInstructions to\n PulseQobjInstructions.\n run_config: Configuration of the runtime environment.\n user_pulselib: User pulse library from previous schedule.\n\n Returns:\n A list of converted instructions, the user pulse library dictionary (from pulse name to\n pulse samples), and the maximum number of readout memory slots used by this Schedule.\n \"\"\"\n max_memory_slot = 0\n qobj_instructions = []\n\n acquire_instruction_map = defaultdict(list)\n for time, instruction in schedule.instructions:\n\n if (isinstance(instruction, instructions.Play) and\n isinstance(instruction.pulse, library.ParametricPulse)):\n pulse_shape = ParametricPulseShapes(type(instruction.pulse)).name\n if pulse_shape not in run_config.parametric_pulses:\n instruction = instructions.Play(instruction.pulse.get_sample_pulse(),\n instruction.channel,\n name=instruction.name)\n\n if (isinstance(instruction, instructions.Play) and\n isinstance(instruction.pulse, library.Waveform)):\n name = hashlib.sha256(instruction.pulse.samples).hexdigest()\n instruction = instructions.Play(\n library.Waveform(name=name, samples=instruction.pulse.samples),\n channel=instruction.channel,\n name=name)\n user_pulselib[name] = instruction.pulse.samples\n\n if isinstance(instruction, instructions.Acquire):\n if instruction.mem_slot:\n max_memory_slot = max(max_memory_slot, instruction.mem_slot.index)\n # Acquires have a single AcquireChannel per inst, but we have to bundle them\n # together into the Qobj as one instruction with many channels\n acquire_instruction_map[(time, instruction.duration)].append(instruction)\n continue\n\n if isinstance(instruction, (instructions.Delay, instructions.Directive)):\n # delay instructions are ignored as timing is explicit within qobj\n continue\n\n qobj_instructions.append(instruction_converter(time, instruction))\n\n if acquire_instruction_map:\n if hasattr(run_config, 'meas_map'):\n _validate_meas_map(acquire_instruction_map, run_config.meas_map)\n for (time, _), instrs in acquire_instruction_map.items():\n qobj_instructions.append(\n instruction_converter.convert_bundled_acquires(\n time,\n instrs\n ),\n )\n\n return qobj_instructions, max_memory_slot\n\n\ndef _validate_meas_map(instruction_map: Dict[Tuple[int, instructions.Acquire],\n List[instructions.Acquire]],\n meas_map: List[List[int]]) -> None:\n \"\"\"Validate all qubits tied in ``meas_map`` are to be acquired.\n\n Args:\n instruction_map: A dictionary grouping Acquire instructions according to their start time\n and duration.\n meas_map: List of groups of qubits that must be acquired together.\n\n Raises:\n QiskitError: If the instructions do not satisfy the measurement map.\n \"\"\"\n meas_map_sets = [set(m) for m in meas_map]\n\n # Check each acquisition time individually\n for _, instrs in instruction_map.items():\n measured_qubits = set()\n for inst in instrs:\n measured_qubits.add(inst.channel.index)\n\n for meas_set in meas_map_sets:\n intersection = measured_qubits.intersection(meas_set)\n if intersection and intersection != meas_set:\n raise QiskitError('Qubits to be acquired: {0} do not satisfy required qubits '\n 'in measurement map: {1}'.format(measured_qubits, meas_set))\n\n\ndef _assemble_config(lo_converter: converters.LoConfigConverter,\n experiment_config: Dict[str, Any],\n run_config: RunConfig) -> qobj.PulseQobjConfig:\n \"\"\"Assembles the QobjConfiguration from experimental config and runtime config.\n\n Args:\n lo_converter: The configured frequency converter and validator.\n experiment_config: Schedules to assemble.\n run_config: Configuration of the runtime environment.\n\n Returns:\n The assembled PulseQobjConfig.\n \"\"\"\n qobj_config = run_config.to_dict()\n qobj_config.update(experiment_config)\n\n # Run config not needed in qobj config\n qobj_config.pop('meas_map', None)\n qobj_config.pop('qubit_lo_range', None)\n qobj_config.pop('meas_lo_range', None)\n\n # convert enums to serialized values\n meas_return = qobj_config.get('meas_return', 'avg')\n if isinstance(meas_return, qobj_utils.MeasReturnType):\n qobj_config['meas_return'] = meas_return.value\n\n meas_level = qobj_config.get('meas_level', 2)\n if isinstance(meas_level, qobj_utils.MeasLevel):\n qobj_config['meas_level'] = meas_level.value\n\n # convert lo frequencies to Hz\n qobj_config['qubit_lo_freq'] = [freq / 1e9 for freq in qobj_config['qubit_lo_freq']]\n qobj_config['meas_lo_freq'] = [freq / 1e9 for freq in qobj_config['meas_lo_freq']]\n\n # frequency sweep config\n schedule_los = qobj_config.pop('schedule_los', [])\n if len(schedule_los) == 1:\n lo_dict = schedule_los[0]\n q_los = lo_converter.get_qubit_los(lo_dict)\n # Hz -> GHz\n if q_los:\n qobj_config['qubit_lo_freq'] = [freq / 1e9 for freq in q_los]\n m_los = lo_converter.get_meas_los(lo_dict)\n if m_los:\n qobj_config['meas_lo_freq'] = [freq / 1e9 for freq in m_los]\n\n return qobj.PulseQobjConfig(**qobj_config)\n", "path": "qiskit/assembler/assemble_schedules.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n# This code is part of Qiskit.\n#\n# (C) Copyright IBM 2017, 2019.\n#\n# This code is licensed under the Apache License, Version 2.0. You may\n# obtain a copy of this license in the LICENSE.txt file in the root directory\n# of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.\n#\n# Any modifications or derivative works of this code must retain this\n# copyright notice, and modified files need to carry a notice indicating\n# that they have been altered from the originals.\n\n\"\"\"Assemble function for converting a list of circuits into a qobj.\"\"\"\nfrom collections import defaultdict\nfrom typing import Any, Dict, List, Tuple\nimport hashlib\n\nfrom qiskit import qobj, pulse\nfrom qiskit.assembler.run_config import RunConfig\nfrom qiskit.exceptions import QiskitError\nfrom qiskit.pulse import instructions, transforms, library\nfrom qiskit.qobj import utils as qobj_utils, converters\nfrom qiskit.qobj.converters.pulse_instruction import ParametricPulseShapes\n\n\ndef assemble_schedules(schedules: List[pulse.Schedule],\n qobj_id: int,\n qobj_header: qobj.QobjHeader,\n run_config: RunConfig) -> qobj.PulseQobj:\n \"\"\"Assembles a list of schedules into a qobj that can be run on the backend.\n\n Args:\n schedules: Schedules to assemble.\n qobj_id: Identifier for the generated qobj.\n qobj_header: Header to pass to the results.\n run_config: Configuration of the runtime environment.\n\n Returns:\n The Qobj to be run on the backends.\n\n Raises:\n QiskitError: when frequency settings are not supplied.\n \"\"\"\n if not hasattr(run_config, 'qubit_lo_freq'):\n raise QiskitError('qubit_lo_freq must be supplied.')\n if not hasattr(run_config, 'meas_lo_freq'):\n raise QiskitError('meas_lo_freq must be supplied.')\n\n lo_converter = converters.LoConfigConverter(qobj.PulseQobjExperimentConfig,\n **run_config.to_dict())\n experiments, experiment_config = _assemble_experiments(schedules,\n lo_converter,\n run_config)\n qobj_config = _assemble_config(lo_converter, experiment_config, run_config)\n\n return qobj.PulseQobj(experiments=experiments,\n qobj_id=qobj_id,\n header=qobj_header,\n config=qobj_config)\n\n\ndef _assemble_experiments(\n schedules: List[pulse.Schedule],\n lo_converter: converters.LoConfigConverter,\n run_config: RunConfig\n) -> Tuple[List[qobj.PulseQobjExperiment], Dict[str, Any]]:\n \"\"\"Assembles a list of schedules into PulseQobjExperiments, and returns related metadata that\n will be assembled into the Qobj configuration.\n\n Args:\n schedules: Schedules to assemble.\n lo_converter: The configured frequency converter and validator.\n run_config: Configuration of the runtime environment.\n\n Returns:\n The list of assembled experiments, and the dictionary of related experiment config.\n\n Raises:\n QiskitError: when frequency settings are not compatible with the experiments.\n \"\"\"\n freq_configs = [lo_converter(lo_dict) for lo_dict in getattr(run_config, 'schedule_los', [])]\n\n if len(schedules) > 1 and len(freq_configs) not in [0, 1, len(schedules)]:\n raise QiskitError('Invalid frequency setting is specified. If the frequency is specified, '\n 'it should be configured the same for all schedules, configured for each '\n 'schedule, or a list of frequencies should be provided for a single '\n 'frequency sweep schedule.')\n\n instruction_converter = getattr(run_config,\n 'instruction_converter',\n converters.InstructionToQobjConverter)\n instruction_converter = instruction_converter(qobj.PulseQobjInstruction,\n **run_config.to_dict())\n\n schedules = [\n sched if isinstance(sched, pulse.Schedule) else pulse.Schedule(sched) for sched in schedules\n ]\n compressed_schedules = transforms.compress_pulses(schedules)\n\n user_pulselib = {}\n experiments = []\n for idx, schedule in enumerate(compressed_schedules):\n qobj_instructions, max_memory_slot = _assemble_instructions(\n schedule,\n instruction_converter,\n run_config,\n user_pulselib)\n\n # TODO: add other experimental header items (see circuit assembler)\n qobj_experiment_header = qobj.QobjExperimentHeader(\n memory_slots=max_memory_slot + 1, # Memory slots are 0 indexed\n name=schedule.name or 'Experiment-%d' % idx)\n\n experiment = qobj.PulseQobjExperiment(\n header=qobj_experiment_header,\n instructions=qobj_instructions)\n if freq_configs:\n # This handles the cases where one frequency setting applies to all experiments and\n # where each experiment has a different frequency\n freq_idx = idx if len(freq_configs) != 1 else 0\n experiment.config = freq_configs[freq_idx]\n\n experiments.append(experiment)\n\n # Frequency sweep\n if freq_configs and len(experiments) == 1:\n experiment = experiments[0]\n experiments = []\n for freq_config in freq_configs:\n experiments.append(qobj.PulseQobjExperiment(\n header=experiment.header,\n instructions=experiment.instructions,\n config=freq_config))\n\n # Top level Qobj configuration\n experiment_config = {\n 'pulse_library': [qobj.PulseLibraryItem(name=name, samples=samples)\n for name, samples in user_pulselib.items()],\n 'memory_slots': max([exp.header.memory_slots for exp in experiments])\n }\n\n return experiments, experiment_config\n\n\ndef _assemble_instructions(\n schedule: pulse.Schedule,\n instruction_converter: converters.InstructionToQobjConverter,\n run_config: RunConfig,\n user_pulselib: Dict[str, List[complex]]\n) -> Tuple[List[qobj.PulseQobjInstruction], int]:\n \"\"\"Assembles the instructions in a schedule into a list of PulseQobjInstructions and returns\n related metadata that will be assembled into the Qobj configuration. Lookup table for\n pulses defined in all experiments are registered in ``user_pulselib``. This object should be\n mutable python dictionary so that items are properly updated after each instruction assemble.\n The dictionary is not returned to avoid redundancy.\n\n Args:\n schedule: Schedule to assemble.\n instruction_converter: A converter instance which can convert PulseInstructions to\n PulseQobjInstructions.\n run_config: Configuration of the runtime environment.\n user_pulselib: User pulse library from previous schedule.\n\n Returns:\n A list of converted instructions, the user pulse library dictionary (from pulse name to\n pulse samples), and the maximum number of readout memory slots used by this Schedule.\n \"\"\"\n max_memory_slot = 0\n qobj_instructions = []\n\n acquire_instruction_map = defaultdict(list)\n for time, instruction in schedule.instructions:\n\n if (isinstance(instruction, instructions.Play) and\n isinstance(instruction.pulse, library.ParametricPulse)):\n pulse_shape = ParametricPulseShapes(type(instruction.pulse)).name\n if pulse_shape not in run_config.parametric_pulses:\n instruction = instructions.Play(instruction.pulse.get_sample_pulse(),\n instruction.channel,\n name=instruction.name)\n\n if (isinstance(instruction, instructions.Play) and\n isinstance(instruction.pulse, library.Waveform)):\n name = hashlib.sha256(instruction.pulse.samples).hexdigest()\n instruction = instructions.Play(\n library.Waveform(name=name, samples=instruction.pulse.samples),\n channel=instruction.channel,\n name=name)\n user_pulselib[name] = instruction.pulse.samples\n\n if isinstance(instruction, instructions.Acquire):\n if instruction.mem_slot:\n max_memory_slot = max(max_memory_slot, instruction.mem_slot.index)\n # Acquires have a single AcquireChannel per inst, but we have to bundle them\n # together into the Qobj as one instruction with many channels\n acquire_instruction_map[(time, instruction.duration)].append(instruction)\n continue\n\n if isinstance(instruction, (instructions.Delay, instructions.Directive)):\n # delay instructions are ignored as timing is explicit within qobj\n continue\n\n qobj_instructions.append(instruction_converter(time, instruction))\n\n if acquire_instruction_map:\n if hasattr(run_config, 'meas_map'):\n _validate_meas_map(acquire_instruction_map, run_config.meas_map)\n for (time, _), instrs in acquire_instruction_map.items():\n qobj_instructions.append(\n instruction_converter.convert_bundled_acquires(\n time,\n instrs\n ),\n )\n\n return qobj_instructions, max_memory_slot\n\n\ndef _validate_meas_map(instruction_map: Dict[Tuple[int, instructions.Acquire],\n List[instructions.Acquire]],\n meas_map: List[List[int]]) -> None:\n \"\"\"Validate all qubits tied in ``meas_map`` are to be acquired.\n\n Args:\n instruction_map: A dictionary grouping Acquire instructions according to their start time\n and duration.\n meas_map: List of groups of qubits that must be acquired together.\n\n Raises:\n QiskitError: If the instructions do not satisfy the measurement map.\n \"\"\"\n meas_map_sets = [set(m) for m in meas_map]\n\n # Check each acquisition time individually\n for _, instrs in instruction_map.items():\n measured_qubits = set()\n for inst in instrs:\n measured_qubits.add(inst.channel.index)\n\n for meas_set in meas_map_sets:\n intersection = measured_qubits.intersection(meas_set)\n if intersection and intersection != meas_set:\n raise QiskitError('Qubits to be acquired: {0} do not satisfy required qubits '\n 'in measurement map: {1}'.format(measured_qubits, meas_set))\n\n\ndef _assemble_config(lo_converter: converters.LoConfigConverter,\n experiment_config: Dict[str, Any],\n run_config: RunConfig) -> qobj.PulseQobjConfig:\n \"\"\"Assembles the QobjConfiguration from experimental config and runtime config.\n\n Args:\n lo_converter: The configured frequency converter and validator.\n experiment_config: Schedules to assemble.\n run_config: Configuration of the runtime environment.\n\n Returns:\n The assembled PulseQobjConfig.\n \"\"\"\n qobj_config = run_config.to_dict()\n qobj_config.update(experiment_config)\n\n # Run config not needed in qobj config\n qobj_config.pop('meas_map', None)\n qobj_config.pop('qubit_lo_range', None)\n qobj_config.pop('meas_lo_range', None)\n\n # convert enums to serialized values\n meas_return = qobj_config.get('meas_return', 'avg')\n if isinstance(meas_return, qobj_utils.MeasReturnType):\n qobj_config['meas_return'] = meas_return.value\n\n meas_level = qobj_config.get('meas_level', 2)\n if isinstance(meas_level, qobj_utils.MeasLevel):\n qobj_config['meas_level'] = meas_level.value\n\n # convert lo frequencies to Hz\n qobj_config['qubit_lo_freq'] = [freq / 1e9 for freq in qobj_config['qubit_lo_freq']]\n qobj_config['meas_lo_freq'] = [freq / 1e9 for freq in qobj_config['meas_lo_freq']]\n\n # frequency sweep config\n schedule_los = qobj_config.pop('schedule_los', [])\n if len(schedule_los) == 1:\n lo_dict = schedule_los[0]\n q_los = lo_converter.get_qubit_los(lo_dict)\n # Hz -> GHz\n if q_los:\n qobj_config['qubit_lo_freq'] = [freq / 1e9 for freq in q_los]\n m_los = lo_converter.get_meas_los(lo_dict)\n if m_los:\n qobj_config['meas_lo_freq'] = [freq / 1e9 for freq in m_los]\n\n return qobj.PulseQobjConfig(**qobj_config)\n", "path": "qiskit/assembler/assemble_schedules.py"}]}
| 3,909 | 147 |
gh_patches_debug_1565
|
rasdani/github-patches
|
git_diff
|
kserve__kserve-3020
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
response id in response should return request id if present
/kind bug
**What steps did you take and what happened:**
[A clear and concise description of what the bug is.]
When a request is sent with request id, the response should contain the request id so that the response and request can be easily co-related. Most frameworks and applications return the request id as the response id.
**What did you expect to happen:**
Return a generated uuid as response id if no request id is sent but return the request id if available.
**Environment:**
- KServe Version: 0.10.1
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `python/kserve/kserve/utils/utils.py`
Content:
```
1 # Copyright 2021 The KServe Authors.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import os
16 import sys
17 import uuid
18 from kserve.protocol.grpc.grpc_predict_v2_pb2 import InferParameter
19 from typing import Dict, Union
20
21 from kserve.utils.numpy_codec import from_np_dtype
22 import pandas as pd
23 import numpy as np
24 import psutil
25 from cloudevents.conversion import to_binary, to_structured
26 from cloudevents.http import CloudEvent
27 from grpc import ServicerContext
28 from kserve.protocol.infer_type import InferOutput, InferRequest, InferResponse
29
30
31 def is_running_in_k8s():
32 return os.path.isdir('/var/run/secrets/kubernetes.io/')
33
34
35 def get_current_k8s_namespace():
36 with open('/var/run/secrets/kubernetes.io/serviceaccount/namespace', 'r') as f:
37 return f.readline()
38
39
40 def get_default_target_namespace():
41 if not is_running_in_k8s():
42 return 'default'
43 return get_current_k8s_namespace()
44
45
46 def get_isvc_namespace(inferenceservice):
47 return inferenceservice.metadata.namespace or get_default_target_namespace()
48
49
50 def get_ig_namespace(inferencegraph):
51 return inferencegraph.metadata.namespace or get_default_target_namespace()
52
53
54 def cpu_count():
55 """Get the available CPU count for this system.
56 Takes the minimum value from the following locations:
57 - Total system cpus available on the host.
58 - CPU Affinity (if set)
59 - Cgroups limit (if set)
60 """
61 count = os.cpu_count()
62
63 # Check CPU affinity if available
64 try:
65 affinity_count = len(psutil.Process().cpu_affinity())
66 if affinity_count > 0:
67 count = min(count, affinity_count)
68 except Exception:
69 pass
70
71 # Check cgroups if available
72 if sys.platform == "linux":
73 try:
74 with open("/sys/fs/cgroup/cpu,cpuacct/cpu.cfs_quota_us") as f:
75 quota = int(f.read())
76 with open("/sys/fs/cgroup/cpu,cpuacct/cpu.cfs_period_us") as f:
77 period = int(f.read())
78 cgroups_count = int(quota / period)
79 if cgroups_count > 0:
80 count = min(count, cgroups_count)
81 except Exception:
82 pass
83
84 return count
85
86
87 def is_structured_cloudevent(body: Dict) -> bool:
88 """Returns True if the JSON request body resembles a structured CloudEvent"""
89 return "time" in body \
90 and "type" in body \
91 and "source" in body \
92 and "id" in body \
93 and "specversion" in body \
94 and "data" in body
95
96
97 def create_response_cloudevent(model_name: str, response: Dict, req_attributes: Dict,
98 binary_event=False) -> tuple:
99 ce_attributes = {}
100
101 if os.getenv("CE_MERGE", "false").lower() == "true":
102 if binary_event:
103 ce_attributes = req_attributes
104 if "datacontenttype" in ce_attributes: # Optional field so must check
105 del ce_attributes["datacontenttype"]
106 else:
107 ce_attributes = req_attributes
108
109 # Remove these fields so we generate new ones
110 del ce_attributes["id"]
111 del ce_attributes["time"]
112
113 ce_attributes["type"] = os.getenv("CE_TYPE", "io.kserve.inference.response")
114 ce_attributes["source"] = os.getenv("CE_SOURCE", f"io.kserve.inference.{model_name}")
115
116 event = CloudEvent(ce_attributes, response)
117
118 if binary_event:
119 event_headers, event_body = to_binary(event)
120 else:
121 event_headers, event_body = to_structured(event)
122
123 return event_headers, event_body
124
125
126 def generate_uuid() -> str:
127 return str(uuid.uuid4())
128
129
130 def to_headers(context: ServicerContext) -> Dict[str, str]:
131 metadata = context.invocation_metadata()
132 if hasattr(context, "trailing_metadata"):
133 metadata += context.trailing_metadata()
134 headers = {}
135 for metadatum in metadata:
136 headers[metadatum.key] = metadatum.value
137
138 return headers
139
140
141 def get_predict_input(payload: Union[Dict, InferRequest]) -> Union[np.ndarray, pd.DataFrame]:
142 if isinstance(payload, Dict):
143 instances = payload["inputs"] if "inputs" in payload else payload["instances"]
144 if len(instances) == 0:
145 return np.array(instances)
146 if isinstance(instances[0], Dict):
147 dfs = []
148 for input in instances:
149 dfs.append(pd.DataFrame(input))
150 inputs = pd.concat(dfs, axis=0)
151 return inputs
152 else:
153 return np.array(instances)
154
155 elif isinstance(payload, InferRequest):
156 content_type = ''
157 parameters = payload.parameters
158 if parameters:
159 if isinstance(parameters.get("content_type"), InferParameter):
160 # for v2 grpc, we get InferParameter obj eg: {"content_type": string_param: "pd"}
161 content_type = str(parameters.get("content_type").string_param)
162 else:
163 # for v2 http, we get string eg: {"content_type": "pd"}
164 content_type = parameters.get("content_type")
165
166 if content_type == "pd":
167 return payload.as_dataframe()
168 else:
169 input = payload.inputs[0]
170 return input.as_numpy()
171
172
173 def get_predict_response(payload: Union[Dict, InferRequest], result: Union[np.ndarray, pd.DataFrame],
174 model_name: str) -> Union[Dict, InferResponse]:
175 if isinstance(payload, Dict):
176 infer_outputs = result
177 if isinstance(result, pd.DataFrame):
178 infer_outputs = []
179 for label, row in result.iterrows():
180 infer_outputs.append(row.to_dict())
181 elif isinstance(result, np.ndarray):
182 infer_outputs = result.tolist()
183 return {"predictions": infer_outputs}
184 elif isinstance(payload, InferRequest):
185 infer_outputs = []
186 if isinstance(result, pd.DataFrame):
187 for col in result.columns:
188 infer_output = InferOutput(
189 name=col,
190 shape=list(result[col].shape),
191 datatype=from_np_dtype(result[col].dtype),
192 data=result[col].tolist()
193 )
194 infer_outputs.append(infer_output)
195 else:
196 infer_output = InferOutput(
197 name="output-0",
198 shape=list(result.shape),
199 datatype=from_np_dtype(result.dtype),
200 data=result.flatten().tolist()
201 )
202 infer_outputs.append(infer_output)
203 return InferResponse(
204 model_name=model_name,
205 infer_outputs=infer_outputs,
206 response_id=generate_uuid()
207 )
208
209
210 def strtobool(val: str) -> bool:
211 """Convert a string representation of truth to True or False.
212
213 True values are 'y', 'yes', 't', 'true', 'on', and '1'; false values
214 are 'n', 'no', 'f', 'false', 'off', and '0'. Raises ValueError if
215 'val' is anything else.
216
217 Adapted from deprecated `distutils`
218 https://github.com/python/cpython/blob/3.11/Lib/distutils/util.py
219 """
220 val = val.lower()
221 if val in ('y', 'yes', 't', 'true', 'on', '1'):
222 return True
223 elif val in ('n', 'no', 'f', 'false', 'off', '0'):
224 return False
225 else:
226 raise ValueError("invalid truth value %r" % (val,))
227
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/python/kserve/kserve/utils/utils.py b/python/kserve/kserve/utils/utils.py
--- a/python/kserve/kserve/utils/utils.py
+++ b/python/kserve/kserve/utils/utils.py
@@ -203,7 +203,7 @@
return InferResponse(
model_name=model_name,
infer_outputs=infer_outputs,
- response_id=generate_uuid()
+ response_id=payload.id if payload.id else generate_uuid()
)
|
{"golden_diff": "diff --git a/python/kserve/kserve/utils/utils.py b/python/kserve/kserve/utils/utils.py\n--- a/python/kserve/kserve/utils/utils.py\n+++ b/python/kserve/kserve/utils/utils.py\n@@ -203,7 +203,7 @@\n return InferResponse(\n model_name=model_name,\n infer_outputs=infer_outputs,\n- response_id=generate_uuid()\n+ response_id=payload.id if payload.id else generate_uuid()\n )\n", "issue": "response id in response should return request id if present\n/kind bug\r\n\r\n**What steps did you take and what happened:**\r\n[A clear and concise description of what the bug is.]\r\n\r\nWhen a request is sent with request id, the response should contain the request id so that the response and request can be easily co-related. Most frameworks and applications return the request id as the response id.\r\n\r\n**What did you expect to happen:**\r\nReturn a generated uuid as response id if no request id is sent but return the request id if available.\r\n\r\n**Environment:**\r\n\r\n- KServe Version: 0.10.1\r\n\r\n\n", "before_files": [{"content": "# Copyright 2021 The KServe Authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\nimport sys\nimport uuid\nfrom kserve.protocol.grpc.grpc_predict_v2_pb2 import InferParameter\nfrom typing import Dict, Union\n\nfrom kserve.utils.numpy_codec import from_np_dtype\nimport pandas as pd\nimport numpy as np\nimport psutil\nfrom cloudevents.conversion import to_binary, to_structured\nfrom cloudevents.http import CloudEvent\nfrom grpc import ServicerContext\nfrom kserve.protocol.infer_type import InferOutput, InferRequest, InferResponse\n\n\ndef is_running_in_k8s():\n return os.path.isdir('/var/run/secrets/kubernetes.io/')\n\n\ndef get_current_k8s_namespace():\n with open('/var/run/secrets/kubernetes.io/serviceaccount/namespace', 'r') as f:\n return f.readline()\n\n\ndef get_default_target_namespace():\n if not is_running_in_k8s():\n return 'default'\n return get_current_k8s_namespace()\n\n\ndef get_isvc_namespace(inferenceservice):\n return inferenceservice.metadata.namespace or get_default_target_namespace()\n\n\ndef get_ig_namespace(inferencegraph):\n return inferencegraph.metadata.namespace or get_default_target_namespace()\n\n\ndef cpu_count():\n \"\"\"Get the available CPU count for this system.\n Takes the minimum value from the following locations:\n - Total system cpus available on the host.\n - CPU Affinity (if set)\n - Cgroups limit (if set)\n \"\"\"\n count = os.cpu_count()\n\n # Check CPU affinity if available\n try:\n affinity_count = len(psutil.Process().cpu_affinity())\n if affinity_count > 0:\n count = min(count, affinity_count)\n except Exception:\n pass\n\n # Check cgroups if available\n if sys.platform == \"linux\":\n try:\n with open(\"/sys/fs/cgroup/cpu,cpuacct/cpu.cfs_quota_us\") as f:\n quota = int(f.read())\n with open(\"/sys/fs/cgroup/cpu,cpuacct/cpu.cfs_period_us\") as f:\n period = int(f.read())\n cgroups_count = int(quota / period)\n if cgroups_count > 0:\n count = min(count, cgroups_count)\n except Exception:\n pass\n\n return count\n\n\ndef is_structured_cloudevent(body: Dict) -> bool:\n \"\"\"Returns True if the JSON request body resembles a structured CloudEvent\"\"\"\n return \"time\" in body \\\n and \"type\" in body \\\n and \"source\" in body \\\n and \"id\" in body \\\n and \"specversion\" in body \\\n and \"data\" in body\n\n\ndef create_response_cloudevent(model_name: str, response: Dict, req_attributes: Dict,\n binary_event=False) -> tuple:\n ce_attributes = {}\n\n if os.getenv(\"CE_MERGE\", \"false\").lower() == \"true\":\n if binary_event:\n ce_attributes = req_attributes\n if \"datacontenttype\" in ce_attributes: # Optional field so must check\n del ce_attributes[\"datacontenttype\"]\n else:\n ce_attributes = req_attributes\n\n # Remove these fields so we generate new ones\n del ce_attributes[\"id\"]\n del ce_attributes[\"time\"]\n\n ce_attributes[\"type\"] = os.getenv(\"CE_TYPE\", \"io.kserve.inference.response\")\n ce_attributes[\"source\"] = os.getenv(\"CE_SOURCE\", f\"io.kserve.inference.{model_name}\")\n\n event = CloudEvent(ce_attributes, response)\n\n if binary_event:\n event_headers, event_body = to_binary(event)\n else:\n event_headers, event_body = to_structured(event)\n\n return event_headers, event_body\n\n\ndef generate_uuid() -> str:\n return str(uuid.uuid4())\n\n\ndef to_headers(context: ServicerContext) -> Dict[str, str]:\n metadata = context.invocation_metadata()\n if hasattr(context, \"trailing_metadata\"):\n metadata += context.trailing_metadata()\n headers = {}\n for metadatum in metadata:\n headers[metadatum.key] = metadatum.value\n\n return headers\n\n\ndef get_predict_input(payload: Union[Dict, InferRequest]) -> Union[np.ndarray, pd.DataFrame]:\n if isinstance(payload, Dict):\n instances = payload[\"inputs\"] if \"inputs\" in payload else payload[\"instances\"]\n if len(instances) == 0:\n return np.array(instances)\n if isinstance(instances[0], Dict):\n dfs = []\n for input in instances:\n dfs.append(pd.DataFrame(input))\n inputs = pd.concat(dfs, axis=0)\n return inputs\n else:\n return np.array(instances)\n\n elif isinstance(payload, InferRequest):\n content_type = ''\n parameters = payload.parameters\n if parameters:\n if isinstance(parameters.get(\"content_type\"), InferParameter):\n # for v2 grpc, we get InferParameter obj eg: {\"content_type\": string_param: \"pd\"}\n content_type = str(parameters.get(\"content_type\").string_param)\n else:\n # for v2 http, we get string eg: {\"content_type\": \"pd\"}\n content_type = parameters.get(\"content_type\")\n\n if content_type == \"pd\":\n return payload.as_dataframe()\n else:\n input = payload.inputs[0]\n return input.as_numpy()\n\n\ndef get_predict_response(payload: Union[Dict, InferRequest], result: Union[np.ndarray, pd.DataFrame],\n model_name: str) -> Union[Dict, InferResponse]:\n if isinstance(payload, Dict):\n infer_outputs = result\n if isinstance(result, pd.DataFrame):\n infer_outputs = []\n for label, row in result.iterrows():\n infer_outputs.append(row.to_dict())\n elif isinstance(result, np.ndarray):\n infer_outputs = result.tolist()\n return {\"predictions\": infer_outputs}\n elif isinstance(payload, InferRequest):\n infer_outputs = []\n if isinstance(result, pd.DataFrame):\n for col in result.columns:\n infer_output = InferOutput(\n name=col,\n shape=list(result[col].shape),\n datatype=from_np_dtype(result[col].dtype),\n data=result[col].tolist()\n )\n infer_outputs.append(infer_output)\n else:\n infer_output = InferOutput(\n name=\"output-0\",\n shape=list(result.shape),\n datatype=from_np_dtype(result.dtype),\n data=result.flatten().tolist()\n )\n infer_outputs.append(infer_output)\n return InferResponse(\n model_name=model_name,\n infer_outputs=infer_outputs,\n response_id=generate_uuid()\n )\n\n\ndef strtobool(val: str) -> bool:\n \"\"\"Convert a string representation of truth to True or False.\n\n True values are 'y', 'yes', 't', 'true', 'on', and '1'; false values\n are 'n', 'no', 'f', 'false', 'off', and '0'. Raises ValueError if\n 'val' is anything else.\n\n Adapted from deprecated `distutils`\n https://github.com/python/cpython/blob/3.11/Lib/distutils/util.py\n \"\"\"\n val = val.lower()\n if val in ('y', 'yes', 't', 'true', 'on', '1'):\n return True\n elif val in ('n', 'no', 'f', 'false', 'off', '0'):\n return False\n else:\n raise ValueError(\"invalid truth value %r\" % (val,))\n", "path": "python/kserve/kserve/utils/utils.py"}], "after_files": [{"content": "# Copyright 2021 The KServe Authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\nimport sys\nimport uuid\nfrom kserve.protocol.grpc.grpc_predict_v2_pb2 import InferParameter\nfrom typing import Dict, Union\n\nfrom kserve.utils.numpy_codec import from_np_dtype\nimport pandas as pd\nimport numpy as np\nimport psutil\nfrom cloudevents.conversion import to_binary, to_structured\nfrom cloudevents.http import CloudEvent\nfrom grpc import ServicerContext\nfrom kserve.protocol.infer_type import InferOutput, InferRequest, InferResponse\n\n\ndef is_running_in_k8s():\n return os.path.isdir('/var/run/secrets/kubernetes.io/')\n\n\ndef get_current_k8s_namespace():\n with open('/var/run/secrets/kubernetes.io/serviceaccount/namespace', 'r') as f:\n return f.readline()\n\n\ndef get_default_target_namespace():\n if not is_running_in_k8s():\n return 'default'\n return get_current_k8s_namespace()\n\n\ndef get_isvc_namespace(inferenceservice):\n return inferenceservice.metadata.namespace or get_default_target_namespace()\n\n\ndef get_ig_namespace(inferencegraph):\n return inferencegraph.metadata.namespace or get_default_target_namespace()\n\n\ndef cpu_count():\n \"\"\"Get the available CPU count for this system.\n Takes the minimum value from the following locations:\n - Total system cpus available on the host.\n - CPU Affinity (if set)\n - Cgroups limit (if set)\n \"\"\"\n count = os.cpu_count()\n\n # Check CPU affinity if available\n try:\n affinity_count = len(psutil.Process().cpu_affinity())\n if affinity_count > 0:\n count = min(count, affinity_count)\n except Exception:\n pass\n\n # Check cgroups if available\n if sys.platform == \"linux\":\n try:\n with open(\"/sys/fs/cgroup/cpu,cpuacct/cpu.cfs_quota_us\") as f:\n quota = int(f.read())\n with open(\"/sys/fs/cgroup/cpu,cpuacct/cpu.cfs_period_us\") as f:\n period = int(f.read())\n cgroups_count = int(quota / period)\n if cgroups_count > 0:\n count = min(count, cgroups_count)\n except Exception:\n pass\n\n return count\n\n\ndef is_structured_cloudevent(body: Dict) -> bool:\n \"\"\"Returns True if the JSON request body resembles a structured CloudEvent\"\"\"\n return \"time\" in body \\\n and \"type\" in body \\\n and \"source\" in body \\\n and \"id\" in body \\\n and \"specversion\" in body \\\n and \"data\" in body\n\n\ndef create_response_cloudevent(model_name: str, response: Dict, req_attributes: Dict,\n binary_event=False) -> tuple:\n ce_attributes = {}\n\n if os.getenv(\"CE_MERGE\", \"false\").lower() == \"true\":\n if binary_event:\n ce_attributes = req_attributes\n if \"datacontenttype\" in ce_attributes: # Optional field so must check\n del ce_attributes[\"datacontenttype\"]\n else:\n ce_attributes = req_attributes\n\n # Remove these fields so we generate new ones\n del ce_attributes[\"id\"]\n del ce_attributes[\"time\"]\n\n ce_attributes[\"type\"] = os.getenv(\"CE_TYPE\", \"io.kserve.inference.response\")\n ce_attributes[\"source\"] = os.getenv(\"CE_SOURCE\", f\"io.kserve.inference.{model_name}\")\n\n event = CloudEvent(ce_attributes, response)\n\n if binary_event:\n event_headers, event_body = to_binary(event)\n else:\n event_headers, event_body = to_structured(event)\n\n return event_headers, event_body\n\n\ndef generate_uuid() -> str:\n return str(uuid.uuid4())\n\n\ndef to_headers(context: ServicerContext) -> Dict[str, str]:\n metadata = context.invocation_metadata()\n if hasattr(context, \"trailing_metadata\"):\n metadata += context.trailing_metadata()\n headers = {}\n for metadatum in metadata:\n headers[metadatum.key] = metadatum.value\n\n return headers\n\n\ndef get_predict_input(payload: Union[Dict, InferRequest]) -> Union[np.ndarray, pd.DataFrame]:\n if isinstance(payload, Dict):\n instances = payload[\"inputs\"] if \"inputs\" in payload else payload[\"instances\"]\n if len(instances) == 0:\n return np.array(instances)\n if isinstance(instances[0], Dict):\n dfs = []\n for input in instances:\n dfs.append(pd.DataFrame(input))\n inputs = pd.concat(dfs, axis=0)\n return inputs\n else:\n return np.array(instances)\n\n elif isinstance(payload, InferRequest):\n content_type = ''\n parameters = payload.parameters\n if parameters:\n if isinstance(parameters.get(\"content_type\"), InferParameter):\n # for v2 grpc, we get InferParameter obj eg: {\"content_type\": string_param: \"pd\"}\n content_type = str(parameters.get(\"content_type\").string_param)\n else:\n # for v2 http, we get string eg: {\"content_type\": \"pd\"}\n content_type = parameters.get(\"content_type\")\n\n if content_type == \"pd\":\n return payload.as_dataframe()\n else:\n input = payload.inputs[0]\n return input.as_numpy()\n\n\ndef get_predict_response(payload: Union[Dict, InferRequest], result: Union[np.ndarray, pd.DataFrame],\n model_name: str) -> Union[Dict, InferResponse]:\n if isinstance(payload, Dict):\n infer_outputs = result\n if isinstance(result, pd.DataFrame):\n infer_outputs = []\n for label, row in result.iterrows():\n infer_outputs.append(row.to_dict())\n elif isinstance(result, np.ndarray):\n infer_outputs = result.tolist()\n return {\"predictions\": infer_outputs}\n elif isinstance(payload, InferRequest):\n infer_outputs = []\n if isinstance(result, pd.DataFrame):\n for col in result.columns:\n infer_output = InferOutput(\n name=col,\n shape=list(result[col].shape),\n datatype=from_np_dtype(result[col].dtype),\n data=result[col].tolist()\n )\n infer_outputs.append(infer_output)\n else:\n infer_output = InferOutput(\n name=\"output-0\",\n shape=list(result.shape),\n datatype=from_np_dtype(result.dtype),\n data=result.flatten().tolist()\n )\n infer_outputs.append(infer_output)\n return InferResponse(\n model_name=model_name,\n infer_outputs=infer_outputs,\n response_id=payload.id if payload.id else generate_uuid()\n )\n\n\ndef strtobool(val: str) -> bool:\n \"\"\"Convert a string representation of truth to True or False.\n\n True values are 'y', 'yes', 't', 'true', 'on', and '1'; false values\n are 'n', 'no', 'f', 'false', 'off', and '0'. Raises ValueError if\n 'val' is anything else.\n\n Adapted from deprecated `distutils`\n https://github.com/python/cpython/blob/3.11/Lib/distutils/util.py\n \"\"\"\n val = val.lower()\n if val in ('y', 'yes', 't', 'true', 'on', '1'):\n return True\n elif val in ('n', 'no', 'f', 'false', 'off', '0'):\n return False\n else:\n raise ValueError(\"invalid truth value %r\" % (val,))\n", "path": "python/kserve/kserve/utils/utils.py"}]}
| 2,679 | 100 |
gh_patches_debug_2976
|
rasdani/github-patches
|
git_diff
|
qtile__qtile-1644
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Can't use asyncio event loop in widgets
I am creating a widget that uses asyncio to run some external command (with `asyncio.create_subprocess_exec`). It doesn't work, and raises the `RuntimeError("Cannot add child handler, the child watcher does not have a loop attached")` exception instead.
If my understanding of the code is correct, calling `set_event_loop` after `new_event_loop` should fix this issue, but I'm not sure whether it will cause other problems.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `libqtile/core/session_manager.py`
Content:
```
1 import asyncio
2 import os
3
4 from libqtile import ipc
5 from libqtile.backend import base
6 from libqtile.core.manager import Qtile
7
8
9 class SessionManager:
10 def __init__(
11 self, kore: base.Core, config, *, fname: str = None, no_spawn=False, state=None
12 ) -> None:
13 """Manages a qtile session
14
15 :param kore:
16 The core backend to use for the session.
17 :param config:
18 The configuration to use for the qtile instance.
19 :param fname:
20 The file name to use as the qtile socket file.
21 :param no_spawn:
22 If the instance has already been started, then don't re-run the
23 startup once hook.
24 :param state:
25 The state to restart the qtile instance with.
26 """
27 eventloop = asyncio.new_event_loop()
28
29 self.qtile = Qtile(kore, config, eventloop, no_spawn=no_spawn, state=state)
30
31 if fname is None:
32 # Dots might appear in the host part of the display name
33 # during remote X sessions. Let's strip the host part first
34 display_name = kore.display_name
35 display_number = display_name.partition(":")[2]
36 if "." not in display_number:
37 display_name += ".0"
38 fname = ipc.find_sockfile(display_name)
39
40 if os.path.exists(fname):
41 os.unlink(fname)
42 self.server = ipc.Server(fname, self.qtile.server.call, eventloop)
43
44 def loop(self) -> None:
45 """Run the event loop"""
46 with self.server:
47 self.qtile.loop()
48
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/libqtile/core/session_manager.py b/libqtile/core/session_manager.py
--- a/libqtile/core/session_manager.py
+++ b/libqtile/core/session_manager.py
@@ -25,6 +25,7 @@
The state to restart the qtile instance with.
"""
eventloop = asyncio.new_event_loop()
+ asyncio.set_event_loop(eventloop)
self.qtile = Qtile(kore, config, eventloop, no_spawn=no_spawn, state=state)
|
{"golden_diff": "diff --git a/libqtile/core/session_manager.py b/libqtile/core/session_manager.py\n--- a/libqtile/core/session_manager.py\n+++ b/libqtile/core/session_manager.py\n@@ -25,6 +25,7 @@\n The state to restart the qtile instance with.\n \"\"\"\n eventloop = asyncio.new_event_loop()\n+ asyncio.set_event_loop(eventloop)\n \n self.qtile = Qtile(kore, config, eventloop, no_spawn=no_spawn, state=state)\n", "issue": "Can't use asyncio event loop in widgets\nI am creating a widget that uses asyncio to run some external command (with `asyncio.create_subprocess_exec`). It doesn't work, and raises the `RuntimeError(\"Cannot add child handler, the child watcher does not have a loop attached\")` exception instead.\r\n\r\nIf my understanding of the code is correct, calling `set_event_loop` after `new_event_loop` should fix this issue, but I'm not sure whether it will cause other problems.\n", "before_files": [{"content": "import asyncio\nimport os\n\nfrom libqtile import ipc\nfrom libqtile.backend import base\nfrom libqtile.core.manager import Qtile\n\n\nclass SessionManager:\n def __init__(\n self, kore: base.Core, config, *, fname: str = None, no_spawn=False, state=None\n ) -> None:\n \"\"\"Manages a qtile session\n\n :param kore:\n The core backend to use for the session.\n :param config:\n The configuration to use for the qtile instance.\n :param fname:\n The file name to use as the qtile socket file.\n :param no_spawn:\n If the instance has already been started, then don't re-run the\n startup once hook.\n :param state:\n The state to restart the qtile instance with.\n \"\"\"\n eventloop = asyncio.new_event_loop()\n\n self.qtile = Qtile(kore, config, eventloop, no_spawn=no_spawn, state=state)\n\n if fname is None:\n # Dots might appear in the host part of the display name\n # during remote X sessions. Let's strip the host part first\n display_name = kore.display_name\n display_number = display_name.partition(\":\")[2]\n if \".\" not in display_number:\n display_name += \".0\"\n fname = ipc.find_sockfile(display_name)\n\n if os.path.exists(fname):\n os.unlink(fname)\n self.server = ipc.Server(fname, self.qtile.server.call, eventloop)\n\n def loop(self) -> None:\n \"\"\"Run the event loop\"\"\"\n with self.server:\n self.qtile.loop()\n", "path": "libqtile/core/session_manager.py"}], "after_files": [{"content": "import asyncio\nimport os\n\nfrom libqtile import ipc\nfrom libqtile.backend import base\nfrom libqtile.core.manager import Qtile\n\n\nclass SessionManager:\n def __init__(\n self, kore: base.Core, config, *, fname: str = None, no_spawn=False, state=None\n ) -> None:\n \"\"\"Manages a qtile session\n\n :param kore:\n The core backend to use for the session.\n :param config:\n The configuration to use for the qtile instance.\n :param fname:\n The file name to use as the qtile socket file.\n :param no_spawn:\n If the instance has already been started, then don't re-run the\n startup once hook.\n :param state:\n The state to restart the qtile instance with.\n \"\"\"\n eventloop = asyncio.new_event_loop()\n asyncio.set_event_loop(eventloop)\n\n self.qtile = Qtile(kore, config, eventloop, no_spawn=no_spawn, state=state)\n\n if fname is None:\n # Dots might appear in the host part of the display name\n # during remote X sessions. Let's strip the host part first\n display_name = kore.display_name\n display_number = display_name.partition(\":\")[2]\n if \".\" not in display_number:\n display_name += \".0\"\n fname = ipc.find_sockfile(display_name)\n\n if os.path.exists(fname):\n os.unlink(fname)\n self.server = ipc.Server(fname, self.qtile.server.call, eventloop)\n\n def loop(self) -> None:\n \"\"\"Run the event loop\"\"\"\n with self.server:\n self.qtile.loop()\n", "path": "libqtile/core/session_manager.py"}]}
| 800 | 108 |
gh_patches_debug_17499
|
rasdani/github-patches
|
git_diff
|
pyinstaller__pyinstaller-7183
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Hooks: Runtime hook for subprocess block launching standalone cmd
<!--
Welcome to the PyInstaller issue tracker! Before creating an issue, please heed the following:
1. This tracker should only be used to report bugs and request features / enhancements to PyInstaller
- For questions and general support, use the discussions forum.
2. Use the search function before creating a new issue. Duplicates will be closed and directed to
the original discussion.
3. When making a bug report, make sure you provide all required information. The easier it is for
maintainers to reproduce, the faster it'll be fixed.
-->
<!-- +++ ONLY TEXT +++ DO NOT POST IMAGES +++ -->
## Description of the issue
In windowed build using `PySide2`, `subprocess.Popen(["cmd"])` no longer work (cmd open then close immediately). I figured out that the issue come from the subprocess hook (since v4.8, pr #6364). If I comment out this file, `cmd` start showing again and stay alive.
### Context information (for bug reports)
* Output of `pyinstaller --version`: ```5.4.1```
* Version of Python: 3.7 / 3.8 / 3.9 / 3.10
* Platform: Windows
* How you installed Python: python.org/downloads
* Did you also try this on another platform? Does it work there? → not relevant on other platform.
### A minimal example program which shows the error
A cmd shows up at start, if you comment the hook it stays alive, if you don't the cmd disappear instantly.
```
import subprocess
import sys
from PySide2 import QtWidgets
class CmdExemple(QtWidgets.QMainWindow):
def __init__(self):
super().__init__()
p = subprocess.Popen(["cmd"])
if __name__ == "__main__":
app = QtWidgets.QApplication(sys.argv)
window = CmdExemple()
window.show()
exitCode = app.exec_()
sys.exit(exitCode)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `PyInstaller/hooks/rthooks/pyi_rth_subprocess.py`
Content:
```
1 #-----------------------------------------------------------------------------
2 # Copyright (c) 2021-2022, PyInstaller Development Team.
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 #
7 # The full license is in the file COPYING.txt, distributed with this software.
8 #
9 # SPDX-License-Identifier: Apache-2.0
10 #-----------------------------------------------------------------------------
11
12 import subprocess
13 import sys
14 import io
15
16
17 class Popen(subprocess.Popen):
18
19 # In windowed mode, force any unused pipes (stdin, stdout and stderr) to be DEVNULL instead of inheriting the
20 # invalid corresponding handles from this parent process.
21 if sys.platform == "win32" and not isinstance(sys.stdout, io.IOBase):
22
23 def _get_handles(self, stdin, stdout, stderr):
24 stdin, stdout, stderr = (subprocess.DEVNULL if pipe is None else pipe for pipe in (stdin, stdout, stderr))
25 return super()._get_handles(stdin, stdout, stderr)
26
27
28 subprocess.Popen = Popen
29
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/PyInstaller/hooks/rthooks/pyi_rth_subprocess.py b/PyInstaller/hooks/rthooks/pyi_rth_subprocess.py
deleted file mode 100644
--- a/PyInstaller/hooks/rthooks/pyi_rth_subprocess.py
+++ /dev/null
@@ -1,28 +0,0 @@
-#-----------------------------------------------------------------------------
-# Copyright (c) 2021-2022, PyInstaller Development Team.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-#
-# The full license is in the file COPYING.txt, distributed with this software.
-#
-# SPDX-License-Identifier: Apache-2.0
-#-----------------------------------------------------------------------------
-
-import subprocess
-import sys
-import io
-
-
-class Popen(subprocess.Popen):
-
- # In windowed mode, force any unused pipes (stdin, stdout and stderr) to be DEVNULL instead of inheriting the
- # invalid corresponding handles from this parent process.
- if sys.platform == "win32" and not isinstance(sys.stdout, io.IOBase):
-
- def _get_handles(self, stdin, stdout, stderr):
- stdin, stdout, stderr = (subprocess.DEVNULL if pipe is None else pipe for pipe in (stdin, stdout, stderr))
- return super()._get_handles(stdin, stdout, stderr)
-
-
-subprocess.Popen = Popen
|
{"golden_diff": "diff --git a/PyInstaller/hooks/rthooks/pyi_rth_subprocess.py b/PyInstaller/hooks/rthooks/pyi_rth_subprocess.py\ndeleted file mode 100644\n--- a/PyInstaller/hooks/rthooks/pyi_rth_subprocess.py\n+++ /dev/null\n@@ -1,28 +0,0 @@\n-#-----------------------------------------------------------------------------\n-# Copyright (c) 2021-2022, PyInstaller Development Team.\n-#\n-# Licensed under the Apache License, Version 2.0 (the \"License\");\n-# you may not use this file except in compliance with the License.\n-#\n-# The full license is in the file COPYING.txt, distributed with this software.\n-#\n-# SPDX-License-Identifier: Apache-2.0\n-#-----------------------------------------------------------------------------\n-\n-import subprocess\n-import sys\n-import io\n-\n-\n-class Popen(subprocess.Popen):\n-\n- # In windowed mode, force any unused pipes (stdin, stdout and stderr) to be DEVNULL instead of inheriting the\n- # invalid corresponding handles from this parent process.\n- if sys.platform == \"win32\" and not isinstance(sys.stdout, io.IOBase):\n-\n- def _get_handles(self, stdin, stdout, stderr):\n- stdin, stdout, stderr = (subprocess.DEVNULL if pipe is None else pipe for pipe in (stdin, stdout, stderr))\n- return super()._get_handles(stdin, stdout, stderr)\n-\n-\n-subprocess.Popen = Popen\n", "issue": "Hooks: Runtime hook for subprocess block launching standalone cmd\n<!--\r\nWelcome to the PyInstaller issue tracker! Before creating an issue, please heed the following:\r\n\r\n1. This tracker should only be used to report bugs and request features / enhancements to PyInstaller\r\n - For questions and general support, use the discussions forum.\r\n2. Use the search function before creating a new issue. Duplicates will be closed and directed to\r\n the original discussion.\r\n3. When making a bug report, make sure you provide all required information. The easier it is for\r\n maintainers to reproduce, the faster it'll be fixed.\r\n-->\r\n\r\n<!-- +++ ONLY TEXT +++ DO NOT POST IMAGES +++ -->\r\n\r\n## Description of the issue\r\nIn windowed build using `PySide2`, `subprocess.Popen([\"cmd\"])` no longer work (cmd open then close immediately). I figured out that the issue come from the subprocess hook (since v4.8, pr #6364). If I comment out this file, `cmd` start showing again and stay alive.\r\n\r\n### Context information (for bug reports)\r\n\r\n* Output of `pyinstaller --version`: ```5.4.1```\r\n* Version of Python: 3.7 / 3.8 / 3.9 / 3.10\r\n* Platform: Windows\r\n* How you installed Python: python.org/downloads\r\n* Did you also try this on another platform? Does it work there? \u2192 not relevant on other platform.\r\n\r\n### A minimal example program which shows the error\r\nA cmd shows up at start, if you comment the hook it stays alive, if you don't the cmd disappear instantly.\r\n\r\n```\r\nimport subprocess\r\nimport sys\r\n\r\nfrom PySide2 import QtWidgets\r\n\r\nclass CmdExemple(QtWidgets.QMainWindow):\r\n def __init__(self):\r\n super().__init__()\r\n p = subprocess.Popen([\"cmd\"])\r\n\r\nif __name__ == \"__main__\":\r\n app = QtWidgets.QApplication(sys.argv)\r\n window = CmdExemple()\r\n window.show()\r\n exitCode = app.exec_()\r\n sys.exit(exitCode)\r\n```\r\n\n", "before_files": [{"content": "#-----------------------------------------------------------------------------\n# Copyright (c) 2021-2022, PyInstaller Development Team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n#\n# The full license is in the file COPYING.txt, distributed with this software.\n#\n# SPDX-License-Identifier: Apache-2.0\n#-----------------------------------------------------------------------------\n\nimport subprocess\nimport sys\nimport io\n\n\nclass Popen(subprocess.Popen):\n\n # In windowed mode, force any unused pipes (stdin, stdout and stderr) to be DEVNULL instead of inheriting the\n # invalid corresponding handles from this parent process.\n if sys.platform == \"win32\" and not isinstance(sys.stdout, io.IOBase):\n\n def _get_handles(self, stdin, stdout, stderr):\n stdin, stdout, stderr = (subprocess.DEVNULL if pipe is None else pipe for pipe in (stdin, stdout, stderr))\n return super()._get_handles(stdin, stdout, stderr)\n\n\nsubprocess.Popen = Popen\n", "path": "PyInstaller/hooks/rthooks/pyi_rth_subprocess.py"}], "after_files": [{"content": null, "path": "PyInstaller/hooks/rthooks/pyi_rth_subprocess.py"}]}
| 975 | 322 |
gh_patches_debug_14873
|
rasdani/github-patches
|
git_diff
|
TencentBlueKing__bk-user-410
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[优化] HTTP API 数据源同步报错
对应API 没有按照要求, 返回`count/results`, 此时取空
实际上这里的逻辑会`results`的第一条, 处理; 但是没有很好地校验
会报错
```
Task bkuser_core.categories.tasks.adapter_sync[78744136-5e83-4605-8503-d4d8ed90f9e3] raised unexpected: IndexError('list index out of range',)
Traceback (most recent call last):
File "/usr/local/lib/python3.6/site-packages/celery/app/trace.py", line 412, in trace_task
R = retval = fun(*args, **kwargs)
File "/usr/local/lib/python3.6/site-packages/celery/app/trace.py", line 704, in __protected_call__
return self.run(*args, **kwargs)
File "/usr/local/lib/python3.6/site-packages/celery/app/autoretry.py", line 50, in run
raise task.retry(exc=exc, **retry_kwargs)
File "/usr/local/lib/python3.6/site-packages/celery/app/task.py", line 706, in retry
raise_with_context(exc)
File "/usr/local/lib/python3.6/site-packages/celery/app/autoretry.py", line 35, in run
return task._orig_run(*args, **kwargs)
File "/app/bkuser_core/categories/tasks.py", line 111, in adapter_sync
plugin.sync(instance_id=instance_id, task_id=task_id, *args, **kwargs)
File "/app/bkuser_core/categories/plugins/plugin.py", line 124, in sync
syncer.sync(*args, **kwargs)
File "/app/bkuser_core/categories/plugins/custom/sycner.py", line 45, in sync
self._sync_department()
File "/app/bkuser_core/categories/plugins/custom/sycner.py", line 50, in _sync_department
self._load2sync_manager(self.client.fetch_departments())
File "/app/bkuser_core/categories/plugins/custom/sycner.py", line 74, in _load2sync_manager
category=self.category, db_sync_manager=self.db_sync_manager, items=items, context=self.context
File "/app/bkuser_core/categories/plugins/custom/helpers.py", line 277, in init_helper
return _map[items.custom_type](
File "/app/bkuser_core/categories/plugins/custom/models.py", line 81, in custom_type
return type(list(self.items_map.values())[0])
IndexError: list index out of range
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/api/bkuser_core/categories/plugins/custom/client.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 """
3 TencentBlueKing is pleased to support the open source community by making 蓝鲸智云-用户管理(Bk-User) available.
4 Copyright (C) 2017-2021 THL A29 Limited, a Tencent company. All rights reserved.
5 Licensed under the MIT License (the "License"); you may not use this file except in compliance with the License.
6 You may obtain a copy of the License at http://opensource.org/licenses/MIT
7 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
8 an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
9 specific language governing permissions and limitations under the License.
10 """
11 import logging
12 from dataclasses import dataclass
13 from typing import Optional
14
15 import curlify
16 import requests
17
18 from bkuser_core.categories.plugins.custom.exceptions import CustomAPIRequestFailed
19 from bkuser_core.categories.plugins.custom.models import CustomDepartment, CustomProfile, CustomTypeList
20 from bkuser_core.user_settings.loader import ConfigProvider
21
22 logger = logging.getLogger(__name__)
23
24
25 @dataclass
26 class PageInfo:
27 page: int
28 page_size: int
29
30
31 @dataclass
32 class CustomDataClient:
33 category_id: int
34 api_host: str
35 paths: dict
36
37 @classmethod
38 def from_config(cls):
39 """从配置中创建客户端"""
40
41 def __post_init__(self):
42 self.config_loader = ConfigProvider(self.category_id)
43
44 def _fetch_items(self, path: str):
45 url = "/".join(s.strip("/") for s in [self.api_host, path])
46 resp = requests.get(url, timeout=30)
47
48 curl_format = curlify.to_curl(resp.request)
49 logger.debug("going to call: %s", url)
50 if resp.status_code >= 400:
51 logger.error(
52 "failed to request api, status code: %s cUrl format: %s",
53 resp.status_code,
54 curl_format,
55 )
56 raise CustomAPIRequestFailed()
57
58 try:
59 resp_body = resp.json()
60 except Exception as e:
61 logger.exception("failed to parse resp as json, cUrl format: %s", curl_format)
62 raise CustomAPIRequestFailed() from e
63
64 # results not present in response body
65 if "results" not in resp_body:
66 logger.error("no `results` in response, cUrl format: %s", curl_format)
67 raise CustomAPIRequestFailed("there got no `results` in response body")
68
69 results = resp_body.get("results", [])
70 # results not a list
71 if not isinstance(results, list):
72 logger.error("`results` in response is not a list, cUrl format: %s", curl_format)
73 raise CustomAPIRequestFailed("the `results` in response is not a list")
74
75 return results
76
77 def fetch_profiles(self, page_info: Optional[PageInfo] = None) -> CustomTypeList:
78 """获取 profile 对象列表"""
79 results = self._fetch_items(path=self.paths["profile"])
80 return CustomTypeList.from_list([CustomProfile.from_dict(x) for x in results])
81
82 def fetch_departments(self, page_info: Optional[PageInfo] = None) -> CustomTypeList:
83 """获取 department 对象列表"""
84 results = self._fetch_items(path=self.paths["department"])
85 return CustomTypeList.from_list([CustomDepartment.from_dict(x) for x in results])
86
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/api/bkuser_core/categories/plugins/custom/client.py b/src/api/bkuser_core/categories/plugins/custom/client.py
--- a/src/api/bkuser_core/categories/plugins/custom/client.py
+++ b/src/api/bkuser_core/categories/plugins/custom/client.py
@@ -72,6 +72,12 @@
logger.error("`results` in response is not a list, cUrl format: %s", curl_format)
raise CustomAPIRequestFailed("the `results` in response is not a list")
+ # currently, if the results is empty, CustomTypeList.custom_type will raise IndexError(task fail)
+ # so, here, we should check here: results size should not be empty
+ if not results:
+ logger.error("`results` in response is empty, cUrl format: %s", curl_format)
+ raise CustomAPIRequestFailed("the `results` in response is empty")
+
return results
def fetch_profiles(self, page_info: Optional[PageInfo] = None) -> CustomTypeList:
|
{"golden_diff": "diff --git a/src/api/bkuser_core/categories/plugins/custom/client.py b/src/api/bkuser_core/categories/plugins/custom/client.py\n--- a/src/api/bkuser_core/categories/plugins/custom/client.py\n+++ b/src/api/bkuser_core/categories/plugins/custom/client.py\n@@ -72,6 +72,12 @@\n logger.error(\"`results` in response is not a list, cUrl format: %s\", curl_format)\n raise CustomAPIRequestFailed(\"the `results` in response is not a list\")\n \n+ # currently, if the results is empty, CustomTypeList.custom_type will raise IndexError(task fail)\n+ # so, here, we should check here: results size should not be empty\n+ if not results:\n+ logger.error(\"`results` in response is empty, cUrl format: %s\", curl_format)\n+ raise CustomAPIRequestFailed(\"the `results` in response is empty\")\n+\n return results\n \n def fetch_profiles(self, page_info: Optional[PageInfo] = None) -> CustomTypeList:\n", "issue": "[\u4f18\u5316] HTTP API \u6570\u636e\u6e90\u540c\u6b65\u62a5\u9519\n\u5bf9\u5e94API \u6ca1\u6709\u6309\u7167\u8981\u6c42, \u8fd4\u56de`count/results`, \u6b64\u65f6\u53d6\u7a7a\r\n\r\n\u5b9e\u9645\u4e0a\u8fd9\u91cc\u7684\u903b\u8f91\u4f1a`results`\u7684\u7b2c\u4e00\u6761, \u5904\u7406; \u4f46\u662f\u6ca1\u6709\u5f88\u597d\u5730\u6821\u9a8c\r\n\r\n\u4f1a\u62a5\u9519\r\n\r\n```\r\nTask bkuser_core.categories.tasks.adapter_sync[78744136-5e83-4605-8503-d4d8ed90f9e3] raised unexpected: IndexError('list index out of range',)\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.6/site-packages/celery/app/trace.py\", line 412, in trace_task\r\n R = retval = fun(*args, **kwargs)\r\n File \"/usr/local/lib/python3.6/site-packages/celery/app/trace.py\", line 704, in __protected_call__\r\n return self.run(*args, **kwargs)\r\n File \"/usr/local/lib/python3.6/site-packages/celery/app/autoretry.py\", line 50, in run\r\n raise task.retry(exc=exc, **retry_kwargs)\r\n File \"/usr/local/lib/python3.6/site-packages/celery/app/task.py\", line 706, in retry\r\n raise_with_context(exc)\r\n File \"/usr/local/lib/python3.6/site-packages/celery/app/autoretry.py\", line 35, in run\r\n return task._orig_run(*args, **kwargs)\r\n File \"/app/bkuser_core/categories/tasks.py\", line 111, in adapter_sync\r\n plugin.sync(instance_id=instance_id, task_id=task_id, *args, **kwargs)\r\n File \"/app/bkuser_core/categories/plugins/plugin.py\", line 124, in sync\r\n syncer.sync(*args, **kwargs)\r\n File \"/app/bkuser_core/categories/plugins/custom/sycner.py\", line 45, in sync\r\n self._sync_department()\r\n File \"/app/bkuser_core/categories/plugins/custom/sycner.py\", line 50, in _sync_department\r\n self._load2sync_manager(self.client.fetch_departments())\r\n File \"/app/bkuser_core/categories/plugins/custom/sycner.py\", line 74, in _load2sync_manager\r\n category=self.category, db_sync_manager=self.db_sync_manager, items=items, context=self.context\r\n File \"/app/bkuser_core/categories/plugins/custom/helpers.py\", line 277, in init_helper\r\n return _map[items.custom_type](\r\n File \"/app/bkuser_core/categories/plugins/custom/models.py\", line 81, in custom_type\r\n return type(list(self.items_map.values())[0])\r\nIndexError: list index out of range\r\n```\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\nTencentBlueKing is pleased to support the open source community by making \u84dd\u9cb8\u667a\u4e91-\u7528\u6237\u7ba1\u7406(Bk-User) available.\nCopyright (C) 2017-2021 THL A29 Limited, a Tencent company. All rights reserved.\nLicensed under the MIT License (the \"License\"); you may not use this file except in compliance with the License.\nYou may obtain a copy of the License at http://opensource.org/licenses/MIT\nUnless required by applicable law or agreed to in writing, software distributed under the License is distributed on\nan \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the\nspecific language governing permissions and limitations under the License.\n\"\"\"\nimport logging\nfrom dataclasses import dataclass\nfrom typing import Optional\n\nimport curlify\nimport requests\n\nfrom bkuser_core.categories.plugins.custom.exceptions import CustomAPIRequestFailed\nfrom bkuser_core.categories.plugins.custom.models import CustomDepartment, CustomProfile, CustomTypeList\nfrom bkuser_core.user_settings.loader import ConfigProvider\n\nlogger = logging.getLogger(__name__)\n\n\n@dataclass\nclass PageInfo:\n page: int\n page_size: int\n\n\n@dataclass\nclass CustomDataClient:\n category_id: int\n api_host: str\n paths: dict\n\n @classmethod\n def from_config(cls):\n \"\"\"\u4ece\u914d\u7f6e\u4e2d\u521b\u5efa\u5ba2\u6237\u7aef\"\"\"\n\n def __post_init__(self):\n self.config_loader = ConfigProvider(self.category_id)\n\n def _fetch_items(self, path: str):\n url = \"/\".join(s.strip(\"/\") for s in [self.api_host, path])\n resp = requests.get(url, timeout=30)\n\n curl_format = curlify.to_curl(resp.request)\n logger.debug(\"going to call: %s\", url)\n if resp.status_code >= 400:\n logger.error(\n \"failed to request api, status code: %s cUrl format: %s\",\n resp.status_code,\n curl_format,\n )\n raise CustomAPIRequestFailed()\n\n try:\n resp_body = resp.json()\n except Exception as e:\n logger.exception(\"failed to parse resp as json, cUrl format: %s\", curl_format)\n raise CustomAPIRequestFailed() from e\n\n # results not present in response body\n if \"results\" not in resp_body:\n logger.error(\"no `results` in response, cUrl format: %s\", curl_format)\n raise CustomAPIRequestFailed(\"there got no `results` in response body\")\n\n results = resp_body.get(\"results\", [])\n # results not a list\n if not isinstance(results, list):\n logger.error(\"`results` in response is not a list, cUrl format: %s\", curl_format)\n raise CustomAPIRequestFailed(\"the `results` in response is not a list\")\n\n return results\n\n def fetch_profiles(self, page_info: Optional[PageInfo] = None) -> CustomTypeList:\n \"\"\"\u83b7\u53d6 profile \u5bf9\u8c61\u5217\u8868\"\"\"\n results = self._fetch_items(path=self.paths[\"profile\"])\n return CustomTypeList.from_list([CustomProfile.from_dict(x) for x in results])\n\n def fetch_departments(self, page_info: Optional[PageInfo] = None) -> CustomTypeList:\n \"\"\"\u83b7\u53d6 department \u5bf9\u8c61\u5217\u8868\"\"\"\n results = self._fetch_items(path=self.paths[\"department\"])\n return CustomTypeList.from_list([CustomDepartment.from_dict(x) for x in results])\n", "path": "src/api/bkuser_core/categories/plugins/custom/client.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\nTencentBlueKing is pleased to support the open source community by making \u84dd\u9cb8\u667a\u4e91-\u7528\u6237\u7ba1\u7406(Bk-User) available.\nCopyright (C) 2017-2021 THL A29 Limited, a Tencent company. All rights reserved.\nLicensed under the MIT License (the \"License\"); you may not use this file except in compliance with the License.\nYou may obtain a copy of the License at http://opensource.org/licenses/MIT\nUnless required by applicable law or agreed to in writing, software distributed under the License is distributed on\nan \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the\nspecific language governing permissions and limitations under the License.\n\"\"\"\nimport logging\nfrom dataclasses import dataclass\nfrom typing import Optional\n\nimport curlify\nimport requests\n\nfrom bkuser_core.categories.plugins.custom.exceptions import CustomAPIRequestFailed\nfrom bkuser_core.categories.plugins.custom.models import CustomDepartment, CustomProfile, CustomTypeList\nfrom bkuser_core.user_settings.loader import ConfigProvider\n\nlogger = logging.getLogger(__name__)\n\n\n@dataclass\nclass PageInfo:\n page: int\n page_size: int\n\n\n@dataclass\nclass CustomDataClient:\n category_id: int\n api_host: str\n paths: dict\n\n @classmethod\n def from_config(cls):\n \"\"\"\u4ece\u914d\u7f6e\u4e2d\u521b\u5efa\u5ba2\u6237\u7aef\"\"\"\n\n def __post_init__(self):\n self.config_loader = ConfigProvider(self.category_id)\n\n def _fetch_items(self, path: str):\n url = \"/\".join(s.strip(\"/\") for s in [self.api_host, path])\n resp = requests.get(url, timeout=30)\n\n curl_format = curlify.to_curl(resp.request)\n logger.debug(\"going to call: %s\", url)\n if resp.status_code >= 400:\n logger.error(\n \"failed to request api, status code: %s cUrl format: %s\",\n resp.status_code,\n curl_format,\n )\n raise CustomAPIRequestFailed()\n\n try:\n resp_body = resp.json()\n except Exception as e:\n logger.exception(\"failed to parse resp as json, cUrl format: %s\", curl_format)\n raise CustomAPIRequestFailed() from e\n\n # results not present in response body\n if \"results\" not in resp_body:\n logger.error(\"no `results` in response, cUrl format: %s\", curl_format)\n raise CustomAPIRequestFailed(\"there got no `results` in response body\")\n\n results = resp_body.get(\"results\", [])\n # results not a list\n if not isinstance(results, list):\n logger.error(\"`results` in response is not a list, cUrl format: %s\", curl_format)\n raise CustomAPIRequestFailed(\"the `results` in response is not a list\")\n\n # currently, if the results is empty, CustomTypeList.custom_type will raise IndexError(task fail)\n # so, here, we should check here: results size should not be empty\n if not results:\n logger.error(\"`results` in response is empty, cUrl format: %s\", curl_format)\n raise CustomAPIRequestFailed(\"the `results` in response is empty\")\n\n return results\n\n def fetch_profiles(self, page_info: Optional[PageInfo] = None) -> CustomTypeList:\n \"\"\"\u83b7\u53d6 profile \u5bf9\u8c61\u5217\u8868\"\"\"\n results = self._fetch_items(path=self.paths[\"profile\"])\n return CustomTypeList.from_list([CustomProfile.from_dict(x) for x in results])\n\n def fetch_departments(self, page_info: Optional[PageInfo] = None) -> CustomTypeList:\n \"\"\"\u83b7\u53d6 department \u5bf9\u8c61\u5217\u8868\"\"\"\n results = self._fetch_items(path=self.paths[\"department\"])\n return CustomTypeList.from_list([CustomDepartment.from_dict(x) for x in results])\n", "path": "src/api/bkuser_core/categories/plugins/custom/client.py"}]}
| 1,775 | 224 |
gh_patches_debug_15510
|
rasdani/github-patches
|
git_diff
|
searxng__searxng-2035
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug: duckduckgo engine
**Version of SearXNG, commit number if you are using on master branch and stipulate if you forked SearXNG**
Repository: https://github.com/searxng/searxng
Branch: master
Version: 2022.09.09-eb3d185e
<!-- Check if these values are correct -->
**How did you install SearXNG?**
<!-- Did you install SearXNG using the official wiki or using searxng-docker
or manually by executing the searx/webapp.py file? -->
**What happened?**
<!-- A clear and concise description of what the bug is. -->
installed via docker / when running a search, duck duck go is sending an access denied error. this did not happen before
**How To Reproduce**
<!-- How can we reproduce this issue? (as minimally and as precisely as possible) -->
**Expected behavior**
<!-- A clear and concise description of what you expected to happen. -->
**Screenshots & Logs**
<!-- If applicable, add screenshots, logs to help explain your problem. -->
**Additional context**
<!-- Add any other context about the problem here. -->
**Technical report**
Error
* Error: httpx.ReadTimeout
* Percentage: 0
* Parameters: `(None, None, 'lite.duckduckgo.com')`
* File name: `searx/search/processors/online.py:107`
* Function: `_send_http_request`
* Code: `response = req(params['url'], **request_args)`
Error
* Error: searx.exceptions.SearxEngineAccessDeniedException
* Percentage: 0
* Parameters: `('HTTP error 403',)`
* File name: `searx/search/processors/online.py:107`
* Function: `_send_http_request`
* Code: `response = req(params['url'], **request_args)`
Bug: duckduckgo engine
**Version of SearXNG, commit number if you are using on master branch and stipulate if you forked SearXNG**
Repository: https://github.com/searxng/searxng
Branch: master
Version: 2022.09.09-eb3d185e
<!-- Check if these values are correct -->
**How did you install SearXNG?**
<!-- Did you install SearXNG using the official wiki or using searxng-docker
or manually by executing the searx/webapp.py file? -->
**What happened?**
<!-- A clear and concise description of what the bug is. -->
installed via docker / when running a search, duck duck go is sending an access denied error. this did not happen before
**How To Reproduce**
<!-- How can we reproduce this issue? (as minimally and as precisely as possible) -->
**Expected behavior**
<!-- A clear and concise description of what you expected to happen. -->
**Screenshots & Logs**
<!-- If applicable, add screenshots, logs to help explain your problem. -->
**Additional context**
<!-- Add any other context about the problem here. -->
**Technical report**
Error
* Error: httpx.ReadTimeout
* Percentage: 0
* Parameters: `(None, None, 'lite.duckduckgo.com')`
* File name: `searx/search/processors/online.py:107`
* Function: `_send_http_request`
* Code: `response = req(params['url'], **request_args)`
Error
* Error: searx.exceptions.SearxEngineAccessDeniedException
* Percentage: 0
* Parameters: `('HTTP error 403',)`
* File name: `searx/search/processors/online.py:107`
* Function: `_send_http_request`
* Code: `response = req(params['url'], **request_args)`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `searx/engines/duckduckgo.py`
Content:
```
1 # SPDX-License-Identifier: AGPL-3.0-or-later
2 # lint: pylint
3 """DuckDuckGo Lite
4 """
5
6 from json import loads
7
8 from lxml.html import fromstring
9
10 from searx.utils import (
11 dict_subset,
12 eval_xpath,
13 eval_xpath_getindex,
14 extract_text,
15 match_language,
16 )
17 from searx.network import get
18
19 # about
20 about = {
21 "website": 'https://lite.duckduckgo.com/lite',
22 "wikidata_id": 'Q12805',
23 "official_api_documentation": 'https://duckduckgo.com/api',
24 "use_official_api": False,
25 "require_api_key": False,
26 "results": 'HTML',
27 }
28
29 # engine dependent config
30 categories = ['general', 'web']
31 paging = True
32 supported_languages_url = 'https://duckduckgo.com/util/u588.js'
33 time_range_support = True
34 send_accept_language_header = True
35
36 language_aliases = {
37 'ar-SA': 'ar-XA',
38 'es-419': 'es-XL',
39 'ja': 'jp-JP',
40 'ko': 'kr-KR',
41 'sl-SI': 'sl-SL',
42 'zh-TW': 'tzh-TW',
43 'zh-HK': 'tzh-HK',
44 }
45
46 time_range_dict = {'day': 'd', 'week': 'w', 'month': 'm', 'year': 'y'}
47
48 # search-url
49 url = 'https://lite.duckduckgo.com/lite'
50 url_ping = 'https://duckduckgo.com/t/sl_l'
51
52 # match query's language to a region code that duckduckgo will accept
53 def get_region_code(lang, lang_list=None):
54 if lang == 'all':
55 return None
56
57 lang_code = match_language(lang, lang_list or [], language_aliases, 'wt-WT')
58 lang_parts = lang_code.split('-')
59
60 # country code goes first
61 return lang_parts[1].lower() + '-' + lang_parts[0].lower()
62
63
64 def request(query, params):
65
66 params['url'] = url
67 params['method'] = 'POST'
68
69 params['data']['q'] = query
70
71 # The API is not documented, so we do some reverse engineering and emulate
72 # what https://lite.duckduckgo.com/lite/ does when you press "next Page"
73 # link again and again ..
74
75 params['headers']['Content-Type'] = 'application/x-www-form-urlencoded'
76
77 # initial page does not have an offset
78 if params['pageno'] == 2:
79 # second page does have an offset of 30
80 offset = (params['pageno'] - 1) * 30
81 params['data']['s'] = offset
82 params['data']['dc'] = offset + 1
83
84 elif params['pageno'] > 2:
85 # third and following pages do have an offset of 30 + n*50
86 offset = 30 + (params['pageno'] - 2) * 50
87 params['data']['s'] = offset
88 params['data']['dc'] = offset + 1
89
90 # initial page does not have additional data in the input form
91 if params['pageno'] > 1:
92 # request the second page (and more pages) needs 'o' and 'api' arguments
93 params['data']['o'] = 'json'
94 params['data']['api'] = 'd.js'
95
96 # initial page does not have additional data in the input form
97 if params['pageno'] > 2:
98 # request the third page (and more pages) some more arguments
99 params['data']['nextParams'] = ''
100 params['data']['v'] = ''
101 params['data']['vqd'] = ''
102
103 region_code = get_region_code(params['language'], supported_languages)
104 if region_code:
105 params['data']['kl'] = region_code
106 params['cookies']['kl'] = region_code
107
108 params['data']['df'] = ''
109 if params['time_range'] in time_range_dict:
110 params['data']['df'] = time_range_dict[params['time_range']]
111 params['cookies']['df'] = time_range_dict[params['time_range']]
112
113 logger.debug("param data: %s", params['data'])
114 logger.debug("param cookies: %s", params['cookies'])
115 return params
116
117
118 # get response from search-request
119 def response(resp):
120
121 headers_ping = dict_subset(resp.request.headers, ['User-Agent', 'Accept-Encoding', 'Accept', 'Cookie'])
122 get(url_ping, headers=headers_ping)
123
124 if resp.status_code == 303:
125 return []
126
127 results = []
128 doc = fromstring(resp.text)
129
130 result_table = eval_xpath(doc, '//html/body/form/div[@class="filters"]/table')
131 if not len(result_table) >= 3:
132 # no more results
133 return []
134 result_table = result_table[2]
135
136 tr_rows = eval_xpath(result_table, './/tr')
137
138 # In the last <tr> is the form of the 'previous/next page' links
139 tr_rows = tr_rows[:-1]
140
141 len_tr_rows = len(tr_rows)
142 offset = 0
143
144 while len_tr_rows >= offset + 4:
145
146 # assemble table rows we need to scrap
147 tr_title = tr_rows[offset]
148 tr_content = tr_rows[offset + 1]
149 offset += 4
150
151 # ignore sponsored Adds <tr class="result-sponsored">
152 if tr_content.get('class') == 'result-sponsored':
153 continue
154
155 a_tag = eval_xpath_getindex(tr_title, './/td//a[@class="result-link"]', 0, None)
156 if a_tag is None:
157 continue
158
159 td_content = eval_xpath_getindex(tr_content, './/td[@class="result-snippet"]', 0, None)
160 if td_content is None:
161 continue
162
163 results.append(
164 {
165 'title': a_tag.text_content(),
166 'content': extract_text(td_content),
167 'url': a_tag.get('href'),
168 }
169 )
170
171 return results
172
173
174 # get supported languages from their site
175 def _fetch_supported_languages(resp):
176
177 # response is a js file with regions as an embedded object
178 response_page = resp.text
179 response_page = response_page[response_page.find('regions:{') + 8 :]
180 response_page = response_page[: response_page.find('}') + 1]
181
182 regions_json = loads(response_page)
183 supported_languages = map((lambda x: x[3:] + '-' + x[:2].upper()), regions_json.keys())
184
185 return list(supported_languages)
186
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/searx/engines/duckduckgo.py b/searx/engines/duckduckgo.py
--- a/searx/engines/duckduckgo.py
+++ b/searx/engines/duckduckgo.py
@@ -18,7 +18,7 @@
# about
about = {
- "website": 'https://lite.duckduckgo.com/lite',
+ "website": 'https://lite.duckduckgo.com/lite/',
"wikidata_id": 'Q12805',
"official_api_documentation": 'https://duckduckgo.com/api',
"use_official_api": False,
@@ -46,7 +46,7 @@
time_range_dict = {'day': 'd', 'week': 'w', 'month': 'm', 'year': 'y'}
# search-url
-url = 'https://lite.duckduckgo.com/lite'
+url = 'https://lite.duckduckgo.com/lite/'
url_ping = 'https://duckduckgo.com/t/sl_l'
# match query's language to a region code that duckduckgo will accept
|
{"golden_diff": "diff --git a/searx/engines/duckduckgo.py b/searx/engines/duckduckgo.py\n--- a/searx/engines/duckduckgo.py\n+++ b/searx/engines/duckduckgo.py\n@@ -18,7 +18,7 @@\n \n # about\n about = {\n- \"website\": 'https://lite.duckduckgo.com/lite',\n+ \"website\": 'https://lite.duckduckgo.com/lite/',\n \"wikidata_id\": 'Q12805',\n \"official_api_documentation\": 'https://duckduckgo.com/api',\n \"use_official_api\": False,\n@@ -46,7 +46,7 @@\n time_range_dict = {'day': 'd', 'week': 'w', 'month': 'm', 'year': 'y'}\n \n # search-url\n-url = 'https://lite.duckduckgo.com/lite'\n+url = 'https://lite.duckduckgo.com/lite/'\n url_ping = 'https://duckduckgo.com/t/sl_l'\n \n # match query's language to a region code that duckduckgo will accept\n", "issue": "Bug: duckduckgo engine\n**Version of SearXNG, commit number if you are using on master branch and stipulate if you forked SearXNG**\r\nRepository: https://github.com/searxng/searxng\r\nBranch: master\r\nVersion: 2022.09.09-eb3d185e\r\n<!-- Check if these values are correct -->\r\n\r\n**How did you install SearXNG?**\r\n<!-- Did you install SearXNG using the official wiki or using searxng-docker\r\nor manually by executing the searx/webapp.py file? -->\r\n**What happened?**\r\n<!-- A clear and concise description of what the bug is. -->\r\ninstalled via docker / when running a search, duck duck go is sending an access denied error. this did not happen before\r\n**How To Reproduce**\r\n<!-- How can we reproduce this issue? (as minimally and as precisely as possible) -->\r\n\r\n**Expected behavior**\r\n<!-- A clear and concise description of what you expected to happen. -->\r\n\r\n**Screenshots & Logs**\r\n<!-- If applicable, add screenshots, logs to help explain your problem. -->\r\n\r\n**Additional context**\r\n<!-- Add any other context about the problem here. -->\r\n\r\n**Technical report**\r\n\r\nError\r\n * Error: httpx.ReadTimeout\r\n * Percentage: 0\r\n * Parameters: `(None, None, 'lite.duckduckgo.com')`\r\n * File name: `searx/search/processors/online.py:107`\r\n * Function: `_send_http_request`\r\n * Code: `response = req(params['url'], **request_args)`\r\n\r\nError\r\n * Error: searx.exceptions.SearxEngineAccessDeniedException\r\n * Percentage: 0\r\n * Parameters: `('HTTP error 403',)`\r\n * File name: `searx/search/processors/online.py:107`\r\n * Function: `_send_http_request`\r\n * Code: `response = req(params['url'], **request_args)`\r\n\r\n\nBug: duckduckgo engine\n**Version of SearXNG, commit number if you are using on master branch and stipulate if you forked SearXNG**\r\nRepository: https://github.com/searxng/searxng\r\nBranch: master\r\nVersion: 2022.09.09-eb3d185e\r\n<!-- Check if these values are correct -->\r\n\r\n**How did you install SearXNG?**\r\n<!-- Did you install SearXNG using the official wiki or using searxng-docker\r\nor manually by executing the searx/webapp.py file? -->\r\n**What happened?**\r\n<!-- A clear and concise description of what the bug is. -->\r\ninstalled via docker / when running a search, duck duck go is sending an access denied error. this did not happen before\r\n**How To Reproduce**\r\n<!-- How can we reproduce this issue? (as minimally and as precisely as possible) -->\r\n\r\n**Expected behavior**\r\n<!-- A clear and concise description of what you expected to happen. -->\r\n\r\n**Screenshots & Logs**\r\n<!-- If applicable, add screenshots, logs to help explain your problem. -->\r\n\r\n**Additional context**\r\n<!-- Add any other context about the problem here. -->\r\n\r\n**Technical report**\r\n\r\nError\r\n * Error: httpx.ReadTimeout\r\n * Percentage: 0\r\n * Parameters: `(None, None, 'lite.duckduckgo.com')`\r\n * File name: `searx/search/processors/online.py:107`\r\n * Function: `_send_http_request`\r\n * Code: `response = req(params['url'], **request_args)`\r\n\r\nError\r\n * Error: searx.exceptions.SearxEngineAccessDeniedException\r\n * Percentage: 0\r\n * Parameters: `('HTTP error 403',)`\r\n * File name: `searx/search/processors/online.py:107`\r\n * Function: `_send_http_request`\r\n * Code: `response = req(params['url'], **request_args)`\r\n\r\n\n", "before_files": [{"content": "# SPDX-License-Identifier: AGPL-3.0-or-later\n# lint: pylint\n\"\"\"DuckDuckGo Lite\n\"\"\"\n\nfrom json import loads\n\nfrom lxml.html import fromstring\n\nfrom searx.utils import (\n dict_subset,\n eval_xpath,\n eval_xpath_getindex,\n extract_text,\n match_language,\n)\nfrom searx.network import get\n\n# about\nabout = {\n \"website\": 'https://lite.duckduckgo.com/lite',\n \"wikidata_id\": 'Q12805',\n \"official_api_documentation\": 'https://duckduckgo.com/api',\n \"use_official_api\": False,\n \"require_api_key\": False,\n \"results\": 'HTML',\n}\n\n# engine dependent config\ncategories = ['general', 'web']\npaging = True\nsupported_languages_url = 'https://duckduckgo.com/util/u588.js'\ntime_range_support = True\nsend_accept_language_header = True\n\nlanguage_aliases = {\n 'ar-SA': 'ar-XA',\n 'es-419': 'es-XL',\n 'ja': 'jp-JP',\n 'ko': 'kr-KR',\n 'sl-SI': 'sl-SL',\n 'zh-TW': 'tzh-TW',\n 'zh-HK': 'tzh-HK',\n}\n\ntime_range_dict = {'day': 'd', 'week': 'w', 'month': 'm', 'year': 'y'}\n\n# search-url\nurl = 'https://lite.duckduckgo.com/lite'\nurl_ping = 'https://duckduckgo.com/t/sl_l'\n\n# match query's language to a region code that duckduckgo will accept\ndef get_region_code(lang, lang_list=None):\n if lang == 'all':\n return None\n\n lang_code = match_language(lang, lang_list or [], language_aliases, 'wt-WT')\n lang_parts = lang_code.split('-')\n\n # country code goes first\n return lang_parts[1].lower() + '-' + lang_parts[0].lower()\n\n\ndef request(query, params):\n\n params['url'] = url\n params['method'] = 'POST'\n\n params['data']['q'] = query\n\n # The API is not documented, so we do some reverse engineering and emulate\n # what https://lite.duckduckgo.com/lite/ does when you press \"next Page\"\n # link again and again ..\n\n params['headers']['Content-Type'] = 'application/x-www-form-urlencoded'\n\n # initial page does not have an offset\n if params['pageno'] == 2:\n # second page does have an offset of 30\n offset = (params['pageno'] - 1) * 30\n params['data']['s'] = offset\n params['data']['dc'] = offset + 1\n\n elif params['pageno'] > 2:\n # third and following pages do have an offset of 30 + n*50\n offset = 30 + (params['pageno'] - 2) * 50\n params['data']['s'] = offset\n params['data']['dc'] = offset + 1\n\n # initial page does not have additional data in the input form\n if params['pageno'] > 1:\n # request the second page (and more pages) needs 'o' and 'api' arguments\n params['data']['o'] = 'json'\n params['data']['api'] = 'd.js'\n\n # initial page does not have additional data in the input form\n if params['pageno'] > 2:\n # request the third page (and more pages) some more arguments\n params['data']['nextParams'] = ''\n params['data']['v'] = ''\n params['data']['vqd'] = ''\n\n region_code = get_region_code(params['language'], supported_languages)\n if region_code:\n params['data']['kl'] = region_code\n params['cookies']['kl'] = region_code\n\n params['data']['df'] = ''\n if params['time_range'] in time_range_dict:\n params['data']['df'] = time_range_dict[params['time_range']]\n params['cookies']['df'] = time_range_dict[params['time_range']]\n\n logger.debug(\"param data: %s\", params['data'])\n logger.debug(\"param cookies: %s\", params['cookies'])\n return params\n\n\n# get response from search-request\ndef response(resp):\n\n headers_ping = dict_subset(resp.request.headers, ['User-Agent', 'Accept-Encoding', 'Accept', 'Cookie'])\n get(url_ping, headers=headers_ping)\n\n if resp.status_code == 303:\n return []\n\n results = []\n doc = fromstring(resp.text)\n\n result_table = eval_xpath(doc, '//html/body/form/div[@class=\"filters\"]/table')\n if not len(result_table) >= 3:\n # no more results\n return []\n result_table = result_table[2]\n\n tr_rows = eval_xpath(result_table, './/tr')\n\n # In the last <tr> is the form of the 'previous/next page' links\n tr_rows = tr_rows[:-1]\n\n len_tr_rows = len(tr_rows)\n offset = 0\n\n while len_tr_rows >= offset + 4:\n\n # assemble table rows we need to scrap\n tr_title = tr_rows[offset]\n tr_content = tr_rows[offset + 1]\n offset += 4\n\n # ignore sponsored Adds <tr class=\"result-sponsored\">\n if tr_content.get('class') == 'result-sponsored':\n continue\n\n a_tag = eval_xpath_getindex(tr_title, './/td//a[@class=\"result-link\"]', 0, None)\n if a_tag is None:\n continue\n\n td_content = eval_xpath_getindex(tr_content, './/td[@class=\"result-snippet\"]', 0, None)\n if td_content is None:\n continue\n\n results.append(\n {\n 'title': a_tag.text_content(),\n 'content': extract_text(td_content),\n 'url': a_tag.get('href'),\n }\n )\n\n return results\n\n\n# get supported languages from their site\ndef _fetch_supported_languages(resp):\n\n # response is a js file with regions as an embedded object\n response_page = resp.text\n response_page = response_page[response_page.find('regions:{') + 8 :]\n response_page = response_page[: response_page.find('}') + 1]\n\n regions_json = loads(response_page)\n supported_languages = map((lambda x: x[3:] + '-' + x[:2].upper()), regions_json.keys())\n\n return list(supported_languages)\n", "path": "searx/engines/duckduckgo.py"}], "after_files": [{"content": "# SPDX-License-Identifier: AGPL-3.0-or-later\n# lint: pylint\n\"\"\"DuckDuckGo Lite\n\"\"\"\n\nfrom json import loads\n\nfrom lxml.html import fromstring\n\nfrom searx.utils import (\n dict_subset,\n eval_xpath,\n eval_xpath_getindex,\n extract_text,\n match_language,\n)\nfrom searx.network import get\n\n# about\nabout = {\n \"website\": 'https://lite.duckduckgo.com/lite/',\n \"wikidata_id\": 'Q12805',\n \"official_api_documentation\": 'https://duckduckgo.com/api',\n \"use_official_api\": False,\n \"require_api_key\": False,\n \"results\": 'HTML',\n}\n\n# engine dependent config\ncategories = ['general', 'web']\npaging = True\nsupported_languages_url = 'https://duckduckgo.com/util/u588.js'\ntime_range_support = True\nsend_accept_language_header = True\n\nlanguage_aliases = {\n 'ar-SA': 'ar-XA',\n 'es-419': 'es-XL',\n 'ja': 'jp-JP',\n 'ko': 'kr-KR',\n 'sl-SI': 'sl-SL',\n 'zh-TW': 'tzh-TW',\n 'zh-HK': 'tzh-HK',\n}\n\ntime_range_dict = {'day': 'd', 'week': 'w', 'month': 'm', 'year': 'y'}\n\n# search-url\nurl = 'https://lite.duckduckgo.com/lite/'\nurl_ping = 'https://duckduckgo.com/t/sl_l'\n\n# match query's language to a region code that duckduckgo will accept\ndef get_region_code(lang, lang_list=None):\n if lang == 'all':\n return None\n\n lang_code = match_language(lang, lang_list or [], language_aliases, 'wt-WT')\n lang_parts = lang_code.split('-')\n\n # country code goes first\n return lang_parts[1].lower() + '-' + lang_parts[0].lower()\n\n\ndef request(query, params):\n\n params['url'] = url\n params['method'] = 'POST'\n\n params['data']['q'] = query\n\n # The API is not documented, so we do some reverse engineering and emulate\n # what https://lite.duckduckgo.com/lite/ does when you press \"next Page\"\n # link again and again ..\n\n params['headers']['Content-Type'] = 'application/x-www-form-urlencoded'\n\n # initial page does not have an offset\n if params['pageno'] == 2:\n # second page does have an offset of 30\n offset = (params['pageno'] - 1) * 30\n params['data']['s'] = offset\n params['data']['dc'] = offset + 1\n\n elif params['pageno'] > 2:\n # third and following pages do have an offset of 30 + n*50\n offset = 30 + (params['pageno'] - 2) * 50\n params['data']['s'] = offset\n params['data']['dc'] = offset + 1\n\n # initial page does not have additional data in the input form\n if params['pageno'] > 1:\n # request the second page (and more pages) needs 'o' and 'api' arguments\n params['data']['o'] = 'json'\n params['data']['api'] = 'd.js'\n\n # initial page does not have additional data in the input form\n if params['pageno'] > 2:\n # request the third page (and more pages) some more arguments\n params['data']['nextParams'] = ''\n params['data']['v'] = ''\n params['data']['vqd'] = ''\n\n region_code = get_region_code(params['language'], supported_languages)\n if region_code:\n params['data']['kl'] = region_code\n params['cookies']['kl'] = region_code\n\n params['data']['df'] = ''\n if params['time_range'] in time_range_dict:\n params['data']['df'] = time_range_dict[params['time_range']]\n params['cookies']['df'] = time_range_dict[params['time_range']]\n\n logger.debug(\"param data: %s\", params['data'])\n logger.debug(\"param cookies: %s\", params['cookies'])\n return params\n\n\n# get response from search-request\ndef response(resp):\n\n headers_ping = dict_subset(resp.request.headers, ['User-Agent', 'Accept-Encoding', 'Accept', 'Cookie'])\n get(url_ping, headers=headers_ping)\n\n if resp.status_code == 303:\n return []\n\n results = []\n doc = fromstring(resp.text)\n\n result_table = eval_xpath(doc, '//html/body/form/div[@class=\"filters\"]/table')\n if not len(result_table) >= 3:\n # no more results\n return []\n result_table = result_table[2]\n\n tr_rows = eval_xpath(result_table, './/tr')\n\n # In the last <tr> is the form of the 'previous/next page' links\n tr_rows = tr_rows[:-1]\n\n len_tr_rows = len(tr_rows)\n offset = 0\n\n while len_tr_rows >= offset + 4:\n\n # assemble table rows we need to scrap\n tr_title = tr_rows[offset]\n tr_content = tr_rows[offset + 1]\n offset += 4\n\n # ignore sponsored Adds <tr class=\"result-sponsored\">\n if tr_content.get('class') == 'result-sponsored':\n continue\n\n a_tag = eval_xpath_getindex(tr_title, './/td//a[@class=\"result-link\"]', 0, None)\n if a_tag is None:\n continue\n\n td_content = eval_xpath_getindex(tr_content, './/td[@class=\"result-snippet\"]', 0, None)\n if td_content is None:\n continue\n\n results.append(\n {\n 'title': a_tag.text_content(),\n 'content': extract_text(td_content),\n 'url': a_tag.get('href'),\n }\n )\n\n return results\n\n\n# get supported languages from their site\ndef _fetch_supported_languages(resp):\n\n # response is a js file with regions as an embedded object\n response_page = resp.text\n response_page = response_page[response_page.find('regions:{') + 8 :]\n response_page = response_page[: response_page.find('}') + 1]\n\n regions_json = loads(response_page)\n supported_languages = map((lambda x: x[3:] + '-' + x[:2].upper()), regions_json.keys())\n\n return list(supported_languages)\n", "path": "searx/engines/duckduckgo.py"}]}
| 3,043 | 253 |
gh_patches_debug_28587
|
rasdani/github-patches
|
git_diff
|
PlasmaPy__PlasmaPy-138
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Check consistency of argument ordering in physics
Here are a few example signatures straight from `physics.transport`:
```
def Coulomb_logarithm(n_e, T, particles, V=None):
def Debye_length(T_e, n_e):
def Debye_number(T_e, n_e):
def upper_hybrid_frequency(B, n_e):
```
It would be nice to ensure that non-keyword arguments, where applicable, have the same ordering - like in other scientific packages, like Numpy, a consistent API is helpful for being able to call multiple functions without having to check the signature each time you call them.
Any consistent ordering would be welcome - but common sense takes precedence.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `plasmapy/physics/transport.py`
Content:
```
1 """Functions to calculate transport coefficients."""
2
3 from astropy import units
4 import numpy as np
5 from ..utils import check_quantity, _check_relativistic
6 from ..constants import (m_p, m_e, c, mu0, k_B, e, eps0, pi, h, hbar)
7 from ..atomic import (ion_mass, charge_state)
8 from .parameters import Debye_length
9
10
11 @check_quantity({"n_e": {"units": units.m**-3},
12 "T": {"units": units.K, "can_be_negative": False}
13 })
14 def Coulomb_logarithm(n_e, T, particles, V=None):
15 r"""Estimates the Coulomb logarithm.
16
17 Parameters
18 ----------
19 n_e : Quantity
20 The electron density in units convertible to per cubic meter.
21
22 T : Quantity
23 Temperature in units of temperature or energy per particle,
24 which is assumed to be equal for both the test particle and
25 the target particle
26
27 particles : tuple
28 A tuple containing string representations of the test particle
29 (listed first) and the target particle (listed second)
30
31 V : Quantity, optional
32 The relative velocity between particles. If not provided,
33 thermal velocity is assumed: :math:`\mu V^2 \sim 3 k_B T`
34 where `mu` is the reduced mass.
35
36 Returns
37 -------
38 lnLambda : float or numpy.ndarray
39 An estimate of the Coulomb logarithm that is accurate to
40 roughly its reciprocal.
41
42 Raises
43 ------
44 ValueError
45 If the mass or charge of either particle cannot be found, or
46 any of the inputs contain incorrect values.
47
48 UnitConversionError
49 If the units on any of the inputs are incorrect
50
51 UserWarning
52 If the inputted velocity is greater than 80% of the speed of
53 light.
54
55 TypeError
56 If the n_e, T, or V are not Quantities.
57
58 Notes
59 -----
60 The Coulomb logarithm is given by
61
62 .. math::
63 \ln{\Lambda} \equiv \ln\left( \frac{b_{max}}{b_{min}} \right)
64
65 where :math:`b_{min}` and :math:`b_{max}` are the inner and outer
66 impact parameters for Coulomb collisions _[1].
67
68 The outer impact parameter is given by the Debye length:
69 :math:`b_{min} = \lambda_D` which is a function of electron
70 temperature and electron density. At distances greater than the
71 Debye length, electric fields from other particles will be
72 screened out due to electrons rearranging themselves.
73
74 The choice of inner impact parameter is more controversial. There
75 are two main possibilities. The first possibility is that the
76 inner impact parameter corresponds to a deflection angle of 90
77 degrees. The second possibility is that the inner impact
78 parameter is a de Broglie wavelength, :math:`\lambda_B`
79 corresponding to the reduced mass of the two particles and the
80 relative velocity between collisions. This function uses the
81 standard practice of choosing the inner impact parameter to be the
82 maximum of these two possibilities. Some inconsistencies exist in
83 the literature on how to define the inner impact parameter _[2].
84
85 Errors associated with the Coulomb logarithm are of order its
86 inverse If the Coulomb logarithm is of order unity, then the
87 assumptions made in the standard analysis of Coulomb collisions
88 are invalid.
89
90 Examples
91 --------
92 >>> from astropy import units as u
93 >>> Coulomb_logarithm(T=1e6*units.K, n_e=1e19*units.m**-3, ('e', 'p'))
94 14.748259780491056
95 >>> Coulomb_logarithm(1e6*units.K, 1e19*units.m**-3, ('e', 'p'),
96 V=1e6*u.m/u.s)
97
98 References
99 ----------
100 .. [1] Physics of Fully Ionized Gases, L. Spitzer (1962)
101
102 .. [2] Comparison of Coulomb Collision Rates in the Plasma Physics
103 and Magnetically Confined Fusion Literature, W. Fundamenski and
104 O.E. Garcia, EFDA–JET–R(07)01
105 (http://www.euro-fusionscipub.org/wp-content/uploads/2014/11/EFDR07001.pdf)
106
107 """
108
109 if not isinstance(particles, (list, tuple)) or len(particles) != 2:
110 raise ValueError("The third input of Coulomb_logarithm must be a list "
111 "or tuple containing representations of two charged "
112 "particles.")
113
114 masses = np.zeros(2)*units.kg
115 charges = np.zeros(2)*units.C
116
117 for particle, i in zip(particles, range(2)):
118
119 try:
120 masses[i] = ion_mass(particles[i])
121 except Exception:
122 raise ValueError("Unable to find mass of particle: " +
123 str(particles[i]) + " in Coulomb_logarithm.")
124
125 try:
126 charges[i] = np.abs(e*charge_state(particles[i]))
127 if charges[i] is None:
128 raise
129 except Exception:
130 raise ValueError("Unable to find charge of particle: " +
131 str(particles[i]) + " in Coulomb_logarithm.")
132
133 reduced_mass = masses[0] * masses[1] / (masses[0] + masses[1])
134
135 # The outer impact parameter is the Debye length. At distances
136 # greater than the Debye length, the electrostatic potential of a
137 # single particle is screened out by the electrostatic potentials
138 # of other particles. Past this distance, the electric fields of
139 # individual particles do not affect each other much. This
140 # expression neglects screening by heavier ions.
141
142 T = T.to(units.K, equivalencies=units.temperature_energy())
143
144 b_max = Debye_length(T, n_e)
145
146 # The choice of inner impact parameter is more controversial.
147 # There are two broad possibilities, and the expressions in the
148 # literature often differ by factors of order unity or by
149 # interchanging the reduced mass with the test particle mass.
150
151 # The relative velocity is a source of uncertainty. It is
152 # reasonable to make an assumption relating the thermal energy to
153 # the kinetic energy: reduced_mass*velocity**2 is approximately
154 # equal to 3*k_B*T.
155
156 # If no relative velocity is inputted, then we make an assumption
157 # that relates the thermal energy to the kinetic energy:
158 # reduced_mass*velocity**2 is approximately equal to 3*k_B*T.
159
160 if V is None:
161 V = np.sqrt(3 * k_B * T / reduced_mass)
162 else:
163 _check_relativistic(V, 'Coulomb_logarithm', betafrac=0.8)
164
165 # The first possibility is that the inner impact parameter
166 # corresponds to a deflection of 90 degrees, which is valid when
167 # classical effects dominate.
168
169 b_perp = charges[0] * charges[1] / (4 * pi * eps0 * reduced_mass * V**2)
170
171 # The second possibility is that the inner impact parameter is a
172 # de Broglie wavelength. There remains some ambiguity as to which
173 # mass to choose to go into the de Broglie wavelength calculation.
174 # Here we use the reduced mass, which will be of the same order as
175 # mass of the smaller particle and thus the longer de Broglie
176 # wavelength.
177
178 b_deBroglie = hbar / (2 * reduced_mass * V)
179
180 # Coulomb-style collisions will not happen for impact parameters
181 # shorter than either of these two impact parameters, so we choose
182 # the larger of these two possibilities.
183
184 b_min = np.zeros_like(b_perp)
185
186 for i in range(b_min.size):
187
188 if b_perp.flat[i] > b_deBroglie.flat[i]:
189 b_min.flat[i] = b_perp.flat[i]
190 else:
191 b_min.flat[i] = b_deBroglie.flat[i]
192
193 # Now that we know how many approximations have to go into plasma
194 # transport theory, we shall celebrate by returning the Coulomb
195 # logarithm.
196
197 ln_Lambda = np.log(b_max/b_min)
198 ln_Lambda = ln_Lambda.to(units.dimensionless_unscaled).value
199
200 return ln_Lambda
201
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/plasmapy/physics/transport.py b/plasmapy/physics/transport.py
--- a/plasmapy/physics/transport.py
+++ b/plasmapy/physics/transport.py
@@ -8,21 +8,22 @@
from .parameters import Debye_length
-@check_quantity({"n_e": {"units": units.m**-3},
- "T": {"units": units.K, "can_be_negative": False}
+@check_quantity({"T": {"units": units.K, "can_be_negative": False},
+ "n_e": {"units": units.m**-3}
})
-def Coulomb_logarithm(n_e, T, particles, V=None):
+def Coulomb_logarithm(T, n_e, particles, V=None):
r"""Estimates the Coulomb logarithm.
Parameters
----------
- n_e : Quantity
- The electron density in units convertible to per cubic meter.
T : Quantity
- Temperature in units of temperature or energy per particle,
- which is assumed to be equal for both the test particle and
- the target particle
+ Temperature in units of temperature or energy per particle,
+ which is assumed to be equal for both the test particle and
+ the target particle
+
+ n_e : Quantity
+ The electron density in units convertible to per cubic meter.
particles : tuple
A tuple containing string representations of the test particle
@@ -90,9 +91,9 @@
Examples
--------
>>> from astropy import units as u
- >>> Coulomb_logarithm(T=1e6*units.K, n_e=1e19*units.m**-3, ('e', 'p'))
+ >>> Coulomb_logarithm(T=1e6*u.K, n_e=1e19*u.m**-3, ('e', 'p'))
14.748259780491056
- >>> Coulomb_logarithm(1e6*units.K, 1e19*units.m**-3, ('e', 'p'),
+ >>> Coulomb_logarithm(1e6*u.K, 1e19*u.m**-3, ('e', 'p'),
V=1e6*u.m/u.s)
References
|
{"golden_diff": "diff --git a/plasmapy/physics/transport.py b/plasmapy/physics/transport.py\n--- a/plasmapy/physics/transport.py\n+++ b/plasmapy/physics/transport.py\n@@ -8,21 +8,22 @@\n from .parameters import Debye_length\n \n \n-@check_quantity({\"n_e\": {\"units\": units.m**-3},\n- \"T\": {\"units\": units.K, \"can_be_negative\": False}\n+@check_quantity({\"T\": {\"units\": units.K, \"can_be_negative\": False},\n+ \"n_e\": {\"units\": units.m**-3}\n })\n-def Coulomb_logarithm(n_e, T, particles, V=None):\n+def Coulomb_logarithm(T, n_e, particles, V=None):\n r\"\"\"Estimates the Coulomb logarithm.\n \n Parameters\n ----------\n- n_e : Quantity\n- The electron density in units convertible to per cubic meter.\n \n T : Quantity\n- Temperature in units of temperature or energy per particle,\n- which is assumed to be equal for both the test particle and\n- the target particle\n+ Temperature in units of temperature or energy per particle,\n+ which is assumed to be equal for both the test particle and\n+ the target particle\n+\n+ n_e : Quantity\n+ The electron density in units convertible to per cubic meter.\n \n particles : tuple\n A tuple containing string representations of the test particle\n@@ -90,9 +91,9 @@\n Examples\n --------\n >>> from astropy import units as u\n- >>> Coulomb_logarithm(T=1e6*units.K, n_e=1e19*units.m**-3, ('e', 'p'))\n+ >>> Coulomb_logarithm(T=1e6*u.K, n_e=1e19*u.m**-3, ('e', 'p'))\n 14.748259780491056\n- >>> Coulomb_logarithm(1e6*units.K, 1e19*units.m**-3, ('e', 'p'),\n+ >>> Coulomb_logarithm(1e6*u.K, 1e19*u.m**-3, ('e', 'p'),\n V=1e6*u.m/u.s)\n \n References\n", "issue": "Check consistency of argument ordering in physics\nHere are a few example signatures straight from `physics.transport`:\r\n\r\n```\r\ndef Coulomb_logarithm(n_e, T, particles, V=None):\r\ndef Debye_length(T_e, n_e):\r\ndef Debye_number(T_e, n_e):\r\ndef upper_hybrid_frequency(B, n_e):\r\n```\r\nIt would be nice to ensure that non-keyword arguments, where applicable, have the same ordering - like in other scientific packages, like Numpy, a consistent API is helpful for being able to call multiple functions without having to check the signature each time you call them.\r\n\r\nAny consistent ordering would be welcome - but common sense takes precedence.\n", "before_files": [{"content": "\"\"\"Functions to calculate transport coefficients.\"\"\"\n\nfrom astropy import units\nimport numpy as np\nfrom ..utils import check_quantity, _check_relativistic\nfrom ..constants import (m_p, m_e, c, mu0, k_B, e, eps0, pi, h, hbar)\nfrom ..atomic import (ion_mass, charge_state)\nfrom .parameters import Debye_length\n\n\n@check_quantity({\"n_e\": {\"units\": units.m**-3},\n \"T\": {\"units\": units.K, \"can_be_negative\": False}\n })\ndef Coulomb_logarithm(n_e, T, particles, V=None):\n r\"\"\"Estimates the Coulomb logarithm.\n\n Parameters\n ----------\n n_e : Quantity\n The electron density in units convertible to per cubic meter.\n\n T : Quantity\n Temperature in units of temperature or energy per particle,\n which is assumed to be equal for both the test particle and\n the target particle\n\n particles : tuple\n A tuple containing string representations of the test particle\n (listed first) and the target particle (listed second)\n\n V : Quantity, optional\n The relative velocity between particles. If not provided,\n thermal velocity is assumed: :math:`\\mu V^2 \\sim 3 k_B T`\n where `mu` is the reduced mass.\n\n Returns\n -------\n lnLambda : float or numpy.ndarray\n An estimate of the Coulomb logarithm that is accurate to\n roughly its reciprocal.\n\n Raises\n ------\n ValueError\n If the mass or charge of either particle cannot be found, or\n any of the inputs contain incorrect values.\n\n UnitConversionError\n If the units on any of the inputs are incorrect\n\n UserWarning\n If the inputted velocity is greater than 80% of the speed of\n light.\n\n TypeError\n If the n_e, T, or V are not Quantities.\n\n Notes\n -----\n The Coulomb logarithm is given by\n\n .. math::\n \\ln{\\Lambda} \\equiv \\ln\\left( \\frac{b_{max}}{b_{min}} \\right)\n\n where :math:`b_{min}` and :math:`b_{max}` are the inner and outer\n impact parameters for Coulomb collisions _[1].\n\n The outer impact parameter is given by the Debye length:\n :math:`b_{min} = \\lambda_D` which is a function of electron\n temperature and electron density. At distances greater than the\n Debye length, electric fields from other particles will be\n screened out due to electrons rearranging themselves.\n\n The choice of inner impact parameter is more controversial. There\n are two main possibilities. The first possibility is that the\n inner impact parameter corresponds to a deflection angle of 90\n degrees. The second possibility is that the inner impact\n parameter is a de Broglie wavelength, :math:`\\lambda_B`\n corresponding to the reduced mass of the two particles and the\n relative velocity between collisions. This function uses the\n standard practice of choosing the inner impact parameter to be the\n maximum of these two possibilities. Some inconsistencies exist in\n the literature on how to define the inner impact parameter _[2].\n\n Errors associated with the Coulomb logarithm are of order its\n inverse If the Coulomb logarithm is of order unity, then the\n assumptions made in the standard analysis of Coulomb collisions\n are invalid.\n\n Examples\n --------\n >>> from astropy import units as u\n >>> Coulomb_logarithm(T=1e6*units.K, n_e=1e19*units.m**-3, ('e', 'p'))\n 14.748259780491056\n >>> Coulomb_logarithm(1e6*units.K, 1e19*units.m**-3, ('e', 'p'),\n V=1e6*u.m/u.s)\n\n References\n ----------\n .. [1] Physics of Fully Ionized Gases, L. Spitzer (1962)\n\n .. [2] Comparison of Coulomb Collision Rates in the Plasma Physics\n and Magnetically Confined Fusion Literature, W. Fundamenski and\n O.E. Garcia, EFDA\u2013JET\u2013R(07)01\n (http://www.euro-fusionscipub.org/wp-content/uploads/2014/11/EFDR07001.pdf)\n\n \"\"\"\n\n if not isinstance(particles, (list, tuple)) or len(particles) != 2:\n raise ValueError(\"The third input of Coulomb_logarithm must be a list \"\n \"or tuple containing representations of two charged \"\n \"particles.\")\n\n masses = np.zeros(2)*units.kg\n charges = np.zeros(2)*units.C\n\n for particle, i in zip(particles, range(2)):\n\n try:\n masses[i] = ion_mass(particles[i])\n except Exception:\n raise ValueError(\"Unable to find mass of particle: \" +\n str(particles[i]) + \" in Coulomb_logarithm.\")\n\n try:\n charges[i] = np.abs(e*charge_state(particles[i]))\n if charges[i] is None:\n raise\n except Exception:\n raise ValueError(\"Unable to find charge of particle: \" +\n str(particles[i]) + \" in Coulomb_logarithm.\")\n\n reduced_mass = masses[0] * masses[1] / (masses[0] + masses[1])\n\n # The outer impact parameter is the Debye length. At distances\n # greater than the Debye length, the electrostatic potential of a\n # single particle is screened out by the electrostatic potentials\n # of other particles. Past this distance, the electric fields of\n # individual particles do not affect each other much. This\n # expression neglects screening by heavier ions.\n\n T = T.to(units.K, equivalencies=units.temperature_energy())\n\n b_max = Debye_length(T, n_e)\n\n # The choice of inner impact parameter is more controversial.\n # There are two broad possibilities, and the expressions in the\n # literature often differ by factors of order unity or by\n # interchanging the reduced mass with the test particle mass.\n\n # The relative velocity is a source of uncertainty. It is\n # reasonable to make an assumption relating the thermal energy to\n # the kinetic energy: reduced_mass*velocity**2 is approximately\n # equal to 3*k_B*T.\n\n # If no relative velocity is inputted, then we make an assumption\n # that relates the thermal energy to the kinetic energy:\n # reduced_mass*velocity**2 is approximately equal to 3*k_B*T.\n\n if V is None:\n V = np.sqrt(3 * k_B * T / reduced_mass)\n else:\n _check_relativistic(V, 'Coulomb_logarithm', betafrac=0.8)\n\n # The first possibility is that the inner impact parameter\n # corresponds to a deflection of 90 degrees, which is valid when\n # classical effects dominate.\n\n b_perp = charges[0] * charges[1] / (4 * pi * eps0 * reduced_mass * V**2)\n\n # The second possibility is that the inner impact parameter is a\n # de Broglie wavelength. There remains some ambiguity as to which\n # mass to choose to go into the de Broglie wavelength calculation.\n # Here we use the reduced mass, which will be of the same order as\n # mass of the smaller particle and thus the longer de Broglie\n # wavelength.\n\n b_deBroglie = hbar / (2 * reduced_mass * V)\n\n # Coulomb-style collisions will not happen for impact parameters\n # shorter than either of these two impact parameters, so we choose\n # the larger of these two possibilities.\n\n b_min = np.zeros_like(b_perp)\n\n for i in range(b_min.size):\n\n if b_perp.flat[i] > b_deBroglie.flat[i]:\n b_min.flat[i] = b_perp.flat[i]\n else:\n b_min.flat[i] = b_deBroglie.flat[i]\n\n # Now that we know how many approximations have to go into plasma\n # transport theory, we shall celebrate by returning the Coulomb\n # logarithm.\n\n ln_Lambda = np.log(b_max/b_min)\n ln_Lambda = ln_Lambda.to(units.dimensionless_unscaled).value\n\n return ln_Lambda\n", "path": "plasmapy/physics/transport.py"}], "after_files": [{"content": "\"\"\"Functions to calculate transport coefficients.\"\"\"\n\nfrom astropy import units\nimport numpy as np\nfrom ..utils import check_quantity, _check_relativistic\nfrom ..constants import (m_p, m_e, c, mu0, k_B, e, eps0, pi, h, hbar)\nfrom ..atomic import (ion_mass, charge_state)\nfrom .parameters import Debye_length\n\n\n@check_quantity({\"T\": {\"units\": units.K, \"can_be_negative\": False},\n \"n_e\": {\"units\": units.m**-3}\n })\ndef Coulomb_logarithm(T, n_e, particles, V=None):\n r\"\"\"Estimates the Coulomb logarithm.\n\n Parameters\n ----------\n\n T : Quantity\n Temperature in units of temperature or energy per particle,\n which is assumed to be equal for both the test particle and\n the target particle\n\n n_e : Quantity\n The electron density in units convertible to per cubic meter.\n\n particles : tuple\n A tuple containing string representations of the test particle\n (listed first) and the target particle (listed second)\n\n V : Quantity, optional\n The relative velocity between particles. If not provided,\n thermal velocity is assumed: :math:`\\mu V^2 \\sim 3 k_B T`\n where `mu` is the reduced mass.\n\n Returns\n -------\n lnLambda : float or numpy.ndarray\n An estimate of the Coulomb logarithm that is accurate to\n roughly its reciprocal.\n\n Raises\n ------\n ValueError\n If the mass or charge of either particle cannot be found, or\n any of the inputs contain incorrect values.\n\n UnitConversionError\n If the units on any of the inputs are incorrect\n\n UserWarning\n If the inputted velocity is greater than 80% of the speed of\n light.\n\n TypeError\n If the n_e, T, or V are not Quantities.\n\n Notes\n -----\n The Coulomb logarithm is given by\n\n .. math::\n \\ln{\\Lambda} \\equiv \\ln\\left( \\frac{b_{max}}{b_{min}} \\right)\n\n where :math:`b_{min}` and :math:`b_{max}` are the inner and outer\n impact parameters for Coulomb collisions _[1].\n\n The outer impact parameter is given by the Debye length:\n :math:`b_{min} = \\lambda_D` which is a function of electron\n temperature and electron density. At distances greater than the\n Debye length, electric fields from other particles will be\n screened out due to electrons rearranging themselves.\n\n The choice of inner impact parameter is more controversial. There\n are two main possibilities. The first possibility is that the\n inner impact parameter corresponds to a deflection angle of 90\n degrees. The second possibility is that the inner impact\n parameter is a de Broglie wavelength, :math:`\\lambda_B`\n corresponding to the reduced mass of the two particles and the\n relative velocity between collisions. This function uses the\n standard practice of choosing the inner impact parameter to be the\n maximum of these two possibilities. Some inconsistencies exist in\n the literature on how to define the inner impact parameter _[2].\n\n Errors associated with the Coulomb logarithm are of order its\n inverse If the Coulomb logarithm is of order unity, then the\n assumptions made in the standard analysis of Coulomb collisions\n are invalid.\n\n Examples\n --------\n >>> from astropy import units as u\n >>> Coulomb_logarithm(T=1e6*u.K, n_e=1e19*u.m**-3, ('e', 'p'))\n 14.748259780491056\n >>> Coulomb_logarithm(1e6*u.K, 1e19*u.m**-3, ('e', 'p'),\n V=1e6*u.m/u.s)\n\n References\n ----------\n .. [1] Physics of Fully Ionized Gases, L. Spitzer (1962)\n\n .. [2] Comparison of Coulomb Collision Rates in the Plasma Physics\n and Magnetically Confined Fusion Literature, W. Fundamenski and\n O.E. Garcia, EFDA\u2013JET\u2013R(07)01\n (http://www.euro-fusionscipub.org/wp-content/uploads/2014/11/EFDR07001.pdf)\n\n \"\"\"\n\n if not isinstance(particles, (list, tuple)) or len(particles) != 2:\n raise ValueError(\"The third input of Coulomb_logarithm must be a list \"\n \"or tuple containing representations of two charged \"\n \"particles.\")\n\n masses = np.zeros(2)*units.kg\n charges = np.zeros(2)*units.C\n\n for particle, i in zip(particles, range(2)):\n\n try:\n masses[i] = ion_mass(particles[i])\n except Exception:\n raise ValueError(\"Unable to find mass of particle: \" +\n str(particles[i]) + \" in Coulomb_logarithm.\")\n\n try:\n charges[i] = np.abs(e*charge_state(particles[i]))\n if charges[i] is None:\n raise\n except Exception:\n raise ValueError(\"Unable to find charge of particle: \" +\n str(particles[i]) + \" in Coulomb_logarithm.\")\n\n reduced_mass = masses[0] * masses[1] / (masses[0] + masses[1])\n\n # The outer impact parameter is the Debye length. At distances\n # greater than the Debye length, the electrostatic potential of a\n # single particle is screened out by the electrostatic potentials\n # of other particles. Past this distance, the electric fields of\n # individual particles do not affect each other much. This\n # expression neglects screening by heavier ions.\n\n T = T.to(units.K, equivalencies=units.temperature_energy())\n\n b_max = Debye_length(T, n_e)\n\n # The choice of inner impact parameter is more controversial.\n # There are two broad possibilities, and the expressions in the\n # literature often differ by factors of order unity or by\n # interchanging the reduced mass with the test particle mass.\n\n # The relative velocity is a source of uncertainty. It is\n # reasonable to make an assumption relating the thermal energy to\n # the kinetic energy: reduced_mass*velocity**2 is approximately\n # equal to 3*k_B*T.\n\n # If no relative velocity is inputted, then we make an assumption\n # that relates the thermal energy to the kinetic energy:\n # reduced_mass*velocity**2 is approximately equal to 3*k_B*T.\n\n if V is None:\n V = np.sqrt(3 * k_B * T / reduced_mass)\n else:\n _check_relativistic(V, 'Coulomb_logarithm', betafrac=0.8)\n\n # The first possibility is that the inner impact parameter\n # corresponds to a deflection of 90 degrees, which is valid when\n # classical effects dominate.\n\n b_perp = charges[0] * charges[1] / (4 * pi * eps0 * reduced_mass * V**2)\n\n # The second possibility is that the inner impact parameter is a\n # de Broglie wavelength. There remains some ambiguity as to which\n # mass to choose to go into the de Broglie wavelength calculation.\n # Here we use the reduced mass, which will be of the same order as\n # mass of the smaller particle and thus the longer de Broglie\n # wavelength.\n\n b_deBroglie = hbar / (2 * reduced_mass * V)\n\n # Coulomb-style collisions will not happen for impact parameters\n # shorter than either of these two impact parameters, so we choose\n # the larger of these two possibilities.\n\n b_min = np.zeros_like(b_perp)\n\n for i in range(b_min.size):\n\n if b_perp.flat[i] > b_deBroglie.flat[i]:\n b_min.flat[i] = b_perp.flat[i]\n else:\n b_min.flat[i] = b_deBroglie.flat[i]\n\n # Now that we know how many approximations have to go into plasma\n # transport theory, we shall celebrate by returning the Coulomb\n # logarithm.\n\n ln_Lambda = np.log(b_max/b_min)\n ln_Lambda = ln_Lambda.to(units.dimensionless_unscaled).value\n\n return ln_Lambda\n", "path": "plasmapy/physics/transport.py"}]}
| 2,794 | 522 |
gh_patches_debug_26936
|
rasdani/github-patches
|
git_diff
|
kartoza__prj.app-435
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
500 on bad certificate number
# Problem
When I try and add a bad certificate number, then I get a 500, I should get a 404.
See:
http://staging.changelog.qgis.org/en/qgis/certificate/0246242/
# Proposed Solution
Return a 404
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `django_project/certification/views/certificate.py`
Content:
```
1 # coding=utf-8
2 from django.http import Http404
3 from django.views.generic import CreateView, DetailView
4 from django.core.urlresolvers import reverse
5 from braces.views import LoginRequiredMixin
6 from ..models import Certificate, Course, Attendee
7 from ..forms import CertificateForm
8
9
10 class CertificateMixin(object):
11 """Mixin class to provide standard settings for Certificate."""
12
13 model = Certificate
14 form_class = CertificateForm
15
16
17 class CertificateCreateView(
18 LoginRequiredMixin, CertificateMixin, CreateView):
19 """Create view for Certificate."""
20
21 context_object_name = 'certificate'
22 template_name = 'certificate/create.html'
23
24 def get_success_url(self):
25 """Define the redirect URL.
26
27 After successful creation of the object, the User will be redirected
28 to the Course detail page.
29
30 :returns: URL
31 :rtype: HttpResponse
32 """
33
34 return reverse('course-detail', kwargs={
35 'project_slug': self.project_slug,
36 'organisation_slug': self.organisation_slug,
37 'slug': self.course_slug
38 })
39
40 def get_context_data(self, **kwargs):
41 """Get the context data which is passed to a template.
42
43 :param kwargs: Any arguments to pass to the superclass.
44 :type kwargs: dict
45
46 :returns: Context data which will be passed to the template.
47 :rtype: dict
48 """
49
50 context = super(
51 CertificateCreateView, self).get_context_data(**kwargs)
52 context['course'] = Course.objects.get(slug=self.course_slug)
53 context['attendee'] = Attendee.objects.get(pk=self.pk)
54 return context
55
56 def get_form_kwargs(self):
57 """Get keyword arguments from form.
58
59 :returns keyword argument from the form
60 :rtype: dict
61 """
62
63 kwargs = super(CertificateCreateView, self).get_form_kwargs()
64 self.project_slug = self.kwargs.get('project_slug', None)
65 self.organisation_slug = self.kwargs.get('organisation_slug', None)
66 self.course_slug = self.kwargs.get('course_slug', None)
67 self.pk = self.kwargs.get('pk', None)
68 self.course = Course.objects.get(slug=self.course_slug)
69 self.attendee = Attendee.objects.get(pk=self.pk)
70 kwargs.update({
71 'user': self.request.user,
72 'course': self.course,
73 'attendee': self.attendee,
74 })
75 return kwargs
76
77
78 class CertificateDetailView(DetailView):
79 """Detail view for Certificate."""
80
81 model = Certificate
82 context_object_name = 'certificate'
83 template_name = 'certificate/detail.html'
84
85 def get_context_data(self, **kwargs):
86 """Get the context data which is passed to a template.
87
88 :param kwargs: Any arguments to pass to the superclass.
89 :type kwargs: dict
90
91 :returns: Context data which will be passed to the template.
92 :rtype: dict
93 """
94
95 self.certificateID = self.kwargs.get('id', None)
96 context = super(
97 CertificateDetailView, self).get_context_data(**kwargs)
98 context['certificate'] = \
99 Certificate.objects.get(certificateID=self.certificateID)
100 return context
101
102 def get_queryset(self):
103 """Get the queryset for this view.
104
105 :returns: Queryset which is all certificate in the
106 corresponding organisation.
107 :rtype: QuerySet
108 """
109
110 qs = Certificate.objects.all()
111 return qs
112
113 def get_object(self, queryset=None):
114 """Get the object for this view.
115
116 :param queryset: A query set
117 :type queryset: QuerySet
118
119 :returns: Queryset which is filtered to only show a certificate
120 depends on the input certificate ID.
121 :rtype: QuerySet
122 :raises: Http404
123 """
124
125 if queryset is None:
126 queryset = self.get_queryset()
127 certificateID = self.kwargs.get('id', None)
128 if certificateID:
129 obj = queryset.get(
130 certificateID=certificateID)
131 return obj
132 else:
133 raise Http404('Sorry! Certificate by this ID is not exist.')
134
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/django_project/certification/views/certificate.py b/django_project/certification/views/certificate.py
--- a/django_project/certification/views/certificate.py
+++ b/django_project/certification/views/certificate.py
@@ -93,10 +93,15 @@
"""
self.certificateID = self.kwargs.get('id', None)
+ self.project_slug = self.kwargs.get('project_slug', None)
context = super(
CertificateDetailView, self).get_context_data(**kwargs)
- context['certificate'] = \
- Certificate.objects.get(certificateID=self.certificateID)
+ issued_id = \
+ Certificate.objects.all().values_list('certificateID', flat=True)
+ if self.certificateID in issued_id:
+ context['certificate'] = \
+ Certificate.objects.get(certificateID=self.certificateID)
+ context['project_slug'] = self.project_slug
return context
def get_queryset(self):
@@ -126,8 +131,10 @@
queryset = self.get_queryset()
certificateID = self.kwargs.get('id', None)
if certificateID:
- obj = queryset.get(
- certificateID=certificateID)
- return obj
+ try:
+ obj = queryset.get(certificateID=certificateID)
+ return obj
+ except Certificate.DoesNotExist:
+ return None
else:
raise Http404('Sorry! Certificate by this ID is not exist.')
|
{"golden_diff": "diff --git a/django_project/certification/views/certificate.py b/django_project/certification/views/certificate.py\n--- a/django_project/certification/views/certificate.py\n+++ b/django_project/certification/views/certificate.py\n@@ -93,10 +93,15 @@\n \"\"\"\n \n self.certificateID = self.kwargs.get('id', None)\n+ self.project_slug = self.kwargs.get('project_slug', None)\n context = super(\n CertificateDetailView, self).get_context_data(**kwargs)\n- context['certificate'] = \\\n- Certificate.objects.get(certificateID=self.certificateID)\n+ issued_id = \\\n+ Certificate.objects.all().values_list('certificateID', flat=True)\n+ if self.certificateID in issued_id:\n+ context['certificate'] = \\\n+ Certificate.objects.get(certificateID=self.certificateID)\n+ context['project_slug'] = self.project_slug\n return context\n \n def get_queryset(self):\n@@ -126,8 +131,10 @@\n queryset = self.get_queryset()\n certificateID = self.kwargs.get('id', None)\n if certificateID:\n- obj = queryset.get(\n- certificateID=certificateID)\n- return obj\n+ try:\n+ obj = queryset.get(certificateID=certificateID)\n+ return obj\n+ except Certificate.DoesNotExist:\n+ return None\n else:\n raise Http404('Sorry! Certificate by this ID is not exist.')\n", "issue": "500 on bad certificate number\n# Problem\r\n\r\nWhen I try and add a bad certificate number, then I get a 500, I should get a 404.\r\nSee:\r\nhttp://staging.changelog.qgis.org/en/qgis/certificate/0246242/\r\n\r\n# Proposed Solution\r\n\r\nReturn a 404\n", "before_files": [{"content": "# coding=utf-8\nfrom django.http import Http404\nfrom django.views.generic import CreateView, DetailView\nfrom django.core.urlresolvers import reverse\nfrom braces.views import LoginRequiredMixin\nfrom ..models import Certificate, Course, Attendee\nfrom ..forms import CertificateForm\n\n\nclass CertificateMixin(object):\n \"\"\"Mixin class to provide standard settings for Certificate.\"\"\"\n\n model = Certificate\n form_class = CertificateForm\n\n\nclass CertificateCreateView(\n LoginRequiredMixin, CertificateMixin, CreateView):\n \"\"\"Create view for Certificate.\"\"\"\n\n context_object_name = 'certificate'\n template_name = 'certificate/create.html'\n\n def get_success_url(self):\n \"\"\"Define the redirect URL.\n\n After successful creation of the object, the User will be redirected\n to the Course detail page.\n\n :returns: URL\n :rtype: HttpResponse\n \"\"\"\n\n return reverse('course-detail', kwargs={\n 'project_slug': self.project_slug,\n 'organisation_slug': self.organisation_slug,\n 'slug': self.course_slug\n })\n\n def get_context_data(self, **kwargs):\n \"\"\"Get the context data which is passed to a template.\n\n :param kwargs: Any arguments to pass to the superclass.\n :type kwargs: dict\n\n :returns: Context data which will be passed to the template.\n :rtype: dict\n \"\"\"\n\n context = super(\n CertificateCreateView, self).get_context_data(**kwargs)\n context['course'] = Course.objects.get(slug=self.course_slug)\n context['attendee'] = Attendee.objects.get(pk=self.pk)\n return context\n\n def get_form_kwargs(self):\n \"\"\"Get keyword arguments from form.\n\n :returns keyword argument from the form\n :rtype: dict\n \"\"\"\n\n kwargs = super(CertificateCreateView, self).get_form_kwargs()\n self.project_slug = self.kwargs.get('project_slug', None)\n self.organisation_slug = self.kwargs.get('organisation_slug', None)\n self.course_slug = self.kwargs.get('course_slug', None)\n self.pk = self.kwargs.get('pk', None)\n self.course = Course.objects.get(slug=self.course_slug)\n self.attendee = Attendee.objects.get(pk=self.pk)\n kwargs.update({\n 'user': self.request.user,\n 'course': self.course,\n 'attendee': self.attendee,\n })\n return kwargs\n\n\nclass CertificateDetailView(DetailView):\n \"\"\"Detail view for Certificate.\"\"\"\n\n model = Certificate\n context_object_name = 'certificate'\n template_name = 'certificate/detail.html'\n\n def get_context_data(self, **kwargs):\n \"\"\"Get the context data which is passed to a template.\n\n :param kwargs: Any arguments to pass to the superclass.\n :type kwargs: dict\n\n :returns: Context data which will be passed to the template.\n :rtype: dict\n \"\"\"\n\n self.certificateID = self.kwargs.get('id', None)\n context = super(\n CertificateDetailView, self).get_context_data(**kwargs)\n context['certificate'] = \\\n Certificate.objects.get(certificateID=self.certificateID)\n return context\n\n def get_queryset(self):\n \"\"\"Get the queryset for this view.\n\n :returns: Queryset which is all certificate in the\n corresponding organisation.\n :rtype: QuerySet\n \"\"\"\n\n qs = Certificate.objects.all()\n return qs\n\n def get_object(self, queryset=None):\n \"\"\"Get the object for this view.\n\n :param queryset: A query set\n :type queryset: QuerySet\n\n :returns: Queryset which is filtered to only show a certificate\n depends on the input certificate ID.\n :rtype: QuerySet\n :raises: Http404\n \"\"\"\n\n if queryset is None:\n queryset = self.get_queryset()\n certificateID = self.kwargs.get('id', None)\n if certificateID:\n obj = queryset.get(\n certificateID=certificateID)\n return obj\n else:\n raise Http404('Sorry! Certificate by this ID is not exist.')\n", "path": "django_project/certification/views/certificate.py"}], "after_files": [{"content": "# coding=utf-8\nfrom django.http import Http404\nfrom django.views.generic import CreateView, DetailView\nfrom django.core.urlresolvers import reverse\nfrom braces.views import LoginRequiredMixin\nfrom ..models import Certificate, Course, Attendee\nfrom ..forms import CertificateForm\n\n\nclass CertificateMixin(object):\n \"\"\"Mixin class to provide standard settings for Certificate.\"\"\"\n\n model = Certificate\n form_class = CertificateForm\n\n\nclass CertificateCreateView(\n LoginRequiredMixin, CertificateMixin, CreateView):\n \"\"\"Create view for Certificate.\"\"\"\n\n context_object_name = 'certificate'\n template_name = 'certificate/create.html'\n\n def get_success_url(self):\n \"\"\"Define the redirect URL.\n\n After successful creation of the object, the User will be redirected\n to the Course detail page.\n\n :returns: URL\n :rtype: HttpResponse\n \"\"\"\n\n return reverse('course-detail', kwargs={\n 'project_slug': self.project_slug,\n 'organisation_slug': self.organisation_slug,\n 'slug': self.course_slug\n })\n\n def get_context_data(self, **kwargs):\n \"\"\"Get the context data which is passed to a template.\n\n :param kwargs: Any arguments to pass to the superclass.\n :type kwargs: dict\n\n :returns: Context data which will be passed to the template.\n :rtype: dict\n \"\"\"\n\n context = super(\n CertificateCreateView, self).get_context_data(**kwargs)\n context['course'] = Course.objects.get(slug=self.course_slug)\n context['attendee'] = Attendee.objects.get(pk=self.pk)\n return context\n\n def get_form_kwargs(self):\n \"\"\"Get keyword arguments from form.\n\n :returns keyword argument from the form\n :rtype: dict\n \"\"\"\n\n kwargs = super(CertificateCreateView, self).get_form_kwargs()\n self.project_slug = self.kwargs.get('project_slug', None)\n self.organisation_slug = self.kwargs.get('organisation_slug', None)\n self.course_slug = self.kwargs.get('course_slug', None)\n self.pk = self.kwargs.get('pk', None)\n self.course = Course.objects.get(slug=self.course_slug)\n self.attendee = Attendee.objects.get(pk=self.pk)\n kwargs.update({\n 'user': self.request.user,\n 'course': self.course,\n 'attendee': self.attendee,\n })\n return kwargs\n\n\nclass CertificateDetailView(DetailView):\n \"\"\"Detail view for Certificate.\"\"\"\n\n model = Certificate\n context_object_name = 'certificate'\n template_name = 'certificate/detail.html'\n\n def get_context_data(self, **kwargs):\n \"\"\"Get the context data which is passed to a template.\n\n :param kwargs: Any arguments to pass to the superclass.\n :type kwargs: dict\n\n :returns: Context data which will be passed to the template.\n :rtype: dict\n \"\"\"\n\n self.certificateID = self.kwargs.get('id', None)\n self.project_slug = self.kwargs.get('project_slug', None)\n context = super(\n CertificateDetailView, self).get_context_data(**kwargs)\n issued_id = \\\n Certificate.objects.all().values_list('certificateID', flat=True)\n if self.certificateID in issued_id:\n context['certificate'] = \\\n Certificate.objects.get(certificateID=self.certificateID)\n context['project_slug'] = self.project_slug\n return context\n\n def get_queryset(self):\n \"\"\"Get the queryset for this view.\n\n :returns: Queryset which is all certificate in the\n corresponding organisation.\n :rtype: QuerySet\n \"\"\"\n\n qs = Certificate.objects.all()\n return qs\n\n def get_object(self, queryset=None):\n \"\"\"Get the object for this view.\n\n :param queryset: A query set\n :type queryset: QuerySet\n\n :returns: Queryset which is filtered to only show a certificate\n depends on the input certificate ID.\n :rtype: QuerySet\n :raises: Http404\n \"\"\"\n\n if queryset is None:\n queryset = self.get_queryset()\n certificateID = self.kwargs.get('id', None)\n if certificateID:\n try:\n obj = queryset.get(certificateID=certificateID)\n return obj\n except Certificate.DoesNotExist:\n return None\n else:\n raise Http404('Sorry! Certificate by this ID is not exist.')\n", "path": "django_project/certification/views/certificate.py"}]}
| 1,506 | 323 |
gh_patches_debug_6999
|
rasdani/github-patches
|
git_diff
|
qutebrowser__qutebrowser-7793
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
prompt_queue is None at shutdown
Seeing this in various crash reports:
```pytb
Traceback (most recent call last):
File "/usr/lib/python3.9/site-packages/qutebrowser/misc/quitter.py", line 225, in shutdown
if prompt.prompt_queue.shutdown():
AttributeError: 'NoneType' object has no attribute 'shutdown'
```
https://crashes.qutebrowser.org/lists?search=prompt_queue.shutdown
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `qutebrowser/misc/quitter.py`
Content:
```
1 # Copyright 2014-2021 Florian Bruhin (The Compiler) <[email protected]>
2 #
3 # This file is part of qutebrowser.
4 #
5 # qutebrowser is free software: you can redistribute it and/or modify
6 # it under the terms of the GNU General Public License as published by
7 # the Free Software Foundation, either version 3 of the License, or
8 # (at your option) any later version.
9 #
10 # qutebrowser is distributed in the hope that it will be useful,
11 # but WITHOUT ANY WARRANTY; without even the implied warranty of
12 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
13 # GNU General Public License for more details.
14 #
15 # You should have received a copy of the GNU General Public License
16 # along with qutebrowser. If not, see <https://www.gnu.org/licenses/>.
17
18 """Helpers related to quitting qutebrowser cleanly."""
19
20 import os
21 import os.path
22 import sys
23 import json
24 import atexit
25 import shutil
26 import argparse
27 import tokenize
28 import functools
29 import subprocess
30 from typing import Iterable, Mapping, MutableSequence, Sequence, cast
31
32 from qutebrowser.qt.core import QObject, pyqtSignal, QTimer
33 try:
34 import hunter
35 except ImportError:
36 hunter = None
37
38 import qutebrowser
39 from qutebrowser.api import cmdutils
40 from qutebrowser.utils import log, qtlog
41 from qutebrowser.misc import sessions, ipc, objects
42 from qutebrowser.mainwindow import prompt
43 from qutebrowser.completion.models import miscmodels
44
45
46 instance = cast('Quitter', None)
47
48
49 class Quitter(QObject):
50
51 """Utility class to quit/restart the QApplication.
52
53 Attributes:
54 quit_status: The current quitting status.
55 is_shutting_down: Whether we're currently shutting down.
56 _args: The argparse namespace.
57 """
58
59 shutting_down = pyqtSignal() # Emitted immediately before shut down
60
61 def __init__(self, *,
62 args: argparse.Namespace,
63 parent: QObject = None) -> None:
64 super().__init__(parent)
65 self.quit_status = {
66 'crash': True,
67 'tabs': False,
68 'main': False,
69 }
70 self.is_shutting_down = False
71 self._args = args
72
73 def on_last_window_closed(self) -> None:
74 """Slot which gets invoked when the last window was closed."""
75 self.shutdown(last_window=True)
76
77 def _compile_modules(self) -> None:
78 """Compile all modules to catch SyntaxErrors."""
79 if os.path.basename(sys.argv[0]) == 'qutebrowser':
80 # Launched via launcher script
81 return
82 elif hasattr(sys, 'frozen'):
83 return
84 else:
85 path = os.path.abspath(os.path.dirname(qutebrowser.__file__))
86 if not os.path.isdir(path):
87 # Probably running from a python egg.
88 return
89
90 for dirpath, _dirnames, filenames in os.walk(path):
91 for fn in filenames:
92 if os.path.splitext(fn)[1] == '.py' and os.path.isfile(fn):
93 with tokenize.open(os.path.join(dirpath, fn)) as f:
94 compile(f.read(), fn, 'exec')
95
96 def _get_restart_args(
97 self, pages: Iterable[str] = (),
98 session: str = None,
99 override_args: Mapping[str, str] = None
100 ) -> Sequence[str]:
101 """Get args to relaunch qutebrowser.
102
103 Args:
104 pages: The pages to re-open.
105 session: The session to load, or None.
106 override_args: Argument overrides as a dict.
107
108 Return:
109 The commandline as a list of strings.
110 """
111 if os.path.basename(sys.argv[0]) == 'qutebrowser':
112 # Launched via launcher script
113 args = [sys.argv[0]]
114 elif hasattr(sys, 'frozen'):
115 args = [sys.executable]
116 else:
117 args = [sys.executable, '-m', 'qutebrowser']
118
119 # Add all open pages so they get reopened.
120 page_args: MutableSequence[str] = []
121 for win in pages:
122 page_args.extend(win)
123 page_args.append('')
124
125 # Serialize the argparse namespace into json and pass that to the new
126 # process via --json-args.
127 # We do this as there's no way to "unparse" the namespace while
128 # ignoring some arguments.
129 argdict = vars(self._args)
130 argdict['session'] = None
131 argdict['url'] = []
132 argdict['command'] = page_args[:-1]
133 argdict['json_args'] = None
134 # Ensure the given session (or none at all) gets opened.
135 if session is None:
136 argdict['session'] = None
137 argdict['override_restore'] = True
138 else:
139 argdict['session'] = session
140 argdict['override_restore'] = False
141 # Ensure :restart works with --temp-basedir
142 if self._args.temp_basedir:
143 argdict['temp_basedir'] = False
144 argdict['temp_basedir_restarted'] = True
145
146 if override_args is not None:
147 argdict.update(override_args)
148
149 # Dump the data
150 data = json.dumps(argdict)
151 args += ['--json-args', data]
152
153 log.destroy.debug("args: {}".format(args))
154
155 return args
156
157 def restart(self, pages: Sequence[str] = (),
158 session: str = None,
159 override_args: Mapping[str, str] = None) -> bool:
160 """Inner logic to restart qutebrowser.
161
162 The "better" way to restart is to pass a session (_restart usually) as
163 that'll save the complete state.
164
165 However we don't do that (and pass a list of pages instead) when we
166 restart because of an exception, as that's a lot simpler and we don't
167 want to risk anything going wrong.
168
169 Args:
170 pages: A list of URLs to open.
171 session: The session to load, or None.
172 override_args: Argument overrides as a dict.
173
174 Return:
175 True if the restart succeeded, False otherwise.
176 """
177 self._compile_modules()
178 log.destroy.debug("sys.executable: {}".format(sys.executable))
179 log.destroy.debug("sys.path: {}".format(sys.path))
180 log.destroy.debug("sys.argv: {}".format(sys.argv))
181 log.destroy.debug("frozen: {}".format(hasattr(sys, 'frozen')))
182
183 # Save the session if one is given.
184 if session is not None:
185 sessions.session_manager.save(session, with_private=True)
186
187 # Make sure we're not accepting a connection from the new process
188 # before we fully exited.
189 assert ipc.server is not None
190 ipc.server.shutdown()
191
192 # Open a new process and immediately shutdown the existing one
193 try:
194 args = self._get_restart_args(pages, session, override_args)
195 subprocess.Popen(args) # pylint: disable=consider-using-with
196 except OSError:
197 log.destroy.exception("Failed to restart")
198 return False
199 else:
200 return True
201
202 def shutdown(self, status: int = 0,
203 session: sessions.ArgType = None,
204 last_window: bool = False,
205 is_restart: bool = False) -> None:
206 """Quit qutebrowser.
207
208 Args:
209 status: The status code to exit with.
210 session: A session name if saving should be forced.
211 last_window: If the shutdown was triggered due to the last window
212 closing.
213 is_restart: If we're planning to restart.
214 """
215 if self.is_shutting_down:
216 return
217 self.is_shutting_down = True
218 log.destroy.debug("Shutting down with status {}, session {}...".format(
219 status, session))
220
221 sessions.shutdown(session, last_window=last_window)
222 prompt.prompt_queue.shutdown()
223
224 # If shutdown was called while we were asking a question, we're in
225 # a still sub-eventloop (which gets quit now) and not in the main
226 # one.
227 # But there's also other situations where it's problematic to shut down
228 # immediately (e.g. when we're just starting up).
229 # This means we need to defer the real shutdown to when we're back
230 # in the real main event loop, or we'll get a segfault.
231 log.destroy.debug("Deferring shutdown stage 2")
232 QTimer.singleShot(
233 0, functools.partial(self._shutdown_2, status, is_restart=is_restart))
234
235 def _shutdown_2(self, status: int, is_restart: bool) -> None:
236 """Second stage of shutdown."""
237 log.destroy.debug("Stage 2 of shutting down...")
238
239 # Tell everything to shut itself down
240 self.shutting_down.emit()
241
242 # Delete temp basedir
243 if ((self._args.temp_basedir or self._args.temp_basedir_restarted) and
244 not is_restart):
245 atexit.register(shutil.rmtree, self._args.basedir,
246 ignore_errors=True)
247
248 # Now we can hopefully quit without segfaults
249 log.destroy.debug("Deferring QApplication::exit...")
250 # We use a singleshot timer to exit here to minimize the likelihood of
251 # segfaults.
252 QTimer.singleShot(0, functools.partial(self._shutdown_3, status))
253
254 def _shutdown_3(self, status: int) -> None:
255 """Finally shut down the QApplication."""
256 log.destroy.debug("Now calling QApplication::exit.")
257 if 'debug-exit' in objects.debug_flags:
258 if hunter is None:
259 print("Not logging late shutdown because hunter could not be "
260 "imported!", file=sys.stderr)
261 else:
262 print("Now logging late shutdown.", file=sys.stderr)
263 hunter.trace()
264 objects.qapp.exit(status)
265
266
267 @cmdutils.register(name='quit')
268 @cmdutils.argument('session', completion=miscmodels.session)
269 def quit_(save: bool = False,
270 session: sessions.ArgType = None) -> None:
271 """Quit qutebrowser.
272
273 Args:
274 save: When given, save the open windows even if auto_save.session
275 is turned off.
276 session: The name of the session to save.
277 """
278 if session is not None and not save:
279 raise cmdutils.CommandError("Session name given without --save!")
280 if save and session is None:
281 session = sessions.default
282
283 instance.shutdown(session=session)
284
285
286 @cmdutils.register()
287 def restart() -> None:
288 """Restart qutebrowser while keeping existing tabs open."""
289 try:
290 ok = instance.restart(session='_restart')
291 except sessions.SessionError as e:
292 log.destroy.exception("Failed to save session!")
293 raise cmdutils.CommandError("Failed to save session: {}!"
294 .format(e))
295 except SyntaxError as e:
296 log.destroy.exception("Got SyntaxError")
297 raise cmdutils.CommandError("SyntaxError in {}:{}: {}".format(
298 e.filename, e.lineno, e))
299 if ok:
300 instance.shutdown(is_restart=True)
301
302
303 def init(args: argparse.Namespace) -> None:
304 """Initialize the global Quitter instance."""
305 global instance
306 instance = Quitter(args=args, parent=objects.qapp)
307 instance.shutting_down.connect(qtlog.shutdown_log)
308 objects.qapp.lastWindowClosed.connect(instance.on_last_window_closed)
309
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/qutebrowser/misc/quitter.py b/qutebrowser/misc/quitter.py
--- a/qutebrowser/misc/quitter.py
+++ b/qutebrowser/misc/quitter.py
@@ -219,7 +219,8 @@
status, session))
sessions.shutdown(session, last_window=last_window)
- prompt.prompt_queue.shutdown()
+ if prompt.prompt_queue is not None:
+ prompt.prompt_queue.shutdown()
# If shutdown was called while we were asking a question, we're in
# a still sub-eventloop (which gets quit now) and not in the main
|
{"golden_diff": "diff --git a/qutebrowser/misc/quitter.py b/qutebrowser/misc/quitter.py\n--- a/qutebrowser/misc/quitter.py\n+++ b/qutebrowser/misc/quitter.py\n@@ -219,7 +219,8 @@\n status, session))\n \n sessions.shutdown(session, last_window=last_window)\n- prompt.prompt_queue.shutdown()\n+ if prompt.prompt_queue is not None:\n+ prompt.prompt_queue.shutdown()\n \n # If shutdown was called while we were asking a question, we're in\n # a still sub-eventloop (which gets quit now) and not in the main\n", "issue": "prompt_queue is None at shutdown\nSeeing this in various crash reports:\r\n\r\n```pytb\r\nTraceback (most recent call last):\r\n File \"/usr/lib/python3.9/site-packages/qutebrowser/misc/quitter.py\", line 225, in shutdown\r\n if prompt.prompt_queue.shutdown():\r\nAttributeError: 'NoneType' object has no attribute 'shutdown'\r\n```\r\n\r\nhttps://crashes.qutebrowser.org/lists?search=prompt_queue.shutdown\n", "before_files": [{"content": "# Copyright 2014-2021 Florian Bruhin (The Compiler) <[email protected]>\n#\n# This file is part of qutebrowser.\n#\n# qutebrowser is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# qutebrowser is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with qutebrowser. If not, see <https://www.gnu.org/licenses/>.\n\n\"\"\"Helpers related to quitting qutebrowser cleanly.\"\"\"\n\nimport os\nimport os.path\nimport sys\nimport json\nimport atexit\nimport shutil\nimport argparse\nimport tokenize\nimport functools\nimport subprocess\nfrom typing import Iterable, Mapping, MutableSequence, Sequence, cast\n\nfrom qutebrowser.qt.core import QObject, pyqtSignal, QTimer\ntry:\n import hunter\nexcept ImportError:\n hunter = None\n\nimport qutebrowser\nfrom qutebrowser.api import cmdutils\nfrom qutebrowser.utils import log, qtlog\nfrom qutebrowser.misc import sessions, ipc, objects\nfrom qutebrowser.mainwindow import prompt\nfrom qutebrowser.completion.models import miscmodels\n\n\ninstance = cast('Quitter', None)\n\n\nclass Quitter(QObject):\n\n \"\"\"Utility class to quit/restart the QApplication.\n\n Attributes:\n quit_status: The current quitting status.\n is_shutting_down: Whether we're currently shutting down.\n _args: The argparse namespace.\n \"\"\"\n\n shutting_down = pyqtSignal() # Emitted immediately before shut down\n\n def __init__(self, *,\n args: argparse.Namespace,\n parent: QObject = None) -> None:\n super().__init__(parent)\n self.quit_status = {\n 'crash': True,\n 'tabs': False,\n 'main': False,\n }\n self.is_shutting_down = False\n self._args = args\n\n def on_last_window_closed(self) -> None:\n \"\"\"Slot which gets invoked when the last window was closed.\"\"\"\n self.shutdown(last_window=True)\n\n def _compile_modules(self) -> None:\n \"\"\"Compile all modules to catch SyntaxErrors.\"\"\"\n if os.path.basename(sys.argv[0]) == 'qutebrowser':\n # Launched via launcher script\n return\n elif hasattr(sys, 'frozen'):\n return\n else:\n path = os.path.abspath(os.path.dirname(qutebrowser.__file__))\n if not os.path.isdir(path):\n # Probably running from a python egg.\n return\n\n for dirpath, _dirnames, filenames in os.walk(path):\n for fn in filenames:\n if os.path.splitext(fn)[1] == '.py' and os.path.isfile(fn):\n with tokenize.open(os.path.join(dirpath, fn)) as f:\n compile(f.read(), fn, 'exec')\n\n def _get_restart_args(\n self, pages: Iterable[str] = (),\n session: str = None,\n override_args: Mapping[str, str] = None\n ) -> Sequence[str]:\n \"\"\"Get args to relaunch qutebrowser.\n\n Args:\n pages: The pages to re-open.\n session: The session to load, or None.\n override_args: Argument overrides as a dict.\n\n Return:\n The commandline as a list of strings.\n \"\"\"\n if os.path.basename(sys.argv[0]) == 'qutebrowser':\n # Launched via launcher script\n args = [sys.argv[0]]\n elif hasattr(sys, 'frozen'):\n args = [sys.executable]\n else:\n args = [sys.executable, '-m', 'qutebrowser']\n\n # Add all open pages so they get reopened.\n page_args: MutableSequence[str] = []\n for win in pages:\n page_args.extend(win)\n page_args.append('')\n\n # Serialize the argparse namespace into json and pass that to the new\n # process via --json-args.\n # We do this as there's no way to \"unparse\" the namespace while\n # ignoring some arguments.\n argdict = vars(self._args)\n argdict['session'] = None\n argdict['url'] = []\n argdict['command'] = page_args[:-1]\n argdict['json_args'] = None\n # Ensure the given session (or none at all) gets opened.\n if session is None:\n argdict['session'] = None\n argdict['override_restore'] = True\n else:\n argdict['session'] = session\n argdict['override_restore'] = False\n # Ensure :restart works with --temp-basedir\n if self._args.temp_basedir:\n argdict['temp_basedir'] = False\n argdict['temp_basedir_restarted'] = True\n\n if override_args is not None:\n argdict.update(override_args)\n\n # Dump the data\n data = json.dumps(argdict)\n args += ['--json-args', data]\n\n log.destroy.debug(\"args: {}\".format(args))\n\n return args\n\n def restart(self, pages: Sequence[str] = (),\n session: str = None,\n override_args: Mapping[str, str] = None) -> bool:\n \"\"\"Inner logic to restart qutebrowser.\n\n The \"better\" way to restart is to pass a session (_restart usually) as\n that'll save the complete state.\n\n However we don't do that (and pass a list of pages instead) when we\n restart because of an exception, as that's a lot simpler and we don't\n want to risk anything going wrong.\n\n Args:\n pages: A list of URLs to open.\n session: The session to load, or None.\n override_args: Argument overrides as a dict.\n\n Return:\n True if the restart succeeded, False otherwise.\n \"\"\"\n self._compile_modules()\n log.destroy.debug(\"sys.executable: {}\".format(sys.executable))\n log.destroy.debug(\"sys.path: {}\".format(sys.path))\n log.destroy.debug(\"sys.argv: {}\".format(sys.argv))\n log.destroy.debug(\"frozen: {}\".format(hasattr(sys, 'frozen')))\n\n # Save the session if one is given.\n if session is not None:\n sessions.session_manager.save(session, with_private=True)\n\n # Make sure we're not accepting a connection from the new process\n # before we fully exited.\n assert ipc.server is not None\n ipc.server.shutdown()\n\n # Open a new process and immediately shutdown the existing one\n try:\n args = self._get_restart_args(pages, session, override_args)\n subprocess.Popen(args) # pylint: disable=consider-using-with\n except OSError:\n log.destroy.exception(\"Failed to restart\")\n return False\n else:\n return True\n\n def shutdown(self, status: int = 0,\n session: sessions.ArgType = None,\n last_window: bool = False,\n is_restart: bool = False) -> None:\n \"\"\"Quit qutebrowser.\n\n Args:\n status: The status code to exit with.\n session: A session name if saving should be forced.\n last_window: If the shutdown was triggered due to the last window\n closing.\n is_restart: If we're planning to restart.\n \"\"\"\n if self.is_shutting_down:\n return\n self.is_shutting_down = True\n log.destroy.debug(\"Shutting down with status {}, session {}...\".format(\n status, session))\n\n sessions.shutdown(session, last_window=last_window)\n prompt.prompt_queue.shutdown()\n\n # If shutdown was called while we were asking a question, we're in\n # a still sub-eventloop (which gets quit now) and not in the main\n # one.\n # But there's also other situations where it's problematic to shut down\n # immediately (e.g. when we're just starting up).\n # This means we need to defer the real shutdown to when we're back\n # in the real main event loop, or we'll get a segfault.\n log.destroy.debug(\"Deferring shutdown stage 2\")\n QTimer.singleShot(\n 0, functools.partial(self._shutdown_2, status, is_restart=is_restart))\n\n def _shutdown_2(self, status: int, is_restart: bool) -> None:\n \"\"\"Second stage of shutdown.\"\"\"\n log.destroy.debug(\"Stage 2 of shutting down...\")\n\n # Tell everything to shut itself down\n self.shutting_down.emit()\n\n # Delete temp basedir\n if ((self._args.temp_basedir or self._args.temp_basedir_restarted) and\n not is_restart):\n atexit.register(shutil.rmtree, self._args.basedir,\n ignore_errors=True)\n\n # Now we can hopefully quit without segfaults\n log.destroy.debug(\"Deferring QApplication::exit...\")\n # We use a singleshot timer to exit here to minimize the likelihood of\n # segfaults.\n QTimer.singleShot(0, functools.partial(self._shutdown_3, status))\n\n def _shutdown_3(self, status: int) -> None:\n \"\"\"Finally shut down the QApplication.\"\"\"\n log.destroy.debug(\"Now calling QApplication::exit.\")\n if 'debug-exit' in objects.debug_flags:\n if hunter is None:\n print(\"Not logging late shutdown because hunter could not be \"\n \"imported!\", file=sys.stderr)\n else:\n print(\"Now logging late shutdown.\", file=sys.stderr)\n hunter.trace()\n objects.qapp.exit(status)\n\n\[email protected](name='quit')\[email protected]('session', completion=miscmodels.session)\ndef quit_(save: bool = False,\n session: sessions.ArgType = None) -> None:\n \"\"\"Quit qutebrowser.\n\n Args:\n save: When given, save the open windows even if auto_save.session\n is turned off.\n session: The name of the session to save.\n \"\"\"\n if session is not None and not save:\n raise cmdutils.CommandError(\"Session name given without --save!\")\n if save and session is None:\n session = sessions.default\n\n instance.shutdown(session=session)\n\n\[email protected]()\ndef restart() -> None:\n \"\"\"Restart qutebrowser while keeping existing tabs open.\"\"\"\n try:\n ok = instance.restart(session='_restart')\n except sessions.SessionError as e:\n log.destroy.exception(\"Failed to save session!\")\n raise cmdutils.CommandError(\"Failed to save session: {}!\"\n .format(e))\n except SyntaxError as e:\n log.destroy.exception(\"Got SyntaxError\")\n raise cmdutils.CommandError(\"SyntaxError in {}:{}: {}\".format(\n e.filename, e.lineno, e))\n if ok:\n instance.shutdown(is_restart=True)\n\n\ndef init(args: argparse.Namespace) -> None:\n \"\"\"Initialize the global Quitter instance.\"\"\"\n global instance\n instance = Quitter(args=args, parent=objects.qapp)\n instance.shutting_down.connect(qtlog.shutdown_log)\n objects.qapp.lastWindowClosed.connect(instance.on_last_window_closed)\n", "path": "qutebrowser/misc/quitter.py"}], "after_files": [{"content": "# Copyright 2014-2021 Florian Bruhin (The Compiler) <[email protected]>\n#\n# This file is part of qutebrowser.\n#\n# qutebrowser is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# qutebrowser is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with qutebrowser. If not, see <https://www.gnu.org/licenses/>.\n\n\"\"\"Helpers related to quitting qutebrowser cleanly.\"\"\"\n\nimport os\nimport os.path\nimport sys\nimport json\nimport atexit\nimport shutil\nimport argparse\nimport tokenize\nimport functools\nimport subprocess\nfrom typing import Iterable, Mapping, MutableSequence, Sequence, cast\n\nfrom qutebrowser.qt.core import QObject, pyqtSignal, QTimer\ntry:\n import hunter\nexcept ImportError:\n hunter = None\n\nimport qutebrowser\nfrom qutebrowser.api import cmdutils\nfrom qutebrowser.utils import log, qtlog\nfrom qutebrowser.misc import sessions, ipc, objects\nfrom qutebrowser.mainwindow import prompt\nfrom qutebrowser.completion.models import miscmodels\n\n\ninstance = cast('Quitter', None)\n\n\nclass Quitter(QObject):\n\n \"\"\"Utility class to quit/restart the QApplication.\n\n Attributes:\n quit_status: The current quitting status.\n is_shutting_down: Whether we're currently shutting down.\n _args: The argparse namespace.\n \"\"\"\n\n shutting_down = pyqtSignal() # Emitted immediately before shut down\n\n def __init__(self, *,\n args: argparse.Namespace,\n parent: QObject = None) -> None:\n super().__init__(parent)\n self.quit_status = {\n 'crash': True,\n 'tabs': False,\n 'main': False,\n }\n self.is_shutting_down = False\n self._args = args\n\n def on_last_window_closed(self) -> None:\n \"\"\"Slot which gets invoked when the last window was closed.\"\"\"\n self.shutdown(last_window=True)\n\n def _compile_modules(self) -> None:\n \"\"\"Compile all modules to catch SyntaxErrors.\"\"\"\n if os.path.basename(sys.argv[0]) == 'qutebrowser':\n # Launched via launcher script\n return\n elif hasattr(sys, 'frozen'):\n return\n else:\n path = os.path.abspath(os.path.dirname(qutebrowser.__file__))\n if not os.path.isdir(path):\n # Probably running from a python egg.\n return\n\n for dirpath, _dirnames, filenames in os.walk(path):\n for fn in filenames:\n if os.path.splitext(fn)[1] == '.py' and os.path.isfile(fn):\n with tokenize.open(os.path.join(dirpath, fn)) as f:\n compile(f.read(), fn, 'exec')\n\n def _get_restart_args(\n self, pages: Iterable[str] = (),\n session: str = None,\n override_args: Mapping[str, str] = None\n ) -> Sequence[str]:\n \"\"\"Get args to relaunch qutebrowser.\n\n Args:\n pages: The pages to re-open.\n session: The session to load, or None.\n override_args: Argument overrides as a dict.\n\n Return:\n The commandline as a list of strings.\n \"\"\"\n if os.path.basename(sys.argv[0]) == 'qutebrowser':\n # Launched via launcher script\n args = [sys.argv[0]]\n elif hasattr(sys, 'frozen'):\n args = [sys.executable]\n else:\n args = [sys.executable, '-m', 'qutebrowser']\n\n # Add all open pages so they get reopened.\n page_args: MutableSequence[str] = []\n for win in pages:\n page_args.extend(win)\n page_args.append('')\n\n # Serialize the argparse namespace into json and pass that to the new\n # process via --json-args.\n # We do this as there's no way to \"unparse\" the namespace while\n # ignoring some arguments.\n argdict = vars(self._args)\n argdict['session'] = None\n argdict['url'] = []\n argdict['command'] = page_args[:-1]\n argdict['json_args'] = None\n # Ensure the given session (or none at all) gets opened.\n if session is None:\n argdict['session'] = None\n argdict['override_restore'] = True\n else:\n argdict['session'] = session\n argdict['override_restore'] = False\n # Ensure :restart works with --temp-basedir\n if self._args.temp_basedir:\n argdict['temp_basedir'] = False\n argdict['temp_basedir_restarted'] = True\n\n if override_args is not None:\n argdict.update(override_args)\n\n # Dump the data\n data = json.dumps(argdict)\n args += ['--json-args', data]\n\n log.destroy.debug(\"args: {}\".format(args))\n\n return args\n\n def restart(self, pages: Sequence[str] = (),\n session: str = None,\n override_args: Mapping[str, str] = None) -> bool:\n \"\"\"Inner logic to restart qutebrowser.\n\n The \"better\" way to restart is to pass a session (_restart usually) as\n that'll save the complete state.\n\n However we don't do that (and pass a list of pages instead) when we\n restart because of an exception, as that's a lot simpler and we don't\n want to risk anything going wrong.\n\n Args:\n pages: A list of URLs to open.\n session: The session to load, or None.\n override_args: Argument overrides as a dict.\n\n Return:\n True if the restart succeeded, False otherwise.\n \"\"\"\n self._compile_modules()\n log.destroy.debug(\"sys.executable: {}\".format(sys.executable))\n log.destroy.debug(\"sys.path: {}\".format(sys.path))\n log.destroy.debug(\"sys.argv: {}\".format(sys.argv))\n log.destroy.debug(\"frozen: {}\".format(hasattr(sys, 'frozen')))\n\n # Save the session if one is given.\n if session is not None:\n sessions.session_manager.save(session, with_private=True)\n\n # Make sure we're not accepting a connection from the new process\n # before we fully exited.\n assert ipc.server is not None\n ipc.server.shutdown()\n\n # Open a new process and immediately shutdown the existing one\n try:\n args = self._get_restart_args(pages, session, override_args)\n subprocess.Popen(args) # pylint: disable=consider-using-with\n except OSError:\n log.destroy.exception(\"Failed to restart\")\n return False\n else:\n return True\n\n def shutdown(self, status: int = 0,\n session: sessions.ArgType = None,\n last_window: bool = False,\n is_restart: bool = False) -> None:\n \"\"\"Quit qutebrowser.\n\n Args:\n status: The status code to exit with.\n session: A session name if saving should be forced.\n last_window: If the shutdown was triggered due to the last window\n closing.\n is_restart: If we're planning to restart.\n \"\"\"\n if self.is_shutting_down:\n return\n self.is_shutting_down = True\n log.destroy.debug(\"Shutting down with status {}, session {}...\".format(\n status, session))\n\n sessions.shutdown(session, last_window=last_window)\n if prompt.prompt_queue is not None:\n prompt.prompt_queue.shutdown()\n\n # If shutdown was called while we were asking a question, we're in\n # a still sub-eventloop (which gets quit now) and not in the main\n # one.\n # But there's also other situations where it's problematic to shut down\n # immediately (e.g. when we're just starting up).\n # This means we need to defer the real shutdown to when we're back\n # in the real main event loop, or we'll get a segfault.\n log.destroy.debug(\"Deferring shutdown stage 2\")\n QTimer.singleShot(\n 0, functools.partial(self._shutdown_2, status, is_restart=is_restart))\n\n def _shutdown_2(self, status: int, is_restart: bool) -> None:\n \"\"\"Second stage of shutdown.\"\"\"\n log.destroy.debug(\"Stage 2 of shutting down...\")\n\n # Tell everything to shut itself down\n self.shutting_down.emit()\n\n # Delete temp basedir\n if ((self._args.temp_basedir or self._args.temp_basedir_restarted) and\n not is_restart):\n atexit.register(shutil.rmtree, self._args.basedir,\n ignore_errors=True)\n\n # Now we can hopefully quit without segfaults\n log.destroy.debug(\"Deferring QApplication::exit...\")\n # We use a singleshot timer to exit here to minimize the likelihood of\n # segfaults.\n QTimer.singleShot(0, functools.partial(self._shutdown_3, status))\n\n def _shutdown_3(self, status: int) -> None:\n \"\"\"Finally shut down the QApplication.\"\"\"\n log.destroy.debug(\"Now calling QApplication::exit.\")\n if 'debug-exit' in objects.debug_flags:\n if hunter is None:\n print(\"Not logging late shutdown because hunter could not be \"\n \"imported!\", file=sys.stderr)\n else:\n print(\"Now logging late shutdown.\", file=sys.stderr)\n hunter.trace()\n objects.qapp.exit(status)\n\n\[email protected](name='quit')\[email protected]('session', completion=miscmodels.session)\ndef quit_(save: bool = False,\n session: sessions.ArgType = None) -> None:\n \"\"\"Quit qutebrowser.\n\n Args:\n save: When given, save the open windows even if auto_save.session\n is turned off.\n session: The name of the session to save.\n \"\"\"\n if session is not None and not save:\n raise cmdutils.CommandError(\"Session name given without --save!\")\n if save and session is None:\n session = sessions.default\n\n instance.shutdown(session=session)\n\n\[email protected]()\ndef restart() -> None:\n \"\"\"Restart qutebrowser while keeping existing tabs open.\"\"\"\n try:\n ok = instance.restart(session='_restart')\n except sessions.SessionError as e:\n log.destroy.exception(\"Failed to save session!\")\n raise cmdutils.CommandError(\"Failed to save session: {}!\"\n .format(e))\n except SyntaxError as e:\n log.destroy.exception(\"Got SyntaxError\")\n raise cmdutils.CommandError(\"SyntaxError in {}:{}: {}\".format(\n e.filename, e.lineno, e))\n if ok:\n instance.shutdown(is_restart=True)\n\n\ndef init(args: argparse.Namespace) -> None:\n \"\"\"Initialize the global Quitter instance.\"\"\"\n global instance\n instance = Quitter(args=args, parent=objects.qapp)\n instance.shutting_down.connect(qtlog.shutdown_log)\n objects.qapp.lastWindowClosed.connect(instance.on_last_window_closed)\n", "path": "qutebrowser/misc/quitter.py"}]}
| 3,612 | 132 |
gh_patches_debug_15443
|
rasdani/github-patches
|
git_diff
|
yt-dlp__yt-dlp-4043
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
www.breitbart.com
### Checklist
- [X] I'm reporting a new site support request
- [X] I've verified that I'm running yt-dlp version **2022.05.18** ([update instructions](https://github.com/yt-dlp/yt-dlp#update)) or later (specify commit)
- [X] I've checked that all provided URLs are playable in a browser with the same IP and same login details
- [X] I've checked that none of provided URLs [violate any copyrights](https://github.com/ytdl-org/youtube-dl#can-you-add-support-for-this-anime-video-site-or-site-which-shows-current-movies-for-free) or contain any [DRM](https://en.wikipedia.org/wiki/Digital_rights_management) to the best of my knowledge
- [X] I've searched the [bugtracker](https://github.com/yt-dlp/yt-dlp/issues?q=) for similar issues including closed ones. DO NOT post duplicates
- [X] I've read the [guidelines for opening an issue](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#opening-an-issue)
- [X] I've read about [sharing account credentials](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#are-you-willing-to-share-account-details-if-needed) and am willing to share it if required
### Region
_No response_
### Example URLs
https://www.breitbart.com/clips/2022/06/08/kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere/
### Description
Embedded Fox News video not detected. Can be played in Firefox and even be downloaded using an extension named HLS Dowloader.
### Verbose log
```shell
"C:\Users\a\Desktop\MPC-BE\yt-dlp.exe" -vU https://www.breitbart.com/clips/2022/06/08/kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere/
[debug] Command-line config: ['-vU', 'https://www.breitbart.com/clips/2022/06/08/kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere/']
[debug] Encodings: locale cp1252, fs utf-8, pref cp1252, out utf-8, error utf-8, screen utf-8
[debug] yt-dlp version 2022.05.18 [b14d523] (win_exe)
[debug] Python version 3.7.9 (CPython 32bit) - Windows-10-10.0.19041-SP0
[debug] Checking exe version: ffprobe -bsfs
[debug] Checking exe version: avprobe -bsfs
[debug] Checking exe version: ffmpeg -bsfs
[debug] Checking exe version: avconv -bsfs
[debug] exe versions: none
[debug] Optional libraries: Cryptodome-3.14.1, brotli-1.0.9, certifi-2021.10.08, mutagen-1.45.1, sqlite3-2.6.0, websockets-10.3
[debug] Proxy map: {}
Latest version: 2022.05.18, Current version: 2022.05.18
yt-dlp is up to date (2022.05.18)
[debug] [generic] Extracting URL: https://www.breitbart.com/clips/2022/06/08/kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere/
[generic] kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere: Requesting header
WARNING: [generic] Falling back on generic information extractor.
[generic] kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere: Downloading webpage
[generic] kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere: Extracting information
[debug] Looking for video embeds
[debug] Identified a Open Graph video info
[debug] Default format spec: best/bestvideo+bestaudio
[info] kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere-21285488: Downloading 1 format(s): 0
[debug] Invoking http downloader on "https://media.breitbart.com/media/2022/06/kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere-21285488.mp3"
[debug] File locking is not supported on this platform. Proceeding without locking
[download] Destination: Kennedy - 'Price of Gas Is So High that It Would Be Cheaper to Buy Cocaine and Just Run Everywhere' [kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere-21285488].mp3
[download] 100% of 997.70KiB in 00:00
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `yt_dlp/extractor/foxnews.py`
Content:
```
1 import re
2
3 from .amp import AMPIE
4 from .common import InfoExtractor
5
6
7 class FoxNewsIE(AMPIE):
8 IE_NAME = 'foxnews'
9 IE_DESC = 'Fox News and Fox Business Video'
10 _VALID_URL = r'https?://(?P<host>video\.(?:insider\.)?fox(?:news|business)\.com)/v/(?:video-embed\.html\?video_id=)?(?P<id>\d+)'
11 _TESTS = [
12 {
13 'url': 'http://video.foxnews.com/v/3937480/frozen-in-time/#sp=show-clips',
14 'md5': '32aaded6ba3ef0d1c04e238d01031e5e',
15 'info_dict': {
16 'id': '3937480',
17 'ext': 'flv',
18 'title': 'Frozen in Time',
19 'description': '16-year-old girl is size of toddler',
20 'duration': 265,
21 'timestamp': 1304411491,
22 'upload_date': '20110503',
23 'thumbnail': r're:^https?://.*\.jpg$',
24 },
25 },
26 {
27 'url': 'http://video.foxnews.com/v/3922535568001/rep-luis-gutierrez-on-if-obamas-immigration-plan-is-legal/#sp=show-clips',
28 'md5': '5846c64a1ea05ec78175421b8323e2df',
29 'info_dict': {
30 'id': '3922535568001',
31 'ext': 'mp4',
32 'title': "Rep. Luis Gutierrez on if Obama's immigration plan is legal",
33 'description': "Congressman discusses president's plan",
34 'duration': 292,
35 'timestamp': 1417662047,
36 'upload_date': '20141204',
37 'thumbnail': r're:^https?://.*\.jpg$',
38 },
39 'params': {
40 # m3u8 download
41 'skip_download': True,
42 },
43 },
44 {
45 'url': 'http://video.foxnews.com/v/video-embed.html?video_id=3937480&d=video.foxnews.com',
46 'only_matching': True,
47 },
48 {
49 'url': 'http://video.foxbusiness.com/v/4442309889001',
50 'only_matching': True,
51 },
52 {
53 # From http://insider.foxnews.com/2016/08/25/univ-wisconsin-student-group-pushing-silence-certain-words
54 'url': 'http://video.insider.foxnews.com/v/video-embed.html?video_id=5099377331001&autoplay=true&share_url=http://insider.foxnews.com/2016/08/25/univ-wisconsin-student-group-pushing-silence-certain-words&share_title=Student%20Group:%20Saying%20%27Politically%20Correct,%27%20%27Trash%27%20and%20%27Lame%27%20Is%20Offensive&share=true',
55 'only_matching': True,
56 },
57 ]
58
59 @staticmethod
60 def _extract_urls(webpage):
61 return [
62 mobj.group('url')
63 for mobj in re.finditer(
64 r'<(?:amp-)?iframe[^>]+\bsrc=(["\'])(?P<url>(?:https?:)?//video\.foxnews\.com/v/video-embed\.html?.*?\bvideo_id=\d+.*?)\1',
65 webpage)]
66
67 def _real_extract(self, url):
68 host, video_id = self._match_valid_url(url).groups()
69
70 info = self._extract_feed_info(
71 'http://%s/v/feed/video/%s.js?template=fox' % (host, video_id))
72 info['id'] = video_id
73 return info
74
75
76 class FoxNewsArticleIE(InfoExtractor):
77 _VALID_URL = r'https?://(?:www\.)?(?:insider\.)?foxnews\.com/(?!v)([^/]+/)+(?P<id>[a-z-]+)'
78 IE_NAME = 'foxnews:article'
79
80 _TESTS = [{
81 # data-video-id
82 'url': 'http://www.foxnews.com/politics/2016/09/08/buzz-about-bud-clinton-camp-denies-claims-wore-earpiece-at-forum.html',
83 'md5': '83d44e1aff1433e7a29a7b537d1700b5',
84 'info_dict': {
85 'id': '5116295019001',
86 'ext': 'mp4',
87 'title': 'Trump and Clinton asked to defend positions on Iraq War',
88 'description': 'Veterans react on \'The Kelly File\'',
89 'timestamp': 1473301045,
90 'upload_date': '20160908',
91 },
92 }, {
93 # iframe embed
94 'url': 'http://www.foxnews.com/us/2018/03/09/parkland-survivor-kyle-kashuv-on-meeting-trump-his-app-to-prevent-another-school-shooting.amp.html?__twitter_impression=true',
95 'info_dict': {
96 'id': '5748266721001',
97 'ext': 'flv',
98 'title': 'Kyle Kashuv has a positive message for the Trump White House',
99 'description': 'Marjory Stoneman Douglas student disagrees with classmates.',
100 'thumbnail': r're:^https?://.*\.jpg$',
101 'duration': 229,
102 'timestamp': 1520594670,
103 'upload_date': '20180309',
104 },
105 'params': {
106 'skip_download': True,
107 },
108 }, {
109 'url': 'http://insider.foxnews.com/2016/08/25/univ-wisconsin-student-group-pushing-silence-certain-words',
110 'only_matching': True,
111 }]
112
113 def _real_extract(self, url):
114 display_id = self._match_id(url)
115 webpage = self._download_webpage(url, display_id)
116
117 video_id = self._html_search_regex(
118 r'data-video-id=([\'"])(?P<id>[^\'"]+)\1',
119 webpage, 'video ID', group='id', default=None)
120 if video_id:
121 return self.url_result(
122 'http://video.foxnews.com/v/' + video_id, FoxNewsIE.ie_key())
123
124 return self.url_result(
125 FoxNewsIE._extract_urls(webpage)[0], FoxNewsIE.ie_key())
126
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/yt_dlp/extractor/foxnews.py b/yt_dlp/extractor/foxnews.py
--- a/yt_dlp/extractor/foxnews.py
+++ b/yt_dlp/extractor/foxnews.py
@@ -59,10 +59,13 @@
@staticmethod
def _extract_urls(webpage):
return [
- mobj.group('url')
+ f'https://video.foxnews.com/v/video-embed.html?video_id={mobj.group("video_id")}'
for mobj in re.finditer(
- r'<(?:amp-)?iframe[^>]+\bsrc=(["\'])(?P<url>(?:https?:)?//video\.foxnews\.com/v/video-embed\.html?.*?\bvideo_id=\d+.*?)\1',
- webpage)]
+ r'''(?x)
+ <(?:script|(?:amp-)?iframe)[^>]+\bsrc=["\']
+ (?:https?:)?//video\.foxnews\.com/v/(?:video-embed\.html|embed\.js)\?
+ (?:[^>"\']+&)?(?:video_)?id=(?P<video_id>\d+)
+ ''', webpage)]
def _real_extract(self, url):
host, video_id = self._match_valid_url(url).groups()
|
{"golden_diff": "diff --git a/yt_dlp/extractor/foxnews.py b/yt_dlp/extractor/foxnews.py\n--- a/yt_dlp/extractor/foxnews.py\n+++ b/yt_dlp/extractor/foxnews.py\n@@ -59,10 +59,13 @@\n @staticmethod\n def _extract_urls(webpage):\n return [\n- mobj.group('url')\n+ f'https://video.foxnews.com/v/video-embed.html?video_id={mobj.group(\"video_id\")}'\n for mobj in re.finditer(\n- r'<(?:amp-)?iframe[^>]+\\bsrc=([\"\\'])(?P<url>(?:https?:)?//video\\.foxnews\\.com/v/video-embed\\.html?.*?\\bvideo_id=\\d+.*?)\\1',\n- webpage)]\n+ r'''(?x)\n+ <(?:script|(?:amp-)?iframe)[^>]+\\bsrc=[\"\\']\n+ (?:https?:)?//video\\.foxnews\\.com/v/(?:video-embed\\.html|embed\\.js)\\?\n+ (?:[^>\"\\']+&)?(?:video_)?id=(?P<video_id>\\d+)\n+ ''', webpage)]\n \n def _real_extract(self, url):\n host, video_id = self._match_valid_url(url).groups()\n", "issue": "www.breitbart.com\n### Checklist\n\n- [X] I'm reporting a new site support request\n- [X] I've verified that I'm running yt-dlp version **2022.05.18** ([update instructions](https://github.com/yt-dlp/yt-dlp#update)) or later (specify commit)\n- [X] I've checked that all provided URLs are playable in a browser with the same IP and same login details\n- [X] I've checked that none of provided URLs [violate any copyrights](https://github.com/ytdl-org/youtube-dl#can-you-add-support-for-this-anime-video-site-or-site-which-shows-current-movies-for-free) or contain any [DRM](https://en.wikipedia.org/wiki/Digital_rights_management) to the best of my knowledge\n- [X] I've searched the [bugtracker](https://github.com/yt-dlp/yt-dlp/issues?q=) for similar issues including closed ones. DO NOT post duplicates\n- [X] I've read the [guidelines for opening an issue](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#opening-an-issue)\n- [X] I've read about [sharing account credentials](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#are-you-willing-to-share-account-details-if-needed) and am willing to share it if required\n\n### Region\n\n_No response_\n\n### Example URLs\n\nhttps://www.breitbart.com/clips/2022/06/08/kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere/\n\n### Description\n\nEmbedded Fox News video not detected. Can be played in Firefox and even be downloaded using an extension named HLS Dowloader.\n\n### Verbose log\n\n```shell\n\"C:\\Users\\a\\Desktop\\MPC-BE\\yt-dlp.exe\" -vU https://www.breitbart.com/clips/2022/06/08/kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere/\r\n[debug] Command-line config: ['-vU', 'https://www.breitbart.com/clips/2022/06/08/kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere/']\r\n[debug] Encodings: locale cp1252, fs utf-8, pref cp1252, out utf-8, error utf-8, screen utf-8\r\n[debug] yt-dlp version 2022.05.18 [b14d523] (win_exe)\r\n[debug] Python version 3.7.9 (CPython 32bit) - Windows-10-10.0.19041-SP0\r\n[debug] Checking exe version: ffprobe -bsfs\r\n[debug] Checking exe version: avprobe -bsfs\r\n[debug] Checking exe version: ffmpeg -bsfs\r\n[debug] Checking exe version: avconv -bsfs\r\n[debug] exe versions: none\r\n[debug] Optional libraries: Cryptodome-3.14.1, brotli-1.0.9, certifi-2021.10.08, mutagen-1.45.1, sqlite3-2.6.0, websockets-10.3\r\n[debug] Proxy map: {}\r\nLatest version: 2022.05.18, Current version: 2022.05.18\r\nyt-dlp is up to date (2022.05.18)\r\n[debug] [generic] Extracting URL: https://www.breitbart.com/clips/2022/06/08/kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere/\r\n[generic] kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere: Requesting header\r\nWARNING: [generic] Falling back on generic information extractor.\r\n[generic] kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere: Downloading webpage\r\n[generic] kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere: Extracting information\r\n[debug] Looking for video embeds\r\n[debug] Identified a Open Graph video info\r\n[debug] Default format spec: best/bestvideo+bestaudio\r\n[info] kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere-21285488: Downloading 1 format(s): 0\r\n[debug] Invoking http downloader on \"https://media.breitbart.com/media/2022/06/kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere-21285488.mp3\"\r\n[debug] File locking is not supported on this platform. Proceeding without locking\r\n[download] Destination: Kennedy - 'Price of Gas Is So High that It Would Be Cheaper to Buy Cocaine and Just Run Everywhere' [kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere-21285488].mp3\r\n[download] 100% of 997.70KiB in 00:00\n```\n\n", "before_files": [{"content": "import re\n\nfrom .amp import AMPIE\nfrom .common import InfoExtractor\n\n\nclass FoxNewsIE(AMPIE):\n IE_NAME = 'foxnews'\n IE_DESC = 'Fox News and Fox Business Video'\n _VALID_URL = r'https?://(?P<host>video\\.(?:insider\\.)?fox(?:news|business)\\.com)/v/(?:video-embed\\.html\\?video_id=)?(?P<id>\\d+)'\n _TESTS = [\n {\n 'url': 'http://video.foxnews.com/v/3937480/frozen-in-time/#sp=show-clips',\n 'md5': '32aaded6ba3ef0d1c04e238d01031e5e',\n 'info_dict': {\n 'id': '3937480',\n 'ext': 'flv',\n 'title': 'Frozen in Time',\n 'description': '16-year-old girl is size of toddler',\n 'duration': 265,\n 'timestamp': 1304411491,\n 'upload_date': '20110503',\n 'thumbnail': r're:^https?://.*\\.jpg$',\n },\n },\n {\n 'url': 'http://video.foxnews.com/v/3922535568001/rep-luis-gutierrez-on-if-obamas-immigration-plan-is-legal/#sp=show-clips',\n 'md5': '5846c64a1ea05ec78175421b8323e2df',\n 'info_dict': {\n 'id': '3922535568001',\n 'ext': 'mp4',\n 'title': \"Rep. Luis Gutierrez on if Obama's immigration plan is legal\",\n 'description': \"Congressman discusses president's plan\",\n 'duration': 292,\n 'timestamp': 1417662047,\n 'upload_date': '20141204',\n 'thumbnail': r're:^https?://.*\\.jpg$',\n },\n 'params': {\n # m3u8 download\n 'skip_download': True,\n },\n },\n {\n 'url': 'http://video.foxnews.com/v/video-embed.html?video_id=3937480&d=video.foxnews.com',\n 'only_matching': True,\n },\n {\n 'url': 'http://video.foxbusiness.com/v/4442309889001',\n 'only_matching': True,\n },\n {\n # From http://insider.foxnews.com/2016/08/25/univ-wisconsin-student-group-pushing-silence-certain-words\n 'url': 'http://video.insider.foxnews.com/v/video-embed.html?video_id=5099377331001&autoplay=true&share_url=http://insider.foxnews.com/2016/08/25/univ-wisconsin-student-group-pushing-silence-certain-words&share_title=Student%20Group:%20Saying%20%27Politically%20Correct,%27%20%27Trash%27%20and%20%27Lame%27%20Is%20Offensive&share=true',\n 'only_matching': True,\n },\n ]\n\n @staticmethod\n def _extract_urls(webpage):\n return [\n mobj.group('url')\n for mobj in re.finditer(\n r'<(?:amp-)?iframe[^>]+\\bsrc=([\"\\'])(?P<url>(?:https?:)?//video\\.foxnews\\.com/v/video-embed\\.html?.*?\\bvideo_id=\\d+.*?)\\1',\n webpage)]\n\n def _real_extract(self, url):\n host, video_id = self._match_valid_url(url).groups()\n\n info = self._extract_feed_info(\n 'http://%s/v/feed/video/%s.js?template=fox' % (host, video_id))\n info['id'] = video_id\n return info\n\n\nclass FoxNewsArticleIE(InfoExtractor):\n _VALID_URL = r'https?://(?:www\\.)?(?:insider\\.)?foxnews\\.com/(?!v)([^/]+/)+(?P<id>[a-z-]+)'\n IE_NAME = 'foxnews:article'\n\n _TESTS = [{\n # data-video-id\n 'url': 'http://www.foxnews.com/politics/2016/09/08/buzz-about-bud-clinton-camp-denies-claims-wore-earpiece-at-forum.html',\n 'md5': '83d44e1aff1433e7a29a7b537d1700b5',\n 'info_dict': {\n 'id': '5116295019001',\n 'ext': 'mp4',\n 'title': 'Trump and Clinton asked to defend positions on Iraq War',\n 'description': 'Veterans react on \\'The Kelly File\\'',\n 'timestamp': 1473301045,\n 'upload_date': '20160908',\n },\n }, {\n # iframe embed\n 'url': 'http://www.foxnews.com/us/2018/03/09/parkland-survivor-kyle-kashuv-on-meeting-trump-his-app-to-prevent-another-school-shooting.amp.html?__twitter_impression=true',\n 'info_dict': {\n 'id': '5748266721001',\n 'ext': 'flv',\n 'title': 'Kyle Kashuv has a positive message for the Trump White House',\n 'description': 'Marjory Stoneman Douglas student disagrees with classmates.',\n 'thumbnail': r're:^https?://.*\\.jpg$',\n 'duration': 229,\n 'timestamp': 1520594670,\n 'upload_date': '20180309',\n },\n 'params': {\n 'skip_download': True,\n },\n }, {\n 'url': 'http://insider.foxnews.com/2016/08/25/univ-wisconsin-student-group-pushing-silence-certain-words',\n 'only_matching': True,\n }]\n\n def _real_extract(self, url):\n display_id = self._match_id(url)\n webpage = self._download_webpage(url, display_id)\n\n video_id = self._html_search_regex(\n r'data-video-id=([\\'\"])(?P<id>[^\\'\"]+)\\1',\n webpage, 'video ID', group='id', default=None)\n if video_id:\n return self.url_result(\n 'http://video.foxnews.com/v/' + video_id, FoxNewsIE.ie_key())\n\n return self.url_result(\n FoxNewsIE._extract_urls(webpage)[0], FoxNewsIE.ie_key())\n", "path": "yt_dlp/extractor/foxnews.py"}], "after_files": [{"content": "import re\n\nfrom .amp import AMPIE\nfrom .common import InfoExtractor\n\n\nclass FoxNewsIE(AMPIE):\n IE_NAME = 'foxnews'\n IE_DESC = 'Fox News and Fox Business Video'\n _VALID_URL = r'https?://(?P<host>video\\.(?:insider\\.)?fox(?:news|business)\\.com)/v/(?:video-embed\\.html\\?video_id=)?(?P<id>\\d+)'\n _TESTS = [\n {\n 'url': 'http://video.foxnews.com/v/3937480/frozen-in-time/#sp=show-clips',\n 'md5': '32aaded6ba3ef0d1c04e238d01031e5e',\n 'info_dict': {\n 'id': '3937480',\n 'ext': 'flv',\n 'title': 'Frozen in Time',\n 'description': '16-year-old girl is size of toddler',\n 'duration': 265,\n 'timestamp': 1304411491,\n 'upload_date': '20110503',\n 'thumbnail': r're:^https?://.*\\.jpg$',\n },\n },\n {\n 'url': 'http://video.foxnews.com/v/3922535568001/rep-luis-gutierrez-on-if-obamas-immigration-plan-is-legal/#sp=show-clips',\n 'md5': '5846c64a1ea05ec78175421b8323e2df',\n 'info_dict': {\n 'id': '3922535568001',\n 'ext': 'mp4',\n 'title': \"Rep. Luis Gutierrez on if Obama's immigration plan is legal\",\n 'description': \"Congressman discusses president's plan\",\n 'duration': 292,\n 'timestamp': 1417662047,\n 'upload_date': '20141204',\n 'thumbnail': r're:^https?://.*\\.jpg$',\n },\n 'params': {\n # m3u8 download\n 'skip_download': True,\n },\n },\n {\n 'url': 'http://video.foxnews.com/v/video-embed.html?video_id=3937480&d=video.foxnews.com',\n 'only_matching': True,\n },\n {\n 'url': 'http://video.foxbusiness.com/v/4442309889001',\n 'only_matching': True,\n },\n {\n # From http://insider.foxnews.com/2016/08/25/univ-wisconsin-student-group-pushing-silence-certain-words\n 'url': 'http://video.insider.foxnews.com/v/video-embed.html?video_id=5099377331001&autoplay=true&share_url=http://insider.foxnews.com/2016/08/25/univ-wisconsin-student-group-pushing-silence-certain-words&share_title=Student%20Group:%20Saying%20%27Politically%20Correct,%27%20%27Trash%27%20and%20%27Lame%27%20Is%20Offensive&share=true',\n 'only_matching': True,\n },\n ]\n\n @staticmethod\n def _extract_urls(webpage):\n return [\n f'https://video.foxnews.com/v/video-embed.html?video_id={mobj.group(\"video_id\")}'\n for mobj in re.finditer(\n r'''(?x)\n <(?:script|(?:amp-)?iframe)[^>]+\\bsrc=[\"\\']\n (?:https?:)?//video\\.foxnews\\.com/v/(?:video-embed\\.html|embed\\.js)\\?\n (?:[^>\"\\']+&)?(?:video_)?id=(?P<video_id>\\d+)\n ''', webpage)]\n\n def _real_extract(self, url):\n host, video_id = self._match_valid_url(url).groups()\n\n info = self._extract_feed_info(\n 'http://%s/v/feed/video/%s.js?template=fox' % (host, video_id))\n info['id'] = video_id\n return info\n\n\nclass FoxNewsArticleIE(InfoExtractor):\n _VALID_URL = r'https?://(?:www\\.)?(?:insider\\.)?foxnews\\.com/(?!v)([^/]+/)+(?P<id>[a-z-]+)'\n IE_NAME = 'foxnews:article'\n\n _TESTS = [{\n # data-video-id\n 'url': 'http://www.foxnews.com/politics/2016/09/08/buzz-about-bud-clinton-camp-denies-claims-wore-earpiece-at-forum.html',\n 'md5': '83d44e1aff1433e7a29a7b537d1700b5',\n 'info_dict': {\n 'id': '5116295019001',\n 'ext': 'mp4',\n 'title': 'Trump and Clinton asked to defend positions on Iraq War',\n 'description': 'Veterans react on \\'The Kelly File\\'',\n 'timestamp': 1473301045,\n 'upload_date': '20160908',\n },\n }, {\n # iframe embed\n 'url': 'http://www.foxnews.com/us/2018/03/09/parkland-survivor-kyle-kashuv-on-meeting-trump-his-app-to-prevent-another-school-shooting.amp.html?__twitter_impression=true',\n 'info_dict': {\n 'id': '5748266721001',\n 'ext': 'flv',\n 'title': 'Kyle Kashuv has a positive message for the Trump White House',\n 'description': 'Marjory Stoneman Douglas student disagrees with classmates.',\n 'thumbnail': r're:^https?://.*\\.jpg$',\n 'duration': 229,\n 'timestamp': 1520594670,\n 'upload_date': '20180309',\n },\n 'params': {\n 'skip_download': True,\n },\n }, {\n 'url': 'http://insider.foxnews.com/2016/08/25/univ-wisconsin-student-group-pushing-silence-certain-words',\n 'only_matching': True,\n }]\n\n def _real_extract(self, url):\n display_id = self._match_id(url)\n webpage = self._download_webpage(url, display_id)\n\n video_id = self._html_search_regex(\n r'data-video-id=([\\'\"])(?P<id>[^\\'\"]+)\\1',\n webpage, 'video ID', group='id', default=None)\n if video_id:\n return self.url_result(\n 'http://video.foxnews.com/v/' + video_id, FoxNewsIE.ie_key())\n\n return self.url_result(\n FoxNewsIE._extract_urls(webpage)[0], FoxNewsIE.ie_key())\n", "path": "yt_dlp/extractor/foxnews.py"}]}
| 3,438 | 298 |
gh_patches_debug_34950
|
rasdani/github-patches
|
git_diff
|
jupyterhub__jupyterhub-2971
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
singleuser server version check spams the logs
**Describe the bug**
We have ~277 active single user servers in our deployment right now and on restart of the hub service we see this for each one:
> Mar 4 09:20:45 hub-7bccd48cd5-mp4fk hub [W 2020-03-04 15:20:45.996 JupyterHub _version:56] jupyterhub version 1.2.0dev != jupyterhub-singleuser version 1.1.0. This could cause failure to authenticate and result in redirect loops!
My only complaint is that logging that per server is redundant and spams the logs. Can we just log that once per restart of the hub?
**To Reproduce**
Have the jupyterhub and jupyterhub-singleuser services at different minor versions.
**Expected behavior**
Just log the warning once since there is no user/server specific context in the message.
**Compute Information**
- 1.2.0dev - we're running with a custom build based on b4391d0f796864a5b01167701d95eafce3ad987e so that we can pick up the performance fix for issue #2928.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `jupyterhub/_version.py`
Content:
```
1 """JupyterHub version info"""
2 # Copyright (c) Jupyter Development Team.
3 # Distributed under the terms of the Modified BSD License.
4
5 version_info = (
6 1,
7 2,
8 0,
9 # "", # release (b1, rc1, or "" for final or dev)
10 "dev", # dev or nothing for beta/rc/stable releases
11 )
12
13 # pep 440 version: no dot before beta/rc, but before .dev
14 # 0.1.0rc1
15 # 0.1.0a1
16 # 0.1.0b1.dev
17 # 0.1.0.dev
18
19 __version__ = ".".join(map(str, version_info[:3])) + ".".join(version_info[3:])
20
21
22 def _check_version(hub_version, singleuser_version, log):
23 """Compare Hub and single-user server versions"""
24 if not hub_version:
25 log.warning(
26 "Hub has no version header, which means it is likely < 0.8. Expected %s",
27 __version__,
28 )
29 return
30
31 if not singleuser_version:
32 log.warning(
33 "Single-user server has no version header, which means it is likely < 0.8. Expected %s",
34 __version__,
35 )
36 return
37
38 # compare minor X.Y versions
39 if hub_version != singleuser_version:
40 from distutils.version import LooseVersion as V
41
42 hub_major_minor = V(hub_version).version[:2]
43 singleuser_major_minor = V(singleuser_version).version[:2]
44 extra = ""
45 if singleuser_major_minor == hub_major_minor:
46 # patch-level mismatch or lower, log difference at debug-level
47 # because this should be fine
48 log_method = log.debug
49 else:
50 # log warning-level for more significant mismatch, such as 0.8 vs 0.9, etc.
51 log_method = log.warning
52 extra = " This could cause failure to authenticate and result in redirect loops!"
53 log_method(
54 "jupyterhub version %s != jupyterhub-singleuser version %s." + extra,
55 hub_version,
56 singleuser_version,
57 )
58 else:
59 log.debug(
60 "jupyterhub and jupyterhub-singleuser both on version %s" % hub_version
61 )
62
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/jupyterhub/_version.py b/jupyterhub/_version.py
--- a/jupyterhub/_version.py
+++ b/jupyterhub/_version.py
@@ -18,6 +18,15 @@
__version__ = ".".join(map(str, version_info[:3])) + ".".join(version_info[3:])
+# Singleton flag to only log the major/minor mismatch warning once per mismatch combo.
+_version_mismatch_warning_logged = {}
+
+
+def reset_globals():
+ """Used to reset globals between test cases."""
+ global _version_mismatch_warning_logged
+ _version_mismatch_warning_logged = {}
+
def _check_version(hub_version, singleuser_version, log):
"""Compare Hub and single-user server versions"""
@@ -42,19 +51,27 @@
hub_major_minor = V(hub_version).version[:2]
singleuser_major_minor = V(singleuser_version).version[:2]
extra = ""
+ do_log = True
if singleuser_major_minor == hub_major_minor:
# patch-level mismatch or lower, log difference at debug-level
# because this should be fine
log_method = log.debug
else:
# log warning-level for more significant mismatch, such as 0.8 vs 0.9, etc.
- log_method = log.warning
- extra = " This could cause failure to authenticate and result in redirect loops!"
- log_method(
- "jupyterhub version %s != jupyterhub-singleuser version %s." + extra,
- hub_version,
- singleuser_version,
- )
+ key = '%s-%s' % (hub_version, singleuser_version)
+ global _version_mismatch_warning_logged
+ if _version_mismatch_warning_logged.get(key):
+ do_log = False # We already logged this warning so don't log it again.
+ else:
+ log_method = log.warning
+ extra = " This could cause failure to authenticate and result in redirect loops!"
+ _version_mismatch_warning_logged[key] = True
+ if do_log:
+ log_method(
+ "jupyterhub version %s != jupyterhub-singleuser version %s." + extra,
+ hub_version,
+ singleuser_version,
+ )
else:
log.debug(
"jupyterhub and jupyterhub-singleuser both on version %s" % hub_version
|
{"golden_diff": "diff --git a/jupyterhub/_version.py b/jupyterhub/_version.py\n--- a/jupyterhub/_version.py\n+++ b/jupyterhub/_version.py\n@@ -18,6 +18,15 @@\n \n __version__ = \".\".join(map(str, version_info[:3])) + \".\".join(version_info[3:])\n \n+# Singleton flag to only log the major/minor mismatch warning once per mismatch combo.\n+_version_mismatch_warning_logged = {}\n+\n+\n+def reset_globals():\n+ \"\"\"Used to reset globals between test cases.\"\"\"\n+ global _version_mismatch_warning_logged\n+ _version_mismatch_warning_logged = {}\n+\n \n def _check_version(hub_version, singleuser_version, log):\n \"\"\"Compare Hub and single-user server versions\"\"\"\n@@ -42,19 +51,27 @@\n hub_major_minor = V(hub_version).version[:2]\n singleuser_major_minor = V(singleuser_version).version[:2]\n extra = \"\"\n+ do_log = True\n if singleuser_major_minor == hub_major_minor:\n # patch-level mismatch or lower, log difference at debug-level\n # because this should be fine\n log_method = log.debug\n else:\n # log warning-level for more significant mismatch, such as 0.8 vs 0.9, etc.\n- log_method = log.warning\n- extra = \" This could cause failure to authenticate and result in redirect loops!\"\n- log_method(\n- \"jupyterhub version %s != jupyterhub-singleuser version %s.\" + extra,\n- hub_version,\n- singleuser_version,\n- )\n+ key = '%s-%s' % (hub_version, singleuser_version)\n+ global _version_mismatch_warning_logged\n+ if _version_mismatch_warning_logged.get(key):\n+ do_log = False # We already logged this warning so don't log it again.\n+ else:\n+ log_method = log.warning\n+ extra = \" This could cause failure to authenticate and result in redirect loops!\"\n+ _version_mismatch_warning_logged[key] = True\n+ if do_log:\n+ log_method(\n+ \"jupyterhub version %s != jupyterhub-singleuser version %s.\" + extra,\n+ hub_version,\n+ singleuser_version,\n+ )\n else:\n log.debug(\n \"jupyterhub and jupyterhub-singleuser both on version %s\" % hub_version\n", "issue": "singleuser server version check spams the logs\n**Describe the bug**\r\n\r\nWe have ~277 active single user servers in our deployment right now and on restart of the hub service we see this for each one:\r\n\r\n> Mar 4 09:20:45 hub-7bccd48cd5-mp4fk hub [W 2020-03-04 15:20:45.996 JupyterHub _version:56] jupyterhub version 1.2.0dev != jupyterhub-singleuser version 1.1.0. This could cause failure to authenticate and result in redirect loops! \r\n\r\nMy only complaint is that logging that per server is redundant and spams the logs. Can we just log that once per restart of the hub?\r\n\r\n**To Reproduce**\r\n\r\nHave the jupyterhub and jupyterhub-singleuser services at different minor versions.\r\n\r\n**Expected behavior**\r\n\r\nJust log the warning once since there is no user/server specific context in the message.\r\n\r\n**Compute Information**\r\n - 1.2.0dev - we're running with a custom build based on b4391d0f796864a5b01167701d95eafce3ad987e so that we can pick up the performance fix for issue #2928.\n", "before_files": [{"content": "\"\"\"JupyterHub version info\"\"\"\n# Copyright (c) Jupyter Development Team.\n# Distributed under the terms of the Modified BSD License.\n\nversion_info = (\n 1,\n 2,\n 0,\n # \"\", # release (b1, rc1, or \"\" for final or dev)\n \"dev\", # dev or nothing for beta/rc/stable releases\n)\n\n# pep 440 version: no dot before beta/rc, but before .dev\n# 0.1.0rc1\n# 0.1.0a1\n# 0.1.0b1.dev\n# 0.1.0.dev\n\n__version__ = \".\".join(map(str, version_info[:3])) + \".\".join(version_info[3:])\n\n\ndef _check_version(hub_version, singleuser_version, log):\n \"\"\"Compare Hub and single-user server versions\"\"\"\n if not hub_version:\n log.warning(\n \"Hub has no version header, which means it is likely < 0.8. Expected %s\",\n __version__,\n )\n return\n\n if not singleuser_version:\n log.warning(\n \"Single-user server has no version header, which means it is likely < 0.8. Expected %s\",\n __version__,\n )\n return\n\n # compare minor X.Y versions\n if hub_version != singleuser_version:\n from distutils.version import LooseVersion as V\n\n hub_major_minor = V(hub_version).version[:2]\n singleuser_major_minor = V(singleuser_version).version[:2]\n extra = \"\"\n if singleuser_major_minor == hub_major_minor:\n # patch-level mismatch or lower, log difference at debug-level\n # because this should be fine\n log_method = log.debug\n else:\n # log warning-level for more significant mismatch, such as 0.8 vs 0.9, etc.\n log_method = log.warning\n extra = \" This could cause failure to authenticate and result in redirect loops!\"\n log_method(\n \"jupyterhub version %s != jupyterhub-singleuser version %s.\" + extra,\n hub_version,\n singleuser_version,\n )\n else:\n log.debug(\n \"jupyterhub and jupyterhub-singleuser both on version %s\" % hub_version\n )\n", "path": "jupyterhub/_version.py"}], "after_files": [{"content": "\"\"\"JupyterHub version info\"\"\"\n# Copyright (c) Jupyter Development Team.\n# Distributed under the terms of the Modified BSD License.\n\nversion_info = (\n 1,\n 2,\n 0,\n # \"\", # release (b1, rc1, or \"\" for final or dev)\n \"dev\", # dev or nothing for beta/rc/stable releases\n)\n\n# pep 440 version: no dot before beta/rc, but before .dev\n# 0.1.0rc1\n# 0.1.0a1\n# 0.1.0b1.dev\n# 0.1.0.dev\n\n__version__ = \".\".join(map(str, version_info[:3])) + \".\".join(version_info[3:])\n\n# Singleton flag to only log the major/minor mismatch warning once per mismatch combo.\n_version_mismatch_warning_logged = {}\n\n\ndef reset_globals():\n \"\"\"Used to reset globals between test cases.\"\"\"\n global _version_mismatch_warning_logged\n _version_mismatch_warning_logged = {}\n\n\ndef _check_version(hub_version, singleuser_version, log):\n \"\"\"Compare Hub and single-user server versions\"\"\"\n if not hub_version:\n log.warning(\n \"Hub has no version header, which means it is likely < 0.8. Expected %s\",\n __version__,\n )\n return\n\n if not singleuser_version:\n log.warning(\n \"Single-user server has no version header, which means it is likely < 0.8. Expected %s\",\n __version__,\n )\n return\n\n # compare minor X.Y versions\n if hub_version != singleuser_version:\n from distutils.version import LooseVersion as V\n\n hub_major_minor = V(hub_version).version[:2]\n singleuser_major_minor = V(singleuser_version).version[:2]\n extra = \"\"\n do_log = True\n if singleuser_major_minor == hub_major_minor:\n # patch-level mismatch or lower, log difference at debug-level\n # because this should be fine\n log_method = log.debug\n else:\n # log warning-level for more significant mismatch, such as 0.8 vs 0.9, etc.\n key = '%s-%s' % (hub_version, singleuser_version)\n global _version_mismatch_warning_logged\n if _version_mismatch_warning_logged.get(key):\n do_log = False # We already logged this warning so don't log it again.\n else:\n log_method = log.warning\n extra = \" This could cause failure to authenticate and result in redirect loops!\"\n _version_mismatch_warning_logged[key] = True\n if do_log:\n log_method(\n \"jupyterhub version %s != jupyterhub-singleuser version %s.\" + extra,\n hub_version,\n singleuser_version,\n )\n else:\n log.debug(\n \"jupyterhub and jupyterhub-singleuser both on version %s\" % hub_version\n )\n", "path": "jupyterhub/_version.py"}]}
| 1,171 | 528 |
gh_patches_debug_35171
|
rasdani/github-patches
|
git_diff
|
awslabs__gluonts-709
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Tracking: mxnet 1.6
### To update
- [x] documentation
- [x] README.md
- [x] test-dependencies
### Fix
- [x] https://github.com/awslabs/gluon-ts/issues/583
### Other
- [x] Update `numpy~1.18`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/gluonts/model/seq2seq/_forking_network.py`
Content:
```
1 # Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License").
4 # You may not use this file except in compliance with the License.
5 # A copy of the License is located at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # or in the "license" file accompanying this file. This file is distributed
10 # on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either
11 # express or implied. See the License for the specific language governing
12 # permissions and limitations under the License.
13
14 # Third-party imports
15 from mxnet import gluon, nd
16
17 # First-party imports
18 from gluonts.block.decoder import Seq2SeqDecoder
19 from gluonts.block.enc2dec import Seq2SeqEnc2Dec
20 from gluonts.block.encoder import Seq2SeqEncoder
21 from gluonts.block.quantile_output import QuantileOutput
22 from gluonts.core.component import validated
23 from gluonts.model.common import Tensor
24
25 nd_None = nd.array([])
26
27
28 class ForkingSeq2SeqNetworkBase(gluon.HybridBlock):
29 """
30 Base network for the :class:`ForkingSeq2SeqEstimator`.
31
32 Parameters
33 ----------
34 encoder: Seq2SeqEncoder
35 encoder block
36 enc2dec: Seq2SeqEnc2Dec
37 encoder to decoder mapping block
38 decoder: Seq2SeqDecoder
39 decoder block
40 quantile_output: QuantileOutput
41 quantile output block
42 kwargs: dict
43 dictionary of Gluon HybridBlock parameters
44 """
45
46 @validated()
47 def __init__(
48 self,
49 encoder: Seq2SeqEncoder,
50 enc2dec: Seq2SeqEnc2Dec,
51 decoder: Seq2SeqDecoder,
52 quantile_output: QuantileOutput,
53 **kwargs,
54 ) -> None:
55 super().__init__(**kwargs)
56
57 self.encoder = encoder
58 self.enc2dec = enc2dec
59 self.decoder = decoder
60 self.quantile_output = quantile_output
61
62 with self.name_scope():
63 self.quantile_proj = quantile_output.get_quantile_proj()
64 self.loss = quantile_output.get_loss()
65
66
67 class ForkingSeq2SeqTrainingNetwork(ForkingSeq2SeqNetworkBase):
68 # noinspection PyMethodOverriding
69 def hybrid_forward(
70 self, F, past_target: Tensor, future_target: Tensor
71 ) -> Tensor:
72 """
73 Parameters
74 ----------
75 F: mx.symbol or mx.ndarray
76 Gluon function space
77 past_target: Tensor
78 FIXME
79 future_target: Tensor
80 shape (num_ts, encoder_length, 1) FIXME
81
82 Returns
83 -------
84 loss with shape (FIXME, FIXME)
85 """
86
87 # FIXME: can we factor out a common prefix in the base network?
88 feat_static_real = nd_None
89 past_feat_dynamic_real = nd_None
90 future_feat_dynamic_real = nd_None
91
92 enc_output_static, enc_output_dynamic = self.encoder(
93 past_target, feat_static_real, past_feat_dynamic_real
94 )
95
96 dec_input_static, dec_input_dynamic, _ = self.enc2dec(
97 enc_output_static, enc_output_dynamic, future_feat_dynamic_real
98 )
99
100 dec_output = self.decoder(dec_input_dynamic, dec_input_static)
101 dec_dist_output = self.quantile_proj(dec_output)
102
103 loss = self.loss(future_target, dec_dist_output)
104 return loss.mean(axis=1)
105
106
107 class ForkingSeq2SeqPredictionNetwork(ForkingSeq2SeqNetworkBase):
108 # noinspection PyMethodOverriding
109 def hybrid_forward(self, F, past_target: Tensor) -> Tensor:
110 """
111 Parameters
112 ----------
113 F: mx.symbol or mx.ndarray
114 Gluon function space
115 past_target: Tensor
116 FIXME
117
118 Returns
119 -------
120 prediction tensor with shape (FIXME, FIXME)
121 """
122
123 # FIXME: can we factor out a common prefix in the base network?
124 feat_static_real = nd_None
125 past_feat_dynamic_real = nd_None
126 future_feat_dynamic_real = nd_None
127
128 enc_output_static, enc_output_dynamic = self.encoder(
129 past_target, feat_static_real, past_feat_dynamic_real
130 )
131
132 enc_output_static = (
133 nd_None if enc_output_static is None else enc_output_static
134 )
135
136 dec_inp_static, dec_inp_dynamic, _ = self.enc2dec(
137 enc_output_static, enc_output_dynamic, future_feat_dynamic_real
138 )
139
140 dec_output = self.decoder(dec_inp_dynamic, dec_inp_static)
141 fcst_output = F.slice_axis(dec_output, axis=1, begin=-1, end=None)
142 fcst_output = F.squeeze(fcst_output, axis=1)
143
144 predictions = self.quantile_proj(fcst_output).swapaxes(2, 1)
145 return predictions
146
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/gluonts/model/seq2seq/_forking_network.py b/src/gluonts/model/seq2seq/_forking_network.py
--- a/src/gluonts/model/seq2seq/_forking_network.py
+++ b/src/gluonts/model/seq2seq/_forking_network.py
@@ -12,7 +12,8 @@
# permissions and limitations under the License.
# Third-party imports
-from mxnet import gluon, nd
+import mxnet as mx
+from mxnet import gluon
# First-party imports
from gluonts.block.decoder import Seq2SeqDecoder
@@ -22,8 +23,6 @@
from gluonts.core.component import validated
from gluonts.model.common import Tensor
-nd_None = nd.array([])
-
class ForkingSeq2SeqNetworkBase(gluon.HybridBlock):
"""
@@ -85,9 +84,9 @@
"""
# FIXME: can we factor out a common prefix in the base network?
- feat_static_real = nd_None
- past_feat_dynamic_real = nd_None
- future_feat_dynamic_real = nd_None
+ feat_static_real = F.zeros(shape=(1,))
+ past_feat_dynamic_real = F.zeros(shape=(1,))
+ future_feat_dynamic_real = F.zeros(shape=(1,))
enc_output_static, enc_output_dynamic = self.encoder(
past_target, feat_static_real, past_feat_dynamic_real
@@ -121,16 +120,18 @@
"""
# FIXME: can we factor out a common prefix in the base network?
- feat_static_real = nd_None
- past_feat_dynamic_real = nd_None
- future_feat_dynamic_real = nd_None
+ feat_static_real = F.zeros(shape=(1,))
+ past_feat_dynamic_real = F.zeros(shape=(1,))
+ future_feat_dynamic_real = F.zeros(shape=(1,))
enc_output_static, enc_output_dynamic = self.encoder(
past_target, feat_static_real, past_feat_dynamic_real
)
enc_output_static = (
- nd_None if enc_output_static is None else enc_output_static
+ F.zeros(shape=(1,))
+ if enc_output_static is None
+ else enc_output_static
)
dec_inp_static, dec_inp_dynamic, _ = self.enc2dec(
|
{"golden_diff": "diff --git a/src/gluonts/model/seq2seq/_forking_network.py b/src/gluonts/model/seq2seq/_forking_network.py\n--- a/src/gluonts/model/seq2seq/_forking_network.py\n+++ b/src/gluonts/model/seq2seq/_forking_network.py\n@@ -12,7 +12,8 @@\n # permissions and limitations under the License.\n \n # Third-party imports\n-from mxnet import gluon, nd\n+import mxnet as mx\n+from mxnet import gluon\n \n # First-party imports\n from gluonts.block.decoder import Seq2SeqDecoder\n@@ -22,8 +23,6 @@\n from gluonts.core.component import validated\n from gluonts.model.common import Tensor\n \n-nd_None = nd.array([])\n-\n \n class ForkingSeq2SeqNetworkBase(gluon.HybridBlock):\n \"\"\"\n@@ -85,9 +84,9 @@\n \"\"\"\n \n # FIXME: can we factor out a common prefix in the base network?\n- feat_static_real = nd_None\n- past_feat_dynamic_real = nd_None\n- future_feat_dynamic_real = nd_None\n+ feat_static_real = F.zeros(shape=(1,))\n+ past_feat_dynamic_real = F.zeros(shape=(1,))\n+ future_feat_dynamic_real = F.zeros(shape=(1,))\n \n enc_output_static, enc_output_dynamic = self.encoder(\n past_target, feat_static_real, past_feat_dynamic_real\n@@ -121,16 +120,18 @@\n \"\"\"\n \n # FIXME: can we factor out a common prefix in the base network?\n- feat_static_real = nd_None\n- past_feat_dynamic_real = nd_None\n- future_feat_dynamic_real = nd_None\n+ feat_static_real = F.zeros(shape=(1,))\n+ past_feat_dynamic_real = F.zeros(shape=(1,))\n+ future_feat_dynamic_real = F.zeros(shape=(1,))\n \n enc_output_static, enc_output_dynamic = self.encoder(\n past_target, feat_static_real, past_feat_dynamic_real\n )\n \n enc_output_static = (\n- nd_None if enc_output_static is None else enc_output_static\n+ F.zeros(shape=(1,))\n+ if enc_output_static is None\n+ else enc_output_static\n )\n \n dec_inp_static, dec_inp_dynamic, _ = self.enc2dec(\n", "issue": "Tracking: mxnet 1.6\n### To update\r\n\r\n- [x] documentation\r\n- [x] README.md\r\n- [x] test-dependencies\r\n\r\n### Fix\r\n\r\n- [x] https://github.com/awslabs/gluon-ts/issues/583\r\n\r\n### Other\r\n\r\n- [x] Update `numpy~1.18`\n", "before_files": [{"content": "# Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\").\n# You may not use this file except in compliance with the License.\n# A copy of the License is located at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# or in the \"license\" file accompanying this file. This file is distributed\n# on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either\n# express or implied. See the License for the specific language governing\n# permissions and limitations under the License.\n\n# Third-party imports\nfrom mxnet import gluon, nd\n\n# First-party imports\nfrom gluonts.block.decoder import Seq2SeqDecoder\nfrom gluonts.block.enc2dec import Seq2SeqEnc2Dec\nfrom gluonts.block.encoder import Seq2SeqEncoder\nfrom gluonts.block.quantile_output import QuantileOutput\nfrom gluonts.core.component import validated\nfrom gluonts.model.common import Tensor\n\nnd_None = nd.array([])\n\n\nclass ForkingSeq2SeqNetworkBase(gluon.HybridBlock):\n \"\"\"\n Base network for the :class:`ForkingSeq2SeqEstimator`.\n\n Parameters\n ----------\n encoder: Seq2SeqEncoder\n encoder block\n enc2dec: Seq2SeqEnc2Dec\n encoder to decoder mapping block\n decoder: Seq2SeqDecoder\n decoder block\n quantile_output: QuantileOutput\n quantile output block\n kwargs: dict\n dictionary of Gluon HybridBlock parameters\n \"\"\"\n\n @validated()\n def __init__(\n self,\n encoder: Seq2SeqEncoder,\n enc2dec: Seq2SeqEnc2Dec,\n decoder: Seq2SeqDecoder,\n quantile_output: QuantileOutput,\n **kwargs,\n ) -> None:\n super().__init__(**kwargs)\n\n self.encoder = encoder\n self.enc2dec = enc2dec\n self.decoder = decoder\n self.quantile_output = quantile_output\n\n with self.name_scope():\n self.quantile_proj = quantile_output.get_quantile_proj()\n self.loss = quantile_output.get_loss()\n\n\nclass ForkingSeq2SeqTrainingNetwork(ForkingSeq2SeqNetworkBase):\n # noinspection PyMethodOverriding\n def hybrid_forward(\n self, F, past_target: Tensor, future_target: Tensor\n ) -> Tensor:\n \"\"\"\n Parameters\n ----------\n F: mx.symbol or mx.ndarray\n Gluon function space\n past_target: Tensor\n FIXME\n future_target: Tensor\n shape (num_ts, encoder_length, 1) FIXME\n\n Returns\n -------\n loss with shape (FIXME, FIXME)\n \"\"\"\n\n # FIXME: can we factor out a common prefix in the base network?\n feat_static_real = nd_None\n past_feat_dynamic_real = nd_None\n future_feat_dynamic_real = nd_None\n\n enc_output_static, enc_output_dynamic = self.encoder(\n past_target, feat_static_real, past_feat_dynamic_real\n )\n\n dec_input_static, dec_input_dynamic, _ = self.enc2dec(\n enc_output_static, enc_output_dynamic, future_feat_dynamic_real\n )\n\n dec_output = self.decoder(dec_input_dynamic, dec_input_static)\n dec_dist_output = self.quantile_proj(dec_output)\n\n loss = self.loss(future_target, dec_dist_output)\n return loss.mean(axis=1)\n\n\nclass ForkingSeq2SeqPredictionNetwork(ForkingSeq2SeqNetworkBase):\n # noinspection PyMethodOverriding\n def hybrid_forward(self, F, past_target: Tensor) -> Tensor:\n \"\"\"\n Parameters\n ----------\n F: mx.symbol or mx.ndarray\n Gluon function space\n past_target: Tensor\n FIXME\n\n Returns\n -------\n prediction tensor with shape (FIXME, FIXME)\n \"\"\"\n\n # FIXME: can we factor out a common prefix in the base network?\n feat_static_real = nd_None\n past_feat_dynamic_real = nd_None\n future_feat_dynamic_real = nd_None\n\n enc_output_static, enc_output_dynamic = self.encoder(\n past_target, feat_static_real, past_feat_dynamic_real\n )\n\n enc_output_static = (\n nd_None if enc_output_static is None else enc_output_static\n )\n\n dec_inp_static, dec_inp_dynamic, _ = self.enc2dec(\n enc_output_static, enc_output_dynamic, future_feat_dynamic_real\n )\n\n dec_output = self.decoder(dec_inp_dynamic, dec_inp_static)\n fcst_output = F.slice_axis(dec_output, axis=1, begin=-1, end=None)\n fcst_output = F.squeeze(fcst_output, axis=1)\n\n predictions = self.quantile_proj(fcst_output).swapaxes(2, 1)\n return predictions\n", "path": "src/gluonts/model/seq2seq/_forking_network.py"}], "after_files": [{"content": "# Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\").\n# You may not use this file except in compliance with the License.\n# A copy of the License is located at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# or in the \"license\" file accompanying this file. This file is distributed\n# on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either\n# express or implied. See the License for the specific language governing\n# permissions and limitations under the License.\n\n# Third-party imports\nimport mxnet as mx\nfrom mxnet import gluon\n\n# First-party imports\nfrom gluonts.block.decoder import Seq2SeqDecoder\nfrom gluonts.block.enc2dec import Seq2SeqEnc2Dec\nfrom gluonts.block.encoder import Seq2SeqEncoder\nfrom gluonts.block.quantile_output import QuantileOutput\nfrom gluonts.core.component import validated\nfrom gluonts.model.common import Tensor\n\n\nclass ForkingSeq2SeqNetworkBase(gluon.HybridBlock):\n \"\"\"\n Base network for the :class:`ForkingSeq2SeqEstimator`.\n\n Parameters\n ----------\n encoder: Seq2SeqEncoder\n encoder block\n enc2dec: Seq2SeqEnc2Dec\n encoder to decoder mapping block\n decoder: Seq2SeqDecoder\n decoder block\n quantile_output: QuantileOutput\n quantile output block\n kwargs: dict\n dictionary of Gluon HybridBlock parameters\n \"\"\"\n\n @validated()\n def __init__(\n self,\n encoder: Seq2SeqEncoder,\n enc2dec: Seq2SeqEnc2Dec,\n decoder: Seq2SeqDecoder,\n quantile_output: QuantileOutput,\n **kwargs,\n ) -> None:\n super().__init__(**kwargs)\n\n self.encoder = encoder\n self.enc2dec = enc2dec\n self.decoder = decoder\n self.quantile_output = quantile_output\n\n with self.name_scope():\n self.quantile_proj = quantile_output.get_quantile_proj()\n self.loss = quantile_output.get_loss()\n\n\nclass ForkingSeq2SeqTrainingNetwork(ForkingSeq2SeqNetworkBase):\n # noinspection PyMethodOverriding\n def hybrid_forward(\n self, F, past_target: Tensor, future_target: Tensor\n ) -> Tensor:\n \"\"\"\n Parameters\n ----------\n F: mx.symbol or mx.ndarray\n Gluon function space\n past_target: Tensor\n FIXME\n future_target: Tensor\n shape (num_ts, encoder_length, 1) FIXME\n\n Returns\n -------\n loss with shape (FIXME, FIXME)\n \"\"\"\n\n # FIXME: can we factor out a common prefix in the base network?\n feat_static_real = F.zeros(shape=(1,))\n past_feat_dynamic_real = F.zeros(shape=(1,))\n future_feat_dynamic_real = F.zeros(shape=(1,))\n\n enc_output_static, enc_output_dynamic = self.encoder(\n past_target, feat_static_real, past_feat_dynamic_real\n )\n\n dec_input_static, dec_input_dynamic, _ = self.enc2dec(\n enc_output_static, enc_output_dynamic, future_feat_dynamic_real\n )\n\n dec_output = self.decoder(dec_input_dynamic, dec_input_static)\n dec_dist_output = self.quantile_proj(dec_output)\n\n loss = self.loss(future_target, dec_dist_output)\n return loss.mean(axis=1)\n\n\nclass ForkingSeq2SeqPredictionNetwork(ForkingSeq2SeqNetworkBase):\n # noinspection PyMethodOverriding\n def hybrid_forward(self, F, past_target: Tensor) -> Tensor:\n \"\"\"\n Parameters\n ----------\n F: mx.symbol or mx.ndarray\n Gluon function space\n past_target: Tensor\n FIXME\n\n Returns\n -------\n prediction tensor with shape (FIXME, FIXME)\n \"\"\"\n\n # FIXME: can we factor out a common prefix in the base network?\n feat_static_real = F.zeros(shape=(1,))\n past_feat_dynamic_real = F.zeros(shape=(1,))\n future_feat_dynamic_real = F.zeros(shape=(1,))\n\n enc_output_static, enc_output_dynamic = self.encoder(\n past_target, feat_static_real, past_feat_dynamic_real\n )\n\n enc_output_static = (\n F.zeros(shape=(1,))\n if enc_output_static is None\n else enc_output_static\n )\n\n dec_inp_static, dec_inp_dynamic, _ = self.enc2dec(\n enc_output_static, enc_output_dynamic, future_feat_dynamic_real\n )\n\n dec_output = self.decoder(dec_inp_dynamic, dec_inp_static)\n fcst_output = F.slice_axis(dec_output, axis=1, begin=-1, end=None)\n fcst_output = F.squeeze(fcst_output, axis=1)\n\n predictions = self.quantile_proj(fcst_output).swapaxes(2, 1)\n return predictions\n", "path": "src/gluonts/model/seq2seq/_forking_network.py"}]}
| 1,729 | 514 |
gh_patches_debug_35010
|
rasdani/github-patches
|
git_diff
|
ephios-dev__ephios-884
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Improve calendar design
As a user, I expect the event calendar view to display the shifts in small boxes with times inside of each calendar day (similiar to Google Calendar etc.)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ephios/core/calendar.py`
Content:
```
1 from calendar import HTMLCalendar, day_abbr
2 from datetime import date, datetime
3 from itertools import groupby
4
5 from django.utils.formats import date_format
6 from django.utils.translation import gettext as _
7
8
9 class ShiftCalendar(HTMLCalendar):
10 cssclass_month = "table table-fixed"
11
12 def __init__(self, shifts, *args, **kwargs):
13 super().__init__(*args, **kwargs)
14 self.shifts = {
15 k: list(v) for (k, v) in groupby(shifts, lambda shift: shift.start_time.date().day)
16 }
17
18 def formatmonth(self, theyear, themonth, withyear=True):
19 self.year, self.month = theyear, themonth
20 return super().formatmonth(theyear, themonth)
21
22 def formatmonthname(self, theyear, themonth, withyear=True):
23 dt = datetime(theyear, themonth, 1)
24 return f'<tr><th colspan="7" class="month">{date_format(dt, format="b Y")}</th></tr>'
25
26 def formatweekday(self, day):
27 return f'<th class="{self.cssclasses[day]}">{_(day_abbr[day])}</th>'
28
29 def formatday(self, day, weekday):
30 if day != 0:
31 cssclass = self.cssclasses[weekday]
32 if date.today() == date(self.year, self.month, day):
33 cssclass += " calendar-today"
34 if day in self.shifts:
35 cssclass += " filled"
36 body = ["<br />"]
37 for shift in self.shifts[day]:
38 body.append(f'<a href="{shift.event.get_absolute_url()}">')
39 body.append(shift.event.title)
40 body.append("</a><br />")
41 return self.day_cell(cssclass, f"{day} {''.join(body)}")
42 return self.day_cell(cssclass, day)
43 return self.day_cell("noday", " ")
44
45 def day_cell(self, cssclass, body):
46 return f'<td class="calendar-row-height p-1 break-word {cssclass}">{body}</td>'
47
```
Path: `ephios/extra/colors.py`
Content:
```
1 # inspired by https://jfelix.info/blog/how-to-make-a-text-color-fit-any-background-color
2 from math import sqrt
3
4 from ephios.core.models import EventType
5
6
7 def calculate_luminance(rgb: tuple):
8 r, g, b = map(
9 lambda channel: channel / 255 / 12.92
10 if channel / 255 <= 0.03928
11 else ((channel / 255 + 0.055) / 1.055) ** 2.4,
12 rgb,
13 )
14 return 0.2126 * r + 0.7152 * g + 0.0722 * b
15
16
17 def get_text_color_for_background(background_luminance: int):
18 return "#000000" if background_luminance > sqrt(1.05 * 0.05) - 0.05 else "#ffffff"
19
20
21 def get_eventtype_color_style(eventtype: EventType):
22 luminance = calculate_luminance(
23 (
24 int(eventtype.color[1:3], 16),
25 int(eventtype.color[3:5], 16),
26 int(eventtype.color[5:7], 16),
27 )
28 )
29 text_color = get_text_color_for_background(luminance)
30 return f".badge-{eventtype.pk}-color{{background-color:{eventtype.color};color:{text_color}}}"
31
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ephios/core/calendar.py b/ephios/core/calendar.py
--- a/ephios/core/calendar.py
+++ b/ephios/core/calendar.py
@@ -2,6 +2,7 @@
from datetime import date, datetime
from itertools import groupby
+from django.template.loader import render_to_string
from django.utils.formats import date_format
from django.utils.translation import gettext as _
@@ -24,23 +25,20 @@
return f'<tr><th colspan="7" class="month">{date_format(dt, format="b Y")}</th></tr>'
def formatweekday(self, day):
- return f'<th class="{self.cssclasses[day]}">{_(day_abbr[day])}</th>'
+ return f'<th class="text-center {self.cssclasses[day]}">{_(day_abbr[day])}</th>'
def formatday(self, day, weekday):
if day != 0:
cssclass = self.cssclasses[weekday]
- if date.today() == date(self.year, self.month, day):
- cssclass += " calendar-today"
+ today = date.today() == date(self.year, self.month, day)
if day in self.shifts:
cssclass += " filled"
- body = ["<br />"]
- for shift in self.shifts[day]:
- body.append(f'<a href="{shift.event.get_absolute_url()}">')
- body.append(shift.event.title)
- body.append("</a><br />")
- return self.day_cell(cssclass, f"{day} {''.join(body)}")
- return self.day_cell(cssclass, day)
+ content = render_to_string(
+ "core/fragments/calendar_day.html",
+ {"day": day, "shifts": self.shifts.get(day, None), "today": today},
+ )
+ return self.day_cell(cssclass, content)
return self.day_cell("noday", " ")
def day_cell(self, cssclass, body):
- return f'<td class="calendar-row-height p-1 break-word {cssclass}">{body}</td>'
+ return f'<td class="calendar-row-height p-0 pe-1 p-lg-1 {cssclass}">{body}</td>'
diff --git a/ephios/extra/colors.py b/ephios/extra/colors.py
--- a/ephios/extra/colors.py
+++ b/ephios/extra/colors.py
@@ -27,4 +27,6 @@
)
)
text_color = get_text_color_for_background(luminance)
- return f".badge-{eventtype.pk}-color{{background-color:{eventtype.color};color:{text_color}}}"
+ return (
+ f".eventtype-{eventtype.pk}-color{{background-color:{eventtype.color};color:{text_color}}}"
+ )
|
{"golden_diff": "diff --git a/ephios/core/calendar.py b/ephios/core/calendar.py\n--- a/ephios/core/calendar.py\n+++ b/ephios/core/calendar.py\n@@ -2,6 +2,7 @@\n from datetime import date, datetime\n from itertools import groupby\n \n+from django.template.loader import render_to_string\n from django.utils.formats import date_format\n from django.utils.translation import gettext as _\n \n@@ -24,23 +25,20 @@\n return f'<tr><th colspan=\"7\" class=\"month\">{date_format(dt, format=\"b Y\")}</th></tr>'\n \n def formatweekday(self, day):\n- return f'<th class=\"{self.cssclasses[day]}\">{_(day_abbr[day])}</th>'\n+ return f'<th class=\"text-center {self.cssclasses[day]}\">{_(day_abbr[day])}</th>'\n \n def formatday(self, day, weekday):\n if day != 0:\n cssclass = self.cssclasses[weekday]\n- if date.today() == date(self.year, self.month, day):\n- cssclass += \" calendar-today\"\n+ today = date.today() == date(self.year, self.month, day)\n if day in self.shifts:\n cssclass += \" filled\"\n- body = [\"<br />\"]\n- for shift in self.shifts[day]:\n- body.append(f'<a href=\"{shift.event.get_absolute_url()}\">')\n- body.append(shift.event.title)\n- body.append(\"</a><br />\")\n- return self.day_cell(cssclass, f\"{day} {''.join(body)}\")\n- return self.day_cell(cssclass, day)\n+ content = render_to_string(\n+ \"core/fragments/calendar_day.html\",\n+ {\"day\": day, \"shifts\": self.shifts.get(day, None), \"today\": today},\n+ )\n+ return self.day_cell(cssclass, content)\n return self.day_cell(\"noday\", \" \")\n \n def day_cell(self, cssclass, body):\n- return f'<td class=\"calendar-row-height p-1 break-word {cssclass}\">{body}</td>'\n+ return f'<td class=\"calendar-row-height p-0 pe-1 p-lg-1 {cssclass}\">{body}</td>'\ndiff --git a/ephios/extra/colors.py b/ephios/extra/colors.py\n--- a/ephios/extra/colors.py\n+++ b/ephios/extra/colors.py\n@@ -27,4 +27,6 @@\n )\n )\n text_color = get_text_color_for_background(luminance)\n- return f\".badge-{eventtype.pk}-color{{background-color:{eventtype.color};color:{text_color}}}\"\n+ return (\n+ f\".eventtype-{eventtype.pk}-color{{background-color:{eventtype.color};color:{text_color}}}\"\n+ )\n", "issue": "Improve calendar design\nAs a user, I expect the event calendar view to display the shifts in small boxes with times inside of each calendar day (similiar to Google Calendar etc.)\n", "before_files": [{"content": "from calendar import HTMLCalendar, day_abbr\nfrom datetime import date, datetime\nfrom itertools import groupby\n\nfrom django.utils.formats import date_format\nfrom django.utils.translation import gettext as _\n\n\nclass ShiftCalendar(HTMLCalendar):\n cssclass_month = \"table table-fixed\"\n\n def __init__(self, shifts, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.shifts = {\n k: list(v) for (k, v) in groupby(shifts, lambda shift: shift.start_time.date().day)\n }\n\n def formatmonth(self, theyear, themonth, withyear=True):\n self.year, self.month = theyear, themonth\n return super().formatmonth(theyear, themonth)\n\n def formatmonthname(self, theyear, themonth, withyear=True):\n dt = datetime(theyear, themonth, 1)\n return f'<tr><th colspan=\"7\" class=\"month\">{date_format(dt, format=\"b Y\")}</th></tr>'\n\n def formatweekday(self, day):\n return f'<th class=\"{self.cssclasses[day]}\">{_(day_abbr[day])}</th>'\n\n def formatday(self, day, weekday):\n if day != 0:\n cssclass = self.cssclasses[weekday]\n if date.today() == date(self.year, self.month, day):\n cssclass += \" calendar-today\"\n if day in self.shifts:\n cssclass += \" filled\"\n body = [\"<br />\"]\n for shift in self.shifts[day]:\n body.append(f'<a href=\"{shift.event.get_absolute_url()}\">')\n body.append(shift.event.title)\n body.append(\"</a><br />\")\n return self.day_cell(cssclass, f\"{day} {''.join(body)}\")\n return self.day_cell(cssclass, day)\n return self.day_cell(\"noday\", \" \")\n\n def day_cell(self, cssclass, body):\n return f'<td class=\"calendar-row-height p-1 break-word {cssclass}\">{body}</td>'\n", "path": "ephios/core/calendar.py"}, {"content": "# inspired by https://jfelix.info/blog/how-to-make-a-text-color-fit-any-background-color\nfrom math import sqrt\n\nfrom ephios.core.models import EventType\n\n\ndef calculate_luminance(rgb: tuple):\n r, g, b = map(\n lambda channel: channel / 255 / 12.92\n if channel / 255 <= 0.03928\n else ((channel / 255 + 0.055) / 1.055) ** 2.4,\n rgb,\n )\n return 0.2126 * r + 0.7152 * g + 0.0722 * b\n\n\ndef get_text_color_for_background(background_luminance: int):\n return \"#000000\" if background_luminance > sqrt(1.05 * 0.05) - 0.05 else \"#ffffff\"\n\n\ndef get_eventtype_color_style(eventtype: EventType):\n luminance = calculate_luminance(\n (\n int(eventtype.color[1:3], 16),\n int(eventtype.color[3:5], 16),\n int(eventtype.color[5:7], 16),\n )\n )\n text_color = get_text_color_for_background(luminance)\n return f\".badge-{eventtype.pk}-color{{background-color:{eventtype.color};color:{text_color}}}\"\n", "path": "ephios/extra/colors.py"}], "after_files": [{"content": "from calendar import HTMLCalendar, day_abbr\nfrom datetime import date, datetime\nfrom itertools import groupby\n\nfrom django.template.loader import render_to_string\nfrom django.utils.formats import date_format\nfrom django.utils.translation import gettext as _\n\n\nclass ShiftCalendar(HTMLCalendar):\n cssclass_month = \"table table-fixed\"\n\n def __init__(self, shifts, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.shifts = {\n k: list(v) for (k, v) in groupby(shifts, lambda shift: shift.start_time.date().day)\n }\n\n def formatmonth(self, theyear, themonth, withyear=True):\n self.year, self.month = theyear, themonth\n return super().formatmonth(theyear, themonth)\n\n def formatmonthname(self, theyear, themonth, withyear=True):\n dt = datetime(theyear, themonth, 1)\n return f'<tr><th colspan=\"7\" class=\"month\">{date_format(dt, format=\"b Y\")}</th></tr>'\n\n def formatweekday(self, day):\n return f'<th class=\"text-center {self.cssclasses[day]}\">{_(day_abbr[day])}</th>'\n\n def formatday(self, day, weekday):\n if day != 0:\n cssclass = self.cssclasses[weekday]\n today = date.today() == date(self.year, self.month, day)\n if day in self.shifts:\n cssclass += \" filled\"\n content = render_to_string(\n \"core/fragments/calendar_day.html\",\n {\"day\": day, \"shifts\": self.shifts.get(day, None), \"today\": today},\n )\n return self.day_cell(cssclass, content)\n return self.day_cell(\"noday\", \" \")\n\n def day_cell(self, cssclass, body):\n return f'<td class=\"calendar-row-height p-0 pe-1 p-lg-1 {cssclass}\">{body}</td>'\n", "path": "ephios/core/calendar.py"}, {"content": "# inspired by https://jfelix.info/blog/how-to-make-a-text-color-fit-any-background-color\nfrom math import sqrt\n\nfrom ephios.core.models import EventType\n\n\ndef calculate_luminance(rgb: tuple):\n r, g, b = map(\n lambda channel: channel / 255 / 12.92\n if channel / 255 <= 0.03928\n else ((channel / 255 + 0.055) / 1.055) ** 2.4,\n rgb,\n )\n return 0.2126 * r + 0.7152 * g + 0.0722 * b\n\n\ndef get_text_color_for_background(background_luminance: int):\n return \"#000000\" if background_luminance > sqrt(1.05 * 0.05) - 0.05 else \"#ffffff\"\n\n\ndef get_eventtype_color_style(eventtype: EventType):\n luminance = calculate_luminance(\n (\n int(eventtype.color[1:3], 16),\n int(eventtype.color[3:5], 16),\n int(eventtype.color[5:7], 16),\n )\n )\n text_color = get_text_color_for_background(luminance)\n return (\n f\".eventtype-{eventtype.pk}-color{{background-color:{eventtype.color};color:{text_color}}}\"\n )\n", "path": "ephios/extra/colors.py"}]}
| 1,225 | 627 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.