
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.1k
25.4k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 582
39.1k
| num_tokens
int64 271
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_43814
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-1135
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Celery Instrumentation with apply_async function
I have a basic django application which uses celery to call a method using apply_async and delay functions. I am trying to integrate Otel into my django application. I am using 0.10b0 version of all Otel libraries. I have used celery-auto instrumentation for produce the spans/traces. But I see that the celery-auto instrumentation isnt working.
**Steps to reproduce**
I have attached my code in order to reproduce the issue.
1. Run the python application using
`python manage.py runserver`
<img width="684" alt="Screen Shot 2020-07-01 at 1 54 05 PM" src="https://user-images.githubusercontent.com/11060386/86276134-5bf37780-bba2-11ea-951e-75cca763ee55.png">
2. Then also start the celery worker using
celery -A django_email_celery worker --loglevel=info
<img width="1352" alt="Screen Shot 2020-07-01 at 1 55 11 PM" src="https://user-images.githubusercontent.com/11060386/86276219-82b1ae00-bba2-11ea-9a8d-96454683a694.png">
**What is the expected behavior?**
Once you hit the `localhost` url, I see the trace and spans created by the Otel. But I was expecting the `traceid` to continue from method `index()` in `views.py` to `send_log` in `tasks.py`.
**What is the actual behavior?**
But then the a new trace is being created at the `send_log`.
<img width="748" alt="Screen Shot 2020-07-01 at 1 59 29 PM" src="https://user-images.githubusercontent.com/11060386/86276630-331fb200-bba3-11ea-9eab-5df16112a275.png">
<img width="1336" alt="Screen Shot 2020-07-01 at 2 01 44 PM" src="https://user-images.githubusercontent.com/11060386/86276746-737f3000-bba3-11ea-8750-be0e416399f0.png">
**Other Info**
I have added celery instrumentation in `celery.py` file
[django_email_celery.zip](https://github.com/open-telemetry/opentelemetry-python/files/4859611/django_email_celery.zip)
@ocelotl @codeboten
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `instrumentation/opentelemetry-instrumentation-celery/src/opentelemetry/instrumentation/celery/__init__.py`
Content:
```
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 """
15 Instrument `celery`_ to trace Celery applications.
16
17 .. _celery: https://pypi.org/project/celery/
18
19 Usage
20 -----
21
22 * Start broker backend
23
24 .. code::
25
26 docker run -p 5672:5672 rabbitmq
27
28
29 * Run instrumented task
30
31 .. code:: python
32
33 from opentelemetry.instrumentation.celery import CeleryInstrumentor
34
35 CeleryInstrumentor().instrument()
36
37 from celery import Celery
38
39 app = Celery("tasks", broker="amqp://localhost")
40
41 @app.task
42 def add(x, y):
43 return x + y
44
45 add.delay(42, 50)
46
47 API
48 ---
49 """
50
51 import logging
52 import signal
53
54 from celery import signals # pylint: disable=no-name-in-module
55
56 from opentelemetry import trace
57 from opentelemetry.instrumentation.celery import utils
58 from opentelemetry.instrumentation.celery.version import __version__
59 from opentelemetry.instrumentation.instrumentor import BaseInstrumentor
60 from opentelemetry.trace.status import Status, StatusCanonicalCode
61
62 logger = logging.getLogger(__name__)
63
64 # Task operations
65 _TASK_TAG_KEY = "celery.action"
66 _TASK_APPLY_ASYNC = "apply_async"
67 _TASK_RUN = "run"
68
69 _TASK_RETRY_REASON_KEY = "celery.retry.reason"
70 _TASK_REVOKED_REASON_KEY = "celery.revoked.reason"
71 _TASK_REVOKED_TERMINATED_SIGNAL_KEY = "celery.terminated.signal"
72 _TASK_NAME_KEY = "celery.task_name"
73 _MESSAGE_ID_ATTRIBUTE_NAME = "messaging.message_id"
74
75
76 class CeleryInstrumentor(BaseInstrumentor):
77 def _instrument(self, **kwargs):
78 tracer_provider = kwargs.get("tracer_provider")
79
80 # pylint: disable=attribute-defined-outside-init
81 self._tracer = trace.get_tracer(__name__, __version__, tracer_provider)
82
83 signals.task_prerun.connect(self._trace_prerun, weak=False)
84 signals.task_postrun.connect(self._trace_postrun, weak=False)
85 signals.before_task_publish.connect(
86 self._trace_before_publish, weak=False
87 )
88 signals.after_task_publish.connect(
89 self._trace_after_publish, weak=False
90 )
91 signals.task_failure.connect(self._trace_failure, weak=False)
92 signals.task_retry.connect(self._trace_retry, weak=False)
93
94 def _uninstrument(self, **kwargs):
95 signals.task_prerun.disconnect(self._trace_prerun)
96 signals.task_postrun.disconnect(self._trace_postrun)
97 signals.before_task_publish.disconnect(self._trace_before_publish)
98 signals.after_task_publish.disconnect(self._trace_after_publish)
99 signals.task_failure.disconnect(self._trace_failure)
100 signals.task_retry.disconnect(self._trace_retry)
101
102 def _trace_prerun(self, *args, **kwargs):
103 task = utils.retrieve_task(kwargs)
104 task_id = utils.retrieve_task_id(kwargs)
105
106 if task is None or task_id is None:
107 return
108
109 logger.debug("prerun signal start task_id=%s", task_id)
110
111 span = self._tracer.start_span(task.name, kind=trace.SpanKind.CONSUMER)
112
113 activation = self._tracer.use_span(span, end_on_exit=True)
114 activation.__enter__()
115 utils.attach_span(task, task_id, (span, activation))
116
117 @staticmethod
118 def _trace_postrun(*args, **kwargs):
119 task = utils.retrieve_task(kwargs)
120 task_id = utils.retrieve_task_id(kwargs)
121
122 if task is None or task_id is None:
123 return
124
125 logger.debug("postrun signal task_id=%s", task_id)
126
127 # retrieve and finish the Span
128 span, activation = utils.retrieve_span(task, task_id)
129 if span is None:
130 logger.warning("no existing span found for task_id=%s", task_id)
131 return
132
133 # request context tags
134 span.set_attribute(_TASK_TAG_KEY, _TASK_RUN)
135 utils.set_attributes_from_context(span, kwargs)
136 utils.set_attributes_from_context(span, task.request)
137 span.set_attribute(_TASK_NAME_KEY, task.name)
138
139 activation.__exit__(None, None, None)
140 utils.detach_span(task, task_id)
141
142 def _trace_before_publish(self, *args, **kwargs):
143 task = utils.retrieve_task_from_sender(kwargs)
144 task_id = utils.retrieve_task_id_from_message(kwargs)
145
146 if task is None or task_id is None:
147 return
148
149 span = self._tracer.start_span(task.name, kind=trace.SpanKind.PRODUCER)
150
151 # apply some attributes here because most of the data is not available
152 span.set_attribute(_TASK_TAG_KEY, _TASK_APPLY_ASYNC)
153 span.set_attribute(_MESSAGE_ID_ATTRIBUTE_NAME, task_id)
154 span.set_attribute(_TASK_NAME_KEY, task.name)
155 utils.set_attributes_from_context(span, kwargs)
156
157 activation = self._tracer.use_span(span, end_on_exit=True)
158 activation.__enter__()
159 utils.attach_span(task, task_id, (span, activation), is_publish=True)
160
161 @staticmethod
162 def _trace_after_publish(*args, **kwargs):
163 task = utils.retrieve_task_from_sender(kwargs)
164 task_id = utils.retrieve_task_id_from_message(kwargs)
165
166 if task is None or task_id is None:
167 return
168
169 # retrieve and finish the Span
170 _, activation = utils.retrieve_span(task, task_id, is_publish=True)
171 if activation is None:
172 logger.warning("no existing span found for task_id=%s", task_id)
173 return
174
175 activation.__exit__(None, None, None)
176 utils.detach_span(task, task_id, is_publish=True)
177
178 @staticmethod
179 def _trace_failure(*args, **kwargs):
180 task = utils.retrieve_task_from_sender(kwargs)
181 task_id = utils.retrieve_task_id(kwargs)
182
183 if task is None or task_id is None:
184 return
185
186 # retrieve and pass exception info to activation
187 span, _ = utils.retrieve_span(task, task_id)
188 if span is None:
189 return
190
191 status_kwargs = {"canonical_code": StatusCanonicalCode.UNKNOWN}
192
193 ex = kwargs.get("einfo")
194
195 if (
196 hasattr(task, "throws")
197 and ex is not None
198 and isinstance(ex.exception, task.throws)
199 ):
200 return
201
202 if ex is not None:
203 status_kwargs["description"] = str(ex)
204
205 span.set_status(Status(**status_kwargs))
206
207 @staticmethod
208 def _trace_retry(*args, **kwargs):
209 task = utils.retrieve_task_from_sender(kwargs)
210 task_id = utils.retrieve_task_id_from_request(kwargs)
211 reason = utils.retrieve_reason(kwargs)
212
213 if task is None or task_id is None or reason is None:
214 return
215
216 span, _ = utils.retrieve_span(task, task_id)
217 if span is None:
218 return
219
220 # Add retry reason metadata to span
221 # Use `str(reason)` instead of `reason.message` in case we get
222 # something that isn't an `Exception`
223 span.set_attribute(_TASK_RETRY_REASON_KEY, str(reason))
224
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/instrumentation/opentelemetry-instrumentation-celery/src/opentelemetry/instrumentation/celery/__init__.py b/instrumentation/opentelemetry-instrumentation-celery/src/opentelemetry/instrumentation/celery/__init__.py
--- a/instrumentation/opentelemetry-instrumentation-celery/src/opentelemetry/instrumentation/celery/__init__.py
+++ b/instrumentation/opentelemetry-instrumentation-celery/src/opentelemetry/instrumentation/celery/__init__.py
@@ -30,11 +30,20 @@
.. code:: python
+ from opentelemetry import trace
+ from opentelemetry.sdk.trace import TracerProvider
+ from opentelemetry.sdk.trace.export import BatchExportSpanProcessor
from opentelemetry.instrumentation.celery import CeleryInstrumentor
- CeleryInstrumentor().instrument()
-
from celery import Celery
+ from celery.signals import worker_process_init
+
+ @worker_process_init.connect(weak=False)
+ def init_celery_tracing(*args, **kwargs):
+ trace.set_tracer_provider(TracerProvider())
+ span_processor = BatchExportSpanProcessor(ConsoleSpanExporter())
+ trace.get_tracer_provider().add_span_processor(span_processor)
+ CeleryInstrumentor().instrument()
app = Celery("tasks", broker="amqp://localhost")
@@ -50,13 +59,15 @@
import logging
import signal
+from collections.abc import Iterable
from celery import signals # pylint: disable=no-name-in-module
-from opentelemetry import trace
+from opentelemetry import propagators, trace
from opentelemetry.instrumentation.celery import utils
from opentelemetry.instrumentation.celery.version import __version__
from opentelemetry.instrumentation.instrumentor import BaseInstrumentor
+from opentelemetry.trace.propagation import get_current_span
from opentelemetry.trace.status import Status, StatusCanonicalCode
logger = logging.getLogger(__name__)
@@ -106,9 +117,16 @@
if task is None or task_id is None:
return
+ request = task.request
+ tracectx = propagators.extract(carrier_extractor, request) or {}
+ parent = get_current_span(tracectx)
+
logger.debug("prerun signal start task_id=%s", task_id)
- span = self._tracer.start_span(task.name, kind=trace.SpanKind.CONSUMER)
+ operation_name = "{0}/{1}".format(_TASK_RUN, task.name)
+ span = self._tracer.start_span(
+ operation_name, parent=parent, kind=trace.SpanKind.CONSUMER
+ )
activation = self._tracer.use_span(span, end_on_exit=True)
activation.__enter__()
@@ -146,7 +164,10 @@
if task is None or task_id is None:
return
- span = self._tracer.start_span(task.name, kind=trace.SpanKind.PRODUCER)
+ operation_name = "{0}/{1}".format(_TASK_APPLY_ASYNC, task.name)
+ span = self._tracer.start_span(
+ operation_name, kind=trace.SpanKind.PRODUCER
+ )
# apply some attributes here because most of the data is not available
span.set_attribute(_TASK_TAG_KEY, _TASK_APPLY_ASYNC)
@@ -158,6 +179,10 @@
activation.__enter__()
utils.attach_span(task, task_id, (span, activation), is_publish=True)
+ headers = kwargs.get("headers")
+ if headers:
+ propagators.inject(type(headers).__setitem__, headers)
+
@staticmethod
def _trace_after_publish(*args, **kwargs):
task = utils.retrieve_task_from_sender(kwargs)
@@ -221,3 +246,10 @@
# Use `str(reason)` instead of `reason.message` in case we get
# something that isn't an `Exception`
span.set_attribute(_TASK_RETRY_REASON_KEY, str(reason))
+
+
+def carrier_extractor(carrier, key):
+ value = getattr(carrier, key, [])
+ if isinstance(value, str) or not isinstance(value, Iterable):
+ value = (value,)
+ return value
|
{"golden_diff": "diff --git a/instrumentation/opentelemetry-instrumentation-celery/src/opentelemetry/instrumentation/celery/__init__.py b/instrumentation/opentelemetry-instrumentation-celery/src/opentelemetry/instrumentation/celery/__init__.py\n--- a/instrumentation/opentelemetry-instrumentation-celery/src/opentelemetry/instrumentation/celery/__init__.py\n+++ b/instrumentation/opentelemetry-instrumentation-celery/src/opentelemetry/instrumentation/celery/__init__.py\n@@ -30,11 +30,20 @@\n \n .. code:: python\n \n+ from opentelemetry import trace\n+ from opentelemetry.sdk.trace import TracerProvider\n+ from opentelemetry.sdk.trace.export import BatchExportSpanProcessor\n from opentelemetry.instrumentation.celery import CeleryInstrumentor\n \n- CeleryInstrumentor().instrument()\n-\n from celery import Celery\n+ from celery.signals import worker_process_init\n+\n+ @worker_process_init.connect(weak=False)\n+ def init_celery_tracing(*args, **kwargs):\n+ trace.set_tracer_provider(TracerProvider())\n+ span_processor = BatchExportSpanProcessor(ConsoleSpanExporter())\n+ trace.get_tracer_provider().add_span_processor(span_processor)\n+ CeleryInstrumentor().instrument()\n \n app = Celery(\"tasks\", broker=\"amqp://localhost\")\n \n@@ -50,13 +59,15 @@\n \n import logging\n import signal\n+from collections.abc import Iterable\n \n from celery import signals # pylint: disable=no-name-in-module\n \n-from opentelemetry import trace\n+from opentelemetry import propagators, trace\n from opentelemetry.instrumentation.celery import utils\n from opentelemetry.instrumentation.celery.version import __version__\n from opentelemetry.instrumentation.instrumentor import BaseInstrumentor\n+from opentelemetry.trace.propagation import get_current_span\n from opentelemetry.trace.status import Status, StatusCanonicalCode\n \n logger = logging.getLogger(__name__)\n@@ -106,9 +117,16 @@\n if task is None or task_id is None:\n return\n \n+ request = task.request\n+ tracectx = propagators.extract(carrier_extractor, request) or {}\n+ parent = get_current_span(tracectx)\n+\n logger.debug(\"prerun signal start task_id=%s\", task_id)\n \n- span = self._tracer.start_span(task.name, kind=trace.SpanKind.CONSUMER)\n+ operation_name = \"{0}/{1}\".format(_TASK_RUN, task.name)\n+ span = self._tracer.start_span(\n+ operation_name, parent=parent, kind=trace.SpanKind.CONSUMER\n+ )\n \n activation = self._tracer.use_span(span, end_on_exit=True)\n activation.__enter__()\n@@ -146,7 +164,10 @@\n if task is None or task_id is None:\n return\n \n- span = self._tracer.start_span(task.name, kind=trace.SpanKind.PRODUCER)\n+ operation_name = \"{0}/{1}\".format(_TASK_APPLY_ASYNC, task.name)\n+ span = self._tracer.start_span(\n+ operation_name, kind=trace.SpanKind.PRODUCER\n+ )\n \n # apply some attributes here because most of the data is not available\n span.set_attribute(_TASK_TAG_KEY, _TASK_APPLY_ASYNC)\n@@ -158,6 +179,10 @@\n activation.__enter__()\n utils.attach_span(task, task_id, (span, activation), is_publish=True)\n \n+ headers = kwargs.get(\"headers\")\n+ if headers:\n+ propagators.inject(type(headers).__setitem__, headers)\n+\n @staticmethod\n def _trace_after_publish(*args, **kwargs):\n task = utils.retrieve_task_from_sender(kwargs)\n@@ -221,3 +246,10 @@\n # Use `str(reason)` instead of `reason.message` in case we get\n # something that isn't an `Exception`\n span.set_attribute(_TASK_RETRY_REASON_KEY, str(reason))\n+\n+\n+def carrier_extractor(carrier, key):\n+ value = getattr(carrier, key, [])\n+ if isinstance(value, str) or not isinstance(value, Iterable):\n+ value = (value,)\n+ return value\n", "issue": "Celery Instrumentation with apply_async function\nI have a basic django application which uses celery to call a method using apply_async and delay functions. I am trying to integrate Otel into my django application. I am using 0.10b0 version of all Otel libraries. I have used celery-auto instrumentation for produce the spans/traces. But I see that the celery-auto instrumentation isnt working. \r\n\r\n**Steps to reproduce**\r\nI have attached my code in order to reproduce the issue. \r\n1. Run the python application using \r\n`python manage.py runserver`\r\n<img width=\"684\" alt=\"Screen Shot 2020-07-01 at 1 54 05 PM\" src=\"https://user-images.githubusercontent.com/11060386/86276134-5bf37780-bba2-11ea-951e-75cca763ee55.png\">\r\n\r\n2. Then also start the celery worker using\r\ncelery -A django_email_celery worker --loglevel=info\r\n<img width=\"1352\" alt=\"Screen Shot 2020-07-01 at 1 55 11 PM\" src=\"https://user-images.githubusercontent.com/11060386/86276219-82b1ae00-bba2-11ea-9a8d-96454683a694.png\">\r\n\r\n\r\n**What is the expected behavior?**\r\nOnce you hit the `localhost` url, I see the trace and spans created by the Otel. But I was expecting the `traceid` to continue from method `index()` in `views.py` to `send_log` in `tasks.py`. \r\n\r\n**What is the actual behavior?**\r\nBut then the a new trace is being created at the `send_log`. \r\n<img width=\"748\" alt=\"Screen Shot 2020-07-01 at 1 59 29 PM\" src=\"https://user-images.githubusercontent.com/11060386/86276630-331fb200-bba3-11ea-9eab-5df16112a275.png\">\r\n<img width=\"1336\" alt=\"Screen Shot 2020-07-01 at 2 01 44 PM\" src=\"https://user-images.githubusercontent.com/11060386/86276746-737f3000-bba3-11ea-8750-be0e416399f0.png\">\r\n\r\n**Other Info**\r\nI have added celery instrumentation in `celery.py` file\r\n\r\n[django_email_celery.zip](https://github.com/open-telemetry/opentelemetry-python/files/4859611/django_email_celery.zip)\r\n\r\n@ocelotl @codeboten \n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"\nInstrument `celery`_ to trace Celery applications.\n\n.. _celery: https://pypi.org/project/celery/\n\nUsage\n-----\n\n* Start broker backend\n\n.. code::\n\n docker run -p 5672:5672 rabbitmq\n\n\n* Run instrumented task\n\n.. code:: python\n\n from opentelemetry.instrumentation.celery import CeleryInstrumentor\n\n CeleryInstrumentor().instrument()\n\n from celery import Celery\n\n app = Celery(\"tasks\", broker=\"amqp://localhost\")\n\n @app.task\n def add(x, y):\n return x + y\n\n add.delay(42, 50)\n\nAPI\n---\n\"\"\"\n\nimport logging\nimport signal\n\nfrom celery import signals # pylint: disable=no-name-in-module\n\nfrom opentelemetry import trace\nfrom opentelemetry.instrumentation.celery import utils\nfrom opentelemetry.instrumentation.celery.version import __version__\nfrom opentelemetry.instrumentation.instrumentor import BaseInstrumentor\nfrom opentelemetry.trace.status import Status, StatusCanonicalCode\n\nlogger = logging.getLogger(__name__)\n\n# Task operations\n_TASK_TAG_KEY = \"celery.action\"\n_TASK_APPLY_ASYNC = \"apply_async\"\n_TASK_RUN = \"run\"\n\n_TASK_RETRY_REASON_KEY = \"celery.retry.reason\"\n_TASK_REVOKED_REASON_KEY = \"celery.revoked.reason\"\n_TASK_REVOKED_TERMINATED_SIGNAL_KEY = \"celery.terminated.signal\"\n_TASK_NAME_KEY = \"celery.task_name\"\n_MESSAGE_ID_ATTRIBUTE_NAME = \"messaging.message_id\"\n\n\nclass CeleryInstrumentor(BaseInstrumentor):\n def _instrument(self, **kwargs):\n tracer_provider = kwargs.get(\"tracer_provider\")\n\n # pylint: disable=attribute-defined-outside-init\n self._tracer = trace.get_tracer(__name__, __version__, tracer_provider)\n\n signals.task_prerun.connect(self._trace_prerun, weak=False)\n signals.task_postrun.connect(self._trace_postrun, weak=False)\n signals.before_task_publish.connect(\n self._trace_before_publish, weak=False\n )\n signals.after_task_publish.connect(\n self._trace_after_publish, weak=False\n )\n signals.task_failure.connect(self._trace_failure, weak=False)\n signals.task_retry.connect(self._trace_retry, weak=False)\n\n def _uninstrument(self, **kwargs):\n signals.task_prerun.disconnect(self._trace_prerun)\n signals.task_postrun.disconnect(self._trace_postrun)\n signals.before_task_publish.disconnect(self._trace_before_publish)\n signals.after_task_publish.disconnect(self._trace_after_publish)\n signals.task_failure.disconnect(self._trace_failure)\n signals.task_retry.disconnect(self._trace_retry)\n\n def _trace_prerun(self, *args, **kwargs):\n task = utils.retrieve_task(kwargs)\n task_id = utils.retrieve_task_id(kwargs)\n\n if task is None or task_id is None:\n return\n\n logger.debug(\"prerun signal start task_id=%s\", task_id)\n\n span = self._tracer.start_span(task.name, kind=trace.SpanKind.CONSUMER)\n\n activation = self._tracer.use_span(span, end_on_exit=True)\n activation.__enter__()\n utils.attach_span(task, task_id, (span, activation))\n\n @staticmethod\n def _trace_postrun(*args, **kwargs):\n task = utils.retrieve_task(kwargs)\n task_id = utils.retrieve_task_id(kwargs)\n\n if task is None or task_id is None:\n return\n\n logger.debug(\"postrun signal task_id=%s\", task_id)\n\n # retrieve and finish the Span\n span, activation = utils.retrieve_span(task, task_id)\n if span is None:\n logger.warning(\"no existing span found for task_id=%s\", task_id)\n return\n\n # request context tags\n span.set_attribute(_TASK_TAG_KEY, _TASK_RUN)\n utils.set_attributes_from_context(span, kwargs)\n utils.set_attributes_from_context(span, task.request)\n span.set_attribute(_TASK_NAME_KEY, task.name)\n\n activation.__exit__(None, None, None)\n utils.detach_span(task, task_id)\n\n def _trace_before_publish(self, *args, **kwargs):\n task = utils.retrieve_task_from_sender(kwargs)\n task_id = utils.retrieve_task_id_from_message(kwargs)\n\n if task is None or task_id is None:\n return\n\n span = self._tracer.start_span(task.name, kind=trace.SpanKind.PRODUCER)\n\n # apply some attributes here because most of the data is not available\n span.set_attribute(_TASK_TAG_KEY, _TASK_APPLY_ASYNC)\n span.set_attribute(_MESSAGE_ID_ATTRIBUTE_NAME, task_id)\n span.set_attribute(_TASK_NAME_KEY, task.name)\n utils.set_attributes_from_context(span, kwargs)\n\n activation = self._tracer.use_span(span, end_on_exit=True)\n activation.__enter__()\n utils.attach_span(task, task_id, (span, activation), is_publish=True)\n\n @staticmethod\n def _trace_after_publish(*args, **kwargs):\n task = utils.retrieve_task_from_sender(kwargs)\n task_id = utils.retrieve_task_id_from_message(kwargs)\n\n if task is None or task_id is None:\n return\n\n # retrieve and finish the Span\n _, activation = utils.retrieve_span(task, task_id, is_publish=True)\n if activation is None:\n logger.warning(\"no existing span found for task_id=%s\", task_id)\n return\n\n activation.__exit__(None, None, None)\n utils.detach_span(task, task_id, is_publish=True)\n\n @staticmethod\n def _trace_failure(*args, **kwargs):\n task = utils.retrieve_task_from_sender(kwargs)\n task_id = utils.retrieve_task_id(kwargs)\n\n if task is None or task_id is None:\n return\n\n # retrieve and pass exception info to activation\n span, _ = utils.retrieve_span(task, task_id)\n if span is None:\n return\n\n status_kwargs = {\"canonical_code\": StatusCanonicalCode.UNKNOWN}\n\n ex = kwargs.get(\"einfo\")\n\n if (\n hasattr(task, \"throws\")\n and ex is not None\n and isinstance(ex.exception, task.throws)\n ):\n return\n\n if ex is not None:\n status_kwargs[\"description\"] = str(ex)\n\n span.set_status(Status(**status_kwargs))\n\n @staticmethod\n def _trace_retry(*args, **kwargs):\n task = utils.retrieve_task_from_sender(kwargs)\n task_id = utils.retrieve_task_id_from_request(kwargs)\n reason = utils.retrieve_reason(kwargs)\n\n if task is None or task_id is None or reason is None:\n return\n\n span, _ = utils.retrieve_span(task, task_id)\n if span is None:\n return\n\n # Add retry reason metadata to span\n # Use `str(reason)` instead of `reason.message` in case we get\n # something that isn't an `Exception`\n span.set_attribute(_TASK_RETRY_REASON_KEY, str(reason))\n", "path": "instrumentation/opentelemetry-instrumentation-celery/src/opentelemetry/instrumentation/celery/__init__.py"}], "after_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"\nInstrument `celery`_ to trace Celery applications.\n\n.. _celery: https://pypi.org/project/celery/\n\nUsage\n-----\n\n* Start broker backend\n\n.. code::\n\n docker run -p 5672:5672 rabbitmq\n\n\n* Run instrumented task\n\n.. code:: python\n\n from opentelemetry import trace\n from opentelemetry.sdk.trace import TracerProvider\n from opentelemetry.sdk.trace.export import BatchExportSpanProcessor\n from opentelemetry.instrumentation.celery import CeleryInstrumentor\n\n from celery import Celery\n from celery.signals import worker_process_init\n\n @worker_process_init.connect(weak=False)\n def init_celery_tracing(*args, **kwargs):\n trace.set_tracer_provider(TracerProvider())\n span_processor = BatchExportSpanProcessor(ConsoleSpanExporter())\n trace.get_tracer_provider().add_span_processor(span_processor)\n CeleryInstrumentor().instrument()\n\n app = Celery(\"tasks\", broker=\"amqp://localhost\")\n\n @app.task\n def add(x, y):\n return x + y\n\n add.delay(42, 50)\n\nAPI\n---\n\"\"\"\n\nimport logging\nimport signal\nfrom collections.abc import Iterable\n\nfrom celery import signals # pylint: disable=no-name-in-module\n\nfrom opentelemetry import propagators, trace\nfrom opentelemetry.instrumentation.celery import utils\nfrom opentelemetry.instrumentation.celery.version import __version__\nfrom opentelemetry.instrumentation.instrumentor import BaseInstrumentor\nfrom opentelemetry.trace.propagation import get_current_span\nfrom opentelemetry.trace.status import Status, StatusCanonicalCode\n\nlogger = logging.getLogger(__name__)\n\n# Task operations\n_TASK_TAG_KEY = \"celery.action\"\n_TASK_APPLY_ASYNC = \"apply_async\"\n_TASK_RUN = \"run\"\n\n_TASK_RETRY_REASON_KEY = \"celery.retry.reason\"\n_TASK_REVOKED_REASON_KEY = \"celery.revoked.reason\"\n_TASK_REVOKED_TERMINATED_SIGNAL_KEY = \"celery.terminated.signal\"\n_TASK_NAME_KEY = \"celery.task_name\"\n_MESSAGE_ID_ATTRIBUTE_NAME = \"messaging.message_id\"\n\n\nclass CeleryInstrumentor(BaseInstrumentor):\n def _instrument(self, **kwargs):\n tracer_provider = kwargs.get(\"tracer_provider\")\n\n # pylint: disable=attribute-defined-outside-init\n self._tracer = trace.get_tracer(__name__, __version__, tracer_provider)\n\n signals.task_prerun.connect(self._trace_prerun, weak=False)\n signals.task_postrun.connect(self._trace_postrun, weak=False)\n signals.before_task_publish.connect(\n self._trace_before_publish, weak=False\n )\n signals.after_task_publish.connect(\n self._trace_after_publish, weak=False\n )\n signals.task_failure.connect(self._trace_failure, weak=False)\n signals.task_retry.connect(self._trace_retry, weak=False)\n\n def _uninstrument(self, **kwargs):\n signals.task_prerun.disconnect(self._trace_prerun)\n signals.task_postrun.disconnect(self._trace_postrun)\n signals.before_task_publish.disconnect(self._trace_before_publish)\n signals.after_task_publish.disconnect(self._trace_after_publish)\n signals.task_failure.disconnect(self._trace_failure)\n signals.task_retry.disconnect(self._trace_retry)\n\n def _trace_prerun(self, *args, **kwargs):\n task = utils.retrieve_task(kwargs)\n task_id = utils.retrieve_task_id(kwargs)\n\n if task is None or task_id is None:\n return\n\n request = task.request\n tracectx = propagators.extract(carrier_extractor, request) or {}\n parent = get_current_span(tracectx)\n\n logger.debug(\"prerun signal start task_id=%s\", task_id)\n\n operation_name = \"{0}/{1}\".format(_TASK_RUN, task.name)\n span = self._tracer.start_span(\n operation_name, parent=parent, kind=trace.SpanKind.CONSUMER\n )\n\n activation = self._tracer.use_span(span, end_on_exit=True)\n activation.__enter__()\n utils.attach_span(task, task_id, (span, activation))\n\n @staticmethod\n def _trace_postrun(*args, **kwargs):\n task = utils.retrieve_task(kwargs)\n task_id = utils.retrieve_task_id(kwargs)\n\n if task is None or task_id is None:\n return\n\n logger.debug(\"postrun signal task_id=%s\", task_id)\n\n # retrieve and finish the Span\n span, activation = utils.retrieve_span(task, task_id)\n if span is None:\n logger.warning(\"no existing span found for task_id=%s\", task_id)\n return\n\n # request context tags\n span.set_attribute(_TASK_TAG_KEY, _TASK_RUN)\n utils.set_attributes_from_context(span, kwargs)\n utils.set_attributes_from_context(span, task.request)\n span.set_attribute(_TASK_NAME_KEY, task.name)\n\n activation.__exit__(None, None, None)\n utils.detach_span(task, task_id)\n\n def _trace_before_publish(self, *args, **kwargs):\n task = utils.retrieve_task_from_sender(kwargs)\n task_id = utils.retrieve_task_id_from_message(kwargs)\n\n if task is None or task_id is None:\n return\n\n operation_name = \"{0}/{1}\".format(_TASK_APPLY_ASYNC, task.name)\n span = self._tracer.start_span(\n operation_name, kind=trace.SpanKind.PRODUCER\n )\n\n # apply some attributes here because most of the data is not available\n span.set_attribute(_TASK_TAG_KEY, _TASK_APPLY_ASYNC)\n span.set_attribute(_MESSAGE_ID_ATTRIBUTE_NAME, task_id)\n span.set_attribute(_TASK_NAME_KEY, task.name)\n utils.set_attributes_from_context(span, kwargs)\n\n activation = self._tracer.use_span(span, end_on_exit=True)\n activation.__enter__()\n utils.attach_span(task, task_id, (span, activation), is_publish=True)\n\n headers = kwargs.get(\"headers\")\n if headers:\n propagators.inject(type(headers).__setitem__, headers)\n\n @staticmethod\n def _trace_after_publish(*args, **kwargs):\n task = utils.retrieve_task_from_sender(kwargs)\n task_id = utils.retrieve_task_id_from_message(kwargs)\n\n if task is None or task_id is None:\n return\n\n # retrieve and finish the Span\n _, activation = utils.retrieve_span(task, task_id, is_publish=True)\n if activation is None:\n logger.warning(\"no existing span found for task_id=%s\", task_id)\n return\n\n activation.__exit__(None, None, None)\n utils.detach_span(task, task_id, is_publish=True)\n\n @staticmethod\n def _trace_failure(*args, **kwargs):\n task = utils.retrieve_task_from_sender(kwargs)\n task_id = utils.retrieve_task_id(kwargs)\n\n if task is None or task_id is None:\n return\n\n # retrieve and pass exception info to activation\n span, _ = utils.retrieve_span(task, task_id)\n if span is None:\n return\n\n status_kwargs = {\"canonical_code\": StatusCanonicalCode.UNKNOWN}\n\n ex = kwargs.get(\"einfo\")\n\n if (\n hasattr(task, \"throws\")\n and ex is not None\n and isinstance(ex.exception, task.throws)\n ):\n return\n\n if ex is not None:\n status_kwargs[\"description\"] = str(ex)\n\n span.set_status(Status(**status_kwargs))\n\n @staticmethod\n def _trace_retry(*args, **kwargs):\n task = utils.retrieve_task_from_sender(kwargs)\n task_id = utils.retrieve_task_id_from_request(kwargs)\n reason = utils.retrieve_reason(kwargs)\n\n if task is None or task_id is None or reason is None:\n return\n\n span, _ = utils.retrieve_span(task, task_id)\n if span is None:\n return\n\n # Add retry reason metadata to span\n # Use `str(reason)` instead of `reason.message` in case we get\n # something that isn't an `Exception`\n span.set_attribute(_TASK_RETRY_REASON_KEY, str(reason))\n\n\ndef carrier_extractor(carrier, key):\n value = getattr(carrier, key, [])\n if isinstance(value, str) or not isinstance(value, Iterable):\n value = (value,)\n return value\n", "path": "instrumentation/opentelemetry-instrumentation-celery/src/opentelemetry/instrumentation/celery/__init__.py"}]}
| 3,159 | 939 |
gh_patches_debug_38480
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-1149
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add support for PEX_INTERPRETER `-c`, `-m` and `-` special modes to PEX venvs.
#1128 lands a Venv tool that creates a venv from a PEX file with an entrypoint that fully emulates PEX behavior except for handling `-c`, `-m` and `-` special modes when `PEX_INTERPRETER` is activated. Implement these modes so that a PEX venv can be counted on to work exactly like a PEX file.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pex/tools/commands/venv.py`
Content:
```
1 # Copyright 2020 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 from __future__ import absolute_import
5
6 import errno
7 import os
8 import shutil
9 import zipfile
10 from argparse import ArgumentParser, Namespace
11 from textwrap import dedent
12
13 from pex import pex_builder, pex_warnings
14 from pex.common import chmod_plus_x, safe_mkdir
15 from pex.environment import PEXEnvironment
16 from pex.pex import PEX
17 from pex.tools.command import Command, Error, Ok, Result
18 from pex.tools.commands.virtualenv import PipUnavailableError, Virtualenv
19 from pex.tracer import TRACER
20 from pex.typing import TYPE_CHECKING
21
22 if TYPE_CHECKING:
23 from typing import Tuple
24
25
26 # N.B.: We can't use shutil.copytree since we copy from multiple source locations to the same site
27 # packages directory destination. Since we're forced to stray from the stdlib here, support for
28 # hardlinks is added to provide a measurable speed up and disk space savings when possible.
29 def _copytree(
30 src, # type: str
31 dst, # type: str
32 exclude=(), # type: Tuple[str, ...]
33 collisions_ok=False, # type: bool
34 ):
35 # type: (...) -> None
36 safe_mkdir(dst)
37 link = True
38 for root, dirs, files in os.walk(src, topdown=True, followlinks=False):
39 if src == root:
40 dirs[:] = [d for d in dirs if d not in exclude]
41 files[:] = [f for f in files if f not in exclude]
42
43 for d in dirs:
44 try:
45 os.mkdir(os.path.join(dst, os.path.relpath(os.path.join(root, d), src)))
46 except OSError as e:
47 if e.errno != errno.EEXIST:
48 raise e
49
50 for f in files:
51 src_entry = os.path.join(root, f)
52 dst_entry = os.path.join(dst, os.path.relpath(src_entry, src))
53 try:
54 if link:
55 try:
56 os.link(src_entry, dst_entry)
57 continue
58 except OSError as e:
59 if e.errno != errno.EXDEV:
60 raise e
61 link = False
62 shutil.copy(src_entry, dst_entry)
63 except OSError as e:
64 if e.errno == errno.EEXIST:
65 pex_warnings.warn(
66 "Failed to overwrite {} with {}: {}".format(dst_entry, src_entry, e)
67 )
68 if not collisions_ok:
69 raise e
70
71
72 class Venv(Command):
73 """Creates a venv from the PEX file."""
74
75 def add_arguments(self, parser):
76 # type: (ArgumentParser) -> None
77 parser.add_argument(
78 "venv",
79 nargs=1,
80 metavar="PATH",
81 help="The directory to create the virtual environment in.",
82 )
83 parser.add_argument(
84 "-b",
85 "--bin-path",
86 choices=("prepend", "append"),
87 default=None,
88 help="Add the venv bin dir to the PATH in the __main__.py script.",
89 )
90 parser.add_argument(
91 "-f",
92 "--force",
93 action="store_true",
94 default=False,
95 help="If the venv directory already exists, overwrite it.",
96 )
97 parser.add_argument(
98 "--collisions-ok",
99 action="store_true",
100 default=False,
101 help=(
102 "Don't error if population of the venv encounters distributions in the PEX file "
103 "with colliding files."
104 ),
105 )
106 parser.add_argument(
107 "-p",
108 "--pip",
109 action="store_true",
110 default=False,
111 help="Add pip to the venv.",
112 )
113
114 def run(
115 self,
116 pex, # type: PEX
117 options, # type: Namespace
118 ):
119 # type: (...) -> Result
120
121 # 0. Create an empty virtual environment to populate with the PEX code and dependencies.
122 venv = Virtualenv.create(options.venv[0], interpreter=pex.interpreter, force=options.force)
123
124 # 1. Populate the venv with the PEX contents.
125 pex_info = pex.pex_info()
126 if zipfile.is_zipfile(pex.path()):
127 PEXEnvironment.explode_code(
128 pex.path(), pex_info, venv.site_packages_dir, exclude=("__main__.py",)
129 )
130 else:
131 _copytree(
132 src=pex.path(),
133 dst=venv.site_packages_dir,
134 exclude=(pex_info.internal_cache, pex_builder.BOOTSTRAP_DIR, "__main__.py"),
135 )
136
137 for dist in pex.activate():
138 _copytree(
139 src=dist.location,
140 dst=venv.site_packages_dir,
141 exclude=("bin",),
142 collisions_ok=options.collisions_ok,
143 )
144 dist_bin_dir = os.path.join(dist.location, "bin")
145 if os.path.isdir(dist_bin_dir):
146 _copytree(dist_bin_dir, venv.bin_dir, collisions_ok=options.collisions_ok)
147
148 # 2. Add a __main__ to the root of the venv for running the venv dir like a loose PEX dir
149 # and a main.py for running as a script.
150 main_contents = dedent(
151 """\
152 #!{venv_python} -sE
153
154 import os
155 import sys
156
157 python = {venv_python!r}
158 if sys.executable != python:
159 os.execv(python, [python, "-sE"] + sys.argv)
160
161 os.environ["VIRTUAL_ENV"] = {venv_dir!r}
162 sys.path.extend(os.environ.get("PEX_EXTRA_SYS_PATH", "").split(os.pathsep))
163
164 bin_dir = {venv_bin_dir!r}
165 bin_path = {bin_path!r}
166 if bin_path:
167 PATH = os.environ.get("PATH", "").split(os.pathsep)
168 if bin_path == "prepend":
169 PATH = [bin_dir] + PATH
170 else:
171 PATH.append(bin_dir)
172 os.environ["PATH"] = os.pathsep.join(PATH)
173
174 PEX_OVERRIDE_KEYS = ("PEX_INTERPRETER", "PEX_SCRIPT", "PEX_MODULE")
175 pex_overrides = dict(
176 (key, os.environ.pop(key)) for key in PEX_OVERRIDE_KEYS if key in os.environ
177 )
178 if len(pex_overrides) > 1:
179 sys.stderr.write(
180 "Can only specify one of {{overrides}}; found: {{found}}\\n".format(
181 overrides=", ".join(PEX_OVERRIDE_KEYS),
182 found=" ".join("{{}}={{}}".format(k, v) for k, v in pex_overrides.items())
183 )
184 )
185 sys.exit(1)
186
187 pex_script = pex_overrides.get("PEX_SCRIPT")
188 if pex_script:
189 script_path = os.path.join(bin_dir, pex_script)
190 os.execv(script_path, [script_path] + sys.argv[1:])
191
192 # TODO(John Sirois): Support `-c`, `-m` and `-` special modes when PEX_INTERPRETER is
193 # activated like PEX files do: https://github.com/pantsbuild/pex/issues/1136
194 pex_interpreter = pex_overrides.get("PEX_INTERPRETER", "").lower()
195 entry_point = (
196 "code:interact"
197 if pex_interpreter in ("1", "true")
198 else pex_overrides.get("PEX_MODULE", {entry_point!r} or "code:interact")
199 )
200 module_name, _, function = entry_point.partition(":")
201 if not function:
202 import runpy
203 runpy.run_module(module_name, run_name="__main__")
204 else:
205 import importlib
206 module = importlib.import_module(module_name)
207 # N.B.: Functions may be hung off top-level objects in the module namespace,
208 # e.g.: Class.method; so we drill down through any attributes to the final function
209 # object.
210 namespace, func = module, None
211 for attr in function.split("."):
212 func = namespace = getattr(namespace, attr)
213 func()
214 """.format(
215 venv_python=venv.interpreter.binary,
216 bin_path=options.bin_path,
217 venv_dir=venv.venv_dir,
218 venv_bin_dir=venv.bin_dir,
219 entry_point=pex_info.entry_point,
220 )
221 )
222 with open(venv.join_path("__main__.py"), "w") as fp:
223 fp.write(main_contents)
224 chmod_plus_x(fp.name)
225 os.symlink(os.path.basename(fp.name), venv.join_path("pex"))
226
227 # 3. Re-write any (console) scripts to use the venv Python.
228 for script in venv.rewrite_scripts(python_args="-sE"):
229 TRACER.log("Re-writing {}".format(script))
230
231 if options.pip:
232 try:
233 venv.install_pip()
234 except PipUnavailableError as e:
235 return Error(
236 "The virtual environment was successfully created, but Pip was not "
237 "installed:\n{}".format(e)
238 )
239
240 return Ok()
241
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pex/tools/commands/venv.py b/pex/tools/commands/venv.py
--- a/pex/tools/commands/venv.py
+++ b/pex/tools/commands/venv.py
@@ -189,14 +189,47 @@
script_path = os.path.join(bin_dir, pex_script)
os.execv(script_path, [script_path] + sys.argv[1:])
- # TODO(John Sirois): Support `-c`, `-m` and `-` special modes when PEX_INTERPRETER is
- # activated like PEX files do: https://github.com/pantsbuild/pex/issues/1136
- pex_interpreter = pex_overrides.get("PEX_INTERPRETER", "").lower()
+ pex_interpreter = pex_overrides.get("PEX_INTERPRETER", "").lower() in ("1", "true")
+ PEX_INTERPRETER_ENTRYPOINT = "code:interact"
entry_point = (
- "code:interact"
- if pex_interpreter in ("1", "true")
- else pex_overrides.get("PEX_MODULE", {entry_point!r} or "code:interact")
+ PEX_INTERPRETER_ENTRYPOINT
+ if pex_interpreter
+ else pex_overrides.get("PEX_MODULE", {entry_point!r} or PEX_INTERPRETER_ENTRYPOINT)
)
+ if entry_point == PEX_INTERPRETER_ENTRYPOINT and len(sys.argv) > 1:
+ args = sys.argv[1:]
+ arg = args[0]
+ if arg == "-m":
+ if len(args) < 2:
+ sys.stderr.write("Argument expected for the -m option\\n")
+ sys.exit(2)
+ entry_point = module = args[1]
+ sys.argv = args[1:]
+ # Fall through to entry_point handling below.
+ else:
+ filename = arg
+ sys.argv = args
+ if arg == "-c":
+ if len(args) < 2:
+ sys.stderr.write("Argument expected for the -c option\\n")
+ sys.exit(2)
+ filename = "-c <cmd>"
+ content = args[1]
+ sys.argv = ["-c"] + args[2:]
+ elif arg == "-":
+ content = sys.stdin.read()
+ else:
+ with open(arg) as fp:
+ content = fp.read()
+
+ ast = compile(content, filename, "exec", flags=0, dont_inherit=1)
+ globals_map = globals().copy()
+ globals_map["__name__"] = "__main__"
+ globals_map["__file__"] = filename
+ locals_map = globals_map
+ {exec_ast}
+ sys.exit(0)
+
module_name, _, function = entry_point.partition(":")
if not function:
import runpy
@@ -217,6 +250,11 @@
venv_dir=venv.venv_dir,
venv_bin_dir=venv.bin_dir,
entry_point=pex_info.entry_point,
+ exec_ast=(
+ "exec ast in globals_map, locals_map"
+ if venv.interpreter.version[0] == 2
+ else "exec(ast, globals_map, locals_map)"
+ ),
)
)
with open(venv.join_path("__main__.py"), "w") as fp:
|
{"golden_diff": "diff --git a/pex/tools/commands/venv.py b/pex/tools/commands/venv.py\n--- a/pex/tools/commands/venv.py\n+++ b/pex/tools/commands/venv.py\n@@ -189,14 +189,47 @@\n script_path = os.path.join(bin_dir, pex_script)\n os.execv(script_path, [script_path] + sys.argv[1:])\n \n- # TODO(John Sirois): Support `-c`, `-m` and `-` special modes when PEX_INTERPRETER is\n- # activated like PEX files do: https://github.com/pantsbuild/pex/issues/1136\n- pex_interpreter = pex_overrides.get(\"PEX_INTERPRETER\", \"\").lower()\n+ pex_interpreter = pex_overrides.get(\"PEX_INTERPRETER\", \"\").lower() in (\"1\", \"true\")\n+ PEX_INTERPRETER_ENTRYPOINT = \"code:interact\"\n entry_point = (\n- \"code:interact\"\n- if pex_interpreter in (\"1\", \"true\")\n- else pex_overrides.get(\"PEX_MODULE\", {entry_point!r} or \"code:interact\")\n+ PEX_INTERPRETER_ENTRYPOINT\n+ if pex_interpreter\n+ else pex_overrides.get(\"PEX_MODULE\", {entry_point!r} or PEX_INTERPRETER_ENTRYPOINT)\n )\n+ if entry_point == PEX_INTERPRETER_ENTRYPOINT and len(sys.argv) > 1:\n+ args = sys.argv[1:]\n+ arg = args[0]\n+ if arg == \"-m\":\n+ if len(args) < 2:\n+ sys.stderr.write(\"Argument expected for the -m option\\\\n\")\n+ sys.exit(2)\n+ entry_point = module = args[1]\n+ sys.argv = args[1:]\n+ # Fall through to entry_point handling below.\n+ else:\n+ filename = arg\n+ sys.argv = args\n+ if arg == \"-c\":\n+ if len(args) < 2:\n+ sys.stderr.write(\"Argument expected for the -c option\\\\n\")\n+ sys.exit(2)\n+ filename = \"-c <cmd>\"\n+ content = args[1]\n+ sys.argv = [\"-c\"] + args[2:]\n+ elif arg == \"-\":\n+ content = sys.stdin.read()\n+ else:\n+ with open(arg) as fp:\n+ content = fp.read()\n+ \n+ ast = compile(content, filename, \"exec\", flags=0, dont_inherit=1)\n+ globals_map = globals().copy()\n+ globals_map[\"__name__\"] = \"__main__\"\n+ globals_map[\"__file__\"] = filename\n+ locals_map = globals_map\n+ {exec_ast}\n+ sys.exit(0)\n+\n module_name, _, function = entry_point.partition(\":\")\n if not function:\n import runpy\n@@ -217,6 +250,11 @@\n venv_dir=venv.venv_dir,\n venv_bin_dir=venv.bin_dir,\n entry_point=pex_info.entry_point,\n+ exec_ast=(\n+ \"exec ast in globals_map, locals_map\"\n+ if venv.interpreter.version[0] == 2\n+ else \"exec(ast, globals_map, locals_map)\"\n+ ),\n )\n )\n with open(venv.join_path(\"__main__.py\"), \"w\") as fp:\n", "issue": "Add support for PEX_INTERPRETER `-c`, `-m` and `-` special modes to PEX venvs.\n#1128 lands a Venv tool that creates a venv from a PEX file with an entrypoint that fully emulates PEX behavior except for handling `-c`, `-m` and `-` special modes when `PEX_INTERPRETER` is activated. Implement these modes so that a PEX venv can be counted on to work exactly like a PEX file.\n", "before_files": [{"content": "# Copyright 2020 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\nfrom __future__ import absolute_import\n\nimport errno\nimport os\nimport shutil\nimport zipfile\nfrom argparse import ArgumentParser, Namespace\nfrom textwrap import dedent\n\nfrom pex import pex_builder, pex_warnings\nfrom pex.common import chmod_plus_x, safe_mkdir\nfrom pex.environment import PEXEnvironment\nfrom pex.pex import PEX\nfrom pex.tools.command import Command, Error, Ok, Result\nfrom pex.tools.commands.virtualenv import PipUnavailableError, Virtualenv\nfrom pex.tracer import TRACER\nfrom pex.typing import TYPE_CHECKING\n\nif TYPE_CHECKING:\n from typing import Tuple\n\n\n# N.B.: We can't use shutil.copytree since we copy from multiple source locations to the same site\n# packages directory destination. Since we're forced to stray from the stdlib here, support for\n# hardlinks is added to provide a measurable speed up and disk space savings when possible.\ndef _copytree(\n src, # type: str\n dst, # type: str\n exclude=(), # type: Tuple[str, ...]\n collisions_ok=False, # type: bool\n):\n # type: (...) -> None\n safe_mkdir(dst)\n link = True\n for root, dirs, files in os.walk(src, topdown=True, followlinks=False):\n if src == root:\n dirs[:] = [d for d in dirs if d not in exclude]\n files[:] = [f for f in files if f not in exclude]\n\n for d in dirs:\n try:\n os.mkdir(os.path.join(dst, os.path.relpath(os.path.join(root, d), src)))\n except OSError as e:\n if e.errno != errno.EEXIST:\n raise e\n\n for f in files:\n src_entry = os.path.join(root, f)\n dst_entry = os.path.join(dst, os.path.relpath(src_entry, src))\n try:\n if link:\n try:\n os.link(src_entry, dst_entry)\n continue\n except OSError as e:\n if e.errno != errno.EXDEV:\n raise e\n link = False\n shutil.copy(src_entry, dst_entry)\n except OSError as e:\n if e.errno == errno.EEXIST:\n pex_warnings.warn(\n \"Failed to overwrite {} with {}: {}\".format(dst_entry, src_entry, e)\n )\n if not collisions_ok:\n raise e\n\n\nclass Venv(Command):\n \"\"\"Creates a venv from the PEX file.\"\"\"\n\n def add_arguments(self, parser):\n # type: (ArgumentParser) -> None\n parser.add_argument(\n \"venv\",\n nargs=1,\n metavar=\"PATH\",\n help=\"The directory to create the virtual environment in.\",\n )\n parser.add_argument(\n \"-b\",\n \"--bin-path\",\n choices=(\"prepend\", \"append\"),\n default=None,\n help=\"Add the venv bin dir to the PATH in the __main__.py script.\",\n )\n parser.add_argument(\n \"-f\",\n \"--force\",\n action=\"store_true\",\n default=False,\n help=\"If the venv directory already exists, overwrite it.\",\n )\n parser.add_argument(\n \"--collisions-ok\",\n action=\"store_true\",\n default=False,\n help=(\n \"Don't error if population of the venv encounters distributions in the PEX file \"\n \"with colliding files.\"\n ),\n )\n parser.add_argument(\n \"-p\",\n \"--pip\",\n action=\"store_true\",\n default=False,\n help=\"Add pip to the venv.\",\n )\n\n def run(\n self,\n pex, # type: PEX\n options, # type: Namespace\n ):\n # type: (...) -> Result\n\n # 0. Create an empty virtual environment to populate with the PEX code and dependencies.\n venv = Virtualenv.create(options.venv[0], interpreter=pex.interpreter, force=options.force)\n\n # 1. Populate the venv with the PEX contents.\n pex_info = pex.pex_info()\n if zipfile.is_zipfile(pex.path()):\n PEXEnvironment.explode_code(\n pex.path(), pex_info, venv.site_packages_dir, exclude=(\"__main__.py\",)\n )\n else:\n _copytree(\n src=pex.path(),\n dst=venv.site_packages_dir,\n exclude=(pex_info.internal_cache, pex_builder.BOOTSTRAP_DIR, \"__main__.py\"),\n )\n\n for dist in pex.activate():\n _copytree(\n src=dist.location,\n dst=venv.site_packages_dir,\n exclude=(\"bin\",),\n collisions_ok=options.collisions_ok,\n )\n dist_bin_dir = os.path.join(dist.location, \"bin\")\n if os.path.isdir(dist_bin_dir):\n _copytree(dist_bin_dir, venv.bin_dir, collisions_ok=options.collisions_ok)\n\n # 2. Add a __main__ to the root of the venv for running the venv dir like a loose PEX dir\n # and a main.py for running as a script.\n main_contents = dedent(\n \"\"\"\\\n #!{venv_python} -sE\n\n import os\n import sys\n\n python = {venv_python!r}\n if sys.executable != python:\n os.execv(python, [python, \"-sE\"] + sys.argv)\n\n os.environ[\"VIRTUAL_ENV\"] = {venv_dir!r}\n sys.path.extend(os.environ.get(\"PEX_EXTRA_SYS_PATH\", \"\").split(os.pathsep))\n\n bin_dir = {venv_bin_dir!r}\n bin_path = {bin_path!r}\n if bin_path:\n PATH = os.environ.get(\"PATH\", \"\").split(os.pathsep)\n if bin_path == \"prepend\":\n PATH = [bin_dir] + PATH\n else:\n PATH.append(bin_dir)\n os.environ[\"PATH\"] = os.pathsep.join(PATH)\n\n PEX_OVERRIDE_KEYS = (\"PEX_INTERPRETER\", \"PEX_SCRIPT\", \"PEX_MODULE\")\n pex_overrides = dict(\n (key, os.environ.pop(key)) for key in PEX_OVERRIDE_KEYS if key in os.environ\n )\n if len(pex_overrides) > 1:\n sys.stderr.write(\n \"Can only specify one of {{overrides}}; found: {{found}}\\\\n\".format(\n overrides=\", \".join(PEX_OVERRIDE_KEYS),\n found=\" \".join(\"{{}}={{}}\".format(k, v) for k, v in pex_overrides.items())\n )\n )\n sys.exit(1)\n\n pex_script = pex_overrides.get(\"PEX_SCRIPT\")\n if pex_script:\n script_path = os.path.join(bin_dir, pex_script)\n os.execv(script_path, [script_path] + sys.argv[1:])\n\n # TODO(John Sirois): Support `-c`, `-m` and `-` special modes when PEX_INTERPRETER is\n # activated like PEX files do: https://github.com/pantsbuild/pex/issues/1136\n pex_interpreter = pex_overrides.get(\"PEX_INTERPRETER\", \"\").lower()\n entry_point = (\n \"code:interact\"\n if pex_interpreter in (\"1\", \"true\")\n else pex_overrides.get(\"PEX_MODULE\", {entry_point!r} or \"code:interact\")\n )\n module_name, _, function = entry_point.partition(\":\")\n if not function:\n import runpy\n runpy.run_module(module_name, run_name=\"__main__\")\n else:\n import importlib\n module = importlib.import_module(module_name)\n # N.B.: Functions may be hung off top-level objects in the module namespace,\n # e.g.: Class.method; so we drill down through any attributes to the final function\n # object.\n namespace, func = module, None\n for attr in function.split(\".\"):\n func = namespace = getattr(namespace, attr)\n func()\n \"\"\".format(\n venv_python=venv.interpreter.binary,\n bin_path=options.bin_path,\n venv_dir=venv.venv_dir,\n venv_bin_dir=venv.bin_dir,\n entry_point=pex_info.entry_point,\n )\n )\n with open(venv.join_path(\"__main__.py\"), \"w\") as fp:\n fp.write(main_contents)\n chmod_plus_x(fp.name)\n os.symlink(os.path.basename(fp.name), venv.join_path(\"pex\"))\n\n # 3. Re-write any (console) scripts to use the venv Python.\n for script in venv.rewrite_scripts(python_args=\"-sE\"):\n TRACER.log(\"Re-writing {}\".format(script))\n\n if options.pip:\n try:\n venv.install_pip()\n except PipUnavailableError as e:\n return Error(\n \"The virtual environment was successfully created, but Pip was not \"\n \"installed:\\n{}\".format(e)\n )\n\n return Ok()\n", "path": "pex/tools/commands/venv.py"}], "after_files": [{"content": "# Copyright 2020 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\nfrom __future__ import absolute_import\n\nimport errno\nimport os\nimport shutil\nimport zipfile\nfrom argparse import ArgumentParser, Namespace\nfrom textwrap import dedent\n\nfrom pex import pex_builder, pex_warnings\nfrom pex.common import chmod_plus_x, safe_mkdir\nfrom pex.environment import PEXEnvironment\nfrom pex.pex import PEX\nfrom pex.tools.command import Command, Error, Ok, Result\nfrom pex.tools.commands.virtualenv import PipUnavailableError, Virtualenv\nfrom pex.tracer import TRACER\nfrom pex.typing import TYPE_CHECKING\n\nif TYPE_CHECKING:\n from typing import Tuple\n\n\n# N.B.: We can't use shutil.copytree since we copy from multiple source locations to the same site\n# packages directory destination. Since we're forced to stray from the stdlib here, support for\n# hardlinks is added to provide a measurable speed up and disk space savings when possible.\ndef _copytree(\n src, # type: str\n dst, # type: str\n exclude=(), # type: Tuple[str, ...]\n collisions_ok=False, # type: bool\n):\n # type: (...) -> None\n safe_mkdir(dst)\n link = True\n for root, dirs, files in os.walk(src, topdown=True, followlinks=False):\n if src == root:\n dirs[:] = [d for d in dirs if d not in exclude]\n files[:] = [f for f in files if f not in exclude]\n\n for d in dirs:\n try:\n os.mkdir(os.path.join(dst, os.path.relpath(os.path.join(root, d), src)))\n except OSError as e:\n if e.errno != errno.EEXIST:\n raise e\n\n for f in files:\n src_entry = os.path.join(root, f)\n dst_entry = os.path.join(dst, os.path.relpath(src_entry, src))\n try:\n if link:\n try:\n os.link(src_entry, dst_entry)\n continue\n except OSError as e:\n if e.errno != errno.EXDEV:\n raise e\n link = False\n shutil.copy(src_entry, dst_entry)\n except OSError as e:\n if e.errno == errno.EEXIST:\n pex_warnings.warn(\n \"Failed to overwrite {} with {}: {}\".format(dst_entry, src_entry, e)\n )\n if not collisions_ok:\n raise e\n\n\nclass Venv(Command):\n \"\"\"Creates a venv from the PEX file.\"\"\"\n\n def add_arguments(self, parser):\n # type: (ArgumentParser) -> None\n parser.add_argument(\n \"venv\",\n nargs=1,\n metavar=\"PATH\",\n help=\"The directory to create the virtual environment in.\",\n )\n parser.add_argument(\n \"-b\",\n \"--bin-path\",\n choices=(\"prepend\", \"append\"),\n default=None,\n help=\"Add the venv bin dir to the PATH in the __main__.py script.\",\n )\n parser.add_argument(\n \"-f\",\n \"--force\",\n action=\"store_true\",\n default=False,\n help=\"If the venv directory already exists, overwrite it.\",\n )\n parser.add_argument(\n \"--collisions-ok\",\n action=\"store_true\",\n default=False,\n help=(\n \"Don't error if population of the venv encounters distributions in the PEX file \"\n \"with colliding files.\"\n ),\n )\n parser.add_argument(\n \"-p\",\n \"--pip\",\n action=\"store_true\",\n default=False,\n help=\"Add pip to the venv.\",\n )\n\n def run(\n self,\n pex, # type: PEX\n options, # type: Namespace\n ):\n # type: (...) -> Result\n\n # 0. Create an empty virtual environment to populate with the PEX code and dependencies.\n venv = Virtualenv.create(options.venv[0], interpreter=pex.interpreter, force=options.force)\n\n # 1. Populate the venv with the PEX contents.\n pex_info = pex.pex_info()\n if zipfile.is_zipfile(pex.path()):\n PEXEnvironment.explode_code(\n pex.path(), pex_info, venv.site_packages_dir, exclude=(\"__main__.py\",)\n )\n else:\n _copytree(\n src=pex.path(),\n dst=venv.site_packages_dir,\n exclude=(pex_info.internal_cache, pex_builder.BOOTSTRAP_DIR, \"__main__.py\"),\n )\n\n for dist in pex.activate():\n _copytree(\n src=dist.location,\n dst=venv.site_packages_dir,\n exclude=(\"bin\",),\n collisions_ok=options.collisions_ok,\n )\n dist_bin_dir = os.path.join(dist.location, \"bin\")\n if os.path.isdir(dist_bin_dir):\n _copytree(dist_bin_dir, venv.bin_dir, collisions_ok=options.collisions_ok)\n\n # 2. Add a __main__ to the root of the venv for running the venv dir like a loose PEX dir\n # and a main.py for running as a script.\n main_contents = dedent(\n \"\"\"\\\n #!{venv_python} -sE\n\n import os\n import sys\n\n python = {venv_python!r}\n if sys.executable != python:\n os.execv(python, [python, \"-sE\"] + sys.argv)\n\n os.environ[\"VIRTUAL_ENV\"] = {venv_dir!r}\n sys.path.extend(os.environ.get(\"PEX_EXTRA_SYS_PATH\", \"\").split(os.pathsep))\n\n bin_dir = {venv_bin_dir!r}\n bin_path = {bin_path!r}\n if bin_path:\n PATH = os.environ.get(\"PATH\", \"\").split(os.pathsep)\n if bin_path == \"prepend\":\n PATH = [bin_dir] + PATH\n else:\n PATH.append(bin_dir)\n os.environ[\"PATH\"] = os.pathsep.join(PATH)\n\n PEX_OVERRIDE_KEYS = (\"PEX_INTERPRETER\", \"PEX_SCRIPT\", \"PEX_MODULE\")\n pex_overrides = dict(\n (key, os.environ.pop(key)) for key in PEX_OVERRIDE_KEYS if key in os.environ\n )\n if len(pex_overrides) > 1:\n sys.stderr.write(\n \"Can only specify one of {{overrides}}; found: {{found}}\\\\n\".format(\n overrides=\", \".join(PEX_OVERRIDE_KEYS),\n found=\" \".join(\"{{}}={{}}\".format(k, v) for k, v in pex_overrides.items())\n )\n )\n sys.exit(1)\n\n pex_script = pex_overrides.get(\"PEX_SCRIPT\")\n if pex_script:\n script_path = os.path.join(bin_dir, pex_script)\n os.execv(script_path, [script_path] + sys.argv[1:])\n\n pex_interpreter = pex_overrides.get(\"PEX_INTERPRETER\", \"\").lower() in (\"1\", \"true\")\n PEX_INTERPRETER_ENTRYPOINT = \"code:interact\"\n entry_point = (\n PEX_INTERPRETER_ENTRYPOINT\n if pex_interpreter\n else pex_overrides.get(\"PEX_MODULE\", {entry_point!r} or PEX_INTERPRETER_ENTRYPOINT)\n )\n if entry_point == PEX_INTERPRETER_ENTRYPOINT and len(sys.argv) > 1:\n args = sys.argv[1:]\n arg = args[0]\n if arg == \"-m\":\n if len(args) < 2:\n sys.stderr.write(\"Argument expected for the -m option\\\\n\")\n sys.exit(2)\n entry_point = module = args[1]\n sys.argv = args[1:]\n # Fall through to entry_point handling below.\n else:\n filename = arg\n sys.argv = args\n if arg == \"-c\":\n if len(args) < 2:\n sys.stderr.write(\"Argument expected for the -c option\\\\n\")\n sys.exit(2)\n filename = \"-c <cmd>\"\n content = args[1]\n sys.argv = [\"-c\"] + args[2:]\n elif arg == \"-\":\n content = sys.stdin.read()\n else:\n with open(arg) as fp:\n content = fp.read()\n \n ast = compile(content, filename, \"exec\", flags=0, dont_inherit=1)\n globals_map = globals().copy()\n globals_map[\"__name__\"] = \"__main__\"\n globals_map[\"__file__\"] = filename\n locals_map = globals_map\n {exec_ast}\n sys.exit(0)\n\n module_name, _, function = entry_point.partition(\":\")\n if not function:\n import runpy\n runpy.run_module(module_name, run_name=\"__main__\")\n else:\n import importlib\n module = importlib.import_module(module_name)\n # N.B.: Functions may be hung off top-level objects in the module namespace,\n # e.g.: Class.method; so we drill down through any attributes to the final function\n # object.\n namespace, func = module, None\n for attr in function.split(\".\"):\n func = namespace = getattr(namespace, attr)\n func()\n \"\"\".format(\n venv_python=venv.interpreter.binary,\n bin_path=options.bin_path,\n venv_dir=venv.venv_dir,\n venv_bin_dir=venv.bin_dir,\n entry_point=pex_info.entry_point,\n exec_ast=(\n \"exec ast in globals_map, locals_map\"\n if venv.interpreter.version[0] == 2\n else \"exec(ast, globals_map, locals_map)\"\n ),\n )\n )\n with open(venv.join_path(\"__main__.py\"), \"w\") as fp:\n fp.write(main_contents)\n chmod_plus_x(fp.name)\n os.symlink(os.path.basename(fp.name), venv.join_path(\"pex\"))\n\n # 3. Re-write any (console) scripts to use the venv Python.\n for script in venv.rewrite_scripts(python_args=\"-sE\"):\n TRACER.log(\"Re-writing {}\".format(script))\n\n if options.pip:\n try:\n venv.install_pip()\n except PipUnavailableError as e:\n return Error(\n \"The virtual environment was successfully created, but Pip was not \"\n \"installed:\\n{}\".format(e)\n )\n\n return Ok()\n", "path": "pex/tools/commands/venv.py"}]}
| 2,971 | 776 |
gh_patches_debug_13620
|
rasdani/github-patches
|
git_diff
|
python-poetry__poetry-5880
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Poetry inheriting issue for git-client on github.com
- [X] I am on the [latest](https://github.com/python-poetry/poetry/releases/latest) Poetry version.
- [X] I have searched the [issues](https://github.com/python-poetry/poetry/issues) of this repo and believe that this is not a duplicate.
- [X] If an exception occurs when executing a command, I executed it again in debug mode (`-vvv` option).
- **OS version and name**: Linux Mint 20, Py3.8.2 virtualenv
- **Poetry version**: 1.1.2
- **Link of a [Gist](https://gist.github.com/) with the contents of your pyproject.toml file**:
## Issue
While `installing` or `locking`, if the github git repo is wrong (e.g. returns a 404 in a browser), then poetry (sometimes) shows an authentication error and ask for the username for that url.
```Updating dependencies
Resolving dependencies...
1: fact: actions-gateway is 0.7.0
1: derived: actions-gateway
Username for 'https://github.com':
```
The pyproject.toml has a git dependency like
```
Flask-Pika = { git = "https://github.com/rienafairefr/flask_pika.git", rev= "b2b4d68186c52ae034b39f4fb56fe86786b3a055"}
```
The typo is hard to see, it should be `flask-pika` instead of `flask_pika`
If the command is run without verbose output, then the "Username for 'https://github.com':" is sometimes shown only for a fraction of a second, so the command may never terminate and it's hard to know why.
Not sure poetry can or should mitigate the problem that comes from a lower level.
The problem comes (pretty sure) from github.com returning a 401 when it should return a 404:
```
GET /inexistent-user/inexistent-repo/info/refs?service=git-upload-pack
Host github.com
User-Agent: git/inexistent-version
```
gives us
```
HTTP/1.1 401 Authorization Required
Server: GitHub Babel 2.0
```
This makes the git client (which is called in a subprocess by poetry) to ask for authentication.
setting the GIT_ASKPASS variable to false while caling `git` is an option, the credentials to use for a git dependency should be provided by poetry, not leaving `git` to figure it out by itself
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/poetry/vcs/git/system.py`
Content:
```
1 from __future__ import annotations
2
3 import subprocess
4
5 from typing import TYPE_CHECKING
6
7 from dulwich.client import find_git_command
8
9
10 if TYPE_CHECKING:
11 from pathlib import Path
12 from typing import Any
13
14
15 class SystemGit:
16 @classmethod
17 def clone(cls, repository: str, dest: Path) -> str:
18 cls._check_parameter(repository)
19
20 return cls.run("clone", "--recurse-submodules", "--", repository, str(dest))
21
22 @classmethod
23 def checkout(cls, rev: str, target: Path | None = None) -> str:
24 args = []
25
26 if target:
27 args += [
28 "--git-dir",
29 (target / ".git").as_posix(),
30 "--work-tree",
31 target.as_posix(),
32 ]
33
34 cls._check_parameter(rev)
35
36 args += ["checkout", rev]
37
38 return cls.run(*args)
39
40 @staticmethod
41 def run(*args: Any, **kwargs: Any) -> str:
42 folder = kwargs.pop("folder", None)
43 if folder:
44 args = (
45 "--git-dir",
46 (folder / ".git").as_posix(),
47 "--work-tree",
48 folder.as_posix(),
49 ) + args
50
51 git_command = find_git_command()
52 return (
53 subprocess.check_output(git_command + list(args), stderr=subprocess.STDOUT)
54 .decode()
55 .strip()
56 )
57
58 @staticmethod
59 def _check_parameter(parameter: str) -> None:
60 """
61 Checks a git parameter to avoid unwanted code execution.
62 """
63 if parameter.strip().startswith("-"):
64 raise RuntimeError(f"Invalid Git parameter: {parameter}")
65
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/poetry/vcs/git/system.py b/src/poetry/vcs/git/system.py
--- a/src/poetry/vcs/git/system.py
+++ b/src/poetry/vcs/git/system.py
@@ -1,5 +1,6 @@
from __future__ import annotations
+import os
import subprocess
from typing import TYPE_CHECKING
@@ -49,8 +50,14 @@
) + args
git_command = find_git_command()
+ env = os.environ.copy()
+ env["GIT_TERMINAL_PROMPT"] = "0"
return (
- subprocess.check_output(git_command + list(args), stderr=subprocess.STDOUT)
+ subprocess.check_output(
+ git_command + list(args),
+ stderr=subprocess.STDOUT,
+ env=env,
+ )
.decode()
.strip()
)
|
{"golden_diff": "diff --git a/src/poetry/vcs/git/system.py b/src/poetry/vcs/git/system.py\n--- a/src/poetry/vcs/git/system.py\n+++ b/src/poetry/vcs/git/system.py\n@@ -1,5 +1,6 @@\n from __future__ import annotations\n \n+import os\n import subprocess\n \n from typing import TYPE_CHECKING\n@@ -49,8 +50,14 @@\n ) + args\n \n git_command = find_git_command()\n+ env = os.environ.copy()\n+ env[\"GIT_TERMINAL_PROMPT\"] = \"0\"\n return (\n- subprocess.check_output(git_command + list(args), stderr=subprocess.STDOUT)\n+ subprocess.check_output(\n+ git_command + list(args),\n+ stderr=subprocess.STDOUT,\n+ env=env,\n+ )\n .decode()\n .strip()\n )\n", "issue": "Poetry inheriting issue for git-client on github.com\n- [X] I am on the [latest](https://github.com/python-poetry/poetry/releases/latest) Poetry version. \r\n- [X] I have searched the [issues](https://github.com/python-poetry/poetry/issues) of this repo and believe that this is not a duplicate.\r\n- [X] If an exception occurs when executing a command, I executed it again in debug mode (`-vvv` option).\r\n\r\n- **OS version and name**: Linux Mint 20, Py3.8.2 virtualenv\r\n- **Poetry version**: 1.1.2\r\n- **Link of a [Gist](https://gist.github.com/) with the contents of your pyproject.toml file**: \r\n\r\n## Issue\r\nWhile `installing` or `locking`, if the github git repo is wrong (e.g. returns a 404 in a browser), then poetry (sometimes) shows an authentication error and ask for the username for that url. \r\n\r\n```Updating dependencies\r\nResolving dependencies...\r\n 1: fact: actions-gateway is 0.7.0\r\n 1: derived: actions-gateway\r\nUsername for 'https://github.com':\r\n```\r\nThe pyproject.toml has a git dependency like\r\n```\r\nFlask-Pika = { git = \"https://github.com/rienafairefr/flask_pika.git\", rev= \"b2b4d68186c52ae034b39f4fb56fe86786b3a055\"}\r\n```\r\nThe typo is hard to see, it should be `flask-pika` instead of `flask_pika`\r\n\r\nIf the command is run without verbose output, then the \"Username for 'https://github.com':\" is sometimes shown only for a fraction of a second, so the command may never terminate and it's hard to know why.\r\n\r\nNot sure poetry can or should mitigate the problem that comes from a lower level.\r\n\r\nThe problem comes (pretty sure) from github.com returning a 401 when it should return a 404:\r\n```\r\nGET /inexistent-user/inexistent-repo/info/refs?service=git-upload-pack\r\nHost github.com\r\nUser-Agent: git/inexistent-version\r\n```\r\ngives us\r\n```\r\nHTTP/1.1 401 Authorization Required\r\nServer: GitHub Babel 2.0\r\n```\r\nThis makes the git client (which is called in a subprocess by poetry) to ask for authentication. \r\n\r\nsetting the GIT_ASKPASS variable to false while caling `git` is an option, the credentials to use for a git dependency should be provided by poetry, not leaving `git` to figure it out by itself\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nimport subprocess\n\nfrom typing import TYPE_CHECKING\n\nfrom dulwich.client import find_git_command\n\n\nif TYPE_CHECKING:\n from pathlib import Path\n from typing import Any\n\n\nclass SystemGit:\n @classmethod\n def clone(cls, repository: str, dest: Path) -> str:\n cls._check_parameter(repository)\n\n return cls.run(\"clone\", \"--recurse-submodules\", \"--\", repository, str(dest))\n\n @classmethod\n def checkout(cls, rev: str, target: Path | None = None) -> str:\n args = []\n\n if target:\n args += [\n \"--git-dir\",\n (target / \".git\").as_posix(),\n \"--work-tree\",\n target.as_posix(),\n ]\n\n cls._check_parameter(rev)\n\n args += [\"checkout\", rev]\n\n return cls.run(*args)\n\n @staticmethod\n def run(*args: Any, **kwargs: Any) -> str:\n folder = kwargs.pop(\"folder\", None)\n if folder:\n args = (\n \"--git-dir\",\n (folder / \".git\").as_posix(),\n \"--work-tree\",\n folder.as_posix(),\n ) + args\n\n git_command = find_git_command()\n return (\n subprocess.check_output(git_command + list(args), stderr=subprocess.STDOUT)\n .decode()\n .strip()\n )\n\n @staticmethod\n def _check_parameter(parameter: str) -> None:\n \"\"\"\n Checks a git parameter to avoid unwanted code execution.\n \"\"\"\n if parameter.strip().startswith(\"-\"):\n raise RuntimeError(f\"Invalid Git parameter: {parameter}\")\n", "path": "src/poetry/vcs/git/system.py"}], "after_files": [{"content": "from __future__ import annotations\n\nimport os\nimport subprocess\n\nfrom typing import TYPE_CHECKING\n\nfrom dulwich.client import find_git_command\n\n\nif TYPE_CHECKING:\n from pathlib import Path\n from typing import Any\n\n\nclass SystemGit:\n @classmethod\n def clone(cls, repository: str, dest: Path) -> str:\n cls._check_parameter(repository)\n\n return cls.run(\"clone\", \"--recurse-submodules\", \"--\", repository, str(dest))\n\n @classmethod\n def checkout(cls, rev: str, target: Path | None = None) -> str:\n args = []\n\n if target:\n args += [\n \"--git-dir\",\n (target / \".git\").as_posix(),\n \"--work-tree\",\n target.as_posix(),\n ]\n\n cls._check_parameter(rev)\n\n args += [\"checkout\", rev]\n\n return cls.run(*args)\n\n @staticmethod\n def run(*args: Any, **kwargs: Any) -> str:\n folder = kwargs.pop(\"folder\", None)\n if folder:\n args = (\n \"--git-dir\",\n (folder / \".git\").as_posix(),\n \"--work-tree\",\n folder.as_posix(),\n ) + args\n\n git_command = find_git_command()\n env = os.environ.copy()\n env[\"GIT_TERMINAL_PROMPT\"] = \"0\"\n return (\n subprocess.check_output(\n git_command + list(args),\n stderr=subprocess.STDOUT,\n env=env,\n )\n .decode()\n .strip()\n )\n\n @staticmethod\n def _check_parameter(parameter: str) -> None:\n \"\"\"\n Checks a git parameter to avoid unwanted code execution.\n \"\"\"\n if parameter.strip().startswith(\"-\"):\n raise RuntimeError(f\"Invalid Git parameter: {parameter}\")\n", "path": "src/poetry/vcs/git/system.py"}]}
| 1,328 | 189 |
gh_patches_debug_26049
|
rasdani/github-patches
|
git_diff
|
mindee__doctr-384
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[utils] Add visualization capabilities for independent tasks
Visualization is end-to-end for the moment dynamic, but this means that a static version is not currently available, nor that there is a visualization option for text detection or text recognition only. We should discuss and add visualization for the following blocks:
- [ ] Text detection: display bounding boxes of detected items over the image
- [ ] Text recognition: display the label and confidence in a corner of the crop
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `doctr/utils/visualization.py`
Content:
```
1 # Copyright (C) 2021, Mindee.
2
3 # This program is licensed under the Apache License version 2.
4 # See LICENSE or go to <https://www.apache.org/licenses/LICENSE-2.0.txt> for full license details.
5
6 import matplotlib.pyplot as plt
7 from matplotlib.figure import Figure
8 import matplotlib.patches as patches
9 import mplcursors
10 from PIL import ImageFont, ImageDraw, Image
11 import numpy as np
12 import cv2
13 from typing import Tuple, List, Dict, Any, Union, Optional
14
15 from .common_types import BoundingBox, RotatedBbox
16
17 __all__ = ['visualize_page', 'synthetize_page']
18
19
20 def rect_patch(
21 geometry: BoundingBox,
22 page_dimensions: Tuple[int, int],
23 label: Optional[str] = None,
24 color: Tuple[float, float, float] = (0, 0, 0),
25 alpha: float = 0.3,
26 linewidth: int = 2,
27 fill: bool = True,
28 ) -> patches.Rectangle:
29 """Create a matplotlib rectangular patch for the element
30
31 Args:
32 geometry: bounding box of the element
33 page_dimensions: dimensions of the Page
34 label: label to display when hovered
35 color: color to draw box
36 alpha: opacity parameter to fill the boxes, 0 = transparent
37 linewidth: line width
38 fill: whether the patch should be filled
39
40 Returns:
41 a rectangular Patch
42 """
43
44 if len(geometry) != 2 or any(not isinstance(elt, tuple) or len(elt) != 2 for elt in geometry):
45 raise ValueError("invalid geometry format")
46
47 # Unpack
48 height, width = page_dimensions
49 (xmin, ymin), (xmax, ymax) = geometry
50 # Switch to absolute coords
51 xmin, w = xmin * width, (xmax - xmin) * width
52 ymin, h = ymin * height, (ymax - ymin) * height
53
54 return patches.Rectangle(
55 (xmin, ymin),
56 w,
57 h,
58 fill=fill,
59 linewidth=linewidth,
60 edgecolor=(*color, alpha),
61 facecolor=(*color, alpha),
62 label=label,
63 )
64
65
66 def polygon_patch(
67 geometry: RotatedBbox,
68 page_dimensions: Tuple[int, int],
69 label: Optional[str] = None,
70 color: Tuple[float, float, float] = (0, 0, 0),
71 alpha: float = 0.3,
72 linewidth: int = 2,
73 fill: bool = True,
74 ) -> patches.Polygon:
75 """Create a matplotlib polygon patch for the element
76
77 Args:
78 geometry: bounding box of the element
79 page_dimensions: dimensions of the Page
80 label: label to display when hovered
81 color: color to draw box
82 alpha: opacity parameter to fill the boxes, 0 = transparent
83 linewidth: line width
84 fill: whether the patch should be filled
85
86 Returns:
87 a polygon Patch
88 """
89
90 if len(geometry) != 5 or any(not isinstance(elt, float) for elt in geometry):
91 raise ValueError("invalid geometry format")
92
93 # Unpack
94 height, width = page_dimensions
95 x, y, w, h, a = geometry
96 # Switch to absolute coords
97 x, w = x * width, w * width
98 y, h = y * height, h * height
99 points = cv2.boxPoints(((x, y), (w, h), a))
100
101 return patches.Polygon(
102 points,
103 fill=fill,
104 linewidth=linewidth,
105 edgecolor=(*color, alpha),
106 facecolor=(*color, alpha),
107 label=label,
108 )
109
110
111 def create_obj_patch(
112 geometry: Union[BoundingBox, RotatedBbox],
113 page_dimensions: Tuple[int, int],
114 **kwargs: Any,
115 ) -> patches.Patch:
116 """Create a matplotlib patch for the element
117
118 Args:
119 geometry: bounding box (straight or rotated) of the element
120 page_dimensions: dimensions of the page
121
122 Returns:
123 a matplotlib Patch
124 """
125 if isinstance(geometry, tuple):
126 if len(geometry) == 2:
127 return rect_patch(geometry, page_dimensions, **kwargs) # type: ignore[arg-type]
128 elif len(geometry) == 5:
129 return polygon_patch(geometry, page_dimensions, **kwargs) # type: ignore[arg-type]
130
131 raise ValueError("invalid geometry format")
132
133
134 def visualize_page(
135 page: Dict[str, Any],
136 image: np.ndarray,
137 words_only: bool = True,
138 display_artefacts: bool = True,
139 scale: float = 10,
140 interactive: bool = True,
141 add_labels: bool = True,
142 **kwargs: Any,
143 ) -> Figure:
144 """Visualize a full page with predicted blocks, lines and words
145
146 Example::
147 >>> import numpy as np
148 >>> import matplotlib.pyplot as plt
149 >>> from doctr.utils.visualization import visualize_page
150 >>> from doctr.models import ocr_db_crnn
151 >>> model = ocr_db_crnn(pretrained=True)
152 >>> input_page = (255 * np.random.rand(600, 800, 3)).astype(np.uint8)
153 >>> out = model([[input_page]])
154 >>> visualize_page(out[0].pages[0].export(), input_page)
155 >>> plt.show()
156
157 Args:
158 page: the exported Page of a Document
159 image: np array of the page, needs to have the same shape than page['dimensions']
160 words_only: whether only words should be displayed
161 display_artefacts: whether artefacts should be displayed
162 scale: figsize of the largest windows side
163 interactive: whether the plot should be interactive
164 add_labels: for static plot, adds text labels on top of bounding box
165 """
166 # Get proper scale and aspect ratio
167 h, w = image.shape[:2]
168 size = (scale * w / h, scale) if h > w else (scale, h / w * scale)
169 fig, ax = plt.subplots(figsize=size)
170 # Display the image
171 ax.imshow(image)
172 # hide both axis
173 ax.axis('off')
174
175 if interactive:
176 artists: List[patches.Patch] = [] # instantiate an empty list of patches (to be drawn on the page)
177
178 for block in page['blocks']:
179 if not words_only:
180 rect = create_obj_patch(block['geometry'], page['dimensions'],
181 label='block', color=(0, 1, 0), linewidth=1, **kwargs)
182 # add patch on figure
183 ax.add_patch(rect)
184 if interactive:
185 # add patch to cursor's artists
186 artists.append(rect)
187
188 for line in block['lines']:
189 if not words_only:
190 rect = create_obj_patch(line['geometry'], page['dimensions'],
191 label='line', color=(1, 0, 0), linewidth=1, **kwargs)
192 ax.add_patch(rect)
193 if interactive:
194 artists.append(rect)
195
196 for word in line['words']:
197 rect = create_obj_patch(word['geometry'], page['dimensions'],
198 label=f"{word['value']} (confidence: {word['confidence']:.2%})",
199 color=(0, 0, 1), **kwargs)
200 ax.add_patch(rect)
201 if interactive:
202 artists.append(rect)
203 elif add_labels:
204 if len(word['geometry']) == 5:
205 text_loc = (
206 int(page['dimensions'][1] * (word['geometry'][0] - word['geometry'][2] / 2)),
207 int(page['dimensions'][0] * (word['geometry'][1] - word['geometry'][3] / 2))
208 )
209 else:
210 text_loc = (
211 int(page['dimensions'][1] * word['geometry'][0][0]),
212 int(page['dimensions'][0] * word['geometry'][0][1])
213 )
214 ax.text(
215 *text_loc,
216 word['value'],
217 size=10,
218 alpha=0.5,
219 color=(0, 0, 1),
220 )
221
222 if display_artefacts:
223 for artefact in block['artefacts']:
224 rect = create_obj_patch(
225 artefact['geometry'],
226 page['dimensions'],
227 label='artefact',
228 color=(0.5, 0.5, 0.5),
229 linewidth=1,
230 **kwargs
231 )
232 ax.add_patch(rect)
233 if interactive:
234 artists.append(rect)
235
236 if interactive:
237 # Create mlp Cursor to hover patches in artists
238 mplcursors.Cursor(artists, hover=2).connect("add", lambda sel: sel.annotation.set_text(sel.artist.get_label()))
239 fig.tight_layout(pad=0.)
240
241 return fig
242
243
244 def synthetize_page(
245 page: Dict[str, Any],
246 draw_proba: bool = False,
247 font_size: int = 13,
248 ) -> np.ndarray:
249 """Draw a the content of the element page (OCR response) on a blank page.
250
251 Args:
252 page: exported Page object to represent
253 draw_proba: if True, draw words in colors to represent confidence. Blue: p=1, red: p=0
254 font_size: size of the font, default font = 13
255
256 Return:
257 A np array (drawn page)
258 """
259 # Draw template
260 h, w = page["dimensions"]
261 response = 255 * np.ones((h, w, 3), dtype=np.int32)
262
263 # Draw each word
264 for block in page["blocks"]:
265 for line in block["lines"]:
266 for word in line["words"]:
267 # Get aboslute word geometry
268 (xmin, ymin), (xmax, ymax) = word["geometry"]
269 xmin, xmax = int(w * xmin), int(w * xmax)
270 ymin, ymax = int(h * ymin), int(h * ymax)
271
272 # White drawing context adapted to font size, 0.75 factor to convert pts --> pix
273 h_box, w_box = ymax - ymin, xmax - xmin
274 h_font, w_font = font_size, int(font_size * w_box / (h_box * 0.75))
275 img = Image.new('RGB', (w_font, h_font), color=(255, 255, 255))
276 d = ImageDraw.Draw(img)
277
278 # Draw in black the value of the word
279 d.text((0, 0), word["value"], font=ImageFont.load_default(), fill=(0, 0, 0))
280
281 # Resize back to box size
282 img = img.resize((w_box, h_box), Image.NEAREST)
283
284 # Colorize if draw_proba
285 if draw_proba:
286 p = int(255 * word["confidence"])
287 mask = np.where(np.array(img) == 0, 1, 0)
288 proba = np.array([255 - p, 0, p])
289 color = mask * proba[np.newaxis, np.newaxis, :]
290 white_mask = 255 * (1 - mask)
291 img = color + white_mask
292
293 # Write to response page
294 response[ymin:ymax, xmin:xmax, :] = np.array(img)
295
296 return response
297
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/doctr/utils/visualization.py b/doctr/utils/visualization.py
--- a/doctr/utils/visualization.py
+++ b/doctr/utils/visualization.py
@@ -8,13 +8,14 @@
import matplotlib.patches as patches
import mplcursors
from PIL import ImageFont, ImageDraw, Image
+from copy import deepcopy
import numpy as np
import cv2
from typing import Tuple, List, Dict, Any, Union, Optional
from .common_types import BoundingBox, RotatedBbox
-__all__ = ['visualize_page', 'synthetize_page']
+__all__ = ['visualize_page', 'synthetize_page', 'draw_boxes']
def rect_patch(
@@ -294,3 +295,34 @@
response[ymin:ymax, xmin:xmax, :] = np.array(img)
return response
+
+
+def draw_boxes(
+ boxes: np.ndarray,
+ image: np.ndarray,
+ color: Optional[Tuple] = None,
+ **kwargs
+) -> None:
+ """Draw an array of relative straight boxes on an image
+
+ Args:
+ boxes: array of relative boxes, of shape (*, 4)
+ image: np array, float32 or uint8
+ """
+ h, w = image.shape[:2]
+ # Convert boxes to absolute coords
+ _boxes = deepcopy(boxes)
+ _boxes[:, [0, 2]] *= w
+ _boxes[:, [1, 3]] *= h
+ _boxes = _boxes.astype(np.int32)
+ for box in _boxes.tolist():
+ xmin, ymin, xmax, ymax = box
+ image = cv2.rectangle(
+ image,
+ (xmin, ymin),
+ (xmax, ymax),
+ color=color if isinstance(color, tuple) else (0, 0, 255),
+ thickness=2
+ )
+ plt.imshow(image)
+ plt.plot(**kwargs)
|
{"golden_diff": "diff --git a/doctr/utils/visualization.py b/doctr/utils/visualization.py\n--- a/doctr/utils/visualization.py\n+++ b/doctr/utils/visualization.py\n@@ -8,13 +8,14 @@\n import matplotlib.patches as patches\n import mplcursors\n from PIL import ImageFont, ImageDraw, Image\n+from copy import deepcopy\n import numpy as np\n import cv2\n from typing import Tuple, List, Dict, Any, Union, Optional\n \n from .common_types import BoundingBox, RotatedBbox\n \n-__all__ = ['visualize_page', 'synthetize_page']\n+__all__ = ['visualize_page', 'synthetize_page', 'draw_boxes']\n \n \n def rect_patch(\n@@ -294,3 +295,34 @@\n response[ymin:ymax, xmin:xmax, :] = np.array(img)\n \n return response\n+\n+\n+def draw_boxes(\n+ boxes: np.ndarray,\n+ image: np.ndarray,\n+ color: Optional[Tuple] = None,\n+ **kwargs\n+) -> None:\n+ \"\"\"Draw an array of relative straight boxes on an image\n+\n+ Args:\n+ boxes: array of relative boxes, of shape (*, 4)\n+ image: np array, float32 or uint8\n+ \"\"\"\n+ h, w = image.shape[:2]\n+ # Convert boxes to absolute coords\n+ _boxes = deepcopy(boxes)\n+ _boxes[:, [0, 2]] *= w\n+ _boxes[:, [1, 3]] *= h\n+ _boxes = _boxes.astype(np.int32)\n+ for box in _boxes.tolist():\n+ xmin, ymin, xmax, ymax = box\n+ image = cv2.rectangle(\n+ image,\n+ (xmin, ymin),\n+ (xmax, ymax),\n+ color=color if isinstance(color, tuple) else (0, 0, 255),\n+ thickness=2\n+ )\n+ plt.imshow(image)\n+ plt.plot(**kwargs)\n", "issue": "[utils] Add visualization capabilities for independent tasks\nVisualization is end-to-end for the moment dynamic, but this means that a static version is not currently available, nor that there is a visualization option for text detection or text recognition only. We should discuss and add visualization for the following blocks:\r\n- [ ] Text detection: display bounding boxes of detected items over the image\r\n- [ ] Text recognition: display the label and confidence in a corner of the crop\n", "before_files": [{"content": "# Copyright (C) 2021, Mindee.\n\n# This program is licensed under the Apache License version 2.\n# See LICENSE or go to <https://www.apache.org/licenses/LICENSE-2.0.txt> for full license details.\n\nimport matplotlib.pyplot as plt\nfrom matplotlib.figure import Figure\nimport matplotlib.patches as patches\nimport mplcursors\nfrom PIL import ImageFont, ImageDraw, Image\nimport numpy as np\nimport cv2\nfrom typing import Tuple, List, Dict, Any, Union, Optional\n\nfrom .common_types import BoundingBox, RotatedBbox\n\n__all__ = ['visualize_page', 'synthetize_page']\n\n\ndef rect_patch(\n geometry: BoundingBox,\n page_dimensions: Tuple[int, int],\n label: Optional[str] = None,\n color: Tuple[float, float, float] = (0, 0, 0),\n alpha: float = 0.3,\n linewidth: int = 2,\n fill: bool = True,\n) -> patches.Rectangle:\n \"\"\"Create a matplotlib rectangular patch for the element\n\n Args:\n geometry: bounding box of the element\n page_dimensions: dimensions of the Page\n label: label to display when hovered\n color: color to draw box\n alpha: opacity parameter to fill the boxes, 0 = transparent\n linewidth: line width\n fill: whether the patch should be filled\n\n Returns:\n a rectangular Patch\n \"\"\"\n\n if len(geometry) != 2 or any(not isinstance(elt, tuple) or len(elt) != 2 for elt in geometry):\n raise ValueError(\"invalid geometry format\")\n\n # Unpack\n height, width = page_dimensions\n (xmin, ymin), (xmax, ymax) = geometry\n # Switch to absolute coords\n xmin, w = xmin * width, (xmax - xmin) * width\n ymin, h = ymin * height, (ymax - ymin) * height\n\n return patches.Rectangle(\n (xmin, ymin),\n w,\n h,\n fill=fill,\n linewidth=linewidth,\n edgecolor=(*color, alpha),\n facecolor=(*color, alpha),\n label=label,\n )\n\n\ndef polygon_patch(\n geometry: RotatedBbox,\n page_dimensions: Tuple[int, int],\n label: Optional[str] = None,\n color: Tuple[float, float, float] = (0, 0, 0),\n alpha: float = 0.3,\n linewidth: int = 2,\n fill: bool = True,\n) -> patches.Polygon:\n \"\"\"Create a matplotlib polygon patch for the element\n\n Args:\n geometry: bounding box of the element\n page_dimensions: dimensions of the Page\n label: label to display when hovered\n color: color to draw box\n alpha: opacity parameter to fill the boxes, 0 = transparent\n linewidth: line width\n fill: whether the patch should be filled\n\n Returns:\n a polygon Patch\n \"\"\"\n\n if len(geometry) != 5 or any(not isinstance(elt, float) for elt in geometry):\n raise ValueError(\"invalid geometry format\")\n\n # Unpack\n height, width = page_dimensions\n x, y, w, h, a = geometry\n # Switch to absolute coords\n x, w = x * width, w * width\n y, h = y * height, h * height\n points = cv2.boxPoints(((x, y), (w, h), a))\n\n return patches.Polygon(\n points,\n fill=fill,\n linewidth=linewidth,\n edgecolor=(*color, alpha),\n facecolor=(*color, alpha),\n label=label,\n )\n\n\ndef create_obj_patch(\n geometry: Union[BoundingBox, RotatedBbox],\n page_dimensions: Tuple[int, int],\n **kwargs: Any,\n) -> patches.Patch:\n \"\"\"Create a matplotlib patch for the element\n\n Args:\n geometry: bounding box (straight or rotated) of the element\n page_dimensions: dimensions of the page\n\n Returns:\n a matplotlib Patch\n \"\"\"\n if isinstance(geometry, tuple):\n if len(geometry) == 2:\n return rect_patch(geometry, page_dimensions, **kwargs) # type: ignore[arg-type]\n elif len(geometry) == 5:\n return polygon_patch(geometry, page_dimensions, **kwargs) # type: ignore[arg-type]\n\n raise ValueError(\"invalid geometry format\")\n\n\ndef visualize_page(\n page: Dict[str, Any],\n image: np.ndarray,\n words_only: bool = True,\n display_artefacts: bool = True,\n scale: float = 10,\n interactive: bool = True,\n add_labels: bool = True,\n **kwargs: Any,\n) -> Figure:\n \"\"\"Visualize a full page with predicted blocks, lines and words\n\n Example::\n >>> import numpy as np\n >>> import matplotlib.pyplot as plt\n >>> from doctr.utils.visualization import visualize_page\n >>> from doctr.models import ocr_db_crnn\n >>> model = ocr_db_crnn(pretrained=True)\n >>> input_page = (255 * np.random.rand(600, 800, 3)).astype(np.uint8)\n >>> out = model([[input_page]])\n >>> visualize_page(out[0].pages[0].export(), input_page)\n >>> plt.show()\n\n Args:\n page: the exported Page of a Document\n image: np array of the page, needs to have the same shape than page['dimensions']\n words_only: whether only words should be displayed\n display_artefacts: whether artefacts should be displayed\n scale: figsize of the largest windows side\n interactive: whether the plot should be interactive\n add_labels: for static plot, adds text labels on top of bounding box\n \"\"\"\n # Get proper scale and aspect ratio\n h, w = image.shape[:2]\n size = (scale * w / h, scale) if h > w else (scale, h / w * scale)\n fig, ax = plt.subplots(figsize=size)\n # Display the image\n ax.imshow(image)\n # hide both axis\n ax.axis('off')\n\n if interactive:\n artists: List[patches.Patch] = [] # instantiate an empty list of patches (to be drawn on the page)\n\n for block in page['blocks']:\n if not words_only:\n rect = create_obj_patch(block['geometry'], page['dimensions'],\n label='block', color=(0, 1, 0), linewidth=1, **kwargs)\n # add patch on figure\n ax.add_patch(rect)\n if interactive:\n # add patch to cursor's artists\n artists.append(rect)\n\n for line in block['lines']:\n if not words_only:\n rect = create_obj_patch(line['geometry'], page['dimensions'],\n label='line', color=(1, 0, 0), linewidth=1, **kwargs)\n ax.add_patch(rect)\n if interactive:\n artists.append(rect)\n\n for word in line['words']:\n rect = create_obj_patch(word['geometry'], page['dimensions'],\n label=f\"{word['value']} (confidence: {word['confidence']:.2%})\",\n color=(0, 0, 1), **kwargs)\n ax.add_patch(rect)\n if interactive:\n artists.append(rect)\n elif add_labels:\n if len(word['geometry']) == 5:\n text_loc = (\n int(page['dimensions'][1] * (word['geometry'][0] - word['geometry'][2] / 2)),\n int(page['dimensions'][0] * (word['geometry'][1] - word['geometry'][3] / 2))\n )\n else:\n text_loc = (\n int(page['dimensions'][1] * word['geometry'][0][0]),\n int(page['dimensions'][0] * word['geometry'][0][1])\n )\n ax.text(\n *text_loc,\n word['value'],\n size=10,\n alpha=0.5,\n color=(0, 0, 1),\n )\n\n if display_artefacts:\n for artefact in block['artefacts']:\n rect = create_obj_patch(\n artefact['geometry'],\n page['dimensions'],\n label='artefact',\n color=(0.5, 0.5, 0.5),\n linewidth=1,\n **kwargs\n )\n ax.add_patch(rect)\n if interactive:\n artists.append(rect)\n\n if interactive:\n # Create mlp Cursor to hover patches in artists\n mplcursors.Cursor(artists, hover=2).connect(\"add\", lambda sel: sel.annotation.set_text(sel.artist.get_label()))\n fig.tight_layout(pad=0.)\n\n return fig\n\n\ndef synthetize_page(\n page: Dict[str, Any],\n draw_proba: bool = False,\n font_size: int = 13,\n) -> np.ndarray:\n \"\"\"Draw a the content of the element page (OCR response) on a blank page.\n\n Args:\n page: exported Page object to represent\n draw_proba: if True, draw words in colors to represent confidence. Blue: p=1, red: p=0\n font_size: size of the font, default font = 13\n\n Return:\n A np array (drawn page)\n \"\"\"\n # Draw template\n h, w = page[\"dimensions\"]\n response = 255 * np.ones((h, w, 3), dtype=np.int32)\n\n # Draw each word\n for block in page[\"blocks\"]:\n for line in block[\"lines\"]:\n for word in line[\"words\"]:\n # Get aboslute word geometry\n (xmin, ymin), (xmax, ymax) = word[\"geometry\"]\n xmin, xmax = int(w * xmin), int(w * xmax)\n ymin, ymax = int(h * ymin), int(h * ymax)\n\n # White drawing context adapted to font size, 0.75 factor to convert pts --> pix\n h_box, w_box = ymax - ymin, xmax - xmin\n h_font, w_font = font_size, int(font_size * w_box / (h_box * 0.75))\n img = Image.new('RGB', (w_font, h_font), color=(255, 255, 255))\n d = ImageDraw.Draw(img)\n\n # Draw in black the value of the word\n d.text((0, 0), word[\"value\"], font=ImageFont.load_default(), fill=(0, 0, 0))\n\n # Resize back to box size\n img = img.resize((w_box, h_box), Image.NEAREST)\n\n # Colorize if draw_proba\n if draw_proba:\n p = int(255 * word[\"confidence\"])\n mask = np.where(np.array(img) == 0, 1, 0)\n proba = np.array([255 - p, 0, p])\n color = mask * proba[np.newaxis, np.newaxis, :]\n white_mask = 255 * (1 - mask)\n img = color + white_mask\n\n # Write to response page\n response[ymin:ymax, xmin:xmax, :] = np.array(img)\n\n return response\n", "path": "doctr/utils/visualization.py"}], "after_files": [{"content": "# Copyright (C) 2021, Mindee.\n\n# This program is licensed under the Apache License version 2.\n# See LICENSE or go to <https://www.apache.org/licenses/LICENSE-2.0.txt> for full license details.\n\nimport matplotlib.pyplot as plt\nfrom matplotlib.figure import Figure\nimport matplotlib.patches as patches\nimport mplcursors\nfrom PIL import ImageFont, ImageDraw, Image\nfrom copy import deepcopy\nimport numpy as np\nimport cv2\nfrom typing import Tuple, List, Dict, Any, Union, Optional\n\nfrom .common_types import BoundingBox, RotatedBbox\n\n__all__ = ['visualize_page', 'synthetize_page', 'draw_boxes']\n\n\ndef rect_patch(\n geometry: BoundingBox,\n page_dimensions: Tuple[int, int],\n label: Optional[str] = None,\n color: Tuple[float, float, float] = (0, 0, 0),\n alpha: float = 0.3,\n linewidth: int = 2,\n fill: bool = True,\n) -> patches.Rectangle:\n \"\"\"Create a matplotlib rectangular patch for the element\n\n Args:\n geometry: bounding box of the element\n page_dimensions: dimensions of the Page\n label: label to display when hovered\n color: color to draw box\n alpha: opacity parameter to fill the boxes, 0 = transparent\n linewidth: line width\n fill: whether the patch should be filled\n\n Returns:\n a rectangular Patch\n \"\"\"\n\n if len(geometry) != 2 or any(not isinstance(elt, tuple) or len(elt) != 2 for elt in geometry):\n raise ValueError(\"invalid geometry format\")\n\n # Unpack\n height, width = page_dimensions\n (xmin, ymin), (xmax, ymax) = geometry\n # Switch to absolute coords\n xmin, w = xmin * width, (xmax - xmin) * width\n ymin, h = ymin * height, (ymax - ymin) * height\n\n return patches.Rectangle(\n (xmin, ymin),\n w,\n h,\n fill=fill,\n linewidth=linewidth,\n edgecolor=(*color, alpha),\n facecolor=(*color, alpha),\n label=label,\n )\n\n\ndef polygon_patch(\n geometry: RotatedBbox,\n page_dimensions: Tuple[int, int],\n label: Optional[str] = None,\n color: Tuple[float, float, float] = (0, 0, 0),\n alpha: float = 0.3,\n linewidth: int = 2,\n fill: bool = True,\n) -> patches.Polygon:\n \"\"\"Create a matplotlib polygon patch for the element\n\n Args:\n geometry: bounding box of the element\n page_dimensions: dimensions of the Page\n label: label to display when hovered\n color: color to draw box\n alpha: opacity parameter to fill the boxes, 0 = transparent\n linewidth: line width\n fill: whether the patch should be filled\n\n Returns:\n a polygon Patch\n \"\"\"\n\n if len(geometry) != 5 or any(not isinstance(elt, float) for elt in geometry):\n raise ValueError(\"invalid geometry format\")\n\n # Unpack\n height, width = page_dimensions\n x, y, w, h, a = geometry\n # Switch to absolute coords\n x, w = x * width, w * width\n y, h = y * height, h * height\n points = cv2.boxPoints(((x, y), (w, h), a))\n\n return patches.Polygon(\n points,\n fill=fill,\n linewidth=linewidth,\n edgecolor=(*color, alpha),\n facecolor=(*color, alpha),\n label=label,\n )\n\n\ndef create_obj_patch(\n geometry: Union[BoundingBox, RotatedBbox],\n page_dimensions: Tuple[int, int],\n **kwargs: Any,\n) -> patches.Patch:\n \"\"\"Create a matplotlib patch for the element\n\n Args:\n geometry: bounding box (straight or rotated) of the element\n page_dimensions: dimensions of the page\n\n Returns:\n a matplotlib Patch\n \"\"\"\n if isinstance(geometry, tuple):\n if len(geometry) == 2:\n return rect_patch(geometry, page_dimensions, **kwargs) # type: ignore[arg-type]\n elif len(geometry) == 5:\n return polygon_patch(geometry, page_dimensions, **kwargs) # type: ignore[arg-type]\n\n raise ValueError(\"invalid geometry format\")\n\n\ndef visualize_page(\n page: Dict[str, Any],\n image: np.ndarray,\n words_only: bool = True,\n display_artefacts: bool = True,\n scale: float = 10,\n interactive: bool = True,\n add_labels: bool = True,\n **kwargs: Any,\n) -> Figure:\n \"\"\"Visualize a full page with predicted blocks, lines and words\n\n Example::\n >>> import numpy as np\n >>> import matplotlib.pyplot as plt\n >>> from doctr.utils.visualization import visualize_page\n >>> from doctr.models import ocr_db_crnn\n >>> model = ocr_db_crnn(pretrained=True)\n >>> input_page = (255 * np.random.rand(600, 800, 3)).astype(np.uint8)\n >>> out = model([[input_page]])\n >>> visualize_page(out[0].pages[0].export(), input_page)\n >>> plt.show()\n\n Args:\n page: the exported Page of a Document\n image: np array of the page, needs to have the same shape than page['dimensions']\n words_only: whether only words should be displayed\n display_artefacts: whether artefacts should be displayed\n scale: figsize of the largest windows side\n interactive: whether the plot should be interactive\n add_labels: for static plot, adds text labels on top of bounding box\n \"\"\"\n # Get proper scale and aspect ratio\n h, w = image.shape[:2]\n size = (scale * w / h, scale) if h > w else (scale, h / w * scale)\n fig, ax = plt.subplots(figsize=size)\n # Display the image\n ax.imshow(image)\n # hide both axis\n ax.axis('off')\n\n if interactive:\n artists: List[patches.Patch] = [] # instantiate an empty list of patches (to be drawn on the page)\n\n for block in page['blocks']:\n if not words_only:\n rect = create_obj_patch(block['geometry'], page['dimensions'],\n label='block', color=(0, 1, 0), linewidth=1, **kwargs)\n # add patch on figure\n ax.add_patch(rect)\n if interactive:\n # add patch to cursor's artists\n artists.append(rect)\n\n for line in block['lines']:\n if not words_only:\n rect = create_obj_patch(line['geometry'], page['dimensions'],\n label='line', color=(1, 0, 0), linewidth=1, **kwargs)\n ax.add_patch(rect)\n if interactive:\n artists.append(rect)\n\n for word in line['words']:\n rect = create_obj_patch(word['geometry'], page['dimensions'],\n label=f\"{word['value']} (confidence: {word['confidence']:.2%})\",\n color=(0, 0, 1), **kwargs)\n ax.add_patch(rect)\n if interactive:\n artists.append(rect)\n elif add_labels:\n if len(word['geometry']) == 5:\n text_loc = (\n int(page['dimensions'][1] * (word['geometry'][0] - word['geometry'][2] / 2)),\n int(page['dimensions'][0] * (word['geometry'][1] - word['geometry'][3] / 2))\n )\n else:\n text_loc = (\n int(page['dimensions'][1] * word['geometry'][0][0]),\n int(page['dimensions'][0] * word['geometry'][0][1])\n )\n ax.text(\n *text_loc,\n word['value'],\n size=10,\n alpha=0.5,\n color=(0, 0, 1),\n )\n\n if display_artefacts:\n for artefact in block['artefacts']:\n rect = create_obj_patch(\n artefact['geometry'],\n page['dimensions'],\n label='artefact',\n color=(0.5, 0.5, 0.5),\n linewidth=1,\n **kwargs\n )\n ax.add_patch(rect)\n if interactive:\n artists.append(rect)\n\n if interactive:\n # Create mlp Cursor to hover patches in artists\n mplcursors.Cursor(artists, hover=2).connect(\"add\", lambda sel: sel.annotation.set_text(sel.artist.get_label()))\n fig.tight_layout(pad=0.)\n\n return fig\n\n\ndef synthetize_page(\n page: Dict[str, Any],\n draw_proba: bool = False,\n font_size: int = 13,\n) -> np.ndarray:\n \"\"\"Draw a the content of the element page (OCR response) on a blank page.\n\n Args:\n page: exported Page object to represent\n draw_proba: if True, draw words in colors to represent confidence. Blue: p=1, red: p=0\n font_size: size of the font, default font = 13\n\n Return:\n A np array (drawn page)\n \"\"\"\n # Draw template\n h, w = page[\"dimensions\"]\n response = 255 * np.ones((h, w, 3), dtype=np.int32)\n\n # Draw each word\n for block in page[\"blocks\"]:\n for line in block[\"lines\"]:\n for word in line[\"words\"]:\n # Get aboslute word geometry\n (xmin, ymin), (xmax, ymax) = word[\"geometry\"]\n xmin, xmax = int(w * xmin), int(w * xmax)\n ymin, ymax = int(h * ymin), int(h * ymax)\n\n # White drawing context adapted to font size, 0.75 factor to convert pts --> pix\n h_box, w_box = ymax - ymin, xmax - xmin\n h_font, w_font = font_size, int(font_size * w_box / (h_box * 0.75))\n img = Image.new('RGB', (w_font, h_font), color=(255, 255, 255))\n d = ImageDraw.Draw(img)\n\n # Draw in black the value of the word\n d.text((0, 0), word[\"value\"], font=ImageFont.load_default(), fill=(0, 0, 0))\n\n # Resize back to box size\n img = img.resize((w_box, h_box), Image.NEAREST)\n\n # Colorize if draw_proba\n if draw_proba:\n p = int(255 * word[\"confidence\"])\n mask = np.where(np.array(img) == 0, 1, 0)\n proba = np.array([255 - p, 0, p])\n color = mask * proba[np.newaxis, np.newaxis, :]\n white_mask = 255 * (1 - mask)\n img = color + white_mask\n\n # Write to response page\n response[ymin:ymax, xmin:xmax, :] = np.array(img)\n\n return response\n\n\ndef draw_boxes(\n boxes: np.ndarray,\n image: np.ndarray,\n color: Optional[Tuple] = None,\n **kwargs\n) -> None:\n \"\"\"Draw an array of relative straight boxes on an image\n\n Args:\n boxes: array of relative boxes, of shape (*, 4)\n image: np array, float32 or uint8\n \"\"\"\n h, w = image.shape[:2]\n # Convert boxes to absolute coords\n _boxes = deepcopy(boxes)\n _boxes[:, [0, 2]] *= w\n _boxes[:, [1, 3]] *= h\n _boxes = _boxes.astype(np.int32)\n for box in _boxes.tolist():\n xmin, ymin, xmax, ymax = box\n image = cv2.rectangle(\n image,\n (xmin, ymin),\n (xmax, ymax),\n color=color if isinstance(color, tuple) else (0, 0, 255),\n thickness=2\n )\n plt.imshow(image)\n plt.plot(**kwargs)\n", "path": "doctr/utils/visualization.py"}]}
| 3,594 | 448 |
gh_patches_debug_21889
|
rasdani/github-patches
|
git_diff
|
spack__spack-8799
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
intel-tbb broken if no transactional memory
I tried to install intel-tbb on an old Intel x86-64 cluster at Rice.
The build fails with:
% spack install intel-tbb
...
21 /work/hpc/krentel/work/spack-repo/lib/spack/env/gcc/g++ -o scheduler.o -c -MMD -DTBB_USE_DEBUG -DDO_ITT_NOTIFY -g -O0 -DUSE_PTHREAD -m64 -mrtm -fPIC -D__TBB_BUILD=1 -Wall -Wno-parentheses -Wno-non-virtual-dtor -I../../src -I../../src/rml/include -I../../include ../../src/tbb/scheduler.cpp
22 /tmp/cchPyt9b.s: Assembler messages:
>> 23 /tmp/cchPyt9b.s:672: Error: no such instruction: `xtest'
>> 24 /tmp/cchPyt9b.s:691: Error: no such instruction: `xend'
The problem is that xtest and xend are transactional memory
instructions and either the machine or the compiler don't understand
transactional memory.
/proc/cpuinfo reports:
processor : 11
vendor_id : GenuineIntel
cpu family : 6
model : 44
model name : Intel(R) Xeon(R) CPU X5660 @ 2.80GHz
stepping : 2
microcode : 16
cpu MHz : 2800.047
cache size : 12288 KB
...
flags : fpu vme de pse tsc msr pae mce cx8 apic mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good xtopology nonstop_tsc aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm pcid dca sse4_1 sse4_2 popcnt aes lahf_lm arat epb dtherm tpr_shadow vnmi flexpriority ept vpid
Looking inside the tbb source, we see in include/tbb/tbb_config.h:
#define __TBB_TSX_AVAILABLE ((__TBB_x86_32 || __TBB_x86_64) && !__TBB_DEFINE_MIC)
So, the real problem is that Intel thinks that all 64-bit x86 machines
(except Xeon Phi/MIC) have transactional memory, and that's not true.
One solution would be to patch the #define to 0, but that would
disable all transactional memory.
I guess a more spack-ish solution would be to add a 'transactional-memory'
variant to intel-tbb and conditionally apply a patch, or otherwise set
__TBB_TSX_AVAILABLE to 0.
But what I really want is a better way to auto test if the given
machine (or host machine in a cross compile) supports some feature, in
this case transactional memory. I'll open a separate issue for that.
Thanks,
--Mark
P.S. I did search for intel-tbb, but I didn't find anything related to
transactional memory.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `var/spack/repos/builtin/packages/intel-tbb/package.py`
Content:
```
1 ##############################################################################
2 # Copyright (c) 2013-2018, Lawrence Livermore National Security, LLC.
3 # Produced at the Lawrence Livermore National Laboratory.
4 #
5 # This file is part of Spack.
6 # Created by Todd Gamblin, [email protected], All rights reserved.
7 # LLNL-CODE-647188
8 #
9 # For details, see https://github.com/spack/spack
10 # Please also see the NOTICE and LICENSE files for our notice and the LGPL.
11 #
12 # This program is free software; you can redistribute it and/or modify
13 # it under the terms of the GNU Lesser General Public License (as
14 # published by the Free Software Foundation) version 2.1, February 1999.
15 #
16 # This program is distributed in the hope that it will be useful, but
17 # WITHOUT ANY WARRANTY; without even the IMPLIED WARRANTY OF
18 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the terms and
19 # conditions of the GNU Lesser General Public License for more details.
20 #
21 # You should have received a copy of the GNU Lesser General Public
22 # License along with this program; if not, write to the Free Software
23 # Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA
24 ##############################################################################
25 from spack import *
26 import glob
27 import inspect
28 import platform
29
30
31 class IntelTbb(Package):
32 """Widely used C++ template library for task parallelism.
33 Intel Threading Building Blocks (Intel TBB) lets you easily write parallel
34 C++ programs that take full advantage of multicore performance, that are
35 portable and composable, and that have future-proof scalability.
36 """
37 homepage = "http://www.threadingbuildingblocks.org/"
38
39 # See url_for_version() below.
40 version('2018.4', '5e2e6ba0e25624a94331c945856551c2')
41 version('2018.3', 'cd2e136598ffa5c136f077ee85a35b4c')
42 version('2018.2', '0b8dfe30917a54e40828eeb0ed7562ae')
43 version('2018.1', 'b2f2fa09adf44a22f4024049907f774b')
44 version('2018', '7fb30d5ea2545f26ce02757d9ab05e6c')
45 version('2017.8', '7240f57f1aeea0e266a5e17ae68fdc16')
46 version('2017.7', '364f2a4b80e978f38a69cbf7c466b898')
47 version('2017.6', 'ec21254af4fc2a29574c272f501a3138')
48 version('2017.5', '85b41c64102c052e24d8a39f6193e599')
49 version('2017.4', '71526b2fef098515e212302d1455de7d')
50 version('2017.3', 'd7622eeaafeff8d271c7aa684bd82ddb')
51 version('2017.2', '9605cbea96998a10a186fc72c35cbd76')
52 version('2017.1', '6c0fe8aa7bc911a85e8e522e620511b3')
53 version('2017', '9e7f9ea684ecf84ac74dcd3c6012cfa6')
54 version('4.4.6', '20e15206f70c2651bfc964e451a443a0')
55 version('4.4.5', '531a67cd98f9b4ec8ece95c5f8193a83')
56 version('4.4.4', '61531b2e8684e06a621dcdca1a7a420e')
57 version('4.4.3', '8e3e39e1fdfb3f7c3a5ac8ec1afe186e')
58 version('4.4.2', 'e92b110e8eb238741b00e3789b39969e')
59 version('4.4.1', 'a02c9958f02c1b5f3626874219979ae8')
60 version('4.4', '1d512085221996eae6cec04e1a4cd3dd')
61
62 provides('tbb')
63
64 conflicts('%[email protected]:', when='@:4.4.3',
65 msg='4.4.4 or later required for GCC >= 6.1.')
66
67 variant('shared', default=True,
68 description='Builds a shared version of TBB libraries')
69
70 variant('cxxstd',
71 default='default',
72 values=('default', '98', '11', '14', '17'),
73 multi=False,
74 description='Use the specified C++ standard when building.')
75
76 # Build and install CMake config files if we're new enough.
77 depends_on('[email protected]:', type='build', when='@2017.0:')
78
79 # Deactivate use of RTM with GCC when on an OS with an elderly assembler.
80 patch("tbb_gcc_rtm_key.patch", level=0, when='%[email protected]: os=rhel6')
81 patch("tbb_gcc_rtm_key.patch", level=0, when='%[email protected]: os=scientific6')
82 patch("tbb_gcc_rtm_key.patch", level=0, when='%[email protected]: os=centos6')
83
84 # Patch cmakeConfig.cmake.in to find the libraries where we install them.
85 patch("tbb_cmakeConfig.patch", level=0, when='@2017.0:')
86
87 def url_for_version(self, version):
88 url = 'https://github.com/01org/tbb/archive/{0}.tar.gz'
89 if (version[0] >= 2017) and len(version) > 1:
90 return url.format('{0}_U{1}'.format(version[0], version[1]))
91 else:
92 return url.format(version)
93
94 def coerce_to_spack(self, tbb_build_subdir):
95 for compiler in ["icc", "gcc", "clang"]:
96 fs = glob.glob(join_path(tbb_build_subdir,
97 "*.%s.inc" % compiler))
98 for f in fs:
99 lines = open(f).readlines()
100 of = open(f, "w")
101 for l in lines:
102 if l.strip().startswith("CPLUS ="):
103 of.write("# coerced to spack\n")
104 of.write("CPLUS = $(CXX)\n")
105 elif l.strip().startswith("CPLUS ="):
106 of.write("# coerced to spack\n")
107 of.write("CONLY = $(CC)\n")
108 else:
109 of.write(l)
110
111 def install(self, spec, prefix):
112 # We need to follow TBB's compiler selection logic to get the proper
113 # build + link flags but we still need to use spack's compiler wrappers
114 # to accomplish this, we do two things:
115 #
116 # * Look at the spack spec to determine which compiler we should pass
117 # to tbb's Makefile;
118 #
119 # * patch tbb's build system to use the compiler wrappers (CC, CXX) for
120 # icc, gcc, clang (see coerce_to_spack());
121 #
122 self.coerce_to_spack("build")
123
124 if spec.satisfies('%clang'):
125 tbb_compiler = "clang"
126 elif spec.satisfies('%intel'):
127 tbb_compiler = "icc"
128 else:
129 tbb_compiler = "gcc"
130
131 mkdirp(prefix)
132 mkdirp(prefix.lib)
133
134 make_opts = []
135
136 # Static builds of TBB are enabled by including 'big_iron.inc' file
137 # See caveats in 'big_iron.inc' for limits on using TBB statically
138 # Lore states this file must be handed to make before other options
139 if '+shared' not in self.spec:
140 make_opts.append("extra_inc=big_iron.inc")
141
142 if spec.variants['cxxstd'].value != 'default':
143 make_opts.append('stdver=c++{0}'.
144 format(spec.variants['cxxstd'].value))
145
146 #
147 # tbb does not have a configure script or make install target
148 # we simply call make, and try to put the pieces together
149 #
150 make_opts.append("compiler={0}".format(tbb_compiler))
151 make(*make_opts)
152
153 # install headers to {prefix}/include
154 install_tree('include', prefix.include)
155
156 # install libs to {prefix}/lib
157 tbb_lib_names = ["libtbb",
158 "libtbbmalloc",
159 "libtbbmalloc_proxy"]
160
161 for lib_name in tbb_lib_names:
162 # install release libs
163 fs = glob.glob(join_path("build", "*release", lib_name + ".*"))
164 for f in fs:
165 install(f, prefix.lib)
166 # install debug libs if they exist
167 fs = glob.glob(join_path("build", "*debug", lib_name + "_debug.*"))
168 for f in fs:
169 install(f, prefix.lib)
170
171 if self.spec.satisfies('@2017.0:'):
172 # Generate and install the CMake Config file.
173 cmake_args = ('-DTBB_ROOT={0}'.format(prefix),
174 '-DTBB_OS={0}'.format(platform.system()),
175 '-P',
176 'tbb_config_generator.cmake')
177 with working_dir(join_path(self.stage.source_path, 'cmake')):
178 inspect.getmodule(self).cmake(*cmake_args)
179
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/var/spack/repos/builtin/packages/intel-tbb/package.py b/var/spack/repos/builtin/packages/intel-tbb/package.py
--- a/var/spack/repos/builtin/packages/intel-tbb/package.py
+++ b/var/spack/repos/builtin/packages/intel-tbb/package.py
@@ -73,6 +73,9 @@
multi=False,
description='Use the specified C++ standard when building.')
+ variant('tm', default=True,
+ description='Enable use of transactional memory on x86')
+
# Build and install CMake config files if we're new enough.
depends_on('[email protected]:', type='build', when='@2017.0:')
@@ -84,6 +87,9 @@
# Patch cmakeConfig.cmake.in to find the libraries where we install them.
patch("tbb_cmakeConfig.patch", level=0, when='@2017.0:')
+ # Some very old systems don't support transactional memory.
+ patch("disable-tm.patch", when='~tm')
+
def url_for_version(self, version):
url = 'https://github.com/01org/tbb/archive/{0}.tar.gz'
if (version[0] >= 2017) and len(version) > 1:
|
{"golden_diff": "diff --git a/var/spack/repos/builtin/packages/intel-tbb/package.py b/var/spack/repos/builtin/packages/intel-tbb/package.py\n--- a/var/spack/repos/builtin/packages/intel-tbb/package.py\n+++ b/var/spack/repos/builtin/packages/intel-tbb/package.py\n@@ -73,6 +73,9 @@\n multi=False,\n description='Use the specified C++ standard when building.')\n \n+ variant('tm', default=True,\n+ description='Enable use of transactional memory on x86')\n+\n # Build and install CMake config files if we're new enough.\n depends_on('[email protected]:', type='build', when='@2017.0:')\n \n@@ -84,6 +87,9 @@\n # Patch cmakeConfig.cmake.in to find the libraries where we install them.\n patch(\"tbb_cmakeConfig.patch\", level=0, when='@2017.0:')\n \n+ # Some very old systems don't support transactional memory.\n+ patch(\"disable-tm.patch\", when='~tm')\n+\n def url_for_version(self, version):\n url = 'https://github.com/01org/tbb/archive/{0}.tar.gz'\n if (version[0] >= 2017) and len(version) > 1:\n", "issue": "intel-tbb broken if no transactional memory\nI tried to install intel-tbb on an old Intel x86-64 cluster at Rice.\r\nThe build fails with:\r\n\r\n% spack install intel-tbb\r\n...\r\n 21 /work/hpc/krentel/work/spack-repo/lib/spack/env/gcc/g++ -o scheduler.o -c -MMD -DTBB_USE_DEBUG -DDO_ITT_NOTIFY -g -O0 -DUSE_PTHREAD -m64 -mrtm -fPIC -D__TBB_BUILD=1 -Wall -Wno-parentheses -Wno-non-virtual-dtor -I../../src -I../../src/rml/include -I../../include ../../src/tbb/scheduler.cpp\r\n 22 /tmp/cchPyt9b.s: Assembler messages:\r\n >> 23 /tmp/cchPyt9b.s:672: Error: no such instruction: `xtest'\r\n >> 24 /tmp/cchPyt9b.s:691: Error: no such instruction: `xend'\r\n\r\nThe problem is that xtest and xend are transactional memory\r\ninstructions and either the machine or the compiler don't understand\r\ntransactional memory.\r\n\r\n/proc/cpuinfo reports:\r\n\r\nprocessor\t: 11\r\nvendor_id\t: GenuineIntel\r\ncpu family\t: 6\r\nmodel\t\t: 44\r\nmodel name\t: Intel(R) Xeon(R) CPU X5660 @ 2.80GHz\r\nstepping\t: 2\r\nmicrocode\t: 16\r\ncpu MHz\t\t: 2800.047\r\ncache size\t: 12288 KB\r\n...\r\nflags\t\t: fpu vme de pse tsc msr pae mce cx8 apic mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good xtopology nonstop_tsc aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm pcid dca sse4_1 sse4_2 popcnt aes lahf_lm arat epb dtherm tpr_shadow vnmi flexpriority ept vpid\r\n\r\nLooking inside the tbb source, we see in include/tbb/tbb_config.h:\r\n\r\n#define __TBB_TSX_AVAILABLE ((__TBB_x86_32 || __TBB_x86_64) && !__TBB_DEFINE_MIC)\r\n\r\nSo, the real problem is that Intel thinks that all 64-bit x86 machines\r\n(except Xeon Phi/MIC) have transactional memory, and that's not true.\r\n\r\nOne solution would be to patch the #define to 0, but that would\r\ndisable all transactional memory.\r\n\r\nI guess a more spack-ish solution would be to add a 'transactional-memory'\r\nvariant to intel-tbb and conditionally apply a patch, or otherwise set\r\n__TBB_TSX_AVAILABLE to 0.\r\n\r\nBut what I really want is a better way to auto test if the given\r\nmachine (or host machine in a cross compile) supports some feature, in\r\nthis case transactional memory. I'll open a separate issue for that.\r\n\r\nThanks,\r\n\r\n--Mark\r\n\r\nP.S. I did search for intel-tbb, but I didn't find anything related to\r\ntransactional memory.\r\n\n", "before_files": [{"content": "##############################################################################\n# Copyright (c) 2013-2018, Lawrence Livermore National Security, LLC.\n# Produced at the Lawrence Livermore National Laboratory.\n#\n# This file is part of Spack.\n# Created by Todd Gamblin, [email protected], All rights reserved.\n# LLNL-CODE-647188\n#\n# For details, see https://github.com/spack/spack\n# Please also see the NOTICE and LICENSE files for our notice and the LGPL.\n#\n# This program is free software; you can redistribute it and/or modify\n# it under the terms of the GNU Lesser General Public License (as\n# published by the Free Software Foundation) version 2.1, February 1999.\n#\n# This program is distributed in the hope that it will be useful, but\n# WITHOUT ANY WARRANTY; without even the IMPLIED WARRANTY OF\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the terms and\n# conditions of the GNU Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this program; if not, write to the Free Software\n# Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA\n##############################################################################\nfrom spack import *\nimport glob\nimport inspect\nimport platform\n\n\nclass IntelTbb(Package):\n \"\"\"Widely used C++ template library for task parallelism.\n Intel Threading Building Blocks (Intel TBB) lets you easily write parallel\n C++ programs that take full advantage of multicore performance, that are\n portable and composable, and that have future-proof scalability.\n \"\"\"\n homepage = \"http://www.threadingbuildingblocks.org/\"\n\n # See url_for_version() below.\n version('2018.4', '5e2e6ba0e25624a94331c945856551c2')\n version('2018.3', 'cd2e136598ffa5c136f077ee85a35b4c')\n version('2018.2', '0b8dfe30917a54e40828eeb0ed7562ae')\n version('2018.1', 'b2f2fa09adf44a22f4024049907f774b')\n version('2018', '7fb30d5ea2545f26ce02757d9ab05e6c')\n version('2017.8', '7240f57f1aeea0e266a5e17ae68fdc16')\n version('2017.7', '364f2a4b80e978f38a69cbf7c466b898')\n version('2017.6', 'ec21254af4fc2a29574c272f501a3138')\n version('2017.5', '85b41c64102c052e24d8a39f6193e599')\n version('2017.4', '71526b2fef098515e212302d1455de7d')\n version('2017.3', 'd7622eeaafeff8d271c7aa684bd82ddb')\n version('2017.2', '9605cbea96998a10a186fc72c35cbd76')\n version('2017.1', '6c0fe8aa7bc911a85e8e522e620511b3')\n version('2017', '9e7f9ea684ecf84ac74dcd3c6012cfa6')\n version('4.4.6', '20e15206f70c2651bfc964e451a443a0')\n version('4.4.5', '531a67cd98f9b4ec8ece95c5f8193a83')\n version('4.4.4', '61531b2e8684e06a621dcdca1a7a420e')\n version('4.4.3', '8e3e39e1fdfb3f7c3a5ac8ec1afe186e')\n version('4.4.2', 'e92b110e8eb238741b00e3789b39969e')\n version('4.4.1', 'a02c9958f02c1b5f3626874219979ae8')\n version('4.4', '1d512085221996eae6cec04e1a4cd3dd')\n\n provides('tbb')\n\n conflicts('%[email protected]:', when='@:4.4.3',\n msg='4.4.4 or later required for GCC >= 6.1.')\n\n variant('shared', default=True,\n description='Builds a shared version of TBB libraries')\n\n variant('cxxstd',\n default='default',\n values=('default', '98', '11', '14', '17'),\n multi=False,\n description='Use the specified C++ standard when building.')\n\n # Build and install CMake config files if we're new enough.\n depends_on('[email protected]:', type='build', when='@2017.0:')\n\n # Deactivate use of RTM with GCC when on an OS with an elderly assembler.\n patch(\"tbb_gcc_rtm_key.patch\", level=0, when='%[email protected]: os=rhel6')\n patch(\"tbb_gcc_rtm_key.patch\", level=0, when='%[email protected]: os=scientific6')\n patch(\"tbb_gcc_rtm_key.patch\", level=0, when='%[email protected]: os=centos6')\n\n # Patch cmakeConfig.cmake.in to find the libraries where we install them.\n patch(\"tbb_cmakeConfig.patch\", level=0, when='@2017.0:')\n\n def url_for_version(self, version):\n url = 'https://github.com/01org/tbb/archive/{0}.tar.gz'\n if (version[0] >= 2017) and len(version) > 1:\n return url.format('{0}_U{1}'.format(version[0], version[1]))\n else:\n return url.format(version)\n\n def coerce_to_spack(self, tbb_build_subdir):\n for compiler in [\"icc\", \"gcc\", \"clang\"]:\n fs = glob.glob(join_path(tbb_build_subdir,\n \"*.%s.inc\" % compiler))\n for f in fs:\n lines = open(f).readlines()\n of = open(f, \"w\")\n for l in lines:\n if l.strip().startswith(\"CPLUS =\"):\n of.write(\"# coerced to spack\\n\")\n of.write(\"CPLUS = $(CXX)\\n\")\n elif l.strip().startswith(\"CPLUS =\"):\n of.write(\"# coerced to spack\\n\")\n of.write(\"CONLY = $(CC)\\n\")\n else:\n of.write(l)\n\n def install(self, spec, prefix):\n # We need to follow TBB's compiler selection logic to get the proper\n # build + link flags but we still need to use spack's compiler wrappers\n # to accomplish this, we do two things:\n #\n # * Look at the spack spec to determine which compiler we should pass\n # to tbb's Makefile;\n #\n # * patch tbb's build system to use the compiler wrappers (CC, CXX) for\n # icc, gcc, clang (see coerce_to_spack());\n #\n self.coerce_to_spack(\"build\")\n\n if spec.satisfies('%clang'):\n tbb_compiler = \"clang\"\n elif spec.satisfies('%intel'):\n tbb_compiler = \"icc\"\n else:\n tbb_compiler = \"gcc\"\n\n mkdirp(prefix)\n mkdirp(prefix.lib)\n\n make_opts = []\n\n # Static builds of TBB are enabled by including 'big_iron.inc' file\n # See caveats in 'big_iron.inc' for limits on using TBB statically\n # Lore states this file must be handed to make before other options\n if '+shared' not in self.spec:\n make_opts.append(\"extra_inc=big_iron.inc\")\n\n if spec.variants['cxxstd'].value != 'default':\n make_opts.append('stdver=c++{0}'.\n format(spec.variants['cxxstd'].value))\n\n #\n # tbb does not have a configure script or make install target\n # we simply call make, and try to put the pieces together\n #\n make_opts.append(\"compiler={0}\".format(tbb_compiler))\n make(*make_opts)\n\n # install headers to {prefix}/include\n install_tree('include', prefix.include)\n\n # install libs to {prefix}/lib\n tbb_lib_names = [\"libtbb\",\n \"libtbbmalloc\",\n \"libtbbmalloc_proxy\"]\n\n for lib_name in tbb_lib_names:\n # install release libs\n fs = glob.glob(join_path(\"build\", \"*release\", lib_name + \".*\"))\n for f in fs:\n install(f, prefix.lib)\n # install debug libs if they exist\n fs = glob.glob(join_path(\"build\", \"*debug\", lib_name + \"_debug.*\"))\n for f in fs:\n install(f, prefix.lib)\n\n if self.spec.satisfies('@2017.0:'):\n # Generate and install the CMake Config file.\n cmake_args = ('-DTBB_ROOT={0}'.format(prefix),\n '-DTBB_OS={0}'.format(platform.system()),\n '-P',\n 'tbb_config_generator.cmake')\n with working_dir(join_path(self.stage.source_path, 'cmake')):\n inspect.getmodule(self).cmake(*cmake_args)\n", "path": "var/spack/repos/builtin/packages/intel-tbb/package.py"}], "after_files": [{"content": "##############################################################################\n# Copyright (c) 2013-2018, Lawrence Livermore National Security, LLC.\n# Produced at the Lawrence Livermore National Laboratory.\n#\n# This file is part of Spack.\n# Created by Todd Gamblin, [email protected], All rights reserved.\n# LLNL-CODE-647188\n#\n# For details, see https://github.com/spack/spack\n# Please also see the NOTICE and LICENSE files for our notice and the LGPL.\n#\n# This program is free software; you can redistribute it and/or modify\n# it under the terms of the GNU Lesser General Public License (as\n# published by the Free Software Foundation) version 2.1, February 1999.\n#\n# This program is distributed in the hope that it will be useful, but\n# WITHOUT ANY WARRANTY; without even the IMPLIED WARRANTY OF\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the terms and\n# conditions of the GNU Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this program; if not, write to the Free Software\n# Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA\n##############################################################################\nfrom spack import *\nimport glob\nimport inspect\nimport platform\n\n\nclass IntelTbb(Package):\n \"\"\"Widely used C++ template library for task parallelism.\n Intel Threading Building Blocks (Intel TBB) lets you easily write parallel\n C++ programs that take full advantage of multicore performance, that are\n portable and composable, and that have future-proof scalability.\n \"\"\"\n homepage = \"http://www.threadingbuildingblocks.org/\"\n\n # See url_for_version() below.\n version('2018.4', '5e2e6ba0e25624a94331c945856551c2')\n version('2018.3', 'cd2e136598ffa5c136f077ee85a35b4c')\n version('2018.2', '0b8dfe30917a54e40828eeb0ed7562ae')\n version('2018.1', 'b2f2fa09adf44a22f4024049907f774b')\n version('2018', '7fb30d5ea2545f26ce02757d9ab05e6c')\n version('2017.8', '7240f57f1aeea0e266a5e17ae68fdc16')\n version('2017.7', '364f2a4b80e978f38a69cbf7c466b898')\n version('2017.6', 'ec21254af4fc2a29574c272f501a3138')\n version('2017.5', '85b41c64102c052e24d8a39f6193e599')\n version('2017.4', '71526b2fef098515e212302d1455de7d')\n version('2017.3', 'd7622eeaafeff8d271c7aa684bd82ddb')\n version('2017.2', '9605cbea96998a10a186fc72c35cbd76')\n version('2017.1', '6c0fe8aa7bc911a85e8e522e620511b3')\n version('2017', '9e7f9ea684ecf84ac74dcd3c6012cfa6')\n version('4.4.6', '20e15206f70c2651bfc964e451a443a0')\n version('4.4.5', '531a67cd98f9b4ec8ece95c5f8193a83')\n version('4.4.4', '61531b2e8684e06a621dcdca1a7a420e')\n version('4.4.3', '8e3e39e1fdfb3f7c3a5ac8ec1afe186e')\n version('4.4.2', 'e92b110e8eb238741b00e3789b39969e')\n version('4.4.1', 'a02c9958f02c1b5f3626874219979ae8')\n version('4.4', '1d512085221996eae6cec04e1a4cd3dd')\n\n provides('tbb')\n\n conflicts('%[email protected]:', when='@:4.4.3',\n msg='4.4.4 or later required for GCC >= 6.1.')\n\n variant('shared', default=True,\n description='Builds a shared version of TBB libraries')\n\n variant('cxxstd',\n default='default',\n values=('default', '98', '11', '14', '17'),\n multi=False,\n description='Use the specified C++ standard when building.')\n\n variant('tm', default=True,\n description='Enable use of transactional memory on x86')\n\n # Build and install CMake config files if we're new enough.\n depends_on('[email protected]:', type='build', when='@2017.0:')\n\n # Deactivate use of RTM with GCC when on an OS with an elderly assembler.\n patch(\"tbb_gcc_rtm_key.patch\", level=0, when='%[email protected]: os=rhel6')\n patch(\"tbb_gcc_rtm_key.patch\", level=0, when='%[email protected]: os=scientific6')\n patch(\"tbb_gcc_rtm_key.patch\", level=0, when='%[email protected]: os=centos6')\n\n # Patch cmakeConfig.cmake.in to find the libraries where we install them.\n patch(\"tbb_cmakeConfig.patch\", level=0, when='@2017.0:')\n\n # Some very old systems don't support transactional memory.\n patch(\"disable-tm.patch\", when='~tm')\n\n def url_for_version(self, version):\n url = 'https://github.com/01org/tbb/archive/{0}.tar.gz'\n if (version[0] >= 2017) and len(version) > 1:\n return url.format('{0}_U{1}'.format(version[0], version[1]))\n else:\n return url.format(version)\n\n def coerce_to_spack(self, tbb_build_subdir):\n for compiler in [\"icc\", \"gcc\", \"clang\"]:\n fs = glob.glob(join_path(tbb_build_subdir,\n \"*.%s.inc\" % compiler))\n for f in fs:\n lines = open(f).readlines()\n of = open(f, \"w\")\n for l in lines:\n if l.strip().startswith(\"CPLUS =\"):\n of.write(\"# coerced to spack\\n\")\n of.write(\"CPLUS = $(CXX)\\n\")\n elif l.strip().startswith(\"CPLUS =\"):\n of.write(\"# coerced to spack\\n\")\n of.write(\"CONLY = $(CC)\\n\")\n else:\n of.write(l)\n\n def install(self, spec, prefix):\n # We need to follow TBB's compiler selection logic to get the proper\n # build + link flags but we still need to use spack's compiler wrappers\n # to accomplish this, we do two things:\n #\n # * Look at the spack spec to determine which compiler we should pass\n # to tbb's Makefile;\n #\n # * patch tbb's build system to use the compiler wrappers (CC, CXX) for\n # icc, gcc, clang (see coerce_to_spack());\n #\n self.coerce_to_spack(\"build\")\n\n if spec.satisfies('%clang'):\n tbb_compiler = \"clang\"\n elif spec.satisfies('%intel'):\n tbb_compiler = \"icc\"\n else:\n tbb_compiler = \"gcc\"\n\n mkdirp(prefix)\n mkdirp(prefix.lib)\n\n make_opts = []\n\n # Static builds of TBB are enabled by including 'big_iron.inc' file\n # See caveats in 'big_iron.inc' for limits on using TBB statically\n # Lore states this file must be handed to make before other options\n if '+shared' not in self.spec:\n make_opts.append(\"extra_inc=big_iron.inc\")\n\n if spec.variants['cxxstd'].value != 'default':\n make_opts.append('stdver=c++{0}'.\n format(spec.variants['cxxstd'].value))\n\n #\n # tbb does not have a configure script or make install target\n # we simply call make, and try to put the pieces together\n #\n make_opts.append(\"compiler={0}\".format(tbb_compiler))\n make(*make_opts)\n\n # install headers to {prefix}/include\n install_tree('include', prefix.include)\n\n # install libs to {prefix}/lib\n tbb_lib_names = [\"libtbb\",\n \"libtbbmalloc\",\n \"libtbbmalloc_proxy\"]\n\n for lib_name in tbb_lib_names:\n # install release libs\n fs = glob.glob(join_path(\"build\", \"*release\", lib_name + \".*\"))\n for f in fs:\n install(f, prefix.lib)\n # install debug libs if they exist\n fs = glob.glob(join_path(\"build\", \"*debug\", lib_name + \"_debug.*\"))\n for f in fs:\n install(f, prefix.lib)\n\n if self.spec.satisfies('@2017.0:'):\n # Generate and install the CMake Config file.\n cmake_args = ('-DTBB_ROOT={0}'.format(prefix),\n '-DTBB_OS={0}'.format(platform.system()),\n '-P',\n 'tbb_config_generator.cmake')\n with working_dir(join_path(self.stage.source_path, 'cmake')):\n inspect.getmodule(self).cmake(*cmake_args)\n", "path": "var/spack/repos/builtin/packages/intel-tbb/package.py"}]}
| 3,888 | 295 |
gh_patches_debug_37099
|
rasdani/github-patches
|
git_diff
|
pre-commit__pre-commit-2885
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Avoid unquoting weirdness of Windows for `language: r`
### search you tried in the issue tracker
never, r, found
### describe your issue
Multiple reports in https://github.com/lorenzwalthert/precommit (https://github.com/lorenzwalthert/precommit/issues/441, https://github.com/lorenzwalthert/precommit/issues/473) were raised and describe a problem with (un)quoting the long string that runs when `language: r` is setup in `Rscript -e 'xxx'` where `'xxx'` contains [multiple levels of quotes](https://github.com/pre-commit/pre-commit/blob/6896025288691aafd015a4681c59dc105e61b614/pre_commit/languages/r.py#L101). For the readers convenience, the output looks like:
```
[INFO] Installing environment for https://github.com/lorenzwalthert/precommit.
[INFO] Once installed this environment will be reused.
[INFO] This may take a few minutes...
[INFO] Restored changes from C:\Users\USER\.cache\pre-commit\patch1678401203-36472.
An unexpected error has occurred: CalledProcessError: command: ('C:/PROGRA~1/R/R-41~1.0\\bin\\Rscript.exe', '--vanilla', '-e', ' options(install.packages.compile.from.source = "never", pkgType = "binary")\n prefix_dir <- \'C:\\\\Users\\\\USER\\\\.cache\\\\pre-commit\\\\repovawmpj_r\'\n options(\n repos = c(CRAN = "https://cran.rstudio.com"),\n renv.consent = TRUE\n )\n source("renv/activate.R")\n renv::restore()\n activate_statement <- paste0(\n \'suppressWarnings({\',\n \'old <- setwd("\', getwd(), \'"); \',\n \'source("renv/activate.R"); \',\n \'setwd(old); \',\n \'renv::load("\', getwd(), \'");})\'\n )\n writeLines(activate_statement, \'activate.R\')\n is_package <- tryCatch(\n {\n path_desc <- file.path(prefix_dir, \'DESCRIPTION\')\n suppressWarnings(desc <- read.dcf(path_desc))\n "Package" %in% colnames(desc)\n },\n error = function(...) FALSE\n )\n if (is_package) {\n renv::install(prefix_dir)\n }\n \n ')
return code: 1
stdout: (none)
stderr:
During startup - Warning messages:
1: Setting LC_COLLATE=en_US.UTF-8 failed
2: Setting LC_CTYPE=en_US.UTF-8 failed
3: Setting LC_MONETARY=en_US.UTF-8 failed
4: Setting LC_TIME=en_US.UTF-8 failed
Error in options(install.packages.compile.from.source = never, pkgType = binary) :
object 'never' not found
Execution halted
Check the log at C:\Users\USER\.cache\pre-commit\pre-commit.log
```
The solution described by @asottile in https://github.com/lorenzwalthert/precommit/issues/473#issuecomment-1511498032 is to probably write the contents to a temporary file and avoid unquoting within the expression (i.e. the term after `-e`). This should be quite straight forward.
Question is if we can create a good test first to reproduce the offending behavior and whether or not there are tools already in pre-commit to deal with temp files etc. that we could use.
### pre-commit --version
precommit 3.1.1
### .pre-commit-config.yaml
```yaml
repos:
- repo: https://github.com/lorenzwalthert/precommit
rev: v0.3.2.9007
hooks:
- id: style-files
```
### ~/.cache/pre-commit/pre-commit.log (if present)
_No response_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pre_commit/languages/r.py`
Content:
```
1 from __future__ import annotations
2
3 import contextlib
4 import os
5 import shlex
6 import shutil
7 from typing import Generator
8 from typing import Sequence
9
10 from pre_commit import lang_base
11 from pre_commit.envcontext import envcontext
12 from pre_commit.envcontext import PatchesT
13 from pre_commit.envcontext import UNSET
14 from pre_commit.prefix import Prefix
15 from pre_commit.util import cmd_output_b
16 from pre_commit.util import win_exe
17
18 ENVIRONMENT_DIR = 'renv'
19 RSCRIPT_OPTS = ('--no-save', '--no-restore', '--no-site-file', '--no-environ')
20 get_default_version = lang_base.basic_get_default_version
21 health_check = lang_base.basic_health_check
22
23
24 def get_env_patch(venv: str) -> PatchesT:
25 return (
26 ('R_PROFILE_USER', os.path.join(venv, 'activate.R')),
27 ('RENV_PROJECT', UNSET),
28 )
29
30
31 @contextlib.contextmanager
32 def in_env(prefix: Prefix, version: str) -> Generator[None, None, None]:
33 envdir = lang_base.environment_dir(prefix, ENVIRONMENT_DIR, version)
34 with envcontext(get_env_patch(envdir)):
35 yield
36
37
38 def _prefix_if_file_entry(
39 entry: list[str],
40 prefix: Prefix,
41 *,
42 is_local: bool,
43 ) -> Sequence[str]:
44 if entry[1] == '-e' or is_local:
45 return entry[1:]
46 else:
47 return (prefix.path(entry[1]),)
48
49
50 def _rscript_exec() -> str:
51 r_home = os.environ.get('R_HOME')
52 if r_home is None:
53 return 'Rscript'
54 else:
55 return os.path.join(r_home, 'bin', win_exe('Rscript'))
56
57
58 def _entry_validate(entry: list[str]) -> None:
59 """
60 Allowed entries:
61 # Rscript -e expr
62 # Rscript path/to/file
63 """
64 if entry[0] != 'Rscript':
65 raise ValueError('entry must start with `Rscript`.')
66
67 if entry[1] == '-e':
68 if len(entry) > 3:
69 raise ValueError('You can supply at most one expression.')
70 elif len(entry) > 2:
71 raise ValueError(
72 'The only valid syntax is `Rscript -e {expr}`'
73 'or `Rscript path/to/hook/script`',
74 )
75
76
77 def _cmd_from_hook(
78 prefix: Prefix,
79 entry: str,
80 args: Sequence[str],
81 *,
82 is_local: bool,
83 ) -> tuple[str, ...]:
84 cmd = shlex.split(entry)
85 _entry_validate(cmd)
86
87 cmd_part = _prefix_if_file_entry(cmd, prefix, is_local=is_local)
88 return (cmd[0], *RSCRIPT_OPTS, *cmd_part, *args)
89
90
91 def install_environment(
92 prefix: Prefix,
93 version: str,
94 additional_dependencies: Sequence[str],
95 ) -> None:
96 lang_base.assert_version_default('r', version)
97
98 env_dir = lang_base.environment_dir(prefix, ENVIRONMENT_DIR, version)
99 os.makedirs(env_dir, exist_ok=True)
100 shutil.copy(prefix.path('renv.lock'), env_dir)
101 shutil.copytree(prefix.path('renv'), os.path.join(env_dir, 'renv'))
102
103 r_code_inst_environment = f"""\
104 prefix_dir <- {prefix.prefix_dir!r}
105 options(
106 repos = c(CRAN = "https://cran.rstudio.com"),
107 renv.consent = TRUE
108 )
109 source("renv/activate.R")
110 renv::restore()
111 activate_statement <- paste0(
112 'suppressWarnings({{',
113 'old <- setwd("', getwd(), '"); ',
114 'source("renv/activate.R"); ',
115 'setwd(old); ',
116 'renv::load("', getwd(), '");}})'
117 )
118 writeLines(activate_statement, 'activate.R')
119 is_package <- tryCatch(
120 {{
121 path_desc <- file.path(prefix_dir, 'DESCRIPTION')
122 suppressWarnings(desc <- read.dcf(path_desc))
123 "Package" %in% colnames(desc)
124 }},
125 error = function(...) FALSE
126 )
127 if (is_package) {{
128 renv::install(prefix_dir)
129 }}
130 """
131
132 cmd_output_b(
133 _rscript_exec(), '--vanilla', '-e',
134 _inline_r_setup(r_code_inst_environment),
135 cwd=env_dir,
136 )
137 if additional_dependencies:
138 r_code_inst_add = 'renv::install(commandArgs(trailingOnly = TRUE))'
139 with in_env(prefix, version):
140 cmd_output_b(
141 _rscript_exec(), *RSCRIPT_OPTS, '-e',
142 _inline_r_setup(r_code_inst_add),
143 *additional_dependencies,
144 cwd=env_dir,
145 )
146
147
148 def _inline_r_setup(code: str) -> str:
149 """
150 Some behaviour of R cannot be configured via env variables, but can
151 only be configured via R options once R has started. These are set here.
152 """
153 with_option = f"""\
154 options(install.packages.compile.from.source = "never", pkgType = "binary")
155 {code}
156 """
157 return with_option
158
159
160 def run_hook(
161 prefix: Prefix,
162 entry: str,
163 args: Sequence[str],
164 file_args: Sequence[str],
165 *,
166 is_local: bool,
167 require_serial: bool,
168 color: bool,
169 ) -> tuple[int, bytes]:
170 cmd = _cmd_from_hook(prefix, entry, args, is_local=is_local)
171 return lang_base.run_xargs(
172 cmd,
173 file_args,
174 require_serial=require_serial,
175 color=color,
176 )
177
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pre_commit/languages/r.py b/pre_commit/languages/r.py
--- a/pre_commit/languages/r.py
+++ b/pre_commit/languages/r.py
@@ -4,6 +4,8 @@
import os
import shlex
import shutil
+import tempfile
+import textwrap
from typing import Generator
from typing import Sequence
@@ -21,6 +23,19 @@
health_check = lang_base.basic_health_check
[email protected]
+def _r_code_in_tempfile(code: str) -> Generator[str, None, None]:
+ """
+ To avoid quoting and escaping issues, avoid `Rscript [options] -e {expr}`
+ but use `Rscript [options] path/to/file_with_expr.R`
+ """
+ with tempfile.TemporaryDirectory() as tmpdir:
+ fname = os.path.join(tmpdir, 'script.R')
+ with open(fname, 'w') as f:
+ f.write(_inline_r_setup(textwrap.dedent(code)))
+ yield fname
+
+
def get_env_patch(venv: str) -> PatchesT:
return (
('R_PROFILE_USER', os.path.join(venv, 'activate.R')),
@@ -129,20 +144,19 @@
}}
"""
- cmd_output_b(
- _rscript_exec(), '--vanilla', '-e',
- _inline_r_setup(r_code_inst_environment),
- cwd=env_dir,
- )
+ with _r_code_in_tempfile(r_code_inst_environment) as f:
+ cmd_output_b(_rscript_exec(), '--vanilla', f, cwd=env_dir)
+
if additional_dependencies:
r_code_inst_add = 'renv::install(commandArgs(trailingOnly = TRUE))'
with in_env(prefix, version):
- cmd_output_b(
- _rscript_exec(), *RSCRIPT_OPTS, '-e',
- _inline_r_setup(r_code_inst_add),
- *additional_dependencies,
- cwd=env_dir,
- )
+ with _r_code_in_tempfile(r_code_inst_add) as f:
+ cmd_output_b(
+ _rscript_exec(), *RSCRIPT_OPTS,
+ f,
+ *additional_dependencies,
+ cwd=env_dir,
+ )
def _inline_r_setup(code: str) -> str:
@@ -150,11 +164,16 @@
Some behaviour of R cannot be configured via env variables, but can
only be configured via R options once R has started. These are set here.
"""
- with_option = f"""\
- options(install.packages.compile.from.source = "never", pkgType = "binary")
- {code}
- """
- return with_option
+ with_option = [
+ textwrap.dedent("""\
+ options(
+ install.packages.compile.from.source = "never",
+ pkgType = "binary"
+ )
+ """),
+ code,
+ ]
+ return '\n'.join(with_option)
def run_hook(
|
{"golden_diff": "diff --git a/pre_commit/languages/r.py b/pre_commit/languages/r.py\n--- a/pre_commit/languages/r.py\n+++ b/pre_commit/languages/r.py\n@@ -4,6 +4,8 @@\n import os\n import shlex\n import shutil\n+import tempfile\n+import textwrap\n from typing import Generator\n from typing import Sequence\n \n@@ -21,6 +23,19 @@\n health_check = lang_base.basic_health_check\n \n \[email protected]\n+def _r_code_in_tempfile(code: str) -> Generator[str, None, None]:\n+ \"\"\"\n+ To avoid quoting and escaping issues, avoid `Rscript [options] -e {expr}`\n+ but use `Rscript [options] path/to/file_with_expr.R`\n+ \"\"\"\n+ with tempfile.TemporaryDirectory() as tmpdir:\n+ fname = os.path.join(tmpdir, 'script.R')\n+ with open(fname, 'w') as f:\n+ f.write(_inline_r_setup(textwrap.dedent(code)))\n+ yield fname\n+\n+\n def get_env_patch(venv: str) -> PatchesT:\n return (\n ('R_PROFILE_USER', os.path.join(venv, 'activate.R')),\n@@ -129,20 +144,19 @@\n }}\n \"\"\"\n \n- cmd_output_b(\n- _rscript_exec(), '--vanilla', '-e',\n- _inline_r_setup(r_code_inst_environment),\n- cwd=env_dir,\n- )\n+ with _r_code_in_tempfile(r_code_inst_environment) as f:\n+ cmd_output_b(_rscript_exec(), '--vanilla', f, cwd=env_dir)\n+\n if additional_dependencies:\n r_code_inst_add = 'renv::install(commandArgs(trailingOnly = TRUE))'\n with in_env(prefix, version):\n- cmd_output_b(\n- _rscript_exec(), *RSCRIPT_OPTS, '-e',\n- _inline_r_setup(r_code_inst_add),\n- *additional_dependencies,\n- cwd=env_dir,\n- )\n+ with _r_code_in_tempfile(r_code_inst_add) as f:\n+ cmd_output_b(\n+ _rscript_exec(), *RSCRIPT_OPTS,\n+ f,\n+ *additional_dependencies,\n+ cwd=env_dir,\n+ )\n \n \n def _inline_r_setup(code: str) -> str:\n@@ -150,11 +164,16 @@\n Some behaviour of R cannot be configured via env variables, but can\n only be configured via R options once R has started. These are set here.\n \"\"\"\n- with_option = f\"\"\"\\\n- options(install.packages.compile.from.source = \"never\", pkgType = \"binary\")\n- {code}\n- \"\"\"\n- return with_option\n+ with_option = [\n+ textwrap.dedent(\"\"\"\\\n+ options(\n+ install.packages.compile.from.source = \"never\",\n+ pkgType = \"binary\"\n+ )\n+ \"\"\"),\n+ code,\n+ ]\n+ return '\\n'.join(with_option)\n \n \n def run_hook(\n", "issue": "Avoid unquoting weirdness of Windows for `language: r`\n### search you tried in the issue tracker\n\nnever, r, found\n\n### describe your issue\n\nMultiple reports in https://github.com/lorenzwalthert/precommit (https://github.com/lorenzwalthert/precommit/issues/441, https://github.com/lorenzwalthert/precommit/issues/473) were raised and describe a problem with (un)quoting the long string that runs when `language: r` is setup in `Rscript -e 'xxx'` where `'xxx'` contains [multiple levels of quotes](https://github.com/pre-commit/pre-commit/blob/6896025288691aafd015a4681c59dc105e61b614/pre_commit/languages/r.py#L101). For the readers convenience, the output looks like:\r\n```\r\n[INFO] Installing environment for https://github.com/lorenzwalthert/precommit.\r\n[INFO] Once installed this environment will be reused.\r\n[INFO] This may take a few minutes...\r\n[INFO] Restored changes from C:\\Users\\USER\\.cache\\pre-commit\\patch1678401203-36472.\r\nAn unexpected error has occurred: CalledProcessError: command: ('C:/PROGRA~1/R/R-41~1.0\\\\bin\\\\Rscript.exe', '--vanilla', '-e', ' options(install.packages.compile.from.source = \"never\", pkgType = \"binary\")\\n prefix_dir <- \\'C:\\\\\\\\Users\\\\\\\\USER\\\\\\\\.cache\\\\\\\\pre-commit\\\\\\\\repovawmpj_r\\'\\n options(\\n repos = c(CRAN = \"https://cran.rstudio.com\"),\\n renv.consent = TRUE\\n )\\n source(\"renv/activate.R\")\\n renv::restore()\\n activate_statement <- paste0(\\n \\'suppressWarnings({\\',\\n \\'old <- setwd(\"\\', getwd(), \\'\"); \\',\\n \\'source(\"renv/activate.R\"); \\',\\n \\'setwd(old); \\',\\n \\'renv::load(\"\\', getwd(), \\'\");})\\'\\n )\\n writeLines(activate_statement, \\'activate.R\\')\\n is_package <- tryCatch(\\n {\\n path_desc <- file.path(prefix_dir, \\'DESCRIPTION\\')\\n suppressWarnings(desc <- read.dcf(path_desc))\\n \"Package\" %in% colnames(desc)\\n },\\n error = function(...) FALSE\\n )\\n if (is_package) {\\n renv::install(prefix_dir)\\n }\\n \\n ')\r\nreturn code: 1\r\nstdout: (none)\r\nstderr:\r\n During startup - Warning messages:\r\n 1: Setting LC_COLLATE=en_US.UTF-8 failed \r\n 2: Setting LC_CTYPE=en_US.UTF-8 failed \r\n 3: Setting LC_MONETARY=en_US.UTF-8 failed \r\n 4: Setting LC_TIME=en_US.UTF-8 failed \r\n Error in options(install.packages.compile.from.source = never, pkgType = binary) : \r\n object 'never' not found\r\n Execution halted\r\nCheck the log at C:\\Users\\USER\\.cache\\pre-commit\\pre-commit.log\r\n```\r\n\r\n\r\nThe solution described by @asottile in https://github.com/lorenzwalthert/precommit/issues/473#issuecomment-1511498032 is to probably write the contents to a temporary file and avoid unquoting within the expression (i.e. the term after `-e`). This should be quite straight forward.\r\n\r\nQuestion is if we can create a good test first to reproduce the offending behavior and whether or not there are tools already in pre-commit to deal with temp files etc. that we could use.\r\n\r\n\n\n### pre-commit --version\n\nprecommit 3.1.1\n\n### .pre-commit-config.yaml\n\n```yaml\nrepos:\r\n- repo: https://github.com/lorenzwalthert/precommit\r\n rev: v0.3.2.9007\r\n hooks:\r\n - id: style-files\n```\n\n\n### ~/.cache/pre-commit/pre-commit.log (if present)\n\n_No response_\n", "before_files": [{"content": "from __future__ import annotations\n\nimport contextlib\nimport os\nimport shlex\nimport shutil\nfrom typing import Generator\nfrom typing import Sequence\n\nfrom pre_commit import lang_base\nfrom pre_commit.envcontext import envcontext\nfrom pre_commit.envcontext import PatchesT\nfrom pre_commit.envcontext import UNSET\nfrom pre_commit.prefix import Prefix\nfrom pre_commit.util import cmd_output_b\nfrom pre_commit.util import win_exe\n\nENVIRONMENT_DIR = 'renv'\nRSCRIPT_OPTS = ('--no-save', '--no-restore', '--no-site-file', '--no-environ')\nget_default_version = lang_base.basic_get_default_version\nhealth_check = lang_base.basic_health_check\n\n\ndef get_env_patch(venv: str) -> PatchesT:\n return (\n ('R_PROFILE_USER', os.path.join(venv, 'activate.R')),\n ('RENV_PROJECT', UNSET),\n )\n\n\[email protected]\ndef in_env(prefix: Prefix, version: str) -> Generator[None, None, None]:\n envdir = lang_base.environment_dir(prefix, ENVIRONMENT_DIR, version)\n with envcontext(get_env_patch(envdir)):\n yield\n\n\ndef _prefix_if_file_entry(\n entry: list[str],\n prefix: Prefix,\n *,\n is_local: bool,\n) -> Sequence[str]:\n if entry[1] == '-e' or is_local:\n return entry[1:]\n else:\n return (prefix.path(entry[1]),)\n\n\ndef _rscript_exec() -> str:\n r_home = os.environ.get('R_HOME')\n if r_home is None:\n return 'Rscript'\n else:\n return os.path.join(r_home, 'bin', win_exe('Rscript'))\n\n\ndef _entry_validate(entry: list[str]) -> None:\n \"\"\"\n Allowed entries:\n # Rscript -e expr\n # Rscript path/to/file\n \"\"\"\n if entry[0] != 'Rscript':\n raise ValueError('entry must start with `Rscript`.')\n\n if entry[1] == '-e':\n if len(entry) > 3:\n raise ValueError('You can supply at most one expression.')\n elif len(entry) > 2:\n raise ValueError(\n 'The only valid syntax is `Rscript -e {expr}`'\n 'or `Rscript path/to/hook/script`',\n )\n\n\ndef _cmd_from_hook(\n prefix: Prefix,\n entry: str,\n args: Sequence[str],\n *,\n is_local: bool,\n) -> tuple[str, ...]:\n cmd = shlex.split(entry)\n _entry_validate(cmd)\n\n cmd_part = _prefix_if_file_entry(cmd, prefix, is_local=is_local)\n return (cmd[0], *RSCRIPT_OPTS, *cmd_part, *args)\n\n\ndef install_environment(\n prefix: Prefix,\n version: str,\n additional_dependencies: Sequence[str],\n) -> None:\n lang_base.assert_version_default('r', version)\n\n env_dir = lang_base.environment_dir(prefix, ENVIRONMENT_DIR, version)\n os.makedirs(env_dir, exist_ok=True)\n shutil.copy(prefix.path('renv.lock'), env_dir)\n shutil.copytree(prefix.path('renv'), os.path.join(env_dir, 'renv'))\n\n r_code_inst_environment = f\"\"\"\\\n prefix_dir <- {prefix.prefix_dir!r}\n options(\n repos = c(CRAN = \"https://cran.rstudio.com\"),\n renv.consent = TRUE\n )\n source(\"renv/activate.R\")\n renv::restore()\n activate_statement <- paste0(\n 'suppressWarnings({{',\n 'old <- setwd(\"', getwd(), '\"); ',\n 'source(\"renv/activate.R\"); ',\n 'setwd(old); ',\n 'renv::load(\"', getwd(), '\");}})'\n )\n writeLines(activate_statement, 'activate.R')\n is_package <- tryCatch(\n {{\n path_desc <- file.path(prefix_dir, 'DESCRIPTION')\n suppressWarnings(desc <- read.dcf(path_desc))\n \"Package\" %in% colnames(desc)\n }},\n error = function(...) FALSE\n )\n if (is_package) {{\n renv::install(prefix_dir)\n }}\n \"\"\"\n\n cmd_output_b(\n _rscript_exec(), '--vanilla', '-e',\n _inline_r_setup(r_code_inst_environment),\n cwd=env_dir,\n )\n if additional_dependencies:\n r_code_inst_add = 'renv::install(commandArgs(trailingOnly = TRUE))'\n with in_env(prefix, version):\n cmd_output_b(\n _rscript_exec(), *RSCRIPT_OPTS, '-e',\n _inline_r_setup(r_code_inst_add),\n *additional_dependencies,\n cwd=env_dir,\n )\n\n\ndef _inline_r_setup(code: str) -> str:\n \"\"\"\n Some behaviour of R cannot be configured via env variables, but can\n only be configured via R options once R has started. These are set here.\n \"\"\"\n with_option = f\"\"\"\\\n options(install.packages.compile.from.source = \"never\", pkgType = \"binary\")\n {code}\n \"\"\"\n return with_option\n\n\ndef run_hook(\n prefix: Prefix,\n entry: str,\n args: Sequence[str],\n file_args: Sequence[str],\n *,\n is_local: bool,\n require_serial: bool,\n color: bool,\n) -> tuple[int, bytes]:\n cmd = _cmd_from_hook(prefix, entry, args, is_local=is_local)\n return lang_base.run_xargs(\n cmd,\n file_args,\n require_serial=require_serial,\n color=color,\n )\n", "path": "pre_commit/languages/r.py"}], "after_files": [{"content": "from __future__ import annotations\n\nimport contextlib\nimport os\nimport shlex\nimport shutil\nimport tempfile\nimport textwrap\nfrom typing import Generator\nfrom typing import Sequence\n\nfrom pre_commit import lang_base\nfrom pre_commit.envcontext import envcontext\nfrom pre_commit.envcontext import PatchesT\nfrom pre_commit.envcontext import UNSET\nfrom pre_commit.prefix import Prefix\nfrom pre_commit.util import cmd_output_b\nfrom pre_commit.util import win_exe\n\nENVIRONMENT_DIR = 'renv'\nRSCRIPT_OPTS = ('--no-save', '--no-restore', '--no-site-file', '--no-environ')\nget_default_version = lang_base.basic_get_default_version\nhealth_check = lang_base.basic_health_check\n\n\[email protected]\ndef _r_code_in_tempfile(code: str) -> Generator[str, None, None]:\n \"\"\"\n To avoid quoting and escaping issues, avoid `Rscript [options] -e {expr}`\n but use `Rscript [options] path/to/file_with_expr.R`\n \"\"\"\n with tempfile.TemporaryDirectory() as tmpdir:\n fname = os.path.join(tmpdir, 'script.R')\n with open(fname, 'w') as f:\n f.write(_inline_r_setup(textwrap.dedent(code)))\n yield fname\n\n\ndef get_env_patch(venv: str) -> PatchesT:\n return (\n ('R_PROFILE_USER', os.path.join(venv, 'activate.R')),\n ('RENV_PROJECT', UNSET),\n )\n\n\[email protected]\ndef in_env(prefix: Prefix, version: str) -> Generator[None, None, None]:\n envdir = lang_base.environment_dir(prefix, ENVIRONMENT_DIR, version)\n with envcontext(get_env_patch(envdir)):\n yield\n\n\ndef _prefix_if_file_entry(\n entry: list[str],\n prefix: Prefix,\n *,\n is_local: bool,\n) -> Sequence[str]:\n if entry[1] == '-e' or is_local:\n return entry[1:]\n else:\n return (prefix.path(entry[1]),)\n\n\ndef _rscript_exec() -> str:\n r_home = os.environ.get('R_HOME')\n if r_home is None:\n return 'Rscript'\n else:\n return os.path.join(r_home, 'bin', win_exe('Rscript'))\n\n\ndef _entry_validate(entry: list[str]) -> None:\n \"\"\"\n Allowed entries:\n # Rscript -e expr\n # Rscript path/to/file\n \"\"\"\n if entry[0] != 'Rscript':\n raise ValueError('entry must start with `Rscript`.')\n\n if entry[1] == '-e':\n if len(entry) > 3:\n raise ValueError('You can supply at most one expression.')\n elif len(entry) > 2:\n raise ValueError(\n 'The only valid syntax is `Rscript -e {expr}`'\n 'or `Rscript path/to/hook/script`',\n )\n\n\ndef _cmd_from_hook(\n prefix: Prefix,\n entry: str,\n args: Sequence[str],\n *,\n is_local: bool,\n) -> tuple[str, ...]:\n cmd = shlex.split(entry)\n _entry_validate(cmd)\n\n cmd_part = _prefix_if_file_entry(cmd, prefix, is_local=is_local)\n return (cmd[0], *RSCRIPT_OPTS, *cmd_part, *args)\n\n\ndef install_environment(\n prefix: Prefix,\n version: str,\n additional_dependencies: Sequence[str],\n) -> None:\n lang_base.assert_version_default('r', version)\n\n env_dir = lang_base.environment_dir(prefix, ENVIRONMENT_DIR, version)\n os.makedirs(env_dir, exist_ok=True)\n shutil.copy(prefix.path('renv.lock'), env_dir)\n shutil.copytree(prefix.path('renv'), os.path.join(env_dir, 'renv'))\n\n r_code_inst_environment = f\"\"\"\\\n prefix_dir <- {prefix.prefix_dir!r}\n options(\n repos = c(CRAN = \"https://cran.rstudio.com\"),\n renv.consent = TRUE\n )\n source(\"renv/activate.R\")\n renv::restore()\n activate_statement <- paste0(\n 'suppressWarnings({{',\n 'old <- setwd(\"', getwd(), '\"); ',\n 'source(\"renv/activate.R\"); ',\n 'setwd(old); ',\n 'renv::load(\"', getwd(), '\");}})'\n )\n writeLines(activate_statement, 'activate.R')\n is_package <- tryCatch(\n {{\n path_desc <- file.path(prefix_dir, 'DESCRIPTION')\n suppressWarnings(desc <- read.dcf(path_desc))\n \"Package\" %in% colnames(desc)\n }},\n error = function(...) FALSE\n )\n if (is_package) {{\n renv::install(prefix_dir)\n }}\n \"\"\"\n\n with _r_code_in_tempfile(r_code_inst_environment) as f:\n cmd_output_b(_rscript_exec(), '--vanilla', f, cwd=env_dir)\n\n if additional_dependencies:\n r_code_inst_add = 'renv::install(commandArgs(trailingOnly = TRUE))'\n with in_env(prefix, version):\n with _r_code_in_tempfile(r_code_inst_add) as f:\n cmd_output_b(\n _rscript_exec(), *RSCRIPT_OPTS,\n f,\n *additional_dependencies,\n cwd=env_dir,\n )\n\n\ndef _inline_r_setup(code: str) -> str:\n \"\"\"\n Some behaviour of R cannot be configured via env variables, but can\n only be configured via R options once R has started. These are set here.\n \"\"\"\n with_option = [\n textwrap.dedent(\"\"\"\\\n options(\n install.packages.compile.from.source = \"never\",\n pkgType = \"binary\"\n )\n \"\"\"),\n code,\n ]\n return '\\n'.join(with_option)\n\n\ndef run_hook(\n prefix: Prefix,\n entry: str,\n args: Sequence[str],\n file_args: Sequence[str],\n *,\n is_local: bool,\n require_serial: bool,\n color: bool,\n) -> tuple[int, bytes]:\n cmd = _cmd_from_hook(prefix, entry, args, is_local=is_local)\n return lang_base.run_xargs(\n cmd,\n file_args,\n require_serial=require_serial,\n color=color,\n )\n", "path": "pre_commit/languages/r.py"}]}
| 2,835 | 674 |
gh_patches_debug_4318
|
rasdani/github-patches
|
git_diff
|
streamlit__streamlit-3939
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Auto-reload doesn't work with subdirs
### Summary
Auto-reload doesn’t work if both the app file and a secondary module are in the same subdir. While this doesn't affect app behavior, it's a pretty critical bug because you need to manually restart Streamlit all the time in this configuration.
### Steps to reproduce
Create a project dir like this:
.
|- subdir
|- streamlit_app.py # this imports secondary
|- secondary.py
And then run:
streamlit run subdir/streamlit_app.py
This will run the app but it won’t show a reload prompt when secondary.py changes. Instead, you need to manually rerun the Streamlit app. See also this [discussion on Slack](https://streamlit.slack.com/archives/C019AE89C2C/p1627346650027100). (Btw if streamlit_app.py is in root and only secondary.py is in subdir, this works).
### Debug info
- Streamlit version: 0.87
- Python version: 3.8
- Pipenv
- OS version: MacOS
- Browser version: Chrome
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lib/streamlit/watcher/local_sources_watcher.py`
Content:
```
1 # Copyright 2018-2021 Streamlit Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import os
16 import sys
17 import collections
18 import typing as t
19 import types
20
21 from streamlit import config
22 from streamlit import file_util
23 from streamlit.folder_black_list import FolderBlackList
24
25 from streamlit.logger import get_logger
26 from streamlit.watcher.file_watcher import (
27 get_default_file_watcher_class,
28 NoOpFileWatcher,
29 )
30
31 LOGGER = get_logger(__name__)
32
33 WatchedModule = collections.namedtuple("WatchedModule", ["watcher", "module_name"])
34
35 # This needs to be initialized lazily to avoid calling config.get_option() and
36 # thus initializing config options when this file is first imported.
37 FileWatcher = None
38
39
40 class LocalSourcesWatcher(object):
41 def __init__(self, report, on_file_changed):
42 self._report = report
43 self._on_file_changed = on_file_changed
44 self._is_closed = False
45
46 # Blacklist for folders that should not be watched
47 self._folder_black_list = FolderBlackList(
48 config.get_option("server.folderWatchBlacklist")
49 )
50
51 # A dict of filepath -> WatchedModule.
52 self._watched_modules = {}
53
54 self._register_watcher(
55 self._report.script_path,
56 module_name=None, # Only the root script has None here.
57 )
58
59 def on_file_changed(self, filepath):
60 if filepath not in self._watched_modules:
61 LOGGER.error("Received event for non-watched file: %s", filepath)
62 return
63
64 # Workaround:
65 # Delete all watched modules so we can guarantee changes to the
66 # updated module are reflected on reload.
67 #
68 # In principle, for reloading a given module, we only need to unload
69 # the module itself and all of the modules which import it (directly
70 # or indirectly) such that when we exec the application code, the
71 # changes are reloaded and reflected in the running application.
72 #
73 # However, determining all import paths for a given loaded module is
74 # non-trivial, and so as a workaround we simply unload all watched
75 # modules.
76 for wm in self._watched_modules.values():
77 if wm.module_name is not None and wm.module_name in sys.modules:
78 del sys.modules[wm.module_name]
79
80 self._on_file_changed()
81
82 def close(self):
83 for wm in self._watched_modules.values():
84 wm.watcher.close()
85 self._watched_modules = {}
86 self._is_closed = True
87
88 def _register_watcher(self, filepath, module_name):
89 global FileWatcher
90 if FileWatcher is None:
91 FileWatcher = get_default_file_watcher_class()
92
93 if FileWatcher is NoOpFileWatcher:
94 return
95
96 try:
97 wm = WatchedModule(
98 watcher=FileWatcher(filepath, self.on_file_changed),
99 module_name=module_name,
100 )
101 except PermissionError:
102 # If you don't have permission to read this file, don't even add it
103 # to watchers.
104 return
105
106 self._watched_modules[filepath] = wm
107
108 def _deregister_watcher(self, filepath):
109 if filepath not in self._watched_modules:
110 return
111
112 if filepath == self._report.script_path:
113 return
114
115 wm = self._watched_modules[filepath]
116 wm.watcher.close()
117 del self._watched_modules[filepath]
118
119 def _file_is_new(self, filepath):
120 return filepath not in self._watched_modules
121
122 def _file_should_be_watched(self, filepath):
123 # Using short circuiting for performance.
124 return self._file_is_new(filepath) and (
125 file_util.file_is_in_folder_glob(filepath, self._report.script_folder)
126 or file_util.file_in_pythonpath(filepath)
127 )
128
129 def update_watched_modules(self):
130 if self._is_closed:
131 return
132
133 modules_paths = {
134 name: self._exclude_blacklisted_paths(get_module_paths(module))
135 for name, module in dict(sys.modules).items()
136 }
137
138 self._register_necessary_watchers(modules_paths)
139
140 def _register_necessary_watchers(
141 self, module_paths: t.Dict[str, t.Set[str]]
142 ) -> None:
143 for name, paths in module_paths.items():
144 for path in paths:
145 if self._file_should_be_watched(path):
146 self._register_watcher(path, name)
147
148 def _exclude_blacklisted_paths(self, paths: t.Set[str]) -> t.Set[str]:
149 return {p for p in paths if not self._folder_black_list.is_blacklisted(p)}
150
151
152 def get_module_paths(module: types.ModuleType) -> t.Set[str]:
153 paths_extractors = [
154 # https://docs.python.org/3/reference/datamodel.html
155 # __file__ is the pathname of the file from which the module was loaded
156 # if it was loaded from a file.
157 # The __file__ attribute may be missing for certain types of modules
158 lambda m: [m.__file__],
159 # https://docs.python.org/3/reference/import.html#__spec__
160 # The __spec__ attribute is set to the module spec that was used
161 # when importing the module. one exception is __main__,
162 # where __spec__ is set to None in some cases.
163 # https://www.python.org/dev/peps/pep-0451/#id16
164 # "origin" in an import context means the system
165 # (or resource within a system) from which a module originates
166 # ... It is up to the loader to decide on how to interpret
167 # and use a module's origin, if at all.
168 lambda m: [m.__spec__.origin],
169 # https://www.python.org/dev/peps/pep-0420/
170 # Handling of "namespace packages" in which the __path__ attribute
171 # is a _NamespacePath object with a _path attribute containing
172 # the various paths of the package.
173 lambda m: [p for p in m.__path__._path],
174 ]
175
176 all_paths = set()
177 for extract_paths in paths_extractors:
178 potential_paths = []
179 try:
180 potential_paths = extract_paths(module)
181 except AttributeError:
182 pass
183 except Exception as e:
184 LOGGER.warning(f"Examining the path of {module.__name__} raised: {e}")
185
186 all_paths.update([str(p) for p in potential_paths if _is_valid_path(p)])
187 return all_paths
188
189
190 def _is_valid_path(path: t.Optional[str]) -> bool:
191 return isinstance(path, str) and (os.path.isfile(path) or os.path.isdir(path))
192
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lib/streamlit/watcher/local_sources_watcher.py b/lib/streamlit/watcher/local_sources_watcher.py
--- a/lib/streamlit/watcher/local_sources_watcher.py
+++ b/lib/streamlit/watcher/local_sources_watcher.py
@@ -183,7 +183,9 @@
except Exception as e:
LOGGER.warning(f"Examining the path of {module.__name__} raised: {e}")
- all_paths.update([str(p) for p in potential_paths if _is_valid_path(p)])
+ all_paths.update(
+ [os.path.abspath(str(p)) for p in potential_paths if _is_valid_path(p)]
+ )
return all_paths
|
{"golden_diff": "diff --git a/lib/streamlit/watcher/local_sources_watcher.py b/lib/streamlit/watcher/local_sources_watcher.py\n--- a/lib/streamlit/watcher/local_sources_watcher.py\n+++ b/lib/streamlit/watcher/local_sources_watcher.py\n@@ -183,7 +183,9 @@\n except Exception as e:\n LOGGER.warning(f\"Examining the path of {module.__name__} raised: {e}\")\n \n- all_paths.update([str(p) for p in potential_paths if _is_valid_path(p)])\n+ all_paths.update(\n+ [os.path.abspath(str(p)) for p in potential_paths if _is_valid_path(p)]\n+ )\n return all_paths\n", "issue": "Auto-reload doesn't work with subdirs\n### Summary\r\n\r\nAuto-reload doesn\u2019t work if both the app file and a secondary module are in the same subdir. While this doesn't affect app behavior, it's a pretty critical bug because you need to manually restart Streamlit all the time in this configuration.\r\n\r\n\r\n### Steps to reproduce\r\n\r\nCreate a project dir like this:\r\n\r\n .\r\n |- subdir\r\n |- streamlit_app.py # this imports secondary\r\n |- secondary.py\r\n\r\nAnd then run:\r\n\r\n streamlit run subdir/streamlit_app.py\r\n\r\nThis will run the app but it won\u2019t show a reload prompt when secondary.py changes. Instead, you need to manually rerun the Streamlit app. See also this [discussion on Slack](https://streamlit.slack.com/archives/C019AE89C2C/p1627346650027100). (Btw if streamlit_app.py is in root and only secondary.py is in subdir, this works).\r\n\r\n\r\n### Debug info\r\n\r\n- Streamlit version: 0.87\r\n- Python version: 3.8\r\n- Pipenv\r\n- OS version: MacOS\r\n- Browser version: Chrome\r\n\r\n\n", "before_files": [{"content": "# Copyright 2018-2021 Streamlit Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\nimport sys\nimport collections\nimport typing as t\nimport types\n\nfrom streamlit import config\nfrom streamlit import file_util\nfrom streamlit.folder_black_list import FolderBlackList\n\nfrom streamlit.logger import get_logger\nfrom streamlit.watcher.file_watcher import (\n get_default_file_watcher_class,\n NoOpFileWatcher,\n)\n\nLOGGER = get_logger(__name__)\n\nWatchedModule = collections.namedtuple(\"WatchedModule\", [\"watcher\", \"module_name\"])\n\n# This needs to be initialized lazily to avoid calling config.get_option() and\n# thus initializing config options when this file is first imported.\nFileWatcher = None\n\n\nclass LocalSourcesWatcher(object):\n def __init__(self, report, on_file_changed):\n self._report = report\n self._on_file_changed = on_file_changed\n self._is_closed = False\n\n # Blacklist for folders that should not be watched\n self._folder_black_list = FolderBlackList(\n config.get_option(\"server.folderWatchBlacklist\")\n )\n\n # A dict of filepath -> WatchedModule.\n self._watched_modules = {}\n\n self._register_watcher(\n self._report.script_path,\n module_name=None, # Only the root script has None here.\n )\n\n def on_file_changed(self, filepath):\n if filepath not in self._watched_modules:\n LOGGER.error(\"Received event for non-watched file: %s\", filepath)\n return\n\n # Workaround:\n # Delete all watched modules so we can guarantee changes to the\n # updated module are reflected on reload.\n #\n # In principle, for reloading a given module, we only need to unload\n # the module itself and all of the modules which import it (directly\n # or indirectly) such that when we exec the application code, the\n # changes are reloaded and reflected in the running application.\n #\n # However, determining all import paths for a given loaded module is\n # non-trivial, and so as a workaround we simply unload all watched\n # modules.\n for wm in self._watched_modules.values():\n if wm.module_name is not None and wm.module_name in sys.modules:\n del sys.modules[wm.module_name]\n\n self._on_file_changed()\n\n def close(self):\n for wm in self._watched_modules.values():\n wm.watcher.close()\n self._watched_modules = {}\n self._is_closed = True\n\n def _register_watcher(self, filepath, module_name):\n global FileWatcher\n if FileWatcher is None:\n FileWatcher = get_default_file_watcher_class()\n\n if FileWatcher is NoOpFileWatcher:\n return\n\n try:\n wm = WatchedModule(\n watcher=FileWatcher(filepath, self.on_file_changed),\n module_name=module_name,\n )\n except PermissionError:\n # If you don't have permission to read this file, don't even add it\n # to watchers.\n return\n\n self._watched_modules[filepath] = wm\n\n def _deregister_watcher(self, filepath):\n if filepath not in self._watched_modules:\n return\n\n if filepath == self._report.script_path:\n return\n\n wm = self._watched_modules[filepath]\n wm.watcher.close()\n del self._watched_modules[filepath]\n\n def _file_is_new(self, filepath):\n return filepath not in self._watched_modules\n\n def _file_should_be_watched(self, filepath):\n # Using short circuiting for performance.\n return self._file_is_new(filepath) and (\n file_util.file_is_in_folder_glob(filepath, self._report.script_folder)\n or file_util.file_in_pythonpath(filepath)\n )\n\n def update_watched_modules(self):\n if self._is_closed:\n return\n\n modules_paths = {\n name: self._exclude_blacklisted_paths(get_module_paths(module))\n for name, module in dict(sys.modules).items()\n }\n\n self._register_necessary_watchers(modules_paths)\n\n def _register_necessary_watchers(\n self, module_paths: t.Dict[str, t.Set[str]]\n ) -> None:\n for name, paths in module_paths.items():\n for path in paths:\n if self._file_should_be_watched(path):\n self._register_watcher(path, name)\n\n def _exclude_blacklisted_paths(self, paths: t.Set[str]) -> t.Set[str]:\n return {p for p in paths if not self._folder_black_list.is_blacklisted(p)}\n\n\ndef get_module_paths(module: types.ModuleType) -> t.Set[str]:\n paths_extractors = [\n # https://docs.python.org/3/reference/datamodel.html\n # __file__ is the pathname of the file from which the module was loaded\n # if it was loaded from a file.\n # The __file__ attribute may be missing for certain types of modules\n lambda m: [m.__file__],\n # https://docs.python.org/3/reference/import.html#__spec__\n # The __spec__ attribute is set to the module spec that was used\n # when importing the module. one exception is __main__,\n # where __spec__ is set to None in some cases.\n # https://www.python.org/dev/peps/pep-0451/#id16\n # \"origin\" in an import context means the system\n # (or resource within a system) from which a module originates\n # ... It is up to the loader to decide on how to interpret\n # and use a module's origin, if at all.\n lambda m: [m.__spec__.origin],\n # https://www.python.org/dev/peps/pep-0420/\n # Handling of \"namespace packages\" in which the __path__ attribute\n # is a _NamespacePath object with a _path attribute containing\n # the various paths of the package.\n lambda m: [p for p in m.__path__._path],\n ]\n\n all_paths = set()\n for extract_paths in paths_extractors:\n potential_paths = []\n try:\n potential_paths = extract_paths(module)\n except AttributeError:\n pass\n except Exception as e:\n LOGGER.warning(f\"Examining the path of {module.__name__} raised: {e}\")\n\n all_paths.update([str(p) for p in potential_paths if _is_valid_path(p)])\n return all_paths\n\n\ndef _is_valid_path(path: t.Optional[str]) -> bool:\n return isinstance(path, str) and (os.path.isfile(path) or os.path.isdir(path))\n", "path": "lib/streamlit/watcher/local_sources_watcher.py"}], "after_files": [{"content": "# Copyright 2018-2021 Streamlit Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\nimport sys\nimport collections\nimport typing as t\nimport types\n\nfrom streamlit import config\nfrom streamlit import file_util\nfrom streamlit.folder_black_list import FolderBlackList\n\nfrom streamlit.logger import get_logger\nfrom streamlit.watcher.file_watcher import (\n get_default_file_watcher_class,\n NoOpFileWatcher,\n)\n\nLOGGER = get_logger(__name__)\n\nWatchedModule = collections.namedtuple(\"WatchedModule\", [\"watcher\", \"module_name\"])\n\n# This needs to be initialized lazily to avoid calling config.get_option() and\n# thus initializing config options when this file is first imported.\nFileWatcher = None\n\n\nclass LocalSourcesWatcher(object):\n def __init__(self, report, on_file_changed):\n self._report = report\n self._on_file_changed = on_file_changed\n self._is_closed = False\n\n # Blacklist for folders that should not be watched\n self._folder_black_list = FolderBlackList(\n config.get_option(\"server.folderWatchBlacklist\")\n )\n\n # A dict of filepath -> WatchedModule.\n self._watched_modules = {}\n\n self._register_watcher(\n self._report.script_path,\n module_name=None, # Only the root script has None here.\n )\n\n def on_file_changed(self, filepath):\n if filepath not in self._watched_modules:\n LOGGER.error(\"Received event for non-watched file: %s\", filepath)\n return\n\n # Workaround:\n # Delete all watched modules so we can guarantee changes to the\n # updated module are reflected on reload.\n #\n # In principle, for reloading a given module, we only need to unload\n # the module itself and all of the modules which import it (directly\n # or indirectly) such that when we exec the application code, the\n # changes are reloaded and reflected in the running application.\n #\n # However, determining all import paths for a given loaded module is\n # non-trivial, and so as a workaround we simply unload all watched\n # modules.\n for wm in self._watched_modules.values():\n if wm.module_name is not None and wm.module_name in sys.modules:\n del sys.modules[wm.module_name]\n\n self._on_file_changed()\n\n def close(self):\n for wm in self._watched_modules.values():\n wm.watcher.close()\n self._watched_modules = {}\n self._is_closed = True\n\n def _register_watcher(self, filepath, module_name):\n global FileWatcher\n if FileWatcher is None:\n FileWatcher = get_default_file_watcher_class()\n\n if FileWatcher is NoOpFileWatcher:\n return\n\n try:\n wm = WatchedModule(\n watcher=FileWatcher(filepath, self.on_file_changed),\n module_name=module_name,\n )\n except PermissionError:\n # If you don't have permission to read this file, don't even add it\n # to watchers.\n return\n\n self._watched_modules[filepath] = wm\n\n def _deregister_watcher(self, filepath):\n if filepath not in self._watched_modules:\n return\n\n if filepath == self._report.script_path:\n return\n\n wm = self._watched_modules[filepath]\n wm.watcher.close()\n del self._watched_modules[filepath]\n\n def _file_is_new(self, filepath):\n return filepath not in self._watched_modules\n\n def _file_should_be_watched(self, filepath):\n # Using short circuiting for performance.\n return self._file_is_new(filepath) and (\n file_util.file_is_in_folder_glob(filepath, self._report.script_folder)\n or file_util.file_in_pythonpath(filepath)\n )\n\n def update_watched_modules(self):\n if self._is_closed:\n return\n\n modules_paths = {\n name: self._exclude_blacklisted_paths(get_module_paths(module))\n for name, module in dict(sys.modules).items()\n }\n\n self._register_necessary_watchers(modules_paths)\n\n def _register_necessary_watchers(\n self, module_paths: t.Dict[str, t.Set[str]]\n ) -> None:\n for name, paths in module_paths.items():\n for path in paths:\n if self._file_should_be_watched(path):\n self._register_watcher(path, name)\n\n def _exclude_blacklisted_paths(self, paths: t.Set[str]) -> t.Set[str]:\n return {p for p in paths if not self._folder_black_list.is_blacklisted(p)}\n\n\ndef get_module_paths(module: types.ModuleType) -> t.Set[str]:\n paths_extractors = [\n # https://docs.python.org/3/reference/datamodel.html\n # __file__ is the pathname of the file from which the module was loaded\n # if it was loaded from a file.\n # The __file__ attribute may be missing for certain types of modules\n lambda m: [m.__file__],\n # https://docs.python.org/3/reference/import.html#__spec__\n # The __spec__ attribute is set to the module spec that was used\n # when importing the module. one exception is __main__,\n # where __spec__ is set to None in some cases.\n # https://www.python.org/dev/peps/pep-0451/#id16\n # \"origin\" in an import context means the system\n # (or resource within a system) from which a module originates\n # ... It is up to the loader to decide on how to interpret\n # and use a module's origin, if at all.\n lambda m: [m.__spec__.origin],\n # https://www.python.org/dev/peps/pep-0420/\n # Handling of \"namespace packages\" in which the __path__ attribute\n # is a _NamespacePath object with a _path attribute containing\n # the various paths of the package.\n lambda m: [p for p in m.__path__._path],\n ]\n\n all_paths = set()\n for extract_paths in paths_extractors:\n potential_paths = []\n try:\n potential_paths = extract_paths(module)\n except AttributeError:\n pass\n except Exception as e:\n LOGGER.warning(f\"Examining the path of {module.__name__} raised: {e}\")\n\n all_paths.update(\n [os.path.abspath(str(p)) for p in potential_paths if _is_valid_path(p)]\n )\n return all_paths\n\n\ndef _is_valid_path(path: t.Optional[str]) -> bool:\n return isinstance(path, str) and (os.path.isfile(path) or os.path.isdir(path))\n", "path": "lib/streamlit/watcher/local_sources_watcher.py"}]}
| 2,556 | 150 |
gh_patches_debug_11799
|
rasdani/github-patches
|
git_diff
|
avocado-framework__avocado-4154
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Bug] Avocado crash with TypeError
With the following change on the time-sensitive job Avocado crashes:
```python
diff --git a/selftests/pre_release/jobs/timesensitive.py b/selftests/pre_release/jobs/timesensitive.py
index a9fbebcd..456719aa 100755
--- a/selftests/pre_release/jobs/timesensitive.py
+++ b/selftests/pre_release/jobs/timesensitive.py
@@ -4,6 +4,7 @@ import os
import sys
from avocado.core.job import Job
+from avocado.core.suite import TestSuite
THIS_DIR = os.path.dirname(os.path.abspath(__file__))
ROOT_DIR = os.path.dirname(os.path.dirname(os.path.dirname(THIS_DIR)))
@@ -19,6 +20,7 @@ CONFIG = {
if __name__ == '__main__':
- with Job(CONFIG) as j:
+ suite = TestSuite.from_config(CONFIG)
+ with Job(CONFIG, [suite]) as j:
os.environ['AVOCADO_CHECK_LEVEL'] = '3'
sys.exit(j.run())
```
Crash:
```
[wrampazz@wrampazz avocado.dev]$ selftests/pre_release/jobs/timesensitive.py
JOB ID : 5c1cf735be942802efc655a82ec84e46c1301080
JOB LOG : /home/wrampazz/avocado/job-results/job-2020-08-27T16.12-5c1cf73/job.log
Avocado crashed: TypeError: expected str, bytes or os.PathLike object, not NoneType
Traceback (most recent call last):
File "/home/wrampazz/src/avocado/avocado.dev/avocado/core/job.py", line 605, in run_tests
summary |= suite.run(self)
File "/home/wrampazz/src/avocado/avocado.dev/avocado/core/suite.py", line 266, in run
return self.runner.run_suite(job, self)
File "/home/wrampazz/src/avocado/avocado.dev/avocado/plugins/runner_nrunner.py", line 237, in run_suite
loop.run_until_complete(asyncio.wait_for(asyncio.gather(*workers),
File "/usr/lib64/python3.8/asyncio/base_events.py", line 616, in run_until_complete
return future.result()
File "/usr/lib64/python3.8/asyncio/tasks.py", line 455, in wait_for
return await fut
File "/home/wrampazz/src/avocado/avocado.dev/avocado/core/task/statemachine.py", line 155, in run
await self.start()
File "/home/wrampazz/src/avocado/avocado.dev/avocado/core/task/statemachine.py", line 113, in start
start_ok = await self._spawner.spawn_task(runtime_task)
File "/home/wrampazz/src/avocado/avocado.dev/avocado/plugins/spawners/process.py", line 29, in spawn_task
runtime_task.spawner_handle = await asyncio.create_subprocess_exec(
File "/usr/lib64/python3.8/asyncio/subprocess.py", line 236, in create_subprocess_exec
transport, protocol = await loop.subprocess_exec(
File "/usr/lib64/python3.8/asyncio/base_events.py", line 1630, in subprocess_exec
transport = await self._make_subprocess_transport(
File "/usr/lib64/python3.8/asyncio/unix_events.py", line 197, in _make_subprocess_transport
transp = _UnixSubprocessTransport(self, protocol, args, shell,
File "/usr/lib64/python3.8/asyncio/base_subprocess.py", line 36, in __init__
self._start(args=args, shell=shell, stdin=stdin, stdout=stdout,
File "/usr/lib64/python3.8/asyncio/unix_events.py", line 789, in _start
self._proc = subprocess.Popen(
File "/usr/lib64/python3.8/subprocess.py", line 854, in __init__
self._execute_child(args, executable, preexec_fn, close_fds,
File "/usr/lib64/python3.8/subprocess.py", line 1637, in _execute_child
self.pid = _posixsubprocess.fork_exec(
TypeError: expected str, bytes or os.PathLike object, not NoneType
Please include the traceback info and command line used on your bug report
Report bugs visiting https://github.com/avocado-framework/avocado/issues/new
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `selftests/pre_release/jobs/timesensitive.py`
Content:
```
1 #!/bin/env python3
2
3 import os
4 import sys
5
6 from avocado.core.job import Job
7
8 THIS_DIR = os.path.dirname(os.path.abspath(__file__))
9 ROOT_DIR = os.path.dirname(os.path.dirname(os.path.dirname(THIS_DIR)))
10
11
12 CONFIG = {
13 'run.test_runner': 'nrunner',
14 'run.references': [os.path.join(ROOT_DIR, 'selftests', 'unit'),
15 os.path.join(ROOT_DIR, 'selftests', 'functional')],
16 'filter.by_tags.tags': ['parallel:1'],
17 'nrunner.max_parallel_tasks': 1,
18 }
19
20
21 if __name__ == '__main__':
22 with Job(CONFIG) as j:
23 os.environ['AVOCADO_CHECK_LEVEL'] = '3'
24 sys.exit(j.run())
25
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/selftests/pre_release/jobs/timesensitive.py b/selftests/pre_release/jobs/timesensitive.py
--- a/selftests/pre_release/jobs/timesensitive.py
+++ b/selftests/pre_release/jobs/timesensitive.py
@@ -14,11 +14,12 @@
'run.references': [os.path.join(ROOT_DIR, 'selftests', 'unit'),
os.path.join(ROOT_DIR, 'selftests', 'functional')],
'filter.by_tags.tags': ['parallel:1'],
+ 'nrunner.status_server_uri': '127.0.0.1:8888',
'nrunner.max_parallel_tasks': 1,
}
if __name__ == '__main__':
- with Job(CONFIG) as j:
+ with Job.from_config(CONFIG) as j:
os.environ['AVOCADO_CHECK_LEVEL'] = '3'
sys.exit(j.run())
|
{"golden_diff": "diff --git a/selftests/pre_release/jobs/timesensitive.py b/selftests/pre_release/jobs/timesensitive.py\n--- a/selftests/pre_release/jobs/timesensitive.py\n+++ b/selftests/pre_release/jobs/timesensitive.py\n@@ -14,11 +14,12 @@\n 'run.references': [os.path.join(ROOT_DIR, 'selftests', 'unit'),\n os.path.join(ROOT_DIR, 'selftests', 'functional')],\n 'filter.by_tags.tags': ['parallel:1'],\n+ 'nrunner.status_server_uri': '127.0.0.1:8888',\n 'nrunner.max_parallel_tasks': 1,\n }\n \n \n if __name__ == '__main__':\n- with Job(CONFIG) as j:\n+ with Job.from_config(CONFIG) as j:\n os.environ['AVOCADO_CHECK_LEVEL'] = '3'\n sys.exit(j.run())\n", "issue": "[Bug] Avocado crash with TypeError\nWith the following change on the time-sensitive job Avocado crashes:\r\n\r\n```python\r\ndiff --git a/selftests/pre_release/jobs/timesensitive.py b/selftests/pre_release/jobs/timesensitive.py\r\nindex a9fbebcd..456719aa 100755\r\n--- a/selftests/pre_release/jobs/timesensitive.py\r\n+++ b/selftests/pre_release/jobs/timesensitive.py\r\n@@ -4,6 +4,7 @@ import os\r\n import sys\r\n \r\n from avocado.core.job import Job\r\n+from avocado.core.suite import TestSuite\r\n \r\n THIS_DIR = os.path.dirname(os.path.abspath(__file__))\r\n ROOT_DIR = os.path.dirname(os.path.dirname(os.path.dirname(THIS_DIR)))\r\n@@ -19,6 +20,7 @@ CONFIG = {\r\n \r\n \r\n if __name__ == '__main__':\r\n- with Job(CONFIG) as j:\r\n+ suite = TestSuite.from_config(CONFIG)\r\n+ with Job(CONFIG, [suite]) as j:\r\n os.environ['AVOCADO_CHECK_LEVEL'] = '3'\r\n sys.exit(j.run())\r\n```\r\n\r\nCrash:\r\n\r\n```\r\n[wrampazz@wrampazz avocado.dev]$ selftests/pre_release/jobs/timesensitive.py\r\nJOB ID : 5c1cf735be942802efc655a82ec84e46c1301080\r\nJOB LOG : /home/wrampazz/avocado/job-results/job-2020-08-27T16.12-5c1cf73/job.log\r\n\r\nAvocado crashed: TypeError: expected str, bytes or os.PathLike object, not NoneType\r\nTraceback (most recent call last):\r\n\r\n File \"/home/wrampazz/src/avocado/avocado.dev/avocado/core/job.py\", line 605, in run_tests\r\n summary |= suite.run(self)\r\n\r\n File \"/home/wrampazz/src/avocado/avocado.dev/avocado/core/suite.py\", line 266, in run\r\n return self.runner.run_suite(job, self)\r\n\r\n File \"/home/wrampazz/src/avocado/avocado.dev/avocado/plugins/runner_nrunner.py\", line 237, in run_suite\r\n loop.run_until_complete(asyncio.wait_for(asyncio.gather(*workers),\r\n\r\n File \"/usr/lib64/python3.8/asyncio/base_events.py\", line 616, in run_until_complete\r\n return future.result()\r\n\r\n File \"/usr/lib64/python3.8/asyncio/tasks.py\", line 455, in wait_for\r\n return await fut\r\n\r\n File \"/home/wrampazz/src/avocado/avocado.dev/avocado/core/task/statemachine.py\", line 155, in run\r\n await self.start()\r\n\r\n File \"/home/wrampazz/src/avocado/avocado.dev/avocado/core/task/statemachine.py\", line 113, in start\r\n start_ok = await self._spawner.spawn_task(runtime_task)\r\n\r\n File \"/home/wrampazz/src/avocado/avocado.dev/avocado/plugins/spawners/process.py\", line 29, in spawn_task\r\n runtime_task.spawner_handle = await asyncio.create_subprocess_exec(\r\n\r\n File \"/usr/lib64/python3.8/asyncio/subprocess.py\", line 236, in create_subprocess_exec\r\n transport, protocol = await loop.subprocess_exec(\r\n\r\n File \"/usr/lib64/python3.8/asyncio/base_events.py\", line 1630, in subprocess_exec\r\n transport = await self._make_subprocess_transport(\r\n\r\n File \"/usr/lib64/python3.8/asyncio/unix_events.py\", line 197, in _make_subprocess_transport\r\n transp = _UnixSubprocessTransport(self, protocol, args, shell,\r\n\r\n File \"/usr/lib64/python3.8/asyncio/base_subprocess.py\", line 36, in __init__\r\n self._start(args=args, shell=shell, stdin=stdin, stdout=stdout,\r\n\r\n File \"/usr/lib64/python3.8/asyncio/unix_events.py\", line 789, in _start\r\n self._proc = subprocess.Popen(\r\n\r\n File \"/usr/lib64/python3.8/subprocess.py\", line 854, in __init__\r\n self._execute_child(args, executable, preexec_fn, close_fds,\r\n\r\n File \"/usr/lib64/python3.8/subprocess.py\", line 1637, in _execute_child\r\n self.pid = _posixsubprocess.fork_exec(\r\n\r\nTypeError: expected str, bytes or os.PathLike object, not NoneType\r\n\r\nPlease include the traceback info and command line used on your bug report\r\nReport bugs visiting https://github.com/avocado-framework/avocado/issues/new\r\n```\n", "before_files": [{"content": "#!/bin/env python3\n\nimport os\nimport sys\n\nfrom avocado.core.job import Job\n\nTHIS_DIR = os.path.dirname(os.path.abspath(__file__))\nROOT_DIR = os.path.dirname(os.path.dirname(os.path.dirname(THIS_DIR)))\n\n\nCONFIG = {\n 'run.test_runner': 'nrunner',\n 'run.references': [os.path.join(ROOT_DIR, 'selftests', 'unit'),\n os.path.join(ROOT_DIR, 'selftests', 'functional')],\n 'filter.by_tags.tags': ['parallel:1'],\n 'nrunner.max_parallel_tasks': 1,\n }\n\n\nif __name__ == '__main__':\n with Job(CONFIG) as j:\n os.environ['AVOCADO_CHECK_LEVEL'] = '3'\n sys.exit(j.run())\n", "path": "selftests/pre_release/jobs/timesensitive.py"}], "after_files": [{"content": "#!/bin/env python3\n\nimport os\nimport sys\n\nfrom avocado.core.job import Job\n\nTHIS_DIR = os.path.dirname(os.path.abspath(__file__))\nROOT_DIR = os.path.dirname(os.path.dirname(os.path.dirname(THIS_DIR)))\n\n\nCONFIG = {\n 'run.test_runner': 'nrunner',\n 'run.references': [os.path.join(ROOT_DIR, 'selftests', 'unit'),\n os.path.join(ROOT_DIR, 'selftests', 'functional')],\n 'filter.by_tags.tags': ['parallel:1'],\n 'nrunner.status_server_uri': '127.0.0.1:8888',\n 'nrunner.max_parallel_tasks': 1,\n }\n\n\nif __name__ == '__main__':\n with Job.from_config(CONFIG) as j:\n os.environ['AVOCADO_CHECK_LEVEL'] = '3'\n sys.exit(j.run())\n", "path": "selftests/pre_release/jobs/timesensitive.py"}]}
| 1,533 | 198 |
gh_patches_debug_50798
|
rasdani/github-patches
|
git_diff
|
googleapis__google-cloud-python-3056
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
RTD build is broken
Can look at this, leaving as note as reminder.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # Copyright 2016 Google Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import os
16
17 from setuptools import find_packages
18 from setuptools import setup
19
20
21 PACKAGE_ROOT = os.path.abspath(os.path.dirname(__file__))
22
23 with open(os.path.join(PACKAGE_ROOT, 'README.rst')) as file_obj:
24 README = file_obj.read()
25
26 # NOTE: This is duplicated throughout and we should try to
27 # consolidate.
28 SETUP_BASE = {
29 'author': 'Google Cloud Platform',
30 'author_email': '[email protected]',
31 'scripts': [],
32 'url': 'https://github.com/GoogleCloudPlatform/google-cloud-python',
33 'license': 'Apache 2.0',
34 'platforms': 'Posix; MacOS X; Windows',
35 'include_package_data': True,
36 'zip_safe': False,
37 'classifiers': [
38 'Development Status :: 4 - Beta',
39 'Intended Audience :: Developers',
40 'License :: OSI Approved :: Apache Software License',
41 'Operating System :: OS Independent',
42 'Programming Language :: Python :: 2',
43 'Programming Language :: Python :: 2.7',
44 'Programming Language :: Python :: 3',
45 'Programming Language :: Python :: 3.4',
46 'Programming Language :: Python :: 3.5',
47 'Topic :: Internet',
48 ],
49 }
50
51
52 REQUIREMENTS = [
53 'google-cloud-bigquery >= 0.22.1, < 0.23dev',
54 'google-cloud-bigtable >= 0.22.0, < 0.23dev',
55 'google-cloud-core >= 0.22.1, < 0.23dev',
56 'google-cloud-datastore >= 0.22.0, < 0.23dev',
57 'google-cloud-dns >= 0.22.0, < 0.23dev',
58 'google-cloud-error-reporting >= 0.22.0, < 0.23dev',
59 'google-cloud-language >= 0.22.1, < 0.23dev',
60 'google-cloud-logging >= 0.22.0, < 0.23dev',
61 'google-cloud-monitoring >= 0.22.0, < 0.23dev',
62 'google-cloud-pubsub >= 0.22.0, < 0.23dev',
63 'google-cloud-resource-manager >= 0.22.0, < 0.23dev',
64 'google-cloud-storage >= 0.22.0, < 0.23dev',
65 'google-cloud-translate >= 0.22.0, < 0.23dev',
66 'google-cloud-vision >= 0.22.0, < 0.23dev',
67 'google-cloud-runtimeconfig >= 0.22.0, < 0.23dev',
68 ]
69
70 setup(
71 name='google-cloud',
72 version='0.22.0',
73 description='API Client library for Google Cloud',
74 long_description=README,
75 install_requires=REQUIREMENTS,
76 **SETUP_BASE
77 )
78
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -52,7 +52,7 @@
REQUIREMENTS = [
'google-cloud-bigquery >= 0.22.1, < 0.23dev',
'google-cloud-bigtable >= 0.22.0, < 0.23dev',
- 'google-cloud-core >= 0.22.1, < 0.23dev',
+ 'google-cloud-core >= 0.23.0, < 0.24dev',
'google-cloud-datastore >= 0.22.0, < 0.23dev',
'google-cloud-dns >= 0.22.0, < 0.23dev',
'google-cloud-error-reporting >= 0.22.0, < 0.23dev',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -52,7 +52,7 @@\n REQUIREMENTS = [\n 'google-cloud-bigquery >= 0.22.1, < 0.23dev',\n 'google-cloud-bigtable >= 0.22.0, < 0.23dev',\n- 'google-cloud-core >= 0.22.1, < 0.23dev',\n+ 'google-cloud-core >= 0.23.0, < 0.24dev',\n 'google-cloud-datastore >= 0.22.0, < 0.23dev',\n 'google-cloud-dns >= 0.22.0, < 0.23dev',\n 'google-cloud-error-reporting >= 0.22.0, < 0.23dev',\n", "issue": "RTD build is broken\nCan look at this, leaving as note as reminder.\n", "before_files": [{"content": "# Copyright 2016 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\n\nfrom setuptools import find_packages\nfrom setuptools import setup\n\n\nPACKAGE_ROOT = os.path.abspath(os.path.dirname(__file__))\n\nwith open(os.path.join(PACKAGE_ROOT, 'README.rst')) as file_obj:\n README = file_obj.read()\n\n# NOTE: This is duplicated throughout and we should try to\n# consolidate.\nSETUP_BASE = {\n 'author': 'Google Cloud Platform',\n 'author_email': '[email protected]',\n 'scripts': [],\n 'url': 'https://github.com/GoogleCloudPlatform/google-cloud-python',\n 'license': 'Apache 2.0',\n 'platforms': 'Posix; MacOS X; Windows',\n 'include_package_data': True,\n 'zip_safe': False,\n 'classifiers': [\n 'Development Status :: 4 - Beta',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: Apache Software License',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Topic :: Internet',\n ],\n}\n\n\nREQUIREMENTS = [\n 'google-cloud-bigquery >= 0.22.1, < 0.23dev',\n 'google-cloud-bigtable >= 0.22.0, < 0.23dev',\n 'google-cloud-core >= 0.22.1, < 0.23dev',\n 'google-cloud-datastore >= 0.22.0, < 0.23dev',\n 'google-cloud-dns >= 0.22.0, < 0.23dev',\n 'google-cloud-error-reporting >= 0.22.0, < 0.23dev',\n 'google-cloud-language >= 0.22.1, < 0.23dev',\n 'google-cloud-logging >= 0.22.0, < 0.23dev',\n 'google-cloud-monitoring >= 0.22.0, < 0.23dev',\n 'google-cloud-pubsub >= 0.22.0, < 0.23dev',\n 'google-cloud-resource-manager >= 0.22.0, < 0.23dev',\n 'google-cloud-storage >= 0.22.0, < 0.23dev',\n 'google-cloud-translate >= 0.22.0, < 0.23dev',\n 'google-cloud-vision >= 0.22.0, < 0.23dev',\n 'google-cloud-runtimeconfig >= 0.22.0, < 0.23dev',\n]\n\nsetup(\n name='google-cloud',\n version='0.22.0',\n description='API Client library for Google Cloud',\n long_description=README,\n install_requires=REQUIREMENTS,\n **SETUP_BASE\n)\n", "path": "setup.py"}], "after_files": [{"content": "# Copyright 2016 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\n\nfrom setuptools import find_packages\nfrom setuptools import setup\n\n\nPACKAGE_ROOT = os.path.abspath(os.path.dirname(__file__))\n\nwith open(os.path.join(PACKAGE_ROOT, 'README.rst')) as file_obj:\n README = file_obj.read()\n\n# NOTE: This is duplicated throughout and we should try to\n# consolidate.\nSETUP_BASE = {\n 'author': 'Google Cloud Platform',\n 'author_email': '[email protected]',\n 'scripts': [],\n 'url': 'https://github.com/GoogleCloudPlatform/google-cloud-python',\n 'license': 'Apache 2.0',\n 'platforms': 'Posix; MacOS X; Windows',\n 'include_package_data': True,\n 'zip_safe': False,\n 'classifiers': [\n 'Development Status :: 4 - Beta',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: Apache Software License',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Topic :: Internet',\n ],\n}\n\n\nREQUIREMENTS = [\n 'google-cloud-bigquery >= 0.22.1, < 0.23dev',\n 'google-cloud-bigtable >= 0.22.0, < 0.23dev',\n 'google-cloud-core >= 0.23.0, < 0.24dev',\n 'google-cloud-datastore >= 0.22.0, < 0.23dev',\n 'google-cloud-dns >= 0.22.0, < 0.23dev',\n 'google-cloud-error-reporting >= 0.22.0, < 0.23dev',\n 'google-cloud-language >= 0.22.1, < 0.23dev',\n 'google-cloud-logging >= 0.22.0, < 0.23dev',\n 'google-cloud-monitoring >= 0.22.0, < 0.23dev',\n 'google-cloud-pubsub >= 0.22.0, < 0.23dev',\n 'google-cloud-resource-manager >= 0.22.0, < 0.23dev',\n 'google-cloud-storage >= 0.22.0, < 0.23dev',\n 'google-cloud-translate >= 0.22.0, < 0.23dev',\n 'google-cloud-vision >= 0.22.0, < 0.23dev',\n 'google-cloud-runtimeconfig >= 0.22.0, < 0.23dev',\n]\n\nsetup(\n name='google-cloud',\n version='0.22.0',\n description='API Client library for Google Cloud',\n long_description=README,\n install_requires=REQUIREMENTS,\n **SETUP_BASE\n)\n", "path": "setup.py"}]}
| 1,224 | 198 |
gh_patches_debug_7161
|
rasdani/github-patches
|
git_diff
|
dbt-labs__dbt-core-2559
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
BigQuery project alias is ignored in config
### Describe the bug
A user reported that a config like:
```
{{ config(project='myproject') }}
...
```
has regressed in dbt v0.17.0. While this config worked in a BQ project in dbt v0.16.1, they reported that they needed to change `project` to `database` to apply the configuration in dbt v0.17.0.
This issue needs to be reproduced - there may be other factors that impact the incidence of this regression.
### Steps To Reproduce
```
-- models/my_model.sql
{{ config(project='custom_project') }}
select 1 as id
```
```
dbt run
```
Confirm that the model was _not_ build into the custom project override
### Expected behavior
The model should be built into the project defined in the `project` config. Database-specific aliases should applied to config names.
### System information
**Which database are you using dbt with?**
- [x] bigquery
**The output of `dbt --version`:**
```
0.17.0
```
**The operating system you're using:** Windows
**The output of `python --version`:** Unknown
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `core/dbt/context/context_config.py`
Content:
```
1 from copy import deepcopy
2 from dataclasses import dataclass
3 from typing import List, Iterator, Dict, Any, TypeVar, Union
4
5 from dbt.config import RuntimeConfig, Project
6 from dbt.contracts.graph.model_config import BaseConfig, get_config_for
7 from dbt.exceptions import InternalException
8 from dbt.legacy_config_updater import ConfigUpdater, IsFQNResource
9 from dbt.node_types import NodeType
10 from dbt.utils import fqn_search
11
12
13 @dataclass
14 class ModelParts(IsFQNResource):
15 fqn: List[str]
16 resource_type: NodeType
17 package_name: str
18
19
20 class LegacyContextConfig:
21 def __init__(
22 self,
23 active_project: RuntimeConfig,
24 own_project: Project,
25 fqn: List[str],
26 node_type: NodeType,
27 ):
28 self._config = None
29 self.active_project: RuntimeConfig = active_project
30 self.own_project: Project = own_project
31
32 self.model = ModelParts(
33 fqn=fqn,
34 resource_type=node_type,
35 package_name=self.own_project.project_name,
36 )
37
38 self.updater = ConfigUpdater(active_project.credentials.type)
39
40 # the config options defined within the model
41 self.in_model_config: Dict[str, Any] = {}
42
43 def get_default(self) -> Dict[str, Any]:
44 defaults = {"enabled": True, "materialized": "view"}
45
46 if self.model.resource_type == NodeType.Seed:
47 defaults['materialized'] = 'seed'
48 elif self.model.resource_type == NodeType.Snapshot:
49 defaults['materialized'] = 'snapshot'
50
51 if self.model.resource_type == NodeType.Test:
52 defaults['severity'] = 'ERROR'
53
54 return defaults
55
56 def build_config_dict(self, base: bool = False) -> Dict[str, Any]:
57 defaults = self.get_default()
58 active_config = self.load_config_from_active_project()
59
60 if self.active_project.project_name == self.own_project.project_name:
61 cfg = self.updater.merge(
62 defaults, active_config, self.in_model_config
63 )
64 else:
65 own_config = self.load_config_from_own_project()
66
67 cfg = self.updater.merge(
68 defaults, own_config, self.in_model_config, active_config
69 )
70
71 return cfg
72
73 def _translate_adapter_aliases(self, config: Dict[str, Any]):
74 return self.active_project.credentials.translate_aliases(config)
75
76 def update_in_model_config(self, config: Dict[str, Any]) -> None:
77 config = self._translate_adapter_aliases(config)
78 self.updater.update_into(self.in_model_config, config)
79
80 def load_config_from_own_project(self) -> Dict[str, Any]:
81 return self.updater.get_project_config(self.model, self.own_project)
82
83 def load_config_from_active_project(self) -> Dict[str, Any]:
84 return self.updater.get_project_config(self.model, self.active_project)
85
86
87 T = TypeVar('T', bound=BaseConfig)
88
89
90 class ContextConfigGenerator:
91 def __init__(self, active_project: RuntimeConfig):
92 self.active_project = active_project
93
94 def get_node_project(self, project_name: str):
95 if project_name == self.active_project.project_name:
96 return self.active_project
97 dependencies = self.active_project.load_dependencies()
98 if project_name not in dependencies:
99 raise InternalException(
100 f'Project name {project_name} not found in dependencies '
101 f'(found {list(dependencies)})'
102 )
103 return dependencies[project_name]
104
105 def project_configs(
106 self, project: Project, fqn: List[str], resource_type: NodeType
107 ) -> Iterator[Dict[str, Any]]:
108 if resource_type == NodeType.Seed:
109 model_configs = project.seeds
110 elif resource_type == NodeType.Snapshot:
111 model_configs = project.snapshots
112 elif resource_type == NodeType.Source:
113 model_configs = project.sources
114 else:
115 model_configs = project.models
116 for level_config in fqn_search(model_configs, fqn):
117 result = {}
118 for key, value in level_config.items():
119 if key.startswith('+'):
120 result[key[1:]] = deepcopy(value)
121 elif not isinstance(value, dict):
122 result[key] = deepcopy(value)
123
124 yield result
125
126 def active_project_configs(
127 self, fqn: List[str], resource_type: NodeType
128 ) -> Iterator[Dict[str, Any]]:
129 return self.project_configs(self.active_project, fqn, resource_type)
130
131 def _update_from_config(
132 self, result: T, partial: Dict[str, Any], validate: bool = False
133 ) -> T:
134 return result.update_from(
135 partial,
136 self.active_project.credentials.type,
137 validate=validate
138 )
139
140 def calculate_node_config(
141 self,
142 config_calls: List[Dict[str, Any]],
143 fqn: List[str],
144 resource_type: NodeType,
145 project_name: str,
146 base: bool,
147 ) -> BaseConfig:
148 own_config = self.get_node_project(project_name)
149 # defaults, own_config, config calls, active_config (if != own_config)
150 config_cls = get_config_for(resource_type, base=base)
151 # Calculate the defaults. We don't want to validate the defaults,
152 # because it might be invalid in the case of required config members
153 # (such as on snapshots!)
154 result = config_cls.from_dict({}, validate=False)
155 for fqn_config in self.project_configs(own_config, fqn, resource_type):
156 result = self._update_from_config(result, fqn_config)
157 for config_call in config_calls:
158 result = self._update_from_config(result, config_call)
159
160 if own_config.project_name != self.active_project.project_name:
161 for fqn_config in self.active_project_configs(fqn, resource_type):
162 result = self._update_from_config(result, fqn_config)
163
164 # this is mostly impactful in the snapshot config case
165 return result.finalize_and_validate()
166
167
168 class ContextConfig:
169 def __init__(
170 self,
171 active_project: RuntimeConfig,
172 fqn: List[str],
173 resource_type: NodeType,
174 project_name: str,
175 ) -> None:
176 self.config_calls: List[Dict[str, Any]] = []
177 self.cfg_source = ContextConfigGenerator(active_project)
178 self.fqn = fqn
179 self.resource_type = resource_type
180 self.project_name = project_name
181
182 def update_in_model_config(self, opts: Dict[str, Any]) -> None:
183 self.config_calls.append(opts)
184
185 def build_config_dict(self, base: bool = False) -> Dict[str, Any]:
186 return self.cfg_source.calculate_node_config(
187 config_calls=self.config_calls,
188 fqn=self.fqn,
189 resource_type=self.resource_type,
190 project_name=self.project_name,
191 base=base,
192 ).to_dict()
193
194
195 ContextConfigType = Union[LegacyContextConfig, ContextConfig]
196
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/core/dbt/context/context_config.py b/core/dbt/context/context_config.py
--- a/core/dbt/context/context_config.py
+++ b/core/dbt/context/context_config.py
@@ -131,8 +131,9 @@
def _update_from_config(
self, result: T, partial: Dict[str, Any], validate: bool = False
) -> T:
+ translated = self.active_project.credentials.translate_aliases(partial)
return result.update_from(
- partial,
+ translated,
self.active_project.credentials.type,
validate=validate
)
|
{"golden_diff": "diff --git a/core/dbt/context/context_config.py b/core/dbt/context/context_config.py\n--- a/core/dbt/context/context_config.py\n+++ b/core/dbt/context/context_config.py\n@@ -131,8 +131,9 @@\n def _update_from_config(\n self, result: T, partial: Dict[str, Any], validate: bool = False\n ) -> T:\n+ translated = self.active_project.credentials.translate_aliases(partial)\n return result.update_from(\n- partial,\n+ translated,\n self.active_project.credentials.type,\n validate=validate\n )\n", "issue": "BigQuery project alias is ignored in config\n### Describe the bug\r\nA user reported that a config like:\r\n```\r\n{{ config(project='myproject') }}\r\n\r\n...\r\n```\r\n\r\nhas regressed in dbt v0.17.0. While this config worked in a BQ project in dbt v0.16.1, they reported that they needed to change `project` to `database` to apply the configuration in dbt v0.17.0.\r\n\r\nThis issue needs to be reproduced - there may be other factors that impact the incidence of this regression.\r\n\r\n### Steps To Reproduce\r\n```\r\n-- models/my_model.sql\r\n\r\n{{ config(project='custom_project') }}\r\n\r\nselect 1 as id\r\n```\r\n\r\n```\r\ndbt run\r\n```\r\n\r\nConfirm that the model was _not_ build into the custom project override\r\n\r\n### Expected behavior\r\nThe model should be built into the project defined in the `project` config. Database-specific aliases should applied to config names.\r\n\r\n### System information\r\n**Which database are you using dbt with?**\r\n- [x] bigquery\r\n\r\n\r\n**The output of `dbt --version`:**\r\n```\r\n0.17.0\r\n```\r\n\r\n**The operating system you're using:** Windows\r\n**The output of `python --version`:** Unknown\n", "before_files": [{"content": "from copy import deepcopy\nfrom dataclasses import dataclass\nfrom typing import List, Iterator, Dict, Any, TypeVar, Union\n\nfrom dbt.config import RuntimeConfig, Project\nfrom dbt.contracts.graph.model_config import BaseConfig, get_config_for\nfrom dbt.exceptions import InternalException\nfrom dbt.legacy_config_updater import ConfigUpdater, IsFQNResource\nfrom dbt.node_types import NodeType\nfrom dbt.utils import fqn_search\n\n\n@dataclass\nclass ModelParts(IsFQNResource):\n fqn: List[str]\n resource_type: NodeType\n package_name: str\n\n\nclass LegacyContextConfig:\n def __init__(\n self,\n active_project: RuntimeConfig,\n own_project: Project,\n fqn: List[str],\n node_type: NodeType,\n ):\n self._config = None\n self.active_project: RuntimeConfig = active_project\n self.own_project: Project = own_project\n\n self.model = ModelParts(\n fqn=fqn,\n resource_type=node_type,\n package_name=self.own_project.project_name,\n )\n\n self.updater = ConfigUpdater(active_project.credentials.type)\n\n # the config options defined within the model\n self.in_model_config: Dict[str, Any] = {}\n\n def get_default(self) -> Dict[str, Any]:\n defaults = {\"enabled\": True, \"materialized\": \"view\"}\n\n if self.model.resource_type == NodeType.Seed:\n defaults['materialized'] = 'seed'\n elif self.model.resource_type == NodeType.Snapshot:\n defaults['materialized'] = 'snapshot'\n\n if self.model.resource_type == NodeType.Test:\n defaults['severity'] = 'ERROR'\n\n return defaults\n\n def build_config_dict(self, base: bool = False) -> Dict[str, Any]:\n defaults = self.get_default()\n active_config = self.load_config_from_active_project()\n\n if self.active_project.project_name == self.own_project.project_name:\n cfg = self.updater.merge(\n defaults, active_config, self.in_model_config\n )\n else:\n own_config = self.load_config_from_own_project()\n\n cfg = self.updater.merge(\n defaults, own_config, self.in_model_config, active_config\n )\n\n return cfg\n\n def _translate_adapter_aliases(self, config: Dict[str, Any]):\n return self.active_project.credentials.translate_aliases(config)\n\n def update_in_model_config(self, config: Dict[str, Any]) -> None:\n config = self._translate_adapter_aliases(config)\n self.updater.update_into(self.in_model_config, config)\n\n def load_config_from_own_project(self) -> Dict[str, Any]:\n return self.updater.get_project_config(self.model, self.own_project)\n\n def load_config_from_active_project(self) -> Dict[str, Any]:\n return self.updater.get_project_config(self.model, self.active_project)\n\n\nT = TypeVar('T', bound=BaseConfig)\n\n\nclass ContextConfigGenerator:\n def __init__(self, active_project: RuntimeConfig):\n self.active_project = active_project\n\n def get_node_project(self, project_name: str):\n if project_name == self.active_project.project_name:\n return self.active_project\n dependencies = self.active_project.load_dependencies()\n if project_name not in dependencies:\n raise InternalException(\n f'Project name {project_name} not found in dependencies '\n f'(found {list(dependencies)})'\n )\n return dependencies[project_name]\n\n def project_configs(\n self, project: Project, fqn: List[str], resource_type: NodeType\n ) -> Iterator[Dict[str, Any]]:\n if resource_type == NodeType.Seed:\n model_configs = project.seeds\n elif resource_type == NodeType.Snapshot:\n model_configs = project.snapshots\n elif resource_type == NodeType.Source:\n model_configs = project.sources\n else:\n model_configs = project.models\n for level_config in fqn_search(model_configs, fqn):\n result = {}\n for key, value in level_config.items():\n if key.startswith('+'):\n result[key[1:]] = deepcopy(value)\n elif not isinstance(value, dict):\n result[key] = deepcopy(value)\n\n yield result\n\n def active_project_configs(\n self, fqn: List[str], resource_type: NodeType\n ) -> Iterator[Dict[str, Any]]:\n return self.project_configs(self.active_project, fqn, resource_type)\n\n def _update_from_config(\n self, result: T, partial: Dict[str, Any], validate: bool = False\n ) -> T:\n return result.update_from(\n partial,\n self.active_project.credentials.type,\n validate=validate\n )\n\n def calculate_node_config(\n self,\n config_calls: List[Dict[str, Any]],\n fqn: List[str],\n resource_type: NodeType,\n project_name: str,\n base: bool,\n ) -> BaseConfig:\n own_config = self.get_node_project(project_name)\n # defaults, own_config, config calls, active_config (if != own_config)\n config_cls = get_config_for(resource_type, base=base)\n # Calculate the defaults. We don't want to validate the defaults,\n # because it might be invalid in the case of required config members\n # (such as on snapshots!)\n result = config_cls.from_dict({}, validate=False)\n for fqn_config in self.project_configs(own_config, fqn, resource_type):\n result = self._update_from_config(result, fqn_config)\n for config_call in config_calls:\n result = self._update_from_config(result, config_call)\n\n if own_config.project_name != self.active_project.project_name:\n for fqn_config in self.active_project_configs(fqn, resource_type):\n result = self._update_from_config(result, fqn_config)\n\n # this is mostly impactful in the snapshot config case\n return result.finalize_and_validate()\n\n\nclass ContextConfig:\n def __init__(\n self,\n active_project: RuntimeConfig,\n fqn: List[str],\n resource_type: NodeType,\n project_name: str,\n ) -> None:\n self.config_calls: List[Dict[str, Any]] = []\n self.cfg_source = ContextConfigGenerator(active_project)\n self.fqn = fqn\n self.resource_type = resource_type\n self.project_name = project_name\n\n def update_in_model_config(self, opts: Dict[str, Any]) -> None:\n self.config_calls.append(opts)\n\n def build_config_dict(self, base: bool = False) -> Dict[str, Any]:\n return self.cfg_source.calculate_node_config(\n config_calls=self.config_calls,\n fqn=self.fqn,\n resource_type=self.resource_type,\n project_name=self.project_name,\n base=base,\n ).to_dict()\n\n\nContextConfigType = Union[LegacyContextConfig, ContextConfig]\n", "path": "core/dbt/context/context_config.py"}], "after_files": [{"content": "from copy import deepcopy\nfrom dataclasses import dataclass\nfrom typing import List, Iterator, Dict, Any, TypeVar, Union\n\nfrom dbt.config import RuntimeConfig, Project\nfrom dbt.contracts.graph.model_config import BaseConfig, get_config_for\nfrom dbt.exceptions import InternalException\nfrom dbt.legacy_config_updater import ConfigUpdater, IsFQNResource\nfrom dbt.node_types import NodeType\nfrom dbt.utils import fqn_search\n\n\n@dataclass\nclass ModelParts(IsFQNResource):\n fqn: List[str]\n resource_type: NodeType\n package_name: str\n\n\nclass LegacyContextConfig:\n def __init__(\n self,\n active_project: RuntimeConfig,\n own_project: Project,\n fqn: List[str],\n node_type: NodeType,\n ):\n self._config = None\n self.active_project: RuntimeConfig = active_project\n self.own_project: Project = own_project\n\n self.model = ModelParts(\n fqn=fqn,\n resource_type=node_type,\n package_name=self.own_project.project_name,\n )\n\n self.updater = ConfigUpdater(active_project.credentials.type)\n\n # the config options defined within the model\n self.in_model_config: Dict[str, Any] = {}\n\n def get_default(self) -> Dict[str, Any]:\n defaults = {\"enabled\": True, \"materialized\": \"view\"}\n\n if self.model.resource_type == NodeType.Seed:\n defaults['materialized'] = 'seed'\n elif self.model.resource_type == NodeType.Snapshot:\n defaults['materialized'] = 'snapshot'\n\n if self.model.resource_type == NodeType.Test:\n defaults['severity'] = 'ERROR'\n\n return defaults\n\n def build_config_dict(self, base: bool = False) -> Dict[str, Any]:\n defaults = self.get_default()\n active_config = self.load_config_from_active_project()\n\n if self.active_project.project_name == self.own_project.project_name:\n cfg = self.updater.merge(\n defaults, active_config, self.in_model_config\n )\n else:\n own_config = self.load_config_from_own_project()\n\n cfg = self.updater.merge(\n defaults, own_config, self.in_model_config, active_config\n )\n\n return cfg\n\n def _translate_adapter_aliases(self, config: Dict[str, Any]):\n return self.active_project.credentials.translate_aliases(config)\n\n def update_in_model_config(self, config: Dict[str, Any]) -> None:\n config = self._translate_adapter_aliases(config)\n self.updater.update_into(self.in_model_config, config)\n\n def load_config_from_own_project(self) -> Dict[str, Any]:\n return self.updater.get_project_config(self.model, self.own_project)\n\n def load_config_from_active_project(self) -> Dict[str, Any]:\n return self.updater.get_project_config(self.model, self.active_project)\n\n\nT = TypeVar('T', bound=BaseConfig)\n\n\nclass ContextConfigGenerator:\n def __init__(self, active_project: RuntimeConfig):\n self.active_project = active_project\n\n def get_node_project(self, project_name: str):\n if project_name == self.active_project.project_name:\n return self.active_project\n dependencies = self.active_project.load_dependencies()\n if project_name not in dependencies:\n raise InternalException(\n f'Project name {project_name} not found in dependencies '\n f'(found {list(dependencies)})'\n )\n return dependencies[project_name]\n\n def project_configs(\n self, project: Project, fqn: List[str], resource_type: NodeType\n ) -> Iterator[Dict[str, Any]]:\n if resource_type == NodeType.Seed:\n model_configs = project.seeds\n elif resource_type == NodeType.Snapshot:\n model_configs = project.snapshots\n elif resource_type == NodeType.Source:\n model_configs = project.sources\n else:\n model_configs = project.models\n for level_config in fqn_search(model_configs, fqn):\n result = {}\n for key, value in level_config.items():\n if key.startswith('+'):\n result[key[1:]] = deepcopy(value)\n elif not isinstance(value, dict):\n result[key] = deepcopy(value)\n\n yield result\n\n def active_project_configs(\n self, fqn: List[str], resource_type: NodeType\n ) -> Iterator[Dict[str, Any]]:\n return self.project_configs(self.active_project, fqn, resource_type)\n\n def _update_from_config(\n self, result: T, partial: Dict[str, Any], validate: bool = False\n ) -> T:\n translated = self.active_project.credentials.translate_aliases(partial)\n return result.update_from(\n translated,\n self.active_project.credentials.type,\n validate=validate\n )\n\n def calculate_node_config(\n self,\n config_calls: List[Dict[str, Any]],\n fqn: List[str],\n resource_type: NodeType,\n project_name: str,\n base: bool,\n ) -> BaseConfig:\n own_config = self.get_node_project(project_name)\n # defaults, own_config, config calls, active_config (if != own_config)\n config_cls = get_config_for(resource_type, base=base)\n # Calculate the defaults. We don't want to validate the defaults,\n # because it might be invalid in the case of required config members\n # (such as on snapshots!)\n result = config_cls.from_dict({}, validate=False)\n for fqn_config in self.project_configs(own_config, fqn, resource_type):\n result = self._update_from_config(result, fqn_config)\n for config_call in config_calls:\n result = self._update_from_config(result, config_call)\n\n if own_config.project_name != self.active_project.project_name:\n for fqn_config in self.active_project_configs(fqn, resource_type):\n result = self._update_from_config(result, fqn_config)\n\n # this is mostly impactful in the snapshot config case\n return result.finalize_and_validate()\n\n\nclass ContextConfig:\n def __init__(\n self,\n active_project: RuntimeConfig,\n fqn: List[str],\n resource_type: NodeType,\n project_name: str,\n ) -> None:\n self.config_calls: List[Dict[str, Any]] = []\n self.cfg_source = ContextConfigGenerator(active_project)\n self.fqn = fqn\n self.resource_type = resource_type\n self.project_name = project_name\n\n def update_in_model_config(self, opts: Dict[str, Any]) -> None:\n self.config_calls.append(opts)\n\n def build_config_dict(self, base: bool = False) -> Dict[str, Any]:\n return self.cfg_source.calculate_node_config(\n config_calls=self.config_calls,\n fqn=self.fqn,\n resource_type=self.resource_type,\n project_name=self.project_name,\n base=base,\n ).to_dict()\n\n\nContextConfigType = Union[LegacyContextConfig, ContextConfig]\n", "path": "core/dbt/context/context_config.py"}]}
| 2,478 | 127 |
gh_patches_debug_20462
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-6763
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
@spider=western_union in Poland list `amenity=money_transfer` POIs not actually existing as separate objects
very similar to #5881
It would be better to drop main tag over showing it like this. And in this case it seems dubious to me is it mappable as all on https://www.openstreetmap.org/node/5873034793 bank note.
https://www.alltheplaces.xyz/map/#16.47/50.076332/20.032325
https://location.westernunion.com/pl/malopolskie/krakow/e6d7165e8f86df94dacd8de6f1bfc780
I can visit that place and check in which form Western Union appears there.
[WesternUnion] Remove top level tag
Fixes #5889
@spider=western_union in Poland list `amenity=money_transfer` POIs not actually existing as separate objects
very similar to #5881
It would be better to drop main tag over showing it like this. And in this case it seems dubious to me is it mappable as all on https://www.openstreetmap.org/node/5873034793 bank note.
https://www.alltheplaces.xyz/map/#16.47/50.076332/20.032325
https://location.westernunion.com/pl/malopolskie/krakow/e6d7165e8f86df94dacd8de6f1bfc780
I can visit that place and check in which form Western Union appears there.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `locations/spiders/western_union.py`
Content:
```
1 import json
2
3 from scrapy import Spider
4 from scrapy.downloadermiddlewares.retry import get_retry_request
5 from scrapy.http import JsonRequest
6
7 from locations.categories import Categories
8 from locations.dict_parser import DictParser
9 from locations.geo import point_locations
10 from locations.hours import OpeningHours
11
12
13 class WesternUnionSpider(Spider):
14 name = "western_union"
15 item_attributes = {"brand": "Western Union", "brand_wikidata": "Q861042", "extras": Categories.MONEY_TRANSFER.value}
16 allowed_domains = ["www.westernunion.com"]
17 # start_urls[0] is a GraphQL endpoint.
18 start_urls = ["https://www.westernunion.com/router/"]
19 download_delay = 0.2
20
21 def request_page(self, latitude, longitude, page_number):
22 # An access code for querying the GraphQL endpoint is
23 # required, This is constant across different browser
24 # sessions and the same for all users of the website.
25 headers = {
26 "x-wu-accesscode": "RtYV3XDz9EA",
27 "x-wu-operationName": "locations",
28 }
29 # The GraphQL query does not appear to allow for the page
30 # size to be increased. Typically the page size is observed
31 # by default to be 15 results per page.
32 #
33 # A radius of 350km is used by the API to search around each
34 # provided coordinate. There does not appear to be a way to
35 # specify an alternative radius.
36 data = {
37 "query": "query locations($req:LocationInput) { locations(input: $req) }",
38 "variables": {
39 "req": {
40 "longitude": longitude,
41 "latitude": latitude,
42 "country": "US", # Seemingly has no effect.
43 "openNow": "",
44 "services": [],
45 "sortOrder": "Distance",
46 "pageNumber": str(page_number),
47 }
48 },
49 }
50 yield JsonRequest(url=self.start_urls[0], method="POST", headers=headers, data=data)
51
52 def start_requests(self):
53 # The GraphQL query searches for locations within a 350km
54 # radius of supplied coordinates, then returns locations in
55 # pages of 15 locations each page.
56 for lat, lon in point_locations("earth_centroids_iseadgg_346km_radius.csv"):
57 yield from self.request_page(lat, lon, 1)
58
59 def parse(self, response):
60 # If crawling too fast, the server responds with a JSON
61 # blob containing an error message. Schedule a retry.
62 if "results" not in response.json()["data"]["locations"]:
63 if "errorCode" in response.json()["data"]["locations"]:
64 if response.json()["data"]["locations"]["errorCode"] == 500:
65 yield get_retry_request(
66 response.request, spider=self, max_retry_times=5, reason="Retry after rate limiting error"
67 )
68 return
69 # In case of an unhandled error, skip parsing.
70 return
71
72 # Parse the 15 (or fewer) locations from the response provided.
73 for location in response.json()["data"]["locations"]["results"]:
74 item = DictParser.parse(location)
75 item["website"] = "https://location.westernunion.com/" + location["detailsUrl"]
76 item["opening_hours"] = OpeningHours()
77 hours_string = " ".join([f"{day}: {hours}" for (day, hours) in location["detail.hours"].items()])
78 item["opening_hours"].add_ranges_from_string(hours_string)
79 yield item
80
81 # On the first response per radius search of a coordinate,
82 # generate requests for all subsequent pages of results
83 # found by the API within the 350km search radius.
84 request_data = json.loads(response.request.body)
85 current_page = int(request_data["variables"]["req"]["pageNumber"])
86 total_pages = response.json()["data"]["locations"]["pageCount"]
87 if current_page == 1 and total_pages > 1:
88 for page_number in range(2, total_pages, 1):
89 yield from self.request_page(
90 request_data["variables"]["req"]["latitude"],
91 request_data["variables"]["req"]["longitude"],
92 page_number,
93 )
94
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/locations/spiders/western_union.py b/locations/spiders/western_union.py
--- a/locations/spiders/western_union.py
+++ b/locations/spiders/western_union.py
@@ -4,7 +4,6 @@
from scrapy.downloadermiddlewares.retry import get_retry_request
from scrapy.http import JsonRequest
-from locations.categories import Categories
from locations.dict_parser import DictParser
from locations.geo import point_locations
from locations.hours import OpeningHours
@@ -12,7 +11,11 @@
class WesternUnionSpider(Spider):
name = "western_union"
- item_attributes = {"brand": "Western Union", "brand_wikidata": "Q861042", "extras": Categories.MONEY_TRANSFER.value}
+ item_attributes = {
+ "brand": "Western Union",
+ "brand_wikidata": "Q861042",
+ "extras": {"money_transfer": "western_union"},
+ }
allowed_domains = ["www.westernunion.com"]
# start_urls[0] is a GraphQL endpoint.
start_urls = ["https://www.westernunion.com/router/"]
|
{"golden_diff": "diff --git a/locations/spiders/western_union.py b/locations/spiders/western_union.py\n--- a/locations/spiders/western_union.py\n+++ b/locations/spiders/western_union.py\n@@ -4,7 +4,6 @@\n from scrapy.downloadermiddlewares.retry import get_retry_request\n from scrapy.http import JsonRequest\n \n-from locations.categories import Categories\n from locations.dict_parser import DictParser\n from locations.geo import point_locations\n from locations.hours import OpeningHours\n@@ -12,7 +11,11 @@\n \n class WesternUnionSpider(Spider):\n name = \"western_union\"\n- item_attributes = {\"brand\": \"Western Union\", \"brand_wikidata\": \"Q861042\", \"extras\": Categories.MONEY_TRANSFER.value}\n+ item_attributes = {\n+ \"brand\": \"Western Union\",\n+ \"brand_wikidata\": \"Q861042\",\n+ \"extras\": {\"money_transfer\": \"western_union\"},\n+ }\n allowed_domains = [\"www.westernunion.com\"]\n # start_urls[0] is a GraphQL endpoint.\n start_urls = [\"https://www.westernunion.com/router/\"]\n", "issue": "@spider=western_union in Poland list `amenity=money_transfer` POIs not actually existing as separate objects\nvery similar to #5881\r\n\r\nIt would be better to drop main tag over showing it like this. And in this case it seems dubious to me is it mappable as all on https://www.openstreetmap.org/node/5873034793 bank note.\r\n\r\nhttps://www.alltheplaces.xyz/map/#16.47/50.076332/20.032325\r\n\r\nhttps://location.westernunion.com/pl/malopolskie/krakow/e6d7165e8f86df94dacd8de6f1bfc780\r\n\r\nI can visit that place and check in which form Western Union appears there.\n[WesternUnion] Remove top level tag\nFixes #5889\n@spider=western_union in Poland list `amenity=money_transfer` POIs not actually existing as separate objects\nvery similar to #5881\r\n\r\nIt would be better to drop main tag over showing it like this. And in this case it seems dubious to me is it mappable as all on https://www.openstreetmap.org/node/5873034793 bank note.\r\n\r\nhttps://www.alltheplaces.xyz/map/#16.47/50.076332/20.032325\r\n\r\nhttps://location.westernunion.com/pl/malopolskie/krakow/e6d7165e8f86df94dacd8de6f1bfc780\r\n\r\nI can visit that place and check in which form Western Union appears there.\n", "before_files": [{"content": "import json\n\nfrom scrapy import Spider\nfrom scrapy.downloadermiddlewares.retry import get_retry_request\nfrom scrapy.http import JsonRequest\n\nfrom locations.categories import Categories\nfrom locations.dict_parser import DictParser\nfrom locations.geo import point_locations\nfrom locations.hours import OpeningHours\n\n\nclass WesternUnionSpider(Spider):\n name = \"western_union\"\n item_attributes = {\"brand\": \"Western Union\", \"brand_wikidata\": \"Q861042\", \"extras\": Categories.MONEY_TRANSFER.value}\n allowed_domains = [\"www.westernunion.com\"]\n # start_urls[0] is a GraphQL endpoint.\n start_urls = [\"https://www.westernunion.com/router/\"]\n download_delay = 0.2\n\n def request_page(self, latitude, longitude, page_number):\n # An access code for querying the GraphQL endpoint is\n # required, This is constant across different browser\n # sessions and the same for all users of the website.\n headers = {\n \"x-wu-accesscode\": \"RtYV3XDz9EA\",\n \"x-wu-operationName\": \"locations\",\n }\n # The GraphQL query does not appear to allow for the page\n # size to be increased. Typically the page size is observed\n # by default to be 15 results per page.\n #\n # A radius of 350km is used by the API to search around each\n # provided coordinate. There does not appear to be a way to\n # specify an alternative radius.\n data = {\n \"query\": \"query locations($req:LocationInput) { locations(input: $req) }\",\n \"variables\": {\n \"req\": {\n \"longitude\": longitude,\n \"latitude\": latitude,\n \"country\": \"US\", # Seemingly has no effect.\n \"openNow\": \"\",\n \"services\": [],\n \"sortOrder\": \"Distance\",\n \"pageNumber\": str(page_number),\n }\n },\n }\n yield JsonRequest(url=self.start_urls[0], method=\"POST\", headers=headers, data=data)\n\n def start_requests(self):\n # The GraphQL query searches for locations within a 350km\n # radius of supplied coordinates, then returns locations in\n # pages of 15 locations each page.\n for lat, lon in point_locations(\"earth_centroids_iseadgg_346km_radius.csv\"):\n yield from self.request_page(lat, lon, 1)\n\n def parse(self, response):\n # If crawling too fast, the server responds with a JSON\n # blob containing an error message. Schedule a retry.\n if \"results\" not in response.json()[\"data\"][\"locations\"]:\n if \"errorCode\" in response.json()[\"data\"][\"locations\"]:\n if response.json()[\"data\"][\"locations\"][\"errorCode\"] == 500:\n yield get_retry_request(\n response.request, spider=self, max_retry_times=5, reason=\"Retry after rate limiting error\"\n )\n return\n # In case of an unhandled error, skip parsing.\n return\n\n # Parse the 15 (or fewer) locations from the response provided.\n for location in response.json()[\"data\"][\"locations\"][\"results\"]:\n item = DictParser.parse(location)\n item[\"website\"] = \"https://location.westernunion.com/\" + location[\"detailsUrl\"]\n item[\"opening_hours\"] = OpeningHours()\n hours_string = \" \".join([f\"{day}: {hours}\" for (day, hours) in location[\"detail.hours\"].items()])\n item[\"opening_hours\"].add_ranges_from_string(hours_string)\n yield item\n\n # On the first response per radius search of a coordinate,\n # generate requests for all subsequent pages of results\n # found by the API within the 350km search radius.\n request_data = json.loads(response.request.body)\n current_page = int(request_data[\"variables\"][\"req\"][\"pageNumber\"])\n total_pages = response.json()[\"data\"][\"locations\"][\"pageCount\"]\n if current_page == 1 and total_pages > 1:\n for page_number in range(2, total_pages, 1):\n yield from self.request_page(\n request_data[\"variables\"][\"req\"][\"latitude\"],\n request_data[\"variables\"][\"req\"][\"longitude\"],\n page_number,\n )\n", "path": "locations/spiders/western_union.py"}], "after_files": [{"content": "import json\n\nfrom scrapy import Spider\nfrom scrapy.downloadermiddlewares.retry import get_retry_request\nfrom scrapy.http import JsonRequest\n\nfrom locations.dict_parser import DictParser\nfrom locations.geo import point_locations\nfrom locations.hours import OpeningHours\n\n\nclass WesternUnionSpider(Spider):\n name = \"western_union\"\n item_attributes = {\n \"brand\": \"Western Union\",\n \"brand_wikidata\": \"Q861042\",\n \"extras\": {\"money_transfer\": \"western_union\"},\n }\n allowed_domains = [\"www.westernunion.com\"]\n # start_urls[0] is a GraphQL endpoint.\n start_urls = [\"https://www.westernunion.com/router/\"]\n download_delay = 0.2\n\n def request_page(self, latitude, longitude, page_number):\n # An access code for querying the GraphQL endpoint is\n # required, This is constant across different browser\n # sessions and the same for all users of the website.\n headers = {\n \"x-wu-accesscode\": \"RtYV3XDz9EA\",\n \"x-wu-operationName\": \"locations\",\n }\n # The GraphQL query does not appear to allow for the page\n # size to be increased. Typically the page size is observed\n # by default to be 15 results per page.\n #\n # A radius of 350km is used by the API to search around each\n # provided coordinate. There does not appear to be a way to\n # specify an alternative radius.\n data = {\n \"query\": \"query locations($req:LocationInput) { locations(input: $req) }\",\n \"variables\": {\n \"req\": {\n \"longitude\": longitude,\n \"latitude\": latitude,\n \"country\": \"US\", # Seemingly has no effect.\n \"openNow\": \"\",\n \"services\": [],\n \"sortOrder\": \"Distance\",\n \"pageNumber\": str(page_number),\n }\n },\n }\n yield JsonRequest(url=self.start_urls[0], method=\"POST\", headers=headers, data=data)\n\n def start_requests(self):\n # The GraphQL query searches for locations within a 350km\n # radius of supplied coordinates, then returns locations in\n # pages of 15 locations each page.\n for lat, lon in point_locations(\"earth_centroids_iseadgg_346km_radius.csv\"):\n yield from self.request_page(lat, lon, 1)\n\n def parse(self, response):\n # If crawling too fast, the server responds with a JSON\n # blob containing an error message. Schedule a retry.\n if \"results\" not in response.json()[\"data\"][\"locations\"]:\n if \"errorCode\" in response.json()[\"data\"][\"locations\"]:\n if response.json()[\"data\"][\"locations\"][\"errorCode\"] == 500:\n yield get_retry_request(\n response.request, spider=self, max_retry_times=5, reason=\"Retry after rate limiting error\"\n )\n return\n # In case of an unhandled error, skip parsing.\n return\n\n # Parse the 15 (or fewer) locations from the response provided.\n for location in response.json()[\"data\"][\"locations\"][\"results\"]:\n item = DictParser.parse(location)\n item[\"website\"] = \"https://location.westernunion.com/\" + location[\"detailsUrl\"]\n item[\"opening_hours\"] = OpeningHours()\n hours_string = \" \".join([f\"{day}: {hours}\" for (day, hours) in location[\"detail.hours\"].items()])\n item[\"opening_hours\"].add_ranges_from_string(hours_string)\n yield item\n\n # On the first response per radius search of a coordinate,\n # generate requests for all subsequent pages of results\n # found by the API within the 350km search radius.\n request_data = json.loads(response.request.body)\n current_page = int(request_data[\"variables\"][\"req\"][\"pageNumber\"])\n total_pages = response.json()[\"data\"][\"locations\"][\"pageCount\"]\n if current_page == 1 and total_pages > 1:\n for page_number in range(2, total_pages, 1):\n yield from self.request_page(\n request_data[\"variables\"][\"req\"][\"latitude\"],\n request_data[\"variables\"][\"req\"][\"longitude\"],\n page_number,\n )\n", "path": "locations/spiders/western_union.py"}]}
| 1,733 | 256 |
gh_patches_debug_15839
|
rasdani/github-patches
|
git_diff
|
PaddlePaddle__models-3191
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
PaddleRL policy_gradient Typo
default_main_program误写为defaul_main_program
all_act_prob 未被声明为成员变量
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `legacy/PaddleRL/policy_gradient/brain.py`
Content:
```
1 import numpy as np
2 import paddle.fluid as fluid
3 # reproducible
4 np.random.seed(1)
5
6
7 class PolicyGradient:
8 def __init__(
9 self,
10 n_actions,
11 n_features,
12 learning_rate=0.01,
13 reward_decay=0.95,
14 output_graph=False, ):
15 self.n_actions = n_actions
16 self.n_features = n_features
17 self.lr = learning_rate
18 self.gamma = reward_decay
19
20 self.ep_obs, self.ep_as, self.ep_rs = [], [], []
21
22 self.place = fluid.CPUPlace()
23 self.exe = fluid.Executor(self.place)
24
25 def build_net(self):
26
27 obs = fluid.layers.data(
28 name='obs', shape=[self.n_features], dtype='float32')
29 acts = fluid.layers.data(name='acts', shape=[1], dtype='int64')
30 vt = fluid.layers.data(name='vt', shape=[1], dtype='float32')
31 # fc1
32 fc1 = fluid.layers.fc(input=obs, size=10, act="tanh") # tanh activation
33 # fc2
34 all_act_prob = fluid.layers.fc(input=fc1,
35 size=self.n_actions,
36 act="softmax")
37 self.inferece_program = fluid.defaul_main_program().clone()
38 # to maximize total reward (log_p * R) is to minimize -(log_p * R)
39 neg_log_prob = fluid.layers.cross_entropy(
40 input=self.all_act_prob,
41 label=acts) # this is negative log of chosen action
42 neg_log_prob_weight = fluid.layers.elementwise_mul(x=neg_log_prob, y=vt)
43 loss = fluid.layers.reduce_mean(
44 neg_log_prob_weight) # reward guided loss
45
46 sgd_optimizer = fluid.optimizer.SGD(self.lr)
47 sgd_optimizer.minimize(loss)
48 self.exe.run(fluid.default_startup_program())
49
50 def choose_action(self, observation):
51 prob_weights = self.exe.run(self.inferece_program,
52 feed={"obs": observation[np.newaxis, :]},
53 fetch_list=[self.all_act_prob])
54 prob_weights = np.array(prob_weights[0])
55 # select action w.r.t the actions prob
56 action = np.random.choice(
57 range(prob_weights.shape[1]), p=prob_weights.ravel())
58 return action
59
60 def store_transition(self, s, a, r):
61 self.ep_obs.append(s)
62 self.ep_as.append(a)
63 self.ep_rs.append(r)
64
65 def learn(self):
66 # discount and normalize episode reward
67 discounted_ep_rs_norm = self._discount_and_norm_rewards()
68 tensor_obs = np.vstack(self.ep_obs).astype("float32")
69 tensor_as = np.array(self.ep_as).astype("int64")
70 tensor_as = tensor_as.reshape([tensor_as.shape[0], 1])
71 tensor_vt = discounted_ep_rs_norm.astype("float32")[:, np.newaxis]
72 # train on episode
73 self.exe.run(
74 fluid.default_main_program(),
75 feed={
76 "obs": tensor_obs, # shape=[None, n_obs]
77 "acts": tensor_as, # shape=[None, ]
78 "vt": tensor_vt # shape=[None, ]
79 })
80 self.ep_obs, self.ep_as, self.ep_rs = [], [], [] # empty episode data
81 return discounted_ep_rs_norm
82
83 def _discount_and_norm_rewards(self):
84 # discount episode rewards
85 discounted_ep_rs = np.zeros_like(self.ep_rs)
86 running_add = 0
87 for t in reversed(range(0, len(self.ep_rs))):
88 running_add = running_add * self.gamma + self.ep_rs[t]
89 discounted_ep_rs[t] = running_add
90
91 # normalize episode rewards
92 discounted_ep_rs -= np.mean(discounted_ep_rs)
93 discounted_ep_rs /= np.std(discounted_ep_rs)
94 return discounted_ep_rs
95
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/legacy/PaddleRL/policy_gradient/brain.py b/legacy/PaddleRL/policy_gradient/brain.py
--- a/legacy/PaddleRL/policy_gradient/brain.py
+++ b/legacy/PaddleRL/policy_gradient/brain.py
@@ -31,10 +31,10 @@
# fc1
fc1 = fluid.layers.fc(input=obs, size=10, act="tanh") # tanh activation
# fc2
- all_act_prob = fluid.layers.fc(input=fc1,
+ self.all_act_prob = fluid.layers.fc(input=fc1,
size=self.n_actions,
act="softmax")
- self.inferece_program = fluid.defaul_main_program().clone()
+ self.inferece_program = fluid.default_main_program().clone()
# to maximize total reward (log_p * R) is to minimize -(log_p * R)
neg_log_prob = fluid.layers.cross_entropy(
input=self.all_act_prob,
|
{"golden_diff": "diff --git a/legacy/PaddleRL/policy_gradient/brain.py b/legacy/PaddleRL/policy_gradient/brain.py\n--- a/legacy/PaddleRL/policy_gradient/brain.py\n+++ b/legacy/PaddleRL/policy_gradient/brain.py\n@@ -31,10 +31,10 @@\n # fc1\n fc1 = fluid.layers.fc(input=obs, size=10, act=\"tanh\") # tanh activation\n # fc2\n- all_act_prob = fluid.layers.fc(input=fc1,\n+ self.all_act_prob = fluid.layers.fc(input=fc1,\n size=self.n_actions,\n act=\"softmax\")\n- self.inferece_program = fluid.defaul_main_program().clone()\n+ self.inferece_program = fluid.default_main_program().clone()\n # to maximize total reward (log_p * R) is to minimize -(log_p * R)\n neg_log_prob = fluid.layers.cross_entropy(\n input=self.all_act_prob,\n", "issue": "PaddleRL policy_gradient Typo\ndefault_main_program\u8bef\u5199\u4e3adefaul_main_program\r\nall_act_prob \u672a\u88ab\u58f0\u660e\u4e3a\u6210\u5458\u53d8\u91cf\n", "before_files": [{"content": "import numpy as np\nimport paddle.fluid as fluid\n# reproducible\nnp.random.seed(1)\n\n\nclass PolicyGradient:\n def __init__(\n self,\n n_actions,\n n_features,\n learning_rate=0.01,\n reward_decay=0.95,\n output_graph=False, ):\n self.n_actions = n_actions\n self.n_features = n_features\n self.lr = learning_rate\n self.gamma = reward_decay\n\n self.ep_obs, self.ep_as, self.ep_rs = [], [], []\n\n self.place = fluid.CPUPlace()\n self.exe = fluid.Executor(self.place)\n\n def build_net(self):\n\n obs = fluid.layers.data(\n name='obs', shape=[self.n_features], dtype='float32')\n acts = fluid.layers.data(name='acts', shape=[1], dtype='int64')\n vt = fluid.layers.data(name='vt', shape=[1], dtype='float32')\n # fc1\n fc1 = fluid.layers.fc(input=obs, size=10, act=\"tanh\") # tanh activation\n # fc2\n all_act_prob = fluid.layers.fc(input=fc1,\n size=self.n_actions,\n act=\"softmax\")\n self.inferece_program = fluid.defaul_main_program().clone()\n # to maximize total reward (log_p * R) is to minimize -(log_p * R)\n neg_log_prob = fluid.layers.cross_entropy(\n input=self.all_act_prob,\n label=acts) # this is negative log of chosen action\n neg_log_prob_weight = fluid.layers.elementwise_mul(x=neg_log_prob, y=vt)\n loss = fluid.layers.reduce_mean(\n neg_log_prob_weight) # reward guided loss\n\n sgd_optimizer = fluid.optimizer.SGD(self.lr)\n sgd_optimizer.minimize(loss)\n self.exe.run(fluid.default_startup_program())\n\n def choose_action(self, observation):\n prob_weights = self.exe.run(self.inferece_program,\n feed={\"obs\": observation[np.newaxis, :]},\n fetch_list=[self.all_act_prob])\n prob_weights = np.array(prob_weights[0])\n # select action w.r.t the actions prob\n action = np.random.choice(\n range(prob_weights.shape[1]), p=prob_weights.ravel())\n return action\n\n def store_transition(self, s, a, r):\n self.ep_obs.append(s)\n self.ep_as.append(a)\n self.ep_rs.append(r)\n\n def learn(self):\n # discount and normalize episode reward\n discounted_ep_rs_norm = self._discount_and_norm_rewards()\n tensor_obs = np.vstack(self.ep_obs).astype(\"float32\")\n tensor_as = np.array(self.ep_as).astype(\"int64\")\n tensor_as = tensor_as.reshape([tensor_as.shape[0], 1])\n tensor_vt = discounted_ep_rs_norm.astype(\"float32\")[:, np.newaxis]\n # train on episode\n self.exe.run(\n fluid.default_main_program(),\n feed={\n \"obs\": tensor_obs, # shape=[None, n_obs]\n \"acts\": tensor_as, # shape=[None, ]\n \"vt\": tensor_vt # shape=[None, ]\n })\n self.ep_obs, self.ep_as, self.ep_rs = [], [], [] # empty episode data\n return discounted_ep_rs_norm\n\n def _discount_and_norm_rewards(self):\n # discount episode rewards\n discounted_ep_rs = np.zeros_like(self.ep_rs)\n running_add = 0\n for t in reversed(range(0, len(self.ep_rs))):\n running_add = running_add * self.gamma + self.ep_rs[t]\n discounted_ep_rs[t] = running_add\n\n # normalize episode rewards\n discounted_ep_rs -= np.mean(discounted_ep_rs)\n discounted_ep_rs /= np.std(discounted_ep_rs)\n return discounted_ep_rs\n", "path": "legacy/PaddleRL/policy_gradient/brain.py"}], "after_files": [{"content": "import numpy as np\nimport paddle.fluid as fluid\n# reproducible\nnp.random.seed(1)\n\n\nclass PolicyGradient:\n def __init__(\n self,\n n_actions,\n n_features,\n learning_rate=0.01,\n reward_decay=0.95,\n output_graph=False, ):\n self.n_actions = n_actions\n self.n_features = n_features\n self.lr = learning_rate\n self.gamma = reward_decay\n\n self.ep_obs, self.ep_as, self.ep_rs = [], [], []\n\n self.place = fluid.CPUPlace()\n self.exe = fluid.Executor(self.place)\n\n def build_net(self):\n\n obs = fluid.layers.data(\n name='obs', shape=[self.n_features], dtype='float32')\n acts = fluid.layers.data(name='acts', shape=[1], dtype='int64')\n vt = fluid.layers.data(name='vt', shape=[1], dtype='float32')\n # fc1\n fc1 = fluid.layers.fc(input=obs, size=10, act=\"tanh\") # tanh activation\n # fc2\n self.all_act_prob = fluid.layers.fc(input=fc1,\n size=self.n_actions,\n act=\"softmax\")\n self.inferece_program = fluid.default_main_program().clone()\n # to maximize total reward (log_p * R) is to minimize -(log_p * R)\n neg_log_prob = fluid.layers.cross_entropy(\n input=self.all_act_prob,\n label=acts) # this is negative log of chosen action\n neg_log_prob_weight = fluid.layers.elementwise_mul(x=neg_log_prob, y=vt)\n loss = fluid.layers.reduce_mean(\n neg_log_prob_weight) # reward guided loss\n\n sgd_optimizer = fluid.optimizer.SGD(self.lr)\n sgd_optimizer.minimize(loss)\n self.exe.run(fluid.default_startup_program())\n\n def choose_action(self, observation):\n prob_weights = self.exe.run(self.inferece_program,\n feed={\"obs\": observation[np.newaxis, :]},\n fetch_list=[self.all_act_prob])\n prob_weights = np.array(prob_weights[0])\n # select action w.r.t the actions prob\n action = np.random.choice(\n range(prob_weights.shape[1]), p=prob_weights.ravel())\n return action\n\n def store_transition(self, s, a, r):\n self.ep_obs.append(s)\n self.ep_as.append(a)\n self.ep_rs.append(r)\n\n def learn(self):\n # discount and normalize episode reward\n discounted_ep_rs_norm = self._discount_and_norm_rewards()\n tensor_obs = np.vstack(self.ep_obs).astype(\"float32\")\n tensor_as = np.array(self.ep_as).astype(\"int64\")\n tensor_as = tensor_as.reshape([tensor_as.shape[0], 1])\n tensor_vt = discounted_ep_rs_norm.astype(\"float32\")[:, np.newaxis]\n # train on episode\n self.exe.run(\n fluid.default_main_program(),\n feed={\n \"obs\": tensor_obs, # shape=[None, n_obs]\n \"acts\": tensor_as, # shape=[None, ]\n \"vt\": tensor_vt # shape=[None, ]\n })\n self.ep_obs, self.ep_as, self.ep_rs = [], [], [] # empty episode data\n return discounted_ep_rs_norm\n\n def _discount_and_norm_rewards(self):\n # discount episode rewards\n discounted_ep_rs = np.zeros_like(self.ep_rs)\n running_add = 0\n for t in reversed(range(0, len(self.ep_rs))):\n running_add = running_add * self.gamma + self.ep_rs[t]\n discounted_ep_rs[t] = running_add\n\n # normalize episode rewards\n discounted_ep_rs -= np.mean(discounted_ep_rs)\n discounted_ep_rs /= np.std(discounted_ep_rs)\n return discounted_ep_rs\n", "path": "legacy/PaddleRL/policy_gradient/brain.py"}]}
| 1,308 | 216 |
gh_patches_debug_4887
|
rasdani/github-patches
|
git_diff
|
pulp__pulpcore-265
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Update CI files for branch 3.39
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pulpcore/app/serializers/task.py`
Content:
```
1 from gettext import gettext as _
2
3 from rest_framework import serializers
4
5 from pulpcore.app import models
6 from pulpcore.app.serializers import (
7 IdentityField,
8 ModelSerializer,
9 ProgressReportSerializer,
10 RelatedField,
11 )
12 from pulpcore.app.util import get_viewset_for_model
13
14
15 class CreatedResourceSerializer(RelatedField):
16
17 def to_representation(self, data):
18 # If the content object was deleted
19 if data.content_object is None:
20 return None
21 try:
22 if not data.content_object.complete:
23 return None
24 except AttributeError:
25 pass
26 viewset = get_viewset_for_model(data.content_object)
27
28 # serializer contains all serialized fields because we are passing
29 # 'None' to the request's context
30 serializer = viewset.serializer_class(data.content_object, context={'request': None})
31 return serializer.data.get('_href')
32
33 class Meta:
34 model = models.CreatedResource
35 fields = []
36
37
38 class TaskSerializer(ModelSerializer):
39 _href = IdentityField(view_name='tasks-detail')
40 state = serializers.CharField(
41 help_text=_("The current state of the task. The possible values include:"
42 " 'waiting', 'skipped', 'running', 'completed', 'failed' and 'canceled'."),
43 read_only=True
44 )
45 name = serializers.CharField(
46 help_text=_("The name of task.")
47 )
48 started_at = serializers.DateTimeField(
49 help_text=_("Timestamp of the when this task started execution."),
50 read_only=True
51 )
52 finished_at = serializers.DateTimeField(
53 help_text=_("Timestamp of the when this task stopped execution."),
54 read_only=True
55 )
56 non_fatal_errors = serializers.JSONField(
57 help_text=_("A JSON Object of non-fatal errors encountered during the execution of this "
58 "task."),
59 read_only=True
60 )
61 error = serializers.JSONField(
62 help_text=_("A JSON Object of a fatal error encountered during the execution of this "
63 "task."),
64 read_only=True
65 )
66 worker = RelatedField(
67 help_text=_("The worker associated with this task."
68 " This field is empty if a worker is not yet assigned."),
69 read_only=True,
70 view_name='workers-detail'
71 )
72 parent = RelatedField(
73 help_text=_("The parent task that spawned this task."),
74 read_only=True,
75 view_name='tasks-detail'
76 )
77 spawned_tasks = RelatedField(
78 help_text=_("Any tasks spawned by this task."),
79 many=True,
80 read_only=True,
81 view_name='tasks-detail'
82 )
83 progress_reports = ProgressReportSerializer(
84 many=True,
85 read_only=True
86 )
87 created_resources = CreatedResourceSerializer(
88 help_text=_('Resources created by this task.'),
89 many=True,
90 read_only=True,
91 view_name='None' # This is a polymorphic field. The serializer does not need a view name.
92 )
93
94 class Meta:
95 model = models.Task
96 fields = ModelSerializer.Meta.fields + ('state', 'name', 'started_at',
97 'finished_at', 'non_fatal_errors', 'error',
98 'worker', 'parent', 'spawned_tasks',
99 'progress_reports', 'created_resources')
100
101
102 class MinimalTaskSerializer(TaskSerializer):
103
104 class Meta:
105 model = models.Task
106 fields = ModelSerializer.Meta.fields + ('name', 'state', 'started_at', 'finished_at',
107 'worker', 'parent')
108
109
110 class TaskCancelSerializer(ModelSerializer):
111 state = serializers.CharField(
112 help_text=_("The desired state of the task. Only 'canceled' is accepted."),
113 )
114
115 class Meta:
116 model = models.Task
117 fields = ('state',)
118
119
120 class ContentAppStatusSerializer(ModelSerializer):
121 name = serializers.CharField(
122 help_text=_('The name of the worker.'),
123 read_only=True
124 )
125 last_heartbeat = serializers.DateTimeField(
126 help_text=_('Timestamp of the last time the worker talked to the service.'),
127 read_only=True
128 )
129
130 class Meta:
131 model = models.ContentAppStatus
132 fields = ('name', 'last_heartbeat')
133
134
135 class WorkerSerializer(ModelSerializer):
136 _href = IdentityField(view_name='workers-detail')
137
138 name = serializers.CharField(
139 help_text=_('The name of the worker.'),
140 read_only=True
141 )
142 last_heartbeat = serializers.DateTimeField(
143 help_text=_('Timestamp of the last time the worker talked to the service.'),
144 read_only=True
145 )
146 online = serializers.BooleanField(
147 help_text=_('True if the worker is considered online, otherwise False'),
148 read_only=True
149 )
150 missing = serializers.BooleanField(
151 help_text=_('True if the worker is considerd missing, otherwise False'),
152 read_only=True
153 )
154 # disable "created" because we don't care about it
155 created = None
156
157 class Meta:
158 model = models.Worker
159 _base_fields = tuple(set(ModelSerializer.Meta.fields) - set(['created']))
160 fields = _base_fields + ('name', 'last_heartbeat', 'online', 'missing')
161
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pulpcore/app/serializers/task.py b/pulpcore/app/serializers/task.py
--- a/pulpcore/app/serializers/task.py
+++ b/pulpcore/app/serializers/task.py
@@ -58,7 +58,8 @@
"task."),
read_only=True
)
- error = serializers.JSONField(
+ error = serializers.DictField(
+ child=serializers.JSONField(),
help_text=_("A JSON Object of a fatal error encountered during the execution of this "
"task."),
read_only=True
|
{"golden_diff": "diff --git a/pulpcore/app/serializers/task.py b/pulpcore/app/serializers/task.py\n--- a/pulpcore/app/serializers/task.py\n+++ b/pulpcore/app/serializers/task.py\n@@ -58,7 +58,8 @@\n \"task.\"),\n read_only=True\n )\n- error = serializers.JSONField(\n+ error = serializers.DictField(\n+ child=serializers.JSONField(),\n help_text=_(\"A JSON Object of a fatal error encountered during the execution of this \"\n \"task.\"),\n read_only=True\n", "issue": "Update CI files for branch 3.39\n\n", "before_files": [{"content": "from gettext import gettext as _\n\nfrom rest_framework import serializers\n\nfrom pulpcore.app import models\nfrom pulpcore.app.serializers import (\n IdentityField,\n ModelSerializer,\n ProgressReportSerializer,\n RelatedField,\n)\nfrom pulpcore.app.util import get_viewset_for_model\n\n\nclass CreatedResourceSerializer(RelatedField):\n\n def to_representation(self, data):\n # If the content object was deleted\n if data.content_object is None:\n return None\n try:\n if not data.content_object.complete:\n return None\n except AttributeError:\n pass\n viewset = get_viewset_for_model(data.content_object)\n\n # serializer contains all serialized fields because we are passing\n # 'None' to the request's context\n serializer = viewset.serializer_class(data.content_object, context={'request': None})\n return serializer.data.get('_href')\n\n class Meta:\n model = models.CreatedResource\n fields = []\n\n\nclass TaskSerializer(ModelSerializer):\n _href = IdentityField(view_name='tasks-detail')\n state = serializers.CharField(\n help_text=_(\"The current state of the task. The possible values include:\"\n \" 'waiting', 'skipped', 'running', 'completed', 'failed' and 'canceled'.\"),\n read_only=True\n )\n name = serializers.CharField(\n help_text=_(\"The name of task.\")\n )\n started_at = serializers.DateTimeField(\n help_text=_(\"Timestamp of the when this task started execution.\"),\n read_only=True\n )\n finished_at = serializers.DateTimeField(\n help_text=_(\"Timestamp of the when this task stopped execution.\"),\n read_only=True\n )\n non_fatal_errors = serializers.JSONField(\n help_text=_(\"A JSON Object of non-fatal errors encountered during the execution of this \"\n \"task.\"),\n read_only=True\n )\n error = serializers.JSONField(\n help_text=_(\"A JSON Object of a fatal error encountered during the execution of this \"\n \"task.\"),\n read_only=True\n )\n worker = RelatedField(\n help_text=_(\"The worker associated with this task.\"\n \" This field is empty if a worker is not yet assigned.\"),\n read_only=True,\n view_name='workers-detail'\n )\n parent = RelatedField(\n help_text=_(\"The parent task that spawned this task.\"),\n read_only=True,\n view_name='tasks-detail'\n )\n spawned_tasks = RelatedField(\n help_text=_(\"Any tasks spawned by this task.\"),\n many=True,\n read_only=True,\n view_name='tasks-detail'\n )\n progress_reports = ProgressReportSerializer(\n many=True,\n read_only=True\n )\n created_resources = CreatedResourceSerializer(\n help_text=_('Resources created by this task.'),\n many=True,\n read_only=True,\n view_name='None' # This is a polymorphic field. The serializer does not need a view name.\n )\n\n class Meta:\n model = models.Task\n fields = ModelSerializer.Meta.fields + ('state', 'name', 'started_at',\n 'finished_at', 'non_fatal_errors', 'error',\n 'worker', 'parent', 'spawned_tasks',\n 'progress_reports', 'created_resources')\n\n\nclass MinimalTaskSerializer(TaskSerializer):\n\n class Meta:\n model = models.Task\n fields = ModelSerializer.Meta.fields + ('name', 'state', 'started_at', 'finished_at',\n 'worker', 'parent')\n\n\nclass TaskCancelSerializer(ModelSerializer):\n state = serializers.CharField(\n help_text=_(\"The desired state of the task. Only 'canceled' is accepted.\"),\n )\n\n class Meta:\n model = models.Task\n fields = ('state',)\n\n\nclass ContentAppStatusSerializer(ModelSerializer):\n name = serializers.CharField(\n help_text=_('The name of the worker.'),\n read_only=True\n )\n last_heartbeat = serializers.DateTimeField(\n help_text=_('Timestamp of the last time the worker talked to the service.'),\n read_only=True\n )\n\n class Meta:\n model = models.ContentAppStatus\n fields = ('name', 'last_heartbeat')\n\n\nclass WorkerSerializer(ModelSerializer):\n _href = IdentityField(view_name='workers-detail')\n\n name = serializers.CharField(\n help_text=_('The name of the worker.'),\n read_only=True\n )\n last_heartbeat = serializers.DateTimeField(\n help_text=_('Timestamp of the last time the worker talked to the service.'),\n read_only=True\n )\n online = serializers.BooleanField(\n help_text=_('True if the worker is considered online, otherwise False'),\n read_only=True\n )\n missing = serializers.BooleanField(\n help_text=_('True if the worker is considerd missing, otherwise False'),\n read_only=True\n )\n # disable \"created\" because we don't care about it\n created = None\n\n class Meta:\n model = models.Worker\n _base_fields = tuple(set(ModelSerializer.Meta.fields) - set(['created']))\n fields = _base_fields + ('name', 'last_heartbeat', 'online', 'missing')\n", "path": "pulpcore/app/serializers/task.py"}], "after_files": [{"content": "from gettext import gettext as _\n\nfrom rest_framework import serializers\n\nfrom pulpcore.app import models\nfrom pulpcore.app.serializers import (\n IdentityField,\n ModelSerializer,\n ProgressReportSerializer,\n RelatedField,\n)\nfrom pulpcore.app.util import get_viewset_for_model\n\n\nclass CreatedResourceSerializer(RelatedField):\n\n def to_representation(self, data):\n # If the content object was deleted\n if data.content_object is None:\n return None\n try:\n if not data.content_object.complete:\n return None\n except AttributeError:\n pass\n viewset = get_viewset_for_model(data.content_object)\n\n # serializer contains all serialized fields because we are passing\n # 'None' to the request's context\n serializer = viewset.serializer_class(data.content_object, context={'request': None})\n return serializer.data.get('_href')\n\n class Meta:\n model = models.CreatedResource\n fields = []\n\n\nclass TaskSerializer(ModelSerializer):\n _href = IdentityField(view_name='tasks-detail')\n state = serializers.CharField(\n help_text=_(\"The current state of the task. The possible values include:\"\n \" 'waiting', 'skipped', 'running', 'completed', 'failed' and 'canceled'.\"),\n read_only=True\n )\n name = serializers.CharField(\n help_text=_(\"The name of task.\")\n )\n started_at = serializers.DateTimeField(\n help_text=_(\"Timestamp of the when this task started execution.\"),\n read_only=True\n )\n finished_at = serializers.DateTimeField(\n help_text=_(\"Timestamp of the when this task stopped execution.\"),\n read_only=True\n )\n non_fatal_errors = serializers.JSONField(\n help_text=_(\"A JSON Object of non-fatal errors encountered during the execution of this \"\n \"task.\"),\n read_only=True\n )\n error = serializers.DictField(\n child=serializers.JSONField(),\n help_text=_(\"A JSON Object of a fatal error encountered during the execution of this \"\n \"task.\"),\n read_only=True\n )\n worker = RelatedField(\n help_text=_(\"The worker associated with this task.\"\n \" This field is empty if a worker is not yet assigned.\"),\n read_only=True,\n view_name='workers-detail'\n )\n parent = RelatedField(\n help_text=_(\"The parent task that spawned this task.\"),\n read_only=True,\n view_name='tasks-detail'\n )\n spawned_tasks = RelatedField(\n help_text=_(\"Any tasks spawned by this task.\"),\n many=True,\n read_only=True,\n view_name='tasks-detail'\n )\n progress_reports = ProgressReportSerializer(\n many=True,\n read_only=True\n )\n created_resources = CreatedResourceSerializer(\n help_text=_('Resources created by this task.'),\n many=True,\n read_only=True,\n view_name='None' # This is a polymorphic field. The serializer does not need a view name.\n )\n\n class Meta:\n model = models.Task\n fields = ModelSerializer.Meta.fields + ('state', 'name', 'started_at',\n 'finished_at', 'non_fatal_errors', 'error',\n 'worker', 'parent', 'spawned_tasks',\n 'progress_reports', 'created_resources')\n\n\nclass MinimalTaskSerializer(TaskSerializer):\n\n class Meta:\n model = models.Task\n fields = ModelSerializer.Meta.fields + ('name', 'state', 'started_at', 'finished_at',\n 'worker', 'parent')\n\n\nclass TaskCancelSerializer(ModelSerializer):\n state = serializers.CharField(\n help_text=_(\"The desired state of the task. Only 'canceled' is accepted.\"),\n )\n\n class Meta:\n model = models.Task\n fields = ('state',)\n\n\nclass ContentAppStatusSerializer(ModelSerializer):\n name = serializers.CharField(\n help_text=_('The name of the worker.'),\n read_only=True\n )\n last_heartbeat = serializers.DateTimeField(\n help_text=_('Timestamp of the last time the worker talked to the service.'),\n read_only=True\n )\n\n class Meta:\n model = models.ContentAppStatus\n fields = ('name', 'last_heartbeat')\n\n\nclass WorkerSerializer(ModelSerializer):\n _href = IdentityField(view_name='workers-detail')\n\n name = serializers.CharField(\n help_text=_('The name of the worker.'),\n read_only=True\n )\n last_heartbeat = serializers.DateTimeField(\n help_text=_('Timestamp of the last time the worker talked to the service.'),\n read_only=True\n )\n online = serializers.BooleanField(\n help_text=_('True if the worker is considered online, otherwise False'),\n read_only=True\n )\n missing = serializers.BooleanField(\n help_text=_('True if the worker is considerd missing, otherwise False'),\n read_only=True\n )\n # disable \"created\" because we don't care about it\n created = None\n\n class Meta:\n model = models.Worker\n _base_fields = tuple(set(ModelSerializer.Meta.fields) - set(['created']))\n fields = _base_fields + ('name', 'last_heartbeat', 'online', 'missing')\n", "path": "pulpcore/app/serializers/task.py"}]}
| 1,707 | 123 |
gh_patches_debug_20726
|
rasdani/github-patches
|
git_diff
|
aws-cloudformation__cfn-lint-274
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
E3001 Missing properties raised as an error when they're not required
*cfn-lint version: 0.4.2*
*Description of issue.*
An error about missing properties is not always useful. There are resources which don't necessarily need properties.
Please provide as much information as possible:
* Template linting issues:
```
"WaitCondition": {
"Type": "AWS::CloudFormation::WaitCondition",
"CreationPolicy": {
"ResourceSignal": {
"Timeout": "PT15M",
"Count": {
"Ref": "TargetCapacity"
}
}
}
}
```
Getting `E3001 Properties not defined for resource WaitCondition`
* Feature request:
I'm not sure if there's a list of resources which don't need properties in many situations. S3 buckets and WaitCondition seem like good candidates for not raising this.
[AWS docs](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/parameters-section-structure.html) say:
> Use the optional Parameters section to customize your templates.
so it doesn't sound like it needs to be provided.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/cfnlint/rules/resources/Configuration.py`
Content:
```
1 """
2 Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.
3
4 Permission is hereby granted, free of charge, to any person obtaining a copy of this
5 software and associated documentation files (the "Software"), to deal in the Software
6 without restriction, including without limitation the rights to use, copy, modify,
7 merge, publish, distribute, sublicense, and/or sell copies of the Software, and to
8 permit persons to whom the Software is furnished to do so.
9
10 THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,
11 INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A
12 PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT
13 HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
14 OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
15 SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
16 """
17 from cfnlint import CloudFormationLintRule
18 from cfnlint import RuleMatch
19 import cfnlint.helpers
20
21
22 class Configuration(CloudFormationLintRule):
23 """Check Base Resource Configuration"""
24 id = 'E3001'
25 shortdesc = 'Basic CloudFormation Resource Check'
26 description = 'Making sure the basic CloudFormation resources ' + \
27 'are properly configured'
28 source_url = 'https://github.com/awslabs/cfn-python-lint'
29 tags = ['resources']
30
31 def match(self, cfn):
32 """Check CloudFormation Resources"""
33
34 matches = list()
35
36 valid_attributes = [
37 'CreationPolicy',
38 'DeletionPolicy',
39 'DependsOn',
40 'Metadata',
41 'UpdatePolicy',
42 'Properties',
43 'Type',
44 'Condition'
45 ]
46
47 valid_custom_attributes = [
48 'Version',
49 'Properties',
50 'DependsOn',
51 'Metadata',
52 'Condition',
53 'Type',
54 ]
55
56 resources = cfn.template.get('Resources', {})
57 if not isinstance(resources, dict):
58 message = 'Resource not properly configured'
59 matches.append(RuleMatch(['Resources'], message))
60 else:
61 for resource_name, resource_values in cfn.template.get('Resources', {}).items():
62 self.logger.debug('Validating resource %s base configuration', resource_name)
63 if not isinstance(resource_values, dict):
64 message = 'Resource not properly configured at {0}'
65 matches.append(RuleMatch(
66 ['Resources', resource_name],
67 message.format(resource_name)
68 ))
69 continue
70 resource_type = resource_values.get('Type', '')
71 check_attributes = []
72 if resource_type.startswith('Custom::') or resource_type == 'AWS::CloudFormation::CustomResource':
73 check_attributes = valid_custom_attributes
74 else:
75 check_attributes = valid_attributes
76
77 for property_key, _ in resource_values.items():
78 if property_key not in check_attributes:
79 message = 'Invalid resource attribute {0} for resource {1}'
80 matches.append(RuleMatch(
81 ['Resources', resource_name, property_key],
82 message.format(property_key, resource_name)))
83
84 resource_type = resource_values.get('Type', '')
85 if not resource_type:
86 message = 'Type not defined for resource {0}'
87 matches.append(RuleMatch(
88 ['Resources', resource_name],
89 message.format(resource_name)
90 ))
91 else:
92 self.logger.debug('Check resource types by region...')
93 for region, specs in cfnlint.helpers.RESOURCE_SPECS.items():
94 if region in cfn.regions:
95 if resource_type not in specs['ResourceTypes']:
96 if not resource_type.startswith(('Custom::', 'AWS::Serverless::')):
97 message = 'Invalid or unsupported Type {0} for resource {1} in {2}'
98 matches.append(RuleMatch(
99 ['Resources', resource_name, 'Type'],
100 message.format(resource_type, resource_name, region)
101 ))
102
103 if 'Properties' not in resource_values:
104 resource_spec = cfnlint.helpers.RESOURCE_SPECS['us-east-1']
105 if resource_type in resource_spec['ResourceTypes']:
106 properties_spec = resource_spec['ResourceTypes'][resource_type]['Properties']
107 # pylint: disable=len-as-condition
108 if len(properties_spec) > 0:
109 required = 0
110 for _, property_spec in properties_spec.items():
111 if property_spec.get('Required', False):
112 required += 1
113 if required > 0:
114 message = 'Properties not defined for resource {0}'
115 matches.append(RuleMatch(
116 ['Resources', resource_name],
117 message.format(resource_name)
118 ))
119
120 return matches
121
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/cfnlint/rules/resources/Configuration.py b/src/cfnlint/rules/resources/Configuration.py
--- a/src/cfnlint/rules/resources/Configuration.py
+++ b/src/cfnlint/rules/resources/Configuration.py
@@ -111,10 +111,13 @@
if property_spec.get('Required', False):
required += 1
if required > 0:
- message = 'Properties not defined for resource {0}'
- matches.append(RuleMatch(
- ['Resources', resource_name],
- message.format(resource_name)
- ))
+ if resource_type == 'AWS::CloudFormation::WaitCondition' and 'CreationPolicy' in resource_values.keys():
+ self.logger.debug('Exception to required properties section as CreationPolicy is defined.')
+ else:
+ message = 'Properties not defined for resource {0}'
+ matches.append(RuleMatch(
+ ['Resources', resource_name],
+ message.format(resource_name)
+ ))
return matches
|
{"golden_diff": "diff --git a/src/cfnlint/rules/resources/Configuration.py b/src/cfnlint/rules/resources/Configuration.py\n--- a/src/cfnlint/rules/resources/Configuration.py\n+++ b/src/cfnlint/rules/resources/Configuration.py\n@@ -111,10 +111,13 @@\n if property_spec.get('Required', False):\n required += 1\n if required > 0:\n- message = 'Properties not defined for resource {0}'\n- matches.append(RuleMatch(\n- ['Resources', resource_name],\n- message.format(resource_name)\n- ))\n+ if resource_type == 'AWS::CloudFormation::WaitCondition' and 'CreationPolicy' in resource_values.keys():\n+ self.logger.debug('Exception to required properties section as CreationPolicy is defined.')\n+ else:\n+ message = 'Properties not defined for resource {0}'\n+ matches.append(RuleMatch(\n+ ['Resources', resource_name],\n+ message.format(resource_name)\n+ ))\n \n return matches\n", "issue": "E3001 Missing properties raised as an error when they're not required\n*cfn-lint version: 0.4.2*\r\n\r\n*Description of issue.*\r\n\r\nAn error about missing properties is not always useful. There are resources which don't necessarily need properties.\r\n\r\nPlease provide as much information as possible:\r\n* Template linting issues:\r\n```\r\n \"WaitCondition\": {\r\n \"Type\": \"AWS::CloudFormation::WaitCondition\",\r\n \"CreationPolicy\": {\r\n \"ResourceSignal\": {\r\n \"Timeout\": \"PT15M\",\r\n \"Count\": {\r\n \"Ref\": \"TargetCapacity\"\r\n }\r\n }\r\n }\r\n }\r\n```\r\nGetting `E3001 Properties not defined for resource WaitCondition`\r\n\r\n* Feature request:\r\n\r\nI'm not sure if there's a list of resources which don't need properties in many situations. S3 buckets and WaitCondition seem like good candidates for not raising this.\r\n[AWS docs](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/parameters-section-structure.html) say:\r\n> Use the optional Parameters section to customize your templates.\r\nso it doesn't sound like it needs to be provided.\n", "before_files": [{"content": "\"\"\"\n Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n\n Permission is hereby granted, free of charge, to any person obtaining a copy of this\n software and associated documentation files (the \"Software\"), to deal in the Software\n without restriction, including without limitation the rights to use, copy, modify,\n merge, publish, distribute, sublicense, and/or sell copies of the Software, and to\n permit persons to whom the Software is furnished to do so.\n\n THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,\n INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A\n PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT\n HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION\n OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\"\"\"\nfrom cfnlint import CloudFormationLintRule\nfrom cfnlint import RuleMatch\nimport cfnlint.helpers\n\n\nclass Configuration(CloudFormationLintRule):\n \"\"\"Check Base Resource Configuration\"\"\"\n id = 'E3001'\n shortdesc = 'Basic CloudFormation Resource Check'\n description = 'Making sure the basic CloudFormation resources ' + \\\n 'are properly configured'\n source_url = 'https://github.com/awslabs/cfn-python-lint'\n tags = ['resources']\n\n def match(self, cfn):\n \"\"\"Check CloudFormation Resources\"\"\"\n\n matches = list()\n\n valid_attributes = [\n 'CreationPolicy',\n 'DeletionPolicy',\n 'DependsOn',\n 'Metadata',\n 'UpdatePolicy',\n 'Properties',\n 'Type',\n 'Condition'\n ]\n\n valid_custom_attributes = [\n 'Version',\n 'Properties',\n 'DependsOn',\n 'Metadata',\n 'Condition',\n 'Type',\n ]\n\n resources = cfn.template.get('Resources', {})\n if not isinstance(resources, dict):\n message = 'Resource not properly configured'\n matches.append(RuleMatch(['Resources'], message))\n else:\n for resource_name, resource_values in cfn.template.get('Resources', {}).items():\n self.logger.debug('Validating resource %s base configuration', resource_name)\n if not isinstance(resource_values, dict):\n message = 'Resource not properly configured at {0}'\n matches.append(RuleMatch(\n ['Resources', resource_name],\n message.format(resource_name)\n ))\n continue\n resource_type = resource_values.get('Type', '')\n check_attributes = []\n if resource_type.startswith('Custom::') or resource_type == 'AWS::CloudFormation::CustomResource':\n check_attributes = valid_custom_attributes\n else:\n check_attributes = valid_attributes\n\n for property_key, _ in resource_values.items():\n if property_key not in check_attributes:\n message = 'Invalid resource attribute {0} for resource {1}'\n matches.append(RuleMatch(\n ['Resources', resource_name, property_key],\n message.format(property_key, resource_name)))\n\n resource_type = resource_values.get('Type', '')\n if not resource_type:\n message = 'Type not defined for resource {0}'\n matches.append(RuleMatch(\n ['Resources', resource_name],\n message.format(resource_name)\n ))\n else:\n self.logger.debug('Check resource types by region...')\n for region, specs in cfnlint.helpers.RESOURCE_SPECS.items():\n if region in cfn.regions:\n if resource_type not in specs['ResourceTypes']:\n if not resource_type.startswith(('Custom::', 'AWS::Serverless::')):\n message = 'Invalid or unsupported Type {0} for resource {1} in {2}'\n matches.append(RuleMatch(\n ['Resources', resource_name, 'Type'],\n message.format(resource_type, resource_name, region)\n ))\n\n if 'Properties' not in resource_values:\n resource_spec = cfnlint.helpers.RESOURCE_SPECS['us-east-1']\n if resource_type in resource_spec['ResourceTypes']:\n properties_spec = resource_spec['ResourceTypes'][resource_type]['Properties']\n # pylint: disable=len-as-condition\n if len(properties_spec) > 0:\n required = 0\n for _, property_spec in properties_spec.items():\n if property_spec.get('Required', False):\n required += 1\n if required > 0:\n message = 'Properties not defined for resource {0}'\n matches.append(RuleMatch(\n ['Resources', resource_name],\n message.format(resource_name)\n ))\n\n return matches\n", "path": "src/cfnlint/rules/resources/Configuration.py"}], "after_files": [{"content": "\"\"\"\n Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n\n Permission is hereby granted, free of charge, to any person obtaining a copy of this\n software and associated documentation files (the \"Software\"), to deal in the Software\n without restriction, including without limitation the rights to use, copy, modify,\n merge, publish, distribute, sublicense, and/or sell copies of the Software, and to\n permit persons to whom the Software is furnished to do so.\n\n THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,\n INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A\n PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT\n HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION\n OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\"\"\"\nfrom cfnlint import CloudFormationLintRule\nfrom cfnlint import RuleMatch\nimport cfnlint.helpers\n\n\nclass Configuration(CloudFormationLintRule):\n \"\"\"Check Base Resource Configuration\"\"\"\n id = 'E3001'\n shortdesc = 'Basic CloudFormation Resource Check'\n description = 'Making sure the basic CloudFormation resources ' + \\\n 'are properly configured'\n source_url = 'https://github.com/awslabs/cfn-python-lint'\n tags = ['resources']\n\n def match(self, cfn):\n \"\"\"Check CloudFormation Resources\"\"\"\n\n matches = list()\n\n valid_attributes = [\n 'CreationPolicy',\n 'DeletionPolicy',\n 'DependsOn',\n 'Metadata',\n 'UpdatePolicy',\n 'Properties',\n 'Type',\n 'Condition'\n ]\n\n valid_custom_attributes = [\n 'Version',\n 'Properties',\n 'DependsOn',\n 'Metadata',\n 'Condition',\n 'Type',\n ]\n\n resources = cfn.template.get('Resources', {})\n if not isinstance(resources, dict):\n message = 'Resource not properly configured'\n matches.append(RuleMatch(['Resources'], message))\n else:\n for resource_name, resource_values in cfn.template.get('Resources', {}).items():\n self.logger.debug('Validating resource %s base configuration', resource_name)\n if not isinstance(resource_values, dict):\n message = 'Resource not properly configured at {0}'\n matches.append(RuleMatch(\n ['Resources', resource_name],\n message.format(resource_name)\n ))\n continue\n resource_type = resource_values.get('Type', '')\n check_attributes = []\n if resource_type.startswith('Custom::') or resource_type == 'AWS::CloudFormation::CustomResource':\n check_attributes = valid_custom_attributes\n else:\n check_attributes = valid_attributes\n\n for property_key, _ in resource_values.items():\n if property_key not in check_attributes:\n message = 'Invalid resource attribute {0} for resource {1}'\n matches.append(RuleMatch(\n ['Resources', resource_name, property_key],\n message.format(property_key, resource_name)))\n\n resource_type = resource_values.get('Type', '')\n if not resource_type:\n message = 'Type not defined for resource {0}'\n matches.append(RuleMatch(\n ['Resources', resource_name],\n message.format(resource_name)\n ))\n else:\n self.logger.debug('Check resource types by region...')\n for region, specs in cfnlint.helpers.RESOURCE_SPECS.items():\n if region in cfn.regions:\n if resource_type not in specs['ResourceTypes']:\n if not resource_type.startswith(('Custom::', 'AWS::Serverless::')):\n message = 'Invalid or unsupported Type {0} for resource {1} in {2}'\n matches.append(RuleMatch(\n ['Resources', resource_name, 'Type'],\n message.format(resource_type, resource_name, region)\n ))\n\n if 'Properties' not in resource_values:\n resource_spec = cfnlint.helpers.RESOURCE_SPECS['us-east-1']\n if resource_type in resource_spec['ResourceTypes']:\n properties_spec = resource_spec['ResourceTypes'][resource_type]['Properties']\n # pylint: disable=len-as-condition\n if len(properties_spec) > 0:\n required = 0\n for _, property_spec in properties_spec.items():\n if property_spec.get('Required', False):\n required += 1\n if required > 0:\n if resource_type == 'AWS::CloudFormation::WaitCondition' and 'CreationPolicy' in resource_values.keys():\n self.logger.debug('Exception to required properties section as CreationPolicy is defined.')\n else:\n message = 'Properties not defined for resource {0}'\n matches.append(RuleMatch(\n ['Resources', resource_name],\n message.format(resource_name)\n ))\n\n return matches\n", "path": "src/cfnlint/rules/resources/Configuration.py"}]}
| 1,738 | 216 |
gh_patches_debug_26697
|
rasdani/github-patches
|
git_diff
|
dask__distributed-327
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
LZ4 compression fails on very large frames
This causes a complete halt of the system. We could consider framing or punting.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `distributed/protocol.py`
Content:
```
1 """
2 The distributed message protocol consists of the following parts:
3
4 1. The length of the header, stored as a uint32
5 2. The header, stored as msgpack.
6 If there are no fields in the header then we skip it entirely.
7 3. The payload, stored as possibly compressed msgpack
8 4. A sentinel value
9
10 **Header**
11
12 The Header contains the following fields:
13
14 * **compression**: string, optional
15 One of the following: ``'snappy', 'lz4', 'zlib'`` or missing for None
16
17 **Payload**
18
19 The payload is any msgpack serializable value. It may be compressed based
20 on the header.
21
22 **Sentinel**
23
24 We often terminate each message with a sentinel value. This happens
25 outside of this module though and is not baked in.
26 """
27 from __future__ import print_function, division, absolute_import
28
29 import random
30 import struct
31
32 try:
33 import pandas.msgpack as msgpack
34 except ImportError:
35 import msgpack
36
37 from toolz import first, keymap, identity, merge
38
39 from .utils import ignoring
40 from .compatibility import unicode
41
42
43 compressions = {None: {'compress': identity,
44 'decompress': identity}}
45
46 default_compression = None
47
48
49 with ignoring(ImportError):
50 import zlib
51 compressions['zlib'] = {'compress': zlib.compress,
52 'decompress': zlib.decompress}
53
54 with ignoring(ImportError):
55 import snappy
56 compressions['snappy'] = {'compress': snappy.compress,
57 'decompress': snappy.decompress}
58 default_compression = 'snappy'
59
60 with ignoring(ImportError):
61 import lz4
62 compressions['lz4'] = {'compress': lz4.LZ4_compress,
63 'decompress': lz4.LZ4_uncompress}
64 default_compression = 'lz4'
65
66
67 def dumps(msg):
68 """ Transform Python value to bytestream suitable for communication """
69 small_header = {}
70
71 if isinstance(msg, dict):
72 big = {k: v for k, v in msg.items()
73 if isinstance(v, bytes) and len(v) > 1e6}
74 else:
75 big = False
76 if big:
77 small = {k: v for k, v in msg.items() if k not in big}
78 else:
79 small = msg
80
81 frames = dumps_msgpack(small)
82 if big:
83 frames += dumps_big_byte_dict(big)
84
85 return frames
86
87
88 def loads(frames):
89 """ Transform bytestream back into Python value """
90 header, payload, frames = frames[0], frames[1], frames[2:]
91 msg = loads_msgpack(header, payload)
92
93 if frames:
94 big = loads_big_byte_dict(*frames)
95 msg.update(big)
96
97 return msg
98
99
100 def byte_sample(b, size, n):
101 """ Sample a bytestring from many locations """
102 starts = [random.randint(0, len(b) - size) for j in range(n)]
103 ends = []
104 for i, start in enumerate(starts[:-1]):
105 ends.append(min(start + size, starts[i + 1]))
106 ends.append(starts[-1] + size)
107
108 return b''.join([b[start:end] for start, end in zip(starts, ends)])
109
110
111 def maybe_compress(payload, compression=default_compression, min_size=1e4,
112 sample_size=1e4, nsamples=5):
113 """ Maybe compress payload
114
115 1. We don't compress small messages
116 2. We sample the payload in a few spots, compress that, and if it doesn't
117 do any good we return the original
118 3. We then compress the full original, it it doesn't compress well then we
119 return the original
120 4. We return the compressed result
121 """
122 if not compression:
123 return None, payload
124 if len(payload) < min_size:
125 return None, payload
126
127 min_size = int(min_size)
128 sample_size = int(sample_size)
129
130 compress = compressions[compression]['compress']
131
132 # Compress a sample, return original if not very compressed
133 sample = byte_sample(payload, sample_size, nsamples)
134 if len(compress(sample)) > 0.9 * len(sample): # not very compressible
135 return None, payload
136
137 compressed = compress(payload)
138 if len(compressed) > 0.9 * len(payload): # not very compressible
139 return None, payload
140
141 return compression, compress(payload)
142
143
144 def dumps_msgpack(msg):
145 """ Dump msg into header and payload, both bytestrings
146
147 All of the message must be msgpack encodable
148
149 See Also:
150 loads_msgpack
151 """
152 header = {}
153 payload = msgpack.dumps(msg, use_bin_type=True)
154
155 fmt, payload = maybe_compress(payload)
156 if fmt:
157 header['compression'] = fmt
158
159 if header:
160 header_bytes = msgpack.dumps(header, use_bin_type=True)
161 else:
162 header_bytes = b''
163
164 return [header_bytes, payload]
165
166
167 def loads_msgpack(header, payload):
168 """ Read msgpack header and payload back to Python object
169
170 See Also:
171 dumps_msgpack
172 """
173 if header:
174 header = msgpack.loads(header, encoding='utf8')
175 else:
176 header = {}
177
178 if header.get('compression'):
179 try:
180 decompress = compressions[header['compression']]['decompress']
181 payload = decompress(payload)
182 except KeyError:
183 raise ValueError("Data is compressed as %s but we don't have this"
184 " installed" % header['compression'].decode())
185
186 return msgpack.loads(payload, encoding='utf8')
187
188
189 def dumps_big_byte_dict(d):
190 """ Serialize large byte dictionary to sequence of frames
191
192 The input must be a dictionary and all values of that dictionary must be
193 bytestrings. These should probably be large.
194
195 Returns a sequence of frames, one header followed by each of the values
196
197 See Also:
198 loads_big_byte_dict
199 """
200 assert isinstance(d, dict) and all(isinstance(v, bytes) for v in d.values())
201 keys, values = zip(*d.items())
202
203 compress = compressions[default_compression]['compress']
204 compression = []
205 values2 = []
206 for v in values:
207 fmt, vv = maybe_compress(v)
208 compression.append(fmt)
209 values2.append(vv)
210
211 header = {'encoding': 'big-byte-dict',
212 'keys': keys,
213 'compression': compression}
214
215 return [msgpack.dumps(header, use_bin_type=True)] + values2
216
217
218 def loads_big_byte_dict(header, *values):
219 """ Deserialize big-byte frames to large byte dictionary
220
221 See Also:
222 dumps_big_byte_dict
223 """
224 header = msgpack.loads(header, encoding='utf8')
225
226 values2 = [compressions[c]['decompress'](v)
227 for c, v in zip(header['compression'], values)]
228 return dict(zip(header['keys'], values2))
229
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/distributed/protocol.py b/distributed/protocol.py
--- a/distributed/protocol.py
+++ b/distributed/protocol.py
@@ -198,6 +198,17 @@
loads_big_byte_dict
"""
assert isinstance(d, dict) and all(isinstance(v, bytes) for v in d.values())
+ shards = {}
+ for k, v in list(d.items()):
+ if len(v) >= 2**31:
+ L = []
+ for i, j in enumerate(range(0, len(v), 2**30)):
+ key = '.shard-%d-%s' % (i, k)
+ d[key] = v[j: j + 2**30]
+ L.append(key)
+ del d[k]
+ shards[k] = L
+
keys, values = zip(*d.items())
compress = compressions[default_compression]['compress']
@@ -211,6 +222,8 @@
header = {'encoding': 'big-byte-dict',
'keys': keys,
'compression': compression}
+ if shards:
+ header['shards'] = shards
return [msgpack.dumps(header, use_bin_type=True)] + values2
@@ -225,4 +238,8 @@
values2 = [compressions[c]['decompress'](v)
for c, v in zip(header['compression'], values)]
- return dict(zip(header['keys'], values2))
+ result = dict(zip(header['keys'], values2))
+
+ for k, keys in header.get('shards', {}).items():
+ result[k] = b''.join(result.pop(kk) for kk in keys)
+ return result
|
{"golden_diff": "diff --git a/distributed/protocol.py b/distributed/protocol.py\n--- a/distributed/protocol.py\n+++ b/distributed/protocol.py\n@@ -198,6 +198,17 @@\n loads_big_byte_dict\n \"\"\"\n assert isinstance(d, dict) and all(isinstance(v, bytes) for v in d.values())\n+ shards = {}\n+ for k, v in list(d.items()):\n+ if len(v) >= 2**31:\n+ L = []\n+ for i, j in enumerate(range(0, len(v), 2**30)):\n+ key = '.shard-%d-%s' % (i, k)\n+ d[key] = v[j: j + 2**30]\n+ L.append(key)\n+ del d[k]\n+ shards[k] = L\n+\n keys, values = zip(*d.items())\n \n compress = compressions[default_compression]['compress']\n@@ -211,6 +222,8 @@\n header = {'encoding': 'big-byte-dict',\n 'keys': keys,\n 'compression': compression}\n+ if shards:\n+ header['shards'] = shards\n \n return [msgpack.dumps(header, use_bin_type=True)] + values2\n \n@@ -225,4 +238,8 @@\n \n values2 = [compressions[c]['decompress'](v)\n for c, v in zip(header['compression'], values)]\n- return dict(zip(header['keys'], values2))\n+ result = dict(zip(header['keys'], values2))\n+\n+ for k, keys in header.get('shards', {}).items():\n+ result[k] = b''.join(result.pop(kk) for kk in keys)\n+ return result\n", "issue": "LZ4 compression fails on very large frames\nThis causes a complete halt of the system. We could consider framing or punting.\n\n", "before_files": [{"content": "\"\"\"\nThe distributed message protocol consists of the following parts:\n\n1. The length of the header, stored as a uint32\n2. The header, stored as msgpack.\n If there are no fields in the header then we skip it entirely.\n3. The payload, stored as possibly compressed msgpack\n4. A sentinel value\n\n**Header**\n\nThe Header contains the following fields:\n\n* **compression**: string, optional\n One of the following: ``'snappy', 'lz4', 'zlib'`` or missing for None\n\n**Payload**\n\nThe payload is any msgpack serializable value. It may be compressed based\non the header.\n\n**Sentinel**\n\nWe often terminate each message with a sentinel value. This happens\noutside of this module though and is not baked in.\n\"\"\"\nfrom __future__ import print_function, division, absolute_import\n\nimport random\nimport struct\n\ntry:\n import pandas.msgpack as msgpack\nexcept ImportError:\n import msgpack\n\nfrom toolz import first, keymap, identity, merge\n\nfrom .utils import ignoring\nfrom .compatibility import unicode\n\n\ncompressions = {None: {'compress': identity,\n 'decompress': identity}}\n\ndefault_compression = None\n\n\nwith ignoring(ImportError):\n import zlib\n compressions['zlib'] = {'compress': zlib.compress,\n 'decompress': zlib.decompress}\n\nwith ignoring(ImportError):\n import snappy\n compressions['snappy'] = {'compress': snappy.compress,\n 'decompress': snappy.decompress}\n default_compression = 'snappy'\n\nwith ignoring(ImportError):\n import lz4\n compressions['lz4'] = {'compress': lz4.LZ4_compress,\n 'decompress': lz4.LZ4_uncompress}\n default_compression = 'lz4'\n\n\ndef dumps(msg):\n \"\"\" Transform Python value to bytestream suitable for communication \"\"\"\n small_header = {}\n\n if isinstance(msg, dict):\n big = {k: v for k, v in msg.items()\n if isinstance(v, bytes) and len(v) > 1e6}\n else:\n big = False\n if big:\n small = {k: v for k, v in msg.items() if k not in big}\n else:\n small = msg\n\n frames = dumps_msgpack(small)\n if big:\n frames += dumps_big_byte_dict(big)\n\n return frames\n\n\ndef loads(frames):\n \"\"\" Transform bytestream back into Python value \"\"\"\n header, payload, frames = frames[0], frames[1], frames[2:]\n msg = loads_msgpack(header, payload)\n\n if frames:\n big = loads_big_byte_dict(*frames)\n msg.update(big)\n\n return msg\n\n\ndef byte_sample(b, size, n):\n \"\"\" Sample a bytestring from many locations \"\"\"\n starts = [random.randint(0, len(b) - size) for j in range(n)]\n ends = []\n for i, start in enumerate(starts[:-1]):\n ends.append(min(start + size, starts[i + 1]))\n ends.append(starts[-1] + size)\n\n return b''.join([b[start:end] for start, end in zip(starts, ends)])\n\n\ndef maybe_compress(payload, compression=default_compression, min_size=1e4,\n sample_size=1e4, nsamples=5):\n \"\"\" Maybe compress payload\n\n 1. We don't compress small messages\n 2. We sample the payload in a few spots, compress that, and if it doesn't\n do any good we return the original\n 3. We then compress the full original, it it doesn't compress well then we\n return the original\n 4. We return the compressed result\n \"\"\"\n if not compression:\n return None, payload\n if len(payload) < min_size:\n return None, payload\n\n min_size = int(min_size)\n sample_size = int(sample_size)\n\n compress = compressions[compression]['compress']\n\n # Compress a sample, return original if not very compressed\n sample = byte_sample(payload, sample_size, nsamples)\n if len(compress(sample)) > 0.9 * len(sample): # not very compressible\n return None, payload\n\n compressed = compress(payload)\n if len(compressed) > 0.9 * len(payload): # not very compressible\n return None, payload\n\n return compression, compress(payload)\n\n\ndef dumps_msgpack(msg):\n \"\"\" Dump msg into header and payload, both bytestrings\n\n All of the message must be msgpack encodable\n\n See Also:\n loads_msgpack\n \"\"\"\n header = {}\n payload = msgpack.dumps(msg, use_bin_type=True)\n\n fmt, payload = maybe_compress(payload)\n if fmt:\n header['compression'] = fmt\n\n if header:\n header_bytes = msgpack.dumps(header, use_bin_type=True)\n else:\n header_bytes = b''\n\n return [header_bytes, payload]\n\n\ndef loads_msgpack(header, payload):\n \"\"\" Read msgpack header and payload back to Python object\n\n See Also:\n dumps_msgpack\n \"\"\"\n if header:\n header = msgpack.loads(header, encoding='utf8')\n else:\n header = {}\n\n if header.get('compression'):\n try:\n decompress = compressions[header['compression']]['decompress']\n payload = decompress(payload)\n except KeyError:\n raise ValueError(\"Data is compressed as %s but we don't have this\"\n \" installed\" % header['compression'].decode())\n\n return msgpack.loads(payload, encoding='utf8')\n\n\ndef dumps_big_byte_dict(d):\n \"\"\" Serialize large byte dictionary to sequence of frames\n\n The input must be a dictionary and all values of that dictionary must be\n bytestrings. These should probably be large.\n\n Returns a sequence of frames, one header followed by each of the values\n\n See Also:\n loads_big_byte_dict\n \"\"\"\n assert isinstance(d, dict) and all(isinstance(v, bytes) for v in d.values())\n keys, values = zip(*d.items())\n\n compress = compressions[default_compression]['compress']\n compression = []\n values2 = []\n for v in values:\n fmt, vv = maybe_compress(v)\n compression.append(fmt)\n values2.append(vv)\n\n header = {'encoding': 'big-byte-dict',\n 'keys': keys,\n 'compression': compression}\n\n return [msgpack.dumps(header, use_bin_type=True)] + values2\n\n\ndef loads_big_byte_dict(header, *values):\n \"\"\" Deserialize big-byte frames to large byte dictionary\n\n See Also:\n dumps_big_byte_dict\n \"\"\"\n header = msgpack.loads(header, encoding='utf8')\n\n values2 = [compressions[c]['decompress'](v)\n for c, v in zip(header['compression'], values)]\n return dict(zip(header['keys'], values2))\n", "path": "distributed/protocol.py"}], "after_files": [{"content": "\"\"\"\nThe distributed message protocol consists of the following parts:\n\n1. The length of the header, stored as a uint32\n2. The header, stored as msgpack.\n If there are no fields in the header then we skip it entirely.\n3. The payload, stored as possibly compressed msgpack\n4. A sentinel value\n\n**Header**\n\nThe Header contains the following fields:\n\n* **compression**: string, optional\n One of the following: ``'snappy', 'lz4', 'zlib'`` or missing for None\n\n**Payload**\n\nThe payload is any msgpack serializable value. It may be compressed based\non the header.\n\n**Sentinel**\n\nWe often terminate each message with a sentinel value. This happens\noutside of this module though and is not baked in.\n\"\"\"\nfrom __future__ import print_function, division, absolute_import\n\nimport random\nimport struct\n\ntry:\n import pandas.msgpack as msgpack\nexcept ImportError:\n import msgpack\n\nfrom toolz import first, keymap, identity, merge\n\nfrom .utils import ignoring\nfrom .compatibility import unicode\n\n\ncompressions = {None: {'compress': identity,\n 'decompress': identity}}\n\ndefault_compression = None\n\n\nwith ignoring(ImportError):\n import zlib\n compressions['zlib'] = {'compress': zlib.compress,\n 'decompress': zlib.decompress}\n\nwith ignoring(ImportError):\n import snappy\n compressions['snappy'] = {'compress': snappy.compress,\n 'decompress': snappy.decompress}\n default_compression = 'snappy'\n\nwith ignoring(ImportError):\n import lz4\n compressions['lz4'] = {'compress': lz4.LZ4_compress,\n 'decompress': lz4.LZ4_uncompress}\n default_compression = 'lz4'\n\n\ndef dumps(msg):\n \"\"\" Transform Python value to bytestream suitable for communication \"\"\"\n small_header = {}\n\n if isinstance(msg, dict):\n big = {k: v for k, v in msg.items()\n if isinstance(v, bytes) and len(v) > 1e6}\n else:\n big = False\n if big:\n small = {k: v for k, v in msg.items() if k not in big}\n else:\n small = msg\n\n frames = dumps_msgpack(small)\n if big:\n frames += dumps_big_byte_dict(big)\n\n return frames\n\n\ndef loads(frames):\n \"\"\" Transform bytestream back into Python value \"\"\"\n header, payload, frames = frames[0], frames[1], frames[2:]\n msg = loads_msgpack(header, payload)\n\n if frames:\n big = loads_big_byte_dict(*frames)\n msg.update(big)\n\n return msg\n\n\ndef byte_sample(b, size, n):\n \"\"\" Sample a bytestring from many locations \"\"\"\n starts = [random.randint(0, len(b) - size) for j in range(n)]\n ends = []\n for i, start in enumerate(starts[:-1]):\n ends.append(min(start + size, starts[i + 1]))\n ends.append(starts[-1] + size)\n\n return b''.join([b[start:end] for start, end in zip(starts, ends)])\n\n\ndef maybe_compress(payload, compression=default_compression, min_size=1e4,\n sample_size=1e4, nsamples=5):\n \"\"\" Maybe compress payload\n\n 1. We don't compress small messages\n 2. We sample the payload in a few spots, compress that, and if it doesn't\n do any good we return the original\n 3. We then compress the full original, it it doesn't compress well then we\n return the original\n 4. We return the compressed result\n \"\"\"\n if not compression:\n return None, payload\n if len(payload) < min_size:\n return None, payload\n\n min_size = int(min_size)\n sample_size = int(sample_size)\n\n compress = compressions[compression]['compress']\n\n # Compress a sample, return original if not very compressed\n sample = byte_sample(payload, sample_size, nsamples)\n if len(compress(sample)) > 0.9 * len(sample): # not very compressible\n return None, payload\n\n compressed = compress(payload)\n if len(compressed) > 0.9 * len(payload): # not very compressible\n return None, payload\n\n return compression, compress(payload)\n\n\ndef dumps_msgpack(msg):\n \"\"\" Dump msg into header and payload, both bytestrings\n\n All of the message must be msgpack encodable\n\n See Also:\n loads_msgpack\n \"\"\"\n header = {}\n payload = msgpack.dumps(msg, use_bin_type=True)\n\n fmt, payload = maybe_compress(payload)\n if fmt:\n header['compression'] = fmt\n\n if header:\n header_bytes = msgpack.dumps(header, use_bin_type=True)\n else:\n header_bytes = b''\n\n return [header_bytes, payload]\n\n\ndef loads_msgpack(header, payload):\n \"\"\" Read msgpack header and payload back to Python object\n\n See Also:\n dumps_msgpack\n \"\"\"\n if header:\n header = msgpack.loads(header, encoding='utf8')\n else:\n header = {}\n\n if header.get('compression'):\n try:\n decompress = compressions[header['compression']]['decompress']\n payload = decompress(payload)\n except KeyError:\n raise ValueError(\"Data is compressed as %s but we don't have this\"\n \" installed\" % header['compression'].decode())\n\n return msgpack.loads(payload, encoding='utf8')\n\n\ndef dumps_big_byte_dict(d):\n \"\"\" Serialize large byte dictionary to sequence of frames\n\n The input must be a dictionary and all values of that dictionary must be\n bytestrings. These should probably be large.\n\n Returns a sequence of frames, one header followed by each of the values\n\n See Also:\n loads_big_byte_dict\n \"\"\"\n assert isinstance(d, dict) and all(isinstance(v, bytes) for v in d.values())\n shards = {}\n for k, v in list(d.items()):\n if len(v) >= 2**31:\n L = []\n for i, j in enumerate(range(0, len(v), 2**30)):\n key = '.shard-%d-%s' % (i, k)\n d[key] = v[j: j + 2**30]\n L.append(key)\n del d[k]\n shards[k] = L\n\n keys, values = zip(*d.items())\n\n compress = compressions[default_compression]['compress']\n compression = []\n values2 = []\n for v in values:\n fmt, vv = maybe_compress(v)\n compression.append(fmt)\n values2.append(vv)\n\n header = {'encoding': 'big-byte-dict',\n 'keys': keys,\n 'compression': compression}\n if shards:\n header['shards'] = shards\n\n return [msgpack.dumps(header, use_bin_type=True)] + values2\n\n\ndef loads_big_byte_dict(header, *values):\n \"\"\" Deserialize big-byte frames to large byte dictionary\n\n See Also:\n dumps_big_byte_dict\n \"\"\"\n header = msgpack.loads(header, encoding='utf8')\n\n values2 = [compressions[c]['decompress'](v)\n for c, v in zip(header['compression'], values)]\n result = dict(zip(header['keys'], values2))\n\n for k, keys in header.get('shards', {}).items():\n result[k] = b''.join(result.pop(kk) for kk in keys)\n return result\n", "path": "distributed/protocol.py"}]}
| 2,411 | 387 |
gh_patches_debug_15796
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-contrib-543
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
psycopg2-binary dependency conflict
**Describe your environment**
```
> pip freeze | grep psyco
opentelemetry-instrumentation-psycopg2==0.22b0
psycopg2==2.8.6
```
**Steps to reproduce**
Install `psycopg2` instead of `psycopg2-binary`
**What is the expected behavior?**
No error message popping up
**What is the actual behavior?**
The instrumentation library will throw this error for every run.
```
DependencyConflict: requested: "psycopg2-binary >= 2.7.3.1" but found: "None"
```
**Additional context**
The instrumentation actually works as expected for `psycopg2`. So, the package instrumented should be both `psycopg2-binary` and `psycopg`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py`
Content:
```
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 # DO NOT EDIT. THIS FILE WAS AUTOGENERATED FROM INSTRUMENTATION PACKAGES.
16 # RUN `python scripts/generate_instrumentation_bootstrap.py` TO REGENERATE.
17
18 libraries = {
19 "aiohttp": {
20 "library": "aiohttp ~= 3.0",
21 "instrumentation": "opentelemetry-instrumentation-aiohttp-client==0.23.dev0",
22 },
23 "aiopg": {
24 "library": "aiopg >= 0.13.0",
25 "instrumentation": "opentelemetry-instrumentation-aiopg==0.23.dev0",
26 },
27 "asgiref": {
28 "library": "asgiref ~= 3.0",
29 "instrumentation": "opentelemetry-instrumentation-asgi==0.23.dev0",
30 },
31 "asyncpg": {
32 "library": "asyncpg >= 0.12.0",
33 "instrumentation": "opentelemetry-instrumentation-asyncpg==0.23.dev0",
34 },
35 "boto": {
36 "library": "boto~=2.0",
37 "instrumentation": "opentelemetry-instrumentation-boto==0.23.dev0",
38 },
39 "botocore": {
40 "library": "botocore ~= 1.0",
41 "instrumentation": "opentelemetry-instrumentation-botocore==0.23.dev0",
42 },
43 "celery": {
44 "library": "celery >= 4.0, < 6.0",
45 "instrumentation": "opentelemetry-instrumentation-celery==0.23.dev0",
46 },
47 "django": {
48 "library": "django >= 1.10",
49 "instrumentation": "opentelemetry-instrumentation-django==0.23.dev0",
50 },
51 "elasticsearch": {
52 "library": "elasticsearch >= 2.0",
53 "instrumentation": "opentelemetry-instrumentation-elasticsearch==0.23.dev0",
54 },
55 "falcon": {
56 "library": "falcon ~= 2.0",
57 "instrumentation": "opentelemetry-instrumentation-falcon==0.23.dev0",
58 },
59 "fastapi": {
60 "library": "fastapi ~= 0.58.1",
61 "instrumentation": "opentelemetry-instrumentation-fastapi==0.23.dev0",
62 },
63 "flask": {
64 "library": "flask ~= 1.0",
65 "instrumentation": "opentelemetry-instrumentation-flask==0.23.dev0",
66 },
67 "grpcio": {
68 "library": "grpcio ~= 1.27",
69 "instrumentation": "opentelemetry-instrumentation-grpc==0.23.dev0",
70 },
71 "httpx": {
72 "library": "httpx >= 0.18.0, < 0.19.0",
73 "instrumentation": "opentelemetry-instrumentation-httpx==0.23.dev0",
74 },
75 "jinja2": {
76 "library": "jinja2~=2.7",
77 "instrumentation": "opentelemetry-instrumentation-jinja2==0.23.dev0",
78 },
79 "mysql-connector-python": {
80 "library": "mysql-connector-python ~= 8.0",
81 "instrumentation": "opentelemetry-instrumentation-mysql==0.23.dev0",
82 },
83 "psycopg2-binary": {
84 "library": "psycopg2-binary >= 2.7.3.1",
85 "instrumentation": "opentelemetry-instrumentation-psycopg2==0.23.dev0",
86 },
87 "pymemcache": {
88 "library": "pymemcache ~= 1.3",
89 "instrumentation": "opentelemetry-instrumentation-pymemcache==0.23.dev0",
90 },
91 "pymongo": {
92 "library": "pymongo ~= 3.1",
93 "instrumentation": "opentelemetry-instrumentation-pymongo==0.23.dev0",
94 },
95 "PyMySQL": {
96 "library": "PyMySQL ~= 0.10.1",
97 "instrumentation": "opentelemetry-instrumentation-pymysql==0.23.dev0",
98 },
99 "pyramid": {
100 "library": "pyramid >= 1.7",
101 "instrumentation": "opentelemetry-instrumentation-pyramid==0.23.dev0",
102 },
103 "redis": {
104 "library": "redis >= 2.6",
105 "instrumentation": "opentelemetry-instrumentation-redis==0.23.dev0",
106 },
107 "requests": {
108 "library": "requests ~= 2.0",
109 "instrumentation": "opentelemetry-instrumentation-requests==0.23.dev0",
110 },
111 "scikit-learn": {
112 "library": "scikit-learn ~= 0.24.0",
113 "instrumentation": "opentelemetry-instrumentation-sklearn==0.23.dev0",
114 },
115 "sqlalchemy": {
116 "library": "sqlalchemy",
117 "instrumentation": "opentelemetry-instrumentation-sqlalchemy==0.23.dev0",
118 },
119 "starlette": {
120 "library": "starlette ~= 0.13.0",
121 "instrumentation": "opentelemetry-instrumentation-starlette==0.23.dev0",
122 },
123 "tornado": {
124 "library": "tornado >= 6.0",
125 "instrumentation": "opentelemetry-instrumentation-tornado==0.23.dev0",
126 },
127 "urllib3": {
128 "library": "urllib3 >= 1.0.0, < 2.0.0",
129 "instrumentation": "opentelemetry-instrumentation-urllib3==0.23.dev0",
130 },
131 }
132 default_instrumentations = [
133 "opentelemetry-instrumentation-dbapi==0.23.dev0",
134 "opentelemetry-instrumentation-logging==0.23.dev0",
135 "opentelemetry-instrumentation-sqlite3==0.23.dev0",
136 "opentelemetry-instrumentation-urllib==0.23.dev0",
137 "opentelemetry-instrumentation-wsgi==0.23.dev0",
138 ]
139
```
Path: `instrumentation/opentelemetry-instrumentation-psycopg2/src/opentelemetry/instrumentation/psycopg2/package.py`
Content:
```
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15
16 _instruments = ("psycopg2-binary >= 2.7.3.1",)
17
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/instrumentation/opentelemetry-instrumentation-psycopg2/src/opentelemetry/instrumentation/psycopg2/package.py b/instrumentation/opentelemetry-instrumentation-psycopg2/src/opentelemetry/instrumentation/psycopg2/package.py
--- a/instrumentation/opentelemetry-instrumentation-psycopg2/src/opentelemetry/instrumentation/psycopg2/package.py
+++ b/instrumentation/opentelemetry-instrumentation-psycopg2/src/opentelemetry/instrumentation/psycopg2/package.py
@@ -13,4 +13,4 @@
# limitations under the License.
-_instruments = ("psycopg2-binary >= 2.7.3.1",)
+_instruments = ("psycopg2 >= 2.7.3.1",)
diff --git a/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py b/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py
--- a/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py
+++ b/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py
@@ -80,8 +80,8 @@
"library": "mysql-connector-python ~= 8.0",
"instrumentation": "opentelemetry-instrumentation-mysql==0.23.dev0",
},
- "psycopg2-binary": {
- "library": "psycopg2-binary >= 2.7.3.1",
+ "psycopg2": {
+ "library": "psycopg2 >= 2.7.3.1",
"instrumentation": "opentelemetry-instrumentation-psycopg2==0.23.dev0",
},
"pymemcache": {
|
{"golden_diff": "diff --git a/instrumentation/opentelemetry-instrumentation-psycopg2/src/opentelemetry/instrumentation/psycopg2/package.py b/instrumentation/opentelemetry-instrumentation-psycopg2/src/opentelemetry/instrumentation/psycopg2/package.py\n--- a/instrumentation/opentelemetry-instrumentation-psycopg2/src/opentelemetry/instrumentation/psycopg2/package.py\n+++ b/instrumentation/opentelemetry-instrumentation-psycopg2/src/opentelemetry/instrumentation/psycopg2/package.py\n@@ -13,4 +13,4 @@\n # limitations under the License.\n \n \n-_instruments = (\"psycopg2-binary >= 2.7.3.1\",)\n+_instruments = (\"psycopg2 >= 2.7.3.1\",)\ndiff --git a/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py b/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py\n--- a/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py\n+++ b/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py\n@@ -80,8 +80,8 @@\n \"library\": \"mysql-connector-python ~= 8.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-mysql==0.23.dev0\",\n },\n- \"psycopg2-binary\": {\n- \"library\": \"psycopg2-binary >= 2.7.3.1\",\n+ \"psycopg2\": {\n+ \"library\": \"psycopg2 >= 2.7.3.1\",\n \"instrumentation\": \"opentelemetry-instrumentation-psycopg2==0.23.dev0\",\n },\n \"pymemcache\": {\n", "issue": "psycopg2-binary dependency conflict\n**Describe your environment** \r\n```\r\n> pip freeze | grep psyco\r\nopentelemetry-instrumentation-psycopg2==0.22b0\r\npsycopg2==2.8.6\r\n```\r\n\r\n**Steps to reproduce**\r\nInstall `psycopg2` instead of `psycopg2-binary`\r\n\r\n**What is the expected behavior?**\r\nNo error message popping up\r\n\r\n**What is the actual behavior?**\r\nThe instrumentation library will throw this error for every run.\r\n```\r\nDependencyConflict: requested: \"psycopg2-binary >= 2.7.3.1\" but found: \"None\"\r\n```\r\n\r\n**Additional context**\r\nThe instrumentation actually works as expected for `psycopg2`. So, the package instrumented should be both `psycopg2-binary` and `psycopg`\r\n\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n# DO NOT EDIT. THIS FILE WAS AUTOGENERATED FROM INSTRUMENTATION PACKAGES.\n# RUN `python scripts/generate_instrumentation_bootstrap.py` TO REGENERATE.\n\nlibraries = {\n \"aiohttp\": {\n \"library\": \"aiohttp ~= 3.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-aiohttp-client==0.23.dev0\",\n },\n \"aiopg\": {\n \"library\": \"aiopg >= 0.13.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-aiopg==0.23.dev0\",\n },\n \"asgiref\": {\n \"library\": \"asgiref ~= 3.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-asgi==0.23.dev0\",\n },\n \"asyncpg\": {\n \"library\": \"asyncpg >= 0.12.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-asyncpg==0.23.dev0\",\n },\n \"boto\": {\n \"library\": \"boto~=2.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-boto==0.23.dev0\",\n },\n \"botocore\": {\n \"library\": \"botocore ~= 1.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-botocore==0.23.dev0\",\n },\n \"celery\": {\n \"library\": \"celery >= 4.0, < 6.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-celery==0.23.dev0\",\n },\n \"django\": {\n \"library\": \"django >= 1.10\",\n \"instrumentation\": \"opentelemetry-instrumentation-django==0.23.dev0\",\n },\n \"elasticsearch\": {\n \"library\": \"elasticsearch >= 2.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-elasticsearch==0.23.dev0\",\n },\n \"falcon\": {\n \"library\": \"falcon ~= 2.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-falcon==0.23.dev0\",\n },\n \"fastapi\": {\n \"library\": \"fastapi ~= 0.58.1\",\n \"instrumentation\": \"opentelemetry-instrumentation-fastapi==0.23.dev0\",\n },\n \"flask\": {\n \"library\": \"flask ~= 1.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-flask==0.23.dev0\",\n },\n \"grpcio\": {\n \"library\": \"grpcio ~= 1.27\",\n \"instrumentation\": \"opentelemetry-instrumentation-grpc==0.23.dev0\",\n },\n \"httpx\": {\n \"library\": \"httpx >= 0.18.0, < 0.19.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-httpx==0.23.dev0\",\n },\n \"jinja2\": {\n \"library\": \"jinja2~=2.7\",\n \"instrumentation\": \"opentelemetry-instrumentation-jinja2==0.23.dev0\",\n },\n \"mysql-connector-python\": {\n \"library\": \"mysql-connector-python ~= 8.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-mysql==0.23.dev0\",\n },\n \"psycopg2-binary\": {\n \"library\": \"psycopg2-binary >= 2.7.3.1\",\n \"instrumentation\": \"opentelemetry-instrumentation-psycopg2==0.23.dev0\",\n },\n \"pymemcache\": {\n \"library\": \"pymemcache ~= 1.3\",\n \"instrumentation\": \"opentelemetry-instrumentation-pymemcache==0.23.dev0\",\n },\n \"pymongo\": {\n \"library\": \"pymongo ~= 3.1\",\n \"instrumentation\": \"opentelemetry-instrumentation-pymongo==0.23.dev0\",\n },\n \"PyMySQL\": {\n \"library\": \"PyMySQL ~= 0.10.1\",\n \"instrumentation\": \"opentelemetry-instrumentation-pymysql==0.23.dev0\",\n },\n \"pyramid\": {\n \"library\": \"pyramid >= 1.7\",\n \"instrumentation\": \"opentelemetry-instrumentation-pyramid==0.23.dev0\",\n },\n \"redis\": {\n \"library\": \"redis >= 2.6\",\n \"instrumentation\": \"opentelemetry-instrumentation-redis==0.23.dev0\",\n },\n \"requests\": {\n \"library\": \"requests ~= 2.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-requests==0.23.dev0\",\n },\n \"scikit-learn\": {\n \"library\": \"scikit-learn ~= 0.24.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-sklearn==0.23.dev0\",\n },\n \"sqlalchemy\": {\n \"library\": \"sqlalchemy\",\n \"instrumentation\": \"opentelemetry-instrumentation-sqlalchemy==0.23.dev0\",\n },\n \"starlette\": {\n \"library\": \"starlette ~= 0.13.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-starlette==0.23.dev0\",\n },\n \"tornado\": {\n \"library\": \"tornado >= 6.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-tornado==0.23.dev0\",\n },\n \"urllib3\": {\n \"library\": \"urllib3 >= 1.0.0, < 2.0.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-urllib3==0.23.dev0\",\n },\n}\ndefault_instrumentations = [\n \"opentelemetry-instrumentation-dbapi==0.23.dev0\",\n \"opentelemetry-instrumentation-logging==0.23.dev0\",\n \"opentelemetry-instrumentation-sqlite3==0.23.dev0\",\n \"opentelemetry-instrumentation-urllib==0.23.dev0\",\n \"opentelemetry-instrumentation-wsgi==0.23.dev0\",\n]\n", "path": "opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py"}, {"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\n_instruments = (\"psycopg2-binary >= 2.7.3.1\",)\n", "path": "instrumentation/opentelemetry-instrumentation-psycopg2/src/opentelemetry/instrumentation/psycopg2/package.py"}], "after_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n# DO NOT EDIT. THIS FILE WAS AUTOGENERATED FROM INSTRUMENTATION PACKAGES.\n# RUN `python scripts/generate_instrumentation_bootstrap.py` TO REGENERATE.\n\nlibraries = {\n \"aiohttp\": {\n \"library\": \"aiohttp ~= 3.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-aiohttp-client==0.23.dev0\",\n },\n \"aiopg\": {\n \"library\": \"aiopg >= 0.13.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-aiopg==0.23.dev0\",\n },\n \"asgiref\": {\n \"library\": \"asgiref ~= 3.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-asgi==0.23.dev0\",\n },\n \"asyncpg\": {\n \"library\": \"asyncpg >= 0.12.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-asyncpg==0.23.dev0\",\n },\n \"boto\": {\n \"library\": \"boto~=2.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-boto==0.23.dev0\",\n },\n \"botocore\": {\n \"library\": \"botocore ~= 1.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-botocore==0.23.dev0\",\n },\n \"celery\": {\n \"library\": \"celery >= 4.0, < 6.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-celery==0.23.dev0\",\n },\n \"django\": {\n \"library\": \"django >= 1.10\",\n \"instrumentation\": \"opentelemetry-instrumentation-django==0.23.dev0\",\n },\n \"elasticsearch\": {\n \"library\": \"elasticsearch >= 2.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-elasticsearch==0.23.dev0\",\n },\n \"falcon\": {\n \"library\": \"falcon ~= 2.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-falcon==0.23.dev0\",\n },\n \"fastapi\": {\n \"library\": \"fastapi ~= 0.58.1\",\n \"instrumentation\": \"opentelemetry-instrumentation-fastapi==0.23.dev0\",\n },\n \"flask\": {\n \"library\": \"flask ~= 1.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-flask==0.23.dev0\",\n },\n \"grpcio\": {\n \"library\": \"grpcio ~= 1.27\",\n \"instrumentation\": \"opentelemetry-instrumentation-grpc==0.23.dev0\",\n },\n \"httpx\": {\n \"library\": \"httpx >= 0.18.0, < 0.19.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-httpx==0.23.dev0\",\n },\n \"jinja2\": {\n \"library\": \"jinja2~=2.7\",\n \"instrumentation\": \"opentelemetry-instrumentation-jinja2==0.23.dev0\",\n },\n \"mysql-connector-python\": {\n \"library\": \"mysql-connector-python ~= 8.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-mysql==0.23.dev0\",\n },\n \"psycopg2\": {\n \"library\": \"psycopg2 >= 2.7.3.1\",\n \"instrumentation\": \"opentelemetry-instrumentation-psycopg2==0.23.dev0\",\n },\n \"pymemcache\": {\n \"library\": \"pymemcache ~= 1.3\",\n \"instrumentation\": \"opentelemetry-instrumentation-pymemcache==0.23.dev0\",\n },\n \"pymongo\": {\n \"library\": \"pymongo ~= 3.1\",\n \"instrumentation\": \"opentelemetry-instrumentation-pymongo==0.23.dev0\",\n },\n \"PyMySQL\": {\n \"library\": \"PyMySQL ~= 0.10.1\",\n \"instrumentation\": \"opentelemetry-instrumentation-pymysql==0.23.dev0\",\n },\n \"pyramid\": {\n \"library\": \"pyramid >= 1.7\",\n \"instrumentation\": \"opentelemetry-instrumentation-pyramid==0.23.dev0\",\n },\n \"redis\": {\n \"library\": \"redis >= 2.6\",\n \"instrumentation\": \"opentelemetry-instrumentation-redis==0.23.dev0\",\n },\n \"requests\": {\n \"library\": \"requests ~= 2.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-requests==0.23.dev0\",\n },\n \"scikit-learn\": {\n \"library\": \"scikit-learn ~= 0.24.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-sklearn==0.23.dev0\",\n },\n \"sqlalchemy\": {\n \"library\": \"sqlalchemy\",\n \"instrumentation\": \"opentelemetry-instrumentation-sqlalchemy==0.23.dev0\",\n },\n \"starlette\": {\n \"library\": \"starlette ~= 0.13.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-starlette==0.23.dev0\",\n },\n \"tornado\": {\n \"library\": \"tornado >= 6.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-tornado==0.23.dev0\",\n },\n \"urllib3\": {\n \"library\": \"urllib3 >= 1.0.0, < 2.0.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-urllib3==0.23.dev0\",\n },\n}\ndefault_instrumentations = [\n \"opentelemetry-instrumentation-dbapi==0.23.dev0\",\n \"opentelemetry-instrumentation-logging==0.23.dev0\",\n \"opentelemetry-instrumentation-sqlite3==0.23.dev0\",\n \"opentelemetry-instrumentation-urllib==0.23.dev0\",\n \"opentelemetry-instrumentation-wsgi==0.23.dev0\",\n]\n", "path": "opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py"}, {"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\n_instruments = (\"psycopg2 >= 2.7.3.1\",)\n", "path": "instrumentation/opentelemetry-instrumentation-psycopg2/src/opentelemetry/instrumentation/psycopg2/package.py"}]}
| 2,525 | 386 |
gh_patches_debug_633
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-1947
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Release 2.1.110
On the docket:
+ [x] PEX runtime sys.path scrubbing is imperfect. #1944
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pex/version.py`
Content:
```
1 # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 __version__ = "2.1.109"
5
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pex/version.py b/pex/version.py
--- a/pex/version.py
+++ b/pex/version.py
@@ -1,4 +1,4 @@
# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
# Licensed under the Apache License, Version 2.0 (see LICENSE).
-__version__ = "2.1.109"
+__version__ = "2.1.110"
|
{"golden_diff": "diff --git a/pex/version.py b/pex/version.py\n--- a/pex/version.py\n+++ b/pex/version.py\n@@ -1,4 +1,4 @@\n # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n # Licensed under the Apache License, Version 2.0 (see LICENSE).\n \n-__version__ = \"2.1.109\"\n+__version__ = \"2.1.110\"\n", "issue": "Release 2.1.110\nOn the docket:\r\n+ [x] PEX runtime sys.path scrubbing is imperfect. #1944\n", "before_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = \"2.1.109\"\n", "path": "pex/version.py"}], "after_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = \"2.1.110\"\n", "path": "pex/version.py"}]}
| 343 | 98 |
gh_patches_debug_43263
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-3321
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Rules CKV_AWS_18 and CKV_AWS_19 fail if s3 resources are defined in a terraform module
**Describe the issue**
When upgrading the AWS provider in Terraform to a version > 3.75 there has been significant change to the aws_s3_bucket resource. If the S3 resources are referenced in a child module rather than the root level it seems Checkov is still failing CKV_AWS_18 and CKV_AWS_19 based upon our usage. I believe these to be false positives.
CKV_AWS_18: "Ensure the S3 bucket has access logging enabled"
access logging is configured by the resource aws_s3_bucket_logging
CKV_AWS_19: "Ensure all data stored in the S3 bucket is securely encrypted at rest"
encryption at rest is configured by the resource aws_s3_bucket_server_side_encryption_configuration
**Examples**
### modules/s3/main.tf
```
resource "aws_kms_key" "s3_key" {
description = "KMS key 1"
deletion_window_in_days = 10
}
resource "aws_s3_bucket" "bucket" {
bucket = "sample-bucket"
}
resource "aws_s3_bucket_server_side_encryption_configuration" "bucket" {
bucket = aws_s3_bucket.bucket.id
rule {
apply_server_side_encryption_by_default {
kms_master_key_id = aws_kms_key.s3_key.key_id
sse_algorithm = "aws:kms"
}
bucket_key_enabled = false
}
}
resource "aws_s3_bucket_logging" "bucket" {
bucket = aws_s3_bucket.bucket.id
target_bucket = "logging-bucket"
target_prefix = "sample-bucket/"
}
```
### main.tf
```
module "s3" {
source = "./modules/s3"
}
```
Command: checkov -f plan.json --check CKV_AWS_18,CKV_AWS_19 --repo-root-for-plan-enrichment "./"
Expected both rules pass for resource aws_s3_bucket.bucket
**Version (please complete the following information):**
- Checkov Version 2.1.81
**Additional context**
Terraform version: 1.2.6
AWS Provider version: 4.23.0
If I move the contents of the module file to the root module both rules pass as expected.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `checkov/terraform/plan_parser.py`
Content:
```
1 from __future__ import annotations
2
3 import itertools
4 from typing import Optional, Tuple, Dict, List, Any
5
6 from checkov.common.parsers.node import DictNode, ListNode
7 from checkov.terraform.context_parsers.tf_plan import parse
8
9 SIMPLE_TYPES = (str, int, float, bool)
10 TF_PLAN_RESOURCE_ADDRESS = "__address__"
11 TF_PLAN_RESOURCE_CHANGE_ACTIONS = "__change_actions__"
12
13
14 def _is_simple_type(obj: Any) -> bool:
15 if obj is None:
16 return True
17 if isinstance(obj, SIMPLE_TYPES):
18 return True
19 return False
20
21
22 def _is_list_of_simple_types(obj: Any) -> bool:
23 if not isinstance(obj, list):
24 return False
25 for i in obj:
26 if not _is_simple_type(i):
27 return False
28 return True
29
30
31 def _is_list_of_dicts(obj: Any) -> bool:
32 if not isinstance(obj, list):
33 return False
34 for i in obj:
35 if isinstance(i, dict):
36 return True
37 return False
38
39
40 def _hclify(obj: DictNode, conf: Optional[DictNode] = None, parent_key: Optional[str] = None) -> Dict[str, List[Any]]:
41 ret_dict = {}
42 if not isinstance(obj, dict):
43 raise Exception("this method receives only dicts")
44 if hasattr(obj, "start_mark") and hasattr(obj, "end_mark"):
45 obj["start_line"] = obj.start_mark.line
46 obj["end_line"] = obj.end_mark.line
47 for key, value in obj.items():
48 if _is_simple_type(value) or _is_list_of_simple_types(value):
49 if parent_key == "tags":
50 ret_dict[key] = value
51 else:
52 ret_dict[key] = _clean_simple_type_list([value])
53
54 if _is_list_of_dicts(value):
55 child_list = []
56 conf_val = conf.get(key, []) if conf else []
57 for internal_val, internal_conf_val in itertools.zip_longest(value, conf_val):
58 if isinstance(internal_val, dict):
59 child_list.append(_hclify(internal_val, internal_conf_val, parent_key=key))
60 if key == "tags":
61 ret_dict[key] = [child_list]
62 else:
63 ret_dict[key] = child_list
64 if isinstance(value, dict):
65 child_dict = _hclify(value, parent_key=key)
66 if parent_key == "tags":
67 ret_dict[key] = child_dict
68 else:
69 ret_dict[key] = [child_dict]
70 if conf and isinstance(conf, dict):
71 found_ref = False
72 for conf_key in conf.keys() - obj.keys():
73 ref = next((x for x in conf[conf_key].get("references", []) if not x.startswith(("var.", "local."))), None)
74 if ref:
75 ret_dict[conf_key] = [ref]
76 found_ref = True
77 if not found_ref:
78 for value in conf.values():
79 if isinstance(value, dict) and "references" in value.keys():
80 ret_dict["references_"] = value["references"]
81
82 return ret_dict
83
84
85 def _prepare_resource_block(
86 resource: DictNode, conf: Optional[DictNode], resource_changes: dict[str, dict[str, Any]]
87 ) -> tuple[dict[str, dict[str, Any]], bool]:
88 """hclify resource if pre-conditions met.
89
90 :param resource: tf planned_values resource block
91 :param conf: tf configuration resource block
92 :param resource_changes: tf resource_changes block
93
94 :returns:
95 - resource_block: a list of strings representing the header columns
96 - prepared: whether conditions met to prepare data
97 """
98
99 resource_block: Dict[str, Dict[str, Any]] = {}
100 resource_block[resource["type"]] = {}
101 prepared = False
102 mode = ""
103 if "mode" in resource:
104 mode = resource.get("mode")
105 # Rare cases where data block appears in resources with same name as resource block and only partial values
106 # and where *_module resources don't have values field
107 if mode == "managed" and "values" in resource:
108 expressions = conf.get("expressions") if conf else None
109
110 resource_conf = _hclify(resource["values"], expressions)
111 resource_address = resource.get("address")
112 resource_conf[TF_PLAN_RESOURCE_ADDRESS] = resource_address
113
114 changes = resource_changes.get(resource_address)
115 if changes:
116 resource_conf[TF_PLAN_RESOURCE_CHANGE_ACTIONS] = changes.get("change", {}).get("actions") or []
117
118 resource_block[resource["type"]][resource.get("name", "default")] = resource_conf
119 prepared = True
120 return resource_block, prepared
121
122
123 def _find_child_modules(
124 child_modules: ListNode, resource_changes: dict[str, dict[str, Any]]
125 ) -> List[Dict[str, Dict[str, Any]]]:
126 """
127 Find all child modules if any. Including any amount of nested child modules.
128 :type: child_modules: list of tf child_module objects
129 :rtype: resource_blocks: list of hcl resources
130 """
131 resource_blocks = []
132 for child_module in child_modules:
133 if child_module.get("child_modules", []):
134 nested_child_modules = child_module.get("child_modules", [])
135 nested_blocks = _find_child_modules(nested_child_modules, resource_changes)
136 for resource in nested_blocks:
137 resource_blocks.append(resource)
138 for resource in child_module.get("resources", []):
139 resource_block, prepared = _prepare_resource_block(
140 resource=resource,
141 conf=None,
142 resource_changes=resource_changes,
143 )
144 if prepared is True:
145 resource_blocks.append(resource_block)
146 return resource_blocks
147
148
149 def _get_resource_changes(template: dict[str, Any]) -> dict[str, dict[str, Any]]:
150 """Returns a resource address to resource changes dict"""
151
152 resource_changes_map = {}
153
154 resource_changes = template.get("resource_changes")
155 if resource_changes and isinstance(resource_changes, list):
156 resource_changes_map = {
157 change.get("address", ""): change
158 for change in resource_changes
159 }
160
161 return resource_changes_map
162
163
164 def parse_tf_plan(tf_plan_file: str, out_parsing_errors: Dict[str, str]) -> Tuple[Optional[Dict[str, Any]], Optional[List[Tuple[int, str]]]]:
165 """
166 :type tf_plan_file: str - path to plan file
167 :rtype: tf_definition dictionary and template_lines of the plan file
168 """
169 tf_definition: Dict[str, Any] = {"resource": []}
170 template, template_lines = parse(tf_plan_file, out_parsing_errors)
171 if not template:
172 return None, None
173
174 resource_changes = _get_resource_changes(template=template)
175
176 for resource in template.get("planned_values", {}).get("root_module", {}).get("resources", []):
177 conf = next(
178 (
179 x
180 for x in template.get("configuration", {}).get("root_module", {}).get("resources", [])
181 if x["type"] == resource["type"] and x["name"] == resource["name"]
182 ),
183 None,
184 )
185 resource_block, prepared = _prepare_resource_block(
186 resource=resource,
187 conf=conf,
188 resource_changes=resource_changes,
189 )
190 if prepared is True:
191 tf_definition["resource"].append(resource_block)
192 child_modules = template.get("planned_values", {}).get("root_module", {}).get("child_modules", [])
193 # Terraform supports modules within modules so we need to search
194 # in nested modules to find all resource blocks
195 resource_blocks = _find_child_modules(child_modules, resource_changes)
196 for resource in resource_blocks:
197 tf_definition["resource"].append(resource)
198 return tf_definition, template_lines
199
200
201 def _clean_simple_type_list(value_list: List[Any]) -> List[Any]:
202 """
203 Given a list of simple types return a cleaned list of simple types.
204 Converts booleans that are input as strings back to booleans to maintain consistent expectations for later evaluation.
205 Sometimes Terraform Plan will output Map values as strings regardless of boolean input.
206 """
207 for i in range(len(value_list)):
208 if isinstance(value_list[i], str):
209 lower_case_value = value_list[i].lower()
210 if lower_case_value == "true":
211 value_list[i] = True
212 if lower_case_value == "false":
213 value_list[i] = False
214 return value_list
215
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/checkov/terraform/plan_parser.py b/checkov/terraform/plan_parser.py
--- a/checkov/terraform/plan_parser.py
+++ b/checkov/terraform/plan_parser.py
@@ -121,24 +121,50 @@
def _find_child_modules(
- child_modules: ListNode, resource_changes: dict[str, dict[str, Any]]
+ child_modules: ListNode, resource_changes: dict[str, dict[str, Any]], root_module_conf: dict[str, Any]
) -> List[Dict[str, Dict[str, Any]]]:
+ """ Find all child modules if any. Including any amount of nested child modules.
+
+ :param child_modules: list of terraform child_module objects
+ :param resource_changes: a resource address to resource changes dict
+ :param root_module_conf: configuration block of the root module
+ :returns:
+ list of terraform resource blocks
"""
- Find all child modules if any. Including any amount of nested child modules.
- :type: child_modules: list of tf child_module objects
- :rtype: resource_blocks: list of hcl resources
- """
+
resource_blocks = []
for child_module in child_modules:
- if child_module.get("child_modules", []):
- nested_child_modules = child_module.get("child_modules", [])
- nested_blocks = _find_child_modules(nested_child_modules, resource_changes)
+ nested_child_modules = child_module.get("child_modules", [])
+ if nested_child_modules:
+ nested_blocks = _find_child_modules(
+ child_modules=nested_child_modules,
+ resource_changes=resource_changes,
+ root_module_conf=root_module_conf
+ )
for resource in nested_blocks:
resource_blocks.append(resource)
+
+ module_address = child_module.get("address", "")
+ module_call_resources = _get_module_call_resources(
+ module_address=module_address,
+ root_module_conf=root_module_conf,
+ )
+
for resource in child_module.get("resources", []):
+ module_call_conf = None
+ if module_address and module_call_resources:
+ module_call_conf = next(
+ (
+ module_call_resource
+ for module_call_resource in module_call_resources
+ if f"{module_address}.{module_call_resource['address']}" == resource["address"]
+ ),
+ None
+ )
+
resource_block, prepared = _prepare_resource_block(
resource=resource,
- conf=None,
+ conf=module_call_conf,
resource_changes=resource_changes,
)
if prepared is True:
@@ -146,6 +172,18 @@
return resource_blocks
+def _get_module_call_resources(module_address: str, root_module_conf: dict[str, Any]) -> list[dict[str, Any]]:
+ """Extracts the resources from the 'module_calls' block under 'configuration'"""
+
+ for module_name in module_address.split("."):
+ if module_name == "module":
+ # module names are always prefixed with 'module.', therefore skip it
+ continue
+ root_module_conf = root_module_conf.get("module_calls", {}).get(module_name, {}).get("module", {})
+
+ return root_module_conf.get("resources", [])
+
+
def _get_resource_changes(template: dict[str, Any]) -> dict[str, dict[str, Any]]:
"""Returns a resource address to resource changes dict"""
@@ -190,9 +228,14 @@
if prepared is True:
tf_definition["resource"].append(resource_block)
child_modules = template.get("planned_values", {}).get("root_module", {}).get("child_modules", [])
+ root_module_conf = template.get("configuration", {}).get("root_module", {})
# Terraform supports modules within modules so we need to search
# in nested modules to find all resource blocks
- resource_blocks = _find_child_modules(child_modules, resource_changes)
+ resource_blocks = _find_child_modules(
+ child_modules=child_modules,
+ resource_changes=resource_changes,
+ root_module_conf=root_module_conf,
+ )
for resource in resource_blocks:
tf_definition["resource"].append(resource)
return tf_definition, template_lines
|
{"golden_diff": "diff --git a/checkov/terraform/plan_parser.py b/checkov/terraform/plan_parser.py\n--- a/checkov/terraform/plan_parser.py\n+++ b/checkov/terraform/plan_parser.py\n@@ -121,24 +121,50 @@\n \n \n def _find_child_modules(\n- child_modules: ListNode, resource_changes: dict[str, dict[str, Any]]\n+ child_modules: ListNode, resource_changes: dict[str, dict[str, Any]], root_module_conf: dict[str, Any]\n ) -> List[Dict[str, Dict[str, Any]]]:\n+ \"\"\" Find all child modules if any. Including any amount of nested child modules.\n+\n+ :param child_modules: list of terraform child_module objects\n+ :param resource_changes: a resource address to resource changes dict\n+ :param root_module_conf: configuration block of the root module\n+ :returns:\n+ list of terraform resource blocks\n \"\"\"\n- Find all child modules if any. Including any amount of nested child modules.\n- :type: child_modules: list of tf child_module objects\n- :rtype: resource_blocks: list of hcl resources\n- \"\"\"\n+\n resource_blocks = []\n for child_module in child_modules:\n- if child_module.get(\"child_modules\", []):\n- nested_child_modules = child_module.get(\"child_modules\", [])\n- nested_blocks = _find_child_modules(nested_child_modules, resource_changes)\n+ nested_child_modules = child_module.get(\"child_modules\", [])\n+ if nested_child_modules:\n+ nested_blocks = _find_child_modules(\n+ child_modules=nested_child_modules,\n+ resource_changes=resource_changes,\n+ root_module_conf=root_module_conf\n+ )\n for resource in nested_blocks:\n resource_blocks.append(resource)\n+\n+ module_address = child_module.get(\"address\", \"\")\n+ module_call_resources = _get_module_call_resources(\n+ module_address=module_address,\n+ root_module_conf=root_module_conf,\n+ )\n+\n for resource in child_module.get(\"resources\", []):\n+ module_call_conf = None\n+ if module_address and module_call_resources:\n+ module_call_conf = next(\n+ (\n+ module_call_resource\n+ for module_call_resource in module_call_resources\n+ if f\"{module_address}.{module_call_resource['address']}\" == resource[\"address\"]\n+ ),\n+ None\n+ )\n+\n resource_block, prepared = _prepare_resource_block(\n resource=resource,\n- conf=None,\n+ conf=module_call_conf,\n resource_changes=resource_changes,\n )\n if prepared is True:\n@@ -146,6 +172,18 @@\n return resource_blocks\n \n \n+def _get_module_call_resources(module_address: str, root_module_conf: dict[str, Any]) -> list[dict[str, Any]]:\n+ \"\"\"Extracts the resources from the 'module_calls' block under 'configuration'\"\"\"\n+\n+ for module_name in module_address.split(\".\"):\n+ if module_name == \"module\":\n+ # module names are always prefixed with 'module.', therefore skip it\n+ continue\n+ root_module_conf = root_module_conf.get(\"module_calls\", {}).get(module_name, {}).get(\"module\", {})\n+\n+ return root_module_conf.get(\"resources\", [])\n+\n+\n def _get_resource_changes(template: dict[str, Any]) -> dict[str, dict[str, Any]]:\n \"\"\"Returns a resource address to resource changes dict\"\"\"\n \n@@ -190,9 +228,14 @@\n if prepared is True:\n tf_definition[\"resource\"].append(resource_block)\n child_modules = template.get(\"planned_values\", {}).get(\"root_module\", {}).get(\"child_modules\", [])\n+ root_module_conf = template.get(\"configuration\", {}).get(\"root_module\", {})\n # Terraform supports modules within modules so we need to search\n # in nested modules to find all resource blocks\n- resource_blocks = _find_child_modules(child_modules, resource_changes)\n+ resource_blocks = _find_child_modules(\n+ child_modules=child_modules,\n+ resource_changes=resource_changes,\n+ root_module_conf=root_module_conf,\n+ )\n for resource in resource_blocks:\n tf_definition[\"resource\"].append(resource)\n return tf_definition, template_lines\n", "issue": "Rules CKV_AWS_18 and CKV_AWS_19 fail if s3 resources are defined in a terraform module\n**Describe the issue**\r\n\r\nWhen upgrading the AWS provider in Terraform to a version > 3.75 there has been significant change to the aws_s3_bucket resource. If the S3 resources are referenced in a child module rather than the root level it seems Checkov is still failing CKV_AWS_18 and CKV_AWS_19 based upon our usage. I believe these to be false positives.\r\n\r\nCKV_AWS_18: \"Ensure the S3 bucket has access logging enabled\"\r\n\r\naccess logging is configured by the resource aws_s3_bucket_logging\r\n\r\nCKV_AWS_19: \"Ensure all data stored in the S3 bucket is securely encrypted at rest\"\r\n\r\nencryption at rest is configured by the resource aws_s3_bucket_server_side_encryption_configuration\r\n\r\n**Examples**\r\n\r\n### modules/s3/main.tf\r\n\r\n```\r\n\r\nresource \"aws_kms_key\" \"s3_key\" {\r\n description = \"KMS key 1\"\r\n deletion_window_in_days = 10\r\n}\r\n\r\nresource \"aws_s3_bucket\" \"bucket\" {\r\n bucket = \"sample-bucket\"\r\n}\r\n\r\nresource \"aws_s3_bucket_server_side_encryption_configuration\" \"bucket\" {\r\n bucket = aws_s3_bucket.bucket.id\r\n\r\n rule {\r\n apply_server_side_encryption_by_default {\r\n kms_master_key_id = aws_kms_key.s3_key.key_id\r\n sse_algorithm = \"aws:kms\"\r\n }\r\n bucket_key_enabled = false\r\n }\r\n}\r\n\r\nresource \"aws_s3_bucket_logging\" \"bucket\" {\r\n bucket = aws_s3_bucket.bucket.id\r\n\r\n target_bucket = \"logging-bucket\"\r\n target_prefix = \"sample-bucket/\"\r\n}\r\n\r\n```\r\n### main.tf\r\n\r\n```\r\n\r\nmodule \"s3\" {\r\n source = \"./modules/s3\"\r\n}\r\n\r\n```\r\n\r\nCommand: checkov -f plan.json --check CKV_AWS_18,CKV_AWS_19 --repo-root-for-plan-enrichment \"./\"\r\n\r\nExpected both rules pass for resource aws_s3_bucket.bucket\r\n\r\n**Version (please complete the following information):**\r\n - Checkov Version 2.1.81\r\n\r\n**Additional context**\r\nTerraform version: 1.2.6\r\nAWS Provider version: 4.23.0\r\n\r\nIf I move the contents of the module file to the root module both rules pass as expected.\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nimport itertools\nfrom typing import Optional, Tuple, Dict, List, Any\n\nfrom checkov.common.parsers.node import DictNode, ListNode\nfrom checkov.terraform.context_parsers.tf_plan import parse\n\nSIMPLE_TYPES = (str, int, float, bool)\nTF_PLAN_RESOURCE_ADDRESS = \"__address__\"\nTF_PLAN_RESOURCE_CHANGE_ACTIONS = \"__change_actions__\"\n\n\ndef _is_simple_type(obj: Any) -> bool:\n if obj is None:\n return True\n if isinstance(obj, SIMPLE_TYPES):\n return True\n return False\n\n\ndef _is_list_of_simple_types(obj: Any) -> bool:\n if not isinstance(obj, list):\n return False\n for i in obj:\n if not _is_simple_type(i):\n return False\n return True\n\n\ndef _is_list_of_dicts(obj: Any) -> bool:\n if not isinstance(obj, list):\n return False\n for i in obj:\n if isinstance(i, dict):\n return True\n return False\n\n\ndef _hclify(obj: DictNode, conf: Optional[DictNode] = None, parent_key: Optional[str] = None) -> Dict[str, List[Any]]:\n ret_dict = {}\n if not isinstance(obj, dict):\n raise Exception(\"this method receives only dicts\")\n if hasattr(obj, \"start_mark\") and hasattr(obj, \"end_mark\"):\n obj[\"start_line\"] = obj.start_mark.line\n obj[\"end_line\"] = obj.end_mark.line\n for key, value in obj.items():\n if _is_simple_type(value) or _is_list_of_simple_types(value):\n if parent_key == \"tags\":\n ret_dict[key] = value\n else:\n ret_dict[key] = _clean_simple_type_list([value])\n\n if _is_list_of_dicts(value):\n child_list = []\n conf_val = conf.get(key, []) if conf else []\n for internal_val, internal_conf_val in itertools.zip_longest(value, conf_val):\n if isinstance(internal_val, dict):\n child_list.append(_hclify(internal_val, internal_conf_val, parent_key=key))\n if key == \"tags\":\n ret_dict[key] = [child_list]\n else:\n ret_dict[key] = child_list\n if isinstance(value, dict):\n child_dict = _hclify(value, parent_key=key)\n if parent_key == \"tags\":\n ret_dict[key] = child_dict\n else:\n ret_dict[key] = [child_dict]\n if conf and isinstance(conf, dict):\n found_ref = False\n for conf_key in conf.keys() - obj.keys():\n ref = next((x for x in conf[conf_key].get(\"references\", []) if not x.startswith((\"var.\", \"local.\"))), None)\n if ref:\n ret_dict[conf_key] = [ref]\n found_ref = True\n if not found_ref:\n for value in conf.values():\n if isinstance(value, dict) and \"references\" in value.keys():\n ret_dict[\"references_\"] = value[\"references\"]\n\n return ret_dict\n\n\ndef _prepare_resource_block(\n resource: DictNode, conf: Optional[DictNode], resource_changes: dict[str, dict[str, Any]]\n) -> tuple[dict[str, dict[str, Any]], bool]:\n \"\"\"hclify resource if pre-conditions met.\n\n :param resource: tf planned_values resource block\n :param conf: tf configuration resource block\n :param resource_changes: tf resource_changes block\n\n :returns:\n - resource_block: a list of strings representing the header columns\n - prepared: whether conditions met to prepare data\n \"\"\"\n\n resource_block: Dict[str, Dict[str, Any]] = {}\n resource_block[resource[\"type\"]] = {}\n prepared = False\n mode = \"\"\n if \"mode\" in resource:\n mode = resource.get(\"mode\")\n # Rare cases where data block appears in resources with same name as resource block and only partial values\n # and where *_module resources don't have values field\n if mode == \"managed\" and \"values\" in resource:\n expressions = conf.get(\"expressions\") if conf else None\n\n resource_conf = _hclify(resource[\"values\"], expressions)\n resource_address = resource.get(\"address\")\n resource_conf[TF_PLAN_RESOURCE_ADDRESS] = resource_address\n\n changes = resource_changes.get(resource_address)\n if changes:\n resource_conf[TF_PLAN_RESOURCE_CHANGE_ACTIONS] = changes.get(\"change\", {}).get(\"actions\") or []\n\n resource_block[resource[\"type\"]][resource.get(\"name\", \"default\")] = resource_conf\n prepared = True\n return resource_block, prepared\n\n\ndef _find_child_modules(\n child_modules: ListNode, resource_changes: dict[str, dict[str, Any]]\n) -> List[Dict[str, Dict[str, Any]]]:\n \"\"\"\n Find all child modules if any. Including any amount of nested child modules.\n :type: child_modules: list of tf child_module objects\n :rtype: resource_blocks: list of hcl resources\n \"\"\"\n resource_blocks = []\n for child_module in child_modules:\n if child_module.get(\"child_modules\", []):\n nested_child_modules = child_module.get(\"child_modules\", [])\n nested_blocks = _find_child_modules(nested_child_modules, resource_changes)\n for resource in nested_blocks:\n resource_blocks.append(resource)\n for resource in child_module.get(\"resources\", []):\n resource_block, prepared = _prepare_resource_block(\n resource=resource,\n conf=None,\n resource_changes=resource_changes,\n )\n if prepared is True:\n resource_blocks.append(resource_block)\n return resource_blocks\n\n\ndef _get_resource_changes(template: dict[str, Any]) -> dict[str, dict[str, Any]]:\n \"\"\"Returns a resource address to resource changes dict\"\"\"\n\n resource_changes_map = {}\n\n resource_changes = template.get(\"resource_changes\")\n if resource_changes and isinstance(resource_changes, list):\n resource_changes_map = {\n change.get(\"address\", \"\"): change\n for change in resource_changes\n }\n\n return resource_changes_map\n\n\ndef parse_tf_plan(tf_plan_file: str, out_parsing_errors: Dict[str, str]) -> Tuple[Optional[Dict[str, Any]], Optional[List[Tuple[int, str]]]]:\n \"\"\"\n :type tf_plan_file: str - path to plan file\n :rtype: tf_definition dictionary and template_lines of the plan file\n \"\"\"\n tf_definition: Dict[str, Any] = {\"resource\": []}\n template, template_lines = parse(tf_plan_file, out_parsing_errors)\n if not template:\n return None, None\n\n resource_changes = _get_resource_changes(template=template)\n\n for resource in template.get(\"planned_values\", {}).get(\"root_module\", {}).get(\"resources\", []):\n conf = next(\n (\n x\n for x in template.get(\"configuration\", {}).get(\"root_module\", {}).get(\"resources\", [])\n if x[\"type\"] == resource[\"type\"] and x[\"name\"] == resource[\"name\"]\n ),\n None,\n )\n resource_block, prepared = _prepare_resource_block(\n resource=resource,\n conf=conf,\n resource_changes=resource_changes,\n )\n if prepared is True:\n tf_definition[\"resource\"].append(resource_block)\n child_modules = template.get(\"planned_values\", {}).get(\"root_module\", {}).get(\"child_modules\", [])\n # Terraform supports modules within modules so we need to search\n # in nested modules to find all resource blocks\n resource_blocks = _find_child_modules(child_modules, resource_changes)\n for resource in resource_blocks:\n tf_definition[\"resource\"].append(resource)\n return tf_definition, template_lines\n\n\ndef _clean_simple_type_list(value_list: List[Any]) -> List[Any]:\n \"\"\"\n Given a list of simple types return a cleaned list of simple types.\n Converts booleans that are input as strings back to booleans to maintain consistent expectations for later evaluation.\n Sometimes Terraform Plan will output Map values as strings regardless of boolean input.\n \"\"\"\n for i in range(len(value_list)):\n if isinstance(value_list[i], str):\n lower_case_value = value_list[i].lower()\n if lower_case_value == \"true\":\n value_list[i] = True\n if lower_case_value == \"false\":\n value_list[i] = False \n return value_list\n", "path": "checkov/terraform/plan_parser.py"}], "after_files": [{"content": "from __future__ import annotations\n\nimport itertools\nfrom typing import Optional, Tuple, Dict, List, Any\n\nfrom checkov.common.parsers.node import DictNode, ListNode\nfrom checkov.terraform.context_parsers.tf_plan import parse\n\nSIMPLE_TYPES = (str, int, float, bool)\nTF_PLAN_RESOURCE_ADDRESS = \"__address__\"\nTF_PLAN_RESOURCE_CHANGE_ACTIONS = \"__change_actions__\"\n\n\ndef _is_simple_type(obj: Any) -> bool:\n if obj is None:\n return True\n if isinstance(obj, SIMPLE_TYPES):\n return True\n return False\n\n\ndef _is_list_of_simple_types(obj: Any) -> bool:\n if not isinstance(obj, list):\n return False\n for i in obj:\n if not _is_simple_type(i):\n return False\n return True\n\n\ndef _is_list_of_dicts(obj: Any) -> bool:\n if not isinstance(obj, list):\n return False\n for i in obj:\n if isinstance(i, dict):\n return True\n return False\n\n\ndef _hclify(obj: DictNode, conf: Optional[DictNode] = None, parent_key: Optional[str] = None) -> Dict[str, List[Any]]:\n ret_dict = {}\n if not isinstance(obj, dict):\n raise Exception(\"this method receives only dicts\")\n if hasattr(obj, \"start_mark\") and hasattr(obj, \"end_mark\"):\n obj[\"start_line\"] = obj.start_mark.line\n obj[\"end_line\"] = obj.end_mark.line\n for key, value in obj.items():\n if _is_simple_type(value) or _is_list_of_simple_types(value):\n if parent_key == \"tags\":\n ret_dict[key] = value\n else:\n ret_dict[key] = _clean_simple_type_list([value])\n\n if _is_list_of_dicts(value):\n child_list = []\n conf_val = conf.get(key, []) if conf else []\n for internal_val, internal_conf_val in itertools.zip_longest(value, conf_val):\n if isinstance(internal_val, dict):\n child_list.append(_hclify(internal_val, internal_conf_val, parent_key=key))\n if key == \"tags\":\n ret_dict[key] = [child_list]\n else:\n ret_dict[key] = child_list\n if isinstance(value, dict):\n child_dict = _hclify(value, parent_key=key)\n if parent_key == \"tags\":\n ret_dict[key] = child_dict\n else:\n ret_dict[key] = [child_dict]\n if conf and isinstance(conf, dict):\n found_ref = False\n for conf_key in conf.keys() - obj.keys():\n ref = next((x for x in conf[conf_key].get(\"references\", []) if not x.startswith((\"var.\", \"local.\"))), None)\n if ref:\n ret_dict[conf_key] = [ref]\n found_ref = True\n if not found_ref:\n for value in conf.values():\n if isinstance(value, dict) and \"references\" in value.keys():\n ret_dict[\"references_\"] = value[\"references\"]\n\n return ret_dict\n\n\ndef _prepare_resource_block(\n resource: DictNode, conf: Optional[DictNode], resource_changes: dict[str, dict[str, Any]]\n) -> tuple[dict[str, dict[str, Any]], bool]:\n \"\"\"hclify resource if pre-conditions met.\n\n :param resource: tf planned_values resource block\n :param conf: tf configuration resource block\n :param resource_changes: tf resource_changes block\n\n :returns:\n - resource_block: a list of strings representing the header columns\n - prepared: whether conditions met to prepare data\n \"\"\"\n\n resource_block: Dict[str, Dict[str, Any]] = {}\n resource_block[resource[\"type\"]] = {}\n prepared = False\n mode = \"\"\n if \"mode\" in resource:\n mode = resource.get(\"mode\")\n # Rare cases where data block appears in resources with same name as resource block and only partial values\n # and where *_module resources don't have values field\n if mode == \"managed\" and \"values\" in resource:\n expressions = conf.get(\"expressions\") if conf else None\n\n resource_conf = _hclify(resource[\"values\"], expressions)\n resource_address = resource.get(\"address\")\n resource_conf[TF_PLAN_RESOURCE_ADDRESS] = resource_address\n\n changes = resource_changes.get(resource_address)\n if changes:\n resource_conf[TF_PLAN_RESOURCE_CHANGE_ACTIONS] = changes.get(\"change\", {}).get(\"actions\") or []\n\n resource_block[resource[\"type\"]][resource.get(\"name\", \"default\")] = resource_conf\n prepared = True\n return resource_block, prepared\n\n\ndef _find_child_modules(\n child_modules: ListNode, resource_changes: dict[str, dict[str, Any]], root_module_conf: dict[str, Any]\n) -> List[Dict[str, Dict[str, Any]]]:\n \"\"\" Find all child modules if any. Including any amount of nested child modules.\n\n :param child_modules: list of terraform child_module objects\n :param resource_changes: a resource address to resource changes dict\n :param root_module_conf: configuration block of the root module\n :returns:\n list of terraform resource blocks\n \"\"\"\n\n resource_blocks = []\n for child_module in child_modules:\n nested_child_modules = child_module.get(\"child_modules\", [])\n if nested_child_modules:\n nested_blocks = _find_child_modules(\n child_modules=nested_child_modules,\n resource_changes=resource_changes,\n root_module_conf=root_module_conf\n )\n for resource in nested_blocks:\n resource_blocks.append(resource)\n\n module_address = child_module.get(\"address\", \"\")\n module_call_resources = _get_module_call_resources(\n module_address=module_address,\n root_module_conf=root_module_conf,\n )\n\n for resource in child_module.get(\"resources\", []):\n module_call_conf = None\n if module_address and module_call_resources:\n module_call_conf = next(\n (\n module_call_resource\n for module_call_resource in module_call_resources\n if f\"{module_address}.{module_call_resource['address']}\" == resource[\"address\"]\n ),\n None\n )\n\n resource_block, prepared = _prepare_resource_block(\n resource=resource,\n conf=module_call_conf,\n resource_changes=resource_changes,\n )\n if prepared is True:\n resource_blocks.append(resource_block)\n return resource_blocks\n\n\ndef _get_module_call_resources(module_address: str, root_module_conf: dict[str, Any]) -> list[dict[str, Any]]:\n \"\"\"Extracts the resources from the 'module_calls' block under 'configuration'\"\"\"\n\n for module_name in module_address.split(\".\"):\n if module_name == \"module\":\n # module names are always prefixed with 'module.', therefore skip it\n continue\n root_module_conf = root_module_conf.get(\"module_calls\", {}).get(module_name, {}).get(\"module\", {})\n\n return root_module_conf.get(\"resources\", [])\n\n\ndef _get_resource_changes(template: dict[str, Any]) -> dict[str, dict[str, Any]]:\n \"\"\"Returns a resource address to resource changes dict\"\"\"\n\n resource_changes_map = {}\n\n resource_changes = template.get(\"resource_changes\")\n if resource_changes and isinstance(resource_changes, list):\n resource_changes_map = {\n change.get(\"address\", \"\"): change\n for change in resource_changes\n }\n\n return resource_changes_map\n\n\ndef parse_tf_plan(tf_plan_file: str, out_parsing_errors: Dict[str, str]) -> Tuple[Optional[Dict[str, Any]], Optional[List[Tuple[int, str]]]]:\n \"\"\"\n :type tf_plan_file: str - path to plan file\n :rtype: tf_definition dictionary and template_lines of the plan file\n \"\"\"\n tf_definition: Dict[str, Any] = {\"resource\": []}\n template, template_lines = parse(tf_plan_file, out_parsing_errors)\n if not template:\n return None, None\n\n resource_changes = _get_resource_changes(template=template)\n\n for resource in template.get(\"planned_values\", {}).get(\"root_module\", {}).get(\"resources\", []):\n conf = next(\n (\n x\n for x in template.get(\"configuration\", {}).get(\"root_module\", {}).get(\"resources\", [])\n if x[\"type\"] == resource[\"type\"] and x[\"name\"] == resource[\"name\"]\n ),\n None,\n )\n resource_block, prepared = _prepare_resource_block(\n resource=resource,\n conf=conf,\n resource_changes=resource_changes,\n )\n if prepared is True:\n tf_definition[\"resource\"].append(resource_block)\n child_modules = template.get(\"planned_values\", {}).get(\"root_module\", {}).get(\"child_modules\", [])\n root_module_conf = template.get(\"configuration\", {}).get(\"root_module\", {})\n # Terraform supports modules within modules so we need to search\n # in nested modules to find all resource blocks\n resource_blocks = _find_child_modules(\n child_modules=child_modules,\n resource_changes=resource_changes,\n root_module_conf=root_module_conf,\n )\n for resource in resource_blocks:\n tf_definition[\"resource\"].append(resource)\n return tf_definition, template_lines\n\n\ndef _clean_simple_type_list(value_list: List[Any]) -> List[Any]:\n \"\"\"\n Given a list of simple types return a cleaned list of simple types.\n Converts booleans that are input as strings back to booleans to maintain consistent expectations for later evaluation.\n Sometimes Terraform Plan will output Map values as strings regardless of boolean input.\n \"\"\"\n for i in range(len(value_list)):\n if isinstance(value_list[i], str):\n lower_case_value = value_list[i].lower()\n if lower_case_value == \"true\":\n value_list[i] = True\n if lower_case_value == \"false\":\n value_list[i] = False \n return value_list\n", "path": "checkov/terraform/plan_parser.py"}]}
| 3,117 | 920 |
gh_patches_debug_3203
|
rasdani/github-patches
|
git_diff
|
dmlc__gluon-nlp-678
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
clip_grad_global_norm doc needs notice on usage (was: clip_grad_global_norm produces problematic results)
I tried to use mulitple gpus to train the language model (e.g., AWD-LSTM), but the behaviour is not expected. I paste the training logs in the first 2 epochs as follows. I set hyper-parameters `alpha` and `beta` to zeros.
The logs with gradient clipping:
4 GPUS:
```
[Epoch 0 Batch 200/372] current loss 8.72, ppl 6128.99, throughput 660.63 samples/s, lr 29.57
[Epoch 0] throughput 45928.01 samples/s
[Epoch 0] time cost 52.74s, valid loss 8.34, valid ppl 4199.37,lr 30.00
[Epoch 0] test loss 8.31, test ppl 4053.50
[Epoch 1 Batch 200/372] current loss 8.47, ppl 4790.62, throughput 701.91 samples/s, lr 15.00
[Epoch 1] throughput 47520.37 samples/s
[Epoch 1] time cost 51.10s, valid loss 8.82, valid ppl 6737.68,lr 30.00
```
1 GPU:
```
[Epoch 0 Batch 200/372] current loss 7.70, ppl 2205.38, throughput 295.53 samples/s, lr 29.57
[Epoch 0] throughput 19927.64 samples/s
[Epoch 0] time cost 112.08s, valid loss 6.81, valid ppl 907.20,lr 30.00
[Epoch 0] test loss 6.74, test ppl 849.29
[Epoch 1 Batch 200/372] current loss 7.02, ppl 1116.47, throughput 302.28 samples/s, lr 15.00
[Epoch 1] throughput 20606.80 samples/s
[Epoch 1] time cost 108.55s, valid loss 6.51, valid ppl 671.14,lr 30.00
```
The logs without gradient clipping:
4 GPUS:
```
[Epoch 0 Batch 200/372] current loss 7.67, ppl 2153.44, throughput 775.13 samples/s, lr 29.57
[Epoch 0] throughput 53775.66 samples/s
[Epoch 0] time cost 46.28s, valid loss 6.78, valid ppl 881.91,lr 30.00
[Epoch 0] test loss 6.71, test ppl 821.79
[Epoch 1 Batch 200/372] current loss 7.00, ppl 1099.21, throughput 831.20 samples/s, lr 15.00
[Epoch 1] throughput 56021.61 samples/s
[Epoch 1] time cost 44.62s, valid loss 6.48, valid ppl 650.45,lr 30.00
```
1 GPU:
```
[Epoch 0 Batch 200/372] current loss 7.69, ppl 2182.02, throughput 309.02 samples/s, lr 29.57
[Epoch 0] throughput 20760.28 samples/s
[Epoch 0] time cost 107.76s, valid loss 6.76, valid ppl 865.22,lr 30.00
[Epoch 0] test loss 6.70, test ppl 809.79
[Epoch 1 Batch 200/372] current loss 7.01, ppl 1110.89, throughput 307.27 samples/s, lr 15.00
[Epoch 1] throughput 20919.05 samples/s
[Epoch 1] time cost 106.92s, valid loss 6.51, valid ppl 673.24,lr 30.00
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/gluonnlp/utils/parameter.py`
Content:
```
1 # coding: utf-8
2
3 # Licensed to the Apache Software Foundation (ASF) under one
4 # or more contributor license agreements. See the NOTICE file
5 # distributed with this work for additional information
6 # regarding copyright ownership. The ASF licenses this file
7 # to you under the Apache License, Version 2.0 (the
8 # "License"); you may not use this file except in compliance
9 # with the License. You may obtain a copy of the License at
10 #
11 # http://www.apache.org/licenses/LICENSE-2.0
12 #
13 # Unless required by applicable law or agreed to in writing,
14 # software distributed under the License is distributed on an
15 # "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
16 # KIND, either express or implied. See the License for the
17 # specific language governing permissions and limitations
18 # under the License.
19 """Utility functions for parameters."""
20
21 __all__ = ['clip_grad_global_norm']
22
23 import warnings
24
25 import numpy as np
26 from mxnet import nd
27
28 def clip_grad_global_norm(parameters, max_norm, check_isfinite=True):
29 """Rescales gradients of parameters so that the sum of their 2-norm is smaller than `max_norm`.
30 If gradients exist for more than one context for a parameter, user needs to explicitly call
31 ``trainer.allreduce_grads`` so that the gradients are summed first before calculating
32 the 2-norm.
33
34 .. note::
35
36 This function is only for use when `update_on_kvstore` is set to False in trainer.
37
38 Example::
39
40 trainer = Trainer(net.collect_params(), update_on_kvstore=False, ...)
41 for x, y in mx.gluon.utils.split_and_load(X, [mx.gpu(0), mx.gpu(1)]):
42 with mx.autograd.record():
43 y = net(x)
44 loss = loss_fn(y, label)
45 loss.backward()
46 trainer.allreduce_grads()
47 nlp.utils.clip_grad_global_norm(net.collect_params().values(), max_norm)
48 trainer.update(batch_size)
49 ...
50
51 Parameters
52 ----------
53 parameters : list of Parameters
54 max_norm : float
55 check_isfinite : bool, default True
56 If True, check that the total_norm is finite (not nan or inf). This
57 requires a blocking .asscalar() call.
58
59 Returns
60 -------
61 NDArray or float
62 Total norm. Return type is NDArray of shape (1,) if check_isfinite is
63 False. Otherwise a float is returned.
64
65 """
66 def _norm(array):
67 if array.stype == 'default':
68 x = array.reshape((-1))
69 return nd.dot(x, x)
70 return array.norm().square()
71
72 arrays = []
73 i = 0
74 for p in parameters:
75 if p.grad_req != 'null':
76 grad_list = p.list_grad()
77 arrays.append(grad_list[i % len(grad_list)])
78 i += 1
79 assert len(arrays) > 0, 'No parameter found available for gradient norm clipping.'
80 ctx, dtype = arrays[0].context, arrays[0].dtype
81 total_norm = nd.add_n(*[_norm(arr).as_in_context(ctx) for arr in arrays])
82 total_norm = nd.sqrt(total_norm)
83 if check_isfinite:
84 total_norm = total_norm.asscalar()
85 if not np.isfinite(total_norm):
86 warnings.warn(
87 UserWarning('nan or inf is detected. '
88 'Clipping results will be undefined.'), stacklevel=2)
89 scale = max_norm / (total_norm + 1e-8)
90 if check_isfinite:
91 scale = nd.array([scale], dtype=dtype, ctx=ctx)
92 scale = nd.min(nd.concat(scale, nd.ones((1,), dtype=dtype, ctx=ctx), dim=0))
93 for p in parameters:
94 if p.grad_req != 'null':
95 for arr in p.list_grad():
96 arr *= scale.as_in_context(arr.context)
97 return total_norm
98
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/gluonnlp/utils/parameter.py b/src/gluonnlp/utils/parameter.py
--- a/src/gluonnlp/utils/parameter.py
+++ b/src/gluonnlp/utils/parameter.py
@@ -34,6 +34,9 @@
.. note::
This function is only for use when `update_on_kvstore` is set to False in trainer.
+ In cases where training happens on multiple contexts, this method should be used in
+ conjunction with ``trainer.allreduce_grads()`` and ``trainer.update()``.
+ (**not** ``trainer.step()``)
Example::
|
{"golden_diff": "diff --git a/src/gluonnlp/utils/parameter.py b/src/gluonnlp/utils/parameter.py\n--- a/src/gluonnlp/utils/parameter.py\n+++ b/src/gluonnlp/utils/parameter.py\n@@ -34,6 +34,9 @@\n .. note::\n \n This function is only for use when `update_on_kvstore` is set to False in trainer.\n+ In cases where training happens on multiple contexts, this method should be used in\n+ conjunction with ``trainer.allreduce_grads()`` and ``trainer.update()``.\n+ (**not** ``trainer.step()``)\n \n Example::\n", "issue": "clip_grad_global_norm doc needs notice on usage (was: clip_grad_global_norm produces problematic results)\nI tried to use mulitple gpus to train the language model (e.g., AWD-LSTM), but the behaviour is not expected. I paste the training logs in the first 2 epochs as follows. I set hyper-parameters `alpha` and `beta` to zeros.\r\n\r\nThe logs with gradient clipping:\r\n\r\n4 GPUS:\r\n```\r\n[Epoch 0 Batch 200/372] current loss 8.72, ppl 6128.99, throughput 660.63 samples/s, lr 29.57\r\n[Epoch 0] throughput 45928.01 samples/s\r\n[Epoch 0] time cost 52.74s, valid loss 8.34, valid ppl 4199.37\uff0clr 30.00\r\n[Epoch 0] test loss 8.31, test ppl 4053.50\r\n[Epoch 1 Batch 200/372] current loss 8.47, ppl 4790.62, throughput 701.91 samples/s, lr 15.00\r\n[Epoch 1] throughput 47520.37 samples/s\r\n[Epoch 1] time cost 51.10s, valid loss 8.82, valid ppl 6737.68\uff0clr 30.00\r\n```\r\n\r\n1 GPU:\r\n```\r\n[Epoch 0 Batch 200/372] current loss 7.70, ppl 2205.38, throughput 295.53 samples/s, lr 29.57\r\n[Epoch 0] throughput 19927.64 samples/s\r\n[Epoch 0] time cost 112.08s, valid loss 6.81, valid ppl 907.20\uff0clr 30.00\r\n[Epoch 0] test loss 6.74, test ppl 849.29\r\n[Epoch 1 Batch 200/372] current loss 7.02, ppl 1116.47, throughput 302.28 samples/s, lr 15.00\r\n[Epoch 1] throughput 20606.80 samples/s\r\n[Epoch 1] time cost 108.55s, valid loss 6.51, valid ppl 671.14\uff0clr 30.00\r\n```\r\n\r\nThe logs without gradient clipping:\r\n\r\n4 GPUS:\r\n```\r\n[Epoch 0 Batch 200/372] current loss 7.67, ppl 2153.44, throughput 775.13 samples/s, lr 29.57\r\n[Epoch 0] throughput 53775.66 samples/s\r\n[Epoch 0] time cost 46.28s, valid loss 6.78, valid ppl 881.91\uff0clr 30.00\r\n[Epoch 0] test loss 6.71, test ppl 821.79\r\n[Epoch 1 Batch 200/372] current loss 7.00, ppl 1099.21, throughput 831.20 samples/s, lr 15.00\r\n[Epoch 1] throughput 56021.61 samples/s\r\n[Epoch 1] time cost 44.62s, valid loss 6.48, valid ppl 650.45\uff0clr 30.00\r\n```\r\n\r\n1 GPU:\r\n```\r\n[Epoch 0 Batch 200/372] current loss 7.69, ppl 2182.02, throughput 309.02 samples/s, lr 29.57\r\n[Epoch 0] throughput 20760.28 samples/s\r\n[Epoch 0] time cost 107.76s, valid loss 6.76, valid ppl 865.22\uff0clr 30.00\r\n[Epoch 0] test loss 6.70, test ppl 809.79\r\n[Epoch 1 Batch 200/372] current loss 7.01, ppl 1110.89, throughput 307.27 samples/s, lr 15.00\r\n[Epoch 1] throughput 20919.05 samples/s\r\n[Epoch 1] time cost 106.92s, valid loss 6.51, valid ppl 673.24\uff0clr 30.00\r\n```\n", "before_files": [{"content": "# coding: utf-8\n\n# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\n\"\"\"Utility functions for parameters.\"\"\"\n\n__all__ = ['clip_grad_global_norm']\n\nimport warnings\n\nimport numpy as np\nfrom mxnet import nd\n\ndef clip_grad_global_norm(parameters, max_norm, check_isfinite=True):\n \"\"\"Rescales gradients of parameters so that the sum of their 2-norm is smaller than `max_norm`.\n If gradients exist for more than one context for a parameter, user needs to explicitly call\n ``trainer.allreduce_grads`` so that the gradients are summed first before calculating\n the 2-norm.\n\n .. note::\n\n This function is only for use when `update_on_kvstore` is set to False in trainer.\n\n Example::\n\n trainer = Trainer(net.collect_params(), update_on_kvstore=False, ...)\n for x, y in mx.gluon.utils.split_and_load(X, [mx.gpu(0), mx.gpu(1)]):\n with mx.autograd.record():\n y = net(x)\n loss = loss_fn(y, label)\n loss.backward()\n trainer.allreduce_grads()\n nlp.utils.clip_grad_global_norm(net.collect_params().values(), max_norm)\n trainer.update(batch_size)\n ...\n\n Parameters\n ----------\n parameters : list of Parameters\n max_norm : float\n check_isfinite : bool, default True\n If True, check that the total_norm is finite (not nan or inf). This\n requires a blocking .asscalar() call.\n\n Returns\n -------\n NDArray or float\n Total norm. Return type is NDArray of shape (1,) if check_isfinite is\n False. Otherwise a float is returned.\n\n \"\"\"\n def _norm(array):\n if array.stype == 'default':\n x = array.reshape((-1))\n return nd.dot(x, x)\n return array.norm().square()\n\n arrays = []\n i = 0\n for p in parameters:\n if p.grad_req != 'null':\n grad_list = p.list_grad()\n arrays.append(grad_list[i % len(grad_list)])\n i += 1\n assert len(arrays) > 0, 'No parameter found available for gradient norm clipping.'\n ctx, dtype = arrays[0].context, arrays[0].dtype\n total_norm = nd.add_n(*[_norm(arr).as_in_context(ctx) for arr in arrays])\n total_norm = nd.sqrt(total_norm)\n if check_isfinite:\n total_norm = total_norm.asscalar()\n if not np.isfinite(total_norm):\n warnings.warn(\n UserWarning('nan or inf is detected. '\n 'Clipping results will be undefined.'), stacklevel=2)\n scale = max_norm / (total_norm + 1e-8)\n if check_isfinite:\n scale = nd.array([scale], dtype=dtype, ctx=ctx)\n scale = nd.min(nd.concat(scale, nd.ones((1,), dtype=dtype, ctx=ctx), dim=0))\n for p in parameters:\n if p.grad_req != 'null':\n for arr in p.list_grad():\n arr *= scale.as_in_context(arr.context)\n return total_norm\n", "path": "src/gluonnlp/utils/parameter.py"}], "after_files": [{"content": "# coding: utf-8\n\n# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\n\"\"\"Utility functions for parameters.\"\"\"\n\n__all__ = ['clip_grad_global_norm']\n\nimport warnings\n\nimport numpy as np\nfrom mxnet import nd\n\ndef clip_grad_global_norm(parameters, max_norm, check_isfinite=True):\n \"\"\"Rescales gradients of parameters so that the sum of their 2-norm is smaller than `max_norm`.\n If gradients exist for more than one context for a parameter, user needs to explicitly call\n ``trainer.allreduce_grads`` so that the gradients are summed first before calculating\n the 2-norm.\n\n .. note::\n\n This function is only for use when `update_on_kvstore` is set to False in trainer.\n In cases where training happens on multiple contexts, this method should be used in\n conjunction with ``trainer.allreduce_grads()`` and ``trainer.update()``.\n (**not** ``trainer.step()``)\n\n Example::\n\n trainer = Trainer(net.collect_params(), update_on_kvstore=False, ...)\n for x, y in mx.gluon.utils.split_and_load(X, [mx.gpu(0), mx.gpu(1)]):\n with mx.autograd.record():\n y = net(x)\n loss = loss_fn(y, label)\n loss.backward()\n trainer.allreduce_grads()\n nlp.utils.clip_grad_global_norm(net.collect_params().values(), max_norm)\n trainer.update(batch_size)\n ...\n\n Parameters\n ----------\n parameters : list of Parameters\n max_norm : float\n check_isfinite : bool, default True\n If True, check that the total_norm is finite (not nan or inf). This\n requires a blocking .asscalar() call.\n\n Returns\n -------\n NDArray or float\n Total norm. Return type is NDArray of shape (1,) if check_isfinite is\n False. Otherwise a float is returned.\n\n \"\"\"\n def _norm(array):\n if array.stype == 'default':\n x = array.reshape((-1))\n return nd.dot(x, x)\n return array.norm().square()\n\n arrays = []\n i = 0\n for p in parameters:\n if p.grad_req != 'null':\n grad_list = p.list_grad()\n arrays.append(grad_list[i % len(grad_list)])\n i += 1\n assert len(arrays) > 0, 'No parameter found available for gradient norm clipping.'\n ctx, dtype = arrays[0].context, arrays[0].dtype\n total_norm = nd.add_n(*[_norm(arr).as_in_context(ctx) for arr in arrays])\n total_norm = nd.sqrt(total_norm)\n if check_isfinite:\n total_norm = total_norm.asscalar()\n if not np.isfinite(total_norm):\n warnings.warn(\n UserWarning('nan or inf is detected. '\n 'Clipping results will be undefined.'), stacklevel=2)\n scale = max_norm / (total_norm + 1e-8)\n if check_isfinite:\n scale = nd.array([scale], dtype=dtype, ctx=ctx)\n scale = nd.min(nd.concat(scale, nd.ones((1,), dtype=dtype, ctx=ctx), dim=0))\n for p in parameters:\n if p.grad_req != 'null':\n for arr in p.list_grad():\n arr *= scale.as_in_context(arr.context)\n return total_norm\n", "path": "src/gluonnlp/utils/parameter.py"}]}
| 2,398 | 138 |
gh_patches_debug_21152
|
rasdani/github-patches
|
git_diff
|
blakeblackshear__frigate-8723
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Catch time zone tzlocal error
### Describe the problem you are having
Im always seeing this message, unfortunately i did exactly what this message is tellimg me.
I'm currently using beta5, but also tested with stable.
The docker-host (debian 12) also uses this timezone.
```
timedatectl | grep "Time zone"
Time zone: Europe/Vienna (CET, +0100)
```
I configured it in the docker-compose. I also tried a different City, with the same result.
I also tried to remove this. What am i missing?
```
environment:
- TZ="Europe/Vienna"
# - TZ="Europe/Berlin"
```
### Version
beta5
### Frigate config file
```yaml
empty default config!
```
### Relevant log output
```shell
zoneinfo._common.ZoneInfoNotFoundError: 'tzlocal() does not support non-zoneinfo timezones like "Europe/Vienna". \nPlease use a timezone in the form of Continent/City'
```
### FFprobe output from your camera
```shell
-
```
### Frigate stats
```json
-
```
### Operating system
Debian
### Install method
Docker Compose
### Coral version
Other
### Network connection
Wired
### Camera make and model
-
### Any other information that may be helpful
-
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `frigate/util/builtin.py`
Content:
```
1 """Utilities for builtin types manipulation."""
2
3 import copy
4 import datetime
5 import logging
6 import re
7 import shlex
8 import urllib.parse
9 from collections import Counter
10 from collections.abc import Mapping
11 from pathlib import Path
12 from typing import Any, Tuple
13
14 import numpy as np
15 import pytz
16 import yaml
17 from ruamel.yaml import YAML
18 from tzlocal import get_localzone
19
20 from frigate.const import REGEX_HTTP_CAMERA_USER_PASS, REGEX_RTSP_CAMERA_USER_PASS
21
22 logger = logging.getLogger(__name__)
23
24
25 class EventsPerSecond:
26 def __init__(self, max_events=1000, last_n_seconds=10):
27 self._start = None
28 self._max_events = max_events
29 self._last_n_seconds = last_n_seconds
30 self._timestamps = []
31
32 def start(self):
33 self._start = datetime.datetime.now().timestamp()
34
35 def update(self):
36 now = datetime.datetime.now().timestamp()
37 if self._start is None:
38 self._start = now
39 self._timestamps.append(now)
40 # truncate the list when it goes 100 over the max_size
41 if len(self._timestamps) > self._max_events + 100:
42 self._timestamps = self._timestamps[(1 - self._max_events) :]
43 self.expire_timestamps(now)
44
45 def eps(self):
46 now = datetime.datetime.now().timestamp()
47 if self._start is None:
48 self._start = now
49 # compute the (approximate) events in the last n seconds
50 self.expire_timestamps(now)
51 seconds = min(now - self._start, self._last_n_seconds)
52 # avoid divide by zero
53 if seconds == 0:
54 seconds = 1
55 return len(self._timestamps) / seconds
56
57 # remove aged out timestamps
58 def expire_timestamps(self, now):
59 threshold = now - self._last_n_seconds
60 while self._timestamps and self._timestamps[0] < threshold:
61 del self._timestamps[0]
62
63
64 def deep_merge(dct1: dict, dct2: dict, override=False, merge_lists=False) -> dict:
65 """
66 :param dct1: First dict to merge
67 :param dct2: Second dict to merge
68 :param override: if same key exists in both dictionaries, should override? otherwise ignore. (default=True)
69 :return: The merge dictionary
70 """
71 merged = copy.deepcopy(dct1)
72 for k, v2 in dct2.items():
73 if k in merged:
74 v1 = merged[k]
75 if isinstance(v1, dict) and isinstance(v2, Mapping):
76 merged[k] = deep_merge(v1, v2, override)
77 elif isinstance(v1, list) and isinstance(v2, list):
78 if merge_lists:
79 merged[k] = v1 + v2
80 else:
81 if override:
82 merged[k] = copy.deepcopy(v2)
83 else:
84 merged[k] = copy.deepcopy(v2)
85 return merged
86
87
88 def load_config_with_no_duplicates(raw_config) -> dict:
89 """Get config ensuring duplicate keys are not allowed."""
90
91 # https://stackoverflow.com/a/71751051
92 # important to use SafeLoader here to avoid RCE
93 class PreserveDuplicatesLoader(yaml.loader.SafeLoader):
94 pass
95
96 def map_constructor(loader, node, deep=False):
97 keys = [loader.construct_object(node, deep=deep) for node, _ in node.value]
98 vals = [loader.construct_object(node, deep=deep) for _, node in node.value]
99 key_count = Counter(keys)
100 data = {}
101 for key, val in zip(keys, vals):
102 if key_count[key] > 1:
103 raise ValueError(
104 f"Config input {key} is defined multiple times for the same field, this is not allowed."
105 )
106 else:
107 data[key] = val
108 return data
109
110 PreserveDuplicatesLoader.add_constructor(
111 yaml.resolver.BaseResolver.DEFAULT_MAPPING_TAG, map_constructor
112 )
113 return yaml.load(raw_config, PreserveDuplicatesLoader)
114
115
116 def clean_camera_user_pass(line: str) -> str:
117 """Removes user and password from line."""
118 rtsp_cleaned = re.sub(REGEX_RTSP_CAMERA_USER_PASS, "://*:*@", line)
119 return re.sub(REGEX_HTTP_CAMERA_USER_PASS, "user=*&password=*", rtsp_cleaned)
120
121
122 def escape_special_characters(path: str) -> str:
123 """Cleans reserved characters to encodings for ffmpeg."""
124 try:
125 found = re.search(REGEX_RTSP_CAMERA_USER_PASS, path).group(0)[3:-1]
126 pw = found[(found.index(":") + 1) :]
127 return path.replace(pw, urllib.parse.quote_plus(pw))
128 except AttributeError:
129 # path does not have user:pass
130 return path
131
132
133 def get_ffmpeg_arg_list(arg: Any) -> list:
134 """Use arg if list or convert to list format."""
135 return arg if isinstance(arg, list) else shlex.split(arg)
136
137
138 def load_labels(path, encoding="utf-8", prefill=91):
139 """Loads labels from file (with or without index numbers).
140 Args:
141 path: path to label file.
142 encoding: label file encoding.
143 Returns:
144 Dictionary mapping indices to labels.
145 """
146 with open(path, "r", encoding=encoding) as f:
147 labels = {index: "unknown" for index in range(prefill)}
148 lines = f.readlines()
149 if not lines:
150 return {}
151
152 if lines[0].split(" ", maxsplit=1)[0].isdigit():
153 pairs = [line.split(" ", maxsplit=1) for line in lines]
154 labels.update({int(index): label.strip() for index, label in pairs})
155 else:
156 labels.update({index: line.strip() for index, line in enumerate(lines)})
157 return labels
158
159
160 def get_tz_modifiers(tz_name: str) -> Tuple[str, str, int]:
161 seconds_offset = (
162 datetime.datetime.now(pytz.timezone(tz_name)).utcoffset().total_seconds()
163 )
164 hours_offset = int(seconds_offset / 60 / 60)
165 minutes_offset = int(seconds_offset / 60 - hours_offset * 60)
166 hour_modifier = f"{hours_offset} hour"
167 minute_modifier = f"{minutes_offset} minute"
168 return hour_modifier, minute_modifier, seconds_offset
169
170
171 def to_relative_box(
172 width: int, height: int, box: Tuple[int, int, int, int]
173 ) -> Tuple[int, int, int, int]:
174 return (
175 box[0] / width, # x
176 box[1] / height, # y
177 (box[2] - box[0]) / width, # w
178 (box[3] - box[1]) / height, # h
179 )
180
181
182 def create_mask(frame_shape, mask):
183 mask_img = np.zeros(frame_shape, np.uint8)
184 mask_img[:] = 255
185
186
187 def update_yaml_from_url(file_path, url):
188 parsed_url = urllib.parse.urlparse(url)
189 query_string = urllib.parse.parse_qs(parsed_url.query, keep_blank_values=True)
190
191 for key_path_str, new_value_list in query_string.items():
192 key_path = key_path_str.split(".")
193 for i in range(len(key_path)):
194 try:
195 index = int(key_path[i])
196 key_path[i] = (key_path[i - 1], index)
197 key_path.pop(i - 1)
198 except ValueError:
199 pass
200 new_value = new_value_list[0]
201 update_yaml_file(file_path, key_path, new_value)
202
203
204 def update_yaml_file(file_path, key_path, new_value):
205 yaml = YAML()
206 with open(file_path, "r") as f:
207 data = yaml.load(f)
208
209 data = update_yaml(data, key_path, new_value)
210
211 with open(file_path, "w") as f:
212 yaml.dump(data, f)
213
214
215 def update_yaml(data, key_path, new_value):
216 temp = data
217 for key in key_path[:-1]:
218 if isinstance(key, tuple):
219 if key[0] not in temp:
220 temp[key[0]] = [{}] * max(1, key[1] + 1)
221 elif len(temp[key[0]]) <= key[1]:
222 temp[key[0]] += [{}] * (key[1] - len(temp[key[0]]) + 1)
223 temp = temp[key[0]][key[1]]
224 else:
225 if key not in temp:
226 temp[key] = {}
227 temp = temp[key]
228
229 last_key = key_path[-1]
230 if new_value == "":
231 if isinstance(last_key, tuple):
232 del temp[last_key[0]][last_key[1]]
233 else:
234 del temp[last_key]
235 else:
236 if isinstance(last_key, tuple):
237 if last_key[0] not in temp:
238 temp[last_key[0]] = [{}] * max(1, last_key[1] + 1)
239 elif len(temp[last_key[0]]) <= last_key[1]:
240 temp[last_key[0]] += [{}] * (last_key[1] - len(temp[last_key[0]]) + 1)
241 temp[last_key[0]][last_key[1]] = new_value
242 else:
243 if (
244 last_key in temp
245 and isinstance(temp[last_key], dict)
246 and isinstance(new_value, dict)
247 ):
248 temp[last_key].update(new_value)
249 else:
250 temp[last_key] = new_value
251
252 return data
253
254
255 def find_by_key(dictionary, target_key):
256 if target_key in dictionary:
257 return dictionary[target_key]
258 else:
259 for value in dictionary.values():
260 if isinstance(value, dict):
261 result = find_by_key(value, target_key)
262 if result is not None:
263 return result
264 return None
265
266
267 def get_tomorrow_at_time(hour: int) -> datetime.datetime:
268 """Returns the datetime of the following day at 2am."""
269 tomorrow = datetime.datetime.now(get_localzone()) + datetime.timedelta(days=1)
270 return tomorrow.replace(hour=hour, minute=0, second=0).astimezone(
271 datetime.timezone.utc
272 )
273
274
275 def clear_and_unlink(file: Path, missing_ok: bool = True) -> None:
276 """clear file then unlink to avoid space retained by file descriptors."""
277 if not missing_ok and not file.exists():
278 raise FileNotFoundError()
279
280 # empty contents of file before unlinking https://github.com/blakeblackshear/frigate/issues/4769
281 with open(file, "w"):
282 pass
283
284 file.unlink(missing_ok=missing_ok)
285
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/frigate/util/builtin.py b/frigate/util/builtin.py
--- a/frigate/util/builtin.py
+++ b/frigate/util/builtin.py
@@ -16,6 +16,7 @@
import yaml
from ruamel.yaml import YAML
from tzlocal import get_localzone
+from zoneinfo import ZoneInfoNotFoundError
from frigate.const import REGEX_HTTP_CAMERA_USER_PASS, REGEX_RTSP_CAMERA_USER_PASS
@@ -266,7 +267,16 @@
def get_tomorrow_at_time(hour: int) -> datetime.datetime:
"""Returns the datetime of the following day at 2am."""
- tomorrow = datetime.datetime.now(get_localzone()) + datetime.timedelta(days=1)
+ try:
+ tomorrow = datetime.datetime.now(get_localzone()) + datetime.timedelta(days=1)
+ except ZoneInfoNotFoundError:
+ tomorrow = datetime.datetime.now(datetime.timezone.utc) + datetime.timedelta(
+ days=1
+ )
+ logger.warning(
+ "Using utc for maintenance due to missing or incorrect timezone set"
+ )
+
return tomorrow.replace(hour=hour, minute=0, second=0).astimezone(
datetime.timezone.utc
)
|
{"golden_diff": "diff --git a/frigate/util/builtin.py b/frigate/util/builtin.py\n--- a/frigate/util/builtin.py\n+++ b/frigate/util/builtin.py\n@@ -16,6 +16,7 @@\n import yaml\n from ruamel.yaml import YAML\n from tzlocal import get_localzone\n+from zoneinfo import ZoneInfoNotFoundError\n \n from frigate.const import REGEX_HTTP_CAMERA_USER_PASS, REGEX_RTSP_CAMERA_USER_PASS\n \n@@ -266,7 +267,16 @@\n \n def get_tomorrow_at_time(hour: int) -> datetime.datetime:\n \"\"\"Returns the datetime of the following day at 2am.\"\"\"\n- tomorrow = datetime.datetime.now(get_localzone()) + datetime.timedelta(days=1)\n+ try:\n+ tomorrow = datetime.datetime.now(get_localzone()) + datetime.timedelta(days=1)\n+ except ZoneInfoNotFoundError:\n+ tomorrow = datetime.datetime.now(datetime.timezone.utc) + datetime.timedelta(\n+ days=1\n+ )\n+ logger.warning(\n+ \"Using utc for maintenance due to missing or incorrect timezone set\"\n+ )\n+\n return tomorrow.replace(hour=hour, minute=0, second=0).astimezone(\n datetime.timezone.utc\n )\n", "issue": "Catch time zone tzlocal error\n### Describe the problem you are having\n\nIm always seeing this message, unfortunately i did exactly what this message is tellimg me.\r\nI'm currently using beta5, but also tested with stable.\r\n\r\n\r\nThe docker-host (debian 12) also uses this timezone. \r\n```\r\ntimedatectl | grep \"Time zone\"\r\nTime zone: Europe/Vienna (CET, +0100)\r\n```\r\n\r\nI configured it in the docker-compose. I also tried a different City, with the same result. \r\nI also tried to remove this. What am i missing?\r\n```\r\n environment:\r\n - TZ=\"Europe/Vienna\"\r\n# - TZ=\"Europe/Berlin\" \r\n\r\n```\n\n### Version\n\nbeta5\n\n### Frigate config file\n\n```yaml\nempty default config!\n```\n\n\n### Relevant log output\n\n```shell\nzoneinfo._common.ZoneInfoNotFoundError: 'tzlocal() does not support non-zoneinfo timezones like \"Europe/Vienna\". \\nPlease use a timezone in the form of Continent/City'\n```\n\n\n### FFprobe output from your camera\n\n```shell\n-\n```\n\n\n### Frigate stats\n\n```json\n-\n```\n\n\n### Operating system\n\nDebian\n\n### Install method\n\nDocker Compose\n\n### Coral version\n\nOther\n\n### Network connection\n\nWired\n\n### Camera make and model\n\n-\n\n### Any other information that may be helpful\n\n-\n", "before_files": [{"content": "\"\"\"Utilities for builtin types manipulation.\"\"\"\n\nimport copy\nimport datetime\nimport logging\nimport re\nimport shlex\nimport urllib.parse\nfrom collections import Counter\nfrom collections.abc import Mapping\nfrom pathlib import Path\nfrom typing import Any, Tuple\n\nimport numpy as np\nimport pytz\nimport yaml\nfrom ruamel.yaml import YAML\nfrom tzlocal import get_localzone\n\nfrom frigate.const import REGEX_HTTP_CAMERA_USER_PASS, REGEX_RTSP_CAMERA_USER_PASS\n\nlogger = logging.getLogger(__name__)\n\n\nclass EventsPerSecond:\n def __init__(self, max_events=1000, last_n_seconds=10):\n self._start = None\n self._max_events = max_events\n self._last_n_seconds = last_n_seconds\n self._timestamps = []\n\n def start(self):\n self._start = datetime.datetime.now().timestamp()\n\n def update(self):\n now = datetime.datetime.now().timestamp()\n if self._start is None:\n self._start = now\n self._timestamps.append(now)\n # truncate the list when it goes 100 over the max_size\n if len(self._timestamps) > self._max_events + 100:\n self._timestamps = self._timestamps[(1 - self._max_events) :]\n self.expire_timestamps(now)\n\n def eps(self):\n now = datetime.datetime.now().timestamp()\n if self._start is None:\n self._start = now\n # compute the (approximate) events in the last n seconds\n self.expire_timestamps(now)\n seconds = min(now - self._start, self._last_n_seconds)\n # avoid divide by zero\n if seconds == 0:\n seconds = 1\n return len(self._timestamps) / seconds\n\n # remove aged out timestamps\n def expire_timestamps(self, now):\n threshold = now - self._last_n_seconds\n while self._timestamps and self._timestamps[0] < threshold:\n del self._timestamps[0]\n\n\ndef deep_merge(dct1: dict, dct2: dict, override=False, merge_lists=False) -> dict:\n \"\"\"\n :param dct1: First dict to merge\n :param dct2: Second dict to merge\n :param override: if same key exists in both dictionaries, should override? otherwise ignore. (default=True)\n :return: The merge dictionary\n \"\"\"\n merged = copy.deepcopy(dct1)\n for k, v2 in dct2.items():\n if k in merged:\n v1 = merged[k]\n if isinstance(v1, dict) and isinstance(v2, Mapping):\n merged[k] = deep_merge(v1, v2, override)\n elif isinstance(v1, list) and isinstance(v2, list):\n if merge_lists:\n merged[k] = v1 + v2\n else:\n if override:\n merged[k] = copy.deepcopy(v2)\n else:\n merged[k] = copy.deepcopy(v2)\n return merged\n\n\ndef load_config_with_no_duplicates(raw_config) -> dict:\n \"\"\"Get config ensuring duplicate keys are not allowed.\"\"\"\n\n # https://stackoverflow.com/a/71751051\n # important to use SafeLoader here to avoid RCE\n class PreserveDuplicatesLoader(yaml.loader.SafeLoader):\n pass\n\n def map_constructor(loader, node, deep=False):\n keys = [loader.construct_object(node, deep=deep) for node, _ in node.value]\n vals = [loader.construct_object(node, deep=deep) for _, node in node.value]\n key_count = Counter(keys)\n data = {}\n for key, val in zip(keys, vals):\n if key_count[key] > 1:\n raise ValueError(\n f\"Config input {key} is defined multiple times for the same field, this is not allowed.\"\n )\n else:\n data[key] = val\n return data\n\n PreserveDuplicatesLoader.add_constructor(\n yaml.resolver.BaseResolver.DEFAULT_MAPPING_TAG, map_constructor\n )\n return yaml.load(raw_config, PreserveDuplicatesLoader)\n\n\ndef clean_camera_user_pass(line: str) -> str:\n \"\"\"Removes user and password from line.\"\"\"\n rtsp_cleaned = re.sub(REGEX_RTSP_CAMERA_USER_PASS, \"://*:*@\", line)\n return re.sub(REGEX_HTTP_CAMERA_USER_PASS, \"user=*&password=*\", rtsp_cleaned)\n\n\ndef escape_special_characters(path: str) -> str:\n \"\"\"Cleans reserved characters to encodings for ffmpeg.\"\"\"\n try:\n found = re.search(REGEX_RTSP_CAMERA_USER_PASS, path).group(0)[3:-1]\n pw = found[(found.index(\":\") + 1) :]\n return path.replace(pw, urllib.parse.quote_plus(pw))\n except AttributeError:\n # path does not have user:pass\n return path\n\n\ndef get_ffmpeg_arg_list(arg: Any) -> list:\n \"\"\"Use arg if list or convert to list format.\"\"\"\n return arg if isinstance(arg, list) else shlex.split(arg)\n\n\ndef load_labels(path, encoding=\"utf-8\", prefill=91):\n \"\"\"Loads labels from file (with or without index numbers).\n Args:\n path: path to label file.\n encoding: label file encoding.\n Returns:\n Dictionary mapping indices to labels.\n \"\"\"\n with open(path, \"r\", encoding=encoding) as f:\n labels = {index: \"unknown\" for index in range(prefill)}\n lines = f.readlines()\n if not lines:\n return {}\n\n if lines[0].split(\" \", maxsplit=1)[0].isdigit():\n pairs = [line.split(\" \", maxsplit=1) for line in lines]\n labels.update({int(index): label.strip() for index, label in pairs})\n else:\n labels.update({index: line.strip() for index, line in enumerate(lines)})\n return labels\n\n\ndef get_tz_modifiers(tz_name: str) -> Tuple[str, str, int]:\n seconds_offset = (\n datetime.datetime.now(pytz.timezone(tz_name)).utcoffset().total_seconds()\n )\n hours_offset = int(seconds_offset / 60 / 60)\n minutes_offset = int(seconds_offset / 60 - hours_offset * 60)\n hour_modifier = f\"{hours_offset} hour\"\n minute_modifier = f\"{minutes_offset} minute\"\n return hour_modifier, minute_modifier, seconds_offset\n\n\ndef to_relative_box(\n width: int, height: int, box: Tuple[int, int, int, int]\n) -> Tuple[int, int, int, int]:\n return (\n box[0] / width, # x\n box[1] / height, # y\n (box[2] - box[0]) / width, # w\n (box[3] - box[1]) / height, # h\n )\n\n\ndef create_mask(frame_shape, mask):\n mask_img = np.zeros(frame_shape, np.uint8)\n mask_img[:] = 255\n\n\ndef update_yaml_from_url(file_path, url):\n parsed_url = urllib.parse.urlparse(url)\n query_string = urllib.parse.parse_qs(parsed_url.query, keep_blank_values=True)\n\n for key_path_str, new_value_list in query_string.items():\n key_path = key_path_str.split(\".\")\n for i in range(len(key_path)):\n try:\n index = int(key_path[i])\n key_path[i] = (key_path[i - 1], index)\n key_path.pop(i - 1)\n except ValueError:\n pass\n new_value = new_value_list[0]\n update_yaml_file(file_path, key_path, new_value)\n\n\ndef update_yaml_file(file_path, key_path, new_value):\n yaml = YAML()\n with open(file_path, \"r\") as f:\n data = yaml.load(f)\n\n data = update_yaml(data, key_path, new_value)\n\n with open(file_path, \"w\") as f:\n yaml.dump(data, f)\n\n\ndef update_yaml(data, key_path, new_value):\n temp = data\n for key in key_path[:-1]:\n if isinstance(key, tuple):\n if key[0] not in temp:\n temp[key[0]] = [{}] * max(1, key[1] + 1)\n elif len(temp[key[0]]) <= key[1]:\n temp[key[0]] += [{}] * (key[1] - len(temp[key[0]]) + 1)\n temp = temp[key[0]][key[1]]\n else:\n if key not in temp:\n temp[key] = {}\n temp = temp[key]\n\n last_key = key_path[-1]\n if new_value == \"\":\n if isinstance(last_key, tuple):\n del temp[last_key[0]][last_key[1]]\n else:\n del temp[last_key]\n else:\n if isinstance(last_key, tuple):\n if last_key[0] not in temp:\n temp[last_key[0]] = [{}] * max(1, last_key[1] + 1)\n elif len(temp[last_key[0]]) <= last_key[1]:\n temp[last_key[0]] += [{}] * (last_key[1] - len(temp[last_key[0]]) + 1)\n temp[last_key[0]][last_key[1]] = new_value\n else:\n if (\n last_key in temp\n and isinstance(temp[last_key], dict)\n and isinstance(new_value, dict)\n ):\n temp[last_key].update(new_value)\n else:\n temp[last_key] = new_value\n\n return data\n\n\ndef find_by_key(dictionary, target_key):\n if target_key in dictionary:\n return dictionary[target_key]\n else:\n for value in dictionary.values():\n if isinstance(value, dict):\n result = find_by_key(value, target_key)\n if result is not None:\n return result\n return None\n\n\ndef get_tomorrow_at_time(hour: int) -> datetime.datetime:\n \"\"\"Returns the datetime of the following day at 2am.\"\"\"\n tomorrow = datetime.datetime.now(get_localzone()) + datetime.timedelta(days=1)\n return tomorrow.replace(hour=hour, minute=0, second=0).astimezone(\n datetime.timezone.utc\n )\n\n\ndef clear_and_unlink(file: Path, missing_ok: bool = True) -> None:\n \"\"\"clear file then unlink to avoid space retained by file descriptors.\"\"\"\n if not missing_ok and not file.exists():\n raise FileNotFoundError()\n\n # empty contents of file before unlinking https://github.com/blakeblackshear/frigate/issues/4769\n with open(file, \"w\"):\n pass\n\n file.unlink(missing_ok=missing_ok)\n", "path": "frigate/util/builtin.py"}], "after_files": [{"content": "\"\"\"Utilities for builtin types manipulation.\"\"\"\n\nimport copy\nimport datetime\nimport logging\nimport re\nimport shlex\nimport urllib.parse\nfrom collections import Counter\nfrom collections.abc import Mapping\nfrom pathlib import Path\nfrom typing import Any, Tuple\n\nimport numpy as np\nimport pytz\nimport yaml\nfrom ruamel.yaml import YAML\nfrom tzlocal import get_localzone\nfrom zoneinfo import ZoneInfoNotFoundError\n\nfrom frigate.const import REGEX_HTTP_CAMERA_USER_PASS, REGEX_RTSP_CAMERA_USER_PASS\n\nlogger = logging.getLogger(__name__)\n\n\nclass EventsPerSecond:\n def __init__(self, max_events=1000, last_n_seconds=10):\n self._start = None\n self._max_events = max_events\n self._last_n_seconds = last_n_seconds\n self._timestamps = []\n\n def start(self):\n self._start = datetime.datetime.now().timestamp()\n\n def update(self):\n now = datetime.datetime.now().timestamp()\n if self._start is None:\n self._start = now\n self._timestamps.append(now)\n # truncate the list when it goes 100 over the max_size\n if len(self._timestamps) > self._max_events + 100:\n self._timestamps = self._timestamps[(1 - self._max_events) :]\n self.expire_timestamps(now)\n\n def eps(self):\n now = datetime.datetime.now().timestamp()\n if self._start is None:\n self._start = now\n # compute the (approximate) events in the last n seconds\n self.expire_timestamps(now)\n seconds = min(now - self._start, self._last_n_seconds)\n # avoid divide by zero\n if seconds == 0:\n seconds = 1\n return len(self._timestamps) / seconds\n\n # remove aged out timestamps\n def expire_timestamps(self, now):\n threshold = now - self._last_n_seconds\n while self._timestamps and self._timestamps[0] < threshold:\n del self._timestamps[0]\n\n\ndef deep_merge(dct1: dict, dct2: dict, override=False, merge_lists=False) -> dict:\n \"\"\"\n :param dct1: First dict to merge\n :param dct2: Second dict to merge\n :param override: if same key exists in both dictionaries, should override? otherwise ignore. (default=True)\n :return: The merge dictionary\n \"\"\"\n merged = copy.deepcopy(dct1)\n for k, v2 in dct2.items():\n if k in merged:\n v1 = merged[k]\n if isinstance(v1, dict) and isinstance(v2, Mapping):\n merged[k] = deep_merge(v1, v2, override)\n elif isinstance(v1, list) and isinstance(v2, list):\n if merge_lists:\n merged[k] = v1 + v2\n else:\n if override:\n merged[k] = copy.deepcopy(v2)\n else:\n merged[k] = copy.deepcopy(v2)\n return merged\n\n\ndef load_config_with_no_duplicates(raw_config) -> dict:\n \"\"\"Get config ensuring duplicate keys are not allowed.\"\"\"\n\n # https://stackoverflow.com/a/71751051\n # important to use SafeLoader here to avoid RCE\n class PreserveDuplicatesLoader(yaml.loader.SafeLoader):\n pass\n\n def map_constructor(loader, node, deep=False):\n keys = [loader.construct_object(node, deep=deep) for node, _ in node.value]\n vals = [loader.construct_object(node, deep=deep) for _, node in node.value]\n key_count = Counter(keys)\n data = {}\n for key, val in zip(keys, vals):\n if key_count[key] > 1:\n raise ValueError(\n f\"Config input {key} is defined multiple times for the same field, this is not allowed.\"\n )\n else:\n data[key] = val\n return data\n\n PreserveDuplicatesLoader.add_constructor(\n yaml.resolver.BaseResolver.DEFAULT_MAPPING_TAG, map_constructor\n )\n return yaml.load(raw_config, PreserveDuplicatesLoader)\n\n\ndef clean_camera_user_pass(line: str) -> str:\n \"\"\"Removes user and password from line.\"\"\"\n rtsp_cleaned = re.sub(REGEX_RTSP_CAMERA_USER_PASS, \"://*:*@\", line)\n return re.sub(REGEX_HTTP_CAMERA_USER_PASS, \"user=*&password=*\", rtsp_cleaned)\n\n\ndef escape_special_characters(path: str) -> str:\n \"\"\"Cleans reserved characters to encodings for ffmpeg.\"\"\"\n try:\n found = re.search(REGEX_RTSP_CAMERA_USER_PASS, path).group(0)[3:-1]\n pw = found[(found.index(\":\") + 1) :]\n return path.replace(pw, urllib.parse.quote_plus(pw))\n except AttributeError:\n # path does not have user:pass\n return path\n\n\ndef get_ffmpeg_arg_list(arg: Any) -> list:\n \"\"\"Use arg if list or convert to list format.\"\"\"\n return arg if isinstance(arg, list) else shlex.split(arg)\n\n\ndef load_labels(path, encoding=\"utf-8\", prefill=91):\n \"\"\"Loads labels from file (with or without index numbers).\n Args:\n path: path to label file.\n encoding: label file encoding.\n Returns:\n Dictionary mapping indices to labels.\n \"\"\"\n with open(path, \"r\", encoding=encoding) as f:\n labels = {index: \"unknown\" for index in range(prefill)}\n lines = f.readlines()\n if not lines:\n return {}\n\n if lines[0].split(\" \", maxsplit=1)[0].isdigit():\n pairs = [line.split(\" \", maxsplit=1) for line in lines]\n labels.update({int(index): label.strip() for index, label in pairs})\n else:\n labels.update({index: line.strip() for index, line in enumerate(lines)})\n return labels\n\n\ndef get_tz_modifiers(tz_name: str) -> Tuple[str, str, int]:\n seconds_offset = (\n datetime.datetime.now(pytz.timezone(tz_name)).utcoffset().total_seconds()\n )\n hours_offset = int(seconds_offset / 60 / 60)\n minutes_offset = int(seconds_offset / 60 - hours_offset * 60)\n hour_modifier = f\"{hours_offset} hour\"\n minute_modifier = f\"{minutes_offset} minute\"\n return hour_modifier, minute_modifier, seconds_offset\n\n\ndef to_relative_box(\n width: int, height: int, box: Tuple[int, int, int, int]\n) -> Tuple[int, int, int, int]:\n return (\n box[0] / width, # x\n box[1] / height, # y\n (box[2] - box[0]) / width, # w\n (box[3] - box[1]) / height, # h\n )\n\n\ndef create_mask(frame_shape, mask):\n mask_img = np.zeros(frame_shape, np.uint8)\n mask_img[:] = 255\n\n\ndef update_yaml_from_url(file_path, url):\n parsed_url = urllib.parse.urlparse(url)\n query_string = urllib.parse.parse_qs(parsed_url.query, keep_blank_values=True)\n\n for key_path_str, new_value_list in query_string.items():\n key_path = key_path_str.split(\".\")\n for i in range(len(key_path)):\n try:\n index = int(key_path[i])\n key_path[i] = (key_path[i - 1], index)\n key_path.pop(i - 1)\n except ValueError:\n pass\n new_value = new_value_list[0]\n update_yaml_file(file_path, key_path, new_value)\n\n\ndef update_yaml_file(file_path, key_path, new_value):\n yaml = YAML()\n with open(file_path, \"r\") as f:\n data = yaml.load(f)\n\n data = update_yaml(data, key_path, new_value)\n\n with open(file_path, \"w\") as f:\n yaml.dump(data, f)\n\n\ndef update_yaml(data, key_path, new_value):\n temp = data\n for key in key_path[:-1]:\n if isinstance(key, tuple):\n if key[0] not in temp:\n temp[key[0]] = [{}] * max(1, key[1] + 1)\n elif len(temp[key[0]]) <= key[1]:\n temp[key[0]] += [{}] * (key[1] - len(temp[key[0]]) + 1)\n temp = temp[key[0]][key[1]]\n else:\n if key not in temp:\n temp[key] = {}\n temp = temp[key]\n\n last_key = key_path[-1]\n if new_value == \"\":\n if isinstance(last_key, tuple):\n del temp[last_key[0]][last_key[1]]\n else:\n del temp[last_key]\n else:\n if isinstance(last_key, tuple):\n if last_key[0] not in temp:\n temp[last_key[0]] = [{}] * max(1, last_key[1] + 1)\n elif len(temp[last_key[0]]) <= last_key[1]:\n temp[last_key[0]] += [{}] * (last_key[1] - len(temp[last_key[0]]) + 1)\n temp[last_key[0]][last_key[1]] = new_value\n else:\n if (\n last_key in temp\n and isinstance(temp[last_key], dict)\n and isinstance(new_value, dict)\n ):\n temp[last_key].update(new_value)\n else:\n temp[last_key] = new_value\n\n return data\n\n\ndef find_by_key(dictionary, target_key):\n if target_key in dictionary:\n return dictionary[target_key]\n else:\n for value in dictionary.values():\n if isinstance(value, dict):\n result = find_by_key(value, target_key)\n if result is not None:\n return result\n return None\n\n\ndef get_tomorrow_at_time(hour: int) -> datetime.datetime:\n \"\"\"Returns the datetime of the following day at 2am.\"\"\"\n try:\n tomorrow = datetime.datetime.now(get_localzone()) + datetime.timedelta(days=1)\n except ZoneInfoNotFoundError:\n tomorrow = datetime.datetime.now(datetime.timezone.utc) + datetime.timedelta(\n days=1\n )\n logger.warning(\n \"Using utc for maintenance due to missing or incorrect timezone set\"\n )\n\n return tomorrow.replace(hour=hour, minute=0, second=0).astimezone(\n datetime.timezone.utc\n )\n\n\ndef clear_and_unlink(file: Path, missing_ok: bool = True) -> None:\n \"\"\"clear file then unlink to avoid space retained by file descriptors.\"\"\"\n if not missing_ok and not file.exists():\n raise FileNotFoundError()\n\n # empty contents of file before unlinking https://github.com/blakeblackshear/frigate/issues/4769\n with open(file, \"w\"):\n pass\n\n file.unlink(missing_ok=missing_ok)\n", "path": "frigate/util/builtin.py"}]}
| 3,628 | 262 |
gh_patches_debug_27478
|
rasdani/github-patches
|
git_diff
|
ckan__ckan-5604
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Download options in Datatables_view do not work
**CKAN version**
2.9
**Describe the bug**
Using datatables_view as a default resource view, which works well. Apart from the nicer UI and pagination, one benefit of the view is that you can download a filtered version of the resource (https://github.com/ckan/ckan/pull/4497). However, none of the datatables_view download buttons work to download the filtered data.
**Steps to reproduce**
1. Add a CSV resource to a dataset
2. Create a datatables resource view (labeled 'Table' in the resource view picklist)
3. Go to resource view and try to use the Download button for any format type
4. A 404 error page replaces the datatables control
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ckanext/datatablesview/blueprint.py`
Content:
```
1 # encoding: utf-8
2
3 from six.moves.urllib.parse import urlencode
4
5 from flask import Blueprint
6 from six import text_type
7
8 from ckan.common import json
9 from ckan.plugins.toolkit import get_action, request, h
10
11 datatablesview = Blueprint(u'datatablesview', __name__)
12
13
14 def merge_filters(view_filters, user_filters_str):
15 u'''
16 view filters are built as part of the view, user filters
17 are selected by the user interacting with the view. Any filters
18 selected by user may only tighten filters set in the view,
19 others are ignored.
20
21 >>> merge_filters({
22 ... u'Department': [u'BTDT'], u'OnTime_Status': [u'ONTIME']},
23 ... u'CASE_STATUS:Open|CASE_STATUS:Closed|Department:INFO')
24 {u'Department': [u'BTDT'],
25 u'OnTime_Status': [u'ONTIME'],
26 u'CASE_STATUS': [u'Open', u'Closed']}
27 '''
28 filters = dict(view_filters)
29 if not user_filters_str:
30 return filters
31 user_filters = {}
32 for k_v in user_filters_str.split(u'|'):
33 k, sep, v = k_v.partition(u':')
34 if k not in view_filters or v in view_filters[k]:
35 user_filters.setdefault(k, []).append(v)
36 for k in user_filters:
37 filters[k] = user_filters[k]
38 return filters
39
40
41 def ajax(resource_view_id):
42 resource_view = get_action(u'resource_view_show'
43 )(None, {
44 u'id': resource_view_id
45 })
46
47 draw = int(request.form[u'draw'])
48 search_text = text_type(request.form[u'search[value]'])
49 offset = int(request.form[u'start'])
50 limit = int(request.form[u'length'])
51 view_filters = resource_view.get(u'filters', {})
52 user_filters = text_type(request.form[u'filters'])
53 filters = merge_filters(view_filters, user_filters)
54
55 datastore_search = get_action(u'datastore_search')
56 unfiltered_response = datastore_search(
57 None, {
58 u"resource_id": resource_view[u'resource_id'],
59 u"limit": 0,
60 u"filters": view_filters,
61 }
62 )
63
64 cols = [f[u'id'] for f in unfiltered_response[u'fields']]
65 if u'show_fields' in resource_view:
66 cols = [c for c in cols if c in resource_view[u'show_fields']]
67
68 sort_list = []
69 i = 0
70 while True:
71 if u'order[%d][column]' % i not in request.form:
72 break
73 sort_by_num = int(request.form[u'order[%d][column]' % i])
74 sort_order = (
75 u'desc' if request.form[u'order[%d][dir]' %
76 i] == u'desc' else u'asc'
77 )
78 sort_list.append(cols[sort_by_num] + u' ' + sort_order)
79 i += 1
80
81 response = datastore_search(
82 None, {
83 u"q": search_text,
84 u"resource_id": resource_view[u'resource_id'],
85 u"offset": offset,
86 u"limit": limit,
87 u"sort": u', '.join(sort_list),
88 u"filters": filters,
89 }
90 )
91
92 return json.dumps({
93 u'draw': draw,
94 u'iTotalRecords': unfiltered_response.get(u'total', 0),
95 u'iTotalDisplayRecords': response.get(u'total', 0),
96 u'aaData': [[text_type(row.get(colname, u''))
97 for colname in cols]
98 for row in response[u'records']],
99 })
100
101
102 def filtered_download(resource_view_id):
103 params = json.loads(request.params[u'params'])
104 resource_view = get_action(u'resource_view_show'
105 )(None, {
106 u'id': resource_view_id
107 })
108
109 search_text = text_type(params[u'search'][u'value'])
110 view_filters = resource_view.get(u'filters', {})
111 user_filters = text_type(params[u'filters'])
112 filters = merge_filters(view_filters, user_filters)
113
114 datastore_search = get_action(u'datastore_search')
115 unfiltered_response = datastore_search(
116 None, {
117 u"resource_id": resource_view[u'resource_id'],
118 u"limit": 0,
119 u"filters": view_filters,
120 }
121 )
122
123 cols = [f[u'id'] for f in unfiltered_response[u'fields']]
124 if u'show_fields' in resource_view:
125 cols = [c for c in cols if c in resource_view[u'show_fields']]
126
127 sort_list = []
128 for order in params[u'order']:
129 sort_by_num = int(order[u'column'])
130 sort_order = (u'desc' if order[u'dir'] == u'desc' else u'asc')
131 sort_list.append(cols[sort_by_num] + u' ' + sort_order)
132
133 cols = [c for (c, v) in zip(cols, params[u'visible']) if v]
134
135 h.redirect_to(
136 h.
137 url_for(u'datastore.dump', resource_id=resource_view[u'resource_id']) +
138 u'?' + urlencode({
139 u'q': search_text,
140 u'sort': u','.join(sort_list),
141 u'filters': json.dumps(filters),
142 u'format': request.params[u'format'],
143 u'fields': u','.join(cols),
144 })
145 )
146
147
148 datatablesview.add_url_rule(
149 u'/datatables/ajax/<resource_view_id>', view_func=ajax, methods=[u'POST']
150 )
151
152 datatablesview.add_url_rule(
153 u'/datatables/filtered-download/<resource_view_id>',
154 view_func=filtered_download
155 )
156
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ckanext/datatablesview/blueprint.py b/ckanext/datatablesview/blueprint.py
--- a/ckanext/datatablesview/blueprint.py
+++ b/ckanext/datatablesview/blueprint.py
@@ -100,7 +100,7 @@
def filtered_download(resource_view_id):
- params = json.loads(request.params[u'params'])
+ params = json.loads(request.form[u'params'])
resource_view = get_action(u'resource_view_show'
)(None, {
u'id': resource_view_id
@@ -132,14 +132,14 @@
cols = [c for (c, v) in zip(cols, params[u'visible']) if v]
- h.redirect_to(
+ return h.redirect_to(
h.
url_for(u'datastore.dump', resource_id=resource_view[u'resource_id']) +
u'?' + urlencode({
u'q': search_text,
u'sort': u','.join(sort_list),
u'filters': json.dumps(filters),
- u'format': request.params[u'format'],
+ u'format': request.form[u'format'],
u'fields': u','.join(cols),
})
)
@@ -151,5 +151,5 @@
datatablesview.add_url_rule(
u'/datatables/filtered-download/<resource_view_id>',
- view_func=filtered_download
+ view_func=filtered_download, methods=[u'POST']
)
|
{"golden_diff": "diff --git a/ckanext/datatablesview/blueprint.py b/ckanext/datatablesview/blueprint.py\n--- a/ckanext/datatablesview/blueprint.py\n+++ b/ckanext/datatablesview/blueprint.py\n@@ -100,7 +100,7 @@\n \n \n def filtered_download(resource_view_id):\n- params = json.loads(request.params[u'params'])\n+ params = json.loads(request.form[u'params'])\n resource_view = get_action(u'resource_view_show'\n )(None, {\n u'id': resource_view_id\n@@ -132,14 +132,14 @@\n \n cols = [c for (c, v) in zip(cols, params[u'visible']) if v]\n \n- h.redirect_to(\n+ return h.redirect_to(\n h.\n url_for(u'datastore.dump', resource_id=resource_view[u'resource_id']) +\n u'?' + urlencode({\n u'q': search_text,\n u'sort': u','.join(sort_list),\n u'filters': json.dumps(filters),\n- u'format': request.params[u'format'],\n+ u'format': request.form[u'format'],\n u'fields': u','.join(cols),\n })\n )\n@@ -151,5 +151,5 @@\n \n datatablesview.add_url_rule(\n u'/datatables/filtered-download/<resource_view_id>',\n- view_func=filtered_download\n+ view_func=filtered_download, methods=[u'POST']\n )\n", "issue": "Download options in Datatables_view do not work\n**CKAN version**\r\n2.9\r\n\r\n**Describe the bug**\r\nUsing datatables_view as a default resource view, which works well. Apart from the nicer UI and pagination, one benefit of the view is that you can download a filtered version of the resource (https://github.com/ckan/ckan/pull/4497). However, none of the datatables_view download buttons work to download the filtered data.\r\n\r\n**Steps to reproduce**\r\n\r\n1. Add a CSV resource to a dataset\r\n2. Create a datatables resource view (labeled 'Table' in the resource view picklist)\r\n3. Go to resource view and try to use the Download button for any format type\r\n4. A 404 error page replaces the datatables control\r\n\r\n\n", "before_files": [{"content": "# encoding: utf-8\n\nfrom six.moves.urllib.parse import urlencode\n\nfrom flask import Blueprint\nfrom six import text_type\n\nfrom ckan.common import json\nfrom ckan.plugins.toolkit import get_action, request, h\n\ndatatablesview = Blueprint(u'datatablesview', __name__)\n\n\ndef merge_filters(view_filters, user_filters_str):\n u'''\n view filters are built as part of the view, user filters\n are selected by the user interacting with the view. Any filters\n selected by user may only tighten filters set in the view,\n others are ignored.\n\n >>> merge_filters({\n ... u'Department': [u'BTDT'], u'OnTime_Status': [u'ONTIME']},\n ... u'CASE_STATUS:Open|CASE_STATUS:Closed|Department:INFO')\n {u'Department': [u'BTDT'],\n u'OnTime_Status': [u'ONTIME'],\n u'CASE_STATUS': [u'Open', u'Closed']}\n '''\n filters = dict(view_filters)\n if not user_filters_str:\n return filters\n user_filters = {}\n for k_v in user_filters_str.split(u'|'):\n k, sep, v = k_v.partition(u':')\n if k not in view_filters or v in view_filters[k]:\n user_filters.setdefault(k, []).append(v)\n for k in user_filters:\n filters[k] = user_filters[k]\n return filters\n\n\ndef ajax(resource_view_id):\n resource_view = get_action(u'resource_view_show'\n )(None, {\n u'id': resource_view_id\n })\n\n draw = int(request.form[u'draw'])\n search_text = text_type(request.form[u'search[value]'])\n offset = int(request.form[u'start'])\n limit = int(request.form[u'length'])\n view_filters = resource_view.get(u'filters', {})\n user_filters = text_type(request.form[u'filters'])\n filters = merge_filters(view_filters, user_filters)\n\n datastore_search = get_action(u'datastore_search')\n unfiltered_response = datastore_search(\n None, {\n u\"resource_id\": resource_view[u'resource_id'],\n u\"limit\": 0,\n u\"filters\": view_filters,\n }\n )\n\n cols = [f[u'id'] for f in unfiltered_response[u'fields']]\n if u'show_fields' in resource_view:\n cols = [c for c in cols if c in resource_view[u'show_fields']]\n\n sort_list = []\n i = 0\n while True:\n if u'order[%d][column]' % i not in request.form:\n break\n sort_by_num = int(request.form[u'order[%d][column]' % i])\n sort_order = (\n u'desc' if request.form[u'order[%d][dir]' %\n i] == u'desc' else u'asc'\n )\n sort_list.append(cols[sort_by_num] + u' ' + sort_order)\n i += 1\n\n response = datastore_search(\n None, {\n u\"q\": search_text,\n u\"resource_id\": resource_view[u'resource_id'],\n u\"offset\": offset,\n u\"limit\": limit,\n u\"sort\": u', '.join(sort_list),\n u\"filters\": filters,\n }\n )\n\n return json.dumps({\n u'draw': draw,\n u'iTotalRecords': unfiltered_response.get(u'total', 0),\n u'iTotalDisplayRecords': response.get(u'total', 0),\n u'aaData': [[text_type(row.get(colname, u''))\n for colname in cols]\n for row in response[u'records']],\n })\n\n\ndef filtered_download(resource_view_id):\n params = json.loads(request.params[u'params'])\n resource_view = get_action(u'resource_view_show'\n )(None, {\n u'id': resource_view_id\n })\n\n search_text = text_type(params[u'search'][u'value'])\n view_filters = resource_view.get(u'filters', {})\n user_filters = text_type(params[u'filters'])\n filters = merge_filters(view_filters, user_filters)\n\n datastore_search = get_action(u'datastore_search')\n unfiltered_response = datastore_search(\n None, {\n u\"resource_id\": resource_view[u'resource_id'],\n u\"limit\": 0,\n u\"filters\": view_filters,\n }\n )\n\n cols = [f[u'id'] for f in unfiltered_response[u'fields']]\n if u'show_fields' in resource_view:\n cols = [c for c in cols if c in resource_view[u'show_fields']]\n\n sort_list = []\n for order in params[u'order']:\n sort_by_num = int(order[u'column'])\n sort_order = (u'desc' if order[u'dir'] == u'desc' else u'asc')\n sort_list.append(cols[sort_by_num] + u' ' + sort_order)\n\n cols = [c for (c, v) in zip(cols, params[u'visible']) if v]\n\n h.redirect_to(\n h.\n url_for(u'datastore.dump', resource_id=resource_view[u'resource_id']) +\n u'?' + urlencode({\n u'q': search_text,\n u'sort': u','.join(sort_list),\n u'filters': json.dumps(filters),\n u'format': request.params[u'format'],\n u'fields': u','.join(cols),\n })\n )\n\n\ndatatablesview.add_url_rule(\n u'/datatables/ajax/<resource_view_id>', view_func=ajax, methods=[u'POST']\n)\n\ndatatablesview.add_url_rule(\n u'/datatables/filtered-download/<resource_view_id>',\n view_func=filtered_download\n)\n", "path": "ckanext/datatablesview/blueprint.py"}], "after_files": [{"content": "# encoding: utf-8\n\nfrom six.moves.urllib.parse import urlencode\n\nfrom flask import Blueprint\nfrom six import text_type\n\nfrom ckan.common import json\nfrom ckan.plugins.toolkit import get_action, request, h\n\ndatatablesview = Blueprint(u'datatablesview', __name__)\n\n\ndef merge_filters(view_filters, user_filters_str):\n u'''\n view filters are built as part of the view, user filters\n are selected by the user interacting with the view. Any filters\n selected by user may only tighten filters set in the view,\n others are ignored.\n\n >>> merge_filters({\n ... u'Department': [u'BTDT'], u'OnTime_Status': [u'ONTIME']},\n ... u'CASE_STATUS:Open|CASE_STATUS:Closed|Department:INFO')\n {u'Department': [u'BTDT'],\n u'OnTime_Status': [u'ONTIME'],\n u'CASE_STATUS': [u'Open', u'Closed']}\n '''\n filters = dict(view_filters)\n if not user_filters_str:\n return filters\n user_filters = {}\n for k_v in user_filters_str.split(u'|'):\n k, sep, v = k_v.partition(u':')\n if k not in view_filters or v in view_filters[k]:\n user_filters.setdefault(k, []).append(v)\n for k in user_filters:\n filters[k] = user_filters[k]\n return filters\n\n\ndef ajax(resource_view_id):\n resource_view = get_action(u'resource_view_show'\n )(None, {\n u'id': resource_view_id\n })\n\n draw = int(request.form[u'draw'])\n search_text = text_type(request.form[u'search[value]'])\n offset = int(request.form[u'start'])\n limit = int(request.form[u'length'])\n view_filters = resource_view.get(u'filters', {})\n user_filters = text_type(request.form[u'filters'])\n filters = merge_filters(view_filters, user_filters)\n\n datastore_search = get_action(u'datastore_search')\n unfiltered_response = datastore_search(\n None, {\n u\"resource_id\": resource_view[u'resource_id'],\n u\"limit\": 0,\n u\"filters\": view_filters,\n }\n )\n\n cols = [f[u'id'] for f in unfiltered_response[u'fields']]\n if u'show_fields' in resource_view:\n cols = [c for c in cols if c in resource_view[u'show_fields']]\n\n sort_list = []\n i = 0\n while True:\n if u'order[%d][column]' % i not in request.form:\n break\n sort_by_num = int(request.form[u'order[%d][column]' % i])\n sort_order = (\n u'desc' if request.form[u'order[%d][dir]' %\n i] == u'desc' else u'asc'\n )\n sort_list.append(cols[sort_by_num] + u' ' + sort_order)\n i += 1\n\n response = datastore_search(\n None, {\n u\"q\": search_text,\n u\"resource_id\": resource_view[u'resource_id'],\n u\"offset\": offset,\n u\"limit\": limit,\n u\"sort\": u', '.join(sort_list),\n u\"filters\": filters,\n }\n )\n\n return json.dumps({\n u'draw': draw,\n u'iTotalRecords': unfiltered_response.get(u'total', 0),\n u'iTotalDisplayRecords': response.get(u'total', 0),\n u'aaData': [[text_type(row.get(colname, u''))\n for colname in cols]\n for row in response[u'records']],\n })\n\n\ndef filtered_download(resource_view_id):\n params = json.loads(request.form[u'params'])\n resource_view = get_action(u'resource_view_show'\n )(None, {\n u'id': resource_view_id\n })\n\n search_text = text_type(params[u'search'][u'value'])\n view_filters = resource_view.get(u'filters', {})\n user_filters = text_type(params[u'filters'])\n filters = merge_filters(view_filters, user_filters)\n\n datastore_search = get_action(u'datastore_search')\n unfiltered_response = datastore_search(\n None, {\n u\"resource_id\": resource_view[u'resource_id'],\n u\"limit\": 0,\n u\"filters\": view_filters,\n }\n )\n\n cols = [f[u'id'] for f in unfiltered_response[u'fields']]\n if u'show_fields' in resource_view:\n cols = [c for c in cols if c in resource_view[u'show_fields']]\n\n sort_list = []\n for order in params[u'order']:\n sort_by_num = int(order[u'column'])\n sort_order = (u'desc' if order[u'dir'] == u'desc' else u'asc')\n sort_list.append(cols[sort_by_num] + u' ' + sort_order)\n\n cols = [c for (c, v) in zip(cols, params[u'visible']) if v]\n\n return h.redirect_to(\n h.\n url_for(u'datastore.dump', resource_id=resource_view[u'resource_id']) +\n u'?' + urlencode({\n u'q': search_text,\n u'sort': u','.join(sort_list),\n u'filters': json.dumps(filters),\n u'format': request.form[u'format'],\n u'fields': u','.join(cols),\n })\n )\n\n\ndatatablesview.add_url_rule(\n u'/datatables/ajax/<resource_view_id>', view_func=ajax, methods=[u'POST']\n)\n\ndatatablesview.add_url_rule(\n u'/datatables/filtered-download/<resource_view_id>',\n view_func=filtered_download, methods=[u'POST']\n)\n", "path": "ckanext/datatablesview/blueprint.py"}]}
| 2,039 | 327 |
gh_patches_debug_32676
|
rasdani/github-patches
|
git_diff
|
PaddlePaddle__models-347
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Enable the log of gradient clipping in training
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `deep_speech_2/train.py`
Content:
```
1 """Trainer for DeepSpeech2 model."""
2 from __future__ import absolute_import
3 from __future__ import division
4 from __future__ import print_function
5
6 import argparse
7 import functools
8 import paddle.v2 as paddle
9 from model_utils.model import DeepSpeech2Model
10 from data_utils.data import DataGenerator
11 from utils.utility import add_arguments, print_arguments
12
13 parser = argparse.ArgumentParser(description=__doc__)
14 add_arg = functools.partial(add_arguments, argparser=parser)
15 # yapf: disable
16 add_arg('batch_size', int, 256, "Minibatch size.")
17 add_arg('trainer_count', int, 8, "# of Trainers (CPUs or GPUs).")
18 add_arg('num_passes', int, 200, "# of training epochs.")
19 add_arg('num_proc_data', int, 12, "# of CPUs for data preprocessing.")
20 add_arg('num_conv_layers', int, 2, "# of convolution layers.")
21 add_arg('num_rnn_layers', int, 3, "# of recurrent layers.")
22 add_arg('rnn_layer_size', int, 2048, "# of recurrent cells per layer.")
23 add_arg('num_iter_print', int, 100, "Every # iterations for printing "
24 "train cost.")
25 add_arg('learning_rate', float, 5e-4, "Learning rate.")
26 add_arg('max_duration', float, 27.0, "Longest audio duration allowed.")
27 add_arg('min_duration', float, 0.0, "Shortest audio duration allowed.")
28 add_arg('test_off', bool, False, "Turn off testing.")
29 add_arg('use_sortagrad', bool, True, "Use SortaGrad or not.")
30 add_arg('use_gpu', bool, True, "Use GPU or not.")
31 add_arg('use_gru', bool, False, "Use GRUs instead of simple RNNs.")
32 add_arg('is_local', bool, True, "Use pserver or not.")
33 add_arg('share_rnn_weights',bool, True, "Share input-hidden weights across "
34 "bi-directional RNNs. Not for GRU.")
35 add_arg('train_manifest', str,
36 'data/librispeech/manifest.train',
37 "Filepath of train manifest.")
38 add_arg('dev_manifest', str,
39 'data/librispeech/manifest.dev-clean',
40 "Filepath of validation manifest.")
41 add_arg('mean_std_path', str,
42 'data/librispeech/mean_std.npz',
43 "Filepath of normalizer's mean & std.")
44 add_arg('vocab_path', str,
45 'data/librispeech/vocab.txt',
46 "Filepath of vocabulary.")
47 add_arg('init_model_path', str,
48 None,
49 "If None, the training starts from scratch, "
50 "otherwise, it resumes from the pre-trained model.")
51 add_arg('output_model_dir', str,
52 "./checkpoints/libri",
53 "Directory for saving checkpoints.")
54 add_arg('augment_conf_path',str,
55 'conf/augmentation.config',
56 "Filepath of augmentation configuration file (json-format).")
57 add_arg('specgram_type', str,
58 'linear',
59 "Audio feature type. Options: linear, mfcc.",
60 choices=['linear', 'mfcc'])
61 add_arg('shuffle_method', str,
62 'batch_shuffle_clipped',
63 "Shuffle method.",
64 choices=['instance_shuffle', 'batch_shuffle', 'batch_shuffle_clipped'])
65 # yapf: disable
66 args = parser.parse_args()
67
68
69 def train():
70 """DeepSpeech2 training."""
71 train_generator = DataGenerator(
72 vocab_filepath=args.vocab_path,
73 mean_std_filepath=args.mean_std_path,
74 augmentation_config=open(args.augment_conf_path, 'r').read(),
75 max_duration=args.max_duration,
76 min_duration=args.min_duration,
77 specgram_type=args.specgram_type,
78 num_threads=args.num_proc_data)
79 dev_generator = DataGenerator(
80 vocab_filepath=args.vocab_path,
81 mean_std_filepath=args.mean_std_path,
82 augmentation_config="{}",
83 specgram_type=args.specgram_type,
84 num_threads=args.num_proc_data)
85 train_batch_reader = train_generator.batch_reader_creator(
86 manifest_path=args.train_manifest,
87 batch_size=args.batch_size,
88 min_batch_size=args.trainer_count,
89 sortagrad=args.use_sortagrad if args.init_model_path is None else False,
90 shuffle_method=args.shuffle_method)
91 dev_batch_reader = dev_generator.batch_reader_creator(
92 manifest_path=args.dev_manifest,
93 batch_size=args.batch_size,
94 min_batch_size=1, # must be 1, but will have errors.
95 sortagrad=False,
96 shuffle_method=None)
97
98 ds2_model = DeepSpeech2Model(
99 vocab_size=train_generator.vocab_size,
100 num_conv_layers=args.num_conv_layers,
101 num_rnn_layers=args.num_rnn_layers,
102 rnn_layer_size=args.rnn_layer_size,
103 use_gru=args.use_gru,
104 pretrained_model_path=args.init_model_path,
105 share_rnn_weights=args.share_rnn_weights)
106 ds2_model.train(
107 train_batch_reader=train_batch_reader,
108 dev_batch_reader=dev_batch_reader,
109 feeding_dict=train_generator.feeding,
110 learning_rate=args.learning_rate,
111 gradient_clipping=400,
112 num_passes=args.num_passes,
113 num_iterations_print=args.num_iter_print,
114 output_model_dir=args.output_model_dir,
115 is_local=args.is_local,
116 test_off=args.test_off)
117
118
119 def main():
120 print_arguments(args)
121 paddle.init(use_gpu=args.use_gpu, trainer_count=args.trainer_count)
122 train()
123
124
125 if __name__ == '__main__':
126 main()
127
```
Path: `deep_speech_2/decoders/swig_wrapper.py`
Content:
```
1 """Wrapper for various CTC decoders in SWIG."""
2 from __future__ import absolute_import
3 from __future__ import division
4 from __future__ import print_function
5
6 import swig_decoders
7
8
9 class Scorer(swig_decoders.Scorer):
10 """Wrapper for Scorer.
11
12 :param alpha: Parameter associated with language model. Don't use
13 language model when alpha = 0.
14 :type alpha: float
15 :param beta: Parameter associated with word count. Don't use word
16 count when beta = 0.
17 :type beta: float
18 :model_path: Path to load language model.
19 :type model_path: basestring
20 """
21
22 def __init__(self, alpha, beta, model_path, vocabulary):
23 swig_decoders.Scorer.__init__(self, alpha, beta, model_path, vocabulary)
24
25
26 def ctc_greedy_decoder(probs_seq, vocabulary):
27 """Wrapper for ctc best path decoder in swig.
28
29 :param probs_seq: 2-D list of probability distributions over each time
30 step, with each element being a list of normalized
31 probabilities over vocabulary and blank.
32 :type probs_seq: 2-D list
33 :param vocabulary: Vocabulary list.
34 :type vocabulary: list
35 :return: Decoding result string.
36 :rtype: basestring
37 """
38 return swig_decoders.ctc_greedy_decoder(probs_seq.tolist(), vocabulary)
39
40
41 def ctc_beam_search_decoder(probs_seq,
42 vocabulary,
43 beam_size,
44 cutoff_prob=1.0,
45 cutoff_top_n=40,
46 ext_scoring_func=None):
47 """Wrapper for the CTC Beam Search Decoder.
48
49 :param probs_seq: 2-D list of probability distributions over each time
50 step, with each element being a list of normalized
51 probabilities over vocabulary and blank.
52 :type probs_seq: 2-D list
53 :param vocabulary: Vocabulary list.
54 :type vocabulary: list
55 :param beam_size: Width for beam search.
56 :type beam_size: int
57 :param cutoff_prob: Cutoff probability in pruning,
58 default 1.0, no pruning.
59 :type cutoff_prob: float
60 :param cutoff_top_n: Cutoff number in pruning, only top cutoff_top_n
61 characters with highest probs in vocabulary will be
62 used in beam search, default 40.
63 :type cutoff_top_n: int
64 :param ext_scoring_func: External scoring function for
65 partially decoded sentence, e.g. word count
66 or language model.
67 :type external_scoring_func: callable
68 :return: List of tuples of log probability and sentence as decoding
69 results, in descending order of the probability.
70 :rtype: list
71 """
72 return swig_decoders.ctc_beam_search_decoder(probs_seq.tolist(), vocabulary,
73 beam_size, cutoff_prob,
74 cutoff_top_n, ext_scoring_func)
75
76
77 def ctc_beam_search_decoder_batch(probs_split,
78 vocabulary,
79 beam_size,
80 num_processes,
81 cutoff_prob=1.0,
82 cutoff_top_n=40,
83 ext_scoring_func=None):
84 """Wrapper for the batched CTC beam search decoder.
85
86 :param probs_seq: 3-D list with each element as an instance of 2-D list
87 of probabilities used by ctc_beam_search_decoder().
88 :type probs_seq: 3-D list
89 :param vocabulary: Vocabulary list.
90 :type vocabulary: list
91 :param beam_size: Width for beam search.
92 :type beam_size: int
93 :param num_processes: Number of parallel processes.
94 :type num_processes: int
95 :param cutoff_prob: Cutoff probability in vocabulary pruning,
96 default 1.0, no pruning.
97 :type cutoff_prob: float
98 :param cutoff_top_n: Cutoff number in pruning, only top cutoff_top_n
99 characters with highest probs in vocabulary will be
100 used in beam search, default 40.
101 :type cutoff_top_n: int
102 :param num_processes: Number of parallel processes.
103 :type num_processes: int
104 :param ext_scoring_func: External scoring function for
105 partially decoded sentence, e.g. word count
106 or language model.
107 :type external_scoring_function: callable
108 :return: List of tuples of log probability and sentence as decoding
109 results, in descending order of the probability.
110 :rtype: list
111 """
112 probs_split = [probs_seq.tolist() for probs_seq in probs_split]
113
114 return swig_decoders.ctc_beam_search_decoder_batch(
115 probs_split, vocabulary, beam_size, num_processes, cutoff_prob,
116 cutoff_top_n, ext_scoring_func)
117
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/deep_speech_2/decoders/swig_wrapper.py b/deep_speech_2/decoders/swig_wrapper.py
--- a/deep_speech_2/decoders/swig_wrapper.py
+++ b/deep_speech_2/decoders/swig_wrapper.py
@@ -35,7 +35,8 @@
:return: Decoding result string.
:rtype: basestring
"""
- return swig_decoders.ctc_greedy_decoder(probs_seq.tolist(), vocabulary)
+ result = swig_decoders.ctc_greedy_decoder(probs_seq.tolist(), vocabulary)
+ return result.decode('utf-8')
def ctc_beam_search_decoder(probs_seq,
@@ -69,9 +70,11 @@
results, in descending order of the probability.
:rtype: list
"""
- return swig_decoders.ctc_beam_search_decoder(probs_seq.tolist(), vocabulary,
- beam_size, cutoff_prob,
- cutoff_top_n, ext_scoring_func)
+ beam_results = swig_decoders.ctc_beam_search_decoder(
+ probs_seq.tolist(), vocabulary, beam_size, cutoff_prob, cutoff_top_n,
+ ext_scoring_func)
+ beam_results = [(res[0], res[1].decode('utf-8')) for res in beam_results]
+ return beam_results
def ctc_beam_search_decoder_batch(probs_split,
@@ -111,6 +114,11 @@
"""
probs_split = [probs_seq.tolist() for probs_seq in probs_split]
- return swig_decoders.ctc_beam_search_decoder_batch(
+ batch_beam_results = swig_decoders.ctc_beam_search_decoder_batch(
probs_split, vocabulary, beam_size, num_processes, cutoff_prob,
cutoff_top_n, ext_scoring_func)
+ batch_beam_results = [
+ [(res[0], res[1].decode("utf-8")) for res in beam_results]
+ for beam_results in batch_beam_results
+ ]
+ return batch_beam_results
diff --git a/deep_speech_2/train.py b/deep_speech_2/train.py
--- a/deep_speech_2/train.py
+++ b/deep_speech_2/train.py
@@ -118,7 +118,9 @@
def main():
print_arguments(args)
- paddle.init(use_gpu=args.use_gpu, trainer_count=args.trainer_count)
+ paddle.init(use_gpu=args.use_gpu,
+ trainer_count=args.trainer_count,
+ log_clipping=True)
train()
|
{"golden_diff": "diff --git a/deep_speech_2/decoders/swig_wrapper.py b/deep_speech_2/decoders/swig_wrapper.py\n--- a/deep_speech_2/decoders/swig_wrapper.py\n+++ b/deep_speech_2/decoders/swig_wrapper.py\n@@ -35,7 +35,8 @@\n :return: Decoding result string.\n :rtype: basestring\n \"\"\"\n- return swig_decoders.ctc_greedy_decoder(probs_seq.tolist(), vocabulary)\n+ result = swig_decoders.ctc_greedy_decoder(probs_seq.tolist(), vocabulary)\n+ return result.decode('utf-8')\n \n \n def ctc_beam_search_decoder(probs_seq,\n@@ -69,9 +70,11 @@\n results, in descending order of the probability.\n :rtype: list\n \"\"\"\n- return swig_decoders.ctc_beam_search_decoder(probs_seq.tolist(), vocabulary,\n- beam_size, cutoff_prob,\n- cutoff_top_n, ext_scoring_func)\n+ beam_results = swig_decoders.ctc_beam_search_decoder(\n+ probs_seq.tolist(), vocabulary, beam_size, cutoff_prob, cutoff_top_n,\n+ ext_scoring_func)\n+ beam_results = [(res[0], res[1].decode('utf-8')) for res in beam_results]\n+ return beam_results\n \n \n def ctc_beam_search_decoder_batch(probs_split,\n@@ -111,6 +114,11 @@\n \"\"\"\n probs_split = [probs_seq.tolist() for probs_seq in probs_split]\n \n- return swig_decoders.ctc_beam_search_decoder_batch(\n+ batch_beam_results = swig_decoders.ctc_beam_search_decoder_batch(\n probs_split, vocabulary, beam_size, num_processes, cutoff_prob,\n cutoff_top_n, ext_scoring_func)\n+ batch_beam_results = [\n+ [(res[0], res[1].decode(\"utf-8\")) for res in beam_results]\n+ for beam_results in batch_beam_results\n+ ]\n+ return batch_beam_results\ndiff --git a/deep_speech_2/train.py b/deep_speech_2/train.py\n--- a/deep_speech_2/train.py\n+++ b/deep_speech_2/train.py\n@@ -118,7 +118,9 @@\n \n def main():\n print_arguments(args)\n- paddle.init(use_gpu=args.use_gpu, trainer_count=args.trainer_count)\n+ paddle.init(use_gpu=args.use_gpu,\n+ trainer_count=args.trainer_count,\n+ log_clipping=True)\n train()\n", "issue": "Enable the log of gradient clipping in training\n\n", "before_files": [{"content": "\"\"\"Trainer for DeepSpeech2 model.\"\"\"\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport argparse\nimport functools\nimport paddle.v2 as paddle\nfrom model_utils.model import DeepSpeech2Model\nfrom data_utils.data import DataGenerator\nfrom utils.utility import add_arguments, print_arguments\n\nparser = argparse.ArgumentParser(description=__doc__)\nadd_arg = functools.partial(add_arguments, argparser=parser)\n# yapf: disable\nadd_arg('batch_size', int, 256, \"Minibatch size.\")\nadd_arg('trainer_count', int, 8, \"# of Trainers (CPUs or GPUs).\")\nadd_arg('num_passes', int, 200, \"# of training epochs.\")\nadd_arg('num_proc_data', int, 12, \"# of CPUs for data preprocessing.\")\nadd_arg('num_conv_layers', int, 2, \"# of convolution layers.\")\nadd_arg('num_rnn_layers', int, 3, \"# of recurrent layers.\")\nadd_arg('rnn_layer_size', int, 2048, \"# of recurrent cells per layer.\")\nadd_arg('num_iter_print', int, 100, \"Every # iterations for printing \"\n \"train cost.\")\nadd_arg('learning_rate', float, 5e-4, \"Learning rate.\")\nadd_arg('max_duration', float, 27.0, \"Longest audio duration allowed.\")\nadd_arg('min_duration', float, 0.0, \"Shortest audio duration allowed.\")\nadd_arg('test_off', bool, False, \"Turn off testing.\")\nadd_arg('use_sortagrad', bool, True, \"Use SortaGrad or not.\")\nadd_arg('use_gpu', bool, True, \"Use GPU or not.\")\nadd_arg('use_gru', bool, False, \"Use GRUs instead of simple RNNs.\")\nadd_arg('is_local', bool, True, \"Use pserver or not.\")\nadd_arg('share_rnn_weights',bool, True, \"Share input-hidden weights across \"\n \"bi-directional RNNs. Not for GRU.\")\nadd_arg('train_manifest', str,\n 'data/librispeech/manifest.train',\n \"Filepath of train manifest.\")\nadd_arg('dev_manifest', str,\n 'data/librispeech/manifest.dev-clean',\n \"Filepath of validation manifest.\")\nadd_arg('mean_std_path', str,\n 'data/librispeech/mean_std.npz',\n \"Filepath of normalizer's mean & std.\")\nadd_arg('vocab_path', str,\n 'data/librispeech/vocab.txt',\n \"Filepath of vocabulary.\")\nadd_arg('init_model_path', str,\n None,\n \"If None, the training starts from scratch, \"\n \"otherwise, it resumes from the pre-trained model.\")\nadd_arg('output_model_dir', str,\n \"./checkpoints/libri\",\n \"Directory for saving checkpoints.\")\nadd_arg('augment_conf_path',str,\n 'conf/augmentation.config',\n \"Filepath of augmentation configuration file (json-format).\")\nadd_arg('specgram_type', str,\n 'linear',\n \"Audio feature type. Options: linear, mfcc.\",\n choices=['linear', 'mfcc'])\nadd_arg('shuffle_method', str,\n 'batch_shuffle_clipped',\n \"Shuffle method.\",\n choices=['instance_shuffle', 'batch_shuffle', 'batch_shuffle_clipped'])\n# yapf: disable\nargs = parser.parse_args()\n\n\ndef train():\n \"\"\"DeepSpeech2 training.\"\"\"\n train_generator = DataGenerator(\n vocab_filepath=args.vocab_path,\n mean_std_filepath=args.mean_std_path,\n augmentation_config=open(args.augment_conf_path, 'r').read(),\n max_duration=args.max_duration,\n min_duration=args.min_duration,\n specgram_type=args.specgram_type,\n num_threads=args.num_proc_data)\n dev_generator = DataGenerator(\n vocab_filepath=args.vocab_path,\n mean_std_filepath=args.mean_std_path,\n augmentation_config=\"{}\",\n specgram_type=args.specgram_type,\n num_threads=args.num_proc_data)\n train_batch_reader = train_generator.batch_reader_creator(\n manifest_path=args.train_manifest,\n batch_size=args.batch_size,\n min_batch_size=args.trainer_count,\n sortagrad=args.use_sortagrad if args.init_model_path is None else False,\n shuffle_method=args.shuffle_method)\n dev_batch_reader = dev_generator.batch_reader_creator(\n manifest_path=args.dev_manifest,\n batch_size=args.batch_size,\n min_batch_size=1, # must be 1, but will have errors.\n sortagrad=False,\n shuffle_method=None)\n\n ds2_model = DeepSpeech2Model(\n vocab_size=train_generator.vocab_size,\n num_conv_layers=args.num_conv_layers,\n num_rnn_layers=args.num_rnn_layers,\n rnn_layer_size=args.rnn_layer_size,\n use_gru=args.use_gru,\n pretrained_model_path=args.init_model_path,\n share_rnn_weights=args.share_rnn_weights)\n ds2_model.train(\n train_batch_reader=train_batch_reader,\n dev_batch_reader=dev_batch_reader,\n feeding_dict=train_generator.feeding,\n learning_rate=args.learning_rate,\n gradient_clipping=400,\n num_passes=args.num_passes,\n num_iterations_print=args.num_iter_print,\n output_model_dir=args.output_model_dir,\n is_local=args.is_local,\n test_off=args.test_off)\n\n\ndef main():\n print_arguments(args)\n paddle.init(use_gpu=args.use_gpu, trainer_count=args.trainer_count)\n train()\n\n\nif __name__ == '__main__':\n main()\n", "path": "deep_speech_2/train.py"}, {"content": "\"\"\"Wrapper for various CTC decoders in SWIG.\"\"\"\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport swig_decoders\n\n\nclass Scorer(swig_decoders.Scorer):\n \"\"\"Wrapper for Scorer.\n\n :param alpha: Parameter associated with language model. Don't use\n language model when alpha = 0.\n :type alpha: float\n :param beta: Parameter associated with word count. Don't use word\n count when beta = 0.\n :type beta: float\n :model_path: Path to load language model.\n :type model_path: basestring\n \"\"\"\n\n def __init__(self, alpha, beta, model_path, vocabulary):\n swig_decoders.Scorer.__init__(self, alpha, beta, model_path, vocabulary)\n\n\ndef ctc_greedy_decoder(probs_seq, vocabulary):\n \"\"\"Wrapper for ctc best path decoder in swig.\n\n :param probs_seq: 2-D list of probability distributions over each time\n step, with each element being a list of normalized\n probabilities over vocabulary and blank.\n :type probs_seq: 2-D list\n :param vocabulary: Vocabulary list.\n :type vocabulary: list\n :return: Decoding result string.\n :rtype: basestring\n \"\"\"\n return swig_decoders.ctc_greedy_decoder(probs_seq.tolist(), vocabulary)\n\n\ndef ctc_beam_search_decoder(probs_seq,\n vocabulary,\n beam_size,\n cutoff_prob=1.0,\n cutoff_top_n=40,\n ext_scoring_func=None):\n \"\"\"Wrapper for the CTC Beam Search Decoder.\n\n :param probs_seq: 2-D list of probability distributions over each time\n step, with each element being a list of normalized\n probabilities over vocabulary and blank.\n :type probs_seq: 2-D list\n :param vocabulary: Vocabulary list.\n :type vocabulary: list\n :param beam_size: Width for beam search.\n :type beam_size: int\n :param cutoff_prob: Cutoff probability in pruning,\n default 1.0, no pruning.\n :type cutoff_prob: float\n :param cutoff_top_n: Cutoff number in pruning, only top cutoff_top_n\n characters with highest probs in vocabulary will be\n used in beam search, default 40.\n :type cutoff_top_n: int\n :param ext_scoring_func: External scoring function for\n partially decoded sentence, e.g. word count\n or language model.\n :type external_scoring_func: callable\n :return: List of tuples of log probability and sentence as decoding\n results, in descending order of the probability.\n :rtype: list\n \"\"\"\n return swig_decoders.ctc_beam_search_decoder(probs_seq.tolist(), vocabulary,\n beam_size, cutoff_prob,\n cutoff_top_n, ext_scoring_func)\n\n\ndef ctc_beam_search_decoder_batch(probs_split,\n vocabulary,\n beam_size,\n num_processes,\n cutoff_prob=1.0,\n cutoff_top_n=40,\n ext_scoring_func=None):\n \"\"\"Wrapper for the batched CTC beam search decoder.\n\n :param probs_seq: 3-D list with each element as an instance of 2-D list\n of probabilities used by ctc_beam_search_decoder().\n :type probs_seq: 3-D list\n :param vocabulary: Vocabulary list.\n :type vocabulary: list\n :param beam_size: Width for beam search.\n :type beam_size: int\n :param num_processes: Number of parallel processes.\n :type num_processes: int\n :param cutoff_prob: Cutoff probability in vocabulary pruning,\n default 1.0, no pruning.\n :type cutoff_prob: float\n :param cutoff_top_n: Cutoff number in pruning, only top cutoff_top_n\n characters with highest probs in vocabulary will be\n used in beam search, default 40.\n :type cutoff_top_n: int\n :param num_processes: Number of parallel processes.\n :type num_processes: int\n :param ext_scoring_func: External scoring function for\n partially decoded sentence, e.g. word count\n or language model.\n :type external_scoring_function: callable\n :return: List of tuples of log probability and sentence as decoding\n results, in descending order of the probability.\n :rtype: list\n \"\"\"\n probs_split = [probs_seq.tolist() for probs_seq in probs_split]\n\n return swig_decoders.ctc_beam_search_decoder_batch(\n probs_split, vocabulary, beam_size, num_processes, cutoff_prob,\n cutoff_top_n, ext_scoring_func)\n", "path": "deep_speech_2/decoders/swig_wrapper.py"}], "after_files": [{"content": "\"\"\"Trainer for DeepSpeech2 model.\"\"\"\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport argparse\nimport functools\nimport paddle.v2 as paddle\nfrom model_utils.model import DeepSpeech2Model\nfrom data_utils.data import DataGenerator\nfrom utils.utility import add_arguments, print_arguments\n\nparser = argparse.ArgumentParser(description=__doc__)\nadd_arg = functools.partial(add_arguments, argparser=parser)\n# yapf: disable\nadd_arg('batch_size', int, 256, \"Minibatch size.\")\nadd_arg('trainer_count', int, 8, \"# of Trainers (CPUs or GPUs).\")\nadd_arg('num_passes', int, 200, \"# of training epochs.\")\nadd_arg('num_proc_data', int, 12, \"# of CPUs for data preprocessing.\")\nadd_arg('num_conv_layers', int, 2, \"# of convolution layers.\")\nadd_arg('num_rnn_layers', int, 3, \"# of recurrent layers.\")\nadd_arg('rnn_layer_size', int, 2048, \"# of recurrent cells per layer.\")\nadd_arg('num_iter_print', int, 100, \"Every # iterations for printing \"\n \"train cost.\")\nadd_arg('learning_rate', float, 5e-4, \"Learning rate.\")\nadd_arg('max_duration', float, 27.0, \"Longest audio duration allowed.\")\nadd_arg('min_duration', float, 0.0, \"Shortest audio duration allowed.\")\nadd_arg('test_off', bool, False, \"Turn off testing.\")\nadd_arg('use_sortagrad', bool, True, \"Use SortaGrad or not.\")\nadd_arg('use_gpu', bool, True, \"Use GPU or not.\")\nadd_arg('use_gru', bool, False, \"Use GRUs instead of simple RNNs.\")\nadd_arg('is_local', bool, True, \"Use pserver or not.\")\nadd_arg('share_rnn_weights',bool, True, \"Share input-hidden weights across \"\n \"bi-directional RNNs. Not for GRU.\")\nadd_arg('train_manifest', str,\n 'data/librispeech/manifest.train',\n \"Filepath of train manifest.\")\nadd_arg('dev_manifest', str,\n 'data/librispeech/manifest.dev-clean',\n \"Filepath of validation manifest.\")\nadd_arg('mean_std_path', str,\n 'data/librispeech/mean_std.npz',\n \"Filepath of normalizer's mean & std.\")\nadd_arg('vocab_path', str,\n 'data/librispeech/vocab.txt',\n \"Filepath of vocabulary.\")\nadd_arg('init_model_path', str,\n None,\n \"If None, the training starts from scratch, \"\n \"otherwise, it resumes from the pre-trained model.\")\nadd_arg('output_model_dir', str,\n \"./checkpoints/libri\",\n \"Directory for saving checkpoints.\")\nadd_arg('augment_conf_path',str,\n 'conf/augmentation.config',\n \"Filepath of augmentation configuration file (json-format).\")\nadd_arg('specgram_type', str,\n 'linear',\n \"Audio feature type. Options: linear, mfcc.\",\n choices=['linear', 'mfcc'])\nadd_arg('shuffle_method', str,\n 'batch_shuffle_clipped',\n \"Shuffle method.\",\n choices=['instance_shuffle', 'batch_shuffle', 'batch_shuffle_clipped'])\n# yapf: disable\nargs = parser.parse_args()\n\n\ndef train():\n \"\"\"DeepSpeech2 training.\"\"\"\n train_generator = DataGenerator(\n vocab_filepath=args.vocab_path,\n mean_std_filepath=args.mean_std_path,\n augmentation_config=open(args.augment_conf_path, 'r').read(),\n max_duration=args.max_duration,\n min_duration=args.min_duration,\n specgram_type=args.specgram_type,\n num_threads=args.num_proc_data)\n dev_generator = DataGenerator(\n vocab_filepath=args.vocab_path,\n mean_std_filepath=args.mean_std_path,\n augmentation_config=\"{}\",\n specgram_type=args.specgram_type,\n num_threads=args.num_proc_data)\n train_batch_reader = train_generator.batch_reader_creator(\n manifest_path=args.train_manifest,\n batch_size=args.batch_size,\n min_batch_size=args.trainer_count,\n sortagrad=args.use_sortagrad if args.init_model_path is None else False,\n shuffle_method=args.shuffle_method)\n dev_batch_reader = dev_generator.batch_reader_creator(\n manifest_path=args.dev_manifest,\n batch_size=args.batch_size,\n min_batch_size=1, # must be 1, but will have errors.\n sortagrad=False,\n shuffle_method=None)\n\n ds2_model = DeepSpeech2Model(\n vocab_size=train_generator.vocab_size,\n num_conv_layers=args.num_conv_layers,\n num_rnn_layers=args.num_rnn_layers,\n rnn_layer_size=args.rnn_layer_size,\n use_gru=args.use_gru,\n pretrained_model_path=args.init_model_path,\n share_rnn_weights=args.share_rnn_weights)\n ds2_model.train(\n train_batch_reader=train_batch_reader,\n dev_batch_reader=dev_batch_reader,\n feeding_dict=train_generator.feeding,\n learning_rate=args.learning_rate,\n gradient_clipping=400,\n num_passes=args.num_passes,\n num_iterations_print=args.num_iter_print,\n output_model_dir=args.output_model_dir,\n is_local=args.is_local,\n test_off=args.test_off)\n\n\ndef main():\n print_arguments(args)\n paddle.init(use_gpu=args.use_gpu,\n trainer_count=args.trainer_count,\n log_clipping=True)\n train()\n\n\nif __name__ == '__main__':\n main()\n", "path": "deep_speech_2/train.py"}, {"content": "\"\"\"Wrapper for various CTC decoders in SWIG.\"\"\"\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport swig_decoders\n\n\nclass Scorer(swig_decoders.Scorer):\n \"\"\"Wrapper for Scorer.\n\n :param alpha: Parameter associated with language model. Don't use\n language model when alpha = 0.\n :type alpha: float\n :param beta: Parameter associated with word count. Don't use word\n count when beta = 0.\n :type beta: float\n :model_path: Path to load language model.\n :type model_path: basestring\n \"\"\"\n\n def __init__(self, alpha, beta, model_path, vocabulary):\n swig_decoders.Scorer.__init__(self, alpha, beta, model_path, vocabulary)\n\n\ndef ctc_greedy_decoder(probs_seq, vocabulary):\n \"\"\"Wrapper for ctc best path decoder in swig.\n\n :param probs_seq: 2-D list of probability distributions over each time\n step, with each element being a list of normalized\n probabilities over vocabulary and blank.\n :type probs_seq: 2-D list\n :param vocabulary: Vocabulary list.\n :type vocabulary: list\n :return: Decoding result string.\n :rtype: basestring\n \"\"\"\n result = swig_decoders.ctc_greedy_decoder(probs_seq.tolist(), vocabulary)\n return result.decode('utf-8')\n\n\ndef ctc_beam_search_decoder(probs_seq,\n vocabulary,\n beam_size,\n cutoff_prob=1.0,\n cutoff_top_n=40,\n ext_scoring_func=None):\n \"\"\"Wrapper for the CTC Beam Search Decoder.\n\n :param probs_seq: 2-D list of probability distributions over each time\n step, with each element being a list of normalized\n probabilities over vocabulary and blank.\n :type probs_seq: 2-D list\n :param vocabulary: Vocabulary list.\n :type vocabulary: list\n :param beam_size: Width for beam search.\n :type beam_size: int\n :param cutoff_prob: Cutoff probability in pruning,\n default 1.0, no pruning.\n :type cutoff_prob: float\n :param cutoff_top_n: Cutoff number in pruning, only top cutoff_top_n\n characters with highest probs in vocabulary will be\n used in beam search, default 40.\n :type cutoff_top_n: int\n :param ext_scoring_func: External scoring function for\n partially decoded sentence, e.g. word count\n or language model.\n :type external_scoring_func: callable\n :return: List of tuples of log probability and sentence as decoding\n results, in descending order of the probability.\n :rtype: list\n \"\"\"\n beam_results = swig_decoders.ctc_beam_search_decoder(\n probs_seq.tolist(), vocabulary, beam_size, cutoff_prob, cutoff_top_n,\n ext_scoring_func)\n beam_results = [(res[0], res[1].decode('utf-8')) for res in beam_results]\n return beam_results\n\n\ndef ctc_beam_search_decoder_batch(probs_split,\n vocabulary,\n beam_size,\n num_processes,\n cutoff_prob=1.0,\n cutoff_top_n=40,\n ext_scoring_func=None):\n \"\"\"Wrapper for the batched CTC beam search decoder.\n\n :param probs_seq: 3-D list with each element as an instance of 2-D list\n of probabilities used by ctc_beam_search_decoder().\n :type probs_seq: 3-D list\n :param vocabulary: Vocabulary list.\n :type vocabulary: list\n :param beam_size: Width for beam search.\n :type beam_size: int\n :param num_processes: Number of parallel processes.\n :type num_processes: int\n :param cutoff_prob: Cutoff probability in vocabulary pruning,\n default 1.0, no pruning.\n :type cutoff_prob: float\n :param cutoff_top_n: Cutoff number in pruning, only top cutoff_top_n\n characters with highest probs in vocabulary will be\n used in beam search, default 40.\n :type cutoff_top_n: int\n :param num_processes: Number of parallel processes.\n :type num_processes: int\n :param ext_scoring_func: External scoring function for\n partially decoded sentence, e.g. word count\n or language model.\n :type external_scoring_function: callable\n :return: List of tuples of log probability and sentence as decoding\n results, in descending order of the probability.\n :rtype: list\n \"\"\"\n probs_split = [probs_seq.tolist() for probs_seq in probs_split]\n\n batch_beam_results = swig_decoders.ctc_beam_search_decoder_batch(\n probs_split, vocabulary, beam_size, num_processes, cutoff_prob,\n cutoff_top_n, ext_scoring_func)\n batch_beam_results = [\n [(res[0], res[1].decode(\"utf-8\")) for res in beam_results]\n for beam_results in batch_beam_results\n ]\n return batch_beam_results\n", "path": "deep_speech_2/decoders/swig_wrapper.py"}]}
| 3,063 | 563 |
gh_patches_debug_16943
|
rasdani/github-patches
|
git_diff
|
mne-tools__mne-bids-1095
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
doc build fails because of mne (main)
> ImportError: cannot import name 'psd_welch' from 'mne.time_frequency' (/home/circleci/mne_bids_env/lib/python3.9/site-packages/mne/time_frequency/__init__.py)
https://app.circleci.com/pipelines/github/mne-tools/mne-bids/4820/workflows/813d1bc7-3b45-463b-af0e-3d5ddab39dc7/jobs/6961
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/convert_nirs_to_bids.py`
Content:
```
1 """
2 ====================================
3 13. Convert NIRS data to BIDS format
4 ====================================
5
6 In this example, we use MNE-BIDS to create a BIDS-compatible directory of NIRS
7 data. Specifically, we will follow these steps:
8
9 1. Download some NIRS data
10
11 2. Load the data, extract information, and save it in a new BIDS directory.
12
13 3. Check the result and compare it with the standard.
14
15 4. Cite ``mne-bids``.
16
17 .. currentmodule:: mne_bids
18
19 """ # noqa: E501
20
21 # Authors: Robert Luke <[email protected]>
22 #
23 # License: BSD-3-Clause
24
25 # %%
26 # We are importing everything we need for this example:
27 import os.path as op
28 import pathlib
29 import shutil
30
31 import mne
32 import mne_nirs # For convenient downloading of example data
33
34 from mne_bids import write_raw_bids, BIDSPath, print_dir_tree
35 from mne_bids.stats import count_events
36
37 # %%
38 # Download the data
39 # -----------------
40 #
41 # First, we need some data to work with. We will use the
42 # `Finger Tapping Dataset <https://github.com/rob-luke/BIDS-NIRS-Tapping>`_
43 # available on GitHub.
44 # We will use the MNE-NIRS package which includes convenient functions to
45 # download openly available datasets.
46
47 data_dir = pathlib.Path(mne_nirs.datasets.fnirs_motor_group.data_path())
48
49 # Let's see whether the data has been downloaded using a quick visualization
50 # of the directory tree.
51 print_dir_tree(data_dir)
52
53 # %%
54 # The data are already in BIDS format. However, we will just use one of the
55 # SNIRF files and demonstrate how this could be used to generate a new BIDS
56 # compliant dataset from this single file.
57
58 # Specify file to use as input to BIDS generation process
59 file_path = data_dir / "sub-01" / "nirs" / "sub-01_task-tapping_nirs.snirf"
60
61 # %%
62 # Convert to BIDS
63 # ---------------
64 #
65 # Let's start with loading the data and updating the annotations.
66 # We are reading the data using MNE-Python's ``io`` module and the
67 # :func:`mne.io.read_raw_snirf` function.
68 # Note that we must use the ``preload=False`` parameter, which is the default
69 # in MNE-Python.
70 # It prevents the data from being loaded and modified when converting to BIDS.
71
72 # Load the data
73 raw = mne.io.read_raw_snirf(file_path, preload=False)
74 raw.info['line_freq'] = 50 # specify power line frequency as required by BIDS
75
76 # Sanity check, show the optode positions
77 raw.plot_sensors()
78
79 # %%
80 # I also like to rename the annotations to something meaningful and
81 # set the duration of each stimulus
82
83 trigger_info = {'1.0': 'Control',
84 '2.0': 'Tapping/Left',
85 '3.0': 'Tapping/Right'}
86 raw.annotations.rename(trigger_info)
87 raw.annotations.set_durations(5.0)
88
89
90 # %%
91 # With these steps, we have everything to start a new BIDS directory using
92 # our data.
93 #
94 # To do that, we can use :func:`write_raw_bids`
95 #
96 # Generally, :func:`write_raw_bids` tries to extract as much
97 # meta data as possible from the raw data and then formats it in a BIDS
98 # compatible way. :func:`write_raw_bids` takes a bunch of inputs, most of
99 # which are however optional. The required inputs are:
100 #
101 # * :code:`raw`
102 # * :code:`bids_basename`
103 # * :code:`bids_root`
104 #
105 # ... as you can see in the docstring:
106 print(write_raw_bids.__doc__)
107
108 # zero padding to account for >100 subjects in this dataset
109 subject_id = '01'
110
111 # define a task name and a directory where to save the data to
112 task = 'Tapping'
113 bids_root = data_dir.with_name(data_dir.name + '-bids')
114 print(bids_root)
115
116 # %%
117 # To ensure the output path doesn't contain any leftover files from previous
118 # tests and example runs, we simply delete it.
119 #
120 # .. warning:: Do not delete directories that may contain important data!
121 #
122
123 if op.exists(bids_root):
124 shutil.rmtree(bids_root)
125
126 # %%
127 # The data contains annotations; which will be converted to events
128 # automatically by MNE-BIDS when writing the BIDS data:
129
130 print(raw.annotations)
131
132 # %%
133 # Finally, let's write the BIDS data!
134
135 bids_path = BIDSPath(subject=subject_id, task=task, root=bids_root)
136 write_raw_bids(raw, bids_path, overwrite=True)
137
138 # %%
139 # What does our fresh BIDS directory look like?
140 print_dir_tree(bids_root)
141
142 # %%
143 # Finally let's get an overview of the events on the whole dataset
144
145 counts = count_events(bids_root)
146 counts
147
148 # %%
149 # We can see that MNE-BIDS wrote several important files related to subject 1
150 # for us:
151 #
152 # * ``optodes.tsv`` containing the optode coordinates and
153 # ``coordsystem.json``, which contains the metadata about the optode
154 # coordinates.
155 # * The actual SNIRF data file (with a proper BIDS name) and an accompanying
156 # ``*_nirs.json`` file that contains metadata about the NIRS recording.
157 # * The ``*scans.json`` file lists all data recordings with their acquisition
158 # date. This file becomes more handy once there are multiple sessions and
159 # recordings to keep track of.
160 # * And finally, ``channels.tsv`` and ``events.tsv`` which contain even further
161 # metadata.
162 #
163 # Next to the subject specific files, MNE-BIDS also created several experiment
164 # specific files. However, we will not go into detail for them in this example.
165 #
166 # Cite mne-bids
167 # -------------
168 # After a lot of work was done by MNE-BIDS, it's fair to cite the software
169 # when preparing a manuscript and/or a dataset publication.
170 #
171 # We can see that the appropriate citations are already written in the
172 # ``README`` file.
173 #
174 # If you are preparing a manuscript, please make sure to also cite MNE-BIDS
175 # there.
176 readme = op.join(bids_root, 'README')
177 with open(readme, 'r', encoding='utf-8-sig') as fid:
178 text = fid.read()
179 print(text)
180
181
182 # %%
183 # Now it's time to manually check the BIDS directory and the meta files to add
184 # all the information that MNE-BIDS could not infer. For instance, you must
185 # describe Authors.
186 #
187 # Remember that there is a convenient javascript tool to validate all your BIDS
188 # directories called the "BIDS-validator", available as a web version and a
189 # command line tool:
190 #
191 # Web version: https://bids-standard.github.io/bids-validator/
192 #
193 # Command line tool: https://www.npmjs.com/package/bids-validator
194
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/convert_nirs_to_bids.py b/examples/convert_nirs_to_bids.py
--- a/examples/convert_nirs_to_bids.py
+++ b/examples/convert_nirs_to_bids.py
@@ -29,7 +29,7 @@
import shutil
import mne
-import mne_nirs # For convenient downloading of example data
+from mne_nirs import datasets # For convenient downloading of example data
from mne_bids import write_raw_bids, BIDSPath, print_dir_tree
from mne_bids.stats import count_events
@@ -44,7 +44,7 @@
# We will use the MNE-NIRS package which includes convenient functions to
# download openly available datasets.
-data_dir = pathlib.Path(mne_nirs.datasets.fnirs_motor_group.data_path())
+data_dir = pathlib.Path(datasets.fnirs_motor_group.data_path())
# Let's see whether the data has been downloaded using a quick visualization
# of the directory tree.
|
{"golden_diff": "diff --git a/examples/convert_nirs_to_bids.py b/examples/convert_nirs_to_bids.py\n--- a/examples/convert_nirs_to_bids.py\n+++ b/examples/convert_nirs_to_bids.py\n@@ -29,7 +29,7 @@\n import shutil\n \n import mne\n-import mne_nirs # For convenient downloading of example data\n+from mne_nirs import datasets # For convenient downloading of example data\n \n from mne_bids import write_raw_bids, BIDSPath, print_dir_tree\n from mne_bids.stats import count_events\n@@ -44,7 +44,7 @@\n # We will use the MNE-NIRS package which includes convenient functions to\n # download openly available datasets.\n \n-data_dir = pathlib.Path(mne_nirs.datasets.fnirs_motor_group.data_path())\n+data_dir = pathlib.Path(datasets.fnirs_motor_group.data_path())\n \n # Let's see whether the data has been downloaded using a quick visualization\n # of the directory tree.\n", "issue": "doc build fails because of mne (main)\n> ImportError: cannot import name 'psd_welch' from 'mne.time_frequency' (/home/circleci/mne_bids_env/lib/python3.9/site-packages/mne/time_frequency/__init__.py)\r\n\r\n\r\nhttps://app.circleci.com/pipelines/github/mne-tools/mne-bids/4820/workflows/813d1bc7-3b45-463b-af0e-3d5ddab39dc7/jobs/6961\n", "before_files": [{"content": "\"\"\"\n====================================\n13. Convert NIRS data to BIDS format\n====================================\n\nIn this example, we use MNE-BIDS to create a BIDS-compatible directory of NIRS\ndata. Specifically, we will follow these steps:\n\n1. Download some NIRS data\n\n2. Load the data, extract information, and save it in a new BIDS directory.\n\n3. Check the result and compare it with the standard.\n\n4. Cite ``mne-bids``.\n\n.. currentmodule:: mne_bids\n\n\"\"\" # noqa: E501\n\n# Authors: Robert Luke <[email protected]>\n#\n# License: BSD-3-Clause\n\n# %%\n# We are importing everything we need for this example:\nimport os.path as op\nimport pathlib\nimport shutil\n\nimport mne\nimport mne_nirs # For convenient downloading of example data\n\nfrom mne_bids import write_raw_bids, BIDSPath, print_dir_tree\nfrom mne_bids.stats import count_events\n\n# %%\n# Download the data\n# -----------------\n#\n# First, we need some data to work with. We will use the\n# `Finger Tapping Dataset <https://github.com/rob-luke/BIDS-NIRS-Tapping>`_\n# available on GitHub.\n# We will use the MNE-NIRS package which includes convenient functions to\n# download openly available datasets.\n\ndata_dir = pathlib.Path(mne_nirs.datasets.fnirs_motor_group.data_path())\n\n# Let's see whether the data has been downloaded using a quick visualization\n# of the directory tree.\nprint_dir_tree(data_dir)\n\n# %%\n# The data are already in BIDS format. However, we will just use one of the\n# SNIRF files and demonstrate how this could be used to generate a new BIDS\n# compliant dataset from this single file.\n\n# Specify file to use as input to BIDS generation process\nfile_path = data_dir / \"sub-01\" / \"nirs\" / \"sub-01_task-tapping_nirs.snirf\"\n\n# %%\n# Convert to BIDS\n# ---------------\n#\n# Let's start with loading the data and updating the annotations.\n# We are reading the data using MNE-Python's ``io`` module and the\n# :func:`mne.io.read_raw_snirf` function.\n# Note that we must use the ``preload=False`` parameter, which is the default\n# in MNE-Python.\n# It prevents the data from being loaded and modified when converting to BIDS.\n\n# Load the data\nraw = mne.io.read_raw_snirf(file_path, preload=False)\nraw.info['line_freq'] = 50 # specify power line frequency as required by BIDS\n\n# Sanity check, show the optode positions\nraw.plot_sensors()\n\n# %%\n# I also like to rename the annotations to something meaningful and\n# set the duration of each stimulus\n\ntrigger_info = {'1.0': 'Control',\n '2.0': 'Tapping/Left',\n '3.0': 'Tapping/Right'}\nraw.annotations.rename(trigger_info)\nraw.annotations.set_durations(5.0)\n\n\n# %%\n# With these steps, we have everything to start a new BIDS directory using\n# our data.\n#\n# To do that, we can use :func:`write_raw_bids`\n#\n# Generally, :func:`write_raw_bids` tries to extract as much\n# meta data as possible from the raw data and then formats it in a BIDS\n# compatible way. :func:`write_raw_bids` takes a bunch of inputs, most of\n# which are however optional. The required inputs are:\n#\n# * :code:`raw`\n# * :code:`bids_basename`\n# * :code:`bids_root`\n#\n# ... as you can see in the docstring:\nprint(write_raw_bids.__doc__)\n\n# zero padding to account for >100 subjects in this dataset\nsubject_id = '01'\n\n# define a task name and a directory where to save the data to\ntask = 'Tapping'\nbids_root = data_dir.with_name(data_dir.name + '-bids')\nprint(bids_root)\n\n# %%\n# To ensure the output path doesn't contain any leftover files from previous\n# tests and example runs, we simply delete it.\n#\n# .. warning:: Do not delete directories that may contain important data!\n#\n\nif op.exists(bids_root):\n shutil.rmtree(bids_root)\n\n# %%\n# The data contains annotations; which will be converted to events\n# automatically by MNE-BIDS when writing the BIDS data:\n\nprint(raw.annotations)\n\n# %%\n# Finally, let's write the BIDS data!\n\nbids_path = BIDSPath(subject=subject_id, task=task, root=bids_root)\nwrite_raw_bids(raw, bids_path, overwrite=True)\n\n# %%\n# What does our fresh BIDS directory look like?\nprint_dir_tree(bids_root)\n\n# %%\n# Finally let's get an overview of the events on the whole dataset\n\ncounts = count_events(bids_root)\ncounts\n\n# %%\n# We can see that MNE-BIDS wrote several important files related to subject 1\n# for us:\n#\n# * ``optodes.tsv`` containing the optode coordinates and\n# ``coordsystem.json``, which contains the metadata about the optode\n# coordinates.\n# * The actual SNIRF data file (with a proper BIDS name) and an accompanying\n# ``*_nirs.json`` file that contains metadata about the NIRS recording.\n# * The ``*scans.json`` file lists all data recordings with their acquisition\n# date. This file becomes more handy once there are multiple sessions and\n# recordings to keep track of.\n# * And finally, ``channels.tsv`` and ``events.tsv`` which contain even further\n# metadata.\n#\n# Next to the subject specific files, MNE-BIDS also created several experiment\n# specific files. However, we will not go into detail for them in this example.\n#\n# Cite mne-bids\n# -------------\n# After a lot of work was done by MNE-BIDS, it's fair to cite the software\n# when preparing a manuscript and/or a dataset publication.\n#\n# We can see that the appropriate citations are already written in the\n# ``README`` file.\n#\n# If you are preparing a manuscript, please make sure to also cite MNE-BIDS\n# there.\nreadme = op.join(bids_root, 'README')\nwith open(readme, 'r', encoding='utf-8-sig') as fid:\n text = fid.read()\nprint(text)\n\n\n# %%\n# Now it's time to manually check the BIDS directory and the meta files to add\n# all the information that MNE-BIDS could not infer. For instance, you must\n# describe Authors.\n#\n# Remember that there is a convenient javascript tool to validate all your BIDS\n# directories called the \"BIDS-validator\", available as a web version and a\n# command line tool:\n#\n# Web version: https://bids-standard.github.io/bids-validator/\n#\n# Command line tool: https://www.npmjs.com/package/bids-validator\n", "path": "examples/convert_nirs_to_bids.py"}], "after_files": [{"content": "\"\"\"\n====================================\n13. Convert NIRS data to BIDS format\n====================================\n\nIn this example, we use MNE-BIDS to create a BIDS-compatible directory of NIRS\ndata. Specifically, we will follow these steps:\n\n1. Download some NIRS data\n\n2. Load the data, extract information, and save it in a new BIDS directory.\n\n3. Check the result and compare it with the standard.\n\n4. Cite ``mne-bids``.\n\n.. currentmodule:: mne_bids\n\n\"\"\" # noqa: E501\n\n# Authors: Robert Luke <[email protected]>\n#\n# License: BSD-3-Clause\n\n# %%\n# We are importing everything we need for this example:\nimport os.path as op\nimport pathlib\nimport shutil\n\nimport mne\nfrom mne_nirs import datasets # For convenient downloading of example data\n\nfrom mne_bids import write_raw_bids, BIDSPath, print_dir_tree\nfrom mne_bids.stats import count_events\n\n# %%\n# Download the data\n# -----------------\n#\n# First, we need some data to work with. We will use the\n# `Finger Tapping Dataset <https://github.com/rob-luke/BIDS-NIRS-Tapping>`_\n# available on GitHub.\n# We will use the MNE-NIRS package which includes convenient functions to\n# download openly available datasets.\n\ndata_dir = pathlib.Path(datasets.fnirs_motor_group.data_path())\n\n# Let's see whether the data has been downloaded using a quick visualization\n# of the directory tree.\nprint_dir_tree(data_dir)\n\n# %%\n# The data are already in BIDS format. However, we will just use one of the\n# SNIRF files and demonstrate how this could be used to generate a new BIDS\n# compliant dataset from this single file.\n\n# Specify file to use as input to BIDS generation process\nfile_path = data_dir / \"sub-01\" / \"nirs\" / \"sub-01_task-tapping_nirs.snirf\"\n\n# %%\n# Convert to BIDS\n# ---------------\n#\n# Let's start with loading the data and updating the annotations.\n# We are reading the data using MNE-Python's ``io`` module and the\n# :func:`mne.io.read_raw_snirf` function.\n# Note that we must use the ``preload=False`` parameter, which is the default\n# in MNE-Python.\n# It prevents the data from being loaded and modified when converting to BIDS.\n\n# Load the data\nraw = mne.io.read_raw_snirf(file_path, preload=False)\nraw.info['line_freq'] = 50 # specify power line frequency as required by BIDS\n\n# Sanity check, show the optode positions\nraw.plot_sensors()\n\n# %%\n# I also like to rename the annotations to something meaningful and\n# set the duration of each stimulus\n\ntrigger_info = {'1.0': 'Control',\n '2.0': 'Tapping/Left',\n '3.0': 'Tapping/Right'}\nraw.annotations.rename(trigger_info)\nraw.annotations.set_durations(5.0)\n\n\n# %%\n# With these steps, we have everything to start a new BIDS directory using\n# our data.\n#\n# To do that, we can use :func:`write_raw_bids`\n#\n# Generally, :func:`write_raw_bids` tries to extract as much\n# meta data as possible from the raw data and then formats it in a BIDS\n# compatible way. :func:`write_raw_bids` takes a bunch of inputs, most of\n# which are however optional. The required inputs are:\n#\n# * :code:`raw`\n# * :code:`bids_basename`\n# * :code:`bids_root`\n#\n# ... as you can see in the docstring:\nprint(write_raw_bids.__doc__)\n\n# zero padding to account for >100 subjects in this dataset\nsubject_id = '01'\n\n# define a task name and a directory where to save the data to\ntask = 'Tapping'\nbids_root = data_dir.with_name(data_dir.name + '-bids')\nprint(bids_root)\n\n# %%\n# To ensure the output path doesn't contain any leftover files from previous\n# tests and example runs, we simply delete it.\n#\n# .. warning:: Do not delete directories that may contain important data!\n#\n\nif op.exists(bids_root):\n shutil.rmtree(bids_root)\n\n# %%\n# The data contains annotations; which will be converted to events\n# automatically by MNE-BIDS when writing the BIDS data:\n\nprint(raw.annotations)\n\n# %%\n# Finally, let's write the BIDS data!\n\nbids_path = BIDSPath(subject=subject_id, task=task, root=bids_root)\nwrite_raw_bids(raw, bids_path, overwrite=True)\n\n# %%\n# What does our fresh BIDS directory look like?\nprint_dir_tree(bids_root)\n\n# %%\n# Finally let's get an overview of the events on the whole dataset\n\ncounts = count_events(bids_root)\ncounts\n\n# %%\n# We can see that MNE-BIDS wrote several important files related to subject 1\n# for us:\n#\n# * ``optodes.tsv`` containing the optode coordinates and\n# ``coordsystem.json``, which contains the metadata about the optode\n# coordinates.\n# * The actual SNIRF data file (with a proper BIDS name) and an accompanying\n# ``*_nirs.json`` file that contains metadata about the NIRS recording.\n# * The ``*scans.json`` file lists all data recordings with their acquisition\n# date. This file becomes more handy once there are multiple sessions and\n# recordings to keep track of.\n# * And finally, ``channels.tsv`` and ``events.tsv`` which contain even further\n# metadata.\n#\n# Next to the subject specific files, MNE-BIDS also created several experiment\n# specific files. However, we will not go into detail for them in this example.\n#\n# Cite mne-bids\n# -------------\n# After a lot of work was done by MNE-BIDS, it's fair to cite the software\n# when preparing a manuscript and/or a dataset publication.\n#\n# We can see that the appropriate citations are already written in the\n# ``README`` file.\n#\n# If you are preparing a manuscript, please make sure to also cite MNE-BIDS\n# there.\nreadme = op.join(bids_root, 'README')\nwith open(readme, 'r', encoding='utf-8-sig') as fid:\n text = fid.read()\nprint(text)\n\n\n# %%\n# Now it's time to manually check the BIDS directory and the meta files to add\n# all the information that MNE-BIDS could not infer. For instance, you must\n# describe Authors.\n#\n# Remember that there is a convenient javascript tool to validate all your BIDS\n# directories called the \"BIDS-validator\", available as a web version and a\n# command line tool:\n#\n# Web version: https://bids-standard.github.io/bids-validator/\n#\n# Command line tool: https://www.npmjs.com/package/bids-validator\n", "path": "examples/convert_nirs_to_bids.py"}]}
| 2,403 | 216 |
gh_patches_debug_34522
|
rasdani/github-patches
|
git_diff
|
mkdocs__mkdocs-402
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Not all headers are automatically linked
I have an API reference site for a project that's hosted on ReadTheDocs using mkdocs as the documentation engine. Headers that contain things like `<code>` blocks aren't linked, while all others seem to be.
I can reproduce this locally with a plain mkdocs install using the RTD theme.
Here's an example:
http://carbon.lpghatguy.com/en/latest/Classes/Collections.Tuple/
All three of the methods in that page should be automatically linked in the sidebar navigation, but only the one without any fancy decoration is. All of them have been given valid HTML ids, so they're possible to link, they just aren't.
The markdown for that page, which works around a couple RTD bugs and doesn't look that great, is here:
https://raw.githubusercontent.com/lua-carbon/carbon/master/docs/Classes/Collections.Tuple.md
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mkdocs/compat.py`
Content:
```
1 # coding: utf-8
2 """Python 2/3 compatibility module."""
3 import sys
4
5 PY2 = int(sys.version[0]) == 2
6
7 if PY2:
8 from urlparse import urljoin, urlparse, urlunparse
9 import urllib
10 urlunquote = urllib.unquote
11
12 import SimpleHTTPServer as httpserver
13 httpserver = httpserver
14 import SocketServer
15 socketserver = SocketServer
16
17 import itertools
18 zip = itertools.izip
19
20 text_type = unicode
21 binary_type = str
22 string_types = (str, unicode)
23 unicode = unicode
24 basestring = basestring
25 else: # PY3
26 from urllib.parse import urljoin, urlparse, urlunparse, unquote
27 urlunquote = unquote
28
29 import http.server as httpserver
30 httpserver = httpserver
31 import socketserver
32 socketserver = socketserver
33
34 zip = zip
35
36 text_type = str
37 binary_type = bytes
38 string_types = (str,)
39 unicode = str
40 basestring = (str, bytes)
41
```
Path: `mkdocs/toc.py`
Content:
```
1 # coding: utf-8
2
3 """
4 Deals with generating the per-page table of contents.
5
6 For the sake of simplicity we use an existing markdown extension to generate
7 an HTML table of contents, and then parse that into the underlying data.
8
9 The steps we take to generate a table of contents are:
10
11 * Pre-process the markdown, injecting a [TOC] marker.
12 * Generate HTML from markdown.
13 * Post-process the HTML, spliting the content and the table of contents.
14 * Parse table of contents HTML into the underlying data structure.
15 """
16
17 import re
18
19 TOC_LINK_REGEX = re.compile('<a href=["]([^"]*)["]>([^<]*)</a>')
20
21
22 class TableOfContents(object):
23 """
24 Represents the table of contents for a given page.
25 """
26 def __init__(self, html):
27 self.items = _parse_html_table_of_contents(html)
28
29 def __iter__(self):
30 return iter(self.items)
31
32 def __str__(self):
33 return ''.join([str(item) for item in self])
34
35
36 class AnchorLink(object):
37 """
38 A single entry in the table of contents.
39 """
40 def __init__(self, title, url):
41 self.title, self.url = title, url
42 self.children = []
43
44 def __str__(self):
45 return self._indent_print()
46
47 def _indent_print(self, depth=0):
48 indent = ' ' * depth
49 ret = '%s%s - %s\n' % (indent, self.title, self.url)
50 for item in self.children:
51 ret += item._indent_print(depth + 1)
52 return ret
53
54
55 def _parse_html_table_of_contents(html):
56 """
57 Given a table of contents string that has been automatically generated by
58 the markdown library, parse it into a tree of AnchorLink instances.
59
60 Returns a list of all the parent AnchorLink instances.
61 """
62 lines = html.splitlines()[2:-2]
63 parents = []
64 ret = []
65 for line in lines:
66 match = TOC_LINK_REGEX.search(line)
67 if match:
68 href, title = match.groups()
69 nav = AnchorLink(title, href)
70 # Add the item to its parent if required. If it is a topmost
71 # item then instead append it to our return value.
72 if parents:
73 parents[-1].children.append(nav)
74 else:
75 ret.append(nav)
76 # If this item has children, store it as the current parent
77 if line.endswith('<ul>'):
78 parents.append(nav)
79 elif line.startswith('</ul>'):
80 if parents:
81 parents.pop()
82
83 # For the table of contents, always mark the first element as active
84 if ret:
85 ret[0].active = True
86
87 return ret
88
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mkdocs/compat.py b/mkdocs/compat.py
--- a/mkdocs/compat.py
+++ b/mkdocs/compat.py
@@ -13,6 +13,7 @@
httpserver = httpserver
import SocketServer
socketserver = SocketServer
+ from HTMLParser import HTMLParser
import itertools
zip = itertools.izip
@@ -30,6 +31,7 @@
httpserver = httpserver
import socketserver
socketserver = socketserver
+ from html.parser import HTMLParser
zip = zip
diff --git a/mkdocs/toc.py b/mkdocs/toc.py
--- a/mkdocs/toc.py
+++ b/mkdocs/toc.py
@@ -14,9 +14,7 @@
* Parse table of contents HTML into the underlying data structure.
"""
-import re
-
-TOC_LINK_REGEX = re.compile('<a href=["]([^"]*)["]>([^<]*)</a>')
+from mkdocs.compat import HTMLParser
class TableOfContents(object):
@@ -52,6 +50,32 @@
return ret
+class TOCParser(HTMLParser):
+
+ def __init__(self):
+ HTMLParser.__init__(self)
+ self.links = []
+
+ self.in_anchor = True
+ self.attrs = None
+ self.title = ''
+
+ def handle_starttag(self, tag, attrs):
+
+ if tag == 'a':
+ self.in_anchor = True
+ self.attrs = dict(attrs)
+
+ def handle_endtag(self, tag):
+ if tag == 'a':
+ self.in_anchor = False
+
+ def handle_data(self, data):
+
+ if self.in_anchor:
+ self.title += data
+
+
def _parse_html_table_of_contents(html):
"""
Given a table of contents string that has been automatically generated by
@@ -63,9 +87,11 @@
parents = []
ret = []
for line in lines:
- match = TOC_LINK_REGEX.search(line)
- if match:
- href, title = match.groups()
+ parser = TOCParser()
+ parser.feed(line)
+ if parser.title:
+ href = parser.attrs['href']
+ title = parser.title
nav = AnchorLink(title, href)
# Add the item to its parent if required. If it is a topmost
# item then instead append it to our return value.
|
{"golden_diff": "diff --git a/mkdocs/compat.py b/mkdocs/compat.py\n--- a/mkdocs/compat.py\n+++ b/mkdocs/compat.py\n@@ -13,6 +13,7 @@\n httpserver = httpserver\n import SocketServer\n socketserver = SocketServer\n+ from HTMLParser import HTMLParser\n \n import itertools\n zip = itertools.izip\n@@ -30,6 +31,7 @@\n httpserver = httpserver\n import socketserver\n socketserver = socketserver\n+ from html.parser import HTMLParser\n \n zip = zip\n \ndiff --git a/mkdocs/toc.py b/mkdocs/toc.py\n--- a/mkdocs/toc.py\n+++ b/mkdocs/toc.py\n@@ -14,9 +14,7 @@\n * Parse table of contents HTML into the underlying data structure.\n \"\"\"\n \n-import re\n-\n-TOC_LINK_REGEX = re.compile('<a href=[\"]([^\"]*)[\"]>([^<]*)</a>')\n+from mkdocs.compat import HTMLParser\n \n \n class TableOfContents(object):\n@@ -52,6 +50,32 @@\n return ret\n \n \n+class TOCParser(HTMLParser):\n+\n+ def __init__(self):\n+ HTMLParser.__init__(self)\n+ self.links = []\n+\n+ self.in_anchor = True\n+ self.attrs = None\n+ self.title = ''\n+\n+ def handle_starttag(self, tag, attrs):\n+\n+ if tag == 'a':\n+ self.in_anchor = True\n+ self.attrs = dict(attrs)\n+\n+ def handle_endtag(self, tag):\n+ if tag == 'a':\n+ self.in_anchor = False\n+\n+ def handle_data(self, data):\n+\n+ if self.in_anchor:\n+ self.title += data\n+\n+\n def _parse_html_table_of_contents(html):\n \"\"\"\n Given a table of contents string that has been automatically generated by\n@@ -63,9 +87,11 @@\n parents = []\n ret = []\n for line in lines:\n- match = TOC_LINK_REGEX.search(line)\n- if match:\n- href, title = match.groups()\n+ parser = TOCParser()\n+ parser.feed(line)\n+ if parser.title:\n+ href = parser.attrs['href']\n+ title = parser.title\n nav = AnchorLink(title, href)\n # Add the item to its parent if required. If it is a topmost\n # item then instead append it to our return value.\n", "issue": "Not all headers are automatically linked\nI have an API reference site for a project that's hosted on ReadTheDocs using mkdocs as the documentation engine. Headers that contain things like `<code>` blocks aren't linked, while all others seem to be.\n\nI can reproduce this locally with a plain mkdocs install using the RTD theme.\n\nHere's an example:\nhttp://carbon.lpghatguy.com/en/latest/Classes/Collections.Tuple/\n\nAll three of the methods in that page should be automatically linked in the sidebar navigation, but only the one without any fancy decoration is. All of them have been given valid HTML ids, so they're possible to link, they just aren't.\n\nThe markdown for that page, which works around a couple RTD bugs and doesn't look that great, is here:\nhttps://raw.githubusercontent.com/lua-carbon/carbon/master/docs/Classes/Collections.Tuple.md\n\n", "before_files": [{"content": "# coding: utf-8\n\"\"\"Python 2/3 compatibility module.\"\"\"\nimport sys\n\nPY2 = int(sys.version[0]) == 2\n\nif PY2:\n from urlparse import urljoin, urlparse, urlunparse\n import urllib\n urlunquote = urllib.unquote\n\n import SimpleHTTPServer as httpserver\n httpserver = httpserver\n import SocketServer\n socketserver = SocketServer\n\n import itertools\n zip = itertools.izip\n\n text_type = unicode\n binary_type = str\n string_types = (str, unicode)\n unicode = unicode\n basestring = basestring\nelse: # PY3\n from urllib.parse import urljoin, urlparse, urlunparse, unquote\n urlunquote = unquote\n\n import http.server as httpserver\n httpserver = httpserver\n import socketserver\n socketserver = socketserver\n\n zip = zip\n\n text_type = str\n binary_type = bytes\n string_types = (str,)\n unicode = str\n basestring = (str, bytes)\n", "path": "mkdocs/compat.py"}, {"content": "# coding: utf-8\n\n\"\"\"\nDeals with generating the per-page table of contents.\n\nFor the sake of simplicity we use an existing markdown extension to generate\nan HTML table of contents, and then parse that into the underlying data.\n\nThe steps we take to generate a table of contents are:\n\n* Pre-process the markdown, injecting a [TOC] marker.\n* Generate HTML from markdown.\n* Post-process the HTML, spliting the content and the table of contents.\n* Parse table of contents HTML into the underlying data structure.\n\"\"\"\n\nimport re\n\nTOC_LINK_REGEX = re.compile('<a href=[\"]([^\"]*)[\"]>([^<]*)</a>')\n\n\nclass TableOfContents(object):\n \"\"\"\n Represents the table of contents for a given page.\n \"\"\"\n def __init__(self, html):\n self.items = _parse_html_table_of_contents(html)\n\n def __iter__(self):\n return iter(self.items)\n\n def __str__(self):\n return ''.join([str(item) for item in self])\n\n\nclass AnchorLink(object):\n \"\"\"\n A single entry in the table of contents.\n \"\"\"\n def __init__(self, title, url):\n self.title, self.url = title, url\n self.children = []\n\n def __str__(self):\n return self._indent_print()\n\n def _indent_print(self, depth=0):\n indent = ' ' * depth\n ret = '%s%s - %s\\n' % (indent, self.title, self.url)\n for item in self.children:\n ret += item._indent_print(depth + 1)\n return ret\n\n\ndef _parse_html_table_of_contents(html):\n \"\"\"\n Given a table of contents string that has been automatically generated by\n the markdown library, parse it into a tree of AnchorLink instances.\n\n Returns a list of all the parent AnchorLink instances.\n \"\"\"\n lines = html.splitlines()[2:-2]\n parents = []\n ret = []\n for line in lines:\n match = TOC_LINK_REGEX.search(line)\n if match:\n href, title = match.groups()\n nav = AnchorLink(title, href)\n # Add the item to its parent if required. If it is a topmost\n # item then instead append it to our return value.\n if parents:\n parents[-1].children.append(nav)\n else:\n ret.append(nav)\n # If this item has children, store it as the current parent\n if line.endswith('<ul>'):\n parents.append(nav)\n elif line.startswith('</ul>'):\n if parents:\n parents.pop()\n\n # For the table of contents, always mark the first element as active\n if ret:\n ret[0].active = True\n\n return ret\n", "path": "mkdocs/toc.py"}], "after_files": [{"content": "# coding: utf-8\n\"\"\"Python 2/3 compatibility module.\"\"\"\nimport sys\n\nPY2 = int(sys.version[0]) == 2\n\nif PY2:\n from urlparse import urljoin, urlparse, urlunparse\n import urllib\n urlunquote = urllib.unquote\n\n import SimpleHTTPServer as httpserver\n httpserver = httpserver\n import SocketServer\n socketserver = SocketServer\n from HTMLParser import HTMLParser\n\n import itertools\n zip = itertools.izip\n\n text_type = unicode\n binary_type = str\n string_types = (str, unicode)\n unicode = unicode\n basestring = basestring\nelse: # PY3\n from urllib.parse import urljoin, urlparse, urlunparse, unquote\n urlunquote = unquote\n\n import http.server as httpserver\n httpserver = httpserver\n import socketserver\n socketserver = socketserver\n from html.parser import HTMLParser\n\n zip = zip\n\n text_type = str\n binary_type = bytes\n string_types = (str,)\n unicode = str\n basestring = (str, bytes)\n", "path": "mkdocs/compat.py"}, {"content": "# coding: utf-8\n\n\"\"\"\nDeals with generating the per-page table of contents.\n\nFor the sake of simplicity we use an existing markdown extension to generate\nan HTML table of contents, and then parse that into the underlying data.\n\nThe steps we take to generate a table of contents are:\n\n* Pre-process the markdown, injecting a [TOC] marker.\n* Generate HTML from markdown.\n* Post-process the HTML, spliting the content and the table of contents.\n* Parse table of contents HTML into the underlying data structure.\n\"\"\"\n\nfrom mkdocs.compat import HTMLParser\n\n\nclass TableOfContents(object):\n \"\"\"\n Represents the table of contents for a given page.\n \"\"\"\n def __init__(self, html):\n self.items = _parse_html_table_of_contents(html)\n\n def __iter__(self):\n return iter(self.items)\n\n def __str__(self):\n return ''.join([str(item) for item in self])\n\n\nclass AnchorLink(object):\n \"\"\"\n A single entry in the table of contents.\n \"\"\"\n def __init__(self, title, url):\n self.title, self.url = title, url\n self.children = []\n\n def __str__(self):\n return self._indent_print()\n\n def _indent_print(self, depth=0):\n indent = ' ' * depth\n ret = '%s%s - %s\\n' % (indent, self.title, self.url)\n for item in self.children:\n ret += item._indent_print(depth + 1)\n return ret\n\n\nclass TOCParser(HTMLParser):\n\n def __init__(self):\n HTMLParser.__init__(self)\n self.links = []\n\n self.in_anchor = True\n self.attrs = None\n self.title = ''\n\n def handle_starttag(self, tag, attrs):\n\n if tag == 'a':\n self.in_anchor = True\n self.attrs = dict(attrs)\n\n def handle_endtag(self, tag):\n if tag == 'a':\n self.in_anchor = False\n\n def handle_data(self, data):\n\n if self.in_anchor:\n self.title += data\n\n\ndef _parse_html_table_of_contents(html):\n \"\"\"\n Given a table of contents string that has been automatically generated by\n the markdown library, parse it into a tree of AnchorLink instances.\n\n Returns a list of all the parent AnchorLink instances.\n \"\"\"\n lines = html.splitlines()[2:-2]\n parents = []\n ret = []\n for line in lines:\n parser = TOCParser()\n parser.feed(line)\n if parser.title:\n href = parser.attrs['href']\n title = parser.title\n nav = AnchorLink(title, href)\n # Add the item to its parent if required. If it is a topmost\n # item then instead append it to our return value.\n if parents:\n parents[-1].children.append(nav)\n else:\n ret.append(nav)\n # If this item has children, store it as the current parent\n if line.endswith('<ul>'):\n parents.append(nav)\n elif line.startswith('</ul>'):\n if parents:\n parents.pop()\n\n # For the table of contents, always mark the first element as active\n if ret:\n ret[0].active = True\n\n return ret\n", "path": "mkdocs/toc.py"}]}
| 1,532 | 558 |
gh_patches_debug_15267
|
rasdani/github-patches
|
git_diff
|
networkx__networkx-2996
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
metric_closure will throw KeyError with unconnected graph
Suggest checking connectedness with `nx.is_connected()` on entry to `metric_closure()` and throwing a more informative error if not.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `networkx/algorithms/approximation/steinertree.py`
Content:
```
1 from itertools import combinations, chain
2
3 from networkx.utils import pairwise, not_implemented_for
4 import networkx as nx
5
6 __all__ = ['metric_closure', 'steiner_tree']
7
8
9 @not_implemented_for('directed')
10 def metric_closure(G, weight='weight'):
11 """ Return the metric closure of a graph.
12
13 The metric closure of a graph *G* is the complete graph in which each edge
14 is weighted by the shortest path distance between the nodes in *G* .
15
16 Parameters
17 ----------
18 G : NetworkX graph
19
20 Returns
21 -------
22 NetworkX graph
23 Metric closure of the graph `G`.
24
25 """
26 M = nx.Graph()
27
28 seen = set()
29 Gnodes = set(G)
30 for u, (distance, path) in nx.all_pairs_dijkstra(G, weight=weight):
31 seen.add(u)
32 for v in Gnodes - seen:
33 M.add_edge(u, v, distance=distance[v], path=path[v])
34
35 return M
36
37
38 @not_implemented_for('directed')
39 def steiner_tree(G, terminal_nodes, weight='weight'):
40 """ Return an approximation to the minimum Steiner tree of a graph.
41
42 Parameters
43 ----------
44 G : NetworkX graph
45
46 terminal_nodes : list
47 A list of terminal nodes for which minimum steiner tree is
48 to be found.
49
50 Returns
51 -------
52 NetworkX graph
53 Approximation to the minimum steiner tree of `G` induced by
54 `terminal_nodes` .
55
56 Notes
57 -----
58 Steiner tree can be approximated by computing the minimum spanning
59 tree of the subgraph of the metric closure of the graph induced by the
60 terminal nodes, where the metric closure of *G* is the complete graph in
61 which each edge is weighted by the shortest path distance between the
62 nodes in *G* .
63 This algorithm produces a tree whose weight is within a (2 - (2 / t))
64 factor of the weight of the optimal Steiner tree where *t* is number of
65 terminal nodes.
66
67 """
68 # M is the subgraph of the metric closure induced by the terminal nodes of
69 # G.
70 M = metric_closure(G, weight=weight)
71 # Use the 'distance' attribute of each edge provided by the metric closure
72 # graph.
73 H = M.subgraph(terminal_nodes)
74 mst_edges = nx.minimum_spanning_edges(H, weight='distance', data=True)
75 # Create an iterator over each edge in each shortest path; repeats are okay
76 edges = chain.from_iterable(pairwise(d['path']) for u, v, d in mst_edges)
77 T = G.edge_subgraph(edges)
78 return T
79
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/networkx/algorithms/approximation/steinertree.py b/networkx/algorithms/approximation/steinertree.py
--- a/networkx/algorithms/approximation/steinertree.py
+++ b/networkx/algorithms/approximation/steinertree.py
@@ -25,11 +25,22 @@
"""
M = nx.Graph()
- seen = set()
Gnodes = set(G)
- for u, (distance, path) in nx.all_pairs_dijkstra(G, weight=weight):
- seen.add(u)
- for v in Gnodes - seen:
+
+ # check for connected graph while processing first node
+ all_paths_iter = nx.all_pairs_dijkstra(G, weight=weight)
+ u, (distance, path) = next(all_paths_iter)
+ if Gnodes - set(distance):
+ msg = "G is not a connected graph. metric_closure is not defined."
+ raise nx.NetworkXError(msg)
+ Gnodes.remove(u)
+ for v in Gnodes:
+ M.add_edge(u, v, distance=distance[v], path=path[v])
+
+ # first node done -- now process the rest
+ for u, (distance, path) in all_paths_iter:
+ Gnodes.remove(u)
+ for v in Gnodes:
M.add_edge(u, v, distance=distance[v], path=path[v])
return M
|
{"golden_diff": "diff --git a/networkx/algorithms/approximation/steinertree.py b/networkx/algorithms/approximation/steinertree.py\n--- a/networkx/algorithms/approximation/steinertree.py\n+++ b/networkx/algorithms/approximation/steinertree.py\n@@ -25,11 +25,22 @@\n \"\"\"\n M = nx.Graph()\n \n- seen = set()\n Gnodes = set(G)\n- for u, (distance, path) in nx.all_pairs_dijkstra(G, weight=weight):\n- seen.add(u)\n- for v in Gnodes - seen:\n+\n+ # check for connected graph while processing first node\n+ all_paths_iter = nx.all_pairs_dijkstra(G, weight=weight)\n+ u, (distance, path) = next(all_paths_iter)\n+ if Gnodes - set(distance):\n+ msg = \"G is not a connected graph. metric_closure is not defined.\"\n+ raise nx.NetworkXError(msg)\n+ Gnodes.remove(u)\n+ for v in Gnodes:\n+ M.add_edge(u, v, distance=distance[v], path=path[v])\n+\n+ # first node done -- now process the rest\n+ for u, (distance, path) in all_paths_iter:\n+ Gnodes.remove(u)\n+ for v in Gnodes:\n M.add_edge(u, v, distance=distance[v], path=path[v])\n \n return M\n", "issue": "metric_closure will throw KeyError with unconnected graph\nSuggest checking connectedness with `nx.is_connected()` on entry to `metric_closure()` and throwing a more informative error if not.\n", "before_files": [{"content": "from itertools import combinations, chain\n\nfrom networkx.utils import pairwise, not_implemented_for\nimport networkx as nx\n\n__all__ = ['metric_closure', 'steiner_tree']\n\n\n@not_implemented_for('directed')\ndef metric_closure(G, weight='weight'):\n \"\"\" Return the metric closure of a graph.\n\n The metric closure of a graph *G* is the complete graph in which each edge\n is weighted by the shortest path distance between the nodes in *G* .\n\n Parameters\n ----------\n G : NetworkX graph\n\n Returns\n -------\n NetworkX graph\n Metric closure of the graph `G`.\n\n \"\"\"\n M = nx.Graph()\n\n seen = set()\n Gnodes = set(G)\n for u, (distance, path) in nx.all_pairs_dijkstra(G, weight=weight):\n seen.add(u)\n for v in Gnodes - seen:\n M.add_edge(u, v, distance=distance[v], path=path[v])\n\n return M\n\n\n@not_implemented_for('directed')\ndef steiner_tree(G, terminal_nodes, weight='weight'):\n \"\"\" Return an approximation to the minimum Steiner tree of a graph.\n\n Parameters\n ----------\n G : NetworkX graph\n\n terminal_nodes : list\n A list of terminal nodes for which minimum steiner tree is\n to be found.\n\n Returns\n -------\n NetworkX graph\n Approximation to the minimum steiner tree of `G` induced by\n `terminal_nodes` .\n\n Notes\n -----\n Steiner tree can be approximated by computing the minimum spanning\n tree of the subgraph of the metric closure of the graph induced by the\n terminal nodes, where the metric closure of *G* is the complete graph in\n which each edge is weighted by the shortest path distance between the\n nodes in *G* .\n This algorithm produces a tree whose weight is within a (2 - (2 / t))\n factor of the weight of the optimal Steiner tree where *t* is number of\n terminal nodes.\n\n \"\"\"\n # M is the subgraph of the metric closure induced by the terminal nodes of\n # G.\n M = metric_closure(G, weight=weight)\n # Use the 'distance' attribute of each edge provided by the metric closure\n # graph.\n H = M.subgraph(terminal_nodes)\n mst_edges = nx.minimum_spanning_edges(H, weight='distance', data=True)\n # Create an iterator over each edge in each shortest path; repeats are okay\n edges = chain.from_iterable(pairwise(d['path']) for u, v, d in mst_edges)\n T = G.edge_subgraph(edges)\n return T\n", "path": "networkx/algorithms/approximation/steinertree.py"}], "after_files": [{"content": "from itertools import combinations, chain\n\nfrom networkx.utils import pairwise, not_implemented_for\nimport networkx as nx\n\n__all__ = ['metric_closure', 'steiner_tree']\n\n\n@not_implemented_for('directed')\ndef metric_closure(G, weight='weight'):\n \"\"\" Return the metric closure of a graph.\n\n The metric closure of a graph *G* is the complete graph in which each edge\n is weighted by the shortest path distance between the nodes in *G* .\n\n Parameters\n ----------\n G : NetworkX graph\n\n Returns\n -------\n NetworkX graph\n Metric closure of the graph `G`.\n\n \"\"\"\n M = nx.Graph()\n\n Gnodes = set(G)\n\n # check for connected graph while processing first node\n all_paths_iter = nx.all_pairs_dijkstra(G, weight=weight)\n u, (distance, path) = next(all_paths_iter)\n if Gnodes - set(distance):\n msg = \"G is not a connected graph. metric_closure is not defined.\"\n raise nx.NetworkXError(msg)\n Gnodes.remove(u)\n for v in Gnodes:\n M.add_edge(u, v, distance=distance[v], path=path[v])\n\n # first node done -- now process the rest\n for u, (distance, path) in all_paths_iter:\n Gnodes.remove(u)\n for v in Gnodes:\n M.add_edge(u, v, distance=distance[v], path=path[v])\n\n return M\n\n\n@not_implemented_for('directed')\ndef steiner_tree(G, terminal_nodes, weight='weight'):\n \"\"\" Return an approximation to the minimum Steiner tree of a graph.\n\n Parameters\n ----------\n G : NetworkX graph\n\n terminal_nodes : list\n A list of terminal nodes for which minimum steiner tree is\n to be found.\n\n Returns\n -------\n NetworkX graph\n Approximation to the minimum steiner tree of `G` induced by\n `terminal_nodes` .\n\n Notes\n -----\n Steiner tree can be approximated by computing the minimum spanning\n tree of the subgraph of the metric closure of the graph induced by the\n terminal nodes, where the metric closure of *G* is the complete graph in\n which each edge is weighted by the shortest path distance between the\n nodes in *G* .\n This algorithm produces a tree whose weight is within a (2 - (2 / t))\n factor of the weight of the optimal Steiner tree where *t* is number of\n terminal nodes.\n\n \"\"\"\n # M is the subgraph of the metric closure induced by the terminal nodes of\n # G.\n M = metric_closure(G, weight=weight)\n # Use the 'distance' attribute of each edge provided by the metric closure\n # graph.\n H = M.subgraph(terminal_nodes)\n mst_edges = nx.minimum_spanning_edges(H, weight='distance', data=True)\n # Create an iterator over each edge in each shortest path; repeats are okay\n edges = chain.from_iterable(pairwise(d['path']) for u, v, d in mst_edges)\n T = G.edge_subgraph(edges)\n return T\n", "path": "networkx/algorithms/approximation/steinertree.py"}]}
| 1,040 | 313 |
gh_patches_debug_2370
|
rasdani/github-patches
|
git_diff
|
getredash__redash-1110
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Mixed view_only in multiple data_source_groups blocks query executions
A user belonging to multiple groups that have access to one data source but with different access levels can not execute queries on that data source.
For example, if a user belongs to built-in `default` group and you have set `view_only` for all data sources in this group to true, adding this user to a new group to allow full access to one of the data sources will not work.
This is caused by `group_level` definition in `def has_access()` in [permissions.py](https://github.com/getredash/redash/blob/master/redash/permissions.py):
```
required_level = 1 if need_view_only else 2
group_level = 1 if any(flatten([object_groups[group] for group in matching_groups])) else 2
return required_level <= group_level
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `redash/permissions.py`
Content:
```
1 from flask_login import current_user
2 from flask_restful import abort
3 import functools
4 from funcy import any, flatten
5
6 view_only = True
7 not_view_only = False
8
9
10 def has_access(object_groups, user, need_view_only):
11 if 'admin' in user.permissions:
12 return True
13
14 matching_groups = set(object_groups.keys()).intersection(user.groups)
15
16 if not matching_groups:
17 return False
18
19 required_level = 1 if need_view_only else 2
20 group_level = 1 if any(flatten([object_groups[group] for group in matching_groups])) else 2
21
22 return required_level <= group_level
23
24
25 def require_access(object_groups, user, need_view_only):
26 if not has_access(object_groups, user, need_view_only):
27 abort(403)
28
29
30 class require_permissions(object):
31 def __init__(self, permissions):
32 self.permissions = permissions
33
34 def __call__(self, fn):
35 @functools.wraps(fn)
36 def decorated(*args, **kwargs):
37 has_permissions = current_user.has_permissions(self.permissions)
38
39 if has_permissions:
40 return fn(*args, **kwargs)
41 else:
42 abort(403)
43
44 return decorated
45
46
47 def require_permission(permission):
48 return require_permissions((permission,))
49
50
51 def require_admin(fn):
52 return require_permission('admin')(fn)
53
54
55 def require_super_admin(fn):
56 return require_permission('super_admin')(fn)
57
58
59 def has_permission_or_owner(permission, object_owner_id):
60 return int(object_owner_id) == current_user.id or current_user.has_permission(permission)
61
62
63 def is_admin_or_owner(object_owner_id):
64 return has_permission_or_owner('admin', object_owner_id)
65
66
67 def require_permission_or_owner(permission, object_owner_id):
68 if not has_permission_or_owner(permission, object_owner_id):
69 abort(403)
70
71
72 def require_admin_or_owner(object_owner_id):
73 if not is_admin_or_owner(object_owner_id):
74 abort(403, message="You don't have permission to edit this resource.")
75
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/redash/permissions.py b/redash/permissions.py
--- a/redash/permissions.py
+++ b/redash/permissions.py
@@ -17,7 +17,8 @@
return False
required_level = 1 if need_view_only else 2
- group_level = 1 if any(flatten([object_groups[group] for group in matching_groups])) else 2
+
+ group_level = 1 if all(flatten([object_groups[group] for group in matching_groups])) else 2
return required_level <= group_level
|
{"golden_diff": "diff --git a/redash/permissions.py b/redash/permissions.py\n--- a/redash/permissions.py\n+++ b/redash/permissions.py\n@@ -17,7 +17,8 @@\n return False\n \n required_level = 1 if need_view_only else 2\n- group_level = 1 if any(flatten([object_groups[group] for group in matching_groups])) else 2\n+\n+ group_level = 1 if all(flatten([object_groups[group] for group in matching_groups])) else 2\n \n return required_level <= group_level\n", "issue": "Mixed view_only in multiple data_source_groups blocks query executions\nA user belonging to multiple groups that have access to one data source but with different access levels can not execute queries on that data source.\n\nFor example, if a user belongs to built-in `default` group and you have set `view_only` for all data sources in this group to true, adding this user to a new group to allow full access to one of the data sources will not work.\n\nThis is caused by `group_level` definition in `def has_access()` in [permissions.py](https://github.com/getredash/redash/blob/master/redash/permissions.py):\n\n```\nrequired_level = 1 if need_view_only else 2\ngroup_level = 1 if any(flatten([object_groups[group] for group in matching_groups])) else 2\n\nreturn required_level <= group_level\n```\n\n", "before_files": [{"content": "from flask_login import current_user\nfrom flask_restful import abort\nimport functools\nfrom funcy import any, flatten\n\nview_only = True\nnot_view_only = False\n\n\ndef has_access(object_groups, user, need_view_only):\n if 'admin' in user.permissions:\n return True\n\n matching_groups = set(object_groups.keys()).intersection(user.groups)\n\n if not matching_groups:\n return False\n\n required_level = 1 if need_view_only else 2\n group_level = 1 if any(flatten([object_groups[group] for group in matching_groups])) else 2\n\n return required_level <= group_level\n\n\ndef require_access(object_groups, user, need_view_only):\n if not has_access(object_groups, user, need_view_only):\n abort(403)\n\n\nclass require_permissions(object):\n def __init__(self, permissions):\n self.permissions = permissions\n\n def __call__(self, fn):\n @functools.wraps(fn)\n def decorated(*args, **kwargs):\n has_permissions = current_user.has_permissions(self.permissions)\n\n if has_permissions:\n return fn(*args, **kwargs)\n else:\n abort(403)\n\n return decorated\n\n\ndef require_permission(permission):\n return require_permissions((permission,))\n\n\ndef require_admin(fn):\n return require_permission('admin')(fn)\n\n\ndef require_super_admin(fn):\n return require_permission('super_admin')(fn)\n\n\ndef has_permission_or_owner(permission, object_owner_id):\n return int(object_owner_id) == current_user.id or current_user.has_permission(permission)\n\n\ndef is_admin_or_owner(object_owner_id):\n return has_permission_or_owner('admin', object_owner_id)\n\n\ndef require_permission_or_owner(permission, object_owner_id):\n if not has_permission_or_owner(permission, object_owner_id):\n abort(403)\n\n\ndef require_admin_or_owner(object_owner_id):\n if not is_admin_or_owner(object_owner_id):\n abort(403, message=\"You don't have permission to edit this resource.\")\n", "path": "redash/permissions.py"}], "after_files": [{"content": "from flask_login import current_user\nfrom flask_restful import abort\nimport functools\nfrom funcy import any, flatten\n\nview_only = True\nnot_view_only = False\n\n\ndef has_access(object_groups, user, need_view_only):\n if 'admin' in user.permissions:\n return True\n\n matching_groups = set(object_groups.keys()).intersection(user.groups)\n\n if not matching_groups:\n return False\n\n required_level = 1 if need_view_only else 2\n\n group_level = 1 if all(flatten([object_groups[group] for group in matching_groups])) else 2\n\n return required_level <= group_level\n\n\ndef require_access(object_groups, user, need_view_only):\n if not has_access(object_groups, user, need_view_only):\n abort(403)\n\n\nclass require_permissions(object):\n def __init__(self, permissions):\n self.permissions = permissions\n\n def __call__(self, fn):\n @functools.wraps(fn)\n def decorated(*args, **kwargs):\n has_permissions = current_user.has_permissions(self.permissions)\n\n if has_permissions:\n return fn(*args, **kwargs)\n else:\n abort(403)\n\n return decorated\n\n\ndef require_permission(permission):\n return require_permissions((permission,))\n\n\ndef require_admin(fn):\n return require_permission('admin')(fn)\n\n\ndef require_super_admin(fn):\n return require_permission('super_admin')(fn)\n\n\ndef has_permission_or_owner(permission, object_owner_id):\n return int(object_owner_id) == current_user.id or current_user.has_permission(permission)\n\n\ndef is_admin_or_owner(object_owner_id):\n return has_permission_or_owner('admin', object_owner_id)\n\n\ndef require_permission_or_owner(permission, object_owner_id):\n if not has_permission_or_owner(permission, object_owner_id):\n abort(403)\n\n\ndef require_admin_or_owner(object_owner_id):\n if not is_admin_or_owner(object_owner_id):\n abort(403, message=\"You don't have permission to edit this resource.\")\n", "path": "redash/permissions.py"}]}
| 1,018 | 123 |
gh_patches_debug_38981
|
rasdani/github-patches
|
git_diff
|
aws-cloudformation__cfn-lint-1690
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Doesn't catch CodePipeline OutputArtifacts need to be uniquely named
cfn-lint 0.35.1
*Description of issue.*
The linter doesn't catch that CodePipeline `OutputArtifacts` need to be uniquely named.
Please provide as much information as possible:
* Template linting issues:
* Please provide a CloudFormation sample that generated the issue.
This template generates the error `UPDATE_FAILED | Output Artifact Bundle name must be unique within the pipeline. CreateOutput has been used more than once.`
<details>
```yaml
AWSTemplateFormatVersion: "2010-09-09"
Description: The AWS CloudFormation template for this Serverless application
Resources:
ServerlessDeploymentPipeline:
Type: AWS::CodePipeline::Pipeline
Properties:
ArtifactStores:
- Region: ca-central-1
ArtifactStore:
Type: S3
Location: my-artifact-bucket
Name: my-code-pipeline
RestartExecutionOnUpdate: false
RoleArn: arn:aws:iam::000000000000:role/root
Stages:
- Name: Source
Actions:
- Name: SourceAction
ActionTypeId:
Category: Source
Owner: AWS
Version: "1"
Provider: S3
OutputArtifacts:
- Name: SourceArtifact
Configuration:
S3Bucket: my-source-bucket
S3ObjectKey: source-item.zip
RunOrder: 1
- Name: DeployToEnvA
Actions:
- Name: CreateChangeSetEnvA
Region: us-east-1
ActionTypeId:
Category: Deploy
Owner: AWS
Version: "1"
Provider: CloudFormation
InputArtifacts:
- Name: SourceArtifact
OutputArtifacts:
- Name: CreateOutput
Configuration:
ActionMode: CHANGE_SET_REPLACE
StackName: my-service-env-a
Capabilities: CAPABILITY_NAMED_IAM
RoleArn: arn:aws:iam::000000000000:role/root
TemplatePath: SourceArtifact::env-a-us-east-1.json
ChangeSetName: ChangeSet
RunOrder: 1
RoleArn: arn:aws:iam::000000000000:role/root
- Name: CreateChangeSetEnvB
Region: us-east-1
ActionTypeId:
Category: Deploy
Owner: AWS
Version: "1"
Provider: CloudFormation
InputArtifacts:
- Name: SourceArtifact
OutputArtifacts:
- Name: CreateOutput
Configuration:
ActionMode: CHANGE_SET_REPLACE
StackName: my-service-env-b
Capabilities: CAPABILITY_NAMED_IAM
RoleArn: arn:aws:iam::000000000000:role/root
TemplatePath: SourceArtifact::env-b-us-east-1.json
ChangeSetName: ChangeSet
RunOrder: 1
RoleArn: arn:aws:iam::000000000000:role/root
```
</details>
* If present, please add links to the (official) documentation for clarification.
- > Every output artifact in the pipeline must have a unique name.
[Source](https://docs.aws.amazon.com/codepipeline/latest/userguide/welcome-introducing-artifacts.html)
* Validate if the issue still exists with the latest version of `cfn-lint` and/or the latest Spec files: :heavy_check_mark: `0.35.1` is the latest version
Cfn-lint uses the [CloudFormation Resource Specifications](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/cfn-resource-specification.html) as the base to do validation. These files are included as part of the application version. Please update to the latest version of `cfn-lint` or update the spec files manually (`cfn-lint -u`)
:heavy_check_mark: I have also tried after running `cfn-lint -u`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/cfnlint/rules/resources/codepipeline/CodepipelineStageActions.py`
Content:
```
1 """
2 Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
3 SPDX-License-Identifier: MIT-0
4 """
5 import re
6 import six
7 from cfnlint.rules import CloudFormationLintRule
8 from cfnlint.rules import RuleMatch
9
10
11 class CodepipelineStageActions(CloudFormationLintRule):
12 """Check if CodePipeline Stage Actions are set up properly."""
13 id = 'E2541'
14 shortdesc = 'CodePipeline Stage Actions'
15 description = 'See if CodePipeline stage actions are set correctly'
16 source_url = 'https://docs.aws.amazon.com/codepipeline/latest/userguide/reference-pipeline-structure.html#pipeline-requirements'
17 tags = ['resources', 'codepipeline']
18
19 CONSTRAINTS = {
20 'AWS': {
21 'Source': {
22 'S3': {
23 'InputArtifactRange': 0,
24 'OutputArtifactRange': 1,
25 },
26 'CodeCommit': {
27 'InputArtifactRange': 0,
28 'OutputArtifactRange': 1,
29 },
30 'ECR': {
31 'InputArtifactRange': 0,
32 'OutputArtifactRange': 1,
33 }
34 },
35 'Test': {
36 'CodeBuild': {
37 'InputArtifactRange': (1, 5),
38 'OutputArtifactRange': (0, 5),
39 },
40 'DeviceFarm': {
41 'InputArtifactRange': 1,
42 'OutputArtifactRange': 0,
43 }
44 },
45 'Build': {
46 'CodeBuild': {
47 'InputArtifactRange': (1, 5),
48 'OutputArtifactRange': (0, 5),
49 }
50 },
51 'Approval': {
52 'Manual': {
53 'InputArtifactRange': 0,
54 'OutputArtifactRange': 0,
55 }
56 },
57 'Deploy': {
58 'S3': {
59 'InputArtifactRange': 1,
60 'OutputArtifactRange': 0,
61 },
62 'CloudFormation': {
63 'InputArtifactRange': (0, 10),
64 'OutputArtifactRange': (0, 1),
65 },
66 'CodeDeploy': {
67 'InputArtifactRange': 1,
68 'OutputArtifactRange': 0,
69 },
70 'ElasticBeanstalk': {
71 'InputArtifactRange': 1,
72 'OutputArtifactRange': 0,
73 },
74 'OpsWorks': {
75 'InputArtifactRange': 1,
76 'OutputArtifactRange': 0,
77 },
78 'ECS': {
79 'InputArtifactRange': 1,
80 'OutputArtifactRange': 0,
81 },
82 'ServiceCatalog': {
83 'InputArtifactRange': 1,
84 'OutputArtifactRange': 0,
85 },
86 },
87 'Invoke': {
88 'Lambda': {
89 'InputArtifactRange': (0, 5),
90 'OutputArtifactRange': (0, 5),
91 }
92 }
93 },
94 'ThirdParty': {
95 'Source': {
96 'GitHub': {
97 'InputArtifactRange': 0,
98 'OutputArtifactRange': 1,
99 }
100 },
101 'Deploy': {
102 'AlexaSkillsKit': {
103 'InputArtifactRange': (0, 2),
104 'OutputArtifactRange': 0,
105 },
106 },
107 },
108 'Custom': {
109 'Build': {
110 'Jenkins': {
111 'InputArtifactRange': (0, 5),
112 'OutputArtifactRange': (0, 5),
113 },
114 },
115 'Test': {
116 'Jenkins': {
117 'InputArtifactRange': (0, 5),
118 'OutputArtifactRange': (0, 5),
119 },
120 },
121 },
122 }
123
124 KEY_MAP = {
125 'InputArtifacts': 'InputArtifactRange',
126 'OutputArtifacts': 'OutputArtifactRange',
127 }
128
129 def check_artifact_counts(self, action, artifact_type, path):
130 """Check that artifact counts are within valid ranges."""
131 matches = []
132
133 action_type_id = action.get('ActionTypeId')
134 owner = action_type_id.get('Owner')
135 category = action_type_id.get('Category')
136 provider = action_type_id.get('Provider')
137
138 if isinstance(owner, dict) or isinstance(category, dict) or isinstance(provider, dict):
139 self.logger.debug('owner, category, provider need to be strings to validate. Skipping.')
140 return matches
141
142 constraints = self.CONSTRAINTS.get(owner, {}).get(category, {}).get(provider, {})
143 if not constraints:
144 return matches
145 artifact_count = len(action.get(artifact_type, []))
146
147 constraint_key = self.KEY_MAP[artifact_type]
148 if isinstance(constraints[constraint_key], tuple):
149 min_, max_ = constraints[constraint_key]
150 if not (min_ <= artifact_count <= max_):
151 message = (
152 'Action "{action}" declares {number} {artifact_type} which is not in '
153 'expected range [{a}, {b}].'
154 ).format(
155 action=action['Name'],
156 number=artifact_count,
157 artifact_type=artifact_type,
158 a=min_,
159 b=max_
160 )
161 matches.append(RuleMatch(
162 path + [artifact_type],
163 message
164 ))
165 else:
166 if artifact_count != constraints[constraint_key]:
167 message = (
168 'Action "{action}" declares {number} {artifact_type} which is not the '
169 'expected number [{a}].'
170 ).format(
171 action=action['Name'],
172 number=artifact_count,
173 artifact_type=artifact_type,
174 a=constraints[constraint_key]
175 )
176 matches.append(RuleMatch(
177 path + [artifact_type],
178 message
179 ))
180
181 return matches
182
183 def check_version(self, action, path):
184 """Check that action type version is valid."""
185 matches = []
186
187 REGEX_VERSION_STRING = re.compile(r'^[0-9A-Za-z_-]+$')
188 LENGTH_MIN = 1
189 LENGTH_MAX = 9
190
191 version = action.get('ActionTypeId', {}).get('Version')
192 if isinstance(version, dict):
193 self.logger.debug('Unable to validate version when an object is used. Skipping')
194 elif isinstance(version, (six.string_types)):
195 if not LENGTH_MIN <= len(version) <= LENGTH_MAX:
196 message = 'Version string ({0}) must be between {1} and {2} characters in length.'
197 matches.append(RuleMatch(
198 path + ['ActionTypeId', 'Version'],
199 message.format(version, LENGTH_MIN, LENGTH_MAX)))
200 elif not re.match(REGEX_VERSION_STRING, version):
201 message = 'Version string must match the pattern [0-9A-Za-z_-]+.'
202 matches.append(RuleMatch(
203 path + ['ActionTypeId', 'Version'],
204 message
205 ))
206 return matches
207
208 def check_names_unique(self, action, path, action_names):
209 """Check that action names are unique."""
210 matches = []
211
212 action_name = action.get('Name')
213 if isinstance(action_name, six.string_types):
214 if action.get('Name') in action_names:
215 message = 'All action names within a stage must be unique. ({name})'.format(
216 name=action.get('Name')
217 )
218 matches.append(RuleMatch(path + ['Name'], message))
219 action_names.add(action.get('Name'))
220
221 return matches
222
223 def match(self, cfn):
224 """Check that stage actions are set up properly."""
225 matches = []
226
227 resources = cfn.get_resource_properties(['AWS::CodePipeline::Pipeline'])
228 for resource in resources:
229 path = resource['Path']
230 properties = resource['Value']
231
232 s_stages = properties.get_safe('Stages', path)
233 for s_stage_v, s_stage_p in s_stages:
234 if not isinstance(s_stage_v, list):
235 self.logger.debug(
236 'Stages not list. Should have been caught by generic linting.')
237 return matches
238
239 for l_i_stage, l_i_path in s_stage_v.items_safe(s_stage_p):
240 action_names = set()
241 s_actions = l_i_stage.get_safe('Actions', l_i_path)
242 for s_action_v, s_action_p in s_actions:
243 if not isinstance(s_action_v, list):
244 self.logger.debug(
245 'Actions not list. Should have been caught by generic linting.')
246 return matches
247
248 for l_i_a_action, l_i_a_path in s_action_v.items_safe(s_action_p):
249 try:
250 full_path = path + l_i_path + l_i_a_path
251 matches.extend(self.check_names_unique(
252 l_i_a_action, full_path, action_names))
253 matches.extend(self.check_version(l_i_a_action, full_path))
254 matches.extend(self.check_artifact_counts(
255 l_i_a_action, 'InputArtifacts', full_path))
256 matches.extend(self.check_artifact_counts(
257 l_i_a_action, 'OutputArtifacts', full_path))
258 except AttributeError as err:
259 self.logger.debug('Got AttributeError. Should have been caught by generic linting. '
260 'Ignoring the error here: %s', str(err))
261
262 return matches
263
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/cfnlint/rules/resources/codepipeline/CodepipelineStageActions.py b/src/cfnlint/rules/resources/codepipeline/CodepipelineStageActions.py
--- a/src/cfnlint/rules/resources/codepipeline/CodepipelineStageActions.py
+++ b/src/cfnlint/rules/resources/codepipeline/CodepipelineStageActions.py
@@ -220,6 +220,35 @@
return matches
+ def check_artifact_names(self, action, path, artifact_names):
+ """Check that output artifact names are unique and inputs are from previous stage outputs."""
+ matches = []
+
+ input_artifacts = action.get('InputArtifacts')
+ if isinstance(input_artifacts, list):
+ for input_artifact in input_artifacts:
+ artifact_name = input_artifact.get('Name')
+ if isinstance(artifact_name, six.string_types):
+ if not artifact_name in artifact_names:
+ message = 'Every input artifact for an action must match the output artifact of an action earlier in the pipeline. ({name})'.format(
+ name=artifact_name
+ )
+ matches.append(RuleMatch(path + ['InputArtifacts', 'Name'], message))
+
+ output_artifacts = action.get('OutputArtifacts')
+ if isinstance(output_artifacts, list):
+ for output_artifact in output_artifacts:
+ artifact_name = output_artifact.get('Name')
+ if isinstance(artifact_name, six.string_types):
+ if artifact_name in artifact_names:
+ message = 'Every output artifact in the pipeline must have a unique name. ({name})'.format(
+ name=artifact_name
+ )
+ matches.append(RuleMatch(path + ['OutputArtifacts', 'Name'], message))
+ artifact_names.add(artifact_name)
+
+ return matches
+
def match(self, cfn):
"""Check that stage actions are set up properly."""
matches = []
@@ -228,6 +257,7 @@
for resource in resources:
path = resource['Path']
properties = resource['Value']
+ artifact_names = set()
s_stages = properties.get_safe('Stages', path)
for s_stage_v, s_stage_p in s_stages:
@@ -255,6 +285,8 @@
l_i_a_action, 'InputArtifacts', full_path))
matches.extend(self.check_artifact_counts(
l_i_a_action, 'OutputArtifacts', full_path))
+ matches.extend(self.check_artifact_names(
+ l_i_a_action, full_path, artifact_names))
except AttributeError as err:
self.logger.debug('Got AttributeError. Should have been caught by generic linting. '
'Ignoring the error here: %s', str(err))
|
{"golden_diff": "diff --git a/src/cfnlint/rules/resources/codepipeline/CodepipelineStageActions.py b/src/cfnlint/rules/resources/codepipeline/CodepipelineStageActions.py\n--- a/src/cfnlint/rules/resources/codepipeline/CodepipelineStageActions.py\n+++ b/src/cfnlint/rules/resources/codepipeline/CodepipelineStageActions.py\n@@ -220,6 +220,35 @@\n \n return matches\n \n+ def check_artifact_names(self, action, path, artifact_names):\n+ \"\"\"Check that output artifact names are unique and inputs are from previous stage outputs.\"\"\"\n+ matches = []\n+\n+ input_artifacts = action.get('InputArtifacts')\n+ if isinstance(input_artifacts, list):\n+ for input_artifact in input_artifacts:\n+ artifact_name = input_artifact.get('Name')\n+ if isinstance(artifact_name, six.string_types):\n+ if not artifact_name in artifact_names:\n+ message = 'Every input artifact for an action must match the output artifact of an action earlier in the pipeline. ({name})'.format(\n+ name=artifact_name\n+ )\n+ matches.append(RuleMatch(path + ['InputArtifacts', 'Name'], message))\n+\n+ output_artifacts = action.get('OutputArtifacts')\n+ if isinstance(output_artifacts, list):\n+ for output_artifact in output_artifacts:\n+ artifact_name = output_artifact.get('Name')\n+ if isinstance(artifact_name, six.string_types):\n+ if artifact_name in artifact_names:\n+ message = 'Every output artifact in the pipeline must have a unique name. ({name})'.format(\n+ name=artifact_name\n+ )\n+ matches.append(RuleMatch(path + ['OutputArtifacts', 'Name'], message))\n+ artifact_names.add(artifact_name)\n+\n+ return matches\n+\n def match(self, cfn):\n \"\"\"Check that stage actions are set up properly.\"\"\"\n matches = []\n@@ -228,6 +257,7 @@\n for resource in resources:\n path = resource['Path']\n properties = resource['Value']\n+ artifact_names = set()\n \n s_stages = properties.get_safe('Stages', path)\n for s_stage_v, s_stage_p in s_stages:\n@@ -255,6 +285,8 @@\n l_i_a_action, 'InputArtifacts', full_path))\n matches.extend(self.check_artifact_counts(\n l_i_a_action, 'OutputArtifacts', full_path))\n+ matches.extend(self.check_artifact_names(\n+ l_i_a_action, full_path, artifact_names))\n except AttributeError as err:\n self.logger.debug('Got AttributeError. Should have been caught by generic linting. '\n 'Ignoring the error here: %s', str(err))\n", "issue": "Doesn't catch CodePipeline OutputArtifacts need to be uniquely named\ncfn-lint 0.35.1\r\n\r\n*Description of issue.*\r\nThe linter doesn't catch that CodePipeline `OutputArtifacts` need to be uniquely named.\r\n\r\nPlease provide as much information as possible:\r\n* Template linting issues: \r\n * Please provide a CloudFormation sample that generated the issue.\r\n\r\nThis template generates the error `UPDATE_FAILED | Output Artifact Bundle name must be unique within the pipeline. CreateOutput has been used more than once.`\r\n\r\n<details>\r\n\r\n```yaml\r\nAWSTemplateFormatVersion: \"2010-09-09\"\r\nDescription: The AWS CloudFormation template for this Serverless application\r\nResources:\r\n ServerlessDeploymentPipeline:\r\n Type: AWS::CodePipeline::Pipeline\r\n Properties:\r\n ArtifactStores:\r\n - Region: ca-central-1\r\n ArtifactStore:\r\n Type: S3\r\n Location: my-artifact-bucket\r\n Name: my-code-pipeline\r\n RestartExecutionOnUpdate: false\r\n RoleArn: arn:aws:iam::000000000000:role/root\r\n Stages:\r\n - Name: Source\r\n Actions:\r\n - Name: SourceAction\r\n ActionTypeId:\r\n Category: Source\r\n Owner: AWS\r\n Version: \"1\"\r\n Provider: S3\r\n OutputArtifacts:\r\n - Name: SourceArtifact\r\n Configuration:\r\n S3Bucket: my-source-bucket\r\n S3ObjectKey: source-item.zip\r\n RunOrder: 1\r\n - Name: DeployToEnvA\r\n Actions:\r\n - Name: CreateChangeSetEnvA\r\n Region: us-east-1\r\n ActionTypeId:\r\n Category: Deploy\r\n Owner: AWS\r\n Version: \"1\"\r\n Provider: CloudFormation\r\n InputArtifacts:\r\n - Name: SourceArtifact\r\n OutputArtifacts:\r\n - Name: CreateOutput\r\n Configuration:\r\n ActionMode: CHANGE_SET_REPLACE\r\n StackName: my-service-env-a\r\n Capabilities: CAPABILITY_NAMED_IAM\r\n RoleArn: arn:aws:iam::000000000000:role/root\r\n TemplatePath: SourceArtifact::env-a-us-east-1.json\r\n ChangeSetName: ChangeSet\r\n RunOrder: 1\r\n RoleArn: arn:aws:iam::000000000000:role/root\r\n - Name: CreateChangeSetEnvB\r\n Region: us-east-1\r\n ActionTypeId:\r\n Category: Deploy\r\n Owner: AWS\r\n Version: \"1\"\r\n Provider: CloudFormation\r\n InputArtifacts:\r\n - Name: SourceArtifact\r\n OutputArtifacts:\r\n - Name: CreateOutput\r\n Configuration:\r\n ActionMode: CHANGE_SET_REPLACE\r\n StackName: my-service-env-b\r\n Capabilities: CAPABILITY_NAMED_IAM\r\n RoleArn: arn:aws:iam::000000000000:role/root\r\n TemplatePath: SourceArtifact::env-b-us-east-1.json\r\n ChangeSetName: ChangeSet\r\n RunOrder: 1\r\n RoleArn: arn:aws:iam::000000000000:role/root\r\n\r\n```\r\n\r\n</details>\r\n\r\n * If present, please add links to the (official) documentation for clarification.\r\n - > Every output artifact in the pipeline must have a unique name. \r\n\r\n [Source](https://docs.aws.amazon.com/codepipeline/latest/userguide/welcome-introducing-artifacts.html)\r\n * Validate if the issue still exists with the latest version of `cfn-lint` and/or the latest Spec files: :heavy_check_mark: `0.35.1` is the latest version\r\n\r\n\r\n\r\nCfn-lint uses the [CloudFormation Resource Specifications](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/cfn-resource-specification.html) as the base to do validation. These files are included as part of the application version. Please update to the latest version of `cfn-lint` or update the spec files manually (`cfn-lint -u`)\r\n\r\n:heavy_check_mark: I have also tried after running `cfn-lint -u`\n", "before_files": [{"content": "\"\"\"\nCopyright Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\nimport re\nimport six\nfrom cfnlint.rules import CloudFormationLintRule\nfrom cfnlint.rules import RuleMatch\n\n\nclass CodepipelineStageActions(CloudFormationLintRule):\n \"\"\"Check if CodePipeline Stage Actions are set up properly.\"\"\"\n id = 'E2541'\n shortdesc = 'CodePipeline Stage Actions'\n description = 'See if CodePipeline stage actions are set correctly'\n source_url = 'https://docs.aws.amazon.com/codepipeline/latest/userguide/reference-pipeline-structure.html#pipeline-requirements'\n tags = ['resources', 'codepipeline']\n\n CONSTRAINTS = {\n 'AWS': {\n 'Source': {\n 'S3': {\n 'InputArtifactRange': 0,\n 'OutputArtifactRange': 1,\n },\n 'CodeCommit': {\n 'InputArtifactRange': 0,\n 'OutputArtifactRange': 1,\n },\n 'ECR': {\n 'InputArtifactRange': 0,\n 'OutputArtifactRange': 1,\n }\n },\n 'Test': {\n 'CodeBuild': {\n 'InputArtifactRange': (1, 5),\n 'OutputArtifactRange': (0, 5),\n },\n 'DeviceFarm': {\n 'InputArtifactRange': 1,\n 'OutputArtifactRange': 0,\n }\n },\n 'Build': {\n 'CodeBuild': {\n 'InputArtifactRange': (1, 5),\n 'OutputArtifactRange': (0, 5),\n }\n },\n 'Approval': {\n 'Manual': {\n 'InputArtifactRange': 0,\n 'OutputArtifactRange': 0,\n }\n },\n 'Deploy': {\n 'S3': {\n 'InputArtifactRange': 1,\n 'OutputArtifactRange': 0,\n },\n 'CloudFormation': {\n 'InputArtifactRange': (0, 10),\n 'OutputArtifactRange': (0, 1),\n },\n 'CodeDeploy': {\n 'InputArtifactRange': 1,\n 'OutputArtifactRange': 0,\n },\n 'ElasticBeanstalk': {\n 'InputArtifactRange': 1,\n 'OutputArtifactRange': 0,\n },\n 'OpsWorks': {\n 'InputArtifactRange': 1,\n 'OutputArtifactRange': 0,\n },\n 'ECS': {\n 'InputArtifactRange': 1,\n 'OutputArtifactRange': 0,\n },\n 'ServiceCatalog': {\n 'InputArtifactRange': 1,\n 'OutputArtifactRange': 0,\n },\n },\n 'Invoke': {\n 'Lambda': {\n 'InputArtifactRange': (0, 5),\n 'OutputArtifactRange': (0, 5),\n }\n }\n },\n 'ThirdParty': {\n 'Source': {\n 'GitHub': {\n 'InputArtifactRange': 0,\n 'OutputArtifactRange': 1,\n }\n },\n 'Deploy': {\n 'AlexaSkillsKit': {\n 'InputArtifactRange': (0, 2),\n 'OutputArtifactRange': 0,\n },\n },\n },\n 'Custom': {\n 'Build': {\n 'Jenkins': {\n 'InputArtifactRange': (0, 5),\n 'OutputArtifactRange': (0, 5),\n },\n },\n 'Test': {\n 'Jenkins': {\n 'InputArtifactRange': (0, 5),\n 'OutputArtifactRange': (0, 5),\n },\n },\n },\n }\n\n KEY_MAP = {\n 'InputArtifacts': 'InputArtifactRange',\n 'OutputArtifacts': 'OutputArtifactRange',\n }\n\n def check_artifact_counts(self, action, artifact_type, path):\n \"\"\"Check that artifact counts are within valid ranges.\"\"\"\n matches = []\n\n action_type_id = action.get('ActionTypeId')\n owner = action_type_id.get('Owner')\n category = action_type_id.get('Category')\n provider = action_type_id.get('Provider')\n\n if isinstance(owner, dict) or isinstance(category, dict) or isinstance(provider, dict):\n self.logger.debug('owner, category, provider need to be strings to validate. Skipping.')\n return matches\n\n constraints = self.CONSTRAINTS.get(owner, {}).get(category, {}).get(provider, {})\n if not constraints:\n return matches\n artifact_count = len(action.get(artifact_type, []))\n\n constraint_key = self.KEY_MAP[artifact_type]\n if isinstance(constraints[constraint_key], tuple):\n min_, max_ = constraints[constraint_key]\n if not (min_ <= artifact_count <= max_):\n message = (\n 'Action \"{action}\" declares {number} {artifact_type} which is not in '\n 'expected range [{a}, {b}].'\n ).format(\n action=action['Name'],\n number=artifact_count,\n artifact_type=artifact_type,\n a=min_,\n b=max_\n )\n matches.append(RuleMatch(\n path + [artifact_type],\n message\n ))\n else:\n if artifact_count != constraints[constraint_key]:\n message = (\n 'Action \"{action}\" declares {number} {artifact_type} which is not the '\n 'expected number [{a}].'\n ).format(\n action=action['Name'],\n number=artifact_count,\n artifact_type=artifact_type,\n a=constraints[constraint_key]\n )\n matches.append(RuleMatch(\n path + [artifact_type],\n message\n ))\n\n return matches\n\n def check_version(self, action, path):\n \"\"\"Check that action type version is valid.\"\"\"\n matches = []\n\n REGEX_VERSION_STRING = re.compile(r'^[0-9A-Za-z_-]+$')\n LENGTH_MIN = 1\n LENGTH_MAX = 9\n\n version = action.get('ActionTypeId', {}).get('Version')\n if isinstance(version, dict):\n self.logger.debug('Unable to validate version when an object is used. Skipping')\n elif isinstance(version, (six.string_types)):\n if not LENGTH_MIN <= len(version) <= LENGTH_MAX:\n message = 'Version string ({0}) must be between {1} and {2} characters in length.'\n matches.append(RuleMatch(\n path + ['ActionTypeId', 'Version'],\n message.format(version, LENGTH_MIN, LENGTH_MAX)))\n elif not re.match(REGEX_VERSION_STRING, version):\n message = 'Version string must match the pattern [0-9A-Za-z_-]+.'\n matches.append(RuleMatch(\n path + ['ActionTypeId', 'Version'],\n message\n ))\n return matches\n\n def check_names_unique(self, action, path, action_names):\n \"\"\"Check that action names are unique.\"\"\"\n matches = []\n\n action_name = action.get('Name')\n if isinstance(action_name, six.string_types):\n if action.get('Name') in action_names:\n message = 'All action names within a stage must be unique. ({name})'.format(\n name=action.get('Name')\n )\n matches.append(RuleMatch(path + ['Name'], message))\n action_names.add(action.get('Name'))\n\n return matches\n\n def match(self, cfn):\n \"\"\"Check that stage actions are set up properly.\"\"\"\n matches = []\n\n resources = cfn.get_resource_properties(['AWS::CodePipeline::Pipeline'])\n for resource in resources:\n path = resource['Path']\n properties = resource['Value']\n\n s_stages = properties.get_safe('Stages', path)\n for s_stage_v, s_stage_p in s_stages:\n if not isinstance(s_stage_v, list):\n self.logger.debug(\n 'Stages not list. Should have been caught by generic linting.')\n return matches\n\n for l_i_stage, l_i_path in s_stage_v.items_safe(s_stage_p):\n action_names = set()\n s_actions = l_i_stage.get_safe('Actions', l_i_path)\n for s_action_v, s_action_p in s_actions:\n if not isinstance(s_action_v, list):\n self.logger.debug(\n 'Actions not list. Should have been caught by generic linting.')\n return matches\n\n for l_i_a_action, l_i_a_path in s_action_v.items_safe(s_action_p):\n try:\n full_path = path + l_i_path + l_i_a_path\n matches.extend(self.check_names_unique(\n l_i_a_action, full_path, action_names))\n matches.extend(self.check_version(l_i_a_action, full_path))\n matches.extend(self.check_artifact_counts(\n l_i_a_action, 'InputArtifacts', full_path))\n matches.extend(self.check_artifact_counts(\n l_i_a_action, 'OutputArtifacts', full_path))\n except AttributeError as err:\n self.logger.debug('Got AttributeError. Should have been caught by generic linting. '\n 'Ignoring the error here: %s', str(err))\n\n return matches\n", "path": "src/cfnlint/rules/resources/codepipeline/CodepipelineStageActions.py"}], "after_files": [{"content": "\"\"\"\nCopyright Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\nimport re\nimport six\nfrom cfnlint.rules import CloudFormationLintRule\nfrom cfnlint.rules import RuleMatch\n\n\nclass CodepipelineStageActions(CloudFormationLintRule):\n \"\"\"Check if CodePipeline Stage Actions are set up properly.\"\"\"\n id = 'E2541'\n shortdesc = 'CodePipeline Stage Actions'\n description = 'See if CodePipeline stage actions are set correctly'\n source_url = 'https://docs.aws.amazon.com/codepipeline/latest/userguide/reference-pipeline-structure.html#pipeline-requirements'\n tags = ['resources', 'codepipeline']\n\n CONSTRAINTS = {\n 'AWS': {\n 'Source': {\n 'S3': {\n 'InputArtifactRange': 0,\n 'OutputArtifactRange': 1,\n },\n 'CodeCommit': {\n 'InputArtifactRange': 0,\n 'OutputArtifactRange': 1,\n },\n 'ECR': {\n 'InputArtifactRange': 0,\n 'OutputArtifactRange': 1,\n }\n },\n 'Test': {\n 'CodeBuild': {\n 'InputArtifactRange': (1, 5),\n 'OutputArtifactRange': (0, 5),\n },\n 'DeviceFarm': {\n 'InputArtifactRange': 1,\n 'OutputArtifactRange': 0,\n }\n },\n 'Build': {\n 'CodeBuild': {\n 'InputArtifactRange': (1, 5),\n 'OutputArtifactRange': (0, 5),\n }\n },\n 'Approval': {\n 'Manual': {\n 'InputArtifactRange': 0,\n 'OutputArtifactRange': 0,\n }\n },\n 'Deploy': {\n 'S3': {\n 'InputArtifactRange': 1,\n 'OutputArtifactRange': 0,\n },\n 'CloudFormation': {\n 'InputArtifactRange': (0, 10),\n 'OutputArtifactRange': (0, 1),\n },\n 'CodeDeploy': {\n 'InputArtifactRange': 1,\n 'OutputArtifactRange': 0,\n },\n 'ElasticBeanstalk': {\n 'InputArtifactRange': 1,\n 'OutputArtifactRange': 0,\n },\n 'OpsWorks': {\n 'InputArtifactRange': 1,\n 'OutputArtifactRange': 0,\n },\n 'ECS': {\n 'InputArtifactRange': 1,\n 'OutputArtifactRange': 0,\n },\n 'ServiceCatalog': {\n 'InputArtifactRange': 1,\n 'OutputArtifactRange': 0,\n },\n },\n 'Invoke': {\n 'Lambda': {\n 'InputArtifactRange': (0, 5),\n 'OutputArtifactRange': (0, 5),\n }\n }\n },\n 'ThirdParty': {\n 'Source': {\n 'GitHub': {\n 'InputArtifactRange': 0,\n 'OutputArtifactRange': 1,\n }\n },\n 'Deploy': {\n 'AlexaSkillsKit': {\n 'InputArtifactRange': (0, 2),\n 'OutputArtifactRange': 0,\n },\n },\n },\n 'Custom': {\n 'Build': {\n 'Jenkins': {\n 'InputArtifactRange': (0, 5),\n 'OutputArtifactRange': (0, 5),\n },\n },\n 'Test': {\n 'Jenkins': {\n 'InputArtifactRange': (0, 5),\n 'OutputArtifactRange': (0, 5),\n },\n },\n },\n }\n\n KEY_MAP = {\n 'InputArtifacts': 'InputArtifactRange',\n 'OutputArtifacts': 'OutputArtifactRange',\n }\n\n def check_artifact_counts(self, action, artifact_type, path):\n \"\"\"Check that artifact counts are within valid ranges.\"\"\"\n matches = []\n\n action_type_id = action.get('ActionTypeId')\n owner = action_type_id.get('Owner')\n category = action_type_id.get('Category')\n provider = action_type_id.get('Provider')\n\n if isinstance(owner, dict) or isinstance(category, dict) or isinstance(provider, dict):\n self.logger.debug('owner, category, provider need to be strings to validate. Skipping.')\n return matches\n\n constraints = self.CONSTRAINTS.get(owner, {}).get(category, {}).get(provider, {})\n if not constraints:\n return matches\n artifact_count = len(action.get(artifact_type, []))\n\n constraint_key = self.KEY_MAP[artifact_type]\n if isinstance(constraints[constraint_key], tuple):\n min_, max_ = constraints[constraint_key]\n if not (min_ <= artifact_count <= max_):\n message = (\n 'Action \"{action}\" declares {number} {artifact_type} which is not in '\n 'expected range [{a}, {b}].'\n ).format(\n action=action['Name'],\n number=artifact_count,\n artifact_type=artifact_type,\n a=min_,\n b=max_\n )\n matches.append(RuleMatch(\n path + [artifact_type],\n message\n ))\n else:\n if artifact_count != constraints[constraint_key]:\n message = (\n 'Action \"{action}\" declares {number} {artifact_type} which is not the '\n 'expected number [{a}].'\n ).format(\n action=action['Name'],\n number=artifact_count,\n artifact_type=artifact_type,\n a=constraints[constraint_key]\n )\n matches.append(RuleMatch(\n path + [artifact_type],\n message\n ))\n\n return matches\n\n def check_version(self, action, path):\n \"\"\"Check that action type version is valid.\"\"\"\n matches = []\n\n REGEX_VERSION_STRING = re.compile(r'^[0-9A-Za-z_-]+$')\n LENGTH_MIN = 1\n LENGTH_MAX = 9\n\n version = action.get('ActionTypeId', {}).get('Version')\n if isinstance(version, dict):\n self.logger.debug('Unable to validate version when an object is used. Skipping')\n elif isinstance(version, (six.string_types)):\n if not LENGTH_MIN <= len(version) <= LENGTH_MAX:\n message = 'Version string ({0}) must be between {1} and {2} characters in length.'\n matches.append(RuleMatch(\n path + ['ActionTypeId', 'Version'],\n message.format(version, LENGTH_MIN, LENGTH_MAX)))\n elif not re.match(REGEX_VERSION_STRING, version):\n message = 'Version string must match the pattern [0-9A-Za-z_-]+.'\n matches.append(RuleMatch(\n path + ['ActionTypeId', 'Version'],\n message\n ))\n return matches\n\n def check_names_unique(self, action, path, action_names):\n \"\"\"Check that action names are unique.\"\"\"\n matches = []\n\n action_name = action.get('Name')\n if isinstance(action_name, six.string_types):\n if action.get('Name') in action_names:\n message = 'All action names within a stage must be unique. ({name})'.format(\n name=action.get('Name')\n )\n matches.append(RuleMatch(path + ['Name'], message))\n action_names.add(action.get('Name'))\n\n return matches\n\n def check_artifact_names(self, action, path, artifact_names):\n \"\"\"Check that output artifact names are unique and inputs are from previous stage outputs.\"\"\"\n matches = []\n\n input_artifacts = action.get('InputArtifacts')\n if isinstance(input_artifacts, list):\n for input_artifact in input_artifacts:\n artifact_name = input_artifact.get('Name')\n if isinstance(artifact_name, six.string_types):\n if not artifact_name in artifact_names:\n message = 'Every input artifact for an action must match the output artifact of an action earlier in the pipeline. ({name})'.format(\n name=artifact_name\n )\n matches.append(RuleMatch(path + ['InputArtifacts', 'Name'], message))\n\n output_artifacts = action.get('OutputArtifacts')\n if isinstance(output_artifacts, list):\n for output_artifact in output_artifacts:\n artifact_name = output_artifact.get('Name')\n if isinstance(artifact_name, six.string_types):\n if artifact_name in artifact_names:\n message = 'Every output artifact in the pipeline must have a unique name. ({name})'.format(\n name=artifact_name\n )\n matches.append(RuleMatch(path + ['OutputArtifacts', 'Name'], message))\n artifact_names.add(artifact_name)\n\n return matches\n\n def match(self, cfn):\n \"\"\"Check that stage actions are set up properly.\"\"\"\n matches = []\n\n resources = cfn.get_resource_properties(['AWS::CodePipeline::Pipeline'])\n for resource in resources:\n path = resource['Path']\n properties = resource['Value']\n artifact_names = set()\n\n s_stages = properties.get_safe('Stages', path)\n for s_stage_v, s_stage_p in s_stages:\n if not isinstance(s_stage_v, list):\n self.logger.debug(\n 'Stages not list. Should have been caught by generic linting.')\n return matches\n\n for l_i_stage, l_i_path in s_stage_v.items_safe(s_stage_p):\n action_names = set()\n s_actions = l_i_stage.get_safe('Actions', l_i_path)\n for s_action_v, s_action_p in s_actions:\n if not isinstance(s_action_v, list):\n self.logger.debug(\n 'Actions not list. Should have been caught by generic linting.')\n return matches\n\n for l_i_a_action, l_i_a_path in s_action_v.items_safe(s_action_p):\n try:\n full_path = path + l_i_path + l_i_a_path\n matches.extend(self.check_names_unique(\n l_i_a_action, full_path, action_names))\n matches.extend(self.check_version(l_i_a_action, full_path))\n matches.extend(self.check_artifact_counts(\n l_i_a_action, 'InputArtifacts', full_path))\n matches.extend(self.check_artifact_counts(\n l_i_a_action, 'OutputArtifacts', full_path))\n matches.extend(self.check_artifact_names(\n l_i_a_action, full_path, artifact_names))\n except AttributeError as err:\n self.logger.debug('Got AttributeError. Should have been caught by generic linting. '\n 'Ignoring the error here: %s', str(err))\n\n return matches\n", "path": "src/cfnlint/rules/resources/codepipeline/CodepipelineStageActions.py"}]}
| 3,793 | 595 |
gh_patches_debug_19237
|
rasdani/github-patches
|
git_diff
|
bokeh__bokeh-8048
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Customize warning formatter
I'm trying out the imminent bokeh release with the dask dashboard. I get hundreds of lines like the following:
```python
/home/mrocklin/Software/anaconda/lib/python3.6/site-packages/bokeh/models/sources.py:91: BokehUserWarning: ColumnD)
"Current lengths: %s" % ", ".join(sorted(str((k, len(v))) for k, v in data.items())), BokehUserWarning))
```
Clearly I'm doing something wrong in my code, and it's great to know about it. However, two things would make this nicer:
1. Getting some sort of information about the cause of the failure. It looks like an informative error message was attempted, but rather than getting a nice result I get the code instead.
2. These are filling up my terminal at the rate that I update my plots. It might be nice to only warn once or twice.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bokeh/__init__.py`
Content:
```
1 #-----------------------------------------------------------------------------
2 # Copyright (c) 2012 - 2017, Anaconda, Inc. All rights reserved.
3 #
4 # Powered by the Bokeh Development Team.
5 #
6 # The full license is in the file LICENSE.txt, distributed with this software.
7 #-----------------------------------------------------------------------------
8 ''' Bokeh is a Python interactive visualization library that targets modern
9 web browsers for presentation.
10
11 Its goal is to provide elegant, concise construction of versatile graphics,
12 and also deliver this capability with high-performance interactivity over large
13 or streaming datasets. Bokeh can help anyone who would like to quickly and
14 easily create interactive plots, dashboards, and data applications.
15
16 For full documentation, please visit: https://bokeh.pydata.org
17
18 '''
19
20 #-----------------------------------------------------------------------------
21 # Boilerplate
22 #-----------------------------------------------------------------------------
23 from __future__ import absolute_import, division, print_function, unicode_literals
24
25 import logging
26 log = logging.getLogger(__name__)
27
28 #-----------------------------------------------------------------------------
29 # General API
30 #-----------------------------------------------------------------------------
31
32 __all__ = (
33 '__version__',
34 'license',
35 'sampledata',
36 )
37
38 # configure Bokeh version
39 from .util.version import __version__; __version__
40
41 def license():
42 ''' Print the Bokeh license to the console.
43
44 Returns:
45 None
46
47 '''
48 from os.path import join
49 with open(join(__path__[0], 'LICENSE.txt')) as lic:
50 print(lic.read())
51
52 # expose sample data module
53 from . import sampledata; sampledata
54
55 #-----------------------------------------------------------------------------
56 # Code
57 #-----------------------------------------------------------------------------
58
59 # configure Bokeh logger
60 from .util import logconfig
61 del logconfig
62
63 # Configure warnings to always show, despite Python's active efforts to hide them from users.
64 import warnings
65 from .util.warnings import BokehDeprecationWarning, BokehUserWarning
66 warnings.simplefilter('always', BokehDeprecationWarning)
67 warnings.simplefilter('always', BokehUserWarning)
68 del BokehDeprecationWarning, BokehUserWarning
69 del warnings
70
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/bokeh/__init__.py b/bokeh/__init__.py
--- a/bokeh/__init__.py
+++ b/bokeh/__init__.py
@@ -60,10 +60,21 @@
from .util import logconfig
del logconfig
-# Configure warnings to always show, despite Python's active efforts to hide them from users.
+# Configure warnings to always show nice mssages, despite Python's active
+# efforts to hide them from users.
import warnings
from .util.warnings import BokehDeprecationWarning, BokehUserWarning
warnings.simplefilter('always', BokehDeprecationWarning)
warnings.simplefilter('always', BokehUserWarning)
+
+original_formatwarning = warnings.formatwarning
+def _formatwarning(message, category, filename, lineno, line=None):
+ from .util.warnings import BokehDeprecationWarning, BokehUserWarning
+ if category not in (BokehDeprecationWarning, BokehUserWarning):
+ return original_formatwarning(message, category, filename, lineno, line)
+ return "%s: %s\n" % (category.__name__, message)
+warnings.formatwarning = _formatwarning
+
+del _formatwarning
del BokehDeprecationWarning, BokehUserWarning
del warnings
|
{"golden_diff": "diff --git a/bokeh/__init__.py b/bokeh/__init__.py\n--- a/bokeh/__init__.py\n+++ b/bokeh/__init__.py\n@@ -60,10 +60,21 @@\n from .util import logconfig\n del logconfig\n \n-# Configure warnings to always show, despite Python's active efforts to hide them from users.\n+# Configure warnings to always show nice mssages, despite Python's active\n+# efforts to hide them from users.\n import warnings\n from .util.warnings import BokehDeprecationWarning, BokehUserWarning\n warnings.simplefilter('always', BokehDeprecationWarning)\n warnings.simplefilter('always', BokehUserWarning)\n+\n+original_formatwarning = warnings.formatwarning\n+def _formatwarning(message, category, filename, lineno, line=None):\n+ from .util.warnings import BokehDeprecationWarning, BokehUserWarning\n+ if category not in (BokehDeprecationWarning, BokehUserWarning):\n+ return original_formatwarning(message, category, filename, lineno, line)\n+ return \"%s: %s\\n\" % (category.__name__, message)\n+warnings.formatwarning = _formatwarning\n+\n+del _formatwarning\n del BokehDeprecationWarning, BokehUserWarning\n del warnings\n", "issue": "Customize warning formatter\nI'm trying out the imminent bokeh release with the dask dashboard. I get hundreds of lines like the following:\r\n\r\n```python\r\n/home/mrocklin/Software/anaconda/lib/python3.6/site-packages/bokeh/models/sources.py:91: BokehUserWarning: ColumnD)\r\n \"Current lengths: %s\" % \", \".join(sorted(str((k, len(v))) for k, v in data.items())), BokehUserWarning))\r\n```\r\n\r\nClearly I'm doing something wrong in my code, and it's great to know about it. However, two things would make this nicer:\r\n\r\n1. Getting some sort of information about the cause of the failure. It looks like an informative error message was attempted, but rather than getting a nice result I get the code instead.\r\n2. These are filling up my terminal at the rate that I update my plots. It might be nice to only warn once or twice.\n", "before_files": [{"content": "#-----------------------------------------------------------------------------\n# Copyright (c) 2012 - 2017, Anaconda, Inc. All rights reserved.\n#\n# Powered by the Bokeh Development Team.\n#\n# The full license is in the file LICENSE.txt, distributed with this software.\n#-----------------------------------------------------------------------------\n''' Bokeh is a Python interactive visualization library that targets modern\nweb browsers for presentation.\n\nIts goal is to provide elegant, concise construction of versatile graphics,\nand also deliver this capability with high-performance interactivity over large\nor streaming datasets. Bokeh can help anyone who would like to quickly and\neasily create interactive plots, dashboards, and data applications.\n\nFor full documentation, please visit: https://bokeh.pydata.org\n\n'''\n\n#-----------------------------------------------------------------------------\n# Boilerplate\n#-----------------------------------------------------------------------------\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport logging\nlog = logging.getLogger(__name__)\n\n#-----------------------------------------------------------------------------\n# General API\n#-----------------------------------------------------------------------------\n\n__all__ = (\n '__version__',\n 'license',\n 'sampledata',\n)\n\n# configure Bokeh version\nfrom .util.version import __version__; __version__\n\ndef license():\n ''' Print the Bokeh license to the console.\n\n Returns:\n None\n\n '''\n from os.path import join\n with open(join(__path__[0], 'LICENSE.txt')) as lic:\n print(lic.read())\n\n# expose sample data module\nfrom . import sampledata; sampledata\n\n#-----------------------------------------------------------------------------\n# Code\n#-----------------------------------------------------------------------------\n\n# configure Bokeh logger\nfrom .util import logconfig\ndel logconfig\n\n# Configure warnings to always show, despite Python's active efforts to hide them from users.\nimport warnings\nfrom .util.warnings import BokehDeprecationWarning, BokehUserWarning\nwarnings.simplefilter('always', BokehDeprecationWarning)\nwarnings.simplefilter('always', BokehUserWarning)\ndel BokehDeprecationWarning, BokehUserWarning\ndel warnings\n", "path": "bokeh/__init__.py"}], "after_files": [{"content": "#-----------------------------------------------------------------------------\n# Copyright (c) 2012 - 2017, Anaconda, Inc. All rights reserved.\n#\n# Powered by the Bokeh Development Team.\n#\n# The full license is in the file LICENSE.txt, distributed with this software.\n#-----------------------------------------------------------------------------\n''' Bokeh is a Python interactive visualization library that targets modern\nweb browsers for presentation.\n\nIts goal is to provide elegant, concise construction of versatile graphics,\nand also deliver this capability with high-performance interactivity over large\nor streaming datasets. Bokeh can help anyone who would like to quickly and\neasily create interactive plots, dashboards, and data applications.\n\nFor full documentation, please visit: https://bokeh.pydata.org\n\n'''\n\n#-----------------------------------------------------------------------------\n# Boilerplate\n#-----------------------------------------------------------------------------\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport logging\nlog = logging.getLogger(__name__)\n\n#-----------------------------------------------------------------------------\n# General API\n#-----------------------------------------------------------------------------\n\n__all__ = (\n '__version__',\n 'license',\n 'sampledata',\n)\n\n# configure Bokeh version\nfrom .util.version import __version__; __version__\n\ndef license():\n ''' Print the Bokeh license to the console.\n\n Returns:\n None\n\n '''\n from os.path import join\n with open(join(__path__[0], 'LICENSE.txt')) as lic:\n print(lic.read())\n\n# expose sample data module\nfrom . import sampledata; sampledata\n\n#-----------------------------------------------------------------------------\n# Code\n#-----------------------------------------------------------------------------\n\n# configure Bokeh logger\nfrom .util import logconfig\ndel logconfig\n\n# Configure warnings to always show nice mssages, despite Python's active\n# efforts to hide them from users.\nimport warnings\nfrom .util.warnings import BokehDeprecationWarning, BokehUserWarning\nwarnings.simplefilter('always', BokehDeprecationWarning)\nwarnings.simplefilter('always', BokehUserWarning)\n\noriginal_formatwarning = warnings.formatwarning\ndef _formatwarning(message, category, filename, lineno, line=None):\n from .util.warnings import BokehDeprecationWarning, BokehUserWarning\n if category not in (BokehDeprecationWarning, BokehUserWarning):\n return original_formatwarning(message, category, filename, lineno, line)\n return \"%s: %s\\n\" % (category.__name__, message)\nwarnings.formatwarning = _formatwarning\n\ndel _formatwarning\ndel BokehDeprecationWarning, BokehUserWarning\ndel warnings\n", "path": "bokeh/__init__.py"}]}
| 1,007 | 284 |
gh_patches_debug_15703
|
rasdani/github-patches
|
git_diff
|
zigpy__zha-device-handlers-278
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Keen Home Smart Vent Models
I've been having problems with the Keen Home Smart Vent Quirks and realized that there are additional models that need the DoublingPowerConfigurationCluster on them. I validated that the following manufacturer/models work when added but am unable to submit the change myself.
("Keen Home Inc", "SV01-410-MP-1.1")
("Keen Home Inc", "SV01-410-MP-1.0")
("Keen Home Inc", "SV01-410-MP-1.5")
("Keen Home Inc", "SV02-410-MP-1.3")
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `zhaquirks/keenhome/sv02612mp13.py`
Content:
```
1 """Smart vent quirk."""
2 from zigpy.profiles import zha
3 from zigpy.quirks import CustomDevice
4 from zigpy.zcl.clusters.general import (
5 Basic,
6 Groups,
7 Identify,
8 LevelControl,
9 OnOff,
10 Ota,
11 PollControl,
12 Scenes,
13 )
14 from zigpy.zcl.clusters.measurement import PressureMeasurement, TemperatureMeasurement
15
16 from .. import DoublingPowerConfigurationCluster
17 from ..const import (
18 DEVICE_TYPE,
19 ENDPOINTS,
20 INPUT_CLUSTERS,
21 MODELS_INFO,
22 OUTPUT_CLUSTERS,
23 PROFILE_ID,
24 )
25
26 DIAGNOSTICS_CLUSTER_ID = 0x0B05 # decimal = 2821
27 KEEN1_CLUSTER_ID = 0xFC01 # decimal = 64513
28 KEEN2_CLUSTER_ID = 0xFC02 # decimal = 64514
29
30
31 class KeenHomeSmartVent(CustomDevice):
32 """Custom device representing Keen Home Smart Vent."""
33
34 signature = {
35 # <SimpleDescriptor endpoint=1 profile=260 device_type=3
36 # device_version=0
37 # input_clusters=[
38 # 0, 1, 3, 4, 5, 6, 8, 32, 1026, 1027, 2821, 64513, 64514]
39 # output_clusters=[25]>
40 MODELS_INFO: [("Keen Home Inc", "SV02-612-MP-1.3")],
41 ENDPOINTS: {
42 1: {
43 PROFILE_ID: zha.PROFILE_ID,
44 DEVICE_TYPE: zha.DeviceType.LEVEL_CONTROLLABLE_OUTPUT,
45 INPUT_CLUSTERS: [
46 Basic.cluster_id,
47 DoublingPowerConfigurationCluster.cluster_id,
48 Identify.cluster_id,
49 Groups.cluster_id,
50 Scenes.cluster_id,
51 OnOff.cluster_id,
52 LevelControl.cluster_id,
53 PollControl.cluster_id,
54 TemperatureMeasurement.cluster_id,
55 PressureMeasurement.cluster_id,
56 DIAGNOSTICS_CLUSTER_ID,
57 KEEN1_CLUSTER_ID,
58 KEEN2_CLUSTER_ID,
59 ],
60 OUTPUT_CLUSTERS: [Ota.cluster_id],
61 }
62 },
63 }
64
65 replacement = {
66 ENDPOINTS: {
67 1: {
68 PROFILE_ID: zha.PROFILE_ID,
69 INPUT_CLUSTERS: [
70 Basic.cluster_id,
71 DoublingPowerConfigurationCluster,
72 Identify.cluster_id,
73 Groups.cluster_id,
74 Scenes.cluster_id,
75 OnOff.cluster_id,
76 LevelControl.cluster_id,
77 PollControl.cluster_id,
78 TemperatureMeasurement.cluster_id,
79 PressureMeasurement.cluster_id,
80 DIAGNOSTICS_CLUSTER_ID,
81 KEEN1_CLUSTER_ID,
82 KEEN2_CLUSTER_ID,
83 ],
84 OUTPUT_CLUSTERS: [Ota.cluster_id],
85 }
86 }
87 }
88
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/zhaquirks/keenhome/sv02612mp13.py b/zhaquirks/keenhome/sv02612mp13.py
--- a/zhaquirks/keenhome/sv02612mp13.py
+++ b/zhaquirks/keenhome/sv02612mp13.py
@@ -37,7 +37,18 @@
# input_clusters=[
# 0, 1, 3, 4, 5, 6, 8, 32, 1026, 1027, 2821, 64513, 64514]
# output_clusters=[25]>
- MODELS_INFO: [("Keen Home Inc", "SV02-612-MP-1.3")],
+ MODELS_INFO: [
+ ("Keen Home Inc", "SV01-410-MP-1.0"),
+ ("Keen Home Inc", "SV01-410-MP-1.1"),
+ ("Keen Home Inc", "SV01-410-MP-1.4"),
+ ("Keen Home Inc", "SV01-410-MP-1.5"),
+ ("Keen Home Inc", "SV02-410-MP-1.3"),
+ ("Keen Home Inc", "SV01-412-MP-1.0"),
+ ("Keen Home Inc", "SV01-610-MP-1.0"),
+ ("Keen Home Inc", "SV02-610-MP-1.3"),
+ ("Keen Home Inc", "SV01-612-MP-1.0"),
+ ("Keen Home Inc", "SV02-612-MP-1.3"),
+ ],
ENDPOINTS: {
1: {
PROFILE_ID: zha.PROFILE_ID,
|
{"golden_diff": "diff --git a/zhaquirks/keenhome/sv02612mp13.py b/zhaquirks/keenhome/sv02612mp13.py\n--- a/zhaquirks/keenhome/sv02612mp13.py\n+++ b/zhaquirks/keenhome/sv02612mp13.py\n@@ -37,7 +37,18 @@\n # input_clusters=[\n # 0, 1, 3, 4, 5, 6, 8, 32, 1026, 1027, 2821, 64513, 64514]\n # output_clusters=[25]>\n- MODELS_INFO: [(\"Keen Home Inc\", \"SV02-612-MP-1.3\")],\n+ MODELS_INFO: [\n+ (\"Keen Home Inc\", \"SV01-410-MP-1.0\"),\n+ (\"Keen Home Inc\", \"SV01-410-MP-1.1\"),\n+ (\"Keen Home Inc\", \"SV01-410-MP-1.4\"),\n+ (\"Keen Home Inc\", \"SV01-410-MP-1.5\"),\n+ (\"Keen Home Inc\", \"SV02-410-MP-1.3\"),\n+ (\"Keen Home Inc\", \"SV01-412-MP-1.0\"),\n+ (\"Keen Home Inc\", \"SV01-610-MP-1.0\"),\n+ (\"Keen Home Inc\", \"SV02-610-MP-1.3\"),\n+ (\"Keen Home Inc\", \"SV01-612-MP-1.0\"),\n+ (\"Keen Home Inc\", \"SV02-612-MP-1.3\"),\n+ ],\n ENDPOINTS: {\n 1: {\n PROFILE_ID: zha.PROFILE_ID,\n", "issue": "Keen Home Smart Vent Models\nI've been having problems with the Keen Home Smart Vent Quirks and realized that there are additional models that need the DoublingPowerConfigurationCluster on them. I validated that the following manufacturer/models work when added but am unable to submit the change myself.\r\n\r\n(\"Keen Home Inc\", \"SV01-410-MP-1.1\")\r\n(\"Keen Home Inc\", \"SV01-410-MP-1.0\")\r\n(\"Keen Home Inc\", \"SV01-410-MP-1.5\")\r\n(\"Keen Home Inc\", \"SV02-410-MP-1.3\")\n", "before_files": [{"content": "\"\"\"Smart vent quirk.\"\"\"\nfrom zigpy.profiles import zha\nfrom zigpy.quirks import CustomDevice\nfrom zigpy.zcl.clusters.general import (\n Basic,\n Groups,\n Identify,\n LevelControl,\n OnOff,\n Ota,\n PollControl,\n Scenes,\n)\nfrom zigpy.zcl.clusters.measurement import PressureMeasurement, TemperatureMeasurement\n\nfrom .. import DoublingPowerConfigurationCluster\nfrom ..const import (\n DEVICE_TYPE,\n ENDPOINTS,\n INPUT_CLUSTERS,\n MODELS_INFO,\n OUTPUT_CLUSTERS,\n PROFILE_ID,\n)\n\nDIAGNOSTICS_CLUSTER_ID = 0x0B05 # decimal = 2821\nKEEN1_CLUSTER_ID = 0xFC01 # decimal = 64513\nKEEN2_CLUSTER_ID = 0xFC02 # decimal = 64514\n\n\nclass KeenHomeSmartVent(CustomDevice):\n \"\"\"Custom device representing Keen Home Smart Vent.\"\"\"\n\n signature = {\n # <SimpleDescriptor endpoint=1 profile=260 device_type=3\n # device_version=0\n # input_clusters=[\n # 0, 1, 3, 4, 5, 6, 8, 32, 1026, 1027, 2821, 64513, 64514]\n # output_clusters=[25]>\n MODELS_INFO: [(\"Keen Home Inc\", \"SV02-612-MP-1.3\")],\n ENDPOINTS: {\n 1: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.LEVEL_CONTROLLABLE_OUTPUT,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n DoublingPowerConfigurationCluster.cluster_id,\n Identify.cluster_id,\n Groups.cluster_id,\n Scenes.cluster_id,\n OnOff.cluster_id,\n LevelControl.cluster_id,\n PollControl.cluster_id,\n TemperatureMeasurement.cluster_id,\n PressureMeasurement.cluster_id,\n DIAGNOSTICS_CLUSTER_ID,\n KEEN1_CLUSTER_ID,\n KEEN2_CLUSTER_ID,\n ],\n OUTPUT_CLUSTERS: [Ota.cluster_id],\n }\n },\n }\n\n replacement = {\n ENDPOINTS: {\n 1: {\n PROFILE_ID: zha.PROFILE_ID,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n DoublingPowerConfigurationCluster,\n Identify.cluster_id,\n Groups.cluster_id,\n Scenes.cluster_id,\n OnOff.cluster_id,\n LevelControl.cluster_id,\n PollControl.cluster_id,\n TemperatureMeasurement.cluster_id,\n PressureMeasurement.cluster_id,\n DIAGNOSTICS_CLUSTER_ID,\n KEEN1_CLUSTER_ID,\n KEEN2_CLUSTER_ID,\n ],\n OUTPUT_CLUSTERS: [Ota.cluster_id],\n }\n }\n }\n", "path": "zhaquirks/keenhome/sv02612mp13.py"}], "after_files": [{"content": "\"\"\"Smart vent quirk.\"\"\"\nfrom zigpy.profiles import zha\nfrom zigpy.quirks import CustomDevice\nfrom zigpy.zcl.clusters.general import (\n Basic,\n Groups,\n Identify,\n LevelControl,\n OnOff,\n Ota,\n PollControl,\n Scenes,\n)\nfrom zigpy.zcl.clusters.measurement import PressureMeasurement, TemperatureMeasurement\n\nfrom .. import DoublingPowerConfigurationCluster\nfrom ..const import (\n DEVICE_TYPE,\n ENDPOINTS,\n INPUT_CLUSTERS,\n MODELS_INFO,\n OUTPUT_CLUSTERS,\n PROFILE_ID,\n)\n\nDIAGNOSTICS_CLUSTER_ID = 0x0B05 # decimal = 2821\nKEEN1_CLUSTER_ID = 0xFC01 # decimal = 64513\nKEEN2_CLUSTER_ID = 0xFC02 # decimal = 64514\n\n\nclass KeenHomeSmartVent(CustomDevice):\n \"\"\"Custom device representing Keen Home Smart Vent.\"\"\"\n\n signature = {\n # <SimpleDescriptor endpoint=1 profile=260 device_type=3\n # device_version=0\n # input_clusters=[\n # 0, 1, 3, 4, 5, 6, 8, 32, 1026, 1027, 2821, 64513, 64514]\n # output_clusters=[25]>\n MODELS_INFO: [\n (\"Keen Home Inc\", \"SV01-410-MP-1.0\"),\n (\"Keen Home Inc\", \"SV01-410-MP-1.1\"),\n (\"Keen Home Inc\", \"SV01-410-MP-1.4\"),\n (\"Keen Home Inc\", \"SV01-410-MP-1.5\"),\n (\"Keen Home Inc\", \"SV02-410-MP-1.3\"),\n (\"Keen Home Inc\", \"SV01-412-MP-1.0\"),\n (\"Keen Home Inc\", \"SV01-610-MP-1.0\"),\n (\"Keen Home Inc\", \"SV02-610-MP-1.3\"),\n (\"Keen Home Inc\", \"SV01-612-MP-1.0\"),\n (\"Keen Home Inc\", \"SV02-612-MP-1.3\"),\n ],\n ENDPOINTS: {\n 1: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.LEVEL_CONTROLLABLE_OUTPUT,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n DoublingPowerConfigurationCluster.cluster_id,\n Identify.cluster_id,\n Groups.cluster_id,\n Scenes.cluster_id,\n OnOff.cluster_id,\n LevelControl.cluster_id,\n PollControl.cluster_id,\n TemperatureMeasurement.cluster_id,\n PressureMeasurement.cluster_id,\n DIAGNOSTICS_CLUSTER_ID,\n KEEN1_CLUSTER_ID,\n KEEN2_CLUSTER_ID,\n ],\n OUTPUT_CLUSTERS: [Ota.cluster_id],\n }\n },\n }\n\n replacement = {\n ENDPOINTS: {\n 1: {\n PROFILE_ID: zha.PROFILE_ID,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n DoublingPowerConfigurationCluster,\n Identify.cluster_id,\n Groups.cluster_id,\n Scenes.cluster_id,\n OnOff.cluster_id,\n LevelControl.cluster_id,\n PollControl.cluster_id,\n TemperatureMeasurement.cluster_id,\n PressureMeasurement.cluster_id,\n DIAGNOSTICS_CLUSTER_ID,\n KEEN1_CLUSTER_ID,\n KEEN2_CLUSTER_ID,\n ],\n OUTPUT_CLUSTERS: [Ota.cluster_id],\n }\n }\n }\n", "path": "zhaquirks/keenhome/sv02612mp13.py"}]}
| 1,204 | 462 |
gh_patches_debug_14133
|
rasdani/github-patches
|
git_diff
|
ResonantGeoData__ResonantGeoData-311
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
psycopg2.errors.UniqueViolation: duplicate key value error
When running the demo data commands that I have, if the celery worker is set up to run in the background, an integretiy error for duplicate keys happens on the `image_entry.save()` call here:
https://github.com/ResonantGeoData/ResonantGeoData/blob/998a6c3995b4421c3632979a249fb78d66e1108f/rgd/geodata/models/imagery/etl.py#L69
The error:
```
Traceback (most recent call last):
File "/usr/local/lib/python3.8/site-packages/django/db/backends/utils.py", line 84, in _execute
return self.cursor.execute(sql, params)
psycopg2.errors.UniqueViolation: duplicate key value violates unique constraint "geodata_imageentry_image_file_id_key"
DETAIL: Key (image_file_id)=(14) already exists.
```
This is making me think that when we create a new `ImageEntry` in the tasks, there is some sort of race condition between jobs for the same `ImageFile`... which shouldn't happen? I'm not really sure what is going on here.
## Steps to reproduce
1. Clear the database volume
2. Apply migrations: `docker-compose run --rm django ./manage.py migrate`
3. In one session, launch the celery worker: `docker-compose up celery` and wait until ready
4. In another session, run the Landsat demo data command: `docker-compose run --rm django ./manage.py landsat_data -c 3`
- Use the changes from #296
5. Observe the error
## Error Message
<details>
```
Traceback (most recent call last):
File "/usr/local/lib/python3.8/site-packages/django/db/backends/utils.py", line 84, in _execute
return self.cursor.execute(sql, params)
psycopg2.errors.UniqueViolation: duplicate key value violates unique constraint "geodata_imageentry_image_file_id_key"
DETAIL: Key (image_file_id)=(14) already exists.
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "./manage.py", line 28, in <module>
main()
File "./manage.py", line 24, in main
execute_from_command_line(sys.argv)
File "/usr/local/lib/python3.8/site-packages/django/core/management/__init__.py", line 419, in execute_from_command_line
utility.execute()
File "/usr/local/lib/python3.8/site-packages/django/core/management/__init__.py", line 413, in execute
self.fetch_command(subcommand).run_from_argv(self.argv)
File "/usr/local/lib/python3.8/site-packages/django/core/management/base.py", line 354, in run_from_argv
self.execute(*args, **cmd_options)
File "/usr/local/lib/python3.8/site-packages/django/core/management/base.py", line 398, in execute
output = self.handle(*args, **options)
File "/opt/django-project/rgd/geodata/management/commands/landsat_data.py", line 49, in handle
helper.load_raster_files(_get_landsat_urls(count))
File "/opt/django-project/rgd/geodata/management/commands/_data_helper.py", line 80, in load_raster_files
imentries = load_image_files(
File "/opt/django-project/rgd/geodata/management/commands/_data_helper.py", line 56, in load_image_files
result = load_image_files(imfile)
File "/opt/django-project/rgd/geodata/management/commands/_data_helper.py", line 60, in load_image_files
read_image_file(entry)
File "/opt/django-project/rgd/geodata/models/imagery/etl.py", line 129, in read_image_file
_read_image_to_entry(image_entry, file_path)
File "/opt/django-project/rgd/geodata/models/imagery/etl.py", line 69, in _read_image_to_entry
image_entry.save()
File "/opt/django-project/rgd/geodata/models/common.py", line 51, in save
super(ModifiableEntry, self).save(*args, **kwargs)
File "/usr/local/lib/python3.8/site-packages/django/db/models/base.py", line 726, in save
self.save_base(using=using, force_insert=force_insert,
File "/usr/local/lib/python3.8/site-packages/django/db/models/base.py", line 763, in save_base
updated = self._save_table(
File "/usr/local/lib/python3.8/site-packages/django/db/models/base.py", line 868, in _save_table
results = self._do_insert(cls._base_manager, using, fields, returning_fields, raw)
File "/usr/local/lib/python3.8/site-packages/django/db/models/base.py", line 906, in _do_insert
return manager._insert(
File "/usr/local/lib/python3.8/site-packages/django/db/models/manager.py", line 85, in manager_method
return getattr(self.get_queryset(), name)(*args, **kwargs)
File "/usr/local/lib/python3.8/site-packages/django/db/models/query.py", line 1268, in _insert
return query.get_compiler(using=using).execute_sql(returning_fields)
File "/usr/local/lib/python3.8/site-packages/django/db/models/sql/compiler.py", line 1410, in execute_sql
cursor.execute(sql, params)
File "/usr/local/lib/python3.8/site-packages/django/db/backends/utils.py", line 98, in execute
return super().execute(sql, params)
File "/usr/local/lib/python3.8/site-packages/django/db/backends/utils.py", line 66, in execute
return self._execute_with_wrappers(sql, params, many=False, executor=self._execute)
File "/usr/local/lib/python3.8/site-packages/django/db/backends/utils.py", line 75, in _execute_with_wrappers
return executor(sql, params, many, context)
File "/usr/local/lib/python3.8/site-packages/django/db/backends/utils.py", line 84, in _execute
return self.cursor.execute(sql, params)
File "/usr/local/lib/python3.8/site-packages/django/db/utils.py", line 90, in __exit__
raise dj_exc_value.with_traceback(traceback) from exc_value
File "/usr/local/lib/python3.8/site-packages/django/db/backends/utils.py", line 84, in _execute
return self.cursor.execute(sql, params)
django.db.utils.IntegrityError: duplicate key value violates unique constraint "geodata_imageentry_image_file_id_key"
DETAIL: Key (image_file_id)=(14) already exists.
```
</details>
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `rgd/geodata/management/commands/_data_helper.py`
Content:
```
1 from functools import reduce
2 import os
3 from urllib.request import urlopen
4
5 from django.db.models import Count
6
7 from rgd.geodata import models, tasks
8 from rgd.geodata.datastore import datastore, registry
9 from rgd.geodata.models.imagery.etl import read_image_file
10 from rgd.utility import get_or_create_no_commit
11
12
13 def _get_or_download_checksum_file(name):
14 # Check if there is already an image file with this sha or URL
15 # to avoid duplicating data
16 try:
17 _ = urlopen(name) # HACK: see if URL first
18 try:
19 file_entry = models.ChecksumFile.objects.get(url=name)
20 except models.ChecksumFile.DoesNotExist:
21 file_entry = models.ChecksumFile()
22 file_entry.url = name
23 file_entry.type = models.FileSourceType.URL
24 file_entry.save()
25 except ValueError:
26 sha = registry[name].split(':')[1] # NOTE: assumes sha512
27 try:
28 file_entry = models.ChecksumFile.objects.get(checksum=sha)
29 except models.ChecksumFile.DoesNotExist:
30 path = datastore.fetch(name)
31 file_entry = models.ChecksumFile()
32 file_entry.name = name
33 file_entry.file.save(os.path.basename(path), open(path, 'rb'))
34 file_entry.type = models.FileSourceType.FILE_FIELD
35 file_entry.save()
36 tasks.task_checksum_file_post_save.delay(file_entry.id)
37 return file_entry
38
39
40 def _get_or_create_file_model(model, name, skip_signal=False):
41 # For models that point to a `ChecksumFile`
42 file_entry = _get_or_download_checksum_file(name)
43 entry, _ = model.objects.get_or_create(file=file_entry)
44 # In case the last population failed
45 if skip_signal:
46 entry.skip_signal = True
47 if entry.status != models.mixins.Status.SUCCEEDED:
48 entry.save()
49 return entry
50
51
52 def load_image_files(image_files):
53 ids = []
54 for imfile in image_files:
55 if isinstance(imfile, (list, tuple)):
56 result = load_image_files(imfile)
57 else:
58 # Run `read_image_file` sequentially to ensure `ImageEntry` is generated
59 entry = _get_or_create_file_model(models.ImageFile, imfile, skip_signal=True)
60 read_image_file(entry)
61 result = entry.imageentry.pk
62 ids.append(result)
63 return ids
64
65
66 def load_raster_files(raster_files):
67 ids = []
68 for rf in raster_files:
69 imentries = load_image_files(
70 [
71 rf,
72 ]
73 )
74 for pks in imentries:
75 if not isinstance(pks, (list, tuple)):
76 pks = [
77 pks,
78 ]
79 # Check if an ImageSet already exists containing all of these images
80 q = models.ImageSet.objects.annotate(count=Count('images')).filter(count=len(pks))
81 imsets = reduce(lambda p, id: q.filter(images=id), pks, q).values()
82 if len(imsets) > 0:
83 # Grab first, could be N-many
84 imset = models.ImageSet.objects.get(id=imsets[0]['id'])
85 else:
86 images = models.ImageEntry.objects.filter(pk__in=pks).all()
87 imset = models.ImageSet()
88 imset.save() # Have to save before adding to ManyToManyField
89 for image in images:
90 imset.images.add(image)
91 imset.save()
92 # Make raster of that image set
93 raster, created = models.RasterEntry.objects.get_or_create(image_set=imset)
94 if not created and raster.status != models.mixins.Status.SUCCEEDED:
95 raster.save()
96 ids.append(raster.pk)
97 return ids
98
99
100 def load_shape_files(shape_files):
101 ids = []
102 for shpfile in shape_files:
103 entry = _get_or_create_file_model(models.GeometryArchive, shpfile)
104 ids.append(entry.geometryentry.pk)
105 return ids
106
107
108 def load_fmv_files(fmv_files):
109 raise NotImplementedError('FMV ETL with Docker is still broken.')
110
111
112 def load_kwcoco_archives(archives):
113 ids = []
114 for fspec, farch in archives:
115 spec = _get_or_download_checksum_file(fspec)
116 arch = _get_or_download_checksum_file(farch)
117 ds, _ = get_or_create_no_commit(models.KWCOCOArchive, spec_file=spec, image_archive=arch)
118 ds.save()
119 ids.append(ds.id)
120 return ids
121
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/rgd/geodata/management/commands/_data_helper.py b/rgd/geodata/management/commands/_data_helper.py
--- a/rgd/geodata/management/commands/_data_helper.py
+++ b/rgd/geodata/management/commands/_data_helper.py
@@ -40,11 +40,12 @@
def _get_or_create_file_model(model, name, skip_signal=False):
# For models that point to a `ChecksumFile`
file_entry = _get_or_download_checksum_file(name)
- entry, _ = model.objects.get_or_create(file=file_entry)
+ # No commit in case we need to skip the signal
+ entry, created = get_or_create_no_commit(model, file=file_entry)
# In case the last population failed
if skip_signal:
entry.skip_signal = True
- if entry.status != models.mixins.Status.SUCCEEDED:
+ if created or entry.status != models.mixins.Status.SUCCEEDED:
entry.save()
return entry
|
{"golden_diff": "diff --git a/rgd/geodata/management/commands/_data_helper.py b/rgd/geodata/management/commands/_data_helper.py\n--- a/rgd/geodata/management/commands/_data_helper.py\n+++ b/rgd/geodata/management/commands/_data_helper.py\n@@ -40,11 +40,12 @@\n def _get_or_create_file_model(model, name, skip_signal=False):\n # For models that point to a `ChecksumFile`\n file_entry = _get_or_download_checksum_file(name)\n- entry, _ = model.objects.get_or_create(file=file_entry)\n+ # No commit in case we need to skip the signal\n+ entry, created = get_or_create_no_commit(model, file=file_entry)\n # In case the last population failed\n if skip_signal:\n entry.skip_signal = True\n- if entry.status != models.mixins.Status.SUCCEEDED:\n+ if created or entry.status != models.mixins.Status.SUCCEEDED:\n entry.save()\n return entry\n", "issue": "psycopg2.errors.UniqueViolation: duplicate key value error\nWhen running the demo data commands that I have, if the celery worker is set up to run in the background, an integretiy error for duplicate keys happens on the `image_entry.save()` call here:\r\n\r\nhttps://github.com/ResonantGeoData/ResonantGeoData/blob/998a6c3995b4421c3632979a249fb78d66e1108f/rgd/geodata/models/imagery/etl.py#L69\r\n\r\nThe error:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.8/site-packages/django/db/backends/utils.py\", line 84, in _execute\r\n return self.cursor.execute(sql, params)\r\npsycopg2.errors.UniqueViolation: duplicate key value violates unique constraint \"geodata_imageentry_image_file_id_key\"\r\nDETAIL: Key (image_file_id)=(14) already exists.\r\n```\r\n\r\nThis is making me think that when we create a new `ImageEntry` in the tasks, there is some sort of race condition between jobs for the same `ImageFile`... which shouldn't happen? I'm not really sure what is going on here.\r\n \r\n\r\n## Steps to reproduce\r\n\r\n1. Clear the database volume\r\n2. Apply migrations: `docker-compose run --rm django ./manage.py migrate`\r\n3. In one session, launch the celery worker: `docker-compose up celery` and wait until ready\r\n4. In another session, run the Landsat demo data command: `docker-compose run --rm django ./manage.py landsat_data -c 3`\r\n - Use the changes from #296 \r\n5. Observe the error\r\n\r\n## Error Message\r\n\r\n<details>\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.8/site-packages/django/db/backends/utils.py\", line 84, in _execute\r\n return self.cursor.execute(sql, params)\r\npsycopg2.errors.UniqueViolation: duplicate key value violates unique constraint \"geodata_imageentry_image_file_id_key\"\r\nDETAIL: Key (image_file_id)=(14) already exists.\r\n\r\n\r\nThe above exception was the direct cause of the following exception:\r\n\r\nTraceback (most recent call last):\r\n File \"./manage.py\", line 28, in <module>\r\n main()\r\n File \"./manage.py\", line 24, in main\r\n execute_from_command_line(sys.argv)\r\n File \"/usr/local/lib/python3.8/site-packages/django/core/management/__init__.py\", line 419, in execute_from_command_line\r\n utility.execute()\r\n File \"/usr/local/lib/python3.8/site-packages/django/core/management/__init__.py\", line 413, in execute\r\n self.fetch_command(subcommand).run_from_argv(self.argv)\r\n File \"/usr/local/lib/python3.8/site-packages/django/core/management/base.py\", line 354, in run_from_argv\r\n self.execute(*args, **cmd_options)\r\n File \"/usr/local/lib/python3.8/site-packages/django/core/management/base.py\", line 398, in execute\r\n output = self.handle(*args, **options)\r\n File \"/opt/django-project/rgd/geodata/management/commands/landsat_data.py\", line 49, in handle\r\n helper.load_raster_files(_get_landsat_urls(count))\r\n File \"/opt/django-project/rgd/geodata/management/commands/_data_helper.py\", line 80, in load_raster_files\r\n imentries = load_image_files(\r\n File \"/opt/django-project/rgd/geodata/management/commands/_data_helper.py\", line 56, in load_image_files\r\n result = load_image_files(imfile)\r\n File \"/opt/django-project/rgd/geodata/management/commands/_data_helper.py\", line 60, in load_image_files\r\n read_image_file(entry)\r\n File \"/opt/django-project/rgd/geodata/models/imagery/etl.py\", line 129, in read_image_file\r\n _read_image_to_entry(image_entry, file_path)\r\n File \"/opt/django-project/rgd/geodata/models/imagery/etl.py\", line 69, in _read_image_to_entry\r\n image_entry.save()\r\n File \"/opt/django-project/rgd/geodata/models/common.py\", line 51, in save\r\n super(ModifiableEntry, self).save(*args, **kwargs)\r\n File \"/usr/local/lib/python3.8/site-packages/django/db/models/base.py\", line 726, in save\r\n self.save_base(using=using, force_insert=force_insert,\r\n File \"/usr/local/lib/python3.8/site-packages/django/db/models/base.py\", line 763, in save_base\r\n updated = self._save_table(\r\n File \"/usr/local/lib/python3.8/site-packages/django/db/models/base.py\", line 868, in _save_table\r\n results = self._do_insert(cls._base_manager, using, fields, returning_fields, raw)\r\n File \"/usr/local/lib/python3.8/site-packages/django/db/models/base.py\", line 906, in _do_insert\r\n return manager._insert(\r\n File \"/usr/local/lib/python3.8/site-packages/django/db/models/manager.py\", line 85, in manager_method\r\n return getattr(self.get_queryset(), name)(*args, **kwargs)\r\n File \"/usr/local/lib/python3.8/site-packages/django/db/models/query.py\", line 1268, in _insert\r\n return query.get_compiler(using=using).execute_sql(returning_fields)\r\n File \"/usr/local/lib/python3.8/site-packages/django/db/models/sql/compiler.py\", line 1410, in execute_sql\r\n cursor.execute(sql, params)\r\n File \"/usr/local/lib/python3.8/site-packages/django/db/backends/utils.py\", line 98, in execute\r\n return super().execute(sql, params)\r\n File \"/usr/local/lib/python3.8/site-packages/django/db/backends/utils.py\", line 66, in execute\r\n return self._execute_with_wrappers(sql, params, many=False, executor=self._execute)\r\n File \"/usr/local/lib/python3.8/site-packages/django/db/backends/utils.py\", line 75, in _execute_with_wrappers\r\n return executor(sql, params, many, context)\r\n File \"/usr/local/lib/python3.8/site-packages/django/db/backends/utils.py\", line 84, in _execute\r\n return self.cursor.execute(sql, params)\r\n File \"/usr/local/lib/python3.8/site-packages/django/db/utils.py\", line 90, in __exit__\r\n raise dj_exc_value.with_traceback(traceback) from exc_value\r\n File \"/usr/local/lib/python3.8/site-packages/django/db/backends/utils.py\", line 84, in _execute\r\n return self.cursor.execute(sql, params)\r\ndjango.db.utils.IntegrityError: duplicate key value violates unique constraint \"geodata_imageentry_image_file_id_key\"\r\nDETAIL: Key (image_file_id)=(14) already exists.\r\n```\r\n\r\n</details>\n", "before_files": [{"content": "from functools import reduce\nimport os\nfrom urllib.request import urlopen\n\nfrom django.db.models import Count\n\nfrom rgd.geodata import models, tasks\nfrom rgd.geodata.datastore import datastore, registry\nfrom rgd.geodata.models.imagery.etl import read_image_file\nfrom rgd.utility import get_or_create_no_commit\n\n\ndef _get_or_download_checksum_file(name):\n # Check if there is already an image file with this sha or URL\n # to avoid duplicating data\n try:\n _ = urlopen(name) # HACK: see if URL first\n try:\n file_entry = models.ChecksumFile.objects.get(url=name)\n except models.ChecksumFile.DoesNotExist:\n file_entry = models.ChecksumFile()\n file_entry.url = name\n file_entry.type = models.FileSourceType.URL\n file_entry.save()\n except ValueError:\n sha = registry[name].split(':')[1] # NOTE: assumes sha512\n try:\n file_entry = models.ChecksumFile.objects.get(checksum=sha)\n except models.ChecksumFile.DoesNotExist:\n path = datastore.fetch(name)\n file_entry = models.ChecksumFile()\n file_entry.name = name\n file_entry.file.save(os.path.basename(path), open(path, 'rb'))\n file_entry.type = models.FileSourceType.FILE_FIELD\n file_entry.save()\n tasks.task_checksum_file_post_save.delay(file_entry.id)\n return file_entry\n\n\ndef _get_or_create_file_model(model, name, skip_signal=False):\n # For models that point to a `ChecksumFile`\n file_entry = _get_or_download_checksum_file(name)\n entry, _ = model.objects.get_or_create(file=file_entry)\n # In case the last population failed\n if skip_signal:\n entry.skip_signal = True\n if entry.status != models.mixins.Status.SUCCEEDED:\n entry.save()\n return entry\n\n\ndef load_image_files(image_files):\n ids = []\n for imfile in image_files:\n if isinstance(imfile, (list, tuple)):\n result = load_image_files(imfile)\n else:\n # Run `read_image_file` sequentially to ensure `ImageEntry` is generated\n entry = _get_or_create_file_model(models.ImageFile, imfile, skip_signal=True)\n read_image_file(entry)\n result = entry.imageentry.pk\n ids.append(result)\n return ids\n\n\ndef load_raster_files(raster_files):\n ids = []\n for rf in raster_files:\n imentries = load_image_files(\n [\n rf,\n ]\n )\n for pks in imentries:\n if not isinstance(pks, (list, tuple)):\n pks = [\n pks,\n ]\n # Check if an ImageSet already exists containing all of these images\n q = models.ImageSet.objects.annotate(count=Count('images')).filter(count=len(pks))\n imsets = reduce(lambda p, id: q.filter(images=id), pks, q).values()\n if len(imsets) > 0:\n # Grab first, could be N-many\n imset = models.ImageSet.objects.get(id=imsets[0]['id'])\n else:\n images = models.ImageEntry.objects.filter(pk__in=pks).all()\n imset = models.ImageSet()\n imset.save() # Have to save before adding to ManyToManyField\n for image in images:\n imset.images.add(image)\n imset.save()\n # Make raster of that image set\n raster, created = models.RasterEntry.objects.get_or_create(image_set=imset)\n if not created and raster.status != models.mixins.Status.SUCCEEDED:\n raster.save()\n ids.append(raster.pk)\n return ids\n\n\ndef load_shape_files(shape_files):\n ids = []\n for shpfile in shape_files:\n entry = _get_or_create_file_model(models.GeometryArchive, shpfile)\n ids.append(entry.geometryentry.pk)\n return ids\n\n\ndef load_fmv_files(fmv_files):\n raise NotImplementedError('FMV ETL with Docker is still broken.')\n\n\ndef load_kwcoco_archives(archives):\n ids = []\n for fspec, farch in archives:\n spec = _get_or_download_checksum_file(fspec)\n arch = _get_or_download_checksum_file(farch)\n ds, _ = get_or_create_no_commit(models.KWCOCOArchive, spec_file=spec, image_archive=arch)\n ds.save()\n ids.append(ds.id)\n return ids\n", "path": "rgd/geodata/management/commands/_data_helper.py"}], "after_files": [{"content": "from functools import reduce\nimport os\nfrom urllib.request import urlopen\n\nfrom django.db.models import Count\n\nfrom rgd.geodata import models, tasks\nfrom rgd.geodata.datastore import datastore, registry\nfrom rgd.geodata.models.imagery.etl import read_image_file\nfrom rgd.utility import get_or_create_no_commit\n\n\ndef _get_or_download_checksum_file(name):\n # Check if there is already an image file with this sha or URL\n # to avoid duplicating data\n try:\n _ = urlopen(name) # HACK: see if URL first\n try:\n file_entry = models.ChecksumFile.objects.get(url=name)\n except models.ChecksumFile.DoesNotExist:\n file_entry = models.ChecksumFile()\n file_entry.url = name\n file_entry.type = models.FileSourceType.URL\n file_entry.save()\n except ValueError:\n sha = registry[name].split(':')[1] # NOTE: assumes sha512\n try:\n file_entry = models.ChecksumFile.objects.get(checksum=sha)\n except models.ChecksumFile.DoesNotExist:\n path = datastore.fetch(name)\n file_entry = models.ChecksumFile()\n file_entry.name = name\n file_entry.file.save(os.path.basename(path), open(path, 'rb'))\n file_entry.type = models.FileSourceType.FILE_FIELD\n file_entry.save()\n tasks.task_checksum_file_post_save.delay(file_entry.id)\n return file_entry\n\n\ndef _get_or_create_file_model(model, name, skip_signal=False):\n # For models that point to a `ChecksumFile`\n file_entry = _get_or_download_checksum_file(name)\n # No commit in case we need to skip the signal\n entry, created = get_or_create_no_commit(model, file=file_entry)\n # In case the last population failed\n if skip_signal:\n entry.skip_signal = True\n if created or entry.status != models.mixins.Status.SUCCEEDED:\n entry.save()\n return entry\n\n\ndef load_image_files(image_files):\n ids = []\n for imfile in image_files:\n if isinstance(imfile, (list, tuple)):\n result = load_image_files(imfile)\n else:\n # Run `read_image_file` sequentially to ensure `ImageEntry` is generated\n entry = _get_or_create_file_model(models.ImageFile, imfile, skip_signal=True)\n read_image_file(entry)\n result = entry.imageentry.pk\n ids.append(result)\n return ids\n\n\ndef load_raster_files(raster_files):\n ids = []\n for rf in raster_files:\n imentries = load_image_files(\n [\n rf,\n ]\n )\n for pks in imentries:\n if not isinstance(pks, (list, tuple)):\n pks = [\n pks,\n ]\n # Check if an ImageSet already exists containing all of these images\n q = models.ImageSet.objects.annotate(count=Count('images')).filter(count=len(pks))\n imsets = reduce(lambda p, id: q.filter(images=id), pks, q).values()\n if len(imsets) > 0:\n # Grab first, could be N-many\n imset = models.ImageSet.objects.get(id=imsets[0]['id'])\n else:\n images = models.ImageEntry.objects.filter(pk__in=pks).all()\n imset = models.ImageSet()\n imset.save() # Have to save before adding to ManyToManyField\n for image in images:\n imset.images.add(image)\n imset.save()\n # Make raster of that image set\n raster, created = models.RasterEntry.objects.get_or_create(image_set=imset)\n if not created and raster.status != models.mixins.Status.SUCCEEDED:\n raster.save()\n ids.append(raster.pk)\n return ids\n\n\ndef load_shape_files(shape_files):\n ids = []\n for shpfile in shape_files:\n entry = _get_or_create_file_model(models.GeometryArchive, shpfile)\n ids.append(entry.geometryentry.pk)\n return ids\n\n\ndef load_fmv_files(fmv_files):\n raise NotImplementedError('FMV ETL with Docker is still broken.')\n\n\ndef load_kwcoco_archives(archives):\n ids = []\n for fspec, farch in archives:\n spec = _get_or_download_checksum_file(fspec)\n arch = _get_or_download_checksum_file(farch)\n ds, _ = get_or_create_no_commit(models.KWCOCOArchive, spec_file=spec, image_archive=arch)\n ds.save()\n ids.append(ds.id)\n return ids\n", "path": "rgd/geodata/management/commands/_data_helper.py"}]}
| 3,032 | 220 |
gh_patches_debug_22805
|
rasdani/github-patches
|
git_diff
|
yt-dlp__yt-dlp-5628
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Gronkh.tv Unsupported URL, new URL not recognized
### DO NOT REMOVE OR SKIP THE ISSUE TEMPLATE
- [X] I understand that I will be **blocked** if I remove or skip any mandatory\* field
### Checklist
- [X] I'm reporting a broken site
- [X] I've verified that I'm running yt-dlp version **2022.11.11** ([update instructions](https://github.com/yt-dlp/yt-dlp#update)) or later (specify commit)
- [X] I've checked that all provided URLs are playable in a browser with the same IP and same login details
- [X] I've checked that all URLs and arguments with special characters are [properly quoted or escaped](https://github.com/yt-dlp/yt-dlp/wiki/FAQ#video-url-contains-an-ampersand--and-im-getting-some-strange-output-1-2839-or-v-is-not-recognized-as-an-internal-or-external-command)
- [X] I've searched the [bugtracker](https://github.com/yt-dlp/yt-dlp/issues?q=) for similar issues **including closed ones**. DO NOT post duplicates
- [X] I've read the [guidelines for opening an issue](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#opening-an-issue)
- [X] I've read about [sharing account credentials](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#are-you-willing-to-share-account-details-if-needed) and I'm willing to share it if required
### Region
_No response_
### Provide a description that is worded well enough to be understood
Gronkh.tv seems to have changed a part of the URL for streams from /stream/ to /streams/ (plural now).
The old URLs are still supported, as the test URL redirects to the new URL. But calling yt-dlp with the new URL is raising an "Unsupported URL"-error, because yt-dlp is not recognizing the new url.
I confirmed it as source of the error by changing _VALID_URL in the extractor yt_dlp/extractor/gronkh.py, after which it worked fine. I don't know whether both URLs will stay valid, or just the plural-version, as there seems to be still much work done on the site, so maybe support both?
Old URL: https://gronkh.tv/stream/536
New URL: https://gronkh.tv/streams/536
### Provide verbose output that clearly demonstrates the problem
- [X] Run **your** yt-dlp command with **-vU** flag added (`yt-dlp -vU <your command line>`)
- [X] Copy the WHOLE output (starting with `[debug] Command-line config`) and insert it below
### Complete Verbose Output
```shell
[debug] Command-line config: ['--format', 'bestvideo[height<=720]+bestaudio/best[height<=720]', '--restrict-filenames', '--output', '[%(extractor)s][%(channel)s] %(title)s [%(id)s].%(ext)s', '--no-overwrites', '--no-playlist', '--all-subs', '--embed-subs', '-vU', '--merge-output-format', 'mkv', 'https://gronkh.tv/streams/536']
[debug] Encodings: locale UTF-8, fs utf-8, pref UTF-8, out utf-8, error utf-8, screen utf-8
[debug] yt-dlp version 2022.11.11 [8b644025b] (source)
[debug] Lazy loading extractors is disabled
[debug] Plugins: ['SamplePluginIE', 'SamplePluginPP']
[debug] Git HEAD: 692e9ccbe
[debug] Python 3.10.8 (CPython x86_64 64bit) - Linux-6.0.0-2-amd64-x86_64-with-glibc2.35 (OpenSSL 3.0.5 5 Jul 2022, glibc 2.35)
[debug] exe versions: ffmpeg 5.1.2 (fdk,setts), ffprobe 5.1.2
[debug] Optional libraries: Cryptodome-3.11.0, brotli-1.0.9, certifi-2022.06.15, pyxattr-0.7.2, secretstorage-3.3.3, sqlite3-2.6.0
[debug] Proxy map: {}
[debug] Loaded 1725 extractors
[debug] Fetching release info: https://api.github.com/repos/yt-dlp/yt-dlp/releases/latest
Latest version: 2022.11.11, Current version: 2022.11.11
yt-dlp is up to date (2022.11.11)
[debug] [generic] Extracting URL: https://gronkh.tv/streams/536
[generic] 536: Downloading webpage
WARNING: [generic] Falling back on generic information extractor
[generic] 536: Extracting information
[debug] Looking for embeds
ERROR: Unsupported URL: https://gronkh.tv/streams/536
Traceback (most recent call last):
File "/path/to/yt-dlp/yt_dlp/YoutubeDL.py", line 1493, in wrapper
return func(self, *args, **kwargs)
File "/path/to/yt-dlp/yt_dlp/YoutubeDL.py", line 1569, in __extract_info
ie_result = ie.extract(url)
File "/path/to/yt-dlp/yt_dlp/extractor/common.py", line 674, in extract
ie_result = self._real_extract(url)
File "/path/to/yt-dlp/yt_dlp/extractor/generic.py", line 2721, in _real_extract
raise UnsupportedError(url)
yt_dlp.utils.UnsupportedError: Unsupported URL: https://gronkh.tv/streams/536
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `yt_dlp/extractor/gronkh.py`
Content:
```
1 import functools
2
3 from .common import InfoExtractor
4 from ..utils import (
5 OnDemandPagedList,
6 traverse_obj,
7 unified_strdate,
8 )
9
10
11 class GronkhIE(InfoExtractor):
12 _VALID_URL = r'https?://(?:www\.)?gronkh\.tv/(?:watch/)?stream/(?P<id>\d+)'
13
14 _TESTS = [{
15 'url': 'https://gronkh.tv/stream/536',
16 'info_dict': {
17 'id': '536',
18 'ext': 'mp4',
19 'title': 'GTV0536, 2021-10-01 - MARTHA IS DEAD #FREiAB1830 !FF7 !horde !archiv',
20 'view_count': 19491,
21 'thumbnail': 'https://01.cdn.vod.farm/preview/6436746cce14e25f751260a692872b9b.jpg',
22 'upload_date': '20211001'
23 },
24 'params': {'skip_download': True}
25 }, {
26 'url': 'https://gronkh.tv/watch/stream/546',
27 'only_matching': True,
28 }]
29
30 def _real_extract(self, url):
31 id = self._match_id(url)
32 data_json = self._download_json(f'https://api.gronkh.tv/v1/video/info?episode={id}', id)
33 m3u8_url = self._download_json(f'https://api.gronkh.tv/v1/video/playlist?episode={id}', id)['playlist_url']
34 formats, subtitles = self._extract_m3u8_formats_and_subtitles(m3u8_url, id)
35 if data_json.get('vtt_url'):
36 subtitles.setdefault('en', []).append({
37 'url': data_json['vtt_url'],
38 'ext': 'vtt',
39 })
40 return {
41 'id': id,
42 'title': data_json.get('title'),
43 'view_count': data_json.get('views'),
44 'thumbnail': data_json.get('preview_url'),
45 'upload_date': unified_strdate(data_json.get('created_at')),
46 'formats': formats,
47 'subtitles': subtitles,
48 }
49
50
51 class GronkhFeedIE(InfoExtractor):
52 _VALID_URL = r'https?://(?:www\.)?gronkh\.tv(?:/feed)?/?(?:#|$)'
53 IE_NAME = 'gronkh:feed'
54
55 _TESTS = [{
56 'url': 'https://gronkh.tv/feed',
57 'info_dict': {
58 'id': 'feed',
59 },
60 'playlist_count': 16,
61 }, {
62 'url': 'https://gronkh.tv',
63 'only_matching': True,
64 }]
65
66 def _entries(self):
67 for type_ in ('recent', 'views'):
68 info = self._download_json(
69 f'https://api.gronkh.tv/v1/video/discovery/{type_}', 'feed', note=f'Downloading {type_} API JSON')
70 for item in traverse_obj(info, ('discovery', ...)) or []:
71 yield self.url_result(f'https://gronkh.tv/watch/stream/{item["episode"]}', GronkhIE, item.get('title'))
72
73 def _real_extract(self, url):
74 return self.playlist_result(self._entries(), 'feed')
75
76
77 class GronkhVodsIE(InfoExtractor):
78 _VALID_URL = r'https?://(?:www\.)?gronkh\.tv/vods/streams/?(?:#|$)'
79 IE_NAME = 'gronkh:vods'
80
81 _TESTS = [{
82 'url': 'https://gronkh.tv/vods/streams',
83 'info_dict': {
84 'id': 'vods',
85 },
86 'playlist_mincount': 150,
87 }]
88 _PER_PAGE = 25
89
90 def _fetch_page(self, page):
91 items = traverse_obj(self._download_json(
92 'https://api.gronkh.tv/v1/search', 'vods', query={'offset': self._PER_PAGE * page, 'first': self._PER_PAGE},
93 note=f'Downloading stream video page {page + 1}'), ('results', 'videos', ...))
94 for item in items or []:
95 yield self.url_result(f'https://gronkh.tv/watch/stream/{item["episode"]}', GronkhIE, item['episode'], item.get('title'))
96
97 def _real_extract(self, url):
98 entries = OnDemandPagedList(functools.partial(self._fetch_page), self._PER_PAGE)
99 return self.playlist_result(entries, 'vods')
100
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/yt_dlp/extractor/gronkh.py b/yt_dlp/extractor/gronkh.py
--- a/yt_dlp/extractor/gronkh.py
+++ b/yt_dlp/extractor/gronkh.py
@@ -9,15 +9,26 @@
class GronkhIE(InfoExtractor):
- _VALID_URL = r'https?://(?:www\.)?gronkh\.tv/(?:watch/)?stream/(?P<id>\d+)'
+ _VALID_URL = r'https?://(?:www\.)?gronkh\.tv/(?:watch/)?streams?/(?P<id>\d+)'
_TESTS = [{
+ 'url': 'https://gronkh.tv/streams/657',
+ 'info_dict': {
+ 'id': '657',
+ 'ext': 'mp4',
+ 'title': 'H.O.R.D.E. - DAS ZWEiTE ZEiTALTER 🎲 Session 1',
+ 'view_count': int,
+ 'thumbnail': 'https://01.cdn.vod.farm/preview/9e2555d3a23bf4e5c5b7c6b3b70a9d84.jpg',
+ 'upload_date': '20221111'
+ },
+ 'params': {'skip_download': True}
+ }, {
'url': 'https://gronkh.tv/stream/536',
'info_dict': {
'id': '536',
'ext': 'mp4',
'title': 'GTV0536, 2021-10-01 - MARTHA IS DEAD #FREiAB1830 !FF7 !horde !archiv',
- 'view_count': 19491,
+ 'view_count': int,
'thumbnail': 'https://01.cdn.vod.farm/preview/6436746cce14e25f751260a692872b9b.jpg',
'upload_date': '20211001'
},
|
{"golden_diff": "diff --git a/yt_dlp/extractor/gronkh.py b/yt_dlp/extractor/gronkh.py\n--- a/yt_dlp/extractor/gronkh.py\n+++ b/yt_dlp/extractor/gronkh.py\n@@ -9,15 +9,26 @@\n \n \n class GronkhIE(InfoExtractor):\n- _VALID_URL = r'https?://(?:www\\.)?gronkh\\.tv/(?:watch/)?stream/(?P<id>\\d+)'\n+ _VALID_URL = r'https?://(?:www\\.)?gronkh\\.tv/(?:watch/)?streams?/(?P<id>\\d+)'\n \n _TESTS = [{\n+ 'url': 'https://gronkh.tv/streams/657',\n+ 'info_dict': {\n+ 'id': '657',\n+ 'ext': 'mp4',\n+ 'title': 'H.O.R.D.E. - DAS ZWEiTE ZEiTALTER \ud83c\udfb2 Session 1',\n+ 'view_count': int,\n+ 'thumbnail': 'https://01.cdn.vod.farm/preview/9e2555d3a23bf4e5c5b7c6b3b70a9d84.jpg',\n+ 'upload_date': '20221111'\n+ },\n+ 'params': {'skip_download': True}\n+ }, {\n 'url': 'https://gronkh.tv/stream/536',\n 'info_dict': {\n 'id': '536',\n 'ext': 'mp4',\n 'title': 'GTV0536, 2021-10-01 - MARTHA IS DEAD #FREiAB1830 !FF7 !horde !archiv',\n- 'view_count': 19491,\n+ 'view_count': int,\n 'thumbnail': 'https://01.cdn.vod.farm/preview/6436746cce14e25f751260a692872b9b.jpg',\n 'upload_date': '20211001'\n },\n", "issue": "Gronkh.tv Unsupported URL, new URL not recognized\n### DO NOT REMOVE OR SKIP THE ISSUE TEMPLATE\n\n- [X] I understand that I will be **blocked** if I remove or skip any mandatory\\* field\n\n### Checklist\n\n- [X] I'm reporting a broken site\n- [X] I've verified that I'm running yt-dlp version **2022.11.11** ([update instructions](https://github.com/yt-dlp/yt-dlp#update)) or later (specify commit)\n- [X] I've checked that all provided URLs are playable in a browser with the same IP and same login details\n- [X] I've checked that all URLs and arguments with special characters are [properly quoted or escaped](https://github.com/yt-dlp/yt-dlp/wiki/FAQ#video-url-contains-an-ampersand--and-im-getting-some-strange-output-1-2839-or-v-is-not-recognized-as-an-internal-or-external-command)\n- [X] I've searched the [bugtracker](https://github.com/yt-dlp/yt-dlp/issues?q=) for similar issues **including closed ones**. DO NOT post duplicates\n- [X] I've read the [guidelines for opening an issue](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#opening-an-issue)\n- [X] I've read about [sharing account credentials](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#are-you-willing-to-share-account-details-if-needed) and I'm willing to share it if required\n\n### Region\n\n_No response_\n\n### Provide a description that is worded well enough to be understood\n\nGronkh.tv seems to have changed a part of the URL for streams from /stream/ to /streams/ (plural now).\r\nThe old URLs are still supported, as the test URL redirects to the new URL. But calling yt-dlp with the new URL is raising an \"Unsupported URL\"-error, because yt-dlp is not recognizing the new url.\r\n\r\nI confirmed it as source of the error by changing _VALID_URL in the extractor yt_dlp/extractor/gronkh.py, after which it worked fine. I don't know whether both URLs will stay valid, or just the plural-version, as there seems to be still much work done on the site, so maybe support both?\r\n\r\nOld URL: https://gronkh.tv/stream/536\r\nNew URL: https://gronkh.tv/streams/536\r\n\r\n\n\n### Provide verbose output that clearly demonstrates the problem\n\n- [X] Run **your** yt-dlp command with **-vU** flag added (`yt-dlp -vU <your command line>`)\n- [X] Copy the WHOLE output (starting with `[debug] Command-line config`) and insert it below\n\n### Complete Verbose Output\n\n```shell\n[debug] Command-line config: ['--format', 'bestvideo[height<=720]+bestaudio/best[height<=720]', '--restrict-filenames', '--output', '[%(extractor)s][%(channel)s] %(title)s [%(id)s].%(ext)s', '--no-overwrites', '--no-playlist', '--all-subs', '--embed-subs', '-vU', '--merge-output-format', 'mkv', 'https://gronkh.tv/streams/536']\r\n[debug] Encodings: locale UTF-8, fs utf-8, pref UTF-8, out utf-8, error utf-8, screen utf-8\r\n[debug] yt-dlp version 2022.11.11 [8b644025b] (source)\r\n[debug] Lazy loading extractors is disabled\r\n[debug] Plugins: ['SamplePluginIE', 'SamplePluginPP']\r\n[debug] Git HEAD: 692e9ccbe\r\n[debug] Python 3.10.8 (CPython x86_64 64bit) - Linux-6.0.0-2-amd64-x86_64-with-glibc2.35 (OpenSSL 3.0.5 5 Jul 2022, glibc 2.35)\r\n[debug] exe versions: ffmpeg 5.1.2 (fdk,setts), ffprobe 5.1.2\r\n[debug] Optional libraries: Cryptodome-3.11.0, brotli-1.0.9, certifi-2022.06.15, pyxattr-0.7.2, secretstorage-3.3.3, sqlite3-2.6.0\r\n[debug] Proxy map: {}\r\n[debug] Loaded 1725 extractors\r\n[debug] Fetching release info: https://api.github.com/repos/yt-dlp/yt-dlp/releases/latest\r\nLatest version: 2022.11.11, Current version: 2022.11.11\r\nyt-dlp is up to date (2022.11.11)\r\n[debug] [generic] Extracting URL: https://gronkh.tv/streams/536\r\n[generic] 536: Downloading webpage\r\nWARNING: [generic] Falling back on generic information extractor\r\n[generic] 536: Extracting information\r\n[debug] Looking for embeds\r\nERROR: Unsupported URL: https://gronkh.tv/streams/536\r\nTraceback (most recent call last):\r\n File \"/path/to/yt-dlp/yt_dlp/YoutubeDL.py\", line 1493, in wrapper\r\n return func(self, *args, **kwargs)\r\n File \"/path/to/yt-dlp/yt_dlp/YoutubeDL.py\", line 1569, in __extract_info\r\n ie_result = ie.extract(url)\r\n File \"/path/to/yt-dlp/yt_dlp/extractor/common.py\", line 674, in extract\r\n ie_result = self._real_extract(url)\r\n File \"/path/to/yt-dlp/yt_dlp/extractor/generic.py\", line 2721, in _real_extract\r\n raise UnsupportedError(url)\r\nyt_dlp.utils.UnsupportedError: Unsupported URL: https://gronkh.tv/streams/536\n```\n\n", "before_files": [{"content": "import functools\n\nfrom .common import InfoExtractor\nfrom ..utils import (\n OnDemandPagedList,\n traverse_obj,\n unified_strdate,\n)\n\n\nclass GronkhIE(InfoExtractor):\n _VALID_URL = r'https?://(?:www\\.)?gronkh\\.tv/(?:watch/)?stream/(?P<id>\\d+)'\n\n _TESTS = [{\n 'url': 'https://gronkh.tv/stream/536',\n 'info_dict': {\n 'id': '536',\n 'ext': 'mp4',\n 'title': 'GTV0536, 2021-10-01 - MARTHA IS DEAD #FREiAB1830 !FF7 !horde !archiv',\n 'view_count': 19491,\n 'thumbnail': 'https://01.cdn.vod.farm/preview/6436746cce14e25f751260a692872b9b.jpg',\n 'upload_date': '20211001'\n },\n 'params': {'skip_download': True}\n }, {\n 'url': 'https://gronkh.tv/watch/stream/546',\n 'only_matching': True,\n }]\n\n def _real_extract(self, url):\n id = self._match_id(url)\n data_json = self._download_json(f'https://api.gronkh.tv/v1/video/info?episode={id}', id)\n m3u8_url = self._download_json(f'https://api.gronkh.tv/v1/video/playlist?episode={id}', id)['playlist_url']\n formats, subtitles = self._extract_m3u8_formats_and_subtitles(m3u8_url, id)\n if data_json.get('vtt_url'):\n subtitles.setdefault('en', []).append({\n 'url': data_json['vtt_url'],\n 'ext': 'vtt',\n })\n return {\n 'id': id,\n 'title': data_json.get('title'),\n 'view_count': data_json.get('views'),\n 'thumbnail': data_json.get('preview_url'),\n 'upload_date': unified_strdate(data_json.get('created_at')),\n 'formats': formats,\n 'subtitles': subtitles,\n }\n\n\nclass GronkhFeedIE(InfoExtractor):\n _VALID_URL = r'https?://(?:www\\.)?gronkh\\.tv(?:/feed)?/?(?:#|$)'\n IE_NAME = 'gronkh:feed'\n\n _TESTS = [{\n 'url': 'https://gronkh.tv/feed',\n 'info_dict': {\n 'id': 'feed',\n },\n 'playlist_count': 16,\n }, {\n 'url': 'https://gronkh.tv',\n 'only_matching': True,\n }]\n\n def _entries(self):\n for type_ in ('recent', 'views'):\n info = self._download_json(\n f'https://api.gronkh.tv/v1/video/discovery/{type_}', 'feed', note=f'Downloading {type_} API JSON')\n for item in traverse_obj(info, ('discovery', ...)) or []:\n yield self.url_result(f'https://gronkh.tv/watch/stream/{item[\"episode\"]}', GronkhIE, item.get('title'))\n\n def _real_extract(self, url):\n return self.playlist_result(self._entries(), 'feed')\n\n\nclass GronkhVodsIE(InfoExtractor):\n _VALID_URL = r'https?://(?:www\\.)?gronkh\\.tv/vods/streams/?(?:#|$)'\n IE_NAME = 'gronkh:vods'\n\n _TESTS = [{\n 'url': 'https://gronkh.tv/vods/streams',\n 'info_dict': {\n 'id': 'vods',\n },\n 'playlist_mincount': 150,\n }]\n _PER_PAGE = 25\n\n def _fetch_page(self, page):\n items = traverse_obj(self._download_json(\n 'https://api.gronkh.tv/v1/search', 'vods', query={'offset': self._PER_PAGE * page, 'first': self._PER_PAGE},\n note=f'Downloading stream video page {page + 1}'), ('results', 'videos', ...))\n for item in items or []:\n yield self.url_result(f'https://gronkh.tv/watch/stream/{item[\"episode\"]}', GronkhIE, item['episode'], item.get('title'))\n\n def _real_extract(self, url):\n entries = OnDemandPagedList(functools.partial(self._fetch_page), self._PER_PAGE)\n return self.playlist_result(entries, 'vods')\n", "path": "yt_dlp/extractor/gronkh.py"}], "after_files": [{"content": "import functools\n\nfrom .common import InfoExtractor\nfrom ..utils import (\n OnDemandPagedList,\n traverse_obj,\n unified_strdate,\n)\n\n\nclass GronkhIE(InfoExtractor):\n _VALID_URL = r'https?://(?:www\\.)?gronkh\\.tv/(?:watch/)?streams?/(?P<id>\\d+)'\n\n _TESTS = [{\n 'url': 'https://gronkh.tv/streams/657',\n 'info_dict': {\n 'id': '657',\n 'ext': 'mp4',\n 'title': 'H.O.R.D.E. - DAS ZWEiTE ZEiTALTER \ud83c\udfb2 Session 1',\n 'view_count': int,\n 'thumbnail': 'https://01.cdn.vod.farm/preview/9e2555d3a23bf4e5c5b7c6b3b70a9d84.jpg',\n 'upload_date': '20221111'\n },\n 'params': {'skip_download': True}\n }, {\n 'url': 'https://gronkh.tv/stream/536',\n 'info_dict': {\n 'id': '536',\n 'ext': 'mp4',\n 'title': 'GTV0536, 2021-10-01 - MARTHA IS DEAD #FREiAB1830 !FF7 !horde !archiv',\n 'view_count': int,\n 'thumbnail': 'https://01.cdn.vod.farm/preview/6436746cce14e25f751260a692872b9b.jpg',\n 'upload_date': '20211001'\n },\n 'params': {'skip_download': True}\n }, {\n 'url': 'https://gronkh.tv/watch/stream/546',\n 'only_matching': True,\n }]\n\n def _real_extract(self, url):\n id = self._match_id(url)\n data_json = self._download_json(f'https://api.gronkh.tv/v1/video/info?episode={id}', id)\n m3u8_url = self._download_json(f'https://api.gronkh.tv/v1/video/playlist?episode={id}', id)['playlist_url']\n formats, subtitles = self._extract_m3u8_formats_and_subtitles(m3u8_url, id)\n if data_json.get('vtt_url'):\n subtitles.setdefault('en', []).append({\n 'url': data_json['vtt_url'],\n 'ext': 'vtt',\n })\n return {\n 'id': id,\n 'title': data_json.get('title'),\n 'view_count': data_json.get('views'),\n 'thumbnail': data_json.get('preview_url'),\n 'upload_date': unified_strdate(data_json.get('created_at')),\n 'formats': formats,\n 'subtitles': subtitles,\n }\n\n\nclass GronkhFeedIE(InfoExtractor):\n _VALID_URL = r'https?://(?:www\\.)?gronkh\\.tv(?:/feed)?/?(?:#|$)'\n IE_NAME = 'gronkh:feed'\n\n _TESTS = [{\n 'url': 'https://gronkh.tv/feed',\n 'info_dict': {\n 'id': 'feed',\n },\n 'playlist_count': 16,\n }, {\n 'url': 'https://gronkh.tv',\n 'only_matching': True,\n }]\n\n def _entries(self):\n for type_ in ('recent', 'views'):\n info = self._download_json(\n f'https://api.gronkh.tv/v1/video/discovery/{type_}', 'feed', note=f'Downloading {type_} API JSON')\n for item in traverse_obj(info, ('discovery', ...)) or []:\n yield self.url_result(f'https://gronkh.tv/watch/stream/{item[\"episode\"]}', GronkhIE, item.get('title'))\n\n def _real_extract(self, url):\n return self.playlist_result(self._entries(), 'feed')\n\n\nclass GronkhVodsIE(InfoExtractor):\n _VALID_URL = r'https?://(?:www\\.)?gronkh\\.tv/vods/streams/?(?:#|$)'\n IE_NAME = 'gronkh:vods'\n\n _TESTS = [{\n 'url': 'https://gronkh.tv/vods/streams',\n 'info_dict': {\n 'id': 'vods',\n },\n 'playlist_mincount': 150,\n }]\n _PER_PAGE = 25\n\n def _fetch_page(self, page):\n items = traverse_obj(self._download_json(\n 'https://api.gronkh.tv/v1/search', 'vods', query={'offset': self._PER_PAGE * page, 'first': self._PER_PAGE},\n note=f'Downloading stream video page {page + 1}'), ('results', 'videos', ...))\n for item in items or []:\n yield self.url_result(f'https://gronkh.tv/watch/stream/{item[\"episode\"]}', GronkhIE, item['episode'], item.get('title'))\n\n def _real_extract(self, url):\n entries = OnDemandPagedList(functools.partial(self._fetch_page), self._PER_PAGE)\n return self.playlist_result(entries, 'vods')\n", "path": "yt_dlp/extractor/gronkh.py"}]}
| 2,865 | 499 |
gh_patches_debug_64890
|
rasdani/github-patches
|
git_diff
|
streamlit__streamlit-5583
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Emojis are not valid if they have a variant selector character attached
### Summary
Emojis are not valid if they are prefixed with a variant selector character. This is a hidden character that is used as prefix for the emoji (more information [here](https://stackoverflow.com/questions/38100329/what-does-u-ufe0f-in-an-emoji-mean-is-it-the-same-if-i-delete-it)).
### Steps to reproduce
[](https://issues.streamlitapp.com/?issue=gh-5564)
Code snippet:
```python
st.error("This is an error", icon="🚨") # Works fine
st.error("This is an error", icon="️🚨") # Throws an error
```
The reason is that the second example is prefix with this hidden unicode character: `%uFE0F`:
```python
st.write(len("🚨")) # 1
st.write(len("️🚨")) # 2
```
**Expected behavior:**
Should not raise an exception.
**Actual behavior:**
Raises a `StreamlitAPIException` if used for `st.error`, `st.info`, ...
### Is this a regression?
no
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lib/streamlit/string_util.py`
Content:
```
1 # Copyright (c) Streamlit Inc. (2018-2022) Snowflake Inc. (2022)
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import re
16 import textwrap
17 from datetime import datetime
18 from typing import TYPE_CHECKING, Any, Tuple, cast
19
20 from streamlit.emojis import ALL_EMOJIS
21 from streamlit.errors import StreamlitAPIException
22
23 if TYPE_CHECKING:
24 from streamlit.type_util import SupportsStr
25
26
27 # The ESCAPED_EMOJI list is sorted in descending order to make that longer emoji appear
28 # first in the regex compiled below. This ensures that we grab the full emoji in a
29 # multi-character emoji sequence that starts with a shorter emoji (emoji are weird...).
30 ESCAPED_EMOJI = [re.escape(e) for e in sorted(ALL_EMOJIS, reverse=True)]
31 EMOJI_EXTRACTION_REGEX = re.compile(f"^({'|'.join(ESCAPED_EMOJI)})[_ -]*(.*)")
32
33
34 def decode_ascii(string: bytes) -> str:
35 """Decodes a string as ascii."""
36 return string.decode("ascii")
37
38
39 def clean_text(text: "SupportsStr") -> str:
40 """Convert an object to text, dedent it, and strip whitespace."""
41 return textwrap.dedent(str(text)).strip()
42
43
44 def is_emoji(text: str) -> bool:
45 """Check if input string is a valid emoji."""
46 return text in ALL_EMOJIS
47
48
49 def extract_leading_emoji(text: str) -> Tuple[str, str]:
50 """Return a tuple containing the first emoji found in the given string and
51 the rest of the string (minus an optional separator between the two).
52 """
53 re_match = re.search(EMOJI_EXTRACTION_REGEX, text)
54 if re_match is None:
55 return "", text
56
57 # This cast to Any+type annotation weirdness is done because
58 # cast(re.Match[str], ...) explodes at runtime since Python interprets it
59 # as an attempt to index into re.Match instead of as a type annotation.
60 re_match: re.Match[str] = cast(Any, re_match)
61 return re_match.group(1), re_match.group(2)
62
63
64 def escape_markdown(raw_string: str) -> str:
65 """Returns a new string which escapes all markdown metacharacters.
66
67 Args
68 ----
69 raw_string : str
70 A string, possibly with markdown metacharacters, e.g. "1 * 2"
71
72 Returns
73 -------
74 A string with all metacharacters escaped.
75
76 Examples
77 --------
78 ::
79 escape_markdown("1 * 2") -> "1 \\* 2"
80 """
81 metacharacters = ["\\", "*", "-", "=", "`", "!", "#", "|"]
82 result = raw_string
83 for character in metacharacters:
84 result = result.replace(character, "\\" + character)
85 return result
86
87
88 TEXTCHARS = bytearray({7, 8, 9, 10, 12, 13, 27} | set(range(0x20, 0x100)) - {0x7F})
89
90
91 def is_binary_string(inp):
92 """Guess if an input bytesarray can be encoded as a string."""
93 # From https://stackoverflow.com/a/7392391
94 return bool(inp.translate(None, TEXTCHARS))
95
96
97 def clean_filename(name: str) -> str:
98 """
99 Taken from https://github.com/django/django/blob/196a99da5d9c4c33a78259a58d38fb114a4d2ee8/django/utils/text.py#L225-L238
100
101 Return the given string converted to a string that can be used for a clean
102 filename. Remove leading and trailing spaces; convert other spaces to
103 underscores; and remove anything that is not an alphanumeric, dash,
104 underscore, or dot.
105 """
106 s = str(name).strip().replace(" ", "_")
107 s = re.sub(r"(?u)[^-\w.]", "", s)
108
109 if s in {"", ".", ".."}:
110 raise StreamlitAPIException("Could not derive file name from '%s'" % name)
111 return s
112
113
114 def snake_case_to_camel_case(snake_case_string: str) -> str:
115 """Transform input string from snake_case to CamelCase."""
116 words = snake_case_string.split("_")
117 capitalized_words_arr = []
118
119 for word in words:
120 if word:
121 try:
122 capitalized_words_arr.append(word.title())
123 except Exception:
124 capitalized_words_arr.append(word)
125 return "".join(capitalized_words_arr)
126
127
128 def append_date_time_to_string(input_string: str) -> str:
129 """Append datetime string to input string.
130 Returns datetime string if input is empty string.
131 """
132 now = datetime.now()
133
134 if not input_string:
135 return now.strftime("%Y-%m-%d_%H-%M-%S")
136 else:
137 return f'{input_string}_{now.strftime("%Y-%m-%d_%H-%M-%S")}'
138
139
140 def generate_download_filename_from_title(title_string: str) -> str:
141 """Generated download filename from page title string."""
142
143 title_string = title_string.replace(" · Streamlit", "")
144 file_name_string = clean_filename(title_string)
145 title_string = snake_case_to_camel_case(file_name_string)
146 return append_date_time_to_string(title_string)
147
148
149 def simplify_number(num: int) -> str:
150 """Simplifies number into Human readable format, returns str"""
151 num_converted = float("{:.2g}".format(num))
152 magnitude = 0
153 while abs(num_converted) >= 1000:
154 magnitude += 1
155 num_converted /= 1000.0
156 return "{}{}".format(
157 "{:f}".format(num_converted).rstrip("0").rstrip("."),
158 ["", "k", "m", "b", "t"][magnitude],
159 )
160
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lib/streamlit/string_util.py b/lib/streamlit/string_util.py
--- a/lib/streamlit/string_util.py
+++ b/lib/streamlit/string_util.py
@@ -43,7 +43,7 @@
def is_emoji(text: str) -> bool:
"""Check if input string is a valid emoji."""
- return text in ALL_EMOJIS
+ return text.replace("\U0000FE0F", "") in ALL_EMOJIS
def extract_leading_emoji(text: str) -> Tuple[str, str]:
|
{"golden_diff": "diff --git a/lib/streamlit/string_util.py b/lib/streamlit/string_util.py\n--- a/lib/streamlit/string_util.py\n+++ b/lib/streamlit/string_util.py\n@@ -43,7 +43,7 @@\n \n def is_emoji(text: str) -> bool:\n \"\"\"Check if input string is a valid emoji.\"\"\"\n- return text in ALL_EMOJIS\n+ return text.replace(\"\\U0000FE0F\", \"\") in ALL_EMOJIS\n \n \n def extract_leading_emoji(text: str) -> Tuple[str, str]:\n", "issue": "Emojis are not valid if they have a variant selector character attached\n### Summary\r\n\r\nEmojis are not valid if they are prefixed with a variant selector character. This is a hidden character that is used as prefix for the emoji (more information [here](https://stackoverflow.com/questions/38100329/what-does-u-ufe0f-in-an-emoji-mean-is-it-the-same-if-i-delete-it)).\r\n\r\n### Steps to reproduce\r\n\r\n[](https://issues.streamlitapp.com/?issue=gh-5564)\r\n\r\nCode snippet:\r\n\r\n```python\r\nst.error(\"This is an error\", icon=\"\ud83d\udea8\") # Works fine\r\nst.error(\"This is an error\", icon=\"\ufe0f\ud83d\udea8\") # Throws an error\r\n```\r\n\r\nThe reason is that the second example is prefix with this hidden unicode character: `%uFE0F`:\r\n\r\n```python\r\nst.write(len(\"\ud83d\udea8\")) # 1\r\nst.write(len(\"\ufe0f\ud83d\udea8\")) # 2\r\n```\r\n\r\n**Expected behavior:**\r\n\r\nShould not raise an exception.\r\n\r\n**Actual behavior:**\r\n\r\nRaises a `StreamlitAPIException` if used for `st.error`, `st.info`, ...\r\n\r\n### Is this a regression?\r\n\r\nno\n", "before_files": [{"content": "# Copyright (c) Streamlit Inc. (2018-2022) Snowflake Inc. (2022)\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport re\nimport textwrap\nfrom datetime import datetime\nfrom typing import TYPE_CHECKING, Any, Tuple, cast\n\nfrom streamlit.emojis import ALL_EMOJIS\nfrom streamlit.errors import StreamlitAPIException\n\nif TYPE_CHECKING:\n from streamlit.type_util import SupportsStr\n\n\n# The ESCAPED_EMOJI list is sorted in descending order to make that longer emoji appear\n# first in the regex compiled below. This ensures that we grab the full emoji in a\n# multi-character emoji sequence that starts with a shorter emoji (emoji are weird...).\nESCAPED_EMOJI = [re.escape(e) for e in sorted(ALL_EMOJIS, reverse=True)]\nEMOJI_EXTRACTION_REGEX = re.compile(f\"^({'|'.join(ESCAPED_EMOJI)})[_ -]*(.*)\")\n\n\ndef decode_ascii(string: bytes) -> str:\n \"\"\"Decodes a string as ascii.\"\"\"\n return string.decode(\"ascii\")\n\n\ndef clean_text(text: \"SupportsStr\") -> str:\n \"\"\"Convert an object to text, dedent it, and strip whitespace.\"\"\"\n return textwrap.dedent(str(text)).strip()\n\n\ndef is_emoji(text: str) -> bool:\n \"\"\"Check if input string is a valid emoji.\"\"\"\n return text in ALL_EMOJIS\n\n\ndef extract_leading_emoji(text: str) -> Tuple[str, str]:\n \"\"\"Return a tuple containing the first emoji found in the given string and\n the rest of the string (minus an optional separator between the two).\n \"\"\"\n re_match = re.search(EMOJI_EXTRACTION_REGEX, text)\n if re_match is None:\n return \"\", text\n\n # This cast to Any+type annotation weirdness is done because\n # cast(re.Match[str], ...) explodes at runtime since Python interprets it\n # as an attempt to index into re.Match instead of as a type annotation.\n re_match: re.Match[str] = cast(Any, re_match)\n return re_match.group(1), re_match.group(2)\n\n\ndef escape_markdown(raw_string: str) -> str:\n \"\"\"Returns a new string which escapes all markdown metacharacters.\n\n Args\n ----\n raw_string : str\n A string, possibly with markdown metacharacters, e.g. \"1 * 2\"\n\n Returns\n -------\n A string with all metacharacters escaped.\n\n Examples\n --------\n ::\n escape_markdown(\"1 * 2\") -> \"1 \\\\* 2\"\n \"\"\"\n metacharacters = [\"\\\\\", \"*\", \"-\", \"=\", \"`\", \"!\", \"#\", \"|\"]\n result = raw_string\n for character in metacharacters:\n result = result.replace(character, \"\\\\\" + character)\n return result\n\n\nTEXTCHARS = bytearray({7, 8, 9, 10, 12, 13, 27} | set(range(0x20, 0x100)) - {0x7F})\n\n\ndef is_binary_string(inp):\n \"\"\"Guess if an input bytesarray can be encoded as a string.\"\"\"\n # From https://stackoverflow.com/a/7392391\n return bool(inp.translate(None, TEXTCHARS))\n\n\ndef clean_filename(name: str) -> str:\n \"\"\"\n Taken from https://github.com/django/django/blob/196a99da5d9c4c33a78259a58d38fb114a4d2ee8/django/utils/text.py#L225-L238\n\n Return the given string converted to a string that can be used for a clean\n filename. Remove leading and trailing spaces; convert other spaces to\n underscores; and remove anything that is not an alphanumeric, dash,\n underscore, or dot.\n \"\"\"\n s = str(name).strip().replace(\" \", \"_\")\n s = re.sub(r\"(?u)[^-\\w.]\", \"\", s)\n\n if s in {\"\", \".\", \"..\"}:\n raise StreamlitAPIException(\"Could not derive file name from '%s'\" % name)\n return s\n\n\ndef snake_case_to_camel_case(snake_case_string: str) -> str:\n \"\"\"Transform input string from snake_case to CamelCase.\"\"\"\n words = snake_case_string.split(\"_\")\n capitalized_words_arr = []\n\n for word in words:\n if word:\n try:\n capitalized_words_arr.append(word.title())\n except Exception:\n capitalized_words_arr.append(word)\n return \"\".join(capitalized_words_arr)\n\n\ndef append_date_time_to_string(input_string: str) -> str:\n \"\"\"Append datetime string to input string.\n Returns datetime string if input is empty string.\n \"\"\"\n now = datetime.now()\n\n if not input_string:\n return now.strftime(\"%Y-%m-%d_%H-%M-%S\")\n else:\n return f'{input_string}_{now.strftime(\"%Y-%m-%d_%H-%M-%S\")}'\n\n\ndef generate_download_filename_from_title(title_string: str) -> str:\n \"\"\"Generated download filename from page title string.\"\"\"\n\n title_string = title_string.replace(\" \u00b7 Streamlit\", \"\")\n file_name_string = clean_filename(title_string)\n title_string = snake_case_to_camel_case(file_name_string)\n return append_date_time_to_string(title_string)\n\n\ndef simplify_number(num: int) -> str:\n \"\"\"Simplifies number into Human readable format, returns str\"\"\"\n num_converted = float(\"{:.2g}\".format(num))\n magnitude = 0\n while abs(num_converted) >= 1000:\n magnitude += 1\n num_converted /= 1000.0\n return \"{}{}\".format(\n \"{:f}\".format(num_converted).rstrip(\"0\").rstrip(\".\"),\n [\"\", \"k\", \"m\", \"b\", \"t\"][magnitude],\n )\n", "path": "lib/streamlit/string_util.py"}], "after_files": [{"content": "# Copyright (c) Streamlit Inc. (2018-2022) Snowflake Inc. (2022)\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport re\nimport textwrap\nfrom datetime import datetime\nfrom typing import TYPE_CHECKING, Any, Tuple, cast\n\nfrom streamlit.emojis import ALL_EMOJIS\nfrom streamlit.errors import StreamlitAPIException\n\nif TYPE_CHECKING:\n from streamlit.type_util import SupportsStr\n\n\n# The ESCAPED_EMOJI list is sorted in descending order to make that longer emoji appear\n# first in the regex compiled below. This ensures that we grab the full emoji in a\n# multi-character emoji sequence that starts with a shorter emoji (emoji are weird...).\nESCAPED_EMOJI = [re.escape(e) for e in sorted(ALL_EMOJIS, reverse=True)]\nEMOJI_EXTRACTION_REGEX = re.compile(f\"^({'|'.join(ESCAPED_EMOJI)})[_ -]*(.*)\")\n\n\ndef decode_ascii(string: bytes) -> str:\n \"\"\"Decodes a string as ascii.\"\"\"\n return string.decode(\"ascii\")\n\n\ndef clean_text(text: \"SupportsStr\") -> str:\n \"\"\"Convert an object to text, dedent it, and strip whitespace.\"\"\"\n return textwrap.dedent(str(text)).strip()\n\n\ndef is_emoji(text: str) -> bool:\n \"\"\"Check if input string is a valid emoji.\"\"\"\n return text.replace(\"\\U0000FE0F\", \"\") in ALL_EMOJIS\n\n\ndef extract_leading_emoji(text: str) -> Tuple[str, str]:\n \"\"\"Return a tuple containing the first emoji found in the given string and\n the rest of the string (minus an optional separator between the two).\n \"\"\"\n re_match = re.search(EMOJI_EXTRACTION_REGEX, text)\n if re_match is None:\n return \"\", text\n\n # This cast to Any+type annotation weirdness is done because\n # cast(re.Match[str], ...) explodes at runtime since Python interprets it\n # as an attempt to index into re.Match instead of as a type annotation.\n re_match: re.Match[str] = cast(Any, re_match)\n return re_match.group(1), re_match.group(2)\n\n\ndef escape_markdown(raw_string: str) -> str:\n \"\"\"Returns a new string which escapes all markdown metacharacters.\n\n Args\n ----\n raw_string : str\n A string, possibly with markdown metacharacters, e.g. \"1 * 2\"\n\n Returns\n -------\n A string with all metacharacters escaped.\n\n Examples\n --------\n ::\n escape_markdown(\"1 * 2\") -> \"1 \\\\* 2\"\n \"\"\"\n metacharacters = [\"\\\\\", \"*\", \"-\", \"=\", \"`\", \"!\", \"#\", \"|\"]\n result = raw_string\n for character in metacharacters:\n result = result.replace(character, \"\\\\\" + character)\n return result\n\n\nTEXTCHARS = bytearray({7, 8, 9, 10, 12, 13, 27} | set(range(0x20, 0x100)) - {0x7F})\n\n\ndef is_binary_string(inp):\n \"\"\"Guess if an input bytesarray can be encoded as a string.\"\"\"\n # From https://stackoverflow.com/a/7392391\n return bool(inp.translate(None, TEXTCHARS))\n\n\ndef clean_filename(name: str) -> str:\n \"\"\"\n Taken from https://github.com/django/django/blob/196a99da5d9c4c33a78259a58d38fb114a4d2ee8/django/utils/text.py#L225-L238\n\n Return the given string converted to a string that can be used for a clean\n filename. Remove leading and trailing spaces; convert other spaces to\n underscores; and remove anything that is not an alphanumeric, dash,\n underscore, or dot.\n \"\"\"\n s = str(name).strip().replace(\" \", \"_\")\n s = re.sub(r\"(?u)[^-\\w.]\", \"\", s)\n\n if s in {\"\", \".\", \"..\"}:\n raise StreamlitAPIException(\"Could not derive file name from '%s'\" % name)\n return s\n\n\ndef snake_case_to_camel_case(snake_case_string: str) -> str:\n \"\"\"Transform input string from snake_case to CamelCase.\"\"\"\n words = snake_case_string.split(\"_\")\n capitalized_words_arr = []\n\n for word in words:\n if word:\n try:\n capitalized_words_arr.append(word.title())\n except Exception:\n capitalized_words_arr.append(word)\n return \"\".join(capitalized_words_arr)\n\n\ndef append_date_time_to_string(input_string: str) -> str:\n \"\"\"Append datetime string to input string.\n Returns datetime string if input is empty string.\n \"\"\"\n now = datetime.now()\n\n if not input_string:\n return now.strftime(\"%Y-%m-%d_%H-%M-%S\")\n else:\n return f'{input_string}_{now.strftime(\"%Y-%m-%d_%H-%M-%S\")}'\n\n\ndef generate_download_filename_from_title(title_string: str) -> str:\n \"\"\"Generated download filename from page title string.\"\"\"\n\n title_string = title_string.replace(\" \u00b7 Streamlit\", \"\")\n file_name_string = clean_filename(title_string)\n title_string = snake_case_to_camel_case(file_name_string)\n return append_date_time_to_string(title_string)\n\n\ndef simplify_number(num: int) -> str:\n \"\"\"Simplifies number into Human readable format, returns str\"\"\"\n num_converted = float(\"{:.2g}\".format(num))\n magnitude = 0\n while abs(num_converted) >= 1000:\n magnitude += 1\n num_converted /= 1000.0\n return \"{}{}\".format(\n \"{:f}\".format(num_converted).rstrip(\"0\").rstrip(\".\"),\n [\"\", \"k\", \"m\", \"b\", \"t\"][magnitude],\n )\n", "path": "lib/streamlit/string_util.py"}]}
| 2,340 | 122 |
gh_patches_debug_39193
|
rasdani/github-patches
|
git_diff
|
CiviWiki__OpenCiviWiki-943
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Create reset password view under the accounts app.
Currently, when the user wants to reset the password, they go to a Django admin page, which has a different look. Newly implemented registration and login views have been created under the '/accounts/' path. This task is to replace the current reset password page with a page that looks like the registration and login pages.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `project/core/urls.py`
Content:
```
1 """civiwiki URL Configuration
2
3 The `urlpatterns` list routes URLs to views. For more information please see:
4 https://docs.djangoproject.com/en/1.8/topics/http/urls/
5 Examples:
6 Function views
7 1. Add an import: from my_app import views
8 2. Add a URL to urlpatterns: url(r'^$', views.home, name='home')
9 Class-based views
10 1. Add an import: from other_app.views import Home
11 2. Add a URL to urlpatterns: url(r'^$', Home.as_view(), name='home')
12 Including another URLconf
13 1. Add an import: from blog import urls as blog_urls
14 2. Add a URL to urlpatterns: url(r'^blog/', include(blog_urls))
15 """
16 import django.contrib.auth.views as auth_views
17
18 from django.conf.urls import include, url
19 from django.contrib import admin
20 from django.conf import settings
21 from django.urls import path
22 from django.views.static import serve
23 from django.views.generic.base import RedirectView
24
25 from api import urls as api
26 from accounts import urls as accounts_urls
27 from accounts.views import RegisterView
28 from frontend_views import urls as frontend_views
29
30
31
32 urlpatterns = [
33 path("admin/", admin.site.urls),
34 url(r"^api/", include(api)),
35 url(r"^auth/", include(accounts_urls)),
36
37 # New accounts paths. These currently implement user registration/authentication in
38 # parallel to the current authentication.
39 path('accounts/register', RegisterView.as_view(), name='accounts_register'),
40 path(
41 'accounts/login',
42 auth_views.LoginView.as_view(template_name='accounts/register/login.html'),
43 name='accounts_login',
44 ),
45
46 url(
47 "^inbox/notifications/",
48 include("notifications.urls", namespace="notifications"),
49 ),
50 ]
51
52 urlpatterns += [
53 # A redirect for favicons at the root of the site
54 url(r"^favicon\.ico$", RedirectView.as_view(url="/static/favicon/favicon.ico")),
55 url(
56 r"^favicon-32x32\.png$",
57 RedirectView.as_view(url="/static/favicon/favicon-32x32.png"),
58 ),
59 url(
60 r"^apple-touch-icon\.png$",
61 RedirectView.as_view(url="/static/favicon/apple-touch-icon.png"),
62 ),
63 url(
64 r"^mstile-144x144\.png$",
65 RedirectView.as_view(url="/static/favicon/mstile-144x144.png"),
66 ),
67 # Media and Static file Serve Setup.
68 url(
69 r"^media/(?P<path>.*)$",
70 serve,
71 {"document_root": settings.MEDIA_ROOT, "show_indexes": True},
72 ),
73 url(r"^static/(?P<path>.*)$", serve, {"document_root": settings.STATIC_ROOT}),
74 url(r"^", include(frontend_views)),
75
76 ]
77
```
Path: `project/accounts/views.py`
Content:
```
1 """
2 Class based views.
3
4 This module will include views for the accounts app.
5 """
6
7 from django.conf import settings
8 from django.views.generic.edit import FormView
9 from django.contrib.auth import views as auth_views
10 from django.contrib.auth import authenticate, login
11 from django.contrib.auth.tokens import PasswordResetTokenGenerator
12 from django.contrib.sites.shortcuts import get_current_site
13 from django.utils.encoding import force_bytes
14 from django.utils.http import int_to_base36
15 from django.utils.crypto import salted_hmac
16 from django.utils.http import urlsafe_base64_encode
17
18 from api.models.account import Account
19
20 from .forms import AccountRegistrationForm
21 from .models import User
22 from .authentication import send_activation_email
23
24
25 class AccountActivationTokenGenerator(PasswordResetTokenGenerator):
26 """Token Generator for Email Confirmation"""
27
28 key_salt = "django.contrib.auth.tokens.PasswordResetTokenGenerator"
29
30 def _make_token_with_timestamp(self, user, timestamp):
31 """ Token function pulled from Django 1.11 """
32 ts_b36 = int_to_base36(timestamp)
33
34 hash = salted_hmac(
35 self.key_salt, str(user.pk) + str(timestamp)
36 ).hexdigest()[::2]
37 return "%s-%s" % (ts_b36, hash)
38
39
40 class RegisterView(FormView):
41 """
42 A form view that handles user registration.
43 """
44 template_name = 'accounts/register/register.html'
45 form_class = AccountRegistrationForm
46 success_url = '/'
47
48 def _create_user(self, form):
49 username = form.cleaned_data['username']
50 password = form.cleaned_data['password']
51 email = form.cleaned_data['email']
52
53 user = User.objects.create_user(username, email, password)
54
55 account = Account(user=user)
56 if hasattr(settings, 'CLOSED_BETA') and not settings.CLOSED_BETA:
57 account.beta_access = True
58 account.save()
59
60 user.is_active = True
61 user.save()
62
63 return user
64
65 def _send_email(self, user):
66 domain = get_current_site(self.request).domain
67 send_activation_email(user, domain)
68
69 def _login(self, user):
70 login(self.request, user)
71
72 def form_valid(self, form):
73 user = self._create_user(form)
74
75 self._send_email(user)
76 self._login(user)
77
78 return super(RegisterView, self).form_valid(form)
79
```
Path: `project/core/settings.py`
Content:
```
1 """
2 Django settings for civiwiki project.
3 Darius Calliet May 12, 2016
4
5 Production settings file to select proper environment variables.
6 """
7 import os
8
9 # False if not in os.environ
10 DEBUG = os.getenv("DEBUG", False)
11
12 # defaults to second value if not found in os.environ
13 DJANGO_HOST = os.getenv("DJANGO_HOST", "LOCALHOST")
14
15 BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
16 SECRET_KEY = os.getenv("DJANGO_SECRET_KEY", "TEST_KEY_FOR_DEVELOPMENT")
17 ALLOWED_HOSTS = [".herokuapp.com", ".civiwiki.org", "127.0.0.1", "localhost", "0.0.0.0"]
18
19 INSTALLED_APPS = (
20 "django.contrib.admin",
21 "django.contrib.auth",
22 "django.contrib.contenttypes",
23 "django.contrib.sessions",
24 "django.contrib.messages",
25 "django.contrib.staticfiles",
26 "django_extensions",
27 "storages",
28 "core", # TODO: consider removing this, if we can move the decorators, etc. to an actual app
29 "api",
30 "rest_framework",
31 "accounts",
32 "threads",
33 "frontend_views",
34 "notifications",
35 "corsheaders",
36 "taggit",
37 )
38
39 MIDDLEWARE = [
40 "corsheaders.middleware.CorsMiddleware",
41 "django.middleware.security.SecurityMiddleware",
42 "whitenoise.middleware.WhiteNoiseMiddleware",
43 "django.contrib.sessions.middleware.SessionMiddleware",
44 "django.middleware.common.CommonMiddleware",
45 "django.middleware.csrf.CsrfViewMiddleware",
46 "django.contrib.auth.middleware.AuthenticationMiddleware",
47 # 'django.contrib.auth.middleware.SessionAuthenticationMiddleware',
48 "django.contrib.messages.middleware.MessageMiddleware",
49 "django.middleware.clickjacking.XFrameOptionsMiddleware",
50 ]
51
52 CSRF_USE_SESSIONS = (
53 True # Store the CSRF token in the users session instead of in a cookie
54 )
55
56 CORS_ORIGIN_ALLOW_ALL = True
57 ROOT_URLCONF = "core.urls"
58 LOGIN_URL = "/login"
59
60 # SSL Setup
61 if DJANGO_HOST != "LOCALHOST":
62 SECURE_PROXY_SSL_HEADER = ("HTTP_X_FORWARDED_PROTO", "https")
63 SECURE_SSL_REDIRECT = True
64 SESSION_COOKIE_SECURE = True
65 CSRF_COOKIE_SECURE = True
66
67 # Internationalization & Localization
68 LANGUAGE_CODE = "en-us"
69 TIME_ZONE = "UTC"
70 USE_I18N = True
71 USE_L10N = True
72 USE_TZ = True
73
74 TEMPLATES = [
75 {
76 "BACKEND": "django.template.backends.django.DjangoTemplates",
77 "DIRS": [
78 os.path.join(BASE_DIR, "threads/templates/threads"), os.path.join(BASE_DIR, "accounts/templates/accounts")
79 ], # TODO: Add non-webapp template directory
80 "APP_DIRS": True,
81 "OPTIONS": {
82 "context_processors": [
83 "django.template.context_processors.debug",
84 "django.template.context_processors.request",
85 "django.contrib.auth.context_processors.auth",
86 "django.contrib.messages.context_processors.messages",
87 ],
88 },
89 },
90 ]
91
92 WSGI_APPLICATION = "core.wsgi.application"
93
94 # Apex Contact for Production Errors
95 ADMINS = [("Development Team", "[email protected]")]
96
97 # AWS S3 Setup
98 if "AWS_STORAGE_BUCKET_NAME" not in os.environ:
99 MEDIA_URL = "/media/"
100 MEDIA_ROOT = os.path.join(BASE_DIR, "media")
101 else:
102 AWS_STORAGE_BUCKET_NAME = os.getenv("AWS_STORAGE_BUCKET_NAME")
103 AWS_S3_ACCESS_KEY_ID = os.getenv("AWS_S3_ACCESS_KEY_ID")
104 AWS_S3_SECRET_ACCESS_KEY = os.getenv("AWS_S3_SECRET_ACCESS_KEY")
105 DEFAULT_FILE_STORAGE = "storages.backends.s3boto.S3BotoStorage"
106 AWS_S3_SECURE_URLS = False
107 AWS_QUERYSTRING_AUTH = False
108
109 STATIC_URL = "/static/"
110 STATICFILES_DIRS = (os.path.join(BASE_DIR, "threads/templates/static"),)
111 STATIC_ROOT = os.path.join(BASE_DIR, "staticfiles")
112
113 # TODO: re-organize and simplify staticfiles settings
114 if "CIVIWIKI_LOCAL_NAME" not in os.environ:
115 STATICFILES_STORAGE = "whitenoise.storage.CompressedManifestStaticFilesStorage"
116
117 # Use DATABASE_URL in production
118 DATABASE_URL = os.getenv("DATABASE_URL")
119
120 if DATABASE_URL is not None:
121 DATABASES = {"default": DATABASE_URL}
122 else:
123 # Default to sqlite for simplicity in development
124 DATABASES = {
125 "default": {
126 "ENGINE": "django.db.backends.sqlite3",
127 "NAME": BASE_DIR + "/" + "db.sqlite3",
128 }
129 }
130
131 # Email Backend Setup
132 if "EMAIL_HOST" not in os.environ:
133 EMAIL_BACKEND = "django.core.mail.backends.console.EmailBackend"
134 EMAIL_HOST_USER = "[email protected]"
135 else:
136 EMAIL_BACKEND = "django.core.mail.backends.smtp.EmailBackend"
137 EMAIL_HOST = os.getenv("EMAIL_HOST")
138 EMAIL_PORT = os.getenv("EMAIL_PORT")
139 EMAIL_HOST_USER = os.getenv("EMAIL_HOST_USER")
140 EMAIL_HOST_PASSWORD = os.getenv("EMAIL_HOST_PASSWORD")
141 EMAIL_USE_SSL = True
142 DEFAULT_FROM_EMAIL = EMAIL_HOST
143
144 # Notification API Settings
145 NOTIFICATIONS_SOFT_DELETE = True
146 NOTIFICATIONS_USE_JSONFIELD = True
147
148 # Django REST API Settings
149 DEFAULT_RENDERER_CLASSES = ("rest_framework.renderers.JSONRenderer",)
150
151 DEFAULT_AUTHENTICATION_CLASSES = ("rest_framework.authentication.BasicAuthentication",)
152
153 if DEBUG:
154 # Browsable HTML - Enabled only in Debug mode (dev)
155 DEFAULT_RENDERER_CLASSES = DEFAULT_RENDERER_CLASSES + (
156 "rest_framework.renderers.BrowsableAPIRenderer",
157 )
158
159 DEFAULT_AUTHENTICATION_CLASSES = (
160 "api.authentication.CsrfExemptSessionAuthentication",
161 ) + DEFAULT_AUTHENTICATION_CLASSES
162
163 REST_FRAMEWORK = {
164 "DEFAULT_PERMISSION_CLASSES": ("rest_framework.permissions.IsAuthenticated",),
165 "DEFAULT_RENDERER_CLASSES": DEFAULT_RENDERER_CLASSES,
166 "DEFAULT_AUTHENTICATION_CLASSES": DEFAULT_AUTHENTICATION_CLASSES,
167 }
168
169 # CORS Settings
170 CORS_ORIGIN_ALLOW_ALL = True
171
172 # Custom User model
173 AUTH_USER_MODEL = 'accounts.User'
174
175 APPEND_SLASH = False
176
177 DEFAULT_AUTO_FIELD = 'django.db.models.AutoField'
178
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/project/accounts/views.py b/project/accounts/views.py
--- a/project/accounts/views.py
+++ b/project/accounts/views.py
@@ -14,6 +14,7 @@
from django.utils.http import int_to_base36
from django.utils.crypto import salted_hmac
from django.utils.http import urlsafe_base64_encode
+from django.urls import reverse_lazy
from api.models.account import Account
@@ -76,3 +77,24 @@
self._login(user)
return super(RegisterView, self).form_valid(form)
+
+
+class PasswordResetView(auth_views.PasswordResetView):
+ template_name = 'accounts/users/password_reset.html'
+ email_template_name = 'accounts/users/password_reset_email.html'
+ subject_template_name = 'accounts/users/password_reset_subject.txt'
+ from_email = settings.EMAIL_HOST_USER
+ success_url = reverse_lazy('accounts_password_reset_done')
+
+
+class PasswordResetDoneView(auth_views.PasswordResetDoneView):
+ template_name = 'accounts/users/password_reset_done.html'
+
+
+class PasswordResetConfirmView(auth_views.PasswordResetConfirmView):
+ template_name = 'accounts/users/password_reset_confirm.html'
+ success_url = reverse_lazy('accounts_password_reset_complete')
+
+
+class PasswordResetCompleteView(auth_views.PasswordResetCompleteView):
+ template_name = 'accounts/users/password_reset_complete.html'
diff --git a/project/core/settings.py b/project/core/settings.py
--- a/project/core/settings.py
+++ b/project/core/settings.py
@@ -175,3 +175,23 @@
APPEND_SLASH = False
DEFAULT_AUTO_FIELD = 'django.db.models.AutoField'
+
+LOGIN_REDIRECT_URL = '/'
+
+AUTH_PASSWORD_VALIDATORS = [
+ {
+ 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator',
+ },
+ {
+ 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator',
+ 'OPTIONS': {
+ 'min_length': 8,
+ }
+ },
+ {
+ 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator',
+ },
+ {
+ 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator',
+ },
+]
diff --git a/project/core/urls.py b/project/core/urls.py
--- a/project/core/urls.py
+++ b/project/core/urls.py
@@ -24,7 +24,8 @@
from api import urls as api
from accounts import urls as accounts_urls
-from accounts.views import RegisterView
+from accounts.views import (RegisterView, PasswordResetView, PasswordResetDoneView,
+ PasswordResetConfirmView, PasswordResetCompleteView)
from frontend_views import urls as frontend_views
@@ -43,6 +44,28 @@
name='accounts_login',
),
+ path(
+ 'accounts/password_reset',
+ PasswordResetView.as_view(),
+ name='accounts_password_reset',
+ ),
+
+ path(
+ 'accounts/password_reset_done',
+ PasswordResetDoneView.as_view(),
+ name='accounts_password_reset_done',
+ ),
+ path(
+ 'accounts/password_reset_confirm/<uidb64>/<token>',
+ PasswordResetConfirmView.as_view(),
+ name='accounts_password_reset_confirm',
+ ),
+
+ path(
+ 'accounts/password_reset_complete',
+ PasswordResetCompleteView.as_view(),
+ name='accounts_password_reset_complete',
+ ),
url(
"^inbox/notifications/",
include("notifications.urls", namespace="notifications"),
|
{"golden_diff": "diff --git a/project/accounts/views.py b/project/accounts/views.py\n--- a/project/accounts/views.py\n+++ b/project/accounts/views.py\n@@ -14,6 +14,7 @@\n from django.utils.http import int_to_base36\n from django.utils.crypto import salted_hmac\n from django.utils.http import urlsafe_base64_encode\n+from django.urls import reverse_lazy\n \n from api.models.account import Account\n \n@@ -76,3 +77,24 @@\n self._login(user)\n \n return super(RegisterView, self).form_valid(form)\n+\n+\n+class PasswordResetView(auth_views.PasswordResetView):\n+ template_name = 'accounts/users/password_reset.html'\n+ email_template_name = 'accounts/users/password_reset_email.html'\n+ subject_template_name = 'accounts/users/password_reset_subject.txt'\n+ from_email = settings.EMAIL_HOST_USER\n+ success_url = reverse_lazy('accounts_password_reset_done')\n+\n+\n+class PasswordResetDoneView(auth_views.PasswordResetDoneView):\n+ template_name = 'accounts/users/password_reset_done.html'\n+\n+\n+class PasswordResetConfirmView(auth_views.PasswordResetConfirmView):\n+ template_name = 'accounts/users/password_reset_confirm.html'\n+ success_url = reverse_lazy('accounts_password_reset_complete')\n+\n+\n+class PasswordResetCompleteView(auth_views.PasswordResetCompleteView):\n+ template_name = 'accounts/users/password_reset_complete.html'\ndiff --git a/project/core/settings.py b/project/core/settings.py\n--- a/project/core/settings.py\n+++ b/project/core/settings.py\n@@ -175,3 +175,23 @@\n APPEND_SLASH = False\n \n DEFAULT_AUTO_FIELD = 'django.db.models.AutoField'\n+\n+LOGIN_REDIRECT_URL = '/'\n+\n+AUTH_PASSWORD_VALIDATORS = [\n+ {\n+ 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator',\n+ },\n+ {\n+ 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator',\n+ 'OPTIONS': {\n+ 'min_length': 8,\n+ }\n+ },\n+ {\n+ 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator',\n+ },\n+ {\n+ 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator',\n+ },\n+]\ndiff --git a/project/core/urls.py b/project/core/urls.py\n--- a/project/core/urls.py\n+++ b/project/core/urls.py\n@@ -24,7 +24,8 @@\n \n from api import urls as api\n from accounts import urls as accounts_urls\n-from accounts.views import RegisterView\n+from accounts.views import (RegisterView, PasswordResetView, PasswordResetDoneView,\n+ PasswordResetConfirmView, PasswordResetCompleteView)\n from frontend_views import urls as frontend_views\n \n \n@@ -43,6 +44,28 @@\n name='accounts_login',\n ),\n \n+ path(\n+ 'accounts/password_reset',\n+ PasswordResetView.as_view(),\n+ name='accounts_password_reset',\n+ ),\n+\n+ path(\n+ 'accounts/password_reset_done',\n+ PasswordResetDoneView.as_view(),\n+ name='accounts_password_reset_done',\n+ ),\n+ path(\n+ 'accounts/password_reset_confirm/<uidb64>/<token>',\n+ PasswordResetConfirmView.as_view(),\n+ name='accounts_password_reset_confirm',\n+ ),\n+\n+ path(\n+ 'accounts/password_reset_complete',\n+ PasswordResetCompleteView.as_view(),\n+ name='accounts_password_reset_complete',\n+ ),\n url(\n \"^inbox/notifications/\",\n include(\"notifications.urls\", namespace=\"notifications\"),\n", "issue": "Create reset password view under the accounts app.\nCurrently, when the user wants to reset the password, they go to a Django admin page, which has a different look. Newly implemented registration and login views have been created under the '/accounts/' path. This task is to replace the current reset password page with a page that looks like the registration and login pages.\n", "before_files": [{"content": "\"\"\"civiwiki URL Configuration\n\nThe `urlpatterns` list routes URLs to views. For more information please see:\n https://docs.djangoproject.com/en/1.8/topics/http/urls/\nExamples:\nFunction views\n 1. Add an import: from my_app import views\n 2. Add a URL to urlpatterns: url(r'^$', views.home, name='home')\nClass-based views\n 1. Add an import: from other_app.views import Home\n 2. Add a URL to urlpatterns: url(r'^$', Home.as_view(), name='home')\nIncluding another URLconf\n 1. Add an import: from blog import urls as blog_urls\n 2. Add a URL to urlpatterns: url(r'^blog/', include(blog_urls))\n\"\"\"\nimport django.contrib.auth.views as auth_views\n\nfrom django.conf.urls import include, url\nfrom django.contrib import admin\nfrom django.conf import settings\nfrom django.urls import path\nfrom django.views.static import serve\nfrom django.views.generic.base import RedirectView\n\nfrom api import urls as api\nfrom accounts import urls as accounts_urls\nfrom accounts.views import RegisterView\nfrom frontend_views import urls as frontend_views\n\n\n\nurlpatterns = [\n path(\"admin/\", admin.site.urls),\n url(r\"^api/\", include(api)),\n url(r\"^auth/\", include(accounts_urls)),\n\n # New accounts paths. These currently implement user registration/authentication in\n # parallel to the current authentication.\n path('accounts/register', RegisterView.as_view(), name='accounts_register'),\n path(\n 'accounts/login',\n auth_views.LoginView.as_view(template_name='accounts/register/login.html'),\n name='accounts_login',\n ),\n\n url(\n \"^inbox/notifications/\",\n include(\"notifications.urls\", namespace=\"notifications\"),\n ),\n]\n\nurlpatterns += [\n # A redirect for favicons at the root of the site\n url(r\"^favicon\\.ico$\", RedirectView.as_view(url=\"/static/favicon/favicon.ico\")),\n url(\n r\"^favicon-32x32\\.png$\",\n RedirectView.as_view(url=\"/static/favicon/favicon-32x32.png\"),\n ),\n url(\n r\"^apple-touch-icon\\.png$\",\n RedirectView.as_view(url=\"/static/favicon/apple-touch-icon.png\"),\n ),\n url(\n r\"^mstile-144x144\\.png$\",\n RedirectView.as_view(url=\"/static/favicon/mstile-144x144.png\"),\n ),\n # Media and Static file Serve Setup.\n url(\n r\"^media/(?P<path>.*)$\",\n serve,\n {\"document_root\": settings.MEDIA_ROOT, \"show_indexes\": True},\n ),\n url(r\"^static/(?P<path>.*)$\", serve, {\"document_root\": settings.STATIC_ROOT}),\n url(r\"^\", include(frontend_views)),\n\n]\n", "path": "project/core/urls.py"}, {"content": "\"\"\"\nClass based views.\n\nThis module will include views for the accounts app.\n\"\"\"\n\nfrom django.conf import settings\nfrom django.views.generic.edit import FormView\nfrom django.contrib.auth import views as auth_views\nfrom django.contrib.auth import authenticate, login\nfrom django.contrib.auth.tokens import PasswordResetTokenGenerator\nfrom django.contrib.sites.shortcuts import get_current_site\nfrom django.utils.encoding import force_bytes\nfrom django.utils.http import int_to_base36\nfrom django.utils.crypto import salted_hmac\nfrom django.utils.http import urlsafe_base64_encode\n\nfrom api.models.account import Account\n\nfrom .forms import AccountRegistrationForm\nfrom .models import User\nfrom .authentication import send_activation_email\n\n\nclass AccountActivationTokenGenerator(PasswordResetTokenGenerator):\n \"\"\"Token Generator for Email Confirmation\"\"\"\n\n key_salt = \"django.contrib.auth.tokens.PasswordResetTokenGenerator\"\n\n def _make_token_with_timestamp(self, user, timestamp):\n \"\"\" Token function pulled from Django 1.11 \"\"\"\n ts_b36 = int_to_base36(timestamp)\n\n hash = salted_hmac(\n self.key_salt, str(user.pk) + str(timestamp)\n ).hexdigest()[::2]\n return \"%s-%s\" % (ts_b36, hash)\n\n\nclass RegisterView(FormView):\n \"\"\"\n A form view that handles user registration.\n \"\"\"\n template_name = 'accounts/register/register.html'\n form_class = AccountRegistrationForm\n success_url = '/'\n\n def _create_user(self, form):\n username = form.cleaned_data['username']\n password = form.cleaned_data['password']\n email = form.cleaned_data['email']\n\n user = User.objects.create_user(username, email, password)\n\n account = Account(user=user)\n if hasattr(settings, 'CLOSED_BETA') and not settings.CLOSED_BETA:\n account.beta_access = True\n account.save()\n\n user.is_active = True\n user.save()\n\n return user\n\n def _send_email(self, user):\n domain = get_current_site(self.request).domain\n send_activation_email(user, domain)\n\n def _login(self, user):\n login(self.request, user)\n\n def form_valid(self, form):\n user = self._create_user(form)\n\n self._send_email(user)\n self._login(user)\n\n return super(RegisterView, self).form_valid(form)\n", "path": "project/accounts/views.py"}, {"content": "\"\"\"\nDjango settings for civiwiki project.\nDarius Calliet May 12, 2016\n\nProduction settings file to select proper environment variables.\n\"\"\"\nimport os\n\n# False if not in os.environ\nDEBUG = os.getenv(\"DEBUG\", False)\n\n# defaults to second value if not found in os.environ\nDJANGO_HOST = os.getenv(\"DJANGO_HOST\", \"LOCALHOST\")\n\nBASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\nSECRET_KEY = os.getenv(\"DJANGO_SECRET_KEY\", \"TEST_KEY_FOR_DEVELOPMENT\")\nALLOWED_HOSTS = [\".herokuapp.com\", \".civiwiki.org\", \"127.0.0.1\", \"localhost\", \"0.0.0.0\"]\n\nINSTALLED_APPS = (\n \"django.contrib.admin\",\n \"django.contrib.auth\",\n \"django.contrib.contenttypes\",\n \"django.contrib.sessions\",\n \"django.contrib.messages\",\n \"django.contrib.staticfiles\",\n \"django_extensions\",\n \"storages\",\n \"core\", # TODO: consider removing this, if we can move the decorators, etc. to an actual app\n \"api\",\n \"rest_framework\",\n \"accounts\",\n \"threads\",\n \"frontend_views\",\n \"notifications\",\n \"corsheaders\",\n \"taggit\",\n)\n\nMIDDLEWARE = [\n \"corsheaders.middleware.CorsMiddleware\",\n \"django.middleware.security.SecurityMiddleware\",\n \"whitenoise.middleware.WhiteNoiseMiddleware\",\n \"django.contrib.sessions.middleware.SessionMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n \"django.middleware.csrf.CsrfViewMiddleware\",\n \"django.contrib.auth.middleware.AuthenticationMiddleware\",\n # 'django.contrib.auth.middleware.SessionAuthenticationMiddleware',\n \"django.contrib.messages.middleware.MessageMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n]\n\nCSRF_USE_SESSIONS = (\n True # Store the CSRF token in the users session instead of in a cookie\n)\n\nCORS_ORIGIN_ALLOW_ALL = True\nROOT_URLCONF = \"core.urls\"\nLOGIN_URL = \"/login\"\n\n# SSL Setup\nif DJANGO_HOST != \"LOCALHOST\":\n SECURE_PROXY_SSL_HEADER = (\"HTTP_X_FORWARDED_PROTO\", \"https\")\n SECURE_SSL_REDIRECT = True\n SESSION_COOKIE_SECURE = True\n CSRF_COOKIE_SECURE = True\n\n# Internationalization & Localization\nLANGUAGE_CODE = \"en-us\"\nTIME_ZONE = \"UTC\"\nUSE_I18N = True\nUSE_L10N = True\nUSE_TZ = True\n\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [\n os.path.join(BASE_DIR, \"threads/templates/threads\"), os.path.join(BASE_DIR, \"accounts/templates/accounts\")\n ], # TODO: Add non-webapp template directory\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.request\",\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n ],\n },\n },\n]\n\nWSGI_APPLICATION = \"core.wsgi.application\"\n\n# Apex Contact for Production Errors\nADMINS = [(\"Development Team\", \"[email protected]\")]\n\n# AWS S3 Setup\nif \"AWS_STORAGE_BUCKET_NAME\" not in os.environ:\n MEDIA_URL = \"/media/\"\n MEDIA_ROOT = os.path.join(BASE_DIR, \"media\")\nelse:\n AWS_STORAGE_BUCKET_NAME = os.getenv(\"AWS_STORAGE_BUCKET_NAME\")\n AWS_S3_ACCESS_KEY_ID = os.getenv(\"AWS_S3_ACCESS_KEY_ID\")\n AWS_S3_SECRET_ACCESS_KEY = os.getenv(\"AWS_S3_SECRET_ACCESS_KEY\")\n DEFAULT_FILE_STORAGE = \"storages.backends.s3boto.S3BotoStorage\"\n AWS_S3_SECURE_URLS = False\n AWS_QUERYSTRING_AUTH = False\n\nSTATIC_URL = \"/static/\"\nSTATICFILES_DIRS = (os.path.join(BASE_DIR, \"threads/templates/static\"),)\nSTATIC_ROOT = os.path.join(BASE_DIR, \"staticfiles\")\n\n# TODO: re-organize and simplify staticfiles settings\nif \"CIVIWIKI_LOCAL_NAME\" not in os.environ:\n STATICFILES_STORAGE = \"whitenoise.storage.CompressedManifestStaticFilesStorage\"\n\n# Use DATABASE_URL in production\nDATABASE_URL = os.getenv(\"DATABASE_URL\")\n\nif DATABASE_URL is not None:\n DATABASES = {\"default\": DATABASE_URL}\nelse:\n # Default to sqlite for simplicity in development\n DATABASES = {\n \"default\": {\n \"ENGINE\": \"django.db.backends.sqlite3\",\n \"NAME\": BASE_DIR + \"/\" + \"db.sqlite3\",\n }\n }\n\n# Email Backend Setup\nif \"EMAIL_HOST\" not in os.environ:\n EMAIL_BACKEND = \"django.core.mail.backends.console.EmailBackend\"\n EMAIL_HOST_USER = \"[email protected]\"\nelse:\n EMAIL_BACKEND = \"django.core.mail.backends.smtp.EmailBackend\"\n EMAIL_HOST = os.getenv(\"EMAIL_HOST\")\n EMAIL_PORT = os.getenv(\"EMAIL_PORT\")\n EMAIL_HOST_USER = os.getenv(\"EMAIL_HOST_USER\")\n EMAIL_HOST_PASSWORD = os.getenv(\"EMAIL_HOST_PASSWORD\")\n EMAIL_USE_SSL = True\n DEFAULT_FROM_EMAIL = EMAIL_HOST\n\n# Notification API Settings\nNOTIFICATIONS_SOFT_DELETE = True\nNOTIFICATIONS_USE_JSONFIELD = True\n\n# Django REST API Settings\nDEFAULT_RENDERER_CLASSES = (\"rest_framework.renderers.JSONRenderer\",)\n\nDEFAULT_AUTHENTICATION_CLASSES = (\"rest_framework.authentication.BasicAuthentication\",)\n\nif DEBUG:\n # Browsable HTML - Enabled only in Debug mode (dev)\n DEFAULT_RENDERER_CLASSES = DEFAULT_RENDERER_CLASSES + (\n \"rest_framework.renderers.BrowsableAPIRenderer\",\n )\n\n DEFAULT_AUTHENTICATION_CLASSES = (\n \"api.authentication.CsrfExemptSessionAuthentication\",\n ) + DEFAULT_AUTHENTICATION_CLASSES\n\nREST_FRAMEWORK = {\n \"DEFAULT_PERMISSION_CLASSES\": (\"rest_framework.permissions.IsAuthenticated\",),\n \"DEFAULT_RENDERER_CLASSES\": DEFAULT_RENDERER_CLASSES,\n \"DEFAULT_AUTHENTICATION_CLASSES\": DEFAULT_AUTHENTICATION_CLASSES,\n}\n\n# CORS Settings\nCORS_ORIGIN_ALLOW_ALL = True\n\n# Custom User model\nAUTH_USER_MODEL = 'accounts.User'\n\nAPPEND_SLASH = False\n\nDEFAULT_AUTO_FIELD = 'django.db.models.AutoField'\n", "path": "project/core/settings.py"}], "after_files": [{"content": "\"\"\"civiwiki URL Configuration\n\nThe `urlpatterns` list routes URLs to views. For more information please see:\n https://docs.djangoproject.com/en/1.8/topics/http/urls/\nExamples:\nFunction views\n 1. Add an import: from my_app import views\n 2. Add a URL to urlpatterns: url(r'^$', views.home, name='home')\nClass-based views\n 1. Add an import: from other_app.views import Home\n 2. Add a URL to urlpatterns: url(r'^$', Home.as_view(), name='home')\nIncluding another URLconf\n 1. Add an import: from blog import urls as blog_urls\n 2. Add a URL to urlpatterns: url(r'^blog/', include(blog_urls))\n\"\"\"\nimport django.contrib.auth.views as auth_views\n\nfrom django.conf.urls import include, url\nfrom django.contrib import admin\nfrom django.conf import settings\nfrom django.urls import path\nfrom django.views.static import serve\nfrom django.views.generic.base import RedirectView\n\nfrom api import urls as api\nfrom accounts import urls as accounts_urls\nfrom accounts.views import (RegisterView, PasswordResetView, PasswordResetDoneView,\n PasswordResetConfirmView, PasswordResetCompleteView)\nfrom frontend_views import urls as frontend_views\n\n\n\nurlpatterns = [\n path(\"admin/\", admin.site.urls),\n url(r\"^api/\", include(api)),\n url(r\"^auth/\", include(accounts_urls)),\n\n # New accounts paths. These currently implement user registration/authentication in\n # parallel to the current authentication.\n path('accounts/register', RegisterView.as_view(), name='accounts_register'),\n path(\n 'accounts/login',\n auth_views.LoginView.as_view(template_name='accounts/register/login.html'),\n name='accounts_login',\n ),\n\n path(\n 'accounts/password_reset',\n PasswordResetView.as_view(),\n name='accounts_password_reset',\n ),\n\n path(\n 'accounts/password_reset_done',\n PasswordResetDoneView.as_view(),\n name='accounts_password_reset_done',\n ),\n path(\n 'accounts/password_reset_confirm/<uidb64>/<token>',\n PasswordResetConfirmView.as_view(),\n name='accounts_password_reset_confirm',\n ),\n\n path(\n 'accounts/password_reset_complete',\n PasswordResetCompleteView.as_view(),\n name='accounts_password_reset_complete',\n ),\n url(\n \"^inbox/notifications/\",\n include(\"notifications.urls\", namespace=\"notifications\"),\n ),\n]\n\nurlpatterns += [\n # A redirect for favicons at the root of the site\n url(r\"^favicon\\.ico$\", RedirectView.as_view(url=\"/static/favicon/favicon.ico\")),\n url(\n r\"^favicon-32x32\\.png$\",\n RedirectView.as_view(url=\"/static/favicon/favicon-32x32.png\"),\n ),\n url(\n r\"^apple-touch-icon\\.png$\",\n RedirectView.as_view(url=\"/static/favicon/apple-touch-icon.png\"),\n ),\n url(\n r\"^mstile-144x144\\.png$\",\n RedirectView.as_view(url=\"/static/favicon/mstile-144x144.png\"),\n ),\n # Media and Static file Serve Setup.\n url(\n r\"^media/(?P<path>.*)$\",\n serve,\n {\"document_root\": settings.MEDIA_ROOT, \"show_indexes\": True},\n ),\n url(r\"^static/(?P<path>.*)$\", serve, {\"document_root\": settings.STATIC_ROOT}),\n url(r\"^\", include(frontend_views)),\n\n]\n", "path": "project/core/urls.py"}, {"content": "\"\"\"\nClass based views.\n\nThis module will include views for the accounts app.\n\"\"\"\n\nfrom django.conf import settings\nfrom django.views.generic.edit import FormView\nfrom django.contrib.auth import views as auth_views\nfrom django.contrib.auth import authenticate, login\nfrom django.contrib.auth.tokens import PasswordResetTokenGenerator\nfrom django.contrib.sites.shortcuts import get_current_site\nfrom django.utils.encoding import force_bytes\nfrom django.utils.http import int_to_base36\nfrom django.utils.crypto import salted_hmac\nfrom django.utils.http import urlsafe_base64_encode\nfrom django.urls import reverse_lazy\n\nfrom api.models.account import Account\n\nfrom .forms import AccountRegistrationForm\nfrom .models import User\nfrom .authentication import send_activation_email\n\n\nclass AccountActivationTokenGenerator(PasswordResetTokenGenerator):\n \"\"\"Token Generator for Email Confirmation\"\"\"\n\n key_salt = \"django.contrib.auth.tokens.PasswordResetTokenGenerator\"\n\n def _make_token_with_timestamp(self, user, timestamp):\n \"\"\" Token function pulled from Django 1.11 \"\"\"\n ts_b36 = int_to_base36(timestamp)\n\n hash = salted_hmac(\n self.key_salt, str(user.pk) + str(timestamp)\n ).hexdigest()[::2]\n return \"%s-%s\" % (ts_b36, hash)\n\n\nclass RegisterView(FormView):\n \"\"\"\n A form view that handles user registration.\n \"\"\"\n template_name = 'accounts/register/register.html'\n form_class = AccountRegistrationForm\n success_url = '/'\n\n def _create_user(self, form):\n username = form.cleaned_data['username']\n password = form.cleaned_data['password']\n email = form.cleaned_data['email']\n\n user = User.objects.create_user(username, email, password)\n\n account = Account(user=user)\n if hasattr(settings, 'CLOSED_BETA') and not settings.CLOSED_BETA:\n account.beta_access = True\n account.save()\n\n user.is_active = True\n user.save()\n\n return user\n\n def _send_email(self, user):\n domain = get_current_site(self.request).domain\n send_activation_email(user, domain)\n\n def _login(self, user):\n login(self.request, user)\n\n def form_valid(self, form):\n user = self._create_user(form)\n\n self._send_email(user)\n self._login(user)\n\n return super(RegisterView, self).form_valid(form)\n\n\nclass PasswordResetView(auth_views.PasswordResetView):\n template_name = 'accounts/users/password_reset.html'\n email_template_name = 'accounts/users/password_reset_email.html'\n subject_template_name = 'accounts/users/password_reset_subject.txt'\n from_email = settings.EMAIL_HOST_USER\n success_url = reverse_lazy('accounts_password_reset_done')\n\n\nclass PasswordResetDoneView(auth_views.PasswordResetDoneView):\n template_name = 'accounts/users/password_reset_done.html'\n\n\nclass PasswordResetConfirmView(auth_views.PasswordResetConfirmView):\n template_name = 'accounts/users/password_reset_confirm.html'\n success_url = reverse_lazy('accounts_password_reset_complete')\n\n\nclass PasswordResetCompleteView(auth_views.PasswordResetCompleteView):\n template_name = 'accounts/users/password_reset_complete.html'\n", "path": "project/accounts/views.py"}, {"content": "\"\"\"\nDjango settings for civiwiki project.\nDarius Calliet May 12, 2016\n\nProduction settings file to select proper environment variables.\n\"\"\"\nimport os\n\n# False if not in os.environ\nDEBUG = os.getenv(\"DEBUG\", False)\n\n# defaults to second value if not found in os.environ\nDJANGO_HOST = os.getenv(\"DJANGO_HOST\", \"LOCALHOST\")\n\nBASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\nSECRET_KEY = os.getenv(\"DJANGO_SECRET_KEY\", \"TEST_KEY_FOR_DEVELOPMENT\")\nALLOWED_HOSTS = [\".herokuapp.com\", \".civiwiki.org\", \"127.0.0.1\", \"localhost\", \"0.0.0.0\"]\n\nINSTALLED_APPS = (\n \"django.contrib.admin\",\n \"django.contrib.auth\",\n \"django.contrib.contenttypes\",\n \"django.contrib.sessions\",\n \"django.contrib.messages\",\n \"django.contrib.staticfiles\",\n \"django_extensions\",\n \"storages\",\n \"core\", # TODO: consider removing this, if we can move the decorators, etc. to an actual app\n \"api\",\n \"rest_framework\",\n \"accounts\",\n \"threads\",\n \"frontend_views\",\n \"notifications\",\n \"corsheaders\",\n \"taggit\",\n)\n\nMIDDLEWARE = [\n \"corsheaders.middleware.CorsMiddleware\",\n \"django.middleware.security.SecurityMiddleware\",\n \"whitenoise.middleware.WhiteNoiseMiddleware\",\n \"django.contrib.sessions.middleware.SessionMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n \"django.middleware.csrf.CsrfViewMiddleware\",\n \"django.contrib.auth.middleware.AuthenticationMiddleware\",\n # 'django.contrib.auth.middleware.SessionAuthenticationMiddleware',\n \"django.contrib.messages.middleware.MessageMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n]\n\nCSRF_USE_SESSIONS = (\n True # Store the CSRF token in the users session instead of in a cookie\n)\n\nCORS_ORIGIN_ALLOW_ALL = True\nROOT_URLCONF = \"core.urls\"\nLOGIN_URL = \"/login\"\n\n# SSL Setup\nif DJANGO_HOST != \"LOCALHOST\":\n SECURE_PROXY_SSL_HEADER = (\"HTTP_X_FORWARDED_PROTO\", \"https\")\n SECURE_SSL_REDIRECT = True\n SESSION_COOKIE_SECURE = True\n CSRF_COOKIE_SECURE = True\n\n# Internationalization & Localization\nLANGUAGE_CODE = \"en-us\"\nTIME_ZONE = \"UTC\"\nUSE_I18N = True\nUSE_L10N = True\nUSE_TZ = True\n\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [\n os.path.join(BASE_DIR, \"threads/templates/threads\"), os.path.join(BASE_DIR, \"accounts/templates/accounts\")\n ], # TODO: Add non-webapp template directory\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.request\",\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n ],\n },\n },\n]\n\nWSGI_APPLICATION = \"core.wsgi.application\"\n\n# Apex Contact for Production Errors\nADMINS = [(\"Development Team\", \"[email protected]\")]\n\n# AWS S3 Setup\nif \"AWS_STORAGE_BUCKET_NAME\" not in os.environ:\n MEDIA_URL = \"/media/\"\n MEDIA_ROOT = os.path.join(BASE_DIR, \"media\")\nelse:\n AWS_STORAGE_BUCKET_NAME = os.getenv(\"AWS_STORAGE_BUCKET_NAME\")\n AWS_S3_ACCESS_KEY_ID = os.getenv(\"AWS_S3_ACCESS_KEY_ID\")\n AWS_S3_SECRET_ACCESS_KEY = os.getenv(\"AWS_S3_SECRET_ACCESS_KEY\")\n DEFAULT_FILE_STORAGE = \"storages.backends.s3boto.S3BotoStorage\"\n AWS_S3_SECURE_URLS = False\n AWS_QUERYSTRING_AUTH = False\n\nSTATIC_URL = \"/static/\"\nSTATICFILES_DIRS = (os.path.join(BASE_DIR, \"threads/templates/static\"),)\nSTATIC_ROOT = os.path.join(BASE_DIR, \"staticfiles\")\n\n# TODO: re-organize and simplify staticfiles settings\nif \"CIVIWIKI_LOCAL_NAME\" not in os.environ:\n STATICFILES_STORAGE = \"whitenoise.storage.CompressedManifestStaticFilesStorage\"\n\n# Use DATABASE_URL in production\nDATABASE_URL = os.getenv(\"DATABASE_URL\")\n\nif DATABASE_URL is not None:\n DATABASES = {\"default\": DATABASE_URL}\nelse:\n # Default to sqlite for simplicity in development\n DATABASES = {\n \"default\": {\n \"ENGINE\": \"django.db.backends.sqlite3\",\n \"NAME\": BASE_DIR + \"/\" + \"db.sqlite3\",\n }\n }\n\n# Email Backend Setup\nif \"EMAIL_HOST\" not in os.environ:\n EMAIL_BACKEND = \"django.core.mail.backends.console.EmailBackend\"\n EMAIL_HOST_USER = \"[email protected]\"\nelse:\n EMAIL_BACKEND = \"django.core.mail.backends.smtp.EmailBackend\"\n EMAIL_HOST = os.getenv(\"EMAIL_HOST\")\n EMAIL_PORT = os.getenv(\"EMAIL_PORT\")\n EMAIL_HOST_USER = os.getenv(\"EMAIL_HOST_USER\")\n EMAIL_HOST_PASSWORD = os.getenv(\"EMAIL_HOST_PASSWORD\")\n EMAIL_USE_SSL = True\n DEFAULT_FROM_EMAIL = EMAIL_HOST\n\n# Notification API Settings\nNOTIFICATIONS_SOFT_DELETE = True\nNOTIFICATIONS_USE_JSONFIELD = True\n\n# Django REST API Settings\nDEFAULT_RENDERER_CLASSES = (\"rest_framework.renderers.JSONRenderer\",)\n\nDEFAULT_AUTHENTICATION_CLASSES = (\"rest_framework.authentication.BasicAuthentication\",)\n\nif DEBUG:\n # Browsable HTML - Enabled only in Debug mode (dev)\n DEFAULT_RENDERER_CLASSES = DEFAULT_RENDERER_CLASSES + (\n \"rest_framework.renderers.BrowsableAPIRenderer\",\n )\n\n DEFAULT_AUTHENTICATION_CLASSES = (\n \"api.authentication.CsrfExemptSessionAuthentication\",\n ) + DEFAULT_AUTHENTICATION_CLASSES\n\nREST_FRAMEWORK = {\n \"DEFAULT_PERMISSION_CLASSES\": (\"rest_framework.permissions.IsAuthenticated\",),\n \"DEFAULT_RENDERER_CLASSES\": DEFAULT_RENDERER_CLASSES,\n \"DEFAULT_AUTHENTICATION_CLASSES\": DEFAULT_AUTHENTICATION_CLASSES,\n}\n\n# CORS Settings\nCORS_ORIGIN_ALLOW_ALL = True\n\n# Custom User model\nAUTH_USER_MODEL = 'accounts.User'\n\nAPPEND_SLASH = False\n\nDEFAULT_AUTO_FIELD = 'django.db.models.AutoField'\n\nLOGIN_REDIRECT_URL = '/'\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator',\n 'OPTIONS': {\n 'min_length': 8,\n }\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator',\n },\n]\n", "path": "project/core/settings.py"}]}
| 3,500 | 761 |
gh_patches_debug_5900
|
rasdani/github-patches
|
git_diff
|
AnalogJ__lexicon-1660
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Can't use lexicon with pending Cloudflare domains
I cannot use Lexicon with a domain that is `pending` (not `active`) in Cloudflare. It's useful to to be able to manipulate DNS records for `pending` domains before changing nameservers to minimize disruption.
## Context
1. Add a domain (e.g., `example.com`) in Cloudflare.
2. Do not change the nameservers for `example.com` to point to Cloudflare so that it remains with a `pending` status.
3. Add an API token in Cloudflare with Zone.DNS Edit and Zone.Zone Read permissions.
## Example
```sh
$ lexicon --version
lexicon 3.12.0
$ lexicon cloudflare --auth-token abc...XYZ list example.com A
Traceback (most recent call last):
File "/home/user/.local/bin/lexicon", line 8, in <module>
sys.exit(main())
File "/home/user/.local/pipx/venvs/dns-lexicon/lib/python3.9/site-packages/lexicon/cli.py", line 132, in main
results = client.execute()
File "/home/user/.local/pipx/venvs/dns-lexicon/lib/python3.9/site-packages/lexicon/client.py", line 81, in execute
self.provider.authenticate()
File "/home/user/.local/pipx/venvs/dns-lexicon/lib/python3.9/site-packages/lexicon/providers/base.py", line 73, in authenticate
self._authenticate()
File "/home/user/.local/pipx/venvs/dns-lexicon/lib/python3.9/site-packages/lexicon/providers/cloudflare.py", line 51, in _authenticate
raise AuthenticationError("No domain found")
lexicon.exceptions.AuthenticationError: No domain found
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lexicon/providers/cloudflare.py`
Content:
```
1 """Module provider for Cloudflare"""
2 import json
3 import logging
4
5 import requests
6
7 from lexicon.exceptions import AuthenticationError
8 from lexicon.providers.base import Provider as BaseProvider
9
10 LOGGER = logging.getLogger(__name__)
11
12 NAMESERVER_DOMAINS = ["cloudflare.com"]
13
14
15 def provider_parser(subparser):
16 """Return the parser for this provider"""
17 subparser.description = """
18 There are two ways to provide an authentication granting edition to the target CloudFlare DNS zone.
19 1 - A Global API key, with --auth-username and --auth-token flags.
20 2 - An unscoped API token (permissions Zone:Zone(read) + Zone:DNS(edit) for all zones), with --auth-token flag.
21 3 - A scoped API token (permissions Zone:Zone(read) + Zone:DNS(edit) for one zone), with --auth-token and --zone-id flags.
22 """
23 subparser.add_argument(
24 "--auth-username",
25 help="specify email address for authentication (for Global API key only)",
26 )
27 subparser.add_argument(
28 "--auth-token",
29 help="specify token for authentication (Global API key or API token)",
30 )
31 subparser.add_argument(
32 "--zone-id",
33 help="specify the zone id (if set, API token can be scoped to the target zone)",
34 )
35
36
37 class Provider(BaseProvider):
38 """Provider class for Cloudflare"""
39
40 def __init__(self, config):
41 super(Provider, self).__init__(config)
42 self.domain_id = None
43 self.api_endpoint = "https://api.cloudflare.com/client/v4"
44
45 def _authenticate(self):
46 zone_id = self._get_provider_option("zone_id")
47 if not zone_id:
48 payload = self._get("/zones", {"name": self.domain, "status": "active"})
49
50 if not payload["result"]:
51 raise AuthenticationError("No domain found")
52 if len(payload["result"]) > 1:
53 raise AuthenticationError(
54 "Too many domains found. This should not happen"
55 )
56
57 self.domain_id = payload["result"][0]["id"]
58 else:
59 payload = self._get(f"/zones/{zone_id}")
60
61 if not payload["result"]:
62 raise AuthenticationError(f"No domain found for Zone ID {zone_id}")
63
64 self.domain_id = zone_id
65
66 # Create record. If record already exists with the same content, do nothing'
67 def _create_record(self, rtype, name, content):
68 content, cf_data = self._format_content(rtype, content)
69 data = {
70 "type": rtype,
71 "name": self._full_name(name),
72 "content": content,
73 "data": cf_data,
74 }
75 if self._get_lexicon_option("ttl"):
76 data["ttl"] = self._get_lexicon_option("ttl")
77
78 payload = {"success": True}
79 try:
80 payload = self._post(f"/zones/{self.domain_id}/dns_records", data)
81 except requests.exceptions.HTTPError as err:
82 already_exists = next(
83 (
84 True
85 for error in err.response.json()["errors"]
86 if error["code"] == 81057
87 ),
88 False,
89 )
90 if not already_exists:
91 raise
92
93 LOGGER.debug("create_record: %s", payload["success"])
94 return payload["success"]
95
96 # List all records. Return an empty list if no records found
97 # type, name and content are used to filter records.
98 # If possible filter during the query, otherwise filter after response is received.
99 def _list_records(self, rtype=None, name=None, content=None):
100 filter_obj = {"per_page": 100}
101 if rtype:
102 filter_obj["type"] = rtype
103 if name:
104 filter_obj["name"] = self._full_name(name)
105 if content:
106 filter_obj["content"] = content
107
108 records = []
109 while True:
110 payload = self._get(f"/zones/{self.domain_id}/dns_records", filter_obj)
111
112 LOGGER.debug("payload: %s", payload)
113
114 for record in payload["result"]:
115 processed_record = {
116 "type": record["type"],
117 "name": record["name"],
118 "ttl": record["ttl"],
119 "content": record["content"],
120 "id": record["id"],
121 }
122 records.append(processed_record)
123
124 pages = payload["result_info"]["total_pages"]
125 page = payload["result_info"]["page"]
126 if page >= pages:
127 break
128 filter_obj["page"] = page + 1
129
130 LOGGER.debug("list_records: %s", records)
131 LOGGER.debug("Number of records retrieved: %d", len(records))
132 return records
133
134 # Create or update a record.
135 def _update_record(self, identifier, rtype=None, name=None, content=None):
136 if identifier is None:
137 records = self._list_records(rtype, name)
138 if len(records) == 1:
139 identifier = records[0]["id"]
140 elif len(records) < 1:
141 raise Exception(
142 "No records found matching type and name - won't update"
143 )
144 else:
145 raise Exception(
146 "Multiple records found matching type and name - won't update"
147 )
148
149 data = {}
150 if rtype:
151 data["type"] = rtype
152 if name:
153 data["name"] = self._full_name(name)
154 if content:
155 data["content"] = content
156 if self._get_lexicon_option("ttl"):
157 data["ttl"] = self._get_lexicon_option("ttl")
158
159 payload = self._put(f"/zones/{self.domain_id}/dns_records/{identifier}", data)
160
161 LOGGER.debug("update_record: %s", payload["success"])
162 return payload["success"]
163
164 # Delete an existing record.
165 # If record does not exist, do nothing.
166 def _delete_record(self, identifier=None, rtype=None, name=None, content=None):
167 delete_record_id = []
168 if not identifier:
169 records = self._list_records(rtype, name, content)
170 delete_record_id = [record["id"] for record in records]
171 else:
172 delete_record_id.append(identifier)
173
174 LOGGER.debug("delete_records: %s", delete_record_id)
175
176 for record_id in delete_record_id:
177 self._delete(f"/zones/{self.domain_id}/dns_records/{record_id}")
178
179 LOGGER.debug("delete_record: %s", True)
180 return True
181
182 # Helpers
183 def _request(self, action="GET", url="/", data=None, query_params=None):
184 if data is None:
185 data = {}
186 if query_params is None:
187 query_params = {}
188 headers = {"Content-Type": "application/json"}
189 if self._get_provider_option("auth_username"):
190 headers["X-Auth-Email"] = self._get_provider_option("auth_username")
191 headers["X-Auth-Key"] = self._get_provider_option("auth_token")
192 else:
193 headers[
194 "Authorization"
195 ] = f"Bearer {self._get_provider_option('auth_token')}"
196 response = requests.request(
197 action,
198 self.api_endpoint + url,
199 params=query_params,
200 data=json.dumps(data),
201 headers=headers,
202 )
203 # if the request fails for any reason, throw an error.
204 response.raise_for_status()
205 return response.json()
206
207 def _format_content(self, rtype, content):
208 """
209 Special case handling from some record types that Cloudflare needs
210 formatted differently
211
212 Returns new values for the content and data properties to be sent
213 on the request
214 """
215 data = None
216 if rtype == "SSHFP":
217 # For some reason the CloudFlare API does not let you set content
218 # directly when creating an SSHFP record. You need to pass the
219 # fields that make up the record seperately, then the API joins
220 # them back together
221 _fp = content.split(" ")
222 data = {"algorithm": _fp[0], "type": _fp[1], "fingerprint": _fp[2]}
223 content = None
224
225 return content, data
226
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lexicon/providers/cloudflare.py b/lexicon/providers/cloudflare.py
--- a/lexicon/providers/cloudflare.py
+++ b/lexicon/providers/cloudflare.py
@@ -45,7 +45,7 @@
def _authenticate(self):
zone_id = self._get_provider_option("zone_id")
if not zone_id:
- payload = self._get("/zones", {"name": self.domain, "status": "active"})
+ payload = self._get("/zones", {"name": self.domain})
if not payload["result"]:
raise AuthenticationError("No domain found")
|
{"golden_diff": "diff --git a/lexicon/providers/cloudflare.py b/lexicon/providers/cloudflare.py\n--- a/lexicon/providers/cloudflare.py\n+++ b/lexicon/providers/cloudflare.py\n@@ -45,7 +45,7 @@\n def _authenticate(self):\n zone_id = self._get_provider_option(\"zone_id\")\n if not zone_id:\n- payload = self._get(\"/zones\", {\"name\": self.domain, \"status\": \"active\"})\n+ payload = self._get(\"/zones\", {\"name\": self.domain})\n \n if not payload[\"result\"]:\n raise AuthenticationError(\"No domain found\")\n", "issue": "Can't use lexicon with pending Cloudflare domains\nI cannot use Lexicon with a domain that is `pending` (not `active`) in Cloudflare. It's useful to to be able to manipulate DNS records for `pending` domains before changing nameservers to minimize disruption.\r\n\r\n## Context\r\n\r\n1. Add a domain (e.g., `example.com`) in Cloudflare.\r\n2. Do not change the nameservers for `example.com` to point to Cloudflare so that it remains with a `pending` status.\r\n3. Add an API token in Cloudflare with Zone.DNS Edit and Zone.Zone Read permissions.\r\n\r\n## Example\r\n\r\n```sh\r\n$ lexicon --version\r\nlexicon 3.12.0\r\n$ lexicon cloudflare --auth-token abc...XYZ list example.com A\r\nTraceback (most recent call last):\r\n File \"/home/user/.local/bin/lexicon\", line 8, in <module>\r\n sys.exit(main())\r\n File \"/home/user/.local/pipx/venvs/dns-lexicon/lib/python3.9/site-packages/lexicon/cli.py\", line 132, in main\r\n results = client.execute()\r\n File \"/home/user/.local/pipx/venvs/dns-lexicon/lib/python3.9/site-packages/lexicon/client.py\", line 81, in execute\r\n self.provider.authenticate()\r\n File \"/home/user/.local/pipx/venvs/dns-lexicon/lib/python3.9/site-packages/lexicon/providers/base.py\", line 73, in authenticate\r\n self._authenticate()\r\n File \"/home/user/.local/pipx/venvs/dns-lexicon/lib/python3.9/site-packages/lexicon/providers/cloudflare.py\", line 51, in _authenticate\r\n raise AuthenticationError(\"No domain found\")\r\nlexicon.exceptions.AuthenticationError: No domain found\r\n```\n", "before_files": [{"content": "\"\"\"Module provider for Cloudflare\"\"\"\nimport json\nimport logging\n\nimport requests\n\nfrom lexicon.exceptions import AuthenticationError\nfrom lexicon.providers.base import Provider as BaseProvider\n\nLOGGER = logging.getLogger(__name__)\n\nNAMESERVER_DOMAINS = [\"cloudflare.com\"]\n\n\ndef provider_parser(subparser):\n \"\"\"Return the parser for this provider\"\"\"\n subparser.description = \"\"\"\n There are two ways to provide an authentication granting edition to the target CloudFlare DNS zone.\n 1 - A Global API key, with --auth-username and --auth-token flags.\n 2 - An unscoped API token (permissions Zone:Zone(read) + Zone:DNS(edit) for all zones), with --auth-token flag.\n 3 - A scoped API token (permissions Zone:Zone(read) + Zone:DNS(edit) for one zone), with --auth-token and --zone-id flags.\n \"\"\"\n subparser.add_argument(\n \"--auth-username\",\n help=\"specify email address for authentication (for Global API key only)\",\n )\n subparser.add_argument(\n \"--auth-token\",\n help=\"specify token for authentication (Global API key or API token)\",\n )\n subparser.add_argument(\n \"--zone-id\",\n help=\"specify the zone id (if set, API token can be scoped to the target zone)\",\n )\n\n\nclass Provider(BaseProvider):\n \"\"\"Provider class for Cloudflare\"\"\"\n\n def __init__(self, config):\n super(Provider, self).__init__(config)\n self.domain_id = None\n self.api_endpoint = \"https://api.cloudflare.com/client/v4\"\n\n def _authenticate(self):\n zone_id = self._get_provider_option(\"zone_id\")\n if not zone_id:\n payload = self._get(\"/zones\", {\"name\": self.domain, \"status\": \"active\"})\n\n if not payload[\"result\"]:\n raise AuthenticationError(\"No domain found\")\n if len(payload[\"result\"]) > 1:\n raise AuthenticationError(\n \"Too many domains found. This should not happen\"\n )\n\n self.domain_id = payload[\"result\"][0][\"id\"]\n else:\n payload = self._get(f\"/zones/{zone_id}\")\n\n if not payload[\"result\"]:\n raise AuthenticationError(f\"No domain found for Zone ID {zone_id}\")\n\n self.domain_id = zone_id\n\n # Create record. If record already exists with the same content, do nothing'\n def _create_record(self, rtype, name, content):\n content, cf_data = self._format_content(rtype, content)\n data = {\n \"type\": rtype,\n \"name\": self._full_name(name),\n \"content\": content,\n \"data\": cf_data,\n }\n if self._get_lexicon_option(\"ttl\"):\n data[\"ttl\"] = self._get_lexicon_option(\"ttl\")\n\n payload = {\"success\": True}\n try:\n payload = self._post(f\"/zones/{self.domain_id}/dns_records\", data)\n except requests.exceptions.HTTPError as err:\n already_exists = next(\n (\n True\n for error in err.response.json()[\"errors\"]\n if error[\"code\"] == 81057\n ),\n False,\n )\n if not already_exists:\n raise\n\n LOGGER.debug(\"create_record: %s\", payload[\"success\"])\n return payload[\"success\"]\n\n # List all records. Return an empty list if no records found\n # type, name and content are used to filter records.\n # If possible filter during the query, otherwise filter after response is received.\n def _list_records(self, rtype=None, name=None, content=None):\n filter_obj = {\"per_page\": 100}\n if rtype:\n filter_obj[\"type\"] = rtype\n if name:\n filter_obj[\"name\"] = self._full_name(name)\n if content:\n filter_obj[\"content\"] = content\n\n records = []\n while True:\n payload = self._get(f\"/zones/{self.domain_id}/dns_records\", filter_obj)\n\n LOGGER.debug(\"payload: %s\", payload)\n\n for record in payload[\"result\"]:\n processed_record = {\n \"type\": record[\"type\"],\n \"name\": record[\"name\"],\n \"ttl\": record[\"ttl\"],\n \"content\": record[\"content\"],\n \"id\": record[\"id\"],\n }\n records.append(processed_record)\n\n pages = payload[\"result_info\"][\"total_pages\"]\n page = payload[\"result_info\"][\"page\"]\n if page >= pages:\n break\n filter_obj[\"page\"] = page + 1\n\n LOGGER.debug(\"list_records: %s\", records)\n LOGGER.debug(\"Number of records retrieved: %d\", len(records))\n return records\n\n # Create or update a record.\n def _update_record(self, identifier, rtype=None, name=None, content=None):\n if identifier is None:\n records = self._list_records(rtype, name)\n if len(records) == 1:\n identifier = records[0][\"id\"]\n elif len(records) < 1:\n raise Exception(\n \"No records found matching type and name - won't update\"\n )\n else:\n raise Exception(\n \"Multiple records found matching type and name - won't update\"\n )\n\n data = {}\n if rtype:\n data[\"type\"] = rtype\n if name:\n data[\"name\"] = self._full_name(name)\n if content:\n data[\"content\"] = content\n if self._get_lexicon_option(\"ttl\"):\n data[\"ttl\"] = self._get_lexicon_option(\"ttl\")\n\n payload = self._put(f\"/zones/{self.domain_id}/dns_records/{identifier}\", data)\n\n LOGGER.debug(\"update_record: %s\", payload[\"success\"])\n return payload[\"success\"]\n\n # Delete an existing record.\n # If record does not exist, do nothing.\n def _delete_record(self, identifier=None, rtype=None, name=None, content=None):\n delete_record_id = []\n if not identifier:\n records = self._list_records(rtype, name, content)\n delete_record_id = [record[\"id\"] for record in records]\n else:\n delete_record_id.append(identifier)\n\n LOGGER.debug(\"delete_records: %s\", delete_record_id)\n\n for record_id in delete_record_id:\n self._delete(f\"/zones/{self.domain_id}/dns_records/{record_id}\")\n\n LOGGER.debug(\"delete_record: %s\", True)\n return True\n\n # Helpers\n def _request(self, action=\"GET\", url=\"/\", data=None, query_params=None):\n if data is None:\n data = {}\n if query_params is None:\n query_params = {}\n headers = {\"Content-Type\": \"application/json\"}\n if self._get_provider_option(\"auth_username\"):\n headers[\"X-Auth-Email\"] = self._get_provider_option(\"auth_username\")\n headers[\"X-Auth-Key\"] = self._get_provider_option(\"auth_token\")\n else:\n headers[\n \"Authorization\"\n ] = f\"Bearer {self._get_provider_option('auth_token')}\"\n response = requests.request(\n action,\n self.api_endpoint + url,\n params=query_params,\n data=json.dumps(data),\n headers=headers,\n )\n # if the request fails for any reason, throw an error.\n response.raise_for_status()\n return response.json()\n\n def _format_content(self, rtype, content):\n \"\"\"\n Special case handling from some record types that Cloudflare needs\n formatted differently\n\n Returns new values for the content and data properties to be sent\n on the request\n \"\"\"\n data = None\n if rtype == \"SSHFP\":\n # For some reason the CloudFlare API does not let you set content\n # directly when creating an SSHFP record. You need to pass the\n # fields that make up the record seperately, then the API joins\n # them back together\n _fp = content.split(\" \")\n data = {\"algorithm\": _fp[0], \"type\": _fp[1], \"fingerprint\": _fp[2]}\n content = None\n\n return content, data\n", "path": "lexicon/providers/cloudflare.py"}], "after_files": [{"content": "\"\"\"Module provider for Cloudflare\"\"\"\nimport json\nimport logging\n\nimport requests\n\nfrom lexicon.exceptions import AuthenticationError\nfrom lexicon.providers.base import Provider as BaseProvider\n\nLOGGER = logging.getLogger(__name__)\n\nNAMESERVER_DOMAINS = [\"cloudflare.com\"]\n\n\ndef provider_parser(subparser):\n \"\"\"Return the parser for this provider\"\"\"\n subparser.description = \"\"\"\n There are two ways to provide an authentication granting edition to the target CloudFlare DNS zone.\n 1 - A Global API key, with --auth-username and --auth-token flags.\n 2 - An unscoped API token (permissions Zone:Zone(read) + Zone:DNS(edit) for all zones), with --auth-token flag.\n 3 - A scoped API token (permissions Zone:Zone(read) + Zone:DNS(edit) for one zone), with --auth-token and --zone-id flags.\n \"\"\"\n subparser.add_argument(\n \"--auth-username\",\n help=\"specify email address for authentication (for Global API key only)\",\n )\n subparser.add_argument(\n \"--auth-token\",\n help=\"specify token for authentication (Global API key or API token)\",\n )\n subparser.add_argument(\n \"--zone-id\",\n help=\"specify the zone id (if set, API token can be scoped to the target zone)\",\n )\n\n\nclass Provider(BaseProvider):\n \"\"\"Provider class for Cloudflare\"\"\"\n\n def __init__(self, config):\n super(Provider, self).__init__(config)\n self.domain_id = None\n self.api_endpoint = \"https://api.cloudflare.com/client/v4\"\n\n def _authenticate(self):\n zone_id = self._get_provider_option(\"zone_id\")\n if not zone_id:\n payload = self._get(\"/zones\", {\"name\": self.domain})\n\n if not payload[\"result\"]:\n raise AuthenticationError(\"No domain found\")\n if len(payload[\"result\"]) > 1:\n raise AuthenticationError(\n \"Too many domains found. This should not happen\"\n )\n\n self.domain_id = payload[\"result\"][0][\"id\"]\n else:\n payload = self._get(f\"/zones/{zone_id}\")\n\n if not payload[\"result\"]:\n raise AuthenticationError(f\"No domain found for Zone ID {zone_id}\")\n\n self.domain_id = zone_id\n\n # Create record. If record already exists with the same content, do nothing'\n def _create_record(self, rtype, name, content):\n content, cf_data = self._format_content(rtype, content)\n data = {\n \"type\": rtype,\n \"name\": self._full_name(name),\n \"content\": content,\n \"data\": cf_data,\n }\n if self._get_lexicon_option(\"ttl\"):\n data[\"ttl\"] = self._get_lexicon_option(\"ttl\")\n\n payload = {\"success\": True}\n try:\n payload = self._post(f\"/zones/{self.domain_id}/dns_records\", data)\n except requests.exceptions.HTTPError as err:\n already_exists = next(\n (\n True\n for error in err.response.json()[\"errors\"]\n if error[\"code\"] == 81057\n ),\n False,\n )\n if not already_exists:\n raise\n\n LOGGER.debug(\"create_record: %s\", payload[\"success\"])\n return payload[\"success\"]\n\n # List all records. Return an empty list if no records found\n # type, name and content are used to filter records.\n # If possible filter during the query, otherwise filter after response is received.\n def _list_records(self, rtype=None, name=None, content=None):\n filter_obj = {\"per_page\": 100}\n if rtype:\n filter_obj[\"type\"] = rtype\n if name:\n filter_obj[\"name\"] = self._full_name(name)\n if content:\n filter_obj[\"content\"] = content\n\n records = []\n while True:\n payload = self._get(f\"/zones/{self.domain_id}/dns_records\", filter_obj)\n\n LOGGER.debug(\"payload: %s\", payload)\n\n for record in payload[\"result\"]:\n processed_record = {\n \"type\": record[\"type\"],\n \"name\": record[\"name\"],\n \"ttl\": record[\"ttl\"],\n \"content\": record[\"content\"],\n \"id\": record[\"id\"],\n }\n records.append(processed_record)\n\n pages = payload[\"result_info\"][\"total_pages\"]\n page = payload[\"result_info\"][\"page\"]\n if page >= pages:\n break\n filter_obj[\"page\"] = page + 1\n\n LOGGER.debug(\"list_records: %s\", records)\n LOGGER.debug(\"Number of records retrieved: %d\", len(records))\n return records\n\n # Create or update a record.\n def _update_record(self, identifier, rtype=None, name=None, content=None):\n if identifier is None:\n records = self._list_records(rtype, name)\n if len(records) == 1:\n identifier = records[0][\"id\"]\n elif len(records) < 1:\n raise Exception(\n \"No records found matching type and name - won't update\"\n )\n else:\n raise Exception(\n \"Multiple records found matching type and name - won't update\"\n )\n\n data = {}\n if rtype:\n data[\"type\"] = rtype\n if name:\n data[\"name\"] = self._full_name(name)\n if content:\n data[\"content\"] = content\n if self._get_lexicon_option(\"ttl\"):\n data[\"ttl\"] = self._get_lexicon_option(\"ttl\")\n\n payload = self._put(f\"/zones/{self.domain_id}/dns_records/{identifier}\", data)\n\n LOGGER.debug(\"update_record: %s\", payload[\"success\"])\n return payload[\"success\"]\n\n # Delete an existing record.\n # If record does not exist, do nothing.\n def _delete_record(self, identifier=None, rtype=None, name=None, content=None):\n delete_record_id = []\n if not identifier:\n records = self._list_records(rtype, name, content)\n delete_record_id = [record[\"id\"] for record in records]\n else:\n delete_record_id.append(identifier)\n\n LOGGER.debug(\"delete_records: %s\", delete_record_id)\n\n for record_id in delete_record_id:\n self._delete(f\"/zones/{self.domain_id}/dns_records/{record_id}\")\n\n LOGGER.debug(\"delete_record: %s\", True)\n return True\n\n # Helpers\n def _request(self, action=\"GET\", url=\"/\", data=None, query_params=None):\n if data is None:\n data = {}\n if query_params is None:\n query_params = {}\n headers = {\"Content-Type\": \"application/json\"}\n if self._get_provider_option(\"auth_username\"):\n headers[\"X-Auth-Email\"] = self._get_provider_option(\"auth_username\")\n headers[\"X-Auth-Key\"] = self._get_provider_option(\"auth_token\")\n else:\n headers[\n \"Authorization\"\n ] = f\"Bearer {self._get_provider_option('auth_token')}\"\n response = requests.request(\n action,\n self.api_endpoint + url,\n params=query_params,\n data=json.dumps(data),\n headers=headers,\n )\n # if the request fails for any reason, throw an error.\n response.raise_for_status()\n return response.json()\n\n def _format_content(self, rtype, content):\n \"\"\"\n Special case handling from some record types that Cloudflare needs\n formatted differently\n\n Returns new values for the content and data properties to be sent\n on the request\n \"\"\"\n data = None\n if rtype == \"SSHFP\":\n # For some reason the CloudFlare API does not let you set content\n # directly when creating an SSHFP record. You need to pass the\n # fields that make up the record seperately, then the API joins\n # them back together\n _fp = content.split(\" \")\n data = {\"algorithm\": _fp[0], \"type\": _fp[1], \"fingerprint\": _fp[2]}\n content = None\n\n return content, data\n", "path": "lexicon/providers/cloudflare.py"}]}
| 2,985 | 132 |
gh_patches_debug_5525
|
rasdani/github-patches
|
git_diff
|
zulip__zulip-16512
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
New line character issue when using create_user management command
The create_user management command reads password from a text file created by the server admin. To run this command I tried creating this text file using VIM, nano and echo (` echo pass > password.txt` without using `-n` flag). Each and every time new line character was automatically added to the end of the file. So if I set the content of file as `helloworld` and try to login to the server by entering `helloworld` it would not let me login since `\n` is missing. It was not obvious to me that the extra `\n` added by editors was the reason behind the server rejecting the credentials.
Should we remove the trailing `\n` character while reading the password from file?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `zerver/management/commands/create_user.py`
Content:
```
1 import argparse
2 import sys
3 from typing import Any
4
5 from django.core import validators
6 from django.core.exceptions import ValidationError
7 from django.core.management.base import CommandError
8 from django.db.utils import IntegrityError
9
10 from zerver.lib.actions import do_create_user
11 from zerver.lib.initial_password import initial_password
12 from zerver.lib.management import ZulipBaseCommand
13
14
15 class Command(ZulipBaseCommand):
16 help = """Create the specified user with a default initial password.
17
18 Set tos_version=None, so that the user needs to do a ToS flow on login.
19
20 Omit both <email> and <full name> for interactive user creation.
21 """
22
23 def add_arguments(self, parser: argparse.ArgumentParser) -> None:
24 parser.add_argument('--this-user-has-accepted-the-tos',
25 dest='tos',
26 action="store_true",
27 help='Acknowledgement that the user has already accepted the ToS.')
28 parser.add_argument('--password',
29 help='password of new user. For development only.'
30 'Note that we recommend against setting '
31 'passwords this way, since they can be snooped by any user account '
32 'on the server via `ps -ef` or by any superuser with'
33 'read access to the user\'s bash history.')
34 parser.add_argument('--password-file',
35 help='The file containing the password of the new user.')
36 parser.add_argument('email', metavar='<email>', nargs='?', default=argparse.SUPPRESS,
37 help='email address of new user')
38 parser.add_argument('full_name', metavar='<full name>', nargs='?',
39 default=argparse.SUPPRESS,
40 help='full name of new user')
41 self.add_realm_args(parser, True, "The name of the existing realm to which to add the user.")
42
43 def handle(self, *args: Any, **options: Any) -> None:
44 if not options["tos"]:
45 raise CommandError("""You must confirm that this user has accepted the
46 Terms of Service by passing --this-user-has-accepted-the-tos.""")
47 realm = self.get_realm(options)
48 assert realm is not None # Should be ensured by parser
49
50 try:
51 email = options['email']
52 full_name = options['full_name']
53 try:
54 validators.validate_email(email)
55 except ValidationError:
56 raise CommandError("Invalid email address.")
57 except KeyError:
58 if 'email' in options or 'full_name' in options:
59 raise CommandError("""Either specify an email and full name as two
60 parameters, or specify no parameters for interactive user creation.""")
61 else:
62 while True:
63 email = input("Email: ")
64 try:
65 validators.validate_email(email)
66 break
67 except ValidationError:
68 print("Invalid email address.", file=sys.stderr)
69 full_name = input("Full name: ")
70
71 try:
72 if options['password_file'] is not None:
73 with open(options['password_file']) as f:
74 pw = f.read()
75 elif options['password'] is not None:
76 pw = options['password']
77 else:
78 user_initial_password = initial_password(email)
79 if user_initial_password is None:
80 raise CommandError("Password is unusable.")
81 pw = user_initial_password
82 do_create_user(
83 email,
84 pw,
85 realm,
86 full_name,
87 acting_user=None,
88 )
89 except IntegrityError:
90 raise CommandError("User already exists.")
91
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/zerver/management/commands/create_user.py b/zerver/management/commands/create_user.py
--- a/zerver/management/commands/create_user.py
+++ b/zerver/management/commands/create_user.py
@@ -71,7 +71,7 @@
try:
if options['password_file'] is not None:
with open(options['password_file']) as f:
- pw = f.read()
+ pw = f.read().strip()
elif options['password'] is not None:
pw = options['password']
else:
|
{"golden_diff": "diff --git a/zerver/management/commands/create_user.py b/zerver/management/commands/create_user.py\n--- a/zerver/management/commands/create_user.py\n+++ b/zerver/management/commands/create_user.py\n@@ -71,7 +71,7 @@\n try:\n if options['password_file'] is not None:\n with open(options['password_file']) as f:\n- pw = f.read()\n+ pw = f.read().strip()\n elif options['password'] is not None:\n pw = options['password']\n else:\n", "issue": "New line character issue when using create_user management command \nThe create_user management command reads password from a text file created by the server admin. To run this command I tried creating this text file using VIM, nano and echo (` echo pass > password.txt` without using `-n` flag). Each and every time new line character was automatically added to the end of the file. So if I set the content of file as `helloworld` and try to login to the server by entering `helloworld` it would not let me login since `\\n` is missing. It was not obvious to me that the extra `\\n` added by editors was the reason behind the server rejecting the credentials.\r\n\r\nShould we remove the trailing `\\n` character while reading the password from file?\n", "before_files": [{"content": "import argparse\nimport sys\nfrom typing import Any\n\nfrom django.core import validators\nfrom django.core.exceptions import ValidationError\nfrom django.core.management.base import CommandError\nfrom django.db.utils import IntegrityError\n\nfrom zerver.lib.actions import do_create_user\nfrom zerver.lib.initial_password import initial_password\nfrom zerver.lib.management import ZulipBaseCommand\n\n\nclass Command(ZulipBaseCommand):\n help = \"\"\"Create the specified user with a default initial password.\n\nSet tos_version=None, so that the user needs to do a ToS flow on login.\n\nOmit both <email> and <full name> for interactive user creation.\n\"\"\"\n\n def add_arguments(self, parser: argparse.ArgumentParser) -> None:\n parser.add_argument('--this-user-has-accepted-the-tos',\n dest='tos',\n action=\"store_true\",\n help='Acknowledgement that the user has already accepted the ToS.')\n parser.add_argument('--password',\n help='password of new user. For development only.'\n 'Note that we recommend against setting '\n 'passwords this way, since they can be snooped by any user account '\n 'on the server via `ps -ef` or by any superuser with'\n 'read access to the user\\'s bash history.')\n parser.add_argument('--password-file',\n help='The file containing the password of the new user.')\n parser.add_argument('email', metavar='<email>', nargs='?', default=argparse.SUPPRESS,\n help='email address of new user')\n parser.add_argument('full_name', metavar='<full name>', nargs='?',\n default=argparse.SUPPRESS,\n help='full name of new user')\n self.add_realm_args(parser, True, \"The name of the existing realm to which to add the user.\")\n\n def handle(self, *args: Any, **options: Any) -> None:\n if not options[\"tos\"]:\n raise CommandError(\"\"\"You must confirm that this user has accepted the\nTerms of Service by passing --this-user-has-accepted-the-tos.\"\"\")\n realm = self.get_realm(options)\n assert realm is not None # Should be ensured by parser\n\n try:\n email = options['email']\n full_name = options['full_name']\n try:\n validators.validate_email(email)\n except ValidationError:\n raise CommandError(\"Invalid email address.\")\n except KeyError:\n if 'email' in options or 'full_name' in options:\n raise CommandError(\"\"\"Either specify an email and full name as two\nparameters, or specify no parameters for interactive user creation.\"\"\")\n else:\n while True:\n email = input(\"Email: \")\n try:\n validators.validate_email(email)\n break\n except ValidationError:\n print(\"Invalid email address.\", file=sys.stderr)\n full_name = input(\"Full name: \")\n\n try:\n if options['password_file'] is not None:\n with open(options['password_file']) as f:\n pw = f.read()\n elif options['password'] is not None:\n pw = options['password']\n else:\n user_initial_password = initial_password(email)\n if user_initial_password is None:\n raise CommandError(\"Password is unusable.\")\n pw = user_initial_password\n do_create_user(\n email,\n pw,\n realm,\n full_name,\n acting_user=None,\n )\n except IntegrityError:\n raise CommandError(\"User already exists.\")\n", "path": "zerver/management/commands/create_user.py"}], "after_files": [{"content": "import argparse\nimport sys\nfrom typing import Any\n\nfrom django.core import validators\nfrom django.core.exceptions import ValidationError\nfrom django.core.management.base import CommandError\nfrom django.db.utils import IntegrityError\n\nfrom zerver.lib.actions import do_create_user\nfrom zerver.lib.initial_password import initial_password\nfrom zerver.lib.management import ZulipBaseCommand\n\n\nclass Command(ZulipBaseCommand):\n help = \"\"\"Create the specified user with a default initial password.\n\nSet tos_version=None, so that the user needs to do a ToS flow on login.\n\nOmit both <email> and <full name> for interactive user creation.\n\"\"\"\n\n def add_arguments(self, parser: argparse.ArgumentParser) -> None:\n parser.add_argument('--this-user-has-accepted-the-tos',\n dest='tos',\n action=\"store_true\",\n help='Acknowledgement that the user has already accepted the ToS.')\n parser.add_argument('--password',\n help='password of new user. For development only.'\n 'Note that we recommend against setting '\n 'passwords this way, since they can be snooped by any user account '\n 'on the server via `ps -ef` or by any superuser with'\n 'read access to the user\\'s bash history.')\n parser.add_argument('--password-file',\n help='The file containing the password of the new user.')\n parser.add_argument('email', metavar='<email>', nargs='?', default=argparse.SUPPRESS,\n help='email address of new user')\n parser.add_argument('full_name', metavar='<full name>', nargs='?',\n default=argparse.SUPPRESS,\n help='full name of new user')\n self.add_realm_args(parser, True, \"The name of the existing realm to which to add the user.\")\n\n def handle(self, *args: Any, **options: Any) -> None:\n if not options[\"tos\"]:\n raise CommandError(\"\"\"You must confirm that this user has accepted the\nTerms of Service by passing --this-user-has-accepted-the-tos.\"\"\")\n realm = self.get_realm(options)\n assert realm is not None # Should be ensured by parser\n\n try:\n email = options['email']\n full_name = options['full_name']\n try:\n validators.validate_email(email)\n except ValidationError:\n raise CommandError(\"Invalid email address.\")\n except KeyError:\n if 'email' in options or 'full_name' in options:\n raise CommandError(\"\"\"Either specify an email and full name as two\nparameters, or specify no parameters for interactive user creation.\"\"\")\n else:\n while True:\n email = input(\"Email: \")\n try:\n validators.validate_email(email)\n break\n except ValidationError:\n print(\"Invalid email address.\", file=sys.stderr)\n full_name = input(\"Full name: \")\n\n try:\n if options['password_file'] is not None:\n with open(options['password_file']) as f:\n pw = f.read().strip()\n elif options['password'] is not None:\n pw = options['password']\n else:\n user_initial_password = initial_password(email)\n if user_initial_password is None:\n raise CommandError(\"Password is unusable.\")\n pw = user_initial_password\n do_create_user(\n email,\n pw,\n realm,\n full_name,\n acting_user=None,\n )\n except IntegrityError:\n raise CommandError(\"User already exists.\")\n", "path": "zerver/management/commands/create_user.py"}]}
| 1,316 | 121 |
gh_patches_debug_5166
|
rasdani/github-patches
|
git_diff
|
pytorch__pytorch-1934
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
torch.is_tensor(torch.HalfTensor()) returns False.
The problem is [here](https://github.com/pytorch/pytorch/blob/master/torch/__init__.py#L274).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `torch/__init__.py`
Content:
```
1 """
2 The torch package contains data structures for multi-dimensional
3 tensors and mathematical operations over these are defined.
4 Additionally, it provides many utilities for efficient serializing of
5 Tensors and arbitrary types, and other useful utilities.
6
7 It has a CUDA counterpart, that enables you to run your tensor computations
8 on an NVIDIA GPU with compute capability >= 2.0.
9 """
10
11 import sys
12 from ._utils import _import_dotted_name
13 from .version import __version__
14
15 __all__ = [
16 'typename', 'is_tensor', 'is_storage', 'set_default_tensor_type',
17 'set_rng_state', 'get_rng_state', 'manual_seed', 'initial_seed',
18 'save', 'load', 'set_printoptions', 'chunk', 'split', 'stack', 'matmul',
19 'DoubleStorage', 'FloatStorage', 'LongStorage', 'IntStorage',
20 'ShortStorage', 'CharStorage', 'ByteStorage',
21 'DoubleTensor', 'FloatTensor', 'LongTensor', 'IntTensor',
22 'ShortTensor', 'CharTensor', 'ByteTensor',
23 ]
24
25 ################################################################################
26 # Load the extension module
27 ################################################################################
28
29 # Loading the extension with RTLD_GLOBAL option allows to not link extension
30 # modules against the _C shared object. Their missing THP symbols will be
31 # automatically filled by the dynamic loader.
32 import os as _dl_flags
33
34 # if we have numpy, it *must* be imported before the call to setdlopenflags()
35 # or there is risk that later c modules will segfault when importing numpy
36 try:
37 import numpy as np
38 except:
39 pass
40
41 # first check if the os package has the required flags
42 if not hasattr(_dl_flags, 'RTLD_GLOBAL') or not hasattr(_dl_flags, 'RTLD_NOW'):
43 try:
44 # next try if DLFCN exists
45 import DLFCN as _dl_flags
46 except ImportError:
47 # as a last attempt, use compile-time constants
48 import torch._dl as _dl_flags
49
50 old_flags = sys.getdlopenflags()
51 sys.setdlopenflags(_dl_flags.RTLD_GLOBAL | _dl_flags.RTLD_NOW)
52
53 from torch._C import *
54
55 __all__ += [name for name in dir(_C)
56 if name[0] != '_' and
57 not name.endswith('Base')]
58
59 sys.setdlopenflags(old_flags)
60 del _dl_flags
61 del old_flags
62
63 ################################################################################
64 # Define basic utilities
65 ################################################################################
66
67
68 def typename(o):
69 module = ''
70 class_name = ''
71 if hasattr(o, '__module__') and o.__module__ != 'builtins' \
72 and o.__module__ != '__builtin__' and o.__module__ is not None:
73 module = o.__module__ + '.'
74
75 if hasattr(o, '__qualname__'):
76 class_name = o.__qualname__
77 elif hasattr(o, '__name__'):
78 class_name = o.__name__
79 else:
80 class_name = o.__class__.__name__
81
82 return module + class_name
83
84
85 def is_tensor(obj):
86 r"""Returns True if `obj` is a pytorch tensor.
87
88 Args:
89 obj (Object): Object to test
90 """
91 return type(obj) in _tensor_classes
92
93
94 def is_storage(obj):
95 r"""Returns True if `obj` is a pytorch storage object.
96
97 Args:
98 obj (Object): Object to test
99 """
100 return type(obj) in _storage_classes
101
102
103 def set_default_tensor_type(t):
104 global Tensor
105 global Storage
106 Tensor = _import_dotted_name(t)
107 Storage = _import_dotted_name(t.replace('Tensor', 'Storage'))
108 _C._set_default_tensor_type(Tensor)
109
110
111 def set_rng_state(new_state):
112 r"""Sets the random number generator state.
113
114 Args:
115 new_state (torch.ByteTensor): The desired state
116 """
117 default_generator.set_state(new_state)
118
119
120 def get_rng_state():
121 r"""Returns the random number generator state as a ByteTensor."""
122 return default_generator.get_state()
123
124
125 def manual_seed(seed):
126 r"""Sets the seed for generating random numbers. And returns a
127 `torch._C.Generator` object.
128
129 Args:
130 seed (int or long): The desired seed.
131 """
132 if torch.cuda.is_available() and not torch.cuda._in_bad_fork:
133 torch.cuda.manual_seed_all(seed)
134
135 return default_generator.manual_seed(seed)
136
137
138 def initial_seed():
139 r"""Returns the initial seed for generating random numbers as a
140 python `long`.
141 """
142 return default_generator.initial_seed()
143
144
145 from .serialization import save, load
146 from ._tensor_str import set_printoptions
147
148 ################################################################################
149 # Define Storage and Tensor classes
150 ################################################################################
151
152 from .storage import _StorageBase
153 from .tensor import _TensorBase
154
155
156 class DoubleStorage(_C.DoubleStorageBase, _StorageBase):
157 pass
158
159
160 class FloatStorage(_C.FloatStorageBase, _StorageBase):
161 pass
162
163
164 class HalfStorage(_C.HalfStorageBase, _StorageBase):
165 pass
166
167
168 class LongStorage(_C.LongStorageBase, _StorageBase):
169 pass
170
171
172 class IntStorage(_C.IntStorageBase, _StorageBase):
173 pass
174
175
176 class ShortStorage(_C.ShortStorageBase, _StorageBase):
177 pass
178
179
180 class CharStorage(_C.CharStorageBase, _StorageBase):
181 pass
182
183
184 class ByteStorage(_C.ByteStorageBase, _StorageBase):
185 pass
186
187
188 class DoubleTensor(_C.DoubleTensorBase, _TensorBase):
189
190 def is_signed(self):
191 return True
192
193 @classmethod
194 def storage_type(cls):
195 return DoubleStorage
196
197
198 class FloatTensor(_C.FloatTensorBase, _TensorBase):
199
200 def is_signed(self):
201 return True
202
203 @classmethod
204 def storage_type(cls):
205 return FloatStorage
206
207
208 class HalfTensor(_C.HalfTensorBase, _TensorBase):
209
210 def is_signed(self):
211 return True
212
213 @classmethod
214 def storage_type(cls):
215 return HalfStorage
216
217
218 class LongTensor(_C.LongTensorBase, _TensorBase):
219
220 def is_signed(self):
221 return True
222
223 @classmethod
224 def storage_type(cls):
225 return LongStorage
226
227
228 class IntTensor(_C.IntTensorBase, _TensorBase):
229
230 def is_signed(self):
231 return True
232
233 @classmethod
234 def storage_type(cls):
235 return IntStorage
236
237
238 class ShortTensor(_C.ShortTensorBase, _TensorBase):
239
240 def is_signed(self):
241 return True
242
243 @classmethod
244 def storage_type(cls):
245 return ShortStorage
246
247
248 class CharTensor(_C.CharTensorBase, _TensorBase):
249
250 def is_signed(self):
251 # TODO
252 return False
253
254 @classmethod
255 def storage_type(cls):
256 return CharStorage
257
258
259 class ByteTensor(_C.ByteTensorBase, _TensorBase):
260
261 def is_signed(self):
262 return False
263
264 @classmethod
265 def storage_type(cls):
266 return ByteStorage
267
268
269 _storage_classes = {
270 DoubleStorage, FloatStorage, LongStorage, IntStorage, ShortStorage,
271 CharStorage, ByteStorage,
272 }
273
274 _tensor_classes = {
275 DoubleTensor, FloatTensor, LongTensor, IntTensor, ShortTensor,
276 CharTensor, ByteTensor,
277 }
278
279
280 set_default_tensor_type('torch.FloatTensor')
281
282 ################################################################################
283 # Import interface functions defined in Python
284 ################################################################################
285
286 from .functional import *
287
288
289 ################################################################################
290 # Initialize extension
291 ################################################################################
292
293 def manager_path():
294 import os
295 path = os.path.join(os.path.abspath(os.path.dirname(__file__)), 'lib', 'torch_shm_manager')
296 if not os.path.exists(path):
297 raise RuntimeError("Unable to find torch_shm_manager at " + path)
298 return path.encode('utf-8')
299
300
301 # Shared memory manager needs to know the exact location of manager executable
302 _C._initExtension(manager_path())
303 del manager_path
304
305 ################################################################################
306 # Remove unnecessary members
307 ################################################################################
308
309 del DoubleStorageBase
310 del FloatStorageBase
311 del LongStorageBase
312 del IntStorageBase
313 del ShortStorageBase
314 del CharStorageBase
315 del ByteStorageBase
316 del DoubleTensorBase
317 del FloatTensorBase
318 del LongTensorBase
319 del IntTensorBase
320 del ShortTensorBase
321 del CharTensorBase
322 del ByteTensorBase
323
324 del SparseDoubleTensorBase
325 del SparseFloatTensorBase
326 del SparseLongTensorBase
327 del SparseIntTensorBase
328 del SparseShortTensorBase
329 del SparseCharTensorBase
330 del SparseByteTensorBase
331
332 ################################################################################
333 # Import most common subpackages
334 ################################################################################
335
336 import torch.cuda
337 import torch.autograd
338 import torch.nn
339 import torch.optim
340 import torch.multiprocessing
341 import torch.sparse
342 import torch.utils.backcompat
343 _C._init_names(list(torch._tensor_classes) + list(torch._storage_classes))
344
345 # attach docstrings to torch and tensor functions
346 from . import _torch_docs, _tensor_docs, _storage_docs
347 del _torch_docs, _tensor_docs, _storage_docs
348
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/torch/__init__.py b/torch/__init__.py
--- a/torch/__init__.py
+++ b/torch/__init__.py
@@ -268,12 +268,12 @@
_storage_classes = {
DoubleStorage, FloatStorage, LongStorage, IntStorage, ShortStorage,
- CharStorage, ByteStorage,
+ CharStorage, ByteStorage, HalfStorage
}
_tensor_classes = {
DoubleTensor, FloatTensor, LongTensor, IntTensor, ShortTensor,
- CharTensor, ByteTensor,
+ CharTensor, ByteTensor, HalfTensor
}
|
{"golden_diff": "diff --git a/torch/__init__.py b/torch/__init__.py\n--- a/torch/__init__.py\n+++ b/torch/__init__.py\n@@ -268,12 +268,12 @@\n \n _storage_classes = {\n DoubleStorage, FloatStorage, LongStorage, IntStorage, ShortStorage,\n- CharStorage, ByteStorage,\n+ CharStorage, ByteStorage, HalfStorage\n }\n \n _tensor_classes = {\n DoubleTensor, FloatTensor, LongTensor, IntTensor, ShortTensor,\n- CharTensor, ByteTensor,\n+ CharTensor, ByteTensor, HalfTensor\n }\n", "issue": "torch.is_tensor(torch.HalfTensor()) returns False. \nThe problem is [here](https://github.com/pytorch/pytorch/blob/master/torch/__init__.py#L274).\n", "before_files": [{"content": "\"\"\"\nThe torch package contains data structures for multi-dimensional\ntensors and mathematical operations over these are defined.\nAdditionally, it provides many utilities for efficient serializing of\nTensors and arbitrary types, and other useful utilities.\n\nIt has a CUDA counterpart, that enables you to run your tensor computations\non an NVIDIA GPU with compute capability >= 2.0.\n\"\"\"\n\nimport sys\nfrom ._utils import _import_dotted_name\nfrom .version import __version__\n\n__all__ = [\n 'typename', 'is_tensor', 'is_storage', 'set_default_tensor_type',\n 'set_rng_state', 'get_rng_state', 'manual_seed', 'initial_seed',\n 'save', 'load', 'set_printoptions', 'chunk', 'split', 'stack', 'matmul',\n 'DoubleStorage', 'FloatStorage', 'LongStorage', 'IntStorage',\n 'ShortStorage', 'CharStorage', 'ByteStorage',\n 'DoubleTensor', 'FloatTensor', 'LongTensor', 'IntTensor',\n 'ShortTensor', 'CharTensor', 'ByteTensor',\n]\n\n################################################################################\n# Load the extension module\n################################################################################\n\n# Loading the extension with RTLD_GLOBAL option allows to not link extension\n# modules against the _C shared object. Their missing THP symbols will be\n# automatically filled by the dynamic loader.\nimport os as _dl_flags\n\n# if we have numpy, it *must* be imported before the call to setdlopenflags()\n# or there is risk that later c modules will segfault when importing numpy\ntry:\n import numpy as np\nexcept:\n pass\n\n# first check if the os package has the required flags\nif not hasattr(_dl_flags, 'RTLD_GLOBAL') or not hasattr(_dl_flags, 'RTLD_NOW'):\n try:\n # next try if DLFCN exists\n import DLFCN as _dl_flags\n except ImportError:\n # as a last attempt, use compile-time constants\n import torch._dl as _dl_flags\n\nold_flags = sys.getdlopenflags()\nsys.setdlopenflags(_dl_flags.RTLD_GLOBAL | _dl_flags.RTLD_NOW)\n\nfrom torch._C import *\n\n__all__ += [name for name in dir(_C)\n if name[0] != '_' and\n not name.endswith('Base')]\n\nsys.setdlopenflags(old_flags)\ndel _dl_flags\ndel old_flags\n\n################################################################################\n# Define basic utilities\n################################################################################\n\n\ndef typename(o):\n module = ''\n class_name = ''\n if hasattr(o, '__module__') and o.__module__ != 'builtins' \\\n and o.__module__ != '__builtin__' and o.__module__ is not None:\n module = o.__module__ + '.'\n\n if hasattr(o, '__qualname__'):\n class_name = o.__qualname__\n elif hasattr(o, '__name__'):\n class_name = o.__name__\n else:\n class_name = o.__class__.__name__\n\n return module + class_name\n\n\ndef is_tensor(obj):\n r\"\"\"Returns True if `obj` is a pytorch tensor.\n\n Args:\n obj (Object): Object to test\n \"\"\"\n return type(obj) in _tensor_classes\n\n\ndef is_storage(obj):\n r\"\"\"Returns True if `obj` is a pytorch storage object.\n\n Args:\n obj (Object): Object to test\n \"\"\"\n return type(obj) in _storage_classes\n\n\ndef set_default_tensor_type(t):\n global Tensor\n global Storage\n Tensor = _import_dotted_name(t)\n Storage = _import_dotted_name(t.replace('Tensor', 'Storage'))\n _C._set_default_tensor_type(Tensor)\n\n\ndef set_rng_state(new_state):\n r\"\"\"Sets the random number generator state.\n\n Args:\n new_state (torch.ByteTensor): The desired state\n \"\"\"\n default_generator.set_state(new_state)\n\n\ndef get_rng_state():\n r\"\"\"Returns the random number generator state as a ByteTensor.\"\"\"\n return default_generator.get_state()\n\n\ndef manual_seed(seed):\n r\"\"\"Sets the seed for generating random numbers. And returns a\n `torch._C.Generator` object.\n\n Args:\n seed (int or long): The desired seed.\n \"\"\"\n if torch.cuda.is_available() and not torch.cuda._in_bad_fork:\n torch.cuda.manual_seed_all(seed)\n\n return default_generator.manual_seed(seed)\n\n\ndef initial_seed():\n r\"\"\"Returns the initial seed for generating random numbers as a\n python `long`.\n \"\"\"\n return default_generator.initial_seed()\n\n\nfrom .serialization import save, load\nfrom ._tensor_str import set_printoptions\n\n################################################################################\n# Define Storage and Tensor classes\n################################################################################\n\nfrom .storage import _StorageBase\nfrom .tensor import _TensorBase\n\n\nclass DoubleStorage(_C.DoubleStorageBase, _StorageBase):\n pass\n\n\nclass FloatStorage(_C.FloatStorageBase, _StorageBase):\n pass\n\n\nclass HalfStorage(_C.HalfStorageBase, _StorageBase):\n pass\n\n\nclass LongStorage(_C.LongStorageBase, _StorageBase):\n pass\n\n\nclass IntStorage(_C.IntStorageBase, _StorageBase):\n pass\n\n\nclass ShortStorage(_C.ShortStorageBase, _StorageBase):\n pass\n\n\nclass CharStorage(_C.CharStorageBase, _StorageBase):\n pass\n\n\nclass ByteStorage(_C.ByteStorageBase, _StorageBase):\n pass\n\n\nclass DoubleTensor(_C.DoubleTensorBase, _TensorBase):\n\n def is_signed(self):\n return True\n\n @classmethod\n def storage_type(cls):\n return DoubleStorage\n\n\nclass FloatTensor(_C.FloatTensorBase, _TensorBase):\n\n def is_signed(self):\n return True\n\n @classmethod\n def storage_type(cls):\n return FloatStorage\n\n\nclass HalfTensor(_C.HalfTensorBase, _TensorBase):\n\n def is_signed(self):\n return True\n\n @classmethod\n def storage_type(cls):\n return HalfStorage\n\n\nclass LongTensor(_C.LongTensorBase, _TensorBase):\n\n def is_signed(self):\n return True\n\n @classmethod\n def storage_type(cls):\n return LongStorage\n\n\nclass IntTensor(_C.IntTensorBase, _TensorBase):\n\n def is_signed(self):\n return True\n\n @classmethod\n def storage_type(cls):\n return IntStorage\n\n\nclass ShortTensor(_C.ShortTensorBase, _TensorBase):\n\n def is_signed(self):\n return True\n\n @classmethod\n def storage_type(cls):\n return ShortStorage\n\n\nclass CharTensor(_C.CharTensorBase, _TensorBase):\n\n def is_signed(self):\n # TODO\n return False\n\n @classmethod\n def storage_type(cls):\n return CharStorage\n\n\nclass ByteTensor(_C.ByteTensorBase, _TensorBase):\n\n def is_signed(self):\n return False\n\n @classmethod\n def storage_type(cls):\n return ByteStorage\n\n\n_storage_classes = {\n DoubleStorage, FloatStorage, LongStorage, IntStorage, ShortStorage,\n CharStorage, ByteStorage,\n}\n\n_tensor_classes = {\n DoubleTensor, FloatTensor, LongTensor, IntTensor, ShortTensor,\n CharTensor, ByteTensor,\n}\n\n\nset_default_tensor_type('torch.FloatTensor')\n\n################################################################################\n# Import interface functions defined in Python\n################################################################################\n\nfrom .functional import *\n\n\n################################################################################\n# Initialize extension\n################################################################################\n\ndef manager_path():\n import os\n path = os.path.join(os.path.abspath(os.path.dirname(__file__)), 'lib', 'torch_shm_manager')\n if not os.path.exists(path):\n raise RuntimeError(\"Unable to find torch_shm_manager at \" + path)\n return path.encode('utf-8')\n\n\n# Shared memory manager needs to know the exact location of manager executable\n_C._initExtension(manager_path())\ndel manager_path\n\n################################################################################\n# Remove unnecessary members\n################################################################################\n\ndel DoubleStorageBase\ndel FloatStorageBase\ndel LongStorageBase\ndel IntStorageBase\ndel ShortStorageBase\ndel CharStorageBase\ndel ByteStorageBase\ndel DoubleTensorBase\ndel FloatTensorBase\ndel LongTensorBase\ndel IntTensorBase\ndel ShortTensorBase\ndel CharTensorBase\ndel ByteTensorBase\n\ndel SparseDoubleTensorBase\ndel SparseFloatTensorBase\ndel SparseLongTensorBase\ndel SparseIntTensorBase\ndel SparseShortTensorBase\ndel SparseCharTensorBase\ndel SparseByteTensorBase\n\n################################################################################\n# Import most common subpackages\n################################################################################\n\nimport torch.cuda\nimport torch.autograd\nimport torch.nn\nimport torch.optim\nimport torch.multiprocessing\nimport torch.sparse\nimport torch.utils.backcompat\n_C._init_names(list(torch._tensor_classes) + list(torch._storage_classes))\n\n# attach docstrings to torch and tensor functions\nfrom . import _torch_docs, _tensor_docs, _storage_docs\ndel _torch_docs, _tensor_docs, _storage_docs\n", "path": "torch/__init__.py"}], "after_files": [{"content": "\"\"\"\nThe torch package contains data structures for multi-dimensional\ntensors and mathematical operations over these are defined.\nAdditionally, it provides many utilities for efficient serializing of\nTensors and arbitrary types, and other useful utilities.\n\nIt has a CUDA counterpart, that enables you to run your tensor computations\non an NVIDIA GPU with compute capability >= 2.0.\n\"\"\"\n\nimport sys\nfrom ._utils import _import_dotted_name\nfrom .version import __version__\n\n__all__ = [\n 'typename', 'is_tensor', 'is_storage', 'set_default_tensor_type',\n 'set_rng_state', 'get_rng_state', 'manual_seed', 'initial_seed',\n 'save', 'load', 'set_printoptions', 'chunk', 'split', 'stack', 'matmul',\n 'DoubleStorage', 'FloatStorage', 'LongStorage', 'IntStorage',\n 'ShortStorage', 'CharStorage', 'ByteStorage',\n 'DoubleTensor', 'FloatTensor', 'LongTensor', 'IntTensor',\n 'ShortTensor', 'CharTensor', 'ByteTensor',\n]\n\n################################################################################\n# Load the extension module\n################################################################################\n\n# Loading the extension with RTLD_GLOBAL option allows to not link extension\n# modules against the _C shared object. Their missing THP symbols will be\n# automatically filled by the dynamic loader.\nimport os as _dl_flags\n\n# if we have numpy, it *must* be imported before the call to setdlopenflags()\n# or there is risk that later c modules will segfault when importing numpy\ntry:\n import numpy as np\nexcept:\n pass\n\n# first check if the os package has the required flags\nif not hasattr(_dl_flags, 'RTLD_GLOBAL') or not hasattr(_dl_flags, 'RTLD_NOW'):\n try:\n # next try if DLFCN exists\n import DLFCN as _dl_flags\n except ImportError:\n # as a last attempt, use compile-time constants\n import torch._dl as _dl_flags\n\nold_flags = sys.getdlopenflags()\nsys.setdlopenflags(_dl_flags.RTLD_GLOBAL | _dl_flags.RTLD_NOW)\n\nfrom torch._C import *\n\n__all__ += [name for name in dir(_C)\n if name[0] != '_' and\n not name.endswith('Base')]\n\nsys.setdlopenflags(old_flags)\ndel _dl_flags\ndel old_flags\n\n################################################################################\n# Define basic utilities\n################################################################################\n\n\ndef typename(o):\n module = ''\n class_name = ''\n if hasattr(o, '__module__') and o.__module__ != 'builtins' \\\n and o.__module__ != '__builtin__' and o.__module__ is not None:\n module = o.__module__ + '.'\n\n if hasattr(o, '__qualname__'):\n class_name = o.__qualname__\n elif hasattr(o, '__name__'):\n class_name = o.__name__\n else:\n class_name = o.__class__.__name__\n\n return module + class_name\n\n\ndef is_tensor(obj):\n r\"\"\"Returns True if `obj` is a pytorch tensor.\n\n Args:\n obj (Object): Object to test\n \"\"\"\n return type(obj) in _tensor_classes\n\n\ndef is_storage(obj):\n r\"\"\"Returns True if `obj` is a pytorch storage object.\n\n Args:\n obj (Object): Object to test\n \"\"\"\n return type(obj) in _storage_classes\n\n\ndef set_default_tensor_type(t):\n global Tensor\n global Storage\n Tensor = _import_dotted_name(t)\n Storage = _import_dotted_name(t.replace('Tensor', 'Storage'))\n _C._set_default_tensor_type(Tensor)\n\n\ndef set_rng_state(new_state):\n r\"\"\"Sets the random number generator state.\n\n Args:\n new_state (torch.ByteTensor): The desired state\n \"\"\"\n default_generator.set_state(new_state)\n\n\ndef get_rng_state():\n r\"\"\"Returns the random number generator state as a ByteTensor.\"\"\"\n return default_generator.get_state()\n\n\ndef manual_seed(seed):\n r\"\"\"Sets the seed for generating random numbers. And returns a\n `torch._C.Generator` object.\n\n Args:\n seed (int or long): The desired seed.\n \"\"\"\n if torch.cuda.is_available() and not torch.cuda._in_bad_fork:\n torch.cuda.manual_seed_all(seed)\n\n return default_generator.manual_seed(seed)\n\n\ndef initial_seed():\n r\"\"\"Returns the initial seed for generating random numbers as a\n python `long`.\n \"\"\"\n return default_generator.initial_seed()\n\n\nfrom .serialization import save, load\nfrom ._tensor_str import set_printoptions\n\n################################################################################\n# Define Storage and Tensor classes\n################################################################################\n\nfrom .storage import _StorageBase\nfrom .tensor import _TensorBase\n\n\nclass DoubleStorage(_C.DoubleStorageBase, _StorageBase):\n pass\n\n\nclass FloatStorage(_C.FloatStorageBase, _StorageBase):\n pass\n\n\nclass HalfStorage(_C.HalfStorageBase, _StorageBase):\n pass\n\n\nclass LongStorage(_C.LongStorageBase, _StorageBase):\n pass\n\n\nclass IntStorage(_C.IntStorageBase, _StorageBase):\n pass\n\n\nclass ShortStorage(_C.ShortStorageBase, _StorageBase):\n pass\n\n\nclass CharStorage(_C.CharStorageBase, _StorageBase):\n pass\n\n\nclass ByteStorage(_C.ByteStorageBase, _StorageBase):\n pass\n\n\nclass DoubleTensor(_C.DoubleTensorBase, _TensorBase):\n\n def is_signed(self):\n return True\n\n @classmethod\n def storage_type(cls):\n return DoubleStorage\n\n\nclass FloatTensor(_C.FloatTensorBase, _TensorBase):\n\n def is_signed(self):\n return True\n\n @classmethod\n def storage_type(cls):\n return FloatStorage\n\n\nclass HalfTensor(_C.HalfTensorBase, _TensorBase):\n\n def is_signed(self):\n return True\n\n @classmethod\n def storage_type(cls):\n return HalfStorage\n\n\nclass LongTensor(_C.LongTensorBase, _TensorBase):\n\n def is_signed(self):\n return True\n\n @classmethod\n def storage_type(cls):\n return LongStorage\n\n\nclass IntTensor(_C.IntTensorBase, _TensorBase):\n\n def is_signed(self):\n return True\n\n @classmethod\n def storage_type(cls):\n return IntStorage\n\n\nclass ShortTensor(_C.ShortTensorBase, _TensorBase):\n\n def is_signed(self):\n return True\n\n @classmethod\n def storage_type(cls):\n return ShortStorage\n\n\nclass CharTensor(_C.CharTensorBase, _TensorBase):\n\n def is_signed(self):\n # TODO\n return False\n\n @classmethod\n def storage_type(cls):\n return CharStorage\n\n\nclass ByteTensor(_C.ByteTensorBase, _TensorBase):\n\n def is_signed(self):\n return False\n\n @classmethod\n def storage_type(cls):\n return ByteStorage\n\n\n_storage_classes = {\n DoubleStorage, FloatStorage, LongStorage, IntStorage, ShortStorage,\n CharStorage, ByteStorage, HalfStorage\n}\n\n_tensor_classes = {\n DoubleTensor, FloatTensor, LongTensor, IntTensor, ShortTensor,\n CharTensor, ByteTensor, HalfTensor\n}\n\n\nset_default_tensor_type('torch.FloatTensor')\n\n################################################################################\n# Import interface functions defined in Python\n################################################################################\n\nfrom .functional import *\n\n\n################################################################################\n# Initialize extension\n################################################################################\n\ndef manager_path():\n import os\n path = os.path.join(os.path.abspath(os.path.dirname(__file__)), 'lib', 'torch_shm_manager')\n if not os.path.exists(path):\n raise RuntimeError(\"Unable to find torch_shm_manager at \" + path)\n return path.encode('utf-8')\n\n\n# Shared memory manager needs to know the exact location of manager executable\n_C._initExtension(manager_path())\ndel manager_path\n\n################################################################################\n# Remove unnecessary members\n################################################################################\n\ndel DoubleStorageBase\ndel FloatStorageBase\ndel LongStorageBase\ndel IntStorageBase\ndel ShortStorageBase\ndel CharStorageBase\ndel ByteStorageBase\ndel DoubleTensorBase\ndel FloatTensorBase\ndel LongTensorBase\ndel IntTensorBase\ndel ShortTensorBase\ndel CharTensorBase\ndel ByteTensorBase\n\ndel SparseDoubleTensorBase\ndel SparseFloatTensorBase\ndel SparseLongTensorBase\ndel SparseIntTensorBase\ndel SparseShortTensorBase\ndel SparseCharTensorBase\ndel SparseByteTensorBase\n\n################################################################################\n# Import most common subpackages\n################################################################################\n\nimport torch.cuda\nimport torch.autograd\nimport torch.nn\nimport torch.optim\nimport torch.multiprocessing\nimport torch.sparse\nimport torch.utils.backcompat\n_C._init_names(list(torch._tensor_classes) + list(torch._storage_classes))\n\n# attach docstrings to torch and tensor functions\nfrom . import _torch_docs, _tensor_docs, _storage_docs\ndel _torch_docs, _tensor_docs, _storage_docs\n", "path": "torch/__init__.py"}]}
| 3,168 | 136 |
gh_patches_debug_37361
|
rasdani/github-patches
|
git_diff
|
mindsdb__lightwood-1204
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Improve "Unit" mixer documentation
We don't have a docstring for this mixer. The challenge here is to eloquently describe what this mixer does (hint: it can be used when encoders themselves are the models, e.g. pretrained language models that receive a single column as input).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lightwood/mixer/unit.py`
Content:
```
1 """
2 2021.07.16
3
4 For encoders that already fine-tune on the targets (namely text)
5 the unity mixer just arg-maxes the output of the encoder.
6 """
7
8 from typing import List, Optional
9
10 import torch
11 import pandas as pd
12
13 from lightwood.helpers.log import log
14 from lightwood.mixer.base import BaseMixer
15 from lightwood.encoder.base import BaseEncoder
16 from lightwood.data.encoded_ds import EncodedDs
17 from lightwood.api.types import PredictionArguments
18
19
20 class Unit(BaseMixer):
21 def __init__(self, stop_after: float, target_encoder: BaseEncoder):
22 super().__init__(stop_after)
23 self.target_encoder = target_encoder
24 self.supports_proba = False
25 self.stable = True
26
27 def fit(self, train_data: EncodedDs, dev_data: EncodedDs) -> None:
28 log.info("Unit Mixer just borrows from encoder")
29
30 def partial_fit(self, train_data: EncodedDs, dev_data: EncodedDs, args: Optional[dict] = None) -> None:
31 pass
32
33 def __call__(self, ds: EncodedDs,
34 args: PredictionArguments = PredictionArguments()) -> pd.DataFrame:
35 if args.predict_proba:
36 # @TODO: depending on the target encoder, this might be enabled
37 log.warning('This model does not output probability estimates')
38
39 decoded_predictions: List[object] = []
40
41 for X, _ in ds:
42 decoded_prediction = self.target_encoder.decode(torch.unsqueeze(X, 0))
43 decoded_predictions.extend(decoded_prediction)
44
45 ydf = pd.DataFrame({"prediction": decoded_predictions})
46 return ydf
47
```
Path: `lightwood/mixer/base.py`
Content:
```
1 from typing import Optional
2 import pandas as pd
3
4 from lightwood.data.encoded_ds import EncodedDs
5 from lightwood.api.types import PredictionArguments
6
7
8 class BaseMixer:
9 """
10 Base class for all mixers.
11
12 Mixers are the backbone of all Lightwood machine learning models. They intake encoded feature representations for every column, and are tasked with learning to fulfill the predictive requirements stated in a problem definition.
13
14 There are two important methods for any mixer to work:
15 1. `fit()` contains all logic to train the mixer with the training data that has been encoded by all the (already trained) Lightwood encoders for any given task.
16 2. `__call__()` is executed to generate predictions once the mixer has been trained using `fit()`.
17
18 An additional `partial_fit()` method is used to update any mixer that has already been trained.
19
20 Class Attributes:
21 - stable: If set to `True`, this mixer should always work. Any mixer with `stable=False` can be expected to fail under some circumstances.
22 - fit_data_len: Length of the training data.
23 - supports_proba: For classification tasks, whether the mixer supports yielding per-class scores rather than only returning the predicted label.
24 - trains_once: If True, the mixer is trained once during learn, using all available input data (`train` and `dev` splits for training, `test` for validation). Otherwise, it trains once with the `train`` split & `dev` for validation, and optionally (depending on the problem definition `fit_on_all` and mixer-wise `fit_on_dev` arguments) a second time after post-training analysis via partial_fit, with `train` and `dev` splits as training subset, and `test` split as validation. Should only be set to True for mixers that don't require post-training analysis, as otherwise actual validation data would be treated as a held-out portion, which is a mistake.
25 """ # noqa
26 stable: bool
27 fit_data_len: int # @TODO (Patricio): should this really be in `BaseMixer`?
28 supports_proba: bool
29 trains_once: bool
30
31 def __init__(self, stop_after: float):
32 """
33 :param stop_after: Time budget to train this mixer.
34 """
35 self.stop_after = stop_after
36 self.supports_proba = False
37 self.trains_once = False
38
39 def fit(self, train_data: EncodedDs, dev_data: EncodedDs) -> None:
40 """
41 Fits/trains a mixer with training data.
42
43 :param train_data: encoded representations of the training data subset.
44 :param dev_data: encoded representations of the "dev" data subset. This can be used as an internal validation subset (e.g. it is used for early stopping in the default `Neural` mixer).
45
46 """ # noqa
47 raise NotImplementedError()
48
49 def __call__(self, ds: EncodedDs,
50 args: PredictionArguments = PredictionArguments()) -> pd.DataFrame:
51 """
52 Calls a trained mixer to predict the target column given some input data.
53
54 :param ds: encoded representations of input data.
55 :param args: a `lightwood.api.types.PredictionArguments` object, including all relevant inference-time arguments to customize the behavior.
56 :return:
57 """ # noqa
58 raise NotImplementedError()
59
60 def partial_fit(self, train_data: EncodedDs, dev_data: EncodedDs, adjust_args: Optional[dict] = None) -> None:
61 """
62 Partially fits/trains a mixer with new training data. This is a somewhat experimental method, and it aims at updating pre-existing Lightwood predictors.
63
64 :param train_data: encoded representations of the new training data subset.
65 :param dev_data: encoded representations of new the "dev" data subset. As in `fit()`, this can be used as an internal validation subset.
66 :param adjust_args: optional arguments to customize the finetuning process.
67
68 """ # noqa
69 pass
70
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lightwood/mixer/base.py b/lightwood/mixer/base.py
--- a/lightwood/mixer/base.py
+++ b/lightwood/mixer/base.py
@@ -30,7 +30,7 @@
def __init__(self, stop_after: float):
"""
- :param stop_after: Time budget to train this mixer.
+ :param stop_after: Time budget (in seconds) to train this mixer.
"""
self.stop_after = stop_after
self.supports_proba = False
diff --git a/lightwood/mixer/unit.py b/lightwood/mixer/unit.py
--- a/lightwood/mixer/unit.py
+++ b/lightwood/mixer/unit.py
@@ -1,10 +1,3 @@
-"""
-2021.07.16
-
-For encoders that already fine-tune on the targets (namely text)
-the unity mixer just arg-maxes the output of the encoder.
-"""
-
from typing import List, Optional
import torch
@@ -19,19 +12,35 @@
class Unit(BaseMixer):
def __init__(self, stop_after: float, target_encoder: BaseEncoder):
+ """
+ The "Unit" mixer serves as a simple wrapper around a target encoder, essentially borrowing
+ the encoder's functionality for predictions. In other words, it simply arg-maxes the output of the encoder
+
+ Used with encoders that already fine-tune on the targets (namely, pre-trained text ML models).
+
+ Attributes:
+ :param target_encoder: An instance of a Lightwood BaseEncoder. This encoder is used to decode predictions.
+ :param stop_after (float): Time budget (in seconds) to train this mixer.
+ """ # noqa
super().__init__(stop_after)
self.target_encoder = target_encoder
self.supports_proba = False
self.stable = True
def fit(self, train_data: EncodedDs, dev_data: EncodedDs) -> None:
- log.info("Unit Mixer just borrows from encoder")
+ log.info("Unit mixer does not require training, it passes through predictions from its encoders.")
def partial_fit(self, train_data: EncodedDs, dev_data: EncodedDs, args: Optional[dict] = None) -> None:
pass
def __call__(self, ds: EncodedDs,
args: PredictionArguments = PredictionArguments()) -> pd.DataFrame:
+ """
+ Makes predictions using the provided EncodedDs dataset.
+ Mixer decodes predictions using the target encoder and returns them in a pandas DataFrame.
+
+ :returns ydf (pd.DataFrame): a data frame containing the decoded predictions.
+ """
if args.predict_proba:
# @TODO: depending on the target encoder, this might be enabled
log.warning('This model does not output probability estimates')
|
{"golden_diff": "diff --git a/lightwood/mixer/base.py b/lightwood/mixer/base.py\n--- a/lightwood/mixer/base.py\n+++ b/lightwood/mixer/base.py\n@@ -30,7 +30,7 @@\n \n def __init__(self, stop_after: float):\n \"\"\"\n- :param stop_after: Time budget to train this mixer.\n+ :param stop_after: Time budget (in seconds) to train this mixer.\n \"\"\"\n self.stop_after = stop_after\n self.supports_proba = False\ndiff --git a/lightwood/mixer/unit.py b/lightwood/mixer/unit.py\n--- a/lightwood/mixer/unit.py\n+++ b/lightwood/mixer/unit.py\n@@ -1,10 +1,3 @@\n-\"\"\"\n-2021.07.16\n-\n-For encoders that already fine-tune on the targets (namely text)\n-the unity mixer just arg-maxes the output of the encoder.\n-\"\"\"\n-\n from typing import List, Optional\n \n import torch\n@@ -19,19 +12,35 @@\n \n class Unit(BaseMixer):\n def __init__(self, stop_after: float, target_encoder: BaseEncoder):\n+ \"\"\"\n+ The \"Unit\" mixer serves as a simple wrapper around a target encoder, essentially borrowing \n+ the encoder's functionality for predictions. In other words, it simply arg-maxes the output of the encoder\n+\n+ Used with encoders that already fine-tune on the targets (namely, pre-trained text ML models).\n+ \n+ Attributes:\n+ :param target_encoder: An instance of a Lightwood BaseEncoder. This encoder is used to decode predictions.\n+ :param stop_after (float): Time budget (in seconds) to train this mixer. \n+ \"\"\" # noqa\n super().__init__(stop_after)\n self.target_encoder = target_encoder\n self.supports_proba = False\n self.stable = True\n \n def fit(self, train_data: EncodedDs, dev_data: EncodedDs) -> None:\n- log.info(\"Unit Mixer just borrows from encoder\")\n+ log.info(\"Unit mixer does not require training, it passes through predictions from its encoders.\")\n \n def partial_fit(self, train_data: EncodedDs, dev_data: EncodedDs, args: Optional[dict] = None) -> None:\n pass\n \n def __call__(self, ds: EncodedDs,\n args: PredictionArguments = PredictionArguments()) -> pd.DataFrame:\n+ \"\"\"\n+ Makes predictions using the provided EncodedDs dataset.\n+ Mixer decodes predictions using the target encoder and returns them in a pandas DataFrame.\n+\n+ :returns ydf (pd.DataFrame): a data frame containing the decoded predictions.\n+ \"\"\"\n if args.predict_proba:\n # @TODO: depending on the target encoder, this might be enabled\n log.warning('This model does not output probability estimates')\n", "issue": "Improve \"Unit\" mixer documentation\nWe don't have a docstring for this mixer. The challenge here is to eloquently describe what this mixer does (hint: it can be used when encoders themselves are the models, e.g. pretrained language models that receive a single column as input).\n", "before_files": [{"content": "\"\"\"\n2021.07.16\n\nFor encoders that already fine-tune on the targets (namely text)\nthe unity mixer just arg-maxes the output of the encoder.\n\"\"\"\n\nfrom typing import List, Optional\n\nimport torch\nimport pandas as pd\n\nfrom lightwood.helpers.log import log\nfrom lightwood.mixer.base import BaseMixer\nfrom lightwood.encoder.base import BaseEncoder\nfrom lightwood.data.encoded_ds import EncodedDs\nfrom lightwood.api.types import PredictionArguments\n\n\nclass Unit(BaseMixer):\n def __init__(self, stop_after: float, target_encoder: BaseEncoder):\n super().__init__(stop_after)\n self.target_encoder = target_encoder\n self.supports_proba = False\n self.stable = True\n\n def fit(self, train_data: EncodedDs, dev_data: EncodedDs) -> None:\n log.info(\"Unit Mixer just borrows from encoder\")\n\n def partial_fit(self, train_data: EncodedDs, dev_data: EncodedDs, args: Optional[dict] = None) -> None:\n pass\n\n def __call__(self, ds: EncodedDs,\n args: PredictionArguments = PredictionArguments()) -> pd.DataFrame:\n if args.predict_proba:\n # @TODO: depending on the target encoder, this might be enabled\n log.warning('This model does not output probability estimates')\n\n decoded_predictions: List[object] = []\n\n for X, _ in ds:\n decoded_prediction = self.target_encoder.decode(torch.unsqueeze(X, 0))\n decoded_predictions.extend(decoded_prediction)\n\n ydf = pd.DataFrame({\"prediction\": decoded_predictions})\n return ydf\n", "path": "lightwood/mixer/unit.py"}, {"content": "from typing import Optional\nimport pandas as pd\n\nfrom lightwood.data.encoded_ds import EncodedDs\nfrom lightwood.api.types import PredictionArguments\n\n\nclass BaseMixer:\n \"\"\"\n Base class for all mixers.\n\n Mixers are the backbone of all Lightwood machine learning models. They intake encoded feature representations for every column, and are tasked with learning to fulfill the predictive requirements stated in a problem definition.\n \n There are two important methods for any mixer to work:\n 1. `fit()` contains all logic to train the mixer with the training data that has been encoded by all the (already trained) Lightwood encoders for any given task.\n 2. `__call__()` is executed to generate predictions once the mixer has been trained using `fit()`. \n \n An additional `partial_fit()` method is used to update any mixer that has already been trained.\n\n Class Attributes:\n - stable: If set to `True`, this mixer should always work. Any mixer with `stable=False` can be expected to fail under some circumstances.\n - fit_data_len: Length of the training data.\n - supports_proba: For classification tasks, whether the mixer supports yielding per-class scores rather than only returning the predicted label. \n - trains_once: If True, the mixer is trained once during learn, using all available input data (`train` and `dev` splits for training, `test` for validation). Otherwise, it trains once with the `train`` split & `dev` for validation, and optionally (depending on the problem definition `fit_on_all` and mixer-wise `fit_on_dev` arguments) a second time after post-training analysis via partial_fit, with `train` and `dev` splits as training subset, and `test` split as validation. Should only be set to True for mixers that don't require post-training analysis, as otherwise actual validation data would be treated as a held-out portion, which is a mistake. \n \"\"\" # noqa\n stable: bool\n fit_data_len: int # @TODO (Patricio): should this really be in `BaseMixer`?\n supports_proba: bool\n trains_once: bool\n\n def __init__(self, stop_after: float):\n \"\"\"\n :param stop_after: Time budget to train this mixer.\n \"\"\"\n self.stop_after = stop_after\n self.supports_proba = False\n self.trains_once = False\n\n def fit(self, train_data: EncodedDs, dev_data: EncodedDs) -> None:\n \"\"\"\n Fits/trains a mixer with training data. \n \n :param train_data: encoded representations of the training data subset. \n :param dev_data: encoded representations of the \"dev\" data subset. This can be used as an internal validation subset (e.g. it is used for early stopping in the default `Neural` mixer). \n \n \"\"\" # noqa\n raise NotImplementedError()\n\n def __call__(self, ds: EncodedDs,\n args: PredictionArguments = PredictionArguments()) -> pd.DataFrame:\n \"\"\"\n Calls a trained mixer to predict the target column given some input data.\n \n :param ds: encoded representations of input data.\n :param args: a `lightwood.api.types.PredictionArguments` object, including all relevant inference-time arguments to customize the behavior.\n :return: \n \"\"\" # noqa\n raise NotImplementedError()\n\n def partial_fit(self, train_data: EncodedDs, dev_data: EncodedDs, adjust_args: Optional[dict] = None) -> None:\n \"\"\"\n Partially fits/trains a mixer with new training data. This is a somewhat experimental method, and it aims at updating pre-existing Lightwood predictors. \n\n :param train_data: encoded representations of the new training data subset. \n :param dev_data: encoded representations of new the \"dev\" data subset. As in `fit()`, this can be used as an internal validation subset. \n :param adjust_args: optional arguments to customize the finetuning process.\n\n \"\"\" # noqa\n pass\n", "path": "lightwood/mixer/base.py"}], "after_files": [{"content": "from typing import List, Optional\n\nimport torch\nimport pandas as pd\n\nfrom lightwood.helpers.log import log\nfrom lightwood.mixer.base import BaseMixer\nfrom lightwood.encoder.base import BaseEncoder\nfrom lightwood.data.encoded_ds import EncodedDs\nfrom lightwood.api.types import PredictionArguments\n\n\nclass Unit(BaseMixer):\n def __init__(self, stop_after: float, target_encoder: BaseEncoder):\n \"\"\"\n The \"Unit\" mixer serves as a simple wrapper around a target encoder, essentially borrowing \n the encoder's functionality for predictions. In other words, it simply arg-maxes the output of the encoder\n\n Used with encoders that already fine-tune on the targets (namely, pre-trained text ML models).\n \n Attributes:\n :param target_encoder: An instance of a Lightwood BaseEncoder. This encoder is used to decode predictions.\n :param stop_after (float): Time budget (in seconds) to train this mixer. \n \"\"\" # noqa\n super().__init__(stop_after)\n self.target_encoder = target_encoder\n self.supports_proba = False\n self.stable = True\n\n def fit(self, train_data: EncodedDs, dev_data: EncodedDs) -> None:\n log.info(\"Unit mixer does not require training, it passes through predictions from its encoders.\")\n\n def partial_fit(self, train_data: EncodedDs, dev_data: EncodedDs, args: Optional[dict] = None) -> None:\n pass\n\n def __call__(self, ds: EncodedDs,\n args: PredictionArguments = PredictionArguments()) -> pd.DataFrame:\n \"\"\"\n Makes predictions using the provided EncodedDs dataset.\n Mixer decodes predictions using the target encoder and returns them in a pandas DataFrame.\n\n :returns ydf (pd.DataFrame): a data frame containing the decoded predictions.\n \"\"\"\n if args.predict_proba:\n # @TODO: depending on the target encoder, this might be enabled\n log.warning('This model does not output probability estimates')\n\n decoded_predictions: List[object] = []\n\n for X, _ in ds:\n decoded_prediction = self.target_encoder.decode(torch.unsqueeze(X, 0))\n decoded_predictions.extend(decoded_prediction)\n\n ydf = pd.DataFrame({\"prediction\": decoded_predictions})\n return ydf\n", "path": "lightwood/mixer/unit.py"}, {"content": "from typing import Optional\nimport pandas as pd\n\nfrom lightwood.data.encoded_ds import EncodedDs\nfrom lightwood.api.types import PredictionArguments\n\n\nclass BaseMixer:\n \"\"\"\n Base class for all mixers.\n\n Mixers are the backbone of all Lightwood machine learning models. They intake encoded feature representations for every column, and are tasked with learning to fulfill the predictive requirements stated in a problem definition.\n \n There are two important methods for any mixer to work:\n 1. `fit()` contains all logic to train the mixer with the training data that has been encoded by all the (already trained) Lightwood encoders for any given task.\n 2. `__call__()` is executed to generate predictions once the mixer has been trained using `fit()`. \n \n An additional `partial_fit()` method is used to update any mixer that has already been trained.\n\n Class Attributes:\n - stable: If set to `True`, this mixer should always work. Any mixer with `stable=False` can be expected to fail under some circumstances.\n - fit_data_len: Length of the training data.\n - supports_proba: For classification tasks, whether the mixer supports yielding per-class scores rather than only returning the predicted label. \n - trains_once: If True, the mixer is trained once during learn, using all available input data (`train` and `dev` splits for training, `test` for validation). Otherwise, it trains once with the `train`` split & `dev` for validation, and optionally (depending on the problem definition `fit_on_all` and mixer-wise `fit_on_dev` arguments) a second time after post-training analysis via partial_fit, with `train` and `dev` splits as training subset, and `test` split as validation. Should only be set to True for mixers that don't require post-training analysis, as otherwise actual validation data would be treated as a held-out portion, which is a mistake. \n \"\"\" # noqa\n stable: bool\n fit_data_len: int # @TODO (Patricio): should this really be in `BaseMixer`?\n supports_proba: bool\n trains_once: bool\n\n def __init__(self, stop_after: float):\n \"\"\"\n :param stop_after: Time budget (in seconds) to train this mixer.\n \"\"\"\n self.stop_after = stop_after\n self.supports_proba = False\n self.trains_once = False\n\n def fit(self, train_data: EncodedDs, dev_data: EncodedDs) -> None:\n \"\"\"\n Fits/trains a mixer with training data. \n \n :param train_data: encoded representations of the training data subset. \n :param dev_data: encoded representations of the \"dev\" data subset. This can be used as an internal validation subset (e.g. it is used for early stopping in the default `Neural` mixer). \n \n \"\"\" # noqa\n raise NotImplementedError()\n\n def __call__(self, ds: EncodedDs,\n args: PredictionArguments = PredictionArguments()) -> pd.DataFrame:\n \"\"\"\n Calls a trained mixer to predict the target column given some input data.\n \n :param ds: encoded representations of input data.\n :param args: a `lightwood.api.types.PredictionArguments` object, including all relevant inference-time arguments to customize the behavior.\n :return: \n \"\"\" # noqa\n raise NotImplementedError()\n\n def partial_fit(self, train_data: EncodedDs, dev_data: EncodedDs, adjust_args: Optional[dict] = None) -> None:\n \"\"\"\n Partially fits/trains a mixer with new training data. This is a somewhat experimental method, and it aims at updating pre-existing Lightwood predictors. \n\n :param train_data: encoded representations of the new training data subset. \n :param dev_data: encoded representations of new the \"dev\" data subset. As in `fit()`, this can be used as an internal validation subset. \n :param adjust_args: optional arguments to customize the finetuning process.\n\n \"\"\" # noqa\n pass\n", "path": "lightwood/mixer/base.py"}]}
| 1,779 | 625 |
gh_patches_debug_36257
|
rasdani/github-patches
|
git_diff
|
SeldonIO__MLServer-1319
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Load local artefacts in HuggingFace runtime
Support loading artifacts from provided model-URI
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `runtimes/huggingface/mlserver_huggingface/common.py`
Content:
```
1 import json
2 import numpy as np
3
4 from typing import Callable
5 from functools import partial
6 from mlserver.settings import ModelSettings
7
8 import torch
9 import tensorflow as tf
10
11 from optimum.pipelines import pipeline as opt_pipeline
12 from transformers.pipelines import pipeline as trf_pipeline
13 from transformers.pipelines.base import Pipeline
14
15 from .settings import HuggingFaceSettings
16
17
18 OPTIMUM_ACCELERATOR = "ort"
19
20 _PipelineConstructor = Callable[..., Pipeline]
21
22
23 def load_pipeline_from_settings(
24 hf_settings: HuggingFaceSettings, settings: ModelSettings
25 ) -> Pipeline:
26 # TODO: Support URI for locally downloaded artifacts
27 # uri = model_parameters.uri
28 pipeline = _get_pipeline_class(hf_settings)
29
30 batch_size = 1
31 if settings.max_batch_size:
32 batch_size = settings.max_batch_size
33
34 tokenizer = hf_settings.pretrained_tokenizer
35 if not tokenizer:
36 tokenizer = hf_settings.pretrained_model
37 if hf_settings.framework == "tf":
38 if hf_settings.inter_op_threads is not None:
39 tf.config.threading.set_inter_op_parallelism_threads(
40 hf_settings.inter_op_threads
41 )
42 if hf_settings.intra_op_threads is not None:
43 tf.config.threading.set_intra_op_parallelism_threads(
44 hf_settings.intra_op_threads
45 )
46 elif hf_settings.framework == "pt":
47 if hf_settings.inter_op_threads is not None:
48 torch.set_num_interop_threads(hf_settings.inter_op_threads)
49 if hf_settings.intra_op_threads is not None:
50 torch.set_num_threads(hf_settings.intra_op_threads)
51
52 hf_pipeline = pipeline(
53 hf_settings.task_name,
54 model=hf_settings.pretrained_model,
55 tokenizer=tokenizer,
56 device=hf_settings.device,
57 batch_size=batch_size,
58 framework=hf_settings.framework,
59 )
60
61 # If max_batch_size > 0 we need to ensure tokens are padded
62 if settings.max_batch_size:
63 model = hf_pipeline.model
64 eos_token_id = model.config.eos_token_id
65 hf_pipeline.tokenizer.pad_token_id = [str(eos_token_id)] # type: ignore
66
67 return hf_pipeline
68
69
70 def _get_pipeline_class(hf_settings: HuggingFaceSettings) -> _PipelineConstructor:
71 if hf_settings.optimum_model:
72 return partial(opt_pipeline, accelerator=OPTIMUM_ACCELERATOR)
73
74 return trf_pipeline
75
76
77 class NumpyEncoder(json.JSONEncoder):
78 def default(self, obj):
79 if isinstance(obj, np.ndarray):
80 return obj.tolist()
81 return json.JSONEncoder.default(self, obj)
82
```
Path: `runtimes/huggingface/mlserver_huggingface/settings.py`
Content:
```
1 import os
2 import orjson
3
4 from typing import Optional, Dict, Union, NewType
5 from pydantic import BaseSettings
6 from distutils.util import strtobool
7 from transformers.pipelines import SUPPORTED_TASKS
8
9 try:
10 # Optimum 1.7 changed the import name from `SUPPORTED_TASKS` to
11 # `ORT_SUPPORTED_TASKS`.
12 # We'll try to import the more recent one, falling back to the previous
13 # import name if not present.
14 # https://github.com/huggingface/optimum/blob/987b02e4f6e2a1c9325b364ff764da2e57e89902/optimum/pipelines/__init__.py#L18
15 from optimum.pipelines import ORT_SUPPORTED_TASKS as SUPPORTED_OPTIMUM_TASKS
16 except ImportError:
17 from optimum.pipelines import SUPPORTED_TASKS as SUPPORTED_OPTIMUM_TASKS
18
19 from mlserver.settings import ModelSettings
20
21 from .errors import (
22 MissingHuggingFaceSettings,
23 InvalidTransformersTask,
24 InvalidOptimumTask,
25 InvalidModelParameter,
26 InvalidModelParameterType,
27 )
28
29 ENV_PREFIX_HUGGINGFACE_SETTINGS = "MLSERVER_MODEL_HUGGINGFACE_"
30 PARAMETERS_ENV_NAME = "PREDICTIVE_UNIT_PARAMETERS"
31
32
33 class HuggingFaceSettings(BaseSettings):
34 """
35 Parameters that apply only to HuggingFace models
36 """
37
38 class Config:
39 env_prefix = ENV_PREFIX_HUGGINGFACE_SETTINGS
40
41 # TODO: Document fields
42 task: str = ""
43 """
44 Pipeline task to load.
45 You can see the available Optimum and Transformers tasks available in the
46 links below:
47
48 - `Optimum Tasks <https://huggingface.co/docs/optimum/onnxruntime/usage_guides/pipelines#inference-pipelines-with-the-onnx-runtime-accelerator>`_
49 - `Transformer Tasks <https://huggingface.co/docs/transformers/task_summary>`_
50 """ # noqa: E501
51
52 task_suffix: str = ""
53 """
54 Suffix to append to the base task name.
55 Useful for, e.g. translation tasks which require a suffix on the task name
56 to specify source and target.
57 """
58
59 pretrained_model: Optional[str] = None
60 """
61 Name of the model that should be loaded in the pipeline.
62 """
63
64 pretrained_tokenizer: Optional[str] = None
65 """
66 Name of the tokenizer that should be loaded in the pipeline.
67 """
68
69 framework: Optional[str] = None
70 """
71 The framework to use, either "pt" for PyTorch or "tf" for TensorFlow.
72 """
73
74 optimum_model: bool = False
75 """
76 Flag to decide whether the pipeline should use a Optimum-optimised model or
77 the standard Transformers model.
78 Under the hood, this will enable the model to use the optimised ONNX
79 runtime.
80 """
81
82 device: int = -1
83 """
84 Device in which this pipeline will be loaded (e.g., "cpu", "cuda:1", "mps",
85 or a GPU ordinal rank like 1).
86 """
87
88 inter_op_threads: Optional[int] = None
89 """
90 Threads used for parallelism between independent operations.
91 PyTorch:
92 https://pytorch.org/docs/stable/notes/cpu_threading_torchscript_inference.html
93 Tensorflow:
94 https://www.tensorflow.org/api_docs/python/tf/config/threading/set_inter_op_parallelism_threads
95 """
96
97 intra_op_threads: Optional[int] = None
98 """
99 Threads used within an individual op for parallelism.
100 PyTorch:
101 https://pytorch.org/docs/stable/notes/cpu_threading_torchscript_inference.html
102 Tensorflow:
103 https://www.tensorflow.org/api_docs/python/tf/config/threading/set_intra_op_parallelism_threads
104 """
105
106 @property
107 def task_name(self):
108 if self.task == "translation":
109 return f"{self.task}{self.task_suffix}"
110 return self.task
111
112
113 EXTRA_TYPE_DICT = {
114 "INT": int,
115 "FLOAT": float,
116 "DOUBLE": float,
117 "STRING": str,
118 "BOOL": bool,
119 }
120
121 ExtraDict = NewType("ExtraDict", Dict[str, Union[str, bool, float, int]])
122
123
124 def parse_parameters_from_env() -> ExtraDict:
125 """
126 This method parses the environment variables injected via SCv1.
127
128 At least an empty dict is always returned.
129 """
130 # TODO: Once support for SCv1 is deprecated, we should remove this method and rely
131 # purely on settings coming via the `model-settings.json` file.
132 parameters = orjson.loads(os.environ.get(PARAMETERS_ENV_NAME, "[]"))
133
134 parsed_parameters: ExtraDict = ExtraDict({})
135
136 # Guard: Exit early if there's no parameters
137 if len(parameters) == 0:
138 return parsed_parameters
139
140 for param in parameters:
141 name = param.get("name")
142 value = param.get("value")
143 type_ = param.get("type")
144 if type_ == "BOOL":
145 parsed_parameters[name] = bool(strtobool(value))
146 else:
147 try:
148 parsed_parameters[name] = EXTRA_TYPE_DICT[type_](value)
149 except ValueError:
150 raise InvalidModelParameter(name, value, type_)
151 except KeyError:
152 raise InvalidModelParameterType(type_)
153
154 return parsed_parameters
155
156
157 def get_huggingface_settings(model_settings: ModelSettings) -> HuggingFaceSettings:
158 """Get the HuggingFace settings provided to the runtime"""
159
160 env_params = parse_parameters_from_env()
161 extra = merge_huggingface_settings_extra(model_settings, env_params)
162 hf_settings = HuggingFaceSettings(**extra) # type: ignore
163
164 if hf_settings.task not in SUPPORTED_TASKS:
165 raise InvalidTransformersTask(hf_settings.task, SUPPORTED_TASKS.keys())
166
167 if hf_settings.optimum_model:
168 if hf_settings.task not in SUPPORTED_OPTIMUM_TASKS:
169 raise InvalidOptimumTask(hf_settings.task, SUPPORTED_OPTIMUM_TASKS.keys())
170
171 return hf_settings
172
173
174 def merge_huggingface_settings_extra(
175 model_settings: ModelSettings, env_params: ExtraDict
176 ) -> ExtraDict:
177 """
178 This function returns the Extra field of the Settings.
179
180 It merges them, iff they're both present, from the
181 environment AND model settings file. Precedence is
182 giving to the environment.
183 """
184
185 # Both `parameters` and `extra` are Optional, so we
186 # need to get the value, or nothing.
187 settings_params = (
188 model_settings.parameters.extra
189 if model_settings.parameters is not None
190 else None
191 )
192
193 if settings_params is None and env_params == {}:
194 # There must be settings provided by at least the environment OR model settings
195 raise MissingHuggingFaceSettings()
196
197 # Set the default value
198 settings_params = settings_params or {}
199
200 # Overwrite any conflicting keys, giving precedence to the environment
201 settings_params.update(env_params)
202
203 return ExtraDict(settings_params)
204
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/runtimes/huggingface/mlserver_huggingface/common.py b/runtimes/huggingface/mlserver_huggingface/common.py
--- a/runtimes/huggingface/mlserver_huggingface/common.py
+++ b/runtimes/huggingface/mlserver_huggingface/common.py
@@ -23,14 +23,15 @@
def load_pipeline_from_settings(
hf_settings: HuggingFaceSettings, settings: ModelSettings
) -> Pipeline:
- # TODO: Support URI for locally downloaded artifacts
- # uri = model_parameters.uri
pipeline = _get_pipeline_class(hf_settings)
batch_size = 1
if settings.max_batch_size:
batch_size = settings.max_batch_size
+ model = hf_settings.pretrained_model
+ if not model:
+ model = settings.parameters.uri # type: ignore
tokenizer = hf_settings.pretrained_tokenizer
if not tokenizer:
tokenizer = hf_settings.pretrained_model
@@ -51,7 +52,7 @@
hf_pipeline = pipeline(
hf_settings.task_name,
- model=hf_settings.pretrained_model,
+ model=model,
tokenizer=tokenizer,
device=hf_settings.device,
batch_size=batch_size,
@@ -61,7 +62,7 @@
# If max_batch_size > 0 we need to ensure tokens are padded
if settings.max_batch_size:
model = hf_pipeline.model
- eos_token_id = model.config.eos_token_id
+ eos_token_id = model.config.eos_token_id # type: ignore
hf_pipeline.tokenizer.pad_token_id = [str(eos_token_id)] # type: ignore
return hf_pipeline
diff --git a/runtimes/huggingface/mlserver_huggingface/settings.py b/runtimes/huggingface/mlserver_huggingface/settings.py
--- a/runtimes/huggingface/mlserver_huggingface/settings.py
+++ b/runtimes/huggingface/mlserver_huggingface/settings.py
@@ -2,7 +2,7 @@
import orjson
from typing import Optional, Dict, Union, NewType
-from pydantic import BaseSettings
+from pydantic import BaseSettings, Extra
from distutils.util import strtobool
from transformers.pipelines import SUPPORTED_TASKS
@@ -37,6 +37,7 @@
class Config:
env_prefix = ENV_PREFIX_HUGGINGFACE_SETTINGS
+ extra = Extra.ignore
# TODO: Document fields
task: str = ""
|
{"golden_diff": "diff --git a/runtimes/huggingface/mlserver_huggingface/common.py b/runtimes/huggingface/mlserver_huggingface/common.py\n--- a/runtimes/huggingface/mlserver_huggingface/common.py\n+++ b/runtimes/huggingface/mlserver_huggingface/common.py\n@@ -23,14 +23,15 @@\n def load_pipeline_from_settings(\n hf_settings: HuggingFaceSettings, settings: ModelSettings\n ) -> Pipeline:\n- # TODO: Support URI for locally downloaded artifacts\n- # uri = model_parameters.uri\n pipeline = _get_pipeline_class(hf_settings)\n \n batch_size = 1\n if settings.max_batch_size:\n batch_size = settings.max_batch_size\n \n+ model = hf_settings.pretrained_model\n+ if not model:\n+ model = settings.parameters.uri # type: ignore\n tokenizer = hf_settings.pretrained_tokenizer\n if not tokenizer:\n tokenizer = hf_settings.pretrained_model\n@@ -51,7 +52,7 @@\n \n hf_pipeline = pipeline(\n hf_settings.task_name,\n- model=hf_settings.pretrained_model,\n+ model=model,\n tokenizer=tokenizer,\n device=hf_settings.device,\n batch_size=batch_size,\n@@ -61,7 +62,7 @@\n # If max_batch_size > 0 we need to ensure tokens are padded\n if settings.max_batch_size:\n model = hf_pipeline.model\n- eos_token_id = model.config.eos_token_id\n+ eos_token_id = model.config.eos_token_id # type: ignore\n hf_pipeline.tokenizer.pad_token_id = [str(eos_token_id)] # type: ignore\n \n return hf_pipeline\ndiff --git a/runtimes/huggingface/mlserver_huggingface/settings.py b/runtimes/huggingface/mlserver_huggingface/settings.py\n--- a/runtimes/huggingface/mlserver_huggingface/settings.py\n+++ b/runtimes/huggingface/mlserver_huggingface/settings.py\n@@ -2,7 +2,7 @@\n import orjson\n \n from typing import Optional, Dict, Union, NewType\n-from pydantic import BaseSettings\n+from pydantic import BaseSettings, Extra\n from distutils.util import strtobool\n from transformers.pipelines import SUPPORTED_TASKS\n \n@@ -37,6 +37,7 @@\n \n class Config:\n env_prefix = ENV_PREFIX_HUGGINGFACE_SETTINGS\n+ extra = Extra.ignore\n \n # TODO: Document fields\n task: str = \"\"\n", "issue": "Load local artefacts in HuggingFace runtime\nSupport loading artifacts from provided model-URI\n", "before_files": [{"content": "import json\nimport numpy as np\n\nfrom typing import Callable\nfrom functools import partial\nfrom mlserver.settings import ModelSettings\n\nimport torch\nimport tensorflow as tf\n\nfrom optimum.pipelines import pipeline as opt_pipeline\nfrom transformers.pipelines import pipeline as trf_pipeline\nfrom transformers.pipelines.base import Pipeline\n\nfrom .settings import HuggingFaceSettings\n\n\nOPTIMUM_ACCELERATOR = \"ort\"\n\n_PipelineConstructor = Callable[..., Pipeline]\n\n\ndef load_pipeline_from_settings(\n hf_settings: HuggingFaceSettings, settings: ModelSettings\n) -> Pipeline:\n # TODO: Support URI for locally downloaded artifacts\n # uri = model_parameters.uri\n pipeline = _get_pipeline_class(hf_settings)\n\n batch_size = 1\n if settings.max_batch_size:\n batch_size = settings.max_batch_size\n\n tokenizer = hf_settings.pretrained_tokenizer\n if not tokenizer:\n tokenizer = hf_settings.pretrained_model\n if hf_settings.framework == \"tf\":\n if hf_settings.inter_op_threads is not None:\n tf.config.threading.set_inter_op_parallelism_threads(\n hf_settings.inter_op_threads\n )\n if hf_settings.intra_op_threads is not None:\n tf.config.threading.set_intra_op_parallelism_threads(\n hf_settings.intra_op_threads\n )\n elif hf_settings.framework == \"pt\":\n if hf_settings.inter_op_threads is not None:\n torch.set_num_interop_threads(hf_settings.inter_op_threads)\n if hf_settings.intra_op_threads is not None:\n torch.set_num_threads(hf_settings.intra_op_threads)\n\n hf_pipeline = pipeline(\n hf_settings.task_name,\n model=hf_settings.pretrained_model,\n tokenizer=tokenizer,\n device=hf_settings.device,\n batch_size=batch_size,\n framework=hf_settings.framework,\n )\n\n # If max_batch_size > 0 we need to ensure tokens are padded\n if settings.max_batch_size:\n model = hf_pipeline.model\n eos_token_id = model.config.eos_token_id\n hf_pipeline.tokenizer.pad_token_id = [str(eos_token_id)] # type: ignore\n\n return hf_pipeline\n\n\ndef _get_pipeline_class(hf_settings: HuggingFaceSettings) -> _PipelineConstructor:\n if hf_settings.optimum_model:\n return partial(opt_pipeline, accelerator=OPTIMUM_ACCELERATOR)\n\n return trf_pipeline\n\n\nclass NumpyEncoder(json.JSONEncoder):\n def default(self, obj):\n if isinstance(obj, np.ndarray):\n return obj.tolist()\n return json.JSONEncoder.default(self, obj)\n", "path": "runtimes/huggingface/mlserver_huggingface/common.py"}, {"content": "import os\nimport orjson\n\nfrom typing import Optional, Dict, Union, NewType\nfrom pydantic import BaseSettings\nfrom distutils.util import strtobool\nfrom transformers.pipelines import SUPPORTED_TASKS\n\ntry:\n # Optimum 1.7 changed the import name from `SUPPORTED_TASKS` to\n # `ORT_SUPPORTED_TASKS`.\n # We'll try to import the more recent one, falling back to the previous\n # import name if not present.\n # https://github.com/huggingface/optimum/blob/987b02e4f6e2a1c9325b364ff764da2e57e89902/optimum/pipelines/__init__.py#L18\n from optimum.pipelines import ORT_SUPPORTED_TASKS as SUPPORTED_OPTIMUM_TASKS\nexcept ImportError:\n from optimum.pipelines import SUPPORTED_TASKS as SUPPORTED_OPTIMUM_TASKS\n\nfrom mlserver.settings import ModelSettings\n\nfrom .errors import (\n MissingHuggingFaceSettings,\n InvalidTransformersTask,\n InvalidOptimumTask,\n InvalidModelParameter,\n InvalidModelParameterType,\n)\n\nENV_PREFIX_HUGGINGFACE_SETTINGS = \"MLSERVER_MODEL_HUGGINGFACE_\"\nPARAMETERS_ENV_NAME = \"PREDICTIVE_UNIT_PARAMETERS\"\n\n\nclass HuggingFaceSettings(BaseSettings):\n \"\"\"\n Parameters that apply only to HuggingFace models\n \"\"\"\n\n class Config:\n env_prefix = ENV_PREFIX_HUGGINGFACE_SETTINGS\n\n # TODO: Document fields\n task: str = \"\"\n \"\"\"\n Pipeline task to load.\n You can see the available Optimum and Transformers tasks available in the\n links below:\n\n - `Optimum Tasks <https://huggingface.co/docs/optimum/onnxruntime/usage_guides/pipelines#inference-pipelines-with-the-onnx-runtime-accelerator>`_\n - `Transformer Tasks <https://huggingface.co/docs/transformers/task_summary>`_\n \"\"\" # noqa: E501\n\n task_suffix: str = \"\"\n \"\"\"\n Suffix to append to the base task name.\n Useful for, e.g. translation tasks which require a suffix on the task name\n to specify source and target.\n \"\"\"\n\n pretrained_model: Optional[str] = None\n \"\"\"\n Name of the model that should be loaded in the pipeline.\n \"\"\"\n\n pretrained_tokenizer: Optional[str] = None\n \"\"\"\n Name of the tokenizer that should be loaded in the pipeline.\n \"\"\"\n\n framework: Optional[str] = None\n \"\"\"\n The framework to use, either \"pt\" for PyTorch or \"tf\" for TensorFlow.\n \"\"\"\n\n optimum_model: bool = False\n \"\"\"\n Flag to decide whether the pipeline should use a Optimum-optimised model or\n the standard Transformers model.\n Under the hood, this will enable the model to use the optimised ONNX\n runtime.\n \"\"\"\n\n device: int = -1\n \"\"\"\n Device in which this pipeline will be loaded (e.g., \"cpu\", \"cuda:1\", \"mps\",\n or a GPU ordinal rank like 1).\n \"\"\"\n\n inter_op_threads: Optional[int] = None\n \"\"\"\n Threads used for parallelism between independent operations.\n PyTorch:\n https://pytorch.org/docs/stable/notes/cpu_threading_torchscript_inference.html\n Tensorflow:\n https://www.tensorflow.org/api_docs/python/tf/config/threading/set_inter_op_parallelism_threads\n \"\"\"\n\n intra_op_threads: Optional[int] = None\n \"\"\"\n Threads used within an individual op for parallelism.\n PyTorch:\n https://pytorch.org/docs/stable/notes/cpu_threading_torchscript_inference.html\n Tensorflow:\n https://www.tensorflow.org/api_docs/python/tf/config/threading/set_intra_op_parallelism_threads\n \"\"\"\n\n @property\n def task_name(self):\n if self.task == \"translation\":\n return f\"{self.task}{self.task_suffix}\"\n return self.task\n\n\nEXTRA_TYPE_DICT = {\n \"INT\": int,\n \"FLOAT\": float,\n \"DOUBLE\": float,\n \"STRING\": str,\n \"BOOL\": bool,\n}\n\nExtraDict = NewType(\"ExtraDict\", Dict[str, Union[str, bool, float, int]])\n\n\ndef parse_parameters_from_env() -> ExtraDict:\n \"\"\"\n This method parses the environment variables injected via SCv1.\n\n At least an empty dict is always returned.\n \"\"\"\n # TODO: Once support for SCv1 is deprecated, we should remove this method and rely\n # purely on settings coming via the `model-settings.json` file.\n parameters = orjson.loads(os.environ.get(PARAMETERS_ENV_NAME, \"[]\"))\n\n parsed_parameters: ExtraDict = ExtraDict({})\n\n # Guard: Exit early if there's no parameters\n if len(parameters) == 0:\n return parsed_parameters\n\n for param in parameters:\n name = param.get(\"name\")\n value = param.get(\"value\")\n type_ = param.get(\"type\")\n if type_ == \"BOOL\":\n parsed_parameters[name] = bool(strtobool(value))\n else:\n try:\n parsed_parameters[name] = EXTRA_TYPE_DICT[type_](value)\n except ValueError:\n raise InvalidModelParameter(name, value, type_)\n except KeyError:\n raise InvalidModelParameterType(type_)\n\n return parsed_parameters\n\n\ndef get_huggingface_settings(model_settings: ModelSettings) -> HuggingFaceSettings:\n \"\"\"Get the HuggingFace settings provided to the runtime\"\"\"\n\n env_params = parse_parameters_from_env()\n extra = merge_huggingface_settings_extra(model_settings, env_params)\n hf_settings = HuggingFaceSettings(**extra) # type: ignore\n\n if hf_settings.task not in SUPPORTED_TASKS:\n raise InvalidTransformersTask(hf_settings.task, SUPPORTED_TASKS.keys())\n\n if hf_settings.optimum_model:\n if hf_settings.task not in SUPPORTED_OPTIMUM_TASKS:\n raise InvalidOptimumTask(hf_settings.task, SUPPORTED_OPTIMUM_TASKS.keys())\n\n return hf_settings\n\n\ndef merge_huggingface_settings_extra(\n model_settings: ModelSettings, env_params: ExtraDict\n) -> ExtraDict:\n \"\"\"\n This function returns the Extra field of the Settings.\n\n It merges them, iff they're both present, from the\n environment AND model settings file. Precedence is\n giving to the environment.\n \"\"\"\n\n # Both `parameters` and `extra` are Optional, so we\n # need to get the value, or nothing.\n settings_params = (\n model_settings.parameters.extra\n if model_settings.parameters is not None\n else None\n )\n\n if settings_params is None and env_params == {}:\n # There must be settings provided by at least the environment OR model settings\n raise MissingHuggingFaceSettings()\n\n # Set the default value\n settings_params = settings_params or {}\n\n # Overwrite any conflicting keys, giving precedence to the environment\n settings_params.update(env_params)\n\n return ExtraDict(settings_params)\n", "path": "runtimes/huggingface/mlserver_huggingface/settings.py"}], "after_files": [{"content": "import json\nimport numpy as np\n\nfrom typing import Callable\nfrom functools import partial\nfrom mlserver.settings import ModelSettings\n\nimport torch\nimport tensorflow as tf\n\nfrom optimum.pipelines import pipeline as opt_pipeline\nfrom transformers.pipelines import pipeline as trf_pipeline\nfrom transformers.pipelines.base import Pipeline\n\nfrom .settings import HuggingFaceSettings\n\n\nOPTIMUM_ACCELERATOR = \"ort\"\n\n_PipelineConstructor = Callable[..., Pipeline]\n\n\ndef load_pipeline_from_settings(\n hf_settings: HuggingFaceSettings, settings: ModelSettings\n) -> Pipeline:\n pipeline = _get_pipeline_class(hf_settings)\n\n batch_size = 1\n if settings.max_batch_size:\n batch_size = settings.max_batch_size\n\n model = hf_settings.pretrained_model\n if not model:\n model = settings.parameters.uri # type: ignore\n tokenizer = hf_settings.pretrained_tokenizer\n if not tokenizer:\n tokenizer = hf_settings.pretrained_model\n if hf_settings.framework == \"tf\":\n if hf_settings.inter_op_threads is not None:\n tf.config.threading.set_inter_op_parallelism_threads(\n hf_settings.inter_op_threads\n )\n if hf_settings.intra_op_threads is not None:\n tf.config.threading.set_intra_op_parallelism_threads(\n hf_settings.intra_op_threads\n )\n elif hf_settings.framework == \"pt\":\n if hf_settings.inter_op_threads is not None:\n torch.set_num_interop_threads(hf_settings.inter_op_threads)\n if hf_settings.intra_op_threads is not None:\n torch.set_num_threads(hf_settings.intra_op_threads)\n\n hf_pipeline = pipeline(\n hf_settings.task_name,\n model=model,\n tokenizer=tokenizer,\n device=hf_settings.device,\n batch_size=batch_size,\n framework=hf_settings.framework,\n )\n\n # If max_batch_size > 0 we need to ensure tokens are padded\n if settings.max_batch_size:\n model = hf_pipeline.model\n eos_token_id = model.config.eos_token_id # type: ignore\n hf_pipeline.tokenizer.pad_token_id = [str(eos_token_id)] # type: ignore\n\n return hf_pipeline\n\n\ndef _get_pipeline_class(hf_settings: HuggingFaceSettings) -> _PipelineConstructor:\n if hf_settings.optimum_model:\n return partial(opt_pipeline, accelerator=OPTIMUM_ACCELERATOR)\n\n return trf_pipeline\n\n\nclass NumpyEncoder(json.JSONEncoder):\n def default(self, obj):\n if isinstance(obj, np.ndarray):\n return obj.tolist()\n return json.JSONEncoder.default(self, obj)\n", "path": "runtimes/huggingface/mlserver_huggingface/common.py"}, {"content": "import os\nimport orjson\n\nfrom typing import Optional, Dict, Union, NewType\nfrom pydantic import BaseSettings, Extra\nfrom distutils.util import strtobool\nfrom transformers.pipelines import SUPPORTED_TASKS\n\ntry:\n # Optimum 1.7 changed the import name from `SUPPORTED_TASKS` to\n # `ORT_SUPPORTED_TASKS`.\n # We'll try to import the more recent one, falling back to the previous\n # import name if not present.\n # https://github.com/huggingface/optimum/blob/987b02e4f6e2a1c9325b364ff764da2e57e89902/optimum/pipelines/__init__.py#L18\n from optimum.pipelines import ORT_SUPPORTED_TASKS as SUPPORTED_OPTIMUM_TASKS\nexcept ImportError:\n from optimum.pipelines import SUPPORTED_TASKS as SUPPORTED_OPTIMUM_TASKS\n\nfrom mlserver.settings import ModelSettings\n\nfrom .errors import (\n MissingHuggingFaceSettings,\n InvalidTransformersTask,\n InvalidOptimumTask,\n InvalidModelParameter,\n InvalidModelParameterType,\n)\n\nENV_PREFIX_HUGGINGFACE_SETTINGS = \"MLSERVER_MODEL_HUGGINGFACE_\"\nPARAMETERS_ENV_NAME = \"PREDICTIVE_UNIT_PARAMETERS\"\n\n\nclass HuggingFaceSettings(BaseSettings):\n \"\"\"\n Parameters that apply only to HuggingFace models\n \"\"\"\n\n class Config:\n env_prefix = ENV_PREFIX_HUGGINGFACE_SETTINGS\n extra = Extra.ignore\n\n # TODO: Document fields\n task: str = \"\"\n \"\"\"\n Pipeline task to load.\n You can see the available Optimum and Transformers tasks available in the\n links below:\n\n - `Optimum Tasks <https://huggingface.co/docs/optimum/onnxruntime/usage_guides/pipelines#inference-pipelines-with-the-onnx-runtime-accelerator>`_\n - `Transformer Tasks <https://huggingface.co/docs/transformers/task_summary>`_\n \"\"\" # noqa: E501\n\n task_suffix: str = \"\"\n \"\"\"\n Suffix to append to the base task name.\n Useful for, e.g. translation tasks which require a suffix on the task name\n to specify source and target.\n \"\"\"\n\n pretrained_model: Optional[str] = None\n \"\"\"\n Name of the model that should be loaded in the pipeline.\n \"\"\"\n\n pretrained_tokenizer: Optional[str] = None\n \"\"\"\n Name of the tokenizer that should be loaded in the pipeline.\n \"\"\"\n\n framework: Optional[str] = None\n \"\"\"\n The framework to use, either \"pt\" for PyTorch or \"tf\" for TensorFlow.\n \"\"\"\n\n optimum_model: bool = False\n \"\"\"\n Flag to decide whether the pipeline should use a Optimum-optimised model or\n the standard Transformers model.\n Under the hood, this will enable the model to use the optimised ONNX\n runtime.\n \"\"\"\n\n device: int = -1\n \"\"\"\n Device in which this pipeline will be loaded (e.g., \"cpu\", \"cuda:1\", \"mps\",\n or a GPU ordinal rank like 1).\n \"\"\"\n\n inter_op_threads: Optional[int] = None\n \"\"\"\n Threads used for parallelism between independent operations.\n PyTorch:\n https://pytorch.org/docs/stable/notes/cpu_threading_torchscript_inference.html\n Tensorflow:\n https://www.tensorflow.org/api_docs/python/tf/config/threading/set_inter_op_parallelism_threads\n \"\"\"\n\n intra_op_threads: Optional[int] = None\n \"\"\"\n Threads used within an individual op for parallelism.\n PyTorch:\n https://pytorch.org/docs/stable/notes/cpu_threading_torchscript_inference.html\n Tensorflow:\n https://www.tensorflow.org/api_docs/python/tf/config/threading/set_intra_op_parallelism_threads\n \"\"\"\n\n @property\n def task_name(self):\n if self.task == \"translation\":\n return f\"{self.task}{self.task_suffix}\"\n return self.task\n\n\nEXTRA_TYPE_DICT = {\n \"INT\": int,\n \"FLOAT\": float,\n \"DOUBLE\": float,\n \"STRING\": str,\n \"BOOL\": bool,\n}\n\nExtraDict = NewType(\"ExtraDict\", Dict[str, Union[str, bool, float, int]])\n\n\ndef parse_parameters_from_env() -> ExtraDict:\n \"\"\"\n This method parses the environment variables injected via SCv1.\n\n At least an empty dict is always returned.\n \"\"\"\n # TODO: Once support for SCv1 is deprecated, we should remove this method and rely\n # purely on settings coming via the `model-settings.json` file.\n parameters = orjson.loads(os.environ.get(PARAMETERS_ENV_NAME, \"[]\"))\n\n parsed_parameters: ExtraDict = ExtraDict({})\n\n # Guard: Exit early if there's no parameters\n if len(parameters) == 0:\n return parsed_parameters\n\n for param in parameters:\n name = param.get(\"name\")\n value = param.get(\"value\")\n type_ = param.get(\"type\")\n if type_ == \"BOOL\":\n parsed_parameters[name] = bool(strtobool(value))\n else:\n try:\n parsed_parameters[name] = EXTRA_TYPE_DICT[type_](value)\n except ValueError:\n raise InvalidModelParameter(name, value, type_)\n except KeyError:\n raise InvalidModelParameterType(type_)\n\n return parsed_parameters\n\n\ndef get_huggingface_settings(model_settings: ModelSettings) -> HuggingFaceSettings:\n \"\"\"Get the HuggingFace settings provided to the runtime\"\"\"\n\n env_params = parse_parameters_from_env()\n extra = merge_huggingface_settings_extra(model_settings, env_params)\n hf_settings = HuggingFaceSettings(**extra) # type: ignore\n\n if hf_settings.task not in SUPPORTED_TASKS:\n raise InvalidTransformersTask(hf_settings.task, SUPPORTED_TASKS.keys())\n\n if hf_settings.optimum_model:\n if hf_settings.task not in SUPPORTED_OPTIMUM_TASKS:\n raise InvalidOptimumTask(hf_settings.task, SUPPORTED_OPTIMUM_TASKS.keys())\n\n return hf_settings\n\n\ndef merge_huggingface_settings_extra(\n model_settings: ModelSettings, env_params: ExtraDict\n) -> ExtraDict:\n \"\"\"\n This function returns the Extra field of the Settings.\n\n It merges them, iff they're both present, from the\n environment AND model settings file. Precedence is\n giving to the environment.\n \"\"\"\n\n # Both `parameters` and `extra` are Optional, so we\n # need to get the value, or nothing.\n settings_params = (\n model_settings.parameters.extra\n if model_settings.parameters is not None\n else None\n )\n\n if settings_params is None and env_params == {}:\n # There must be settings provided by at least the environment OR model settings\n raise MissingHuggingFaceSettings()\n\n # Set the default value\n settings_params = settings_params or {}\n\n # Overwrite any conflicting keys, giving precedence to the environment\n settings_params.update(env_params)\n\n return ExtraDict(settings_params)\n", "path": "runtimes/huggingface/mlserver_huggingface/settings.py"}]}
| 3,058 | 547 |
gh_patches_debug_11448
|
rasdani/github-patches
|
git_diff
|
matrix-org__synapse-12177
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
RC versions of dependencies don't satisfy the run-time dependency checker; `Need Twisted>=18.9.0, but got Twisted==21.7.0rc3` (1.54.0rc1 suspected regression)
When deploying `1.54.0rc1` to matrix.org and some personal homeservers that had an RC of Twisted installed, the dependency checker complained:
`Need Twisted>=18.9.0, but got Twisted==21.7.0rc3`
For some reason it appears that being an RC makes the version insufficient, even though the version is higher. Using the non-RC version works fine.
Possibly fall-out from https://github.com/matrix-org/synapse/pull/12088?
I wonder if the same logic as e.g. `pip` is being used, in that it would never select an RC version as being satisfactory unless it was a hard match?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `synapse/util/check_dependencies.py`
Content:
```
1 # Copyright 2022 The Matrix.org Foundation C.I.C.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 #
15
16 """
17 This module exposes a single function which checks synapse's dependencies are present
18 and correctly versioned. It makes use of `importlib.metadata` to do so. The details
19 are a bit murky: there's no easy way to get a map from "extras" to the packages they
20 require. But this is probably just symptomatic of Python's package management.
21 """
22
23 import logging
24 from typing import Iterable, NamedTuple, Optional
25
26 from packaging.requirements import Requirement
27
28 DISTRIBUTION_NAME = "matrix-synapse"
29
30 try:
31 from importlib import metadata
32 except ImportError:
33 import importlib_metadata as metadata # type: ignore[no-redef]
34
35 __all__ = ["check_requirements"]
36
37
38 class DependencyException(Exception):
39 @property
40 def message(self) -> str:
41 return "\n".join(
42 [
43 "Missing Requirements: %s" % (", ".join(self.dependencies),),
44 "To install run:",
45 " pip install --upgrade --force %s" % (" ".join(self.dependencies),),
46 "",
47 ]
48 )
49
50 @property
51 def dependencies(self) -> Iterable[str]:
52 for i in self.args[0]:
53 yield '"' + i + '"'
54
55
56 DEV_EXTRAS = {"lint", "mypy", "test", "dev"}
57 RUNTIME_EXTRAS = (
58 set(metadata.metadata(DISTRIBUTION_NAME).get_all("Provides-Extra")) - DEV_EXTRAS
59 )
60 VERSION = metadata.version(DISTRIBUTION_NAME)
61
62
63 def _is_dev_dependency(req: Requirement) -> bool:
64 return req.marker is not None and any(
65 req.marker.evaluate({"extra": e}) for e in DEV_EXTRAS
66 )
67
68
69 class Dependency(NamedTuple):
70 requirement: Requirement
71 must_be_installed: bool
72
73
74 def _generic_dependencies() -> Iterable[Dependency]:
75 """Yield pairs (requirement, must_be_installed)."""
76 requirements = metadata.requires(DISTRIBUTION_NAME)
77 assert requirements is not None
78 for raw_requirement in requirements:
79 req = Requirement(raw_requirement)
80 if _is_dev_dependency(req):
81 continue
82
83 # https://packaging.pypa.io/en/latest/markers.html#usage notes that
84 # > Evaluating an extra marker with no environment is an error
85 # so we pass in a dummy empty extra value here.
86 must_be_installed = req.marker is None or req.marker.evaluate({"extra": ""})
87 yield Dependency(req, must_be_installed)
88
89
90 def _dependencies_for_extra(extra: str) -> Iterable[Dependency]:
91 """Yield additional dependencies needed for a given `extra`."""
92 requirements = metadata.requires(DISTRIBUTION_NAME)
93 assert requirements is not None
94 for raw_requirement in requirements:
95 req = Requirement(raw_requirement)
96 if _is_dev_dependency(req):
97 continue
98 # Exclude mandatory deps by only selecting deps needed with this extra.
99 if (
100 req.marker is not None
101 and req.marker.evaluate({"extra": extra})
102 and not req.marker.evaluate({"extra": ""})
103 ):
104 yield Dependency(req, True)
105
106
107 def _not_installed(requirement: Requirement, extra: Optional[str] = None) -> str:
108 if extra:
109 return (
110 f"Synapse {VERSION} needs {requirement.name} for {extra}, "
111 f"but it is not installed"
112 )
113 else:
114 return f"Synapse {VERSION} needs {requirement.name}, but it is not installed"
115
116
117 def _incorrect_version(
118 requirement: Requirement, got: str, extra: Optional[str] = None
119 ) -> str:
120 if extra:
121 return (
122 f"Synapse {VERSION} needs {requirement} for {extra}, "
123 f"but got {requirement.name}=={got}"
124 )
125 else:
126 return (
127 f"Synapse {VERSION} needs {requirement}, but got {requirement.name}=={got}"
128 )
129
130
131 def check_requirements(extra: Optional[str] = None) -> None:
132 """Check Synapse's dependencies are present and correctly versioned.
133
134 If provided, `extra` must be the name of an pacakging extra (e.g. "saml2" in
135 `pip install matrix-synapse[saml2]`).
136
137 If `extra` is None, this function checks that
138 - all mandatory dependencies are installed and correctly versioned, and
139 - each optional dependency that's installed is correctly versioned.
140
141 If `extra` is not None, this function checks that
142 - the dependencies needed for that extra are installed and correctly versioned.
143
144 :raises DependencyException: if a dependency is missing or incorrectly versioned.
145 :raises ValueError: if this extra does not exist.
146 """
147 # First work out which dependencies are required, and which are optional.
148 if extra is None:
149 dependencies = _generic_dependencies()
150 elif extra in RUNTIME_EXTRAS:
151 dependencies = _dependencies_for_extra(extra)
152 else:
153 raise ValueError(f"Synapse {VERSION} does not provide the feature '{extra}'")
154
155 deps_unfulfilled = []
156 errors = []
157
158 for (requirement, must_be_installed) in dependencies:
159 try:
160 dist: metadata.Distribution = metadata.distribution(requirement.name)
161 except metadata.PackageNotFoundError:
162 if must_be_installed:
163 deps_unfulfilled.append(requirement.name)
164 errors.append(_not_installed(requirement, extra))
165 else:
166 if not requirement.specifier.contains(dist.version):
167 deps_unfulfilled.append(requirement.name)
168 errors.append(_incorrect_version(requirement, dist.version, extra))
169
170 if deps_unfulfilled:
171 for err in errors:
172 logging.error(err)
173
174 raise DependencyException(deps_unfulfilled)
175
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/synapse/util/check_dependencies.py b/synapse/util/check_dependencies.py
--- a/synapse/util/check_dependencies.py
+++ b/synapse/util/check_dependencies.py
@@ -163,7 +163,8 @@
deps_unfulfilled.append(requirement.name)
errors.append(_not_installed(requirement, extra))
else:
- if not requirement.specifier.contains(dist.version):
+ # We specify prereleases=True to allow prereleases such as RCs.
+ if not requirement.specifier.contains(dist.version, prereleases=True):
deps_unfulfilled.append(requirement.name)
errors.append(_incorrect_version(requirement, dist.version, extra))
|
{"golden_diff": "diff --git a/synapse/util/check_dependencies.py b/synapse/util/check_dependencies.py\n--- a/synapse/util/check_dependencies.py\n+++ b/synapse/util/check_dependencies.py\n@@ -163,7 +163,8 @@\n deps_unfulfilled.append(requirement.name)\n errors.append(_not_installed(requirement, extra))\n else:\n- if not requirement.specifier.contains(dist.version):\n+ # We specify prereleases=True to allow prereleases such as RCs.\n+ if not requirement.specifier.contains(dist.version, prereleases=True):\n deps_unfulfilled.append(requirement.name)\n errors.append(_incorrect_version(requirement, dist.version, extra))\n", "issue": "RC versions of dependencies don't satisfy the run-time dependency checker; `Need Twisted>=18.9.0, but got Twisted==21.7.0rc3` (1.54.0rc1 suspected regression)\nWhen deploying `1.54.0rc1` to matrix.org and some personal homeservers that had an RC of Twisted installed, the dependency checker complained:\r\n\r\n`Need Twisted>=18.9.0, but got Twisted==21.7.0rc3`\r\n\r\nFor some reason it appears that being an RC makes the version insufficient, even though the version is higher. Using the non-RC version works fine.\r\n\r\nPossibly fall-out from https://github.com/matrix-org/synapse/pull/12088?\r\n\r\nI wonder if the same logic as e.g. `pip` is being used, in that it would never select an RC version as being satisfactory unless it was a hard match?\n", "before_files": [{"content": "# Copyright 2022 The Matrix.org Foundation C.I.C.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\n\"\"\"\nThis module exposes a single function which checks synapse's dependencies are present\nand correctly versioned. It makes use of `importlib.metadata` to do so. The details\nare a bit murky: there's no easy way to get a map from \"extras\" to the packages they\nrequire. But this is probably just symptomatic of Python's package management.\n\"\"\"\n\nimport logging\nfrom typing import Iterable, NamedTuple, Optional\n\nfrom packaging.requirements import Requirement\n\nDISTRIBUTION_NAME = \"matrix-synapse\"\n\ntry:\n from importlib import metadata\nexcept ImportError:\n import importlib_metadata as metadata # type: ignore[no-redef]\n\n__all__ = [\"check_requirements\"]\n\n\nclass DependencyException(Exception):\n @property\n def message(self) -> str:\n return \"\\n\".join(\n [\n \"Missing Requirements: %s\" % (\", \".join(self.dependencies),),\n \"To install run:\",\n \" pip install --upgrade --force %s\" % (\" \".join(self.dependencies),),\n \"\",\n ]\n )\n\n @property\n def dependencies(self) -> Iterable[str]:\n for i in self.args[0]:\n yield '\"' + i + '\"'\n\n\nDEV_EXTRAS = {\"lint\", \"mypy\", \"test\", \"dev\"}\nRUNTIME_EXTRAS = (\n set(metadata.metadata(DISTRIBUTION_NAME).get_all(\"Provides-Extra\")) - DEV_EXTRAS\n)\nVERSION = metadata.version(DISTRIBUTION_NAME)\n\n\ndef _is_dev_dependency(req: Requirement) -> bool:\n return req.marker is not None and any(\n req.marker.evaluate({\"extra\": e}) for e in DEV_EXTRAS\n )\n\n\nclass Dependency(NamedTuple):\n requirement: Requirement\n must_be_installed: bool\n\n\ndef _generic_dependencies() -> Iterable[Dependency]:\n \"\"\"Yield pairs (requirement, must_be_installed).\"\"\"\n requirements = metadata.requires(DISTRIBUTION_NAME)\n assert requirements is not None\n for raw_requirement in requirements:\n req = Requirement(raw_requirement)\n if _is_dev_dependency(req):\n continue\n\n # https://packaging.pypa.io/en/latest/markers.html#usage notes that\n # > Evaluating an extra marker with no environment is an error\n # so we pass in a dummy empty extra value here.\n must_be_installed = req.marker is None or req.marker.evaluate({\"extra\": \"\"})\n yield Dependency(req, must_be_installed)\n\n\ndef _dependencies_for_extra(extra: str) -> Iterable[Dependency]:\n \"\"\"Yield additional dependencies needed for a given `extra`.\"\"\"\n requirements = metadata.requires(DISTRIBUTION_NAME)\n assert requirements is not None\n for raw_requirement in requirements:\n req = Requirement(raw_requirement)\n if _is_dev_dependency(req):\n continue\n # Exclude mandatory deps by only selecting deps needed with this extra.\n if (\n req.marker is not None\n and req.marker.evaluate({\"extra\": extra})\n and not req.marker.evaluate({\"extra\": \"\"})\n ):\n yield Dependency(req, True)\n\n\ndef _not_installed(requirement: Requirement, extra: Optional[str] = None) -> str:\n if extra:\n return (\n f\"Synapse {VERSION} needs {requirement.name} for {extra}, \"\n f\"but it is not installed\"\n )\n else:\n return f\"Synapse {VERSION} needs {requirement.name}, but it is not installed\"\n\n\ndef _incorrect_version(\n requirement: Requirement, got: str, extra: Optional[str] = None\n) -> str:\n if extra:\n return (\n f\"Synapse {VERSION} needs {requirement} for {extra}, \"\n f\"but got {requirement.name}=={got}\"\n )\n else:\n return (\n f\"Synapse {VERSION} needs {requirement}, but got {requirement.name}=={got}\"\n )\n\n\ndef check_requirements(extra: Optional[str] = None) -> None:\n \"\"\"Check Synapse's dependencies are present and correctly versioned.\n\n If provided, `extra` must be the name of an pacakging extra (e.g. \"saml2\" in\n `pip install matrix-synapse[saml2]`).\n\n If `extra` is None, this function checks that\n - all mandatory dependencies are installed and correctly versioned, and\n - each optional dependency that's installed is correctly versioned.\n\n If `extra` is not None, this function checks that\n - the dependencies needed for that extra are installed and correctly versioned.\n\n :raises DependencyException: if a dependency is missing or incorrectly versioned.\n :raises ValueError: if this extra does not exist.\n \"\"\"\n # First work out which dependencies are required, and which are optional.\n if extra is None:\n dependencies = _generic_dependencies()\n elif extra in RUNTIME_EXTRAS:\n dependencies = _dependencies_for_extra(extra)\n else:\n raise ValueError(f\"Synapse {VERSION} does not provide the feature '{extra}'\")\n\n deps_unfulfilled = []\n errors = []\n\n for (requirement, must_be_installed) in dependencies:\n try:\n dist: metadata.Distribution = metadata.distribution(requirement.name)\n except metadata.PackageNotFoundError:\n if must_be_installed:\n deps_unfulfilled.append(requirement.name)\n errors.append(_not_installed(requirement, extra))\n else:\n if not requirement.specifier.contains(dist.version):\n deps_unfulfilled.append(requirement.name)\n errors.append(_incorrect_version(requirement, dist.version, extra))\n\n if deps_unfulfilled:\n for err in errors:\n logging.error(err)\n\n raise DependencyException(deps_unfulfilled)\n", "path": "synapse/util/check_dependencies.py"}], "after_files": [{"content": "# Copyright 2022 The Matrix.org Foundation C.I.C.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\n\"\"\"\nThis module exposes a single function which checks synapse's dependencies are present\nand correctly versioned. It makes use of `importlib.metadata` to do so. The details\nare a bit murky: there's no easy way to get a map from \"extras\" to the packages they\nrequire. But this is probably just symptomatic of Python's package management.\n\"\"\"\n\nimport logging\nfrom typing import Iterable, NamedTuple, Optional\n\nfrom packaging.requirements import Requirement\n\nDISTRIBUTION_NAME = \"matrix-synapse\"\n\ntry:\n from importlib import metadata\nexcept ImportError:\n import importlib_metadata as metadata # type: ignore[no-redef]\n\n__all__ = [\"check_requirements\"]\n\n\nclass DependencyException(Exception):\n @property\n def message(self) -> str:\n return \"\\n\".join(\n [\n \"Missing Requirements: %s\" % (\", \".join(self.dependencies),),\n \"To install run:\",\n \" pip install --upgrade --force %s\" % (\" \".join(self.dependencies),),\n \"\",\n ]\n )\n\n @property\n def dependencies(self) -> Iterable[str]:\n for i in self.args[0]:\n yield '\"' + i + '\"'\n\n\nDEV_EXTRAS = {\"lint\", \"mypy\", \"test\", \"dev\"}\nRUNTIME_EXTRAS = (\n set(metadata.metadata(DISTRIBUTION_NAME).get_all(\"Provides-Extra\")) - DEV_EXTRAS\n)\nVERSION = metadata.version(DISTRIBUTION_NAME)\n\n\ndef _is_dev_dependency(req: Requirement) -> bool:\n return req.marker is not None and any(\n req.marker.evaluate({\"extra\": e}) for e in DEV_EXTRAS\n )\n\n\nclass Dependency(NamedTuple):\n requirement: Requirement\n must_be_installed: bool\n\n\ndef _generic_dependencies() -> Iterable[Dependency]:\n \"\"\"Yield pairs (requirement, must_be_installed).\"\"\"\n requirements = metadata.requires(DISTRIBUTION_NAME)\n assert requirements is not None\n for raw_requirement in requirements:\n req = Requirement(raw_requirement)\n if _is_dev_dependency(req):\n continue\n\n # https://packaging.pypa.io/en/latest/markers.html#usage notes that\n # > Evaluating an extra marker with no environment is an error\n # so we pass in a dummy empty extra value here.\n must_be_installed = req.marker is None or req.marker.evaluate({\"extra\": \"\"})\n yield Dependency(req, must_be_installed)\n\n\ndef _dependencies_for_extra(extra: str) -> Iterable[Dependency]:\n \"\"\"Yield additional dependencies needed for a given `extra`.\"\"\"\n requirements = metadata.requires(DISTRIBUTION_NAME)\n assert requirements is not None\n for raw_requirement in requirements:\n req = Requirement(raw_requirement)\n if _is_dev_dependency(req):\n continue\n # Exclude mandatory deps by only selecting deps needed with this extra.\n if (\n req.marker is not None\n and req.marker.evaluate({\"extra\": extra})\n and not req.marker.evaluate({\"extra\": \"\"})\n ):\n yield Dependency(req, True)\n\n\ndef _not_installed(requirement: Requirement, extra: Optional[str] = None) -> str:\n if extra:\n return (\n f\"Synapse {VERSION} needs {requirement.name} for {extra}, \"\n f\"but it is not installed\"\n )\n else:\n return f\"Synapse {VERSION} needs {requirement.name}, but it is not installed\"\n\n\ndef _incorrect_version(\n requirement: Requirement, got: str, extra: Optional[str] = None\n) -> str:\n if extra:\n return (\n f\"Synapse {VERSION} needs {requirement} for {extra}, \"\n f\"but got {requirement.name}=={got}\"\n )\n else:\n return (\n f\"Synapse {VERSION} needs {requirement}, but got {requirement.name}=={got}\"\n )\n\n\ndef check_requirements(extra: Optional[str] = None) -> None:\n \"\"\"Check Synapse's dependencies are present and correctly versioned.\n\n If provided, `extra` must be the name of an pacakging extra (e.g. \"saml2\" in\n `pip install matrix-synapse[saml2]`).\n\n If `extra` is None, this function checks that\n - all mandatory dependencies are installed and correctly versioned, and\n - each optional dependency that's installed is correctly versioned.\n\n If `extra` is not None, this function checks that\n - the dependencies needed for that extra are installed and correctly versioned.\n\n :raises DependencyException: if a dependency is missing or incorrectly versioned.\n :raises ValueError: if this extra does not exist.\n \"\"\"\n # First work out which dependencies are required, and which are optional.\n if extra is None:\n dependencies = _generic_dependencies()\n elif extra in RUNTIME_EXTRAS:\n dependencies = _dependencies_for_extra(extra)\n else:\n raise ValueError(f\"Synapse {VERSION} does not provide the feature '{extra}'\")\n\n deps_unfulfilled = []\n errors = []\n\n for (requirement, must_be_installed) in dependencies:\n try:\n dist: metadata.Distribution = metadata.distribution(requirement.name)\n except metadata.PackageNotFoundError:\n if must_be_installed:\n deps_unfulfilled.append(requirement.name)\n errors.append(_not_installed(requirement, extra))\n else:\n # We specify prereleases=True to allow prereleases such as RCs.\n if not requirement.specifier.contains(dist.version, prereleases=True):\n deps_unfulfilled.append(requirement.name)\n errors.append(_incorrect_version(requirement, dist.version, extra))\n\n if deps_unfulfilled:\n for err in errors:\n logging.error(err)\n\n raise DependencyException(deps_unfulfilled)\n", "path": "synapse/util/check_dependencies.py"}]}
| 2,250 | 145 |
gh_patches_debug_6993
|
rasdani/github-patches
|
git_diff
|
modin-project__modin-3542
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`fsspec` should be explicitly stated in setup.py and env files
`fsspec` package became required dependency after https://github.com/modin-project/modin/pull/3529
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 from setuptools import setup, find_packages
2 import versioneer
3 import os
4 from setuptools.dist import Distribution
5
6 try:
7 from wheel.bdist_wheel import bdist_wheel
8
9 HAS_WHEEL = True
10 except ImportError:
11 HAS_WHEEL = False
12
13 with open("README.md", "r", encoding="utf-8") as fh:
14 long_description = fh.read()
15
16 if HAS_WHEEL:
17
18 class ModinWheel(bdist_wheel):
19 def finalize_options(self):
20 bdist_wheel.finalize_options(self)
21 self.root_is_pure = False
22
23 def get_tag(self):
24 _, _, plat = bdist_wheel.get_tag(self)
25 py = "py3"
26 abi = "none"
27 return py, abi, plat
28
29
30 class ModinDistribution(Distribution):
31 def __init__(self, *attrs):
32 Distribution.__init__(self, *attrs)
33 if HAS_WHEEL:
34 self.cmdclass["bdist_wheel"] = ModinWheel
35
36 def is_pure(self):
37 return False
38
39
40 dask_deps = ["dask>=2.22.0", "distributed>=2.22.0"]
41 ray_deps = ["ray[default]>=1.4.0", "pyarrow>=1.0"]
42 remote_deps = ["rpyc==4.1.5", "cloudpickle", "boto3"]
43 spreadsheet_deps = ["modin-spreadsheet>=0.1.0"]
44 sql_deps = ["dfsql>=0.4.2"]
45 all_deps = dask_deps + ray_deps + remote_deps + spreadsheet_deps
46
47 # dfsql does not support Windows yet
48 if os.name != 'nt':
49 all_deps += sql_deps
50
51 setup(
52 name="modin",
53 version=versioneer.get_version(),
54 cmdclass=versioneer.get_cmdclass(),
55 distclass=ModinDistribution,
56 description="Modin: Make your pandas code run faster by changing one line of code.",
57 packages=find_packages(),
58 include_package_data=True,
59 license="Apache 2",
60 url="https://github.com/modin-project/modin",
61 long_description=long_description,
62 long_description_content_type="text/markdown",
63 install_requires=["pandas==1.3.3", "packaging", "numpy>=1.16.5"],
64 extras_require={
65 # can be installed by pip install modin[dask]
66 "dask": dask_deps,
67 "ray": ray_deps,
68 "remote": remote_deps,
69 "spreadsheet": spreadsheet_deps,
70 "sql": sql_deps,
71 "all": all_deps,
72 },
73 python_requires=">=3.7.1",
74 )
75
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -60,7 +60,7 @@
url="https://github.com/modin-project/modin",
long_description=long_description,
long_description_content_type="text/markdown",
- install_requires=["pandas==1.3.3", "packaging", "numpy>=1.16.5"],
+ install_requires=["pandas==1.3.3", "packaging", "numpy>=1.16.5", "fsspec"],
extras_require={
# can be installed by pip install modin[dask]
"dask": dask_deps,
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -60,7 +60,7 @@\n url=\"https://github.com/modin-project/modin\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n- install_requires=[\"pandas==1.3.3\", \"packaging\", \"numpy>=1.16.5\"],\n+ install_requires=[\"pandas==1.3.3\", \"packaging\", \"numpy>=1.16.5\", \"fsspec\"],\n extras_require={\n # can be installed by pip install modin[dask]\n \"dask\": dask_deps,\n", "issue": "`fsspec` should be explicitly stated in setup.py and env files\n`fsspec` package became required dependency after https://github.com/modin-project/modin/pull/3529\n", "before_files": [{"content": "from setuptools import setup, find_packages\nimport versioneer\nimport os\nfrom setuptools.dist import Distribution\n\ntry:\n from wheel.bdist_wheel import bdist_wheel\n\n HAS_WHEEL = True\nexcept ImportError:\n HAS_WHEEL = False\n\nwith open(\"README.md\", \"r\", encoding=\"utf-8\") as fh:\n long_description = fh.read()\n\nif HAS_WHEEL:\n\n class ModinWheel(bdist_wheel):\n def finalize_options(self):\n bdist_wheel.finalize_options(self)\n self.root_is_pure = False\n\n def get_tag(self):\n _, _, plat = bdist_wheel.get_tag(self)\n py = \"py3\"\n abi = \"none\"\n return py, abi, plat\n\n\nclass ModinDistribution(Distribution):\n def __init__(self, *attrs):\n Distribution.__init__(self, *attrs)\n if HAS_WHEEL:\n self.cmdclass[\"bdist_wheel\"] = ModinWheel\n\n def is_pure(self):\n return False\n\n\ndask_deps = [\"dask>=2.22.0\", \"distributed>=2.22.0\"]\nray_deps = [\"ray[default]>=1.4.0\", \"pyarrow>=1.0\"]\nremote_deps = [\"rpyc==4.1.5\", \"cloudpickle\", \"boto3\"]\nspreadsheet_deps = [\"modin-spreadsheet>=0.1.0\"]\nsql_deps = [\"dfsql>=0.4.2\"]\nall_deps = dask_deps + ray_deps + remote_deps + spreadsheet_deps\n\n# dfsql does not support Windows yet\nif os.name != 'nt':\n all_deps += sql_deps\n\nsetup(\n name=\"modin\",\n version=versioneer.get_version(),\n cmdclass=versioneer.get_cmdclass(),\n distclass=ModinDistribution,\n description=\"Modin: Make your pandas code run faster by changing one line of code.\",\n packages=find_packages(),\n include_package_data=True,\n license=\"Apache 2\",\n url=\"https://github.com/modin-project/modin\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n install_requires=[\"pandas==1.3.3\", \"packaging\", \"numpy>=1.16.5\"],\n extras_require={\n # can be installed by pip install modin[dask]\n \"dask\": dask_deps,\n \"ray\": ray_deps,\n \"remote\": remote_deps,\n \"spreadsheet\": spreadsheet_deps,\n \"sql\": sql_deps,\n \"all\": all_deps,\n },\n python_requires=\">=3.7.1\",\n)\n", "path": "setup.py"}], "after_files": [{"content": "from setuptools import setup, find_packages\nimport versioneer\nimport os\nfrom setuptools.dist import Distribution\n\ntry:\n from wheel.bdist_wheel import bdist_wheel\n\n HAS_WHEEL = True\nexcept ImportError:\n HAS_WHEEL = False\n\nwith open(\"README.md\", \"r\", encoding=\"utf-8\") as fh:\n long_description = fh.read()\n\nif HAS_WHEEL:\n\n class ModinWheel(bdist_wheel):\n def finalize_options(self):\n bdist_wheel.finalize_options(self)\n self.root_is_pure = False\n\n def get_tag(self):\n _, _, plat = bdist_wheel.get_tag(self)\n py = \"py3\"\n abi = \"none\"\n return py, abi, plat\n\n\nclass ModinDistribution(Distribution):\n def __init__(self, *attrs):\n Distribution.__init__(self, *attrs)\n if HAS_WHEEL:\n self.cmdclass[\"bdist_wheel\"] = ModinWheel\n\n def is_pure(self):\n return False\n\n\ndask_deps = [\"dask>=2.22.0\", \"distributed>=2.22.0\"]\nray_deps = [\"ray[default]>=1.4.0\", \"pyarrow>=1.0\"]\nremote_deps = [\"rpyc==4.1.5\", \"cloudpickle\", \"boto3\"]\nspreadsheet_deps = [\"modin-spreadsheet>=0.1.0\"]\nsql_deps = [\"dfsql>=0.4.2\"]\nall_deps = dask_deps + ray_deps + remote_deps + spreadsheet_deps\n\n# dfsql does not support Windows yet\nif os.name != 'nt':\n all_deps += sql_deps\n\nsetup(\n name=\"modin\",\n version=versioneer.get_version(),\n cmdclass=versioneer.get_cmdclass(),\n distclass=ModinDistribution,\n description=\"Modin: Make your pandas code run faster by changing one line of code.\",\n packages=find_packages(),\n include_package_data=True,\n license=\"Apache 2\",\n url=\"https://github.com/modin-project/modin\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n install_requires=[\"pandas==1.3.3\", \"packaging\", \"numpy>=1.16.5\", \"fsspec\"],\n extras_require={\n # can be installed by pip install modin[dask]\n \"dask\": dask_deps,\n \"ray\": ray_deps,\n \"remote\": remote_deps,\n \"spreadsheet\": spreadsheet_deps,\n \"sql\": sql_deps,\n \"all\": all_deps,\n },\n python_requires=\">=3.7.1\",\n)\n", "path": "setup.py"}]}
| 1,006 | 149 |
gh_patches_debug_31195
|
rasdani/github-patches
|
git_diff
|
hpcaitech__ColossalAI-2695
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[tensor] fix some unittests
[tensor] fix some unittests
[tensor] fix some unittests
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `colossalai/auto_parallel/tensor_shard/deprecated/op_handler/strategy_generator.py`
Content:
```
1 from dataclasses import dataclass
2 from abc import ABC, abstractmethod
3 from typing import List, Dict
4 from colossalai.device.device_mesh import DeviceMesh
5
6 __all__ = ['IntermediateStrategy', 'StrategyGenerator']
7
8
9 @dataclass
10 class IntermediateStrategy:
11 """
12 IntermediateStrategy contains the subset of meta information for ShardingStrategy. It is
13 to store the essential information regarding the tensor sharding and leave other meta information to OperatorHandler.
14
15 Args:
16 name (str): name of the sharding strategy.
17 dim_partition_dict (Dict[Dict]): stores the tensor to dim partition dict mapping.
18 all_reduce_dims (List[int]): stores the dimensions which require an all-reduce operation.
19 """
20 name: str
21 dim_partition_dict: Dict[str, Dict[int, List[int]]]
22 all_reduce_axis: List[int] = None
23
24
25 class StrategyGenerator(ABC):
26 """
27 StrategyGenerator is used to generate the same group of sharding strategies.
28 """
29
30 def __init__(self, device_mesh: DeviceMesh):
31 self.device_mesh = device_mesh
32
33 @abstractmethod
34 def generate(self) -> List[IntermediateStrategy]:
35 """
36 """
37 pass
38
39 @abstractmethod
40 def validate(self, *args, **kwargs) -> bool:
41 """
42 Validate if the operands are of desired shape.
43 If True, means this generator can be used for the current operation.
44 """
45 pass
46
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/colossalai/auto_parallel/tensor_shard/deprecated/op_handler/strategy_generator.py b/colossalai/auto_parallel/tensor_shard/deprecated/op_handler/strategy_generator.py
--- a/colossalai/auto_parallel/tensor_shard/deprecated/op_handler/strategy_generator.py
+++ b/colossalai/auto_parallel/tensor_shard/deprecated/op_handler/strategy_generator.py
@@ -1,6 +1,7 @@
-from dataclasses import dataclass
from abc import ABC, abstractmethod
-from typing import List, Dict
+from dataclasses import dataclass
+from typing import Dict, List
+
from colossalai.device.device_mesh import DeviceMesh
__all__ = ['IntermediateStrategy', 'StrategyGenerator']
@@ -9,7 +10,7 @@
@dataclass
class IntermediateStrategy:
"""
- IntermediateStrategy contains the subset of meta information for ShardingStrategy. It is
+ IntermediateStrategy contains the subset of meta information for ShardingStrategy. It is
to store the essential information regarding the tensor sharding and leave other meta information to OperatorHandler.
Args:
@@ -24,7 +25,7 @@
class StrategyGenerator(ABC):
"""
- StrategyGenerator is used to generate the same group of sharding strategies.
+ StrategyGenerator is used to generate the same group of sharding strategies.
"""
def __init__(self, device_mesh: DeviceMesh):
@@ -39,7 +40,7 @@
@abstractmethod
def validate(self, *args, **kwargs) -> bool:
"""
- Validate if the operands are of desired shape.
+ Validate if the operands are of desired shape.
If True, means this generator can be used for the current operation.
"""
pass
|
{"golden_diff": "diff --git a/colossalai/auto_parallel/tensor_shard/deprecated/op_handler/strategy_generator.py b/colossalai/auto_parallel/tensor_shard/deprecated/op_handler/strategy_generator.py\n--- a/colossalai/auto_parallel/tensor_shard/deprecated/op_handler/strategy_generator.py\n+++ b/colossalai/auto_parallel/tensor_shard/deprecated/op_handler/strategy_generator.py\n@@ -1,6 +1,7 @@\n-from dataclasses import dataclass\n from abc import ABC, abstractmethod\n-from typing import List, Dict\n+from dataclasses import dataclass\n+from typing import Dict, List\n+\n from colossalai.device.device_mesh import DeviceMesh\n \n __all__ = ['IntermediateStrategy', 'StrategyGenerator']\n@@ -9,7 +10,7 @@\n @dataclass\n class IntermediateStrategy:\n \"\"\"\n- IntermediateStrategy contains the subset of meta information for ShardingStrategy. It is \n+ IntermediateStrategy contains the subset of meta information for ShardingStrategy. It is\n to store the essential information regarding the tensor sharding and leave other meta information to OperatorHandler.\n \n Args:\n@@ -24,7 +25,7 @@\n \n class StrategyGenerator(ABC):\n \"\"\"\n- StrategyGenerator is used to generate the same group of sharding strategies. \n+ StrategyGenerator is used to generate the same group of sharding strategies.\n \"\"\"\n \n def __init__(self, device_mesh: DeviceMesh):\n@@ -39,7 +40,7 @@\n @abstractmethod\n def validate(self, *args, **kwargs) -> bool:\n \"\"\"\n- Validate if the operands are of desired shape. \n+ Validate if the operands are of desired shape.\n If True, means this generator can be used for the current operation.\n \"\"\"\n pass\n", "issue": "[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n", "before_files": [{"content": "from dataclasses import dataclass\nfrom abc import ABC, abstractmethod\nfrom typing import List, Dict\nfrom colossalai.device.device_mesh import DeviceMesh\n\n__all__ = ['IntermediateStrategy', 'StrategyGenerator']\n\n\n@dataclass\nclass IntermediateStrategy:\n \"\"\"\n IntermediateStrategy contains the subset of meta information for ShardingStrategy. It is \n to store the essential information regarding the tensor sharding and leave other meta information to OperatorHandler.\n\n Args:\n name (str): name of the sharding strategy.\n dim_partition_dict (Dict[Dict]): stores the tensor to dim partition dict mapping.\n all_reduce_dims (List[int]): stores the dimensions which require an all-reduce operation.\n \"\"\"\n name: str\n dim_partition_dict: Dict[str, Dict[int, List[int]]]\n all_reduce_axis: List[int] = None\n\n\nclass StrategyGenerator(ABC):\n \"\"\"\n StrategyGenerator is used to generate the same group of sharding strategies. \n \"\"\"\n\n def __init__(self, device_mesh: DeviceMesh):\n self.device_mesh = device_mesh\n\n @abstractmethod\n def generate(self) -> List[IntermediateStrategy]:\n \"\"\"\n \"\"\"\n pass\n\n @abstractmethod\n def validate(self, *args, **kwargs) -> bool:\n \"\"\"\n Validate if the operands are of desired shape. \n If True, means this generator can be used for the current operation.\n \"\"\"\n pass\n", "path": "colossalai/auto_parallel/tensor_shard/deprecated/op_handler/strategy_generator.py"}], "after_files": [{"content": "from abc import ABC, abstractmethod\nfrom dataclasses import dataclass\nfrom typing import Dict, List\n\nfrom colossalai.device.device_mesh import DeviceMesh\n\n__all__ = ['IntermediateStrategy', 'StrategyGenerator']\n\n\n@dataclass\nclass IntermediateStrategy:\n \"\"\"\n IntermediateStrategy contains the subset of meta information for ShardingStrategy. It is\n to store the essential information regarding the tensor sharding and leave other meta information to OperatorHandler.\n\n Args:\n name (str): name of the sharding strategy.\n dim_partition_dict (Dict[Dict]): stores the tensor to dim partition dict mapping.\n all_reduce_dims (List[int]): stores the dimensions which require an all-reduce operation.\n \"\"\"\n name: str\n dim_partition_dict: Dict[str, Dict[int, List[int]]]\n all_reduce_axis: List[int] = None\n\n\nclass StrategyGenerator(ABC):\n \"\"\"\n StrategyGenerator is used to generate the same group of sharding strategies.\n \"\"\"\n\n def __init__(self, device_mesh: DeviceMesh):\n self.device_mesh = device_mesh\n\n @abstractmethod\n def generate(self) -> List[IntermediateStrategy]:\n \"\"\"\n \"\"\"\n pass\n\n @abstractmethod\n def validate(self, *args, **kwargs) -> bool:\n \"\"\"\n Validate if the operands are of desired shape.\n If True, means this generator can be used for the current operation.\n \"\"\"\n pass\n", "path": "colossalai/auto_parallel/tensor_shard/deprecated/op_handler/strategy_generator.py"}]}
| 683 | 381 |
gh_patches_debug_11434
|
rasdani/github-patches
|
git_diff
|
Lightning-AI__pytorch-lightning-837
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
advanced profiler description fails for python 3.6
## 🐛 Bug
Python 3.6 doesn't have the `pstats.SortKey.CUMULATIVE` enum so the profiler description breaks.
### To Reproduce
Steps to reproduce the behavior:
Use Python 3.6, pass in the AdvancedProfiler, get report at end of a training run.
```
profiler = AdvancedProfiler(line_count_restriction=10)
trainer = Trainer(profiler=profiler)
trainer.fit(model)
```
Stack trace:
```
164 for action_name, pr in self.profiled_actions.items():
165 s = io.StringIO()
--> 166 sortby = pstats.SortKey.CUMULATIVE
167 ps = pstats.Stats(pr, stream=s).strip_dirs().sort_stats(sortby)
168 ps.print_stats(self.line_count_restriction)
AttributeError: module 'pstats' has no attribute 'SortKey'
```
#### Code sample
```
from pytorch_lightning import Trainer
from pytorch_lightning.profiler import AdvancedProfiler
from argparse import Namespace
from pl_examples.basic_examples.lightning_module_template import LightningTemplateModel
# define model
hparams = {
"batch_size": 128,
"in_features": 784,
"hidden_dim": 512,
"drop_prob": 0.0,
"out_features": 10,
"learning_rate": 5e-3,
"data_root": "data"
}
hparams = Namespace(**hparams)
model = LightningTemplateModel(hparams)
# overfit on small batch
profiler = AdvancedProfiler(line_count_restriction=10)
trainer = Trainer(profiler=profiler, overfit_pct=0.05, min_epochs=10)
trainer.fit(model)
```
### Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
### Environment
Collecting environment information...
PyTorch version: 1.4.0
Is debug build: No
CUDA used to build PyTorch: 10.1
OS: Ubuntu 18.04.3 LTS
GCC version: (Ubuntu 7.4.0-1ubuntu1~18.04.1) 7.4.0
CMake version: version 3.12.0
Python version: 3.6
Is CUDA available: Yes
CUDA runtime version: 10.0.130
GPU models and configuration: GPU 0: Tesla P100-PCIE-16GB
Nvidia driver version: 418.67
cuDNN version: /usr/lib/x86_64-linux-gnu/libcudnn.so.7.6.5
Versions of relevant libraries:
[pip3] numpy==1.17.5
[pip3] pytorch-lightning==0.6.1.dev0
[pip3] torch==1.4.0
[pip3] torchsummary==1.5.1
[pip3] torchtext==0.3.1
[pip3] torchvision==0.5.0
[conda] Could not collect
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pytorch_lightning/profiler/profiler.py`
Content:
```
1 from contextlib import contextmanager
2 from collections import defaultdict
3 import time
4 import numpy as np
5 import cProfile
6 import pstats
7 import io
8 from abc import ABC, abstractmethod
9 import logging
10
11 logger = logging.getLogger(__name__)
12
13
14 class BaseProfiler(ABC):
15 """
16 If you wish to write a custom profiler, you should inhereit from this class.
17 """
18
19 @abstractmethod
20 def start(self, action_name):
21 """
22 Defines how to start recording an action.
23 """
24 pass
25
26 @abstractmethod
27 def stop(self, action_name):
28 """
29 Defines how to record the duration once an action is complete.
30 """
31 pass
32
33 @contextmanager
34 def profile(self, action_name):
35 """
36 Yields a context manager to encapsulate the scope of a profiled action.
37
38 Example::
39
40 with self.profile('load training data'):
41 # load training data code
42
43 The profiler will start once you've entered the context and will automatically
44 stop once you exit the code block.
45 """
46 try:
47 self.start(action_name)
48 yield action_name
49 finally:
50 self.stop(action_name)
51
52 def profile_iterable(self, iterable, action_name):
53 iterator = iter(iterable)
54 while True:
55 try:
56 self.start(action_name)
57 value = next(iterator)
58 self.stop(action_name)
59 yield value
60 except StopIteration:
61 self.stop(action_name)
62 break
63
64 def describe(self):
65 """
66 Logs a profile report after the conclusion of the training run.
67 """
68 pass
69
70
71 class PassThroughProfiler(BaseProfiler):
72 """
73 This class should be used when you don't want the (small) overhead of profiling.
74 The Trainer uses this class by default.
75 """
76
77 def __init__(self):
78 pass
79
80 def start(self, action_name):
81 pass
82
83 def stop(self, action_name):
84 pass
85
86
87 class Profiler(BaseProfiler):
88 """
89 This profiler simply records the duration of actions (in seconds) and reports
90 the mean duration of each action and the total time spent over the entire training run.
91 """
92
93 def __init__(self):
94 self.current_actions = {}
95 self.recorded_durations = defaultdict(list)
96
97 def start(self, action_name):
98 if action_name in self.current_actions:
99 raise ValueError(
100 f"Attempted to start {action_name} which has already started."
101 )
102 self.current_actions[action_name] = time.monotonic()
103
104 def stop(self, action_name):
105 end_time = time.monotonic()
106 if action_name not in self.current_actions:
107 raise ValueError(
108 f"Attempting to stop recording an action ({action_name}) which was never started."
109 )
110 start_time = self.current_actions.pop(action_name)
111 duration = end_time - start_time
112 self.recorded_durations[action_name].append(duration)
113
114 def describe(self):
115 output_string = "\n\nProfiler Report\n"
116
117 def log_row(action, mean, total):
118 return f"\n{action:<20s}\t| {mean:<15}\t| {total:<15}"
119
120 output_string += log_row("Action", "Mean duration (s)", "Total time (s)")
121 output_string += f"\n{'-' * 65}"
122 for action, durations in self.recorded_durations.items():
123 output_string += log_row(
124 action, f"{np.mean(durations):.5}", f"{np.sum(durations):.5}",
125 )
126 output_string += "\n"
127 logger.info(output_string)
128
129
130 class AdvancedProfiler(BaseProfiler):
131 """
132 This profiler uses Python's cProfiler to record more detailed information about
133 time spent in each function call recorded during a given action. The output is quite
134 verbose and you should only use this if you want very detailed reports.
135 """
136
137 def __init__(self, output_filename=None, line_count_restriction=1.0):
138 """
139 :param output_filename (str): optionally save profile results to file instead of printing
140 to std out when training is finished.
141 :param line_count_restriction (int|float): this can be used to limit the number of functions
142 reported for each action. either an integer (to select a count of lines),
143 or a decimal fraction between 0.0 and 1.0 inclusive (to select a percentage of lines)
144 """
145 self.profiled_actions = {}
146 self.output_filename = output_filename
147 self.line_count_restriction = line_count_restriction
148
149 def start(self, action_name):
150 if action_name not in self.profiled_actions:
151 self.profiled_actions[action_name] = cProfile.Profile()
152 self.profiled_actions[action_name].enable()
153
154 def stop(self, action_name):
155 pr = self.profiled_actions.get(action_name)
156 if pr is None:
157 raise ValueError(
158 f"Attempting to stop recording an action ({action_name}) which was never started."
159 )
160 pr.disable()
161
162 def describe(self):
163 self.recorded_stats = {}
164 for action_name, pr in self.profiled_actions.items():
165 s = io.StringIO()
166 sortby = pstats.SortKey.CUMULATIVE
167 ps = pstats.Stats(pr, stream=s).strip_dirs().sort_stats(sortby)
168 ps.print_stats(self.line_count_restriction)
169 self.recorded_stats[action_name] = s.getvalue()
170 if self.output_filename is not None:
171 # save to file
172 with open(self.output_filename, "w") as f:
173 for action, stats in self.recorded_stats.items():
174 f.write(f"Profile stats for: {action}")
175 f.write(stats)
176 else:
177 # log to standard out
178 output_string = "\nProfiler Report\n"
179 for action, stats in self.recorded_stats.items():
180 output_string += f"\nProfile stats for: {action}\n{stats}"
181 logger.info(output_string)
182
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pytorch_lightning/profiler/profiler.py b/pytorch_lightning/profiler/profiler.py
--- a/pytorch_lightning/profiler/profiler.py
+++ b/pytorch_lightning/profiler/profiler.py
@@ -163,8 +163,7 @@
self.recorded_stats = {}
for action_name, pr in self.profiled_actions.items():
s = io.StringIO()
- sortby = pstats.SortKey.CUMULATIVE
- ps = pstats.Stats(pr, stream=s).strip_dirs().sort_stats(sortby)
+ ps = pstats.Stats(pr, stream=s).strip_dirs().sort_stats('cumulative')
ps.print_stats(self.line_count_restriction)
self.recorded_stats[action_name] = s.getvalue()
if self.output_filename is not None:
|
{"golden_diff": "diff --git a/pytorch_lightning/profiler/profiler.py b/pytorch_lightning/profiler/profiler.py\n--- a/pytorch_lightning/profiler/profiler.py\n+++ b/pytorch_lightning/profiler/profiler.py\n@@ -163,8 +163,7 @@\n self.recorded_stats = {}\n for action_name, pr in self.profiled_actions.items():\n s = io.StringIO()\n- sortby = pstats.SortKey.CUMULATIVE\n- ps = pstats.Stats(pr, stream=s).strip_dirs().sort_stats(sortby)\n+ ps = pstats.Stats(pr, stream=s).strip_dirs().sort_stats('cumulative')\n ps.print_stats(self.line_count_restriction)\n self.recorded_stats[action_name] = s.getvalue()\n if self.output_filename is not None:\n", "issue": "advanced profiler description fails for python 3.6\n## \ud83d\udc1b Bug\r\n\r\nPython 3.6 doesn't have the `pstats.SortKey.CUMULATIVE` enum so the profiler description breaks.\r\n\r\n### To Reproduce\r\n\r\nSteps to reproduce the behavior:\r\n\r\nUse Python 3.6, pass in the AdvancedProfiler, get report at end of a training run. \r\n\r\n```\r\nprofiler = AdvancedProfiler(line_count_restriction=10)\r\ntrainer = Trainer(profiler=profiler)\r\ntrainer.fit(model)\r\n```\r\n\r\nStack trace:\r\n```\r\n 164 for action_name, pr in self.profiled_actions.items():\r\n 165 s = io.StringIO()\r\n--> 166 sortby = pstats.SortKey.CUMULATIVE\r\n 167 ps = pstats.Stats(pr, stream=s).strip_dirs().sort_stats(sortby)\r\n 168 ps.print_stats(self.line_count_restriction)\r\n\r\nAttributeError: module 'pstats' has no attribute 'SortKey'\r\n```\r\n\r\n\r\n#### Code sample\r\n\r\n```\r\nfrom pytorch_lightning import Trainer\r\nfrom pytorch_lightning.profiler import AdvancedProfiler\r\nfrom argparse import Namespace\r\nfrom pl_examples.basic_examples.lightning_module_template import LightningTemplateModel\r\n\r\n\r\n# define model\r\nhparams = {\r\n \"batch_size\": 128,\r\n \"in_features\": 784,\r\n \"hidden_dim\": 512,\r\n \"drop_prob\": 0.0,\r\n \"out_features\": 10,\r\n \"learning_rate\": 5e-3,\r\n \"data_root\": \"data\"\r\n}\r\nhparams = Namespace(**hparams)\r\nmodel = LightningTemplateModel(hparams)\r\n\r\n# overfit on small batch\r\nprofiler = AdvancedProfiler(line_count_restriction=10)\r\ntrainer = Trainer(profiler=profiler, overfit_pct=0.05, min_epochs=10)\r\ntrainer.fit(model)\r\n```\r\n\r\n### Expected behavior\r\n\r\n<!-- A clear and concise description of what you expected to happen. -->\r\n\r\n### Environment\r\n\r\nCollecting environment information...\r\nPyTorch version: 1.4.0\r\nIs debug build: No\r\nCUDA used to build PyTorch: 10.1\r\n\r\nOS: Ubuntu 18.04.3 LTS\r\nGCC version: (Ubuntu 7.4.0-1ubuntu1~18.04.1) 7.4.0\r\nCMake version: version 3.12.0\r\n\r\nPython version: 3.6\r\nIs CUDA available: Yes\r\nCUDA runtime version: 10.0.130\r\nGPU models and configuration: GPU 0: Tesla P100-PCIE-16GB\r\nNvidia driver version: 418.67\r\ncuDNN version: /usr/lib/x86_64-linux-gnu/libcudnn.so.7.6.5\r\n\r\nVersions of relevant libraries:\r\n[pip3] numpy==1.17.5\r\n[pip3] pytorch-lightning==0.6.1.dev0\r\n[pip3] torch==1.4.0\r\n[pip3] torchsummary==1.5.1\r\n[pip3] torchtext==0.3.1\r\n[pip3] torchvision==0.5.0\r\n[conda] Could not collect\r\n\r\n\r\n\n", "before_files": [{"content": "from contextlib import contextmanager\nfrom collections import defaultdict\nimport time\nimport numpy as np\nimport cProfile\nimport pstats\nimport io\nfrom abc import ABC, abstractmethod\nimport logging\n\nlogger = logging.getLogger(__name__)\n\n\nclass BaseProfiler(ABC):\n \"\"\"\n If you wish to write a custom profiler, you should inhereit from this class.\n \"\"\"\n\n @abstractmethod\n def start(self, action_name):\n \"\"\"\n Defines how to start recording an action.\n \"\"\"\n pass\n\n @abstractmethod\n def stop(self, action_name):\n \"\"\"\n Defines how to record the duration once an action is complete.\n \"\"\"\n pass\n\n @contextmanager\n def profile(self, action_name):\n \"\"\"\n Yields a context manager to encapsulate the scope of a profiled action.\n\n Example::\n\n with self.profile('load training data'):\n # load training data code\n\n The profiler will start once you've entered the context and will automatically\n stop once you exit the code block.\n \"\"\"\n try:\n self.start(action_name)\n yield action_name\n finally:\n self.stop(action_name)\n\n def profile_iterable(self, iterable, action_name):\n iterator = iter(iterable)\n while True:\n try:\n self.start(action_name)\n value = next(iterator)\n self.stop(action_name)\n yield value\n except StopIteration:\n self.stop(action_name)\n break\n\n def describe(self):\n \"\"\"\n Logs a profile report after the conclusion of the training run.\n \"\"\"\n pass\n\n\nclass PassThroughProfiler(BaseProfiler):\n \"\"\"\n This class should be used when you don't want the (small) overhead of profiling.\n The Trainer uses this class by default.\n \"\"\"\n\n def __init__(self):\n pass\n\n def start(self, action_name):\n pass\n\n def stop(self, action_name):\n pass\n\n\nclass Profiler(BaseProfiler):\n \"\"\"\n This profiler simply records the duration of actions (in seconds) and reports\n the mean duration of each action and the total time spent over the entire training run.\n \"\"\"\n\n def __init__(self):\n self.current_actions = {}\n self.recorded_durations = defaultdict(list)\n\n def start(self, action_name):\n if action_name in self.current_actions:\n raise ValueError(\n f\"Attempted to start {action_name} which has already started.\"\n )\n self.current_actions[action_name] = time.monotonic()\n\n def stop(self, action_name):\n end_time = time.monotonic()\n if action_name not in self.current_actions:\n raise ValueError(\n f\"Attempting to stop recording an action ({action_name}) which was never started.\"\n )\n start_time = self.current_actions.pop(action_name)\n duration = end_time - start_time\n self.recorded_durations[action_name].append(duration)\n\n def describe(self):\n output_string = \"\\n\\nProfiler Report\\n\"\n\n def log_row(action, mean, total):\n return f\"\\n{action:<20s}\\t| {mean:<15}\\t| {total:<15}\"\n\n output_string += log_row(\"Action\", \"Mean duration (s)\", \"Total time (s)\")\n output_string += f\"\\n{'-' * 65}\"\n for action, durations in self.recorded_durations.items():\n output_string += log_row(\n action, f\"{np.mean(durations):.5}\", f\"{np.sum(durations):.5}\",\n )\n output_string += \"\\n\"\n logger.info(output_string)\n\n\nclass AdvancedProfiler(BaseProfiler):\n \"\"\"\n This profiler uses Python's cProfiler to record more detailed information about\n time spent in each function call recorded during a given action. The output is quite\n verbose and you should only use this if you want very detailed reports.\n \"\"\"\n\n def __init__(self, output_filename=None, line_count_restriction=1.0):\n \"\"\"\n :param output_filename (str): optionally save profile results to file instead of printing\n to std out when training is finished.\n :param line_count_restriction (int|float): this can be used to limit the number of functions\n reported for each action. either an integer (to select a count of lines),\n or a decimal fraction between 0.0 and 1.0 inclusive (to select a percentage of lines)\n \"\"\"\n self.profiled_actions = {}\n self.output_filename = output_filename\n self.line_count_restriction = line_count_restriction\n\n def start(self, action_name):\n if action_name not in self.profiled_actions:\n self.profiled_actions[action_name] = cProfile.Profile()\n self.profiled_actions[action_name].enable()\n\n def stop(self, action_name):\n pr = self.profiled_actions.get(action_name)\n if pr is None:\n raise ValueError(\n f\"Attempting to stop recording an action ({action_name}) which was never started.\"\n )\n pr.disable()\n\n def describe(self):\n self.recorded_stats = {}\n for action_name, pr in self.profiled_actions.items():\n s = io.StringIO()\n sortby = pstats.SortKey.CUMULATIVE\n ps = pstats.Stats(pr, stream=s).strip_dirs().sort_stats(sortby)\n ps.print_stats(self.line_count_restriction)\n self.recorded_stats[action_name] = s.getvalue()\n if self.output_filename is not None:\n # save to file\n with open(self.output_filename, \"w\") as f:\n for action, stats in self.recorded_stats.items():\n f.write(f\"Profile stats for: {action}\")\n f.write(stats)\n else:\n # log to standard out\n output_string = \"\\nProfiler Report\\n\"\n for action, stats in self.recorded_stats.items():\n output_string += f\"\\nProfile stats for: {action}\\n{stats}\"\n logger.info(output_string)\n", "path": "pytorch_lightning/profiler/profiler.py"}], "after_files": [{"content": "from contextlib import contextmanager\nfrom collections import defaultdict\nimport time\nimport numpy as np\nimport cProfile\nimport pstats\nimport io\nfrom abc import ABC, abstractmethod\nimport logging\n\nlogger = logging.getLogger(__name__)\n\n\nclass BaseProfiler(ABC):\n \"\"\"\n If you wish to write a custom profiler, you should inhereit from this class.\n \"\"\"\n\n @abstractmethod\n def start(self, action_name):\n \"\"\"\n Defines how to start recording an action.\n \"\"\"\n pass\n\n @abstractmethod\n def stop(self, action_name):\n \"\"\"\n Defines how to record the duration once an action is complete.\n \"\"\"\n pass\n\n @contextmanager\n def profile(self, action_name):\n \"\"\"\n Yields a context manager to encapsulate the scope of a profiled action.\n\n Example::\n\n with self.profile('load training data'):\n # load training data code\n\n The profiler will start once you've entered the context and will automatically\n stop once you exit the code block.\n \"\"\"\n try:\n self.start(action_name)\n yield action_name\n finally:\n self.stop(action_name)\n\n def profile_iterable(self, iterable, action_name):\n iterator = iter(iterable)\n while True:\n try:\n self.start(action_name)\n value = next(iterator)\n self.stop(action_name)\n yield value\n except StopIteration:\n self.stop(action_name)\n break\n\n def describe(self):\n \"\"\"\n Logs a profile report after the conclusion of the training run.\n \"\"\"\n pass\n\n\nclass PassThroughProfiler(BaseProfiler):\n \"\"\"\n This class should be used when you don't want the (small) overhead of profiling.\n The Trainer uses this class by default.\n \"\"\"\n\n def __init__(self):\n pass\n\n def start(self, action_name):\n pass\n\n def stop(self, action_name):\n pass\n\n\nclass Profiler(BaseProfiler):\n \"\"\"\n This profiler simply records the duration of actions (in seconds) and reports\n the mean duration of each action and the total time spent over the entire training run.\n \"\"\"\n\n def __init__(self):\n self.current_actions = {}\n self.recorded_durations = defaultdict(list)\n\n def start(self, action_name):\n if action_name in self.current_actions:\n raise ValueError(\n f\"Attempted to start {action_name} which has already started.\"\n )\n self.current_actions[action_name] = time.monotonic()\n\n def stop(self, action_name):\n end_time = time.monotonic()\n if action_name not in self.current_actions:\n raise ValueError(\n f\"Attempting to stop recording an action ({action_name}) which was never started.\"\n )\n start_time = self.current_actions.pop(action_name)\n duration = end_time - start_time\n self.recorded_durations[action_name].append(duration)\n\n def describe(self):\n output_string = \"\\n\\nProfiler Report\\n\"\n\n def log_row(action, mean, total):\n return f\"\\n{action:<20s}\\t| {mean:<15}\\t| {total:<15}\"\n\n output_string += log_row(\"Action\", \"Mean duration (s)\", \"Total time (s)\")\n output_string += f\"\\n{'-' * 65}\"\n for action, durations in self.recorded_durations.items():\n output_string += log_row(\n action, f\"{np.mean(durations):.5}\", f\"{np.sum(durations):.5}\",\n )\n output_string += \"\\n\"\n logger.info(output_string)\n\n\nclass AdvancedProfiler(BaseProfiler):\n \"\"\"\n This profiler uses Python's cProfiler to record more detailed information about\n time spent in each function call recorded during a given action. The output is quite\n verbose and you should only use this if you want very detailed reports.\n \"\"\"\n\n def __init__(self, output_filename=None, line_count_restriction=1.0):\n \"\"\"\n :param output_filename (str): optionally save profile results to file instead of printing\n to std out when training is finished.\n :param line_count_restriction (int|float): this can be used to limit the number of functions\n reported for each action. either an integer (to select a count of lines),\n or a decimal fraction between 0.0 and 1.0 inclusive (to select a percentage of lines)\n \"\"\"\n self.profiled_actions = {}\n self.output_filename = output_filename\n self.line_count_restriction = line_count_restriction\n\n def start(self, action_name):\n if action_name not in self.profiled_actions:\n self.profiled_actions[action_name] = cProfile.Profile()\n self.profiled_actions[action_name].enable()\n\n def stop(self, action_name):\n pr = self.profiled_actions.get(action_name)\n if pr is None:\n raise ValueError(\n f\"Attempting to stop recording an action ({action_name}) which was never started.\"\n )\n pr.disable()\n\n def describe(self):\n self.recorded_stats = {}\n for action_name, pr in self.profiled_actions.items():\n s = io.StringIO()\n ps = pstats.Stats(pr, stream=s).strip_dirs().sort_stats('cumulative')\n ps.print_stats(self.line_count_restriction)\n self.recorded_stats[action_name] = s.getvalue()\n if self.output_filename is not None:\n # save to file\n with open(self.output_filename, \"w\") as f:\n for action, stats in self.recorded_stats.items():\n f.write(f\"Profile stats for: {action}\")\n f.write(stats)\n else:\n # log to standard out\n output_string = \"\\nProfiler Report\\n\"\n for action, stats in self.recorded_stats.items():\n output_string += f\"\\nProfile stats for: {action}\\n{stats}\"\n logger.info(output_string)\n", "path": "pytorch_lightning/profiler/profiler.py"}]}
| 2,677 | 177 |
gh_patches_debug_3293
|
rasdani/github-patches
|
git_diff
|
python-pillow__Pillow-3493
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
How to tell at run time whether libjpeg-turbo version of libjpeg is used?
tl;dr:
Is there some way to accomplish: `PIL.Image.libjpeg_turbo_is_enabled()`?
The full story:
Is there a way to tell from a pre-built Pillow whether it was built against `libjpeg-turbo` or not?
This is assuming that all I have is `libjpeg.so.X.X` and no way to tell where it came from.
I see there is a symbol in the library:
```
nm _imaging.cpython-36m-x86_64-linux-gnu.so | grep -I turbo
000000000007e5a0 D libjpeg_turbo_version
```
but I don't know how to access its value from python.
If there is a way to tell the same from from shell using `ldd`/`nm` or other linker tools, it'd do too.
The intention is to be able to tell a user at run-time to re-build Pillow after installing `libjpeg-turbo` to gain speed. The problem is that It's not enough to build Pillow against `libjpeg-turbo`. Given how conda/pip dependencies work, a new prebuilt package of `Pillow` could get swapped in as a dependency for some other package and the user won't know that they now run a less efficient `Pillow` unless they watch closely any install/update logs.
Currently the only solution I can think of (in conda env) is to take the output of:
cd ~/anaconda3/envs/pytorch-dev/lib/python3.6/site-packages/PIL
ldd _imaging.cpython-36m-x86_64-linux-gnu.so | grep libjpeg
which wold give me something like:
libjpeg.so.8 => ~/anaconda3/envs/pytorch-dev/lib/libjpeg.so.8
And then to try to match it to:
grep libjpeg ~/anaconda3/envs/pytorch-dev/conda-meta/libjpeg-turbo-2.0.1-h470a237_0.json
which may work. There is a problem with this approach
It's very likely that conda is going to reinstall `jpeg` since many packages depend on it, and when it does, there is going to be 2 libjpeg libs.
ldd _imaging.cpython-36m-x86_64-linux-gnu.so | grep libjpeg
libjpeg.so.8 => /home/stas/anaconda3/envs/pytorch-dev/lib/libjpeg.so.8 (0x00007f92628c8000)
libjpeg.so.9 => /home/stas/anaconda3/envs/pytorch-dev/lib/./libjpeg.so.9 (0x00007f9261c4e000)
And now I can no longer tell which is which, since I can no longer tell which of the two Pillow will load at run time. Well, I can go one step further and check /proc/<pid>/maps to get the library, but it's getting more and more convoluted. And I won't even know how to do the same on non-linux platform. And this is just for the conda setup, for pip setup it'd be something else.
Also what happens if `libjpeg-turbo` and `libjpeg` are the same version?
Perhaps there is an easier way? Any chance to have `PIL.Image.libjpeg_turbo_is_enabled()`?
Thank you.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/PIL/features.py`
Content:
```
1 from . import Image
2
3 modules = {
4 "pil": "PIL._imaging",
5 "tkinter": "PIL._tkinter_finder",
6 "freetype2": "PIL._imagingft",
7 "littlecms2": "PIL._imagingcms",
8 "webp": "PIL._webp",
9 }
10
11
12 def check_module(feature):
13 if not (feature in modules):
14 raise ValueError("Unknown module %s" % feature)
15
16 module = modules[feature]
17
18 try:
19 __import__(module)
20 return True
21 except ImportError:
22 return False
23
24
25 def get_supported_modules():
26 return [f for f in modules if check_module(f)]
27
28
29 codecs = {
30 "jpg": "jpeg",
31 "jpg_2000": "jpeg2k",
32 "zlib": "zip",
33 "libtiff": "libtiff"
34 }
35
36
37 def check_codec(feature):
38 if feature not in codecs:
39 raise ValueError("Unknown codec %s" % feature)
40
41 codec = codecs[feature]
42
43 return codec + "_encoder" in dir(Image.core)
44
45
46 def get_supported_codecs():
47 return [f for f in codecs if check_codec(f)]
48
49
50 features = {
51 "webp_anim": ("PIL._webp", 'HAVE_WEBPANIM'),
52 "webp_mux": ("PIL._webp", 'HAVE_WEBPMUX'),
53 "transp_webp": ("PIL._webp", "HAVE_TRANSPARENCY"),
54 "raqm": ("PIL._imagingft", "HAVE_RAQM")
55 }
56
57
58 def check_feature(feature):
59 if feature not in features:
60 raise ValueError("Unknown feature %s" % feature)
61
62 module, flag = features[feature]
63
64 try:
65 imported_module = __import__(module, fromlist=['PIL'])
66 return getattr(imported_module, flag)
67 except ImportError:
68 return None
69
70
71 def get_supported_features():
72 return [f for f in features if check_feature(f)]
73
74
75 def check(feature):
76 return (feature in modules and check_module(feature) or
77 feature in codecs and check_codec(feature) or
78 feature in features and check_feature(feature))
79
80
81 def get_supported():
82 ret = get_supported_modules()
83 ret.extend(get_supported_features())
84 ret.extend(get_supported_codecs())
85 return ret
86
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/PIL/features.py b/src/PIL/features.py
--- a/src/PIL/features.py
+++ b/src/PIL/features.py
@@ -51,7 +51,8 @@
"webp_anim": ("PIL._webp", 'HAVE_WEBPANIM'),
"webp_mux": ("PIL._webp", 'HAVE_WEBPMUX'),
"transp_webp": ("PIL._webp", "HAVE_TRANSPARENCY"),
- "raqm": ("PIL._imagingft", "HAVE_RAQM")
+ "raqm": ("PIL._imagingft", "HAVE_RAQM"),
+ "libjpeg_turbo": ("PIL._imaging", "HAVE_LIBJPEGTURBO"),
}
|
{"golden_diff": "diff --git a/src/PIL/features.py b/src/PIL/features.py\n--- a/src/PIL/features.py\n+++ b/src/PIL/features.py\n@@ -51,7 +51,8 @@\n \"webp_anim\": (\"PIL._webp\", 'HAVE_WEBPANIM'),\n \"webp_mux\": (\"PIL._webp\", 'HAVE_WEBPMUX'),\n \"transp_webp\": (\"PIL._webp\", \"HAVE_TRANSPARENCY\"),\n- \"raqm\": (\"PIL._imagingft\", \"HAVE_RAQM\")\n+ \"raqm\": (\"PIL._imagingft\", \"HAVE_RAQM\"),\n+ \"libjpeg_turbo\": (\"PIL._imaging\", \"HAVE_LIBJPEGTURBO\"),\n }\n", "issue": "How to tell at run time whether libjpeg-turbo version of libjpeg is used?\ntl;dr:\r\n\r\nIs there some way to accomplish: `PIL.Image.libjpeg_turbo_is_enabled()`?\r\n\r\nThe full story:\r\n\r\nIs there a way to tell from a pre-built Pillow whether it was built against `libjpeg-turbo` or not?\r\n\r\nThis is assuming that all I have is `libjpeg.so.X.X` and no way to tell where it came from.\r\n\r\nI see there is a symbol in the library:\r\n```\r\nnm _imaging.cpython-36m-x86_64-linux-gnu.so | grep -I turbo\r\n000000000007e5a0 D libjpeg_turbo_version\r\n```\r\nbut I don't know how to access its value from python.\r\n\r\nIf there is a way to tell the same from from shell using `ldd`/`nm` or other linker tools, it'd do too.\r\n\r\nThe intention is to be able to tell a user at run-time to re-build Pillow after installing `libjpeg-turbo` to gain speed. The problem is that It's not enough to build Pillow against `libjpeg-turbo`. Given how conda/pip dependencies work, a new prebuilt package of `Pillow` could get swapped in as a dependency for some other package and the user won't know that they now run a less efficient `Pillow` unless they watch closely any install/update logs.\r\n\r\nCurrently the only solution I can think of (in conda env) is to take the output of:\r\n\r\n cd ~/anaconda3/envs/pytorch-dev/lib/python3.6/site-packages/PIL\r\n ldd _imaging.cpython-36m-x86_64-linux-gnu.so | grep libjpeg\r\n\r\nwhich wold give me something like:\r\n\r\n libjpeg.so.8 => ~/anaconda3/envs/pytorch-dev/lib/libjpeg.so.8\r\n\r\nAnd then to try to match it to:\r\n\r\n grep libjpeg ~/anaconda3/envs/pytorch-dev/conda-meta/libjpeg-turbo-2.0.1-h470a237_0.json\r\n\r\nwhich may work. There is a problem with this approach\r\n\r\nIt's very likely that conda is going to reinstall `jpeg` since many packages depend on it, and when it does, there is going to be 2 libjpeg libs.\r\n\r\n ldd _imaging.cpython-36m-x86_64-linux-gnu.so | grep libjpeg\r\n libjpeg.so.8 => /home/stas/anaconda3/envs/pytorch-dev/lib/libjpeg.so.8 (0x00007f92628c8000)\r\n libjpeg.so.9 => /home/stas/anaconda3/envs/pytorch-dev/lib/./libjpeg.so.9 (0x00007f9261c4e000)\r\n\r\nAnd now I can no longer tell which is which, since I can no longer tell which of the two Pillow will load at run time. Well, I can go one step further and check /proc/<pid>/maps to get the library, but it's getting more and more convoluted. And I won't even know how to do the same on non-linux platform. And this is just for the conda setup, for pip setup it'd be something else.\r\n\r\nAlso what happens if `libjpeg-turbo` and `libjpeg` are the same version?\r\n\r\nPerhaps there is an easier way? Any chance to have `PIL.Image.libjpeg_turbo_is_enabled()`?\r\n\r\nThank you.\r\n\n", "before_files": [{"content": "from . import Image\n\nmodules = {\n \"pil\": \"PIL._imaging\",\n \"tkinter\": \"PIL._tkinter_finder\",\n \"freetype2\": \"PIL._imagingft\",\n \"littlecms2\": \"PIL._imagingcms\",\n \"webp\": \"PIL._webp\",\n}\n\n\ndef check_module(feature):\n if not (feature in modules):\n raise ValueError(\"Unknown module %s\" % feature)\n\n module = modules[feature]\n\n try:\n __import__(module)\n return True\n except ImportError:\n return False\n\n\ndef get_supported_modules():\n return [f for f in modules if check_module(f)]\n\n\ncodecs = {\n \"jpg\": \"jpeg\",\n \"jpg_2000\": \"jpeg2k\",\n \"zlib\": \"zip\",\n \"libtiff\": \"libtiff\"\n}\n\n\ndef check_codec(feature):\n if feature not in codecs:\n raise ValueError(\"Unknown codec %s\" % feature)\n\n codec = codecs[feature]\n\n return codec + \"_encoder\" in dir(Image.core)\n\n\ndef get_supported_codecs():\n return [f for f in codecs if check_codec(f)]\n\n\nfeatures = {\n \"webp_anim\": (\"PIL._webp\", 'HAVE_WEBPANIM'),\n \"webp_mux\": (\"PIL._webp\", 'HAVE_WEBPMUX'),\n \"transp_webp\": (\"PIL._webp\", \"HAVE_TRANSPARENCY\"),\n \"raqm\": (\"PIL._imagingft\", \"HAVE_RAQM\")\n}\n\n\ndef check_feature(feature):\n if feature not in features:\n raise ValueError(\"Unknown feature %s\" % feature)\n\n module, flag = features[feature]\n\n try:\n imported_module = __import__(module, fromlist=['PIL'])\n return getattr(imported_module, flag)\n except ImportError:\n return None\n\n\ndef get_supported_features():\n return [f for f in features if check_feature(f)]\n\n\ndef check(feature):\n return (feature in modules and check_module(feature) or\n feature in codecs and check_codec(feature) or\n feature in features and check_feature(feature))\n\n\ndef get_supported():\n ret = get_supported_modules()\n ret.extend(get_supported_features())\n ret.extend(get_supported_codecs())\n return ret\n", "path": "src/PIL/features.py"}], "after_files": [{"content": "from . import Image\n\nmodules = {\n \"pil\": \"PIL._imaging\",\n \"tkinter\": \"PIL._tkinter_finder\",\n \"freetype2\": \"PIL._imagingft\",\n \"littlecms2\": \"PIL._imagingcms\",\n \"webp\": \"PIL._webp\",\n}\n\n\ndef check_module(feature):\n if not (feature in modules):\n raise ValueError(\"Unknown module %s\" % feature)\n\n module = modules[feature]\n\n try:\n __import__(module)\n return True\n except ImportError:\n return False\n\n\ndef get_supported_modules():\n return [f for f in modules if check_module(f)]\n\n\ncodecs = {\n \"jpg\": \"jpeg\",\n \"jpg_2000\": \"jpeg2k\",\n \"zlib\": \"zip\",\n \"libtiff\": \"libtiff\"\n}\n\n\ndef check_codec(feature):\n if feature not in codecs:\n raise ValueError(\"Unknown codec %s\" % feature)\n\n codec = codecs[feature]\n\n return codec + \"_encoder\" in dir(Image.core)\n\n\ndef get_supported_codecs():\n return [f for f in codecs if check_codec(f)]\n\n\nfeatures = {\n \"webp_anim\": (\"PIL._webp\", 'HAVE_WEBPANIM'),\n \"webp_mux\": (\"PIL._webp\", 'HAVE_WEBPMUX'),\n \"transp_webp\": (\"PIL._webp\", \"HAVE_TRANSPARENCY\"),\n \"raqm\": (\"PIL._imagingft\", \"HAVE_RAQM\"),\n \"libjpeg_turbo\": (\"PIL._imaging\", \"HAVE_LIBJPEGTURBO\"),\n}\n\n\ndef check_feature(feature):\n if feature not in features:\n raise ValueError(\"Unknown feature %s\" % feature)\n\n module, flag = features[feature]\n\n try:\n imported_module = __import__(module, fromlist=['PIL'])\n return getattr(imported_module, flag)\n except ImportError:\n return None\n\n\ndef get_supported_features():\n return [f for f in features if check_feature(f)]\n\n\ndef check(feature):\n return (feature in modules and check_module(feature) or\n feature in codecs and check_codec(feature) or\n feature in features and check_feature(feature))\n\n\ndef get_supported():\n ret = get_supported_modules()\n ret.extend(get_supported_features())\n ret.extend(get_supported_codecs())\n return ret\n", "path": "src/PIL/features.py"}]}
| 1,716 | 167 |
gh_patches_debug_31120
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-1365
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
catch a simple bug of handling url
### Checklist
- [x] This is a bug report.
### Description
catch a simple bug of returning url.
### Version
streamlink 0.9.0
### Unexpected behavior
for example
```sh
streamlink http://www.huya.com/1547946968 "best"
```
it reports:
requests.exceptions.MissingSchema: Invalid URL '//ws.streamhls.huya.com/huyalive/30765679-2523417567-10837995924416888832-2789253832-10057-A-1512526581-1_1200/playlist.m3u8': No schema supplied. Perhaps you meant http:////ws.streamhls.huya.com/huyalive/30765679-2523417567-10837995924416888832-2789253832-10057-A-1512526581-1_1200/playlist.m3u8?
### Expected behavior
but if you replace with the m3u8 url above, by **removing // header**, it will work.
The equivalent successful example are as follows:
```sh
streamlink ws.streamhls.huya.com/huyalive/30765679-2523417567-10837995924416888832-2789253832-10057-A-1512526581-1_1200/playlist.m3u8 "best"
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/streamlink/plugins/huya.py`
Content:
```
1 import re
2
3 from requests.adapters import HTTPAdapter
4
5 from streamlink.plugin import Plugin
6 from streamlink.plugin.api import http, validate
7 from streamlink.stream import HLSStream
8 from streamlink.plugin.api import useragents
9
10 HUYA_URL = "http://m.huya.com/%s"
11
12 _url_re = re.compile(r'http(s)?://(www\.)?huya.com/(?P<channel>[^/]+)', re.VERBOSE)
13 _hls_re = re.compile(r'^\s*<video\s+id="html5player-video"\s+src="(?P<url>[^"]+)"', re.MULTILINE)
14
15 _hls_schema = validate.Schema(
16 validate.all(
17 validate.transform(_hls_re.search),
18 validate.any(
19 None,
20 validate.all(
21 validate.get('url'),
22 validate.transform(str)
23 )
24 )
25 )
26 )
27
28 class Huya(Plugin):
29 @classmethod
30 def can_handle_url(self, url):
31 return _url_re.match(url)
32
33 def _get_streams(self):
34 match = _url_re.match(self.url)
35 channel = match.group("channel")
36
37 http.headers.update({"User-Agent": useragents.IPAD})
38 #Some problem with SSL on huya.com now, do not use https
39
40 hls_url = http.get(HUYA_URL % channel, schema=_hls_schema)
41 yield "live", HLSStream(self.session, hls_url)
42
43 __plugin__ = Huya
44
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/streamlink/plugins/huya.py b/src/streamlink/plugins/huya.py
--- a/src/streamlink/plugins/huya.py
+++ b/src/streamlink/plugins/huya.py
@@ -1,11 +1,10 @@
import re
-from requests.adapters import HTTPAdapter
-
from streamlink.plugin import Plugin
from streamlink.plugin.api import http, validate
from streamlink.stream import HLSStream
from streamlink.plugin.api import useragents
+from streamlink.utils import update_scheme
HUYA_URL = "http://m.huya.com/%s"
@@ -13,17 +12,18 @@
_hls_re = re.compile(r'^\s*<video\s+id="html5player-video"\s+src="(?P<url>[^"]+)"', re.MULTILINE)
_hls_schema = validate.Schema(
- validate.all(
- validate.transform(_hls_re.search),
- validate.any(
- None,
- validate.all(
- validate.get('url'),
- validate.transform(str)
- )
- )
+ validate.all(
+ validate.transform(_hls_re.search),
+ validate.any(
+ None,
+ validate.all(
+ validate.get('url'),
+ validate.transform(str)
)
)
+ )
+)
+
class Huya(Plugin):
@classmethod
@@ -35,9 +35,10 @@
channel = match.group("channel")
http.headers.update({"User-Agent": useragents.IPAD})
- #Some problem with SSL on huya.com now, do not use https
+ # Some problem with SSL on huya.com now, do not use https
hls_url = http.get(HUYA_URL % channel, schema=_hls_schema)
- yield "live", HLSStream(self.session, hls_url)
+ yield "live", HLSStream(self.session, update_scheme("http://", hls_url))
+
__plugin__ = Huya
|
{"golden_diff": "diff --git a/src/streamlink/plugins/huya.py b/src/streamlink/plugins/huya.py\n--- a/src/streamlink/plugins/huya.py\n+++ b/src/streamlink/plugins/huya.py\n@@ -1,11 +1,10 @@\n import re\n \n-from requests.adapters import HTTPAdapter\n-\n from streamlink.plugin import Plugin\n from streamlink.plugin.api import http, validate\n from streamlink.stream import HLSStream\n from streamlink.plugin.api import useragents\n+from streamlink.utils import update_scheme\n \n HUYA_URL = \"http://m.huya.com/%s\"\n \n@@ -13,17 +12,18 @@\n _hls_re = re.compile(r'^\\s*<video\\s+id=\"html5player-video\"\\s+src=\"(?P<url>[^\"]+)\"', re.MULTILINE)\n \n _hls_schema = validate.Schema(\n- validate.all(\n- validate.transform(_hls_re.search),\n- validate.any(\n- None,\n- validate.all(\n- validate.get('url'),\n- validate.transform(str)\n- )\n- )\n+ validate.all(\n+ validate.transform(_hls_re.search),\n+ validate.any(\n+ None,\n+ validate.all(\n+ validate.get('url'),\n+ validate.transform(str)\n )\n )\n+ )\n+)\n+\n \n class Huya(Plugin):\n @classmethod\n@@ -35,9 +35,10 @@\n channel = match.group(\"channel\")\n \n http.headers.update({\"User-Agent\": useragents.IPAD})\n- #Some problem with SSL on huya.com now, do not use https\n+ # Some problem with SSL on huya.com now, do not use https\n \n hls_url = http.get(HUYA_URL % channel, schema=_hls_schema)\n- yield \"live\", HLSStream(self.session, hls_url)\n+ yield \"live\", HLSStream(self.session, update_scheme(\"http://\", hls_url))\n+\n \n __plugin__ = Huya\n", "issue": "catch a simple bug of handling url\n\r\n### Checklist\r\n\r\n- [x] This is a bug report.\r\n\r\n### Description\r\n\r\ncatch a simple bug of returning url. \r\n\r\n### Version\r\nstreamlink 0.9.0\r\n\r\n### Unexpected behavior\r\nfor example\r\n```sh\r\nstreamlink http://www.huya.com/1547946968 \"best\"\r\n```\r\nit reports:\r\nrequests.exceptions.MissingSchema: Invalid URL '//ws.streamhls.huya.com/huyalive/30765679-2523417567-10837995924416888832-2789253832-10057-A-1512526581-1_1200/playlist.m3u8': No schema supplied. Perhaps you meant http:////ws.streamhls.huya.com/huyalive/30765679-2523417567-10837995924416888832-2789253832-10057-A-1512526581-1_1200/playlist.m3u8?\r\n\r\n### Expected behavior\r\nbut if you replace with the m3u8 url above, by **removing // header**, it will work.\r\nThe equivalent successful example are as follows:\r\n```sh\r\nstreamlink ws.streamhls.huya.com/huyalive/30765679-2523417567-10837995924416888832-2789253832-10057-A-1512526581-1_1200/playlist.m3u8 \"best\"\r\n```\n", "before_files": [{"content": "import re\n\nfrom requests.adapters import HTTPAdapter\n\nfrom streamlink.plugin import Plugin\nfrom streamlink.plugin.api import http, validate\nfrom streamlink.stream import HLSStream\nfrom streamlink.plugin.api import useragents\n\nHUYA_URL = \"http://m.huya.com/%s\"\n\n_url_re = re.compile(r'http(s)?://(www\\.)?huya.com/(?P<channel>[^/]+)', re.VERBOSE)\n_hls_re = re.compile(r'^\\s*<video\\s+id=\"html5player-video\"\\s+src=\"(?P<url>[^\"]+)\"', re.MULTILINE)\n\n_hls_schema = validate.Schema(\n validate.all(\n validate.transform(_hls_re.search),\n validate.any(\n None,\n validate.all(\n validate.get('url'),\n validate.transform(str)\n )\n )\n )\n )\n\nclass Huya(Plugin):\n @classmethod\n def can_handle_url(self, url):\n return _url_re.match(url)\n\n def _get_streams(self):\n match = _url_re.match(self.url)\n channel = match.group(\"channel\")\n\n http.headers.update({\"User-Agent\": useragents.IPAD})\n #Some problem with SSL on huya.com now, do not use https\n\n hls_url = http.get(HUYA_URL % channel, schema=_hls_schema)\n yield \"live\", HLSStream(self.session, hls_url)\n\n__plugin__ = Huya\n", "path": "src/streamlink/plugins/huya.py"}], "after_files": [{"content": "import re\n\nfrom streamlink.plugin import Plugin\nfrom streamlink.plugin.api import http, validate\nfrom streamlink.stream import HLSStream\nfrom streamlink.plugin.api import useragents\nfrom streamlink.utils import update_scheme\n\nHUYA_URL = \"http://m.huya.com/%s\"\n\n_url_re = re.compile(r'http(s)?://(www\\.)?huya.com/(?P<channel>[^/]+)', re.VERBOSE)\n_hls_re = re.compile(r'^\\s*<video\\s+id=\"html5player-video\"\\s+src=\"(?P<url>[^\"]+)\"', re.MULTILINE)\n\n_hls_schema = validate.Schema(\n validate.all(\n validate.transform(_hls_re.search),\n validate.any(\n None,\n validate.all(\n validate.get('url'),\n validate.transform(str)\n )\n )\n )\n)\n\n\nclass Huya(Plugin):\n @classmethod\n def can_handle_url(self, url):\n return _url_re.match(url)\n\n def _get_streams(self):\n match = _url_re.match(self.url)\n channel = match.group(\"channel\")\n\n http.headers.update({\"User-Agent\": useragents.IPAD})\n # Some problem with SSL on huya.com now, do not use https\n\n hls_url = http.get(HUYA_URL % channel, schema=_hls_schema)\n yield \"live\", HLSStream(self.session, update_scheme(\"http://\", hls_url))\n\n\n__plugin__ = Huya\n", "path": "src/streamlink/plugins/huya.py"}]}
| 1,086 | 433 |
gh_patches_debug_4108
|
rasdani/github-patches
|
git_diff
|
google__timesketch-1821
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
tagger analyzer not functiong properly
**Describe the bug**
After upgrade TimeSketch to version: 20210602 the tagger analyzer is not functioning with custom tags
**To Reproduce**
Steps to reproduce the behavior:
1. Import plaso file with evtx data
2. Add the following tagging rule to tags.yaml
```yaml
logon_tagger:
query_string: 'data_type: "windows:evtx:record" AND source_name: "Microsoft-Windows-Security-Auditing" AND event_identifier: 4688'
tags: ['logon']
save_search: true
search_name: 'logon'
```
3. run tagger analyzer
4. See error
**Expected behavior**
The tagger analyzer to run correctly as in previous versions.
**Desktop (please complete the following information):**
-OS:Ubuntu 20.04.2 LTS
-Browser : Firefox
-Version: 86.0
**Additional context**
The following exception is thrown once the tagger analyzer is ran:
```
Traceback (most recent call last): File "/usr/local/lib/python3.8/dist-packages/timesketch/lib/analyzers/interface.py", line 995, in run_wrapper result = self.run() File "/usr/local/lib/python3.8/dist-packages/timesketch/lib/analyzers/tagger.py", line 48, in run tag_result = self.tagger(name, tag_config) File "/usr/local/lib/python3.8/dist-packages/timesketch/lib/analyzers/tagger.py", line 100, in tagger if expression: UnboundLocalError: local variable 'expression' referenced before assignment
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `timesketch/lib/analyzers/tagger.py`
Content:
```
1 """Analyzer plugin for tagging."""
2 import logging
3
4 from timesketch.lib import emojis
5 from timesketch.lib.analyzers import interface
6 from timesketch.lib.analyzers import manager
7 from timesketch.lib.analyzers import utils
8
9
10 logger = logging.getLogger('timesketch.analyzers.tagger')
11
12
13 class TaggerSketchPlugin(interface.BaseAnalyzer):
14 """Analyzer for tagging events."""
15
16 NAME = 'tagger'
17 DISPLAY_NAME = 'Tagger'
18 DESCRIPTION = 'Tag events based on pre-defined rules'
19
20 CONFIG_FILE = 'tags.yaml'
21
22 def __init__(self, index_name, sketch_id, timeline_id=None, config=None):
23 """Initialize The Sketch Analyzer.
24
25 Args:
26 index_name: Elasticsearch index name
27 sketch_id: Sketch ID
28 timeline_id: The ID of the timeline.
29 config: Optional dict that contains the configuration for the
30 analyzer. If not provided, the default YAML file will be used.
31 """
32 self.index_name = index_name
33 self._config = config
34 super().__init__(index_name, sketch_id, timeline_id=timeline_id)
35
36 def run(self):
37 """Entry point for the analyzer.
38
39 Returns:
40 String with summary of the analyzer result.
41 """
42 config = self._config or interface.get_yaml_config(self.CONFIG_FILE)
43 if not config:
44 return 'Unable to parse the config file.'
45
46 tag_results = []
47 for name, tag_config in iter(config.items()):
48 tag_result = self.tagger(name, tag_config)
49 if tag_result and not tag_result.startswith('0 events tagged'):
50 tag_results.append(tag_result)
51
52 if tag_results:
53 return ', '.join(tag_results)
54 return 'No tags applied'
55
56 def tagger(self, name, config):
57 """Tag and add emojis to events.
58
59 Args:
60 name: String with the name describing what will be tagged.
61 config: A dict that contains the configuration See data/tags.yaml
62 for fields and documentation of what needs to be defined.
63
64 Returns:
65 String with summary of the analyzer result.
66 """
67 query = config.get('query_string')
68 query_dsl = config.get('query_dsl')
69 save_search = config.get('save_search', False)
70 # For legacy reasons to support both save_search and
71 # create_view parameters.
72 if not save_search:
73 save_search = config.get('create_view', False)
74
75 search_name = config.get('search_name', None)
76 # For legacy reasons to support both search_name and view_name.
77 if search_name is None:
78 search_name = config.get('view_name', name)
79
80 tags = config.get('tags', [])
81 emoji_names = config.get('emojis', [])
82 emojis_to_add = [emojis.get_emoji(x) for x in emoji_names]
83
84 expression_string = config.get('regular_expression', '')
85 attributes = None
86 if expression_string:
87 expression = utils.compile_regular_expression(
88 expression_string=expression_string,
89 expression_flags=config.get('re_flags'))
90
91 attribute = config.get('re_attribute')
92 if attribute:
93 attributes = [attribute]
94
95 event_counter = 0
96 events = self.event_stream(
97 query_string=query, query_dsl=query_dsl, return_fields=attributes)
98
99 for event in events:
100 if expression:
101 value = event.source.get(attributes[0])
102 if value:
103 result = expression.findall(value)
104 if not result:
105 # Skip counting this tag since the regular expression
106 # didn't find anything.
107 continue
108
109 event_counter += 1
110 event.add_tags(tags)
111 event.add_emojis(emojis_to_add)
112
113 # Commit the event to the datastore.
114 event.commit()
115
116 if save_search and event_counter:
117 self.sketch.add_view(
118 search_name, self.NAME, query_string=query, query_dsl=query_dsl)
119
120 return '{0:d} events tagged for [{1:s}]'.format(event_counter, name)
121
122
123 manager.AnalysisManager.register_analyzer(TaggerSketchPlugin)
124
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/timesketch/lib/analyzers/tagger.py b/timesketch/lib/analyzers/tagger.py
--- a/timesketch/lib/analyzers/tagger.py
+++ b/timesketch/lib/analyzers/tagger.py
@@ -83,6 +83,7 @@
expression_string = config.get('regular_expression', '')
attributes = None
+ expression = None
if expression_string:
expression = utils.compile_regular_expression(
expression_string=expression_string,
|
{"golden_diff": "diff --git a/timesketch/lib/analyzers/tagger.py b/timesketch/lib/analyzers/tagger.py\n--- a/timesketch/lib/analyzers/tagger.py\n+++ b/timesketch/lib/analyzers/tagger.py\n@@ -83,6 +83,7 @@\n \n expression_string = config.get('regular_expression', '')\n attributes = None\n+ expression = None\n if expression_string:\n expression = utils.compile_regular_expression(\n expression_string=expression_string,\n", "issue": "tagger analyzer not functiong properly \n**Describe the bug**\r\nAfter upgrade TimeSketch to version: 20210602 the tagger analyzer is not functioning with custom tags\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Import plaso file with evtx data \r\n2. Add the following tagging rule to tags.yaml\r\n```yaml\r\nlogon_tagger: \r\n query_string: 'data_type: \"windows:evtx:record\" AND source_name: \"Microsoft-Windows-Security-Auditing\" AND event_identifier: 4688'\r\n tags: ['logon']\r\n save_search: true\r\n search_name: 'logon'\r\n```\r\n3. run tagger analyzer\r\n4. See error\r\n\r\n**Expected behavior**\r\nThe tagger analyzer to run correctly as in previous versions.\r\n\r\n**Desktop (please complete the following information):**\r\n-OS:Ubuntu 20.04.2 LTS\r\n-Browser : Firefox\r\n-Version: 86.0\r\n\r\n**Additional context**\r\nThe following exception is thrown once the tagger analyzer is ran:\r\n```\r\nTraceback (most recent call last): File \"/usr/local/lib/python3.8/dist-packages/timesketch/lib/analyzers/interface.py\", line 995, in run_wrapper result = self.run() File \"/usr/local/lib/python3.8/dist-packages/timesketch/lib/analyzers/tagger.py\", line 48, in run tag_result = self.tagger(name, tag_config) File \"/usr/local/lib/python3.8/dist-packages/timesketch/lib/analyzers/tagger.py\", line 100, in tagger if expression: UnboundLocalError: local variable 'expression' referenced before assignment\r\n``` \r\n\n", "before_files": [{"content": "\"\"\"Analyzer plugin for tagging.\"\"\"\nimport logging\n\nfrom timesketch.lib import emojis\nfrom timesketch.lib.analyzers import interface\nfrom timesketch.lib.analyzers import manager\nfrom timesketch.lib.analyzers import utils\n\n\nlogger = logging.getLogger('timesketch.analyzers.tagger')\n\n\nclass TaggerSketchPlugin(interface.BaseAnalyzer):\n \"\"\"Analyzer for tagging events.\"\"\"\n\n NAME = 'tagger'\n DISPLAY_NAME = 'Tagger'\n DESCRIPTION = 'Tag events based on pre-defined rules'\n\n CONFIG_FILE = 'tags.yaml'\n\n def __init__(self, index_name, sketch_id, timeline_id=None, config=None):\n \"\"\"Initialize The Sketch Analyzer.\n\n Args:\n index_name: Elasticsearch index name\n sketch_id: Sketch ID\n timeline_id: The ID of the timeline.\n config: Optional dict that contains the configuration for the\n analyzer. If not provided, the default YAML file will be used.\n \"\"\"\n self.index_name = index_name\n self._config = config\n super().__init__(index_name, sketch_id, timeline_id=timeline_id)\n\n def run(self):\n \"\"\"Entry point for the analyzer.\n\n Returns:\n String with summary of the analyzer result.\n \"\"\"\n config = self._config or interface.get_yaml_config(self.CONFIG_FILE)\n if not config:\n return 'Unable to parse the config file.'\n\n tag_results = []\n for name, tag_config in iter(config.items()):\n tag_result = self.tagger(name, tag_config)\n if tag_result and not tag_result.startswith('0 events tagged'):\n tag_results.append(tag_result)\n\n if tag_results:\n return ', '.join(tag_results)\n return 'No tags applied'\n\n def tagger(self, name, config):\n \"\"\"Tag and add emojis to events.\n\n Args:\n name: String with the name describing what will be tagged.\n config: A dict that contains the configuration See data/tags.yaml\n for fields and documentation of what needs to be defined.\n\n Returns:\n String with summary of the analyzer result.\n \"\"\"\n query = config.get('query_string')\n query_dsl = config.get('query_dsl')\n save_search = config.get('save_search', False)\n # For legacy reasons to support both save_search and\n # create_view parameters.\n if not save_search:\n save_search = config.get('create_view', False)\n\n search_name = config.get('search_name', None)\n # For legacy reasons to support both search_name and view_name.\n if search_name is None:\n search_name = config.get('view_name', name)\n\n tags = config.get('tags', [])\n emoji_names = config.get('emojis', [])\n emojis_to_add = [emojis.get_emoji(x) for x in emoji_names]\n\n expression_string = config.get('regular_expression', '')\n attributes = None\n if expression_string:\n expression = utils.compile_regular_expression(\n expression_string=expression_string,\n expression_flags=config.get('re_flags'))\n\n attribute = config.get('re_attribute')\n if attribute:\n attributes = [attribute]\n\n event_counter = 0\n events = self.event_stream(\n query_string=query, query_dsl=query_dsl, return_fields=attributes)\n\n for event in events:\n if expression:\n value = event.source.get(attributes[0])\n if value:\n result = expression.findall(value)\n if not result:\n # Skip counting this tag since the regular expression\n # didn't find anything.\n continue\n\n event_counter += 1\n event.add_tags(tags)\n event.add_emojis(emojis_to_add)\n\n # Commit the event to the datastore.\n event.commit()\n\n if save_search and event_counter:\n self.sketch.add_view(\n search_name, self.NAME, query_string=query, query_dsl=query_dsl)\n\n return '{0:d} events tagged for [{1:s}]'.format(event_counter, name)\n\n\nmanager.AnalysisManager.register_analyzer(TaggerSketchPlugin)\n", "path": "timesketch/lib/analyzers/tagger.py"}], "after_files": [{"content": "\"\"\"Analyzer plugin for tagging.\"\"\"\nimport logging\n\nfrom timesketch.lib import emojis\nfrom timesketch.lib.analyzers import interface\nfrom timesketch.lib.analyzers import manager\nfrom timesketch.lib.analyzers import utils\n\n\nlogger = logging.getLogger('timesketch.analyzers.tagger')\n\n\nclass TaggerSketchPlugin(interface.BaseAnalyzer):\n \"\"\"Analyzer for tagging events.\"\"\"\n\n NAME = 'tagger'\n DISPLAY_NAME = 'Tagger'\n DESCRIPTION = 'Tag events based on pre-defined rules'\n\n CONFIG_FILE = 'tags.yaml'\n\n def __init__(self, index_name, sketch_id, timeline_id=None, config=None):\n \"\"\"Initialize The Sketch Analyzer.\n\n Args:\n index_name: Elasticsearch index name\n sketch_id: Sketch ID\n timeline_id: The ID of the timeline.\n config: Optional dict that contains the configuration for the\n analyzer. If not provided, the default YAML file will be used.\n \"\"\"\n self.index_name = index_name\n self._config = config\n super().__init__(index_name, sketch_id, timeline_id=timeline_id)\n\n def run(self):\n \"\"\"Entry point for the analyzer.\n\n Returns:\n String with summary of the analyzer result.\n \"\"\"\n config = self._config or interface.get_yaml_config(self.CONFIG_FILE)\n if not config:\n return 'Unable to parse the config file.'\n\n tag_results = []\n for name, tag_config in iter(config.items()):\n tag_result = self.tagger(name, tag_config)\n if tag_result and not tag_result.startswith('0 events tagged'):\n tag_results.append(tag_result)\n\n if tag_results:\n return ', '.join(tag_results)\n return 'No tags applied'\n\n def tagger(self, name, config):\n \"\"\"Tag and add emojis to events.\n\n Args:\n name: String with the name describing what will be tagged.\n config: A dict that contains the configuration See data/tags.yaml\n for fields and documentation of what needs to be defined.\n\n Returns:\n String with summary of the analyzer result.\n \"\"\"\n query = config.get('query_string')\n query_dsl = config.get('query_dsl')\n save_search = config.get('save_search', False)\n # For legacy reasons to support both save_search and\n # create_view parameters.\n if not save_search:\n save_search = config.get('create_view', False)\n\n search_name = config.get('search_name', None)\n # For legacy reasons to support both search_name and view_name.\n if search_name is None:\n search_name = config.get('view_name', name)\n\n tags = config.get('tags', [])\n emoji_names = config.get('emojis', [])\n emojis_to_add = [emojis.get_emoji(x) for x in emoji_names]\n\n expression_string = config.get('regular_expression', '')\n attributes = None\n expression = None\n if expression_string:\n expression = utils.compile_regular_expression(\n expression_string=expression_string,\n expression_flags=config.get('re_flags'))\n\n attribute = config.get('re_attribute')\n if attribute:\n attributes = [attribute]\n\n event_counter = 0\n events = self.event_stream(\n query_string=query, query_dsl=query_dsl, return_fields=attributes)\n\n for event in events:\n if expression:\n value = event.source.get(attributes[0])\n if value:\n result = expression.findall(value)\n if not result:\n # Skip counting this tag since the regular expression\n # didn't find anything.\n continue\n\n event_counter += 1\n event.add_tags(tags)\n event.add_emojis(emojis_to_add)\n\n # Commit the event to the datastore.\n event.commit()\n\n if save_search and event_counter:\n self.sketch.add_view(\n search_name, self.NAME, query_string=query, query_dsl=query_dsl)\n\n return '{0:d} events tagged for [{1:s}]'.format(event_counter, name)\n\n\nmanager.AnalysisManager.register_analyzer(TaggerSketchPlugin)\n", "path": "timesketch/lib/analyzers/tagger.py"}]}
| 1,763 | 111 |
gh_patches_debug_559
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-702
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Release 1.6.6
On the docket:
+ [x] Release more flexible pex binaries. #654
+ [x] If sys.executable is not on PATH a pex will re-exec itself forever. #700
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pex/version.py`
Content:
```
1 # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 __version__ = '1.6.5'
5
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pex/version.py b/pex/version.py
--- a/pex/version.py
+++ b/pex/version.py
@@ -1,4 +1,4 @@
# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
# Licensed under the Apache License, Version 2.0 (see LICENSE).
-__version__ = '1.6.5'
+__version__ = '1.6.6'
|
{"golden_diff": "diff --git a/pex/version.py b/pex/version.py\n--- a/pex/version.py\n+++ b/pex/version.py\n@@ -1,4 +1,4 @@\n # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n # Licensed under the Apache License, Version 2.0 (see LICENSE).\n \n-__version__ = '1.6.5'\n+__version__ = '1.6.6'\n", "issue": "Release 1.6.6\nOn the docket:\r\n+ [x] Release more flexible pex binaries. #654\r\n+ [x] If sys.executable is not on PATH a pex will re-exec itself forever. #700\n", "before_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = '1.6.5'\n", "path": "pex/version.py"}], "after_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = '1.6.6'\n", "path": "pex/version.py"}]}
| 361 | 94 |
gh_patches_debug_9878
|
rasdani/github-patches
|
git_diff
|
buildbot__buildbot-3423
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Tracker for `RolesFromDomain`
This is to track the implementation of `RolesFromDomain`, which implements role setting depending on the email domain of the user.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `master/buildbot/www/authz/roles.py`
Content:
```
1 # This file is part of Buildbot. Buildbot is free software: you can
2 # redistribute it and/or modify it under the terms of the GNU General Public
3 # License as published by the Free Software Foundation, version 2.
4 #
5 # This program is distributed in the hope that it will be useful, but WITHOUT
6 # ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
7 # FOR A PARTICULAR PURPOSE. See the GNU General Public License for more
8 # details.
9 #
10 # You should have received a copy of the GNU General Public License along with
11 # this program; if not, write to the Free Software Foundation, Inc., 51
12 # Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
13 #
14 # Copyright Buildbot Team Members
15
16 from __future__ import absolute_import
17 from __future__ import print_function
18 from future.utils import iteritems
19
20
21 class RolesFromBase(object):
22
23 def __init__(self):
24 pass
25
26 def getRolesFromUser(self, userDetails):
27 return []
28
29 def setAuthz(self, authz):
30 self.authz = authz
31 self.master = authz.master
32
33
34 class RolesFromGroups(RolesFromBase):
35
36 def __init__(self, groupPrefix=""):
37 RolesFromBase.__init__(self)
38 self.groupPrefix = groupPrefix
39
40 def getRolesFromUser(self, userDetails):
41 roles = []
42 if 'groups' in userDetails:
43 for group in userDetails['groups']:
44 if group.startswith(self.groupPrefix):
45 roles.append(group[len(self.groupPrefix):])
46 return roles
47
48
49 class RolesFromEmails(RolesFromBase):
50
51 def __init__(self, **kwargs):
52 RolesFromBase.__init__(self)
53 self.roles = {}
54 for role, emails in iteritems(kwargs):
55 for email in emails:
56 self.roles.setdefault(email, []).append(role)
57
58 def getRolesFromUser(self, userDetails):
59 if 'email' in userDetails:
60 return self.roles.get(userDetails['email'], [])
61 return []
62
63
64 class RolesFromOwner(RolesFromBase):
65
66 def __init__(self, role):
67 RolesFromBase.__init__(self)
68 self.role = role
69
70 def getRolesFromUser(self, userDetails, owner):
71 if 'email' in userDetails:
72 if userDetails['email'] == owner and owner is not None:
73 return [self.role]
74 return []
75
76
77 class RolesFromUsername(RolesFromBase):
78 def __init__(self, roles, usernames):
79 self.roles = roles
80 if None in usernames:
81 from buildbot import config
82 config.error('Usernames cannot be None')
83 self.usernames = usernames
84
85 def getRolesFromUser(self, userDetails):
86 if userDetails.get('username') in self.usernames:
87 return self.roles
88 return []
89
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/master/buildbot/www/authz/roles.py b/master/buildbot/www/authz/roles.py
--- a/master/buildbot/www/authz/roles.py
+++ b/master/buildbot/www/authz/roles.py
@@ -61,6 +61,24 @@
return []
+class RolesFromDomain(RolesFromEmails):
+
+ def __init__(self, **kwargs):
+ RolesFromBase.__init__(self)
+
+ self.domain_roles = {}
+ for role, domains in iteritems(kwargs):
+ for domain in domains:
+ self.domain_roles.setdefault(domain, []).append(role)
+
+ def getRolesFromUser(self, userDetails):
+ if 'email' in userDetails:
+ email = userDetails['email']
+ edomain = email.split('@')[-1]
+ return self.domain_roles.get(edomain, [])
+ return []
+
+
class RolesFromOwner(RolesFromBase):
def __init__(self, role):
|
{"golden_diff": "diff --git a/master/buildbot/www/authz/roles.py b/master/buildbot/www/authz/roles.py\n--- a/master/buildbot/www/authz/roles.py\n+++ b/master/buildbot/www/authz/roles.py\n@@ -61,6 +61,24 @@\n return []\n \n \n+class RolesFromDomain(RolesFromEmails):\n+\n+ def __init__(self, **kwargs):\n+ RolesFromBase.__init__(self)\n+\n+ self.domain_roles = {}\n+ for role, domains in iteritems(kwargs):\n+ for domain in domains:\n+ self.domain_roles.setdefault(domain, []).append(role)\n+\n+ def getRolesFromUser(self, userDetails):\n+ if 'email' in userDetails:\n+ email = userDetails['email']\n+ edomain = email.split('@')[-1]\n+ return self.domain_roles.get(edomain, [])\n+ return []\n+\n+\n class RolesFromOwner(RolesFromBase):\n \n def __init__(self, role):\n", "issue": "Tracker for `RolesFromDomain`\nThis is to track the implementation of `RolesFromDomain`, which implements role setting depending on the email domain of the user.\n", "before_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\nfrom __future__ import absolute_import\nfrom __future__ import print_function\nfrom future.utils import iteritems\n\n\nclass RolesFromBase(object):\n\n def __init__(self):\n pass\n\n def getRolesFromUser(self, userDetails):\n return []\n\n def setAuthz(self, authz):\n self.authz = authz\n self.master = authz.master\n\n\nclass RolesFromGroups(RolesFromBase):\n\n def __init__(self, groupPrefix=\"\"):\n RolesFromBase.__init__(self)\n self.groupPrefix = groupPrefix\n\n def getRolesFromUser(self, userDetails):\n roles = []\n if 'groups' in userDetails:\n for group in userDetails['groups']:\n if group.startswith(self.groupPrefix):\n roles.append(group[len(self.groupPrefix):])\n return roles\n\n\nclass RolesFromEmails(RolesFromBase):\n\n def __init__(self, **kwargs):\n RolesFromBase.__init__(self)\n self.roles = {}\n for role, emails in iteritems(kwargs):\n for email in emails:\n self.roles.setdefault(email, []).append(role)\n\n def getRolesFromUser(self, userDetails):\n if 'email' in userDetails:\n return self.roles.get(userDetails['email'], [])\n return []\n\n\nclass RolesFromOwner(RolesFromBase):\n\n def __init__(self, role):\n RolesFromBase.__init__(self)\n self.role = role\n\n def getRolesFromUser(self, userDetails, owner):\n if 'email' in userDetails:\n if userDetails['email'] == owner and owner is not None:\n return [self.role]\n return []\n\n\nclass RolesFromUsername(RolesFromBase):\n def __init__(self, roles, usernames):\n self.roles = roles\n if None in usernames:\n from buildbot import config\n config.error('Usernames cannot be None')\n self.usernames = usernames\n\n def getRolesFromUser(self, userDetails):\n if userDetails.get('username') in self.usernames:\n return self.roles\n return []\n", "path": "master/buildbot/www/authz/roles.py"}], "after_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\nfrom __future__ import absolute_import\nfrom __future__ import print_function\nfrom future.utils import iteritems\n\n\nclass RolesFromBase(object):\n\n def __init__(self):\n pass\n\n def getRolesFromUser(self, userDetails):\n return []\n\n def setAuthz(self, authz):\n self.authz = authz\n self.master = authz.master\n\n\nclass RolesFromGroups(RolesFromBase):\n\n def __init__(self, groupPrefix=\"\"):\n RolesFromBase.__init__(self)\n self.groupPrefix = groupPrefix\n\n def getRolesFromUser(self, userDetails):\n roles = []\n if 'groups' in userDetails:\n for group in userDetails['groups']:\n if group.startswith(self.groupPrefix):\n roles.append(group[len(self.groupPrefix):])\n return roles\n\n\nclass RolesFromEmails(RolesFromBase):\n\n def __init__(self, **kwargs):\n RolesFromBase.__init__(self)\n self.roles = {}\n for role, emails in iteritems(kwargs):\n for email in emails:\n self.roles.setdefault(email, []).append(role)\n\n def getRolesFromUser(self, userDetails):\n if 'email' in userDetails:\n return self.roles.get(userDetails['email'], [])\n return []\n\n\nclass RolesFromDomain(RolesFromEmails):\n\n def __init__(self, **kwargs):\n RolesFromBase.__init__(self)\n\n self.domain_roles = {}\n for role, domains in iteritems(kwargs):\n for domain in domains:\n self.domain_roles.setdefault(domain, []).append(role)\n\n def getRolesFromUser(self, userDetails):\n if 'email' in userDetails:\n email = userDetails['email']\n edomain = email.split('@')[-1]\n return self.domain_roles.get(edomain, [])\n return []\n\n\nclass RolesFromOwner(RolesFromBase):\n\n def __init__(self, role):\n RolesFromBase.__init__(self)\n self.role = role\n\n def getRolesFromUser(self, userDetails, owner):\n if 'email' in userDetails:\n if userDetails['email'] == owner and owner is not None:\n return [self.role]\n return []\n\n\nclass RolesFromUsername(RolesFromBase):\n def __init__(self, roles, usernames):\n self.roles = roles\n if None in usernames:\n from buildbot import config\n config.error('Usernames cannot be None')\n self.usernames = usernames\n\n def getRolesFromUser(self, userDetails):\n if userDetails.get('username') in self.usernames:\n return self.roles\n return []\n", "path": "master/buildbot/www/authz/roles.py"}]}
| 1,070 | 211 |
gh_patches_debug_11052
|
rasdani/github-patches
|
git_diff
|
pyg-team__pytorch_geometric-8831
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
in utils.subgraph.py RuntimeError: indices should be either on cpu or on the same device as the indexed tensor (cpu)
### 🐛 Describe the bug
in utils.subgraph.py
edge_mask = node_mask[edge_index[0]] & node_mask[edge_index[1]]
RuntimeError: indices should be either on cpu or on the same device as the indexed tensor (cpu)
because edge_index on 'cuda:0' and node_mask on 'cpu'
being solved with: node_mask=node_mask.to(device=device)
### Versions
last version
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `torch_geometric/transforms/largest_connected_components.py`
Content:
```
1 import torch
2
3 from torch_geometric.data import Data
4 from torch_geometric.data.datapipes import functional_transform
5 from torch_geometric.transforms import BaseTransform
6 from torch_geometric.utils import to_scipy_sparse_matrix
7
8
9 @functional_transform('largest_connected_components')
10 class LargestConnectedComponents(BaseTransform):
11 r"""Selects the subgraph that corresponds to the
12 largest connected components in the graph
13 (functional name: :obj:`largest_connected_components`).
14
15 Args:
16 num_components (int, optional): Number of largest components to keep
17 (default: :obj:`1`)
18 connection (str, optional): Type of connection to use for directed
19 graphs, can be either :obj:`'strong'` or :obj:`'weak'`.
20 Nodes `i` and `j` are strongly connected if a path
21 exists both from `i` to `j` and from `j` to `i`. A directed graph
22 is weakly connected if replacing all of its directed edges with
23 undirected edges produces a connected (undirected) graph.
24 (default: :obj:`'weak'`)
25 """
26 def __init__(
27 self,
28 num_components: int = 1,
29 connection: str = 'weak',
30 ) -> None:
31 assert connection in ['strong', 'weak'], 'Unknown connection type'
32 self.num_components = num_components
33 self.connection = connection
34
35 def forward(self, data: Data) -> Data:
36 import numpy as np
37 import scipy.sparse as sp
38
39 assert data.edge_index is not None
40
41 adj = to_scipy_sparse_matrix(data.edge_index, num_nodes=data.num_nodes)
42
43 num_components, component = sp.csgraph.connected_components(
44 adj, connection=self.connection)
45
46 if num_components <= self.num_components:
47 return data
48
49 _, count = np.unique(component, return_counts=True)
50 subset = np.in1d(component, count.argsort()[-self.num_components:])
51
52 return data.subgraph(torch.from_numpy(subset).to(torch.bool))
53
54 def __repr__(self) -> str:
55 return f'{self.__class__.__name__}({self.num_components})'
56
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/torch_geometric/transforms/largest_connected_components.py b/torch_geometric/transforms/largest_connected_components.py
--- a/torch_geometric/transforms/largest_connected_components.py
+++ b/torch_geometric/transforms/largest_connected_components.py
@@ -47,9 +47,11 @@
return data
_, count = np.unique(component, return_counts=True)
- subset = np.in1d(component, count.argsort()[-self.num_components:])
+ subset_np = np.in1d(component, count.argsort()[-self.num_components:])
+ subset = torch.from_numpy(subset_np)
+ subset = subset.to(data.edge_index.device, torch.bool)
- return data.subgraph(torch.from_numpy(subset).to(torch.bool))
+ return data.subgraph(subset)
def __repr__(self) -> str:
return f'{self.__class__.__name__}({self.num_components})'
|
{"golden_diff": "diff --git a/torch_geometric/transforms/largest_connected_components.py b/torch_geometric/transforms/largest_connected_components.py\n--- a/torch_geometric/transforms/largest_connected_components.py\n+++ b/torch_geometric/transforms/largest_connected_components.py\n@@ -47,9 +47,11 @@\n return data\n \n _, count = np.unique(component, return_counts=True)\n- subset = np.in1d(component, count.argsort()[-self.num_components:])\n+ subset_np = np.in1d(component, count.argsort()[-self.num_components:])\n+ subset = torch.from_numpy(subset_np)\n+ subset = subset.to(data.edge_index.device, torch.bool)\n \n- return data.subgraph(torch.from_numpy(subset).to(torch.bool))\n+ return data.subgraph(subset)\n \n def __repr__(self) -> str:\n return f'{self.__class__.__name__}({self.num_components})'\n", "issue": "in utils.subgraph.py RuntimeError: indices should be either on cpu or on the same device as the indexed tensor (cpu)\n### \ud83d\udc1b Describe the bug\n\nin utils.subgraph.py\r\n\r\nedge_mask = node_mask[edge_index[0]] & node_mask[edge_index[1]]\r\n\r\nRuntimeError: indices should be either on cpu or on the same device as the indexed tensor (cpu)\r\n\r\nbecause edge_index on 'cuda:0' and node_mask on 'cpu'\r\n\r\nbeing solved with: node_mask=node_mask.to(device=device)\r\n\r\n\r\n\n\n### Versions\n\nlast version\n", "before_files": [{"content": "import torch\n\nfrom torch_geometric.data import Data\nfrom torch_geometric.data.datapipes import functional_transform\nfrom torch_geometric.transforms import BaseTransform\nfrom torch_geometric.utils import to_scipy_sparse_matrix\n\n\n@functional_transform('largest_connected_components')\nclass LargestConnectedComponents(BaseTransform):\n r\"\"\"Selects the subgraph that corresponds to the\n largest connected components in the graph\n (functional name: :obj:`largest_connected_components`).\n\n Args:\n num_components (int, optional): Number of largest components to keep\n (default: :obj:`1`)\n connection (str, optional): Type of connection to use for directed\n graphs, can be either :obj:`'strong'` or :obj:`'weak'`.\n Nodes `i` and `j` are strongly connected if a path\n exists both from `i` to `j` and from `j` to `i`. A directed graph\n is weakly connected if replacing all of its directed edges with\n undirected edges produces a connected (undirected) graph.\n (default: :obj:`'weak'`)\n \"\"\"\n def __init__(\n self,\n num_components: int = 1,\n connection: str = 'weak',\n ) -> None:\n assert connection in ['strong', 'weak'], 'Unknown connection type'\n self.num_components = num_components\n self.connection = connection\n\n def forward(self, data: Data) -> Data:\n import numpy as np\n import scipy.sparse as sp\n\n assert data.edge_index is not None\n\n adj = to_scipy_sparse_matrix(data.edge_index, num_nodes=data.num_nodes)\n\n num_components, component = sp.csgraph.connected_components(\n adj, connection=self.connection)\n\n if num_components <= self.num_components:\n return data\n\n _, count = np.unique(component, return_counts=True)\n subset = np.in1d(component, count.argsort()[-self.num_components:])\n\n return data.subgraph(torch.from_numpy(subset).to(torch.bool))\n\n def __repr__(self) -> str:\n return f'{self.__class__.__name__}({self.num_components})'\n", "path": "torch_geometric/transforms/largest_connected_components.py"}], "after_files": [{"content": "import torch\n\nfrom torch_geometric.data import Data\nfrom torch_geometric.data.datapipes import functional_transform\nfrom torch_geometric.transforms import BaseTransform\nfrom torch_geometric.utils import to_scipy_sparse_matrix\n\n\n@functional_transform('largest_connected_components')\nclass LargestConnectedComponents(BaseTransform):\n r\"\"\"Selects the subgraph that corresponds to the\n largest connected components in the graph\n (functional name: :obj:`largest_connected_components`).\n\n Args:\n num_components (int, optional): Number of largest components to keep\n (default: :obj:`1`)\n connection (str, optional): Type of connection to use for directed\n graphs, can be either :obj:`'strong'` or :obj:`'weak'`.\n Nodes `i` and `j` are strongly connected if a path\n exists both from `i` to `j` and from `j` to `i`. A directed graph\n is weakly connected if replacing all of its directed edges with\n undirected edges produces a connected (undirected) graph.\n (default: :obj:`'weak'`)\n \"\"\"\n def __init__(\n self,\n num_components: int = 1,\n connection: str = 'weak',\n ) -> None:\n assert connection in ['strong', 'weak'], 'Unknown connection type'\n self.num_components = num_components\n self.connection = connection\n\n def forward(self, data: Data) -> Data:\n import numpy as np\n import scipy.sparse as sp\n\n assert data.edge_index is not None\n\n adj = to_scipy_sparse_matrix(data.edge_index, num_nodes=data.num_nodes)\n\n num_components, component = sp.csgraph.connected_components(\n adj, connection=self.connection)\n\n if num_components <= self.num_components:\n return data\n\n _, count = np.unique(component, return_counts=True)\n subset_np = np.in1d(component, count.argsort()[-self.num_components:])\n subset = torch.from_numpy(subset_np)\n subset = subset.to(data.edge_index.device, torch.bool)\n\n return data.subgraph(subset)\n\n def __repr__(self) -> str:\n return f'{self.__class__.__name__}({self.num_components})'\n", "path": "torch_geometric/transforms/largest_connected_components.py"}]}
| 947 | 201 |
gh_patches_debug_15420
|
rasdani/github-patches
|
git_diff
|
CTPUG__wafer-474
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Sponsors with multiple packages are listed for each package
When a sponsor takes multiple packages (sponsorship and add-on package, for example), they are listed in the sponsor list and sponsor menu for each package, which is a bit surprising. See Microsoft from PyCon ZA 2018, for example.

We should list sponsors only once, and add some decent way of marking that sponsors have taken multiple packages in the list.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `wafer/sponsors/models.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 import logging
4
5 from django.core.validators import MinValueValidator
6 from django.db import models
7 from django.db.models.signals import post_save
8 from django.urls import reverse
9 from django.utils.encoding import python_2_unicode_compatible
10 from django.utils.translation import ugettext_lazy as _
11
12 from markitup.fields import MarkupField
13
14 from wafer.menu import menu_logger, refresh_menu_cache
15
16 logger = logging.getLogger(__name__)
17
18
19 @python_2_unicode_compatible
20 class File(models.Model):
21 """A file for use in sponsor and sponshorship package descriptions."""
22 name = models.CharField(max_length=255)
23 description = models.TextField(blank=True)
24 item = models.FileField(upload_to='sponsors_files')
25
26 def __str__(self):
27 return u'%s (%s)' % (self.name, self.item.url)
28
29
30 @python_2_unicode_compatible
31 class SponsorshipPackage(models.Model):
32 """A description of a sponsorship package."""
33 order = models.IntegerField(default=1)
34 name = models.CharField(max_length=255)
35 number_available = models.IntegerField(
36 null=True, validators=[MinValueValidator(0)])
37 currency = models.CharField(
38 max_length=16, default='$',
39 help_text=_("Currency symbol for the sponsorship amount."))
40 price = models.DecimalField(
41 max_digits=12, decimal_places=2,
42 help_text=_("Amount to be sponsored."))
43 short_description = models.TextField(
44 help_text=_("One sentence overview of the package."))
45 description = MarkupField(
46 help_text=_("Describe what the package gives the sponsor."))
47 files = models.ManyToManyField(
48 File, related_name="packages", blank=True,
49 help_text=_("Images and other files for use in"
50 " the description markdown field."))
51 # We use purely ascii help text, to avoid issues with the migrations
52 # not handling unicode help text nicely.
53 symbol = models.CharField(
54 max_length=1, blank=True,
55 help_text=_("Optional symbol to display in the sponsors list "
56 "next to sponsors who have sponsored at this list, "
57 "(for example *)."))
58
59 class Meta:
60 ordering = ['order', '-price', 'name']
61
62 def __str__(self):
63 return u'%s (amount: %.0f)' % (self.name, self.price)
64
65 def number_claimed(self):
66 return self.sponsors.count()
67
68
69 @python_2_unicode_compatible
70 class Sponsor(models.Model):
71 """A conference sponsor."""
72 order = models.IntegerField(default=1)
73 name = models.CharField(max_length=255)
74 packages = models.ManyToManyField(SponsorshipPackage,
75 related_name="sponsors")
76 description = MarkupField(
77 help_text=_("Write some nice things about the sponsor."))
78 url = models.URLField(
79 default="", blank=True,
80 help_text=_("Url to link back to the sponsor if required"))
81
82 class Meta:
83 ordering = ['order', 'name', 'id']
84
85 def __str__(self):
86 return u'%s' % (self.name,)
87
88 def get_absolute_url(self):
89 return reverse('wafer_sponsor', args=(self.pk,))
90
91 def symbols(self):
92 """Return a string of the symbols of all the packages this sponsor has
93 taken."""
94 packages = self.packages.all()
95 symbols = u"".join(p.symbol for p in packages)
96 return symbols
97
98 @property
99 def symbol(self):
100 """The symbol of the highest level package this sponsor has taken."""
101 package = self.packages.first()
102 if package:
103 return package.symbol
104 return u""
105
106
107 class TaggedFile(models.Model):
108 """Tags for files associated with a given sponsor"""
109 tag_name = models.CharField(max_length=255, null=False)
110 tagged_file = models.ForeignKey(File, on_delete=models.CASCADE)
111 sponsor = models.ForeignKey(Sponsor, related_name="files",
112 on_delete=models.CASCADE)
113
114
115 def sponsor_menu(
116 root_menu, menu="sponsors", label=_("Sponsors"),
117 sponsors_item=_("Our sponsors"),
118 packages_item=_("Sponsorship packages")):
119 """Add sponsor menu links."""
120 root_menu.add_menu(menu, label, items=[])
121 for sponsor in (
122 Sponsor.objects.all()
123 .order_by('packages', 'order', 'id')
124 .prefetch_related('packages')):
125 symbols = sponsor.symbols()
126 if symbols:
127 item_name = u"» %s %s" % (sponsor.name, symbols)
128 else:
129 item_name = u"» %s" % (sponsor.name,)
130 with menu_logger(logger, "sponsor %r" % (sponsor.name,)):
131 root_menu.add_item(
132 item_name, sponsor.get_absolute_url(), menu=menu)
133
134 if sponsors_item:
135 with menu_logger(logger, "sponsors page link"):
136 root_menu.add_item(
137 sponsors_item, reverse("wafer_sponsors"), menu)
138 if packages_item:
139 with menu_logger(logger, "sponsorship package page link"):
140 root_menu.add_item(
141 packages_item, reverse("wafer_sponsorship_packages"), menu)
142
143
144 post_save.connect(refresh_menu_cache, sender=Sponsor)
145
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/wafer/sponsors/models.py b/wafer/sponsors/models.py
--- a/wafer/sponsors/models.py
+++ b/wafer/sponsors/models.py
@@ -118,10 +118,15 @@
packages_item=_("Sponsorship packages")):
"""Add sponsor menu links."""
root_menu.add_menu(menu, label, items=[])
+ added_to_menu = set()
for sponsor in (
Sponsor.objects.all()
.order_by('packages', 'order', 'id')
.prefetch_related('packages')):
+ if sponsor in added_to_menu:
+ # We've already added this in a previous packaged
+ continue
+ added_to_menu.add(sponsor)
symbols = sponsor.symbols()
if symbols:
item_name = u"» %s %s" % (sponsor.name, symbols)
|
{"golden_diff": "diff --git a/wafer/sponsors/models.py b/wafer/sponsors/models.py\n--- a/wafer/sponsors/models.py\n+++ b/wafer/sponsors/models.py\n@@ -118,10 +118,15 @@\n packages_item=_(\"Sponsorship packages\")):\n \"\"\"Add sponsor menu links.\"\"\"\n root_menu.add_menu(menu, label, items=[])\n+ added_to_menu = set()\n for sponsor in (\n Sponsor.objects.all()\n .order_by('packages', 'order', 'id')\n .prefetch_related('packages')):\n+ if sponsor in added_to_menu:\n+ # We've already added this in a previous packaged\n+ continue\n+ added_to_menu.add(sponsor)\n symbols = sponsor.symbols()\n if symbols:\n item_name = u\"\u00bb %s %s\" % (sponsor.name, symbols)\n", "issue": "Sponsors with multiple packages are listed for each package\nWhen a sponsor takes multiple packages (sponsorship and add-on package, for example), they are listed in the sponsor list and sponsor menu for each package, which is a bit surprising. See Microsoft from PyCon ZA 2018, for example.\r\n\r\n\r\n\r\n\r\nWe should list sponsors only once, and add some decent way of marking that sponsors have taken multiple packages in the list.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\nimport logging\n\nfrom django.core.validators import MinValueValidator\nfrom django.db import models\nfrom django.db.models.signals import post_save\nfrom django.urls import reverse\nfrom django.utils.encoding import python_2_unicode_compatible\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom markitup.fields import MarkupField\n\nfrom wafer.menu import menu_logger, refresh_menu_cache\n\nlogger = logging.getLogger(__name__)\n\n\n@python_2_unicode_compatible\nclass File(models.Model):\n \"\"\"A file for use in sponsor and sponshorship package descriptions.\"\"\"\n name = models.CharField(max_length=255)\n description = models.TextField(blank=True)\n item = models.FileField(upload_to='sponsors_files')\n\n def __str__(self):\n return u'%s (%s)' % (self.name, self.item.url)\n\n\n@python_2_unicode_compatible\nclass SponsorshipPackage(models.Model):\n \"\"\"A description of a sponsorship package.\"\"\"\n order = models.IntegerField(default=1)\n name = models.CharField(max_length=255)\n number_available = models.IntegerField(\n null=True, validators=[MinValueValidator(0)])\n currency = models.CharField(\n max_length=16, default='$',\n help_text=_(\"Currency symbol for the sponsorship amount.\"))\n price = models.DecimalField(\n max_digits=12, decimal_places=2,\n help_text=_(\"Amount to be sponsored.\"))\n short_description = models.TextField(\n help_text=_(\"One sentence overview of the package.\"))\n description = MarkupField(\n help_text=_(\"Describe what the package gives the sponsor.\"))\n files = models.ManyToManyField(\n File, related_name=\"packages\", blank=True,\n help_text=_(\"Images and other files for use in\"\n \" the description markdown field.\"))\n # We use purely ascii help text, to avoid issues with the migrations\n # not handling unicode help text nicely.\n symbol = models.CharField(\n max_length=1, blank=True,\n help_text=_(\"Optional symbol to display in the sponsors list \"\n \"next to sponsors who have sponsored at this list, \"\n \"(for example *).\"))\n\n class Meta:\n ordering = ['order', '-price', 'name']\n\n def __str__(self):\n return u'%s (amount: %.0f)' % (self.name, self.price)\n\n def number_claimed(self):\n return self.sponsors.count()\n\n\n@python_2_unicode_compatible\nclass Sponsor(models.Model):\n \"\"\"A conference sponsor.\"\"\"\n order = models.IntegerField(default=1)\n name = models.CharField(max_length=255)\n packages = models.ManyToManyField(SponsorshipPackage,\n related_name=\"sponsors\")\n description = MarkupField(\n help_text=_(\"Write some nice things about the sponsor.\"))\n url = models.URLField(\n default=\"\", blank=True,\n help_text=_(\"Url to link back to the sponsor if required\"))\n\n class Meta:\n ordering = ['order', 'name', 'id']\n\n def __str__(self):\n return u'%s' % (self.name,)\n\n def get_absolute_url(self):\n return reverse('wafer_sponsor', args=(self.pk,))\n\n def symbols(self):\n \"\"\"Return a string of the symbols of all the packages this sponsor has\n taken.\"\"\"\n packages = self.packages.all()\n symbols = u\"\".join(p.symbol for p in packages)\n return symbols\n\n @property\n def symbol(self):\n \"\"\"The symbol of the highest level package this sponsor has taken.\"\"\"\n package = self.packages.first()\n if package:\n return package.symbol\n return u\"\"\n\n\nclass TaggedFile(models.Model):\n \"\"\"Tags for files associated with a given sponsor\"\"\"\n tag_name = models.CharField(max_length=255, null=False)\n tagged_file = models.ForeignKey(File, on_delete=models.CASCADE)\n sponsor = models.ForeignKey(Sponsor, related_name=\"files\",\n on_delete=models.CASCADE)\n\n\ndef sponsor_menu(\n root_menu, menu=\"sponsors\", label=_(\"Sponsors\"),\n sponsors_item=_(\"Our sponsors\"),\n packages_item=_(\"Sponsorship packages\")):\n \"\"\"Add sponsor menu links.\"\"\"\n root_menu.add_menu(menu, label, items=[])\n for sponsor in (\n Sponsor.objects.all()\n .order_by('packages', 'order', 'id')\n .prefetch_related('packages')):\n symbols = sponsor.symbols()\n if symbols:\n item_name = u\"\u00bb %s %s\" % (sponsor.name, symbols)\n else:\n item_name = u\"\u00bb %s\" % (sponsor.name,)\n with menu_logger(logger, \"sponsor %r\" % (sponsor.name,)):\n root_menu.add_item(\n item_name, sponsor.get_absolute_url(), menu=menu)\n\n if sponsors_item:\n with menu_logger(logger, \"sponsors page link\"):\n root_menu.add_item(\n sponsors_item, reverse(\"wafer_sponsors\"), menu)\n if packages_item:\n with menu_logger(logger, \"sponsorship package page link\"):\n root_menu.add_item(\n packages_item, reverse(\"wafer_sponsorship_packages\"), menu)\n\n\npost_save.connect(refresh_menu_cache, sender=Sponsor)\n", "path": "wafer/sponsors/models.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\nimport logging\n\nfrom django.core.validators import MinValueValidator\nfrom django.db import models\nfrom django.db.models.signals import post_save\nfrom django.urls import reverse\nfrom django.utils.encoding import python_2_unicode_compatible\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom markitup.fields import MarkupField\n\nfrom wafer.menu import menu_logger, refresh_menu_cache\n\nlogger = logging.getLogger(__name__)\n\n\n@python_2_unicode_compatible\nclass File(models.Model):\n \"\"\"A file for use in sponsor and sponshorship package descriptions.\"\"\"\n name = models.CharField(max_length=255)\n description = models.TextField(blank=True)\n item = models.FileField(upload_to='sponsors_files')\n\n def __str__(self):\n return u'%s (%s)' % (self.name, self.item.url)\n\n\n@python_2_unicode_compatible\nclass SponsorshipPackage(models.Model):\n \"\"\"A description of a sponsorship package.\"\"\"\n order = models.IntegerField(default=1)\n name = models.CharField(max_length=255)\n number_available = models.IntegerField(\n null=True, validators=[MinValueValidator(0)])\n currency = models.CharField(\n max_length=16, default='$',\n help_text=_(\"Currency symbol for the sponsorship amount.\"))\n price = models.DecimalField(\n max_digits=12, decimal_places=2,\n help_text=_(\"Amount to be sponsored.\"))\n short_description = models.TextField(\n help_text=_(\"One sentence overview of the package.\"))\n description = MarkupField(\n help_text=_(\"Describe what the package gives the sponsor.\"))\n files = models.ManyToManyField(\n File, related_name=\"packages\", blank=True,\n help_text=_(\"Images and other files for use in\"\n \" the description markdown field.\"))\n # We use purely ascii help text, to avoid issues with the migrations\n # not handling unicode help text nicely.\n symbol = models.CharField(\n max_length=1, blank=True,\n help_text=_(\"Optional symbol to display in the sponsors list \"\n \"next to sponsors who have sponsored at this list, \"\n \"(for example *).\"))\n\n class Meta:\n ordering = ['order', '-price', 'name']\n\n def __str__(self):\n return u'%s (amount: %.0f)' % (self.name, self.price)\n\n def number_claimed(self):\n return self.sponsors.count()\n\n\n@python_2_unicode_compatible\nclass Sponsor(models.Model):\n \"\"\"A conference sponsor.\"\"\"\n order = models.IntegerField(default=1)\n name = models.CharField(max_length=255)\n packages = models.ManyToManyField(SponsorshipPackage,\n related_name=\"sponsors\")\n description = MarkupField(\n help_text=_(\"Write some nice things about the sponsor.\"))\n url = models.URLField(\n default=\"\", blank=True,\n help_text=_(\"Url to link back to the sponsor if required\"))\n\n class Meta:\n ordering = ['order', 'name', 'id']\n\n def __str__(self):\n return u'%s' % (self.name,)\n\n def get_absolute_url(self):\n return reverse('wafer_sponsor', args=(self.pk,))\n\n def symbols(self):\n \"\"\"Return a string of the symbols of all the packages this sponsor has\n taken.\"\"\"\n packages = self.packages.all()\n symbols = u\"\".join(p.symbol for p in packages)\n return symbols\n\n @property\n def symbol(self):\n \"\"\"The symbol of the highest level package this sponsor has taken.\"\"\"\n package = self.packages.first()\n if package:\n return package.symbol\n return u\"\"\n\n\nclass TaggedFile(models.Model):\n \"\"\"Tags for files associated with a given sponsor\"\"\"\n tag_name = models.CharField(max_length=255, null=False)\n tagged_file = models.ForeignKey(File, on_delete=models.CASCADE)\n sponsor = models.ForeignKey(Sponsor, related_name=\"files\",\n on_delete=models.CASCADE)\n\n\ndef sponsor_menu(\n root_menu, menu=\"sponsors\", label=_(\"Sponsors\"),\n sponsors_item=_(\"Our sponsors\"),\n packages_item=_(\"Sponsorship packages\")):\n \"\"\"Add sponsor menu links.\"\"\"\n root_menu.add_menu(menu, label, items=[])\n added_to_menu = set()\n for sponsor in (\n Sponsor.objects.all()\n .order_by('packages', 'order', 'id')\n .prefetch_related('packages')):\n if sponsor in added_to_menu:\n # We've already added this in a previous packaged\n continue\n added_to_menu.add(sponsor)\n symbols = sponsor.symbols()\n if symbols:\n item_name = u\"\u00bb %s %s\" % (sponsor.name, symbols)\n else:\n item_name = u\"\u00bb %s\" % (sponsor.name,)\n with menu_logger(logger, \"sponsor %r\" % (sponsor.name,)):\n root_menu.add_item(\n item_name, sponsor.get_absolute_url(), menu=menu)\n\n if sponsors_item:\n with menu_logger(logger, \"sponsors page link\"):\n root_menu.add_item(\n sponsors_item, reverse(\"wafer_sponsors\"), menu)\n if packages_item:\n with menu_logger(logger, \"sponsorship package page link\"):\n root_menu.add_item(\n packages_item, reverse(\"wafer_sponsorship_packages\"), menu)\n\n\npost_save.connect(refresh_menu_cache, sender=Sponsor)\n", "path": "wafer/sponsors/models.py"}]}
| 1,839 | 189 |
gh_patches_debug_1799
|
rasdani/github-patches
|
git_diff
|
Parsl__parsl-705
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
With TorqueProvider, submit stderr/stdout does not go to runinfo
This happens on both NSCC and Blue Waters. The submit script has
```
#PBS -o /mnt/a/u/sciteam/woodard/simple-tests/runinfo/001/submit_scripts/parsl.parsl.auto.1542146393.457273.submit.stdout
#PBS -e /mnt/a/u/sciteam/woodard/simple-tests/runinfo/001/submit_scripts/parsl.parsl.auto.1542146393.457273.submit.stderr
```
but the stdout goes to `$HOME/parsl.parsl.auto.1542146393.457273.o9212235`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `parsl/providers/torque/template.py`
Content:
```
1 template_string = '''#!/bin/bash
2
3 #PBS -S /bin/bash
4 #PBS -N ${jobname}
5 #PBS -m n
6 #PBS -k eo
7 #PBS -l walltime=$walltime
8 #PBS -l nodes=${nodes_per_block}:ppn=${tasks_per_node}
9 #PBS -o ${submit_script_dir}/${jobname}.submit.stdout
10 #PBS -e ${submit_script_dir}/${jobname}.submit.stderr
11 ${scheduler_options}
12
13 ${worker_init}
14
15 export JOBNAME="${jobname}"
16
17 ${user_script}
18
19 '''
20
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/parsl/providers/torque/template.py b/parsl/providers/torque/template.py
--- a/parsl/providers/torque/template.py
+++ b/parsl/providers/torque/template.py
@@ -3,7 +3,6 @@
#PBS -S /bin/bash
#PBS -N ${jobname}
#PBS -m n
-#PBS -k eo
#PBS -l walltime=$walltime
#PBS -l nodes=${nodes_per_block}:ppn=${tasks_per_node}
#PBS -o ${submit_script_dir}/${jobname}.submit.stdout
|
{"golden_diff": "diff --git a/parsl/providers/torque/template.py b/parsl/providers/torque/template.py\n--- a/parsl/providers/torque/template.py\n+++ b/parsl/providers/torque/template.py\n@@ -3,7 +3,6 @@\n #PBS -S /bin/bash\n #PBS -N ${jobname}\n #PBS -m n\n-#PBS -k eo\n #PBS -l walltime=$walltime\n #PBS -l nodes=${nodes_per_block}:ppn=${tasks_per_node}\n #PBS -o ${submit_script_dir}/${jobname}.submit.stdout\n", "issue": "With TorqueProvider, submit stderr/stdout does not go to runinfo\nThis happens on both NSCC and Blue Waters. The submit script has\r\n\r\n```\r\n#PBS -o /mnt/a/u/sciteam/woodard/simple-tests/runinfo/001/submit_scripts/parsl.parsl.auto.1542146393.457273.submit.stdout\r\n#PBS -e /mnt/a/u/sciteam/woodard/simple-tests/runinfo/001/submit_scripts/parsl.parsl.auto.1542146393.457273.submit.stderr\r\n```\r\n\r\nbut the stdout goes to `$HOME/parsl.parsl.auto.1542146393.457273.o9212235`\n", "before_files": [{"content": "template_string = '''#!/bin/bash\n\n#PBS -S /bin/bash\n#PBS -N ${jobname}\n#PBS -m n\n#PBS -k eo\n#PBS -l walltime=$walltime\n#PBS -l nodes=${nodes_per_block}:ppn=${tasks_per_node}\n#PBS -o ${submit_script_dir}/${jobname}.submit.stdout\n#PBS -e ${submit_script_dir}/${jobname}.submit.stderr\n${scheduler_options}\n\n${worker_init}\n\nexport JOBNAME=\"${jobname}\"\n\n${user_script}\n\n'''\n", "path": "parsl/providers/torque/template.py"}], "after_files": [{"content": "template_string = '''#!/bin/bash\n\n#PBS -S /bin/bash\n#PBS -N ${jobname}\n#PBS -m n\n#PBS -l walltime=$walltime\n#PBS -l nodes=${nodes_per_block}:ppn=${tasks_per_node}\n#PBS -o ${submit_script_dir}/${jobname}.submit.stdout\n#PBS -e ${submit_script_dir}/${jobname}.submit.stderr\n${scheduler_options}\n\n${worker_init}\n\nexport JOBNAME=\"${jobname}\"\n\n${user_script}\n\n'''\n", "path": "parsl/providers/torque/template.py"}]}
| 592 | 125 |
gh_patches_debug_39618
|
rasdani/github-patches
|
git_diff
|
Lightning-AI__torchmetrics-249
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add option to compute root_mean_squared_error
## 🚀 Feature
Allow the user to choose between MSE and RMSE.
### Motivation
In a physical domain the RMSE, which is essentially the mean of distances, may be significantly more intuitive than the MSE. Therefore, it would be nice to have the option to choose the preferd metric.
### Pitch
Similar to the implementation in [scikit-learn](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.mean_squared_error.html#sklearn.metrics.mean_squared_error) one could simply pass `squared=False` to the `MeanSquaredError` module or the `mean_squared_error` function.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `torchmetrics/functional/regression/mean_squared_error.py`
Content:
```
1 # Copyright The PyTorch Lightning team.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 from typing import Tuple
15
16 import torch
17 from torch import Tensor
18
19 from torchmetrics.utilities.checks import _check_same_shape
20
21
22 def _mean_squared_error_update(preds: Tensor, target: Tensor) -> Tuple[Tensor, int]:
23 _check_same_shape(preds, target)
24 diff = preds - target
25 sum_squared_error = torch.sum(diff * diff)
26 n_obs = target.numel()
27 return sum_squared_error, n_obs
28
29
30 def _mean_squared_error_compute(sum_squared_error: Tensor, n_obs: int) -> Tensor:
31 return sum_squared_error / n_obs
32
33
34 def mean_squared_error(preds: Tensor, target: Tensor) -> Tensor:
35 """
36 Computes mean squared error
37
38 Args:
39 preds: estimated labels
40 target: ground truth labels
41
42 Return:
43 Tensor with MSE
44
45 Example:
46 >>> from torchmetrics.functional import mean_squared_error
47 >>> x = torch.tensor([0., 1, 2, 3])
48 >>> y = torch.tensor([0., 1, 2, 2])
49 >>> mean_squared_error(x, y)
50 tensor(0.2500)
51 """
52 sum_squared_error, n_obs = _mean_squared_error_update(preds, target)
53 return _mean_squared_error_compute(sum_squared_error, n_obs)
54
```
Path: `torchmetrics/regression/mean_squared_error.py`
Content:
```
1 # Copyright The PyTorch Lightning team.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 from typing import Any, Callable, Optional
15
16 import torch
17 from torch import Tensor, tensor
18
19 from torchmetrics.functional.regression.mean_squared_error import (
20 _mean_squared_error_compute,
21 _mean_squared_error_update,
22 )
23 from torchmetrics.metric import Metric
24
25
26 class MeanSquaredError(Metric):
27 r"""
28 Computes `mean squared error <https://en.wikipedia.org/wiki/Mean_squared_error>`_ (MSE):
29
30 .. math:: \text{MSE} = \frac{1}{N}\sum_i^N(y_i - \hat{y_i})^2
31
32 Where :math:`y` is a tensor of target values, and :math:`\hat{y}` is a tensor of predictions.
33
34 Args:
35 compute_on_step:
36 Forward only calls ``update()`` and return None if this is set to False. default: True
37 dist_sync_on_step:
38 Synchronize metric state across processes at each ``forward()``
39 before returning the value at the step. default: False
40 process_group:
41 Specify the process group on which synchronization is called. default: None (which selects the entire world)
42
43 Example:
44 >>> from torchmetrics import MeanSquaredError
45 >>> target = torch.tensor([2.5, 5.0, 4.0, 8.0])
46 >>> preds = torch.tensor([3.0, 5.0, 2.5, 7.0])
47 >>> mean_squared_error = MeanSquaredError()
48 >>> mean_squared_error(preds, target)
49 tensor(0.8750)
50
51 """
52
53 def __init__(
54 self,
55 compute_on_step: bool = True,
56 dist_sync_on_step: bool = False,
57 process_group: Optional[Any] = None,
58 dist_sync_fn: Callable = None,
59 ):
60 super().__init__(
61 compute_on_step=compute_on_step,
62 dist_sync_on_step=dist_sync_on_step,
63 process_group=process_group,
64 dist_sync_fn=dist_sync_fn,
65 )
66
67 self.add_state("sum_squared_error", default=tensor(0.0), dist_reduce_fx="sum")
68 self.add_state("total", default=tensor(0), dist_reduce_fx="sum")
69
70 def update(self, preds: Tensor, target: Tensor):
71 """
72 Update state with predictions and targets.
73
74 Args:
75 preds: Predictions from model
76 target: Ground truth values
77 """
78 sum_squared_error, n_obs = _mean_squared_error_update(preds, target)
79
80 self.sum_squared_error += sum_squared_error
81 self.total += n_obs
82
83 def compute(self):
84 """
85 Computes mean squared error over state.
86 """
87 return _mean_squared_error_compute(self.sum_squared_error, self.total)
88
89 @property
90 def is_differentiable(self):
91 return True
92
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/torchmetrics/functional/regression/mean_squared_error.py b/torchmetrics/functional/regression/mean_squared_error.py
--- a/torchmetrics/functional/regression/mean_squared_error.py
+++ b/torchmetrics/functional/regression/mean_squared_error.py
@@ -27,17 +27,18 @@
return sum_squared_error, n_obs
-def _mean_squared_error_compute(sum_squared_error: Tensor, n_obs: int) -> Tensor:
- return sum_squared_error / n_obs
+def _mean_squared_error_compute(sum_squared_error: Tensor, n_obs: int, squared: bool = True) -> Tensor:
+ return sum_squared_error / n_obs if squared else torch.sqrt(sum_squared_error / n_obs)
-def mean_squared_error(preds: Tensor, target: Tensor) -> Tensor:
+def mean_squared_error(preds: Tensor, target: Tensor, squared: bool = True) -> Tensor:
"""
Computes mean squared error
Args:
preds: estimated labels
target: ground truth labels
+ squared: returns RMSE value if set to False
Return:
Tensor with MSE
@@ -50,4 +51,4 @@
tensor(0.2500)
"""
sum_squared_error, n_obs = _mean_squared_error_update(preds, target)
- return _mean_squared_error_compute(sum_squared_error, n_obs)
+ return _mean_squared_error_compute(sum_squared_error, n_obs, squared=squared)
diff --git a/torchmetrics/regression/mean_squared_error.py b/torchmetrics/regression/mean_squared_error.py
--- a/torchmetrics/regression/mean_squared_error.py
+++ b/torchmetrics/regression/mean_squared_error.py
@@ -39,6 +39,8 @@
before returning the value at the step. default: False
process_group:
Specify the process group on which synchronization is called. default: None (which selects the entire world)
+ squared:
+ If True returns MSE value, if False returns RMSE value.
Example:
>>> from torchmetrics import MeanSquaredError
@@ -56,6 +58,7 @@
dist_sync_on_step: bool = False,
process_group: Optional[Any] = None,
dist_sync_fn: Callable = None,
+ squared: bool = True,
):
super().__init__(
compute_on_step=compute_on_step,
@@ -66,6 +69,7 @@
self.add_state("sum_squared_error", default=tensor(0.0), dist_reduce_fx="sum")
self.add_state("total", default=tensor(0), dist_reduce_fx="sum")
+ self.squared = squared
def update(self, preds: Tensor, target: Tensor):
"""
@@ -84,7 +88,7 @@
"""
Computes mean squared error over state.
"""
- return _mean_squared_error_compute(self.sum_squared_error, self.total)
+ return _mean_squared_error_compute(self.sum_squared_error, self.total, squared=self.squared)
@property
def is_differentiable(self):
|
{"golden_diff": "diff --git a/torchmetrics/functional/regression/mean_squared_error.py b/torchmetrics/functional/regression/mean_squared_error.py\n--- a/torchmetrics/functional/regression/mean_squared_error.py\n+++ b/torchmetrics/functional/regression/mean_squared_error.py\n@@ -27,17 +27,18 @@\n return sum_squared_error, n_obs\n \n \n-def _mean_squared_error_compute(sum_squared_error: Tensor, n_obs: int) -> Tensor:\n- return sum_squared_error / n_obs\n+def _mean_squared_error_compute(sum_squared_error: Tensor, n_obs: int, squared: bool = True) -> Tensor:\n+ return sum_squared_error / n_obs if squared else torch.sqrt(sum_squared_error / n_obs)\n \n \n-def mean_squared_error(preds: Tensor, target: Tensor) -> Tensor:\n+def mean_squared_error(preds: Tensor, target: Tensor, squared: bool = True) -> Tensor:\n \"\"\"\n Computes mean squared error\n \n Args:\n preds: estimated labels\n target: ground truth labels\n+ squared: returns RMSE value if set to False\n \n Return:\n Tensor with MSE\n@@ -50,4 +51,4 @@\n tensor(0.2500)\n \"\"\"\n sum_squared_error, n_obs = _mean_squared_error_update(preds, target)\n- return _mean_squared_error_compute(sum_squared_error, n_obs)\n+ return _mean_squared_error_compute(sum_squared_error, n_obs, squared=squared)\ndiff --git a/torchmetrics/regression/mean_squared_error.py b/torchmetrics/regression/mean_squared_error.py\n--- a/torchmetrics/regression/mean_squared_error.py\n+++ b/torchmetrics/regression/mean_squared_error.py\n@@ -39,6 +39,8 @@\n before returning the value at the step. default: False\n process_group:\n Specify the process group on which synchronization is called. default: None (which selects the entire world)\n+ squared:\n+ If True returns MSE value, if False returns RMSE value.\n \n Example:\n >>> from torchmetrics import MeanSquaredError\n@@ -56,6 +58,7 @@\n dist_sync_on_step: bool = False,\n process_group: Optional[Any] = None,\n dist_sync_fn: Callable = None,\n+ squared: bool = True,\n ):\n super().__init__(\n compute_on_step=compute_on_step,\n@@ -66,6 +69,7 @@\n \n self.add_state(\"sum_squared_error\", default=tensor(0.0), dist_reduce_fx=\"sum\")\n self.add_state(\"total\", default=tensor(0), dist_reduce_fx=\"sum\")\n+ self.squared = squared\n \n def update(self, preds: Tensor, target: Tensor):\n \"\"\"\n@@ -84,7 +88,7 @@\n \"\"\"\n Computes mean squared error over state.\n \"\"\"\n- return _mean_squared_error_compute(self.sum_squared_error, self.total)\n+ return _mean_squared_error_compute(self.sum_squared_error, self.total, squared=self.squared)\n \n @property\n def is_differentiable(self):\n", "issue": "Add option to compute root_mean_squared_error\n## \ud83d\ude80 Feature\r\nAllow the user to choose between MSE and RMSE.\r\n\r\n### Motivation\r\nIn a physical domain the RMSE, which is essentially the mean of distances, may be significantly more intuitive than the MSE. Therefore, it would be nice to have the option to choose the preferd metric.\r\n\r\n### Pitch\r\nSimilar to the implementation in [scikit-learn](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.mean_squared_error.html#sklearn.metrics.mean_squared_error) one could simply pass `squared=False` to the `MeanSquaredError` module or the `mean_squared_error` function.\r\n\n", "before_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom typing import Tuple\n\nimport torch\nfrom torch import Tensor\n\nfrom torchmetrics.utilities.checks import _check_same_shape\n\n\ndef _mean_squared_error_update(preds: Tensor, target: Tensor) -> Tuple[Tensor, int]:\n _check_same_shape(preds, target)\n diff = preds - target\n sum_squared_error = torch.sum(diff * diff)\n n_obs = target.numel()\n return sum_squared_error, n_obs\n\n\ndef _mean_squared_error_compute(sum_squared_error: Tensor, n_obs: int) -> Tensor:\n return sum_squared_error / n_obs\n\n\ndef mean_squared_error(preds: Tensor, target: Tensor) -> Tensor:\n \"\"\"\n Computes mean squared error\n\n Args:\n preds: estimated labels\n target: ground truth labels\n\n Return:\n Tensor with MSE\n\n Example:\n >>> from torchmetrics.functional import mean_squared_error\n >>> x = torch.tensor([0., 1, 2, 3])\n >>> y = torch.tensor([0., 1, 2, 2])\n >>> mean_squared_error(x, y)\n tensor(0.2500)\n \"\"\"\n sum_squared_error, n_obs = _mean_squared_error_update(preds, target)\n return _mean_squared_error_compute(sum_squared_error, n_obs)\n", "path": "torchmetrics/functional/regression/mean_squared_error.py"}, {"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom typing import Any, Callable, Optional\n\nimport torch\nfrom torch import Tensor, tensor\n\nfrom torchmetrics.functional.regression.mean_squared_error import (\n _mean_squared_error_compute,\n _mean_squared_error_update,\n)\nfrom torchmetrics.metric import Metric\n\n\nclass MeanSquaredError(Metric):\n r\"\"\"\n Computes `mean squared error <https://en.wikipedia.org/wiki/Mean_squared_error>`_ (MSE):\n\n .. math:: \\text{MSE} = \\frac{1}{N}\\sum_i^N(y_i - \\hat{y_i})^2\n\n Where :math:`y` is a tensor of target values, and :math:`\\hat{y}` is a tensor of predictions.\n\n Args:\n compute_on_step:\n Forward only calls ``update()`` and return None if this is set to False. default: True\n dist_sync_on_step:\n Synchronize metric state across processes at each ``forward()``\n before returning the value at the step. default: False\n process_group:\n Specify the process group on which synchronization is called. default: None (which selects the entire world)\n\n Example:\n >>> from torchmetrics import MeanSquaredError\n >>> target = torch.tensor([2.5, 5.0, 4.0, 8.0])\n >>> preds = torch.tensor([3.0, 5.0, 2.5, 7.0])\n >>> mean_squared_error = MeanSquaredError()\n >>> mean_squared_error(preds, target)\n tensor(0.8750)\n\n \"\"\"\n\n def __init__(\n self,\n compute_on_step: bool = True,\n dist_sync_on_step: bool = False,\n process_group: Optional[Any] = None,\n dist_sync_fn: Callable = None,\n ):\n super().__init__(\n compute_on_step=compute_on_step,\n dist_sync_on_step=dist_sync_on_step,\n process_group=process_group,\n dist_sync_fn=dist_sync_fn,\n )\n\n self.add_state(\"sum_squared_error\", default=tensor(0.0), dist_reduce_fx=\"sum\")\n self.add_state(\"total\", default=tensor(0), dist_reduce_fx=\"sum\")\n\n def update(self, preds: Tensor, target: Tensor):\n \"\"\"\n Update state with predictions and targets.\n\n Args:\n preds: Predictions from model\n target: Ground truth values\n \"\"\"\n sum_squared_error, n_obs = _mean_squared_error_update(preds, target)\n\n self.sum_squared_error += sum_squared_error\n self.total += n_obs\n\n def compute(self):\n \"\"\"\n Computes mean squared error over state.\n \"\"\"\n return _mean_squared_error_compute(self.sum_squared_error, self.total)\n\n @property\n def is_differentiable(self):\n return True\n", "path": "torchmetrics/regression/mean_squared_error.py"}], "after_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom typing import Tuple\n\nimport torch\nfrom torch import Tensor\n\nfrom torchmetrics.utilities.checks import _check_same_shape\n\n\ndef _mean_squared_error_update(preds: Tensor, target: Tensor) -> Tuple[Tensor, int]:\n _check_same_shape(preds, target)\n diff = preds - target\n sum_squared_error = torch.sum(diff * diff)\n n_obs = target.numel()\n return sum_squared_error, n_obs\n\n\ndef _mean_squared_error_compute(sum_squared_error: Tensor, n_obs: int, squared: bool = True) -> Tensor:\n return sum_squared_error / n_obs if squared else torch.sqrt(sum_squared_error / n_obs)\n\n\ndef mean_squared_error(preds: Tensor, target: Tensor, squared: bool = True) -> Tensor:\n \"\"\"\n Computes mean squared error\n\n Args:\n preds: estimated labels\n target: ground truth labels\n squared: returns RMSE value if set to False\n\n Return:\n Tensor with MSE\n\n Example:\n >>> from torchmetrics.functional import mean_squared_error\n >>> x = torch.tensor([0., 1, 2, 3])\n >>> y = torch.tensor([0., 1, 2, 2])\n >>> mean_squared_error(x, y)\n tensor(0.2500)\n \"\"\"\n sum_squared_error, n_obs = _mean_squared_error_update(preds, target)\n return _mean_squared_error_compute(sum_squared_error, n_obs, squared=squared)\n", "path": "torchmetrics/functional/regression/mean_squared_error.py"}, {"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom typing import Any, Callable, Optional\n\nimport torch\nfrom torch import Tensor, tensor\n\nfrom torchmetrics.functional.regression.mean_squared_error import (\n _mean_squared_error_compute,\n _mean_squared_error_update,\n)\nfrom torchmetrics.metric import Metric\n\n\nclass MeanSquaredError(Metric):\n r\"\"\"\n Computes `mean squared error <https://en.wikipedia.org/wiki/Mean_squared_error>`_ (MSE):\n\n .. math:: \\text{MSE} = \\frac{1}{N}\\sum_i^N(y_i - \\hat{y_i})^2\n\n Where :math:`y` is a tensor of target values, and :math:`\\hat{y}` is a tensor of predictions.\n\n Args:\n compute_on_step:\n Forward only calls ``update()`` and return None if this is set to False. default: True\n dist_sync_on_step:\n Synchronize metric state across processes at each ``forward()``\n before returning the value at the step. default: False\n process_group:\n Specify the process group on which synchronization is called. default: None (which selects the entire world)\n squared:\n If True returns MSE value, if False returns RMSE value.\n\n Example:\n >>> from torchmetrics import MeanSquaredError\n >>> target = torch.tensor([2.5, 5.0, 4.0, 8.0])\n >>> preds = torch.tensor([3.0, 5.0, 2.5, 7.0])\n >>> mean_squared_error = MeanSquaredError()\n >>> mean_squared_error(preds, target)\n tensor(0.8750)\n\n \"\"\"\n\n def __init__(\n self,\n compute_on_step: bool = True,\n dist_sync_on_step: bool = False,\n process_group: Optional[Any] = None,\n dist_sync_fn: Callable = None,\n squared: bool = True,\n ):\n super().__init__(\n compute_on_step=compute_on_step,\n dist_sync_on_step=dist_sync_on_step,\n process_group=process_group,\n dist_sync_fn=dist_sync_fn,\n )\n\n self.add_state(\"sum_squared_error\", default=tensor(0.0), dist_reduce_fx=\"sum\")\n self.add_state(\"total\", default=tensor(0), dist_reduce_fx=\"sum\")\n self.squared = squared\n\n def update(self, preds: Tensor, target: Tensor):\n \"\"\"\n Update state with predictions and targets.\n\n Args:\n preds: Predictions from model\n target: Ground truth values\n \"\"\"\n sum_squared_error, n_obs = _mean_squared_error_update(preds, target)\n\n self.sum_squared_error += sum_squared_error\n self.total += n_obs\n\n def compute(self):\n \"\"\"\n Computes mean squared error over state.\n \"\"\"\n return _mean_squared_error_compute(self.sum_squared_error, self.total, squared=self.squared)\n\n @property\n def is_differentiable(self):\n return True\n", "path": "torchmetrics/regression/mean_squared_error.py"}]}
| 1,847 | 674 |
gh_patches_debug_8877
|
rasdani/github-patches
|
git_diff
|
Mailu__Mailu-951
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Internal Error with setup
Hi,
Thanks for the work !
I want to try the new version with setup.mailu.io + Docker stack. However I have already this when I want to generate my compose:
> Internal Server Error
> The server encountered an internal error and was unable to complete your request. Either the server is overloaded or there is an error in the application.
Is it normal?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup/server.py`
Content:
```
1 import flask
2 import flask_bootstrap
3 import redis
4 import json
5 import os
6 import jinja2
7 import uuid
8 import string
9 import random
10 import ipaddress
11 import hashlib
12 import time
13
14
15 version = os.getenv("this_version", "master")
16 static_url_path = "/" + version + "/static"
17 app = flask.Flask(__name__, static_url_path=static_url_path)
18 flask_bootstrap.Bootstrap(app)
19 db = redis.StrictRedis(host='redis', port=6379, db=0)
20
21
22 def render_flavor(flavor, template, data):
23 return flask.render_template(
24 os.path.join(flavor, template),
25 **data
26 )
27
28
29 @app.add_template_global
30 def secret(length=16):
31 charset = string.ascii_uppercase + string.digits
32 return ''.join(
33 random.SystemRandom().choice(charset)
34 for _ in range(length)
35 )
36
37 #Original copied from https://github.com/andrewlkho/ulagen
38 def random_ipv6_subnet():
39 eui64 = uuid.getnode() >> 24 << 48 | 0xfffe000000 | uuid.getnode() & 0xffffff
40 eui64_canon = "-".join([format(eui64, "02X")[i:i+2] for i in range(0, 18, 2)])
41
42 h = hashlib.sha1()
43 h.update((eui64_canon + str(time.time() - time.mktime((1900, 1, 1, 0, 0, 0, 0, 1, -1)))).encode('utf-8'))
44 globalid = h.hexdigest()[0:10]
45
46 prefix = ":".join(("fd" + globalid[0:2], globalid[2:6], globalid[6:10]))
47 return prefix
48
49 def build_app(path):
50
51 app.jinja_env.trim_blocks = True
52 app.jinja_env.lstrip_blocks = True
53
54 @app.context_processor
55 def app_context():
56 return dict(versions=os.getenv("VERSIONS","master").split(','))
57
58 prefix_bp = flask.Blueprint(version, __name__)
59 prefix_bp.jinja_loader = jinja2.ChoiceLoader([
60 jinja2.FileSystemLoader(os.path.join(path, "templates")),
61 jinja2.FileSystemLoader(os.path.join(path, "flavors"))
62 ])
63
64 root_bp = flask.Blueprint("root", __name__)
65 root_bp.jinja_loader = jinja2.ChoiceLoader([
66 jinja2.FileSystemLoader(os.path.join(path, "templates")),
67 jinja2.FileSystemLoader(os.path.join(path, "flavors"))
68 ])
69
70 @prefix_bp.context_processor
71 @root_bp.context_processor
72 def bp_context(version=version):
73 return dict(version=version)
74
75 @prefix_bp.route("/")
76 @root_bp.route("/")
77 def wizard():
78 return flask.render_template('wizard.html')
79
80 @prefix_bp.route("/submit_flavor", methods=["POST"])
81 @root_bp.route("/submit_flavor", methods=["POST"])
82 def submit_flavor():
83 data = flask.request.form.copy()
84 subnet6 = random_ipv6_subnet()
85 steps = sorted(os.listdir(os.path.join(path, "templates", "steps", data["flavor"])))
86 return flask.render_template('wizard.html', flavor=data["flavor"], steps=steps, subnet6=subnet6)
87
88 @prefix_bp.route("/submit", methods=["POST"])
89 @root_bp.route("/submit", methods=["POST"])
90 def submit():
91 data = flask.request.form.copy()
92 data['uid'] = str(uuid.uuid4())
93 data['dns'] = str(ipaddress.IPv4Network(data['subnet'])[-2])
94 db.set(data['uid'], json.dumps(data))
95 return flask.redirect(flask.url_for('.setup', uid=data['uid']))
96
97 @prefix_bp.route("/setup/<uid>", methods=["GET"])
98 @root_bp.route("/setup/<uid>", methods=["GET"])
99 def setup(uid):
100 data = json.loads(db.get(uid))
101 flavor = data.get("flavor", "compose")
102 rendered = render_flavor(flavor, "setup.html", data)
103 return flask.render_template("setup.html", contents=rendered)
104
105 @prefix_bp.route("/file/<uid>/<filepath>", methods=["GET"])
106 @root_bp.route("/file/<uid>/<filepath>", methods=["GET"])
107 def file(uid, filepath):
108 data = json.loads(db.get(uid))
109 flavor = data.get("flavor", "compose")
110 return flask.Response(
111 render_flavor(flavor, filepath, data),
112 mimetype="application/text"
113 )
114
115 app.register_blueprint(prefix_bp, url_prefix="/{}".format(version))
116 app.register_blueprint(root_bp)
117
118
119 if __name__ == "__main__":
120 build_app("/tmp/mailutest")
121 app.run(debug=True)
122
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup/server.py b/setup/server.py
--- a/setup/server.py
+++ b/setup/server.py
@@ -90,7 +90,10 @@
def submit():
data = flask.request.form.copy()
data['uid'] = str(uuid.uuid4())
- data['dns'] = str(ipaddress.IPv4Network(data['subnet'])[-2])
+ try:
+ data['dns'] = str(ipaddress.IPv4Network(data['subnet'])[-2])
+ except ValueError as err:
+ return "Error while generating files: " + str(err)
db.set(data['uid'], json.dumps(data))
return flask.redirect(flask.url_for('.setup', uid=data['uid']))
|
{"golden_diff": "diff --git a/setup/server.py b/setup/server.py\n--- a/setup/server.py\n+++ b/setup/server.py\n@@ -90,7 +90,10 @@\n def submit():\n data = flask.request.form.copy()\n data['uid'] = str(uuid.uuid4())\n- data['dns'] = str(ipaddress.IPv4Network(data['subnet'])[-2])\n+ try:\n+ data['dns'] = str(ipaddress.IPv4Network(data['subnet'])[-2])\n+ except ValueError as err:\n+ return \"Error while generating files: \" + str(err)\n db.set(data['uid'], json.dumps(data))\n return flask.redirect(flask.url_for('.setup', uid=data['uid']))\n", "issue": "Internal Error with setup\nHi,\r\n\r\nThanks for the work !\r\n\r\nI want to try the new version with setup.mailu.io + Docker stack. However I have already this when I want to generate my compose:\r\n\r\n> Internal Server Error\r\n> The server encountered an internal error and was unable to complete your request. Either the server is overloaded or there is an error in the application.\r\n\r\nIs it normal?\n", "before_files": [{"content": "import flask\nimport flask_bootstrap\nimport redis\nimport json\nimport os\nimport jinja2\nimport uuid\nimport string\nimport random\nimport ipaddress\nimport hashlib\nimport time\n\n\nversion = os.getenv(\"this_version\", \"master\")\nstatic_url_path = \"/\" + version + \"/static\"\napp = flask.Flask(__name__, static_url_path=static_url_path)\nflask_bootstrap.Bootstrap(app)\ndb = redis.StrictRedis(host='redis', port=6379, db=0)\n\n\ndef render_flavor(flavor, template, data):\n return flask.render_template(\n os.path.join(flavor, template),\n **data\n )\n\n\[email protected]_template_global\ndef secret(length=16):\n charset = string.ascii_uppercase + string.digits\n return ''.join(\n random.SystemRandom().choice(charset)\n for _ in range(length)\n )\n\n#Original copied from https://github.com/andrewlkho/ulagen\ndef random_ipv6_subnet():\n eui64 = uuid.getnode() >> 24 << 48 | 0xfffe000000 | uuid.getnode() & 0xffffff\n eui64_canon = \"-\".join([format(eui64, \"02X\")[i:i+2] for i in range(0, 18, 2)])\n\n h = hashlib.sha1()\n h.update((eui64_canon + str(time.time() - time.mktime((1900, 1, 1, 0, 0, 0, 0, 1, -1)))).encode('utf-8'))\n globalid = h.hexdigest()[0:10]\n\n prefix = \":\".join((\"fd\" + globalid[0:2], globalid[2:6], globalid[6:10]))\n return prefix\n\ndef build_app(path):\n\n app.jinja_env.trim_blocks = True\n app.jinja_env.lstrip_blocks = True\n\n @app.context_processor\n def app_context():\n return dict(versions=os.getenv(\"VERSIONS\",\"master\").split(','))\n\n prefix_bp = flask.Blueprint(version, __name__)\n prefix_bp.jinja_loader = jinja2.ChoiceLoader([\n jinja2.FileSystemLoader(os.path.join(path, \"templates\")),\n jinja2.FileSystemLoader(os.path.join(path, \"flavors\"))\n ])\n\n root_bp = flask.Blueprint(\"root\", __name__)\n root_bp.jinja_loader = jinja2.ChoiceLoader([\n jinja2.FileSystemLoader(os.path.join(path, \"templates\")),\n jinja2.FileSystemLoader(os.path.join(path, \"flavors\"))\n ])\n\n @prefix_bp.context_processor\n @root_bp.context_processor\n def bp_context(version=version):\n return dict(version=version)\n\n @prefix_bp.route(\"/\")\n @root_bp.route(\"/\")\n def wizard():\n return flask.render_template('wizard.html')\n\n @prefix_bp.route(\"/submit_flavor\", methods=[\"POST\"])\n @root_bp.route(\"/submit_flavor\", methods=[\"POST\"])\n def submit_flavor():\n data = flask.request.form.copy()\n subnet6 = random_ipv6_subnet()\n steps = sorted(os.listdir(os.path.join(path, \"templates\", \"steps\", data[\"flavor\"])))\n return flask.render_template('wizard.html', flavor=data[\"flavor\"], steps=steps, subnet6=subnet6)\n\n @prefix_bp.route(\"/submit\", methods=[\"POST\"])\n @root_bp.route(\"/submit\", methods=[\"POST\"])\n def submit():\n data = flask.request.form.copy()\n data['uid'] = str(uuid.uuid4())\n data['dns'] = str(ipaddress.IPv4Network(data['subnet'])[-2])\n db.set(data['uid'], json.dumps(data))\n return flask.redirect(flask.url_for('.setup', uid=data['uid']))\n\n @prefix_bp.route(\"/setup/<uid>\", methods=[\"GET\"])\n @root_bp.route(\"/setup/<uid>\", methods=[\"GET\"])\n def setup(uid):\n data = json.loads(db.get(uid))\n flavor = data.get(\"flavor\", \"compose\")\n rendered = render_flavor(flavor, \"setup.html\", data)\n return flask.render_template(\"setup.html\", contents=rendered)\n\n @prefix_bp.route(\"/file/<uid>/<filepath>\", methods=[\"GET\"])\n @root_bp.route(\"/file/<uid>/<filepath>\", methods=[\"GET\"])\n def file(uid, filepath):\n data = json.loads(db.get(uid))\n flavor = data.get(\"flavor\", \"compose\")\n return flask.Response(\n render_flavor(flavor, filepath, data),\n mimetype=\"application/text\"\n )\n\n app.register_blueprint(prefix_bp, url_prefix=\"/{}\".format(version))\n app.register_blueprint(root_bp)\n\n\nif __name__ == \"__main__\":\n build_app(\"/tmp/mailutest\")\n app.run(debug=True)\n", "path": "setup/server.py"}], "after_files": [{"content": "import flask\nimport flask_bootstrap\nimport redis\nimport json\nimport os\nimport jinja2\nimport uuid\nimport string\nimport random\nimport ipaddress\nimport hashlib\nimport time\n\n\nversion = os.getenv(\"this_version\", \"master\")\nstatic_url_path = \"/\" + version + \"/static\"\napp = flask.Flask(__name__, static_url_path=static_url_path)\nflask_bootstrap.Bootstrap(app)\ndb = redis.StrictRedis(host='redis', port=6379, db=0)\n\n\ndef render_flavor(flavor, template, data):\n return flask.render_template(\n os.path.join(flavor, template),\n **data\n )\n\n\[email protected]_template_global\ndef secret(length=16):\n charset = string.ascii_uppercase + string.digits\n return ''.join(\n random.SystemRandom().choice(charset)\n for _ in range(length)\n )\n\n#Original copied from https://github.com/andrewlkho/ulagen\ndef random_ipv6_subnet():\n eui64 = uuid.getnode() >> 24 << 48 | 0xfffe000000 | uuid.getnode() & 0xffffff\n eui64_canon = \"-\".join([format(eui64, \"02X\")[i:i+2] for i in range(0, 18, 2)])\n\n h = hashlib.sha1()\n h.update((eui64_canon + str(time.time() - time.mktime((1900, 1, 1, 0, 0, 0, 0, 1, -1)))).encode('utf-8'))\n globalid = h.hexdigest()[0:10]\n\n prefix = \":\".join((\"fd\" + globalid[0:2], globalid[2:6], globalid[6:10]))\n return prefix\n\ndef build_app(path):\n\n app.jinja_env.trim_blocks = True\n app.jinja_env.lstrip_blocks = True\n\n @app.context_processor\n def app_context():\n return dict(versions=os.getenv(\"VERSIONS\",\"master\").split(','))\n\n prefix_bp = flask.Blueprint(version, __name__)\n prefix_bp.jinja_loader = jinja2.ChoiceLoader([\n jinja2.FileSystemLoader(os.path.join(path, \"templates\")),\n jinja2.FileSystemLoader(os.path.join(path, \"flavors\"))\n ])\n\n root_bp = flask.Blueprint(\"root\", __name__)\n root_bp.jinja_loader = jinja2.ChoiceLoader([\n jinja2.FileSystemLoader(os.path.join(path, \"templates\")),\n jinja2.FileSystemLoader(os.path.join(path, \"flavors\"))\n ])\n\n @prefix_bp.context_processor\n @root_bp.context_processor\n def bp_context(version=version):\n return dict(version=version)\n\n @prefix_bp.route(\"/\")\n @root_bp.route(\"/\")\n def wizard():\n return flask.render_template('wizard.html')\n\n @prefix_bp.route(\"/submit_flavor\", methods=[\"POST\"])\n @root_bp.route(\"/submit_flavor\", methods=[\"POST\"])\n def submit_flavor():\n data = flask.request.form.copy()\n subnet6 = random_ipv6_subnet()\n steps = sorted(os.listdir(os.path.join(path, \"templates\", \"steps\", data[\"flavor\"])))\n return flask.render_template('wizard.html', flavor=data[\"flavor\"], steps=steps, subnet6=subnet6)\n\n @prefix_bp.route(\"/submit\", methods=[\"POST\"])\n @root_bp.route(\"/submit\", methods=[\"POST\"])\n def submit():\n data = flask.request.form.copy()\n data['uid'] = str(uuid.uuid4())\n try:\n data['dns'] = str(ipaddress.IPv4Network(data['subnet'])[-2])\n except ValueError as err:\n return \"Error while generating files: \" + str(err)\n db.set(data['uid'], json.dumps(data))\n return flask.redirect(flask.url_for('.setup', uid=data['uid']))\n\n @prefix_bp.route(\"/setup/<uid>\", methods=[\"GET\"])\n @root_bp.route(\"/setup/<uid>\", methods=[\"GET\"])\n def setup(uid):\n data = json.loads(db.get(uid))\n flavor = data.get(\"flavor\", \"compose\")\n rendered = render_flavor(flavor, \"setup.html\", data)\n return flask.render_template(\"setup.html\", contents=rendered)\n\n @prefix_bp.route(\"/file/<uid>/<filepath>\", methods=[\"GET\"])\n @root_bp.route(\"/file/<uid>/<filepath>\", methods=[\"GET\"])\n def file(uid, filepath):\n data = json.loads(db.get(uid))\n flavor = data.get(\"flavor\", \"compose\")\n return flask.Response(\n render_flavor(flavor, filepath, data),\n mimetype=\"application/text\"\n )\n\n app.register_blueprint(prefix_bp, url_prefix=\"/{}\".format(version))\n app.register_blueprint(root_bp)\n\n\nif __name__ == \"__main__\":\n build_app(\"/tmp/mailutest\")\n app.run(debug=True)\n", "path": "setup/server.py"}]}
| 1,644 | 154 |
gh_patches_debug_12554
|
rasdani/github-patches
|
git_diff
|
tensorflow__model-optimization-576
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Pruning: Training with Near 100% Target Sparsity Fails
**Describe the bug**
Pruning with high target sparsity (e.g. 0.99) causes a error.
**System information**
TensorFlow installed from (source or binary):
TensorFlow version: any
TensorFlow Model Optimization version: 0.2.1
Python version: any
**Describe the expected behavior**
Target sparsity of 0.99 should work.
**Describe the current behavior**
Training errors out with something like:
InvalidArgumentError: indices = -1 is not in [0, 40)
[[{{node prune_low_magnitude_dense_1/cond/cond/pruning_ops/GatherV2}}]]
**Code to reproduce the issue**
testPruneWithHighSparsity_Fails in prune_integration_test.py
Can search for "model-optimization/issues/215" in codebase to find unit test also.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `tensorflow_model_optimization/python/core/sparsity/keras/pruning_impl.py`
Content:
```
1 # Copyright 2019 The TensorFlow Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ==============================================================================
15 """Helper functions to add support for magnitude-based model pruning."""
16
17 from __future__ import absolute_import
18 from __future__ import division
19 from __future__ import print_function
20
21 import tensorflow as tf
22
23 from tensorflow.python.ops import summary_ops_v2
24 from tensorflow.python.summary import summary as summary_ops_v1
25 from tensorflow_model_optimization.python.core.keras import compat as tf_compat
26 from tensorflow_model_optimization.python.core.sparsity.keras import pruning_utils
27
28
29 class Pruning(object):
30 """Implementation of magnitude-based weight pruning."""
31
32 def __init__(self, training_step_fn, pruning_vars, pruning_schedule,
33 block_size, block_pooling_type):
34 """The logic for magnitude-based pruning weight tensors.
35
36 Args:
37 training_step_fn: A callable that returns the training step.
38 pruning_vars: A list of (weight, mask, threshold) tuples
39 pruning_schedule: A `PruningSchedule` object that controls pruning rate
40 throughout training.
41 block_size: The dimensions (height, weight) for the block sparse pattern
42 in rank-2 weight tensors.
43 block_pooling_type: (optional) The function to use to pool weights in the
44 block. Must be 'AVG' or 'MAX'.
45 """
46 self._pruning_vars = pruning_vars
47 self._pruning_schedule = pruning_schedule
48 self._block_size = list(block_size)
49 self._block_pooling_type = block_pooling_type
50 self._validate_block()
51
52 # Training step
53 self._step_fn = training_step_fn
54
55 self._validate_block()
56
57 def _validate_block(self):
58 if self._block_size != [1, 1]:
59 for weight, _, _ in self._pruning_vars:
60 if weight.get_shape().ndims != 2:
61 raise ValueError('Block Sparsity can only be used for layers which '
62 'have 2-dimensional weights.')
63
64 def _update_mask(self, weights):
65 """Updates the mask for a given weight tensor.
66
67 This functions first estimates the threshold value such that
68 a given fraction of weights have magnitude less than
69 the threshold.
70
71 Args:
72 weights: The weight tensor that needs to be masked.
73
74 Returns:
75 new_threshold: The new value of the threshold based on weights, and
76 sparsity at the current global_step
77 new_mask: A numpy array of the same size and shape as weights containing
78 0 or 1 to indicate which of the values in weights falls below
79 the threshold
80
81 Raises:
82 ValueError: if sparsity is not defined
83 """
84 sparsity = self._pruning_schedule(self._step_fn())[1]
85 with tf.name_scope('pruning_ops'):
86 abs_weights = tf.math.abs(weights)
87 k = tf.dtypes.cast(
88 tf.math.round(
89 tf.dtypes.cast(tf.size(abs_weights), tf.float32) *
90 (1 - sparsity)), tf.int32)
91 # Sort the entire array
92 values, _ = tf.math.top_k(
93 tf.reshape(abs_weights, [-1]), k=tf.size(abs_weights))
94 # Grab the (k-1)th value
95
96 current_threshold = tf.gather(values, k - 1)
97 new_mask = tf.dtypes.cast(
98 tf.math.greater_equal(abs_weights, current_threshold), weights.dtype)
99 return current_threshold, new_mask
100
101 def _maybe_update_block_mask(self, weights):
102 """Performs block-granular masking of the weights.
103
104 Block pruning occurs only if the block_height or block_width is > 1 and
105 if the weight tensor, when squeezed, has ndims = 2. Otherwise, elementwise
106 pruning occurs.
107 Args:
108 weights: The weight tensor that needs to be masked.
109
110 Returns:
111 new_threshold: The new value of the threshold based on weights, and
112 sparsity at the current global_step
113 new_mask: A numpy array of the same size and shape as weights containing
114 0 or 1 to indicate which of the values in weights falls below
115 the threshold
116
117 Raises:
118 ValueError: if block pooling function is not AVG or MAX
119 """
120 if self._block_size == [1, 1]:
121 return self._update_mask(weights)
122
123 # TODO(pulkitb): Check if squeeze operations should now be removed since
124 # we are only accepting 2-D weights.
125
126 squeezed_weights = tf.squeeze(weights)
127 abs_weights = tf.math.abs(squeezed_weights)
128 pooled_weights = pruning_utils.factorized_pool(
129 abs_weights,
130 window_shape=self._block_size,
131 pooling_type=self._block_pooling_type,
132 strides=self._block_size,
133 padding='SAME')
134
135 if pooled_weights.get_shape().ndims != 2:
136 pooled_weights = tf.squeeze(pooled_weights)
137
138 new_threshold, new_mask = self._update_mask(pooled_weights)
139
140 updated_mask = pruning_utils.expand_tensor(new_mask, self._block_size)
141 sliced_mask = tf.slice(
142 updated_mask, [0, 0],
143 [squeezed_weights.get_shape()[0],
144 squeezed_weights.get_shape()[1]])
145 return new_threshold, tf.reshape(sliced_mask, tf.shape(weights))
146
147 def _weight_assign_objs(self):
148 """Gather the assign objs for assigning weights<=weights*mask.
149
150 The objs are ops for graph execution and tensors for eager
151 execution.
152
153 Returns:
154 group of objs for weight assignment.
155 """
156
157 def update_fn(distribution, values_and_vars):
158 # TODO(yunluli): Need this ReduceOp because the weight is created by the
159 # layer wrapped, so we don't have control of its aggregation policy. May
160 # be able to optimize this when distribution strategy supports easier
161 # update to mirrored variables in replica context.
162 reduced_values = distribution.extended.batch_reduce_to(
163 tf.distribute.ReduceOp.MEAN, values_and_vars)
164 var_list = [v for _, v in values_and_vars]
165 values_and_vars = zip(reduced_values, var_list)
166
167 def update_var(variable, reduced_value):
168 return tf_compat.assign(variable, reduced_value)
169
170 update_objs = []
171 for value, var in values_and_vars:
172 update_objs.append(
173 distribution.extended.update(var, update_var, args=(value,)))
174
175 return tf.group(update_objs)
176
177 assign_objs = []
178
179 if tf.distribute.get_replica_context():
180 values_and_vars = []
181 for weight, mask, _ in self._pruning_vars:
182 masked_weight = tf.math.multiply(weight, mask)
183 values_and_vars.append((masked_weight, weight))
184 if values_and_vars:
185 assign_objs.append(tf.distribute.get_replica_context().merge_call(
186 update_fn, args=(values_and_vars,)))
187 else:
188 for weight, mask, _ in self._pruning_vars:
189 masked_weight = tf.math.multiply(weight, mask)
190 assign_objs.append(tf_compat.assign(weight, masked_weight))
191
192 return assign_objs
193
194 def weight_mask_op(self):
195 return tf.group(self._weight_assign_objs())
196
197 def conditional_mask_update(self):
198 """Returns an op to updates masks as per the pruning schedule."""
199
200 def maybe_update_masks():
201 return self._pruning_schedule(self._step_fn())[0]
202
203 def no_update():
204 return tf.no_op()
205
206 def mask_update():
207 """Updates mask without distribution strategy."""
208
209 def update():
210 assign_objs = []
211
212 for weight, mask, threshold in self._pruning_vars:
213 new_threshold, new_mask = self._maybe_update_block_mask(weight)
214 assign_objs.append(tf_compat.assign(threshold, new_threshold))
215 assign_objs.append(tf_compat.assign(mask, new_mask))
216
217 return tf.group(assign_objs)
218
219 return tf.cond(maybe_update_masks(), update, no_update)
220
221 def mask_update_distributed(distribution):
222 """Updates mask with distribution strategy."""
223
224 def update(var, value):
225 return tf_compat.assign(var, value)
226
227 def update_distributed():
228 """Gather distributed update objs.
229
230 The objs are ops for graph execution and tensors for eager
231 execution.
232 """
233 assign_objs = []
234
235 for weight, mask, threshold in self._pruning_vars:
236 new_threshold, new_mask = self._maybe_update_block_mask(weight)
237 assign_objs.append(
238 distribution.extended.update(mask, update, (new_mask,)))
239 assign_objs.append(
240 distribution.extended.update(threshold, update, (new_threshold,)))
241
242 return tf.group(assign_objs)
243
244 return tf.cond(maybe_update_masks(), update_distributed, no_update)
245
246 if tf.distribute.get_replica_context():
247 return tf.distribute.get_replica_context().merge_call(
248 mask_update_distributed)
249 else:
250 return mask_update()
251
252 def add_pruning_summaries(self):
253 """Adds summaries of weight sparsities and thresholds."""
254 # b/(139939526): update to use public API.
255 summary = summary_ops_v1
256 if tf.executing_eagerly():
257 summary = summary_ops_v2
258 summary.scalar('sparsity', self._pruning_schedule(self._step_fn())[1])
259 for _, mask, threshold in self._pruning_vars:
260 summary.scalar(mask.name + '/sparsity', 1.0 - tf.math.reduce_mean(mask))
261 summary.scalar(threshold.name + '/threshold', threshold)
262
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/tensorflow_model_optimization/python/core/sparsity/keras/pruning_impl.py b/tensorflow_model_optimization/python/core/sparsity/keras/pruning_impl.py
--- a/tensorflow_model_optimization/python/core/sparsity/keras/pruning_impl.py
+++ b/tensorflow_model_optimization/python/core/sparsity/keras/pruning_impl.py
@@ -85,9 +85,12 @@
with tf.name_scope('pruning_ops'):
abs_weights = tf.math.abs(weights)
k = tf.dtypes.cast(
- tf.math.round(
- tf.dtypes.cast(tf.size(abs_weights), tf.float32) *
- (1 - sparsity)), tf.int32)
+ tf.math.maximum(
+ tf.math.round(
+ tf.dtypes.cast(tf.size(abs_weights), tf.float32) *
+ (1 - sparsity)),
+ 1),
+ tf.int32)
# Sort the entire array
values, _ = tf.math.top_k(
tf.reshape(abs_weights, [-1]), k=tf.size(abs_weights))
|
{"golden_diff": "diff --git a/tensorflow_model_optimization/python/core/sparsity/keras/pruning_impl.py b/tensorflow_model_optimization/python/core/sparsity/keras/pruning_impl.py\n--- a/tensorflow_model_optimization/python/core/sparsity/keras/pruning_impl.py\n+++ b/tensorflow_model_optimization/python/core/sparsity/keras/pruning_impl.py\n@@ -85,9 +85,12 @@\n with tf.name_scope('pruning_ops'):\n abs_weights = tf.math.abs(weights)\n k = tf.dtypes.cast(\n- tf.math.round(\n- tf.dtypes.cast(tf.size(abs_weights), tf.float32) *\n- (1 - sparsity)), tf.int32)\n+ tf.math.maximum(\n+ tf.math.round(\n+ tf.dtypes.cast(tf.size(abs_weights), tf.float32) *\n+ (1 - sparsity)),\n+ 1),\n+ tf.int32)\n # Sort the entire array\n values, _ = tf.math.top_k(\n tf.reshape(abs_weights, [-1]), k=tf.size(abs_weights))\n", "issue": "Pruning: Training with Near 100% Target Sparsity Fails\n**Describe the bug**\r\nPruning with high target sparsity (e.g. 0.99) causes a error.\r\n\r\n**System information**\r\n\r\nTensorFlow installed from (source or binary):\r\n\r\nTensorFlow version: any\r\n\r\nTensorFlow Model Optimization version: 0.2.1\r\n\r\nPython version: any\r\n\r\n**Describe the expected behavior**\r\nTarget sparsity of 0.99 should work. \r\n\r\n**Describe the current behavior**\r\nTraining errors out with something like:\r\n\r\nInvalidArgumentError: indices = -1 is not in [0, 40)\r\n\t [[{{node prune_low_magnitude_dense_1/cond/cond/pruning_ops/GatherV2}}]]\r\n\r\n**Code to reproduce the issue**\r\ntestPruneWithHighSparsity_Fails in prune_integration_test.py\r\n\r\nCan search for \"model-optimization/issues/215\" in codebase to find unit test also.\r\n\r\n\n", "before_files": [{"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"Helper functions to add support for magnitude-based model pruning.\"\"\"\n\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport tensorflow as tf\n\nfrom tensorflow.python.ops import summary_ops_v2\nfrom tensorflow.python.summary import summary as summary_ops_v1\nfrom tensorflow_model_optimization.python.core.keras import compat as tf_compat\nfrom tensorflow_model_optimization.python.core.sparsity.keras import pruning_utils\n\n\nclass Pruning(object):\n \"\"\"Implementation of magnitude-based weight pruning.\"\"\"\n\n def __init__(self, training_step_fn, pruning_vars, pruning_schedule,\n block_size, block_pooling_type):\n \"\"\"The logic for magnitude-based pruning weight tensors.\n\n Args:\n training_step_fn: A callable that returns the training step.\n pruning_vars: A list of (weight, mask, threshold) tuples\n pruning_schedule: A `PruningSchedule` object that controls pruning rate\n throughout training.\n block_size: The dimensions (height, weight) for the block sparse pattern\n in rank-2 weight tensors.\n block_pooling_type: (optional) The function to use to pool weights in the\n block. Must be 'AVG' or 'MAX'.\n \"\"\"\n self._pruning_vars = pruning_vars\n self._pruning_schedule = pruning_schedule\n self._block_size = list(block_size)\n self._block_pooling_type = block_pooling_type\n self._validate_block()\n\n # Training step\n self._step_fn = training_step_fn\n\n self._validate_block()\n\n def _validate_block(self):\n if self._block_size != [1, 1]:\n for weight, _, _ in self._pruning_vars:\n if weight.get_shape().ndims != 2:\n raise ValueError('Block Sparsity can only be used for layers which '\n 'have 2-dimensional weights.')\n\n def _update_mask(self, weights):\n \"\"\"Updates the mask for a given weight tensor.\n\n This functions first estimates the threshold value such that\n a given fraction of weights have magnitude less than\n the threshold.\n\n Args:\n weights: The weight tensor that needs to be masked.\n\n Returns:\n new_threshold: The new value of the threshold based on weights, and\n sparsity at the current global_step\n new_mask: A numpy array of the same size and shape as weights containing\n 0 or 1 to indicate which of the values in weights falls below\n the threshold\n\n Raises:\n ValueError: if sparsity is not defined\n \"\"\"\n sparsity = self._pruning_schedule(self._step_fn())[1]\n with tf.name_scope('pruning_ops'):\n abs_weights = tf.math.abs(weights)\n k = tf.dtypes.cast(\n tf.math.round(\n tf.dtypes.cast(tf.size(abs_weights), tf.float32) *\n (1 - sparsity)), tf.int32)\n # Sort the entire array\n values, _ = tf.math.top_k(\n tf.reshape(abs_weights, [-1]), k=tf.size(abs_weights))\n # Grab the (k-1)th value\n\n current_threshold = tf.gather(values, k - 1)\n new_mask = tf.dtypes.cast(\n tf.math.greater_equal(abs_weights, current_threshold), weights.dtype)\n return current_threshold, new_mask\n\n def _maybe_update_block_mask(self, weights):\n \"\"\"Performs block-granular masking of the weights.\n\n Block pruning occurs only if the block_height or block_width is > 1 and\n if the weight tensor, when squeezed, has ndims = 2. Otherwise, elementwise\n pruning occurs.\n Args:\n weights: The weight tensor that needs to be masked.\n\n Returns:\n new_threshold: The new value of the threshold based on weights, and\n sparsity at the current global_step\n new_mask: A numpy array of the same size and shape as weights containing\n 0 or 1 to indicate which of the values in weights falls below\n the threshold\n\n Raises:\n ValueError: if block pooling function is not AVG or MAX\n \"\"\"\n if self._block_size == [1, 1]:\n return self._update_mask(weights)\n\n # TODO(pulkitb): Check if squeeze operations should now be removed since\n # we are only accepting 2-D weights.\n\n squeezed_weights = tf.squeeze(weights)\n abs_weights = tf.math.abs(squeezed_weights)\n pooled_weights = pruning_utils.factorized_pool(\n abs_weights,\n window_shape=self._block_size,\n pooling_type=self._block_pooling_type,\n strides=self._block_size,\n padding='SAME')\n\n if pooled_weights.get_shape().ndims != 2:\n pooled_weights = tf.squeeze(pooled_weights)\n\n new_threshold, new_mask = self._update_mask(pooled_weights)\n\n updated_mask = pruning_utils.expand_tensor(new_mask, self._block_size)\n sliced_mask = tf.slice(\n updated_mask, [0, 0],\n [squeezed_weights.get_shape()[0],\n squeezed_weights.get_shape()[1]])\n return new_threshold, tf.reshape(sliced_mask, tf.shape(weights))\n\n def _weight_assign_objs(self):\n \"\"\"Gather the assign objs for assigning weights<=weights*mask.\n\n The objs are ops for graph execution and tensors for eager\n execution.\n\n Returns:\n group of objs for weight assignment.\n \"\"\"\n\n def update_fn(distribution, values_and_vars):\n # TODO(yunluli): Need this ReduceOp because the weight is created by the\n # layer wrapped, so we don't have control of its aggregation policy. May\n # be able to optimize this when distribution strategy supports easier\n # update to mirrored variables in replica context.\n reduced_values = distribution.extended.batch_reduce_to(\n tf.distribute.ReduceOp.MEAN, values_and_vars)\n var_list = [v for _, v in values_and_vars]\n values_and_vars = zip(reduced_values, var_list)\n\n def update_var(variable, reduced_value):\n return tf_compat.assign(variable, reduced_value)\n\n update_objs = []\n for value, var in values_and_vars:\n update_objs.append(\n distribution.extended.update(var, update_var, args=(value,)))\n\n return tf.group(update_objs)\n\n assign_objs = []\n\n if tf.distribute.get_replica_context():\n values_and_vars = []\n for weight, mask, _ in self._pruning_vars:\n masked_weight = tf.math.multiply(weight, mask)\n values_and_vars.append((masked_weight, weight))\n if values_and_vars:\n assign_objs.append(tf.distribute.get_replica_context().merge_call(\n update_fn, args=(values_and_vars,)))\n else:\n for weight, mask, _ in self._pruning_vars:\n masked_weight = tf.math.multiply(weight, mask)\n assign_objs.append(tf_compat.assign(weight, masked_weight))\n\n return assign_objs\n\n def weight_mask_op(self):\n return tf.group(self._weight_assign_objs())\n\n def conditional_mask_update(self):\n \"\"\"Returns an op to updates masks as per the pruning schedule.\"\"\"\n\n def maybe_update_masks():\n return self._pruning_schedule(self._step_fn())[0]\n\n def no_update():\n return tf.no_op()\n\n def mask_update():\n \"\"\"Updates mask without distribution strategy.\"\"\"\n\n def update():\n assign_objs = []\n\n for weight, mask, threshold in self._pruning_vars:\n new_threshold, new_mask = self._maybe_update_block_mask(weight)\n assign_objs.append(tf_compat.assign(threshold, new_threshold))\n assign_objs.append(tf_compat.assign(mask, new_mask))\n\n return tf.group(assign_objs)\n\n return tf.cond(maybe_update_masks(), update, no_update)\n\n def mask_update_distributed(distribution):\n \"\"\"Updates mask with distribution strategy.\"\"\"\n\n def update(var, value):\n return tf_compat.assign(var, value)\n\n def update_distributed():\n \"\"\"Gather distributed update objs.\n\n The objs are ops for graph execution and tensors for eager\n execution.\n \"\"\"\n assign_objs = []\n\n for weight, mask, threshold in self._pruning_vars:\n new_threshold, new_mask = self._maybe_update_block_mask(weight)\n assign_objs.append(\n distribution.extended.update(mask, update, (new_mask,)))\n assign_objs.append(\n distribution.extended.update(threshold, update, (new_threshold,)))\n\n return tf.group(assign_objs)\n\n return tf.cond(maybe_update_masks(), update_distributed, no_update)\n\n if tf.distribute.get_replica_context():\n return tf.distribute.get_replica_context().merge_call(\n mask_update_distributed)\n else:\n return mask_update()\n\n def add_pruning_summaries(self):\n \"\"\"Adds summaries of weight sparsities and thresholds.\"\"\"\n # b/(139939526): update to use public API.\n summary = summary_ops_v1\n if tf.executing_eagerly():\n summary = summary_ops_v2\n summary.scalar('sparsity', self._pruning_schedule(self._step_fn())[1])\n for _, mask, threshold in self._pruning_vars:\n summary.scalar(mask.name + '/sparsity', 1.0 - tf.math.reduce_mean(mask))\n summary.scalar(threshold.name + '/threshold', threshold)\n", "path": "tensorflow_model_optimization/python/core/sparsity/keras/pruning_impl.py"}], "after_files": [{"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"Helper functions to add support for magnitude-based model pruning.\"\"\"\n\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport tensorflow as tf\n\nfrom tensorflow.python.ops import summary_ops_v2\nfrom tensorflow.python.summary import summary as summary_ops_v1\nfrom tensorflow_model_optimization.python.core.keras import compat as tf_compat\nfrom tensorflow_model_optimization.python.core.sparsity.keras import pruning_utils\n\n\nclass Pruning(object):\n \"\"\"Implementation of magnitude-based weight pruning.\"\"\"\n\n def __init__(self, training_step_fn, pruning_vars, pruning_schedule,\n block_size, block_pooling_type):\n \"\"\"The logic for magnitude-based pruning weight tensors.\n\n Args:\n training_step_fn: A callable that returns the training step.\n pruning_vars: A list of (weight, mask, threshold) tuples\n pruning_schedule: A `PruningSchedule` object that controls pruning rate\n throughout training.\n block_size: The dimensions (height, weight) for the block sparse pattern\n in rank-2 weight tensors.\n block_pooling_type: (optional) The function to use to pool weights in the\n block. Must be 'AVG' or 'MAX'.\n \"\"\"\n self._pruning_vars = pruning_vars\n self._pruning_schedule = pruning_schedule\n self._block_size = list(block_size)\n self._block_pooling_type = block_pooling_type\n self._validate_block()\n\n # Training step\n self._step_fn = training_step_fn\n\n self._validate_block()\n\n def _validate_block(self):\n if self._block_size != [1, 1]:\n for weight, _, _ in self._pruning_vars:\n if weight.get_shape().ndims != 2:\n raise ValueError('Block Sparsity can only be used for layers which '\n 'have 2-dimensional weights.')\n\n def _update_mask(self, weights):\n \"\"\"Updates the mask for a given weight tensor.\n\n This functions first estimates the threshold value such that\n a given fraction of weights have magnitude less than\n the threshold.\n\n Args:\n weights: The weight tensor that needs to be masked.\n\n Returns:\n new_threshold: The new value of the threshold based on weights, and\n sparsity at the current global_step\n new_mask: A numpy array of the same size and shape as weights containing\n 0 or 1 to indicate which of the values in weights falls below\n the threshold\n\n Raises:\n ValueError: if sparsity is not defined\n \"\"\"\n sparsity = self._pruning_schedule(self._step_fn())[1]\n with tf.name_scope('pruning_ops'):\n abs_weights = tf.math.abs(weights)\n k = tf.dtypes.cast(\n tf.math.maximum(\n tf.math.round(\n tf.dtypes.cast(tf.size(abs_weights), tf.float32) *\n (1 - sparsity)),\n 1),\n tf.int32)\n # Sort the entire array\n values, _ = tf.math.top_k(\n tf.reshape(abs_weights, [-1]), k=tf.size(abs_weights))\n # Grab the (k-1)th value\n\n current_threshold = tf.gather(values, k - 1)\n new_mask = tf.dtypes.cast(\n tf.math.greater_equal(abs_weights, current_threshold), weights.dtype)\n return current_threshold, new_mask\n\n def _maybe_update_block_mask(self, weights):\n \"\"\"Performs block-granular masking of the weights.\n\n Block pruning occurs only if the block_height or block_width is > 1 and\n if the weight tensor, when squeezed, has ndims = 2. Otherwise, elementwise\n pruning occurs.\n Args:\n weights: The weight tensor that needs to be masked.\n\n Returns:\n new_threshold: The new value of the threshold based on weights, and\n sparsity at the current global_step\n new_mask: A numpy array of the same size and shape as weights containing\n 0 or 1 to indicate which of the values in weights falls below\n the threshold\n\n Raises:\n ValueError: if block pooling function is not AVG or MAX\n \"\"\"\n if self._block_size == [1, 1]:\n return self._update_mask(weights)\n\n # TODO(pulkitb): Check if squeeze operations should now be removed since\n # we are only accepting 2-D weights.\n\n squeezed_weights = tf.squeeze(weights)\n abs_weights = tf.math.abs(squeezed_weights)\n pooled_weights = pruning_utils.factorized_pool(\n abs_weights,\n window_shape=self._block_size,\n pooling_type=self._block_pooling_type,\n strides=self._block_size,\n padding='SAME')\n\n if pooled_weights.get_shape().ndims != 2:\n pooled_weights = tf.squeeze(pooled_weights)\n\n new_threshold, new_mask = self._update_mask(pooled_weights)\n\n updated_mask = pruning_utils.expand_tensor(new_mask, self._block_size)\n sliced_mask = tf.slice(\n updated_mask, [0, 0],\n [squeezed_weights.get_shape()[0],\n squeezed_weights.get_shape()[1]])\n return new_threshold, tf.reshape(sliced_mask, tf.shape(weights))\n\n def _weight_assign_objs(self):\n \"\"\"Gather the assign objs for assigning weights<=weights*mask.\n\n The objs are ops for graph execution and tensors for eager\n execution.\n\n Returns:\n group of objs for weight assignment.\n \"\"\"\n\n def update_fn(distribution, values_and_vars):\n # TODO(yunluli): Need this ReduceOp because the weight is created by the\n # layer wrapped, so we don't have control of its aggregation policy. May\n # be able to optimize this when distribution strategy supports easier\n # update to mirrored variables in replica context.\n reduced_values = distribution.extended.batch_reduce_to(\n tf.distribute.ReduceOp.MEAN, values_and_vars)\n var_list = [v for _, v in values_and_vars]\n values_and_vars = zip(reduced_values, var_list)\n\n def update_var(variable, reduced_value):\n return tf_compat.assign(variable, reduced_value)\n\n update_objs = []\n for value, var in values_and_vars:\n update_objs.append(\n distribution.extended.update(var, update_var, args=(value,)))\n\n return tf.group(update_objs)\n\n assign_objs = []\n\n if tf.distribute.get_replica_context():\n values_and_vars = []\n for weight, mask, _ in self._pruning_vars:\n masked_weight = tf.math.multiply(weight, mask)\n values_and_vars.append((masked_weight, weight))\n if values_and_vars:\n assign_objs.append(tf.distribute.get_replica_context().merge_call(\n update_fn, args=(values_and_vars,)))\n else:\n for weight, mask, _ in self._pruning_vars:\n masked_weight = tf.math.multiply(weight, mask)\n assign_objs.append(tf_compat.assign(weight, masked_weight))\n\n return assign_objs\n\n def weight_mask_op(self):\n return tf.group(self._weight_assign_objs())\n\n def conditional_mask_update(self):\n \"\"\"Returns an op to updates masks as per the pruning schedule.\"\"\"\n\n def maybe_update_masks():\n return self._pruning_schedule(self._step_fn())[0]\n\n def no_update():\n return tf.no_op()\n\n def mask_update():\n \"\"\"Updates mask without distribution strategy.\"\"\"\n\n def update():\n assign_objs = []\n\n for weight, mask, threshold in self._pruning_vars:\n new_threshold, new_mask = self._maybe_update_block_mask(weight)\n assign_objs.append(tf_compat.assign(threshold, new_threshold))\n assign_objs.append(tf_compat.assign(mask, new_mask))\n\n return tf.group(assign_objs)\n\n return tf.cond(maybe_update_masks(), update, no_update)\n\n def mask_update_distributed(distribution):\n \"\"\"Updates mask with distribution strategy.\"\"\"\n\n def update(var, value):\n return tf_compat.assign(var, value)\n\n def update_distributed():\n \"\"\"Gather distributed update objs.\n\n The objs are ops for graph execution and tensors for eager\n execution.\n \"\"\"\n assign_objs = []\n\n for weight, mask, threshold in self._pruning_vars:\n new_threshold, new_mask = self._maybe_update_block_mask(weight)\n assign_objs.append(\n distribution.extended.update(mask, update, (new_mask,)))\n assign_objs.append(\n distribution.extended.update(threshold, update, (new_threshold,)))\n\n return tf.group(assign_objs)\n\n return tf.cond(maybe_update_masks(), update_distributed, no_update)\n\n if tf.distribute.get_replica_context():\n return tf.distribute.get_replica_context().merge_call(\n mask_update_distributed)\n else:\n return mask_update()\n\n def add_pruning_summaries(self):\n \"\"\"Adds summaries of weight sparsities and thresholds.\"\"\"\n # b/(139939526): update to use public API.\n summary = summary_ops_v1\n if tf.executing_eagerly():\n summary = summary_ops_v2\n summary.scalar('sparsity', self._pruning_schedule(self._step_fn())[1])\n for _, mask, threshold in self._pruning_vars:\n summary.scalar(mask.name + '/sparsity', 1.0 - tf.math.reduce_mean(mask))\n summary.scalar(threshold.name + '/threshold', threshold)\n", "path": "tensorflow_model_optimization/python/core/sparsity/keras/pruning_impl.py"}]}
| 3,293 | 237 |
gh_patches_debug_21411
|
rasdani/github-patches
|
git_diff
|
pytorch__text-385
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Translation splits error when not downloading dataset first
Thanks @AngusMonroe for finding this! The problem is that the absence of dataset is not addressed when creating splits. Minimal example:
```
from torchtext.datasets import Multi30k
from torchtext.data import Field
EN = Field()
DE = Field()
ds = Multi30k.splits(('.de','.en'),[('de',DE),('en',EN)],'data/multi30k')
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `torchtext/datasets/translation.py`
Content:
```
1 import os
2 import xml.etree.ElementTree as ET
3 import glob
4 import io
5
6 from .. import data
7
8
9 class TranslationDataset(data.Dataset):
10 """Defines a dataset for machine translation."""
11
12 @staticmethod
13 def sort_key(ex):
14 return data.interleave_keys(len(ex.src), len(ex.trg))
15
16 def __init__(self, path, exts, fields, **kwargs):
17 """Create a TranslationDataset given paths and fields.
18
19 Arguments:
20 path: Common prefix of paths to the data files for both languages.
21 exts: A tuple containing the extension to path for each language.
22 fields: A tuple containing the fields that will be used for data
23 in each language.
24 Remaining keyword arguments: Passed to the constructor of
25 data.Dataset.
26 """
27 if not isinstance(fields[0], (tuple, list)):
28 fields = [('src', fields[0]), ('trg', fields[1])]
29
30 src_path, trg_path = tuple(os.path.expanduser(path + x) for x in exts)
31
32 examples = []
33 with open(src_path) as src_file, open(trg_path) as trg_file:
34 for src_line, trg_line in zip(src_file, trg_file):
35 src_line, trg_line = src_line.strip(), trg_line.strip()
36 if src_line != '' and trg_line != '':
37 examples.append(data.Example.fromlist(
38 [src_line, trg_line], fields))
39
40 super(TranslationDataset, self).__init__(examples, fields, **kwargs)
41
42 @classmethod
43 def splits(cls, exts, fields, path=None, root='.data',
44 train='train', validation='val', test='test', **kwargs):
45 """Create dataset objects for splits of a TranslationDataset.
46
47 Arguments:
48 path (str): Common prefix of the splits' file paths, or None to use
49 the result of cls.download(root).
50 root: Root dataset storage directory. Default is '.data'.
51 exts: A tuple containing the extension to path for each language.
52 fields: A tuple containing the fields that will be used for data
53 in each language.
54 train: The prefix of the train data. Default: 'train'.
55 validation: The prefix of the validation data. Default: 'val'.
56 test: The prefix of the test data. Default: 'test'.
57 Remaining keyword arguments: Passed to the splits method of
58 Dataset.
59 """
60 if path is None:
61 path = cls.download(root)
62
63 train_data = None if train is None else cls(
64 os.path.join(path, train), exts, fields, **kwargs)
65 val_data = None if validation is None else cls(
66 os.path.join(path, validation), exts, fields, **kwargs)
67 test_data = None if test is None else cls(
68 os.path.join(path, test), exts, fields, **kwargs)
69 return tuple(d for d in (train_data, val_data, test_data)
70 if d is not None)
71
72
73 class Multi30k(TranslationDataset):
74 """The small-dataset WMT 2016 multimodal task, also known as Flickr30k"""
75
76 urls = ['http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/training.tar.gz',
77 'http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/validation.tar.gz',
78 'http://www.quest.dcs.shef.ac.uk/'
79 'wmt17_files_mmt/mmt_task1_test2016.tar.gz']
80 name = 'multi30k'
81 dirname = ''
82
83 @classmethod
84 def splits(cls, exts, fields, root='.data',
85 train='train', validation='val', test='test2016', **kwargs):
86 """Create dataset objects for splits of the Multi30k dataset.
87
88 Arguments:
89
90 root: Root dataset storage directory. Default is '.data'.
91 exts: A tuple containing the extension to path for each language.
92 fields: A tuple containing the fields that will be used for data
93 in each language.
94 train: The prefix of the train data. Default: 'train'.
95 validation: The prefix of the validation data. Default: 'val'.
96 test: The prefix of the test data. Default: 'test'.
97 Remaining keyword arguments: Passed to the splits method of
98 Dataset.
99 """
100 path = os.path.join('data', cls.name)
101 return super(Multi30k, cls).splits(
102 exts, fields, path, root, train, validation, test, **kwargs)
103
104
105 class IWSLT(TranslationDataset):
106 """The IWSLT 2016 TED talk translation task"""
107
108 base_url = 'https://wit3.fbk.eu/archive/2016-01//texts/{}/{}/{}.tgz'
109 name = 'iwslt'
110 base_dirname = '{}-{}'
111
112 @classmethod
113 def splits(cls, exts, fields, root='.data',
114 train='train', validation='IWSLT16.TED.tst2013',
115 test='IWSLT16.TED.tst2014', **kwargs):
116 """Create dataset objects for splits of the IWSLT dataset.
117
118 Arguments:
119
120 root: Root dataset storage directory. Default is '.data'.
121 exts: A tuple containing the extension to path for each language.
122 fields: A tuple containing the fields that will be used for data
123 in each language.
124 train: The prefix of the train data. Default: 'train'.
125 validation: The prefix of the validation data. Default: 'val'.
126 test: The prefix of the test data. Default: 'test'.
127 Remaining keyword arguments: Passed to the splits method of
128 Dataset.
129 """
130 cls.dirname = cls.base_dirname.format(exts[0][1:], exts[1][1:])
131 cls.urls = [cls.base_url.format(exts[0][1:], exts[1][1:], cls.dirname)]
132 check = os.path.join(root, cls.name, cls.dirname)
133 path = cls.download(root, check=check)
134
135 train = '.'.join([train, cls.dirname])
136 validation = '.'.join([validation, cls.dirname])
137 if test is not None:
138 test = '.'.join([test, cls.dirname])
139
140 if not os.path.exists(os.path.join(path, train) + exts[0]):
141 cls.clean(path)
142
143 train_data = None if train is None else cls(
144 os.path.join(path, train), exts, fields, **kwargs)
145 val_data = None if validation is None else cls(
146 os.path.join(path, validation), exts, fields, **kwargs)
147 test_data = None if test is None else cls(
148 os.path.join(path, test), exts, fields, **kwargs)
149 return tuple(d for d in (train_data, val_data, test_data)
150 if d is not None)
151
152 @staticmethod
153 def clean(path):
154 for f_xml in glob.iglob(os.path.join(path, '*.xml')):
155 print(f_xml)
156 f_txt = os.path.splitext(f_xml)[0]
157 with io.open(f_txt, mode='w', encoding='utf-8') as fd_txt:
158 root = ET.parse(f_xml).getroot()[0]
159 for doc in root.findall('doc'):
160 for e in doc.findall('seg'):
161 fd_txt.write(e.text.strip() + '\n')
162
163 xml_tags = ['<url', '<keywords', '<talkid', '<description',
164 '<reviewer', '<translator', '<title', '<speaker']
165 for f_orig in glob.iglob(os.path.join(path, 'train.tags*')):
166 print(f_orig)
167 f_txt = f_orig.replace('.tags', '')
168 with io.open(f_txt, mode='w', encoding='utf-8') as fd_txt, \
169 io.open(f_orig, mode='r', encoding='utf-8') as fd_orig:
170 for l in fd_orig:
171 if not any(tag in l for tag in xml_tags):
172 fd_txt.write(l.strip() + '\n')
173
174
175 class WMT14(TranslationDataset):
176 """The WMT 2014 English-German dataset, as preprocessed by Google Brain.
177
178 Though this download contains test sets from 2015 and 2016, the train set
179 differs slightly from WMT 2015 and 2016 and significantly from WMT 2017."""
180
181 urls = [('https://drive.google.com/uc?export=download&'
182 'id=0B_bZck-ksdkpM25jRUN2X2UxMm8', 'wmt16_en_de.tar.gz')]
183 name = 'wmt14'
184 dirname = ''
185
186 @classmethod
187 def splits(cls, exts, fields, root='.data',
188 train='train.tok.clean.bpe.32000',
189 validation='newstest2013.tok.bpe.32000',
190 test='newstest2014.tok.bpe.32000', **kwargs):
191 """Create dataset objects for splits of the WMT 2014 dataset.
192
193 Arguments:
194
195 root: Root dataset storage directory. Default is '.data'.
196 exts: A tuple containing the extensions for each language. Must be
197 either ('.en', '.de') or the reverse.
198 fields: A tuple containing the fields that will be used for data
199 in each language.
200 train: The prefix of the train data. Default:
201 'train.tok.clean.bpe.32000'.
202 validation: The prefix of the validation data. Default:
203 'newstest2013.tok.bpe.32000'.
204 test: The prefix of the test data. Default:
205 'newstest2014.tok.bpe.32000'.
206 Remaining keyword arguments: Passed to the splits method of
207 Dataset.
208 """
209 path = os.path.join('data', cls.name)
210 return super(WMT14, cls).splits(
211 exts, fields, path, root, train, validation, test, **kwargs)
212
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/torchtext/datasets/translation.py b/torchtext/datasets/translation.py
--- a/torchtext/datasets/translation.py
+++ b/torchtext/datasets/translation.py
@@ -97,7 +97,9 @@
Remaining keyword arguments: Passed to the splits method of
Dataset.
"""
- path = os.path.join('data', cls.name)
+ expected_folder = os.path.join(root, cls.name)
+ path = expected_folder if os.path.exists(expected_folder) else None
+
return super(Multi30k, cls).splits(
exts, fields, path, root, train, validation, test, **kwargs)
@@ -206,6 +208,8 @@
Remaining keyword arguments: Passed to the splits method of
Dataset.
"""
- path = os.path.join('data', cls.name)
+ expected_folder = os.path.join(root, cls.name)
+ path = expected_folder if os.path.exists(expected_folder) else None
+
return super(WMT14, cls).splits(
exts, fields, path, root, train, validation, test, **kwargs)
|
{"golden_diff": "diff --git a/torchtext/datasets/translation.py b/torchtext/datasets/translation.py\n--- a/torchtext/datasets/translation.py\n+++ b/torchtext/datasets/translation.py\n@@ -97,7 +97,9 @@\n Remaining keyword arguments: Passed to the splits method of\n Dataset.\n \"\"\"\n- path = os.path.join('data', cls.name)\n+ expected_folder = os.path.join(root, cls.name)\n+ path = expected_folder if os.path.exists(expected_folder) else None\n+\n return super(Multi30k, cls).splits(\n exts, fields, path, root, train, validation, test, **kwargs)\n \n@@ -206,6 +208,8 @@\n Remaining keyword arguments: Passed to the splits method of\n Dataset.\n \"\"\"\n- path = os.path.join('data', cls.name)\n+ expected_folder = os.path.join(root, cls.name)\n+ path = expected_folder if os.path.exists(expected_folder) else None\n+\n return super(WMT14, cls).splits(\n exts, fields, path, root, train, validation, test, **kwargs)\n", "issue": "Translation splits error when not downloading dataset first\nThanks @AngusMonroe for finding this! The problem is that the absence of dataset is not addressed when creating splits. Minimal example:\r\n\r\n```\r\n\r\nfrom torchtext.datasets import Multi30k\r\nfrom torchtext.data import Field\r\nEN = Field()\r\nDE = Field()\r\nds = Multi30k.splits(('.de','.en'),[('de',DE),('en',EN)],'data/multi30k')\r\n```\r\n\n", "before_files": [{"content": "import os\nimport xml.etree.ElementTree as ET\nimport glob\nimport io\n\nfrom .. import data\n\n\nclass TranslationDataset(data.Dataset):\n \"\"\"Defines a dataset for machine translation.\"\"\"\n\n @staticmethod\n def sort_key(ex):\n return data.interleave_keys(len(ex.src), len(ex.trg))\n\n def __init__(self, path, exts, fields, **kwargs):\n \"\"\"Create a TranslationDataset given paths and fields.\n\n Arguments:\n path: Common prefix of paths to the data files for both languages.\n exts: A tuple containing the extension to path for each language.\n fields: A tuple containing the fields that will be used for data\n in each language.\n Remaining keyword arguments: Passed to the constructor of\n data.Dataset.\n \"\"\"\n if not isinstance(fields[0], (tuple, list)):\n fields = [('src', fields[0]), ('trg', fields[1])]\n\n src_path, trg_path = tuple(os.path.expanduser(path + x) for x in exts)\n\n examples = []\n with open(src_path) as src_file, open(trg_path) as trg_file:\n for src_line, trg_line in zip(src_file, trg_file):\n src_line, trg_line = src_line.strip(), trg_line.strip()\n if src_line != '' and trg_line != '':\n examples.append(data.Example.fromlist(\n [src_line, trg_line], fields))\n\n super(TranslationDataset, self).__init__(examples, fields, **kwargs)\n\n @classmethod\n def splits(cls, exts, fields, path=None, root='.data',\n train='train', validation='val', test='test', **kwargs):\n \"\"\"Create dataset objects for splits of a TranslationDataset.\n\n Arguments:\n path (str): Common prefix of the splits' file paths, or None to use\n the result of cls.download(root).\n root: Root dataset storage directory. Default is '.data'.\n exts: A tuple containing the extension to path for each language.\n fields: A tuple containing the fields that will be used for data\n in each language.\n train: The prefix of the train data. Default: 'train'.\n validation: The prefix of the validation data. Default: 'val'.\n test: The prefix of the test data. Default: 'test'.\n Remaining keyword arguments: Passed to the splits method of\n Dataset.\n \"\"\"\n if path is None:\n path = cls.download(root)\n\n train_data = None if train is None else cls(\n os.path.join(path, train), exts, fields, **kwargs)\n val_data = None if validation is None else cls(\n os.path.join(path, validation), exts, fields, **kwargs)\n test_data = None if test is None else cls(\n os.path.join(path, test), exts, fields, **kwargs)\n return tuple(d for d in (train_data, val_data, test_data)\n if d is not None)\n\n\nclass Multi30k(TranslationDataset):\n \"\"\"The small-dataset WMT 2016 multimodal task, also known as Flickr30k\"\"\"\n\n urls = ['http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/training.tar.gz',\n 'http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/validation.tar.gz',\n 'http://www.quest.dcs.shef.ac.uk/'\n 'wmt17_files_mmt/mmt_task1_test2016.tar.gz']\n name = 'multi30k'\n dirname = ''\n\n @classmethod\n def splits(cls, exts, fields, root='.data',\n train='train', validation='val', test='test2016', **kwargs):\n \"\"\"Create dataset objects for splits of the Multi30k dataset.\n\n Arguments:\n\n root: Root dataset storage directory. Default is '.data'.\n exts: A tuple containing the extension to path for each language.\n fields: A tuple containing the fields that will be used for data\n in each language.\n train: The prefix of the train data. Default: 'train'.\n validation: The prefix of the validation data. Default: 'val'.\n test: The prefix of the test data. Default: 'test'.\n Remaining keyword arguments: Passed to the splits method of\n Dataset.\n \"\"\"\n path = os.path.join('data', cls.name)\n return super(Multi30k, cls).splits(\n exts, fields, path, root, train, validation, test, **kwargs)\n\n\nclass IWSLT(TranslationDataset):\n \"\"\"The IWSLT 2016 TED talk translation task\"\"\"\n\n base_url = 'https://wit3.fbk.eu/archive/2016-01//texts/{}/{}/{}.tgz'\n name = 'iwslt'\n base_dirname = '{}-{}'\n\n @classmethod\n def splits(cls, exts, fields, root='.data',\n train='train', validation='IWSLT16.TED.tst2013',\n test='IWSLT16.TED.tst2014', **kwargs):\n \"\"\"Create dataset objects for splits of the IWSLT dataset.\n\n Arguments:\n\n root: Root dataset storage directory. Default is '.data'.\n exts: A tuple containing the extension to path for each language.\n fields: A tuple containing the fields that will be used for data\n in each language.\n train: The prefix of the train data. Default: 'train'.\n validation: The prefix of the validation data. Default: 'val'.\n test: The prefix of the test data. Default: 'test'.\n Remaining keyword arguments: Passed to the splits method of\n Dataset.\n \"\"\"\n cls.dirname = cls.base_dirname.format(exts[0][1:], exts[1][1:])\n cls.urls = [cls.base_url.format(exts[0][1:], exts[1][1:], cls.dirname)]\n check = os.path.join(root, cls.name, cls.dirname)\n path = cls.download(root, check=check)\n\n train = '.'.join([train, cls.dirname])\n validation = '.'.join([validation, cls.dirname])\n if test is not None:\n test = '.'.join([test, cls.dirname])\n\n if not os.path.exists(os.path.join(path, train) + exts[0]):\n cls.clean(path)\n\n train_data = None if train is None else cls(\n os.path.join(path, train), exts, fields, **kwargs)\n val_data = None if validation is None else cls(\n os.path.join(path, validation), exts, fields, **kwargs)\n test_data = None if test is None else cls(\n os.path.join(path, test), exts, fields, **kwargs)\n return tuple(d for d in (train_data, val_data, test_data)\n if d is not None)\n\n @staticmethod\n def clean(path):\n for f_xml in glob.iglob(os.path.join(path, '*.xml')):\n print(f_xml)\n f_txt = os.path.splitext(f_xml)[0]\n with io.open(f_txt, mode='w', encoding='utf-8') as fd_txt:\n root = ET.parse(f_xml).getroot()[0]\n for doc in root.findall('doc'):\n for e in doc.findall('seg'):\n fd_txt.write(e.text.strip() + '\\n')\n\n xml_tags = ['<url', '<keywords', '<talkid', '<description',\n '<reviewer', '<translator', '<title', '<speaker']\n for f_orig in glob.iglob(os.path.join(path, 'train.tags*')):\n print(f_orig)\n f_txt = f_orig.replace('.tags', '')\n with io.open(f_txt, mode='w', encoding='utf-8') as fd_txt, \\\n io.open(f_orig, mode='r', encoding='utf-8') as fd_orig:\n for l in fd_orig:\n if not any(tag in l for tag in xml_tags):\n fd_txt.write(l.strip() + '\\n')\n\n\nclass WMT14(TranslationDataset):\n \"\"\"The WMT 2014 English-German dataset, as preprocessed by Google Brain.\n\n Though this download contains test sets from 2015 and 2016, the train set\n differs slightly from WMT 2015 and 2016 and significantly from WMT 2017.\"\"\"\n\n urls = [('https://drive.google.com/uc?export=download&'\n 'id=0B_bZck-ksdkpM25jRUN2X2UxMm8', 'wmt16_en_de.tar.gz')]\n name = 'wmt14'\n dirname = ''\n\n @classmethod\n def splits(cls, exts, fields, root='.data',\n train='train.tok.clean.bpe.32000',\n validation='newstest2013.tok.bpe.32000',\n test='newstest2014.tok.bpe.32000', **kwargs):\n \"\"\"Create dataset objects for splits of the WMT 2014 dataset.\n\n Arguments:\n\n root: Root dataset storage directory. Default is '.data'.\n exts: A tuple containing the extensions for each language. Must be\n either ('.en', '.de') or the reverse.\n fields: A tuple containing the fields that will be used for data\n in each language.\n train: The prefix of the train data. Default:\n 'train.tok.clean.bpe.32000'.\n validation: The prefix of the validation data. Default:\n 'newstest2013.tok.bpe.32000'.\n test: The prefix of the test data. Default:\n 'newstest2014.tok.bpe.32000'.\n Remaining keyword arguments: Passed to the splits method of\n Dataset.\n \"\"\"\n path = os.path.join('data', cls.name)\n return super(WMT14, cls).splits(\n exts, fields, path, root, train, validation, test, **kwargs)\n", "path": "torchtext/datasets/translation.py"}], "after_files": [{"content": "import os\nimport xml.etree.ElementTree as ET\nimport glob\nimport io\n\nfrom .. import data\n\n\nclass TranslationDataset(data.Dataset):\n \"\"\"Defines a dataset for machine translation.\"\"\"\n\n @staticmethod\n def sort_key(ex):\n return data.interleave_keys(len(ex.src), len(ex.trg))\n\n def __init__(self, path, exts, fields, **kwargs):\n \"\"\"Create a TranslationDataset given paths and fields.\n\n Arguments:\n path: Common prefix of paths to the data files for both languages.\n exts: A tuple containing the extension to path for each language.\n fields: A tuple containing the fields that will be used for data\n in each language.\n Remaining keyword arguments: Passed to the constructor of\n data.Dataset.\n \"\"\"\n if not isinstance(fields[0], (tuple, list)):\n fields = [('src', fields[0]), ('trg', fields[1])]\n\n src_path, trg_path = tuple(os.path.expanduser(path + x) for x in exts)\n\n examples = []\n with open(src_path) as src_file, open(trg_path) as trg_file:\n for src_line, trg_line in zip(src_file, trg_file):\n src_line, trg_line = src_line.strip(), trg_line.strip()\n if src_line != '' and trg_line != '':\n examples.append(data.Example.fromlist(\n [src_line, trg_line], fields))\n\n super(TranslationDataset, self).__init__(examples, fields, **kwargs)\n\n @classmethod\n def splits(cls, exts, fields, path=None, root='.data',\n train='train', validation='val', test='test', **kwargs):\n \"\"\"Create dataset objects for splits of a TranslationDataset.\n\n Arguments:\n path (str): Common prefix of the splits' file paths, or None to use\n the result of cls.download(root).\n root: Root dataset storage directory. Default is '.data'.\n exts: A tuple containing the extension to path for each language.\n fields: A tuple containing the fields that will be used for data\n in each language.\n train: The prefix of the train data. Default: 'train'.\n validation: The prefix of the validation data. Default: 'val'.\n test: The prefix of the test data. Default: 'test'.\n Remaining keyword arguments: Passed to the splits method of\n Dataset.\n \"\"\"\n if path is None:\n path = cls.download(root)\n\n train_data = None if train is None else cls(\n os.path.join(path, train), exts, fields, **kwargs)\n val_data = None if validation is None else cls(\n os.path.join(path, validation), exts, fields, **kwargs)\n test_data = None if test is None else cls(\n os.path.join(path, test), exts, fields, **kwargs)\n return tuple(d for d in (train_data, val_data, test_data)\n if d is not None)\n\n\nclass Multi30k(TranslationDataset):\n \"\"\"The small-dataset WMT 2016 multimodal task, also known as Flickr30k\"\"\"\n\n urls = ['http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/training.tar.gz',\n 'http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/validation.tar.gz',\n 'http://www.quest.dcs.shef.ac.uk/'\n 'wmt17_files_mmt/mmt_task1_test2016.tar.gz']\n name = 'multi30k'\n dirname = ''\n\n @classmethod\n def splits(cls, exts, fields, root='.data',\n train='train', validation='val', test='test2016', **kwargs):\n \"\"\"Create dataset objects for splits of the Multi30k dataset.\n\n Arguments:\n\n root: Root dataset storage directory. Default is '.data'.\n exts: A tuple containing the extension to path for each language.\n fields: A tuple containing the fields that will be used for data\n in each language.\n train: The prefix of the train data. Default: 'train'.\n validation: The prefix of the validation data. Default: 'val'.\n test: The prefix of the test data. Default: 'test'.\n Remaining keyword arguments: Passed to the splits method of\n Dataset.\n \"\"\"\n expected_folder = os.path.join(root, cls.name)\n path = expected_folder if os.path.exists(expected_folder) else None\n\n return super(Multi30k, cls).splits(\n exts, fields, path, root, train, validation, test, **kwargs)\n\n\nclass IWSLT(TranslationDataset):\n \"\"\"The IWSLT 2016 TED talk translation task\"\"\"\n\n base_url = 'https://wit3.fbk.eu/archive/2016-01//texts/{}/{}/{}.tgz'\n name = 'iwslt'\n base_dirname = '{}-{}'\n\n @classmethod\n def splits(cls, exts, fields, root='.data',\n train='train', validation='IWSLT16.TED.tst2013',\n test='IWSLT16.TED.tst2014', **kwargs):\n \"\"\"Create dataset objects for splits of the IWSLT dataset.\n\n Arguments:\n\n root: Root dataset storage directory. Default is '.data'.\n exts: A tuple containing the extension to path for each language.\n fields: A tuple containing the fields that will be used for data\n in each language.\n train: The prefix of the train data. Default: 'train'.\n validation: The prefix of the validation data. Default: 'val'.\n test: The prefix of the test data. Default: 'test'.\n Remaining keyword arguments: Passed to the splits method of\n Dataset.\n \"\"\"\n cls.dirname = cls.base_dirname.format(exts[0][1:], exts[1][1:])\n cls.urls = [cls.base_url.format(exts[0][1:], exts[1][1:], cls.dirname)]\n check = os.path.join(root, cls.name, cls.dirname)\n path = cls.download(root, check=check)\n\n train = '.'.join([train, cls.dirname])\n validation = '.'.join([validation, cls.dirname])\n if test is not None:\n test = '.'.join([test, cls.dirname])\n\n if not os.path.exists(os.path.join(path, train) + exts[0]):\n cls.clean(path)\n\n train_data = None if train is None else cls(\n os.path.join(path, train), exts, fields, **kwargs)\n val_data = None if validation is None else cls(\n os.path.join(path, validation), exts, fields, **kwargs)\n test_data = None if test is None else cls(\n os.path.join(path, test), exts, fields, **kwargs)\n return tuple(d for d in (train_data, val_data, test_data)\n if d is not None)\n\n @staticmethod\n def clean(path):\n for f_xml in glob.iglob(os.path.join(path, '*.xml')):\n print(f_xml)\n f_txt = os.path.splitext(f_xml)[0]\n with io.open(f_txt, mode='w', encoding='utf-8') as fd_txt:\n root = ET.parse(f_xml).getroot()[0]\n for doc in root.findall('doc'):\n for e in doc.findall('seg'):\n fd_txt.write(e.text.strip() + '\\n')\n\n xml_tags = ['<url', '<keywords', '<talkid', '<description',\n '<reviewer', '<translator', '<title', '<speaker']\n for f_orig in glob.iglob(os.path.join(path, 'train.tags*')):\n print(f_orig)\n f_txt = f_orig.replace('.tags', '')\n with io.open(f_txt, mode='w', encoding='utf-8') as fd_txt, \\\n io.open(f_orig, mode='r', encoding='utf-8') as fd_orig:\n for l in fd_orig:\n if not any(tag in l for tag in xml_tags):\n fd_txt.write(l.strip() + '\\n')\n\n\nclass WMT14(TranslationDataset):\n \"\"\"The WMT 2014 English-German dataset, as preprocessed by Google Brain.\n\n Though this download contains test sets from 2015 and 2016, the train set\n differs slightly from WMT 2015 and 2016 and significantly from WMT 2017.\"\"\"\n\n urls = [('https://drive.google.com/uc?export=download&'\n 'id=0B_bZck-ksdkpM25jRUN2X2UxMm8', 'wmt16_en_de.tar.gz')]\n name = 'wmt14'\n dirname = ''\n\n @classmethod\n def splits(cls, exts, fields, root='.data',\n train='train.tok.clean.bpe.32000',\n validation='newstest2013.tok.bpe.32000',\n test='newstest2014.tok.bpe.32000', **kwargs):\n \"\"\"Create dataset objects for splits of the WMT 2014 dataset.\n\n Arguments:\n\n root: Root dataset storage directory. Default is '.data'.\n exts: A tuple containing the extensions for each language. Must be\n either ('.en', '.de') or the reverse.\n fields: A tuple containing the fields that will be used for data\n in each language.\n train: The prefix of the train data. Default:\n 'train.tok.clean.bpe.32000'.\n validation: The prefix of the validation data. Default:\n 'newstest2013.tok.bpe.32000'.\n test: The prefix of the test data. Default:\n 'newstest2014.tok.bpe.32000'.\n Remaining keyword arguments: Passed to the splits method of\n Dataset.\n \"\"\"\n expected_folder = os.path.join(root, cls.name)\n path = expected_folder if os.path.exists(expected_folder) else None\n\n return super(WMT14, cls).splits(\n exts, fields, path, root, train, validation, test, **kwargs)\n", "path": "torchtext/datasets/translation.py"}]}
| 3,109 | 256 |
gh_patches_debug_29687
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-4041
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Please support Verify=False option for tools.get() as is currently supported for tools.download()
To help us debug your issue please explain:
- [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md).
- [1.8.4] I've specified the Conan version, operating system version and any tool that can be relevant.
- [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conans/client/tools/net.py`
Content:
```
1 import os
2
3 from conans.client.rest.uploader_downloader import Downloader
4 from conans.client.tools.files import unzip, check_md5, check_sha1, check_sha256
5 from conans.errors import ConanException
6 from conans.util.fallbacks import default_output, default_requester
7
8
9 def get(url, md5='', sha1='', sha256='', destination=".", filename="", keep_permissions=False,
10 pattern=None, requester=None, output=None):
11 """ high level downloader + unzipper + (optional hash checker) + delete temporary zip
12 """
13 if not filename and ("?" in url or "=" in url):
14 raise ConanException("Cannot deduce file name form url. Use 'filename' parameter.")
15
16 filename = filename or os.path.basename(url)
17 download(url, filename, out=output, requester=requester)
18
19 if md5:
20 check_md5(filename, md5)
21 if sha1:
22 check_sha1(filename, sha1)
23 if sha256:
24 check_sha256(filename, sha256)
25
26 unzip(filename, destination=destination, keep_permissions=keep_permissions, pattern=pattern,
27 output=output)
28 os.unlink(filename)
29
30
31 def ftp_download(ip, filename, login='', password=''):
32 import ftplib
33 try:
34 ftp = ftplib.FTP(ip, login, password)
35 ftp.login()
36 filepath, filename = os.path.split(filename)
37 if filepath:
38 ftp.cwd(filepath)
39 with open(filename, 'wb') as f:
40 ftp.retrbinary('RETR ' + filename, f.write)
41 except Exception as e:
42 raise ConanException("Error in FTP download from %s\n%s" % (ip, str(e)))
43 finally:
44 try:
45 ftp.quit()
46 except:
47 pass
48
49
50 def download(url, filename, verify=True, out=None, retry=2, retry_wait=5, overwrite=False,
51 auth=None, headers=None, requester=None):
52 out = default_output(out, 'conans.client.tools.net.download')
53 requester = default_requester(requester, 'conans.client.tools.net.download')
54
55 downloader = Downloader(requester=requester, output=out, verify=verify)
56 downloader.download(url, filename, retry=retry, retry_wait=retry_wait, overwrite=overwrite,
57 auth=auth, headers=headers)
58 out.writeln("")
59
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/conans/client/tools/net.py b/conans/client/tools/net.py
--- a/conans/client/tools/net.py
+++ b/conans/client/tools/net.py
@@ -7,14 +7,16 @@
def get(url, md5='', sha1='', sha256='', destination=".", filename="", keep_permissions=False,
- pattern=None, requester=None, output=None):
+ pattern=None, requester=None, output=None, verify=True, retry=None, retry_wait=None,
+ overwrite=False, auth=None, headers=None):
""" high level downloader + unzipper + (optional hash checker) + delete temporary zip
"""
if not filename and ("?" in url or "=" in url):
raise ConanException("Cannot deduce file name form url. Use 'filename' parameter.")
filename = filename or os.path.basename(url)
- download(url, filename, out=output, requester=requester)
+ download(url, filename, out=output, requester=requester, verify=verify, retry=retry,
+ retry_wait=retry_wait, overwrite=overwrite, auth=auth, headers=headers)
if md5:
check_md5(filename, md5)
@@ -47,8 +49,14 @@
pass
-def download(url, filename, verify=True, out=None, retry=2, retry_wait=5, overwrite=False,
+def download(url, filename, verify=True, out=None, retry=None, retry_wait=None, overwrite=False,
auth=None, headers=None, requester=None):
+
+ if retry is None:
+ retry = 2
+ if retry_wait is None:
+ retry_wait = 5
+
out = default_output(out, 'conans.client.tools.net.download')
requester = default_requester(requester, 'conans.client.tools.net.download')
|
{"golden_diff": "diff --git a/conans/client/tools/net.py b/conans/client/tools/net.py\n--- a/conans/client/tools/net.py\n+++ b/conans/client/tools/net.py\n@@ -7,14 +7,16 @@\n \n \n def get(url, md5='', sha1='', sha256='', destination=\".\", filename=\"\", keep_permissions=False,\n- pattern=None, requester=None, output=None):\n+ pattern=None, requester=None, output=None, verify=True, retry=None, retry_wait=None,\n+ overwrite=False, auth=None, headers=None):\n \"\"\" high level downloader + unzipper + (optional hash checker) + delete temporary zip\n \"\"\"\n if not filename and (\"?\" in url or \"=\" in url):\n raise ConanException(\"Cannot deduce file name form url. Use 'filename' parameter.\")\n \n filename = filename or os.path.basename(url)\n- download(url, filename, out=output, requester=requester)\n+ download(url, filename, out=output, requester=requester, verify=verify, retry=retry,\n+ retry_wait=retry_wait, overwrite=overwrite, auth=auth, headers=headers)\n \n if md5:\n check_md5(filename, md5)\n@@ -47,8 +49,14 @@\n pass\n \n \n-def download(url, filename, verify=True, out=None, retry=2, retry_wait=5, overwrite=False,\n+def download(url, filename, verify=True, out=None, retry=None, retry_wait=None, overwrite=False,\n auth=None, headers=None, requester=None):\n+\n+ if retry is None:\n+ retry = 2\n+ if retry_wait is None:\n+ retry_wait = 5\n+\n out = default_output(out, 'conans.client.tools.net.download')\n requester = default_requester(requester, 'conans.client.tools.net.download')\n", "issue": "Please support Verify=False option for tools.get() as is currently supported for tools.download()\nTo help us debug your issue please explain:\r\n\r\n- [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md).\r\n- [1.8.4] I've specified the Conan version, operating system version and any tool that can be relevant.\r\n- [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion.\r\n\r\n\n", "before_files": [{"content": "import os\n\nfrom conans.client.rest.uploader_downloader import Downloader\nfrom conans.client.tools.files import unzip, check_md5, check_sha1, check_sha256\nfrom conans.errors import ConanException\nfrom conans.util.fallbacks import default_output, default_requester\n\n\ndef get(url, md5='', sha1='', sha256='', destination=\".\", filename=\"\", keep_permissions=False,\n pattern=None, requester=None, output=None):\n \"\"\" high level downloader + unzipper + (optional hash checker) + delete temporary zip\n \"\"\"\n if not filename and (\"?\" in url or \"=\" in url):\n raise ConanException(\"Cannot deduce file name form url. Use 'filename' parameter.\")\n\n filename = filename or os.path.basename(url)\n download(url, filename, out=output, requester=requester)\n\n if md5:\n check_md5(filename, md5)\n if sha1:\n check_sha1(filename, sha1)\n if sha256:\n check_sha256(filename, sha256)\n\n unzip(filename, destination=destination, keep_permissions=keep_permissions, pattern=pattern,\n output=output)\n os.unlink(filename)\n\n\ndef ftp_download(ip, filename, login='', password=''):\n import ftplib\n try:\n ftp = ftplib.FTP(ip, login, password)\n ftp.login()\n filepath, filename = os.path.split(filename)\n if filepath:\n ftp.cwd(filepath)\n with open(filename, 'wb') as f:\n ftp.retrbinary('RETR ' + filename, f.write)\n except Exception as e:\n raise ConanException(\"Error in FTP download from %s\\n%s\" % (ip, str(e)))\n finally:\n try:\n ftp.quit()\n except:\n pass\n\n\ndef download(url, filename, verify=True, out=None, retry=2, retry_wait=5, overwrite=False,\n auth=None, headers=None, requester=None):\n out = default_output(out, 'conans.client.tools.net.download')\n requester = default_requester(requester, 'conans.client.tools.net.download')\n\n downloader = Downloader(requester=requester, output=out, verify=verify)\n downloader.download(url, filename, retry=retry, retry_wait=retry_wait, overwrite=overwrite,\n auth=auth, headers=headers)\n out.writeln(\"\")\n", "path": "conans/client/tools/net.py"}], "after_files": [{"content": "import os\n\nfrom conans.client.rest.uploader_downloader import Downloader\nfrom conans.client.tools.files import unzip, check_md5, check_sha1, check_sha256\nfrom conans.errors import ConanException\nfrom conans.util.fallbacks import default_output, default_requester\n\n\ndef get(url, md5='', sha1='', sha256='', destination=\".\", filename=\"\", keep_permissions=False,\n pattern=None, requester=None, output=None, verify=True, retry=None, retry_wait=None,\n overwrite=False, auth=None, headers=None):\n \"\"\" high level downloader + unzipper + (optional hash checker) + delete temporary zip\n \"\"\"\n if not filename and (\"?\" in url or \"=\" in url):\n raise ConanException(\"Cannot deduce file name form url. Use 'filename' parameter.\")\n\n filename = filename or os.path.basename(url)\n download(url, filename, out=output, requester=requester, verify=verify, retry=retry,\n retry_wait=retry_wait, overwrite=overwrite, auth=auth, headers=headers)\n\n if md5:\n check_md5(filename, md5)\n if sha1:\n check_sha1(filename, sha1)\n if sha256:\n check_sha256(filename, sha256)\n\n unzip(filename, destination=destination, keep_permissions=keep_permissions, pattern=pattern,\n output=output)\n os.unlink(filename)\n\n\ndef ftp_download(ip, filename, login='', password=''):\n import ftplib\n try:\n ftp = ftplib.FTP(ip, login, password)\n ftp.login()\n filepath, filename = os.path.split(filename)\n if filepath:\n ftp.cwd(filepath)\n with open(filename, 'wb') as f:\n ftp.retrbinary('RETR ' + filename, f.write)\n except Exception as e:\n raise ConanException(\"Error in FTP download from %s\\n%s\" % (ip, str(e)))\n finally:\n try:\n ftp.quit()\n except:\n pass\n\n\ndef download(url, filename, verify=True, out=None, retry=None, retry_wait=None, overwrite=False,\n auth=None, headers=None, requester=None):\n\n if retry is None:\n retry = 2\n if retry_wait is None:\n retry_wait = 5\n\n out = default_output(out, 'conans.client.tools.net.download')\n requester = default_requester(requester, 'conans.client.tools.net.download')\n\n downloader = Downloader(requester=requester, output=out, verify=verify)\n downloader.download(url, filename, retry=retry, retry_wait=retry_wait, overwrite=overwrite,\n auth=auth, headers=headers)\n out.writeln(\"\")\n", "path": "conans/client/tools/net.py"}]}
| 983 | 389 |
gh_patches_debug_1227
|
rasdani/github-patches
|
git_diff
|
mosaicml__composer-79
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add Colab Example
* Add Example Jupyter notebook to the examples folder
* Add "Open in Colab" to the README.md
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # Copyright 2021 MosaicML. All Rights Reserved.
2
3 import os
4 import sys
5
6 import setuptools
7 from setuptools import setup
8
9
10 def package_files(directory):
11 # from https://stackoverflow.com/a/36693250
12 paths = []
13 for (path, directories, filenames) in os.walk(directory):
14 for filename in filenames:
15 paths.append(os.path.join('..', path, filename))
16 return paths
17
18
19 with open("README.md", "r", encoding="utf-8") as fh:
20 long_description = fh.read()
21
22 install_requires = [
23 "pyyaml>=5.4.1",
24 "tqdm>=4.62.3",
25 "torchmetrics>=0.5.1",
26 "torch_optimizer==0.1.0",
27 "torchvision>=0.9.0",
28 "torch>=1.9",
29 "argparse>=1.4.0",
30 "yahp>=0.0.10",
31 ]
32 extra_deps = {}
33
34 extra_deps['base'] = []
35
36 extra_deps['dev'] = [
37 'junitparser>=2.1.1',
38 'coverage[toml]>=6.1.1',
39 'pytest>=6.2.0',
40 'yapf>=0.13.0',
41 'isort>=5.9.3',
42 'yamllint>=1.26.2',
43 'pytest-timeout>=1.4.2',
44 'recommonmark>=0.7.1',
45 'sphinx>=4.2.0',
46 'sphinx_copybutton>=0.4.0',
47 'sphinx_markdown_tables>=0.0.15',
48 'sphinx-argparse>=0.3.1',
49 'sphinxcontrib.katex>=0.8.6',
50 'sphinxext.opengraph>=0.4.2',
51 'sphinx_rtd_theme>=1.0.0',
52 'myst-parser>=0.15.2',
53 ]
54 extra_deps['wandb'] = ['wandb>=0.12.2']
55
56 extra_deps['nlp'] = [
57 'transformers>=4.11.3',
58 'datasets>=1.14.0',
59 ]
60
61 extra_deps['unet'] = [
62 'monai>=0.7.0',
63 'scikit-learn>=1.0.1',
64 ]
65
66 extra_deps['all'] = set(dep for deps in extra_deps.values() for dep in deps)
67
68 setup(
69 name="mosaicml",
70 version="0.2.4",
71 author="MosaicML",
72 author_email="[email protected]",
73 description="composing methods for ML training efficiency",
74 long_description=long_description,
75 long_description_content_type="text/markdown",
76 url="https://github.com/mosaicml/composer",
77 include_package_data=True,
78 package_data={
79 "composer": ['py.typed'],
80 "": package_files('composer/yamls'),
81 },
82 packages=setuptools.find_packages(include=["composer"]),
83 classifiers=[
84 "Programming Language :: Python :: 3",
85 ],
86 install_requires=install_requires,
87 entry_points={
88 'console_scripts': ['composer = composer.cli.launcher:main',],
89 },
90 extras_require=extra_deps,
91 dependency_links=['https://developer.download.nvidia.com/compute/redist'],
92 python_requires='>=3.7',
93 ext_package="composer",
94 )
95
96 # only visible if user installs with verbose -v flag
97 # Printing to stdout as not to interfere with setup.py CLI flags (e.g. --version)
98 print("*" * 20, file=sys.stderr)
99 print(
100 "\nNOTE: For best performance, we recommend installing Pillow-SIMD "
101 "\nfor accelerated image processing operations. To install:"
102 "\n\n\t pip uninstall pillow && pip install pillow-simd\n",
103 file=sys.stderr)
104 print("*" * 20, file=sys.stderr)
105
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -49,6 +49,7 @@
'sphinxcontrib.katex>=0.8.6',
'sphinxext.opengraph>=0.4.2',
'sphinx_rtd_theme>=1.0.0',
+ 'testbook>=0.4.2',
'myst-parser>=0.15.2',
]
extra_deps['wandb'] = ['wandb>=0.12.2']
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -49,6 +49,7 @@\n 'sphinxcontrib.katex>=0.8.6',\n 'sphinxext.opengraph>=0.4.2',\n 'sphinx_rtd_theme>=1.0.0',\n+ 'testbook>=0.4.2',\n 'myst-parser>=0.15.2',\n ]\n extra_deps['wandb'] = ['wandb>=0.12.2']\n", "issue": "Add Colab Example\n* Add Example Jupyter notebook to the examples folder\r\n* Add \"Open in Colab\" to the README.md\r\n\n", "before_files": [{"content": "# Copyright 2021 MosaicML. All Rights Reserved.\n\nimport os\nimport sys\n\nimport setuptools\nfrom setuptools import setup\n\n\ndef package_files(directory):\n # from https://stackoverflow.com/a/36693250\n paths = []\n for (path, directories, filenames) in os.walk(directory):\n for filename in filenames:\n paths.append(os.path.join('..', path, filename))\n return paths\n\n\nwith open(\"README.md\", \"r\", encoding=\"utf-8\") as fh:\n long_description = fh.read()\n\ninstall_requires = [\n \"pyyaml>=5.4.1\",\n \"tqdm>=4.62.3\",\n \"torchmetrics>=0.5.1\",\n \"torch_optimizer==0.1.0\",\n \"torchvision>=0.9.0\",\n \"torch>=1.9\",\n \"argparse>=1.4.0\",\n \"yahp>=0.0.10\",\n]\nextra_deps = {}\n\nextra_deps['base'] = []\n\nextra_deps['dev'] = [\n 'junitparser>=2.1.1',\n 'coverage[toml]>=6.1.1',\n 'pytest>=6.2.0',\n 'yapf>=0.13.0',\n 'isort>=5.9.3',\n 'yamllint>=1.26.2',\n 'pytest-timeout>=1.4.2',\n 'recommonmark>=0.7.1',\n 'sphinx>=4.2.0',\n 'sphinx_copybutton>=0.4.0',\n 'sphinx_markdown_tables>=0.0.15',\n 'sphinx-argparse>=0.3.1',\n 'sphinxcontrib.katex>=0.8.6',\n 'sphinxext.opengraph>=0.4.2',\n 'sphinx_rtd_theme>=1.0.0',\n 'myst-parser>=0.15.2',\n]\nextra_deps['wandb'] = ['wandb>=0.12.2']\n\nextra_deps['nlp'] = [\n 'transformers>=4.11.3',\n 'datasets>=1.14.0',\n]\n\nextra_deps['unet'] = [\n 'monai>=0.7.0',\n 'scikit-learn>=1.0.1',\n]\n\nextra_deps['all'] = set(dep for deps in extra_deps.values() for dep in deps)\n\nsetup(\n name=\"mosaicml\",\n version=\"0.2.4\",\n author=\"MosaicML\",\n author_email=\"[email protected]\",\n description=\"composing methods for ML training efficiency\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n url=\"https://github.com/mosaicml/composer\",\n include_package_data=True,\n package_data={\n \"composer\": ['py.typed'],\n \"\": package_files('composer/yamls'),\n },\n packages=setuptools.find_packages(include=[\"composer\"]),\n classifiers=[\n \"Programming Language :: Python :: 3\",\n ],\n install_requires=install_requires,\n entry_points={\n 'console_scripts': ['composer = composer.cli.launcher:main',],\n },\n extras_require=extra_deps,\n dependency_links=['https://developer.download.nvidia.com/compute/redist'],\n python_requires='>=3.7',\n ext_package=\"composer\",\n)\n\n# only visible if user installs with verbose -v flag\n# Printing to stdout as not to interfere with setup.py CLI flags (e.g. --version)\nprint(\"*\" * 20, file=sys.stderr)\nprint(\n \"\\nNOTE: For best performance, we recommend installing Pillow-SIMD \"\n \"\\nfor accelerated image processing operations. To install:\"\n \"\\n\\n\\t pip uninstall pillow && pip install pillow-simd\\n\",\n file=sys.stderr)\nprint(\"*\" * 20, file=sys.stderr)\n", "path": "setup.py"}], "after_files": [{"content": "# Copyright 2021 MosaicML. All Rights Reserved.\n\nimport os\nimport sys\n\nimport setuptools\nfrom setuptools import setup\n\n\ndef package_files(directory):\n # from https://stackoverflow.com/a/36693250\n paths = []\n for (path, directories, filenames) in os.walk(directory):\n for filename in filenames:\n paths.append(os.path.join('..', path, filename))\n return paths\n\n\nwith open(\"README.md\", \"r\", encoding=\"utf-8\") as fh:\n long_description = fh.read()\n\ninstall_requires = [\n \"pyyaml>=5.4.1\",\n \"tqdm>=4.62.3\",\n \"torchmetrics>=0.5.1\",\n \"torch_optimizer==0.1.0\",\n \"torchvision>=0.9.0\",\n \"torch>=1.9\",\n \"argparse>=1.4.0\",\n \"yahp>=0.0.10\",\n]\nextra_deps = {}\n\nextra_deps['base'] = []\n\nextra_deps['dev'] = [\n 'junitparser>=2.1.1',\n 'coverage[toml]>=6.1.1',\n 'pytest>=6.2.0',\n 'yapf>=0.13.0',\n 'isort>=5.9.3',\n 'yamllint>=1.26.2',\n 'pytest-timeout>=1.4.2',\n 'recommonmark>=0.7.1',\n 'sphinx>=4.2.0',\n 'sphinx_copybutton>=0.4.0',\n 'sphinx_markdown_tables>=0.0.15',\n 'sphinx-argparse>=0.3.1',\n 'sphinxcontrib.katex>=0.8.6',\n 'sphinxext.opengraph>=0.4.2',\n 'sphinx_rtd_theme>=1.0.0',\n 'testbook>=0.4.2',\n 'myst-parser>=0.15.2',\n]\nextra_deps['wandb'] = ['wandb>=0.12.2']\n\nextra_deps['nlp'] = [\n 'transformers>=4.11.3',\n 'datasets>=1.14.0',\n]\n\nextra_deps['unet'] = [\n 'monai>=0.7.0',\n 'scikit-learn>=1.0.1',\n]\n\nextra_deps['all'] = set(dep for deps in extra_deps.values() for dep in deps)\n\nsetup(\n name=\"mosaicml\",\n version=\"0.2.4\",\n author=\"MosaicML\",\n author_email=\"[email protected]\",\n description=\"composing methods for ML training efficiency\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n url=\"https://github.com/mosaicml/composer\",\n include_package_data=True,\n package_data={\n \"composer\": ['py.typed'],\n \"\": package_files('composer/yamls'),\n },\n packages=setuptools.find_packages(include=[\"composer\"]),\n classifiers=[\n \"Programming Language :: Python :: 3\",\n ],\n install_requires=install_requires,\n entry_points={\n 'console_scripts': ['composer = composer.cli.launcher:main',],\n },\n extras_require=extra_deps,\n dependency_links=['https://developer.download.nvidia.com/compute/redist'],\n python_requires='>=3.7',\n ext_package=\"composer\",\n)\n\n# only visible if user installs with verbose -v flag\n# Printing to stdout as not to interfere with setup.py CLI flags (e.g. --version)\nprint(\"*\" * 20, file=sys.stderr)\nprint(\n \"\\nNOTE: For best performance, we recommend installing Pillow-SIMD \"\n \"\\nfor accelerated image processing operations. To install:\"\n \"\\n\\n\\t pip uninstall pillow && pip install pillow-simd\\n\",\n file=sys.stderr)\nprint(\"*\" * 20, file=sys.stderr)\n", "path": "setup.py"}]}
| 1,356 | 119 |
gh_patches_debug_16369
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-653
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Inline Terraform Skips Broken – v1.0.612
**Describe the bug**
Checkov errors immediately if there are any skips defined in my Terraform resources. Behavior is correct on 1.0.611 but is broken on 1.0.612 and 1.0.613.
**To Reproduce**
Steps to reproduce the behavior:
1. Create a test resource in Terraform
```
resource "aws_s3_bucket" "mybucket" {
#checkov:skip=CKV_AWS_19:Data in this bucket does not need encryption.
bucket = "my-bucket"
acl = "private"
}
```
2. Run `checkov -d .` on v1.0.612 or v1.0.613.
3. See error
**Expected behavior**
Checkov scans my resources using all checks except CKV_AWS_19.
**Output**
```
checkov -d .
Traceback (most recent call last):
File "/usr/local/bin/checkov", line 5, in <module>
run()
File "/usr/local/lib/python3.9/site-packages/checkov/main.py", line 63, in run
scan_reports = runner_registry.run(root_folder=root_folder, external_checks_dir=external_checks_dir,
File "/usr/local/lib/python3.9/site-packages/checkov/common/runners/runner_registry.py", line 30, in run
scan_report = runner.run(root_folder, external_checks_dir=external_checks_dir, files=files,
File "/usr/local/lib/python3.9/site-packages/checkov/terraform/runner.py", line 55, in run
self.check_tf_definition(report, root_folder, runner_filter, collect_skip_comments)
File "/usr/local/lib/python3.9/site-packages/checkov/terraform/runner.py", line 89, in check_tf_definition
definitions_context = parser_registry.enrich_definitions_context(definition, collect_skip_comments)
File "/usr/local/lib/python3.9/site-packages/checkov/terraform/context_parsers/registry.py", line 28, in enrich_definitions_context
self.definitions_context[tf_file][definition_type] = context_parser.run(tf_file, definition_blocks, collect_skip_comments)
File "/usr/local/lib/python3.9/site-packages/checkov/terraform/context_parsers/base_parser.py", line 118, in run
self.context = self._collect_skip_comments(definition_blocks)
File "/usr/local/lib/python3.9/site-packages/checkov/terraform/context_parsers/base_parser.py", line 87, in _collect_skip_comments
if skip_check['id'] in bc_id_mapping:
TypeError: argument of type 'NoneType' is not iterable
```
**Desktop (please complete the following information):**
- Mac 10.15.7
- 1.0.612, 1.0.613
**Additional context**
I imagine this may have to do with the change at https://github.com/bridgecrewio/checkov/commit/751b0aace12dfd0f0f24cd042a659f9eab3bf24d#diff-79435bbd626a6a0ce4070183c5f5070eb31621991464e9948ec5de7d021ad15aR65
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `checkov/terraform/context_parsers/base_parser.py`
Content:
```
1 import logging
2 import re
3 from abc import ABC, abstractmethod
4 from itertools import islice
5
6 import dpath.util
7
8 from checkov.common.comment.enum import COMMENT_REGEX
9 from checkov.common.models.enums import ContextCategories
10 from checkov.terraform.context_parsers.registry import parser_registry
11 from checkov.common.bridgecrew.platform_integration import bc_integration
12
13 OPEN_CURLY = '{'
14 CLOSE_CURLY = '}'
15
16
17 class BaseContextParser(ABC):
18 definition_type = ""
19 tf_file = ""
20 file_lines = []
21 context = {}
22
23 def __init__(self, definition_type):
24 self.logger = logging.getLogger("{}".format(self.__module__))
25 if definition_type.upper() not in ContextCategories.__members__:
26 self.logger.error("Terraform context parser type not supported yet")
27 raise Exception()
28 self.definition_type = definition_type
29 parser_registry.register(self)
30
31 @abstractmethod
32 def get_entity_context_path(self, entity_block):
33 """
34 returns the entity's path in the context parser
35 :param entity_block: entity definition block
36 :return: list of nested entity's keys in the context parser
37 """
38 raise NotImplementedError
39
40 def _is_block_signature(self, line_num, line_tokens, entity_context_path):
41 """
42 Determine if the given tokenized line token is the entity signature line
43 :param line_num: The line number in the file
44 :param line_tokens: list of line tokens
45 :param entity_context_path: the entity's path in the context parser
46 :return: True/False
47 """
48 block_type = self.get_block_type()
49 return all(x in line_tokens for x in [block_type] + entity_context_path)
50
51 @staticmethod
52 def _trim_whitespaces_linebreaks(text):
53 return text.strip()
54
55 def _filter_file_lines(self):
56 parsed_file_lines = [(ind, self._trim_whitespaces_linebreaks(line)) for (ind, line) in self.file_lines]
57 self.filtered_lines = [(ind, line) for (ind, line) in parsed_file_lines if line]
58 return self.filtered_lines
59
60 def _read_file_lines(self):
61 with(open(self.tf_file, 'r')) as file:
62 file.seek(0)
63 file_lines = [(ind + 1, line) for (ind, line) in
64 list(enumerate(file.readlines()))]
65 return file_lines
66
67 def _collect_skip_comments(self, definition_blocks):
68 """
69 Collects checkov skip comments to all definition blocks
70 :param definition_blocks: parsed definition blocks
71 :return: context enriched with with skipped checks per skipped entity
72 """
73 bc_id_mapping = bc_integration.get_id_mapping()
74 parsed_file_lines = self.filtered_lines
75 comments = [(line_num, {"id": re.search(COMMENT_REGEX, x).group(2),
76 "suppress_comment": re.search(COMMENT_REGEX, x).group(3)[1:] if re.search(COMMENT_REGEX,
77 x).group(3)
78 else "No comment provided"}) for (line_num, x) in
79 parsed_file_lines if re.search(COMMENT_REGEX, x)]
80 for entity_block in definition_blocks:
81 skipped_checks = []
82 entity_context_path = self.get_entity_context_path(entity_block)
83 context_search = dpath.search(self.context, entity_context_path, yielded=True)
84 for _, entity_context in context_search:
85 for (skip_check_line_num, skip_check) in comments:
86 if entity_context['start_line'] < skip_check_line_num < entity_context['end_line']:
87 if skip_check['id'] in bc_id_mapping:
88 skip_check['id'] = bc_id_mapping[skip_check['id']]
89 skipped_checks.append(skip_check)
90 dpath.new(self.context, entity_context_path + ['skipped_checks'], skipped_checks)
91 return self.context
92
93 def _compute_definition_end_line(self, start_line_num):
94 """ Given the code block's start line, compute the block's end line
95 :param start_line_num: code block's first line number (the signature line)
96 :return: the code block's last line number
97 """
98 parsed_file_lines = self.filtered_lines
99 start_line_idx = [line_num for (line_num, _) in parsed_file_lines].index(start_line_num)
100 i = 1
101 end_line_num = 0
102 for (line_num, line) in islice(parsed_file_lines, start_line_idx + 1, None):
103 if OPEN_CURLY in line:
104 i = i + 1
105 if CLOSE_CURLY in line:
106 i = i - 1
107 if i == 0:
108 end_line_num = line_num
109 break
110 return end_line_num
111
112 def run(self, tf_file, definition_blocks, collect_skip_comments=True):
113 self.tf_file = tf_file
114 self.context = {}
115 self.file_lines = self._read_file_lines()
116 self.context = self.enrich_definition_block(definition_blocks)
117 if collect_skip_comments:
118 self.context = self._collect_skip_comments(definition_blocks)
119 return self.context
120
121 def get_block_type(self):
122 return self.definition_type
123
124 def enrich_definition_block(self, definition_blocks):
125 """
126 Enrich the context of a Terraform block
127 :param definition_blocks: Terraform block, key-value dictionary
128 :return: Enriched block context
129 """
130 parsed_file_lines = self._filter_file_lines()
131 potential_block_start_lines = [(ind, line) for (ind, line) in parsed_file_lines if line.startswith(self.get_block_type())]
132 for i, entity_block in enumerate(definition_blocks):
133 entity_context_path = self.get_entity_context_path(entity_block)
134 for line_num, line in potential_block_start_lines:
135 line_tokens = [x.replace('"', "") for x in line.split()]
136 if self._is_block_signature(line_num, line_tokens, entity_context_path):
137 logging.debug(f'created context for {" ".join(entity_context_path)}')
138 start_line = line_num
139 end_line = self._compute_definition_end_line(line_num)
140 dpath.new(self.context, entity_context_path + ["start_line"], start_line)
141 dpath.new(self.context, entity_context_path + ["end_line"], end_line)
142 dpath.new(self.context, entity_context_path + ["code_lines"],
143 self.file_lines[start_line - 1: end_line])
144 potential_block_start_lines.remove((line_num, line))
145 break
146 return self.context
147
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/checkov/terraform/context_parsers/base_parser.py b/checkov/terraform/context_parsers/base_parser.py
--- a/checkov/terraform/context_parsers/base_parser.py
+++ b/checkov/terraform/context_parsers/base_parser.py
@@ -84,7 +84,7 @@
for _, entity_context in context_search:
for (skip_check_line_num, skip_check) in comments:
if entity_context['start_line'] < skip_check_line_num < entity_context['end_line']:
- if skip_check['id'] in bc_id_mapping:
+ if bc_id_mapping and skip_check['id'] in bc_id_mapping:
skip_check['id'] = bc_id_mapping[skip_check['id']]
skipped_checks.append(skip_check)
dpath.new(self.context, entity_context_path + ['skipped_checks'], skipped_checks)
|
{"golden_diff": "diff --git a/checkov/terraform/context_parsers/base_parser.py b/checkov/terraform/context_parsers/base_parser.py\n--- a/checkov/terraform/context_parsers/base_parser.py\n+++ b/checkov/terraform/context_parsers/base_parser.py\n@@ -84,7 +84,7 @@\n for _, entity_context in context_search:\n for (skip_check_line_num, skip_check) in comments:\n if entity_context['start_line'] < skip_check_line_num < entity_context['end_line']:\n- if skip_check['id'] in bc_id_mapping:\n+ if bc_id_mapping and skip_check['id'] in bc_id_mapping:\n skip_check['id'] = bc_id_mapping[skip_check['id']]\n skipped_checks.append(skip_check)\n dpath.new(self.context, entity_context_path + ['skipped_checks'], skipped_checks)\n", "issue": "Inline Terraform Skips Broken \u2013 v1.0.612\n**Describe the bug**\r\nCheckov errors immediately if there are any skips defined in my Terraform resources. Behavior is correct on 1.0.611 but is broken on 1.0.612 and 1.0.613.\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Create a test resource in Terraform\r\n```\r\nresource \"aws_s3_bucket\" \"mybucket\" {\r\n #checkov:skip=CKV_AWS_19:Data in this bucket does not need encryption.\r\n bucket = \"my-bucket\"\r\n acl = \"private\"\r\n}\r\n```\r\n2. Run `checkov -d .` on v1.0.612 or v1.0.613.\r\n3. See error\r\n\r\n**Expected behavior**\r\nCheckov scans my resources using all checks except CKV_AWS_19.\r\n\r\n**Output**\r\n```\r\ncheckov -d .\r\nTraceback (most recent call last):\r\n File \"/usr/local/bin/checkov\", line 5, in <module>\r\n run()\r\n File \"/usr/local/lib/python3.9/site-packages/checkov/main.py\", line 63, in run\r\n scan_reports = runner_registry.run(root_folder=root_folder, external_checks_dir=external_checks_dir,\r\n File \"/usr/local/lib/python3.9/site-packages/checkov/common/runners/runner_registry.py\", line 30, in run\r\n scan_report = runner.run(root_folder, external_checks_dir=external_checks_dir, files=files,\r\n File \"/usr/local/lib/python3.9/site-packages/checkov/terraform/runner.py\", line 55, in run\r\n self.check_tf_definition(report, root_folder, runner_filter, collect_skip_comments)\r\n File \"/usr/local/lib/python3.9/site-packages/checkov/terraform/runner.py\", line 89, in check_tf_definition\r\n definitions_context = parser_registry.enrich_definitions_context(definition, collect_skip_comments)\r\n File \"/usr/local/lib/python3.9/site-packages/checkov/terraform/context_parsers/registry.py\", line 28, in enrich_definitions_context\r\n self.definitions_context[tf_file][definition_type] = context_parser.run(tf_file, definition_blocks, collect_skip_comments)\r\n File \"/usr/local/lib/python3.9/site-packages/checkov/terraform/context_parsers/base_parser.py\", line 118, in run\r\n self.context = self._collect_skip_comments(definition_blocks)\r\n File \"/usr/local/lib/python3.9/site-packages/checkov/terraform/context_parsers/base_parser.py\", line 87, in _collect_skip_comments\r\n if skip_check['id'] in bc_id_mapping:\r\nTypeError: argument of type 'NoneType' is not iterable\r\n```\r\n\r\n**Desktop (please complete the following information):**\r\n - Mac 10.15.7\r\n - 1.0.612, 1.0.613\r\n\r\n**Additional context**\r\nI imagine this may have to do with the change at https://github.com/bridgecrewio/checkov/commit/751b0aace12dfd0f0f24cd042a659f9eab3bf24d#diff-79435bbd626a6a0ce4070183c5f5070eb31621991464e9948ec5de7d021ad15aR65\r\n\n", "before_files": [{"content": "import logging\nimport re\nfrom abc import ABC, abstractmethod\nfrom itertools import islice\n\nimport dpath.util\n\nfrom checkov.common.comment.enum import COMMENT_REGEX\nfrom checkov.common.models.enums import ContextCategories\nfrom checkov.terraform.context_parsers.registry import parser_registry\nfrom checkov.common.bridgecrew.platform_integration import bc_integration\n\nOPEN_CURLY = '{'\nCLOSE_CURLY = '}'\n\n\nclass BaseContextParser(ABC):\n definition_type = \"\"\n tf_file = \"\"\n file_lines = []\n context = {}\n\n def __init__(self, definition_type):\n self.logger = logging.getLogger(\"{}\".format(self.__module__))\n if definition_type.upper() not in ContextCategories.__members__:\n self.logger.error(\"Terraform context parser type not supported yet\")\n raise Exception()\n self.definition_type = definition_type\n parser_registry.register(self)\n\n @abstractmethod\n def get_entity_context_path(self, entity_block):\n \"\"\"\n returns the entity's path in the context parser\n :param entity_block: entity definition block\n :return: list of nested entity's keys in the context parser\n \"\"\"\n raise NotImplementedError\n\n def _is_block_signature(self, line_num, line_tokens, entity_context_path):\n \"\"\"\n Determine if the given tokenized line token is the entity signature line\n :param line_num: The line number in the file\n :param line_tokens: list of line tokens\n :param entity_context_path: the entity's path in the context parser\n :return: True/False\n \"\"\"\n block_type = self.get_block_type()\n return all(x in line_tokens for x in [block_type] + entity_context_path)\n\n @staticmethod\n def _trim_whitespaces_linebreaks(text):\n return text.strip()\n\n def _filter_file_lines(self):\n parsed_file_lines = [(ind, self._trim_whitespaces_linebreaks(line)) for (ind, line) in self.file_lines]\n self.filtered_lines = [(ind, line) for (ind, line) in parsed_file_lines if line]\n return self.filtered_lines\n\n def _read_file_lines(self):\n with(open(self.tf_file, 'r')) as file:\n file.seek(0)\n file_lines = [(ind + 1, line) for (ind, line) in\n list(enumerate(file.readlines()))]\n return file_lines\n\n def _collect_skip_comments(self, definition_blocks):\n \"\"\"\n Collects checkov skip comments to all definition blocks\n :param definition_blocks: parsed definition blocks\n :return: context enriched with with skipped checks per skipped entity\n \"\"\"\n bc_id_mapping = bc_integration.get_id_mapping()\n parsed_file_lines = self.filtered_lines\n comments = [(line_num, {\"id\": re.search(COMMENT_REGEX, x).group(2),\n \"suppress_comment\": re.search(COMMENT_REGEX, x).group(3)[1:] if re.search(COMMENT_REGEX,\n x).group(3)\n else \"No comment provided\"}) for (line_num, x) in\n parsed_file_lines if re.search(COMMENT_REGEX, x)]\n for entity_block in definition_blocks:\n skipped_checks = []\n entity_context_path = self.get_entity_context_path(entity_block)\n context_search = dpath.search(self.context, entity_context_path, yielded=True)\n for _, entity_context in context_search:\n for (skip_check_line_num, skip_check) in comments:\n if entity_context['start_line'] < skip_check_line_num < entity_context['end_line']:\n if skip_check['id'] in bc_id_mapping:\n skip_check['id'] = bc_id_mapping[skip_check['id']]\n skipped_checks.append(skip_check)\n dpath.new(self.context, entity_context_path + ['skipped_checks'], skipped_checks)\n return self.context\n\n def _compute_definition_end_line(self, start_line_num):\n \"\"\" Given the code block's start line, compute the block's end line\n :param start_line_num: code block's first line number (the signature line)\n :return: the code block's last line number\n \"\"\"\n parsed_file_lines = self.filtered_lines\n start_line_idx = [line_num for (line_num, _) in parsed_file_lines].index(start_line_num)\n i = 1\n end_line_num = 0\n for (line_num, line) in islice(parsed_file_lines, start_line_idx + 1, None):\n if OPEN_CURLY in line:\n i = i + 1\n if CLOSE_CURLY in line:\n i = i - 1\n if i == 0:\n end_line_num = line_num\n break\n return end_line_num\n\n def run(self, tf_file, definition_blocks, collect_skip_comments=True):\n self.tf_file = tf_file\n self.context = {}\n self.file_lines = self._read_file_lines()\n self.context = self.enrich_definition_block(definition_blocks)\n if collect_skip_comments:\n self.context = self._collect_skip_comments(definition_blocks)\n return self.context\n\n def get_block_type(self):\n return self.definition_type\n\n def enrich_definition_block(self, definition_blocks):\n \"\"\"\n Enrich the context of a Terraform block\n :param definition_blocks: Terraform block, key-value dictionary\n :return: Enriched block context\n \"\"\"\n parsed_file_lines = self._filter_file_lines()\n potential_block_start_lines = [(ind, line) for (ind, line) in parsed_file_lines if line.startswith(self.get_block_type())]\n for i, entity_block in enumerate(definition_blocks):\n entity_context_path = self.get_entity_context_path(entity_block)\n for line_num, line in potential_block_start_lines:\n line_tokens = [x.replace('\"', \"\") for x in line.split()]\n if self._is_block_signature(line_num, line_tokens, entity_context_path):\n logging.debug(f'created context for {\" \".join(entity_context_path)}')\n start_line = line_num\n end_line = self._compute_definition_end_line(line_num)\n dpath.new(self.context, entity_context_path + [\"start_line\"], start_line)\n dpath.new(self.context, entity_context_path + [\"end_line\"], end_line)\n dpath.new(self.context, entity_context_path + [\"code_lines\"],\n self.file_lines[start_line - 1: end_line])\n potential_block_start_lines.remove((line_num, line))\n break\n return self.context\n", "path": "checkov/terraform/context_parsers/base_parser.py"}], "after_files": [{"content": "import logging\nimport re\nfrom abc import ABC, abstractmethod\nfrom itertools import islice\n\nimport dpath.util\n\nfrom checkov.common.comment.enum import COMMENT_REGEX\nfrom checkov.common.models.enums import ContextCategories\nfrom checkov.terraform.context_parsers.registry import parser_registry\nfrom checkov.common.bridgecrew.platform_integration import bc_integration\n\nOPEN_CURLY = '{'\nCLOSE_CURLY = '}'\n\n\nclass BaseContextParser(ABC):\n definition_type = \"\"\n tf_file = \"\"\n file_lines = []\n context = {}\n\n def __init__(self, definition_type):\n self.logger = logging.getLogger(\"{}\".format(self.__module__))\n if definition_type.upper() not in ContextCategories.__members__:\n self.logger.error(\"Terraform context parser type not supported yet\")\n raise Exception()\n self.definition_type = definition_type\n parser_registry.register(self)\n\n @abstractmethod\n def get_entity_context_path(self, entity_block):\n \"\"\"\n returns the entity's path in the context parser\n :param entity_block: entity definition block\n :return: list of nested entity's keys in the context parser\n \"\"\"\n raise NotImplementedError\n\n def _is_block_signature(self, line_num, line_tokens, entity_context_path):\n \"\"\"\n Determine if the given tokenized line token is the entity signature line\n :param line_num: The line number in the file\n :param line_tokens: list of line tokens\n :param entity_context_path: the entity's path in the context parser\n :return: True/False\n \"\"\"\n block_type = self.get_block_type()\n return all(x in line_tokens for x in [block_type] + entity_context_path)\n\n @staticmethod\n def _trim_whitespaces_linebreaks(text):\n return text.strip()\n\n def _filter_file_lines(self):\n parsed_file_lines = [(ind, self._trim_whitespaces_linebreaks(line)) for (ind, line) in self.file_lines]\n self.filtered_lines = [(ind, line) for (ind, line) in parsed_file_lines if line]\n return self.filtered_lines\n\n def _read_file_lines(self):\n with(open(self.tf_file, 'r')) as file:\n file.seek(0)\n file_lines = [(ind + 1, line) for (ind, line) in\n list(enumerate(file.readlines()))]\n return file_lines\n\n def _collect_skip_comments(self, definition_blocks):\n \"\"\"\n Collects checkov skip comments to all definition blocks\n :param definition_blocks: parsed definition blocks\n :return: context enriched with with skipped checks per skipped entity\n \"\"\"\n bc_id_mapping = bc_integration.get_id_mapping()\n parsed_file_lines = self.filtered_lines\n comments = [(line_num, {\"id\": re.search(COMMENT_REGEX, x).group(2),\n \"suppress_comment\": re.search(COMMENT_REGEX, x).group(3)[1:] if re.search(COMMENT_REGEX,\n x).group(3)\n else \"No comment provided\"}) for (line_num, x) in\n parsed_file_lines if re.search(COMMENT_REGEX, x)]\n for entity_block in definition_blocks:\n skipped_checks = []\n entity_context_path = self.get_entity_context_path(entity_block)\n context_search = dpath.search(self.context, entity_context_path, yielded=True)\n for _, entity_context in context_search:\n for (skip_check_line_num, skip_check) in comments:\n if entity_context['start_line'] < skip_check_line_num < entity_context['end_line']:\n if bc_id_mapping and skip_check['id'] in bc_id_mapping:\n skip_check['id'] = bc_id_mapping[skip_check['id']]\n skipped_checks.append(skip_check)\n dpath.new(self.context, entity_context_path + ['skipped_checks'], skipped_checks)\n return self.context\n\n def _compute_definition_end_line(self, start_line_num):\n \"\"\" Given the code block's start line, compute the block's end line\n :param start_line_num: code block's first line number (the signature line)\n :return: the code block's last line number\n \"\"\"\n parsed_file_lines = self.filtered_lines\n start_line_idx = [line_num for (line_num, _) in parsed_file_lines].index(start_line_num)\n i = 1\n end_line_num = 0\n for (line_num, line) in islice(parsed_file_lines, start_line_idx + 1, None):\n if OPEN_CURLY in line:\n i = i + 1\n if CLOSE_CURLY in line:\n i = i - 1\n if i == 0:\n end_line_num = line_num\n break\n return end_line_num\n\n def run(self, tf_file, definition_blocks, collect_skip_comments=True):\n self.tf_file = tf_file\n self.context = {}\n self.file_lines = self._read_file_lines()\n self.context = self.enrich_definition_block(definition_blocks)\n if collect_skip_comments:\n self.context = self._collect_skip_comments(definition_blocks)\n return self.context\n\n def get_block_type(self):\n return self.definition_type\n\n def enrich_definition_block(self, definition_blocks):\n \"\"\"\n Enrich the context of a Terraform block\n :param definition_blocks: Terraform block, key-value dictionary\n :return: Enriched block context\n \"\"\"\n parsed_file_lines = self._filter_file_lines()\n potential_block_start_lines = [(ind, line) for (ind, line) in parsed_file_lines if line.startswith(self.get_block_type())]\n for i, entity_block in enumerate(definition_blocks):\n entity_context_path = self.get_entity_context_path(entity_block)\n for line_num, line in potential_block_start_lines:\n line_tokens = [x.replace('\"', \"\") for x in line.split()]\n if self._is_block_signature(line_num, line_tokens, entity_context_path):\n logging.debug(f'created context for {\" \".join(entity_context_path)}')\n start_line = line_num\n end_line = self._compute_definition_end_line(line_num)\n dpath.new(self.context, entity_context_path + [\"start_line\"], start_line)\n dpath.new(self.context, entity_context_path + [\"end_line\"], end_line)\n dpath.new(self.context, entity_context_path + [\"code_lines\"],\n self.file_lines[start_line - 1: end_line])\n potential_block_start_lines.remove((line_num, line))\n break\n return self.context\n", "path": "checkov/terraform/context_parsers/base_parser.py"}]}
| 2,736 | 179 |
gh_patches_debug_28905
|
rasdani/github-patches
|
git_diff
|
ckan__ckan-6953
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Robots.txt can no longer be easily customised
**CKAN version**
2.9
**Describe the bug**
`robots.txt` was moved back to the `public` directory as part of #4801. However, this reverts the implementation of https://github.com/ckan/ideas-and-roadmap/issues/178 and makes it harder to customise the file (it can still be overridden with a different version, but not using Jinja syntax).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ckan/views/home.py`
Content:
```
1 # encoding: utf-8
2
3 from __future__ import annotations
4
5 from urllib.parse import urlencode
6 from typing import Any, Optional, cast, List, Tuple
7
8 from flask import Blueprint, abort, redirect, request
9
10 import ckan.model as model
11 import ckan.logic as logic
12 import ckan.lib.base as base
13 import ckan.lib.search as search
14 import ckan.lib.helpers as h
15
16 from ckan.common import g, config, current_user, _
17 from ckan.types import Context
18
19
20 CACHE_PARAMETERS = [u'__cache', u'__no_cache__']
21
22
23 home = Blueprint(u'home', __name__)
24
25
26 @home.before_request
27 def before_request() -> None:
28 u'''set context and check authorization'''
29 try:
30 context = cast(Context, {
31 u'model': model,
32 u'user': current_user.name,
33 u'auth_user_obj': current_user})
34 logic.check_access(u'site_read', context)
35 except logic.NotAuthorized:
36 abort(403)
37
38
39 def index() -> str:
40 u'''display home page'''
41 try:
42 context = cast(Context, {
43 u'model': model,
44 u'session': model.Session,
45 u'user': current_user.name,
46 u'auth_user_obj': current_user
47 }
48 )
49
50 data_dict: dict[str, Any] = {
51 u'q': u'*:*',
52 u'facet.field': h.facets(),
53 u'rows': 4,
54 u'start': 0,
55 u'sort': u'view_recent desc',
56 u'fq': u'capacity:"public"'}
57 query = logic.get_action(u'package_search')(context, data_dict)
58 g.package_count = query['count']
59 g.datasets = query['results']
60
61 org_label = h.humanize_entity_type(
62 u'organization',
63 h.default_group_type(u'organization'),
64 u'facet label') or _(u'Organizations')
65
66 group_label = h.humanize_entity_type(
67 u'group',
68 h.default_group_type(u'group'),
69 u'facet label') or _(u'Groups')
70
71 g.facet_titles = {
72 u'organization': org_label,
73 u'groups': group_label,
74 u'tags': _(u'Tags'),
75 u'res_format': _(u'Formats'),
76 u'license': _(u'Licenses'),
77 }
78
79 except search.SearchError:
80 g.package_count = 0
81
82 if current_user.is_authenticated and not current_user.email:
83 url = h.url_for('user.edit')
84 msg = _(u'Please <a href="%s">update your profile</a>'
85 u' and add your email address. ') % url + \
86 _(u'%s uses your email address'
87 u' if you need to reset your password.') \
88 % config.get_value(u'ckan.site_title')
89 h.flash_notice(msg, allow_html=True)
90 return base.render(u'home/index.html', extra_vars={})
91
92
93 def about() -> str:
94 u''' display about page'''
95 return base.render(u'home/about.html', extra_vars={})
96
97
98 def redirect_locale(target_locale: str, path: Optional[str] = None) -> Any:
99
100 target = f'/{target_locale}/{path}' if path else f'/{target_locale}'
101
102 if request.args:
103 target += f'?{urlencode(request.args)}'
104
105 return redirect(target, code=308)
106
107
108 util_rules: List[Tuple[str, Any]] = [
109 (u'/', index),
110 (u'/about', about)
111 ]
112 for rule, view_func in util_rules:
113 home.add_url_rule(rule, view_func=view_func)
114
115 locales_mapping: List[Tuple[str, str]] = [
116 ('zh_TW', 'zh_Hant_TW'),
117 ('zh_CN', 'zh_Hans_CN'),
118 ('no', 'nb_NO'),
119 ]
120
121 for locale in locales_mapping:
122
123 legacy_locale = locale[0]
124 new_locale = locale[1]
125
126 home.add_url_rule(
127 f'/{legacy_locale}/',
128 view_func=redirect_locale,
129 defaults={'target_locale': new_locale}
130 )
131
132 home.add_url_rule(
133 f'/{legacy_locale}/<path:path>',
134 view_func=redirect_locale,
135 defaults={'target_locale': new_locale}
136 )
137
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ckan/views/home.py b/ckan/views/home.py
--- a/ckan/views/home.py
+++ b/ckan/views/home.py
@@ -5,7 +5,7 @@
from urllib.parse import urlencode
from typing import Any, Optional, cast, List, Tuple
-from flask import Blueprint, abort, redirect, request
+from flask import Blueprint, make_response, abort, redirect, request
import ckan.model as model
import ckan.logic as logic
@@ -14,7 +14,7 @@
import ckan.lib.helpers as h
from ckan.common import g, config, current_user, _
-from ckan.types import Context
+from ckan.types import Context, Response
CACHE_PARAMETERS = [u'__cache', u'__no_cache__']
@@ -95,6 +95,13 @@
return base.render(u'home/about.html', extra_vars={})
+def robots_txt() -> Response:
+ '''display robots.txt'''
+ resp = make_response(base.render('home/robots.txt'))
+ resp.headers['Content-Type'] = "text/plain; charset=utf-8"
+ return resp
+
+
def redirect_locale(target_locale: str, path: Optional[str] = None) -> Any:
target = f'/{target_locale}/{path}' if path else f'/{target_locale}'
@@ -107,7 +114,8 @@
util_rules: List[Tuple[str, Any]] = [
(u'/', index),
- (u'/about', about)
+ (u'/about', about),
+ (u'/robots.txt', robots_txt)
]
for rule, view_func in util_rules:
home.add_url_rule(rule, view_func=view_func)
|
{"golden_diff": "diff --git a/ckan/views/home.py b/ckan/views/home.py\n--- a/ckan/views/home.py\n+++ b/ckan/views/home.py\n@@ -5,7 +5,7 @@\n from urllib.parse import urlencode\n from typing import Any, Optional, cast, List, Tuple\n \n-from flask import Blueprint, abort, redirect, request\n+from flask import Blueprint, make_response, abort, redirect, request\n \n import ckan.model as model\n import ckan.logic as logic\n@@ -14,7 +14,7 @@\n import ckan.lib.helpers as h\n \n from ckan.common import g, config, current_user, _\n-from ckan.types import Context\n+from ckan.types import Context, Response\n \n \n CACHE_PARAMETERS = [u'__cache', u'__no_cache__']\n@@ -95,6 +95,13 @@\n return base.render(u'home/about.html', extra_vars={})\n \n \n+def robots_txt() -> Response:\n+ '''display robots.txt'''\n+ resp = make_response(base.render('home/robots.txt'))\n+ resp.headers['Content-Type'] = \"text/plain; charset=utf-8\"\n+ return resp\n+\n+\n def redirect_locale(target_locale: str, path: Optional[str] = None) -> Any:\n \n target = f'/{target_locale}/{path}' if path else f'/{target_locale}'\n@@ -107,7 +114,8 @@\n \n util_rules: List[Tuple[str, Any]] = [\n (u'/', index),\n- (u'/about', about)\n+ (u'/about', about),\n+ (u'/robots.txt', robots_txt)\n ]\n for rule, view_func in util_rules:\n home.add_url_rule(rule, view_func=view_func)\n", "issue": "Robots.txt can no longer be easily customised\n**CKAN version**\r\n\r\n2.9\r\n\r\n**Describe the bug**\r\n\r\n`robots.txt` was moved back to the `public` directory as part of #4801. However, this reverts the implementation of https://github.com/ckan/ideas-and-roadmap/issues/178 and makes it harder to customise the file (it can still be overridden with a different version, but not using Jinja syntax).\r\n\n", "before_files": [{"content": "# encoding: utf-8\n\nfrom __future__ import annotations\n\nfrom urllib.parse import urlencode\nfrom typing import Any, Optional, cast, List, Tuple\n\nfrom flask import Blueprint, abort, redirect, request\n\nimport ckan.model as model\nimport ckan.logic as logic\nimport ckan.lib.base as base\nimport ckan.lib.search as search\nimport ckan.lib.helpers as h\n\nfrom ckan.common import g, config, current_user, _\nfrom ckan.types import Context\n\n\nCACHE_PARAMETERS = [u'__cache', u'__no_cache__']\n\n\nhome = Blueprint(u'home', __name__)\n\n\[email protected]_request\ndef before_request() -> None:\n u'''set context and check authorization'''\n try:\n context = cast(Context, {\n u'model': model,\n u'user': current_user.name,\n u'auth_user_obj': current_user})\n logic.check_access(u'site_read', context)\n except logic.NotAuthorized:\n abort(403)\n\n\ndef index() -> str:\n u'''display home page'''\n try:\n context = cast(Context, {\n u'model': model,\n u'session': model.Session,\n u'user': current_user.name,\n u'auth_user_obj': current_user\n }\n )\n\n data_dict: dict[str, Any] = {\n u'q': u'*:*',\n u'facet.field': h.facets(),\n u'rows': 4,\n u'start': 0,\n u'sort': u'view_recent desc',\n u'fq': u'capacity:\"public\"'}\n query = logic.get_action(u'package_search')(context, data_dict)\n g.package_count = query['count']\n g.datasets = query['results']\n\n org_label = h.humanize_entity_type(\n u'organization',\n h.default_group_type(u'organization'),\n u'facet label') or _(u'Organizations')\n\n group_label = h.humanize_entity_type(\n u'group',\n h.default_group_type(u'group'),\n u'facet label') or _(u'Groups')\n\n g.facet_titles = {\n u'organization': org_label,\n u'groups': group_label,\n u'tags': _(u'Tags'),\n u'res_format': _(u'Formats'),\n u'license': _(u'Licenses'),\n }\n\n except search.SearchError:\n g.package_count = 0\n\n if current_user.is_authenticated and not current_user.email:\n url = h.url_for('user.edit')\n msg = _(u'Please <a href=\"%s\">update your profile</a>'\n u' and add your email address. ') % url + \\\n _(u'%s uses your email address'\n u' if you need to reset your password.') \\\n % config.get_value(u'ckan.site_title')\n h.flash_notice(msg, allow_html=True)\n return base.render(u'home/index.html', extra_vars={})\n\n\ndef about() -> str:\n u''' display about page'''\n return base.render(u'home/about.html', extra_vars={})\n\n\ndef redirect_locale(target_locale: str, path: Optional[str] = None) -> Any:\n\n target = f'/{target_locale}/{path}' if path else f'/{target_locale}'\n\n if request.args:\n target += f'?{urlencode(request.args)}'\n\n return redirect(target, code=308)\n\n\nutil_rules: List[Tuple[str, Any]] = [\n (u'/', index),\n (u'/about', about)\n]\nfor rule, view_func in util_rules:\n home.add_url_rule(rule, view_func=view_func)\n\nlocales_mapping: List[Tuple[str, str]] = [\n ('zh_TW', 'zh_Hant_TW'),\n ('zh_CN', 'zh_Hans_CN'),\n ('no', 'nb_NO'),\n]\n\nfor locale in locales_mapping:\n\n legacy_locale = locale[0]\n new_locale = locale[1]\n\n home.add_url_rule(\n f'/{legacy_locale}/',\n view_func=redirect_locale,\n defaults={'target_locale': new_locale}\n )\n\n home.add_url_rule(\n f'/{legacy_locale}/<path:path>',\n view_func=redirect_locale,\n defaults={'target_locale': new_locale}\n )\n", "path": "ckan/views/home.py"}], "after_files": [{"content": "# encoding: utf-8\n\nfrom __future__ import annotations\n\nfrom urllib.parse import urlencode\nfrom typing import Any, Optional, cast, List, Tuple\n\nfrom flask import Blueprint, make_response, abort, redirect, request\n\nimport ckan.model as model\nimport ckan.logic as logic\nimport ckan.lib.base as base\nimport ckan.lib.search as search\nimport ckan.lib.helpers as h\n\nfrom ckan.common import g, config, current_user, _\nfrom ckan.types import Context, Response\n\n\nCACHE_PARAMETERS = [u'__cache', u'__no_cache__']\n\n\nhome = Blueprint(u'home', __name__)\n\n\[email protected]_request\ndef before_request() -> None:\n u'''set context and check authorization'''\n try:\n context = cast(Context, {\n u'model': model,\n u'user': current_user.name,\n u'auth_user_obj': current_user})\n logic.check_access(u'site_read', context)\n except logic.NotAuthorized:\n abort(403)\n\n\ndef index() -> str:\n u'''display home page'''\n try:\n context = cast(Context, {\n u'model': model,\n u'session': model.Session,\n u'user': current_user.name,\n u'auth_user_obj': current_user\n }\n )\n\n data_dict: dict[str, Any] = {\n u'q': u'*:*',\n u'facet.field': h.facets(),\n u'rows': 4,\n u'start': 0,\n u'sort': u'view_recent desc',\n u'fq': u'capacity:\"public\"'}\n query = logic.get_action(u'package_search')(context, data_dict)\n g.package_count = query['count']\n g.datasets = query['results']\n\n org_label = h.humanize_entity_type(\n u'organization',\n h.default_group_type(u'organization'),\n u'facet label') or _(u'Organizations')\n\n group_label = h.humanize_entity_type(\n u'group',\n h.default_group_type(u'group'),\n u'facet label') or _(u'Groups')\n\n g.facet_titles = {\n u'organization': org_label,\n u'groups': group_label,\n u'tags': _(u'Tags'),\n u'res_format': _(u'Formats'),\n u'license': _(u'Licenses'),\n }\n\n except search.SearchError:\n g.package_count = 0\n\n if current_user.is_authenticated and not current_user.email:\n url = h.url_for('user.edit')\n msg = _(u'Please <a href=\"%s\">update your profile</a>'\n u' and add your email address. ') % url + \\\n _(u'%s uses your email address'\n u' if you need to reset your password.') \\\n % config.get_value(u'ckan.site_title')\n h.flash_notice(msg, allow_html=True)\n return base.render(u'home/index.html', extra_vars={})\n\n\ndef about() -> str:\n u''' display about page'''\n return base.render(u'home/about.html', extra_vars={})\n\n\ndef robots_txt() -> Response:\n '''display robots.txt'''\n resp = make_response(base.render('home/robots.txt'))\n resp.headers['Content-Type'] = \"text/plain; charset=utf-8\"\n return resp\n\n\ndef redirect_locale(target_locale: str, path: Optional[str] = None) -> Any:\n\n target = f'/{target_locale}/{path}' if path else f'/{target_locale}'\n\n if request.args:\n target += f'?{urlencode(request.args)}'\n\n return redirect(target, code=308)\n\n\nutil_rules: List[Tuple[str, Any]] = [\n (u'/', index),\n (u'/about', about),\n (u'/robots.txt', robots_txt)\n]\nfor rule, view_func in util_rules:\n home.add_url_rule(rule, view_func=view_func)\n\nlocales_mapping: List[Tuple[str, str]] = [\n ('zh_TW', 'zh_Hant_TW'),\n ('zh_CN', 'zh_Hans_CN'),\n ('no', 'nb_NO'),\n]\n\nfor locale in locales_mapping:\n\n legacy_locale = locale[0]\n new_locale = locale[1]\n\n home.add_url_rule(\n f'/{legacy_locale}/',\n view_func=redirect_locale,\n defaults={'target_locale': new_locale}\n )\n\n home.add_url_rule(\n f'/{legacy_locale}/<path:path>',\n view_func=redirect_locale,\n defaults={'target_locale': new_locale}\n )\n", "path": "ckan/views/home.py"}]}
| 1,602 | 379 |
gh_patches_debug_22453
|
rasdani/github-patches
|
git_diff
|
microsoft__Qcodes-4122
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Keithley6500 does not set mode correctly
###
The Keithley6500 driver does not set the mode correctly.
### Steps to reproduce
```python
from qcodes.instrument_drivers.tektronix.Keithley_6500 import Keithley_6500
keithley_1 = Keithley_6500("keithley_1", address="TCPIP0::192.168.2.105::inst0::INSTR")
keithley_1.mode('dc voltage')
```
### Expected behaviour
The mode on the instrument to be set to DC voltage
### Actual behaviour
The instrument shows a message on the front panel that the parameter value should be specified as a string. In Python, the commands are executed without exception.
### System
Windows 10
If you are using a released version of qcodes (recommended):
0.31.0
###
Following the manual:
https://download.tek.com/manual/DMM6500-901-01B_Sept_2019_Ref.pdf
the solution is simply to add quotes around the mode value in the command.
Related to #1541
I will add a PR shortly.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `qcodes/instrument_drivers/tektronix/Keithley_6500.py`
Content:
```
1 from typing import Any, TypeVar, Callable
2 from functools import partial
3 from typing import Union
4
5 from qcodes import VisaInstrument
6 from qcodes.utils.validators import Bool, Enum, Ints, MultiType, Numbers
7
8 T = TypeVar("T")
9
10
11 def _parse_output_string(string_value: str) -> str:
12 """ Parses and cleans string output of the multimeter. Removes the surrounding
13 whitespace, newline characters and quotes from the parsed data. Some results
14 are converted for readablitity (e.g. mov changes to moving).
15
16 Args:
17 string_value: The data returned from the multimeter reading commands.
18
19 Returns:
20 The cleaned-up output of the multimeter.
21 """
22 s = string_value.strip().lower()
23 if (s[0] == s[-1]) and s.startswith(("'", '"')):
24 s = s[1:-1]
25
26 conversions = {'mov': 'moving', 'rep': 'repeat'}
27 if s in conversions.keys():
28 s = conversions[s]
29 return s
30
31
32 def _parse_output_bool(numeric_value: float) -> bool:
33 """ Parses and converts the value to boolean type. True is 1.
34
35 Args:
36 numeric_value: The numerical value to convert.
37
38 Returns:
39 The boolean representation of the numeric value.
40 """
41 return bool(numeric_value)
42
43
44 class CommandSetError(Exception):
45 pass
46
47
48 class Keithley_6500(VisaInstrument):
49
50 def __init__(
51 self,
52 name: str,
53 address: str,
54 reset_device: bool = False,
55 **kwargs: Any):
56 """ Driver for the Keithley 6500 multimeter. Based on the Keithley 2000 driver,
57 commands have been adapted for the Keithley 6500. This driver does not contain
58 all commands available, but only the ones most commonly used.
59
60 Status: beta-version.
61
62 Args:
63 name (str): The name used internally by QCoDeS in the DataSet.
64 address (str): The VISA device address.
65 reset_device (bool): Reset the device on startup if true.
66 """
67 super().__init__(name, address, terminator='\n', **kwargs)
68
69 command_set = self.ask('*LANG?')
70 if command_set != 'SCPI':
71 error_msg = "This driver only compatible with the 'SCPI' command " \
72 "set, not '{}' set".format(command_set)
73 raise CommandSetError(error_msg)
74
75 self._trigger_sent = False
76
77 self._mode_map = {'ac current': 'CURR:AC', 'dc current': 'CURR:DC', 'ac voltage': 'VOLT:AC',
78 'dc voltage': 'VOLT:DC', '2w resistance': 'RES', '4w resistance': 'FRES',
79 'temperature': 'TEMP', 'frequency': 'FREQ'}
80
81 self.add_parameter('mode',
82 get_cmd='SENS:FUNC?',
83 set_cmd="SENS:FUNC {}",
84 val_mapping=self._mode_map)
85
86 self.add_parameter('nplc',
87 get_cmd=partial(
88 self._get_mode_param, 'NPLC', float),
89 set_cmd=partial(self._set_mode_param, 'NPLC'),
90 vals=Numbers(min_value=0.01, max_value=10))
91
92 # TODO: validator, this one is more difficult since different modes
93 # require different validation ranges.
94 self.add_parameter('range',
95 get_cmd=partial(
96 self._get_mode_param, 'RANG', float),
97 set_cmd=partial(self._set_mode_param, 'RANG'),
98 vals=Numbers())
99
100 self.add_parameter('auto_range_enabled',
101 get_cmd=partial(self._get_mode_param,
102 'RANG:AUTO', _parse_output_bool),
103 set_cmd=partial(self._set_mode_param, 'RANG:AUTO'),
104 vals=Bool())
105
106 self.add_parameter('digits',
107 get_cmd='DISP:VOLT:DC:DIG?', get_parser=int,
108 set_cmd='DISP:VOLT:DC:DIG? {}',
109 vals=Ints(min_value=4, max_value=7))
110
111 self.add_parameter('averaging_type',
112 get_cmd=partial(self._get_mode_param,
113 'AVER:TCON', _parse_output_string),
114 set_cmd=partial(self._set_mode_param, 'AVER:TCON'),
115 vals=Enum('moving', 'repeat'))
116
117 self.add_parameter('averaging_count',
118 get_cmd=partial(self._get_mode_param,
119 'AVER:COUN', int),
120 set_cmd=partial(self._set_mode_param, 'AVER:COUN'),
121 vals=Ints(min_value=1, max_value=100))
122
123 self.add_parameter('averaging_enabled',
124 get_cmd=partial(self._get_mode_param,
125 'AVER:STAT', _parse_output_bool),
126 set_cmd=partial(self._set_mode_param, 'AVER:STAT'),
127 vals=Bool())
128
129 # Global parameters
130 self.add_parameter('display_backlight',
131 docstring='Control the brightness of the display '
132 'backligt. Off turns the display off and'
133 'Blackout also turns off indicators and '
134 'key lights on the device.',
135 get_cmd='DISP:LIGH:STAT?',
136 set_cmd='DISP:LIGH:STAT {}',
137 val_mapping={'On 100': 'ON100',
138 'On 75': 'ON75',
139 'On 50': 'ON50',
140 'On 25': 'ON25',
141 'Off': 'OFF',
142 'Blackout': 'BLACkout'})
143
144 self.add_parameter('trigger_count',
145 get_parser=int,
146 get_cmd='ROUT:SCAN:COUN:SCAN?',
147 set_cmd='ROUT:SCAN:COUN:SCAN {}',
148 vals=MultiType(Ints(min_value=1, max_value=9999),
149 Enum('inf', 'default', 'minimum', 'maximum')))
150
151 for trigger in range(1, 5):
152 self.add_parameter('trigger%i_delay' % trigger,
153 docstring='Set and read trigger delay for '
154 'timer %i.' % trigger,
155 get_parser=float,
156 get_cmd='TRIG:TIM%i:DEL?' % trigger,
157 set_cmd='TRIG:TIM%i:DEL {}' % trigger,
158 unit='s', vals=Numbers(min_value=0,
159 max_value=999999.999))
160
161 self.add_parameter('trigger%i_source' % trigger,
162 docstring='Set the trigger source for '
163 'timer %i.' % trigger,
164 get_cmd='TRIG:TIM%i:STAR:STIM?' % trigger,
165 set_cmd='TRIG:TIM%i:STAR:STIM {}' % trigger,
166 val_mapping={'immediate': 'NONE',
167 'timer1': 'TIM1',
168 'timer2': 'TIM2',
169 'timer3': 'TIM3',
170 'timer4': 'TIM4',
171 'notify1': 'NOT1',
172 'notify2': 'NOT2',
173 'notify3': 'NOT3',
174 'front-panel': 'DISP',
175 'bus': 'COMM',
176 'external': 'EXT'})
177
178 # Control interval between scans; the default value from the instrument is 0,
179 # hence 0 is included in the validator's range of this parameter.
180 self.add_parameter('trigger_timer',
181 get_parser=float,
182 get_cmd='ROUT:SCAN:INT?',
183 set_cmd='ROUT:SCAN:INT {}',
184 unit='s', vals=Numbers(min_value=0, max_value=999999.999))
185
186 self.add_parameter('amplitude',
187 get_cmd=self._read_next_value,
188 set_cmd=False,
189 unit='a.u.')
190
191 if reset_device:
192 self.reset()
193 self.write('FORM:DATA ASCII')
194 self.connect_message()
195
196 def reset(self) -> None:
197 """ Reset the device """
198 self.write('*RST')
199
200 def _read_next_value(self) -> float:
201 return float(self.ask('READ?'))
202
203 def _get_mode_param(self, parameter: str, parser: Callable[[str], T]) -> T:
204 """ Reads the current mode of the multimeter and ask for the given parameter.
205
206 Args:
207 parameter: The asked parameter after getting the current mode.
208 parser: A function that parses the input buffer read.
209
210 Returns:
211 Any: the parsed ask command. The parser determines the return data-type.
212 """
213 mode = _parse_output_string(self._mode_map[self.mode()])
214 cmd = f'{mode}:{parameter}?'
215 return parser(self.ask(cmd))
216
217 def _set_mode_param(self, parameter: str, value: Union[str, float, bool]) -> None:
218 """ Gets the current mode of the multimeter and sets the given parameter.
219
220 Args:
221 parameter: The set parameter after getting the current mode.
222 value: Value to set
223 """
224 if isinstance(value, bool):
225 value = int(value)
226
227 mode = _parse_output_string(self._mode_map[self.mode()])
228 cmd = f'{mode}:{parameter} {value}'
229 self.write(cmd)
230
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/qcodes/instrument_drivers/tektronix/Keithley_6500.py b/qcodes/instrument_drivers/tektronix/Keithley_6500.py
--- a/qcodes/instrument_drivers/tektronix/Keithley_6500.py
+++ b/qcodes/instrument_drivers/tektronix/Keithley_6500.py
@@ -1,6 +1,5 @@
-from typing import Any, TypeVar, Callable
from functools import partial
-from typing import Union
+from typing import Any, Callable, TypeVar, Union
from qcodes import VisaInstrument
from qcodes.utils.validators import Bool, Enum, Ints, MultiType, Numbers
@@ -78,10 +77,12 @@
'dc voltage': 'VOLT:DC', '2w resistance': 'RES', '4w resistance': 'FRES',
'temperature': 'TEMP', 'frequency': 'FREQ'}
- self.add_parameter('mode',
- get_cmd='SENS:FUNC?',
- set_cmd="SENS:FUNC {}",
- val_mapping=self._mode_map)
+ self.add_parameter(
+ "mode",
+ get_cmd="SENS:FUNC?",
+ set_cmd="SENS:FUNC '{}'",
+ val_mapping=self._mode_map,
+ )
self.add_parameter('nplc',
get_cmd=partial(
|
{"golden_diff": "diff --git a/qcodes/instrument_drivers/tektronix/Keithley_6500.py b/qcodes/instrument_drivers/tektronix/Keithley_6500.py\n--- a/qcodes/instrument_drivers/tektronix/Keithley_6500.py\n+++ b/qcodes/instrument_drivers/tektronix/Keithley_6500.py\n@@ -1,6 +1,5 @@\n-from typing import Any, TypeVar, Callable\n from functools import partial\n-from typing import Union\n+from typing import Any, Callable, TypeVar, Union\n \n from qcodes import VisaInstrument\n from qcodes.utils.validators import Bool, Enum, Ints, MultiType, Numbers\n@@ -78,10 +77,12 @@\n 'dc voltage': 'VOLT:DC', '2w resistance': 'RES', '4w resistance': 'FRES',\n 'temperature': 'TEMP', 'frequency': 'FREQ'}\n \n- self.add_parameter('mode',\n- get_cmd='SENS:FUNC?',\n- set_cmd=\"SENS:FUNC {}\",\n- val_mapping=self._mode_map)\n+ self.add_parameter(\n+ \"mode\",\n+ get_cmd=\"SENS:FUNC?\",\n+ set_cmd=\"SENS:FUNC '{}'\",\n+ val_mapping=self._mode_map,\n+ )\n \n self.add_parameter('nplc',\n get_cmd=partial(\n", "issue": "Keithley6500 does not set mode correctly\n###\r\nThe Keithley6500 driver does not set the mode correctly.\r\n\r\n### Steps to reproduce\r\n```python\r\nfrom qcodes.instrument_drivers.tektronix.Keithley_6500 import Keithley_6500\r\nkeithley_1 = Keithley_6500(\"keithley_1\", address=\"TCPIP0::192.168.2.105::inst0::INSTR\")\r\nkeithley_1.mode('dc voltage')\r\n```\r\n\r\n### Expected behaviour\r\nThe mode on the instrument to be set to DC voltage\r\n\r\n### Actual behaviour\r\nThe instrument shows a message on the front panel that the parameter value should be specified as a string. In Python, the commands are executed without exception.\r\n\r\n### System\r\nWindows 10\r\n\r\nIf you are using a released version of qcodes (recommended):\r\n0.31.0\r\n\r\n###\r\nFollowing the manual:\r\nhttps://download.tek.com/manual/DMM6500-901-01B_Sept_2019_Ref.pdf\r\nthe solution is simply to add quotes around the mode value in the command. \r\n\r\nRelated to #1541\r\n\r\nI will add a PR shortly.\n", "before_files": [{"content": "from typing import Any, TypeVar, Callable\nfrom functools import partial\nfrom typing import Union\n\nfrom qcodes import VisaInstrument\nfrom qcodes.utils.validators import Bool, Enum, Ints, MultiType, Numbers\n\nT = TypeVar(\"T\")\n\n\ndef _parse_output_string(string_value: str) -> str:\n \"\"\" Parses and cleans string output of the multimeter. Removes the surrounding\n whitespace, newline characters and quotes from the parsed data. Some results\n are converted for readablitity (e.g. mov changes to moving).\n\n Args:\n string_value: The data returned from the multimeter reading commands.\n\n Returns:\n The cleaned-up output of the multimeter.\n \"\"\"\n s = string_value.strip().lower()\n if (s[0] == s[-1]) and s.startswith((\"'\", '\"')):\n s = s[1:-1]\n\n conversions = {'mov': 'moving', 'rep': 'repeat'}\n if s in conversions.keys():\n s = conversions[s]\n return s\n\n\ndef _parse_output_bool(numeric_value: float) -> bool:\n \"\"\" Parses and converts the value to boolean type. True is 1.\n\n Args:\n numeric_value: The numerical value to convert.\n\n Returns:\n The boolean representation of the numeric value.\n \"\"\"\n return bool(numeric_value)\n\n\nclass CommandSetError(Exception):\n pass\n\n\nclass Keithley_6500(VisaInstrument):\n\n def __init__(\n self,\n name: str,\n address: str,\n reset_device: bool = False,\n **kwargs: Any):\n \"\"\" Driver for the Keithley 6500 multimeter. Based on the Keithley 2000 driver,\n commands have been adapted for the Keithley 6500. This driver does not contain\n all commands available, but only the ones most commonly used.\n\n Status: beta-version.\n\n Args:\n name (str): The name used internally by QCoDeS in the DataSet.\n address (str): The VISA device address.\n reset_device (bool): Reset the device on startup if true.\n \"\"\"\n super().__init__(name, address, terminator='\\n', **kwargs)\n\n command_set = self.ask('*LANG?')\n if command_set != 'SCPI':\n error_msg = \"This driver only compatible with the 'SCPI' command \" \\\n \"set, not '{}' set\".format(command_set)\n raise CommandSetError(error_msg)\n\n self._trigger_sent = False\n\n self._mode_map = {'ac current': 'CURR:AC', 'dc current': 'CURR:DC', 'ac voltage': 'VOLT:AC',\n 'dc voltage': 'VOLT:DC', '2w resistance': 'RES', '4w resistance': 'FRES',\n 'temperature': 'TEMP', 'frequency': 'FREQ'}\n\n self.add_parameter('mode',\n get_cmd='SENS:FUNC?',\n set_cmd=\"SENS:FUNC {}\",\n val_mapping=self._mode_map)\n\n self.add_parameter('nplc',\n get_cmd=partial(\n self._get_mode_param, 'NPLC', float),\n set_cmd=partial(self._set_mode_param, 'NPLC'),\n vals=Numbers(min_value=0.01, max_value=10))\n\n # TODO: validator, this one is more difficult since different modes\n # require different validation ranges.\n self.add_parameter('range',\n get_cmd=partial(\n self._get_mode_param, 'RANG', float),\n set_cmd=partial(self._set_mode_param, 'RANG'),\n vals=Numbers())\n\n self.add_parameter('auto_range_enabled',\n get_cmd=partial(self._get_mode_param,\n 'RANG:AUTO', _parse_output_bool),\n set_cmd=partial(self._set_mode_param, 'RANG:AUTO'),\n vals=Bool())\n\n self.add_parameter('digits',\n get_cmd='DISP:VOLT:DC:DIG?', get_parser=int,\n set_cmd='DISP:VOLT:DC:DIG? {}',\n vals=Ints(min_value=4, max_value=7))\n\n self.add_parameter('averaging_type',\n get_cmd=partial(self._get_mode_param,\n 'AVER:TCON', _parse_output_string),\n set_cmd=partial(self._set_mode_param, 'AVER:TCON'),\n vals=Enum('moving', 'repeat'))\n\n self.add_parameter('averaging_count',\n get_cmd=partial(self._get_mode_param,\n 'AVER:COUN', int),\n set_cmd=partial(self._set_mode_param, 'AVER:COUN'),\n vals=Ints(min_value=1, max_value=100))\n\n self.add_parameter('averaging_enabled',\n get_cmd=partial(self._get_mode_param,\n 'AVER:STAT', _parse_output_bool),\n set_cmd=partial(self._set_mode_param, 'AVER:STAT'),\n vals=Bool())\n\n # Global parameters\n self.add_parameter('display_backlight',\n docstring='Control the brightness of the display '\n 'backligt. Off turns the display off and'\n 'Blackout also turns off indicators and '\n 'key lights on the device.',\n get_cmd='DISP:LIGH:STAT?',\n set_cmd='DISP:LIGH:STAT {}',\n val_mapping={'On 100': 'ON100',\n 'On 75': 'ON75',\n 'On 50': 'ON50',\n 'On 25': 'ON25',\n 'Off': 'OFF',\n 'Blackout': 'BLACkout'})\n\n self.add_parameter('trigger_count',\n get_parser=int,\n get_cmd='ROUT:SCAN:COUN:SCAN?',\n set_cmd='ROUT:SCAN:COUN:SCAN {}',\n vals=MultiType(Ints(min_value=1, max_value=9999),\n Enum('inf', 'default', 'minimum', 'maximum')))\n\n for trigger in range(1, 5):\n self.add_parameter('trigger%i_delay' % trigger,\n docstring='Set and read trigger delay for '\n 'timer %i.' % trigger,\n get_parser=float,\n get_cmd='TRIG:TIM%i:DEL?' % trigger,\n set_cmd='TRIG:TIM%i:DEL {}' % trigger,\n unit='s', vals=Numbers(min_value=0,\n max_value=999999.999))\n\n self.add_parameter('trigger%i_source' % trigger,\n docstring='Set the trigger source for '\n 'timer %i.' % trigger,\n get_cmd='TRIG:TIM%i:STAR:STIM?' % trigger,\n set_cmd='TRIG:TIM%i:STAR:STIM {}' % trigger,\n val_mapping={'immediate': 'NONE',\n 'timer1': 'TIM1',\n 'timer2': 'TIM2',\n 'timer3': 'TIM3',\n 'timer4': 'TIM4',\n 'notify1': 'NOT1',\n 'notify2': 'NOT2',\n 'notify3': 'NOT3',\n 'front-panel': 'DISP',\n 'bus': 'COMM',\n 'external': 'EXT'})\n\n # Control interval between scans; the default value from the instrument is 0,\n # hence 0 is included in the validator's range of this parameter.\n self.add_parameter('trigger_timer',\n get_parser=float,\n get_cmd='ROUT:SCAN:INT?',\n set_cmd='ROUT:SCAN:INT {}',\n unit='s', vals=Numbers(min_value=0, max_value=999999.999))\n\n self.add_parameter('amplitude',\n get_cmd=self._read_next_value,\n set_cmd=False,\n unit='a.u.')\n\n if reset_device:\n self.reset()\n self.write('FORM:DATA ASCII')\n self.connect_message()\n\n def reset(self) -> None:\n \"\"\" Reset the device \"\"\"\n self.write('*RST')\n\n def _read_next_value(self) -> float:\n return float(self.ask('READ?'))\n\n def _get_mode_param(self, parameter: str, parser: Callable[[str], T]) -> T:\n \"\"\" Reads the current mode of the multimeter and ask for the given parameter.\n\n Args:\n parameter: The asked parameter after getting the current mode.\n parser: A function that parses the input buffer read.\n\n Returns:\n Any: the parsed ask command. The parser determines the return data-type.\n \"\"\"\n mode = _parse_output_string(self._mode_map[self.mode()])\n cmd = f'{mode}:{parameter}?'\n return parser(self.ask(cmd))\n\n def _set_mode_param(self, parameter: str, value: Union[str, float, bool]) -> None:\n \"\"\" Gets the current mode of the multimeter and sets the given parameter.\n\n Args:\n parameter: The set parameter after getting the current mode.\n value: Value to set\n \"\"\"\n if isinstance(value, bool):\n value = int(value)\n\n mode = _parse_output_string(self._mode_map[self.mode()])\n cmd = f'{mode}:{parameter} {value}'\n self.write(cmd)\n", "path": "qcodes/instrument_drivers/tektronix/Keithley_6500.py"}], "after_files": [{"content": "from functools import partial\nfrom typing import Any, Callable, TypeVar, Union\n\nfrom qcodes import VisaInstrument\nfrom qcodes.utils.validators import Bool, Enum, Ints, MultiType, Numbers\n\nT = TypeVar(\"T\")\n\n\ndef _parse_output_string(string_value: str) -> str:\n \"\"\" Parses and cleans string output of the multimeter. Removes the surrounding\n whitespace, newline characters and quotes from the parsed data. Some results\n are converted for readablitity (e.g. mov changes to moving).\n\n Args:\n string_value: The data returned from the multimeter reading commands.\n\n Returns:\n The cleaned-up output of the multimeter.\n \"\"\"\n s = string_value.strip().lower()\n if (s[0] == s[-1]) and s.startswith((\"'\", '\"')):\n s = s[1:-1]\n\n conversions = {'mov': 'moving', 'rep': 'repeat'}\n if s in conversions.keys():\n s = conversions[s]\n return s\n\n\ndef _parse_output_bool(numeric_value: float) -> bool:\n \"\"\" Parses and converts the value to boolean type. True is 1.\n\n Args:\n numeric_value: The numerical value to convert.\n\n Returns:\n The boolean representation of the numeric value.\n \"\"\"\n return bool(numeric_value)\n\n\nclass CommandSetError(Exception):\n pass\n\n\nclass Keithley_6500(VisaInstrument):\n\n def __init__(\n self,\n name: str,\n address: str,\n reset_device: bool = False,\n **kwargs: Any):\n \"\"\" Driver for the Keithley 6500 multimeter. Based on the Keithley 2000 driver,\n commands have been adapted for the Keithley 6500. This driver does not contain\n all commands available, but only the ones most commonly used.\n\n Status: beta-version.\n\n Args:\n name (str): The name used internally by QCoDeS in the DataSet.\n address (str): The VISA device address.\n reset_device (bool): Reset the device on startup if true.\n \"\"\"\n super().__init__(name, address, terminator='\\n', **kwargs)\n\n command_set = self.ask('*LANG?')\n if command_set != 'SCPI':\n error_msg = \"This driver only compatible with the 'SCPI' command \" \\\n \"set, not '{}' set\".format(command_set)\n raise CommandSetError(error_msg)\n\n self._trigger_sent = False\n\n self._mode_map = {'ac current': 'CURR:AC', 'dc current': 'CURR:DC', 'ac voltage': 'VOLT:AC',\n 'dc voltage': 'VOLT:DC', '2w resistance': 'RES', '4w resistance': 'FRES',\n 'temperature': 'TEMP', 'frequency': 'FREQ'}\n\n self.add_parameter(\n \"mode\",\n get_cmd=\"SENS:FUNC?\",\n set_cmd=\"SENS:FUNC '{}'\",\n val_mapping=self._mode_map,\n )\n\n self.add_parameter('nplc',\n get_cmd=partial(\n self._get_mode_param, 'NPLC', float),\n set_cmd=partial(self._set_mode_param, 'NPLC'),\n vals=Numbers(min_value=0.01, max_value=10))\n\n # TODO: validator, this one is more difficult since different modes\n # require different validation ranges.\n self.add_parameter('range',\n get_cmd=partial(\n self._get_mode_param, 'RANG', float),\n set_cmd=partial(self._set_mode_param, 'RANG'),\n vals=Numbers())\n\n self.add_parameter('auto_range_enabled',\n get_cmd=partial(self._get_mode_param,\n 'RANG:AUTO', _parse_output_bool),\n set_cmd=partial(self._set_mode_param, 'RANG:AUTO'),\n vals=Bool())\n\n self.add_parameter('digits',\n get_cmd='DISP:VOLT:DC:DIG?', get_parser=int,\n set_cmd='DISP:VOLT:DC:DIG? {}',\n vals=Ints(min_value=4, max_value=7))\n\n self.add_parameter('averaging_type',\n get_cmd=partial(self._get_mode_param,\n 'AVER:TCON', _parse_output_string),\n set_cmd=partial(self._set_mode_param, 'AVER:TCON'),\n vals=Enum('moving', 'repeat'))\n\n self.add_parameter('averaging_count',\n get_cmd=partial(self._get_mode_param,\n 'AVER:COUN', int),\n set_cmd=partial(self._set_mode_param, 'AVER:COUN'),\n vals=Ints(min_value=1, max_value=100))\n\n self.add_parameter('averaging_enabled',\n get_cmd=partial(self._get_mode_param,\n 'AVER:STAT', _parse_output_bool),\n set_cmd=partial(self._set_mode_param, 'AVER:STAT'),\n vals=Bool())\n\n # Global parameters\n self.add_parameter('display_backlight',\n docstring='Control the brightness of the display '\n 'backligt. Off turns the display off and'\n 'Blackout also turns off indicators and '\n 'key lights on the device.',\n get_cmd='DISP:LIGH:STAT?',\n set_cmd='DISP:LIGH:STAT {}',\n val_mapping={'On 100': 'ON100',\n 'On 75': 'ON75',\n 'On 50': 'ON50',\n 'On 25': 'ON25',\n 'Off': 'OFF',\n 'Blackout': 'BLACkout'})\n\n self.add_parameter('trigger_count',\n get_parser=int,\n get_cmd='ROUT:SCAN:COUN:SCAN?',\n set_cmd='ROUT:SCAN:COUN:SCAN {}',\n vals=MultiType(Ints(min_value=1, max_value=9999),\n Enum('inf', 'default', 'minimum', 'maximum')))\n\n for trigger in range(1, 5):\n self.add_parameter('trigger%i_delay' % trigger,\n docstring='Set and read trigger delay for '\n 'timer %i.' % trigger,\n get_parser=float,\n get_cmd='TRIG:TIM%i:DEL?' % trigger,\n set_cmd='TRIG:TIM%i:DEL {}' % trigger,\n unit='s', vals=Numbers(min_value=0,\n max_value=999999.999))\n\n self.add_parameter('trigger%i_source' % trigger,\n docstring='Set the trigger source for '\n 'timer %i.' % trigger,\n get_cmd='TRIG:TIM%i:STAR:STIM?' % trigger,\n set_cmd='TRIG:TIM%i:STAR:STIM {}' % trigger,\n val_mapping={'immediate': 'NONE',\n 'timer1': 'TIM1',\n 'timer2': 'TIM2',\n 'timer3': 'TIM3',\n 'timer4': 'TIM4',\n 'notify1': 'NOT1',\n 'notify2': 'NOT2',\n 'notify3': 'NOT3',\n 'front-panel': 'DISP',\n 'bus': 'COMM',\n 'external': 'EXT'})\n\n # Control interval between scans; the default value from the instrument is 0,\n # hence 0 is included in the validator's range of this parameter.\n self.add_parameter('trigger_timer',\n get_parser=float,\n get_cmd='ROUT:SCAN:INT?',\n set_cmd='ROUT:SCAN:INT {}',\n unit='s', vals=Numbers(min_value=0, max_value=999999.999))\n\n self.add_parameter('amplitude',\n get_cmd=self._read_next_value,\n set_cmd=False,\n unit='a.u.')\n\n if reset_device:\n self.reset()\n self.write('FORM:DATA ASCII')\n self.connect_message()\n\n def reset(self) -> None:\n \"\"\" Reset the device \"\"\"\n self.write('*RST')\n\n def _read_next_value(self) -> float:\n return float(self.ask('READ?'))\n\n def _get_mode_param(self, parameter: str, parser: Callable[[str], T]) -> T:\n \"\"\" Reads the current mode of the multimeter and ask for the given parameter.\n\n Args:\n parameter: The asked parameter after getting the current mode.\n parser: A function that parses the input buffer read.\n\n Returns:\n Any: the parsed ask command. The parser determines the return data-type.\n \"\"\"\n mode = _parse_output_string(self._mode_map[self.mode()])\n cmd = f'{mode}:{parameter}?'\n return parser(self.ask(cmd))\n\n def _set_mode_param(self, parameter: str, value: Union[str, float, bool]) -> None:\n \"\"\" Gets the current mode of the multimeter and sets the given parameter.\n\n Args:\n parameter: The set parameter after getting the current mode.\n value: Value to set\n \"\"\"\n if isinstance(value, bool):\n value = int(value)\n\n mode = _parse_output_string(self._mode_map[self.mode()])\n cmd = f'{mode}:{parameter} {value}'\n self.write(cmd)\n", "path": "qcodes/instrument_drivers/tektronix/Keithley_6500.py"}]}
| 3,128 | 307 |
gh_patches_debug_25545
|
rasdani/github-patches
|
git_diff
|
mitmproxy__mitmproxy-4909
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Crash when invoking replay.server.count from console
#### Problem Description
Invoking `replay.server.count` from the console causes a crash. I don't think it happens all the time, but see below for repeatable reproduction.
#### Steps to reproduce the behavior:
1. Start `mitmproxy`
2. Hit `n` to create a new flow
3. Hit Enter
4. Hit `r` to issue the request
5. With the same flow selected, issue the command `:replay.server @focus`
6. Issue the command `:replay.server.count`
Sample stack trace:
```python
File "/home/elespike/venvs/mitmproxy/lib/python3.9/site-packages/mitmproxy/tools/console/grideditor/editors.py", line 222, in __init__
if not isinstance(vals[0], list):
TypeError: 'int' object is not subscriptable
```
#### System Information
```
Mitmproxy: 7.0.4
Python: 3.9.2
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mitmproxy/addons/dumper.py`
Content:
```
1 import itertools
2 import shutil
3 from typing import IO, Optional, Union
4
5 import click
6
7 from mitmproxy import contentviews
8 from mitmproxy import ctx
9 from mitmproxy import exceptions
10 from mitmproxy import flowfilter
11 from mitmproxy import http
12 from mitmproxy import flow
13 from mitmproxy.tcp import TCPFlow, TCPMessage
14 from mitmproxy.utils import human
15 from mitmproxy.utils import strutils
16 from mitmproxy.websocket import WebSocketMessage, WebSocketData
17 from wsproto.frame_protocol import CloseReason
18
19
20 def indent(n: int, text: str) -> str:
21 l = str(text).strip().splitlines()
22 pad = " " * n
23 return "\n".join(pad + i for i in l)
24
25
26 def colorful(line, styles):
27 yield " " # we can already indent here
28 for (style, text) in line:
29 yield click.style(text, **styles.get(style, {}))
30
31
32 class Dumper:
33 def __init__(self, outfile=None):
34 self.filter: Optional[flowfilter.TFilter] = None
35 self.outfp: Optional[IO] = outfile
36
37 def load(self, loader):
38 loader.add_option(
39 "flow_detail", int, 1,
40 """
41 The display detail level for flows in mitmdump: 0 (almost quiet) to 3 (very verbose).
42 0: shortened request URL, response status code, WebSocket and TCP message notifications.
43 1: full request URL with response status code
44 2: 1 + HTTP headers
45 3: 2 + truncated response content, content of WebSocket and TCP messages
46 4: 3 + nothing is truncated
47 """
48 )
49 loader.add_option(
50 "dumper_default_contentview", str, "auto",
51 "The default content view mode.",
52 choices=[i.name.lower() for i in contentviews.views]
53 )
54 loader.add_option(
55 "dumper_filter", Optional[str], None,
56 "Limit which flows are dumped."
57 )
58
59 def configure(self, updated):
60 if "dumper_filter" in updated:
61 if ctx.options.dumper_filter:
62 try:
63 self.filter = flowfilter.parse(ctx.options.dumper_filter)
64 except ValueError as e:
65 raise exceptions.OptionsError(str(e)) from e
66 else:
67 self.filter = None
68
69 def echo(self, text: str, ident=None, **style):
70 if ident:
71 text = indent(ident, text)
72 click.secho(text, file=self.outfp, err=False, **style)
73 if self.outfp:
74 self.outfp.flush()
75
76 def _echo_headers(self, headers: http.Headers):
77 for k, v in headers.fields:
78 ks = strutils.bytes_to_escaped_str(k)
79 vs = strutils.bytes_to_escaped_str(v)
80 out = "{}: {}".format(
81 click.style(ks, fg="blue"),
82 click.style(vs)
83 )
84 self.echo(out, ident=4)
85
86 def _echo_trailers(self, trailers: Optional[http.Headers]):
87 if not trailers:
88 return
89 self.echo(click.style("--- HTTP Trailers", fg="magenta"), ident=4)
90 self._echo_headers(trailers)
91
92 def _echo_message(
93 self,
94 message: Union[http.Message, TCPMessage, WebSocketMessage],
95 flow: Union[http.HTTPFlow, TCPFlow]
96 ):
97 _, lines, error = contentviews.get_message_content_view(
98 ctx.options.dumper_default_contentview,
99 message,
100 flow
101 )
102 if error:
103 ctx.log.debug(error)
104
105 if ctx.options.flow_detail == 3:
106 lines_to_echo = itertools.islice(lines, 70)
107 else:
108 lines_to_echo = lines
109
110 styles = dict(
111 highlight=dict(bold=True),
112 offset=dict(fg="blue"),
113 header=dict(fg="green", bold=True),
114 text=dict(fg="green")
115 )
116
117 content = "\r\n".join(
118 "".join(colorful(line, styles)) for line in lines_to_echo
119 )
120 if content:
121 self.echo("")
122 self.echo(content)
123
124 if next(lines, None):
125 self.echo("(cut off)", ident=4, dim=True)
126
127 if ctx.options.flow_detail >= 2:
128 self.echo("")
129
130 def _echo_request_line(self, flow: http.HTTPFlow) -> None:
131 if flow.is_replay == "request":
132 client = click.style("[replay]", fg="yellow", bold=True)
133 elif flow.client_conn.peername:
134 client = click.style(
135 strutils.escape_control_characters(
136 human.format_address(flow.client_conn.peername)
137 )
138 )
139 else: # pragma: no cover
140 # this should not happen, but we're defensive here.
141 client = ""
142
143 pushed = ' PUSH_PROMISE' if 'h2-pushed-stream' in flow.metadata else ''
144 method = flow.request.method + pushed
145 method_color = dict(
146 GET="green",
147 DELETE="red"
148 ).get(method.upper(), "magenta")
149 method = click.style(
150 strutils.escape_control_characters(method),
151 fg=method_color,
152 bold=True
153 )
154 if ctx.options.showhost:
155 url = flow.request.pretty_url
156 else:
157 url = flow.request.url
158
159 if ctx.options.flow_detail <= 1:
160 # We need to truncate before applying styles, so we just focus on the URL.
161 terminal_width_limit = max(shutil.get_terminal_size()[0] - 25, 50)
162 if len(url) > terminal_width_limit:
163 url = url[:terminal_width_limit] + "…"
164 url = click.style(strutils.escape_control_characters(url), bold=True)
165
166 http_version = ""
167 if (
168 not (flow.request.is_http10 or flow.request.is_http11)
169 or flow.request.http_version != getattr(flow.response, "http_version", "HTTP/1.1")
170 ):
171 # Hide version for h1 <-> h1 connections.
172 http_version = " " + flow.request.http_version
173
174 self.echo(f"{client}: {method} {url}{http_version}")
175
176 def _echo_response_line(self, flow: http.HTTPFlow) -> None:
177 if flow.is_replay == "response":
178 replay_str = "[replay]"
179 replay = click.style(replay_str, fg="yellow", bold=True)
180 else:
181 replay_str = ""
182 replay = ""
183
184 assert flow.response
185 code_int = flow.response.status_code
186 code_color = None
187 if 200 <= code_int < 300:
188 code_color = "green"
189 elif 300 <= code_int < 400:
190 code_color = "magenta"
191 elif 400 <= code_int < 600:
192 code_color = "red"
193 code = click.style(
194 str(code_int),
195 fg=code_color,
196 bold=True,
197 blink=(code_int == 418),
198 )
199
200 if not flow.response.is_http2:
201 reason = flow.response.reason
202 else:
203 reason = http.status_codes.RESPONSES.get(flow.response.status_code, "")
204 reason = click.style(
205 strutils.escape_control_characters(reason),
206 fg=code_color,
207 bold=True
208 )
209
210 if flow.response.raw_content is None:
211 size = "(content missing)"
212 else:
213 size = human.pretty_size(len(flow.response.raw_content))
214 size = click.style(size, bold=True)
215
216 http_version = ""
217 if (
218 not (flow.response.is_http10 or flow.response.is_http11)
219 or flow.request.http_version != flow.response.http_version
220 ):
221 # Hide version for h1 <-> h1 connections.
222 http_version = f"{flow.response.http_version} "
223
224 arrows = click.style(" <<", bold=True)
225 if ctx.options.flow_detail == 1:
226 # This aligns the HTTP response code with the HTTP request method:
227 # 127.0.0.1:59519: GET http://example.com/
228 # << 304 Not Modified 0b
229 pad = max(0,
230 len(human.format_address(flow.client_conn.peername)) - (2 + len(http_version) + len(replay_str)))
231 arrows = " " * pad + arrows
232
233 self.echo(f"{replay}{arrows} {http_version}{code} {reason} {size}")
234
235 def echo_flow(self, f: http.HTTPFlow) -> None:
236 if f.request:
237 self._echo_request_line(f)
238 if ctx.options.flow_detail >= 2:
239 self._echo_headers(f.request.headers)
240 if ctx.options.flow_detail >= 3:
241 self._echo_message(f.request, f)
242 if ctx.options.flow_detail >= 2:
243 self._echo_trailers(f.request.trailers)
244
245 if f.response:
246 self._echo_response_line(f)
247 if ctx.options.flow_detail >= 2:
248 self._echo_headers(f.response.headers)
249 if ctx.options.flow_detail >= 3:
250 self._echo_message(f.response, f)
251 if ctx.options.flow_detail >= 2:
252 self._echo_trailers(f.response.trailers)
253
254 if f.error:
255 msg = strutils.escape_control_characters(f.error.msg)
256 self.echo(f" << {msg}", bold=True, fg="red")
257
258 def match(self, f):
259 if ctx.options.flow_detail == 0:
260 return False
261 if not self.filter:
262 return True
263 elif flowfilter.match(self.filter, f):
264 return True
265 return False
266
267 def response(self, f):
268 if self.match(f):
269 self.echo_flow(f)
270
271 def error(self, f):
272 if self.match(f):
273 self.echo_flow(f)
274
275 def websocket_message(self, f: http.HTTPFlow):
276 assert f.websocket is not None # satisfy type checker
277 if self.match(f):
278 message = f.websocket.messages[-1]
279
280 direction = "->" if message.from_client else "<-"
281 self.echo(
282 f"{human.format_address(f.client_conn.peername)} "
283 f"{direction} WebSocket {message.type.name.lower()} message "
284 f"{direction} {human.format_address(f.server_conn.address)}{f.request.path}"
285 )
286 if ctx.options.flow_detail >= 3:
287 self._echo_message(message, f)
288
289 def websocket_end(self, f: http.HTTPFlow):
290 assert f.websocket is not None # satisfy type checker
291 if self.match(f):
292 if f.websocket.close_code in {1000, 1001, 1005}:
293 c = 'client' if f.websocket.closed_by_client else 'server'
294 self.echo(f"WebSocket connection closed by {c}: {f.websocket.close_code} {f.websocket.close_reason}")
295 else:
296 error = flow.Error(f"WebSocket Error: {self.format_websocket_error(f.websocket)}")
297 self.echo(
298 f"Error in WebSocket connection to {human.format_address(f.server_conn.address)}: {error}",
299 fg="red"
300 )
301
302 def format_websocket_error(self, websocket: WebSocketData) -> str:
303 try:
304 ret = CloseReason(websocket.close_code).name
305 except ValueError:
306 ret = f"UNKNOWN_ERROR={websocket.close_code}"
307 if websocket.close_reason:
308 ret += f" (reason: {websocket.close_reason})"
309 return ret
310
311 def tcp_error(self, f):
312 if self.match(f):
313 self.echo(
314 f"Error in TCP connection to {human.format_address(f.server_conn.address)}: {f.error}",
315 fg="red"
316 )
317
318 def tcp_message(self, f):
319 if self.match(f):
320 message = f.messages[-1]
321 direction = "->" if message.from_client else "<-"
322 self.echo("{client} {direction} tcp {direction} {server}".format(
323 client=human.format_address(f.client_conn.peername),
324 server=human.format_address(f.server_conn.address),
325 direction=direction,
326 ))
327 if ctx.options.flow_detail >= 3:
328 self._echo_message(message, f)
329
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mitmproxy/addons/dumper.py b/mitmproxy/addons/dumper.py
--- a/mitmproxy/addons/dumper.py
+++ b/mitmproxy/addons/dumper.py
@@ -38,10 +38,10 @@
loader.add_option(
"flow_detail", int, 1,
"""
- The display detail level for flows in mitmdump: 0 (almost quiet) to 3 (very verbose).
- 0: shortened request URL, response status code, WebSocket and TCP message notifications.
- 1: full request URL with response status code
- 2: 1 + HTTP headers
+ The display detail level for flows in mitmdump: 0 (quiet) to 4 (very verbose).
+ 0: no output
+ 1: shortened request URL with response status code
+ 2: full request URL with response status code and HTTP headers
3: 2 + truncated response content, content of WebSocket and TCP messages
4: 3 + nothing is truncated
"""
@@ -156,7 +156,7 @@
else:
url = flow.request.url
- if ctx.options.flow_detail <= 1:
+ if ctx.options.flow_detail == 1:
# We need to truncate before applying styles, so we just focus on the URL.
terminal_width_limit = max(shutil.get_terminal_size()[0] - 25, 50)
if len(url) > terminal_width_limit:
|
{"golden_diff": "diff --git a/mitmproxy/addons/dumper.py b/mitmproxy/addons/dumper.py\n--- a/mitmproxy/addons/dumper.py\n+++ b/mitmproxy/addons/dumper.py\n@@ -38,10 +38,10 @@\n loader.add_option(\n \"flow_detail\", int, 1,\n \"\"\"\n- The display detail level for flows in mitmdump: 0 (almost quiet) to 3 (very verbose).\n- 0: shortened request URL, response status code, WebSocket and TCP message notifications.\n- 1: full request URL with response status code\n- 2: 1 + HTTP headers\n+ The display detail level for flows in mitmdump: 0 (quiet) to 4 (very verbose).\n+ 0: no output\n+ 1: shortened request URL with response status code\n+ 2: full request URL with response status code and HTTP headers\n 3: 2 + truncated response content, content of WebSocket and TCP messages\n 4: 3 + nothing is truncated\n \"\"\"\n@@ -156,7 +156,7 @@\n else:\n url = flow.request.url\n \n- if ctx.options.flow_detail <= 1:\n+ if ctx.options.flow_detail == 1:\n # We need to truncate before applying styles, so we just focus on the URL.\n terminal_width_limit = max(shutil.get_terminal_size()[0] - 25, 50)\n if len(url) > terminal_width_limit:\n", "issue": "Crash when invoking replay.server.count from console\n#### Problem Description\r\nInvoking `replay.server.count` from the console causes a crash. I don't think it happens all the time, but see below for repeatable reproduction.\r\n\r\n#### Steps to reproduce the behavior:\r\n1. Start `mitmproxy`\r\n2. Hit `n` to create a new flow\r\n3. Hit Enter\r\n4. Hit `r` to issue the request\r\n5. With the same flow selected, issue the command `:replay.server @focus`\r\n6. Issue the command `:replay.server.count`\r\n\r\nSample stack trace:\r\n```python\r\n File \"/home/elespike/venvs/mitmproxy/lib/python3.9/site-packages/mitmproxy/tools/console/grideditor/editors.py\", line 222, in __init__\r\n if not isinstance(vals[0], list):\r\nTypeError: 'int' object is not subscriptable\r\n```\r\n\r\n#### System Information\r\n```\r\nMitmproxy: 7.0.4\r\nPython: 3.9.2\r\n```\n", "before_files": [{"content": "import itertools\nimport shutil\nfrom typing import IO, Optional, Union\n\nimport click\n\nfrom mitmproxy import contentviews\nfrom mitmproxy import ctx\nfrom mitmproxy import exceptions\nfrom mitmproxy import flowfilter\nfrom mitmproxy import http\nfrom mitmproxy import flow\nfrom mitmproxy.tcp import TCPFlow, TCPMessage\nfrom mitmproxy.utils import human\nfrom mitmproxy.utils import strutils\nfrom mitmproxy.websocket import WebSocketMessage, WebSocketData\nfrom wsproto.frame_protocol import CloseReason\n\n\ndef indent(n: int, text: str) -> str:\n l = str(text).strip().splitlines()\n pad = \" \" * n\n return \"\\n\".join(pad + i for i in l)\n\n\ndef colorful(line, styles):\n yield \" \" # we can already indent here\n for (style, text) in line:\n yield click.style(text, **styles.get(style, {}))\n\n\nclass Dumper:\n def __init__(self, outfile=None):\n self.filter: Optional[flowfilter.TFilter] = None\n self.outfp: Optional[IO] = outfile\n\n def load(self, loader):\n loader.add_option(\n \"flow_detail\", int, 1,\n \"\"\"\n The display detail level for flows in mitmdump: 0 (almost quiet) to 3 (very verbose).\n 0: shortened request URL, response status code, WebSocket and TCP message notifications.\n 1: full request URL with response status code\n 2: 1 + HTTP headers\n 3: 2 + truncated response content, content of WebSocket and TCP messages\n 4: 3 + nothing is truncated\n \"\"\"\n )\n loader.add_option(\n \"dumper_default_contentview\", str, \"auto\",\n \"The default content view mode.\",\n choices=[i.name.lower() for i in contentviews.views]\n )\n loader.add_option(\n \"dumper_filter\", Optional[str], None,\n \"Limit which flows are dumped.\"\n )\n\n def configure(self, updated):\n if \"dumper_filter\" in updated:\n if ctx.options.dumper_filter:\n try:\n self.filter = flowfilter.parse(ctx.options.dumper_filter)\n except ValueError as e:\n raise exceptions.OptionsError(str(e)) from e\n else:\n self.filter = None\n\n def echo(self, text: str, ident=None, **style):\n if ident:\n text = indent(ident, text)\n click.secho(text, file=self.outfp, err=False, **style)\n if self.outfp:\n self.outfp.flush()\n\n def _echo_headers(self, headers: http.Headers):\n for k, v in headers.fields:\n ks = strutils.bytes_to_escaped_str(k)\n vs = strutils.bytes_to_escaped_str(v)\n out = \"{}: {}\".format(\n click.style(ks, fg=\"blue\"),\n click.style(vs)\n )\n self.echo(out, ident=4)\n\n def _echo_trailers(self, trailers: Optional[http.Headers]):\n if not trailers:\n return\n self.echo(click.style(\"--- HTTP Trailers\", fg=\"magenta\"), ident=4)\n self._echo_headers(trailers)\n\n def _echo_message(\n self,\n message: Union[http.Message, TCPMessage, WebSocketMessage],\n flow: Union[http.HTTPFlow, TCPFlow]\n ):\n _, lines, error = contentviews.get_message_content_view(\n ctx.options.dumper_default_contentview,\n message,\n flow\n )\n if error:\n ctx.log.debug(error)\n\n if ctx.options.flow_detail == 3:\n lines_to_echo = itertools.islice(lines, 70)\n else:\n lines_to_echo = lines\n\n styles = dict(\n highlight=dict(bold=True),\n offset=dict(fg=\"blue\"),\n header=dict(fg=\"green\", bold=True),\n text=dict(fg=\"green\")\n )\n\n content = \"\\r\\n\".join(\n \"\".join(colorful(line, styles)) for line in lines_to_echo\n )\n if content:\n self.echo(\"\")\n self.echo(content)\n\n if next(lines, None):\n self.echo(\"(cut off)\", ident=4, dim=True)\n\n if ctx.options.flow_detail >= 2:\n self.echo(\"\")\n\n def _echo_request_line(self, flow: http.HTTPFlow) -> None:\n if flow.is_replay == \"request\":\n client = click.style(\"[replay]\", fg=\"yellow\", bold=True)\n elif flow.client_conn.peername:\n client = click.style(\n strutils.escape_control_characters(\n human.format_address(flow.client_conn.peername)\n )\n )\n else: # pragma: no cover\n # this should not happen, but we're defensive here.\n client = \"\"\n\n pushed = ' PUSH_PROMISE' if 'h2-pushed-stream' in flow.metadata else ''\n method = flow.request.method + pushed\n method_color = dict(\n GET=\"green\",\n DELETE=\"red\"\n ).get(method.upper(), \"magenta\")\n method = click.style(\n strutils.escape_control_characters(method),\n fg=method_color,\n bold=True\n )\n if ctx.options.showhost:\n url = flow.request.pretty_url\n else:\n url = flow.request.url\n\n if ctx.options.flow_detail <= 1:\n # We need to truncate before applying styles, so we just focus on the URL.\n terminal_width_limit = max(shutil.get_terminal_size()[0] - 25, 50)\n if len(url) > terminal_width_limit:\n url = url[:terminal_width_limit] + \"\u2026\"\n url = click.style(strutils.escape_control_characters(url), bold=True)\n\n http_version = \"\"\n if (\n not (flow.request.is_http10 or flow.request.is_http11)\n or flow.request.http_version != getattr(flow.response, \"http_version\", \"HTTP/1.1\")\n ):\n # Hide version for h1 <-> h1 connections.\n http_version = \" \" + flow.request.http_version\n\n self.echo(f\"{client}: {method} {url}{http_version}\")\n\n def _echo_response_line(self, flow: http.HTTPFlow) -> None:\n if flow.is_replay == \"response\":\n replay_str = \"[replay]\"\n replay = click.style(replay_str, fg=\"yellow\", bold=True)\n else:\n replay_str = \"\"\n replay = \"\"\n\n assert flow.response\n code_int = flow.response.status_code\n code_color = None\n if 200 <= code_int < 300:\n code_color = \"green\"\n elif 300 <= code_int < 400:\n code_color = \"magenta\"\n elif 400 <= code_int < 600:\n code_color = \"red\"\n code = click.style(\n str(code_int),\n fg=code_color,\n bold=True,\n blink=(code_int == 418),\n )\n\n if not flow.response.is_http2:\n reason = flow.response.reason\n else:\n reason = http.status_codes.RESPONSES.get(flow.response.status_code, \"\")\n reason = click.style(\n strutils.escape_control_characters(reason),\n fg=code_color,\n bold=True\n )\n\n if flow.response.raw_content is None:\n size = \"(content missing)\"\n else:\n size = human.pretty_size(len(flow.response.raw_content))\n size = click.style(size, bold=True)\n\n http_version = \"\"\n if (\n not (flow.response.is_http10 or flow.response.is_http11)\n or flow.request.http_version != flow.response.http_version\n ):\n # Hide version for h1 <-> h1 connections.\n http_version = f\"{flow.response.http_version} \"\n\n arrows = click.style(\" <<\", bold=True)\n if ctx.options.flow_detail == 1:\n # This aligns the HTTP response code with the HTTP request method:\n # 127.0.0.1:59519: GET http://example.com/\n # << 304 Not Modified 0b\n pad = max(0,\n len(human.format_address(flow.client_conn.peername)) - (2 + len(http_version) + len(replay_str)))\n arrows = \" \" * pad + arrows\n\n self.echo(f\"{replay}{arrows} {http_version}{code} {reason} {size}\")\n\n def echo_flow(self, f: http.HTTPFlow) -> None:\n if f.request:\n self._echo_request_line(f)\n if ctx.options.flow_detail >= 2:\n self._echo_headers(f.request.headers)\n if ctx.options.flow_detail >= 3:\n self._echo_message(f.request, f)\n if ctx.options.flow_detail >= 2:\n self._echo_trailers(f.request.trailers)\n\n if f.response:\n self._echo_response_line(f)\n if ctx.options.flow_detail >= 2:\n self._echo_headers(f.response.headers)\n if ctx.options.flow_detail >= 3:\n self._echo_message(f.response, f)\n if ctx.options.flow_detail >= 2:\n self._echo_trailers(f.response.trailers)\n\n if f.error:\n msg = strutils.escape_control_characters(f.error.msg)\n self.echo(f\" << {msg}\", bold=True, fg=\"red\")\n\n def match(self, f):\n if ctx.options.flow_detail == 0:\n return False\n if not self.filter:\n return True\n elif flowfilter.match(self.filter, f):\n return True\n return False\n\n def response(self, f):\n if self.match(f):\n self.echo_flow(f)\n\n def error(self, f):\n if self.match(f):\n self.echo_flow(f)\n\n def websocket_message(self, f: http.HTTPFlow):\n assert f.websocket is not None # satisfy type checker\n if self.match(f):\n message = f.websocket.messages[-1]\n\n direction = \"->\" if message.from_client else \"<-\"\n self.echo(\n f\"{human.format_address(f.client_conn.peername)} \"\n f\"{direction} WebSocket {message.type.name.lower()} message \"\n f\"{direction} {human.format_address(f.server_conn.address)}{f.request.path}\"\n )\n if ctx.options.flow_detail >= 3:\n self._echo_message(message, f)\n\n def websocket_end(self, f: http.HTTPFlow):\n assert f.websocket is not None # satisfy type checker\n if self.match(f):\n if f.websocket.close_code in {1000, 1001, 1005}:\n c = 'client' if f.websocket.closed_by_client else 'server'\n self.echo(f\"WebSocket connection closed by {c}: {f.websocket.close_code} {f.websocket.close_reason}\")\n else:\n error = flow.Error(f\"WebSocket Error: {self.format_websocket_error(f.websocket)}\")\n self.echo(\n f\"Error in WebSocket connection to {human.format_address(f.server_conn.address)}: {error}\",\n fg=\"red\"\n )\n\n def format_websocket_error(self, websocket: WebSocketData) -> str:\n try:\n ret = CloseReason(websocket.close_code).name\n except ValueError:\n ret = f\"UNKNOWN_ERROR={websocket.close_code}\"\n if websocket.close_reason:\n ret += f\" (reason: {websocket.close_reason})\"\n return ret\n\n def tcp_error(self, f):\n if self.match(f):\n self.echo(\n f\"Error in TCP connection to {human.format_address(f.server_conn.address)}: {f.error}\",\n fg=\"red\"\n )\n\n def tcp_message(self, f):\n if self.match(f):\n message = f.messages[-1]\n direction = \"->\" if message.from_client else \"<-\"\n self.echo(\"{client} {direction} tcp {direction} {server}\".format(\n client=human.format_address(f.client_conn.peername),\n server=human.format_address(f.server_conn.address),\n direction=direction,\n ))\n if ctx.options.flow_detail >= 3:\n self._echo_message(message, f)\n", "path": "mitmproxy/addons/dumper.py"}], "after_files": [{"content": "import itertools\nimport shutil\nfrom typing import IO, Optional, Union\n\nimport click\n\nfrom mitmproxy import contentviews\nfrom mitmproxy import ctx\nfrom mitmproxy import exceptions\nfrom mitmproxy import flowfilter\nfrom mitmproxy import http\nfrom mitmproxy import flow\nfrom mitmproxy.tcp import TCPFlow, TCPMessage\nfrom mitmproxy.utils import human\nfrom mitmproxy.utils import strutils\nfrom mitmproxy.websocket import WebSocketMessage, WebSocketData\nfrom wsproto.frame_protocol import CloseReason\n\n\ndef indent(n: int, text: str) -> str:\n l = str(text).strip().splitlines()\n pad = \" \" * n\n return \"\\n\".join(pad + i for i in l)\n\n\ndef colorful(line, styles):\n yield \" \" # we can already indent here\n for (style, text) in line:\n yield click.style(text, **styles.get(style, {}))\n\n\nclass Dumper:\n def __init__(self, outfile=None):\n self.filter: Optional[flowfilter.TFilter] = None\n self.outfp: Optional[IO] = outfile\n\n def load(self, loader):\n loader.add_option(\n \"flow_detail\", int, 1,\n \"\"\"\n The display detail level for flows in mitmdump: 0 (quiet) to 4 (very verbose).\n 0: no output\n 1: shortened request URL with response status code\n 2: full request URL with response status code and HTTP headers\n 3: 2 + truncated response content, content of WebSocket and TCP messages\n 4: 3 + nothing is truncated\n \"\"\"\n )\n loader.add_option(\n \"dumper_default_contentview\", str, \"auto\",\n \"The default content view mode.\",\n choices=[i.name.lower() for i in contentviews.views]\n )\n loader.add_option(\n \"dumper_filter\", Optional[str], None,\n \"Limit which flows are dumped.\"\n )\n\n def configure(self, updated):\n if \"dumper_filter\" in updated:\n if ctx.options.dumper_filter:\n try:\n self.filter = flowfilter.parse(ctx.options.dumper_filter)\n except ValueError as e:\n raise exceptions.OptionsError(str(e)) from e\n else:\n self.filter = None\n\n def echo(self, text: str, ident=None, **style):\n if ident:\n text = indent(ident, text)\n click.secho(text, file=self.outfp, err=False, **style)\n if self.outfp:\n self.outfp.flush()\n\n def _echo_headers(self, headers: http.Headers):\n for k, v in headers.fields:\n ks = strutils.bytes_to_escaped_str(k)\n vs = strutils.bytes_to_escaped_str(v)\n out = \"{}: {}\".format(\n click.style(ks, fg=\"blue\"),\n click.style(vs)\n )\n self.echo(out, ident=4)\n\n def _echo_trailers(self, trailers: Optional[http.Headers]):\n if not trailers:\n return\n self.echo(click.style(\"--- HTTP Trailers\", fg=\"magenta\"), ident=4)\n self._echo_headers(trailers)\n\n def _echo_message(\n self,\n message: Union[http.Message, TCPMessage, WebSocketMessage],\n flow: Union[http.HTTPFlow, TCPFlow]\n ):\n _, lines, error = contentviews.get_message_content_view(\n ctx.options.dumper_default_contentview,\n message,\n flow\n )\n if error:\n ctx.log.debug(error)\n\n if ctx.options.flow_detail == 3:\n lines_to_echo = itertools.islice(lines, 70)\n else:\n lines_to_echo = lines\n\n styles = dict(\n highlight=dict(bold=True),\n offset=dict(fg=\"blue\"),\n header=dict(fg=\"green\", bold=True),\n text=dict(fg=\"green\")\n )\n\n content = \"\\r\\n\".join(\n \"\".join(colorful(line, styles)) for line in lines_to_echo\n )\n if content:\n self.echo(\"\")\n self.echo(content)\n\n if next(lines, None):\n self.echo(\"(cut off)\", ident=4, dim=True)\n\n if ctx.options.flow_detail >= 2:\n self.echo(\"\")\n\n def _echo_request_line(self, flow: http.HTTPFlow) -> None:\n if flow.is_replay == \"request\":\n client = click.style(\"[replay]\", fg=\"yellow\", bold=True)\n elif flow.client_conn.peername:\n client = click.style(\n strutils.escape_control_characters(\n human.format_address(flow.client_conn.peername)\n )\n )\n else: # pragma: no cover\n # this should not happen, but we're defensive here.\n client = \"\"\n\n pushed = ' PUSH_PROMISE' if 'h2-pushed-stream' in flow.metadata else ''\n method = flow.request.method + pushed\n method_color = dict(\n GET=\"green\",\n DELETE=\"red\"\n ).get(method.upper(), \"magenta\")\n method = click.style(\n strutils.escape_control_characters(method),\n fg=method_color,\n bold=True\n )\n if ctx.options.showhost:\n url = flow.request.pretty_url\n else:\n url = flow.request.url\n\n if ctx.options.flow_detail == 1:\n # We need to truncate before applying styles, so we just focus on the URL.\n terminal_width_limit = max(shutil.get_terminal_size()[0] - 25, 50)\n if len(url) > terminal_width_limit:\n url = url[:terminal_width_limit] + \"\u2026\"\n url = click.style(strutils.escape_control_characters(url), bold=True)\n\n http_version = \"\"\n if (\n not (flow.request.is_http10 or flow.request.is_http11)\n or flow.request.http_version != getattr(flow.response, \"http_version\", \"HTTP/1.1\")\n ):\n # Hide version for h1 <-> h1 connections.\n http_version = \" \" + flow.request.http_version\n\n self.echo(f\"{client}: {method} {url}{http_version}\")\n\n def _echo_response_line(self, flow: http.HTTPFlow) -> None:\n if flow.is_replay == \"response\":\n replay_str = \"[replay]\"\n replay = click.style(replay_str, fg=\"yellow\", bold=True)\n else:\n replay_str = \"\"\n replay = \"\"\n\n assert flow.response\n code_int = flow.response.status_code\n code_color = None\n if 200 <= code_int < 300:\n code_color = \"green\"\n elif 300 <= code_int < 400:\n code_color = \"magenta\"\n elif 400 <= code_int < 600:\n code_color = \"red\"\n code = click.style(\n str(code_int),\n fg=code_color,\n bold=True,\n blink=(code_int == 418),\n )\n\n if not flow.response.is_http2:\n reason = flow.response.reason\n else:\n reason = http.status_codes.RESPONSES.get(flow.response.status_code, \"\")\n reason = click.style(\n strutils.escape_control_characters(reason),\n fg=code_color,\n bold=True\n )\n\n if flow.response.raw_content is None:\n size = \"(content missing)\"\n else:\n size = human.pretty_size(len(flow.response.raw_content))\n size = click.style(size, bold=True)\n\n http_version = \"\"\n if (\n not (flow.response.is_http10 or flow.response.is_http11)\n or flow.request.http_version != flow.response.http_version\n ):\n # Hide version for h1 <-> h1 connections.\n http_version = f\"{flow.response.http_version} \"\n\n arrows = click.style(\" <<\", bold=True)\n if ctx.options.flow_detail == 1:\n # This aligns the HTTP response code with the HTTP request method:\n # 127.0.0.1:59519: GET http://example.com/\n # << 304 Not Modified 0b\n pad = max(0,\n len(human.format_address(flow.client_conn.peername)) - (2 + len(http_version) + len(replay_str)))\n arrows = \" \" * pad + arrows\n\n self.echo(f\"{replay}{arrows} {http_version}{code} {reason} {size}\")\n\n def echo_flow(self, f: http.HTTPFlow) -> None:\n if f.request:\n self._echo_request_line(f)\n if ctx.options.flow_detail >= 2:\n self._echo_headers(f.request.headers)\n if ctx.options.flow_detail >= 3:\n self._echo_message(f.request, f)\n if ctx.options.flow_detail >= 2:\n self._echo_trailers(f.request.trailers)\n\n if f.response:\n self._echo_response_line(f)\n if ctx.options.flow_detail >= 2:\n self._echo_headers(f.response.headers)\n if ctx.options.flow_detail >= 3:\n self._echo_message(f.response, f)\n if ctx.options.flow_detail >= 2:\n self._echo_trailers(f.response.trailers)\n\n if f.error:\n msg = strutils.escape_control_characters(f.error.msg)\n self.echo(f\" << {msg}\", bold=True, fg=\"red\")\n\n def match(self, f):\n if ctx.options.flow_detail == 0:\n return False\n if not self.filter:\n return True\n elif flowfilter.match(self.filter, f):\n return True\n return False\n\n def response(self, f):\n if self.match(f):\n self.echo_flow(f)\n\n def error(self, f):\n if self.match(f):\n self.echo_flow(f)\n\n def websocket_message(self, f: http.HTTPFlow):\n assert f.websocket is not None # satisfy type checker\n if self.match(f):\n message = f.websocket.messages[-1]\n\n direction = \"->\" if message.from_client else \"<-\"\n self.echo(\n f\"{human.format_address(f.client_conn.peername)} \"\n f\"{direction} WebSocket {message.type.name.lower()} message \"\n f\"{direction} {human.format_address(f.server_conn.address)}{f.request.path}\"\n )\n if ctx.options.flow_detail >= 3:\n self._echo_message(message, f)\n\n def websocket_end(self, f: http.HTTPFlow):\n assert f.websocket is not None # satisfy type checker\n if self.match(f):\n if f.websocket.close_code in {1000, 1001, 1005}:\n c = 'client' if f.websocket.closed_by_client else 'server'\n self.echo(f\"WebSocket connection closed by {c}: {f.websocket.close_code} {f.websocket.close_reason}\")\n else:\n error = flow.Error(f\"WebSocket Error: {self.format_websocket_error(f.websocket)}\")\n self.echo(\n f\"Error in WebSocket connection to {human.format_address(f.server_conn.address)}: {error}\",\n fg=\"red\"\n )\n\n def format_websocket_error(self, websocket: WebSocketData) -> str:\n try:\n ret = CloseReason(websocket.close_code).name\n except ValueError:\n ret = f\"UNKNOWN_ERROR={websocket.close_code}\"\n if websocket.close_reason:\n ret += f\" (reason: {websocket.close_reason})\"\n return ret\n\n def tcp_error(self, f):\n if self.match(f):\n self.echo(\n f\"Error in TCP connection to {human.format_address(f.server_conn.address)}: {f.error}\",\n fg=\"red\"\n )\n\n def tcp_message(self, f):\n if self.match(f):\n message = f.messages[-1]\n direction = \"->\" if message.from_client else \"<-\"\n self.echo(\"{client} {direction} tcp {direction} {server}\".format(\n client=human.format_address(f.client_conn.peername),\n server=human.format_address(f.server_conn.address),\n direction=direction,\n ))\n if ctx.options.flow_detail >= 3:\n self._echo_message(message, f)\n", "path": "mitmproxy/addons/dumper.py"}]}
| 3,978 | 334 |
gh_patches_debug_6042
|
rasdani/github-patches
|
git_diff
|
saleor__saleor-4802
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Wrong AddressForm for Ireland
### What I'm trying to achieve
I tried to use address form validation for Ireland. Unfortunately, our API returns for that country that `country_area` is not required, but `AddressFormIE` requires it.
### Steps to reproduce the problem
1. Send `CheckoutShippingAddressUpdate` without `country_area` - API returns validation error.
Another way to expect that problem is adding `IE` to the `test_address_form_for_country` test function - it fails.
### What I expected to happen
API and form validation should be consistent - if `i18naddress` says that field is not required, it is not required.
### Screenshots
<!-- If applicable, add screenshots to help explain your problem. -->
n/a
**System information**
Operating system: n/a
Browser: n/a
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `saleor/account/i18n.py`
Content:
```
1 from collections import defaultdict
2
3 import i18naddress
4 from django import forms
5 from django.core.exceptions import ValidationError
6 from django.forms.forms import BoundField
7 from django.utils.translation import pgettext_lazy
8 from django_countries import countries
9
10 from .models import Address
11 from .validators import validate_possible_number
12 from .widgets import DatalistTextWidget, PhonePrefixWidget
13
14 COUNTRY_FORMS = {}
15 UNKNOWN_COUNTRIES = set()
16
17 AREA_TYPE_TRANSLATIONS = {
18 "area": pgettext_lazy("Address field", "Area"),
19 "county": pgettext_lazy("Address field", "County"),
20 "department": pgettext_lazy("Address field", "Department"),
21 "district": pgettext_lazy("Address field", "District"),
22 "do_si": pgettext_lazy("Address field", "Do/si"),
23 "eircode": pgettext_lazy("Address field", "Eircode"),
24 "emirate": pgettext_lazy("Address field", "Emirate"),
25 "island": pgettext_lazy("Address field", "Island"),
26 "neighborhood": pgettext_lazy("Address field", "Neighborhood"),
27 "oblast": pgettext_lazy("Address field", "Oblast"),
28 "parish": pgettext_lazy("Address field", "Parish"),
29 "pin": pgettext_lazy("Address field", "PIN"),
30 "postal": pgettext_lazy("Address field", "Postal code"),
31 "prefecture": pgettext_lazy("Address field", "Prefecture"),
32 "province": pgettext_lazy("Address field", "Province"),
33 "state": pgettext_lazy("Address field", "State"),
34 "suburb": pgettext_lazy("Address field", "Suburb"),
35 "townland": pgettext_lazy("Address field", "Townland"),
36 "village_township": pgettext_lazy("Address field", "Village/township"),
37 "zip": pgettext_lazy("Address field", "ZIP code"),
38 }
39
40
41 class PossiblePhoneNumberFormField(forms.CharField):
42 """A phone input field."""
43
44 def __init__(self, *args, **kwargs):
45 super().__init__(*args, **kwargs)
46 self.widget.input_type = "tel"
47
48
49 class CountryAreaChoiceField(forms.ChoiceField):
50 widget = DatalistTextWidget
51
52 def valid_value(self, value):
53 return True
54
55
56 class AddressMetaForm(forms.ModelForm):
57 # This field is never visible in UI
58 preview = forms.BooleanField(initial=False, required=False)
59
60 class Meta:
61 model = Address
62 fields = ["country", "preview"]
63 labels = {"country": pgettext_lazy("Country", "Country")}
64
65 def clean(self):
66 data = super().clean()
67 if data.get("preview"):
68 self.data = self.data.copy()
69 self.data["preview"] = False
70 return data
71
72
73 class AddressForm(forms.ModelForm):
74
75 AUTOCOMPLETE_MAPPING = [
76 ("first_name", "given-name"),
77 ("last_name", "family-name"),
78 ("company_name", "organization"),
79 ("street_address_1", "address-line1"),
80 ("street_address_2", "address-line2"),
81 ("city", "address-level2"),
82 ("postal_code", "postal-code"),
83 ("country_area", "address-level1"),
84 ("country", "country"),
85 ("city_area", "address-level3"),
86 ("phone", "tel"),
87 ("email", "email"),
88 ]
89
90 class Meta:
91 model = Address
92 exclude = []
93 labels = {
94 "first_name": pgettext_lazy("Personal name", "Given name"),
95 "last_name": pgettext_lazy("Personal name", "Family name"),
96 "company_name": pgettext_lazy(
97 "Company or organization", "Company or organization"
98 ),
99 "street_address_1": pgettext_lazy("Address", "Address"),
100 "street_address_2": "",
101 "city": pgettext_lazy("City", "City"),
102 "city_area": pgettext_lazy("City area", "District"),
103 "postal_code": pgettext_lazy("Postal code", "Postal code"),
104 "country": pgettext_lazy("Country", "Country"),
105 "country_area": pgettext_lazy("Country area", "State or province"),
106 "phone": pgettext_lazy("Phone number", "Phone number"),
107 }
108 placeholders = {
109 "street_address_1": pgettext_lazy(
110 "Address", "Street address, P.O. box, company name"
111 ),
112 "street_address_2": pgettext_lazy(
113 "Address", "Apartment, suite, unit, building, floor, etc"
114 ),
115 }
116
117 phone = PossiblePhoneNumberFormField(widget=PhonePrefixWidget, required=False)
118
119 def __init__(self, *args, **kwargs):
120 autocomplete_type = kwargs.pop("autocomplete_type", None)
121 super().__init__(*args, **kwargs)
122 # countries order was taken as defined in the model,
123 # not being sorted accordingly to the selected language
124 self.fields["country"].choices = sorted(
125 COUNTRY_CHOICES, key=lambda choice: choice[1]
126 )
127 autocomplete_dict = defaultdict(lambda: "off", self.AUTOCOMPLETE_MAPPING)
128 for field_name, field in self.fields.items():
129 if autocomplete_type:
130 autocomplete = "%s %s" % (
131 autocomplete_type,
132 autocomplete_dict[field_name],
133 )
134 else:
135 autocomplete = autocomplete_dict[field_name]
136 field.widget.attrs["autocomplete"] = autocomplete
137 field.widget.attrs["placeholder"] = (
138 field.label if not hasattr(field, "placeholder") else field.placeholder
139 )
140
141 def clean(self):
142 data = super().clean()
143 phone = data.get("phone")
144 country = data.get("country")
145 if phone:
146 try:
147 data["phone"] = validate_possible_number(phone, country)
148 except forms.ValidationError as error:
149 self.add_error("phone", error)
150 return data
151
152
153 class CountryAwareAddressForm(AddressForm):
154
155 I18N_MAPPING = [
156 ("name", ["first_name", "last_name"]),
157 ("street_address", ["street_address_1", "street_address_2"]),
158 ("city_area", ["city_area"]),
159 ("country_area", ["country_area"]),
160 ("company_name", ["company_name"]),
161 ("postal_code", ["postal_code"]),
162 ("city", ["city"]),
163 ("sorting_code", []),
164 ("country_code", ["country"]),
165 ]
166
167 class Meta:
168 model = Address
169 exclude = []
170
171 def add_field_errors(self, errors):
172 field_mapping = dict(self.I18N_MAPPING)
173 for field_name, error_code in errors.items():
174 local_fields = field_mapping[field_name]
175 for field in local_fields:
176 try:
177 error_msg = self.fields[field].error_messages[error_code]
178 except KeyError:
179 error_msg = pgettext_lazy(
180 "Address form", "This value is invalid for selected country"
181 )
182 self.add_error(field, ValidationError(error_msg, code=error_code))
183
184 def validate_address(self, data):
185 try:
186 data["country_code"] = data.get("country", "")
187 if data["street_address_1"] or data["street_address_2"]:
188 data["street_address"] = "%s\n%s" % (
189 data["street_address_1"],
190 data["street_address_2"],
191 )
192 data = i18naddress.normalize_address(data)
193 del data["sorting_code"]
194 except i18naddress.InvalidAddress as exc:
195 self.add_field_errors(exc.errors)
196 return data
197
198 def clean(self):
199 data = super().clean()
200 return self.validate_address(data)
201
202
203 def get_address_form_class(country_code):
204 return COUNTRY_FORMS[country_code]
205
206
207 def get_form_i18n_lines(form_instance):
208 country_code = form_instance.i18n_country_code
209 try:
210 fields_order = i18naddress.get_field_order({"country_code": country_code})
211 except ValueError:
212 fields_order = i18naddress.get_field_order({})
213 field_mapping = dict(form_instance.I18N_MAPPING)
214
215 def _convert_to_bound_fields(form, i18n_field_names):
216 bound_fields = []
217 for field_name in i18n_field_names:
218 local_fields = field_mapping[field_name]
219 for local_name in local_fields:
220 local_field = form_instance.fields[local_name]
221 bound_field = BoundField(form, local_field, local_name)
222 bound_fields.append(bound_field)
223 return bound_fields
224
225 if fields_order:
226 return [_convert_to_bound_fields(form_instance, line) for line in fields_order]
227
228
229 def update_base_fields(form_class, i18n_rules):
230 for field_name, label_value in AddressForm.Meta.labels.items():
231 field = form_class.base_fields[field_name]
232 field.label = label_value
233
234 for field_name, placeholder_value in AddressForm.Meta.placeholders.items():
235 field = form_class.base_fields[field_name]
236 field.placeholder = placeholder_value
237
238 if i18n_rules.country_area_choices:
239 form_class.base_fields["country_area"] = CountryAreaChoiceField(
240 choices=i18n_rules.country_area_choices
241 )
242
243 labels_map = {
244 "country_area": i18n_rules.country_area_type,
245 "postal_code": i18n_rules.postal_code_type,
246 "city_area": i18n_rules.city_area_type,
247 }
248
249 for field_name, area_type in labels_map.items():
250 field = form_class.base_fields[field_name]
251 field.label = AREA_TYPE_TRANSLATIONS[area_type]
252
253 hidden_fields = i18naddress.KNOWN_FIELDS - i18n_rules.allowed_fields
254 for field_name in hidden_fields:
255 if field_name in form_class.base_fields:
256 form_class.base_fields[field_name].widget = forms.HiddenInput()
257
258 country_field = form_class.base_fields["country"]
259 country_field.choices = COUNTRY_CHOICES
260
261
262 def construct_address_form(country_code, i18n_rules):
263 class_name = "AddressForm%s" % country_code
264 base_class = CountryAwareAddressForm
265 form_kwargs = {
266 "Meta": type(str("Meta"), (base_class.Meta, object), {}),
267 "formfield_callback": None,
268 }
269 class_ = type(base_class)(str(class_name), (base_class,), form_kwargs)
270 update_base_fields(class_, i18n_rules)
271 class_.i18n_country_code = country_code
272 class_.i18n_fields_order = property(get_form_i18n_lines)
273 return class_
274
275
276 for country in countries.countries.keys():
277 try:
278 country_rules = i18naddress.get_validation_rules({"country_code": country})
279 except ValueError:
280 country_rules = i18naddress.get_validation_rules({})
281 UNKNOWN_COUNTRIES.add(country)
282
283 COUNTRY_CHOICES = [
284 (code, label)
285 for code, label in countries.countries.items()
286 if code not in UNKNOWN_COUNTRIES
287 ]
288 # Sort choices list by country name
289 COUNTRY_CHOICES = sorted(COUNTRY_CHOICES, key=lambda choice: choice[1])
290
291 for country, label in COUNTRY_CHOICES:
292 country_rules = i18naddress.get_validation_rules({"country_code": country})
293 COUNTRY_FORMS[country] = construct_address_form(country, country_rules)
294
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/saleor/account/i18n.py b/saleor/account/i18n.py
--- a/saleor/account/i18n.py
+++ b/saleor/account/i18n.py
@@ -236,8 +236,9 @@
field.placeholder = placeholder_value
if i18n_rules.country_area_choices:
+ required = "country_area" in i18n_rules.required_fields
form_class.base_fields["country_area"] = CountryAreaChoiceField(
- choices=i18n_rules.country_area_choices
+ choices=i18n_rules.country_area_choices, required=required
)
labels_map = {
|
{"golden_diff": "diff --git a/saleor/account/i18n.py b/saleor/account/i18n.py\n--- a/saleor/account/i18n.py\n+++ b/saleor/account/i18n.py\n@@ -236,8 +236,9 @@\n field.placeholder = placeholder_value\n \n if i18n_rules.country_area_choices:\n+ required = \"country_area\" in i18n_rules.required_fields\n form_class.base_fields[\"country_area\"] = CountryAreaChoiceField(\n- choices=i18n_rules.country_area_choices\n+ choices=i18n_rules.country_area_choices, required=required\n )\n \n labels_map = {\n", "issue": "Wrong AddressForm for Ireland\n### What I'm trying to achieve\r\nI tried to use address form validation for Ireland. Unfortunately, our API returns for that country that `country_area` is not required, but `AddressFormIE` requires it. \r\n\r\n### Steps to reproduce the problem\r\n1. Send `CheckoutShippingAddressUpdate` without `country_area` - API returns validation error.\r\n\r\nAnother way to expect that problem is adding `IE` to the `test_address_form_for_country` test function - it fails.\r\n\r\n### What I expected to happen\r\nAPI and form validation should be consistent - if `i18naddress` says that field is not required, it is not required.\r\n\r\n### Screenshots\r\n<!-- If applicable, add screenshots to help explain your problem. -->\r\nn/a\r\n\r\n**System information**\r\nOperating system: n/a\r\nBrowser: n/a\r\n\n", "before_files": [{"content": "from collections import defaultdict\n\nimport i18naddress\nfrom django import forms\nfrom django.core.exceptions import ValidationError\nfrom django.forms.forms import BoundField\nfrom django.utils.translation import pgettext_lazy\nfrom django_countries import countries\n\nfrom .models import Address\nfrom .validators import validate_possible_number\nfrom .widgets import DatalistTextWidget, PhonePrefixWidget\n\nCOUNTRY_FORMS = {}\nUNKNOWN_COUNTRIES = set()\n\nAREA_TYPE_TRANSLATIONS = {\n \"area\": pgettext_lazy(\"Address field\", \"Area\"),\n \"county\": pgettext_lazy(\"Address field\", \"County\"),\n \"department\": pgettext_lazy(\"Address field\", \"Department\"),\n \"district\": pgettext_lazy(\"Address field\", \"District\"),\n \"do_si\": pgettext_lazy(\"Address field\", \"Do/si\"),\n \"eircode\": pgettext_lazy(\"Address field\", \"Eircode\"),\n \"emirate\": pgettext_lazy(\"Address field\", \"Emirate\"),\n \"island\": pgettext_lazy(\"Address field\", \"Island\"),\n \"neighborhood\": pgettext_lazy(\"Address field\", \"Neighborhood\"),\n \"oblast\": pgettext_lazy(\"Address field\", \"Oblast\"),\n \"parish\": pgettext_lazy(\"Address field\", \"Parish\"),\n \"pin\": pgettext_lazy(\"Address field\", \"PIN\"),\n \"postal\": pgettext_lazy(\"Address field\", \"Postal code\"),\n \"prefecture\": pgettext_lazy(\"Address field\", \"Prefecture\"),\n \"province\": pgettext_lazy(\"Address field\", \"Province\"),\n \"state\": pgettext_lazy(\"Address field\", \"State\"),\n \"suburb\": pgettext_lazy(\"Address field\", \"Suburb\"),\n \"townland\": pgettext_lazy(\"Address field\", \"Townland\"),\n \"village_township\": pgettext_lazy(\"Address field\", \"Village/township\"),\n \"zip\": pgettext_lazy(\"Address field\", \"ZIP code\"),\n}\n\n\nclass PossiblePhoneNumberFormField(forms.CharField):\n \"\"\"A phone input field.\"\"\"\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.widget.input_type = \"tel\"\n\n\nclass CountryAreaChoiceField(forms.ChoiceField):\n widget = DatalistTextWidget\n\n def valid_value(self, value):\n return True\n\n\nclass AddressMetaForm(forms.ModelForm):\n # This field is never visible in UI\n preview = forms.BooleanField(initial=False, required=False)\n\n class Meta:\n model = Address\n fields = [\"country\", \"preview\"]\n labels = {\"country\": pgettext_lazy(\"Country\", \"Country\")}\n\n def clean(self):\n data = super().clean()\n if data.get(\"preview\"):\n self.data = self.data.copy()\n self.data[\"preview\"] = False\n return data\n\n\nclass AddressForm(forms.ModelForm):\n\n AUTOCOMPLETE_MAPPING = [\n (\"first_name\", \"given-name\"),\n (\"last_name\", \"family-name\"),\n (\"company_name\", \"organization\"),\n (\"street_address_1\", \"address-line1\"),\n (\"street_address_2\", \"address-line2\"),\n (\"city\", \"address-level2\"),\n (\"postal_code\", \"postal-code\"),\n (\"country_area\", \"address-level1\"),\n (\"country\", \"country\"),\n (\"city_area\", \"address-level3\"),\n (\"phone\", \"tel\"),\n (\"email\", \"email\"),\n ]\n\n class Meta:\n model = Address\n exclude = []\n labels = {\n \"first_name\": pgettext_lazy(\"Personal name\", \"Given name\"),\n \"last_name\": pgettext_lazy(\"Personal name\", \"Family name\"),\n \"company_name\": pgettext_lazy(\n \"Company or organization\", \"Company or organization\"\n ),\n \"street_address_1\": pgettext_lazy(\"Address\", \"Address\"),\n \"street_address_2\": \"\",\n \"city\": pgettext_lazy(\"City\", \"City\"),\n \"city_area\": pgettext_lazy(\"City area\", \"District\"),\n \"postal_code\": pgettext_lazy(\"Postal code\", \"Postal code\"),\n \"country\": pgettext_lazy(\"Country\", \"Country\"),\n \"country_area\": pgettext_lazy(\"Country area\", \"State or province\"),\n \"phone\": pgettext_lazy(\"Phone number\", \"Phone number\"),\n }\n placeholders = {\n \"street_address_1\": pgettext_lazy(\n \"Address\", \"Street address, P.O. box, company name\"\n ),\n \"street_address_2\": pgettext_lazy(\n \"Address\", \"Apartment, suite, unit, building, floor, etc\"\n ),\n }\n\n phone = PossiblePhoneNumberFormField(widget=PhonePrefixWidget, required=False)\n\n def __init__(self, *args, **kwargs):\n autocomplete_type = kwargs.pop(\"autocomplete_type\", None)\n super().__init__(*args, **kwargs)\n # countries order was taken as defined in the model,\n # not being sorted accordingly to the selected language\n self.fields[\"country\"].choices = sorted(\n COUNTRY_CHOICES, key=lambda choice: choice[1]\n )\n autocomplete_dict = defaultdict(lambda: \"off\", self.AUTOCOMPLETE_MAPPING)\n for field_name, field in self.fields.items():\n if autocomplete_type:\n autocomplete = \"%s %s\" % (\n autocomplete_type,\n autocomplete_dict[field_name],\n )\n else:\n autocomplete = autocomplete_dict[field_name]\n field.widget.attrs[\"autocomplete\"] = autocomplete\n field.widget.attrs[\"placeholder\"] = (\n field.label if not hasattr(field, \"placeholder\") else field.placeholder\n )\n\n def clean(self):\n data = super().clean()\n phone = data.get(\"phone\")\n country = data.get(\"country\")\n if phone:\n try:\n data[\"phone\"] = validate_possible_number(phone, country)\n except forms.ValidationError as error:\n self.add_error(\"phone\", error)\n return data\n\n\nclass CountryAwareAddressForm(AddressForm):\n\n I18N_MAPPING = [\n (\"name\", [\"first_name\", \"last_name\"]),\n (\"street_address\", [\"street_address_1\", \"street_address_2\"]),\n (\"city_area\", [\"city_area\"]),\n (\"country_area\", [\"country_area\"]),\n (\"company_name\", [\"company_name\"]),\n (\"postal_code\", [\"postal_code\"]),\n (\"city\", [\"city\"]),\n (\"sorting_code\", []),\n (\"country_code\", [\"country\"]),\n ]\n\n class Meta:\n model = Address\n exclude = []\n\n def add_field_errors(self, errors):\n field_mapping = dict(self.I18N_MAPPING)\n for field_name, error_code in errors.items():\n local_fields = field_mapping[field_name]\n for field in local_fields:\n try:\n error_msg = self.fields[field].error_messages[error_code]\n except KeyError:\n error_msg = pgettext_lazy(\n \"Address form\", \"This value is invalid for selected country\"\n )\n self.add_error(field, ValidationError(error_msg, code=error_code))\n\n def validate_address(self, data):\n try:\n data[\"country_code\"] = data.get(\"country\", \"\")\n if data[\"street_address_1\"] or data[\"street_address_2\"]:\n data[\"street_address\"] = \"%s\\n%s\" % (\n data[\"street_address_1\"],\n data[\"street_address_2\"],\n )\n data = i18naddress.normalize_address(data)\n del data[\"sorting_code\"]\n except i18naddress.InvalidAddress as exc:\n self.add_field_errors(exc.errors)\n return data\n\n def clean(self):\n data = super().clean()\n return self.validate_address(data)\n\n\ndef get_address_form_class(country_code):\n return COUNTRY_FORMS[country_code]\n\n\ndef get_form_i18n_lines(form_instance):\n country_code = form_instance.i18n_country_code\n try:\n fields_order = i18naddress.get_field_order({\"country_code\": country_code})\n except ValueError:\n fields_order = i18naddress.get_field_order({})\n field_mapping = dict(form_instance.I18N_MAPPING)\n\n def _convert_to_bound_fields(form, i18n_field_names):\n bound_fields = []\n for field_name in i18n_field_names:\n local_fields = field_mapping[field_name]\n for local_name in local_fields:\n local_field = form_instance.fields[local_name]\n bound_field = BoundField(form, local_field, local_name)\n bound_fields.append(bound_field)\n return bound_fields\n\n if fields_order:\n return [_convert_to_bound_fields(form_instance, line) for line in fields_order]\n\n\ndef update_base_fields(form_class, i18n_rules):\n for field_name, label_value in AddressForm.Meta.labels.items():\n field = form_class.base_fields[field_name]\n field.label = label_value\n\n for field_name, placeholder_value in AddressForm.Meta.placeholders.items():\n field = form_class.base_fields[field_name]\n field.placeholder = placeholder_value\n\n if i18n_rules.country_area_choices:\n form_class.base_fields[\"country_area\"] = CountryAreaChoiceField(\n choices=i18n_rules.country_area_choices\n )\n\n labels_map = {\n \"country_area\": i18n_rules.country_area_type,\n \"postal_code\": i18n_rules.postal_code_type,\n \"city_area\": i18n_rules.city_area_type,\n }\n\n for field_name, area_type in labels_map.items():\n field = form_class.base_fields[field_name]\n field.label = AREA_TYPE_TRANSLATIONS[area_type]\n\n hidden_fields = i18naddress.KNOWN_FIELDS - i18n_rules.allowed_fields\n for field_name in hidden_fields:\n if field_name in form_class.base_fields:\n form_class.base_fields[field_name].widget = forms.HiddenInput()\n\n country_field = form_class.base_fields[\"country\"]\n country_field.choices = COUNTRY_CHOICES\n\n\ndef construct_address_form(country_code, i18n_rules):\n class_name = \"AddressForm%s\" % country_code\n base_class = CountryAwareAddressForm\n form_kwargs = {\n \"Meta\": type(str(\"Meta\"), (base_class.Meta, object), {}),\n \"formfield_callback\": None,\n }\n class_ = type(base_class)(str(class_name), (base_class,), form_kwargs)\n update_base_fields(class_, i18n_rules)\n class_.i18n_country_code = country_code\n class_.i18n_fields_order = property(get_form_i18n_lines)\n return class_\n\n\nfor country in countries.countries.keys():\n try:\n country_rules = i18naddress.get_validation_rules({\"country_code\": country})\n except ValueError:\n country_rules = i18naddress.get_validation_rules({})\n UNKNOWN_COUNTRIES.add(country)\n\nCOUNTRY_CHOICES = [\n (code, label)\n for code, label in countries.countries.items()\n if code not in UNKNOWN_COUNTRIES\n]\n# Sort choices list by country name\nCOUNTRY_CHOICES = sorted(COUNTRY_CHOICES, key=lambda choice: choice[1])\n\nfor country, label in COUNTRY_CHOICES:\n country_rules = i18naddress.get_validation_rules({\"country_code\": country})\n COUNTRY_FORMS[country] = construct_address_form(country, country_rules)\n", "path": "saleor/account/i18n.py"}], "after_files": [{"content": "from collections import defaultdict\n\nimport i18naddress\nfrom django import forms\nfrom django.core.exceptions import ValidationError\nfrom django.forms.forms import BoundField\nfrom django.utils.translation import pgettext_lazy\nfrom django_countries import countries\n\nfrom .models import Address\nfrom .validators import validate_possible_number\nfrom .widgets import DatalistTextWidget, PhonePrefixWidget\n\nCOUNTRY_FORMS = {}\nUNKNOWN_COUNTRIES = set()\n\nAREA_TYPE_TRANSLATIONS = {\n \"area\": pgettext_lazy(\"Address field\", \"Area\"),\n \"county\": pgettext_lazy(\"Address field\", \"County\"),\n \"department\": pgettext_lazy(\"Address field\", \"Department\"),\n \"district\": pgettext_lazy(\"Address field\", \"District\"),\n \"do_si\": pgettext_lazy(\"Address field\", \"Do/si\"),\n \"eircode\": pgettext_lazy(\"Address field\", \"Eircode\"),\n \"emirate\": pgettext_lazy(\"Address field\", \"Emirate\"),\n \"island\": pgettext_lazy(\"Address field\", \"Island\"),\n \"neighborhood\": pgettext_lazy(\"Address field\", \"Neighborhood\"),\n \"oblast\": pgettext_lazy(\"Address field\", \"Oblast\"),\n \"parish\": pgettext_lazy(\"Address field\", \"Parish\"),\n \"pin\": pgettext_lazy(\"Address field\", \"PIN\"),\n \"postal\": pgettext_lazy(\"Address field\", \"Postal code\"),\n \"prefecture\": pgettext_lazy(\"Address field\", \"Prefecture\"),\n \"province\": pgettext_lazy(\"Address field\", \"Province\"),\n \"state\": pgettext_lazy(\"Address field\", \"State\"),\n \"suburb\": pgettext_lazy(\"Address field\", \"Suburb\"),\n \"townland\": pgettext_lazy(\"Address field\", \"Townland\"),\n \"village_township\": pgettext_lazy(\"Address field\", \"Village/township\"),\n \"zip\": pgettext_lazy(\"Address field\", \"ZIP code\"),\n}\n\n\nclass PossiblePhoneNumberFormField(forms.CharField):\n \"\"\"A phone input field.\"\"\"\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.widget.input_type = \"tel\"\n\n\nclass CountryAreaChoiceField(forms.ChoiceField):\n widget = DatalistTextWidget\n\n def valid_value(self, value):\n return True\n\n\nclass AddressMetaForm(forms.ModelForm):\n # This field is never visible in UI\n preview = forms.BooleanField(initial=False, required=False)\n\n class Meta:\n model = Address\n fields = [\"country\", \"preview\"]\n labels = {\"country\": pgettext_lazy(\"Country\", \"Country\")}\n\n def clean(self):\n data = super().clean()\n if data.get(\"preview\"):\n self.data = self.data.copy()\n self.data[\"preview\"] = False\n return data\n\n\nclass AddressForm(forms.ModelForm):\n\n AUTOCOMPLETE_MAPPING = [\n (\"first_name\", \"given-name\"),\n (\"last_name\", \"family-name\"),\n (\"company_name\", \"organization\"),\n (\"street_address_1\", \"address-line1\"),\n (\"street_address_2\", \"address-line2\"),\n (\"city\", \"address-level2\"),\n (\"postal_code\", \"postal-code\"),\n (\"country_area\", \"address-level1\"),\n (\"country\", \"country\"),\n (\"city_area\", \"address-level3\"),\n (\"phone\", \"tel\"),\n (\"email\", \"email\"),\n ]\n\n class Meta:\n model = Address\n exclude = []\n labels = {\n \"first_name\": pgettext_lazy(\"Personal name\", \"Given name\"),\n \"last_name\": pgettext_lazy(\"Personal name\", \"Family name\"),\n \"company_name\": pgettext_lazy(\n \"Company or organization\", \"Company or organization\"\n ),\n \"street_address_1\": pgettext_lazy(\"Address\", \"Address\"),\n \"street_address_2\": \"\",\n \"city\": pgettext_lazy(\"City\", \"City\"),\n \"city_area\": pgettext_lazy(\"City area\", \"District\"),\n \"postal_code\": pgettext_lazy(\"Postal code\", \"Postal code\"),\n \"country\": pgettext_lazy(\"Country\", \"Country\"),\n \"country_area\": pgettext_lazy(\"Country area\", \"State or province\"),\n \"phone\": pgettext_lazy(\"Phone number\", \"Phone number\"),\n }\n placeholders = {\n \"street_address_1\": pgettext_lazy(\n \"Address\", \"Street address, P.O. box, company name\"\n ),\n \"street_address_2\": pgettext_lazy(\n \"Address\", \"Apartment, suite, unit, building, floor, etc\"\n ),\n }\n\n phone = PossiblePhoneNumberFormField(widget=PhonePrefixWidget, required=False)\n\n def __init__(self, *args, **kwargs):\n autocomplete_type = kwargs.pop(\"autocomplete_type\", None)\n super().__init__(*args, **kwargs)\n # countries order was taken as defined in the model,\n # not being sorted accordingly to the selected language\n self.fields[\"country\"].choices = sorted(\n COUNTRY_CHOICES, key=lambda choice: choice[1]\n )\n autocomplete_dict = defaultdict(lambda: \"off\", self.AUTOCOMPLETE_MAPPING)\n for field_name, field in self.fields.items():\n if autocomplete_type:\n autocomplete = \"%s %s\" % (\n autocomplete_type,\n autocomplete_dict[field_name],\n )\n else:\n autocomplete = autocomplete_dict[field_name]\n field.widget.attrs[\"autocomplete\"] = autocomplete\n field.widget.attrs[\"placeholder\"] = (\n field.label if not hasattr(field, \"placeholder\") else field.placeholder\n )\n\n def clean(self):\n data = super().clean()\n phone = data.get(\"phone\")\n country = data.get(\"country\")\n if phone:\n try:\n data[\"phone\"] = validate_possible_number(phone, country)\n except forms.ValidationError as error:\n self.add_error(\"phone\", error)\n return data\n\n\nclass CountryAwareAddressForm(AddressForm):\n\n I18N_MAPPING = [\n (\"name\", [\"first_name\", \"last_name\"]),\n (\"street_address\", [\"street_address_1\", \"street_address_2\"]),\n (\"city_area\", [\"city_area\"]),\n (\"country_area\", [\"country_area\"]),\n (\"company_name\", [\"company_name\"]),\n (\"postal_code\", [\"postal_code\"]),\n (\"city\", [\"city\"]),\n (\"sorting_code\", []),\n (\"country_code\", [\"country\"]),\n ]\n\n class Meta:\n model = Address\n exclude = []\n\n def add_field_errors(self, errors):\n field_mapping = dict(self.I18N_MAPPING)\n for field_name, error_code in errors.items():\n local_fields = field_mapping[field_name]\n for field in local_fields:\n try:\n error_msg = self.fields[field].error_messages[error_code]\n except KeyError:\n error_msg = pgettext_lazy(\n \"Address form\", \"This value is invalid for selected country\"\n )\n self.add_error(field, ValidationError(error_msg, code=error_code))\n\n def validate_address(self, data):\n try:\n data[\"country_code\"] = data.get(\"country\", \"\")\n if data[\"street_address_1\"] or data[\"street_address_2\"]:\n data[\"street_address\"] = \"%s\\n%s\" % (\n data[\"street_address_1\"],\n data[\"street_address_2\"],\n )\n data = i18naddress.normalize_address(data)\n del data[\"sorting_code\"]\n except i18naddress.InvalidAddress as exc:\n self.add_field_errors(exc.errors)\n return data\n\n def clean(self):\n data = super().clean()\n return self.validate_address(data)\n\n\ndef get_address_form_class(country_code):\n return COUNTRY_FORMS[country_code]\n\n\ndef get_form_i18n_lines(form_instance):\n country_code = form_instance.i18n_country_code\n try:\n fields_order = i18naddress.get_field_order({\"country_code\": country_code})\n except ValueError:\n fields_order = i18naddress.get_field_order({})\n field_mapping = dict(form_instance.I18N_MAPPING)\n\n def _convert_to_bound_fields(form, i18n_field_names):\n bound_fields = []\n for field_name in i18n_field_names:\n local_fields = field_mapping[field_name]\n for local_name in local_fields:\n local_field = form_instance.fields[local_name]\n bound_field = BoundField(form, local_field, local_name)\n bound_fields.append(bound_field)\n return bound_fields\n\n if fields_order:\n return [_convert_to_bound_fields(form_instance, line) for line in fields_order]\n\n\ndef update_base_fields(form_class, i18n_rules):\n for field_name, label_value in AddressForm.Meta.labels.items():\n field = form_class.base_fields[field_name]\n field.label = label_value\n\n for field_name, placeholder_value in AddressForm.Meta.placeholders.items():\n field = form_class.base_fields[field_name]\n field.placeholder = placeholder_value\n\n if i18n_rules.country_area_choices:\n required = \"country_area\" in i18n_rules.required_fields\n form_class.base_fields[\"country_area\"] = CountryAreaChoiceField(\n choices=i18n_rules.country_area_choices, required=required\n )\n\n labels_map = {\n \"country_area\": i18n_rules.country_area_type,\n \"postal_code\": i18n_rules.postal_code_type,\n \"city_area\": i18n_rules.city_area_type,\n }\n\n for field_name, area_type in labels_map.items():\n field = form_class.base_fields[field_name]\n field.label = AREA_TYPE_TRANSLATIONS[area_type]\n\n hidden_fields = i18naddress.KNOWN_FIELDS - i18n_rules.allowed_fields\n for field_name in hidden_fields:\n if field_name in form_class.base_fields:\n form_class.base_fields[field_name].widget = forms.HiddenInput()\n\n country_field = form_class.base_fields[\"country\"]\n country_field.choices = COUNTRY_CHOICES\n\n\ndef construct_address_form(country_code, i18n_rules):\n class_name = \"AddressForm%s\" % country_code\n base_class = CountryAwareAddressForm\n form_kwargs = {\n \"Meta\": type(str(\"Meta\"), (base_class.Meta, object), {}),\n \"formfield_callback\": None,\n }\n class_ = type(base_class)(str(class_name), (base_class,), form_kwargs)\n update_base_fields(class_, i18n_rules)\n class_.i18n_country_code = country_code\n class_.i18n_fields_order = property(get_form_i18n_lines)\n return class_\n\n\nfor country in countries.countries.keys():\n try:\n country_rules = i18naddress.get_validation_rules({\"country_code\": country})\n except ValueError:\n country_rules = i18naddress.get_validation_rules({})\n UNKNOWN_COUNTRIES.add(country)\n\nCOUNTRY_CHOICES = [\n (code, label)\n for code, label in countries.countries.items()\n if code not in UNKNOWN_COUNTRIES\n]\n# Sort choices list by country name\nCOUNTRY_CHOICES = sorted(COUNTRY_CHOICES, key=lambda choice: choice[1])\n\nfor country, label in COUNTRY_CHOICES:\n country_rules = i18naddress.get_validation_rules({\"country_code\": country})\n COUNTRY_FORMS[country] = construct_address_form(country, country_rules)\n", "path": "saleor/account/i18n.py"}]}
| 3,619 | 148 |
gh_patches_debug_4130
|
rasdani/github-patches
|
git_diff
|
plone__Products.CMFPlone-3534
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Missing resource breaks rendering viewlet.resourceregistries.js
if there's a typo or a missing JS resource defined in the resource registries, the `viewlet.resourceregistries.js` gives a traceback and all JS resources are missing.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `Products/CMFPlone/resources/utils.py`
Content:
```
1 from Acquisition import aq_base
2 from Acquisition import aq_inner
3 from Acquisition import aq_parent
4 from plone.base.interfaces.resources import OVERRIDE_RESOURCE_DIRECTORY_NAME
5 from plone.resource.file import FilesystemFile
6 from plone.resource.interfaces import IResourceDirectory
7 from Products.CMFCore.Expression import createExprContext
8 from Products.CMFCore.utils import getToolByName
9 from zExceptions import NotFound
10 from zope.component import queryUtility
11
12 import logging
13
14
15 PRODUCTION_RESOURCE_DIRECTORY = "production"
16 logger = logging.getLogger(__name__)
17
18
19 def get_production_resource_directory():
20 persistent_directory = queryUtility(IResourceDirectory, name="persistent")
21 if persistent_directory is None:
22 return ""
23 container = persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]
24 try:
25 production_folder = container[PRODUCTION_RESOURCE_DIRECTORY]
26 except NotFound:
27 return "%s/++unique++1" % PRODUCTION_RESOURCE_DIRECTORY
28 if "timestamp.txt" not in production_folder:
29 return "%s/++unique++1" % PRODUCTION_RESOURCE_DIRECTORY
30 timestamp = production_folder.readFile("timestamp.txt")
31 if isinstance(timestamp, bytes):
32 timestamp = timestamp.decode()
33 return "{}/++unique++{}".format(PRODUCTION_RESOURCE_DIRECTORY, timestamp)
34
35
36 def get_resource(context, path):
37 if path.startswith("++plone++"):
38 # ++plone++ resources can be customized, we return their override
39 # value if any
40 overrides = get_override_directory(context)
41 filepath = path[9:]
42 if overrides.isFile(filepath):
43 return overrides.readFile(filepath)
44
45 if "?" in path:
46 # Example from plone.session:
47 # "acl_users/session/refresh?session_refresh=true&type=css&minutes=5"
48 # Traversing will not work then. In this example we could split on "?"
49 # and traverse to the first part, acl_users/session/refresh, but this
50 # gives a function, and this fails when we call it below, missing a
51 # REQUEST argument
52 return
53 try:
54 resource = context.unrestrictedTraverse(path)
55 except (NotFound, AttributeError):
56 logger.warning(
57 f"Could not find resource {path}. You may have to create it first."
58 ) # noqa
59 return
60
61 if isinstance(resource, FilesystemFile):
62 (directory, sep, filename) = path.rpartition("/")
63 return context.unrestrictedTraverse(directory).readFile(filename)
64
65 # calling the resource may modify the header, i.e. the content-type.
66 # we do not want this, so keep the original header intact.
67 response_before = context.REQUEST.response
68 context.REQUEST.response = response_before.__class__()
69 if hasattr(aq_base(resource), "GET"):
70 # for FileResource
71 result = resource.GET()
72 else:
73 # any BrowserView
74 result = resource()
75 context.REQUEST.response = response_before
76 return result
77
78
79 def get_override_directory(context):
80 persistent_directory = queryUtility(IResourceDirectory, name="persistent")
81 if persistent_directory is None:
82 return
83 if OVERRIDE_RESOURCE_DIRECTORY_NAME not in persistent_directory:
84 persistent_directory.makeDirectory(OVERRIDE_RESOURCE_DIRECTORY_NAME)
85 return persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]
86
87
88 def evaluateExpression(expression, context):
89 """Evaluate an object's TALES condition to see if it should be
90 displayed."""
91 try:
92 if expression.text and context is not None:
93 portal = getToolByName(context, "portal_url").getPortalObject()
94
95 # Find folder (code courtesy of CMFCore.ActionsTool)
96 if context is None or not hasattr(context, "aq_base"):
97 folder = portal
98 else:
99 folder = context
100 # Search up the containment hierarchy until we find an
101 # object that claims it's PrincipiaFolderish.
102 while folder is not None:
103 if getattr(aq_base(folder), "isPrincipiaFolderish", 0):
104 # found it.
105 break
106 else:
107 folder = aq_parent(aq_inner(folder))
108
109 __traceback_info__ = (folder, portal, context, expression)
110 ec = createExprContext(folder, portal, context)
111 # add 'context' as an alias for 'object'
112 ec.setGlobal("context", context)
113 return expression(ec)
114 return True
115 except AttributeError:
116 return True
117
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/Products/CMFPlone/resources/utils.py b/Products/CMFPlone/resources/utils.py
--- a/Products/CMFPlone/resources/utils.py
+++ b/Products/CMFPlone/resources/utils.py
@@ -52,7 +52,7 @@
return
try:
resource = context.unrestrictedTraverse(path)
- except (NotFound, AttributeError):
+ except (NotFound, AttributeError, KeyError):
logger.warning(
f"Could not find resource {path}. You may have to create it first."
) # noqa
|
{"golden_diff": "diff --git a/Products/CMFPlone/resources/utils.py b/Products/CMFPlone/resources/utils.py\n--- a/Products/CMFPlone/resources/utils.py\n+++ b/Products/CMFPlone/resources/utils.py\n@@ -52,7 +52,7 @@\n return\n try:\n resource = context.unrestrictedTraverse(path)\n- except (NotFound, AttributeError):\n+ except (NotFound, AttributeError, KeyError):\n logger.warning(\n f\"Could not find resource {path}. You may have to create it first.\"\n ) # noqa\n", "issue": "Missing resource breaks rendering viewlet.resourceregistries.js\nif there's a typo or a missing JS resource defined in the resource registries, the `viewlet.resourceregistries.js` gives a traceback and all JS resources are missing.\n", "before_files": [{"content": "from Acquisition import aq_base\nfrom Acquisition import aq_inner\nfrom Acquisition import aq_parent\nfrom plone.base.interfaces.resources import OVERRIDE_RESOURCE_DIRECTORY_NAME\nfrom plone.resource.file import FilesystemFile\nfrom plone.resource.interfaces import IResourceDirectory\nfrom Products.CMFCore.Expression import createExprContext\nfrom Products.CMFCore.utils import getToolByName\nfrom zExceptions import NotFound\nfrom zope.component import queryUtility\n\nimport logging\n\n\nPRODUCTION_RESOURCE_DIRECTORY = \"production\"\nlogger = logging.getLogger(__name__)\n\n\ndef get_production_resource_directory():\n persistent_directory = queryUtility(IResourceDirectory, name=\"persistent\")\n if persistent_directory is None:\n return \"\"\n container = persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]\n try:\n production_folder = container[PRODUCTION_RESOURCE_DIRECTORY]\n except NotFound:\n return \"%s/++unique++1\" % PRODUCTION_RESOURCE_DIRECTORY\n if \"timestamp.txt\" not in production_folder:\n return \"%s/++unique++1\" % PRODUCTION_RESOURCE_DIRECTORY\n timestamp = production_folder.readFile(\"timestamp.txt\")\n if isinstance(timestamp, bytes):\n timestamp = timestamp.decode()\n return \"{}/++unique++{}\".format(PRODUCTION_RESOURCE_DIRECTORY, timestamp)\n\n\ndef get_resource(context, path):\n if path.startswith(\"++plone++\"):\n # ++plone++ resources can be customized, we return their override\n # value if any\n overrides = get_override_directory(context)\n filepath = path[9:]\n if overrides.isFile(filepath):\n return overrides.readFile(filepath)\n\n if \"?\" in path:\n # Example from plone.session:\n # \"acl_users/session/refresh?session_refresh=true&type=css&minutes=5\"\n # Traversing will not work then. In this example we could split on \"?\"\n # and traverse to the first part, acl_users/session/refresh, but this\n # gives a function, and this fails when we call it below, missing a\n # REQUEST argument\n return\n try:\n resource = context.unrestrictedTraverse(path)\n except (NotFound, AttributeError):\n logger.warning(\n f\"Could not find resource {path}. You may have to create it first.\"\n ) # noqa\n return\n\n if isinstance(resource, FilesystemFile):\n (directory, sep, filename) = path.rpartition(\"/\")\n return context.unrestrictedTraverse(directory).readFile(filename)\n\n # calling the resource may modify the header, i.e. the content-type.\n # we do not want this, so keep the original header intact.\n response_before = context.REQUEST.response\n context.REQUEST.response = response_before.__class__()\n if hasattr(aq_base(resource), \"GET\"):\n # for FileResource\n result = resource.GET()\n else:\n # any BrowserView\n result = resource()\n context.REQUEST.response = response_before\n return result\n\n\ndef get_override_directory(context):\n persistent_directory = queryUtility(IResourceDirectory, name=\"persistent\")\n if persistent_directory is None:\n return\n if OVERRIDE_RESOURCE_DIRECTORY_NAME not in persistent_directory:\n persistent_directory.makeDirectory(OVERRIDE_RESOURCE_DIRECTORY_NAME)\n return persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]\n\n\ndef evaluateExpression(expression, context):\n \"\"\"Evaluate an object's TALES condition to see if it should be\n displayed.\"\"\"\n try:\n if expression.text and context is not None:\n portal = getToolByName(context, \"portal_url\").getPortalObject()\n\n # Find folder (code courtesy of CMFCore.ActionsTool)\n if context is None or not hasattr(context, \"aq_base\"):\n folder = portal\n else:\n folder = context\n # Search up the containment hierarchy until we find an\n # object that claims it's PrincipiaFolderish.\n while folder is not None:\n if getattr(aq_base(folder), \"isPrincipiaFolderish\", 0):\n # found it.\n break\n else:\n folder = aq_parent(aq_inner(folder))\n\n __traceback_info__ = (folder, portal, context, expression)\n ec = createExprContext(folder, portal, context)\n # add 'context' as an alias for 'object'\n ec.setGlobal(\"context\", context)\n return expression(ec)\n return True\n except AttributeError:\n return True\n", "path": "Products/CMFPlone/resources/utils.py"}], "after_files": [{"content": "from Acquisition import aq_base\nfrom Acquisition import aq_inner\nfrom Acquisition import aq_parent\nfrom plone.base.interfaces.resources import OVERRIDE_RESOURCE_DIRECTORY_NAME\nfrom plone.resource.file import FilesystemFile\nfrom plone.resource.interfaces import IResourceDirectory\nfrom Products.CMFCore.Expression import createExprContext\nfrom Products.CMFCore.utils import getToolByName\nfrom zExceptions import NotFound\nfrom zope.component import queryUtility\n\nimport logging\n\n\nPRODUCTION_RESOURCE_DIRECTORY = \"production\"\nlogger = logging.getLogger(__name__)\n\n\ndef get_production_resource_directory():\n persistent_directory = queryUtility(IResourceDirectory, name=\"persistent\")\n if persistent_directory is None:\n return \"\"\n container = persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]\n try:\n production_folder = container[PRODUCTION_RESOURCE_DIRECTORY]\n except NotFound:\n return \"%s/++unique++1\" % PRODUCTION_RESOURCE_DIRECTORY\n if \"timestamp.txt\" not in production_folder:\n return \"%s/++unique++1\" % PRODUCTION_RESOURCE_DIRECTORY\n timestamp = production_folder.readFile(\"timestamp.txt\")\n if isinstance(timestamp, bytes):\n timestamp = timestamp.decode()\n return \"{}/++unique++{}\".format(PRODUCTION_RESOURCE_DIRECTORY, timestamp)\n\n\ndef get_resource(context, path):\n if path.startswith(\"++plone++\"):\n # ++plone++ resources can be customized, we return their override\n # value if any\n overrides = get_override_directory(context)\n filepath = path[9:]\n if overrides.isFile(filepath):\n return overrides.readFile(filepath)\n\n if \"?\" in path:\n # Example from plone.session:\n # \"acl_users/session/refresh?session_refresh=true&type=css&minutes=5\"\n # Traversing will not work then. In this example we could split on \"?\"\n # and traverse to the first part, acl_users/session/refresh, but this\n # gives a function, and this fails when we call it below, missing a\n # REQUEST argument\n return\n try:\n resource = context.unrestrictedTraverse(path)\n except (NotFound, AttributeError, KeyError):\n logger.warning(\n f\"Could not find resource {path}. You may have to create it first.\"\n ) # noqa\n return\n\n if isinstance(resource, FilesystemFile):\n (directory, sep, filename) = path.rpartition(\"/\")\n return context.unrestrictedTraverse(directory).readFile(filename)\n\n # calling the resource may modify the header, i.e. the content-type.\n # we do not want this, so keep the original header intact.\n response_before = context.REQUEST.response\n context.REQUEST.response = response_before.__class__()\n if hasattr(aq_base(resource), \"GET\"):\n # for FileResource\n result = resource.GET()\n else:\n # any BrowserView\n result = resource()\n context.REQUEST.response = response_before\n return result\n\n\ndef get_override_directory(context):\n persistent_directory = queryUtility(IResourceDirectory, name=\"persistent\")\n if persistent_directory is None:\n return\n if OVERRIDE_RESOURCE_DIRECTORY_NAME not in persistent_directory:\n persistent_directory.makeDirectory(OVERRIDE_RESOURCE_DIRECTORY_NAME)\n return persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]\n\n\ndef evaluateExpression(expression, context):\n \"\"\"Evaluate an object's TALES condition to see if it should be\n displayed.\"\"\"\n try:\n if expression.text and context is not None:\n portal = getToolByName(context, \"portal_url\").getPortalObject()\n\n # Find folder (code courtesy of CMFCore.ActionsTool)\n if context is None or not hasattr(context, \"aq_base\"):\n folder = portal\n else:\n folder = context\n # Search up the containment hierarchy until we find an\n # object that claims it's PrincipiaFolderish.\n while folder is not None:\n if getattr(aq_base(folder), \"isPrincipiaFolderish\", 0):\n # found it.\n break\n else:\n folder = aq_parent(aq_inner(folder))\n\n __traceback_info__ = (folder, portal, context, expression)\n ec = createExprContext(folder, portal, context)\n # add 'context' as an alias for 'object'\n ec.setGlobal(\"context\", context)\n return expression(ec)\n return True\n except AttributeError:\n return True\n", "path": "Products/CMFPlone/resources/utils.py"}]}
| 1,471 | 126 |
gh_patches_debug_7624
|
rasdani/github-patches
|
git_diff
|
pytorch__ignite-522
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug in ConfusionMatrix
When passing in the groundtruth `y` with the format of `shape (batch_size, num_categories, ...) and contains ground-truth class indices`, flattened one-hot encoding tensor `y_ohe_t` will result in wrong order with respect to that of prediction. https://github.com/pytorch/ignite/blob/fc85e25dc4f938d780b4c425acb2d40f6cac6f24/ignite/metrics/confusion_matrix.py#L79-L80
https://github.com/pytorch/ignite/blob/fc85e25dc4f938d780b4c425acb2d40f6cac6f24/ignite/metrics/confusion_matrix.py#L82-L83
For example:
```python
y_pred # shape (B, C, H, W)
indices = torch.argmax(y_pred, dim=1) # shape (B, H, W)
y_pred_ohe = to_onehot(indices.reshape(-1), # shape (B*H*W)
self.num_classes) # shape (B*H*W, C)
y # shape (B, C, H, W), C: num of classes
y_ohe_t = (y.transpose(1, -1) # shape (B, W, H, C)
.reshape(y.shape[1], -1)) # reshape (B, W, H, C) into (C, B*W*H) and the value order is totally wrong
```
Expected behavior:
```python
y_ohe_t = y.transpose(0, 1).reshape(y.shape[1], -1)
# (B, C, H, W) --> (C, B, H, W) --> (C, B*H*W)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ignite/metrics/confusion_matrix.py`
Content:
```
1 import numbers
2
3 import torch
4
5 from ignite.metrics import Metric, MetricsLambda
6 from ignite.exceptions import NotComputableError
7 from ignite.utils import to_onehot
8
9
10 class ConfusionMatrix(Metric):
11 """Calculates confusion matrix for multi-class data.
12
13 - `update` must receive output of the form `(y_pred, y)`.
14 - `y_pred` must contain logits and has the following shape (batch_size, num_categories, ...)
15 - `y` can be of two types:
16 - shape (batch_size, num_categories, ...)
17 - shape (batch_size, ...) and contains ground-truth class indices
18
19 Args:
20 num_classes (int): number of classes. In case of images, num_classes should also count the background index 0.
21 average (str, optional): confusion matrix values averaging schema: None, "samples", "recall", "precision".
22 Default is None. If `average="samples"` then confusion matrix values are normalized by the number of seen
23 samples. If `average="recall"` then confusion matrix values are normalized such that diagonal values
24 represent class recalls. If `average="precision"` then confusion matrix values are normalized such that
25 diagonal values represent class precisions.
26 output_transform (callable, optional): a callable that is used to transform the
27 :class:`~ignite.engine.Engine`'s `process_function`'s output into the
28 form expected by the metric. This can be useful if, for example, you have a multi-output model and
29 you want to compute the metric with respect to one of the outputs.
30 """
31
32 def __init__(self, num_classes, average=None, output_transform=lambda x: x):
33 if average is not None and average not in ("samples", "recall", "precision"):
34 raise ValueError("Argument average can None or one of ['samples', 'recall', 'precision']")
35
36 self.num_classes = num_classes
37 self._num_examples = 0
38 self.average = average
39 self.confusion_matrix = None
40 super(ConfusionMatrix, self).__init__(output_transform=output_transform)
41
42 def reset(self):
43 self.confusion_matrix = torch.zeros(self.num_classes, self.num_classes, dtype=torch.float)
44 self._num_examples = 0
45
46 def _check_shape(self, output):
47 y_pred, y = output
48
49 if y_pred.ndimension() < 2:
50 raise ValueError("y_pred must have shape (batch_size, num_categories, ...), "
51 "but given {}".format(y_pred.shape))
52
53 if y_pred.shape[1] != self.num_classes:
54 raise ValueError("y_pred does not have correct number of categories: {} vs {}"
55 .format(y_pred.shape[1], self.num_classes))
56
57 if not (y.ndimension() == y_pred.ndimension() or y.ndimension() + 1 == y_pred.ndimension()):
58 raise ValueError("y_pred must have shape (batch_size, num_categories, ...) and y must have "
59 "shape of (batch_size, num_categories, ...) or (batch_size, ...), "
60 "but given {} vs {}.".format(y.shape, y_pred.shape))
61
62 y_shape = y.shape
63 y_pred_shape = y_pred.shape
64
65 if y.ndimension() + 1 == y_pred.ndimension():
66 y_pred_shape = (y_pred_shape[0],) + y_pred_shape[2:]
67
68 if y_shape != y_pred_shape:
69 raise ValueError("y and y_pred must have compatible shapes.")
70
71 return y_pred, y
72
73 def update(self, output):
74 y_pred, y = self._check_shape(output)
75
76 if y_pred.shape != y.shape:
77 y_ohe = to_onehot(y.reshape(-1), self.num_classes)
78 y_ohe_t = y_ohe.transpose(0, 1).float()
79 else:
80 y_ohe_t = y.transpose(1, -1).reshape(y.shape[1], -1).float()
81
82 indices = torch.argmax(y_pred, dim=1)
83 y_pred_ohe = to_onehot(indices.reshape(-1), self.num_classes)
84 y_pred_ohe = y_pred_ohe.float()
85
86 if self.confusion_matrix.type() != y_ohe_t.type():
87 self.confusion_matrix = self.confusion_matrix.type_as(y_ohe_t)
88
89 self.confusion_matrix += torch.matmul(y_ohe_t, y_pred_ohe).float()
90 self._num_examples += y_pred.shape[0]
91
92 def compute(self):
93 if self._num_examples == 0:
94 raise NotComputableError('Confusion matrix must have at least one example before it can be computed.')
95 if self.average:
96 if self.average == "samples":
97 return self.confusion_matrix / self._num_examples
98 elif self.average == "recall":
99 return self.confusion_matrix / (self.confusion_matrix.sum(dim=1) + 1e-15)
100 elif self.average == "precision":
101 return self.confusion_matrix / (self.confusion_matrix.sum(dim=0) + 1e-15)
102 return self.confusion_matrix.cpu()
103
104
105 def IoU(cm, ignore_index=None):
106 """Calculates Intersection over Union
107
108 Args:
109 cm (ConfusionMatrix): instance of confusion matrix metric
110 ignore_index (int, optional): index to ignore, e.g. background index
111
112 Returns:
113 MetricsLambda
114
115 Examples:
116
117 .. code-block:: python
118
119 train_evaluator = ...
120
121 cm = ConfusionMatrix(num_classes=num_classes)
122 IoU(cm, ignore_index=0).attach(train_evaluator, 'IoU')
123
124 state = train_evaluator.run(train_dataset)
125 # state.metrics['IoU'] -> tensor of shape (num_classes - 1, )
126
127 """
128 if not isinstance(cm, ConfusionMatrix):
129 raise TypeError("Argument cm should be instance of ConfusionMatrix, but given {}".format(type(cm)))
130
131 if ignore_index is not None:
132 if not (isinstance(ignore_index, numbers.Integral) and 0 <= ignore_index < cm.num_classes):
133 raise ValueError("ignore_index should be non-negative integer, but given {}".format(ignore_index))
134
135 # Increase floating point precision
136 cm = cm.type(torch.float64)
137 iou = cm.diag() / (cm.sum(dim=1) + cm.sum(dim=0) - cm.diag() + 1e-15)
138 if ignore_index is not None:
139
140 def ignore_index_fn(iou_vector):
141 if ignore_index >= len(iou_vector):
142 raise ValueError("ignore_index {} is larger than the length of IoU vector {}"
143 .format(ignore_index, len(iou_vector)))
144 indices = list(range(len(iou_vector)))
145 indices.remove(ignore_index)
146 return iou_vector[indices]
147
148 return MetricsLambda(ignore_index_fn, iou)
149 else:
150 return iou
151
152
153 def mIoU(cm, ignore_index=None):
154 """Calculates mean Intersection over Union
155
156 Args:
157 cm (ConfusionMatrix): instance of confusion matrix metric
158 ignore_index (int, optional): index to ignore, e.g. background index
159
160 Returns:
161 MetricsLambda
162
163 Examples:
164
165 .. code-block:: python
166
167 train_evaluator = ...
168
169 cm = ConfusionMatrix(num_classes=num_classes)
170 mIoU(cm, ignore_index=0).attach(train_evaluator, 'mean IoU')
171
172 state = train_evaluator.run(train_dataset)
173 # state.metrics['mean IoU'] -> scalar
174
175
176 """
177 return IoU(cm=cm, ignore_index=ignore_index).mean()
178
179
180 def cmAccuracy(cm):
181 """
182 Calculates accuracy using :class:`~ignite.metrics.ConfusionMatrix` metric.
183 Args:
184 cm (ConfusionMatrix): instance of confusion matrix metric
185
186 Returns:
187 MetricsLambda
188 """
189 # Increase floating point precision
190 cm = cm.type(torch.float64)
191 return cm.diag().sum() / (cm.sum() + 1e-15)
192
193
194 def cmPrecision(cm, average=True):
195 """
196 Calculates precision using :class:`~ignite.metrics.ConfusionMatrix` metric.
197 Args:
198 cm (ConfusionMatrix): instance of confusion matrix metric
199 average (bool, optional): if True metric value is averaged over all classes
200 Returns:
201 MetricsLambda
202 """
203
204 # Increase floating point precision
205 cm = cm.type(torch.float64)
206 precision = cm.diag() / (cm.sum(dim=0) + 1e-15)
207 if average:
208 return precision.mean()
209 return precision
210
211
212 def cmRecall(cm, average=True):
213 """
214 Calculates recall using :class:`~ignite.metrics.ConfusionMatrix` metric.
215 Args:
216 cm (ConfusionMatrix): instance of confusion matrix metric
217 average (bool, optional): if True metric value is averaged over all classes
218 Returns:
219 MetricsLambda
220 """
221
222 # Increase floating point precision
223 cm = cm.type(torch.float64)
224 recall = cm.diag() / (cm.sum(dim=1) + 1e-15)
225 if average:
226 return recall.mean()
227 return recall
228
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ignite/metrics/confusion_matrix.py b/ignite/metrics/confusion_matrix.py
--- a/ignite/metrics/confusion_matrix.py
+++ b/ignite/metrics/confusion_matrix.py
@@ -77,7 +77,7 @@
y_ohe = to_onehot(y.reshape(-1), self.num_classes)
y_ohe_t = y_ohe.transpose(0, 1).float()
else:
- y_ohe_t = y.transpose(1, -1).reshape(y.shape[1], -1).float()
+ y_ohe_t = y.transpose(0, 1).reshape(y.shape[1], -1).float()
indices = torch.argmax(y_pred, dim=1)
y_pred_ohe = to_onehot(indices.reshape(-1), self.num_classes)
|
{"golden_diff": "diff --git a/ignite/metrics/confusion_matrix.py b/ignite/metrics/confusion_matrix.py\n--- a/ignite/metrics/confusion_matrix.py\n+++ b/ignite/metrics/confusion_matrix.py\n@@ -77,7 +77,7 @@\n y_ohe = to_onehot(y.reshape(-1), self.num_classes)\n y_ohe_t = y_ohe.transpose(0, 1).float()\n else:\n- y_ohe_t = y.transpose(1, -1).reshape(y.shape[1], -1).float()\n+ y_ohe_t = y.transpose(0, 1).reshape(y.shape[1], -1).float()\n \n indices = torch.argmax(y_pred, dim=1)\n y_pred_ohe = to_onehot(indices.reshape(-1), self.num_classes)\n", "issue": "Bug in ConfusionMatrix\nWhen passing in the groundtruth `y` with the format of `shape (batch_size, num_categories, ...) and contains ground-truth class indices`, flattened one-hot encoding tensor `y_ohe_t` will result in wrong order with respect to that of prediction. https://github.com/pytorch/ignite/blob/fc85e25dc4f938d780b4c425acb2d40f6cac6f24/ignite/metrics/confusion_matrix.py#L79-L80\r\n\r\nhttps://github.com/pytorch/ignite/blob/fc85e25dc4f938d780b4c425acb2d40f6cac6f24/ignite/metrics/confusion_matrix.py#L82-L83\r\nFor example:\r\n```python\r\ny_pred # shape (B, C, H, W)\r\nindices = torch.argmax(y_pred, dim=1) # shape (B, H, W)\r\ny_pred_ohe = to_onehot(indices.reshape(-1), # shape (B*H*W)\r\n self.num_classes) # shape (B*H*W, C)\r\n\r\ny # shape (B, C, H, W), C: num of classes\r\ny_ohe_t = (y.transpose(1, -1) # shape (B, W, H, C)\r\n .reshape(y.shape[1], -1)) # reshape (B, W, H, C) into (C, B*W*H) and the value order is totally wrong\r\n```\r\nExpected behavior:\r\n```python\r\ny_ohe_t = y.transpose(0, 1).reshape(y.shape[1], -1)\r\n# (B, C, H, W) --> (C, B, H, W) --> (C, B*H*W)\r\n```\n", "before_files": [{"content": "import numbers\n\nimport torch\n\nfrom ignite.metrics import Metric, MetricsLambda\nfrom ignite.exceptions import NotComputableError\nfrom ignite.utils import to_onehot\n\n\nclass ConfusionMatrix(Metric):\n \"\"\"Calculates confusion matrix for multi-class data.\n\n - `update` must receive output of the form `(y_pred, y)`.\n - `y_pred` must contain logits and has the following shape (batch_size, num_categories, ...)\n - `y` can be of two types:\n - shape (batch_size, num_categories, ...)\n - shape (batch_size, ...) and contains ground-truth class indices\n\n Args:\n num_classes (int): number of classes. In case of images, num_classes should also count the background index 0.\n average (str, optional): confusion matrix values averaging schema: None, \"samples\", \"recall\", \"precision\".\n Default is None. If `average=\"samples\"` then confusion matrix values are normalized by the number of seen\n samples. If `average=\"recall\"` then confusion matrix values are normalized such that diagonal values\n represent class recalls. If `average=\"precision\"` then confusion matrix values are normalized such that\n diagonal values represent class precisions.\n output_transform (callable, optional): a callable that is used to transform the\n :class:`~ignite.engine.Engine`'s `process_function`'s output into the\n form expected by the metric. This can be useful if, for example, you have a multi-output model and\n you want to compute the metric with respect to one of the outputs.\n \"\"\"\n\n def __init__(self, num_classes, average=None, output_transform=lambda x: x):\n if average is not None and average not in (\"samples\", \"recall\", \"precision\"):\n raise ValueError(\"Argument average can None or one of ['samples', 'recall', 'precision']\")\n\n self.num_classes = num_classes\n self._num_examples = 0\n self.average = average\n self.confusion_matrix = None\n super(ConfusionMatrix, self).__init__(output_transform=output_transform)\n\n def reset(self):\n self.confusion_matrix = torch.zeros(self.num_classes, self.num_classes, dtype=torch.float)\n self._num_examples = 0\n\n def _check_shape(self, output):\n y_pred, y = output\n\n if y_pred.ndimension() < 2:\n raise ValueError(\"y_pred must have shape (batch_size, num_categories, ...), \"\n \"but given {}\".format(y_pred.shape))\n\n if y_pred.shape[1] != self.num_classes:\n raise ValueError(\"y_pred does not have correct number of categories: {} vs {}\"\n .format(y_pred.shape[1], self.num_classes))\n\n if not (y.ndimension() == y_pred.ndimension() or y.ndimension() + 1 == y_pred.ndimension()):\n raise ValueError(\"y_pred must have shape (batch_size, num_categories, ...) and y must have \"\n \"shape of (batch_size, num_categories, ...) or (batch_size, ...), \"\n \"but given {} vs {}.\".format(y.shape, y_pred.shape))\n\n y_shape = y.shape\n y_pred_shape = y_pred.shape\n\n if y.ndimension() + 1 == y_pred.ndimension():\n y_pred_shape = (y_pred_shape[0],) + y_pred_shape[2:]\n\n if y_shape != y_pred_shape:\n raise ValueError(\"y and y_pred must have compatible shapes.\")\n\n return y_pred, y\n\n def update(self, output):\n y_pred, y = self._check_shape(output)\n\n if y_pred.shape != y.shape:\n y_ohe = to_onehot(y.reshape(-1), self.num_classes)\n y_ohe_t = y_ohe.transpose(0, 1).float()\n else:\n y_ohe_t = y.transpose(1, -1).reshape(y.shape[1], -1).float()\n\n indices = torch.argmax(y_pred, dim=1)\n y_pred_ohe = to_onehot(indices.reshape(-1), self.num_classes)\n y_pred_ohe = y_pred_ohe.float()\n\n if self.confusion_matrix.type() != y_ohe_t.type():\n self.confusion_matrix = self.confusion_matrix.type_as(y_ohe_t)\n\n self.confusion_matrix += torch.matmul(y_ohe_t, y_pred_ohe).float()\n self._num_examples += y_pred.shape[0]\n\n def compute(self):\n if self._num_examples == 0:\n raise NotComputableError('Confusion matrix must have at least one example before it can be computed.')\n if self.average:\n if self.average == \"samples\":\n return self.confusion_matrix / self._num_examples\n elif self.average == \"recall\":\n return self.confusion_matrix / (self.confusion_matrix.sum(dim=1) + 1e-15)\n elif self.average == \"precision\":\n return self.confusion_matrix / (self.confusion_matrix.sum(dim=0) + 1e-15)\n return self.confusion_matrix.cpu()\n\n\ndef IoU(cm, ignore_index=None):\n \"\"\"Calculates Intersection over Union\n\n Args:\n cm (ConfusionMatrix): instance of confusion matrix metric\n ignore_index (int, optional): index to ignore, e.g. background index\n\n Returns:\n MetricsLambda\n\n Examples:\n\n .. code-block:: python\n\n train_evaluator = ...\n\n cm = ConfusionMatrix(num_classes=num_classes)\n IoU(cm, ignore_index=0).attach(train_evaluator, 'IoU')\n\n state = train_evaluator.run(train_dataset)\n # state.metrics['IoU'] -> tensor of shape (num_classes - 1, )\n\n \"\"\"\n if not isinstance(cm, ConfusionMatrix):\n raise TypeError(\"Argument cm should be instance of ConfusionMatrix, but given {}\".format(type(cm)))\n\n if ignore_index is not None:\n if not (isinstance(ignore_index, numbers.Integral) and 0 <= ignore_index < cm.num_classes):\n raise ValueError(\"ignore_index should be non-negative integer, but given {}\".format(ignore_index))\n\n # Increase floating point precision\n cm = cm.type(torch.float64)\n iou = cm.diag() / (cm.sum(dim=1) + cm.sum(dim=0) - cm.diag() + 1e-15)\n if ignore_index is not None:\n\n def ignore_index_fn(iou_vector):\n if ignore_index >= len(iou_vector):\n raise ValueError(\"ignore_index {} is larger than the length of IoU vector {}\"\n .format(ignore_index, len(iou_vector)))\n indices = list(range(len(iou_vector)))\n indices.remove(ignore_index)\n return iou_vector[indices]\n\n return MetricsLambda(ignore_index_fn, iou)\n else:\n return iou\n\n\ndef mIoU(cm, ignore_index=None):\n \"\"\"Calculates mean Intersection over Union\n\n Args:\n cm (ConfusionMatrix): instance of confusion matrix metric\n ignore_index (int, optional): index to ignore, e.g. background index\n\n Returns:\n MetricsLambda\n\n Examples:\n\n .. code-block:: python\n\n train_evaluator = ...\n\n cm = ConfusionMatrix(num_classes=num_classes)\n mIoU(cm, ignore_index=0).attach(train_evaluator, 'mean IoU')\n\n state = train_evaluator.run(train_dataset)\n # state.metrics['mean IoU'] -> scalar\n\n\n \"\"\"\n return IoU(cm=cm, ignore_index=ignore_index).mean()\n\n\ndef cmAccuracy(cm):\n \"\"\"\n Calculates accuracy using :class:`~ignite.metrics.ConfusionMatrix` metric.\n Args:\n cm (ConfusionMatrix): instance of confusion matrix metric\n\n Returns:\n MetricsLambda\n \"\"\"\n # Increase floating point precision\n cm = cm.type(torch.float64)\n return cm.diag().sum() / (cm.sum() + 1e-15)\n\n\ndef cmPrecision(cm, average=True):\n \"\"\"\n Calculates precision using :class:`~ignite.metrics.ConfusionMatrix` metric.\n Args:\n cm (ConfusionMatrix): instance of confusion matrix metric\n average (bool, optional): if True metric value is averaged over all classes\n Returns:\n MetricsLambda\n \"\"\"\n\n # Increase floating point precision\n cm = cm.type(torch.float64)\n precision = cm.diag() / (cm.sum(dim=0) + 1e-15)\n if average:\n return precision.mean()\n return precision\n\n\ndef cmRecall(cm, average=True):\n \"\"\"\n Calculates recall using :class:`~ignite.metrics.ConfusionMatrix` metric.\n Args:\n cm (ConfusionMatrix): instance of confusion matrix metric\n average (bool, optional): if True metric value is averaged over all classes\n Returns:\n MetricsLambda\n \"\"\"\n\n # Increase floating point precision\n cm = cm.type(torch.float64)\n recall = cm.diag() / (cm.sum(dim=1) + 1e-15)\n if average:\n return recall.mean()\n return recall\n", "path": "ignite/metrics/confusion_matrix.py"}], "after_files": [{"content": "import numbers\n\nimport torch\n\nfrom ignite.metrics import Metric, MetricsLambda\nfrom ignite.exceptions import NotComputableError\nfrom ignite.utils import to_onehot\n\n\nclass ConfusionMatrix(Metric):\n \"\"\"Calculates confusion matrix for multi-class data.\n\n - `update` must receive output of the form `(y_pred, y)`.\n - `y_pred` must contain logits and has the following shape (batch_size, num_categories, ...)\n - `y` can be of two types:\n - shape (batch_size, num_categories, ...)\n - shape (batch_size, ...) and contains ground-truth class indices\n\n Args:\n num_classes (int): number of classes. In case of images, num_classes should also count the background index 0.\n average (str, optional): confusion matrix values averaging schema: None, \"samples\", \"recall\", \"precision\".\n Default is None. If `average=\"samples\"` then confusion matrix values are normalized by the number of seen\n samples. If `average=\"recall\"` then confusion matrix values are normalized such that diagonal values\n represent class recalls. If `average=\"precision\"` then confusion matrix values are normalized such that\n diagonal values represent class precisions.\n output_transform (callable, optional): a callable that is used to transform the\n :class:`~ignite.engine.Engine`'s `process_function`'s output into the\n form expected by the metric. This can be useful if, for example, you have a multi-output model and\n you want to compute the metric with respect to one of the outputs.\n \"\"\"\n\n def __init__(self, num_classes, average=None, output_transform=lambda x: x):\n if average is not None and average not in (\"samples\", \"recall\", \"precision\"):\n raise ValueError(\"Argument average can None or one of ['samples', 'recall', 'precision']\")\n\n self.num_classes = num_classes\n self._num_examples = 0\n self.average = average\n self.confusion_matrix = None\n super(ConfusionMatrix, self).__init__(output_transform=output_transform)\n\n def reset(self):\n self.confusion_matrix = torch.zeros(self.num_classes, self.num_classes, dtype=torch.float)\n self._num_examples = 0\n\n def _check_shape(self, output):\n y_pred, y = output\n\n if y_pred.ndimension() < 2:\n raise ValueError(\"y_pred must have shape (batch_size, num_categories, ...), \"\n \"but given {}\".format(y_pred.shape))\n\n if y_pred.shape[1] != self.num_classes:\n raise ValueError(\"y_pred does not have correct number of categories: {} vs {}\"\n .format(y_pred.shape[1], self.num_classes))\n\n if not (y.ndimension() == y_pred.ndimension() or y.ndimension() + 1 == y_pred.ndimension()):\n raise ValueError(\"y_pred must have shape (batch_size, num_categories, ...) and y must have \"\n \"shape of (batch_size, num_categories, ...) or (batch_size, ...), \"\n \"but given {} vs {}.\".format(y.shape, y_pred.shape))\n\n y_shape = y.shape\n y_pred_shape = y_pred.shape\n\n if y.ndimension() + 1 == y_pred.ndimension():\n y_pred_shape = (y_pred_shape[0],) + y_pred_shape[2:]\n\n if y_shape != y_pred_shape:\n raise ValueError(\"y and y_pred must have compatible shapes.\")\n\n return y_pred, y\n\n def update(self, output):\n y_pred, y = self._check_shape(output)\n\n if y_pred.shape != y.shape:\n y_ohe = to_onehot(y.reshape(-1), self.num_classes)\n y_ohe_t = y_ohe.transpose(0, 1).float()\n else:\n y_ohe_t = y.transpose(0, 1).reshape(y.shape[1], -1).float()\n\n indices = torch.argmax(y_pred, dim=1)\n y_pred_ohe = to_onehot(indices.reshape(-1), self.num_classes)\n y_pred_ohe = y_pred_ohe.float()\n\n if self.confusion_matrix.type() != y_ohe_t.type():\n self.confusion_matrix = self.confusion_matrix.type_as(y_ohe_t)\n\n self.confusion_matrix += torch.matmul(y_ohe_t, y_pred_ohe).float()\n self._num_examples += y_pred.shape[0]\n\n def compute(self):\n if self._num_examples == 0:\n raise NotComputableError('Confusion matrix must have at least one example before it can be computed.')\n if self.average:\n if self.average == \"samples\":\n return self.confusion_matrix / self._num_examples\n elif self.average == \"recall\":\n return self.confusion_matrix / (self.confusion_matrix.sum(dim=1) + 1e-15)\n elif self.average == \"precision\":\n return self.confusion_matrix / (self.confusion_matrix.sum(dim=0) + 1e-15)\n return self.confusion_matrix.cpu()\n\n\ndef IoU(cm, ignore_index=None):\n \"\"\"Calculates Intersection over Union\n\n Args:\n cm (ConfusionMatrix): instance of confusion matrix metric\n ignore_index (int, optional): index to ignore, e.g. background index\n\n Returns:\n MetricsLambda\n\n Examples:\n\n .. code-block:: python\n\n train_evaluator = ...\n\n cm = ConfusionMatrix(num_classes=num_classes)\n IoU(cm, ignore_index=0).attach(train_evaluator, 'IoU')\n\n state = train_evaluator.run(train_dataset)\n # state.metrics['IoU'] -> tensor of shape (num_classes - 1, )\n\n \"\"\"\n if not isinstance(cm, ConfusionMatrix):\n raise TypeError(\"Argument cm should be instance of ConfusionMatrix, but given {}\".format(type(cm)))\n\n if ignore_index is not None:\n if not (isinstance(ignore_index, numbers.Integral) and 0 <= ignore_index < cm.num_classes):\n raise ValueError(\"ignore_index should be non-negative integer, but given {}\".format(ignore_index))\n\n # Increase floating point precision\n cm = cm.type(torch.float64)\n iou = cm.diag() / (cm.sum(dim=1) + cm.sum(dim=0) - cm.diag() + 1e-15)\n if ignore_index is not None:\n\n def ignore_index_fn(iou_vector):\n if ignore_index >= len(iou_vector):\n raise ValueError(\"ignore_index {} is larger than the length of IoU vector {}\"\n .format(ignore_index, len(iou_vector)))\n indices = list(range(len(iou_vector)))\n indices.remove(ignore_index)\n return iou_vector[indices]\n\n return MetricsLambda(ignore_index_fn, iou)\n else:\n return iou\n\n\ndef mIoU(cm, ignore_index=None):\n \"\"\"Calculates mean Intersection over Union\n\n Args:\n cm (ConfusionMatrix): instance of confusion matrix metric\n ignore_index (int, optional): index to ignore, e.g. background index\n\n Returns:\n MetricsLambda\n\n Examples:\n\n .. code-block:: python\n\n train_evaluator = ...\n\n cm = ConfusionMatrix(num_classes=num_classes)\n mIoU(cm, ignore_index=0).attach(train_evaluator, 'mean IoU')\n\n state = train_evaluator.run(train_dataset)\n # state.metrics['mean IoU'] -> scalar\n\n\n \"\"\"\n return IoU(cm=cm, ignore_index=ignore_index).mean()\n\n\ndef cmAccuracy(cm):\n \"\"\"\n Calculates accuracy using :class:`~ignite.metrics.ConfusionMatrix` metric.\n Args:\n cm (ConfusionMatrix): instance of confusion matrix metric\n\n Returns:\n MetricsLambda\n \"\"\"\n # Increase floating point precision\n cm = cm.type(torch.float64)\n return cm.diag().sum() / (cm.sum() + 1e-15)\n\n\ndef cmPrecision(cm, average=True):\n \"\"\"\n Calculates precision using :class:`~ignite.metrics.ConfusionMatrix` metric.\n Args:\n cm (ConfusionMatrix): instance of confusion matrix metric\n average (bool, optional): if True metric value is averaged over all classes\n Returns:\n MetricsLambda\n \"\"\"\n\n # Increase floating point precision\n cm = cm.type(torch.float64)\n precision = cm.diag() / (cm.sum(dim=0) + 1e-15)\n if average:\n return precision.mean()\n return precision\n\n\ndef cmRecall(cm, average=True):\n \"\"\"\n Calculates recall using :class:`~ignite.metrics.ConfusionMatrix` metric.\n Args:\n cm (ConfusionMatrix): instance of confusion matrix metric\n average (bool, optional): if True metric value is averaged over all classes\n Returns:\n MetricsLambda\n \"\"\"\n\n # Increase floating point precision\n cm = cm.type(torch.float64)\n recall = cm.diag() / (cm.sum(dim=1) + 1e-15)\n if average:\n return recall.mean()\n return recall\n", "path": "ignite/metrics/confusion_matrix.py"}]}
| 3,212 | 177 |
gh_patches_debug_45
|
rasdani/github-patches
|
git_diff
|
conda-forge__conda-smithy-1140
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Not compatible with ruamel.yaml 0.16
Fails with,
```
Traceback (most recent call last):
File "/home/travis/miniconda/bin/conda-smithy", line 10, in <module>
sys.exit(main())
File "/home/travis/miniconda/lib/python3.7/site-packages/conda_smithy/cli.py", line 470, in main
args.subcommand_func(args)
File "/home/travis/miniconda/lib/python3.7/site-packages/conda_smithy/cli.py", line 217, in __call__
args.feedstock_directory, owner, repo
File "/home/travis/miniconda/lib/python3.7/site-packages/conda_smithy/ci_register.py", line 351, in travis_token_update_conda_forge_config
] = travis_encrypt_binstar_token(slug, item)
File "/home/travis/miniconda/lib/python3.7/contextlib.py", line 119, in __exit__
next(self.gen)
File "/home/travis/miniconda/lib/python3.7/site-packages/conda_smithy/utils.py", line 92, in update_conda_forge_config
fh.write(yaml.dump(code))
File "/home/travis/miniconda/lib/python3.7/site-packages/ruamel/yaml/main.py", line 448, in dump
raise TypeError('Need a stream argument when not dumping from context manager')
TypeError: Need a stream argument when not dumping from context manager
```
cc @ocefpaf, @scopatz
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conda_smithy/utils.py`
Content:
```
1 import shutil
2 import tempfile
3 import jinja2
4 import datetime
5 import time
6 import os
7 import sys
8 from collections import defaultdict
9 from contextlib import contextmanager
10
11 import ruamel.yaml
12
13
14 # define global yaml API
15 # roundrip-loader and allowing duplicate keys
16 # for handling # [filter] / # [not filter]
17 yaml = ruamel.yaml.YAML(typ="rt")
18 yaml.allow_duplicate_keys = True
19
20
21 @contextmanager
22 def tmp_directory():
23 tmp_dir = tempfile.mkdtemp("_recipe")
24 yield tmp_dir
25 shutil.rmtree(tmp_dir)
26
27
28 class NullUndefined(jinja2.Undefined):
29 def __unicode__(self):
30 return self._undefined_name
31
32 def __getattr__(self, name):
33 return "{}.{}".format(self, name)
34
35 def __getitem__(self, name):
36 return '{}["{}"]'.format(self, name)
37
38
39 class MockOS(dict):
40 def __init__(self):
41 self.environ = defaultdict(lambda: "")
42 self.sep = "/"
43
44
45 def render_meta_yaml(text):
46 env = jinja2.Environment(undefined=NullUndefined)
47
48 # stub out cb3 jinja2 functions - they are not important for linting
49 # if we don't stub them out, the ruamel.yaml load fails to interpret them
50 # we can't just use conda-build's api.render functionality, because it would apply selectors
51 env.globals.update(
52 dict(
53 compiler=lambda x: x + "_compiler_stub",
54 pin_subpackage=lambda *args, **kwargs: "subpackage_stub",
55 pin_compatible=lambda *args, **kwargs: "compatible_pin_stub",
56 cdt=lambda *args, **kwargs: "cdt_stub",
57 load_file_regex=lambda *args, **kwargs: defaultdict(lambda: ""),
58 datetime=datetime,
59 time=time,
60 target_platform="linux-64",
61 )
62 )
63 mockos = MockOS()
64 py_ver = "3.7"
65 context = {"os": mockos, "environ": mockos.environ, "PY_VER": py_ver}
66 content = env.from_string(text).render(context)
67 return content
68
69
70 @contextmanager
71 def update_conda_forge_config(feedstock_directory):
72 """Utility method used to update conda forge configuration files
73
74 Uage:
75 >>> with update_conda_forge_config(somepath) as cfg:
76 ... cfg['foo'] = 'bar'
77 """
78 forge_yaml = os.path.join(feedstock_directory, "conda-forge.yml")
79 if os.path.exists(forge_yaml):
80 with open(forge_yaml, "r") as fh:
81 code = yaml.load(fh)
82 else:
83 code = {}
84
85 # Code could come in as an empty list.
86 if not code:
87 code = {}
88
89 yield code
90
91 with open(forge_yaml, "w") as fh:
92 fh.write(yaml.dump(code))
93
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/conda_smithy/utils.py b/conda_smithy/utils.py
--- a/conda_smithy/utils.py
+++ b/conda_smithy/utils.py
@@ -88,5 +88,4 @@
yield code
- with open(forge_yaml, "w") as fh:
- fh.write(yaml.dump(code))
+ yaml.dump(code, forge_yaml)
|
{"golden_diff": "diff --git a/conda_smithy/utils.py b/conda_smithy/utils.py\n--- a/conda_smithy/utils.py\n+++ b/conda_smithy/utils.py\n@@ -88,5 +88,4 @@\n \n yield code\n \n- with open(forge_yaml, \"w\") as fh:\n- fh.write(yaml.dump(code))\n+ yaml.dump(code, forge_yaml)\n", "issue": "Not compatible with ruamel.yaml 0.16\nFails with,\r\n\r\n```\r\nTraceback (most recent call last):\r\n\r\n File \"/home/travis/miniconda/bin/conda-smithy\", line 10, in <module>\r\n\r\n sys.exit(main())\r\n\r\n File \"/home/travis/miniconda/lib/python3.7/site-packages/conda_smithy/cli.py\", line 470, in main\r\n\r\n args.subcommand_func(args)\r\n\r\n File \"/home/travis/miniconda/lib/python3.7/site-packages/conda_smithy/cli.py\", line 217, in __call__\r\n\r\n args.feedstock_directory, owner, repo\r\n\r\n File \"/home/travis/miniconda/lib/python3.7/site-packages/conda_smithy/ci_register.py\", line 351, in travis_token_update_conda_forge_config\r\n\r\n ] = travis_encrypt_binstar_token(slug, item)\r\n\r\n File \"/home/travis/miniconda/lib/python3.7/contextlib.py\", line 119, in __exit__\r\n\r\n next(self.gen)\r\n\r\n File \"/home/travis/miniconda/lib/python3.7/site-packages/conda_smithy/utils.py\", line 92, in update_conda_forge_config\r\n\r\n fh.write(yaml.dump(code))\r\n\r\n File \"/home/travis/miniconda/lib/python3.7/site-packages/ruamel/yaml/main.py\", line 448, in dump\r\n\r\n raise TypeError('Need a stream argument when not dumping from context manager')\r\n\r\nTypeError: Need a stream argument when not dumping from context manager\r\n```\r\n\r\ncc @ocefpaf, @scopatz\n", "before_files": [{"content": "import shutil\nimport tempfile\nimport jinja2\nimport datetime\nimport time\nimport os\nimport sys\nfrom collections import defaultdict\nfrom contextlib import contextmanager\n\nimport ruamel.yaml\n\n\n# define global yaml API\n# roundrip-loader and allowing duplicate keys\n# for handling # [filter] / # [not filter]\nyaml = ruamel.yaml.YAML(typ=\"rt\")\nyaml.allow_duplicate_keys = True\n\n\n@contextmanager\ndef tmp_directory():\n tmp_dir = tempfile.mkdtemp(\"_recipe\")\n yield tmp_dir\n shutil.rmtree(tmp_dir)\n\n\nclass NullUndefined(jinja2.Undefined):\n def __unicode__(self):\n return self._undefined_name\n\n def __getattr__(self, name):\n return \"{}.{}\".format(self, name)\n\n def __getitem__(self, name):\n return '{}[\"{}\"]'.format(self, name)\n\n\nclass MockOS(dict):\n def __init__(self):\n self.environ = defaultdict(lambda: \"\")\n self.sep = \"/\"\n\n\ndef render_meta_yaml(text):\n env = jinja2.Environment(undefined=NullUndefined)\n\n # stub out cb3 jinja2 functions - they are not important for linting\n # if we don't stub them out, the ruamel.yaml load fails to interpret them\n # we can't just use conda-build's api.render functionality, because it would apply selectors\n env.globals.update(\n dict(\n compiler=lambda x: x + \"_compiler_stub\",\n pin_subpackage=lambda *args, **kwargs: \"subpackage_stub\",\n pin_compatible=lambda *args, **kwargs: \"compatible_pin_stub\",\n cdt=lambda *args, **kwargs: \"cdt_stub\",\n load_file_regex=lambda *args, **kwargs: defaultdict(lambda: \"\"),\n datetime=datetime,\n time=time,\n target_platform=\"linux-64\",\n )\n )\n mockos = MockOS()\n py_ver = \"3.7\"\n context = {\"os\": mockos, \"environ\": mockos.environ, \"PY_VER\": py_ver}\n content = env.from_string(text).render(context)\n return content\n\n\n@contextmanager\ndef update_conda_forge_config(feedstock_directory):\n \"\"\"Utility method used to update conda forge configuration files\n\n Uage:\n >>> with update_conda_forge_config(somepath) as cfg:\n ... cfg['foo'] = 'bar'\n \"\"\"\n forge_yaml = os.path.join(feedstock_directory, \"conda-forge.yml\")\n if os.path.exists(forge_yaml):\n with open(forge_yaml, \"r\") as fh:\n code = yaml.load(fh)\n else:\n code = {}\n\n # Code could come in as an empty list.\n if not code:\n code = {}\n\n yield code\n\n with open(forge_yaml, \"w\") as fh:\n fh.write(yaml.dump(code))\n", "path": "conda_smithy/utils.py"}], "after_files": [{"content": "import shutil\nimport tempfile\nimport jinja2\nimport datetime\nimport time\nimport os\nimport sys\nfrom collections import defaultdict\nfrom contextlib import contextmanager\n\nimport ruamel.yaml\n\n\n# define global yaml API\n# roundrip-loader and allowing duplicate keys\n# for handling # [filter] / # [not filter]\nyaml = ruamel.yaml.YAML(typ=\"rt\")\nyaml.allow_duplicate_keys = True\n\n\n@contextmanager\ndef tmp_directory():\n tmp_dir = tempfile.mkdtemp(\"_recipe\")\n yield tmp_dir\n shutil.rmtree(tmp_dir)\n\n\nclass NullUndefined(jinja2.Undefined):\n def __unicode__(self):\n return self._undefined_name\n\n def __getattr__(self, name):\n return \"{}.{}\".format(self, name)\n\n def __getitem__(self, name):\n return '{}[\"{}\"]'.format(self, name)\n\n\nclass MockOS(dict):\n def __init__(self):\n self.environ = defaultdict(lambda: \"\")\n self.sep = \"/\"\n\n\ndef render_meta_yaml(text):\n env = jinja2.Environment(undefined=NullUndefined)\n\n # stub out cb3 jinja2 functions - they are not important for linting\n # if we don't stub them out, the ruamel.yaml load fails to interpret them\n # we can't just use conda-build's api.render functionality, because it would apply selectors\n env.globals.update(\n dict(\n compiler=lambda x: x + \"_compiler_stub\",\n pin_subpackage=lambda *args, **kwargs: \"subpackage_stub\",\n pin_compatible=lambda *args, **kwargs: \"compatible_pin_stub\",\n cdt=lambda *args, **kwargs: \"cdt_stub\",\n load_file_regex=lambda *args, **kwargs: defaultdict(lambda: \"\"),\n datetime=datetime,\n time=time,\n target_platform=\"linux-64\",\n )\n )\n mockos = MockOS()\n py_ver = \"3.7\"\n context = {\"os\": mockos, \"environ\": mockos.environ, \"PY_VER\": py_ver}\n content = env.from_string(text).render(context)\n return content\n\n\n@contextmanager\ndef update_conda_forge_config(feedstock_directory):\n \"\"\"Utility method used to update conda forge configuration files\n\n Uage:\n >>> with update_conda_forge_config(somepath) as cfg:\n ... cfg['foo'] = 'bar'\n \"\"\"\n forge_yaml = os.path.join(feedstock_directory, \"conda-forge.yml\")\n if os.path.exists(forge_yaml):\n with open(forge_yaml, \"r\") as fh:\n code = yaml.load(fh)\n else:\n code = {}\n\n # Code could come in as an empty list.\n if not code:\n code = {}\n\n yield code\n\n yaml.dump(code, forge_yaml)\n", "path": "conda_smithy/utils.py"}]}
| 1,409 | 89 |
gh_patches_debug_4146
|
rasdani/github-patches
|
git_diff
|
streamlit__streamlit-7267
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
When "upload_file_request_handler.py" returns 400 error, we can see session ID.
# Summary
We make application on Microsoft Azure App Service with streamlit.
When we conducted a test of uploading file with `st.file_uploader`, it returned 400 error and **session ID** as string.
We checked your codes and noticed that we have 400 error, `streamlit/lib/streamlit/server/upload_file_request_handler.py` returns error code 400, reason and session ID on line 126-128.
This problem may lead to security incidents like XSS.
Please check it.
# Steps to reproduce
Code snippet:
```
import streamlit as st
uploaded_file = st.file_uploader("uploading Excel files", type="xlsx", key="xlsx_up")
if uploaded_file is not None:
st.write("Success")
```
How the error occurred cannot be provided due to confidentiality,
## Expected behavior:
When we have 400 error, streamlit will return only error code and error reason without session ID.
## Actual behavior:
When we have 400 error, streamlit returns error code and error reason with session ID
Screenshots cannot be uploaded due to confidentiality.
## Is this a regression?
That is, did this use to work the way you expected in the past?
yes / no
⇒no
# Debug info
- Streamlit version: (get it with `$ streamlit version`)
⇒0.74.1
- Python version: (get it with `$ python --version`)
⇒3.7
- Using Conda? PipEnv? PyEnv? Pex?
⇒Pip
- OS version:
⇒Linux
- Browser version:
⇒Chrome 88.0.4324.150
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lib/streamlit/web/server/upload_file_request_handler.py`
Content:
```
1 # Copyright (c) Streamlit Inc. (2018-2022) Snowflake Inc. (2022)
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from typing import Any, Callable, Dict, List
16
17 import tornado.httputil
18 import tornado.web
19
20 from streamlit import config
21 from streamlit.logger import get_logger
22 from streamlit.runtime.memory_uploaded_file_manager import MemoryUploadedFileManager
23 from streamlit.runtime.uploaded_file_manager import UploadedFileManager, UploadedFileRec
24 from streamlit.web.server import routes, server_util
25
26 LOGGER = get_logger(__name__)
27
28
29 class UploadFileRequestHandler(tornado.web.RequestHandler):
30 """Implements the POST /upload_file endpoint."""
31
32 def initialize(
33 self,
34 file_mgr: MemoryUploadedFileManager,
35 is_active_session: Callable[[str], bool],
36 ):
37 """
38 Parameters
39 ----------
40 file_mgr : UploadedFileManager
41 The server's singleton UploadedFileManager. All file uploads
42 go here.
43 is_active_session:
44 A function that returns true if a session_id belongs to an active
45 session.
46 """
47 self._file_mgr = file_mgr
48 self._is_active_session = is_active_session
49
50 def set_default_headers(self):
51 self.set_header("Access-Control-Allow-Methods", "PUT, OPTIONS, DELETE")
52 self.set_header("Access-Control-Allow-Headers", "Content-Type")
53 if config.get_option("server.enableXsrfProtection"):
54 self.set_header(
55 "Access-Control-Allow-Origin",
56 server_util.get_url(config.get_option("browser.serverAddress")),
57 )
58 self.set_header("Access-Control-Allow-Headers", "X-Xsrftoken, Content-Type")
59 self.set_header("Vary", "Origin")
60 self.set_header("Access-Control-Allow-Credentials", "true")
61 elif routes.allow_cross_origin_requests():
62 self.set_header("Access-Control-Allow-Origin", "*")
63
64 def options(self, **kwargs):
65 """/OPTIONS handler for preflight CORS checks.
66
67 When a browser is making a CORS request, it may sometimes first
68 send an OPTIONS request, to check whether the server understands the
69 CORS protocol. This is optional, and doesn't happen for every request
70 or in every browser. If an OPTIONS request does get sent, and is not
71 then handled by the server, the browser will fail the underlying
72 request.
73
74 The proper way to handle this is to send a 204 response ("no content")
75 with the CORS headers attached. (These headers are automatically added
76 to every outgoing response, including OPTIONS responses,
77 via set_default_headers().)
78
79 See https://developer.mozilla.org/en-US/docs/Glossary/Preflight_request
80 """
81 self.set_status(204)
82 self.finish()
83
84 def put(self, **kwargs):
85 """Receive an uploaded file and add it to our UploadedFileManager."""
86
87 args: Dict[str, List[bytes]] = {}
88 files: Dict[str, List[Any]] = {}
89
90 session_id = self.path_kwargs["session_id"]
91 file_id = self.path_kwargs["file_id"]
92
93 tornado.httputil.parse_body_arguments(
94 content_type=self.request.headers["Content-Type"],
95 body=self.request.body,
96 arguments=args,
97 files=files,
98 )
99
100 try:
101 if not self._is_active_session(session_id):
102 raise Exception(f"Invalid session_id: '{session_id}'")
103 except Exception as e:
104 self.send_error(400, reason=str(e))
105 return
106
107 uploaded_files: List[UploadedFileRec] = []
108
109 for _, flist in files.items():
110 for file in flist:
111 uploaded_files.append(
112 UploadedFileRec(
113 file_id=file_id,
114 name=file["filename"],
115 type=file["content_type"],
116 data=file["body"],
117 )
118 )
119
120 if len(uploaded_files) != 1:
121 self.send_error(
122 400, reason=f"Expected 1 file, but got {len(uploaded_files)}"
123 )
124 return
125
126 self._file_mgr.add_file(session_id=session_id, file=uploaded_files[0])
127 self.set_status(204)
128
129 def delete(self, **kwargs):
130 """Delete file request handler."""
131 session_id = self.path_kwargs["session_id"]
132 file_id = self.path_kwargs["file_id"]
133
134 self._file_mgr.remove_file(session_id=session_id, file_id=file_id)
135 self.set_status(204)
136
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lib/streamlit/web/server/upload_file_request_handler.py b/lib/streamlit/web/server/upload_file_request_handler.py
--- a/lib/streamlit/web/server/upload_file_request_handler.py
+++ b/lib/streamlit/web/server/upload_file_request_handler.py
@@ -99,7 +99,7 @@
try:
if not self._is_active_session(session_id):
- raise Exception(f"Invalid session_id: '{session_id}'")
+ raise Exception(f"Invalid session_id")
except Exception as e:
self.send_error(400, reason=str(e))
return
|
{"golden_diff": "diff --git a/lib/streamlit/web/server/upload_file_request_handler.py b/lib/streamlit/web/server/upload_file_request_handler.py\n--- a/lib/streamlit/web/server/upload_file_request_handler.py\n+++ b/lib/streamlit/web/server/upload_file_request_handler.py\n@@ -99,7 +99,7 @@\n \n try:\n if not self._is_active_session(session_id):\n- raise Exception(f\"Invalid session_id: '{session_id}'\")\n+ raise Exception(f\"Invalid session_id\")\n except Exception as e:\n self.send_error(400, reason=str(e))\n return\n", "issue": "When \"upload_file_request_handler.py\" returns 400 error, we can see session ID.\n# Summary\r\n\r\nWe make application on Microsoft Azure App Service with streamlit.\r\nWhen we conducted a test of uploading file with `st.file_uploader`, it returned 400 error and **session ID** as string.\r\nWe checked your codes and noticed that we have 400 error, `streamlit/lib/streamlit/server/upload_file_request_handler.py` returns error code 400, reason and session ID on line 126-128.\r\nThis problem may lead to security incidents like XSS.\r\nPlease check it.\r\n\r\n# Steps to reproduce\r\n\r\nCode snippet:\r\n\r\n```\r\nimport streamlit as st\r\n\r\nuploaded_file = st.file_uploader(\"uploading Excel files\", type=\"xlsx\", key=\"xlsx_up\")\r\nif uploaded_file is not None:\r\n st.write(\"Success\")\r\n\r\n```\r\nHow the error occurred cannot be provided due to confidentiality,\r\n\r\n## Expected behavior:\r\n\r\nWhen we have 400 error, streamlit will return only error code and error reason without session ID.\r\n\r\n## Actual behavior:\r\n\r\nWhen we have 400 error, streamlit returns error code and error reason with session ID\r\nScreenshots cannot be uploaded due to confidentiality.\r\n\r\n## Is this a regression?\r\n\r\nThat is, did this use to work the way you expected in the past?\r\nyes / no\r\n\u21d2no\r\n\r\n# Debug info\r\n\r\n- Streamlit version: (get it with `$ streamlit version`)\r\n\u21d20.74.1\r\n- Python version: (get it with `$ python --version`)\r\n\u21d23.7\r\n- Using Conda? PipEnv? PyEnv? Pex?\r\n\u21d2Pip\r\n- OS version:\r\n\u21d2Linux\r\n- Browser version:\r\n\u21d2Chrome 88.0.4324.150\n", "before_files": [{"content": "# Copyright (c) Streamlit Inc. (2018-2022) Snowflake Inc. (2022)\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom typing import Any, Callable, Dict, List\n\nimport tornado.httputil\nimport tornado.web\n\nfrom streamlit import config\nfrom streamlit.logger import get_logger\nfrom streamlit.runtime.memory_uploaded_file_manager import MemoryUploadedFileManager\nfrom streamlit.runtime.uploaded_file_manager import UploadedFileManager, UploadedFileRec\nfrom streamlit.web.server import routes, server_util\n\nLOGGER = get_logger(__name__)\n\n\nclass UploadFileRequestHandler(tornado.web.RequestHandler):\n \"\"\"Implements the POST /upload_file endpoint.\"\"\"\n\n def initialize(\n self,\n file_mgr: MemoryUploadedFileManager,\n is_active_session: Callable[[str], bool],\n ):\n \"\"\"\n Parameters\n ----------\n file_mgr : UploadedFileManager\n The server's singleton UploadedFileManager. All file uploads\n go here.\n is_active_session:\n A function that returns true if a session_id belongs to an active\n session.\n \"\"\"\n self._file_mgr = file_mgr\n self._is_active_session = is_active_session\n\n def set_default_headers(self):\n self.set_header(\"Access-Control-Allow-Methods\", \"PUT, OPTIONS, DELETE\")\n self.set_header(\"Access-Control-Allow-Headers\", \"Content-Type\")\n if config.get_option(\"server.enableXsrfProtection\"):\n self.set_header(\n \"Access-Control-Allow-Origin\",\n server_util.get_url(config.get_option(\"browser.serverAddress\")),\n )\n self.set_header(\"Access-Control-Allow-Headers\", \"X-Xsrftoken, Content-Type\")\n self.set_header(\"Vary\", \"Origin\")\n self.set_header(\"Access-Control-Allow-Credentials\", \"true\")\n elif routes.allow_cross_origin_requests():\n self.set_header(\"Access-Control-Allow-Origin\", \"*\")\n\n def options(self, **kwargs):\n \"\"\"/OPTIONS handler for preflight CORS checks.\n\n When a browser is making a CORS request, it may sometimes first\n send an OPTIONS request, to check whether the server understands the\n CORS protocol. This is optional, and doesn't happen for every request\n or in every browser. If an OPTIONS request does get sent, and is not\n then handled by the server, the browser will fail the underlying\n request.\n\n The proper way to handle this is to send a 204 response (\"no content\")\n with the CORS headers attached. (These headers are automatically added\n to every outgoing response, including OPTIONS responses,\n via set_default_headers().)\n\n See https://developer.mozilla.org/en-US/docs/Glossary/Preflight_request\n \"\"\"\n self.set_status(204)\n self.finish()\n\n def put(self, **kwargs):\n \"\"\"Receive an uploaded file and add it to our UploadedFileManager.\"\"\"\n\n args: Dict[str, List[bytes]] = {}\n files: Dict[str, List[Any]] = {}\n\n session_id = self.path_kwargs[\"session_id\"]\n file_id = self.path_kwargs[\"file_id\"]\n\n tornado.httputil.parse_body_arguments(\n content_type=self.request.headers[\"Content-Type\"],\n body=self.request.body,\n arguments=args,\n files=files,\n )\n\n try:\n if not self._is_active_session(session_id):\n raise Exception(f\"Invalid session_id: '{session_id}'\")\n except Exception as e:\n self.send_error(400, reason=str(e))\n return\n\n uploaded_files: List[UploadedFileRec] = []\n\n for _, flist in files.items():\n for file in flist:\n uploaded_files.append(\n UploadedFileRec(\n file_id=file_id,\n name=file[\"filename\"],\n type=file[\"content_type\"],\n data=file[\"body\"],\n )\n )\n\n if len(uploaded_files) != 1:\n self.send_error(\n 400, reason=f\"Expected 1 file, but got {len(uploaded_files)}\"\n )\n return\n\n self._file_mgr.add_file(session_id=session_id, file=uploaded_files[0])\n self.set_status(204)\n\n def delete(self, **kwargs):\n \"\"\"Delete file request handler.\"\"\"\n session_id = self.path_kwargs[\"session_id\"]\n file_id = self.path_kwargs[\"file_id\"]\n\n self._file_mgr.remove_file(session_id=session_id, file_id=file_id)\n self.set_status(204)\n", "path": "lib/streamlit/web/server/upload_file_request_handler.py"}], "after_files": [{"content": "# Copyright (c) Streamlit Inc. (2018-2022) Snowflake Inc. (2022)\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom typing import Any, Callable, Dict, List\n\nimport tornado.httputil\nimport tornado.web\n\nfrom streamlit import config\nfrom streamlit.logger import get_logger\nfrom streamlit.runtime.memory_uploaded_file_manager import MemoryUploadedFileManager\nfrom streamlit.runtime.uploaded_file_manager import UploadedFileManager, UploadedFileRec\nfrom streamlit.web.server import routes, server_util\n\nLOGGER = get_logger(__name__)\n\n\nclass UploadFileRequestHandler(tornado.web.RequestHandler):\n \"\"\"Implements the POST /upload_file endpoint.\"\"\"\n\n def initialize(\n self,\n file_mgr: MemoryUploadedFileManager,\n is_active_session: Callable[[str], bool],\n ):\n \"\"\"\n Parameters\n ----------\n file_mgr : UploadedFileManager\n The server's singleton UploadedFileManager. All file uploads\n go here.\n is_active_session:\n A function that returns true if a session_id belongs to an active\n session.\n \"\"\"\n self._file_mgr = file_mgr\n self._is_active_session = is_active_session\n\n def set_default_headers(self):\n self.set_header(\"Access-Control-Allow-Methods\", \"PUT, OPTIONS, DELETE\")\n self.set_header(\"Access-Control-Allow-Headers\", \"Content-Type\")\n if config.get_option(\"server.enableXsrfProtection\"):\n self.set_header(\n \"Access-Control-Allow-Origin\",\n server_util.get_url(config.get_option(\"browser.serverAddress\")),\n )\n self.set_header(\"Access-Control-Allow-Headers\", \"X-Xsrftoken, Content-Type\")\n self.set_header(\"Vary\", \"Origin\")\n self.set_header(\"Access-Control-Allow-Credentials\", \"true\")\n elif routes.allow_cross_origin_requests():\n self.set_header(\"Access-Control-Allow-Origin\", \"*\")\n\n def options(self, **kwargs):\n \"\"\"/OPTIONS handler for preflight CORS checks.\n\n When a browser is making a CORS request, it may sometimes first\n send an OPTIONS request, to check whether the server understands the\n CORS protocol. This is optional, and doesn't happen for every request\n or in every browser. If an OPTIONS request does get sent, and is not\n then handled by the server, the browser will fail the underlying\n request.\n\n The proper way to handle this is to send a 204 response (\"no content\")\n with the CORS headers attached. (These headers are automatically added\n to every outgoing response, including OPTIONS responses,\n via set_default_headers().)\n\n See https://developer.mozilla.org/en-US/docs/Glossary/Preflight_request\n \"\"\"\n self.set_status(204)\n self.finish()\n\n def put(self, **kwargs):\n \"\"\"Receive an uploaded file and add it to our UploadedFileManager.\"\"\"\n\n args: Dict[str, List[bytes]] = {}\n files: Dict[str, List[Any]] = {}\n\n session_id = self.path_kwargs[\"session_id\"]\n file_id = self.path_kwargs[\"file_id\"]\n\n tornado.httputil.parse_body_arguments(\n content_type=self.request.headers[\"Content-Type\"],\n body=self.request.body,\n arguments=args,\n files=files,\n )\n\n try:\n if not self._is_active_session(session_id):\n raise Exception(f\"Invalid session_id\")\n except Exception as e:\n self.send_error(400, reason=str(e))\n return\n\n uploaded_files: List[UploadedFileRec] = []\n\n for _, flist in files.items():\n for file in flist:\n uploaded_files.append(\n UploadedFileRec(\n file_id=file_id,\n name=file[\"filename\"],\n type=file[\"content_type\"],\n data=file[\"body\"],\n )\n )\n\n if len(uploaded_files) != 1:\n self.send_error(\n 400, reason=f\"Expected 1 file, but got {len(uploaded_files)}\"\n )\n return\n\n self._file_mgr.add_file(session_id=session_id, file=uploaded_files[0])\n self.set_status(204)\n\n def delete(self, **kwargs):\n \"\"\"Delete file request handler.\"\"\"\n session_id = self.path_kwargs[\"session_id\"]\n file_id = self.path_kwargs[\"file_id\"]\n\n self._file_mgr.remove_file(session_id=session_id, file_id=file_id)\n self.set_status(204)\n", "path": "lib/streamlit/web/server/upload_file_request_handler.py"}]}
| 2,006 | 126 |
gh_patches_debug_1144
|
rasdani/github-patches
|
git_diff
|
pulp__pulpcore-4727
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
pulp file python package reporting wrongly
Starting with pulpcore 3.40 the pulp_file plugins python package started reporting as pulp_file instead of pulp-file.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pulp_file/app/__init__.py`
Content:
```
1 from pulpcore.plugin import PulpPluginAppConfig
2
3
4 class PulpFilePluginAppConfig(PulpPluginAppConfig):
5 """
6 Entry point for pulp_file plugin.
7 """
8
9 name = "pulp_file.app"
10 label = "file"
11 version = "3.41.1.dev"
12 python_package_name = "pulp_file" # TODO Add python_module_name
13 domain_compatible = True
14
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pulp_file/app/__init__.py b/pulp_file/app/__init__.py
--- a/pulp_file/app/__init__.py
+++ b/pulp_file/app/__init__.py
@@ -9,5 +9,5 @@
name = "pulp_file.app"
label = "file"
version = "3.41.1.dev"
- python_package_name = "pulp_file" # TODO Add python_module_name
+ python_package_name = "pulp-file" # TODO Add python_module_name
domain_compatible = True
|
{"golden_diff": "diff --git a/pulp_file/app/__init__.py b/pulp_file/app/__init__.py\n--- a/pulp_file/app/__init__.py\n+++ b/pulp_file/app/__init__.py\n@@ -9,5 +9,5 @@\n name = \"pulp_file.app\"\n label = \"file\"\n version = \"3.41.1.dev\"\n- python_package_name = \"pulp_file\" # TODO Add python_module_name\n+ python_package_name = \"pulp-file\" # TODO Add python_module_name\n domain_compatible = True\n", "issue": "pulp file python package reporting wrongly\nStarting with pulpcore 3.40 the pulp_file plugins python package started reporting as pulp_file instead of pulp-file.\n", "before_files": [{"content": "from pulpcore.plugin import PulpPluginAppConfig\n\n\nclass PulpFilePluginAppConfig(PulpPluginAppConfig):\n \"\"\"\n Entry point for pulp_file plugin.\n \"\"\"\n\n name = \"pulp_file.app\"\n label = \"file\"\n version = \"3.41.1.dev\"\n python_package_name = \"pulp_file\" # TODO Add python_module_name\n domain_compatible = True\n", "path": "pulp_file/app/__init__.py"}], "after_files": [{"content": "from pulpcore.plugin import PulpPluginAppConfig\n\n\nclass PulpFilePluginAppConfig(PulpPluginAppConfig):\n \"\"\"\n Entry point for pulp_file plugin.\n \"\"\"\n\n name = \"pulp_file.app\"\n label = \"file\"\n version = \"3.41.1.dev\"\n python_package_name = \"pulp-file\" # TODO Add python_module_name\n domain_compatible = True\n", "path": "pulp_file/app/__init__.py"}]}
| 405 | 126 |
gh_patches_debug_37463
|
rasdani/github-patches
|
git_diff
|
pyro-ppl__numpyro-806
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Update docstring of Neal's funnel example
We have updated [funnel](https://github.com/pyro-ppl/numpyro/blob/master/examples/funnel.py) example to use `reparam` handler, but the docstring is not updated yet.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/funnel.py`
Content:
```
1 # Copyright Contributors to the Pyro project.
2 # SPDX-License-Identifier: Apache-2.0
3
4 """
5 Example: Neal's Funnel
6 ======================
7
8 This example, which is adapted from [1], illustrates how to leverage non-centered
9 parameterization using the class :class:`numpyro.distributions.TransformedDistribution`.
10 We will examine the difference between two types of parameterizations on the
11 10-dimensional Neal's funnel distribution. As we will see, HMC gets trouble at
12 the neck of the funnel if centered parameterization is used. On the contrary,
13 the problem can be solved by using non-centered parameterization.
14
15 Using non-centered parameterization through TransformedDistribution in NumPyro
16 has the same effect as the automatic reparameterisation technique introduced in
17 [2]. However, in [2], users need to implement a (non-trivial) reparameterization
18 rule for each type of transform. Instead, in NumPyro the only requirement to let
19 inference algorithms know to do reparameterization automatically is to declare
20 the random variable as a transformed distribution.
21
22 **References:**
23
24 1. *Stan User's Guide*, https://mc-stan.org/docs/2_19/stan-users-guide/reparameterization-section.html
25 2. Maria I. Gorinova, Dave Moore, Matthew D. Hoffman (2019), "Automatic
26 Reparameterisation of Probabilistic Programs", (https://arxiv.org/abs/1906.03028)
27 """
28
29 import argparse
30 import os
31
32 import matplotlib.pyplot as plt
33
34 from jax import random
35 import jax.numpy as jnp
36
37 import numpyro
38 import numpyro.distributions as dist
39 from numpyro.infer import MCMC, NUTS, Predictive
40 from numpyro.infer.reparam import LocScaleReparam
41
42
43 def model(dim=10):
44 y = numpyro.sample('y', dist.Normal(0, 3))
45 numpyro.sample('x', dist.Normal(jnp.zeros(dim - 1), jnp.exp(y / 2)))
46
47
48 def reparam_model(dim=10):
49 y = numpyro.sample('y', dist.Normal(0, 3))
50 with numpyro.handlers.reparam(config={'x': LocScaleReparam(0)}):
51 numpyro.sample('x', dist.Normal(jnp.zeros(dim - 1), jnp.exp(y / 2)))
52
53
54 def run_inference(model, args, rng_key):
55 kernel = NUTS(model)
56 mcmc = MCMC(kernel, args.num_warmup, args.num_samples, num_chains=args.num_chains,
57 progress_bar=False if "NUMPYRO_SPHINXBUILD" in os.environ else True)
58 mcmc.run(rng_key)
59 mcmc.print_summary()
60 return mcmc.get_samples()
61
62
63 def main(args):
64 rng_key = random.PRNGKey(0)
65
66 # do inference with centered parameterization
67 print("============================= Centered Parameterization ==============================")
68 samples = run_inference(model, args, rng_key)
69
70 # do inference with non-centered parameterization
71 print("\n=========================== Non-centered Parameterization ============================")
72 reparam_samples = run_inference(reparam_model, args, rng_key)
73 # collect deterministic sites
74 reparam_samples = Predictive(reparam_model, reparam_samples, return_sites=['x', 'y'])(
75 random.PRNGKey(1))
76
77 # make plots
78 fig, (ax1, ax2) = plt.subplots(2, 1, sharex=True, figsize=(8, 8))
79
80 ax1.plot(samples['x'][:, 0], samples['y'], "go", alpha=0.3)
81 ax1.set(xlim=(-20, 20), ylim=(-9, 9), ylabel='y',
82 title='Funnel samples with centered parameterization')
83
84 ax2.plot(reparam_samples['x'][:, 0], reparam_samples['y'], "go", alpha=0.3)
85 ax2.set(xlim=(-20, 20), ylim=(-9, 9), xlabel='x[0]', ylabel='y',
86 title='Funnel samples with non-centered parameterization')
87
88 plt.savefig('funnel_plot.pdf')
89 plt.tight_layout()
90
91
92 if __name__ == "__main__":
93 assert numpyro.__version__.startswith('0.4.1')
94 parser = argparse.ArgumentParser(description="Non-centered reparameterization example")
95 parser.add_argument("-n", "--num-samples", nargs="?", default=1000, type=int)
96 parser.add_argument("--num-warmup", nargs='?', default=1000, type=int)
97 parser.add_argument("--num-chains", nargs='?', default=1, type=int)
98 parser.add_argument("--device", default='cpu', type=str, help='use "cpu" or "gpu".')
99 args = parser.parse_args()
100
101 numpyro.set_platform(args.device)
102 numpyro.set_host_device_count(args.num_chains)
103
104 main(args)
105
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/funnel.py b/examples/funnel.py
--- a/examples/funnel.py
+++ b/examples/funnel.py
@@ -6,18 +6,15 @@
======================
This example, which is adapted from [1], illustrates how to leverage non-centered
-parameterization using the class :class:`numpyro.distributions.TransformedDistribution`.
+parameterization using the :class:`~numpyro.handlers.reparam` handler.
We will examine the difference between two types of parameterizations on the
10-dimensional Neal's funnel distribution. As we will see, HMC gets trouble at
the neck of the funnel if centered parameterization is used. On the contrary,
the problem can be solved by using non-centered parameterization.
-Using non-centered parameterization through TransformedDistribution in NumPyro
-has the same effect as the automatic reparameterisation technique introduced in
-[2]. However, in [2], users need to implement a (non-trivial) reparameterization
-rule for each type of transform. Instead, in NumPyro the only requirement to let
-inference algorithms know to do reparameterization automatically is to declare
-the random variable as a transformed distribution.
+Using non-centered parameterization through :class:`~numpyro.infer.reparam.LocScaleReparam`
+or :class:`~numpyro.infer.reparam.TransformReparam` in NumPyro has the same effect as
+the automatic reparameterisation technique introduced in [2].
**References:**
@@ -36,6 +33,7 @@
import numpyro
import numpyro.distributions as dist
+from numpyro.handlers import reparam
from numpyro.infer import MCMC, NUTS, Predictive
from numpyro.infer.reparam import LocScaleReparam
@@ -45,10 +43,7 @@
numpyro.sample('x', dist.Normal(jnp.zeros(dim - 1), jnp.exp(y / 2)))
-def reparam_model(dim=10):
- y = numpyro.sample('y', dist.Normal(0, 3))
- with numpyro.handlers.reparam(config={'x': LocScaleReparam(0)}):
- numpyro.sample('x', dist.Normal(jnp.zeros(dim - 1), jnp.exp(y / 2)))
+reparam_model = reparam(model, config={'x': LocScaleReparam(0)})
def run_inference(model, args, rng_key):
@@ -56,7 +51,7 @@
mcmc = MCMC(kernel, args.num_warmup, args.num_samples, num_chains=args.num_chains,
progress_bar=False if "NUMPYRO_SPHINXBUILD" in os.environ else True)
mcmc.run(rng_key)
- mcmc.print_summary()
+ mcmc.print_summary(exclude_deterministic=False)
return mcmc.get_samples()
|
{"golden_diff": "diff --git a/examples/funnel.py b/examples/funnel.py\n--- a/examples/funnel.py\n+++ b/examples/funnel.py\n@@ -6,18 +6,15 @@\n ======================\n \n This example, which is adapted from [1], illustrates how to leverage non-centered\n-parameterization using the class :class:`numpyro.distributions.TransformedDistribution`.\n+parameterization using the :class:`~numpyro.handlers.reparam` handler.\n We will examine the difference between two types of parameterizations on the\n 10-dimensional Neal's funnel distribution. As we will see, HMC gets trouble at\n the neck of the funnel if centered parameterization is used. On the contrary,\n the problem can be solved by using non-centered parameterization.\n \n-Using non-centered parameterization through TransformedDistribution in NumPyro\n-has the same effect as the automatic reparameterisation technique introduced in\n-[2]. However, in [2], users need to implement a (non-trivial) reparameterization\n-rule for each type of transform. Instead, in NumPyro the only requirement to let\n-inference algorithms know to do reparameterization automatically is to declare\n-the random variable as a transformed distribution.\n+Using non-centered parameterization through :class:`~numpyro.infer.reparam.LocScaleReparam`\n+or :class:`~numpyro.infer.reparam.TransformReparam` in NumPyro has the same effect as\n+the automatic reparameterisation technique introduced in [2].\n \n **References:**\n \n@@ -36,6 +33,7 @@\n \n import numpyro\n import numpyro.distributions as dist\n+from numpyro.handlers import reparam\n from numpyro.infer import MCMC, NUTS, Predictive\n from numpyro.infer.reparam import LocScaleReparam\n \n@@ -45,10 +43,7 @@\n numpyro.sample('x', dist.Normal(jnp.zeros(dim - 1), jnp.exp(y / 2)))\n \n \n-def reparam_model(dim=10):\n- y = numpyro.sample('y', dist.Normal(0, 3))\n- with numpyro.handlers.reparam(config={'x': LocScaleReparam(0)}):\n- numpyro.sample('x', dist.Normal(jnp.zeros(dim - 1), jnp.exp(y / 2)))\n+reparam_model = reparam(model, config={'x': LocScaleReparam(0)})\n \n \n def run_inference(model, args, rng_key):\n@@ -56,7 +51,7 @@\n mcmc = MCMC(kernel, args.num_warmup, args.num_samples, num_chains=args.num_chains,\n progress_bar=False if \"NUMPYRO_SPHINXBUILD\" in os.environ else True)\n mcmc.run(rng_key)\n- mcmc.print_summary()\n+ mcmc.print_summary(exclude_deterministic=False)\n return mcmc.get_samples()\n", "issue": "Update docstring of Neal's funnel example\nWe have updated [funnel](https://github.com/pyro-ppl/numpyro/blob/master/examples/funnel.py) example to use `reparam` handler, but the docstring is not updated yet.\n", "before_files": [{"content": "# Copyright Contributors to the Pyro project.\n# SPDX-License-Identifier: Apache-2.0\n\n\"\"\"\nExample: Neal's Funnel\n======================\n\nThis example, which is adapted from [1], illustrates how to leverage non-centered\nparameterization using the class :class:`numpyro.distributions.TransformedDistribution`.\nWe will examine the difference between two types of parameterizations on the\n10-dimensional Neal's funnel distribution. As we will see, HMC gets trouble at\nthe neck of the funnel if centered parameterization is used. On the contrary,\nthe problem can be solved by using non-centered parameterization.\n\nUsing non-centered parameterization through TransformedDistribution in NumPyro\nhas the same effect as the automatic reparameterisation technique introduced in\n[2]. However, in [2], users need to implement a (non-trivial) reparameterization\nrule for each type of transform. Instead, in NumPyro the only requirement to let\ninference algorithms know to do reparameterization automatically is to declare\nthe random variable as a transformed distribution.\n\n**References:**\n\n 1. *Stan User's Guide*, https://mc-stan.org/docs/2_19/stan-users-guide/reparameterization-section.html\n 2. Maria I. Gorinova, Dave Moore, Matthew D. Hoffman (2019), \"Automatic\n Reparameterisation of Probabilistic Programs\", (https://arxiv.org/abs/1906.03028)\n\"\"\"\n\nimport argparse\nimport os\n\nimport matplotlib.pyplot as plt\n\nfrom jax import random\nimport jax.numpy as jnp\n\nimport numpyro\nimport numpyro.distributions as dist\nfrom numpyro.infer import MCMC, NUTS, Predictive\nfrom numpyro.infer.reparam import LocScaleReparam\n\n\ndef model(dim=10):\n y = numpyro.sample('y', dist.Normal(0, 3))\n numpyro.sample('x', dist.Normal(jnp.zeros(dim - 1), jnp.exp(y / 2)))\n\n\ndef reparam_model(dim=10):\n y = numpyro.sample('y', dist.Normal(0, 3))\n with numpyro.handlers.reparam(config={'x': LocScaleReparam(0)}):\n numpyro.sample('x', dist.Normal(jnp.zeros(dim - 1), jnp.exp(y / 2)))\n\n\ndef run_inference(model, args, rng_key):\n kernel = NUTS(model)\n mcmc = MCMC(kernel, args.num_warmup, args.num_samples, num_chains=args.num_chains,\n progress_bar=False if \"NUMPYRO_SPHINXBUILD\" in os.environ else True)\n mcmc.run(rng_key)\n mcmc.print_summary()\n return mcmc.get_samples()\n\n\ndef main(args):\n rng_key = random.PRNGKey(0)\n\n # do inference with centered parameterization\n print(\"============================= Centered Parameterization ==============================\")\n samples = run_inference(model, args, rng_key)\n\n # do inference with non-centered parameterization\n print(\"\\n=========================== Non-centered Parameterization ============================\")\n reparam_samples = run_inference(reparam_model, args, rng_key)\n # collect deterministic sites\n reparam_samples = Predictive(reparam_model, reparam_samples, return_sites=['x', 'y'])(\n random.PRNGKey(1))\n\n # make plots\n fig, (ax1, ax2) = plt.subplots(2, 1, sharex=True, figsize=(8, 8))\n\n ax1.plot(samples['x'][:, 0], samples['y'], \"go\", alpha=0.3)\n ax1.set(xlim=(-20, 20), ylim=(-9, 9), ylabel='y',\n title='Funnel samples with centered parameterization')\n\n ax2.plot(reparam_samples['x'][:, 0], reparam_samples['y'], \"go\", alpha=0.3)\n ax2.set(xlim=(-20, 20), ylim=(-9, 9), xlabel='x[0]', ylabel='y',\n title='Funnel samples with non-centered parameterization')\n\n plt.savefig('funnel_plot.pdf')\n plt.tight_layout()\n\n\nif __name__ == \"__main__\":\n assert numpyro.__version__.startswith('0.4.1')\n parser = argparse.ArgumentParser(description=\"Non-centered reparameterization example\")\n parser.add_argument(\"-n\", \"--num-samples\", nargs=\"?\", default=1000, type=int)\n parser.add_argument(\"--num-warmup\", nargs='?', default=1000, type=int)\n parser.add_argument(\"--num-chains\", nargs='?', default=1, type=int)\n parser.add_argument(\"--device\", default='cpu', type=str, help='use \"cpu\" or \"gpu\".')\n args = parser.parse_args()\n\n numpyro.set_platform(args.device)\n numpyro.set_host_device_count(args.num_chains)\n\n main(args)\n", "path": "examples/funnel.py"}], "after_files": [{"content": "# Copyright Contributors to the Pyro project.\n# SPDX-License-Identifier: Apache-2.0\n\n\"\"\"\nExample: Neal's Funnel\n======================\n\nThis example, which is adapted from [1], illustrates how to leverage non-centered\nparameterization using the :class:`~numpyro.handlers.reparam` handler.\nWe will examine the difference between two types of parameterizations on the\n10-dimensional Neal's funnel distribution. As we will see, HMC gets trouble at\nthe neck of the funnel if centered parameterization is used. On the contrary,\nthe problem can be solved by using non-centered parameterization.\n\nUsing non-centered parameterization through :class:`~numpyro.infer.reparam.LocScaleReparam`\nor :class:`~numpyro.infer.reparam.TransformReparam` in NumPyro has the same effect as\nthe automatic reparameterisation technique introduced in [2].\n\n**References:**\n\n 1. *Stan User's Guide*, https://mc-stan.org/docs/2_19/stan-users-guide/reparameterization-section.html\n 2. Maria I. Gorinova, Dave Moore, Matthew D. Hoffman (2019), \"Automatic\n Reparameterisation of Probabilistic Programs\", (https://arxiv.org/abs/1906.03028)\n\"\"\"\n\nimport argparse\nimport os\n\nimport matplotlib.pyplot as plt\n\nfrom jax import random\nimport jax.numpy as jnp\n\nimport numpyro\nimport numpyro.distributions as dist\nfrom numpyro.handlers import reparam\nfrom numpyro.infer import MCMC, NUTS, Predictive\nfrom numpyro.infer.reparam import LocScaleReparam\n\n\ndef model(dim=10):\n y = numpyro.sample('y', dist.Normal(0, 3))\n numpyro.sample('x', dist.Normal(jnp.zeros(dim - 1), jnp.exp(y / 2)))\n\n\nreparam_model = reparam(model, config={'x': LocScaleReparam(0)})\n\n\ndef run_inference(model, args, rng_key):\n kernel = NUTS(model)\n mcmc = MCMC(kernel, args.num_warmup, args.num_samples, num_chains=args.num_chains,\n progress_bar=False if \"NUMPYRO_SPHINXBUILD\" in os.environ else True)\n mcmc.run(rng_key)\n mcmc.print_summary(exclude_deterministic=False)\n return mcmc.get_samples()\n\n\ndef main(args):\n rng_key = random.PRNGKey(0)\n\n # do inference with centered parameterization\n print(\"============================= Centered Parameterization ==============================\")\n samples = run_inference(model, args, rng_key)\n\n # do inference with non-centered parameterization\n print(\"\\n=========================== Non-centered Parameterization ============================\")\n reparam_samples = run_inference(reparam_model, args, rng_key)\n # collect deterministic sites\n reparam_samples = Predictive(reparam_model, reparam_samples, return_sites=['x', 'y'])(\n random.PRNGKey(1))\n\n # make plots\n fig, (ax1, ax2) = plt.subplots(2, 1, sharex=True, figsize=(8, 8))\n\n ax1.plot(samples['x'][:, 0], samples['y'], \"go\", alpha=0.3)\n ax1.set(xlim=(-20, 20), ylim=(-9, 9), ylabel='y',\n title='Funnel samples with centered parameterization')\n\n ax2.plot(reparam_samples['x'][:, 0], reparam_samples['y'], \"go\", alpha=0.3)\n ax2.set(xlim=(-20, 20), ylim=(-9, 9), xlabel='x[0]', ylabel='y',\n title='Funnel samples with non-centered parameterization')\n\n plt.savefig('funnel_plot.pdf')\n plt.tight_layout()\n\n\nif __name__ == \"__main__\":\n assert numpyro.__version__.startswith('0.4.1')\n parser = argparse.ArgumentParser(description=\"Non-centered reparameterization example\")\n parser.add_argument(\"-n\", \"--num-samples\", nargs=\"?\", default=1000, type=int)\n parser.add_argument(\"--num-warmup\", nargs='?', default=1000, type=int)\n parser.add_argument(\"--num-chains\", nargs='?', default=1, type=int)\n parser.add_argument(\"--device\", default='cpu', type=str, help='use \"cpu\" or \"gpu\".')\n args = parser.parse_args()\n\n numpyro.set_platform(args.device)\n numpyro.set_host_device_count(args.num_chains)\n\n main(args)\n", "path": "examples/funnel.py"}]}
| 1,599 | 615 |
gh_patches_debug_17316
|
rasdani/github-patches
|
git_diff
|
jazzband__pip-tools-483
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Unnamed editable dependency raises AttributeError on second run
An editable dependency without a name raises an AttributeError when pip-compile is run the second time without the --upgrade flag.
##### Environment Versions
1. CentOS 7
1. Python version: Python 3.5.2
1. pip version: pip 9.0.1
1. pip-tools version: pip-compile, version 1.8.1
##### Steps to replicate
foo.in:
```
-e .
```
run:
```
pip-compile foo.in
pip-compile foo.in
```
##### Expected result
```
#
# This file is autogenerated by pip-compile
# To update, run:
#
# pip-compile --output-file foo.txt foo.in
#
-e file:///home/eric/projects/foo
```
(Well, not really the *hoped for* result due to #204.)
##### Actual result
```
Traceback (most recent call last):
File "/home/eric/projects/foo/.env/bin/pip-compile", line 11, in <module>
sys.exit(cli())
File "/home/eric/projects/foo/.env/lib64/python3.5/site-packages/click/core.py", line 722, in __call__
return self.main(*args, **kwargs)
File "/home/eric/projects/foo/.env/lib64/python3.5/site-packages/click/core.py", line 697, in main
rv = self.invoke(ctx)
File "/home/eric/projects/foo/.env/lib64/python3.5/site-packages/click/core.py", line 895, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/home/eric/projects/foo/.env/lib64/python3.5/site-packages/click/core.py", line 535, in invoke
return callback(*args, **kwargs)
File "/home/eric/projects/foo/.env/lib64/python3.5/site-packages/piptools/scripts/compile.py", line 139, in cli
key = key_from_req(ireq.req)
File "/home/eric/projects/foo/.env/lib64/python3.5/site-packages/piptools/utils.py", line 41, in key_from_req
key = req.name
AttributeError: 'NoneType' object has no attribute 'name'
```
I think this could be fixed in compile.py (around line 138) by waiting to see if `is_pinned_requirement` returns True before trying to get the key. Something like...
```
for ireq in ireqs:
if is_pinned_requirement(ireq):
key = key_from_req(ireq.req)
existing_pins[key] = ireq
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `piptools/scripts/compile.py`
Content:
```
1 # coding: utf-8
2 from __future__ import (absolute_import, division, print_function,
3 unicode_literals)
4
5 import optparse
6 import os
7 import sys
8 import tempfile
9 from collections import OrderedDict
10
11 import pip
12 from pip.req import InstallRequirement, parse_requirements
13
14 from .. import click
15 from ..exceptions import PipToolsError
16 from ..logging import log
17 from ..repositories import LocalRequirementsRepository, PyPIRepository
18 from ..resolver import Resolver
19 from ..utils import (assert_compatible_pip_version, is_pinned_requirement,
20 key_from_req)
21 from ..writer import OutputWriter
22
23 # Make sure we're using a compatible version of pip
24 assert_compatible_pip_version()
25
26 DEFAULT_REQUIREMENTS_FILE = 'requirements.in'
27
28
29 class PipCommand(pip.basecommand.Command):
30 name = 'PipCommand'
31
32
33 @click.command()
34 @click.version_option()
35 @click.option('-v', '--verbose', is_flag=True, help="Show more output")
36 @click.option('-n', '--dry-run', is_flag=True, help="Only show what would happen, don't change anything")
37 @click.option('-p', '--pre', is_flag=True, default=None, help="Allow resolving to prereleases (default is not)")
38 @click.option('-r', '--rebuild', is_flag=True, help="Clear any caches upfront, rebuild from scratch")
39 @click.option('-f', '--find-links', multiple=True, help="Look for archives in this directory or on this HTML page", envvar='PIP_FIND_LINKS') # noqa
40 @click.option('-i', '--index-url', help="Change index URL (defaults to PyPI)", envvar='PIP_INDEX_URL')
41 @click.option('--extra-index-url', multiple=True, help="Add additional index URL to search", envvar='PIP_EXTRA_INDEX_URL') # noqa
42 @click.option('--client-cert', help="Path to SSL client certificate, a single file containing the private key and the certificate in PEM format.") # noqa
43 @click.option('--trusted-host', multiple=True, envvar='PIP_TRUSTED_HOST',
44 help="Mark this host as trusted, even though it does not have "
45 "valid or any HTTPS.")
46 @click.option('--header/--no-header', is_flag=True, default=True,
47 help="Add header to generated file")
48 @click.option('--index/--no-index', is_flag=True, default=True,
49 help="Add index URL to generated file")
50 @click.option('--annotate/--no-annotate', is_flag=True, default=True,
51 help="Annotate results, indicating where dependencies come from")
52 @click.option('-U', '--upgrade', is_flag=True, default=False,
53 help='Try to upgrade all dependencies to their latest versions')
54 @click.option('-P', '--upgrade-package', 'upgrade_packages', nargs=1, multiple=True,
55 help="Specify particular packages to upgrade.")
56 @click.option('-o', '--output-file', nargs=1, type=str, default=None,
57 help=('Output file name. Required if more than one input file is given. '
58 'Will be derived from input file otherwise.'))
59 @click.option('--allow-unsafe', is_flag=True, default=False,
60 help="Pin packages considered unsafe: pip, setuptools & distribute")
61 @click.option('--generate-hashes', is_flag=True, default=False,
62 help="Generate pip 8 style hashes in the resulting requirements file.")
63 @click.option('--max-rounds', default=10,
64 help="Maximum number of rounds before resolving the requirements aborts.")
65 @click.argument('src_files', nargs=-1, type=click.Path(exists=True, allow_dash=True))
66 def cli(verbose, dry_run, pre, rebuild, find_links, index_url, extra_index_url,
67 client_cert, trusted_host, header, index, annotate, upgrade, upgrade_packages,
68 output_file, allow_unsafe, generate_hashes, src_files, max_rounds):
69 """Compiles requirements.txt from requirements.in specs."""
70 log.verbose = verbose
71
72 if len(src_files) == 0:
73 if os.path.exists(DEFAULT_REQUIREMENTS_FILE):
74 src_files = (DEFAULT_REQUIREMENTS_FILE,)
75 elif os.path.exists('setup.py'):
76 src_files = ('setup.py',)
77 if not output_file:
78 output_file = 'requirements.txt'
79 else:
80 raise click.BadParameter(("If you do not specify an input file, "
81 "the default is {} or setup.py").format(DEFAULT_REQUIREMENTS_FILE))
82
83 if len(src_files) == 1 and src_files[0] == '-':
84 if not output_file:
85 raise click.BadParameter('--output-file is required if input is from stdin')
86
87 if len(src_files) > 1 and not output_file:
88 raise click.BadParameter('--output-file is required if two or more input files are given.')
89
90 if output_file:
91 dst_file = output_file
92 else:
93 base_name, _, _ = src_files[0].rpartition('.')
94 dst_file = base_name + '.txt'
95
96 if upgrade and upgrade_packages:
97 raise click.BadParameter('Only one of --upgrade or --upgrade-package can be provided as an argument.')
98
99 ###
100 # Setup
101 ###
102
103 pip_command = get_pip_command()
104
105 pip_args = []
106 if find_links:
107 for link in find_links:
108 pip_args.extend(['-f', link])
109 if index_url:
110 pip_args.extend(['-i', index_url])
111 if extra_index_url:
112 for extra_index in extra_index_url:
113 pip_args.extend(['--extra-index-url', extra_index])
114 if client_cert:
115 pip_args.extend(['--client-cert', client_cert])
116 if pre:
117 pip_args.extend(['--pre'])
118 if trusted_host:
119 for host in trusted_host:
120 pip_args.extend(['--trusted-host', host])
121
122 pip_options, _ = pip_command.parse_args(pip_args)
123
124 session = pip_command._build_session(pip_options)
125 repository = PyPIRepository(pip_options, session)
126
127 # Pre-parse the inline package upgrade specs: they should take precedence
128 # over the stuff in the requirements files
129 upgrade_packages = [InstallRequirement.from_line(pkg)
130 for pkg in upgrade_packages]
131
132 # Proxy with a LocalRequirementsRepository if --upgrade is not specified
133 # (= default invocation)
134 if not (upgrade or upgrade_packages) and os.path.exists(dst_file):
135 existing_pins = {}
136 ireqs = parse_requirements(dst_file, finder=repository.finder, session=repository.session, options=pip_options)
137 for ireq in ireqs:
138 key = key_from_req(ireq.req)
139
140 if is_pinned_requirement(ireq):
141 existing_pins[key] = ireq
142 repository = LocalRequirementsRepository(existing_pins, repository)
143
144 log.debug('Using indexes:')
145 # remove duplicate index urls before processing
146 repository.finder.index_urls = list(OrderedDict.fromkeys(repository.finder.index_urls))
147 for index_url in repository.finder.index_urls:
148 log.debug(' {}'.format(index_url))
149
150 if repository.finder.find_links:
151 log.debug('')
152 log.debug('Configuration:')
153 for find_link in repository.finder.find_links:
154 log.debug(' -f {}'.format(find_link))
155
156 ###
157 # Parsing/collecting initial requirements
158 ###
159
160 constraints = []
161 for src_file in src_files:
162 is_setup_file = os.path.basename(src_file) == 'setup.py'
163 if is_setup_file or src_file == '-':
164 # pip requires filenames and not files. Since we want to support
165 # piping from stdin, we need to briefly save the input from stdin
166 # to a temporary file and have pip read that. also used for
167 # reading requirements from install_requires in setup.py.
168 tmpfile = tempfile.NamedTemporaryFile(mode='wt', delete=False)
169 if is_setup_file:
170 from distutils.core import run_setup
171 dist = run_setup(src_file)
172 tmpfile.write('\n'.join(dist.install_requires))
173 else:
174 tmpfile.write(sys.stdin.read())
175 tmpfile.flush()
176 constraints.extend(parse_requirements(
177 tmpfile.name, finder=repository.finder, session=repository.session, options=pip_options))
178 else:
179 constraints.extend(parse_requirements(
180 src_file, finder=repository.finder, session=repository.session, options=pip_options))
181
182 try:
183 resolver = Resolver(constraints, repository, prereleases=pre,
184 clear_caches=rebuild, allow_unsafe=allow_unsafe)
185 results = resolver.resolve(max_rounds=max_rounds)
186 if generate_hashes:
187 hashes = resolver.resolve_hashes(results)
188 else:
189 hashes = None
190 except PipToolsError as e:
191 log.error(str(e))
192 sys.exit(2)
193
194 log.debug('')
195
196 ##
197 # Output
198 ##
199
200 # Compute reverse dependency annotations statically, from the
201 # dependency cache that the resolver has populated by now.
202 #
203 # TODO (1a): reverse deps for any editable package are lost
204 # what SHOULD happen is that they are cached in memory, just
205 # not persisted to disk!
206 #
207 # TODO (1b): perhaps it's easiest if the dependency cache has an API
208 # that could take InstallRequirements directly, like:
209 #
210 # cache.set(ireq, ...)
211 #
212 # then, when ireq is editable, it would store in
213 #
214 # editables[egg_name][link_without_fragment] = deps
215 # editables['pip-tools']['git+...ols.git@future'] = {'click>=3.0', 'six'}
216 #
217 # otherwise:
218 #
219 # self[as_name_version_tuple(ireq)] = {'click>=3.0', 'six'}
220 #
221 reverse_dependencies = None
222 if annotate:
223 reverse_dependencies = resolver.reverse_dependencies(results)
224
225 writer = OutputWriter(src_files, dst_file, dry_run=dry_run,
226 emit_header=header, emit_index=index,
227 annotate=annotate,
228 generate_hashes=generate_hashes,
229 default_index_url=repository.DEFAULT_INDEX_URL,
230 index_urls=repository.finder.index_urls,
231 trusted_hosts=pip_options.trusted_hosts,
232 format_control=repository.finder.format_control)
233 writer.write(results=results,
234 reverse_dependencies=reverse_dependencies,
235 primary_packages={key_from_req(ireq.req) for ireq in constraints},
236 markers={key_from_req(ireq.req): ireq.markers
237 for ireq in constraints if ireq.markers},
238 hashes=hashes)
239
240 if dry_run:
241 log.warning('Dry-run, so nothing updated.')
242
243
244 def get_pip_command():
245 # Use pip's parser for pip.conf management and defaults.
246 # General options (find_links, index_url, extra_index_url, trusted_host,
247 # and pre) are defered to pip.
248 pip_command = PipCommand()
249 index_opts = pip.cmdoptions.make_option_group(
250 pip.cmdoptions.index_group,
251 pip_command.parser,
252 )
253 pip_command.parser.insert_option_group(0, index_opts)
254 pip_command.parser.add_option(optparse.Option('--pre', action='store_true', default=False))
255
256 return pip_command
257
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/piptools/scripts/compile.py b/piptools/scripts/compile.py
--- a/piptools/scripts/compile.py
+++ b/piptools/scripts/compile.py
@@ -132,13 +132,8 @@
# Proxy with a LocalRequirementsRepository if --upgrade is not specified
# (= default invocation)
if not (upgrade or upgrade_packages) and os.path.exists(dst_file):
- existing_pins = {}
ireqs = parse_requirements(dst_file, finder=repository.finder, session=repository.session, options=pip_options)
- for ireq in ireqs:
- key = key_from_req(ireq.req)
-
- if is_pinned_requirement(ireq):
- existing_pins[key] = ireq
+ existing_pins = {key_from_req(ireq.req): ireq for ireq in ireqs if is_pinned_requirement(ireq)}
repository = LocalRequirementsRepository(existing_pins, repository)
log.debug('Using indexes:')
|
{"golden_diff": "diff --git a/piptools/scripts/compile.py b/piptools/scripts/compile.py\n--- a/piptools/scripts/compile.py\n+++ b/piptools/scripts/compile.py\n@@ -132,13 +132,8 @@\n # Proxy with a LocalRequirementsRepository if --upgrade is not specified\n # (= default invocation)\n if not (upgrade or upgrade_packages) and os.path.exists(dst_file):\n- existing_pins = {}\n ireqs = parse_requirements(dst_file, finder=repository.finder, session=repository.session, options=pip_options)\n- for ireq in ireqs:\n- key = key_from_req(ireq.req)\n-\n- if is_pinned_requirement(ireq):\n- existing_pins[key] = ireq\n+ existing_pins = {key_from_req(ireq.req): ireq for ireq in ireqs if is_pinned_requirement(ireq)}\n repository = LocalRequirementsRepository(existing_pins, repository)\n \n log.debug('Using indexes:')\n", "issue": "Unnamed editable dependency raises AttributeError on second run\nAn editable dependency without a name raises an AttributeError when pip-compile is run the second time without the --upgrade flag.\r\n\r\n##### Environment Versions\r\n\r\n1. CentOS 7\r\n1. Python version: Python 3.5.2\r\n1. pip version: pip 9.0.1\r\n1. pip-tools version: pip-compile, version 1.8.1\r\n\r\n##### Steps to replicate\r\nfoo.in:\r\n\r\n```\r\n-e .\r\n```\r\nrun:\r\n\r\n```\r\npip-compile foo.in\r\npip-compile foo.in\r\n```\r\n\r\n##### Expected result\r\n\r\n```\r\n#\r\n# This file is autogenerated by pip-compile\r\n# To update, run:\r\n#\r\n# pip-compile --output-file foo.txt foo.in\r\n#\r\n-e file:///home/eric/projects/foo\r\n```\r\n(Well, not really the *hoped for* result due to #204.)\r\n##### Actual result\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/home/eric/projects/foo/.env/bin/pip-compile\", line 11, in <module>\r\n sys.exit(cli())\r\n File \"/home/eric/projects/foo/.env/lib64/python3.5/site-packages/click/core.py\", line 722, in __call__\r\n return self.main(*args, **kwargs)\r\n File \"/home/eric/projects/foo/.env/lib64/python3.5/site-packages/click/core.py\", line 697, in main\r\n rv = self.invoke(ctx)\r\n File \"/home/eric/projects/foo/.env/lib64/python3.5/site-packages/click/core.py\", line 895, in invoke\r\n return ctx.invoke(self.callback, **ctx.params)\r\n File \"/home/eric/projects/foo/.env/lib64/python3.5/site-packages/click/core.py\", line 535, in invoke\r\n return callback(*args, **kwargs)\r\n File \"/home/eric/projects/foo/.env/lib64/python3.5/site-packages/piptools/scripts/compile.py\", line 139, in cli\r\n key = key_from_req(ireq.req)\r\n File \"/home/eric/projects/foo/.env/lib64/python3.5/site-packages/piptools/utils.py\", line 41, in key_from_req\r\n key = req.name\r\nAttributeError: 'NoneType' object has no attribute 'name'\r\n```\r\nI think this could be fixed in compile.py (around line 138) by waiting to see if `is_pinned_requirement` returns True before trying to get the key. Something like...\r\n\r\n```\r\n for ireq in ireqs:\r\n\r\n if is_pinned_requirement(ireq):\r\n key = key_from_req(ireq.req)\r\n existing_pins[key] = ireq\r\n```\n", "before_files": [{"content": "# coding: utf-8\nfrom __future__ import (absolute_import, division, print_function,\n unicode_literals)\n\nimport optparse\nimport os\nimport sys\nimport tempfile\nfrom collections import OrderedDict\n\nimport pip\nfrom pip.req import InstallRequirement, parse_requirements\n\nfrom .. import click\nfrom ..exceptions import PipToolsError\nfrom ..logging import log\nfrom ..repositories import LocalRequirementsRepository, PyPIRepository\nfrom ..resolver import Resolver\nfrom ..utils import (assert_compatible_pip_version, is_pinned_requirement,\n key_from_req)\nfrom ..writer import OutputWriter\n\n# Make sure we're using a compatible version of pip\nassert_compatible_pip_version()\n\nDEFAULT_REQUIREMENTS_FILE = 'requirements.in'\n\n\nclass PipCommand(pip.basecommand.Command):\n name = 'PipCommand'\n\n\[email protected]()\[email protected]_option()\[email protected]('-v', '--verbose', is_flag=True, help=\"Show more output\")\[email protected]('-n', '--dry-run', is_flag=True, help=\"Only show what would happen, don't change anything\")\[email protected]('-p', '--pre', is_flag=True, default=None, help=\"Allow resolving to prereleases (default is not)\")\[email protected]('-r', '--rebuild', is_flag=True, help=\"Clear any caches upfront, rebuild from scratch\")\[email protected]('-f', '--find-links', multiple=True, help=\"Look for archives in this directory or on this HTML page\", envvar='PIP_FIND_LINKS') # noqa\[email protected]('-i', '--index-url', help=\"Change index URL (defaults to PyPI)\", envvar='PIP_INDEX_URL')\[email protected]('--extra-index-url', multiple=True, help=\"Add additional index URL to search\", envvar='PIP_EXTRA_INDEX_URL') # noqa\[email protected]('--client-cert', help=\"Path to SSL client certificate, a single file containing the private key and the certificate in PEM format.\") # noqa\[email protected]('--trusted-host', multiple=True, envvar='PIP_TRUSTED_HOST',\n help=\"Mark this host as trusted, even though it does not have \"\n \"valid or any HTTPS.\")\[email protected]('--header/--no-header', is_flag=True, default=True,\n help=\"Add header to generated file\")\[email protected]('--index/--no-index', is_flag=True, default=True,\n help=\"Add index URL to generated file\")\[email protected]('--annotate/--no-annotate', is_flag=True, default=True,\n help=\"Annotate results, indicating where dependencies come from\")\[email protected]('-U', '--upgrade', is_flag=True, default=False,\n help='Try to upgrade all dependencies to their latest versions')\[email protected]('-P', '--upgrade-package', 'upgrade_packages', nargs=1, multiple=True,\n help=\"Specify particular packages to upgrade.\")\[email protected]('-o', '--output-file', nargs=1, type=str, default=None,\n help=('Output file name. Required if more than one input file is given. '\n 'Will be derived from input file otherwise.'))\[email protected]('--allow-unsafe', is_flag=True, default=False,\n help=\"Pin packages considered unsafe: pip, setuptools & distribute\")\[email protected]('--generate-hashes', is_flag=True, default=False,\n help=\"Generate pip 8 style hashes in the resulting requirements file.\")\[email protected]('--max-rounds', default=10,\n help=\"Maximum number of rounds before resolving the requirements aborts.\")\[email protected]('src_files', nargs=-1, type=click.Path(exists=True, allow_dash=True))\ndef cli(verbose, dry_run, pre, rebuild, find_links, index_url, extra_index_url,\n client_cert, trusted_host, header, index, annotate, upgrade, upgrade_packages,\n output_file, allow_unsafe, generate_hashes, src_files, max_rounds):\n \"\"\"Compiles requirements.txt from requirements.in specs.\"\"\"\n log.verbose = verbose\n\n if len(src_files) == 0:\n if os.path.exists(DEFAULT_REQUIREMENTS_FILE):\n src_files = (DEFAULT_REQUIREMENTS_FILE,)\n elif os.path.exists('setup.py'):\n src_files = ('setup.py',)\n if not output_file:\n output_file = 'requirements.txt'\n else:\n raise click.BadParameter((\"If you do not specify an input file, \"\n \"the default is {} or setup.py\").format(DEFAULT_REQUIREMENTS_FILE))\n\n if len(src_files) == 1 and src_files[0] == '-':\n if not output_file:\n raise click.BadParameter('--output-file is required if input is from stdin')\n\n if len(src_files) > 1 and not output_file:\n raise click.BadParameter('--output-file is required if two or more input files are given.')\n\n if output_file:\n dst_file = output_file\n else:\n base_name, _, _ = src_files[0].rpartition('.')\n dst_file = base_name + '.txt'\n\n if upgrade and upgrade_packages:\n raise click.BadParameter('Only one of --upgrade or --upgrade-package can be provided as an argument.')\n\n ###\n # Setup\n ###\n\n pip_command = get_pip_command()\n\n pip_args = []\n if find_links:\n for link in find_links:\n pip_args.extend(['-f', link])\n if index_url:\n pip_args.extend(['-i', index_url])\n if extra_index_url:\n for extra_index in extra_index_url:\n pip_args.extend(['--extra-index-url', extra_index])\n if client_cert:\n pip_args.extend(['--client-cert', client_cert])\n if pre:\n pip_args.extend(['--pre'])\n if trusted_host:\n for host in trusted_host:\n pip_args.extend(['--trusted-host', host])\n\n pip_options, _ = pip_command.parse_args(pip_args)\n\n session = pip_command._build_session(pip_options)\n repository = PyPIRepository(pip_options, session)\n\n # Pre-parse the inline package upgrade specs: they should take precedence\n # over the stuff in the requirements files\n upgrade_packages = [InstallRequirement.from_line(pkg)\n for pkg in upgrade_packages]\n\n # Proxy with a LocalRequirementsRepository if --upgrade is not specified\n # (= default invocation)\n if not (upgrade or upgrade_packages) and os.path.exists(dst_file):\n existing_pins = {}\n ireqs = parse_requirements(dst_file, finder=repository.finder, session=repository.session, options=pip_options)\n for ireq in ireqs:\n key = key_from_req(ireq.req)\n\n if is_pinned_requirement(ireq):\n existing_pins[key] = ireq\n repository = LocalRequirementsRepository(existing_pins, repository)\n\n log.debug('Using indexes:')\n # remove duplicate index urls before processing\n repository.finder.index_urls = list(OrderedDict.fromkeys(repository.finder.index_urls))\n for index_url in repository.finder.index_urls:\n log.debug(' {}'.format(index_url))\n\n if repository.finder.find_links:\n log.debug('')\n log.debug('Configuration:')\n for find_link in repository.finder.find_links:\n log.debug(' -f {}'.format(find_link))\n\n ###\n # Parsing/collecting initial requirements\n ###\n\n constraints = []\n for src_file in src_files:\n is_setup_file = os.path.basename(src_file) == 'setup.py'\n if is_setup_file or src_file == '-':\n # pip requires filenames and not files. Since we want to support\n # piping from stdin, we need to briefly save the input from stdin\n # to a temporary file and have pip read that. also used for\n # reading requirements from install_requires in setup.py.\n tmpfile = tempfile.NamedTemporaryFile(mode='wt', delete=False)\n if is_setup_file:\n from distutils.core import run_setup\n dist = run_setup(src_file)\n tmpfile.write('\\n'.join(dist.install_requires))\n else:\n tmpfile.write(sys.stdin.read())\n tmpfile.flush()\n constraints.extend(parse_requirements(\n tmpfile.name, finder=repository.finder, session=repository.session, options=pip_options))\n else:\n constraints.extend(parse_requirements(\n src_file, finder=repository.finder, session=repository.session, options=pip_options))\n\n try:\n resolver = Resolver(constraints, repository, prereleases=pre,\n clear_caches=rebuild, allow_unsafe=allow_unsafe)\n results = resolver.resolve(max_rounds=max_rounds)\n if generate_hashes:\n hashes = resolver.resolve_hashes(results)\n else:\n hashes = None\n except PipToolsError as e:\n log.error(str(e))\n sys.exit(2)\n\n log.debug('')\n\n ##\n # Output\n ##\n\n # Compute reverse dependency annotations statically, from the\n # dependency cache that the resolver has populated by now.\n #\n # TODO (1a): reverse deps for any editable package are lost\n # what SHOULD happen is that they are cached in memory, just\n # not persisted to disk!\n #\n # TODO (1b): perhaps it's easiest if the dependency cache has an API\n # that could take InstallRequirements directly, like:\n #\n # cache.set(ireq, ...)\n #\n # then, when ireq is editable, it would store in\n #\n # editables[egg_name][link_without_fragment] = deps\n # editables['pip-tools']['git+...ols.git@future'] = {'click>=3.0', 'six'}\n #\n # otherwise:\n #\n # self[as_name_version_tuple(ireq)] = {'click>=3.0', 'six'}\n #\n reverse_dependencies = None\n if annotate:\n reverse_dependencies = resolver.reverse_dependencies(results)\n\n writer = OutputWriter(src_files, dst_file, dry_run=dry_run,\n emit_header=header, emit_index=index,\n annotate=annotate,\n generate_hashes=generate_hashes,\n default_index_url=repository.DEFAULT_INDEX_URL,\n index_urls=repository.finder.index_urls,\n trusted_hosts=pip_options.trusted_hosts,\n format_control=repository.finder.format_control)\n writer.write(results=results,\n reverse_dependencies=reverse_dependencies,\n primary_packages={key_from_req(ireq.req) for ireq in constraints},\n markers={key_from_req(ireq.req): ireq.markers\n for ireq in constraints if ireq.markers},\n hashes=hashes)\n\n if dry_run:\n log.warning('Dry-run, so nothing updated.')\n\n\ndef get_pip_command():\n # Use pip's parser for pip.conf management and defaults.\n # General options (find_links, index_url, extra_index_url, trusted_host,\n # and pre) are defered to pip.\n pip_command = PipCommand()\n index_opts = pip.cmdoptions.make_option_group(\n pip.cmdoptions.index_group,\n pip_command.parser,\n )\n pip_command.parser.insert_option_group(0, index_opts)\n pip_command.parser.add_option(optparse.Option('--pre', action='store_true', default=False))\n\n return pip_command\n", "path": "piptools/scripts/compile.py"}], "after_files": [{"content": "# coding: utf-8\nfrom __future__ import (absolute_import, division, print_function,\n unicode_literals)\n\nimport optparse\nimport os\nimport sys\nimport tempfile\nfrom collections import OrderedDict\n\nimport pip\nfrom pip.req import InstallRequirement, parse_requirements\n\nfrom .. import click\nfrom ..exceptions import PipToolsError\nfrom ..logging import log\nfrom ..repositories import LocalRequirementsRepository, PyPIRepository\nfrom ..resolver import Resolver\nfrom ..utils import (assert_compatible_pip_version, is_pinned_requirement,\n key_from_req)\nfrom ..writer import OutputWriter\n\n# Make sure we're using a compatible version of pip\nassert_compatible_pip_version()\n\nDEFAULT_REQUIREMENTS_FILE = 'requirements.in'\n\n\nclass PipCommand(pip.basecommand.Command):\n name = 'PipCommand'\n\n\[email protected]()\[email protected]_option()\[email protected]('-v', '--verbose', is_flag=True, help=\"Show more output\")\[email protected]('-n', '--dry-run', is_flag=True, help=\"Only show what would happen, don't change anything\")\[email protected]('-p', '--pre', is_flag=True, default=None, help=\"Allow resolving to prereleases (default is not)\")\[email protected]('-r', '--rebuild', is_flag=True, help=\"Clear any caches upfront, rebuild from scratch\")\[email protected]('-f', '--find-links', multiple=True, help=\"Look for archives in this directory or on this HTML page\", envvar='PIP_FIND_LINKS') # noqa\[email protected]('-i', '--index-url', help=\"Change index URL (defaults to PyPI)\", envvar='PIP_INDEX_URL')\[email protected]('--extra-index-url', multiple=True, help=\"Add additional index URL to search\", envvar='PIP_EXTRA_INDEX_URL') # noqa\[email protected]('--client-cert', help=\"Path to SSL client certificate, a single file containing the private key and the certificate in PEM format.\") # noqa\[email protected]('--trusted-host', multiple=True, envvar='PIP_TRUSTED_HOST',\n help=\"Mark this host as trusted, even though it does not have \"\n \"valid or any HTTPS.\")\[email protected]('--header/--no-header', is_flag=True, default=True,\n help=\"Add header to generated file\")\[email protected]('--index/--no-index', is_flag=True, default=True,\n help=\"Add index URL to generated file\")\[email protected]('--annotate/--no-annotate', is_flag=True, default=True,\n help=\"Annotate results, indicating where dependencies come from\")\[email protected]('-U', '--upgrade', is_flag=True, default=False,\n help='Try to upgrade all dependencies to their latest versions')\[email protected]('-P', '--upgrade-package', 'upgrade_packages', nargs=1, multiple=True,\n help=\"Specify particular packages to upgrade.\")\[email protected]('-o', '--output-file', nargs=1, type=str, default=None,\n help=('Output file name. Required if more than one input file is given. '\n 'Will be derived from input file otherwise.'))\[email protected]('--allow-unsafe', is_flag=True, default=False,\n help=\"Pin packages considered unsafe: pip, setuptools & distribute\")\[email protected]('--generate-hashes', is_flag=True, default=False,\n help=\"Generate pip 8 style hashes in the resulting requirements file.\")\[email protected]('--max-rounds', default=10,\n help=\"Maximum number of rounds before resolving the requirements aborts.\")\[email protected]('src_files', nargs=-1, type=click.Path(exists=True, allow_dash=True))\ndef cli(verbose, dry_run, pre, rebuild, find_links, index_url, extra_index_url,\n client_cert, trusted_host, header, index, annotate, upgrade, upgrade_packages,\n output_file, allow_unsafe, generate_hashes, src_files, max_rounds):\n \"\"\"Compiles requirements.txt from requirements.in specs.\"\"\"\n log.verbose = verbose\n\n if len(src_files) == 0:\n if os.path.exists(DEFAULT_REQUIREMENTS_FILE):\n src_files = (DEFAULT_REQUIREMENTS_FILE,)\n elif os.path.exists('setup.py'):\n src_files = ('setup.py',)\n if not output_file:\n output_file = 'requirements.txt'\n else:\n raise click.BadParameter((\"If you do not specify an input file, \"\n \"the default is {} or setup.py\").format(DEFAULT_REQUIREMENTS_FILE))\n\n if len(src_files) == 1 and src_files[0] == '-':\n if not output_file:\n raise click.BadParameter('--output-file is required if input is from stdin')\n\n if len(src_files) > 1 and not output_file:\n raise click.BadParameter('--output-file is required if two or more input files are given.')\n\n if output_file:\n dst_file = output_file\n else:\n base_name, _, _ = src_files[0].rpartition('.')\n dst_file = base_name + '.txt'\n\n if upgrade and upgrade_packages:\n raise click.BadParameter('Only one of --upgrade or --upgrade-package can be provided as an argument.')\n\n ###\n # Setup\n ###\n\n pip_command = get_pip_command()\n\n pip_args = []\n if find_links:\n for link in find_links:\n pip_args.extend(['-f', link])\n if index_url:\n pip_args.extend(['-i', index_url])\n if extra_index_url:\n for extra_index in extra_index_url:\n pip_args.extend(['--extra-index-url', extra_index])\n if client_cert:\n pip_args.extend(['--client-cert', client_cert])\n if pre:\n pip_args.extend(['--pre'])\n if trusted_host:\n for host in trusted_host:\n pip_args.extend(['--trusted-host', host])\n\n pip_options, _ = pip_command.parse_args(pip_args)\n\n session = pip_command._build_session(pip_options)\n repository = PyPIRepository(pip_options, session)\n\n # Pre-parse the inline package upgrade specs: they should take precedence\n # over the stuff in the requirements files\n upgrade_packages = [InstallRequirement.from_line(pkg)\n for pkg in upgrade_packages]\n\n # Proxy with a LocalRequirementsRepository if --upgrade is not specified\n # (= default invocation)\n if not (upgrade or upgrade_packages) and os.path.exists(dst_file):\n ireqs = parse_requirements(dst_file, finder=repository.finder, session=repository.session, options=pip_options)\n existing_pins = {key_from_req(ireq.req): ireq for ireq in ireqs if is_pinned_requirement(ireq)}\n repository = LocalRequirementsRepository(existing_pins, repository)\n\n log.debug('Using indexes:')\n # remove duplicate index urls before processing\n repository.finder.index_urls = list(OrderedDict.fromkeys(repository.finder.index_urls))\n for index_url in repository.finder.index_urls:\n log.debug(' {}'.format(index_url))\n\n if repository.finder.find_links:\n log.debug('')\n log.debug('Configuration:')\n for find_link in repository.finder.find_links:\n log.debug(' -f {}'.format(find_link))\n\n ###\n # Parsing/collecting initial requirements\n ###\n\n constraints = []\n for src_file in src_files:\n is_setup_file = os.path.basename(src_file) == 'setup.py'\n if is_setup_file or src_file == '-':\n # pip requires filenames and not files. Since we want to support\n # piping from stdin, we need to briefly save the input from stdin\n # to a temporary file and have pip read that. also used for\n # reading requirements from install_requires in setup.py.\n tmpfile = tempfile.NamedTemporaryFile(mode='wt', delete=False)\n if is_setup_file:\n from distutils.core import run_setup\n dist = run_setup(src_file)\n tmpfile.write('\\n'.join(dist.install_requires))\n else:\n tmpfile.write(sys.stdin.read())\n tmpfile.flush()\n constraints.extend(parse_requirements(\n tmpfile.name, finder=repository.finder, session=repository.session, options=pip_options))\n else:\n constraints.extend(parse_requirements(\n src_file, finder=repository.finder, session=repository.session, options=pip_options))\n\n try:\n resolver = Resolver(constraints, repository, prereleases=pre,\n clear_caches=rebuild, allow_unsafe=allow_unsafe)\n results = resolver.resolve(max_rounds=max_rounds)\n if generate_hashes:\n hashes = resolver.resolve_hashes(results)\n else:\n hashes = None\n except PipToolsError as e:\n log.error(str(e))\n sys.exit(2)\n\n log.debug('')\n\n ##\n # Output\n ##\n\n # Compute reverse dependency annotations statically, from the\n # dependency cache that the resolver has populated by now.\n #\n # TODO (1a): reverse deps for any editable package are lost\n # what SHOULD happen is that they are cached in memory, just\n # not persisted to disk!\n #\n # TODO (1b): perhaps it's easiest if the dependency cache has an API\n # that could take InstallRequirements directly, like:\n #\n # cache.set(ireq, ...)\n #\n # then, when ireq is editable, it would store in\n #\n # editables[egg_name][link_without_fragment] = deps\n # editables['pip-tools']['git+...ols.git@future'] = {'click>=3.0', 'six'}\n #\n # otherwise:\n #\n # self[as_name_version_tuple(ireq)] = {'click>=3.0', 'six'}\n #\n reverse_dependencies = None\n if annotate:\n reverse_dependencies = resolver.reverse_dependencies(results)\n\n writer = OutputWriter(src_files, dst_file, dry_run=dry_run,\n emit_header=header, emit_index=index,\n annotate=annotate,\n generate_hashes=generate_hashes,\n default_index_url=repository.DEFAULT_INDEX_URL,\n index_urls=repository.finder.index_urls,\n trusted_hosts=pip_options.trusted_hosts,\n format_control=repository.finder.format_control)\n writer.write(results=results,\n reverse_dependencies=reverse_dependencies,\n primary_packages={key_from_req(ireq.req) for ireq in constraints},\n markers={key_from_req(ireq.req): ireq.markers\n for ireq in constraints if ireq.markers},\n hashes=hashes)\n\n if dry_run:\n log.warning('Dry-run, so nothing updated.')\n\n\ndef get_pip_command():\n # Use pip's parser for pip.conf management and defaults.\n # General options (find_links, index_url, extra_index_url, trusted_host,\n # and pre) are defered to pip.\n pip_command = PipCommand()\n index_opts = pip.cmdoptions.make_option_group(\n pip.cmdoptions.index_group,\n pip_command.parser,\n )\n pip_command.parser.insert_option_group(0, index_opts)\n pip_command.parser.add_option(optparse.Option('--pre', action='store_true', default=False))\n\n return pip_command\n", "path": "piptools/scripts/compile.py"}]}
| 3,884 | 218 |
gh_patches_debug_5834
|
rasdani/github-patches
|
git_diff
|
urllib3__urllib3-706
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
urllib3 1.11 does not provide the extra 'secure'
I tried with Python 2.7 and 2.6 inside different virtualenv.
``` bash
pip install 'urllib3[secure]'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2
3 from distutils.core import setup
4
5 import os
6 import re
7
8 try:
9 import setuptools
10 except ImportError:
11 pass # No 'develop' command, oh well.
12
13 base_path = os.path.dirname(__file__)
14
15 # Get the version (borrowed from SQLAlchemy)
16 fp = open(os.path.join(base_path, 'urllib3', '__init__.py'))
17 VERSION = re.compile(r".*__version__ = '(.*?)'",
18 re.S).match(fp.read()).group(1)
19 fp.close()
20
21
22 version = VERSION
23
24 setup(name='urllib3',
25 version=version,
26 description="HTTP library with thread-safe connection pooling, file post, and more.",
27 long_description=open('README.rst').read() + '\n\n' + open('CHANGES.rst').read(),
28 classifiers=[
29 'Environment :: Web Environment',
30 'Intended Audience :: Developers',
31 'License :: OSI Approved :: MIT License',
32 'Operating System :: OS Independent',
33 'Programming Language :: Python',
34 'Programming Language :: Python :: 2',
35 'Programming Language :: Python :: 3',
36 'Topic :: Internet :: WWW/HTTP',
37 'Topic :: Software Development :: Libraries',
38 ],
39 keywords='urllib httplib threadsafe filepost http https ssl pooling',
40 author='Andrey Petrov',
41 author_email='[email protected]',
42 url='http://urllib3.readthedocs.org/',
43 license='MIT',
44 packages=['urllib3',
45 'urllib3.packages', 'urllib3.packages.ssl_match_hostname',
46 'urllib3.contrib', 'urllib3.util',
47 ],
48 requires=[],
49 tests_require=[
50 # These are a less-specific subset of dev-requirements.txt, for the
51 # convenience of distro package maintainers.
52 'nose',
53 'mock',
54 'tornado',
55 ],
56 test_suite='test',
57 extras_require={
58 'secure;python_version<="2.7"': [
59 'pyOpenSSL',
60 'ndg-httpsclient',
61 'pyasn1',
62 'certifi',
63 ],
64 'secure;python_version>"2.7"': [
65 'certifi',
66 ],
67 },
68 )
69
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -55,14 +55,11 @@
],
test_suite='test',
extras_require={
- 'secure;python_version<="2.7"': [
+ 'secure': [
'pyOpenSSL',
'ndg-httpsclient',
'pyasn1',
'certifi',
],
- 'secure;python_version>"2.7"': [
- 'certifi',
- ],
},
)
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -55,14 +55,11 @@\n ],\n test_suite='test',\n extras_require={\n- 'secure;python_version<=\"2.7\"': [\n+ 'secure': [\n 'pyOpenSSL',\n 'ndg-httpsclient',\n 'pyasn1',\n 'certifi',\n ],\n- 'secure;python_version>\"2.7\"': [\n- 'certifi',\n- ],\n },\n )\n", "issue": "urllib3 1.11 does not provide the extra 'secure'\nI tried with Python 2.7 and 2.6 inside different virtualenv.\n\n``` bash\npip install 'urllib3[secure]'\n```\n\n", "before_files": [{"content": "#!/usr/bin/env python\n\nfrom distutils.core import setup\n\nimport os\nimport re\n\ntry:\n import setuptools\nexcept ImportError:\n pass # No 'develop' command, oh well.\n\nbase_path = os.path.dirname(__file__)\n\n# Get the version (borrowed from SQLAlchemy)\nfp = open(os.path.join(base_path, 'urllib3', '__init__.py'))\nVERSION = re.compile(r\".*__version__ = '(.*?)'\",\n re.S).match(fp.read()).group(1)\nfp.close()\n\n\nversion = VERSION\n\nsetup(name='urllib3',\n version=version,\n description=\"HTTP library with thread-safe connection pooling, file post, and more.\",\n long_description=open('README.rst').read() + '\\n\\n' + open('CHANGES.rst').read(),\n classifiers=[\n 'Environment :: Web Environment',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: MIT License',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 3',\n 'Topic :: Internet :: WWW/HTTP',\n 'Topic :: Software Development :: Libraries',\n ],\n keywords='urllib httplib threadsafe filepost http https ssl pooling',\n author='Andrey Petrov',\n author_email='[email protected]',\n url='http://urllib3.readthedocs.org/',\n license='MIT',\n packages=['urllib3',\n 'urllib3.packages', 'urllib3.packages.ssl_match_hostname',\n 'urllib3.contrib', 'urllib3.util',\n ],\n requires=[],\n tests_require=[\n # These are a less-specific subset of dev-requirements.txt, for the\n # convenience of distro package maintainers.\n 'nose',\n 'mock',\n 'tornado',\n ],\n test_suite='test',\n extras_require={\n 'secure;python_version<=\"2.7\"': [\n 'pyOpenSSL',\n 'ndg-httpsclient',\n 'pyasn1',\n 'certifi',\n ],\n 'secure;python_version>\"2.7\"': [\n 'certifi',\n ],\n },\n )\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\n\nfrom distutils.core import setup\n\nimport os\nimport re\n\ntry:\n import setuptools\nexcept ImportError:\n pass # No 'develop' command, oh well.\n\nbase_path = os.path.dirname(__file__)\n\n# Get the version (borrowed from SQLAlchemy)\nfp = open(os.path.join(base_path, 'urllib3', '__init__.py'))\nVERSION = re.compile(r\".*__version__ = '(.*?)'\",\n re.S).match(fp.read()).group(1)\nfp.close()\n\n\nversion = VERSION\n\nsetup(name='urllib3',\n version=version,\n description=\"HTTP library with thread-safe connection pooling, file post, and more.\",\n long_description=open('README.rst').read() + '\\n\\n' + open('CHANGES.rst').read(),\n classifiers=[\n 'Environment :: Web Environment',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: MIT License',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 3',\n 'Topic :: Internet :: WWW/HTTP',\n 'Topic :: Software Development :: Libraries',\n ],\n keywords='urllib httplib threadsafe filepost http https ssl pooling',\n author='Andrey Petrov',\n author_email='[email protected]',\n url='http://urllib3.readthedocs.org/',\n license='MIT',\n packages=['urllib3',\n 'urllib3.packages', 'urllib3.packages.ssl_match_hostname',\n 'urllib3.contrib', 'urllib3.util',\n ],\n requires=[],\n tests_require=[\n # These are a less-specific subset of dev-requirements.txt, for the\n # convenience of distro package maintainers.\n 'nose',\n 'mock',\n 'tornado',\n ],\n test_suite='test',\n extras_require={\n 'secure': [\n 'pyOpenSSL',\n 'ndg-httpsclient',\n 'pyasn1',\n 'certifi',\n ],\n },\n )\n", "path": "setup.py"}]}
| 915 | 121 |
gh_patches_debug_10566
|
rasdani/github-patches
|
git_diff
|
getpelican__pelican-2393
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Unclear error message running pelican.server
Hello,
I recently upgraded from 3.7.1 to master. After building my site, I tried to run the server via `python -m pelican.server`, as previously. I got a new message:
server.py: error: the following arguments are required: path
Ok, cool. I don't have to cd into output/ any more to run the server. Running `python -m pelican.server outupt/`:
TypeError: __init__() missing 1 required positional argument: 'RequestHandlerClass'
That is... less than helpful. Googling doesn't have any pertinent info. After a little digging, I found the master branch docs already specify the new `pelican --listen` and that resolved it.
It took me a little bit to figure out what was going on - I wasn't expecting the command line UI to change on a minor version, and the message ended up being totally unrelated to what had actually happened.
I think it would be helpful for people upgrading from previous versions to give a clearer error message, maybe 'The pelican server should be run via `pelican --listen`'.
Thanks for all the work so far!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pelican/server.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 from __future__ import print_function, unicode_literals
3
4 import argparse
5 import logging
6 import os
7 import posixpath
8 import ssl
9 import sys
10
11 try:
12 from magic import from_file as magic_from_file
13 except ImportError:
14 magic_from_file = None
15
16 from six.moves import BaseHTTPServer
17 from six.moves import SimpleHTTPServer as srvmod
18 from six.moves import urllib
19
20
21 def parse_arguments():
22 parser = argparse.ArgumentParser(
23 description='Pelican Development Server',
24 formatter_class=argparse.ArgumentDefaultsHelpFormatter
25 )
26 parser.add_argument("port", default=8000, type=int, nargs="?",
27 help="Port to Listen On")
28 parser.add_argument("server", default="", nargs="?",
29 help="Interface to Listen On")
30 parser.add_argument('--ssl', action="store_true",
31 help='Activate SSL listener')
32 parser.add_argument('--cert', default="./cert.pem", nargs="?",
33 help='Path to certificate file. ' +
34 'Relative to current directory')
35 parser.add_argument('--key', default="./key.pem", nargs="?",
36 help='Path to certificate key file. ' +
37 'Relative to current directory')
38 parser.add_argument('path', default=".",
39 help='Path to pelican source directory to serve. ' +
40 'Relative to current directory')
41 return parser.parse_args()
42
43
44 class ComplexHTTPRequestHandler(srvmod.SimpleHTTPRequestHandler):
45 SUFFIXES = ['', '.html', '/index.html']
46 RSTRIP_PATTERNS = ['', '/']
47
48 def translate_path(self, path):
49 # abandon query parameters
50 path = path.split('?', 1)[0]
51 path = path.split('#', 1)[0]
52 # Don't forget explicit trailing slash when normalizing. Issue17324
53 trailing_slash = path.rstrip().endswith('/')
54 path = urllib.parse.unquote(path)
55 path = posixpath.normpath(path)
56 words = path.split('/')
57 words = filter(None, words)
58 path = self.base_path
59 for word in words:
60 if os.path.dirname(word) or word in (os.curdir, os.pardir):
61 # Ignore components that are not a simple file/directory name
62 continue
63 path = os.path.join(path, word)
64 if trailing_slash:
65 path += '/'
66 return path
67
68 def do_GET(self):
69 # cut off a query string
70 if '?' in self.path:
71 self.path, _ = self.path.split('?', 1)
72
73 found = False
74 # Try to detect file by applying various suffixes and stripping
75 # patterns.
76 for rstrip_pattern in self.RSTRIP_PATTERNS:
77 if found:
78 break
79 for suffix in self.SUFFIXES:
80 if not hasattr(self, 'original_path'):
81 self.original_path = self.path
82
83 self.path = self.original_path.rstrip(rstrip_pattern) + suffix
84 path = self.translate_path(self.path)
85
86 if os.path.exists(path):
87 srvmod.SimpleHTTPRequestHandler.do_GET(self)
88 logging.info("Found `%s`.", self.path)
89 found = True
90 break
91
92 logging.info("Tried to find `%s`, but it doesn't exist.", path)
93
94 if not found:
95 # Fallback if there were no matches
96 logging.warning("Unable to find `%s` or variations.",
97 self.original_path)
98
99 def guess_type(self, path):
100 """Guess at the mime type for the specified file.
101 """
102 mimetype = srvmod.SimpleHTTPRequestHandler.guess_type(self, path)
103
104 # If the default guess is too generic, try the python-magic library
105 if mimetype == 'application/octet-stream' and magic_from_file:
106 mimetype = magic_from_file(path, mime=True)
107
108 return mimetype
109
110
111 class RootedHTTPServer(BaseHTTPServer.HTTPServer):
112 def __init__(self, base_path, *args, **kwargs):
113 BaseHTTPServer.HTTPServer.__init__(self, *args, **kwargs)
114 self.RequestHandlerClass.base_path = base_path
115
116
117 if __name__ == '__main__':
118 args = parse_arguments()
119 RootedHTTPServer.allow_reuse_address = True
120 try:
121 httpd = RootedHTTPServer(
122 (args.server, args.port),
123 ComplexHTTPRequestHandler)
124 if args.ssl:
125 httpd.socket = ssl.wrap_socket(
126 httpd.socket, keyfile=args.key,
127 certfile=args.cert, server_side=True)
128 except ssl.SSLError as e:
129 logging.error("Couldn't open certificate file %s or key file %s",
130 args.cert, args.key)
131 logging.error("Could not listen on port %s, server %s.",
132 args.port, args.server)
133 sys.exit(getattr(e, 'exitcode', 1))
134
135 logging.info("Serving at port %s, server %s.",
136 args.port, args.server)
137 try:
138 httpd.serve_forever()
139 except KeyboardInterrupt as e:
140 logging.info("Shutting down server.")
141 httpd.socket.close()
142
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pelican/server.py b/pelican/server.py
--- a/pelican/server.py
+++ b/pelican/server.py
@@ -131,6 +131,11 @@
logging.error("Could not listen on port %s, server %s.",
args.port, args.server)
sys.exit(getattr(e, 'exitcode', 1))
+ except TypeError as e:
+ logging.error("'python -m pelican.server' is deprecated. The " +
+ "Pelican development server should be run via " +
+ "'pelican --listen'")
+ sys.exit(getattr(e, 'exitcode', 1))
logging.info("Serving at port %s, server %s.",
args.port, args.server)
|
{"golden_diff": "diff --git a/pelican/server.py b/pelican/server.py\n--- a/pelican/server.py\n+++ b/pelican/server.py\n@@ -131,6 +131,11 @@\n logging.error(\"Could not listen on port %s, server %s.\",\n args.port, args.server)\n sys.exit(getattr(e, 'exitcode', 1))\n+ except TypeError as e:\n+ logging.error(\"'python -m pelican.server' is deprecated. The \" +\n+ \"Pelican development server should be run via \" +\n+ \"'pelican --listen'\")\n+ sys.exit(getattr(e, 'exitcode', 1))\n \n logging.info(\"Serving at port %s, server %s.\",\n args.port, args.server)\n", "issue": "Unclear error message running pelican.server \nHello,\r\n\r\nI recently upgraded from 3.7.1 to master. After building my site, I tried to run the server via `python -m pelican.server`, as previously. I got a new message:\r\n\r\n server.py: error: the following arguments are required: path\r\n\r\nOk, cool. I don't have to cd into output/ any more to run the server. Running `python -m pelican.server outupt/`:\r\n\r\n TypeError: __init__() missing 1 required positional argument: 'RequestHandlerClass'\r\n\r\nThat is... less than helpful. Googling doesn't have any pertinent info. After a little digging, I found the master branch docs already specify the new `pelican --listen` and that resolved it.\r\n\r\nIt took me a little bit to figure out what was going on - I wasn't expecting the command line UI to change on a minor version, and the message ended up being totally unrelated to what had actually happened.\r\n\r\nI think it would be helpful for people upgrading from previous versions to give a clearer error message, maybe 'The pelican server should be run via `pelican --listen`'.\r\n\r\nThanks for all the work so far!\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import print_function, unicode_literals\n\nimport argparse\nimport logging\nimport os\nimport posixpath\nimport ssl\nimport sys\n\ntry:\n from magic import from_file as magic_from_file\nexcept ImportError:\n magic_from_file = None\n\nfrom six.moves import BaseHTTPServer\nfrom six.moves import SimpleHTTPServer as srvmod\nfrom six.moves import urllib\n\n\ndef parse_arguments():\n parser = argparse.ArgumentParser(\n description='Pelican Development Server',\n formatter_class=argparse.ArgumentDefaultsHelpFormatter\n )\n parser.add_argument(\"port\", default=8000, type=int, nargs=\"?\",\n help=\"Port to Listen On\")\n parser.add_argument(\"server\", default=\"\", nargs=\"?\",\n help=\"Interface to Listen On\")\n parser.add_argument('--ssl', action=\"store_true\",\n help='Activate SSL listener')\n parser.add_argument('--cert', default=\"./cert.pem\", nargs=\"?\",\n help='Path to certificate file. ' +\n 'Relative to current directory')\n parser.add_argument('--key', default=\"./key.pem\", nargs=\"?\",\n help='Path to certificate key file. ' +\n 'Relative to current directory')\n parser.add_argument('path', default=\".\",\n help='Path to pelican source directory to serve. ' +\n 'Relative to current directory')\n return parser.parse_args()\n\n\nclass ComplexHTTPRequestHandler(srvmod.SimpleHTTPRequestHandler):\n SUFFIXES = ['', '.html', '/index.html']\n RSTRIP_PATTERNS = ['', '/']\n\n def translate_path(self, path):\n # abandon query parameters\n path = path.split('?', 1)[0]\n path = path.split('#', 1)[0]\n # Don't forget explicit trailing slash when normalizing. Issue17324\n trailing_slash = path.rstrip().endswith('/')\n path = urllib.parse.unquote(path)\n path = posixpath.normpath(path)\n words = path.split('/')\n words = filter(None, words)\n path = self.base_path\n for word in words:\n if os.path.dirname(word) or word in (os.curdir, os.pardir):\n # Ignore components that are not a simple file/directory name\n continue\n path = os.path.join(path, word)\n if trailing_slash:\n path += '/'\n return path\n\n def do_GET(self):\n # cut off a query string\n if '?' in self.path:\n self.path, _ = self.path.split('?', 1)\n\n found = False\n # Try to detect file by applying various suffixes and stripping\n # patterns.\n for rstrip_pattern in self.RSTRIP_PATTERNS:\n if found:\n break\n for suffix in self.SUFFIXES:\n if not hasattr(self, 'original_path'):\n self.original_path = self.path\n\n self.path = self.original_path.rstrip(rstrip_pattern) + suffix\n path = self.translate_path(self.path)\n\n if os.path.exists(path):\n srvmod.SimpleHTTPRequestHandler.do_GET(self)\n logging.info(\"Found `%s`.\", self.path)\n found = True\n break\n\n logging.info(\"Tried to find `%s`, but it doesn't exist.\", path)\n\n if not found:\n # Fallback if there were no matches\n logging.warning(\"Unable to find `%s` or variations.\",\n self.original_path)\n\n def guess_type(self, path):\n \"\"\"Guess at the mime type for the specified file.\n \"\"\"\n mimetype = srvmod.SimpleHTTPRequestHandler.guess_type(self, path)\n\n # If the default guess is too generic, try the python-magic library\n if mimetype == 'application/octet-stream' and magic_from_file:\n mimetype = magic_from_file(path, mime=True)\n\n return mimetype\n\n\nclass RootedHTTPServer(BaseHTTPServer.HTTPServer):\n def __init__(self, base_path, *args, **kwargs):\n BaseHTTPServer.HTTPServer.__init__(self, *args, **kwargs)\n self.RequestHandlerClass.base_path = base_path\n\n\nif __name__ == '__main__':\n args = parse_arguments()\n RootedHTTPServer.allow_reuse_address = True\n try:\n httpd = RootedHTTPServer(\n (args.server, args.port),\n ComplexHTTPRequestHandler)\n if args.ssl:\n httpd.socket = ssl.wrap_socket(\n httpd.socket, keyfile=args.key,\n certfile=args.cert, server_side=True)\n except ssl.SSLError as e:\n logging.error(\"Couldn't open certificate file %s or key file %s\",\n args.cert, args.key)\n logging.error(\"Could not listen on port %s, server %s.\",\n args.port, args.server)\n sys.exit(getattr(e, 'exitcode', 1))\n\n logging.info(\"Serving at port %s, server %s.\",\n args.port, args.server)\n try:\n httpd.serve_forever()\n except KeyboardInterrupt as e:\n logging.info(\"Shutting down server.\")\n httpd.socket.close()\n", "path": "pelican/server.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import print_function, unicode_literals\n\nimport argparse\nimport logging\nimport os\nimport posixpath\nimport ssl\nimport sys\n\ntry:\n from magic import from_file as magic_from_file\nexcept ImportError:\n magic_from_file = None\n\nfrom six.moves import BaseHTTPServer\nfrom six.moves import SimpleHTTPServer as srvmod\nfrom six.moves import urllib\n\n\ndef parse_arguments():\n parser = argparse.ArgumentParser(\n description='Pelican Development Server',\n formatter_class=argparse.ArgumentDefaultsHelpFormatter\n )\n parser.add_argument(\"port\", default=8000, type=int, nargs=\"?\",\n help=\"Port to Listen On\")\n parser.add_argument(\"server\", default=\"\", nargs=\"?\",\n help=\"Interface to Listen On\")\n parser.add_argument('--ssl', action=\"store_true\",\n help='Activate SSL listener')\n parser.add_argument('--cert', default=\"./cert.pem\", nargs=\"?\",\n help='Path to certificate file. ' +\n 'Relative to current directory')\n parser.add_argument('--key', default=\"./key.pem\", nargs=\"?\",\n help='Path to certificate key file. ' +\n 'Relative to current directory')\n parser.add_argument('path', default=\".\",\n help='Path to pelican source directory to serve. ' +\n 'Relative to current directory')\n return parser.parse_args()\n\n\nclass ComplexHTTPRequestHandler(srvmod.SimpleHTTPRequestHandler):\n SUFFIXES = ['', '.html', '/index.html']\n RSTRIP_PATTERNS = ['', '/']\n\n def translate_path(self, path):\n # abandon query parameters\n path = path.split('?', 1)[0]\n path = path.split('#', 1)[0]\n # Don't forget explicit trailing slash when normalizing. Issue17324\n trailing_slash = path.rstrip().endswith('/')\n path = urllib.parse.unquote(path)\n path = posixpath.normpath(path)\n words = path.split('/')\n words = filter(None, words)\n path = self.base_path\n for word in words:\n if os.path.dirname(word) or word in (os.curdir, os.pardir):\n # Ignore components that are not a simple file/directory name\n continue\n path = os.path.join(path, word)\n if trailing_slash:\n path += '/'\n return path\n\n def do_GET(self):\n # cut off a query string\n if '?' in self.path:\n self.path, _ = self.path.split('?', 1)\n\n found = False\n # Try to detect file by applying various suffixes and stripping\n # patterns.\n for rstrip_pattern in self.RSTRIP_PATTERNS:\n if found:\n break\n for suffix in self.SUFFIXES:\n if not hasattr(self, 'original_path'):\n self.original_path = self.path\n\n self.path = self.original_path.rstrip(rstrip_pattern) + suffix\n path = self.translate_path(self.path)\n\n if os.path.exists(path):\n srvmod.SimpleHTTPRequestHandler.do_GET(self)\n logging.info(\"Found `%s`.\", self.path)\n found = True\n break\n\n logging.info(\"Tried to find `%s`, but it doesn't exist.\", path)\n\n if not found:\n # Fallback if there were no matches\n logging.warning(\"Unable to find `%s` or variations.\",\n self.original_path)\n\n def guess_type(self, path):\n \"\"\"Guess at the mime type for the specified file.\n \"\"\"\n mimetype = srvmod.SimpleHTTPRequestHandler.guess_type(self, path)\n\n # If the default guess is too generic, try the python-magic library\n if mimetype == 'application/octet-stream' and magic_from_file:\n mimetype = magic_from_file(path, mime=True)\n\n return mimetype\n\n\nclass RootedHTTPServer(BaseHTTPServer.HTTPServer):\n def __init__(self, base_path, *args, **kwargs):\n BaseHTTPServer.HTTPServer.__init__(self, *args, **kwargs)\n self.RequestHandlerClass.base_path = base_path\n\n\nif __name__ == '__main__':\n args = parse_arguments()\n RootedHTTPServer.allow_reuse_address = True\n try:\n httpd = RootedHTTPServer(\n (args.server, args.port),\n ComplexHTTPRequestHandler)\n if args.ssl:\n httpd.socket = ssl.wrap_socket(\n httpd.socket, keyfile=args.key,\n certfile=args.cert, server_side=True)\n except ssl.SSLError as e:\n logging.error(\"Couldn't open certificate file %s or key file %s\",\n args.cert, args.key)\n logging.error(\"Could not listen on port %s, server %s.\",\n args.port, args.server)\n sys.exit(getattr(e, 'exitcode', 1))\n except TypeError as e:\n logging.error(\"'python -m pelican.server' is deprecated. The \" +\n \"Pelican development server should be run via \" +\n \"'pelican --listen'\")\n sys.exit(getattr(e, 'exitcode', 1))\n\n logging.info(\"Serving at port %s, server %s.\",\n args.port, args.server)\n try:\n httpd.serve_forever()\n except KeyboardInterrupt as e:\n logging.info(\"Shutting down server.\")\n httpd.socket.close()\n", "path": "pelican/server.py"}]}
| 1,908 | 168 |
gh_patches_debug_12412
|
rasdani/github-patches
|
git_diff
|
holoviz__hvplot-693
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
sample_data try/except import wrapper fails
#### ALL software version info
hvplot: 0.7.3
#### Description of expected behavior and the observed behavior
The following import fails, despite the all-catching `except` in the code?? (Honestly stumped)
```python
from hvplot.sample_data import us_crime, airline_flights
```
```python
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
/tmp/ipykernel_3185062/1788543639.py in <module>
----> 1 from hvplot.sample_data import us_crime, airline_flights
~/miniconda3/envs/py39/lib/python3.9/site-packages/hvplot/sample_data.py in <module>
23 # Add catalogue entries to namespace
24 for _c in catalogue:
---> 25 globals()[_c] = catalogue[_c]
~/miniconda3/envs/py39/lib/python3.9/site-packages/intake/catalog/base.py in __getitem__(self, key)
398 if e.container == 'catalog':
399 return e(name=key)
--> 400 return e()
401 if isinstance(key, str) and '.' in key:
402 key = key.split('.')
~/miniconda3/envs/py39/lib/python3.9/site-packages/intake/catalog/entry.py in __call__(self, persist, **kwargs)
75 raise ValueError('Persist value (%s) not understood' % persist)
76 persist = persist or self._pmode
---> 77 s = self.get(**kwargs)
78 if persist != 'never' and isinstance(s, PersistMixin) and s.has_been_persisted:
79 from ..container.persist import store
~/miniconda3/envs/py39/lib/python3.9/site-packages/intake/catalog/local.py in get(self, **user_parameters)
287 return self._default_source
288
--> 289 plugin, open_args = self._create_open_args(user_parameters)
290 data_source = plugin(**open_args)
291 data_source.catalog_object = self._catalog
~/miniconda3/envs/py39/lib/python3.9/site-packages/intake/catalog/local.py in _create_open_args(self, user_parameters)
261
262 if len(self._plugin) == 0:
--> 263 raise ValueError('No plugins loaded for this entry: %s\n'
264 'A listing of installable plugins can be found '
265 'at https://intake.readthedocs.io/en/latest/plugin'
ValueError: No plugins loaded for this entry: parquet
A listing of installable plugins can be found at https://intake.readthedocs.io/en/latest/plugin-directory.html .
```
For reference, this is the code in 0.7.3:
```python
import os
try:
from intake import open_catalog
except:
raise ImportError('Loading hvPlot sample data requires intake '
'and intake-parquet. Install it using conda or '
'pip before loading data.')
```
How can intake throw a ValueError??
#### Complete, minimal, self-contained example code that reproduces the issue
* Have only the package `intake` installed, no other intake-subpackages.
* Execute : `from hvplot.sample_data import us_crime, airline_flights`
```
# code goes here between backticks
from hvplot.sample_data import us_crime, airline_flights
```
#### Stack traceback and/or browser JavaScript console output
```python
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
/tmp/ipykernel_3185062/1788543639.py in <module>
----> 1 from hvplot.sample_data import us_crime, airline_flights
~/miniconda3/envs/py39/lib/python3.9/site-packages/hvplot/sample_data.py in <module>
23 # Add catalogue entries to namespace
24 for _c in catalogue:
---> 25 globals()[_c] = catalogue[_c]
~/miniconda3/envs/py39/lib/python3.9/site-packages/intake/catalog/base.py in __getitem__(self, key)
398 if e.container == 'catalog':
399 return e(name=key)
--> 400 return e()
401 if isinstance(key, str) and '.' in key:
402 key = key.split('.')
~/miniconda3/envs/py39/lib/python3.9/site-packages/intake/catalog/entry.py in __call__(self, persist, **kwargs)
75 raise ValueError('Persist value (%s) not understood' % persist)
76 persist = persist or self._pmode
---> 77 s = self.get(**kwargs)
78 if persist != 'never' and isinstance(s, PersistMixin) and s.has_been_persisted:
79 from ..container.persist import store
~/miniconda3/envs/py39/lib/python3.9/site-packages/intake/catalog/local.py in get(self, **user_parameters)
287 return self._default_source
288
--> 289 plugin, open_args = self._create_open_args(user_parameters)
290 data_source = plugin(**open_args)
291 data_source.catalog_object = self._catalog
~/miniconda3/envs/py39/lib/python3.9/site-packages/intake/catalog/local.py in _create_open_args(self, user_parameters)
261
262 if len(self._plugin) == 0:
--> 263 raise ValueError('No plugins loaded for this entry: %s\n'
264 'A listing of installable plugins can be found '
265 'at https://intake.readthedocs.io/en/latest/plugin'
ValueError: No plugins loaded for this entry: parquet
A listing of installable plugins can be found at https://intake.readthedocs.io/en/latest/plugin-directory.html .
```
#### Additional info
The list of required package is now this:
* intake-parquet
* intake-xarray
* s3fs
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `hvplot/sample_data.py`
Content:
```
1 """
2 Loads hvPlot sample data using intake catalogue.
3 """
4
5 import os
6
7 try:
8 from intake import open_catalog
9 except:
10 raise ImportError('Loading hvPlot sample data requires intake '
11 'and intake-parquet. Install it using conda or '
12 'pip before loading data.')
13
14 _file_path = os.path.dirname(__file__)
15 if os.path.isdir(os.path.join(_file_path, 'examples')):
16 _cat_path = os.path.join(_file_path, 'examples', 'datasets.yaml')
17 else:
18 _cat_path = os.path.join(_file_path, '..', 'examples', 'datasets.yaml')
19
20 # Load catalogue
21 catalogue = open_catalog(_cat_path)
22
23 # Add catalogue entries to namespace
24 for _c in catalogue:
25 globals()[_c] = catalogue[_c]
26
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/hvplot/sample_data.py b/hvplot/sample_data.py
--- a/hvplot/sample_data.py
+++ b/hvplot/sample_data.py
@@ -6,10 +6,18 @@
try:
from intake import open_catalog
+ import intake_parquet # noqa
+ import intake_xarray # noqa
+ import s3fs # noqa
except:
- raise ImportError('Loading hvPlot sample data requires intake '
- 'and intake-parquet. Install it using conda or '
- 'pip before loading data.')
+ raise ImportError(
+ """Loading hvPlot sample data requires:
+ * intake
+ * intake-parquet
+ * intake-xarray
+ * s3fs
+ Install these using conda or pip before loading data."""
+ )
_file_path = os.path.dirname(__file__)
if os.path.isdir(os.path.join(_file_path, 'examples')):
|
{"golden_diff": "diff --git a/hvplot/sample_data.py b/hvplot/sample_data.py\n--- a/hvplot/sample_data.py\n+++ b/hvplot/sample_data.py\n@@ -6,10 +6,18 @@\n \n try:\n from intake import open_catalog\n+ import intake_parquet # noqa\n+ import intake_xarray # noqa\n+ import s3fs # noqa\n except:\n- raise ImportError('Loading hvPlot sample data requires intake '\n- 'and intake-parquet. Install it using conda or '\n- 'pip before loading data.')\n+ raise ImportError(\n+ \"\"\"Loading hvPlot sample data requires:\n+ * intake\n+ * intake-parquet\n+ * intake-xarray\n+ * s3fs\n+ Install these using conda or pip before loading data.\"\"\"\n+ )\n \n _file_path = os.path.dirname(__file__)\n if os.path.isdir(os.path.join(_file_path, 'examples')):\n", "issue": "sample_data try/except import wrapper fails\n#### ALL software version info\r\nhvplot: 0.7.3\r\n\r\n#### Description of expected behavior and the observed behavior\r\nThe following import fails, despite the all-catching `except` in the code?? (Honestly stumped)\r\n\r\n```python\r\nfrom hvplot.sample_data import us_crime, airline_flights\r\n```\r\n```python\r\n---------------------------------------------------------------------------\r\nValueError Traceback (most recent call last)\r\n/tmp/ipykernel_3185062/1788543639.py in <module>\r\n----> 1 from hvplot.sample_data import us_crime, airline_flights\r\n\r\n~/miniconda3/envs/py39/lib/python3.9/site-packages/hvplot/sample_data.py in <module>\r\n 23 # Add catalogue entries to namespace\r\n 24 for _c in catalogue:\r\n---> 25 globals()[_c] = catalogue[_c]\r\n\r\n~/miniconda3/envs/py39/lib/python3.9/site-packages/intake/catalog/base.py in __getitem__(self, key)\r\n 398 if e.container == 'catalog':\r\n 399 return e(name=key)\r\n--> 400 return e()\r\n 401 if isinstance(key, str) and '.' in key:\r\n 402 key = key.split('.')\r\n\r\n~/miniconda3/envs/py39/lib/python3.9/site-packages/intake/catalog/entry.py in __call__(self, persist, **kwargs)\r\n 75 raise ValueError('Persist value (%s) not understood' % persist)\r\n 76 persist = persist or self._pmode\r\n---> 77 s = self.get(**kwargs)\r\n 78 if persist != 'never' and isinstance(s, PersistMixin) and s.has_been_persisted:\r\n 79 from ..container.persist import store\r\n\r\n~/miniconda3/envs/py39/lib/python3.9/site-packages/intake/catalog/local.py in get(self, **user_parameters)\r\n 287 return self._default_source\r\n 288 \r\n--> 289 plugin, open_args = self._create_open_args(user_parameters)\r\n 290 data_source = plugin(**open_args)\r\n 291 data_source.catalog_object = self._catalog\r\n\r\n~/miniconda3/envs/py39/lib/python3.9/site-packages/intake/catalog/local.py in _create_open_args(self, user_parameters)\r\n 261 \r\n 262 if len(self._plugin) == 0:\r\n--> 263 raise ValueError('No plugins loaded for this entry: %s\\n'\r\n 264 'A listing of installable plugins can be found '\r\n 265 'at https://intake.readthedocs.io/en/latest/plugin'\r\n\r\nValueError: No plugins loaded for this entry: parquet\r\nA listing of installable plugins can be found at https://intake.readthedocs.io/en/latest/plugin-directory.html .\r\n```\r\nFor reference, this is the code in 0.7.3:\r\n```python\r\nimport os\r\n\r\ntry:\r\n from intake import open_catalog\r\nexcept:\r\n raise ImportError('Loading hvPlot sample data requires intake '\r\n 'and intake-parquet. Install it using conda or '\r\n 'pip before loading data.')\r\n```\r\nHow can intake throw a ValueError??\r\n\r\n#### Complete, minimal, self-contained example code that reproduces the issue\r\n\r\n* Have only the package `intake` installed, no other intake-subpackages.\r\n* Execute : `from hvplot.sample_data import us_crime, airline_flights`\r\n\r\n```\r\n# code goes here between backticks\r\nfrom hvplot.sample_data import us_crime, airline_flights\r\n```\r\n\r\n#### Stack traceback and/or browser JavaScript console output\r\n```python\r\n---------------------------------------------------------------------------\r\nValueError Traceback (most recent call last)\r\n/tmp/ipykernel_3185062/1788543639.py in <module>\r\n----> 1 from hvplot.sample_data import us_crime, airline_flights\r\n\r\n~/miniconda3/envs/py39/lib/python3.9/site-packages/hvplot/sample_data.py in <module>\r\n 23 # Add catalogue entries to namespace\r\n 24 for _c in catalogue:\r\n---> 25 globals()[_c] = catalogue[_c]\r\n\r\n~/miniconda3/envs/py39/lib/python3.9/site-packages/intake/catalog/base.py in __getitem__(self, key)\r\n 398 if e.container == 'catalog':\r\n 399 return e(name=key)\r\n--> 400 return e()\r\n 401 if isinstance(key, str) and '.' in key:\r\n 402 key = key.split('.')\r\n\r\n~/miniconda3/envs/py39/lib/python3.9/site-packages/intake/catalog/entry.py in __call__(self, persist, **kwargs)\r\n 75 raise ValueError('Persist value (%s) not understood' % persist)\r\n 76 persist = persist or self._pmode\r\n---> 77 s = self.get(**kwargs)\r\n 78 if persist != 'never' and isinstance(s, PersistMixin) and s.has_been_persisted:\r\n 79 from ..container.persist import store\r\n\r\n~/miniconda3/envs/py39/lib/python3.9/site-packages/intake/catalog/local.py in get(self, **user_parameters)\r\n 287 return self._default_source\r\n 288 \r\n--> 289 plugin, open_args = self._create_open_args(user_parameters)\r\n 290 data_source = plugin(**open_args)\r\n 291 data_source.catalog_object = self._catalog\r\n\r\n~/miniconda3/envs/py39/lib/python3.9/site-packages/intake/catalog/local.py in _create_open_args(self, user_parameters)\r\n 261 \r\n 262 if len(self._plugin) == 0:\r\n--> 263 raise ValueError('No plugins loaded for this entry: %s\\n'\r\n 264 'A listing of installable plugins can be found '\r\n 265 'at https://intake.readthedocs.io/en/latest/plugin'\r\n\r\nValueError: No plugins loaded for this entry: parquet\r\nA listing of installable plugins can be found at https://intake.readthedocs.io/en/latest/plugin-directory.html .\r\n```\r\n#### Additional info\r\nThe list of required package is now this:\r\n\r\n* intake-parquet\r\n* intake-xarray\r\n* s3fs\r\n\r\n\n", "before_files": [{"content": "\"\"\"\nLoads hvPlot sample data using intake catalogue.\n\"\"\"\n\nimport os\n\ntry:\n from intake import open_catalog\nexcept:\n raise ImportError('Loading hvPlot sample data requires intake '\n 'and intake-parquet. Install it using conda or '\n 'pip before loading data.')\n\n_file_path = os.path.dirname(__file__)\nif os.path.isdir(os.path.join(_file_path, 'examples')):\n _cat_path = os.path.join(_file_path, 'examples', 'datasets.yaml')\nelse:\n _cat_path = os.path.join(_file_path, '..', 'examples', 'datasets.yaml')\n\n# Load catalogue\ncatalogue = open_catalog(_cat_path)\n\n# Add catalogue entries to namespace\nfor _c in catalogue:\n globals()[_c] = catalogue[_c]\n", "path": "hvplot/sample_data.py"}], "after_files": [{"content": "\"\"\"\nLoads hvPlot sample data using intake catalogue.\n\"\"\"\n\nimport os\n\ntry:\n from intake import open_catalog\n import intake_parquet # noqa\n import intake_xarray # noqa\n import s3fs # noqa\nexcept:\n raise ImportError(\n \"\"\"Loading hvPlot sample data requires:\n * intake\n * intake-parquet\n * intake-xarray\n * s3fs\n Install these using conda or pip before loading data.\"\"\"\n )\n\n_file_path = os.path.dirname(__file__)\nif os.path.isdir(os.path.join(_file_path, 'examples')):\n _cat_path = os.path.join(_file_path, 'examples', 'datasets.yaml')\nelse:\n _cat_path = os.path.join(_file_path, '..', 'examples', 'datasets.yaml')\n\n# Load catalogue\ncatalogue = open_catalog(_cat_path)\n\n# Add catalogue entries to namespace\nfor _c in catalogue:\n globals()[_c] = catalogue[_c]\n", "path": "hvplot/sample_data.py"}]}
| 1,900 | 208 |
gh_patches_debug_21452
|
rasdani/github-patches
|
git_diff
|
Lightning-Universe__lightning-flash-1367
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ModuleNotFoundError: No module named 'icevision.backbones'
Using an example snippet from the README:
Icevision is the latest version from GitHub master.
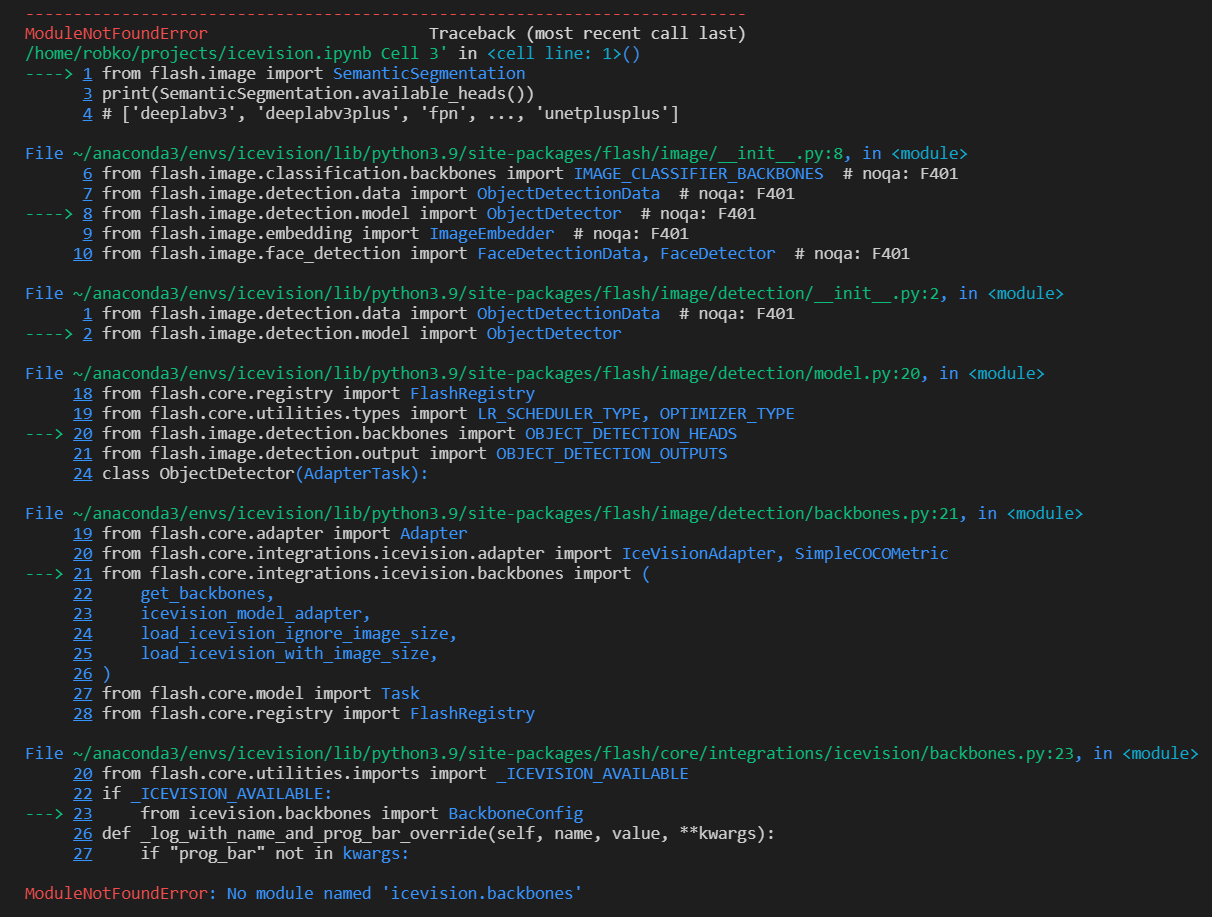
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2 # Copyright The PyTorch Lightning team.
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15 import glob
16 import os
17 from functools import partial
18 from importlib.util import module_from_spec, spec_from_file_location
19 from itertools import chain
20
21 from setuptools import find_packages, setup
22
23 # https://packaging.python.org/guides/single-sourcing-package-version/
24 # http://blog.ionelmc.ro/2014/05/25/python-packaging/
25 _PATH_ROOT = os.path.dirname(__file__)
26 _PATH_REQUIRE = os.path.join(_PATH_ROOT, "requirements")
27
28
29 def _load_py_module(fname, pkg="flash"):
30 spec = spec_from_file_location(
31 os.path.join(pkg, fname),
32 os.path.join(_PATH_ROOT, pkg, fname),
33 )
34 py = module_from_spec(spec)
35 spec.loader.exec_module(py)
36 return py
37
38
39 about = _load_py_module("__about__.py")
40 setup_tools = _load_py_module("setup_tools.py")
41
42 long_description = setup_tools._load_readme_description(
43 _PATH_ROOT,
44 homepage=about.__homepage__,
45 ver=about.__version__,
46 )
47
48
49 def _expand_reqs(extras: dict, keys: list) -> list:
50 return list(chain(*[extras[ex] for ex in keys]))
51
52
53 base_req = setup_tools._load_requirements(path_dir=_PATH_ROOT, file_name="requirements.txt")
54 # find all extra requirements
55 _load_req = partial(setup_tools._load_requirements, path_dir=_PATH_REQUIRE)
56 found_req_files = sorted(os.path.basename(p) for p in glob.glob(os.path.join(_PATH_REQUIRE, "*.txt")))
57 # remove datatype prefix
58 found_req_names = [os.path.splitext(req)[0].replace("datatype_", "") for req in found_req_files]
59 # define basic and extra extras
60 extras_req = {
61 name: _load_req(file_name=fname) for name, fname in zip(found_req_names, found_req_files) if "_" not in name
62 }
63 extras_req.update(
64 {
65 name: extras_req[name.split("_")[0]] + _load_req(file_name=fname)
66 for name, fname in zip(found_req_names, found_req_files)
67 if "_" in name
68 }
69 )
70 # some extra combinations
71 extras_req["vision"] = _expand_reqs(extras_req, ["image", "video"])
72 extras_req["core"] = _expand_reqs(extras_req, ["image", "tabular", "text"])
73 extras_req["all"] = _expand_reqs(extras_req, ["vision", "tabular", "text", "audio"])
74 extras_req["dev"] = _expand_reqs(extras_req, ["all", "test", "docs"])
75 # filter the uniques
76 extras_req = {n: list(set(req)) for n, req in extras_req.items()}
77
78 # https://packaging.python.org/discussions/install-requires-vs-requirements /
79 # keep the meta-data here for simplicity in reading this file... it's not obvious
80 # what happens and to non-engineers they won't know to look in init ...
81 # the goal of the project is simplicity for researchers, don't want to add too much
82 # engineer specific practices
83 setup(
84 name="lightning-flash",
85 version=about.__version__,
86 description=about.__docs__,
87 author=about.__author__,
88 author_email=about.__author_email__,
89 url=about.__homepage__,
90 download_url="https://github.com/PyTorchLightning/lightning-flash",
91 license=about.__license__,
92 packages=find_packages(exclude=["tests", "tests.*"]),
93 long_description=long_description,
94 long_description_content_type="text/markdown",
95 include_package_data=True,
96 extras_require=extras_req,
97 entry_points={
98 "console_scripts": ["flash=flash.__main__:main"],
99 },
100 zip_safe=False,
101 keywords=["deep learning", "pytorch", "AI"],
102 python_requires=">=3.6",
103 install_requires=base_req,
104 project_urls={
105 "Bug Tracker": "https://github.com/PyTorchLightning/lightning-flash/issues",
106 "Documentation": "https://lightning-flash.rtfd.io/en/latest/",
107 "Source Code": "https://github.com/PyTorchLightning/lightning-flash",
108 },
109 classifiers=[
110 "Environment :: Console",
111 "Natural Language :: English",
112 # How mature is this project? Common values are
113 # 3 - Alpha, 4 - Beta, 5 - Production/Stable
114 "Development Status :: 4 - Beta",
115 # Indicate who your project is intended for
116 "Intended Audience :: Developers",
117 "Topic :: Scientific/Engineering :: Artificial Intelligence",
118 "Topic :: Scientific/Engineering :: Image Recognition",
119 "Topic :: Scientific/Engineering :: Information Analysis",
120 # Pick your license as you wish
121 # 'License :: OSI Approved :: BSD License',
122 "Operating System :: OS Independent",
123 # Specify the Python versions you support here. In particular, ensure
124 # that you indicate whether you support Python 2, Python 3 or both.
125 "Programming Language :: Python :: 3",
126 "Programming Language :: Python :: 3.6",
127 "Programming Language :: Python :: 3.7",
128 "Programming Language :: Python :: 3.8",
129 "Programming Language :: Python :: 3.9",
130 "Programming Language :: Python :: 3.10",
131 ],
132 )
133
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -99,7 +99,7 @@
},
zip_safe=False,
keywords=["deep learning", "pytorch", "AI"],
- python_requires=">=3.6",
+ python_requires=">=3.7",
install_requires=base_req,
project_urls={
"Bug Tracker": "https://github.com/PyTorchLightning/lightning-flash/issues",
@@ -123,10 +123,8 @@
# Specify the Python versions you support here. In particular, ensure
# that you indicate whether you support Python 2, Python 3 or both.
"Programming Language :: Python :: 3",
- "Programming Language :: Python :: 3.6",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
- "Programming Language :: Python :: 3.10",
],
)
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -99,7 +99,7 @@\n },\n zip_safe=False,\n keywords=[\"deep learning\", \"pytorch\", \"AI\"],\n- python_requires=\">=3.6\",\n+ python_requires=\">=3.7\",\n install_requires=base_req,\n project_urls={\n \"Bug Tracker\": \"https://github.com/PyTorchLightning/lightning-flash/issues\",\n@@ -123,10 +123,8 @@\n # Specify the Python versions you support here. In particular, ensure\n # that you indicate whether you support Python 2, Python 3 or both.\n \"Programming Language :: Python :: 3\",\n- \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n- \"Programming Language :: Python :: 3.10\",\n ],\n )\n", "issue": "ModuleNotFoundError: No module named 'icevision.backbones'\nUsing an example snippet from the README:\r\nIcevision is the latest version from GitHub master.\r\n\r\n\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\n# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport glob\nimport os\nfrom functools import partial\nfrom importlib.util import module_from_spec, spec_from_file_location\nfrom itertools import chain\n\nfrom setuptools import find_packages, setup\n\n# https://packaging.python.org/guides/single-sourcing-package-version/\n# http://blog.ionelmc.ro/2014/05/25/python-packaging/\n_PATH_ROOT = os.path.dirname(__file__)\n_PATH_REQUIRE = os.path.join(_PATH_ROOT, \"requirements\")\n\n\ndef _load_py_module(fname, pkg=\"flash\"):\n spec = spec_from_file_location(\n os.path.join(pkg, fname),\n os.path.join(_PATH_ROOT, pkg, fname),\n )\n py = module_from_spec(spec)\n spec.loader.exec_module(py)\n return py\n\n\nabout = _load_py_module(\"__about__.py\")\nsetup_tools = _load_py_module(\"setup_tools.py\")\n\nlong_description = setup_tools._load_readme_description(\n _PATH_ROOT,\n homepage=about.__homepage__,\n ver=about.__version__,\n)\n\n\ndef _expand_reqs(extras: dict, keys: list) -> list:\n return list(chain(*[extras[ex] for ex in keys]))\n\n\nbase_req = setup_tools._load_requirements(path_dir=_PATH_ROOT, file_name=\"requirements.txt\")\n# find all extra requirements\n_load_req = partial(setup_tools._load_requirements, path_dir=_PATH_REQUIRE)\nfound_req_files = sorted(os.path.basename(p) for p in glob.glob(os.path.join(_PATH_REQUIRE, \"*.txt\")))\n# remove datatype prefix\nfound_req_names = [os.path.splitext(req)[0].replace(\"datatype_\", \"\") for req in found_req_files]\n# define basic and extra extras\nextras_req = {\n name: _load_req(file_name=fname) for name, fname in zip(found_req_names, found_req_files) if \"_\" not in name\n}\nextras_req.update(\n {\n name: extras_req[name.split(\"_\")[0]] + _load_req(file_name=fname)\n for name, fname in zip(found_req_names, found_req_files)\n if \"_\" in name\n }\n)\n# some extra combinations\nextras_req[\"vision\"] = _expand_reqs(extras_req, [\"image\", \"video\"])\nextras_req[\"core\"] = _expand_reqs(extras_req, [\"image\", \"tabular\", \"text\"])\nextras_req[\"all\"] = _expand_reqs(extras_req, [\"vision\", \"tabular\", \"text\", \"audio\"])\nextras_req[\"dev\"] = _expand_reqs(extras_req, [\"all\", \"test\", \"docs\"])\n# filter the uniques\nextras_req = {n: list(set(req)) for n, req in extras_req.items()}\n\n# https://packaging.python.org/discussions/install-requires-vs-requirements /\n# keep the meta-data here for simplicity in reading this file... it's not obvious\n# what happens and to non-engineers they won't know to look in init ...\n# the goal of the project is simplicity for researchers, don't want to add too much\n# engineer specific practices\nsetup(\n name=\"lightning-flash\",\n version=about.__version__,\n description=about.__docs__,\n author=about.__author__,\n author_email=about.__author_email__,\n url=about.__homepage__,\n download_url=\"https://github.com/PyTorchLightning/lightning-flash\",\n license=about.__license__,\n packages=find_packages(exclude=[\"tests\", \"tests.*\"]),\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n include_package_data=True,\n extras_require=extras_req,\n entry_points={\n \"console_scripts\": [\"flash=flash.__main__:main\"],\n },\n zip_safe=False,\n keywords=[\"deep learning\", \"pytorch\", \"AI\"],\n python_requires=\">=3.6\",\n install_requires=base_req,\n project_urls={\n \"Bug Tracker\": \"https://github.com/PyTorchLightning/lightning-flash/issues\",\n \"Documentation\": \"https://lightning-flash.rtfd.io/en/latest/\",\n \"Source Code\": \"https://github.com/PyTorchLightning/lightning-flash\",\n },\n classifiers=[\n \"Environment :: Console\",\n \"Natural Language :: English\",\n # How mature is this project? Common values are\n # 3 - Alpha, 4 - Beta, 5 - Production/Stable\n \"Development Status :: 4 - Beta\",\n # Indicate who your project is intended for\n \"Intended Audience :: Developers\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n \"Topic :: Scientific/Engineering :: Image Recognition\",\n \"Topic :: Scientific/Engineering :: Information Analysis\",\n # Pick your license as you wish\n # 'License :: OSI Approved :: BSD License',\n \"Operating System :: OS Independent\",\n # Specify the Python versions you support here. In particular, ensure\n # that you indicate whether you support Python 2, Python 3 or both.\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n ],\n)\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport glob\nimport os\nfrom functools import partial\nfrom importlib.util import module_from_spec, spec_from_file_location\nfrom itertools import chain\n\nfrom setuptools import find_packages, setup\n\n# https://packaging.python.org/guides/single-sourcing-package-version/\n# http://blog.ionelmc.ro/2014/05/25/python-packaging/\n_PATH_ROOT = os.path.dirname(__file__)\n_PATH_REQUIRE = os.path.join(_PATH_ROOT, \"requirements\")\n\n\ndef _load_py_module(fname, pkg=\"flash\"):\n spec = spec_from_file_location(\n os.path.join(pkg, fname),\n os.path.join(_PATH_ROOT, pkg, fname),\n )\n py = module_from_spec(spec)\n spec.loader.exec_module(py)\n return py\n\n\nabout = _load_py_module(\"__about__.py\")\nsetup_tools = _load_py_module(\"setup_tools.py\")\n\nlong_description = setup_tools._load_readme_description(\n _PATH_ROOT,\n homepage=about.__homepage__,\n ver=about.__version__,\n)\n\n\ndef _expand_reqs(extras: dict, keys: list) -> list:\n return list(chain(*[extras[ex] for ex in keys]))\n\n\nbase_req = setup_tools._load_requirements(path_dir=_PATH_ROOT, file_name=\"requirements.txt\")\n# find all extra requirements\n_load_req = partial(setup_tools._load_requirements, path_dir=_PATH_REQUIRE)\nfound_req_files = sorted(os.path.basename(p) for p in glob.glob(os.path.join(_PATH_REQUIRE, \"*.txt\")))\n# remove datatype prefix\nfound_req_names = [os.path.splitext(req)[0].replace(\"datatype_\", \"\") for req in found_req_files]\n# define basic and extra extras\nextras_req = {\n name: _load_req(file_name=fname) for name, fname in zip(found_req_names, found_req_files) if \"_\" not in name\n}\nextras_req.update(\n {\n name: extras_req[name.split(\"_\")[0]] + _load_req(file_name=fname)\n for name, fname in zip(found_req_names, found_req_files)\n if \"_\" in name\n }\n)\n# some extra combinations\nextras_req[\"vision\"] = _expand_reqs(extras_req, [\"image\", \"video\"])\nextras_req[\"core\"] = _expand_reqs(extras_req, [\"image\", \"tabular\", \"text\"])\nextras_req[\"all\"] = _expand_reqs(extras_req, [\"vision\", \"tabular\", \"text\", \"audio\"])\nextras_req[\"dev\"] = _expand_reqs(extras_req, [\"all\", \"test\", \"docs\"])\n# filter the uniques\nextras_req = {n: list(set(req)) for n, req in extras_req.items()}\n\n# https://packaging.python.org/discussions/install-requires-vs-requirements /\n# keep the meta-data here for simplicity in reading this file... it's not obvious\n# what happens and to non-engineers they won't know to look in init ...\n# the goal of the project is simplicity for researchers, don't want to add too much\n# engineer specific practices\nsetup(\n name=\"lightning-flash\",\n version=about.__version__,\n description=about.__docs__,\n author=about.__author__,\n author_email=about.__author_email__,\n url=about.__homepage__,\n download_url=\"https://github.com/PyTorchLightning/lightning-flash\",\n license=about.__license__,\n packages=find_packages(exclude=[\"tests\", \"tests.*\"]),\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n include_package_data=True,\n extras_require=extras_req,\n entry_points={\n \"console_scripts\": [\"flash=flash.__main__:main\"],\n },\n zip_safe=False,\n keywords=[\"deep learning\", \"pytorch\", \"AI\"],\n python_requires=\">=3.7\",\n install_requires=base_req,\n project_urls={\n \"Bug Tracker\": \"https://github.com/PyTorchLightning/lightning-flash/issues\",\n \"Documentation\": \"https://lightning-flash.rtfd.io/en/latest/\",\n \"Source Code\": \"https://github.com/PyTorchLightning/lightning-flash\",\n },\n classifiers=[\n \"Environment :: Console\",\n \"Natural Language :: English\",\n # How mature is this project? Common values are\n # 3 - Alpha, 4 - Beta, 5 - Production/Stable\n \"Development Status :: 4 - Beta\",\n # Indicate who your project is intended for\n \"Intended Audience :: Developers\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n \"Topic :: Scientific/Engineering :: Image Recognition\",\n \"Topic :: Scientific/Engineering :: Information Analysis\",\n # Pick your license as you wish\n # 'License :: OSI Approved :: BSD License',\n \"Operating System :: OS Independent\",\n # Specify the Python versions you support here. In particular, ensure\n # that you indicate whether you support Python 2, Python 3 or both.\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n ],\n)\n", "path": "setup.py"}]}
| 1,966 | 228 |
gh_patches_debug_34817
|
rasdani/github-patches
|
git_diff
|
YunoHost__apps-1524
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Simplify current version
As discuss at YunoHost Meeting 06/10/2022, remove the comment after the shipped version
Close #1522
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `tools/README-generator/make_readme.py`
Content:
```
1 #! /usr/bin/env python3
2
3 import argparse
4 import json
5 import os
6 import yaml
7 from pathlib import Path
8
9 from jinja2 import Environment, FileSystemLoader
10
11 def value_for_lang(values, lang):
12 if not isinstance(values, dict):
13 return values
14 if lang in values:
15 return values[lang]
16 elif "en" in values:
17 return values["en"]
18 else:
19 return list(values.values())[0]
20
21 def generate_READMEs(app_path: str):
22
23 app_path = Path(app_path)
24
25 if not app_path.exists():
26 raise Exception("App path provided doesn't exists ?!")
27
28 manifest = json.load(open(app_path / "manifest.json"))
29 upstream = manifest.get("upstream", {})
30
31 catalog = json.load(open(Path(os.path.abspath(__file__)).parent.parent.parent / "apps.json"))
32 from_catalog = catalog.get(manifest['id'], {})
33
34 antifeatures_list = yaml.load(open(Path(os.path.abspath(__file__)).parent.parent.parent / "antifeatures.yml"), Loader=yaml.SafeLoader)
35 antifeatures_list = {e['id']: e for e in antifeatures_list}
36
37 if not upstream and not (app_path / "doc" / "DISCLAIMER.md").exists():
38 print(
39 "There's no 'upstream' key in the manifest, and doc/DISCLAIMER.md doesn't exists - therefore assuming that we shall not auto-update the README.md for this app yet."
40 )
41 return
42
43 env = Environment(loader=FileSystemLoader(Path(__file__).parent / "templates"))
44
45 for lang, lang_suffix in [("en", ""), ("fr", "_fr")]:
46
47 template = env.get_template(f"README{lang_suffix}.md.j2")
48
49 if (app_path / "doc" / f"DESCRIPTION{lang_suffix}.md").exists():
50 description = (app_path / "doc" / f"DESCRIPTION{lang_suffix}.md").read_text()
51 # Fallback to english if maintainer too lazy to translate the description
52 elif (app_path / "doc" / "DESCRIPTION.md").exists():
53 description = (app_path / "doc" / "DESCRIPTION.md").read_text()
54 else:
55 description = None
56
57 if (app_path / "doc" / "screenshots").exists():
58 screenshots = os.listdir(os.path.join(app_path, "doc", "screenshots"))
59 if ".gitkeep" in screenshots:
60 screenshots.remove(".gitkeep")
61 else:
62 screenshots = []
63
64 if (app_path / "doc" / f"DISCLAIMER{lang_suffix}.md").exists():
65 disclaimer = (app_path / "doc" / f"DISCLAIMER{lang_suffix}.md").read_text()
66 # Fallback to english if maintainer too lazy to translate the disclaimer idk
67 elif (app_path / "doc" / "DISCLAIMER.md").exists():
68 disclaimer = (app_path / "doc" / "DISCLAIMER.md").read_text()
69 else:
70 disclaimer = None
71
72 # Get the current branch using git inside the app path
73 default_branch = from_catalog.get('branch', 'master')
74 current_branch = os.popen(f"git -C {app_path} rev-parse --abbrev-ref HEAD").read().strip()
75
76 if default_branch != current_branch:
77 os.system(f"git -C {app_path} fetch origin {default_branch} 2>/dev/null")
78 default_branch_version = os.popen(f"git -C {app_path} show FETCH_HEAD:manifest.json | jq -r .version").read().strip()
79 else:
80 default_branch_version = None # we don't care in that case
81
82 # TODO: Add url to the documentation... and actually create that documentation :D
83 antifeatures = {a: antifeatures_list[a] for a in from_catalog.get('antifeatures', [])}
84 for k, v in antifeatures.items():
85 antifeatures[k]['title'] = value_for_lang(v['title'], lang_suffix)
86 if manifest.get("antifeatures", {}).get(k, None):
87 antifeatures[k]['description'] = value_for_lang(manifest.get("antifeatures", {}).get(k, None), lang_suffix)
88 else:
89 antifeatures[k]['description'] = value_for_lang(antifeatures[k]['description'], lang_suffix)
90
91 out = template.render(
92 lang=lang,
93 upstream=upstream,
94 description=description,
95 screenshots=screenshots,
96 disclaimer=disclaimer,
97 antifeatures=antifeatures,
98 manifest=manifest,
99 current_branch=current_branch,
100 default_branch=default_branch,
101 default_branch_version=default_branch_version,
102 )
103 (app_path / f"README{lang_suffix}.md").write_text(out)
104
105
106 if __name__ == "__main__":
107 parser = argparse.ArgumentParser(
108 description="Automatically (re)generate README for apps"
109 )
110 parser.add_argument(
111 "app_path", help="Path to the app to generate/update READMEs for"
112 )
113
114 args = parser.parse_args()
115 generate_READMEs(args.app_path)
116
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/tools/README-generator/make_readme.py b/tools/README-generator/make_readme.py
--- a/tools/README-generator/make_readme.py
+++ b/tools/README-generator/make_readme.py
@@ -32,7 +32,7 @@
from_catalog = catalog.get(manifest['id'], {})
antifeatures_list = yaml.load(open(Path(os.path.abspath(__file__)).parent.parent.parent / "antifeatures.yml"), Loader=yaml.SafeLoader)
- antifeatures_list = {e['id']: e for e in antifeatures_list}
+ antifeatures_list = { e['id']: e for e in antifeatures_list }
if not upstream and not (app_path / "doc" / "DISCLAIMER.md").exists():
print(
@@ -69,18 +69,8 @@
else:
disclaimer = None
- # Get the current branch using git inside the app path
- default_branch = from_catalog.get('branch', 'master')
- current_branch = os.popen(f"git -C {app_path} rev-parse --abbrev-ref HEAD").read().strip()
-
- if default_branch != current_branch:
- os.system(f"git -C {app_path} fetch origin {default_branch} 2>/dev/null")
- default_branch_version = os.popen(f"git -C {app_path} show FETCH_HEAD:manifest.json | jq -r .version").read().strip()
- else:
- default_branch_version = None # we don't care in that case
-
# TODO: Add url to the documentation... and actually create that documentation :D
- antifeatures = {a: antifeatures_list[a] for a in from_catalog.get('antifeatures', [])}
+ antifeatures = { a: antifeatures_list[a] for a in from_catalog.get('antifeatures', [])}
for k, v in antifeatures.items():
antifeatures[k]['title'] = value_for_lang(v['title'], lang_suffix)
if manifest.get("antifeatures", {}).get(k, None):
@@ -96,9 +86,6 @@
disclaimer=disclaimer,
antifeatures=antifeatures,
manifest=manifest,
- current_branch=current_branch,
- default_branch=default_branch,
- default_branch_version=default_branch_version,
)
(app_path / f"README{lang_suffix}.md").write_text(out)
|
{"golden_diff": "diff --git a/tools/README-generator/make_readme.py b/tools/README-generator/make_readme.py\n--- a/tools/README-generator/make_readme.py\n+++ b/tools/README-generator/make_readme.py\n@@ -32,7 +32,7 @@\n from_catalog = catalog.get(manifest['id'], {})\n \n antifeatures_list = yaml.load(open(Path(os.path.abspath(__file__)).parent.parent.parent / \"antifeatures.yml\"), Loader=yaml.SafeLoader)\n- antifeatures_list = {e['id']: e for e in antifeatures_list}\n+ antifeatures_list = { e['id']: e for e in antifeatures_list }\n \n if not upstream and not (app_path / \"doc\" / \"DISCLAIMER.md\").exists():\n print(\n@@ -69,18 +69,8 @@\n else:\n disclaimer = None\n \n- # Get the current branch using git inside the app path\n- default_branch = from_catalog.get('branch', 'master')\n- current_branch = os.popen(f\"git -C {app_path} rev-parse --abbrev-ref HEAD\").read().strip()\n-\n- if default_branch != current_branch:\n- os.system(f\"git -C {app_path} fetch origin {default_branch} 2>/dev/null\")\n- default_branch_version = os.popen(f\"git -C {app_path} show FETCH_HEAD:manifest.json | jq -r .version\").read().strip()\n- else:\n- default_branch_version = None # we don't care in that case\n-\n # TODO: Add url to the documentation... and actually create that documentation :D\n- antifeatures = {a: antifeatures_list[a] for a in from_catalog.get('antifeatures', [])}\n+ antifeatures = { a: antifeatures_list[a] for a in from_catalog.get('antifeatures', [])}\n for k, v in antifeatures.items():\n antifeatures[k]['title'] = value_for_lang(v['title'], lang_suffix)\n if manifest.get(\"antifeatures\", {}).get(k, None):\n@@ -96,9 +86,6 @@\n disclaimer=disclaimer,\n antifeatures=antifeatures,\n manifest=manifest,\n- current_branch=current_branch,\n- default_branch=default_branch,\n- default_branch_version=default_branch_version,\n )\n (app_path / f\"README{lang_suffix}.md\").write_text(out)\n", "issue": "Simplify current version\nAs discuss at YunoHost Meeting 06/10/2022, remove the comment after the shipped version\r\nClose #1522\n", "before_files": [{"content": "#! /usr/bin/env python3\n\nimport argparse\nimport json\nimport os\nimport yaml\nfrom pathlib import Path\n\nfrom jinja2 import Environment, FileSystemLoader\n\ndef value_for_lang(values, lang):\n if not isinstance(values, dict):\n return values\n if lang in values:\n return values[lang]\n elif \"en\" in values:\n return values[\"en\"]\n else:\n return list(values.values())[0]\n\ndef generate_READMEs(app_path: str):\n\n app_path = Path(app_path)\n\n if not app_path.exists():\n raise Exception(\"App path provided doesn't exists ?!\")\n\n manifest = json.load(open(app_path / \"manifest.json\"))\n upstream = manifest.get(\"upstream\", {})\n\n catalog = json.load(open(Path(os.path.abspath(__file__)).parent.parent.parent / \"apps.json\"))\n from_catalog = catalog.get(manifest['id'], {})\n\n antifeatures_list = yaml.load(open(Path(os.path.abspath(__file__)).parent.parent.parent / \"antifeatures.yml\"), Loader=yaml.SafeLoader)\n antifeatures_list = {e['id']: e for e in antifeatures_list}\n\n if not upstream and not (app_path / \"doc\" / \"DISCLAIMER.md\").exists():\n print(\n \"There's no 'upstream' key in the manifest, and doc/DISCLAIMER.md doesn't exists - therefore assuming that we shall not auto-update the README.md for this app yet.\"\n )\n return\n\n env = Environment(loader=FileSystemLoader(Path(__file__).parent / \"templates\"))\n\n for lang, lang_suffix in [(\"en\", \"\"), (\"fr\", \"_fr\")]:\n\n template = env.get_template(f\"README{lang_suffix}.md.j2\")\n\n if (app_path / \"doc\" / f\"DESCRIPTION{lang_suffix}.md\").exists():\n description = (app_path / \"doc\" / f\"DESCRIPTION{lang_suffix}.md\").read_text()\n # Fallback to english if maintainer too lazy to translate the description\n elif (app_path / \"doc\" / \"DESCRIPTION.md\").exists():\n description = (app_path / \"doc\" / \"DESCRIPTION.md\").read_text()\n else:\n description = None\n\n if (app_path / \"doc\" / \"screenshots\").exists():\n screenshots = os.listdir(os.path.join(app_path, \"doc\", \"screenshots\"))\n if \".gitkeep\" in screenshots:\n screenshots.remove(\".gitkeep\")\n else:\n screenshots = []\n\n if (app_path / \"doc\" / f\"DISCLAIMER{lang_suffix}.md\").exists():\n disclaimer = (app_path / \"doc\" / f\"DISCLAIMER{lang_suffix}.md\").read_text()\n # Fallback to english if maintainer too lazy to translate the disclaimer idk\n elif (app_path / \"doc\" / \"DISCLAIMER.md\").exists():\n disclaimer = (app_path / \"doc\" / \"DISCLAIMER.md\").read_text()\n else:\n disclaimer = None\n\n # Get the current branch using git inside the app path\n default_branch = from_catalog.get('branch', 'master')\n current_branch = os.popen(f\"git -C {app_path} rev-parse --abbrev-ref HEAD\").read().strip()\n\n if default_branch != current_branch:\n os.system(f\"git -C {app_path} fetch origin {default_branch} 2>/dev/null\")\n default_branch_version = os.popen(f\"git -C {app_path} show FETCH_HEAD:manifest.json | jq -r .version\").read().strip()\n else:\n default_branch_version = None # we don't care in that case\n\n # TODO: Add url to the documentation... and actually create that documentation :D\n antifeatures = {a: antifeatures_list[a] for a in from_catalog.get('antifeatures', [])}\n for k, v in antifeatures.items():\n antifeatures[k]['title'] = value_for_lang(v['title'], lang_suffix)\n if manifest.get(\"antifeatures\", {}).get(k, None):\n antifeatures[k]['description'] = value_for_lang(manifest.get(\"antifeatures\", {}).get(k, None), lang_suffix)\n else:\n antifeatures[k]['description'] = value_for_lang(antifeatures[k]['description'], lang_suffix)\n\n out = template.render(\n lang=lang,\n upstream=upstream,\n description=description,\n screenshots=screenshots,\n disclaimer=disclaimer,\n antifeatures=antifeatures,\n manifest=manifest,\n current_branch=current_branch,\n default_branch=default_branch,\n default_branch_version=default_branch_version,\n )\n (app_path / f\"README{lang_suffix}.md\").write_text(out)\n\n\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser(\n description=\"Automatically (re)generate README for apps\"\n )\n parser.add_argument(\n \"app_path\", help=\"Path to the app to generate/update READMEs for\"\n )\n\n args = parser.parse_args()\n generate_READMEs(args.app_path)\n", "path": "tools/README-generator/make_readme.py"}], "after_files": [{"content": "#! /usr/bin/env python3\n\nimport argparse\nimport json\nimport os\nimport yaml\nfrom pathlib import Path\n\nfrom jinja2 import Environment, FileSystemLoader\n\ndef value_for_lang(values, lang):\n if not isinstance(values, dict):\n return values\n if lang in values:\n return values[lang]\n elif \"en\" in values:\n return values[\"en\"]\n else:\n return list(values.values())[0]\n\ndef generate_READMEs(app_path: str):\n\n app_path = Path(app_path)\n\n if not app_path.exists():\n raise Exception(\"App path provided doesn't exists ?!\")\n\n manifest = json.load(open(app_path / \"manifest.json\"))\n upstream = manifest.get(\"upstream\", {})\n\n catalog = json.load(open(Path(os.path.abspath(__file__)).parent.parent.parent / \"apps.json\"))\n from_catalog = catalog.get(manifest['id'], {})\n\n antifeatures_list = yaml.load(open(Path(os.path.abspath(__file__)).parent.parent.parent / \"antifeatures.yml\"), Loader=yaml.SafeLoader)\n antifeatures_list = { e['id']: e for e in antifeatures_list }\n\n if not upstream and not (app_path / \"doc\" / \"DISCLAIMER.md\").exists():\n print(\n \"There's no 'upstream' key in the manifest, and doc/DISCLAIMER.md doesn't exists - therefore assuming that we shall not auto-update the README.md for this app yet.\"\n )\n return\n\n env = Environment(loader=FileSystemLoader(Path(__file__).parent / \"templates\"))\n\n for lang, lang_suffix in [(\"en\", \"\"), (\"fr\", \"_fr\")]:\n\n template = env.get_template(f\"README{lang_suffix}.md.j2\")\n\n if (app_path / \"doc\" / f\"DESCRIPTION{lang_suffix}.md\").exists():\n description = (app_path / \"doc\" / f\"DESCRIPTION{lang_suffix}.md\").read_text()\n # Fallback to english if maintainer too lazy to translate the description\n elif (app_path / \"doc\" / \"DESCRIPTION.md\").exists():\n description = (app_path / \"doc\" / \"DESCRIPTION.md\").read_text()\n else:\n description = None\n\n if (app_path / \"doc\" / \"screenshots\").exists():\n screenshots = os.listdir(os.path.join(app_path, \"doc\", \"screenshots\"))\n if \".gitkeep\" in screenshots:\n screenshots.remove(\".gitkeep\")\n else:\n screenshots = []\n\n if (app_path / \"doc\" / f\"DISCLAIMER{lang_suffix}.md\").exists():\n disclaimer = (app_path / \"doc\" / f\"DISCLAIMER{lang_suffix}.md\").read_text()\n # Fallback to english if maintainer too lazy to translate the disclaimer idk\n elif (app_path / \"doc\" / \"DISCLAIMER.md\").exists():\n disclaimer = (app_path / \"doc\" / \"DISCLAIMER.md\").read_text()\n else:\n disclaimer = None\n\n # TODO: Add url to the documentation... and actually create that documentation :D\n antifeatures = { a: antifeatures_list[a] for a in from_catalog.get('antifeatures', [])}\n for k, v in antifeatures.items():\n antifeatures[k]['title'] = value_for_lang(v['title'], lang_suffix)\n if manifest.get(\"antifeatures\", {}).get(k, None):\n antifeatures[k]['description'] = value_for_lang(manifest.get(\"antifeatures\", {}).get(k, None), lang_suffix)\n else:\n antifeatures[k]['description'] = value_for_lang(antifeatures[k]['description'], lang_suffix)\n\n out = template.render(\n lang=lang,\n upstream=upstream,\n description=description,\n screenshots=screenshots,\n disclaimer=disclaimer,\n antifeatures=antifeatures,\n manifest=manifest,\n )\n (app_path / f\"README{lang_suffix}.md\").write_text(out)\n\n\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser(\n description=\"Automatically (re)generate README for apps\"\n )\n parser.add_argument(\n \"app_path\", help=\"Path to the app to generate/update READMEs for\"\n )\n\n args = parser.parse_args()\n generate_READMEs(args.app_path)\n", "path": "tools/README-generator/make_readme.py"}]}
| 1,640 | 537 |
gh_patches_debug_12752
|
rasdani/github-patches
|
git_diff
|
iterative__dvc-1734
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
logger: colorama is not outputting colors correctly on windows
version: `0.30.1`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `dvc/logger.py`
Content:
```
1 """Manages logger for dvc repo."""
2
3 from __future__ import unicode_literals
4
5 from dvc.exceptions import DvcException
6 from dvc.utils.compat import str
7 from dvc.progress import progress_aware
8
9 import re
10 import sys
11 import logging
12 import traceback
13
14 from contextlib import contextmanager
15
16 import colorama
17
18
19 @progress_aware
20 def info(message):
21 """Prints an info message."""
22 logger.info(message)
23
24
25 def debug(message):
26 """Prints a debug message."""
27 prefix = colorize("Debug", color="blue")
28
29 out = "{prefix}: {message}".format(prefix=prefix, message=message)
30
31 logger.debug(out)
32
33
34 @progress_aware
35 def warning(message, parse_exception=False):
36 """Prints a warning message."""
37 prefix = colorize("Warning", color="yellow")
38
39 exception, stack_trace = None, ""
40 if parse_exception:
41 exception, stack_trace = _parse_exc()
42
43 out = "{prefix}: {description}".format(
44 prefix=prefix, description=_description(message, exception)
45 )
46
47 if stack_trace:
48 out += "\n{stack_trace}".format(stack_trace=stack_trace)
49
50 logger.warning(out)
51
52
53 @progress_aware
54 def error(message=None):
55 """Prints an error message."""
56 prefix = colorize("Error", color="red")
57
58 exception, stack_trace = _parse_exc()
59
60 out = (
61 "{prefix}: {description}"
62 "\n"
63 "{stack_trace}"
64 "\n"
65 "{footer}".format(
66 prefix=prefix,
67 description=_description(message, exception),
68 stack_trace=stack_trace,
69 footer=_footer(),
70 )
71 )
72
73 logger.error(out)
74
75
76 def box(message, border_color=None):
77 """Prints a message in a box.
78
79 Args:
80 message (unicode): message to print.
81 border_color (unicode): name of a color to outline the box with.
82 """
83 lines = message.split("\n")
84 max_width = max(_visual_width(line) for line in lines)
85
86 padding_horizontal = 5
87 padding_vertical = 1
88
89 box_size_horizontal = max_width + (padding_horizontal * 2)
90
91 chars = {"corner": "+", "horizontal": "-", "vertical": "|", "empty": " "}
92
93 margin = "{corner}{line}{corner}\n".format(
94 corner=chars["corner"], line=chars["horizontal"] * box_size_horizontal
95 )
96
97 padding_lines = [
98 "{border}{space}{border}\n".format(
99 border=colorize(chars["vertical"], color=border_color),
100 space=chars["empty"] * box_size_horizontal,
101 )
102 * padding_vertical
103 ]
104
105 content_lines = [
106 "{border}{space}{content}{space}{border}\n".format(
107 border=colorize(chars["vertical"], color=border_color),
108 space=chars["empty"] * padding_horizontal,
109 content=_visual_center(line, max_width),
110 )
111 for line in lines
112 ]
113
114 box_str = "{margin}{padding}{content}{padding}{margin}".format(
115 margin=colorize(margin, color=border_color),
116 padding="".join(padding_lines),
117 content="".join(content_lines),
118 )
119
120 logger.info(box_str)
121
122
123 def level():
124 """Returns current log level."""
125 return logger.getEffectiveLevel()
126
127
128 def set_level(level_name):
129 """Sets log level.
130
131 Args:
132 level_name (str): log level name. E.g. info, debug, warning, error,
133 critical.
134 """
135 if not level_name:
136 return
137
138 levels = {
139 "info": logging.INFO,
140 "debug": logging.DEBUG,
141 "warning": logging.WARNING,
142 "error": logging.ERROR,
143 "critical": logging.CRITICAL,
144 }
145
146 logger.setLevel(levels.get(level_name))
147
148
149 def be_quiet():
150 """Disables all messages except critical ones."""
151 logger.setLevel(logging.CRITICAL)
152
153
154 def be_verbose():
155 """Enables all messages."""
156 logger.setLevel(logging.DEBUG)
157
158
159 @contextmanager
160 def verbose():
161 """Enables verbose mode for the context."""
162 previous_level = level()
163 be_verbose()
164 yield
165 logger.setLevel(previous_level)
166
167
168 @contextmanager
169 def quiet():
170 """Enables quiet mode for the context."""
171 previous_level = level()
172 be_quiet()
173 yield
174 logger.setLevel(previous_level)
175
176
177 def is_quiet():
178 """Returns whether or not all messages except critical ones are
179 disabled.
180 """
181 return level() == logging.CRITICAL
182
183
184 def is_verbose():
185 """Returns whether or not all messages are enabled."""
186 return level() == logging.DEBUG
187
188
189 def colorize(message, color=None):
190 """Returns a message in a specified color."""
191 if not color:
192 return message
193
194 colors = {
195 "green": colorama.Fore.GREEN,
196 "yellow": colorama.Fore.YELLOW,
197 "blue": colorama.Fore.BLUE,
198 "red": colorama.Fore.RED,
199 }
200
201 return "{color}{message}{nc}".format(
202 color=colors.get(color, ""), message=message, nc=colorama.Fore.RESET
203 )
204
205
206 def _init_colorama():
207 colorama.init()
208
209
210 def set_default_level():
211 """Sets default log level."""
212 logger.setLevel(logging.INFO)
213
214
215 def _add_handlers():
216 formatter = "%(message)s"
217
218 class _LogLevelFilter(logging.Filter):
219 # pylint: disable=too-few-public-methods
220 def filter(self, record):
221 return record.levelno <= logging.WARNING
222
223 sh_out = logging.StreamHandler(sys.stdout)
224 sh_out.setFormatter(logging.Formatter(formatter))
225 sh_out.setLevel(logging.DEBUG)
226 sh_out.addFilter(_LogLevelFilter())
227
228 sh_err = logging.StreamHandler(sys.stderr)
229 sh_err.setFormatter(logging.Formatter(formatter))
230 sh_err.setLevel(logging.ERROR)
231
232 logger.addHandler(sh_out)
233 logger.addHandler(sh_err)
234
235
236 def _walk_exc(exc):
237 exc_list = [str(exc)]
238 tb_list = [traceback.format_exc()]
239
240 # NOTE: parsing chained exceptions. See dvc/exceptions.py for more info.
241 while hasattr(exc, "cause") and exc.cause is not None:
242 exc_list.append(str(exc.cause))
243 if hasattr(exc, "cause_tb") and exc.cause_tb is not None:
244 tb_list.insert(0, str(exc.cause_tb))
245 exc = exc.cause
246
247 return exc_list, tb_list
248
249
250 def _parse_exc():
251 exc = sys.exc_info()[1]
252 if not exc:
253 return (None, "")
254
255 exc_list, tb_list = _walk_exc(exc)
256
257 exception = ": ".join(exc_list)
258
259 if is_verbose():
260 stack_trace = "{line}\n{stack_trace}{line}\n".format(
261 line=colorize("-" * 60, color="red"),
262 stack_trace="\n".join(tb_list),
263 )
264 else:
265 stack_trace = ""
266
267 return (exception, stack_trace)
268
269
270 def _description(message, exception):
271 if exception and message:
272 description = "{message} - {exception}"
273 elif exception:
274 description = "{exception}"
275 elif message:
276 description = "{message}"
277 else:
278 raise DvcException(
279 "Unexpected error - either exception or message must be provided"
280 )
281
282 return description.format(message=message, exception=exception)
283
284
285 def _footer():
286 return "{phrase} Hit us up at {url}, we are always happy to help!".format(
287 phrase=colorize("Having any troubles?", "yellow"),
288 url=colorize("https://dvc.org/support", "blue"),
289 )
290
291
292 def _visual_width(line):
293 """Get the the number of columns required to display a string"""
294
295 return len(re.sub(colorama.ansitowin32.AnsiToWin32.ANSI_CSI_RE, "", line))
296
297
298 def _visual_center(line, width):
299 """Center align string according to it's visual width"""
300
301 spaces = max(width - _visual_width(line), 0)
302 left_padding = int(spaces / 2)
303 right_padding = spaces - left_padding
304
305 return (left_padding * " ") + line + (right_padding * " ")
306
307
308 logger = logging.getLogger("dvc") # pylint: disable=invalid-name
309
310 set_default_level()
311 _add_handlers()
312 _init_colorama()
313
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/dvc/logger.py b/dvc/logger.py
--- a/dvc/logger.py
+++ b/dvc/logger.py
@@ -203,16 +203,16 @@
)
-def _init_colorama():
- colorama.init()
-
-
def set_default_level():
"""Sets default log level."""
logger.setLevel(logging.INFO)
def _add_handlers():
+ # NOTE: We need to initialize colorama before setting the stream handlers
+ # so it can wrap stdout/stderr and convert color codes to Windows.
+ colorama.init()
+
formatter = "%(message)s"
class _LogLevelFilter(logging.Filter):
@@ -309,4 +309,3 @@
set_default_level()
_add_handlers()
-_init_colorama()
|
{"golden_diff": "diff --git a/dvc/logger.py b/dvc/logger.py\n--- a/dvc/logger.py\n+++ b/dvc/logger.py\n@@ -203,16 +203,16 @@\n )\n \n \n-def _init_colorama():\n- colorama.init()\n-\n-\n def set_default_level():\n \"\"\"Sets default log level.\"\"\"\n logger.setLevel(logging.INFO)\n \n \n def _add_handlers():\n+ # NOTE: We need to initialize colorama before setting the stream handlers\n+ # so it can wrap stdout/stderr and convert color codes to Windows.\n+ colorama.init()\n+\n formatter = \"%(message)s\"\n \n class _LogLevelFilter(logging.Filter):\n@@ -309,4 +309,3 @@\n \n set_default_level()\n _add_handlers()\n-_init_colorama()\n", "issue": "logger: colorama is not outputting colors correctly on windows\nversion: `0.30.1`\r\n\r\n\r\n\n", "before_files": [{"content": "\"\"\"Manages logger for dvc repo.\"\"\"\n\nfrom __future__ import unicode_literals\n\nfrom dvc.exceptions import DvcException\nfrom dvc.utils.compat import str\nfrom dvc.progress import progress_aware\n\nimport re\nimport sys\nimport logging\nimport traceback\n\nfrom contextlib import contextmanager\n\nimport colorama\n\n\n@progress_aware\ndef info(message):\n \"\"\"Prints an info message.\"\"\"\n logger.info(message)\n\n\ndef debug(message):\n \"\"\"Prints a debug message.\"\"\"\n prefix = colorize(\"Debug\", color=\"blue\")\n\n out = \"{prefix}: {message}\".format(prefix=prefix, message=message)\n\n logger.debug(out)\n\n\n@progress_aware\ndef warning(message, parse_exception=False):\n \"\"\"Prints a warning message.\"\"\"\n prefix = colorize(\"Warning\", color=\"yellow\")\n\n exception, stack_trace = None, \"\"\n if parse_exception:\n exception, stack_trace = _parse_exc()\n\n out = \"{prefix}: {description}\".format(\n prefix=prefix, description=_description(message, exception)\n )\n\n if stack_trace:\n out += \"\\n{stack_trace}\".format(stack_trace=stack_trace)\n\n logger.warning(out)\n\n\n@progress_aware\ndef error(message=None):\n \"\"\"Prints an error message.\"\"\"\n prefix = colorize(\"Error\", color=\"red\")\n\n exception, stack_trace = _parse_exc()\n\n out = (\n \"{prefix}: {description}\"\n \"\\n\"\n \"{stack_trace}\"\n \"\\n\"\n \"{footer}\".format(\n prefix=prefix,\n description=_description(message, exception),\n stack_trace=stack_trace,\n footer=_footer(),\n )\n )\n\n logger.error(out)\n\n\ndef box(message, border_color=None):\n \"\"\"Prints a message in a box.\n\n Args:\n message (unicode): message to print.\n border_color (unicode): name of a color to outline the box with.\n \"\"\"\n lines = message.split(\"\\n\")\n max_width = max(_visual_width(line) for line in lines)\n\n padding_horizontal = 5\n padding_vertical = 1\n\n box_size_horizontal = max_width + (padding_horizontal * 2)\n\n chars = {\"corner\": \"+\", \"horizontal\": \"-\", \"vertical\": \"|\", \"empty\": \" \"}\n\n margin = \"{corner}{line}{corner}\\n\".format(\n corner=chars[\"corner\"], line=chars[\"horizontal\"] * box_size_horizontal\n )\n\n padding_lines = [\n \"{border}{space}{border}\\n\".format(\n border=colorize(chars[\"vertical\"], color=border_color),\n space=chars[\"empty\"] * box_size_horizontal,\n )\n * padding_vertical\n ]\n\n content_lines = [\n \"{border}{space}{content}{space}{border}\\n\".format(\n border=colorize(chars[\"vertical\"], color=border_color),\n space=chars[\"empty\"] * padding_horizontal,\n content=_visual_center(line, max_width),\n )\n for line in lines\n ]\n\n box_str = \"{margin}{padding}{content}{padding}{margin}\".format(\n margin=colorize(margin, color=border_color),\n padding=\"\".join(padding_lines),\n content=\"\".join(content_lines),\n )\n\n logger.info(box_str)\n\n\ndef level():\n \"\"\"Returns current log level.\"\"\"\n return logger.getEffectiveLevel()\n\n\ndef set_level(level_name):\n \"\"\"Sets log level.\n\n Args:\n level_name (str): log level name. E.g. info, debug, warning, error,\n critical.\n \"\"\"\n if not level_name:\n return\n\n levels = {\n \"info\": logging.INFO,\n \"debug\": logging.DEBUG,\n \"warning\": logging.WARNING,\n \"error\": logging.ERROR,\n \"critical\": logging.CRITICAL,\n }\n\n logger.setLevel(levels.get(level_name))\n\n\ndef be_quiet():\n \"\"\"Disables all messages except critical ones.\"\"\"\n logger.setLevel(logging.CRITICAL)\n\n\ndef be_verbose():\n \"\"\"Enables all messages.\"\"\"\n logger.setLevel(logging.DEBUG)\n\n\n@contextmanager\ndef verbose():\n \"\"\"Enables verbose mode for the context.\"\"\"\n previous_level = level()\n be_verbose()\n yield\n logger.setLevel(previous_level)\n\n\n@contextmanager\ndef quiet():\n \"\"\"Enables quiet mode for the context.\"\"\"\n previous_level = level()\n be_quiet()\n yield\n logger.setLevel(previous_level)\n\n\ndef is_quiet():\n \"\"\"Returns whether or not all messages except critical ones are\n disabled.\n \"\"\"\n return level() == logging.CRITICAL\n\n\ndef is_verbose():\n \"\"\"Returns whether or not all messages are enabled.\"\"\"\n return level() == logging.DEBUG\n\n\ndef colorize(message, color=None):\n \"\"\"Returns a message in a specified color.\"\"\"\n if not color:\n return message\n\n colors = {\n \"green\": colorama.Fore.GREEN,\n \"yellow\": colorama.Fore.YELLOW,\n \"blue\": colorama.Fore.BLUE,\n \"red\": colorama.Fore.RED,\n }\n\n return \"{color}{message}{nc}\".format(\n color=colors.get(color, \"\"), message=message, nc=colorama.Fore.RESET\n )\n\n\ndef _init_colorama():\n colorama.init()\n\n\ndef set_default_level():\n \"\"\"Sets default log level.\"\"\"\n logger.setLevel(logging.INFO)\n\n\ndef _add_handlers():\n formatter = \"%(message)s\"\n\n class _LogLevelFilter(logging.Filter):\n # pylint: disable=too-few-public-methods\n def filter(self, record):\n return record.levelno <= logging.WARNING\n\n sh_out = logging.StreamHandler(sys.stdout)\n sh_out.setFormatter(logging.Formatter(formatter))\n sh_out.setLevel(logging.DEBUG)\n sh_out.addFilter(_LogLevelFilter())\n\n sh_err = logging.StreamHandler(sys.stderr)\n sh_err.setFormatter(logging.Formatter(formatter))\n sh_err.setLevel(logging.ERROR)\n\n logger.addHandler(sh_out)\n logger.addHandler(sh_err)\n\n\ndef _walk_exc(exc):\n exc_list = [str(exc)]\n tb_list = [traceback.format_exc()]\n\n # NOTE: parsing chained exceptions. See dvc/exceptions.py for more info.\n while hasattr(exc, \"cause\") and exc.cause is not None:\n exc_list.append(str(exc.cause))\n if hasattr(exc, \"cause_tb\") and exc.cause_tb is not None:\n tb_list.insert(0, str(exc.cause_tb))\n exc = exc.cause\n\n return exc_list, tb_list\n\n\ndef _parse_exc():\n exc = sys.exc_info()[1]\n if not exc:\n return (None, \"\")\n\n exc_list, tb_list = _walk_exc(exc)\n\n exception = \": \".join(exc_list)\n\n if is_verbose():\n stack_trace = \"{line}\\n{stack_trace}{line}\\n\".format(\n line=colorize(\"-\" * 60, color=\"red\"),\n stack_trace=\"\\n\".join(tb_list),\n )\n else:\n stack_trace = \"\"\n\n return (exception, stack_trace)\n\n\ndef _description(message, exception):\n if exception and message:\n description = \"{message} - {exception}\"\n elif exception:\n description = \"{exception}\"\n elif message:\n description = \"{message}\"\n else:\n raise DvcException(\n \"Unexpected error - either exception or message must be provided\"\n )\n\n return description.format(message=message, exception=exception)\n\n\ndef _footer():\n return \"{phrase} Hit us up at {url}, we are always happy to help!\".format(\n phrase=colorize(\"Having any troubles?\", \"yellow\"),\n url=colorize(\"https://dvc.org/support\", \"blue\"),\n )\n\n\ndef _visual_width(line):\n \"\"\"Get the the number of columns required to display a string\"\"\"\n\n return len(re.sub(colorama.ansitowin32.AnsiToWin32.ANSI_CSI_RE, \"\", line))\n\n\ndef _visual_center(line, width):\n \"\"\"Center align string according to it's visual width\"\"\"\n\n spaces = max(width - _visual_width(line), 0)\n left_padding = int(spaces / 2)\n right_padding = spaces - left_padding\n\n return (left_padding * \" \") + line + (right_padding * \" \")\n\n\nlogger = logging.getLogger(\"dvc\") # pylint: disable=invalid-name\n\nset_default_level()\n_add_handlers()\n_init_colorama()\n", "path": "dvc/logger.py"}], "after_files": [{"content": "\"\"\"Manages logger for dvc repo.\"\"\"\n\nfrom __future__ import unicode_literals\n\nfrom dvc.exceptions import DvcException\nfrom dvc.utils.compat import str\nfrom dvc.progress import progress_aware\n\nimport re\nimport sys\nimport logging\nimport traceback\n\nfrom contextlib import contextmanager\n\nimport colorama\n\n\n@progress_aware\ndef info(message):\n \"\"\"Prints an info message.\"\"\"\n logger.info(message)\n\n\ndef debug(message):\n \"\"\"Prints a debug message.\"\"\"\n prefix = colorize(\"Debug\", color=\"blue\")\n\n out = \"{prefix}: {message}\".format(prefix=prefix, message=message)\n\n logger.debug(out)\n\n\n@progress_aware\ndef warning(message, parse_exception=False):\n \"\"\"Prints a warning message.\"\"\"\n prefix = colorize(\"Warning\", color=\"yellow\")\n\n exception, stack_trace = None, \"\"\n if parse_exception:\n exception, stack_trace = _parse_exc()\n\n out = \"{prefix}: {description}\".format(\n prefix=prefix, description=_description(message, exception)\n )\n\n if stack_trace:\n out += \"\\n{stack_trace}\".format(stack_trace=stack_trace)\n\n logger.warning(out)\n\n\n@progress_aware\ndef error(message=None):\n \"\"\"Prints an error message.\"\"\"\n prefix = colorize(\"Error\", color=\"red\")\n\n exception, stack_trace = _parse_exc()\n\n out = (\n \"{prefix}: {description}\"\n \"\\n\"\n \"{stack_trace}\"\n \"\\n\"\n \"{footer}\".format(\n prefix=prefix,\n description=_description(message, exception),\n stack_trace=stack_trace,\n footer=_footer(),\n )\n )\n\n logger.error(out)\n\n\ndef box(message, border_color=None):\n \"\"\"Prints a message in a box.\n\n Args:\n message (unicode): message to print.\n border_color (unicode): name of a color to outline the box with.\n \"\"\"\n lines = message.split(\"\\n\")\n max_width = max(_visual_width(line) for line in lines)\n\n padding_horizontal = 5\n padding_vertical = 1\n\n box_size_horizontal = max_width + (padding_horizontal * 2)\n\n chars = {\"corner\": \"+\", \"horizontal\": \"-\", \"vertical\": \"|\", \"empty\": \" \"}\n\n margin = \"{corner}{line}{corner}\\n\".format(\n corner=chars[\"corner\"], line=chars[\"horizontal\"] * box_size_horizontal\n )\n\n padding_lines = [\n \"{border}{space}{border}\\n\".format(\n border=colorize(chars[\"vertical\"], color=border_color),\n space=chars[\"empty\"] * box_size_horizontal,\n )\n * padding_vertical\n ]\n\n content_lines = [\n \"{border}{space}{content}{space}{border}\\n\".format(\n border=colorize(chars[\"vertical\"], color=border_color),\n space=chars[\"empty\"] * padding_horizontal,\n content=_visual_center(line, max_width),\n )\n for line in lines\n ]\n\n box_str = \"{margin}{padding}{content}{padding}{margin}\".format(\n margin=colorize(margin, color=border_color),\n padding=\"\".join(padding_lines),\n content=\"\".join(content_lines),\n )\n\n logger.info(box_str)\n\n\ndef level():\n \"\"\"Returns current log level.\"\"\"\n return logger.getEffectiveLevel()\n\n\ndef set_level(level_name):\n \"\"\"Sets log level.\n\n Args:\n level_name (str): log level name. E.g. info, debug, warning, error,\n critical.\n \"\"\"\n if not level_name:\n return\n\n levels = {\n \"info\": logging.INFO,\n \"debug\": logging.DEBUG,\n \"warning\": logging.WARNING,\n \"error\": logging.ERROR,\n \"critical\": logging.CRITICAL,\n }\n\n logger.setLevel(levels.get(level_name))\n\n\ndef be_quiet():\n \"\"\"Disables all messages except critical ones.\"\"\"\n logger.setLevel(logging.CRITICAL)\n\n\ndef be_verbose():\n \"\"\"Enables all messages.\"\"\"\n logger.setLevel(logging.DEBUG)\n\n\n@contextmanager\ndef verbose():\n \"\"\"Enables verbose mode for the context.\"\"\"\n previous_level = level()\n be_verbose()\n yield\n logger.setLevel(previous_level)\n\n\n@contextmanager\ndef quiet():\n \"\"\"Enables quiet mode for the context.\"\"\"\n previous_level = level()\n be_quiet()\n yield\n logger.setLevel(previous_level)\n\n\ndef is_quiet():\n \"\"\"Returns whether or not all messages except critical ones are\n disabled.\n \"\"\"\n return level() == logging.CRITICAL\n\n\ndef is_verbose():\n \"\"\"Returns whether or not all messages are enabled.\"\"\"\n return level() == logging.DEBUG\n\n\ndef colorize(message, color=None):\n \"\"\"Returns a message in a specified color.\"\"\"\n if not color:\n return message\n\n colors = {\n \"green\": colorama.Fore.GREEN,\n \"yellow\": colorama.Fore.YELLOW,\n \"blue\": colorama.Fore.BLUE,\n \"red\": colorama.Fore.RED,\n }\n\n return \"{color}{message}{nc}\".format(\n color=colors.get(color, \"\"), message=message, nc=colorama.Fore.RESET\n )\n\n\ndef set_default_level():\n \"\"\"Sets default log level.\"\"\"\n logger.setLevel(logging.INFO)\n\n\ndef _add_handlers():\n # NOTE: We need to initialize colorama before setting the stream handlers\n # so it can wrap stdout/stderr and convert color codes to Windows.\n colorama.init()\n\n formatter = \"%(message)s\"\n\n class _LogLevelFilter(logging.Filter):\n # pylint: disable=too-few-public-methods\n def filter(self, record):\n return record.levelno <= logging.WARNING\n\n sh_out = logging.StreamHandler(sys.stdout)\n sh_out.setFormatter(logging.Formatter(formatter))\n sh_out.setLevel(logging.DEBUG)\n sh_out.addFilter(_LogLevelFilter())\n\n sh_err = logging.StreamHandler(sys.stderr)\n sh_err.setFormatter(logging.Formatter(formatter))\n sh_err.setLevel(logging.ERROR)\n\n logger.addHandler(sh_out)\n logger.addHandler(sh_err)\n\n\ndef _walk_exc(exc):\n exc_list = [str(exc)]\n tb_list = [traceback.format_exc()]\n\n # NOTE: parsing chained exceptions. See dvc/exceptions.py for more info.\n while hasattr(exc, \"cause\") and exc.cause is not None:\n exc_list.append(str(exc.cause))\n if hasattr(exc, \"cause_tb\") and exc.cause_tb is not None:\n tb_list.insert(0, str(exc.cause_tb))\n exc = exc.cause\n\n return exc_list, tb_list\n\n\ndef _parse_exc():\n exc = sys.exc_info()[1]\n if not exc:\n return (None, \"\")\n\n exc_list, tb_list = _walk_exc(exc)\n\n exception = \": \".join(exc_list)\n\n if is_verbose():\n stack_trace = \"{line}\\n{stack_trace}{line}\\n\".format(\n line=colorize(\"-\" * 60, color=\"red\"),\n stack_trace=\"\\n\".join(tb_list),\n )\n else:\n stack_trace = \"\"\n\n return (exception, stack_trace)\n\n\ndef _description(message, exception):\n if exception and message:\n description = \"{message} - {exception}\"\n elif exception:\n description = \"{exception}\"\n elif message:\n description = \"{message}\"\n else:\n raise DvcException(\n \"Unexpected error - either exception or message must be provided\"\n )\n\n return description.format(message=message, exception=exception)\n\n\ndef _footer():\n return \"{phrase} Hit us up at {url}, we are always happy to help!\".format(\n phrase=colorize(\"Having any troubles?\", \"yellow\"),\n url=colorize(\"https://dvc.org/support\", \"blue\"),\n )\n\n\ndef _visual_width(line):\n \"\"\"Get the the number of columns required to display a string\"\"\"\n\n return len(re.sub(colorama.ansitowin32.AnsiToWin32.ANSI_CSI_RE, \"\", line))\n\n\ndef _visual_center(line, width):\n \"\"\"Center align string according to it's visual width\"\"\"\n\n spaces = max(width - _visual_width(line), 0)\n left_padding = int(spaces / 2)\n right_padding = spaces - left_padding\n\n return (left_padding * \" \") + line + (right_padding * \" \")\n\n\nlogger = logging.getLogger(\"dvc\") # pylint: disable=invalid-name\n\nset_default_level()\n_add_handlers()\n", "path": "dvc/logger.py"}]}
| 3,003 | 172 |
gh_patches_debug_1027
|
rasdani/github-patches
|
git_diff
|
cocotb__cocotb-1776
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
coroutines that return before their first yield cause the simulator to shutdown
Repro:
```python
@cocotb.test()
def test_func_empty(dut):
""" Test that a function can complete before the first yield """
@cocotb.coroutine
def func_empty():
print("This line runs")
return
yield # needed to make this a coroutine
yield func_empty()
print("This line is never reached")
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cocotb/ipython_support.py`
Content:
```
1 # Copyright cocotb contributors
2 # Licensed under the Revised BSD License, see LICENSE for details.
3 # SPDX-License-Identifier: BSD-3-Clause
4 import IPython
5 from IPython.terminal.ipapp import load_default_config
6 from IPython.terminal.prompts import Prompts, Token
7
8 import cocotb
9
10
11 class SimTimePrompt(Prompts):
12 """ custom prompt that shows the sim time after a trigger fires """
13 _show_time = 1
14
15 def in_prompt_tokens(self, cli=None):
16 tokens = super().in_prompt_tokens()
17 if self._show_time == self.shell.execution_count:
18 tokens = [
19 (Token.Comment, "sim time: {}".format(cocotb.utils.get_sim_time())),
20 (Token.Text, "\n"),
21 ] + tokens
22 return tokens
23
24
25 def _runner(shell, x):
26 """ Handler for async functions """
27 ret = cocotb.scheduler.queue_function(x)
28 shell.prompts._show_time = shell.execution_count
29 return ret
30
31
32 async def embed(user_ns: dict = {}):
33 """
34 Start an ipython shell in the current coroutine.
35
36 Unlike using :func:`IPython.embed` directly, the :keyword:`await` keyword
37 can be used directly from the shell to wait for triggers.
38 The :keyword:`yield` keyword from the legacy :ref:`yield-syntax` is not supported.
39
40 This coroutine will complete only when the user exits the interactive session.
41
42 Args:
43 user_ns:
44 The variables to have made available in the shell.
45 Passing ``locals()`` is often a good idea.
46 ``cocotb`` will automatically be included.
47
48 Notes:
49
50 If your simulator does not provide an appropriate ``stdin``, you may
51 find you cannot type in the resulting shell. Using simulators in batch
52 or non-GUI mode may resolve this. This feature is experimental, and
53 not all simulators are supported.
54 """
55 # ensure cocotb is in the namespace, for convenience
56 default_ns = dict(cocotb=cocotb)
57 default_ns.update(user_ns)
58
59 # build the config to enable `await`
60 c = load_default_config()
61 c.TerminalInteractiveShell.loop_runner = lambda x: _runner(shell, x)
62 c.TerminalInteractiveShell.autoawait = True
63
64 # create a shell with access to the dut, and cocotb pre-imported
65 shell = IPython.terminal.embed.InteractiveShellEmbed(
66 user_ns=default_ns,
67 config=c,
68 )
69
70 # add our custom prompts
71 shell.prompts = SimTimePrompt(shell)
72
73 # start the shell in a background thread
74 @cocotb.external
75 def run_shell():
76 shell()
77 await run_shell()
78
79
80 @cocotb.test()
81 async def run_ipython(dut):
82 """ A test that launches an interactive Python shell.
83
84 Do not call this directly - use this as ``make MODULE=cocotb.ipython_support``.
85
86 Within the shell, a global ``dut`` variable pointing to the design will be present.
87 """
88 await cocotb.triggers.Timer(0) # workaround for gh-637
89 await embed(user_ns=dict(dut=dut))
90
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/cocotb/ipython_support.py b/cocotb/ipython_support.py
--- a/cocotb/ipython_support.py
+++ b/cocotb/ipython_support.py
@@ -85,5 +85,4 @@
Within the shell, a global ``dut`` variable pointing to the design will be present.
"""
- await cocotb.triggers.Timer(0) # workaround for gh-637
await embed(user_ns=dict(dut=dut))
|
{"golden_diff": "diff --git a/cocotb/ipython_support.py b/cocotb/ipython_support.py\n--- a/cocotb/ipython_support.py\n+++ b/cocotb/ipython_support.py\n@@ -85,5 +85,4 @@\n \n Within the shell, a global ``dut`` variable pointing to the design will be present.\n \"\"\"\n- await cocotb.triggers.Timer(0) # workaround for gh-637\n await embed(user_ns=dict(dut=dut))\n", "issue": "coroutines that return before their first yield cause the simulator to shutdown\nRepro:\r\n```python\r\[email protected]()\r\ndef test_func_empty(dut):\r\n \"\"\" Test that a function can complete before the first yield \"\"\"\r\n @cocotb.coroutine\r\n def func_empty():\r\n print(\"This line runs\")\r\n return\r\n yield # needed to make this a coroutine\r\n yield func_empty()\r\n print(\"This line is never reached\")\r\n```\n", "before_files": [{"content": "# Copyright cocotb contributors\n# Licensed under the Revised BSD License, see LICENSE for details.\n# SPDX-License-Identifier: BSD-3-Clause\nimport IPython\nfrom IPython.terminal.ipapp import load_default_config\nfrom IPython.terminal.prompts import Prompts, Token\n\nimport cocotb\n\n\nclass SimTimePrompt(Prompts):\n \"\"\" custom prompt that shows the sim time after a trigger fires \"\"\"\n _show_time = 1\n\n def in_prompt_tokens(self, cli=None):\n tokens = super().in_prompt_tokens()\n if self._show_time == self.shell.execution_count:\n tokens = [\n (Token.Comment, \"sim time: {}\".format(cocotb.utils.get_sim_time())),\n (Token.Text, \"\\n\"),\n ] + tokens\n return tokens\n\n\ndef _runner(shell, x):\n \"\"\" Handler for async functions \"\"\"\n ret = cocotb.scheduler.queue_function(x)\n shell.prompts._show_time = shell.execution_count\n return ret\n\n\nasync def embed(user_ns: dict = {}):\n \"\"\"\n Start an ipython shell in the current coroutine.\n\n Unlike using :func:`IPython.embed` directly, the :keyword:`await` keyword\n can be used directly from the shell to wait for triggers.\n The :keyword:`yield` keyword from the legacy :ref:`yield-syntax` is not supported.\n\n This coroutine will complete only when the user exits the interactive session.\n\n Args:\n user_ns:\n The variables to have made available in the shell.\n Passing ``locals()`` is often a good idea.\n ``cocotb`` will automatically be included.\n\n Notes:\n\n If your simulator does not provide an appropriate ``stdin``, you may\n find you cannot type in the resulting shell. Using simulators in batch\n or non-GUI mode may resolve this. This feature is experimental, and\n not all simulators are supported.\n \"\"\"\n # ensure cocotb is in the namespace, for convenience\n default_ns = dict(cocotb=cocotb)\n default_ns.update(user_ns)\n\n # build the config to enable `await`\n c = load_default_config()\n c.TerminalInteractiveShell.loop_runner = lambda x: _runner(shell, x)\n c.TerminalInteractiveShell.autoawait = True\n\n # create a shell with access to the dut, and cocotb pre-imported\n shell = IPython.terminal.embed.InteractiveShellEmbed(\n user_ns=default_ns,\n config=c,\n )\n\n # add our custom prompts\n shell.prompts = SimTimePrompt(shell)\n\n # start the shell in a background thread\n @cocotb.external\n def run_shell():\n shell()\n await run_shell()\n\n\[email protected]()\nasync def run_ipython(dut):\n \"\"\" A test that launches an interactive Python shell.\n\n Do not call this directly - use this as ``make MODULE=cocotb.ipython_support``.\n\n Within the shell, a global ``dut`` variable pointing to the design will be present.\n \"\"\"\n await cocotb.triggers.Timer(0) # workaround for gh-637\n await embed(user_ns=dict(dut=dut))\n", "path": "cocotb/ipython_support.py"}], "after_files": [{"content": "# Copyright cocotb contributors\n# Licensed under the Revised BSD License, see LICENSE for details.\n# SPDX-License-Identifier: BSD-3-Clause\nimport IPython\nfrom IPython.terminal.ipapp import load_default_config\nfrom IPython.terminal.prompts import Prompts, Token\n\nimport cocotb\n\n\nclass SimTimePrompt(Prompts):\n \"\"\" custom prompt that shows the sim time after a trigger fires \"\"\"\n _show_time = 1\n\n def in_prompt_tokens(self, cli=None):\n tokens = super().in_prompt_tokens()\n if self._show_time == self.shell.execution_count:\n tokens = [\n (Token.Comment, \"sim time: {}\".format(cocotb.utils.get_sim_time())),\n (Token.Text, \"\\n\"),\n ] + tokens\n return tokens\n\n\ndef _runner(shell, x):\n \"\"\" Handler for async functions \"\"\"\n ret = cocotb.scheduler.queue_function(x)\n shell.prompts._show_time = shell.execution_count\n return ret\n\n\nasync def embed(user_ns: dict = {}):\n \"\"\"\n Start an ipython shell in the current coroutine.\n\n Unlike using :func:`IPython.embed` directly, the :keyword:`await` keyword\n can be used directly from the shell to wait for triggers.\n The :keyword:`yield` keyword from the legacy :ref:`yield-syntax` is not supported.\n\n This coroutine will complete only when the user exits the interactive session.\n\n Args:\n user_ns:\n The variables to have made available in the shell.\n Passing ``locals()`` is often a good idea.\n ``cocotb`` will automatically be included.\n\n Notes:\n\n If your simulator does not provide an appropriate ``stdin``, you may\n find you cannot type in the resulting shell. Using simulators in batch\n or non-GUI mode may resolve this. This feature is experimental, and\n not all simulators are supported.\n \"\"\"\n # ensure cocotb is in the namespace, for convenience\n default_ns = dict(cocotb=cocotb)\n default_ns.update(user_ns)\n\n # build the config to enable `await`\n c = load_default_config()\n c.TerminalInteractiveShell.loop_runner = lambda x: _runner(shell, x)\n c.TerminalInteractiveShell.autoawait = True\n\n # create a shell with access to the dut, and cocotb pre-imported\n shell = IPython.terminal.embed.InteractiveShellEmbed(\n user_ns=default_ns,\n config=c,\n )\n\n # add our custom prompts\n shell.prompts = SimTimePrompt(shell)\n\n # start the shell in a background thread\n @cocotb.external\n def run_shell():\n shell()\n await run_shell()\n\n\[email protected]()\nasync def run_ipython(dut):\n \"\"\" A test that launches an interactive Python shell.\n\n Do not call this directly - use this as ``make MODULE=cocotb.ipython_support``.\n\n Within the shell, a global ``dut`` variable pointing to the design will be present.\n \"\"\"\n await embed(user_ns=dict(dut=dut))\n", "path": "cocotb/ipython_support.py"}]}
| 1,224 | 116 |
gh_patches_debug_12046
|
rasdani/github-patches
|
git_diff
|
ibis-project__ibis-5700
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
bug: Combining union and order_by generates invalid BigQuery SQL
### What happened?
Hi Ibis team,
When applying union operation on table expression with order_by, it generates bad SQL.
A simple code piece can reproduce the issue:
```
import ibis
conn = ibis.bigquery.connect(
project_id='garrettwu-test-project-2',
dataset_id='bigquery-public-data.stackoverflow')
table = conn.table('posts_questions')
t = table.order_by("id")
unioned = ibis.union(t, t)
print(unioned.compile())
unioned.execute()
```
Generated SQL:
```
SELECT t0.*
FROM `bigquery-public-data.stackoverflow.posts_questions` t0
ORDER BY t0.`id` ASC
UNION ALL
SELECT t0.*
FROM `bigquery-public-data.stackoverflow.posts_questions` t0
ORDER BY t0.`id` ASC
```
Error:
```
BadRequest: 400 Syntax error: Expected end of input but got keyword UNION at [4:1]
```
(Full message in log output)
Same operation used to work for some previous commits.
### What version of ibis are you using?
master
Since the operation worked for versions sometime ago, we tried to run "git bisect" to locate the bad commit. It looks like https://github.com/ibis-project/ibis/pull/5571 is the one.
### What backend(s) are you using, if any?
BigQuery
### Relevant log output
```sh
# Error Message
---------------------------------------------------------------------------
BadRequest Traceback (most recent call last)
Cell In[11], line 1
----> 1 unioned.execute()
File ~/src/ibis/ibis/expr/types/core.py:303, in Expr.execute(self, limit, timecontext, params, **kwargs)
276 def execute(
277 self,
278 limit: int | str | None = 'default',
(...)
281 **kwargs: Any,
282 ):
283 """Execute an expression against its backend if one exists.
284
285 Parameters
(...)
301 Keyword arguments
302 """
--> 303 return self._find_backend(use_default=True).execute(
304 self, limit=limit, timecontext=timecontext, params=params, **kwargs
305 )
File ~/src/ibis/ibis/backends/bigquery/__init__.py:298, in Backend.execute(self, expr, params, limit, **kwargs)
296 sql = query_ast.compile()
297 self._log(sql)
--> 298 cursor = self.raw_sql(sql, params=params, **kwargs)
299 schema = self.ast_schema(query_ast, **kwargs)
300 result = self.fetch_from_cursor(cursor, schema)
File ~/src/ibis/ibis/backends/bigquery/__init__.py:255, in Backend.raw_sql(self, query, results, params)
242 def raw_sql(self, query: str, results=False, params=None):
243 query_parameters = [
244 bigquery_param(
245 param.type(),
(...)
253 for param, value in (params or {}).items()
254 ]
--> 255 return self._execute(query, results=results, query_parameters=query_parameters)
File ~/src/ibis/ibis/backends/bigquery/__init__.py:239, in Backend._execute(self, stmt, results, query_parameters)
235 job_config.use_legacy_sql = False # False by default in >=0.28
236 query = self.client.query(
237 stmt, job_config=job_config, project=self.billing_project
238 )
--> 239 query.result() # blocks until finished
240 return BigQueryCursor(query)
File ~/src/bigframes/venv/lib/python3.10/site-packages/google/cloud/bigquery/job/query.py:1499, in QueryJob.result(self, page_size, max_results, retry, timeout, start_index, job_retry)
1496 if retry_do_query is not None and job_retry is not None:
1497 do_get_result = job_retry(do_get_result)
-> 1499 do_get_result()
1501 except exceptions.GoogleAPICallError as exc:
1502 exc.message = _EXCEPTION_FOOTER_TEMPLATE.format(
1503 message=exc.message, location=self.location, job_id=self.job_id
1504 )
File ~/src/bigframes/venv/lib/python3.10/site-packages/google/api_core/retry.py:349, in Retry.__call__.<locals>.retry_wrapped_func(*args, **kwargs)
345 target = functools.partial(func, *args, **kwargs)
346 sleep_generator = exponential_sleep_generator(
347 self._initial, self._maximum, multiplier=self._multiplier
348 )
--> 349 return retry_target(
350 target,
351 self._predicate,
352 sleep_generator,
353 self._timeout,
354 on_error=on_error,
355 )
File ~/src/bigframes/venv/lib/python3.10/site-packages/google/api_core/retry.py:191, in retry_target(target, predicate, sleep_generator, timeout, on_error, **kwargs)
189 for sleep in sleep_generator:
190 try:
--> 191 return target()
193 # pylint: disable=broad-except
194 # This function explicitly must deal with broad exceptions.
195 except Exception as exc:
File ~/src/bigframes/venv/lib/python3.10/site-packages/google/cloud/bigquery/job/query.py:1489, in QueryJob.result.<locals>.do_get_result()
1486 self._retry_do_query = retry_do_query
1487 self._job_retry = job_retry
-> 1489 super(QueryJob, self).result(retry=retry, timeout=timeout)
1491 # Since the job could already be "done" (e.g. got a finished job
1492 # via client.get_job), the superclass call to done() might not
1493 # set the self._query_results cache.
1494 self._reload_query_results(retry=retry, timeout=timeout)
File ~/src/bigframes/venv/lib/python3.10/site-packages/google/cloud/bigquery/job/base.py:728, in _AsyncJob.result(self, retry, timeout)
725 self._begin(retry=retry, timeout=timeout)
727 kwargs = {} if retry is DEFAULT_RETRY else {"retry": retry}
--> 728 return super(_AsyncJob, self).result(timeout=timeout, **kwargs)
File ~/src/bigframes/venv/lib/python3.10/site-packages/google/api_core/future/polling.py:261, in PollingFuture.result(self, timeout, retry, polling)
256 self._blocking_poll(timeout=timeout, retry=retry, polling=polling)
258 if self._exception is not None:
259 # pylint: disable=raising-bad-type
260 # Pylint doesn't recognize that this is valid in this case.
--> 261 raise self._exception
263 return self._result
BadRequest: 400 Syntax error: Expected end of input but got keyword UNION at [4:1]
Location: US
Job ID: 7d6ccc8d-f948-4d60-b681-7a23eb5179da
```
### Code of Conduct
- [X] I agree to follow this project's Code of Conduct
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ibis/backends/base/sql/compiler/base.py`
Content:
```
1 from __future__ import annotations
2
3 import abc
4 from itertools import chain
5
6 import toolz
7
8 import ibis.expr.analysis as an
9 import ibis.expr.operations as ops
10 from ibis import util
11
12
13 class DML(abc.ABC):
14 @abc.abstractmethod
15 def compile(self):
16 pass
17
18
19 class DDL(abc.ABC):
20 @abc.abstractmethod
21 def compile(self):
22 pass
23
24
25 class QueryAST:
26 __slots__ = 'context', 'dml', 'setup_queries', 'teardown_queries'
27
28 def __init__(self, context, dml, setup_queries=None, teardown_queries=None):
29 self.context = context
30 self.dml = dml
31 self.setup_queries = setup_queries
32 self.teardown_queries = teardown_queries
33
34 @property
35 def queries(self):
36 return [self.dml]
37
38 def compile(self):
39 compiled_setup_queries = [q.compile() for q in self.setup_queries]
40 compiled_queries = [q.compile() for q in self.queries]
41 compiled_teardown_queries = [q.compile() for q in self.teardown_queries]
42 return self.context.collapse(
43 list(
44 chain(
45 compiled_setup_queries,
46 compiled_queries,
47 compiled_teardown_queries,
48 )
49 )
50 )
51
52
53 class SetOp(DML):
54 def __init__(self, tables, node, context, distincts):
55 assert isinstance(node, ops.Node)
56 assert all(isinstance(table, ops.Node) for table in tables)
57 self.context = context
58 self.tables = tables
59 self.table_set = node
60 self.distincts = distincts
61 self.filters = []
62
63 @classmethod
64 def keyword(cls, distinct):
65 return cls._keyword + (not distinct) * " ALL"
66
67 def _get_keyword_list(self):
68 return map(self.keyword, self.distincts)
69
70 def _extract_subqueries(self):
71 self.subqueries = an.find_subqueries(
72 [self.table_set, *self.filters], min_dependents=2
73 )
74 for subquery in self.subqueries:
75 self.context.set_extracted(subquery)
76
77 def format_subqueries(self):
78 context = self.context
79 subqueries = self.subqueries
80
81 return ',\n'.join(
82 '{} AS (\n{}\n)'.format(
83 context.get_ref(expr),
84 util.indent(context.get_compiled_expr(expr), 2),
85 )
86 for expr in subqueries
87 )
88
89 def format_relation(self, expr):
90 ref = self.context.get_ref(expr)
91 if ref is not None:
92 return f'SELECT *\nFROM {ref}'
93 return self.context.get_compiled_expr(expr)
94
95 def compile(self):
96 self._extract_subqueries()
97
98 extracted = self.format_subqueries()
99
100 buf = []
101
102 if extracted:
103 buf.append(f'WITH {extracted}')
104
105 buf.extend(
106 toolz.interleave(
107 (
108 map(self.format_relation, self.tables),
109 self._get_keyword_list(),
110 )
111 )
112 )
113 return '\n'.join(buf)
114
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ibis/backends/base/sql/compiler/base.py b/ibis/backends/base/sql/compiler/base.py
--- a/ibis/backends/base/sql/compiler/base.py
+++ b/ibis/backends/base/sql/compiler/base.py
@@ -68,8 +68,12 @@
return map(self.keyword, self.distincts)
def _extract_subqueries(self):
+ # extract any subquery to avoid generating incorrect sql when at least
+ # one of the set operands is invalid outside of being a subquery
+ #
+ # for example: SELECT * FROM t ORDER BY x UNION ...
self.subqueries = an.find_subqueries(
- [self.table_set, *self.filters], min_dependents=2
+ [self.table_set, *self.filters], min_dependents=1
)
for subquery in self.subqueries:
self.context.set_extracted(subquery)
|
{"golden_diff": "diff --git a/ibis/backends/base/sql/compiler/base.py b/ibis/backends/base/sql/compiler/base.py\n--- a/ibis/backends/base/sql/compiler/base.py\n+++ b/ibis/backends/base/sql/compiler/base.py\n@@ -68,8 +68,12 @@\n return map(self.keyword, self.distincts)\n \n def _extract_subqueries(self):\n+ # extract any subquery to avoid generating incorrect sql when at least\n+ # one of the set operands is invalid outside of being a subquery\n+ #\n+ # for example: SELECT * FROM t ORDER BY x UNION ...\n self.subqueries = an.find_subqueries(\n- [self.table_set, *self.filters], min_dependents=2\n+ [self.table_set, *self.filters], min_dependents=1\n )\n for subquery in self.subqueries:\n self.context.set_extracted(subquery)\n", "issue": "bug: Combining union and order_by generates invalid BigQuery SQL\n### What happened?\n\nHi Ibis team,\r\n\r\nWhen applying union operation on table expression with order_by, it generates bad SQL.\r\n\r\nA simple code piece can reproduce the issue:\r\n```\r\nimport ibis\r\n\r\nconn = ibis.bigquery.connect(\r\n project_id='garrettwu-test-project-2',\r\n dataset_id='bigquery-public-data.stackoverflow')\r\n\r\ntable = conn.table('posts_questions')\r\n\r\nt = table.order_by(\"id\")\r\n\r\nunioned = ibis.union(t, t)\r\n\r\nprint(unioned.compile())\r\n\r\nunioned.execute()\r\n```\r\nGenerated SQL:\r\n```\r\nSELECT t0.*\r\nFROM `bigquery-public-data.stackoverflow.posts_questions` t0\r\nORDER BY t0.`id` ASC\r\nUNION ALL\r\nSELECT t0.*\r\nFROM `bigquery-public-data.stackoverflow.posts_questions` t0\r\nORDER BY t0.`id` ASC\r\n```\r\nError:\r\n```\r\nBadRequest: 400 Syntax error: Expected end of input but got keyword UNION at [4:1]\r\n```\r\n(Full message in log output)\r\n\r\nSame operation used to work for some previous commits.\n\n### What version of ibis are you using?\n\nmaster\r\n\r\nSince the operation worked for versions sometime ago, we tried to run \"git bisect\" to locate the bad commit. It looks like https://github.com/ibis-project/ibis/pull/5571 is the one.\n\n### What backend(s) are you using, if any?\n\nBigQuery\n\n### Relevant log output\n\n```sh\n# Error Message\r\n---------------------------------------------------------------------------\r\nBadRequest Traceback (most recent call last)\r\nCell In[11], line 1\r\n----> 1 unioned.execute()\r\n\r\nFile ~/src/ibis/ibis/expr/types/core.py:303, in Expr.execute(self, limit, timecontext, params, **kwargs)\r\n 276 def execute(\r\n 277 self,\r\n 278 limit: int | str | None = 'default',\r\n (...)\r\n 281 **kwargs: Any,\r\n 282 ):\r\n 283 \"\"\"Execute an expression against its backend if one exists.\r\n 284 \r\n 285 Parameters\r\n (...)\r\n 301 Keyword arguments\r\n 302 \"\"\"\r\n--> 303 return self._find_backend(use_default=True).execute(\r\n 304 self, limit=limit, timecontext=timecontext, params=params, **kwargs\r\n 305 )\r\n\r\nFile ~/src/ibis/ibis/backends/bigquery/__init__.py:298, in Backend.execute(self, expr, params, limit, **kwargs)\r\n 296 sql = query_ast.compile()\r\n 297 self._log(sql)\r\n--> 298 cursor = self.raw_sql(sql, params=params, **kwargs)\r\n 299 schema = self.ast_schema(query_ast, **kwargs)\r\n 300 result = self.fetch_from_cursor(cursor, schema)\r\n\r\nFile ~/src/ibis/ibis/backends/bigquery/__init__.py:255, in Backend.raw_sql(self, query, results, params)\r\n 242 def raw_sql(self, query: str, results=False, params=None):\r\n 243 query_parameters = [\r\n 244 bigquery_param(\r\n 245 param.type(),\r\n (...)\r\n 253 for param, value in (params or {}).items()\r\n 254 ]\r\n--> 255 return self._execute(query, results=results, query_parameters=query_parameters)\r\n\r\nFile ~/src/ibis/ibis/backends/bigquery/__init__.py:239, in Backend._execute(self, stmt, results, query_parameters)\r\n 235 job_config.use_legacy_sql = False # False by default in >=0.28\r\n 236 query = self.client.query(\r\n 237 stmt, job_config=job_config, project=self.billing_project\r\n 238 )\r\n--> 239 query.result() # blocks until finished\r\n 240 return BigQueryCursor(query)\r\n\r\nFile ~/src/bigframes/venv/lib/python3.10/site-packages/google/cloud/bigquery/job/query.py:1499, in QueryJob.result(self, page_size, max_results, retry, timeout, start_index, job_retry)\r\n 1496 if retry_do_query is not None and job_retry is not None:\r\n 1497 do_get_result = job_retry(do_get_result)\r\n-> 1499 do_get_result()\r\n 1501 except exceptions.GoogleAPICallError as exc:\r\n 1502 exc.message = _EXCEPTION_FOOTER_TEMPLATE.format(\r\n 1503 message=exc.message, location=self.location, job_id=self.job_id\r\n 1504 )\r\n\r\nFile ~/src/bigframes/venv/lib/python3.10/site-packages/google/api_core/retry.py:349, in Retry.__call__.<locals>.retry_wrapped_func(*args, **kwargs)\r\n 345 target = functools.partial(func, *args, **kwargs)\r\n 346 sleep_generator = exponential_sleep_generator(\r\n 347 self._initial, self._maximum, multiplier=self._multiplier\r\n 348 )\r\n--> 349 return retry_target(\r\n 350 target,\r\n 351 self._predicate,\r\n 352 sleep_generator,\r\n 353 self._timeout,\r\n 354 on_error=on_error,\r\n 355 )\r\n\r\nFile ~/src/bigframes/venv/lib/python3.10/site-packages/google/api_core/retry.py:191, in retry_target(target, predicate, sleep_generator, timeout, on_error, **kwargs)\r\n 189 for sleep in sleep_generator:\r\n 190 try:\r\n--> 191 return target()\r\n 193 # pylint: disable=broad-except\r\n 194 # This function explicitly must deal with broad exceptions.\r\n 195 except Exception as exc:\r\n\r\nFile ~/src/bigframes/venv/lib/python3.10/site-packages/google/cloud/bigquery/job/query.py:1489, in QueryJob.result.<locals>.do_get_result()\r\n 1486 self._retry_do_query = retry_do_query\r\n 1487 self._job_retry = job_retry\r\n-> 1489 super(QueryJob, self).result(retry=retry, timeout=timeout)\r\n 1491 # Since the job could already be \"done\" (e.g. got a finished job\r\n 1492 # via client.get_job), the superclass call to done() might not\r\n 1493 # set the self._query_results cache.\r\n 1494 self._reload_query_results(retry=retry, timeout=timeout)\r\n\r\nFile ~/src/bigframes/venv/lib/python3.10/site-packages/google/cloud/bigquery/job/base.py:728, in _AsyncJob.result(self, retry, timeout)\r\n 725 self._begin(retry=retry, timeout=timeout)\r\n 727 kwargs = {} if retry is DEFAULT_RETRY else {\"retry\": retry}\r\n--> 728 return super(_AsyncJob, self).result(timeout=timeout, **kwargs)\r\n\r\nFile ~/src/bigframes/venv/lib/python3.10/site-packages/google/api_core/future/polling.py:261, in PollingFuture.result(self, timeout, retry, polling)\r\n 256 self._blocking_poll(timeout=timeout, retry=retry, polling=polling)\r\n 258 if self._exception is not None:\r\n 259 # pylint: disable=raising-bad-type\r\n 260 # Pylint doesn't recognize that this is valid in this case.\r\n--> 261 raise self._exception\r\n 263 return self._result\r\n\r\nBadRequest: 400 Syntax error: Expected end of input but got keyword UNION at [4:1]\r\n\r\nLocation: US\r\nJob ID: 7d6ccc8d-f948-4d60-b681-7a23eb5179da\n```\n\n\n### Code of Conduct\n\n- [X] I agree to follow this project's Code of Conduct\n", "before_files": [{"content": "from __future__ import annotations\n\nimport abc\nfrom itertools import chain\n\nimport toolz\n\nimport ibis.expr.analysis as an\nimport ibis.expr.operations as ops\nfrom ibis import util\n\n\nclass DML(abc.ABC):\n @abc.abstractmethod\n def compile(self):\n pass\n\n\nclass DDL(abc.ABC):\n @abc.abstractmethod\n def compile(self):\n pass\n\n\nclass QueryAST:\n __slots__ = 'context', 'dml', 'setup_queries', 'teardown_queries'\n\n def __init__(self, context, dml, setup_queries=None, teardown_queries=None):\n self.context = context\n self.dml = dml\n self.setup_queries = setup_queries\n self.teardown_queries = teardown_queries\n\n @property\n def queries(self):\n return [self.dml]\n\n def compile(self):\n compiled_setup_queries = [q.compile() for q in self.setup_queries]\n compiled_queries = [q.compile() for q in self.queries]\n compiled_teardown_queries = [q.compile() for q in self.teardown_queries]\n return self.context.collapse(\n list(\n chain(\n compiled_setup_queries,\n compiled_queries,\n compiled_teardown_queries,\n )\n )\n )\n\n\nclass SetOp(DML):\n def __init__(self, tables, node, context, distincts):\n assert isinstance(node, ops.Node)\n assert all(isinstance(table, ops.Node) for table in tables)\n self.context = context\n self.tables = tables\n self.table_set = node\n self.distincts = distincts\n self.filters = []\n\n @classmethod\n def keyword(cls, distinct):\n return cls._keyword + (not distinct) * \" ALL\"\n\n def _get_keyword_list(self):\n return map(self.keyword, self.distincts)\n\n def _extract_subqueries(self):\n self.subqueries = an.find_subqueries(\n [self.table_set, *self.filters], min_dependents=2\n )\n for subquery in self.subqueries:\n self.context.set_extracted(subquery)\n\n def format_subqueries(self):\n context = self.context\n subqueries = self.subqueries\n\n return ',\\n'.join(\n '{} AS (\\n{}\\n)'.format(\n context.get_ref(expr),\n util.indent(context.get_compiled_expr(expr), 2),\n )\n for expr in subqueries\n )\n\n def format_relation(self, expr):\n ref = self.context.get_ref(expr)\n if ref is not None:\n return f'SELECT *\\nFROM {ref}'\n return self.context.get_compiled_expr(expr)\n\n def compile(self):\n self._extract_subqueries()\n\n extracted = self.format_subqueries()\n\n buf = []\n\n if extracted:\n buf.append(f'WITH {extracted}')\n\n buf.extend(\n toolz.interleave(\n (\n map(self.format_relation, self.tables),\n self._get_keyword_list(),\n )\n )\n )\n return '\\n'.join(buf)\n", "path": "ibis/backends/base/sql/compiler/base.py"}], "after_files": [{"content": "from __future__ import annotations\n\nimport abc\nfrom itertools import chain\n\nimport toolz\n\nimport ibis.expr.analysis as an\nimport ibis.expr.operations as ops\nfrom ibis import util\n\n\nclass DML(abc.ABC):\n @abc.abstractmethod\n def compile(self):\n pass\n\n\nclass DDL(abc.ABC):\n @abc.abstractmethod\n def compile(self):\n pass\n\n\nclass QueryAST:\n __slots__ = 'context', 'dml', 'setup_queries', 'teardown_queries'\n\n def __init__(self, context, dml, setup_queries=None, teardown_queries=None):\n self.context = context\n self.dml = dml\n self.setup_queries = setup_queries\n self.teardown_queries = teardown_queries\n\n @property\n def queries(self):\n return [self.dml]\n\n def compile(self):\n compiled_setup_queries = [q.compile() for q in self.setup_queries]\n compiled_queries = [q.compile() for q in self.queries]\n compiled_teardown_queries = [q.compile() for q in self.teardown_queries]\n return self.context.collapse(\n list(\n chain(\n compiled_setup_queries,\n compiled_queries,\n compiled_teardown_queries,\n )\n )\n )\n\n\nclass SetOp(DML):\n def __init__(self, tables, node, context, distincts):\n assert isinstance(node, ops.Node)\n assert all(isinstance(table, ops.Node) for table in tables)\n self.context = context\n self.tables = tables\n self.table_set = node\n self.distincts = distincts\n self.filters = []\n\n @classmethod\n def keyword(cls, distinct):\n return cls._keyword + (not distinct) * \" ALL\"\n\n def _get_keyword_list(self):\n return map(self.keyword, self.distincts)\n\n def _extract_subqueries(self):\n # extract any subquery to avoid generating incorrect sql when at least\n # one of the set operands is invalid outside of being a subquery\n #\n # for example: SELECT * FROM t ORDER BY x UNION ...\n self.subqueries = an.find_subqueries(\n [self.table_set, *self.filters], min_dependents=1\n )\n for subquery in self.subqueries:\n self.context.set_extracted(subquery)\n\n def format_subqueries(self):\n context = self.context\n subqueries = self.subqueries\n\n return ',\\n'.join(\n '{} AS (\\n{}\\n)'.format(\n context.get_ref(expr),\n util.indent(context.get_compiled_expr(expr), 2),\n )\n for expr in subqueries\n )\n\n def format_relation(self, expr):\n ref = self.context.get_ref(expr)\n if ref is not None:\n return f'SELECT *\\nFROM {ref}'\n return self.context.get_compiled_expr(expr)\n\n def compile(self):\n self._extract_subqueries()\n\n extracted = self.format_subqueries()\n\n buf = []\n\n if extracted:\n buf.append(f'WITH {extracted}')\n\n buf.extend(\n toolz.interleave(\n (\n map(self.format_relation, self.tables),\n self._get_keyword_list(),\n )\n )\n )\n return '\\n'.join(buf)\n", "path": "ibis/backends/base/sql/compiler/base.py"}]}
| 2,992 | 200 |
gh_patches_debug_40680
|
rasdani/github-patches
|
git_diff
|
electricitymaps__electricitymaps-contrib-1789
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add US-MISO day ahead wind & solar forecasts
Both Wind Production and Total Load seem available with a day-head forecast from the following webpage https://www.misoenergy.org/markets-and-operations/real-time-displays/
These forecasts could be added to the MISO parser
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `parsers/US_MISO.py`
Content:
```
1 #!/usr/bin/env python3
2
3 """Parser for the MISO area of the United States."""
4
5 import requests
6 from dateutil import parser, tz
7
8 mix_url = 'https://api.misoenergy.org/MISORTWDDataBroker/DataBrokerServices.asmx?messageType' \
9 '=getfuelmix&returnType=json'
10
11 mapping = {'Coal': 'coal',
12 'Natural Gas': 'gas',
13 'Nuclear': 'nuclear',
14 'Wind': 'wind',
15 'Other': 'unknown'}
16
17
18 # To quote the MISO data source;
19 # "The category listed as “Other” is the combination of Hydro, Pumped Storage Hydro, Diesel, Demand Response Resources,
20 # External Asynchronous Resources and a varied assortment of solid waste, garbage and wood pulp burners".
21
22 # Timestamp reported by data source is in format 23-Jan-2018 - Interval 11:45 EST
23 # Unsure exactly why EST is used, possibly due to operational connections with PJM.
24
25
26 def get_json_data(logger, session=None):
27 """Returns 5 minute generation data in json format."""
28
29 s = session or requests.session()
30 json_data = s.get(mix_url).json()
31
32 return json_data
33
34
35 def data_processer(json_data, logger):
36 """
37 Identifies any unknown fuel types and logs a warning.
38 Returns a tuple containing datetime object and production dictionary.
39 """
40
41 generation = json_data['Fuel']['Type']
42
43 production = {}
44 for fuel in generation:
45 try:
46 k = mapping[fuel['CATEGORY']]
47 except KeyError as e:
48 logger.warning("Key '{}' is missing from the MISO fuel mapping.".format(
49 fuel['CATEGORY']))
50 k = 'unknown'
51 v = float(fuel['ACT'])
52 production[k] = production.get(k, 0.0) + v
53
54 # Remove unneeded parts of timestamp to allow datetime parsing.
55 timestamp = json_data['RefId']
56 split_time = timestamp.split(" ")
57 time_junk = {1, 2} # set literal
58 useful_time_parts = [v for i, v in enumerate(split_time) if i not in time_junk]
59
60 if useful_time_parts[-1] != 'EST':
61 raise ValueError('Timezone reported for US-MISO has changed.')
62
63 time_data = " ".join(useful_time_parts)
64 tzinfos = {"EST": tz.gettz('America/New_York')}
65 dt = parser.parse(time_data, tzinfos=tzinfos)
66
67 return dt, production
68
69
70 def fetch_production(zone_key='US-MISO', session=None, target_datetime=None, logger=None):
71 """
72 Requests the last known production mix (in MW) of a given country
73 Arguments:
74 zone_key (optional) -- used in case a parser is able to fetch multiple countries
75 session (optional) -- request session passed in order to re-use an existing session
76 Return:
77 A dictionary in the form:
78 {
79 'zoneKey': 'FR',
80 'datetime': '2017-01-01T00:00:00Z',
81 'production': {
82 'biomass': 0.0,
83 'coal': 0.0,
84 'gas': 0.0,
85 'hydro': 0.0,
86 'nuclear': null,
87 'oil': 0.0,
88 'solar': 0.0,
89 'wind': 0.0,
90 'geothermal': 0.0,
91 'unknown': 0.0
92 },
93 'storage': {
94 'hydro': -10.0,
95 },
96 'source': 'mysource.com'
97 }
98 """
99 if target_datetime:
100 raise NotImplementedError('This parser is not yet able to parse past dates')
101
102 json_data = get_json_data(logger, session=session)
103 processed_data = data_processer(json_data, logger)
104
105 data = {
106 'zoneKey': zone_key,
107 'datetime': processed_data[0],
108 'production': processed_data[1],
109 'storage': {},
110 'source': 'misoenergy.org'
111 }
112
113 return data
114
115
116 if __name__ == '__main__':
117 print('fetch_production() ->')
118 print(fetch_production())
119
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/parsers/US_MISO.py b/parsers/US_MISO.py
--- a/parsers/US_MISO.py
+++ b/parsers/US_MISO.py
@@ -2,6 +2,7 @@
"""Parser for the MISO area of the United States."""
+import logging
import requests
from dateutil import parser, tz
@@ -14,6 +15,7 @@
'Wind': 'wind',
'Other': 'unknown'}
+wind_forecast_url = 'https://api.misoenergy.org/MISORTWDDataBroker/DataBrokerServices.asmx?messageType=getWindForecast&returnType=json'
# To quote the MISO data source;
# "The category listed as “Other” is the combination of Hydro, Pumped Storage Hydro, Diesel, Demand Response Resources,
@@ -67,12 +69,14 @@
return dt, production
-def fetch_production(zone_key='US-MISO', session=None, target_datetime=None, logger=None):
+def fetch_production(zone_key='US-MISO', session=None, target_datetime=None, logger=logging.getLogger(__name__)):
"""
Requests the last known production mix (in MW) of a given country
Arguments:
zone_key (optional) -- used in case a parser is able to fetch multiple countries
session (optional) -- request session passed in order to re-use an existing session
+ target_datetime (optional) -- used if parser can fetch data for a specific day
+ logger (optional) -- handles logging when parser is run as main
Return:
A dictionary in the form:
{
@@ -96,6 +100,7 @@
'source': 'mysource.com'
}
"""
+
if target_datetime:
raise NotImplementedError('This parser is not yet able to parse past dates')
@@ -113,6 +118,48 @@
return data
+def fetch_wind_forecast(zone_key='US-MISO', session=None, target_datetime=None, logger=None):
+ """
+ Requests the day ahead wind forecast (in MW) of a given zone
+ Arguments:
+ zone_key (optional) -- used in case a parser is able to fetch multiple countries
+ session (optional) -- request session passed in order to re-use an existing session
+ target_datetime (optional) -- used if parser can fetch data for a specific day
+ logger (optional) -- handles logging when parser is run as main
+ Return:
+ A list of dictionaries in the form:
+ {
+ 'source': 'misoenergy.org',
+ 'production': {'wind': 12932.0},
+ 'datetime': '2019-01-01T00:00:00Z',
+ 'zoneKey': 'US-MISO'
+ }
+ """
+
+ if target_datetime:
+ raise NotImplementedError('This parser is not yet able to parse past dates')
+
+ s = session or requests.Session()
+ req = s.get(wind_forecast_url)
+ raw_json = req.json()
+ raw_data = raw_json['Forecast']
+
+ data = []
+ for item in raw_data:
+ dt = parser.parse(item['DateTimeEST']).replace(tzinfo=tz.gettz('America/New_York'))
+ value = float(item['Value'])
+
+ datapoint = {'datetime': dt,
+ 'production': {'wind': value},
+ 'source': 'misoenergy.org',
+ 'zoneKey': zone_key}
+ data.append(datapoint)
+
+ return data
+
+
if __name__ == '__main__':
print('fetch_production() ->')
print(fetch_production())
+ print('fetch_wind_forecast() ->')
+ print(fetch_wind_forecast())
|
{"golden_diff": "diff --git a/parsers/US_MISO.py b/parsers/US_MISO.py\n--- a/parsers/US_MISO.py\n+++ b/parsers/US_MISO.py\n@@ -2,6 +2,7 @@\n \n \"\"\"Parser for the MISO area of the United States.\"\"\"\n \n+import logging\n import requests\n from dateutil import parser, tz\n \n@@ -14,6 +15,7 @@\n 'Wind': 'wind',\n 'Other': 'unknown'}\n \n+wind_forecast_url = 'https://api.misoenergy.org/MISORTWDDataBroker/DataBrokerServices.asmx?messageType=getWindForecast&returnType=json'\n \n # To quote the MISO data source;\n # \"The category listed as \u201cOther\u201d is the combination of Hydro, Pumped Storage Hydro, Diesel, Demand Response Resources,\n@@ -67,12 +69,14 @@\n return dt, production\n \n \n-def fetch_production(zone_key='US-MISO', session=None, target_datetime=None, logger=None):\n+def fetch_production(zone_key='US-MISO', session=None, target_datetime=None, logger=logging.getLogger(__name__)):\n \"\"\"\n Requests the last known production mix (in MW) of a given country\n Arguments:\n zone_key (optional) -- used in case a parser is able to fetch multiple countries\n session (optional) -- request session passed in order to re-use an existing session\n+ target_datetime (optional) -- used if parser can fetch data for a specific day\n+ logger (optional) -- handles logging when parser is run as main\n Return:\n A dictionary in the form:\n {\n@@ -96,6 +100,7 @@\n 'source': 'mysource.com'\n }\n \"\"\"\n+\n if target_datetime:\n raise NotImplementedError('This parser is not yet able to parse past dates')\n \n@@ -113,6 +118,48 @@\n return data\n \n \n+def fetch_wind_forecast(zone_key='US-MISO', session=None, target_datetime=None, logger=None):\n+ \"\"\"\n+ Requests the day ahead wind forecast (in MW) of a given zone\n+ Arguments:\n+ zone_key (optional) -- used in case a parser is able to fetch multiple countries\n+ session (optional) -- request session passed in order to re-use an existing session\n+ target_datetime (optional) -- used if parser can fetch data for a specific day\n+ logger (optional) -- handles logging when parser is run as main\n+ Return:\n+ A list of dictionaries in the form:\n+ {\n+ 'source': 'misoenergy.org',\n+ 'production': {'wind': 12932.0},\n+ 'datetime': '2019-01-01T00:00:00Z',\n+ 'zoneKey': 'US-MISO'\n+ }\n+ \"\"\"\n+\n+ if target_datetime:\n+ raise NotImplementedError('This parser is not yet able to parse past dates')\n+\n+ s = session or requests.Session()\n+ req = s.get(wind_forecast_url)\n+ raw_json = req.json()\n+ raw_data = raw_json['Forecast']\n+\n+ data = []\n+ for item in raw_data:\n+ dt = parser.parse(item['DateTimeEST']).replace(tzinfo=tz.gettz('America/New_York'))\n+ value = float(item['Value'])\n+\n+ datapoint = {'datetime': dt,\n+ 'production': {'wind': value},\n+ 'source': 'misoenergy.org',\n+ 'zoneKey': zone_key}\n+ data.append(datapoint)\n+\n+ return data\n+\n+\n if __name__ == '__main__':\n print('fetch_production() ->')\n print(fetch_production())\n+ print('fetch_wind_forecast() ->')\n+ print(fetch_wind_forecast())\n", "issue": "Add US-MISO day ahead wind & solar forecasts\nBoth Wind Production and Total Load seem available with a day-head forecast from the following webpage https://www.misoenergy.org/markets-and-operations/real-time-displays/\r\n\r\nThese forecasts could be added to the MISO parser \r\n\n", "before_files": [{"content": "#!/usr/bin/env python3\n\n\"\"\"Parser for the MISO area of the United States.\"\"\"\n\nimport requests\nfrom dateutil import parser, tz\n\nmix_url = 'https://api.misoenergy.org/MISORTWDDataBroker/DataBrokerServices.asmx?messageType' \\\n '=getfuelmix&returnType=json'\n\nmapping = {'Coal': 'coal',\n 'Natural Gas': 'gas',\n 'Nuclear': 'nuclear',\n 'Wind': 'wind',\n 'Other': 'unknown'}\n\n\n# To quote the MISO data source;\n# \"The category listed as \u201cOther\u201d is the combination of Hydro, Pumped Storage Hydro, Diesel, Demand Response Resources,\n# External Asynchronous Resources and a varied assortment of solid waste, garbage and wood pulp burners\".\n\n# Timestamp reported by data source is in format 23-Jan-2018 - Interval 11:45 EST\n# Unsure exactly why EST is used, possibly due to operational connections with PJM.\n\n\ndef get_json_data(logger, session=None):\n \"\"\"Returns 5 minute generation data in json format.\"\"\"\n\n s = session or requests.session()\n json_data = s.get(mix_url).json()\n\n return json_data\n\n\ndef data_processer(json_data, logger):\n \"\"\"\n Identifies any unknown fuel types and logs a warning.\n Returns a tuple containing datetime object and production dictionary.\n \"\"\"\n\n generation = json_data['Fuel']['Type']\n\n production = {}\n for fuel in generation:\n try:\n k = mapping[fuel['CATEGORY']]\n except KeyError as e:\n logger.warning(\"Key '{}' is missing from the MISO fuel mapping.\".format(\n fuel['CATEGORY']))\n k = 'unknown'\n v = float(fuel['ACT'])\n production[k] = production.get(k, 0.0) + v\n\n # Remove unneeded parts of timestamp to allow datetime parsing.\n timestamp = json_data['RefId']\n split_time = timestamp.split(\" \")\n time_junk = {1, 2} # set literal\n useful_time_parts = [v for i, v in enumerate(split_time) if i not in time_junk]\n\n if useful_time_parts[-1] != 'EST':\n raise ValueError('Timezone reported for US-MISO has changed.')\n\n time_data = \" \".join(useful_time_parts)\n tzinfos = {\"EST\": tz.gettz('America/New_York')}\n dt = parser.parse(time_data, tzinfos=tzinfos)\n\n return dt, production\n\n\ndef fetch_production(zone_key='US-MISO', session=None, target_datetime=None, logger=None):\n \"\"\"\n Requests the last known production mix (in MW) of a given country\n Arguments:\n zone_key (optional) -- used in case a parser is able to fetch multiple countries\n session (optional) -- request session passed in order to re-use an existing session\n Return:\n A dictionary in the form:\n {\n 'zoneKey': 'FR',\n 'datetime': '2017-01-01T00:00:00Z',\n 'production': {\n 'biomass': 0.0,\n 'coal': 0.0,\n 'gas': 0.0,\n 'hydro': 0.0,\n 'nuclear': null,\n 'oil': 0.0,\n 'solar': 0.0,\n 'wind': 0.0,\n 'geothermal': 0.0,\n 'unknown': 0.0\n },\n 'storage': {\n 'hydro': -10.0,\n },\n 'source': 'mysource.com'\n }\n \"\"\"\n if target_datetime:\n raise NotImplementedError('This parser is not yet able to parse past dates')\n\n json_data = get_json_data(logger, session=session)\n processed_data = data_processer(json_data, logger)\n\n data = {\n 'zoneKey': zone_key,\n 'datetime': processed_data[0],\n 'production': processed_data[1],\n 'storage': {},\n 'source': 'misoenergy.org'\n }\n\n return data\n\n\nif __name__ == '__main__':\n print('fetch_production() ->')\n print(fetch_production())\n", "path": "parsers/US_MISO.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n\n\"\"\"Parser for the MISO area of the United States.\"\"\"\n\nimport logging\nimport requests\nfrom dateutil import parser, tz\n\nmix_url = 'https://api.misoenergy.org/MISORTWDDataBroker/DataBrokerServices.asmx?messageType' \\\n '=getfuelmix&returnType=json'\n\nmapping = {'Coal': 'coal',\n 'Natural Gas': 'gas',\n 'Nuclear': 'nuclear',\n 'Wind': 'wind',\n 'Other': 'unknown'}\n\nwind_forecast_url = 'https://api.misoenergy.org/MISORTWDDataBroker/DataBrokerServices.asmx?messageType=getWindForecast&returnType=json'\n\n# To quote the MISO data source;\n# \"The category listed as \u201cOther\u201d is the combination of Hydro, Pumped Storage Hydro, Diesel, Demand Response Resources,\n# External Asynchronous Resources and a varied assortment of solid waste, garbage and wood pulp burners\".\n\n# Timestamp reported by data source is in format 23-Jan-2018 - Interval 11:45 EST\n# Unsure exactly why EST is used, possibly due to operational connections with PJM.\n\n\ndef get_json_data(logger, session=None):\n \"\"\"Returns 5 minute generation data in json format.\"\"\"\n\n s = session or requests.session()\n json_data = s.get(mix_url).json()\n\n return json_data\n\n\ndef data_processer(json_data, logger):\n \"\"\"\n Identifies any unknown fuel types and logs a warning.\n Returns a tuple containing datetime object and production dictionary.\n \"\"\"\n\n generation = json_data['Fuel']['Type']\n\n production = {}\n for fuel in generation:\n try:\n k = mapping[fuel['CATEGORY']]\n except KeyError as e:\n logger.warning(\"Key '{}' is missing from the MISO fuel mapping.\".format(\n fuel['CATEGORY']))\n k = 'unknown'\n v = float(fuel['ACT'])\n production[k] = production.get(k, 0.0) + v\n\n # Remove unneeded parts of timestamp to allow datetime parsing.\n timestamp = json_data['RefId']\n split_time = timestamp.split(\" \")\n time_junk = {1, 2} # set literal\n useful_time_parts = [v for i, v in enumerate(split_time) if i not in time_junk]\n\n if useful_time_parts[-1] != 'EST':\n raise ValueError('Timezone reported for US-MISO has changed.')\n\n time_data = \" \".join(useful_time_parts)\n tzinfos = {\"EST\": tz.gettz('America/New_York')}\n dt = parser.parse(time_data, tzinfos=tzinfos)\n\n return dt, production\n\n\ndef fetch_production(zone_key='US-MISO', session=None, target_datetime=None, logger=logging.getLogger(__name__)):\n \"\"\"\n Requests the last known production mix (in MW) of a given country\n Arguments:\n zone_key (optional) -- used in case a parser is able to fetch multiple countries\n session (optional) -- request session passed in order to re-use an existing session\n target_datetime (optional) -- used if parser can fetch data for a specific day\n logger (optional) -- handles logging when parser is run as main\n Return:\n A dictionary in the form:\n {\n 'zoneKey': 'FR',\n 'datetime': '2017-01-01T00:00:00Z',\n 'production': {\n 'biomass': 0.0,\n 'coal': 0.0,\n 'gas': 0.0,\n 'hydro': 0.0,\n 'nuclear': null,\n 'oil': 0.0,\n 'solar': 0.0,\n 'wind': 0.0,\n 'geothermal': 0.0,\n 'unknown': 0.0\n },\n 'storage': {\n 'hydro': -10.0,\n },\n 'source': 'mysource.com'\n }\n \"\"\"\n\n if target_datetime:\n raise NotImplementedError('This parser is not yet able to parse past dates')\n\n json_data = get_json_data(logger, session=session)\n processed_data = data_processer(json_data, logger)\n\n data = {\n 'zoneKey': zone_key,\n 'datetime': processed_data[0],\n 'production': processed_data[1],\n 'storage': {},\n 'source': 'misoenergy.org'\n }\n\n return data\n\n\ndef fetch_wind_forecast(zone_key='US-MISO', session=None, target_datetime=None, logger=None):\n \"\"\"\n Requests the day ahead wind forecast (in MW) of a given zone\n Arguments:\n zone_key (optional) -- used in case a parser is able to fetch multiple countries\n session (optional) -- request session passed in order to re-use an existing session\n target_datetime (optional) -- used if parser can fetch data for a specific day\n logger (optional) -- handles logging when parser is run as main\n Return:\n A list of dictionaries in the form:\n {\n 'source': 'misoenergy.org',\n 'production': {'wind': 12932.0},\n 'datetime': '2019-01-01T00:00:00Z',\n 'zoneKey': 'US-MISO'\n }\n \"\"\"\n\n if target_datetime:\n raise NotImplementedError('This parser is not yet able to parse past dates')\n\n s = session or requests.Session()\n req = s.get(wind_forecast_url)\n raw_json = req.json()\n raw_data = raw_json['Forecast']\n\n data = []\n for item in raw_data:\n dt = parser.parse(item['DateTimeEST']).replace(tzinfo=tz.gettz('America/New_York'))\n value = float(item['Value'])\n\n datapoint = {'datetime': dt,\n 'production': {'wind': value},\n 'source': 'misoenergy.org',\n 'zoneKey': zone_key}\n data.append(datapoint)\n\n return data\n\n\nif __name__ == '__main__':\n print('fetch_production() ->')\n print(fetch_production())\n print('fetch_wind_forecast() ->')\n print(fetch_wind_forecast())\n", "path": "parsers/US_MISO.py"}]}
| 1,489 | 837 |
gh_patches_debug_8492
|
rasdani/github-patches
|
git_diff
|
Textualize__textual-3050
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Binding for `]` renders incorrectly in `Footer`
The binding `Binding("ctrl+right_square_bracket", "toggle_indent_width", "Cycle indent width")` renders like this:
<img width="431" alt="image" src="https://github.com/Textualize/textual/assets/5740731/2c2bd6fa-288b-4205-aba0-48eb1b6c41e0">
It should probably render as `Ctrl+]`.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/textual/keys.py`
Content:
```
1 from __future__ import annotations
2
3 import unicodedata
4 from enum import Enum
5
6
7 # Adapted from prompt toolkit https://github.com/prompt-toolkit/python-prompt-toolkit/blob/master/prompt_toolkit/keys.py
8 class Keys(str, Enum): # type: ignore[no-redef]
9 """
10 List of keys for use in key bindings.
11
12 Note that this is an "StrEnum", all values can be compared against
13 strings.
14 """
15
16 @property
17 def value(self) -> str:
18 return super().value
19
20 Escape = "escape" # Also Control-[
21 ShiftEscape = "shift+escape"
22 Return = "return"
23
24 ControlAt = "ctrl+@" # Also Control-Space.
25
26 ControlA = "ctrl+a"
27 ControlB = "ctrl+b"
28 ControlC = "ctrl+c"
29 ControlD = "ctrl+d"
30 ControlE = "ctrl+e"
31 ControlF = "ctrl+f"
32 ControlG = "ctrl+g"
33 ControlH = "ctrl+h"
34 ControlI = "ctrl+i" # Tab
35 ControlJ = "ctrl+j" # Newline
36 ControlK = "ctrl+k"
37 ControlL = "ctrl+l"
38 ControlM = "ctrl+m" # Carriage return
39 ControlN = "ctrl+n"
40 ControlO = "ctrl+o"
41 ControlP = "ctrl+p"
42 ControlQ = "ctrl+q"
43 ControlR = "ctrl+r"
44 ControlS = "ctrl+s"
45 ControlT = "ctrl+t"
46 ControlU = "ctrl+u"
47 ControlV = "ctrl+v"
48 ControlW = "ctrl+w"
49 ControlX = "ctrl+x"
50 ControlY = "ctrl+y"
51 ControlZ = "ctrl+z"
52
53 Control1 = "ctrl+1"
54 Control2 = "ctrl+2"
55 Control3 = "ctrl+3"
56 Control4 = "ctrl+4"
57 Control5 = "ctrl+5"
58 Control6 = "ctrl+6"
59 Control7 = "ctrl+7"
60 Control8 = "ctrl+8"
61 Control9 = "ctrl+9"
62 Control0 = "ctrl+0"
63
64 ControlShift1 = "ctrl+shift+1"
65 ControlShift2 = "ctrl+shift+2"
66 ControlShift3 = "ctrl+shift+3"
67 ControlShift4 = "ctrl+shift+4"
68 ControlShift5 = "ctrl+shift+5"
69 ControlShift6 = "ctrl+shift+6"
70 ControlShift7 = "ctrl+shift+7"
71 ControlShift8 = "ctrl+shift+8"
72 ControlShift9 = "ctrl+shift+9"
73 ControlShift0 = "ctrl+shift+0"
74
75 ControlBackslash = "ctrl+backslash"
76 ControlSquareClose = "ctrl+right_square_bracket"
77 ControlCircumflex = "ctrl+circumflex_accent"
78 ControlUnderscore = "ctrl+underscore"
79
80 Left = "left"
81 Right = "right"
82 Up = "up"
83 Down = "down"
84 Home = "home"
85 End = "end"
86 Insert = "insert"
87 Delete = "delete"
88 PageUp = "pageup"
89 PageDown = "pagedown"
90
91 ControlLeft = "ctrl+left"
92 ControlRight = "ctrl+right"
93 ControlUp = "ctrl+up"
94 ControlDown = "ctrl+down"
95 ControlHome = "ctrl+home"
96 ControlEnd = "ctrl+end"
97 ControlInsert = "ctrl+insert"
98 ControlDelete = "ctrl+delete"
99 ControlPageUp = "ctrl+pageup"
100 ControlPageDown = "ctrl+pagedown"
101
102 ShiftLeft = "shift+left"
103 ShiftRight = "shift+right"
104 ShiftUp = "shift+up"
105 ShiftDown = "shift+down"
106 ShiftHome = "shift+home"
107 ShiftEnd = "shift+end"
108 ShiftInsert = "shift+insert"
109 ShiftDelete = "shift+delete"
110 ShiftPageUp = "shift+pageup"
111 ShiftPageDown = "shift+pagedown"
112
113 ControlShiftLeft = "ctrl+shift+left"
114 ControlShiftRight = "ctrl+shift+right"
115 ControlShiftUp = "ctrl+shift+up"
116 ControlShiftDown = "ctrl+shift+down"
117 ControlShiftHome = "ctrl+shift+home"
118 ControlShiftEnd = "ctrl+shift+end"
119 ControlShiftInsert = "ctrl+shift+insert"
120 ControlShiftDelete = "ctrl+shift+delete"
121 ControlShiftPageUp = "ctrl+shift+pageup"
122 ControlShiftPageDown = "ctrl+shift+pagedown"
123
124 BackTab = "shift+tab" # shift + tab
125
126 F1 = "f1"
127 F2 = "f2"
128 F3 = "f3"
129 F4 = "f4"
130 F5 = "f5"
131 F6 = "f6"
132 F7 = "f7"
133 F8 = "f8"
134 F9 = "f9"
135 F10 = "f10"
136 F11 = "f11"
137 F12 = "f12"
138 F13 = "f13"
139 F14 = "f14"
140 F15 = "f15"
141 F16 = "f16"
142 F17 = "f17"
143 F18 = "f18"
144 F19 = "f19"
145 F20 = "f20"
146 F21 = "f21"
147 F22 = "f22"
148 F23 = "f23"
149 F24 = "f24"
150
151 ControlF1 = "ctrl+f1"
152 ControlF2 = "ctrl+f2"
153 ControlF3 = "ctrl+f3"
154 ControlF4 = "ctrl+f4"
155 ControlF5 = "ctrl+f5"
156 ControlF6 = "ctrl+f6"
157 ControlF7 = "ctrl+f7"
158 ControlF8 = "ctrl+f8"
159 ControlF9 = "ctrl+f9"
160 ControlF10 = "ctrl+f10"
161 ControlF11 = "ctrl+f11"
162 ControlF12 = "ctrl+f12"
163 ControlF13 = "ctrl+f13"
164 ControlF14 = "ctrl+f14"
165 ControlF15 = "ctrl+f15"
166 ControlF16 = "ctrl+f16"
167 ControlF17 = "ctrl+f17"
168 ControlF18 = "ctrl+f18"
169 ControlF19 = "ctrl+f19"
170 ControlF20 = "ctrl+f20"
171 ControlF21 = "ctrl+f21"
172 ControlF22 = "ctrl+f22"
173 ControlF23 = "ctrl+f23"
174 ControlF24 = "ctrl+f24"
175
176 # Matches any key.
177 Any = "<any>"
178
179 # Special.
180 ScrollUp = "<scroll-up>"
181 ScrollDown = "<scroll-down>"
182
183 # For internal use: key which is ignored.
184 # (The key binding for this key should not do anything.)
185 Ignore = "<ignore>"
186
187 # Some 'Key' aliases (for backwardshift+compatibility).
188 ControlSpace = "ctrl-at"
189 Tab = "tab"
190 Space = "space"
191 Enter = "enter"
192 Backspace = "backspace"
193
194 # ShiftControl was renamed to ControlShift in
195 # 888fcb6fa4efea0de8333177e1bbc792f3ff3c24 (20 Feb 2020).
196 ShiftControlLeft = ControlShiftLeft
197 ShiftControlRight = ControlShiftRight
198 ShiftControlHome = ControlShiftHome
199 ShiftControlEnd = ControlShiftEnd
200
201
202 # Unicode db contains some obscure names
203 # This mapping replaces them with more common terms
204 KEY_NAME_REPLACEMENTS = {
205 "solidus": "slash",
206 "reverse_solidus": "backslash",
207 "commercial_at": "at",
208 "hyphen_minus": "minus",
209 "plus_sign": "plus",
210 "low_line": "underscore",
211 }
212 REPLACED_KEYS = {value: key for key, value in KEY_NAME_REPLACEMENTS.items()}
213
214 # Convert the friendly versions of character key Unicode names
215 # back to their original names.
216 # This is because we go from Unicode to friendly by replacing spaces and dashes
217 # with underscores, which cannot be undone by replacing underscores with spaces/dashes.
218 KEY_TO_UNICODE_NAME = {
219 "exclamation_mark": "EXCLAMATION MARK",
220 "quotation_mark": "QUOTATION MARK",
221 "number_sign": "NUMBER SIGN",
222 "dollar_sign": "DOLLAR SIGN",
223 "percent_sign": "PERCENT SIGN",
224 "left_parenthesis": "LEFT PARENTHESIS",
225 "right_parenthesis": "RIGHT PARENTHESIS",
226 "plus_sign": "PLUS SIGN",
227 "hyphen_minus": "HYPHEN-MINUS",
228 "full_stop": "FULL STOP",
229 "less_than_sign": "LESS-THAN SIGN",
230 "equals_sign": "EQUALS SIGN",
231 "greater_than_sign": "GREATER-THAN SIGN",
232 "question_mark": "QUESTION MARK",
233 "commercial_at": "COMMERCIAL AT",
234 "left_square_bracket": "LEFT SQUARE BRACKET",
235 "reverse_solidus": "REVERSE SOLIDUS",
236 "right_square_bracket": "RIGHT SQUARE BRACKET",
237 "circumflex_accent": "CIRCUMFLEX ACCENT",
238 "low_line": "LOW LINE",
239 "grave_accent": "GRAVE ACCENT",
240 "left_curly_bracket": "LEFT CURLY BRACKET",
241 "vertical_line": "VERTICAL LINE",
242 "right_curly_bracket": "RIGHT CURLY BRACKET",
243 }
244
245 # Some keys have aliases. For example, if you press `ctrl+m` on your keyboard,
246 # it's treated the same way as if you press `enter`. Key handlers `key_ctrl_m` and
247 # `key_enter` are both valid in this case.
248 KEY_ALIASES = {
249 "tab": ["ctrl+i"],
250 "enter": ["ctrl+m"],
251 "escape": ["ctrl+left_square_brace"],
252 "ctrl+at": ["ctrl+space"],
253 "ctrl+j": ["newline"],
254 }
255
256 KEY_DISPLAY_ALIASES = {
257 "up": "↑",
258 "down": "↓",
259 "left": "←",
260 "right": "→",
261 "backspace": "⌫",
262 "escape": "ESC",
263 "enter": "⏎",
264 "minus": "-",
265 "space": "SPACE",
266 }
267
268
269 def _get_unicode_name_from_key(key: str) -> str:
270 """Get the best guess for the Unicode name of the char corresponding to the key.
271
272 This function can be seen as a pseudo-inverse of the function `_character_to_key`.
273 """
274 return KEY_TO_UNICODE_NAME.get(key, key.upper())
275
276
277 def _get_key_aliases(key: str) -> list[str]:
278 """Return all aliases for the given key, including the key itself"""
279 return [key] + KEY_ALIASES.get(key, [])
280
281
282 def _get_key_display(key: str) -> str:
283 """Given a key (i.e. the `key` string argument to Binding __init__),
284 return the value that should be displayed in the app when referring
285 to this key (e.g. in the Footer widget)."""
286 display_alias = KEY_DISPLAY_ALIASES.get(key)
287 if display_alias:
288 return display_alias
289
290 original_key = REPLACED_KEYS.get(key, key)
291 tentative_unicode_name = _get_unicode_name_from_key(original_key)
292 try:
293 unicode_character = unicodedata.lookup(tentative_unicode_name)
294 except KeyError:
295 return tentative_unicode_name
296
297 # Check if printable. `delete` for example maps to a control sequence
298 # which we don't want to write to the terminal.
299 if unicode_character.isprintable():
300 return unicode_character
301 return tentative_unicode_name
302
303
304 def _character_to_key(character: str) -> str:
305 """Convert a single character to a key value.
306
307 This transformation can be undone by the function `_get_unicode_name_from_key`.
308 """
309 if not character.isalnum():
310 key = unicodedata.name(character).lower().replace("-", "_").replace(" ", "_")
311 else:
312 key = character
313 key = KEY_NAME_REPLACEMENTS.get(key, key)
314 return key
315
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/textual/keys.py b/src/textual/keys.py
--- a/src/textual/keys.py
+++ b/src/textual/keys.py
@@ -283,6 +283,9 @@
"""Given a key (i.e. the `key` string argument to Binding __init__),
return the value that should be displayed in the app when referring
to this key (e.g. in the Footer widget)."""
+ if "+" in key:
+ return "+".join([_get_key_display(key) for key in key.split("+")])
+
display_alias = KEY_DISPLAY_ALIASES.get(key)
if display_alias:
return display_alias
|
{"golden_diff": "diff --git a/src/textual/keys.py b/src/textual/keys.py\n--- a/src/textual/keys.py\n+++ b/src/textual/keys.py\n@@ -283,6 +283,9 @@\n \"\"\"Given a key (i.e. the `key` string argument to Binding __init__),\n return the value that should be displayed in the app when referring\n to this key (e.g. in the Footer widget).\"\"\"\n+ if \"+\" in key:\n+ return \"+\".join([_get_key_display(key) for key in key.split(\"+\")])\n+\n display_alias = KEY_DISPLAY_ALIASES.get(key)\n if display_alias:\n return display_alias\n", "issue": "Binding for `]` renders incorrectly in `Footer`\nThe binding `Binding(\"ctrl+right_square_bracket\", \"toggle_indent_width\", \"Cycle indent width\")` renders like this:\r\n\r\n<img width=\"431\" alt=\"image\" src=\"https://github.com/Textualize/textual/assets/5740731/2c2bd6fa-288b-4205-aba0-48eb1b6c41e0\">\r\n\r\nIt should probably render as `Ctrl+]`.\n", "before_files": [{"content": "from __future__ import annotations\n\nimport unicodedata\nfrom enum import Enum\n\n\n# Adapted from prompt toolkit https://github.com/prompt-toolkit/python-prompt-toolkit/blob/master/prompt_toolkit/keys.py\nclass Keys(str, Enum): # type: ignore[no-redef]\n \"\"\"\n List of keys for use in key bindings.\n\n Note that this is an \"StrEnum\", all values can be compared against\n strings.\n \"\"\"\n\n @property\n def value(self) -> str:\n return super().value\n\n Escape = \"escape\" # Also Control-[\n ShiftEscape = \"shift+escape\"\n Return = \"return\"\n\n ControlAt = \"ctrl+@\" # Also Control-Space.\n\n ControlA = \"ctrl+a\"\n ControlB = \"ctrl+b\"\n ControlC = \"ctrl+c\"\n ControlD = \"ctrl+d\"\n ControlE = \"ctrl+e\"\n ControlF = \"ctrl+f\"\n ControlG = \"ctrl+g\"\n ControlH = \"ctrl+h\"\n ControlI = \"ctrl+i\" # Tab\n ControlJ = \"ctrl+j\" # Newline\n ControlK = \"ctrl+k\"\n ControlL = \"ctrl+l\"\n ControlM = \"ctrl+m\" # Carriage return\n ControlN = \"ctrl+n\"\n ControlO = \"ctrl+o\"\n ControlP = \"ctrl+p\"\n ControlQ = \"ctrl+q\"\n ControlR = \"ctrl+r\"\n ControlS = \"ctrl+s\"\n ControlT = \"ctrl+t\"\n ControlU = \"ctrl+u\"\n ControlV = \"ctrl+v\"\n ControlW = \"ctrl+w\"\n ControlX = \"ctrl+x\"\n ControlY = \"ctrl+y\"\n ControlZ = \"ctrl+z\"\n\n Control1 = \"ctrl+1\"\n Control2 = \"ctrl+2\"\n Control3 = \"ctrl+3\"\n Control4 = \"ctrl+4\"\n Control5 = \"ctrl+5\"\n Control6 = \"ctrl+6\"\n Control7 = \"ctrl+7\"\n Control8 = \"ctrl+8\"\n Control9 = \"ctrl+9\"\n Control0 = \"ctrl+0\"\n\n ControlShift1 = \"ctrl+shift+1\"\n ControlShift2 = \"ctrl+shift+2\"\n ControlShift3 = \"ctrl+shift+3\"\n ControlShift4 = \"ctrl+shift+4\"\n ControlShift5 = \"ctrl+shift+5\"\n ControlShift6 = \"ctrl+shift+6\"\n ControlShift7 = \"ctrl+shift+7\"\n ControlShift8 = \"ctrl+shift+8\"\n ControlShift9 = \"ctrl+shift+9\"\n ControlShift0 = \"ctrl+shift+0\"\n\n ControlBackslash = \"ctrl+backslash\"\n ControlSquareClose = \"ctrl+right_square_bracket\"\n ControlCircumflex = \"ctrl+circumflex_accent\"\n ControlUnderscore = \"ctrl+underscore\"\n\n Left = \"left\"\n Right = \"right\"\n Up = \"up\"\n Down = \"down\"\n Home = \"home\"\n End = \"end\"\n Insert = \"insert\"\n Delete = \"delete\"\n PageUp = \"pageup\"\n PageDown = \"pagedown\"\n\n ControlLeft = \"ctrl+left\"\n ControlRight = \"ctrl+right\"\n ControlUp = \"ctrl+up\"\n ControlDown = \"ctrl+down\"\n ControlHome = \"ctrl+home\"\n ControlEnd = \"ctrl+end\"\n ControlInsert = \"ctrl+insert\"\n ControlDelete = \"ctrl+delete\"\n ControlPageUp = \"ctrl+pageup\"\n ControlPageDown = \"ctrl+pagedown\"\n\n ShiftLeft = \"shift+left\"\n ShiftRight = \"shift+right\"\n ShiftUp = \"shift+up\"\n ShiftDown = \"shift+down\"\n ShiftHome = \"shift+home\"\n ShiftEnd = \"shift+end\"\n ShiftInsert = \"shift+insert\"\n ShiftDelete = \"shift+delete\"\n ShiftPageUp = \"shift+pageup\"\n ShiftPageDown = \"shift+pagedown\"\n\n ControlShiftLeft = \"ctrl+shift+left\"\n ControlShiftRight = \"ctrl+shift+right\"\n ControlShiftUp = \"ctrl+shift+up\"\n ControlShiftDown = \"ctrl+shift+down\"\n ControlShiftHome = \"ctrl+shift+home\"\n ControlShiftEnd = \"ctrl+shift+end\"\n ControlShiftInsert = \"ctrl+shift+insert\"\n ControlShiftDelete = \"ctrl+shift+delete\"\n ControlShiftPageUp = \"ctrl+shift+pageup\"\n ControlShiftPageDown = \"ctrl+shift+pagedown\"\n\n BackTab = \"shift+tab\" # shift + tab\n\n F1 = \"f1\"\n F2 = \"f2\"\n F3 = \"f3\"\n F4 = \"f4\"\n F5 = \"f5\"\n F6 = \"f6\"\n F7 = \"f7\"\n F8 = \"f8\"\n F9 = \"f9\"\n F10 = \"f10\"\n F11 = \"f11\"\n F12 = \"f12\"\n F13 = \"f13\"\n F14 = \"f14\"\n F15 = \"f15\"\n F16 = \"f16\"\n F17 = \"f17\"\n F18 = \"f18\"\n F19 = \"f19\"\n F20 = \"f20\"\n F21 = \"f21\"\n F22 = \"f22\"\n F23 = \"f23\"\n F24 = \"f24\"\n\n ControlF1 = \"ctrl+f1\"\n ControlF2 = \"ctrl+f2\"\n ControlF3 = \"ctrl+f3\"\n ControlF4 = \"ctrl+f4\"\n ControlF5 = \"ctrl+f5\"\n ControlF6 = \"ctrl+f6\"\n ControlF7 = \"ctrl+f7\"\n ControlF8 = \"ctrl+f8\"\n ControlF9 = \"ctrl+f9\"\n ControlF10 = \"ctrl+f10\"\n ControlF11 = \"ctrl+f11\"\n ControlF12 = \"ctrl+f12\"\n ControlF13 = \"ctrl+f13\"\n ControlF14 = \"ctrl+f14\"\n ControlF15 = \"ctrl+f15\"\n ControlF16 = \"ctrl+f16\"\n ControlF17 = \"ctrl+f17\"\n ControlF18 = \"ctrl+f18\"\n ControlF19 = \"ctrl+f19\"\n ControlF20 = \"ctrl+f20\"\n ControlF21 = \"ctrl+f21\"\n ControlF22 = \"ctrl+f22\"\n ControlF23 = \"ctrl+f23\"\n ControlF24 = \"ctrl+f24\"\n\n # Matches any key.\n Any = \"<any>\"\n\n # Special.\n ScrollUp = \"<scroll-up>\"\n ScrollDown = \"<scroll-down>\"\n\n # For internal use: key which is ignored.\n # (The key binding for this key should not do anything.)\n Ignore = \"<ignore>\"\n\n # Some 'Key' aliases (for backwardshift+compatibility).\n ControlSpace = \"ctrl-at\"\n Tab = \"tab\"\n Space = \"space\"\n Enter = \"enter\"\n Backspace = \"backspace\"\n\n # ShiftControl was renamed to ControlShift in\n # 888fcb6fa4efea0de8333177e1bbc792f3ff3c24 (20 Feb 2020).\n ShiftControlLeft = ControlShiftLeft\n ShiftControlRight = ControlShiftRight\n ShiftControlHome = ControlShiftHome\n ShiftControlEnd = ControlShiftEnd\n\n\n# Unicode db contains some obscure names\n# This mapping replaces them with more common terms\nKEY_NAME_REPLACEMENTS = {\n \"solidus\": \"slash\",\n \"reverse_solidus\": \"backslash\",\n \"commercial_at\": \"at\",\n \"hyphen_minus\": \"minus\",\n \"plus_sign\": \"plus\",\n \"low_line\": \"underscore\",\n}\nREPLACED_KEYS = {value: key for key, value in KEY_NAME_REPLACEMENTS.items()}\n\n# Convert the friendly versions of character key Unicode names\n# back to their original names.\n# This is because we go from Unicode to friendly by replacing spaces and dashes\n# with underscores, which cannot be undone by replacing underscores with spaces/dashes.\nKEY_TO_UNICODE_NAME = {\n \"exclamation_mark\": \"EXCLAMATION MARK\",\n \"quotation_mark\": \"QUOTATION MARK\",\n \"number_sign\": \"NUMBER SIGN\",\n \"dollar_sign\": \"DOLLAR SIGN\",\n \"percent_sign\": \"PERCENT SIGN\",\n \"left_parenthesis\": \"LEFT PARENTHESIS\",\n \"right_parenthesis\": \"RIGHT PARENTHESIS\",\n \"plus_sign\": \"PLUS SIGN\",\n \"hyphen_minus\": \"HYPHEN-MINUS\",\n \"full_stop\": \"FULL STOP\",\n \"less_than_sign\": \"LESS-THAN SIGN\",\n \"equals_sign\": \"EQUALS SIGN\",\n \"greater_than_sign\": \"GREATER-THAN SIGN\",\n \"question_mark\": \"QUESTION MARK\",\n \"commercial_at\": \"COMMERCIAL AT\",\n \"left_square_bracket\": \"LEFT SQUARE BRACKET\",\n \"reverse_solidus\": \"REVERSE SOLIDUS\",\n \"right_square_bracket\": \"RIGHT SQUARE BRACKET\",\n \"circumflex_accent\": \"CIRCUMFLEX ACCENT\",\n \"low_line\": \"LOW LINE\",\n \"grave_accent\": \"GRAVE ACCENT\",\n \"left_curly_bracket\": \"LEFT CURLY BRACKET\",\n \"vertical_line\": \"VERTICAL LINE\",\n \"right_curly_bracket\": \"RIGHT CURLY BRACKET\",\n}\n\n# Some keys have aliases. For example, if you press `ctrl+m` on your keyboard,\n# it's treated the same way as if you press `enter`. Key handlers `key_ctrl_m` and\n# `key_enter` are both valid in this case.\nKEY_ALIASES = {\n \"tab\": [\"ctrl+i\"],\n \"enter\": [\"ctrl+m\"],\n \"escape\": [\"ctrl+left_square_brace\"],\n \"ctrl+at\": [\"ctrl+space\"],\n \"ctrl+j\": [\"newline\"],\n}\n\nKEY_DISPLAY_ALIASES = {\n \"up\": \"\u2191\",\n \"down\": \"\u2193\",\n \"left\": \"\u2190\",\n \"right\": \"\u2192\",\n \"backspace\": \"\u232b\",\n \"escape\": \"ESC\",\n \"enter\": \"\u23ce\",\n \"minus\": \"-\",\n \"space\": \"SPACE\",\n}\n\n\ndef _get_unicode_name_from_key(key: str) -> str:\n \"\"\"Get the best guess for the Unicode name of the char corresponding to the key.\n\n This function can be seen as a pseudo-inverse of the function `_character_to_key`.\n \"\"\"\n return KEY_TO_UNICODE_NAME.get(key, key.upper())\n\n\ndef _get_key_aliases(key: str) -> list[str]:\n \"\"\"Return all aliases for the given key, including the key itself\"\"\"\n return [key] + KEY_ALIASES.get(key, [])\n\n\ndef _get_key_display(key: str) -> str:\n \"\"\"Given a key (i.e. the `key` string argument to Binding __init__),\n return the value that should be displayed in the app when referring\n to this key (e.g. in the Footer widget).\"\"\"\n display_alias = KEY_DISPLAY_ALIASES.get(key)\n if display_alias:\n return display_alias\n\n original_key = REPLACED_KEYS.get(key, key)\n tentative_unicode_name = _get_unicode_name_from_key(original_key)\n try:\n unicode_character = unicodedata.lookup(tentative_unicode_name)\n except KeyError:\n return tentative_unicode_name\n\n # Check if printable. `delete` for example maps to a control sequence\n # which we don't want to write to the terminal.\n if unicode_character.isprintable():\n return unicode_character\n return tentative_unicode_name\n\n\ndef _character_to_key(character: str) -> str:\n \"\"\"Convert a single character to a key value.\n\n This transformation can be undone by the function `_get_unicode_name_from_key`.\n \"\"\"\n if not character.isalnum():\n key = unicodedata.name(character).lower().replace(\"-\", \"_\").replace(\" \", \"_\")\n else:\n key = character\n key = KEY_NAME_REPLACEMENTS.get(key, key)\n return key\n", "path": "src/textual/keys.py"}], "after_files": [{"content": "from __future__ import annotations\n\nimport unicodedata\nfrom enum import Enum\n\n\n# Adapted from prompt toolkit https://github.com/prompt-toolkit/python-prompt-toolkit/blob/master/prompt_toolkit/keys.py\nclass Keys(str, Enum): # type: ignore[no-redef]\n \"\"\"\n List of keys for use in key bindings.\n\n Note that this is an \"StrEnum\", all values can be compared against\n strings.\n \"\"\"\n\n @property\n def value(self) -> str:\n return super().value\n\n Escape = \"escape\" # Also Control-[\n ShiftEscape = \"shift+escape\"\n Return = \"return\"\n\n ControlAt = \"ctrl+@\" # Also Control-Space.\n\n ControlA = \"ctrl+a\"\n ControlB = \"ctrl+b\"\n ControlC = \"ctrl+c\"\n ControlD = \"ctrl+d\"\n ControlE = \"ctrl+e\"\n ControlF = \"ctrl+f\"\n ControlG = \"ctrl+g\"\n ControlH = \"ctrl+h\"\n ControlI = \"ctrl+i\" # Tab\n ControlJ = \"ctrl+j\" # Newline\n ControlK = \"ctrl+k\"\n ControlL = \"ctrl+l\"\n ControlM = \"ctrl+m\" # Carriage return\n ControlN = \"ctrl+n\"\n ControlO = \"ctrl+o\"\n ControlP = \"ctrl+p\"\n ControlQ = \"ctrl+q\"\n ControlR = \"ctrl+r\"\n ControlS = \"ctrl+s\"\n ControlT = \"ctrl+t\"\n ControlU = \"ctrl+u\"\n ControlV = \"ctrl+v\"\n ControlW = \"ctrl+w\"\n ControlX = \"ctrl+x\"\n ControlY = \"ctrl+y\"\n ControlZ = \"ctrl+z\"\n\n Control1 = \"ctrl+1\"\n Control2 = \"ctrl+2\"\n Control3 = \"ctrl+3\"\n Control4 = \"ctrl+4\"\n Control5 = \"ctrl+5\"\n Control6 = \"ctrl+6\"\n Control7 = \"ctrl+7\"\n Control8 = \"ctrl+8\"\n Control9 = \"ctrl+9\"\n Control0 = \"ctrl+0\"\n\n ControlShift1 = \"ctrl+shift+1\"\n ControlShift2 = \"ctrl+shift+2\"\n ControlShift3 = \"ctrl+shift+3\"\n ControlShift4 = \"ctrl+shift+4\"\n ControlShift5 = \"ctrl+shift+5\"\n ControlShift6 = \"ctrl+shift+6\"\n ControlShift7 = \"ctrl+shift+7\"\n ControlShift8 = \"ctrl+shift+8\"\n ControlShift9 = \"ctrl+shift+9\"\n ControlShift0 = \"ctrl+shift+0\"\n\n ControlBackslash = \"ctrl+backslash\"\n ControlSquareClose = \"ctrl+right_square_bracket\"\n ControlCircumflex = \"ctrl+circumflex_accent\"\n ControlUnderscore = \"ctrl+underscore\"\n\n Left = \"left\"\n Right = \"right\"\n Up = \"up\"\n Down = \"down\"\n Home = \"home\"\n End = \"end\"\n Insert = \"insert\"\n Delete = \"delete\"\n PageUp = \"pageup\"\n PageDown = \"pagedown\"\n\n ControlLeft = \"ctrl+left\"\n ControlRight = \"ctrl+right\"\n ControlUp = \"ctrl+up\"\n ControlDown = \"ctrl+down\"\n ControlHome = \"ctrl+home\"\n ControlEnd = \"ctrl+end\"\n ControlInsert = \"ctrl+insert\"\n ControlDelete = \"ctrl+delete\"\n ControlPageUp = \"ctrl+pageup\"\n ControlPageDown = \"ctrl+pagedown\"\n\n ShiftLeft = \"shift+left\"\n ShiftRight = \"shift+right\"\n ShiftUp = \"shift+up\"\n ShiftDown = \"shift+down\"\n ShiftHome = \"shift+home\"\n ShiftEnd = \"shift+end\"\n ShiftInsert = \"shift+insert\"\n ShiftDelete = \"shift+delete\"\n ShiftPageUp = \"shift+pageup\"\n ShiftPageDown = \"shift+pagedown\"\n\n ControlShiftLeft = \"ctrl+shift+left\"\n ControlShiftRight = \"ctrl+shift+right\"\n ControlShiftUp = \"ctrl+shift+up\"\n ControlShiftDown = \"ctrl+shift+down\"\n ControlShiftHome = \"ctrl+shift+home\"\n ControlShiftEnd = \"ctrl+shift+end\"\n ControlShiftInsert = \"ctrl+shift+insert\"\n ControlShiftDelete = \"ctrl+shift+delete\"\n ControlShiftPageUp = \"ctrl+shift+pageup\"\n ControlShiftPageDown = \"ctrl+shift+pagedown\"\n\n BackTab = \"shift+tab\" # shift + tab\n\n F1 = \"f1\"\n F2 = \"f2\"\n F3 = \"f3\"\n F4 = \"f4\"\n F5 = \"f5\"\n F6 = \"f6\"\n F7 = \"f7\"\n F8 = \"f8\"\n F9 = \"f9\"\n F10 = \"f10\"\n F11 = \"f11\"\n F12 = \"f12\"\n F13 = \"f13\"\n F14 = \"f14\"\n F15 = \"f15\"\n F16 = \"f16\"\n F17 = \"f17\"\n F18 = \"f18\"\n F19 = \"f19\"\n F20 = \"f20\"\n F21 = \"f21\"\n F22 = \"f22\"\n F23 = \"f23\"\n F24 = \"f24\"\n\n ControlF1 = \"ctrl+f1\"\n ControlF2 = \"ctrl+f2\"\n ControlF3 = \"ctrl+f3\"\n ControlF4 = \"ctrl+f4\"\n ControlF5 = \"ctrl+f5\"\n ControlF6 = \"ctrl+f6\"\n ControlF7 = \"ctrl+f7\"\n ControlF8 = \"ctrl+f8\"\n ControlF9 = \"ctrl+f9\"\n ControlF10 = \"ctrl+f10\"\n ControlF11 = \"ctrl+f11\"\n ControlF12 = \"ctrl+f12\"\n ControlF13 = \"ctrl+f13\"\n ControlF14 = \"ctrl+f14\"\n ControlF15 = \"ctrl+f15\"\n ControlF16 = \"ctrl+f16\"\n ControlF17 = \"ctrl+f17\"\n ControlF18 = \"ctrl+f18\"\n ControlF19 = \"ctrl+f19\"\n ControlF20 = \"ctrl+f20\"\n ControlF21 = \"ctrl+f21\"\n ControlF22 = \"ctrl+f22\"\n ControlF23 = \"ctrl+f23\"\n ControlF24 = \"ctrl+f24\"\n\n # Matches any key.\n Any = \"<any>\"\n\n # Special.\n ScrollUp = \"<scroll-up>\"\n ScrollDown = \"<scroll-down>\"\n\n # For internal use: key which is ignored.\n # (The key binding for this key should not do anything.)\n Ignore = \"<ignore>\"\n\n # Some 'Key' aliases (for backwardshift+compatibility).\n ControlSpace = \"ctrl-at\"\n Tab = \"tab\"\n Space = \"space\"\n Enter = \"enter\"\n Backspace = \"backspace\"\n\n # ShiftControl was renamed to ControlShift in\n # 888fcb6fa4efea0de8333177e1bbc792f3ff3c24 (20 Feb 2020).\n ShiftControlLeft = ControlShiftLeft\n ShiftControlRight = ControlShiftRight\n ShiftControlHome = ControlShiftHome\n ShiftControlEnd = ControlShiftEnd\n\n\n# Unicode db contains some obscure names\n# This mapping replaces them with more common terms\nKEY_NAME_REPLACEMENTS = {\n \"solidus\": \"slash\",\n \"reverse_solidus\": \"backslash\",\n \"commercial_at\": \"at\",\n \"hyphen_minus\": \"minus\",\n \"plus_sign\": \"plus\",\n \"low_line\": \"underscore\",\n}\nREPLACED_KEYS = {value: key for key, value in KEY_NAME_REPLACEMENTS.items()}\n\n# Convert the friendly versions of character key Unicode names\n# back to their original names.\n# This is because we go from Unicode to friendly by replacing spaces and dashes\n# with underscores, which cannot be undone by replacing underscores with spaces/dashes.\nKEY_TO_UNICODE_NAME = {\n \"exclamation_mark\": \"EXCLAMATION MARK\",\n \"quotation_mark\": \"QUOTATION MARK\",\n \"number_sign\": \"NUMBER SIGN\",\n \"dollar_sign\": \"DOLLAR SIGN\",\n \"percent_sign\": \"PERCENT SIGN\",\n \"left_parenthesis\": \"LEFT PARENTHESIS\",\n \"right_parenthesis\": \"RIGHT PARENTHESIS\",\n \"plus_sign\": \"PLUS SIGN\",\n \"hyphen_minus\": \"HYPHEN-MINUS\",\n \"full_stop\": \"FULL STOP\",\n \"less_than_sign\": \"LESS-THAN SIGN\",\n \"equals_sign\": \"EQUALS SIGN\",\n \"greater_than_sign\": \"GREATER-THAN SIGN\",\n \"question_mark\": \"QUESTION MARK\",\n \"commercial_at\": \"COMMERCIAL AT\",\n \"left_square_bracket\": \"LEFT SQUARE BRACKET\",\n \"reverse_solidus\": \"REVERSE SOLIDUS\",\n \"right_square_bracket\": \"RIGHT SQUARE BRACKET\",\n \"circumflex_accent\": \"CIRCUMFLEX ACCENT\",\n \"low_line\": \"LOW LINE\",\n \"grave_accent\": \"GRAVE ACCENT\",\n \"left_curly_bracket\": \"LEFT CURLY BRACKET\",\n \"vertical_line\": \"VERTICAL LINE\",\n \"right_curly_bracket\": \"RIGHT CURLY BRACKET\",\n}\n\n# Some keys have aliases. For example, if you press `ctrl+m` on your keyboard,\n# it's treated the same way as if you press `enter`. Key handlers `key_ctrl_m` and\n# `key_enter` are both valid in this case.\nKEY_ALIASES = {\n \"tab\": [\"ctrl+i\"],\n \"enter\": [\"ctrl+m\"],\n \"escape\": [\"ctrl+left_square_brace\"],\n \"ctrl+at\": [\"ctrl+space\"],\n \"ctrl+j\": [\"newline\"],\n}\n\nKEY_DISPLAY_ALIASES = {\n \"up\": \"\u2191\",\n \"down\": \"\u2193\",\n \"left\": \"\u2190\",\n \"right\": \"\u2192\",\n \"backspace\": \"\u232b\",\n \"escape\": \"ESC\",\n \"enter\": \"\u23ce\",\n \"minus\": \"-\",\n \"space\": \"SPACE\",\n}\n\n\ndef _get_unicode_name_from_key(key: str) -> str:\n \"\"\"Get the best guess for the Unicode name of the char corresponding to the key.\n\n This function can be seen as a pseudo-inverse of the function `_character_to_key`.\n \"\"\"\n return KEY_TO_UNICODE_NAME.get(key, key.upper())\n\n\ndef _get_key_aliases(key: str) -> list[str]:\n \"\"\"Return all aliases for the given key, including the key itself\"\"\"\n return [key] + KEY_ALIASES.get(key, [])\n\n\ndef _get_key_display(key: str) -> str:\n \"\"\"Given a key (i.e. the `key` string argument to Binding __init__),\n return the value that should be displayed in the app when referring\n to this key (e.g. in the Footer widget).\"\"\"\n if \"+\" in key:\n return \"+\".join([_get_key_display(key) for key in key.split(\"+\")])\n\n display_alias = KEY_DISPLAY_ALIASES.get(key)\n if display_alias:\n return display_alias\n\n original_key = REPLACED_KEYS.get(key, key)\n tentative_unicode_name = _get_unicode_name_from_key(original_key)\n try:\n unicode_character = unicodedata.lookup(tentative_unicode_name)\n except KeyError:\n return tentative_unicode_name\n\n # Check if printable. `delete` for example maps to a control sequence\n # which we don't want to write to the terminal.\n if unicode_character.isprintable():\n return unicode_character\n return tentative_unicode_name\n\n\ndef _character_to_key(character: str) -> str:\n \"\"\"Convert a single character to a key value.\n\n This transformation can be undone by the function `_get_unicode_name_from_key`.\n \"\"\"\n if not character.isalnum():\n key = unicodedata.name(character).lower().replace(\"-\", \"_\").replace(\" \", \"_\")\n else:\n key = character\n key = KEY_NAME_REPLACEMENTS.get(key, key)\n return key\n", "path": "src/textual/keys.py"}]}
| 4,000 | 151 |
gh_patches_debug_18998
|
rasdani/github-patches
|
git_diff
|
Qiskit__qiskit-2328
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Better error messaging when graphviz is not present
_For reference, this was originally posted by @jaygambetta in https://github.com/Qiskit/qiskit-terra/issues/2281#issuecomment-489417445_
> @ajavadia and @mtreinish it has been lost where to find how to add this dependencies outside pip. It is in the doc for the function https://github.com/Qiskit/qiskit-terra/blob/master/qiskit/visualization/dag_visualization.py but I think we need to make this clearer in the documentation in the Qiskit repo.
>
> I would split this into two issues --
> 1. In terra add better error messaging. If you call drag_drawer and you don't have graphviz give that this dependency needs to be installed on your system.
> 2. in qiskit add a documentation on how to setup the dag drawer for different operating systems.
This is issue is about the first item.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `qiskit/visualization/dag_visualization.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # This code is part of Qiskit.
4 #
5 # (C) Copyright IBM 2017, 2018.
6 #
7 # This code is licensed under the Apache License, Version 2.0. You may
8 # obtain a copy of this license in the LICENSE.txt file in the root directory
9 # of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.
10 #
11 # Any modifications or derivative works of this code must retain this
12 # copyright notice, and modified files need to carry a notice indicating
13 # that they have been altered from the originals.
14
15 # pylint: disable=invalid-name
16
17 """
18 Visualization function for DAG circuit representation.
19 """
20
21 import sys
22 from .exceptions import VisualizationError
23
24
25 def dag_drawer(dag, scale=0.7, filename=None, style='color'):
26 """Plot the directed acyclic graph (dag) to represent operation dependencies
27 in a quantum circuit.
28
29 Note this function leverages
30 `pydot <https://github.com/erocarrera/pydot>`_ (via
31 `nxpd <https://github.com/chebee7i/nxpd`_) to generate the graph, which
32 means that having `Graphviz <https://www.graphviz.org/>`_ installed on your
33 system is required for this to work.
34
35 Args:
36 dag (DAGCircuit): The dag to draw.
37 scale (float): scaling factor
38 filename (str): file path to save image to (format inferred from name)
39 style (str): 'plain': B&W graph
40 'color' (default): color input/output/op nodes
41
42 Returns:
43 Ipython.display.Image: if in Jupyter notebook and not saving to file,
44 otherwise None.
45
46 Raises:
47 VisualizationError: when style is not recognized.
48 ImportError: when nxpd or pydot not installed.
49 """
50 try:
51 import nxpd
52 import pydot # pylint: disable=unused-import
53 except ImportError:
54 raise ImportError("dag_drawer requires nxpd, pydot, and Graphviz. "
55 "Run 'pip install nxpd pydot', and install graphviz")
56
57 G = dag.to_networkx()
58 G.graph['dpi'] = 100 * scale
59
60 if style == 'plain':
61 pass
62 elif style == 'color':
63 for node in G.nodes:
64 n = G.nodes[node]
65 n['label'] = node.name
66 if node.type == 'op':
67 n['color'] = 'blue'
68 n['style'] = 'filled'
69 n['fillcolor'] = 'lightblue'
70 if node.type == 'in':
71 n['color'] = 'black'
72 n['style'] = 'filled'
73 n['fillcolor'] = 'green'
74 if node.type == 'out':
75 n['color'] = 'black'
76 n['style'] = 'filled'
77 n['fillcolor'] = 'red'
78 for e in G.edges(data=True):
79 e[2]['label'] = e[2]['name']
80 else:
81 raise VisualizationError("Unrecognized style for the dag_drawer.")
82
83 if filename:
84 show = False
85 elif ('ipykernel' in sys.modules) and ('spyder' not in sys.modules):
86 show = 'ipynb'
87 else:
88 show = True
89
90 return nxpd.draw(G, filename=filename, show=show)
91
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/qiskit/visualization/dag_visualization.py b/qiskit/visualization/dag_visualization.py
--- a/qiskit/visualization/dag_visualization.py
+++ b/qiskit/visualization/dag_visualization.py
@@ -51,8 +51,8 @@
import nxpd
import pydot # pylint: disable=unused-import
except ImportError:
- raise ImportError("dag_drawer requires nxpd, pydot, and Graphviz. "
- "Run 'pip install nxpd pydot', and install graphviz")
+ raise ImportError("dag_drawer requires nxpd and pydot. "
+ "Run 'pip install nxpd pydot'.")
G = dag.to_networkx()
G.graph['dpi'] = 100 * scale
@@ -87,4 +87,9 @@
else:
show = True
- return nxpd.draw(G, filename=filename, show=show)
+ try:
+ return nxpd.draw(G, filename=filename, show=show)
+ except nxpd.pydot.InvocationException:
+ raise VisualizationError("dag_drawer requires GraphViz installed in the system. "
+ "Check https://www.graphviz.org/download/ for details on "
+ "how to install GraphViz in your system.")
|
{"golden_diff": "diff --git a/qiskit/visualization/dag_visualization.py b/qiskit/visualization/dag_visualization.py\n--- a/qiskit/visualization/dag_visualization.py\n+++ b/qiskit/visualization/dag_visualization.py\n@@ -51,8 +51,8 @@\n import nxpd\n import pydot # pylint: disable=unused-import\n except ImportError:\n- raise ImportError(\"dag_drawer requires nxpd, pydot, and Graphviz. \"\n- \"Run 'pip install nxpd pydot', and install graphviz\")\n+ raise ImportError(\"dag_drawer requires nxpd and pydot. \"\n+ \"Run 'pip install nxpd pydot'.\")\n \n G = dag.to_networkx()\n G.graph['dpi'] = 100 * scale\n@@ -87,4 +87,9 @@\n else:\n show = True\n \n- return nxpd.draw(G, filename=filename, show=show)\n+ try:\n+ return nxpd.draw(G, filename=filename, show=show)\n+ except nxpd.pydot.InvocationException:\n+ raise VisualizationError(\"dag_drawer requires GraphViz installed in the system. \"\n+ \"Check https://www.graphviz.org/download/ for details on \"\n+ \"how to install GraphViz in your system.\")\n", "issue": "Better error messaging when graphviz is not present\n_For reference, this was originally posted by @jaygambetta in https://github.com/Qiskit/qiskit-terra/issues/2281#issuecomment-489417445_\r\n\r\n> @ajavadia and @mtreinish it has been lost where to find how to add this dependencies outside pip. It is in the doc for the function https://github.com/Qiskit/qiskit-terra/blob/master/qiskit/visualization/dag_visualization.py but I think we need to make this clearer in the documentation in the Qiskit repo. \r\n>\r\n> I would split this into two issues -- \r\n> 1. In terra add better error messaging. If you call drag_drawer and you don't have graphviz give that this dependency needs to be installed on your system. \r\n> 2. in qiskit add a documentation on how to setup the dag drawer for different operating systems.\r\n\r\nThis is issue is about the first item. \n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# This code is part of Qiskit.\n#\n# (C) Copyright IBM 2017, 2018.\n#\n# This code is licensed under the Apache License, Version 2.0. You may\n# obtain a copy of this license in the LICENSE.txt file in the root directory\n# of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.\n#\n# Any modifications or derivative works of this code must retain this\n# copyright notice, and modified files need to carry a notice indicating\n# that they have been altered from the originals.\n\n# pylint: disable=invalid-name\n\n\"\"\"\nVisualization function for DAG circuit representation.\n\"\"\"\n\nimport sys\nfrom .exceptions import VisualizationError\n\n\ndef dag_drawer(dag, scale=0.7, filename=None, style='color'):\n \"\"\"Plot the directed acyclic graph (dag) to represent operation dependencies\n in a quantum circuit.\n\n Note this function leverages\n `pydot <https://github.com/erocarrera/pydot>`_ (via\n `nxpd <https://github.com/chebee7i/nxpd`_) to generate the graph, which\n means that having `Graphviz <https://www.graphviz.org/>`_ installed on your\n system is required for this to work.\n\n Args:\n dag (DAGCircuit): The dag to draw.\n scale (float): scaling factor\n filename (str): file path to save image to (format inferred from name)\n style (str): 'plain': B&W graph\n 'color' (default): color input/output/op nodes\n\n Returns:\n Ipython.display.Image: if in Jupyter notebook and not saving to file,\n otherwise None.\n\n Raises:\n VisualizationError: when style is not recognized.\n ImportError: when nxpd or pydot not installed.\n \"\"\"\n try:\n import nxpd\n import pydot # pylint: disable=unused-import\n except ImportError:\n raise ImportError(\"dag_drawer requires nxpd, pydot, and Graphviz. \"\n \"Run 'pip install nxpd pydot', and install graphviz\")\n\n G = dag.to_networkx()\n G.graph['dpi'] = 100 * scale\n\n if style == 'plain':\n pass\n elif style == 'color':\n for node in G.nodes:\n n = G.nodes[node]\n n['label'] = node.name\n if node.type == 'op':\n n['color'] = 'blue'\n n['style'] = 'filled'\n n['fillcolor'] = 'lightblue'\n if node.type == 'in':\n n['color'] = 'black'\n n['style'] = 'filled'\n n['fillcolor'] = 'green'\n if node.type == 'out':\n n['color'] = 'black'\n n['style'] = 'filled'\n n['fillcolor'] = 'red'\n for e in G.edges(data=True):\n e[2]['label'] = e[2]['name']\n else:\n raise VisualizationError(\"Unrecognized style for the dag_drawer.\")\n\n if filename:\n show = False\n elif ('ipykernel' in sys.modules) and ('spyder' not in sys.modules):\n show = 'ipynb'\n else:\n show = True\n\n return nxpd.draw(G, filename=filename, show=show)\n", "path": "qiskit/visualization/dag_visualization.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n# This code is part of Qiskit.\n#\n# (C) Copyright IBM 2017, 2018.\n#\n# This code is licensed under the Apache License, Version 2.0. You may\n# obtain a copy of this license in the LICENSE.txt file in the root directory\n# of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.\n#\n# Any modifications or derivative works of this code must retain this\n# copyright notice, and modified files need to carry a notice indicating\n# that they have been altered from the originals.\n\n# pylint: disable=invalid-name\n\n\"\"\"\nVisualization function for DAG circuit representation.\n\"\"\"\n\nimport sys\nfrom .exceptions import VisualizationError\n\n\ndef dag_drawer(dag, scale=0.7, filename=None, style='color'):\n \"\"\"Plot the directed acyclic graph (dag) to represent operation dependencies\n in a quantum circuit.\n\n Note this function leverages\n `pydot <https://github.com/erocarrera/pydot>`_ (via\n `nxpd <https://github.com/chebee7i/nxpd`_) to generate the graph, which\n means that having `Graphviz <https://www.graphviz.org/>`_ installed on your\n system is required for this to work.\n\n Args:\n dag (DAGCircuit): The dag to draw.\n scale (float): scaling factor\n filename (str): file path to save image to (format inferred from name)\n style (str): 'plain': B&W graph\n 'color' (default): color input/output/op nodes\n\n Returns:\n Ipython.display.Image: if in Jupyter notebook and not saving to file,\n otherwise None.\n\n Raises:\n VisualizationError: when style is not recognized.\n ImportError: when nxpd or pydot not installed.\n \"\"\"\n try:\n import nxpd\n import pydot # pylint: disable=unused-import\n except ImportError:\n raise ImportError(\"dag_drawer requires nxpd and pydot. \"\n \"Run 'pip install nxpd pydot'.\")\n\n G = dag.to_networkx()\n G.graph['dpi'] = 100 * scale\n\n if style == 'plain':\n pass\n elif style == 'color':\n for node in G.nodes:\n n = G.nodes[node]\n n['label'] = node.name\n if node.type == 'op':\n n['color'] = 'blue'\n n['style'] = 'filled'\n n['fillcolor'] = 'lightblue'\n if node.type == 'in':\n n['color'] = 'black'\n n['style'] = 'filled'\n n['fillcolor'] = 'green'\n if node.type == 'out':\n n['color'] = 'black'\n n['style'] = 'filled'\n n['fillcolor'] = 'red'\n for e in G.edges(data=True):\n e[2]['label'] = e[2]['name']\n else:\n raise VisualizationError(\"Unrecognized style for the dag_drawer.\")\n\n if filename:\n show = False\n elif ('ipykernel' in sys.modules) and ('spyder' not in sys.modules):\n show = 'ipynb'\n else:\n show = True\n\n try:\n return nxpd.draw(G, filename=filename, show=show)\n except nxpd.pydot.InvocationException:\n raise VisualizationError(\"dag_drawer requires GraphViz installed in the system. \"\n \"Check https://www.graphviz.org/download/ for details on \"\n \"how to install GraphViz in your system.\")\n", "path": "qiskit/visualization/dag_visualization.py"}]}
| 1,393 | 287 |
gh_patches_debug_7436
|
rasdani/github-patches
|
git_diff
|
mathesar-foundation__mathesar-2713
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Django erroneously reports makemigrations is needed
There is a problem with Django migration changes detector when running `migrate` command after setting up Django using `django,setup()`. For some reason, it is considering `mathesar.models.query.UIQuery` model to be missing.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mathesar/admin.py`
Content:
```
1 from django.contrib import admin
2 from django.contrib.auth.admin import UserAdmin
3
4 from mathesar.models.base import Table, Schema, DataFile
5 from mathesar.models.users import User
6
7
8 class MathesarUserAdmin(UserAdmin):
9 model = User
10
11 fieldsets = (
12 (None, {'fields': ('username', 'password')}),
13 ('Personal info', {'fields': ('full_name', 'short_name', 'email',)}),
14 ('Permissions', {
15 'fields': ('is_active', 'is_staff', 'is_superuser', 'groups'),
16 }),
17 ('Important dates', {'fields': ('last_login', 'date_joined')}),
18 )
19
20
21 admin.site.register(Table)
22 admin.site.register(Schema)
23 admin.site.register(DataFile)
24 admin.site.register(User, MathesarUserAdmin)
25
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mathesar/admin.py b/mathesar/admin.py
--- a/mathesar/admin.py
+++ b/mathesar/admin.py
@@ -3,6 +3,7 @@
from mathesar.models.base import Table, Schema, DataFile
from mathesar.models.users import User
+from mathesar.models.query import UIQuery
class MathesarUserAdmin(UserAdmin):
@@ -22,3 +23,4 @@
admin.site.register(Schema)
admin.site.register(DataFile)
admin.site.register(User, MathesarUserAdmin)
+admin.site.register(UIQuery)
|
{"golden_diff": "diff --git a/mathesar/admin.py b/mathesar/admin.py\n--- a/mathesar/admin.py\n+++ b/mathesar/admin.py\n@@ -3,6 +3,7 @@\n \n from mathesar.models.base import Table, Schema, DataFile\n from mathesar.models.users import User\n+from mathesar.models.query import UIQuery\n \n \n class MathesarUserAdmin(UserAdmin):\n@@ -22,3 +23,4 @@\n admin.site.register(Schema)\n admin.site.register(DataFile)\n admin.site.register(User, MathesarUserAdmin)\n+admin.site.register(UIQuery)\n", "issue": "Django erroneously reports makemigrations is needed\nThere is a problem with Django migration changes detector when running `migrate` command after setting up Django using `django,setup()`. For some reason, it is considering `mathesar.models.query.UIQuery` model to be missing. \n", "before_files": [{"content": "from django.contrib import admin\nfrom django.contrib.auth.admin import UserAdmin\n\nfrom mathesar.models.base import Table, Schema, DataFile\nfrom mathesar.models.users import User\n\n\nclass MathesarUserAdmin(UserAdmin):\n model = User\n\n fieldsets = (\n (None, {'fields': ('username', 'password')}),\n ('Personal info', {'fields': ('full_name', 'short_name', 'email',)}),\n ('Permissions', {\n 'fields': ('is_active', 'is_staff', 'is_superuser', 'groups'),\n }),\n ('Important dates', {'fields': ('last_login', 'date_joined')}),\n )\n\n\nadmin.site.register(Table)\nadmin.site.register(Schema)\nadmin.site.register(DataFile)\nadmin.site.register(User, MathesarUserAdmin)\n", "path": "mathesar/admin.py"}], "after_files": [{"content": "from django.contrib import admin\nfrom django.contrib.auth.admin import UserAdmin\n\nfrom mathesar.models.base import Table, Schema, DataFile\nfrom mathesar.models.users import User\nfrom mathesar.models.query import UIQuery\n\n\nclass MathesarUserAdmin(UserAdmin):\n model = User\n\n fieldsets = (\n (None, {'fields': ('username', 'password')}),\n ('Personal info', {'fields': ('full_name', 'short_name', 'email',)}),\n ('Permissions', {\n 'fields': ('is_active', 'is_staff', 'is_superuser', 'groups'),\n }),\n ('Important dates', {'fields': ('last_login', 'date_joined')}),\n )\n\n\nadmin.site.register(Table)\nadmin.site.register(Schema)\nadmin.site.register(DataFile)\nadmin.site.register(User, MathesarUserAdmin)\nadmin.site.register(UIQuery)\n", "path": "mathesar/admin.py"}]}
| 526 | 120 |
gh_patches_debug_2153
|
rasdani/github-patches
|
git_diff
|
encode__uvicorn-943
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Docs: workers = 1 when WEB_CONCURRENCY is not set
Hello, thanks for this great ASGI server 🙂
I have an application that must use only one worker (it's not thread-safe), and so I wanted to confirm that, by default, uvicorn only uses one worker. But I had to read the source code
https://github.com/encode/uvicorn/blob/afb2d565c8dae859bcef4c76b3c6dc3f3077314d/uvicorn/config.py#L177
...to confirm that when `WEB_CONCURRENCY` is not defined, and `workers` is not specified, 1 is used.
Would you accept a PR adding that information to the docs (there are 4-5 places where this can be added)?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `uvicorn/main.py`
Content:
```
1 import logging
2 import platform
3 import ssl
4 import sys
5 import typing
6
7 import click
8
9 import uvicorn
10 from uvicorn.config import (
11 HTTP_PROTOCOLS,
12 INTERFACES,
13 LIFESPAN,
14 LOG_LEVELS,
15 LOGGING_CONFIG,
16 LOOP_SETUPS,
17 SSL_PROTOCOL_VERSION,
18 WS_PROTOCOLS,
19 Config,
20 )
21 from uvicorn.server import Server, ServerState # noqa: F401 # Used to be defined here.
22 from uvicorn.supervisors import ChangeReload, Multiprocess
23
24 LEVEL_CHOICES = click.Choice(LOG_LEVELS.keys())
25 HTTP_CHOICES = click.Choice(HTTP_PROTOCOLS.keys())
26 WS_CHOICES = click.Choice(WS_PROTOCOLS.keys())
27 LIFESPAN_CHOICES = click.Choice(LIFESPAN.keys())
28 LOOP_CHOICES = click.Choice([key for key in LOOP_SETUPS.keys() if key != "none"])
29 INTERFACE_CHOICES = click.Choice(INTERFACES)
30
31 logger = logging.getLogger("uvicorn.error")
32
33
34 def print_version(ctx, param, value):
35 if not value or ctx.resilient_parsing:
36 return
37 click.echo(
38 "Running uvicorn %s with %s %s on %s"
39 % (
40 uvicorn.__version__,
41 platform.python_implementation(),
42 platform.python_version(),
43 platform.system(),
44 )
45 )
46 ctx.exit()
47
48
49 @click.command()
50 @click.argument("app")
51 @click.option(
52 "--host",
53 type=str,
54 default="127.0.0.1",
55 help="Bind socket to this host.",
56 show_default=True,
57 )
58 @click.option(
59 "--port",
60 type=int,
61 default=8000,
62 help="Bind socket to this port.",
63 show_default=True,
64 )
65 @click.option("--uds", type=str, default=None, help="Bind to a UNIX domain socket.")
66 @click.option(
67 "--fd", type=int, default=None, help="Bind to socket from this file descriptor."
68 )
69 @click.option(
70 "--debug", is_flag=True, default=False, help="Enable debug mode.", hidden=True
71 )
72 @click.option("--reload", is_flag=True, default=False, help="Enable auto-reload.")
73 @click.option(
74 "--reload-dir",
75 "reload_dirs",
76 multiple=True,
77 help="Set reload directories explicitly, instead of using the current working"
78 " directory.",
79 )
80 @click.option(
81 "--reload-delay",
82 type=float,
83 default=0.25,
84 show_default=True,
85 help="Delay between previous and next check if application needs to be."
86 " Defaults to 0.25s.",
87 )
88 @click.option(
89 "--workers",
90 default=None,
91 type=int,
92 help="Number of worker processes. Defaults to the $WEB_CONCURRENCY environment"
93 " variable if available. Not valid with --reload.",
94 )
95 @click.option(
96 "--loop",
97 type=LOOP_CHOICES,
98 default="auto",
99 help="Event loop implementation.",
100 show_default=True,
101 )
102 @click.option(
103 "--http",
104 type=HTTP_CHOICES,
105 default="auto",
106 help="HTTP protocol implementation.",
107 show_default=True,
108 )
109 @click.option(
110 "--ws",
111 type=WS_CHOICES,
112 default="auto",
113 help="WebSocket protocol implementation.",
114 show_default=True,
115 )
116 @click.option(
117 "--lifespan",
118 type=LIFESPAN_CHOICES,
119 default="auto",
120 help="Lifespan implementation.",
121 show_default=True,
122 )
123 @click.option(
124 "--interface",
125 type=INTERFACE_CHOICES,
126 default="auto",
127 help="Select ASGI3, ASGI2, or WSGI as the application interface.",
128 show_default=True,
129 )
130 @click.option(
131 "--env-file",
132 type=click.Path(exists=True),
133 default=None,
134 help="Environment configuration file.",
135 show_default=True,
136 )
137 @click.option(
138 "--log-config",
139 type=click.Path(exists=True),
140 default=None,
141 help="Logging configuration file. Supported formats: .ini, .json, .yaml.",
142 show_default=True,
143 )
144 @click.option(
145 "--log-level",
146 type=LEVEL_CHOICES,
147 default=None,
148 help="Log level. [default: info]",
149 show_default=True,
150 )
151 @click.option(
152 "--access-log/--no-access-log",
153 is_flag=True,
154 default=True,
155 help="Enable/Disable access log.",
156 )
157 @click.option(
158 "--use-colors/--no-use-colors",
159 is_flag=True,
160 default=None,
161 help="Enable/Disable colorized logging.",
162 )
163 @click.option(
164 "--proxy-headers/--no-proxy-headers",
165 is_flag=True,
166 default=True,
167 help="Enable/Disable X-Forwarded-Proto, X-Forwarded-For, X-Forwarded-Port to "
168 "populate remote address info.",
169 )
170 @click.option(
171 "--forwarded-allow-ips",
172 type=str,
173 default=None,
174 help="Comma seperated list of IPs to trust with proxy headers. Defaults to"
175 " the $FORWARDED_ALLOW_IPS environment variable if available, or '127.0.0.1'.",
176 )
177 @click.option(
178 "--root-path",
179 type=str,
180 default="",
181 help="Set the ASGI 'root_path' for applications submounted below a given URL path.",
182 )
183 @click.option(
184 "--limit-concurrency",
185 type=int,
186 default=None,
187 help="Maximum number of concurrent connections or tasks to allow, before issuing"
188 " HTTP 503 responses.",
189 )
190 @click.option(
191 "--backlog",
192 type=int,
193 default=2048,
194 help="Maximum number of connections to hold in backlog",
195 )
196 @click.option(
197 "--limit-max-requests",
198 type=int,
199 default=None,
200 help="Maximum number of requests to service before terminating the process.",
201 )
202 @click.option(
203 "--timeout-keep-alive",
204 type=int,
205 default=5,
206 help="Close Keep-Alive connections if no new data is received within this timeout.",
207 show_default=True,
208 )
209 @click.option(
210 "--ssl-keyfile", type=str, default=None, help="SSL key file", show_default=True
211 )
212 @click.option(
213 "--ssl-certfile",
214 type=str,
215 default=None,
216 help="SSL certificate file",
217 show_default=True,
218 )
219 @click.option(
220 "--ssl-keyfile-password",
221 type=str,
222 default=None,
223 help="SSL keyfile password",
224 show_default=True,
225 )
226 @click.option(
227 "--ssl-version",
228 type=int,
229 default=SSL_PROTOCOL_VERSION,
230 help="SSL version to use (see stdlib ssl module's)",
231 show_default=True,
232 )
233 @click.option(
234 "--ssl-cert-reqs",
235 type=int,
236 default=ssl.CERT_NONE,
237 help="Whether client certificate is required (see stdlib ssl module's)",
238 show_default=True,
239 )
240 @click.option(
241 "--ssl-ca-certs",
242 type=str,
243 default=None,
244 help="CA certificates file",
245 show_default=True,
246 )
247 @click.option(
248 "--ssl-ciphers",
249 type=str,
250 default="TLSv1",
251 help="Ciphers to use (see stdlib ssl module's)",
252 show_default=True,
253 )
254 @click.option(
255 "--header",
256 "headers",
257 multiple=True,
258 help="Specify custom default HTTP response headers as a Name:Value pair",
259 )
260 @click.option(
261 "--version",
262 is_flag=True,
263 callback=print_version,
264 expose_value=False,
265 is_eager=True,
266 help="Display the uvicorn version and exit.",
267 )
268 @click.option(
269 "--app-dir",
270 "app_dir",
271 default=".",
272 show_default=True,
273 help="Look for APP in the specified directory, by adding this to the PYTHONPATH."
274 " Defaults to the current working directory.",
275 )
276 @click.option(
277 "--factory",
278 is_flag=True,
279 default=False,
280 help="Treat APP as an application factory, i.e. a () -> <ASGI app> callable.",
281 show_default=True,
282 )
283 def main(
284 app,
285 host: str,
286 port: int,
287 uds: str,
288 fd: int,
289 loop: str,
290 http: str,
291 ws: str,
292 lifespan: str,
293 interface: str,
294 debug: bool,
295 reload: bool,
296 reload_dirs: typing.List[str],
297 reload_delay: float,
298 workers: int,
299 env_file: str,
300 log_config: str,
301 log_level: str,
302 access_log: bool,
303 proxy_headers: bool,
304 forwarded_allow_ips: str,
305 root_path: str,
306 limit_concurrency: int,
307 backlog: int,
308 limit_max_requests: int,
309 timeout_keep_alive: int,
310 ssl_keyfile: str,
311 ssl_certfile: str,
312 ssl_keyfile_password: str,
313 ssl_version: int,
314 ssl_cert_reqs: int,
315 ssl_ca_certs: str,
316 ssl_ciphers: str,
317 headers: typing.List[str],
318 use_colors: bool,
319 app_dir: str,
320 factory: bool,
321 ):
322 sys.path.insert(0, app_dir)
323
324 kwargs = {
325 "app": app,
326 "host": host,
327 "port": port,
328 "uds": uds,
329 "fd": fd,
330 "loop": loop,
331 "http": http,
332 "ws": ws,
333 "lifespan": lifespan,
334 "env_file": env_file,
335 "log_config": LOGGING_CONFIG if log_config is None else log_config,
336 "log_level": log_level,
337 "access_log": access_log,
338 "interface": interface,
339 "debug": debug,
340 "reload": reload,
341 "reload_dirs": reload_dirs if reload_dirs else None,
342 "reload_delay": reload_delay,
343 "workers": workers,
344 "proxy_headers": proxy_headers,
345 "forwarded_allow_ips": forwarded_allow_ips,
346 "root_path": root_path,
347 "limit_concurrency": limit_concurrency,
348 "backlog": backlog,
349 "limit_max_requests": limit_max_requests,
350 "timeout_keep_alive": timeout_keep_alive,
351 "ssl_keyfile": ssl_keyfile,
352 "ssl_certfile": ssl_certfile,
353 "ssl_keyfile_password": ssl_keyfile_password,
354 "ssl_version": ssl_version,
355 "ssl_cert_reqs": ssl_cert_reqs,
356 "ssl_ca_certs": ssl_ca_certs,
357 "ssl_ciphers": ssl_ciphers,
358 "headers": [header.split(":", 1) for header in headers],
359 "use_colors": use_colors,
360 "factory": factory,
361 }
362 run(**kwargs)
363
364
365 def run(app, **kwargs):
366 config = Config(app, **kwargs)
367 server = Server(config=config)
368
369 if (config.reload or config.workers > 1) and not isinstance(app, str):
370 logger = logging.getLogger("uvicorn.error")
371 logger.warning(
372 "You must pass the application as an import string to enable 'reload' or "
373 "'workers'."
374 )
375 sys.exit(1)
376
377 if config.should_reload:
378 sock = config.bind_socket()
379 supervisor = ChangeReload(config, target=server.run, sockets=[sock])
380 supervisor.run()
381 elif config.workers > 1:
382 sock = config.bind_socket()
383 supervisor = Multiprocess(config, target=server.run, sockets=[sock])
384 supervisor.run()
385 else:
386 server.run()
387
388
389 if __name__ == "__main__":
390 main()
391
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/uvicorn/main.py b/uvicorn/main.py
--- a/uvicorn/main.py
+++ b/uvicorn/main.py
@@ -90,7 +90,7 @@
default=None,
type=int,
help="Number of worker processes. Defaults to the $WEB_CONCURRENCY environment"
- " variable if available. Not valid with --reload.",
+ " variable if available, or 1. Not valid with --reload.",
)
@click.option(
"--loop",
|
{"golden_diff": "diff --git a/uvicorn/main.py b/uvicorn/main.py\n--- a/uvicorn/main.py\n+++ b/uvicorn/main.py\n@@ -90,7 +90,7 @@\n default=None,\n type=int,\n help=\"Number of worker processes. Defaults to the $WEB_CONCURRENCY environment\"\n- \" variable if available. Not valid with --reload.\",\n+ \" variable if available, or 1. Not valid with --reload.\",\n )\n @click.option(\n \"--loop\",\n", "issue": "Docs: workers = 1 when WEB_CONCURRENCY is not set\nHello, thanks for this great ASGI server \ud83d\ude42 \r\n\r\nI have an application that must use only one worker (it's not thread-safe), and so I wanted to confirm that, by default, uvicorn only uses one worker. But I had to read the source code\r\n\r\nhttps://github.com/encode/uvicorn/blob/afb2d565c8dae859bcef4c76b3c6dc3f3077314d/uvicorn/config.py#L177\r\n\r\n...to confirm that when `WEB_CONCURRENCY` is not defined, and `workers` is not specified, 1 is used.\r\n\r\nWould you accept a PR adding that information to the docs (there are 4-5 places where this can be added)?\n", "before_files": [{"content": "import logging\nimport platform\nimport ssl\nimport sys\nimport typing\n\nimport click\n\nimport uvicorn\nfrom uvicorn.config import (\n HTTP_PROTOCOLS,\n INTERFACES,\n LIFESPAN,\n LOG_LEVELS,\n LOGGING_CONFIG,\n LOOP_SETUPS,\n SSL_PROTOCOL_VERSION,\n WS_PROTOCOLS,\n Config,\n)\nfrom uvicorn.server import Server, ServerState # noqa: F401 # Used to be defined here.\nfrom uvicorn.supervisors import ChangeReload, Multiprocess\n\nLEVEL_CHOICES = click.Choice(LOG_LEVELS.keys())\nHTTP_CHOICES = click.Choice(HTTP_PROTOCOLS.keys())\nWS_CHOICES = click.Choice(WS_PROTOCOLS.keys())\nLIFESPAN_CHOICES = click.Choice(LIFESPAN.keys())\nLOOP_CHOICES = click.Choice([key for key in LOOP_SETUPS.keys() if key != \"none\"])\nINTERFACE_CHOICES = click.Choice(INTERFACES)\n\nlogger = logging.getLogger(\"uvicorn.error\")\n\n\ndef print_version(ctx, param, value):\n if not value or ctx.resilient_parsing:\n return\n click.echo(\n \"Running uvicorn %s with %s %s on %s\"\n % (\n uvicorn.__version__,\n platform.python_implementation(),\n platform.python_version(),\n platform.system(),\n )\n )\n ctx.exit()\n\n\[email protected]()\[email protected](\"app\")\[email protected](\n \"--host\",\n type=str,\n default=\"127.0.0.1\",\n help=\"Bind socket to this host.\",\n show_default=True,\n)\[email protected](\n \"--port\",\n type=int,\n default=8000,\n help=\"Bind socket to this port.\",\n show_default=True,\n)\[email protected](\"--uds\", type=str, default=None, help=\"Bind to a UNIX domain socket.\")\[email protected](\n \"--fd\", type=int, default=None, help=\"Bind to socket from this file descriptor.\"\n)\[email protected](\n \"--debug\", is_flag=True, default=False, help=\"Enable debug mode.\", hidden=True\n)\[email protected](\"--reload\", is_flag=True, default=False, help=\"Enable auto-reload.\")\[email protected](\n \"--reload-dir\",\n \"reload_dirs\",\n multiple=True,\n help=\"Set reload directories explicitly, instead of using the current working\"\n \" directory.\",\n)\[email protected](\n \"--reload-delay\",\n type=float,\n default=0.25,\n show_default=True,\n help=\"Delay between previous and next check if application needs to be.\"\n \" Defaults to 0.25s.\",\n)\[email protected](\n \"--workers\",\n default=None,\n type=int,\n help=\"Number of worker processes. Defaults to the $WEB_CONCURRENCY environment\"\n \" variable if available. Not valid with --reload.\",\n)\[email protected](\n \"--loop\",\n type=LOOP_CHOICES,\n default=\"auto\",\n help=\"Event loop implementation.\",\n show_default=True,\n)\[email protected](\n \"--http\",\n type=HTTP_CHOICES,\n default=\"auto\",\n help=\"HTTP protocol implementation.\",\n show_default=True,\n)\[email protected](\n \"--ws\",\n type=WS_CHOICES,\n default=\"auto\",\n help=\"WebSocket protocol implementation.\",\n show_default=True,\n)\[email protected](\n \"--lifespan\",\n type=LIFESPAN_CHOICES,\n default=\"auto\",\n help=\"Lifespan implementation.\",\n show_default=True,\n)\[email protected](\n \"--interface\",\n type=INTERFACE_CHOICES,\n default=\"auto\",\n help=\"Select ASGI3, ASGI2, or WSGI as the application interface.\",\n show_default=True,\n)\[email protected](\n \"--env-file\",\n type=click.Path(exists=True),\n default=None,\n help=\"Environment configuration file.\",\n show_default=True,\n)\[email protected](\n \"--log-config\",\n type=click.Path(exists=True),\n default=None,\n help=\"Logging configuration file. Supported formats: .ini, .json, .yaml.\",\n show_default=True,\n)\[email protected](\n \"--log-level\",\n type=LEVEL_CHOICES,\n default=None,\n help=\"Log level. [default: info]\",\n show_default=True,\n)\[email protected](\n \"--access-log/--no-access-log\",\n is_flag=True,\n default=True,\n help=\"Enable/Disable access log.\",\n)\[email protected](\n \"--use-colors/--no-use-colors\",\n is_flag=True,\n default=None,\n help=\"Enable/Disable colorized logging.\",\n)\[email protected](\n \"--proxy-headers/--no-proxy-headers\",\n is_flag=True,\n default=True,\n help=\"Enable/Disable X-Forwarded-Proto, X-Forwarded-For, X-Forwarded-Port to \"\n \"populate remote address info.\",\n)\[email protected](\n \"--forwarded-allow-ips\",\n type=str,\n default=None,\n help=\"Comma seperated list of IPs to trust with proxy headers. Defaults to\"\n \" the $FORWARDED_ALLOW_IPS environment variable if available, or '127.0.0.1'.\",\n)\[email protected](\n \"--root-path\",\n type=str,\n default=\"\",\n help=\"Set the ASGI 'root_path' for applications submounted below a given URL path.\",\n)\[email protected](\n \"--limit-concurrency\",\n type=int,\n default=None,\n help=\"Maximum number of concurrent connections or tasks to allow, before issuing\"\n \" HTTP 503 responses.\",\n)\[email protected](\n \"--backlog\",\n type=int,\n default=2048,\n help=\"Maximum number of connections to hold in backlog\",\n)\[email protected](\n \"--limit-max-requests\",\n type=int,\n default=None,\n help=\"Maximum number of requests to service before terminating the process.\",\n)\[email protected](\n \"--timeout-keep-alive\",\n type=int,\n default=5,\n help=\"Close Keep-Alive connections if no new data is received within this timeout.\",\n show_default=True,\n)\[email protected](\n \"--ssl-keyfile\", type=str, default=None, help=\"SSL key file\", show_default=True\n)\[email protected](\n \"--ssl-certfile\",\n type=str,\n default=None,\n help=\"SSL certificate file\",\n show_default=True,\n)\[email protected](\n \"--ssl-keyfile-password\",\n type=str,\n default=None,\n help=\"SSL keyfile password\",\n show_default=True,\n)\[email protected](\n \"--ssl-version\",\n type=int,\n default=SSL_PROTOCOL_VERSION,\n help=\"SSL version to use (see stdlib ssl module's)\",\n show_default=True,\n)\[email protected](\n \"--ssl-cert-reqs\",\n type=int,\n default=ssl.CERT_NONE,\n help=\"Whether client certificate is required (see stdlib ssl module's)\",\n show_default=True,\n)\[email protected](\n \"--ssl-ca-certs\",\n type=str,\n default=None,\n help=\"CA certificates file\",\n show_default=True,\n)\[email protected](\n \"--ssl-ciphers\",\n type=str,\n default=\"TLSv1\",\n help=\"Ciphers to use (see stdlib ssl module's)\",\n show_default=True,\n)\[email protected](\n \"--header\",\n \"headers\",\n multiple=True,\n help=\"Specify custom default HTTP response headers as a Name:Value pair\",\n)\[email protected](\n \"--version\",\n is_flag=True,\n callback=print_version,\n expose_value=False,\n is_eager=True,\n help=\"Display the uvicorn version and exit.\",\n)\[email protected](\n \"--app-dir\",\n \"app_dir\",\n default=\".\",\n show_default=True,\n help=\"Look for APP in the specified directory, by adding this to the PYTHONPATH.\"\n \" Defaults to the current working directory.\",\n)\[email protected](\n \"--factory\",\n is_flag=True,\n default=False,\n help=\"Treat APP as an application factory, i.e. a () -> <ASGI app> callable.\",\n show_default=True,\n)\ndef main(\n app,\n host: str,\n port: int,\n uds: str,\n fd: int,\n loop: str,\n http: str,\n ws: str,\n lifespan: str,\n interface: str,\n debug: bool,\n reload: bool,\n reload_dirs: typing.List[str],\n reload_delay: float,\n workers: int,\n env_file: str,\n log_config: str,\n log_level: str,\n access_log: bool,\n proxy_headers: bool,\n forwarded_allow_ips: str,\n root_path: str,\n limit_concurrency: int,\n backlog: int,\n limit_max_requests: int,\n timeout_keep_alive: int,\n ssl_keyfile: str,\n ssl_certfile: str,\n ssl_keyfile_password: str,\n ssl_version: int,\n ssl_cert_reqs: int,\n ssl_ca_certs: str,\n ssl_ciphers: str,\n headers: typing.List[str],\n use_colors: bool,\n app_dir: str,\n factory: bool,\n):\n sys.path.insert(0, app_dir)\n\n kwargs = {\n \"app\": app,\n \"host\": host,\n \"port\": port,\n \"uds\": uds,\n \"fd\": fd,\n \"loop\": loop,\n \"http\": http,\n \"ws\": ws,\n \"lifespan\": lifespan,\n \"env_file\": env_file,\n \"log_config\": LOGGING_CONFIG if log_config is None else log_config,\n \"log_level\": log_level,\n \"access_log\": access_log,\n \"interface\": interface,\n \"debug\": debug,\n \"reload\": reload,\n \"reload_dirs\": reload_dirs if reload_dirs else None,\n \"reload_delay\": reload_delay,\n \"workers\": workers,\n \"proxy_headers\": proxy_headers,\n \"forwarded_allow_ips\": forwarded_allow_ips,\n \"root_path\": root_path,\n \"limit_concurrency\": limit_concurrency,\n \"backlog\": backlog,\n \"limit_max_requests\": limit_max_requests,\n \"timeout_keep_alive\": timeout_keep_alive,\n \"ssl_keyfile\": ssl_keyfile,\n \"ssl_certfile\": ssl_certfile,\n \"ssl_keyfile_password\": ssl_keyfile_password,\n \"ssl_version\": ssl_version,\n \"ssl_cert_reqs\": ssl_cert_reqs,\n \"ssl_ca_certs\": ssl_ca_certs,\n \"ssl_ciphers\": ssl_ciphers,\n \"headers\": [header.split(\":\", 1) for header in headers],\n \"use_colors\": use_colors,\n \"factory\": factory,\n }\n run(**kwargs)\n\n\ndef run(app, **kwargs):\n config = Config(app, **kwargs)\n server = Server(config=config)\n\n if (config.reload or config.workers > 1) and not isinstance(app, str):\n logger = logging.getLogger(\"uvicorn.error\")\n logger.warning(\n \"You must pass the application as an import string to enable 'reload' or \"\n \"'workers'.\"\n )\n sys.exit(1)\n\n if config.should_reload:\n sock = config.bind_socket()\n supervisor = ChangeReload(config, target=server.run, sockets=[sock])\n supervisor.run()\n elif config.workers > 1:\n sock = config.bind_socket()\n supervisor = Multiprocess(config, target=server.run, sockets=[sock])\n supervisor.run()\n else:\n server.run()\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "uvicorn/main.py"}], "after_files": [{"content": "import logging\nimport platform\nimport ssl\nimport sys\nimport typing\n\nimport click\n\nimport uvicorn\nfrom uvicorn.config import (\n HTTP_PROTOCOLS,\n INTERFACES,\n LIFESPAN,\n LOG_LEVELS,\n LOGGING_CONFIG,\n LOOP_SETUPS,\n SSL_PROTOCOL_VERSION,\n WS_PROTOCOLS,\n Config,\n)\nfrom uvicorn.server import Server, ServerState # noqa: F401 # Used to be defined here.\nfrom uvicorn.supervisors import ChangeReload, Multiprocess\n\nLEVEL_CHOICES = click.Choice(LOG_LEVELS.keys())\nHTTP_CHOICES = click.Choice(HTTP_PROTOCOLS.keys())\nWS_CHOICES = click.Choice(WS_PROTOCOLS.keys())\nLIFESPAN_CHOICES = click.Choice(LIFESPAN.keys())\nLOOP_CHOICES = click.Choice([key for key in LOOP_SETUPS.keys() if key != \"none\"])\nINTERFACE_CHOICES = click.Choice(INTERFACES)\n\nlogger = logging.getLogger(\"uvicorn.error\")\n\n\ndef print_version(ctx, param, value):\n if not value or ctx.resilient_parsing:\n return\n click.echo(\n \"Running uvicorn %s with %s %s on %s\"\n % (\n uvicorn.__version__,\n platform.python_implementation(),\n platform.python_version(),\n platform.system(),\n )\n )\n ctx.exit()\n\n\[email protected]()\[email protected](\"app\")\[email protected](\n \"--host\",\n type=str,\n default=\"127.0.0.1\",\n help=\"Bind socket to this host.\",\n show_default=True,\n)\[email protected](\n \"--port\",\n type=int,\n default=8000,\n help=\"Bind socket to this port.\",\n show_default=True,\n)\[email protected](\"--uds\", type=str, default=None, help=\"Bind to a UNIX domain socket.\")\[email protected](\n \"--fd\", type=int, default=None, help=\"Bind to socket from this file descriptor.\"\n)\[email protected](\n \"--debug\", is_flag=True, default=False, help=\"Enable debug mode.\", hidden=True\n)\[email protected](\"--reload\", is_flag=True, default=False, help=\"Enable auto-reload.\")\[email protected](\n \"--reload-dir\",\n \"reload_dirs\",\n multiple=True,\n help=\"Set reload directories explicitly, instead of using the current working\"\n \" directory.\",\n)\[email protected](\n \"--reload-delay\",\n type=float,\n default=0.25,\n show_default=True,\n help=\"Delay between previous and next check if application needs to be.\"\n \" Defaults to 0.25s.\",\n)\[email protected](\n \"--workers\",\n default=None,\n type=int,\n help=\"Number of worker processes. Defaults to the $WEB_CONCURRENCY environment\"\n \" variable if available, or 1. Not valid with --reload.\",\n)\[email protected](\n \"--loop\",\n type=LOOP_CHOICES,\n default=\"auto\",\n help=\"Event loop implementation.\",\n show_default=True,\n)\[email protected](\n \"--http\",\n type=HTTP_CHOICES,\n default=\"auto\",\n help=\"HTTP protocol implementation.\",\n show_default=True,\n)\[email protected](\n \"--ws\",\n type=WS_CHOICES,\n default=\"auto\",\n help=\"WebSocket protocol implementation.\",\n show_default=True,\n)\[email protected](\n \"--lifespan\",\n type=LIFESPAN_CHOICES,\n default=\"auto\",\n help=\"Lifespan implementation.\",\n show_default=True,\n)\[email protected](\n \"--interface\",\n type=INTERFACE_CHOICES,\n default=\"auto\",\n help=\"Select ASGI3, ASGI2, or WSGI as the application interface.\",\n show_default=True,\n)\[email protected](\n \"--env-file\",\n type=click.Path(exists=True),\n default=None,\n help=\"Environment configuration file.\",\n show_default=True,\n)\[email protected](\n \"--log-config\",\n type=click.Path(exists=True),\n default=None,\n help=\"Logging configuration file. Supported formats: .ini, .json, .yaml.\",\n show_default=True,\n)\[email protected](\n \"--log-level\",\n type=LEVEL_CHOICES,\n default=None,\n help=\"Log level. [default: info]\",\n show_default=True,\n)\[email protected](\n \"--access-log/--no-access-log\",\n is_flag=True,\n default=True,\n help=\"Enable/Disable access log.\",\n)\[email protected](\n \"--use-colors/--no-use-colors\",\n is_flag=True,\n default=None,\n help=\"Enable/Disable colorized logging.\",\n)\[email protected](\n \"--proxy-headers/--no-proxy-headers\",\n is_flag=True,\n default=True,\n help=\"Enable/Disable X-Forwarded-Proto, X-Forwarded-For, X-Forwarded-Port to \"\n \"populate remote address info.\",\n)\[email protected](\n \"--forwarded-allow-ips\",\n type=str,\n default=None,\n help=\"Comma seperated list of IPs to trust with proxy headers. Defaults to\"\n \" the $FORWARDED_ALLOW_IPS environment variable if available, or '127.0.0.1'.\",\n)\[email protected](\n \"--root-path\",\n type=str,\n default=\"\",\n help=\"Set the ASGI 'root_path' for applications submounted below a given URL path.\",\n)\[email protected](\n \"--limit-concurrency\",\n type=int,\n default=None,\n help=\"Maximum number of concurrent connections or tasks to allow, before issuing\"\n \" HTTP 503 responses.\",\n)\[email protected](\n \"--backlog\",\n type=int,\n default=2048,\n help=\"Maximum number of connections to hold in backlog\",\n)\[email protected](\n \"--limit-max-requests\",\n type=int,\n default=None,\n help=\"Maximum number of requests to service before terminating the process.\",\n)\[email protected](\n \"--timeout-keep-alive\",\n type=int,\n default=5,\n help=\"Close Keep-Alive connections if no new data is received within this timeout.\",\n show_default=True,\n)\[email protected](\n \"--ssl-keyfile\", type=str, default=None, help=\"SSL key file\", show_default=True\n)\[email protected](\n \"--ssl-certfile\",\n type=str,\n default=None,\n help=\"SSL certificate file\",\n show_default=True,\n)\[email protected](\n \"--ssl-keyfile-password\",\n type=str,\n default=None,\n help=\"SSL keyfile password\",\n show_default=True,\n)\[email protected](\n \"--ssl-version\",\n type=int,\n default=SSL_PROTOCOL_VERSION,\n help=\"SSL version to use (see stdlib ssl module's)\",\n show_default=True,\n)\[email protected](\n \"--ssl-cert-reqs\",\n type=int,\n default=ssl.CERT_NONE,\n help=\"Whether client certificate is required (see stdlib ssl module's)\",\n show_default=True,\n)\[email protected](\n \"--ssl-ca-certs\",\n type=str,\n default=None,\n help=\"CA certificates file\",\n show_default=True,\n)\[email protected](\n \"--ssl-ciphers\",\n type=str,\n default=\"TLSv1\",\n help=\"Ciphers to use (see stdlib ssl module's)\",\n show_default=True,\n)\[email protected](\n \"--header\",\n \"headers\",\n multiple=True,\n help=\"Specify custom default HTTP response headers as a Name:Value pair\",\n)\[email protected](\n \"--version\",\n is_flag=True,\n callback=print_version,\n expose_value=False,\n is_eager=True,\n help=\"Display the uvicorn version and exit.\",\n)\[email protected](\n \"--app-dir\",\n \"app_dir\",\n default=\".\",\n show_default=True,\n help=\"Look for APP in the specified directory, by adding this to the PYTHONPATH.\"\n \" Defaults to the current working directory.\",\n)\[email protected](\n \"--factory\",\n is_flag=True,\n default=False,\n help=\"Treat APP as an application factory, i.e. a () -> <ASGI app> callable.\",\n show_default=True,\n)\ndef main(\n app,\n host: str,\n port: int,\n uds: str,\n fd: int,\n loop: str,\n http: str,\n ws: str,\n lifespan: str,\n interface: str,\n debug: bool,\n reload: bool,\n reload_dirs: typing.List[str],\n reload_delay: float,\n workers: int,\n env_file: str,\n log_config: str,\n log_level: str,\n access_log: bool,\n proxy_headers: bool,\n forwarded_allow_ips: str,\n root_path: str,\n limit_concurrency: int,\n backlog: int,\n limit_max_requests: int,\n timeout_keep_alive: int,\n ssl_keyfile: str,\n ssl_certfile: str,\n ssl_keyfile_password: str,\n ssl_version: int,\n ssl_cert_reqs: int,\n ssl_ca_certs: str,\n ssl_ciphers: str,\n headers: typing.List[str],\n use_colors: bool,\n app_dir: str,\n factory: bool,\n):\n sys.path.insert(0, app_dir)\n\n kwargs = {\n \"app\": app,\n \"host\": host,\n \"port\": port,\n \"uds\": uds,\n \"fd\": fd,\n \"loop\": loop,\n \"http\": http,\n \"ws\": ws,\n \"lifespan\": lifespan,\n \"env_file\": env_file,\n \"log_config\": LOGGING_CONFIG if log_config is None else log_config,\n \"log_level\": log_level,\n \"access_log\": access_log,\n \"interface\": interface,\n \"debug\": debug,\n \"reload\": reload,\n \"reload_dirs\": reload_dirs if reload_dirs else None,\n \"reload_delay\": reload_delay,\n \"workers\": workers,\n \"proxy_headers\": proxy_headers,\n \"forwarded_allow_ips\": forwarded_allow_ips,\n \"root_path\": root_path,\n \"limit_concurrency\": limit_concurrency,\n \"backlog\": backlog,\n \"limit_max_requests\": limit_max_requests,\n \"timeout_keep_alive\": timeout_keep_alive,\n \"ssl_keyfile\": ssl_keyfile,\n \"ssl_certfile\": ssl_certfile,\n \"ssl_keyfile_password\": ssl_keyfile_password,\n \"ssl_version\": ssl_version,\n \"ssl_cert_reqs\": ssl_cert_reqs,\n \"ssl_ca_certs\": ssl_ca_certs,\n \"ssl_ciphers\": ssl_ciphers,\n \"headers\": [header.split(\":\", 1) for header in headers],\n \"use_colors\": use_colors,\n \"factory\": factory,\n }\n run(**kwargs)\n\n\ndef run(app, **kwargs):\n config = Config(app, **kwargs)\n server = Server(config=config)\n\n if (config.reload or config.workers > 1) and not isinstance(app, str):\n logger = logging.getLogger(\"uvicorn.error\")\n logger.warning(\n \"You must pass the application as an import string to enable 'reload' or \"\n \"'workers'.\"\n )\n sys.exit(1)\n\n if config.should_reload:\n sock = config.bind_socket()\n supervisor = ChangeReload(config, target=server.run, sockets=[sock])\n supervisor.run()\n elif config.workers > 1:\n sock = config.bind_socket()\n supervisor = Multiprocess(config, target=server.run, sockets=[sock])\n supervisor.run()\n else:\n server.run()\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "uvicorn/main.py"}]}
| 3,956 | 109 |
gh_patches_debug_8545
|
rasdani/github-patches
|
git_diff
|
googleapis__python-bigquery-1796
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
The _ARROW_SCALAR_IDS_TO_BQ mapping misses LargeStringArray type
#### Environment details
- OS type and version: Linux
- Python version: 3.11.7
- pip version: 23.3.1
- `google-cloud-bigquery` version: 3.16.0
#### Steps to reproduce
Call `bqclient.load_table_from_dataframe` with a dataframe containing a string type. Before pandas 2.2.0, the `pyarrow.array` would detect the type as `pyarrow.lib.StringArray`. After switching to pandas `2.2.0`, the `pyarrow.lib.LargeStringArray` would be returned. But it misses the BQ type mapping.
#### Stack trace
<img width="1470" alt="callstack" src="https://github.com/googleapis/python-bigquery/assets/124939984/fe0c326f-8875-41b5-abff-e91dc3e574da">
The left results are in `pandas 2.2.0` and the right result are from `pandas 2.1.3`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `google/cloud/bigquery/_pyarrow_helpers.py`
Content:
```
1 # Copyright 2023 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Shared helper functions for connecting BigQuery and pyarrow."""
16
17 from typing import Any
18
19 from packaging import version
20
21 try:
22 import pyarrow # type: ignore
23 except ImportError: # pragma: NO COVER
24 pyarrow = None
25
26
27 def pyarrow_datetime():
28 return pyarrow.timestamp("us", tz=None)
29
30
31 def pyarrow_numeric():
32 return pyarrow.decimal128(38, 9)
33
34
35 def pyarrow_bignumeric():
36 # 77th digit is partial.
37 # https://cloud.google.com/bigquery/docs/reference/standard-sql/data-types#decimal_types
38 return pyarrow.decimal256(76, 38)
39
40
41 def pyarrow_time():
42 return pyarrow.time64("us")
43
44
45 def pyarrow_timestamp():
46 return pyarrow.timestamp("us", tz="UTC")
47
48
49 _BQ_TO_ARROW_SCALARS = {}
50 _ARROW_SCALAR_IDS_TO_BQ = {}
51
52 if pyarrow:
53 # This dictionary is duplicated in bigquery_storage/test/unite/test_reader.py
54 # When modifying it be sure to update it there as well.
55 # Note(todo!!): type "BIGNUMERIC"'s matching pyarrow type is added in _pandas_helpers.py
56 _BQ_TO_ARROW_SCALARS = {
57 "BOOL": pyarrow.bool_,
58 "BOOLEAN": pyarrow.bool_,
59 "BYTES": pyarrow.binary,
60 "DATE": pyarrow.date32,
61 "DATETIME": pyarrow_datetime,
62 "FLOAT": pyarrow.float64,
63 "FLOAT64": pyarrow.float64,
64 "GEOGRAPHY": pyarrow.string,
65 "INT64": pyarrow.int64,
66 "INTEGER": pyarrow.int64,
67 "NUMERIC": pyarrow_numeric,
68 "STRING": pyarrow.string,
69 "TIME": pyarrow_time,
70 "TIMESTAMP": pyarrow_timestamp,
71 }
72
73 _ARROW_SCALAR_IDS_TO_BQ = {
74 # https://arrow.apache.org/docs/python/api/datatypes.html#type-classes
75 pyarrow.bool_().id: "BOOL",
76 pyarrow.int8().id: "INT64",
77 pyarrow.int16().id: "INT64",
78 pyarrow.int32().id: "INT64",
79 pyarrow.int64().id: "INT64",
80 pyarrow.uint8().id: "INT64",
81 pyarrow.uint16().id: "INT64",
82 pyarrow.uint32().id: "INT64",
83 pyarrow.uint64().id: "INT64",
84 pyarrow.float16().id: "FLOAT64",
85 pyarrow.float32().id: "FLOAT64",
86 pyarrow.float64().id: "FLOAT64",
87 pyarrow.time32("ms").id: "TIME",
88 pyarrow.time64("ns").id: "TIME",
89 pyarrow.timestamp("ns").id: "TIMESTAMP",
90 pyarrow.date32().id: "DATE",
91 pyarrow.date64().id: "DATETIME", # because millisecond resolution
92 pyarrow.binary().id: "BYTES",
93 pyarrow.string().id: "STRING", # also alias for pyarrow.utf8()
94 # The exact scale and precision don't matter, see below.
95 pyarrow.decimal128(38, scale=9).id: "NUMERIC",
96 }
97
98 # Adds bignumeric support only if pyarrow version >= 3.0.0
99 # Decimal256 support was added to arrow 3.0.0
100 # https://arrow.apache.org/blog/2021/01/25/3.0.0-release/
101 if version.parse(pyarrow.__version__) >= version.parse("3.0.0"):
102 _BQ_TO_ARROW_SCALARS["BIGNUMERIC"] = pyarrow_bignumeric
103 # The exact decimal's scale and precision are not important, as only
104 # the type ID matters, and it's the same for all decimal256 instances.
105 _ARROW_SCALAR_IDS_TO_BQ[pyarrow.decimal256(76, scale=38).id] = "BIGNUMERIC"
106
107
108 def bq_to_arrow_scalars(bq_scalar: str):
109 """
110 Returns:
111 The Arrow scalar type that the input BigQuery scalar type maps to.
112 If it cannot find the BigQuery scalar, return None.
113 """
114 return _BQ_TO_ARROW_SCALARS.get(bq_scalar)
115
116
117 def arrow_scalar_ids_to_bq(arrow_scalar: Any):
118 """
119 Returns:
120 The BigQuery scalar type that the input arrow scalar type maps to.
121 If it cannot find the arrow scalar, return None.
122 """
123 return _ARROW_SCALAR_IDS_TO_BQ.get(arrow_scalar)
124
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/google/cloud/bigquery/_pyarrow_helpers.py b/google/cloud/bigquery/_pyarrow_helpers.py
--- a/google/cloud/bigquery/_pyarrow_helpers.py
+++ b/google/cloud/bigquery/_pyarrow_helpers.py
@@ -91,6 +91,7 @@
pyarrow.date64().id: "DATETIME", # because millisecond resolution
pyarrow.binary().id: "BYTES",
pyarrow.string().id: "STRING", # also alias for pyarrow.utf8()
+ pyarrow.large_string().id: "STRING",
# The exact scale and precision don't matter, see below.
pyarrow.decimal128(38, scale=9).id: "NUMERIC",
}
|
{"golden_diff": "diff --git a/google/cloud/bigquery/_pyarrow_helpers.py b/google/cloud/bigquery/_pyarrow_helpers.py\n--- a/google/cloud/bigquery/_pyarrow_helpers.py\n+++ b/google/cloud/bigquery/_pyarrow_helpers.py\n@@ -91,6 +91,7 @@\n pyarrow.date64().id: \"DATETIME\", # because millisecond resolution\n pyarrow.binary().id: \"BYTES\",\n pyarrow.string().id: \"STRING\", # also alias for pyarrow.utf8()\n+ pyarrow.large_string().id: \"STRING\",\n # The exact scale and precision don't matter, see below.\n pyarrow.decimal128(38, scale=9).id: \"NUMERIC\",\n }\n", "issue": "The _ARROW_SCALAR_IDS_TO_BQ mapping misses LargeStringArray type\n#### Environment details\r\n\r\n - OS type and version: Linux\r\n - Python version: 3.11.7\r\n - pip version: 23.3.1\r\n - `google-cloud-bigquery` version: 3.16.0\r\n\r\n#### Steps to reproduce\r\n\r\nCall `bqclient.load_table_from_dataframe` with a dataframe containing a string type. Before pandas 2.2.0, the `pyarrow.array` would detect the type as `pyarrow.lib.StringArray`. After switching to pandas `2.2.0`, the `pyarrow.lib.LargeStringArray` would be returned. But it misses the BQ type mapping.\r\n\r\n\r\n#### Stack trace\r\n\r\n<img width=\"1470\" alt=\"callstack\" src=\"https://github.com/googleapis/python-bigquery/assets/124939984/fe0c326f-8875-41b5-abff-e91dc3e574da\">\r\n\r\nThe left results are in `pandas 2.2.0` and the right result are from `pandas 2.1.3`\r\n\r\n\n", "before_files": [{"content": "# Copyright 2023 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Shared helper functions for connecting BigQuery and pyarrow.\"\"\"\n\nfrom typing import Any\n\nfrom packaging import version\n\ntry:\n import pyarrow # type: ignore\nexcept ImportError: # pragma: NO COVER\n pyarrow = None\n\n\ndef pyarrow_datetime():\n return pyarrow.timestamp(\"us\", tz=None)\n\n\ndef pyarrow_numeric():\n return pyarrow.decimal128(38, 9)\n\n\ndef pyarrow_bignumeric():\n # 77th digit is partial.\n # https://cloud.google.com/bigquery/docs/reference/standard-sql/data-types#decimal_types\n return pyarrow.decimal256(76, 38)\n\n\ndef pyarrow_time():\n return pyarrow.time64(\"us\")\n\n\ndef pyarrow_timestamp():\n return pyarrow.timestamp(\"us\", tz=\"UTC\")\n\n\n_BQ_TO_ARROW_SCALARS = {}\n_ARROW_SCALAR_IDS_TO_BQ = {}\n\nif pyarrow:\n # This dictionary is duplicated in bigquery_storage/test/unite/test_reader.py\n # When modifying it be sure to update it there as well.\n # Note(todo!!): type \"BIGNUMERIC\"'s matching pyarrow type is added in _pandas_helpers.py\n _BQ_TO_ARROW_SCALARS = {\n \"BOOL\": pyarrow.bool_,\n \"BOOLEAN\": pyarrow.bool_,\n \"BYTES\": pyarrow.binary,\n \"DATE\": pyarrow.date32,\n \"DATETIME\": pyarrow_datetime,\n \"FLOAT\": pyarrow.float64,\n \"FLOAT64\": pyarrow.float64,\n \"GEOGRAPHY\": pyarrow.string,\n \"INT64\": pyarrow.int64,\n \"INTEGER\": pyarrow.int64,\n \"NUMERIC\": pyarrow_numeric,\n \"STRING\": pyarrow.string,\n \"TIME\": pyarrow_time,\n \"TIMESTAMP\": pyarrow_timestamp,\n }\n\n _ARROW_SCALAR_IDS_TO_BQ = {\n # https://arrow.apache.org/docs/python/api/datatypes.html#type-classes\n pyarrow.bool_().id: \"BOOL\",\n pyarrow.int8().id: \"INT64\",\n pyarrow.int16().id: \"INT64\",\n pyarrow.int32().id: \"INT64\",\n pyarrow.int64().id: \"INT64\",\n pyarrow.uint8().id: \"INT64\",\n pyarrow.uint16().id: \"INT64\",\n pyarrow.uint32().id: \"INT64\",\n pyarrow.uint64().id: \"INT64\",\n pyarrow.float16().id: \"FLOAT64\",\n pyarrow.float32().id: \"FLOAT64\",\n pyarrow.float64().id: \"FLOAT64\",\n pyarrow.time32(\"ms\").id: \"TIME\",\n pyarrow.time64(\"ns\").id: \"TIME\",\n pyarrow.timestamp(\"ns\").id: \"TIMESTAMP\",\n pyarrow.date32().id: \"DATE\",\n pyarrow.date64().id: \"DATETIME\", # because millisecond resolution\n pyarrow.binary().id: \"BYTES\",\n pyarrow.string().id: \"STRING\", # also alias for pyarrow.utf8()\n # The exact scale and precision don't matter, see below.\n pyarrow.decimal128(38, scale=9).id: \"NUMERIC\",\n }\n\n # Adds bignumeric support only if pyarrow version >= 3.0.0\n # Decimal256 support was added to arrow 3.0.0\n # https://arrow.apache.org/blog/2021/01/25/3.0.0-release/\n if version.parse(pyarrow.__version__) >= version.parse(\"3.0.0\"):\n _BQ_TO_ARROW_SCALARS[\"BIGNUMERIC\"] = pyarrow_bignumeric\n # The exact decimal's scale and precision are not important, as only\n # the type ID matters, and it's the same for all decimal256 instances.\n _ARROW_SCALAR_IDS_TO_BQ[pyarrow.decimal256(76, scale=38).id] = \"BIGNUMERIC\"\n\n\ndef bq_to_arrow_scalars(bq_scalar: str):\n \"\"\"\n Returns:\n The Arrow scalar type that the input BigQuery scalar type maps to.\n If it cannot find the BigQuery scalar, return None.\n \"\"\"\n return _BQ_TO_ARROW_SCALARS.get(bq_scalar)\n\n\ndef arrow_scalar_ids_to_bq(arrow_scalar: Any):\n \"\"\"\n Returns:\n The BigQuery scalar type that the input arrow scalar type maps to.\n If it cannot find the arrow scalar, return None.\n \"\"\"\n return _ARROW_SCALAR_IDS_TO_BQ.get(arrow_scalar)\n", "path": "google/cloud/bigquery/_pyarrow_helpers.py"}], "after_files": [{"content": "# Copyright 2023 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Shared helper functions for connecting BigQuery and pyarrow.\"\"\"\n\nfrom typing import Any\n\nfrom packaging import version\n\ntry:\n import pyarrow # type: ignore\nexcept ImportError: # pragma: NO COVER\n pyarrow = None\n\n\ndef pyarrow_datetime():\n return pyarrow.timestamp(\"us\", tz=None)\n\n\ndef pyarrow_numeric():\n return pyarrow.decimal128(38, 9)\n\n\ndef pyarrow_bignumeric():\n # 77th digit is partial.\n # https://cloud.google.com/bigquery/docs/reference/standard-sql/data-types#decimal_types\n return pyarrow.decimal256(76, 38)\n\n\ndef pyarrow_time():\n return pyarrow.time64(\"us\")\n\n\ndef pyarrow_timestamp():\n return pyarrow.timestamp(\"us\", tz=\"UTC\")\n\n\n_BQ_TO_ARROW_SCALARS = {}\n_ARROW_SCALAR_IDS_TO_BQ = {}\n\nif pyarrow:\n # This dictionary is duplicated in bigquery_storage/test/unite/test_reader.py\n # When modifying it be sure to update it there as well.\n # Note(todo!!): type \"BIGNUMERIC\"'s matching pyarrow type is added in _pandas_helpers.py\n _BQ_TO_ARROW_SCALARS = {\n \"BOOL\": pyarrow.bool_,\n \"BOOLEAN\": pyarrow.bool_,\n \"BYTES\": pyarrow.binary,\n \"DATE\": pyarrow.date32,\n \"DATETIME\": pyarrow_datetime,\n \"FLOAT\": pyarrow.float64,\n \"FLOAT64\": pyarrow.float64,\n \"GEOGRAPHY\": pyarrow.string,\n \"INT64\": pyarrow.int64,\n \"INTEGER\": pyarrow.int64,\n \"NUMERIC\": pyarrow_numeric,\n \"STRING\": pyarrow.string,\n \"TIME\": pyarrow_time,\n \"TIMESTAMP\": pyarrow_timestamp,\n }\n\n _ARROW_SCALAR_IDS_TO_BQ = {\n # https://arrow.apache.org/docs/python/api/datatypes.html#type-classes\n pyarrow.bool_().id: \"BOOL\",\n pyarrow.int8().id: \"INT64\",\n pyarrow.int16().id: \"INT64\",\n pyarrow.int32().id: \"INT64\",\n pyarrow.int64().id: \"INT64\",\n pyarrow.uint8().id: \"INT64\",\n pyarrow.uint16().id: \"INT64\",\n pyarrow.uint32().id: \"INT64\",\n pyarrow.uint64().id: \"INT64\",\n pyarrow.float16().id: \"FLOAT64\",\n pyarrow.float32().id: \"FLOAT64\",\n pyarrow.float64().id: \"FLOAT64\",\n pyarrow.time32(\"ms\").id: \"TIME\",\n pyarrow.time64(\"ns\").id: \"TIME\",\n pyarrow.timestamp(\"ns\").id: \"TIMESTAMP\",\n pyarrow.date32().id: \"DATE\",\n pyarrow.date64().id: \"DATETIME\", # because millisecond resolution\n pyarrow.binary().id: \"BYTES\",\n pyarrow.string().id: \"STRING\", # also alias for pyarrow.utf8()\n pyarrow.large_string().id: \"STRING\",\n # The exact scale and precision don't matter, see below.\n pyarrow.decimal128(38, scale=9).id: \"NUMERIC\",\n }\n\n # Adds bignumeric support only if pyarrow version >= 3.0.0\n # Decimal256 support was added to arrow 3.0.0\n # https://arrow.apache.org/blog/2021/01/25/3.0.0-release/\n if version.parse(pyarrow.__version__) >= version.parse(\"3.0.0\"):\n _BQ_TO_ARROW_SCALARS[\"BIGNUMERIC\"] = pyarrow_bignumeric\n # The exact decimal's scale and precision are not important, as only\n # the type ID matters, and it's the same for all decimal256 instances.\n _ARROW_SCALAR_IDS_TO_BQ[pyarrow.decimal256(76, scale=38).id] = \"BIGNUMERIC\"\n\n\ndef bq_to_arrow_scalars(bq_scalar: str):\n \"\"\"\n Returns:\n The Arrow scalar type that the input BigQuery scalar type maps to.\n If it cannot find the BigQuery scalar, return None.\n \"\"\"\n return _BQ_TO_ARROW_SCALARS.get(bq_scalar)\n\n\ndef arrow_scalar_ids_to_bq(arrow_scalar: Any):\n \"\"\"\n Returns:\n The BigQuery scalar type that the input arrow scalar type maps to.\n If it cannot find the arrow scalar, return None.\n \"\"\"\n return _ARROW_SCALAR_IDS_TO_BQ.get(arrow_scalar)\n", "path": "google/cloud/bigquery/_pyarrow_helpers.py"}]}
| 1,980 | 160 |
gh_patches_debug_21866
|
rasdani/github-patches
|
git_diff
|
electricitymaps__electricitymaps-contrib-2220
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
US-DUK/EIA parser returns data for wrong date if EIA does not have data
Found this obscure error when parsing data for US-DUK.
Traceback:
`Traceback (most recent call last):
File "test_parser.py", line 86, in <module>
print(test_parser())
File "/home/rob/anaconda3/envs/contrib/lib/python3.7/site-packages/click/core.py", line 764, in __call__
return self.main(*args, **kwargs)
File "/home/rob/anaconda3/envs/contrib/lib/python3.7/site-packages/click/core.py", line 717, in main
rv = self.invoke(ctx)
File "/home/rob/anaconda3/envs/contrib/lib/python3.7/site-packages/click/core.py", line 956, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/home/rob/anaconda3/envs/contrib/lib/python3.7/site-packages/click/core.py", line 555, in invoke
return callback(*args, **kwargs)
File "test_parser.py", line 49, in test_parser
res = parser(*args, target_datetime=target_datetime)
File "/home/rob/tmrow/electricitymap-contrib/parsers/EIA.py", line 120, in fetch_production_mix
return merge_production_outputs(mixes, zone_key, merge_source='eia.gov')
File "/home/rob/tmrow/electricitymap-contrib/parsers/ENTSOE.py", line 886, in merge_production_outputs
axis=1)
File "/home/rob/anaconda3/envs/contrib/lib/python3.7/site-packages/pandas/core/frame.py", line 3487, in __setitem__
self._set_item(key, value)
File "/home/rob/anaconda3/envs/contrib/lib/python3.7/site-packages/pandas/core/frame.py", line 3563, in _set_item
self._ensure_valid_index(value)
File "/home/rob/anaconda3/envs/contrib/lib/python3.7/site-packages/pandas/core/frame.py", line 3543, in _ensure_valid_index
"Cannot set a frame with no defined index "
`
In the case of 'other' production for US-DUK, the EIA data is incomplete (see image)
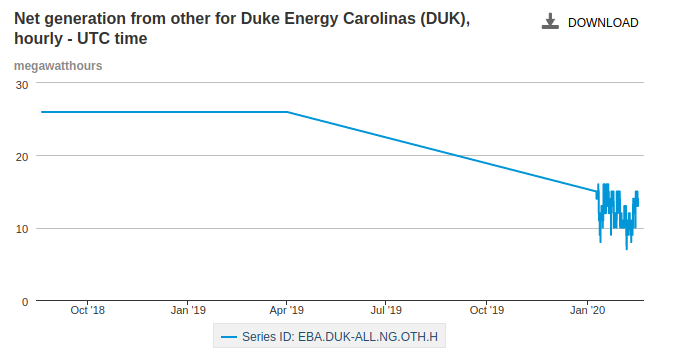
So when scraping historic data, the eiapy function 'last from' returns the last 24 datapoints that it can get, which is for a date far in the past, then our parser breaks when trying to merge these in ENTSOE.merge_production_outputs
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `parsers/EIA.py`
Content:
```
1 #!/usr/bin/env python3
2 """Parser for U.S. Energy Information Administration, https://www.eia.gov/ .
3
4 Aggregates and standardizes data from most of the US ISOs,
5 and exposes them via a unified API.
6
7 Requires an API key, set in the EIA_KEY environment variable. Get one here:
8 https://www.eia.gov/opendata/register.php
9 """
10 import datetime
11 import os
12
13 import arrow
14 from dateutil import parser, tz
15 os.environ.setdefault('EIA_KEY', 'eia_key')
16 from eiapy import Series
17 import requests
18
19 from .lib.validation import validate
20 from .ENTSOE import merge_production_outputs
21
22 EXCHANGES = {
23 'MX-BC->US-CA': 'EBA.CISO-CFE.ID.H',
24 'US-BPA->US-IPC': 'EBA.BPAT-IPCO.ID.H',
25 'US-SPP->US-TX': 'SWPP.ID.H-EBA.ERCO',
26 'US-MISO->US-PJM': 'EBA.MISO-PJM.ID.H',
27 'US-MISO->US-SPP': 'EBA.MISO-SWPP.ID.H',
28 'US-NEISO->US-NY': 'EBA.ISNE-NYIS.ID.H',
29 'US-NY->US-PJM': 'EBA.NYIS-PJM.ID.H'
30 }
31 # based on https://www.eia.gov/beta/electricity/gridmonitor/dashboard/electric_overview/US48/US48
32 # or https://www.eia.gov/opendata/qb.php?category=3390101
33 # List includes regions and Balancing Authorities.
34 REGIONS = {
35 'US-BPA': 'BPAT',
36 'US-CA': 'CAL',
37 'US-CAR': 'CAR',
38 'US-DUK': 'DUK', #Duke Energy Carolinas
39 'US-SPP': 'CENT',
40 'US-FL': 'FLA',
41 'US-PJM': 'MIDA',
42 'US-MISO': 'MIDW',
43 'US-NEISO': 'NE',
44 'US-NEVP': 'NEVP', #Nevada Power Company
45 'US-NY': 'NY',
46 'US-NW': 'NW',
47 'US-SC': 'SC', #South Carolina Public Service Authority
48 'US-SE': 'SE',
49 'US-SEC': 'SEC',
50 'US-SOCO': 'SOCO', #Southern Company Services Inc - Trans
51 'US-SWPP': 'SWPP', #Southwest Power Pool
52 'US-SVERI': 'SW',
53 'US-TN': 'TEN',
54 'US-TX': 'TEX',
55 }
56 TYPES = {
57 # 'biomass': 'BM', # not currently supported
58 'coal': 'COL',
59 'gas': 'NG',
60 'hydro': 'WAT',
61 'nuclear': 'NUC',
62 'oil': 'OIL',
63 'unknown': 'OTH',
64 'solar': 'SUN',
65 'wind': 'WND',
66 }
67 PRODUCTION_SERIES = 'EBA.%s-ALL.NG.H'
68 PRODUCTION_MIX_SERIES = 'EBA.%s-ALL.NG.%s.H'
69 DEMAND_SERIES = 'EBA.%s-ALL.D.H'
70 FORECAST_SERIES = 'EBA.%s-ALL.DF.H'
71
72
73 def fetch_consumption_forecast(zone_key, session=None, target_datetime=None, logger=None):
74 return _fetch_series(zone_key, FORECAST_SERIES % REGIONS[zone_key],
75 session=session, target_datetime=target_datetime,
76 logger=logger)
77
78
79 def fetch_production(zone_key, session=None, target_datetime=None, logger=None):
80 return _fetch_series(zone_key, PRODUCTION_SERIES % REGIONS[zone_key],
81 session=session, target_datetime=target_datetime,
82 logger=logger)
83
84
85 def fetch_consumption(zone_key, session=None, target_datetime=None, logger=None):
86 consumption = _fetch_series(zone_key, DEMAND_SERIES % REGIONS[zone_key],
87 session=session, target_datetime=target_datetime,
88 logger=logger)
89 for point in consumption:
90 point['consumption'] = point.pop('value')
91
92 return consumption
93
94
95 def fetch_production_mix(zone_key, session=None, target_datetime=None, logger=None):
96 mixes = []
97 for type, code in TYPES.items():
98 series = PRODUCTION_MIX_SERIES % (REGIONS[zone_key], code)
99 mix = _fetch_series(zone_key, series, session=session,
100 target_datetime=target_datetime, logger=logger)
101 if not mix:
102 continue
103 for point in mix:
104 if type == 'hydro' and point['value'] < 0:
105 point.update({
106 'production': {},# required by merge_production_outputs()
107 'storage': {type: point.pop('value')},
108 })
109 else:
110 point.update({
111 'production': {type: point.pop('value')},
112 'storage': {}, # required by merge_production_outputs()
113 })
114
115 #replace small negative values (>-5) with 0s This is necessary for solar
116 point = validate(point, logger=logger, remove_negative=True)
117 mixes.append(mix)
118
119 return merge_production_outputs(mixes, zone_key, merge_source='eia.gov')
120
121
122 def fetch_exchange(zone_key1, zone_key2, session=None, target_datetime=None, logger=None):
123 sortedcodes = '->'.join(sorted([zone_key1, zone_key2]))
124 exchange = _fetch_series(sortedcodes, EXCHANGES[sortedcodes], session=session,
125 target_datetime=target_datetime, logger=logger)
126 for point in exchange:
127 point.update({
128 'sortedZoneKeys': point.pop('zoneKey'),
129 'netFlow': point.pop('value'),
130 })
131 if sortedcodes == 'MX-BC->US-CA':
132 point['netFlow'] = -point['netFlow']
133
134 return exchange
135
136
137 def _fetch_series(zone_key, series_id, session=None, target_datetime=None,
138 logger=None):
139 """Fetches and converts a data series."""
140 key = os.environ['EIA_KEY']
141 assert key and key != 'eia_key', key
142
143 s = session or requests.Session()
144 series = Series(series_id=series_id, session=s)
145
146 if target_datetime:
147 utc = tz.gettz('UTC')
148 #eia currently only accepts utc timestamps in the form YYYYMMDDTHHZ
149 dt = target_datetime.astimezone(utc).strftime('%Y%m%dT%HZ')
150 raw_data = series.last_from(24, end=dt)
151 else:
152 # Get the last 24 hours available.
153 raw_data = series.last(24)
154
155 # UTC timestamp with no offset returned.
156 if not raw_data.get('series'):
157 # Series doesn't exist. Probably requesting a fuel from a region that
158 # doesn't have any capacity for that fuel type.
159 return []
160
161 return [{
162 'zoneKey': zone_key,
163 'datetime': parser.parse(datapoint[0]),
164 'value': datapoint[1],
165 'source': 'eia.gov',
166 } for datapoint in raw_data['series'][0]['data']]
167
168
169 def main():
170 "Main method, never used by the Electricity Map backend, but handy for testing."
171 from pprint import pprint
172 pprint(fetch_consumption_forecast('US-NY'))
173 pprint(fetch_production('US-SEC'))
174 pprint(fetch_production_mix('US-TN'))
175 pprint(fetch_consumption('US-CAR'))
176 pprint(fetch_exchange('MX-BC', 'US-CA'))
177
178
179 if __name__ == '__main__':
180 main()
181
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/parsers/EIA.py b/parsers/EIA.py
--- a/parsers/EIA.py
+++ b/parsers/EIA.py
@@ -98,6 +98,7 @@
series = PRODUCTION_MIX_SERIES % (REGIONS[zone_key], code)
mix = _fetch_series(zone_key, series, session=session,
target_datetime=target_datetime, logger=logger)
+
if not mix:
continue
for point in mix:
@@ -146,8 +147,9 @@
if target_datetime:
utc = tz.gettz('UTC')
#eia currently only accepts utc timestamps in the form YYYYMMDDTHHZ
- dt = target_datetime.astimezone(utc).strftime('%Y%m%dT%HZ')
- raw_data = series.last_from(24, end=dt)
+ end = target_datetime.astimezone(utc).strftime('%Y%m%dT%HZ')
+ start = (target_datetime.astimezone(utc) - datetime.timedelta(days=1)).strftime('%Y%m%dT%HZ')
+ raw_data = series.get_data(start=start, end=end)
else:
# Get the last 24 hours available.
raw_data = series.last(24)
|
{"golden_diff": "diff --git a/parsers/EIA.py b/parsers/EIA.py\n--- a/parsers/EIA.py\n+++ b/parsers/EIA.py\n@@ -98,6 +98,7 @@\n series = PRODUCTION_MIX_SERIES % (REGIONS[zone_key], code)\n mix = _fetch_series(zone_key, series, session=session,\n target_datetime=target_datetime, logger=logger)\n+\n if not mix:\n continue\n for point in mix:\n@@ -146,8 +147,9 @@\n if target_datetime:\n utc = tz.gettz('UTC')\n #eia currently only accepts utc timestamps in the form YYYYMMDDTHHZ\n- dt = target_datetime.astimezone(utc).strftime('%Y%m%dT%HZ')\n- raw_data = series.last_from(24, end=dt)\n+ end = target_datetime.astimezone(utc).strftime('%Y%m%dT%HZ')\n+ start = (target_datetime.astimezone(utc) - datetime.timedelta(days=1)).strftime('%Y%m%dT%HZ')\n+ raw_data = series.get_data(start=start, end=end)\n else:\n # Get the last 24 hours available.\n raw_data = series.last(24)\n", "issue": "US-DUK/EIA parser returns data for wrong date if EIA does not have data\nFound this obscure error when parsing data for US-DUK. \r\nTraceback: \r\n\r\n`Traceback (most recent call last):\r\n File \"test_parser.py\", line 86, in <module>\r\n print(test_parser())\r\n File \"/home/rob/anaconda3/envs/contrib/lib/python3.7/site-packages/click/core.py\", line 764, in __call__\r\n return self.main(*args, **kwargs)\r\n File \"/home/rob/anaconda3/envs/contrib/lib/python3.7/site-packages/click/core.py\", line 717, in main\r\n rv = self.invoke(ctx)\r\n File \"/home/rob/anaconda3/envs/contrib/lib/python3.7/site-packages/click/core.py\", line 956, in invoke\r\n return ctx.invoke(self.callback, **ctx.params)\r\n File \"/home/rob/anaconda3/envs/contrib/lib/python3.7/site-packages/click/core.py\", line 555, in invoke\r\n return callback(*args, **kwargs)\r\n File \"test_parser.py\", line 49, in test_parser\r\n res = parser(*args, target_datetime=target_datetime)\r\n File \"/home/rob/tmrow/electricitymap-contrib/parsers/EIA.py\", line 120, in fetch_production_mix\r\n return merge_production_outputs(mixes, zone_key, merge_source='eia.gov')\r\n File \"/home/rob/tmrow/electricitymap-contrib/parsers/ENTSOE.py\", line 886, in merge_production_outputs\r\n axis=1)\r\n File \"/home/rob/anaconda3/envs/contrib/lib/python3.7/site-packages/pandas/core/frame.py\", line 3487, in __setitem__\r\n self._set_item(key, value)\r\n File \"/home/rob/anaconda3/envs/contrib/lib/python3.7/site-packages/pandas/core/frame.py\", line 3563, in _set_item\r\n self._ensure_valid_index(value)\r\n File \"/home/rob/anaconda3/envs/contrib/lib/python3.7/site-packages/pandas/core/frame.py\", line 3543, in _ensure_valid_index\r\n \"Cannot set a frame with no defined index \"\r\n`\r\n\r\nIn the case of 'other' production for US-DUK, the EIA data is incomplete (see image) \r\n\r\nSo when scraping historic data, the eiapy function 'last from' returns the last 24 datapoints that it can get, which is for a date far in the past, then our parser breaks when trying to merge these in ENTSOE.merge_production_outputs \n", "before_files": [{"content": "#!/usr/bin/env python3\n\"\"\"Parser for U.S. Energy Information Administration, https://www.eia.gov/ .\n\nAggregates and standardizes data from most of the US ISOs,\nand exposes them via a unified API.\n\nRequires an API key, set in the EIA_KEY environment variable. Get one here:\nhttps://www.eia.gov/opendata/register.php\n\"\"\"\nimport datetime\nimport os\n\nimport arrow\nfrom dateutil import parser, tz\nos.environ.setdefault('EIA_KEY', 'eia_key')\nfrom eiapy import Series\nimport requests\n\nfrom .lib.validation import validate\nfrom .ENTSOE import merge_production_outputs\n\nEXCHANGES = {\n 'MX-BC->US-CA': 'EBA.CISO-CFE.ID.H',\n 'US-BPA->US-IPC': 'EBA.BPAT-IPCO.ID.H',\n 'US-SPP->US-TX': 'SWPP.ID.H-EBA.ERCO',\n 'US-MISO->US-PJM': 'EBA.MISO-PJM.ID.H',\n 'US-MISO->US-SPP': 'EBA.MISO-SWPP.ID.H',\n 'US-NEISO->US-NY': 'EBA.ISNE-NYIS.ID.H',\n 'US-NY->US-PJM': 'EBA.NYIS-PJM.ID.H'\n}\n# based on https://www.eia.gov/beta/electricity/gridmonitor/dashboard/electric_overview/US48/US48\n# or https://www.eia.gov/opendata/qb.php?category=3390101\n# List includes regions and Balancing Authorities. \nREGIONS = {\n 'US-BPA': 'BPAT',\n 'US-CA': 'CAL',\n 'US-CAR': 'CAR',\n 'US-DUK': 'DUK', #Duke Energy Carolinas\n 'US-SPP': 'CENT',\n 'US-FL': 'FLA',\n 'US-PJM': 'MIDA',\n 'US-MISO': 'MIDW',\n 'US-NEISO': 'NE',\n 'US-NEVP': 'NEVP', #Nevada Power Company\n 'US-NY': 'NY',\n 'US-NW': 'NW',\n 'US-SC': 'SC', #South Carolina Public Service Authority\n 'US-SE': 'SE',\n 'US-SEC': 'SEC',\n 'US-SOCO': 'SOCO', #Southern Company Services Inc - Trans\n 'US-SWPP': 'SWPP', #Southwest Power Pool\n 'US-SVERI': 'SW',\n 'US-TN': 'TEN',\n 'US-TX': 'TEX',\n}\nTYPES = {\n # 'biomass': 'BM', # not currently supported\n 'coal': 'COL',\n 'gas': 'NG',\n 'hydro': 'WAT',\n 'nuclear': 'NUC',\n 'oil': 'OIL',\n 'unknown': 'OTH',\n 'solar': 'SUN',\n 'wind': 'WND',\n}\nPRODUCTION_SERIES = 'EBA.%s-ALL.NG.H'\nPRODUCTION_MIX_SERIES = 'EBA.%s-ALL.NG.%s.H'\nDEMAND_SERIES = 'EBA.%s-ALL.D.H'\nFORECAST_SERIES = 'EBA.%s-ALL.DF.H'\n\n\ndef fetch_consumption_forecast(zone_key, session=None, target_datetime=None, logger=None):\n return _fetch_series(zone_key, FORECAST_SERIES % REGIONS[zone_key],\n session=session, target_datetime=target_datetime,\n logger=logger)\n\n\ndef fetch_production(zone_key, session=None, target_datetime=None, logger=None):\n return _fetch_series(zone_key, PRODUCTION_SERIES % REGIONS[zone_key],\n session=session, target_datetime=target_datetime,\n logger=logger)\n\n\ndef fetch_consumption(zone_key, session=None, target_datetime=None, logger=None):\n consumption = _fetch_series(zone_key, DEMAND_SERIES % REGIONS[zone_key],\n session=session, target_datetime=target_datetime,\n logger=logger)\n for point in consumption:\n point['consumption'] = point.pop('value')\n\n return consumption\n\n\ndef fetch_production_mix(zone_key, session=None, target_datetime=None, logger=None):\n mixes = []\n for type, code in TYPES.items():\n series = PRODUCTION_MIX_SERIES % (REGIONS[zone_key], code)\n mix = _fetch_series(zone_key, series, session=session,\n target_datetime=target_datetime, logger=logger)\n if not mix:\n continue\n for point in mix:\n if type == 'hydro' and point['value'] < 0:\n point.update({\n 'production': {},# required by merge_production_outputs()\n 'storage': {type: point.pop('value')},\n })\n else:\n point.update({\n 'production': {type: point.pop('value')},\n 'storage': {}, # required by merge_production_outputs()\n })\n\n #replace small negative values (>-5) with 0s This is necessary for solar\n point = validate(point, logger=logger, remove_negative=True)\n mixes.append(mix)\n\n return merge_production_outputs(mixes, zone_key, merge_source='eia.gov')\n\n\ndef fetch_exchange(zone_key1, zone_key2, session=None, target_datetime=None, logger=None):\n sortedcodes = '->'.join(sorted([zone_key1, zone_key2]))\n exchange = _fetch_series(sortedcodes, EXCHANGES[sortedcodes], session=session,\n target_datetime=target_datetime, logger=logger)\n for point in exchange:\n point.update({\n 'sortedZoneKeys': point.pop('zoneKey'),\n 'netFlow': point.pop('value'),\n })\n if sortedcodes == 'MX-BC->US-CA':\n point['netFlow'] = -point['netFlow']\n\n return exchange\n\n\ndef _fetch_series(zone_key, series_id, session=None, target_datetime=None,\n logger=None):\n \"\"\"Fetches and converts a data series.\"\"\"\n key = os.environ['EIA_KEY']\n assert key and key != 'eia_key', key\n\n s = session or requests.Session()\n series = Series(series_id=series_id, session=s)\n\n if target_datetime:\n utc = tz.gettz('UTC')\n #eia currently only accepts utc timestamps in the form YYYYMMDDTHHZ\n dt = target_datetime.astimezone(utc).strftime('%Y%m%dT%HZ')\n raw_data = series.last_from(24, end=dt)\n else:\n # Get the last 24 hours available.\n raw_data = series.last(24)\n\n # UTC timestamp with no offset returned.\n if not raw_data.get('series'):\n # Series doesn't exist. Probably requesting a fuel from a region that\n # doesn't have any capacity for that fuel type.\n return []\n\n return [{\n 'zoneKey': zone_key,\n 'datetime': parser.parse(datapoint[0]),\n 'value': datapoint[1],\n 'source': 'eia.gov',\n } for datapoint in raw_data['series'][0]['data']]\n\n\ndef main():\n \"Main method, never used by the Electricity Map backend, but handy for testing.\"\n from pprint import pprint\n pprint(fetch_consumption_forecast('US-NY'))\n pprint(fetch_production('US-SEC'))\n pprint(fetch_production_mix('US-TN'))\n pprint(fetch_consumption('US-CAR'))\n pprint(fetch_exchange('MX-BC', 'US-CA'))\n\n\nif __name__ == '__main__':\n main()\n", "path": "parsers/EIA.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n\"\"\"Parser for U.S. Energy Information Administration, https://www.eia.gov/ .\n\nAggregates and standardizes data from most of the US ISOs,\nand exposes them via a unified API.\n\nRequires an API key, set in the EIA_KEY environment variable. Get one here:\nhttps://www.eia.gov/opendata/register.php\n\"\"\"\nimport datetime\nimport os\n\nimport arrow\nfrom dateutil import parser, tz\nos.environ.setdefault('EIA_KEY', 'eia_key')\nfrom eiapy import Series\nimport requests\n\nfrom .lib.validation import validate\nfrom .ENTSOE import merge_production_outputs\n\nEXCHANGES = {\n 'MX-BC->US-CA': 'EBA.CISO-CFE.ID.H',\n 'US-BPA->US-IPC': 'EBA.BPAT-IPCO.ID.H',\n 'US-SPP->US-TX': 'SWPP.ID.H-EBA.ERCO',\n 'US-MISO->US-PJM': 'EBA.MISO-PJM.ID.H',\n 'US-MISO->US-SPP': 'EBA.MISO-SWPP.ID.H',\n 'US-NEISO->US-NY': 'EBA.ISNE-NYIS.ID.H',\n 'US-NY->US-PJM': 'EBA.NYIS-PJM.ID.H'\n}\n# based on https://www.eia.gov/beta/electricity/gridmonitor/dashboard/electric_overview/US48/US48\n# or https://www.eia.gov/opendata/qb.php?category=3390101\n# List includes regions and Balancing Authorities. \nREGIONS = {\n 'US-BPA': 'BPAT',\n 'US-CA': 'CAL',\n 'US-CAR': 'CAR',\n 'US-DUK': 'DUK', #Duke Energy Carolinas\n 'US-SPP': 'CENT',\n 'US-FL': 'FLA',\n 'US-PJM': 'MIDA',\n 'US-MISO': 'MIDW',\n 'US-NEISO': 'NE',\n 'US-NEVP': 'NEVP', #Nevada Power Company\n 'US-NY': 'NY',\n 'US-NW': 'NW',\n 'US-SC': 'SC', #South Carolina Public Service Authority\n 'US-SE': 'SE',\n 'US-SEC': 'SEC',\n 'US-SOCO': 'SOCO', #Southern Company Services Inc - Trans\n 'US-SWPP': 'SWPP', #Southwest Power Pool\n 'US-SVERI': 'SW',\n 'US-TN': 'TEN',\n 'US-TX': 'TEX',\n}\nTYPES = {\n # 'biomass': 'BM', # not currently supported\n 'coal': 'COL',\n 'gas': 'NG',\n 'hydro': 'WAT',\n 'nuclear': 'NUC',\n 'oil': 'OIL',\n 'unknown': 'OTH',\n 'solar': 'SUN',\n 'wind': 'WND',\n}\nPRODUCTION_SERIES = 'EBA.%s-ALL.NG.H'\nPRODUCTION_MIX_SERIES = 'EBA.%s-ALL.NG.%s.H'\nDEMAND_SERIES = 'EBA.%s-ALL.D.H'\nFORECAST_SERIES = 'EBA.%s-ALL.DF.H'\n\n\ndef fetch_consumption_forecast(zone_key, session=None, target_datetime=None, logger=None):\n return _fetch_series(zone_key, FORECAST_SERIES % REGIONS[zone_key],\n session=session, target_datetime=target_datetime,\n logger=logger)\n\n\ndef fetch_production(zone_key, session=None, target_datetime=None, logger=None):\n return _fetch_series(zone_key, PRODUCTION_SERIES % REGIONS[zone_key],\n session=session, target_datetime=target_datetime,\n logger=logger)\n\n\ndef fetch_consumption(zone_key, session=None, target_datetime=None, logger=None):\n consumption = _fetch_series(zone_key, DEMAND_SERIES % REGIONS[zone_key],\n session=session, target_datetime=target_datetime,\n logger=logger)\n for point in consumption:\n point['consumption'] = point.pop('value')\n\n return consumption\n\n\ndef fetch_production_mix(zone_key, session=None, target_datetime=None, logger=None):\n mixes = []\n for type, code in TYPES.items():\n series = PRODUCTION_MIX_SERIES % (REGIONS[zone_key], code)\n mix = _fetch_series(zone_key, series, session=session,\n target_datetime=target_datetime, logger=logger)\n\n if not mix:\n continue\n for point in mix:\n if type == 'hydro' and point['value'] < 0:\n point.update({\n 'production': {},# required by merge_production_outputs()\n 'storage': {type: point.pop('value')},\n })\n else:\n point.update({\n 'production': {type: point.pop('value')},\n 'storage': {}, # required by merge_production_outputs()\n })\n\n #replace small negative values (>-5) with 0s This is necessary for solar\n point = validate(point, logger=logger, remove_negative=True)\n mixes.append(mix)\n\n return merge_production_outputs(mixes, zone_key, merge_source='eia.gov')\n\n\ndef fetch_exchange(zone_key1, zone_key2, session=None, target_datetime=None, logger=None):\n sortedcodes = '->'.join(sorted([zone_key1, zone_key2]))\n exchange = _fetch_series(sortedcodes, EXCHANGES[sortedcodes], session=session,\n target_datetime=target_datetime, logger=logger)\n for point in exchange:\n point.update({\n 'sortedZoneKeys': point.pop('zoneKey'),\n 'netFlow': point.pop('value'),\n })\n if sortedcodes == 'MX-BC->US-CA':\n point['netFlow'] = -point['netFlow']\n\n return exchange\n\n\ndef _fetch_series(zone_key, series_id, session=None, target_datetime=None,\n logger=None):\n \"\"\"Fetches and converts a data series.\"\"\"\n key = os.environ['EIA_KEY']\n assert key and key != 'eia_key', key\n\n s = session or requests.Session()\n series = Series(series_id=series_id, session=s)\n\n if target_datetime:\n utc = tz.gettz('UTC')\n #eia currently only accepts utc timestamps in the form YYYYMMDDTHHZ\n end = target_datetime.astimezone(utc).strftime('%Y%m%dT%HZ')\n start = (target_datetime.astimezone(utc) - datetime.timedelta(days=1)).strftime('%Y%m%dT%HZ')\n raw_data = series.get_data(start=start, end=end)\n else:\n # Get the last 24 hours available.\n raw_data = series.last(24)\n\n # UTC timestamp with no offset returned.\n if not raw_data.get('series'):\n # Series doesn't exist. Probably requesting a fuel from a region that\n # doesn't have any capacity for that fuel type.\n return []\n\n return [{\n 'zoneKey': zone_key,\n 'datetime': parser.parse(datapoint[0]),\n 'value': datapoint[1],\n 'source': 'eia.gov',\n } for datapoint in raw_data['series'][0]['data']]\n\n\ndef main():\n \"Main method, never used by the Electricity Map backend, but handy for testing.\"\n from pprint import pprint\n pprint(fetch_consumption_forecast('US-NY'))\n pprint(fetch_production('US-SEC'))\n pprint(fetch_production_mix('US-TN'))\n pprint(fetch_consumption('US-CAR'))\n pprint(fetch_exchange('MX-BC', 'US-CA'))\n\n\nif __name__ == '__main__':\n main()\n", "path": "parsers/EIA.py"}]}
| 3,004 | 272 |
gh_patches_debug_773
|
rasdani/github-patches
|
git_diff
|
python-pillow__Pillow-4788
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
PSD Plugin does not register a MIME type
The [`PSDImagePlugin`](https://github.com/python-pillow/Pillow/blob/master/src/PIL/PsdImagePlugin.py) does not register a MIME type as I'd expect it to. The correct MIME for PSD images, according to IANA, is ["image/vnd.adobe.photoshop"](https://www.iana.org/assignments/media-types/image/vnd.adobe.photoshop).
Is there a reason this isn't registered?
PSD Plugin does not register a MIME type
The [`PSDImagePlugin`](https://github.com/python-pillow/Pillow/blob/master/src/PIL/PsdImagePlugin.py) does not register a MIME type as I'd expect it to. The correct MIME for PSD images, according to IANA, is ["image/vnd.adobe.photoshop"](https://www.iana.org/assignments/media-types/image/vnd.adobe.photoshop).
Is there a reason this isn't registered?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/PIL/PsdImagePlugin.py`
Content:
```
1 #
2 # The Python Imaging Library
3 # $Id$
4 #
5 # Adobe PSD 2.5/3.0 file handling
6 #
7 # History:
8 # 1995-09-01 fl Created
9 # 1997-01-03 fl Read most PSD images
10 # 1997-01-18 fl Fixed P and CMYK support
11 # 2001-10-21 fl Added seek/tell support (for layers)
12 #
13 # Copyright (c) 1997-2001 by Secret Labs AB.
14 # Copyright (c) 1995-2001 by Fredrik Lundh
15 #
16 # See the README file for information on usage and redistribution.
17 #
18
19 import io
20
21 from . import Image, ImageFile, ImagePalette
22 from ._binary import i8, i16be as i16, i32be as i32
23
24 MODES = {
25 # (photoshop mode, bits) -> (pil mode, required channels)
26 (0, 1): ("1", 1),
27 (0, 8): ("L", 1),
28 (1, 8): ("L", 1),
29 (2, 8): ("P", 1),
30 (3, 8): ("RGB", 3),
31 (4, 8): ("CMYK", 4),
32 (7, 8): ("L", 1), # FIXME: multilayer
33 (8, 8): ("L", 1), # duotone
34 (9, 8): ("LAB", 3),
35 }
36
37
38 # --------------------------------------------------------------------.
39 # read PSD images
40
41
42 def _accept(prefix):
43 return prefix[:4] == b"8BPS"
44
45
46 ##
47 # Image plugin for Photoshop images.
48
49
50 class PsdImageFile(ImageFile.ImageFile):
51
52 format = "PSD"
53 format_description = "Adobe Photoshop"
54 _close_exclusive_fp_after_loading = False
55
56 def _open(self):
57
58 read = self.fp.read
59
60 #
61 # header
62
63 s = read(26)
64 if not _accept(s) or i16(s[4:]) != 1:
65 raise SyntaxError("not a PSD file")
66
67 psd_bits = i16(s[22:])
68 psd_channels = i16(s[12:])
69 psd_mode = i16(s[24:])
70
71 mode, channels = MODES[(psd_mode, psd_bits)]
72
73 if channels > psd_channels:
74 raise OSError("not enough channels")
75
76 self.mode = mode
77 self._size = i32(s[18:]), i32(s[14:])
78
79 #
80 # color mode data
81
82 size = i32(read(4))
83 if size:
84 data = read(size)
85 if mode == "P" and size == 768:
86 self.palette = ImagePalette.raw("RGB;L", data)
87
88 #
89 # image resources
90
91 self.resources = []
92
93 size = i32(read(4))
94 if size:
95 # load resources
96 end = self.fp.tell() + size
97 while self.fp.tell() < end:
98 read(4) # signature
99 id = i16(read(2))
100 name = read(i8(read(1)))
101 if not (len(name) & 1):
102 read(1) # padding
103 data = read(i32(read(4)))
104 if len(data) & 1:
105 read(1) # padding
106 self.resources.append((id, name, data))
107 if id == 1039: # ICC profile
108 self.info["icc_profile"] = data
109
110 #
111 # layer and mask information
112
113 self.layers = []
114
115 size = i32(read(4))
116 if size:
117 end = self.fp.tell() + size
118 size = i32(read(4))
119 if size:
120 self.layers = _layerinfo(self.fp)
121 self.fp.seek(end)
122 self.n_frames = len(self.layers)
123 self.is_animated = self.n_frames > 1
124
125 #
126 # image descriptor
127
128 self.tile = _maketile(self.fp, mode, (0, 0) + self.size, channels)
129
130 # keep the file open
131 self.__fp = self.fp
132 self.frame = 1
133 self._min_frame = 1
134
135 def seek(self, layer):
136 if not self._seek_check(layer):
137 return
138
139 # seek to given layer (1..max)
140 try:
141 name, mode, bbox, tile = self.layers[layer - 1]
142 self.mode = mode
143 self.tile = tile
144 self.frame = layer
145 self.fp = self.__fp
146 return name, bbox
147 except IndexError as e:
148 raise EOFError("no such layer") from e
149
150 def tell(self):
151 # return layer number (0=image, 1..max=layers)
152 return self.frame
153
154 def load_prepare(self):
155 # create image memory if necessary
156 if not self.im or self.im.mode != self.mode or self.im.size != self.size:
157 self.im = Image.core.fill(self.mode, self.size, 0)
158 # create palette (optional)
159 if self.mode == "P":
160 Image.Image.load(self)
161
162 def _close__fp(self):
163 try:
164 if self.__fp != self.fp:
165 self.__fp.close()
166 except AttributeError:
167 pass
168 finally:
169 self.__fp = None
170
171
172 def _layerinfo(file):
173 # read layerinfo block
174 layers = []
175 read = file.read
176 for i in range(abs(i16(read(2)))):
177
178 # bounding box
179 y0 = i32(read(4))
180 x0 = i32(read(4))
181 y1 = i32(read(4))
182 x1 = i32(read(4))
183
184 # image info
185 info = []
186 mode = []
187 types = list(range(i16(read(2))))
188 if len(types) > 4:
189 continue
190
191 for i in types:
192 type = i16(read(2))
193
194 if type == 65535:
195 m = "A"
196 else:
197 m = "RGBA"[type]
198
199 mode.append(m)
200 size = i32(read(4))
201 info.append((m, size))
202
203 # figure out the image mode
204 mode.sort()
205 if mode == ["R"]:
206 mode = "L"
207 elif mode == ["B", "G", "R"]:
208 mode = "RGB"
209 elif mode == ["A", "B", "G", "R"]:
210 mode = "RGBA"
211 else:
212 mode = None # unknown
213
214 # skip over blend flags and extra information
215 read(12) # filler
216 name = ""
217 size = i32(read(4)) # length of the extra data field
218 combined = 0
219 if size:
220 data_end = file.tell() + size
221
222 length = i32(read(4))
223 if length:
224 file.seek(length - 16, io.SEEK_CUR)
225 combined += length + 4
226
227 length = i32(read(4))
228 if length:
229 file.seek(length, io.SEEK_CUR)
230 combined += length + 4
231
232 length = i8(read(1))
233 if length:
234 # Don't know the proper encoding,
235 # Latin-1 should be a good guess
236 name = read(length).decode("latin-1", "replace")
237 combined += length + 1
238
239 file.seek(data_end)
240 layers.append((name, mode, (x0, y0, x1, y1)))
241
242 # get tiles
243 i = 0
244 for name, mode, bbox in layers:
245 tile = []
246 for m in mode:
247 t = _maketile(file, m, bbox, 1)
248 if t:
249 tile.extend(t)
250 layers[i] = name, mode, bbox, tile
251 i += 1
252
253 return layers
254
255
256 def _maketile(file, mode, bbox, channels):
257
258 tile = None
259 read = file.read
260
261 compression = i16(read(2))
262
263 xsize = bbox[2] - bbox[0]
264 ysize = bbox[3] - bbox[1]
265
266 offset = file.tell()
267
268 if compression == 0:
269 #
270 # raw compression
271 tile = []
272 for channel in range(channels):
273 layer = mode[channel]
274 if mode == "CMYK":
275 layer += ";I"
276 tile.append(("raw", bbox, offset, layer))
277 offset = offset + xsize * ysize
278
279 elif compression == 1:
280 #
281 # packbits compression
282 i = 0
283 tile = []
284 bytecount = read(channels * ysize * 2)
285 offset = file.tell()
286 for channel in range(channels):
287 layer = mode[channel]
288 if mode == "CMYK":
289 layer += ";I"
290 tile.append(("packbits", bbox, offset, layer))
291 for y in range(ysize):
292 offset = offset + i16(bytecount[i : i + 2])
293 i += 2
294
295 file.seek(offset)
296
297 if offset & 1:
298 read(1) # padding
299
300 return tile
301
302
303 # --------------------------------------------------------------------
304 # registry
305
306
307 Image.register_open(PsdImageFile.format, PsdImageFile, _accept)
308
309 Image.register_extension(PsdImageFile.format, ".psd")
310
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/PIL/PsdImagePlugin.py b/src/PIL/PsdImagePlugin.py
--- a/src/PIL/PsdImagePlugin.py
+++ b/src/PIL/PsdImagePlugin.py
@@ -307,3 +307,5 @@
Image.register_open(PsdImageFile.format, PsdImageFile, _accept)
Image.register_extension(PsdImageFile.format, ".psd")
+
+Image.register_mime(PsdImageFile.format, "image/vnd.adobe.photoshop")
|
{"golden_diff": "diff --git a/src/PIL/PsdImagePlugin.py b/src/PIL/PsdImagePlugin.py\n--- a/src/PIL/PsdImagePlugin.py\n+++ b/src/PIL/PsdImagePlugin.py\n@@ -307,3 +307,5 @@\n Image.register_open(PsdImageFile.format, PsdImageFile, _accept)\n \n Image.register_extension(PsdImageFile.format, \".psd\")\n+\n+Image.register_mime(PsdImageFile.format, \"image/vnd.adobe.photoshop\")\n", "issue": "PSD Plugin does not register a MIME type\nThe [`PSDImagePlugin`](https://github.com/python-pillow/Pillow/blob/master/src/PIL/PsdImagePlugin.py) does not register a MIME type as I'd expect it to. The correct MIME for PSD images, according to IANA, is [\"image/vnd.adobe.photoshop\"](https://www.iana.org/assignments/media-types/image/vnd.adobe.photoshop).\r\n\r\nIs there a reason this isn't registered?\nPSD Plugin does not register a MIME type\nThe [`PSDImagePlugin`](https://github.com/python-pillow/Pillow/blob/master/src/PIL/PsdImagePlugin.py) does not register a MIME type as I'd expect it to. The correct MIME for PSD images, according to IANA, is [\"image/vnd.adobe.photoshop\"](https://www.iana.org/assignments/media-types/image/vnd.adobe.photoshop).\r\n\r\nIs there a reason this isn't registered?\n", "before_files": [{"content": "#\n# The Python Imaging Library\n# $Id$\n#\n# Adobe PSD 2.5/3.0 file handling\n#\n# History:\n# 1995-09-01 fl Created\n# 1997-01-03 fl Read most PSD images\n# 1997-01-18 fl Fixed P and CMYK support\n# 2001-10-21 fl Added seek/tell support (for layers)\n#\n# Copyright (c) 1997-2001 by Secret Labs AB.\n# Copyright (c) 1995-2001 by Fredrik Lundh\n#\n# See the README file for information on usage and redistribution.\n#\n\nimport io\n\nfrom . import Image, ImageFile, ImagePalette\nfrom ._binary import i8, i16be as i16, i32be as i32\n\nMODES = {\n # (photoshop mode, bits) -> (pil mode, required channels)\n (0, 1): (\"1\", 1),\n (0, 8): (\"L\", 1),\n (1, 8): (\"L\", 1),\n (2, 8): (\"P\", 1),\n (3, 8): (\"RGB\", 3),\n (4, 8): (\"CMYK\", 4),\n (7, 8): (\"L\", 1), # FIXME: multilayer\n (8, 8): (\"L\", 1), # duotone\n (9, 8): (\"LAB\", 3),\n}\n\n\n# --------------------------------------------------------------------.\n# read PSD images\n\n\ndef _accept(prefix):\n return prefix[:4] == b\"8BPS\"\n\n\n##\n# Image plugin for Photoshop images.\n\n\nclass PsdImageFile(ImageFile.ImageFile):\n\n format = \"PSD\"\n format_description = \"Adobe Photoshop\"\n _close_exclusive_fp_after_loading = False\n\n def _open(self):\n\n read = self.fp.read\n\n #\n # header\n\n s = read(26)\n if not _accept(s) or i16(s[4:]) != 1:\n raise SyntaxError(\"not a PSD file\")\n\n psd_bits = i16(s[22:])\n psd_channels = i16(s[12:])\n psd_mode = i16(s[24:])\n\n mode, channels = MODES[(psd_mode, psd_bits)]\n\n if channels > psd_channels:\n raise OSError(\"not enough channels\")\n\n self.mode = mode\n self._size = i32(s[18:]), i32(s[14:])\n\n #\n # color mode data\n\n size = i32(read(4))\n if size:\n data = read(size)\n if mode == \"P\" and size == 768:\n self.palette = ImagePalette.raw(\"RGB;L\", data)\n\n #\n # image resources\n\n self.resources = []\n\n size = i32(read(4))\n if size:\n # load resources\n end = self.fp.tell() + size\n while self.fp.tell() < end:\n read(4) # signature\n id = i16(read(2))\n name = read(i8(read(1)))\n if not (len(name) & 1):\n read(1) # padding\n data = read(i32(read(4)))\n if len(data) & 1:\n read(1) # padding\n self.resources.append((id, name, data))\n if id == 1039: # ICC profile\n self.info[\"icc_profile\"] = data\n\n #\n # layer and mask information\n\n self.layers = []\n\n size = i32(read(4))\n if size:\n end = self.fp.tell() + size\n size = i32(read(4))\n if size:\n self.layers = _layerinfo(self.fp)\n self.fp.seek(end)\n self.n_frames = len(self.layers)\n self.is_animated = self.n_frames > 1\n\n #\n # image descriptor\n\n self.tile = _maketile(self.fp, mode, (0, 0) + self.size, channels)\n\n # keep the file open\n self.__fp = self.fp\n self.frame = 1\n self._min_frame = 1\n\n def seek(self, layer):\n if not self._seek_check(layer):\n return\n\n # seek to given layer (1..max)\n try:\n name, mode, bbox, tile = self.layers[layer - 1]\n self.mode = mode\n self.tile = tile\n self.frame = layer\n self.fp = self.__fp\n return name, bbox\n except IndexError as e:\n raise EOFError(\"no such layer\") from e\n\n def tell(self):\n # return layer number (0=image, 1..max=layers)\n return self.frame\n\n def load_prepare(self):\n # create image memory if necessary\n if not self.im or self.im.mode != self.mode or self.im.size != self.size:\n self.im = Image.core.fill(self.mode, self.size, 0)\n # create palette (optional)\n if self.mode == \"P\":\n Image.Image.load(self)\n\n def _close__fp(self):\n try:\n if self.__fp != self.fp:\n self.__fp.close()\n except AttributeError:\n pass\n finally:\n self.__fp = None\n\n\ndef _layerinfo(file):\n # read layerinfo block\n layers = []\n read = file.read\n for i in range(abs(i16(read(2)))):\n\n # bounding box\n y0 = i32(read(4))\n x0 = i32(read(4))\n y1 = i32(read(4))\n x1 = i32(read(4))\n\n # image info\n info = []\n mode = []\n types = list(range(i16(read(2))))\n if len(types) > 4:\n continue\n\n for i in types:\n type = i16(read(2))\n\n if type == 65535:\n m = \"A\"\n else:\n m = \"RGBA\"[type]\n\n mode.append(m)\n size = i32(read(4))\n info.append((m, size))\n\n # figure out the image mode\n mode.sort()\n if mode == [\"R\"]:\n mode = \"L\"\n elif mode == [\"B\", \"G\", \"R\"]:\n mode = \"RGB\"\n elif mode == [\"A\", \"B\", \"G\", \"R\"]:\n mode = \"RGBA\"\n else:\n mode = None # unknown\n\n # skip over blend flags and extra information\n read(12) # filler\n name = \"\"\n size = i32(read(4)) # length of the extra data field\n combined = 0\n if size:\n data_end = file.tell() + size\n\n length = i32(read(4))\n if length:\n file.seek(length - 16, io.SEEK_CUR)\n combined += length + 4\n\n length = i32(read(4))\n if length:\n file.seek(length, io.SEEK_CUR)\n combined += length + 4\n\n length = i8(read(1))\n if length:\n # Don't know the proper encoding,\n # Latin-1 should be a good guess\n name = read(length).decode(\"latin-1\", \"replace\")\n combined += length + 1\n\n file.seek(data_end)\n layers.append((name, mode, (x0, y0, x1, y1)))\n\n # get tiles\n i = 0\n for name, mode, bbox in layers:\n tile = []\n for m in mode:\n t = _maketile(file, m, bbox, 1)\n if t:\n tile.extend(t)\n layers[i] = name, mode, bbox, tile\n i += 1\n\n return layers\n\n\ndef _maketile(file, mode, bbox, channels):\n\n tile = None\n read = file.read\n\n compression = i16(read(2))\n\n xsize = bbox[2] - bbox[0]\n ysize = bbox[3] - bbox[1]\n\n offset = file.tell()\n\n if compression == 0:\n #\n # raw compression\n tile = []\n for channel in range(channels):\n layer = mode[channel]\n if mode == \"CMYK\":\n layer += \";I\"\n tile.append((\"raw\", bbox, offset, layer))\n offset = offset + xsize * ysize\n\n elif compression == 1:\n #\n # packbits compression\n i = 0\n tile = []\n bytecount = read(channels * ysize * 2)\n offset = file.tell()\n for channel in range(channels):\n layer = mode[channel]\n if mode == \"CMYK\":\n layer += \";I\"\n tile.append((\"packbits\", bbox, offset, layer))\n for y in range(ysize):\n offset = offset + i16(bytecount[i : i + 2])\n i += 2\n\n file.seek(offset)\n\n if offset & 1:\n read(1) # padding\n\n return tile\n\n\n# --------------------------------------------------------------------\n# registry\n\n\nImage.register_open(PsdImageFile.format, PsdImageFile, _accept)\n\nImage.register_extension(PsdImageFile.format, \".psd\")\n", "path": "src/PIL/PsdImagePlugin.py"}], "after_files": [{"content": "#\n# The Python Imaging Library\n# $Id$\n#\n# Adobe PSD 2.5/3.0 file handling\n#\n# History:\n# 1995-09-01 fl Created\n# 1997-01-03 fl Read most PSD images\n# 1997-01-18 fl Fixed P and CMYK support\n# 2001-10-21 fl Added seek/tell support (for layers)\n#\n# Copyright (c) 1997-2001 by Secret Labs AB.\n# Copyright (c) 1995-2001 by Fredrik Lundh\n#\n# See the README file for information on usage and redistribution.\n#\n\nimport io\n\nfrom . import Image, ImageFile, ImagePalette\nfrom ._binary import i8, i16be as i16, i32be as i32\n\nMODES = {\n # (photoshop mode, bits) -> (pil mode, required channels)\n (0, 1): (\"1\", 1),\n (0, 8): (\"L\", 1),\n (1, 8): (\"L\", 1),\n (2, 8): (\"P\", 1),\n (3, 8): (\"RGB\", 3),\n (4, 8): (\"CMYK\", 4),\n (7, 8): (\"L\", 1), # FIXME: multilayer\n (8, 8): (\"L\", 1), # duotone\n (9, 8): (\"LAB\", 3),\n}\n\n\n# --------------------------------------------------------------------.\n# read PSD images\n\n\ndef _accept(prefix):\n return prefix[:4] == b\"8BPS\"\n\n\n##\n# Image plugin for Photoshop images.\n\n\nclass PsdImageFile(ImageFile.ImageFile):\n\n format = \"PSD\"\n format_description = \"Adobe Photoshop\"\n _close_exclusive_fp_after_loading = False\n\n def _open(self):\n\n read = self.fp.read\n\n #\n # header\n\n s = read(26)\n if not _accept(s) or i16(s[4:]) != 1:\n raise SyntaxError(\"not a PSD file\")\n\n psd_bits = i16(s[22:])\n psd_channels = i16(s[12:])\n psd_mode = i16(s[24:])\n\n mode, channels = MODES[(psd_mode, psd_bits)]\n\n if channels > psd_channels:\n raise OSError(\"not enough channels\")\n\n self.mode = mode\n self._size = i32(s[18:]), i32(s[14:])\n\n #\n # color mode data\n\n size = i32(read(4))\n if size:\n data = read(size)\n if mode == \"P\" and size == 768:\n self.palette = ImagePalette.raw(\"RGB;L\", data)\n\n #\n # image resources\n\n self.resources = []\n\n size = i32(read(4))\n if size:\n # load resources\n end = self.fp.tell() + size\n while self.fp.tell() < end:\n read(4) # signature\n id = i16(read(2))\n name = read(i8(read(1)))\n if not (len(name) & 1):\n read(1) # padding\n data = read(i32(read(4)))\n if len(data) & 1:\n read(1) # padding\n self.resources.append((id, name, data))\n if id == 1039: # ICC profile\n self.info[\"icc_profile\"] = data\n\n #\n # layer and mask information\n\n self.layers = []\n\n size = i32(read(4))\n if size:\n end = self.fp.tell() + size\n size = i32(read(4))\n if size:\n self.layers = _layerinfo(self.fp)\n self.fp.seek(end)\n self.n_frames = len(self.layers)\n self.is_animated = self.n_frames > 1\n\n #\n # image descriptor\n\n self.tile = _maketile(self.fp, mode, (0, 0) + self.size, channels)\n\n # keep the file open\n self.__fp = self.fp\n self.frame = 1\n self._min_frame = 1\n\n def seek(self, layer):\n if not self._seek_check(layer):\n return\n\n # seek to given layer (1..max)\n try:\n name, mode, bbox, tile = self.layers[layer - 1]\n self.mode = mode\n self.tile = tile\n self.frame = layer\n self.fp = self.__fp\n return name, bbox\n except IndexError as e:\n raise EOFError(\"no such layer\") from e\n\n def tell(self):\n # return layer number (0=image, 1..max=layers)\n return self.frame\n\n def load_prepare(self):\n # create image memory if necessary\n if not self.im or self.im.mode != self.mode or self.im.size != self.size:\n self.im = Image.core.fill(self.mode, self.size, 0)\n # create palette (optional)\n if self.mode == \"P\":\n Image.Image.load(self)\n\n def _close__fp(self):\n try:\n if self.__fp != self.fp:\n self.__fp.close()\n except AttributeError:\n pass\n finally:\n self.__fp = None\n\n\ndef _layerinfo(file):\n # read layerinfo block\n layers = []\n read = file.read\n for i in range(abs(i16(read(2)))):\n\n # bounding box\n y0 = i32(read(4))\n x0 = i32(read(4))\n y1 = i32(read(4))\n x1 = i32(read(4))\n\n # image info\n info = []\n mode = []\n types = list(range(i16(read(2))))\n if len(types) > 4:\n continue\n\n for i in types:\n type = i16(read(2))\n\n if type == 65535:\n m = \"A\"\n else:\n m = \"RGBA\"[type]\n\n mode.append(m)\n size = i32(read(4))\n info.append((m, size))\n\n # figure out the image mode\n mode.sort()\n if mode == [\"R\"]:\n mode = \"L\"\n elif mode == [\"B\", \"G\", \"R\"]:\n mode = \"RGB\"\n elif mode == [\"A\", \"B\", \"G\", \"R\"]:\n mode = \"RGBA\"\n else:\n mode = None # unknown\n\n # skip over blend flags and extra information\n read(12) # filler\n name = \"\"\n size = i32(read(4)) # length of the extra data field\n combined = 0\n if size:\n data_end = file.tell() + size\n\n length = i32(read(4))\n if length:\n file.seek(length - 16, io.SEEK_CUR)\n combined += length + 4\n\n length = i32(read(4))\n if length:\n file.seek(length, io.SEEK_CUR)\n combined += length + 4\n\n length = i8(read(1))\n if length:\n # Don't know the proper encoding,\n # Latin-1 should be a good guess\n name = read(length).decode(\"latin-1\", \"replace\")\n combined += length + 1\n\n file.seek(data_end)\n layers.append((name, mode, (x0, y0, x1, y1)))\n\n # get tiles\n i = 0\n for name, mode, bbox in layers:\n tile = []\n for m in mode:\n t = _maketile(file, m, bbox, 1)\n if t:\n tile.extend(t)\n layers[i] = name, mode, bbox, tile\n i += 1\n\n return layers\n\n\ndef _maketile(file, mode, bbox, channels):\n\n tile = None\n read = file.read\n\n compression = i16(read(2))\n\n xsize = bbox[2] - bbox[0]\n ysize = bbox[3] - bbox[1]\n\n offset = file.tell()\n\n if compression == 0:\n #\n # raw compression\n tile = []\n for channel in range(channels):\n layer = mode[channel]\n if mode == \"CMYK\":\n layer += \";I\"\n tile.append((\"raw\", bbox, offset, layer))\n offset = offset + xsize * ysize\n\n elif compression == 1:\n #\n # packbits compression\n i = 0\n tile = []\n bytecount = read(channels * ysize * 2)\n offset = file.tell()\n for channel in range(channels):\n layer = mode[channel]\n if mode == \"CMYK\":\n layer += \";I\"\n tile.append((\"packbits\", bbox, offset, layer))\n for y in range(ysize):\n offset = offset + i16(bytecount[i : i + 2])\n i += 2\n\n file.seek(offset)\n\n if offset & 1:\n read(1) # padding\n\n return tile\n\n\n# --------------------------------------------------------------------\n# registry\n\n\nImage.register_open(PsdImageFile.format, PsdImageFile, _accept)\n\nImage.register_extension(PsdImageFile.format, \".psd\")\n\nImage.register_mime(PsdImageFile.format, \"image/vnd.adobe.photoshop\")\n", "path": "src/PIL/PsdImagePlugin.py"}]}
| 3,422 | 108 |
gh_patches_debug_41090
|
rasdani/github-patches
|
git_diff
|
deepset-ai__haystack-7983
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add `max_retries` and `timeout` params to all `AzureOpenAI` classes
**Is your feature request related to a problem? Please describe.**
Currently all `OpenAI` related classes (e.g. `OpenAIDocumentEmbedder`, `OpenAIChatGenerator`) can be initialised by setting `max_retries` and `timeout` params.
The corresponding `AzureOpenAI` don't always have the same params.
**Describe the solution you'd like**
It would be nice to have these params in the `AzureOpenAI` classes
**Describe alternatives you've considered**
Subclass `AzureOpenAI` and create custom components.
**Additional context**
cc @anakin87 :)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `haystack/components/generators/azure.py`
Content:
```
1 # SPDX-FileCopyrightText: 2022-present deepset GmbH <[email protected]>
2 #
3 # SPDX-License-Identifier: Apache-2.0
4
5 import os
6 from typing import Any, Callable, Dict, Optional
7
8 # pylint: disable=import-error
9 from openai.lib.azure import AzureOpenAI
10
11 from haystack import component, default_from_dict, default_to_dict, logging
12 from haystack.components.generators import OpenAIGenerator
13 from haystack.dataclasses import StreamingChunk
14 from haystack.utils import Secret, deserialize_callable, deserialize_secrets_inplace, serialize_callable
15
16 logger = logging.getLogger(__name__)
17
18
19 @component
20 class AzureOpenAIGenerator(OpenAIGenerator):
21 """
22 A Generator component that uses OpenAI's large language models (LLMs) on Azure to generate text.
23
24 It supports gpt-4 and gpt-3.5-turbo family of models.
25
26 Users can pass any text generation parameters valid for the `openai.ChatCompletion.create` method
27 directly to this component via the `**generation_kwargs` parameter in __init__ or the `**generation_kwargs`
28 parameter in `run` method.
29
30 For more details on OpenAI models deployed on Azure, refer to the Microsoft
31 [documentation](https://learn.microsoft.com/en-us/azure/ai-services/openai/).
32
33 Usage example:
34 ```python
35 from haystack.components.generators import AzureOpenAIGenerator
36 from haystack.utils import Secret
37 client = AzureOpenAIGenerator(
38 azure_endpoint="<Your Azure endpoint e.g. `https://your-company.azure.openai.com/>",
39 api_key=Secret.from_token("<your-api-key>"),
40 azure_deployment="<this a model name, e.g. gpt-35-turbo>")
41 response = client.run("What's Natural Language Processing? Be brief.")
42 print(response)
43 ```
44
45 ```
46 >> {'replies': ['Natural Language Processing (NLP) is a branch of artificial intelligence that focuses on
47 >> the interaction between computers and human language. It involves enabling computers to understand, interpret,
48 >> and respond to natural human language in a way that is both meaningful and useful.'], 'meta': [{'model':
49 >> 'gpt-3.5-turbo-0613', 'index': 0, 'finish_reason': 'stop', 'usage': {'prompt_tokens': 16,
50 >> 'completion_tokens': 49, 'total_tokens': 65}}]}
51 ```
52 """
53
54 # pylint: disable=super-init-not-called
55 def __init__(
56 self,
57 azure_endpoint: Optional[str] = None,
58 api_version: Optional[str] = "2023-05-15",
59 azure_deployment: Optional[str] = "gpt-35-turbo",
60 api_key: Optional[Secret] = Secret.from_env_var("AZURE_OPENAI_API_KEY", strict=False),
61 azure_ad_token: Optional[Secret] = Secret.from_env_var("AZURE_OPENAI_AD_TOKEN", strict=False),
62 organization: Optional[str] = None,
63 streaming_callback: Optional[Callable[[StreamingChunk], None]] = None,
64 system_prompt: Optional[str] = None,
65 timeout: Optional[float] = None,
66 generation_kwargs: Optional[Dict[str, Any]] = None,
67 ):
68 """
69 Initialize the Azure OpenAI Generator.
70
71 :param azure_endpoint: The endpoint of the deployed model, e.g. `https://example-resource.azure.openai.com/`
72 :param api_version: The version of the API to use. Defaults to 2023-05-15
73 :param azure_deployment: The deployment of the model, usually the model name.
74 :param api_key: The API key to use for authentication.
75 :param azure_ad_token: [Azure Active Directory token](https://www.microsoft.com/en-us/security/business/identity-access/microsoft-entra-id)
76 :param organization: The Organization ID, defaults to `None`. See
77 [production best practices](https://platform.openai.com/docs/guides/production-best-practices/setting-up-your-organization).
78 :param streaming_callback: A callback function that is called when a new token is received from the stream.
79 The callback function accepts StreamingChunk as an argument.
80 :param system_prompt: The prompt to use for the system. If not provided, the system prompt will be
81 :param timeout: The timeout to be passed to the underlying `AzureOpenAI` client.
82 :param generation_kwargs: Other parameters to use for the model. These parameters are all sent directly to
83 the OpenAI endpoint. See OpenAI [documentation](https://platform.openai.com/docs/api-reference/chat) for
84 more details.
85 Some of the supported parameters:
86 - `max_tokens`: The maximum number of tokens the output text can have.
87 - `temperature`: What sampling temperature to use. Higher values mean the model will take more risks.
88 Try 0.9 for more creative applications and 0 (argmax sampling) for ones with a well-defined answer.
89 - `top_p`: An alternative to sampling with temperature, called nucleus sampling, where the model
90 considers the results of the tokens with top_p probability mass. So 0.1 means only the tokens
91 comprising the top 10% probability mass are considered.
92 - `n`: How many completions to generate for each prompt. For example, if the LLM gets 3 prompts and n is 2,
93 it will generate two completions for each of the three prompts, ending up with 6 completions in total.
94 - `stop`: One or more sequences after which the LLM should stop generating tokens.
95 - `presence_penalty`: What penalty to apply if a token is already present at all. Bigger values mean
96 the model will be less likely to repeat the same token in the text.
97 - `frequency_penalty`: What penalty to apply if a token has already been generated in the text.
98 Bigger values mean the model will be less likely to repeat the same token in the text.
99 - `logit_bias`: Add a logit bias to specific tokens. The keys of the dictionary are tokens, and the
100 values are the bias to add to that token.
101 """
102 # We intentionally do not call super().__init__ here because we only need to instantiate the client to interact
103 # with the API.
104
105 # Why is this here?
106 # AzureOpenAI init is forcing us to use an init method that takes either base_url or azure_endpoint as not
107 # None init parameters. This way we accommodate the use case where env var AZURE_OPENAI_ENDPOINT is set instead
108 # of passing it as a parameter.
109 azure_endpoint = azure_endpoint or os.environ.get("AZURE_OPENAI_ENDPOINT")
110 if not azure_endpoint:
111 raise ValueError("Please provide an Azure endpoint or set the environment variable AZURE_OPENAI_ENDPOINT.")
112
113 if api_key is None and azure_ad_token is None:
114 raise ValueError("Please provide an API key or an Azure Active Directory token.")
115
116 # The check above makes mypy incorrectly infer that api_key is never None,
117 # which propagates the incorrect type.
118 self.api_key = api_key # type: ignore
119 self.azure_ad_token = azure_ad_token
120 self.generation_kwargs = generation_kwargs or {}
121 self.system_prompt = system_prompt
122 self.streaming_callback = streaming_callback
123 self.api_version = api_version
124 self.azure_endpoint = azure_endpoint
125 self.azure_deployment = azure_deployment
126 self.organization = organization
127 self.model: str = azure_deployment or "gpt-35-turbo"
128 self.timeout = timeout
129
130 self.client = AzureOpenAI(
131 api_version=api_version,
132 azure_endpoint=azure_endpoint,
133 azure_deployment=azure_deployment,
134 api_key=api_key.resolve_value() if api_key is not None else None,
135 azure_ad_token=azure_ad_token.resolve_value() if azure_ad_token is not None else None,
136 organization=organization,
137 timeout=timeout,
138 )
139
140 def to_dict(self) -> Dict[str, Any]:
141 """
142 Serialize this component to a dictionary.
143
144 :returns:
145 The serialized component as a dictionary.
146 """
147 callback_name = serialize_callable(self.streaming_callback) if self.streaming_callback else None
148 return default_to_dict(
149 self,
150 azure_endpoint=self.azure_endpoint,
151 azure_deployment=self.azure_deployment,
152 organization=self.organization,
153 api_version=self.api_version,
154 streaming_callback=callback_name,
155 generation_kwargs=self.generation_kwargs,
156 system_prompt=self.system_prompt,
157 api_key=self.api_key.to_dict() if self.api_key is not None else None,
158 azure_ad_token=self.azure_ad_token.to_dict() if self.azure_ad_token is not None else None,
159 timeout=self.timeout,
160 )
161
162 @classmethod
163 def from_dict(cls, data: Dict[str, Any]) -> "AzureOpenAIGenerator":
164 """
165 Deserialize this component from a dictionary.
166
167 :param data:
168 The dictionary representation of this component.
169 :returns:
170 The deserialized component instance.
171 """
172 deserialize_secrets_inplace(data["init_parameters"], keys=["api_key", "azure_ad_token"])
173 init_params = data.get("init_parameters", {})
174 serialized_callback_handler = init_params.get("streaming_callback")
175 if serialized_callback_handler:
176 data["init_parameters"]["streaming_callback"] = deserialize_callable(serialized_callback_handler)
177 return default_from_dict(cls, data)
178
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/haystack/components/generators/azure.py b/haystack/components/generators/azure.py
--- a/haystack/components/generators/azure.py
+++ b/haystack/components/generators/azure.py
@@ -63,6 +63,7 @@
streaming_callback: Optional[Callable[[StreamingChunk], None]] = None,
system_prompt: Optional[str] = None,
timeout: Optional[float] = None,
+ max_retries: Optional[int] = None,
generation_kwargs: Optional[Dict[str, Any]] = None,
):
"""
@@ -78,7 +79,10 @@
:param streaming_callback: A callback function that is called when a new token is received from the stream.
The callback function accepts StreamingChunk as an argument.
:param system_prompt: The prompt to use for the system. If not provided, the system prompt will be
- :param timeout: The timeout to be passed to the underlying `AzureOpenAI` client.
+ :param timeout: The timeout to be passed to the underlying `AzureOpenAI` client, if not set it is
+ inferred from the `OPENAI_TIMEOUT` environment variable or set to 30.
+ :param max_retries: Maximum retries to establish contact with AzureOpenAI if it returns an internal error,
+ if not set it is inferred from the `OPENAI_MAX_RETRIES` environment variable or set to 5.
:param generation_kwargs: Other parameters to use for the model. These parameters are all sent directly to
the OpenAI endpoint. See OpenAI [documentation](https://platform.openai.com/docs/api-reference/chat) for
more details.
@@ -125,7 +129,8 @@
self.azure_deployment = azure_deployment
self.organization = organization
self.model: str = azure_deployment or "gpt-35-turbo"
- self.timeout = timeout
+ self.timeout = timeout or float(os.environ.get("OPENAI_TIMEOUT", 30.0))
+ self.max_retries = max_retries or int(os.environ.get("OPENAI_MAX_RETRIES", 5))
self.client = AzureOpenAI(
api_version=api_version,
@@ -134,7 +139,8 @@
api_key=api_key.resolve_value() if api_key is not None else None,
azure_ad_token=azure_ad_token.resolve_value() if azure_ad_token is not None else None,
organization=organization,
- timeout=timeout,
+ timeout=self.timeout,
+ max_retries=self.max_retries,
)
def to_dict(self) -> Dict[str, Any]:
@@ -157,6 +163,7 @@
api_key=self.api_key.to_dict() if self.api_key is not None else None,
azure_ad_token=self.azure_ad_token.to_dict() if self.azure_ad_token is not None else None,
timeout=self.timeout,
+ max_retries=self.max_retries,
)
@classmethod
|
{"golden_diff": "diff --git a/haystack/components/generators/azure.py b/haystack/components/generators/azure.py\n--- a/haystack/components/generators/azure.py\n+++ b/haystack/components/generators/azure.py\n@@ -63,6 +63,7 @@\n streaming_callback: Optional[Callable[[StreamingChunk], None]] = None,\n system_prompt: Optional[str] = None,\n timeout: Optional[float] = None,\n+ max_retries: Optional[int] = None,\n generation_kwargs: Optional[Dict[str, Any]] = None,\n ):\n \"\"\"\n@@ -78,7 +79,10 @@\n :param streaming_callback: A callback function that is called when a new token is received from the stream.\n The callback function accepts StreamingChunk as an argument.\n :param system_prompt: The prompt to use for the system. If not provided, the system prompt will be\n- :param timeout: The timeout to be passed to the underlying `AzureOpenAI` client.\n+ :param timeout: The timeout to be passed to the underlying `AzureOpenAI` client, if not set it is\n+ inferred from the `OPENAI_TIMEOUT` environment variable or set to 30.\n+ :param max_retries: Maximum retries to establish contact with AzureOpenAI if it returns an internal error,\n+ if not set it is inferred from the `OPENAI_MAX_RETRIES` environment variable or set to 5.\n :param generation_kwargs: Other parameters to use for the model. These parameters are all sent directly to\n the OpenAI endpoint. See OpenAI [documentation](https://platform.openai.com/docs/api-reference/chat) for\n more details.\n@@ -125,7 +129,8 @@\n self.azure_deployment = azure_deployment\n self.organization = organization\n self.model: str = azure_deployment or \"gpt-35-turbo\"\n- self.timeout = timeout\n+ self.timeout = timeout or float(os.environ.get(\"OPENAI_TIMEOUT\", 30.0))\n+ self.max_retries = max_retries or int(os.environ.get(\"OPENAI_MAX_RETRIES\", 5))\n \n self.client = AzureOpenAI(\n api_version=api_version,\n@@ -134,7 +139,8 @@\n api_key=api_key.resolve_value() if api_key is not None else None,\n azure_ad_token=azure_ad_token.resolve_value() if azure_ad_token is not None else None,\n organization=organization,\n- timeout=timeout,\n+ timeout=self.timeout,\n+ max_retries=self.max_retries,\n )\n \n def to_dict(self) -> Dict[str, Any]:\n@@ -157,6 +163,7 @@\n api_key=self.api_key.to_dict() if self.api_key is not None else None,\n azure_ad_token=self.azure_ad_token.to_dict() if self.azure_ad_token is not None else None,\n timeout=self.timeout,\n+ max_retries=self.max_retries,\n )\n \n @classmethod\n", "issue": "Add `max_retries` and `timeout` params to all `AzureOpenAI` classes\n**Is your feature request related to a problem? Please describe.**\r\n\r\nCurrently all `OpenAI` related classes (e.g. `OpenAIDocumentEmbedder`, `OpenAIChatGenerator`) can be initialised by setting `max_retries` and `timeout` params.\r\n\r\nThe corresponding `AzureOpenAI` don't always have the same params.\r\n\r\n**Describe the solution you'd like**\r\n\r\nIt would be nice to have these params in the `AzureOpenAI` classes\r\n\r\n**Describe alternatives you've considered**\r\n\r\nSubclass `AzureOpenAI` and create custom components.\r\n\r\n**Additional context**\r\n\r\ncc @anakin87 :)\n", "before_files": [{"content": "# SPDX-FileCopyrightText: 2022-present deepset GmbH <[email protected]>\n#\n# SPDX-License-Identifier: Apache-2.0\n\nimport os\nfrom typing import Any, Callable, Dict, Optional\n\n# pylint: disable=import-error\nfrom openai.lib.azure import AzureOpenAI\n\nfrom haystack import component, default_from_dict, default_to_dict, logging\nfrom haystack.components.generators import OpenAIGenerator\nfrom haystack.dataclasses import StreamingChunk\nfrom haystack.utils import Secret, deserialize_callable, deserialize_secrets_inplace, serialize_callable\n\nlogger = logging.getLogger(__name__)\n\n\n@component\nclass AzureOpenAIGenerator(OpenAIGenerator):\n \"\"\"\n A Generator component that uses OpenAI's large language models (LLMs) on Azure to generate text.\n\n It supports gpt-4 and gpt-3.5-turbo family of models.\n\n Users can pass any text generation parameters valid for the `openai.ChatCompletion.create` method\n directly to this component via the `**generation_kwargs` parameter in __init__ or the `**generation_kwargs`\n parameter in `run` method.\n\n For more details on OpenAI models deployed on Azure, refer to the Microsoft\n [documentation](https://learn.microsoft.com/en-us/azure/ai-services/openai/).\n\n Usage example:\n ```python\n from haystack.components.generators import AzureOpenAIGenerator\n from haystack.utils import Secret\n client = AzureOpenAIGenerator(\n azure_endpoint=\"<Your Azure endpoint e.g. `https://your-company.azure.openai.com/>\",\n api_key=Secret.from_token(\"<your-api-key>\"),\n azure_deployment=\"<this a model name, e.g. gpt-35-turbo>\")\n response = client.run(\"What's Natural Language Processing? Be brief.\")\n print(response)\n ```\n\n ```\n >> {'replies': ['Natural Language Processing (NLP) is a branch of artificial intelligence that focuses on\n >> the interaction between computers and human language. It involves enabling computers to understand, interpret,\n >> and respond to natural human language in a way that is both meaningful and useful.'], 'meta': [{'model':\n >> 'gpt-3.5-turbo-0613', 'index': 0, 'finish_reason': 'stop', 'usage': {'prompt_tokens': 16,\n >> 'completion_tokens': 49, 'total_tokens': 65}}]}\n ```\n \"\"\"\n\n # pylint: disable=super-init-not-called\n def __init__(\n self,\n azure_endpoint: Optional[str] = None,\n api_version: Optional[str] = \"2023-05-15\",\n azure_deployment: Optional[str] = \"gpt-35-turbo\",\n api_key: Optional[Secret] = Secret.from_env_var(\"AZURE_OPENAI_API_KEY\", strict=False),\n azure_ad_token: Optional[Secret] = Secret.from_env_var(\"AZURE_OPENAI_AD_TOKEN\", strict=False),\n organization: Optional[str] = None,\n streaming_callback: Optional[Callable[[StreamingChunk], None]] = None,\n system_prompt: Optional[str] = None,\n timeout: Optional[float] = None,\n generation_kwargs: Optional[Dict[str, Any]] = None,\n ):\n \"\"\"\n Initialize the Azure OpenAI Generator.\n\n :param azure_endpoint: The endpoint of the deployed model, e.g. `https://example-resource.azure.openai.com/`\n :param api_version: The version of the API to use. Defaults to 2023-05-15\n :param azure_deployment: The deployment of the model, usually the model name.\n :param api_key: The API key to use for authentication.\n :param azure_ad_token: [Azure Active Directory token](https://www.microsoft.com/en-us/security/business/identity-access/microsoft-entra-id)\n :param organization: The Organization ID, defaults to `None`. See\n [production best practices](https://platform.openai.com/docs/guides/production-best-practices/setting-up-your-organization).\n :param streaming_callback: A callback function that is called when a new token is received from the stream.\n The callback function accepts StreamingChunk as an argument.\n :param system_prompt: The prompt to use for the system. If not provided, the system prompt will be\n :param timeout: The timeout to be passed to the underlying `AzureOpenAI` client.\n :param generation_kwargs: Other parameters to use for the model. These parameters are all sent directly to\n the OpenAI endpoint. See OpenAI [documentation](https://platform.openai.com/docs/api-reference/chat) for\n more details.\n Some of the supported parameters:\n - `max_tokens`: The maximum number of tokens the output text can have.\n - `temperature`: What sampling temperature to use. Higher values mean the model will take more risks.\n Try 0.9 for more creative applications and 0 (argmax sampling) for ones with a well-defined answer.\n - `top_p`: An alternative to sampling with temperature, called nucleus sampling, where the model\n considers the results of the tokens with top_p probability mass. So 0.1 means only the tokens\n comprising the top 10% probability mass are considered.\n - `n`: How many completions to generate for each prompt. For example, if the LLM gets 3 prompts and n is 2,\n it will generate two completions for each of the three prompts, ending up with 6 completions in total.\n - `stop`: One or more sequences after which the LLM should stop generating tokens.\n - `presence_penalty`: What penalty to apply if a token is already present at all. Bigger values mean\n the model will be less likely to repeat the same token in the text.\n - `frequency_penalty`: What penalty to apply if a token has already been generated in the text.\n Bigger values mean the model will be less likely to repeat the same token in the text.\n - `logit_bias`: Add a logit bias to specific tokens. The keys of the dictionary are tokens, and the\n values are the bias to add to that token.\n \"\"\"\n # We intentionally do not call super().__init__ here because we only need to instantiate the client to interact\n # with the API.\n\n # Why is this here?\n # AzureOpenAI init is forcing us to use an init method that takes either base_url or azure_endpoint as not\n # None init parameters. This way we accommodate the use case where env var AZURE_OPENAI_ENDPOINT is set instead\n # of passing it as a parameter.\n azure_endpoint = azure_endpoint or os.environ.get(\"AZURE_OPENAI_ENDPOINT\")\n if not azure_endpoint:\n raise ValueError(\"Please provide an Azure endpoint or set the environment variable AZURE_OPENAI_ENDPOINT.\")\n\n if api_key is None and azure_ad_token is None:\n raise ValueError(\"Please provide an API key or an Azure Active Directory token.\")\n\n # The check above makes mypy incorrectly infer that api_key is never None,\n # which propagates the incorrect type.\n self.api_key = api_key # type: ignore\n self.azure_ad_token = azure_ad_token\n self.generation_kwargs = generation_kwargs or {}\n self.system_prompt = system_prompt\n self.streaming_callback = streaming_callback\n self.api_version = api_version\n self.azure_endpoint = azure_endpoint\n self.azure_deployment = azure_deployment\n self.organization = organization\n self.model: str = azure_deployment or \"gpt-35-turbo\"\n self.timeout = timeout\n\n self.client = AzureOpenAI(\n api_version=api_version,\n azure_endpoint=azure_endpoint,\n azure_deployment=azure_deployment,\n api_key=api_key.resolve_value() if api_key is not None else None,\n azure_ad_token=azure_ad_token.resolve_value() if azure_ad_token is not None else None,\n organization=organization,\n timeout=timeout,\n )\n\n def to_dict(self) -> Dict[str, Any]:\n \"\"\"\n Serialize this component to a dictionary.\n\n :returns:\n The serialized component as a dictionary.\n \"\"\"\n callback_name = serialize_callable(self.streaming_callback) if self.streaming_callback else None\n return default_to_dict(\n self,\n azure_endpoint=self.azure_endpoint,\n azure_deployment=self.azure_deployment,\n organization=self.organization,\n api_version=self.api_version,\n streaming_callback=callback_name,\n generation_kwargs=self.generation_kwargs,\n system_prompt=self.system_prompt,\n api_key=self.api_key.to_dict() if self.api_key is not None else None,\n azure_ad_token=self.azure_ad_token.to_dict() if self.azure_ad_token is not None else None,\n timeout=self.timeout,\n )\n\n @classmethod\n def from_dict(cls, data: Dict[str, Any]) -> \"AzureOpenAIGenerator\":\n \"\"\"\n Deserialize this component from a dictionary.\n\n :param data:\n The dictionary representation of this component.\n :returns:\n The deserialized component instance.\n \"\"\"\n deserialize_secrets_inplace(data[\"init_parameters\"], keys=[\"api_key\", \"azure_ad_token\"])\n init_params = data.get(\"init_parameters\", {})\n serialized_callback_handler = init_params.get(\"streaming_callback\")\n if serialized_callback_handler:\n data[\"init_parameters\"][\"streaming_callback\"] = deserialize_callable(serialized_callback_handler)\n return default_from_dict(cls, data)\n", "path": "haystack/components/generators/azure.py"}], "after_files": [{"content": "# SPDX-FileCopyrightText: 2022-present deepset GmbH <[email protected]>\n#\n# SPDX-License-Identifier: Apache-2.0\n\nimport os\nfrom typing import Any, Callable, Dict, Optional\n\n# pylint: disable=import-error\nfrom openai.lib.azure import AzureOpenAI\n\nfrom haystack import component, default_from_dict, default_to_dict, logging\nfrom haystack.components.generators import OpenAIGenerator\nfrom haystack.dataclasses import StreamingChunk\nfrom haystack.utils import Secret, deserialize_callable, deserialize_secrets_inplace, serialize_callable\n\nlogger = logging.getLogger(__name__)\n\n\n@component\nclass AzureOpenAIGenerator(OpenAIGenerator):\n \"\"\"\n A Generator component that uses OpenAI's large language models (LLMs) on Azure to generate text.\n\n It supports gpt-4 and gpt-3.5-turbo family of models.\n\n Users can pass any text generation parameters valid for the `openai.ChatCompletion.create` method\n directly to this component via the `**generation_kwargs` parameter in __init__ or the `**generation_kwargs`\n parameter in `run` method.\n\n For more details on OpenAI models deployed on Azure, refer to the Microsoft\n [documentation](https://learn.microsoft.com/en-us/azure/ai-services/openai/).\n\n Usage example:\n ```python\n from haystack.components.generators import AzureOpenAIGenerator\n from haystack.utils import Secret\n client = AzureOpenAIGenerator(\n azure_endpoint=\"<Your Azure endpoint e.g. `https://your-company.azure.openai.com/>\",\n api_key=Secret.from_token(\"<your-api-key>\"),\n azure_deployment=\"<this a model name, e.g. gpt-35-turbo>\")\n response = client.run(\"What's Natural Language Processing? Be brief.\")\n print(response)\n ```\n\n ```\n >> {'replies': ['Natural Language Processing (NLP) is a branch of artificial intelligence that focuses on\n >> the interaction between computers and human language. It involves enabling computers to understand, interpret,\n >> and respond to natural human language in a way that is both meaningful and useful.'], 'meta': [{'model':\n >> 'gpt-3.5-turbo-0613', 'index': 0, 'finish_reason': 'stop', 'usage': {'prompt_tokens': 16,\n >> 'completion_tokens': 49, 'total_tokens': 65}}]}\n ```\n \"\"\"\n\n # pylint: disable=super-init-not-called\n def __init__(\n self,\n azure_endpoint: Optional[str] = None,\n api_version: Optional[str] = \"2023-05-15\",\n azure_deployment: Optional[str] = \"gpt-35-turbo\",\n api_key: Optional[Secret] = Secret.from_env_var(\"AZURE_OPENAI_API_KEY\", strict=False),\n azure_ad_token: Optional[Secret] = Secret.from_env_var(\"AZURE_OPENAI_AD_TOKEN\", strict=False),\n organization: Optional[str] = None,\n streaming_callback: Optional[Callable[[StreamingChunk], None]] = None,\n system_prompt: Optional[str] = None,\n timeout: Optional[float] = None,\n max_retries: Optional[int] = None,\n generation_kwargs: Optional[Dict[str, Any]] = None,\n ):\n \"\"\"\n Initialize the Azure OpenAI Generator.\n\n :param azure_endpoint: The endpoint of the deployed model, e.g. `https://example-resource.azure.openai.com/`\n :param api_version: The version of the API to use. Defaults to 2023-05-15\n :param azure_deployment: The deployment of the model, usually the model name.\n :param api_key: The API key to use for authentication.\n :param azure_ad_token: [Azure Active Directory token](https://www.microsoft.com/en-us/security/business/identity-access/microsoft-entra-id)\n :param organization: The Organization ID, defaults to `None`. See\n [production best practices](https://platform.openai.com/docs/guides/production-best-practices/setting-up-your-organization).\n :param streaming_callback: A callback function that is called when a new token is received from the stream.\n The callback function accepts StreamingChunk as an argument.\n :param system_prompt: The prompt to use for the system. If not provided, the system prompt will be\n :param timeout: The timeout to be passed to the underlying `AzureOpenAI` client, if not set it is\n inferred from the `OPENAI_TIMEOUT` environment variable or set to 30.\n :param max_retries: Maximum retries to establish contact with AzureOpenAI if it returns an internal error,\n if not set it is inferred from the `OPENAI_MAX_RETRIES` environment variable or set to 5.\n :param generation_kwargs: Other parameters to use for the model. These parameters are all sent directly to\n the OpenAI endpoint. See OpenAI [documentation](https://platform.openai.com/docs/api-reference/chat) for\n more details.\n Some of the supported parameters:\n - `max_tokens`: The maximum number of tokens the output text can have.\n - `temperature`: What sampling temperature to use. Higher values mean the model will take more risks.\n Try 0.9 for more creative applications and 0 (argmax sampling) for ones with a well-defined answer.\n - `top_p`: An alternative to sampling with temperature, called nucleus sampling, where the model\n considers the results of the tokens with top_p probability mass. So 0.1 means only the tokens\n comprising the top 10% probability mass are considered.\n - `n`: How many completions to generate for each prompt. For example, if the LLM gets 3 prompts and n is 2,\n it will generate two completions for each of the three prompts, ending up with 6 completions in total.\n - `stop`: One or more sequences after which the LLM should stop generating tokens.\n - `presence_penalty`: What penalty to apply if a token is already present at all. Bigger values mean\n the model will be less likely to repeat the same token in the text.\n - `frequency_penalty`: What penalty to apply if a token has already been generated in the text.\n Bigger values mean the model will be less likely to repeat the same token in the text.\n - `logit_bias`: Add a logit bias to specific tokens. The keys of the dictionary are tokens, and the\n values are the bias to add to that token.\n \"\"\"\n # We intentionally do not call super().__init__ here because we only need to instantiate the client to interact\n # with the API.\n\n # Why is this here?\n # AzureOpenAI init is forcing us to use an init method that takes either base_url or azure_endpoint as not\n # None init parameters. This way we accommodate the use case where env var AZURE_OPENAI_ENDPOINT is set instead\n # of passing it as a parameter.\n azure_endpoint = azure_endpoint or os.environ.get(\"AZURE_OPENAI_ENDPOINT\")\n if not azure_endpoint:\n raise ValueError(\"Please provide an Azure endpoint or set the environment variable AZURE_OPENAI_ENDPOINT.\")\n\n if api_key is None and azure_ad_token is None:\n raise ValueError(\"Please provide an API key or an Azure Active Directory token.\")\n\n # The check above makes mypy incorrectly infer that api_key is never None,\n # which propagates the incorrect type.\n self.api_key = api_key # type: ignore\n self.azure_ad_token = azure_ad_token\n self.generation_kwargs = generation_kwargs or {}\n self.system_prompt = system_prompt\n self.streaming_callback = streaming_callback\n self.api_version = api_version\n self.azure_endpoint = azure_endpoint\n self.azure_deployment = azure_deployment\n self.organization = organization\n self.model: str = azure_deployment or \"gpt-35-turbo\"\n self.timeout = timeout or float(os.environ.get(\"OPENAI_TIMEOUT\", 30.0))\n self.max_retries = max_retries or int(os.environ.get(\"OPENAI_MAX_RETRIES\", 5))\n\n self.client = AzureOpenAI(\n api_version=api_version,\n azure_endpoint=azure_endpoint,\n azure_deployment=azure_deployment,\n api_key=api_key.resolve_value() if api_key is not None else None,\n azure_ad_token=azure_ad_token.resolve_value() if azure_ad_token is not None else None,\n organization=organization,\n timeout=self.timeout,\n max_retries=self.max_retries,\n )\n\n def to_dict(self) -> Dict[str, Any]:\n \"\"\"\n Serialize this component to a dictionary.\n\n :returns:\n The serialized component as a dictionary.\n \"\"\"\n callback_name = serialize_callable(self.streaming_callback) if self.streaming_callback else None\n return default_to_dict(\n self,\n azure_endpoint=self.azure_endpoint,\n azure_deployment=self.azure_deployment,\n organization=self.organization,\n api_version=self.api_version,\n streaming_callback=callback_name,\n generation_kwargs=self.generation_kwargs,\n system_prompt=self.system_prompt,\n api_key=self.api_key.to_dict() if self.api_key is not None else None,\n azure_ad_token=self.azure_ad_token.to_dict() if self.azure_ad_token is not None else None,\n timeout=self.timeout,\n max_retries=self.max_retries,\n )\n\n @classmethod\n def from_dict(cls, data: Dict[str, Any]) -> \"AzureOpenAIGenerator\":\n \"\"\"\n Deserialize this component from a dictionary.\n\n :param data:\n The dictionary representation of this component.\n :returns:\n The deserialized component instance.\n \"\"\"\n deserialize_secrets_inplace(data[\"init_parameters\"], keys=[\"api_key\", \"azure_ad_token\"])\n init_params = data.get(\"init_parameters\", {})\n serialized_callback_handler = init_params.get(\"streaming_callback\")\n if serialized_callback_handler:\n data[\"init_parameters\"][\"streaming_callback\"] = deserialize_callable(serialized_callback_handler)\n return default_from_dict(cls, data)\n", "path": "haystack/components/generators/azure.py"}]}
| 2,867 | 658 |
gh_patches_debug_8727
|
rasdani/github-patches
|
git_diff
|
cloudtools__troposphere-531
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
S3ObjectVersion is spelled "SS3ObjectVersion" in the lambda Code object validation
I just noticed [this](https://github.com/cloudtools/troposphere/blob/1f67fb140f5b94cf0f29213a7300bad3ea046a0f/troposphere/awslambda.py#L31) while I was reading through the code. I haven't run into problems as I haven't had to use this particular key, but it looks like something you might want to know about.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `troposphere/awslambda.py`
Content:
```
1 from . import AWSObject, AWSProperty
2 from .validators import positive_integer
3
4 MEMORY_VALUES = [x for x in range(128, 1600, 64)]
5
6
7 def validate_memory_size(memory_value):
8 """ Validate memory size for Lambda Function
9 :param memory_value: The memory size specified in the Function
10 :return: The provided memory size if it is valid
11 """
12 memory_value = int(positive_integer(memory_value))
13 if memory_value not in MEMORY_VALUES:
14 raise ValueError("Lambda Function memory size must be one of:\n %s" %
15 ", ".join(str(mb) for mb in MEMORY_VALUES))
16 return memory_value
17
18
19 class Code(AWSProperty):
20 props = {
21 'S3Bucket': (basestring, False),
22 'S3Key': (basestring, False),
23 'S3ObjectVersion': (basestring, False),
24 'ZipFile': (basestring, False)
25 }
26
27 def validate(self):
28 zip_file = self.properties.get('ZipFile')
29 s3_bucket = self.properties.get('S3Bucket')
30 s3_key = self.properties.get('S3Key')
31 s3_object_version = self.properties.get('SS3ObjectVersion')
32
33 if zip_file and s3_bucket:
34 raise ValueError("You can't specify both 'S3Bucket' and 'ZipFile'")
35 if zip_file and s3_key:
36 raise ValueError("You can't specify both 'S3Key' and 'ZipFile'")
37 if zip_file and s3_object_version:
38 raise ValueError(
39 "You can't specify both 'S3ObjectVersion' and 'ZipFile'"
40 )
41 if not zip_file and not (s3_bucket and s3_key):
42 raise ValueError(
43 "You must specify a bucket location (both the 'S3Bucket' and "
44 "'S3Key' properties) or the 'ZipFile' property"
45 )
46
47
48 class VPCConfig(AWSProperty):
49
50 props = {
51 'SecurityGroupIds': (list, True),
52 'SubnetIds': (list, True),
53 }
54
55
56 class EventSourceMapping(AWSObject):
57 resource_type = "AWS::Lambda::EventSourceMapping"
58
59 props = {
60 'BatchSize': (positive_integer, False),
61 'Enabled': (bool, False),
62 'EventSourceArn': (basestring, True),
63 'FunctionName': (basestring, True),
64 'StartingPosition': (basestring, True),
65 }
66
67
68 class Function(AWSObject):
69 resource_type = "AWS::Lambda::Function"
70
71 props = {
72 'Code': (Code, True),
73 'Description': (basestring, False),
74 'FunctionName': (basestring, False),
75 'Handler': (basestring, True),
76 'MemorySize': (validate_memory_size, False),
77 'Role': (basestring, True),
78 'Runtime': (basestring, True),
79 'Timeout': (positive_integer, False),
80 'VpcConfig': (VPCConfig, False),
81 }
82
83
84 class Permission(AWSObject):
85 resource_type = "AWS::Lambda::Permission"
86
87 props = {
88 'Action': (basestring, True),
89 'FunctionName': (basestring, True),
90 'Principal': (basestring, True),
91 'SourceAccount': (basestring, False),
92 'SourceArn': (basestring, False),
93 }
94
95
96 class Alias(AWSObject):
97 resource_type = "AWS::Lambda::Alias"
98
99 props = {
100 'Description': (basestring, False),
101 'FunctionName': (basestring, True),
102 'FunctionVersion': (basestring, True),
103 'Name': (basestring, True),
104 }
105
106
107 class Version(AWSObject):
108 resource_type = "AWS::Lambda::Version"
109
110 props = {
111 'CodeSha256': (basestring, False),
112 'Description': (basestring, False),
113 'FunctionName': (basestring, True),
114 }
115
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/troposphere/awslambda.py b/troposphere/awslambda.py
--- a/troposphere/awslambda.py
+++ b/troposphere/awslambda.py
@@ -28,7 +28,7 @@
zip_file = self.properties.get('ZipFile')
s3_bucket = self.properties.get('S3Bucket')
s3_key = self.properties.get('S3Key')
- s3_object_version = self.properties.get('SS3ObjectVersion')
+ s3_object_version = self.properties.get('S3ObjectVersion')
if zip_file and s3_bucket:
raise ValueError("You can't specify both 'S3Bucket' and 'ZipFile'")
|
{"golden_diff": "diff --git a/troposphere/awslambda.py b/troposphere/awslambda.py\n--- a/troposphere/awslambda.py\n+++ b/troposphere/awslambda.py\n@@ -28,7 +28,7 @@\n zip_file = self.properties.get('ZipFile')\n s3_bucket = self.properties.get('S3Bucket')\n s3_key = self.properties.get('S3Key')\n- s3_object_version = self.properties.get('SS3ObjectVersion')\n+ s3_object_version = self.properties.get('S3ObjectVersion')\n \n if zip_file and s3_bucket:\n raise ValueError(\"You can't specify both 'S3Bucket' and 'ZipFile'\")\n", "issue": "S3ObjectVersion is spelled \"SS3ObjectVersion\" in the lambda Code object validation\nI just noticed [this](https://github.com/cloudtools/troposphere/blob/1f67fb140f5b94cf0f29213a7300bad3ea046a0f/troposphere/awslambda.py#L31) while I was reading through the code. I haven't run into problems as I haven't had to use this particular key, but it looks like something you might want to know about.\n\n", "before_files": [{"content": "from . import AWSObject, AWSProperty\nfrom .validators import positive_integer\n\nMEMORY_VALUES = [x for x in range(128, 1600, 64)]\n\n\ndef validate_memory_size(memory_value):\n \"\"\" Validate memory size for Lambda Function\n :param memory_value: The memory size specified in the Function\n :return: The provided memory size if it is valid\n \"\"\"\n memory_value = int(positive_integer(memory_value))\n if memory_value not in MEMORY_VALUES:\n raise ValueError(\"Lambda Function memory size must be one of:\\n %s\" %\n \", \".join(str(mb) for mb in MEMORY_VALUES))\n return memory_value\n\n\nclass Code(AWSProperty):\n props = {\n 'S3Bucket': (basestring, False),\n 'S3Key': (basestring, False),\n 'S3ObjectVersion': (basestring, False),\n 'ZipFile': (basestring, False)\n }\n\n def validate(self):\n zip_file = self.properties.get('ZipFile')\n s3_bucket = self.properties.get('S3Bucket')\n s3_key = self.properties.get('S3Key')\n s3_object_version = self.properties.get('SS3ObjectVersion')\n\n if zip_file and s3_bucket:\n raise ValueError(\"You can't specify both 'S3Bucket' and 'ZipFile'\")\n if zip_file and s3_key:\n raise ValueError(\"You can't specify both 'S3Key' and 'ZipFile'\")\n if zip_file and s3_object_version:\n raise ValueError(\n \"You can't specify both 'S3ObjectVersion' and 'ZipFile'\"\n )\n if not zip_file and not (s3_bucket and s3_key):\n raise ValueError(\n \"You must specify a bucket location (both the 'S3Bucket' and \"\n \"'S3Key' properties) or the 'ZipFile' property\"\n )\n\n\nclass VPCConfig(AWSProperty):\n\n props = {\n 'SecurityGroupIds': (list, True),\n 'SubnetIds': (list, True),\n }\n\n\nclass EventSourceMapping(AWSObject):\n resource_type = \"AWS::Lambda::EventSourceMapping\"\n\n props = {\n 'BatchSize': (positive_integer, False),\n 'Enabled': (bool, False),\n 'EventSourceArn': (basestring, True),\n 'FunctionName': (basestring, True),\n 'StartingPosition': (basestring, True),\n }\n\n\nclass Function(AWSObject):\n resource_type = \"AWS::Lambda::Function\"\n\n props = {\n 'Code': (Code, True),\n 'Description': (basestring, False),\n 'FunctionName': (basestring, False),\n 'Handler': (basestring, True),\n 'MemorySize': (validate_memory_size, False),\n 'Role': (basestring, True),\n 'Runtime': (basestring, True),\n 'Timeout': (positive_integer, False),\n 'VpcConfig': (VPCConfig, False),\n }\n\n\nclass Permission(AWSObject):\n resource_type = \"AWS::Lambda::Permission\"\n\n props = {\n 'Action': (basestring, True),\n 'FunctionName': (basestring, True),\n 'Principal': (basestring, True),\n 'SourceAccount': (basestring, False),\n 'SourceArn': (basestring, False),\n }\n\n\nclass Alias(AWSObject):\n resource_type = \"AWS::Lambda::Alias\"\n\n props = {\n 'Description': (basestring, False),\n 'FunctionName': (basestring, True),\n 'FunctionVersion': (basestring, True),\n 'Name': (basestring, True),\n }\n\n\nclass Version(AWSObject):\n resource_type = \"AWS::Lambda::Version\"\n\n props = {\n 'CodeSha256': (basestring, False),\n 'Description': (basestring, False),\n 'FunctionName': (basestring, True),\n }\n", "path": "troposphere/awslambda.py"}], "after_files": [{"content": "from . import AWSObject, AWSProperty\nfrom .validators import positive_integer\n\nMEMORY_VALUES = [x for x in range(128, 1600, 64)]\n\n\ndef validate_memory_size(memory_value):\n \"\"\" Validate memory size for Lambda Function\n :param memory_value: The memory size specified in the Function\n :return: The provided memory size if it is valid\n \"\"\"\n memory_value = int(positive_integer(memory_value))\n if memory_value not in MEMORY_VALUES:\n raise ValueError(\"Lambda Function memory size must be one of:\\n %s\" %\n \", \".join(str(mb) for mb in MEMORY_VALUES))\n return memory_value\n\n\nclass Code(AWSProperty):\n props = {\n 'S3Bucket': (basestring, False),\n 'S3Key': (basestring, False),\n 'S3ObjectVersion': (basestring, False),\n 'ZipFile': (basestring, False)\n }\n\n def validate(self):\n zip_file = self.properties.get('ZipFile')\n s3_bucket = self.properties.get('S3Bucket')\n s3_key = self.properties.get('S3Key')\n s3_object_version = self.properties.get('S3ObjectVersion')\n\n if zip_file and s3_bucket:\n raise ValueError(\"You can't specify both 'S3Bucket' and 'ZipFile'\")\n if zip_file and s3_key:\n raise ValueError(\"You can't specify both 'S3Key' and 'ZipFile'\")\n if zip_file and s3_object_version:\n raise ValueError(\n \"You can't specify both 'S3ObjectVersion' and 'ZipFile'\"\n )\n if not zip_file and not (s3_bucket and s3_key):\n raise ValueError(\n \"You must specify a bucket location (both the 'S3Bucket' and \"\n \"'S3Key' properties) or the 'ZipFile' property\"\n )\n\n\nclass VPCConfig(AWSProperty):\n\n props = {\n 'SecurityGroupIds': (list, True),\n 'SubnetIds': (list, True),\n }\n\n\nclass EventSourceMapping(AWSObject):\n resource_type = \"AWS::Lambda::EventSourceMapping\"\n\n props = {\n 'BatchSize': (positive_integer, False),\n 'Enabled': (bool, False),\n 'EventSourceArn': (basestring, True),\n 'FunctionName': (basestring, True),\n 'StartingPosition': (basestring, True),\n }\n\n\nclass Function(AWSObject):\n resource_type = \"AWS::Lambda::Function\"\n\n props = {\n 'Code': (Code, True),\n 'Description': (basestring, False),\n 'FunctionName': (basestring, False),\n 'Handler': (basestring, True),\n 'MemorySize': (validate_memory_size, False),\n 'Role': (basestring, True),\n 'Runtime': (basestring, True),\n 'Timeout': (positive_integer, False),\n 'VpcConfig': (VPCConfig, False),\n }\n\n\nclass Permission(AWSObject):\n resource_type = \"AWS::Lambda::Permission\"\n\n props = {\n 'Action': (basestring, True),\n 'FunctionName': (basestring, True),\n 'Principal': (basestring, True),\n 'SourceAccount': (basestring, False),\n 'SourceArn': (basestring, False),\n }\n\n\nclass Alias(AWSObject):\n resource_type = \"AWS::Lambda::Alias\"\n\n props = {\n 'Description': (basestring, False),\n 'FunctionName': (basestring, True),\n 'FunctionVersion': (basestring, True),\n 'Name': (basestring, True),\n }\n\n\nclass Version(AWSObject):\n resource_type = \"AWS::Lambda::Version\"\n\n props = {\n 'CodeSha256': (basestring, False),\n 'Description': (basestring, False),\n 'FunctionName': (basestring, True),\n }\n", "path": "troposphere/awslambda.py"}]}
| 1,483 | 154 |
gh_patches_debug_40451
|
rasdani/github-patches
|
git_diff
|
openstates__openstates-scrapers-2761
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
MN: People scraper return none
State: _MN__ (be sure to include in ticket title)
when attempting to scrape MN people the following error is returned:
`
pupa.exceptions.ScrapeError: no objects returned from MNPersonScraper scrape
`
any advice ?
The CSV needed is still available. MN did recently update their site, and I was getting an assertion error that was fixed with I updated the links it was looking for. But now getting the "no objects returned" error :/
[dpaste](http://dpaste.com/1EKJ757)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `openstates/mn/people.py`
Content:
```
1 import collections
2 import logging
3 import lxml.html
4 import re
5
6 from pupa.scrape import Person, Scraper
7 from spatula import Page, CSV, Spatula
8 from openstates.utils import validate_phone_number, validate_email_address
9
10 PARTIES = {
11 'DFL': 'Democratic-Farmer-Labor',
12 'R': 'Republican',
13 }
14
15
16 class SenList(CSV):
17 url = 'http://www.senate.mn/members/member_list_ascii.php?ls='
18 _html_url = 'http://www.senate.mn/members/index.php'
19
20 def __init__(self, scraper, url=None, *, obj=None, **kwargs):
21 super().__init__(scraper, url=url, obj=obj, **kwargs)
22 self._scrape_extra_info()
23
24 def _scrape_extra_info(self):
25 self.extra_info = collections.defaultdict(dict)
26
27 resp = self.scraper.get(self._html_url)
28 doc = lxml.html.fromstring(resp.text)
29 doc.make_links_absolute(self._html_url)
30 xpath = ('//div[@id="hide_show_alpha_all"]'
31 '//td[@style="vertical-align:top;"]')
32 for td in doc.xpath(xpath):
33 main_link, email_link = td.xpath('.//a')
34 name = main_link.text_content().split(' (')[0]
35 leg = self.extra_info[name]
36 leg['office_phone'] = next(filter(
37 lambda string: re.match(r'\d{3}-\d{3}-\d{4}', string),
38 td.xpath('.//p/text()')
39 )).strip()
40 leg['url'] = main_link.get('href')
41 leg['image'] = td.xpath('./preceding-sibling::td//img/@src')[0]
42 if 'mailto:' in email_link.get('href'):
43 leg['email'] = email_link.get('href').replace('mailto:', '')
44
45 logger = logging.getLogger("pupa")
46 logger.info('collected preliminary data on {} legislators'
47 .format(len(self.extra_info)))
48 assert self.extra_info
49
50 def handle_list_item(self, row):
51 if not row['First Name']:
52 return
53 name = '{} {}'.format(row['First Name'], row['Last Name'])
54 party = PARTIES[row['Party']]
55 leg = Person(name=name, district=row['District'].lstrip('0'),
56 party=party, primary_org='upper', role='Senator',
57 image=self.extra_info[name]['image'])
58 leg.add_link(self.extra_info[name]['url'])
59 leg.add_contact_detail(type='voice',
60 value=self.extra_info[name]['office_phone'], note='capitol')
61 if 'email' in self.extra_info[name]:
62 leg.add_contact_detail(type='email',
63 value=self.extra_info[name]['email'], note='capitol')
64
65 row['Zipcode'] = row['Zipcode'].strip()
66 # Accommodate for multiple address column naming conventions.
67 address1_fields = [row.get('Address'), row.get('Office Building')]
68 address2_fields = [row.get('Address2'), row.get('Office Address')]
69 row['Address'] = next((a for a in address1_fields if a is not
70 None), False)
71 row['Address2'] = next((a for a in address2_fields if a is not
72 None), False)
73
74 if (a in row['Address2'] for a in ['95 University Avenue W',
75 '100 Rev. Dr. Martin Luther King']):
76 address = ('{Address}\n{Address2}\n{City}, {State} {Zipcode}'
77 .format(**row))
78 if 'Rm. Number' in row:
79 address = '{0} {1}'.format(row['Rm. Number'], address)
80 leg.add_contact_detail(type='address', value=address,
81 note='capitol')
82 elif row['Address2']:
83 address = ('{Address}\n{Address2}\n{City}, {State} {Zipcode}'
84 .format(**row))
85 leg.add_contact_detail(type='address', value=address,
86 note='district')
87 else:
88 address = '{Address}\n{City}, {State} {Zipcode}'.format(**row)
89 leg.add_contact_detail(type='address', value=address,
90 note='district')
91
92 leg.add_source(self.url)
93 leg.add_source(self._html_url)
94
95 return leg
96
97 def handle_page(self):
98 yield super(SenList, self).handle_page()
99
100
101 class RepList(Page):
102 url = 'http://www.house.leg.state.mn.us/members/hmem.asp'
103 list_xpath = '//div[@id="hide_show_alpha_all"]/table/tr/td/table/tr'
104
105 def handle_list_item(self, item):
106 photo_url = item.xpath('./td[1]/a/img/@src')[0]
107 info_nodes = item.xpath('./td[2]/p/a')
108 name_text = info_nodes[0].xpath('./b/text()')[0]
109 url = info_nodes[0].get('href')
110
111 name_match = re.match(r'^(.+)\(([0-9]{2}[AB]), ([A-Z]+)\)$', name_text)
112 name = name_match.group(1).strip()
113 district = name_match.group(2).lstrip('0').upper()
114 party_text = name_match.group(3)
115 party = PARTIES[party_text]
116
117 info_texts = [x.strip() for x in item.xpath(
118 './td[2]/p/text()[normalize-space() and preceding-sibling::br]'
119 ) if x.strip()]
120 address = '\n'.join((info_texts[0], info_texts[1]))
121
122 phone_text = info_texts[2]
123 if validate_phone_number(phone_text):
124 phone = phone_text
125
126 email_node = info_nodes[1]
127 email_text = email_node.text
128 email_text = email_text.replace('Email: ', '').strip()
129 if validate_email_address(email_text):
130 email = email_text
131
132 rep = Person(name=name, district=district, party=party,
133 primary_org='lower', role='Representative',
134 image=photo_url)
135 rep.add_link(url)
136 rep.add_contact_detail(type='address', value=address, note='capitol')
137 rep.add_contact_detail(type='voice', value=phone, note='capitol')
138 rep.add_contact_detail(type='email', value=email, note='capitol')
139 rep.add_source(self.url)
140
141 yield rep
142
143
144 class MNPersonScraper(Scraper, Spatula):
145 def scrape(self):
146 yield from self.scrape_page_items(SenList)
147 yield from self.scrape_page_items(RepList)
148
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/openstates/mn/people.py b/openstates/mn/people.py
--- a/openstates/mn/people.py
+++ b/openstates/mn/people.py
@@ -27,18 +27,18 @@
resp = self.scraper.get(self._html_url)
doc = lxml.html.fromstring(resp.text)
doc.make_links_absolute(self._html_url)
- xpath = ('//div[@id="hide_show_alpha_all"]'
- '//td[@style="vertical-align:top;"]')
- for td in doc.xpath(xpath):
- main_link, email_link = td.xpath('.//a')
+ xpath = ('//div[@id="alphabetically"]'
+ '//div[@class="media my-3"]')
+ for div in doc.xpath(xpath):
+ main_link, email_link = filter(lambda link: link.get('href'), div.xpath('.//a'))
name = main_link.text_content().split(' (')[0]
leg = self.extra_info[name]
leg['office_phone'] = next(filter(
- lambda string: re.match(r'\d{3}-\d{3}-\d{4}', string),
- td.xpath('.//p/text()')
+ lambda string: re.match(r'\d{3}-\d{3}-\d{4}', string.strip()),
+ div.xpath('.//text()')
)).strip()
leg['url'] = main_link.get('href')
- leg['image'] = td.xpath('./preceding-sibling::td//img/@src')[0]
+ leg['image'] = div.xpath('.//img/@src')[0]
if 'mailto:' in email_link.get('href'):
leg['email'] = email_link.get('href').replace('mailto:', '')
@@ -100,13 +100,12 @@
class RepList(Page):
url = 'http://www.house.leg.state.mn.us/members/hmem.asp'
- list_xpath = '//div[@id="hide_show_alpha_all"]/table/tr/td/table/tr'
+ list_xpath = '//div[@id="Alpha"]//div[@class="media my-3"]'
def handle_list_item(self, item):
- photo_url = item.xpath('./td[1]/a/img/@src')[0]
- info_nodes = item.xpath('./td[2]/p/a')
- name_text = info_nodes[0].xpath('./b/text()')[0]
- url = info_nodes[0].get('href')
+ photo_url = item.xpath('./img/@src')[0]
+ url = item.xpath('.//h5/a/@href')[0]
+ name_text = item.xpath('.//h5/a/b/text()')[0]
name_match = re.match(r'^(.+)\(([0-9]{2}[AB]), ([A-Z]+)\)$', name_text)
name = name_match.group(1).strip()
@@ -115,7 +114,7 @@
party = PARTIES[party_text]
info_texts = [x.strip() for x in item.xpath(
- './td[2]/p/text()[normalize-space() and preceding-sibling::br]'
+ './div/text()[normalize-space()]'
) if x.strip()]
address = '\n'.join((info_texts[0], info_texts[1]))
@@ -123,9 +122,7 @@
if validate_phone_number(phone_text):
phone = phone_text
- email_node = info_nodes[1]
- email_text = email_node.text
- email_text = email_text.replace('Email: ', '').strip()
+ email_text = item.xpath('.//a/@href')[1].replace('mailto:', '').strip()
if validate_email_address(email_text):
email = email_text
|
{"golden_diff": "diff --git a/openstates/mn/people.py b/openstates/mn/people.py\n--- a/openstates/mn/people.py\n+++ b/openstates/mn/people.py\n@@ -27,18 +27,18 @@\n resp = self.scraper.get(self._html_url)\n doc = lxml.html.fromstring(resp.text)\n doc.make_links_absolute(self._html_url)\n- xpath = ('//div[@id=\"hide_show_alpha_all\"]'\n- '//td[@style=\"vertical-align:top;\"]')\n- for td in doc.xpath(xpath):\n- main_link, email_link = td.xpath('.//a')\n+ xpath = ('//div[@id=\"alphabetically\"]'\n+ '//div[@class=\"media my-3\"]')\n+ for div in doc.xpath(xpath):\n+ main_link, email_link = filter(lambda link: link.get('href'), div.xpath('.//a'))\n name = main_link.text_content().split(' (')[0]\n leg = self.extra_info[name]\n leg['office_phone'] = next(filter(\n- lambda string: re.match(r'\\d{3}-\\d{3}-\\d{4}', string),\n- td.xpath('.//p/text()')\n+ lambda string: re.match(r'\\d{3}-\\d{3}-\\d{4}', string.strip()),\n+ div.xpath('.//text()')\n )).strip()\n leg['url'] = main_link.get('href')\n- leg['image'] = td.xpath('./preceding-sibling::td//img/@src')[0]\n+ leg['image'] = div.xpath('.//img/@src')[0]\n if 'mailto:' in email_link.get('href'):\n leg['email'] = email_link.get('href').replace('mailto:', '')\n \n@@ -100,13 +100,12 @@\n \n class RepList(Page):\n url = 'http://www.house.leg.state.mn.us/members/hmem.asp'\n- list_xpath = '//div[@id=\"hide_show_alpha_all\"]/table/tr/td/table/tr'\n+ list_xpath = '//div[@id=\"Alpha\"]//div[@class=\"media my-3\"]'\n \n def handle_list_item(self, item):\n- photo_url = item.xpath('./td[1]/a/img/@src')[0]\n- info_nodes = item.xpath('./td[2]/p/a')\n- name_text = info_nodes[0].xpath('./b/text()')[0]\n- url = info_nodes[0].get('href')\n+ photo_url = item.xpath('./img/@src')[0]\n+ url = item.xpath('.//h5/a/@href')[0]\n+ name_text = item.xpath('.//h5/a/b/text()')[0]\n \n name_match = re.match(r'^(.+)\\(([0-9]{2}[AB]), ([A-Z]+)\\)$', name_text)\n name = name_match.group(1).strip()\n@@ -115,7 +114,7 @@\n party = PARTIES[party_text]\n \n info_texts = [x.strip() for x in item.xpath(\n- './td[2]/p/text()[normalize-space() and preceding-sibling::br]'\n+ './div/text()[normalize-space()]'\n ) if x.strip()]\n address = '\\n'.join((info_texts[0], info_texts[1]))\n \n@@ -123,9 +122,7 @@\n if validate_phone_number(phone_text):\n phone = phone_text\n \n- email_node = info_nodes[1]\n- email_text = email_node.text\n- email_text = email_text.replace('Email: ', '').strip()\n+ email_text = item.xpath('.//a/@href')[1].replace('mailto:', '').strip()\n if validate_email_address(email_text):\n email = email_text\n", "issue": "MN: People scraper return none\nState: _MN__ (be sure to include in ticket title)\r\n\r\nwhen attempting to scrape MN people the following error is returned:\r\n\r\n`\r\npupa.exceptions.ScrapeError: no objects returned from MNPersonScraper scrape\r\n`\r\n\r\nany advice ?\r\n\r\nThe CSV needed is still available. MN did recently update their site, and I was getting an assertion error that was fixed with I updated the links it was looking for. But now getting the \"no objects returned\" error :/\r\n\r\n[dpaste](http://dpaste.com/1EKJ757)\r\n\n", "before_files": [{"content": "import collections\nimport logging\nimport lxml.html\nimport re\n\nfrom pupa.scrape import Person, Scraper\nfrom spatula import Page, CSV, Spatula\nfrom openstates.utils import validate_phone_number, validate_email_address\n\nPARTIES = {\n 'DFL': 'Democratic-Farmer-Labor',\n 'R': 'Republican',\n}\n\n\nclass SenList(CSV):\n url = 'http://www.senate.mn/members/member_list_ascii.php?ls='\n _html_url = 'http://www.senate.mn/members/index.php'\n\n def __init__(self, scraper, url=None, *, obj=None, **kwargs):\n super().__init__(scraper, url=url, obj=obj, **kwargs)\n self._scrape_extra_info()\n\n def _scrape_extra_info(self):\n self.extra_info = collections.defaultdict(dict)\n\n resp = self.scraper.get(self._html_url)\n doc = lxml.html.fromstring(resp.text)\n doc.make_links_absolute(self._html_url)\n xpath = ('//div[@id=\"hide_show_alpha_all\"]'\n '//td[@style=\"vertical-align:top;\"]')\n for td in doc.xpath(xpath):\n main_link, email_link = td.xpath('.//a')\n name = main_link.text_content().split(' (')[0]\n leg = self.extra_info[name]\n leg['office_phone'] = next(filter(\n lambda string: re.match(r'\\d{3}-\\d{3}-\\d{4}', string),\n td.xpath('.//p/text()')\n )).strip()\n leg['url'] = main_link.get('href')\n leg['image'] = td.xpath('./preceding-sibling::td//img/@src')[0]\n if 'mailto:' in email_link.get('href'):\n leg['email'] = email_link.get('href').replace('mailto:', '')\n\n logger = logging.getLogger(\"pupa\")\n logger.info('collected preliminary data on {} legislators'\n .format(len(self.extra_info)))\n assert self.extra_info\n\n def handle_list_item(self, row):\n if not row['First Name']:\n return\n name = '{} {}'.format(row['First Name'], row['Last Name'])\n party = PARTIES[row['Party']]\n leg = Person(name=name, district=row['District'].lstrip('0'),\n party=party, primary_org='upper', role='Senator',\n image=self.extra_info[name]['image'])\n leg.add_link(self.extra_info[name]['url'])\n leg.add_contact_detail(type='voice',\n value=self.extra_info[name]['office_phone'], note='capitol')\n if 'email' in self.extra_info[name]:\n leg.add_contact_detail(type='email',\n value=self.extra_info[name]['email'], note='capitol')\n\n row['Zipcode'] = row['Zipcode'].strip()\n # Accommodate for multiple address column naming conventions.\n address1_fields = [row.get('Address'), row.get('Office Building')]\n address2_fields = [row.get('Address2'), row.get('Office Address')]\n row['Address'] = next((a for a in address1_fields if a is not\n None), False)\n row['Address2'] = next((a for a in address2_fields if a is not\n None), False)\n\n if (a in row['Address2'] for a in ['95 University Avenue W',\n '100 Rev. Dr. Martin Luther King']):\n address = ('{Address}\\n{Address2}\\n{City}, {State} {Zipcode}'\n .format(**row))\n if 'Rm. Number' in row:\n address = '{0} {1}'.format(row['Rm. Number'], address)\n leg.add_contact_detail(type='address', value=address,\n note='capitol')\n elif row['Address2']:\n address = ('{Address}\\n{Address2}\\n{City}, {State} {Zipcode}'\n .format(**row))\n leg.add_contact_detail(type='address', value=address,\n note='district')\n else:\n address = '{Address}\\n{City}, {State} {Zipcode}'.format(**row)\n leg.add_contact_detail(type='address', value=address,\n note='district')\n\n leg.add_source(self.url)\n leg.add_source(self._html_url)\n\n return leg\n\n def handle_page(self):\n yield super(SenList, self).handle_page()\n\n\nclass RepList(Page):\n url = 'http://www.house.leg.state.mn.us/members/hmem.asp'\n list_xpath = '//div[@id=\"hide_show_alpha_all\"]/table/tr/td/table/tr'\n\n def handle_list_item(self, item):\n photo_url = item.xpath('./td[1]/a/img/@src')[0]\n info_nodes = item.xpath('./td[2]/p/a')\n name_text = info_nodes[0].xpath('./b/text()')[0]\n url = info_nodes[0].get('href')\n\n name_match = re.match(r'^(.+)\\(([0-9]{2}[AB]), ([A-Z]+)\\)$', name_text)\n name = name_match.group(1).strip()\n district = name_match.group(2).lstrip('0').upper()\n party_text = name_match.group(3)\n party = PARTIES[party_text]\n\n info_texts = [x.strip() for x in item.xpath(\n './td[2]/p/text()[normalize-space() and preceding-sibling::br]'\n ) if x.strip()]\n address = '\\n'.join((info_texts[0], info_texts[1]))\n\n phone_text = info_texts[2]\n if validate_phone_number(phone_text):\n phone = phone_text\n\n email_node = info_nodes[1]\n email_text = email_node.text\n email_text = email_text.replace('Email: ', '').strip()\n if validate_email_address(email_text):\n email = email_text\n\n rep = Person(name=name, district=district, party=party,\n primary_org='lower', role='Representative',\n image=photo_url)\n rep.add_link(url)\n rep.add_contact_detail(type='address', value=address, note='capitol')\n rep.add_contact_detail(type='voice', value=phone, note='capitol')\n rep.add_contact_detail(type='email', value=email, note='capitol')\n rep.add_source(self.url)\n\n yield rep\n\n\nclass MNPersonScraper(Scraper, Spatula):\n def scrape(self):\n yield from self.scrape_page_items(SenList)\n yield from self.scrape_page_items(RepList)\n", "path": "openstates/mn/people.py"}], "after_files": [{"content": "import collections\nimport logging\nimport lxml.html\nimport re\n\nfrom pupa.scrape import Person, Scraper\nfrom spatula import Page, CSV, Spatula\nfrom openstates.utils import validate_phone_number, validate_email_address\n\nPARTIES = {\n 'DFL': 'Democratic-Farmer-Labor',\n 'R': 'Republican',\n}\n\n\nclass SenList(CSV):\n url = 'http://www.senate.mn/members/member_list_ascii.php?ls='\n _html_url = 'http://www.senate.mn/members/index.php'\n\n def __init__(self, scraper, url=None, *, obj=None, **kwargs):\n super().__init__(scraper, url=url, obj=obj, **kwargs)\n self._scrape_extra_info()\n\n def _scrape_extra_info(self):\n self.extra_info = collections.defaultdict(dict)\n\n resp = self.scraper.get(self._html_url)\n doc = lxml.html.fromstring(resp.text)\n doc.make_links_absolute(self._html_url)\n xpath = ('//div[@id=\"alphabetically\"]'\n '//div[@class=\"media my-3\"]')\n for div in doc.xpath(xpath):\n main_link, email_link = filter(lambda link: link.get('href'), div.xpath('.//a'))\n name = main_link.text_content().split(' (')[0]\n leg = self.extra_info[name]\n leg['office_phone'] = next(filter(\n lambda string: re.match(r'\\d{3}-\\d{3}-\\d{4}', string.strip()),\n div.xpath('.//text()')\n )).strip()\n leg['url'] = main_link.get('href')\n leg['image'] = div.xpath('.//img/@src')[0]\n if 'mailto:' in email_link.get('href'):\n leg['email'] = email_link.get('href').replace('mailto:', '')\n\n logger = logging.getLogger(\"pupa\")\n logger.info('collected preliminary data on {} legislators'\n .format(len(self.extra_info)))\n assert self.extra_info\n\n def handle_list_item(self, row):\n if not row['First Name']:\n return\n name = '{} {}'.format(row['First Name'], row['Last Name'])\n party = PARTIES[row['Party']]\n leg = Person(name=name, district=row['District'].lstrip('0'),\n party=party, primary_org='upper', role='Senator',\n image=self.extra_info[name]['image'])\n leg.add_link(self.extra_info[name]['url'])\n leg.add_contact_detail(type='voice',\n value=self.extra_info[name]['office_phone'], note='capitol')\n if 'email' in self.extra_info[name]:\n leg.add_contact_detail(type='email',\n value=self.extra_info[name]['email'], note='capitol')\n\n row['Zipcode'] = row['Zipcode'].strip()\n # Accommodate for multiple address column naming conventions.\n address1_fields = [row.get('Address'), row.get('Office Building')]\n address2_fields = [row.get('Address2'), row.get('Office Address')]\n row['Address'] = next((a for a in address1_fields if a is not\n None), False)\n row['Address2'] = next((a for a in address2_fields if a is not\n None), False)\n\n if (a in row['Address2'] for a in ['95 University Avenue W',\n '100 Rev. Dr. Martin Luther King']):\n address = ('{Address}\\n{Address2}\\n{City}, {State} {Zipcode}'\n .format(**row))\n if 'Rm. Number' in row:\n address = '{0} {1}'.format(row['Rm. Number'], address)\n leg.add_contact_detail(type='address', value=address,\n note='capitol')\n elif row['Address2']:\n address = ('{Address}\\n{Address2}\\n{City}, {State} {Zipcode}'\n .format(**row))\n leg.add_contact_detail(type='address', value=address,\n note='district')\n else:\n address = '{Address}\\n{City}, {State} {Zipcode}'.format(**row)\n leg.add_contact_detail(type='address', value=address,\n note='district')\n\n leg.add_source(self.url)\n leg.add_source(self._html_url)\n\n return leg\n\n def handle_page(self):\n yield super(SenList, self).handle_page()\n\n\nclass RepList(Page):\n url = 'http://www.house.leg.state.mn.us/members/hmem.asp'\n list_xpath = '//div[@id=\"Alpha\"]//div[@class=\"media my-3\"]'\n\n def handle_list_item(self, item):\n photo_url = item.xpath('./img/@src')[0]\n url = item.xpath('.//h5/a/@href')[0]\n name_text = item.xpath('.//h5/a/b/text()')[0]\n\n name_match = re.match(r'^(.+)\\(([0-9]{2}[AB]), ([A-Z]+)\\)$', name_text)\n name = name_match.group(1).strip()\n district = name_match.group(2).lstrip('0').upper()\n party_text = name_match.group(3)\n party = PARTIES[party_text]\n\n info_texts = [x.strip() for x in item.xpath(\n './div/text()[normalize-space()]'\n ) if x.strip()]\n address = '\\n'.join((info_texts[0], info_texts[1]))\n\n phone_text = info_texts[2]\n if validate_phone_number(phone_text):\n phone = phone_text\n\n email_text = item.xpath('.//a/@href')[1].replace('mailto:', '').strip()\n if validate_email_address(email_text):\n email = email_text\n\n rep = Person(name=name, district=district, party=party,\n primary_org='lower', role='Representative',\n image=photo_url)\n rep.add_link(url)\n rep.add_contact_detail(type='address', value=address, note='capitol')\n rep.add_contact_detail(type='voice', value=phone, note='capitol')\n rep.add_contact_detail(type='email', value=email, note='capitol')\n rep.add_source(self.url)\n\n yield rep\n\n\nclass MNPersonScraper(Scraper, Spatula):\n def scrape(self):\n yield from self.scrape_page_items(SenList)\n yield from self.scrape_page_items(RepList)\n", "path": "openstates/mn/people.py"}]}
| 2,147 | 826 |
gh_patches_debug_39888
|
rasdani/github-patches
|
git_diff
|
fonttools__fonttools-1205
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[ttGlyphPen] decompose components if transform overflows F2Dot14
https://github.com/googlei18n/ufo2ft/issues/217
The UFO GLIF spec allows any numbers for xScale, xyScale, yxScale, yScale, xOffset, yOffset, however the OpenType glyf spec uses F2Dot14 numbers, which are encoded as a signed 16-bit integer and therefore can only contain values from -32768 (-0x8000, or -2.0) to +32767 included (0x7FFF, or +1.99993896484375...).
We can't let the `struct.error` propagate.
I think we have to handle the case of +2.0 specially, and treat it as if it were 1.99993896484375. By doing that we can support truetype component transforms in the range -2.0 to +2.0 (inclusive), for the sake of simplicity.
Then, we also need to have the ttGlyphPen decompose the components if their transform values are less than -2.0 or they are greater than +2.0 (not greater and equal), as these can't fit in the TrueType glyf table.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `Lib/fontTools/pens/ttGlyphPen.py`
Content:
```
1 from __future__ import print_function, division, absolute_import
2 from fontTools.misc.py23 import *
3 from array import array
4 from fontTools.pens.basePen import AbstractPen
5 from fontTools.pens.transformPen import TransformPen
6 from fontTools.ttLib.tables import ttProgram
7 from fontTools.ttLib.tables._g_l_y_f import Glyph
8 from fontTools.ttLib.tables._g_l_y_f import GlyphComponent
9 from fontTools.ttLib.tables._g_l_y_f import GlyphCoordinates
10
11
12 __all__ = ["TTGlyphPen"]
13
14
15 class TTGlyphPen(AbstractPen):
16 """Pen used for drawing to a TrueType glyph."""
17
18 def __init__(self, glyphSet):
19 self.glyphSet = glyphSet
20 self.init()
21
22 def init(self):
23 self.points = []
24 self.endPts = []
25 self.types = []
26 self.components = []
27
28 def _addPoint(self, pt, onCurve):
29 self.points.append(pt)
30 self.types.append(onCurve)
31
32 def _popPoint(self):
33 self.points.pop()
34 self.types.pop()
35
36 def _isClosed(self):
37 return (
38 (not self.points) or
39 (self.endPts and self.endPts[-1] == len(self.points) - 1))
40
41 def lineTo(self, pt):
42 self._addPoint(pt, 1)
43
44 def moveTo(self, pt):
45 assert self._isClosed(), '"move"-type point must begin a new contour.'
46 self._addPoint(pt, 1)
47
48 def qCurveTo(self, *points):
49 assert len(points) >= 1
50 for pt in points[:-1]:
51 self._addPoint(pt, 0)
52
53 # last point is None if there are no on-curve points
54 if points[-1] is not None:
55 self._addPoint(points[-1], 1)
56
57 def closePath(self):
58 endPt = len(self.points) - 1
59
60 # ignore anchors (one-point paths)
61 if endPt == 0 or (self.endPts and endPt == self.endPts[-1] + 1):
62 self._popPoint()
63 return
64
65 # if first and last point on this path are the same, remove last
66 startPt = 0
67 if self.endPts:
68 startPt = self.endPts[-1] + 1
69 if self.points[startPt] == self.points[endPt]:
70 self._popPoint()
71 endPt -= 1
72
73 self.endPts.append(endPt)
74
75 def endPath(self):
76 # TrueType contours are always "closed"
77 self.closePath()
78
79 def addComponent(self, glyphName, transformation):
80 self.components.append((glyphName, transformation))
81
82 def glyph(self, componentFlags=0x4):
83 assert self._isClosed(), "Didn't close last contour."
84
85 components = []
86 for glyphName, transformation in self.components:
87 if self.points:
88 # can't have both, so decompose the glyph
89 tpen = TransformPen(self, transformation)
90 self.glyphSet[glyphName].draw(tpen)
91 continue
92
93 component = GlyphComponent()
94 component.glyphName = glyphName
95 if transformation[:4] != (1, 0, 0, 1):
96 component.transform = (transformation[:2], transformation[2:4])
97 component.x, component.y = transformation[4:]
98 component.flags = componentFlags
99 components.append(component)
100
101 glyph = Glyph()
102 glyph.coordinates = GlyphCoordinates(self.points)
103 glyph.endPtsOfContours = self.endPts
104 glyph.flags = array("B", self.types)
105 self.init()
106
107 if components:
108 glyph.components = components
109 glyph.numberOfContours = -1
110 else:
111 glyph.numberOfContours = len(glyph.endPtsOfContours)
112 glyph.program = ttProgram.Program()
113 glyph.program.fromBytecode(b"")
114
115 return glyph
116
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/Lib/fontTools/pens/ttGlyphPen.py b/Lib/fontTools/pens/ttGlyphPen.py
--- a/Lib/fontTools/pens/ttGlyphPen.py
+++ b/Lib/fontTools/pens/ttGlyphPen.py
@@ -12,11 +12,32 @@
__all__ = ["TTGlyphPen"]
-class TTGlyphPen(AbstractPen):
- """Pen used for drawing to a TrueType glyph."""
+# the max value that can still fit in an F2Dot14:
+# 1.99993896484375
+MAX_F2DOT14 = 0x7FFF / (1 << 14)
+
- def __init__(self, glyphSet):
+class TTGlyphPen(AbstractPen):
+ """Pen used for drawing to a TrueType glyph.
+
+ If `handleOverflowingTransforms` is True, the components' transform values
+ are checked that they don't overflow the limits of a F2Dot14 number:
+ -2.0 <= v < +2.0. If any transform value exceeds these, the composite
+ glyph is decomposed.
+ An exception to this rule is done for values that are very close to +2.0
+ (both for consistency with the -2.0 case, and for the relative frequency
+ these occur in real fonts). When almost +2.0 values occur (and all other
+ values are within the range -2.0 <= x <= +2.0), they are clamped to the
+ maximum positive value that can still be encoded as an F2Dot14: i.e.
+ 1.99993896484375.
+ If False, no check is done and all components are translated unmodified
+ into the glyf table, followed by an inevitable `struct.error` once an
+ attempt is made to compile them.
+ """
+
+ def __init__(self, glyphSet, handleOverflowingTransforms=True):
self.glyphSet = glyphSet
+ self.handleOverflowingTransforms = handleOverflowingTransforms
self.init()
def init(self):
@@ -82,19 +103,33 @@
def glyph(self, componentFlags=0x4):
assert self._isClosed(), "Didn't close last contour."
+ if self.handleOverflowingTransforms:
+ # we can't encode transform values > 2 or < -2 in F2Dot14,
+ # so we must decompose the glyph if any transform exceeds these
+ overflowing = any(s > 2 or s < -2
+ for (glyphName, transformation) in self.components
+ for s in transformation[:4])
+
components = []
for glyphName, transformation in self.components:
- if self.points:
- # can't have both, so decompose the glyph
+ if (self.points or
+ (self.handleOverflowingTransforms and overflowing)):
+ # can't have both coordinates and components, so decompose
tpen = TransformPen(self, transformation)
self.glyphSet[glyphName].draw(tpen)
continue
component = GlyphComponent()
component.glyphName = glyphName
- if transformation[:4] != (1, 0, 0, 1):
- component.transform = (transformation[:2], transformation[2:4])
component.x, component.y = transformation[4:]
+ transformation = transformation[:4]
+ if transformation != (1, 0, 0, 1):
+ if (self.handleOverflowingTransforms and
+ any(MAX_F2DOT14 < s <= 2 for s in transformation)):
+ # clamp values ~= +2.0 so we can keep the component
+ transformation = tuple(MAX_F2DOT14 if MAX_F2DOT14 < s <= 2
+ else s for s in transformation)
+ component.transform = (transformation[:2], transformation[2:])
component.flags = componentFlags
components.append(component)
|
{"golden_diff": "diff --git a/Lib/fontTools/pens/ttGlyphPen.py b/Lib/fontTools/pens/ttGlyphPen.py\n--- a/Lib/fontTools/pens/ttGlyphPen.py\n+++ b/Lib/fontTools/pens/ttGlyphPen.py\n@@ -12,11 +12,32 @@\n __all__ = [\"TTGlyphPen\"]\n \n \n-class TTGlyphPen(AbstractPen):\n- \"\"\"Pen used for drawing to a TrueType glyph.\"\"\"\n+# the max value that can still fit in an F2Dot14:\n+# 1.99993896484375\n+MAX_F2DOT14 = 0x7FFF / (1 << 14)\n+\n \n- def __init__(self, glyphSet):\n+class TTGlyphPen(AbstractPen):\n+ \"\"\"Pen used for drawing to a TrueType glyph.\n+\n+ If `handleOverflowingTransforms` is True, the components' transform values\n+ are checked that they don't overflow the limits of a F2Dot14 number:\n+ -2.0 <= v < +2.0. If any transform value exceeds these, the composite\n+ glyph is decomposed.\n+ An exception to this rule is done for values that are very close to +2.0\n+ (both for consistency with the -2.0 case, and for the relative frequency\n+ these occur in real fonts). When almost +2.0 values occur (and all other\n+ values are within the range -2.0 <= x <= +2.0), they are clamped to the\n+ maximum positive value that can still be encoded as an F2Dot14: i.e.\n+ 1.99993896484375.\n+ If False, no check is done and all components are translated unmodified\n+ into the glyf table, followed by an inevitable `struct.error` once an\n+ attempt is made to compile them.\n+ \"\"\"\n+\n+ def __init__(self, glyphSet, handleOverflowingTransforms=True):\n self.glyphSet = glyphSet\n+ self.handleOverflowingTransforms = handleOverflowingTransforms\n self.init()\n \n def init(self):\n@@ -82,19 +103,33 @@\n def glyph(self, componentFlags=0x4):\n assert self._isClosed(), \"Didn't close last contour.\"\n \n+ if self.handleOverflowingTransforms:\n+ # we can't encode transform values > 2 or < -2 in F2Dot14,\n+ # so we must decompose the glyph if any transform exceeds these\n+ overflowing = any(s > 2 or s < -2\n+ for (glyphName, transformation) in self.components\n+ for s in transformation[:4])\n+\n components = []\n for glyphName, transformation in self.components:\n- if self.points:\n- # can't have both, so decompose the glyph\n+ if (self.points or\n+ (self.handleOverflowingTransforms and overflowing)):\n+ # can't have both coordinates and components, so decompose\n tpen = TransformPen(self, transformation)\n self.glyphSet[glyphName].draw(tpen)\n continue\n \n component = GlyphComponent()\n component.glyphName = glyphName\n- if transformation[:4] != (1, 0, 0, 1):\n- component.transform = (transformation[:2], transformation[2:4])\n component.x, component.y = transformation[4:]\n+ transformation = transformation[:4]\n+ if transformation != (1, 0, 0, 1):\n+ if (self.handleOverflowingTransforms and\n+ any(MAX_F2DOT14 < s <= 2 for s in transformation)):\n+ # clamp values ~= +2.0 so we can keep the component\n+ transformation = tuple(MAX_F2DOT14 if MAX_F2DOT14 < s <= 2\n+ else s for s in transformation)\n+ component.transform = (transformation[:2], transformation[2:])\n component.flags = componentFlags\n components.append(component)\n", "issue": "[ttGlyphPen] decompose components if transform overflows F2Dot14\nhttps://github.com/googlei18n/ufo2ft/issues/217\r\n\r\nThe UFO GLIF spec allows any numbers for xScale, xyScale, yxScale, yScale, xOffset, yOffset, however the OpenType glyf spec uses F2Dot14 numbers, which are encoded as a signed 16-bit integer and therefore can only contain values from -32768 (-0x8000, or -2.0) to +32767 included (0x7FFF, or +1.99993896484375...).\r\n\r\nWe can't let the `struct.error` propagate.\r\n\r\nI think we have to handle the case of +2.0 specially, and treat it as if it were 1.99993896484375. By doing that we can support truetype component transforms in the range -2.0 to +2.0 (inclusive), for the sake of simplicity.\r\n\r\nThen, we also need to have the ttGlyphPen decompose the components if their transform values are less than -2.0 or they are greater than +2.0 (not greater and equal), as these can't fit in the TrueType glyf table.\r\n\r\n\n", "before_files": [{"content": "from __future__ import print_function, division, absolute_import\nfrom fontTools.misc.py23 import *\nfrom array import array\nfrom fontTools.pens.basePen import AbstractPen\nfrom fontTools.pens.transformPen import TransformPen\nfrom fontTools.ttLib.tables import ttProgram\nfrom fontTools.ttLib.tables._g_l_y_f import Glyph\nfrom fontTools.ttLib.tables._g_l_y_f import GlyphComponent\nfrom fontTools.ttLib.tables._g_l_y_f import GlyphCoordinates\n\n\n__all__ = [\"TTGlyphPen\"]\n\n\nclass TTGlyphPen(AbstractPen):\n \"\"\"Pen used for drawing to a TrueType glyph.\"\"\"\n\n def __init__(self, glyphSet):\n self.glyphSet = glyphSet\n self.init()\n\n def init(self):\n self.points = []\n self.endPts = []\n self.types = []\n self.components = []\n\n def _addPoint(self, pt, onCurve):\n self.points.append(pt)\n self.types.append(onCurve)\n\n def _popPoint(self):\n self.points.pop()\n self.types.pop()\n\n def _isClosed(self):\n return (\n (not self.points) or\n (self.endPts and self.endPts[-1] == len(self.points) - 1))\n\n def lineTo(self, pt):\n self._addPoint(pt, 1)\n\n def moveTo(self, pt):\n assert self._isClosed(), '\"move\"-type point must begin a new contour.'\n self._addPoint(pt, 1)\n\n def qCurveTo(self, *points):\n assert len(points) >= 1\n for pt in points[:-1]:\n self._addPoint(pt, 0)\n\n # last point is None if there are no on-curve points\n if points[-1] is not None:\n self._addPoint(points[-1], 1)\n\n def closePath(self):\n endPt = len(self.points) - 1\n\n # ignore anchors (one-point paths)\n if endPt == 0 or (self.endPts and endPt == self.endPts[-1] + 1):\n self._popPoint()\n return\n\n # if first and last point on this path are the same, remove last\n startPt = 0\n if self.endPts:\n startPt = self.endPts[-1] + 1\n if self.points[startPt] == self.points[endPt]:\n self._popPoint()\n endPt -= 1\n\n self.endPts.append(endPt)\n\n def endPath(self):\n # TrueType contours are always \"closed\"\n self.closePath()\n\n def addComponent(self, glyphName, transformation):\n self.components.append((glyphName, transformation))\n\n def glyph(self, componentFlags=0x4):\n assert self._isClosed(), \"Didn't close last contour.\"\n\n components = []\n for glyphName, transformation in self.components:\n if self.points:\n # can't have both, so decompose the glyph\n tpen = TransformPen(self, transformation)\n self.glyphSet[glyphName].draw(tpen)\n continue\n\n component = GlyphComponent()\n component.glyphName = glyphName\n if transformation[:4] != (1, 0, 0, 1):\n component.transform = (transformation[:2], transformation[2:4])\n component.x, component.y = transformation[4:]\n component.flags = componentFlags\n components.append(component)\n\n glyph = Glyph()\n glyph.coordinates = GlyphCoordinates(self.points)\n glyph.endPtsOfContours = self.endPts\n glyph.flags = array(\"B\", self.types)\n self.init()\n\n if components:\n glyph.components = components\n glyph.numberOfContours = -1\n else:\n glyph.numberOfContours = len(glyph.endPtsOfContours)\n glyph.program = ttProgram.Program()\n glyph.program.fromBytecode(b\"\")\n\n return glyph\n", "path": "Lib/fontTools/pens/ttGlyphPen.py"}], "after_files": [{"content": "from __future__ import print_function, division, absolute_import\nfrom fontTools.misc.py23 import *\nfrom array import array\nfrom fontTools.pens.basePen import AbstractPen\nfrom fontTools.pens.transformPen import TransformPen\nfrom fontTools.ttLib.tables import ttProgram\nfrom fontTools.ttLib.tables._g_l_y_f import Glyph\nfrom fontTools.ttLib.tables._g_l_y_f import GlyphComponent\nfrom fontTools.ttLib.tables._g_l_y_f import GlyphCoordinates\n\n\n__all__ = [\"TTGlyphPen\"]\n\n\n# the max value that can still fit in an F2Dot14:\n# 1.99993896484375\nMAX_F2DOT14 = 0x7FFF / (1 << 14)\n\n\nclass TTGlyphPen(AbstractPen):\n \"\"\"Pen used for drawing to a TrueType glyph.\n\n If `handleOverflowingTransforms` is True, the components' transform values\n are checked that they don't overflow the limits of a F2Dot14 number:\n -2.0 <= v < +2.0. If any transform value exceeds these, the composite\n glyph is decomposed.\n An exception to this rule is done for values that are very close to +2.0\n (both for consistency with the -2.0 case, and for the relative frequency\n these occur in real fonts). When almost +2.0 values occur (and all other\n values are within the range -2.0 <= x <= +2.0), they are clamped to the\n maximum positive value that can still be encoded as an F2Dot14: i.e.\n 1.99993896484375.\n If False, no check is done and all components are translated unmodified\n into the glyf table, followed by an inevitable `struct.error` once an\n attempt is made to compile them.\n \"\"\"\n\n def __init__(self, glyphSet, handleOverflowingTransforms=True):\n self.glyphSet = glyphSet\n self.handleOverflowingTransforms = handleOverflowingTransforms\n self.init()\n\n def init(self):\n self.points = []\n self.endPts = []\n self.types = []\n self.components = []\n\n def _addPoint(self, pt, onCurve):\n self.points.append(pt)\n self.types.append(onCurve)\n\n def _popPoint(self):\n self.points.pop()\n self.types.pop()\n\n def _isClosed(self):\n return (\n (not self.points) or\n (self.endPts and self.endPts[-1] == len(self.points) - 1))\n\n def lineTo(self, pt):\n self._addPoint(pt, 1)\n\n def moveTo(self, pt):\n assert self._isClosed(), '\"move\"-type point must begin a new contour.'\n self._addPoint(pt, 1)\n\n def qCurveTo(self, *points):\n assert len(points) >= 1\n for pt in points[:-1]:\n self._addPoint(pt, 0)\n\n # last point is None if there are no on-curve points\n if points[-1] is not None:\n self._addPoint(points[-1], 1)\n\n def closePath(self):\n endPt = len(self.points) - 1\n\n # ignore anchors (one-point paths)\n if endPt == 0 or (self.endPts and endPt == self.endPts[-1] + 1):\n self._popPoint()\n return\n\n # if first and last point on this path are the same, remove last\n startPt = 0\n if self.endPts:\n startPt = self.endPts[-1] + 1\n if self.points[startPt] == self.points[endPt]:\n self._popPoint()\n endPt -= 1\n\n self.endPts.append(endPt)\n\n def endPath(self):\n # TrueType contours are always \"closed\"\n self.closePath()\n\n def addComponent(self, glyphName, transformation):\n self.components.append((glyphName, transformation))\n\n def glyph(self, componentFlags=0x4):\n assert self._isClosed(), \"Didn't close last contour.\"\n\n if self.handleOverflowingTransforms:\n # we can't encode transform values > 2 or < -2 in F2Dot14,\n # so we must decompose the glyph if any transform exceeds these\n overflowing = any(s > 2 or s < -2\n for (glyphName, transformation) in self.components\n for s in transformation[:4])\n\n components = []\n for glyphName, transformation in self.components:\n if (self.points or\n (self.handleOverflowingTransforms and overflowing)):\n # can't have both coordinates and components, so decompose\n tpen = TransformPen(self, transformation)\n self.glyphSet[glyphName].draw(tpen)\n continue\n\n component = GlyphComponent()\n component.glyphName = glyphName\n component.x, component.y = transformation[4:]\n transformation = transformation[:4]\n if transformation != (1, 0, 0, 1):\n if (self.handleOverflowingTransforms and\n any(MAX_F2DOT14 < s <= 2 for s in transformation)):\n # clamp values ~= +2.0 so we can keep the component\n transformation = tuple(MAX_F2DOT14 if MAX_F2DOT14 < s <= 2\n else s for s in transformation)\n component.transform = (transformation[:2], transformation[2:])\n component.flags = componentFlags\n components.append(component)\n\n glyph = Glyph()\n glyph.coordinates = GlyphCoordinates(self.points)\n glyph.endPtsOfContours = self.endPts\n glyph.flags = array(\"B\", self.types)\n self.init()\n\n if components:\n glyph.components = components\n glyph.numberOfContours = -1\n else:\n glyph.numberOfContours = len(glyph.endPtsOfContours)\n glyph.program = ttProgram.Program()\n glyph.program.fromBytecode(b\"\")\n\n return glyph\n", "path": "Lib/fontTools/pens/ttGlyphPen.py"}]}
| 1,639 | 911 |
gh_patches_debug_20275
|
rasdani/github-patches
|
git_diff
|
mdn__kuma-7055
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Our flake8 tests suddenly failed
**Summary**
Builds from `master` currently fail in Python linting.
It's because the version of [flake8 used in TravisCI](https://github.com/mdn/kuma/blob/59afefbe55ca8456203baa96ba421f1fa3b63ede/.travis.yml#L17-L18) don't match what we have in our pyproject.toml.
Today a new release of flake8 came out that broke our master. [Example](https://travis-ci.com/github/mdn/kuma/jobs/332498567)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kuma/search/views.py`
Content:
```
1 from django.shortcuts import render
2 from django.urls import reverse_lazy
3 from django.views.decorators.cache import never_cache
4 from django.views.decorators.http import require_GET
5 from django.views.generic import RedirectView
6 from ratelimit.decorators import ratelimit
7
8 from kuma.api.v1.views import search as search_api
9 from kuma.core.decorators import shared_cache_control
10 from kuma.core.utils import is_wiki
11
12 from .search import SearchView
13
14 # Since the search endpoint accepts user input (via query parameters) and its
15 # response is compressed, use rate limiting to mitigate the BREACH attack
16 # (see http://breachattack.com/). It still needs to allow a user to click
17 # the filter switches (bug 1426968).
18 # Alternate: forbid gzip by setting Content-Encoding: identity
19 @never_cache
20 @require_GET
21 @ratelimit(key="user_or_ip", rate="25/m", block=True)
22 def search(request, *args, **kwargs):
23 """
24 The search view.
25 """
26 if is_wiki(request):
27 return wiki_search(request, *args, **kwargs)
28
29 # The underlying v1 API supports searching without a 'q' but the web
30 # UI doesn't. For example, the search input field requires a value.
31 # So we match that here too.
32 if not request.GET.get("q", "").strip():
33 status = 400
34 context = {"results": {}}
35 else:
36 results = search_api(request, *args, **kwargs).data
37
38 # Determine if there were validation errors
39 error = results.get("error") or results.get("q")
40 # If q is returned in the data, there was a validation error for that field,
41 # so return 400 status.
42 status = 200 if results.get("q") is None else 400
43 # If there was an error with the pagination you'll get...
44 if results.get("detail"):
45 error = str(results["detail"])
46 status = 400
47
48 context = {"results": {"results": None if error else results, "error": error}}
49 return render(request, "search/react.html", context, status=status)
50
51
52 wiki_search = SearchView.as_view()
53
54
55 class SearchRedirectView(RedirectView):
56 permanent = True
57
58 def get_redirect_url(self, *args, **kwargs):
59 query_string = self.request.META.get("QUERY_STRING")
60 url = reverse_lazy(
61 "api.v1.search", kwargs={"locale": self.request.LANGUAGE_CODE}
62 )
63 if query_string:
64 url += "?" + query_string
65 return url
66
67
68 @shared_cache_control(s_maxage=60 * 60 * 24 * 7)
69 def plugin(request):
70 """Render an OpenSearch Plugin."""
71 return render(
72 request,
73 "search/plugin.html",
74 {"locale": request.LANGUAGE_CODE},
75 content_type="application/opensearchdescription+xml",
76 )
77
```
Path: `kuma/users/models.py`
Content:
```
1 import datetime
2
3 from django.conf import settings
4 from django.contrib.auth.models import AbstractUser
5 from django.contrib.auth.tokens import default_token_generator
6 from django.core import validators
7 from django.core.cache import cache
8 from django.db import models, transaction
9 from django.db.models import Max
10 from django.dispatch import receiver
11 from django.utils import timezone
12 from django.utils.encoding import force_bytes
13 from django.utils.functional import cached_property
14 from django.utils.http import urlsafe_base64_encode
15 from django.utils.translation import gettext_lazy as _
16
17 from kuma.core.urlresolvers import reverse
18
19 from .constants import USERNAME_REGEX
20
21
22 class UserBan(models.Model):
23 user = models.ForeignKey(
24 settings.AUTH_USER_MODEL,
25 related_name="bans",
26 verbose_name="Banned user",
27 on_delete=models.CASCADE,
28 )
29 by = models.ForeignKey(
30 settings.AUTH_USER_MODEL,
31 related_name="bans_issued",
32 verbose_name="Banned by",
33 on_delete=models.PROTECT,
34 )
35 reason = models.TextField()
36 date = models.DateField(default=datetime.date.today)
37 is_active = models.BooleanField(default=True, help_text="(Is ban active)")
38
39 def __str__(self):
40 message = _("%(banned_user)s banned by %(banned_by)s") % {
41 "banned_user": self.user,
42 "banned_by": self.by,
43 }
44 if not self.is_active:
45 message = _("%s (no longer active)") % message
46 return message
47
48
49 class User(AbstractUser):
50 """
51 Our custom user class.
52 """
53
54 timezone = models.CharField(
55 verbose_name=_("Timezone"),
56 max_length=42,
57 blank=True,
58 default=settings.TIME_ZONE,
59 # Note the deliberate omission of the `choices=` here.
60 # That's because there's no good way to list all possible
61 # timezones as a 2-D tuple. The *name* of the timezone rarely
62 # changes but the human-friendly description of it easily does.
63 )
64 locale = models.CharField(
65 max_length=7,
66 default=settings.LANGUAGE_CODE,
67 choices=settings.SORTED_LANGUAGES,
68 verbose_name=_("Language"),
69 blank=True,
70 db_index=True,
71 )
72 homepage = models.URLField(
73 verbose_name=_("Homepage"),
74 max_length=255,
75 blank=True,
76 error_messages={
77 "invalid": _(
78 "This URL has an invalid format. "
79 "Valid URLs look like http://example.com/my_page."
80 )
81 },
82 )
83 title = models.CharField(verbose_name=_("Title"), max_length=255, blank=True,)
84 fullname = models.CharField(verbose_name=_("Name"), max_length=255, blank=True,)
85 organization = models.CharField(
86 verbose_name=_("Organization"), max_length=255, blank=True,
87 )
88 location = models.CharField(verbose_name=_("Location"), max_length=255, blank=True,)
89 bio = models.TextField(verbose_name=_("About Me"), blank=True,)
90 irc_nickname = models.CharField(
91 verbose_name=_("IRC nickname"), max_length=255, blank=True,
92 )
93
94 is_newsletter_subscribed = models.BooleanField(default=False)
95
96 WEBSITE_VALIDATORS = {
97 "website": validators.RegexValidator(
98 r"^https?://", _("Enter a valid website URL."), "invalid",
99 ),
100 "twitter": validators.RegexValidator(
101 r"^https?://twitter\.com/", _("Enter a valid Twitter URL."), "invalid",
102 ),
103 "github": validators.RegexValidator(
104 r"^https?://github\.com/", _("Enter a valid GitHub URL."), "invalid",
105 ),
106 "stackoverflow": validators.RegexValidator(
107 r"^https?://([a-z]{2}\.)?stackoverflow\.com/users/",
108 _("Enter a valid Stack Overflow URL."),
109 "invalid",
110 ),
111 "linkedin": validators.RegexValidator(
112 r"^https?://((www|\w\w)\.)?linkedin.com/((in/[^/]+/?)|(pub/[^/]+/((\w|\d)+/?){3}))$",
113 _("Enter a valid LinkedIn URL."),
114 "invalid",
115 ),
116 "mozillians": validators.RegexValidator(
117 r"^https?://mozillians\.org/u/",
118 _("Enter a valid Mozillians URL."),
119 "invalid",
120 ),
121 "facebook": validators.RegexValidator(
122 r"^https?://www\.facebook\.com/",
123 _("Enter a valid Facebook URL."),
124 "invalid",
125 ),
126 "discourse": validators.RegexValidator(
127 r"^https://discourse\.mozilla\.org/u/",
128 _("Enter a valid Discourse URL."),
129 "invalid",
130 ),
131 }
132
133 # a bunch of user URLs
134 website_url = models.TextField(
135 _("Website"), blank=True, validators=[WEBSITE_VALIDATORS["website"]],
136 )
137 mozillians_url = models.TextField(
138 _("Mozillians"), blank=True, validators=[WEBSITE_VALIDATORS["mozillians"]],
139 )
140 github_url = models.TextField(
141 _("GitHub"), blank=True, validators=[WEBSITE_VALIDATORS["github"]],
142 )
143 is_github_url_public = models.BooleanField(_("Public GitHub URL"), default=False,)
144 twitter_url = models.TextField(
145 _("Twitter"), blank=True, validators=[WEBSITE_VALIDATORS["twitter"]],
146 )
147 linkedin_url = models.TextField(
148 _("LinkedIn"), blank=True, validators=[WEBSITE_VALIDATORS["linkedin"]],
149 )
150 facebook_url = models.TextField(
151 _("Facebook"), blank=True, validators=[WEBSITE_VALIDATORS["facebook"]],
152 )
153 stackoverflow_url = models.TextField(
154 _("Stack Overflow"),
155 blank=True,
156 validators=[WEBSITE_VALIDATORS["stackoverflow"]],
157 )
158 discourse_url = models.TextField(
159 _("Discourse"), blank=True, validators=[WEBSITE_VALIDATORS["discourse"]],
160 )
161 stripe_customer_id = models.CharField(max_length=255, blank=True)
162
163 subscriber_number = models.PositiveIntegerField(blank=True, null=True)
164
165 class Meta:
166 db_table = "auth_user"
167
168 @property
169 def has_legacy_username(self):
170 return not USERNAME_REGEX.search(self.username)
171
172 @cached_property
173 def is_beta_tester(self):
174 return settings.BETA_GROUP_NAME in self.groups.values_list("name", flat=True)
175
176 @cached_property
177 def active_ban(self):
178 """
179 Returns the first active ban for the user or None.
180 """
181 return self.bans.filter(is_active=True).first()
182
183 def wiki_revisions(self, count=5):
184 return (
185 self.created_revisions.prefetch_related("document")
186 .defer("content", "summary")
187 .order_by("-id")[:count]
188 )
189
190 def allows_editing_by(self, user):
191 return user.is_staff or user.is_superuser or user.pk == self.pk
192
193 def get_recovery_url(self):
194 """Creates a recovery URL for the user."""
195 uidb64 = urlsafe_base64_encode(force_bytes(self.pk))
196 token = default_token_generator.make_token(self)
197 link = reverse("users.recover", kwargs={"token": token, "uidb64": uidb64})
198 return link
199
200 def set_next_subscriber_number_and_save(self):
201 assert not self.subscriber_number, "already set"
202 lock_key = f"set_next_subscriber_number_and_save"
203 # By locking "globally", we get to be certain that our query to get
204 # the current highest `subscriber_number`, gets done alone.
205 with cache.lock(lock_key):
206 highest_number = User.get_highest_subscriber_number()
207 User.objects.filter(id=self.id).update(subscriber_number=highest_number + 1)
208
209 @classmethod
210 def get_highest_subscriber_number(cls):
211 return (
212 cls.objects.filter(subscriber_number__isnull=False).aggregate(
213 number=Max("subscriber_number")
214 )["number"]
215 or 0
216 )
217
218
219 class UserSubscription(models.Model):
220 user = models.ForeignKey(User, on_delete=models.CASCADE)
221 stripe_subscription_id = models.CharField(max_length=255, blank=True)
222 canceled = models.DateTimeField(null=True)
223 created = models.DateTimeField(auto_now_add=True)
224 updated = models.DateTimeField(auto_now=True)
225
226 def __str__(self):
227 return (
228 f"{self.user.username} ({self.stripe_subscription_id})"
229 f"{' CANCELED' if self.canceled else ''}"
230 )
231
232 @classmethod
233 # The reason we make this (class) method transaction atomic is because this
234 # use of `update_or_create` will actually trigger a `post_save` signal
235 # on the `User` model which will set the `User.subscriber_number` if needed.
236 # So, this way we're pre-emptively making sure these two things are atomically
237 # connected.
238 @transaction.atomic()
239 def set_active(cls, user, stripe_subscription_id):
240 cls.objects.update_or_create(
241 stripe_subscription_id=stripe_subscription_id,
242 user=user,
243 defaults={"canceled": None, "updated": timezone.now()},
244 )
245
246 @classmethod
247 def set_canceled(cls, user, stripe_subscription_id):
248 cls.objects.update_or_create(
249 stripe_subscription_id=stripe_subscription_id,
250 user=user,
251 defaults={"canceled": timezone.now(), "updated": timezone.now()},
252 )
253
254
255 @receiver(models.signals.post_save, sender=UserSubscription)
256 def set_user_subscriber_number(sender, instance, **kwargs):
257 if not instance.canceled and not instance.user.subscriber_number:
258 instance.user.set_next_subscriber_number_and_save()
259
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kuma/search/views.py b/kuma/search/views.py
--- a/kuma/search/views.py
+++ b/kuma/search/views.py
@@ -11,6 +11,7 @@
from .search import SearchView
+
# Since the search endpoint accepts user input (via query parameters) and its
# response is compressed, use rate limiting to mitigate the BREACH attack
# (see http://breachattack.com/). It still needs to allow a user to click
diff --git a/kuma/users/models.py b/kuma/users/models.py
--- a/kuma/users/models.py
+++ b/kuma/users/models.py
@@ -199,7 +199,7 @@
def set_next_subscriber_number_and_save(self):
assert not self.subscriber_number, "already set"
- lock_key = f"set_next_subscriber_number_and_save"
+ lock_key = "set_next_subscriber_number_and_save"
# By locking "globally", we get to be certain that our query to get
# the current highest `subscriber_number`, gets done alone.
with cache.lock(lock_key):
|
{"golden_diff": "diff --git a/kuma/search/views.py b/kuma/search/views.py\n--- a/kuma/search/views.py\n+++ b/kuma/search/views.py\n@@ -11,6 +11,7 @@\n \n from .search import SearchView\n \n+\n # Since the search endpoint accepts user input (via query parameters) and its\n # response is compressed, use rate limiting to mitigate the BREACH attack\n # (see http://breachattack.com/). It still needs to allow a user to click\ndiff --git a/kuma/users/models.py b/kuma/users/models.py\n--- a/kuma/users/models.py\n+++ b/kuma/users/models.py\n@@ -199,7 +199,7 @@\n \n def set_next_subscriber_number_and_save(self):\n assert not self.subscriber_number, \"already set\"\n- lock_key = f\"set_next_subscriber_number_and_save\"\n+ lock_key = \"set_next_subscriber_number_and_save\"\n # By locking \"globally\", we get to be certain that our query to get\n # the current highest `subscriber_number`, gets done alone.\n with cache.lock(lock_key):\n", "issue": "Our flake8 tests suddenly failed\n**Summary**\r\nBuilds from `master` currently fail in Python linting. \r\nIt's because the version of [flake8 used in TravisCI](https://github.com/mdn/kuma/blob/59afefbe55ca8456203baa96ba421f1fa3b63ede/.travis.yml#L17-L18) don't match what we have in our pyproject.toml. \r\nToday a new release of flake8 came out that broke our master. [Example](https://travis-ci.com/github/mdn/kuma/jobs/332498567)\r\n\n", "before_files": [{"content": "from django.shortcuts import render\nfrom django.urls import reverse_lazy\nfrom django.views.decorators.cache import never_cache\nfrom django.views.decorators.http import require_GET\nfrom django.views.generic import RedirectView\nfrom ratelimit.decorators import ratelimit\n\nfrom kuma.api.v1.views import search as search_api\nfrom kuma.core.decorators import shared_cache_control\nfrom kuma.core.utils import is_wiki\n\nfrom .search import SearchView\n\n# Since the search endpoint accepts user input (via query parameters) and its\n# response is compressed, use rate limiting to mitigate the BREACH attack\n# (see http://breachattack.com/). It still needs to allow a user to click\n# the filter switches (bug 1426968).\n# Alternate: forbid gzip by setting Content-Encoding: identity\n@never_cache\n@require_GET\n@ratelimit(key=\"user_or_ip\", rate=\"25/m\", block=True)\ndef search(request, *args, **kwargs):\n \"\"\"\n The search view.\n \"\"\"\n if is_wiki(request):\n return wiki_search(request, *args, **kwargs)\n\n # The underlying v1 API supports searching without a 'q' but the web\n # UI doesn't. For example, the search input field requires a value.\n # So we match that here too.\n if not request.GET.get(\"q\", \"\").strip():\n status = 400\n context = {\"results\": {}}\n else:\n results = search_api(request, *args, **kwargs).data\n\n # Determine if there were validation errors\n error = results.get(\"error\") or results.get(\"q\")\n # If q is returned in the data, there was a validation error for that field,\n # so return 400 status.\n status = 200 if results.get(\"q\") is None else 400\n # If there was an error with the pagination you'll get...\n if results.get(\"detail\"):\n error = str(results[\"detail\"])\n status = 400\n\n context = {\"results\": {\"results\": None if error else results, \"error\": error}}\n return render(request, \"search/react.html\", context, status=status)\n\n\nwiki_search = SearchView.as_view()\n\n\nclass SearchRedirectView(RedirectView):\n permanent = True\n\n def get_redirect_url(self, *args, **kwargs):\n query_string = self.request.META.get(\"QUERY_STRING\")\n url = reverse_lazy(\n \"api.v1.search\", kwargs={\"locale\": self.request.LANGUAGE_CODE}\n )\n if query_string:\n url += \"?\" + query_string\n return url\n\n\n@shared_cache_control(s_maxage=60 * 60 * 24 * 7)\ndef plugin(request):\n \"\"\"Render an OpenSearch Plugin.\"\"\"\n return render(\n request,\n \"search/plugin.html\",\n {\"locale\": request.LANGUAGE_CODE},\n content_type=\"application/opensearchdescription+xml\",\n )\n", "path": "kuma/search/views.py"}, {"content": "import datetime\n\nfrom django.conf import settings\nfrom django.contrib.auth.models import AbstractUser\nfrom django.contrib.auth.tokens import default_token_generator\nfrom django.core import validators\nfrom django.core.cache import cache\nfrom django.db import models, transaction\nfrom django.db.models import Max\nfrom django.dispatch import receiver\nfrom django.utils import timezone\nfrom django.utils.encoding import force_bytes\nfrom django.utils.functional import cached_property\nfrom django.utils.http import urlsafe_base64_encode\nfrom django.utils.translation import gettext_lazy as _\n\nfrom kuma.core.urlresolvers import reverse\n\nfrom .constants import USERNAME_REGEX\n\n\nclass UserBan(models.Model):\n user = models.ForeignKey(\n settings.AUTH_USER_MODEL,\n related_name=\"bans\",\n verbose_name=\"Banned user\",\n on_delete=models.CASCADE,\n )\n by = models.ForeignKey(\n settings.AUTH_USER_MODEL,\n related_name=\"bans_issued\",\n verbose_name=\"Banned by\",\n on_delete=models.PROTECT,\n )\n reason = models.TextField()\n date = models.DateField(default=datetime.date.today)\n is_active = models.BooleanField(default=True, help_text=\"(Is ban active)\")\n\n def __str__(self):\n message = _(\"%(banned_user)s banned by %(banned_by)s\") % {\n \"banned_user\": self.user,\n \"banned_by\": self.by,\n }\n if not self.is_active:\n message = _(\"%s (no longer active)\") % message\n return message\n\n\nclass User(AbstractUser):\n \"\"\"\n Our custom user class.\n \"\"\"\n\n timezone = models.CharField(\n verbose_name=_(\"Timezone\"),\n max_length=42,\n blank=True,\n default=settings.TIME_ZONE,\n # Note the deliberate omission of the `choices=` here.\n # That's because there's no good way to list all possible\n # timezones as a 2-D tuple. The *name* of the timezone rarely\n # changes but the human-friendly description of it easily does.\n )\n locale = models.CharField(\n max_length=7,\n default=settings.LANGUAGE_CODE,\n choices=settings.SORTED_LANGUAGES,\n verbose_name=_(\"Language\"),\n blank=True,\n db_index=True,\n )\n homepage = models.URLField(\n verbose_name=_(\"Homepage\"),\n max_length=255,\n blank=True,\n error_messages={\n \"invalid\": _(\n \"This URL has an invalid format. \"\n \"Valid URLs look like http://example.com/my_page.\"\n )\n },\n )\n title = models.CharField(verbose_name=_(\"Title\"), max_length=255, blank=True,)\n fullname = models.CharField(verbose_name=_(\"Name\"), max_length=255, blank=True,)\n organization = models.CharField(\n verbose_name=_(\"Organization\"), max_length=255, blank=True,\n )\n location = models.CharField(verbose_name=_(\"Location\"), max_length=255, blank=True,)\n bio = models.TextField(verbose_name=_(\"About Me\"), blank=True,)\n irc_nickname = models.CharField(\n verbose_name=_(\"IRC nickname\"), max_length=255, blank=True,\n )\n\n is_newsletter_subscribed = models.BooleanField(default=False)\n\n WEBSITE_VALIDATORS = {\n \"website\": validators.RegexValidator(\n r\"^https?://\", _(\"Enter a valid website URL.\"), \"invalid\",\n ),\n \"twitter\": validators.RegexValidator(\n r\"^https?://twitter\\.com/\", _(\"Enter a valid Twitter URL.\"), \"invalid\",\n ),\n \"github\": validators.RegexValidator(\n r\"^https?://github\\.com/\", _(\"Enter a valid GitHub URL.\"), \"invalid\",\n ),\n \"stackoverflow\": validators.RegexValidator(\n r\"^https?://([a-z]{2}\\.)?stackoverflow\\.com/users/\",\n _(\"Enter a valid Stack Overflow URL.\"),\n \"invalid\",\n ),\n \"linkedin\": validators.RegexValidator(\n r\"^https?://((www|\\w\\w)\\.)?linkedin.com/((in/[^/]+/?)|(pub/[^/]+/((\\w|\\d)+/?){3}))$\",\n _(\"Enter a valid LinkedIn URL.\"),\n \"invalid\",\n ),\n \"mozillians\": validators.RegexValidator(\n r\"^https?://mozillians\\.org/u/\",\n _(\"Enter a valid Mozillians URL.\"),\n \"invalid\",\n ),\n \"facebook\": validators.RegexValidator(\n r\"^https?://www\\.facebook\\.com/\",\n _(\"Enter a valid Facebook URL.\"),\n \"invalid\",\n ),\n \"discourse\": validators.RegexValidator(\n r\"^https://discourse\\.mozilla\\.org/u/\",\n _(\"Enter a valid Discourse URL.\"),\n \"invalid\",\n ),\n }\n\n # a bunch of user URLs\n website_url = models.TextField(\n _(\"Website\"), blank=True, validators=[WEBSITE_VALIDATORS[\"website\"]],\n )\n mozillians_url = models.TextField(\n _(\"Mozillians\"), blank=True, validators=[WEBSITE_VALIDATORS[\"mozillians\"]],\n )\n github_url = models.TextField(\n _(\"GitHub\"), blank=True, validators=[WEBSITE_VALIDATORS[\"github\"]],\n )\n is_github_url_public = models.BooleanField(_(\"Public GitHub URL\"), default=False,)\n twitter_url = models.TextField(\n _(\"Twitter\"), blank=True, validators=[WEBSITE_VALIDATORS[\"twitter\"]],\n )\n linkedin_url = models.TextField(\n _(\"LinkedIn\"), blank=True, validators=[WEBSITE_VALIDATORS[\"linkedin\"]],\n )\n facebook_url = models.TextField(\n _(\"Facebook\"), blank=True, validators=[WEBSITE_VALIDATORS[\"facebook\"]],\n )\n stackoverflow_url = models.TextField(\n _(\"Stack Overflow\"),\n blank=True,\n validators=[WEBSITE_VALIDATORS[\"stackoverflow\"]],\n )\n discourse_url = models.TextField(\n _(\"Discourse\"), blank=True, validators=[WEBSITE_VALIDATORS[\"discourse\"]],\n )\n stripe_customer_id = models.CharField(max_length=255, blank=True)\n\n subscriber_number = models.PositiveIntegerField(blank=True, null=True)\n\n class Meta:\n db_table = \"auth_user\"\n\n @property\n def has_legacy_username(self):\n return not USERNAME_REGEX.search(self.username)\n\n @cached_property\n def is_beta_tester(self):\n return settings.BETA_GROUP_NAME in self.groups.values_list(\"name\", flat=True)\n\n @cached_property\n def active_ban(self):\n \"\"\"\n Returns the first active ban for the user or None.\n \"\"\"\n return self.bans.filter(is_active=True).first()\n\n def wiki_revisions(self, count=5):\n return (\n self.created_revisions.prefetch_related(\"document\")\n .defer(\"content\", \"summary\")\n .order_by(\"-id\")[:count]\n )\n\n def allows_editing_by(self, user):\n return user.is_staff or user.is_superuser or user.pk == self.pk\n\n def get_recovery_url(self):\n \"\"\"Creates a recovery URL for the user.\"\"\"\n uidb64 = urlsafe_base64_encode(force_bytes(self.pk))\n token = default_token_generator.make_token(self)\n link = reverse(\"users.recover\", kwargs={\"token\": token, \"uidb64\": uidb64})\n return link\n\n def set_next_subscriber_number_and_save(self):\n assert not self.subscriber_number, \"already set\"\n lock_key = f\"set_next_subscriber_number_and_save\"\n # By locking \"globally\", we get to be certain that our query to get\n # the current highest `subscriber_number`, gets done alone.\n with cache.lock(lock_key):\n highest_number = User.get_highest_subscriber_number()\n User.objects.filter(id=self.id).update(subscriber_number=highest_number + 1)\n\n @classmethod\n def get_highest_subscriber_number(cls):\n return (\n cls.objects.filter(subscriber_number__isnull=False).aggregate(\n number=Max(\"subscriber_number\")\n )[\"number\"]\n or 0\n )\n\n\nclass UserSubscription(models.Model):\n user = models.ForeignKey(User, on_delete=models.CASCADE)\n stripe_subscription_id = models.CharField(max_length=255, blank=True)\n canceled = models.DateTimeField(null=True)\n created = models.DateTimeField(auto_now_add=True)\n updated = models.DateTimeField(auto_now=True)\n\n def __str__(self):\n return (\n f\"{self.user.username} ({self.stripe_subscription_id})\"\n f\"{' CANCELED' if self.canceled else ''}\"\n )\n\n @classmethod\n # The reason we make this (class) method transaction atomic is because this\n # use of `update_or_create` will actually trigger a `post_save` signal\n # on the `User` model which will set the `User.subscriber_number` if needed.\n # So, this way we're pre-emptively making sure these two things are atomically\n # connected.\n @transaction.atomic()\n def set_active(cls, user, stripe_subscription_id):\n cls.objects.update_or_create(\n stripe_subscription_id=stripe_subscription_id,\n user=user,\n defaults={\"canceled\": None, \"updated\": timezone.now()},\n )\n\n @classmethod\n def set_canceled(cls, user, stripe_subscription_id):\n cls.objects.update_or_create(\n stripe_subscription_id=stripe_subscription_id,\n user=user,\n defaults={\"canceled\": timezone.now(), \"updated\": timezone.now()},\n )\n\n\n@receiver(models.signals.post_save, sender=UserSubscription)\ndef set_user_subscriber_number(sender, instance, **kwargs):\n if not instance.canceled and not instance.user.subscriber_number:\n instance.user.set_next_subscriber_number_and_save()\n", "path": "kuma/users/models.py"}], "after_files": [{"content": "from django.shortcuts import render\nfrom django.urls import reverse_lazy\nfrom django.views.decorators.cache import never_cache\nfrom django.views.decorators.http import require_GET\nfrom django.views.generic import RedirectView\nfrom ratelimit.decorators import ratelimit\n\nfrom kuma.api.v1.views import search as search_api\nfrom kuma.core.decorators import shared_cache_control\nfrom kuma.core.utils import is_wiki\n\nfrom .search import SearchView\n\n\n# Since the search endpoint accepts user input (via query parameters) and its\n# response is compressed, use rate limiting to mitigate the BREACH attack\n# (see http://breachattack.com/). It still needs to allow a user to click\n# the filter switches (bug 1426968).\n# Alternate: forbid gzip by setting Content-Encoding: identity\n@never_cache\n@require_GET\n@ratelimit(key=\"user_or_ip\", rate=\"25/m\", block=True)\ndef search(request, *args, **kwargs):\n \"\"\"\n The search view.\n \"\"\"\n if is_wiki(request):\n return wiki_search(request, *args, **kwargs)\n\n # The underlying v1 API supports searching without a 'q' but the web\n # UI doesn't. For example, the search input field requires a value.\n # So we match that here too.\n if not request.GET.get(\"q\", \"\").strip():\n status = 400\n context = {\"results\": {}}\n else:\n results = search_api(request, *args, **kwargs).data\n\n # Determine if there were validation errors\n error = results.get(\"error\") or results.get(\"q\")\n # If q is returned in the data, there was a validation error for that field,\n # so return 400 status.\n status = 200 if results.get(\"q\") is None else 400\n # If there was an error with the pagination you'll get...\n if results.get(\"detail\"):\n error = str(results[\"detail\"])\n status = 400\n\n context = {\"results\": {\"results\": None if error else results, \"error\": error}}\n return render(request, \"search/react.html\", context, status=status)\n\n\nwiki_search = SearchView.as_view()\n\n\nclass SearchRedirectView(RedirectView):\n permanent = True\n\n def get_redirect_url(self, *args, **kwargs):\n query_string = self.request.META.get(\"QUERY_STRING\")\n url = reverse_lazy(\n \"api.v1.search\", kwargs={\"locale\": self.request.LANGUAGE_CODE}\n )\n if query_string:\n url += \"?\" + query_string\n return url\n\n\n@shared_cache_control(s_maxage=60 * 60 * 24 * 7)\ndef plugin(request):\n \"\"\"Render an OpenSearch Plugin.\"\"\"\n return render(\n request,\n \"search/plugin.html\",\n {\"locale\": request.LANGUAGE_CODE},\n content_type=\"application/opensearchdescription+xml\",\n )\n", "path": "kuma/search/views.py"}, {"content": "import datetime\n\nfrom django.conf import settings\nfrom django.contrib.auth.models import AbstractUser\nfrom django.contrib.auth.tokens import default_token_generator\nfrom django.core import validators\nfrom django.core.cache import cache\nfrom django.db import models, transaction\nfrom django.db.models import Max\nfrom django.dispatch import receiver\nfrom django.utils import timezone\nfrom django.utils.encoding import force_bytes\nfrom django.utils.functional import cached_property\nfrom django.utils.http import urlsafe_base64_encode\nfrom django.utils.translation import gettext_lazy as _\n\nfrom kuma.core.urlresolvers import reverse\n\nfrom .constants import USERNAME_REGEX\n\n\nclass UserBan(models.Model):\n user = models.ForeignKey(\n settings.AUTH_USER_MODEL,\n related_name=\"bans\",\n verbose_name=\"Banned user\",\n on_delete=models.CASCADE,\n )\n by = models.ForeignKey(\n settings.AUTH_USER_MODEL,\n related_name=\"bans_issued\",\n verbose_name=\"Banned by\",\n on_delete=models.PROTECT,\n )\n reason = models.TextField()\n date = models.DateField(default=datetime.date.today)\n is_active = models.BooleanField(default=True, help_text=\"(Is ban active)\")\n\n def __str__(self):\n message = _(\"%(banned_user)s banned by %(banned_by)s\") % {\n \"banned_user\": self.user,\n \"banned_by\": self.by,\n }\n if not self.is_active:\n message = _(\"%s (no longer active)\") % message\n return message\n\n\nclass User(AbstractUser):\n \"\"\"\n Our custom user class.\n \"\"\"\n\n timezone = models.CharField(\n verbose_name=_(\"Timezone\"),\n max_length=42,\n blank=True,\n default=settings.TIME_ZONE,\n # Note the deliberate omission of the `choices=` here.\n # That's because there's no good way to list all possible\n # timezones as a 2-D tuple. The *name* of the timezone rarely\n # changes but the human-friendly description of it easily does.\n )\n locale = models.CharField(\n max_length=7,\n default=settings.LANGUAGE_CODE,\n choices=settings.SORTED_LANGUAGES,\n verbose_name=_(\"Language\"),\n blank=True,\n db_index=True,\n )\n homepage = models.URLField(\n verbose_name=_(\"Homepage\"),\n max_length=255,\n blank=True,\n error_messages={\n \"invalid\": _(\n \"This URL has an invalid format. \"\n \"Valid URLs look like http://example.com/my_page.\"\n )\n },\n )\n title = models.CharField(verbose_name=_(\"Title\"), max_length=255, blank=True,)\n fullname = models.CharField(verbose_name=_(\"Name\"), max_length=255, blank=True,)\n organization = models.CharField(\n verbose_name=_(\"Organization\"), max_length=255, blank=True,\n )\n location = models.CharField(verbose_name=_(\"Location\"), max_length=255, blank=True,)\n bio = models.TextField(verbose_name=_(\"About Me\"), blank=True,)\n irc_nickname = models.CharField(\n verbose_name=_(\"IRC nickname\"), max_length=255, blank=True,\n )\n\n is_newsletter_subscribed = models.BooleanField(default=False)\n\n WEBSITE_VALIDATORS = {\n \"website\": validators.RegexValidator(\n r\"^https?://\", _(\"Enter a valid website URL.\"), \"invalid\",\n ),\n \"twitter\": validators.RegexValidator(\n r\"^https?://twitter\\.com/\", _(\"Enter a valid Twitter URL.\"), \"invalid\",\n ),\n \"github\": validators.RegexValidator(\n r\"^https?://github\\.com/\", _(\"Enter a valid GitHub URL.\"), \"invalid\",\n ),\n \"stackoverflow\": validators.RegexValidator(\n r\"^https?://([a-z]{2}\\.)?stackoverflow\\.com/users/\",\n _(\"Enter a valid Stack Overflow URL.\"),\n \"invalid\",\n ),\n \"linkedin\": validators.RegexValidator(\n r\"^https?://((www|\\w\\w)\\.)?linkedin.com/((in/[^/]+/?)|(pub/[^/]+/((\\w|\\d)+/?){3}))$\",\n _(\"Enter a valid LinkedIn URL.\"),\n \"invalid\",\n ),\n \"mozillians\": validators.RegexValidator(\n r\"^https?://mozillians\\.org/u/\",\n _(\"Enter a valid Mozillians URL.\"),\n \"invalid\",\n ),\n \"facebook\": validators.RegexValidator(\n r\"^https?://www\\.facebook\\.com/\",\n _(\"Enter a valid Facebook URL.\"),\n \"invalid\",\n ),\n \"discourse\": validators.RegexValidator(\n r\"^https://discourse\\.mozilla\\.org/u/\",\n _(\"Enter a valid Discourse URL.\"),\n \"invalid\",\n ),\n }\n\n # a bunch of user URLs\n website_url = models.TextField(\n _(\"Website\"), blank=True, validators=[WEBSITE_VALIDATORS[\"website\"]],\n )\n mozillians_url = models.TextField(\n _(\"Mozillians\"), blank=True, validators=[WEBSITE_VALIDATORS[\"mozillians\"]],\n )\n github_url = models.TextField(\n _(\"GitHub\"), blank=True, validators=[WEBSITE_VALIDATORS[\"github\"]],\n )\n is_github_url_public = models.BooleanField(_(\"Public GitHub URL\"), default=False,)\n twitter_url = models.TextField(\n _(\"Twitter\"), blank=True, validators=[WEBSITE_VALIDATORS[\"twitter\"]],\n )\n linkedin_url = models.TextField(\n _(\"LinkedIn\"), blank=True, validators=[WEBSITE_VALIDATORS[\"linkedin\"]],\n )\n facebook_url = models.TextField(\n _(\"Facebook\"), blank=True, validators=[WEBSITE_VALIDATORS[\"facebook\"]],\n )\n stackoverflow_url = models.TextField(\n _(\"Stack Overflow\"),\n blank=True,\n validators=[WEBSITE_VALIDATORS[\"stackoverflow\"]],\n )\n discourse_url = models.TextField(\n _(\"Discourse\"), blank=True, validators=[WEBSITE_VALIDATORS[\"discourse\"]],\n )\n stripe_customer_id = models.CharField(max_length=255, blank=True)\n\n subscriber_number = models.PositiveIntegerField(blank=True, null=True)\n\n class Meta:\n db_table = \"auth_user\"\n\n @property\n def has_legacy_username(self):\n return not USERNAME_REGEX.search(self.username)\n\n @cached_property\n def is_beta_tester(self):\n return settings.BETA_GROUP_NAME in self.groups.values_list(\"name\", flat=True)\n\n @cached_property\n def active_ban(self):\n \"\"\"\n Returns the first active ban for the user or None.\n \"\"\"\n return self.bans.filter(is_active=True).first()\n\n def wiki_revisions(self, count=5):\n return (\n self.created_revisions.prefetch_related(\"document\")\n .defer(\"content\", \"summary\")\n .order_by(\"-id\")[:count]\n )\n\n def allows_editing_by(self, user):\n return user.is_staff or user.is_superuser or user.pk == self.pk\n\n def get_recovery_url(self):\n \"\"\"Creates a recovery URL for the user.\"\"\"\n uidb64 = urlsafe_base64_encode(force_bytes(self.pk))\n token = default_token_generator.make_token(self)\n link = reverse(\"users.recover\", kwargs={\"token\": token, \"uidb64\": uidb64})\n return link\n\n def set_next_subscriber_number_and_save(self):\n assert not self.subscriber_number, \"already set\"\n lock_key = \"set_next_subscriber_number_and_save\"\n # By locking \"globally\", we get to be certain that our query to get\n # the current highest `subscriber_number`, gets done alone.\n with cache.lock(lock_key):\n highest_number = User.get_highest_subscriber_number()\n User.objects.filter(id=self.id).update(subscriber_number=highest_number + 1)\n\n @classmethod\n def get_highest_subscriber_number(cls):\n return (\n cls.objects.filter(subscriber_number__isnull=False).aggregate(\n number=Max(\"subscriber_number\")\n )[\"number\"]\n or 0\n )\n\n\nclass UserSubscription(models.Model):\n user = models.ForeignKey(User, on_delete=models.CASCADE)\n stripe_subscription_id = models.CharField(max_length=255, blank=True)\n canceled = models.DateTimeField(null=True)\n created = models.DateTimeField(auto_now_add=True)\n updated = models.DateTimeField(auto_now=True)\n\n def __str__(self):\n return (\n f\"{self.user.username} ({self.stripe_subscription_id})\"\n f\"{' CANCELED' if self.canceled else ''}\"\n )\n\n @classmethod\n # The reason we make this (class) method transaction atomic is because this\n # use of `update_or_create` will actually trigger a `post_save` signal\n # on the `User` model which will set the `User.subscriber_number` if needed.\n # So, this way we're pre-emptively making sure these two things are atomically\n # connected.\n @transaction.atomic()\n def set_active(cls, user, stripe_subscription_id):\n cls.objects.update_or_create(\n stripe_subscription_id=stripe_subscription_id,\n user=user,\n defaults={\"canceled\": None, \"updated\": timezone.now()},\n )\n\n @classmethod\n def set_canceled(cls, user, stripe_subscription_id):\n cls.objects.update_or_create(\n stripe_subscription_id=stripe_subscription_id,\n user=user,\n defaults={\"canceled\": timezone.now(), \"updated\": timezone.now()},\n )\n\n\n@receiver(models.signals.post_save, sender=UserSubscription)\ndef set_user_subscriber_number(sender, instance, **kwargs):\n if not instance.canceled and not instance.user.subscriber_number:\n instance.user.set_next_subscriber_number_and_save()\n", "path": "kuma/users/models.py"}]}
| 3,911 | 243 |
gh_patches_debug_17440
|
rasdani/github-patches
|
git_diff
|
edgedb__edgedb-999
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Consider renaming std::datetime_trunc to std::datetime_truncate
We generally don't use abbreviations in our functions naming and this looks like an oversight.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `edb/edgeql/pygments/meta.py`
Content:
```
1 # AUTOGENERATED BY EdgeDB WITH
2 # $ edb gen-meta-grammars edgeql
3
4
5 from __future__ import annotations
6
7
8 class EdgeQL:
9 reserved_keywords = (
10 "__source__",
11 "__subject__",
12 "__type__",
13 "alter",
14 "analyze",
15 "and",
16 "anyarray",
17 "anytuple",
18 "anytype",
19 "begin",
20 "case",
21 "check",
22 "commit",
23 "configure",
24 "create",
25 "deallocate",
26 "declare",
27 "delete",
28 "describe",
29 "detached",
30 "discard",
31 "distinct",
32 "do",
33 "drop",
34 "else",
35 "empty",
36 "end",
37 "execute",
38 "exists",
39 "explain",
40 "extending",
41 "fetch",
42 "filter",
43 "for",
44 "function",
45 "get",
46 "global",
47 "grant",
48 "group",
49 "if",
50 "ilike",
51 "import",
52 "in",
53 "insert",
54 "introspect",
55 "is",
56 "like",
57 "limit",
58 "listen",
59 "load",
60 "lock",
61 "match",
62 "module",
63 "move",
64 "not",
65 "notify",
66 "offset",
67 "optional",
68 "or",
69 "order",
70 "over",
71 "partition",
72 "policy",
73 "prepare",
74 "raise",
75 "refresh",
76 "reindex",
77 "release",
78 "reset",
79 "revoke",
80 "rollback",
81 "select",
82 "set",
83 "start",
84 "typeof",
85 "union",
86 "update",
87 "variadic",
88 "when",
89 "window",
90 "with",
91 )
92 unreserved_keywords = (
93 "abstract",
94 "after",
95 "alias",
96 "all",
97 "allow",
98 "annotation",
99 "as",
100 "asc",
101 "assignment",
102 "before",
103 "by",
104 "cardinality",
105 "cast",
106 "config",
107 "constraint",
108 "database",
109 "ddl",
110 "default",
111 "deferrable",
112 "deferred",
113 "delegated",
114 "desc",
115 "emit",
116 "explicit",
117 "expression",
118 "final",
119 "first",
120 "from",
121 "implicit",
122 "index",
123 "infix",
124 "inheritable",
125 "into",
126 "isolation",
127 "last",
128 "link",
129 "migration",
130 "multi",
131 "named",
132 "object",
133 "of",
134 "oids",
135 "on",
136 "only",
137 "operator",
138 "overloaded",
139 "postfix",
140 "prefix",
141 "property",
142 "read",
143 "rename",
144 "repeatable",
145 "required",
146 "restrict",
147 "role",
148 "savepoint",
149 "scalar",
150 "schema",
151 "sdl",
152 "serializable",
153 "session",
154 "single",
155 "source",
156 "system",
157 "target",
158 "ternary",
159 "text",
160 "then",
161 "to",
162 "transaction",
163 "type",
164 "using",
165 "verbose",
166 "view",
167 "write",
168 )
169 bool_literals = (
170 "false",
171 "true",
172 )
173 type_builtins = (
174 "Object",
175 "anyenum",
176 "anyfloat",
177 "anyint",
178 "anyreal",
179 "anyscalar",
180 "array",
181 "bool",
182 "bytes",
183 "datetime",
184 "decimal",
185 "duration",
186 "enum",
187 "float32",
188 "float64",
189 "int16",
190 "int32",
191 "int64",
192 "json",
193 "local_date",
194 "local_datetime",
195 "local_time",
196 "sequence",
197 "str",
198 "tuple",
199 "uuid",
200 )
201 module_builtins = (
202 "cfg",
203 "math",
204 "schema",
205 "std",
206 "stdgraphql",
207 "sys",
208 "cal",
209 )
210 constraint_builtins = (
211 "constraint",
212 "exclusive",
213 "expression",
214 "len_value",
215 "max_ex_value",
216 "max_len_value",
217 "max_value",
218 "min_ex_value",
219 "min_len_value",
220 "min_value",
221 "one_of",
222 "regexp",
223 )
224 fn_builtins = (
225 "abs",
226 "advisory_lock",
227 "advisory_unlock",
228 "advisory_unlock_all",
229 "all",
230 "any",
231 "array_agg",
232 "array_get",
233 "array_unpack",
234 "bytes_get_bit",
235 "ceil",
236 "contains",
237 "count",
238 "date_get",
239 "datetime_current",
240 "datetime_get",
241 "datetime_of_statement",
242 "datetime_of_transaction",
243 "datetime_trunc",
244 "duration_trunc",
245 "enumerate",
246 "find",
247 "floor",
248 "get_transaction_isolation",
249 "get_version",
250 "get_version_as_str",
251 "json_array_unpack",
252 "json_get",
253 "json_object_unpack",
254 "json_typeof",
255 "len",
256 "lg",
257 "ln",
258 "log",
259 "max",
260 "mean",
261 "min",
262 "random",
263 "re_match",
264 "re_match_all",
265 "re_replace",
266 "re_test",
267 "round",
268 "sleep",
269 "stddev",
270 "stddev_pop",
271 "str_lower",
272 "str_lpad",
273 "str_ltrim",
274 "str_repeat",
275 "str_rpad",
276 "str_rtrim",
277 "str_title",
278 "str_trim",
279 "str_upper",
280 "sum",
281 "time_get",
282 "to_datetime",
283 "to_decimal",
284 "to_duration",
285 "to_float32",
286 "to_float64",
287 "to_int16",
288 "to_int32",
289 "to_int64",
290 "to_json",
291 "to_local_date",
292 "to_local_datetime",
293 "to_local_time",
294 "to_str",
295 "uuid_generate_v1mc",
296 "var",
297 "var_pop",
298 )
299 operators = (
300 "!=",
301 "%",
302 "*",
303 "+",
304 "++",
305 "-",
306 "/",
307 "//",
308 ":=",
309 "<",
310 "<=",
311 "=",
312 ">",
313 ">=",
314 "?!=",
315 "?=",
316 "??",
317 "^",
318 )
319 navigation = (
320 ".<",
321 ".>",
322 "@",
323 ".",
324 )
325
```
Path: `edb/server/defines.py`
Content:
```
1 #
2 # This source file is part of the EdgeDB open source project.
3 #
4 # Copyright 2016-present MagicStack Inc. and the EdgeDB authors.
5 #
6 # Licensed under the Apache License, Version 2.0 (the "License");
7 # you may not use this file except in compliance with the License.
8 # You may obtain a copy of the License at
9 #
10 # http://www.apache.org/licenses/LICENSE-2.0
11 #
12 # Unless required by applicable law or agreed to in writing, software
13 # distributed under the License is distributed on an "AS IS" BASIS,
14 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
15 # See the License for the specific language governing permissions and
16 # limitations under the License.
17 #
18
19
20 from __future__ import annotations
21
22 EDGEDB_PORT = 5656
23 EDGEDB_SUPERUSER = 'edgedb'
24 EDGEDB_TEMPLATE_DB = 'edgedb0'
25 EDGEDB_SUPERUSER_DB = 'edgedb'
26 EDGEDB_ENCODING = 'utf-8'
27 EDGEDB_VISIBLE_METADATA_PREFIX = r'EdgeDB metadata follows, do not modify.\n'
28
29 # Increment this whenever the database layout or stdlib changes.
30 EDGEDB_CATALOG_VERSION = 20191219_00_00
31
32 # Resource limit on open FDs for the server process.
33 # By default, at least on macOS, the max number of open FDs
34 # is 256, which is low and can cause 'edb test' to hang.
35 # We try to bump the rlimit on server start if pemitted.
36 EDGEDB_MIN_RLIMIT_NOFILE = 2048
37
38
39 _MAX_QUERIES_CACHE = 1000
40
41 _QUERY_ROLLING_AVG_LEN = 10
42 _QUERIES_ROLLING_AVG_LEN = 300
43
44 DEFAULT_MODULE_ALIAS = 'default'
45
46
47 HTTP_PORT_QUERY_CACHE_SIZE = 500
48 HTTP_PORT_MAX_CONCURRENCY = 250
49
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/edb/edgeql/pygments/meta.py b/edb/edgeql/pygments/meta.py
--- a/edb/edgeql/pygments/meta.py
+++ b/edb/edgeql/pygments/meta.py
@@ -240,8 +240,8 @@
"datetime_get",
"datetime_of_statement",
"datetime_of_transaction",
- "datetime_trunc",
- "duration_trunc",
+ "datetime_truncate",
+ "duration_truncate",
"enumerate",
"find",
"floor",
diff --git a/edb/server/defines.py b/edb/server/defines.py
--- a/edb/server/defines.py
+++ b/edb/server/defines.py
@@ -27,7 +27,7 @@
EDGEDB_VISIBLE_METADATA_PREFIX = r'EdgeDB metadata follows, do not modify.\n'
# Increment this whenever the database layout or stdlib changes.
-EDGEDB_CATALOG_VERSION = 20191219_00_00
+EDGEDB_CATALOG_VERSION = 20191220_00_00
# Resource limit on open FDs for the server process.
# By default, at least on macOS, the max number of open FDs
|
{"golden_diff": "diff --git a/edb/edgeql/pygments/meta.py b/edb/edgeql/pygments/meta.py\n--- a/edb/edgeql/pygments/meta.py\n+++ b/edb/edgeql/pygments/meta.py\n@@ -240,8 +240,8 @@\n \"datetime_get\",\n \"datetime_of_statement\",\n \"datetime_of_transaction\",\n- \"datetime_trunc\",\n- \"duration_trunc\",\n+ \"datetime_truncate\",\n+ \"duration_truncate\",\n \"enumerate\",\n \"find\",\n \"floor\",\ndiff --git a/edb/server/defines.py b/edb/server/defines.py\n--- a/edb/server/defines.py\n+++ b/edb/server/defines.py\n@@ -27,7 +27,7 @@\n EDGEDB_VISIBLE_METADATA_PREFIX = r'EdgeDB metadata follows, do not modify.\\n'\n \n # Increment this whenever the database layout or stdlib changes.\n-EDGEDB_CATALOG_VERSION = 20191219_00_00\n+EDGEDB_CATALOG_VERSION = 20191220_00_00\n \n # Resource limit on open FDs for the server process.\n # By default, at least on macOS, the max number of open FDs\n", "issue": "Consider renaming std::datetime_trunc to std::datetime_truncate\nWe generally don't use abbreviations in our functions naming and this looks like an oversight.\n", "before_files": [{"content": "# AUTOGENERATED BY EdgeDB WITH\n# $ edb gen-meta-grammars edgeql\n\n\nfrom __future__ import annotations\n\n\nclass EdgeQL:\n reserved_keywords = (\n \"__source__\",\n \"__subject__\",\n \"__type__\",\n \"alter\",\n \"analyze\",\n \"and\",\n \"anyarray\",\n \"anytuple\",\n \"anytype\",\n \"begin\",\n \"case\",\n \"check\",\n \"commit\",\n \"configure\",\n \"create\",\n \"deallocate\",\n \"declare\",\n \"delete\",\n \"describe\",\n \"detached\",\n \"discard\",\n \"distinct\",\n \"do\",\n \"drop\",\n \"else\",\n \"empty\",\n \"end\",\n \"execute\",\n \"exists\",\n \"explain\",\n \"extending\",\n \"fetch\",\n \"filter\",\n \"for\",\n \"function\",\n \"get\",\n \"global\",\n \"grant\",\n \"group\",\n \"if\",\n \"ilike\",\n \"import\",\n \"in\",\n \"insert\",\n \"introspect\",\n \"is\",\n \"like\",\n \"limit\",\n \"listen\",\n \"load\",\n \"lock\",\n \"match\",\n \"module\",\n \"move\",\n \"not\",\n \"notify\",\n \"offset\",\n \"optional\",\n \"or\",\n \"order\",\n \"over\",\n \"partition\",\n \"policy\",\n \"prepare\",\n \"raise\",\n \"refresh\",\n \"reindex\",\n \"release\",\n \"reset\",\n \"revoke\",\n \"rollback\",\n \"select\",\n \"set\",\n \"start\",\n \"typeof\",\n \"union\",\n \"update\",\n \"variadic\",\n \"when\",\n \"window\",\n \"with\",\n )\n unreserved_keywords = (\n \"abstract\",\n \"after\",\n \"alias\",\n \"all\",\n \"allow\",\n \"annotation\",\n \"as\",\n \"asc\",\n \"assignment\",\n \"before\",\n \"by\",\n \"cardinality\",\n \"cast\",\n \"config\",\n \"constraint\",\n \"database\",\n \"ddl\",\n \"default\",\n \"deferrable\",\n \"deferred\",\n \"delegated\",\n \"desc\",\n \"emit\",\n \"explicit\",\n \"expression\",\n \"final\",\n \"first\",\n \"from\",\n \"implicit\",\n \"index\",\n \"infix\",\n \"inheritable\",\n \"into\",\n \"isolation\",\n \"last\",\n \"link\",\n \"migration\",\n \"multi\",\n \"named\",\n \"object\",\n \"of\",\n \"oids\",\n \"on\",\n \"only\",\n \"operator\",\n \"overloaded\",\n \"postfix\",\n \"prefix\",\n \"property\",\n \"read\",\n \"rename\",\n \"repeatable\",\n \"required\",\n \"restrict\",\n \"role\",\n \"savepoint\",\n \"scalar\",\n \"schema\",\n \"sdl\",\n \"serializable\",\n \"session\",\n \"single\",\n \"source\",\n \"system\",\n \"target\",\n \"ternary\",\n \"text\",\n \"then\",\n \"to\",\n \"transaction\",\n \"type\",\n \"using\",\n \"verbose\",\n \"view\",\n \"write\",\n )\n bool_literals = (\n \"false\",\n \"true\",\n )\n type_builtins = (\n \"Object\",\n \"anyenum\",\n \"anyfloat\",\n \"anyint\",\n \"anyreal\",\n \"anyscalar\",\n \"array\",\n \"bool\",\n \"bytes\",\n \"datetime\",\n \"decimal\",\n \"duration\",\n \"enum\",\n \"float32\",\n \"float64\",\n \"int16\",\n \"int32\",\n \"int64\",\n \"json\",\n \"local_date\",\n \"local_datetime\",\n \"local_time\",\n \"sequence\",\n \"str\",\n \"tuple\",\n \"uuid\",\n )\n module_builtins = (\n \"cfg\",\n \"math\",\n \"schema\",\n \"std\",\n \"stdgraphql\",\n \"sys\",\n \"cal\",\n )\n constraint_builtins = (\n \"constraint\",\n \"exclusive\",\n \"expression\",\n \"len_value\",\n \"max_ex_value\",\n \"max_len_value\",\n \"max_value\",\n \"min_ex_value\",\n \"min_len_value\",\n \"min_value\",\n \"one_of\",\n \"regexp\",\n )\n fn_builtins = (\n \"abs\",\n \"advisory_lock\",\n \"advisory_unlock\",\n \"advisory_unlock_all\",\n \"all\",\n \"any\",\n \"array_agg\",\n \"array_get\",\n \"array_unpack\",\n \"bytes_get_bit\",\n \"ceil\",\n \"contains\",\n \"count\",\n \"date_get\",\n \"datetime_current\",\n \"datetime_get\",\n \"datetime_of_statement\",\n \"datetime_of_transaction\",\n \"datetime_trunc\",\n \"duration_trunc\",\n \"enumerate\",\n \"find\",\n \"floor\",\n \"get_transaction_isolation\",\n \"get_version\",\n \"get_version_as_str\",\n \"json_array_unpack\",\n \"json_get\",\n \"json_object_unpack\",\n \"json_typeof\",\n \"len\",\n \"lg\",\n \"ln\",\n \"log\",\n \"max\",\n \"mean\",\n \"min\",\n \"random\",\n \"re_match\",\n \"re_match_all\",\n \"re_replace\",\n \"re_test\",\n \"round\",\n \"sleep\",\n \"stddev\",\n \"stddev_pop\",\n \"str_lower\",\n \"str_lpad\",\n \"str_ltrim\",\n \"str_repeat\",\n \"str_rpad\",\n \"str_rtrim\",\n \"str_title\",\n \"str_trim\",\n \"str_upper\",\n \"sum\",\n \"time_get\",\n \"to_datetime\",\n \"to_decimal\",\n \"to_duration\",\n \"to_float32\",\n \"to_float64\",\n \"to_int16\",\n \"to_int32\",\n \"to_int64\",\n \"to_json\",\n \"to_local_date\",\n \"to_local_datetime\",\n \"to_local_time\",\n \"to_str\",\n \"uuid_generate_v1mc\",\n \"var\",\n \"var_pop\",\n )\n operators = (\n \"!=\",\n \"%\",\n \"*\",\n \"+\",\n \"++\",\n \"-\",\n \"/\",\n \"//\",\n \":=\",\n \"<\",\n \"<=\",\n \"=\",\n \">\",\n \">=\",\n \"?!=\",\n \"?=\",\n \"??\",\n \"^\",\n )\n navigation = (\n \".<\",\n \".>\",\n \"@\",\n \".\",\n )\n", "path": "edb/edgeql/pygments/meta.py"}, {"content": "#\n# This source file is part of the EdgeDB open source project.\n#\n# Copyright 2016-present MagicStack Inc. and the EdgeDB authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\n\nfrom __future__ import annotations\n\nEDGEDB_PORT = 5656\nEDGEDB_SUPERUSER = 'edgedb'\nEDGEDB_TEMPLATE_DB = 'edgedb0'\nEDGEDB_SUPERUSER_DB = 'edgedb'\nEDGEDB_ENCODING = 'utf-8'\nEDGEDB_VISIBLE_METADATA_PREFIX = r'EdgeDB metadata follows, do not modify.\\n'\n\n# Increment this whenever the database layout or stdlib changes.\nEDGEDB_CATALOG_VERSION = 20191219_00_00\n\n# Resource limit on open FDs for the server process.\n# By default, at least on macOS, the max number of open FDs\n# is 256, which is low and can cause 'edb test' to hang.\n# We try to bump the rlimit on server start if pemitted.\nEDGEDB_MIN_RLIMIT_NOFILE = 2048\n\n\n_MAX_QUERIES_CACHE = 1000\n\n_QUERY_ROLLING_AVG_LEN = 10\n_QUERIES_ROLLING_AVG_LEN = 300\n\nDEFAULT_MODULE_ALIAS = 'default'\n\n\nHTTP_PORT_QUERY_CACHE_SIZE = 500\nHTTP_PORT_MAX_CONCURRENCY = 250\n", "path": "edb/server/defines.py"}], "after_files": [{"content": "# AUTOGENERATED BY EdgeDB WITH\n# $ edb gen-meta-grammars edgeql\n\n\nfrom __future__ import annotations\n\n\nclass EdgeQL:\n reserved_keywords = (\n \"__source__\",\n \"__subject__\",\n \"__type__\",\n \"alter\",\n \"analyze\",\n \"and\",\n \"anyarray\",\n \"anytuple\",\n \"anytype\",\n \"begin\",\n \"case\",\n \"check\",\n \"commit\",\n \"configure\",\n \"create\",\n \"deallocate\",\n \"declare\",\n \"delete\",\n \"describe\",\n \"detached\",\n \"discard\",\n \"distinct\",\n \"do\",\n \"drop\",\n \"else\",\n \"empty\",\n \"end\",\n \"execute\",\n \"exists\",\n \"explain\",\n \"extending\",\n \"fetch\",\n \"filter\",\n \"for\",\n \"function\",\n \"get\",\n \"global\",\n \"grant\",\n \"group\",\n \"if\",\n \"ilike\",\n \"import\",\n \"in\",\n \"insert\",\n \"introspect\",\n \"is\",\n \"like\",\n \"limit\",\n \"listen\",\n \"load\",\n \"lock\",\n \"match\",\n \"module\",\n \"move\",\n \"not\",\n \"notify\",\n \"offset\",\n \"optional\",\n \"or\",\n \"order\",\n \"over\",\n \"partition\",\n \"policy\",\n \"prepare\",\n \"raise\",\n \"refresh\",\n \"reindex\",\n \"release\",\n \"reset\",\n \"revoke\",\n \"rollback\",\n \"select\",\n \"set\",\n \"start\",\n \"typeof\",\n \"union\",\n \"update\",\n \"variadic\",\n \"when\",\n \"window\",\n \"with\",\n )\n unreserved_keywords = (\n \"abstract\",\n \"after\",\n \"alias\",\n \"all\",\n \"allow\",\n \"annotation\",\n \"as\",\n \"asc\",\n \"assignment\",\n \"before\",\n \"by\",\n \"cardinality\",\n \"cast\",\n \"config\",\n \"constraint\",\n \"database\",\n \"ddl\",\n \"default\",\n \"deferrable\",\n \"deferred\",\n \"delegated\",\n \"desc\",\n \"emit\",\n \"explicit\",\n \"expression\",\n \"final\",\n \"first\",\n \"from\",\n \"implicit\",\n \"index\",\n \"infix\",\n \"inheritable\",\n \"into\",\n \"isolation\",\n \"last\",\n \"link\",\n \"migration\",\n \"multi\",\n \"named\",\n \"object\",\n \"of\",\n \"oids\",\n \"on\",\n \"only\",\n \"operator\",\n \"overloaded\",\n \"postfix\",\n \"prefix\",\n \"property\",\n \"read\",\n \"rename\",\n \"repeatable\",\n \"required\",\n \"restrict\",\n \"role\",\n \"savepoint\",\n \"scalar\",\n \"schema\",\n \"sdl\",\n \"serializable\",\n \"session\",\n \"single\",\n \"source\",\n \"system\",\n \"target\",\n \"ternary\",\n \"text\",\n \"then\",\n \"to\",\n \"transaction\",\n \"type\",\n \"using\",\n \"verbose\",\n \"view\",\n \"write\",\n )\n bool_literals = (\n \"false\",\n \"true\",\n )\n type_builtins = (\n \"Object\",\n \"anyenum\",\n \"anyfloat\",\n \"anyint\",\n \"anyreal\",\n \"anyscalar\",\n \"array\",\n \"bool\",\n \"bytes\",\n \"datetime\",\n \"decimal\",\n \"duration\",\n \"enum\",\n \"float32\",\n \"float64\",\n \"int16\",\n \"int32\",\n \"int64\",\n \"json\",\n \"local_date\",\n \"local_datetime\",\n \"local_time\",\n \"sequence\",\n \"str\",\n \"tuple\",\n \"uuid\",\n )\n module_builtins = (\n \"cfg\",\n \"math\",\n \"schema\",\n \"std\",\n \"stdgraphql\",\n \"sys\",\n \"cal\",\n )\n constraint_builtins = (\n \"constraint\",\n \"exclusive\",\n \"expression\",\n \"len_value\",\n \"max_ex_value\",\n \"max_len_value\",\n \"max_value\",\n \"min_ex_value\",\n \"min_len_value\",\n \"min_value\",\n \"one_of\",\n \"regexp\",\n )\n fn_builtins = (\n \"abs\",\n \"advisory_lock\",\n \"advisory_unlock\",\n \"advisory_unlock_all\",\n \"all\",\n \"any\",\n \"array_agg\",\n \"array_get\",\n \"array_unpack\",\n \"bytes_get_bit\",\n \"ceil\",\n \"contains\",\n \"count\",\n \"date_get\",\n \"datetime_current\",\n \"datetime_get\",\n \"datetime_of_statement\",\n \"datetime_of_transaction\",\n \"datetime_truncate\",\n \"duration_truncate\",\n \"enumerate\",\n \"find\",\n \"floor\",\n \"get_transaction_isolation\",\n \"get_version\",\n \"get_version_as_str\",\n \"json_array_unpack\",\n \"json_get\",\n \"json_object_unpack\",\n \"json_typeof\",\n \"len\",\n \"lg\",\n \"ln\",\n \"log\",\n \"max\",\n \"mean\",\n \"min\",\n \"random\",\n \"re_match\",\n \"re_match_all\",\n \"re_replace\",\n \"re_test\",\n \"round\",\n \"sleep\",\n \"stddev\",\n \"stddev_pop\",\n \"str_lower\",\n \"str_lpad\",\n \"str_ltrim\",\n \"str_repeat\",\n \"str_rpad\",\n \"str_rtrim\",\n \"str_title\",\n \"str_trim\",\n \"str_upper\",\n \"sum\",\n \"time_get\",\n \"to_datetime\",\n \"to_decimal\",\n \"to_duration\",\n \"to_float32\",\n \"to_float64\",\n \"to_int16\",\n \"to_int32\",\n \"to_int64\",\n \"to_json\",\n \"to_local_date\",\n \"to_local_datetime\",\n \"to_local_time\",\n \"to_str\",\n \"uuid_generate_v1mc\",\n \"var\",\n \"var_pop\",\n )\n operators = (\n \"!=\",\n \"%\",\n \"*\",\n \"+\",\n \"++\",\n \"-\",\n \"/\",\n \"//\",\n \":=\",\n \"<\",\n \"<=\",\n \"=\",\n \">\",\n \">=\",\n \"?!=\",\n \"?=\",\n \"??\",\n \"^\",\n )\n navigation = (\n \".<\",\n \".>\",\n \"@\",\n \".\",\n )\n", "path": "edb/edgeql/pygments/meta.py"}, {"content": "#\n# This source file is part of the EdgeDB open source project.\n#\n# Copyright 2016-present MagicStack Inc. and the EdgeDB authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\n\nfrom __future__ import annotations\n\nEDGEDB_PORT = 5656\nEDGEDB_SUPERUSER = 'edgedb'\nEDGEDB_TEMPLATE_DB = 'edgedb0'\nEDGEDB_SUPERUSER_DB = 'edgedb'\nEDGEDB_ENCODING = 'utf-8'\nEDGEDB_VISIBLE_METADATA_PREFIX = r'EdgeDB metadata follows, do not modify.\\n'\n\n# Increment this whenever the database layout or stdlib changes.\nEDGEDB_CATALOG_VERSION = 20191220_00_00\n\n# Resource limit on open FDs for the server process.\n# By default, at least on macOS, the max number of open FDs\n# is 256, which is low and can cause 'edb test' to hang.\n# We try to bump the rlimit on server start if pemitted.\nEDGEDB_MIN_RLIMIT_NOFILE = 2048\n\n\n_MAX_QUERIES_CACHE = 1000\n\n_QUERY_ROLLING_AVG_LEN = 10\n_QUERIES_ROLLING_AVG_LEN = 300\n\nDEFAULT_MODULE_ALIAS = 'default'\n\n\nHTTP_PORT_QUERY_CACHE_SIZE = 500\nHTTP_PORT_MAX_CONCURRENCY = 250\n", "path": "edb/server/defines.py"}]}
| 3,142 | 277 |
gh_patches_debug_35625
|
rasdani/github-patches
|
git_diff
|
coreruleset__coreruleset-3416
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Remaining issues with automatic changelog PR generation
This is coming along nicely. Still a few hiccups:
* The linter complains the title of the PR itself is not a conventional commit message. Suggestion: Prefix with `chore:`. That passes.
* The mapped dev name come with a prefix `@`. (-> `@Ervin Hegedüs`). This should be removed.
* There is 1 message per dev merging a PR per day. Yesterday we had 2 dev merging 1 PR, this leading to 2 Changelog PRs trying to add something to the same original CHANGES file, obviously resulting in a conflict. Can be resolved by hand, but a single Changelog PR per day would be easier for handling.
* The PRs are now changing the first few lines of the CHANGES file. I suggest to shift this down a bit to get a better looking file without having these new entries sticking out on top. Suggestion: Add the entries following the first line matching the pattern `/^## Version/`.
I have resolved the conflict right in the GUI and I have also rewritten the Changelog message by hand right in the GUI. I think that works smoothly. Then self-approval, then merging.
We do not usually self-approve, but on these administrative updates, we should keep the work to an absolute minimum.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `.github/create-changelog-prs.py`
Content:
```
1 #! /usr/bin/env python
2
3 import subprocess
4 import json
5 import datetime
6 import tempfile
7 import sys
8 import os
9 import shutil
10 import re
11
12 DEVELOPERS = dict()
13
14 def get_pr(repository: str, number: int) -> dict:
15 command = f"""gh pr view \
16 --repo "{repository}" \
17 "{number}" \
18 --json mergeCommit,mergedBy,title,author,baseRefName,number
19 """
20 proc = subprocess.Popen(command, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
21 pr_json, errors = proc.communicate()
22 if proc.returncode != 0:
23 print(errors)
24 exit(1)
25 return json.loads(pr_json)
26
27 def get_prs(repository: str, day: datetime.date) -> list:
28 print(f"Fetching PRs for {day}")
29 command = f"""gh search prs \
30 --repo "{repository}" \
31 --merged-at "{day}" \
32 --json number
33 """
34 proc = subprocess.Popen(command, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
35 prs_json, errors = proc.communicate()
36 if proc.returncode != 0:
37 print(errors)
38 exit(1)
39 prs = list()
40 for result in json.loads(prs_json):
41 prs.append(get_pr(repository, result["number"]))
42
43 return prs
44
45 def parse_prs(prs: list) -> dict:
46 pr_map = dict()
47 for pr in prs:
48 merged_by = pr["mergedBy"]["login"]
49 if merged_by not in pr:
50 pr_list = list()
51 pr_map[merged_by] = pr_list
52 else:
53 pr_list = pr_map[merged_by]
54 pr_list.append(pr)
55 return pr_map
56
57
58 def create_prs(repository: str, merged_by_prs_map: dict, day: datetime.date):
59 for author in merged_by_prs_map.keys():
60 create_pr(repository, author, merged_by_prs_map[author], day)
61
62 def create_pr(repository: str, merged_by: str, prs: list, day: datetime.date):
63 if len(prs) == 0:
64 return
65 print(f"Creating changelog PR for @{merged_by}")
66
67 sample_pr = prs[0]
68 base_branch = sample_pr["baseRefName"]
69 pr_branch_name = create_pr_branch(day, merged_by, base_branch)
70 pr_body, changelog_lines = generate_content(prs, merged_by)
71 create_commit(changelog_lines)
72 push_pr_branch(pr_branch_name)
73
74 command = f"""gh pr create \
75 --repo "{repository}" \
76 --assignee "{merged_by}" \
77 --base "{base_branch}" \
78 --label "changelog-pr" \
79 --title "Changelog updates for {day}, merged by @{merged_by}" \
80 --body '{pr_body}'
81 """
82
83 proc = subprocess.Popen(command, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
84 outs, errors = proc.communicate()
85 if proc.returncode != 0:
86 print(errors)
87 exit(1)
88 print(f"Created PR: {outs.decode()}")
89
90 def create_commit(changelog_lines: str):
91 new_changelog = tempfile.NamedTemporaryFile(delete=False, delete_on_close=False)
92 new_changelog.write(changelog_lines.encode())
93 with open('CHANGES.md', 'rt') as changelog:
94 new_changelog.write(changelog.read().encode())
95
96 new_changelog.close()
97 os.remove('CHANGES.md')
98 shutil.move(new_changelog.name, 'CHANGES.md')
99
100 command = "git commit CHANGES.md -m 'Add pending changelog entries to changelog'"
101 proc = subprocess.Popen(command, shell=True, stderr=subprocess.PIPE)
102 _, errors = proc.communicate()
103 if proc.returncode != 0:
104 print(errors)
105 exit(1)
106
107 def generate_content(prs: list, merged_by: str) -> (str, str):
108 changelog_lines = f"Entries for PRs merged by {merged_by}:\n"
109 pr_body = f"This PR was auto-generated to update the changelog with the following entries, merged by @{merged_by}:\n```\n"
110 pr_links = ""
111 for pr in prs:
112 pr_number = pr["number"]
113 pr_title = pr["title"]
114 pr_author = get_pr_author_name(pr["author"]["login"])
115 new_line = f"* {pr_title} (@{pr_author}) [#{pr_number}]\n"
116 pr_body += new_line
117 pr_links += f"- #{pr_number}\n"
118
119 changelog_lines += new_line
120 pr_body += "```\n\n" + pr_links
121 changelog_lines += "\n\n"
122
123 return pr_body, changelog_lines
124
125 def get_pr_author_name(login: str) -> str:
126 if len(DEVELOPERS) == 0:
127 parse_contributors()
128
129 return DEVELOPERS[login] if login in DEVELOPERS else login
130
131 def parse_contributors():
132 regex = re.compile(r'^\s*?-\s*?\[([^]]+)\]\s*?\(http.*/([^/]+)\s*?\)')
133 with open('CONTRIBUTORS.md', 'rt') as handle:
134 line = handle.readline()
135 while not ('##' in line and 'Contributors' in line):
136 match = regex.match(line)
137 if match:
138 DEVELOPERS[match.group(2)] = match.group(1)
139 line = handle.readline()
140
141 def create_pr_branch(day: datetime.date, author: str, base_branch: str) -> str:
142 branch_name = f"changelog-updates-for-{day}-{author} {base_branch}"
143 command = f"git checkout -b {branch_name}"
144 proc = subprocess.Popen(command, shell=True, stderr=subprocess.PIPE)
145 _, errors = proc.communicate()
146 if proc.returncode != 0:
147 print(errors)
148 exit(1)
149
150 return branch_name
151
152 def push_pr_branch(branch_name: str):
153 command = f"git push origin {branch_name}"
154 proc = subprocess.Popen(command, shell=True, stderr=subprocess.PIPE)
155 _, errors = proc.communicate()
156 if proc.returncode != 0:
157 print(errors)
158 exit(1)
159
160 def run(source_repository: str, target_repository: str, today: datetime.date):
161 day = today - datetime.timedelta(days=1)
162 prs = get_prs(source_repository, day)
163 prs_length = len(prs)
164 print(f"Found {prs_length} PRs")
165 if prs_length == 0:
166 return
167
168 merged_by_prs_map = parse_prs(prs)
169 create_prs(target_repository, merged_by_prs_map, day)
170
171 if __name__ == "__main__":
172 # disable pager
173 os.environ["GH_PAGER"] = ''
174 # set variables for Git
175 os.environ["GIT_AUTHOR_NAME"] = "changelog-pr-bot"
176 os.environ["GIT_AUTHOR_EMAIL"] = "[email protected]"
177 os.environ["GIT_COMMITTER_NAME"] = "changelog-pr-bot"
178 os.environ["GIT_COMMITTER_EMAIL"] = "[email protected]"
179
180 source_repository = 'coreruleset/coreruleset'
181 target_repository = source_repository
182 # the cron schedule for the workflow uses UTC
183 today = datetime.datetime.now(datetime.timezone.utc).date()
184
185 if len(sys.argv) > 1:
186 source_repository = sys.argv[1]
187 if len(sys.argv) > 2:
188 target_repository = sys.argv[2]
189 if len(sys.argv) > 3:
190 today = datetime.date.fromisoformat(sys.argv[3])
191 run(source_repository, target_repository, today)
192
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/.github/create-changelog-prs.py b/.github/create-changelog-prs.py
--- a/.github/create-changelog-prs.py
+++ b/.github/create-changelog-prs.py
@@ -6,7 +6,6 @@
import tempfile
import sys
import os
-import shutil
import re
DEVELOPERS = dict()
@@ -76,7 +75,7 @@
--assignee "{merged_by}" \
--base "{base_branch}" \
--label "changelog-pr" \
- --title "Changelog updates for {day}, merged by @{merged_by}" \
+ --title "chore: changelog updates for {day}, merged by @{merged_by}" \
--body '{pr_body}'
"""
@@ -88,16 +87,10 @@
print(f"Created PR: {outs.decode()}")
def create_commit(changelog_lines: str):
- new_changelog = tempfile.NamedTemporaryFile(delete=False, delete_on_close=False)
- new_changelog.write(changelog_lines.encode())
- with open('CHANGES.md', 'rt') as changelog:
- new_changelog.write(changelog.read().encode())
+ with open('.changes-pending.md', 'at') as changelog:
+ changelog.write(changelog_lines.encode())
- new_changelog.close()
- os.remove('CHANGES.md')
- shutil.move(new_changelog.name, 'CHANGES.md')
-
- command = "git commit CHANGES.md -m 'Add pending changelog entries to changelog'"
+ command = "git commit .changes-pending.md -m 'Add pending changelog entries'"
proc = subprocess.Popen(command, shell=True, stderr=subprocess.PIPE)
_, errors = proc.communicate()
if proc.returncode != 0:
@@ -112,7 +105,7 @@
pr_number = pr["number"]
pr_title = pr["title"]
pr_author = get_pr_author_name(pr["author"]["login"])
- new_line = f"* {pr_title} (@{pr_author}) [#{pr_number}]\n"
+ new_line = f"* {pr_title} ({pr_author}) [#{pr_number}]\n"
pr_body += new_line
pr_links += f"- #{pr_number}\n"
@@ -126,7 +119,7 @@
if len(DEVELOPERS) == 0:
parse_contributors()
- return DEVELOPERS[login] if login in DEVELOPERS else login
+ return DEVELOPERS[login] if login in DEVELOPERS else f"@{login}"
def parse_contributors():
regex = re.compile(r'^\s*?-\s*?\[([^]]+)\]\s*?\(http.*/([^/]+)\s*?\)')
|
{"golden_diff": "diff --git a/.github/create-changelog-prs.py b/.github/create-changelog-prs.py\n--- a/.github/create-changelog-prs.py\n+++ b/.github/create-changelog-prs.py\n@@ -6,7 +6,6 @@\n import tempfile\n import sys\n import os\n-import shutil\n import re\n \n DEVELOPERS = dict()\n@@ -76,7 +75,7 @@\n \t\t--assignee \"{merged_by}\" \\\n \t\t--base \"{base_branch}\" \\\n \t\t--label \"changelog-pr\" \\\n-\t\t--title \"Changelog updates for {day}, merged by @{merged_by}\" \\\n+\t\t--title \"chore: changelog updates for {day}, merged by @{merged_by}\" \\\n \t\t--body '{pr_body}'\n \t\"\"\"\n \n@@ -88,16 +87,10 @@\n \tprint(f\"Created PR: {outs.decode()}\")\n \n def create_commit(changelog_lines: str):\n-\tnew_changelog = tempfile.NamedTemporaryFile(delete=False, delete_on_close=False)\n-\tnew_changelog.write(changelog_lines.encode())\n-\twith open('CHANGES.md', 'rt') as changelog:\n-\t\tnew_changelog.write(changelog.read().encode())\n+\twith open('.changes-pending.md', 'at') as changelog:\n+\t\tchangelog.write(changelog_lines.encode())\n \n-\tnew_changelog.close()\n-\tos.remove('CHANGES.md')\n-\tshutil.move(new_changelog.name, 'CHANGES.md')\n-\n-\tcommand = \"git commit CHANGES.md -m 'Add pending changelog entries to changelog'\"\n+\tcommand = \"git commit .changes-pending.md -m 'Add pending changelog entries'\"\n \tproc = subprocess.Popen(command, shell=True, stderr=subprocess.PIPE)\n \t_, errors = proc.communicate()\n \tif proc.returncode != 0:\n@@ -112,7 +105,7 @@\n \t\tpr_number = pr[\"number\"]\n \t\tpr_title = pr[\"title\"]\n \t\tpr_author = get_pr_author_name(pr[\"author\"][\"login\"])\n-\t\tnew_line = f\"* {pr_title} (@{pr_author}) [#{pr_number}]\\n\"\n+\t\tnew_line = f\"* {pr_title} ({pr_author}) [#{pr_number}]\\n\"\n \t\tpr_body += new_line\n \t\tpr_links += f\"- #{pr_number}\\n\"\n \n@@ -126,7 +119,7 @@\n \tif len(DEVELOPERS) == 0:\n \t\tparse_contributors()\n \n-\treturn DEVELOPERS[login] if login in DEVELOPERS else login\n+\treturn DEVELOPERS[login] if login in DEVELOPERS else f\"@{login}\"\n \n def parse_contributors():\n \tregex = re.compile(r'^\\s*?-\\s*?\\[([^]]+)\\]\\s*?\\(http.*/([^/]+)\\s*?\\)')\n", "issue": "Remaining issues with automatic changelog PR generation\nThis is coming along nicely. Still a few hiccups:\r\n\r\n* The linter complains the title of the PR itself is not a conventional commit message. Suggestion: Prefix with `chore:`. That passes.\r\n* The mapped dev name come with a prefix `@`. (-> `@Ervin Heged\u00fcs`). This should be removed.\r\n* There is 1 message per dev merging a PR per day. Yesterday we had 2 dev merging 1 PR, this leading to 2 Changelog PRs trying to add something to the same original CHANGES file, obviously resulting in a conflict. Can be resolved by hand, but a single Changelog PR per day would be easier for handling.\r\n* The PRs are now changing the first few lines of the CHANGES file. I suggest to shift this down a bit to get a better looking file without having these new entries sticking out on top. Suggestion: Add the entries following the first line matching the pattern `/^## Version/`.\r\n\r\n\r\nI have resolved the conflict right in the GUI and I have also rewritten the Changelog message by hand right in the GUI. I think that works smoothly. Then self-approval, then merging.\r\n\r\nWe do not usually self-approve, but on these administrative updates, we should keep the work to an absolute minimum.\n", "before_files": [{"content": "#! /usr/bin/env python\n\nimport subprocess\nimport json\nimport datetime\nimport tempfile\nimport sys\nimport os\nimport shutil\nimport re\n\nDEVELOPERS = dict()\n\ndef get_pr(repository: str, number: int) -> dict:\n\tcommand = f\"\"\"gh pr view \\\n\t\t--repo \"{repository}\" \\\n\t\t\"{number}\" \\\n\t\t--json mergeCommit,mergedBy,title,author,baseRefName,number\n\t\"\"\"\n\tproc = subprocess.Popen(command, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)\n\tpr_json, errors = proc.communicate()\n\tif proc.returncode != 0:\n\t\tprint(errors)\n\t\texit(1)\n\treturn json.loads(pr_json)\n\ndef get_prs(repository: str, day: datetime.date) -> list:\n\tprint(f\"Fetching PRs for {day}\")\n\tcommand = f\"\"\"gh search prs \\\n\t\t--repo \"{repository}\" \\\n\t\t--merged-at \"{day}\" \\\n\t\t--json number\n\t\"\"\"\n\tproc = subprocess.Popen(command, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)\n\tprs_json, errors = proc.communicate()\n\tif proc.returncode != 0:\n\t\tprint(errors)\n\t\texit(1)\n\tprs = list()\n\tfor result in json.loads(prs_json):\n\t\tprs.append(get_pr(repository, result[\"number\"]))\n\n\treturn prs\n\ndef parse_prs(prs: list) -> dict:\n\tpr_map = dict()\n\tfor pr in prs:\n\t\tmerged_by = pr[\"mergedBy\"][\"login\"]\n\t\tif merged_by not in pr:\n\t\t\tpr_list = list()\n\t\t\tpr_map[merged_by] = pr_list\n\t\telse:\n\t\t\tpr_list = pr_map[merged_by]\n\t\tpr_list.append(pr)\n\treturn pr_map\n\n\ndef create_prs(repository: str, merged_by_prs_map: dict, day: datetime.date):\n\tfor author in merged_by_prs_map.keys():\n\t\tcreate_pr(repository, author, merged_by_prs_map[author], day)\n\ndef create_pr(repository: str, merged_by: str, prs: list, day: datetime.date):\n\tif len(prs) == 0:\n\t\treturn\n\tprint(f\"Creating changelog PR for @{merged_by}\")\n\n\tsample_pr = prs[0]\n\tbase_branch = sample_pr[\"baseRefName\"]\n\tpr_branch_name = create_pr_branch(day, merged_by, base_branch)\n\tpr_body, changelog_lines = generate_content(prs, merged_by)\n\tcreate_commit(changelog_lines)\n\tpush_pr_branch(pr_branch_name)\n\n\tcommand = f\"\"\"gh pr create \\\n\t\t--repo \"{repository}\" \\\n\t\t--assignee \"{merged_by}\" \\\n\t\t--base \"{base_branch}\" \\\n\t\t--label \"changelog-pr\" \\\n\t\t--title \"Changelog updates for {day}, merged by @{merged_by}\" \\\n\t\t--body '{pr_body}'\n\t\"\"\"\n\n\tproc = subprocess.Popen(command, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)\n\touts, errors = proc.communicate()\n\tif proc.returncode != 0:\n\t\tprint(errors)\n\t\texit(1)\n\tprint(f\"Created PR: {outs.decode()}\")\n\ndef create_commit(changelog_lines: str):\n\tnew_changelog = tempfile.NamedTemporaryFile(delete=False, delete_on_close=False)\n\tnew_changelog.write(changelog_lines.encode())\n\twith open('CHANGES.md', 'rt') as changelog:\n\t\tnew_changelog.write(changelog.read().encode())\n\n\tnew_changelog.close()\n\tos.remove('CHANGES.md')\n\tshutil.move(new_changelog.name, 'CHANGES.md')\n\n\tcommand = \"git commit CHANGES.md -m 'Add pending changelog entries to changelog'\"\n\tproc = subprocess.Popen(command, shell=True, stderr=subprocess.PIPE)\n\t_, errors = proc.communicate()\n\tif proc.returncode != 0:\n\t\tprint(errors)\n\t\texit(1)\n\ndef generate_content(prs: list, merged_by: str) -> (str, str):\n\tchangelog_lines = f\"Entries for PRs merged by {merged_by}:\\n\"\n\tpr_body = f\"This PR was auto-generated to update the changelog with the following entries, merged by @{merged_by}:\\n```\\n\"\n\tpr_links = \"\"\n\tfor pr in prs:\n\t\tpr_number = pr[\"number\"]\n\t\tpr_title = pr[\"title\"]\n\t\tpr_author = get_pr_author_name(pr[\"author\"][\"login\"])\n\t\tnew_line = f\"* {pr_title} (@{pr_author}) [#{pr_number}]\\n\"\n\t\tpr_body += new_line\n\t\tpr_links += f\"- #{pr_number}\\n\"\n\n\t\tchangelog_lines += new_line\n\tpr_body += \"```\\n\\n\" + pr_links\n\tchangelog_lines += \"\\n\\n\"\n\n\treturn pr_body, changelog_lines\n\ndef get_pr_author_name(login: str) -> str:\n\tif len(DEVELOPERS) == 0:\n\t\tparse_contributors()\n\n\treturn DEVELOPERS[login] if login in DEVELOPERS else login\n\ndef parse_contributors():\n\tregex = re.compile(r'^\\s*?-\\s*?\\[([^]]+)\\]\\s*?\\(http.*/([^/]+)\\s*?\\)')\n\twith open('CONTRIBUTORS.md', 'rt') as handle:\n\t\tline = handle.readline()\n\t\twhile not ('##' in line and 'Contributors' in line):\n\t\t\tmatch = regex.match(line)\n\t\t\tif match:\n\t\t\t\tDEVELOPERS[match.group(2)] = match.group(1)\n\t\t\tline = handle.readline()\n\ndef create_pr_branch(day: datetime.date, author: str, base_branch: str) -> str:\n\tbranch_name = f\"changelog-updates-for-{day}-{author} {base_branch}\"\n\tcommand = f\"git checkout -b {branch_name}\"\n\tproc = subprocess.Popen(command, shell=True, stderr=subprocess.PIPE)\n\t_, errors = proc.communicate()\n\tif proc.returncode != 0:\n\t\tprint(errors)\n\t\texit(1)\n\n\treturn branch_name\n\ndef push_pr_branch(branch_name: str):\n\tcommand = f\"git push origin {branch_name}\"\n\tproc = subprocess.Popen(command, shell=True, stderr=subprocess.PIPE)\n\t_, errors = proc.communicate()\n\tif proc.returncode != 0:\n\t\tprint(errors)\n\t\texit(1)\n\ndef run(source_repository: str, target_repository: str, today: datetime.date):\n\tday = today - datetime.timedelta(days=1)\n\tprs = get_prs(source_repository, day)\n\tprs_length = len(prs)\n\tprint(f\"Found {prs_length} PRs\")\n\tif prs_length == 0:\n\t\treturn\n\n\tmerged_by_prs_map = parse_prs(prs)\n\tcreate_prs(target_repository, merged_by_prs_map, day)\n\nif __name__ == \"__main__\":\n\t# disable pager\n\tos.environ[\"GH_PAGER\"] = ''\n\t# set variables for Git\n\tos.environ[\"GIT_AUTHOR_NAME\"] = \"changelog-pr-bot\"\n\tos.environ[\"GIT_AUTHOR_EMAIL\"] = \"[email protected]\"\n\tos.environ[\"GIT_COMMITTER_NAME\"] = \"changelog-pr-bot\"\n\tos.environ[\"GIT_COMMITTER_EMAIL\"] = \"[email protected]\"\n\n\tsource_repository = 'coreruleset/coreruleset'\n\ttarget_repository = source_repository\n\t# the cron schedule for the workflow uses UTC\n\ttoday = datetime.datetime.now(datetime.timezone.utc).date()\n\n\tif len(sys.argv) > 1:\n\t\tsource_repository = sys.argv[1]\n\tif len(sys.argv) > 2:\n\t\ttarget_repository = sys.argv[2]\n\tif len(sys.argv) > 3:\n\t\ttoday = datetime.date.fromisoformat(sys.argv[3])\n\trun(source_repository, target_repository, today)\n", "path": ".github/create-changelog-prs.py"}], "after_files": [{"content": "#! /usr/bin/env python\n\nimport subprocess\nimport json\nimport datetime\nimport tempfile\nimport sys\nimport os\nimport re\n\nDEVELOPERS = dict()\n\ndef get_pr(repository: str, number: int) -> dict:\n\tcommand = f\"\"\"gh pr view \\\n\t\t--repo \"{repository}\" \\\n\t\t\"{number}\" \\\n\t\t--json mergeCommit,mergedBy,title,author,baseRefName,number\n\t\"\"\"\n\tproc = subprocess.Popen(command, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)\n\tpr_json, errors = proc.communicate()\n\tif proc.returncode != 0:\n\t\tprint(errors)\n\t\texit(1)\n\treturn json.loads(pr_json)\n\ndef get_prs(repository: str, day: datetime.date) -> list:\n\tprint(f\"Fetching PRs for {day}\")\n\tcommand = f\"\"\"gh search prs \\\n\t\t--repo \"{repository}\" \\\n\t\t--merged-at \"{day}\" \\\n\t\t--json number\n\t\"\"\"\n\tproc = subprocess.Popen(command, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)\n\tprs_json, errors = proc.communicate()\n\tif proc.returncode != 0:\n\t\tprint(errors)\n\t\texit(1)\n\tprs = list()\n\tfor result in json.loads(prs_json):\n\t\tprs.append(get_pr(repository, result[\"number\"]))\n\n\treturn prs\n\ndef parse_prs(prs: list) -> dict:\n\tpr_map = dict()\n\tfor pr in prs:\n\t\tmerged_by = pr[\"mergedBy\"][\"login\"]\n\t\tif merged_by not in pr:\n\t\t\tpr_list = list()\n\t\t\tpr_map[merged_by] = pr_list\n\t\telse:\n\t\t\tpr_list = pr_map[merged_by]\n\t\tpr_list.append(pr)\n\treturn pr_map\n\n\ndef create_prs(repository: str, merged_by_prs_map: dict, day: datetime.date):\n\tfor author in merged_by_prs_map.keys():\n\t\tcreate_pr(repository, author, merged_by_prs_map[author], day)\n\ndef create_pr(repository: str, merged_by: str, prs: list, day: datetime.date):\n\tif len(prs) == 0:\n\t\treturn\n\tprint(f\"Creating changelog PR for @{merged_by}\")\n\n\tsample_pr = prs[0]\n\tbase_branch = sample_pr[\"baseRefName\"]\n\tpr_branch_name = create_pr_branch(day, merged_by, base_branch)\n\tpr_body, changelog_lines = generate_content(prs, merged_by)\n\tcreate_commit(changelog_lines)\n\tpush_pr_branch(pr_branch_name)\n\n\tcommand = f\"\"\"gh pr create \\\n\t\t--repo \"{repository}\" \\\n\t\t--assignee \"{merged_by}\" \\\n\t\t--base \"{base_branch}\" \\\n\t\t--label \"changelog-pr\" \\\n\t\t--title \"chore: changelog updates for {day}, merged by @{merged_by}\" \\\n\t\t--body '{pr_body}'\n\t\"\"\"\n\n\tproc = subprocess.Popen(command, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)\n\touts, errors = proc.communicate()\n\tif proc.returncode != 0:\n\t\tprint(errors)\n\t\texit(1)\n\tprint(f\"Created PR: {outs.decode()}\")\n\ndef create_commit(changelog_lines: str):\n\twith open('.changes-pending.md', 'at') as changelog:\n\t\tchangelog.write(changelog_lines.encode())\n\n\tcommand = \"git commit .changes-pending.md -m 'Add pending changelog entries'\"\n\tproc = subprocess.Popen(command, shell=True, stderr=subprocess.PIPE)\n\t_, errors = proc.communicate()\n\tif proc.returncode != 0:\n\t\tprint(errors)\n\t\texit(1)\n\ndef generate_content(prs: list, merged_by: str) -> (str, str):\n\tchangelog_lines = f\"Entries for PRs merged by {merged_by}:\\n\"\n\tpr_body = f\"This PR was auto-generated to update the changelog with the following entries, merged by @{merged_by}:\\n```\\n\"\n\tpr_links = \"\"\n\tfor pr in prs:\n\t\tpr_number = pr[\"number\"]\n\t\tpr_title = pr[\"title\"]\n\t\tpr_author = get_pr_author_name(pr[\"author\"][\"login\"])\n\t\tnew_line = f\"* {pr_title} ({pr_author}) [#{pr_number}]\\n\"\n\t\tpr_body += new_line\n\t\tpr_links += f\"- #{pr_number}\\n\"\n\n\t\tchangelog_lines += new_line\n\tpr_body += \"```\\n\\n\" + pr_links\n\tchangelog_lines += \"\\n\\n\"\n\n\treturn pr_body, changelog_lines\n\ndef get_pr_author_name(login: str) -> str:\n\tif len(DEVELOPERS) == 0:\n\t\tparse_contributors()\n\n\treturn DEVELOPERS[login] if login in DEVELOPERS else f\"@{login}\"\n\ndef parse_contributors():\n\tregex = re.compile(r'^\\s*?-\\s*?\\[([^]]+)\\]\\s*?\\(http.*/([^/]+)\\s*?\\)')\n\twith open('CONTRIBUTORS.md', 'rt') as handle:\n\t\tline = handle.readline()\n\t\twhile not ('##' in line and 'Contributors' in line):\n\t\t\tmatch = regex.match(line)\n\t\t\tif match:\n\t\t\t\tDEVELOPERS[match.group(2)] = match.group(1)\n\t\t\tline = handle.readline()\n\ndef create_pr_branch(day: datetime.date, author: str, base_branch: str) -> str:\n\tbranch_name = f\"changelog-updates-for-{day}-{author} {base_branch}\"\n\tcommand = f\"git checkout -b {branch_name}\"\n\tproc = subprocess.Popen(command, shell=True, stderr=subprocess.PIPE)\n\t_, errors = proc.communicate()\n\tif proc.returncode != 0:\n\t\tprint(errors)\n\t\texit(1)\n\n\treturn branch_name\n\ndef push_pr_branch(branch_name: str):\n\tcommand = f\"git push origin {branch_name}\"\n\tproc = subprocess.Popen(command, shell=True, stderr=subprocess.PIPE)\n\t_, errors = proc.communicate()\n\tif proc.returncode != 0:\n\t\tprint(errors)\n\t\texit(1)\n\ndef run(source_repository: str, target_repository: str, today: datetime.date):\n\tday = today - datetime.timedelta(days=1)\n\tprs = get_prs(source_repository, day)\n\tprs_length = len(prs)\n\tprint(f\"Found {prs_length} PRs\")\n\tif prs_length == 0:\n\t\treturn\n\n\tmerged_by_prs_map = parse_prs(prs)\n\tcreate_prs(target_repository, merged_by_prs_map, day)\n\nif __name__ == \"__main__\":\n\t# disable pager\n\tos.environ[\"GH_PAGER\"] = ''\n\t# set variables for Git\n\tos.environ[\"GIT_AUTHOR_NAME\"] = \"changelog-pr-bot\"\n\tos.environ[\"GIT_AUTHOR_EMAIL\"] = \"[email protected]\"\n\tos.environ[\"GIT_COMMITTER_NAME\"] = \"changelog-pr-bot\"\n\tos.environ[\"GIT_COMMITTER_EMAIL\"] = \"[email protected]\"\n\n\tsource_repository = 'coreruleset/coreruleset'\n\ttarget_repository = source_repository\n\t# the cron schedule for the workflow uses UTC\n\ttoday = datetime.datetime.now(datetime.timezone.utc).date()\n\n\tif len(sys.argv) > 1:\n\t\tsource_repository = sys.argv[1]\n\tif len(sys.argv) > 2:\n\t\ttarget_repository = sys.argv[2]\n\tif len(sys.argv) > 3:\n\t\ttoday = datetime.date.fromisoformat(sys.argv[3])\n\trun(source_repository, target_repository, today)\n", "path": ".github/create-changelog-prs.py"}]}
| 2,707 | 613 |
gh_patches_debug_27363
|
rasdani/github-patches
|
git_diff
|
aws__aws-cli-2816
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
aws cloudformation deploy command could not wait stack create/update more than 10 minutes
Hi,
I am doing some tests by my side and I've run the aws cli in debug mode trying to find why the aws cli commands hangs up on long CloudFormation create/update processes, I could find that the 'aws cloudformation deploy' command checks the CloudFormation Stack status every 5 seconds and then, after approximately 10 minutes and 30 seconds the code returns the error:
--- Error ---
"WaiterError: Waiter StackCreateComplete failed: Max attempts exceeded"
--- Error ---
I think the check period could be greater, then the aws cli command could wait more time, or increase the number of max attempts, but I think the first option it's better. Could you please take a look at this?
tests:
> time aws cloudformation deploy --template-file cfn-rolling-deployment.yaml --stack-name rollindeployment-test --capabilities CAPABILITY_NAMED_IAM
Waiting for changeset to be created..
Waiting for stack create/update to complete
Failed to create/update the stack. Run the following command
to fetch the list of events leading up to the failure
aws cloudformation describe-stack-events --stack-name rollindeployment-test
aws cloudformation deploy --template-file cfn-rolling-deployment.yaml 0.90s user 0.13s system 0% cpu 10:29.37 total
---
Traceback:
---
2017-08-09 10:48:41,571 - MainThread - botocore.hooks - DEBUG - Event needs-retry.cloudformation.DescribeStacks: calling handler <botocore.retryhandler.RetryHandler object at 0x10e3ac550>
2017-08-09 10:48:41,571 - MainThread - botocore.retryhandler - DEBUG - No retry needed.
2017-08-09 10:48:41,571 - MainThread - awscli.customizations.cloudformation.deployer - DEBUG - Execute changeset waiter exception
Traceback (most recent call last):
File "/usr/local/Cellar/awscli/1.11.129/libexec/lib/python2.7/site-packages/awscli/customizations/cloudformation/deployer.py", line 177, in wait_for_execute
waiter.wait(StackName=stack_name)
File "/usr/local/Cellar/awscli/1.11.129/libexec/lib/python2.7/site-packages/botocore/waiter.py", line 53, in wait
Waiter.wait(self, **kwargs)
File "/usr/local/Cellar/awscli/1.11.129/libexec/lib/python2.7/site-packages/botocore/waiter.py", line 327, in wait
last_response=response
WaiterError: Waiter StackCreateComplete failed: Max attempts exceeded
2017-08-09 10:48:41,573 - MainThread - awscli.clidriver - DEBUG - Exception caught in main()
Traceback (most recent call last):
File "/usr/local/Cellar/awscli/1.11.129/libexec/lib/python2.7/site-packages/awscli/clidriver.py", line 200, in main
return command_table[parsed_args.command](remaining, parsed_args)
File "/usr/local/Cellar/awscli/1.11.129/libexec/lib/python2.7/site-packages/awscli/clidriver.py", line 338, in __call__
return command_table[parsed_args.operation](remaining, parsed_globals)
File "/usr/local/Cellar/awscli/1.11.129/libexec/lib/python2.7/site-packages/awscli/customizations/commands.py", line 187, in __call__
return self._run_main(parsed_args, parsed_globals)
File "/usr/local/Cellar/awscli/1.11.129/libexec/lib/python2.7/site-packages/awscli/customizations/cloudformation/deploy.py", line 160, in _run_main
parsed_args.execute_changeset)
File "/usr/local/Cellar/awscli/1.11.129/libexec/lib/python2.7/site-packages/awscli/customizations/cloudformation/deploy.py", line 172, in deploy
deployer.wait_for_execute(stack_name, result.changeset_type)
File "/usr/local/Cellar/awscli/1.11.129/libexec/lib/python2.7/site-packages/awscli/customizations/cloudformation/deployer.py", line 181, in wait_for_execute
raise exceptions.DeployFailedError(stack_name=stack_name)
DeployFailedError: Failed to create/update the stack. Run the following command
to fetch the list of events leading up to the failure
aws cloudformation describe-stack-events --stack-name rollindeployment-test2
2017-08-09 10:48:41,575 - MainThread - awscli.clidriver - DEBUG - Exiting with rc 255
Failed to create/update the stack. Run the following command
to fetch the list of events leading up to the failure
aws cloudformation describe-stack-events --stack-name rollindeployment-test2
aws cloudformation deploy --template-file cfn-rolling-deployment.yaml 0 1.21s user 0.16s system 0% cpu 10:31.42 total
Changed waiter.config.delay from 5 seconds to 10 seconds
The documentation below mentions the following with regards to: aws cloudformation wait stack-create-complete [1]
[1] http://docs.aws.amazon.com/cli/latest/reference/cloudformation/wait/stack-create-complete.html
"Wait until stack status is CREATE_COMPLETE. It will poll every 30 seconds until a successful state has been reached.
This will exit with a return code of 255 after 120 failed checks."
This should be technically be 30 seconds not 5 seconds or 10 seconds because:
120 calls at 30 seconds intervals will equal 3600 seconds/1 hour until the "Max attempts exceeded" which to confirms with CloudFormations 1 hour* timeout.
I understand that it is a fine line between performance (speed) and consistency, but unfortunately some services like CloudFront take time to build.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `awscli/customizations/cloudformation/deployer.py`
Content:
```
1 # Copyright 2012-2015 Amazon.com, Inc. or its affiliates. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License"). You
4 # may not use this file except in compliance with the License. A copy of
5 # the License is located at
6 #
7 # http://aws.amazon.com/apache2.0/
8 #
9 # or in the "license" file accompanying this file. This file is
10 # distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF
11 # ANY KIND, either express or implied. See the License for the specific
12 # language governing permissions and limitations under the License.
13
14 import sys
15 import time
16 import logging
17 import botocore
18 import collections
19
20 from awscli.customizations.cloudformation import exceptions
21 from datetime import datetime
22
23 LOG = logging.getLogger(__name__)
24
25 ChangeSetResult = collections.namedtuple(
26 "ChangeSetResult", ["changeset_id", "changeset_type"])
27
28
29 class Deployer(object):
30
31 def __init__(self, cloudformation_client,
32 changeset_prefix="awscli-cloudformation-package-deploy-"):
33 self._client = cloudformation_client
34 self.changeset_prefix = changeset_prefix
35
36 def has_stack(self, stack_name):
37 """
38 Checks if a CloudFormation stack with given name exists
39
40 :param stack_name: Name or ID of the stack
41 :return: True if stack exists. False otherwise
42 """
43 try:
44 resp = self._client.describe_stacks(StackName=stack_name)
45 if len(resp["Stacks"]) != 1:
46 return False
47
48 # When you run CreateChangeSet on a a stack that does not exist,
49 # CloudFormation will create a stack and set it's status
50 # REVIEW_IN_PROGRESS. However this stack is cannot be manipulated
51 # by "update" commands. Under this circumstances, we treat like
52 # this stack does not exist and call CreateChangeSet will
53 # ChangeSetType set to CREATE and not UPDATE.
54 stack = resp["Stacks"][0]
55 return stack["StackStatus"] != "REVIEW_IN_PROGRESS"
56
57 except botocore.exceptions.ClientError as e:
58 # If a stack does not exist, describe_stacks will throw an
59 # exception. Unfortunately we don't have a better way than parsing
60 # the exception msg to understand the nature of this exception.
61 msg = str(e)
62
63 if "Stack with id {0} does not exist".format(stack_name) in msg:
64 LOG.debug("Stack with id {0} does not exist".format(
65 stack_name))
66 return False
67 else:
68 # We don't know anything about this exception. Don't handle
69 LOG.debug("Unable to get stack details.", exc_info=e)
70 raise e
71
72 def create_changeset(self, stack_name, cfn_template,
73 parameter_values, capabilities, role_arn,
74 notification_arns):
75 """
76 Call Cloudformation to create a changeset and wait for it to complete
77
78 :param stack_name: Name or ID of stack
79 :param cfn_template: CloudFormation template string
80 :param parameter_values: Template parameters object
81 :param capabilities: Array of capabilities passed to CloudFormation
82 :return:
83 """
84
85 now = datetime.utcnow().isoformat()
86 description = "Created by AWS CLI at {0} UTC".format(now)
87
88 # Each changeset will get a unique name based on time
89 changeset_name = self.changeset_prefix + str(int(time.time()))
90
91 changeset_type = "UPDATE"
92 if not self.has_stack(stack_name):
93 changeset_type = "CREATE"
94 # When creating a new stack, UsePreviousValue=True is invalid.
95 # For such parameters, users should either override with new value,
96 # or set a Default value in template to successfully create a stack.
97 parameter_values = [x for x in parameter_values
98 if not x.get("UsePreviousValue", False)]
99
100 kwargs = {
101 'ChangeSetName': changeset_name,
102 'StackName': stack_name,
103 'TemplateBody': cfn_template,
104 'ChangeSetType': changeset_type,
105 'Parameters': parameter_values,
106 'Capabilities': capabilities,
107 'Description': description,
108 }
109 # don't set these arguments if not specified to use existing values
110 if role_arn is not None:
111 kwargs['RoleARN'] = role_arn
112 if notification_arns is not None:
113 kwargs['NotificationARNs'] = notification_arns
114 try:
115 resp = self._client.create_change_set(**kwargs)
116 return ChangeSetResult(resp["Id"], changeset_type)
117 except Exception as ex:
118 LOG.debug("Unable to create changeset", exc_info=ex)
119 raise ex
120
121 def wait_for_changeset(self, changeset_id, stack_name):
122 """
123 Waits until the changeset creation completes
124
125 :param changeset_id: ID or name of the changeset
126 :param stack_name: Stack name
127 :return: Latest status of the create-change-set operation
128 """
129 sys.stdout.write("Waiting for changeset to be created..\n")
130 sys.stdout.flush()
131
132 # Wait for changeset to be created
133 waiter = self._client.get_waiter("change_set_create_complete")
134 # Poll every 5 seconds. Changeset creation should be fast
135 waiter.config.delay = 5
136 try:
137 waiter.wait(ChangeSetName=changeset_id, StackName=stack_name)
138 except botocore.exceptions.WaiterError as ex:
139 LOG.debug("Create changeset waiter exception", exc_info=ex)
140
141 resp = ex.last_response
142 status = resp["Status"]
143 reason = resp["StatusReason"]
144
145 if status == "FAILED" and \
146 "No updates are to be performed" in reason:
147 raise exceptions.ChangeEmptyError(stack_name=stack_name)
148
149 raise RuntimeError("Failed to create the changeset: {0} "
150 "Status: {1}. Reason: {2}"
151 .format(ex, status, reason))
152
153 def execute_changeset(self, changeset_id, stack_name):
154 """
155 Calls CloudFormation to execute changeset
156
157 :param changeset_id: ID of the changeset
158 :param stack_name: Name or ID of the stack
159 :return: Response from execute-change-set call
160 """
161 return self._client.execute_change_set(
162 ChangeSetName=changeset_id,
163 StackName=stack_name)
164
165 def wait_for_execute(self, stack_name, changeset_type):
166
167 sys.stdout.write("Waiting for stack create/update to complete\n")
168 sys.stdout.flush()
169
170 # Pick the right waiter
171 if changeset_type == "CREATE":
172 waiter = self._client.get_waiter("stack_create_complete")
173 elif changeset_type == "UPDATE":
174 waiter = self._client.get_waiter("stack_update_complete")
175 else:
176 raise RuntimeError("Invalid changeset type {0}"
177 .format(changeset_type))
178
179 # Poll every 5 seconds. Optimizing for the case when the stack has only
180 # minimal changes, such the Code for Lambda Function
181 waiter.config.delay = 5
182
183 try:
184 waiter.wait(StackName=stack_name)
185 except botocore.exceptions.WaiterError as ex:
186 LOG.debug("Execute changeset waiter exception", exc_info=ex)
187
188 raise exceptions.DeployFailedError(stack_name=stack_name)
189
190 def create_and_wait_for_changeset(self, stack_name, cfn_template,
191 parameter_values, capabilities, role_arn,
192 notification_arns):
193
194 result = self.create_changeset(
195 stack_name, cfn_template, parameter_values, capabilities,
196 role_arn, notification_arns)
197
198 self.wait_for_changeset(result.changeset_id, stack_name)
199
200 return result
201
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/awscli/customizations/cloudformation/deployer.py b/awscli/customizations/cloudformation/deployer.py
--- a/awscli/customizations/cloudformation/deployer.py
+++ b/awscli/customizations/cloudformation/deployer.py
@@ -132,9 +132,10 @@
# Wait for changeset to be created
waiter = self._client.get_waiter("change_set_create_complete")
# Poll every 5 seconds. Changeset creation should be fast
- waiter.config.delay = 5
+ waiter_config = {'Delay': 5}
try:
- waiter.wait(ChangeSetName=changeset_id, StackName=stack_name)
+ waiter.wait(ChangeSetName=changeset_id, StackName=stack_name,
+ WaiterConfig=waiter_config)
except botocore.exceptions.WaiterError as ex:
LOG.debug("Create changeset waiter exception", exc_info=ex)
@@ -178,10 +179,13 @@
# Poll every 5 seconds. Optimizing for the case when the stack has only
# minimal changes, such the Code for Lambda Function
- waiter.config.delay = 5
+ waiter_config = {
+ 'Delay': 5,
+ 'MaxAttempts': 720,
+ }
try:
- waiter.wait(StackName=stack_name)
+ waiter.wait(StackName=stack_name, WaiterConfig=waiter_config)
except botocore.exceptions.WaiterError as ex:
LOG.debug("Execute changeset waiter exception", exc_info=ex)
|
{"golden_diff": "diff --git a/awscli/customizations/cloudformation/deployer.py b/awscli/customizations/cloudformation/deployer.py\n--- a/awscli/customizations/cloudformation/deployer.py\n+++ b/awscli/customizations/cloudformation/deployer.py\n@@ -132,9 +132,10 @@\n # Wait for changeset to be created\n waiter = self._client.get_waiter(\"change_set_create_complete\")\n # Poll every 5 seconds. Changeset creation should be fast\n- waiter.config.delay = 5\n+ waiter_config = {'Delay': 5}\n try:\n- waiter.wait(ChangeSetName=changeset_id, StackName=stack_name)\n+ waiter.wait(ChangeSetName=changeset_id, StackName=stack_name,\n+ WaiterConfig=waiter_config)\n except botocore.exceptions.WaiterError as ex:\n LOG.debug(\"Create changeset waiter exception\", exc_info=ex)\n \n@@ -178,10 +179,13 @@\n \n # Poll every 5 seconds. Optimizing for the case when the stack has only\n # minimal changes, such the Code for Lambda Function\n- waiter.config.delay = 5\n+ waiter_config = {\n+ 'Delay': 5,\n+ 'MaxAttempts': 720,\n+ }\n \n try:\n- waiter.wait(StackName=stack_name)\n+ waiter.wait(StackName=stack_name, WaiterConfig=waiter_config)\n except botocore.exceptions.WaiterError as ex:\n LOG.debug(\"Execute changeset waiter exception\", exc_info=ex)\n", "issue": "aws cloudformation deploy command could not wait stack create/update more than 10 minutes\nHi,\r\n\r\nI am doing some tests by my side and I've run the aws cli in debug mode trying to find why the aws cli commands hangs up on long CloudFormation create/update processes, I could find that the 'aws cloudformation deploy' command checks the CloudFormation Stack status every 5 seconds and then, after approximately 10 minutes and 30 seconds the code returns the error:\r\n\r\n--- Error ---\r\n\"WaiterError: Waiter StackCreateComplete failed: Max attempts exceeded\"\r\n--- Error ---\r\n\r\nI think the check period could be greater, then the aws cli command could wait more time, or increase the number of max attempts, but I think the first option it's better. Could you please take a look at this?\r\n\r\ntests:\r\n\r\n> time aws cloudformation deploy --template-file cfn-rolling-deployment.yaml --stack-name rollindeployment-test --capabilities CAPABILITY_NAMED_IAM\r\nWaiting for changeset to be created..\r\nWaiting for stack create/update to complete\r\n\r\nFailed to create/update the stack. Run the following command\r\nto fetch the list of events leading up to the failure\r\naws cloudformation describe-stack-events --stack-name rollindeployment-test\r\naws cloudformation deploy --template-file cfn-rolling-deployment.yaml 0.90s user 0.13s system 0% cpu 10:29.37 total\r\n\r\n---\r\nTraceback:\r\n---\r\n2017-08-09 10:48:41,571 - MainThread - botocore.hooks - DEBUG - Event needs-retry.cloudformation.DescribeStacks: calling handler <botocore.retryhandler.RetryHandler object at 0x10e3ac550>\r\n2017-08-09 10:48:41,571 - MainThread - botocore.retryhandler - DEBUG - No retry needed.\r\n2017-08-09 10:48:41,571 - MainThread - awscli.customizations.cloudformation.deployer - DEBUG - Execute changeset waiter exception\r\nTraceback (most recent call last):\r\n File \"/usr/local/Cellar/awscli/1.11.129/libexec/lib/python2.7/site-packages/awscli/customizations/cloudformation/deployer.py\", line 177, in wait_for_execute\r\n waiter.wait(StackName=stack_name)\r\n File \"/usr/local/Cellar/awscli/1.11.129/libexec/lib/python2.7/site-packages/botocore/waiter.py\", line 53, in wait\r\n Waiter.wait(self, **kwargs)\r\n File \"/usr/local/Cellar/awscli/1.11.129/libexec/lib/python2.7/site-packages/botocore/waiter.py\", line 327, in wait\r\n last_response=response\r\nWaiterError: Waiter StackCreateComplete failed: Max attempts exceeded\r\n2017-08-09 10:48:41,573 - MainThread - awscli.clidriver - DEBUG - Exception caught in main()\r\nTraceback (most recent call last):\r\n File \"/usr/local/Cellar/awscli/1.11.129/libexec/lib/python2.7/site-packages/awscli/clidriver.py\", line 200, in main\r\n return command_table[parsed_args.command](remaining, parsed_args)\r\n File \"/usr/local/Cellar/awscli/1.11.129/libexec/lib/python2.7/site-packages/awscli/clidriver.py\", line 338, in __call__\r\n return command_table[parsed_args.operation](remaining, parsed_globals)\r\n File \"/usr/local/Cellar/awscli/1.11.129/libexec/lib/python2.7/site-packages/awscli/customizations/commands.py\", line 187, in __call__\r\n return self._run_main(parsed_args, parsed_globals)\r\n File \"/usr/local/Cellar/awscli/1.11.129/libexec/lib/python2.7/site-packages/awscli/customizations/cloudformation/deploy.py\", line 160, in _run_main\r\n parsed_args.execute_changeset)\r\n File \"/usr/local/Cellar/awscli/1.11.129/libexec/lib/python2.7/site-packages/awscli/customizations/cloudformation/deploy.py\", line 172, in deploy\r\n deployer.wait_for_execute(stack_name, result.changeset_type)\r\n File \"/usr/local/Cellar/awscli/1.11.129/libexec/lib/python2.7/site-packages/awscli/customizations/cloudformation/deployer.py\", line 181, in wait_for_execute\r\n raise exceptions.DeployFailedError(stack_name=stack_name)\r\nDeployFailedError: Failed to create/update the stack. Run the following command\r\nto fetch the list of events leading up to the failure\r\naws cloudformation describe-stack-events --stack-name rollindeployment-test2\r\n2017-08-09 10:48:41,575 - MainThread - awscli.clidriver - DEBUG - Exiting with rc 255\r\n\r\nFailed to create/update the stack. Run the following command\r\nto fetch the list of events leading up to the failure\r\naws cloudformation describe-stack-events --stack-name rollindeployment-test2\r\naws cloudformation deploy --template-file cfn-rolling-deployment.yaml 0 1.21s user 0.16s system 0% cpu 10:31.42 total\r\n\nChanged waiter.config.delay from 5 seconds to 10 seconds\nThe documentation below mentions the following with regards to: aws cloudformation wait stack-create-complete [1]\r\n[1] http://docs.aws.amazon.com/cli/latest/reference/cloudformation/wait/stack-create-complete.html\r\n\r\n\"Wait until stack status is CREATE_COMPLETE. It will poll every 30 seconds until a successful state has been reached. \r\nThis will exit with a return code of 255 after 120 failed checks.\"\r\n\r\nThis should be technically be 30 seconds not 5 seconds or 10 seconds because: \r\n120 calls at 30 seconds intervals will equal 3600 seconds/1 hour until the \"Max attempts exceeded\" which to confirms with CloudFormations 1 hour* timeout.\r\n\r\nI understand that it is a fine line between performance (speed) and consistency, but unfortunately some services like CloudFront take time to build.\n", "before_files": [{"content": "# Copyright 2012-2015 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\"). You\n# may not use this file except in compliance with the License. A copy of\n# the License is located at\n#\n# http://aws.amazon.com/apache2.0/\n#\n# or in the \"license\" file accompanying this file. This file is\n# distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF\n# ANY KIND, either express or implied. See the License for the specific\n# language governing permissions and limitations under the License.\n\nimport sys\nimport time\nimport logging\nimport botocore\nimport collections\n\nfrom awscli.customizations.cloudformation import exceptions\nfrom datetime import datetime\n\nLOG = logging.getLogger(__name__)\n\nChangeSetResult = collections.namedtuple(\n \"ChangeSetResult\", [\"changeset_id\", \"changeset_type\"])\n\n\nclass Deployer(object):\n\n def __init__(self, cloudformation_client,\n changeset_prefix=\"awscli-cloudformation-package-deploy-\"):\n self._client = cloudformation_client\n self.changeset_prefix = changeset_prefix\n\n def has_stack(self, stack_name):\n \"\"\"\n Checks if a CloudFormation stack with given name exists\n\n :param stack_name: Name or ID of the stack\n :return: True if stack exists. False otherwise\n \"\"\"\n try:\n resp = self._client.describe_stacks(StackName=stack_name)\n if len(resp[\"Stacks\"]) != 1:\n return False\n\n # When you run CreateChangeSet on a a stack that does not exist,\n # CloudFormation will create a stack and set it's status\n # REVIEW_IN_PROGRESS. However this stack is cannot be manipulated\n # by \"update\" commands. Under this circumstances, we treat like\n # this stack does not exist and call CreateChangeSet will\n # ChangeSetType set to CREATE and not UPDATE.\n stack = resp[\"Stacks\"][0]\n return stack[\"StackStatus\"] != \"REVIEW_IN_PROGRESS\"\n\n except botocore.exceptions.ClientError as e:\n # If a stack does not exist, describe_stacks will throw an\n # exception. Unfortunately we don't have a better way than parsing\n # the exception msg to understand the nature of this exception.\n msg = str(e)\n\n if \"Stack with id {0} does not exist\".format(stack_name) in msg:\n LOG.debug(\"Stack with id {0} does not exist\".format(\n stack_name))\n return False\n else:\n # We don't know anything about this exception. Don't handle\n LOG.debug(\"Unable to get stack details.\", exc_info=e)\n raise e\n\n def create_changeset(self, stack_name, cfn_template,\n parameter_values, capabilities, role_arn,\n notification_arns):\n \"\"\"\n Call Cloudformation to create a changeset and wait for it to complete\n\n :param stack_name: Name or ID of stack\n :param cfn_template: CloudFormation template string\n :param parameter_values: Template parameters object\n :param capabilities: Array of capabilities passed to CloudFormation\n :return:\n \"\"\"\n\n now = datetime.utcnow().isoformat()\n description = \"Created by AWS CLI at {0} UTC\".format(now)\n\n # Each changeset will get a unique name based on time\n changeset_name = self.changeset_prefix + str(int(time.time()))\n\n changeset_type = \"UPDATE\"\n if not self.has_stack(stack_name):\n changeset_type = \"CREATE\"\n # When creating a new stack, UsePreviousValue=True is invalid.\n # For such parameters, users should either override with new value,\n # or set a Default value in template to successfully create a stack.\n parameter_values = [x for x in parameter_values\n if not x.get(\"UsePreviousValue\", False)]\n\n kwargs = {\n 'ChangeSetName': changeset_name,\n 'StackName': stack_name,\n 'TemplateBody': cfn_template,\n 'ChangeSetType': changeset_type,\n 'Parameters': parameter_values,\n 'Capabilities': capabilities,\n 'Description': description,\n }\n # don't set these arguments if not specified to use existing values\n if role_arn is not None:\n kwargs['RoleARN'] = role_arn\n if notification_arns is not None:\n kwargs['NotificationARNs'] = notification_arns\n try:\n resp = self._client.create_change_set(**kwargs)\n return ChangeSetResult(resp[\"Id\"], changeset_type)\n except Exception as ex:\n LOG.debug(\"Unable to create changeset\", exc_info=ex)\n raise ex\n\n def wait_for_changeset(self, changeset_id, stack_name):\n \"\"\"\n Waits until the changeset creation completes\n\n :param changeset_id: ID or name of the changeset\n :param stack_name: Stack name\n :return: Latest status of the create-change-set operation\n \"\"\"\n sys.stdout.write(\"Waiting for changeset to be created..\\n\")\n sys.stdout.flush()\n\n # Wait for changeset to be created\n waiter = self._client.get_waiter(\"change_set_create_complete\")\n # Poll every 5 seconds. Changeset creation should be fast\n waiter.config.delay = 5\n try:\n waiter.wait(ChangeSetName=changeset_id, StackName=stack_name)\n except botocore.exceptions.WaiterError as ex:\n LOG.debug(\"Create changeset waiter exception\", exc_info=ex)\n\n resp = ex.last_response\n status = resp[\"Status\"]\n reason = resp[\"StatusReason\"]\n\n if status == \"FAILED\" and \\\n \"No updates are to be performed\" in reason:\n raise exceptions.ChangeEmptyError(stack_name=stack_name)\n\n raise RuntimeError(\"Failed to create the changeset: {0} \"\n \"Status: {1}. Reason: {2}\"\n .format(ex, status, reason))\n\n def execute_changeset(self, changeset_id, stack_name):\n \"\"\"\n Calls CloudFormation to execute changeset\n\n :param changeset_id: ID of the changeset\n :param stack_name: Name or ID of the stack\n :return: Response from execute-change-set call\n \"\"\"\n return self._client.execute_change_set(\n ChangeSetName=changeset_id,\n StackName=stack_name)\n\n def wait_for_execute(self, stack_name, changeset_type):\n\n sys.stdout.write(\"Waiting for stack create/update to complete\\n\")\n sys.stdout.flush()\n\n # Pick the right waiter\n if changeset_type == \"CREATE\":\n waiter = self._client.get_waiter(\"stack_create_complete\")\n elif changeset_type == \"UPDATE\":\n waiter = self._client.get_waiter(\"stack_update_complete\")\n else:\n raise RuntimeError(\"Invalid changeset type {0}\"\n .format(changeset_type))\n\n # Poll every 5 seconds. Optimizing for the case when the stack has only\n # minimal changes, such the Code for Lambda Function\n waiter.config.delay = 5\n\n try:\n waiter.wait(StackName=stack_name)\n except botocore.exceptions.WaiterError as ex:\n LOG.debug(\"Execute changeset waiter exception\", exc_info=ex)\n\n raise exceptions.DeployFailedError(stack_name=stack_name)\n\n def create_and_wait_for_changeset(self, stack_name, cfn_template,\n parameter_values, capabilities, role_arn,\n notification_arns):\n\n result = self.create_changeset(\n stack_name, cfn_template, parameter_values, capabilities,\n role_arn, notification_arns)\n\n self.wait_for_changeset(result.changeset_id, stack_name)\n\n return result\n", "path": "awscli/customizations/cloudformation/deployer.py"}], "after_files": [{"content": "# Copyright 2012-2015 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\"). You\n# may not use this file except in compliance with the License. A copy of\n# the License is located at\n#\n# http://aws.amazon.com/apache2.0/\n#\n# or in the \"license\" file accompanying this file. This file is\n# distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF\n# ANY KIND, either express or implied. See the License for the specific\n# language governing permissions and limitations under the License.\n\nimport sys\nimport time\nimport logging\nimport botocore\nimport collections\n\nfrom awscli.customizations.cloudformation import exceptions\nfrom datetime import datetime\n\nLOG = logging.getLogger(__name__)\n\nChangeSetResult = collections.namedtuple(\n \"ChangeSetResult\", [\"changeset_id\", \"changeset_type\"])\n\n\nclass Deployer(object):\n\n def __init__(self, cloudformation_client,\n changeset_prefix=\"awscli-cloudformation-package-deploy-\"):\n self._client = cloudformation_client\n self.changeset_prefix = changeset_prefix\n\n def has_stack(self, stack_name):\n \"\"\"\n Checks if a CloudFormation stack with given name exists\n\n :param stack_name: Name or ID of the stack\n :return: True if stack exists. False otherwise\n \"\"\"\n try:\n resp = self._client.describe_stacks(StackName=stack_name)\n if len(resp[\"Stacks\"]) != 1:\n return False\n\n # When you run CreateChangeSet on a a stack that does not exist,\n # CloudFormation will create a stack and set it's status\n # REVIEW_IN_PROGRESS. However this stack is cannot be manipulated\n # by \"update\" commands. Under this circumstances, we treat like\n # this stack does not exist and call CreateChangeSet will\n # ChangeSetType set to CREATE and not UPDATE.\n stack = resp[\"Stacks\"][0]\n return stack[\"StackStatus\"] != \"REVIEW_IN_PROGRESS\"\n\n except botocore.exceptions.ClientError as e:\n # If a stack does not exist, describe_stacks will throw an\n # exception. Unfortunately we don't have a better way than parsing\n # the exception msg to understand the nature of this exception.\n msg = str(e)\n\n if \"Stack with id {0} does not exist\".format(stack_name) in msg:\n LOG.debug(\"Stack with id {0} does not exist\".format(\n stack_name))\n return False\n else:\n # We don't know anything about this exception. Don't handle\n LOG.debug(\"Unable to get stack details.\", exc_info=e)\n raise e\n\n def create_changeset(self, stack_name, cfn_template,\n parameter_values, capabilities, role_arn,\n notification_arns):\n \"\"\"\n Call Cloudformation to create a changeset and wait for it to complete\n\n :param stack_name: Name or ID of stack\n :param cfn_template: CloudFormation template string\n :param parameter_values: Template parameters object\n :param capabilities: Array of capabilities passed to CloudFormation\n :return:\n \"\"\"\n\n now = datetime.utcnow().isoformat()\n description = \"Created by AWS CLI at {0} UTC\".format(now)\n\n # Each changeset will get a unique name based on time\n changeset_name = self.changeset_prefix + str(int(time.time()))\n\n changeset_type = \"UPDATE\"\n if not self.has_stack(stack_name):\n changeset_type = \"CREATE\"\n # When creating a new stack, UsePreviousValue=True is invalid.\n # For such parameters, users should either override with new value,\n # or set a Default value in template to successfully create a stack.\n parameter_values = [x for x in parameter_values\n if not x.get(\"UsePreviousValue\", False)]\n\n kwargs = {\n 'ChangeSetName': changeset_name,\n 'StackName': stack_name,\n 'TemplateBody': cfn_template,\n 'ChangeSetType': changeset_type,\n 'Parameters': parameter_values,\n 'Capabilities': capabilities,\n 'Description': description,\n }\n # don't set these arguments if not specified to use existing values\n if role_arn is not None:\n kwargs['RoleARN'] = role_arn\n if notification_arns is not None:\n kwargs['NotificationARNs'] = notification_arns\n try:\n resp = self._client.create_change_set(**kwargs)\n return ChangeSetResult(resp[\"Id\"], changeset_type)\n except Exception as ex:\n LOG.debug(\"Unable to create changeset\", exc_info=ex)\n raise ex\n\n def wait_for_changeset(self, changeset_id, stack_name):\n \"\"\"\n Waits until the changeset creation completes\n\n :param changeset_id: ID or name of the changeset\n :param stack_name: Stack name\n :return: Latest status of the create-change-set operation\n \"\"\"\n sys.stdout.write(\"Waiting for changeset to be created..\\n\")\n sys.stdout.flush()\n\n # Wait for changeset to be created\n waiter = self._client.get_waiter(\"change_set_create_complete\")\n # Poll every 5 seconds. Changeset creation should be fast\n waiter_config = {'Delay': 5}\n try:\n waiter.wait(ChangeSetName=changeset_id, StackName=stack_name,\n WaiterConfig=waiter_config)\n except botocore.exceptions.WaiterError as ex:\n LOG.debug(\"Create changeset waiter exception\", exc_info=ex)\n\n resp = ex.last_response\n status = resp[\"Status\"]\n reason = resp[\"StatusReason\"]\n\n if status == \"FAILED\" and \\\n \"No updates are to be performed\" in reason:\n raise exceptions.ChangeEmptyError(stack_name=stack_name)\n\n raise RuntimeError(\"Failed to create the changeset: {0} \"\n \"Status: {1}. Reason: {2}\"\n .format(ex, status, reason))\n\n def execute_changeset(self, changeset_id, stack_name):\n \"\"\"\n Calls CloudFormation to execute changeset\n\n :param changeset_id: ID of the changeset\n :param stack_name: Name or ID of the stack\n :return: Response from execute-change-set call\n \"\"\"\n return self._client.execute_change_set(\n ChangeSetName=changeset_id,\n StackName=stack_name)\n\n def wait_for_execute(self, stack_name, changeset_type):\n\n sys.stdout.write(\"Waiting for stack create/update to complete\\n\")\n sys.stdout.flush()\n\n # Pick the right waiter\n if changeset_type == \"CREATE\":\n waiter = self._client.get_waiter(\"stack_create_complete\")\n elif changeset_type == \"UPDATE\":\n waiter = self._client.get_waiter(\"stack_update_complete\")\n else:\n raise RuntimeError(\"Invalid changeset type {0}\"\n .format(changeset_type))\n\n # Poll every 5 seconds. Optimizing for the case when the stack has only\n # minimal changes, such the Code for Lambda Function\n waiter_config = {\n 'Delay': 5,\n 'MaxAttempts': 720,\n }\n\n try:\n waiter.wait(StackName=stack_name, WaiterConfig=waiter_config)\n except botocore.exceptions.WaiterError as ex:\n LOG.debug(\"Execute changeset waiter exception\", exc_info=ex)\n\n raise exceptions.DeployFailedError(stack_name=stack_name)\n\n def create_and_wait_for_changeset(self, stack_name, cfn_template,\n parameter_values, capabilities, role_arn,\n notification_arns):\n\n result = self.create_changeset(\n stack_name, cfn_template, parameter_values, capabilities,\n role_arn, notification_arns)\n\n self.wait_for_changeset(result.changeset_id, stack_name)\n\n return result\n", "path": "awscli/customizations/cloudformation/deployer.py"}]}
| 3,863 | 348 |
gh_patches_debug_21473
|
rasdani/github-patches
|
git_diff
|
bokeh__bokeh-5331
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
syntax error in util/deprecation.py
line 24:
message += " " + extra.trim()
results in error: AttributeError: 'str' object has no attribute 'trim'
it should be instead:
message += " " + extra.strip()
that fixes the problem. I needed that change to get the happiness demo to run
Helmut Strey
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bokeh/util/deprecation.py`
Content:
```
1 import six
2 import warnings
3
4 class BokehDeprecationWarning(DeprecationWarning):
5 """ A specific ``DeprecationWarning`` subclass for Bokeh deprecations.
6 Used to selectively filter Bokeh deprecations for unconditional display.
7
8 """
9
10 def warn(message, stacklevel=2):
11 warnings.warn(message, BokehDeprecationWarning, stacklevel=stacklevel)
12
13 def deprecated(since_or_msg, old=None, new=None, extra=None):
14 """ Issue a nicely formatted deprecation warning. """
15
16 if isinstance(since_or_msg, tuple):
17 if old is None or new is None:
18 raise ValueError("deprecated entity and a replacement are required")
19
20 since = "%d.%d.%d" % since_or_msg
21 message = "%(old)s was deprecated in Bokeh %(since)s and will be removed, use %(new)s instead."
22 message = message % dict(old=old, since=since, new=new)
23 if extra is not None:
24 message += " " + extra.trim()
25 elif isinstance(since_or_msg, six.string_types):
26 if not (old is None and new is None and extra is None):
27 raise ValueError("deprecated(message) signature doesn't allow extra arguments")
28
29 message = since_or_msg
30 else:
31 raise ValueError("expected a version tuple or string message")
32
33 warn(message)
34
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/bokeh/util/deprecation.py b/bokeh/util/deprecation.py
--- a/bokeh/util/deprecation.py
+++ b/bokeh/util/deprecation.py
@@ -17,11 +17,14 @@
if old is None or new is None:
raise ValueError("deprecated entity and a replacement are required")
+ if len(since_or_msg) != 3 or not all(isinstance(x, int) and x >=0 for x in since_or_msg):
+ raise ValueError("invalid version tuple: %r" % (since_or_msg,))
+
since = "%d.%d.%d" % since_or_msg
message = "%(old)s was deprecated in Bokeh %(since)s and will be removed, use %(new)s instead."
message = message % dict(old=old, since=since, new=new)
if extra is not None:
- message += " " + extra.trim()
+ message += " " + extra.strip()
elif isinstance(since_or_msg, six.string_types):
if not (old is None and new is None and extra is None):
raise ValueError("deprecated(message) signature doesn't allow extra arguments")
|
{"golden_diff": "diff --git a/bokeh/util/deprecation.py b/bokeh/util/deprecation.py\n--- a/bokeh/util/deprecation.py\n+++ b/bokeh/util/deprecation.py\n@@ -17,11 +17,14 @@\n if old is None or new is None:\n raise ValueError(\"deprecated entity and a replacement are required\")\n \n+ if len(since_or_msg) != 3 or not all(isinstance(x, int) and x >=0 for x in since_or_msg):\n+ raise ValueError(\"invalid version tuple: %r\" % (since_or_msg,))\n+\n since = \"%d.%d.%d\" % since_or_msg\n message = \"%(old)s was deprecated in Bokeh %(since)s and will be removed, use %(new)s instead.\"\n message = message % dict(old=old, since=since, new=new)\n if extra is not None:\n- message += \" \" + extra.trim()\n+ message += \" \" + extra.strip()\n elif isinstance(since_or_msg, six.string_types):\n if not (old is None and new is None and extra is None):\n raise ValueError(\"deprecated(message) signature doesn't allow extra arguments\")\n", "issue": "syntax error in util/deprecation.py\nline 24:\n message += \" \" + extra.trim()\nresults in error: AttributeError: 'str' object has no attribute 'trim'\n\nit should be instead:\n message += \" \" + extra.strip()\n\nthat fixes the problem. I needed that change to get the happiness demo to run\n\nHelmut Strey\n\n", "before_files": [{"content": "import six\nimport warnings\n\nclass BokehDeprecationWarning(DeprecationWarning):\n \"\"\" A specific ``DeprecationWarning`` subclass for Bokeh deprecations.\n Used to selectively filter Bokeh deprecations for unconditional display.\n\n \"\"\"\n\ndef warn(message, stacklevel=2):\n warnings.warn(message, BokehDeprecationWarning, stacklevel=stacklevel)\n\ndef deprecated(since_or_msg, old=None, new=None, extra=None):\n \"\"\" Issue a nicely formatted deprecation warning. \"\"\"\n\n if isinstance(since_or_msg, tuple):\n if old is None or new is None:\n raise ValueError(\"deprecated entity and a replacement are required\")\n\n since = \"%d.%d.%d\" % since_or_msg\n message = \"%(old)s was deprecated in Bokeh %(since)s and will be removed, use %(new)s instead.\"\n message = message % dict(old=old, since=since, new=new)\n if extra is not None:\n message += \" \" + extra.trim()\n elif isinstance(since_or_msg, six.string_types):\n if not (old is None and new is None and extra is None):\n raise ValueError(\"deprecated(message) signature doesn't allow extra arguments\")\n\n message = since_or_msg\n else:\n raise ValueError(\"expected a version tuple or string message\")\n\n warn(message)\n", "path": "bokeh/util/deprecation.py"}], "after_files": [{"content": "import six\nimport warnings\n\nclass BokehDeprecationWarning(DeprecationWarning):\n \"\"\" A specific ``DeprecationWarning`` subclass for Bokeh deprecations.\n Used to selectively filter Bokeh deprecations for unconditional display.\n\n \"\"\"\n\ndef warn(message, stacklevel=2):\n warnings.warn(message, BokehDeprecationWarning, stacklevel=stacklevel)\n\ndef deprecated(since_or_msg, old=None, new=None, extra=None):\n \"\"\" Issue a nicely formatted deprecation warning. \"\"\"\n\n if isinstance(since_or_msg, tuple):\n if old is None or new is None:\n raise ValueError(\"deprecated entity and a replacement are required\")\n\n if len(since_or_msg) != 3 or not all(isinstance(x, int) and x >=0 for x in since_or_msg):\n raise ValueError(\"invalid version tuple: %r\" % (since_or_msg,))\n\n since = \"%d.%d.%d\" % since_or_msg\n message = \"%(old)s was deprecated in Bokeh %(since)s and will be removed, use %(new)s instead.\"\n message = message % dict(old=old, since=since, new=new)\n if extra is not None:\n message += \" \" + extra.strip()\n elif isinstance(since_or_msg, six.string_types):\n if not (old is None and new is None and extra is None):\n raise ValueError(\"deprecated(message) signature doesn't allow extra arguments\")\n\n message = since_or_msg\n else:\n raise ValueError(\"expected a version tuple or string message\")\n\n warn(message)\n", "path": "bokeh/util/deprecation.py"}]}
| 683 | 254 |
gh_patches_debug_8749
|
rasdani/github-patches
|
git_diff
|
saleor__saleor-5160
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Errors occur when update a page
### What I'm trying to achieve
Update a `Page`
### Steps to reproduce the problem
1. Call `Mutation.pageUpdate ` with `input: {}`
```bash
web_1 | ERROR saleor.graphql.errors.unhandled A query failed unexpectedly [PID:8:Thread-52]
web_1 | Traceback (most recent call last):
web_1 | File "/usr/local/lib/python3.8/site-packages/promise/promise.py", line 489, in _resolve_from_executor
web_1 | executor(resolve, reject)
web_1 | File "/usr/local/lib/python3.8/site-packages/promise/promise.py", line 756, in executor
web_1 | return resolve(f(*args, **kwargs))
web_1 | File "/usr/local/lib/python3.8/site-packages/graphql/execution/middleware.py", line 75, in make_it_promise
web_1 | return next(*args, **kwargs)
web_1 | File "/app/saleor/graphql/core/mutations.py", line 279, in mutate
web_1 | response = cls.perform_mutation(root, info, **data)
web_1 | File "/app/saleor/graphql/core/mutations.py", line 448, in perform_mutation
web_1 | cleaned_input = cls.clean_input(info, instance, data)
web_1 | File "/app/saleor/graphql/page/mutations.py", line 43, in clean_input
web_1 | cleaned_input["slug"] = slugify(cleaned_input["title"])
web_1 | KeyError: 'title'
```
### What I expected to happen
should update a `Page` without error
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `saleor/graphql/page/mutations.py`
Content:
```
1 import graphene
2 from django.utils.text import slugify
3
4 from ...core.permissions import PagePermissions
5 from ...page import models
6 from ..core.mutations import ModelDeleteMutation, ModelMutation
7 from ..core.types.common import SeoInput
8 from ..core.utils import clean_seo_fields
9
10
11 class PageInput(graphene.InputObjectType):
12 slug = graphene.String(description="Page internal name.")
13 title = graphene.String(description="Page title.")
14 content = graphene.String(
15 description=("Page content. May consist of ordinary text, HTML and images.")
16 )
17 content_json = graphene.JSONString(description="Page content in JSON format.")
18 is_published = graphene.Boolean(
19 description="Determines if page is visible in the storefront."
20 )
21 publication_date = graphene.String(
22 description="Publication date. ISO 8601 standard."
23 )
24 seo = SeoInput(description="Search engine optimization fields.")
25
26
27 class PageCreate(ModelMutation):
28 class Arguments:
29 input = PageInput(
30 required=True, description="Fields required to create a page."
31 )
32
33 class Meta:
34 description = "Creates a new page."
35 model = models.Page
36 permissions = (PagePermissions.MANAGE_PAGES,)
37
38 @classmethod
39 def clean_input(cls, info, instance, data):
40 cleaned_input = super().clean_input(info, instance, data)
41 slug = cleaned_input.get("slug", "")
42 if not slug:
43 cleaned_input["slug"] = slugify(cleaned_input["title"])
44 clean_seo_fields(cleaned_input)
45 return cleaned_input
46
47
48 class PageUpdate(PageCreate):
49 class Arguments:
50 id = graphene.ID(required=True, description="ID of a page to update.")
51 input = PageInput(
52 required=True, description="Fields required to update a page."
53 )
54
55 class Meta:
56 description = "Updates an existing page."
57 model = models.Page
58
59
60 class PageDelete(ModelDeleteMutation):
61 class Arguments:
62 id = graphene.ID(required=True, description="ID of a page to delete.")
63
64 class Meta:
65 description = "Deletes a page."
66 model = models.Page
67 permissions = (PagePermissions.MANAGE_PAGES,)
68
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/saleor/graphql/page/mutations.py b/saleor/graphql/page/mutations.py
--- a/saleor/graphql/page/mutations.py
+++ b/saleor/graphql/page/mutations.py
@@ -39,8 +39,9 @@
def clean_input(cls, info, instance, data):
cleaned_input = super().clean_input(info, instance, data)
slug = cleaned_input.get("slug", "")
- if not slug:
- cleaned_input["slug"] = slugify(cleaned_input["title"])
+ title = cleaned_input.get("title", "")
+ if title and not slug:
+ cleaned_input["slug"] = slugify(title)
clean_seo_fields(cleaned_input)
return cleaned_input
|
{"golden_diff": "diff --git a/saleor/graphql/page/mutations.py b/saleor/graphql/page/mutations.py\n--- a/saleor/graphql/page/mutations.py\n+++ b/saleor/graphql/page/mutations.py\n@@ -39,8 +39,9 @@\n def clean_input(cls, info, instance, data):\n cleaned_input = super().clean_input(info, instance, data)\n slug = cleaned_input.get(\"slug\", \"\")\n- if not slug:\n- cleaned_input[\"slug\"] = slugify(cleaned_input[\"title\"])\n+ title = cleaned_input.get(\"title\", \"\")\n+ if title and not slug:\n+ cleaned_input[\"slug\"] = slugify(title)\n clean_seo_fields(cleaned_input)\n return cleaned_input\n", "issue": "Errors occur when update a page\n### What I'm trying to achieve\r\nUpdate a `Page`\r\n\r\n### Steps to reproduce the problem\r\n1. Call `Mutation.pageUpdate ` with `input: {}`\r\n```bash\r\nweb_1 | ERROR saleor.graphql.errors.unhandled A query failed unexpectedly [PID:8:Thread-52]\r\nweb_1 | Traceback (most recent call last):\r\nweb_1 | File \"/usr/local/lib/python3.8/site-packages/promise/promise.py\", line 489, in _resolve_from_executor\r\nweb_1 | executor(resolve, reject)\r\nweb_1 | File \"/usr/local/lib/python3.8/site-packages/promise/promise.py\", line 756, in executor\r\nweb_1 | return resolve(f(*args, **kwargs))\r\nweb_1 | File \"/usr/local/lib/python3.8/site-packages/graphql/execution/middleware.py\", line 75, in make_it_promise\r\nweb_1 | return next(*args, **kwargs)\r\nweb_1 | File \"/app/saleor/graphql/core/mutations.py\", line 279, in mutate\r\nweb_1 | response = cls.perform_mutation(root, info, **data)\r\nweb_1 | File \"/app/saleor/graphql/core/mutations.py\", line 448, in perform_mutation\r\nweb_1 | cleaned_input = cls.clean_input(info, instance, data)\r\nweb_1 | File \"/app/saleor/graphql/page/mutations.py\", line 43, in clean_input\r\nweb_1 | cleaned_input[\"slug\"] = slugify(cleaned_input[\"title\"])\r\nweb_1 | KeyError: 'title'\r\n```\r\n\r\n### What I expected to happen\r\nshould update a `Page` without error\r\n\r\n\n", "before_files": [{"content": "import graphene\nfrom django.utils.text import slugify\n\nfrom ...core.permissions import PagePermissions\nfrom ...page import models\nfrom ..core.mutations import ModelDeleteMutation, ModelMutation\nfrom ..core.types.common import SeoInput\nfrom ..core.utils import clean_seo_fields\n\n\nclass PageInput(graphene.InputObjectType):\n slug = graphene.String(description=\"Page internal name.\")\n title = graphene.String(description=\"Page title.\")\n content = graphene.String(\n description=(\"Page content. May consist of ordinary text, HTML and images.\")\n )\n content_json = graphene.JSONString(description=\"Page content in JSON format.\")\n is_published = graphene.Boolean(\n description=\"Determines if page is visible in the storefront.\"\n )\n publication_date = graphene.String(\n description=\"Publication date. ISO 8601 standard.\"\n )\n seo = SeoInput(description=\"Search engine optimization fields.\")\n\n\nclass PageCreate(ModelMutation):\n class Arguments:\n input = PageInput(\n required=True, description=\"Fields required to create a page.\"\n )\n\n class Meta:\n description = \"Creates a new page.\"\n model = models.Page\n permissions = (PagePermissions.MANAGE_PAGES,)\n\n @classmethod\n def clean_input(cls, info, instance, data):\n cleaned_input = super().clean_input(info, instance, data)\n slug = cleaned_input.get(\"slug\", \"\")\n if not slug:\n cleaned_input[\"slug\"] = slugify(cleaned_input[\"title\"])\n clean_seo_fields(cleaned_input)\n return cleaned_input\n\n\nclass PageUpdate(PageCreate):\n class Arguments:\n id = graphene.ID(required=True, description=\"ID of a page to update.\")\n input = PageInput(\n required=True, description=\"Fields required to update a page.\"\n )\n\n class Meta:\n description = \"Updates an existing page.\"\n model = models.Page\n\n\nclass PageDelete(ModelDeleteMutation):\n class Arguments:\n id = graphene.ID(required=True, description=\"ID of a page to delete.\")\n\n class Meta:\n description = \"Deletes a page.\"\n model = models.Page\n permissions = (PagePermissions.MANAGE_PAGES,)\n", "path": "saleor/graphql/page/mutations.py"}], "after_files": [{"content": "import graphene\nfrom django.utils.text import slugify\n\nfrom ...core.permissions import PagePermissions\nfrom ...page import models\nfrom ..core.mutations import ModelDeleteMutation, ModelMutation\nfrom ..core.types.common import SeoInput\nfrom ..core.utils import clean_seo_fields\n\n\nclass PageInput(graphene.InputObjectType):\n slug = graphene.String(description=\"Page internal name.\")\n title = graphene.String(description=\"Page title.\")\n content = graphene.String(\n description=(\"Page content. May consist of ordinary text, HTML and images.\")\n )\n content_json = graphene.JSONString(description=\"Page content in JSON format.\")\n is_published = graphene.Boolean(\n description=\"Determines if page is visible in the storefront.\"\n )\n publication_date = graphene.String(\n description=\"Publication date. ISO 8601 standard.\"\n )\n seo = SeoInput(description=\"Search engine optimization fields.\")\n\n\nclass PageCreate(ModelMutation):\n class Arguments:\n input = PageInput(\n required=True, description=\"Fields required to create a page.\"\n )\n\n class Meta:\n description = \"Creates a new page.\"\n model = models.Page\n permissions = (PagePermissions.MANAGE_PAGES,)\n\n @classmethod\n def clean_input(cls, info, instance, data):\n cleaned_input = super().clean_input(info, instance, data)\n slug = cleaned_input.get(\"slug\", \"\")\n title = cleaned_input.get(\"title\", \"\")\n if title and not slug:\n cleaned_input[\"slug\"] = slugify(title)\n clean_seo_fields(cleaned_input)\n return cleaned_input\n\n\nclass PageUpdate(PageCreate):\n class Arguments:\n id = graphene.ID(required=True, description=\"ID of a page to update.\")\n input = PageInput(\n required=True, description=\"Fields required to update a page.\"\n )\n\n class Meta:\n description = \"Updates an existing page.\"\n model = models.Page\n\n\nclass PageDelete(ModelDeleteMutation):\n class Arguments:\n id = graphene.ID(required=True, description=\"ID of a page to delete.\")\n\n class Meta:\n description = \"Deletes a page.\"\n model = models.Page\n permissions = (PagePermissions.MANAGE_PAGES,)\n", "path": "saleor/graphql/page/mutations.py"}]}
| 1,242 | 159 |
gh_patches_debug_37638
|
rasdani/github-patches
|
git_diff
|
akvo__akvo-rsr-3791
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add thematic labels to indicator
The granular way of working with thematic labels attached to indicators is extremely prone to error at the FE due to the complexity of handling it, waiting for IDs assigned from backend for each label, etc. This will decrease UX as the component will have to freeze to wait for backend syncs and will break the normal pattern of auto-saving.
In order to wrap this up properly we need to have a simpler way of editing the labels attached to indicator, namely as a simple list of label **values**:
```
thematic_labels: [31, 17]
```
This property would need to be added to the indicator and to allow GET & PATCH.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `akvo/rest/filters.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # Akvo Reporting is covered by the GNU Affero General Public License.
4 # See more details in the license.txt file located at the root folder of the Akvo RSR module.
5 # For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.
6
7 import ast
8
9 from django.db.models import Q
10 from django.core.exceptions import FieldError
11
12 from rest_framework import filters
13 from rest_framework.exceptions import APIException
14
15
16 class RSRGenericFilterBackend(filters.BaseFilterBackend):
17
18 def filter_queryset(self, request, queryset, view):
19 """
20 Return a queryset possibly filtered by query param values.
21 The filter looks for the query param keys filter and exclude
22 For each of these query param the value is evaluated using ast.literal_eval() and used as
23 kwargs in queryset.filter and queryset.exclude respectively.
24
25 Example URLs:
26 https://rsr.akvo.org/rest/v1/project/?filter={'title__icontains':'water','currency':'EUR'}
27 https://rsr.akvo.org/rest/v1/project/?filter={'title__icontains':'water'}&exclude={'currency':'EUR'}
28
29 It's also possible to specify models to be included in select_related() and
30 prefetch_related() calls on the queryset, but specifying these in lists of strings as the
31 values for the query sting params select_relates and prefetch_related.
32
33 Example:
34 https://rsr.akvo.org/rest/v1/project/?filter={'partners__in':[42,43]}&prefetch_related=['partners']
35
36 Finally limited support for filtering on multiple arguments using logical OR between
37 those expressions is available. To use this supply two or more query string keywords on the
38 form q_filter1, q_filter2... where the value is a dict that can be used as a kwarg in a Q
39 object. All those Q objects created are used in a queryset.filter() call concatenated using
40 the | operator.
41 """
42 def eval_query_value(request, key):
43 """
44 Use ast.literal_eval() to evaluate a query string value as a python data type object
45 :param request: the django request object
46 :param param: the query string param key
47 :return: a python data type object, or None if literal_eval() fails
48 """
49 value = request.query_params.get(key, None)
50 try:
51 return ast.literal_eval(value)
52 except (ValueError, SyntaxError):
53 return None
54
55 qs_params = ['filter', 'exclude', 'select_related', 'prefetch_related']
56
57 # evaluate each query string param, and apply the queryset method with the same name
58 for param in qs_params:
59 args_or_kwargs = eval_query_value(request, param)
60 if args_or_kwargs:
61 # filter and exclude are called with a dict kwarg, the _related methods with a list
62 try:
63 if param in ['filter', 'exclude', ]:
64 queryset = getattr(queryset, param)(**args_or_kwargs)
65 else:
66 queryset = getattr(queryset, param)(*args_or_kwargs)
67
68 except FieldError as e:
69 raise APIException("Error in request: {message}".format(message=e.message))
70
71 # support for Q expressions, limited to OR-concatenated filtering
72 if request.query_params.get('q_filter1', None):
73 i = 1
74 q_queries = []
75 while request.query_params.get('q_filter{}'.format(i), None):
76 query_arg = eval_query_value(request, 'q_filter{}'.format(i))
77 if query_arg:
78 q_queries += [query_arg]
79 i += 1
80
81 q_expr = Q(**q_queries[0])
82 for query in q_queries[1:]:
83 q_expr = q_expr | Q(**query)
84
85 queryset = queryset.filter(q_expr)
86
87 return queryset
88
```
Path: `akvo/rest/serializers/indicator.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # Akvo RSR is covered by the GNU Affero General Public License.
4 # See more details in the license.txt file located at the root folder of the Akvo RSR module.
5 # For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.
6
7 from akvo.rest.serializers.indicator_period import (
8 IndicatorPeriodFrameworkSerializer, IndicatorPeriodFrameworkLiteSerializer)
9 from akvo.rest.serializers.indicator_dimension_name import IndicatorDimensionNameSerializer
10 from akvo.rest.serializers.rsr_serializer import BaseRSRSerializer
11 from akvo.rsr.models import Indicator, IndicatorDimensionName
12
13 from rest_framework import serializers
14
15
16 class IndicatorSerializer(BaseRSRSerializer):
17
18 result_unicode = serializers.ReadOnlyField(source='result.__unicode__')
19 measure_label = serializers.ReadOnlyField(source='iati_measure_unicode')
20 children_aggregate_percentage = serializers.ReadOnlyField()
21 dimension_names = serializers.PrimaryKeyRelatedField(
22 many=True, queryset=IndicatorDimensionName.objects.all())
23
24 class Meta:
25 model = Indicator
26 fields = '__all__'
27
28 # TODO: add validation for parent_indicator
29
30
31 class IndicatorFrameworkSerializer(BaseRSRSerializer):
32
33 periods = IndicatorPeriodFrameworkSerializer(many=True, required=False, read_only=True)
34 parent_indicator = serializers.ReadOnlyField(source='parent_indicator_id')
35 children_aggregate_percentage = serializers.ReadOnlyField()
36 dimension_names = IndicatorDimensionNameSerializer(many=True, required=False, read_only=True)
37
38 class Meta:
39 model = Indicator
40 fields = '__all__'
41
42
43 class IndicatorFrameworkLiteSerializer(BaseRSRSerializer):
44
45 periods = IndicatorPeriodFrameworkLiteSerializer(many=True, required=False, read_only=True)
46 parent_indicator = serializers.ReadOnlyField(source='parent_indicator_id')
47 children_aggregate_percentage = serializers.ReadOnlyField()
48 dimension_names = IndicatorDimensionNameSerializer(many=True, required=False, read_only=True)
49
50 class Meta:
51 model = Indicator
52 fields = '__all__'
53
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/akvo/rest/filters.py b/akvo/rest/filters.py
--- a/akvo/rest/filters.py
+++ b/akvo/rest/filters.py
@@ -84,4 +84,4 @@
queryset = queryset.filter(q_expr)
- return queryset
+ return queryset.distinct()
diff --git a/akvo/rest/serializers/indicator.py b/akvo/rest/serializers/indicator.py
--- a/akvo/rest/serializers/indicator.py
+++ b/akvo/rest/serializers/indicator.py
@@ -8,11 +8,29 @@
IndicatorPeriodFrameworkSerializer, IndicatorPeriodFrameworkLiteSerializer)
from akvo.rest.serializers.indicator_dimension_name import IndicatorDimensionNameSerializer
from akvo.rest.serializers.rsr_serializer import BaseRSRSerializer
-from akvo.rsr.models import Indicator, IndicatorDimensionName
+from akvo.rsr.models import Indicator, IndicatorDimensionName, IndicatorLabel
from rest_framework import serializers
+class LabelListingField(serializers.RelatedField):
+
+ def to_representation(self, labels):
+ return list(labels.values_list('label_id', flat=True))
+
+ def to_internal_value(self, org_label_ids):
+ indicator = self.root.instance
+ existing_labels = set(indicator.labels.values_list('label_id', flat=True))
+ new_labels = set(org_label_ids) - existing_labels
+ deleted_labels = existing_labels - set(org_label_ids)
+ labels = [IndicatorLabel(indicator=indicator, label_id=org_label_id) for org_label_id in new_labels]
+ IndicatorLabel.objects.bulk_create(labels)
+ if deleted_labels:
+ IndicatorLabel.objects.filter(label_id__in=deleted_labels).delete()
+
+ return indicator.labels.all()
+
+
class IndicatorSerializer(BaseRSRSerializer):
result_unicode = serializers.ReadOnlyField(source='result.__unicode__')
@@ -34,6 +52,7 @@
parent_indicator = serializers.ReadOnlyField(source='parent_indicator_id')
children_aggregate_percentage = serializers.ReadOnlyField()
dimension_names = IndicatorDimensionNameSerializer(many=True, required=False, read_only=True)
+ labels = LabelListingField(queryset=IndicatorLabel.objects.all(), required=False)
class Meta:
model = Indicator
@@ -46,6 +65,7 @@
parent_indicator = serializers.ReadOnlyField(source='parent_indicator_id')
children_aggregate_percentage = serializers.ReadOnlyField()
dimension_names = IndicatorDimensionNameSerializer(many=True, required=False, read_only=True)
+ labels = LabelListingField(read_only=True)
class Meta:
model = Indicator
|
{"golden_diff": "diff --git a/akvo/rest/filters.py b/akvo/rest/filters.py\n--- a/akvo/rest/filters.py\n+++ b/akvo/rest/filters.py\n@@ -84,4 +84,4 @@\n \n queryset = queryset.filter(q_expr)\n \n- return queryset\n+ return queryset.distinct()\ndiff --git a/akvo/rest/serializers/indicator.py b/akvo/rest/serializers/indicator.py\n--- a/akvo/rest/serializers/indicator.py\n+++ b/akvo/rest/serializers/indicator.py\n@@ -8,11 +8,29 @@\n IndicatorPeriodFrameworkSerializer, IndicatorPeriodFrameworkLiteSerializer)\n from akvo.rest.serializers.indicator_dimension_name import IndicatorDimensionNameSerializer\n from akvo.rest.serializers.rsr_serializer import BaseRSRSerializer\n-from akvo.rsr.models import Indicator, IndicatorDimensionName\n+from akvo.rsr.models import Indicator, IndicatorDimensionName, IndicatorLabel\n \n from rest_framework import serializers\n \n \n+class LabelListingField(serializers.RelatedField):\n+\n+ def to_representation(self, labels):\n+ return list(labels.values_list('label_id', flat=True))\n+\n+ def to_internal_value(self, org_label_ids):\n+ indicator = self.root.instance\n+ existing_labels = set(indicator.labels.values_list('label_id', flat=True))\n+ new_labels = set(org_label_ids) - existing_labels\n+ deleted_labels = existing_labels - set(org_label_ids)\n+ labels = [IndicatorLabel(indicator=indicator, label_id=org_label_id) for org_label_id in new_labels]\n+ IndicatorLabel.objects.bulk_create(labels)\n+ if deleted_labels:\n+ IndicatorLabel.objects.filter(label_id__in=deleted_labels).delete()\n+\n+ return indicator.labels.all()\n+\n+\n class IndicatorSerializer(BaseRSRSerializer):\n \n result_unicode = serializers.ReadOnlyField(source='result.__unicode__')\n@@ -34,6 +52,7 @@\n parent_indicator = serializers.ReadOnlyField(source='parent_indicator_id')\n children_aggregate_percentage = serializers.ReadOnlyField()\n dimension_names = IndicatorDimensionNameSerializer(many=True, required=False, read_only=True)\n+ labels = LabelListingField(queryset=IndicatorLabel.objects.all(), required=False)\n \n class Meta:\n model = Indicator\n@@ -46,6 +65,7 @@\n parent_indicator = serializers.ReadOnlyField(source='parent_indicator_id')\n children_aggregate_percentage = serializers.ReadOnlyField()\n dimension_names = IndicatorDimensionNameSerializer(many=True, required=False, read_only=True)\n+ labels = LabelListingField(read_only=True)\n \n class Meta:\n model = Indicator\n", "issue": "Add thematic labels to indicator\nThe granular way of working with thematic labels attached to indicators is extremely prone to error at the FE due to the complexity of handling it, waiting for IDs assigned from backend for each label, etc. This will decrease UX as the component will have to freeze to wait for backend syncs and will break the normal pattern of auto-saving.\r\nIn order to wrap this up properly we need to have a simpler way of editing the labels attached to indicator, namely as a simple list of label **values**:\r\n\r\n```\r\nthematic_labels: [31, 17]\r\n```\r\n\r\nThis property would need to be added to the indicator and to allow GET & PATCH.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Akvo Reporting is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\nimport ast\n\nfrom django.db.models import Q\nfrom django.core.exceptions import FieldError\n\nfrom rest_framework import filters\nfrom rest_framework.exceptions import APIException\n\n\nclass RSRGenericFilterBackend(filters.BaseFilterBackend):\n\n def filter_queryset(self, request, queryset, view):\n \"\"\"\n Return a queryset possibly filtered by query param values.\n The filter looks for the query param keys filter and exclude\n For each of these query param the value is evaluated using ast.literal_eval() and used as\n kwargs in queryset.filter and queryset.exclude respectively.\n\n Example URLs:\n https://rsr.akvo.org/rest/v1/project/?filter={'title__icontains':'water','currency':'EUR'}\n https://rsr.akvo.org/rest/v1/project/?filter={'title__icontains':'water'}&exclude={'currency':'EUR'}\n\n It's also possible to specify models to be included in select_related() and\n prefetch_related() calls on the queryset, but specifying these in lists of strings as the\n values for the query sting params select_relates and prefetch_related.\n\n Example:\n https://rsr.akvo.org/rest/v1/project/?filter={'partners__in':[42,43]}&prefetch_related=['partners']\n\n Finally limited support for filtering on multiple arguments using logical OR between\n those expressions is available. To use this supply two or more query string keywords on the\n form q_filter1, q_filter2... where the value is a dict that can be used as a kwarg in a Q\n object. All those Q objects created are used in a queryset.filter() call concatenated using\n the | operator.\n \"\"\"\n def eval_query_value(request, key):\n \"\"\"\n Use ast.literal_eval() to evaluate a query string value as a python data type object\n :param request: the django request object\n :param param: the query string param key\n :return: a python data type object, or None if literal_eval() fails\n \"\"\"\n value = request.query_params.get(key, None)\n try:\n return ast.literal_eval(value)\n except (ValueError, SyntaxError):\n return None\n\n qs_params = ['filter', 'exclude', 'select_related', 'prefetch_related']\n\n # evaluate each query string param, and apply the queryset method with the same name\n for param in qs_params:\n args_or_kwargs = eval_query_value(request, param)\n if args_or_kwargs:\n # filter and exclude are called with a dict kwarg, the _related methods with a list\n try:\n if param in ['filter', 'exclude', ]:\n queryset = getattr(queryset, param)(**args_or_kwargs)\n else:\n queryset = getattr(queryset, param)(*args_or_kwargs)\n\n except FieldError as e:\n raise APIException(\"Error in request: {message}\".format(message=e.message))\n\n # support for Q expressions, limited to OR-concatenated filtering\n if request.query_params.get('q_filter1', None):\n i = 1\n q_queries = []\n while request.query_params.get('q_filter{}'.format(i), None):\n query_arg = eval_query_value(request, 'q_filter{}'.format(i))\n if query_arg:\n q_queries += [query_arg]\n i += 1\n\n q_expr = Q(**q_queries[0])\n for query in q_queries[1:]:\n q_expr = q_expr | Q(**query)\n\n queryset = queryset.filter(q_expr)\n\n return queryset\n", "path": "akvo/rest/filters.py"}, {"content": "# -*- coding: utf-8 -*-\n\n# Akvo RSR is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\nfrom akvo.rest.serializers.indicator_period import (\n IndicatorPeriodFrameworkSerializer, IndicatorPeriodFrameworkLiteSerializer)\nfrom akvo.rest.serializers.indicator_dimension_name import IndicatorDimensionNameSerializer\nfrom akvo.rest.serializers.rsr_serializer import BaseRSRSerializer\nfrom akvo.rsr.models import Indicator, IndicatorDimensionName\n\nfrom rest_framework import serializers\n\n\nclass IndicatorSerializer(BaseRSRSerializer):\n\n result_unicode = serializers.ReadOnlyField(source='result.__unicode__')\n measure_label = serializers.ReadOnlyField(source='iati_measure_unicode')\n children_aggregate_percentage = serializers.ReadOnlyField()\n dimension_names = serializers.PrimaryKeyRelatedField(\n many=True, queryset=IndicatorDimensionName.objects.all())\n\n class Meta:\n model = Indicator\n fields = '__all__'\n\n # TODO: add validation for parent_indicator\n\n\nclass IndicatorFrameworkSerializer(BaseRSRSerializer):\n\n periods = IndicatorPeriodFrameworkSerializer(many=True, required=False, read_only=True)\n parent_indicator = serializers.ReadOnlyField(source='parent_indicator_id')\n children_aggregate_percentage = serializers.ReadOnlyField()\n dimension_names = IndicatorDimensionNameSerializer(many=True, required=False, read_only=True)\n\n class Meta:\n model = Indicator\n fields = '__all__'\n\n\nclass IndicatorFrameworkLiteSerializer(BaseRSRSerializer):\n\n periods = IndicatorPeriodFrameworkLiteSerializer(many=True, required=False, read_only=True)\n parent_indicator = serializers.ReadOnlyField(source='parent_indicator_id')\n children_aggregate_percentage = serializers.ReadOnlyField()\n dimension_names = IndicatorDimensionNameSerializer(many=True, required=False, read_only=True)\n\n class Meta:\n model = Indicator\n fields = '__all__'\n", "path": "akvo/rest/serializers/indicator.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Akvo Reporting is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\nimport ast\n\nfrom django.db.models import Q\nfrom django.core.exceptions import FieldError\n\nfrom rest_framework import filters\nfrom rest_framework.exceptions import APIException\n\n\nclass RSRGenericFilterBackend(filters.BaseFilterBackend):\n\n def filter_queryset(self, request, queryset, view):\n \"\"\"\n Return a queryset possibly filtered by query param values.\n The filter looks for the query param keys filter and exclude\n For each of these query param the value is evaluated using ast.literal_eval() and used as\n kwargs in queryset.filter and queryset.exclude respectively.\n\n Example URLs:\n https://rsr.akvo.org/rest/v1/project/?filter={'title__icontains':'water','currency':'EUR'}\n https://rsr.akvo.org/rest/v1/project/?filter={'title__icontains':'water'}&exclude={'currency':'EUR'}\n\n It's also possible to specify models to be included in select_related() and\n prefetch_related() calls on the queryset, but specifying these in lists of strings as the\n values for the query sting params select_relates and prefetch_related.\n\n Example:\n https://rsr.akvo.org/rest/v1/project/?filter={'partners__in':[42,43]}&prefetch_related=['partners']\n\n Finally limited support for filtering on multiple arguments using logical OR between\n those expressions is available. To use this supply two or more query string keywords on the\n form q_filter1, q_filter2... where the value is a dict that can be used as a kwarg in a Q\n object. All those Q objects created are used in a queryset.filter() call concatenated using\n the | operator.\n \"\"\"\n def eval_query_value(request, key):\n \"\"\"\n Use ast.literal_eval() to evaluate a query string value as a python data type object\n :param request: the django request object\n :param param: the query string param key\n :return: a python data type object, or None if literal_eval() fails\n \"\"\"\n value = request.query_params.get(key, None)\n try:\n return ast.literal_eval(value)\n except (ValueError, SyntaxError):\n return None\n\n qs_params = ['filter', 'exclude', 'select_related', 'prefetch_related']\n\n # evaluate each query string param, and apply the queryset method with the same name\n for param in qs_params:\n args_or_kwargs = eval_query_value(request, param)\n if args_or_kwargs:\n # filter and exclude are called with a dict kwarg, the _related methods with a list\n try:\n if param in ['filter', 'exclude', ]:\n queryset = getattr(queryset, param)(**args_or_kwargs)\n else:\n queryset = getattr(queryset, param)(*args_or_kwargs)\n\n except FieldError as e:\n raise APIException(\"Error in request: {message}\".format(message=e.message))\n\n # support for Q expressions, limited to OR-concatenated filtering\n if request.query_params.get('q_filter1', None):\n i = 1\n q_queries = []\n while request.query_params.get('q_filter{}'.format(i), None):\n query_arg = eval_query_value(request, 'q_filter{}'.format(i))\n if query_arg:\n q_queries += [query_arg]\n i += 1\n\n q_expr = Q(**q_queries[0])\n for query in q_queries[1:]:\n q_expr = q_expr | Q(**query)\n\n queryset = queryset.filter(q_expr)\n\n return queryset.distinct()\n", "path": "akvo/rest/filters.py"}, {"content": "# -*- coding: utf-8 -*-\n\n# Akvo RSR is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\nfrom akvo.rest.serializers.indicator_period import (\n IndicatorPeriodFrameworkSerializer, IndicatorPeriodFrameworkLiteSerializer)\nfrom akvo.rest.serializers.indicator_dimension_name import IndicatorDimensionNameSerializer\nfrom akvo.rest.serializers.rsr_serializer import BaseRSRSerializer\nfrom akvo.rsr.models import Indicator, IndicatorDimensionName, IndicatorLabel\n\nfrom rest_framework import serializers\n\n\nclass LabelListingField(serializers.RelatedField):\n\n def to_representation(self, labels):\n return list(labels.values_list('label_id', flat=True))\n\n def to_internal_value(self, org_label_ids):\n indicator = self.root.instance\n existing_labels = set(indicator.labels.values_list('label_id', flat=True))\n new_labels = set(org_label_ids) - existing_labels\n deleted_labels = existing_labels - set(org_label_ids)\n labels = [IndicatorLabel(indicator=indicator, label_id=org_label_id) for org_label_id in new_labels]\n IndicatorLabel.objects.bulk_create(labels)\n if deleted_labels:\n IndicatorLabel.objects.filter(label_id__in=deleted_labels).delete()\n\n return indicator.labels.all()\n\n\nclass IndicatorSerializer(BaseRSRSerializer):\n\n result_unicode = serializers.ReadOnlyField(source='result.__unicode__')\n measure_label = serializers.ReadOnlyField(source='iati_measure_unicode')\n children_aggregate_percentage = serializers.ReadOnlyField()\n dimension_names = serializers.PrimaryKeyRelatedField(\n many=True, queryset=IndicatorDimensionName.objects.all())\n\n class Meta:\n model = Indicator\n fields = '__all__'\n\n # TODO: add validation for parent_indicator\n\n\nclass IndicatorFrameworkSerializer(BaseRSRSerializer):\n\n periods = IndicatorPeriodFrameworkSerializer(many=True, required=False, read_only=True)\n parent_indicator = serializers.ReadOnlyField(source='parent_indicator_id')\n children_aggregate_percentage = serializers.ReadOnlyField()\n dimension_names = IndicatorDimensionNameSerializer(many=True, required=False, read_only=True)\n labels = LabelListingField(queryset=IndicatorLabel.objects.all(), required=False)\n\n class Meta:\n model = Indicator\n fields = '__all__'\n\n\nclass IndicatorFrameworkLiteSerializer(BaseRSRSerializer):\n\n periods = IndicatorPeriodFrameworkLiteSerializer(many=True, required=False, read_only=True)\n parent_indicator = serializers.ReadOnlyField(source='parent_indicator_id')\n children_aggregate_percentage = serializers.ReadOnlyField()\n dimension_names = IndicatorDimensionNameSerializer(many=True, required=False, read_only=True)\n labels = LabelListingField(read_only=True)\n\n class Meta:\n model = Indicator\n fields = '__all__'\n", "path": "akvo/rest/serializers/indicator.py"}]}
| 1,918 | 566 |
gh_patches_debug_5801
|
rasdani/github-patches
|
git_diff
|
sosreport__sos-3281
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Some MAAS config files missing from collection
Currently we're only collecting `/var/lib/maas/dhcp`, meaning that we're missing other key config files that would help with troubleshooting MAAS issues, e.g., `/var/lib/maas/http`. I'd suggest to add the below paths to be collected:
* /var/lib/maas/http/*
* /var/lib/maas/*.conf
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sos/report/plugins/maas.py`
Content:
```
1 # Copyright (C) 2013 Adam Stokes <[email protected]>
2 #
3 # This file is part of the sos project: https://github.com/sosreport/sos
4 #
5 # This copyrighted material is made available to anyone wishing to use,
6 # modify, copy, or redistribute it subject to the terms and conditions of
7 # version 2 of the GNU General Public License.
8 #
9 # See the LICENSE file in the source distribution for further information.
10
11 from sos.report.plugins import Plugin, UbuntuPlugin, PluginOpt
12
13
14 class Maas(Plugin, UbuntuPlugin):
15
16 short_desc = 'Ubuntu Metal-As-A-Service'
17
18 plugin_name = 'maas'
19 profiles = ('sysmgmt',)
20 packages = ('maas', 'maas-common')
21
22 services = (
23 # For the deb:
24 'maas-dhcpd',
25 'maas-dhcpd6',
26 'maas-http',
27 'maas-proxy',
28 'maas-rackd',
29 'maas-regiond',
30 'maas-syslog',
31 # For the snap:
32 'snap.maas.supervisor',
33 )
34
35 option_list = [
36 PluginOpt('profile-name', default='', val_type=str,
37 desc='Name of the remote API'),
38 PluginOpt('url', default='', val_type=str,
39 desc='URL of the remote API'),
40 PluginOpt('credentials', default='', val_type=str,
41 desc='Credentials, or the API key')
42 ]
43
44 def _has_login_options(self):
45 return self.get_option("url") and self.get_option("credentials") \
46 and self.get_option("profile-name")
47
48 def _remote_api_login(self):
49 ret = self.exec_cmd(
50 "maas login %s %s %s" % (
51 self.get_option("profile-name"),
52 self.get_option("url"),
53 self.get_option("credentials")
54 )
55 )
56
57 return ret['status'] == 0
58
59 def _is_snap_installed(self):
60 maas_pkg = self.policy.package_manager.pkg_by_name('maas')
61 if maas_pkg:
62 return maas_pkg['pkg_manager'] == 'snap'
63 return False
64
65 def setup(self):
66 self._is_snap = self._is_snap_installed()
67 if self._is_snap:
68 self.add_cmd_output([
69 'snap info maas',
70 'maas status'
71 ])
72 # Don't send secrets
73 self.add_forbidden_path("/var/snap/maas/current/bind/session.key")
74 self.add_copy_spec([
75 "/var/snap/maas/common/log",
76 "/var/snap/maas/common/snap_mode",
77 "/var/snap/maas/current/*.conf",
78 "/var/snap/maas/current/bind",
79 "/var/snap/maas/current/http",
80 "/var/snap/maas/current/supervisord",
81 "/var/snap/maas/current/preseeds",
82 "/var/snap/maas/current/proxy",
83 "/var/snap/maas/current/rsyslog",
84 ])
85 else:
86 self.add_copy_spec([
87 "/etc/squid-deb-proxy",
88 "/etc/maas",
89 "/var/lib/maas/dhcp*",
90 "/var/log/apache2*",
91 "/var/log/maas*",
92 "/var/log/upstart/maas-*",
93 ])
94 self.add_cmd_output([
95 "apt-cache policy maas-*",
96 "apt-cache policy python-django-*",
97 ])
98
99 if self.is_installed("maas-region-controller"):
100 self.add_cmd_output([
101 "maas-region dumpdata",
102 ])
103
104 if self._has_login_options():
105 if self._remote_api_login():
106 self.add_cmd_output("maas %s commissioning-results list" %
107 self.get_option("profile-name"))
108 else:
109 self._log_error(
110 "Cannot login into MAAS remote API with provided creds.")
111
112 def postproc(self):
113 if self._is_snap:
114 regiond_path = "/var/snap/maas/current/maas/regiond.conf"
115 else:
116 regiond_path = "/etc/maas/regiond.conf"
117 self.do_file_sub(regiond_path,
118 r"(database_pass\s*:\s*)(.*)",
119 r"\1********")
120
121 # vim: set et ts=4 sw=4 :
122
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sos/report/plugins/maas.py b/sos/report/plugins/maas.py
--- a/sos/report/plugins/maas.py
+++ b/sos/report/plugins/maas.py
@@ -87,6 +87,9 @@
"/etc/squid-deb-proxy",
"/etc/maas",
"/var/lib/maas/dhcp*",
+ "/var/lib/maas/http/*.conf",
+ "/var/lib/maas/*.conf",
+ "/var/lib/maas/rsyslog",
"/var/log/apache2*",
"/var/log/maas*",
"/var/log/upstart/maas-*",
|
{"golden_diff": "diff --git a/sos/report/plugins/maas.py b/sos/report/plugins/maas.py\n--- a/sos/report/plugins/maas.py\n+++ b/sos/report/plugins/maas.py\n@@ -87,6 +87,9 @@\n \"/etc/squid-deb-proxy\",\n \"/etc/maas\",\n \"/var/lib/maas/dhcp*\",\n+ \"/var/lib/maas/http/*.conf\",\n+ \"/var/lib/maas/*.conf\",\n+ \"/var/lib/maas/rsyslog\",\n \"/var/log/apache2*\",\n \"/var/log/maas*\",\n \"/var/log/upstart/maas-*\",\n", "issue": "Some MAAS config files missing from collection\nCurrently we're only collecting `/var/lib/maas/dhcp`, meaning that we're missing other key config files that would help with troubleshooting MAAS issues, e.g., `/var/lib/maas/http`. I'd suggest to add the below paths to be collected:\r\n\r\n* /var/lib/maas/http/*\r\n* /var/lib/maas/*.conf\n", "before_files": [{"content": "# Copyright (C) 2013 Adam Stokes <[email protected]>\n#\n# This file is part of the sos project: https://github.com/sosreport/sos\n#\n# This copyrighted material is made available to anyone wishing to use,\n# modify, copy, or redistribute it subject to the terms and conditions of\n# version 2 of the GNU General Public License.\n#\n# See the LICENSE file in the source distribution for further information.\n\nfrom sos.report.plugins import Plugin, UbuntuPlugin, PluginOpt\n\n\nclass Maas(Plugin, UbuntuPlugin):\n\n short_desc = 'Ubuntu Metal-As-A-Service'\n\n plugin_name = 'maas'\n profiles = ('sysmgmt',)\n packages = ('maas', 'maas-common')\n\n services = (\n # For the deb:\n 'maas-dhcpd',\n 'maas-dhcpd6',\n 'maas-http',\n 'maas-proxy',\n 'maas-rackd',\n 'maas-regiond',\n 'maas-syslog',\n # For the snap:\n 'snap.maas.supervisor',\n )\n\n option_list = [\n PluginOpt('profile-name', default='', val_type=str,\n desc='Name of the remote API'),\n PluginOpt('url', default='', val_type=str,\n desc='URL of the remote API'),\n PluginOpt('credentials', default='', val_type=str,\n desc='Credentials, or the API key')\n ]\n\n def _has_login_options(self):\n return self.get_option(\"url\") and self.get_option(\"credentials\") \\\n and self.get_option(\"profile-name\")\n\n def _remote_api_login(self):\n ret = self.exec_cmd(\n \"maas login %s %s %s\" % (\n self.get_option(\"profile-name\"),\n self.get_option(\"url\"),\n self.get_option(\"credentials\")\n )\n )\n\n return ret['status'] == 0\n\n def _is_snap_installed(self):\n maas_pkg = self.policy.package_manager.pkg_by_name('maas')\n if maas_pkg:\n return maas_pkg['pkg_manager'] == 'snap'\n return False\n\n def setup(self):\n self._is_snap = self._is_snap_installed()\n if self._is_snap:\n self.add_cmd_output([\n 'snap info maas',\n 'maas status'\n ])\n # Don't send secrets\n self.add_forbidden_path(\"/var/snap/maas/current/bind/session.key\")\n self.add_copy_spec([\n \"/var/snap/maas/common/log\",\n \"/var/snap/maas/common/snap_mode\",\n \"/var/snap/maas/current/*.conf\",\n \"/var/snap/maas/current/bind\",\n \"/var/snap/maas/current/http\",\n \"/var/snap/maas/current/supervisord\",\n \"/var/snap/maas/current/preseeds\",\n \"/var/snap/maas/current/proxy\",\n \"/var/snap/maas/current/rsyslog\",\n ])\n else:\n self.add_copy_spec([\n \"/etc/squid-deb-proxy\",\n \"/etc/maas\",\n \"/var/lib/maas/dhcp*\",\n \"/var/log/apache2*\",\n \"/var/log/maas*\",\n \"/var/log/upstart/maas-*\",\n ])\n self.add_cmd_output([\n \"apt-cache policy maas-*\",\n \"apt-cache policy python-django-*\",\n ])\n\n if self.is_installed(\"maas-region-controller\"):\n self.add_cmd_output([\n \"maas-region dumpdata\",\n ])\n\n if self._has_login_options():\n if self._remote_api_login():\n self.add_cmd_output(\"maas %s commissioning-results list\" %\n self.get_option(\"profile-name\"))\n else:\n self._log_error(\n \"Cannot login into MAAS remote API with provided creds.\")\n\n def postproc(self):\n if self._is_snap:\n regiond_path = \"/var/snap/maas/current/maas/regiond.conf\"\n else:\n regiond_path = \"/etc/maas/regiond.conf\"\n self.do_file_sub(regiond_path,\n r\"(database_pass\\s*:\\s*)(.*)\",\n r\"\\1********\")\n\n# vim: set et ts=4 sw=4 :\n", "path": "sos/report/plugins/maas.py"}], "after_files": [{"content": "# Copyright (C) 2013 Adam Stokes <[email protected]>\n#\n# This file is part of the sos project: https://github.com/sosreport/sos\n#\n# This copyrighted material is made available to anyone wishing to use,\n# modify, copy, or redistribute it subject to the terms and conditions of\n# version 2 of the GNU General Public License.\n#\n# See the LICENSE file in the source distribution for further information.\n\nfrom sos.report.plugins import Plugin, UbuntuPlugin, PluginOpt\n\n\nclass Maas(Plugin, UbuntuPlugin):\n\n short_desc = 'Ubuntu Metal-As-A-Service'\n\n plugin_name = 'maas'\n profiles = ('sysmgmt',)\n packages = ('maas', 'maas-common')\n\n services = (\n # For the deb:\n 'maas-dhcpd',\n 'maas-dhcpd6',\n 'maas-http',\n 'maas-proxy',\n 'maas-rackd',\n 'maas-regiond',\n 'maas-syslog',\n # For the snap:\n 'snap.maas.supervisor',\n )\n\n option_list = [\n PluginOpt('profile-name', default='', val_type=str,\n desc='Name of the remote API'),\n PluginOpt('url', default='', val_type=str,\n desc='URL of the remote API'),\n PluginOpt('credentials', default='', val_type=str,\n desc='Credentials, or the API key')\n ]\n\n def _has_login_options(self):\n return self.get_option(\"url\") and self.get_option(\"credentials\") \\\n and self.get_option(\"profile-name\")\n\n def _remote_api_login(self):\n ret = self.exec_cmd(\n \"maas login %s %s %s\" % (\n self.get_option(\"profile-name\"),\n self.get_option(\"url\"),\n self.get_option(\"credentials\")\n )\n )\n\n return ret['status'] == 0\n\n def _is_snap_installed(self):\n maas_pkg = self.policy.package_manager.pkg_by_name('maas')\n if maas_pkg:\n return maas_pkg['pkg_manager'] == 'snap'\n return False\n\n def setup(self):\n self._is_snap = self._is_snap_installed()\n if self._is_snap:\n self.add_cmd_output([\n 'snap info maas',\n 'maas status'\n ])\n # Don't send secrets\n self.add_forbidden_path(\"/var/snap/maas/current/bind/session.key\")\n self.add_copy_spec([\n \"/var/snap/maas/common/log\",\n \"/var/snap/maas/common/snap_mode\",\n \"/var/snap/maas/current/*.conf\",\n \"/var/snap/maas/current/bind\",\n \"/var/snap/maas/current/http\",\n \"/var/snap/maas/current/supervisord\",\n \"/var/snap/maas/current/preseeds\",\n \"/var/snap/maas/current/proxy\",\n \"/var/snap/maas/current/rsyslog\",\n ])\n else:\n self.add_copy_spec([\n \"/etc/squid-deb-proxy\",\n \"/etc/maas\",\n \"/var/lib/maas/dhcp*\",\n \"/var/lib/maas/http/*.conf\",\n \"/var/lib/maas/*.conf\",\n \"/var/lib/maas/rsyslog\",\n \"/var/log/apache2*\",\n \"/var/log/maas*\",\n \"/var/log/upstart/maas-*\",\n ])\n self.add_cmd_output([\n \"apt-cache policy maas-*\",\n \"apt-cache policy python-django-*\",\n ])\n\n if self.is_installed(\"maas-region-controller\"):\n self.add_cmd_output([\n \"maas-region dumpdata\",\n ])\n\n if self._has_login_options():\n if self._remote_api_login():\n self.add_cmd_output(\"maas %s commissioning-results list\" %\n self.get_option(\"profile-name\"))\n else:\n self._log_error(\n \"Cannot login into MAAS remote API with provided creds.\")\n\n def postproc(self):\n if self._is_snap:\n regiond_path = \"/var/snap/maas/current/maas/regiond.conf\"\n else:\n regiond_path = \"/etc/maas/regiond.conf\"\n self.do_file_sub(regiond_path,\n r\"(database_pass\\s*:\\s*)(.*)\",\n r\"\\1********\")\n\n# vim: set et ts=4 sw=4 :\n", "path": "sos/report/plugins/maas.py"}]}
| 1,537 | 147 |
gh_patches_debug_3578
|
rasdani/github-patches
|
git_diff
|
HypothesisWorks__hypothesis-2248
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Internal error for unique lists
```python
from hypothesis import given, strategies as st
@given(st.lists(st.sampled_from([0, 0.0]), unique=True, min_size=1))
def t(x): pass
t()
```
triggers an assertion via `conjecture.utils.integer_range(data, lower=0, upper=-1)`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `hypothesis-python/src/hypothesis/searchstrategy/collections.py`
Content:
```
1 # coding=utf-8
2 #
3 # This file is part of Hypothesis, which may be found at
4 # https://github.com/HypothesisWorks/hypothesis/
5 #
6 # Most of this work is copyright (C) 2013-2019 David R. MacIver
7 # ([email protected]), but it contains contributions by others. See
8 # CONTRIBUTING.rst for a full list of people who may hold copyright, and
9 # consult the git log if you need to determine who owns an individual
10 # contribution.
11 #
12 # This Source Code Form is subject to the terms of the Mozilla Public License,
13 # v. 2.0. If a copy of the MPL was not distributed with this file, You can
14 # obtain one at https://mozilla.org/MPL/2.0/.
15 #
16 # END HEADER
17
18 from __future__ import absolute_import, division, print_function
19
20 from collections import OrderedDict
21
22 import hypothesis.internal.conjecture.utils as cu
23 from hypothesis.errors import InvalidArgument
24 from hypothesis.internal.conjecture.junkdrawer import LazySequenceCopy
25 from hypothesis.internal.conjecture.utils import combine_labels
26 from hypothesis.searchstrategy.strategies import (
27 MappedSearchStrategy,
28 SearchStrategy,
29 filter_not_satisfied,
30 )
31
32
33 class TupleStrategy(SearchStrategy):
34 """A strategy responsible for fixed length tuples based on heterogenous
35 strategies for each of their elements."""
36
37 def __init__(self, strategies):
38 SearchStrategy.__init__(self)
39 self.element_strategies = tuple(strategies)
40
41 def do_validate(self):
42 for s in self.element_strategies:
43 s.validate()
44
45 def calc_label(self):
46 return combine_labels(
47 self.class_label, *[s.label for s in self.element_strategies]
48 )
49
50 def __repr__(self):
51 if len(self.element_strategies) == 1:
52 tuple_string = "%s," % (repr(self.element_strategies[0]),)
53 else:
54 tuple_string = ", ".join(map(repr, self.element_strategies))
55 return "TupleStrategy((%s))" % (tuple_string,)
56
57 def calc_has_reusable_values(self, recur):
58 return all(recur(e) for e in self.element_strategies)
59
60 def do_draw(self, data):
61 return tuple(data.draw(e) for e in self.element_strategies)
62
63 def calc_is_empty(self, recur):
64 return any(recur(e) for e in self.element_strategies)
65
66
67 class ListStrategy(SearchStrategy):
68 """A strategy for lists which takes a strategy for its elements and the
69 allowed lengths, and generates lists with the correct size and contents."""
70
71 def __init__(self, elements, min_size=0, max_size=float("inf")):
72 SearchStrategy.__init__(self)
73 self.min_size = min_size or 0
74 self.max_size = max_size if max_size is not None else float("inf")
75 assert 0 <= self.min_size <= self.max_size
76 self.average_size = min(
77 max(self.min_size * 2, self.min_size + 5),
78 0.5 * (self.min_size + self.max_size),
79 )
80 self.element_strategy = elements
81
82 def calc_label(self):
83 return combine_labels(self.class_label, self.element_strategy.label)
84
85 def do_validate(self):
86 self.element_strategy.validate()
87 if self.is_empty:
88 raise InvalidArgument(
89 (
90 "Cannot create non-empty lists with elements drawn from "
91 "strategy %r because it has no values."
92 )
93 % (self.element_strategy,)
94 )
95 if self.element_strategy.is_empty and 0 < self.max_size < float("inf"):
96 raise InvalidArgument(
97 "Cannot create a collection of max_size=%r, because no "
98 "elements can be drawn from the element strategy %r"
99 % (self.max_size, self.element_strategy)
100 )
101
102 def calc_is_empty(self, recur):
103 if self.min_size == 0:
104 return False
105 else:
106 return recur(self.element_strategy)
107
108 def do_draw(self, data):
109 if self.element_strategy.is_empty:
110 assert self.min_size == 0
111 return []
112
113 elements = cu.many(
114 data,
115 min_size=self.min_size,
116 max_size=self.max_size,
117 average_size=self.average_size,
118 )
119 result = []
120 while elements.more():
121 result.append(data.draw(self.element_strategy))
122 return result
123
124 def __repr__(self):
125 return "%s(%r, min_size=%r, max_size=%r)" % (
126 self.__class__.__name__,
127 self.element_strategy,
128 self.min_size,
129 self.max_size,
130 )
131
132
133 class UniqueListStrategy(ListStrategy):
134 def __init__(self, elements, min_size, max_size, keys):
135 super(UniqueListStrategy, self).__init__(elements, min_size, max_size)
136 self.keys = keys
137
138 def do_draw(self, data):
139 if self.element_strategy.is_empty:
140 assert self.min_size == 0
141 return []
142
143 elements = cu.many(
144 data,
145 min_size=self.min_size,
146 max_size=self.max_size,
147 average_size=self.average_size,
148 )
149 seen_sets = tuple(set() for _ in self.keys)
150 result = []
151
152 # We construct a filtered strategy here rather than using a check-and-reject
153 # approach because some strategies have special logic for generation under a
154 # filter, and FilteredStrategy can consolidate multiple filters.
155 filtered = self.element_strategy.filter(
156 lambda val: all(
157 key(val) not in seen for (key, seen) in zip(self.keys, seen_sets)
158 )
159 )
160 while elements.more():
161 value = filtered.filtered_strategy.do_filtered_draw(
162 data=data, filter_strategy=filtered
163 )
164 if value is filter_not_satisfied:
165 elements.reject()
166 else:
167 for key, seen in zip(self.keys, seen_sets):
168 seen.add(key(value))
169 result.append(value)
170 assert self.max_size >= len(result) >= self.min_size
171 return result
172
173
174 class UniqueSampledListStrategy(ListStrategy):
175 def __init__(self, elements, min_size, max_size, keys):
176 super(UniqueSampledListStrategy, self).__init__(elements, min_size, max_size)
177 self.keys = keys
178
179 def do_draw(self, data):
180 should_draw = cu.many(
181 data,
182 min_size=self.min_size,
183 max_size=self.max_size,
184 average_size=self.average_size,
185 )
186 seen_sets = tuple(set() for _ in self.keys)
187 result = []
188
189 remaining = LazySequenceCopy(self.element_strategy.elements)
190
191 while should_draw.more():
192 i = len(remaining) - 1
193 j = cu.integer_range(data, 0, i)
194 if j != i:
195 remaining[i], remaining[j] = remaining[j], remaining[i]
196 value = remaining.pop()
197
198 if all(key(value) not in seen for (key, seen) in zip(self.keys, seen_sets)):
199 for key, seen in zip(self.keys, seen_sets):
200 seen.add(key(value))
201 result.append(value)
202 else:
203 should_draw.reject()
204 assert self.max_size >= len(result) >= self.min_size
205 return result
206
207
208 class FixedKeysDictStrategy(MappedSearchStrategy):
209 """A strategy which produces dicts with a fixed set of keys, given a
210 strategy for each of their equivalent values.
211
212 e.g. {'foo' : some_int_strategy} would generate dicts with the single
213 key 'foo' mapping to some integer.
214 """
215
216 def __init__(self, strategy_dict):
217 self.dict_type = type(strategy_dict)
218
219 if isinstance(strategy_dict, OrderedDict):
220 self.keys = tuple(strategy_dict.keys())
221 else:
222 try:
223 self.keys = tuple(sorted(strategy_dict.keys()))
224 except TypeError:
225 self.keys = tuple(sorted(strategy_dict.keys(), key=repr))
226 super(FixedKeysDictStrategy, self).__init__(
227 strategy=TupleStrategy(strategy_dict[k] for k in self.keys)
228 )
229
230 def calc_is_empty(self, recur):
231 return recur(self.mapped_strategy)
232
233 def __repr__(self):
234 return "FixedKeysDictStrategy(%r, %r)" % (self.keys, self.mapped_strategy)
235
236 def pack(self, value):
237 return self.dict_type(zip(self.keys, value))
238
239
240 class FixedAndOptionalKeysDictStrategy(SearchStrategy):
241 """A strategy which produces dicts with a fixed set of keys, given a
242 strategy for each of their equivalent values.
243
244 e.g. {'foo' : some_int_strategy} would generate dicts with the single
245 key 'foo' mapping to some integer.
246 """
247
248 def __init__(self, strategy_dict, optional):
249 self.required = strategy_dict
250 self.fixed = FixedKeysDictStrategy(strategy_dict)
251 self.optional = optional
252
253 if isinstance(self.optional, OrderedDict):
254 self.optional_keys = tuple(self.optional.keys())
255 else:
256 try:
257 self.optional_keys = tuple(sorted(self.optional.keys()))
258 except TypeError:
259 self.optional_keys = tuple(sorted(self.optional.keys(), key=repr))
260
261 def calc_is_empty(self, recur):
262 return recur(self.fixed)
263
264 def __repr__(self):
265 return "FixedAndOptionalKeysDictStrategy(%r, %r)" % (
266 self.required,
267 self.optional,
268 )
269
270 def do_draw(self, data):
271 result = data.draw(self.fixed)
272 remaining = [k for k in self.optional_keys if not self.optional[k].is_empty]
273 should_draw = cu.many(
274 data, min_size=0, max_size=len(remaining), average_size=len(remaining) / 2
275 )
276 while should_draw.more():
277 j = cu.integer_range(data, 0, len(remaining) - 1)
278 remaining[-1], remaining[j] = remaining[j], remaining[-1]
279 key = remaining.pop()
280 result[key] = data.draw(self.optional[key])
281 return result
282
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/hypothesis-python/src/hypothesis/searchstrategy/collections.py b/hypothesis-python/src/hypothesis/searchstrategy/collections.py
--- a/hypothesis-python/src/hypothesis/searchstrategy/collections.py
+++ b/hypothesis-python/src/hypothesis/searchstrategy/collections.py
@@ -188,7 +188,7 @@
remaining = LazySequenceCopy(self.element_strategy.elements)
- while should_draw.more():
+ while remaining and should_draw.more():
i = len(remaining) - 1
j = cu.integer_range(data, 0, i)
if j != i:
|
{"golden_diff": "diff --git a/hypothesis-python/src/hypothesis/searchstrategy/collections.py b/hypothesis-python/src/hypothesis/searchstrategy/collections.py\n--- a/hypothesis-python/src/hypothesis/searchstrategy/collections.py\n+++ b/hypothesis-python/src/hypothesis/searchstrategy/collections.py\n@@ -188,7 +188,7 @@\n \n remaining = LazySequenceCopy(self.element_strategy.elements)\n \n- while should_draw.more():\n+ while remaining and should_draw.more():\n i = len(remaining) - 1\n j = cu.integer_range(data, 0, i)\n if j != i:\n", "issue": "Internal error for unique lists\n```python\r\nfrom hypothesis import given, strategies as st\r\n\r\n@given(st.lists(st.sampled_from([0, 0.0]), unique=True, min_size=1))\r\ndef t(x): pass\r\n\r\nt()\r\n```\r\n\r\ntriggers an assertion via `conjecture.utils.integer_range(data, lower=0, upper=-1)`\n", "before_files": [{"content": "# coding=utf-8\n#\n# This file is part of Hypothesis, which may be found at\n# https://github.com/HypothesisWorks/hypothesis/\n#\n# Most of this work is copyright (C) 2013-2019 David R. MacIver\n# ([email protected]), but it contains contributions by others. See\n# CONTRIBUTING.rst for a full list of people who may hold copyright, and\n# consult the git log if you need to determine who owns an individual\n# contribution.\n#\n# This Source Code Form is subject to the terms of the Mozilla Public License,\n# v. 2.0. If a copy of the MPL was not distributed with this file, You can\n# obtain one at https://mozilla.org/MPL/2.0/.\n#\n# END HEADER\n\nfrom __future__ import absolute_import, division, print_function\n\nfrom collections import OrderedDict\n\nimport hypothesis.internal.conjecture.utils as cu\nfrom hypothesis.errors import InvalidArgument\nfrom hypothesis.internal.conjecture.junkdrawer import LazySequenceCopy\nfrom hypothesis.internal.conjecture.utils import combine_labels\nfrom hypothesis.searchstrategy.strategies import (\n MappedSearchStrategy,\n SearchStrategy,\n filter_not_satisfied,\n)\n\n\nclass TupleStrategy(SearchStrategy):\n \"\"\"A strategy responsible for fixed length tuples based on heterogenous\n strategies for each of their elements.\"\"\"\n\n def __init__(self, strategies):\n SearchStrategy.__init__(self)\n self.element_strategies = tuple(strategies)\n\n def do_validate(self):\n for s in self.element_strategies:\n s.validate()\n\n def calc_label(self):\n return combine_labels(\n self.class_label, *[s.label for s in self.element_strategies]\n )\n\n def __repr__(self):\n if len(self.element_strategies) == 1:\n tuple_string = \"%s,\" % (repr(self.element_strategies[0]),)\n else:\n tuple_string = \", \".join(map(repr, self.element_strategies))\n return \"TupleStrategy((%s))\" % (tuple_string,)\n\n def calc_has_reusable_values(self, recur):\n return all(recur(e) for e in self.element_strategies)\n\n def do_draw(self, data):\n return tuple(data.draw(e) for e in self.element_strategies)\n\n def calc_is_empty(self, recur):\n return any(recur(e) for e in self.element_strategies)\n\n\nclass ListStrategy(SearchStrategy):\n \"\"\"A strategy for lists which takes a strategy for its elements and the\n allowed lengths, and generates lists with the correct size and contents.\"\"\"\n\n def __init__(self, elements, min_size=0, max_size=float(\"inf\")):\n SearchStrategy.__init__(self)\n self.min_size = min_size or 0\n self.max_size = max_size if max_size is not None else float(\"inf\")\n assert 0 <= self.min_size <= self.max_size\n self.average_size = min(\n max(self.min_size * 2, self.min_size + 5),\n 0.5 * (self.min_size + self.max_size),\n )\n self.element_strategy = elements\n\n def calc_label(self):\n return combine_labels(self.class_label, self.element_strategy.label)\n\n def do_validate(self):\n self.element_strategy.validate()\n if self.is_empty:\n raise InvalidArgument(\n (\n \"Cannot create non-empty lists with elements drawn from \"\n \"strategy %r because it has no values.\"\n )\n % (self.element_strategy,)\n )\n if self.element_strategy.is_empty and 0 < self.max_size < float(\"inf\"):\n raise InvalidArgument(\n \"Cannot create a collection of max_size=%r, because no \"\n \"elements can be drawn from the element strategy %r\"\n % (self.max_size, self.element_strategy)\n )\n\n def calc_is_empty(self, recur):\n if self.min_size == 0:\n return False\n else:\n return recur(self.element_strategy)\n\n def do_draw(self, data):\n if self.element_strategy.is_empty:\n assert self.min_size == 0\n return []\n\n elements = cu.many(\n data,\n min_size=self.min_size,\n max_size=self.max_size,\n average_size=self.average_size,\n )\n result = []\n while elements.more():\n result.append(data.draw(self.element_strategy))\n return result\n\n def __repr__(self):\n return \"%s(%r, min_size=%r, max_size=%r)\" % (\n self.__class__.__name__,\n self.element_strategy,\n self.min_size,\n self.max_size,\n )\n\n\nclass UniqueListStrategy(ListStrategy):\n def __init__(self, elements, min_size, max_size, keys):\n super(UniqueListStrategy, self).__init__(elements, min_size, max_size)\n self.keys = keys\n\n def do_draw(self, data):\n if self.element_strategy.is_empty:\n assert self.min_size == 0\n return []\n\n elements = cu.many(\n data,\n min_size=self.min_size,\n max_size=self.max_size,\n average_size=self.average_size,\n )\n seen_sets = tuple(set() for _ in self.keys)\n result = []\n\n # We construct a filtered strategy here rather than using a check-and-reject\n # approach because some strategies have special logic for generation under a\n # filter, and FilteredStrategy can consolidate multiple filters.\n filtered = self.element_strategy.filter(\n lambda val: all(\n key(val) not in seen for (key, seen) in zip(self.keys, seen_sets)\n )\n )\n while elements.more():\n value = filtered.filtered_strategy.do_filtered_draw(\n data=data, filter_strategy=filtered\n )\n if value is filter_not_satisfied:\n elements.reject()\n else:\n for key, seen in zip(self.keys, seen_sets):\n seen.add(key(value))\n result.append(value)\n assert self.max_size >= len(result) >= self.min_size\n return result\n\n\nclass UniqueSampledListStrategy(ListStrategy):\n def __init__(self, elements, min_size, max_size, keys):\n super(UniqueSampledListStrategy, self).__init__(elements, min_size, max_size)\n self.keys = keys\n\n def do_draw(self, data):\n should_draw = cu.many(\n data,\n min_size=self.min_size,\n max_size=self.max_size,\n average_size=self.average_size,\n )\n seen_sets = tuple(set() for _ in self.keys)\n result = []\n\n remaining = LazySequenceCopy(self.element_strategy.elements)\n\n while should_draw.more():\n i = len(remaining) - 1\n j = cu.integer_range(data, 0, i)\n if j != i:\n remaining[i], remaining[j] = remaining[j], remaining[i]\n value = remaining.pop()\n\n if all(key(value) not in seen for (key, seen) in zip(self.keys, seen_sets)):\n for key, seen in zip(self.keys, seen_sets):\n seen.add(key(value))\n result.append(value)\n else:\n should_draw.reject()\n assert self.max_size >= len(result) >= self.min_size\n return result\n\n\nclass FixedKeysDictStrategy(MappedSearchStrategy):\n \"\"\"A strategy which produces dicts with a fixed set of keys, given a\n strategy for each of their equivalent values.\n\n e.g. {'foo' : some_int_strategy} would generate dicts with the single\n key 'foo' mapping to some integer.\n \"\"\"\n\n def __init__(self, strategy_dict):\n self.dict_type = type(strategy_dict)\n\n if isinstance(strategy_dict, OrderedDict):\n self.keys = tuple(strategy_dict.keys())\n else:\n try:\n self.keys = tuple(sorted(strategy_dict.keys()))\n except TypeError:\n self.keys = tuple(sorted(strategy_dict.keys(), key=repr))\n super(FixedKeysDictStrategy, self).__init__(\n strategy=TupleStrategy(strategy_dict[k] for k in self.keys)\n )\n\n def calc_is_empty(self, recur):\n return recur(self.mapped_strategy)\n\n def __repr__(self):\n return \"FixedKeysDictStrategy(%r, %r)\" % (self.keys, self.mapped_strategy)\n\n def pack(self, value):\n return self.dict_type(zip(self.keys, value))\n\n\nclass FixedAndOptionalKeysDictStrategy(SearchStrategy):\n \"\"\"A strategy which produces dicts with a fixed set of keys, given a\n strategy for each of their equivalent values.\n\n e.g. {'foo' : some_int_strategy} would generate dicts with the single\n key 'foo' mapping to some integer.\n \"\"\"\n\n def __init__(self, strategy_dict, optional):\n self.required = strategy_dict\n self.fixed = FixedKeysDictStrategy(strategy_dict)\n self.optional = optional\n\n if isinstance(self.optional, OrderedDict):\n self.optional_keys = tuple(self.optional.keys())\n else:\n try:\n self.optional_keys = tuple(sorted(self.optional.keys()))\n except TypeError:\n self.optional_keys = tuple(sorted(self.optional.keys(), key=repr))\n\n def calc_is_empty(self, recur):\n return recur(self.fixed)\n\n def __repr__(self):\n return \"FixedAndOptionalKeysDictStrategy(%r, %r)\" % (\n self.required,\n self.optional,\n )\n\n def do_draw(self, data):\n result = data.draw(self.fixed)\n remaining = [k for k in self.optional_keys if not self.optional[k].is_empty]\n should_draw = cu.many(\n data, min_size=0, max_size=len(remaining), average_size=len(remaining) / 2\n )\n while should_draw.more():\n j = cu.integer_range(data, 0, len(remaining) - 1)\n remaining[-1], remaining[j] = remaining[j], remaining[-1]\n key = remaining.pop()\n result[key] = data.draw(self.optional[key])\n return result\n", "path": "hypothesis-python/src/hypothesis/searchstrategy/collections.py"}], "after_files": [{"content": "# coding=utf-8\n#\n# This file is part of Hypothesis, which may be found at\n# https://github.com/HypothesisWorks/hypothesis/\n#\n# Most of this work is copyright (C) 2013-2019 David R. MacIver\n# ([email protected]), but it contains contributions by others. See\n# CONTRIBUTING.rst for a full list of people who may hold copyright, and\n# consult the git log if you need to determine who owns an individual\n# contribution.\n#\n# This Source Code Form is subject to the terms of the Mozilla Public License,\n# v. 2.0. If a copy of the MPL was not distributed with this file, You can\n# obtain one at https://mozilla.org/MPL/2.0/.\n#\n# END HEADER\n\nfrom __future__ import absolute_import, division, print_function\n\nfrom collections import OrderedDict\n\nimport hypothesis.internal.conjecture.utils as cu\nfrom hypothesis.errors import InvalidArgument\nfrom hypothesis.internal.conjecture.junkdrawer import LazySequenceCopy\nfrom hypothesis.internal.conjecture.utils import combine_labels\nfrom hypothesis.searchstrategy.strategies import (\n MappedSearchStrategy,\n SearchStrategy,\n filter_not_satisfied,\n)\n\n\nclass TupleStrategy(SearchStrategy):\n \"\"\"A strategy responsible for fixed length tuples based on heterogenous\n strategies for each of their elements.\"\"\"\n\n def __init__(self, strategies):\n SearchStrategy.__init__(self)\n self.element_strategies = tuple(strategies)\n\n def do_validate(self):\n for s in self.element_strategies:\n s.validate()\n\n def calc_label(self):\n return combine_labels(\n self.class_label, *[s.label for s in self.element_strategies]\n )\n\n def __repr__(self):\n if len(self.element_strategies) == 1:\n tuple_string = \"%s,\" % (repr(self.element_strategies[0]),)\n else:\n tuple_string = \", \".join(map(repr, self.element_strategies))\n return \"TupleStrategy((%s))\" % (tuple_string,)\n\n def calc_has_reusable_values(self, recur):\n return all(recur(e) for e in self.element_strategies)\n\n def do_draw(self, data):\n return tuple(data.draw(e) for e in self.element_strategies)\n\n def calc_is_empty(self, recur):\n return any(recur(e) for e in self.element_strategies)\n\n\nclass ListStrategy(SearchStrategy):\n \"\"\"A strategy for lists which takes a strategy for its elements and the\n allowed lengths, and generates lists with the correct size and contents.\"\"\"\n\n def __init__(self, elements, min_size=0, max_size=float(\"inf\")):\n SearchStrategy.__init__(self)\n self.min_size = min_size or 0\n self.max_size = max_size if max_size is not None else float(\"inf\")\n assert 0 <= self.min_size <= self.max_size\n self.average_size = min(\n max(self.min_size * 2, self.min_size + 5),\n 0.5 * (self.min_size + self.max_size),\n )\n self.element_strategy = elements\n\n def calc_label(self):\n return combine_labels(self.class_label, self.element_strategy.label)\n\n def do_validate(self):\n self.element_strategy.validate()\n if self.is_empty:\n raise InvalidArgument(\n (\n \"Cannot create non-empty lists with elements drawn from \"\n \"strategy %r because it has no values.\"\n )\n % (self.element_strategy,)\n )\n if self.element_strategy.is_empty and 0 < self.max_size < float(\"inf\"):\n raise InvalidArgument(\n \"Cannot create a collection of max_size=%r, because no \"\n \"elements can be drawn from the element strategy %r\"\n % (self.max_size, self.element_strategy)\n )\n\n def calc_is_empty(self, recur):\n if self.min_size == 0:\n return False\n else:\n return recur(self.element_strategy)\n\n def do_draw(self, data):\n if self.element_strategy.is_empty:\n assert self.min_size == 0\n return []\n\n elements = cu.many(\n data,\n min_size=self.min_size,\n max_size=self.max_size,\n average_size=self.average_size,\n )\n result = []\n while elements.more():\n result.append(data.draw(self.element_strategy))\n return result\n\n def __repr__(self):\n return \"%s(%r, min_size=%r, max_size=%r)\" % (\n self.__class__.__name__,\n self.element_strategy,\n self.min_size,\n self.max_size,\n )\n\n\nclass UniqueListStrategy(ListStrategy):\n def __init__(self, elements, min_size, max_size, keys):\n super(UniqueListStrategy, self).__init__(elements, min_size, max_size)\n self.keys = keys\n\n def do_draw(self, data):\n if self.element_strategy.is_empty:\n assert self.min_size == 0\n return []\n\n elements = cu.many(\n data,\n min_size=self.min_size,\n max_size=self.max_size,\n average_size=self.average_size,\n )\n seen_sets = tuple(set() for _ in self.keys)\n result = []\n\n # We construct a filtered strategy here rather than using a check-and-reject\n # approach because some strategies have special logic for generation under a\n # filter, and FilteredStrategy can consolidate multiple filters.\n filtered = self.element_strategy.filter(\n lambda val: all(\n key(val) not in seen for (key, seen) in zip(self.keys, seen_sets)\n )\n )\n while elements.more():\n value = filtered.filtered_strategy.do_filtered_draw(\n data=data, filter_strategy=filtered\n )\n if value is filter_not_satisfied:\n elements.reject()\n else:\n for key, seen in zip(self.keys, seen_sets):\n seen.add(key(value))\n result.append(value)\n assert self.max_size >= len(result) >= self.min_size\n return result\n\n\nclass UniqueSampledListStrategy(ListStrategy):\n def __init__(self, elements, min_size, max_size, keys):\n super(UniqueSampledListStrategy, self).__init__(elements, min_size, max_size)\n self.keys = keys\n\n def do_draw(self, data):\n should_draw = cu.many(\n data,\n min_size=self.min_size,\n max_size=self.max_size,\n average_size=self.average_size,\n )\n seen_sets = tuple(set() for _ in self.keys)\n result = []\n\n remaining = LazySequenceCopy(self.element_strategy.elements)\n\n while remaining and should_draw.more():\n i = len(remaining) - 1\n j = cu.integer_range(data, 0, i)\n if j != i:\n remaining[i], remaining[j] = remaining[j], remaining[i]\n value = remaining.pop()\n\n if all(key(value) not in seen for (key, seen) in zip(self.keys, seen_sets)):\n for key, seen in zip(self.keys, seen_sets):\n seen.add(key(value))\n result.append(value)\n else:\n should_draw.reject()\n assert self.max_size >= len(result) >= self.min_size\n return result\n\n\nclass FixedKeysDictStrategy(MappedSearchStrategy):\n \"\"\"A strategy which produces dicts with a fixed set of keys, given a\n strategy for each of their equivalent values.\n\n e.g. {'foo' : some_int_strategy} would generate dicts with the single\n key 'foo' mapping to some integer.\n \"\"\"\n\n def __init__(self, strategy_dict):\n self.dict_type = type(strategy_dict)\n\n if isinstance(strategy_dict, OrderedDict):\n self.keys = tuple(strategy_dict.keys())\n else:\n try:\n self.keys = tuple(sorted(strategy_dict.keys()))\n except TypeError:\n self.keys = tuple(sorted(strategy_dict.keys(), key=repr))\n super(FixedKeysDictStrategy, self).__init__(\n strategy=TupleStrategy(strategy_dict[k] for k in self.keys)\n )\n\n def calc_is_empty(self, recur):\n return recur(self.mapped_strategy)\n\n def __repr__(self):\n return \"FixedKeysDictStrategy(%r, %r)\" % (self.keys, self.mapped_strategy)\n\n def pack(self, value):\n return self.dict_type(zip(self.keys, value))\n\n\nclass FixedAndOptionalKeysDictStrategy(SearchStrategy):\n \"\"\"A strategy which produces dicts with a fixed set of keys, given a\n strategy for each of their equivalent values.\n\n e.g. {'foo' : some_int_strategy} would generate dicts with the single\n key 'foo' mapping to some integer.\n \"\"\"\n\n def __init__(self, strategy_dict, optional):\n self.required = strategy_dict\n self.fixed = FixedKeysDictStrategy(strategy_dict)\n self.optional = optional\n\n if isinstance(self.optional, OrderedDict):\n self.optional_keys = tuple(self.optional.keys())\n else:\n try:\n self.optional_keys = tuple(sorted(self.optional.keys()))\n except TypeError:\n self.optional_keys = tuple(sorted(self.optional.keys(), key=repr))\n\n def calc_is_empty(self, recur):\n return recur(self.fixed)\n\n def __repr__(self):\n return \"FixedAndOptionalKeysDictStrategy(%r, %r)\" % (\n self.required,\n self.optional,\n )\n\n def do_draw(self, data):\n result = data.draw(self.fixed)\n remaining = [k for k in self.optional_keys if not self.optional[k].is_empty]\n should_draw = cu.many(\n data, min_size=0, max_size=len(remaining), average_size=len(remaining) / 2\n )\n while should_draw.more():\n j = cu.integer_range(data, 0, len(remaining) - 1)\n remaining[-1], remaining[j] = remaining[j], remaining[-1]\n key = remaining.pop()\n result[key] = data.draw(self.optional[key])\n return result\n", "path": "hypothesis-python/src/hypothesis/searchstrategy/collections.py"}]}
| 3,216 | 137 |
gh_patches_debug_20209
|
rasdani/github-patches
|
git_diff
|
OpenCTI-Platform__connectors-672
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Import Document] Connector does not process MD files
## Description
The Import Document connector currently supports plain/text media type, however files with the `.md` file extension are not recognized as a valid document.
## Environment
1. OS (where OpenCTI server runs): AWS ECS Fargate
2. OpenCTI version: 5.1.4
3. OpenCTI client: python
4. Other environment details:
## Reproducible Steps
Steps to create the smallest reproducible scenario:
1. Run the Import External Reference connector to get a .md file OR just upload a .md file to the platform
2. Try to run an enrichment on the .md file
## Expected Output
I would expect that the Import connector would or could import a file, regardless of the file name.
## Actual Output
There is no Output as the connector/platform doesn't recognize the .md file. Only work around is to download the file, rename to a .txt file extension, and upload to the platform.
## Screenshots (optional)
<img width="1483" alt="Screen Shot 2022-04-28 at 9 24 53 AM" src="https://user-images.githubusercontent.com/30411037/165775435-87f694cf-ada9-439f-9cf7-246228283d80.png">
<img width="753" alt="Screen Shot 2022-04-28 at 9 24 20 AM" src="https://user-images.githubusercontent.com/30411037/165775444-fa1ade88-51f8-45a1-9fd8-f1d14002d903.png">
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `internal-import-file/import-document/src/reportimporter/report_parser.py`
Content:
```
1 import logging
2 import os
3 import io
4 from typing import Dict, List, Pattern, IO, Tuple
5
6 import ioc_finder
7 from bs4 import BeautifulSoup
8 from pdfminer.high_level import extract_pages
9 from pdfminer.layout import LTTextContainer
10 from pycti import OpenCTIConnectorHelper
11 from reportimporter.constants import (
12 OBSERVABLE_CLASS,
13 ENTITY_CLASS,
14 RESULT_FORMAT_MATCH,
15 RESULT_FORMAT_TYPE,
16 RESULT_FORMAT_CATEGORY,
17 RESULT_FORMAT_RANGE,
18 MIME_PDF,
19 MIME_TXT,
20 MIME_HTML,
21 MIME_CSV,
22 OBSERVABLE_DETECTION_CUSTOM_REGEX,
23 OBSERVABLE_DETECTION_LIBRARY,
24 )
25 from reportimporter.models import Observable, Entity
26 from reportimporter.util import library_mapping
27
28
29 class ReportParser(object):
30 """
31 Report parser based on IOCParser
32 """
33
34 def __init__(
35 self,
36 helper: OpenCTIConnectorHelper,
37 entity_list: List[Entity],
38 observable_list: List[Observable],
39 ):
40
41 self.helper = helper
42 self.entity_list = entity_list
43 self.observable_list = observable_list
44
45 # Disable INFO logging by pdfminer
46 logging.getLogger("pdfminer").setLevel(logging.WARNING)
47
48 # Supported file types
49 self.supported_file_types = {
50 MIME_PDF: self._parse_pdf,
51 MIME_TXT: self._parse_text,
52 MIME_HTML: self._parse_html,
53 MIME_CSV: self._parse_text,
54 }
55
56 self.library_lookup = library_mapping()
57
58 def _is_whitelisted(self, regex_list: List[Pattern], ind_match: str):
59 for regex in regex_list:
60 self.helper.log_debug(f"Filter regex '{regex}' for value '{ind_match}'")
61 result = regex.search(ind_match)
62 if result:
63 self.helper.log_debug(f"Value {ind_match} is whitelisted with {regex}")
64 return True
65 return False
66
67 def _post_parse_observables(
68 self, ind_match: str, observable: Observable, match_range: Tuple
69 ) -> Dict:
70 self.helper.log_debug(f"Observable match: {ind_match}")
71
72 if self._is_whitelisted(observable.filter_regex, ind_match):
73 return {}
74
75 return self._format_match(
76 OBSERVABLE_CLASS, observable.stix_target, ind_match, match_range
77 )
78
79 def _parse(self, data: str) -> Dict[str, Dict]:
80 list_matches = {}
81
82 # Defang text
83 data = ioc_finder.prepare_text(data)
84
85 for observable in self.observable_list:
86 list_matches.update(self._extract_observable(observable, data))
87
88 for entity in self.entity_list:
89 list_matches = self._extract_entity(entity, list_matches, data)
90
91 self.helper.log_debug(f"Text: '{data}' -> extracts {list_matches}")
92 return list_matches
93
94 def _parse_pdf(self, file_data: IO) -> Dict[str, Dict]:
95 parse_info = {}
96 try:
97 for page_layout in extract_pages(file_data):
98 for element in page_layout:
99 if isinstance(element, LTTextContainer):
100 text = element.get_text()
101 # Parsing with newlines has been deprecated
102 no_newline_text = text.replace("\n", "")
103 parse_info.update(self._parse(no_newline_text))
104
105 # TODO also extract information from images/figures using OCR
106 # https://pdfminersix.readthedocs.io/en/latest/topic/converting_pdf_to_text.html#topic-pdf-to-text-layout
107
108 except Exception as e:
109 logging.exception(f"Pdf Parsing Error: {e}")
110
111 return parse_info
112
113 def _parse_text(self, file_data: IO) -> Dict[str, Dict]:
114 parse_info = {}
115 for text in file_data.readlines():
116 parse_info.update(self._parse(text.decode("utf-8")))
117 return parse_info
118
119 def _parse_html(self, file_data: IO) -> Dict[str, Dict]:
120 parse_info = {}
121 soup = BeautifulSoup(file_data, "html.parser")
122 buf = io.StringIO(soup.get_text())
123 for text in buf.readlines():
124 parse_info.update(self._parse(text))
125 return parse_info
126
127 def run_parser(self, file_path: str, file_type: str) -> List[Dict]:
128 parsing_results = []
129
130 file_parser = self.supported_file_types.get(file_type, None)
131 if not file_parser:
132 raise NotImplementedError(f"No parser available for file type {file_type}")
133
134 if not os.path.isfile(file_path):
135 raise IOError(f"File path is not a file: {file_path}")
136
137 self.helper.log_info(f"Parsing report {file_path} {file_type}")
138
139 try:
140 with open(file_path, "rb") as file_data:
141 parsing_results = file_parser(file_data)
142 except Exception as e:
143 logging.exception(f"Parsing Error: {e}")
144
145 parsing_results = list(parsing_results.values())
146
147 return parsing_results
148
149 @staticmethod
150 def _format_match(
151 format_type: str, category: str, match: str, match_range: Tuple = (0, 0)
152 ) -> Dict:
153 return {
154 RESULT_FORMAT_TYPE: format_type,
155 RESULT_FORMAT_CATEGORY: category,
156 RESULT_FORMAT_MATCH: match,
157 RESULT_FORMAT_RANGE: match_range,
158 }
159
160 @staticmethod
161 def _sco_present(
162 match_list: Dict, entity_range: Tuple, filter_sco_types: List
163 ) -> str:
164 for match_name, match_info in match_list.items():
165 if match_info[RESULT_FORMAT_CATEGORY] in filter_sco_types:
166 if (
167 match_info[RESULT_FORMAT_RANGE][0] <= entity_range[0]
168 and entity_range[1] <= match_info[RESULT_FORMAT_RANGE][1]
169 ):
170 return match_name
171
172 return ""
173
174 def _extract_observable(self, observable: Observable, data: str) -> Dict:
175 list_matches = {}
176 if observable.detection_option == OBSERVABLE_DETECTION_CUSTOM_REGEX:
177 for regex in observable.regex:
178 for match in regex.finditer(data):
179 match_value = match.group()
180
181 ind_match = self._post_parse_observables(
182 match_value, observable, match.span()
183 )
184 if ind_match:
185 list_matches[match.group()] = ind_match
186
187 elif observable.detection_option == OBSERVABLE_DETECTION_LIBRARY:
188 lookup_function = self.library_lookup.get(observable.stix_target, None)
189 if not lookup_function:
190 self.helper.log_error(
191 f"Selected library function is not implemented: {observable.iocfinder_function}"
192 )
193 return {}
194
195 matches = lookup_function(data)
196
197 for match in matches:
198 match_str = str(match)
199 if match_str in data:
200 start = data.index(match_str)
201 elif match_str in data.lower():
202 self.helper.log_debug(
203 f"External library manipulated the extracted value '{match_str}' from the "
204 f"original text '{data}' to lower case"
205 )
206 start = data.lower().index(match_str)
207 else:
208 self.helper.log_error(
209 f"The extracted text '{match_str}' is not part of the original text '{data}'. "
210 f"Please open a GitHub issue to report this problem!"
211 )
212 continue
213
214 ind_match = self._post_parse_observables(
215 match, observable, (start, len(match_str) + start)
216 )
217 if ind_match:
218 list_matches[match] = ind_match
219
220 return list_matches
221
222 def _extract_entity(self, entity: Entity, list_matches: Dict, data: str) -> Dict:
223 regex_list = entity.regex
224
225 observable_keys = []
226 end_index = set()
227 match_dict = {}
228 match_key = ""
229
230 # Run all regexes for entity X
231 for regex in regex_list:
232 for match in regex.finditer(data):
233 match_key = match.group()
234 if match_key in match_dict:
235 match_dict[match_key].append(match.span())
236 else:
237 match_dict[match_key] = [match.span()]
238
239 # No maches for this entity
240 if len(match_dict) == 0:
241 return list_matches
242
243 # Run through all matches for entity X and check if they are part of a domain
244 # yes -> skip
245 # no -> add index to end_index
246 for match, match_indices in match_dict.items():
247 for match_index in match_indices:
248 skip_val = self._sco_present(
249 list_matches, match_index, entity.omit_match_in
250 )
251 if skip_val:
252 self.helper.log_debug(
253 f"Skipping Entity '{match}', it is part of an omitted field '{entity.omit_match_in}' \"{skip_val}\""
254 )
255 else:
256 self.helper.log_debug(
257 f"Entity match: '{match}' of regex: '{regex_list}'"
258 )
259 end_index.add(match_index)
260 if match in list_matches.keys():
261 observable_keys.append(match)
262
263 # Remove all observables which found the same information/Entity match
264 for observable_key in observable_keys:
265 if observable_key in list_matches:
266 del list_matches[observable_key]
267 self.helper.log_debug(
268 f"Value {observable_key} is also matched by entity {entity.name}"
269 )
270
271 # Check if entity was matched at least once in the text
272 # If yes, then add identity to match list
273 if end_index:
274 list_matches[match_key] = self._format_match(
275 ENTITY_CLASS, entity.name, entity.stix_id
276 )
277
278 return list_matches
279
```
Path: `internal-import-file/import-document/src/reportimporter/constants.py`
Content:
```
1 MIME_PDF = "application/pdf"
2 MIME_TXT = "text/plain"
3 MIME_HTML = "text/html"
4 MIME_CSV = "text/csv"
5
6 RESULT_FORMAT_TYPE = "type"
7 RESULT_FORMAT_CATEGORY = "category"
8 RESULT_FORMAT_MATCH = "match"
9 RESULT_FORMAT_RANGE = "range"
10
11 ENTITY_CLASS = "entity"
12 OBSERVABLE_CLASS = "observable"
13
14 CONFIG_PATH = "filter_list"
15 COMMENT_INDICATOR = "#"
16
17 OBSERVABLE_DETECTION_CUSTOM_REGEX = "custom_regex"
18 OBSERVABLE_DETECTION_LIBRARY = "library"
19 OBSERVABLE_DETECTION_OPTIONS = [
20 OBSERVABLE_DETECTION_LIBRARY,
21 OBSERVABLE_DETECTION_CUSTOM_REGEX,
22 ]
23
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/internal-import-file/import-document/src/reportimporter/constants.py b/internal-import-file/import-document/src/reportimporter/constants.py
--- a/internal-import-file/import-document/src/reportimporter/constants.py
+++ b/internal-import-file/import-document/src/reportimporter/constants.py
@@ -2,6 +2,7 @@
MIME_TXT = "text/plain"
MIME_HTML = "text/html"
MIME_CSV = "text/csv"
+MIME_MD = "text/markdown"
RESULT_FORMAT_TYPE = "type"
RESULT_FORMAT_CATEGORY = "category"
diff --git a/internal-import-file/import-document/src/reportimporter/report_parser.py b/internal-import-file/import-document/src/reportimporter/report_parser.py
--- a/internal-import-file/import-document/src/reportimporter/report_parser.py
+++ b/internal-import-file/import-document/src/reportimporter/report_parser.py
@@ -19,6 +19,7 @@
MIME_TXT,
MIME_HTML,
MIME_CSV,
+ MIME_MD,
OBSERVABLE_DETECTION_CUSTOM_REGEX,
OBSERVABLE_DETECTION_LIBRARY,
)
@@ -51,6 +52,7 @@
MIME_TXT: self._parse_text,
MIME_HTML: self._parse_html,
MIME_CSV: self._parse_text,
+ MIME_MD: self._parse_text,
}
self.library_lookup = library_mapping()
|
{"golden_diff": "diff --git a/internal-import-file/import-document/src/reportimporter/constants.py b/internal-import-file/import-document/src/reportimporter/constants.py\n--- a/internal-import-file/import-document/src/reportimporter/constants.py\n+++ b/internal-import-file/import-document/src/reportimporter/constants.py\n@@ -2,6 +2,7 @@\n MIME_TXT = \"text/plain\"\n MIME_HTML = \"text/html\"\n MIME_CSV = \"text/csv\"\n+MIME_MD = \"text/markdown\"\n \n RESULT_FORMAT_TYPE = \"type\"\n RESULT_FORMAT_CATEGORY = \"category\"\ndiff --git a/internal-import-file/import-document/src/reportimporter/report_parser.py b/internal-import-file/import-document/src/reportimporter/report_parser.py\n--- a/internal-import-file/import-document/src/reportimporter/report_parser.py\n+++ b/internal-import-file/import-document/src/reportimporter/report_parser.py\n@@ -19,6 +19,7 @@\n MIME_TXT,\n MIME_HTML,\n MIME_CSV,\n+ MIME_MD,\n OBSERVABLE_DETECTION_CUSTOM_REGEX,\n OBSERVABLE_DETECTION_LIBRARY,\n )\n@@ -51,6 +52,7 @@\n MIME_TXT: self._parse_text,\n MIME_HTML: self._parse_html,\n MIME_CSV: self._parse_text,\n+ MIME_MD: self._parse_text,\n }\n \n self.library_lookup = library_mapping()\n", "issue": "[Import Document] Connector does not process MD files\n## Description\r\n\r\nThe Import Document connector currently supports plain/text media type, however files with the `.md` file extension are not recognized as a valid document. \r\n\r\n## Environment\r\n\r\n1. OS (where OpenCTI server runs): AWS ECS Fargate\r\n2. OpenCTI version: 5.1.4\r\n3. OpenCTI client: python\r\n4. Other environment details:\r\n\r\n## Reproducible Steps\r\n\r\nSteps to create the smallest reproducible scenario:\r\n1. Run the Import External Reference connector to get a .md file OR just upload a .md file to the platform\r\n2. Try to run an enrichment on the .md file\r\n\r\n## Expected Output\r\n\r\nI would expect that the Import connector would or could import a file, regardless of the file name. \r\n\r\n## Actual Output\r\n\r\nThere is no Output as the connector/platform doesn't recognize the .md file. Only work around is to download the file, rename to a .txt file extension, and upload to the platform.\r\n \r\n## Screenshots (optional)\r\n<img width=\"1483\" alt=\"Screen Shot 2022-04-28 at 9 24 53 AM\" src=\"https://user-images.githubusercontent.com/30411037/165775435-87f694cf-ada9-439f-9cf7-246228283d80.png\">\r\n<img width=\"753\" alt=\"Screen Shot 2022-04-28 at 9 24 20 AM\" src=\"https://user-images.githubusercontent.com/30411037/165775444-fa1ade88-51f8-45a1-9fd8-f1d14002d903.png\">\r\n\r\n\n", "before_files": [{"content": "import logging\nimport os\nimport io\nfrom typing import Dict, List, Pattern, IO, Tuple\n\nimport ioc_finder\nfrom bs4 import BeautifulSoup\nfrom pdfminer.high_level import extract_pages\nfrom pdfminer.layout import LTTextContainer\nfrom pycti import OpenCTIConnectorHelper\nfrom reportimporter.constants import (\n OBSERVABLE_CLASS,\n ENTITY_CLASS,\n RESULT_FORMAT_MATCH,\n RESULT_FORMAT_TYPE,\n RESULT_FORMAT_CATEGORY,\n RESULT_FORMAT_RANGE,\n MIME_PDF,\n MIME_TXT,\n MIME_HTML,\n MIME_CSV,\n OBSERVABLE_DETECTION_CUSTOM_REGEX,\n OBSERVABLE_DETECTION_LIBRARY,\n)\nfrom reportimporter.models import Observable, Entity\nfrom reportimporter.util import library_mapping\n\n\nclass ReportParser(object):\n \"\"\"\n Report parser based on IOCParser\n \"\"\"\n\n def __init__(\n self,\n helper: OpenCTIConnectorHelper,\n entity_list: List[Entity],\n observable_list: List[Observable],\n ):\n\n self.helper = helper\n self.entity_list = entity_list\n self.observable_list = observable_list\n\n # Disable INFO logging by pdfminer\n logging.getLogger(\"pdfminer\").setLevel(logging.WARNING)\n\n # Supported file types\n self.supported_file_types = {\n MIME_PDF: self._parse_pdf,\n MIME_TXT: self._parse_text,\n MIME_HTML: self._parse_html,\n MIME_CSV: self._parse_text,\n }\n\n self.library_lookup = library_mapping()\n\n def _is_whitelisted(self, regex_list: List[Pattern], ind_match: str):\n for regex in regex_list:\n self.helper.log_debug(f\"Filter regex '{regex}' for value '{ind_match}'\")\n result = regex.search(ind_match)\n if result:\n self.helper.log_debug(f\"Value {ind_match} is whitelisted with {regex}\")\n return True\n return False\n\n def _post_parse_observables(\n self, ind_match: str, observable: Observable, match_range: Tuple\n ) -> Dict:\n self.helper.log_debug(f\"Observable match: {ind_match}\")\n\n if self._is_whitelisted(observable.filter_regex, ind_match):\n return {}\n\n return self._format_match(\n OBSERVABLE_CLASS, observable.stix_target, ind_match, match_range\n )\n\n def _parse(self, data: str) -> Dict[str, Dict]:\n list_matches = {}\n\n # Defang text\n data = ioc_finder.prepare_text(data)\n\n for observable in self.observable_list:\n list_matches.update(self._extract_observable(observable, data))\n\n for entity in self.entity_list:\n list_matches = self._extract_entity(entity, list_matches, data)\n\n self.helper.log_debug(f\"Text: '{data}' -> extracts {list_matches}\")\n return list_matches\n\n def _parse_pdf(self, file_data: IO) -> Dict[str, Dict]:\n parse_info = {}\n try:\n for page_layout in extract_pages(file_data):\n for element in page_layout:\n if isinstance(element, LTTextContainer):\n text = element.get_text()\n # Parsing with newlines has been deprecated\n no_newline_text = text.replace(\"\\n\", \"\")\n parse_info.update(self._parse(no_newline_text))\n\n # TODO also extract information from images/figures using OCR\n # https://pdfminersix.readthedocs.io/en/latest/topic/converting_pdf_to_text.html#topic-pdf-to-text-layout\n\n except Exception as e:\n logging.exception(f\"Pdf Parsing Error: {e}\")\n\n return parse_info\n\n def _parse_text(self, file_data: IO) -> Dict[str, Dict]:\n parse_info = {}\n for text in file_data.readlines():\n parse_info.update(self._parse(text.decode(\"utf-8\")))\n return parse_info\n\n def _parse_html(self, file_data: IO) -> Dict[str, Dict]:\n parse_info = {}\n soup = BeautifulSoup(file_data, \"html.parser\")\n buf = io.StringIO(soup.get_text())\n for text in buf.readlines():\n parse_info.update(self._parse(text))\n return parse_info\n\n def run_parser(self, file_path: str, file_type: str) -> List[Dict]:\n parsing_results = []\n\n file_parser = self.supported_file_types.get(file_type, None)\n if not file_parser:\n raise NotImplementedError(f\"No parser available for file type {file_type}\")\n\n if not os.path.isfile(file_path):\n raise IOError(f\"File path is not a file: {file_path}\")\n\n self.helper.log_info(f\"Parsing report {file_path} {file_type}\")\n\n try:\n with open(file_path, \"rb\") as file_data:\n parsing_results = file_parser(file_data)\n except Exception as e:\n logging.exception(f\"Parsing Error: {e}\")\n\n parsing_results = list(parsing_results.values())\n\n return parsing_results\n\n @staticmethod\n def _format_match(\n format_type: str, category: str, match: str, match_range: Tuple = (0, 0)\n ) -> Dict:\n return {\n RESULT_FORMAT_TYPE: format_type,\n RESULT_FORMAT_CATEGORY: category,\n RESULT_FORMAT_MATCH: match,\n RESULT_FORMAT_RANGE: match_range,\n }\n\n @staticmethod\n def _sco_present(\n match_list: Dict, entity_range: Tuple, filter_sco_types: List\n ) -> str:\n for match_name, match_info in match_list.items():\n if match_info[RESULT_FORMAT_CATEGORY] in filter_sco_types:\n if (\n match_info[RESULT_FORMAT_RANGE][0] <= entity_range[0]\n and entity_range[1] <= match_info[RESULT_FORMAT_RANGE][1]\n ):\n return match_name\n\n return \"\"\n\n def _extract_observable(self, observable: Observable, data: str) -> Dict:\n list_matches = {}\n if observable.detection_option == OBSERVABLE_DETECTION_CUSTOM_REGEX:\n for regex in observable.regex:\n for match in regex.finditer(data):\n match_value = match.group()\n\n ind_match = self._post_parse_observables(\n match_value, observable, match.span()\n )\n if ind_match:\n list_matches[match.group()] = ind_match\n\n elif observable.detection_option == OBSERVABLE_DETECTION_LIBRARY:\n lookup_function = self.library_lookup.get(observable.stix_target, None)\n if not lookup_function:\n self.helper.log_error(\n f\"Selected library function is not implemented: {observable.iocfinder_function}\"\n )\n return {}\n\n matches = lookup_function(data)\n\n for match in matches:\n match_str = str(match)\n if match_str in data:\n start = data.index(match_str)\n elif match_str in data.lower():\n self.helper.log_debug(\n f\"External library manipulated the extracted value '{match_str}' from the \"\n f\"original text '{data}' to lower case\"\n )\n start = data.lower().index(match_str)\n else:\n self.helper.log_error(\n f\"The extracted text '{match_str}' is not part of the original text '{data}'. \"\n f\"Please open a GitHub issue to report this problem!\"\n )\n continue\n\n ind_match = self._post_parse_observables(\n match, observable, (start, len(match_str) + start)\n )\n if ind_match:\n list_matches[match] = ind_match\n\n return list_matches\n\n def _extract_entity(self, entity: Entity, list_matches: Dict, data: str) -> Dict:\n regex_list = entity.regex\n\n observable_keys = []\n end_index = set()\n match_dict = {}\n match_key = \"\"\n\n # Run all regexes for entity X\n for regex in regex_list:\n for match in regex.finditer(data):\n match_key = match.group()\n if match_key in match_dict:\n match_dict[match_key].append(match.span())\n else:\n match_dict[match_key] = [match.span()]\n\n # No maches for this entity\n if len(match_dict) == 0:\n return list_matches\n\n # Run through all matches for entity X and check if they are part of a domain\n # yes -> skip\n # no -> add index to end_index\n for match, match_indices in match_dict.items():\n for match_index in match_indices:\n skip_val = self._sco_present(\n list_matches, match_index, entity.omit_match_in\n )\n if skip_val:\n self.helper.log_debug(\n f\"Skipping Entity '{match}', it is part of an omitted field '{entity.omit_match_in}' \\\"{skip_val}\\\"\"\n )\n else:\n self.helper.log_debug(\n f\"Entity match: '{match}' of regex: '{regex_list}'\"\n )\n end_index.add(match_index)\n if match in list_matches.keys():\n observable_keys.append(match)\n\n # Remove all observables which found the same information/Entity match\n for observable_key in observable_keys:\n if observable_key in list_matches:\n del list_matches[observable_key]\n self.helper.log_debug(\n f\"Value {observable_key} is also matched by entity {entity.name}\"\n )\n\n # Check if entity was matched at least once in the text\n # If yes, then add identity to match list\n if end_index:\n list_matches[match_key] = self._format_match(\n ENTITY_CLASS, entity.name, entity.stix_id\n )\n\n return list_matches\n", "path": "internal-import-file/import-document/src/reportimporter/report_parser.py"}, {"content": "MIME_PDF = \"application/pdf\"\nMIME_TXT = \"text/plain\"\nMIME_HTML = \"text/html\"\nMIME_CSV = \"text/csv\"\n\nRESULT_FORMAT_TYPE = \"type\"\nRESULT_FORMAT_CATEGORY = \"category\"\nRESULT_FORMAT_MATCH = \"match\"\nRESULT_FORMAT_RANGE = \"range\"\n\nENTITY_CLASS = \"entity\"\nOBSERVABLE_CLASS = \"observable\"\n\nCONFIG_PATH = \"filter_list\"\nCOMMENT_INDICATOR = \"#\"\n\nOBSERVABLE_DETECTION_CUSTOM_REGEX = \"custom_regex\"\nOBSERVABLE_DETECTION_LIBRARY = \"library\"\nOBSERVABLE_DETECTION_OPTIONS = [\n OBSERVABLE_DETECTION_LIBRARY,\n OBSERVABLE_DETECTION_CUSTOM_REGEX,\n]\n", "path": "internal-import-file/import-document/src/reportimporter/constants.py"}], "after_files": [{"content": "import logging\nimport os\nimport io\nfrom typing import Dict, List, Pattern, IO, Tuple\n\nimport ioc_finder\nfrom bs4 import BeautifulSoup\nfrom pdfminer.high_level import extract_pages\nfrom pdfminer.layout import LTTextContainer\nfrom pycti import OpenCTIConnectorHelper\nfrom reportimporter.constants import (\n OBSERVABLE_CLASS,\n ENTITY_CLASS,\n RESULT_FORMAT_MATCH,\n RESULT_FORMAT_TYPE,\n RESULT_FORMAT_CATEGORY,\n RESULT_FORMAT_RANGE,\n MIME_PDF,\n MIME_TXT,\n MIME_HTML,\n MIME_CSV,\n MIME_MD,\n OBSERVABLE_DETECTION_CUSTOM_REGEX,\n OBSERVABLE_DETECTION_LIBRARY,\n)\nfrom reportimporter.models import Observable, Entity\nfrom reportimporter.util import library_mapping\n\n\nclass ReportParser(object):\n \"\"\"\n Report parser based on IOCParser\n \"\"\"\n\n def __init__(\n self,\n helper: OpenCTIConnectorHelper,\n entity_list: List[Entity],\n observable_list: List[Observable],\n ):\n\n self.helper = helper\n self.entity_list = entity_list\n self.observable_list = observable_list\n\n # Disable INFO logging by pdfminer\n logging.getLogger(\"pdfminer\").setLevel(logging.WARNING)\n\n # Supported file types\n self.supported_file_types = {\n MIME_PDF: self._parse_pdf,\n MIME_TXT: self._parse_text,\n MIME_HTML: self._parse_html,\n MIME_CSV: self._parse_text,\n MIME_MD: self._parse_text,\n }\n\n self.library_lookup = library_mapping()\n\n def _is_whitelisted(self, regex_list: List[Pattern], ind_match: str):\n for regex in regex_list:\n self.helper.log_debug(f\"Filter regex '{regex}' for value '{ind_match}'\")\n result = regex.search(ind_match)\n if result:\n self.helper.log_debug(f\"Value {ind_match} is whitelisted with {regex}\")\n return True\n return False\n\n def _post_parse_observables(\n self, ind_match: str, observable: Observable, match_range: Tuple\n ) -> Dict:\n self.helper.log_debug(f\"Observable match: {ind_match}\")\n\n if self._is_whitelisted(observable.filter_regex, ind_match):\n return {}\n\n return self._format_match(\n OBSERVABLE_CLASS, observable.stix_target, ind_match, match_range\n )\n\n def _parse(self, data: str) -> Dict[str, Dict]:\n list_matches = {}\n\n # Defang text\n data = ioc_finder.prepare_text(data)\n\n for observable in self.observable_list:\n list_matches.update(self._extract_observable(observable, data))\n\n for entity in self.entity_list:\n list_matches = self._extract_entity(entity, list_matches, data)\n\n self.helper.log_debug(f\"Text: '{data}' -> extracts {list_matches}\")\n return list_matches\n\n def _parse_pdf(self, file_data: IO) -> Dict[str, Dict]:\n parse_info = {}\n try:\n for page_layout in extract_pages(file_data):\n for element in page_layout:\n if isinstance(element, LTTextContainer):\n text = element.get_text()\n # Parsing with newlines has been deprecated\n no_newline_text = text.replace(\"\\n\", \"\")\n parse_info.update(self._parse(no_newline_text))\n\n # TODO also extract information from images/figures using OCR\n # https://pdfminersix.readthedocs.io/en/latest/topic/converting_pdf_to_text.html#topic-pdf-to-text-layout\n\n except Exception as e:\n logging.exception(f\"Pdf Parsing Error: {e}\")\n\n return parse_info\n\n def _parse_text(self, file_data: IO) -> Dict[str, Dict]:\n parse_info = {}\n for text in file_data.readlines():\n parse_info.update(self._parse(text.decode(\"utf-8\")))\n return parse_info\n\n def _parse_html(self, file_data: IO) -> Dict[str, Dict]:\n parse_info = {}\n soup = BeautifulSoup(file_data, \"html.parser\")\n buf = io.StringIO(soup.get_text())\n for text in buf.readlines():\n parse_info.update(self._parse(text))\n return parse_info\n\n def run_parser(self, file_path: str, file_type: str) -> List[Dict]:\n parsing_results = []\n\n file_parser = self.supported_file_types.get(file_type, None)\n if not file_parser:\n raise NotImplementedError(f\"No parser available for file type {file_type}\")\n\n if not os.path.isfile(file_path):\n raise IOError(f\"File path is not a file: {file_path}\")\n\n self.helper.log_info(f\"Parsing report {file_path} {file_type}\")\n\n try:\n with open(file_path, \"rb\") as file_data:\n parsing_results = file_parser(file_data)\n except Exception as e:\n logging.exception(f\"Parsing Error: {e}\")\n\n parsing_results = list(parsing_results.values())\n\n return parsing_results\n\n @staticmethod\n def _format_match(\n format_type: str, category: str, match: str, match_range: Tuple = (0, 0)\n ) -> Dict:\n return {\n RESULT_FORMAT_TYPE: format_type,\n RESULT_FORMAT_CATEGORY: category,\n RESULT_FORMAT_MATCH: match,\n RESULT_FORMAT_RANGE: match_range,\n }\n\n @staticmethod\n def _sco_present(\n match_list: Dict, entity_range: Tuple, filter_sco_types: List\n ) -> str:\n for match_name, match_info in match_list.items():\n if match_info[RESULT_FORMAT_CATEGORY] in filter_sco_types:\n if (\n match_info[RESULT_FORMAT_RANGE][0] <= entity_range[0]\n and entity_range[1] <= match_info[RESULT_FORMAT_RANGE][1]\n ):\n return match_name\n\n return \"\"\n\n def _extract_observable(self, observable: Observable, data: str) -> Dict:\n list_matches = {}\n if observable.detection_option == OBSERVABLE_DETECTION_CUSTOM_REGEX:\n for regex in observable.regex:\n for match in regex.finditer(data):\n match_value = match.group()\n\n ind_match = self._post_parse_observables(\n match_value, observable, match.span()\n )\n if ind_match:\n list_matches[match.group()] = ind_match\n\n elif observable.detection_option == OBSERVABLE_DETECTION_LIBRARY:\n lookup_function = self.library_lookup.get(observable.stix_target, None)\n if not lookup_function:\n self.helper.log_error(\n f\"Selected library function is not implemented: {observable.iocfinder_function}\"\n )\n return {}\n\n matches = lookup_function(data)\n\n for match in matches:\n match_str = str(match)\n if match_str in data:\n start = data.index(match_str)\n elif match_str in data.lower():\n self.helper.log_debug(\n f\"External library manipulated the extracted value '{match_str}' from the \"\n f\"original text '{data}' to lower case\"\n )\n start = data.lower().index(match_str)\n else:\n self.helper.log_error(\n f\"The extracted text '{match_str}' is not part of the original text '{data}'. \"\n f\"Please open a GitHub issue to report this problem!\"\n )\n continue\n\n ind_match = self._post_parse_observables(\n match, observable, (start, len(match_str) + start)\n )\n if ind_match:\n list_matches[match] = ind_match\n\n return list_matches\n\n def _extract_entity(self, entity: Entity, list_matches: Dict, data: str) -> Dict:\n regex_list = entity.regex\n\n observable_keys = []\n end_index = set()\n match_dict = {}\n match_key = \"\"\n\n # Run all regexes for entity X\n for regex in regex_list:\n for match in regex.finditer(data):\n match_key = match.group()\n if match_key in match_dict:\n match_dict[match_key].append(match.span())\n else:\n match_dict[match_key] = [match.span()]\n\n # No maches for this entity\n if len(match_dict) == 0:\n return list_matches\n\n # Run through all matches for entity X and check if they are part of a domain\n # yes -> skip\n # no -> add index to end_index\n for match, match_indices in match_dict.items():\n for match_index in match_indices:\n skip_val = self._sco_present(\n list_matches, match_index, entity.omit_match_in\n )\n if skip_val:\n self.helper.log_debug(\n f\"Skipping Entity '{match}', it is part of an omitted field '{entity.omit_match_in}' \\\"{skip_val}\\\"\"\n )\n else:\n self.helper.log_debug(\n f\"Entity match: '{match}' of regex: '{regex_list}'\"\n )\n end_index.add(match_index)\n if match in list_matches.keys():\n observable_keys.append(match)\n\n # Remove all observables which found the same information/Entity match\n for observable_key in observable_keys:\n if observable_key in list_matches:\n del list_matches[observable_key]\n self.helper.log_debug(\n f\"Value {observable_key} is also matched by entity {entity.name}\"\n )\n\n # Check if entity was matched at least once in the text\n # If yes, then add identity to match list\n if end_index:\n list_matches[match_key] = self._format_match(\n ENTITY_CLASS, entity.name, entity.stix_id\n )\n\n return list_matches\n", "path": "internal-import-file/import-document/src/reportimporter/report_parser.py"}, {"content": "MIME_PDF = \"application/pdf\"\nMIME_TXT = \"text/plain\"\nMIME_HTML = \"text/html\"\nMIME_CSV = \"text/csv\"\nMIME_MD = \"text/markdown\"\n\nRESULT_FORMAT_TYPE = \"type\"\nRESULT_FORMAT_CATEGORY = \"category\"\nRESULT_FORMAT_MATCH = \"match\"\nRESULT_FORMAT_RANGE = \"range\"\n\nENTITY_CLASS = \"entity\"\nOBSERVABLE_CLASS = \"observable\"\n\nCONFIG_PATH = \"filter_list\"\nCOMMENT_INDICATOR = \"#\"\n\nOBSERVABLE_DETECTION_CUSTOM_REGEX = \"custom_regex\"\nOBSERVABLE_DETECTION_LIBRARY = \"library\"\nOBSERVABLE_DETECTION_OPTIONS = [\n OBSERVABLE_DETECTION_LIBRARY,\n OBSERVABLE_DETECTION_CUSTOM_REGEX,\n]\n", "path": "internal-import-file/import-document/src/reportimporter/constants.py"}]}
| 3,646 | 279 |
gh_patches_debug_20583
|
rasdani/github-patches
|
git_diff
|
scrapy__scrapy-472
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Support some EXSLT extensions by default in `Selector` when using XPath
Some EXSLT extensions are supported by default in `lxml`, provided one registers the corresponding namespaces when using XPath.
See http://www.exslt.org/ and http://lxml.de/xpathxslt.html#regular-expressions-in-xpath
`Selector` could register these by default:
- set manipulation (http://www.exslt.org/set/index.html, namespace `http://exslt.org/sets`)
- and regular expressions (http://www.exslt.org/regexp/index.html, namespace `http://exslt.org/regular-expressions`)
Some examples on how to use set operations:
- http://stackoverflow.com/questions/17722110/xpath-descendants-but-not-by-traversing-this-node/17727726#17727726
- http://stackoverflow.com/questions/18050803/what-is-the-next-tag-after-the-specific-tag-in-html-using-xpath/18055420#18055420
Regarding implementation it would mean registering default namespaces and merging user-provided namespaces.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `scrapy/selector/unified.py`
Content:
```
1 """
2 XPath selectors based on lxml
3 """
4
5 from lxml import etree
6
7 from scrapy.utils.misc import extract_regex
8 from scrapy.utils.trackref import object_ref
9 from scrapy.utils.python import unicode_to_str, flatten
10 from scrapy.utils.decorator import deprecated
11 from scrapy.http import HtmlResponse, XmlResponse
12 from .lxmldocument import LxmlDocument
13 from .csstranslator import ScrapyHTMLTranslator, ScrapyGenericTranslator
14
15
16 __all__ = ['Selector', 'SelectorList']
17
18 _ctgroup = {
19 'html': {'_parser': etree.HTMLParser,
20 '_csstranslator': ScrapyHTMLTranslator(),
21 '_tostring_method': 'html'},
22 'xml': {'_parser': etree.XMLParser,
23 '_csstranslator': ScrapyGenericTranslator(),
24 '_tostring_method': 'xml'},
25 }
26
27
28 def _st(response, st):
29 if st is None:
30 return 'xml' if isinstance(response, XmlResponse) else 'html'
31 elif st in ('xml', 'html'):
32 return st
33 else:
34 raise ValueError('Invalid type: %s' % st)
35
36
37 def _response_from_text(text, st):
38 rt = XmlResponse if st == 'xml' else HtmlResponse
39 return rt(url='about:blank', encoding='utf-8',
40 body=unicode_to_str(text, 'utf-8'))
41
42
43 class Selector(object_ref):
44
45 __slots__ = ['response', 'text', 'namespaces', 'type', '_expr', '_root',
46 '__weakref__', '_parser', '_csstranslator', '_tostring_method']
47
48 _default_type = None
49
50 def __init__(self, response=None, text=None, type=None, namespaces=None,
51 _root=None, _expr=None):
52 self.type = st = _st(response, type or self._default_type)
53 self._parser = _ctgroup[st]['_parser']
54 self._csstranslator = _ctgroup[st]['_csstranslator']
55 self._tostring_method = _ctgroup[st]['_tostring_method']
56
57 if text is not None:
58 response = _response_from_text(text, st)
59
60 if response is not None:
61 _root = LxmlDocument(response, self._parser)
62
63 self.response = response
64 self.namespaces = namespaces
65 self._root = _root
66 self._expr = _expr
67
68 def xpath(self, query):
69 try:
70 xpathev = self._root.xpath
71 except AttributeError:
72 return SelectorList([])
73
74 try:
75 result = xpathev(query, namespaces=self.namespaces)
76 except etree.XPathError:
77 raise ValueError("Invalid XPath: %s" % query)
78
79 if type(result) is not list:
80 result = [result]
81
82 result = [self.__class__(_root=x, _expr=query,
83 namespaces=self.namespaces,
84 type=self.type)
85 for x in result]
86 return SelectorList(result)
87
88 def css(self, query):
89 return self.xpath(self._css2xpath(query))
90
91 def _css2xpath(self, query):
92 return self._csstranslator.css_to_xpath(query)
93
94 def re(self, regex):
95 return extract_regex(regex, self.extract())
96
97 def extract(self):
98 try:
99 return etree.tostring(self._root,
100 method=self._tostring_method,
101 encoding=unicode,
102 with_tail=False)
103 except (AttributeError, TypeError):
104 if self._root is True:
105 return u'1'
106 elif self._root is False:
107 return u'0'
108 else:
109 return unicode(self._root)
110
111 def register_namespace(self, prefix, uri):
112 if self.namespaces is None:
113 self.namespaces = {}
114 self.namespaces[prefix] = uri
115
116 def remove_namespaces(self):
117 for el in self._root.iter('*'):
118 if el.tag.startswith('{'):
119 el.tag = el.tag.split('}', 1)[1]
120 # loop on element attributes also
121 for an in el.attrib.keys():
122 if an.startswith('{'):
123 el.attrib[an.split('}', 1)[1]] = el.attrib.pop(an)
124
125 def __nonzero__(self):
126 return bool(self.extract())
127
128 def __str__(self):
129 data = repr(self.extract()[:40])
130 return "<%s xpath=%r data=%s>" % (type(self).__name__, self._expr, data)
131 __repr__ = __str__
132
133 # Deprecated api
134 @deprecated(use_instead='.xpath()')
135 def select(self, xpath):
136 return self.xpath(xpath)
137
138 @deprecated(use_instead='.extract()')
139 def extract_unquoted(self):
140 return self.extract()
141
142
143 class SelectorList(list):
144
145 def __getslice__(self, i, j):
146 return self.__class__(list.__getslice__(self, i, j))
147
148 def xpath(self, xpath):
149 return self.__class__(flatten([x.xpath(xpath) for x in self]))
150
151 def css(self, xpath):
152 return self.__class__(flatten([x.css(xpath) for x in self]))
153
154 def re(self, regex):
155 return flatten([x.re(regex) for x in self])
156
157 def extract(self):
158 return [x.extract() for x in self]
159
160 @deprecated(use_instead='.extract()')
161 def extract_unquoted(self):
162 return [x.extract_unquoted() for x in self]
163
164 @deprecated(use_instead='.xpath()')
165 def x(self, xpath):
166 return self.select(xpath)
167
168 @deprecated(use_instead='.xpath()')
169 def select(self, xpath):
170 return self.xpath(xpath)
171
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/scrapy/selector/unified.py b/scrapy/selector/unified.py
--- a/scrapy/selector/unified.py
+++ b/scrapy/selector/unified.py
@@ -46,6 +46,17 @@
'__weakref__', '_parser', '_csstranslator', '_tostring_method']
_default_type = None
+ _default_namespaces = {
+ "re": "http://exslt.org/regular-expressions",
+
+ # supported in libxslt:
+ # set:difference
+ # set:has-same-node
+ # set:intersection
+ # set:leading
+ # set:trailing
+ "set": "http://exslt.org/sets"
+ }
def __init__(self, response=None, text=None, type=None, namespaces=None,
_root=None, _expr=None):
@@ -61,7 +72,9 @@
_root = LxmlDocument(response, self._parser)
self.response = response
- self.namespaces = namespaces
+ self.namespaces = dict(self._default_namespaces)
+ if namespaces is not None:
+ self.namespaces.update(namespaces)
self._root = _root
self._expr = _expr
|
{"golden_diff": "diff --git a/scrapy/selector/unified.py b/scrapy/selector/unified.py\n--- a/scrapy/selector/unified.py\n+++ b/scrapy/selector/unified.py\n@@ -46,6 +46,17 @@\n '__weakref__', '_parser', '_csstranslator', '_tostring_method']\n \n _default_type = None\n+ _default_namespaces = {\n+ \"re\": \"http://exslt.org/regular-expressions\",\n+\n+ # supported in libxslt:\n+ # set:difference\n+ # set:has-same-node\n+ # set:intersection\n+ # set:leading\n+ # set:trailing\n+ \"set\": \"http://exslt.org/sets\"\n+ }\n \n def __init__(self, response=None, text=None, type=None, namespaces=None,\n _root=None, _expr=None):\n@@ -61,7 +72,9 @@\n _root = LxmlDocument(response, self._parser)\n \n self.response = response\n- self.namespaces = namespaces\n+ self.namespaces = dict(self._default_namespaces)\n+ if namespaces is not None:\n+ self.namespaces.update(namespaces)\n self._root = _root\n self._expr = _expr\n", "issue": "Support some EXSLT extensions by default in `Selector` when using XPath\nSome EXSLT extensions are supported by default in `lxml`, provided one registers the corresponding namespaces when using XPath.\nSee http://www.exslt.org/ and http://lxml.de/xpathxslt.html#regular-expressions-in-xpath\n\n`Selector` could register these by default:\n- set manipulation (http://www.exslt.org/set/index.html, namespace `http://exslt.org/sets`)\n- and regular expressions (http://www.exslt.org/regexp/index.html, namespace `http://exslt.org/regular-expressions`)\n\nSome examples on how to use set operations:\n- http://stackoverflow.com/questions/17722110/xpath-descendants-but-not-by-traversing-this-node/17727726#17727726\n- http://stackoverflow.com/questions/18050803/what-is-the-next-tag-after-the-specific-tag-in-html-using-xpath/18055420#18055420\n\nRegarding implementation it would mean registering default namespaces and merging user-provided namespaces.\n\n", "before_files": [{"content": "\"\"\"\nXPath selectors based on lxml\n\"\"\"\n\nfrom lxml import etree\n\nfrom scrapy.utils.misc import extract_regex\nfrom scrapy.utils.trackref import object_ref\nfrom scrapy.utils.python import unicode_to_str, flatten\nfrom scrapy.utils.decorator import deprecated\nfrom scrapy.http import HtmlResponse, XmlResponse\nfrom .lxmldocument import LxmlDocument\nfrom .csstranslator import ScrapyHTMLTranslator, ScrapyGenericTranslator\n\n\n__all__ = ['Selector', 'SelectorList']\n\n_ctgroup = {\n 'html': {'_parser': etree.HTMLParser,\n '_csstranslator': ScrapyHTMLTranslator(),\n '_tostring_method': 'html'},\n 'xml': {'_parser': etree.XMLParser,\n '_csstranslator': ScrapyGenericTranslator(),\n '_tostring_method': 'xml'},\n}\n\n\ndef _st(response, st):\n if st is None:\n return 'xml' if isinstance(response, XmlResponse) else 'html'\n elif st in ('xml', 'html'):\n return st\n else:\n raise ValueError('Invalid type: %s' % st)\n\n\ndef _response_from_text(text, st):\n rt = XmlResponse if st == 'xml' else HtmlResponse\n return rt(url='about:blank', encoding='utf-8',\n body=unicode_to_str(text, 'utf-8'))\n\n\nclass Selector(object_ref):\n\n __slots__ = ['response', 'text', 'namespaces', 'type', '_expr', '_root',\n '__weakref__', '_parser', '_csstranslator', '_tostring_method']\n\n _default_type = None\n\n def __init__(self, response=None, text=None, type=None, namespaces=None,\n _root=None, _expr=None):\n self.type = st = _st(response, type or self._default_type)\n self._parser = _ctgroup[st]['_parser']\n self._csstranslator = _ctgroup[st]['_csstranslator']\n self._tostring_method = _ctgroup[st]['_tostring_method']\n\n if text is not None:\n response = _response_from_text(text, st)\n\n if response is not None:\n _root = LxmlDocument(response, self._parser)\n\n self.response = response\n self.namespaces = namespaces\n self._root = _root\n self._expr = _expr\n\n def xpath(self, query):\n try:\n xpathev = self._root.xpath\n except AttributeError:\n return SelectorList([])\n\n try:\n result = xpathev(query, namespaces=self.namespaces)\n except etree.XPathError:\n raise ValueError(\"Invalid XPath: %s\" % query)\n\n if type(result) is not list:\n result = [result]\n\n result = [self.__class__(_root=x, _expr=query,\n namespaces=self.namespaces,\n type=self.type)\n for x in result]\n return SelectorList(result)\n\n def css(self, query):\n return self.xpath(self._css2xpath(query))\n\n def _css2xpath(self, query):\n return self._csstranslator.css_to_xpath(query)\n\n def re(self, regex):\n return extract_regex(regex, self.extract())\n\n def extract(self):\n try:\n return etree.tostring(self._root,\n method=self._tostring_method,\n encoding=unicode,\n with_tail=False)\n except (AttributeError, TypeError):\n if self._root is True:\n return u'1'\n elif self._root is False:\n return u'0'\n else:\n return unicode(self._root)\n\n def register_namespace(self, prefix, uri):\n if self.namespaces is None:\n self.namespaces = {}\n self.namespaces[prefix] = uri\n\n def remove_namespaces(self):\n for el in self._root.iter('*'):\n if el.tag.startswith('{'):\n el.tag = el.tag.split('}', 1)[1]\n # loop on element attributes also\n for an in el.attrib.keys():\n if an.startswith('{'):\n el.attrib[an.split('}', 1)[1]] = el.attrib.pop(an)\n\n def __nonzero__(self):\n return bool(self.extract())\n\n def __str__(self):\n data = repr(self.extract()[:40])\n return \"<%s xpath=%r data=%s>\" % (type(self).__name__, self._expr, data)\n __repr__ = __str__\n\n # Deprecated api\n @deprecated(use_instead='.xpath()')\n def select(self, xpath):\n return self.xpath(xpath)\n\n @deprecated(use_instead='.extract()')\n def extract_unquoted(self):\n return self.extract()\n\n\nclass SelectorList(list):\n\n def __getslice__(self, i, j):\n return self.__class__(list.__getslice__(self, i, j))\n\n def xpath(self, xpath):\n return self.__class__(flatten([x.xpath(xpath) for x in self]))\n\n def css(self, xpath):\n return self.__class__(flatten([x.css(xpath) for x in self]))\n\n def re(self, regex):\n return flatten([x.re(regex) for x in self])\n\n def extract(self):\n return [x.extract() for x in self]\n\n @deprecated(use_instead='.extract()')\n def extract_unquoted(self):\n return [x.extract_unquoted() for x in self]\n\n @deprecated(use_instead='.xpath()')\n def x(self, xpath):\n return self.select(xpath)\n\n @deprecated(use_instead='.xpath()')\n def select(self, xpath):\n return self.xpath(xpath)\n", "path": "scrapy/selector/unified.py"}], "after_files": [{"content": "\"\"\"\nXPath selectors based on lxml\n\"\"\"\n\nfrom lxml import etree\n\nfrom scrapy.utils.misc import extract_regex\nfrom scrapy.utils.trackref import object_ref\nfrom scrapy.utils.python import unicode_to_str, flatten\nfrom scrapy.utils.decorator import deprecated\nfrom scrapy.http import HtmlResponse, XmlResponse\nfrom .lxmldocument import LxmlDocument\nfrom .csstranslator import ScrapyHTMLTranslator, ScrapyGenericTranslator\n\n\n__all__ = ['Selector', 'SelectorList']\n\n_ctgroup = {\n 'html': {'_parser': etree.HTMLParser,\n '_csstranslator': ScrapyHTMLTranslator(),\n '_tostring_method': 'html'},\n 'xml': {'_parser': etree.XMLParser,\n '_csstranslator': ScrapyGenericTranslator(),\n '_tostring_method': 'xml'},\n}\n\n\ndef _st(response, st):\n if st is None:\n return 'xml' if isinstance(response, XmlResponse) else 'html'\n elif st in ('xml', 'html'):\n return st\n else:\n raise ValueError('Invalid type: %s' % st)\n\n\ndef _response_from_text(text, st):\n rt = XmlResponse if st == 'xml' else HtmlResponse\n return rt(url='about:blank', encoding='utf-8',\n body=unicode_to_str(text, 'utf-8'))\n\n\nclass Selector(object_ref):\n\n __slots__ = ['response', 'text', 'namespaces', 'type', '_expr', '_root',\n '__weakref__', '_parser', '_csstranslator', '_tostring_method']\n\n _default_type = None\n _default_namespaces = {\n \"re\": \"http://exslt.org/regular-expressions\",\n\n # supported in libxslt:\n # set:difference\n # set:has-same-node\n # set:intersection\n # set:leading\n # set:trailing\n \"set\": \"http://exslt.org/sets\"\n }\n\n def __init__(self, response=None, text=None, type=None, namespaces=None,\n _root=None, _expr=None):\n self.type = st = _st(response, type or self._default_type)\n self._parser = _ctgroup[st]['_parser']\n self._csstranslator = _ctgroup[st]['_csstranslator']\n self._tostring_method = _ctgroup[st]['_tostring_method']\n\n if text is not None:\n response = _response_from_text(text, st)\n\n if response is not None:\n _root = LxmlDocument(response, self._parser)\n\n self.response = response\n self.namespaces = dict(self._default_namespaces)\n if namespaces is not None:\n self.namespaces.update(namespaces)\n self._root = _root\n self._expr = _expr\n\n def xpath(self, query):\n try:\n xpathev = self._root.xpath\n except AttributeError:\n return SelectorList([])\n\n try:\n result = xpathev(query, namespaces=self.namespaces)\n except etree.XPathError:\n raise ValueError(\"Invalid XPath: %s\" % query)\n\n if type(result) is not list:\n result = [result]\n\n result = [self.__class__(_root=x, _expr=query,\n namespaces=self.namespaces,\n type=self.type)\n for x in result]\n return SelectorList(result)\n\n def css(self, query):\n return self.xpath(self._css2xpath(query))\n\n def _css2xpath(self, query):\n return self._csstranslator.css_to_xpath(query)\n\n def re(self, regex):\n return extract_regex(regex, self.extract())\n\n def extract(self):\n try:\n return etree.tostring(self._root,\n method=self._tostring_method,\n encoding=unicode,\n with_tail=False)\n except (AttributeError, TypeError):\n if self._root is True:\n return u'1'\n elif self._root is False:\n return u'0'\n else:\n return unicode(self._root)\n\n def register_namespace(self, prefix, uri):\n if self.namespaces is None:\n self.namespaces = {}\n self.namespaces[prefix] = uri\n\n def remove_namespaces(self):\n for el in self._root.iter('*'):\n if el.tag.startswith('{'):\n el.tag = el.tag.split('}', 1)[1]\n # loop on element attributes also\n for an in el.attrib.keys():\n if an.startswith('{'):\n el.attrib[an.split('}', 1)[1]] = el.attrib.pop(an)\n\n def __nonzero__(self):\n return bool(self.extract())\n\n def __str__(self):\n data = repr(self.extract()[:40])\n return \"<%s xpath=%r data=%s>\" % (type(self).__name__, self._expr, data)\n __repr__ = __str__\n\n # Deprecated api\n @deprecated(use_instead='.xpath()')\n def select(self, xpath):\n return self.xpath(xpath)\n\n @deprecated(use_instead='.extract()')\n def extract_unquoted(self):\n return self.extract()\n\n\nclass SelectorList(list):\n\n def __getslice__(self, i, j):\n return self.__class__(list.__getslice__(self, i, j))\n\n def xpath(self, xpath):\n return self.__class__(flatten([x.xpath(xpath) for x in self]))\n\n def css(self, xpath):\n return self.__class__(flatten([x.css(xpath) for x in self]))\n\n def re(self, regex):\n return flatten([x.re(regex) for x in self])\n\n def extract(self):\n return [x.extract() for x in self]\n\n @deprecated(use_instead='.extract()')\n def extract_unquoted(self):\n return [x.extract_unquoted() for x in self]\n\n @deprecated(use_instead='.xpath()')\n def x(self, xpath):\n return self.select(xpath)\n\n @deprecated(use_instead='.xpath()')\n def select(self, xpath):\n return self.xpath(xpath)\n", "path": "scrapy/selector/unified.py"}]}
| 2,133 | 285 |
gh_patches_debug_26016
|
rasdani/github-patches
|
git_diff
|
ansible__ansible-36042
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Linux Vserver not detected properly
<!---
Verify first that your issue/request is not already reported on GitHub.
Also test if the latest release, and devel branch are affected too.
-->
##### ISSUE TYPE
<!--- Pick one below and delete the rest -->
- Bug Report
##### COMPONENT NAME
lib/ansible/module_utils/facts/virtual/linux.py
##### ANSIBLE VERSION
ansible 2.4.3.0
config file = /etc/ansible/ansible.cfg
configured module search path = [u'/root/.ansible/plugins/modules', u'/usr/share/ansible/plugins/modules']
ansible python module location = /usr/lib/python2.7/dist-packages/ansible
executable location = /usr/bin/ansible
python version = 2.7.6 (default, Nov 23 2017, 15:49:48) [GCC 4.8.4]
Also present in 'devel' branch.
##### OS / ENVIRONMENT
Host with Linux Vserver:
Linux FQDN 4.1.48-vs2.3.8.6-beng #1 SMP Sun Jan 14 14:33:48 GMT 2018 x86_64 GNU/Linux
##### SUMMARY
Ansible uses /proc/self/status to detect Linux Vserver with:
https://github.com/ansible/ansible/blob/6a223d55760dd21b5063ca2c8296f3ef57dd75e7/lib/ansible/module_utils/facts/virtual/linux.py#L157
This doesn't work on my system, the output of /proc/self/status contains:
```
Cpus_allowed: ff
Cpus_allowed_list: 0-7
Mems_allowed: 00000000,00000001
Mems_allowed_list: 0
VxID: 40024
NxID: 40024
voluntary_ctxt_switches: 0
nonvoluntary_ctxt_switches: 1
```
There are three spaces between 'VxID:' and '40024', the regex only allows one.
Changing the code to:
`if re.match(r'^VxID:\s*\d+', line):`
Fixes this.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lib/ansible/module_utils/facts/virtual/linux.py`
Content:
```
1 # This file is part of Ansible
2 #
3 # Ansible is free software: you can redistribute it and/or modify
4 # it under the terms of the GNU General Public License as published by
5 # the Free Software Foundation, either version 3 of the License, or
6 # (at your option) any later version.
7 #
8 # Ansible is distributed in the hope that it will be useful,
9 # but WITHOUT ANY WARRANTY; without even the implied warranty of
10 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
11 # GNU General Public License for more details.
12 #
13 # You should have received a copy of the GNU General Public License
14 # along with Ansible. If not, see <http://www.gnu.org/licenses/>.
15
16 from __future__ import (absolute_import, division, print_function)
17 __metaclass__ = type
18
19 import glob
20 import os
21 import re
22
23 from ansible.module_utils.facts.virtual.base import Virtual, VirtualCollector
24 from ansible.module_utils.facts.utils import get_file_content, get_file_lines
25
26
27 class LinuxVirtual(Virtual):
28 """
29 This is a Linux-specific subclass of Virtual. It defines
30 - virtualization_type
31 - virtualization_role
32 """
33 platform = 'Linux'
34
35 # For more information, check: http://people.redhat.com/~rjones/virt-what/
36 def get_virtual_facts(self):
37 virtual_facts = {}
38 # lxc/docker
39 if os.path.exists('/proc/1/cgroup'):
40 for line in get_file_lines('/proc/1/cgroup'):
41 if re.search(r'/docker(/|-[0-9a-f]+\.scope)', line):
42 virtual_facts['virtualization_type'] = 'docker'
43 virtual_facts['virtualization_role'] = 'guest'
44 return virtual_facts
45 if re.search('/lxc/', line) or re.search('/machine.slice/machine-lxc', line):
46 virtual_facts['virtualization_type'] = 'lxc'
47 virtual_facts['virtualization_role'] = 'guest'
48 return virtual_facts
49
50 # lxc does not always appear in cgroups anymore but sets 'container=lxc' environment var, requires root privs
51 if os.path.exists('/proc/1/environ'):
52 for line in get_file_lines('/proc/1/environ'):
53 if re.search('container=lxc', line):
54 virtual_facts['virtualization_type'] = 'lxc'
55 virtual_facts['virtualization_role'] = 'guest'
56 return virtual_facts
57
58 if os.path.exists('/proc/vz') and not os.path.exists('/proc/lve'):
59 virtual_facts['virtualization_type'] = 'openvz'
60 if os.path.exists('/proc/bc'):
61 virtual_facts['virtualization_role'] = 'host'
62 else:
63 virtual_facts['virtualization_role'] = 'guest'
64 return virtual_facts
65
66 systemd_container = get_file_content('/run/systemd/container')
67 if systemd_container:
68 virtual_facts['virtualization_type'] = systemd_container
69 virtual_facts['virtualization_role'] = 'guest'
70 return virtual_facts
71
72 if os.path.exists("/proc/xen"):
73 virtual_facts['virtualization_type'] = 'xen'
74 virtual_facts['virtualization_role'] = 'guest'
75 try:
76 for line in get_file_lines('/proc/xen/capabilities'):
77 if "control_d" in line:
78 virtual_facts['virtualization_role'] = 'host'
79 except IOError:
80 pass
81 return virtual_facts
82
83 product_name = get_file_content('/sys/devices/virtual/dmi/id/product_name')
84
85 if product_name in ['KVM', 'Bochs']:
86 virtual_facts['virtualization_type'] = 'kvm'
87 virtual_facts['virtualization_role'] = 'guest'
88 return virtual_facts
89
90 if product_name == 'RHEV Hypervisor':
91 virtual_facts['virtualization_type'] = 'RHEV'
92 virtual_facts['virtualization_role'] = 'guest'
93 return virtual_facts
94
95 if product_name in ['VMware Virtual Platform', 'VMware7,1']:
96 virtual_facts['virtualization_type'] = 'VMware'
97 virtual_facts['virtualization_role'] = 'guest'
98 return virtual_facts
99
100 if product_name in ['OpenStack Compute', 'OpenStack Nova']:
101 virtual_facts['virtualization_type'] = 'openstack'
102 virtual_facts['virtualization_role'] = 'guest'
103 return virtual_facts
104
105 bios_vendor = get_file_content('/sys/devices/virtual/dmi/id/bios_vendor')
106
107 if bios_vendor == 'Xen':
108 virtual_facts['virtualization_type'] = 'xen'
109 virtual_facts['virtualization_role'] = 'guest'
110 return virtual_facts
111
112 if bios_vendor == 'innotek GmbH':
113 virtual_facts['virtualization_type'] = 'virtualbox'
114 virtual_facts['virtualization_role'] = 'guest'
115 return virtual_facts
116
117 if bios_vendor == 'Amazon EC2':
118 virtual_facts['virtualization_type'] = 'kvm'
119 virtual_facts['virtualization_role'] = 'guest'
120 return virtual_facts
121
122 sys_vendor = get_file_content('/sys/devices/virtual/dmi/id/sys_vendor')
123
124 # FIXME: This does also match hyperv
125 if sys_vendor == 'Microsoft Corporation':
126 virtual_facts['virtualization_type'] = 'VirtualPC'
127 virtual_facts['virtualization_role'] = 'guest'
128 return virtual_facts
129
130 if sys_vendor == 'Parallels Software International Inc.':
131 virtual_facts['virtualization_type'] = 'parallels'
132 virtual_facts['virtualization_role'] = 'guest'
133 return virtual_facts
134
135 if sys_vendor == 'QEMU':
136 virtual_facts['virtualization_type'] = 'kvm'
137 virtual_facts['virtualization_role'] = 'guest'
138 return virtual_facts
139
140 if sys_vendor == 'oVirt':
141 virtual_facts['virtualization_type'] = 'kvm'
142 virtual_facts['virtualization_role'] = 'guest'
143 return virtual_facts
144
145 if sys_vendor == 'OpenStack Foundation':
146 virtual_facts['virtualization_type'] = 'openstack'
147 virtual_facts['virtualization_role'] = 'guest'
148 return virtual_facts
149
150 if sys_vendor == 'Amazon EC2':
151 virtual_facts['virtualization_type'] = 'kvm'
152 virtual_facts['virtualization_role'] = 'guest'
153 return virtual_facts
154
155 if os.path.exists('/proc/self/status'):
156 for line in get_file_lines('/proc/self/status'):
157 if re.match(r'^VxID: \d+', line):
158 virtual_facts['virtualization_type'] = 'linux_vserver'
159 if re.match(r'^VxID: 0', line):
160 virtual_facts['virtualization_role'] = 'host'
161 else:
162 virtual_facts['virtualization_role'] = 'guest'
163 return virtual_facts
164
165 if os.path.exists('/proc/cpuinfo'):
166 for line in get_file_lines('/proc/cpuinfo'):
167 if re.match('^model name.*QEMU Virtual CPU', line):
168 virtual_facts['virtualization_type'] = 'kvm'
169 elif re.match('^vendor_id.*User Mode Linux', line):
170 virtual_facts['virtualization_type'] = 'uml'
171 elif re.match('^model name.*UML', line):
172 virtual_facts['virtualization_type'] = 'uml'
173 elif re.match('^machine.*CHRP IBM pSeries .emulated by qemu.', line):
174 virtual_facts['virtualization_type'] = 'kvm'
175 elif re.match('^vendor_id.*PowerVM Lx86', line):
176 virtual_facts['virtualization_type'] = 'powervm_lx86'
177 elif re.match('^vendor_id.*IBM/S390', line):
178 virtual_facts['virtualization_type'] = 'PR/SM'
179 lscpu = self.module.get_bin_path('lscpu')
180 if lscpu:
181 rc, out, err = self.module.run_command(["lscpu"])
182 if rc == 0:
183 for line in out.splitlines():
184 data = line.split(":", 1)
185 key = data[0].strip()
186 if key == 'Hypervisor':
187 virtual_facts['virtualization_type'] = data[1].strip()
188 else:
189 virtual_facts['virtualization_type'] = 'ibm_systemz'
190 else:
191 continue
192 if virtual_facts['virtualization_type'] == 'PR/SM':
193 virtual_facts['virtualization_role'] = 'LPAR'
194 else:
195 virtual_facts['virtualization_role'] = 'guest'
196 return virtual_facts
197
198 # Beware that we can have both kvm and virtualbox running on a single system
199 if os.path.exists("/proc/modules") and os.access('/proc/modules', os.R_OK):
200 modules = []
201 for line in get_file_lines("/proc/modules"):
202 data = line.split(" ", 1)
203 modules.append(data[0])
204
205 if 'kvm' in modules:
206
207 if os.path.isdir('/rhev/'):
208
209 # Check whether this is a RHEV hypervisor (is vdsm running ?)
210 for f in glob.glob('/proc/[0-9]*/comm'):
211 try:
212 if open(f).read().rstrip() == 'vdsm':
213 virtual_facts['virtualization_type'] = 'RHEV'
214 break
215 except:
216 pass
217 else:
218 virtual_facts['virtualization_type'] = 'kvm'
219
220 else:
221 virtual_facts['virtualization_type'] = 'kvm'
222 virtual_facts['virtualization_role'] = 'host'
223
224 return virtual_facts
225
226 if 'vboxdrv' in modules:
227 virtual_facts['virtualization_type'] = 'virtualbox'
228 virtual_facts['virtualization_role'] = 'host'
229 return virtual_facts
230
231 if 'virtio' in modules:
232 virtual_facts['virtualization_type'] = 'kvm'
233 virtual_facts['virtualization_role'] = 'guest'
234 return virtual_facts
235
236 # In older Linux Kernel versions, /sys filesystem is not available
237 # dmidecode is the safest option to parse virtualization related values
238 dmi_bin = self.module.get_bin_path('dmidecode')
239 (rc, out, err) = self.module.run_command('%s -s system-product-name' % dmi_bin)
240 if rc == 0:
241 # Strip out commented lines (specific dmidecode output)
242 vendor_name = ''.join([line.strip() for line in out.splitlines() if not line.startswith('#')])
243 if vendor_name in ['VMware Virtual Platform', 'VMware7,1']:
244 virtual_facts['virtualization_type'] = 'VMware'
245 virtual_facts['virtualization_role'] = 'guest'
246
247 # If none of the above matches, return 'NA' for virtualization_type
248 # and virtualization_role. This allows for proper grouping.
249 virtual_facts['virtualization_type'] = 'NA'
250 virtual_facts['virtualization_role'] = 'NA'
251
252 return virtual_facts
253
254
255 class LinuxVirtualCollector(VirtualCollector):
256 _fact_class = LinuxVirtual
257 _platform = 'Linux'
258
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lib/ansible/module_utils/facts/virtual/linux.py b/lib/ansible/module_utils/facts/virtual/linux.py
--- a/lib/ansible/module_utils/facts/virtual/linux.py
+++ b/lib/ansible/module_utils/facts/virtual/linux.py
@@ -154,9 +154,9 @@
if os.path.exists('/proc/self/status'):
for line in get_file_lines('/proc/self/status'):
- if re.match(r'^VxID: \d+', line):
+ if re.match(r'^VxID:\s+\d+', line):
virtual_facts['virtualization_type'] = 'linux_vserver'
- if re.match(r'^VxID: 0', line):
+ if re.match(r'^VxID:\s+0', line):
virtual_facts['virtualization_role'] = 'host'
else:
virtual_facts['virtualization_role'] = 'guest'
@@ -212,7 +212,7 @@
if open(f).read().rstrip() == 'vdsm':
virtual_facts['virtualization_type'] = 'RHEV'
break
- except:
+ except Exception:
pass
else:
virtual_facts['virtualization_type'] = 'kvm'
|
{"golden_diff": "diff --git a/lib/ansible/module_utils/facts/virtual/linux.py b/lib/ansible/module_utils/facts/virtual/linux.py\n--- a/lib/ansible/module_utils/facts/virtual/linux.py\n+++ b/lib/ansible/module_utils/facts/virtual/linux.py\n@@ -154,9 +154,9 @@\n \n if os.path.exists('/proc/self/status'):\n for line in get_file_lines('/proc/self/status'):\n- if re.match(r'^VxID: \\d+', line):\n+ if re.match(r'^VxID:\\s+\\d+', line):\n virtual_facts['virtualization_type'] = 'linux_vserver'\n- if re.match(r'^VxID: 0', line):\n+ if re.match(r'^VxID:\\s+0', line):\n virtual_facts['virtualization_role'] = 'host'\n else:\n virtual_facts['virtualization_role'] = 'guest'\n@@ -212,7 +212,7 @@\n if open(f).read().rstrip() == 'vdsm':\n virtual_facts['virtualization_type'] = 'RHEV'\n break\n- except:\n+ except Exception:\n pass\n else:\n virtual_facts['virtualization_type'] = 'kvm'\n", "issue": "Linux Vserver not detected properly\n<!---\r\nVerify first that your issue/request is not already reported on GitHub.\r\nAlso test if the latest release, and devel branch are affected too.\r\n-->\r\n\r\n##### ISSUE TYPE\r\n<!--- Pick one below and delete the rest -->\r\n - Bug Report\r\n\r\n##### COMPONENT NAME\r\nlib/ansible/module_utils/facts/virtual/linux.py\r\n\r\n##### ANSIBLE VERSION\r\nansible 2.4.3.0\r\n config file = /etc/ansible/ansible.cfg\r\n configured module search path = [u'/root/.ansible/plugins/modules', u'/usr/share/ansible/plugins/modules']\r\n ansible python module location = /usr/lib/python2.7/dist-packages/ansible\r\n executable location = /usr/bin/ansible\r\n python version = 2.7.6 (default, Nov 23 2017, 15:49:48) [GCC 4.8.4]\r\n\r\nAlso present in 'devel' branch.\r\n\r\n##### OS / ENVIRONMENT\r\nHost with Linux Vserver:\r\nLinux FQDN 4.1.48-vs2.3.8.6-beng #1 SMP Sun Jan 14 14:33:48 GMT 2018 x86_64 GNU/Linux\r\n\r\n##### SUMMARY\r\nAnsible uses /proc/self/status to detect Linux Vserver with:\r\n\r\nhttps://github.com/ansible/ansible/blob/6a223d55760dd21b5063ca2c8296f3ef57dd75e7/lib/ansible/module_utils/facts/virtual/linux.py#L157\r\n\r\nThis doesn't work on my system, the output of /proc/self/status contains:\r\n\r\n```\r\nCpus_allowed: ff\r\nCpus_allowed_list: 0-7\r\nMems_allowed: 00000000,00000001\r\nMems_allowed_list: 0\r\nVxID: 40024\r\nNxID: 40024\r\nvoluntary_ctxt_switches: 0\r\nnonvoluntary_ctxt_switches: 1\r\n```\r\nThere are three spaces between 'VxID:' and '40024', the regex only allows one.\r\n\r\nChanging the code to:\r\n\r\n`if re.match(r'^VxID:\\s*\\d+', line):`\r\n\r\nFixes this.\n", "before_files": [{"content": "# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Ansible is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Ansible. If not, see <http://www.gnu.org/licenses/>.\n\nfrom __future__ import (absolute_import, division, print_function)\n__metaclass__ = type\n\nimport glob\nimport os\nimport re\n\nfrom ansible.module_utils.facts.virtual.base import Virtual, VirtualCollector\nfrom ansible.module_utils.facts.utils import get_file_content, get_file_lines\n\n\nclass LinuxVirtual(Virtual):\n \"\"\"\n This is a Linux-specific subclass of Virtual. It defines\n - virtualization_type\n - virtualization_role\n \"\"\"\n platform = 'Linux'\n\n # For more information, check: http://people.redhat.com/~rjones/virt-what/\n def get_virtual_facts(self):\n virtual_facts = {}\n # lxc/docker\n if os.path.exists('/proc/1/cgroup'):\n for line in get_file_lines('/proc/1/cgroup'):\n if re.search(r'/docker(/|-[0-9a-f]+\\.scope)', line):\n virtual_facts['virtualization_type'] = 'docker'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n if re.search('/lxc/', line) or re.search('/machine.slice/machine-lxc', line):\n virtual_facts['virtualization_type'] = 'lxc'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n # lxc does not always appear in cgroups anymore but sets 'container=lxc' environment var, requires root privs\n if os.path.exists('/proc/1/environ'):\n for line in get_file_lines('/proc/1/environ'):\n if re.search('container=lxc', line):\n virtual_facts['virtualization_type'] = 'lxc'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n if os.path.exists('/proc/vz') and not os.path.exists('/proc/lve'):\n virtual_facts['virtualization_type'] = 'openvz'\n if os.path.exists('/proc/bc'):\n virtual_facts['virtualization_role'] = 'host'\n else:\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n systemd_container = get_file_content('/run/systemd/container')\n if systemd_container:\n virtual_facts['virtualization_type'] = systemd_container\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n if os.path.exists(\"/proc/xen\"):\n virtual_facts['virtualization_type'] = 'xen'\n virtual_facts['virtualization_role'] = 'guest'\n try:\n for line in get_file_lines('/proc/xen/capabilities'):\n if \"control_d\" in line:\n virtual_facts['virtualization_role'] = 'host'\n except IOError:\n pass\n return virtual_facts\n\n product_name = get_file_content('/sys/devices/virtual/dmi/id/product_name')\n\n if product_name in ['KVM', 'Bochs']:\n virtual_facts['virtualization_type'] = 'kvm'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n if product_name == 'RHEV Hypervisor':\n virtual_facts['virtualization_type'] = 'RHEV'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n if product_name in ['VMware Virtual Platform', 'VMware7,1']:\n virtual_facts['virtualization_type'] = 'VMware'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n if product_name in ['OpenStack Compute', 'OpenStack Nova']:\n virtual_facts['virtualization_type'] = 'openstack'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n bios_vendor = get_file_content('/sys/devices/virtual/dmi/id/bios_vendor')\n\n if bios_vendor == 'Xen':\n virtual_facts['virtualization_type'] = 'xen'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n if bios_vendor == 'innotek GmbH':\n virtual_facts['virtualization_type'] = 'virtualbox'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n if bios_vendor == 'Amazon EC2':\n virtual_facts['virtualization_type'] = 'kvm'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n sys_vendor = get_file_content('/sys/devices/virtual/dmi/id/sys_vendor')\n\n # FIXME: This does also match hyperv\n if sys_vendor == 'Microsoft Corporation':\n virtual_facts['virtualization_type'] = 'VirtualPC'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n if sys_vendor == 'Parallels Software International Inc.':\n virtual_facts['virtualization_type'] = 'parallels'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n if sys_vendor == 'QEMU':\n virtual_facts['virtualization_type'] = 'kvm'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n if sys_vendor == 'oVirt':\n virtual_facts['virtualization_type'] = 'kvm'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n if sys_vendor == 'OpenStack Foundation':\n virtual_facts['virtualization_type'] = 'openstack'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n if sys_vendor == 'Amazon EC2':\n virtual_facts['virtualization_type'] = 'kvm'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n if os.path.exists('/proc/self/status'):\n for line in get_file_lines('/proc/self/status'):\n if re.match(r'^VxID: \\d+', line):\n virtual_facts['virtualization_type'] = 'linux_vserver'\n if re.match(r'^VxID: 0', line):\n virtual_facts['virtualization_role'] = 'host'\n else:\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n if os.path.exists('/proc/cpuinfo'):\n for line in get_file_lines('/proc/cpuinfo'):\n if re.match('^model name.*QEMU Virtual CPU', line):\n virtual_facts['virtualization_type'] = 'kvm'\n elif re.match('^vendor_id.*User Mode Linux', line):\n virtual_facts['virtualization_type'] = 'uml'\n elif re.match('^model name.*UML', line):\n virtual_facts['virtualization_type'] = 'uml'\n elif re.match('^machine.*CHRP IBM pSeries .emulated by qemu.', line):\n virtual_facts['virtualization_type'] = 'kvm'\n elif re.match('^vendor_id.*PowerVM Lx86', line):\n virtual_facts['virtualization_type'] = 'powervm_lx86'\n elif re.match('^vendor_id.*IBM/S390', line):\n virtual_facts['virtualization_type'] = 'PR/SM'\n lscpu = self.module.get_bin_path('lscpu')\n if lscpu:\n rc, out, err = self.module.run_command([\"lscpu\"])\n if rc == 0:\n for line in out.splitlines():\n data = line.split(\":\", 1)\n key = data[0].strip()\n if key == 'Hypervisor':\n virtual_facts['virtualization_type'] = data[1].strip()\n else:\n virtual_facts['virtualization_type'] = 'ibm_systemz'\n else:\n continue\n if virtual_facts['virtualization_type'] == 'PR/SM':\n virtual_facts['virtualization_role'] = 'LPAR'\n else:\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n # Beware that we can have both kvm and virtualbox running on a single system\n if os.path.exists(\"/proc/modules\") and os.access('/proc/modules', os.R_OK):\n modules = []\n for line in get_file_lines(\"/proc/modules\"):\n data = line.split(\" \", 1)\n modules.append(data[0])\n\n if 'kvm' in modules:\n\n if os.path.isdir('/rhev/'):\n\n # Check whether this is a RHEV hypervisor (is vdsm running ?)\n for f in glob.glob('/proc/[0-9]*/comm'):\n try:\n if open(f).read().rstrip() == 'vdsm':\n virtual_facts['virtualization_type'] = 'RHEV'\n break\n except:\n pass\n else:\n virtual_facts['virtualization_type'] = 'kvm'\n\n else:\n virtual_facts['virtualization_type'] = 'kvm'\n virtual_facts['virtualization_role'] = 'host'\n\n return virtual_facts\n\n if 'vboxdrv' in modules:\n virtual_facts['virtualization_type'] = 'virtualbox'\n virtual_facts['virtualization_role'] = 'host'\n return virtual_facts\n\n if 'virtio' in modules:\n virtual_facts['virtualization_type'] = 'kvm'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n # In older Linux Kernel versions, /sys filesystem is not available\n # dmidecode is the safest option to parse virtualization related values\n dmi_bin = self.module.get_bin_path('dmidecode')\n (rc, out, err) = self.module.run_command('%s -s system-product-name' % dmi_bin)\n if rc == 0:\n # Strip out commented lines (specific dmidecode output)\n vendor_name = ''.join([line.strip() for line in out.splitlines() if not line.startswith('#')])\n if vendor_name in ['VMware Virtual Platform', 'VMware7,1']:\n virtual_facts['virtualization_type'] = 'VMware'\n virtual_facts['virtualization_role'] = 'guest'\n\n # If none of the above matches, return 'NA' for virtualization_type\n # and virtualization_role. This allows for proper grouping.\n virtual_facts['virtualization_type'] = 'NA'\n virtual_facts['virtualization_role'] = 'NA'\n\n return virtual_facts\n\n\nclass LinuxVirtualCollector(VirtualCollector):\n _fact_class = LinuxVirtual\n _platform = 'Linux'\n", "path": "lib/ansible/module_utils/facts/virtual/linux.py"}], "after_files": [{"content": "# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Ansible is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Ansible. If not, see <http://www.gnu.org/licenses/>.\n\nfrom __future__ import (absolute_import, division, print_function)\n__metaclass__ = type\n\nimport glob\nimport os\nimport re\n\nfrom ansible.module_utils.facts.virtual.base import Virtual, VirtualCollector\nfrom ansible.module_utils.facts.utils import get_file_content, get_file_lines\n\n\nclass LinuxVirtual(Virtual):\n \"\"\"\n This is a Linux-specific subclass of Virtual. It defines\n - virtualization_type\n - virtualization_role\n \"\"\"\n platform = 'Linux'\n\n # For more information, check: http://people.redhat.com/~rjones/virt-what/\n def get_virtual_facts(self):\n virtual_facts = {}\n # lxc/docker\n if os.path.exists('/proc/1/cgroup'):\n for line in get_file_lines('/proc/1/cgroup'):\n if re.search(r'/docker(/|-[0-9a-f]+\\.scope)', line):\n virtual_facts['virtualization_type'] = 'docker'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n if re.search('/lxc/', line) or re.search('/machine.slice/machine-lxc', line):\n virtual_facts['virtualization_type'] = 'lxc'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n # lxc does not always appear in cgroups anymore but sets 'container=lxc' environment var, requires root privs\n if os.path.exists('/proc/1/environ'):\n for line in get_file_lines('/proc/1/environ'):\n if re.search('container=lxc', line):\n virtual_facts['virtualization_type'] = 'lxc'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n if os.path.exists('/proc/vz') and not os.path.exists('/proc/lve'):\n virtual_facts['virtualization_type'] = 'openvz'\n if os.path.exists('/proc/bc'):\n virtual_facts['virtualization_role'] = 'host'\n else:\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n systemd_container = get_file_content('/run/systemd/container')\n if systemd_container:\n virtual_facts['virtualization_type'] = systemd_container\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n if os.path.exists(\"/proc/xen\"):\n virtual_facts['virtualization_type'] = 'xen'\n virtual_facts['virtualization_role'] = 'guest'\n try:\n for line in get_file_lines('/proc/xen/capabilities'):\n if \"control_d\" in line:\n virtual_facts['virtualization_role'] = 'host'\n except IOError:\n pass\n return virtual_facts\n\n product_name = get_file_content('/sys/devices/virtual/dmi/id/product_name')\n\n if product_name in ['KVM', 'Bochs']:\n virtual_facts['virtualization_type'] = 'kvm'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n if product_name == 'RHEV Hypervisor':\n virtual_facts['virtualization_type'] = 'RHEV'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n if product_name in ['VMware Virtual Platform', 'VMware7,1']:\n virtual_facts['virtualization_type'] = 'VMware'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n if product_name in ['OpenStack Compute', 'OpenStack Nova']:\n virtual_facts['virtualization_type'] = 'openstack'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n bios_vendor = get_file_content('/sys/devices/virtual/dmi/id/bios_vendor')\n\n if bios_vendor == 'Xen':\n virtual_facts['virtualization_type'] = 'xen'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n if bios_vendor == 'innotek GmbH':\n virtual_facts['virtualization_type'] = 'virtualbox'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n if bios_vendor == 'Amazon EC2':\n virtual_facts['virtualization_type'] = 'kvm'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n sys_vendor = get_file_content('/sys/devices/virtual/dmi/id/sys_vendor')\n\n # FIXME: This does also match hyperv\n if sys_vendor == 'Microsoft Corporation':\n virtual_facts['virtualization_type'] = 'VirtualPC'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n if sys_vendor == 'Parallels Software International Inc.':\n virtual_facts['virtualization_type'] = 'parallels'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n if sys_vendor == 'QEMU':\n virtual_facts['virtualization_type'] = 'kvm'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n if sys_vendor == 'oVirt':\n virtual_facts['virtualization_type'] = 'kvm'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n if sys_vendor == 'OpenStack Foundation':\n virtual_facts['virtualization_type'] = 'openstack'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n if sys_vendor == 'Amazon EC2':\n virtual_facts['virtualization_type'] = 'kvm'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n if os.path.exists('/proc/self/status'):\n for line in get_file_lines('/proc/self/status'):\n if re.match(r'^VxID:\\s+\\d+', line):\n virtual_facts['virtualization_type'] = 'linux_vserver'\n if re.match(r'^VxID:\\s+0', line):\n virtual_facts['virtualization_role'] = 'host'\n else:\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n if os.path.exists('/proc/cpuinfo'):\n for line in get_file_lines('/proc/cpuinfo'):\n if re.match('^model name.*QEMU Virtual CPU', line):\n virtual_facts['virtualization_type'] = 'kvm'\n elif re.match('^vendor_id.*User Mode Linux', line):\n virtual_facts['virtualization_type'] = 'uml'\n elif re.match('^model name.*UML', line):\n virtual_facts['virtualization_type'] = 'uml'\n elif re.match('^machine.*CHRP IBM pSeries .emulated by qemu.', line):\n virtual_facts['virtualization_type'] = 'kvm'\n elif re.match('^vendor_id.*PowerVM Lx86', line):\n virtual_facts['virtualization_type'] = 'powervm_lx86'\n elif re.match('^vendor_id.*IBM/S390', line):\n virtual_facts['virtualization_type'] = 'PR/SM'\n lscpu = self.module.get_bin_path('lscpu')\n if lscpu:\n rc, out, err = self.module.run_command([\"lscpu\"])\n if rc == 0:\n for line in out.splitlines():\n data = line.split(\":\", 1)\n key = data[0].strip()\n if key == 'Hypervisor':\n virtual_facts['virtualization_type'] = data[1].strip()\n else:\n virtual_facts['virtualization_type'] = 'ibm_systemz'\n else:\n continue\n if virtual_facts['virtualization_type'] == 'PR/SM':\n virtual_facts['virtualization_role'] = 'LPAR'\n else:\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n # Beware that we can have both kvm and virtualbox running on a single system\n if os.path.exists(\"/proc/modules\") and os.access('/proc/modules', os.R_OK):\n modules = []\n for line in get_file_lines(\"/proc/modules\"):\n data = line.split(\" \", 1)\n modules.append(data[0])\n\n if 'kvm' in modules:\n\n if os.path.isdir('/rhev/'):\n\n # Check whether this is a RHEV hypervisor (is vdsm running ?)\n for f in glob.glob('/proc/[0-9]*/comm'):\n try:\n if open(f).read().rstrip() == 'vdsm':\n virtual_facts['virtualization_type'] = 'RHEV'\n break\n except Exception:\n pass\n else:\n virtual_facts['virtualization_type'] = 'kvm'\n\n else:\n virtual_facts['virtualization_type'] = 'kvm'\n virtual_facts['virtualization_role'] = 'host'\n\n return virtual_facts\n\n if 'vboxdrv' in modules:\n virtual_facts['virtualization_type'] = 'virtualbox'\n virtual_facts['virtualization_role'] = 'host'\n return virtual_facts\n\n if 'virtio' in modules:\n virtual_facts['virtualization_type'] = 'kvm'\n virtual_facts['virtualization_role'] = 'guest'\n return virtual_facts\n\n # In older Linux Kernel versions, /sys filesystem is not available\n # dmidecode is the safest option to parse virtualization related values\n dmi_bin = self.module.get_bin_path('dmidecode')\n (rc, out, err) = self.module.run_command('%s -s system-product-name' % dmi_bin)\n if rc == 0:\n # Strip out commented lines (specific dmidecode output)\n vendor_name = ''.join([line.strip() for line in out.splitlines() if not line.startswith('#')])\n if vendor_name in ['VMware Virtual Platform', 'VMware7,1']:\n virtual_facts['virtualization_type'] = 'VMware'\n virtual_facts['virtualization_role'] = 'guest'\n\n # If none of the above matches, return 'NA' for virtualization_type\n # and virtualization_role. This allows for proper grouping.\n virtual_facts['virtualization_type'] = 'NA'\n virtual_facts['virtualization_role'] = 'NA'\n\n return virtual_facts\n\n\nclass LinuxVirtualCollector(VirtualCollector):\n _fact_class = LinuxVirtual\n _platform = 'Linux'\n", "path": "lib/ansible/module_utils/facts/virtual/linux.py"}]}
| 3,910 | 278 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.