
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.1k
25.4k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 582
39.1k
| num_tokens
int64 271
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_54380
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-3284
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Consider turning off template directories in Git for conan config install
To help us debug your issue please explain:
- [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md).
- [x] I've specified the Conan version, operating system version and any tool that can be relevant.
- [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion.
This is with Conan 1.6.0 on Windows 10.
To see this in progress, have a Git installation set up with automatic ctags generation akin to what's described in [Effortless Ctags with Git](https://tbaggery.com/2011/08/08/effortless-ctags-with-git.html).
When doing `conan config install` with a Git URL, I get error messages like this:
```
Traceback (most recent call last):
File "c:\users\kam\.virtualenvs\skel-hv6zqtfh\lib\shutil.py", line 391, in _rmtree_unsafe
os.rmdir(path)
OSError: [WinError 145] The directory is not empty: 'C:\\Users\\kam\\.conan\\tmp_config_install\\config\\.git\\hooks'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "c:\users\kam\.virtualenvs\skel-hv6zqtfh\lib\site-packages\conans\client\command.py", line 1230, in run
method(args[0][1:])
File "c:\users\kam\.virtualenvs\skel-hv6zqtfh\lib\site-packages\conans\client\command.py", line 379, in config
return self._conan.config_install(args.item, verify_ssl, args.type)
File "c:\users\kam\.virtualenvs\skel-hv6zqtfh\lib\site-packages\conans\client\conan_api.py", line 79, in wrapper
return f(*args, **kwargs)
File "c:\users\kam\.virtualenvs\skel-hv6zqtfh\lib\site-packages\conans\client\conan_api.py", line 510, in config_install
return configuration_install(item, self._client_cache, self._user_io.out, verify_ssl, config_type)
File "c:\users\kam\.virtualenvs\skel-hv6zqtfh\lib\site-packages\conans\client\conf\config_installer.py", line 135, in configuration_install
rmdir(tmp_folder)
File "c:\users\kam\.virtualenvs\skel-hv6zqtfh\lib\site-packages\conans\util\files.py", line 202, in rmdir
shutil.rmtree(path, onerror=_change_permissions)
File "c:\users\kam\.virtualenvs\skel-hv6zqtfh\lib\shutil.py", line 494, in rmtree
return _rmtree_unsafe(path, onerror)
File "c:\users\kam\.virtualenvs\skel-hv6zqtfh\lib\shutil.py", line 384, in _rmtree_unsafe
_rmtree_unsafe(fullname, onerror)
File "c:\users\kam\.virtualenvs\skel-hv6zqtfh\lib\shutil.py", line 384, in _rmtree_unsafe
_rmtree_unsafe(fullname, onerror)
File "c:\users\kam\.virtualenvs\skel-hv6zqtfh\lib\shutil.py", line 384, in _rmtree_unsafe
_rmtree_unsafe(fullname, onerror)
File "c:\users\kam\.virtualenvs\skel-hv6zqtfh\lib\shutil.py", line 393, in _rmtree_unsafe
onerror(os.rmdir, path, sys.exc_info())
File "c:\users\kam\.virtualenvs\skel-hv6zqtfh\lib\site-packages\conans\util\files.py", line 197, in _change_permissions
raise OSError("Cannot change permissions for {}! Exception info: {}".format(path, exc_info))
OSError: Cannot change permissions for C:\Users\kam\.conan\tmp_config_install\config\.git\hooks! Exception info: (<class 'OSError'>, OSError(41, 'The directory is not empty'), <traceback object at 0x0000016409078548>)
ERROR: Cannot change permissions for C:\Users\kam\.conan\tmp_config_install\config\.git\hooks! Exception info: (<class 'OSError'>, OSError(41, 'The directory is not empty'), <traceback object at 0x0000016409078548>)
```
The problem boils down to the way files are locked on Windows. It's not possible to delete open files. But the hook starts a background process which has the script files open, and the cleanup of the directory fails. Of course, a second later, the directory can be deleted as files are closed and unlocked.
I've since started reworking my Git template to not start background processes by default, and only run `ctags` in checkouts that I'm actually developing on. This fixes my problem with `conan config install`.
It may make sense, though, to add `-c init.templateDir=` to the `git` command line when working on temporary downloads. It's part of sanitizing the process against user configuration: In a hook, _anything_ can happen, and the errors are obscure and difficult to understand.
`conan config install` is mostly treating a Git repository as a sophisticated form of file archive, and probably doesn't want the user's hooks or other unusual setups from the template.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conans/client/conf/config_installer.py`
Content:
```
1 import os
2 import shutil
3 from six.moves.urllib.parse import urlparse
4
5 from conans.tools import unzip
6 from conans.util.files import rmdir, mkdir
7 from conans.client.remote_registry import RemoteRegistry
8 from conans import tools
9 from conans.errors import ConanException
10 import subprocess
11
12
13 def _hide_password(resource):
14 """
15 Hide password from url/file path
16
17 :param resource: string with url or file path
18 :return: resource with hidden password if present
19 """
20 password = urlparse(resource).password
21 return resource.replace(password, "<hidden>") if password else resource
22
23
24 def _handle_remotes(registry_path, remote_file, output):
25 registry = RemoteRegistry(registry_path, output)
26 new_registry = RemoteRegistry(remote_file, output)
27 registry.define_remotes(new_registry.remotes)
28
29
30 def _handle_profiles(source_folder, target_folder, output):
31 mkdir(target_folder)
32 for root, _, files in os.walk(source_folder):
33 relative_path = os.path.relpath(root, source_folder)
34 if relative_path == ".":
35 relative_path = ""
36 for f in files:
37 profile = os.path.join(relative_path, f)
38 output.info(" Installing profile %s" % profile)
39 shutil.copy(os.path.join(root, f), os.path.join(target_folder, profile))
40
41
42 def _process_git_repo(repo_url, client_cache, output, tmp_folder, verify_ssl):
43 output.info("Trying to clone repo %s" % repo_url)
44
45 with tools.chdir(tmp_folder):
46 try:
47 subprocess.check_output('git -c http.sslVerify=%s clone "%s" config' % (verify_ssl, repo_url),
48 shell=True)
49 output.info("Repo cloned")
50 except Exception as e:
51 raise ConanException("config install error. Can't clone repo: %s" % str(e))
52
53 tmp_folder = os.path.join(tmp_folder, "config")
54 _process_folder(tmp_folder, client_cache, output)
55
56
57 def _process_zip_file(zippath, client_cache, output, tmp_folder, remove=False):
58 unzip(zippath, tmp_folder)
59 if remove:
60 os.unlink(zippath)
61 _process_folder(tmp_folder, client_cache, output)
62
63
64 def _handle_conan_conf(current_conan_conf, new_conan_conf_path):
65 current_conan_conf.read(new_conan_conf_path)
66 with open(current_conan_conf.filename, "w") as f:
67 current_conan_conf.write(f)
68
69
70 def _process_folder(folder, client_cache, output):
71 for root, dirs, files in os.walk(folder):
72 for f in files:
73 if f == "settings.yml":
74 output.info("Installing settings.yml")
75 settings_path = client_cache.settings_path
76 shutil.copy(os.path.join(root, f), settings_path)
77 elif f == "conan.conf":
78 output.info("Processing conan.conf")
79 conan_conf = client_cache.conan_config
80 _handle_conan_conf(conan_conf, os.path.join(root, f))
81 elif f == "remotes.txt":
82 output.info("Defining remotes")
83 registry_path = client_cache.registry
84 _handle_remotes(registry_path, os.path.join(root, f), output)
85 else:
86 relpath = os.path.relpath(root, folder)
87 target_folder = os.path.join(client_cache.conan_folder, relpath)
88 mkdir(target_folder)
89 output.info("Copying file %s to %s" % (f, target_folder))
90 shutil.copy(os.path.join(root, f), target_folder)
91 for d in dirs:
92 if d == "profiles":
93 output.info("Installing profiles")
94 profiles_path = client_cache.profiles_path
95 _handle_profiles(os.path.join(root, d), profiles_path, output)
96 break
97 dirs[:] = [d for d in dirs if d not in ("profiles", ".git")]
98
99
100 def _process_download(item, client_cache, output, tmp_folder, verify_ssl):
101 output.info("Trying to download %s" % _hide_password(item))
102 zippath = os.path.join(tmp_folder, "config.zip")
103 try:
104 tools.download(item, zippath, out=output, verify=verify_ssl)
105 _process_zip_file(zippath, client_cache, output, tmp_folder, remove=True)
106 except Exception as e:
107 raise ConanException("Error while installing config from %s\n%s" % (item, str(e)))
108
109
110 def configuration_install(item, client_cache, output, verify_ssl, config_type=None):
111 tmp_folder = os.path.join(client_cache.conan_folder, "tmp_config_install")
112 # necessary for Mac OSX, where the temp folders in /var/ are symlinks to /private/var/
113 tmp_folder = os.path.realpath(tmp_folder)
114 mkdir(tmp_folder)
115 try:
116 if item is None:
117 try:
118 item = client_cache.conan_config.get_item("general.config_install")
119 except ConanException:
120 raise ConanException("Called config install without arguments and "
121 "'general.config_install' not defined in conan.conf")
122
123 if item.endswith(".git") or config_type == "git":
124 _process_git_repo(item, client_cache, output, tmp_folder, verify_ssl)
125 elif os.path.exists(item):
126 # is a local file
127 _process_zip_file(item, client_cache, output, tmp_folder)
128 elif item.startswith("http"):
129 _process_download(item, client_cache, output, tmp_folder, verify_ssl)
130 else:
131 raise ConanException("I don't know how to process %s" % item)
132 finally:
133 if item:
134 client_cache.conan_config.set_item("general.config_install", item)
135 rmdir(tmp_folder)
136
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/conans/client/conf/config_installer.py b/conans/client/conf/config_installer.py
--- a/conans/client/conf/config_installer.py
+++ b/conans/client/conf/config_installer.py
@@ -44,7 +44,7 @@
with tools.chdir(tmp_folder):
try:
- subprocess.check_output('git -c http.sslVerify=%s clone "%s" config' % (verify_ssl, repo_url),
+ subprocess.check_output('git -c http.sslVerify=%s -c init.templateDir= clone "%s" config' % (verify_ssl, repo_url),
shell=True)
output.info("Repo cloned")
except Exception as e:
|
{"golden_diff": "diff --git a/conans/client/conf/config_installer.py b/conans/client/conf/config_installer.py\n--- a/conans/client/conf/config_installer.py\n+++ b/conans/client/conf/config_installer.py\n@@ -44,7 +44,7 @@\n \n with tools.chdir(tmp_folder):\n try:\n- subprocess.check_output('git -c http.sslVerify=%s clone \"%s\" config' % (verify_ssl, repo_url),\n+ subprocess.check_output('git -c http.sslVerify=%s -c init.templateDir= clone \"%s\" config' % (verify_ssl, repo_url),\n shell=True)\n output.info(\"Repo cloned\")\n except Exception as e:\n", "issue": "Consider turning off template directories in Git for conan config install\nTo help us debug your issue please explain:\r\n\r\n- [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md).\r\n- [x] I've specified the Conan version, operating system version and any tool that can be relevant.\r\n- [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion.\r\n\r\nThis is with Conan 1.6.0 on Windows 10.\r\n\r\nTo see this in progress, have a Git installation set up with automatic ctags generation akin to what's described in [Effortless Ctags with Git](https://tbaggery.com/2011/08/08/effortless-ctags-with-git.html).\r\n\r\nWhen doing `conan config install` with a Git URL, I get error messages like this:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"c:\\users\\kam\\.virtualenvs\\skel-hv6zqtfh\\lib\\shutil.py\", line 391, in _rmtree_unsafe\r\n os.rmdir(path)\r\nOSError: [WinError 145] The directory is not empty: 'C:\\\\Users\\\\kam\\\\.conan\\\\tmp_config_install\\\\config\\\\.git\\\\hooks'\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"c:\\users\\kam\\.virtualenvs\\skel-hv6zqtfh\\lib\\site-packages\\conans\\client\\command.py\", line 1230, in run\r\n method(args[0][1:])\r\n File \"c:\\users\\kam\\.virtualenvs\\skel-hv6zqtfh\\lib\\site-packages\\conans\\client\\command.py\", line 379, in config\r\n return self._conan.config_install(args.item, verify_ssl, args.type)\r\n File \"c:\\users\\kam\\.virtualenvs\\skel-hv6zqtfh\\lib\\site-packages\\conans\\client\\conan_api.py\", line 79, in wrapper\r\n return f(*args, **kwargs)\r\n File \"c:\\users\\kam\\.virtualenvs\\skel-hv6zqtfh\\lib\\site-packages\\conans\\client\\conan_api.py\", line 510, in config_install\r\n return configuration_install(item, self._client_cache, self._user_io.out, verify_ssl, config_type)\r\n File \"c:\\users\\kam\\.virtualenvs\\skel-hv6zqtfh\\lib\\site-packages\\conans\\client\\conf\\config_installer.py\", line 135, in configuration_install\r\n rmdir(tmp_folder)\r\n File \"c:\\users\\kam\\.virtualenvs\\skel-hv6zqtfh\\lib\\site-packages\\conans\\util\\files.py\", line 202, in rmdir\r\n shutil.rmtree(path, onerror=_change_permissions)\r\n File \"c:\\users\\kam\\.virtualenvs\\skel-hv6zqtfh\\lib\\shutil.py\", line 494, in rmtree\r\n return _rmtree_unsafe(path, onerror)\r\n File \"c:\\users\\kam\\.virtualenvs\\skel-hv6zqtfh\\lib\\shutil.py\", line 384, in _rmtree_unsafe\r\n _rmtree_unsafe(fullname, onerror)\r\n File \"c:\\users\\kam\\.virtualenvs\\skel-hv6zqtfh\\lib\\shutil.py\", line 384, in _rmtree_unsafe\r\n _rmtree_unsafe(fullname, onerror)\r\n File \"c:\\users\\kam\\.virtualenvs\\skel-hv6zqtfh\\lib\\shutil.py\", line 384, in _rmtree_unsafe\r\n _rmtree_unsafe(fullname, onerror)\r\n File \"c:\\users\\kam\\.virtualenvs\\skel-hv6zqtfh\\lib\\shutil.py\", line 393, in _rmtree_unsafe\r\n onerror(os.rmdir, path, sys.exc_info())\r\n File \"c:\\users\\kam\\.virtualenvs\\skel-hv6zqtfh\\lib\\site-packages\\conans\\util\\files.py\", line 197, in _change_permissions\r\n raise OSError(\"Cannot change permissions for {}! Exception info: {}\".format(path, exc_info))\r\nOSError: Cannot change permissions for C:\\Users\\kam\\.conan\\tmp_config_install\\config\\.git\\hooks! Exception info: (<class 'OSError'>, OSError(41, 'The directory is not empty'), <traceback object at 0x0000016409078548>)\r\n\r\nERROR: Cannot change permissions for C:\\Users\\kam\\.conan\\tmp_config_install\\config\\.git\\hooks! Exception info: (<class 'OSError'>, OSError(41, 'The directory is not empty'), <traceback object at 0x0000016409078548>)\r\n```\r\n\r\nThe problem boils down to the way files are locked on Windows. It's not possible to delete open files. But the hook starts a background process which has the script files open, and the cleanup of the directory fails. Of course, a second later, the directory can be deleted as files are closed and unlocked.\r\n\r\nI've since started reworking my Git template to not start background processes by default, and only run `ctags` in checkouts that I'm actually developing on. This fixes my problem with `conan config install`.\r\n\r\nIt may make sense, though, to add `-c init.templateDir=` to the `git` command line when working on temporary downloads. It's part of sanitizing the process against user configuration: In a hook, _anything_ can happen, and the errors are obscure and difficult to understand.\r\n\r\n`conan config install` is mostly treating a Git repository as a sophisticated form of file archive, and probably doesn't want the user's hooks or other unusual setups from the template.\r\n\n", "before_files": [{"content": "import os\nimport shutil\nfrom six.moves.urllib.parse import urlparse\n\nfrom conans.tools import unzip\nfrom conans.util.files import rmdir, mkdir\nfrom conans.client.remote_registry import RemoteRegistry\nfrom conans import tools\nfrom conans.errors import ConanException\nimport subprocess\n\n\ndef _hide_password(resource):\n \"\"\"\n Hide password from url/file path\n\n :param resource: string with url or file path\n :return: resource with hidden password if present\n \"\"\"\n password = urlparse(resource).password\n return resource.replace(password, \"<hidden>\") if password else resource\n\n\ndef _handle_remotes(registry_path, remote_file, output):\n registry = RemoteRegistry(registry_path, output)\n new_registry = RemoteRegistry(remote_file, output)\n registry.define_remotes(new_registry.remotes)\n\n\ndef _handle_profiles(source_folder, target_folder, output):\n mkdir(target_folder)\n for root, _, files in os.walk(source_folder):\n relative_path = os.path.relpath(root, source_folder)\n if relative_path == \".\":\n relative_path = \"\"\n for f in files:\n profile = os.path.join(relative_path, f)\n output.info(\" Installing profile %s\" % profile)\n shutil.copy(os.path.join(root, f), os.path.join(target_folder, profile))\n\n\ndef _process_git_repo(repo_url, client_cache, output, tmp_folder, verify_ssl):\n output.info(\"Trying to clone repo %s\" % repo_url)\n\n with tools.chdir(tmp_folder):\n try:\n subprocess.check_output('git -c http.sslVerify=%s clone \"%s\" config' % (verify_ssl, repo_url),\n shell=True)\n output.info(\"Repo cloned\")\n except Exception as e:\n raise ConanException(\"config install error. Can't clone repo: %s\" % str(e))\n\n tmp_folder = os.path.join(tmp_folder, \"config\")\n _process_folder(tmp_folder, client_cache, output)\n\n\ndef _process_zip_file(zippath, client_cache, output, tmp_folder, remove=False):\n unzip(zippath, tmp_folder)\n if remove:\n os.unlink(zippath)\n _process_folder(tmp_folder, client_cache, output)\n\n\ndef _handle_conan_conf(current_conan_conf, new_conan_conf_path):\n current_conan_conf.read(new_conan_conf_path)\n with open(current_conan_conf.filename, \"w\") as f:\n current_conan_conf.write(f)\n\n\ndef _process_folder(folder, client_cache, output):\n for root, dirs, files in os.walk(folder):\n for f in files:\n if f == \"settings.yml\":\n output.info(\"Installing settings.yml\")\n settings_path = client_cache.settings_path\n shutil.copy(os.path.join(root, f), settings_path)\n elif f == \"conan.conf\":\n output.info(\"Processing conan.conf\")\n conan_conf = client_cache.conan_config\n _handle_conan_conf(conan_conf, os.path.join(root, f))\n elif f == \"remotes.txt\":\n output.info(\"Defining remotes\")\n registry_path = client_cache.registry\n _handle_remotes(registry_path, os.path.join(root, f), output)\n else:\n relpath = os.path.relpath(root, folder)\n target_folder = os.path.join(client_cache.conan_folder, relpath)\n mkdir(target_folder)\n output.info(\"Copying file %s to %s\" % (f, target_folder))\n shutil.copy(os.path.join(root, f), target_folder)\n for d in dirs:\n if d == \"profiles\":\n output.info(\"Installing profiles\")\n profiles_path = client_cache.profiles_path\n _handle_profiles(os.path.join(root, d), profiles_path, output)\n break\n dirs[:] = [d for d in dirs if d not in (\"profiles\", \".git\")]\n\n\ndef _process_download(item, client_cache, output, tmp_folder, verify_ssl):\n output.info(\"Trying to download %s\" % _hide_password(item))\n zippath = os.path.join(tmp_folder, \"config.zip\")\n try:\n tools.download(item, zippath, out=output, verify=verify_ssl)\n _process_zip_file(zippath, client_cache, output, tmp_folder, remove=True)\n except Exception as e:\n raise ConanException(\"Error while installing config from %s\\n%s\" % (item, str(e)))\n\n\ndef configuration_install(item, client_cache, output, verify_ssl, config_type=None):\n tmp_folder = os.path.join(client_cache.conan_folder, \"tmp_config_install\")\n # necessary for Mac OSX, where the temp folders in /var/ are symlinks to /private/var/\n tmp_folder = os.path.realpath(tmp_folder)\n mkdir(tmp_folder)\n try:\n if item is None:\n try:\n item = client_cache.conan_config.get_item(\"general.config_install\")\n except ConanException:\n raise ConanException(\"Called config install without arguments and \"\n \"'general.config_install' not defined in conan.conf\")\n\n if item.endswith(\".git\") or config_type == \"git\":\n _process_git_repo(item, client_cache, output, tmp_folder, verify_ssl)\n elif os.path.exists(item):\n # is a local file\n _process_zip_file(item, client_cache, output, tmp_folder)\n elif item.startswith(\"http\"):\n _process_download(item, client_cache, output, tmp_folder, verify_ssl)\n else:\n raise ConanException(\"I don't know how to process %s\" % item)\n finally:\n if item:\n client_cache.conan_config.set_item(\"general.config_install\", item)\n rmdir(tmp_folder)\n", "path": "conans/client/conf/config_installer.py"}], "after_files": [{"content": "import os\nimport shutil\nfrom six.moves.urllib.parse import urlparse\n\nfrom conans.tools import unzip\nfrom conans.util.files import rmdir, mkdir\nfrom conans.client.remote_registry import RemoteRegistry\nfrom conans import tools\nfrom conans.errors import ConanException\nimport subprocess\n\n\ndef _hide_password(resource):\n \"\"\"\n Hide password from url/file path\n\n :param resource: string with url or file path\n :return: resource with hidden password if present\n \"\"\"\n password = urlparse(resource).password\n return resource.replace(password, \"<hidden>\") if password else resource\n\n\ndef _handle_remotes(registry_path, remote_file, output):\n registry = RemoteRegistry(registry_path, output)\n new_registry = RemoteRegistry(remote_file, output)\n registry.define_remotes(new_registry.remotes)\n\n\ndef _handle_profiles(source_folder, target_folder, output):\n mkdir(target_folder)\n for root, _, files in os.walk(source_folder):\n relative_path = os.path.relpath(root, source_folder)\n if relative_path == \".\":\n relative_path = \"\"\n for f in files:\n profile = os.path.join(relative_path, f)\n output.info(\" Installing profile %s\" % profile)\n shutil.copy(os.path.join(root, f), os.path.join(target_folder, profile))\n\n\ndef _process_git_repo(repo_url, client_cache, output, tmp_folder, verify_ssl):\n output.info(\"Trying to clone repo %s\" % repo_url)\n\n with tools.chdir(tmp_folder):\n try:\n subprocess.check_output('git -c http.sslVerify=%s -c init.templateDir= clone \"%s\" config' % (verify_ssl, repo_url),\n shell=True)\n output.info(\"Repo cloned\")\n except Exception as e:\n raise ConanException(\"config install error. Can't clone repo: %s\" % str(e))\n\n tmp_folder = os.path.join(tmp_folder, \"config\")\n _process_folder(tmp_folder, client_cache, output)\n\n\ndef _process_zip_file(zippath, client_cache, output, tmp_folder, remove=False):\n unzip(zippath, tmp_folder)\n if remove:\n os.unlink(zippath)\n _process_folder(tmp_folder, client_cache, output)\n\n\ndef _handle_conan_conf(current_conan_conf, new_conan_conf_path):\n current_conan_conf.read(new_conan_conf_path)\n with open(current_conan_conf.filename, \"w\") as f:\n current_conan_conf.write(f)\n\n\ndef _process_folder(folder, client_cache, output):\n for root, dirs, files in os.walk(folder):\n for f in files:\n if f == \"settings.yml\":\n output.info(\"Installing settings.yml\")\n settings_path = client_cache.settings_path\n shutil.copy(os.path.join(root, f), settings_path)\n elif f == \"conan.conf\":\n output.info(\"Processing conan.conf\")\n conan_conf = client_cache.conan_config\n _handle_conan_conf(conan_conf, os.path.join(root, f))\n elif f == \"remotes.txt\":\n output.info(\"Defining remotes\")\n registry_path = client_cache.registry\n _handle_remotes(registry_path, os.path.join(root, f), output)\n else:\n relpath = os.path.relpath(root, folder)\n target_folder = os.path.join(client_cache.conan_folder, relpath)\n mkdir(target_folder)\n output.info(\"Copying file %s to %s\" % (f, target_folder))\n shutil.copy(os.path.join(root, f), target_folder)\n for d in dirs:\n if d == \"profiles\":\n output.info(\"Installing profiles\")\n profiles_path = client_cache.profiles_path\n _handle_profiles(os.path.join(root, d), profiles_path, output)\n break\n dirs[:] = [d for d in dirs if d not in (\"profiles\", \".git\")]\n\n\ndef _process_download(item, client_cache, output, tmp_folder, verify_ssl):\n output.info(\"Trying to download %s\" % _hide_password(item))\n zippath = os.path.join(tmp_folder, \"config.zip\")\n try:\n tools.download(item, zippath, out=output, verify=verify_ssl)\n _process_zip_file(zippath, client_cache, output, tmp_folder, remove=True)\n except Exception as e:\n raise ConanException(\"Error while installing config from %s\\n%s\" % (item, str(e)))\n\n\ndef configuration_install(item, client_cache, output, verify_ssl, config_type=None):\n tmp_folder = os.path.join(client_cache.conan_folder, \"tmp_config_install\")\n # necessary for Mac OSX, where the temp folders in /var/ are symlinks to /private/var/\n tmp_folder = os.path.realpath(tmp_folder)\n mkdir(tmp_folder)\n try:\n if item is None:\n try:\n item = client_cache.conan_config.get_item(\"general.config_install\")\n except ConanException:\n raise ConanException(\"Called config install without arguments and \"\n \"'general.config_install' not defined in conan.conf\")\n\n if item.endswith(\".git\") or config_type == \"git\":\n _process_git_repo(item, client_cache, output, tmp_folder, verify_ssl)\n elif os.path.exists(item):\n # is a local file\n _process_zip_file(item, client_cache, output, tmp_folder)\n elif item.startswith(\"http\"):\n _process_download(item, client_cache, output, tmp_folder, verify_ssl)\n else:\n raise ConanException(\"I don't know how to process %s\" % item)\n finally:\n if item:\n client_cache.conan_config.set_item(\"general.config_install\", item)\n rmdir(tmp_folder)\n", "path": "conans/client/conf/config_installer.py"}]}
| 3,144 | 146 |
gh_patches_debug_6291
|
rasdani/github-patches
|
git_diff
|
ivy-llc__ivy-16484
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
bitwise_and
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ivy/functional/frontends/paddle/tensor/logic.py`
Content:
```
1 # global
2 import ivy
3 import ivy.functional.frontends.paddle as paddle
4 from ivy.func_wrapper import (
5 with_unsupported_dtypes,
6 handle_out_argument,
7 with_supported_dtypes,
8 )
9 from ivy.functional.frontends.paddle.func_wrapper import (
10 to_ivy_arrays_and_back,
11 )
12
13
14 @with_unsupported_dtypes(
15 {"2.4.2 and below": ("uint8", "int8", "int16", "complex64", "complex128")}, "paddle"
16 )
17 @to_ivy_arrays_and_back
18 def equal(x, y, /, *, name=None):
19 return ivy.equal(x, y)
20
21
22 @with_unsupported_dtypes(
23 {"2.4.2 and below": ("uint8", "int8", "int16", "complex64", "complex128")}, "paddle"
24 )
25 @to_ivy_arrays_and_back
26 def not_equal(x, y, /, *, name=None):
27 return ivy.not_equal(x, y)
28
29
30 @with_unsupported_dtypes(
31 {
32 "2.4.2 and below": (
33 "uint8",
34 "int8",
35 "int16",
36 "float16",
37 "complex64",
38 "complex128",
39 )
40 },
41 "paddle",
42 )
43 @to_ivy_arrays_and_back
44 def equal_all(x, y, /, *, name=None):
45 return paddle.to_tensor([ivy.array_equal(x, y)])
46
47
48 @with_unsupported_dtypes(
49 {"2.4.2 and below": ("bool", "uint8", "int8", "int16", "complex64", "complex128")},
50 "paddle",
51 )
52 @to_ivy_arrays_and_back
53 def greater_than(x, y, /, *, name=None):
54 return ivy.greater(x, y)
55
56
57 @with_unsupported_dtypes(
58 {"2.4.2 and below": ("bool", "uint8", "int8", "int16", "complex64", "complex128")},
59 "paddle",
60 )
61 @to_ivy_arrays_and_back
62 def greater_equal(x, y, /, *, name=None):
63 return ivy.greater_equal(x, y)
64
65
66 @with_unsupported_dtypes(
67 {"2.4.2 and below": ("bool", "uint8", "int8", "int16", "complex64", "complex128")},
68 "paddle",
69 )
70 @to_ivy_arrays_and_back
71 def less_than(x, y, /, *, name=None):
72 return ivy.less(x, y)
73
74
75 @with_unsupported_dtypes(
76 {"2.4.2 and below": ("bool", "uint8", "int8", "int16", "complex64", "complex128")},
77 "paddle",
78 )
79 @to_ivy_arrays_and_back
80 def less_equal(x, y, /, *, name=None):
81 return ivy.less_equal(x, y)
82
83
84 @with_supported_dtypes(
85 {
86 "2.4.2 and below": (
87 "bool",
88 "int8",
89 "int16",
90 "int32",
91 "int64",
92 "float32",
93 "float64",
94 )
95 },
96 "paddle",
97 )
98 @to_ivy_arrays_and_back
99 @handle_out_argument
100 def logical_or(x, y, /, *, name=None, out=None):
101 return ivy.logical_or(x, y, out=out)
102
103
104 @with_supported_dtypes(
105 {
106 "2.4.2 and below": (
107 "bool",
108 "int8",
109 "int16",
110 "int32",
111 "int64",
112 "float32",
113 "float64",
114 )
115 },
116 "paddle",
117 )
118 @to_ivy_arrays_and_back
119 @handle_out_argument
120 def logical_xor(x, y, /, *, name=None, out=None):
121 return ivy.logical_xor(x, y, out=out)
122
123
124 @with_supported_dtypes(
125 {
126 "2.4.2 and below": (
127 "bool",
128 "int8",
129 "int16",
130 "int32",
131 "int64",
132 "float32",
133 "float64",
134 )
135 },
136 "paddle",
137 )
138 @to_ivy_arrays_and_back
139 @handle_out_argument
140 def logical_not(x, /, *, name=None, out=None):
141 return ivy.logical_not(x, out=out)
142
143
144 @with_supported_dtypes(
145 {
146 "2.4.2 and below": (
147 "bool",
148 "uint8",
149 "int8",
150 "int16",
151 "int32",
152 "int64",
153 )
154 },
155 "paddle",
156 )
157 @to_ivy_arrays_and_back
158 @handle_out_argument
159 def bitwise_or(x, y, name=None, out=None):
160 return ivy.bitwise_or(x, y, out=out)
161
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ivy/functional/frontends/paddle/tensor/logic.py b/ivy/functional/frontends/paddle/tensor/logic.py
--- a/ivy/functional/frontends/paddle/tensor/logic.py
+++ b/ivy/functional/frontends/paddle/tensor/logic.py
@@ -158,3 +158,22 @@
@handle_out_argument
def bitwise_or(x, y, name=None, out=None):
return ivy.bitwise_or(x, y, out=out)
+
+
+@with_supported_dtypes(
+ {
+ "2.4.2 and below": (
+ "bool",
+ "uint8",
+ "int8",
+ "int16",
+ "int32",
+ "int64",
+ )
+ },
+ "paddle",
+)
+@to_ivy_arrays_and_back
+@handle_out_argument
+def bitwise_and(x, y, /, *, name=None, out=None):
+ return ivy.bitwise_and(x, y, out=out)
|
{"golden_diff": "diff --git a/ivy/functional/frontends/paddle/tensor/logic.py b/ivy/functional/frontends/paddle/tensor/logic.py\n--- a/ivy/functional/frontends/paddle/tensor/logic.py\n+++ b/ivy/functional/frontends/paddle/tensor/logic.py\n@@ -158,3 +158,22 @@\n @handle_out_argument\n def bitwise_or(x, y, name=None, out=None):\n return ivy.bitwise_or(x, y, out=out)\n+\n+\n+@with_supported_dtypes(\n+ {\n+ \"2.4.2 and below\": (\n+ \"bool\",\n+ \"uint8\",\n+ \"int8\",\n+ \"int16\",\n+ \"int32\",\n+ \"int64\",\n+ )\n+ },\n+ \"paddle\",\n+)\n+@to_ivy_arrays_and_back\n+@handle_out_argument\n+def bitwise_and(x, y, /, *, name=None, out=None):\n+ return ivy.bitwise_and(x, y, out=out)\n", "issue": "bitwise_and\n\n", "before_files": [{"content": "# global\nimport ivy\nimport ivy.functional.frontends.paddle as paddle\nfrom ivy.func_wrapper import (\n with_unsupported_dtypes,\n handle_out_argument,\n with_supported_dtypes,\n)\nfrom ivy.functional.frontends.paddle.func_wrapper import (\n to_ivy_arrays_and_back,\n)\n\n\n@with_unsupported_dtypes(\n {\"2.4.2 and below\": (\"uint8\", \"int8\", \"int16\", \"complex64\", \"complex128\")}, \"paddle\"\n)\n@to_ivy_arrays_and_back\ndef equal(x, y, /, *, name=None):\n return ivy.equal(x, y)\n\n\n@with_unsupported_dtypes(\n {\"2.4.2 and below\": (\"uint8\", \"int8\", \"int16\", \"complex64\", \"complex128\")}, \"paddle\"\n)\n@to_ivy_arrays_and_back\ndef not_equal(x, y, /, *, name=None):\n return ivy.not_equal(x, y)\n\n\n@with_unsupported_dtypes(\n {\n \"2.4.2 and below\": (\n \"uint8\",\n \"int8\",\n \"int16\",\n \"float16\",\n \"complex64\",\n \"complex128\",\n )\n },\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef equal_all(x, y, /, *, name=None):\n return paddle.to_tensor([ivy.array_equal(x, y)])\n\n\n@with_unsupported_dtypes(\n {\"2.4.2 and below\": (\"bool\", \"uint8\", \"int8\", \"int16\", \"complex64\", \"complex128\")},\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef greater_than(x, y, /, *, name=None):\n return ivy.greater(x, y)\n\n\n@with_unsupported_dtypes(\n {\"2.4.2 and below\": (\"bool\", \"uint8\", \"int8\", \"int16\", \"complex64\", \"complex128\")},\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef greater_equal(x, y, /, *, name=None):\n return ivy.greater_equal(x, y)\n\n\n@with_unsupported_dtypes(\n {\"2.4.2 and below\": (\"bool\", \"uint8\", \"int8\", \"int16\", \"complex64\", \"complex128\")},\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef less_than(x, y, /, *, name=None):\n return ivy.less(x, y)\n\n\n@with_unsupported_dtypes(\n {\"2.4.2 and below\": (\"bool\", \"uint8\", \"int8\", \"int16\", \"complex64\", \"complex128\")},\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef less_equal(x, y, /, *, name=None):\n return ivy.less_equal(x, y)\n\n\n@with_supported_dtypes(\n {\n \"2.4.2 and below\": (\n \"bool\",\n \"int8\",\n \"int16\",\n \"int32\",\n \"int64\",\n \"float32\",\n \"float64\",\n )\n },\n \"paddle\",\n)\n@to_ivy_arrays_and_back\n@handle_out_argument\ndef logical_or(x, y, /, *, name=None, out=None):\n return ivy.logical_or(x, y, out=out)\n\n\n@with_supported_dtypes(\n {\n \"2.4.2 and below\": (\n \"bool\",\n \"int8\",\n \"int16\",\n \"int32\",\n \"int64\",\n \"float32\",\n \"float64\",\n )\n },\n \"paddle\",\n)\n@to_ivy_arrays_and_back\n@handle_out_argument\ndef logical_xor(x, y, /, *, name=None, out=None):\n return ivy.logical_xor(x, y, out=out)\n\n\n@with_supported_dtypes(\n {\n \"2.4.2 and below\": (\n \"bool\",\n \"int8\",\n \"int16\",\n \"int32\",\n \"int64\",\n \"float32\",\n \"float64\",\n )\n },\n \"paddle\",\n)\n@to_ivy_arrays_and_back\n@handle_out_argument\ndef logical_not(x, /, *, name=None, out=None):\n return ivy.logical_not(x, out=out)\n\n\n@with_supported_dtypes(\n {\n \"2.4.2 and below\": (\n \"bool\",\n \"uint8\",\n \"int8\",\n \"int16\",\n \"int32\",\n \"int64\",\n )\n },\n \"paddle\",\n)\n@to_ivy_arrays_and_back\n@handle_out_argument\ndef bitwise_or(x, y, name=None, out=None):\n return ivy.bitwise_or(x, y, out=out)\n", "path": "ivy/functional/frontends/paddle/tensor/logic.py"}], "after_files": [{"content": "# global\nimport ivy\nimport ivy.functional.frontends.paddle as paddle\nfrom ivy.func_wrapper import (\n with_unsupported_dtypes,\n handle_out_argument,\n with_supported_dtypes,\n)\nfrom ivy.functional.frontends.paddle.func_wrapper import (\n to_ivy_arrays_and_back,\n)\n\n\n@with_unsupported_dtypes(\n {\"2.4.2 and below\": (\"uint8\", \"int8\", \"int16\", \"complex64\", \"complex128\")}, \"paddle\"\n)\n@to_ivy_arrays_and_back\ndef equal(x, y, /, *, name=None):\n return ivy.equal(x, y)\n\n\n@with_unsupported_dtypes(\n {\"2.4.2 and below\": (\"uint8\", \"int8\", \"int16\", \"complex64\", \"complex128\")}, \"paddle\"\n)\n@to_ivy_arrays_and_back\ndef not_equal(x, y, /, *, name=None):\n return ivy.not_equal(x, y)\n\n\n@with_unsupported_dtypes(\n {\n \"2.4.2 and below\": (\n \"uint8\",\n \"int8\",\n \"int16\",\n \"float16\",\n \"complex64\",\n \"complex128\",\n )\n },\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef equal_all(x, y, /, *, name=None):\n return paddle.to_tensor([ivy.array_equal(x, y)])\n\n\n@with_unsupported_dtypes(\n {\"2.4.2 and below\": (\"bool\", \"uint8\", \"int8\", \"int16\", \"complex64\", \"complex128\")},\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef greater_than(x, y, /, *, name=None):\n return ivy.greater(x, y)\n\n\n@with_unsupported_dtypes(\n {\"2.4.2 and below\": (\"bool\", \"uint8\", \"int8\", \"int16\", \"complex64\", \"complex128\")},\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef greater_equal(x, y, /, *, name=None):\n return ivy.greater_equal(x, y)\n\n\n@with_unsupported_dtypes(\n {\"2.4.2 and below\": (\"bool\", \"uint8\", \"int8\", \"int16\", \"complex64\", \"complex128\")},\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef less_than(x, y, /, *, name=None):\n return ivy.less(x, y)\n\n\n@with_unsupported_dtypes(\n {\"2.4.2 and below\": (\"bool\", \"uint8\", \"int8\", \"int16\", \"complex64\", \"complex128\")},\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef less_equal(x, y, /, *, name=None):\n return ivy.less_equal(x, y)\n\n\n@with_supported_dtypes(\n {\n \"2.4.2 and below\": (\n \"bool\",\n \"int8\",\n \"int16\",\n \"int32\",\n \"int64\",\n \"float32\",\n \"float64\",\n )\n },\n \"paddle\",\n)\n@to_ivy_arrays_and_back\n@handle_out_argument\ndef logical_or(x, y, /, *, name=None, out=None):\n return ivy.logical_or(x, y, out=out)\n\n\n@with_supported_dtypes(\n {\n \"2.4.2 and below\": (\n \"bool\",\n \"int8\",\n \"int16\",\n \"int32\",\n \"int64\",\n \"float32\",\n \"float64\",\n )\n },\n \"paddle\",\n)\n@to_ivy_arrays_and_back\n@handle_out_argument\ndef logical_xor(x, y, /, *, name=None, out=None):\n return ivy.logical_xor(x, y, out=out)\n\n\n@with_supported_dtypes(\n {\n \"2.4.2 and below\": (\n \"bool\",\n \"int8\",\n \"int16\",\n \"int32\",\n \"int64\",\n \"float32\",\n \"float64\",\n )\n },\n \"paddle\",\n)\n@to_ivy_arrays_and_back\n@handle_out_argument\ndef logical_not(x, /, *, name=None, out=None):\n return ivy.logical_not(x, out=out)\n\n\n@with_supported_dtypes(\n {\n \"2.4.2 and below\": (\n \"bool\",\n \"uint8\",\n \"int8\",\n \"int16\",\n \"int32\",\n \"int64\",\n )\n },\n \"paddle\",\n)\n@to_ivy_arrays_and_back\n@handle_out_argument\ndef bitwise_or(x, y, name=None, out=None):\n return ivy.bitwise_or(x, y, out=out)\n\n\n@with_supported_dtypes(\n {\n \"2.4.2 and below\": (\n \"bool\",\n \"uint8\",\n \"int8\",\n \"int16\",\n \"int32\",\n \"int64\",\n )\n },\n \"paddle\",\n)\n@to_ivy_arrays_and_back\n@handle_out_argument\ndef bitwise_and(x, y, /, *, name=None, out=None):\n return ivy.bitwise_and(x, y, out=out)\n", "path": "ivy/functional/frontends/paddle/tensor/logic.py"}]}
| 1,736 | 234 |
gh_patches_debug_4357
|
rasdani/github-patches
|
git_diff
|
OpenEnergyPlatform__oeplatform-1255
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Include the Open Energy Compendium in the navigation bar
## Description of the issue
A first version of the **Open Energy Compendium** is ready for integration.
## Ideas of solution
Link under `About` / `Compendium`
## Workflow checklist
- [x] I am aware of the workflow in [CONTRIBUTING.md](https://github.com/OpenEnergyPlatform/oeplatform/blob/develop/CONTRIBUTING.md)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `oeplatform/settings.py`
Content:
```
1 """
2 Django settings for oeplatform project.
3
4 Generated by 'django-admin startproject' using Django 1.8.5.
5
6 For more information on this file, see
7 https://docs.djangoproject.com/en/1.8/topics/settings/
8
9 For the full list of settings and their values, see
10 https://docs.djangoproject.com/en/1.8/ref/settings/
11 """
12
13 # Build paths inside the project like this: os.path.join(BASE_DIR, ...)
14
15 try:
16 from .securitysettings import * # noqa
17 except ImportError:
18 import logging
19 import os
20
21 logging.error("No securitysettings found. Triggerd in oeplatform/settings.py")
22 SECRET_KEY = os.environ.get("SECRET_KEY", "0")
23 DEFAULT_FROM_EMAIL = os.environ.get("DEFAULT_FROM_EMAIL")
24 URL = os.environ.get("URL")
25
26 # Quick-start development settings - unsuitable for production
27 # See https://docs.djangoproject.com/en/1.8/howto/deployment/checklist/
28
29 # Application definition
30
31 INSTALLED_APPS = (
32 "django.contrib.sites",
33 "django.contrib.admin",
34 "django.contrib.auth",
35 "django.contrib.contenttypes",
36 "django.contrib.sessions",
37 "django.contrib.messages",
38 "django.contrib.staticfiles",
39 "django.contrib.sessions.backends.signed_cookies",
40 "django_bootstrap5",
41 "rest_framework",
42 "rest_framework.authtoken",
43 "modelview",
44 "modelview.templatetags.modelview_extras",
45 "login",
46 "base",
47 "base.templatetags.base_tags",
48 "widget_tweaks",
49 "dataedit",
50 "colorfield",
51 "api",
52 "ontology",
53 "axes",
54 "captcha",
55 "django.contrib.postgres",
56 "fontawesome_5",
57 "django_better_admin_arrayfield",
58 "oeo_viewer",
59 )
60
61 MIDDLEWARE = (
62 "django.contrib.sites.middleware.CurrentSiteMiddleware",
63 "django.contrib.sessions.middleware.SessionMiddleware",
64 "django.middleware.common.CommonMiddleware",
65 "django.middleware.csrf.CsrfViewMiddleware",
66 "django.contrib.auth.middleware.AuthenticationMiddleware",
67 "django.contrib.messages.middleware.MessageMiddleware",
68 "django.middleware.clickjacking.XFrameOptionsMiddleware",
69 "django.middleware.security.SecurityMiddleware",
70 "login.middleware.DetachMiddleware",
71 "axes.middleware.AxesMiddleware",
72 "django.middleware.common.CommonMiddleware",
73 )
74
75 ROOT_URLCONF = "oeplatform.urls"
76
77 EXTERNAL_URLS = {
78 "tutorials_index": "https://openenergyplatform.github.io/academy/",
79 "tutorials_faq": "https://openenergyplatform.github.io/academy/",
80 "tutorials_api1": "https://openenergyplatform.github.io/academy/tutorials/api/OEP_API_tutorial_part1/", # noqa E501
81 "tutorials_licenses": "https://openenergyplatform.github.io/academy/tutorials/metadata/tutorial_open-data-licenses/",
82 # noqa E501
83 "readthedocs": "https://oeplatform.readthedocs.io/en/latest/?badge=latest",
84 }
85
86
87 def external_urls_context_processor(request):
88 """Define hard coded external urls here.
89 Use in templates like this: {{ EXTERNAL_URLS.<name_of_url> }}
90 Also, you may want to add an icon indicating external links, e.g.
91 """
92 return {"EXTERNAL_URLS": EXTERNAL_URLS}
93
94
95 SITE_ID = 1
96
97 TEMPLATES = [
98 {
99 "BACKEND": "django.template.backends.django.DjangoTemplates",
100 "DIRS": [],
101 "APP_DIRS": True,
102 "OPTIONS": {
103 "context_processors": [
104 "django.template.context_processors.debug",
105 "django.template.context_processors.request",
106 "django.contrib.auth.context_processors.auth",
107 "django.contrib.messages.context_processors.messages",
108 "oeplatform.settings.external_urls_context_processor",
109 ]
110 },
111 }
112 ]
113
114 CORS_ORIGIN_WHITELIST = ["http://localhost:3000", "http://127.0.0.1:3000"]
115
116 GRAPHENE = {"SCHEMA": "factsheet.schema.schema"}
117
118 WSGI_APPLICATION = "oeplatform.wsgi.application"
119
120 try:
121 ONTOLOGY_FOLDER # noqa
122 except NameError:
123 ONTOLOGY_FOLDER = "/tmp"
124
125 # Internationalization
126 # https://docs.djangoproject.com/en/1.8/topics/i18n/
127
128 LANGUAGE_CODE = "en-us"
129
130 TIME_ZONE = "Europe/Berlin"
131
132 USE_I18N = True
133
134 USE_L10N = True
135
136 USE_TZ = True
137
138 # Static files (CSS, JavaScript, Images)
139 # https://docs.djangoproject.com/en/1.8/howto/static-files/
140
141 AUTH_USER_MODEL = "login.myuser"
142 LOGIN_URL = "/user/login"
143 LOGIN_REDIRECT_URL = "/"
144
145 REST_FRAMEWORK = {
146 "DEFAULT_AUTHENTICATION_CLASSES": (
147 "rest_framework.authentication.BasicAuthentication",
148 "rest_framework.authentication.SessionAuthentication",
149 "rest_framework.authentication.TokenAuthentication",
150 )
151 }
152
153 AUTHENTICATION_BACKENDS = [
154 # AxesBackend should be the first backend in the AUTHENTICATION_BACKENDS list.
155 "axes.backends.AxesBackend",
156 # custom class extenging Django ModelBackend for login with username OR email
157 "login.backends.ModelBackendWithEmail",
158 ]
159
160 DEFAULT_AUTO_FIELD = "django.db.models.AutoField"
161
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/oeplatform/settings.py b/oeplatform/settings.py
--- a/oeplatform/settings.py
+++ b/oeplatform/settings.py
@@ -81,6 +81,7 @@
"tutorials_licenses": "https://openenergyplatform.github.io/academy/tutorials/metadata/tutorial_open-data-licenses/",
# noqa E501
"readthedocs": "https://oeplatform.readthedocs.io/en/latest/?badge=latest",
+ "compendium": "https://openenergyplatform.github.io/organisation/",
}
|
{"golden_diff": "diff --git a/oeplatform/settings.py b/oeplatform/settings.py\n--- a/oeplatform/settings.py\n+++ b/oeplatform/settings.py\n@@ -81,6 +81,7 @@\n \"tutorials_licenses\": \"https://openenergyplatform.github.io/academy/tutorials/metadata/tutorial_open-data-licenses/\",\n # noqa E501\n \"readthedocs\": \"https://oeplatform.readthedocs.io/en/latest/?badge=latest\",\n+ \"compendium\": \"https://openenergyplatform.github.io/organisation/\",\n }\n", "issue": "Include the Open Energy Compendium in the navigation bar\n## Description of the issue\r\n\r\nA first version of the **Open Energy Compendium** is ready for integration.\r\n\r\n## Ideas of solution\r\n\r\nLink under `About` / `Compendium`\r\n\r\n## Workflow checklist\r\n- [x] I am aware of the workflow in [CONTRIBUTING.md](https://github.com/OpenEnergyPlatform/oeplatform/blob/develop/CONTRIBUTING.md)\r\n\n", "before_files": [{"content": "\"\"\"\nDjango settings for oeplatform project.\n\nGenerated by 'django-admin startproject' using Django 1.8.5.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/1.8/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/1.8/ref/settings/\n\"\"\"\n\n# Build paths inside the project like this: os.path.join(BASE_DIR, ...)\n\ntry:\n from .securitysettings import * # noqa\nexcept ImportError:\n import logging\n import os\n\n logging.error(\"No securitysettings found. Triggerd in oeplatform/settings.py\")\n SECRET_KEY = os.environ.get(\"SECRET_KEY\", \"0\")\n DEFAULT_FROM_EMAIL = os.environ.get(\"DEFAULT_FROM_EMAIL\")\n URL = os.environ.get(\"URL\")\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/1.8/howto/deployment/checklist/\n\n# Application definition\n\nINSTALLED_APPS = (\n \"django.contrib.sites\",\n \"django.contrib.admin\",\n \"django.contrib.auth\",\n \"django.contrib.contenttypes\",\n \"django.contrib.sessions\",\n \"django.contrib.messages\",\n \"django.contrib.staticfiles\",\n \"django.contrib.sessions.backends.signed_cookies\",\n \"django_bootstrap5\",\n \"rest_framework\",\n \"rest_framework.authtoken\",\n \"modelview\",\n \"modelview.templatetags.modelview_extras\",\n \"login\",\n \"base\",\n \"base.templatetags.base_tags\",\n \"widget_tweaks\",\n \"dataedit\",\n \"colorfield\",\n \"api\",\n \"ontology\",\n \"axes\",\n \"captcha\",\n \"django.contrib.postgres\",\n \"fontawesome_5\",\n \"django_better_admin_arrayfield\",\n \"oeo_viewer\",\n)\n\nMIDDLEWARE = (\n \"django.contrib.sites.middleware.CurrentSiteMiddleware\",\n \"django.contrib.sessions.middleware.SessionMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n \"django.middleware.csrf.CsrfViewMiddleware\",\n \"django.contrib.auth.middleware.AuthenticationMiddleware\",\n \"django.contrib.messages.middleware.MessageMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n \"django.middleware.security.SecurityMiddleware\",\n \"login.middleware.DetachMiddleware\",\n \"axes.middleware.AxesMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n)\n\nROOT_URLCONF = \"oeplatform.urls\"\n\nEXTERNAL_URLS = {\n \"tutorials_index\": \"https://openenergyplatform.github.io/academy/\",\n \"tutorials_faq\": \"https://openenergyplatform.github.io/academy/\",\n \"tutorials_api1\": \"https://openenergyplatform.github.io/academy/tutorials/api/OEP_API_tutorial_part1/\", # noqa E501\n \"tutorials_licenses\": \"https://openenergyplatform.github.io/academy/tutorials/metadata/tutorial_open-data-licenses/\",\n # noqa E501\n \"readthedocs\": \"https://oeplatform.readthedocs.io/en/latest/?badge=latest\",\n}\n\n\ndef external_urls_context_processor(request):\n \"\"\"Define hard coded external urls here.\n Use in templates like this: {{ EXTERNAL_URLS.<name_of_url> }}\n Also, you may want to add an icon indicating external links, e.g.\n \"\"\"\n return {\"EXTERNAL_URLS\": EXTERNAL_URLS}\n\n\nSITE_ID = 1\n\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.request\",\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n \"oeplatform.settings.external_urls_context_processor\",\n ]\n },\n }\n]\n\nCORS_ORIGIN_WHITELIST = [\"http://localhost:3000\", \"http://127.0.0.1:3000\"]\n\nGRAPHENE = {\"SCHEMA\": \"factsheet.schema.schema\"}\n\nWSGI_APPLICATION = \"oeplatform.wsgi.application\"\n\ntry:\n ONTOLOGY_FOLDER # noqa\nexcept NameError:\n ONTOLOGY_FOLDER = \"/tmp\"\n\n# Internationalization\n# https://docs.djangoproject.com/en/1.8/topics/i18n/\n\nLANGUAGE_CODE = \"en-us\"\n\nTIME_ZONE = \"Europe/Berlin\"\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/1.8/howto/static-files/\n\nAUTH_USER_MODEL = \"login.myuser\"\nLOGIN_URL = \"/user/login\"\nLOGIN_REDIRECT_URL = \"/\"\n\nREST_FRAMEWORK = {\n \"DEFAULT_AUTHENTICATION_CLASSES\": (\n \"rest_framework.authentication.BasicAuthentication\",\n \"rest_framework.authentication.SessionAuthentication\",\n \"rest_framework.authentication.TokenAuthentication\",\n )\n}\n\nAUTHENTICATION_BACKENDS = [\n # AxesBackend should be the first backend in the AUTHENTICATION_BACKENDS list.\n \"axes.backends.AxesBackend\",\n # custom class extenging Django ModelBackend for login with username OR email\n \"login.backends.ModelBackendWithEmail\",\n]\n\nDEFAULT_AUTO_FIELD = \"django.db.models.AutoField\"\n", "path": "oeplatform/settings.py"}], "after_files": [{"content": "\"\"\"\nDjango settings for oeplatform project.\n\nGenerated by 'django-admin startproject' using Django 1.8.5.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/1.8/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/1.8/ref/settings/\n\"\"\"\n\n# Build paths inside the project like this: os.path.join(BASE_DIR, ...)\n\ntry:\n from .securitysettings import * # noqa\nexcept ImportError:\n import logging\n import os\n\n logging.error(\"No securitysettings found. Triggerd in oeplatform/settings.py\")\n SECRET_KEY = os.environ.get(\"SECRET_KEY\", \"0\")\n DEFAULT_FROM_EMAIL = os.environ.get(\"DEFAULT_FROM_EMAIL\")\n URL = os.environ.get(\"URL\")\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/1.8/howto/deployment/checklist/\n\n# Application definition\n\nINSTALLED_APPS = (\n \"django.contrib.sites\",\n \"django.contrib.admin\",\n \"django.contrib.auth\",\n \"django.contrib.contenttypes\",\n \"django.contrib.sessions\",\n \"django.contrib.messages\",\n \"django.contrib.staticfiles\",\n \"django.contrib.sessions.backends.signed_cookies\",\n \"django_bootstrap5\",\n \"rest_framework\",\n \"rest_framework.authtoken\",\n \"modelview\",\n \"modelview.templatetags.modelview_extras\",\n \"login\",\n \"base\",\n \"base.templatetags.base_tags\",\n \"widget_tweaks\",\n \"dataedit\",\n \"colorfield\",\n \"api\",\n \"ontology\",\n \"axes\",\n \"captcha\",\n \"django.contrib.postgres\",\n \"fontawesome_5\",\n \"django_better_admin_arrayfield\",\n \"oeo_viewer\",\n)\n\nMIDDLEWARE = (\n \"django.contrib.sites.middleware.CurrentSiteMiddleware\",\n \"django.contrib.sessions.middleware.SessionMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n \"django.middleware.csrf.CsrfViewMiddleware\",\n \"django.contrib.auth.middleware.AuthenticationMiddleware\",\n \"django.contrib.messages.middleware.MessageMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n \"django.middleware.security.SecurityMiddleware\",\n \"login.middleware.DetachMiddleware\",\n \"axes.middleware.AxesMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n)\n\nROOT_URLCONF = \"oeplatform.urls\"\n\nEXTERNAL_URLS = {\n \"tutorials_index\": \"https://openenergyplatform.github.io/academy/\",\n \"tutorials_faq\": \"https://openenergyplatform.github.io/academy/\",\n \"tutorials_api1\": \"https://openenergyplatform.github.io/academy/tutorials/api/OEP_API_tutorial_part1/\", # noqa E501\n \"tutorials_licenses\": \"https://openenergyplatform.github.io/academy/tutorials/metadata/tutorial_open-data-licenses/\",\n # noqa E501\n \"readthedocs\": \"https://oeplatform.readthedocs.io/en/latest/?badge=latest\",\n \"compendium\": \"https://openenergyplatform.github.io/organisation/\",\n}\n\n\ndef external_urls_context_processor(request):\n \"\"\"Define hard coded external urls here.\n Use in templates like this: {{ EXTERNAL_URLS.<name_of_url> }}\n Also, you may want to add an icon indicating external links, e.g.\n \"\"\"\n return {\"EXTERNAL_URLS\": EXTERNAL_URLS}\n\n\nSITE_ID = 1\n\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.request\",\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n \"oeplatform.settings.external_urls_context_processor\",\n ]\n },\n }\n]\n\nCORS_ORIGIN_WHITELIST = [\"http://localhost:3000\", \"http://127.0.0.1:3000\"]\n\nGRAPHENE = {\"SCHEMA\": \"factsheet.schema.schema\"}\n\nWSGI_APPLICATION = \"oeplatform.wsgi.application\"\n\ntry:\n ONTOLOGY_FOLDER # noqa\nexcept NameError:\n ONTOLOGY_FOLDER = \"/tmp\"\n\n# Internationalization\n# https://docs.djangoproject.com/en/1.8/topics/i18n/\n\nLANGUAGE_CODE = \"en-us\"\n\nTIME_ZONE = \"Europe/Berlin\"\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/1.8/howto/static-files/\n\nAUTH_USER_MODEL = \"login.myuser\"\nLOGIN_URL = \"/user/login\"\nLOGIN_REDIRECT_URL = \"/\"\n\nREST_FRAMEWORK = {\n \"DEFAULT_AUTHENTICATION_CLASSES\": (\n \"rest_framework.authentication.BasicAuthentication\",\n \"rest_framework.authentication.SessionAuthentication\",\n \"rest_framework.authentication.TokenAuthentication\",\n )\n}\n\nAUTHENTICATION_BACKENDS = [\n # AxesBackend should be the first backend in the AUTHENTICATION_BACKENDS list.\n \"axes.backends.AxesBackend\",\n # custom class extenging Django ModelBackend for login with username OR email\n \"login.backends.ModelBackendWithEmail\",\n]\n\nDEFAULT_AUTO_FIELD = \"django.db.models.AutoField\"\n", "path": "oeplatform/settings.py"}]}
| 1,862 | 121 |
gh_patches_debug_4592
|
rasdani/github-patches
|
git_diff
|
python__mypy-14842
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Wrong recommendation to install `types-backports`
When I import `backports.zoneinfo`, I get
```
src/test_checks.py:29:1: error: Library stubs not installed for "backports.zoneinfo" [import]
src/test_checks.py:29:1: note: Hint: "python3 -m pip install types-backports"
src/test_checks.py:29:1: note: (or run "mypy --install-types" to install all missing stub packages)
src/test_checks.py:29:1: note: See https://mypy.readthedocs.io/en/stable/running_mypy.html#missing-imports
```
However, the `types-backports` package is obsolete since python/typeshed#5997; it was replaced with `types-backports.ssl_match_hostname`. It never provided stubs for `backports.zoneinfo` (which is a py.typed package and doesn't need stubs), only for `ssl_match_hostname`.
`backports.ssl_match_hostname` provides a 3.7+ feature (https://pypi.org/project/backports.ssl_match_hostname/), so it isn't relevant on any supported version of Python and I don't think mypy needs to recommend installing it. I will submit a PR to remove it from the list of recommended packages.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mypy/stubinfo.py`
Content:
```
1 from __future__ import annotations
2
3
4 def is_legacy_bundled_package(prefix: str) -> bool:
5 return prefix in legacy_bundled_packages
6
7
8 def approved_stub_package_exists(prefix: str) -> bool:
9 return is_legacy_bundled_package(prefix) or prefix in non_bundled_packages
10
11
12 def stub_package_name(prefix: str) -> str:
13 return legacy_bundled_packages.get(prefix) or non_bundled_packages[prefix]
14
15
16 # Stubs for these third-party packages used to be shipped with mypy.
17 #
18 # Map package name to PyPI stub distribution name.
19 #
20 # Package name can have one or two components ('a' or 'a.b').
21 legacy_bundled_packages = {
22 "aiofiles": "types-aiofiles",
23 "backports": "types-backports",
24 "backports_abc": "types-backports_abc",
25 "bleach": "types-bleach",
26 "boto": "types-boto",
27 "cachetools": "types-cachetools",
28 "click_spinner": "types-click-spinner",
29 "contextvars": "types-contextvars",
30 "croniter": "types-croniter",
31 "dataclasses": "types-dataclasses",
32 "dateparser": "types-dateparser",
33 "datetimerange": "types-DateTimeRange",
34 "dateutil": "types-python-dateutil",
35 "decorator": "types-decorator",
36 "deprecated": "types-Deprecated",
37 "docutils": "types-docutils",
38 "first": "types-first",
39 "geoip2": "types-geoip2",
40 "gflags": "types-python-gflags",
41 "google.protobuf": "types-protobuf",
42 "markdown": "types-Markdown",
43 "maxminddb": "types-maxminddb",
44 "mock": "types-mock",
45 "OpenSSL": "types-pyOpenSSL",
46 "paramiko": "types-paramiko",
47 "pkg_resources": "types-setuptools",
48 "polib": "types-polib",
49 "pycurl": "types-pycurl",
50 "pymysql": "types-PyMySQL",
51 "pyrfc3339": "types-pyRFC3339",
52 "python2": "types-six",
53 "pytz": "types-pytz",
54 "pyVmomi": "types-pyvmomi",
55 "redis": "types-redis",
56 "requests": "types-requests",
57 "retry": "types-retry",
58 "simplejson": "types-simplejson",
59 "singledispatch": "types-singledispatch",
60 "six": "types-six",
61 "slugify": "types-python-slugify",
62 "tabulate": "types-tabulate",
63 "toml": "types-toml",
64 "typed_ast": "types-typed-ast",
65 "tzlocal": "types-tzlocal",
66 "ujson": "types-ujson",
67 "waitress": "types-waitress",
68 "yaml": "types-PyYAML",
69 }
70
71 # Map package name to PyPI stub distribution name from typeshed.
72 # Stubs for these packages were never bundled with mypy. Don't
73 # include packages that have a release that includes PEP 561 type
74 # information.
75 #
76 # Package name can have one or two components ('a' or 'a.b').
77 #
78 # Note that these packages are omitted for now:
79 # pika: typeshed's stubs are on PyPI as types-pika-ts.
80 # types-pika already exists on PyPI, and is more complete in many ways,
81 # but is a non-typeshed stubs package.
82 non_bundled_packages = {
83 "MySQLdb": "types-mysqlclient",
84 "PIL": "types-Pillow",
85 "PyInstaller": "types-pyinstaller",
86 "Xlib": "types-python-xlib",
87 "annoy": "types-annoy",
88 "appdirs": "types-appdirs",
89 "aws_xray_sdk": "types-aws-xray-sdk",
90 "babel": "types-babel",
91 "backports.ssl_match_hostname": "types-backports.ssl_match_hostname",
92 "braintree": "types-braintree",
93 "bs4": "types-beautifulsoup4",
94 "bugbear": "types-flake8-bugbear",
95 "caldav": "types-caldav",
96 "cffi": "types-cffi",
97 "chevron": "types-chevron",
98 "colorama": "types-colorama",
99 "commonmark": "types-commonmark",
100 "consolemenu": "types-console-menu",
101 "crontab": "types-python-crontab",
102 "d3dshot": "types-D3DShot",
103 "dj_database_url": "types-dj-database-url",
104 "dockerfile_parse": "types-dockerfile-parse",
105 "docopt": "types-docopt",
106 "editdistance": "types-editdistance",
107 "entrypoints": "types-entrypoints",
108 "farmhash": "types-pyfarmhash",
109 "flake8_2020": "types-flake8-2020",
110 "flake8_builtins": "types-flake8-builtins",
111 "flake8_docstrings": "types-flake8-docstrings",
112 "flake8_plugin_utils": "types-flake8-plugin-utils",
113 "flake8_rst_docstrings": "types-flake8-rst-docstrings",
114 "flake8_simplify": "types-flake8-simplify",
115 "flake8_typing_imports": "types-flake8-typing-imports",
116 "flask_cors": "types-Flask-Cors",
117 "flask_migrate": "types-Flask-Migrate",
118 "flask_sqlalchemy": "types-Flask-SQLAlchemy",
119 "fpdf": "types-fpdf2",
120 "gdb": "types-gdb",
121 "google.cloud": "types-google-cloud-ndb",
122 "hdbcli": "types-hdbcli",
123 "html5lib": "types-html5lib",
124 "httplib2": "types-httplib2",
125 "humanfriendly": "types-humanfriendly",
126 "invoke": "types-invoke",
127 "jack": "types-JACK-Client",
128 "jmespath": "types-jmespath",
129 "jose": "types-python-jose",
130 "jsonschema": "types-jsonschema",
131 "keyboard": "types-keyboard",
132 "ldap3": "types-ldap3",
133 "nmap": "types-python-nmap",
134 "oauthlib": "types-oauthlib",
135 "openpyxl": "types-openpyxl",
136 "opentracing": "types-opentracing",
137 "paho.mqtt": "types-paho-mqtt",
138 "parsimonious": "types-parsimonious",
139 "passlib": "types-passlib",
140 "passpy": "types-passpy",
141 "peewee": "types-peewee",
142 "pep8ext_naming": "types-pep8-naming",
143 "playsound": "types-playsound",
144 "psutil": "types-psutil",
145 "psycopg2": "types-psycopg2",
146 "pyaudio": "types-pyaudio",
147 "pyautogui": "types-PyAutoGUI",
148 "pycocotools": "types-pycocotools",
149 "pyflakes": "types-pyflakes",
150 "pygments": "types-Pygments",
151 "pyi_splash": "types-pyinstaller",
152 "pynput": "types-pynput",
153 "pythoncom": "types-pywin32",
154 "pythonwin": "types-pywin32",
155 "pyscreeze": "types-PyScreeze",
156 "pysftp": "types-pysftp",
157 "pytest_lazyfixture": "types-pytest-lazy-fixture",
158 "pywintypes": "types-pywin32",
159 "regex": "types-regex",
160 "send2trash": "types-Send2Trash",
161 "slumber": "types-slumber",
162 "stdlib_list": "types-stdlib-list",
163 "stripe": "types-stripe",
164 "toposort": "types-toposort",
165 "tqdm": "types-tqdm",
166 "tree_sitter": "types-tree-sitter",
167 "tree_sitter_languages": "types-tree-sitter-languages",
168 "ttkthemes": "types-ttkthemes",
169 "urllib3": "types-urllib3",
170 "vobject": "types-vobject",
171 "whatthepatch": "types-whatthepatch",
172 "win32": "types-pywin32",
173 "win32api": "types-pywin32",
174 "win32con": "types-pywin32",
175 "win32com": "types-pywin32",
176 "win32comext": "types-pywin32",
177 "win32gui": "types-pywin32",
178 "xmltodict": "types-xmltodict",
179 "xxhash": "types-xxhash",
180 "zxcvbn": "types-zxcvbn",
181 # Stub packages that are not from typeshed
182 # Since these can be installed automatically via --install-types, we have a high trust bar
183 # for additions here
184 "pandas": "pandas-stubs", # https://github.com/pandas-dev/pandas-stubs
185 "lxml": "lxml-stubs", # https://github.com/lxml/lxml-stubs
186 }
187
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mypy/stubinfo.py b/mypy/stubinfo.py
--- a/mypy/stubinfo.py
+++ b/mypy/stubinfo.py
@@ -20,8 +20,6 @@
# Package name can have one or two components ('a' or 'a.b').
legacy_bundled_packages = {
"aiofiles": "types-aiofiles",
- "backports": "types-backports",
- "backports_abc": "types-backports_abc",
"bleach": "types-bleach",
"boto": "types-boto",
"cachetools": "types-cachetools",
|
{"golden_diff": "diff --git a/mypy/stubinfo.py b/mypy/stubinfo.py\n--- a/mypy/stubinfo.py\n+++ b/mypy/stubinfo.py\n@@ -20,8 +20,6 @@\n # Package name can have one or two components ('a' or 'a.b').\n legacy_bundled_packages = {\n \"aiofiles\": \"types-aiofiles\",\n- \"backports\": \"types-backports\",\n- \"backports_abc\": \"types-backports_abc\",\n \"bleach\": \"types-bleach\",\n \"boto\": \"types-boto\",\n \"cachetools\": \"types-cachetools\",\n", "issue": "Wrong recommendation to install `types-backports`\nWhen I import `backports.zoneinfo`, I get\r\n\r\n```\r\nsrc/test_checks.py:29:1: error: Library stubs not installed for \"backports.zoneinfo\" [import]\r\nsrc/test_checks.py:29:1: note: Hint: \"python3 -m pip install types-backports\"\r\nsrc/test_checks.py:29:1: note: (or run \"mypy --install-types\" to install all missing stub packages)\r\nsrc/test_checks.py:29:1: note: See https://mypy.readthedocs.io/en/stable/running_mypy.html#missing-imports\r\n```\r\n\r\nHowever, the `types-backports` package is obsolete since python/typeshed#5997; it was replaced with `types-backports.ssl_match_hostname`. It never provided stubs for `backports.zoneinfo` (which is a py.typed package and doesn't need stubs), only for `ssl_match_hostname`.\r\n\r\n`backports.ssl_match_hostname` provides a 3.7+ feature (https://pypi.org/project/backports.ssl_match_hostname/), so it isn't relevant on any supported version of Python and I don't think mypy needs to recommend installing it. I will submit a PR to remove it from the list of recommended packages.\n", "before_files": [{"content": "from __future__ import annotations\n\n\ndef is_legacy_bundled_package(prefix: str) -> bool:\n return prefix in legacy_bundled_packages\n\n\ndef approved_stub_package_exists(prefix: str) -> bool:\n return is_legacy_bundled_package(prefix) or prefix in non_bundled_packages\n\n\ndef stub_package_name(prefix: str) -> str:\n return legacy_bundled_packages.get(prefix) or non_bundled_packages[prefix]\n\n\n# Stubs for these third-party packages used to be shipped with mypy.\n#\n# Map package name to PyPI stub distribution name.\n#\n# Package name can have one or two components ('a' or 'a.b').\nlegacy_bundled_packages = {\n \"aiofiles\": \"types-aiofiles\",\n \"backports\": \"types-backports\",\n \"backports_abc\": \"types-backports_abc\",\n \"bleach\": \"types-bleach\",\n \"boto\": \"types-boto\",\n \"cachetools\": \"types-cachetools\",\n \"click_spinner\": \"types-click-spinner\",\n \"contextvars\": \"types-contextvars\",\n \"croniter\": \"types-croniter\",\n \"dataclasses\": \"types-dataclasses\",\n \"dateparser\": \"types-dateparser\",\n \"datetimerange\": \"types-DateTimeRange\",\n \"dateutil\": \"types-python-dateutil\",\n \"decorator\": \"types-decorator\",\n \"deprecated\": \"types-Deprecated\",\n \"docutils\": \"types-docutils\",\n \"first\": \"types-first\",\n \"geoip2\": \"types-geoip2\",\n \"gflags\": \"types-python-gflags\",\n \"google.protobuf\": \"types-protobuf\",\n \"markdown\": \"types-Markdown\",\n \"maxminddb\": \"types-maxminddb\",\n \"mock\": \"types-mock\",\n \"OpenSSL\": \"types-pyOpenSSL\",\n \"paramiko\": \"types-paramiko\",\n \"pkg_resources\": \"types-setuptools\",\n \"polib\": \"types-polib\",\n \"pycurl\": \"types-pycurl\",\n \"pymysql\": \"types-PyMySQL\",\n \"pyrfc3339\": \"types-pyRFC3339\",\n \"python2\": \"types-six\",\n \"pytz\": \"types-pytz\",\n \"pyVmomi\": \"types-pyvmomi\",\n \"redis\": \"types-redis\",\n \"requests\": \"types-requests\",\n \"retry\": \"types-retry\",\n \"simplejson\": \"types-simplejson\",\n \"singledispatch\": \"types-singledispatch\",\n \"six\": \"types-six\",\n \"slugify\": \"types-python-slugify\",\n \"tabulate\": \"types-tabulate\",\n \"toml\": \"types-toml\",\n \"typed_ast\": \"types-typed-ast\",\n \"tzlocal\": \"types-tzlocal\",\n \"ujson\": \"types-ujson\",\n \"waitress\": \"types-waitress\",\n \"yaml\": \"types-PyYAML\",\n}\n\n# Map package name to PyPI stub distribution name from typeshed.\n# Stubs for these packages were never bundled with mypy. Don't\n# include packages that have a release that includes PEP 561 type\n# information.\n#\n# Package name can have one or two components ('a' or 'a.b').\n#\n# Note that these packages are omitted for now:\n# pika: typeshed's stubs are on PyPI as types-pika-ts.\n# types-pika already exists on PyPI, and is more complete in many ways,\n# but is a non-typeshed stubs package.\nnon_bundled_packages = {\n \"MySQLdb\": \"types-mysqlclient\",\n \"PIL\": \"types-Pillow\",\n \"PyInstaller\": \"types-pyinstaller\",\n \"Xlib\": \"types-python-xlib\",\n \"annoy\": \"types-annoy\",\n \"appdirs\": \"types-appdirs\",\n \"aws_xray_sdk\": \"types-aws-xray-sdk\",\n \"babel\": \"types-babel\",\n \"backports.ssl_match_hostname\": \"types-backports.ssl_match_hostname\",\n \"braintree\": \"types-braintree\",\n \"bs4\": \"types-beautifulsoup4\",\n \"bugbear\": \"types-flake8-bugbear\",\n \"caldav\": \"types-caldav\",\n \"cffi\": \"types-cffi\",\n \"chevron\": \"types-chevron\",\n \"colorama\": \"types-colorama\",\n \"commonmark\": \"types-commonmark\",\n \"consolemenu\": \"types-console-menu\",\n \"crontab\": \"types-python-crontab\",\n \"d3dshot\": \"types-D3DShot\",\n \"dj_database_url\": \"types-dj-database-url\",\n \"dockerfile_parse\": \"types-dockerfile-parse\",\n \"docopt\": \"types-docopt\",\n \"editdistance\": \"types-editdistance\",\n \"entrypoints\": \"types-entrypoints\",\n \"farmhash\": \"types-pyfarmhash\",\n \"flake8_2020\": \"types-flake8-2020\",\n \"flake8_builtins\": \"types-flake8-builtins\",\n \"flake8_docstrings\": \"types-flake8-docstrings\",\n \"flake8_plugin_utils\": \"types-flake8-plugin-utils\",\n \"flake8_rst_docstrings\": \"types-flake8-rst-docstrings\",\n \"flake8_simplify\": \"types-flake8-simplify\",\n \"flake8_typing_imports\": \"types-flake8-typing-imports\",\n \"flask_cors\": \"types-Flask-Cors\",\n \"flask_migrate\": \"types-Flask-Migrate\",\n \"flask_sqlalchemy\": \"types-Flask-SQLAlchemy\",\n \"fpdf\": \"types-fpdf2\",\n \"gdb\": \"types-gdb\",\n \"google.cloud\": \"types-google-cloud-ndb\",\n \"hdbcli\": \"types-hdbcli\",\n \"html5lib\": \"types-html5lib\",\n \"httplib2\": \"types-httplib2\",\n \"humanfriendly\": \"types-humanfriendly\",\n \"invoke\": \"types-invoke\",\n \"jack\": \"types-JACK-Client\",\n \"jmespath\": \"types-jmespath\",\n \"jose\": \"types-python-jose\",\n \"jsonschema\": \"types-jsonschema\",\n \"keyboard\": \"types-keyboard\",\n \"ldap3\": \"types-ldap3\",\n \"nmap\": \"types-python-nmap\",\n \"oauthlib\": \"types-oauthlib\",\n \"openpyxl\": \"types-openpyxl\",\n \"opentracing\": \"types-opentracing\",\n \"paho.mqtt\": \"types-paho-mqtt\",\n \"parsimonious\": \"types-parsimonious\",\n \"passlib\": \"types-passlib\",\n \"passpy\": \"types-passpy\",\n \"peewee\": \"types-peewee\",\n \"pep8ext_naming\": \"types-pep8-naming\",\n \"playsound\": \"types-playsound\",\n \"psutil\": \"types-psutil\",\n \"psycopg2\": \"types-psycopg2\",\n \"pyaudio\": \"types-pyaudio\",\n \"pyautogui\": \"types-PyAutoGUI\",\n \"pycocotools\": \"types-pycocotools\",\n \"pyflakes\": \"types-pyflakes\",\n \"pygments\": \"types-Pygments\",\n \"pyi_splash\": \"types-pyinstaller\",\n \"pynput\": \"types-pynput\",\n \"pythoncom\": \"types-pywin32\",\n \"pythonwin\": \"types-pywin32\",\n \"pyscreeze\": \"types-PyScreeze\",\n \"pysftp\": \"types-pysftp\",\n \"pytest_lazyfixture\": \"types-pytest-lazy-fixture\",\n \"pywintypes\": \"types-pywin32\",\n \"regex\": \"types-regex\",\n \"send2trash\": \"types-Send2Trash\",\n \"slumber\": \"types-slumber\",\n \"stdlib_list\": \"types-stdlib-list\",\n \"stripe\": \"types-stripe\",\n \"toposort\": \"types-toposort\",\n \"tqdm\": \"types-tqdm\",\n \"tree_sitter\": \"types-tree-sitter\",\n \"tree_sitter_languages\": \"types-tree-sitter-languages\",\n \"ttkthemes\": \"types-ttkthemes\",\n \"urllib3\": \"types-urllib3\",\n \"vobject\": \"types-vobject\",\n \"whatthepatch\": \"types-whatthepatch\",\n \"win32\": \"types-pywin32\",\n \"win32api\": \"types-pywin32\",\n \"win32con\": \"types-pywin32\",\n \"win32com\": \"types-pywin32\",\n \"win32comext\": \"types-pywin32\",\n \"win32gui\": \"types-pywin32\",\n \"xmltodict\": \"types-xmltodict\",\n \"xxhash\": \"types-xxhash\",\n \"zxcvbn\": \"types-zxcvbn\",\n # Stub packages that are not from typeshed\n # Since these can be installed automatically via --install-types, we have a high trust bar\n # for additions here\n \"pandas\": \"pandas-stubs\", # https://github.com/pandas-dev/pandas-stubs\n \"lxml\": \"lxml-stubs\", # https://github.com/lxml/lxml-stubs\n}\n", "path": "mypy/stubinfo.py"}], "after_files": [{"content": "from __future__ import annotations\n\n\ndef is_legacy_bundled_package(prefix: str) -> bool:\n return prefix in legacy_bundled_packages\n\n\ndef approved_stub_package_exists(prefix: str) -> bool:\n return is_legacy_bundled_package(prefix) or prefix in non_bundled_packages\n\n\ndef stub_package_name(prefix: str) -> str:\n return legacy_bundled_packages.get(prefix) or non_bundled_packages[prefix]\n\n\n# Stubs for these third-party packages used to be shipped with mypy.\n#\n# Map package name to PyPI stub distribution name.\n#\n# Package name can have one or two components ('a' or 'a.b').\nlegacy_bundled_packages = {\n \"aiofiles\": \"types-aiofiles\",\n \"bleach\": \"types-bleach\",\n \"boto\": \"types-boto\",\n \"cachetools\": \"types-cachetools\",\n \"click_spinner\": \"types-click-spinner\",\n \"contextvars\": \"types-contextvars\",\n \"croniter\": \"types-croniter\",\n \"dataclasses\": \"types-dataclasses\",\n \"dateparser\": \"types-dateparser\",\n \"datetimerange\": \"types-DateTimeRange\",\n \"dateutil\": \"types-python-dateutil\",\n \"decorator\": \"types-decorator\",\n \"deprecated\": \"types-Deprecated\",\n \"docutils\": \"types-docutils\",\n \"first\": \"types-first\",\n \"geoip2\": \"types-geoip2\",\n \"gflags\": \"types-python-gflags\",\n \"google.protobuf\": \"types-protobuf\",\n \"markdown\": \"types-Markdown\",\n \"maxminddb\": \"types-maxminddb\",\n \"mock\": \"types-mock\",\n \"OpenSSL\": \"types-pyOpenSSL\",\n \"paramiko\": \"types-paramiko\",\n \"pkg_resources\": \"types-setuptools\",\n \"polib\": \"types-polib\",\n \"pycurl\": \"types-pycurl\",\n \"pymysql\": \"types-PyMySQL\",\n \"pyrfc3339\": \"types-pyRFC3339\",\n \"python2\": \"types-six\",\n \"pytz\": \"types-pytz\",\n \"pyVmomi\": \"types-pyvmomi\",\n \"redis\": \"types-redis\",\n \"requests\": \"types-requests\",\n \"retry\": \"types-retry\",\n \"simplejson\": \"types-simplejson\",\n \"singledispatch\": \"types-singledispatch\",\n \"six\": \"types-six\",\n \"slugify\": \"types-python-slugify\",\n \"tabulate\": \"types-tabulate\",\n \"toml\": \"types-toml\",\n \"typed_ast\": \"types-typed-ast\",\n \"tzlocal\": \"types-tzlocal\",\n \"ujson\": \"types-ujson\",\n \"waitress\": \"types-waitress\",\n \"yaml\": \"types-PyYAML\",\n}\n\n# Map package name to PyPI stub distribution name from typeshed.\n# Stubs for these packages were never bundled with mypy. Don't\n# include packages that have a release that includes PEP 561 type\n# information.\n#\n# Package name can have one or two components ('a' or 'a.b').\n#\n# Note that these packages are omitted for now:\n# pika: typeshed's stubs are on PyPI as types-pika-ts.\n# types-pika already exists on PyPI, and is more complete in many ways,\n# but is a non-typeshed stubs package.\nnon_bundled_packages = {\n \"MySQLdb\": \"types-mysqlclient\",\n \"PIL\": \"types-Pillow\",\n \"PyInstaller\": \"types-pyinstaller\",\n \"Xlib\": \"types-python-xlib\",\n \"annoy\": \"types-annoy\",\n \"appdirs\": \"types-appdirs\",\n \"aws_xray_sdk\": \"types-aws-xray-sdk\",\n \"babel\": \"types-babel\",\n \"backports.ssl_match_hostname\": \"types-backports.ssl_match_hostname\",\n \"braintree\": \"types-braintree\",\n \"bs4\": \"types-beautifulsoup4\",\n \"bugbear\": \"types-flake8-bugbear\",\n \"caldav\": \"types-caldav\",\n \"cffi\": \"types-cffi\",\n \"chevron\": \"types-chevron\",\n \"colorama\": \"types-colorama\",\n \"commonmark\": \"types-commonmark\",\n \"consolemenu\": \"types-console-menu\",\n \"crontab\": \"types-python-crontab\",\n \"d3dshot\": \"types-D3DShot\",\n \"dj_database_url\": \"types-dj-database-url\",\n \"dockerfile_parse\": \"types-dockerfile-parse\",\n \"docopt\": \"types-docopt\",\n \"editdistance\": \"types-editdistance\",\n \"entrypoints\": \"types-entrypoints\",\n \"farmhash\": \"types-pyfarmhash\",\n \"flake8_2020\": \"types-flake8-2020\",\n \"flake8_builtins\": \"types-flake8-builtins\",\n \"flake8_docstrings\": \"types-flake8-docstrings\",\n \"flake8_plugin_utils\": \"types-flake8-plugin-utils\",\n \"flake8_rst_docstrings\": \"types-flake8-rst-docstrings\",\n \"flake8_simplify\": \"types-flake8-simplify\",\n \"flake8_typing_imports\": \"types-flake8-typing-imports\",\n \"flask_cors\": \"types-Flask-Cors\",\n \"flask_migrate\": \"types-Flask-Migrate\",\n \"flask_sqlalchemy\": \"types-Flask-SQLAlchemy\",\n \"fpdf\": \"types-fpdf2\",\n \"gdb\": \"types-gdb\",\n \"google.cloud\": \"types-google-cloud-ndb\",\n \"hdbcli\": \"types-hdbcli\",\n \"html5lib\": \"types-html5lib\",\n \"httplib2\": \"types-httplib2\",\n \"humanfriendly\": \"types-humanfriendly\",\n \"invoke\": \"types-invoke\",\n \"jack\": \"types-JACK-Client\",\n \"jmespath\": \"types-jmespath\",\n \"jose\": \"types-python-jose\",\n \"jsonschema\": \"types-jsonschema\",\n \"keyboard\": \"types-keyboard\",\n \"ldap3\": \"types-ldap3\",\n \"nmap\": \"types-python-nmap\",\n \"oauthlib\": \"types-oauthlib\",\n \"openpyxl\": \"types-openpyxl\",\n \"opentracing\": \"types-opentracing\",\n \"paho.mqtt\": \"types-paho-mqtt\",\n \"parsimonious\": \"types-parsimonious\",\n \"passlib\": \"types-passlib\",\n \"passpy\": \"types-passpy\",\n \"peewee\": \"types-peewee\",\n \"pep8ext_naming\": \"types-pep8-naming\",\n \"playsound\": \"types-playsound\",\n \"psutil\": \"types-psutil\",\n \"psycopg2\": \"types-psycopg2\",\n \"pyaudio\": \"types-pyaudio\",\n \"pyautogui\": \"types-PyAutoGUI\",\n \"pycocotools\": \"types-pycocotools\",\n \"pyflakes\": \"types-pyflakes\",\n \"pygments\": \"types-Pygments\",\n \"pyi_splash\": \"types-pyinstaller\",\n \"pynput\": \"types-pynput\",\n \"pythoncom\": \"types-pywin32\",\n \"pythonwin\": \"types-pywin32\",\n \"pyscreeze\": \"types-PyScreeze\",\n \"pysftp\": \"types-pysftp\",\n \"pytest_lazyfixture\": \"types-pytest-lazy-fixture\",\n \"pywintypes\": \"types-pywin32\",\n \"regex\": \"types-regex\",\n \"send2trash\": \"types-Send2Trash\",\n \"slumber\": \"types-slumber\",\n \"stdlib_list\": \"types-stdlib-list\",\n \"stripe\": \"types-stripe\",\n \"toposort\": \"types-toposort\",\n \"tqdm\": \"types-tqdm\",\n \"tree_sitter\": \"types-tree-sitter\",\n \"tree_sitter_languages\": \"types-tree-sitter-languages\",\n \"ttkthemes\": \"types-ttkthemes\",\n \"urllib3\": \"types-urllib3\",\n \"vobject\": \"types-vobject\",\n \"whatthepatch\": \"types-whatthepatch\",\n \"win32\": \"types-pywin32\",\n \"win32api\": \"types-pywin32\",\n \"win32con\": \"types-pywin32\",\n \"win32com\": \"types-pywin32\",\n \"win32comext\": \"types-pywin32\",\n \"win32gui\": \"types-pywin32\",\n \"xmltodict\": \"types-xmltodict\",\n \"xxhash\": \"types-xxhash\",\n \"zxcvbn\": \"types-zxcvbn\",\n # Stub packages that are not from typeshed\n # Since these can be installed automatically via --install-types, we have a high trust bar\n # for additions here\n \"pandas\": \"pandas-stubs\", # https://github.com/pandas-dev/pandas-stubs\n \"lxml\": \"lxml-stubs\", # https://github.com/lxml/lxml-stubs\n}\n", "path": "mypy/stubinfo.py"}]}
| 3,111 | 145 |
gh_patches_debug_3217
|
rasdani/github-patches
|
git_diff
|
huggingface__text-generation-inference-851
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Watermarking bug
### System Info
using singularity with the container `text-generation-inference:1.0.0` .
i get this error:
```
Traceback (most recent call last):
File "/opt/conda/lib/python3.9/site-packages/text_generation_server/models/flash_causal_lm.py", line 727, in warmup
_, batch = self.generate_token(batch)
File "/opt/conda/lib/python3.9/contextlib.py", line 79, in inner
return func(*args, **kwds)
File "/opt/conda/lib/python3.9/site-packages/text_generation_server/models/flash_causal_lm.py", line 834, in generate_token
next_input_ids, next_token_logprobs = batch.next_token_chooser(
File "/opt/conda/lib/python3.9/site-packages/text_generation_server/utils/tokens.py", line 224, in __call__
scores = self.watermark_processor(input_ids, scores)
File "/opt/conda/lib/python3.9/site-packages/text_generation_server/utils/logits_process.py", line 398, in __call__
scores[i : i + 1] = processor(input_ids[i : i + 1], scores[i : i + 1])
File "/opt/conda/lib/python3.9/site-packages/text_generation_server/utils/watermark.py", line 88, in __call__
greenlist_ids = self._get_greenlist_ids(
File "/opt/conda/lib/python3.9/site-packages/text_generation_server/utils/watermark.py", line 64, in _get_greenlist_ids
greenlist_size = int(max_value * self.gamma)
ValueError: invalid literal for int() with base 10: '0.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50
```
i think `greenlist_size = int(max_value * self.gamma)` should be `greenlist_size = max_value * int(self.gamma)`
I also tried setting the env variables only `export WATERMARK_GAMMA=0.5 && export WATERMARK_DELTA=2.0` and the exact issue.
### Information
- [X] Docker
- [ ] The CLI directly
### Tasks
- [X] An officially supported command
- [ ] My own modifications
### Reproduction
```bash
export USE_FLASH_ATTENTION=True && text-generation-launcher \
--model-id /scratch//models/huggyllama-llama-7b \
--port 61697 \
--max-best-of 5 \
--max-total-tokens 2048 \
--max-input-length 1024 \
--max-batch-prefill-tokens 1024 \
--max-concurrent-requests 20 \
--sharded false \
--num-shard 1 \
--dtype float16 \
--disable-custom-kernels \
--watermark-gamma 0.5 \
--watermark-delta 2
```
### Expected behavior
It should multiply the number not the string `0.5`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `server/text_generation_server/utils/watermark.py`
Content:
```
1 # coding=utf-8
2 # Copyright 2023 Authors of "A Watermark for Large Language Models"
3 # available at https://arxiv.org/abs/2301.10226
4 #
5 # Licensed under the Apache License, Version 2.0 (the "License");
6 # you may not use this file except in compliance with the License.
7 # You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing, software
12 # distributed under the License is distributed on an "AS IS" BASIS,
13 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 # See the License for the specific language governing permissions and
15 # limitations under the License.
16 import os
17
18 import torch
19 from transformers import LogitsProcessor
20 from typing import List, Union
21
22 GAMMA = os.getenv("WATERMARK_GAMMA", 0.5)
23 DELTA = os.getenv("WATERMARK_DELTA", 2.0)
24
25
26 class WatermarkLogitsProcessor(LogitsProcessor):
27 def __init__(
28 self,
29 gamma: float = GAMMA,
30 delta: float = DELTA,
31 hash_key: int = 15485863, # just a large prime number to create a rng seed with sufficient bit width
32 device: str = "cpu",
33 ):
34 # watermarking parameters
35 self.gamma = gamma
36 self.delta = delta
37 self.rng = torch.Generator(device=device)
38 self.hash_key = hash_key
39
40 def _seed_rng(self, input_ids: Union[List[int], torch.LongTensor]):
41 if isinstance(input_ids, list):
42 assert (
43 len(input_ids) >= 1
44 ), "requires at least a 1 token prefix sequence to seed rng"
45 prev_token = input_ids[-1]
46 else:
47 assert len(input_ids) == 1
48 input_ids = input_ids[0]
49 assert (
50 input_ids.shape[-1] >= 1
51 ), "requires at least a 1 token prefix sequence to seed rng"
52 prev_token = input_ids[-1].item()
53 self.rng.manual_seed(self.hash_key * prev_token)
54
55 def _get_greenlist_ids(
56 self,
57 input_ids: Union[List[int], torch.LongTensor],
58 max_value: int,
59 device: torch.device,
60 ) -> List[int]:
61 # seed the rng using the previous tokens/prefix
62 self._seed_rng(input_ids)
63
64 greenlist_size = int(max_value * self.gamma)
65 vocab_permutation = torch.randperm(max_value, device=device, generator=self.rng)
66 greenlist_ids = vocab_permutation[:greenlist_size]
67 return greenlist_ids
68
69 @staticmethod
70 def _calc_greenlist_mask(
71 scores: torch.FloatTensor, greenlist_token_ids
72 ) -> torch.BoolTensor:
73 green_tokens_mask = torch.zeros_like(scores)
74 green_tokens_mask[-1, greenlist_token_ids] = 1
75 final_mask = green_tokens_mask.bool()
76 return final_mask
77
78 @staticmethod
79 def _bias_greenlist_logits(
80 scores: torch.Tensor, greenlist_mask: torch.Tensor, greenlist_bias: float
81 ) -> torch.Tensor:
82 scores[greenlist_mask] = scores[greenlist_mask] + greenlist_bias
83 return scores
84
85 def __call__(
86 self, input_ids: Union[List[int], torch.LongTensor], scores: torch.FloatTensor
87 ) -> torch.FloatTensor:
88 greenlist_ids = self._get_greenlist_ids(
89 input_ids, scores.shape[-1], scores.device
90 )
91 green_tokens_mask = self._calc_greenlist_mask(
92 scores=scores, greenlist_token_ids=greenlist_ids
93 )
94
95 scores = self._bias_greenlist_logits(
96 scores=scores, greenlist_mask=green_tokens_mask, greenlist_bias=self.delta
97 )
98 return scores
99
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/server/text_generation_server/utils/watermark.py b/server/text_generation_server/utils/watermark.py
--- a/server/text_generation_server/utils/watermark.py
+++ b/server/text_generation_server/utils/watermark.py
@@ -19,8 +19,8 @@
from transformers import LogitsProcessor
from typing import List, Union
-GAMMA = os.getenv("WATERMARK_GAMMA", 0.5)
-DELTA = os.getenv("WATERMARK_DELTA", 2.0)
+GAMMA = float(os.getenv("WATERMARK_GAMMA", 0.5))
+DELTA = float(os.getenv("WATERMARK_DELTA", 2.0))
class WatermarkLogitsProcessor(LogitsProcessor):
|
{"golden_diff": "diff --git a/server/text_generation_server/utils/watermark.py b/server/text_generation_server/utils/watermark.py\n--- a/server/text_generation_server/utils/watermark.py\n+++ b/server/text_generation_server/utils/watermark.py\n@@ -19,8 +19,8 @@\n from transformers import LogitsProcessor\n from typing import List, Union\n \n-GAMMA = os.getenv(\"WATERMARK_GAMMA\", 0.5)\n-DELTA = os.getenv(\"WATERMARK_DELTA\", 2.0)\n+GAMMA = float(os.getenv(\"WATERMARK_GAMMA\", 0.5))\n+DELTA = float(os.getenv(\"WATERMARK_DELTA\", 2.0))\n \n \n class WatermarkLogitsProcessor(LogitsProcessor):\n", "issue": "Watermarking bug\n### System Info\n\nusing singularity with the container `text-generation-inference:1.0.0` .\r\n\r\ni get this error:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/opt/conda/lib/python3.9/site-packages/text_generation_server/models/flash_causal_lm.py\", line 727, in warmup\r\n _, batch = self.generate_token(batch)\r\n File \"/opt/conda/lib/python3.9/contextlib.py\", line 79, in inner\r\n return func(*args, **kwds)\r\n File \"/opt/conda/lib/python3.9/site-packages/text_generation_server/models/flash_causal_lm.py\", line 834, in generate_token\r\n next_input_ids, next_token_logprobs = batch.next_token_chooser(\r\n File \"/opt/conda/lib/python3.9/site-packages/text_generation_server/utils/tokens.py\", line 224, in __call__\r\n scores = self.watermark_processor(input_ids, scores)\r\n File \"/opt/conda/lib/python3.9/site-packages/text_generation_server/utils/logits_process.py\", line 398, in __call__\r\n scores[i : i + 1] = processor(input_ids[i : i + 1], scores[i : i + 1])\r\n File \"/opt/conda/lib/python3.9/site-packages/text_generation_server/utils/watermark.py\", line 88, in __call__\r\n greenlist_ids = self._get_greenlist_ids(\r\n File \"/opt/conda/lib/python3.9/site-packages/text_generation_server/utils/watermark.py\", line 64, in _get_greenlist_ids\r\n greenlist_size = int(max_value * self.gamma)\r\nValueError: invalid literal for int() with base 10: '0.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50.50\r\n```\r\n\r\ni think `greenlist_size = int(max_value * self.gamma)` should be `greenlist_size = max_value * int(self.gamma)`\r\n\r\nI also tried setting the env variables only `export WATERMARK_GAMMA=0.5 && export WATERMARK_DELTA=2.0` and the exact issue.\r\n\n\n### Information\n\n- [X] Docker\n- [ ] The CLI directly\n\n### Tasks\n\n- [X] An officially supported command\n- [ ] My own modifications\n\n### Reproduction\n\n```bash\r\nexport USE_FLASH_ATTENTION=True && text-generation-launcher \\\r\n--model-id /scratch//models/huggyllama-llama-7b \\\r\n--port 61697 \\\r\n--max-best-of 5 \\\r\n--max-total-tokens 2048 \\\r\n--max-input-length 1024 \\\r\n--max-batch-prefill-tokens 1024 \\\r\n--max-concurrent-requests 20 \\\r\n--sharded false \\\r\n--num-shard 1 \\\r\n--dtype float16 \\\r\n --disable-custom-kernels \\\r\n--watermark-gamma 0.5 \\\r\n--watermark-delta 2\r\n```\n\n### Expected behavior\n\nIt should multiply the number not the string `0.5`\n", "before_files": [{"content": "# coding=utf-8\n# Copyright 2023 Authors of \"A Watermark for Large Language Models\"\n# available at https://arxiv.org/abs/2301.10226\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport os\n\nimport torch\nfrom transformers import LogitsProcessor\nfrom typing import List, Union\n\nGAMMA = os.getenv(\"WATERMARK_GAMMA\", 0.5)\nDELTA = os.getenv(\"WATERMARK_DELTA\", 2.0)\n\n\nclass WatermarkLogitsProcessor(LogitsProcessor):\n def __init__(\n self,\n gamma: float = GAMMA,\n delta: float = DELTA,\n hash_key: int = 15485863, # just a large prime number to create a rng seed with sufficient bit width\n device: str = \"cpu\",\n ):\n # watermarking parameters\n self.gamma = gamma\n self.delta = delta\n self.rng = torch.Generator(device=device)\n self.hash_key = hash_key\n\n def _seed_rng(self, input_ids: Union[List[int], torch.LongTensor]):\n if isinstance(input_ids, list):\n assert (\n len(input_ids) >= 1\n ), \"requires at least a 1 token prefix sequence to seed rng\"\n prev_token = input_ids[-1]\n else:\n assert len(input_ids) == 1\n input_ids = input_ids[0]\n assert (\n input_ids.shape[-1] >= 1\n ), \"requires at least a 1 token prefix sequence to seed rng\"\n prev_token = input_ids[-1].item()\n self.rng.manual_seed(self.hash_key * prev_token)\n\n def _get_greenlist_ids(\n self,\n input_ids: Union[List[int], torch.LongTensor],\n max_value: int,\n device: torch.device,\n ) -> List[int]:\n # seed the rng using the previous tokens/prefix\n self._seed_rng(input_ids)\n\n greenlist_size = int(max_value * self.gamma)\n vocab_permutation = torch.randperm(max_value, device=device, generator=self.rng)\n greenlist_ids = vocab_permutation[:greenlist_size]\n return greenlist_ids\n\n @staticmethod\n def _calc_greenlist_mask(\n scores: torch.FloatTensor, greenlist_token_ids\n ) -> torch.BoolTensor:\n green_tokens_mask = torch.zeros_like(scores)\n green_tokens_mask[-1, greenlist_token_ids] = 1\n final_mask = green_tokens_mask.bool()\n return final_mask\n\n @staticmethod\n def _bias_greenlist_logits(\n scores: torch.Tensor, greenlist_mask: torch.Tensor, greenlist_bias: float\n ) -> torch.Tensor:\n scores[greenlist_mask] = scores[greenlist_mask] + greenlist_bias\n return scores\n\n def __call__(\n self, input_ids: Union[List[int], torch.LongTensor], scores: torch.FloatTensor\n ) -> torch.FloatTensor:\n greenlist_ids = self._get_greenlist_ids(\n input_ids, scores.shape[-1], scores.device\n )\n green_tokens_mask = self._calc_greenlist_mask(\n scores=scores, greenlist_token_ids=greenlist_ids\n )\n\n scores = self._bias_greenlist_logits(\n scores=scores, greenlist_mask=green_tokens_mask, greenlist_bias=self.delta\n )\n return scores\n", "path": "server/text_generation_server/utils/watermark.py"}], "after_files": [{"content": "# coding=utf-8\n# Copyright 2023 Authors of \"A Watermark for Large Language Models\"\n# available at https://arxiv.org/abs/2301.10226\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport os\n\nimport torch\nfrom transformers import LogitsProcessor\nfrom typing import List, Union\n\nGAMMA = float(os.getenv(\"WATERMARK_GAMMA\", 0.5))\nDELTA = float(os.getenv(\"WATERMARK_DELTA\", 2.0))\n\n\nclass WatermarkLogitsProcessor(LogitsProcessor):\n def __init__(\n self,\n gamma: float = GAMMA,\n delta: float = DELTA,\n hash_key: int = 15485863, # just a large prime number to create a rng seed with sufficient bit width\n device: str = \"cpu\",\n ):\n # watermarking parameters\n self.gamma = gamma\n self.delta = delta\n self.rng = torch.Generator(device=device)\n self.hash_key = hash_key\n\n def _seed_rng(self, input_ids: Union[List[int], torch.LongTensor]):\n if isinstance(input_ids, list):\n assert (\n len(input_ids) >= 1\n ), \"requires at least a 1 token prefix sequence to seed rng\"\n prev_token = input_ids[-1]\n else:\n assert len(input_ids) == 1\n input_ids = input_ids[0]\n assert (\n input_ids.shape[-1] >= 1\n ), \"requires at least a 1 token prefix sequence to seed rng\"\n prev_token = input_ids[-1].item()\n self.rng.manual_seed(self.hash_key * prev_token)\n\n def _get_greenlist_ids(\n self,\n input_ids: Union[List[int], torch.LongTensor],\n max_value: int,\n device: torch.device,\n ) -> List[int]:\n # seed the rng using the previous tokens/prefix\n self._seed_rng(input_ids)\n\n greenlist_size = int(max_value * self.gamma)\n vocab_permutation = torch.randperm(max_value, device=device, generator=self.rng)\n greenlist_ids = vocab_permutation[:greenlist_size]\n return greenlist_ids\n\n @staticmethod\n def _calc_greenlist_mask(\n scores: torch.FloatTensor, greenlist_token_ids\n ) -> torch.BoolTensor:\n green_tokens_mask = torch.zeros_like(scores)\n green_tokens_mask[-1, greenlist_token_ids] = 1\n final_mask = green_tokens_mask.bool()\n return final_mask\n\n @staticmethod\n def _bias_greenlist_logits(\n scores: torch.Tensor, greenlist_mask: torch.Tensor, greenlist_bias: float\n ) -> torch.Tensor:\n scores[greenlist_mask] = scores[greenlist_mask] + greenlist_bias\n return scores\n\n def __call__(\n self, input_ids: Union[List[int], torch.LongTensor], scores: torch.FloatTensor\n ) -> torch.FloatTensor:\n greenlist_ids = self._get_greenlist_ids(\n input_ids, scores.shape[-1], scores.device\n )\n green_tokens_mask = self._calc_greenlist_mask(\n scores=scores, greenlist_token_ids=greenlist_ids\n )\n\n scores = self._bias_greenlist_logits(\n scores=scores, greenlist_mask=green_tokens_mask, greenlist_bias=self.delta\n )\n return scores\n", "path": "server/text_generation_server/utils/watermark.py"}]}
| 2,138 | 160 |
gh_patches_debug_22253
|
rasdani/github-patches
|
git_diff
|
pypa__setuptools-2962
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[BUG] DistutilsMetaFinder breaks distutils imports when old setuptools is higher on path
### setuptools version
setuptools==60.0.4
### Python version
python3.8
### OS
RHEL8, FreeBSD12/13, Ubuntu 20.04
### Additional environment information
Any environment where an old setuptools (eg OS package) is higher in `sys.path`, but a newer setuptools is installed anywhere on `sys.path` (with its distutils shimming `.pth` file active)
### Description
Any import of `distutils` will bomb when a new setuptools is present, but an older setuptools is higher on the path (since the new setuptools' path shim blindly tries to import from `setuptools._distutils`, which doesn't exist in old versions of setuptools). This has probably been the case ever since the distutils shim was created, but now that it's active by default, it's a bigger problem.
The place we hit this was running `pip install` from a venv with `--system-site-packages`- pip's build isolation installs latest `setuptools`, but then shuffles `sys.path` around such that the ancient OS-packaged `setuptools` is higher on the path. The first thing that tries to import `distutils` invokes the metapath finder, which has no validation or recovery and just lets the `ModuleNotFoundError` fly.
At first blush, it seems like the metapath shim's `spec_for_distutils` should try to at least verify the co-location of `setuptools` with the shim impl (ie, that they're under the same path prefix) and/or that the `_distutils` subpackage is available via `find_spec` before it actually imports it. Mixing and matching the shim version with random setuptools versions seems like a recipe for trouble down the road...
I could probably throw together a PR for this if there's a consensus that this approach is sane.
### Expected behavior
The presence of a new-but-not-loadable setuptools on sys.path doesn't break old setuptools/distutils.
### How to Reproduce
(NB: this is a much simpler repro than the OS installed setuptools that's actually failing, but illustrates the problem more easily on any OS)
```
python3 -m venv /tmp/bang && source /tmp/bang/bin/activate # give us a clean venv to work in
python -m pip install 'setuptools>60' # install new setuptools to venv site-packages
python -m pip install 'setuptools<45' -t . # install old setuptools to cwd- higher than site-packages on path for most systems
python -c 'import distutils'
```
### Output
```console
...
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/tmp/bang/lib64/python3.9/site-packages/_distutils_hack/__init__.py", line 92, in create_module
return importlib.import_module('setuptools._distutils')
File "/usr/lib64/python3.9/importlib/__init__.py", line 127, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "/home/mdavis/setuptools/__init__.py", line 6, in <module>
import distutils.core
File "/tmp/bang/lib64/python3.9/site-packages/_distutils_hack/__init__.py", line 92, in create_module
return importlib.import_module('setuptools._distutils')
File "/usr/lib64/python3.9/importlib/__init__.py", line 127, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
ModuleNotFoundError: No module named 'setuptools._distutils'
```
### Code of Conduct
- [X] I agree to follow the PSF Code of Conduct
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `_distutils_hack/__init__.py`
Content:
```
1 import sys
2 import os
3 import re
4 import importlib
5 import warnings
6 import contextlib
7
8
9 is_pypy = '__pypy__' in sys.builtin_module_names
10
11
12 warnings.filterwarnings('ignore',
13 r'.+ distutils\b.+ deprecated',
14 DeprecationWarning)
15
16
17 def warn_distutils_present():
18 if 'distutils' not in sys.modules:
19 return
20 if is_pypy and sys.version_info < (3, 7):
21 # PyPy for 3.6 unconditionally imports distutils, so bypass the warning
22 # https://foss.heptapod.net/pypy/pypy/-/blob/be829135bc0d758997b3566062999ee8b23872b4/lib-python/3/site.py#L250
23 return
24 warnings.warn(
25 "Distutils was imported before Setuptools, but importing Setuptools "
26 "also replaces the `distutils` module in `sys.modules`. This may lead "
27 "to undesirable behaviors or errors. To avoid these issues, avoid "
28 "using distutils directly, ensure that setuptools is installed in the "
29 "traditional way (e.g. not an editable install), and/or make sure "
30 "that setuptools is always imported before distutils.")
31
32
33 def clear_distutils():
34 if 'distutils' not in sys.modules:
35 return
36 warnings.warn("Setuptools is replacing distutils.")
37 mods = [name for name in sys.modules if re.match(r'distutils\b', name)]
38 for name in mods:
39 del sys.modules[name]
40
41
42 def enabled():
43 """
44 Allow selection of distutils by environment variable.
45 """
46 which = os.environ.get('SETUPTOOLS_USE_DISTUTILS', 'local')
47 return which == 'local'
48
49
50 def ensure_local_distutils():
51 clear_distutils()
52
53 # With the DistutilsMetaFinder in place,
54 # perform an import to cause distutils to be
55 # loaded from setuptools._distutils. Ref #2906.
56 with shim():
57 importlib.import_module('distutils')
58
59 # check that submodules load as expected
60 core = importlib.import_module('distutils.core')
61 assert '_distutils' in core.__file__, core.__file__
62
63
64 def do_override():
65 """
66 Ensure that the local copy of distutils is preferred over stdlib.
67
68 See https://github.com/pypa/setuptools/issues/417#issuecomment-392298401
69 for more motivation.
70 """
71 if enabled():
72 warn_distutils_present()
73 ensure_local_distutils()
74
75
76 class DistutilsMetaFinder:
77 def find_spec(self, fullname, path, target=None):
78 if path is not None:
79 return
80
81 method_name = 'spec_for_{fullname}'.format(**locals())
82 method = getattr(self, method_name, lambda: None)
83 return method()
84
85 def spec_for_distutils(self):
86 import importlib.abc
87 import importlib.util
88
89 # In cases of path manipulation during sitecustomize,
90 # Setuptools might actually not be present even though
91 # the hook has been loaded. Allow the caller to fall
92 # back to stdlib behavior. See #2980.
93 if not importlib.util.find_spec('setuptools'):
94 return
95
96 class DistutilsLoader(importlib.abc.Loader):
97
98 def create_module(self, spec):
99 return importlib.import_module('setuptools._distutils')
100
101 def exec_module(self, module):
102 pass
103
104 return importlib.util.spec_from_loader('distutils', DistutilsLoader())
105
106 def spec_for_pip(self):
107 """
108 Ensure stdlib distutils when running under pip.
109 See pypa/pip#8761 for rationale.
110 """
111 if self.pip_imported_during_build():
112 return
113 clear_distutils()
114 self.spec_for_distutils = lambda: None
115
116 @classmethod
117 def pip_imported_during_build(cls):
118 """
119 Detect if pip is being imported in a build script. Ref #2355.
120 """
121 import traceback
122 return any(
123 cls.frame_file_is_setup(frame)
124 for frame, line in traceback.walk_stack(None)
125 )
126
127 @staticmethod
128 def frame_file_is_setup(frame):
129 """
130 Return True if the indicated frame suggests a setup.py file.
131 """
132 # some frames may not have __file__ (#2940)
133 return frame.f_globals.get('__file__', '').endswith('setup.py')
134
135
136 DISTUTILS_FINDER = DistutilsMetaFinder()
137
138
139 def ensure_shim():
140 DISTUTILS_FINDER in sys.meta_path or add_shim()
141
142
143 @contextlib.contextmanager
144 def shim():
145 add_shim()
146 try:
147 yield
148 finally:
149 remove_shim()
150
151
152 def add_shim():
153 sys.meta_path.insert(0, DISTUTILS_FINDER)
154
155
156 def remove_shim():
157 try:
158 sys.meta_path.remove(DISTUTILS_FINDER)
159 except ValueError:
160 pass
161
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/_distutils_hack/__init__.py b/_distutils_hack/__init__.py
--- a/_distutils_hack/__init__.py
+++ b/_distutils_hack/__init__.py
@@ -86,17 +86,23 @@
import importlib.abc
import importlib.util
- # In cases of path manipulation during sitecustomize,
- # Setuptools might actually not be present even though
- # the hook has been loaded. Allow the caller to fall
- # back to stdlib behavior. See #2980.
- if not importlib.util.find_spec('setuptools'):
+ try:
+ mod = importlib.import_module('setuptools._distutils')
+ except Exception:
+ # There are a couple of cases where setuptools._distutils
+ # may not be present:
+ # - An older Setuptools without a local distutils is
+ # taking precedence. Ref #2957.
+ # - Path manipulation during sitecustomize removes
+ # setuptools from the path but only after the hook
+ # has been loaded. Ref #2980.
+ # In either case, fall back to stdlib behavior.
return
class DistutilsLoader(importlib.abc.Loader):
def create_module(self, spec):
- return importlib.import_module('setuptools._distutils')
+ return mod
def exec_module(self, module):
pass
|
{"golden_diff": "diff --git a/_distutils_hack/__init__.py b/_distutils_hack/__init__.py\n--- a/_distutils_hack/__init__.py\n+++ b/_distutils_hack/__init__.py\n@@ -86,17 +86,23 @@\n import importlib.abc\n import importlib.util\n \n- # In cases of path manipulation during sitecustomize,\n- # Setuptools might actually not be present even though\n- # the hook has been loaded. Allow the caller to fall\n- # back to stdlib behavior. See #2980.\n- if not importlib.util.find_spec('setuptools'):\n+ try:\n+ mod = importlib.import_module('setuptools._distutils')\n+ except Exception:\n+ # There are a couple of cases where setuptools._distutils\n+ # may not be present:\n+ # - An older Setuptools without a local distutils is\n+ # taking precedence. Ref #2957.\n+ # - Path manipulation during sitecustomize removes\n+ # setuptools from the path but only after the hook\n+ # has been loaded. Ref #2980.\n+ # In either case, fall back to stdlib behavior.\n return\n \n class DistutilsLoader(importlib.abc.Loader):\n \n def create_module(self, spec):\n- return importlib.import_module('setuptools._distutils')\n+ return mod\n \n def exec_module(self, module):\n pass\n", "issue": "[BUG] DistutilsMetaFinder breaks distutils imports when old setuptools is higher on path\n### setuptools version\r\n\r\nsetuptools==60.0.4\r\n\r\n### Python version\r\n\r\npython3.8\r\n\r\n### OS\r\n\r\nRHEL8, FreeBSD12/13, Ubuntu 20.04\r\n\r\n### Additional environment information\r\n\r\nAny environment where an old setuptools (eg OS package) is higher in `sys.path`, but a newer setuptools is installed anywhere on `sys.path` (with its distutils shimming `.pth` file active)\r\n\r\n### Description\r\n\r\nAny import of `distutils` will bomb when a new setuptools is present, but an older setuptools is higher on the path (since the new setuptools' path shim blindly tries to import from `setuptools._distutils`, which doesn't exist in old versions of setuptools). This has probably been the case ever since the distutils shim was created, but now that it's active by default, it's a bigger problem.\r\n\r\nThe place we hit this was running `pip install` from a venv with `--system-site-packages`- pip's build isolation installs latest `setuptools`, but then shuffles `sys.path` around such that the ancient OS-packaged `setuptools` is higher on the path. The first thing that tries to import `distutils` invokes the metapath finder, which has no validation or recovery and just lets the `ModuleNotFoundError` fly.\r\n\r\nAt first blush, it seems like the metapath shim's `spec_for_distutils` should try to at least verify the co-location of `setuptools` with the shim impl (ie, that they're under the same path prefix) and/or that the `_distutils` subpackage is available via `find_spec` before it actually imports it. Mixing and matching the shim version with random setuptools versions seems like a recipe for trouble down the road...\r\n\r\nI could probably throw together a PR for this if there's a consensus that this approach is sane.\r\n\r\n### Expected behavior\r\n\r\nThe presence of a new-but-not-loadable setuptools on sys.path doesn't break old setuptools/distutils.\r\n\r\n\r\n### How to Reproduce\r\n\r\n(NB: this is a much simpler repro than the OS installed setuptools that's actually failing, but illustrates the problem more easily on any OS)\r\n```\r\npython3 -m venv /tmp/bang && source /tmp/bang/bin/activate # give us a clean venv to work in\r\npython -m pip install 'setuptools>60' # install new setuptools to venv site-packages\r\npython -m pip install 'setuptools<45' -t . # install old setuptools to cwd- higher than site-packages on path for most systems\r\npython -c 'import distutils'\r\n```\r\n\r\n### Output\r\n\r\n```console\r\n...\r\nTraceback (most recent call last):\r\n File \"<string>\", line 1, in <module>\r\n File \"/tmp/bang/lib64/python3.9/site-packages/_distutils_hack/__init__.py\", line 92, in create_module\r\n return importlib.import_module('setuptools._distutils')\r\n File \"/usr/lib64/python3.9/importlib/__init__.py\", line 127, in import_module\r\n return _bootstrap._gcd_import(name[level:], package, level)\r\n File \"/home/mdavis/setuptools/__init__.py\", line 6, in <module>\r\n import distutils.core\r\n File \"/tmp/bang/lib64/python3.9/site-packages/_distutils_hack/__init__.py\", line 92, in create_module\r\n return importlib.import_module('setuptools._distutils')\r\n File \"/usr/lib64/python3.9/importlib/__init__.py\", line 127, in import_module\r\n return _bootstrap._gcd_import(name[level:], package, level)\r\nModuleNotFoundError: No module named 'setuptools._distutils'\r\n\r\n```\r\n\r\n\r\n### Code of Conduct\r\n\r\n- [X] I agree to follow the PSF Code of Conduct\n", "before_files": [{"content": "import sys\nimport os\nimport re\nimport importlib\nimport warnings\nimport contextlib\n\n\nis_pypy = '__pypy__' in sys.builtin_module_names\n\n\nwarnings.filterwarnings('ignore',\n r'.+ distutils\\b.+ deprecated',\n DeprecationWarning)\n\n\ndef warn_distutils_present():\n if 'distutils' not in sys.modules:\n return\n if is_pypy and sys.version_info < (3, 7):\n # PyPy for 3.6 unconditionally imports distutils, so bypass the warning\n # https://foss.heptapod.net/pypy/pypy/-/blob/be829135bc0d758997b3566062999ee8b23872b4/lib-python/3/site.py#L250\n return\n warnings.warn(\n \"Distutils was imported before Setuptools, but importing Setuptools \"\n \"also replaces the `distutils` module in `sys.modules`. This may lead \"\n \"to undesirable behaviors or errors. To avoid these issues, avoid \"\n \"using distutils directly, ensure that setuptools is installed in the \"\n \"traditional way (e.g. not an editable install), and/or make sure \"\n \"that setuptools is always imported before distutils.\")\n\n\ndef clear_distutils():\n if 'distutils' not in sys.modules:\n return\n warnings.warn(\"Setuptools is replacing distutils.\")\n mods = [name for name in sys.modules if re.match(r'distutils\\b', name)]\n for name in mods:\n del sys.modules[name]\n\n\ndef enabled():\n \"\"\"\n Allow selection of distutils by environment variable.\n \"\"\"\n which = os.environ.get('SETUPTOOLS_USE_DISTUTILS', 'local')\n return which == 'local'\n\n\ndef ensure_local_distutils():\n clear_distutils()\n\n # With the DistutilsMetaFinder in place,\n # perform an import to cause distutils to be\n # loaded from setuptools._distutils. Ref #2906.\n with shim():\n importlib.import_module('distutils')\n\n # check that submodules load as expected\n core = importlib.import_module('distutils.core')\n assert '_distutils' in core.__file__, core.__file__\n\n\ndef do_override():\n \"\"\"\n Ensure that the local copy of distutils is preferred over stdlib.\n\n See https://github.com/pypa/setuptools/issues/417#issuecomment-392298401\n for more motivation.\n \"\"\"\n if enabled():\n warn_distutils_present()\n ensure_local_distutils()\n\n\nclass DistutilsMetaFinder:\n def find_spec(self, fullname, path, target=None):\n if path is not None:\n return\n\n method_name = 'spec_for_{fullname}'.format(**locals())\n method = getattr(self, method_name, lambda: None)\n return method()\n\n def spec_for_distutils(self):\n import importlib.abc\n import importlib.util\n\n # In cases of path manipulation during sitecustomize,\n # Setuptools might actually not be present even though\n # the hook has been loaded. Allow the caller to fall\n # back to stdlib behavior. See #2980.\n if not importlib.util.find_spec('setuptools'):\n return\n\n class DistutilsLoader(importlib.abc.Loader):\n\n def create_module(self, spec):\n return importlib.import_module('setuptools._distutils')\n\n def exec_module(self, module):\n pass\n\n return importlib.util.spec_from_loader('distutils', DistutilsLoader())\n\n def spec_for_pip(self):\n \"\"\"\n Ensure stdlib distutils when running under pip.\n See pypa/pip#8761 for rationale.\n \"\"\"\n if self.pip_imported_during_build():\n return\n clear_distutils()\n self.spec_for_distutils = lambda: None\n\n @classmethod\n def pip_imported_during_build(cls):\n \"\"\"\n Detect if pip is being imported in a build script. Ref #2355.\n \"\"\"\n import traceback\n return any(\n cls.frame_file_is_setup(frame)\n for frame, line in traceback.walk_stack(None)\n )\n\n @staticmethod\n def frame_file_is_setup(frame):\n \"\"\"\n Return True if the indicated frame suggests a setup.py file.\n \"\"\"\n # some frames may not have __file__ (#2940)\n return frame.f_globals.get('__file__', '').endswith('setup.py')\n\n\nDISTUTILS_FINDER = DistutilsMetaFinder()\n\n\ndef ensure_shim():\n DISTUTILS_FINDER in sys.meta_path or add_shim()\n\n\[email protected]\ndef shim():\n add_shim()\n try:\n yield\n finally:\n remove_shim()\n\n\ndef add_shim():\n sys.meta_path.insert(0, DISTUTILS_FINDER)\n\n\ndef remove_shim():\n try:\n sys.meta_path.remove(DISTUTILS_FINDER)\n except ValueError:\n pass\n", "path": "_distutils_hack/__init__.py"}], "after_files": [{"content": "import sys\nimport os\nimport re\nimport importlib\nimport warnings\nimport contextlib\n\n\nis_pypy = '__pypy__' in sys.builtin_module_names\n\n\nwarnings.filterwarnings('ignore',\n r'.+ distutils\\b.+ deprecated',\n DeprecationWarning)\n\n\ndef warn_distutils_present():\n if 'distutils' not in sys.modules:\n return\n if is_pypy and sys.version_info < (3, 7):\n # PyPy for 3.6 unconditionally imports distutils, so bypass the warning\n # https://foss.heptapod.net/pypy/pypy/-/blob/be829135bc0d758997b3566062999ee8b23872b4/lib-python/3/site.py#L250\n return\n warnings.warn(\n \"Distutils was imported before Setuptools, but importing Setuptools \"\n \"also replaces the `distutils` module in `sys.modules`. This may lead \"\n \"to undesirable behaviors or errors. To avoid these issues, avoid \"\n \"using distutils directly, ensure that setuptools is installed in the \"\n \"traditional way (e.g. not an editable install), and/or make sure \"\n \"that setuptools is always imported before distutils.\")\n\n\ndef clear_distutils():\n if 'distutils' not in sys.modules:\n return\n warnings.warn(\"Setuptools is replacing distutils.\")\n mods = [name for name in sys.modules if re.match(r'distutils\\b', name)]\n for name in mods:\n del sys.modules[name]\n\n\ndef enabled():\n \"\"\"\n Allow selection of distutils by environment variable.\n \"\"\"\n which = os.environ.get('SETUPTOOLS_USE_DISTUTILS', 'local')\n return which == 'local'\n\n\ndef ensure_local_distutils():\n clear_distutils()\n\n # With the DistutilsMetaFinder in place,\n # perform an import to cause distutils to be\n # loaded from setuptools._distutils. Ref #2906.\n with shim():\n importlib.import_module('distutils')\n\n # check that submodules load as expected\n core = importlib.import_module('distutils.core')\n assert '_distutils' in core.__file__, core.__file__\n\n\ndef do_override():\n \"\"\"\n Ensure that the local copy of distutils is preferred over stdlib.\n\n See https://github.com/pypa/setuptools/issues/417#issuecomment-392298401\n for more motivation.\n \"\"\"\n if enabled():\n warn_distutils_present()\n ensure_local_distutils()\n\n\nclass DistutilsMetaFinder:\n def find_spec(self, fullname, path, target=None):\n if path is not None:\n return\n\n method_name = 'spec_for_{fullname}'.format(**locals())\n method = getattr(self, method_name, lambda: None)\n return method()\n\n def spec_for_distutils(self):\n import importlib.abc\n import importlib.util\n\n try:\n mod = importlib.import_module('setuptools._distutils')\n except Exception:\n # There are a couple of cases where setuptools._distutils\n # may not be present:\n # - An older Setuptools without a local distutils is\n # taking precedence. Ref #2957.\n # - Path manipulation during sitecustomize removes\n # setuptools from the path but only after the hook\n # has been loaded. Ref #2980.\n # In either case, fall back to stdlib behavior.\n return\n\n class DistutilsLoader(importlib.abc.Loader):\n\n def create_module(self, spec):\n return mod\n\n def exec_module(self, module):\n pass\n\n return importlib.util.spec_from_loader('distutils', DistutilsLoader())\n\n def spec_for_pip(self):\n \"\"\"\n Ensure stdlib distutils when running under pip.\n See pypa/pip#8761 for rationale.\n \"\"\"\n if self.pip_imported_during_build():\n return\n clear_distutils()\n self.spec_for_distutils = lambda: None\n\n @classmethod\n def pip_imported_during_build(cls):\n \"\"\"\n Detect if pip is being imported in a build script. Ref #2355.\n \"\"\"\n import traceback\n return any(\n cls.frame_file_is_setup(frame)\n for frame, line in traceback.walk_stack(None)\n )\n\n @staticmethod\n def frame_file_is_setup(frame):\n \"\"\"\n Return True if the indicated frame suggests a setup.py file.\n \"\"\"\n # some frames may not have __file__ (#2940)\n return frame.f_globals.get('__file__', '').endswith('setup.py')\n\n\nDISTUTILS_FINDER = DistutilsMetaFinder()\n\n\ndef ensure_shim():\n DISTUTILS_FINDER in sys.meta_path or add_shim()\n\n\[email protected]\ndef shim():\n add_shim()\n try:\n yield\n finally:\n remove_shim()\n\n\ndef add_shim():\n sys.meta_path.insert(0, DISTUTILS_FINDER)\n\n\ndef remove_shim():\n try:\n sys.meta_path.remove(DISTUTILS_FINDER)\n except ValueError:\n pass\n", "path": "_distutils_hack/__init__.py"}]}
| 2,579 | 327 |
gh_patches_debug_9506
|
rasdani/github-patches
|
git_diff
|
e-valuation__EvaP-574
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
headline css is broken
our headlines don't use h1 h2 etc anymore and look completely broken on firefox mobile.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `evap/staff/templatetags/staff_templatetags.py`
Content:
```
1 from django.template import Library
2
3 from evap.evaluation.models import Semester
4
5 register = Library()
6
7
8 @register.inclusion_tag("staff_semester_menu.html")
9 def include_staff_semester_menu():
10 return dict(semesters=Semester.objects.all()[:5])
11
12 @register.inclusion_tag('staff_course_selection_list.html')
13 def include_staff_course_selection_list(course_forms, btn_label, empty_msg):
14 return {
15 'course_forms': course_forms,
16 'btn_label': btn_label,
17 'empty_msg': empty_msg
18 }
19
20 @register.inclusion_tag('staff_user_labels.html')
21 def include_staff_user_labels(user):
22 return dict(user=user)
23
24 @register.inclusion_tag("staff_questionnaire_index_list.html")
25 def include_staff_questionnaire_index_list(questionnaires, headline):
26 return dict(questionnaires=questionnaires, headline=headline)
27
28 @register.inclusion_tag("staff_semester_view_course.html")
29 def include_staff_semester_view_course(semester, state, course, disable_if_archived, info_only=False):
30 return dict(semester=semester, state=state, course=course, disable_if_archived=disable_if_archived, info_only=info_only)
31
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/evap/staff/templatetags/staff_templatetags.py b/evap/staff/templatetags/staff_templatetags.py
--- a/evap/staff/templatetags/staff_templatetags.py
+++ b/evap/staff/templatetags/staff_templatetags.py
@@ -9,14 +9,6 @@
def include_staff_semester_menu():
return dict(semesters=Semester.objects.all()[:5])
[email protected]_tag('staff_course_selection_list.html')
-def include_staff_course_selection_list(course_forms, btn_label, empty_msg):
- return {
- 'course_forms': course_forms,
- 'btn_label': btn_label,
- 'empty_msg': empty_msg
- }
-
@register.inclusion_tag('staff_user_labels.html')
def include_staff_user_labels(user):
return dict(user=user)
|
{"golden_diff": "diff --git a/evap/staff/templatetags/staff_templatetags.py b/evap/staff/templatetags/staff_templatetags.py\n--- a/evap/staff/templatetags/staff_templatetags.py\n+++ b/evap/staff/templatetags/staff_templatetags.py\n@@ -9,14 +9,6 @@\n def include_staff_semester_menu():\n return dict(semesters=Semester.objects.all()[:5])\n \[email protected]_tag('staff_course_selection_list.html')\n-def include_staff_course_selection_list(course_forms, btn_label, empty_msg):\n- return {\n- 'course_forms': course_forms,\n- 'btn_label': btn_label,\n- 'empty_msg': empty_msg\n- }\n-\n @register.inclusion_tag('staff_user_labels.html')\n def include_staff_user_labels(user):\n return dict(user=user)\n", "issue": "headline css is broken\nour headlines don't use h1 h2 etc anymore and look completely broken on firefox mobile.\n\n", "before_files": [{"content": "from django.template import Library\n\nfrom evap.evaluation.models import Semester\n\nregister = Library()\n\n\[email protected]_tag(\"staff_semester_menu.html\")\ndef include_staff_semester_menu():\n return dict(semesters=Semester.objects.all()[:5])\n\[email protected]_tag('staff_course_selection_list.html')\ndef include_staff_course_selection_list(course_forms, btn_label, empty_msg):\n return {\n 'course_forms': course_forms,\n 'btn_label': btn_label,\n 'empty_msg': empty_msg\n }\n\[email protected]_tag('staff_user_labels.html')\ndef include_staff_user_labels(user):\n return dict(user=user)\n\[email protected]_tag(\"staff_questionnaire_index_list.html\")\ndef include_staff_questionnaire_index_list(questionnaires, headline):\n return dict(questionnaires=questionnaires, headline=headline)\n\[email protected]_tag(\"staff_semester_view_course.html\")\ndef include_staff_semester_view_course(semester, state, course, disable_if_archived, info_only=False):\n return dict(semester=semester, state=state, course=course, disable_if_archived=disable_if_archived, info_only=info_only)\n", "path": "evap/staff/templatetags/staff_templatetags.py"}], "after_files": [{"content": "from django.template import Library\n\nfrom evap.evaluation.models import Semester\n\nregister = Library()\n\n\[email protected]_tag(\"staff_semester_menu.html\")\ndef include_staff_semester_menu():\n return dict(semesters=Semester.objects.all()[:5])\n\[email protected]_tag('staff_user_labels.html')\ndef include_staff_user_labels(user):\n return dict(user=user)\n\[email protected]_tag(\"staff_questionnaire_index_list.html\")\ndef include_staff_questionnaire_index_list(questionnaires, headline):\n return dict(questionnaires=questionnaires, headline=headline)\n\[email protected]_tag(\"staff_semester_view_course.html\")\ndef include_staff_semester_view_course(semester, state, course, disable_if_archived, info_only=False):\n return dict(semester=semester, state=state, course=course, disable_if_archived=disable_if_archived, info_only=info_only)\n", "path": "evap/staff/templatetags/staff_templatetags.py"}]}
| 596 | 206 |
gh_patches_debug_34651
|
rasdani/github-patches
|
git_diff
|
scoutapp__scout_apm_python-499
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Hide scout message about event draining
When `log_level` is set to `ERROR` and logs are redirected to a log file through `log_file_path`, scout still logs a message like: `Scout draining 1 event for up to 2.0 seconds` on STDOUT, is it possible to remove this message from STDOUT?
Thank you!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/scout_apm/core/__init__.py`
Content:
```
1 # coding=utf-8
2 from __future__ import absolute_import, division, print_function, unicode_literals
3
4 import atexit
5 import logging
6 import os
7 import sys
8
9 from scout_apm import instruments
10 from scout_apm.compat import kwargs_only
11 from scout_apm.core import objtrace
12 from scout_apm.core.config import scout_config
13 from scout_apm.core.core_agent_manager import CoreAgentManager
14 from scout_apm.core.metadata import report_app_metadata
15 from scout_apm.core.socket import CoreAgentSocketThread
16
17 logger = logging.getLogger(__name__)
18
19
20 @kwargs_only
21 def install(config=None):
22 global shutdown_registered
23 if config is not None:
24 scout_config.set(**config)
25 scout_config.log()
26
27 if os.name == "nt":
28 logger.info(
29 "APM Not Launching on PID: %s - Windows is not supported", os.getpid()
30 )
31 return False
32
33 if not scout_config.value("monitor"):
34 logger.info(
35 "APM Not Launching on PID: %s - Configuration 'monitor' is not true",
36 os.getpid(),
37 )
38 return False
39
40 instruments.ensure_all_installed()
41 objtrace.enable()
42
43 logger.debug("APM Launching on PID: %s", os.getpid())
44 launched = CoreAgentManager().launch()
45
46 report_app_metadata()
47 if launched:
48 # Stop the thread to avoid running threads pre-fork
49 CoreAgentSocketThread.ensure_stopped()
50
51 if scout_config.value("shutdown_timeout_seconds") > 0.0 and not shutdown_registered:
52 atexit.register(shutdown)
53 shutdown_registered = True
54
55 return True
56
57
58 shutdown_registered = False
59
60
61 def shutdown():
62 timeout_seconds = scout_config.value("shutdown_timeout_seconds")
63
64 def callback(queue_size):
65 print( # noqa: T001
66 (
67 "Scout draining {queue_size} event{s} for up to"
68 + " {timeout_seconds} seconds"
69 ).format(
70 queue_size=queue_size,
71 s=("" if queue_size == 1 else "s"),
72 timeout_seconds=timeout_seconds,
73 ),
74 file=sys.stderr,
75 )
76
77 CoreAgentSocketThread.wait_until_drained(
78 timeout_seconds=timeout_seconds, callback=callback
79 )
80
```
Path: `src/scout_apm/core/config.py`
Content:
```
1 # coding=utf-8
2 from __future__ import absolute_import, division, print_function, unicode_literals
3
4 import logging
5 import os
6 import warnings
7
8 from scout_apm.compat import string_type
9 from scout_apm.core import platform_detection
10
11 logger = logging.getLogger(__name__)
12
13
14 class ScoutConfig(object):
15 """
16 Configuration object for the ScoutApm agent.
17
18 Contains a list of configuration "layers". When a configuration key is
19 looked up, each layer is asked in turn if it knows the value. The first one
20 to answer affirmatively returns the value.
21 """
22
23 def __init__(self):
24 self.layers = [
25 Env(),
26 Python(),
27 Derived(self),
28 Defaults(),
29 Null(),
30 ]
31
32 def value(self, key):
33 value = self.locate_layer_for_key(key).value(key)
34 if key in CONVERSIONS:
35 return CONVERSIONS[key](value)
36 return value
37
38 def locate_layer_for_key(self, key):
39 for layer in self.layers:
40 if layer.has_config(key):
41 return layer
42
43 # Should be unreachable because Null returns None for all keys.
44 raise ValueError("key {!r} not found in any layer".format(key))
45
46 def log(self):
47 logger.debug("Configuration Loaded:")
48 for key in self.known_keys():
49 layer = self.locate_layer_for_key(key)
50 logger.debug(
51 "%-9s: %s = %s", layer.__class__.__name__, key, layer.value(key)
52 )
53
54 def known_keys(self):
55 return [
56 "app_server",
57 "application_root",
58 "core_agent_dir",
59 "core_agent_download",
60 "core_agent_launch",
61 "core_agent_log_level",
62 "core_agent_permissions",
63 "core_agent_version",
64 "disabled_instruments",
65 "download_url",
66 "framework",
67 "framework_version",
68 "hostname",
69 "ignore",
70 "key",
71 "log_level",
72 "monitor",
73 "name",
74 "revision_sha",
75 "scm_subdirectory",
76 "shutdown_timeout_seconds",
77 "socket_path",
78 ]
79
80 def core_agent_permissions(self):
81 try:
82 return int(str(self.value("core_agent_permissions")), 8)
83 except ValueError:
84 logger.exception(
85 "Invalid core_agent_permissions value, using default of 0o700"
86 )
87 return 0o700
88
89 @classmethod
90 def set(cls, **kwargs):
91 """
92 Sets a configuration value for the Scout agent. Values set here will
93 not override values set in ENV.
94 """
95 for key, value in kwargs.items():
96 SCOUT_PYTHON_VALUES[key] = value
97
98 @classmethod
99 def unset(cls, *keys):
100 """
101 Removes a configuration value for the Scout agent.
102 """
103 for key in keys:
104 SCOUT_PYTHON_VALUES.pop(key, None)
105
106 @classmethod
107 def reset_all(cls):
108 """
109 Remove all configuration settings set via `ScoutConfig.set(...)`.
110
111 This is meant for use in testing.
112 """
113 SCOUT_PYTHON_VALUES.clear()
114
115
116 # Module-level data, the ScoutConfig.set(key="value") adds to this
117 SCOUT_PYTHON_VALUES = {}
118
119
120 class Python(object):
121 """
122 A configuration overlay that lets other parts of python set values.
123 """
124
125 def has_config(self, key):
126 return key in SCOUT_PYTHON_VALUES
127
128 def value(self, key):
129 return SCOUT_PYTHON_VALUES[key]
130
131
132 class Env(object):
133 """
134 Reads configuration from environment by prefixing the key
135 requested with "SCOUT_"
136
137 Example: the `key` config looks for SCOUT_KEY
138 environment variable
139 """
140
141 def has_config(self, key):
142 env_key = self.modify_key(key)
143 return env_key in os.environ
144
145 def value(self, key):
146 env_key = self.modify_key(key)
147 return os.environ[env_key]
148
149 def modify_key(self, key):
150 env_key = ("SCOUT_" + key).upper()
151 return env_key
152
153
154 class Derived(object):
155 """
156 A configuration overlay that calculates from other values.
157 """
158
159 def __init__(self, config):
160 """
161 config argument is the overall ScoutConfig var, so we can lookup the
162 components of the derived info.
163 """
164 self.config = config
165
166 def has_config(self, key):
167 return self.lookup_func(key) is not None
168
169 def value(self, key):
170 return self.lookup_func(key)()
171
172 def lookup_func(self, key):
173 """
174 Returns the derive_#{key} function, or None if it isn't defined
175 """
176 func_name = "derive_" + key
177 return getattr(self, func_name, None)
178
179 def derive_socket_path(self):
180 return "{}/{}/scout-agent.sock".format(
181 self.config.value("core_agent_dir"),
182 self.config.value("core_agent_full_name"),
183 )
184
185 def derive_core_agent_full_name(self):
186 triple = self.config.value("core_agent_triple")
187 if not platform_detection.is_valid_triple(triple):
188 warnings.warn("Invalid value for core_agent_triple: {}".format(triple))
189 return "{name}-{version}-{triple}".format(
190 name="scout_apm_core",
191 version=self.config.value("core_agent_version"),
192 triple=triple,
193 )
194
195 def derive_core_agent_triple(self):
196 return platform_detection.get_triple()
197
198
199 class Defaults(object):
200 """
201 Provides default values for important configurations
202 """
203
204 def __init__(self):
205 self.defaults = {
206 "app_server": "",
207 "application_root": "",
208 "core_agent_dir": "/tmp/scout_apm_core",
209 "core_agent_download": True,
210 "core_agent_launch": True,
211 "core_agent_log_level": "info",
212 "core_agent_permissions": 700,
213 "core_agent_version": "v1.2.6", # can be an exact tag name, or 'latest'
214 "disabled_instruments": [],
215 "download_url": "https://s3-us-west-1.amazonaws.com/scout-public-downloads/apm_core_agent/release", # noqa: E501
216 "framework": "",
217 "framework_version": "",
218 "hostname": None,
219 "key": "",
220 "monitor": False,
221 "name": "Python App",
222 "revision_sha": self._git_revision_sha(),
223 "scm_subdirectory": "",
224 "shutdown_timeout_seconds": 2.0,
225 "uri_reporting": "filtered_params",
226 }
227
228 def _git_revision_sha(self):
229 # N.B. The environment variable SCOUT_REVISION_SHA may also be used,
230 # but that will be picked up by Env
231 return os.environ.get("HEROKU_SLUG_COMMIT", "")
232
233 def has_config(self, key):
234 return key in self.defaults
235
236 def value(self, key):
237 return self.defaults[key]
238
239
240 class Null(object):
241 """
242 Always answers that a key is present, but the value is None
243
244 Used as the last step of the layered configuration.
245 """
246
247 def has_config(self, key):
248 return True
249
250 def value(self, key):
251 return None
252
253
254 def convert_to_bool(value):
255 if isinstance(value, bool):
256 return value
257 if isinstance(value, string_type):
258 return value.lower() in ("yes", "true", "t", "1")
259 # Unknown type - default to false?
260 return False
261
262
263 def convert_to_float(value):
264 try:
265 return float(value)
266 except ValueError:
267 return 0.0
268
269
270 def convert_to_list(value):
271 if isinstance(value, list):
272 return value
273 if isinstance(value, tuple):
274 return list(value)
275 if isinstance(value, string_type):
276 # Split on commas
277 return [item.strip() for item in value.split(",") if item]
278 # Unknown type - default to empty?
279 return []
280
281
282 CONVERSIONS = {
283 "core_agent_download": convert_to_bool,
284 "core_agent_launch": convert_to_bool,
285 "disabled_instruments": convert_to_list,
286 "ignore": convert_to_list,
287 "monitor": convert_to_bool,
288 "shutdown_timeout_seconds": convert_to_float,
289 }
290
291
292 scout_config = ScoutConfig()
293
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/scout_apm/core/__init__.py b/src/scout_apm/core/__init__.py
--- a/src/scout_apm/core/__init__.py
+++ b/src/scout_apm/core/__init__.py
@@ -62,17 +62,18 @@
timeout_seconds = scout_config.value("shutdown_timeout_seconds")
def callback(queue_size):
- print( # noqa: T001
- (
- "Scout draining {queue_size} event{s} for up to"
- + " {timeout_seconds} seconds"
- ).format(
- queue_size=queue_size,
- s=("" if queue_size == 1 else "s"),
- timeout_seconds=timeout_seconds,
- ),
- file=sys.stderr,
- )
+ if scout_config.value("shutdown_message_enabled"):
+ print( # noqa: T001
+ (
+ "Scout draining {queue_size} event{s} for up to"
+ + " {timeout_seconds} seconds"
+ ).format(
+ queue_size=queue_size,
+ s=("" if queue_size == 1 else "s"),
+ timeout_seconds=timeout_seconds,
+ ),
+ file=sys.stderr,
+ )
CoreAgentSocketThread.wait_until_drained(
timeout_seconds=timeout_seconds, callback=callback
diff --git a/src/scout_apm/core/config.py b/src/scout_apm/core/config.py
--- a/src/scout_apm/core/config.py
+++ b/src/scout_apm/core/config.py
@@ -73,6 +73,7 @@
"name",
"revision_sha",
"scm_subdirectory",
+ "shutdown_message_enabled",
"shutdown_timeout_seconds",
"socket_path",
]
@@ -221,6 +222,7 @@
"name": "Python App",
"revision_sha": self._git_revision_sha(),
"scm_subdirectory": "",
+ "shutdown_message_enabled": True,
"shutdown_timeout_seconds": 2.0,
"uri_reporting": "filtered_params",
}
@@ -285,6 +287,7 @@
"disabled_instruments": convert_to_list,
"ignore": convert_to_list,
"monitor": convert_to_bool,
+ "shutdown_message_enabled": convert_to_bool,
"shutdown_timeout_seconds": convert_to_float,
}
|
{"golden_diff": "diff --git a/src/scout_apm/core/__init__.py b/src/scout_apm/core/__init__.py\n--- a/src/scout_apm/core/__init__.py\n+++ b/src/scout_apm/core/__init__.py\n@@ -62,17 +62,18 @@\n timeout_seconds = scout_config.value(\"shutdown_timeout_seconds\")\n \n def callback(queue_size):\n- print( # noqa: T001\n- (\n- \"Scout draining {queue_size} event{s} for up to\"\n- + \" {timeout_seconds} seconds\"\n- ).format(\n- queue_size=queue_size,\n- s=(\"\" if queue_size == 1 else \"s\"),\n- timeout_seconds=timeout_seconds,\n- ),\n- file=sys.stderr,\n- )\n+ if scout_config.value(\"shutdown_message_enabled\"):\n+ print( # noqa: T001\n+ (\n+ \"Scout draining {queue_size} event{s} for up to\"\n+ + \" {timeout_seconds} seconds\"\n+ ).format(\n+ queue_size=queue_size,\n+ s=(\"\" if queue_size == 1 else \"s\"),\n+ timeout_seconds=timeout_seconds,\n+ ),\n+ file=sys.stderr,\n+ )\n \n CoreAgentSocketThread.wait_until_drained(\n timeout_seconds=timeout_seconds, callback=callback\ndiff --git a/src/scout_apm/core/config.py b/src/scout_apm/core/config.py\n--- a/src/scout_apm/core/config.py\n+++ b/src/scout_apm/core/config.py\n@@ -73,6 +73,7 @@\n \"name\",\n \"revision_sha\",\n \"scm_subdirectory\",\n+ \"shutdown_message_enabled\",\n \"shutdown_timeout_seconds\",\n \"socket_path\",\n ]\n@@ -221,6 +222,7 @@\n \"name\": \"Python App\",\n \"revision_sha\": self._git_revision_sha(),\n \"scm_subdirectory\": \"\",\n+ \"shutdown_message_enabled\": True,\n \"shutdown_timeout_seconds\": 2.0,\n \"uri_reporting\": \"filtered_params\",\n }\n@@ -285,6 +287,7 @@\n \"disabled_instruments\": convert_to_list,\n \"ignore\": convert_to_list,\n \"monitor\": convert_to_bool,\n+ \"shutdown_message_enabled\": convert_to_bool,\n \"shutdown_timeout_seconds\": convert_to_float,\n }\n", "issue": "Hide scout message about event draining\nWhen `log_level` is set to `ERROR` and logs are redirected to a log file through `log_file_path`, scout still logs a message like: `Scout draining 1 event for up to 2.0 seconds` on STDOUT, is it possible to remove this message from STDOUT?\r\nThank you!\n", "before_files": [{"content": "# coding=utf-8\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport atexit\nimport logging\nimport os\nimport sys\n\nfrom scout_apm import instruments\nfrom scout_apm.compat import kwargs_only\nfrom scout_apm.core import objtrace\nfrom scout_apm.core.config import scout_config\nfrom scout_apm.core.core_agent_manager import CoreAgentManager\nfrom scout_apm.core.metadata import report_app_metadata\nfrom scout_apm.core.socket import CoreAgentSocketThread\n\nlogger = logging.getLogger(__name__)\n\n\n@kwargs_only\ndef install(config=None):\n global shutdown_registered\n if config is not None:\n scout_config.set(**config)\n scout_config.log()\n\n if os.name == \"nt\":\n logger.info(\n \"APM Not Launching on PID: %s - Windows is not supported\", os.getpid()\n )\n return False\n\n if not scout_config.value(\"monitor\"):\n logger.info(\n \"APM Not Launching on PID: %s - Configuration 'monitor' is not true\",\n os.getpid(),\n )\n return False\n\n instruments.ensure_all_installed()\n objtrace.enable()\n\n logger.debug(\"APM Launching on PID: %s\", os.getpid())\n launched = CoreAgentManager().launch()\n\n report_app_metadata()\n if launched:\n # Stop the thread to avoid running threads pre-fork\n CoreAgentSocketThread.ensure_stopped()\n\n if scout_config.value(\"shutdown_timeout_seconds\") > 0.0 and not shutdown_registered:\n atexit.register(shutdown)\n shutdown_registered = True\n\n return True\n\n\nshutdown_registered = False\n\n\ndef shutdown():\n timeout_seconds = scout_config.value(\"shutdown_timeout_seconds\")\n\n def callback(queue_size):\n print( # noqa: T001\n (\n \"Scout draining {queue_size} event{s} for up to\"\n + \" {timeout_seconds} seconds\"\n ).format(\n queue_size=queue_size,\n s=(\"\" if queue_size == 1 else \"s\"),\n timeout_seconds=timeout_seconds,\n ),\n file=sys.stderr,\n )\n\n CoreAgentSocketThread.wait_until_drained(\n timeout_seconds=timeout_seconds, callback=callback\n )\n", "path": "src/scout_apm/core/__init__.py"}, {"content": "# coding=utf-8\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport logging\nimport os\nimport warnings\n\nfrom scout_apm.compat import string_type\nfrom scout_apm.core import platform_detection\n\nlogger = logging.getLogger(__name__)\n\n\nclass ScoutConfig(object):\n \"\"\"\n Configuration object for the ScoutApm agent.\n\n Contains a list of configuration \"layers\". When a configuration key is\n looked up, each layer is asked in turn if it knows the value. The first one\n to answer affirmatively returns the value.\n \"\"\"\n\n def __init__(self):\n self.layers = [\n Env(),\n Python(),\n Derived(self),\n Defaults(),\n Null(),\n ]\n\n def value(self, key):\n value = self.locate_layer_for_key(key).value(key)\n if key in CONVERSIONS:\n return CONVERSIONS[key](value)\n return value\n\n def locate_layer_for_key(self, key):\n for layer in self.layers:\n if layer.has_config(key):\n return layer\n\n # Should be unreachable because Null returns None for all keys.\n raise ValueError(\"key {!r} not found in any layer\".format(key))\n\n def log(self):\n logger.debug(\"Configuration Loaded:\")\n for key in self.known_keys():\n layer = self.locate_layer_for_key(key)\n logger.debug(\n \"%-9s: %s = %s\", layer.__class__.__name__, key, layer.value(key)\n )\n\n def known_keys(self):\n return [\n \"app_server\",\n \"application_root\",\n \"core_agent_dir\",\n \"core_agent_download\",\n \"core_agent_launch\",\n \"core_agent_log_level\",\n \"core_agent_permissions\",\n \"core_agent_version\",\n \"disabled_instruments\",\n \"download_url\",\n \"framework\",\n \"framework_version\",\n \"hostname\",\n \"ignore\",\n \"key\",\n \"log_level\",\n \"monitor\",\n \"name\",\n \"revision_sha\",\n \"scm_subdirectory\",\n \"shutdown_timeout_seconds\",\n \"socket_path\",\n ]\n\n def core_agent_permissions(self):\n try:\n return int(str(self.value(\"core_agent_permissions\")), 8)\n except ValueError:\n logger.exception(\n \"Invalid core_agent_permissions value, using default of 0o700\"\n )\n return 0o700\n\n @classmethod\n def set(cls, **kwargs):\n \"\"\"\n Sets a configuration value for the Scout agent. Values set here will\n not override values set in ENV.\n \"\"\"\n for key, value in kwargs.items():\n SCOUT_PYTHON_VALUES[key] = value\n\n @classmethod\n def unset(cls, *keys):\n \"\"\"\n Removes a configuration value for the Scout agent.\n \"\"\"\n for key in keys:\n SCOUT_PYTHON_VALUES.pop(key, None)\n\n @classmethod\n def reset_all(cls):\n \"\"\"\n Remove all configuration settings set via `ScoutConfig.set(...)`.\n\n This is meant for use in testing.\n \"\"\"\n SCOUT_PYTHON_VALUES.clear()\n\n\n# Module-level data, the ScoutConfig.set(key=\"value\") adds to this\nSCOUT_PYTHON_VALUES = {}\n\n\nclass Python(object):\n \"\"\"\n A configuration overlay that lets other parts of python set values.\n \"\"\"\n\n def has_config(self, key):\n return key in SCOUT_PYTHON_VALUES\n\n def value(self, key):\n return SCOUT_PYTHON_VALUES[key]\n\n\nclass Env(object):\n \"\"\"\n Reads configuration from environment by prefixing the key\n requested with \"SCOUT_\"\n\n Example: the `key` config looks for SCOUT_KEY\n environment variable\n \"\"\"\n\n def has_config(self, key):\n env_key = self.modify_key(key)\n return env_key in os.environ\n\n def value(self, key):\n env_key = self.modify_key(key)\n return os.environ[env_key]\n\n def modify_key(self, key):\n env_key = (\"SCOUT_\" + key).upper()\n return env_key\n\n\nclass Derived(object):\n \"\"\"\n A configuration overlay that calculates from other values.\n \"\"\"\n\n def __init__(self, config):\n \"\"\"\n config argument is the overall ScoutConfig var, so we can lookup the\n components of the derived info.\n \"\"\"\n self.config = config\n\n def has_config(self, key):\n return self.lookup_func(key) is not None\n\n def value(self, key):\n return self.lookup_func(key)()\n\n def lookup_func(self, key):\n \"\"\"\n Returns the derive_#{key} function, or None if it isn't defined\n \"\"\"\n func_name = \"derive_\" + key\n return getattr(self, func_name, None)\n\n def derive_socket_path(self):\n return \"{}/{}/scout-agent.sock\".format(\n self.config.value(\"core_agent_dir\"),\n self.config.value(\"core_agent_full_name\"),\n )\n\n def derive_core_agent_full_name(self):\n triple = self.config.value(\"core_agent_triple\")\n if not platform_detection.is_valid_triple(triple):\n warnings.warn(\"Invalid value for core_agent_triple: {}\".format(triple))\n return \"{name}-{version}-{triple}\".format(\n name=\"scout_apm_core\",\n version=self.config.value(\"core_agent_version\"),\n triple=triple,\n )\n\n def derive_core_agent_triple(self):\n return platform_detection.get_triple()\n\n\nclass Defaults(object):\n \"\"\"\n Provides default values for important configurations\n \"\"\"\n\n def __init__(self):\n self.defaults = {\n \"app_server\": \"\",\n \"application_root\": \"\",\n \"core_agent_dir\": \"/tmp/scout_apm_core\",\n \"core_agent_download\": True,\n \"core_agent_launch\": True,\n \"core_agent_log_level\": \"info\",\n \"core_agent_permissions\": 700,\n \"core_agent_version\": \"v1.2.6\", # can be an exact tag name, or 'latest'\n \"disabled_instruments\": [],\n \"download_url\": \"https://s3-us-west-1.amazonaws.com/scout-public-downloads/apm_core_agent/release\", # noqa: E501\n \"framework\": \"\",\n \"framework_version\": \"\",\n \"hostname\": None,\n \"key\": \"\",\n \"monitor\": False,\n \"name\": \"Python App\",\n \"revision_sha\": self._git_revision_sha(),\n \"scm_subdirectory\": \"\",\n \"shutdown_timeout_seconds\": 2.0,\n \"uri_reporting\": \"filtered_params\",\n }\n\n def _git_revision_sha(self):\n # N.B. The environment variable SCOUT_REVISION_SHA may also be used,\n # but that will be picked up by Env\n return os.environ.get(\"HEROKU_SLUG_COMMIT\", \"\")\n\n def has_config(self, key):\n return key in self.defaults\n\n def value(self, key):\n return self.defaults[key]\n\n\nclass Null(object):\n \"\"\"\n Always answers that a key is present, but the value is None\n\n Used as the last step of the layered configuration.\n \"\"\"\n\n def has_config(self, key):\n return True\n\n def value(self, key):\n return None\n\n\ndef convert_to_bool(value):\n if isinstance(value, bool):\n return value\n if isinstance(value, string_type):\n return value.lower() in (\"yes\", \"true\", \"t\", \"1\")\n # Unknown type - default to false?\n return False\n\n\ndef convert_to_float(value):\n try:\n return float(value)\n except ValueError:\n return 0.0\n\n\ndef convert_to_list(value):\n if isinstance(value, list):\n return value\n if isinstance(value, tuple):\n return list(value)\n if isinstance(value, string_type):\n # Split on commas\n return [item.strip() for item in value.split(\",\") if item]\n # Unknown type - default to empty?\n return []\n\n\nCONVERSIONS = {\n \"core_agent_download\": convert_to_bool,\n \"core_agent_launch\": convert_to_bool,\n \"disabled_instruments\": convert_to_list,\n \"ignore\": convert_to_list,\n \"monitor\": convert_to_bool,\n \"shutdown_timeout_seconds\": convert_to_float,\n}\n\n\nscout_config = ScoutConfig()\n", "path": "src/scout_apm/core/config.py"}], "after_files": [{"content": "# coding=utf-8\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport atexit\nimport logging\nimport os\nimport sys\n\nfrom scout_apm import instruments\nfrom scout_apm.compat import kwargs_only\nfrom scout_apm.core import objtrace\nfrom scout_apm.core.config import scout_config\nfrom scout_apm.core.core_agent_manager import CoreAgentManager\nfrom scout_apm.core.metadata import report_app_metadata\nfrom scout_apm.core.socket import CoreAgentSocketThread\n\nlogger = logging.getLogger(__name__)\n\n\n@kwargs_only\ndef install(config=None):\n global shutdown_registered\n if config is not None:\n scout_config.set(**config)\n scout_config.log()\n\n if os.name == \"nt\":\n logger.info(\n \"APM Not Launching on PID: %s - Windows is not supported\", os.getpid()\n )\n return False\n\n if not scout_config.value(\"monitor\"):\n logger.info(\n \"APM Not Launching on PID: %s - Configuration 'monitor' is not true\",\n os.getpid(),\n )\n return False\n\n instruments.ensure_all_installed()\n objtrace.enable()\n\n logger.debug(\"APM Launching on PID: %s\", os.getpid())\n launched = CoreAgentManager().launch()\n\n report_app_metadata()\n if launched:\n # Stop the thread to avoid running threads pre-fork\n CoreAgentSocketThread.ensure_stopped()\n\n if scout_config.value(\"shutdown_timeout_seconds\") > 0.0 and not shutdown_registered:\n atexit.register(shutdown)\n shutdown_registered = True\n\n return True\n\n\nshutdown_registered = False\n\n\ndef shutdown():\n timeout_seconds = scout_config.value(\"shutdown_timeout_seconds\")\n\n def callback(queue_size):\n if scout_config.value(\"shutdown_message_enabled\"):\n print( # noqa: T001\n (\n \"Scout draining {queue_size} event{s} for up to\"\n + \" {timeout_seconds} seconds\"\n ).format(\n queue_size=queue_size,\n s=(\"\" if queue_size == 1 else \"s\"),\n timeout_seconds=timeout_seconds,\n ),\n file=sys.stderr,\n )\n\n CoreAgentSocketThread.wait_until_drained(\n timeout_seconds=timeout_seconds, callback=callback\n )\n", "path": "src/scout_apm/core/__init__.py"}, {"content": "# coding=utf-8\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport logging\nimport os\nimport warnings\n\nfrom scout_apm.compat import string_type\nfrom scout_apm.core import platform_detection\n\nlogger = logging.getLogger(__name__)\n\n\nclass ScoutConfig(object):\n \"\"\"\n Configuration object for the ScoutApm agent.\n\n Contains a list of configuration \"layers\". When a configuration key is\n looked up, each layer is asked in turn if it knows the value. The first one\n to answer affirmatively returns the value.\n \"\"\"\n\n def __init__(self):\n self.layers = [\n Env(),\n Python(),\n Derived(self),\n Defaults(),\n Null(),\n ]\n\n def value(self, key):\n value = self.locate_layer_for_key(key).value(key)\n if key in CONVERSIONS:\n return CONVERSIONS[key](value)\n return value\n\n def locate_layer_for_key(self, key):\n for layer in self.layers:\n if layer.has_config(key):\n return layer\n\n # Should be unreachable because Null returns None for all keys.\n raise ValueError(\"key {!r} not found in any layer\".format(key))\n\n def log(self):\n logger.debug(\"Configuration Loaded:\")\n for key in self.known_keys():\n layer = self.locate_layer_for_key(key)\n logger.debug(\n \"%-9s: %s = %s\", layer.__class__.__name__, key, layer.value(key)\n )\n\n def known_keys(self):\n return [\n \"app_server\",\n \"application_root\",\n \"core_agent_dir\",\n \"core_agent_download\",\n \"core_agent_launch\",\n \"core_agent_log_level\",\n \"core_agent_permissions\",\n \"core_agent_version\",\n \"disabled_instruments\",\n \"download_url\",\n \"framework\",\n \"framework_version\",\n \"hostname\",\n \"ignore\",\n \"key\",\n \"log_level\",\n \"monitor\",\n \"name\",\n \"revision_sha\",\n \"scm_subdirectory\",\n \"shutdown_message_enabled\",\n \"shutdown_timeout_seconds\",\n \"socket_path\",\n ]\n\n def core_agent_permissions(self):\n try:\n return int(str(self.value(\"core_agent_permissions\")), 8)\n except ValueError:\n logger.exception(\n \"Invalid core_agent_permissions value, using default of 0o700\"\n )\n return 0o700\n\n @classmethod\n def set(cls, **kwargs):\n \"\"\"\n Sets a configuration value for the Scout agent. Values set here will\n not override values set in ENV.\n \"\"\"\n for key, value in kwargs.items():\n SCOUT_PYTHON_VALUES[key] = value\n\n @classmethod\n def unset(cls, *keys):\n \"\"\"\n Removes a configuration value for the Scout agent.\n \"\"\"\n for key in keys:\n SCOUT_PYTHON_VALUES.pop(key, None)\n\n @classmethod\n def reset_all(cls):\n \"\"\"\n Remove all configuration settings set via `ScoutConfig.set(...)`.\n\n This is meant for use in testing.\n \"\"\"\n SCOUT_PYTHON_VALUES.clear()\n\n\n# Module-level data, the ScoutConfig.set(key=\"value\") adds to this\nSCOUT_PYTHON_VALUES = {}\n\n\nclass Python(object):\n \"\"\"\n A configuration overlay that lets other parts of python set values.\n \"\"\"\n\n def has_config(self, key):\n return key in SCOUT_PYTHON_VALUES\n\n def value(self, key):\n return SCOUT_PYTHON_VALUES[key]\n\n\nclass Env(object):\n \"\"\"\n Reads configuration from environment by prefixing the key\n requested with \"SCOUT_\"\n\n Example: the `key` config looks for SCOUT_KEY\n environment variable\n \"\"\"\n\n def has_config(self, key):\n env_key = self.modify_key(key)\n return env_key in os.environ\n\n def value(self, key):\n env_key = self.modify_key(key)\n return os.environ[env_key]\n\n def modify_key(self, key):\n env_key = (\"SCOUT_\" + key).upper()\n return env_key\n\n\nclass Derived(object):\n \"\"\"\n A configuration overlay that calculates from other values.\n \"\"\"\n\n def __init__(self, config):\n \"\"\"\n config argument is the overall ScoutConfig var, so we can lookup the\n components of the derived info.\n \"\"\"\n self.config = config\n\n def has_config(self, key):\n return self.lookup_func(key) is not None\n\n def value(self, key):\n return self.lookup_func(key)()\n\n def lookup_func(self, key):\n \"\"\"\n Returns the derive_#{key} function, or None if it isn't defined\n \"\"\"\n func_name = \"derive_\" + key\n return getattr(self, func_name, None)\n\n def derive_socket_path(self):\n return \"{}/{}/scout-agent.sock\".format(\n self.config.value(\"core_agent_dir\"),\n self.config.value(\"core_agent_full_name\"),\n )\n\n def derive_core_agent_full_name(self):\n triple = self.config.value(\"core_agent_triple\")\n if not platform_detection.is_valid_triple(triple):\n warnings.warn(\"Invalid value for core_agent_triple: {}\".format(triple))\n return \"{name}-{version}-{triple}\".format(\n name=\"scout_apm_core\",\n version=self.config.value(\"core_agent_version\"),\n triple=triple,\n )\n\n def derive_core_agent_triple(self):\n return platform_detection.get_triple()\n\n\nclass Defaults(object):\n \"\"\"\n Provides default values for important configurations\n \"\"\"\n\n def __init__(self):\n self.defaults = {\n \"app_server\": \"\",\n \"application_root\": \"\",\n \"core_agent_dir\": \"/tmp/scout_apm_core\",\n \"core_agent_download\": True,\n \"core_agent_launch\": True,\n \"core_agent_log_level\": \"info\",\n \"core_agent_permissions\": 700,\n \"core_agent_version\": \"v1.2.6\", # can be an exact tag name, or 'latest'\n \"disabled_instruments\": [],\n \"download_url\": \"https://s3-us-west-1.amazonaws.com/scout-public-downloads/apm_core_agent/release\", # noqa: E501\n \"framework\": \"\",\n \"framework_version\": \"\",\n \"hostname\": None,\n \"key\": \"\",\n \"monitor\": False,\n \"name\": \"Python App\",\n \"revision_sha\": self._git_revision_sha(),\n \"scm_subdirectory\": \"\",\n \"shutdown_message_enabled\": True,\n \"shutdown_timeout_seconds\": 2.0,\n \"uri_reporting\": \"filtered_params\",\n }\n\n def _git_revision_sha(self):\n # N.B. The environment variable SCOUT_REVISION_SHA may also be used,\n # but that will be picked up by Env\n return os.environ.get(\"HEROKU_SLUG_COMMIT\", \"\")\n\n def has_config(self, key):\n return key in self.defaults\n\n def value(self, key):\n return self.defaults[key]\n\n\nclass Null(object):\n \"\"\"\n Always answers that a key is present, but the value is None\n\n Used as the last step of the layered configuration.\n \"\"\"\n\n def has_config(self, key):\n return True\n\n def value(self, key):\n return None\n\n\ndef convert_to_bool(value):\n if isinstance(value, bool):\n return value\n if isinstance(value, string_type):\n return value.lower() in (\"yes\", \"true\", \"t\", \"1\")\n # Unknown type - default to false?\n return False\n\n\ndef convert_to_float(value):\n try:\n return float(value)\n except ValueError:\n return 0.0\n\n\ndef convert_to_list(value):\n if isinstance(value, list):\n return value\n if isinstance(value, tuple):\n return list(value)\n if isinstance(value, string_type):\n # Split on commas\n return [item.strip() for item in value.split(\",\") if item]\n # Unknown type - default to empty?\n return []\n\n\nCONVERSIONS = {\n \"core_agent_download\": convert_to_bool,\n \"core_agent_launch\": convert_to_bool,\n \"disabled_instruments\": convert_to_list,\n \"ignore\": convert_to_list,\n \"monitor\": convert_to_bool,\n \"shutdown_message_enabled\": convert_to_bool,\n \"shutdown_timeout_seconds\": convert_to_float,\n}\n\n\nscout_config = ScoutConfig()\n", "path": "src/scout_apm/core/config.py"}]}
| 3,546 | 526 |
gh_patches_debug_22092
|
rasdani/github-patches
|
git_diff
|
Parsl__parsl-777
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Make usage tracking opt-in
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `parsl/config.py`
Content:
```
1 import logging
2
3 from parsl.utils import RepresentationMixin
4 from parsl.executors.threads import ThreadPoolExecutor
5 from parsl.dataflow.error import ConfigurationError
6
7 logger = logging.getLogger(__name__)
8
9
10 class Config(RepresentationMixin):
11 """
12 Specification of Parsl configuration options.
13
14 Parameters
15 ----------
16 executors : list of ParslExecutor, optional
17 List of executor instances to use. Possible executors include :class:`~parsl.executors.threads.ThreadPoolExecutor`,
18 :class:`~parsl.executors.ipp.IPyParallelExecutor`, or :class:`~parsl.executors.swift_t.TurbineExecutor`. Default
19 is [:class:`~parsl.executors.threads.ThreadPoolExecutor()`].
20 app_cache : bool, optional
21 Enable app caching. Default is True.
22 checkpoint_files : list of str, optional
23 List of paths to checkpoint files. Default is None.
24 checkpoint_mode : str, optional
25 Checkpoint mode to use, can be 'dfk_exit', 'task_exit', or 'periodic'. If set to
26 `None`, checkpointing will be disabled. Default is None.
27 checkpoint_period : str, optional
28 Time interval (in "HH:MM:SS") at which to checkpoint completed tasks. Only has an effect if
29 `checkpoint_mode='periodic'`.
30 data_management_max_threads : int, optional
31 Maximum number of threads to allocate for the data manager to use for managing input and output transfers.
32 Default is 10.
33 monitoring_config : MonitoringConfig, optional
34 The config to use for database monitoring. Default is None which does not log to a database.
35 lazy_errors : bool, optional
36 If True, errors from task failures will not be raised until `future.result()` is called. Otherwise, they will
37 be raised as soon as the task returns. Default is True.
38 retries : int, optional
39 Set the number of retries in case of failure. Default is 0.
40 run_dir : str, optional
41 Path to run directory. Default is 'runinfo'.
42 strategy : str, optional
43 Strategy to use for scaling resources according to workflow needs. Can be 'simple' or `None`. If `None`, dynamic
44 scaling will be disabled. Default is 'simple'.
45 usage_tracking : bool, optional
46 Enable usage tracking. Default is True.
47 """
48 def __init__(self,
49 executors=None,
50 app_cache=True,
51 checkpoint_files=None,
52 checkpoint_mode=None,
53 checkpoint_period=None,
54 data_management_max_threads=10,
55 lazy_errors=True,
56 retries=0,
57 run_dir='runinfo',
58 strategy='simple',
59 monitoring_config=None,
60 usage_tracking=True):
61 if executors is None:
62 executors = [ThreadPoolExecutor()]
63 self.executors = executors
64 self.app_cache = app_cache
65 self.checkpoint_files = checkpoint_files
66 self.checkpoint_mode = checkpoint_mode
67 if checkpoint_period is not None:
68 if checkpoint_mode is None:
69 logger.debug('The requested `checkpoint_period={}` will have no effect because `checkpoint_mode=None`'.format(
70 checkpoint_period)
71 )
72 elif checkpoint_mode != 'periodic':
73 logger.debug("Requested checkpoint period of {} only has an effect with checkpoint_mode='periodic'".format(
74 checkpoint_period)
75 )
76 if checkpoint_mode == 'periodic' and checkpoint_period is None:
77 checkpoint_period = "00:30:00"
78 self.checkpoint_period = checkpoint_period
79 self.data_management_max_threads = data_management_max_threads
80 self.lazy_errors = lazy_errors
81 self.retries = retries
82 self.run_dir = run_dir
83 self.strategy = strategy
84 self.usage_tracking = usage_tracking
85 self.monitoring_config = monitoring_config
86
87 @property
88 def executors(self):
89 return self._executors
90
91 @executors.setter
92 def executors(self, executors):
93 labels = [e.label for e in executors]
94 duplicates = [e for n, e in enumerate(labels) if e in labels[:n]]
95 if len(duplicates) > 0:
96 raise ConfigurationError('Executors must have unique labels ({})'.format(
97 ', '.join(['label={}'.format(repr(d)) for d in duplicates])))
98 self._executors = executors
99
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/parsl/config.py b/parsl/config.py
--- a/parsl/config.py
+++ b/parsl/config.py
@@ -43,7 +43,8 @@
Strategy to use for scaling resources according to workflow needs. Can be 'simple' or `None`. If `None`, dynamic
scaling will be disabled. Default is 'simple'.
usage_tracking : bool, optional
- Enable usage tracking. Default is True.
+ Set this field to True to Opt-in to Parsl's usage tracking system. Parsl only collects minimal, non personally-identifiable,
+ information used for reporting to our funding agencies. Default is False.
"""
def __init__(self,
executors=None,
@@ -57,7 +58,7 @@
run_dir='runinfo',
strategy='simple',
monitoring_config=None,
- usage_tracking=True):
+ usage_tracking=False):
if executors is None:
executors = [ThreadPoolExecutor()]
self.executors = executors
|
{"golden_diff": "diff --git a/parsl/config.py b/parsl/config.py\n--- a/parsl/config.py\n+++ b/parsl/config.py\n@@ -43,7 +43,8 @@\n Strategy to use for scaling resources according to workflow needs. Can be 'simple' or `None`. If `None`, dynamic\n scaling will be disabled. Default is 'simple'.\n usage_tracking : bool, optional\n- Enable usage tracking. Default is True.\n+ Set this field to True to Opt-in to Parsl's usage tracking system. Parsl only collects minimal, non personally-identifiable,\n+ information used for reporting to our funding agencies. Default is False.\n \"\"\"\n def __init__(self,\n executors=None,\n@@ -57,7 +58,7 @@\n run_dir='runinfo',\n strategy='simple',\n monitoring_config=None,\n- usage_tracking=True):\n+ usage_tracking=False):\n if executors is None:\n executors = [ThreadPoolExecutor()]\n self.executors = executors\n", "issue": "Make usage tracking opt-in\n\n", "before_files": [{"content": "import logging\n\nfrom parsl.utils import RepresentationMixin\nfrom parsl.executors.threads import ThreadPoolExecutor\nfrom parsl.dataflow.error import ConfigurationError\n\nlogger = logging.getLogger(__name__)\n\n\nclass Config(RepresentationMixin):\n \"\"\"\n Specification of Parsl configuration options.\n\n Parameters\n ----------\n executors : list of ParslExecutor, optional\n List of executor instances to use. Possible executors include :class:`~parsl.executors.threads.ThreadPoolExecutor`,\n :class:`~parsl.executors.ipp.IPyParallelExecutor`, or :class:`~parsl.executors.swift_t.TurbineExecutor`. Default\n is [:class:`~parsl.executors.threads.ThreadPoolExecutor()`].\n app_cache : bool, optional\n Enable app caching. Default is True.\n checkpoint_files : list of str, optional\n List of paths to checkpoint files. Default is None.\n checkpoint_mode : str, optional\n Checkpoint mode to use, can be 'dfk_exit', 'task_exit', or 'periodic'. If set to\n `None`, checkpointing will be disabled. Default is None.\n checkpoint_period : str, optional\n Time interval (in \"HH:MM:SS\") at which to checkpoint completed tasks. Only has an effect if\n `checkpoint_mode='periodic'`.\n data_management_max_threads : int, optional\n Maximum number of threads to allocate for the data manager to use for managing input and output transfers.\n Default is 10.\n monitoring_config : MonitoringConfig, optional\n The config to use for database monitoring. Default is None which does not log to a database.\n lazy_errors : bool, optional\n If True, errors from task failures will not be raised until `future.result()` is called. Otherwise, they will\n be raised as soon as the task returns. Default is True.\n retries : int, optional\n Set the number of retries in case of failure. Default is 0.\n run_dir : str, optional\n Path to run directory. Default is 'runinfo'.\n strategy : str, optional\n Strategy to use for scaling resources according to workflow needs. Can be 'simple' or `None`. If `None`, dynamic\n scaling will be disabled. Default is 'simple'.\n usage_tracking : bool, optional\n Enable usage tracking. Default is True.\n \"\"\"\n def __init__(self,\n executors=None,\n app_cache=True,\n checkpoint_files=None,\n checkpoint_mode=None,\n checkpoint_period=None,\n data_management_max_threads=10,\n lazy_errors=True,\n retries=0,\n run_dir='runinfo',\n strategy='simple',\n monitoring_config=None,\n usage_tracking=True):\n if executors is None:\n executors = [ThreadPoolExecutor()]\n self.executors = executors\n self.app_cache = app_cache\n self.checkpoint_files = checkpoint_files\n self.checkpoint_mode = checkpoint_mode\n if checkpoint_period is not None:\n if checkpoint_mode is None:\n logger.debug('The requested `checkpoint_period={}` will have no effect because `checkpoint_mode=None`'.format(\n checkpoint_period)\n )\n elif checkpoint_mode != 'periodic':\n logger.debug(\"Requested checkpoint period of {} only has an effect with checkpoint_mode='periodic'\".format(\n checkpoint_period)\n )\n if checkpoint_mode == 'periodic' and checkpoint_period is None:\n checkpoint_period = \"00:30:00\"\n self.checkpoint_period = checkpoint_period\n self.data_management_max_threads = data_management_max_threads\n self.lazy_errors = lazy_errors\n self.retries = retries\n self.run_dir = run_dir\n self.strategy = strategy\n self.usage_tracking = usage_tracking\n self.monitoring_config = monitoring_config\n\n @property\n def executors(self):\n return self._executors\n\n @executors.setter\n def executors(self, executors):\n labels = [e.label for e in executors]\n duplicates = [e for n, e in enumerate(labels) if e in labels[:n]]\n if len(duplicates) > 0:\n raise ConfigurationError('Executors must have unique labels ({})'.format(\n ', '.join(['label={}'.format(repr(d)) for d in duplicates])))\n self._executors = executors\n", "path": "parsl/config.py"}], "after_files": [{"content": "import logging\n\nfrom parsl.utils import RepresentationMixin\nfrom parsl.executors.threads import ThreadPoolExecutor\nfrom parsl.dataflow.error import ConfigurationError\n\nlogger = logging.getLogger(__name__)\n\n\nclass Config(RepresentationMixin):\n \"\"\"\n Specification of Parsl configuration options.\n\n Parameters\n ----------\n executors : list of ParslExecutor, optional\n List of executor instances to use. Possible executors include :class:`~parsl.executors.threads.ThreadPoolExecutor`,\n :class:`~parsl.executors.ipp.IPyParallelExecutor`, or :class:`~parsl.executors.swift_t.TurbineExecutor`. Default\n is [:class:`~parsl.executors.threads.ThreadPoolExecutor()`].\n app_cache : bool, optional\n Enable app caching. Default is True.\n checkpoint_files : list of str, optional\n List of paths to checkpoint files. Default is None.\n checkpoint_mode : str, optional\n Checkpoint mode to use, can be 'dfk_exit', 'task_exit', or 'periodic'. If set to\n `None`, checkpointing will be disabled. Default is None.\n checkpoint_period : str, optional\n Time interval (in \"HH:MM:SS\") at which to checkpoint completed tasks. Only has an effect if\n `checkpoint_mode='periodic'`.\n data_management_max_threads : int, optional\n Maximum number of threads to allocate for the data manager to use for managing input and output transfers.\n Default is 10.\n monitoring_config : MonitoringConfig, optional\n The config to use for database monitoring. Default is None which does not log to a database.\n lazy_errors : bool, optional\n If True, errors from task failures will not be raised until `future.result()` is called. Otherwise, they will\n be raised as soon as the task returns. Default is True.\n retries : int, optional\n Set the number of retries in case of failure. Default is 0.\n run_dir : str, optional\n Path to run directory. Default is 'runinfo'.\n strategy : str, optional\n Strategy to use for scaling resources according to workflow needs. Can be 'simple' or `None`. If `None`, dynamic\n scaling will be disabled. Default is 'simple'.\n usage_tracking : bool, optional\n Set this field to True to Opt-in to Parsl's usage tracking system. Parsl only collects minimal, non personally-identifiable,\n information used for reporting to our funding agencies. Default is False.\n \"\"\"\n def __init__(self,\n executors=None,\n app_cache=True,\n checkpoint_files=None,\n checkpoint_mode=None,\n checkpoint_period=None,\n data_management_max_threads=10,\n lazy_errors=True,\n retries=0,\n run_dir='runinfo',\n strategy='simple',\n monitoring_config=None,\n usage_tracking=False):\n if executors is None:\n executors = [ThreadPoolExecutor()]\n self.executors = executors\n self.app_cache = app_cache\n self.checkpoint_files = checkpoint_files\n self.checkpoint_mode = checkpoint_mode\n if checkpoint_period is not None:\n if checkpoint_mode is None:\n logger.debug('The requested `checkpoint_period={}` will have no effect because `checkpoint_mode=None`'.format(\n checkpoint_period)\n )\n elif checkpoint_mode != 'periodic':\n logger.debug(\"Requested checkpoint period of {} only has an effect with checkpoint_mode='periodic'\".format(\n checkpoint_period)\n )\n if checkpoint_mode == 'periodic' and checkpoint_period is None:\n checkpoint_period = \"00:30:00\"\n self.checkpoint_period = checkpoint_period\n self.data_management_max_threads = data_management_max_threads\n self.lazy_errors = lazy_errors\n self.retries = retries\n self.run_dir = run_dir\n self.strategy = strategy\n self.usage_tracking = usage_tracking\n self.monitoring_config = monitoring_config\n\n @property\n def executors(self):\n return self._executors\n\n @executors.setter\n def executors(self, executors):\n labels = [e.label for e in executors]\n duplicates = [e for n, e in enumerate(labels) if e in labels[:n]]\n if len(duplicates) > 0:\n raise ConfigurationError('Executors must have unique labels ({})'.format(\n ', '.join(['label={}'.format(repr(d)) for d in duplicates])))\n self._executors = executors\n", "path": "parsl/config.py"}]}
| 1,373 | 223 |
gh_patches_debug_28892
|
rasdani/github-patches
|
git_diff
|
jupyterhub__jupyterhub-67
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Install problem
I am trying to install Jupyter Hub on an Ubuntu 14.04 server. I followed exact instructions in the README.
I get this error when running "pip install ."
```
moment#2.7.0 share/jupyter/static/components/moment
running css
error: [Errno 2] No such file or directory
----------------------------------------
Cleaning up...
Command /usr/bin/python -c "import setuptools, tokenize;__file__='/tmp/pip-3k3Avh-build/setup.py';exec(compile(getattr(tokenize, 'open', open)(__file__).read().replace('\r\n', '\n'), __file__, 'exec'))" install --record /tmp/pip-jqPTEE-record/install-record.txt --single-version-externally-managed --compile failed with error code 1 in /tmp/pip-3k3Avh-build
Traceback (most recent call last):
File "/usr/bin/pip", line 9, in <module>
load_entry_point('pip==1.5.4', 'console_scripts', 'pip')()
File "/usr/lib/python2.7/dist-packages/pip/__init__.py", line 185, in main
return command.main(cmd_args)
File "/usr/lib/python2.7/dist-packages/pip/basecommand.py", line 161, in main
text = '\n'.join(complete_log)
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe2 in position 4: ordinal not in range(128)
```
My pip version is:
```
pip 1.5.4 from /usr/lib/python2.7/dist-packages (python 2.7)
```
and my bower version is
```
1.3.12
```
and my python version is
```
Python 2.7.6
```
Any idea what is going on? What should I try? Thanks in advance!
Matt
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2 # coding: utf-8
3
4 # Copyright (c) Juptyer Development Team.
5 # Distributed under the terms of the Modified BSD License.
6
7 #-----------------------------------------------------------------------------
8 # Minimal Python version sanity check (from IPython)
9 #-----------------------------------------------------------------------------
10
11 from __future__ import print_function
12
13 import os
14 import sys
15
16 v = sys.version_info
17 if v[:2] < (2,7) or (v[0] >= 3 and v[:2] < (3,3)):
18 error = "ERROR: IPython requires Python version 2.7 or 3.3 or above."
19 print(error, file=sys.stderr)
20 sys.exit(1)
21
22 PY3 = (sys.version_info[0] >= 3)
23
24 if os.name in ('nt', 'dos'):
25 error = "ERROR: Windows is not supported"
26 print(error, file=sys.stderr)
27
28 # At least we're on the python version we need, move on.
29
30 import os
31
32 from glob import glob
33
34 from distutils.core import setup
35 from subprocess import check_call
36
37 try:
38 execfile
39 except NameError:
40 # py3
41 def execfile(fname, globs, locs=None):
42 locs = locs or globs
43 exec(compile(open(fname).read(), fname, "exec"), globs, locs)
44
45 pjoin = os.path.join
46
47 here = os.path.abspath(os.path.dirname(__file__))
48 share_jupyter = pjoin(here, 'share', 'jupyter')
49 static = pjoin(share_jupyter, 'static')
50
51 #---------------------------------------------------------------------------
52 # Build basic package data, etc.
53 #---------------------------------------------------------------------------
54
55 def get_data_files():
56 """Get data files in share/jupyter"""
57
58 data_files = []
59 ntrim = len(here) + 1
60
61 for (d, dirs, filenames) in os.walk(share_jupyter):
62 data_files.append((
63 d[ntrim:],
64 [ pjoin(d, f) for f in filenames ]
65 ))
66 return data_files
67
68
69 ns = {}
70 execfile(pjoin(here, 'jupyterhub', 'version.py'), ns)
71
72 packages = []
73 for d, _, _ in os.walk('jupyterhub'):
74 if os.path.exists(pjoin(d, '__init__.py')):
75 packages.append(d.replace(os.path.sep, '.'))
76
77 setup_args = dict(
78 name = 'jupyterhub',
79 scripts = glob(pjoin('scripts', '*')),
80 packages = packages,
81 # dummy, so that install_data doesn't get skipped
82 # this will be overridden when bower is run anyway
83 data_files = get_data_files() or ['dummy'],
84 version = ns['__version__'],
85 description = """JupyterHub: A multi-user server for Jupyter notebooks""",
86 long_description = "",
87 author = "Jupyter Development Team",
88 author_email = "[email protected]",
89 url = "http://jupyter.org",
90 license = "BSD",
91 platforms = "Linux, Mac OS X",
92 keywords = ['Interactive', 'Interpreter', 'Shell', 'Web'],
93 classifiers = [
94 'Intended Audience :: Developers',
95 'Intended Audience :: Science/Research',
96 'License :: OSI Approved :: BSD License',
97 'Programming Language :: Python',
98 'Programming Language :: Python :: 2',
99 'Programming Language :: Python :: 2.7',
100 'Programming Language :: Python :: 3',
101 'Topic :: System :: Shells',
102 ],
103 )
104
105 #---------------------------------------------------------------------------
106 # custom distutils commands
107 #---------------------------------------------------------------------------
108
109 # imports here, so they are after setuptools import if there was one
110 from distutils.cmd import Command
111 from distutils.command.install import install
112
113 class BaseCommand(Command):
114 """Dumb empty command because Command needs subclasses to override too much"""
115 user_options = []
116
117 def initialize_options(self):
118 pass
119
120 def finalize_options(self):
121 pass
122
123 def get_inputs(self):
124 return []
125
126 def get_outputs(self):
127 return []
128
129
130 class Bower(BaseCommand):
131 description = "fetch static components with bower"
132
133 user_options = []
134
135 def run(self):
136 check_call(['bower', 'install', '--allow-root'])
137 # update data-files in case this created new files
138 self.distribution.data_files = get_data_files()
139
140 class CSS(BaseCommand):
141 description = "compile CSS from LESS"
142
143 user_options = []
144
145 def initialize_options(self):
146 pass
147
148 def finalize_options(self):
149 pass
150
151 def run(self):
152 style_less = pjoin(static, 'less', 'style.less')
153 style_css = pjoin(static, 'css', 'style.min.css')
154 sourcemap = style_css + '.map'
155 check_call([
156 'lessc', '-x', '--verbose',
157 '--source-map-basepath={}'.format(static),
158 '--source-map={}'.format(sourcemap),
159 '--source-map-rootpath=../',
160 style_less, style_css,
161 ])
162 # update data-files in case this created new files
163 self.distribution.data_files = get_data_files()
164
165 # ensure bower is run as part of install
166 install.sub_commands.insert(0, ('bower', None))
167 install.sub_commands.insert(1, ('css', None))
168
169 setup_args['cmdclass'] = {
170 'bower': Bower,
171 'css': CSS,
172 }
173
174
175 # setuptools requirements
176
177 if 'setuptools' in sys.modules:
178 setup_args['zip_safe'] = False
179 from setuptools.command.develop import develop
180 class develop_js_css(develop):
181 def run(self):
182 if not self.uninstall:
183 self.distribution.run_command('bower')
184 self.distribution.run_command('css')
185 develop.run(self)
186 setup_args['cmdclass']['develop'] = develop_js_css
187
188
189 with open('requirements.txt') as f:
190 install_requires = [ line.strip() for line in f.readlines() ]
191 setup_args['install_requires'] = install_requires
192
193 #---------------------------------------------------------------------------
194 # setup
195 #---------------------------------------------------------------------------
196
197 def main():
198 setup(**setup_args)
199
200 if __name__ == '__main__':
201 main()
202
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -133,7 +133,12 @@
user_options = []
def run(self):
- check_call(['bower', 'install', '--allow-root'])
+ try:
+ check_call(['bower', 'install', '--allow-root'])
+ except OSError as e:
+ print("Failed to run bower: %s" % e, file=sys.stderr)
+ print("You can install bower with `npm install -g bower`", file=sys.stderr)
+ raise
# update data-files in case this created new files
self.distribution.data_files = get_data_files()
@@ -152,13 +157,18 @@
style_less = pjoin(static, 'less', 'style.less')
style_css = pjoin(static, 'css', 'style.min.css')
sourcemap = style_css + '.map'
- check_call([
- 'lessc', '-x', '--verbose',
- '--source-map-basepath={}'.format(static),
- '--source-map={}'.format(sourcemap),
- '--source-map-rootpath=../',
- style_less, style_css,
- ])
+ try:
+ check_call([
+ 'lessc', '-x', '--verbose',
+ '--source-map-basepath={}'.format(static),
+ '--source-map={}'.format(sourcemap),
+ '--source-map-rootpath=../',
+ style_less, style_css,
+ ])
+ except OSError as e:
+ print("Failed to run lessc: %s" % e, file=sys.stderr)
+ print("You can install less with `npm install -g less`", file=sys.stderr)
+ raise
# update data-files in case this created new files
self.distribution.data_files = get_data_files()
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -133,7 +133,12 @@\n user_options = []\n \n def run(self):\n- check_call(['bower', 'install', '--allow-root'])\n+ try:\n+ check_call(['bower', 'install', '--allow-root'])\n+ except OSError as e:\n+ print(\"Failed to run bower: %s\" % e, file=sys.stderr)\n+ print(\"You can install bower with `npm install -g bower`\", file=sys.stderr)\n+ raise\n # update data-files in case this created new files\n self.distribution.data_files = get_data_files()\n \n@@ -152,13 +157,18 @@\n style_less = pjoin(static, 'less', 'style.less')\n style_css = pjoin(static, 'css', 'style.min.css')\n sourcemap = style_css + '.map'\n- check_call([\n- 'lessc', '-x', '--verbose',\n- '--source-map-basepath={}'.format(static),\n- '--source-map={}'.format(sourcemap),\n- '--source-map-rootpath=../',\n- style_less, style_css,\n- ])\n+ try:\n+ check_call([\n+ 'lessc', '-x', '--verbose',\n+ '--source-map-basepath={}'.format(static),\n+ '--source-map={}'.format(sourcemap),\n+ '--source-map-rootpath=../',\n+ style_less, style_css,\n+ ])\n+ except OSError as e:\n+ print(\"Failed to run lessc: %s\" % e, file=sys.stderr)\n+ print(\"You can install less with `npm install -g less`\", file=sys.stderr)\n+ raise\n # update data-files in case this created new files\n self.distribution.data_files = get_data_files()\n", "issue": "Install problem\nI am trying to install Jupyter Hub on an Ubuntu 14.04 server. I followed exact instructions in the README.\n\nI get this error when running \"pip install .\"\n\n```\nmoment#2.7.0 share/jupyter/static/components/moment\n\nrunning css\n\nerror: [Errno 2] No such file or directory\n\n----------------------------------------\nCleaning up...\nCommand /usr/bin/python -c \"import setuptools, tokenize;__file__='/tmp/pip-3k3Avh-build/setup.py';exec(compile(getattr(tokenize, 'open', open)(__file__).read().replace('\\r\\n', '\\n'), __file__, 'exec'))\" install --record /tmp/pip-jqPTEE-record/install-record.txt --single-version-externally-managed --compile failed with error code 1 in /tmp/pip-3k3Avh-build\nTraceback (most recent call last):\n File \"/usr/bin/pip\", line 9, in <module>\n load_entry_point('pip==1.5.4', 'console_scripts', 'pip')()\n File \"/usr/lib/python2.7/dist-packages/pip/__init__.py\", line 185, in main\n return command.main(cmd_args)\n File \"/usr/lib/python2.7/dist-packages/pip/basecommand.py\", line 161, in main\n text = '\\n'.join(complete_log)\nUnicodeDecodeError: 'ascii' codec can't decode byte 0xe2 in position 4: ordinal not in range(128)\n```\n\nMy pip version is:\n\n```\npip 1.5.4 from /usr/lib/python2.7/dist-packages (python 2.7)\n```\n\nand my bower version is\n\n```\n1.3.12\n```\n\nand my python version is\n\n```\nPython 2.7.6\n```\n\nAny idea what is going on? What should I try? Thanks in advance!\nMatt\n\n", "before_files": [{"content": "#!/usr/bin/env python\n# coding: utf-8\n\n# Copyright (c) Juptyer Development Team.\n# Distributed under the terms of the Modified BSD License.\n\n#-----------------------------------------------------------------------------\n# Minimal Python version sanity check (from IPython)\n#-----------------------------------------------------------------------------\n\nfrom __future__ import print_function\n\nimport os\nimport sys\n\nv = sys.version_info\nif v[:2] < (2,7) or (v[0] >= 3 and v[:2] < (3,3)):\n error = \"ERROR: IPython requires Python version 2.7 or 3.3 or above.\"\n print(error, file=sys.stderr)\n sys.exit(1)\n\nPY3 = (sys.version_info[0] >= 3)\n\nif os.name in ('nt', 'dos'):\n error = \"ERROR: Windows is not supported\"\n print(error, file=sys.stderr)\n\n# At least we're on the python version we need, move on.\n\nimport os\n\nfrom glob import glob\n\nfrom distutils.core import setup\nfrom subprocess import check_call\n\ntry:\n execfile\nexcept NameError:\n # py3\n def execfile(fname, globs, locs=None):\n locs = locs or globs\n exec(compile(open(fname).read(), fname, \"exec\"), globs, locs)\n\npjoin = os.path.join\n\nhere = os.path.abspath(os.path.dirname(__file__))\nshare_jupyter = pjoin(here, 'share', 'jupyter')\nstatic = pjoin(share_jupyter, 'static')\n\n#---------------------------------------------------------------------------\n# Build basic package data, etc.\n#---------------------------------------------------------------------------\n\ndef get_data_files():\n \"\"\"Get data files in share/jupyter\"\"\"\n \n data_files = []\n ntrim = len(here) + 1\n \n for (d, dirs, filenames) in os.walk(share_jupyter):\n data_files.append((\n d[ntrim:],\n [ pjoin(d, f) for f in filenames ]\n ))\n return data_files\n\n\nns = {}\nexecfile(pjoin(here, 'jupyterhub', 'version.py'), ns)\n\npackages = []\nfor d, _, _ in os.walk('jupyterhub'):\n if os.path.exists(pjoin(d, '__init__.py')):\n packages.append(d.replace(os.path.sep, '.'))\n\nsetup_args = dict(\n name = 'jupyterhub',\n scripts = glob(pjoin('scripts', '*')),\n packages = packages,\n # dummy, so that install_data doesn't get skipped\n # this will be overridden when bower is run anyway\n data_files = get_data_files() or ['dummy'],\n version = ns['__version__'],\n description = \"\"\"JupyterHub: A multi-user server for Jupyter notebooks\"\"\",\n long_description = \"\",\n author = \"Jupyter Development Team\",\n author_email = \"[email protected]\",\n url = \"http://jupyter.org\",\n license = \"BSD\",\n platforms = \"Linux, Mac OS X\",\n keywords = ['Interactive', 'Interpreter', 'Shell', 'Web'],\n classifiers = [\n 'Intended Audience :: Developers',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: BSD License',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Topic :: System :: Shells',\n ],\n)\n\n#---------------------------------------------------------------------------\n# custom distutils commands\n#---------------------------------------------------------------------------\n\n# imports here, so they are after setuptools import if there was one\nfrom distutils.cmd import Command\nfrom distutils.command.install import install\n\nclass BaseCommand(Command):\n \"\"\"Dumb empty command because Command needs subclasses to override too much\"\"\"\n user_options = []\n \n def initialize_options(self):\n pass\n \n def finalize_options(self):\n pass\n \n def get_inputs(self):\n return []\n \n def get_outputs(self):\n return []\n\n\nclass Bower(BaseCommand):\n description = \"fetch static components with bower\"\n \n user_options = []\n \n def run(self):\n check_call(['bower', 'install', '--allow-root'])\n # update data-files in case this created new files\n self.distribution.data_files = get_data_files()\n\nclass CSS(BaseCommand):\n description = \"compile CSS from LESS\"\n \n user_options = []\n \n def initialize_options(self):\n pass\n \n def finalize_options(self):\n pass\n \n def run(self):\n style_less = pjoin(static, 'less', 'style.less')\n style_css = pjoin(static, 'css', 'style.min.css')\n sourcemap = style_css + '.map'\n check_call([\n 'lessc', '-x', '--verbose',\n '--source-map-basepath={}'.format(static),\n '--source-map={}'.format(sourcemap),\n '--source-map-rootpath=../',\n style_less, style_css,\n ])\n # update data-files in case this created new files\n self.distribution.data_files = get_data_files()\n\n# ensure bower is run as part of install\ninstall.sub_commands.insert(0, ('bower', None))\ninstall.sub_commands.insert(1, ('css', None))\n\nsetup_args['cmdclass'] = {\n 'bower': Bower,\n 'css': CSS,\n}\n\n\n# setuptools requirements\n\nif 'setuptools' in sys.modules:\n setup_args['zip_safe'] = False\n from setuptools.command.develop import develop\n class develop_js_css(develop):\n def run(self):\n if not self.uninstall:\n self.distribution.run_command('bower')\n self.distribution.run_command('css')\n develop.run(self)\n setup_args['cmdclass']['develop'] = develop_js_css\n\n\n with open('requirements.txt') as f:\n install_requires = [ line.strip() for line in f.readlines() ]\n setup_args['install_requires'] = install_requires\n\n#---------------------------------------------------------------------------\n# setup\n#---------------------------------------------------------------------------\n\ndef main():\n setup(**setup_args)\n\nif __name__ == '__main__':\n main()\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# coding: utf-8\n\n# Copyright (c) Juptyer Development Team.\n# Distributed under the terms of the Modified BSD License.\n\n#-----------------------------------------------------------------------------\n# Minimal Python version sanity check (from IPython)\n#-----------------------------------------------------------------------------\n\nfrom __future__ import print_function\n\nimport os\nimport sys\n\nv = sys.version_info\nif v[:2] < (2,7) or (v[0] >= 3 and v[:2] < (3,3)):\n error = \"ERROR: IPython requires Python version 2.7 or 3.3 or above.\"\n print(error, file=sys.stderr)\n sys.exit(1)\n\nPY3 = (sys.version_info[0] >= 3)\n\nif os.name in ('nt', 'dos'):\n error = \"ERROR: Windows is not supported\"\n print(error, file=sys.stderr)\n\n# At least we're on the python version we need, move on.\n\nimport os\n\nfrom glob import glob\n\nfrom distutils.core import setup\nfrom subprocess import check_call\n\ntry:\n execfile\nexcept NameError:\n # py3\n def execfile(fname, globs, locs=None):\n locs = locs or globs\n exec(compile(open(fname).read(), fname, \"exec\"), globs, locs)\n\npjoin = os.path.join\n\nhere = os.path.abspath(os.path.dirname(__file__))\nshare_jupyter = pjoin(here, 'share', 'jupyter')\nstatic = pjoin(share_jupyter, 'static')\n\n#---------------------------------------------------------------------------\n# Build basic package data, etc.\n#---------------------------------------------------------------------------\n\ndef get_data_files():\n \"\"\"Get data files in share/jupyter\"\"\"\n \n data_files = []\n ntrim = len(here) + 1\n \n for (d, dirs, filenames) in os.walk(share_jupyter):\n data_files.append((\n d[ntrim:],\n [ pjoin(d, f) for f in filenames ]\n ))\n return data_files\n\n\nns = {}\nexecfile(pjoin(here, 'jupyterhub', 'version.py'), ns)\n\npackages = []\nfor d, _, _ in os.walk('jupyterhub'):\n if os.path.exists(pjoin(d, '__init__.py')):\n packages.append(d.replace(os.path.sep, '.'))\n\nsetup_args = dict(\n name = 'jupyterhub',\n scripts = glob(pjoin('scripts', '*')),\n packages = packages,\n # dummy, so that install_data doesn't get skipped\n # this will be overridden when bower is run anyway\n data_files = get_data_files() or ['dummy'],\n version = ns['__version__'],\n description = \"\"\"JupyterHub: A multi-user server for Jupyter notebooks\"\"\",\n long_description = \"\",\n author = \"Jupyter Development Team\",\n author_email = \"[email protected]\",\n url = \"http://jupyter.org\",\n license = \"BSD\",\n platforms = \"Linux, Mac OS X\",\n keywords = ['Interactive', 'Interpreter', 'Shell', 'Web'],\n classifiers = [\n 'Intended Audience :: Developers',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: BSD License',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Topic :: System :: Shells',\n ],\n)\n\n#---------------------------------------------------------------------------\n# custom distutils commands\n#---------------------------------------------------------------------------\n\n# imports here, so they are after setuptools import if there was one\nfrom distutils.cmd import Command\nfrom distutils.command.install import install\n\nclass BaseCommand(Command):\n \"\"\"Dumb empty command because Command needs subclasses to override too much\"\"\"\n user_options = []\n \n def initialize_options(self):\n pass\n \n def finalize_options(self):\n pass\n \n def get_inputs(self):\n return []\n \n def get_outputs(self):\n return []\n\n\nclass Bower(BaseCommand):\n description = \"fetch static components with bower\"\n \n user_options = []\n \n def run(self):\n try:\n check_call(['bower', 'install', '--allow-root'])\n except OSError as e:\n print(\"Failed to run bower: %s\" % e, file=sys.stderr)\n print(\"You can install bower with `npm install -g bower`\", file=sys.stderr)\n raise\n # update data-files in case this created new files\n self.distribution.data_files = get_data_files()\n\nclass CSS(BaseCommand):\n description = \"compile CSS from LESS\"\n \n user_options = []\n \n def initialize_options(self):\n pass\n \n def finalize_options(self):\n pass\n \n def run(self):\n style_less = pjoin(static, 'less', 'style.less')\n style_css = pjoin(static, 'css', 'style.min.css')\n sourcemap = style_css + '.map'\n try:\n check_call([\n 'lessc', '-x', '--verbose',\n '--source-map-basepath={}'.format(static),\n '--source-map={}'.format(sourcemap),\n '--source-map-rootpath=../',\n style_less, style_css,\n ])\n except OSError as e:\n print(\"Failed to run lessc: %s\" % e, file=sys.stderr)\n print(\"You can install less with `npm install -g less`\", file=sys.stderr)\n raise\n # update data-files in case this created new files\n self.distribution.data_files = get_data_files()\n\n# ensure bower is run as part of install\ninstall.sub_commands.insert(0, ('bower', None))\ninstall.sub_commands.insert(1, ('css', None))\n\nsetup_args['cmdclass'] = {\n 'bower': Bower,\n 'css': CSS,\n}\n\n\n# setuptools requirements\n\nif 'setuptools' in sys.modules:\n setup_args['zip_safe'] = False\n from setuptools.command.develop import develop\n class develop_js_css(develop):\n def run(self):\n if not self.uninstall:\n self.distribution.run_command('bower')\n self.distribution.run_command('css')\n develop.run(self)\n setup_args['cmdclass']['develop'] = develop_js_css\n\n\n with open('requirements.txt') as f:\n install_requires = [ line.strip() for line in f.readlines() ]\n setup_args['install_requires'] = install_requires\n\n#---------------------------------------------------------------------------\n# setup\n#---------------------------------------------------------------------------\n\ndef main():\n setup(**setup_args)\n\nif __name__ == '__main__':\n main()\n", "path": "setup.py"}]}
| 2,502 | 419 |
gh_patches_debug_14485
|
rasdani/github-patches
|
git_diff
|
numpy__numpy-15938
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Building numpy on AIX (xlc and xlf)
<!-- Please describe the issue in detail here, and fill in the fields below -->
build for AIX is not working.
A couple of issues - maybe all simple to fix - still researching the last one...
First one: numpy/fft/_pocketfft.c does not compile -- resolution: `export CFLAGS=-D_LARGE_FILES`
Second issue: Does not find ld_so_aix - expects, it seems, a symbolic link to the correct directory. e.g., calls `/opt/lib/python3.6/config/ld_so_aix` when the actual path is `/opt/lib/python3.6/config-3.6m/ld_so_aix`
Third issue: same issue as issue #6609 - undefined symbols:
```
ld: 0711-317 ERROR: Undefined symbol: .zungqr_
ld: 0711-317 ERROR: Undefined symbol: .zgeqrf_
ld: 0711-317 ERROR: Undefined symbol: .zgelsd_
ld: 0711-317 ERROR: Undefined symbol: .dorgqr_
ld: 0711-317 ERROR: Undefined symbol: .dgeqrf_
ld: 0711-317 ERROR: Undefined symbol: .dgelsd_
```
The first issues are easy to get around - export CFLAGS and add a symbolic link for the generic path.
For the final issue I am going to guess that there is a macro involved - that is adding an underscore to the function being called - as they do exist in liblapack.a
### Reproducing code example:
`python setup.py build`
<!-- Remove these sections for a feature request -->
### Error message:
More detail:
```
ld: 0711-318 ERROR: Undefined symbols were found.
The following symbols are in error:
Symbol Inpndx TY CL Source-File(Object-File) OR Import-File{Shared-object}
RLD: Address Section Rld-type Referencing Symbol
----------------------------------------------------------------------------------------------
.zungqr_ [124] ER PR numpy/linalg/lapack_litemodule.c(build/temp.AIX.6106.1043.64-3.6/numpy/linalg/lapack_litemodule.o)
000002c0 .text R_RBR [10] <.lapack_lite_zungqr>
.zgeqrf_ [128] ER PR numpy/linalg/lapack_litemodule.c(build/temp.AIX.6106.1043.64-3.6/numpy/linalg/lapack_litemodule.o)
00000454 .text R_RBR [12] <.lapack_lite_zgeqrf>
.zgelsd_ [130] ER PR numpy/linalg/lapack_litemodule.c(build/temp.AIX.6106.1043.64-3.6/numpy/linalg/lapack_litemodule.o)
000006fc .text R_RBR [14] <.lapack_lite_zgelsd>
.dorgqr_ [132] ER PR numpy/linalg/lapack_litemodule.c(build/temp.AIX.6106.1043.64-3.6/numpy/linalg/lapack_litemodule.o)
00000920 .text R_RBR [16] <.lapack_lite_dorgqr>
.dgeqrf_ [134] ER PR numpy/linalg/lapack_litemodule.c(build/temp.AIX.6106.1043.64-3.6/numpy/linalg/lapack_litemodule.o)
00000a94 .text R_RBR [18] <.lapack_lite_dgeqrf>
.dgelsd_ [136] ER PR numpy/linalg/lapack_litemodule.c(build/temp.AIX.6106.1043.64-3.6/numpy/linalg/lapack_litemodule.o)
00000d3c .text R_RBR [20] <.lapack_lite_dgelsd>
ER: The return code is 8.
```
Note: They do exist - just without the trailing underscore (_)
```
(py36) root@x066:[/data/prj/python/numpy-1.17.4]nm -Ae /usr/lib/liblapack.a | egrep "zungqr|zgeqrf|zgelsd|dorgqr|dgeqrf|dgelsd"_ | grep -v " U " | egrep ": \.[a-z]"
/usr/lib/liblapack.a[dgeqrf.o]: .dgeqrf T 0
/usr/lib/liblapack.a[dgeqrfp.o]: .dgeqrfp T 0
/usr/lib/liblapack.a[dorgqr.o]: .dorgqr T 0
/usr/lib/liblapack.a[zgelsd.o]: .zgelsd T 0
/usr/lib/liblapack.a[zgeqrf.o]: .zgeqrf T 0
/usr/lib/liblapack.a[zgeqrfp.o]: .zgeqrfp T 0
/usr/lib/liblapack.a[zungqr.o]: .zungqr T 0
```
* UPDATE: this is resolved by adding -DNO_APPEND_FORTRAN to CFLAGS
* Now I am open to suggestions on where and how to best get these automated in setup.py process.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `numpy/fft/setup.py`
Content:
```
1
2 def configuration(parent_package='',top_path=None):
3 from numpy.distutils.misc_util import Configuration
4 config = Configuration('fft', parent_package, top_path)
5
6 config.add_data_dir('tests')
7
8 # Configure pocketfft_internal
9 config.add_extension('_pocketfft_internal',
10 sources=['_pocketfft.c']
11 )
12
13 return config
14
15 if __name__ == '__main__':
16 from numpy.distutils.core import setup
17 setup(configuration=configuration)
18
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/numpy/fft/setup.py b/numpy/fft/setup.py
--- a/numpy/fft/setup.py
+++ b/numpy/fft/setup.py
@@ -1,3 +1,4 @@
+import sys
def configuration(parent_package='',top_path=None):
from numpy.distutils.misc_util import Configuration
@@ -5,9 +6,12 @@
config.add_data_dir('tests')
+ # AIX needs to be told to use large file support - at all times
+ defs = [('_LARGE_FILES', None)] if sys.platform[:3] == "aix" else []
# Configure pocketfft_internal
config.add_extension('_pocketfft_internal',
- sources=['_pocketfft.c']
+ sources=['_pocketfft.c'],
+ define_macros=defs,
)
return config
|
{"golden_diff": "diff --git a/numpy/fft/setup.py b/numpy/fft/setup.py\n--- a/numpy/fft/setup.py\n+++ b/numpy/fft/setup.py\n@@ -1,3 +1,4 @@\n+import sys\n \n def configuration(parent_package='',top_path=None):\n from numpy.distutils.misc_util import Configuration\n@@ -5,9 +6,12 @@\n \n config.add_data_dir('tests')\n \n+ # AIX needs to be told to use large file support - at all times\n+ defs = [('_LARGE_FILES', None)] if sys.platform[:3] == \"aix\" else []\n # Configure pocketfft_internal\n config.add_extension('_pocketfft_internal',\n- sources=['_pocketfft.c']\n+ sources=['_pocketfft.c'],\n+ define_macros=defs,\n )\n \n return config\n", "issue": "Building numpy on AIX (xlc and xlf)\n<!-- Please describe the issue in detail here, and fill in the fields below -->\r\nbuild for AIX is not working.\r\n\r\nA couple of issues - maybe all simple to fix - still researching the last one...\r\n\r\nFirst one: numpy/fft/_pocketfft.c does not compile -- resolution: `export CFLAGS=-D_LARGE_FILES`\r\n\r\nSecond issue: Does not find ld_so_aix - expects, it seems, a symbolic link to the correct directory. e.g., calls `/opt/lib/python3.6/config/ld_so_aix` when the actual path is `/opt/lib/python3.6/config-3.6m/ld_so_aix`\r\n\r\nThird issue: same issue as issue #6609 - undefined symbols:\r\n```\r\nld: 0711-317 ERROR: Undefined symbol: .zungqr_\r\nld: 0711-317 ERROR: Undefined symbol: .zgeqrf_\r\nld: 0711-317 ERROR: Undefined symbol: .zgelsd_\r\nld: 0711-317 ERROR: Undefined symbol: .dorgqr_\r\nld: 0711-317 ERROR: Undefined symbol: .dgeqrf_\r\nld: 0711-317 ERROR: Undefined symbol: .dgelsd_\r\n```\r\n\r\nThe first issues are easy to get around - export CFLAGS and add a symbolic link for the generic path.\r\n\r\nFor the final issue I am going to guess that there is a macro involved - that is adding an underscore to the function being called - as they do exist in liblapack.a\r\n\r\n### Reproducing code example:\r\n\r\n`python setup.py build`\r\n\r\n<!-- Remove these sections for a feature request -->\r\n\r\n### Error message:\r\nMore detail:\r\n```\r\nld: 0711-318 ERROR: Undefined symbols were found.\r\n The following symbols are in error:\r\n Symbol Inpndx TY CL Source-File(Object-File) OR Import-File{Shared-object}\r\n RLD: Address Section Rld-type Referencing Symbol\r\n ----------------------------------------------------------------------------------------------\r\n .zungqr_ [124] ER PR numpy/linalg/lapack_litemodule.c(build/temp.AIX.6106.1043.64-3.6/numpy/linalg/lapack_litemodule.o)\r\n 000002c0 .text R_RBR [10] <.lapack_lite_zungqr>\r\n .zgeqrf_ [128] ER PR numpy/linalg/lapack_litemodule.c(build/temp.AIX.6106.1043.64-3.6/numpy/linalg/lapack_litemodule.o)\r\n 00000454 .text R_RBR [12] <.lapack_lite_zgeqrf>\r\n .zgelsd_ [130] ER PR numpy/linalg/lapack_litemodule.c(build/temp.AIX.6106.1043.64-3.6/numpy/linalg/lapack_litemodule.o)\r\n 000006fc .text R_RBR [14] <.lapack_lite_zgelsd>\r\n .dorgqr_ [132] ER PR numpy/linalg/lapack_litemodule.c(build/temp.AIX.6106.1043.64-3.6/numpy/linalg/lapack_litemodule.o)\r\n 00000920 .text R_RBR [16] <.lapack_lite_dorgqr>\r\n .dgeqrf_ [134] ER PR numpy/linalg/lapack_litemodule.c(build/temp.AIX.6106.1043.64-3.6/numpy/linalg/lapack_litemodule.o)\r\n 00000a94 .text R_RBR [18] <.lapack_lite_dgeqrf>\r\n .dgelsd_ [136] ER PR numpy/linalg/lapack_litemodule.c(build/temp.AIX.6106.1043.64-3.6/numpy/linalg/lapack_litemodule.o)\r\n 00000d3c .text R_RBR [20] <.lapack_lite_dgelsd>\r\nER: The return code is 8.\r\n\r\n\r\n```\r\n\r\nNote: They do exist - just without the trailing underscore (_)\r\n\r\n```\r\n(py36) root@x066:[/data/prj/python/numpy-1.17.4]nm -Ae /usr/lib/liblapack.a | egrep \"zungqr|zgeqrf|zgelsd|dorgqr|dgeqrf|dgelsd\"_ | grep -v \" U \" | egrep \": \\.[a-z]\"\r\n/usr/lib/liblapack.a[dgeqrf.o]: .dgeqrf T 0\r\n/usr/lib/liblapack.a[dgeqrfp.o]: .dgeqrfp T 0\r\n/usr/lib/liblapack.a[dorgqr.o]: .dorgqr T 0\r\n/usr/lib/liblapack.a[zgelsd.o]: .zgelsd T 0\r\n/usr/lib/liblapack.a[zgeqrf.o]: .zgeqrf T 0\r\n/usr/lib/liblapack.a[zgeqrfp.o]: .zgeqrfp T 0\r\n/usr/lib/liblapack.a[zungqr.o]: .zungqr T 0\r\n\r\n```\r\n\r\n* UPDATE: this is resolved by adding -DNO_APPEND_FORTRAN to CFLAGS\r\n\r\n* Now I am open to suggestions on where and how to best get these automated in setup.py process.\n", "before_files": [{"content": "\ndef configuration(parent_package='',top_path=None):\n from numpy.distutils.misc_util import Configuration\n config = Configuration('fft', parent_package, top_path)\n\n config.add_data_dir('tests')\n\n # Configure pocketfft_internal\n config.add_extension('_pocketfft_internal',\n sources=['_pocketfft.c']\n )\n\n return config\n\nif __name__ == '__main__':\n from numpy.distutils.core import setup\n setup(configuration=configuration)\n", "path": "numpy/fft/setup.py"}], "after_files": [{"content": "import sys\n\ndef configuration(parent_package='',top_path=None):\n from numpy.distutils.misc_util import Configuration\n config = Configuration('fft', parent_package, top_path)\n\n config.add_data_dir('tests')\n\n # AIX needs to be told to use large file support - at all times\n defs = [('_LARGE_FILES', None)] if sys.platform[:3] == \"aix\" else []\n # Configure pocketfft_internal\n config.add_extension('_pocketfft_internal',\n sources=['_pocketfft.c'],\n define_macros=defs,\n )\n\n return config\n\nif __name__ == '__main__':\n from numpy.distutils.core import setup\n setup(configuration=configuration)\n", "path": "numpy/fft/setup.py"}]}
| 1,679 | 185 |
gh_patches_debug_43207
|
rasdani/github-patches
|
git_diff
|
refuel-ai__autolabel-539
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Bug]: Send only needed columns in transforms
**Describe the bug**
Currently, in the webpage transform, even if a subset of columns are specified in the output columns, all columns are sent to the final dataset object.
**To Reproduce**
Run the example_webpage_transform and look at the ds.df
**Expected behavior**
We should just return the columns which are present in the output_columns dictionary.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/autolabel/transforms/webpage_transform.py`
Content:
```
1 from autolabel.schema import TransformType
2 from autolabel.transforms import BaseTransform
3 from typing import Dict, Any
4 import asyncio
5 import logging
6 import pandas as pd
7 import ssl
8
9 from autolabel.cache import BaseCache
10
11 logger = logging.getLogger(__name__)
12
13 MAX_RETRIES = 3
14 MAX_KEEPALIVE_CONNECTIONS = 20
15 MAX_CONNECTIONS = 100
16 BACKOFF = 2
17 HEADERS = {}
18 HTML_PARSER = "html.parser"
19
20
21 class WebpageTransform(BaseTransform):
22 def __init__(
23 self,
24 cache: BaseCache,
25 output_columns: Dict[str, Any],
26 url_column: str,
27 timeout: int = 5,
28 headers: Dict[str, str] = HEADERS,
29 ) -> None:
30 super().__init__(cache, output_columns)
31 self.url_column = url_column
32 self.headers = headers
33 self.max_retries = MAX_RETRIES
34 try:
35 from bs4 import BeautifulSoup
36 import httpx
37
38 if not headers.get("User-Agent"):
39 from fake_useragent import UserAgent
40
41 headers["User-Agent"] = UserAgent().random
42
43 self.httpx = httpx
44 self.timeout_time = timeout
45 self.timeout = httpx.Timeout(timeout)
46 limits = httpx.Limits(
47 max_keepalive_connections=MAX_KEEPALIVE_CONNECTIONS,
48 max_connections=MAX_CONNECTIONS,
49 keepalive_expiry=timeout,
50 )
51 self.client = httpx.AsyncClient(
52 timeout=self.timeout, limits=limits, follow_redirects=True
53 )
54 self.client_with_no_verify = httpx.AsyncClient(
55 timeout=self.timeout, limits=limits, follow_redirects=True, verify=False
56 )
57 self.beautiful_soup = BeautifulSoup
58 except ImportError:
59 raise ImportError(
60 "BeautifulSoup, httpx and fake_useragent are required to use the webpage transform. Please install them with the following command: pip install beautifulsoup4 httpx fake_useragent"
61 )
62
63 def name(self) -> str:
64 return TransformType.WEBPAGE_TRANSFORM
65
66 @property
67 def output_columns(self) -> Dict[str, Any]:
68 COLUMN_NAMES = [
69 "content_column",
70 "content_in_bytes_column",
71 "soup_column",
72 "metadata_column",
73 ]
74 return {k: self._output_columns.get(k, k) for k in COLUMN_NAMES}
75
76 def _load_metadata(self, url, soup) -> Dict[str, Any]:
77 metadata = {"url": url}
78 if soup.find("title"):
79 metadata["title"] = soup.find("title").get_text()
80 for meta in soup.find_all("meta"):
81 if meta.get("name") and meta.get("content"):
82 metadata[meta.get("name")] = meta.get("content")
83 elif meta.get("property") and meta.get("content"):
84 metadata[meta.get("property")] = meta.get("content")
85 return metadata
86
87 async def _load_url(
88 self, url: str, verify=True, headers=HEADERS, retry_count=0
89 ) -> Dict[str, Any]:
90 if retry_count >= self.max_retries:
91 logger.warning(f"Max retries reached for URL: {url}")
92 return {}
93
94 try:
95 client = self.client
96 if not verify:
97 client = self.client_with_no_verify
98 response = await client.get(url, headers=headers)
99
100 # TODO: Add support for other parsers
101 content_bytes = response.content
102 soup = self.beautiful_soup(content_bytes, HTML_PARSER)
103 return {
104 "content": soup.get_text(),
105 "content_bytes": content_bytes,
106 "soup": soup,
107 "metadata": self._load_metadata(url, soup),
108 }
109 except self.httpx.ConnectTimeout as e:
110 logger.error(f"Timeout when fetching content from URL: {url}")
111 return {}
112 except ssl.SSLCertVerificationError as e:
113 logger.warning(
114 f"SSL verification error when fetching content from URL: {url}, retrying with verify=False"
115 )
116 await asyncio.sleep(BACKOFF**retry_count)
117 return await self._load_url(
118 url, verify=False, headers=headers, retry_count=retry_count + 1
119 )
120 except Exception as e:
121 logger.error(f"Error fetching content from URL: {url}. Exception: {e}")
122 return {}
123
124 async def _apply(self, row: Dict[str, Any]) -> Dict[str, Any]:
125 url = row[self.url_column]
126 url_response_data = {}
127 if pd.isna(url):
128 logger.warning(f"Empty url in row {row}")
129 else:
130 url_response_data = await self._load_url(url)
131
132 transformed_row = {
133 self.output_columns["content_column"]: url_response_data.get("content"),
134 self.output_columns["content_in_bytes_column"]: url_response_data.get(
135 "content_bytes"
136 ),
137 self.output_columns["soup_column"]: url_response_data.get("soup"),
138 self.output_columns["metadata_column"]: url_response_data.get("metadata"),
139 }
140
141 return transformed_row
142
143 def params(self):
144 return {
145 "url_column": self.url_column,
146 "output_columns": self.output_columns,
147 "timeout": self.timeout_time,
148 }
149
```
Path: `src/autolabel/transforms/pdf.py`
Content:
```
1 from typing import List, Dict, Any
2
3 from autolabel.schema import TransformType
4 from autolabel.transforms import BaseTransform
5 from autolabel.cache import BaseCache
6
7
8 class PDFTransform(BaseTransform):
9 def __init__(
10 self,
11 cache: BaseCache,
12 output_columns: Dict[str, Any],
13 file_path_column: str,
14 ocr_enabled: bool = False,
15 page_header: str = "Page {page_num}: {page_content}",
16 page_sep: str = "\n\n",
17 ) -> None:
18 """The output columns for this class should be in the order: [content_column, num_pages_column]"""
19 super().__init__(cache, output_columns)
20 self.file_path_column = file_path_column
21 self.ocr_enabled = ocr_enabled
22 self.page_format = page_header
23 self.page_sep = page_sep
24
25 if self.ocr_enabled:
26 try:
27 from pdf2image import convert_from_path
28 import pytesseract
29
30 self.convert_from_path = convert_from_path
31 self.pytesseract = pytesseract
32 self.pytesseract.get_tesseract_version()
33 except ImportError:
34 raise ImportError(
35 "pdf2image and pytesseract are required to use the pdf transform with ocr. Please install pdf2image and pytesseract with the following command: pip install pdf2image pytesseract"
36 )
37 except EnvironmentError:
38 raise EnvironmentError(
39 "The tesseract engine is required to use the pdf transform with ocr. Please see https://tesseract-ocr.github.io/tessdoc/Installation.html for installation instructions."
40 )
41 else:
42 try:
43 from langchain.document_loaders import PDFPlumberLoader
44
45 self.PDFPlumberLoader = PDFPlumberLoader
46 except ImportError:
47 raise ImportError(
48 "pdfplumber is required to use the pdf transform. Please install pdfplumber with the following command: pip install pdfplumber"
49 )
50
51 @staticmethod
52 def name() -> str:
53 return TransformType.PDF
54
55 @property
56 def output_columns(self) -> Dict[str, Any]:
57 COLUMN_NAMES = [
58 "content_column",
59 "metadata_column",
60 ]
61 return {k: self._output_columns.get(k, k) for k in COLUMN_NAMES}
62
63 def get_page_texts(self, row: Dict[str, Any]) -> List[str]:
64 """This function gets the text from each page of a PDF file.
65 If OCR is enabled, it uses the pdf2image library to convert the PDF into images and then uses
66 pytesseract to convert the images into text. Otherwise, it uses pdfplumber to extract the text.
67
68 Args:
69 row (Dict[str, Any]): The row of data to be transformed.
70
71 Returns:
72 List[str]: A list of strings containing the text from each page of the PDF.
73 """
74 if self.ocr_enabled:
75 pages = self.convert_from_path(row[self.file_path_column])
76 return [self.pytesseract.image_to_string(page) for page in pages]
77 else:
78 loader = self.PDFPlumberLoader(row[self.file_path_column])
79 return [page.page_content for page in loader.load()]
80
81 async def _apply(self, row: Dict[str, Any]) -> Dict[str, Any]:
82 """This function transforms a PDF file into a string of text.
83 The text is formatted according to the page_format and
84 page_sep parameters and returned as a string.
85
86 Args:
87 row (Dict[str, Any]): The row of data to be transformed.
88
89 Returns:
90 Dict[str, Any]: The dict of output columns.
91 """
92 texts = []
93 for idx, text in enumerate(self.get_page_texts(row)):
94 texts.append(self.page_format.format(page_num=idx + 1, page_content=text))
95 output = self.page_sep.join(texts)
96 transformed_row = {
97 self.output_columns["content_column"]: output,
98 self.output_columns["metadata_column"]: {"num_pages": len(texts)},
99 }
100 return transformed_row
101
102 def params(self):
103 return {
104 "file_path_column": self.file_path_column,
105 "ocr_enabled": self.ocr_enabled,
106 "page_header": self.page_format,
107 "page_sep": self.page_sep,
108 "output_columns": self.output_columns,
109 }
110
```
Path: `src/autolabel/transforms/base.py`
Content:
```
1 from abc import ABC, abstractmethod
2 from typing import Dict, Any
3 from autolabel.cache import BaseCache
4 from autolabel.schema import TransformCacheEntry
5
6
7 class BaseTransform(ABC):
8 """Base class for all transforms."""
9
10 TTL_MS = 60 * 60 * 24 * 7 * 1000 # 1 week
11
12 def __init__(self, cache: BaseCache, output_columns: Dict[str, Any]) -> None:
13 """
14 Initialize a transform.
15 Args:
16 cache: A cache object to use for caching the results of this transform.
17 output_columns: A dictionary of output columns. The keys are the names of the output columns as expected by the transform. The values are the column names they should be mapped to in the dataset.
18 """
19 super().__init__()
20 self._output_columns = output_columns
21 self.cache = cache
22
23 @staticmethod
24 @abstractmethod
25 def name() -> str:
26 """
27 Returns the name of the transform.
28 """
29 pass
30
31 @property
32 @abstractmethod
33 def output_columns(self) -> Dict[str, Any]:
34 """
35 Returns a dictionary of output columns. The keys are the names of the output columns
36 as expected by the transform. The values are the column names they should be mapped to in
37 the dataset.
38 """
39 return self._output_columns
40
41 @abstractmethod
42 async def _apply(self, row: Dict[str, Any]) -> Dict[str, Any]:
43 """
44 Applies the transform to the given row.
45 Args:
46 row: A dictionary representing a row in the dataset. The keys are the column names and the values are the column values.
47 Returns:
48 A dictionary representing the transformed row. The keys are the column names and the values are the column values.
49 """
50 pass
51
52 @abstractmethod
53 def params(self) -> Dict[str, Any]:
54 """
55 Returns a dictionary of parameters that can be used to uniquely identify this transform.
56 Returns:
57 A dictionary of parameters that can be used to uniquely identify this transform.
58 """
59 return {}
60
61 async def apply(self, row: Dict[str, Any]) -> Dict[str, Any]:
62 if self.cache is not None:
63 cache_entry = TransformCacheEntry(
64 transform_name=self.name(),
65 transform_params=self.params(),
66 input=row,
67 ttl_ms=self.TTL_MS,
68 )
69 output = self.cache.lookup(cache_entry)
70
71 if output is not None:
72 # Cache hit
73 return output
74
75 output = await self._apply(row)
76
77 if self.cache is not None:
78 cache_entry.output = output
79 self.cache.update(cache_entry)
80
81 return output
82
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/autolabel/transforms/base.py b/src/autolabel/transforms/base.py
--- a/src/autolabel/transforms/base.py
+++ b/src/autolabel/transforms/base.py
@@ -29,14 +29,13 @@
pass
@property
- @abstractmethod
def output_columns(self) -> Dict[str, Any]:
"""
Returns a dictionary of output columns. The keys are the names of the output columns
as expected by the transform. The values are the column names they should be mapped to in
the dataset.
"""
- return self._output_columns
+ return {k: self._output_columns.get(k, None) for k in self.COLUMN_NAMES}
@abstractmethod
async def _apply(self, row: Dict[str, Any]) -> Dict[str, Any]:
@@ -79,3 +78,15 @@
self.cache.update(cache_entry)
return output
+
+ def _return_output_row(self, row: Dict[str, Any]) -> Dict[str, Any]:
+ """
+ Returns the output row with the correct column names.
+ Args:
+ row: The output row.
+ Returns:
+ The output row with the correct column names.
+ """
+ # remove null key
+ row.pop(None, None)
+ return row
diff --git a/src/autolabel/transforms/pdf.py b/src/autolabel/transforms/pdf.py
--- a/src/autolabel/transforms/pdf.py
+++ b/src/autolabel/transforms/pdf.py
@@ -6,6 +6,11 @@
class PDFTransform(BaseTransform):
+ COLUMN_NAMES = [
+ "content_column",
+ "metadata_column",
+ ]
+
def __init__(
self,
cache: BaseCache,
@@ -52,14 +57,6 @@
def name() -> str:
return TransformType.PDF
- @property
- def output_columns(self) -> Dict[str, Any]:
- COLUMN_NAMES = [
- "content_column",
- "metadata_column",
- ]
- return {k: self._output_columns.get(k, k) for k in COLUMN_NAMES}
-
def get_page_texts(self, row: Dict[str, Any]) -> List[str]:
"""This function gets the text from each page of a PDF file.
If OCR is enabled, it uses the pdf2image library to convert the PDF into images and then uses
@@ -97,7 +94,7 @@
self.output_columns["content_column"]: output,
self.output_columns["metadata_column"]: {"num_pages": len(texts)},
}
- return transformed_row
+ return self._return_output_row(transformed_row)
def params(self):
return {
diff --git a/src/autolabel/transforms/webpage_transform.py b/src/autolabel/transforms/webpage_transform.py
--- a/src/autolabel/transforms/webpage_transform.py
+++ b/src/autolabel/transforms/webpage_transform.py
@@ -19,6 +19,13 @@
class WebpageTransform(BaseTransform):
+ COLUMN_NAMES = [
+ "content_column",
+ "content_in_bytes_column",
+ "soup_column",
+ "metadata_column",
+ ]
+
def __init__(
self,
cache: BaseCache,
@@ -63,16 +70,6 @@
def name(self) -> str:
return TransformType.WEBPAGE_TRANSFORM
- @property
- def output_columns(self) -> Dict[str, Any]:
- COLUMN_NAMES = [
- "content_column",
- "content_in_bytes_column",
- "soup_column",
- "metadata_column",
- ]
- return {k: self._output_columns.get(k, k) for k in COLUMN_NAMES}
-
def _load_metadata(self, url, soup) -> Dict[str, Any]:
metadata = {"url": url}
if soup.find("title"):
@@ -138,7 +135,7 @@
self.output_columns["metadata_column"]: url_response_data.get("metadata"),
}
- return transformed_row
+ return self._return_output_row(transformed_row)
def params(self):
return {
|
{"golden_diff": "diff --git a/src/autolabel/transforms/base.py b/src/autolabel/transforms/base.py\n--- a/src/autolabel/transforms/base.py\n+++ b/src/autolabel/transforms/base.py\n@@ -29,14 +29,13 @@\n pass\n \n @property\n- @abstractmethod\n def output_columns(self) -> Dict[str, Any]:\n \"\"\"\n Returns a dictionary of output columns. The keys are the names of the output columns\n as expected by the transform. The values are the column names they should be mapped to in\n the dataset.\n \"\"\"\n- return self._output_columns\n+ return {k: self._output_columns.get(k, None) for k in self.COLUMN_NAMES}\n \n @abstractmethod\n async def _apply(self, row: Dict[str, Any]) -> Dict[str, Any]:\n@@ -79,3 +78,15 @@\n self.cache.update(cache_entry)\n \n return output\n+\n+ def _return_output_row(self, row: Dict[str, Any]) -> Dict[str, Any]:\n+ \"\"\"\n+ Returns the output row with the correct column names.\n+ Args:\n+ row: The output row.\n+ Returns:\n+ The output row with the correct column names.\n+ \"\"\"\n+ # remove null key\n+ row.pop(None, None)\n+ return row\ndiff --git a/src/autolabel/transforms/pdf.py b/src/autolabel/transforms/pdf.py\n--- a/src/autolabel/transforms/pdf.py\n+++ b/src/autolabel/transforms/pdf.py\n@@ -6,6 +6,11 @@\n \n \n class PDFTransform(BaseTransform):\n+ COLUMN_NAMES = [\n+ \"content_column\",\n+ \"metadata_column\",\n+ ]\n+\n def __init__(\n self,\n cache: BaseCache,\n@@ -52,14 +57,6 @@\n def name() -> str:\n return TransformType.PDF\n \n- @property\n- def output_columns(self) -> Dict[str, Any]:\n- COLUMN_NAMES = [\n- \"content_column\",\n- \"metadata_column\",\n- ]\n- return {k: self._output_columns.get(k, k) for k in COLUMN_NAMES}\n-\n def get_page_texts(self, row: Dict[str, Any]) -> List[str]:\n \"\"\"This function gets the text from each page of a PDF file.\n If OCR is enabled, it uses the pdf2image library to convert the PDF into images and then uses\n@@ -97,7 +94,7 @@\n self.output_columns[\"content_column\"]: output,\n self.output_columns[\"metadata_column\"]: {\"num_pages\": len(texts)},\n }\n- return transformed_row\n+ return self._return_output_row(transformed_row)\n \n def params(self):\n return {\ndiff --git a/src/autolabel/transforms/webpage_transform.py b/src/autolabel/transforms/webpage_transform.py\n--- a/src/autolabel/transforms/webpage_transform.py\n+++ b/src/autolabel/transforms/webpage_transform.py\n@@ -19,6 +19,13 @@\n \n \n class WebpageTransform(BaseTransform):\n+ COLUMN_NAMES = [\n+ \"content_column\",\n+ \"content_in_bytes_column\",\n+ \"soup_column\",\n+ \"metadata_column\",\n+ ]\n+\n def __init__(\n self,\n cache: BaseCache,\n@@ -63,16 +70,6 @@\n def name(self) -> str:\n return TransformType.WEBPAGE_TRANSFORM\n \n- @property\n- def output_columns(self) -> Dict[str, Any]:\n- COLUMN_NAMES = [\n- \"content_column\",\n- \"content_in_bytes_column\",\n- \"soup_column\",\n- \"metadata_column\",\n- ]\n- return {k: self._output_columns.get(k, k) for k in COLUMN_NAMES}\n-\n def _load_metadata(self, url, soup) -> Dict[str, Any]:\n metadata = {\"url\": url}\n if soup.find(\"title\"):\n@@ -138,7 +135,7 @@\n self.output_columns[\"metadata_column\"]: url_response_data.get(\"metadata\"),\n }\n \n- return transformed_row\n+ return self._return_output_row(transformed_row)\n \n def params(self):\n return {\n", "issue": "[Bug]: Send only needed columns in transforms\n**Describe the bug**\r\nCurrently, in the webpage transform, even if a subset of columns are specified in the output columns, all columns are sent to the final dataset object.\r\n\r\n**To Reproduce**\r\nRun the example_webpage_transform and look at the ds.df\r\n\r\n**Expected behavior**\r\nWe should just return the columns which are present in the output_columns dictionary.\r\n\n", "before_files": [{"content": "from autolabel.schema import TransformType\nfrom autolabel.transforms import BaseTransform\nfrom typing import Dict, Any\nimport asyncio\nimport logging\nimport pandas as pd\nimport ssl\n\nfrom autolabel.cache import BaseCache\n\nlogger = logging.getLogger(__name__)\n\nMAX_RETRIES = 3\nMAX_KEEPALIVE_CONNECTIONS = 20\nMAX_CONNECTIONS = 100\nBACKOFF = 2\nHEADERS = {}\nHTML_PARSER = \"html.parser\"\n\n\nclass WebpageTransform(BaseTransform):\n def __init__(\n self,\n cache: BaseCache,\n output_columns: Dict[str, Any],\n url_column: str,\n timeout: int = 5,\n headers: Dict[str, str] = HEADERS,\n ) -> None:\n super().__init__(cache, output_columns)\n self.url_column = url_column\n self.headers = headers\n self.max_retries = MAX_RETRIES\n try:\n from bs4 import BeautifulSoup\n import httpx\n\n if not headers.get(\"User-Agent\"):\n from fake_useragent import UserAgent\n\n headers[\"User-Agent\"] = UserAgent().random\n\n self.httpx = httpx\n self.timeout_time = timeout\n self.timeout = httpx.Timeout(timeout)\n limits = httpx.Limits(\n max_keepalive_connections=MAX_KEEPALIVE_CONNECTIONS,\n max_connections=MAX_CONNECTIONS,\n keepalive_expiry=timeout,\n )\n self.client = httpx.AsyncClient(\n timeout=self.timeout, limits=limits, follow_redirects=True\n )\n self.client_with_no_verify = httpx.AsyncClient(\n timeout=self.timeout, limits=limits, follow_redirects=True, verify=False\n )\n self.beautiful_soup = BeautifulSoup\n except ImportError:\n raise ImportError(\n \"BeautifulSoup, httpx and fake_useragent are required to use the webpage transform. Please install them with the following command: pip install beautifulsoup4 httpx fake_useragent\"\n )\n\n def name(self) -> str:\n return TransformType.WEBPAGE_TRANSFORM\n\n @property\n def output_columns(self) -> Dict[str, Any]:\n COLUMN_NAMES = [\n \"content_column\",\n \"content_in_bytes_column\",\n \"soup_column\",\n \"metadata_column\",\n ]\n return {k: self._output_columns.get(k, k) for k in COLUMN_NAMES}\n\n def _load_metadata(self, url, soup) -> Dict[str, Any]:\n metadata = {\"url\": url}\n if soup.find(\"title\"):\n metadata[\"title\"] = soup.find(\"title\").get_text()\n for meta in soup.find_all(\"meta\"):\n if meta.get(\"name\") and meta.get(\"content\"):\n metadata[meta.get(\"name\")] = meta.get(\"content\")\n elif meta.get(\"property\") and meta.get(\"content\"):\n metadata[meta.get(\"property\")] = meta.get(\"content\")\n return metadata\n\n async def _load_url(\n self, url: str, verify=True, headers=HEADERS, retry_count=0\n ) -> Dict[str, Any]:\n if retry_count >= self.max_retries:\n logger.warning(f\"Max retries reached for URL: {url}\")\n return {}\n\n try:\n client = self.client\n if not verify:\n client = self.client_with_no_verify\n response = await client.get(url, headers=headers)\n\n # TODO: Add support for other parsers\n content_bytes = response.content\n soup = self.beautiful_soup(content_bytes, HTML_PARSER)\n return {\n \"content\": soup.get_text(),\n \"content_bytes\": content_bytes,\n \"soup\": soup,\n \"metadata\": self._load_metadata(url, soup),\n }\n except self.httpx.ConnectTimeout as e:\n logger.error(f\"Timeout when fetching content from URL: {url}\")\n return {}\n except ssl.SSLCertVerificationError as e:\n logger.warning(\n f\"SSL verification error when fetching content from URL: {url}, retrying with verify=False\"\n )\n await asyncio.sleep(BACKOFF**retry_count)\n return await self._load_url(\n url, verify=False, headers=headers, retry_count=retry_count + 1\n )\n except Exception as e:\n logger.error(f\"Error fetching content from URL: {url}. Exception: {e}\")\n return {}\n\n async def _apply(self, row: Dict[str, Any]) -> Dict[str, Any]:\n url = row[self.url_column]\n url_response_data = {}\n if pd.isna(url):\n logger.warning(f\"Empty url in row {row}\")\n else:\n url_response_data = await self._load_url(url)\n\n transformed_row = {\n self.output_columns[\"content_column\"]: url_response_data.get(\"content\"),\n self.output_columns[\"content_in_bytes_column\"]: url_response_data.get(\n \"content_bytes\"\n ),\n self.output_columns[\"soup_column\"]: url_response_data.get(\"soup\"),\n self.output_columns[\"metadata_column\"]: url_response_data.get(\"metadata\"),\n }\n\n return transformed_row\n\n def params(self):\n return {\n \"url_column\": self.url_column,\n \"output_columns\": self.output_columns,\n \"timeout\": self.timeout_time,\n }\n", "path": "src/autolabel/transforms/webpage_transform.py"}, {"content": "from typing import List, Dict, Any\n\nfrom autolabel.schema import TransformType\nfrom autolabel.transforms import BaseTransform\nfrom autolabel.cache import BaseCache\n\n\nclass PDFTransform(BaseTransform):\n def __init__(\n self,\n cache: BaseCache,\n output_columns: Dict[str, Any],\n file_path_column: str,\n ocr_enabled: bool = False,\n page_header: str = \"Page {page_num}: {page_content}\",\n page_sep: str = \"\\n\\n\",\n ) -> None:\n \"\"\"The output columns for this class should be in the order: [content_column, num_pages_column]\"\"\"\n super().__init__(cache, output_columns)\n self.file_path_column = file_path_column\n self.ocr_enabled = ocr_enabled\n self.page_format = page_header\n self.page_sep = page_sep\n\n if self.ocr_enabled:\n try:\n from pdf2image import convert_from_path\n import pytesseract\n\n self.convert_from_path = convert_from_path\n self.pytesseract = pytesseract\n self.pytesseract.get_tesseract_version()\n except ImportError:\n raise ImportError(\n \"pdf2image and pytesseract are required to use the pdf transform with ocr. Please install pdf2image and pytesseract with the following command: pip install pdf2image pytesseract\"\n )\n except EnvironmentError:\n raise EnvironmentError(\n \"The tesseract engine is required to use the pdf transform with ocr. Please see https://tesseract-ocr.github.io/tessdoc/Installation.html for installation instructions.\"\n )\n else:\n try:\n from langchain.document_loaders import PDFPlumberLoader\n\n self.PDFPlumberLoader = PDFPlumberLoader\n except ImportError:\n raise ImportError(\n \"pdfplumber is required to use the pdf transform. Please install pdfplumber with the following command: pip install pdfplumber\"\n )\n\n @staticmethod\n def name() -> str:\n return TransformType.PDF\n\n @property\n def output_columns(self) -> Dict[str, Any]:\n COLUMN_NAMES = [\n \"content_column\",\n \"metadata_column\",\n ]\n return {k: self._output_columns.get(k, k) for k in COLUMN_NAMES}\n\n def get_page_texts(self, row: Dict[str, Any]) -> List[str]:\n \"\"\"This function gets the text from each page of a PDF file.\n If OCR is enabled, it uses the pdf2image library to convert the PDF into images and then uses\n pytesseract to convert the images into text. Otherwise, it uses pdfplumber to extract the text.\n\n Args:\n row (Dict[str, Any]): The row of data to be transformed.\n\n Returns:\n List[str]: A list of strings containing the text from each page of the PDF.\n \"\"\"\n if self.ocr_enabled:\n pages = self.convert_from_path(row[self.file_path_column])\n return [self.pytesseract.image_to_string(page) for page in pages]\n else:\n loader = self.PDFPlumberLoader(row[self.file_path_column])\n return [page.page_content for page in loader.load()]\n\n async def _apply(self, row: Dict[str, Any]) -> Dict[str, Any]:\n \"\"\"This function transforms a PDF file into a string of text.\n The text is formatted according to the page_format and\n page_sep parameters and returned as a string.\n\n Args:\n row (Dict[str, Any]): The row of data to be transformed.\n\n Returns:\n Dict[str, Any]: The dict of output columns.\n \"\"\"\n texts = []\n for idx, text in enumerate(self.get_page_texts(row)):\n texts.append(self.page_format.format(page_num=idx + 1, page_content=text))\n output = self.page_sep.join(texts)\n transformed_row = {\n self.output_columns[\"content_column\"]: output,\n self.output_columns[\"metadata_column\"]: {\"num_pages\": len(texts)},\n }\n return transformed_row\n\n def params(self):\n return {\n \"file_path_column\": self.file_path_column,\n \"ocr_enabled\": self.ocr_enabled,\n \"page_header\": self.page_format,\n \"page_sep\": self.page_sep,\n \"output_columns\": self.output_columns,\n }\n", "path": "src/autolabel/transforms/pdf.py"}, {"content": "from abc import ABC, abstractmethod\nfrom typing import Dict, Any\nfrom autolabel.cache import BaseCache\nfrom autolabel.schema import TransformCacheEntry\n\n\nclass BaseTransform(ABC):\n \"\"\"Base class for all transforms.\"\"\"\n\n TTL_MS = 60 * 60 * 24 * 7 * 1000 # 1 week\n\n def __init__(self, cache: BaseCache, output_columns: Dict[str, Any]) -> None:\n \"\"\"\n Initialize a transform.\n Args:\n cache: A cache object to use for caching the results of this transform.\n output_columns: A dictionary of output columns. The keys are the names of the output columns as expected by the transform. The values are the column names they should be mapped to in the dataset.\n \"\"\"\n super().__init__()\n self._output_columns = output_columns\n self.cache = cache\n\n @staticmethod\n @abstractmethod\n def name() -> str:\n \"\"\"\n Returns the name of the transform.\n \"\"\"\n pass\n\n @property\n @abstractmethod\n def output_columns(self) -> Dict[str, Any]:\n \"\"\"\n Returns a dictionary of output columns. The keys are the names of the output columns\n as expected by the transform. The values are the column names they should be mapped to in\n the dataset.\n \"\"\"\n return self._output_columns\n\n @abstractmethod\n async def _apply(self, row: Dict[str, Any]) -> Dict[str, Any]:\n \"\"\"\n Applies the transform to the given row.\n Args:\n row: A dictionary representing a row in the dataset. The keys are the column names and the values are the column values.\n Returns:\n A dictionary representing the transformed row. The keys are the column names and the values are the column values.\n \"\"\"\n pass\n\n @abstractmethod\n def params(self) -> Dict[str, Any]:\n \"\"\"\n Returns a dictionary of parameters that can be used to uniquely identify this transform.\n Returns:\n A dictionary of parameters that can be used to uniquely identify this transform.\n \"\"\"\n return {}\n\n async def apply(self, row: Dict[str, Any]) -> Dict[str, Any]:\n if self.cache is not None:\n cache_entry = TransformCacheEntry(\n transform_name=self.name(),\n transform_params=self.params(),\n input=row,\n ttl_ms=self.TTL_MS,\n )\n output = self.cache.lookup(cache_entry)\n\n if output is not None:\n # Cache hit\n return output\n\n output = await self._apply(row)\n\n if self.cache is not None:\n cache_entry.output = output\n self.cache.update(cache_entry)\n\n return output\n", "path": "src/autolabel/transforms/base.py"}], "after_files": [{"content": "from autolabel.schema import TransformType\nfrom autolabel.transforms import BaseTransform\nfrom typing import Dict, Any\nimport asyncio\nimport logging\nimport pandas as pd\nimport ssl\n\nfrom autolabel.cache import BaseCache\n\nlogger = logging.getLogger(__name__)\n\nMAX_RETRIES = 3\nMAX_KEEPALIVE_CONNECTIONS = 20\nMAX_CONNECTIONS = 100\nBACKOFF = 2\nHEADERS = {}\nHTML_PARSER = \"html.parser\"\n\n\nclass WebpageTransform(BaseTransform):\n COLUMN_NAMES = [\n \"content_column\",\n \"content_in_bytes_column\",\n \"soup_column\",\n \"metadata_column\",\n ]\n\n def __init__(\n self,\n cache: BaseCache,\n output_columns: Dict[str, Any],\n url_column: str,\n timeout: int = 5,\n headers: Dict[str, str] = HEADERS,\n ) -> None:\n super().__init__(cache, output_columns)\n self.url_column = url_column\n self.headers = headers\n self.max_retries = MAX_RETRIES\n try:\n from bs4 import BeautifulSoup\n import httpx\n\n if not headers.get(\"User-Agent\"):\n from fake_useragent import UserAgent\n\n headers[\"User-Agent\"] = UserAgent().random\n\n self.httpx = httpx\n self.timeout_time = timeout\n self.timeout = httpx.Timeout(timeout)\n limits = httpx.Limits(\n max_keepalive_connections=MAX_KEEPALIVE_CONNECTIONS,\n max_connections=MAX_CONNECTIONS,\n keepalive_expiry=timeout,\n )\n self.client = httpx.AsyncClient(\n timeout=self.timeout, limits=limits, follow_redirects=True\n )\n self.client_with_no_verify = httpx.AsyncClient(\n timeout=self.timeout, limits=limits, follow_redirects=True, verify=False\n )\n self.beautiful_soup = BeautifulSoup\n except ImportError:\n raise ImportError(\n \"BeautifulSoup, httpx and fake_useragent are required to use the webpage transform. Please install them with the following command: pip install beautifulsoup4 httpx fake_useragent\"\n )\n\n def name(self) -> str:\n return TransformType.WEBPAGE_TRANSFORM\n\n def _load_metadata(self, url, soup) -> Dict[str, Any]:\n metadata = {\"url\": url}\n if soup.find(\"title\"):\n metadata[\"title\"] = soup.find(\"title\").get_text()\n for meta in soup.find_all(\"meta\"):\n if meta.get(\"name\") and meta.get(\"content\"):\n metadata[meta.get(\"name\")] = meta.get(\"content\")\n elif meta.get(\"property\") and meta.get(\"content\"):\n metadata[meta.get(\"property\")] = meta.get(\"content\")\n return metadata\n\n async def _load_url(\n self, url: str, verify=True, headers=HEADERS, retry_count=0\n ) -> Dict[str, Any]:\n if retry_count >= self.max_retries:\n logger.warning(f\"Max retries reached for URL: {url}\")\n return {}\n\n try:\n client = self.client\n if not verify:\n client = self.client_with_no_verify\n response = await client.get(url, headers=headers)\n\n # TODO: Add support for other parsers\n content_bytes = response.content\n soup = self.beautiful_soup(content_bytes, HTML_PARSER)\n return {\n \"content\": soup.get_text(),\n \"content_bytes\": content_bytes,\n \"soup\": soup,\n \"metadata\": self._load_metadata(url, soup),\n }\n except self.httpx.ConnectTimeout as e:\n logger.error(f\"Timeout when fetching content from URL: {url}\")\n return {}\n except ssl.SSLCertVerificationError as e:\n logger.warning(\n f\"SSL verification error when fetching content from URL: {url}, retrying with verify=False\"\n )\n await asyncio.sleep(BACKOFF**retry_count)\n return await self._load_url(\n url, verify=False, headers=headers, retry_count=retry_count + 1\n )\n except Exception as e:\n logger.error(f\"Error fetching content from URL: {url}. Exception: {e}\")\n return {}\n\n async def _apply(self, row: Dict[str, Any]) -> Dict[str, Any]:\n url = row[self.url_column]\n url_response_data = {}\n if pd.isna(url):\n logger.warning(f\"Empty url in row {row}\")\n else:\n url_response_data = await self._load_url(url)\n\n transformed_row = {\n self.output_columns[\"content_column\"]: url_response_data.get(\"content\"),\n self.output_columns[\"content_in_bytes_column\"]: url_response_data.get(\n \"content_bytes\"\n ),\n self.output_columns[\"soup_column\"]: url_response_data.get(\"soup\"),\n self.output_columns[\"metadata_column\"]: url_response_data.get(\"metadata\"),\n }\n\n return self._return_output_row(transformed_row)\n\n def params(self):\n return {\n \"url_column\": self.url_column,\n \"output_columns\": self.output_columns,\n \"timeout\": self.timeout_time,\n }\n", "path": "src/autolabel/transforms/webpage_transform.py"}, {"content": "from typing import List, Dict, Any\n\nfrom autolabel.schema import TransformType\nfrom autolabel.transforms import BaseTransform\nfrom autolabel.cache import BaseCache\n\n\nclass PDFTransform(BaseTransform):\n COLUMN_NAMES = [\n \"content_column\",\n \"metadata_column\",\n ]\n\n def __init__(\n self,\n cache: BaseCache,\n output_columns: Dict[str, Any],\n file_path_column: str,\n ocr_enabled: bool = False,\n page_header: str = \"Page {page_num}: {page_content}\",\n page_sep: str = \"\\n\\n\",\n ) -> None:\n \"\"\"The output columns for this class should be in the order: [content_column, num_pages_column]\"\"\"\n super().__init__(cache, output_columns)\n self.file_path_column = file_path_column\n self.ocr_enabled = ocr_enabled\n self.page_format = page_header\n self.page_sep = page_sep\n\n if self.ocr_enabled:\n try:\n from pdf2image import convert_from_path\n import pytesseract\n\n self.convert_from_path = convert_from_path\n self.pytesseract = pytesseract\n self.pytesseract.get_tesseract_version()\n except ImportError:\n raise ImportError(\n \"pdf2image and pytesseract are required to use the pdf transform with ocr. Please install pdf2image and pytesseract with the following command: pip install pdf2image pytesseract\"\n )\n except EnvironmentError:\n raise EnvironmentError(\n \"The tesseract engine is required to use the pdf transform with ocr. Please see https://tesseract-ocr.github.io/tessdoc/Installation.html for installation instructions.\"\n )\n else:\n try:\n from langchain.document_loaders import PDFPlumberLoader\n\n self.PDFPlumberLoader = PDFPlumberLoader\n except ImportError:\n raise ImportError(\n \"pdfplumber is required to use the pdf transform. Please install pdfplumber with the following command: pip install pdfplumber\"\n )\n\n @staticmethod\n def name() -> str:\n return TransformType.PDF\n\n def get_page_texts(self, row: Dict[str, Any]) -> List[str]:\n \"\"\"This function gets the text from each page of a PDF file.\n If OCR is enabled, it uses the pdf2image library to convert the PDF into images and then uses\n pytesseract to convert the images into text. Otherwise, it uses pdfplumber to extract the text.\n\n Args:\n row (Dict[str, Any]): The row of data to be transformed.\n\n Returns:\n List[str]: A list of strings containing the text from each page of the PDF.\n \"\"\"\n if self.ocr_enabled:\n pages = self.convert_from_path(row[self.file_path_column])\n return [self.pytesseract.image_to_string(page) for page in pages]\n else:\n loader = self.PDFPlumberLoader(row[self.file_path_column])\n return [page.page_content for page in loader.load()]\n\n async def _apply(self, row: Dict[str, Any]) -> Dict[str, Any]:\n \"\"\"This function transforms a PDF file into a string of text.\n The text is formatted according to the page_format and\n page_sep parameters and returned as a string.\n\n Args:\n row (Dict[str, Any]): The row of data to be transformed.\n\n Returns:\n Dict[str, Any]: The dict of output columns.\n \"\"\"\n texts = []\n for idx, text in enumerate(self.get_page_texts(row)):\n texts.append(self.page_format.format(page_num=idx + 1, page_content=text))\n output = self.page_sep.join(texts)\n transformed_row = {\n self.output_columns[\"content_column\"]: output,\n self.output_columns[\"metadata_column\"]: {\"num_pages\": len(texts)},\n }\n return self._return_output_row(transformed_row)\n\n def params(self):\n return {\n \"file_path_column\": self.file_path_column,\n \"ocr_enabled\": self.ocr_enabled,\n \"page_header\": self.page_format,\n \"page_sep\": self.page_sep,\n \"output_columns\": self.output_columns,\n }\n", "path": "src/autolabel/transforms/pdf.py"}, {"content": "from abc import ABC, abstractmethod\nfrom typing import Dict, Any\nfrom autolabel.cache import BaseCache\nfrom autolabel.schema import TransformCacheEntry\n\n\nclass BaseTransform(ABC):\n \"\"\"Base class for all transforms.\"\"\"\n\n TTL_MS = 60 * 60 * 24 * 7 * 1000 # 1 week\n\n def __init__(self, cache: BaseCache, output_columns: Dict[str, Any]) -> None:\n \"\"\"\n Initialize a transform.\n Args:\n cache: A cache object to use for caching the results of this transform.\n output_columns: A dictionary of output columns. The keys are the names of the output columns as expected by the transform. The values are the column names they should be mapped to in the dataset.\n \"\"\"\n super().__init__()\n self._output_columns = output_columns\n self.cache = cache\n\n @staticmethod\n @abstractmethod\n def name() -> str:\n \"\"\"\n Returns the name of the transform.\n \"\"\"\n pass\n\n @property\n def output_columns(self) -> Dict[str, Any]:\n \"\"\"\n Returns a dictionary of output columns. The keys are the names of the output columns\n as expected by the transform. The values are the column names they should be mapped to in\n the dataset.\n \"\"\"\n return {k: self._output_columns.get(k, None) for k in self.COLUMN_NAMES}\n\n @abstractmethod\n async def _apply(self, row: Dict[str, Any]) -> Dict[str, Any]:\n \"\"\"\n Applies the transform to the given row.\n Args:\n row: A dictionary representing a row in the dataset. The keys are the column names and the values are the column values.\n Returns:\n A dictionary representing the transformed row. The keys are the column names and the values are the column values.\n \"\"\"\n pass\n\n @abstractmethod\n def params(self) -> Dict[str, Any]:\n \"\"\"\n Returns a dictionary of parameters that can be used to uniquely identify this transform.\n Returns:\n A dictionary of parameters that can be used to uniquely identify this transform.\n \"\"\"\n return {}\n\n async def apply(self, row: Dict[str, Any]) -> Dict[str, Any]:\n if self.cache is not None:\n cache_entry = TransformCacheEntry(\n transform_name=self.name(),\n transform_params=self.params(),\n input=row,\n ttl_ms=self.TTL_MS,\n )\n output = self.cache.lookup(cache_entry)\n\n if output is not None:\n # Cache hit\n return output\n\n output = await self._apply(row)\n\n if self.cache is not None:\n cache_entry.output = output\n self.cache.update(cache_entry)\n\n return output\n\n def _return_output_row(self, row: Dict[str, Any]) -> Dict[str, Any]:\n \"\"\"\n Returns the output row with the correct column names.\n Args:\n row: The output row.\n Returns:\n The output row with the correct column names.\n \"\"\"\n # remove null key\n row.pop(None, None)\n return row\n", "path": "src/autolabel/transforms/base.py"}]}
| 3,701 | 936 |
gh_patches_debug_28454
|
rasdani/github-patches
|
git_diff
|
akvo__akvo-rsr-4439
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Results filter inconsistency, Old vs. New results tab
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `akvo/rest/views/project.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 """Akvo RSR is covered by the GNU Affero General Public License.
3
4 See more details in the license.txt file located at the root folder of the Akvo RSR module.
5 For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.
6 """
7
8 from django.db.models import Q
9 from django.shortcuts import get_object_or_404
10 from django.http import Http404
11 from rest_framework.authentication import SessionAuthentication
12 from rest_framework.decorators import api_view, authentication_classes, permission_classes
13 from rest_framework.permissions import IsAuthenticated
14 from rest_framework.response import Response
15 from rest_framework.status import HTTP_201_CREATED
16 from geojson import Feature, Point, FeatureCollection
17
18 from akvo.codelists.store.default_codelists import SECTOR_CATEGORY
19 from akvo.rest.cache import serialized_project
20 from akvo.rest.serializers import (ProjectSerializer, ProjectExtraSerializer,
21 ProjectExtraDeepSerializer,
22 ProjectIatiExportSerializer,
23 ProjectUpSerializer,
24 TypeaheadOrganisationSerializer,
25 ProjectMetadataSerializer,
26 OrganisationCustomFieldSerializer,
27 ProjectHierarchyRootSerializer,
28 ProjectHierarchyTreeSerializer,)
29 from akvo.rest.models import TastyTokenAuthentication
30 from akvo.rsr.models import Project, OrganisationCustomField, IndicatorPeriodData
31 from akvo.rsr.views.my_rsr import user_viewable_projects
32 from akvo.utils import codelist_choices
33 from ..viewsets import PublicProjectViewSet, ReadOnlyPublicProjectViewSet
34
35
36 class ProjectViewSet(PublicProjectViewSet):
37
38 """
39 Viewset providing Project data.
40 """
41 queryset = Project.objects.prefetch_related(
42 'publishingstatus',
43 'categories',
44 'keywords',
45 'partners',
46 )
47 serializer_class = ProjectSerializer
48 project_relation = ''
49
50 def get_queryset(self):
51 """
52 Allow custom filter for sync_owner, since this field has been replaced by the
53 reporting org partnership.
54 """
55
56 sync_owner = self.request.query_params.get('sync_owner', None)
57 reporting_org = self.request.query_params.get('reporting_org', None)
58
59 reporting_org = reporting_org or sync_owner
60 if reporting_org:
61 self.queryset = self.queryset.filter(
62 partnerships__iati_organisation_role=101,
63 partnerships__organisation__pk=reporting_org
64 ).distinct()
65 return super(ProjectViewSet, self).get_queryset()
66
67
68 class MyProjectsViewSet(PublicProjectViewSet):
69 """Viewset providing listing of projects a user can edit."""
70 queryset = Project.objects.all().select_related('publishingstatus')\
71 .prefetch_related('locations', 'categories', 'related_projects', 'recipient_countries')
72 serializer_class = ProjectMetadataSerializer
73 project_relation = ''
74
75 def get_queryset(self):
76 if self.request.user.is_anonymous:
77 return Project.objects.none()
78 show_restricted = bool(self.request.query_params.get('show_restricted'))
79
80 filter_program = self.request.query_params.get('filter_program')
81 if filter_program:
82 try:
83 filter_program = int(filter_program)
84 except ValueError:
85 filter_program = None
86
87 queryset = user_viewable_projects(self.request.user, show_restricted, filter_program)
88
89 sector = self.request.query_params.get('sector', None)
90 if sector:
91 queryset = queryset.filter(sectors__sector_code=sector)
92 country = self.request.query_params.get('country', None)
93 if country:
94 queryset = queryset.filter(locations__country__iso_code=country)\
95 .union(queryset.filter(recipient_countries__country__iexact=country))
96 return queryset
97
98
99 class ProjectHierarchyViewSet(ReadOnlyPublicProjectViewSet):
100 queryset = Project.objects.none()
101 serializer_class = ProjectHierarchyRootSerializer
102 project_relation = ''
103
104 def get_queryset(self):
105 if self.request.user.is_anonymous:
106 return Project.objects.none()
107 queryset = self.request.user.my_projects()\
108 .published()\
109 .filter(projecthierarchy__isnull=False)
110 return queryset
111
112 def retrieve(self, request, *args, **kwargs):
113 project = get_object_or_404(Project, pk=self.kwargs['pk'])
114 root = project.ancestor()
115 if not self.request.user.has_perm('rsr.view_project', root):
116 raise Http404
117
118 serializer = ProjectHierarchyTreeSerializer(root, context=self.get_serializer_context())
119
120 return Response(serializer.data)
121
122
123 class ProjectIatiExportViewSet(PublicProjectViewSet):
124 """Lean viewset for project data, as used in the My IATI section of RSR."""
125 queryset = Project.objects.only(
126 'id',
127 'title',
128 'is_public',
129 'status',
130 'run_iati_checks',
131 ).prefetch_related(
132 'partners',
133 'iati_checks',
134 'publishingstatus',
135 'partnerships',
136 )
137 serializer_class = ProjectIatiExportSerializer
138 project_relation = ''
139 paginate_by_param = 'limit'
140 max_paginate_by = 50
141
142 def get_queryset(self):
143 """
144 Allow custom filter for sync_owner, since this field has been replaced by the
145 reporting org partnership.
146 """
147 reporting_org = self.request.query_params.get('reporting_org', None)
148 if reporting_org:
149 self.queryset = self.queryset.filter(
150 partnerships__iati_organisation_role=101,
151 partnerships__organisation__pk=reporting_org
152 ).distinct()
153 return super(ProjectIatiExportViewSet, self).get_queryset()
154
155 def list(self, request, *args, **kwargs):
156 projects = self.queryset.filter(run_iati_checks=True)
157 for project in projects:
158 project.update_iati_checks()
159 return super(ProjectIatiExportViewSet, self).list(request, *args, **kwargs)
160
161
162 class ProjectExtraViewSet(ProjectViewSet):
163 r"""
164 Viewset providing extra Project data.
165
166 Allowed parameters are:
167 __limit__ (default 10, max 30),
168 __partnerships\__organisation__ (filter on organisation ID), and
169 __publishingstatus\__status__ (filter on publishing status)
170 """
171
172 queryset = Project.objects.prefetch_related(
173 'publishingstatus',
174 'sectors',
175 'partnerships',
176 'budget_items',
177 'legacy_data',
178 'links',
179 'locations',
180 'locations__country',
181 'planned_disbursements',
182 'policy_markers',
183 'documents',
184 'conditions',
185 'contacts',
186 'project_updates',
187 'recipient_countries',
188 'recipient_regions',
189 'related_projects',
190 'results',
191 'sectors',
192 'transactions',
193 )
194 serializer_class = ProjectExtraSerializer
195 paginate_by_param = 'limit'
196 paginate_by = 10
197 max_paginate_by = 30
198
199
200 class ProjectExtraDeepViewSet(ProjectViewSet):
201 r"""
202 Viewset providing extra deep (depth=2 or bigger) Project data.
203
204 Allowed parameters are:
205 __limit__ (default 5, max 10),
206 __partnerships\__organisation__ (filter on organisation ID), and
207 __publishingstatus\__status__ (filter on publishing status)
208 """
209
210 queryset = Project.objects.prefetch_related(
211 'publishingstatus',
212 'sectors',
213 'partnerships',
214 'budget_items',
215 'legacy_data',
216 'links',
217 'locations',
218 'locations__country',
219 'planned_disbursements',
220 'policy_markers',
221 'documents',
222 'conditions',
223 'contacts',
224 'project_updates',
225 'recipient_countries',
226 'recipient_regions',
227 'related_projects',
228 'results',
229 'sectors',
230 'transactions',
231 )
232 serializer_class = ProjectExtraDeepSerializer
233 paginate_by_param = 'limit'
234 paginate_by = 5
235 max_paginate_by = 10
236
237
238 class ProjectUpViewSet(ProjectViewSet):
239 r"""
240 Viewset providing extra data and limited filtering for Up in one go.
241
242 Allowed parameters are:
243 __limit__ (default 30, max 100),
244 __partnerships\__organisation__ (filter on organisation ID), and
245 __publishingstatus\__status__ (filter on publishing status)
246 """
247
248 queryset = Project.objects.select_related(
249 'primary_location',
250 ).prefetch_related(
251 'publishingstatus',
252 'project_updates',
253 'categories',
254 'keywords',
255 'partners',
256 )
257 serializer_class = ProjectUpSerializer
258 paginate_by_param = 'limit'
259 max_paginate_by = 100
260
261
262 ###############################################################################
263 # Project directory
264 ###############################################################################
265
266 @api_view(['GET'])
267 def project_directory(request):
268 """Return the values for various project filters.
269
270 Based on the current filters, it returns new options for all the (other)
271 filters. This is used to generate dynamic filters.
272
273 """
274
275 page = request.rsr_page
276 projects = _project_list(request)
277 projects_data = [
278 serialized_project(project_id) for project_id in projects.values_list('pk', flat=True)
279 ]
280 organisations = list(projects.all_partners().values('id', 'name', 'long_name'))
281 organisations = TypeaheadOrganisationSerializer(organisations, many=True).data
282
283 custom_fields = (
284 OrganisationCustomField.objects.filter(type='dropdown',
285 organisation=page.organisation,
286 show_in_searchbar=True).order_by('order', 'id')
287 if page else []
288 )
289 sectors = [{'id': id_, 'name': name} for id_, name in codelist_choices(SECTOR_CATEGORY)]
290 response = {
291 'projects': projects_data,
292 'organisation': organisations,
293 'sector': sectors,
294 'custom_fields': OrganisationCustomFieldSerializer(custom_fields, many=True).data,
295 }
296
297 return Response(response)
298
299
300 def _project_list(request):
301 """Return a project queryset based on the request"""
302 # Fetch projects based on whether we are an Akvo site or RSR main site
303 page = request.rsr_page
304 projects = page.projects() if page else Project.objects.all().public().published()
305
306 if not page:
307 # Exclude projects which don't have an image or a title for RSR site
308 projects = projects.exclude(Q(title='') | Q(current_image=''))
309 else:
310 # On partner sites, all projects show up. Partners are expected to fix
311 # their data to fix their pages!
312 pass
313 return projects
314
315
316 @api_view(['GET'])
317 def project_location_geojson(request):
318 """Return a GeoJSON with all the project locations."""
319 projects = _project_list(request).prefetch_related('locations')
320 features = [
321 Feature(geometry=Point((location.longitude, location.latitude)),
322 properties=dict(
323 project_title=project.title,
324 project_subtitle=project.subtitle,
325 project_url=request.build_absolute_uri(project.get_absolute_url()),
326 project_id=project.pk,
327 name=location.name,
328 description=location.description))
329 for project in projects
330 for location in project.locations.all()
331 if location.is_valid()
332 ]
333 response = FeatureCollection(features)
334 return Response(response)
335
336
337 @api_view(['POST'])
338 @permission_classes((IsAuthenticated, ))
339 @authentication_classes([SessionAuthentication, TastyTokenAuthentication])
340 def add_project_to_program(request, program_pk):
341 program = get_object_or_404(Project, pk=program_pk)
342 parent_pk = request.data.get('parent')
343 if parent_pk is not None:
344 program = get_object_or_404(Project, pk=parent_pk)
345
346 project = Project.objects.create()
347 Project.new_project_created(project.id, request.user) # Log creation
348 project.add_to_program(program)
349 # Set user's primary org as accountable partner
350 org = request.user.first_organisation()
351 if org is not None and org != program.reporting_org:
352 project.set_accountable_partner(org)
353 response = ProjectSerializer(project, context=dict(request=request)).data
354 return Response(response, status=HTTP_201_CREATED)
355
356
357 @api_view(['GET'])
358 def project_title(request, project_pk):
359 project = get_object_or_404(Project, pk=project_pk)
360 data = {
361 'title': project.title,
362 'publishing_status': project.publishingstatus.status,
363 'has_hierarchy': project.parents_all().exists() or project.is_hierarchy_root(),
364 'pending_update_count': IndicatorPeriodData.objects.filter(
365 period__indicator__result__project=project,
366 status=IndicatorPeriodData.STATUS_PENDING_CODE
367 ).count()
368 }
369 return Response(data)
370
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/akvo/rest/views/project.py b/akvo/rest/views/project.py
--- a/akvo/rest/views/project.py
+++ b/akvo/rest/views/project.py
@@ -29,7 +29,7 @@
from akvo.rest.models import TastyTokenAuthentication
from akvo.rsr.models import Project, OrganisationCustomField, IndicatorPeriodData
from akvo.rsr.views.my_rsr import user_viewable_projects
-from akvo.utils import codelist_choices
+from akvo.utils import codelist_choices, single_period_dates
from ..viewsets import PublicProjectViewSet, ReadOnlyPublicProjectViewSet
@@ -357,6 +357,9 @@
@api_view(['GET'])
def project_title(request, project_pk):
project = get_object_or_404(Project, pk=project_pk)
+ hierarchy_name = project.uses_single_indicator_period()
+ needs_reporting_timeout_days, _, _ = single_period_dates(hierarchy_name) if hierarchy_name else (None, None, None)
+
data = {
'title': project.title,
'publishing_status': project.publishingstatus.status,
@@ -364,6 +367,7 @@
'pending_update_count': IndicatorPeriodData.objects.filter(
period__indicator__result__project=project,
status=IndicatorPeriodData.STATUS_PENDING_CODE
- ).count()
+ ).count(),
+ 'needs_reporting_timeout_days': needs_reporting_timeout_days,
}
return Response(data)
|
{"golden_diff": "diff --git a/akvo/rest/views/project.py b/akvo/rest/views/project.py\n--- a/akvo/rest/views/project.py\n+++ b/akvo/rest/views/project.py\n@@ -29,7 +29,7 @@\n from akvo.rest.models import TastyTokenAuthentication\n from akvo.rsr.models import Project, OrganisationCustomField, IndicatorPeriodData\n from akvo.rsr.views.my_rsr import user_viewable_projects\n-from akvo.utils import codelist_choices\n+from akvo.utils import codelist_choices, single_period_dates\n from ..viewsets import PublicProjectViewSet, ReadOnlyPublicProjectViewSet\n \n \n@@ -357,6 +357,9 @@\n @api_view(['GET'])\n def project_title(request, project_pk):\n project = get_object_or_404(Project, pk=project_pk)\n+ hierarchy_name = project.uses_single_indicator_period()\n+ needs_reporting_timeout_days, _, _ = single_period_dates(hierarchy_name) if hierarchy_name else (None, None, None)\n+\n data = {\n 'title': project.title,\n 'publishing_status': project.publishingstatus.status,\n@@ -364,6 +367,7 @@\n 'pending_update_count': IndicatorPeriodData.objects.filter(\n period__indicator__result__project=project,\n status=IndicatorPeriodData.STATUS_PENDING_CODE\n- ).count()\n+ ).count(),\n+ 'needs_reporting_timeout_days': needs_reporting_timeout_days,\n }\n return Response(data)\n", "issue": "Results filter inconsistency, Old vs. New results tab\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"Akvo RSR is covered by the GNU Affero General Public License.\n\nSee more details in the license.txt file located at the root folder of the Akvo RSR module.\nFor additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\"\"\"\n\nfrom django.db.models import Q\nfrom django.shortcuts import get_object_or_404\nfrom django.http import Http404\nfrom rest_framework.authentication import SessionAuthentication\nfrom rest_framework.decorators import api_view, authentication_classes, permission_classes\nfrom rest_framework.permissions import IsAuthenticated\nfrom rest_framework.response import Response\nfrom rest_framework.status import HTTP_201_CREATED\nfrom geojson import Feature, Point, FeatureCollection\n\nfrom akvo.codelists.store.default_codelists import SECTOR_CATEGORY\nfrom akvo.rest.cache import serialized_project\nfrom akvo.rest.serializers import (ProjectSerializer, ProjectExtraSerializer,\n ProjectExtraDeepSerializer,\n ProjectIatiExportSerializer,\n ProjectUpSerializer,\n TypeaheadOrganisationSerializer,\n ProjectMetadataSerializer,\n OrganisationCustomFieldSerializer,\n ProjectHierarchyRootSerializer,\n ProjectHierarchyTreeSerializer,)\nfrom akvo.rest.models import TastyTokenAuthentication\nfrom akvo.rsr.models import Project, OrganisationCustomField, IndicatorPeriodData\nfrom akvo.rsr.views.my_rsr import user_viewable_projects\nfrom akvo.utils import codelist_choices\nfrom ..viewsets import PublicProjectViewSet, ReadOnlyPublicProjectViewSet\n\n\nclass ProjectViewSet(PublicProjectViewSet):\n\n \"\"\"\n Viewset providing Project data.\n \"\"\"\n queryset = Project.objects.prefetch_related(\n 'publishingstatus',\n 'categories',\n 'keywords',\n 'partners',\n )\n serializer_class = ProjectSerializer\n project_relation = ''\n\n def get_queryset(self):\n \"\"\"\n Allow custom filter for sync_owner, since this field has been replaced by the\n reporting org partnership.\n \"\"\"\n\n sync_owner = self.request.query_params.get('sync_owner', None)\n reporting_org = self.request.query_params.get('reporting_org', None)\n\n reporting_org = reporting_org or sync_owner\n if reporting_org:\n self.queryset = self.queryset.filter(\n partnerships__iati_organisation_role=101,\n partnerships__organisation__pk=reporting_org\n ).distinct()\n return super(ProjectViewSet, self).get_queryset()\n\n\nclass MyProjectsViewSet(PublicProjectViewSet):\n \"\"\"Viewset providing listing of projects a user can edit.\"\"\"\n queryset = Project.objects.all().select_related('publishingstatus')\\\n .prefetch_related('locations', 'categories', 'related_projects', 'recipient_countries')\n serializer_class = ProjectMetadataSerializer\n project_relation = ''\n\n def get_queryset(self):\n if self.request.user.is_anonymous:\n return Project.objects.none()\n show_restricted = bool(self.request.query_params.get('show_restricted'))\n\n filter_program = self.request.query_params.get('filter_program')\n if filter_program:\n try:\n filter_program = int(filter_program)\n except ValueError:\n filter_program = None\n\n queryset = user_viewable_projects(self.request.user, show_restricted, filter_program)\n\n sector = self.request.query_params.get('sector', None)\n if sector:\n queryset = queryset.filter(sectors__sector_code=sector)\n country = self.request.query_params.get('country', None)\n if country:\n queryset = queryset.filter(locations__country__iso_code=country)\\\n .union(queryset.filter(recipient_countries__country__iexact=country))\n return queryset\n\n\nclass ProjectHierarchyViewSet(ReadOnlyPublicProjectViewSet):\n queryset = Project.objects.none()\n serializer_class = ProjectHierarchyRootSerializer\n project_relation = ''\n\n def get_queryset(self):\n if self.request.user.is_anonymous:\n return Project.objects.none()\n queryset = self.request.user.my_projects()\\\n .published()\\\n .filter(projecthierarchy__isnull=False)\n return queryset\n\n def retrieve(self, request, *args, **kwargs):\n project = get_object_or_404(Project, pk=self.kwargs['pk'])\n root = project.ancestor()\n if not self.request.user.has_perm('rsr.view_project', root):\n raise Http404\n\n serializer = ProjectHierarchyTreeSerializer(root, context=self.get_serializer_context())\n\n return Response(serializer.data)\n\n\nclass ProjectIatiExportViewSet(PublicProjectViewSet):\n \"\"\"Lean viewset for project data, as used in the My IATI section of RSR.\"\"\"\n queryset = Project.objects.only(\n 'id',\n 'title',\n 'is_public',\n 'status',\n 'run_iati_checks',\n ).prefetch_related(\n 'partners',\n 'iati_checks',\n 'publishingstatus',\n 'partnerships',\n )\n serializer_class = ProjectIatiExportSerializer\n project_relation = ''\n paginate_by_param = 'limit'\n max_paginate_by = 50\n\n def get_queryset(self):\n \"\"\"\n Allow custom filter for sync_owner, since this field has been replaced by the\n reporting org partnership.\n \"\"\"\n reporting_org = self.request.query_params.get('reporting_org', None)\n if reporting_org:\n self.queryset = self.queryset.filter(\n partnerships__iati_organisation_role=101,\n partnerships__organisation__pk=reporting_org\n ).distinct()\n return super(ProjectIatiExportViewSet, self).get_queryset()\n\n def list(self, request, *args, **kwargs):\n projects = self.queryset.filter(run_iati_checks=True)\n for project in projects:\n project.update_iati_checks()\n return super(ProjectIatiExportViewSet, self).list(request, *args, **kwargs)\n\n\nclass ProjectExtraViewSet(ProjectViewSet):\n r\"\"\"\n Viewset providing extra Project data.\n\n Allowed parameters are:\n __limit__ (default 10, max 30),\n __partnerships\\__organisation__ (filter on organisation ID), and\n __publishingstatus\\__status__ (filter on publishing status)\n \"\"\"\n\n queryset = Project.objects.prefetch_related(\n 'publishingstatus',\n 'sectors',\n 'partnerships',\n 'budget_items',\n 'legacy_data',\n 'links',\n 'locations',\n 'locations__country',\n 'planned_disbursements',\n 'policy_markers',\n 'documents',\n 'conditions',\n 'contacts',\n 'project_updates',\n 'recipient_countries',\n 'recipient_regions',\n 'related_projects',\n 'results',\n 'sectors',\n 'transactions',\n )\n serializer_class = ProjectExtraSerializer\n paginate_by_param = 'limit'\n paginate_by = 10\n max_paginate_by = 30\n\n\nclass ProjectExtraDeepViewSet(ProjectViewSet):\n r\"\"\"\n Viewset providing extra deep (depth=2 or bigger) Project data.\n\n Allowed parameters are:\n __limit__ (default 5, max 10),\n __partnerships\\__organisation__ (filter on organisation ID), and\n __publishingstatus\\__status__ (filter on publishing status)\n \"\"\"\n\n queryset = Project.objects.prefetch_related(\n 'publishingstatus',\n 'sectors',\n 'partnerships',\n 'budget_items',\n 'legacy_data',\n 'links',\n 'locations',\n 'locations__country',\n 'planned_disbursements',\n 'policy_markers',\n 'documents',\n 'conditions',\n 'contacts',\n 'project_updates',\n 'recipient_countries',\n 'recipient_regions',\n 'related_projects',\n 'results',\n 'sectors',\n 'transactions',\n )\n serializer_class = ProjectExtraDeepSerializer\n paginate_by_param = 'limit'\n paginate_by = 5\n max_paginate_by = 10\n\n\nclass ProjectUpViewSet(ProjectViewSet):\n r\"\"\"\n Viewset providing extra data and limited filtering for Up in one go.\n\n Allowed parameters are:\n __limit__ (default 30, max 100),\n __partnerships\\__organisation__ (filter on organisation ID), and\n __publishingstatus\\__status__ (filter on publishing status)\n \"\"\"\n\n queryset = Project.objects.select_related(\n 'primary_location',\n ).prefetch_related(\n 'publishingstatus',\n 'project_updates',\n 'categories',\n 'keywords',\n 'partners',\n )\n serializer_class = ProjectUpSerializer\n paginate_by_param = 'limit'\n max_paginate_by = 100\n\n\n###############################################################################\n# Project directory\n###############################################################################\n\n@api_view(['GET'])\ndef project_directory(request):\n \"\"\"Return the values for various project filters.\n\n Based on the current filters, it returns new options for all the (other)\n filters. This is used to generate dynamic filters.\n\n \"\"\"\n\n page = request.rsr_page\n projects = _project_list(request)\n projects_data = [\n serialized_project(project_id) for project_id in projects.values_list('pk', flat=True)\n ]\n organisations = list(projects.all_partners().values('id', 'name', 'long_name'))\n organisations = TypeaheadOrganisationSerializer(organisations, many=True).data\n\n custom_fields = (\n OrganisationCustomField.objects.filter(type='dropdown',\n organisation=page.organisation,\n show_in_searchbar=True).order_by('order', 'id')\n if page else []\n )\n sectors = [{'id': id_, 'name': name} for id_, name in codelist_choices(SECTOR_CATEGORY)]\n response = {\n 'projects': projects_data,\n 'organisation': organisations,\n 'sector': sectors,\n 'custom_fields': OrganisationCustomFieldSerializer(custom_fields, many=True).data,\n }\n\n return Response(response)\n\n\ndef _project_list(request):\n \"\"\"Return a project queryset based on the request\"\"\"\n # Fetch projects based on whether we are an Akvo site or RSR main site\n page = request.rsr_page\n projects = page.projects() if page else Project.objects.all().public().published()\n\n if not page:\n # Exclude projects which don't have an image or a title for RSR site\n projects = projects.exclude(Q(title='') | Q(current_image=''))\n else:\n # On partner sites, all projects show up. Partners are expected to fix\n # their data to fix their pages!\n pass\n return projects\n\n\n@api_view(['GET'])\ndef project_location_geojson(request):\n \"\"\"Return a GeoJSON with all the project locations.\"\"\"\n projects = _project_list(request).prefetch_related('locations')\n features = [\n Feature(geometry=Point((location.longitude, location.latitude)),\n properties=dict(\n project_title=project.title,\n project_subtitle=project.subtitle,\n project_url=request.build_absolute_uri(project.get_absolute_url()),\n project_id=project.pk,\n name=location.name,\n description=location.description))\n for project in projects\n for location in project.locations.all()\n if location.is_valid()\n ]\n response = FeatureCollection(features)\n return Response(response)\n\n\n@api_view(['POST'])\n@permission_classes((IsAuthenticated, ))\n@authentication_classes([SessionAuthentication, TastyTokenAuthentication])\ndef add_project_to_program(request, program_pk):\n program = get_object_or_404(Project, pk=program_pk)\n parent_pk = request.data.get('parent')\n if parent_pk is not None:\n program = get_object_or_404(Project, pk=parent_pk)\n\n project = Project.objects.create()\n Project.new_project_created(project.id, request.user) # Log creation\n project.add_to_program(program)\n # Set user's primary org as accountable partner\n org = request.user.first_organisation()\n if org is not None and org != program.reporting_org:\n project.set_accountable_partner(org)\n response = ProjectSerializer(project, context=dict(request=request)).data\n return Response(response, status=HTTP_201_CREATED)\n\n\n@api_view(['GET'])\ndef project_title(request, project_pk):\n project = get_object_or_404(Project, pk=project_pk)\n data = {\n 'title': project.title,\n 'publishing_status': project.publishingstatus.status,\n 'has_hierarchy': project.parents_all().exists() or project.is_hierarchy_root(),\n 'pending_update_count': IndicatorPeriodData.objects.filter(\n period__indicator__result__project=project,\n status=IndicatorPeriodData.STATUS_PENDING_CODE\n ).count()\n }\n return Response(data)\n", "path": "akvo/rest/views/project.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"Akvo RSR is covered by the GNU Affero General Public License.\n\nSee more details in the license.txt file located at the root folder of the Akvo RSR module.\nFor additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\"\"\"\n\nfrom django.db.models import Q\nfrom django.shortcuts import get_object_or_404\nfrom django.http import Http404\nfrom rest_framework.authentication import SessionAuthentication\nfrom rest_framework.decorators import api_view, authentication_classes, permission_classes\nfrom rest_framework.permissions import IsAuthenticated\nfrom rest_framework.response import Response\nfrom rest_framework.status import HTTP_201_CREATED\nfrom geojson import Feature, Point, FeatureCollection\n\nfrom akvo.codelists.store.default_codelists import SECTOR_CATEGORY\nfrom akvo.rest.cache import serialized_project\nfrom akvo.rest.serializers import (ProjectSerializer, ProjectExtraSerializer,\n ProjectExtraDeepSerializer,\n ProjectIatiExportSerializer,\n ProjectUpSerializer,\n TypeaheadOrganisationSerializer,\n ProjectMetadataSerializer,\n OrganisationCustomFieldSerializer,\n ProjectHierarchyRootSerializer,\n ProjectHierarchyTreeSerializer,)\nfrom akvo.rest.models import TastyTokenAuthentication\nfrom akvo.rsr.models import Project, OrganisationCustomField, IndicatorPeriodData\nfrom akvo.rsr.views.my_rsr import user_viewable_projects\nfrom akvo.utils import codelist_choices, single_period_dates\nfrom ..viewsets import PublicProjectViewSet, ReadOnlyPublicProjectViewSet\n\n\nclass ProjectViewSet(PublicProjectViewSet):\n\n \"\"\"\n Viewset providing Project data.\n \"\"\"\n queryset = Project.objects.prefetch_related(\n 'publishingstatus',\n 'categories',\n 'keywords',\n 'partners',\n )\n serializer_class = ProjectSerializer\n project_relation = ''\n\n def get_queryset(self):\n \"\"\"\n Allow custom filter for sync_owner, since this field has been replaced by the\n reporting org partnership.\n \"\"\"\n\n sync_owner = self.request.query_params.get('sync_owner', None)\n reporting_org = self.request.query_params.get('reporting_org', None)\n\n reporting_org = reporting_org or sync_owner\n if reporting_org:\n self.queryset = self.queryset.filter(\n partnerships__iati_organisation_role=101,\n partnerships__organisation__pk=reporting_org\n ).distinct()\n return super(ProjectViewSet, self).get_queryset()\n\n\nclass MyProjectsViewSet(PublicProjectViewSet):\n \"\"\"Viewset providing listing of projects a user can edit.\"\"\"\n queryset = Project.objects.all().select_related('publishingstatus')\\\n .prefetch_related('locations', 'categories', 'related_projects', 'recipient_countries')\n serializer_class = ProjectMetadataSerializer\n project_relation = ''\n\n def get_queryset(self):\n if self.request.user.is_anonymous:\n return Project.objects.none()\n show_restricted = bool(self.request.query_params.get('show_restricted'))\n\n filter_program = self.request.query_params.get('filter_program')\n if filter_program:\n try:\n filter_program = int(filter_program)\n except ValueError:\n filter_program = None\n\n queryset = user_viewable_projects(self.request.user, show_restricted, filter_program)\n\n sector = self.request.query_params.get('sector', None)\n if sector:\n queryset = queryset.filter(sectors__sector_code=sector)\n country = self.request.query_params.get('country', None)\n if country:\n queryset = queryset.filter(locations__country__iso_code=country)\\\n .union(queryset.filter(recipient_countries__country__iexact=country))\n return queryset\n\n\nclass ProjectHierarchyViewSet(ReadOnlyPublicProjectViewSet):\n queryset = Project.objects.none()\n serializer_class = ProjectHierarchyRootSerializer\n project_relation = ''\n\n def get_queryset(self):\n if self.request.user.is_anonymous:\n return Project.objects.none()\n queryset = self.request.user.my_projects()\\\n .published()\\\n .filter(projecthierarchy__isnull=False)\n return queryset\n\n def retrieve(self, request, *args, **kwargs):\n project = get_object_or_404(Project, pk=self.kwargs['pk'])\n root = project.ancestor()\n if not self.request.user.has_perm('rsr.view_project', root):\n raise Http404\n\n serializer = ProjectHierarchyTreeSerializer(root, context=self.get_serializer_context())\n\n return Response(serializer.data)\n\n\nclass ProjectIatiExportViewSet(PublicProjectViewSet):\n \"\"\"Lean viewset for project data, as used in the My IATI section of RSR.\"\"\"\n queryset = Project.objects.only(\n 'id',\n 'title',\n 'is_public',\n 'status',\n 'run_iati_checks',\n ).prefetch_related(\n 'partners',\n 'iati_checks',\n 'publishingstatus',\n 'partnerships',\n )\n serializer_class = ProjectIatiExportSerializer\n project_relation = ''\n paginate_by_param = 'limit'\n max_paginate_by = 50\n\n def get_queryset(self):\n \"\"\"\n Allow custom filter for sync_owner, since this field has been replaced by the\n reporting org partnership.\n \"\"\"\n reporting_org = self.request.query_params.get('reporting_org', None)\n if reporting_org:\n self.queryset = self.queryset.filter(\n partnerships__iati_organisation_role=101,\n partnerships__organisation__pk=reporting_org\n ).distinct()\n return super(ProjectIatiExportViewSet, self).get_queryset()\n\n def list(self, request, *args, **kwargs):\n projects = self.queryset.filter(run_iati_checks=True)\n for project in projects:\n project.update_iati_checks()\n return super(ProjectIatiExportViewSet, self).list(request, *args, **kwargs)\n\n\nclass ProjectExtraViewSet(ProjectViewSet):\n r\"\"\"\n Viewset providing extra Project data.\n\n Allowed parameters are:\n __limit__ (default 10, max 30),\n __partnerships\\__organisation__ (filter on organisation ID), and\n __publishingstatus\\__status__ (filter on publishing status)\n \"\"\"\n\n queryset = Project.objects.prefetch_related(\n 'publishingstatus',\n 'sectors',\n 'partnerships',\n 'budget_items',\n 'legacy_data',\n 'links',\n 'locations',\n 'locations__country',\n 'planned_disbursements',\n 'policy_markers',\n 'documents',\n 'conditions',\n 'contacts',\n 'project_updates',\n 'recipient_countries',\n 'recipient_regions',\n 'related_projects',\n 'results',\n 'sectors',\n 'transactions',\n )\n serializer_class = ProjectExtraSerializer\n paginate_by_param = 'limit'\n paginate_by = 10\n max_paginate_by = 30\n\n\nclass ProjectExtraDeepViewSet(ProjectViewSet):\n r\"\"\"\n Viewset providing extra deep (depth=2 or bigger) Project data.\n\n Allowed parameters are:\n __limit__ (default 5, max 10),\n __partnerships\\__organisation__ (filter on organisation ID), and\n __publishingstatus\\__status__ (filter on publishing status)\n \"\"\"\n\n queryset = Project.objects.prefetch_related(\n 'publishingstatus',\n 'sectors',\n 'partnerships',\n 'budget_items',\n 'legacy_data',\n 'links',\n 'locations',\n 'locations__country',\n 'planned_disbursements',\n 'policy_markers',\n 'documents',\n 'conditions',\n 'contacts',\n 'project_updates',\n 'recipient_countries',\n 'recipient_regions',\n 'related_projects',\n 'results',\n 'sectors',\n 'transactions',\n )\n serializer_class = ProjectExtraDeepSerializer\n paginate_by_param = 'limit'\n paginate_by = 5\n max_paginate_by = 10\n\n\nclass ProjectUpViewSet(ProjectViewSet):\n r\"\"\"\n Viewset providing extra data and limited filtering for Up in one go.\n\n Allowed parameters are:\n __limit__ (default 30, max 100),\n __partnerships\\__organisation__ (filter on organisation ID), and\n __publishingstatus\\__status__ (filter on publishing status)\n \"\"\"\n\n queryset = Project.objects.select_related(\n 'primary_location',\n ).prefetch_related(\n 'publishingstatus',\n 'project_updates',\n 'categories',\n 'keywords',\n 'partners',\n )\n serializer_class = ProjectUpSerializer\n paginate_by_param = 'limit'\n max_paginate_by = 100\n\n\n###############################################################################\n# Project directory\n###############################################################################\n\n@api_view(['GET'])\ndef project_directory(request):\n \"\"\"Return the values for various project filters.\n\n Based on the current filters, it returns new options for all the (other)\n filters. This is used to generate dynamic filters.\n\n \"\"\"\n\n page = request.rsr_page\n projects = _project_list(request)\n projects_data = [\n serialized_project(project_id) for project_id in projects.values_list('pk', flat=True)\n ]\n organisations = list(projects.all_partners().values('id', 'name', 'long_name'))\n organisations = TypeaheadOrganisationSerializer(organisations, many=True).data\n\n custom_fields = (\n OrganisationCustomField.objects.filter(type='dropdown',\n organisation=page.organisation,\n show_in_searchbar=True).order_by('order', 'id')\n if page else []\n )\n sectors = [{'id': id_, 'name': name} for id_, name in codelist_choices(SECTOR_CATEGORY)]\n response = {\n 'projects': projects_data,\n 'organisation': organisations,\n 'sector': sectors,\n 'custom_fields': OrganisationCustomFieldSerializer(custom_fields, many=True).data,\n }\n\n return Response(response)\n\n\ndef _project_list(request):\n \"\"\"Return a project queryset based on the request\"\"\"\n # Fetch projects based on whether we are an Akvo site or RSR main site\n page = request.rsr_page\n projects = page.projects() if page else Project.objects.all().public().published()\n\n if not page:\n # Exclude projects which don't have an image or a title for RSR site\n projects = projects.exclude(Q(title='') | Q(current_image=''))\n else:\n # On partner sites, all projects show up. Partners are expected to fix\n # their data to fix their pages!\n pass\n return projects\n\n\n@api_view(['GET'])\ndef project_location_geojson(request):\n \"\"\"Return a GeoJSON with all the project locations.\"\"\"\n projects = _project_list(request).prefetch_related('locations')\n features = [\n Feature(geometry=Point((location.longitude, location.latitude)),\n properties=dict(\n project_title=project.title,\n project_subtitle=project.subtitle,\n project_url=request.build_absolute_uri(project.get_absolute_url()),\n project_id=project.pk,\n name=location.name,\n description=location.description))\n for project in projects\n for location in project.locations.all()\n if location.is_valid()\n ]\n response = FeatureCollection(features)\n return Response(response)\n\n\n@api_view(['POST'])\n@permission_classes((IsAuthenticated, ))\n@authentication_classes([SessionAuthentication, TastyTokenAuthentication])\ndef add_project_to_program(request, program_pk):\n program = get_object_or_404(Project, pk=program_pk)\n parent_pk = request.data.get('parent')\n if parent_pk is not None:\n program = get_object_or_404(Project, pk=parent_pk)\n\n project = Project.objects.create()\n Project.new_project_created(project.id, request.user) # Log creation\n project.add_to_program(program)\n # Set user's primary org as accountable partner\n org = request.user.first_organisation()\n if org is not None and org != program.reporting_org:\n project.set_accountable_partner(org)\n response = ProjectSerializer(project, context=dict(request=request)).data\n return Response(response, status=HTTP_201_CREATED)\n\n\n@api_view(['GET'])\ndef project_title(request, project_pk):\n project = get_object_or_404(Project, pk=project_pk)\n hierarchy_name = project.uses_single_indicator_period()\n needs_reporting_timeout_days, _, _ = single_period_dates(hierarchy_name) if hierarchy_name else (None, None, None)\n\n data = {\n 'title': project.title,\n 'publishing_status': project.publishingstatus.status,\n 'has_hierarchy': project.parents_all().exists() or project.is_hierarchy_root(),\n 'pending_update_count': IndicatorPeriodData.objects.filter(\n period__indicator__result__project=project,\n status=IndicatorPeriodData.STATUS_PENDING_CODE\n ).count(),\n 'needs_reporting_timeout_days': needs_reporting_timeout_days,\n }\n return Response(data)\n", "path": "akvo/rest/views/project.py"}]}
| 3,938 | 319 |
gh_patches_debug_7167
|
rasdani/github-patches
|
git_diff
|
ansible__awx-13071
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
CyberArk Conjur Secret Lookup - Versioning Does Not Work
### Please confirm the following
- [X] I agree to follow this project's [code of conduct](https://docs.ansible.com/ansible/latest/community/code_of_conduct.html).
- [X] I have checked the [current issues](https://github.com/ansible/awx/issues) for duplicates.
- [X] I understand that AWX is open source software provided for free and that I might not receive a timely response.
### Bug Summary
When providing a version number on the "Metadata" section of the CyberArk Conjur Secret Lookup External Secret Management System pane when defining a secret to retrieve on a credential, the secret value associated with the version number is not returned during execution of the job. Regardless of the version number given, only the latest secret value is ever returned.
### AWX version
Ansible Automation Platform Controller 4.1.1
### Select the relevant components
- [ ] UI
- [ ] API
- [ ] Docs
- [ ] Collection
- [ ] CLI
- [X] Other
### Installation method
N/A
### Modifications
no
### Ansible version
ansible [core 2.12.2]
### Operating system
Red Hat Enterprise Linux release 8.6 (Ootpa)
### Web browser
_No response_
### Steps to reproduce
1. Configure CyberArk Conjur Secret Lookup.
2. Configure Credential to use External Secret Management System.
3. On Metadata, provide a version number not equal to `null` or `1`.
4. Run a job to execute a playbook that has `debug.msg` print the value to STDOUT.
### Expected results
The value returned should change based on the version being requested by the External Secret Management System metadata.
### Actual results
The latest version of the secret is always returned and versioning is ignored.
### Additional information

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `awx/main/credential_plugins/conjur.py`
Content:
```
1 from .plugin import CredentialPlugin, CertFiles, raise_for_status
2
3 import base64
4 from urllib.parse import urljoin, quote
5
6 from django.utils.translation import gettext_lazy as _
7 import requests
8
9
10 conjur_inputs = {
11 'fields': [
12 {
13 'id': 'url',
14 'label': _('Conjur URL'),
15 'type': 'string',
16 'format': 'url',
17 },
18 {
19 'id': 'api_key',
20 'label': _('API Key'),
21 'type': 'string',
22 'secret': True,
23 },
24 {
25 'id': 'account',
26 'label': _('Account'),
27 'type': 'string',
28 },
29 {
30 'id': 'username',
31 'label': _('Username'),
32 'type': 'string',
33 },
34 {'id': 'cacert', 'label': _('Public Key Certificate'), 'type': 'string', 'multiline': True},
35 ],
36 'metadata': [
37 {
38 'id': 'secret_path',
39 'label': _('Secret Identifier'),
40 'type': 'string',
41 'help_text': _('The identifier for the secret e.g., /some/identifier'),
42 },
43 {
44 'id': 'secret_version',
45 'label': _('Secret Version'),
46 'type': 'string',
47 'help_text': _('Used to specify a specific secret version (if left empty, the latest version will be used).'),
48 },
49 ],
50 'required': ['url', 'api_key', 'account', 'username'],
51 }
52
53
54 def conjur_backend(**kwargs):
55 url = kwargs['url']
56 api_key = kwargs['api_key']
57 account = quote(kwargs['account'], safe='')
58 username = quote(kwargs['username'], safe='')
59 secret_path = quote(kwargs['secret_path'], safe='')
60 version = kwargs.get('secret_version')
61 cacert = kwargs.get('cacert', None)
62
63 auth_kwargs = {
64 'headers': {'Content-Type': 'text/plain'},
65 'data': api_key,
66 'allow_redirects': False,
67 }
68
69 with CertFiles(cacert) as cert:
70 # https://www.conjur.org/api.html#authentication-authenticate-post
71 auth_kwargs['verify'] = cert
72 resp = requests.post(urljoin(url, '/'.join(['authn', account, username, 'authenticate'])), **auth_kwargs)
73 raise_for_status(resp)
74 token = base64.b64encode(resp.content).decode('utf-8')
75
76 lookup_kwargs = {
77 'headers': {'Authorization': 'Token token="{}"'.format(token)},
78 'allow_redirects': False,
79 }
80
81 # https://www.conjur.org/api.html#secrets-retrieve-a-secret-get
82 path = urljoin(url, '/'.join(['secrets', account, 'variable', secret_path]))
83 if version:
84 path = '?'.join([path, version])
85
86 with CertFiles(cacert) as cert:
87 lookup_kwargs['verify'] = cert
88 resp = requests.get(path, timeout=30, **lookup_kwargs)
89 raise_for_status(resp)
90 return resp.text
91
92
93 conjur_plugin = CredentialPlugin('CyberArk Conjur Secret Lookup', inputs=conjur_inputs, backend=conjur_backend)
94
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/awx/main/credential_plugins/conjur.py b/awx/main/credential_plugins/conjur.py
--- a/awx/main/credential_plugins/conjur.py
+++ b/awx/main/credential_plugins/conjur.py
@@ -81,7 +81,8 @@
# https://www.conjur.org/api.html#secrets-retrieve-a-secret-get
path = urljoin(url, '/'.join(['secrets', account, 'variable', secret_path]))
if version:
- path = '?'.join([path, version])
+ ver = "version={}".format(version)
+ path = '?'.join([path, ver])
with CertFiles(cacert) as cert:
lookup_kwargs['verify'] = cert
|
{"golden_diff": "diff --git a/awx/main/credential_plugins/conjur.py b/awx/main/credential_plugins/conjur.py\n--- a/awx/main/credential_plugins/conjur.py\n+++ b/awx/main/credential_plugins/conjur.py\n@@ -81,7 +81,8 @@\n # https://www.conjur.org/api.html#secrets-retrieve-a-secret-get\n path = urljoin(url, '/'.join(['secrets', account, 'variable', secret_path]))\n if version:\n- path = '?'.join([path, version])\n+ ver = \"version={}\".format(version)\n+ path = '?'.join([path, ver])\n \n with CertFiles(cacert) as cert:\n lookup_kwargs['verify'] = cert\n", "issue": "CyberArk Conjur Secret Lookup - Versioning Does Not Work\n### Please confirm the following\n\n- [X] I agree to follow this project's [code of conduct](https://docs.ansible.com/ansible/latest/community/code_of_conduct.html).\n- [X] I have checked the [current issues](https://github.com/ansible/awx/issues) for duplicates.\n- [X] I understand that AWX is open source software provided for free and that I might not receive a timely response.\n\n### Bug Summary\n\nWhen providing a version number on the \"Metadata\" section of the CyberArk Conjur Secret Lookup External Secret Management System pane when defining a secret to retrieve on a credential, the secret value associated with the version number is not returned during execution of the job. Regardless of the version number given, only the latest secret value is ever returned.\n\n### AWX version\n\nAnsible Automation Platform Controller 4.1.1\n\n### Select the relevant components\n\n- [ ] UI\n- [ ] API\n- [ ] Docs\n- [ ] Collection\n- [ ] CLI\n- [X] Other\n\n### Installation method\n\nN/A\n\n### Modifications\n\nno\n\n### Ansible version\n\nansible [core 2.12.2]\n\n### Operating system\n\nRed Hat Enterprise Linux release 8.6 (Ootpa)\n\n### Web browser\n\n_No response_\n\n### Steps to reproduce\n\n1. Configure CyberArk Conjur Secret Lookup.\r\n2. Configure Credential to use External Secret Management System.\r\n3. On Metadata, provide a version number not equal to `null` or `1`.\r\n4. Run a job to execute a playbook that has `debug.msg` print the value to STDOUT.\n\n### Expected results\n\nThe value returned should change based on the version being requested by the External Secret Management System metadata.\n\n### Actual results\n\nThe latest version of the secret is always returned and versioning is ignored.\n\n### Additional information\n\n\r\n\n", "before_files": [{"content": "from .plugin import CredentialPlugin, CertFiles, raise_for_status\n\nimport base64\nfrom urllib.parse import urljoin, quote\n\nfrom django.utils.translation import gettext_lazy as _\nimport requests\n\n\nconjur_inputs = {\n 'fields': [\n {\n 'id': 'url',\n 'label': _('Conjur URL'),\n 'type': 'string',\n 'format': 'url',\n },\n {\n 'id': 'api_key',\n 'label': _('API Key'),\n 'type': 'string',\n 'secret': True,\n },\n {\n 'id': 'account',\n 'label': _('Account'),\n 'type': 'string',\n },\n {\n 'id': 'username',\n 'label': _('Username'),\n 'type': 'string',\n },\n {'id': 'cacert', 'label': _('Public Key Certificate'), 'type': 'string', 'multiline': True},\n ],\n 'metadata': [\n {\n 'id': 'secret_path',\n 'label': _('Secret Identifier'),\n 'type': 'string',\n 'help_text': _('The identifier for the secret e.g., /some/identifier'),\n },\n {\n 'id': 'secret_version',\n 'label': _('Secret Version'),\n 'type': 'string',\n 'help_text': _('Used to specify a specific secret version (if left empty, the latest version will be used).'),\n },\n ],\n 'required': ['url', 'api_key', 'account', 'username'],\n}\n\n\ndef conjur_backend(**kwargs):\n url = kwargs['url']\n api_key = kwargs['api_key']\n account = quote(kwargs['account'], safe='')\n username = quote(kwargs['username'], safe='')\n secret_path = quote(kwargs['secret_path'], safe='')\n version = kwargs.get('secret_version')\n cacert = kwargs.get('cacert', None)\n\n auth_kwargs = {\n 'headers': {'Content-Type': 'text/plain'},\n 'data': api_key,\n 'allow_redirects': False,\n }\n\n with CertFiles(cacert) as cert:\n # https://www.conjur.org/api.html#authentication-authenticate-post\n auth_kwargs['verify'] = cert\n resp = requests.post(urljoin(url, '/'.join(['authn', account, username, 'authenticate'])), **auth_kwargs)\n raise_for_status(resp)\n token = base64.b64encode(resp.content).decode('utf-8')\n\n lookup_kwargs = {\n 'headers': {'Authorization': 'Token token=\"{}\"'.format(token)},\n 'allow_redirects': False,\n }\n\n # https://www.conjur.org/api.html#secrets-retrieve-a-secret-get\n path = urljoin(url, '/'.join(['secrets', account, 'variable', secret_path]))\n if version:\n path = '?'.join([path, version])\n\n with CertFiles(cacert) as cert:\n lookup_kwargs['verify'] = cert\n resp = requests.get(path, timeout=30, **lookup_kwargs)\n raise_for_status(resp)\n return resp.text\n\n\nconjur_plugin = CredentialPlugin('CyberArk Conjur Secret Lookup', inputs=conjur_inputs, backend=conjur_backend)\n", "path": "awx/main/credential_plugins/conjur.py"}], "after_files": [{"content": "from .plugin import CredentialPlugin, CertFiles, raise_for_status\n\nimport base64\nfrom urllib.parse import urljoin, quote\n\nfrom django.utils.translation import gettext_lazy as _\nimport requests\n\n\nconjur_inputs = {\n 'fields': [\n {\n 'id': 'url',\n 'label': _('Conjur URL'),\n 'type': 'string',\n 'format': 'url',\n },\n {\n 'id': 'api_key',\n 'label': _('API Key'),\n 'type': 'string',\n 'secret': True,\n },\n {\n 'id': 'account',\n 'label': _('Account'),\n 'type': 'string',\n },\n {\n 'id': 'username',\n 'label': _('Username'),\n 'type': 'string',\n },\n {'id': 'cacert', 'label': _('Public Key Certificate'), 'type': 'string', 'multiline': True},\n ],\n 'metadata': [\n {\n 'id': 'secret_path',\n 'label': _('Secret Identifier'),\n 'type': 'string',\n 'help_text': _('The identifier for the secret e.g., /some/identifier'),\n },\n {\n 'id': 'secret_version',\n 'label': _('Secret Version'),\n 'type': 'string',\n 'help_text': _('Used to specify a specific secret version (if left empty, the latest version will be used).'),\n },\n ],\n 'required': ['url', 'api_key', 'account', 'username'],\n}\n\n\ndef conjur_backend(**kwargs):\n url = kwargs['url']\n api_key = kwargs['api_key']\n account = quote(kwargs['account'], safe='')\n username = quote(kwargs['username'], safe='')\n secret_path = quote(kwargs['secret_path'], safe='')\n version = kwargs.get('secret_version')\n cacert = kwargs.get('cacert', None)\n\n auth_kwargs = {\n 'headers': {'Content-Type': 'text/plain'},\n 'data': api_key,\n 'allow_redirects': False,\n }\n\n with CertFiles(cacert) as cert:\n # https://www.conjur.org/api.html#authentication-authenticate-post\n auth_kwargs['verify'] = cert\n resp = requests.post(urljoin(url, '/'.join(['authn', account, username, 'authenticate'])), **auth_kwargs)\n raise_for_status(resp)\n token = base64.b64encode(resp.content).decode('utf-8')\n\n lookup_kwargs = {\n 'headers': {'Authorization': 'Token token=\"{}\"'.format(token)},\n 'allow_redirects': False,\n }\n\n # https://www.conjur.org/api.html#secrets-retrieve-a-secret-get\n path = urljoin(url, '/'.join(['secrets', account, 'variable', secret_path]))\n if version:\n ver = \"version={}\".format(version)\n path = '?'.join([path, ver])\n\n with CertFiles(cacert) as cert:\n lookup_kwargs['verify'] = cert\n resp = requests.get(path, timeout=30, **lookup_kwargs)\n raise_for_status(resp)\n return resp.text\n\n\nconjur_plugin = CredentialPlugin('CyberArk Conjur Secret Lookup', inputs=conjur_inputs, backend=conjur_backend)\n", "path": "awx/main/credential_plugins/conjur.py"}]}
| 1,596 | 165 |
gh_patches_debug_6661
|
rasdani/github-patches
|
git_diff
|
cocotb__cocotb-1928
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Start testing in Python 3.9
Python 3.9.0b1 is release already, and soon there'll be a full release. We should start running CI against it, to catch things like #1910
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2 ###############################################################################
3 # Copyright (c) 2013 Potential Ventures Ltd
4 # Copyright (c) 2013 SolarFlare Communications Inc
5 # All rights reserved.
6 #
7 # Redistribution and use in source and binary forms, with or without
8 # modification, are permitted provided that the following conditions are met:
9 # * Redistributions of source code must retain the above copyright
10 # notice, this list of conditions and the following disclaimer.
11 # * Redistributions in binary form must reproduce the above copyright
12 # notice, this list of conditions and the following disclaimer in the
13 # documentation and/or other materials provided with the distribution.
14 # * Neither the name of Potential Ventures Ltd,
15 # SolarFlare Communications Inc nor the
16 # names of its contributors may be used to endorse or promote products
17 # derived from this software without specific prior written permission.
18 #
19 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
20 # ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
21 # WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
22 # DISCLAIMED. IN NO EVENT SHALL POTENTIAL VENTURES LTD BE LIABLE FOR ANY
23 # DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
24 # (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
25 # LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
26 # ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
27 # (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
28 # SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
29 ###############################################################################
30
31 import sys
32 if sys.version_info[:2] < (3, 5):
33 msg = [
34 "This version of cocotb requires at least Python 3.5,",
35 "you are running Python %d.%d.%d." % (
36 sys.version_info[0], sys.version_info[1], sys.version_info[2])
37 ]
38 if sys.version_info[0] == 2:
39 msg += [
40 "If you have Python 3 installed on your machine try ",
41 "using 'python3 -m pip' instead of 'pip' to install cocotb."
42 ]
43 msg += [
44 "For more information please refer to the documentation at ",
45 "https://cocotb.readthedocs.io."
46 ]
47
48 raise SystemExit("\n".join(msg))
49
50 import logging
51 from setuptools import setup
52 from setuptools import find_packages
53 from os import path, walk
54 from io import StringIO
55
56 # Note: cocotb is not installed properly yet and is missing dependencies and binaries
57 # We can still import other files next to setup.py, as long as they're in MANIFEST.in
58 from cocotb_build_libs import get_ext, build_ext
59
60
61 def read_file(fname):
62 with open(path.join(path.dirname(__file__), fname), encoding='utf8') as f:
63 return f.read()
64
65
66 def package_files(directory):
67 paths = []
68 for (fpath, directories, filenames) in walk(directory):
69 for filename in filenames:
70 paths.append(path.join('..', fpath, filename))
71 return paths
72
73
74 # this sets the __version__ variable
75 exec(read_file(path.join('cocotb', '_version.py')))
76
77 # store log from build_libs and display at the end in verbose mode
78 # see https://github.com/pypa/pip/issues/6634
79 log_stream = StringIO()
80 handler = logging.StreamHandler(log_stream)
81 log = logging.getLogger("cocotb._build_libs")
82 log.setLevel(logging.INFO)
83 log.addHandler(handler)
84
85 setup(
86 name='cocotb',
87 cmdclass={'build_ext': build_ext},
88 version=__version__, # noqa: F821
89 description='cocotb is a coroutine based cosimulation library for writing VHDL and Verilog testbenches in Python.',
90 url='https://docs.cocotb.org',
91 license='BSD',
92 long_description=read_file('README.md'),
93 long_description_content_type='text/markdown',
94 author='Chris Higgs, Stuart Hodgson',
95 maintainer='cocotb contributors',
96 maintainer_email='[email protected]',
97 install_requires=[],
98 python_requires='>=3.5',
99 packages=find_packages(),
100 include_package_data=True,
101 package_data={'cocotb': package_files('cocotb/share')},
102 ext_modules=get_ext(),
103 entry_points={
104 'console_scripts': [
105 'cocotb-config=cocotb.config:main',
106 ]
107 },
108 platforms='any',
109 classifiers=[
110 "Programming Language :: Python :: 3",
111 "Programming Language :: Python :: 3.5",
112 "Programming Language :: Python :: 3.6",
113 "Programming Language :: Python :: 3.7",
114 "Programming Language :: Python :: 3.8",
115 "License :: OSI Approved :: BSD License",
116 "Topic :: Scientific/Engineering :: Electronic Design Automation (EDA)",
117 ],
118
119 # these appear in the sidebar on PyPI
120 project_urls={
121 "Bug Tracker": "https://github.com/cocotb/cocotb/issues",
122 "Source Code": "https://github.com/cocotb/cocotb",
123 "Documentation": "https://docs.cocotb.org",
124 },
125 )
126
127 print(log_stream.getvalue())
128
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -112,6 +112,7 @@
"Programming Language :: Python :: 3.6",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
+ "Programming Language :: Python :: 3.9",
"License :: OSI Approved :: BSD License",
"Topic :: Scientific/Engineering :: Electronic Design Automation (EDA)",
],
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -112,6 +112,7 @@\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n+ \"Programming Language :: Python :: 3.9\",\n \"License :: OSI Approved :: BSD License\",\n \"Topic :: Scientific/Engineering :: Electronic Design Automation (EDA)\",\n ],\n", "issue": "Start testing in Python 3.9\nPython 3.9.0b1 is release already, and soon there'll be a full release. We should start running CI against it, to catch things like #1910\n", "before_files": [{"content": "#!/usr/bin/env python\n###############################################################################\n# Copyright (c) 2013 Potential Ventures Ltd\n# Copyright (c) 2013 SolarFlare Communications Inc\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n# * Redistributions of source code must retain the above copyright\n# notice, this list of conditions and the following disclaimer.\n# * Redistributions in binary form must reproduce the above copyright\n# notice, this list of conditions and the following disclaimer in the\n# documentation and/or other materials provided with the distribution.\n# * Neither the name of Potential Ventures Ltd,\n# SolarFlare Communications Inc nor the\n# names of its contributors may be used to endorse or promote products\n# derived from this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\" AND\n# ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED\n# WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL POTENTIAL VENTURES LTD BE LIABLE FOR ANY\n# DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES\n# (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;\n# LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND\n# ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT\n# (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS\n# SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n###############################################################################\n\nimport sys\nif sys.version_info[:2] < (3, 5):\n msg = [\n \"This version of cocotb requires at least Python 3.5,\",\n \"you are running Python %d.%d.%d.\" % (\n sys.version_info[0], sys.version_info[1], sys.version_info[2])\n ]\n if sys.version_info[0] == 2:\n msg += [\n \"If you have Python 3 installed on your machine try \",\n \"using 'python3 -m pip' instead of 'pip' to install cocotb.\"\n ]\n msg += [\n \"For more information please refer to the documentation at \",\n \"https://cocotb.readthedocs.io.\"\n ]\n\n raise SystemExit(\"\\n\".join(msg))\n\nimport logging\nfrom setuptools import setup\nfrom setuptools import find_packages\nfrom os import path, walk\nfrom io import StringIO\n\n# Note: cocotb is not installed properly yet and is missing dependencies and binaries\n# We can still import other files next to setup.py, as long as they're in MANIFEST.in\nfrom cocotb_build_libs import get_ext, build_ext\n\n\ndef read_file(fname):\n with open(path.join(path.dirname(__file__), fname), encoding='utf8') as f:\n return f.read()\n\n\ndef package_files(directory):\n paths = []\n for (fpath, directories, filenames) in walk(directory):\n for filename in filenames:\n paths.append(path.join('..', fpath, filename))\n return paths\n\n\n# this sets the __version__ variable\nexec(read_file(path.join('cocotb', '_version.py')))\n\n# store log from build_libs and display at the end in verbose mode\n# see https://github.com/pypa/pip/issues/6634\nlog_stream = StringIO()\nhandler = logging.StreamHandler(log_stream)\nlog = logging.getLogger(\"cocotb._build_libs\")\nlog.setLevel(logging.INFO)\nlog.addHandler(handler)\n\nsetup(\n name='cocotb',\n cmdclass={'build_ext': build_ext},\n version=__version__, # noqa: F821\n description='cocotb is a coroutine based cosimulation library for writing VHDL and Verilog testbenches in Python.',\n url='https://docs.cocotb.org',\n license='BSD',\n long_description=read_file('README.md'),\n long_description_content_type='text/markdown',\n author='Chris Higgs, Stuart Hodgson',\n maintainer='cocotb contributors',\n maintainer_email='[email protected]',\n install_requires=[],\n python_requires='>=3.5',\n packages=find_packages(),\n include_package_data=True,\n package_data={'cocotb': package_files('cocotb/share')},\n ext_modules=get_ext(),\n entry_points={\n 'console_scripts': [\n 'cocotb-config=cocotb.config:main',\n ]\n },\n platforms='any',\n classifiers=[\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"License :: OSI Approved :: BSD License\",\n \"Topic :: Scientific/Engineering :: Electronic Design Automation (EDA)\",\n ],\n\n # these appear in the sidebar on PyPI\n project_urls={\n \"Bug Tracker\": \"https://github.com/cocotb/cocotb/issues\",\n \"Source Code\": \"https://github.com/cocotb/cocotb\",\n \"Documentation\": \"https://docs.cocotb.org\",\n },\n)\n\nprint(log_stream.getvalue())\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\n###############################################################################\n# Copyright (c) 2013 Potential Ventures Ltd\n# Copyright (c) 2013 SolarFlare Communications Inc\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n# * Redistributions of source code must retain the above copyright\n# notice, this list of conditions and the following disclaimer.\n# * Redistributions in binary form must reproduce the above copyright\n# notice, this list of conditions and the following disclaimer in the\n# documentation and/or other materials provided with the distribution.\n# * Neither the name of Potential Ventures Ltd,\n# SolarFlare Communications Inc nor the\n# names of its contributors may be used to endorse or promote products\n# derived from this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\" AND\n# ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED\n# WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL POTENTIAL VENTURES LTD BE LIABLE FOR ANY\n# DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES\n# (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;\n# LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND\n# ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT\n# (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS\n# SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n###############################################################################\n\nimport sys\nif sys.version_info[:2] < (3, 5):\n msg = [\n \"This version of cocotb requires at least Python 3.5,\",\n \"you are running Python %d.%d.%d.\" % (\n sys.version_info[0], sys.version_info[1], sys.version_info[2])\n ]\n if sys.version_info[0] == 2:\n msg += [\n \"If you have Python 3 installed on your machine try \",\n \"using 'python3 -m pip' instead of 'pip' to install cocotb.\"\n ]\n msg += [\n \"For more information please refer to the documentation at \",\n \"https://cocotb.readthedocs.io.\"\n ]\n\n raise SystemExit(\"\\n\".join(msg))\n\nimport logging\nfrom setuptools import setup\nfrom setuptools import find_packages\nfrom os import path, walk\nfrom io import StringIO\n\n# Note: cocotb is not installed properly yet and is missing dependencies and binaries\n# We can still import other files next to setup.py, as long as they're in MANIFEST.in\nfrom cocotb_build_libs import get_ext, build_ext\n\n\ndef read_file(fname):\n with open(path.join(path.dirname(__file__), fname), encoding='utf8') as f:\n return f.read()\n\n\ndef package_files(directory):\n paths = []\n for (fpath, directories, filenames) in walk(directory):\n for filename in filenames:\n paths.append(path.join('..', fpath, filename))\n return paths\n\n\n# this sets the __version__ variable\nexec(read_file(path.join('cocotb', '_version.py')))\n\n# store log from build_libs and display at the end in verbose mode\n# see https://github.com/pypa/pip/issues/6634\nlog_stream = StringIO()\nhandler = logging.StreamHandler(log_stream)\nlog = logging.getLogger(\"cocotb._build_libs\")\nlog.setLevel(logging.INFO)\nlog.addHandler(handler)\n\nsetup(\n name='cocotb',\n cmdclass={'build_ext': build_ext},\n version=__version__, # noqa: F821\n description='cocotb is a coroutine based cosimulation library for writing VHDL and Verilog testbenches in Python.',\n url='https://docs.cocotb.org',\n license='BSD',\n long_description=read_file('README.md'),\n long_description_content_type='text/markdown',\n author='Chris Higgs, Stuart Hodgson',\n maintainer='cocotb contributors',\n maintainer_email='[email protected]',\n install_requires=[],\n python_requires='>=3.5',\n packages=find_packages(),\n include_package_data=True,\n package_data={'cocotb': package_files('cocotb/share')},\n ext_modules=get_ext(),\n entry_points={\n 'console_scripts': [\n 'cocotb-config=cocotb.config:main',\n ]\n },\n platforms='any',\n classifiers=[\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"License :: OSI Approved :: BSD License\",\n \"Topic :: Scientific/Engineering :: Electronic Design Automation (EDA)\",\n ],\n\n # these appear in the sidebar on PyPI\n project_urls={\n \"Bug Tracker\": \"https://github.com/cocotb/cocotb/issues\",\n \"Source Code\": \"https://github.com/cocotb/cocotb\",\n \"Documentation\": \"https://docs.cocotb.org\",\n },\n)\n\nprint(log_stream.getvalue())\n", "path": "setup.py"}]}
| 1,735 | 109 |
gh_patches_debug_31665
|
rasdani/github-patches
|
git_diff
|
mitmproxy__mitmproxy-5879
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Adopt Dependabot
I've only just learned that requires.io has been shut down. A big thank you to @omansion and @atabary for providing such a fantastic service over the years! ❤️
For mitmproxy this probably means we should migrate to Dependabot. This will probably mean a whole lot more PRs, let's see.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 import os
2 import re
3 from codecs import open
4
5 from setuptools import find_packages
6 from setuptools import setup
7
8 # Based on https://github.com/pypa/sampleproject/blob/main/setup.py
9 # and https://python-packaging-user-guide.readthedocs.org/
10
11 here = os.path.abspath(os.path.dirname(__file__))
12
13 with open(os.path.join(here, "README.md"), encoding="utf-8") as f:
14 long_description = f.read()
15 long_description_content_type = "text/markdown"
16
17 with open(os.path.join(here, "mitmproxy/version.py")) as f:
18 match = re.search(r'VERSION = "(.+?)"', f.read())
19 assert match
20 VERSION = match.group(1)
21
22 setup(
23 name="mitmproxy",
24 version=VERSION,
25 description="An interactive, SSL/TLS-capable intercepting proxy for HTTP/1, HTTP/2, and WebSockets.",
26 long_description=long_description,
27 long_description_content_type=long_description_content_type,
28 url="http://mitmproxy.org",
29 author="Aldo Cortesi",
30 author_email="[email protected]",
31 license="MIT",
32 classifiers=[
33 "License :: OSI Approved :: MIT License",
34 "Development Status :: 5 - Production/Stable",
35 "Environment :: Console :: Curses",
36 "Operating System :: MacOS",
37 "Operating System :: POSIX",
38 "Operating System :: Microsoft :: Windows",
39 "Programming Language :: Python :: 3 :: Only",
40 "Programming Language :: Python :: 3.9",
41 "Programming Language :: Python :: 3.10",
42 "Programming Language :: Python :: 3.11",
43 "Programming Language :: Python :: Implementation :: CPython",
44 "Topic :: Security",
45 "Topic :: Internet :: WWW/HTTP",
46 "Topic :: Internet :: Proxy Servers",
47 "Topic :: System :: Networking :: Monitoring",
48 "Topic :: Software Development :: Testing",
49 "Typing :: Typed",
50 ],
51 project_urls={
52 "Documentation": "https://docs.mitmproxy.org/stable/",
53 "Source": "https://github.com/mitmproxy/mitmproxy/",
54 "Tracker": "https://github.com/mitmproxy/mitmproxy/issues",
55 },
56 packages=find_packages(
57 include=[
58 "mitmproxy",
59 "mitmproxy.*",
60 ]
61 ),
62 include_package_data=True,
63 entry_points={
64 "console_scripts": [
65 "mitmproxy = mitmproxy.tools.main:mitmproxy",
66 "mitmdump = mitmproxy.tools.main:mitmdump",
67 "mitmweb = mitmproxy.tools.main:mitmweb",
68 ],
69 "pyinstaller40": [
70 "hook-dirs = mitmproxy.utils.pyinstaller:hook_dirs",
71 ],
72 },
73 python_requires=">=3.9",
74 # https://packaging.python.org/en/latest/discussions/install-requires-vs-requirements/#install-requires
75 # It is not considered best practice to use install_requires to pin dependencies to specific versions.
76 install_requires=[
77 "aioquic_mitmproxy>=0.9.20,<0.10",
78 "asgiref>=3.2.10,<3.6",
79 "Brotli>=1.0,<1.1",
80 "certifi>=2019.9.11", # no semver here - this should always be on the last release!
81 "cryptography>=38.0,<38.1",
82 "flask>=1.1.1,<2.3",
83 "h11>=0.11,<0.15",
84 "h2>=4.1,<5",
85 "hyperframe>=6.0,<7",
86 "kaitaistruct>=0.10,<0.11",
87 "ldap3>=2.8,<2.10",
88 "mitmproxy_wireguard>=0.1.6,<0.2",
89 "msgpack>=1.0.0, <1.1.0",
90 "passlib>=1.6.5, <1.8",
91 "protobuf>=3.14,<5",
92 "pyOpenSSL>=22.1,<22.2",
93 "pyparsing>=2.4.2,<3.1",
94 "pyperclip>=1.6.0,<1.9",
95 "ruamel.yaml>=0.16,<0.18",
96 "sortedcontainers>=2.3,<2.5",
97 "tornado>=6.2,<7",
98 "urwid-mitmproxy>=2.1.1,<2.2",
99 "wsproto>=1.0,<1.3",
100 "publicsuffix2>=2.20190812,<3",
101 "zstandard>=0.11,<0.20",
102 "typing-extensions>=4.3,<4.5; python_version<'3.10'",
103 ],
104 extras_require={
105 ':sys_platform == "win32"': [
106 "pydivert>=2.0.3,<2.2",
107 ],
108 "dev": [
109 "click>=7.0,<8.2",
110 "hypothesis>=5.8,<7",
111 "parver>=0.1,<2.0",
112 "pdoc>=4.0.0",
113 "pyinstaller==5.6.2",
114 "pytest-asyncio>=0.17,<0.21",
115 "pytest-cov>=2.7.1,<4.1",
116 "pytest-timeout>=1.3.3,<2.2",
117 "pytest-xdist>=2.1.0,<3.1",
118 "pytest>=6.1.0,<8",
119 "requests>=2.9.1,<3",
120 "tox>=3.5,<4",
121 "wheel>=0.36.2,<0.39",
122 ],
123 },
124 )
125
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -75,10 +75,10 @@
# It is not considered best practice to use install_requires to pin dependencies to specific versions.
install_requires=[
"aioquic_mitmproxy>=0.9.20,<0.10",
- "asgiref>=3.2.10,<3.6",
+ "asgiref>=3.2.10,<3.7",
"Brotli>=1.0,<1.1",
"certifi>=2019.9.11", # no semver here - this should always be on the last release!
- "cryptography>=38.0,<38.1",
+ "cryptography>=38.0,<39.1",
"flask>=1.1.1,<2.3",
"h11>=0.11,<0.15",
"h2>=4.1,<5",
@@ -89,7 +89,7 @@
"msgpack>=1.0.0, <1.1.0",
"passlib>=1.6.5, <1.8",
"protobuf>=3.14,<5",
- "pyOpenSSL>=22.1,<22.2",
+ "pyOpenSSL>=22.1,<23.1",
"pyparsing>=2.4.2,<3.1",
"pyperclip>=1.6.0,<1.9",
"ruamel.yaml>=0.16,<0.18",
@@ -110,14 +110,14 @@
"hypothesis>=5.8,<7",
"parver>=0.1,<2.0",
"pdoc>=4.0.0",
- "pyinstaller==5.6.2",
+ "pyinstaller==5.7.0",
"pytest-asyncio>=0.17,<0.21",
"pytest-cov>=2.7.1,<4.1",
"pytest-timeout>=1.3.3,<2.2",
- "pytest-xdist>=2.1.0,<3.1",
+ "pytest-xdist>=2.1.0,<3.2",
"pytest>=6.1.0,<8",
"requests>=2.9.1,<3",
- "tox>=3.5,<4",
+ "tox>=3.5,<5",
"wheel>=0.36.2,<0.39",
],
},
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -75,10 +75,10 @@\n # It is not considered best practice to use install_requires to pin dependencies to specific versions.\n install_requires=[\n \"aioquic_mitmproxy>=0.9.20,<0.10\",\n- \"asgiref>=3.2.10,<3.6\",\n+ \"asgiref>=3.2.10,<3.7\",\n \"Brotli>=1.0,<1.1\",\n \"certifi>=2019.9.11\", # no semver here - this should always be on the last release!\n- \"cryptography>=38.0,<38.1\",\n+ \"cryptography>=38.0,<39.1\",\n \"flask>=1.1.1,<2.3\",\n \"h11>=0.11,<0.15\",\n \"h2>=4.1,<5\",\n@@ -89,7 +89,7 @@\n \"msgpack>=1.0.0, <1.1.0\",\n \"passlib>=1.6.5, <1.8\",\n \"protobuf>=3.14,<5\",\n- \"pyOpenSSL>=22.1,<22.2\",\n+ \"pyOpenSSL>=22.1,<23.1\",\n \"pyparsing>=2.4.2,<3.1\",\n \"pyperclip>=1.6.0,<1.9\",\n \"ruamel.yaml>=0.16,<0.18\",\n@@ -110,14 +110,14 @@\n \"hypothesis>=5.8,<7\",\n \"parver>=0.1,<2.0\",\n \"pdoc>=4.0.0\",\n- \"pyinstaller==5.6.2\",\n+ \"pyinstaller==5.7.0\",\n \"pytest-asyncio>=0.17,<0.21\",\n \"pytest-cov>=2.7.1,<4.1\",\n \"pytest-timeout>=1.3.3,<2.2\",\n- \"pytest-xdist>=2.1.0,<3.1\",\n+ \"pytest-xdist>=2.1.0,<3.2\",\n \"pytest>=6.1.0,<8\",\n \"requests>=2.9.1,<3\",\n- \"tox>=3.5,<4\",\n+ \"tox>=3.5,<5\",\n \"wheel>=0.36.2,<0.39\",\n ],\n },\n", "issue": "Adopt Dependabot\nI've only just learned that requires.io has been shut down. A big thank you to @omansion and @atabary for providing such a fantastic service over the years! \u2764\ufe0f\r\n\r\nFor mitmproxy this probably means we should migrate to Dependabot. This will probably mean a whole lot more PRs, let's see.\n", "before_files": [{"content": "import os\nimport re\nfrom codecs import open\n\nfrom setuptools import find_packages\nfrom setuptools import setup\n\n# Based on https://github.com/pypa/sampleproject/blob/main/setup.py\n# and https://python-packaging-user-guide.readthedocs.org/\n\nhere = os.path.abspath(os.path.dirname(__file__))\n\nwith open(os.path.join(here, \"README.md\"), encoding=\"utf-8\") as f:\n long_description = f.read()\nlong_description_content_type = \"text/markdown\"\n\nwith open(os.path.join(here, \"mitmproxy/version.py\")) as f:\n match = re.search(r'VERSION = \"(.+?)\"', f.read())\n assert match\n VERSION = match.group(1)\n\nsetup(\n name=\"mitmproxy\",\n version=VERSION,\n description=\"An interactive, SSL/TLS-capable intercepting proxy for HTTP/1, HTTP/2, and WebSockets.\",\n long_description=long_description,\n long_description_content_type=long_description_content_type,\n url=\"http://mitmproxy.org\",\n author=\"Aldo Cortesi\",\n author_email=\"[email protected]\",\n license=\"MIT\",\n classifiers=[\n \"License :: OSI Approved :: MIT License\",\n \"Development Status :: 5 - Production/Stable\",\n \"Environment :: Console :: Curses\",\n \"Operating System :: MacOS\",\n \"Operating System :: POSIX\",\n \"Operating System :: Microsoft :: Windows\",\n \"Programming Language :: Python :: 3 :: Only\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Programming Language :: Python :: 3.11\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Topic :: Security\",\n \"Topic :: Internet :: WWW/HTTP\",\n \"Topic :: Internet :: Proxy Servers\",\n \"Topic :: System :: Networking :: Monitoring\",\n \"Topic :: Software Development :: Testing\",\n \"Typing :: Typed\",\n ],\n project_urls={\n \"Documentation\": \"https://docs.mitmproxy.org/stable/\",\n \"Source\": \"https://github.com/mitmproxy/mitmproxy/\",\n \"Tracker\": \"https://github.com/mitmproxy/mitmproxy/issues\",\n },\n packages=find_packages(\n include=[\n \"mitmproxy\",\n \"mitmproxy.*\",\n ]\n ),\n include_package_data=True,\n entry_points={\n \"console_scripts\": [\n \"mitmproxy = mitmproxy.tools.main:mitmproxy\",\n \"mitmdump = mitmproxy.tools.main:mitmdump\",\n \"mitmweb = mitmproxy.tools.main:mitmweb\",\n ],\n \"pyinstaller40\": [\n \"hook-dirs = mitmproxy.utils.pyinstaller:hook_dirs\",\n ],\n },\n python_requires=\">=3.9\",\n # https://packaging.python.org/en/latest/discussions/install-requires-vs-requirements/#install-requires\n # It is not considered best practice to use install_requires to pin dependencies to specific versions.\n install_requires=[\n \"aioquic_mitmproxy>=0.9.20,<0.10\",\n \"asgiref>=3.2.10,<3.6\",\n \"Brotli>=1.0,<1.1\",\n \"certifi>=2019.9.11\", # no semver here - this should always be on the last release!\n \"cryptography>=38.0,<38.1\",\n \"flask>=1.1.1,<2.3\",\n \"h11>=0.11,<0.15\",\n \"h2>=4.1,<5\",\n \"hyperframe>=6.0,<7\",\n \"kaitaistruct>=0.10,<0.11\",\n \"ldap3>=2.8,<2.10\",\n \"mitmproxy_wireguard>=0.1.6,<0.2\",\n \"msgpack>=1.0.0, <1.1.0\",\n \"passlib>=1.6.5, <1.8\",\n \"protobuf>=3.14,<5\",\n \"pyOpenSSL>=22.1,<22.2\",\n \"pyparsing>=2.4.2,<3.1\",\n \"pyperclip>=1.6.0,<1.9\",\n \"ruamel.yaml>=0.16,<0.18\",\n \"sortedcontainers>=2.3,<2.5\",\n \"tornado>=6.2,<7\",\n \"urwid-mitmproxy>=2.1.1,<2.2\",\n \"wsproto>=1.0,<1.3\",\n \"publicsuffix2>=2.20190812,<3\",\n \"zstandard>=0.11,<0.20\",\n \"typing-extensions>=4.3,<4.5; python_version<'3.10'\",\n ],\n extras_require={\n ':sys_platform == \"win32\"': [\n \"pydivert>=2.0.3,<2.2\",\n ],\n \"dev\": [\n \"click>=7.0,<8.2\",\n \"hypothesis>=5.8,<7\",\n \"parver>=0.1,<2.0\",\n \"pdoc>=4.0.0\",\n \"pyinstaller==5.6.2\",\n \"pytest-asyncio>=0.17,<0.21\",\n \"pytest-cov>=2.7.1,<4.1\",\n \"pytest-timeout>=1.3.3,<2.2\",\n \"pytest-xdist>=2.1.0,<3.1\",\n \"pytest>=6.1.0,<8\",\n \"requests>=2.9.1,<3\",\n \"tox>=3.5,<4\",\n \"wheel>=0.36.2,<0.39\",\n ],\n },\n)\n", "path": "setup.py"}], "after_files": [{"content": "import os\nimport re\nfrom codecs import open\n\nfrom setuptools import find_packages\nfrom setuptools import setup\n\n# Based on https://github.com/pypa/sampleproject/blob/main/setup.py\n# and https://python-packaging-user-guide.readthedocs.org/\n\nhere = os.path.abspath(os.path.dirname(__file__))\n\nwith open(os.path.join(here, \"README.md\"), encoding=\"utf-8\") as f:\n long_description = f.read()\nlong_description_content_type = \"text/markdown\"\n\nwith open(os.path.join(here, \"mitmproxy/version.py\")) as f:\n match = re.search(r'VERSION = \"(.+?)\"', f.read())\n assert match\n VERSION = match.group(1)\n\nsetup(\n name=\"mitmproxy\",\n version=VERSION,\n description=\"An interactive, SSL/TLS-capable intercepting proxy for HTTP/1, HTTP/2, and WebSockets.\",\n long_description=long_description,\n long_description_content_type=long_description_content_type,\n url=\"http://mitmproxy.org\",\n author=\"Aldo Cortesi\",\n author_email=\"[email protected]\",\n license=\"MIT\",\n classifiers=[\n \"License :: OSI Approved :: MIT License\",\n \"Development Status :: 5 - Production/Stable\",\n \"Environment :: Console :: Curses\",\n \"Operating System :: MacOS\",\n \"Operating System :: POSIX\",\n \"Operating System :: Microsoft :: Windows\",\n \"Programming Language :: Python :: 3 :: Only\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Programming Language :: Python :: 3.11\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Topic :: Security\",\n \"Topic :: Internet :: WWW/HTTP\",\n \"Topic :: Internet :: Proxy Servers\",\n \"Topic :: System :: Networking :: Monitoring\",\n \"Topic :: Software Development :: Testing\",\n \"Typing :: Typed\",\n ],\n project_urls={\n \"Documentation\": \"https://docs.mitmproxy.org/stable/\",\n \"Source\": \"https://github.com/mitmproxy/mitmproxy/\",\n \"Tracker\": \"https://github.com/mitmproxy/mitmproxy/issues\",\n },\n packages=find_packages(\n include=[\n \"mitmproxy\",\n \"mitmproxy.*\",\n ]\n ),\n include_package_data=True,\n entry_points={\n \"console_scripts\": [\n \"mitmproxy = mitmproxy.tools.main:mitmproxy\",\n \"mitmdump = mitmproxy.tools.main:mitmdump\",\n \"mitmweb = mitmproxy.tools.main:mitmweb\",\n ],\n \"pyinstaller40\": [\n \"hook-dirs = mitmproxy.utils.pyinstaller:hook_dirs\",\n ],\n },\n python_requires=\">=3.9\",\n # https://packaging.python.org/en/latest/discussions/install-requires-vs-requirements/#install-requires\n # It is not considered best practice to use install_requires to pin dependencies to specific versions.\n install_requires=[\n \"aioquic_mitmproxy>=0.9.20,<0.10\",\n \"asgiref>=3.2.10,<3.7\",\n \"Brotli>=1.0,<1.1\",\n \"certifi>=2019.9.11\", # no semver here - this should always be on the last release!\n \"cryptography>=38.0,<39.1\",\n \"flask>=1.1.1,<2.3\",\n \"h11>=0.11,<0.15\",\n \"h2>=4.1,<5\",\n \"hyperframe>=6.0,<7\",\n \"kaitaistruct>=0.10,<0.11\",\n \"ldap3>=2.8,<2.10\",\n \"mitmproxy_wireguard>=0.1.6,<0.2\",\n \"msgpack>=1.0.0, <1.1.0\",\n \"passlib>=1.6.5, <1.8\",\n \"protobuf>=3.14,<5\",\n \"pyOpenSSL>=22.1,<23.1\",\n \"pyparsing>=2.4.2,<3.1\",\n \"pyperclip>=1.6.0,<1.9\",\n \"ruamel.yaml>=0.16,<0.18\",\n \"sortedcontainers>=2.3,<2.5\",\n \"tornado>=6.2,<7\",\n \"urwid-mitmproxy>=2.1.1,<2.2\",\n \"wsproto>=1.0,<1.3\",\n \"publicsuffix2>=2.20190812,<3\",\n \"zstandard>=0.11,<0.20\",\n \"typing-extensions>=4.3,<4.5; python_version<'3.10'\",\n ],\n extras_require={\n ':sys_platform == \"win32\"': [\n \"pydivert>=2.0.3,<2.2\",\n ],\n \"dev\": [\n \"click>=7.0,<8.2\",\n \"hypothesis>=5.8,<7\",\n \"parver>=0.1,<2.0\",\n \"pdoc>=4.0.0\",\n \"pyinstaller==5.7.0\",\n \"pytest-asyncio>=0.17,<0.21\",\n \"pytest-cov>=2.7.1,<4.1\",\n \"pytest-timeout>=1.3.3,<2.2\",\n \"pytest-xdist>=2.1.0,<3.2\",\n \"pytest>=6.1.0,<8\",\n \"requests>=2.9.1,<3\",\n \"tox>=3.5,<5\",\n \"wheel>=0.36.2,<0.39\",\n ],\n },\n)\n", "path": "setup.py"}]}
| 1,891 | 602 |
gh_patches_debug_51251
|
rasdani/github-patches
|
git_diff
|
conda__conda-6470
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
conda 4.4 rc2: failure in conda list when editable install has been moved
`conda list` for my root environment is working nicely using conda 4.3, but when upgrading with canary to conda 4.4.0 rc2, the `conda list` command fails with the following error:
```
joris@joris-XPS-13-9350:~/scipy$ conda list
# packages in environment at /home/joris/miniconda3:
#
`$ /home/joris/miniconda3/bin/conda list`
Traceback (most recent call last):
File "/home/joris/miniconda3/lib/python3.5/site-packages/conda/exceptions.py", line 683, in __call__
return func(*args, **kwargs)
File "/home/joris/miniconda3/lib/python3.5/site-packages/conda/cli/main.py", line 78, in _main
exit_code = do_call(args, p)
File "/home/joris/miniconda3/lib/python3.5/site-packages/conda/cli/conda_argparse.py", line 75, in do_call
exit_code = getattr(module, func_name)(args, parser)
File "/home/joris/miniconda3/lib/python3.5/site-packages/conda/cli/main_list.py", line 150, in execute
show_channel_urls=context.show_channel_urls)
File "/home/joris/miniconda3/lib/python3.5/site-packages/conda/cli/main_list.py", line 85, in print_packages
other_python = get_egg_info(prefix)
File "/home/joris/miniconda3/lib/python3.5/site-packages/conda/egg_info.py", line 86, in get_egg_info
for path in get_egg_info_files(join(prefix, sp_dir)):
File "/home/joris/miniconda3/lib/python3.5/site-packages/conda/egg_info.py", line 35, in get_egg_info_files
for egg in get_egg_info_files(reader.readline().strip()):
File "/home/joris/miniconda3/lib/python3.5/site-packages/conda/egg_info.py", line 32, in get_egg_info_files
for fn in os.listdir(sp_dir):
FileNotFoundError: [Errno 2] No such file or directory: '/home/joris/scipy/dateutil'
```
The reason for this is that I once did `pip install -e .` in the '/home/joris/scipy/dateutil' directory to test out a dev install of dateutil. But later I removed it. Until now it was not a problem, but so now it is starting to give problems with conda 4.4.
I know I can fix this by removing it manually from easy-install.pth, but IMO it could be handles more gracefully by conda.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conda/egg_info.py`
Content:
```
1 """
2 Functions related to core conda functionality that relates to manually
3 installed Python packages, e.g. using "python setup.py install", or "pip".
4 """
5 from __future__ import absolute_import, division, print_function, unicode_literals
6
7 from io import open
8 import os
9 from os.path import isdir, isfile, join
10 import re
11 import sys
12
13 from .common.compat import itervalues, on_win
14 from .core.linked_data import linked_data
15 from .misc import rel_path
16 from .models.dist import Dist
17
18
19 def get_site_packages_dir(installed_pkgs):
20 for info in itervalues(installed_pkgs):
21 if info['name'] == 'python':
22 if on_win:
23 stdlib_dir = 'Lib'
24 else:
25 py_ver = info['version'][:3]
26 stdlib_dir = 'lib/python%s' % py_ver
27 return join(stdlib_dir, 'site-packages')
28 return None
29
30
31 def get_egg_info_files(sp_dir):
32 for fn in os.listdir(sp_dir):
33 if fn.endswith('.egg-link'):
34 with open(join(sp_dir, fn), 'r') as reader:
35 for egg in get_egg_info_files(reader.readline().strip()):
36 yield egg
37 if not fn.endswith(('.egg', '.egg-info', '.dist-info')):
38 continue
39 path = join(sp_dir, fn)
40 if isfile(path):
41 yield path
42 elif isdir(path):
43 for path2 in [join(path, 'PKG-INFO'),
44 join(path, 'EGG-INFO', 'PKG-INFO'),
45 join(path, 'METADATA')]:
46 if isfile(path2):
47 yield path2
48
49
50 pat = re.compile(r'(\w+):\s*(\S+)', re.I)
51 def parse_egg_info(path):
52 """
53 Parse an .egg-info file and return its canonical distribution name
54 """
55 info = {}
56 for line in open(path, encoding='utf-8'):
57 line = line.strip()
58 m = pat.match(line)
59 if m:
60 key = m.group(1).lower()
61 info[key] = m.group(2)
62 try:
63 return '%(name)s-%(version)s-<pip>' % info
64 except KeyError:
65 pass
66 return None
67
68
69 def get_egg_info(prefix, all_pkgs=False):
70 """
71 Return a set of canonical names of all Python packages (in `prefix`),
72 by inspecting the .egg-info files inside site-packages.
73 By default, only untracked (not conda installed) .egg-info files are
74 considered. Setting `all_pkgs` to True changes this.
75 """
76 installed_pkgs = linked_data(prefix)
77 sp_dir = get_site_packages_dir(installed_pkgs)
78 if sp_dir is None:
79 return set()
80
81 conda_files = set()
82 for info in itervalues(installed_pkgs):
83 conda_files.update(info.get('files', []))
84
85 res = set()
86 for path in get_egg_info_files(join(prefix, sp_dir)):
87 f = rel_path(prefix, path)
88 if all_pkgs or f not in conda_files:
89 try:
90 dist = parse_egg_info(path)
91 except UnicodeDecodeError:
92 dist = None
93 if dist:
94 res.add(Dist(dist))
95 return res
96
97
98 if __name__ == '__main__':
99 from pprint import pprint
100 pprint(get_egg_info(sys.prefix))
101
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/conda/egg_info.py b/conda/egg_info.py
--- a/conda/egg_info.py
+++ b/conda/egg_info.py
@@ -75,7 +75,7 @@
"""
installed_pkgs = linked_data(prefix)
sp_dir = get_site_packages_dir(installed_pkgs)
- if sp_dir is None:
+ if sp_dir is None or not isdir(join(prefix, sp_dir)):
return set()
conda_files = set()
|
{"golden_diff": "diff --git a/conda/egg_info.py b/conda/egg_info.py\n--- a/conda/egg_info.py\n+++ b/conda/egg_info.py\n@@ -75,7 +75,7 @@\n \"\"\"\n installed_pkgs = linked_data(prefix)\n sp_dir = get_site_packages_dir(installed_pkgs)\n- if sp_dir is None:\n+ if sp_dir is None or not isdir(join(prefix, sp_dir)):\n return set()\n \n conda_files = set()\n", "issue": "conda 4.4 rc2: failure in conda list when editable install has been moved\n`conda list` for my root environment is working nicely using conda 4.3, but when upgrading with canary to conda 4.4.0 rc2, the `conda list` command fails with the following error:\r\n\r\n```\r\njoris@joris-XPS-13-9350:~/scipy$ conda list\r\n# packages in environment at /home/joris/miniconda3:\r\n#\r\n\r\n`$ /home/joris/miniconda3/bin/conda list`\r\n\r\n Traceback (most recent call last):\r\n File \"/home/joris/miniconda3/lib/python3.5/site-packages/conda/exceptions.py\", line 683, in __call__\r\n return func(*args, **kwargs)\r\n File \"/home/joris/miniconda3/lib/python3.5/site-packages/conda/cli/main.py\", line 78, in _main\r\n exit_code = do_call(args, p)\r\n File \"/home/joris/miniconda3/lib/python3.5/site-packages/conda/cli/conda_argparse.py\", line 75, in do_call\r\n exit_code = getattr(module, func_name)(args, parser)\r\n File \"/home/joris/miniconda3/lib/python3.5/site-packages/conda/cli/main_list.py\", line 150, in execute\r\n show_channel_urls=context.show_channel_urls)\r\n File \"/home/joris/miniconda3/lib/python3.5/site-packages/conda/cli/main_list.py\", line 85, in print_packages\r\n other_python = get_egg_info(prefix)\r\n File \"/home/joris/miniconda3/lib/python3.5/site-packages/conda/egg_info.py\", line 86, in get_egg_info\r\n for path in get_egg_info_files(join(prefix, sp_dir)):\r\n File \"/home/joris/miniconda3/lib/python3.5/site-packages/conda/egg_info.py\", line 35, in get_egg_info_files\r\n for egg in get_egg_info_files(reader.readline().strip()):\r\n File \"/home/joris/miniconda3/lib/python3.5/site-packages/conda/egg_info.py\", line 32, in get_egg_info_files\r\n for fn in os.listdir(sp_dir):\r\n FileNotFoundError: [Errno 2] No such file or directory: '/home/joris/scipy/dateutil'\r\n```\r\n\r\nThe reason for this is that I once did `pip install -e .` in the '/home/joris/scipy/dateutil' directory to test out a dev install of dateutil. But later I removed it. Until now it was not a problem, but so now it is starting to give problems with conda 4.4. \r\nI know I can fix this by removing it manually from easy-install.pth, but IMO it could be handles more gracefully by conda.\n", "before_files": [{"content": "\"\"\"\nFunctions related to core conda functionality that relates to manually\ninstalled Python packages, e.g. using \"python setup.py install\", or \"pip\".\n\"\"\"\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nfrom io import open\nimport os\nfrom os.path import isdir, isfile, join\nimport re\nimport sys\n\nfrom .common.compat import itervalues, on_win\nfrom .core.linked_data import linked_data\nfrom .misc import rel_path\nfrom .models.dist import Dist\n\n\ndef get_site_packages_dir(installed_pkgs):\n for info in itervalues(installed_pkgs):\n if info['name'] == 'python':\n if on_win:\n stdlib_dir = 'Lib'\n else:\n py_ver = info['version'][:3]\n stdlib_dir = 'lib/python%s' % py_ver\n return join(stdlib_dir, 'site-packages')\n return None\n\n\ndef get_egg_info_files(sp_dir):\n for fn in os.listdir(sp_dir):\n if fn.endswith('.egg-link'):\n with open(join(sp_dir, fn), 'r') as reader:\n for egg in get_egg_info_files(reader.readline().strip()):\n yield egg\n if not fn.endswith(('.egg', '.egg-info', '.dist-info')):\n continue\n path = join(sp_dir, fn)\n if isfile(path):\n yield path\n elif isdir(path):\n for path2 in [join(path, 'PKG-INFO'),\n join(path, 'EGG-INFO', 'PKG-INFO'),\n join(path, 'METADATA')]:\n if isfile(path2):\n yield path2\n\n\npat = re.compile(r'(\\w+):\\s*(\\S+)', re.I)\ndef parse_egg_info(path):\n \"\"\"\n Parse an .egg-info file and return its canonical distribution name\n \"\"\"\n info = {}\n for line in open(path, encoding='utf-8'):\n line = line.strip()\n m = pat.match(line)\n if m:\n key = m.group(1).lower()\n info[key] = m.group(2)\n try:\n return '%(name)s-%(version)s-<pip>' % info\n except KeyError:\n pass\n return None\n\n\ndef get_egg_info(prefix, all_pkgs=False):\n \"\"\"\n Return a set of canonical names of all Python packages (in `prefix`),\n by inspecting the .egg-info files inside site-packages.\n By default, only untracked (not conda installed) .egg-info files are\n considered. Setting `all_pkgs` to True changes this.\n \"\"\"\n installed_pkgs = linked_data(prefix)\n sp_dir = get_site_packages_dir(installed_pkgs)\n if sp_dir is None:\n return set()\n\n conda_files = set()\n for info in itervalues(installed_pkgs):\n conda_files.update(info.get('files', []))\n\n res = set()\n for path in get_egg_info_files(join(prefix, sp_dir)):\n f = rel_path(prefix, path)\n if all_pkgs or f not in conda_files:\n try:\n dist = parse_egg_info(path)\n except UnicodeDecodeError:\n dist = None\n if dist:\n res.add(Dist(dist))\n return res\n\n\nif __name__ == '__main__':\n from pprint import pprint\n pprint(get_egg_info(sys.prefix))\n", "path": "conda/egg_info.py"}], "after_files": [{"content": "\"\"\"\nFunctions related to core conda functionality that relates to manually\ninstalled Python packages, e.g. using \"python setup.py install\", or \"pip\".\n\"\"\"\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nfrom io import open\nimport os\nfrom os.path import isdir, isfile, join\nimport re\nimport sys\n\nfrom .common.compat import itervalues, on_win\nfrom .core.linked_data import linked_data\nfrom .misc import rel_path\nfrom .models.dist import Dist\n\n\ndef get_site_packages_dir(installed_pkgs):\n for info in itervalues(installed_pkgs):\n if info['name'] == 'python':\n if on_win:\n stdlib_dir = 'Lib'\n else:\n py_ver = info['version'][:3]\n stdlib_dir = 'lib/python%s' % py_ver\n return join(stdlib_dir, 'site-packages')\n return None\n\n\ndef get_egg_info_files(sp_dir):\n for fn in os.listdir(sp_dir):\n if fn.endswith('.egg-link'):\n with open(join(sp_dir, fn), 'r') as reader:\n for egg in get_egg_info_files(reader.readline().strip()):\n yield egg\n if not fn.endswith(('.egg', '.egg-info', '.dist-info')):\n continue\n path = join(sp_dir, fn)\n if isfile(path):\n yield path\n elif isdir(path):\n for path2 in [join(path, 'PKG-INFO'),\n join(path, 'EGG-INFO', 'PKG-INFO'),\n join(path, 'METADATA')]:\n if isfile(path2):\n yield path2\n\n\npat = re.compile(r'(\\w+):\\s*(\\S+)', re.I)\ndef parse_egg_info(path):\n \"\"\"\n Parse an .egg-info file and return its canonical distribution name\n \"\"\"\n info = {}\n for line in open(path, encoding='utf-8'):\n line = line.strip()\n m = pat.match(line)\n if m:\n key = m.group(1).lower()\n info[key] = m.group(2)\n try:\n return '%(name)s-%(version)s-<pip>' % info\n except KeyError:\n pass\n return None\n\n\ndef get_egg_info(prefix, all_pkgs=False):\n \"\"\"\n Return a set of canonical names of all Python packages (in `prefix`),\n by inspecting the .egg-info files inside site-packages.\n By default, only untracked (not conda installed) .egg-info files are\n considered. Setting `all_pkgs` to True changes this.\n \"\"\"\n installed_pkgs = linked_data(prefix)\n sp_dir = get_site_packages_dir(installed_pkgs)\n if sp_dir is None or not isdir(join(prefix, sp_dir)):\n return set()\n\n conda_files = set()\n for info in itervalues(installed_pkgs):\n conda_files.update(info.get('files', []))\n\n res = set()\n for path in get_egg_info_files(join(prefix, sp_dir)):\n f = rel_path(prefix, path)\n if all_pkgs or f not in conda_files:\n try:\n dist = parse_egg_info(path)\n except UnicodeDecodeError:\n dist = None\n if dist:\n res.add(Dist(dist))\n return res\n\n\nif __name__ == '__main__':\n from pprint import pprint\n pprint(get_egg_info(sys.prefix))\n", "path": "conda/egg_info.py"}]}
| 1,819 | 109 |
gh_patches_debug_12347
|
rasdani/github-patches
|
git_diff
|
GeotrekCE__Geotrek-admin-3405
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
API V2 cache problem with custom configuration in nginx.conf.in
API v2 responses doesn't take care about [```X-FORWARDED-PROTO```](https://github.com/GeotrekCE/Geotrek-admin/blob/master/conf/nginx.conf.in#L55) value defined in nginx configuration.
This header is used by django to know if generated url (pictogram, attachment) is http or https.
In some cases, custom configuration in nginx.conf.in to work behind haproxy, API response does not match with headers.
For the moment, any change about it in nginx template should be followed by clearing api_v2 cache in admin panel
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `geotrek/api/v2/viewsets.py`
Content:
```
1 from hashlib import md5
2
3 from django.conf import settings
4 from django_filters.rest_framework.backends import DjangoFilterBackend
5 from mapentity.renderers import GeoJSONRenderer
6 from rest_framework import viewsets, renderers
7 from rest_framework.authentication import BasicAuthentication, SessionAuthentication
8 from rest_framework.generics import get_object_or_404
9 from rest_framework.permissions import IsAuthenticatedOrReadOnly, IsAuthenticated
10
11 from geotrek.api.v2 import pagination as api_pagination, filters as api_filters
12 from geotrek.api.v2.cache import RetrieveCacheResponseMixin
13 from geotrek.api.v2.serializers import override_serializer
14
15
16 class GeotrekViewSet(RetrieveCacheResponseMixin, viewsets.ReadOnlyModelViewSet):
17 filter_backends = (
18 DjangoFilterBackend,
19 api_filters.GeotrekQueryParamsFilter,
20 api_filters.GeotrekPublishedFilter,
21 )
22 pagination_class = api_pagination.StandardResultsSetPagination
23 permission_classes = [IsAuthenticatedOrReadOnly, ] if settings.API_IS_PUBLIC else [IsAuthenticated, ]
24 authentication_classes = [BasicAuthentication, SessionAuthentication]
25 renderer_classes = [renderers.JSONRenderer, renderers.BrowsableAPIRenderer, ] if settings.DEBUG else [renderers.JSONRenderer, ]
26 lookup_value_regex = r'\d+'
27
28 def get_ordered_query_params(self):
29 """ Get multi value query params sorted by key """
30 parameters = self.request.query_params
31 sorted_keys = sorted(parameters.keys())
32 return {k: sorted(parameters.getlist(k)) for k in sorted_keys}
33
34 def get_base_cache_string(self):
35 """ return cache string as url path + ordered query params """
36 return f"{self.request.path}:{self.get_ordered_query_params()}:{self.request.accepted_renderer.format}"
37
38 def get_object_cache_key(self, pk):
39 """ return specific object cache key based on object date_update column"""
40 # don't directly use get_object or get_queryset to avoid select / prefetch and annotation sql queries
41 # insure object exists and doesn't raise exception
42 instance = get_object_or_404(self.get_queryset().model, pk=pk)
43 date_update = instance.date_update
44 return f"{self.get_base_cache_string()}:{date_update.isoformat()}"
45
46 def object_cache_key_func(self, **kwargs):
47 """ cache key md5 for retrieve viewset action """
48 return md5(self.get_object_cache_key(kwargs.get('kwargs').get('pk')).encode("utf-8")).hexdigest()
49
50 def get_serializer_context(self):
51 return {
52 'request': self.request,
53 'kwargs': self.kwargs
54 }
55
56
57 class GeotrekGeometricViewset(GeotrekViewSet):
58 filter_backends = GeotrekViewSet.filter_backends + (
59 api_filters.GeotrekQueryParamsDimensionFilter,
60 api_filters.GeotrekInBBoxFilter,
61 api_filters.GeotrekDistanceToPointFilter,
62 )
63 distance_filter_field = 'geom'
64 bbox_filter_field = 'geom'
65 bbox_filter_include_overlapping = True
66 renderer_classes = GeotrekViewSet.renderer_classes + [GeoJSONRenderer, ]
67
68 def get_serializer_class(self):
69 base_serializer_class = super().get_serializer_class()
70 format_output = self.request.query_params.get('format', 'json')
71 return override_serializer(format_output, base_serializer_class)
72
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/geotrek/api/v2/viewsets.py b/geotrek/api/v2/viewsets.py
--- a/geotrek/api/v2/viewsets.py
+++ b/geotrek/api/v2/viewsets.py
@@ -33,7 +33,8 @@
def get_base_cache_string(self):
""" return cache string as url path + ordered query params """
- return f"{self.request.path}:{self.get_ordered_query_params()}:{self.request.accepted_renderer.format}"
+ proto_scheme = self.request.headers.get('X-Forwarded-Proto', self.request.scheme) # take care about scheme defined in nginx.conf
+ return f"{self.request.path}:{self.get_ordered_query_params()}:{self.request.accepted_renderer.format}:{proto_scheme}"
def get_object_cache_key(self, pk):
""" return specific object cache key based on object date_update column"""
|
{"golden_diff": "diff --git a/geotrek/api/v2/viewsets.py b/geotrek/api/v2/viewsets.py\n--- a/geotrek/api/v2/viewsets.py\n+++ b/geotrek/api/v2/viewsets.py\n@@ -33,7 +33,8 @@\n \n def get_base_cache_string(self):\n \"\"\" return cache string as url path + ordered query params \"\"\"\n- return f\"{self.request.path}:{self.get_ordered_query_params()}:{self.request.accepted_renderer.format}\"\n+ proto_scheme = self.request.headers.get('X-Forwarded-Proto', self.request.scheme) # take care about scheme defined in nginx.conf\n+ return f\"{self.request.path}:{self.get_ordered_query_params()}:{self.request.accepted_renderer.format}:{proto_scheme}\"\n \n def get_object_cache_key(self, pk):\n \"\"\" return specific object cache key based on object date_update column\"\"\"\n", "issue": "API V2 cache problem with custom configuration in nginx.conf.in\nAPI v2 responses doesn't take care about [```X-FORWARDED-PROTO```](https://github.com/GeotrekCE/Geotrek-admin/blob/master/conf/nginx.conf.in#L55) value defined in nginx configuration.\r\nThis header is used by django to know if generated url (pictogram, attachment) is http or https.\r\nIn some cases, custom configuration in nginx.conf.in to work behind haproxy, API response does not match with headers.\r\n\r\nFor the moment, any change about it in nginx template should be followed by clearing api_v2 cache in admin panel\n", "before_files": [{"content": "from hashlib import md5\n\nfrom django.conf import settings\nfrom django_filters.rest_framework.backends import DjangoFilterBackend\nfrom mapentity.renderers import GeoJSONRenderer\nfrom rest_framework import viewsets, renderers\nfrom rest_framework.authentication import BasicAuthentication, SessionAuthentication\nfrom rest_framework.generics import get_object_or_404\nfrom rest_framework.permissions import IsAuthenticatedOrReadOnly, IsAuthenticated\n\nfrom geotrek.api.v2 import pagination as api_pagination, filters as api_filters\nfrom geotrek.api.v2.cache import RetrieveCacheResponseMixin\nfrom geotrek.api.v2.serializers import override_serializer\n\n\nclass GeotrekViewSet(RetrieveCacheResponseMixin, viewsets.ReadOnlyModelViewSet):\n filter_backends = (\n DjangoFilterBackend,\n api_filters.GeotrekQueryParamsFilter,\n api_filters.GeotrekPublishedFilter,\n )\n pagination_class = api_pagination.StandardResultsSetPagination\n permission_classes = [IsAuthenticatedOrReadOnly, ] if settings.API_IS_PUBLIC else [IsAuthenticated, ]\n authentication_classes = [BasicAuthentication, SessionAuthentication]\n renderer_classes = [renderers.JSONRenderer, renderers.BrowsableAPIRenderer, ] if settings.DEBUG else [renderers.JSONRenderer, ]\n lookup_value_regex = r'\\d+'\n\n def get_ordered_query_params(self):\n \"\"\" Get multi value query params sorted by key \"\"\"\n parameters = self.request.query_params\n sorted_keys = sorted(parameters.keys())\n return {k: sorted(parameters.getlist(k)) for k in sorted_keys}\n\n def get_base_cache_string(self):\n \"\"\" return cache string as url path + ordered query params \"\"\"\n return f\"{self.request.path}:{self.get_ordered_query_params()}:{self.request.accepted_renderer.format}\"\n\n def get_object_cache_key(self, pk):\n \"\"\" return specific object cache key based on object date_update column\"\"\"\n # don't directly use get_object or get_queryset to avoid select / prefetch and annotation sql queries\n # insure object exists and doesn't raise exception\n instance = get_object_or_404(self.get_queryset().model, pk=pk)\n date_update = instance.date_update\n return f\"{self.get_base_cache_string()}:{date_update.isoformat()}\"\n\n def object_cache_key_func(self, **kwargs):\n \"\"\" cache key md5 for retrieve viewset action \"\"\"\n return md5(self.get_object_cache_key(kwargs.get('kwargs').get('pk')).encode(\"utf-8\")).hexdigest()\n\n def get_serializer_context(self):\n return {\n 'request': self.request,\n 'kwargs': self.kwargs\n }\n\n\nclass GeotrekGeometricViewset(GeotrekViewSet):\n filter_backends = GeotrekViewSet.filter_backends + (\n api_filters.GeotrekQueryParamsDimensionFilter,\n api_filters.GeotrekInBBoxFilter,\n api_filters.GeotrekDistanceToPointFilter,\n )\n distance_filter_field = 'geom'\n bbox_filter_field = 'geom'\n bbox_filter_include_overlapping = True\n renderer_classes = GeotrekViewSet.renderer_classes + [GeoJSONRenderer, ]\n\n def get_serializer_class(self):\n base_serializer_class = super().get_serializer_class()\n format_output = self.request.query_params.get('format', 'json')\n return override_serializer(format_output, base_serializer_class)\n", "path": "geotrek/api/v2/viewsets.py"}], "after_files": [{"content": "from hashlib import md5\n\nfrom django.conf import settings\nfrom django_filters.rest_framework.backends import DjangoFilterBackend\nfrom mapentity.renderers import GeoJSONRenderer\nfrom rest_framework import viewsets, renderers\nfrom rest_framework.authentication import BasicAuthentication, SessionAuthentication\nfrom rest_framework.generics import get_object_or_404\nfrom rest_framework.permissions import IsAuthenticatedOrReadOnly, IsAuthenticated\n\nfrom geotrek.api.v2 import pagination as api_pagination, filters as api_filters\nfrom geotrek.api.v2.cache import RetrieveCacheResponseMixin\nfrom geotrek.api.v2.serializers import override_serializer\n\n\nclass GeotrekViewSet(RetrieveCacheResponseMixin, viewsets.ReadOnlyModelViewSet):\n filter_backends = (\n DjangoFilterBackend,\n api_filters.GeotrekQueryParamsFilter,\n api_filters.GeotrekPublishedFilter,\n )\n pagination_class = api_pagination.StandardResultsSetPagination\n permission_classes = [IsAuthenticatedOrReadOnly, ] if settings.API_IS_PUBLIC else [IsAuthenticated, ]\n authentication_classes = [BasicAuthentication, SessionAuthentication]\n renderer_classes = [renderers.JSONRenderer, renderers.BrowsableAPIRenderer, ] if settings.DEBUG else [renderers.JSONRenderer, ]\n lookup_value_regex = r'\\d+'\n\n def get_ordered_query_params(self):\n \"\"\" Get multi value query params sorted by key \"\"\"\n parameters = self.request.query_params\n sorted_keys = sorted(parameters.keys())\n return {k: sorted(parameters.getlist(k)) for k in sorted_keys}\n\n def get_base_cache_string(self):\n \"\"\" return cache string as url path + ordered query params \"\"\"\n proto_scheme = self.request.headers.get('X-Forwarded-Proto', self.request.scheme) # take care about scheme defined in nginx.conf\n return f\"{self.request.path}:{self.get_ordered_query_params()}:{self.request.accepted_renderer.format}:{proto_scheme}\"\n\n def get_object_cache_key(self, pk):\n \"\"\" return specific object cache key based on object date_update column\"\"\"\n # don't directly use get_object or get_queryset to avoid select / prefetch and annotation sql queries\n # insure object exists and doesn't raise exception\n instance = get_object_or_404(self.get_queryset().model, pk=pk)\n date_update = instance.date_update\n return f\"{self.get_base_cache_string()}:{date_update.isoformat()}\"\n\n def object_cache_key_func(self, **kwargs):\n \"\"\" cache key md5 for retrieve viewset action \"\"\"\n return md5(self.get_object_cache_key(kwargs.get('kwargs').get('pk')).encode(\"utf-8\")).hexdigest()\n\n def get_serializer_context(self):\n return {\n 'request': self.request,\n 'kwargs': self.kwargs\n }\n\n\nclass GeotrekGeometricViewset(GeotrekViewSet):\n filter_backends = GeotrekViewSet.filter_backends + (\n api_filters.GeotrekQueryParamsDimensionFilter,\n api_filters.GeotrekInBBoxFilter,\n api_filters.GeotrekDistanceToPointFilter,\n )\n distance_filter_field = 'geom'\n bbox_filter_field = 'geom'\n bbox_filter_include_overlapping = True\n renderer_classes = GeotrekViewSet.renderer_classes + [GeoJSONRenderer, ]\n\n def get_serializer_class(self):\n base_serializer_class = super().get_serializer_class()\n format_output = self.request.query_params.get('format', 'json')\n return override_serializer(format_output, base_serializer_class)\n", "path": "geotrek/api/v2/viewsets.py"}]}
| 1,222 | 188 |
gh_patches_debug_3105
|
rasdani/github-patches
|
git_diff
|
Parsl__parsl-414
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
File creation fails if no executor has been loaded
```python
In [53]: file = File('first.txt')
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-53-b5dc63ca042a> in <module>()
----> 1 file = File('first.txt')
~/ci/parsl/parsl/data_provider/files.py in __init__(self, url, dman, cache, caching_dir)
40 self.path = parsed_url.path
41 self.filename = os.path.basename(self.path)
---> 42 self.dman = dman if dman else DataManager.get_data_manager()
43 self.data_future = {}
44 if self.scheme == 'globus':
~/ci/parsl/parsl/data_provider/data_manager.py in get_data_manager(cls, max_threads, executors)
24 def get_data_manager(cls, max_threads=None, executors=None):
25 if cls.default_data_manager is None:
---> 26 cls.default_data_manager = DataManager(max_threads=max_threads, executors=executors)
27 return cls.default_data_manager
28
~/ci/parsl/parsl/data_provider/data_manager.py in __init__(self, max_threads, executors)
37
38 self.label = 'data_manager'
---> 39 self.executors = {e.label: e for e in executors}
40 self.max_threads = max_threads
41 self.files = []
TypeError: 'NoneType' object is not iterable
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `parsl/data_provider/data_manager.py`
Content:
```
1 import os
2 import logging
3 import requests
4 import ftplib
5 import concurrent.futures as cf
6 from parsl.data_provider.scheme import GlobusScheme
7 from parsl.executors.base import ParslExecutor
8 from parsl.data_provider.globus import get_globus
9 from parsl.app.app import App
10
11 logger = logging.getLogger(__name__)
12
13
14 class DataManager(ParslExecutor):
15 """The DataManager is responsible for transferring input and output data.
16
17 It uses the Executor interface, where staging tasks are submitted
18 to it, and DataFutures are returned.
19 """
20
21 default_data_manager = None
22
23 @classmethod
24 def get_data_manager(cls, max_threads=None, executors=None):
25 if cls.default_data_manager is None:
26 cls.default_data_manager = DataManager(max_threads=max_threads, executors=executors)
27 return cls.default_data_manager
28
29 def __init__(self, max_threads=10, executors=None):
30 """Initialize the DataManager.
31
32 Kwargs:
33 - max_threads (int): Number of threads. Default is 10.
34 - executors (list of Executors): Executors for which data transfer will be managed.
35 """
36 self._scaling_enabled = False
37
38 self.label = 'data_manager'
39 self.executors = {e.label: e for e in executors}
40 self.max_threads = max_threads
41 self.files = []
42 self.globus = None
43 self.managed = True
44
45 def start(self):
46 self.executor = cf.ThreadPoolExecutor(max_workers=self.max_threads)
47
48 def submit(self, *args, **kwargs):
49 """Submit a staging app. All optimization should be here."""
50 return self.executor.submit(*args, **kwargs)
51
52 def scale_in(self, blocks, *args, **kwargs):
53 pass
54
55 def scale_out(self, *args, **kwargs):
56 pass
57
58 def shutdown(self, block=False):
59 """Shutdown the ThreadPool.
60
61 Kwargs:
62 - block (bool): To block for confirmations or not
63
64 """
65 x = self.executor.shutdown(wait=block)
66 logger.debug("Done with executor shutdown")
67 return x
68
69 @property
70 def scaling_enabled(self):
71 return self._scaling_enabled
72
73 def add_file(self, file):
74 if file.scheme == 'globus':
75 if not self.globus:
76 self.globus = get_globus()
77 # keep a list of all remote files for optimization purposes (TODO)
78 self.files.append(file)
79 self._set_local_path(file)
80
81 def _set_local_path(self, file):
82 globus_ep = self._get_globus_endpoint()
83 file.local_path = os.path.join(globus_ep['working_dir'], file.filename)
84
85 def _get_globus_endpoint(self, executor_label=None):
86 for executor in self.executors.values():
87 if executor_label is None or executor.label == executor_label:
88 for scheme in executor.storage_access:
89 if isinstance(scheme, GlobusScheme):
90 working_dir = os.path.normpath(executor.working_dir)
91 if scheme.endpoint_path and scheme.local_path:
92 endpoint_path = os.path.normpath(scheme.endpoint_path)
93 local_path = os.path.normpath(scheme.local_path)
94 common_path = os.path.commonpath((local_path, working_dir))
95 if local_path != common_path:
96 raise Exception('"local_path" must be equal or an absolute subpath of "working_dir"')
97 relative_path = os.path.relpath(working_dir, common_path)
98 endpoint_path = os.path.join(endpoint_path, relative_path)
99 else:
100 endpoint_path = working_dir
101 return {'endpoint_uuid': scheme.endpoint_uuid,
102 'endpoint_path': endpoint_path,
103 'working_dir': working_dir}
104 raise Exception('No executor with a Globus endpoint and working_dir defined')
105
106 def stage_in(self, file, executor):
107 """Transport the file from the input source to the executor.
108
109 This function returns a DataFuture.
110
111 Args:
112 - self
113 - file (File) : file to stage in
114 - executor (str) : an executor the file is going to be staged in to.
115 If the executor argument is not specified for a file
116 with 'globus' scheme, the file will be staged in to
117 the first executor with the "globus" key in a config.
118 """
119
120 if file.scheme == 'file':
121 stage_in_app = self._file_stage_in_app()
122 app_fut = stage_in_app(outputs=[file])
123 return app_fut._outputs[0]
124 elif file.scheme == 'ftp':
125 working_dir = self.executors[executor].working_dir
126 stage_in_app = self._ftp_stage_in_app(executor=executor)
127 app_fut = stage_in_app(working_dir, outputs=[file])
128 return app_fut._outputs[0]
129 elif file.scheme == 'http' or file.scheme == 'https':
130 working_dir = self.executors[executor].working_dir
131 stage_in_app = self._http_stage_in_app(executor=executor)
132 app_fut = stage_in_app(working_dir, outputs=[file])
133 return app_fut._outputs[0]
134 elif file.scheme == 'globus':
135 globus_ep = self._get_globus_endpoint(executor)
136 stage_in_app = self._globus_stage_in_app()
137 app_fut = stage_in_app(globus_ep, outputs=[file])
138 return app_fut._outputs[0]
139 else:
140 raise Exception('Staging in with unknown file scheme {} is not supported'.format(file.scheme))
141
142 def _file_stage_in_app(self):
143 return App("python", executors=['data_manager'])(self._file_stage_in)
144
145 def _file_stage_in(self, outputs=[]):
146 pass
147
148 def _ftp_stage_in_app(self, executor):
149 return App("python", executors=[executor])(self._ftp_stage_in)
150
151 def _ftp_stage_in(self, working_dir, outputs=[]):
152 file = outputs[0]
153 if working_dir:
154 os.makedirs(working_dir, exist_ok=True)
155 file.local_path = os.path.join(working_dir, file.filename)
156 else:
157 file.local_path = file.filename
158 with open(file.local_path, 'wb') as f:
159 ftp = ftplib.FTP(file.netloc)
160 ftp.login()
161 ftp.cwd(os.path.dirname(file.path))
162 ftp.retrbinary('RETR {}'.format(file.filename), f.write)
163 ftp.quit()
164
165 def _http_stage_in_app(self, executor):
166 return App("python", executors=[executor])(self._http_stage_in)
167
168 def _http_stage_in(self, working_dir, outputs=[]):
169 file = outputs[0]
170 if working_dir:
171 os.makedirs(working_dir, exist_ok=True)
172 file.local_path = os.path.join(working_dir, file.filename)
173 else:
174 file.local_path = file.filename
175 resp = requests.get(file.url, stream=True)
176 with open(file.local_path, 'wb') as f:
177 for chunk in resp.iter_content(chunk_size=1024):
178 if chunk:
179 f.write(chunk)
180
181 def _globus_stage_in_app(self):
182 return App("python", executors=['data_manager'])(self._globus_stage_in)
183
184 def _globus_stage_in(self, globus_ep, outputs=[]):
185 file = outputs[0]
186 file.local_path = os.path.join(
187 globus_ep['working_dir'], file.filename)
188 dst_path = os.path.join(
189 globus_ep['endpoint_path'], file.filename)
190 self.globus.transfer_file(
191 file.netloc, globus_ep['endpoint_uuid'],
192 file.path, dst_path)
193
194 def stage_out(self, file, executor):
195 """Transport the file from the local filesystem to the remote Globus endpoint.
196
197 This function returns a DataFuture.
198
199 Args:
200 - self
201 - file (File) - file to stage out
202 - executor (str) - Which executor the file is going to be staged out from.
203 If the executor argument is not specified for a file
204 with the 'globus' scheme, the file will be staged in to
205 the first executor with the "globus" key in a config.
206 """
207
208 if file.scheme == 'file':
209 stage_out_app = self._file_stage_out_app()
210 return stage_out_app()
211 elif file.scheme == 'http' or file.scheme == 'https':
212 raise Exception('HTTP/HTTPS file staging out is not supported')
213 elif file.scheme == 'ftp':
214 raise Exception('FTP file staging out is not supported')
215 elif file.scheme == 'globus':
216 globus_ep = self._get_globus_endpoint(executor)
217 stage_out_app = self._globus_stage_out_app()
218 return stage_out_app(globus_ep, inputs=[file])
219 else:
220 raise Exception('Staging out with unknown file scheme {} is not supported'.format(file.scheme))
221
222 def _file_stage_out_app(self):
223 return App("python", executors=['data_manager'])(self._file_stage_out)
224
225 def _file_stage_out(self):
226 pass
227
228 def _globus_stage_out_app(self):
229 return App("python", executors=['data_manager'])(self._globus_stage_out)
230
231 def _globus_stage_out(self, globus_ep, inputs=[]):
232 file = inputs[0]
233 src_path = os.path.join(globus_ep['endpoint_path'], file.filename)
234 self.globus.transfer_file(
235 globus_ep['endpoint_uuid'], file.netloc,
236 src_path, file.path
237 )
238
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/parsl/data_provider/data_manager.py b/parsl/data_provider/data_manager.py
--- a/parsl/data_provider/data_manager.py
+++ b/parsl/data_provider/data_manager.py
@@ -36,6 +36,8 @@
self._scaling_enabled = False
self.label = 'data_manager'
+ if executors is None:
+ executors = []
self.executors = {e.label: e for e in executors}
self.max_threads = max_threads
self.files = []
|
{"golden_diff": "diff --git a/parsl/data_provider/data_manager.py b/parsl/data_provider/data_manager.py\n--- a/parsl/data_provider/data_manager.py\n+++ b/parsl/data_provider/data_manager.py\n@@ -36,6 +36,8 @@\n self._scaling_enabled = False\n \n self.label = 'data_manager'\n+ if executors is None:\n+ executors = []\n self.executors = {e.label: e for e in executors}\n self.max_threads = max_threads\n self.files = []\n", "issue": "File creation fails if no executor has been loaded\n```python\r\nIn [53]: file = File('first.txt')\r\n---------------------------------------------------------------------------\r\nTypeError Traceback (most recent call last)\r\n<ipython-input-53-b5dc63ca042a> in <module>()\r\n----> 1 file = File('first.txt')\r\n\r\n~/ci/parsl/parsl/data_provider/files.py in __init__(self, url, dman, cache, caching_dir)\r\n 40 self.path = parsed_url.path\r\n 41 self.filename = os.path.basename(self.path)\r\n---> 42 self.dman = dman if dman else DataManager.get_data_manager()\r\n 43 self.data_future = {}\r\n 44 if self.scheme == 'globus':\r\n\r\n~/ci/parsl/parsl/data_provider/data_manager.py in get_data_manager(cls, max_threads, executors)\r\n 24 def get_data_manager(cls, max_threads=None, executors=None):\r\n 25 if cls.default_data_manager is None:\r\n---> 26 cls.default_data_manager = DataManager(max_threads=max_threads, executors=executors)\r\n 27 return cls.default_data_manager\r\n 28\r\n\r\n~/ci/parsl/parsl/data_provider/data_manager.py in __init__(self, max_threads, executors)\r\n 37\r\n 38 self.label = 'data_manager'\r\n---> 39 self.executors = {e.label: e for e in executors}\r\n 40 self.max_threads = max_threads\r\n 41 self.files = []\r\n\r\nTypeError: 'NoneType' object is not iterable\r\n```\n", "before_files": [{"content": "import os\nimport logging\nimport requests\nimport ftplib\nimport concurrent.futures as cf\nfrom parsl.data_provider.scheme import GlobusScheme\nfrom parsl.executors.base import ParslExecutor\nfrom parsl.data_provider.globus import get_globus\nfrom parsl.app.app import App\n\nlogger = logging.getLogger(__name__)\n\n\nclass DataManager(ParslExecutor):\n \"\"\"The DataManager is responsible for transferring input and output data.\n\n It uses the Executor interface, where staging tasks are submitted\n to it, and DataFutures are returned.\n \"\"\"\n\n default_data_manager = None\n\n @classmethod\n def get_data_manager(cls, max_threads=None, executors=None):\n if cls.default_data_manager is None:\n cls.default_data_manager = DataManager(max_threads=max_threads, executors=executors)\n return cls.default_data_manager\n\n def __init__(self, max_threads=10, executors=None):\n \"\"\"Initialize the DataManager.\n\n Kwargs:\n - max_threads (int): Number of threads. Default is 10.\n - executors (list of Executors): Executors for which data transfer will be managed.\n \"\"\"\n self._scaling_enabled = False\n\n self.label = 'data_manager'\n self.executors = {e.label: e for e in executors}\n self.max_threads = max_threads\n self.files = []\n self.globus = None\n self.managed = True\n\n def start(self):\n self.executor = cf.ThreadPoolExecutor(max_workers=self.max_threads)\n\n def submit(self, *args, **kwargs):\n \"\"\"Submit a staging app. All optimization should be here.\"\"\"\n return self.executor.submit(*args, **kwargs)\n\n def scale_in(self, blocks, *args, **kwargs):\n pass\n\n def scale_out(self, *args, **kwargs):\n pass\n\n def shutdown(self, block=False):\n \"\"\"Shutdown the ThreadPool.\n\n Kwargs:\n - block (bool): To block for confirmations or not\n\n \"\"\"\n x = self.executor.shutdown(wait=block)\n logger.debug(\"Done with executor shutdown\")\n return x\n\n @property\n def scaling_enabled(self):\n return self._scaling_enabled\n\n def add_file(self, file):\n if file.scheme == 'globus':\n if not self.globus:\n self.globus = get_globus()\n # keep a list of all remote files for optimization purposes (TODO)\n self.files.append(file)\n self._set_local_path(file)\n\n def _set_local_path(self, file):\n globus_ep = self._get_globus_endpoint()\n file.local_path = os.path.join(globus_ep['working_dir'], file.filename)\n\n def _get_globus_endpoint(self, executor_label=None):\n for executor in self.executors.values():\n if executor_label is None or executor.label == executor_label:\n for scheme in executor.storage_access:\n if isinstance(scheme, GlobusScheme):\n working_dir = os.path.normpath(executor.working_dir)\n if scheme.endpoint_path and scheme.local_path:\n endpoint_path = os.path.normpath(scheme.endpoint_path)\n local_path = os.path.normpath(scheme.local_path)\n common_path = os.path.commonpath((local_path, working_dir))\n if local_path != common_path:\n raise Exception('\"local_path\" must be equal or an absolute subpath of \"working_dir\"')\n relative_path = os.path.relpath(working_dir, common_path)\n endpoint_path = os.path.join(endpoint_path, relative_path)\n else:\n endpoint_path = working_dir\n return {'endpoint_uuid': scheme.endpoint_uuid,\n 'endpoint_path': endpoint_path,\n 'working_dir': working_dir}\n raise Exception('No executor with a Globus endpoint and working_dir defined')\n\n def stage_in(self, file, executor):\n \"\"\"Transport the file from the input source to the executor.\n\n This function returns a DataFuture.\n\n Args:\n - self\n - file (File) : file to stage in\n - executor (str) : an executor the file is going to be staged in to.\n If the executor argument is not specified for a file\n with 'globus' scheme, the file will be staged in to\n the first executor with the \"globus\" key in a config.\n \"\"\"\n\n if file.scheme == 'file':\n stage_in_app = self._file_stage_in_app()\n app_fut = stage_in_app(outputs=[file])\n return app_fut._outputs[0]\n elif file.scheme == 'ftp':\n working_dir = self.executors[executor].working_dir\n stage_in_app = self._ftp_stage_in_app(executor=executor)\n app_fut = stage_in_app(working_dir, outputs=[file])\n return app_fut._outputs[0]\n elif file.scheme == 'http' or file.scheme == 'https':\n working_dir = self.executors[executor].working_dir\n stage_in_app = self._http_stage_in_app(executor=executor)\n app_fut = stage_in_app(working_dir, outputs=[file])\n return app_fut._outputs[0]\n elif file.scheme == 'globus':\n globus_ep = self._get_globus_endpoint(executor)\n stage_in_app = self._globus_stage_in_app()\n app_fut = stage_in_app(globus_ep, outputs=[file])\n return app_fut._outputs[0]\n else:\n raise Exception('Staging in with unknown file scheme {} is not supported'.format(file.scheme))\n\n def _file_stage_in_app(self):\n return App(\"python\", executors=['data_manager'])(self._file_stage_in)\n\n def _file_stage_in(self, outputs=[]):\n pass\n\n def _ftp_stage_in_app(self, executor):\n return App(\"python\", executors=[executor])(self._ftp_stage_in)\n\n def _ftp_stage_in(self, working_dir, outputs=[]):\n file = outputs[0]\n if working_dir:\n os.makedirs(working_dir, exist_ok=True)\n file.local_path = os.path.join(working_dir, file.filename)\n else:\n file.local_path = file.filename\n with open(file.local_path, 'wb') as f:\n ftp = ftplib.FTP(file.netloc)\n ftp.login()\n ftp.cwd(os.path.dirname(file.path))\n ftp.retrbinary('RETR {}'.format(file.filename), f.write)\n ftp.quit()\n\n def _http_stage_in_app(self, executor):\n return App(\"python\", executors=[executor])(self._http_stage_in)\n\n def _http_stage_in(self, working_dir, outputs=[]):\n file = outputs[0]\n if working_dir:\n os.makedirs(working_dir, exist_ok=True)\n file.local_path = os.path.join(working_dir, file.filename)\n else:\n file.local_path = file.filename\n resp = requests.get(file.url, stream=True)\n with open(file.local_path, 'wb') as f:\n for chunk in resp.iter_content(chunk_size=1024):\n if chunk:\n f.write(chunk)\n\n def _globus_stage_in_app(self):\n return App(\"python\", executors=['data_manager'])(self._globus_stage_in)\n\n def _globus_stage_in(self, globus_ep, outputs=[]):\n file = outputs[0]\n file.local_path = os.path.join(\n globus_ep['working_dir'], file.filename)\n dst_path = os.path.join(\n globus_ep['endpoint_path'], file.filename)\n self.globus.transfer_file(\n file.netloc, globus_ep['endpoint_uuid'],\n file.path, dst_path)\n\n def stage_out(self, file, executor):\n \"\"\"Transport the file from the local filesystem to the remote Globus endpoint.\n\n This function returns a DataFuture.\n\n Args:\n - self\n - file (File) - file to stage out\n - executor (str) - Which executor the file is going to be staged out from.\n If the executor argument is not specified for a file\n with the 'globus' scheme, the file will be staged in to\n the first executor with the \"globus\" key in a config.\n \"\"\"\n\n if file.scheme == 'file':\n stage_out_app = self._file_stage_out_app()\n return stage_out_app()\n elif file.scheme == 'http' or file.scheme == 'https':\n raise Exception('HTTP/HTTPS file staging out is not supported')\n elif file.scheme == 'ftp':\n raise Exception('FTP file staging out is not supported')\n elif file.scheme == 'globus':\n globus_ep = self._get_globus_endpoint(executor)\n stage_out_app = self._globus_stage_out_app()\n return stage_out_app(globus_ep, inputs=[file])\n else:\n raise Exception('Staging out with unknown file scheme {} is not supported'.format(file.scheme))\n\n def _file_stage_out_app(self):\n return App(\"python\", executors=['data_manager'])(self._file_stage_out)\n\n def _file_stage_out(self):\n pass\n\n def _globus_stage_out_app(self):\n return App(\"python\", executors=['data_manager'])(self._globus_stage_out)\n\n def _globus_stage_out(self, globus_ep, inputs=[]):\n file = inputs[0]\n src_path = os.path.join(globus_ep['endpoint_path'], file.filename)\n self.globus.transfer_file(\n globus_ep['endpoint_uuid'], file.netloc,\n src_path, file.path\n )\n", "path": "parsl/data_provider/data_manager.py"}], "after_files": [{"content": "import os\nimport logging\nimport requests\nimport ftplib\nimport concurrent.futures as cf\nfrom parsl.data_provider.scheme import GlobusScheme\nfrom parsl.executors.base import ParslExecutor\nfrom parsl.data_provider.globus import get_globus\nfrom parsl.app.app import App\n\nlogger = logging.getLogger(__name__)\n\n\nclass DataManager(ParslExecutor):\n \"\"\"The DataManager is responsible for transferring input and output data.\n\n It uses the Executor interface, where staging tasks are submitted\n to it, and DataFutures are returned.\n \"\"\"\n\n default_data_manager = None\n\n @classmethod\n def get_data_manager(cls, max_threads=None, executors=None):\n if cls.default_data_manager is None:\n cls.default_data_manager = DataManager(max_threads=max_threads, executors=executors)\n return cls.default_data_manager\n\n def __init__(self, max_threads=10, executors=None):\n \"\"\"Initialize the DataManager.\n\n Kwargs:\n - max_threads (int): Number of threads. Default is 10.\n - executors (list of Executors): Executors for which data transfer will be managed.\n \"\"\"\n self._scaling_enabled = False\n\n self.label = 'data_manager'\n if executors is None:\n executors = []\n self.executors = {e.label: e for e in executors}\n self.max_threads = max_threads\n self.files = []\n self.globus = None\n self.managed = True\n\n def start(self):\n self.executor = cf.ThreadPoolExecutor(max_workers=self.max_threads)\n\n def submit(self, *args, **kwargs):\n \"\"\"Submit a staging app. All optimization should be here.\"\"\"\n return self.executor.submit(*args, **kwargs)\n\n def scale_in(self, blocks, *args, **kwargs):\n pass\n\n def scale_out(self, *args, **kwargs):\n pass\n\n def shutdown(self, block=False):\n \"\"\"Shutdown the ThreadPool.\n\n Kwargs:\n - block (bool): To block for confirmations or not\n\n \"\"\"\n x = self.executor.shutdown(wait=block)\n logger.debug(\"Done with executor shutdown\")\n return x\n\n @property\n def scaling_enabled(self):\n return self._scaling_enabled\n\n def add_file(self, file):\n if file.scheme == 'globus':\n if not self.globus:\n self.globus = get_globus()\n # keep a list of all remote files for optimization purposes (TODO)\n self.files.append(file)\n self._set_local_path(file)\n\n def _set_local_path(self, file):\n globus_ep = self._get_globus_endpoint()\n file.local_path = os.path.join(globus_ep['working_dir'], file.filename)\n\n def _get_globus_endpoint(self, executor_label=None):\n for executor in self.executors.values():\n if executor_label is None or executor.label == executor_label:\n for scheme in executor.storage_access:\n if isinstance(scheme, GlobusScheme):\n working_dir = os.path.normpath(executor.working_dir)\n if scheme.endpoint_path and scheme.local_path:\n endpoint_path = os.path.normpath(scheme.endpoint_path)\n local_path = os.path.normpath(scheme.local_path)\n common_path = os.path.commonpath((local_path, working_dir))\n if local_path != common_path:\n raise Exception('\"local_path\" must be equal or an absolute subpath of \"working_dir\"')\n relative_path = os.path.relpath(working_dir, common_path)\n endpoint_path = os.path.join(endpoint_path, relative_path)\n else:\n endpoint_path = working_dir\n return {'endpoint_uuid': scheme.endpoint_uuid,\n 'endpoint_path': endpoint_path,\n 'working_dir': working_dir}\n raise Exception('No executor with a Globus endpoint and working_dir defined')\n\n def stage_in(self, file, executor):\n \"\"\"Transport the file from the input source to the executor.\n\n This function returns a DataFuture.\n\n Args:\n - self\n - file (File) : file to stage in\n - executor (str) : an executor the file is going to be staged in to.\n If the executor argument is not specified for a file\n with 'globus' scheme, the file will be staged in to\n the first executor with the \"globus\" key in a config.\n \"\"\"\n\n if file.scheme == 'file':\n stage_in_app = self._file_stage_in_app()\n app_fut = stage_in_app(outputs=[file])\n return app_fut._outputs[0]\n elif file.scheme == 'ftp':\n working_dir = self.executors[executor].working_dir\n stage_in_app = self._ftp_stage_in_app(executor=executor)\n app_fut = stage_in_app(working_dir, outputs=[file])\n return app_fut._outputs[0]\n elif file.scheme == 'http' or file.scheme == 'https':\n working_dir = self.executors[executor].working_dir\n stage_in_app = self._http_stage_in_app(executor=executor)\n app_fut = stage_in_app(working_dir, outputs=[file])\n return app_fut._outputs[0]\n elif file.scheme == 'globus':\n globus_ep = self._get_globus_endpoint(executor)\n stage_in_app = self._globus_stage_in_app()\n app_fut = stage_in_app(globus_ep, outputs=[file])\n return app_fut._outputs[0]\n else:\n raise Exception('Staging in with unknown file scheme {} is not supported'.format(file.scheme))\n\n def _file_stage_in_app(self):\n return App(\"python\", executors=['data_manager'])(self._file_stage_in)\n\n def _file_stage_in(self, outputs=[]):\n pass\n\n def _ftp_stage_in_app(self, executor):\n return App(\"python\", executors=[executor])(self._ftp_stage_in)\n\n def _ftp_stage_in(self, working_dir, outputs=[]):\n file = outputs[0]\n if working_dir:\n os.makedirs(working_dir, exist_ok=True)\n file.local_path = os.path.join(working_dir, file.filename)\n else:\n file.local_path = file.filename\n with open(file.local_path, 'wb') as f:\n ftp = ftplib.FTP(file.netloc)\n ftp.login()\n ftp.cwd(os.path.dirname(file.path))\n ftp.retrbinary('RETR {}'.format(file.filename), f.write)\n ftp.quit()\n\n def _http_stage_in_app(self, executor):\n return App(\"python\", executors=[executor])(self._http_stage_in)\n\n def _http_stage_in(self, working_dir, outputs=[]):\n file = outputs[0]\n if working_dir:\n os.makedirs(working_dir, exist_ok=True)\n file.local_path = os.path.join(working_dir, file.filename)\n else:\n file.local_path = file.filename\n resp = requests.get(file.url, stream=True)\n with open(file.local_path, 'wb') as f:\n for chunk in resp.iter_content(chunk_size=1024):\n if chunk:\n f.write(chunk)\n\n def _globus_stage_in_app(self):\n return App(\"python\", executors=['data_manager'])(self._globus_stage_in)\n\n def _globus_stage_in(self, globus_ep, outputs=[]):\n file = outputs[0]\n file.local_path = os.path.join(\n globus_ep['working_dir'], file.filename)\n dst_path = os.path.join(\n globus_ep['endpoint_path'], file.filename)\n self.globus.transfer_file(\n file.netloc, globus_ep['endpoint_uuid'],\n file.path, dst_path)\n\n def stage_out(self, file, executor):\n \"\"\"Transport the file from the local filesystem to the remote Globus endpoint.\n\n This function returns a DataFuture.\n\n Args:\n - self\n - file (File) - file to stage out\n - executor (str) - Which executor the file is going to be staged out from.\n If the executor argument is not specified for a file\n with the 'globus' scheme, the file will be staged in to\n the first executor with the \"globus\" key in a config.\n \"\"\"\n\n if file.scheme == 'file':\n stage_out_app = self._file_stage_out_app()\n return stage_out_app()\n elif file.scheme == 'http' or file.scheme == 'https':\n raise Exception('HTTP/HTTPS file staging out is not supported')\n elif file.scheme == 'ftp':\n raise Exception('FTP file staging out is not supported')\n elif file.scheme == 'globus':\n globus_ep = self._get_globus_endpoint(executor)\n stage_out_app = self._globus_stage_out_app()\n return stage_out_app(globus_ep, inputs=[file])\n else:\n raise Exception('Staging out with unknown file scheme {} is not supported'.format(file.scheme))\n\n def _file_stage_out_app(self):\n return App(\"python\", executors=['data_manager'])(self._file_stage_out)\n\n def _file_stage_out(self):\n pass\n\n def _globus_stage_out_app(self):\n return App(\"python\", executors=['data_manager'])(self._globus_stage_out)\n\n def _globus_stage_out(self, globus_ep, inputs=[]):\n file = inputs[0]\n src_path = os.path.join(globus_ep['endpoint_path'], file.filename)\n self.globus.transfer_file(\n globus_ep['endpoint_uuid'], file.netloc,\n src_path, file.path\n )\n", "path": "parsl/data_provider/data_manager.py"}]}
| 3,283 | 115 |
gh_patches_debug_34634
|
rasdani/github-patches
|
git_diff
|
saleor__saleor-598
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
shipping address shouldn't be editable while order is processed?
Order has a foreign key to address for shipping address.
With the current model, I think a user is able to change the address while the order is being processed (before shipped without realizing his past order might be affected)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `saleor/checkout/core.py`
Content:
```
1 from __future__ import unicode_literals
2 from functools import wraps
3
4 from django.conf import settings
5 from django.db import transaction
6 from django.forms.models import model_to_dict
7 from django.utils.encoding import smart_text
8 from prices import Price, FixedDiscount
9
10 from ..cart.views import get_or_empty_db_cart
11 from ..core import analytics
12 from ..discount.models import Voucher, NotApplicable
13 from ..order.models import Order
14 from ..shipping.models import ShippingMethodCountry, ANY_COUNTRY
15 from ..userprofile.models import Address, User
16
17 STORAGE_SESSION_KEY = 'checkout_storage'
18
19
20 class Checkout(object):
21
22 VERSION = '1.0.0'
23 modified = False
24
25 def __init__(self, cart, user, tracking_code):
26 self.cart = cart
27 self.storage = {'version': self.VERSION}
28 self.tracking_code = tracking_code
29 self.user = user
30 self.discounts = cart.discounts
31
32 @classmethod
33 def from_storage(cls, storage_data, cart, user, tracking_code):
34 checkout = cls(cart, user, tracking_code)
35 checkout.storage = storage_data
36 try:
37 version = checkout.storage['version']
38 except (TypeError, KeyError):
39 version = None
40 if version != cls.VERSION:
41 checkout.storage = {'version': cls.VERSION}
42 return checkout
43
44 def for_storage(self):
45 return self.storage
46
47 def clear_storage(self):
48 self.storage = None
49 self.modified = True
50
51 def _get_address_from_storage(self, key):
52 address_data = self.storage.get(key)
53 if address_data is not None and address_data.get('id'):
54 try:
55 return Address.objects.get(id=address_data['id'])
56 except Address.DoesNotExist:
57 return None
58 elif address_data:
59 return Address(**address_data)
60 return None
61
62 @property
63 def is_shipping_required(self):
64 return self.cart.is_shipping_required()
65
66 @property
67 def deliveries(self):
68 for partition in self.cart.partition():
69 if self.shipping_method and partition.is_shipping_required():
70 shipping_cost = self.shipping_method.get_total()
71 else:
72 shipping_cost = Price(0, currency=settings.DEFAULT_CURRENCY)
73 total_with_shipping = partition.get_total(
74 discounts=self.cart.discounts) + shipping_cost
75
76 partition = [
77 (item,
78 item.get_price_per_item(discounts=self.cart.discounts),
79 item.get_total(discounts=self.cart.discounts))
80 for item in partition]
81
82 yield partition, shipping_cost, total_with_shipping
83
84 @property
85 def shipping_address(self):
86 address = self._get_address_from_storage('shipping_address')
87 if address is None and self.user.is_authenticated():
88 return self.user.default_shipping_address
89 return address
90
91 @shipping_address.setter
92 def shipping_address(self, address):
93 address_data = model_to_dict(address)
94 address_data['country'] = smart_text(address_data['country'])
95 self.storage['shipping_address'] = address_data
96 self.modified = True
97
98 @property
99 def shipping_method(self):
100 shipping_address = self.shipping_address
101 if shipping_address is not None:
102 shipping_method_country_id = self.storage.get(
103 'shipping_method_country_id')
104 if shipping_method_country_id is not None:
105 try:
106 shipping_method_country = ShippingMethodCountry.objects.get(
107 id=shipping_method_country_id)
108 except ShippingMethodCountry.DoesNotExist:
109 return None
110 shipping_country_code = shipping_address.country.code
111 if (shipping_method_country.country_code == ANY_COUNTRY or
112 shipping_method_country.country_code == shipping_country_code):
113 return shipping_method_country
114
115 @shipping_method.setter
116 def shipping_method(self, shipping_method_country):
117 self.storage['shipping_method_country_id'] = shipping_method_country.id
118 self.modified = True
119
120 @property
121 def email(self):
122 return self.storage.get('email')
123
124 @email.setter
125 def email(self, email):
126 self.storage['email'] = email
127 self.modified = True
128
129 @property
130 def billing_address(self):
131 address = self._get_address_from_storage('billing_address')
132 if address is not None:
133 return address
134 elif self.user.is_authenticated() and self.user.default_billing_address:
135 return self.user.default_billing_address
136 elif self.shipping_address:
137 return self.shipping_address
138
139 @billing_address.setter
140 def billing_address(self, address):
141 address_data = model_to_dict(address)
142 address_data['country'] = smart_text(address_data['country'])
143 self.storage['billing_address'] = address_data
144 self.modified = True
145
146 @property
147 def discount(self):
148 value = self.storage.get('discount_value')
149 currency = self.storage.get('discount_currency')
150 name = self.storage.get('discount_name')
151 if value is not None and name is not None and currency is not None:
152 amount = Price(value, currency=currency)
153 return FixedDiscount(amount, name)
154
155 @discount.setter
156 def discount(self, discount):
157 amount = discount.amount
158 self.storage['discount_value'] = smart_text(amount.net)
159 self.storage['discount_currency'] = amount.currency
160 self.storage['discount_name'] = discount.name
161 self.modified = True
162
163 @discount.deleter
164 def discount(self):
165 if 'discount_value' in self.storage:
166 del self.storage['discount_value']
167 self.modified = True
168 if 'discount_currency' in self.storage:
169 del self.storage['discount_currency']
170 self.modified = True
171 if 'discount_name' in self.storage:
172 del self.storage['discount_name']
173 self.modified = True
174
175 @property
176 def voucher_code(self):
177 return self.storage.get('voucher_code')
178
179 @voucher_code.setter
180 def voucher_code(self, voucher_code):
181 self.storage['voucher_code'] = voucher_code
182 self.modified = True
183
184 @voucher_code.deleter
185 def voucher_code(self):
186 if 'voucher_code' in self.storage:
187 del self.storage['voucher_code']
188 self.modified = True
189
190 @property
191 def is_shipping_same_as_billing(self):
192 return Address.objects.are_identical(
193 self.shipping_address, self.billing_address)
194
195 def _save_address(self, address, is_billing=False, is_shipping=False):
196 if self.user.is_authenticated() and address.id is None:
197 address = User.objects.store_address(
198 self.user, address, shipping=is_shipping, billing=is_billing)
199 elif address.id is None:
200 address.save()
201 return address
202
203 @transaction.atomic
204 def create_order(self):
205 if self.is_shipping_required:
206 shipping_address = self._save_address(
207 self.shipping_address, is_shipping=True)
208 else:
209 shipping_address = None
210 billing_address = self._save_address(
211 self.billing_address, is_billing=True)
212
213 order_data = {
214 'billing_address': billing_address,
215 'shipping_address': shipping_address,
216 'tracking_client_id': self.tracking_code,
217 'total': self.get_total()}
218
219 if self.user.is_authenticated():
220 order_data['user'] = self.user
221 else:
222 # TODO: we should always save email in order not only
223 # for anonymous
224 order_data['anonymous_user_email'] = self.email
225
226 voucher = self._get_voucher()
227 if voucher is not None:
228 discount = self.discount
229 order_data['voucher'] = voucher
230 order_data['discount_amount'] = discount.amount
231 order_data['discount_name'] = discount.name
232
233 order = Order.objects.create(**order_data)
234
235 for partition in self.cart.partition():
236 shipping_required = partition.is_shipping_required()
237 if shipping_required:
238 shipping_price = self.shipping_method.get_total()
239 shipping_method_name = smart_text(self.shipping_method)
240 else:
241 shipping_price = 0
242 shipping_method_name = None
243 group = order.groups.create(
244 shipping_price=shipping_price,
245 shipping_method_name=shipping_method_name)
246 group.add_items_from_partition(
247 partition, discounts=self.cart.discounts)
248
249 if voucher is not None:
250 Voucher.objects.increase_usage(voucher)
251
252 return order
253
254 def _get_voucher(self):
255 voucher_code = self.voucher_code
256 if voucher_code is not None:
257 vouchers = Voucher.objects.active().select_for_update()
258 try:
259 return vouchers.get(code=self.voucher_code)
260 except Voucher.DoesNotExist:
261 return None
262
263 def recalculate_discount(self):
264 voucher = self._get_voucher()
265 if voucher is not None:
266 try:
267 self.discount = voucher.get_discount_for_checkout(self)
268 except NotApplicable:
269 del self.discount
270 del self.voucher_code
271 else:
272 del self.discount
273 del self.voucher_code
274
275 def get_subtotal(self):
276 zero = Price(0, currency=settings.DEFAULT_CURRENCY)
277 cost_iterator = (
278 total - shipping_cost
279 for shipment, shipping_cost, total in self.deliveries)
280 total = sum(cost_iterator, zero)
281 return total
282
283 def get_total(self):
284 zero = Price(0, currency=settings.DEFAULT_CURRENCY)
285 cost_iterator = (
286 total
287 for shipment, shipping_cost, total in self.deliveries)
288 total = sum(cost_iterator, zero)
289 return total if self.discount is None else self.discount.apply(total)
290
291 def get_total_shipping(self):
292 zero = Price(0, currency=settings.DEFAULT_CURRENCY)
293 cost_iterator = (
294 shipping_cost
295 for shipment, shipping_cost, total in self.deliveries)
296 total = sum(cost_iterator, zero)
297 return total
298
299
300 def load_checkout(view):
301 @wraps(view)
302 @get_or_empty_db_cart
303 def func(request, cart):
304 try:
305 session_data = request.session[STORAGE_SESSION_KEY]
306 except KeyError:
307 session_data = ''
308 tracking_code = analytics.get_client_id(request)
309
310 checkout = Checkout.from_storage(
311 session_data, cart, request.user, tracking_code)
312 response = view(request, checkout, cart)
313 if checkout.modified:
314 request.session[STORAGE_SESSION_KEY] = checkout.for_storage()
315 return response
316
317 return func
318
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/saleor/checkout/core.py b/saleor/checkout/core.py
--- a/saleor/checkout/core.py
+++ b/saleor/checkout/core.py
@@ -192,23 +192,36 @@
return Address.objects.are_identical(
self.shipping_address, self.billing_address)
- def _save_address(self, address, is_billing=False, is_shipping=False):
- if self.user.is_authenticated() and address.id is None:
- address = User.objects.store_address(
- self.user, address, shipping=is_shipping, billing=is_billing)
- elif address.id is None:
- address.save()
+ def _add_to_user_address_book(self, address, is_billing=False,
+ is_shipping=False):
+ if self.user.is_authenticated():
+ User.objects.store_address(
+ self.user, address, shipping=is_shipping,
+ billing=is_billing)
+
+ def _get_address_copy(self, address):
+ address.user = None
+ address.pk = None
+ address.save()
return address
+ def _save_order_billing_address(self):
+ return self._get_address_copy(self.billing_address)
+
+ def _save_order_shipping_address(self):
+ return self._get_address_copy(self.shipping_address)
+
@transaction.atomic
def create_order(self):
if self.is_shipping_required:
- shipping_address = self._save_address(
+ shipping_address = self._save_order_shipping_address()
+ self._add_to_user_address_book(
self.shipping_address, is_shipping=True)
else:
shipping_address = None
- billing_address = self._save_address(
- self.billing_address, is_billing=True)
+ billing_address = self._save_order_billing_address()
+ self._add_to_user_address_book(
+ self.shipping_address, is_billing=True)
order_data = {
'billing_address': billing_address,
@@ -306,7 +319,7 @@
except KeyError:
session_data = ''
tracking_code = analytics.get_client_id(request)
-
+
checkout = Checkout.from_storage(
session_data, cart, request.user, tracking_code)
response = view(request, checkout, cart)
|
{"golden_diff": "diff --git a/saleor/checkout/core.py b/saleor/checkout/core.py\n--- a/saleor/checkout/core.py\n+++ b/saleor/checkout/core.py\n@@ -192,23 +192,36 @@\n return Address.objects.are_identical(\n self.shipping_address, self.billing_address)\n \n- def _save_address(self, address, is_billing=False, is_shipping=False):\n- if self.user.is_authenticated() and address.id is None:\n- address = User.objects.store_address(\n- self.user, address, shipping=is_shipping, billing=is_billing)\n- elif address.id is None:\n- address.save()\n+ def _add_to_user_address_book(self, address, is_billing=False,\n+ is_shipping=False):\n+ if self.user.is_authenticated():\n+ User.objects.store_address(\n+ self.user, address, shipping=is_shipping,\n+ billing=is_billing)\n+\n+ def _get_address_copy(self, address):\n+ address.user = None\n+ address.pk = None\n+ address.save()\n return address\n \n+ def _save_order_billing_address(self):\n+ return self._get_address_copy(self.billing_address)\n+\n+ def _save_order_shipping_address(self):\n+ return self._get_address_copy(self.shipping_address)\n+\n @transaction.atomic\n def create_order(self):\n if self.is_shipping_required:\n- shipping_address = self._save_address(\n+ shipping_address = self._save_order_shipping_address()\n+ self._add_to_user_address_book(\n self.shipping_address, is_shipping=True)\n else:\n shipping_address = None\n- billing_address = self._save_address(\n- self.billing_address, is_billing=True)\n+ billing_address = self._save_order_billing_address()\n+ self._add_to_user_address_book(\n+ self.shipping_address, is_billing=True)\n \n order_data = {\n 'billing_address': billing_address,\n@@ -306,7 +319,7 @@\n except KeyError:\n session_data = ''\n tracking_code = analytics.get_client_id(request)\n- \n+\n checkout = Checkout.from_storage(\n session_data, cart, request.user, tracking_code)\n response = view(request, checkout, cart)\n", "issue": "shipping address shouldn't be editable while order is processed?\nOrder has a foreign key to address for shipping address. \nWith the current model, I think a user is able to change the address while the order is being processed (before shipped without realizing his past order might be affected)\n\n", "before_files": [{"content": "from __future__ import unicode_literals\nfrom functools import wraps\n\nfrom django.conf import settings\nfrom django.db import transaction\nfrom django.forms.models import model_to_dict\nfrom django.utils.encoding import smart_text\nfrom prices import Price, FixedDiscount\n\nfrom ..cart.views import get_or_empty_db_cart\nfrom ..core import analytics\nfrom ..discount.models import Voucher, NotApplicable\nfrom ..order.models import Order\nfrom ..shipping.models import ShippingMethodCountry, ANY_COUNTRY\nfrom ..userprofile.models import Address, User\n\nSTORAGE_SESSION_KEY = 'checkout_storage'\n\n\nclass Checkout(object):\n\n VERSION = '1.0.0'\n modified = False\n\n def __init__(self, cart, user, tracking_code):\n self.cart = cart\n self.storage = {'version': self.VERSION}\n self.tracking_code = tracking_code\n self.user = user\n self.discounts = cart.discounts\n\n @classmethod\n def from_storage(cls, storage_data, cart, user, tracking_code):\n checkout = cls(cart, user, tracking_code)\n checkout.storage = storage_data\n try:\n version = checkout.storage['version']\n except (TypeError, KeyError):\n version = None\n if version != cls.VERSION:\n checkout.storage = {'version': cls.VERSION}\n return checkout\n\n def for_storage(self):\n return self.storage\n\n def clear_storage(self):\n self.storage = None\n self.modified = True\n\n def _get_address_from_storage(self, key):\n address_data = self.storage.get(key)\n if address_data is not None and address_data.get('id'):\n try:\n return Address.objects.get(id=address_data['id'])\n except Address.DoesNotExist:\n return None\n elif address_data:\n return Address(**address_data)\n return None\n\n @property\n def is_shipping_required(self):\n return self.cart.is_shipping_required()\n\n @property\n def deliveries(self):\n for partition in self.cart.partition():\n if self.shipping_method and partition.is_shipping_required():\n shipping_cost = self.shipping_method.get_total()\n else:\n shipping_cost = Price(0, currency=settings.DEFAULT_CURRENCY)\n total_with_shipping = partition.get_total(\n discounts=self.cart.discounts) + shipping_cost\n\n partition = [\n (item,\n item.get_price_per_item(discounts=self.cart.discounts),\n item.get_total(discounts=self.cart.discounts))\n for item in partition]\n\n yield partition, shipping_cost, total_with_shipping\n\n @property\n def shipping_address(self):\n address = self._get_address_from_storage('shipping_address')\n if address is None and self.user.is_authenticated():\n return self.user.default_shipping_address\n return address\n\n @shipping_address.setter\n def shipping_address(self, address):\n address_data = model_to_dict(address)\n address_data['country'] = smart_text(address_data['country'])\n self.storage['shipping_address'] = address_data\n self.modified = True\n\n @property\n def shipping_method(self):\n shipping_address = self.shipping_address\n if shipping_address is not None:\n shipping_method_country_id = self.storage.get(\n 'shipping_method_country_id')\n if shipping_method_country_id is not None:\n try:\n shipping_method_country = ShippingMethodCountry.objects.get(\n id=shipping_method_country_id)\n except ShippingMethodCountry.DoesNotExist:\n return None\n shipping_country_code = shipping_address.country.code\n if (shipping_method_country.country_code == ANY_COUNTRY or\n shipping_method_country.country_code == shipping_country_code):\n return shipping_method_country\n\n @shipping_method.setter\n def shipping_method(self, shipping_method_country):\n self.storage['shipping_method_country_id'] = shipping_method_country.id\n self.modified = True\n\n @property\n def email(self):\n return self.storage.get('email')\n\n @email.setter\n def email(self, email):\n self.storage['email'] = email\n self.modified = True\n\n @property\n def billing_address(self):\n address = self._get_address_from_storage('billing_address')\n if address is not None:\n return address\n elif self.user.is_authenticated() and self.user.default_billing_address:\n return self.user.default_billing_address\n elif self.shipping_address:\n return self.shipping_address\n\n @billing_address.setter\n def billing_address(self, address):\n address_data = model_to_dict(address)\n address_data['country'] = smart_text(address_data['country'])\n self.storage['billing_address'] = address_data\n self.modified = True\n\n @property\n def discount(self):\n value = self.storage.get('discount_value')\n currency = self.storage.get('discount_currency')\n name = self.storage.get('discount_name')\n if value is not None and name is not None and currency is not None:\n amount = Price(value, currency=currency)\n return FixedDiscount(amount, name)\n\n @discount.setter\n def discount(self, discount):\n amount = discount.amount\n self.storage['discount_value'] = smart_text(amount.net)\n self.storage['discount_currency'] = amount.currency\n self.storage['discount_name'] = discount.name\n self.modified = True\n\n @discount.deleter\n def discount(self):\n if 'discount_value' in self.storage:\n del self.storage['discount_value']\n self.modified = True\n if 'discount_currency' in self.storage:\n del self.storage['discount_currency']\n self.modified = True\n if 'discount_name' in self.storage:\n del self.storage['discount_name']\n self.modified = True\n\n @property\n def voucher_code(self):\n return self.storage.get('voucher_code')\n\n @voucher_code.setter\n def voucher_code(self, voucher_code):\n self.storage['voucher_code'] = voucher_code\n self.modified = True\n\n @voucher_code.deleter\n def voucher_code(self):\n if 'voucher_code' in self.storage:\n del self.storage['voucher_code']\n self.modified = True\n\n @property\n def is_shipping_same_as_billing(self):\n return Address.objects.are_identical(\n self.shipping_address, self.billing_address)\n\n def _save_address(self, address, is_billing=False, is_shipping=False):\n if self.user.is_authenticated() and address.id is None:\n address = User.objects.store_address(\n self.user, address, shipping=is_shipping, billing=is_billing)\n elif address.id is None:\n address.save()\n return address\n\n @transaction.atomic\n def create_order(self):\n if self.is_shipping_required:\n shipping_address = self._save_address(\n self.shipping_address, is_shipping=True)\n else:\n shipping_address = None\n billing_address = self._save_address(\n self.billing_address, is_billing=True)\n\n order_data = {\n 'billing_address': billing_address,\n 'shipping_address': shipping_address,\n 'tracking_client_id': self.tracking_code,\n 'total': self.get_total()}\n\n if self.user.is_authenticated():\n order_data['user'] = self.user\n else:\n # TODO: we should always save email in order not only\n # for anonymous\n order_data['anonymous_user_email'] = self.email\n\n voucher = self._get_voucher()\n if voucher is not None:\n discount = self.discount\n order_data['voucher'] = voucher\n order_data['discount_amount'] = discount.amount\n order_data['discount_name'] = discount.name\n\n order = Order.objects.create(**order_data)\n\n for partition in self.cart.partition():\n shipping_required = partition.is_shipping_required()\n if shipping_required:\n shipping_price = self.shipping_method.get_total()\n shipping_method_name = smart_text(self.shipping_method)\n else:\n shipping_price = 0\n shipping_method_name = None\n group = order.groups.create(\n shipping_price=shipping_price,\n shipping_method_name=shipping_method_name)\n group.add_items_from_partition(\n partition, discounts=self.cart.discounts)\n\n if voucher is not None:\n Voucher.objects.increase_usage(voucher)\n\n return order\n\n def _get_voucher(self):\n voucher_code = self.voucher_code\n if voucher_code is not None:\n vouchers = Voucher.objects.active().select_for_update()\n try:\n return vouchers.get(code=self.voucher_code)\n except Voucher.DoesNotExist:\n return None\n\n def recalculate_discount(self):\n voucher = self._get_voucher()\n if voucher is not None:\n try:\n self.discount = voucher.get_discount_for_checkout(self)\n except NotApplicable:\n del self.discount\n del self.voucher_code\n else:\n del self.discount\n del self.voucher_code\n\n def get_subtotal(self):\n zero = Price(0, currency=settings.DEFAULT_CURRENCY)\n cost_iterator = (\n total - shipping_cost\n for shipment, shipping_cost, total in self.deliveries)\n total = sum(cost_iterator, zero)\n return total\n\n def get_total(self):\n zero = Price(0, currency=settings.DEFAULT_CURRENCY)\n cost_iterator = (\n total\n for shipment, shipping_cost, total in self.deliveries)\n total = sum(cost_iterator, zero)\n return total if self.discount is None else self.discount.apply(total)\n\n def get_total_shipping(self):\n zero = Price(0, currency=settings.DEFAULT_CURRENCY)\n cost_iterator = (\n shipping_cost\n for shipment, shipping_cost, total in self.deliveries)\n total = sum(cost_iterator, zero)\n return total\n\n\ndef load_checkout(view):\n @wraps(view)\n @get_or_empty_db_cart\n def func(request, cart):\n try:\n session_data = request.session[STORAGE_SESSION_KEY]\n except KeyError:\n session_data = ''\n tracking_code = analytics.get_client_id(request)\n \n checkout = Checkout.from_storage(\n session_data, cart, request.user, tracking_code)\n response = view(request, checkout, cart)\n if checkout.modified:\n request.session[STORAGE_SESSION_KEY] = checkout.for_storage()\n return response\n\n return func\n", "path": "saleor/checkout/core.py"}], "after_files": [{"content": "from __future__ import unicode_literals\nfrom functools import wraps\n\nfrom django.conf import settings\nfrom django.db import transaction\nfrom django.forms.models import model_to_dict\nfrom django.utils.encoding import smart_text\nfrom prices import Price, FixedDiscount\n\nfrom ..cart.views import get_or_empty_db_cart\nfrom ..core import analytics\nfrom ..discount.models import Voucher, NotApplicable\nfrom ..order.models import Order\nfrom ..shipping.models import ShippingMethodCountry, ANY_COUNTRY\nfrom ..userprofile.models import Address, User\n\nSTORAGE_SESSION_KEY = 'checkout_storage'\n\n\nclass Checkout(object):\n\n VERSION = '1.0.0'\n modified = False\n\n def __init__(self, cart, user, tracking_code):\n self.cart = cart\n self.storage = {'version': self.VERSION}\n self.tracking_code = tracking_code\n self.user = user\n self.discounts = cart.discounts\n\n @classmethod\n def from_storage(cls, storage_data, cart, user, tracking_code):\n checkout = cls(cart, user, tracking_code)\n checkout.storage = storage_data\n try:\n version = checkout.storage['version']\n except (TypeError, KeyError):\n version = None\n if version != cls.VERSION:\n checkout.storage = {'version': cls.VERSION}\n return checkout\n\n def for_storage(self):\n return self.storage\n\n def clear_storage(self):\n self.storage = None\n self.modified = True\n\n def _get_address_from_storage(self, key):\n address_data = self.storage.get(key)\n if address_data is not None and address_data.get('id'):\n try:\n return Address.objects.get(id=address_data['id'])\n except Address.DoesNotExist:\n return None\n elif address_data:\n return Address(**address_data)\n return None\n\n @property\n def is_shipping_required(self):\n return self.cart.is_shipping_required()\n\n @property\n def deliveries(self):\n for partition in self.cart.partition():\n if self.shipping_method and partition.is_shipping_required():\n shipping_cost = self.shipping_method.get_total()\n else:\n shipping_cost = Price(0, currency=settings.DEFAULT_CURRENCY)\n total_with_shipping = partition.get_total(\n discounts=self.cart.discounts) + shipping_cost\n\n partition = [\n (item,\n item.get_price_per_item(discounts=self.cart.discounts),\n item.get_total(discounts=self.cart.discounts))\n for item in partition]\n\n yield partition, shipping_cost, total_with_shipping\n\n @property\n def shipping_address(self):\n address = self._get_address_from_storage('shipping_address')\n if address is None and self.user.is_authenticated():\n return self.user.default_shipping_address\n return address\n\n @shipping_address.setter\n def shipping_address(self, address):\n address_data = model_to_dict(address)\n address_data['country'] = smart_text(address_data['country'])\n self.storage['shipping_address'] = address_data\n self.modified = True\n\n @property\n def shipping_method(self):\n shipping_address = self.shipping_address\n if shipping_address is not None:\n shipping_method_country_id = self.storage.get(\n 'shipping_method_country_id')\n if shipping_method_country_id is not None:\n try:\n shipping_method_country = ShippingMethodCountry.objects.get(\n id=shipping_method_country_id)\n except ShippingMethodCountry.DoesNotExist:\n return None\n shipping_country_code = shipping_address.country.code\n if (shipping_method_country.country_code == ANY_COUNTRY or\n shipping_method_country.country_code == shipping_country_code):\n return shipping_method_country\n\n @shipping_method.setter\n def shipping_method(self, shipping_method_country):\n self.storage['shipping_method_country_id'] = shipping_method_country.id\n self.modified = True\n\n @property\n def email(self):\n return self.storage.get('email')\n\n @email.setter\n def email(self, email):\n self.storage['email'] = email\n self.modified = True\n\n @property\n def billing_address(self):\n address = self._get_address_from_storage('billing_address')\n if address is not None:\n return address\n elif self.user.is_authenticated() and self.user.default_billing_address:\n return self.user.default_billing_address\n elif self.shipping_address:\n return self.shipping_address\n\n @billing_address.setter\n def billing_address(self, address):\n address_data = model_to_dict(address)\n address_data['country'] = smart_text(address_data['country'])\n self.storage['billing_address'] = address_data\n self.modified = True\n\n @property\n def discount(self):\n value = self.storage.get('discount_value')\n currency = self.storage.get('discount_currency')\n name = self.storage.get('discount_name')\n if value is not None and name is not None and currency is not None:\n amount = Price(value, currency=currency)\n return FixedDiscount(amount, name)\n\n @discount.setter\n def discount(self, discount):\n amount = discount.amount\n self.storage['discount_value'] = smart_text(amount.net)\n self.storage['discount_currency'] = amount.currency\n self.storage['discount_name'] = discount.name\n self.modified = True\n\n @discount.deleter\n def discount(self):\n if 'discount_value' in self.storage:\n del self.storage['discount_value']\n self.modified = True\n if 'discount_currency' in self.storage:\n del self.storage['discount_currency']\n self.modified = True\n if 'discount_name' in self.storage:\n del self.storage['discount_name']\n self.modified = True\n\n @property\n def voucher_code(self):\n return self.storage.get('voucher_code')\n\n @voucher_code.setter\n def voucher_code(self, voucher_code):\n self.storage['voucher_code'] = voucher_code\n self.modified = True\n\n @voucher_code.deleter\n def voucher_code(self):\n if 'voucher_code' in self.storage:\n del self.storage['voucher_code']\n self.modified = True\n\n @property\n def is_shipping_same_as_billing(self):\n return Address.objects.are_identical(\n self.shipping_address, self.billing_address)\n\n def _add_to_user_address_book(self, address, is_billing=False,\n is_shipping=False):\n if self.user.is_authenticated():\n User.objects.store_address(\n self.user, address, shipping=is_shipping,\n billing=is_billing)\n\n def _get_address_copy(self, address):\n address.user = None\n address.pk = None\n address.save()\n return address\n\n def _save_order_billing_address(self):\n return self._get_address_copy(self.billing_address)\n\n def _save_order_shipping_address(self):\n return self._get_address_copy(self.shipping_address)\n\n @transaction.atomic\n def create_order(self):\n if self.is_shipping_required:\n shipping_address = self._save_order_shipping_address()\n self._add_to_user_address_book(\n self.shipping_address, is_shipping=True)\n else:\n shipping_address = None\n billing_address = self._save_order_billing_address()\n self._add_to_user_address_book(\n self.shipping_address, is_billing=True)\n\n order_data = {\n 'billing_address': billing_address,\n 'shipping_address': shipping_address,\n 'tracking_client_id': self.tracking_code,\n 'total': self.get_total()}\n\n if self.user.is_authenticated():\n order_data['user'] = self.user\n else:\n # TODO: we should always save email in order not only\n # for anonymous\n order_data['anonymous_user_email'] = self.email\n\n voucher = self._get_voucher()\n if voucher is not None:\n discount = self.discount\n order_data['voucher'] = voucher\n order_data['discount_amount'] = discount.amount\n order_data['discount_name'] = discount.name\n\n order = Order.objects.create(**order_data)\n\n for partition in self.cart.partition():\n shipping_required = partition.is_shipping_required()\n if shipping_required:\n shipping_price = self.shipping_method.get_total()\n shipping_method_name = smart_text(self.shipping_method)\n else:\n shipping_price = 0\n shipping_method_name = None\n group = order.groups.create(\n shipping_price=shipping_price,\n shipping_method_name=shipping_method_name)\n group.add_items_from_partition(\n partition, discounts=self.cart.discounts)\n\n if voucher is not None:\n Voucher.objects.increase_usage(voucher)\n\n return order\n\n def _get_voucher(self):\n voucher_code = self.voucher_code\n if voucher_code is not None:\n vouchers = Voucher.objects.active().select_for_update()\n try:\n return vouchers.get(code=self.voucher_code)\n except Voucher.DoesNotExist:\n return None\n\n def recalculate_discount(self):\n voucher = self._get_voucher()\n if voucher is not None:\n try:\n self.discount = voucher.get_discount_for_checkout(self)\n except NotApplicable:\n del self.discount\n del self.voucher_code\n else:\n del self.discount\n del self.voucher_code\n\n def get_subtotal(self):\n zero = Price(0, currency=settings.DEFAULT_CURRENCY)\n cost_iterator = (\n total - shipping_cost\n for shipment, shipping_cost, total in self.deliveries)\n total = sum(cost_iterator, zero)\n return total\n\n def get_total(self):\n zero = Price(0, currency=settings.DEFAULT_CURRENCY)\n cost_iterator = (\n total\n for shipment, shipping_cost, total in self.deliveries)\n total = sum(cost_iterator, zero)\n return total if self.discount is None else self.discount.apply(total)\n\n def get_total_shipping(self):\n zero = Price(0, currency=settings.DEFAULT_CURRENCY)\n cost_iterator = (\n shipping_cost\n for shipment, shipping_cost, total in self.deliveries)\n total = sum(cost_iterator, zero)\n return total\n\n\ndef load_checkout(view):\n @wraps(view)\n @get_or_empty_db_cart\n def func(request, cart):\n try:\n session_data = request.session[STORAGE_SESSION_KEY]\n except KeyError:\n session_data = ''\n tracking_code = analytics.get_client_id(request)\n\n checkout = Checkout.from_storage(\n session_data, cart, request.user, tracking_code)\n response = view(request, checkout, cart)\n if checkout.modified:\n request.session[STORAGE_SESSION_KEY] = checkout.for_storage()\n return response\n\n return func\n", "path": "saleor/checkout/core.py"}]}
| 3,331 | 485 |
gh_patches_debug_35702
|
rasdani/github-patches
|
git_diff
|
keras-team__keras-nlp-980
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Investigate top-p performance
Currently our top-p (nucleus) sampler has the worst performance of our entire sampling offering, likely because of the sort operation we need to do for our softmax probabilities. See [these rough numbers](https://github.com/keras-team/keras-nlp/commit/41af01200c5d9898f381477b6a67a87b6951f844#diff-576c27794bae284efc278336a16d0649aaf599973a64d4b65dc67bc99bb7f000) for example, where top-p is slower than beam, despite needing much less computation on the model itself.
We should see if there is anything we can do to speed up top-p sampling with XLA (e.g. a more XLA friendly sort op).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `keras_nlp/samplers/top_p_sampler.py`
Content:
```
1 # Copyright 2023 The KerasNLP Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 """Top-p Sampler."""
15
16 import tensorflow as tf
17
18 from keras_nlp.api_export import keras_nlp_export
19 from keras_nlp.samplers.sampler import Sampler
20 from keras_nlp.samplers.sampler import call_args_docstring
21 from keras_nlp.utils.python_utils import format_docstring
22
23
24 @format_docstring(call_args=call_args_docstring)
25 @keras_nlp_export("keras_nlp.samplers.TopPSampler")
26 class TopPSampler(Sampler):
27 """Top-P Sampler class.
28
29 This sampler implements top-p search algorithm. Top-p search selects tokens
30 from the smallest subset of output probabilities that sum to greater than
31 `p`. Put in another way, top-p will first order token predictions by
32 likelihood, and ignore all tokens after the cumulative probability of
33 selected tokens exceeds `p`, then select a token from the remaining tokens.
34
35 Args:
36 p: float, the `p` value of top-p.
37 seed: int, defaults to None. The random seed.
38
39 Call Args:
40 {{call_args}}
41
42 Examples:
43 ```python
44 # Use a simple alphabet of lowercase characters with ids in range [0, 25].
45 int_lookup = {i: chr(i + ord('a')) for i in range(26)}
46 char_lookup = {v: k for k, v in int_lookup.items()}
47 batch_size, length, vocab_size = 1, 12, len(int_lookup)
48
49 def next(prompt, cache, index):
50 hidden_states = tf.ones((batch_size, 10))
51 # A uniform distribution over our alphabet.
52 logits = tf.ones((batch_size, vocab_size))
53 return logits, hidden_states, cache
54
55 output = keras_nlp.samplers.TopPSampler(p=0.1)(
56 next=next,
57 prompt=tf.fill((batch_size, length,), char_lookup['z']),
58 index=5,
59 )
60 print(["".join([int_lookup[i] for i in s]) for s in output.numpy()])
61 # >>> ['zzzzzbabcccb']
62 ```
63 """
64
65 def __init__(
66 self,
67 p=0.1,
68 seed=None,
69 ):
70 super().__init__()
71 self.p = p
72 self.seed = seed
73
74 def get_next_token(self, probabilities):
75 # Sort preds in descending order.
76 sorted_preds, sorted_indices = tf.math.top_k(
77 probabilities, k=tf.shape(probabilities)[1], sorted=True
78 )
79 # Calculate cumulative probability distribution.
80 cumulative_probabilities = tf.math.cumsum(sorted_preds, axis=-1)
81 # Create a mask for the tokens to keep.
82 keep_mask = cumulative_probabilities <= self.p
83 # Shift to include the last token that exceed p.
84 shifted_keep_mask = tf.concat(
85 [tf.ones_like(keep_mask[:, :1]), keep_mask[:, :-1]], axis=-1
86 )
87 # Filter out unmasked tokens and sample from filtered distribution.
88 probabilities = tf.where(
89 shifted_keep_mask,
90 sorted_preds,
91 tf.zeros(tf.shape(probabilities), dtype=sorted_preds.dtype),
92 )
93 sorted_next_token = tf.random.categorical(
94 tf.math.log(probabilities), 1, seed=self.seed
95 )
96 return tf.gather_nd(sorted_indices, sorted_next_token, batch_dims=1)
97
98 def get_config(self):
99 config = super().get_config()
100 config.update(
101 {
102 "p": self.p,
103 "seed": self.seed,
104 }
105 )
106 return config
107
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/keras_nlp/samplers/top_p_sampler.py b/keras_nlp/samplers/top_p_sampler.py
--- a/keras_nlp/samplers/top_p_sampler.py
+++ b/keras_nlp/samplers/top_p_sampler.py
@@ -34,6 +34,12 @@
Args:
p: float, the `p` value of top-p.
+ k: int, defaults to None. If set, this argument defines a
+ heuristic "top-k" cutoff applied before the "top-p" sampling. All
+ logits not in the top `k` will be discarded, and the remaining
+ logits will be sorted to find a cutoff point for `p`. Setting this
+ arg can significantly speed sampling up by reducing the number
+ of tokens to sort.
seed: int, defaults to None. The random seed.
Call Args:
@@ -65,16 +71,21 @@
def __init__(
self,
p=0.1,
+ k=None,
seed=None,
):
super().__init__()
self.p = p
+ self.k = k
self.seed = seed
def get_next_token(self, probabilities):
- # Sort preds in descending order.
+ cutoff = tf.shape(probabilities)[1]
+ if self.k is not None:
+ # If `k` is set, only sample from top `k` tokens.
+ cutoff = tf.math.minimum(cutoff, self.k)
sorted_preds, sorted_indices = tf.math.top_k(
- probabilities, k=tf.shape(probabilities)[1], sorted=True
+ probabilities, k=cutoff, sorted=True
)
# Calculate cumulative probability distribution.
cumulative_probabilities = tf.math.cumsum(sorted_preds, axis=-1)
@@ -88,7 +99,7 @@
probabilities = tf.where(
shifted_keep_mask,
sorted_preds,
- tf.zeros(tf.shape(probabilities), dtype=sorted_preds.dtype),
+ tf.zeros(tf.shape(sorted_preds), dtype=sorted_preds.dtype),
)
sorted_next_token = tf.random.categorical(
tf.math.log(probabilities), 1, seed=self.seed
@@ -100,6 +111,7 @@
config.update(
{
"p": self.p,
+ "k": self.k,
"seed": self.seed,
}
)
|
{"golden_diff": "diff --git a/keras_nlp/samplers/top_p_sampler.py b/keras_nlp/samplers/top_p_sampler.py\n--- a/keras_nlp/samplers/top_p_sampler.py\n+++ b/keras_nlp/samplers/top_p_sampler.py\n@@ -34,6 +34,12 @@\n \n Args:\n p: float, the `p` value of top-p.\n+ k: int, defaults to None. If set, this argument defines a\n+ heuristic \"top-k\" cutoff applied before the \"top-p\" sampling. All\n+ logits not in the top `k` will be discarded, and the remaining\n+ logits will be sorted to find a cutoff point for `p`. Setting this\n+ arg can significantly speed sampling up by reducing the number\n+ of tokens to sort.\n seed: int, defaults to None. The random seed.\n \n Call Args:\n@@ -65,16 +71,21 @@\n def __init__(\n self,\n p=0.1,\n+ k=None,\n seed=None,\n ):\n super().__init__()\n self.p = p\n+ self.k = k\n self.seed = seed\n \n def get_next_token(self, probabilities):\n- # Sort preds in descending order.\n+ cutoff = tf.shape(probabilities)[1]\n+ if self.k is not None:\n+ # If `k` is set, only sample from top `k` tokens.\n+ cutoff = tf.math.minimum(cutoff, self.k)\n sorted_preds, sorted_indices = tf.math.top_k(\n- probabilities, k=tf.shape(probabilities)[1], sorted=True\n+ probabilities, k=cutoff, sorted=True\n )\n # Calculate cumulative probability distribution.\n cumulative_probabilities = tf.math.cumsum(sorted_preds, axis=-1)\n@@ -88,7 +99,7 @@\n probabilities = tf.where(\n shifted_keep_mask,\n sorted_preds,\n- tf.zeros(tf.shape(probabilities), dtype=sorted_preds.dtype),\n+ tf.zeros(tf.shape(sorted_preds), dtype=sorted_preds.dtype),\n )\n sorted_next_token = tf.random.categorical(\n tf.math.log(probabilities), 1, seed=self.seed\n@@ -100,6 +111,7 @@\n config.update(\n {\n \"p\": self.p,\n+ \"k\": self.k,\n \"seed\": self.seed,\n }\n )\n", "issue": "Investigate top-p performance\nCurrently our top-p (nucleus) sampler has the worst performance of our entire sampling offering, likely because of the sort operation we need to do for our softmax probabilities. See [these rough numbers](https://github.com/keras-team/keras-nlp/commit/41af01200c5d9898f381477b6a67a87b6951f844#diff-576c27794bae284efc278336a16d0649aaf599973a64d4b65dc67bc99bb7f000) for example, where top-p is slower than beam, despite needing much less computation on the model itself.\r\n\r\nWe should see if there is anything we can do to speed up top-p sampling with XLA (e.g. a more XLA friendly sort op).\n", "before_files": [{"content": "# Copyright 2023 The KerasNLP Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Top-p Sampler.\"\"\"\n\nimport tensorflow as tf\n\nfrom keras_nlp.api_export import keras_nlp_export\nfrom keras_nlp.samplers.sampler import Sampler\nfrom keras_nlp.samplers.sampler import call_args_docstring\nfrom keras_nlp.utils.python_utils import format_docstring\n\n\n@format_docstring(call_args=call_args_docstring)\n@keras_nlp_export(\"keras_nlp.samplers.TopPSampler\")\nclass TopPSampler(Sampler):\n \"\"\"Top-P Sampler class.\n\n This sampler implements top-p search algorithm. Top-p search selects tokens\n from the smallest subset of output probabilities that sum to greater than\n `p`. Put in another way, top-p will first order token predictions by\n likelihood, and ignore all tokens after the cumulative probability of\n selected tokens exceeds `p`, then select a token from the remaining tokens.\n\n Args:\n p: float, the `p` value of top-p.\n seed: int, defaults to None. The random seed.\n\n Call Args:\n {{call_args}}\n\n Examples:\n ```python\n # Use a simple alphabet of lowercase characters with ids in range [0, 25].\n int_lookup = {i: chr(i + ord('a')) for i in range(26)}\n char_lookup = {v: k for k, v in int_lookup.items()}\n batch_size, length, vocab_size = 1, 12, len(int_lookup)\n\n def next(prompt, cache, index):\n hidden_states = tf.ones((batch_size, 10))\n # A uniform distribution over our alphabet.\n logits = tf.ones((batch_size, vocab_size))\n return logits, hidden_states, cache\n\n output = keras_nlp.samplers.TopPSampler(p=0.1)(\n next=next,\n prompt=tf.fill((batch_size, length,), char_lookup['z']),\n index=5,\n )\n print([\"\".join([int_lookup[i] for i in s]) for s in output.numpy()])\n # >>> ['zzzzzbabcccb']\n ```\n \"\"\"\n\n def __init__(\n self,\n p=0.1,\n seed=None,\n ):\n super().__init__()\n self.p = p\n self.seed = seed\n\n def get_next_token(self, probabilities):\n # Sort preds in descending order.\n sorted_preds, sorted_indices = tf.math.top_k(\n probabilities, k=tf.shape(probabilities)[1], sorted=True\n )\n # Calculate cumulative probability distribution.\n cumulative_probabilities = tf.math.cumsum(sorted_preds, axis=-1)\n # Create a mask for the tokens to keep.\n keep_mask = cumulative_probabilities <= self.p\n # Shift to include the last token that exceed p.\n shifted_keep_mask = tf.concat(\n [tf.ones_like(keep_mask[:, :1]), keep_mask[:, :-1]], axis=-1\n )\n # Filter out unmasked tokens and sample from filtered distribution.\n probabilities = tf.where(\n shifted_keep_mask,\n sorted_preds,\n tf.zeros(tf.shape(probabilities), dtype=sorted_preds.dtype),\n )\n sorted_next_token = tf.random.categorical(\n tf.math.log(probabilities), 1, seed=self.seed\n )\n return tf.gather_nd(sorted_indices, sorted_next_token, batch_dims=1)\n\n def get_config(self):\n config = super().get_config()\n config.update(\n {\n \"p\": self.p,\n \"seed\": self.seed,\n }\n )\n return config\n", "path": "keras_nlp/samplers/top_p_sampler.py"}], "after_files": [{"content": "# Copyright 2023 The KerasNLP Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Top-p Sampler.\"\"\"\n\nimport tensorflow as tf\n\nfrom keras_nlp.api_export import keras_nlp_export\nfrom keras_nlp.samplers.sampler import Sampler\nfrom keras_nlp.samplers.sampler import call_args_docstring\nfrom keras_nlp.utils.python_utils import format_docstring\n\n\n@format_docstring(call_args=call_args_docstring)\n@keras_nlp_export(\"keras_nlp.samplers.TopPSampler\")\nclass TopPSampler(Sampler):\n \"\"\"Top-P Sampler class.\n\n This sampler implements top-p search algorithm. Top-p search selects tokens\n from the smallest subset of output probabilities that sum to greater than\n `p`. Put in another way, top-p will first order token predictions by\n likelihood, and ignore all tokens after the cumulative probability of\n selected tokens exceeds `p`, then select a token from the remaining tokens.\n\n Args:\n p: float, the `p` value of top-p.\n k: int, defaults to None. If set, this argument defines a\n heuristic \"top-k\" cutoff applied before the \"top-p\" sampling. All\n logits not in the top `k` will be discarded, and the remaining\n logits will be sorted to find a cutoff point for `p`. Setting this\n arg can significantly speed sampling up by reducing the number\n of tokens to sort.\n seed: int, defaults to None. The random seed.\n\n Call Args:\n {{call_args}}\n\n Examples:\n ```python\n # Use a simple alphabet of lowercase characters with ids in range [0, 25].\n int_lookup = {i: chr(i + ord('a')) for i in range(26)}\n char_lookup = {v: k for k, v in int_lookup.items()}\n batch_size, length, vocab_size = 1, 12, len(int_lookup)\n\n def next(prompt, cache, index):\n hidden_states = tf.ones((batch_size, 10))\n # A uniform distribution over our alphabet.\n logits = tf.ones((batch_size, vocab_size))\n return logits, hidden_states, cache\n\n output = keras_nlp.samplers.TopPSampler(p=0.1)(\n next=next,\n prompt=tf.fill((batch_size, length,), char_lookup['z']),\n index=5,\n )\n print([\"\".join([int_lookup[i] for i in s]) for s in output.numpy()])\n # >>> ['zzzzzbabcccb']\n ```\n \"\"\"\n\n def __init__(\n self,\n p=0.1,\n k=None,\n seed=None,\n ):\n super().__init__()\n self.p = p\n self.k = k\n self.seed = seed\n\n def get_next_token(self, probabilities):\n cutoff = tf.shape(probabilities)[1]\n if self.k is not None:\n # If `k` is set, only sample from top `k` tokens.\n cutoff = tf.math.minimum(cutoff, self.k)\n sorted_preds, sorted_indices = tf.math.top_k(\n probabilities, k=cutoff, sorted=True\n )\n # Calculate cumulative probability distribution.\n cumulative_probabilities = tf.math.cumsum(sorted_preds, axis=-1)\n # Create a mask for the tokens to keep.\n keep_mask = cumulative_probabilities <= self.p\n # Shift to include the last token that exceed p.\n shifted_keep_mask = tf.concat(\n [tf.ones_like(keep_mask[:, :1]), keep_mask[:, :-1]], axis=-1\n )\n # Filter out unmasked tokens and sample from filtered distribution.\n probabilities = tf.where(\n shifted_keep_mask,\n sorted_preds,\n tf.zeros(tf.shape(sorted_preds), dtype=sorted_preds.dtype),\n )\n sorted_next_token = tf.random.categorical(\n tf.math.log(probabilities), 1, seed=self.seed\n )\n return tf.gather_nd(sorted_indices, sorted_next_token, batch_dims=1)\n\n def get_config(self):\n config = super().get_config()\n config.update(\n {\n \"p\": self.p,\n \"k\": self.k,\n \"seed\": self.seed,\n }\n )\n return config\n", "path": "keras_nlp/samplers/top_p_sampler.py"}]}
| 1,579 | 528 |
gh_patches_debug_10598
|
rasdani/github-patches
|
git_diff
|
privacyidea__privacyidea-2479
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Allow PIN change at WebUI
### Top-level intent
Use the pin change during validate when logging in to the webui
### Steps to reproduce
1. configure ``change-pin-on-first-use``
2. configure ``login_mode=privacyIDEA``
3. Login to webui with 2FA
4. The webui will not display any challenge
### Expected outcome
The user should be able to change his PIN
### Actual outcome
Nothing is displayed
I think the problem is, that the input field is "ng-hidden" by some tokentype in the response. The PIN-change-challenge probably is missing some fields in the JSON response, so that dialog is hidden.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `privacyidea/lib/challengeresponsedecorators.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 #
3 # 2020-08-03 Cornelius Kölbel <[email protected]>
4 # Initial writeup
5 #
6 # License: AGPLv3
7 # contact: http://www.privacyidea.org
8 #
9 # This code is free software; you can redistribute it and/or
10 # modify it under the terms of the GNU AFFERO GENERAL PUBLIC LICENSE
11 # License as published by the Free Software Foundation; either
12 # version 3 of the License, or any later version.
13 #
14 # This code is distributed in the hope that it will be useful,
15 # but WITHOUT ANY WARRANTY; without even the implied warranty of
16 # MERCHANTABILITY or FITNE7SS FOR A PARTICULAR PURPOSE. See the
17 # GNU AFFERO GENERAL PUBLIC LICENSE for more details.
18 #
19 # You should have received a copy of the GNU Affero General Public
20 # License along with this program. If not, see <http://www.gnu.org/licenses/>.
21 #
22 """
23 These are the decorator functions for generic challenge response mechanisms:
24
25 * PIN change
26
27 Currently the decorator is only tested in tests/test_lib_token.py
28 """
29 import logging
30
31 from privacyidea.lib.policy import Match
32 from privacyidea.lib.policy import ACTION, SCOPE, check_pin, SCOPE
33 from privacyidea.lib.config import get_from_config
34 from privacyidea.lib.crypto import pass_hash, verify_pass_hash, get_rand_digit_str
35 from privacyidea.models import Challenge
36 from privacyidea.lib.challenge import get_challenges
37 from privacyidea.lib import _
38
39
40 log = logging.getLogger(__name__)
41
42
43 SEED_LENGTH = 16
44
45
46 class CHALLENGE_TYPE(object):
47 PIN_RESET = "generic_pin_reset"
48
49
50 def _create_pin_reset_challenge(token_obj, message, challenge_data=None):
51 validity = int(get_from_config('DefaultChallengeValidityTime', 120))
52 validity = int(get_from_config('PinResetChallengeValidityTime', validity))
53 db_challenge = Challenge(token_obj.token.serial,
54 challenge=CHALLENGE_TYPE.PIN_RESET,
55 data=challenge_data,
56 validitytime=validity)
57 db_challenge.save()
58 token_obj.challenge_janitor()
59 reply_dict = {}
60 reply_dict["multi_challenge"] = [{"transaction_id": db_challenge.transaction_id,
61 "message": message,
62 "serial": token_obj.token.serial,
63 "type": token_obj.token.tokentype}]
64 reply_dict["message"] = message
65 reply_dict["messages"] = [message]
66 reply_dict["transaction_id"] = db_challenge.transaction_id
67 # TODO: This line is deprecated: Add the information for the old administrative triggerchallenge
68 reply_dict["transaction_ids"] = [db_challenge.transaction_id]
69
70 return reply_dict
71
72
73 def generic_challenge_response_reset_pin(wrapped_function, *args, **kwds):
74 """
75 Check if the authentication was successful, but if the token needs to reset
76 its PIN.
77
78 Conditions: To do so we check for "next_pin_change" in the tokeninfo data. This
79 is however easily done using token.is_pin_change().
80
81 Policies: A policy defines, if this PIN reset functionality should be active
82 at all. scope=AUTH, action=CHANGE_PIN_VIA_VALIDATE
83
84 args are:
85 :param tokenobject_list: The list of all the tokens of the user, that will be checked
86 :param passw: The password presented in the authentication. We need this for the PIN reset.
87
88 kwds are:
89 :param options: options dictionary containing g
90 :param user: The user_obj
91 """
92
93 # Before we call the wrapped function, we need to check, if we have a generic challenge
94 # for the given transaction_id and if the token serial matches a given token
95 options = kwds.get("options") or {}
96 user_obj = kwds.get("user")
97 transaction_id = options.get("transaction_id") or options.get("state")
98 if transaction_id:
99 challenges = get_challenges(transaction_id=transaction_id, challenge=CHALLENGE_TYPE.PIN_RESET)
100 if len(challenges) == 1:
101 challenge = challenges[0]
102 # check if challenge matches a token and if it is valid
103 token_obj = next(t for t in args[0] if t.token.serial == challenge.serial)
104 if token_obj:
105 # Then either verify the PIN or set the PIN the first time. The
106 # PIN from the 1st response is stored in challenge.data
107 if challenge.data:
108 # Verify the password
109 if verify_pass_hash(args[1], challenge.data):
110 g = options.get("g")
111 challenge.set_otp_status(True)
112 token_obj.challenge_janitor()
113 # Success, set new PIN and return success
114 token_obj.set_pin(args[1])
115 pinpol = Match.token(g, scope=SCOPE.ENROLL, action=ACTION.CHANGE_PIN_EVERY,
116 token_obj=token_obj).action_values(unique=True)
117 # Set a new next_pin_change
118 if pinpol:
119 # Set a new next pin change
120 token_obj.set_next_pin_change(diff=list(pinpol)[0])
121 else:
122 # Obviously the admin removed the policy for changing pins,
123 # so we will not require to change the PIN again
124 token_obj.del_tokeninfo("next_pin_change")
125 return True, {"message": "PIN successfully set.",
126 "serial": token_obj.token.serial}
127 else:
128 return False, {"serial": token_obj.token.serial,
129 "message": "PINs do not match"}
130 else:
131 # The PIN is presented the first time.
132 # Verify if the PIN adheres to the PIN policies. This is always in the normal user context
133 g = options.get("g")
134 g.logged_in_user = {"role": SCOPE.USER}
135 if user_obj:
136 # check_pin below originally works for logged in users, since only logged in users
137 # are allowed to change the pin. So we need to construct a logged_in_user object, otherwise
138 # check_pin would fail.
139 g.logged_in_user["username"] = user_obj.login
140 g.logged_in_user["realm"] = user_obj.realm
141 check_pin(g, args[1], token_obj.token.tokentype, user_obj)
142 # We need to ask for a 2nd time
143 challenge.set_otp_status(True)
144 seed = get_rand_digit_str(SEED_LENGTH)
145 reply_dict = _create_pin_reset_challenge(token_obj, _("Please enter the new PIN again"),
146 pass_hash(args[1]))
147 return False, reply_dict
148
149 success, reply_dict = wrapped_function(*args, **kwds)
150
151 # After a successful authentication, we might start the PIN change process
152 if success and reply_dict.get("pin_change"):
153 g = options.get("g")
154 # Determine the realm by the serial
155 serial = reply_dict.get("serial")
156 # The tokenlist can contain more than one token. So we get the matching token object
157 token_obj = next(t for t in args[0] if t.token.serial == serial)
158 if g and Match.token(g, scope=SCOPE.AUTH, action=ACTION.CHANGE_PIN_VIA_VALIDATE, token_obj=token_obj).any():
159 reply_dict = _create_pin_reset_challenge(token_obj, _("Please enter a new PIN"))
160 return False, reply_dict
161
162 return success, reply_dict
163
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/privacyidea/lib/challengeresponsedecorators.py b/privacyidea/lib/challengeresponsedecorators.py
--- a/privacyidea/lib/challengeresponsedecorators.py
+++ b/privacyidea/lib/challengeresponsedecorators.py
@@ -59,6 +59,7 @@
reply_dict = {}
reply_dict["multi_challenge"] = [{"transaction_id": db_challenge.transaction_id,
"message": message,
+ "attributes": None,
"serial": token_obj.token.serial,
"type": token_obj.token.tokentype}]
reply_dict["message"] = message
|
{"golden_diff": "diff --git a/privacyidea/lib/challengeresponsedecorators.py b/privacyidea/lib/challengeresponsedecorators.py\n--- a/privacyidea/lib/challengeresponsedecorators.py\n+++ b/privacyidea/lib/challengeresponsedecorators.py\n@@ -59,6 +59,7 @@\n reply_dict = {}\n reply_dict[\"multi_challenge\"] = [{\"transaction_id\": db_challenge.transaction_id,\n \"message\": message,\n+ \"attributes\": None,\n \"serial\": token_obj.token.serial,\n \"type\": token_obj.token.tokentype}]\n reply_dict[\"message\"] = message\n", "issue": "Allow PIN change at WebUI\n\r\n### Top-level intent\r\n\r\nUse the pin change during validate when logging in to the webui\r\n\r\n### Steps to reproduce\r\n\r\n1. configure ``change-pin-on-first-use``\r\n2. configure ``login_mode=privacyIDEA``\r\n3. Login to webui with 2FA\r\n4. The webui will not display any challenge\r\n\r\n### Expected outcome\r\n\r\nThe user should be able to change his PIN\r\n\r\n### Actual outcome\r\n\r\nNothing is displayed\r\n\r\nI think the problem is, that the input field is \"ng-hidden\" by some tokentype in the response. The PIN-change-challenge probably is missing some fields in the JSON response, so that dialog is hidden.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# 2020-08-03 Cornelius K\u00f6lbel <[email protected]>\n# Initial writeup\n#\n# License: AGPLv3\n# contact: http://www.privacyidea.org\n#\n# This code is free software; you can redistribute it and/or\n# modify it under the terms of the GNU AFFERO GENERAL PUBLIC LICENSE\n# License as published by the Free Software Foundation; either\n# version 3 of the License, or any later version.\n#\n# This code is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNE7SS FOR A PARTICULAR PURPOSE. See the\n# GNU AFFERO GENERAL PUBLIC LICENSE for more details.\n#\n# You should have received a copy of the GNU Affero General Public\n# License along with this program. If not, see <http://www.gnu.org/licenses/>.\n#\n\"\"\"\nThese are the decorator functions for generic challenge response mechanisms:\n\n* PIN change\n\nCurrently the decorator is only tested in tests/test_lib_token.py\n\"\"\"\nimport logging\n\nfrom privacyidea.lib.policy import Match\nfrom privacyidea.lib.policy import ACTION, SCOPE, check_pin, SCOPE\nfrom privacyidea.lib.config import get_from_config\nfrom privacyidea.lib.crypto import pass_hash, verify_pass_hash, get_rand_digit_str\nfrom privacyidea.models import Challenge\nfrom privacyidea.lib.challenge import get_challenges\nfrom privacyidea.lib import _\n\n\nlog = logging.getLogger(__name__)\n\n\nSEED_LENGTH = 16\n\n\nclass CHALLENGE_TYPE(object):\n PIN_RESET = \"generic_pin_reset\"\n\n\ndef _create_pin_reset_challenge(token_obj, message, challenge_data=None):\n validity = int(get_from_config('DefaultChallengeValidityTime', 120))\n validity = int(get_from_config('PinResetChallengeValidityTime', validity))\n db_challenge = Challenge(token_obj.token.serial,\n challenge=CHALLENGE_TYPE.PIN_RESET,\n data=challenge_data,\n validitytime=validity)\n db_challenge.save()\n token_obj.challenge_janitor()\n reply_dict = {}\n reply_dict[\"multi_challenge\"] = [{\"transaction_id\": db_challenge.transaction_id,\n \"message\": message,\n \"serial\": token_obj.token.serial,\n \"type\": token_obj.token.tokentype}]\n reply_dict[\"message\"] = message\n reply_dict[\"messages\"] = [message]\n reply_dict[\"transaction_id\"] = db_challenge.transaction_id\n # TODO: This line is deprecated: Add the information for the old administrative triggerchallenge\n reply_dict[\"transaction_ids\"] = [db_challenge.transaction_id]\n\n return reply_dict\n\n\ndef generic_challenge_response_reset_pin(wrapped_function, *args, **kwds):\n \"\"\"\n Check if the authentication was successful, but if the token needs to reset\n its PIN.\n\n Conditions: To do so we check for \"next_pin_change\" in the tokeninfo data. This\n is however easily done using token.is_pin_change().\n\n Policies: A policy defines, if this PIN reset functionality should be active\n at all. scope=AUTH, action=CHANGE_PIN_VIA_VALIDATE\n\n args are:\n :param tokenobject_list: The list of all the tokens of the user, that will be checked\n :param passw: The password presented in the authentication. We need this for the PIN reset.\n\n kwds are:\n :param options: options dictionary containing g\n :param user: The user_obj\n \"\"\"\n\n # Before we call the wrapped function, we need to check, if we have a generic challenge\n # for the given transaction_id and if the token serial matches a given token\n options = kwds.get(\"options\") or {}\n user_obj = kwds.get(\"user\")\n transaction_id = options.get(\"transaction_id\") or options.get(\"state\")\n if transaction_id:\n challenges = get_challenges(transaction_id=transaction_id, challenge=CHALLENGE_TYPE.PIN_RESET)\n if len(challenges) == 1:\n challenge = challenges[0]\n # check if challenge matches a token and if it is valid\n token_obj = next(t for t in args[0] if t.token.serial == challenge.serial)\n if token_obj:\n # Then either verify the PIN or set the PIN the first time. The\n # PIN from the 1st response is stored in challenge.data\n if challenge.data:\n # Verify the password\n if verify_pass_hash(args[1], challenge.data):\n g = options.get(\"g\")\n challenge.set_otp_status(True)\n token_obj.challenge_janitor()\n # Success, set new PIN and return success\n token_obj.set_pin(args[1])\n pinpol = Match.token(g, scope=SCOPE.ENROLL, action=ACTION.CHANGE_PIN_EVERY,\n token_obj=token_obj).action_values(unique=True)\n # Set a new next_pin_change\n if pinpol:\n # Set a new next pin change\n token_obj.set_next_pin_change(diff=list(pinpol)[0])\n else:\n # Obviously the admin removed the policy for changing pins,\n # so we will not require to change the PIN again\n token_obj.del_tokeninfo(\"next_pin_change\")\n return True, {\"message\": \"PIN successfully set.\",\n \"serial\": token_obj.token.serial}\n else:\n return False, {\"serial\": token_obj.token.serial,\n \"message\": \"PINs do not match\"}\n else:\n # The PIN is presented the first time.\n # Verify if the PIN adheres to the PIN policies. This is always in the normal user context\n g = options.get(\"g\")\n g.logged_in_user = {\"role\": SCOPE.USER}\n if user_obj:\n # check_pin below originally works for logged in users, since only logged in users\n # are allowed to change the pin. So we need to construct a logged_in_user object, otherwise\n # check_pin would fail.\n g.logged_in_user[\"username\"] = user_obj.login\n g.logged_in_user[\"realm\"] = user_obj.realm\n check_pin(g, args[1], token_obj.token.tokentype, user_obj)\n # We need to ask for a 2nd time\n challenge.set_otp_status(True)\n seed = get_rand_digit_str(SEED_LENGTH)\n reply_dict = _create_pin_reset_challenge(token_obj, _(\"Please enter the new PIN again\"),\n pass_hash(args[1]))\n return False, reply_dict\n\n success, reply_dict = wrapped_function(*args, **kwds)\n\n # After a successful authentication, we might start the PIN change process\n if success and reply_dict.get(\"pin_change\"):\n g = options.get(\"g\")\n # Determine the realm by the serial\n serial = reply_dict.get(\"serial\")\n # The tokenlist can contain more than one token. So we get the matching token object\n token_obj = next(t for t in args[0] if t.token.serial == serial)\n if g and Match.token(g, scope=SCOPE.AUTH, action=ACTION.CHANGE_PIN_VIA_VALIDATE, token_obj=token_obj).any():\n reply_dict = _create_pin_reset_challenge(token_obj, _(\"Please enter a new PIN\"))\n return False, reply_dict\n\n return success, reply_dict\n", "path": "privacyidea/lib/challengeresponsedecorators.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# 2020-08-03 Cornelius K\u00f6lbel <[email protected]>\n# Initial writeup\n#\n# License: AGPLv3\n# contact: http://www.privacyidea.org\n#\n# This code is free software; you can redistribute it and/or\n# modify it under the terms of the GNU AFFERO GENERAL PUBLIC LICENSE\n# License as published by the Free Software Foundation; either\n# version 3 of the License, or any later version.\n#\n# This code is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNE7SS FOR A PARTICULAR PURPOSE. See the\n# GNU AFFERO GENERAL PUBLIC LICENSE for more details.\n#\n# You should have received a copy of the GNU Affero General Public\n# License along with this program. If not, see <http://www.gnu.org/licenses/>.\n#\n\"\"\"\nThese are the decorator functions for generic challenge response mechanisms:\n\n* PIN change\n\nCurrently the decorator is only tested in tests/test_lib_token.py\n\"\"\"\nimport logging\n\nfrom privacyidea.lib.policy import Match\nfrom privacyidea.lib.policy import ACTION, SCOPE, check_pin, SCOPE\nfrom privacyidea.lib.config import get_from_config\nfrom privacyidea.lib.crypto import pass_hash, verify_pass_hash, get_rand_digit_str\nfrom privacyidea.models import Challenge\nfrom privacyidea.lib.challenge import get_challenges\nfrom privacyidea.lib import _\n\n\nlog = logging.getLogger(__name__)\n\n\nSEED_LENGTH = 16\n\n\nclass CHALLENGE_TYPE(object):\n PIN_RESET = \"generic_pin_reset\"\n\n\ndef _create_pin_reset_challenge(token_obj, message, challenge_data=None):\n validity = int(get_from_config('DefaultChallengeValidityTime', 120))\n validity = int(get_from_config('PinResetChallengeValidityTime', validity))\n db_challenge = Challenge(token_obj.token.serial,\n challenge=CHALLENGE_TYPE.PIN_RESET,\n data=challenge_data,\n validitytime=validity)\n db_challenge.save()\n token_obj.challenge_janitor()\n reply_dict = {}\n reply_dict[\"multi_challenge\"] = [{\"transaction_id\": db_challenge.transaction_id,\n \"message\": message,\n \"attributes\": None,\n \"serial\": token_obj.token.serial,\n \"type\": token_obj.token.tokentype}]\n reply_dict[\"message\"] = message\n reply_dict[\"messages\"] = [message]\n reply_dict[\"transaction_id\"] = db_challenge.transaction_id\n # TODO: This line is deprecated: Add the information for the old administrative triggerchallenge\n reply_dict[\"transaction_ids\"] = [db_challenge.transaction_id]\n\n return reply_dict\n\n\ndef generic_challenge_response_reset_pin(wrapped_function, *args, **kwds):\n \"\"\"\n Check if the authentication was successful, but if the token needs to reset\n its PIN.\n\n Conditions: To do so we check for \"next_pin_change\" in the tokeninfo data. This\n is however easily done using token.is_pin_change().\n\n Policies: A policy defines, if this PIN reset functionality should be active\n at all. scope=AUTH, action=CHANGE_PIN_VIA_VALIDATE\n\n args are:\n :param tokenobject_list: The list of all the tokens of the user, that will be checked\n :param passw: The password presented in the authentication. We need this for the PIN reset.\n\n kwds are:\n :param options: options dictionary containing g\n :param user: The user_obj\n \"\"\"\n\n # Before we call the wrapped function, we need to check, if we have a generic challenge\n # for the given transaction_id and if the token serial matches a given token\n options = kwds.get(\"options\") or {}\n user_obj = kwds.get(\"user\")\n transaction_id = options.get(\"transaction_id\") or options.get(\"state\")\n if transaction_id:\n challenges = get_challenges(transaction_id=transaction_id, challenge=CHALLENGE_TYPE.PIN_RESET)\n if len(challenges) == 1:\n challenge = challenges[0]\n # check if challenge matches a token and if it is valid\n token_obj = next(t for t in args[0] if t.token.serial == challenge.serial)\n if token_obj:\n # Then either verify the PIN or set the PIN the first time. The\n # PIN from the 1st response is stored in challenge.data\n if challenge.data:\n # Verify the password\n if verify_pass_hash(args[1], challenge.data):\n g = options.get(\"g\")\n challenge.set_otp_status(True)\n token_obj.challenge_janitor()\n # Success, set new PIN and return success\n token_obj.set_pin(args[1])\n pinpol = Match.token(g, scope=SCOPE.ENROLL, action=ACTION.CHANGE_PIN_EVERY,\n token_obj=token_obj).action_values(unique=True)\n # Set a new next_pin_change\n if pinpol:\n # Set a new next pin change\n token_obj.set_next_pin_change(diff=list(pinpol)[0])\n else:\n # Obviously the admin removed the policy for changing pins,\n # so we will not require to change the PIN again\n token_obj.del_tokeninfo(\"next_pin_change\")\n return True, {\"message\": \"PIN successfully set.\",\n \"serial\": token_obj.token.serial}\n else:\n return False, {\"serial\": token_obj.token.serial,\n \"message\": \"PINs do not match\"}\n else:\n # The PIN is presented the first time.\n # Verify if the PIN adheres to the PIN policies. This is always in the normal user context\n g = options.get(\"g\")\n g.logged_in_user = {\"role\": SCOPE.USER}\n if user_obj:\n # check_pin below originally works for logged in users, since only logged in users\n # are allowed to change the pin. So we need to construct a logged_in_user object, otherwise\n # check_pin would fail.\n g.logged_in_user[\"username\"] = user_obj.login\n g.logged_in_user[\"realm\"] = user_obj.realm\n check_pin(g, args[1], token_obj.token.tokentype, user_obj)\n # We need to ask for a 2nd time\n challenge.set_otp_status(True)\n seed = get_rand_digit_str(SEED_LENGTH)\n reply_dict = _create_pin_reset_challenge(token_obj, _(\"Please enter the new PIN again\"),\n pass_hash(args[1]))\n return False, reply_dict\n\n success, reply_dict = wrapped_function(*args, **kwds)\n\n # After a successful authentication, we might start the PIN change process\n if success and reply_dict.get(\"pin_change\"):\n g = options.get(\"g\")\n # Determine the realm by the serial\n serial = reply_dict.get(\"serial\")\n # The tokenlist can contain more than one token. So we get the matching token object\n token_obj = next(t for t in args[0] if t.token.serial == serial)\n if g and Match.token(g, scope=SCOPE.AUTH, action=ACTION.CHANGE_PIN_VIA_VALIDATE, token_obj=token_obj).any():\n reply_dict = _create_pin_reset_challenge(token_obj, _(\"Please enter a new PIN\"))\n return False, reply_dict\n\n return success, reply_dict\n", "path": "privacyidea/lib/challengeresponsedecorators.py"}]}
| 2,375 | 145 |
gh_patches_debug_5590
|
rasdani/github-patches
|
git_diff
|
google__timesketch-1910
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Sigma analyzer creates saved search and story even with 0 results
The Sigma analyzer will create a story and saved search even if there are no results from the analyzer.
Fix: Only create saved search and story if there was any events tagged.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `timesketch/lib/analyzers/sigma_tagger.py`
Content:
```
1 """Index analyzer plugin for sigma."""
2 from __future__ import unicode_literals
3
4 import logging
5 import time
6 import elasticsearch
7
8 from flask import current_app
9
10 from timesketch.lib.analyzers import utils
11
12 from timesketch.lib.analyzers import interface
13 from timesketch.lib.analyzers import manager
14 import timesketch.lib.sigma_util as ts_sigma_lib
15
16
17 logger = logging.getLogger('timesketch.analyzers.sigma_tagger')
18
19
20 class SigmaPlugin(interface.BaseAnalyzer):
21 """Analyzer for Sigma."""
22
23 NAME = 'sigma'
24 DISPLAY_NAME = 'Sigma'
25 DESCRIPTION = 'Run pre-defined Sigma rules and tag matching events'
26
27 def run_sigma_rule(self, query, rule_name, tag_list = None):
28 """Runs a sigma rule and applies the appropriate tags.
29
30 Args:
31 query: elastic search query for events to tag.
32 rule_name: rule_name to apply to matching events.
33 tag_list: a list of additional tags to be added to the event(s)
34
35 Returns:
36 int: number of events tagged.
37 """
38 return_fields = []
39 tagged_events_counter = 0
40 events = self.event_stream(
41 query_string=query, return_fields=return_fields)
42 for event in events:
43 ts_sigma_rules = event.source.get('ts_sigma_rule', [])
44 ts_sigma_rules.append(rule_name)
45 event.add_attributes({'ts_sigma_rule': list(set(ts_sigma_rules))})
46 ts_ttp = event.source.get('ts_ttp', [])
47 for tag in tag_list:
48 # special handling for sigma tags that TS considers TTPS
49 # https://car.mitre.org and https://attack.mitre.org
50 if tag.startswith(('attack.', 'car.')):
51 ts_ttp.append(tag)
52 tag_list.remove(tag)
53 event.add_tags(tag_list)
54 if len(ts_ttp) > 0:
55 event.add_attributes({'ts_ttp': list(set(ts_ttp))})
56 event.commit()
57 tagged_events_counter += 1
58 return tagged_events_counter
59
60 def run(self):
61 """Entry point for the analyzer.
62
63 Returns:
64 String with summary of the analyzer result.
65 """
66
67 tags_applied = {}
68 sigma_rule_counter = 0
69 sigma_rules = ts_sigma_lib.get_all_sigma_rules()
70 if sigma_rules is None:
71 logger.error('No Sigma rules found. Check SIGMA_RULES_FOLDERS')
72 problem_strings = []
73 output_strings = []
74
75 for rule in sigma_rules:
76 tags_applied[rule.get('file_name')] = 0
77 try:
78 sigma_rule_counter += 1
79 tagged_events_counter = self.run_sigma_rule(
80 rule.get('es_query'), rule.get('file_name'),
81 tag_list=rule.get('tags'))
82 tags_applied[rule.get('file_name')] += tagged_events_counter
83 if sigma_rule_counter % 10 == 0:
84 logger.debug('Rule {0:d}/{1:d}'.format(
85 sigma_rule_counter, len(sigma_rules)))
86 except elasticsearch.TransportError as e:
87 logger.error(
88 'Timeout executing search for {0:s}: '
89 '{1!s} waiting for 10 seconds'.format(
90 rule.get('file_name'), e), exc_info=True)
91 # this is caused by too many ES queries in short time range
92 # TODO: https://github.com/google/timesketch/issues/1782
93 sleep_time = current_app.config.get(
94 'SIGMA_TAG_DELAY', 15)
95 time.sleep(sleep_time)
96 tagged_events_counter = self.run_sigma_rule(
97 rule.get('es_query'), rule.get('file_name'),
98 tag_list=rule.get('tags'))
99 tags_applied[rule.get('file_name')] += tagged_events_counter
100 # Wide exception handling since there are multiple exceptions that
101 # can be raised by the underlying sigma library.
102 except: # pylint: disable=bare-except
103 logger.error(
104 'Problem with rule in file {0:s}: '.format(
105 rule.get('file_name')), exc_info=True)
106 problem_strings.append('* {0:s}'.format(
107 rule.get('file_name')))
108 continue
109
110 total_tagged_events = sum(tags_applied.values())
111 output_strings.append('Applied {0:d} tags'.format(total_tagged_events))
112
113 if sigma_rule_counter > 0:
114 self.add_sigma_match_view(sigma_rule_counter)
115
116 if len(problem_strings) > 0:
117 output_strings.append('Problematic rules:')
118 output_strings.extend(problem_strings)
119
120 return '\n'.join(output_strings)
121
122 def add_sigma_match_view(self, sigma_rule_counter):
123 """Adds a view with the top 20 matching rules.
124
125 Args:
126 sigma_rule_counter number of matching rules
127
128 """
129 view = self.sketch.add_view(
130 view_name='Sigma Rule matches', analyzer_name=self.NAME,
131 query_string='tag:"sigma*"')
132 agg_params = {
133 'field': 'tag',
134 'limit': 20,
135 'index': [self.timeline_id],
136 }
137 agg_obj = self.sketch.add_aggregation(
138 name='Top 20 Sigma tags', agg_name='field_bucket',
139 agg_params=agg_params, view_id=view.id, chart_type='hbarchart',
140 description='Created by the Sigma analyzer')
141
142 story = self.sketch.add_story('Sigma Rule hits')
143 story.add_text(
144 utils.SIGMA_STORY_HEADER, skip_if_exists=True)
145
146 story.add_text(
147 '## Sigma Analyzer.\n\nThe Sigma '
148 'analyzer takes Events and matches them with Sigma rules.'
149 'In this timeline the analyzer discovered {0:d} '
150 'Sigma tags.\n\nThis is a summary of '
151 'it\'s findings.'.format(sigma_rule_counter))
152 story.add_text(
153 'The top 20 most commonly discovered tags were:')
154 story.add_aggregation(agg_obj)
155 story.add_text(
156 'And an overview of all the discovered search terms:')
157 story.add_view(view)
158
159
160 class RulesSigmaPlugin(SigmaPlugin):
161 """Sigma plugin to run rules."""
162
163 NAME = 'sigma'
164
165 manager.AnalysisManager.register_analyzer(RulesSigmaPlugin)
166
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/timesketch/lib/analyzers/sigma_tagger.py b/timesketch/lib/analyzers/sigma_tagger.py
--- a/timesketch/lib/analyzers/sigma_tagger.py
+++ b/timesketch/lib/analyzers/sigma_tagger.py
@@ -110,7 +110,7 @@
total_tagged_events = sum(tags_applied.values())
output_strings.append('Applied {0:d} tags'.format(total_tagged_events))
- if sigma_rule_counter > 0:
+ if total_tagged_events > 0:
self.add_sigma_match_view(sigma_rule_counter)
if len(problem_strings) > 0:
|
{"golden_diff": "diff --git a/timesketch/lib/analyzers/sigma_tagger.py b/timesketch/lib/analyzers/sigma_tagger.py\n--- a/timesketch/lib/analyzers/sigma_tagger.py\n+++ b/timesketch/lib/analyzers/sigma_tagger.py\n@@ -110,7 +110,7 @@\n total_tagged_events = sum(tags_applied.values())\n output_strings.append('Applied {0:d} tags'.format(total_tagged_events))\n \n- if sigma_rule_counter > 0:\n+ if total_tagged_events > 0:\n self.add_sigma_match_view(sigma_rule_counter)\n \n if len(problem_strings) > 0:\n", "issue": "Sigma analyzer creates saved search and story even with 0 results\nThe Sigma analyzer will create a story and saved search even if there are no results from the analyzer.\r\n\r\nFix: Only create saved search and story if there was any events tagged.\n", "before_files": [{"content": "\"\"\"Index analyzer plugin for sigma.\"\"\"\nfrom __future__ import unicode_literals\n\nimport logging\nimport time\nimport elasticsearch\n\nfrom flask import current_app\n\nfrom timesketch.lib.analyzers import utils\n\nfrom timesketch.lib.analyzers import interface\nfrom timesketch.lib.analyzers import manager\nimport timesketch.lib.sigma_util as ts_sigma_lib\n\n\nlogger = logging.getLogger('timesketch.analyzers.sigma_tagger')\n\n\nclass SigmaPlugin(interface.BaseAnalyzer):\n \"\"\"Analyzer for Sigma.\"\"\"\n\n NAME = 'sigma'\n DISPLAY_NAME = 'Sigma'\n DESCRIPTION = 'Run pre-defined Sigma rules and tag matching events'\n\n def run_sigma_rule(self, query, rule_name, tag_list = None):\n \"\"\"Runs a sigma rule and applies the appropriate tags.\n\n Args:\n query: elastic search query for events to tag.\n rule_name: rule_name to apply to matching events.\n tag_list: a list of additional tags to be added to the event(s)\n\n Returns:\n int: number of events tagged.\n \"\"\"\n return_fields = []\n tagged_events_counter = 0\n events = self.event_stream(\n query_string=query, return_fields=return_fields)\n for event in events:\n ts_sigma_rules = event.source.get('ts_sigma_rule', [])\n ts_sigma_rules.append(rule_name)\n event.add_attributes({'ts_sigma_rule': list(set(ts_sigma_rules))})\n ts_ttp = event.source.get('ts_ttp', [])\n for tag in tag_list:\n # special handling for sigma tags that TS considers TTPS\n # https://car.mitre.org and https://attack.mitre.org\n if tag.startswith(('attack.', 'car.')):\n ts_ttp.append(tag)\n tag_list.remove(tag)\n event.add_tags(tag_list)\n if len(ts_ttp) > 0:\n event.add_attributes({'ts_ttp': list(set(ts_ttp))})\n event.commit()\n tagged_events_counter += 1\n return tagged_events_counter\n\n def run(self):\n \"\"\"Entry point for the analyzer.\n\n Returns:\n String with summary of the analyzer result.\n \"\"\"\n\n tags_applied = {}\n sigma_rule_counter = 0\n sigma_rules = ts_sigma_lib.get_all_sigma_rules()\n if sigma_rules is None:\n logger.error('No Sigma rules found. Check SIGMA_RULES_FOLDERS')\n problem_strings = []\n output_strings = []\n\n for rule in sigma_rules:\n tags_applied[rule.get('file_name')] = 0\n try:\n sigma_rule_counter += 1\n tagged_events_counter = self.run_sigma_rule(\n rule.get('es_query'), rule.get('file_name'),\n tag_list=rule.get('tags'))\n tags_applied[rule.get('file_name')] += tagged_events_counter\n if sigma_rule_counter % 10 == 0:\n logger.debug('Rule {0:d}/{1:d}'.format(\n sigma_rule_counter, len(sigma_rules)))\n except elasticsearch.TransportError as e:\n logger.error(\n 'Timeout executing search for {0:s}: '\n '{1!s} waiting for 10 seconds'.format(\n rule.get('file_name'), e), exc_info=True)\n # this is caused by too many ES queries in short time range\n # TODO: https://github.com/google/timesketch/issues/1782\n sleep_time = current_app.config.get(\n 'SIGMA_TAG_DELAY', 15)\n time.sleep(sleep_time)\n tagged_events_counter = self.run_sigma_rule(\n rule.get('es_query'), rule.get('file_name'),\n tag_list=rule.get('tags'))\n tags_applied[rule.get('file_name')] += tagged_events_counter\n # Wide exception handling since there are multiple exceptions that\n # can be raised by the underlying sigma library.\n except: # pylint: disable=bare-except\n logger.error(\n 'Problem with rule in file {0:s}: '.format(\n rule.get('file_name')), exc_info=True)\n problem_strings.append('* {0:s}'.format(\n rule.get('file_name')))\n continue\n\n total_tagged_events = sum(tags_applied.values())\n output_strings.append('Applied {0:d} tags'.format(total_tagged_events))\n\n if sigma_rule_counter > 0:\n self.add_sigma_match_view(sigma_rule_counter)\n\n if len(problem_strings) > 0:\n output_strings.append('Problematic rules:')\n output_strings.extend(problem_strings)\n\n return '\\n'.join(output_strings)\n\n def add_sigma_match_view(self, sigma_rule_counter):\n \"\"\"Adds a view with the top 20 matching rules.\n\n Args:\n sigma_rule_counter number of matching rules\n\n \"\"\"\n view = self.sketch.add_view(\n view_name='Sigma Rule matches', analyzer_name=self.NAME,\n query_string='tag:\"sigma*\"')\n agg_params = {\n 'field': 'tag',\n 'limit': 20,\n 'index': [self.timeline_id],\n }\n agg_obj = self.sketch.add_aggregation(\n name='Top 20 Sigma tags', agg_name='field_bucket',\n agg_params=agg_params, view_id=view.id, chart_type='hbarchart',\n description='Created by the Sigma analyzer')\n\n story = self.sketch.add_story('Sigma Rule hits')\n story.add_text(\n utils.SIGMA_STORY_HEADER, skip_if_exists=True)\n\n story.add_text(\n '## Sigma Analyzer.\\n\\nThe Sigma '\n 'analyzer takes Events and matches them with Sigma rules.'\n 'In this timeline the analyzer discovered {0:d} '\n 'Sigma tags.\\n\\nThis is a summary of '\n 'it\\'s findings.'.format(sigma_rule_counter))\n story.add_text(\n 'The top 20 most commonly discovered tags were:')\n story.add_aggregation(agg_obj)\n story.add_text(\n 'And an overview of all the discovered search terms:')\n story.add_view(view)\n\n\nclass RulesSigmaPlugin(SigmaPlugin):\n \"\"\"Sigma plugin to run rules.\"\"\"\n\n NAME = 'sigma'\n\nmanager.AnalysisManager.register_analyzer(RulesSigmaPlugin)\n", "path": "timesketch/lib/analyzers/sigma_tagger.py"}], "after_files": [{"content": "\"\"\"Index analyzer plugin for sigma.\"\"\"\nfrom __future__ import unicode_literals\n\nimport logging\nimport time\nimport elasticsearch\n\nfrom flask import current_app\n\nfrom timesketch.lib.analyzers import utils\n\nfrom timesketch.lib.analyzers import interface\nfrom timesketch.lib.analyzers import manager\nimport timesketch.lib.sigma_util as ts_sigma_lib\n\n\nlogger = logging.getLogger('timesketch.analyzers.sigma_tagger')\n\n\nclass SigmaPlugin(interface.BaseAnalyzer):\n \"\"\"Analyzer for Sigma.\"\"\"\n\n NAME = 'sigma'\n DISPLAY_NAME = 'Sigma'\n DESCRIPTION = 'Run pre-defined Sigma rules and tag matching events'\n\n def run_sigma_rule(self, query, rule_name, tag_list = None):\n \"\"\"Runs a sigma rule and applies the appropriate tags.\n\n Args:\n query: elastic search query for events to tag.\n rule_name: rule_name to apply to matching events.\n tag_list: a list of additional tags to be added to the event(s)\n\n Returns:\n int: number of events tagged.\n \"\"\"\n return_fields = []\n tagged_events_counter = 0\n events = self.event_stream(\n query_string=query, return_fields=return_fields)\n for event in events:\n ts_sigma_rules = event.source.get('ts_sigma_rule', [])\n ts_sigma_rules.append(rule_name)\n event.add_attributes({'ts_sigma_rule': list(set(ts_sigma_rules))})\n ts_ttp = event.source.get('ts_ttp', [])\n for tag in tag_list:\n # special handling for sigma tags that TS considers TTPS\n # https://car.mitre.org and https://attack.mitre.org\n if tag.startswith(('attack.', 'car.')):\n ts_ttp.append(tag)\n tag_list.remove(tag)\n event.add_tags(tag_list)\n if len(ts_ttp) > 0:\n event.add_attributes({'ts_ttp': list(set(ts_ttp))})\n event.commit()\n tagged_events_counter += 1\n return tagged_events_counter\n\n def run(self):\n \"\"\"Entry point for the analyzer.\n\n Returns:\n String with summary of the analyzer result.\n \"\"\"\n\n tags_applied = {}\n sigma_rule_counter = 0\n sigma_rules = ts_sigma_lib.get_all_sigma_rules()\n if sigma_rules is None:\n logger.error('No Sigma rules found. Check SIGMA_RULES_FOLDERS')\n problem_strings = []\n output_strings = []\n\n for rule in sigma_rules:\n tags_applied[rule.get('file_name')] = 0\n try:\n sigma_rule_counter += 1\n tagged_events_counter = self.run_sigma_rule(\n rule.get('es_query'), rule.get('file_name'),\n tag_list=rule.get('tags'))\n tags_applied[rule.get('file_name')] += tagged_events_counter\n if sigma_rule_counter % 10 == 0:\n logger.debug('Rule {0:d}/{1:d}'.format(\n sigma_rule_counter, len(sigma_rules)))\n except elasticsearch.TransportError as e:\n logger.error(\n 'Timeout executing search for {0:s}: '\n '{1!s} waiting for 10 seconds'.format(\n rule.get('file_name'), e), exc_info=True)\n # this is caused by too many ES queries in short time range\n # TODO: https://github.com/google/timesketch/issues/1782\n sleep_time = current_app.config.get(\n 'SIGMA_TAG_DELAY', 15)\n time.sleep(sleep_time)\n tagged_events_counter = self.run_sigma_rule(\n rule.get('es_query'), rule.get('file_name'),\n tag_list=rule.get('tags'))\n tags_applied[rule.get('file_name')] += tagged_events_counter\n # Wide exception handling since there are multiple exceptions that\n # can be raised by the underlying sigma library.\n except: # pylint: disable=bare-except\n logger.error(\n 'Problem with rule in file {0:s}: '.format(\n rule.get('file_name')), exc_info=True)\n problem_strings.append('* {0:s}'.format(\n rule.get('file_name')))\n continue\n\n total_tagged_events = sum(tags_applied.values())\n output_strings.append('Applied {0:d} tags'.format(total_tagged_events))\n\n if total_tagged_events > 0:\n self.add_sigma_match_view(sigma_rule_counter)\n\n if len(problem_strings) > 0:\n output_strings.append('Problematic rules:')\n output_strings.extend(problem_strings)\n\n return '\\n'.join(output_strings)\n\n def add_sigma_match_view(self, sigma_rule_counter):\n \"\"\"Adds a view with the top 20 matching rules.\n\n Args:\n sigma_rule_counter number of matching rules\n\n \"\"\"\n view = self.sketch.add_view(\n view_name='Sigma Rule matches', analyzer_name=self.NAME,\n query_string='tag:\"sigma*\"')\n agg_params = {\n 'field': 'tag',\n 'limit': 20,\n 'index': [self.timeline_id],\n }\n agg_obj = self.sketch.add_aggregation(\n name='Top 20 Sigma tags', agg_name='field_bucket',\n agg_params=agg_params, view_id=view.id, chart_type='hbarchart',\n description='Created by the Sigma analyzer')\n\n story = self.sketch.add_story('Sigma Rule hits')\n story.add_text(\n utils.SIGMA_STORY_HEADER, skip_if_exists=True)\n\n story.add_text(\n '## Sigma Analyzer.\\n\\nThe Sigma '\n 'analyzer takes Events and matches them with Sigma rules.'\n 'In this timeline the analyzer discovered {0:d} '\n 'Sigma tags.\\n\\nThis is a summary of '\n 'it\\'s findings.'.format(sigma_rule_counter))\n story.add_text(\n 'The top 20 most commonly discovered tags were:')\n story.add_aggregation(agg_obj)\n story.add_text(\n 'And an overview of all the discovered search terms:')\n story.add_view(view)\n\n\nclass RulesSigmaPlugin(SigmaPlugin):\n \"\"\"Sigma plugin to run rules.\"\"\"\n\n NAME = 'sigma'\n\nmanager.AnalysisManager.register_analyzer(RulesSigmaPlugin)\n", "path": "timesketch/lib/analyzers/sigma_tagger.py"}]}
| 2,027 | 151 |
gh_patches_debug_1796
|
rasdani/github-patches
|
git_diff
|
xonsh__xonsh-3121
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Syntax errors when using bashisms xontrib
At least making assignment statements and entering function definitions at the prompt is
broken when using the included `bashisms` xontrib and prompt toolkit.
## xonfig
```
$ xonfig
+------------------+---------------------+
| xonsh | 0.8.12 |
| Git SHA | 3edd2df7 |
| Commit Date | May 9 07:50:20 2019 |
| Python | 3.7.3 |
| PLY | 3.11 |
| have readline | True |
| prompt toolkit | 2.0.9 |
| shell type | prompt_toolkit2 |
| pygments | 2.3.1 |
| on posix | True |
| on linux | True |
| distro | ubuntu |
| on darwin | False |
| on windows | False |
| on cygwin | False |
| on msys2 | False |
| is superuser | False |
| default encoding | utf-8 |
| xonsh encoding | utf-8 |
| encoding errors | surrogateescape |
+------------------+---------------------+
```
## Expected Behavior
I should be able to create new variables and function definitions, no sweat.
## Current Behavior
Things work fine until I start the shell with the xontrib `bashisms` loaded, or after I start the shell without it and load it later.
Assignment statements appear to go into multiline mode after hitting the return
key, and after a second return key, a stacktrace appears. The assignment
statement does not succeed.
Function definitions at the prompt result in an IndexError and the function is
not defined afterwards.
### Traceback (if applicable)
#### Assignment
```
$ a = 1
$ a
1
$ xontrib load bashisms
$ b = 1
..................................................
Traceback (most recent call last):
File "/home/eddie/source/xonsh/xonsh/ptk2/shell.py", line 173, in _push
code = self.execer.compile(src, mode="single", glbs=self.ctx, locs=None)
File "/home/eddie/source/xonsh/xonsh/execer.py", line 135, in compile
tree = self.parse(input, ctx, mode=mode, filename=filename, transform=transform)
File "/home/eddie/source/xonsh/xonsh/execer.py", line 96, in parse
tree, input = self._parse_ctx_free(input, mode=mode, filename=filename)
File "/home/eddie/source/xonsh/xonsh/execer.py", line 235, in _parse_ctx_free
raise original_error from None
File "/home/eddie/source/xonsh/xonsh/execer.py", line 220, in _parse_ctx_free
debug_level=(self.debug_level > 2),
File "/home/eddie/source/xonsh/xonsh/parsers/base.py", line 543, in parse
tree = self.parser.parse(input=s, lexer=self.lexer, debug=debug_level)
File "/home/eddie/source/xonsh/xonsh/ply/ply/yacc.py", line 335, in parse
return self.parseopt_notrack(input, lexer, debug, tracking, tokenfunc)
File "/home/eddie/source/xonsh/xonsh/ply/ply/yacc.py", line 1203, in parseopt_notrack
tok = call_errorfunc(self.errorfunc, errtoken, self)
File "/home/eddie/source/xonsh/xonsh/ply/ply/yacc.py", line 194, in call_errorfunc
r = errorfunc(token)
File "/home/eddie/source/xonsh/xonsh/parsers/base.py", line 3285, in p_error
self._parse_error("no further code", None)
File "/home/eddie/source/xonsh/xonsh/parsers/base.py", line 676, in _parse_error
raise err
File "<string>", line None
SyntaxError: None: no further code
$ b
Traceback (most recent call last):
File "/home/eddie/source/xonsh/xonsh/built_ins.py", line 560, in _run_binary
p = self.cls(self.cmd, bufsize=bufsize, **kwargs)
File "/home/eddie/source/xonsh/xonsh/proc.py", line 583, in __init__
*args, stdin=stdin, stdout=stdout, stderr=stderr, **kwargs
File "/home/eddie/.pyenv/versions/3.7.3/lib/python3.7/subprocess.py", line 775, in __init__
restore_signals, start_new_session)
File "/home/eddie/.pyenv/versions/3.7.3/lib/python3.7/subprocess.py", line 1522, in _execute_child
raise child_exception_type(errno_num, err_msg, err_filename)
FileNotFoundError: [Errno 2] No such file or directory: 'b': 'b'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/eddie/source/xonsh/xonsh/proc.py", line 1856, in __init__
proc = spec.run(pipeline_group=pipeline_group)
File "/home/eddie/source/xonsh/xonsh/built_ins.py", line 549, in run
p = self._run_binary(kwargs)
File "/home/eddie/source/xonsh/xonsh/built_ins.py", line 571, in _run_binary
raise XonshError(e)
xonsh.tools.XonshError: xonsh: subprocess mode: command not found: b
Did you mean one of the following?
bg: Alias
e: Alias
z: Alias
bc: Command (/usr/bin/bc)
ab: Command (/usr/bin/ab)
b: command not found
```
#### Function definition
```
$ def f():
.................................................. pass
..................................................
$ f
<function __main__.f>
$ xontrib load bashisms
$ def g():
.................................................. pass
..................................................
Traceback (most recent call last):
File "/home/eddie/source/xonsh/xonsh/execer.py", line 220, in _parse_ctx_free
debug_level=(self.debug_level > 2),
File "/home/eddie/source/xonsh/xonsh/parsers/base.py", line 543, in parse
tree = self.parser.parse(input=s, lexer=self.lexer, debug=debug_level)
File "/home/eddie/source/xonsh/xonsh/ply/ply/yacc.py", line 335, in parse
return self.parseopt_notrack(input, lexer, debug, tracking, tokenfunc)
File "/home/eddie/source/xonsh/xonsh/ply/ply/yacc.py", line 1203, in parseopt_notrack
tok = call_errorfunc(self.errorfunc, errtoken, self)
File "/home/eddie/source/xonsh/xonsh/ply/ply/yacc.py", line 194, in call_errorfunc
r = errorfunc(token)
File "/home/eddie/source/xonsh/xonsh/parsers/base.py", line 3295, in p_error
self._parse_error(msg, self.currloc(lineno=p.lineno, column=p.lexpos))
File "/home/eddie/source/xonsh/xonsh/parsers/base.py", line 676, in _parse_error
raise err
File "<string>", line None
SyntaxError: /home/eddie/source/xonsh/xontrib/prompt_ret_code.xsh:3:0: ('code: ',)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/eddie/source/xonsh/xonsh/ptk2/shell.py", line 173, in _push
code = self.execer.compile(src, mode="single", glbs=self.ctx, locs=None)
File "/home/eddie/source/xonsh/xonsh/execer.py", line 135, in compile
tree = self.parse(input, ctx, mode=mode, filename=filename, transform=transform)
File "/home/eddie/source/xonsh/xonsh/execer.py", line 96, in parse
tree, input = self._parse_ctx_free(input, mode=mode, filename=filename)
File "/home/eddie/source/xonsh/xonsh/execer.py", line 242, in _parse_ctx_free
line, nlogical, idx = get_logical_line(lines, idx)
File "/home/eddie/source/xonsh/xonsh/tools.py", line 544, in get_logical_line
line = lines[idx]
IndexError: list index out of range
$ g
Traceback (most recent call last):
File "/home/eddie/source/xonsh/xonsh/built_ins.py", line 560, in _run_binary
p = self.cls(self.cmd, bufsize=bufsize, **kwargs)
File "/home/eddie/source/xonsh/xonsh/proc.py", line 583, in __init__
*args, stdin=stdin, stdout=stdout, stderr=stderr, **kwargs
File "/home/eddie/.pyenv/versions/3.7.3/lib/python3.7/subprocess.py", line 775, in __init__
restore_signals, start_new_session)
File "/home/eddie/.pyenv/versions/3.7.3/lib/python3.7/subprocess.py", line 1522, in _execute_child
raise child_exception_type(errno_num, err_msg, err_filename)
FileNotFoundError: [Errno 2] No such file or directory: 'g': 'g'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/eddie/source/xonsh/xonsh/proc.py", line 1856, in __init__
proc = spec.run(pipeline_group=pipeline_group)
File "/home/eddie/source/xonsh/xonsh/built_ins.py", line 549, in run
p = self._run_binary(kwargs)
File "/home/eddie/source/xonsh/xonsh/built_ins.py", line 571, in _run_binary
raise XonshError(e)
xonsh.tools.XonshError: xonsh: subprocess mode: command not found: g
Did you mean one of the following?
fg: Alias
bg: Alias
e: Alias
z: Alias
ag: Command (/usr/local/bin/ag)
g: command not found
```
## Steps to Reproduce
```
# start w/o bashisms loaded
$ a = 1
$ xontrib load bashisms
$ a = 1
```
or
```
# start w/o bashisms loaded
$ xontrib load bashisms
$ def f():
.................................................. pass
..................................................
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `xontrib/bashisms.py`
Content:
```
1 """Bash-like interface extensions for xonsh."""
2 import shlex
3 import sys
4 import re
5
6 from prompt_toolkit.keys import Keys
7 from prompt_toolkit.filters import Condition, EmacsInsertMode, ViInsertMode
8
9 from xonsh.platform import ptk_shell_type
10
11 __all__ = ()
12
13
14 @events.on_transform_command
15 def bash_preproc(cmd, **kw):
16 bang_previous = {
17 "!": lambda x: x,
18 "$": lambda x: shlex.split(x)[-1],
19 "^": lambda x: shlex.split(x)[0],
20 "*": lambda x: " ".join(shlex.split(x)[1:]),
21 }
22
23 def replace_bang(m):
24 arg = m.group(1)
25 inputs = __xonsh__.history.inps
26
27 # Dissect the previous command.
28 if arg in bang_previous:
29 try:
30 return bang_previous[arg](inputs[-1])
31 except IndexError:
32 print("xonsh: no history for '!{}'".format(arg))
33 return ""
34
35 # Look back in history for a matching command.
36 else:
37 try:
38 return next((x for x in reversed(inputs) if x.startswith(arg)))
39 except StopIteration:
40 print("xonsh: no previous commands match '!{}'".format(arg))
41 return ""
42
43 return re.sub(r"!([!$^*]|[\w]+)", replace_bang, cmd.strip())
44
45
46 @events.on_ptk_create
47 def custom_keybindings(bindings, **kw):
48 if ptk_shell_type() == "prompt_toolkit2":
49 handler = bindings.add
50
51 @Condition
52 def last_command_exists():
53 return len(__xonsh__.history) > 0
54
55 else:
56 handler = bindings.registry.add_binding
57
58 @Condition
59 def last_command_exists(cli):
60 return len(__xonsh__.history) > 0
61
62 insert_mode = ViInsertMode() | EmacsInsertMode()
63
64 @handler(Keys.Escape, ".", filter=last_command_exists & insert_mode)
65 def recall_last_arg(event):
66 arg = __xonsh__.history[-1].cmd.split()[-1]
67 event.current_buffer.insert_text(arg)
68
69
70 def alias(args, stdin=None):
71 ret = 0
72
73 if args:
74 for arg in args:
75 if "=" in arg:
76 # shlex.split to remove quotes, e.g. "foo='echo hey'" into
77 # "foo=echo hey"
78 name, cmd = shlex.split(arg)[0].split("=", 1)
79 aliases[name] = shlex.split(cmd)
80 elif arg in aliases:
81 print("{}={}".format(arg, aliases[arg]))
82 else:
83 print("alias: {}: not found".format(arg), file=sys.stderr)
84 ret = 1
85 else:
86 for alias, cmd in aliases.items():
87 print("{}={}".format(alias, cmd))
88
89 return ret
90
91
92 aliases["alias"] = alias
93
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/xontrib/bashisms.py b/xontrib/bashisms.py
--- a/xontrib/bashisms.py
+++ b/xontrib/bashisms.py
@@ -40,7 +40,7 @@
print("xonsh: no previous commands match '!{}'".format(arg))
return ""
- return re.sub(r"!([!$^*]|[\w]+)", replace_bang, cmd.strip())
+ return re.sub(r"!([!$^*]|[\w]+)", replace_bang, cmd)
@events.on_ptk_create
|
{"golden_diff": "diff --git a/xontrib/bashisms.py b/xontrib/bashisms.py\n--- a/xontrib/bashisms.py\n+++ b/xontrib/bashisms.py\n@@ -40,7 +40,7 @@\n print(\"xonsh: no previous commands match '!{}'\".format(arg))\n return \"\"\n \n- return re.sub(r\"!([!$^*]|[\\w]+)\", replace_bang, cmd.strip())\n+ return re.sub(r\"!([!$^*]|[\\w]+)\", replace_bang, cmd)\n \n \n @events.on_ptk_create\n", "issue": "Syntax errors when using bashisms xontrib\nAt least making assignment statements and entering function definitions at the prompt is \r\nbroken when using the included `bashisms` xontrib and prompt toolkit.\r\n\r\n## xonfig\r\n\r\n```\r\n$ xonfig \r\n+------------------+---------------------+\r\n| xonsh | 0.8.12 |\r\n| Git SHA | 3edd2df7 |\r\n| Commit Date | May 9 07:50:20 2019 |\r\n| Python | 3.7.3 |\r\n| PLY | 3.11 |\r\n| have readline | True |\r\n| prompt toolkit | 2.0.9 |\r\n| shell type | prompt_toolkit2 |\r\n| pygments | 2.3.1 |\r\n| on posix | True |\r\n| on linux | True |\r\n| distro | ubuntu |\r\n| on darwin | False |\r\n| on windows | False |\r\n| on cygwin | False |\r\n| on msys2 | False |\r\n| is superuser | False |\r\n| default encoding | utf-8 |\r\n| xonsh encoding | utf-8 |\r\n| encoding errors | surrogateescape |\r\n+------------------+---------------------+\r\n\r\n```\r\n\r\n## Expected Behavior\r\nI should be able to create new variables and function definitions, no sweat.\r\n\r\n## Current Behavior\r\n\r\nThings work fine until I start the shell with the xontrib `bashisms` loaded, or after I start the shell without it and load it later.\r\n\r\nAssignment statements appear to go into multiline mode after hitting the return\r\nkey, and after a second return key, a stacktrace appears. The assignment\r\nstatement does not succeed.\r\n\r\nFunction definitions at the prompt result in an IndexError and the function is\r\nnot defined afterwards.\r\n\r\n### Traceback (if applicable)\r\n\r\n#### Assignment\r\n\r\n```\r\n$ a = 1 \r\n$ a \r\n1\r\n$ xontrib load bashisms \r\n$ b = 1 \r\n.................................................. \r\nTraceback (most recent call last):\r\n File \"/home/eddie/source/xonsh/xonsh/ptk2/shell.py\", line 173, in _push\r\n code = self.execer.compile(src, mode=\"single\", glbs=self.ctx, locs=None)\r\n File \"/home/eddie/source/xonsh/xonsh/execer.py\", line 135, in compile\r\n tree = self.parse(input, ctx, mode=mode, filename=filename, transform=transform)\r\n File \"/home/eddie/source/xonsh/xonsh/execer.py\", line 96, in parse\r\n tree, input = self._parse_ctx_free(input, mode=mode, filename=filename)\r\n File \"/home/eddie/source/xonsh/xonsh/execer.py\", line 235, in _parse_ctx_free\r\n raise original_error from None\r\n File \"/home/eddie/source/xonsh/xonsh/execer.py\", line 220, in _parse_ctx_free\r\n debug_level=(self.debug_level > 2),\r\n File \"/home/eddie/source/xonsh/xonsh/parsers/base.py\", line 543, in parse\r\n tree = self.parser.parse(input=s, lexer=self.lexer, debug=debug_level)\r\n File \"/home/eddie/source/xonsh/xonsh/ply/ply/yacc.py\", line 335, in parse\r\n return self.parseopt_notrack(input, lexer, debug, tracking, tokenfunc)\r\n File \"/home/eddie/source/xonsh/xonsh/ply/ply/yacc.py\", line 1203, in parseopt_notrack\r\n tok = call_errorfunc(self.errorfunc, errtoken, self)\r\n File \"/home/eddie/source/xonsh/xonsh/ply/ply/yacc.py\", line 194, in call_errorfunc\r\n r = errorfunc(token)\r\n File \"/home/eddie/source/xonsh/xonsh/parsers/base.py\", line 3285, in p_error\r\n self._parse_error(\"no further code\", None)\r\n File \"/home/eddie/source/xonsh/xonsh/parsers/base.py\", line 676, in _parse_error\r\n raise err\r\n File \"<string>\", line None\r\nSyntaxError: None: no further code\r\n$ b \r\nTraceback (most recent call last):\r\n File \"/home/eddie/source/xonsh/xonsh/built_ins.py\", line 560, in _run_binary\r\n p = self.cls(self.cmd, bufsize=bufsize, **kwargs)\r\n File \"/home/eddie/source/xonsh/xonsh/proc.py\", line 583, in __init__\r\n *args, stdin=stdin, stdout=stdout, stderr=stderr, **kwargs\r\n File \"/home/eddie/.pyenv/versions/3.7.3/lib/python3.7/subprocess.py\", line 775, in __init__\r\n restore_signals, start_new_session)\r\n File \"/home/eddie/.pyenv/versions/3.7.3/lib/python3.7/subprocess.py\", line 1522, in _execute_child\r\n raise child_exception_type(errno_num, err_msg, err_filename)\r\nFileNotFoundError: [Errno 2] No such file or directory: 'b': 'b'\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/home/eddie/source/xonsh/xonsh/proc.py\", line 1856, in __init__\r\n proc = spec.run(pipeline_group=pipeline_group)\r\n File \"/home/eddie/source/xonsh/xonsh/built_ins.py\", line 549, in run\r\n p = self._run_binary(kwargs)\r\n File \"/home/eddie/source/xonsh/xonsh/built_ins.py\", line 571, in _run_binary\r\n raise XonshError(e)\r\nxonsh.tools.XonshError: xonsh: subprocess mode: command not found: b\r\nDid you mean one of the following?\r\n bg: Alias\r\n e: Alias\r\n z: Alias\r\n bc: Command (/usr/bin/bc)\r\n ab: Command (/usr/bin/ab)\r\n\r\nb: command not found\r\n```\r\n\r\n#### Function definition\r\n\r\n```\r\n$ def f(): \r\n.................................................. pass \r\n.................................................. \r\n$ f \r\n<function __main__.f>\r\n$ xontrib load bashisms \r\n$ def g(): \r\n.................................................. pass \r\n.................................................. \r\nTraceback (most recent call last):\r\n File \"/home/eddie/source/xonsh/xonsh/execer.py\", line 220, in _parse_ctx_free\r\n debug_level=(self.debug_level > 2),\r\n File \"/home/eddie/source/xonsh/xonsh/parsers/base.py\", line 543, in parse\r\n tree = self.parser.parse(input=s, lexer=self.lexer, debug=debug_level)\r\n File \"/home/eddie/source/xonsh/xonsh/ply/ply/yacc.py\", line 335, in parse\r\n return self.parseopt_notrack(input, lexer, debug, tracking, tokenfunc)\r\n File \"/home/eddie/source/xonsh/xonsh/ply/ply/yacc.py\", line 1203, in parseopt_notrack\r\n tok = call_errorfunc(self.errorfunc, errtoken, self)\r\n File \"/home/eddie/source/xonsh/xonsh/ply/ply/yacc.py\", line 194, in call_errorfunc\r\n r = errorfunc(token)\r\n File \"/home/eddie/source/xonsh/xonsh/parsers/base.py\", line 3295, in p_error\r\n self._parse_error(msg, self.currloc(lineno=p.lineno, column=p.lexpos))\r\n File \"/home/eddie/source/xonsh/xonsh/parsers/base.py\", line 676, in _parse_error\r\n raise err\r\n File \"<string>\", line None\r\nSyntaxError: /home/eddie/source/xonsh/xontrib/prompt_ret_code.xsh:3:0: ('code: ',)\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/home/eddie/source/xonsh/xonsh/ptk2/shell.py\", line 173, in _push\r\n code = self.execer.compile(src, mode=\"single\", glbs=self.ctx, locs=None)\r\n File \"/home/eddie/source/xonsh/xonsh/execer.py\", line 135, in compile\r\n tree = self.parse(input, ctx, mode=mode, filename=filename, transform=transform)\r\n File \"/home/eddie/source/xonsh/xonsh/execer.py\", line 96, in parse\r\n tree, input = self._parse_ctx_free(input, mode=mode, filename=filename)\r\n File \"/home/eddie/source/xonsh/xonsh/execer.py\", line 242, in _parse_ctx_free\r\n line, nlogical, idx = get_logical_line(lines, idx)\r\n File \"/home/eddie/source/xonsh/xonsh/tools.py\", line 544, in get_logical_line\r\n line = lines[idx]\r\nIndexError: list index out of range\r\n$ g \r\nTraceback (most recent call last):\r\n File \"/home/eddie/source/xonsh/xonsh/built_ins.py\", line 560, in _run_binary\r\n p = self.cls(self.cmd, bufsize=bufsize, **kwargs)\r\n File \"/home/eddie/source/xonsh/xonsh/proc.py\", line 583, in __init__\r\n *args, stdin=stdin, stdout=stdout, stderr=stderr, **kwargs\r\n File \"/home/eddie/.pyenv/versions/3.7.3/lib/python3.7/subprocess.py\", line 775, in __init__\r\n restore_signals, start_new_session)\r\n File \"/home/eddie/.pyenv/versions/3.7.3/lib/python3.7/subprocess.py\", line 1522, in _execute_child\r\n raise child_exception_type(errno_num, err_msg, err_filename)\r\nFileNotFoundError: [Errno 2] No such file or directory: 'g': 'g'\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/home/eddie/source/xonsh/xonsh/proc.py\", line 1856, in __init__\r\n proc = spec.run(pipeline_group=pipeline_group)\r\n File \"/home/eddie/source/xonsh/xonsh/built_ins.py\", line 549, in run\r\n p = self._run_binary(kwargs)\r\n File \"/home/eddie/source/xonsh/xonsh/built_ins.py\", line 571, in _run_binary\r\n raise XonshError(e)\r\nxonsh.tools.XonshError: xonsh: subprocess mode: command not found: g\r\nDid you mean one of the following?\r\n fg: Alias\r\n bg: Alias\r\n e: Alias\r\n z: Alias\r\n ag: Command (/usr/local/bin/ag)\r\n\r\ng: command not found\r\n```\r\n\r\n## Steps to Reproduce\r\n\r\n```\r\n# start w/o bashisms loaded\r\n$ a = 1 \r\n$ xontrib load bashisms \r\n$ a = 1 \r\n```\r\n\r\nor\r\n\r\n```\r\n# start w/o bashisms loaded\r\n$ xontrib load bashisms \r\n$ def f(): \r\n.................................................. pass \r\n.................................................. \r\n```\n", "before_files": [{"content": "\"\"\"Bash-like interface extensions for xonsh.\"\"\"\nimport shlex\nimport sys\nimport re\n\nfrom prompt_toolkit.keys import Keys\nfrom prompt_toolkit.filters import Condition, EmacsInsertMode, ViInsertMode\n\nfrom xonsh.platform import ptk_shell_type\n\n__all__ = ()\n\n\[email protected]_transform_command\ndef bash_preproc(cmd, **kw):\n bang_previous = {\n \"!\": lambda x: x,\n \"$\": lambda x: shlex.split(x)[-1],\n \"^\": lambda x: shlex.split(x)[0],\n \"*\": lambda x: \" \".join(shlex.split(x)[1:]),\n }\n\n def replace_bang(m):\n arg = m.group(1)\n inputs = __xonsh__.history.inps\n\n # Dissect the previous command.\n if arg in bang_previous:\n try:\n return bang_previous[arg](inputs[-1])\n except IndexError:\n print(\"xonsh: no history for '!{}'\".format(arg))\n return \"\"\n\n # Look back in history for a matching command.\n else:\n try:\n return next((x for x in reversed(inputs) if x.startswith(arg)))\n except StopIteration:\n print(\"xonsh: no previous commands match '!{}'\".format(arg))\n return \"\"\n\n return re.sub(r\"!([!$^*]|[\\w]+)\", replace_bang, cmd.strip())\n\n\[email protected]_ptk_create\ndef custom_keybindings(bindings, **kw):\n if ptk_shell_type() == \"prompt_toolkit2\":\n handler = bindings.add\n\n @Condition\n def last_command_exists():\n return len(__xonsh__.history) > 0\n\n else:\n handler = bindings.registry.add_binding\n\n @Condition\n def last_command_exists(cli):\n return len(__xonsh__.history) > 0\n\n insert_mode = ViInsertMode() | EmacsInsertMode()\n\n @handler(Keys.Escape, \".\", filter=last_command_exists & insert_mode)\n def recall_last_arg(event):\n arg = __xonsh__.history[-1].cmd.split()[-1]\n event.current_buffer.insert_text(arg)\n\n\ndef alias(args, stdin=None):\n ret = 0\n\n if args:\n for arg in args:\n if \"=\" in arg:\n # shlex.split to remove quotes, e.g. \"foo='echo hey'\" into\n # \"foo=echo hey\"\n name, cmd = shlex.split(arg)[0].split(\"=\", 1)\n aliases[name] = shlex.split(cmd)\n elif arg in aliases:\n print(\"{}={}\".format(arg, aliases[arg]))\n else:\n print(\"alias: {}: not found\".format(arg), file=sys.stderr)\n ret = 1\n else:\n for alias, cmd in aliases.items():\n print(\"{}={}\".format(alias, cmd))\n\n return ret\n\n\naliases[\"alias\"] = alias\n", "path": "xontrib/bashisms.py"}], "after_files": [{"content": "\"\"\"Bash-like interface extensions for xonsh.\"\"\"\nimport shlex\nimport sys\nimport re\n\nfrom prompt_toolkit.keys import Keys\nfrom prompt_toolkit.filters import Condition, EmacsInsertMode, ViInsertMode\n\nfrom xonsh.platform import ptk_shell_type\n\n__all__ = ()\n\n\[email protected]_transform_command\ndef bash_preproc(cmd, **kw):\n bang_previous = {\n \"!\": lambda x: x,\n \"$\": lambda x: shlex.split(x)[-1],\n \"^\": lambda x: shlex.split(x)[0],\n \"*\": lambda x: \" \".join(shlex.split(x)[1:]),\n }\n\n def replace_bang(m):\n arg = m.group(1)\n inputs = __xonsh__.history.inps\n\n # Dissect the previous command.\n if arg in bang_previous:\n try:\n return bang_previous[arg](inputs[-1])\n except IndexError:\n print(\"xonsh: no history for '!{}'\".format(arg))\n return \"\"\n\n # Look back in history for a matching command.\n else:\n try:\n return next((x for x in reversed(inputs) if x.startswith(arg)))\n except StopIteration:\n print(\"xonsh: no previous commands match '!{}'\".format(arg))\n return \"\"\n\n return re.sub(r\"!([!$^*]|[\\w]+)\", replace_bang, cmd)\n\n\[email protected]_ptk_create\ndef custom_keybindings(bindings, **kw):\n if ptk_shell_type() == \"prompt_toolkit2\":\n handler = bindings.add\n\n @Condition\n def last_command_exists():\n return len(__xonsh__.history) > 0\n\n else:\n handler = bindings.registry.add_binding\n\n @Condition\n def last_command_exists(cli):\n return len(__xonsh__.history) > 0\n\n insert_mode = ViInsertMode() | EmacsInsertMode()\n\n @handler(Keys.Escape, \".\", filter=last_command_exists & insert_mode)\n def recall_last_arg(event):\n arg = __xonsh__.history[-1].cmd.split()[-1]\n event.current_buffer.insert_text(arg)\n\n\ndef alias(args, stdin=None):\n ret = 0\n\n if args:\n for arg in args:\n if \"=\" in arg:\n # shlex.split to remove quotes, e.g. \"foo='echo hey'\" into\n # \"foo=echo hey\"\n name, cmd = shlex.split(arg)[0].split(\"=\", 1)\n aliases[name] = shlex.split(cmd)\n elif arg in aliases:\n print(\"{}={}\".format(arg, aliases[arg]))\n else:\n print(\"alias: {}: not found\".format(arg), file=sys.stderr)\n ret = 1\n else:\n for alias, cmd in aliases.items():\n print(\"{}={}\".format(alias, cmd))\n\n return ret\n\n\naliases[\"alias\"] = alias\n", "path": "xontrib/bashisms.py"}]}
| 3,650 | 126 |
gh_patches_debug_20309
|
rasdani/github-patches
|
git_diff
|
cleanlab__cleanlab-397
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
color_sentence matches subtokens
<!-- Briefly summarize the issue. -->
`color_sentence` technically does subtoken matching instead of checking for equality between the tokenized sentence and the given token.
Is this intended?
# Stack trace
```bash
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AssertionError: ('\x1b[31mI\x1b[0mf you and I were to meet', 'If you and \x1b[31mI\x1b[0m were to meet')
```
# Steps to reproduce
Here's a MWE
```python
from cleanlab.internal.token_classification_utils import color_sentence
sentence = "If you and I were to meet"
word = "I"
output = color_sentence(sentence, word)
expected_output = "If you and \x1b[31mI\x1b[0m were to meet"
assert output == expected_output, (output, expected_output)
```
<!-- Be as detailed as possible here. If possible, include a self-contained
runnable example that demonstrates the issue. Remember to supply any data
necessary to run your example, or construct your example with synthetic data.
This is not strictly required, but the more detailed your bug report, the more
quickly we can help you and fix the bug. -->
# Additional information
- **Cleanlab version**: 31d43707014cb5c217ee1e9b014a206d554f2fd3
- **Operating system**: Linux 4.19.128-microsoft-standard
- **Python version**: Python 3.9.12
<!-- Please include any other information that could be helpful for debugging. -->
## Definition of `color_sentence`
https://github.com/cleanlab/cleanlab/blob/31d43707014cb5c217ee1e9b014a206d554f2fd3/cleanlab/internal/token_classification_utils.py#L144-L164
Give better error messages when a class has no examples in `find_label_issues`
Currently, we produce various internal errors when a class is not represented. We should either support missing classes, or we should produce something like a `ValueError("find_label_issues requires that each class has at least one example")`.
Right now, we produce a variety of internal errors (data-dependent).
This can be seen as a dupe of #41 and #89, though it suggests at least fixing the confusing error messages as a stop-gap solution until we decide whether or not to support classes with no examples. Potentially related to #266.
# Steps to reproduce
## Example 1
```python
import cleanlab
import numpy as np
labels = np.array([0, 0, 1, 1])
pred_probs = np.array([[0.1, 0.7, 0.2], [0.1, 0.8, 0.1], [0.7, 0.2, 0.1], [0.8, 0.1, 0.1]])
issues = cleanlab.filter.find_label_issues(labels, pred_probs, n_jobs=1)
```
Produces the result:
```
Traceback (most recent call last):
File ".../error.py", line 6, in <module>
issues = cleanlab.filter.find_label_issues(labels, pred_probs)
File ".../src/cleanlab/env/lib/python3.9/site-packages/cleanlab/filter.py", line 457, in find_label_issues
confident_joint, cl_error_indices = compute_confident_joint(
File ".../src/cleanlab/env/lib/python3.9/site-packages/cleanlab/count.py", line 435, in compute_confident_joint
pred_probs_bool = pred_probs >= thresholds - 1e-6
ValueError: operands could not be broadcast together with shapes (4,3) (2,)
```
## Example 2
```python
import cleanlab
import numpy as np
labels = np.array([0, 0])
pred_probs = np.array([[0.3, 0.7], [0.2, 0.8]])
issues = cleanlab.filter.find_label_issues(labels, pred_probs, n_jobs=1)
```
Produces the result:
```
Traceback (most recent call last):
File ".../error.py", line 6, in <module>
issues = cleanlab.filter.find_label_issues(labels, pred_probs, n_jobs=1)
File ".../src/cleanlab/env/lib/python3.9/site-packages/cleanlab/filter.py", line 561, in find_label_issues
label_issues_masks_per_class = [_prune_by_count(k, args) for k in range(K)]
File ".../src/cleanlab/env/lib/python3.9/site-packages/cleanlab/filter.py", line 561, in <listcomp>
label_issues_masks_per_class = [_prune_by_count(k, args) for k in range(K)]
File ".../src/cleanlab/env/lib/python3.9/site-packages/cleanlab/filter.py", line 204, in _prune_by_count
if label_counts[k] <= min_examples_per_class: # No prune if not at least min_examples_per_class
IndexError: index 1 is out of bounds for axis 0 with size 1
```
# Additional information
- **Cleanlab version**: 2.0.0 (and also reproduced on master = 5e0b62d79790028c6c69a76c6af28c813a27ace5, though the stack traces and exceptions are slightly different there)
- **Operating system**: macOS 12.1, shouldn't be relevant here
- **Python version**: Python 3.9.12
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cleanlab/internal/token_classification_utils.py`
Content:
```
1 import re
2 import string
3 import numpy as np
4 from termcolor import colored
5 from typing import List, Optional, Callable, Tuple
6
7
8 def get_sentence(words: List[str]) -> str:
9 """
10 Get sentence formed by a list of words with minor processing for readability
11
12 Parameters
13 ----------
14 words: List[str]
15 list of word-level tokens
16
17 Returns
18 ----------
19 sentence: string
20 sentence formed by list of word-level tokens
21
22 """
23 sentence = ""
24 for word in words:
25 if word not in string.punctuation or word in ["-", "("]:
26 word = " " + word
27 sentence += word
28 sentence = sentence.replace(" '", "'").replace("( ", "(").strip()
29 return sentence
30
31
32 def filter_sentence(
33 sentences: List[str],
34 condition: Optional[Callable[[str], bool]] = None,
35 ) -> Tuple[List[str], List[bool]]:
36 """
37 Filter sentence based on some condition, and returns filter mask
38
39 Parameters
40 ----------
41 sentences: List[str]
42 list of sentences
43
44 condition: Optional[Callable[[str], bool]]
45 sentence filtering condition
46
47 Returns
48 ---------
49 sentences: List[str]
50 list of sentences filtered
51
52 mask: List[bool]
53 boolean mask such that `mask[i] == True` if the i'th sentence is included in the
54 filtered sentence, otherwise `mask[i] == False`
55
56 """
57 if not condition:
58 condition = lambda sentence: len(sentence) > 1 and "#" not in sentence
59 mask = list(map(condition, sentences))
60 sentences = [sentence for m, sentence in zip(mask, sentences) if m]
61 return sentences, mask
62
63
64 def process_token(token: str, replace: List[Tuple[str, str]] = [("#", "")]) -> str:
65 """
66 Replaces special characters in the tokens
67
68 Parameters
69 ----------
70 token: str
71 token which potentially contains special characters
72
73 replace: List[Tuple[str, str]]
74 list of tuples `(s1, s2)`, where all occurances of s1 are replaced by s2
75
76 Returns
77 ---------
78 processed_token: str
79 processed token whose special character has been replaced
80
81 Note
82 ----
83 Only applies to characters in the original input token.
84 """
85 replace_dict = {re.escape(k): v for (k, v) in replace}
86 pattern = "|".join(replace_dict.keys())
87 compiled_pattern = re.compile(pattern)
88 replacement = lambda match: replace_dict[re.escape(match.group(0))]
89 processed_token = compiled_pattern.sub(replacement, token)
90 return processed_token
91
92
93 def mapping(entities: List[int], maps: List[int]) -> List[int]:
94 """
95 Map a list of entities to its corresponding entities
96
97 Parameters
98 ----------
99 entities: List[int]
100 a list of given entities
101
102 maps: List[int]
103 a list of mapped entities, such that the i'th indexed token should be mapped to `maps[i]`
104
105 Returns
106 ---------
107 mapped_entities: List[int]
108 a list of mapped entities
109
110 Examples
111 --------
112 >>> unique_identities = [0, 1, 2, 3, 4] # ["O", "B-PER", "I-PER", "B-LOC", "I-LOC"]
113 >>> maps = [0, 1, 1, 2, 2] # ["O", "PER", "PER", "LOC", "LOC"]
114 >>> mapping(unique_identities, maps)
115 [0, 1, 1, 2, 2] # ["O", "PER", "PER", "LOC", "LOC"]
116 >>> mapping([0, 0, 4, 4, 3, 4, 0, 2], maps)
117 [0, 0, 2, 2, 2, 2, 0, 1] # ["O", "O", "LOC", "LOC", "LOC", "LOC", "O", "PER"]
118 """
119 f = lambda x: maps[x]
120 return list(map(f, entities))
121
122
123 def merge_probs(probs: np.ndarray, maps: List[int]) -> np.ndarray:
124 """
125 Merges model-predictive probabilities with desired mapping
126
127 Parameters
128 ----------
129 probs:
130 np.array of shape `(N, K)`, where N is the number of tokens, and K is the number of classes for the model
131
132 maps: List[int]
133 a list of mapped index, such that the probability of the token being in the i'th class is mapped to the
134 `maps[i]` index. If `maps[i] == -1`, the i'th column of `probs` is ignored. If `np.any(maps == -1)`, the
135 returned probability is re-normalized.
136
137 Returns
138 ---------
139 probs_merged:
140 np.array of shape `(N, K')`, where K' is the number of new classes. Probablities are merged and
141 re-normalized if necessary.
142
143 """
144 old_classes = probs.shape[1]
145 map_size = np.max(maps) + 1
146 probs_merged = np.zeros([len(probs), map_size], dtype=probs.dtype.type)
147
148 for i in range(old_classes):
149 if maps[i] >= 0:
150 probs_merged[:, maps[i]] += probs[:, i]
151 if -1 in maps:
152 row_sums = probs_merged.sum(axis=1)
153 probs_merged /= row_sums[:, np.newaxis]
154 return probs_merged
155
156
157 def color_sentence(sentence: str, word: str) -> str:
158 """
159 Searches for a given token in the sentence and returns the sentence where the given token is colored red
160
161 Parameters
162 ----------
163 sentence: str
164 a sentence where the word is searched
165
166 word: str
167 keyword to find in `sentence`. Assumes the word exists in token
168
169 Returns
170 ---------
171 colored_sentence: str
172 `sentence` where the first occurance of the word is colored red, using `termcolor.colored`
173
174 """
175 start_idx = sentence.index(word)
176 before, after = sentence[:start_idx], sentence[start_idx + len(word) :]
177 return "%s%s%s" % (before, colored(word, "red"), after)
178
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/cleanlab/internal/token_classification_utils.py b/cleanlab/internal/token_classification_utils.py
--- a/cleanlab/internal/token_classification_utils.py
+++ b/cleanlab/internal/token_classification_utils.py
@@ -160,18 +160,22 @@
Parameters
----------
- sentence: str
+ sentence:
a sentence where the word is searched
- word: str
- keyword to find in `sentence`. Assumes the word exists in token
-
+ word:
+ keyword to find in `sentence`. Assumes the word exists in the sentence.
Returns
---------
- colored_sentence: str
- `sentence` where the first occurance of the word is colored red, using `termcolor.colored`
+ colored_sentence:
+ `sentence` where the every occurance of the word is colored red, using `termcolor.colored`
"""
- start_idx = sentence.index(word)
- before, after = sentence[:start_idx], sentence[start_idx + len(word) :]
- return "%s%s%s" % (before, colored(word, "red"), after)
+ colored_word = colored(word, "red")
+ colored_sentence, number_of_substitions = re.subn(
+ r"\b{}\b".format(word), colored_word, sentence
+ )
+ if number_of_substitions == 0:
+ # Use basic string manipulation if regex fails
+ colored_sentence = sentence.replace(word, colored_word)
+ return colored_sentence
|
{"golden_diff": "diff --git a/cleanlab/internal/token_classification_utils.py b/cleanlab/internal/token_classification_utils.py\n--- a/cleanlab/internal/token_classification_utils.py\n+++ b/cleanlab/internal/token_classification_utils.py\n@@ -160,18 +160,22 @@\n \n Parameters\n ----------\n- sentence: str\n+ sentence:\n a sentence where the word is searched\n \n- word: str\n- keyword to find in `sentence`. Assumes the word exists in token\n-\n+ word:\n+ keyword to find in `sentence`. Assumes the word exists in the sentence.\n Returns\n ---------\n- colored_sentence: str\n- `sentence` where the first occurance of the word is colored red, using `termcolor.colored`\n+ colored_sentence:\n+ `sentence` where the every occurance of the word is colored red, using `termcolor.colored`\n \n \"\"\"\n- start_idx = sentence.index(word)\n- before, after = sentence[:start_idx], sentence[start_idx + len(word) :]\n- return \"%s%s%s\" % (before, colored(word, \"red\"), after)\n+ colored_word = colored(word, \"red\")\n+ colored_sentence, number_of_substitions = re.subn(\n+ r\"\\b{}\\b\".format(word), colored_word, sentence\n+ )\n+ if number_of_substitions == 0:\n+ # Use basic string manipulation if regex fails\n+ colored_sentence = sentence.replace(word, colored_word)\n+ return colored_sentence\n", "issue": "color_sentence matches subtokens \n<!-- Briefly summarize the issue. -->\r\n\r\n`color_sentence` technically does subtoken matching instead of checking for equality between the tokenized sentence and the given token.\r\n\r\nIs this intended?\r\n\r\n# Stack trace\r\n\r\n```bash\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\nAssertionError: ('\\x1b[31mI\\x1b[0mf you and I were to meet', 'If you and \\x1b[31mI\\x1b[0m were to meet')\r\n```\r\n\r\n# Steps to reproduce\r\n\r\nHere's a MWE\r\n\r\n```python\r\nfrom cleanlab.internal.token_classification_utils import color_sentence\r\n\r\nsentence = \"If you and I were to meet\"\r\nword = \"I\"\r\noutput = color_sentence(sentence, word)\r\nexpected_output = \"If you and \\x1b[31mI\\x1b[0m were to meet\"\r\n\r\nassert output == expected_output, (output, expected_output)\r\n```\r\n\r\n<!-- Be as detailed as possible here. If possible, include a self-contained\r\nrunnable example that demonstrates the issue. Remember to supply any data\r\nnecessary to run your example, or construct your example with synthetic data.\r\nThis is not strictly required, but the more detailed your bug report, the more\r\nquickly we can help you and fix the bug. -->\r\n\r\n# Additional information\r\n\r\n- **Cleanlab version**: 31d43707014cb5c217ee1e9b014a206d554f2fd3\r\n- **Operating system**: Linux 4.19.128-microsoft-standard\r\n- **Python version**: Python 3.9.12\r\n\r\n<!-- Please include any other information that could be helpful for debugging. -->\r\n\r\n\r\n## Definition of `color_sentence`\r\n\r\nhttps://github.com/cleanlab/cleanlab/blob/31d43707014cb5c217ee1e9b014a206d554f2fd3/cleanlab/internal/token_classification_utils.py#L144-L164\nGive better error messages when a class has no examples in `find_label_issues`\nCurrently, we produce various internal errors when a class is not represented. We should either support missing classes, or we should produce something like a `ValueError(\"find_label_issues requires that each class has at least one example\")`.\r\n\r\nRight now, we produce a variety of internal errors (data-dependent).\r\n\r\nThis can be seen as a dupe of #41 and #89, though it suggests at least fixing the confusing error messages as a stop-gap solution until we decide whether or not to support classes with no examples. Potentially related to #266.\r\n\r\n# Steps to reproduce\r\n\r\n## Example 1\r\n\r\n```python\r\nimport cleanlab\r\nimport numpy as np\r\n\r\nlabels = np.array([0, 0, 1, 1])\r\npred_probs = np.array([[0.1, 0.7, 0.2], [0.1, 0.8, 0.1], [0.7, 0.2, 0.1], [0.8, 0.1, 0.1]])\r\nissues = cleanlab.filter.find_label_issues(labels, pred_probs, n_jobs=1)\r\n```\r\n\r\nProduces the result:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \".../error.py\", line 6, in <module>\r\n issues = cleanlab.filter.find_label_issues(labels, pred_probs)\r\n File \".../src/cleanlab/env/lib/python3.9/site-packages/cleanlab/filter.py\", line 457, in find_label_issues\r\n confident_joint, cl_error_indices = compute_confident_joint(\r\n File \".../src/cleanlab/env/lib/python3.9/site-packages/cleanlab/count.py\", line 435, in compute_confident_joint\r\n pred_probs_bool = pred_probs >= thresholds - 1e-6\r\nValueError: operands could not be broadcast together with shapes (4,3) (2,)\r\n```\r\n\r\n## Example 2\r\n\r\n```python\r\nimport cleanlab\r\nimport numpy as np\r\n\r\nlabels = np.array([0, 0])\r\npred_probs = np.array([[0.3, 0.7], [0.2, 0.8]])\r\nissues = cleanlab.filter.find_label_issues(labels, pred_probs, n_jobs=1)\r\n```\r\n\r\nProduces the result:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \".../error.py\", line 6, in <module>\r\n issues = cleanlab.filter.find_label_issues(labels, pred_probs, n_jobs=1)\r\n File \".../src/cleanlab/env/lib/python3.9/site-packages/cleanlab/filter.py\", line 561, in find_label_issues\r\n label_issues_masks_per_class = [_prune_by_count(k, args) for k in range(K)]\r\n File \".../src/cleanlab/env/lib/python3.9/site-packages/cleanlab/filter.py\", line 561, in <listcomp>\r\n label_issues_masks_per_class = [_prune_by_count(k, args) for k in range(K)]\r\n File \".../src/cleanlab/env/lib/python3.9/site-packages/cleanlab/filter.py\", line 204, in _prune_by_count\r\n if label_counts[k] <= min_examples_per_class: # No prune if not at least min_examples_per_class\r\nIndexError: index 1 is out of bounds for axis 0 with size 1\r\n```\r\n\r\n# Additional information\r\n\r\n- **Cleanlab version**: 2.0.0 (and also reproduced on master = 5e0b62d79790028c6c69a76c6af28c813a27ace5, though the stack traces and exceptions are slightly different there)\r\n- **Operating system**: macOS 12.1, shouldn't be relevant here\r\n- **Python version**: Python 3.9.12\r\n\n", "before_files": [{"content": "import re\nimport string\nimport numpy as np\nfrom termcolor import colored\nfrom typing import List, Optional, Callable, Tuple\n\n\ndef get_sentence(words: List[str]) -> str:\n \"\"\"\n Get sentence formed by a list of words with minor processing for readability\n\n Parameters\n ----------\n words: List[str]\n list of word-level tokens\n\n Returns\n ----------\n sentence: string\n sentence formed by list of word-level tokens\n\n \"\"\"\n sentence = \"\"\n for word in words:\n if word not in string.punctuation or word in [\"-\", \"(\"]:\n word = \" \" + word\n sentence += word\n sentence = sentence.replace(\" '\", \"'\").replace(\"( \", \"(\").strip()\n return sentence\n\n\ndef filter_sentence(\n sentences: List[str],\n condition: Optional[Callable[[str], bool]] = None,\n) -> Tuple[List[str], List[bool]]:\n \"\"\"\n Filter sentence based on some condition, and returns filter mask\n\n Parameters\n ----------\n sentences: List[str]\n list of sentences\n\n condition: Optional[Callable[[str], bool]]\n sentence filtering condition\n\n Returns\n ---------\n sentences: List[str]\n list of sentences filtered\n\n mask: List[bool]\n boolean mask such that `mask[i] == True` if the i'th sentence is included in the\n filtered sentence, otherwise `mask[i] == False`\n\n \"\"\"\n if not condition:\n condition = lambda sentence: len(sentence) > 1 and \"#\" not in sentence\n mask = list(map(condition, sentences))\n sentences = [sentence for m, sentence in zip(mask, sentences) if m]\n return sentences, mask\n\n\ndef process_token(token: str, replace: List[Tuple[str, str]] = [(\"#\", \"\")]) -> str:\n \"\"\"\n Replaces special characters in the tokens\n\n Parameters\n ----------\n token: str\n token which potentially contains special characters\n\n replace: List[Tuple[str, str]]\n list of tuples `(s1, s2)`, where all occurances of s1 are replaced by s2\n\n Returns\n ---------\n processed_token: str\n processed token whose special character has been replaced\n\n Note\n ----\n Only applies to characters in the original input token.\n \"\"\"\n replace_dict = {re.escape(k): v for (k, v) in replace}\n pattern = \"|\".join(replace_dict.keys())\n compiled_pattern = re.compile(pattern)\n replacement = lambda match: replace_dict[re.escape(match.group(0))]\n processed_token = compiled_pattern.sub(replacement, token)\n return processed_token\n\n\ndef mapping(entities: List[int], maps: List[int]) -> List[int]:\n \"\"\"\n Map a list of entities to its corresponding entities\n\n Parameters\n ----------\n entities: List[int]\n a list of given entities\n\n maps: List[int]\n a list of mapped entities, such that the i'th indexed token should be mapped to `maps[i]`\n\n Returns\n ---------\n mapped_entities: List[int]\n a list of mapped entities\n\n Examples\n --------\n >>> unique_identities = [0, 1, 2, 3, 4] # [\"O\", \"B-PER\", \"I-PER\", \"B-LOC\", \"I-LOC\"]\n >>> maps = [0, 1, 1, 2, 2] # [\"O\", \"PER\", \"PER\", \"LOC\", \"LOC\"]\n >>> mapping(unique_identities, maps)\n [0, 1, 1, 2, 2] # [\"O\", \"PER\", \"PER\", \"LOC\", \"LOC\"]\n >>> mapping([0, 0, 4, 4, 3, 4, 0, 2], maps)\n [0, 0, 2, 2, 2, 2, 0, 1] # [\"O\", \"O\", \"LOC\", \"LOC\", \"LOC\", \"LOC\", \"O\", \"PER\"]\n \"\"\"\n f = lambda x: maps[x]\n return list(map(f, entities))\n\n\ndef merge_probs(probs: np.ndarray, maps: List[int]) -> np.ndarray:\n \"\"\"\n Merges model-predictive probabilities with desired mapping\n\n Parameters\n ----------\n probs:\n np.array of shape `(N, K)`, where N is the number of tokens, and K is the number of classes for the model\n\n maps: List[int]\n a list of mapped index, such that the probability of the token being in the i'th class is mapped to the\n `maps[i]` index. If `maps[i] == -1`, the i'th column of `probs` is ignored. If `np.any(maps == -1)`, the\n returned probability is re-normalized.\n\n Returns\n ---------\n probs_merged:\n np.array of shape `(N, K')`, where K' is the number of new classes. Probablities are merged and\n re-normalized if necessary.\n\n \"\"\"\n old_classes = probs.shape[1]\n map_size = np.max(maps) + 1\n probs_merged = np.zeros([len(probs), map_size], dtype=probs.dtype.type)\n\n for i in range(old_classes):\n if maps[i] >= 0:\n probs_merged[:, maps[i]] += probs[:, i]\n if -1 in maps:\n row_sums = probs_merged.sum(axis=1)\n probs_merged /= row_sums[:, np.newaxis]\n return probs_merged\n\n\ndef color_sentence(sentence: str, word: str) -> str:\n \"\"\"\n Searches for a given token in the sentence and returns the sentence where the given token is colored red\n\n Parameters\n ----------\n sentence: str\n a sentence where the word is searched\n\n word: str\n keyword to find in `sentence`. Assumes the word exists in token\n\n Returns\n ---------\n colored_sentence: str\n `sentence` where the first occurance of the word is colored red, using `termcolor.colored`\n\n \"\"\"\n start_idx = sentence.index(word)\n before, after = sentence[:start_idx], sentence[start_idx + len(word) :]\n return \"%s%s%s\" % (before, colored(word, \"red\"), after)\n", "path": "cleanlab/internal/token_classification_utils.py"}], "after_files": [{"content": "import re\nimport string\nimport numpy as np\nfrom termcolor import colored\nfrom typing import List, Optional, Callable, Tuple\n\n\ndef get_sentence(words: List[str]) -> str:\n \"\"\"\n Get sentence formed by a list of words with minor processing for readability\n\n Parameters\n ----------\n words: List[str]\n list of word-level tokens\n\n Returns\n ----------\n sentence: string\n sentence formed by list of word-level tokens\n\n \"\"\"\n sentence = \"\"\n for word in words:\n if word not in string.punctuation or word in [\"-\", \"(\"]:\n word = \" \" + word\n sentence += word\n sentence = sentence.replace(\" '\", \"'\").replace(\"( \", \"(\").strip()\n return sentence\n\n\ndef filter_sentence(\n sentences: List[str],\n condition: Optional[Callable[[str], bool]] = None,\n) -> Tuple[List[str], List[bool]]:\n \"\"\"\n Filter sentence based on some condition, and returns filter mask\n\n Parameters\n ----------\n sentences: List[str]\n list of sentences\n\n condition: Optional[Callable[[str], bool]]\n sentence filtering condition\n\n Returns\n ---------\n sentences: List[str]\n list of sentences filtered\n\n mask: List[bool]\n boolean mask such that `mask[i] == True` if the i'th sentence is included in the\n filtered sentence, otherwise `mask[i] == False`\n\n \"\"\"\n if not condition:\n condition = lambda sentence: len(sentence) > 1 and \"#\" not in sentence\n mask = list(map(condition, sentences))\n sentences = [sentence for m, sentence in zip(mask, sentences) if m]\n return sentences, mask\n\n\ndef process_token(token: str, replace: List[Tuple[str, str]] = [(\"#\", \"\")]) -> str:\n \"\"\"\n Replaces special characters in the tokens\n\n Parameters\n ----------\n token: str\n token which potentially contains special characters\n\n replace: List[Tuple[str, str]]\n list of tuples `(s1, s2)`, where all occurances of s1 are replaced by s2\n\n Returns\n ---------\n processed_token: str\n processed token whose special character has been replaced\n\n Note\n ----\n Only applies to characters in the original input token.\n \"\"\"\n replace_dict = {re.escape(k): v for (k, v) in replace}\n pattern = \"|\".join(replace_dict.keys())\n compiled_pattern = re.compile(pattern)\n replacement = lambda match: replace_dict[re.escape(match.group(0))]\n processed_token = compiled_pattern.sub(replacement, token)\n return processed_token\n\n\ndef mapping(entities: List[int], maps: List[int]) -> List[int]:\n \"\"\"\n Map a list of entities to its corresponding entities\n\n Parameters\n ----------\n entities: List[int]\n a list of given entities\n\n maps: List[int]\n a list of mapped entities, such that the i'th indexed token should be mapped to `maps[i]`\n\n Returns\n ---------\n mapped_entities: List[int]\n a list of mapped entities\n\n Examples\n --------\n >>> unique_identities = [0, 1, 2, 3, 4] # [\"O\", \"B-PER\", \"I-PER\", \"B-LOC\", \"I-LOC\"]\n >>> maps = [0, 1, 1, 2, 2] # [\"O\", \"PER\", \"PER\", \"LOC\", \"LOC\"]\n >>> mapping(unique_identities, maps)\n [0, 1, 1, 2, 2] # [\"O\", \"PER\", \"PER\", \"LOC\", \"LOC\"]\n >>> mapping([0, 0, 4, 4, 3, 4, 0, 2], maps)\n [0, 0, 2, 2, 2, 2, 0, 1] # [\"O\", \"O\", \"LOC\", \"LOC\", \"LOC\", \"LOC\", \"O\", \"PER\"]\n \"\"\"\n f = lambda x: maps[x]\n return list(map(f, entities))\n\n\ndef merge_probs(probs: np.ndarray, maps: List[int]) -> np.ndarray:\n \"\"\"\n Merges model-predictive probabilities with desired mapping\n\n Parameters\n ----------\n probs:\n np.array of shape `(N, K)`, where N is the number of tokens, and K is the number of classes for the model\n\n maps: List[int]\n a list of mapped index, such that the probability of the token being in the i'th class is mapped to the\n `maps[i]` index. If `maps[i] == -1`, the i'th column of `probs` is ignored. If `np.any(maps == -1)`, the\n returned probability is re-normalized.\n\n Returns\n ---------\n probs_merged:\n np.array of shape `(N, K')`, where K' is the number of new classes. Probablities are merged and\n re-normalized if necessary.\n\n \"\"\"\n old_classes = probs.shape[1]\n map_size = np.max(maps) + 1\n probs_merged = np.zeros([len(probs), map_size], dtype=probs.dtype.type)\n\n for i in range(old_classes):\n if maps[i] >= 0:\n probs_merged[:, maps[i]] += probs[:, i]\n if -1 in maps:\n row_sums = probs_merged.sum(axis=1)\n probs_merged /= row_sums[:, np.newaxis]\n return probs_merged\n\n\ndef color_sentence(sentence: str, word: str) -> str:\n \"\"\"\n Searches for a given token in the sentence and returns the sentence where the given token is colored red\n\n Parameters\n ----------\n sentence:\n a sentence where the word is searched\n\n word:\n keyword to find in `sentence`. Assumes the word exists in the sentence.\n Returns\n ---------\n colored_sentence:\n `sentence` where the every occurance of the word is colored red, using `termcolor.colored`\n\n \"\"\"\n colored_word = colored(word, \"red\")\n colored_sentence, number_of_substitions = re.subn(\n r\"\\b{}\\b\".format(word), colored_word, sentence\n )\n if number_of_substitions == 0:\n # Use basic string manipulation if regex fails\n colored_sentence = sentence.replace(word, colored_word)\n return colored_sentence\n", "path": "cleanlab/internal/token_classification_utils.py"}]}
| 3,360 | 332 |
gh_patches_debug_42723
|
rasdani/github-patches
|
git_diff
|
privacyidea__privacyidea-1796
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Hanging at contacting firebase service
When testing the iOS Push token App the communication to the firebase service hangs some times. It is not clear why.
We could however improve the communication here:
https://github.com/privacyidea/privacyidea/blob/master/privacyidea/lib/smsprovider/FirebaseProvider.py#L76
And reuse an existing access_token as long as it has not expired.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `privacyidea/lib/smsprovider/FirebaseProvider.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 #
3 # 2019-02-12 Cornelius Kölbel <[email protected]>
4 #
5 #
6 # This program is free software: you can redistribute it and/or
7 # modify it under the terms of the GNU Affero General Public
8 # License, version 3, as published by the Free Software Foundation.
9 #
10 # This program is distributed in the hope that it will be useful,
11 # but WITHOUT ANY WARRANTY; without even the implied warranty of
12 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
13 # GNU Affero General Public License for more details.
14 #
15 # You should have received a copy of the
16 # GNU Affero General Public License
17 # along with this program. If not, see <http://www.gnu.org/licenses/>.
18 #
19 #
20
21 __doc__ = """This is the provider class that communicates with Googles
22 Firebase Cloud Messaging Service.
23 This provider is used for the push token and can be used for SMS tokens.
24 """
25
26 from privacyidea.lib.smsprovider.SMSProvider import (ISMSProvider)
27 from privacyidea.lib.error import ConfigAdminError
28 from privacyidea.lib import _
29 import logging
30 from oauth2client.service_account import ServiceAccountCredentials
31 import requests
32 import json
33
34 FIREBASE_URL_SEND = 'https://fcm.googleapis.com/v1/projects/{0!s}/messages:send'
35 SCOPES = ['https://www.googleapis.com/auth/cloud-platform',
36 'https://www.googleapis.com/auth/datastore',
37 'https://www.googleapis.com/auth/devstorage.read_write',
38 'https://www.googleapis.com/auth/firebase',
39 'https://www.googleapis.com/auth/identitytoolkit',
40 'https://www.googleapis.com/auth/userinfo.email']
41
42 log = logging.getLogger(__name__)
43
44
45 class FIREBASE_CONFIG:
46 REGISTRATION_URL = "registration URL"
47 TTL = "time to live"
48 JSON_CONFIG = "JSON config file"
49 PROJECT_ID = "projectid"
50 PROJECT_NUMBER = "projectnumber"
51 APP_ID = "appid"
52 API_KEY = "apikey"
53 APP_ID_IOS = "appidios"
54 API_KEY_IOS = "apikeyios"
55
56
57 class FirebaseProvider(ISMSProvider):
58
59 def submit_message(self, firebase_token, data):
60 """
61 send a message to a registered Firebase client
62 This can be a simple OTP value or a cryptographic challenge response.
63
64 :param firebase_token: The firebase token of the smartphone
65 :type firebase_token: str
66 :param data: the data dictionary part of the message to submit to the phone
67 :type data: dict
68 :return: bool
69 """
70 res = False
71
72 credentials = ServiceAccountCredentials.\
73 from_json_keyfile_name(self.smsgateway.option_dict.get(FIREBASE_CONFIG.JSON_CONFIG),
74 SCOPES)
75
76 access_token_info = credentials.get_access_token()
77
78 # Should we do something with expires in?
79 # expires_in = access_token_info.expires_in
80
81 bearer_token = access_token_info.access_token
82 headers = {
83 'Authorization': u'Bearer {0!s}'.format(bearer_token),
84 'Content-Type': 'application/json; UTF-8',
85 }
86 fcm_message = {
87 "message": {
88 "data": data,
89 "token": firebase_token
90 }
91 }
92
93 url = FIREBASE_URL_SEND.format(self.smsgateway.option_dict.get(FIREBASE_CONFIG.PROJECT_ID))
94 resp = requests.post(url, data=json.dumps(fcm_message), headers=headers)
95
96 if resp.status_code == 200:
97 log.debug("Message sent successfully to Firebase service.")
98 res = True
99 else:
100 log.warning(u"Failed to send message to firebase service: {0!s}".format(resp.text))
101
102 return res
103
104 def check_configuration(self):
105 """
106 This method checks the sanity of the configuration of this provider.
107 If there is a configuration error, than an exception is raised.
108 :return:
109 """
110 json_file = self.smsgateway.option_dict.get(FIREBASE_CONFIG.JSON_CONFIG)
111 server_config = None
112 with open(json_file) as f:
113 server_config = json.load(f)
114 if server_config:
115 if server_config.get("type") != "service_account":
116 raise ConfigAdminError(description="The JSON file is not a valid firebase credentials file.")
117 project_id = self.smsgateway.option_dict.get(FIREBASE_CONFIG.PROJECT_ID)
118 if server_config.get("project_id") != project_id:
119 raise ConfigAdminError(description="The project_id you entered does not match the project_id from the JSON file.")
120
121 else:
122 raise ConfigAdminError(description="Please check your configuration. Can not load JSON file.")
123
124 # We need at least
125 # FIREBASE_CONFIG.API_KEY_IOS and FIREBASE_CONFIG.APP_ID_IOS
126 # or
127 # FIREBASE_CONFIG.API_KEY and FIREBASE_CONFIG.APP_ID
128 android_configured = bool(self.smsgateway.option_dict.get(FIREBASE_CONFIG.APP_ID)) and \
129 bool(self.smsgateway.option_dict.get(FIREBASE_CONFIG.API_KEY))
130 ios_configured = bool(self.smsgateway.option_dict.get(FIREBASE_CONFIG.APP_ID_IOS)) and \
131 bool(self.smsgateway.option_dict.get(FIREBASE_CONFIG.API_KEY_IOS))
132 if not android_configured and not ios_configured:
133 raise ConfigAdminError(description="You need to at least configure either app_id and api_key or"
134 " app_id_ios and api_key_ios.")
135
136 @classmethod
137 def parameters(cls):
138 """
139 Return a dictionary, that describes the parameters and options for the
140 Firebase Provider
141 Parameters are required keys to values.
142
143 :return: dict
144 """
145 params = {"options_allowed": False,
146 "parameters": {
147 FIREBASE_CONFIG.REGISTRATION_URL: {
148 "required": True,
149 "description": _('The URL the Push App should contact in the second enrollment step.'
150 ' Usually it is the endpoint /ttype/push of the privacyIDEA server.')},
151 FIREBASE_CONFIG.TTL: {
152 "required": True,
153 "description": _('The second enrollment step must be completed within this time (in minutes).')
154 },
155 FIREBASE_CONFIG.PROJECT_ID: {
156 "required": True,
157 "description": _("The project ID, that the client should use. Get it from your Firebase console.")
158 },
159 FIREBASE_CONFIG.PROJECT_NUMBER: {
160 "required": True,
161 "description": _(
162 "The project number, that the client should use. Get it from your Firebase console.")
163 },
164 FIREBASE_CONFIG.APP_ID: {
165 "required": False,
166 "description": _(
167 "The App ID, that the Android client should use. Get it from your Firebase console.")
168 },
169 FIREBASE_CONFIG.API_KEY: {
170 "required": False,
171 "description": _(
172 "The API Key, that the Android client should use. Get it from your Firebase console.")
173 },
174 FIREBASE_CONFIG.APP_ID_IOS:{
175 "required": False,
176 "description": _(
177 "The App ID, that the iOS client should use. Get it from your Firebase console.")
178 },
179 FIREBASE_CONFIG.API_KEY_IOS: {
180 "required": False,
181 "description": _(
182 "The API Key, that the iOS client should use. Get it from your Firebase console.")
183 },
184 FIREBASE_CONFIG.JSON_CONFIG: {
185 "required": True,
186 "description": _("The filename of the JSON config file, that allows privacyIDEA to talk"
187 " to the Firebase REST API.")
188 }
189 }
190 }
191 return params
192
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/privacyidea/lib/smsprovider/FirebaseProvider.py b/privacyidea/lib/smsprovider/FirebaseProvider.py
--- a/privacyidea/lib/smsprovider/FirebaseProvider.py
+++ b/privacyidea/lib/smsprovider/FirebaseProvider.py
@@ -25,11 +25,14 @@
from privacyidea.lib.smsprovider.SMSProvider import (ISMSProvider)
from privacyidea.lib.error import ConfigAdminError
+from privacyidea.lib.framework import get_app_local_store
from privacyidea.lib import _
import logging
from oauth2client.service_account import ServiceAccountCredentials
import requests
import json
+import time
+import datetime
FIREBASE_URL_SEND = 'https://fcm.googleapis.com/v1/projects/{0!s}/messages:send'
SCOPES = ['https://www.googleapis.com/auth/cloud-platform',
@@ -42,6 +45,46 @@
log = logging.getLogger(__name__)
+class AccessToken(object):
+
+ def __init__(self, access_token, validity):
+ self.access_token = access_token
+ self.expires_at = time.time() + validity - 10
+
+
+def get_firebase_access_token(config_file_name):
+ """
+ This returns the access token for a given JSON config file name
+
+ :param config_file_name:
+ :return:
+ """
+ fbt = "firebase_token"
+ now = time.time()
+ app_store = get_app_local_store()
+
+ if fbt not in app_store or not isinstance(app_store[fbt], dict):
+ # initialize the firebase_token in the app_store as dict
+ app_store[fbt] = {}
+
+ if not isinstance(app_store[fbt].get(config_file_name), AccessToken) or \
+ now > app_store[fbt].get(config_file_name).expires_at:
+ # If the type of the config is not class AccessToken or
+ # if the token has expired
+ credentials = ServiceAccountCredentials.from_json_keyfile_name(config_file_name, SCOPES)
+ log.debug("Fetching a new access_token for {!r} from firebase...".format(config_file_name))
+ access_token_info = credentials.get_access_token()
+ # Now we set the expiration date for the new access_token with a margin of 10 seconds
+ At = AccessToken(access_token_info.access_token, access_token_info.expires_in)
+ # We do not use a lock here: The worst that could happen is that two threads
+ # fetch new auth tokens concurrently. In this case, one of them wins and is written to the dictionary.
+ app_store[fbt][config_file_name] = At
+ readable_time = datetime.datetime.fromtimestamp(At.expires_at).isoformat()
+ log.debug(u"Setting the expiration for {!r} of the new access_token to {!s}.".format(config_file_name, readable_time))
+
+ return app_store[fbt][config_file_name].access_token
+
+
class FIREBASE_CONFIG:
REGISTRATION_URL = "registration URL"
TTL = "time to live"
@@ -56,6 +99,11 @@
class FirebaseProvider(ISMSProvider):
+ def __init__(self, db_smsprovider_object=None, smsgateway=None):
+ ISMSProvider.__init__(self, db_smsprovider_object, smsgateway)
+ self.access_token_info = None
+ self.access_token_expires_at = 0
+
def submit_message(self, firebase_token, data):
"""
send a message to a registered Firebase client
@@ -69,16 +117,9 @@
"""
res = False
- credentials = ServiceAccountCredentials.\
- from_json_keyfile_name(self.smsgateway.option_dict.get(FIREBASE_CONFIG.JSON_CONFIG),
- SCOPES)
-
- access_token_info = credentials.get_access_token()
-
- # Should we do something with expires in?
- # expires_in = access_token_info.expires_in
+ bearer_token = get_firebase_access_token(self.smsgateway.option_dict.get(
+ FIREBASE_CONFIG.JSON_CONFIG))
- bearer_token = access_token_info.access_token
headers = {
'Authorization': u'Bearer {0!s}'.format(bearer_token),
'Content-Type': 'application/json; UTF-8',
@@ -189,4 +230,4 @@
}
}
return params
-
\ No newline at end of file
+
|
{"golden_diff": "diff --git a/privacyidea/lib/smsprovider/FirebaseProvider.py b/privacyidea/lib/smsprovider/FirebaseProvider.py\n--- a/privacyidea/lib/smsprovider/FirebaseProvider.py\n+++ b/privacyidea/lib/smsprovider/FirebaseProvider.py\n@@ -25,11 +25,14 @@\n \n from privacyidea.lib.smsprovider.SMSProvider import (ISMSProvider)\n from privacyidea.lib.error import ConfigAdminError\n+from privacyidea.lib.framework import get_app_local_store\n from privacyidea.lib import _\n import logging\n from oauth2client.service_account import ServiceAccountCredentials\n import requests\n import json\n+import time\n+import datetime\n \n FIREBASE_URL_SEND = 'https://fcm.googleapis.com/v1/projects/{0!s}/messages:send'\n SCOPES = ['https://www.googleapis.com/auth/cloud-platform',\n@@ -42,6 +45,46 @@\n log = logging.getLogger(__name__)\n \n \n+class AccessToken(object):\n+\n+ def __init__(self, access_token, validity):\n+ self.access_token = access_token\n+ self.expires_at = time.time() + validity - 10\n+\n+\n+def get_firebase_access_token(config_file_name):\n+ \"\"\"\n+ This returns the access token for a given JSON config file name\n+\n+ :param config_file_name:\n+ :return:\n+ \"\"\"\n+ fbt = \"firebase_token\"\n+ now = time.time()\n+ app_store = get_app_local_store()\n+\n+ if fbt not in app_store or not isinstance(app_store[fbt], dict):\n+ # initialize the firebase_token in the app_store as dict\n+ app_store[fbt] = {}\n+\n+ if not isinstance(app_store[fbt].get(config_file_name), AccessToken) or \\\n+ now > app_store[fbt].get(config_file_name).expires_at:\n+ # If the type of the config is not class AccessToken or\n+ # if the token has expired\n+ credentials = ServiceAccountCredentials.from_json_keyfile_name(config_file_name, SCOPES)\n+ log.debug(\"Fetching a new access_token for {!r} from firebase...\".format(config_file_name))\n+ access_token_info = credentials.get_access_token()\n+ # Now we set the expiration date for the new access_token with a margin of 10 seconds\n+ At = AccessToken(access_token_info.access_token, access_token_info.expires_in)\n+ # We do not use a lock here: The worst that could happen is that two threads\n+ # fetch new auth tokens concurrently. In this case, one of them wins and is written to the dictionary.\n+ app_store[fbt][config_file_name] = At\n+ readable_time = datetime.datetime.fromtimestamp(At.expires_at).isoformat()\n+ log.debug(u\"Setting the expiration for {!r} of the new access_token to {!s}.\".format(config_file_name, readable_time))\n+\n+ return app_store[fbt][config_file_name].access_token\n+\n+\n class FIREBASE_CONFIG:\n REGISTRATION_URL = \"registration URL\"\n TTL = \"time to live\"\n@@ -56,6 +99,11 @@\n \n class FirebaseProvider(ISMSProvider):\n \n+ def __init__(self, db_smsprovider_object=None, smsgateway=None):\n+ ISMSProvider.__init__(self, db_smsprovider_object, smsgateway)\n+ self.access_token_info = None\n+ self.access_token_expires_at = 0\n+\n def submit_message(self, firebase_token, data):\n \"\"\"\n send a message to a registered Firebase client\n@@ -69,16 +117,9 @@\n \"\"\"\n res = False\n \n- credentials = ServiceAccountCredentials.\\\n- from_json_keyfile_name(self.smsgateway.option_dict.get(FIREBASE_CONFIG.JSON_CONFIG),\n- SCOPES)\n-\n- access_token_info = credentials.get_access_token()\n-\n- # Should we do something with expires in?\n- # expires_in = access_token_info.expires_in\n+ bearer_token = get_firebase_access_token(self.smsgateway.option_dict.get(\n+ FIREBASE_CONFIG.JSON_CONFIG))\n \n- bearer_token = access_token_info.access_token\n headers = {\n 'Authorization': u'Bearer {0!s}'.format(bearer_token),\n 'Content-Type': 'application/json; UTF-8',\n@@ -189,4 +230,4 @@\n }\n }\n return params\n- \n\\ No newline at end of file\n+\n", "issue": "Hanging at contacting firebase service\nWhen testing the iOS Push token App the communication to the firebase service hangs some times. It is not clear why.\r\n\r\nWe could however improve the communication here:\r\nhttps://github.com/privacyidea/privacyidea/blob/master/privacyidea/lib/smsprovider/FirebaseProvider.py#L76\r\n\r\nAnd reuse an existing access_token as long as it has not expired.\r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# 2019-02-12 Cornelius K\u00f6lbel <[email protected]>\n#\n#\n# This program is free software: you can redistribute it and/or\n# modify it under the terms of the GNU Affero General Public\n# License, version 3, as published by the Free Software Foundation.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU Affero General Public License for more details.\n#\n# You should have received a copy of the\n# GNU Affero General Public License\n# along with this program. If not, see <http://www.gnu.org/licenses/>.\n#\n#\n\n__doc__ = \"\"\"This is the provider class that communicates with Googles\nFirebase Cloud Messaging Service.\nThis provider is used for the push token and can be used for SMS tokens.\n\"\"\"\n\nfrom privacyidea.lib.smsprovider.SMSProvider import (ISMSProvider)\nfrom privacyidea.lib.error import ConfigAdminError\nfrom privacyidea.lib import _\nimport logging\nfrom oauth2client.service_account import ServiceAccountCredentials\nimport requests\nimport json\n\nFIREBASE_URL_SEND = 'https://fcm.googleapis.com/v1/projects/{0!s}/messages:send'\nSCOPES = ['https://www.googleapis.com/auth/cloud-platform',\n 'https://www.googleapis.com/auth/datastore',\n 'https://www.googleapis.com/auth/devstorage.read_write',\n 'https://www.googleapis.com/auth/firebase',\n 'https://www.googleapis.com/auth/identitytoolkit',\n 'https://www.googleapis.com/auth/userinfo.email']\n\nlog = logging.getLogger(__name__)\n\n\nclass FIREBASE_CONFIG:\n REGISTRATION_URL = \"registration URL\"\n TTL = \"time to live\"\n JSON_CONFIG = \"JSON config file\"\n PROJECT_ID = \"projectid\"\n PROJECT_NUMBER = \"projectnumber\"\n APP_ID = \"appid\"\n API_KEY = \"apikey\"\n APP_ID_IOS = \"appidios\"\n API_KEY_IOS = \"apikeyios\"\n\n\nclass FirebaseProvider(ISMSProvider):\n\n def submit_message(self, firebase_token, data):\n \"\"\"\n send a message to a registered Firebase client\n This can be a simple OTP value or a cryptographic challenge response.\n\n :param firebase_token: The firebase token of the smartphone\n :type firebase_token: str\n :param data: the data dictionary part of the message to submit to the phone\n :type data: dict\n :return: bool\n \"\"\"\n res = False\n\n credentials = ServiceAccountCredentials.\\\n from_json_keyfile_name(self.smsgateway.option_dict.get(FIREBASE_CONFIG.JSON_CONFIG),\n SCOPES)\n\n access_token_info = credentials.get_access_token()\n\n # Should we do something with expires in?\n # expires_in = access_token_info.expires_in\n\n bearer_token = access_token_info.access_token\n headers = {\n 'Authorization': u'Bearer {0!s}'.format(bearer_token),\n 'Content-Type': 'application/json; UTF-8',\n }\n fcm_message = {\n \"message\": {\n \"data\": data,\n \"token\": firebase_token\n }\n }\n\n url = FIREBASE_URL_SEND.format(self.smsgateway.option_dict.get(FIREBASE_CONFIG.PROJECT_ID))\n resp = requests.post(url, data=json.dumps(fcm_message), headers=headers)\n\n if resp.status_code == 200:\n log.debug(\"Message sent successfully to Firebase service.\")\n res = True\n else:\n log.warning(u\"Failed to send message to firebase service: {0!s}\".format(resp.text))\n\n return res\n\n def check_configuration(self):\n \"\"\"\n This method checks the sanity of the configuration of this provider.\n If there is a configuration error, than an exception is raised.\n :return:\n \"\"\"\n json_file = self.smsgateway.option_dict.get(FIREBASE_CONFIG.JSON_CONFIG)\n server_config = None\n with open(json_file) as f:\n server_config = json.load(f)\n if server_config:\n if server_config.get(\"type\") != \"service_account\":\n raise ConfigAdminError(description=\"The JSON file is not a valid firebase credentials file.\")\n project_id = self.smsgateway.option_dict.get(FIREBASE_CONFIG.PROJECT_ID)\n if server_config.get(\"project_id\") != project_id:\n raise ConfigAdminError(description=\"The project_id you entered does not match the project_id from the JSON file.\")\n\n else:\n raise ConfigAdminError(description=\"Please check your configuration. Can not load JSON file.\")\n\n # We need at least\n # FIREBASE_CONFIG.API_KEY_IOS and FIREBASE_CONFIG.APP_ID_IOS\n # or\n # FIREBASE_CONFIG.API_KEY and FIREBASE_CONFIG.APP_ID\n android_configured = bool(self.smsgateway.option_dict.get(FIREBASE_CONFIG.APP_ID)) and \\\n bool(self.smsgateway.option_dict.get(FIREBASE_CONFIG.API_KEY))\n ios_configured = bool(self.smsgateway.option_dict.get(FIREBASE_CONFIG.APP_ID_IOS)) and \\\n bool(self.smsgateway.option_dict.get(FIREBASE_CONFIG.API_KEY_IOS))\n if not android_configured and not ios_configured:\n raise ConfigAdminError(description=\"You need to at least configure either app_id and api_key or\"\n \" app_id_ios and api_key_ios.\")\n\n @classmethod\n def parameters(cls):\n \"\"\"\n Return a dictionary, that describes the parameters and options for the\n Firebase Provider\n Parameters are required keys to values.\n\n :return: dict\n \"\"\"\n params = {\"options_allowed\": False,\n \"parameters\": {\n FIREBASE_CONFIG.REGISTRATION_URL: {\n \"required\": True,\n \"description\": _('The URL the Push App should contact in the second enrollment step.'\n ' Usually it is the endpoint /ttype/push of the privacyIDEA server.')},\n FIREBASE_CONFIG.TTL: {\n \"required\": True,\n \"description\": _('The second enrollment step must be completed within this time (in minutes).')\n },\n FIREBASE_CONFIG.PROJECT_ID: {\n \"required\": True,\n \"description\": _(\"The project ID, that the client should use. Get it from your Firebase console.\")\n },\n FIREBASE_CONFIG.PROJECT_NUMBER: {\n \"required\": True,\n \"description\": _(\n \"The project number, that the client should use. Get it from your Firebase console.\")\n },\n FIREBASE_CONFIG.APP_ID: {\n \"required\": False,\n \"description\": _(\n \"The App ID, that the Android client should use. Get it from your Firebase console.\")\n },\n FIREBASE_CONFIG.API_KEY: {\n \"required\": False,\n \"description\": _(\n \"The API Key, that the Android client should use. Get it from your Firebase console.\")\n },\n FIREBASE_CONFIG.APP_ID_IOS:{\n \"required\": False,\n \"description\": _(\n \"The App ID, that the iOS client should use. Get it from your Firebase console.\")\n },\n FIREBASE_CONFIG.API_KEY_IOS: {\n \"required\": False,\n \"description\": _(\n \"The API Key, that the iOS client should use. Get it from your Firebase console.\")\n },\n FIREBASE_CONFIG.JSON_CONFIG: {\n \"required\": True,\n \"description\": _(\"The filename of the JSON config file, that allows privacyIDEA to talk\"\n \" to the Firebase REST API.\")\n }\n }\n }\n return params\n ", "path": "privacyidea/lib/smsprovider/FirebaseProvider.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# 2019-02-12 Cornelius K\u00f6lbel <[email protected]>\n#\n#\n# This program is free software: you can redistribute it and/or\n# modify it under the terms of the GNU Affero General Public\n# License, version 3, as published by the Free Software Foundation.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU Affero General Public License for more details.\n#\n# You should have received a copy of the\n# GNU Affero General Public License\n# along with this program. If not, see <http://www.gnu.org/licenses/>.\n#\n#\n\n__doc__ = \"\"\"This is the provider class that communicates with Googles\nFirebase Cloud Messaging Service.\nThis provider is used for the push token and can be used for SMS tokens.\n\"\"\"\n\nfrom privacyidea.lib.smsprovider.SMSProvider import (ISMSProvider)\nfrom privacyidea.lib.error import ConfigAdminError\nfrom privacyidea.lib.framework import get_app_local_store\nfrom privacyidea.lib import _\nimport logging\nfrom oauth2client.service_account import ServiceAccountCredentials\nimport requests\nimport json\nimport time\nimport datetime\n\nFIREBASE_URL_SEND = 'https://fcm.googleapis.com/v1/projects/{0!s}/messages:send'\nSCOPES = ['https://www.googleapis.com/auth/cloud-platform',\n 'https://www.googleapis.com/auth/datastore',\n 'https://www.googleapis.com/auth/devstorage.read_write',\n 'https://www.googleapis.com/auth/firebase',\n 'https://www.googleapis.com/auth/identitytoolkit',\n 'https://www.googleapis.com/auth/userinfo.email']\n\nlog = logging.getLogger(__name__)\n\n\nclass AccessToken(object):\n\n def __init__(self, access_token, validity):\n self.access_token = access_token\n self.expires_at = time.time() + validity - 10\n\n\ndef get_firebase_access_token(config_file_name):\n \"\"\"\n This returns the access token for a given JSON config file name\n\n :param config_file_name:\n :return:\n \"\"\"\n fbt = \"firebase_token\"\n now = time.time()\n app_store = get_app_local_store()\n\n if fbt not in app_store or not isinstance(app_store[fbt], dict):\n # initialize the firebase_token in the app_store as dict\n app_store[fbt] = {}\n\n if not isinstance(app_store[fbt].get(config_file_name), AccessToken) or \\\n now > app_store[fbt].get(config_file_name).expires_at:\n # If the type of the config is not class AccessToken or\n # if the token has expired\n credentials = ServiceAccountCredentials.from_json_keyfile_name(config_file_name, SCOPES)\n log.debug(\"Fetching a new access_token for {!r} from firebase...\".format(config_file_name))\n access_token_info = credentials.get_access_token()\n # Now we set the expiration date for the new access_token with a margin of 10 seconds\n At = AccessToken(access_token_info.access_token, access_token_info.expires_in)\n # We do not use a lock here: The worst that could happen is that two threads\n # fetch new auth tokens concurrently. In this case, one of them wins and is written to the dictionary.\n app_store[fbt][config_file_name] = At\n readable_time = datetime.datetime.fromtimestamp(At.expires_at).isoformat()\n log.debug(u\"Setting the expiration for {!r} of the new access_token to {!s}.\".format(config_file_name, readable_time))\n\n return app_store[fbt][config_file_name].access_token\n\n\nclass FIREBASE_CONFIG:\n REGISTRATION_URL = \"registration URL\"\n TTL = \"time to live\"\n JSON_CONFIG = \"JSON config file\"\n PROJECT_ID = \"projectid\"\n PROJECT_NUMBER = \"projectnumber\"\n APP_ID = \"appid\"\n API_KEY = \"apikey\"\n APP_ID_IOS = \"appidios\"\n API_KEY_IOS = \"apikeyios\"\n\n\nclass FirebaseProvider(ISMSProvider):\n\n def __init__(self, db_smsprovider_object=None, smsgateway=None):\n ISMSProvider.__init__(self, db_smsprovider_object, smsgateway)\n self.access_token_info = None\n self.access_token_expires_at = 0\n\n def submit_message(self, firebase_token, data):\n \"\"\"\n send a message to a registered Firebase client\n This can be a simple OTP value or a cryptographic challenge response.\n\n :param firebase_token: The firebase token of the smartphone\n :type firebase_token: str\n :param data: the data dictionary part of the message to submit to the phone\n :type data: dict\n :return: bool\n \"\"\"\n res = False\n\n bearer_token = get_firebase_access_token(self.smsgateway.option_dict.get(\n FIREBASE_CONFIG.JSON_CONFIG))\n\n headers = {\n 'Authorization': u'Bearer {0!s}'.format(bearer_token),\n 'Content-Type': 'application/json; UTF-8',\n }\n fcm_message = {\n \"message\": {\n \"data\": data,\n \"token\": firebase_token\n }\n }\n\n url = FIREBASE_URL_SEND.format(self.smsgateway.option_dict.get(FIREBASE_CONFIG.PROJECT_ID))\n resp = requests.post(url, data=json.dumps(fcm_message), headers=headers)\n\n if resp.status_code == 200:\n log.debug(\"Message sent successfully to Firebase service.\")\n res = True\n else:\n log.warning(u\"Failed to send message to firebase service: {0!s}\".format(resp.text))\n\n return res\n\n def check_configuration(self):\n \"\"\"\n This method checks the sanity of the configuration of this provider.\n If there is a configuration error, than an exception is raised.\n :return:\n \"\"\"\n json_file = self.smsgateway.option_dict.get(FIREBASE_CONFIG.JSON_CONFIG)\n server_config = None\n with open(json_file) as f:\n server_config = json.load(f)\n if server_config:\n if server_config.get(\"type\") != \"service_account\":\n raise ConfigAdminError(description=\"The JSON file is not a valid firebase credentials file.\")\n project_id = self.smsgateway.option_dict.get(FIREBASE_CONFIG.PROJECT_ID)\n if server_config.get(\"project_id\") != project_id:\n raise ConfigAdminError(description=\"The project_id you entered does not match the project_id from the JSON file.\")\n\n else:\n raise ConfigAdminError(description=\"Please check your configuration. Can not load JSON file.\")\n\n # We need at least\n # FIREBASE_CONFIG.API_KEY_IOS and FIREBASE_CONFIG.APP_ID_IOS\n # or\n # FIREBASE_CONFIG.API_KEY and FIREBASE_CONFIG.APP_ID\n android_configured = bool(self.smsgateway.option_dict.get(FIREBASE_CONFIG.APP_ID)) and \\\n bool(self.smsgateway.option_dict.get(FIREBASE_CONFIG.API_KEY))\n ios_configured = bool(self.smsgateway.option_dict.get(FIREBASE_CONFIG.APP_ID_IOS)) and \\\n bool(self.smsgateway.option_dict.get(FIREBASE_CONFIG.API_KEY_IOS))\n if not android_configured and not ios_configured:\n raise ConfigAdminError(description=\"You need to at least configure either app_id and api_key or\"\n \" app_id_ios and api_key_ios.\")\n\n @classmethod\n def parameters(cls):\n \"\"\"\n Return a dictionary, that describes the parameters and options for the\n Firebase Provider\n Parameters are required keys to values.\n\n :return: dict\n \"\"\"\n params = {\"options_allowed\": False,\n \"parameters\": {\n FIREBASE_CONFIG.REGISTRATION_URL: {\n \"required\": True,\n \"description\": _('The URL the Push App should contact in the second enrollment step.'\n ' Usually it is the endpoint /ttype/push of the privacyIDEA server.')},\n FIREBASE_CONFIG.TTL: {\n \"required\": True,\n \"description\": _('The second enrollment step must be completed within this time (in minutes).')\n },\n FIREBASE_CONFIG.PROJECT_ID: {\n \"required\": True,\n \"description\": _(\"The project ID, that the client should use. Get it from your Firebase console.\")\n },\n FIREBASE_CONFIG.PROJECT_NUMBER: {\n \"required\": True,\n \"description\": _(\n \"The project number, that the client should use. Get it from your Firebase console.\")\n },\n FIREBASE_CONFIG.APP_ID: {\n \"required\": False,\n \"description\": _(\n \"The App ID, that the Android client should use. Get it from your Firebase console.\")\n },\n FIREBASE_CONFIG.API_KEY: {\n \"required\": False,\n \"description\": _(\n \"The API Key, that the Android client should use. Get it from your Firebase console.\")\n },\n FIREBASE_CONFIG.APP_ID_IOS:{\n \"required\": False,\n \"description\": _(\n \"The App ID, that the iOS client should use. Get it from your Firebase console.\")\n },\n FIREBASE_CONFIG.API_KEY_IOS: {\n \"required\": False,\n \"description\": _(\n \"The API Key, that the iOS client should use. Get it from your Firebase console.\")\n },\n FIREBASE_CONFIG.JSON_CONFIG: {\n \"required\": True,\n \"description\": _(\"The filename of the JSON config file, that allows privacyIDEA to talk\"\n \" to the Firebase REST API.\")\n }\n }\n }\n return params\n \n", "path": "privacyidea/lib/smsprovider/FirebaseProvider.py"}]}
| 2,440 | 973 |
gh_patches_debug_4809
|
rasdani/github-patches
|
git_diff
|
getredash__redash-3563
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Issues with Query Based Dropdown when the value is numeric
When the values the query returns for the dropdown are numeric, we have two issues:
1. We don’t load the correct value because the value from the URL passed as string, while the actual value is a number.
2. We don’t load results at all, because they fail parameter schema validation (the string doesn't match the values the dropdown has, which are numbers).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `redash/utils/parameterized_query.py`
Content:
```
1 import pystache
2 from functools import partial
3 from flask_login import current_user
4 from numbers import Number
5 from redash.utils import mustache_render, json_loads
6 from redash.permissions import require_access, view_only
7 from funcy import distinct
8 from dateutil.parser import parse
9
10
11 def _pluck_name_and_value(default_column, row):
12 row = {k.lower(): v for k, v in row.items()}
13 name_column = "name" if "name" in row.keys() else default_column.lower()
14 value_column = "value" if "value" in row.keys() else default_column.lower()
15
16 return {"name": row[name_column], "value": row[value_column]}
17
18
19 def _load_result(query_id):
20 from redash.authentication.org_resolving import current_org
21 from redash import models
22
23 query = models.Query.get_by_id_and_org(query_id, current_org)
24 require_access(query.data_source.groups, current_user, view_only)
25 query_result = models.QueryResult.get_by_id_and_org(query.latest_query_data_id, current_org)
26
27 return json_loads(query_result.data)
28
29
30 def dropdown_values(query_id):
31 data = _load_result(query_id)
32 first_column = data["columns"][0]["name"]
33 pluck = partial(_pluck_name_and_value, first_column)
34 return map(pluck, data["rows"])
35
36
37 def _collect_key_names(nodes):
38 keys = []
39 for node in nodes._parse_tree:
40 if isinstance(node, pystache.parser._EscapeNode):
41 keys.append(node.key)
42 elif isinstance(node, pystache.parser._SectionNode):
43 keys.append(node.key)
44 keys.extend(_collect_key_names(node.parsed))
45
46 return distinct(keys)
47
48
49 def _collect_query_parameters(query):
50 nodes = pystache.parse(query)
51 keys = _collect_key_names(nodes)
52 return keys
53
54
55 def _parameter_names(parameter_values):
56 names = []
57 for key, value in parameter_values.iteritems():
58 if isinstance(value, dict):
59 for inner_key in value.keys():
60 names.append(u'{}.{}'.format(key, inner_key))
61 else:
62 names.append(key)
63
64 return names
65
66
67 def _is_date(string):
68 try:
69 parse(string)
70 return True
71 except ValueError:
72 return False
73
74
75 def _is_date_range(obj):
76 try:
77 return _is_date(obj["start"]) and _is_date(obj["end"])
78 except (KeyError, TypeError):
79 return False
80
81
82 class ParameterizedQuery(object):
83 def __init__(self, template, schema=None):
84 self.schema = schema or []
85 self.template = template
86 self.query = template
87 self.parameters = {}
88
89 def apply(self, parameters):
90 invalid_parameter_names = [key for (key, value) in parameters.iteritems() if not self._valid(key, value)]
91 if invalid_parameter_names:
92 raise InvalidParameterError(invalid_parameter_names)
93 else:
94 self.parameters.update(parameters)
95 self.query = mustache_render(self.template, self.parameters)
96
97 return self
98
99 def _valid(self, name, value):
100 if not self.schema:
101 return True
102
103 definition = next((definition for definition in self.schema if definition["name"] == name), None)
104
105 if not definition:
106 return False
107
108 validators = {
109 "text": lambda value: isinstance(value, basestring),
110 "number": lambda value: isinstance(value, Number),
111 "enum": lambda value: value in definition["enumOptions"],
112 "query": lambda value: value in [v["value"] for v in dropdown_values(definition["queryId"])],
113 "date": _is_date,
114 "datetime-local": _is_date,
115 "datetime-with-seconds": _is_date,
116 "date-range": _is_date_range,
117 "datetime-range": _is_date_range,
118 "datetime-range-with-seconds": _is_date_range,
119 }
120
121 validate = validators.get(definition["type"], lambda x: False)
122
123 return validate(value)
124
125 @property
126 def is_safe(self):
127 text_parameters = filter(lambda p: p["type"] == "text", self.schema)
128 return not any(text_parameters)
129
130 @property
131 def missing_params(self):
132 query_parameters = set(_collect_query_parameters(self.template))
133 return set(query_parameters) - set(_parameter_names(self.parameters))
134
135 @property
136 def text(self):
137 return self.query
138
139
140 class InvalidParameterError(Exception):
141 def __init__(self, parameters):
142 message = u"The following parameter values are incompatible with their definitions: {}".format(", ".join(parameters))
143 super(InvalidParameterError, self).__init__(message)
144
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/redash/utils/parameterized_query.py b/redash/utils/parameterized_query.py
--- a/redash/utils/parameterized_query.py
+++ b/redash/utils/parameterized_query.py
@@ -13,7 +13,7 @@
name_column = "name" if "name" in row.keys() else default_column.lower()
value_column = "value" if "value" in row.keys() else default_column.lower()
- return {"name": row[name_column], "value": row[value_column]}
+ return {"name": row[name_column], "value": unicode(row[value_column])}
def _load_result(query_id):
|
{"golden_diff": "diff --git a/redash/utils/parameterized_query.py b/redash/utils/parameterized_query.py\n--- a/redash/utils/parameterized_query.py\n+++ b/redash/utils/parameterized_query.py\n@@ -13,7 +13,7 @@\n name_column = \"name\" if \"name\" in row.keys() else default_column.lower()\n value_column = \"value\" if \"value\" in row.keys() else default_column.lower()\n \n- return {\"name\": row[name_column], \"value\": row[value_column]}\n+ return {\"name\": row[name_column], \"value\": unicode(row[value_column])}\n \n \n def _load_result(query_id):\n", "issue": "Issues with Query Based Dropdown when the value is numeric\nWhen the values the query returns for the dropdown are numeric, we have two issues:\r\n\r\n1. We don\u2019t load the correct value because the value from the URL passed as string, while the actual value is a number.\r\n2. We don\u2019t load results at all, because they fail parameter schema validation (the string doesn't match the values the dropdown has, which are numbers).\n", "before_files": [{"content": "import pystache\nfrom functools import partial\nfrom flask_login import current_user\nfrom numbers import Number\nfrom redash.utils import mustache_render, json_loads\nfrom redash.permissions import require_access, view_only\nfrom funcy import distinct\nfrom dateutil.parser import parse\n\n\ndef _pluck_name_and_value(default_column, row):\n row = {k.lower(): v for k, v in row.items()}\n name_column = \"name\" if \"name\" in row.keys() else default_column.lower()\n value_column = \"value\" if \"value\" in row.keys() else default_column.lower()\n\n return {\"name\": row[name_column], \"value\": row[value_column]}\n\n\ndef _load_result(query_id):\n from redash.authentication.org_resolving import current_org\n from redash import models\n\n query = models.Query.get_by_id_and_org(query_id, current_org)\n require_access(query.data_source.groups, current_user, view_only)\n query_result = models.QueryResult.get_by_id_and_org(query.latest_query_data_id, current_org)\n\n return json_loads(query_result.data)\n\n\ndef dropdown_values(query_id):\n data = _load_result(query_id)\n first_column = data[\"columns\"][0][\"name\"]\n pluck = partial(_pluck_name_and_value, first_column)\n return map(pluck, data[\"rows\"])\n\n\ndef _collect_key_names(nodes):\n keys = []\n for node in nodes._parse_tree:\n if isinstance(node, pystache.parser._EscapeNode):\n keys.append(node.key)\n elif isinstance(node, pystache.parser._SectionNode):\n keys.append(node.key)\n keys.extend(_collect_key_names(node.parsed))\n\n return distinct(keys)\n\n\ndef _collect_query_parameters(query):\n nodes = pystache.parse(query)\n keys = _collect_key_names(nodes)\n return keys\n\n\ndef _parameter_names(parameter_values):\n names = []\n for key, value in parameter_values.iteritems():\n if isinstance(value, dict):\n for inner_key in value.keys():\n names.append(u'{}.{}'.format(key, inner_key))\n else:\n names.append(key)\n\n return names\n\n\ndef _is_date(string):\n try:\n parse(string)\n return True\n except ValueError:\n return False\n\n\ndef _is_date_range(obj):\n try:\n return _is_date(obj[\"start\"]) and _is_date(obj[\"end\"])\n except (KeyError, TypeError):\n return False\n\n\nclass ParameterizedQuery(object):\n def __init__(self, template, schema=None):\n self.schema = schema or []\n self.template = template\n self.query = template\n self.parameters = {}\n\n def apply(self, parameters):\n invalid_parameter_names = [key for (key, value) in parameters.iteritems() if not self._valid(key, value)]\n if invalid_parameter_names:\n raise InvalidParameterError(invalid_parameter_names)\n else:\n self.parameters.update(parameters)\n self.query = mustache_render(self.template, self.parameters)\n\n return self\n\n def _valid(self, name, value):\n if not self.schema:\n return True\n\n definition = next((definition for definition in self.schema if definition[\"name\"] == name), None)\n\n if not definition:\n return False\n\n validators = {\n \"text\": lambda value: isinstance(value, basestring),\n \"number\": lambda value: isinstance(value, Number),\n \"enum\": lambda value: value in definition[\"enumOptions\"],\n \"query\": lambda value: value in [v[\"value\"] for v in dropdown_values(definition[\"queryId\"])],\n \"date\": _is_date,\n \"datetime-local\": _is_date,\n \"datetime-with-seconds\": _is_date,\n \"date-range\": _is_date_range,\n \"datetime-range\": _is_date_range,\n \"datetime-range-with-seconds\": _is_date_range,\n }\n\n validate = validators.get(definition[\"type\"], lambda x: False)\n\n return validate(value)\n\n @property\n def is_safe(self):\n text_parameters = filter(lambda p: p[\"type\"] == \"text\", self.schema)\n return not any(text_parameters)\n\n @property\n def missing_params(self):\n query_parameters = set(_collect_query_parameters(self.template))\n return set(query_parameters) - set(_parameter_names(self.parameters))\n\n @property\n def text(self):\n return self.query\n\n\nclass InvalidParameterError(Exception):\n def __init__(self, parameters):\n message = u\"The following parameter values are incompatible with their definitions: {}\".format(\", \".join(parameters))\n super(InvalidParameterError, self).__init__(message)\n", "path": "redash/utils/parameterized_query.py"}], "after_files": [{"content": "import pystache\nfrom functools import partial\nfrom flask_login import current_user\nfrom numbers import Number\nfrom redash.utils import mustache_render, json_loads\nfrom redash.permissions import require_access, view_only\nfrom funcy import distinct\nfrom dateutil.parser import parse\n\n\ndef _pluck_name_and_value(default_column, row):\n row = {k.lower(): v for k, v in row.items()}\n name_column = \"name\" if \"name\" in row.keys() else default_column.lower()\n value_column = \"value\" if \"value\" in row.keys() else default_column.lower()\n\n return {\"name\": row[name_column], \"value\": unicode(row[value_column])}\n\n\ndef _load_result(query_id):\n from redash.authentication.org_resolving import current_org\n from redash import models\n\n query = models.Query.get_by_id_and_org(query_id, current_org)\n require_access(query.data_source.groups, current_user, view_only)\n query_result = models.QueryResult.get_by_id_and_org(query.latest_query_data_id, current_org)\n\n return json_loads(query_result.data)\n\n\ndef dropdown_values(query_id):\n data = _load_result(query_id)\n first_column = data[\"columns\"][0][\"name\"]\n pluck = partial(_pluck_name_and_value, first_column)\n return map(pluck, data[\"rows\"])\n\n\ndef _collect_key_names(nodes):\n keys = []\n for node in nodes._parse_tree:\n if isinstance(node, pystache.parser._EscapeNode):\n keys.append(node.key)\n elif isinstance(node, pystache.parser._SectionNode):\n keys.append(node.key)\n keys.extend(_collect_key_names(node.parsed))\n\n return distinct(keys)\n\n\ndef _collect_query_parameters(query):\n nodes = pystache.parse(query)\n keys = _collect_key_names(nodes)\n return keys\n\n\ndef _parameter_names(parameter_values):\n names = []\n for key, value in parameter_values.iteritems():\n if isinstance(value, dict):\n for inner_key in value.keys():\n names.append(u'{}.{}'.format(key, inner_key))\n else:\n names.append(key)\n\n return names\n\n\ndef _is_date(string):\n try:\n parse(string)\n return True\n except ValueError:\n return False\n\n\ndef _is_date_range(obj):\n try:\n return _is_date(obj[\"start\"]) and _is_date(obj[\"end\"])\n except (KeyError, TypeError):\n return False\n\n\nclass ParameterizedQuery(object):\n def __init__(self, template, schema=None):\n self.schema = schema or []\n self.template = template\n self.query = template\n self.parameters = {}\n\n def apply(self, parameters):\n invalid_parameter_names = [key for (key, value) in parameters.iteritems() if not self._valid(key, value)]\n if invalid_parameter_names:\n raise InvalidParameterError(invalid_parameter_names)\n else:\n self.parameters.update(parameters)\n self.query = mustache_render(self.template, self.parameters)\n\n return self\n\n def _valid(self, name, value):\n if not self.schema:\n return True\n\n definition = next((definition for definition in self.schema if definition[\"name\"] == name), None)\n\n if not definition:\n return False\n\n validators = {\n \"text\": lambda value: isinstance(value, basestring),\n \"number\": lambda value: isinstance(value, Number),\n \"enum\": lambda value: value in definition[\"enumOptions\"],\n \"query\": lambda value: value in [v[\"value\"] for v in dropdown_values(definition[\"queryId\"])],\n \"date\": _is_date,\n \"datetime-local\": _is_date,\n \"datetime-with-seconds\": _is_date,\n \"date-range\": _is_date_range,\n \"datetime-range\": _is_date_range,\n \"datetime-range-with-seconds\": _is_date_range,\n }\n\n validate = validators.get(definition[\"type\"], lambda x: False)\n\n return validate(value)\n\n @property\n def is_safe(self):\n text_parameters = filter(lambda p: p[\"type\"] == \"text\", self.schema)\n return not any(text_parameters)\n\n @property\n def missing_params(self):\n query_parameters = set(_collect_query_parameters(self.template))\n return set(query_parameters) - set(_parameter_names(self.parameters))\n\n @property\n def text(self):\n return self.query\n\n\nclass InvalidParameterError(Exception):\n def __init__(self, parameters):\n message = u\"The following parameter values are incompatible with their definitions: {}\".format(\", \".join(parameters))\n super(InvalidParameterError, self).__init__(message)\n", "path": "redash/utils/parameterized_query.py"}]}
| 1,670 | 141 |
gh_patches_debug_12489
|
rasdani/github-patches
|
git_diff
|
dask__distributed-270
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
WindowsError on dscheduler
So it appears that Bokeh is not found, but I have Bokeh and everything is up to date.
Interesting...
here lieth the traceback:
```
distributed.scheduler - INFO - Start Scheduler at: 192.168.0.7:8786
distributed.scheduler - INFO - http at: 192.168.0.7:9786
distributed.scheduler - WARNING - Could not start Bokeh web UI
Traceback (most recent call last):
File "C:\Anaconda\lib\site-packages\distributed\cli\dscheduler.py", line 88, in main
bokeh_proc = subprocess.Popen(args)
File "C:\Anaconda\lib\subprocess.py", line 710, in __init__
errread, errwrite)
File "C:\Anaconda\lib\subprocess.py", line 958, in _execute_child
startupinfo)
WindowsError: [Error 2] The system cannot find the file specified
Traceback (most recent call last):
File "C:\Anaconda\Scripts\dscheduler-script.py", line 5, in <module>
sys.exit(distributed.cli.dscheduler.go())
File "C:\Anaconda\lib\site-packages\distributed\cli\dscheduler.py", line 107, in go
main()
File "C:\Anaconda\lib\site-packages\click\core.py", line 716, in __call__
return self.main(*args, **kwargs)
File "C:\Anaconda\lib\site-packages\click\core.py", line 696, in main
rv = self.invoke(ctx)
File "C:\Anaconda\lib\site-packages\click\core.py", line 889, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "C:\Anaconda\lib\site-packages\click\core.py", line 534, in invoke
return callback(*args, **kwargs)
File "C:\Anaconda\lib\site-packages\distributed\cli\dscheduler.py", line 100, in main
bokeh_proc.terminate()
UnboundLocalError: local variable 'bokeh_proc' referenced before assignment
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `distributed/cli/dscheduler.py`
Content:
```
1 from __future__ import print_function, division, absolute_import
2
3 import json
4 import logging
5 import multiprocessing
6 import os
7 import socket
8 import subprocess
9 import sys
10 from time import sleep
11
12 import click
13
14 import distributed
15 from distributed import Scheduler
16 from distributed.utils import get_ip
17 from distributed.http import HTTPScheduler
18 from distributed.cli.utils import check_python_3
19 from tornado.ioloop import IOLoop
20
21 logger = logging.getLogger('distributed.scheduler')
22
23 import signal
24
25 def handle_signal(sig, frame):
26 IOLoop.instance().add_callback(IOLoop.instance().stop)
27
28 signal.signal(signal.SIGINT, handle_signal)
29 signal.signal(signal.SIGTERM, handle_signal)
30
31
32 @click.command()
33 @click.argument('center', type=str, default='')
34 @click.option('--port', type=int, default=8786, help="Serving port")
35 @click.option('--http-port', type=int, default=9786, help="HTTP port")
36 @click.option('--bokeh-port', type=int, default=8787, help="HTTP port")
37 @click.option('--bokeh/--no-bokeh', '_bokeh', default=True, show_default=True,
38 required=False, help="Launch Bokeh Web UI")
39 @click.option('--host', type=str, default=None,
40 help="IP or hostname of this server")
41 @click.option('--show/--no-show', default=False, help="Show web UI")
42 @click.option('--bokeh-whitelist', default=None, multiple=True,
43 help="IP addresses to whitelist for bokeh.")
44 def main(center, host, port, http_port, bokeh_port, show, _bokeh, bokeh_whitelist):
45 given_host = host
46 host = host or get_ip()
47 ip = socket.gethostbyname(host)
48 loop = IOLoop.current()
49 scheduler = Scheduler(center, ip=ip,
50 services={('http', http_port): HTTPScheduler})
51 if center:
52 loop.run_sync(scheduler.sync_center)
53 scheduler.start(port)
54
55 if _bokeh:
56 try:
57 import bokeh
58 import distributed.bokeh
59 hosts = ['%s:%d' % (h, bokeh_port) for h in
60 ['localhost', '127.0.0.1', ip, socket.gethostname(),
61 host] + list(bokeh_whitelist)]
62 dirname = os.path.dirname(distributed.__file__)
63 paths = [os.path.join(dirname, 'bokeh', name)
64 for name in ['status', 'tasks']]
65 binname = sys.argv[0][:-len('dscheduler')] + 'bokeh'
66 args = ([binname, 'serve'] + paths +
67 ['--log-level', 'warning',
68 '--check-unused-sessions=50',
69 '--unused-session-lifetime=1',
70 '--port', str(bokeh_port)] +
71 sum([['--host', host] for host in hosts], []))
72 if show:
73 args.append('--show')
74
75 bokeh_options = {'host': host if given_host else '127.0.0.1',
76 'http-port': http_port,
77 'tcp-port': port,
78 'bokeh-port': bokeh_port}
79 with open('.dask-web-ui.json', 'w') as f:
80 json.dump(bokeh_options, f, indent=2)
81
82 if sys.version_info[0] >= 3:
83 from bokeh.command.bootstrap import main
84 ctx = multiprocessing.get_context('spawn')
85 bokeh_proc = ctx.Process(target=main, args=(args,))
86 bokeh_proc.daemon = True
87 bokeh_proc.start()
88 else:
89 bokeh_proc = subprocess.Popen(args)
90
91 logger.info(" Bokeh UI at: http://%s:%d/status/"
92 % (ip, bokeh_port))
93 except ImportError:
94 logger.info("Please install Bokeh to get Web UI")
95 except Exception as e:
96 logger.warn("Could not start Bokeh web UI", exc_info=True)
97
98 loop.start()
99 loop.close()
100 scheduler.stop()
101 bokeh_proc.terminate()
102
103 logger.info("End scheduler at %s:%d", ip, port)
104
105
106 def go():
107 check_python_3()
108 main()
109
110
111 if __name__ == '__main__':
112 go()
113
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/distributed/cli/dscheduler.py b/distributed/cli/dscheduler.py
--- a/distributed/cli/dscheduler.py
+++ b/distributed/cli/dscheduler.py
@@ -62,7 +62,8 @@
dirname = os.path.dirname(distributed.__file__)
paths = [os.path.join(dirname, 'bokeh', name)
for name in ['status', 'tasks']]
- binname = sys.argv[0][:-len('dscheduler')] + 'bokeh'
+ binname = 'bokeh.bat' if 'win' in sys.platform else 'bokeh'
+ binname = os.path.join(os.path.dirname(sys.argv[0]), binname)
args = ([binname, 'serve'] + paths +
['--log-level', 'warning',
'--check-unused-sessions=50',
|
{"golden_diff": "diff --git a/distributed/cli/dscheduler.py b/distributed/cli/dscheduler.py\n--- a/distributed/cli/dscheduler.py\n+++ b/distributed/cli/dscheduler.py\n@@ -62,7 +62,8 @@\n dirname = os.path.dirname(distributed.__file__)\n paths = [os.path.join(dirname, 'bokeh', name)\n for name in ['status', 'tasks']]\n- binname = sys.argv[0][:-len('dscheduler')] + 'bokeh'\n+ binname = 'bokeh.bat' if 'win' in sys.platform else 'bokeh'\n+ binname = os.path.join(os.path.dirname(sys.argv[0]), binname)\n args = ([binname, 'serve'] + paths +\n ['--log-level', 'warning',\n '--check-unused-sessions=50',\n", "issue": "WindowsError on dscheduler\nSo it appears that Bokeh is not found, but I have Bokeh and everything is up to date.\n\nInteresting...\n\nhere lieth the traceback:\n\n```\ndistributed.scheduler - INFO - Start Scheduler at: 192.168.0.7:8786\ndistributed.scheduler - INFO - http at: 192.168.0.7:9786\ndistributed.scheduler - WARNING - Could not start Bokeh web UI\nTraceback (most recent call last):\n File \"C:\\Anaconda\\lib\\site-packages\\distributed\\cli\\dscheduler.py\", line 88, in main\n bokeh_proc = subprocess.Popen(args)\n File \"C:\\Anaconda\\lib\\subprocess.py\", line 710, in __init__\n errread, errwrite)\n File \"C:\\Anaconda\\lib\\subprocess.py\", line 958, in _execute_child\n startupinfo)\nWindowsError: [Error 2] The system cannot find the file specified\nTraceback (most recent call last):\n File \"C:\\Anaconda\\Scripts\\dscheduler-script.py\", line 5, in <module>\n sys.exit(distributed.cli.dscheduler.go())\n File \"C:\\Anaconda\\lib\\site-packages\\distributed\\cli\\dscheduler.py\", line 107, in go\n main()\n File \"C:\\Anaconda\\lib\\site-packages\\click\\core.py\", line 716, in __call__\n return self.main(*args, **kwargs)\n File \"C:\\Anaconda\\lib\\site-packages\\click\\core.py\", line 696, in main\n rv = self.invoke(ctx)\n File \"C:\\Anaconda\\lib\\site-packages\\click\\core.py\", line 889, in invoke\n return ctx.invoke(self.callback, **ctx.params)\n File \"C:\\Anaconda\\lib\\site-packages\\click\\core.py\", line 534, in invoke\n return callback(*args, **kwargs)\n File \"C:\\Anaconda\\lib\\site-packages\\distributed\\cli\\dscheduler.py\", line 100, in main\n bokeh_proc.terminate()\nUnboundLocalError: local variable 'bokeh_proc' referenced before assignment\n```\n\n", "before_files": [{"content": "from __future__ import print_function, division, absolute_import\n\nimport json\nimport logging\nimport multiprocessing\nimport os\nimport socket\nimport subprocess\nimport sys\nfrom time import sleep\n\nimport click\n\nimport distributed\nfrom distributed import Scheduler\nfrom distributed.utils import get_ip\nfrom distributed.http import HTTPScheduler\nfrom distributed.cli.utils import check_python_3\nfrom tornado.ioloop import IOLoop\n\nlogger = logging.getLogger('distributed.scheduler')\n\nimport signal\n\ndef handle_signal(sig, frame):\n IOLoop.instance().add_callback(IOLoop.instance().stop)\n\nsignal.signal(signal.SIGINT, handle_signal)\nsignal.signal(signal.SIGTERM, handle_signal)\n\n\[email protected]()\[email protected]('center', type=str, default='')\[email protected]('--port', type=int, default=8786, help=\"Serving port\")\[email protected]('--http-port', type=int, default=9786, help=\"HTTP port\")\[email protected]('--bokeh-port', type=int, default=8787, help=\"HTTP port\")\[email protected]('--bokeh/--no-bokeh', '_bokeh', default=True, show_default=True,\n required=False, help=\"Launch Bokeh Web UI\")\[email protected]('--host', type=str, default=None,\n help=\"IP or hostname of this server\")\[email protected]('--show/--no-show', default=False, help=\"Show web UI\")\[email protected]('--bokeh-whitelist', default=None, multiple=True,\n help=\"IP addresses to whitelist for bokeh.\")\ndef main(center, host, port, http_port, bokeh_port, show, _bokeh, bokeh_whitelist):\n given_host = host\n host = host or get_ip()\n ip = socket.gethostbyname(host)\n loop = IOLoop.current()\n scheduler = Scheduler(center, ip=ip,\n services={('http', http_port): HTTPScheduler})\n if center:\n loop.run_sync(scheduler.sync_center)\n scheduler.start(port)\n\n if _bokeh:\n try:\n import bokeh\n import distributed.bokeh\n hosts = ['%s:%d' % (h, bokeh_port) for h in\n ['localhost', '127.0.0.1', ip, socket.gethostname(),\n host] + list(bokeh_whitelist)]\n dirname = os.path.dirname(distributed.__file__)\n paths = [os.path.join(dirname, 'bokeh', name)\n for name in ['status', 'tasks']]\n binname = sys.argv[0][:-len('dscheduler')] + 'bokeh'\n args = ([binname, 'serve'] + paths +\n ['--log-level', 'warning',\n '--check-unused-sessions=50',\n '--unused-session-lifetime=1',\n '--port', str(bokeh_port)] +\n sum([['--host', host] for host in hosts], []))\n if show:\n args.append('--show')\n\n bokeh_options = {'host': host if given_host else '127.0.0.1',\n 'http-port': http_port,\n 'tcp-port': port,\n 'bokeh-port': bokeh_port}\n with open('.dask-web-ui.json', 'w') as f:\n json.dump(bokeh_options, f, indent=2)\n\n if sys.version_info[0] >= 3:\n from bokeh.command.bootstrap import main\n ctx = multiprocessing.get_context('spawn')\n bokeh_proc = ctx.Process(target=main, args=(args,))\n bokeh_proc.daemon = True\n bokeh_proc.start()\n else:\n bokeh_proc = subprocess.Popen(args)\n\n logger.info(\" Bokeh UI at: http://%s:%d/status/\"\n % (ip, bokeh_port))\n except ImportError:\n logger.info(\"Please install Bokeh to get Web UI\")\n except Exception as e:\n logger.warn(\"Could not start Bokeh web UI\", exc_info=True)\n\n loop.start()\n loop.close()\n scheduler.stop()\n bokeh_proc.terminate()\n\n logger.info(\"End scheduler at %s:%d\", ip, port)\n\n\ndef go():\n check_python_3()\n main()\n\n\nif __name__ == '__main__':\n go()\n", "path": "distributed/cli/dscheduler.py"}], "after_files": [{"content": "from __future__ import print_function, division, absolute_import\n\nimport json\nimport logging\nimport multiprocessing\nimport os\nimport socket\nimport subprocess\nimport sys\nfrom time import sleep\n\nimport click\n\nimport distributed\nfrom distributed import Scheduler\nfrom distributed.utils import get_ip\nfrom distributed.http import HTTPScheduler\nfrom distributed.cli.utils import check_python_3\nfrom tornado.ioloop import IOLoop\n\nlogger = logging.getLogger('distributed.scheduler')\n\nimport signal\n\ndef handle_signal(sig, frame):\n IOLoop.instance().add_callback(IOLoop.instance().stop)\n\nsignal.signal(signal.SIGINT, handle_signal)\nsignal.signal(signal.SIGTERM, handle_signal)\n\n\[email protected]()\[email protected]('center', type=str, default='')\[email protected]('--port', type=int, default=8786, help=\"Serving port\")\[email protected]('--http-port', type=int, default=9786, help=\"HTTP port\")\[email protected]('--bokeh-port', type=int, default=8787, help=\"HTTP port\")\[email protected]('--bokeh/--no-bokeh', '_bokeh', default=True, show_default=True,\n required=False, help=\"Launch Bokeh Web UI\")\[email protected]('--host', type=str, default=None,\n help=\"IP or hostname of this server\")\[email protected]('--show/--no-show', default=False, help=\"Show web UI\")\[email protected]('--bokeh-whitelist', default=None, multiple=True,\n help=\"IP addresses to whitelist for bokeh.\")\ndef main(center, host, port, http_port, bokeh_port, show, _bokeh, bokeh_whitelist):\n given_host = host\n host = host or get_ip()\n ip = socket.gethostbyname(host)\n loop = IOLoop.current()\n scheduler = Scheduler(center, ip=ip,\n services={('http', http_port): HTTPScheduler})\n if center:\n loop.run_sync(scheduler.sync_center)\n scheduler.start(port)\n\n if _bokeh:\n try:\n import bokeh\n import distributed.bokeh\n hosts = ['%s:%d' % (h, bokeh_port) for h in\n ['localhost', '127.0.0.1', ip, socket.gethostname(),\n host] + list(bokeh_whitelist)]\n dirname = os.path.dirname(distributed.__file__)\n paths = [os.path.join(dirname, 'bokeh', name)\n for name in ['status', 'tasks']]\n binname = 'bokeh.bat' if 'win' in sys.platform else 'bokeh'\n binname = os.path.join(os.path.dirname(sys.argv[0]), binname)\n args = ([binname, 'serve'] + paths +\n ['--log-level', 'warning',\n '--check-unused-sessions=50',\n '--unused-session-lifetime=1',\n '--port', str(bokeh_port)] +\n sum([['--host', host] for host in hosts], []))\n if show:\n args.append('--show')\n\n bokeh_options = {'host': host if given_host else '127.0.0.1',\n 'http-port': http_port,\n 'tcp-port': port,\n 'bokeh-port': bokeh_port}\n with open('.dask-web-ui.json', 'w') as f:\n json.dump(bokeh_options, f, indent=2)\n\n if sys.version_info[0] >= 3:\n from bokeh.command.bootstrap import main\n ctx = multiprocessing.get_context('spawn')\n bokeh_proc = ctx.Process(target=main, args=(args,))\n bokeh_proc.daemon = True\n bokeh_proc.start()\n else:\n bokeh_proc = subprocess.Popen(args)\n\n logger.info(\" Bokeh UI at: http://%s:%d/status/\"\n % (ip, bokeh_port))\n except ImportError:\n logger.info(\"Please install Bokeh to get Web UI\")\n except Exception as e:\n logger.warn(\"Could not start Bokeh web UI\", exc_info=True)\n\n loop.start()\n loop.close()\n scheduler.stop()\n bokeh_proc.terminate()\n\n logger.info(\"End scheduler at %s:%d\", ip, port)\n\n\ndef go():\n check_python_3()\n main()\n\n\nif __name__ == '__main__':\n go()\n", "path": "distributed/cli/dscheduler.py"}]}
| 1,902 | 178 |
gh_patches_debug_33299
|
rasdani/github-patches
|
git_diff
|
blaze__blaze-1134
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
blaze.server does not allow CORS
`blaze.server` sticks with same origin policy so it does not enable CORS requests.. This is an issue for users using bokeh `BlazeDataSources` to map to a blaze server and update data directly on the browser without `bokeh.server` because this `blaze.server` (well, Flask default) configuration will raise an error. Something like:
```
XMLHttpRequest cannot load http://domain:9000/compute.json. No 'Access-Control-Allow-Origin' header is present on the requested resource. Origin 'http://domain:5006' is therefore not allowed access.
```
.
This issue can be fixed by setting (injecting) the CORS policies on `blaze.server`. For instance:
``` Python
server = blaze.Server({'dat': gauss})
def add_crossdomain_headers(response):
response.headers.add('Access-Control-Allow-Origin', '*')
response.headers.add('Access-Control-Allow-Methods', 'GET,POST')
response.headers.add('Access-Control-Allow-Headers', "Origin, X-Requested-With, Content-Type, Accept")
return response
server.app.after_request(add_crossdomain_headers)
server.run(host="127.0.0.1", port=9000)
```
But a probably better solution would be to have some kind of configuration on `blaze.server` itself so users don't have to bother too much trying to find the solution.
NOTE: Flask does expose a `crossdomain` decorator that can be used to decorate views (and that may be a better solution) but I didn't figure out a quick way of using it within `blaze.server` before the views are declared (I may be overlooking something trivial, I honestly didn't have much time to dig in details).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `blaze/server/server.py`
Content:
```
1 from __future__ import absolute_import, division, print_function
2
3 import socket
4
5 import flask
6 from flask import Blueprint, Flask, request
7
8 from toolz import assoc
9
10 from datashape.predicates import iscollection, isscalar
11 from odo import odo
12
13 import blaze
14 from blaze import compute
15 from blaze.expr import utils as expr_utils
16 from blaze.compute import compute_up
17
18 from .serialization import json
19 from ..interactive import InteractiveSymbol, coerce_scalar
20 from ..expr import Expr, symbol
21
22 from datashape import Mono, discover
23
24
25 __all__ = 'Server', 'to_tree', 'from_tree'
26
27 # http://www.speedguide.net/port.php?port=6363
28 # http://en.wikipedia.org/wiki/List_of_TCP_and_UDP_port_numbers
29 DEFAULT_PORT = 6363
30
31
32 api = Blueprint('api', __name__)
33 pickle_extension_api = Blueprint('pickle_extension_api', __name__)
34
35
36 def _get_option(option, options):
37 try:
38 return options[option]
39 except KeyError:
40 # Provides a more informative error message.
41 raise TypeError(
42 'The blaze api must be registered with {option}'.format(
43 option=option,
44 ),
45 )
46
47
48 def _register_api(app, options, first_registration=False):
49 """
50 Register the data with the blueprint.
51 """
52 _get_data.cache[app] = _get_option('data', options)
53 _get_format.cache[app] = dict(
54 (f.name, f) for f in _get_option('formats', options)
55 )
56 # Call the original register function.
57 Blueprint.register(api, app, options, first_registration)
58
59 api.register = _register_api
60
61
62 def _get_data():
63 """
64 Retrieve the current application's data for use in the blaze server
65 endpoints.
66 """
67 return _get_data.cache[flask.current_app]
68 _get_data.cache = {}
69
70
71 def _get_format(name):
72 return _get_format.cache[flask.current_app][name]
73 _get_format.cache = {}
74
75
76 class Server(object):
77
78 """ Blaze Data Server
79
80 Host local data through a web API
81
82 Parameters
83 ----------
84 data : ``dict`` or ``None``, optional
85 A dictionary mapping dataset name to any data format that blaze
86 understands.
87
88 formats : ``iterable[SerializationFormat]``, optional
89 An iterable of supported serialization formats. By default, the
90 server will support JSON.
91 A serialization format is an object that supports:
92 name, loads, and dumps.
93
94 Examples
95 --------
96 >>> from pandas import DataFrame
97 >>> df = DataFrame([[1, 'Alice', 100],
98 ... [2, 'Bob', -200],
99 ... [3, 'Alice', 300],
100 ... [4, 'Dennis', 400],
101 ... [5, 'Bob', -500]],
102 ... columns=['id', 'name', 'amount'])
103
104 >>> server = Server({'accounts': df})
105 >>> server.run() # doctest: +SKIP
106 """
107 __slots__ = 'app', 'data', 'port'
108
109 def __init__(self, data=None, formats=None):
110 app = self.app = Flask('blaze.server.server')
111 if data is None:
112 data = dict()
113 app.register_blueprint(
114 api,
115 data=data,
116 formats=formats if formats is not None else (json,),
117 )
118 self.data = data
119
120 def run(self, *args, **kwargs):
121 """Run the server"""
122 port = kwargs.pop('port', DEFAULT_PORT)
123 self.port = port
124 try:
125 self.app.run(*args, port=port, **kwargs)
126 except socket.error:
127 print("\tOops, couldn't connect on port %d. Is it busy?" % port)
128 if kwargs.get('retry', True):
129 # Attempt to start the server on a new port.
130 self.run(*args, **assoc(kwargs, 'port', port + 1))
131
132
133 @api.route('/datashape')
134 def dataset():
135 return str(discover(_get_data()))
136
137
138 def to_tree(expr, names=None):
139 """ Represent Blaze expression with core data structures
140
141 Transform a Blaze expression into a form using only strings, dicts, lists
142 and base types (int, float, datetime, ....) This form can be useful for
143 serialization.
144
145 Parameters
146 ----------
147
148 expr: Blaze Expression
149
150 Examples
151 --------
152
153 >>> t = symbol('t', 'var * {x: int32, y: int32}')
154 >>> to_tree(t) # doctest: +SKIP
155 {'op': 'Symbol',
156 'args': ['t', 'var * { x : int32, y : int32 }', False]}
157
158
159 >>> to_tree(t.x.sum()) # doctest: +SKIP
160 {'op': 'sum',
161 'args': [
162 {'op': 'Column',
163 'args': [
164 {
165 'op': 'Symbol'
166 'args': ['t', 'var * { x : int32, y : int32 }', False]
167 }
168 'x']
169 }]
170 }
171
172 Simplify expresion using explicit ``names`` dictionary. In the example
173 below we replace the ``Symbol`` node with the string ``'t'``.
174
175 >>> tree = to_tree(t.x, names={t: 't'})
176 >>> tree # doctest: +SKIP
177 {'op': 'Column', 'args': ['t', 'x']}
178
179 >>> from_tree(tree, namespace={'t': t})
180 t.x
181
182 See Also
183 --------
184
185 blaze.server.server.from_tree
186 """
187 if names and expr in names:
188 return names[expr]
189 if isinstance(expr, tuple):
190 return [to_tree(arg, names=names) for arg in expr]
191 if isinstance(expr, expr_utils._slice):
192 return to_tree(expr.as_slice(), names=names)
193 if isinstance(expr, slice):
194 return {'op': 'slice',
195 'args': [to_tree(arg, names=names) for arg in
196 [expr.start, expr.stop, expr.step]]}
197 elif isinstance(expr, Mono):
198 return str(expr)
199 elif isinstance(expr, InteractiveSymbol):
200 return to_tree(symbol(expr._name, expr.dshape), names)
201 elif isinstance(expr, Expr):
202 return {'op': type(expr).__name__,
203 'args': [to_tree(arg, names) for arg in expr._args]}
204 else:
205 return expr
206
207
208 def expression_from_name(name):
209 """
210
211 >>> expression_from_name('By')
212 <class 'blaze.expr.split_apply_combine.By'>
213
214 >>> expression_from_name('And')
215 <class 'blaze.expr.arithmetic.And'>
216 """
217 import blaze
218 if hasattr(blaze, name):
219 return getattr(blaze, name)
220 if hasattr(blaze.expr, name):
221 return getattr(blaze.expr, name)
222 for signature, func in compute_up.funcs.items():
223 try:
224 if signature[0].__name__ == name:
225 return signature[0]
226 except TypeError:
227 pass
228 raise ValueError('%s not found in compute_up' % name)
229
230
231 def from_tree(expr, namespace=None):
232 """ Convert core data structures to Blaze expression
233
234 Core data structure representations created by ``to_tree`` are converted
235 back into Blaze expressions.
236
237 Parameters
238 ----------
239 expr : dict
240
241 Examples
242 --------
243
244 >>> t = symbol('t', 'var * {x: int32, y: int32}')
245 >>> tree = to_tree(t)
246 >>> tree # doctest: +SKIP
247 {'op': 'Symbol',
248 'args': ['t', 'var * { x : int32, y : int32 }', False]}
249
250 >>> from_tree(tree)
251 t
252
253 >>> tree = to_tree(t.x.sum())
254 >>> tree # doctest: +SKIP
255 {'op': 'sum',
256 'args': [
257 {'op': 'Field',
258 'args': [
259 {
260 'op': 'Symbol'
261 'args': ['t', 'var * { x : int32, y : int32 }', False]
262 }
263 'x']
264 }]
265 }
266
267 >>> from_tree(tree)
268 sum(t.x)
269
270 Simplify expresion using explicit ``names`` dictionary. In the example
271 below we replace the ``Symbol`` node with the string ``'t'``.
272
273 >>> tree = to_tree(t.x, names={t: 't'})
274 >>> tree # doctest: +SKIP
275 {'op': 'Field', 'args': ['t', 'x']}
276
277 >>> from_tree(tree, namespace={'t': t})
278 t.x
279
280 See Also
281 --------
282
283 blaze.server.server.to_tree
284 """
285 if isinstance(expr, dict):
286 op, args = expr['op'], expr['args']
287 if 'slice' == op:
288 return expr_utils._slice(*[from_tree(arg, namespace)
289 for arg in args])
290 if hasattr(blaze.expr, op):
291 cls = getattr(blaze.expr, op)
292 else:
293 cls = expression_from_name(op)
294 if 'Symbol' in op:
295 children = [from_tree(arg) for arg in args]
296 else:
297 children = [from_tree(arg, namespace) for arg in args]
298 return cls(*children)
299 elif isinstance(expr, list):
300 return tuple(from_tree(arg, namespace) for arg in expr)
301 if namespace and expr in namespace:
302 return namespace[expr]
303 else:
304 return expr
305
306
307 @api.route('/compute.<serial_format>', methods=['POST', 'PUT', 'GET'])
308 def compserver(serial_format):
309 try:
310 serial = _get_format(serial_format)
311 except KeyError:
312 return 'Unsupported serialization format', 404
313
314 try:
315 payload = serial.loads(request.data)
316 except ValueError:
317 return ("Bad data. Got %s " % request.data, 400) # 400: Bad Request
318
319 ns = payload.get('namespace', dict())
320 dataset = _get_data()
321 ns[':leaf'] = symbol('leaf', discover(dataset))
322
323 expr = from_tree(payload['expr'], namespace=ns)
324 assert len(expr._leaves()) == 1
325 leaf = expr._leaves()[0]
326
327 try:
328 result = compute(expr, {leaf: dataset})
329
330 if iscollection(expr.dshape):
331 result = odo(result, list)
332 elif isscalar(expr.dshape):
333 result = coerce_scalar(result, str(expr.dshape))
334 except NotImplementedError as e:
335 # 501: Not Implemented
336 return ("Computation not supported:\n%s" % e, 501)
337 except Exception as e:
338 # 500: Internal Server Error
339 return ("Computation failed with message:\n%s" % e, 500)
340
341 return serial.dumps({
342 'datashape': str(expr.dshape),
343 'data': result,
344 'names': expr.fields
345 })
346
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/blaze/server/server.py b/blaze/server/server.py
--- a/blaze/server/server.py
+++ b/blaze/server/server.py
@@ -1,12 +1,25 @@
from __future__ import absolute_import, division, print_function
import socket
+import functools
import flask
from flask import Blueprint, Flask, request
+try:
+ from bokeh.server.crossdomain import crossdomain
+except ImportError:
+ def crossdomain(*args, **kwargs):
+ def wrapper(f):
+ @functools.wraps(f)
+ def wrapped(*a, **k):
+ return f(*a, **k)
+ return wrapped
+ return wrapper
+
from toolz import assoc
+from datashape import Mono, discover
from datashape.predicates import iscollection, isscalar
from odo import odo
@@ -19,8 +32,6 @@
from ..interactive import InteractiveSymbol, coerce_scalar
from ..expr import Expr, symbol
-from datashape import Mono, discover
-
__all__ = 'Server', 'to_tree', 'from_tree'
@@ -130,8 +141,9 @@
self.run(*args, **assoc(kwargs, 'port', port + 1))
[email protected]('/datashape')
-def dataset():
[email protected]('/datashape', methods=['GET'])
+@crossdomain(origin='*', methods=['GET'])
+def shape():
return str(discover(_get_data()))
@@ -144,8 +156,8 @@
Parameters
----------
-
- expr: Blaze Expression
+ expr : Expr
+ A Blaze expression
Examples
--------
@@ -304,7 +316,9 @@
return expr
[email protected]('/compute.<serial_format>', methods=['POST', 'PUT', 'GET'])
[email protected]('/compute.<serial_format>',
+ methods=['POST', 'GET', 'HEAD', 'OPTIONS'])
+@crossdomain(origin='*', methods=['POST', 'GET', 'HEAD', 'OPTIONS'])
def compserver(serial_format):
try:
serial = _get_format(serial_format)
|
{"golden_diff": "diff --git a/blaze/server/server.py b/blaze/server/server.py\n--- a/blaze/server/server.py\n+++ b/blaze/server/server.py\n@@ -1,12 +1,25 @@\n from __future__ import absolute_import, division, print_function\n \n import socket\n+import functools\n \n import flask\n from flask import Blueprint, Flask, request\n \n+try:\n+ from bokeh.server.crossdomain import crossdomain\n+except ImportError:\n+ def crossdomain(*args, **kwargs):\n+ def wrapper(f):\n+ @functools.wraps(f)\n+ def wrapped(*a, **k):\n+ return f(*a, **k)\n+ return wrapped\n+ return wrapper\n+\n from toolz import assoc\n \n+from datashape import Mono, discover\n from datashape.predicates import iscollection, isscalar\n from odo import odo\n \n@@ -19,8 +32,6 @@\n from ..interactive import InteractiveSymbol, coerce_scalar\n from ..expr import Expr, symbol\n \n-from datashape import Mono, discover\n-\n \n __all__ = 'Server', 'to_tree', 'from_tree'\n \n@@ -130,8 +141,9 @@\n self.run(*args, **assoc(kwargs, 'port', port + 1))\n \n \[email protected]('/datashape')\n-def dataset():\[email protected]('/datashape', methods=['GET'])\n+@crossdomain(origin='*', methods=['GET'])\n+def shape():\n return str(discover(_get_data()))\n \n \n@@ -144,8 +156,8 @@\n \n Parameters\n ----------\n-\n- expr: Blaze Expression\n+ expr : Expr\n+ A Blaze expression\n \n Examples\n --------\n@@ -304,7 +316,9 @@\n return expr\n \n \[email protected]('/compute.<serial_format>', methods=['POST', 'PUT', 'GET'])\[email protected]('/compute.<serial_format>',\n+ methods=['POST', 'GET', 'HEAD', 'OPTIONS'])\n+@crossdomain(origin='*', methods=['POST', 'GET', 'HEAD', 'OPTIONS'])\n def compserver(serial_format):\n try:\n serial = _get_format(serial_format)\n", "issue": "blaze.server does not allow CORS\n`blaze.server` sticks with same origin policy so it does not enable CORS requests.. This is an issue for users using bokeh `BlazeDataSources` to map to a blaze server and update data directly on the browser without `bokeh.server` because this `blaze.server` (well, Flask default) configuration will raise an error. Something like:\n\n```\n XMLHttpRequest cannot load http://domain:9000/compute.json. No 'Access-Control-Allow-Origin' header is present on the requested resource. Origin 'http://domain:5006' is therefore not allowed access.\n```\n\n.\n\nThis issue can be fixed by setting (injecting) the CORS policies on `blaze.server`. For instance:\n\n``` Python\n server = blaze.Server({'dat': gauss})\n\n def add_crossdomain_headers(response):\n response.headers.add('Access-Control-Allow-Origin', '*')\n response.headers.add('Access-Control-Allow-Methods', 'GET,POST')\n response.headers.add('Access-Control-Allow-Headers', \"Origin, X-Requested-With, Content-Type, Accept\")\n\n return response\n\n server.app.after_request(add_crossdomain_headers)\n server.run(host=\"127.0.0.1\", port=9000)\n\n```\n\nBut a probably better solution would be to have some kind of configuration on `blaze.server` itself so users don't have to bother too much trying to find the solution. \n\nNOTE: Flask does expose a `crossdomain` decorator that can be used to decorate views (and that may be a better solution) but I didn't figure out a quick way of using it within `blaze.server` before the views are declared (I may be overlooking something trivial, I honestly didn't have much time to dig in details).\n\n", "before_files": [{"content": "from __future__ import absolute_import, division, print_function\n\nimport socket\n\nimport flask\nfrom flask import Blueprint, Flask, request\n\nfrom toolz import assoc\n\nfrom datashape.predicates import iscollection, isscalar\nfrom odo import odo\n\nimport blaze\nfrom blaze import compute\nfrom blaze.expr import utils as expr_utils\nfrom blaze.compute import compute_up\n\nfrom .serialization import json\nfrom ..interactive import InteractiveSymbol, coerce_scalar\nfrom ..expr import Expr, symbol\n\nfrom datashape import Mono, discover\n\n\n__all__ = 'Server', 'to_tree', 'from_tree'\n\n# http://www.speedguide.net/port.php?port=6363\n# http://en.wikipedia.org/wiki/List_of_TCP_and_UDP_port_numbers\nDEFAULT_PORT = 6363\n\n\napi = Blueprint('api', __name__)\npickle_extension_api = Blueprint('pickle_extension_api', __name__)\n\n\ndef _get_option(option, options):\n try:\n return options[option]\n except KeyError:\n # Provides a more informative error message.\n raise TypeError(\n 'The blaze api must be registered with {option}'.format(\n option=option,\n ),\n )\n\n\ndef _register_api(app, options, first_registration=False):\n \"\"\"\n Register the data with the blueprint.\n \"\"\"\n _get_data.cache[app] = _get_option('data', options)\n _get_format.cache[app] = dict(\n (f.name, f) for f in _get_option('formats', options)\n )\n # Call the original register function.\n Blueprint.register(api, app, options, first_registration)\n\napi.register = _register_api\n\n\ndef _get_data():\n \"\"\"\n Retrieve the current application's data for use in the blaze server\n endpoints.\n \"\"\"\n return _get_data.cache[flask.current_app]\n_get_data.cache = {}\n\n\ndef _get_format(name):\n return _get_format.cache[flask.current_app][name]\n_get_format.cache = {}\n\n\nclass Server(object):\n\n \"\"\" Blaze Data Server\n\n Host local data through a web API\n\n Parameters\n ----------\n data : ``dict`` or ``None``, optional\n A dictionary mapping dataset name to any data format that blaze\n understands.\n\n formats : ``iterable[SerializationFormat]``, optional\n An iterable of supported serialization formats. By default, the\n server will support JSON.\n A serialization format is an object that supports:\n name, loads, and dumps.\n\n Examples\n --------\n >>> from pandas import DataFrame\n >>> df = DataFrame([[1, 'Alice', 100],\n ... [2, 'Bob', -200],\n ... [3, 'Alice', 300],\n ... [4, 'Dennis', 400],\n ... [5, 'Bob', -500]],\n ... columns=['id', 'name', 'amount'])\n\n >>> server = Server({'accounts': df})\n >>> server.run() # doctest: +SKIP\n \"\"\"\n __slots__ = 'app', 'data', 'port'\n\n def __init__(self, data=None, formats=None):\n app = self.app = Flask('blaze.server.server')\n if data is None:\n data = dict()\n app.register_blueprint(\n api,\n data=data,\n formats=formats if formats is not None else (json,),\n )\n self.data = data\n\n def run(self, *args, **kwargs):\n \"\"\"Run the server\"\"\"\n port = kwargs.pop('port', DEFAULT_PORT)\n self.port = port\n try:\n self.app.run(*args, port=port, **kwargs)\n except socket.error:\n print(\"\\tOops, couldn't connect on port %d. Is it busy?\" % port)\n if kwargs.get('retry', True):\n # Attempt to start the server on a new port.\n self.run(*args, **assoc(kwargs, 'port', port + 1))\n\n\[email protected]('/datashape')\ndef dataset():\n return str(discover(_get_data()))\n\n\ndef to_tree(expr, names=None):\n \"\"\" Represent Blaze expression with core data structures\n\n Transform a Blaze expression into a form using only strings, dicts, lists\n and base types (int, float, datetime, ....) This form can be useful for\n serialization.\n\n Parameters\n ----------\n\n expr: Blaze Expression\n\n Examples\n --------\n\n >>> t = symbol('t', 'var * {x: int32, y: int32}')\n >>> to_tree(t) # doctest: +SKIP\n {'op': 'Symbol',\n 'args': ['t', 'var * { x : int32, y : int32 }', False]}\n\n\n >>> to_tree(t.x.sum()) # doctest: +SKIP\n {'op': 'sum',\n 'args': [\n {'op': 'Column',\n 'args': [\n {\n 'op': 'Symbol'\n 'args': ['t', 'var * { x : int32, y : int32 }', False]\n }\n 'x']\n }]\n }\n\n Simplify expresion using explicit ``names`` dictionary. In the example\n below we replace the ``Symbol`` node with the string ``'t'``.\n\n >>> tree = to_tree(t.x, names={t: 't'})\n >>> tree # doctest: +SKIP\n {'op': 'Column', 'args': ['t', 'x']}\n\n >>> from_tree(tree, namespace={'t': t})\n t.x\n\n See Also\n --------\n\n blaze.server.server.from_tree\n \"\"\"\n if names and expr in names:\n return names[expr]\n if isinstance(expr, tuple):\n return [to_tree(arg, names=names) for arg in expr]\n if isinstance(expr, expr_utils._slice):\n return to_tree(expr.as_slice(), names=names)\n if isinstance(expr, slice):\n return {'op': 'slice',\n 'args': [to_tree(arg, names=names) for arg in\n [expr.start, expr.stop, expr.step]]}\n elif isinstance(expr, Mono):\n return str(expr)\n elif isinstance(expr, InteractiveSymbol):\n return to_tree(symbol(expr._name, expr.dshape), names)\n elif isinstance(expr, Expr):\n return {'op': type(expr).__name__,\n 'args': [to_tree(arg, names) for arg in expr._args]}\n else:\n return expr\n\n\ndef expression_from_name(name):\n \"\"\"\n\n >>> expression_from_name('By')\n <class 'blaze.expr.split_apply_combine.By'>\n\n >>> expression_from_name('And')\n <class 'blaze.expr.arithmetic.And'>\n \"\"\"\n import blaze\n if hasattr(blaze, name):\n return getattr(blaze, name)\n if hasattr(blaze.expr, name):\n return getattr(blaze.expr, name)\n for signature, func in compute_up.funcs.items():\n try:\n if signature[0].__name__ == name:\n return signature[0]\n except TypeError:\n pass\n raise ValueError('%s not found in compute_up' % name)\n\n\ndef from_tree(expr, namespace=None):\n \"\"\" Convert core data structures to Blaze expression\n\n Core data structure representations created by ``to_tree`` are converted\n back into Blaze expressions.\n\n Parameters\n ----------\n expr : dict\n\n Examples\n --------\n\n >>> t = symbol('t', 'var * {x: int32, y: int32}')\n >>> tree = to_tree(t)\n >>> tree # doctest: +SKIP\n {'op': 'Symbol',\n 'args': ['t', 'var * { x : int32, y : int32 }', False]}\n\n >>> from_tree(tree)\n t\n\n >>> tree = to_tree(t.x.sum())\n >>> tree # doctest: +SKIP\n {'op': 'sum',\n 'args': [\n {'op': 'Field',\n 'args': [\n {\n 'op': 'Symbol'\n 'args': ['t', 'var * { x : int32, y : int32 }', False]\n }\n 'x']\n }]\n }\n\n >>> from_tree(tree)\n sum(t.x)\n\n Simplify expresion using explicit ``names`` dictionary. In the example\n below we replace the ``Symbol`` node with the string ``'t'``.\n\n >>> tree = to_tree(t.x, names={t: 't'})\n >>> tree # doctest: +SKIP\n {'op': 'Field', 'args': ['t', 'x']}\n\n >>> from_tree(tree, namespace={'t': t})\n t.x\n\n See Also\n --------\n\n blaze.server.server.to_tree\n \"\"\"\n if isinstance(expr, dict):\n op, args = expr['op'], expr['args']\n if 'slice' == op:\n return expr_utils._slice(*[from_tree(arg, namespace)\n for arg in args])\n if hasattr(blaze.expr, op):\n cls = getattr(blaze.expr, op)\n else:\n cls = expression_from_name(op)\n if 'Symbol' in op:\n children = [from_tree(arg) for arg in args]\n else:\n children = [from_tree(arg, namespace) for arg in args]\n return cls(*children)\n elif isinstance(expr, list):\n return tuple(from_tree(arg, namespace) for arg in expr)\n if namespace and expr in namespace:\n return namespace[expr]\n else:\n return expr\n\n\[email protected]('/compute.<serial_format>', methods=['POST', 'PUT', 'GET'])\ndef compserver(serial_format):\n try:\n serial = _get_format(serial_format)\n except KeyError:\n return 'Unsupported serialization format', 404\n\n try:\n payload = serial.loads(request.data)\n except ValueError:\n return (\"Bad data. Got %s \" % request.data, 400) # 400: Bad Request\n\n ns = payload.get('namespace', dict())\n dataset = _get_data()\n ns[':leaf'] = symbol('leaf', discover(dataset))\n\n expr = from_tree(payload['expr'], namespace=ns)\n assert len(expr._leaves()) == 1\n leaf = expr._leaves()[0]\n\n try:\n result = compute(expr, {leaf: dataset})\n\n if iscollection(expr.dshape):\n result = odo(result, list)\n elif isscalar(expr.dshape):\n result = coerce_scalar(result, str(expr.dshape))\n except NotImplementedError as e:\n # 501: Not Implemented\n return (\"Computation not supported:\\n%s\" % e, 501)\n except Exception as e:\n # 500: Internal Server Error\n return (\"Computation failed with message:\\n%s\" % e, 500)\n\n return serial.dumps({\n 'datashape': str(expr.dshape),\n 'data': result,\n 'names': expr.fields\n })\n", "path": "blaze/server/server.py"}], "after_files": [{"content": "from __future__ import absolute_import, division, print_function\n\nimport socket\nimport functools\n\nimport flask\nfrom flask import Blueprint, Flask, request\n\ntry:\n from bokeh.server.crossdomain import crossdomain\nexcept ImportError:\n def crossdomain(*args, **kwargs):\n def wrapper(f):\n @functools.wraps(f)\n def wrapped(*a, **k):\n return f(*a, **k)\n return wrapped\n return wrapper\n\nfrom toolz import assoc\n\nfrom datashape import Mono, discover\nfrom datashape.predicates import iscollection, isscalar\nfrom odo import odo\n\nimport blaze\nfrom blaze import compute\nfrom blaze.expr import utils as expr_utils\nfrom blaze.compute import compute_up\n\nfrom .serialization import json\nfrom ..interactive import InteractiveSymbol, coerce_scalar\nfrom ..expr import Expr, symbol\n\n\n__all__ = 'Server', 'to_tree', 'from_tree'\n\n# http://www.speedguide.net/port.php?port=6363\n# http://en.wikipedia.org/wiki/List_of_TCP_and_UDP_port_numbers\nDEFAULT_PORT = 6363\n\n\napi = Blueprint('api', __name__)\npickle_extension_api = Blueprint('pickle_extension_api', __name__)\n\n\ndef _get_option(option, options):\n try:\n return options[option]\n except KeyError:\n # Provides a more informative error message.\n raise TypeError(\n 'The blaze api must be registered with {option}'.format(\n option=option,\n ),\n )\n\n\ndef _register_api(app, options, first_registration=False):\n \"\"\"\n Register the data with the blueprint.\n \"\"\"\n _get_data.cache[app] = _get_option('data', options)\n _get_format.cache[app] = dict(\n (f.name, f) for f in _get_option('formats', options)\n )\n # Call the original register function.\n Blueprint.register(api, app, options, first_registration)\n\napi.register = _register_api\n\n\ndef _get_data():\n \"\"\"\n Retrieve the current application's data for use in the blaze server\n endpoints.\n \"\"\"\n return _get_data.cache[flask.current_app]\n_get_data.cache = {}\n\n\ndef _get_format(name):\n return _get_format.cache[flask.current_app][name]\n_get_format.cache = {}\n\n\nclass Server(object):\n\n \"\"\" Blaze Data Server\n\n Host local data through a web API\n\n Parameters\n ----------\n data : ``dict`` or ``None``, optional\n A dictionary mapping dataset name to any data format that blaze\n understands.\n\n formats : ``iterable[SerializationFormat]``, optional\n An iterable of supported serialization formats. By default, the\n server will support JSON.\n A serialization format is an object that supports:\n name, loads, and dumps.\n\n Examples\n --------\n >>> from pandas import DataFrame\n >>> df = DataFrame([[1, 'Alice', 100],\n ... [2, 'Bob', -200],\n ... [3, 'Alice', 300],\n ... [4, 'Dennis', 400],\n ... [5, 'Bob', -500]],\n ... columns=['id', 'name', 'amount'])\n\n >>> server = Server({'accounts': df})\n >>> server.run() # doctest: +SKIP\n \"\"\"\n __slots__ = 'app', 'data', 'port'\n\n def __init__(self, data=None, formats=None):\n app = self.app = Flask('blaze.server.server')\n if data is None:\n data = dict()\n app.register_blueprint(\n api,\n data=data,\n formats=formats if formats is not None else (json,),\n )\n self.data = data\n\n def run(self, *args, **kwargs):\n \"\"\"Run the server\"\"\"\n port = kwargs.pop('port', DEFAULT_PORT)\n self.port = port\n try:\n self.app.run(*args, port=port, **kwargs)\n except socket.error:\n print(\"\\tOops, couldn't connect on port %d. Is it busy?\" % port)\n if kwargs.get('retry', True):\n # Attempt to start the server on a new port.\n self.run(*args, **assoc(kwargs, 'port', port + 1))\n\n\[email protected]('/datashape', methods=['GET'])\n@crossdomain(origin='*', methods=['GET'])\ndef shape():\n return str(discover(_get_data()))\n\n\ndef to_tree(expr, names=None):\n \"\"\" Represent Blaze expression with core data structures\n\n Transform a Blaze expression into a form using only strings, dicts, lists\n and base types (int, float, datetime, ....) This form can be useful for\n serialization.\n\n Parameters\n ----------\n expr : Expr\n A Blaze expression\n\n Examples\n --------\n\n >>> t = symbol('t', 'var * {x: int32, y: int32}')\n >>> to_tree(t) # doctest: +SKIP\n {'op': 'Symbol',\n 'args': ['t', 'var * { x : int32, y : int32 }', False]}\n\n\n >>> to_tree(t.x.sum()) # doctest: +SKIP\n {'op': 'sum',\n 'args': [\n {'op': 'Column',\n 'args': [\n {\n 'op': 'Symbol'\n 'args': ['t', 'var * { x : int32, y : int32 }', False]\n }\n 'x']\n }]\n }\n\n Simplify expresion using explicit ``names`` dictionary. In the example\n below we replace the ``Symbol`` node with the string ``'t'``.\n\n >>> tree = to_tree(t.x, names={t: 't'})\n >>> tree # doctest: +SKIP\n {'op': 'Column', 'args': ['t', 'x']}\n\n >>> from_tree(tree, namespace={'t': t})\n t.x\n\n See Also\n --------\n\n blaze.server.server.from_tree\n \"\"\"\n if names and expr in names:\n return names[expr]\n if isinstance(expr, tuple):\n return [to_tree(arg, names=names) for arg in expr]\n if isinstance(expr, expr_utils._slice):\n return to_tree(expr.as_slice(), names=names)\n if isinstance(expr, slice):\n return {'op': 'slice',\n 'args': [to_tree(arg, names=names) for arg in\n [expr.start, expr.stop, expr.step]]}\n elif isinstance(expr, Mono):\n return str(expr)\n elif isinstance(expr, InteractiveSymbol):\n return to_tree(symbol(expr._name, expr.dshape), names)\n elif isinstance(expr, Expr):\n return {'op': type(expr).__name__,\n 'args': [to_tree(arg, names) for arg in expr._args]}\n else:\n return expr\n\n\ndef expression_from_name(name):\n \"\"\"\n\n >>> expression_from_name('By')\n <class 'blaze.expr.split_apply_combine.By'>\n\n >>> expression_from_name('And')\n <class 'blaze.expr.arithmetic.And'>\n \"\"\"\n import blaze\n if hasattr(blaze, name):\n return getattr(blaze, name)\n if hasattr(blaze.expr, name):\n return getattr(blaze.expr, name)\n for signature, func in compute_up.funcs.items():\n try:\n if signature[0].__name__ == name:\n return signature[0]\n except TypeError:\n pass\n raise ValueError('%s not found in compute_up' % name)\n\n\ndef from_tree(expr, namespace=None):\n \"\"\" Convert core data structures to Blaze expression\n\n Core data structure representations created by ``to_tree`` are converted\n back into Blaze expressions.\n\n Parameters\n ----------\n expr : dict\n\n Examples\n --------\n\n >>> t = symbol('t', 'var * {x: int32, y: int32}')\n >>> tree = to_tree(t)\n >>> tree # doctest: +SKIP\n {'op': 'Symbol',\n 'args': ['t', 'var * { x : int32, y : int32 }', False]}\n\n >>> from_tree(tree)\n t\n\n >>> tree = to_tree(t.x.sum())\n >>> tree # doctest: +SKIP\n {'op': 'sum',\n 'args': [\n {'op': 'Field',\n 'args': [\n {\n 'op': 'Symbol'\n 'args': ['t', 'var * { x : int32, y : int32 }', False]\n }\n 'x']\n }]\n }\n\n >>> from_tree(tree)\n sum(t.x)\n\n Simplify expresion using explicit ``names`` dictionary. In the example\n below we replace the ``Symbol`` node with the string ``'t'``.\n\n >>> tree = to_tree(t.x, names={t: 't'})\n >>> tree # doctest: +SKIP\n {'op': 'Field', 'args': ['t', 'x']}\n\n >>> from_tree(tree, namespace={'t': t})\n t.x\n\n See Also\n --------\n\n blaze.server.server.to_tree\n \"\"\"\n if isinstance(expr, dict):\n op, args = expr['op'], expr['args']\n if 'slice' == op:\n return expr_utils._slice(*[from_tree(arg, namespace)\n for arg in args])\n if hasattr(blaze.expr, op):\n cls = getattr(blaze.expr, op)\n else:\n cls = expression_from_name(op)\n if 'Symbol' in op:\n children = [from_tree(arg) for arg in args]\n else:\n children = [from_tree(arg, namespace) for arg in args]\n return cls(*children)\n elif isinstance(expr, list):\n return tuple(from_tree(arg, namespace) for arg in expr)\n if namespace and expr in namespace:\n return namespace[expr]\n else:\n return expr\n\n\[email protected]('/compute.<serial_format>',\n methods=['POST', 'GET', 'HEAD', 'OPTIONS'])\n@crossdomain(origin='*', methods=['POST', 'GET', 'HEAD', 'OPTIONS'])\ndef compserver(serial_format):\n try:\n serial = _get_format(serial_format)\n except KeyError:\n return 'Unsupported serialization format', 404\n\n try:\n payload = serial.loads(request.data)\n except ValueError:\n return (\"Bad data. Got %s \" % request.data, 400) # 400: Bad Request\n\n ns = payload.get('namespace', dict())\n dataset = _get_data()\n ns[':leaf'] = symbol('leaf', discover(dataset))\n\n expr = from_tree(payload['expr'], namespace=ns)\n assert len(expr._leaves()) == 1\n leaf = expr._leaves()[0]\n\n try:\n result = compute(expr, {leaf: dataset})\n\n if iscollection(expr.dshape):\n result = odo(result, list)\n elif isscalar(expr.dshape):\n result = coerce_scalar(result, str(expr.dshape))\n except NotImplementedError as e:\n # 501: Not Implemented\n return (\"Computation not supported:\\n%s\" % e, 501)\n except Exception as e:\n # 500: Internal Server Error\n return (\"Computation failed with message:\\n%s\" % e, 500)\n\n return serial.dumps({\n 'datashape': str(expr.dshape),\n 'data': result,\n 'names': expr.fields\n })\n", "path": "blaze/server/server.py"}]}
| 3,985 | 476 |
gh_patches_debug_64882
|
rasdani/github-patches
|
git_diff
|
streamlit__streamlit-1931
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add screenshot test for syntax highlighting
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `e2e/scripts/st_code.py`
Content:
```
1 # Copyright 2018-2020 Streamlit Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import streamlit as st
16
17 st.code("# This code is awesome!")
18
19 st.code("")
20
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/e2e/scripts/st_code.py b/e2e/scripts/st_code.py
--- a/e2e/scripts/st_code.py
+++ b/e2e/scripts/st_code.py
@@ -17,3 +17,9 @@
st.code("# This code is awesome!")
st.code("")
+
+code = """
+def hello():
+ print("Hello, Streamlit!")
+"""
+st.code(code, language="python")
|
{"golden_diff": "diff --git a/e2e/scripts/st_code.py b/e2e/scripts/st_code.py\n--- a/e2e/scripts/st_code.py\n+++ b/e2e/scripts/st_code.py\n@@ -17,3 +17,9 @@\n st.code(\"# This code is awesome!\")\n \n st.code(\"\")\n+\n+code = \"\"\"\n+def hello():\n+ print(\"Hello, Streamlit!\")\n+\"\"\"\n+st.code(code, language=\"python\")\n", "issue": "Add screenshot test for syntax highlighting\n\n", "before_files": [{"content": "# Copyright 2018-2020 Streamlit Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport streamlit as st\n\nst.code(\"# This code is awesome!\")\n\nst.code(\"\")\n", "path": "e2e/scripts/st_code.py"}], "after_files": [{"content": "# Copyright 2018-2020 Streamlit Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport streamlit as st\n\nst.code(\"# This code is awesome!\")\n\nst.code(\"\")\n\ncode = \"\"\"\ndef hello():\n print(\"Hello, Streamlit!\")\n\"\"\"\nst.code(code, language=\"python\")\n", "path": "e2e/scripts/st_code.py"}]}
| 455 | 93 |
gh_patches_debug_22091
|
rasdani/github-patches
|
git_diff
|
PennyLaneAI__pennylane-2542
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[BUG] Derivatives of `qml.CommutingEvolution`
In cleaning warnings from the test suite, I found this warning:
```
templates/test_subroutines/test_commuting_evolution.py::TestGradients::test_differentiable_hamiltonian
/Users/christina/Prog/pl/lib/python3.8/site-packages/autograd/tracer.py:14: UserWarning: Output seems independent of input.
warnings.warn("Output seems independent of input.")
```
The effect of `CommutingEvolution` on the state did not change with the time.
This problems seems to stem from [commuting_evolution.py Line 160](https://github.com/PennyLaneAI/pennylane/blob/e55f463bcbca1832505d9440d2f5144543f944fe/pennylane/templates/subroutines/commuting_evolution.py#L160):
```
return qml.templates.ApproxTimeEvolution(hamiltonian, time_and_coeffs[1], 1).decomposition()
```
This line incorrectly indexes into `time_and_coeffs` to try and extract the time. It should instead use `time_and_coeffs[0]`.
Upon fixing that bug, we now find that parameter shift no longer works for `CommutingEvolution`.
These two tests start to fail:
```
==================================================================================== short test summary info ====================================================================================
FAILED templates/test_subroutines/test_commuting_evolution.py::TestGradients::test_two_term_case - assert False
FAILED templates/test_subroutines/test_commuting_evolution.py::TestGradients::test_four_term_case - assert False
```
The tests that fail manually specify the frequencies. If the frequencies are specified, the operation sets its own `grad_recipe`. This `grad_recipe` gives incorrect results. I have yet to track down the problem with the `grad_recipe` property.
In summary, fixing the bug in the creation of the `ApproxTimeEvolution` operation allows finite difference derivatives and derivatives for operations without specified frequencies to work correctly. Since the finite-difference derivatives are now correct, we can see that the parameter-shift gradients never worked correctly.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pennylane/templates/subroutines/commuting_evolution.py`
Content:
```
1 # Copyright 2018-2021 Xanadu Quantum Technologies Inc.
2
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6
7 # http://www.apache.org/licenses/LICENSE-2.0
8
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 r"""
15 Contains the CommutingEvolution template.
16 """
17 # pylint: disable-msg=too-many-arguments,import-outside-toplevel
18 import pennylane as qml
19 from pennylane.operation import Operation, AnyWires
20
21
22 class CommutingEvolution(Operation):
23 r"""Applies the time-evolution operator for a Hamiltonian expressed as a linear combination
24 of mutually commuting Pauli words.
25
26 A commuting Hamiltonian is of the form
27
28 .. math:: H \ = \ \displaystyle\sum_{j} c_j P_j,
29
30 where :math:`P_j` are mutually commutative Pauli words and :math:`c_j` are real coefficients.
31 The time-evolution under a commuting Hamiltonian is given by a unitary of the form
32
33 .. math::
34
35 U(t) \ = \ e^{-i H t} \ = \exp(-i t \displaystyle\sum_j c_j P_j) =
36 \displaystyle\prod_j \exp(-i t c_j P_j).
37
38 If the Hamiltonian has a small number of unique eigenvalues, partial derivatives of observable
39 expectation values, i.e.
40
41 .. math:: \langle 0 | W(t)^\dagger O W(t) | 0 \rangle,
42
43 where :math:`W(t) = V U(t) Y` for some :math:`V` and :math:`Y`, taken with respect to
44 :math:`t` may be efficiently computed through generalized parameter shift rules. When
45 initialized, this template will automatically compute the parameter-shift rule if given the
46 Hamiltonian's eigenvalue frequencies, i.e., the unique positive differences between
47 eigenvalues.
48
49 .. warning::
50
51 This template uses the :class:`~.ApproxTimeEvolution` operation with ``n=1`` in order to
52 implement the time evolution, as a single-step Trotterization is exact for a commuting
53 Hamiltonian.
54
55 - If the input Hamiltonian contains Pauli words which do not commute, the
56 compilation of the time evolution operator to a sequence of gates will
57 not equate to the exact propagation under the given Hamiltonian.
58
59 - Furthermore, if the specified frequencies do not correspond to the
60 true eigenvalue frequency spectrum of the commuting Hamiltonian,
61 computed gradients will be incorrect in general.
62
63 Args:
64 hamiltonian (.Hamiltonian): The commuting Hamiltonian defining the time-evolution operator.
65 The Hamiltonian must be explicitly written
66 in terms of products of Pauli gates (:class:`~.PauliX`, :class:`~.PauliY`,
67 :class:`~.PauliZ`, and :class:`~.Identity`).
68 time (int or float): The time of evolution, namely the parameter :math:`t` in :math:`e^{- i H t}`.
69
70 Keyword args:
71 frequencies (tuple[int or float]): The unique positive differences between eigenvalues in
72 the spectrum of the Hamiltonian. If the frequencies are not given, the cost function
73 partial derivative will be computed using the standard two-term shift rule applied to
74 the constituent Pauli words in the Hamiltonian individually.
75
76 shifts (tuple[int or float]): The parameter shifts to use in obtaining the
77 generalized parameter shift rules. If unspecified, equidistant shifts are used.
78
79 .. details::
80 :title: Usage Details
81
82 The template is used inside a qnode:
83
84 .. code-block:: python
85
86 import pennylane as qml
87
88 n_wires = 2
89 dev = qml.device('default.qubit', wires=n_wires)
90
91 coeffs = [1, -1]
92 obs = [qml.PauliX(0) @ qml.PauliY(1), qml.PauliY(0) @ qml.PauliX(1)]
93 hamiltonian = qml.Hamiltonian(coeffs, obs)
94 frequencies = (2, 4)
95
96 @qml.qnode(dev)
97 def circuit(time):
98 qml.PauliX(0)
99 qml.CommutingEvolution(hamiltonian, time, frequencies)
100 return qml.expval(qml.PauliZ(0))
101
102 >>> circuit(1)
103 0.6536436208636115
104 """
105
106 num_wires = AnyWires
107 grad_method = None
108
109 def __init__(self, hamiltonian, time, frequencies=None, shifts=None, do_queue=True, id=None):
110 # pylint: disable=import-outside-toplevel
111 from pennylane.gradients.general_shift_rules import (
112 generate_shift_rule,
113 )
114
115 if not isinstance(hamiltonian, qml.Hamiltonian):
116 type_name = type(hamiltonian).__name__
117 raise TypeError(f"hamiltonian must be of type pennylane.Hamiltonian, got {type_name}")
118
119 trainable_hamiltonian = qml.math.requires_grad(hamiltonian.coeffs)
120 if frequencies is not None and not trainable_hamiltonian:
121 c, s = generate_shift_rule(frequencies, shifts).T
122 recipe = qml.math.stack([c, qml.math.ones_like(c), s]).T
123 self.grad_recipe = (recipe,) + (None,) * len(hamiltonian.data)
124 self.grad_method = "A"
125
126 self._hyperparameters = {
127 "hamiltonian": hamiltonian,
128 "frequencies": frequencies,
129 "shifts": shifts,
130 }
131
132 super().__init__(
133 time, *hamiltonian.parameters, wires=hamiltonian.wires, do_queue=do_queue, id=id
134 )
135
136 @staticmethod
137 def compute_decomposition(
138 *time_and_coeffs, wires, hamiltonian, **kwargs
139 ): # pylint: disable=arguments-differ,unused-argument
140 r"""Representation of the operator as a product of other operators.
141
142 .. math:: O = O_1 O_2 \dots O_n.
143
144 Args:
145 time_and_coeffs (list[tensor_like or float]): list of coefficients of the Hamiltonian, prepended by the time
146 variable
147 wires (Any or Iterable[Any]): wires that the operator acts on
148 hamiltonian (.Hamiltonian): The commuting Hamiltonian defining the time-evolution operator.
149 frequencies (tuple[int or float]): The unique positive differences between eigenvalues in
150 the spectrum of the Hamiltonian.
151 shifts (tuple[int or float]): The parameter shifts to use in obtaining the
152 generalized parameter shift rules. If unspecified, equidistant shifts are used.
153
154 .. seealso:: :meth:`~.CommutingEvolution.decomposition`.
155
156 Returns:
157 list[.Operator]: decomposition of the operator
158 """
159 # uses standard PauliRot decomposition through ApproxTimeEvolution.
160 hamiltonian = qml.Hamiltonian(time_and_coeffs[1:], hamiltonian.ops)
161 return qml.templates.ApproxTimeEvolution(hamiltonian, time_and_coeffs[1], 1).decomposition()
162
163 def adjoint(self): # pylint: disable=arguments-differ
164
165 hamiltonian = qml.Hamiltonian(self.parameters[1:], self.hyperparameters["hamiltonian"].ops)
166 time = self.parameters[0]
167 frequencies = self.hyperparameters["frequencies"]
168 shifts = self.hyperparameters["shifts"]
169
170 return CommutingEvolution(hamiltonian, -time, frequencies, shifts)
171
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pennylane/templates/subroutines/commuting_evolution.py b/pennylane/templates/subroutines/commuting_evolution.py
--- a/pennylane/templates/subroutines/commuting_evolution.py
+++ b/pennylane/templates/subroutines/commuting_evolution.py
@@ -135,7 +135,7 @@
@staticmethod
def compute_decomposition(
- *time_and_coeffs, wires, hamiltonian, **kwargs
+ time, *coeffs, wires, hamiltonian, **kwargs
): # pylint: disable=arguments-differ,unused-argument
r"""Representation of the operator as a product of other operators.
@@ -157,8 +157,8 @@
list[.Operator]: decomposition of the operator
"""
# uses standard PauliRot decomposition through ApproxTimeEvolution.
- hamiltonian = qml.Hamiltonian(time_and_coeffs[1:], hamiltonian.ops)
- return qml.templates.ApproxTimeEvolution(hamiltonian, time_and_coeffs[1], 1).decomposition()
+ hamiltonian = qml.Hamiltonian(coeffs, hamiltonian.ops)
+ return qml.ApproxTimeEvolution(hamiltonian, time, 1)
def adjoint(self): # pylint: disable=arguments-differ
|
{"golden_diff": "diff --git a/pennylane/templates/subroutines/commuting_evolution.py b/pennylane/templates/subroutines/commuting_evolution.py\n--- a/pennylane/templates/subroutines/commuting_evolution.py\n+++ b/pennylane/templates/subroutines/commuting_evolution.py\n@@ -135,7 +135,7 @@\n \r\n @staticmethod\r\n def compute_decomposition(\r\n- *time_and_coeffs, wires, hamiltonian, **kwargs\r\n+ time, *coeffs, wires, hamiltonian, **kwargs\r\n ): # pylint: disable=arguments-differ,unused-argument\r\n r\"\"\"Representation of the operator as a product of other operators.\r\n \r\n@@ -157,8 +157,8 @@\n list[.Operator]: decomposition of the operator\r\n \"\"\"\r\n # uses standard PauliRot decomposition through ApproxTimeEvolution.\r\n- hamiltonian = qml.Hamiltonian(time_and_coeffs[1:], hamiltonian.ops)\r\n- return qml.templates.ApproxTimeEvolution(hamiltonian, time_and_coeffs[1], 1).decomposition()\r\n+ hamiltonian = qml.Hamiltonian(coeffs, hamiltonian.ops)\r\n+ return qml.ApproxTimeEvolution(hamiltonian, time, 1)\r\n \r\n def adjoint(self): # pylint: disable=arguments-differ\n", "issue": "[BUG] Derivatives of `qml.CommutingEvolution`\nIn cleaning warnings from the test suite, I found this warning:\r\n\r\n```\r\ntemplates/test_subroutines/test_commuting_evolution.py::TestGradients::test_differentiable_hamiltonian\r\n /Users/christina/Prog/pl/lib/python3.8/site-packages/autograd/tracer.py:14: UserWarning: Output seems independent of input.\r\n warnings.warn(\"Output seems independent of input.\")\r\n```\r\n\r\nThe effect of `CommutingEvolution` on the state did not change with the time. \r\nThis problems seems to stem from [commuting_evolution.py Line 160](https://github.com/PennyLaneAI/pennylane/blob/e55f463bcbca1832505d9440d2f5144543f944fe/pennylane/templates/subroutines/commuting_evolution.py#L160):\r\n```\r\n return qml.templates.ApproxTimeEvolution(hamiltonian, time_and_coeffs[1], 1).decomposition()\r\n```\r\nThis line incorrectly indexes into `time_and_coeffs` to try and extract the time. It should instead use `time_and_coeffs[0]`.\r\n\r\nUpon fixing that bug, we now find that parameter shift no longer works for `CommutingEvolution`. \r\n\r\nThese two tests start to fail:\r\n```\r\n==================================================================================== short test summary info ====================================================================================\r\nFAILED templates/test_subroutines/test_commuting_evolution.py::TestGradients::test_two_term_case - assert False\r\nFAILED templates/test_subroutines/test_commuting_evolution.py::TestGradients::test_four_term_case - assert False\r\n```\r\n\r\nThe tests that fail manually specify the frequencies. If the frequencies are specified, the operation sets its own `grad_recipe`. This `grad_recipe` gives incorrect results. I have yet to track down the problem with the `grad_recipe` property.\r\n\r\n\r\nIn summary, fixing the bug in the creation of the `ApproxTimeEvolution` operation allows finite difference derivatives and derivatives for operations without specified frequencies to work correctly. Since the finite-difference derivatives are now correct, we can see that the parameter-shift gradients never worked correctly.\r\n\r\n\n", "before_files": [{"content": "# Copyright 2018-2021 Xanadu Quantum Technologies Inc.\r\n\r\n# Licensed under the Apache License, Version 2.0 (the \"License\");\r\n# you may not use this file except in compliance with the License.\r\n# You may obtain a copy of the License at\r\n\r\n# http://www.apache.org/licenses/LICENSE-2.0\r\n\r\n# Unless required by applicable law or agreed to in writing, software\r\n# distributed under the License is distributed on an \"AS IS\" BASIS,\r\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\r\n# See the License for the specific language governing permissions and\r\n# limitations under the License.\r\nr\"\"\"\r\nContains the CommutingEvolution template.\r\n\"\"\"\r\n# pylint: disable-msg=too-many-arguments,import-outside-toplevel\r\nimport pennylane as qml\r\nfrom pennylane.operation import Operation, AnyWires\r\n\r\n\r\nclass CommutingEvolution(Operation):\r\n r\"\"\"Applies the time-evolution operator for a Hamiltonian expressed as a linear combination\r\n of mutually commuting Pauli words.\r\n\r\n A commuting Hamiltonian is of the form\r\n\r\n .. math:: H \\ = \\ \\displaystyle\\sum_{j} c_j P_j,\r\n\r\n where :math:`P_j` are mutually commutative Pauli words and :math:`c_j` are real coefficients.\r\n The time-evolution under a commuting Hamiltonian is given by a unitary of the form\r\n\r\n .. math::\r\n\r\n U(t) \\ = \\ e^{-i H t} \\ = \\exp(-i t \\displaystyle\\sum_j c_j P_j) =\r\n \\displaystyle\\prod_j \\exp(-i t c_j P_j).\r\n\r\n If the Hamiltonian has a small number of unique eigenvalues, partial derivatives of observable\r\n expectation values, i.e.\r\n\r\n .. math:: \\langle 0 | W(t)^\\dagger O W(t) | 0 \\rangle,\r\n\r\n where :math:`W(t) = V U(t) Y` for some :math:`V` and :math:`Y`, taken with respect to\r\n :math:`t` may be efficiently computed through generalized parameter shift rules. When\r\n initialized, this template will automatically compute the parameter-shift rule if given the\r\n Hamiltonian's eigenvalue frequencies, i.e., the unique positive differences between\r\n eigenvalues.\r\n\r\n .. warning::\r\n\r\n This template uses the :class:`~.ApproxTimeEvolution` operation with ``n=1`` in order to\r\n implement the time evolution, as a single-step Trotterization is exact for a commuting\r\n Hamiltonian.\r\n\r\n - If the input Hamiltonian contains Pauli words which do not commute, the\r\n compilation of the time evolution operator to a sequence of gates will\r\n not equate to the exact propagation under the given Hamiltonian.\r\n\r\n - Furthermore, if the specified frequencies do not correspond to the\r\n true eigenvalue frequency spectrum of the commuting Hamiltonian,\r\n computed gradients will be incorrect in general.\r\n\r\n Args:\r\n hamiltonian (.Hamiltonian): The commuting Hamiltonian defining the time-evolution operator.\r\n The Hamiltonian must be explicitly written\r\n in terms of products of Pauli gates (:class:`~.PauliX`, :class:`~.PauliY`,\r\n :class:`~.PauliZ`, and :class:`~.Identity`).\r\n time (int or float): The time of evolution, namely the parameter :math:`t` in :math:`e^{- i H t}`.\r\n\r\n Keyword args:\r\n frequencies (tuple[int or float]): The unique positive differences between eigenvalues in\r\n the spectrum of the Hamiltonian. If the frequencies are not given, the cost function\r\n partial derivative will be computed using the standard two-term shift rule applied to\r\n the constituent Pauli words in the Hamiltonian individually.\r\n\r\n shifts (tuple[int or float]): The parameter shifts to use in obtaining the\r\n generalized parameter shift rules. If unspecified, equidistant shifts are used.\r\n\r\n .. details::\r\n :title: Usage Details\r\n\r\n The template is used inside a qnode:\r\n\r\n .. code-block:: python\r\n\r\n import pennylane as qml\r\n\r\n n_wires = 2\r\n dev = qml.device('default.qubit', wires=n_wires)\r\n\r\n coeffs = [1, -1]\r\n obs = [qml.PauliX(0) @ qml.PauliY(1), qml.PauliY(0) @ qml.PauliX(1)]\r\n hamiltonian = qml.Hamiltonian(coeffs, obs)\r\n frequencies = (2, 4)\r\n\r\n @qml.qnode(dev)\r\n def circuit(time):\r\n qml.PauliX(0)\r\n qml.CommutingEvolution(hamiltonian, time, frequencies)\r\n return qml.expval(qml.PauliZ(0))\r\n\r\n >>> circuit(1)\r\n 0.6536436208636115\r\n \"\"\"\r\n\r\n num_wires = AnyWires\r\n grad_method = None\r\n\r\n def __init__(self, hamiltonian, time, frequencies=None, shifts=None, do_queue=True, id=None):\r\n # pylint: disable=import-outside-toplevel\r\n from pennylane.gradients.general_shift_rules import (\r\n generate_shift_rule,\r\n )\r\n\r\n if not isinstance(hamiltonian, qml.Hamiltonian):\r\n type_name = type(hamiltonian).__name__\r\n raise TypeError(f\"hamiltonian must be of type pennylane.Hamiltonian, got {type_name}\")\r\n\r\n trainable_hamiltonian = qml.math.requires_grad(hamiltonian.coeffs)\r\n if frequencies is not None and not trainable_hamiltonian:\r\n c, s = generate_shift_rule(frequencies, shifts).T\r\n recipe = qml.math.stack([c, qml.math.ones_like(c), s]).T\r\n self.grad_recipe = (recipe,) + (None,) * len(hamiltonian.data)\r\n self.grad_method = \"A\"\r\n\r\n self._hyperparameters = {\r\n \"hamiltonian\": hamiltonian,\r\n \"frequencies\": frequencies,\r\n \"shifts\": shifts,\r\n }\r\n\r\n super().__init__(\r\n time, *hamiltonian.parameters, wires=hamiltonian.wires, do_queue=do_queue, id=id\r\n )\r\n\r\n @staticmethod\r\n def compute_decomposition(\r\n *time_and_coeffs, wires, hamiltonian, **kwargs\r\n ): # pylint: disable=arguments-differ,unused-argument\r\n r\"\"\"Representation of the operator as a product of other operators.\r\n\r\n .. math:: O = O_1 O_2 \\dots O_n.\r\n\r\n Args:\r\n time_and_coeffs (list[tensor_like or float]): list of coefficients of the Hamiltonian, prepended by the time\r\n variable\r\n wires (Any or Iterable[Any]): wires that the operator acts on\r\n hamiltonian (.Hamiltonian): The commuting Hamiltonian defining the time-evolution operator.\r\n frequencies (tuple[int or float]): The unique positive differences between eigenvalues in\r\n the spectrum of the Hamiltonian.\r\n shifts (tuple[int or float]): The parameter shifts to use in obtaining the\r\n generalized parameter shift rules. If unspecified, equidistant shifts are used.\r\n\r\n .. seealso:: :meth:`~.CommutingEvolution.decomposition`.\r\n\r\n Returns:\r\n list[.Operator]: decomposition of the operator\r\n \"\"\"\r\n # uses standard PauliRot decomposition through ApproxTimeEvolution.\r\n hamiltonian = qml.Hamiltonian(time_and_coeffs[1:], hamiltonian.ops)\r\n return qml.templates.ApproxTimeEvolution(hamiltonian, time_and_coeffs[1], 1).decomposition()\r\n\r\n def adjoint(self): # pylint: disable=arguments-differ\r\n\r\n hamiltonian = qml.Hamiltonian(self.parameters[1:], self.hyperparameters[\"hamiltonian\"].ops)\r\n time = self.parameters[0]\r\n frequencies = self.hyperparameters[\"frequencies\"]\r\n shifts = self.hyperparameters[\"shifts\"]\r\n\r\n return CommutingEvolution(hamiltonian, -time, frequencies, shifts)\r\n", "path": "pennylane/templates/subroutines/commuting_evolution.py"}], "after_files": [{"content": "# Copyright 2018-2021 Xanadu Quantum Technologies Inc.\r\n\r\n# Licensed under the Apache License, Version 2.0 (the \"License\");\r\n# you may not use this file except in compliance with the License.\r\n# You may obtain a copy of the License at\r\n\r\n# http://www.apache.org/licenses/LICENSE-2.0\r\n\r\n# Unless required by applicable law or agreed to in writing, software\r\n# distributed under the License is distributed on an \"AS IS\" BASIS,\r\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\r\n# See the License for the specific language governing permissions and\r\n# limitations under the License.\r\nr\"\"\"\r\nContains the CommutingEvolution template.\r\n\"\"\"\r\n# pylint: disable-msg=too-many-arguments,import-outside-toplevel\r\nimport pennylane as qml\r\nfrom pennylane.operation import Operation, AnyWires\r\n\r\n\r\nclass CommutingEvolution(Operation):\r\n r\"\"\"Applies the time-evolution operator for a Hamiltonian expressed as a linear combination\r\n of mutually commuting Pauli words.\r\n\r\n A commuting Hamiltonian is of the form\r\n\r\n .. math:: H \\ = \\ \\displaystyle\\sum_{j} c_j P_j,\r\n\r\n where :math:`P_j` are mutually commutative Pauli words and :math:`c_j` are real coefficients.\r\n The time-evolution under a commuting Hamiltonian is given by a unitary of the form\r\n\r\n .. math::\r\n\r\n U(t) \\ = \\ e^{-i H t} \\ = \\exp(-i t \\displaystyle\\sum_j c_j P_j) =\r\n \\displaystyle\\prod_j \\exp(-i t c_j P_j).\r\n\r\n If the Hamiltonian has a small number of unique eigenvalues, partial derivatives of observable\r\n expectation values, i.e.\r\n\r\n .. math:: \\langle 0 | W(t)^\\dagger O W(t) | 0 \\rangle,\r\n\r\n where :math:`W(t) = V U(t) Y` for some :math:`V` and :math:`Y`, taken with respect to\r\n :math:`t` may be efficiently computed through generalized parameter shift rules. When\r\n initialized, this template will automatically compute the parameter-shift rule if given the\r\n Hamiltonian's eigenvalue frequencies, i.e., the unique positive differences between\r\n eigenvalues.\r\n\r\n .. warning::\r\n\r\n This template uses the :class:`~.ApproxTimeEvolution` operation with ``n=1`` in order to\r\n implement the time evolution, as a single-step Trotterization is exact for a commuting\r\n Hamiltonian.\r\n\r\n - If the input Hamiltonian contains Pauli words which do not commute, the\r\n compilation of the time evolution operator to a sequence of gates will\r\n not equate to the exact propagation under the given Hamiltonian.\r\n\r\n - Furthermore, if the specified frequencies do not correspond to the\r\n true eigenvalue frequency spectrum of the commuting Hamiltonian,\r\n computed gradients will be incorrect in general.\r\n\r\n Args:\r\n hamiltonian (.Hamiltonian): The commuting Hamiltonian defining the time-evolution operator.\r\n The Hamiltonian must be explicitly written\r\n in terms of products of Pauli gates (:class:`~.PauliX`, :class:`~.PauliY`,\r\n :class:`~.PauliZ`, and :class:`~.Identity`).\r\n time (int or float): The time of evolution, namely the parameter :math:`t` in :math:`e^{- i H t}`.\r\n\r\n Keyword args:\r\n frequencies (tuple[int or float]): The unique positive differences between eigenvalues in\r\n the spectrum of the Hamiltonian. If the frequencies are not given, the cost function\r\n partial derivative will be computed using the standard two-term shift rule applied to\r\n the constituent Pauli words in the Hamiltonian individually.\r\n\r\n shifts (tuple[int or float]): The parameter shifts to use in obtaining the\r\n generalized parameter shift rules. If unspecified, equidistant shifts are used.\r\n\r\n .. details::\r\n :title: Usage Details\r\n\r\n The template is used inside a qnode:\r\n\r\n .. code-block:: python\r\n\r\n import pennylane as qml\r\n\r\n n_wires = 2\r\n dev = qml.device('default.qubit', wires=n_wires)\r\n\r\n coeffs = [1, -1]\r\n obs = [qml.PauliX(0) @ qml.PauliY(1), qml.PauliY(0) @ qml.PauliX(1)]\r\n hamiltonian = qml.Hamiltonian(coeffs, obs)\r\n frequencies = (2, 4)\r\n\r\n @qml.qnode(dev)\r\n def circuit(time):\r\n qml.PauliX(0)\r\n qml.CommutingEvolution(hamiltonian, time, frequencies)\r\n return qml.expval(qml.PauliZ(0))\r\n\r\n >>> circuit(1)\r\n 0.6536436208636115\r\n \"\"\"\r\n\r\n num_wires = AnyWires\r\n grad_method = None\r\n\r\n def __init__(self, hamiltonian, time, frequencies=None, shifts=None, do_queue=True, id=None):\r\n # pylint: disable=import-outside-toplevel\r\n from pennylane.gradients.general_shift_rules import (\r\n generate_shift_rule,\r\n )\r\n\r\n if not isinstance(hamiltonian, qml.Hamiltonian):\r\n type_name = type(hamiltonian).__name__\r\n raise TypeError(f\"hamiltonian must be of type pennylane.Hamiltonian, got {type_name}\")\r\n\r\n trainable_hamiltonian = qml.math.requires_grad(hamiltonian.coeffs)\r\n if frequencies is not None and not trainable_hamiltonian:\r\n c, s = generate_shift_rule(frequencies, shifts).T\r\n recipe = qml.math.stack([c, qml.math.ones_like(c), s]).T\r\n self.grad_recipe = (recipe,) + (None,) * len(hamiltonian.data)\r\n self.grad_method = \"A\"\r\n\r\n self._hyperparameters = {\r\n \"hamiltonian\": hamiltonian,\r\n \"frequencies\": frequencies,\r\n \"shifts\": shifts,\r\n }\r\n\r\n super().__init__(\r\n time, *hamiltonian.parameters, wires=hamiltonian.wires, do_queue=do_queue, id=id\r\n )\r\n\r\n @staticmethod\r\n def compute_decomposition(\r\n time, *coeffs, wires, hamiltonian, **kwargs\r\n ): # pylint: disable=arguments-differ,unused-argument\r\n r\"\"\"Representation of the operator as a product of other operators.\r\n\r\n .. math:: O = O_1 O_2 \\dots O_n.\r\n\r\n Args:\r\n time_and_coeffs (list[tensor_like or float]): list of coefficients of the Hamiltonian, prepended by the time\r\n variable\r\n wires (Any or Iterable[Any]): wires that the operator acts on\r\n hamiltonian (.Hamiltonian): The commuting Hamiltonian defining the time-evolution operator.\r\n frequencies (tuple[int or float]): The unique positive differences between eigenvalues in\r\n the spectrum of the Hamiltonian.\r\n shifts (tuple[int or float]): The parameter shifts to use in obtaining the\r\n generalized parameter shift rules. If unspecified, equidistant shifts are used.\r\n\r\n .. seealso:: :meth:`~.CommutingEvolution.decomposition`.\r\n\r\n Returns:\r\n list[.Operator]: decomposition of the operator\r\n \"\"\"\r\n # uses standard PauliRot decomposition through ApproxTimeEvolution.\r\n hamiltonian = qml.Hamiltonian(coeffs, hamiltonian.ops)\r\n return qml.ApproxTimeEvolution(hamiltonian, time, 1)\r\n\r\n def adjoint(self): # pylint: disable=arguments-differ\r\n\r\n hamiltonian = qml.Hamiltonian(self.parameters[1:], self.hyperparameters[\"hamiltonian\"].ops)\r\n time = self.parameters[0]\r\n frequencies = self.hyperparameters[\"frequencies\"]\r\n shifts = self.hyperparameters[\"shifts\"]\r\n\r\n return CommutingEvolution(hamiltonian, -time, frequencies, shifts)\r\n", "path": "pennylane/templates/subroutines/commuting_evolution.py"}]}
| 2,916 | 305 |
gh_patches_debug_41971
|
rasdani/github-patches
|
git_diff
|
pymedusa__Medusa-3864
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Github Personal Acces Token
### Before submitting your issue:
Enable debug logging in Medusa settings, reproduce the error (be sure to disable after the bug is fixed)
**Python Version**: `2.7.13 (default, Nov 24 2017, 17:33:09) [GCC 6.3.0 20170516]`
**Operating System**: `Linux-3.4.113-bananian-armv7l-with-debian-9.3`
**Locale**: `UTF-8`
**Branch**: [master](../tree/master)
**Database**: `44.9`
**Commit**: pymedusa/Medusa@d6eb72d4e1019e5d1286ae6ac1d7e4b318229ebe
**What you did:** I selected Github personal acces token as authentication method for submitting new issues, entered my token, and tried to submit an issue from within Medusa
**What happened:** It kept giving me the error message that I should enter my username/password
**What you expected:** I expected the issue to be submitted of course but I also expected to still have to enter my username, as is usual AFAIK when logging into Github through a 3rd party service
Unless I'm gravely mistaken (or made an error while entering my login info, but I triple checked it) I think the way of logging in with a git token is wrong, it's missing the username field, and can thus not work.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `medusa/issue_submitter.py`
Content:
```
1 # coding=utf-8
2 """GitHub issue submitter."""
3 from __future__ import unicode_literals
4
5 import difflib
6 import locale
7 import logging
8 import platform
9 import sys
10 from builtins import object
11 from builtins import str
12 from datetime import datetime, timedelta
13
14 from github import InputFileContent
15 from github.GithubException import GithubException, RateLimitExceededException
16
17 from medusa import app, db
18 from medusa.classes import ErrorViewer
19 from medusa.github_client import authenticate, get_github_repo, token_authenticate
20 from medusa.logger.adapters.style import BraceAdapter
21
22 log = BraceAdapter(logging.getLogger(__name__))
23 log.logger.addHandler(logging.NullHandler())
24
25 ISSUE_REPORT = """
26 ### INFO
27 **Python Version**: `{python_version}`
28 **Operating System**: `{os}`
29 **Locale**: `{locale}`
30 **Branch**: [{branch}](../tree/{branch})
31 **Database**: `{db_major_version}.{db_minor_version}`
32 **Commit**: {org}/{repo}@{commit}
33 **Link to Log**: {log_url}
34 ### ERROR
35 {log_line}
36 ---
37 _STAFF NOTIFIED_: @{org}/support @{org}/moderators
38 """
39
40
41 class IssueSubmitter(object):
42 """GitHub issue submitter."""
43
44 MISSING_CREDENTIALS = 'Please set your GitHub Username and Password in the config. Unable to submit issue ticket to GitHub.'
45 DEBUG_NOT_ENABLED = 'Please enable Debug mode in the config. Unable to submit issue ticket to GitHub.'
46 NO_ISSUES = 'No issue to be submitted to GitHub.'
47 UNSUPPORTED_VERSION = 'Please update Medusa, unable to submit issue ticket to GitHub with an outdated version.'
48 ALREADY_RUNNING = 'An issue is already being submitted, please wait for it to complete.'
49 BAD_CREDENTIALS = 'Please check your Github credentials in Medusa settings. Bad Credentials error'
50 RATE_LIMIT = 'Please wait before submit new issues. Github Rate Limit Exceeded error'
51 GITHUB_EXCEPTION = 'Error trying to contact Github. Please try again'
52 EXISTING_ISSUE_LOCKED = 'Issue #{number} is locked, check GitHub to find info about the error.'
53 COMMENTED_EXISTING_ISSUE = 'Commented on existing issue #{number} successfully!'
54 ISSUE_CREATED = 'Your issue ticket #{number} was submitted successfully!'
55
56 TITLE_PREFIX = '[APP SUBMITTED]: '
57
58 def __init__(self):
59 """Initialize class with the default constructor."""
60 self.running = False
61
62 @staticmethod
63 def create_gist(github, logline):
64 """Create a private gist with log data for the specified log line."""
65 context_loglines = logline.get_context_loglines()
66 if context_loglines:
67 content = '\n'.join([str(ll) for ll in context_loglines])
68 return github.get_user().create_gist(False, {'application.log': InputFileContent(content)})
69
70 @staticmethod
71 def create_issue_data(logline, log_url):
72 """Create the issue data expected by github api to be submitted."""
73 try:
74 locale_name = locale.getdefaultlocale()[1]
75 except ValueError:
76 locale_name = 'unknown'
77
78 # Get current DB version
79 main_db_con = db.DBConnection()
80 cur_branch_major_db_version, cur_branch_minor_db_version = main_db_con.checkDBVersion()
81
82 commit = app.CUR_COMMIT_HASH
83 base_url = '../blob/{commit}'.format(commit=commit) if commit else None
84 return ISSUE_REPORT.format(
85 python_version=sys.version[:120].replace('\n', ''),
86 os=platform.platform(),
87 locale=locale_name,
88 branch=app.BRANCH,
89 org=app.GIT_ORG,
90 repo=app.GIT_REPO,
91 commit=commit,
92 db_major_version=cur_branch_major_db_version,
93 db_minor_version=cur_branch_minor_db_version,
94 log_url=log_url or '**No Log available**',
95 log_line=logline.format_to_html(base_url=base_url),
96 )
97
98 @classmethod
99 def find_similar_issues(cls, github_repo, loglines, max_age=timedelta(days=180)):
100 """Find similar issues in the GitHub repository."""
101 results = dict()
102 issues = github_repo.get_issues(state='all', since=datetime.now() - max_age)
103 for issue in issues:
104 if hasattr(issue, 'pull_request') and issue.pull_request:
105 continue
106 issue_title = issue.title
107 if issue_title.startswith(cls.TITLE_PREFIX):
108 issue_title = issue_title[len(cls.TITLE_PREFIX):]
109
110 for logline in loglines:
111 log_title = logline.issue_title
112 if cls.similar(log_title, issue_title):
113 results[logline.key] = issue
114
115 if len(results) >= len(loglines):
116 break
117
118 return results
119
120 @staticmethod
121 def similar(title1, title2, ratio=0.9):
122 """Compare title similarity."""
123 return difflib.SequenceMatcher(None, title1, title2).ratio() >= ratio
124
125 def submit_github_issue(self, version_checker, max_issues=500):
126 """Submit errors to github."""
127 def result(message, level=logging.WARNING):
128 log.log(level, message)
129 return [(message, None)]
130
131 if not app.DEBUG:
132 return result(self.DEBUG_NOT_ENABLED)
133
134 if not (app.GIT_USERNAME and app.GIT_PASSWORD) or app.GIT_TOKEN:
135 return result(self.MISSING_CREDENTIALS)
136
137 if not ErrorViewer.errors:
138 return result(self.NO_ISSUES, logging.INFO)
139
140 if not app.DEVELOPER and version_checker.need_update():
141 return result(self.UNSUPPORTED_VERSION)
142
143 if self.running:
144 return result(self.ALREADY_RUNNING)
145
146 self.running = True
147 try:
148 if app.GIT_AUTH_TYPE:
149 github = token_authenticate(app.GIT_TOKEN)
150 else:
151 github = authenticate(app.GIT_USERNAME, app.GIT_PASSWORD)
152 if not github:
153 return result(self.BAD_CREDENTIALS)
154
155 github_repo = get_github_repo(app.GIT_ORG, app.GIT_REPO, gh=github)
156 loglines = ErrorViewer.errors[:max_issues]
157 similar_issues = self.find_similar_issues(github_repo, loglines)
158
159 return self.submit_issues(github, github_repo, loglines, similar_issues)
160 except RateLimitExceededException:
161 return result(self.RATE_LIMIT)
162 except (GithubException, IOError):
163 return result(self.GITHUB_EXCEPTION)
164 finally:
165 self.running = False
166
167 @classmethod
168 def submit_issues(cls, github, github_repo, loglines, similar_issues):
169 """Submit issues to github."""
170 results = []
171 for line in loglines:
172 gist = cls.create_gist(github, line)
173 message = cls.create_issue_data(line, log_url=gist.html_url if gist else None)
174 similar_issue = similar_issues.get(line.key)
175 issue_id = None
176 if similar_issue:
177 if similar_issue.raw_data['locked']:
178 submitter_result = cls.EXISTING_ISSUE_LOCKED.format(number=similar_issue.number)
179 log.warning(submitter_result)
180 else:
181 similar_issue.create_comment(message)
182 issue_id = similar_issue.number
183 submitter_result = cls.COMMENTED_EXISTING_ISSUE.format(number=issue_id)
184 log.info(submitter_result)
185 ErrorViewer.remove(line)
186 else:
187 issue = github_repo.create_issue('{prefix}{title}'.format(prefix=cls.TITLE_PREFIX, title=line.issue_title), message)
188 issue_id = issue.number
189 submitter_result = cls.ISSUE_CREATED.format(number=issue_id)
190 log.info(submitter_result)
191 ErrorViewer.remove(line)
192 results.append((submitter_result, issue_id))
193
194 return results
195
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/medusa/issue_submitter.py b/medusa/issue_submitter.py
--- a/medusa/issue_submitter.py
+++ b/medusa/issue_submitter.py
@@ -12,7 +12,7 @@
from datetime import datetime, timedelta
from github import InputFileContent
-from github.GithubException import GithubException, RateLimitExceededException
+from github.GithubException import GithubException, RateLimitExceededException, UnknownObjectException
from medusa import app, db
from medusa.classes import ErrorViewer
@@ -41,14 +41,16 @@
class IssueSubmitter(object):
"""GitHub issue submitter."""
- MISSING_CREDENTIALS = 'Please set your GitHub Username and Password in the config. Unable to submit issue ticket to GitHub.'
- DEBUG_NOT_ENABLED = 'Please enable Debug mode in the config. Unable to submit issue ticket to GitHub.'
+ MISSING_CREDENTIALS = 'Please set your GitHub Username and Password in the config. Unable to submit issue ticket to GitHub.'
+ MISSING_CREDENTIALS_TOKEN = 'Please set your GitHub personal access token in the config. Unable to submit issue ticket to GitHub.'
+ DEBUG_NOT_ENABLED = 'Please enable Debug mode in the config. Unable to submit issue ticket to GitHub.'
NO_ISSUES = 'No issue to be submitted to GitHub.'
UNSUPPORTED_VERSION = 'Please update Medusa, unable to submit issue ticket to GitHub with an outdated version.'
ALREADY_RUNNING = 'An issue is already being submitted, please wait for it to complete.'
BAD_CREDENTIALS = 'Please check your Github credentials in Medusa settings. Bad Credentials error'
RATE_LIMIT = 'Please wait before submit new issues. Github Rate Limit Exceeded error'
GITHUB_EXCEPTION = 'Error trying to contact Github. Please try again'
+ GITHUB_UNKNOWNOBJECTEXCEPTION = 'GitHub returned an error "Not Found". If using a token, make sure the proper scopes are selected.'
EXISTING_ISSUE_LOCKED = 'Issue #{number} is locked, check GitHub to find info about the error.'
COMMENTED_EXISTING_ISSUE = 'Commented on existing issue #{number} successfully!'
ISSUE_CREATED = 'Your issue ticket #{number} was submitted successfully!'
@@ -131,7 +133,10 @@
if not app.DEBUG:
return result(self.DEBUG_NOT_ENABLED)
- if not (app.GIT_USERNAME and app.GIT_PASSWORD) or app.GIT_TOKEN:
+ if app.GIT_AUTH_TYPE == 1 and not app.GIT_TOKEN:
+ return result(self.MISSING_CREDENTIALS_TOKEN)
+
+ if app.GIT_AUTH_TYPE == 0 and not (app.GIT_USERNAME and app.GIT_PASSWORD):
return result(self.MISSING_CREDENTIALS)
if not ErrorViewer.errors:
@@ -159,7 +164,10 @@
return self.submit_issues(github, github_repo, loglines, similar_issues)
except RateLimitExceededException:
return result(self.RATE_LIMIT)
- except (GithubException, IOError):
+ except (GithubException, IOError) as error:
+ # If the api return http status 404, authentication or permission issue(token right to create gists)
+ if isinstance(error, UnknownObjectException):
+ return result(self.GITHUB_UNKNOWNOBJECTEXCEPTION)
return result(self.GITHUB_EXCEPTION)
finally:
self.running = False
|
{"golden_diff": "diff --git a/medusa/issue_submitter.py b/medusa/issue_submitter.py\n--- a/medusa/issue_submitter.py\n+++ b/medusa/issue_submitter.py\n@@ -12,7 +12,7 @@\n from datetime import datetime, timedelta\n \n from github import InputFileContent\n-from github.GithubException import GithubException, RateLimitExceededException\n+from github.GithubException import GithubException, RateLimitExceededException, UnknownObjectException\n \n from medusa import app, db\n from medusa.classes import ErrorViewer\n@@ -41,14 +41,16 @@\n class IssueSubmitter(object):\n \"\"\"GitHub issue submitter.\"\"\"\n \n- MISSING_CREDENTIALS = 'Please set your GitHub Username and Password in the config. Unable to submit issue ticket to GitHub.'\n- DEBUG_NOT_ENABLED = 'Please enable Debug mode in the config. Unable to submit issue ticket to GitHub.'\n+ MISSING_CREDENTIALS = 'Please set your GitHub Username and Password in the config. Unable to submit issue ticket to GitHub.'\n+ MISSING_CREDENTIALS_TOKEN = 'Please set your GitHub personal access token in the config. Unable to submit issue ticket to GitHub.'\n+ DEBUG_NOT_ENABLED = 'Please enable Debug mode in the config. Unable to submit issue ticket to GitHub.'\n NO_ISSUES = 'No issue to be submitted to GitHub.'\n UNSUPPORTED_VERSION = 'Please update Medusa, unable to submit issue ticket to GitHub with an outdated version.'\n ALREADY_RUNNING = 'An issue is already being submitted, please wait for it to complete.'\n BAD_CREDENTIALS = 'Please check your Github credentials in Medusa settings. Bad Credentials error'\n RATE_LIMIT = 'Please wait before submit new issues. Github Rate Limit Exceeded error'\n GITHUB_EXCEPTION = 'Error trying to contact Github. Please try again'\n+ GITHUB_UNKNOWNOBJECTEXCEPTION = 'GitHub returned an error \"Not Found\". If using a token, make sure the proper scopes are selected.'\n EXISTING_ISSUE_LOCKED = 'Issue #{number} is locked, check GitHub to find info about the error.'\n COMMENTED_EXISTING_ISSUE = 'Commented on existing issue #{number} successfully!'\n ISSUE_CREATED = 'Your issue ticket #{number} was submitted successfully!'\n@@ -131,7 +133,10 @@\n if not app.DEBUG:\n return result(self.DEBUG_NOT_ENABLED)\n \n- if not (app.GIT_USERNAME and app.GIT_PASSWORD) or app.GIT_TOKEN:\n+ if app.GIT_AUTH_TYPE == 1 and not app.GIT_TOKEN:\n+ return result(self.MISSING_CREDENTIALS_TOKEN)\n+\n+ if app.GIT_AUTH_TYPE == 0 and not (app.GIT_USERNAME and app.GIT_PASSWORD):\n return result(self.MISSING_CREDENTIALS)\n \n if not ErrorViewer.errors:\n@@ -159,7 +164,10 @@\n return self.submit_issues(github, github_repo, loglines, similar_issues)\n except RateLimitExceededException:\n return result(self.RATE_LIMIT)\n- except (GithubException, IOError):\n+ except (GithubException, IOError) as error:\n+ # If the api return http status 404, authentication or permission issue(token right to create gists)\n+ if isinstance(error, UnknownObjectException):\n+ return result(self.GITHUB_UNKNOWNOBJECTEXCEPTION)\n return result(self.GITHUB_EXCEPTION)\n finally:\n self.running = False\n", "issue": "Github Personal Acces Token\n### Before submitting your issue:\r\n\r\nEnable debug logging in Medusa settings, reproduce the error (be sure to disable after the bug is fixed)\r\n**Python Version**: `2.7.13 (default, Nov 24 2017, 17:33:09) [GCC 6.3.0 20170516]`\r\n**Operating System**: `Linux-3.4.113-bananian-armv7l-with-debian-9.3`\r\n**Locale**: `UTF-8`\r\n**Branch**: [master](../tree/master)\r\n**Database**: `44.9`\r\n**Commit**: pymedusa/Medusa@d6eb72d4e1019e5d1286ae6ac1d7e4b318229ebe\r\n**What you did:** I selected Github personal acces token as authentication method for submitting new issues, entered my token, and tried to submit an issue from within Medusa\r\n**What happened:** It kept giving me the error message that I should enter my username/password\r\n**What you expected:** I expected the issue to be submitted of course but I also expected to still have to enter my username, as is usual AFAIK when logging into Github through a 3rd party service \r\n\r\nUnless I'm gravely mistaken (or made an error while entering my login info, but I triple checked it) I think the way of logging in with a git token is wrong, it's missing the username field, and can thus not work.\n", "before_files": [{"content": "# coding=utf-8\n\"\"\"GitHub issue submitter.\"\"\"\nfrom __future__ import unicode_literals\n\nimport difflib\nimport locale\nimport logging\nimport platform\nimport sys\nfrom builtins import object\nfrom builtins import str\nfrom datetime import datetime, timedelta\n\nfrom github import InputFileContent\nfrom github.GithubException import GithubException, RateLimitExceededException\n\nfrom medusa import app, db\nfrom medusa.classes import ErrorViewer\nfrom medusa.github_client import authenticate, get_github_repo, token_authenticate\nfrom medusa.logger.adapters.style import BraceAdapter\n\nlog = BraceAdapter(logging.getLogger(__name__))\nlog.logger.addHandler(logging.NullHandler())\n\nISSUE_REPORT = \"\"\"\n### INFO\n**Python Version**: `{python_version}`\n**Operating System**: `{os}`\n**Locale**: `{locale}`\n**Branch**: [{branch}](../tree/{branch})\n**Database**: `{db_major_version}.{db_minor_version}`\n**Commit**: {org}/{repo}@{commit}\n**Link to Log**: {log_url}\n### ERROR\n{log_line}\n---\n_STAFF NOTIFIED_: @{org}/support @{org}/moderators\n\"\"\"\n\n\nclass IssueSubmitter(object):\n \"\"\"GitHub issue submitter.\"\"\"\n\n MISSING_CREDENTIALS = 'Please set your GitHub Username and Password in the config. Unable to submit issue ticket to GitHub.'\n DEBUG_NOT_ENABLED = 'Please enable Debug mode in the config. Unable to submit issue ticket to GitHub.'\n NO_ISSUES = 'No issue to be submitted to GitHub.'\n UNSUPPORTED_VERSION = 'Please update Medusa, unable to submit issue ticket to GitHub with an outdated version.'\n ALREADY_RUNNING = 'An issue is already being submitted, please wait for it to complete.'\n BAD_CREDENTIALS = 'Please check your Github credentials in Medusa settings. Bad Credentials error'\n RATE_LIMIT = 'Please wait before submit new issues. Github Rate Limit Exceeded error'\n GITHUB_EXCEPTION = 'Error trying to contact Github. Please try again'\n EXISTING_ISSUE_LOCKED = 'Issue #{number} is locked, check GitHub to find info about the error.'\n COMMENTED_EXISTING_ISSUE = 'Commented on existing issue #{number} successfully!'\n ISSUE_CREATED = 'Your issue ticket #{number} was submitted successfully!'\n\n TITLE_PREFIX = '[APP SUBMITTED]: '\n\n def __init__(self):\n \"\"\"Initialize class with the default constructor.\"\"\"\n self.running = False\n\n @staticmethod\n def create_gist(github, logline):\n \"\"\"Create a private gist with log data for the specified log line.\"\"\"\n context_loglines = logline.get_context_loglines()\n if context_loglines:\n content = '\\n'.join([str(ll) for ll in context_loglines])\n return github.get_user().create_gist(False, {'application.log': InputFileContent(content)})\n\n @staticmethod\n def create_issue_data(logline, log_url):\n \"\"\"Create the issue data expected by github api to be submitted.\"\"\"\n try:\n locale_name = locale.getdefaultlocale()[1]\n except ValueError:\n locale_name = 'unknown'\n\n # Get current DB version\n main_db_con = db.DBConnection()\n cur_branch_major_db_version, cur_branch_minor_db_version = main_db_con.checkDBVersion()\n\n commit = app.CUR_COMMIT_HASH\n base_url = '../blob/{commit}'.format(commit=commit) if commit else None\n return ISSUE_REPORT.format(\n python_version=sys.version[:120].replace('\\n', ''),\n os=platform.platform(),\n locale=locale_name,\n branch=app.BRANCH,\n org=app.GIT_ORG,\n repo=app.GIT_REPO,\n commit=commit,\n db_major_version=cur_branch_major_db_version,\n db_minor_version=cur_branch_minor_db_version,\n log_url=log_url or '**No Log available**',\n log_line=logline.format_to_html(base_url=base_url),\n )\n\n @classmethod\n def find_similar_issues(cls, github_repo, loglines, max_age=timedelta(days=180)):\n \"\"\"Find similar issues in the GitHub repository.\"\"\"\n results = dict()\n issues = github_repo.get_issues(state='all', since=datetime.now() - max_age)\n for issue in issues:\n if hasattr(issue, 'pull_request') and issue.pull_request:\n continue\n issue_title = issue.title\n if issue_title.startswith(cls.TITLE_PREFIX):\n issue_title = issue_title[len(cls.TITLE_PREFIX):]\n\n for logline in loglines:\n log_title = logline.issue_title\n if cls.similar(log_title, issue_title):\n results[logline.key] = issue\n\n if len(results) >= len(loglines):\n break\n\n return results\n\n @staticmethod\n def similar(title1, title2, ratio=0.9):\n \"\"\"Compare title similarity.\"\"\"\n return difflib.SequenceMatcher(None, title1, title2).ratio() >= ratio\n\n def submit_github_issue(self, version_checker, max_issues=500):\n \"\"\"Submit errors to github.\"\"\"\n def result(message, level=logging.WARNING):\n log.log(level, message)\n return [(message, None)]\n\n if not app.DEBUG:\n return result(self.DEBUG_NOT_ENABLED)\n\n if not (app.GIT_USERNAME and app.GIT_PASSWORD) or app.GIT_TOKEN:\n return result(self.MISSING_CREDENTIALS)\n\n if not ErrorViewer.errors:\n return result(self.NO_ISSUES, logging.INFO)\n\n if not app.DEVELOPER and version_checker.need_update():\n return result(self.UNSUPPORTED_VERSION)\n\n if self.running:\n return result(self.ALREADY_RUNNING)\n\n self.running = True\n try:\n if app.GIT_AUTH_TYPE:\n github = token_authenticate(app.GIT_TOKEN)\n else:\n github = authenticate(app.GIT_USERNAME, app.GIT_PASSWORD)\n if not github:\n return result(self.BAD_CREDENTIALS)\n\n github_repo = get_github_repo(app.GIT_ORG, app.GIT_REPO, gh=github)\n loglines = ErrorViewer.errors[:max_issues]\n similar_issues = self.find_similar_issues(github_repo, loglines)\n\n return self.submit_issues(github, github_repo, loglines, similar_issues)\n except RateLimitExceededException:\n return result(self.RATE_LIMIT)\n except (GithubException, IOError):\n return result(self.GITHUB_EXCEPTION)\n finally:\n self.running = False\n\n @classmethod\n def submit_issues(cls, github, github_repo, loglines, similar_issues):\n \"\"\"Submit issues to github.\"\"\"\n results = []\n for line in loglines:\n gist = cls.create_gist(github, line)\n message = cls.create_issue_data(line, log_url=gist.html_url if gist else None)\n similar_issue = similar_issues.get(line.key)\n issue_id = None\n if similar_issue:\n if similar_issue.raw_data['locked']:\n submitter_result = cls.EXISTING_ISSUE_LOCKED.format(number=similar_issue.number)\n log.warning(submitter_result)\n else:\n similar_issue.create_comment(message)\n issue_id = similar_issue.number\n submitter_result = cls.COMMENTED_EXISTING_ISSUE.format(number=issue_id)\n log.info(submitter_result)\n ErrorViewer.remove(line)\n else:\n issue = github_repo.create_issue('{prefix}{title}'.format(prefix=cls.TITLE_PREFIX, title=line.issue_title), message)\n issue_id = issue.number\n submitter_result = cls.ISSUE_CREATED.format(number=issue_id)\n log.info(submitter_result)\n ErrorViewer.remove(line)\n results.append((submitter_result, issue_id))\n\n return results\n", "path": "medusa/issue_submitter.py"}], "after_files": [{"content": "# coding=utf-8\n\"\"\"GitHub issue submitter.\"\"\"\nfrom __future__ import unicode_literals\n\nimport difflib\nimport locale\nimport logging\nimport platform\nimport sys\nfrom builtins import object\nfrom builtins import str\nfrom datetime import datetime, timedelta\n\nfrom github import InputFileContent\nfrom github.GithubException import GithubException, RateLimitExceededException, UnknownObjectException\n\nfrom medusa import app, db\nfrom medusa.classes import ErrorViewer\nfrom medusa.github_client import authenticate, get_github_repo, token_authenticate\nfrom medusa.logger.adapters.style import BraceAdapter\n\nlog = BraceAdapter(logging.getLogger(__name__))\nlog.logger.addHandler(logging.NullHandler())\n\nISSUE_REPORT = \"\"\"\n### INFO\n**Python Version**: `{python_version}`\n**Operating System**: `{os}`\n**Locale**: `{locale}`\n**Branch**: [{branch}](../tree/{branch})\n**Database**: `{db_major_version}.{db_minor_version}`\n**Commit**: {org}/{repo}@{commit}\n**Link to Log**: {log_url}\n### ERROR\n{log_line}\n---\n_STAFF NOTIFIED_: @{org}/support @{org}/moderators\n\"\"\"\n\n\nclass IssueSubmitter(object):\n \"\"\"GitHub issue submitter.\"\"\"\n\n MISSING_CREDENTIALS = 'Please set your GitHub Username and Password in the config. Unable to submit issue ticket to GitHub.'\n MISSING_CREDENTIALS_TOKEN = 'Please set your GitHub personal access token in the config. Unable to submit issue ticket to GitHub.'\n DEBUG_NOT_ENABLED = 'Please enable Debug mode in the config. Unable to submit issue ticket to GitHub.'\n NO_ISSUES = 'No issue to be submitted to GitHub.'\n UNSUPPORTED_VERSION = 'Please update Medusa, unable to submit issue ticket to GitHub with an outdated version.'\n ALREADY_RUNNING = 'An issue is already being submitted, please wait for it to complete.'\n BAD_CREDENTIALS = 'Please check your Github credentials in Medusa settings. Bad Credentials error'\n RATE_LIMIT = 'Please wait before submit new issues. Github Rate Limit Exceeded error'\n GITHUB_EXCEPTION = 'Error trying to contact Github. Please try again'\n GITHUB_UNKNOWNOBJECTEXCEPTION = 'GitHub returned an error \"Not Found\". If using a token, make sure the proper scopes are selected.'\n EXISTING_ISSUE_LOCKED = 'Issue #{number} is locked, check GitHub to find info about the error.'\n COMMENTED_EXISTING_ISSUE = 'Commented on existing issue #{number} successfully!'\n ISSUE_CREATED = 'Your issue ticket #{number} was submitted successfully!'\n\n TITLE_PREFIX = '[APP SUBMITTED]: '\n\n def __init__(self):\n \"\"\"Initialize class with the default constructor.\"\"\"\n self.running = False\n\n @staticmethod\n def create_gist(github, logline):\n \"\"\"Create a private gist with log data for the specified log line.\"\"\"\n context_loglines = logline.get_context_loglines()\n if context_loglines:\n content = '\\n'.join([str(ll) for ll in context_loglines])\n return github.get_user().create_gist(False, {'application.log': InputFileContent(content)})\n\n @staticmethod\n def create_issue_data(logline, log_url):\n \"\"\"Create the issue data expected by github api to be submitted.\"\"\"\n try:\n locale_name = locale.getdefaultlocale()[1]\n except ValueError:\n locale_name = 'unknown'\n\n # Get current DB version\n main_db_con = db.DBConnection()\n cur_branch_major_db_version, cur_branch_minor_db_version = main_db_con.checkDBVersion()\n\n commit = app.CUR_COMMIT_HASH\n base_url = '../blob/{commit}'.format(commit=commit) if commit else None\n return ISSUE_REPORT.format(\n python_version=sys.version[:120].replace('\\n', ''),\n os=platform.platform(),\n locale=locale_name,\n branch=app.BRANCH,\n org=app.GIT_ORG,\n repo=app.GIT_REPO,\n commit=commit,\n db_major_version=cur_branch_major_db_version,\n db_minor_version=cur_branch_minor_db_version,\n log_url=log_url or '**No Log available**',\n log_line=logline.format_to_html(base_url=base_url),\n )\n\n @classmethod\n def find_similar_issues(cls, github_repo, loglines, max_age=timedelta(days=180)):\n \"\"\"Find similar issues in the GitHub repository.\"\"\"\n results = dict()\n issues = github_repo.get_issues(state='all', since=datetime.now() - max_age)\n for issue in issues:\n if hasattr(issue, 'pull_request') and issue.pull_request:\n continue\n issue_title = issue.title\n if issue_title.startswith(cls.TITLE_PREFIX):\n issue_title = issue_title[len(cls.TITLE_PREFIX):]\n\n for logline in loglines:\n log_title = logline.issue_title\n if cls.similar(log_title, issue_title):\n results[logline.key] = issue\n\n if len(results) >= len(loglines):\n break\n\n return results\n\n @staticmethod\n def similar(title1, title2, ratio=0.9):\n \"\"\"Compare title similarity.\"\"\"\n return difflib.SequenceMatcher(None, title1, title2).ratio() >= ratio\n\n def submit_github_issue(self, version_checker, max_issues=500):\n \"\"\"Submit errors to github.\"\"\"\n def result(message, level=logging.WARNING):\n log.log(level, message)\n return [(message, None)]\n\n if not app.DEBUG:\n return result(self.DEBUG_NOT_ENABLED)\n\n if app.GIT_AUTH_TYPE == 1 and not app.GIT_TOKEN:\n return result(self.MISSING_CREDENTIALS_TOKEN)\n\n if app.GIT_AUTH_TYPE == 0 and not (app.GIT_USERNAME and app.GIT_PASSWORD):\n return result(self.MISSING_CREDENTIALS)\n\n if not ErrorViewer.errors:\n return result(self.NO_ISSUES, logging.INFO)\n\n if not app.DEVELOPER and version_checker.need_update():\n return result(self.UNSUPPORTED_VERSION)\n\n if self.running:\n return result(self.ALREADY_RUNNING)\n\n self.running = True\n try:\n if app.GIT_AUTH_TYPE:\n github = token_authenticate(app.GIT_TOKEN)\n else:\n github = authenticate(app.GIT_USERNAME, app.GIT_PASSWORD)\n if not github:\n return result(self.BAD_CREDENTIALS)\n\n github_repo = get_github_repo(app.GIT_ORG, app.GIT_REPO, gh=github)\n loglines = ErrorViewer.errors[:max_issues]\n similar_issues = self.find_similar_issues(github_repo, loglines)\n\n return self.submit_issues(github, github_repo, loglines, similar_issues)\n except RateLimitExceededException:\n return result(self.RATE_LIMIT)\n except (GithubException, IOError) as error:\n # If the api return http status 404, authentication or permission issue(token right to create gists)\n if isinstance(error, UnknownObjectException):\n return result(self.GITHUB_UNKNOWNOBJECTEXCEPTION)\n return result(self.GITHUB_EXCEPTION)\n finally:\n self.running = False\n\n @classmethod\n def submit_issues(cls, github, github_repo, loglines, similar_issues):\n \"\"\"Submit issues to github.\"\"\"\n results = []\n for line in loglines:\n gist = cls.create_gist(github, line)\n message = cls.create_issue_data(line, log_url=gist.html_url if gist else None)\n similar_issue = similar_issues.get(line.key)\n issue_id = None\n if similar_issue:\n if similar_issue.raw_data['locked']:\n submitter_result = cls.EXISTING_ISSUE_LOCKED.format(number=similar_issue.number)\n log.warning(submitter_result)\n else:\n similar_issue.create_comment(message)\n issue_id = similar_issue.number\n submitter_result = cls.COMMENTED_EXISTING_ISSUE.format(number=issue_id)\n log.info(submitter_result)\n ErrorViewer.remove(line)\n else:\n issue = github_repo.create_issue('{prefix}{title}'.format(prefix=cls.TITLE_PREFIX, title=line.issue_title), message)\n issue_id = issue.number\n submitter_result = cls.ISSUE_CREATED.format(number=issue_id)\n log.info(submitter_result)\n ErrorViewer.remove(line)\n results.append((submitter_result, issue_id))\n\n return results\n", "path": "medusa/issue_submitter.py"}]}
| 2,713 | 742 |
gh_patches_debug_14740
|
rasdani/github-patches
|
git_diff
|
mdn__kuma-6178
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ClientError (Throttling) in request_cdn_cache_invalidation()
https://sentry.prod.mozaws.net/operations/mdn-prod/issues/6766908/
```
ClientError: An error occurred (Throttling) when calling the CreateInvalidation operation (reached max retries: 4): Rate exceeded
(1 additional frame(s) were not displayed)
...
File "newrelic/hooks/application_celery.py", line 85, in wrapper
return wrapped(*args, **kwargs)
File "celery/app/trace.py", line 648, in __protected_call__
return self.run(*args, **kwargs)
File "kuma/api/tasks.py", line 180, in request_cdn_cache_invalidation
invalidation = client.create_invalidation(
File "botocore/client.py", line 357, in _api_call
return self._make_api_call(operation_name, kwargs)
File "botocore/client.py", line 661, in _make_api_call
raise error_class(parsed_response, operation_name)
ClientError: An error occurred (Throttling) when calling the CreateInvalidation operation (reached max retries: 4): Rate exceeded
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kuma/api/tasks.py`
Content:
```
1
2
3 import json
4 import time
5
6 import boto3
7 from celery import task
8 from django.conf import settings
9 from django.utils.module_loading import import_string
10
11 from kuma.core.utils import chunked
12 from kuma.wiki.models import Document
13
14 from .v1.views import document_api_data, get_content_based_redirect, get_s3_key
15
16
17 _s3_resource = None
18 S3_MAX_KEYS_PER_DELETE = 1000
19
20
21 def get_s3_resource(config=None):
22 """
23 Get or create the S3 resource. This function is not thread-safe, since it
24 uses the default session, rather than a separate session for each thread.
25 We do not use threads however, so we don't have to handle them.
26 """
27 global _s3_resource
28 if _s3_resource is None:
29 _s3_resource = boto3.resource('s3', config=config)
30 return _s3_resource
31
32
33 # The global cloudfront client object to be lazily defined
34 _cloudfront_client = None
35
36
37 def get_cloudfront_client(config=None):
38 """
39 Get or create the CloudFront client. This function is not
40 thread-safe, since it uses the default session, rather than
41 a separate session for each thread.
42 We do not use threads however, so we don't have to handle them.
43 """
44 global _cloudfront_client
45 if _cloudfront_client is None:
46 _cloudfront_client = boto3.client('cloudfront', config=config)
47 return _cloudfront_client
48
49
50 def get_s3_bucket(config=None):
51 """
52 Get the S3 bucket using the name configured in the environment, otherwise
53 return None.
54 """
55 if not settings.MDN_API_S3_BUCKET_NAME:
56 return None
57 s3 = get_s3_resource(config=config)
58 return s3.Bucket(settings.MDN_API_S3_BUCKET_NAME)
59
60
61 @task
62 def unpublish(doc_locale_slug_pairs, log=None, completion_message=None,
63 invalidate_cdn_cache=True):
64 """
65 Delete one or more documents from the S3 bucket serving the document API.
66 """
67 if not log:
68 log = unpublish.get_logger()
69
70 s3_bucket = get_s3_bucket()
71 if not s3_bucket:
72 log.info('Skipping unpublish of {!r}: no S3 bucket configured'.format(
73 doc_locale_slug_pairs))
74 return
75
76 keys_to_delete = (get_s3_key(locale=locale, slug=slug)
77 for locale, slug in doc_locale_slug_pairs)
78
79 for chunk in chunked(keys_to_delete, S3_MAX_KEYS_PER_DELETE):
80 response = s3_bucket.delete_objects(
81 Delete={
82 'Objects': [{'Key': key} for key in chunk]
83 }
84 )
85 for info in response.get('Deleted', ()):
86 log.info('Unpublished {}'.format(info['Key']))
87 for info in response.get('Errors', ()):
88 log.error('Unable to unpublish {}: ({}) {}'.format(
89 info['Key'], info['Code'], info['Message']))
90
91 if completion_message:
92 log.info(completion_message)
93
94 if invalidate_cdn_cache:
95 request_cdn_cache_invalidation.delay(doc_locale_slug_pairs)
96
97
98 @task
99 def publish(doc_pks, log=None, completion_message=None,
100 invalidate_cdn_cache=True):
101 """
102 Publish one or more documents to the S3 bucket serving the document API.
103 """
104 if not log:
105 log = publish.get_logger()
106
107 s3_bucket = get_s3_bucket()
108 if not s3_bucket:
109 log.info(
110 'Skipping publish of {!r}: no S3 bucket configured'.format(doc_pks))
111 return
112
113 if invalidate_cdn_cache:
114 # Use this to turn the document IDs into pairs of (locale, slug).
115 doc_locale_slug_pairs = []
116
117 for pk in doc_pks:
118 try:
119 doc = Document.objects.get(pk=pk)
120 except Document.DoesNotExist:
121 log.error('Document with pk={} does not exist'.format(pk))
122 continue
123
124 if invalidate_cdn_cache:
125 # Build up this list for the benefit of triggering a
126 # CDN cache invalidation.
127 doc_locale_slug_pairs.append((doc.locale, doc.slug))
128
129 kwargs = dict(
130 ACL='public-read',
131 Key=get_s3_key(doc),
132 ContentType='application/json',
133 ContentLanguage=doc.locale,
134 )
135 redirect = get_content_based_redirect(doc)
136 if redirect:
137 redirect_url, is_redirect_to_document = redirect
138 if is_redirect_to_document:
139 kwargs.update(WebsiteRedirectLocation=redirect_url)
140 data = document_api_data(redirect_url=redirect_url)
141 kwargs.update(Body=json.dumps(data))
142 else:
143 data = document_api_data(doc)
144 kwargs.update(Body=json.dumps(data))
145 s3_object = s3_bucket.put_object(**kwargs)
146 log.info('Published {!r}'.format(s3_object))
147
148 if completion_message:
149 log.info(completion_message)
150
151 if invalidate_cdn_cache and doc_locale_slug_pairs:
152 request_cdn_cache_invalidation.delay(doc_locale_slug_pairs)
153
154
155 @task
156 def request_cdn_cache_invalidation(doc_locale_slug_pairs, log=None):
157 """
158 Trigger an attempt to purge the given documents from one or more
159 of the configured CloudFront distributions.
160 """
161 if not log:
162 log = request_cdn_cache_invalidation.get_logger()
163
164 client = get_cloudfront_client()
165 for label, conf in settings.MDN_CLOUDFRONT_DISTRIBUTIONS.items():
166 if not conf['id']:
167 log.info('No Distribution ID available for CloudFront {!r}'.format(
168 label
169 ))
170 continue
171 transform_function = import_string(conf['transform_function'])
172 paths = (
173 transform_function(locale, slug)
174 for locale, slug in doc_locale_slug_pairs
175 )
176 # In case the transform function decided to "opt-out" on a particular
177 # (locale, slug) it might return a falsy value.
178 paths = [x for x in paths if x]
179 if paths:
180 invalidation = client.create_invalidation(
181 DistributionId=conf['id'],
182 InvalidationBatch={
183 'Paths': {
184 'Quantity': len(paths),
185 'Items': paths
186 },
187 # The 'CallerReference' just needs to be a unique string.
188 # By using a timestamp we get slightly more information
189 # than using a UUID or a random string. But it needs to
190 # be sufficiently "different" that's why we use 6
191 # significant figures to avoid the unlikely chance that
192 # this code gets executed concurrently within a small
193 # time window.
194 'CallerReference': '{:.6f}'.format(time.time())
195 }
196 )
197 log.info(
198 'Issued cache invalidation for {!r} in {} distribution'
199 ' (received with {})'.format(
200 paths,
201 label,
202 invalidation['ResponseMetadata']['HTTPStatusCode']
203 )
204 )
205
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kuma/api/tasks.py b/kuma/api/tasks.py
--- a/kuma/api/tasks.py
+++ b/kuma/api/tasks.py
@@ -4,9 +4,11 @@
import time
import boto3
+from botocore.exceptions import ClientError
from celery import task
from django.conf import settings
from django.utils.module_loading import import_string
+from redo import retriable
from kuma.core.utils import chunked
from kuma.wiki.models import Document
@@ -153,6 +155,7 @@
@task
+@retriable(retry_exceptions=(ClientError,))
def request_cdn_cache_invalidation(doc_locale_slug_pairs, log=None):
"""
Trigger an attempt to purge the given documents from one or more
|
{"golden_diff": "diff --git a/kuma/api/tasks.py b/kuma/api/tasks.py\n--- a/kuma/api/tasks.py\n+++ b/kuma/api/tasks.py\n@@ -4,9 +4,11 @@\n import time\n \n import boto3\n+from botocore.exceptions import ClientError\n from celery import task\n from django.conf import settings\n from django.utils.module_loading import import_string\n+from redo import retriable\n \n from kuma.core.utils import chunked\n from kuma.wiki.models import Document\n@@ -153,6 +155,7 @@\n \n \n @task\n+@retriable(retry_exceptions=(ClientError,))\n def request_cdn_cache_invalidation(doc_locale_slug_pairs, log=None):\n \"\"\"\n Trigger an attempt to purge the given documents from one or more\n", "issue": "ClientError (Throttling) in request_cdn_cache_invalidation()\nhttps://sentry.prod.mozaws.net/operations/mdn-prod/issues/6766908/\n\n```\nClientError: An error occurred (Throttling) when calling the CreateInvalidation operation (reached max retries: 4): Rate exceeded\n(1 additional frame(s) were not displayed)\n...\n File \"newrelic/hooks/application_celery.py\", line 85, in wrapper\n return wrapped(*args, **kwargs)\n File \"celery/app/trace.py\", line 648, in __protected_call__\n return self.run(*args, **kwargs)\n File \"kuma/api/tasks.py\", line 180, in request_cdn_cache_invalidation\n invalidation = client.create_invalidation(\n File \"botocore/client.py\", line 357, in _api_call\n return self._make_api_call(operation_name, kwargs)\n File \"botocore/client.py\", line 661, in _make_api_call\n raise error_class(parsed_response, operation_name)\n\nClientError: An error occurred (Throttling) when calling the CreateInvalidation operation (reached max retries: 4): Rate exceeded\n```\n", "before_files": [{"content": "\n\nimport json\nimport time\n\nimport boto3\nfrom celery import task\nfrom django.conf import settings\nfrom django.utils.module_loading import import_string\n\nfrom kuma.core.utils import chunked\nfrom kuma.wiki.models import Document\n\nfrom .v1.views import document_api_data, get_content_based_redirect, get_s3_key\n\n\n_s3_resource = None\nS3_MAX_KEYS_PER_DELETE = 1000\n\n\ndef get_s3_resource(config=None):\n \"\"\"\n Get or create the S3 resource. This function is not thread-safe, since it\n uses the default session, rather than a separate session for each thread.\n We do not use threads however, so we don't have to handle them.\n \"\"\"\n global _s3_resource\n if _s3_resource is None:\n _s3_resource = boto3.resource('s3', config=config)\n return _s3_resource\n\n\n# The global cloudfront client object to be lazily defined\n_cloudfront_client = None\n\n\ndef get_cloudfront_client(config=None):\n \"\"\"\n Get or create the CloudFront client. This function is not\n thread-safe, since it uses the default session, rather than\n a separate session for each thread.\n We do not use threads however, so we don't have to handle them.\n \"\"\"\n global _cloudfront_client\n if _cloudfront_client is None:\n _cloudfront_client = boto3.client('cloudfront', config=config)\n return _cloudfront_client\n\n\ndef get_s3_bucket(config=None):\n \"\"\"\n Get the S3 bucket using the name configured in the environment, otherwise\n return None.\n \"\"\"\n if not settings.MDN_API_S3_BUCKET_NAME:\n return None\n s3 = get_s3_resource(config=config)\n return s3.Bucket(settings.MDN_API_S3_BUCKET_NAME)\n\n\n@task\ndef unpublish(doc_locale_slug_pairs, log=None, completion_message=None,\n invalidate_cdn_cache=True):\n \"\"\"\n Delete one or more documents from the S3 bucket serving the document API.\n \"\"\"\n if not log:\n log = unpublish.get_logger()\n\n s3_bucket = get_s3_bucket()\n if not s3_bucket:\n log.info('Skipping unpublish of {!r}: no S3 bucket configured'.format(\n doc_locale_slug_pairs))\n return\n\n keys_to_delete = (get_s3_key(locale=locale, slug=slug)\n for locale, slug in doc_locale_slug_pairs)\n\n for chunk in chunked(keys_to_delete, S3_MAX_KEYS_PER_DELETE):\n response = s3_bucket.delete_objects(\n Delete={\n 'Objects': [{'Key': key} for key in chunk]\n }\n )\n for info in response.get('Deleted', ()):\n log.info('Unpublished {}'.format(info['Key']))\n for info in response.get('Errors', ()):\n log.error('Unable to unpublish {}: ({}) {}'.format(\n info['Key'], info['Code'], info['Message']))\n\n if completion_message:\n log.info(completion_message)\n\n if invalidate_cdn_cache:\n request_cdn_cache_invalidation.delay(doc_locale_slug_pairs)\n\n\n@task\ndef publish(doc_pks, log=None, completion_message=None,\n invalidate_cdn_cache=True):\n \"\"\"\n Publish one or more documents to the S3 bucket serving the document API.\n \"\"\"\n if not log:\n log = publish.get_logger()\n\n s3_bucket = get_s3_bucket()\n if not s3_bucket:\n log.info(\n 'Skipping publish of {!r}: no S3 bucket configured'.format(doc_pks))\n return\n\n if invalidate_cdn_cache:\n # Use this to turn the document IDs into pairs of (locale, slug).\n doc_locale_slug_pairs = []\n\n for pk in doc_pks:\n try:\n doc = Document.objects.get(pk=pk)\n except Document.DoesNotExist:\n log.error('Document with pk={} does not exist'.format(pk))\n continue\n\n if invalidate_cdn_cache:\n # Build up this list for the benefit of triggering a\n # CDN cache invalidation.\n doc_locale_slug_pairs.append((doc.locale, doc.slug))\n\n kwargs = dict(\n ACL='public-read',\n Key=get_s3_key(doc),\n ContentType='application/json',\n ContentLanguage=doc.locale,\n )\n redirect = get_content_based_redirect(doc)\n if redirect:\n redirect_url, is_redirect_to_document = redirect\n if is_redirect_to_document:\n kwargs.update(WebsiteRedirectLocation=redirect_url)\n data = document_api_data(redirect_url=redirect_url)\n kwargs.update(Body=json.dumps(data))\n else:\n data = document_api_data(doc)\n kwargs.update(Body=json.dumps(data))\n s3_object = s3_bucket.put_object(**kwargs)\n log.info('Published {!r}'.format(s3_object))\n\n if completion_message:\n log.info(completion_message)\n\n if invalidate_cdn_cache and doc_locale_slug_pairs:\n request_cdn_cache_invalidation.delay(doc_locale_slug_pairs)\n\n\n@task\ndef request_cdn_cache_invalidation(doc_locale_slug_pairs, log=None):\n \"\"\"\n Trigger an attempt to purge the given documents from one or more\n of the configured CloudFront distributions.\n \"\"\"\n if not log:\n log = request_cdn_cache_invalidation.get_logger()\n\n client = get_cloudfront_client()\n for label, conf in settings.MDN_CLOUDFRONT_DISTRIBUTIONS.items():\n if not conf['id']:\n log.info('No Distribution ID available for CloudFront {!r}'.format(\n label\n ))\n continue\n transform_function = import_string(conf['transform_function'])\n paths = (\n transform_function(locale, slug)\n for locale, slug in doc_locale_slug_pairs\n )\n # In case the transform function decided to \"opt-out\" on a particular\n # (locale, slug) it might return a falsy value.\n paths = [x for x in paths if x]\n if paths:\n invalidation = client.create_invalidation(\n DistributionId=conf['id'],\n InvalidationBatch={\n 'Paths': {\n 'Quantity': len(paths),\n 'Items': paths\n },\n # The 'CallerReference' just needs to be a unique string.\n # By using a timestamp we get slightly more information\n # than using a UUID or a random string. But it needs to\n # be sufficiently \"different\" that's why we use 6\n # significant figures to avoid the unlikely chance that\n # this code gets executed concurrently within a small\n # time window.\n 'CallerReference': '{:.6f}'.format(time.time())\n }\n )\n log.info(\n 'Issued cache invalidation for {!r} in {} distribution'\n ' (received with {})'.format(\n paths,\n label,\n invalidation['ResponseMetadata']['HTTPStatusCode']\n )\n )\n", "path": "kuma/api/tasks.py"}], "after_files": [{"content": "\n\nimport json\nimport time\n\nimport boto3\nfrom botocore.exceptions import ClientError\nfrom celery import task\nfrom django.conf import settings\nfrom django.utils.module_loading import import_string\nfrom redo import retriable\n\nfrom kuma.core.utils import chunked\nfrom kuma.wiki.models import Document\n\nfrom .v1.views import document_api_data, get_content_based_redirect, get_s3_key\n\n\n_s3_resource = None\nS3_MAX_KEYS_PER_DELETE = 1000\n\n\ndef get_s3_resource(config=None):\n \"\"\"\n Get or create the S3 resource. This function is not thread-safe, since it\n uses the default session, rather than a separate session for each thread.\n We do not use threads however, so we don't have to handle them.\n \"\"\"\n global _s3_resource\n if _s3_resource is None:\n _s3_resource = boto3.resource('s3', config=config)\n return _s3_resource\n\n\n# The global cloudfront client object to be lazily defined\n_cloudfront_client = None\n\n\ndef get_cloudfront_client(config=None):\n \"\"\"\n Get or create the CloudFront client. This function is not\n thread-safe, since it uses the default session, rather than\n a separate session for each thread.\n We do not use threads however, so we don't have to handle them.\n \"\"\"\n global _cloudfront_client\n if _cloudfront_client is None:\n _cloudfront_client = boto3.client('cloudfront', config=config)\n return _cloudfront_client\n\n\ndef get_s3_bucket(config=None):\n \"\"\"\n Get the S3 bucket using the name configured in the environment, otherwise\n return None.\n \"\"\"\n if not settings.MDN_API_S3_BUCKET_NAME:\n return None\n s3 = get_s3_resource(config=config)\n return s3.Bucket(settings.MDN_API_S3_BUCKET_NAME)\n\n\n@task\ndef unpublish(doc_locale_slug_pairs, log=None, completion_message=None,\n invalidate_cdn_cache=True):\n \"\"\"\n Delete one or more documents from the S3 bucket serving the document API.\n \"\"\"\n if not log:\n log = unpublish.get_logger()\n\n s3_bucket = get_s3_bucket()\n if not s3_bucket:\n log.info('Skipping unpublish of {!r}: no S3 bucket configured'.format(\n doc_locale_slug_pairs))\n return\n\n keys_to_delete = (get_s3_key(locale=locale, slug=slug)\n for locale, slug in doc_locale_slug_pairs)\n\n for chunk in chunked(keys_to_delete, S3_MAX_KEYS_PER_DELETE):\n response = s3_bucket.delete_objects(\n Delete={\n 'Objects': [{'Key': key} for key in chunk]\n }\n )\n for info in response.get('Deleted', ()):\n log.info('Unpublished {}'.format(info['Key']))\n for info in response.get('Errors', ()):\n log.error('Unable to unpublish {}: ({}) {}'.format(\n info['Key'], info['Code'], info['Message']))\n\n if completion_message:\n log.info(completion_message)\n\n if invalidate_cdn_cache:\n request_cdn_cache_invalidation.delay(doc_locale_slug_pairs)\n\n\n@task\ndef publish(doc_pks, log=None, completion_message=None,\n invalidate_cdn_cache=True):\n \"\"\"\n Publish one or more documents to the S3 bucket serving the document API.\n \"\"\"\n if not log:\n log = publish.get_logger()\n\n s3_bucket = get_s3_bucket()\n if not s3_bucket:\n log.info(\n 'Skipping publish of {!r}: no S3 bucket configured'.format(doc_pks))\n return\n\n if invalidate_cdn_cache:\n # Use this to turn the document IDs into pairs of (locale, slug).\n doc_locale_slug_pairs = []\n\n for pk in doc_pks:\n try:\n doc = Document.objects.get(pk=pk)\n except Document.DoesNotExist:\n log.error('Document with pk={} does not exist'.format(pk))\n continue\n\n if invalidate_cdn_cache:\n # Build up this list for the benefit of triggering a\n # CDN cache invalidation.\n doc_locale_slug_pairs.append((doc.locale, doc.slug))\n\n kwargs = dict(\n ACL='public-read',\n Key=get_s3_key(doc),\n ContentType='application/json',\n ContentLanguage=doc.locale,\n )\n redirect = get_content_based_redirect(doc)\n if redirect:\n redirect_url, is_redirect_to_document = redirect\n if is_redirect_to_document:\n kwargs.update(WebsiteRedirectLocation=redirect_url)\n data = document_api_data(redirect_url=redirect_url)\n kwargs.update(Body=json.dumps(data))\n else:\n data = document_api_data(doc)\n kwargs.update(Body=json.dumps(data))\n s3_object = s3_bucket.put_object(**kwargs)\n log.info('Published {!r}'.format(s3_object))\n\n if completion_message:\n log.info(completion_message)\n\n if invalidate_cdn_cache and doc_locale_slug_pairs:\n request_cdn_cache_invalidation.delay(doc_locale_slug_pairs)\n\n\n@task\n@retriable(retry_exceptions=(ClientError,))\ndef request_cdn_cache_invalidation(doc_locale_slug_pairs, log=None):\n \"\"\"\n Trigger an attempt to purge the given documents from one or more\n of the configured CloudFront distributions.\n \"\"\"\n if not log:\n log = request_cdn_cache_invalidation.get_logger()\n\n client = get_cloudfront_client()\n for label, conf in settings.MDN_CLOUDFRONT_DISTRIBUTIONS.items():\n if not conf['id']:\n log.info('No Distribution ID available for CloudFront {!r}'.format(\n label\n ))\n continue\n transform_function = import_string(conf['transform_function'])\n paths = (\n transform_function(locale, slug)\n for locale, slug in doc_locale_slug_pairs\n )\n # In case the transform function decided to \"opt-out\" on a particular\n # (locale, slug) it might return a falsy value.\n paths = [x for x in paths if x]\n if paths:\n invalidation = client.create_invalidation(\n DistributionId=conf['id'],\n InvalidationBatch={\n 'Paths': {\n 'Quantity': len(paths),\n 'Items': paths\n },\n # The 'CallerReference' just needs to be a unique string.\n # By using a timestamp we get slightly more information\n # than using a UUID or a random string. But it needs to\n # be sufficiently \"different\" that's why we use 6\n # significant figures to avoid the unlikely chance that\n # this code gets executed concurrently within a small\n # time window.\n 'CallerReference': '{:.6f}'.format(time.time())\n }\n )\n log.info(\n 'Issued cache invalidation for {!r} in {} distribution'\n ' (received with {})'.format(\n paths,\n label,\n invalidation['ResponseMetadata']['HTTPStatusCode']\n )\n )\n", "path": "kuma/api/tasks.py"}]}
| 2,516 | 166 |
gh_patches_debug_34655
|
rasdani/github-patches
|
git_diff
|
modal-labs__modal-examples-708
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Mixtral tutorial doesn't work without huggingface access token
The tutorial for running mixtral on VLLM doesn't work since the model cannot be downloaded without a huggingface access token. This is because mixtral is now a gated model: https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1
```
Image build for im-1P0Aou6cl9H3BAwictbALw failed with the exception: │
│ GatedRepoError('401 Client Error. (Request ID: │
│ Root=1-66213747-475d6ad5261bb9eb4931c4fd;025f8bf1-0bb2-42ac-86a0-743e752004a0)\n\nCannot access gated repo for │
│ url https://huggingface.co/api/models/mistralai/Mixtral-8x7B-Instruct-v0.1/revision/main.\nRepo model │
│ mistralai/Mixtral-8x7B-Instruct-v0.1 is gated. You must be authenticated to access it.')
```
Affected Tutorial: https://modal.com/docs/examples/vllm_mixtral
Affected Code: https://github.com/modal-labs/modal-examples/blob/main/06_gpu_and_ml/llm-serving/vllm_mixtral.py
This can be fixed using a similar approach as done [here]( https://github.com/modal-labs/modal-examples/pull/539) (adding an env var for a `HF_TOKEN`) to the [function call](https://github.com/modal-labs/modal-examples/blob/main/06_gpu_and_ml/llm-serving/vllm_mixtral.py#L45-L49) where the model is downloaded.
Also the tutorial needs to be updated to inform the user that a huggingface access token is required.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `06_gpu_and_ml/llm-serving/vllm_mixtral.py`
Content:
```
1 # # Fast inference with vLLM (Mixtral 8x7B)
2 #
3 # In this example, we show how to run basic inference, using [`vLLM`](https://github.com/vllm-project/vllm)
4 # to take advantage of PagedAttention, which speeds up sequential inferences with optimized key-value caching.
5 #
6 # We are running the [Mixtral 8x7B Instruct](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) model here,
7 # which is a mixture-of-experts model finetuned for conversation.
8 # You can expect ~3 minute cold starts.
9 # For a single request, the throughput is over 50 tokens/second.
10 # The larger the batch of prompts, the higher the throughput (up to hundreds of tokens per second).
11 #
12 # ## Setup
13 #
14 # First we import the components we need from `modal`.
15
16 import os
17 import time
18
19 import modal
20
21 MODEL_DIR = "/model"
22 MODEL_NAME = "mistralai/Mixtral-8x7B-Instruct-v0.1"
23 GPU_CONFIG = modal.gpu.A100(memory=80, count=2)
24
25
26 # ## Define a container image
27 #
28 # We want to create a Modal image which has the model weights pre-saved to a directory. The benefit of this
29 # is that the container no longer has to re-download the model from Huggingface - instead, it will take
30 # advantage of Modal's internal filesystem for faster cold starts.
31 #
32 # ### Download the weights
33 #
34 # We can download the model to a particular directory using the HuggingFace utility function `snapshot_download`.
35 #
36 # Mixtral is beefy, at nearly 100 GB in `safetensors` format, so this can take some time -- at least a few minutes.
37 #
38 # Tip: avoid using global variables in this function. Changes to code outside this function will not be detected and the download step will not re-run.
39 def download_model_to_image(model_dir, model_name):
40 from huggingface_hub import snapshot_download
41 from transformers.utils import move_cache
42
43 os.makedirs(model_dir, exist_ok=True)
44
45 snapshot_download(
46 model_name,
47 local_dir=model_dir,
48 ignore_patterns=["*.pt", "*.bin"], # Using safetensors
49 )
50 move_cache()
51
52
53 # ### Image definition
54 # We’ll start from a Dockerhub image recommended by `vLLM`, and use
55 # run_function to run the function defined above to ensure the weights of
56 # the model are saved within the container image.
57
58 vllm_image = (
59 modal.Image.debian_slim()
60 .pip_install(
61 "vllm==0.4.0.post1",
62 "torch==2.1.2",
63 "transformers==4.39.3",
64 "ray==2.10.0",
65 "hf-transfer==0.1.6",
66 "huggingface_hub==0.22.2",
67 )
68 .env({"HF_HUB_ENABLE_HF_TRANSFER": "1"})
69 .run_function(
70 download_model_to_image,
71 timeout=60 * 20,
72 kwargs={"model_dir": MODEL_DIR, "model_name": MODEL_NAME},
73 )
74 )
75
76 stub = modal.Stub("example-vllm-mixtral")
77
78
79 # ## The model class
80 #
81 # The inference function is best represented with Modal's [class syntax](/docs/guide/lifecycle-functions) and the `@enter` decorator.
82 # This enables us to load the model into memory just once every time a container starts up, and keep it cached
83 # on the GPU for each subsequent invocation of the function.
84 #
85 # The `vLLM` library allows the code to remain quite clean. We do have to patch the multi-GPU setup due to issues with Ray.
86 @stub.cls(
87 gpu=GPU_CONFIG,
88 timeout=60 * 10,
89 container_idle_timeout=60 * 10,
90 allow_concurrent_inputs=10,
91 image=vllm_image,
92 )
93 class Model:
94 @modal.enter()
95 def start_engine(self):
96 from vllm.engine.arg_utils import AsyncEngineArgs
97 from vllm.engine.async_llm_engine import AsyncLLMEngine
98
99 print("🥶 cold starting inference")
100 start = time.monotonic_ns()
101
102 engine_args = AsyncEngineArgs(
103 model=MODEL_DIR,
104 tensor_parallel_size=GPU_CONFIG.count,
105 gpu_memory_utilization=0.90,
106 enforce_eager=False, # capture the graph for faster inference, but slower cold starts
107 disable_log_stats=True, # disable logging so we can stream tokens
108 disable_log_requests=True,
109 )
110 self.template = "<s> [INST] {user} [/INST] "
111
112 # this can take some time!
113 self.engine = AsyncLLMEngine.from_engine_args(engine_args)
114 duration_s = (time.monotonic_ns() - start) / 1e9
115 print(f"🏎️ engine started in {duration_s:.0f}s")
116
117 @modal.method()
118 async def completion_stream(self, user_question):
119 from vllm import SamplingParams
120 from vllm.utils import random_uuid
121
122 sampling_params = SamplingParams(
123 temperature=0.75,
124 max_tokens=128,
125 repetition_penalty=1.1,
126 )
127
128 request_id = random_uuid()
129 result_generator = self.engine.generate(
130 self.template.format(user=user_question),
131 sampling_params,
132 request_id,
133 )
134 index, num_tokens = 0, 0
135 start = time.monotonic_ns()
136 async for output in result_generator:
137 if (
138 output.outputs[0].text
139 and "\ufffd" == output.outputs[0].text[-1]
140 ):
141 continue
142 text_delta = output.outputs[0].text[index:]
143 index = len(output.outputs[0].text)
144 num_tokens = len(output.outputs[0].token_ids)
145
146 yield text_delta
147 duration_s = (time.monotonic_ns() - start) / 1e9
148
149 yield (
150 f"\n\tGenerated {num_tokens} tokens from {MODEL_NAME} in {duration_s:.1f}s,"
151 f" throughput = {num_tokens / duration_s:.0f} tokens/second on {GPU_CONFIG}.\n"
152 )
153
154 @modal.exit()
155 def stop_engine(self):
156 if GPU_CONFIG.count > 1:
157 import ray
158
159 ray.shutdown()
160
161
162 # ## Run the model
163 # We define a [`local_entrypoint`](/docs/guide/apps#entrypoints-for-ephemeral-apps) to call our remote function
164 # sequentially for a list of inputs. You can run this locally with `modal run -q vllm_mixtral.py`. The `q` flag
165 # enables the text to stream in your local terminal.
166 @stub.local_entrypoint()
167 def main():
168 questions = [
169 "Implement a Python function to compute the Fibonacci numbers.",
170 "What is the fable involving a fox and grapes?",
171 "What were the major contributing factors to the fall of the Roman Empire?",
172 "Describe the city of the future, considering advances in technology, environmental changes, and societal shifts.",
173 "What is the product of 9 and 8?",
174 "Who was Emperor Norton I, and what was his significance in San Francisco's history?",
175 ]
176 model = Model()
177 for question in questions:
178 print("Sending new request:", question, "\n\n")
179 for text in model.completion_stream.remote_gen(question):
180 print(text, end="", flush=text.endswith("\n"))
181
182
183 # ## Deploy and invoke the model
184 # Once we deploy this model with `modal deploy text_generation_inference.py`,
185 # we can invoke inference from other apps, sharing the same pool
186 # of GPU containers with all other apps we might need.
187 #
188 # ```
189 # $ python
190 # >>> import modal
191 # >>> f = modal.Function.lookup("example-tgi-Mixtral-8x7B-Instruct-v0.1", "Model.generate")
192 # >>> f.remote("What is the story about the fox and grapes?")
193 # 'The story about the fox and grapes ...
194 # ```
195
196 # ## Coupling a frontend web application
197 #
198 # We can stream inference from a FastAPI backend, also deployed on Modal.
199 #
200 # You can try our deployment [here](https://modal-labs--vllm-mixtral.modal.run).
201
202 from pathlib import Path
203
204 from modal import Mount, asgi_app
205
206 frontend_path = Path(__file__).parent.parent / "llm-frontend"
207
208
209 @stub.function(
210 mounts=[Mount.from_local_dir(frontend_path, remote_path="/assets")],
211 keep_warm=1,
212 allow_concurrent_inputs=20,
213 timeout=60 * 10,
214 )
215 @asgi_app()
216 def vllm_mixtral():
217 import json
218
219 import fastapi
220 import fastapi.staticfiles
221 from fastapi.responses import StreamingResponse
222
223 web_app = fastapi.FastAPI()
224
225 @web_app.get("/stats")
226 async def stats():
227 stats = await Model().completion_stream.get_current_stats.aio()
228 return {
229 "backlog": stats.backlog,
230 "num_total_runners": stats.num_total_runners,
231 "model": MODEL_NAME + " (vLLM)",
232 }
233
234 @web_app.get("/completion/{question}")
235 async def completion(question: str):
236 from urllib.parse import unquote
237
238 async def generate():
239 async for text in Model().completion_stream.remote_gen.aio(
240 unquote(question)
241 ):
242 yield f"data: {json.dumps(dict(text=text), ensure_ascii=False)}\n\n"
243
244 return StreamingResponse(generate(), media_type="text/event-stream")
245
246 web_app.mount(
247 "/", fastapi.staticfiles.StaticFiles(directory="/assets", html=True)
248 )
249 return web_app
250
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/06_gpu_and_ml/llm-serving/vllm_mixtral.py b/06_gpu_and_ml/llm-serving/vllm_mixtral.py
--- a/06_gpu_and_ml/llm-serving/vllm_mixtral.py
+++ b/06_gpu_and_ml/llm-serving/vllm_mixtral.py
@@ -20,6 +20,7 @@
MODEL_DIR = "/model"
MODEL_NAME = "mistralai/Mixtral-8x7B-Instruct-v0.1"
+MODEL_REVISION = "1e637f2d7cb0a9d6fb1922f305cb784995190a83"
GPU_CONFIG = modal.gpu.A100(memory=80, count=2)
@@ -33,10 +34,15 @@
#
# We can download the model to a particular directory using the HuggingFace utility function `snapshot_download`.
#
-# Mixtral is beefy, at nearly 100 GB in `safetensors` format, so this can take some time -- at least a few minutes.
+# For this step to work on a [gated model](https://huggingface.co/docs/hub/en/models-gated)
+# like Mixtral 8x7B, the `HF_TOKEN` environment variable must be set.
+#
+# After [creating a HuggingFace access token](https://huggingface.co/settings/tokens)
+# and accepting the [terms of use](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1),
+# head to the [secrets page](https://modal.com/secrets) to share it with Modal as `huggingface-secret`.
#
-# Tip: avoid using global variables in this function. Changes to code outside this function will not be detected and the download step will not re-run.
-def download_model_to_image(model_dir, model_name):
+# Mixtral is beefy, at nearly 100 GB in `safetensors` format, so this can take some time -- at least a few minutes.
+def download_model_to_image(model_dir, model_name, model_revision):
from huggingface_hub import snapshot_download
from transformers.utils import move_cache
@@ -44,6 +50,7 @@
snapshot_download(
model_name,
+ revision=model_revision,
local_dir=model_dir,
ignore_patterns=["*.pt", "*.bin"], # Using safetensors
)
@@ -69,7 +76,12 @@
.run_function(
download_model_to_image,
timeout=60 * 20,
- kwargs={"model_dir": MODEL_DIR, "model_name": MODEL_NAME},
+ kwargs={
+ "model_dir": MODEL_DIR,
+ "model_name": MODEL_NAME,
+ "model_revision": MODEL_REVISION,
+ },
+ secrets=[modal.Secret.from_name("huggingface-secret")],
)
)
|
{"golden_diff": "diff --git a/06_gpu_and_ml/llm-serving/vllm_mixtral.py b/06_gpu_and_ml/llm-serving/vllm_mixtral.py\n--- a/06_gpu_and_ml/llm-serving/vllm_mixtral.py\n+++ b/06_gpu_and_ml/llm-serving/vllm_mixtral.py\n@@ -20,6 +20,7 @@\n \n MODEL_DIR = \"/model\"\n MODEL_NAME = \"mistralai/Mixtral-8x7B-Instruct-v0.1\"\n+MODEL_REVISION = \"1e637f2d7cb0a9d6fb1922f305cb784995190a83\"\n GPU_CONFIG = modal.gpu.A100(memory=80, count=2)\n \n \n@@ -33,10 +34,15 @@\n #\n # We can download the model to a particular directory using the HuggingFace utility function `snapshot_download`.\n #\n-# Mixtral is beefy, at nearly 100 GB in `safetensors` format, so this can take some time -- at least a few minutes.\n+# For this step to work on a [gated model](https://huggingface.co/docs/hub/en/models-gated)\n+# like Mixtral 8x7B, the `HF_TOKEN` environment variable must be set.\n+#\n+# After [creating a HuggingFace access token](https://huggingface.co/settings/tokens)\n+# and accepting the [terms of use](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1),\n+# head to the [secrets page](https://modal.com/secrets) to share it with Modal as `huggingface-secret`.\n #\n-# Tip: avoid using global variables in this function. Changes to code outside this function will not be detected and the download step will not re-run.\n-def download_model_to_image(model_dir, model_name):\n+# Mixtral is beefy, at nearly 100 GB in `safetensors` format, so this can take some time -- at least a few minutes.\n+def download_model_to_image(model_dir, model_name, model_revision):\n from huggingface_hub import snapshot_download\n from transformers.utils import move_cache\n \n@@ -44,6 +50,7 @@\n \n snapshot_download(\n model_name,\n+ revision=model_revision,\n local_dir=model_dir,\n ignore_patterns=[\"*.pt\", \"*.bin\"], # Using safetensors\n )\n@@ -69,7 +76,12 @@\n .run_function(\n download_model_to_image,\n timeout=60 * 20,\n- kwargs={\"model_dir\": MODEL_DIR, \"model_name\": MODEL_NAME},\n+ kwargs={\n+ \"model_dir\": MODEL_DIR,\n+ \"model_name\": MODEL_NAME,\n+ \"model_revision\": MODEL_REVISION,\n+ },\n+ secrets=[modal.Secret.from_name(\"huggingface-secret\")],\n )\n )\n", "issue": "Mixtral tutorial doesn't work without huggingface access token\nThe tutorial for running mixtral on VLLM doesn't work since the model cannot be downloaded without a huggingface access token. This is because mixtral is now a gated model: https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1\r\n\r\n```\r\nImage build for im-1P0Aou6cl9H3BAwictbALw failed with the exception: \u2502\r\n\u2502 GatedRepoError('401 Client Error. (Request ID: \u2502\r\n\u2502 Root=1-66213747-475d6ad5261bb9eb4931c4fd;025f8bf1-0bb2-42ac-86a0-743e752004a0)\\n\\nCannot access gated repo for \u2502\r\n\u2502 url https://huggingface.co/api/models/mistralai/Mixtral-8x7B-Instruct-v0.1/revision/main.\\nRepo model \u2502\r\n\u2502 mistralai/Mixtral-8x7B-Instruct-v0.1 is gated. You must be authenticated to access it.')\r\n```\r\n\r\nAffected Tutorial: https://modal.com/docs/examples/vllm_mixtral\r\nAffected Code: https://github.com/modal-labs/modal-examples/blob/main/06_gpu_and_ml/llm-serving/vllm_mixtral.py\r\n\r\nThis can be fixed using a similar approach as done [here]( https://github.com/modal-labs/modal-examples/pull/539) (adding an env var for a `HF_TOKEN`) to the [function call](https://github.com/modal-labs/modal-examples/blob/main/06_gpu_and_ml/llm-serving/vllm_mixtral.py#L45-L49) where the model is downloaded.\r\nAlso the tutorial needs to be updated to inform the user that a huggingface access token is required.\n", "before_files": [{"content": "# # Fast inference with vLLM (Mixtral 8x7B)\n#\n# In this example, we show how to run basic inference, using [`vLLM`](https://github.com/vllm-project/vllm)\n# to take advantage of PagedAttention, which speeds up sequential inferences with optimized key-value caching.\n#\n# We are running the [Mixtral 8x7B Instruct](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) model here,\n# which is a mixture-of-experts model finetuned for conversation.\n# You can expect ~3 minute cold starts.\n# For a single request, the throughput is over 50 tokens/second.\n# The larger the batch of prompts, the higher the throughput (up to hundreds of tokens per second).\n#\n# ## Setup\n#\n# First we import the components we need from `modal`.\n\nimport os\nimport time\n\nimport modal\n\nMODEL_DIR = \"/model\"\nMODEL_NAME = \"mistralai/Mixtral-8x7B-Instruct-v0.1\"\nGPU_CONFIG = modal.gpu.A100(memory=80, count=2)\n\n\n# ## Define a container image\n#\n# We want to create a Modal image which has the model weights pre-saved to a directory. The benefit of this\n# is that the container no longer has to re-download the model from Huggingface - instead, it will take\n# advantage of Modal's internal filesystem for faster cold starts.\n#\n# ### Download the weights\n#\n# We can download the model to a particular directory using the HuggingFace utility function `snapshot_download`.\n#\n# Mixtral is beefy, at nearly 100 GB in `safetensors` format, so this can take some time -- at least a few minutes.\n#\n# Tip: avoid using global variables in this function. Changes to code outside this function will not be detected and the download step will not re-run.\ndef download_model_to_image(model_dir, model_name):\n from huggingface_hub import snapshot_download\n from transformers.utils import move_cache\n\n os.makedirs(model_dir, exist_ok=True)\n\n snapshot_download(\n model_name,\n local_dir=model_dir,\n ignore_patterns=[\"*.pt\", \"*.bin\"], # Using safetensors\n )\n move_cache()\n\n\n# ### Image definition\n# We\u2019ll start from a Dockerhub image recommended by `vLLM`, and use\n# run_function to run the function defined above to ensure the weights of\n# the model are saved within the container image.\n\nvllm_image = (\n modal.Image.debian_slim()\n .pip_install(\n \"vllm==0.4.0.post1\",\n \"torch==2.1.2\",\n \"transformers==4.39.3\",\n \"ray==2.10.0\",\n \"hf-transfer==0.1.6\",\n \"huggingface_hub==0.22.2\",\n )\n .env({\"HF_HUB_ENABLE_HF_TRANSFER\": \"1\"})\n .run_function(\n download_model_to_image,\n timeout=60 * 20,\n kwargs={\"model_dir\": MODEL_DIR, \"model_name\": MODEL_NAME},\n )\n)\n\nstub = modal.Stub(\"example-vllm-mixtral\")\n\n\n# ## The model class\n#\n# The inference function is best represented with Modal's [class syntax](/docs/guide/lifecycle-functions) and the `@enter` decorator.\n# This enables us to load the model into memory just once every time a container starts up, and keep it cached\n# on the GPU for each subsequent invocation of the function.\n#\n# The `vLLM` library allows the code to remain quite clean. We do have to patch the multi-GPU setup due to issues with Ray.\[email protected](\n gpu=GPU_CONFIG,\n timeout=60 * 10,\n container_idle_timeout=60 * 10,\n allow_concurrent_inputs=10,\n image=vllm_image,\n)\nclass Model:\n @modal.enter()\n def start_engine(self):\n from vllm.engine.arg_utils import AsyncEngineArgs\n from vllm.engine.async_llm_engine import AsyncLLMEngine\n\n print(\"\ud83e\udd76 cold starting inference\")\n start = time.monotonic_ns()\n\n engine_args = AsyncEngineArgs(\n model=MODEL_DIR,\n tensor_parallel_size=GPU_CONFIG.count,\n gpu_memory_utilization=0.90,\n enforce_eager=False, # capture the graph for faster inference, but slower cold starts\n disable_log_stats=True, # disable logging so we can stream tokens\n disable_log_requests=True,\n )\n self.template = \"<s> [INST] {user} [/INST] \"\n\n # this can take some time!\n self.engine = AsyncLLMEngine.from_engine_args(engine_args)\n duration_s = (time.monotonic_ns() - start) / 1e9\n print(f\"\ud83c\udfce\ufe0f engine started in {duration_s:.0f}s\")\n\n @modal.method()\n async def completion_stream(self, user_question):\n from vllm import SamplingParams\n from vllm.utils import random_uuid\n\n sampling_params = SamplingParams(\n temperature=0.75,\n max_tokens=128,\n repetition_penalty=1.1,\n )\n\n request_id = random_uuid()\n result_generator = self.engine.generate(\n self.template.format(user=user_question),\n sampling_params,\n request_id,\n )\n index, num_tokens = 0, 0\n start = time.monotonic_ns()\n async for output in result_generator:\n if (\n output.outputs[0].text\n and \"\\ufffd\" == output.outputs[0].text[-1]\n ):\n continue\n text_delta = output.outputs[0].text[index:]\n index = len(output.outputs[0].text)\n num_tokens = len(output.outputs[0].token_ids)\n\n yield text_delta\n duration_s = (time.monotonic_ns() - start) / 1e9\n\n yield (\n f\"\\n\\tGenerated {num_tokens} tokens from {MODEL_NAME} in {duration_s:.1f}s,\"\n f\" throughput = {num_tokens / duration_s:.0f} tokens/second on {GPU_CONFIG}.\\n\"\n )\n\n @modal.exit()\n def stop_engine(self):\n if GPU_CONFIG.count > 1:\n import ray\n\n ray.shutdown()\n\n\n# ## Run the model\n# We define a [`local_entrypoint`](/docs/guide/apps#entrypoints-for-ephemeral-apps) to call our remote function\n# sequentially for a list of inputs. You can run this locally with `modal run -q vllm_mixtral.py`. The `q` flag\n# enables the text to stream in your local terminal.\[email protected]_entrypoint()\ndef main():\n questions = [\n \"Implement a Python function to compute the Fibonacci numbers.\",\n \"What is the fable involving a fox and grapes?\",\n \"What were the major contributing factors to the fall of the Roman Empire?\",\n \"Describe the city of the future, considering advances in technology, environmental changes, and societal shifts.\",\n \"What is the product of 9 and 8?\",\n \"Who was Emperor Norton I, and what was his significance in San Francisco's history?\",\n ]\n model = Model()\n for question in questions:\n print(\"Sending new request:\", question, \"\\n\\n\")\n for text in model.completion_stream.remote_gen(question):\n print(text, end=\"\", flush=text.endswith(\"\\n\"))\n\n\n# ## Deploy and invoke the model\n# Once we deploy this model with `modal deploy text_generation_inference.py`,\n# we can invoke inference from other apps, sharing the same pool\n# of GPU containers with all other apps we might need.\n#\n# ```\n# $ python\n# >>> import modal\n# >>> f = modal.Function.lookup(\"example-tgi-Mixtral-8x7B-Instruct-v0.1\", \"Model.generate\")\n# >>> f.remote(\"What is the story about the fox and grapes?\")\n# 'The story about the fox and grapes ...\n# ```\n\n# ## Coupling a frontend web application\n#\n# We can stream inference from a FastAPI backend, also deployed on Modal.\n#\n# You can try our deployment [here](https://modal-labs--vllm-mixtral.modal.run).\n\nfrom pathlib import Path\n\nfrom modal import Mount, asgi_app\n\nfrontend_path = Path(__file__).parent.parent / \"llm-frontend\"\n\n\[email protected](\n mounts=[Mount.from_local_dir(frontend_path, remote_path=\"/assets\")],\n keep_warm=1,\n allow_concurrent_inputs=20,\n timeout=60 * 10,\n)\n@asgi_app()\ndef vllm_mixtral():\n import json\n\n import fastapi\n import fastapi.staticfiles\n from fastapi.responses import StreamingResponse\n\n web_app = fastapi.FastAPI()\n\n @web_app.get(\"/stats\")\n async def stats():\n stats = await Model().completion_stream.get_current_stats.aio()\n return {\n \"backlog\": stats.backlog,\n \"num_total_runners\": stats.num_total_runners,\n \"model\": MODEL_NAME + \" (vLLM)\",\n }\n\n @web_app.get(\"/completion/{question}\")\n async def completion(question: str):\n from urllib.parse import unquote\n\n async def generate():\n async for text in Model().completion_stream.remote_gen.aio(\n unquote(question)\n ):\n yield f\"data: {json.dumps(dict(text=text), ensure_ascii=False)}\\n\\n\"\n\n return StreamingResponse(generate(), media_type=\"text/event-stream\")\n\n web_app.mount(\n \"/\", fastapi.staticfiles.StaticFiles(directory=\"/assets\", html=True)\n )\n return web_app\n", "path": "06_gpu_and_ml/llm-serving/vllm_mixtral.py"}], "after_files": [{"content": "# # Fast inference with vLLM (Mixtral 8x7B)\n#\n# In this example, we show how to run basic inference, using [`vLLM`](https://github.com/vllm-project/vllm)\n# to take advantage of PagedAttention, which speeds up sequential inferences with optimized key-value caching.\n#\n# We are running the [Mixtral 8x7B Instruct](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) model here,\n# which is a mixture-of-experts model finetuned for conversation.\n# You can expect ~3 minute cold starts.\n# For a single request, the throughput is over 50 tokens/second.\n# The larger the batch of prompts, the higher the throughput (up to hundreds of tokens per second).\n#\n# ## Setup\n#\n# First we import the components we need from `modal`.\n\nimport os\nimport time\n\nimport modal\n\nMODEL_DIR = \"/model\"\nMODEL_NAME = \"mistralai/Mixtral-8x7B-Instruct-v0.1\"\nMODEL_REVISION = \"1e637f2d7cb0a9d6fb1922f305cb784995190a83\"\nGPU_CONFIG = modal.gpu.A100(memory=80, count=2)\n\n\n# ## Define a container image\n#\n# We want to create a Modal image which has the model weights pre-saved to a directory. The benefit of this\n# is that the container no longer has to re-download the model from Huggingface - instead, it will take\n# advantage of Modal's internal filesystem for faster cold starts.\n#\n# ### Download the weights\n#\n# We can download the model to a particular directory using the HuggingFace utility function `snapshot_download`.\n#\n# For this step to work on a [gated model](https://huggingface.co/docs/hub/en/models-gated)\n# like Mixtral 8x7B, the `HF_TOKEN` environment variable must be set.\n#\n# After [creating a HuggingFace access token](https://huggingface.co/settings/tokens)\n# and accepting the [terms of use](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1),\n# head to the [secrets page](https://modal.com/secrets) to share it with Modal as `huggingface-secret`.\n#\n# Mixtral is beefy, at nearly 100 GB in `safetensors` format, so this can take some time -- at least a few minutes.\ndef download_model_to_image(model_dir, model_name, model_revision):\n from huggingface_hub import snapshot_download\n from transformers.utils import move_cache\n\n os.makedirs(model_dir, exist_ok=True)\n\n snapshot_download(\n model_name,\n revision=model_revision,\n local_dir=model_dir,\n ignore_patterns=[\"*.pt\", \"*.bin\"], # Using safetensors\n )\n move_cache()\n\n\n# ### Image definition\n# We\u2019ll start from a Dockerhub image recommended by `vLLM`, and use\n# run_function to run the function defined above to ensure the weights of\n# the model are saved within the container image.\n\nvllm_image = (\n modal.Image.debian_slim()\n .pip_install(\n \"vllm==0.4.0.post1\",\n \"torch==2.1.2\",\n \"transformers==4.39.3\",\n \"ray==2.10.0\",\n \"hf-transfer==0.1.6\",\n \"huggingface_hub==0.22.2\",\n )\n .env({\"HF_HUB_ENABLE_HF_TRANSFER\": \"1\"})\n .run_function(\n download_model_to_image,\n timeout=60 * 20,\n kwargs={\n \"model_dir\": MODEL_DIR,\n \"model_name\": MODEL_NAME,\n \"model_revision\": MODEL_REVISION,\n },\n secrets=[modal.Secret.from_name(\"huggingface-secret\")],\n )\n)\n\nstub = modal.Stub(\"example-vllm-mixtral\")\n\n\n# ## The model class\n#\n# The inference function is best represented with Modal's [class syntax](/docs/guide/lifecycle-functions) and the `@enter` decorator.\n# This enables us to load the model into memory just once every time a container starts up, and keep it cached\n# on the GPU for each subsequent invocation of the function.\n#\n# The `vLLM` library allows the code to remain quite clean. We do have to patch the multi-GPU setup due to issues with Ray.\[email protected](\n gpu=GPU_CONFIG,\n timeout=60 * 10,\n container_idle_timeout=60 * 10,\n allow_concurrent_inputs=10,\n image=vllm_image,\n)\nclass Model:\n @modal.enter()\n def start_engine(self):\n from vllm.engine.arg_utils import AsyncEngineArgs\n from vllm.engine.async_llm_engine import AsyncLLMEngine\n\n print(\"\ud83e\udd76 cold starting inference\")\n start = time.monotonic_ns()\n\n engine_args = AsyncEngineArgs(\n model=MODEL_DIR,\n tensor_parallel_size=GPU_CONFIG.count,\n gpu_memory_utilization=0.90,\n enforce_eager=False, # capture the graph for faster inference, but slower cold starts\n disable_log_stats=True, # disable logging so we can stream tokens\n disable_log_requests=True,\n )\n self.template = \"<s> [INST] {user} [/INST] \"\n\n # this can take some time!\n self.engine = AsyncLLMEngine.from_engine_args(engine_args)\n duration_s = (time.monotonic_ns() - start) / 1e9\n print(f\"\ud83c\udfce\ufe0f engine started in {duration_s:.0f}s\")\n\n @modal.method()\n async def completion_stream(self, user_question):\n from vllm import SamplingParams\n from vllm.utils import random_uuid\n\n sampling_params = SamplingParams(\n temperature=0.75,\n max_tokens=128,\n repetition_penalty=1.1,\n )\n\n request_id = random_uuid()\n result_generator = self.engine.generate(\n self.template.format(user=user_question),\n sampling_params,\n request_id,\n )\n index, num_tokens = 0, 0\n start = time.monotonic_ns()\n async for output in result_generator:\n if (\n output.outputs[0].text\n and \"\\ufffd\" == output.outputs[0].text[-1]\n ):\n continue\n text_delta = output.outputs[0].text[index:]\n index = len(output.outputs[0].text)\n num_tokens = len(output.outputs[0].token_ids)\n\n yield text_delta\n duration_s = (time.monotonic_ns() - start) / 1e9\n\n yield (\n f\"\\n\\tGenerated {num_tokens} tokens from {MODEL_NAME} in {duration_s:.1f}s,\"\n f\" throughput = {num_tokens / duration_s:.0f} tokens/second on {GPU_CONFIG}.\\n\"\n )\n\n @modal.exit()\n def stop_engine(self):\n if GPU_CONFIG.count > 1:\n import ray\n\n ray.shutdown()\n\n\n# ## Run the model\n# We define a [`local_entrypoint`](/docs/guide/apps#entrypoints-for-ephemeral-apps) to call our remote function\n# sequentially for a list of inputs. You can run this locally with `modal run -q vllm_mixtral.py`. The `q` flag\n# enables the text to stream in your local terminal.\[email protected]_entrypoint()\ndef main():\n questions = [\n \"Implement a Python function to compute the Fibonacci numbers.\",\n \"What is the fable involving a fox and grapes?\",\n \"What were the major contributing factors to the fall of the Roman Empire?\",\n \"Describe the city of the future, considering advances in technology, environmental changes, and societal shifts.\",\n \"What is the product of 9 and 8?\",\n \"Who was Emperor Norton I, and what was his significance in San Francisco's history?\",\n ]\n model = Model()\n for question in questions:\n print(\"Sending new request:\", question, \"\\n\\n\")\n for text in model.completion_stream.remote_gen(question):\n print(text, end=\"\", flush=text.endswith(\"\\n\"))\n\n\n# ## Deploy and invoke the model\n# Once we deploy this model with `modal deploy text_generation_inference.py`,\n# we can invoke inference from other apps, sharing the same pool\n# of GPU containers with all other apps we might need.\n#\n# ```\n# $ python\n# >>> import modal\n# >>> f = modal.Function.lookup(\"example-tgi-Mixtral-8x7B-Instruct-v0.1\", \"Model.generate\")\n# >>> f.remote(\"What is the story about the fox and grapes?\")\n# 'The story about the fox and grapes ...\n# ```\n\n# ## Coupling a frontend web application\n#\n# We can stream inference from a FastAPI backend, also deployed on Modal.\n#\n# You can try our deployment [here](https://modal-labs--vllm-mixtral.modal.run).\n\nfrom pathlib import Path\n\nfrom modal import Mount, asgi_app\n\nfrontend_path = Path(__file__).parent.parent / \"llm-frontend\"\n\n\[email protected](\n mounts=[Mount.from_local_dir(frontend_path, remote_path=\"/assets\")],\n keep_warm=1,\n allow_concurrent_inputs=20,\n timeout=60 * 10,\n)\n@asgi_app()\ndef vllm_mixtral():\n import json\n\n import fastapi\n import fastapi.staticfiles\n from fastapi.responses import StreamingResponse\n\n web_app = fastapi.FastAPI()\n\n @web_app.get(\"/stats\")\n async def stats():\n stats = await Model().completion_stream.get_current_stats.aio()\n return {\n \"backlog\": stats.backlog,\n \"num_total_runners\": stats.num_total_runners,\n \"model\": MODEL_NAME + \" (vLLM)\",\n }\n\n @web_app.get(\"/completion/{question}\")\n async def completion(question: str):\n from urllib.parse import unquote\n\n async def generate():\n async for text in Model().completion_stream.remote_gen.aio(\n unquote(question)\n ):\n yield f\"data: {json.dumps(dict(text=text), ensure_ascii=False)}\\n\\n\"\n\n return StreamingResponse(generate(), media_type=\"text/event-stream\")\n\n web_app.mount(\n \"/\", fastapi.staticfiles.StaticFiles(directory=\"/assets\", html=True)\n )\n return web_app\n", "path": "06_gpu_and_ml/llm-serving/vllm_mixtral.py"}]}
| 3,492 | 664 |
gh_patches_debug_12659
|
rasdani/github-patches
|
git_diff
|
pwndbg__pwndbg-1611
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Make symbol.get bulletproof against duplicated symbols
@lebr0nli pointed out an interesting case with `symbol.get` failing when Pwntools+Pwndbg is used: https://github.com/pwndbg/pwndbg/pull/1605#discussion_r1126105118
The bug actually does not require Pwntools at all and was partially caused by our `_add_main_to_symbols` hook. I am going to remove that hook in https://github.com/pwndbg/pwndbg/pull/1609 if tests passes, since it seems reduntant.
However, that does not really fix the problem as there may always be duplicated symbols such that `info symbols main` would show:
```
pwndbg> info symbol main
main in section .text of /pwndbg/bug/vaccine
main in section .text of /pwndbg/bug/vaccine
```
This can probably be mitigated by doing something like:
```py
loc_string, *_ = result.split(...)
```
instead of:
```py
loc_string, _ = result.split(...)
```
In the `symbol.get` implementation.
This would also mean we would effectively always assume the first symbol is the one we want to use, but I also do not see a good other way to resolve the duplicated symbol issue.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pwndbg/gdblib/symbol.py`
Content:
```
1 """
2 Looking up addresses for function names / symbols, and
3 vice-versa.
4
5 Uses IDA when available if there isn't sufficient symbol
6 information available.
7 """
8 import re
9
10 import gdb
11
12 import pwndbg.gdblib.android
13 import pwndbg.gdblib.arch
14 import pwndbg.gdblib.elf
15 import pwndbg.gdblib.events
16 import pwndbg.gdblib.file
17 import pwndbg.gdblib.info
18 import pwndbg.gdblib.memory
19 import pwndbg.gdblib.qemu
20 import pwndbg.gdblib.remote
21 import pwndbg.gdblib.stack
22 import pwndbg.gdblib.vmmap
23 import pwndbg.ida
24 import pwndbg.lib.memoize
25
26
27 def _get_debug_file_directory():
28 """
29 Retrieve the debug file directory path.
30
31 The debug file directory path ('show debug-file-directory') is a comma-
32 separated list of directories which GDB will look in to find the binaries
33 currently loaded.
34 """
35 result = gdb.execute("show debug-file-directory", to_string=True, from_tty=False)
36 expr = r'The directory where separate debug symbols are searched for is "(.*)".\n'
37
38 match = re.search(expr, result)
39
40 if match:
41 return match.group(1)
42 return ""
43
44
45 def _set_debug_file_directory(d) -> None:
46 gdb.execute("set debug-file-directory %s" % d, to_string=True, from_tty=False)
47
48
49 def _add_debug_file_directory(d) -> None:
50 current = _get_debug_file_directory()
51 if current:
52 _set_debug_file_directory("%s:%s" % (current, d))
53 else:
54 _set_debug_file_directory(d)
55
56
57 if "/usr/lib/debug" not in _get_debug_file_directory():
58 _add_debug_file_directory("/usr/lib/debug")
59
60
61 @pwndbg.lib.memoize.reset_on_objfile
62 def get(address: int, gdb_only=False) -> str:
63 """
64 Retrieve the name for the symbol located at `address` - either from GDB or from IDA sync
65 Passing `gdb_only=True`
66 """
67 # Note: we do not return "" on `address < pwndbg.gdblib.memory.MMAP_MIN_ADDR`
68 # because this may be used to find out the symbol name on PIE binaries that weren't started yet
69 # and then their symbol addresses can be found by GDB on their (non-rebased) offsets
70
71 # Fast path: GDB's `info symbol` returns 'Numeric constant too large' here
72 if address >= ((1 << 64) - 1):
73 return ""
74
75 # This sucks, but there's not a GDB API for this.
76 result = gdb.execute("info symbol %#x" % int(address), to_string=True, from_tty=False)
77
78 if not gdb_only and result.startswith("No symbol"):
79 address = int(address)
80 exe = pwndbg.gdblib.elf.exe()
81 if exe:
82 exe_map = pwndbg.gdblib.vmmap.find(exe.address)
83 if exe_map and address in exe_map:
84 res = pwndbg.ida.Name(address) or pwndbg.ida.GetFuncOffset(address)
85 return res or ""
86
87 # See https://github.com/bminor/binutils-gdb/blob/d1702fea87aa62dff7de465464097dba63cc8c0f/gdb/printcmd.c#L1594-L1624
88 # The most often encountered formats looks like this:
89 # "main in section .text of /bin/bash"
90 # "main + 3 in section .text of /bin/bash"
91 # "system + 1 in section .text of /lib/x86_64-linux-gnu/libc.so.6"
92 # "No symbol matches system-1"
93 # But there are some others that we have to account for as well
94 if " in section " in result:
95 loc_string, _ = result.split(" in section ")
96 elif " in load address range of " in result:
97 loc_string, _ = result.split(" in load address range of ")
98 elif " overlay section " in result:
99 result, _ = result.split(" overlay section ")
100 loc_string, _ = result.split(" in ")
101 else:
102 loc_string = ""
103
104 # If there is 'main + 87' we want to replace it with 'main+87' etc.
105 return loc_string.replace(" + ", "+")
106
107
108 @pwndbg.lib.memoize.reset_on_objfile
109 def address(symbol: str) -> int:
110 """
111 Get the address for `symbol`
112 """
113 try:
114 symbol_obj = gdb.lookup_symbol(symbol)[0]
115 if symbol_obj:
116 return int(symbol_obj.value().address)
117 except gdb.error as e:
118 # Symbol lookup only throws exceptions on errors, not if it failed to
119 # lookup a symbol. We want to raise these errors so we can handle them
120 # properly, but there are some we haven't figured out how to fix yet, so
121 # we ignore those here
122 skipped_exceptions = []
123
124 # This is exception is being thrown by the Go typeinfo tests, we should
125 # investigate why this is happening and see if we can explicitly check
126 # for it with `gdb.selected_frame()`
127 skipped_exceptions.append("No frame selected")
128
129 # If we try to look up a TLS variable when there is no TLS, this
130 # exception occurs. Ideally we should come up with a way to check for
131 # this case before calling `gdb.lookup_symbol`
132 skipped_exceptions.append("Cannot find thread-local")
133
134 if all(x not in str(e) for x in skipped_exceptions):
135 raise e
136
137 try:
138 # Unfortunately, `gdb.lookup_symbol` does not seem to handle all
139 # symbols, so we need to fallback to using `info address`. See
140 # https://sourceware.org/pipermail/gdb/2022-October/050362.html
141 address = pwndbg.gdblib.info.address(symbol)
142 if address is None or not pwndbg.gdblib.vmmap.find(address):
143 return None
144
145 return address
146
147 except gdb.error:
148 return None
149
150 try:
151 # TODO: We should properly check if we have a connection to the IDA server first
152 address = pwndbg.ida.LocByName(symbol)
153 if address:
154 return address
155 except Exception:
156 pass
157
158 return None
159
160
161 @pwndbg.lib.memoize.reset_on_objfile
162 @pwndbg.lib.memoize.reset_on_thread
163 def static_linkage_symbol_address(symbol: str) -> int:
164 """
165 Get the address for static linkage `symbol`
166 """
167
168 try:
169 if hasattr(gdb, "lookup_static_symbol"):
170 symbol_obj = gdb.lookup_static_symbol(symbol)
171 else:
172 # GDB < 9.x does not have `gdb.lookup_static_symbol`
173 # We will fallback to `gdb.lookup_symbol` here, but the drawback is that we might find incorrect symbol if there is a symbol with the same name which is not static linkage
174 # But this is better than just returning None
175 # TODO/FIXME: Find a way to get the static linkage symbol's address in GDB < 9.x
176 symbol_obj = gdb.lookup_symbol(symbol)[0]
177 return int(symbol_obj.value().address) if symbol_obj else None
178 except gdb.error:
179 return None
180
181
182 @pwndbg.lib.memoize.reset_on_stop
183 @pwndbg.lib.memoize.reset_on_start
184 def selected_frame_source_absolute_filename():
185 """
186 Retrieve the symbol table’s source absolute file name from the selected frame.
187
188 In case of missing symbol table or frame information, None is returned.
189 """
190 try:
191 frame = gdb.selected_frame()
192 except gdb.error:
193 return None
194
195 if not frame:
196 return None
197
198 sal = frame.find_sal()
199 if not sal:
200 return None
201
202 symtab = sal.symtab
203 if not symtab:
204 return None
205
206 return symtab.fullname()
207
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pwndbg/gdblib/symbol.py b/pwndbg/gdblib/symbol.py
--- a/pwndbg/gdblib/symbol.py
+++ b/pwndbg/gdblib/symbol.py
@@ -84,6 +84,10 @@
res = pwndbg.ida.Name(address) or pwndbg.ida.GetFuncOffset(address)
return res or ""
+ # If there are newlines, which means that there are multiple symbols for the address
+ # then use the first one (see also #1610)
+ result = result[: result.index("\n")]
+
# See https://github.com/bminor/binutils-gdb/blob/d1702fea87aa62dff7de465464097dba63cc8c0f/gdb/printcmd.c#L1594-L1624
# The most often encountered formats looks like this:
# "main in section .text of /bin/bash"
|
{"golden_diff": "diff --git a/pwndbg/gdblib/symbol.py b/pwndbg/gdblib/symbol.py\n--- a/pwndbg/gdblib/symbol.py\n+++ b/pwndbg/gdblib/symbol.py\n@@ -84,6 +84,10 @@\n res = pwndbg.ida.Name(address) or pwndbg.ida.GetFuncOffset(address)\n return res or \"\"\n \n+ # If there are newlines, which means that there are multiple symbols for the address\n+ # then use the first one (see also #1610)\n+ result = result[: result.index(\"\\n\")]\n+\n # See https://github.com/bminor/binutils-gdb/blob/d1702fea87aa62dff7de465464097dba63cc8c0f/gdb/printcmd.c#L1594-L1624\n # The most often encountered formats looks like this:\n # \"main in section .text of /bin/bash\"\n", "issue": "Make symbol.get bulletproof against duplicated symbols\n@lebr0nli pointed out an interesting case with `symbol.get` failing when Pwntools+Pwndbg is used: https://github.com/pwndbg/pwndbg/pull/1605#discussion_r1126105118\r\n\r\nThe bug actually does not require Pwntools at all and was partially caused by our `_add_main_to_symbols` hook. I am going to remove that hook in https://github.com/pwndbg/pwndbg/pull/1609 if tests passes, since it seems reduntant.\r\n\r\nHowever, that does not really fix the problem as there may always be duplicated symbols such that `info symbols main` would show:\r\n```\r\npwndbg> info symbol main\r\nmain in section .text of /pwndbg/bug/vaccine\r\nmain in section .text of /pwndbg/bug/vaccine\r\n```\r\n\r\nThis can probably be mitigated by doing something like:\r\n```py\r\nloc_string, *_ = result.split(...)\r\n```\r\n\r\ninstead of:\r\n```py\r\nloc_string, _ = result.split(...)\r\n```\r\n\r\nIn the `symbol.get` implementation.\r\n\r\nThis would also mean we would effectively always assume the first symbol is the one we want to use, but I also do not see a good other way to resolve the duplicated symbol issue.\n", "before_files": [{"content": "\"\"\"\nLooking up addresses for function names / symbols, and\nvice-versa.\n\nUses IDA when available if there isn't sufficient symbol\ninformation available.\n\"\"\"\nimport re\n\nimport gdb\n\nimport pwndbg.gdblib.android\nimport pwndbg.gdblib.arch\nimport pwndbg.gdblib.elf\nimport pwndbg.gdblib.events\nimport pwndbg.gdblib.file\nimport pwndbg.gdblib.info\nimport pwndbg.gdblib.memory\nimport pwndbg.gdblib.qemu\nimport pwndbg.gdblib.remote\nimport pwndbg.gdblib.stack\nimport pwndbg.gdblib.vmmap\nimport pwndbg.ida\nimport pwndbg.lib.memoize\n\n\ndef _get_debug_file_directory():\n \"\"\"\n Retrieve the debug file directory path.\n\n The debug file directory path ('show debug-file-directory') is a comma-\n separated list of directories which GDB will look in to find the binaries\n currently loaded.\n \"\"\"\n result = gdb.execute(\"show debug-file-directory\", to_string=True, from_tty=False)\n expr = r'The directory where separate debug symbols are searched for is \"(.*)\".\\n'\n\n match = re.search(expr, result)\n\n if match:\n return match.group(1)\n return \"\"\n\n\ndef _set_debug_file_directory(d) -> None:\n gdb.execute(\"set debug-file-directory %s\" % d, to_string=True, from_tty=False)\n\n\ndef _add_debug_file_directory(d) -> None:\n current = _get_debug_file_directory()\n if current:\n _set_debug_file_directory(\"%s:%s\" % (current, d))\n else:\n _set_debug_file_directory(d)\n\n\nif \"/usr/lib/debug\" not in _get_debug_file_directory():\n _add_debug_file_directory(\"/usr/lib/debug\")\n\n\[email protected]_on_objfile\ndef get(address: int, gdb_only=False) -> str:\n \"\"\"\n Retrieve the name for the symbol located at `address` - either from GDB or from IDA sync\n Passing `gdb_only=True`\n \"\"\"\n # Note: we do not return \"\" on `address < pwndbg.gdblib.memory.MMAP_MIN_ADDR`\n # because this may be used to find out the symbol name on PIE binaries that weren't started yet\n # and then their symbol addresses can be found by GDB on their (non-rebased) offsets\n\n # Fast path: GDB's `info symbol` returns 'Numeric constant too large' here\n if address >= ((1 << 64) - 1):\n return \"\"\n\n # This sucks, but there's not a GDB API for this.\n result = gdb.execute(\"info symbol %#x\" % int(address), to_string=True, from_tty=False)\n\n if not gdb_only and result.startswith(\"No symbol\"):\n address = int(address)\n exe = pwndbg.gdblib.elf.exe()\n if exe:\n exe_map = pwndbg.gdblib.vmmap.find(exe.address)\n if exe_map and address in exe_map:\n res = pwndbg.ida.Name(address) or pwndbg.ida.GetFuncOffset(address)\n return res or \"\"\n\n # See https://github.com/bminor/binutils-gdb/blob/d1702fea87aa62dff7de465464097dba63cc8c0f/gdb/printcmd.c#L1594-L1624\n # The most often encountered formats looks like this:\n # \"main in section .text of /bin/bash\"\n # \"main + 3 in section .text of /bin/bash\"\n # \"system + 1 in section .text of /lib/x86_64-linux-gnu/libc.so.6\"\n # \"No symbol matches system-1\"\n # But there are some others that we have to account for as well\n if \" in section \" in result:\n loc_string, _ = result.split(\" in section \")\n elif \" in load address range of \" in result:\n loc_string, _ = result.split(\" in load address range of \")\n elif \" overlay section \" in result:\n result, _ = result.split(\" overlay section \")\n loc_string, _ = result.split(\" in \")\n else:\n loc_string = \"\"\n\n # If there is 'main + 87' we want to replace it with 'main+87' etc.\n return loc_string.replace(\" + \", \"+\")\n\n\[email protected]_on_objfile\ndef address(symbol: str) -> int:\n \"\"\"\n Get the address for `symbol`\n \"\"\"\n try:\n symbol_obj = gdb.lookup_symbol(symbol)[0]\n if symbol_obj:\n return int(symbol_obj.value().address)\n except gdb.error as e:\n # Symbol lookup only throws exceptions on errors, not if it failed to\n # lookup a symbol. We want to raise these errors so we can handle them\n # properly, but there are some we haven't figured out how to fix yet, so\n # we ignore those here\n skipped_exceptions = []\n\n # This is exception is being thrown by the Go typeinfo tests, we should\n # investigate why this is happening and see if we can explicitly check\n # for it with `gdb.selected_frame()`\n skipped_exceptions.append(\"No frame selected\")\n\n # If we try to look up a TLS variable when there is no TLS, this\n # exception occurs. Ideally we should come up with a way to check for\n # this case before calling `gdb.lookup_symbol`\n skipped_exceptions.append(\"Cannot find thread-local\")\n\n if all(x not in str(e) for x in skipped_exceptions):\n raise e\n\n try:\n # Unfortunately, `gdb.lookup_symbol` does not seem to handle all\n # symbols, so we need to fallback to using `info address`. See\n # https://sourceware.org/pipermail/gdb/2022-October/050362.html\n address = pwndbg.gdblib.info.address(symbol)\n if address is None or not pwndbg.gdblib.vmmap.find(address):\n return None\n\n return address\n\n except gdb.error:\n return None\n\n try:\n # TODO: We should properly check if we have a connection to the IDA server first\n address = pwndbg.ida.LocByName(symbol)\n if address:\n return address\n except Exception:\n pass\n\n return None\n\n\[email protected]_on_objfile\[email protected]_on_thread\ndef static_linkage_symbol_address(symbol: str) -> int:\n \"\"\"\n Get the address for static linkage `symbol`\n \"\"\"\n\n try:\n if hasattr(gdb, \"lookup_static_symbol\"):\n symbol_obj = gdb.lookup_static_symbol(symbol)\n else:\n # GDB < 9.x does not have `gdb.lookup_static_symbol`\n # We will fallback to `gdb.lookup_symbol` here, but the drawback is that we might find incorrect symbol if there is a symbol with the same name which is not static linkage\n # But this is better than just returning None\n # TODO/FIXME: Find a way to get the static linkage symbol's address in GDB < 9.x\n symbol_obj = gdb.lookup_symbol(symbol)[0]\n return int(symbol_obj.value().address) if symbol_obj else None\n except gdb.error:\n return None\n\n\[email protected]_on_stop\[email protected]_on_start\ndef selected_frame_source_absolute_filename():\n \"\"\"\n Retrieve the symbol table\u2019s source absolute file name from the selected frame.\n\n In case of missing symbol table or frame information, None is returned.\n \"\"\"\n try:\n frame = gdb.selected_frame()\n except gdb.error:\n return None\n\n if not frame:\n return None\n\n sal = frame.find_sal()\n if not sal:\n return None\n\n symtab = sal.symtab\n if not symtab:\n return None\n\n return symtab.fullname()\n", "path": "pwndbg/gdblib/symbol.py"}], "after_files": [{"content": "\"\"\"\nLooking up addresses for function names / symbols, and\nvice-versa.\n\nUses IDA when available if there isn't sufficient symbol\ninformation available.\n\"\"\"\nimport re\n\nimport gdb\n\nimport pwndbg.gdblib.android\nimport pwndbg.gdblib.arch\nimport pwndbg.gdblib.elf\nimport pwndbg.gdblib.events\nimport pwndbg.gdblib.file\nimport pwndbg.gdblib.info\nimport pwndbg.gdblib.memory\nimport pwndbg.gdblib.qemu\nimport pwndbg.gdblib.remote\nimport pwndbg.gdblib.stack\nimport pwndbg.gdblib.vmmap\nimport pwndbg.ida\nimport pwndbg.lib.memoize\n\n\ndef _get_debug_file_directory():\n \"\"\"\n Retrieve the debug file directory path.\n\n The debug file directory path ('show debug-file-directory') is a comma-\n separated list of directories which GDB will look in to find the binaries\n currently loaded.\n \"\"\"\n result = gdb.execute(\"show debug-file-directory\", to_string=True, from_tty=False)\n expr = r'The directory where separate debug symbols are searched for is \"(.*)\".\\n'\n\n match = re.search(expr, result)\n\n if match:\n return match.group(1)\n return \"\"\n\n\ndef _set_debug_file_directory(d) -> None:\n gdb.execute(\"set debug-file-directory %s\" % d, to_string=True, from_tty=False)\n\n\ndef _add_debug_file_directory(d) -> None:\n current = _get_debug_file_directory()\n if current:\n _set_debug_file_directory(\"%s:%s\" % (current, d))\n else:\n _set_debug_file_directory(d)\n\n\nif \"/usr/lib/debug\" not in _get_debug_file_directory():\n _add_debug_file_directory(\"/usr/lib/debug\")\n\n\[email protected]_on_objfile\ndef get(address: int, gdb_only=False) -> str:\n \"\"\"\n Retrieve the name for the symbol located at `address` - either from GDB or from IDA sync\n Passing `gdb_only=True`\n \"\"\"\n # Note: we do not return \"\" on `address < pwndbg.gdblib.memory.MMAP_MIN_ADDR`\n # because this may be used to find out the symbol name on PIE binaries that weren't started yet\n # and then their symbol addresses can be found by GDB on their (non-rebased) offsets\n\n # Fast path: GDB's `info symbol` returns 'Numeric constant too large' here\n if address >= ((1 << 64) - 1):\n return \"\"\n\n # This sucks, but there's not a GDB API for this.\n result = gdb.execute(\"info symbol %#x\" % int(address), to_string=True, from_tty=False)\n\n if not gdb_only and result.startswith(\"No symbol\"):\n address = int(address)\n exe = pwndbg.gdblib.elf.exe()\n if exe:\n exe_map = pwndbg.gdblib.vmmap.find(exe.address)\n if exe_map and address in exe_map:\n res = pwndbg.ida.Name(address) or pwndbg.ida.GetFuncOffset(address)\n return res or \"\"\n\n # If there are newlines, which means that there are multiple symbols for the address\n # then use the first one (see also #1610)\n result = result[: result.index(\"\\n\")]\n\n # See https://github.com/bminor/binutils-gdb/blob/d1702fea87aa62dff7de465464097dba63cc8c0f/gdb/printcmd.c#L1594-L1624\n # The most often encountered formats looks like this:\n # \"main in section .text of /bin/bash\"\n # \"main + 3 in section .text of /bin/bash\"\n # \"system + 1 in section .text of /lib/x86_64-linux-gnu/libc.so.6\"\n # \"No symbol matches system-1\"\n # But there are some others that we have to account for as well\n if \" in section \" in result:\n loc_string, _ = result.split(\" in section \")\n elif \" in load address range of \" in result:\n loc_string, _ = result.split(\" in load address range of \")\n elif \" overlay section \" in result:\n result, _ = result.split(\" overlay section \")\n loc_string, _ = result.split(\" in \")\n else:\n loc_string = \"\"\n\n # If there is 'main + 87' we want to replace it with 'main+87' etc.\n return loc_string.replace(\" + \", \"+\")\n\n\[email protected]_on_objfile\ndef address(symbol: str) -> int:\n \"\"\"\n Get the address for `symbol`\n \"\"\"\n try:\n symbol_obj = gdb.lookup_symbol(symbol)[0]\n if symbol_obj:\n return int(symbol_obj.value().address)\n except gdb.error as e:\n # Symbol lookup only throws exceptions on errors, not if it failed to\n # lookup a symbol. We want to raise these errors so we can handle them\n # properly, but there are some we haven't figured out how to fix yet, so\n # we ignore those here\n skipped_exceptions = []\n\n # This is exception is being thrown by the Go typeinfo tests, we should\n # investigate why this is happening and see if we can explicitly check\n # for it with `gdb.selected_frame()`\n skipped_exceptions.append(\"No frame selected\")\n\n # If we try to look up a TLS variable when there is no TLS, this\n # exception occurs. Ideally we should come up with a way to check for\n # this case before calling `gdb.lookup_symbol`\n skipped_exceptions.append(\"Cannot find thread-local\")\n\n if all(x not in str(e) for x in skipped_exceptions):\n raise e\n\n try:\n # Unfortunately, `gdb.lookup_symbol` does not seem to handle all\n # symbols, so we need to fallback to using `info address`. See\n # https://sourceware.org/pipermail/gdb/2022-October/050362.html\n address = pwndbg.gdblib.info.address(symbol)\n if address is None or not pwndbg.gdblib.vmmap.find(address):\n return None\n\n return address\n\n except gdb.error:\n return None\n\n try:\n # TODO: We should properly check if we have a connection to the IDA server first\n address = pwndbg.ida.LocByName(symbol)\n if address:\n return address\n except Exception:\n pass\n\n return None\n\n\[email protected]_on_objfile\[email protected]_on_thread\ndef static_linkage_symbol_address(symbol: str) -> int:\n \"\"\"\n Get the address for static linkage `symbol`\n \"\"\"\n\n try:\n if hasattr(gdb, \"lookup_static_symbol\"):\n symbol_obj = gdb.lookup_static_symbol(symbol)\n else:\n # GDB < 9.x does not have `gdb.lookup_static_symbol`\n # We will fallback to `gdb.lookup_symbol` here, but the drawback is that we might find incorrect symbol if there is a symbol with the same name which is not static linkage\n # But this is better than just returning None\n # TODO/FIXME: Find a way to get the static linkage symbol's address in GDB < 9.x\n symbol_obj = gdb.lookup_symbol(symbol)[0]\n return int(symbol_obj.value().address) if symbol_obj else None\n except gdb.error:\n return None\n\n\[email protected]_on_stop\[email protected]_on_start\ndef selected_frame_source_absolute_filename():\n \"\"\"\n Retrieve the symbol table\u2019s source absolute file name from the selected frame.\n\n In case of missing symbol table or frame information, None is returned.\n \"\"\"\n try:\n frame = gdb.selected_frame()\n except gdb.error:\n return None\n\n if not frame:\n return None\n\n sal = frame.find_sal()\n if not sal:\n return None\n\n symtab = sal.symtab\n if not symtab:\n return None\n\n return symtab.fullname()\n", "path": "pwndbg/gdblib/symbol.py"}]}
| 2,839 | 225 |
gh_patches_debug_961
|
rasdani/github-patches
|
git_diff
|
urllib3__urllib3-2484
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Test development versions of Python
Uses the `3.11-dev` and `nightly` deadsnakes release streams to test urllib3 against Python versions.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `noxfile.py`
Content:
```
1 import os
2 import shutil
3 import subprocess
4
5 import nox
6
7 SOURCE_FILES = [
8 "docs/",
9 "dummyserver/",
10 "src/",
11 "test/",
12 "noxfile.py",
13 "setup.py",
14 ]
15
16
17 def tests_impl(
18 session: nox.Session,
19 extras: str = "socks,secure,brotli",
20 byte_string_comparisons: bool = True,
21 ) -> None:
22 # Install deps and the package itself.
23 session.install("-r", "dev-requirements.txt")
24 session.install(f".[{extras}]")
25
26 # Show the pip version.
27 session.run("pip", "--version")
28 # Print the Python version and bytesize.
29 session.run("python", "--version")
30 session.run("python", "-c", "import struct; print(struct.calcsize('P') * 8)")
31 # Print OpenSSL information.
32 session.run("python", "-m", "OpenSSL.debug")
33
34 # Inspired from https://github.com/pyca/cryptography
35 # We use parallel mode and then combine here so that coverage.py will take
36 # the paths like .tox/pyXY/lib/pythonX.Y/site-packages/urllib3/__init__.py
37 # and collapse them into src/urllib3/__init__.py.
38
39 session.run(
40 "python",
41 *(("-bb",) if byte_string_comparisons else ()),
42 "-m",
43 "coverage",
44 "run",
45 "--parallel-mode",
46 "-m",
47 "pytest",
48 "-r",
49 "a",
50 "--tb=native",
51 "--no-success-flaky-report",
52 *(session.posargs or ("test/",)),
53 env={"PYTHONWARNINGS": "always::DeprecationWarning"},
54 )
55 session.run("coverage", "combine")
56 session.run("coverage", "report", "-m")
57 session.run("coverage", "xml")
58
59
60 @nox.session(python=["3.7", "3.8", "3.9", "3.10", "pypy"])
61 def test(session: nox.Session) -> None:
62 tests_impl(session)
63
64
65 @nox.session(python=["2.7"])
66 def unsupported_python2(session: nox.Session) -> None:
67 # Can't check both returncode and output with session.run
68 process = subprocess.run(
69 ["python", "setup.py", "install"],
70 env={**session.env},
71 text=True,
72 capture_output=True,
73 )
74 assert process.returncode == 1
75 print(process.stderr)
76 assert "Unsupported Python version" in process.stderr
77
78
79 @nox.session(python=["3"])
80 def test_brotlipy(session: nox.Session) -> None:
81 """Check that if 'brotlipy' is installed instead of 'brotli' or
82 'brotlicffi' that we still don't blow up.
83 """
84 session.install("brotlipy")
85 tests_impl(session, extras="socks,secure", byte_string_comparisons=False)
86
87
88 def git_clone(session: nox.Session, git_url: str) -> None:
89 session.run("git", "clone", "--depth", "1", git_url, external=True)
90
91
92 @nox.session()
93 def downstream_botocore(session: nox.Session) -> None:
94 root = os.getcwd()
95 tmp_dir = session.create_tmp()
96
97 session.cd(tmp_dir)
98 git_clone(session, "https://github.com/boto/botocore")
99 session.chdir("botocore")
100 session.run("git", "rev-parse", "HEAD", external=True)
101 session.run("python", "scripts/ci/install")
102
103 session.cd(root)
104 session.install(".", silent=False)
105 session.cd(f"{tmp_dir}/botocore")
106
107 session.run("python", "-c", "import urllib3; print(urllib3.__version__)")
108 session.run("python", "scripts/ci/run-tests")
109
110
111 @nox.session()
112 def downstream_requests(session: nox.Session) -> None:
113 root = os.getcwd()
114 tmp_dir = session.create_tmp()
115
116 session.cd(tmp_dir)
117 git_clone(session, "https://github.com/psf/requests")
118 session.chdir("requests")
119 session.run("git", "apply", f"{root}/ci/requests.patch", external=True)
120 session.run("git", "rev-parse", "HEAD", external=True)
121 session.install(".[socks]", silent=False)
122 session.install("-r", "requirements-dev.txt", silent=False)
123
124 session.cd(root)
125 session.install(".", silent=False)
126 session.cd(f"{tmp_dir}/requests")
127
128 session.run("python", "-c", "import urllib3; print(urllib3.__version__)")
129 session.run("pytest", "tests")
130
131
132 @nox.session()
133 def format(session: nox.Session) -> None:
134 """Run code formatters."""
135 session.install("pre-commit")
136 session.run("pre-commit", "--version")
137
138 process = subprocess.run(
139 ["pre-commit", "run", "--all-files"],
140 env=session.env,
141 text=True,
142 stdout=subprocess.PIPE,
143 stderr=subprocess.STDOUT,
144 )
145 # Ensure that pre-commit itself ran successfully
146 assert process.returncode in (0, 1)
147
148 lint(session)
149
150
151 @nox.session
152 def lint(session: nox.Session) -> None:
153 session.install("pre-commit")
154 session.run("pre-commit", "run", "--all-files")
155
156 mypy(session)
157
158
159 @nox.session(python="3.8")
160 def mypy(session: nox.Session) -> None:
161 """Run mypy."""
162 session.install("-r", "mypy-requirements.txt")
163 session.run("mypy", "--version")
164 session.run(
165 "mypy",
166 "dummyserver",
167 "noxfile.py",
168 "src/urllib3",
169 "test",
170 )
171
172
173 @nox.session
174 def docs(session: nox.Session) -> None:
175 session.install("-r", "docs/requirements.txt")
176 session.install(".[socks,secure,brotli]")
177
178 session.chdir("docs")
179 if os.path.exists("_build"):
180 shutil.rmtree("_build")
181 session.run("sphinx-build", "-b", "html", "-W", ".", "_build/html")
182
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/noxfile.py b/noxfile.py
--- a/noxfile.py
+++ b/noxfile.py
@@ -57,7 +57,7 @@
session.run("coverage", "xml")
[email protected](python=["3.7", "3.8", "3.9", "3.10", "pypy"])
[email protected](python=["3.7", "3.8", "3.9", "3.10", "3.11", "pypy"])
def test(session: nox.Session) -> None:
tests_impl(session)
|
{"golden_diff": "diff --git a/noxfile.py b/noxfile.py\n--- a/noxfile.py\n+++ b/noxfile.py\n@@ -57,7 +57,7 @@\n session.run(\"coverage\", \"xml\")\n \n \[email protected](python=[\"3.7\", \"3.8\", \"3.9\", \"3.10\", \"pypy\"])\[email protected](python=[\"3.7\", \"3.8\", \"3.9\", \"3.10\", \"3.11\", \"pypy\"])\n def test(session: nox.Session) -> None:\n tests_impl(session)\n", "issue": "Test development versions of Python\nUses the `3.11-dev` and `nightly` deadsnakes release streams to test urllib3 against Python versions.\n", "before_files": [{"content": "import os\nimport shutil\nimport subprocess\n\nimport nox\n\nSOURCE_FILES = [\n \"docs/\",\n \"dummyserver/\",\n \"src/\",\n \"test/\",\n \"noxfile.py\",\n \"setup.py\",\n]\n\n\ndef tests_impl(\n session: nox.Session,\n extras: str = \"socks,secure,brotli\",\n byte_string_comparisons: bool = True,\n) -> None:\n # Install deps and the package itself.\n session.install(\"-r\", \"dev-requirements.txt\")\n session.install(f\".[{extras}]\")\n\n # Show the pip version.\n session.run(\"pip\", \"--version\")\n # Print the Python version and bytesize.\n session.run(\"python\", \"--version\")\n session.run(\"python\", \"-c\", \"import struct; print(struct.calcsize('P') * 8)\")\n # Print OpenSSL information.\n session.run(\"python\", \"-m\", \"OpenSSL.debug\")\n\n # Inspired from https://github.com/pyca/cryptography\n # We use parallel mode and then combine here so that coverage.py will take\n # the paths like .tox/pyXY/lib/pythonX.Y/site-packages/urllib3/__init__.py\n # and collapse them into src/urllib3/__init__.py.\n\n session.run(\n \"python\",\n *((\"-bb\",) if byte_string_comparisons else ()),\n \"-m\",\n \"coverage\",\n \"run\",\n \"--parallel-mode\",\n \"-m\",\n \"pytest\",\n \"-r\",\n \"a\",\n \"--tb=native\",\n \"--no-success-flaky-report\",\n *(session.posargs or (\"test/\",)),\n env={\"PYTHONWARNINGS\": \"always::DeprecationWarning\"},\n )\n session.run(\"coverage\", \"combine\")\n session.run(\"coverage\", \"report\", \"-m\")\n session.run(\"coverage\", \"xml\")\n\n\[email protected](python=[\"3.7\", \"3.8\", \"3.9\", \"3.10\", \"pypy\"])\ndef test(session: nox.Session) -> None:\n tests_impl(session)\n\n\[email protected](python=[\"2.7\"])\ndef unsupported_python2(session: nox.Session) -> None:\n # Can't check both returncode and output with session.run\n process = subprocess.run(\n [\"python\", \"setup.py\", \"install\"],\n env={**session.env},\n text=True,\n capture_output=True,\n )\n assert process.returncode == 1\n print(process.stderr)\n assert \"Unsupported Python version\" in process.stderr\n\n\[email protected](python=[\"3\"])\ndef test_brotlipy(session: nox.Session) -> None:\n \"\"\"Check that if 'brotlipy' is installed instead of 'brotli' or\n 'brotlicffi' that we still don't blow up.\n \"\"\"\n session.install(\"brotlipy\")\n tests_impl(session, extras=\"socks,secure\", byte_string_comparisons=False)\n\n\ndef git_clone(session: nox.Session, git_url: str) -> None:\n session.run(\"git\", \"clone\", \"--depth\", \"1\", git_url, external=True)\n\n\[email protected]()\ndef downstream_botocore(session: nox.Session) -> None:\n root = os.getcwd()\n tmp_dir = session.create_tmp()\n\n session.cd(tmp_dir)\n git_clone(session, \"https://github.com/boto/botocore\")\n session.chdir(\"botocore\")\n session.run(\"git\", \"rev-parse\", \"HEAD\", external=True)\n session.run(\"python\", \"scripts/ci/install\")\n\n session.cd(root)\n session.install(\".\", silent=False)\n session.cd(f\"{tmp_dir}/botocore\")\n\n session.run(\"python\", \"-c\", \"import urllib3; print(urllib3.__version__)\")\n session.run(\"python\", \"scripts/ci/run-tests\")\n\n\[email protected]()\ndef downstream_requests(session: nox.Session) -> None:\n root = os.getcwd()\n tmp_dir = session.create_tmp()\n\n session.cd(tmp_dir)\n git_clone(session, \"https://github.com/psf/requests\")\n session.chdir(\"requests\")\n session.run(\"git\", \"apply\", f\"{root}/ci/requests.patch\", external=True)\n session.run(\"git\", \"rev-parse\", \"HEAD\", external=True)\n session.install(\".[socks]\", silent=False)\n session.install(\"-r\", \"requirements-dev.txt\", silent=False)\n\n session.cd(root)\n session.install(\".\", silent=False)\n session.cd(f\"{tmp_dir}/requests\")\n\n session.run(\"python\", \"-c\", \"import urllib3; print(urllib3.__version__)\")\n session.run(\"pytest\", \"tests\")\n\n\[email protected]()\ndef format(session: nox.Session) -> None:\n \"\"\"Run code formatters.\"\"\"\n session.install(\"pre-commit\")\n session.run(\"pre-commit\", \"--version\")\n\n process = subprocess.run(\n [\"pre-commit\", \"run\", \"--all-files\"],\n env=session.env,\n text=True,\n stdout=subprocess.PIPE,\n stderr=subprocess.STDOUT,\n )\n # Ensure that pre-commit itself ran successfully\n assert process.returncode in (0, 1)\n\n lint(session)\n\n\[email protected]\ndef lint(session: nox.Session) -> None:\n session.install(\"pre-commit\")\n session.run(\"pre-commit\", \"run\", \"--all-files\")\n\n mypy(session)\n\n\[email protected](python=\"3.8\")\ndef mypy(session: nox.Session) -> None:\n \"\"\"Run mypy.\"\"\"\n session.install(\"-r\", \"mypy-requirements.txt\")\n session.run(\"mypy\", \"--version\")\n session.run(\n \"mypy\",\n \"dummyserver\",\n \"noxfile.py\",\n \"src/urllib3\",\n \"test\",\n )\n\n\[email protected]\ndef docs(session: nox.Session) -> None:\n session.install(\"-r\", \"docs/requirements.txt\")\n session.install(\".[socks,secure,brotli]\")\n\n session.chdir(\"docs\")\n if os.path.exists(\"_build\"):\n shutil.rmtree(\"_build\")\n session.run(\"sphinx-build\", \"-b\", \"html\", \"-W\", \".\", \"_build/html\")\n", "path": "noxfile.py"}], "after_files": [{"content": "import os\nimport shutil\nimport subprocess\n\nimport nox\n\nSOURCE_FILES = [\n \"docs/\",\n \"dummyserver/\",\n \"src/\",\n \"test/\",\n \"noxfile.py\",\n \"setup.py\",\n]\n\n\ndef tests_impl(\n session: nox.Session,\n extras: str = \"socks,secure,brotli\",\n byte_string_comparisons: bool = True,\n) -> None:\n # Install deps and the package itself.\n session.install(\"-r\", \"dev-requirements.txt\")\n session.install(f\".[{extras}]\")\n\n # Show the pip version.\n session.run(\"pip\", \"--version\")\n # Print the Python version and bytesize.\n session.run(\"python\", \"--version\")\n session.run(\"python\", \"-c\", \"import struct; print(struct.calcsize('P') * 8)\")\n # Print OpenSSL information.\n session.run(\"python\", \"-m\", \"OpenSSL.debug\")\n\n # Inspired from https://github.com/pyca/cryptography\n # We use parallel mode and then combine here so that coverage.py will take\n # the paths like .tox/pyXY/lib/pythonX.Y/site-packages/urllib3/__init__.py\n # and collapse them into src/urllib3/__init__.py.\n\n session.run(\n \"python\",\n *((\"-bb\",) if byte_string_comparisons else ()),\n \"-m\",\n \"coverage\",\n \"run\",\n \"--parallel-mode\",\n \"-m\",\n \"pytest\",\n \"-r\",\n \"a\",\n \"--tb=native\",\n \"--no-success-flaky-report\",\n *(session.posargs or (\"test/\",)),\n env={\"PYTHONWARNINGS\": \"always::DeprecationWarning\"},\n )\n session.run(\"coverage\", \"combine\")\n session.run(\"coverage\", \"report\", \"-m\")\n session.run(\"coverage\", \"xml\")\n\n\[email protected](python=[\"3.7\", \"3.8\", \"3.9\", \"3.10\", \"3.11\", \"pypy\"])\ndef test(session: nox.Session) -> None:\n tests_impl(session)\n\n\[email protected](python=[\"2.7\"])\ndef unsupported_python2(session: nox.Session) -> None:\n # Can't check both returncode and output with session.run\n process = subprocess.run(\n [\"python\", \"setup.py\", \"install\"],\n env={**session.env},\n text=True,\n capture_output=True,\n )\n assert process.returncode == 1\n print(process.stderr)\n assert \"Unsupported Python version\" in process.stderr\n\n\[email protected](python=[\"3\"])\ndef test_brotlipy(session: nox.Session) -> None:\n \"\"\"Check that if 'brotlipy' is installed instead of 'brotli' or\n 'brotlicffi' that we still don't blow up.\n \"\"\"\n session.install(\"brotlipy\")\n tests_impl(session, extras=\"socks,secure\", byte_string_comparisons=False)\n\n\ndef git_clone(session: nox.Session, git_url: str) -> None:\n session.run(\"git\", \"clone\", \"--depth\", \"1\", git_url, external=True)\n\n\[email protected]()\ndef downstream_botocore(session: nox.Session) -> None:\n root = os.getcwd()\n tmp_dir = session.create_tmp()\n\n session.cd(tmp_dir)\n git_clone(session, \"https://github.com/boto/botocore\")\n session.chdir(\"botocore\")\n session.run(\"git\", \"rev-parse\", \"HEAD\", external=True)\n session.run(\"python\", \"scripts/ci/install\")\n\n session.cd(root)\n session.install(\".\", silent=False)\n session.cd(f\"{tmp_dir}/botocore\")\n\n session.run(\"python\", \"-c\", \"import urllib3; print(urllib3.__version__)\")\n session.run(\"python\", \"scripts/ci/run-tests\")\n\n\[email protected]()\ndef downstream_requests(session: nox.Session) -> None:\n root = os.getcwd()\n tmp_dir = session.create_tmp()\n\n session.cd(tmp_dir)\n git_clone(session, \"https://github.com/psf/requests\")\n session.chdir(\"requests\")\n session.run(\"git\", \"apply\", f\"{root}/ci/requests.patch\", external=True)\n session.run(\"git\", \"rev-parse\", \"HEAD\", external=True)\n session.install(\".[socks]\", silent=False)\n session.install(\"-r\", \"requirements-dev.txt\", silent=False)\n\n session.cd(root)\n session.install(\".\", silent=False)\n session.cd(f\"{tmp_dir}/requests\")\n\n session.run(\"python\", \"-c\", \"import urllib3; print(urllib3.__version__)\")\n session.run(\"pytest\", \"tests\")\n\n\[email protected]()\ndef format(session: nox.Session) -> None:\n \"\"\"Run code formatters.\"\"\"\n session.install(\"pre-commit\")\n session.run(\"pre-commit\", \"--version\")\n\n process = subprocess.run(\n [\"pre-commit\", \"run\", \"--all-files\"],\n env=session.env,\n text=True,\n stdout=subprocess.PIPE,\n stderr=subprocess.STDOUT,\n )\n # Ensure that pre-commit itself ran successfully\n assert process.returncode in (0, 1)\n\n lint(session)\n\n\[email protected]\ndef lint(session: nox.Session) -> None:\n session.install(\"pre-commit\")\n session.run(\"pre-commit\", \"run\", \"--all-files\")\n\n mypy(session)\n\n\[email protected](python=\"3.8\")\ndef mypy(session: nox.Session) -> None:\n \"\"\"Run mypy.\"\"\"\n session.install(\"-r\", \"mypy-requirements.txt\")\n session.run(\"mypy\", \"--version\")\n session.run(\n \"mypy\",\n \"dummyserver\",\n \"noxfile.py\",\n \"src/urllib3\",\n \"test\",\n )\n\n\[email protected]\ndef docs(session: nox.Session) -> None:\n session.install(\"-r\", \"docs/requirements.txt\")\n session.install(\".[socks,secure,brotli]\")\n\n session.chdir(\"docs\")\n if os.path.exists(\"_build\"):\n shutil.rmtree(\"_build\")\n session.run(\"sphinx-build\", \"-b\", \"html\", \"-W\", \".\", \"_build/html\")\n", "path": "noxfile.py"}]}
| 2,066 | 134 |
gh_patches_debug_8889
|
rasdani/github-patches
|
git_diff
|
archlinux__archinstall-1153
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Cyrillic problems (?)
I decided to test new translation and got this

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `archinstall/__init__.py`
Content:
```
1 """Arch Linux installer - guided, templates etc."""
2 import urllib.error
3 import urllib.parse
4 import urllib.request
5 from argparse import ArgumentParser
6
7 from .lib.disk import *
8 from .lib.exceptions import *
9 from .lib.general import *
10 from .lib.hardware import *
11 from .lib.installer import __packages__, Installer, accessibility_tools_in_use
12 from .lib.locale_helpers import *
13 from .lib.luks import *
14 from .lib.mirrors import *
15 from .lib.models.network_configuration import NetworkConfigurationHandler
16 from .lib.networking import *
17 from .lib.output import *
18 from .lib.models.dataclasses import (
19 VersionDef,
20 PackageSearchResult,
21 PackageSearch,
22 LocalPackage
23 )
24 from .lib.packages.packages import (
25 group_search,
26 package_search,
27 find_package,
28 find_packages,
29 installed_package,
30 validate_package_list,
31 )
32 from .lib.profiles import *
33 from .lib.services import *
34 from .lib.storage import *
35 from .lib.systemd import *
36 from .lib.user_interaction import *
37 from .lib.menu import Menu
38 from .lib.menu.list_manager import ListManager
39 from .lib.menu.text_input import TextInput
40 from .lib.menu.global_menu import GlobalMenu
41 from .lib.menu.selection_menu import (
42 Selector,
43 GeneralMenu
44 )
45 from .lib.translation import Translation, DeferredTranslation
46 from .lib.plugins import plugins, load_plugin # This initiates the plugin loading ceremony
47 from .lib.configuration import *
48 parser = ArgumentParser()
49
50 __version__ = "2.4.2"
51 storage['__version__'] = __version__
52
53 # add the custome _ as a builtin, it can now be used anywhere in the
54 # project to mark strings as translatable with _('translate me')
55 DeferredTranslation.install()
56
57
58 def define_arguments():
59 """
60 Define which explicit arguments do we allow.
61 Refer to https://docs.python.org/3/library/argparse.html for documentation and
62 https://docs.python.org/3/howto/argparse.html for a tutorial
63 Remember that the property/entry name python assigns to the parameters is the first string defined as argument and
64 dashes inside it '-' are changed to '_'
65 """
66 parser.add_argument("--config", nargs="?", help="JSON configuration file or URL")
67 parser.add_argument("--creds", nargs="?", help="JSON credentials configuration file")
68 parser.add_argument("--disk_layouts","--disk_layout","--disk-layouts","--disk-layout",nargs="?",
69 help="JSON disk layout file")
70 parser.add_argument("--silent", action="store_true",
71 help="WARNING: Disables all prompts for input and confirmation. If no configuration is provided, this is ignored")
72 parser.add_argument("--dry-run", "--dry_run", action="store_true",
73 help="Generates a configuration file and then exits instead of performing an installation")
74 parser.add_argument("--script", default="guided", nargs="?", help="Script to run for installation", type=str)
75 parser.add_argument("--mount-point","--mount_point", nargs="?", type=str, help="Define an alternate mount point for installation")
76 parser.add_argument("--debug", action="store_true", default=False, help="Adds debug info into the log")
77 parser.add_argument("--plugin", nargs="?", type=str)
78
79 def parse_unspecified_argument_list(unknowns :list, multiple :bool = False, error :bool = False) -> dict:
80 """We accept arguments not defined to the parser. (arguments "ad hoc").
81 Internally argparse return to us a list of words so we have to parse its contents, manually.
82 We accept following individual syntax for each argument
83 --argument value
84 --argument=value
85 --argument = value
86 --argument (boolean as default)
87 the optional paramters to the function alter a bit its behaviour:
88 * multiple allows multivalued arguments, each value separated by whitespace. They're returned as a list
89 * error. If set any non correctly specified argument-value pair to raise an exception. Else, simply notifies the existence of a problem and continues processing.
90
91 To a certain extent, multiple and error are incompatible. In fact, the only error this routine can catch, as of now, is the event
92 argument value value ...
93 which isn't am error if multiple is specified
94 """
95 tmp_list = unknowns[:] # wastes a few bytes, but avoids any collateral effect of the destructive nature of the pop method()
96 config = {}
97 key = None
98 last_key = None
99 while tmp_list:
100 element = tmp_list.pop(0) # retreive an element of the list
101 if element.startswith('--'): # is an argument ?
102 if '=' in element: # uses the arg=value syntax ?
103 key, value = [x.strip() for x in element[2:].split('=', 1)]
104 config[key] = value
105 last_key = key # for multiple handling
106 key = None # we have the kwy value pair we need
107 else:
108 key = element[2:]
109 config[key] = True # every argument starts its lifecycle as boolean
110 else:
111 if element == '=':
112 continue
113 if key:
114 config[key] = element
115 last_key = key # multiple
116 key = None
117 else:
118 if multiple and last_key:
119 if isinstance(config[last_key],str):
120 config[last_key] = [config[last_key],element]
121 else:
122 config[last_key].append(element)
123 elif error:
124 raise ValueError(f"Entry {element} is not related to any argument")
125 else:
126 print(f" We ignore the entry {element} as it isn't related to any argument")
127 return config
128
129 def get_arguments() -> Dict[str, Any]:
130 """ The handling of parameters from the command line
131 Is done on following steps:
132 0) we create a dict to store the arguments and their values
133 1) preprocess.
134 We take those arguments which use Json files, and read them into the argument dict. So each first level entry becomes a argument un it's own right
135 2) Load.
136 We convert the predefined argument list directly into the dict vía the vars() función. Non specified arguments are loaded with value None or false if they are booleans (action="store_true").
137 The name is chosen according to argparse conventions. See above (the first text is used as argument name, but underscore substitutes dash)
138 We then load all the undefined arguments. In this case the names are taken as written.
139 Important. This way explicit command line arguments take precedence over configuración files.
140 3) Amend
141 Change whatever is needed on the configuration dictionary (it could be done in post_process_arguments but this ougth to be left to changes anywhere else in the code, not in the arguments dictionary
142 """
143 config = {}
144 args, unknowns = parser.parse_known_args()
145 # preprocess the json files.
146 # TODO Expand the url access to the other JSON file arguments ?
147 if args.config is not None:
148 try:
149 # First, let's check if this is a URL scheme instead of a filename
150 parsed_url = urllib.parse.urlparse(args.config)
151
152 if not parsed_url.scheme: # The Profile was not a direct match on a remote URL, it must be a local file.
153 if not json_stream_to_structure('--config',args.config,config):
154 exit(1)
155 else: # Attempt to load the configuration from the URL.
156 with urllib.request.urlopen(urllib.request.Request(args.config, headers={'User-Agent': 'ArchInstall'})) as response:
157 config.update(json.loads(response.read()))
158 except Exception as e:
159 raise ValueError(f"Could not load --config because: {e}")
160
161 if args.creds is not None:
162 if not json_stream_to_structure('--creds',args.creds,config):
163 exit(1)
164 # load the parameters. first the known, then the unknowns
165 config.update(vars(args))
166 config.update(parse_unspecified_argument_list(unknowns))
167 # amend the parameters (check internal consistency)
168 # Installation can't be silent if config is not passed
169 if args.config is not None :
170 config["silent"] = args.silent
171 else:
172 config["silent"] = False
173
174 # avoiding a compatibility issue
175 if 'dry-run' in config:
176 del config['dry-run']
177 return config
178
179 def load_config():
180 from .lib.models import NetworkConfiguration
181 """
182 refine and set some arguments. Formerly at the scripts
183 """
184 if arguments.get('harddrives', None) is not None:
185 if type(arguments['harddrives']) is str:
186 arguments['harddrives'] = arguments['harddrives'].split(',')
187 arguments['harddrives'] = [BlockDevice(BlockDev) for BlockDev in arguments['harddrives']]
188 # Temporarily disabling keep_partitions if config file is loaded
189 # Temporary workaround to make Desktop Environments work
190 if arguments.get('profile', None) is not None:
191 if type(arguments.get('profile', None)) is dict:
192 arguments['profile'] = Profile(None, arguments.get('profile', None)['path'])
193 else:
194 arguments['profile'] = Profile(None, arguments.get('profile', None))
195 storage['_desktop_profile'] = arguments.get('desktop-environment', None)
196 if arguments.get('mirror-region', None) is not None:
197 if type(arguments.get('mirror-region', None)) is dict:
198 arguments['mirror-region'] = arguments.get('mirror-region', None)
199 else:
200 selected_region = arguments.get('mirror-region', None)
201 arguments['mirror-region'] = {selected_region: list_mirrors()[selected_region]}
202 if arguments.get('sys-language', None) is not None:
203 arguments['sys-language'] = arguments.get('sys-language', 'en_US')
204 if arguments.get('sys-encoding', None) is not None:
205 arguments['sys-encoding'] = arguments.get('sys-encoding', 'utf-8')
206 if arguments.get('gfx_driver', None) is not None:
207 storage['gfx_driver_packages'] = AVAILABLE_GFX_DRIVERS.get(arguments.get('gfx_driver', None), None)
208 if arguments.get('servers', None) is not None:
209 storage['_selected_servers'] = arguments.get('servers', None)
210 if arguments.get('nic', None) is not None:
211 handler = NetworkConfigurationHandler()
212 handler.parse_arguments(arguments.get('nic'))
213 arguments['nic'] = handler.configuration
214
215 def post_process_arguments(arguments):
216 storage['arguments'] = arguments
217 if arguments.get('mount_point'):
218 storage['MOUNT_POINT'] = arguments['mount_point']
219
220 if arguments.get('debug', False):
221 log(f"Warning: --debug mode will write certain credentials to {storage['LOG_PATH']}/{storage['LOG_FILE']}!", fg="red", level=logging.WARNING)
222
223 if arguments.get('plugin', None):
224 load_plugin(arguments['plugin'])
225
226 if arguments.get('disk_layouts', None) is not None:
227 # if 'disk_layouts' not in storage:
228 # storage['disk_layouts'] = {}
229 layout_storage = {}
230 if not json_stream_to_structure('--disk_layouts',arguments['disk_layouts'],layout_storage):
231 exit(1)
232 else:
233 if arguments.get('harddrives') is None:
234 arguments['harddrives'] = [disk for disk in layout_storage]
235 # backward compatibility. Change partition.format for partition.wipe
236 for disk in layout_storage:
237 for i,partition in enumerate(layout_storage[disk].get('partitions',[])):
238 if 'format' in partition:
239 partition['wipe'] = partition['format']
240 del partition['format']
241 arguments['disk_layouts'] = layout_storage
242
243 load_config()
244
245
246 define_arguments()
247 arguments = get_arguments()
248 post_process_arguments(arguments)
249
250 # @archinstall.plugin decorator hook to programmatically add
251 # plugins in runtime. Useful in profiles and other things.
252 def plugin(f, *args, **kwargs):
253 plugins[f.__name__] = f
254
255
256 def run_as_a_module():
257 """
258 Since we're running this as a 'python -m archinstall' module OR
259 a nuitka3 compiled version of the project.
260 This function and the file __main__ acts as a entry point.
261 """
262
263 # Add another path for finding profiles, so that list_profiles() in Script() can find guided.py, unattended.py etc.
264 storage['PROFILE_PATH'].append(os.path.abspath(f'{os.path.dirname(__file__)}/examples'))
265 try:
266 script = Script(arguments.get('script', None))
267 except ProfileNotFound as err:
268 print(f"Couldn't find file: {err}")
269 sys.exit(1)
270
271 os.chdir(os.path.abspath(os.path.dirname(__file__)))
272
273 # Remove the example directory from the PROFILE_PATH, to avoid guided.py etc shows up in user input questions.
274 storage['PROFILE_PATH'].pop()
275 script.execute()
276
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/archinstall/__init__.py b/archinstall/__init__.py
--- a/archinstall/__init__.py
+++ b/archinstall/__init__.py
@@ -55,6 +55,10 @@
DeferredTranslation.install()
+def set_unicode_font():
+ SysCommand('setfont UniCyr_8x16')
+
+
def define_arguments():
"""
Define which explicit arguments do we allow.
@@ -243,6 +247,9 @@
load_config()
+# to ensure that cyrillic characters work in the installer
+set_unicode_font()
+
define_arguments()
arguments = get_arguments()
post_process_arguments(arguments)
|
{"golden_diff": "diff --git a/archinstall/__init__.py b/archinstall/__init__.py\n--- a/archinstall/__init__.py\n+++ b/archinstall/__init__.py\n@@ -55,6 +55,10 @@\n DeferredTranslation.install()\n \n \n+def set_unicode_font():\n+\tSysCommand('setfont UniCyr_8x16')\n+\n+\n def define_arguments():\n \t\"\"\"\n \tDefine which explicit arguments do we allow.\n@@ -243,6 +247,9 @@\n \tload_config()\n \n \n+# to ensure that cyrillic characters work in the installer\n+set_unicode_font()\n+\n define_arguments()\n arguments = get_arguments()\n post_process_arguments(arguments)\n", "issue": "Cyrillic problems (?)\nI decided to test new translation and got this \r\n\r\n\n", "before_files": [{"content": "\"\"\"Arch Linux installer - guided, templates etc.\"\"\"\nimport urllib.error\nimport urllib.parse\nimport urllib.request\nfrom argparse import ArgumentParser\n\nfrom .lib.disk import *\nfrom .lib.exceptions import *\nfrom .lib.general import *\nfrom .lib.hardware import *\nfrom .lib.installer import __packages__, Installer, accessibility_tools_in_use\nfrom .lib.locale_helpers import *\nfrom .lib.luks import *\nfrom .lib.mirrors import *\nfrom .lib.models.network_configuration import NetworkConfigurationHandler\nfrom .lib.networking import *\nfrom .lib.output import *\nfrom .lib.models.dataclasses import (\n\tVersionDef,\n\tPackageSearchResult,\n\tPackageSearch,\n\tLocalPackage\n)\nfrom .lib.packages.packages import (\n\tgroup_search,\n\tpackage_search,\n\tfind_package,\n\tfind_packages,\n\tinstalled_package,\n\tvalidate_package_list,\n)\nfrom .lib.profiles import *\nfrom .lib.services import *\nfrom .lib.storage import *\nfrom .lib.systemd import *\nfrom .lib.user_interaction import *\nfrom .lib.menu import Menu\nfrom .lib.menu.list_manager import ListManager\nfrom .lib.menu.text_input import TextInput\nfrom .lib.menu.global_menu import GlobalMenu\nfrom .lib.menu.selection_menu import (\n\tSelector,\n\tGeneralMenu\n)\nfrom .lib.translation import Translation, DeferredTranslation\nfrom .lib.plugins import plugins, load_plugin # This initiates the plugin loading ceremony\nfrom .lib.configuration import *\nparser = ArgumentParser()\n\n__version__ = \"2.4.2\"\nstorage['__version__'] = __version__\n\n# add the custome _ as a builtin, it can now be used anywhere in the\n# project to mark strings as translatable with _('translate me')\nDeferredTranslation.install()\n\n\ndef define_arguments():\n\t\"\"\"\n\tDefine which explicit arguments do we allow.\n\tRefer to https://docs.python.org/3/library/argparse.html for documentation and\n\t\t\thttps://docs.python.org/3/howto/argparse.html for a tutorial\n\tRemember that the property/entry name python assigns to the parameters is the first string defined as argument and\n\tdashes inside it '-' are changed to '_'\n\t\"\"\"\n\tparser.add_argument(\"--config\", nargs=\"?\", help=\"JSON configuration file or URL\")\n\tparser.add_argument(\"--creds\", nargs=\"?\", help=\"JSON credentials configuration file\")\n\tparser.add_argument(\"--disk_layouts\",\"--disk_layout\",\"--disk-layouts\",\"--disk-layout\",nargs=\"?\",\n\t\t\t\t\thelp=\"JSON disk layout file\")\n\tparser.add_argument(\"--silent\", action=\"store_true\",\n\t\t\t\t\t\thelp=\"WARNING: Disables all prompts for input and confirmation. If no configuration is provided, this is ignored\")\n\tparser.add_argument(\"--dry-run\", \"--dry_run\", action=\"store_true\",\n\t\t\t\t\t\thelp=\"Generates a configuration file and then exits instead of performing an installation\")\n\tparser.add_argument(\"--script\", default=\"guided\", nargs=\"?\", help=\"Script to run for installation\", type=str)\n\tparser.add_argument(\"--mount-point\",\"--mount_point\", nargs=\"?\", type=str, help=\"Define an alternate mount point for installation\")\n\tparser.add_argument(\"--debug\", action=\"store_true\", default=False, help=\"Adds debug info into the log\")\n\tparser.add_argument(\"--plugin\", nargs=\"?\", type=str)\n\ndef parse_unspecified_argument_list(unknowns :list, multiple :bool = False, error :bool = False) -> dict:\n\t\"\"\"We accept arguments not defined to the parser. (arguments \"ad hoc\").\n\tInternally argparse return to us a list of words so we have to parse its contents, manually.\n\tWe accept following individual syntax for each argument\n\t\t--argument value\n\t\t--argument=value\n\t\t--argument = value\n\t\t--argument (boolean as default)\n\tthe optional paramters to the function alter a bit its behaviour:\n\t* multiple allows multivalued arguments, each value separated by whitespace. They're returned as a list\n\t* error. If set any non correctly specified argument-value pair to raise an exception. Else, simply notifies the existence of a problem and continues processing.\n\n\tTo a certain extent, multiple and error are incompatible. In fact, the only error this routine can catch, as of now, is the event\n\targument value value ...\n\twhich isn't am error if multiple is specified\n\t\"\"\"\n\ttmp_list = unknowns[:] # wastes a few bytes, but avoids any collateral effect of the destructive nature of the pop method()\n\tconfig = {}\n\tkey = None\n\tlast_key = None\n\twhile tmp_list:\n\t\telement = tmp_list.pop(0)\t\t\t # retreive an element of the list\n\t\tif element.startswith('--'):\t\t # is an argument ?\n\t\t\tif '=' in element:\t\t\t\t # uses the arg=value syntax ?\n\t\t\t\tkey, value = [x.strip() for x in element[2:].split('=', 1)]\n\t\t\t\tconfig[key] = value\n\t\t\t\tlast_key = key\t\t\t\t # for multiple handling\n\t\t\t\tkey = None\t\t\t\t\t # we have the kwy value pair we need\n\t\t\telse:\n\t\t\t\tkey = element[2:]\n\t\t\t\tconfig[key] = True # every argument starts its lifecycle as boolean\n\t\telse:\n\t\t\tif element == '=':\n\t\t\t\tcontinue\n\t\t\tif key:\n\t\t\t\tconfig[key] = element\n\t\t\t\tlast_key = key # multiple\n\t\t\t\tkey = None\n\t\t\telse:\n\t\t\t\tif multiple and last_key:\n\t\t\t\t\tif isinstance(config[last_key],str):\n\t\t\t\t\t\tconfig[last_key] = [config[last_key],element]\n\t\t\t\t\telse:\n\t\t\t\t\t\tconfig[last_key].append(element)\n\t\t\t\telif error:\n\t\t\t\t\traise ValueError(f\"Entry {element} is not related to any argument\")\n\t\t\t\telse:\n\t\t\t\t\tprint(f\" We ignore the entry {element} as it isn't related to any argument\")\n\treturn config\n\ndef get_arguments() -> Dict[str, Any]:\n\t\"\"\" The handling of parameters from the command line\n\tIs done on following steps:\n\t0) we create a dict to store the arguments and their values\n\t1) preprocess.\n\t\tWe take those arguments which use Json files, and read them into the argument dict. So each first level entry becomes a argument un it's own right\n\t2) Load.\n\t\tWe convert the predefined argument list directly into the dict v\u00eda the vars() funci\u00f3n. Non specified arguments are loaded with value None or false if they are booleans (action=\"store_true\").\n\t\tThe name is chosen according to argparse conventions. See above (the first text is used as argument name, but underscore substitutes dash)\n\t\tWe then load all the undefined arguments. In this case the names are taken as written.\n\t\tImportant. This way explicit command line arguments take precedence over configuraci\u00f3n files.\n\t3) Amend\n\t\tChange whatever is needed on the configuration dictionary (it could be done in post_process_arguments but this ougth to be left to changes anywhere else in the code, not in the arguments dictionary\n\t\"\"\"\n\tconfig = {}\n\targs, unknowns = parser.parse_known_args()\n\t# preprocess the json files.\n\t# TODO Expand the url access to the other JSON file arguments ?\n\tif args.config is not None:\n\t\ttry:\n\t\t\t# First, let's check if this is a URL scheme instead of a filename\n\t\t\tparsed_url = urllib.parse.urlparse(args.config)\n\n\t\t\tif not parsed_url.scheme: # The Profile was not a direct match on a remote URL, it must be a local file.\n\t\t\t\tif not json_stream_to_structure('--config',args.config,config):\n\t\t\t\t\texit(1)\n\t\t\telse: # Attempt to load the configuration from the URL.\n\t\t\t\twith urllib.request.urlopen(urllib.request.Request(args.config, headers={'User-Agent': 'ArchInstall'})) as response:\n\t\t\t\t\tconfig.update(json.loads(response.read()))\n\t\texcept Exception as e:\n\t\t\traise ValueError(f\"Could not load --config because: {e}\")\n\n\t\tif args.creds is not None:\n\t\t\tif not json_stream_to_structure('--creds',args.creds,config):\n\t\t\t\texit(1)\n\t# load the parameters. first the known, then the unknowns\n\tconfig.update(vars(args))\n\tconfig.update(parse_unspecified_argument_list(unknowns))\n\t# amend the parameters (check internal consistency)\n\t# Installation can't be silent if config is not passed\n\tif args.config is not None :\n\t\tconfig[\"silent\"] = args.silent\n\telse:\n\t\tconfig[\"silent\"] = False\n\n\t# avoiding a compatibility issue\n\tif 'dry-run' in config:\n\t\tdel config['dry-run']\n\treturn config\n\ndef load_config():\n\tfrom .lib.models import NetworkConfiguration\n\t\"\"\"\n\trefine and set some arguments. Formerly at the scripts\n\t\"\"\"\n\tif arguments.get('harddrives', None) is not None:\n\t\tif type(arguments['harddrives']) is str:\n\t\t\targuments['harddrives'] = arguments['harddrives'].split(',')\n\t\targuments['harddrives'] = [BlockDevice(BlockDev) for BlockDev in arguments['harddrives']]\n\t\t# Temporarily disabling keep_partitions if config file is loaded\n\t\t# Temporary workaround to make Desktop Environments work\n\tif arguments.get('profile', None) is not None:\n\t\tif type(arguments.get('profile', None)) is dict:\n\t\t\targuments['profile'] = Profile(None, arguments.get('profile', None)['path'])\n\t\telse:\n\t\t\targuments['profile'] = Profile(None, arguments.get('profile', None))\n\tstorage['_desktop_profile'] = arguments.get('desktop-environment', None)\n\tif arguments.get('mirror-region', None) is not None:\n\t\tif type(arguments.get('mirror-region', None)) is dict:\n\t\t\targuments['mirror-region'] = arguments.get('mirror-region', None)\n\t\telse:\n\t\t\tselected_region = arguments.get('mirror-region', None)\n\t\t\targuments['mirror-region'] = {selected_region: list_mirrors()[selected_region]}\n\tif arguments.get('sys-language', None) is not None:\n\t\targuments['sys-language'] = arguments.get('sys-language', 'en_US')\n\tif arguments.get('sys-encoding', None) is not None:\n\t\targuments['sys-encoding'] = arguments.get('sys-encoding', 'utf-8')\n\tif arguments.get('gfx_driver', None) is not None:\n\t\tstorage['gfx_driver_packages'] = AVAILABLE_GFX_DRIVERS.get(arguments.get('gfx_driver', None), None)\n\tif arguments.get('servers', None) is not None:\n\t\tstorage['_selected_servers'] = arguments.get('servers', None)\n\tif arguments.get('nic', None) is not None:\n\t\thandler = NetworkConfigurationHandler()\n\t\thandler.parse_arguments(arguments.get('nic'))\n\t\targuments['nic'] = handler.configuration\n\ndef post_process_arguments(arguments):\n\tstorage['arguments'] = arguments\n\tif arguments.get('mount_point'):\n\t\tstorage['MOUNT_POINT'] = arguments['mount_point']\n\n\tif arguments.get('debug', False):\n\t\tlog(f\"Warning: --debug mode will write certain credentials to {storage['LOG_PATH']}/{storage['LOG_FILE']}!\", fg=\"red\", level=logging.WARNING)\n\n\tif arguments.get('plugin', None):\n\t\tload_plugin(arguments['plugin'])\n\n\tif arguments.get('disk_layouts', None) is not None:\n\t\t# if 'disk_layouts' not in storage:\n\t\t# \tstorage['disk_layouts'] = {}\n\t\tlayout_storage = {}\n\t\tif not json_stream_to_structure('--disk_layouts',arguments['disk_layouts'],layout_storage):\n\t\t\texit(1)\n\t\telse:\n\t\t\tif arguments.get('harddrives') is None:\n\t\t\t\targuments['harddrives'] = [disk for disk in layout_storage]\n\t\t\t# backward compatibility. Change partition.format for partition.wipe\n\t\t\tfor disk in layout_storage:\n\t\t\t\tfor i,partition in enumerate(layout_storage[disk].get('partitions',[])):\n\t\t\t\t\tif 'format' in partition:\n\t\t\t\t\t\tpartition['wipe'] = partition['format']\n\t\t\t\t\t\tdel partition['format']\n\t\t\targuments['disk_layouts'] = layout_storage\n\n\tload_config()\n\n\ndefine_arguments()\narguments = get_arguments()\npost_process_arguments(arguments)\n\n# @archinstall.plugin decorator hook to programmatically add\n# plugins in runtime. Useful in profiles and other things.\ndef plugin(f, *args, **kwargs):\n\tplugins[f.__name__] = f\n\n\ndef run_as_a_module():\n\t\"\"\"\n\tSince we're running this as a 'python -m archinstall' module OR\n\ta nuitka3 compiled version of the project.\n\tThis function and the file __main__ acts as a entry point.\n\t\"\"\"\n\n\t# Add another path for finding profiles, so that list_profiles() in Script() can find guided.py, unattended.py etc.\n\tstorage['PROFILE_PATH'].append(os.path.abspath(f'{os.path.dirname(__file__)}/examples'))\n\ttry:\n\t\tscript = Script(arguments.get('script', None))\n\texcept ProfileNotFound as err:\n\t\tprint(f\"Couldn't find file: {err}\")\n\t\tsys.exit(1)\n\n\tos.chdir(os.path.abspath(os.path.dirname(__file__)))\n\n\t# Remove the example directory from the PROFILE_PATH, to avoid guided.py etc shows up in user input questions.\n\tstorage['PROFILE_PATH'].pop()\n\tscript.execute()\n", "path": "archinstall/__init__.py"}], "after_files": [{"content": "\"\"\"Arch Linux installer - guided, templates etc.\"\"\"\nimport urllib.error\nimport urllib.parse\nimport urllib.request\nfrom argparse import ArgumentParser\n\nfrom .lib.disk import *\nfrom .lib.exceptions import *\nfrom .lib.general import *\nfrom .lib.hardware import *\nfrom .lib.installer import __packages__, Installer, accessibility_tools_in_use\nfrom .lib.locale_helpers import *\nfrom .lib.luks import *\nfrom .lib.mirrors import *\nfrom .lib.models.network_configuration import NetworkConfigurationHandler\nfrom .lib.networking import *\nfrom .lib.output import *\nfrom .lib.models.dataclasses import (\n\tVersionDef,\n\tPackageSearchResult,\n\tPackageSearch,\n\tLocalPackage\n)\nfrom .lib.packages.packages import (\n\tgroup_search,\n\tpackage_search,\n\tfind_package,\n\tfind_packages,\n\tinstalled_package,\n\tvalidate_package_list,\n)\nfrom .lib.profiles import *\nfrom .lib.services import *\nfrom .lib.storage import *\nfrom .lib.systemd import *\nfrom .lib.user_interaction import *\nfrom .lib.menu import Menu\nfrom .lib.menu.list_manager import ListManager\nfrom .lib.menu.text_input import TextInput\nfrom .lib.menu.global_menu import GlobalMenu\nfrom .lib.menu.selection_menu import (\n\tSelector,\n\tGeneralMenu\n)\nfrom .lib.translation import Translation, DeferredTranslation\nfrom .lib.plugins import plugins, load_plugin # This initiates the plugin loading ceremony\nfrom .lib.configuration import *\nparser = ArgumentParser()\n\n__version__ = \"2.4.2\"\nstorage['__version__'] = __version__\n\n# add the custome _ as a builtin, it can now be used anywhere in the\n# project to mark strings as translatable with _('translate me')\nDeferredTranslation.install()\n\n\ndef set_unicode_font():\n\tSysCommand('setfont UniCyr_8x16')\n\n\ndef define_arguments():\n\t\"\"\"\n\tDefine which explicit arguments do we allow.\n\tRefer to https://docs.python.org/3/library/argparse.html for documentation and\n\t\t\thttps://docs.python.org/3/howto/argparse.html for a tutorial\n\tRemember that the property/entry name python assigns to the parameters is the first string defined as argument and\n\tdashes inside it '-' are changed to '_'\n\t\"\"\"\n\tparser.add_argument(\"--config\", nargs=\"?\", help=\"JSON configuration file or URL\")\n\tparser.add_argument(\"--creds\", nargs=\"?\", help=\"JSON credentials configuration file\")\n\tparser.add_argument(\"--disk_layouts\",\"--disk_layout\",\"--disk-layouts\",\"--disk-layout\",nargs=\"?\",\n\t\t\t\t\thelp=\"JSON disk layout file\")\n\tparser.add_argument(\"--silent\", action=\"store_true\",\n\t\t\t\t\t\thelp=\"WARNING: Disables all prompts for input and confirmation. If no configuration is provided, this is ignored\")\n\tparser.add_argument(\"--dry-run\", \"--dry_run\", action=\"store_true\",\n\t\t\t\t\t\thelp=\"Generates a configuration file and then exits instead of performing an installation\")\n\tparser.add_argument(\"--script\", default=\"guided\", nargs=\"?\", help=\"Script to run for installation\", type=str)\n\tparser.add_argument(\"--mount-point\",\"--mount_point\", nargs=\"?\", type=str, help=\"Define an alternate mount point for installation\")\n\tparser.add_argument(\"--debug\", action=\"store_true\", default=False, help=\"Adds debug info into the log\")\n\tparser.add_argument(\"--plugin\", nargs=\"?\", type=str)\n\ndef parse_unspecified_argument_list(unknowns :list, multiple :bool = False, error :bool = False) -> dict:\n\t\"\"\"We accept arguments not defined to the parser. (arguments \"ad hoc\").\n\tInternally argparse return to us a list of words so we have to parse its contents, manually.\n\tWe accept following individual syntax for each argument\n\t\t--argument value\n\t\t--argument=value\n\t\t--argument = value\n\t\t--argument (boolean as default)\n\tthe optional paramters to the function alter a bit its behaviour:\n\t* multiple allows multivalued arguments, each value separated by whitespace. They're returned as a list\n\t* error. If set any non correctly specified argument-value pair to raise an exception. Else, simply notifies the existence of a problem and continues processing.\n\n\tTo a certain extent, multiple and error are incompatible. In fact, the only error this routine can catch, as of now, is the event\n\targument value value ...\n\twhich isn't am error if multiple is specified\n\t\"\"\"\n\ttmp_list = unknowns[:] # wastes a few bytes, but avoids any collateral effect of the destructive nature of the pop method()\n\tconfig = {}\n\tkey = None\n\tlast_key = None\n\twhile tmp_list:\n\t\telement = tmp_list.pop(0)\t\t\t # retreive an element of the list\n\t\tif element.startswith('--'):\t\t # is an argument ?\n\t\t\tif '=' in element:\t\t\t\t # uses the arg=value syntax ?\n\t\t\t\tkey, value = [x.strip() for x in element[2:].split('=', 1)]\n\t\t\t\tconfig[key] = value\n\t\t\t\tlast_key = key\t\t\t\t # for multiple handling\n\t\t\t\tkey = None\t\t\t\t\t # we have the kwy value pair we need\n\t\t\telse:\n\t\t\t\tkey = element[2:]\n\t\t\t\tconfig[key] = True # every argument starts its lifecycle as boolean\n\t\telse:\n\t\t\tif element == '=':\n\t\t\t\tcontinue\n\t\t\tif key:\n\t\t\t\tconfig[key] = element\n\t\t\t\tlast_key = key # multiple\n\t\t\t\tkey = None\n\t\t\telse:\n\t\t\t\tif multiple and last_key:\n\t\t\t\t\tif isinstance(config[last_key],str):\n\t\t\t\t\t\tconfig[last_key] = [config[last_key],element]\n\t\t\t\t\telse:\n\t\t\t\t\t\tconfig[last_key].append(element)\n\t\t\t\telif error:\n\t\t\t\t\traise ValueError(f\"Entry {element} is not related to any argument\")\n\t\t\t\telse:\n\t\t\t\t\tprint(f\" We ignore the entry {element} as it isn't related to any argument\")\n\treturn config\n\ndef get_arguments() -> Dict[str, Any]:\n\t\"\"\" The handling of parameters from the command line\n\tIs done on following steps:\n\t0) we create a dict to store the arguments and their values\n\t1) preprocess.\n\t\tWe take those arguments which use Json files, and read them into the argument dict. So each first level entry becomes a argument un it's own right\n\t2) Load.\n\t\tWe convert the predefined argument list directly into the dict v\u00eda the vars() funci\u00f3n. Non specified arguments are loaded with value None or false if they are booleans (action=\"store_true\").\n\t\tThe name is chosen according to argparse conventions. See above (the first text is used as argument name, but underscore substitutes dash)\n\t\tWe then load all the undefined arguments. In this case the names are taken as written.\n\t\tImportant. This way explicit command line arguments take precedence over configuraci\u00f3n files.\n\t3) Amend\n\t\tChange whatever is needed on the configuration dictionary (it could be done in post_process_arguments but this ougth to be left to changes anywhere else in the code, not in the arguments dictionary\n\t\"\"\"\n\tconfig = {}\n\targs, unknowns = parser.parse_known_args()\n\t# preprocess the json files.\n\t# TODO Expand the url access to the other JSON file arguments ?\n\tif args.config is not None:\n\t\ttry:\n\t\t\t# First, let's check if this is a URL scheme instead of a filename\n\t\t\tparsed_url = urllib.parse.urlparse(args.config)\n\n\t\t\tif not parsed_url.scheme: # The Profile was not a direct match on a remote URL, it must be a local file.\n\t\t\t\tif not json_stream_to_structure('--config',args.config,config):\n\t\t\t\t\texit(1)\n\t\t\telse: # Attempt to load the configuration from the URL.\n\t\t\t\twith urllib.request.urlopen(urllib.request.Request(args.config, headers={'User-Agent': 'ArchInstall'})) as response:\n\t\t\t\t\tconfig.update(json.loads(response.read()))\n\t\texcept Exception as e:\n\t\t\traise ValueError(f\"Could not load --config because: {e}\")\n\n\t\tif args.creds is not None:\n\t\t\tif not json_stream_to_structure('--creds',args.creds,config):\n\t\t\t\texit(1)\n\t# load the parameters. first the known, then the unknowns\n\tconfig.update(vars(args))\n\tconfig.update(parse_unspecified_argument_list(unknowns))\n\t# amend the parameters (check internal consistency)\n\t# Installation can't be silent if config is not passed\n\tif args.config is not None :\n\t\tconfig[\"silent\"] = args.silent\n\telse:\n\t\tconfig[\"silent\"] = False\n\n\t# avoiding a compatibility issue\n\tif 'dry-run' in config:\n\t\tdel config['dry-run']\n\treturn config\n\ndef load_config():\n\tfrom .lib.models import NetworkConfiguration\n\t\"\"\"\n\trefine and set some arguments. Formerly at the scripts\n\t\"\"\"\n\tif arguments.get('harddrives', None) is not None:\n\t\tif type(arguments['harddrives']) is str:\n\t\t\targuments['harddrives'] = arguments['harddrives'].split(',')\n\t\targuments['harddrives'] = [BlockDevice(BlockDev) for BlockDev in arguments['harddrives']]\n\t\t# Temporarily disabling keep_partitions if config file is loaded\n\t\t# Temporary workaround to make Desktop Environments work\n\tif arguments.get('profile', None) is not None:\n\t\tif type(arguments.get('profile', None)) is dict:\n\t\t\targuments['profile'] = Profile(None, arguments.get('profile', None)['path'])\n\t\telse:\n\t\t\targuments['profile'] = Profile(None, arguments.get('profile', None))\n\tstorage['_desktop_profile'] = arguments.get('desktop-environment', None)\n\tif arguments.get('mirror-region', None) is not None:\n\t\tif type(arguments.get('mirror-region', None)) is dict:\n\t\t\targuments['mirror-region'] = arguments.get('mirror-region', None)\n\t\telse:\n\t\t\tselected_region = arguments.get('mirror-region', None)\n\t\t\targuments['mirror-region'] = {selected_region: list_mirrors()[selected_region]}\n\tif arguments.get('sys-language', None) is not None:\n\t\targuments['sys-language'] = arguments.get('sys-language', 'en_US')\n\tif arguments.get('sys-encoding', None) is not None:\n\t\targuments['sys-encoding'] = arguments.get('sys-encoding', 'utf-8')\n\tif arguments.get('gfx_driver', None) is not None:\n\t\tstorage['gfx_driver_packages'] = AVAILABLE_GFX_DRIVERS.get(arguments.get('gfx_driver', None), None)\n\tif arguments.get('servers', None) is not None:\n\t\tstorage['_selected_servers'] = arguments.get('servers', None)\n\tif arguments.get('nic', None) is not None:\n\t\thandler = NetworkConfigurationHandler()\n\t\thandler.parse_arguments(arguments.get('nic'))\n\t\targuments['nic'] = handler.configuration\n\ndef post_process_arguments(arguments):\n\tstorage['arguments'] = arguments\n\tif arguments.get('mount_point'):\n\t\tstorage['MOUNT_POINT'] = arguments['mount_point']\n\n\tif arguments.get('debug', False):\n\t\tlog(f\"Warning: --debug mode will write certain credentials to {storage['LOG_PATH']}/{storage['LOG_FILE']}!\", fg=\"red\", level=logging.WARNING)\n\n\tif arguments.get('plugin', None):\n\t\tload_plugin(arguments['plugin'])\n\n\tif arguments.get('disk_layouts', None) is not None:\n\t\t# if 'disk_layouts' not in storage:\n\t\t# \tstorage['disk_layouts'] = {}\n\t\tlayout_storage = {}\n\t\tif not json_stream_to_structure('--disk_layouts',arguments['disk_layouts'],layout_storage):\n\t\t\texit(1)\n\t\telse:\n\t\t\tif arguments.get('harddrives') is None:\n\t\t\t\targuments['harddrives'] = [disk for disk in layout_storage]\n\t\t\t# backward compatibility. Change partition.format for partition.wipe\n\t\t\tfor disk in layout_storage:\n\t\t\t\tfor i,partition in enumerate(layout_storage[disk].get('partitions',[])):\n\t\t\t\t\tif 'format' in partition:\n\t\t\t\t\t\tpartition['wipe'] = partition['format']\n\t\t\t\t\t\tdel partition['format']\n\t\t\targuments['disk_layouts'] = layout_storage\n\n\tload_config()\n\n\n# to ensure that cyrillic characters work in the installer\nset_unicode_font()\n\ndefine_arguments()\narguments = get_arguments()\npost_process_arguments(arguments)\n\n# @archinstall.plugin decorator hook to programmatically add\n# plugins in runtime. Useful in profiles and other things.\ndef plugin(f, *args, **kwargs):\n\tplugins[f.__name__] = f\n\n\ndef run_as_a_module():\n\t\"\"\"\n\tSince we're running this as a 'python -m archinstall' module OR\n\ta nuitka3 compiled version of the project.\n\tThis function and the file __main__ acts as a entry point.\n\t\"\"\"\n\n\t# Add another path for finding profiles, so that list_profiles() in Script() can find guided.py, unattended.py etc.\n\tstorage['PROFILE_PATH'].append(os.path.abspath(f'{os.path.dirname(__file__)}/examples'))\n\ttry:\n\t\tscript = Script(arguments.get('script', None))\n\texcept ProfileNotFound as err:\n\t\tprint(f\"Couldn't find file: {err}\")\n\t\tsys.exit(1)\n\n\tos.chdir(os.path.abspath(os.path.dirname(__file__)))\n\n\t# Remove the example directory from the PROFILE_PATH, to avoid guided.py etc shows up in user input questions.\n\tstorage['PROFILE_PATH'].pop()\n\tscript.execute()\n", "path": "archinstall/__init__.py"}]}
| 3,915 | 146 |
gh_patches_debug_8185
|
rasdani/github-patches
|
git_diff
|
openstates__openstates-scrapers-2087
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ID: scrape fails on substitute representative
Once #2053 is merged, the people scraper is blowing up reading https://legislature.idaho.gov/house/membership/ .
Search down to "Scanlin", who you'll find is a "substitute" representative. There's a parsing problem because the scraper expects the name to be bold and the party to not be; in this case "Substitute" is bold only.
For a description of what a "Substitute" is, see http://www.spokesman.com/blogs/boise/2014/mar/16/idahos-legislative-substitute-law-unique/
Just fixing this would leave two legislators in that district, where, as in Highlander, "there can be only one". Representative Kloc, who Scanlin is substituting for, is directly above him.
Assuming that his roll call votes, committee memberships, etc. are registered to the substitute, I believe a fully correct fix for this would involve:
- lookahead for a "Substitute", skipping the current legislator if the next legislator is a substitute.
- rewriting the line parser to skip "Substitute" and just use the text (not bold format) for name/party parsing.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `openstates/id/people.py`
Content:
```
1 import re
2 import lxml.html
3 from pupa.scrape import Scraper, Person
4
5 BASE_URL = 'https://legislature.idaho.gov/%s/membership/'
6 CHAMBERS = {'upper': 'senate', 'lower': 'house'}
7 PARTY = {
8 '(R)': 'Republican',
9 '(D)': 'Democratic',
10 }
11
12 phone_patterns = {
13 'office': re.compile(r'Statehouse'),
14 'business': re.compile(r'Bus'),
15 'home': re.compile(r'Home'),
16 }
17
18 parse_phone_pattern = re.compile(r'tel:(?:\+1)?(\d{10}$)')
19 fax_pattern = re.compile(r'fax\s+\((\d{3})\)\s+(\d{3})-(\d{4})', re.IGNORECASE)
20 address_pattern = re.compile(r', \d{5}')
21 address_replace_pattern = re.compile(r'(\d{5})')
22
23
24 def get_phones(el):
25 phones = {}
26 for link in el.xpath('p/a[@class = "mob-tel"]'):
27 prefix = link.getprevious().tail
28 for label, pattern in phone_patterns.items():
29 if pattern.search(prefix) is not None:
30 phones[label] = parse_phone(link.get('href'))
31 return phones
32
33
34 def parse_phone(phone):
35 res = parse_phone_pattern.search(phone)
36 if res is not None:
37 return res.groups()[0]
38
39
40 def get_fax(el):
41 res = fax_pattern.search(el.text_content())
42 if res is not None:
43 return ''.join(res.groups())
44
45
46 def get_address(el):
47 for br in el.xpath('p/br'):
48 piece = (br.tail or '').strip()
49 res = address_pattern.search(piece)
50 if res is not None:
51 return address_replace_pattern.sub(r'ID \1', piece).strip()
52
53
54 class IDPersonScraper(Scraper):
55 """Legislator data seems to be available for the current term only."""
56 jurisdiction = 'id'
57
58 def scrape(self, chamber=None):
59 if chamber:
60 yield from self.scrape_chamber(chamber)
61 else:
62 yield from self.scrape_chamber('upper')
63 yield from self.scrape_chamber('lower')
64
65 def scrape_chamber(self, chamber):
66 """
67 Scrapes legislators for the current term only
68 """
69 # self.validate_term(term, latest_only=True)
70 url = BASE_URL % CHAMBERS[chamber].lower()
71 index = self.get(url, verify=False).text
72 html = lxml.html.fromstring(index)
73 html.make_links_absolute(url)
74
75 rows = html.xpath('//div[contains(@class, "row-equal-height")]')
76
77 for row in rows:
78 img_url = row.xpath('.//img/@src')[0]
79
80 inner = row.xpath('.//div[@class="vc-column-innner-wrapper"]')[1]
81 if 'Resigned' in inner.text_content():
82 continue
83
84 name = inner.xpath('p/strong')[0].text.replace(u'\xa0', ' ').strip()
85 name = re.sub('\s+', ' ', name)
86 party = PARTY[inner.xpath('p/strong')[0].tail.strip()]
87 email = inner.xpath('p/strong/a')[0].text
88 district = inner.xpath('p/a')[0].text.replace('District ', '')
89
90 person_url = inner.xpath('p/a/@href')[0]
91 # skip roles for now
92 role = ''
93 # for com in inner.xpath('p/a[contains(@href, "committees")]'):
94 # role = com.tail.strip()
95
96 person = Person(name=name, district=district,
97 party=party, primary_org=chamber,
98 image=img_url, role=role)
99 phones = get_phones(inner)
100 phone = phones.get('home') or phones.get('business')
101 office_phone = phones.get('office')
102 address = get_address(inner)
103 fax = get_fax(inner)
104 if address:
105 person.add_contact_detail(type='address', value=address,
106 note='District Office')
107 if phone:
108 person.add_contact_detail(type='voice', value=phone,
109 note='District Office')
110 if fax:
111 person.add_contact_detail(type='fax', value=fax,
112 note='District Office')
113 if email:
114 person.add_contact_detail(type='email', value=email,
115 note='District Office')
116 if office_phone:
117 person.add_contact_detail(type='voice', value=office_phone,
118 note='Capitol Office')
119 person.add_source(url)
120 person.add_link(person_url)
121 yield person
122
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/openstates/id/people.py b/openstates/id/people.py
--- a/openstates/id/people.py
+++ b/openstates/id/people.py
@@ -78,7 +78,8 @@
img_url = row.xpath('.//img/@src')[0]
inner = row.xpath('.//div[@class="vc-column-innner-wrapper"]')[1]
- if 'Resigned' in inner.text_content():
+ inner_text = inner.text_content()
+ if 'Resigned' in inner_text or 'Substitute' in inner_text:
continue
name = inner.xpath('p/strong')[0].text.replace(u'\xa0', ' ').strip()
|
{"golden_diff": "diff --git a/openstates/id/people.py b/openstates/id/people.py\n--- a/openstates/id/people.py\n+++ b/openstates/id/people.py\n@@ -78,7 +78,8 @@\n img_url = row.xpath('.//img/@src')[0]\n \n inner = row.xpath('.//div[@class=\"vc-column-innner-wrapper\"]')[1]\n- if 'Resigned' in inner.text_content():\n+ inner_text = inner.text_content()\n+ if 'Resigned' in inner_text or 'Substitute' in inner_text:\n continue\n \n name = inner.xpath('p/strong')[0].text.replace(u'\\xa0', ' ').strip()\n", "issue": "ID: scrape fails on substitute representative\nOnce #2053 is merged, the people scraper is blowing up reading https://legislature.idaho.gov/house/membership/ . \r\nSearch down to \"Scanlin\", who you'll find is a \"substitute\" representative. There's a parsing problem because the scraper expects the name to be bold and the party to not be; in this case \"Substitute\" is bold only.\r\n\r\nFor a description of what a \"Substitute\" is, see http://www.spokesman.com/blogs/boise/2014/mar/16/idahos-legislative-substitute-law-unique/ \r\n\r\nJust fixing this would leave two legislators in that district, where, as in Highlander, \"there can be only one\". Representative Kloc, who Scanlin is substituting for, is directly above him.\r\n\r\nAssuming that his roll call votes, committee memberships, etc. are registered to the substitute, I believe a fully correct fix for this would involve:\r\n- lookahead for a \"Substitute\", skipping the current legislator if the next legislator is a substitute.\r\n- rewriting the line parser to skip \"Substitute\" and just use the text (not bold format) for name/party parsing.\r\n\n", "before_files": [{"content": "import re\nimport lxml.html\nfrom pupa.scrape import Scraper, Person\n\nBASE_URL = 'https://legislature.idaho.gov/%s/membership/'\nCHAMBERS = {'upper': 'senate', 'lower': 'house'}\nPARTY = {\n '(R)': 'Republican',\n '(D)': 'Democratic',\n}\n\nphone_patterns = {\n 'office': re.compile(r'Statehouse'),\n 'business': re.compile(r'Bus'),\n 'home': re.compile(r'Home'),\n}\n\nparse_phone_pattern = re.compile(r'tel:(?:\\+1)?(\\d{10}$)')\nfax_pattern = re.compile(r'fax\\s+\\((\\d{3})\\)\\s+(\\d{3})-(\\d{4})', re.IGNORECASE)\naddress_pattern = re.compile(r', \\d{5}')\naddress_replace_pattern = re.compile(r'(\\d{5})')\n\n\ndef get_phones(el):\n phones = {}\n for link in el.xpath('p/a[@class = \"mob-tel\"]'):\n prefix = link.getprevious().tail\n for label, pattern in phone_patterns.items():\n if pattern.search(prefix) is not None:\n phones[label] = parse_phone(link.get('href'))\n return phones\n\n\ndef parse_phone(phone):\n res = parse_phone_pattern.search(phone)\n if res is not None:\n return res.groups()[0]\n\n\ndef get_fax(el):\n res = fax_pattern.search(el.text_content())\n if res is not None:\n return ''.join(res.groups())\n\n\ndef get_address(el):\n for br in el.xpath('p/br'):\n piece = (br.tail or '').strip()\n res = address_pattern.search(piece)\n if res is not None:\n return address_replace_pattern.sub(r'ID \\1', piece).strip()\n\n\nclass IDPersonScraper(Scraper):\n \"\"\"Legislator data seems to be available for the current term only.\"\"\"\n jurisdiction = 'id'\n\n def scrape(self, chamber=None):\n if chamber:\n yield from self.scrape_chamber(chamber)\n else:\n yield from self.scrape_chamber('upper')\n yield from self.scrape_chamber('lower')\n\n def scrape_chamber(self, chamber):\n \"\"\"\n Scrapes legislators for the current term only\n \"\"\"\n # self.validate_term(term, latest_only=True)\n url = BASE_URL % CHAMBERS[chamber].lower()\n index = self.get(url, verify=False).text\n html = lxml.html.fromstring(index)\n html.make_links_absolute(url)\n\n rows = html.xpath('//div[contains(@class, \"row-equal-height\")]')\n\n for row in rows:\n img_url = row.xpath('.//img/@src')[0]\n\n inner = row.xpath('.//div[@class=\"vc-column-innner-wrapper\"]')[1]\n if 'Resigned' in inner.text_content():\n continue\n\n name = inner.xpath('p/strong')[0].text.replace(u'\\xa0', ' ').strip()\n name = re.sub('\\s+', ' ', name)\n party = PARTY[inner.xpath('p/strong')[0].tail.strip()]\n email = inner.xpath('p/strong/a')[0].text\n district = inner.xpath('p/a')[0].text.replace('District ', '')\n\n person_url = inner.xpath('p/a/@href')[0]\n # skip roles for now\n role = ''\n # for com in inner.xpath('p/a[contains(@href, \"committees\")]'):\n # role = com.tail.strip()\n\n person = Person(name=name, district=district,\n party=party, primary_org=chamber,\n image=img_url, role=role)\n phones = get_phones(inner)\n phone = phones.get('home') or phones.get('business')\n office_phone = phones.get('office')\n address = get_address(inner)\n fax = get_fax(inner)\n if address:\n person.add_contact_detail(type='address', value=address,\n note='District Office')\n if phone:\n person.add_contact_detail(type='voice', value=phone,\n note='District Office')\n if fax:\n person.add_contact_detail(type='fax', value=fax,\n note='District Office')\n if email:\n person.add_contact_detail(type='email', value=email,\n note='District Office')\n if office_phone:\n person.add_contact_detail(type='voice', value=office_phone,\n note='Capitol Office')\n person.add_source(url)\n person.add_link(person_url)\n yield person\n", "path": "openstates/id/people.py"}], "after_files": [{"content": "import re\nimport lxml.html\nfrom pupa.scrape import Scraper, Person\n\nBASE_URL = 'https://legislature.idaho.gov/%s/membership/'\nCHAMBERS = {'upper': 'senate', 'lower': 'house'}\nPARTY = {\n '(R)': 'Republican',\n '(D)': 'Democratic',\n}\n\nphone_patterns = {\n 'office': re.compile(r'Statehouse'),\n 'business': re.compile(r'Bus'),\n 'home': re.compile(r'Home'),\n}\n\nparse_phone_pattern = re.compile(r'tel:(?:\\+1)?(\\d{10}$)')\nfax_pattern = re.compile(r'fax\\s+\\((\\d{3})\\)\\s+(\\d{3})-(\\d{4})', re.IGNORECASE)\naddress_pattern = re.compile(r', \\d{5}')\naddress_replace_pattern = re.compile(r'(\\d{5})')\n\n\ndef get_phones(el):\n phones = {}\n for link in el.xpath('p/a[@class = \"mob-tel\"]'):\n prefix = link.getprevious().tail\n for label, pattern in phone_patterns.items():\n if pattern.search(prefix) is not None:\n phones[label] = parse_phone(link.get('href'))\n return phones\n\n\ndef parse_phone(phone):\n res = parse_phone_pattern.search(phone)\n if res is not None:\n return res.groups()[0]\n\n\ndef get_fax(el):\n res = fax_pattern.search(el.text_content())\n if res is not None:\n return ''.join(res.groups())\n\n\ndef get_address(el):\n for br in el.xpath('p/br'):\n piece = (br.tail or '').strip()\n res = address_pattern.search(piece)\n if res is not None:\n return address_replace_pattern.sub(r'ID \\1', piece).strip()\n\n\nclass IDPersonScraper(Scraper):\n \"\"\"Legislator data seems to be available for the current term only.\"\"\"\n jurisdiction = 'id'\n\n def scrape(self, chamber=None):\n if chamber:\n yield from self.scrape_chamber(chamber)\n else:\n yield from self.scrape_chamber('upper')\n yield from self.scrape_chamber('lower')\n\n def scrape_chamber(self, chamber):\n \"\"\"\n Scrapes legislators for the current term only\n \"\"\"\n # self.validate_term(term, latest_only=True)\n url = BASE_URL % CHAMBERS[chamber].lower()\n index = self.get(url, verify=False).text\n html = lxml.html.fromstring(index)\n html.make_links_absolute(url)\n\n rows = html.xpath('//div[contains(@class, \"row-equal-height\")]')\n\n for row in rows:\n img_url = row.xpath('.//img/@src')[0]\n\n inner = row.xpath('.//div[@class=\"vc-column-innner-wrapper\"]')[1]\n inner_text = inner.text_content()\n if 'Resigned' in inner_text or 'Substitute' in inner_text:\n continue\n\n name = inner.xpath('p/strong')[0].text.replace(u'\\xa0', ' ').strip()\n name = re.sub('\\s+', ' ', name)\n party = PARTY[inner.xpath('p/strong')[0].tail.strip()]\n email = inner.xpath('p/strong/a')[0].text\n district = inner.xpath('p/a')[0].text.replace('District ', '')\n\n person_url = inner.xpath('p/a/@href')[0]\n # skip roles for now\n role = ''\n # for com in inner.xpath('p/a[contains(@href, \"committees\")]'):\n # role = com.tail.strip()\n\n person = Person(name=name, district=district,\n party=party, primary_org=chamber,\n image=img_url, role=role)\n phones = get_phones(inner)\n phone = phones.get('home') or phones.get('business')\n office_phone = phones.get('office')\n address = get_address(inner)\n fax = get_fax(inner)\n if address:\n person.add_contact_detail(type='address', value=address,\n note='District Office')\n if phone:\n person.add_contact_detail(type='voice', value=phone,\n note='District Office')\n if fax:\n person.add_contact_detail(type='fax', value=fax,\n note='District Office')\n if email:\n person.add_contact_detail(type='email', value=email,\n note='District Office')\n if office_phone:\n person.add_contact_detail(type='voice', value=office_phone,\n note='Capitol Office')\n person.add_source(url)\n person.add_link(person_url)\n yield person\n", "path": "openstates/id/people.py"}]}
| 1,756 | 146 |
gh_patches_debug_4435
|
rasdani/github-patches
|
git_diff
|
pystiche__pystiche-544
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Documentation theme
We are currently using the [ReadTheDocs `sphinx` theme](https://github.com/readthedocs/sphinx_rtd_theme):
https://github.com/pystiche/pystiche/blob/65f4d787e44b1ffbf7e5b6e48298ed8c7460e5a9/docs/source/conf.py#L85-L90
A lot of other projects in the PyData ecosystem have migrated to one common [base theme](https://pydata-sphinx-theme.readthedocs.io/en/latest/). IMHO it looks a lot more modern in comparison.
In terms of accessibility, I think it would be a also good thing if we made the switch so users familiar with `numpy`'s, `pandas`' or any other of the many libraries using that theme, are instantly familiar how to navigate the documentation.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/source/conf.py`
Content:
```
1 import contextlib
2 import os
3 import re
4 import shutil
5 import warnings
6 from datetime import datetime
7 from distutils.util import strtobool
8 from importlib_metadata import metadata as extract_metadata
9 from os import path
10 from unittest import mock
11 from urllib.parse import urljoin
12
13 from sphinx_gallery.sorting import ExampleTitleSortKey, ExplicitOrder
14 from tqdm import tqdm
15
16 import torch
17
18 from pystiche.misc import download_file
19
20 HERE = path.dirname(__file__)
21 PROJECT_ROOT = path.abspath(path.join(HERE, "..", ".."))
22
23
24 def get_bool_env_var(name, default=False):
25 try:
26 return bool(strtobool(os.environ[name]))
27 except KeyError:
28 return default
29
30
31 GITHUB_ACTIONS = get_bool_env_var("GITHUB_ACTIONS")
32 RTD = get_bool_env_var("READTHEDOCS")
33 CI = GITHUB_ACTIONS or RTD or get_bool_env_var("CI")
34
35
36 def project():
37 extension = None
38
39 metadata = extract_metadata("pystiche")
40 project = metadata["name"]
41 author = metadata["author"]
42 copyright = f"{datetime.now().year}, {author}"
43 release = metadata["version"]
44 version = release.split(".dev")[0]
45 config = dict(
46 project=project,
47 author=author,
48 copyright=copyright,
49 release=release,
50 version=version,
51 )
52
53 return extension, config
54
55
56 def autodoc():
57 extensions = [
58 "sphinx.ext.autodoc",
59 "sphinx.ext.napoleon",
60 "sphinx_autodoc_typehints",
61 ]
62
63 config = None
64
65 return extensions, config
66
67
68 def intersphinx():
69 extension = "sphinx.ext.intersphinx"
70 config = dict(
71 intersphinx_mapping={
72 "python": ("https://docs.python.org/3.6", None),
73 "torch": ("https://pytorch.org/docs/stable/", None),
74 "torchvision": ("https://pytorch.org/docs/stable/", None),
75 "PIL": ("https://pillow.readthedocs.io/en/stable/", None),
76 "numpy": ("https://numpy.org/doc/1.18/", None),
77 "requests": ("https://requests.readthedocs.io/en/stable/", None),
78 "matplotlib": ("https://matplotlib.org", None),
79 }
80 )
81 return extension, config
82
83
84 def html():
85 extension = None
86
87 config = dict(html_theme="sphinx_rtd_theme")
88
89 return extension, config
90
91
92 def latex():
93 extension = None
94
95 with open(path.join(HERE, "custom_cmds.tex"), "r") as fh:
96 custom_cmds = fh.read()
97 config = dict(
98 latex_elements={"preamble": custom_cmds},
99 mathjax_inline=[r"\(" + custom_cmds, r"\)"],
100 mathjax_display=[r"\[" + custom_cmds, r"\]"],
101 )
102
103 return extension, config
104
105
106 def bibtex():
107 extension = "sphinxcontrib.bibtex"
108
109 config = dict(bibtex_bibfiles=["references.bib"])
110
111 return extension, config
112
113
114 def doctest():
115 extension = "sphinx.ext.doctest"
116
117 doctest_global_setup = """
118 import torch
119 from torch import nn
120
121 import pystiche
122
123 import warnings
124 warnings.filterwarnings("ignore", category=FutureWarning)
125
126 from unittest import mock
127
128 patcher = mock.patch(
129 "pystiche.enc.models.utils.ModelMultiLayerEncoder.load_state_dict_from_url"
130 )
131 patcher.start()
132 """
133
134 doctest_global_cleanup = """
135 mock.patch.stopall()
136 """
137 config = dict(
138 doctest_global_setup=doctest_global_setup,
139 doctest_global_cleanup=doctest_global_cleanup,
140 )
141
142 return extension, config
143
144
145 def sphinx_gallery():
146 extension = "sphinx_gallery.gen_gallery"
147
148 plot_gallery = get_bool_env_var("PYSTICHE_PLOT_GALLERY", default=not CI)
149 download_gallery = get_bool_env_var("PYSTICHE_DOWNLOAD_GALLERY", default=CI)
150
151 def download():
152 nonlocal extension
153 nonlocal plot_gallery
154
155 # version and release are available as soon as the project config is loaded
156 version = globals()["version"]
157 release = globals()["release"]
158
159 base = "https://download.pystiche.org/galleries/"
160 is_dev = version != release
161 file = "main.zip" if is_dev else f"v{version}.zip"
162
163 url = urljoin(base, file)
164 print(f"Downloading pre-built galleries from {url}")
165 download_file(url, file)
166
167 with contextlib.suppress(FileNotFoundError):
168 shutil.rmtree(path.join(HERE, "galleries"))
169 shutil.unpack_archive(file, extract_dir=".")
170 os.remove(file)
171
172 extension = "sphinx_gallery.load_style"
173 plot_gallery = False
174
175 def show_cuda_memory(func):
176 torch.cuda.reset_peak_memory_stats()
177 out = func()
178
179 stats = torch.cuda.memory_stats()
180 peak_bytes_usage = stats["allocated_bytes.all.peak"]
181 memory = peak_bytes_usage / 1024 ** 2
182
183 return memory, out
184
185 def patch_tqdm():
186 patchers = [mock.patch("tqdm.std._supports_unicode", return_value=True)]
187
188 display = tqdm.display
189 close = tqdm.close
190 displayed = set()
191
192 def display_only_last(self, msg=None, pos=None):
193 if self.n != self.total or self in displayed:
194 return
195
196 display(self, msg=msg, pos=pos)
197 displayed.add(self)
198
199 patchers.append(mock.patch("tqdm.std.tqdm.display", new=display_only_last))
200
201 def close_(self):
202 close(self)
203 with contextlib.suppress(KeyError):
204 displayed.remove(self)
205
206 patchers.append(mock.patch("tqdm.std.tqdm.close", new=close_))
207
208 for patcher in patchers:
209 patcher.start()
210
211 class PysticheExampleTitleSortKey(ExampleTitleSortKey):
212 def __call__(self, filename):
213 # The beginner example *without* pystiche is placed before the example
214 # *with* to clarify the narrative.
215 if filename == "example_nst_without_pystiche.py":
216 return "1"
217 elif filename == "example_nst_with_pystiche.py":
218 return "2"
219 else:
220 return super().__call__(filename)
221
222 def filter_warnings():
223 # See #https://github.com/pytorch/pytorch/issues/60053
224 warnings.filterwarnings(
225 "ignore",
226 category=UserWarning,
227 message=(
228 re.escape(
229 "Named tensors and all their associated APIs are an experimental "
230 "feature and subject to change. Please do not use them for "
231 "anything important until they are released as stable. (Triggered "
232 "internally at /pytorch/c10/core/TensorImpl.h:1156.)"
233 )
234 ),
235 )
236
237 if download_gallery:
238 download()
239
240 if plot_gallery and not torch.cuda.is_available():
241 msg = (
242 "The galleries will be built, but CUDA is not available. "
243 "This will take a long time."
244 )
245 print(msg)
246
247 sphinx_gallery_conf = {
248 "examples_dirs": path.join(PROJECT_ROOT, "examples"),
249 "gallery_dirs": path.join("galleries", "examples"),
250 "filename_pattern": re.escape(os.sep) + r"example_\w+[.]py$",
251 "ignore_pattern": re.escape(os.sep) + r"_\w+[.]py$",
252 "line_numbers": True,
253 "remove_config_comments": True,
254 "plot_gallery": plot_gallery,
255 "subsection_order": ExplicitOrder(
256 [
257 path.join("..", "..", "examples", sub_gallery)
258 for sub_gallery in ("beginner", "advanced")
259 ]
260 ),
261 "within_subsection_order": PysticheExampleTitleSortKey,
262 "show_memory": show_cuda_memory if torch.cuda.is_available() else True,
263 }
264
265 config = dict(sphinx_gallery_conf=sphinx_gallery_conf)
266 filter_warnings()
267
268 patch_tqdm()
269 filter_warnings()
270
271 return extension, config
272
273
274 def logo():
275 extension = None
276
277 config = dict(html_logo="../../logo.svg")
278
279 return extension, config
280
281
282 extensions = []
283 for loader in (
284 project,
285 autodoc,
286 intersphinx,
287 html,
288 latex,
289 bibtex,
290 doctest,
291 sphinx_gallery,
292 logo,
293 ):
294 extension, config = loader()
295
296 if extension:
297 if isinstance(extension, str):
298 extension = (extension,)
299 extensions.extend(extension)
300
301 if config:
302 globals().update(config)
303
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docs/source/conf.py b/docs/source/conf.py
--- a/docs/source/conf.py
+++ b/docs/source/conf.py
@@ -84,7 +84,16 @@
def html():
extension = None
- config = dict(html_theme="sphinx_rtd_theme")
+ config = dict(
+ html_theme="pydata_sphinx_theme",
+ html_theme_options=dict(show_prev_next=False, use_edit_page_button=True),
+ html_context=dict(
+ github_user="pystiche",
+ github_repo="pystiche",
+ github_version="main",
+ doc_path="docs/source",
+ ),
+ )
return extension, config
|
{"golden_diff": "diff --git a/docs/source/conf.py b/docs/source/conf.py\n--- a/docs/source/conf.py\n+++ b/docs/source/conf.py\n@@ -84,7 +84,16 @@\n def html():\n extension = None\n \n- config = dict(html_theme=\"sphinx_rtd_theme\")\n+ config = dict(\n+ html_theme=\"pydata_sphinx_theme\",\n+ html_theme_options=dict(show_prev_next=False, use_edit_page_button=True),\n+ html_context=dict(\n+ github_user=\"pystiche\",\n+ github_repo=\"pystiche\",\n+ github_version=\"main\",\n+ doc_path=\"docs/source\",\n+ ),\n+ )\n \n return extension, config\n", "issue": "Documentation theme\nWe are currently using the [ReadTheDocs `sphinx` theme](https://github.com/readthedocs/sphinx_rtd_theme):\r\n\r\nhttps://github.com/pystiche/pystiche/blob/65f4d787e44b1ffbf7e5b6e48298ed8c7460e5a9/docs/source/conf.py#L85-L90\r\n\r\nA lot of other projects in the PyData ecosystem have migrated to one common [base theme](https://pydata-sphinx-theme.readthedocs.io/en/latest/). IMHO it looks a lot more modern in comparison. \r\n\r\nIn terms of accessibility, I think it would be a also good thing if we made the switch so users familiar with `numpy`'s, `pandas`' or any other of the many libraries using that theme, are instantly familiar how to navigate the documentation.\r\n\r\n\n", "before_files": [{"content": "import contextlib\nimport os\nimport re\nimport shutil\nimport warnings\nfrom datetime import datetime\nfrom distutils.util import strtobool\nfrom importlib_metadata import metadata as extract_metadata\nfrom os import path\nfrom unittest import mock\nfrom urllib.parse import urljoin\n\nfrom sphinx_gallery.sorting import ExampleTitleSortKey, ExplicitOrder\nfrom tqdm import tqdm\n\nimport torch\n\nfrom pystiche.misc import download_file\n\nHERE = path.dirname(__file__)\nPROJECT_ROOT = path.abspath(path.join(HERE, \"..\", \"..\"))\n\n\ndef get_bool_env_var(name, default=False):\n try:\n return bool(strtobool(os.environ[name]))\n except KeyError:\n return default\n\n\nGITHUB_ACTIONS = get_bool_env_var(\"GITHUB_ACTIONS\")\nRTD = get_bool_env_var(\"READTHEDOCS\")\nCI = GITHUB_ACTIONS or RTD or get_bool_env_var(\"CI\")\n\n\ndef project():\n extension = None\n\n metadata = extract_metadata(\"pystiche\")\n project = metadata[\"name\"]\n author = metadata[\"author\"]\n copyright = f\"{datetime.now().year}, {author}\"\n release = metadata[\"version\"]\n version = release.split(\".dev\")[0]\n config = dict(\n project=project,\n author=author,\n copyright=copyright,\n release=release,\n version=version,\n )\n\n return extension, config\n\n\ndef autodoc():\n extensions = [\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.napoleon\",\n \"sphinx_autodoc_typehints\",\n ]\n\n config = None\n\n return extensions, config\n\n\ndef intersphinx():\n extension = \"sphinx.ext.intersphinx\"\n config = dict(\n intersphinx_mapping={\n \"python\": (\"https://docs.python.org/3.6\", None),\n \"torch\": (\"https://pytorch.org/docs/stable/\", None),\n \"torchvision\": (\"https://pytorch.org/docs/stable/\", None),\n \"PIL\": (\"https://pillow.readthedocs.io/en/stable/\", None),\n \"numpy\": (\"https://numpy.org/doc/1.18/\", None),\n \"requests\": (\"https://requests.readthedocs.io/en/stable/\", None),\n \"matplotlib\": (\"https://matplotlib.org\", None),\n }\n )\n return extension, config\n\n\ndef html():\n extension = None\n\n config = dict(html_theme=\"sphinx_rtd_theme\")\n\n return extension, config\n\n\ndef latex():\n extension = None\n\n with open(path.join(HERE, \"custom_cmds.tex\"), \"r\") as fh:\n custom_cmds = fh.read()\n config = dict(\n latex_elements={\"preamble\": custom_cmds},\n mathjax_inline=[r\"\\(\" + custom_cmds, r\"\\)\"],\n mathjax_display=[r\"\\[\" + custom_cmds, r\"\\]\"],\n )\n\n return extension, config\n\n\ndef bibtex():\n extension = \"sphinxcontrib.bibtex\"\n\n config = dict(bibtex_bibfiles=[\"references.bib\"])\n\n return extension, config\n\n\ndef doctest():\n extension = \"sphinx.ext.doctest\"\n\n doctest_global_setup = \"\"\"\nimport torch\nfrom torch import nn\n\nimport pystiche\n\nimport warnings\nwarnings.filterwarnings(\"ignore\", category=FutureWarning)\n\nfrom unittest import mock\n\npatcher = mock.patch(\n \"pystiche.enc.models.utils.ModelMultiLayerEncoder.load_state_dict_from_url\"\n)\npatcher.start()\n\"\"\"\n\n doctest_global_cleanup = \"\"\"\nmock.patch.stopall()\n\"\"\"\n config = dict(\n doctest_global_setup=doctest_global_setup,\n doctest_global_cleanup=doctest_global_cleanup,\n )\n\n return extension, config\n\n\ndef sphinx_gallery():\n extension = \"sphinx_gallery.gen_gallery\"\n\n plot_gallery = get_bool_env_var(\"PYSTICHE_PLOT_GALLERY\", default=not CI)\n download_gallery = get_bool_env_var(\"PYSTICHE_DOWNLOAD_GALLERY\", default=CI)\n\n def download():\n nonlocal extension\n nonlocal plot_gallery\n\n # version and release are available as soon as the project config is loaded\n version = globals()[\"version\"]\n release = globals()[\"release\"]\n\n base = \"https://download.pystiche.org/galleries/\"\n is_dev = version != release\n file = \"main.zip\" if is_dev else f\"v{version}.zip\"\n\n url = urljoin(base, file)\n print(f\"Downloading pre-built galleries from {url}\")\n download_file(url, file)\n\n with contextlib.suppress(FileNotFoundError):\n shutil.rmtree(path.join(HERE, \"galleries\"))\n shutil.unpack_archive(file, extract_dir=\".\")\n os.remove(file)\n\n extension = \"sphinx_gallery.load_style\"\n plot_gallery = False\n\n def show_cuda_memory(func):\n torch.cuda.reset_peak_memory_stats()\n out = func()\n\n stats = torch.cuda.memory_stats()\n peak_bytes_usage = stats[\"allocated_bytes.all.peak\"]\n memory = peak_bytes_usage / 1024 ** 2\n\n return memory, out\n\n def patch_tqdm():\n patchers = [mock.patch(\"tqdm.std._supports_unicode\", return_value=True)]\n\n display = tqdm.display\n close = tqdm.close\n displayed = set()\n\n def display_only_last(self, msg=None, pos=None):\n if self.n != self.total or self in displayed:\n return\n\n display(self, msg=msg, pos=pos)\n displayed.add(self)\n\n patchers.append(mock.patch(\"tqdm.std.tqdm.display\", new=display_only_last))\n\n def close_(self):\n close(self)\n with contextlib.suppress(KeyError):\n displayed.remove(self)\n\n patchers.append(mock.patch(\"tqdm.std.tqdm.close\", new=close_))\n\n for patcher in patchers:\n patcher.start()\n\n class PysticheExampleTitleSortKey(ExampleTitleSortKey):\n def __call__(self, filename):\n # The beginner example *without* pystiche is placed before the example\n # *with* to clarify the narrative.\n if filename == \"example_nst_without_pystiche.py\":\n return \"1\"\n elif filename == \"example_nst_with_pystiche.py\":\n return \"2\"\n else:\n return super().__call__(filename)\n\n def filter_warnings():\n # See #https://github.com/pytorch/pytorch/issues/60053\n warnings.filterwarnings(\n \"ignore\",\n category=UserWarning,\n message=(\n re.escape(\n \"Named tensors and all their associated APIs are an experimental \"\n \"feature and subject to change. Please do not use them for \"\n \"anything important until they are released as stable. (Triggered \"\n \"internally at /pytorch/c10/core/TensorImpl.h:1156.)\"\n )\n ),\n )\n\n if download_gallery:\n download()\n\n if plot_gallery and not torch.cuda.is_available():\n msg = (\n \"The galleries will be built, but CUDA is not available. \"\n \"This will take a long time.\"\n )\n print(msg)\n\n sphinx_gallery_conf = {\n \"examples_dirs\": path.join(PROJECT_ROOT, \"examples\"),\n \"gallery_dirs\": path.join(\"galleries\", \"examples\"),\n \"filename_pattern\": re.escape(os.sep) + r\"example_\\w+[.]py$\",\n \"ignore_pattern\": re.escape(os.sep) + r\"_\\w+[.]py$\",\n \"line_numbers\": True,\n \"remove_config_comments\": True,\n \"plot_gallery\": plot_gallery,\n \"subsection_order\": ExplicitOrder(\n [\n path.join(\"..\", \"..\", \"examples\", sub_gallery)\n for sub_gallery in (\"beginner\", \"advanced\")\n ]\n ),\n \"within_subsection_order\": PysticheExampleTitleSortKey,\n \"show_memory\": show_cuda_memory if torch.cuda.is_available() else True,\n }\n\n config = dict(sphinx_gallery_conf=sphinx_gallery_conf)\n filter_warnings()\n\n patch_tqdm()\n filter_warnings()\n\n return extension, config\n\n\ndef logo():\n extension = None\n\n config = dict(html_logo=\"../../logo.svg\")\n\n return extension, config\n\n\nextensions = []\nfor loader in (\n project,\n autodoc,\n intersphinx,\n html,\n latex,\n bibtex,\n doctest,\n sphinx_gallery,\n logo,\n):\n extension, config = loader()\n\n if extension:\n if isinstance(extension, str):\n extension = (extension,)\n extensions.extend(extension)\n\n if config:\n globals().update(config)\n", "path": "docs/source/conf.py"}], "after_files": [{"content": "import contextlib\nimport os\nimport re\nimport shutil\nimport warnings\nfrom datetime import datetime\nfrom distutils.util import strtobool\nfrom importlib_metadata import metadata as extract_metadata\nfrom os import path\nfrom unittest import mock\nfrom urllib.parse import urljoin\n\nfrom sphinx_gallery.sorting import ExampleTitleSortKey, ExplicitOrder\nfrom tqdm import tqdm\n\nimport torch\n\nfrom pystiche.misc import download_file\n\nHERE = path.dirname(__file__)\nPROJECT_ROOT = path.abspath(path.join(HERE, \"..\", \"..\"))\n\n\ndef get_bool_env_var(name, default=False):\n try:\n return bool(strtobool(os.environ[name]))\n except KeyError:\n return default\n\n\nGITHUB_ACTIONS = get_bool_env_var(\"GITHUB_ACTIONS\")\nRTD = get_bool_env_var(\"READTHEDOCS\")\nCI = GITHUB_ACTIONS or RTD or get_bool_env_var(\"CI\")\n\n\ndef project():\n extension = None\n\n metadata = extract_metadata(\"pystiche\")\n project = metadata[\"name\"]\n author = metadata[\"author\"]\n copyright = f\"{datetime.now().year}, {author}\"\n release = metadata[\"version\"]\n version = release.split(\".dev\")[0]\n config = dict(\n project=project,\n author=author,\n copyright=copyright,\n release=release,\n version=version,\n )\n\n return extension, config\n\n\ndef autodoc():\n extensions = [\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.napoleon\",\n \"sphinx_autodoc_typehints\",\n ]\n\n config = None\n\n return extensions, config\n\n\ndef intersphinx():\n extension = \"sphinx.ext.intersphinx\"\n config = dict(\n intersphinx_mapping={\n \"python\": (\"https://docs.python.org/3.6\", None),\n \"torch\": (\"https://pytorch.org/docs/stable/\", None),\n \"torchvision\": (\"https://pytorch.org/docs/stable/\", None),\n \"PIL\": (\"https://pillow.readthedocs.io/en/stable/\", None),\n \"numpy\": (\"https://numpy.org/doc/1.18/\", None),\n \"requests\": (\"https://requests.readthedocs.io/en/stable/\", None),\n \"matplotlib\": (\"https://matplotlib.org\", None),\n }\n )\n return extension, config\n\n\ndef html():\n extension = None\n\n config = dict(\n html_theme=\"pydata_sphinx_theme\",\n html_theme_options=dict(show_prev_next=False, use_edit_page_button=True),\n html_context=dict(\n github_user=\"pystiche\",\n github_repo=\"pystiche\",\n github_version=\"main\",\n doc_path=\"docs/source\",\n ),\n )\n\n return extension, config\n\n\ndef latex():\n extension = None\n\n with open(path.join(HERE, \"custom_cmds.tex\"), \"r\") as fh:\n custom_cmds = fh.read()\n config = dict(\n latex_elements={\"preamble\": custom_cmds},\n mathjax_inline=[r\"\\(\" + custom_cmds, r\"\\)\"],\n mathjax_display=[r\"\\[\" + custom_cmds, r\"\\]\"],\n )\n\n return extension, config\n\n\ndef bibtex():\n extension = \"sphinxcontrib.bibtex\"\n\n config = dict(bibtex_bibfiles=[\"references.bib\"])\n\n return extension, config\n\n\ndef doctest():\n extension = \"sphinx.ext.doctest\"\n\n doctest_global_setup = \"\"\"\nimport torch\nfrom torch import nn\n\nimport pystiche\n\nimport warnings\nwarnings.filterwarnings(\"ignore\", category=FutureWarning)\n\nfrom unittest import mock\n\npatcher = mock.patch(\n \"pystiche.enc.models.utils.ModelMultiLayerEncoder.load_state_dict_from_url\"\n)\npatcher.start()\n\"\"\"\n\n doctest_global_cleanup = \"\"\"\nmock.patch.stopall()\n\"\"\"\n config = dict(\n doctest_global_setup=doctest_global_setup,\n doctest_global_cleanup=doctest_global_cleanup,\n )\n\n return extension, config\n\n\ndef sphinx_gallery():\n extension = \"sphinx_gallery.gen_gallery\"\n\n plot_gallery = get_bool_env_var(\"PYSTICHE_PLOT_GALLERY\", default=not CI)\n download_gallery = get_bool_env_var(\"PYSTICHE_DOWNLOAD_GALLERY\", default=CI)\n\n def download():\n nonlocal extension\n nonlocal plot_gallery\n\n # version and release are available as soon as the project config is loaded\n version = globals()[\"version\"]\n release = globals()[\"release\"]\n\n base = \"https://download.pystiche.org/galleries/\"\n is_dev = version != release\n file = \"main.zip\" if is_dev else f\"v{version}.zip\"\n\n url = urljoin(base, file)\n print(f\"Downloading pre-built galleries from {url}\")\n download_file(url, file)\n\n with contextlib.suppress(FileNotFoundError):\n shutil.rmtree(path.join(HERE, \"galleries\"))\n shutil.unpack_archive(file, extract_dir=\".\")\n os.remove(file)\n\n extension = \"sphinx_gallery.load_style\"\n plot_gallery = False\n\n def show_cuda_memory(func):\n torch.cuda.reset_peak_memory_stats()\n out = func()\n\n stats = torch.cuda.memory_stats()\n peak_bytes_usage = stats[\"allocated_bytes.all.peak\"]\n memory = peak_bytes_usage / 1024 ** 2\n\n return memory, out\n\n def patch_tqdm():\n patchers = [mock.patch(\"tqdm.std._supports_unicode\", return_value=True)]\n\n display = tqdm.display\n close = tqdm.close\n displayed = set()\n\n def display_only_last(self, msg=None, pos=None):\n if self.n != self.total or self in displayed:\n return\n\n display(self, msg=msg, pos=pos)\n displayed.add(self)\n\n patchers.append(mock.patch(\"tqdm.std.tqdm.display\", new=display_only_last))\n\n def close_(self):\n close(self)\n with contextlib.suppress(KeyError):\n displayed.remove(self)\n\n patchers.append(mock.patch(\"tqdm.std.tqdm.close\", new=close_))\n\n for patcher in patchers:\n patcher.start()\n\n class PysticheExampleTitleSortKey(ExampleTitleSortKey):\n def __call__(self, filename):\n # The beginner example *without* pystiche is placed before the example\n # *with* to clarify the narrative.\n if filename == \"example_nst_without_pystiche.py\":\n return \"1\"\n elif filename == \"example_nst_with_pystiche.py\":\n return \"2\"\n else:\n return super().__call__(filename)\n\n def filter_warnings():\n # See #https://github.com/pytorch/pytorch/issues/60053\n warnings.filterwarnings(\n \"ignore\",\n category=UserWarning,\n message=(\n re.escape(\n \"Named tensors and all their associated APIs are an experimental \"\n \"feature and subject to change. Please do not use them for \"\n \"anything important until they are released as stable. (Triggered \"\n \"internally at /pytorch/c10/core/TensorImpl.h:1156.)\"\n )\n ),\n )\n\n if download_gallery:\n download()\n\n if plot_gallery and not torch.cuda.is_available():\n msg = (\n \"The galleries will be built, but CUDA is not available. \"\n \"This will take a long time.\"\n )\n print(msg)\n\n sphinx_gallery_conf = {\n \"examples_dirs\": path.join(PROJECT_ROOT, \"examples\"),\n \"gallery_dirs\": path.join(\"galleries\", \"examples\"),\n \"filename_pattern\": re.escape(os.sep) + r\"example_\\w+[.]py$\",\n \"ignore_pattern\": re.escape(os.sep) + r\"_\\w+[.]py$\",\n \"line_numbers\": True,\n \"remove_config_comments\": True,\n \"plot_gallery\": plot_gallery,\n \"subsection_order\": ExplicitOrder(\n [\n path.join(\"..\", \"..\", \"examples\", sub_gallery)\n for sub_gallery in (\"beginner\", \"advanced\")\n ]\n ),\n \"within_subsection_order\": PysticheExampleTitleSortKey,\n \"show_memory\": show_cuda_memory if torch.cuda.is_available() else True,\n }\n\n config = dict(sphinx_gallery_conf=sphinx_gallery_conf)\n filter_warnings()\n\n patch_tqdm()\n filter_warnings()\n\n return extension, config\n\n\ndef logo():\n extension = None\n\n config = dict(html_logo=\"../../logo.svg\")\n\n return extension, config\n\n\nextensions = []\nfor loader in (\n project,\n autodoc,\n intersphinx,\n html,\n latex,\n bibtex,\n doctest,\n sphinx_gallery,\n logo,\n):\n extension, config = loader()\n\n if extension:\n if isinstance(extension, str):\n extension = (extension,)\n extensions.extend(extension)\n\n if config:\n globals().update(config)\n", "path": "docs/source/conf.py"}]}
| 3,138 | 149 |
gh_patches_debug_2085
|
rasdani/github-patches
|
git_diff
|
mampfes__hacs_waste_collection_schedule-556
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add StadtService Brühl
Add Source for StadtService Brühl
Update stadtservice_bruehl_de.md
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `custom_components/waste_collection_schedule/waste_collection_schedule/source/stadtservice_bruehl_de.py`
Content:
```
1 import datetime
2 import logging
3
4 import requests
5 from bs4 import BeautifulSoup
6 from waste_collection_schedule import Collection # type: ignore[attr-defined]
7 from waste_collection_schedule.service.ICS import ICS
8
9 TITLE = "StadtService Brühl"
10 DESCRIPTION = "Source für Abfallkalender StadtService Brühl"
11 URL = "https://stadtservice-bruehl.de"
12 TEST_CASES = {"TEST1": {"strasse": "Badorfer Straße", "hnr": "1"}}
13
14 _LOGGER = logging.getLogger(__name__)
15
16
17 class Source:
18 def __init__(self, strasse, hnr):
19 self._strasse = strasse
20 self._hnr = hnr
21 self._ics = ICS()
22
23 def fetch(self):
24
25 today = datetime.date.today()
26 year = today.year
27 # Get District
28 data = {
29 "street": self._strasse,
30 "street_number": self._hnr,
31 "send_street_and_nummber_data": "",
32 }
33
34 r = requests.post(
35 "https://services.stadtservice-bruehl.de/abfallkalender/", data=data
36 )
37 r.raise_for_status()
38
39 soup = BeautifulSoup(r.text, "html.parser")
40
41 for tag in soup.find_all("input", type="hidden"):
42 # print(tag["name"])
43 # print(tag["value"])
44 if tag["name"] == "post_district":
45 post_district = tag["value"]
46
47 if post_district == "":
48 raise Exception("Unable to get district")
49
50 # print(post_district);
51 # Get ICAL
52 data = {
53 "post_year": year,
54 "post_district": post_district,
55 "post_street_name": self._strasse,
56 "post_street_number": self._hnr,
57 "checked_waste_type_hausmuell": "on",
58 "checked_waste_type_gelber_sack": "on",
59 "checked_waste_type_altpapier": "on",
60 "checked_waste_type_bio": "on",
61 "checked_waste_type_weihnachtsbaeume": "on",
62 "checked_waste_type_strassenlaub": "on",
63 "form_page_id": "9",
64 "reminder_time": "8",
65 "send_ics_download_configurator_data": "",
66 }
67
68 r = requests.post(
69 "https://services.stadtservice-bruehl.de/abfallkalender/individuellen-abfuhrkalender-herunterladen/",
70 data=data,
71 )
72 r.raise_for_status()
73
74 dates = self._ics.convert(r.text)
75
76 entries = []
77 for d in dates:
78 entries.append(Collection(d[0], d[1]))
79
80 return entries
81
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/custom_components/waste_collection_schedule/waste_collection_schedule/source/stadtservice_bruehl_de.py b/custom_components/waste_collection_schedule/waste_collection_schedule/source/stadtservice_bruehl_de.py
--- a/custom_components/waste_collection_schedule/waste_collection_schedule/source/stadtservice_bruehl_de.py
+++ b/custom_components/waste_collection_schedule/waste_collection_schedule/source/stadtservice_bruehl_de.py
@@ -18,7 +18,7 @@
def __init__(self, strasse, hnr):
self._strasse = strasse
self._hnr = hnr
- self._ics = ICS()
+ self._ics = ICS(regex="(.*?) \\- ", split_at=", ")
def fetch(self):
|
{"golden_diff": "diff --git a/custom_components/waste_collection_schedule/waste_collection_schedule/source/stadtservice_bruehl_de.py b/custom_components/waste_collection_schedule/waste_collection_schedule/source/stadtservice_bruehl_de.py\n--- a/custom_components/waste_collection_schedule/waste_collection_schedule/source/stadtservice_bruehl_de.py\n+++ b/custom_components/waste_collection_schedule/waste_collection_schedule/source/stadtservice_bruehl_de.py\n@@ -18,7 +18,7 @@\n def __init__(self, strasse, hnr):\n self._strasse = strasse\n self._hnr = hnr\n- self._ics = ICS()\n+ self._ics = ICS(regex=\"(.*?) \\\\- \", split_at=\", \")\n \n def fetch(self):\n", "issue": "Add StadtService Br\u00fchl\nAdd Source for StadtService Br\u00fchl\r\n\r\nUpdate stadtservice_bruehl_de.md\n", "before_files": [{"content": "import datetime\nimport logging\n\nimport requests\nfrom bs4 import BeautifulSoup\nfrom waste_collection_schedule import Collection # type: ignore[attr-defined]\nfrom waste_collection_schedule.service.ICS import ICS\n\nTITLE = \"StadtService Br\u00fchl\"\nDESCRIPTION = \"Source f\u00fcr Abfallkalender StadtService Br\u00fchl\"\nURL = \"https://stadtservice-bruehl.de\"\nTEST_CASES = {\"TEST1\": {\"strasse\": \"Badorfer Stra\u00dfe\", \"hnr\": \"1\"}}\n\n_LOGGER = logging.getLogger(__name__)\n\n\nclass Source:\n def __init__(self, strasse, hnr):\n self._strasse = strasse\n self._hnr = hnr\n self._ics = ICS()\n\n def fetch(self):\n\n today = datetime.date.today()\n year = today.year\n # Get District\n data = {\n \"street\": self._strasse,\n \"street_number\": self._hnr,\n \"send_street_and_nummber_data\": \"\",\n }\n\n r = requests.post(\n \"https://services.stadtservice-bruehl.de/abfallkalender/\", data=data\n )\n r.raise_for_status()\n\n soup = BeautifulSoup(r.text, \"html.parser\")\n\n for tag in soup.find_all(\"input\", type=\"hidden\"):\n # print(tag[\"name\"])\n # print(tag[\"value\"])\n if tag[\"name\"] == \"post_district\":\n post_district = tag[\"value\"]\n\n if post_district == \"\":\n raise Exception(\"Unable to get district\")\n\n # print(post_district);\n # Get ICAL\n data = {\n \"post_year\": year,\n \"post_district\": post_district,\n \"post_street_name\": self._strasse,\n \"post_street_number\": self._hnr,\n \"checked_waste_type_hausmuell\": \"on\",\n \"checked_waste_type_gelber_sack\": \"on\",\n \"checked_waste_type_altpapier\": \"on\",\n \"checked_waste_type_bio\": \"on\",\n \"checked_waste_type_weihnachtsbaeume\": \"on\",\n \"checked_waste_type_strassenlaub\": \"on\",\n \"form_page_id\": \"9\",\n \"reminder_time\": \"8\",\n \"send_ics_download_configurator_data\": \"\",\n }\n\n r = requests.post(\n \"https://services.stadtservice-bruehl.de/abfallkalender/individuellen-abfuhrkalender-herunterladen/\",\n data=data,\n )\n r.raise_for_status()\n\n dates = self._ics.convert(r.text)\n\n entries = []\n for d in dates:\n entries.append(Collection(d[0], d[1]))\n\n return entries\n", "path": "custom_components/waste_collection_schedule/waste_collection_schedule/source/stadtservice_bruehl_de.py"}], "after_files": [{"content": "import datetime\nimport logging\n\nimport requests\nfrom bs4 import BeautifulSoup\nfrom waste_collection_schedule import Collection # type: ignore[attr-defined]\nfrom waste_collection_schedule.service.ICS import ICS\n\nTITLE = \"StadtService Br\u00fchl\"\nDESCRIPTION = \"Source f\u00fcr Abfallkalender StadtService Br\u00fchl\"\nURL = \"https://stadtservice-bruehl.de\"\nTEST_CASES = {\"TEST1\": {\"strasse\": \"Badorfer Stra\u00dfe\", \"hnr\": \"1\"}}\n\n_LOGGER = logging.getLogger(__name__)\n\n\nclass Source:\n def __init__(self, strasse, hnr):\n self._strasse = strasse\n self._hnr = hnr\n self._ics = ICS(regex=\"(.*?) \\\\- \", split_at=\", \")\n\n def fetch(self):\n\n today = datetime.date.today()\n year = today.year\n # Get District\n data = {\n \"street\": self._strasse,\n \"street_number\": self._hnr,\n \"send_street_and_nummber_data\": \"\",\n }\n\n r = requests.post(\n \"https://services.stadtservice-bruehl.de/abfallkalender/\", data=data\n )\n r.raise_for_status()\n\n soup = BeautifulSoup(r.text, \"html.parser\")\n\n for tag in soup.find_all(\"input\", type=\"hidden\"):\n # print(tag[\"name\"])\n # print(tag[\"value\"])\n if tag[\"name\"] == \"post_district\":\n post_district = tag[\"value\"]\n\n if post_district == \"\":\n raise Exception(\"Unable to get district\")\n\n # print(post_district);\n # Get ICAL\n data = {\n \"post_year\": year,\n \"post_district\": post_district,\n \"post_street_name\": self._strasse,\n \"post_street_number\": self._hnr,\n \"checked_waste_type_hausmuell\": \"on\",\n \"checked_waste_type_gelber_sack\": \"on\",\n \"checked_waste_type_altpapier\": \"on\",\n \"checked_waste_type_bio\": \"on\",\n \"checked_waste_type_weihnachtsbaeume\": \"on\",\n \"checked_waste_type_strassenlaub\": \"on\",\n \"form_page_id\": \"9\",\n \"reminder_time\": \"8\",\n \"send_ics_download_configurator_data\": \"\",\n }\n\n r = requests.post(\n \"https://services.stadtservice-bruehl.de/abfallkalender/individuellen-abfuhrkalender-herunterladen/\",\n data=data,\n )\n r.raise_for_status()\n\n dates = self._ics.convert(r.text)\n\n entries = []\n for d in dates:\n entries.append(Collection(d[0], d[1]))\n\n return entries\n", "path": "custom_components/waste_collection_schedule/waste_collection_schedule/source/stadtservice_bruehl_de.py"}]}
| 1,040 | 168 |
gh_patches_debug_4795
|
rasdani/github-patches
|
git_diff
|
netket__netket-211
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Get rid of netket::Qubits class
`netket::Qubits` is really just a `CustomHilbert` with `localstates = {0.0, 1.0}`. No need for code duplication.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `netket/hilbert.py`
Content:
```
1 from ._C_netket.hilbert import *
2
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/netket/hilbert.py b/netket/hilbert.py
--- a/netket/hilbert.py
+++ b/netket/hilbert.py
@@ -1 +1,22 @@
from ._C_netket.hilbert import *
+
+
+def Qubit(graph):
+ """
+ Constructs a new ``Qubit`` given a graph.
+
+ Args:
+ graph: Graph representation of sites.
+
+ Examples:
+ Simple qubit hilbert space.
+
+ ```python
+ >>> from netket.graph import Hypercube
+ >>> from netket.hilbert import Qubit
+ >>> g = Hypercube(length=10,n_dim=2,pbc=True)
+ >>> hi = Qubit(graph=g)
+ >>> print(hi.size)
+ 100
+ """
+ return CustomHilbert(graph, local_states=[0, 1])
|
{"golden_diff": "diff --git a/netket/hilbert.py b/netket/hilbert.py\n--- a/netket/hilbert.py\n+++ b/netket/hilbert.py\n@@ -1 +1,22 @@\n from ._C_netket.hilbert import *\n+\n+\n+def Qubit(graph):\n+ \"\"\"\n+ Constructs a new ``Qubit`` given a graph.\n+\n+ Args:\n+ graph: Graph representation of sites.\n+\n+ Examples:\n+ Simple qubit hilbert space.\n+\n+ ```python\n+ >>> from netket.graph import Hypercube\n+ >>> from netket.hilbert import Qubit\n+ >>> g = Hypercube(length=10,n_dim=2,pbc=True)\n+ >>> hi = Qubit(graph=g)\n+ >>> print(hi.size)\n+ 100\n+ \"\"\"\n+ return CustomHilbert(graph, local_states=[0, 1])\n", "issue": "Get rid of netket::Qubits class\n`netket::Qubits` is really just a `CustomHilbert` with `localstates = {0.0, 1.0}`. No need for code duplication.\n", "before_files": [{"content": "from ._C_netket.hilbert import *\n", "path": "netket/hilbert.py"}], "after_files": [{"content": "from ._C_netket.hilbert import *\n\n\ndef Qubit(graph):\n \"\"\"\n Constructs a new ``Qubit`` given a graph.\n\n Args:\n graph: Graph representation of sites.\n\n Examples:\n Simple qubit hilbert space.\n\n ```python\n >>> from netket.graph import Hypercube\n >>> from netket.hilbert import Qubit\n >>> g = Hypercube(length=10,n_dim=2,pbc=True)\n >>> hi = Qubit(graph=g)\n >>> print(hi.size)\n 100\n \"\"\"\n return CustomHilbert(graph, local_states=[0, 1])\n", "path": "netket/hilbert.py"}]}
| 321 | 201 |
gh_patches_debug_16453
|
rasdani/github-patches
|
git_diff
|
ivy-llc__ivy-18206
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
cast
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ivy/functional/frontends/paddle/tensor/manipulation.py`
Content:
```
1 # global
2 import ivy
3 from ivy.functional.frontends.paddle.func_wrapper import (
4 to_ivy_arrays_and_back,
5 )
6 from ivy.func_wrapper import with_unsupported_dtypes
7
8
9 @to_ivy_arrays_and_back
10 def reshape(x, shape):
11 return ivy.reshape(x, shape)
12
13
14 @with_unsupported_dtypes({"2.5.0 and below": ("float16", "bfloat16")}, "paddle")
15 @to_ivy_arrays_and_back
16 def abs(x, name=None):
17 return ivy.abs(x)
18
19
20 absolute = abs
21
22
23 @to_ivy_arrays_and_back
24 def stack(x, axis=0, name=None):
25 return ivy.stack(x, axis=axis)
26
27
28 @with_unsupported_dtypes({"2.5.0 and below": ("int8", "int16")}, "paddle")
29 @to_ivy_arrays_and_back
30 def concat(x, axis, name=None):
31 return ivy.concat(x, axis=axis)
32
33
34 @with_unsupported_dtypes(
35 {"2.5.0 and below": ("int8", "uint8", "int16", "float16")},
36 "paddle",
37 )
38 @to_ivy_arrays_and_back
39 def tile(x, repeat_times, name=None):
40 return ivy.tile(x, repeats=repeat_times)
41
42
43 @with_unsupported_dtypes(
44 {"2.5.0 and below": ("int16", "complex64", "complex128")},
45 "paddle",
46 )
47 @to_ivy_arrays_and_back
48 def split(x, num_or_sections, axis=0, name=None):
49 return ivy.split(x, num_or_size_splits=num_or_sections, axis=axis)
50
51
52 @with_unsupported_dtypes(
53 {"2.5.0 and below": ("float16", "bfloat16", "int8", "int16")},
54 "paddle",
55 )
56 @to_ivy_arrays_and_back
57 def squeeze(x, axis=None, name=None):
58 return ivy.squeeze(x, axis=axis)
59
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ivy/functional/frontends/paddle/tensor/manipulation.py b/ivy/functional/frontends/paddle/tensor/manipulation.py
--- a/ivy/functional/frontends/paddle/tensor/manipulation.py
+++ b/ivy/functional/frontends/paddle/tensor/manipulation.py
@@ -3,7 +3,10 @@
from ivy.functional.frontends.paddle.func_wrapper import (
to_ivy_arrays_and_back,
)
-from ivy.func_wrapper import with_unsupported_dtypes
+from ivy.func_wrapper import (
+ with_unsupported_dtypes,
+ with_supported_dtypes,
+)
@to_ivy_arrays_and_back
@@ -56,3 +59,22 @@
@to_ivy_arrays_and_back
def squeeze(x, axis=None, name=None):
return ivy.squeeze(x, axis=axis)
+
+
+@with_supported_dtypes(
+ {
+ "2.5.0 and below": (
+ "bool",
+ "float16",
+ "float32",
+ "float64",
+ "int32",
+ "int64",
+ "uint8",
+ )
+ },
+ "paddle",
+)
+@to_ivy_arrays_and_back
+def cast(x, dtype):
+ return ivy.astype(x, dtype)
|
{"golden_diff": "diff --git a/ivy/functional/frontends/paddle/tensor/manipulation.py b/ivy/functional/frontends/paddle/tensor/manipulation.py\n--- a/ivy/functional/frontends/paddle/tensor/manipulation.py\n+++ b/ivy/functional/frontends/paddle/tensor/manipulation.py\n@@ -3,7 +3,10 @@\n from ivy.functional.frontends.paddle.func_wrapper import (\n to_ivy_arrays_and_back,\n )\n-from ivy.func_wrapper import with_unsupported_dtypes\n+from ivy.func_wrapper import (\n+ with_unsupported_dtypes,\n+ with_supported_dtypes,\n+)\n \n \n @to_ivy_arrays_and_back\n@@ -56,3 +59,22 @@\n @to_ivy_arrays_and_back\n def squeeze(x, axis=None, name=None):\n return ivy.squeeze(x, axis=axis)\n+\n+\n+@with_supported_dtypes(\n+ {\n+ \"2.5.0 and below\": (\n+ \"bool\",\n+ \"float16\",\n+ \"float32\",\n+ \"float64\",\n+ \"int32\",\n+ \"int64\",\n+ \"uint8\",\n+ )\n+ },\n+ \"paddle\",\n+)\n+@to_ivy_arrays_and_back\n+def cast(x, dtype):\n+ return ivy.astype(x, dtype)\n", "issue": "cast\n\n", "before_files": [{"content": "# global\nimport ivy\nfrom ivy.functional.frontends.paddle.func_wrapper import (\n to_ivy_arrays_and_back,\n)\nfrom ivy.func_wrapper import with_unsupported_dtypes\n\n\n@to_ivy_arrays_and_back\ndef reshape(x, shape):\n return ivy.reshape(x, shape)\n\n\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef abs(x, name=None):\n return ivy.abs(x)\n\n\nabsolute = abs\n\n\n@to_ivy_arrays_and_back\ndef stack(x, axis=0, name=None):\n return ivy.stack(x, axis=axis)\n\n\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"int8\", \"int16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef concat(x, axis, name=None):\n return ivy.concat(x, axis=axis)\n\n\n@with_unsupported_dtypes(\n {\"2.5.0 and below\": (\"int8\", \"uint8\", \"int16\", \"float16\")},\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef tile(x, repeat_times, name=None):\n return ivy.tile(x, repeats=repeat_times)\n\n\n@with_unsupported_dtypes(\n {\"2.5.0 and below\": (\"int16\", \"complex64\", \"complex128\")},\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef split(x, num_or_sections, axis=0, name=None):\n return ivy.split(x, num_or_size_splits=num_or_sections, axis=axis)\n\n\n@with_unsupported_dtypes(\n {\"2.5.0 and below\": (\"float16\", \"bfloat16\", \"int8\", \"int16\")},\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef squeeze(x, axis=None, name=None):\n return ivy.squeeze(x, axis=axis)\n", "path": "ivy/functional/frontends/paddle/tensor/manipulation.py"}], "after_files": [{"content": "# global\nimport ivy\nfrom ivy.functional.frontends.paddle.func_wrapper import (\n to_ivy_arrays_and_back,\n)\nfrom ivy.func_wrapper import (\n with_unsupported_dtypes,\n with_supported_dtypes,\n)\n\n\n@to_ivy_arrays_and_back\ndef reshape(x, shape):\n return ivy.reshape(x, shape)\n\n\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef abs(x, name=None):\n return ivy.abs(x)\n\n\nabsolute = abs\n\n\n@to_ivy_arrays_and_back\ndef stack(x, axis=0, name=None):\n return ivy.stack(x, axis=axis)\n\n\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"int8\", \"int16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef concat(x, axis, name=None):\n return ivy.concat(x, axis=axis)\n\n\n@with_unsupported_dtypes(\n {\"2.5.0 and below\": (\"int8\", \"uint8\", \"int16\", \"float16\")},\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef tile(x, repeat_times, name=None):\n return ivy.tile(x, repeats=repeat_times)\n\n\n@with_unsupported_dtypes(\n {\"2.5.0 and below\": (\"int16\", \"complex64\", \"complex128\")},\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef split(x, num_or_sections, axis=0, name=None):\n return ivy.split(x, num_or_size_splits=num_or_sections, axis=axis)\n\n\n@with_unsupported_dtypes(\n {\"2.5.0 and below\": (\"float16\", \"bfloat16\", \"int8\", \"int16\")},\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef squeeze(x, axis=None, name=None):\n return ivy.squeeze(x, axis=axis)\n\n\n@with_supported_dtypes(\n {\n \"2.5.0 and below\": (\n \"bool\",\n \"float16\",\n \"float32\",\n \"float64\",\n \"int32\",\n \"int64\",\n \"uint8\",\n )\n },\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef cast(x, dtype):\n return ivy.astype(x, dtype)\n", "path": "ivy/functional/frontends/paddle/tensor/manipulation.py"}]}
| 825 | 298 |
gh_patches_debug_19481
|
rasdani/github-patches
|
git_diff
|
rlworkgroup__garage-1770
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Export TaskSamplers in __init__
This will put them in the public API and make them visible in the API docs
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/garage/experiment/__init__.py`
Content:
```
1 """Experiment functions."""
2 from garage.experiment.local_runner import LocalRunner
3 from garage.experiment.local_tf_runner import LocalTFRunner
4 from garage.experiment.meta_evaluator import MetaEvaluator
5 from garage.experiment.snapshotter import SnapshotConfig, Snapshotter
6 from garage.experiment.task_sampler import TaskSampler
7
8 __all__ = [
9 'LocalRunner',
10 'LocalTFRunner',
11 'MetaEvaluator',
12 'Snapshotter',
13 'SnapshotConfig',
14 'TaskSampler',
15 ]
16
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/garage/experiment/__init__.py b/src/garage/experiment/__init__.py
--- a/src/garage/experiment/__init__.py
+++ b/src/garage/experiment/__init__.py
@@ -1,9 +1,15 @@
"""Experiment functions."""
+# yapf: disable
from garage.experiment.local_runner import LocalRunner
from garage.experiment.local_tf_runner import LocalTFRunner
from garage.experiment.meta_evaluator import MetaEvaluator
from garage.experiment.snapshotter import SnapshotConfig, Snapshotter
-from garage.experiment.task_sampler import TaskSampler
+from garage.experiment.task_sampler import (ConstructEnvsSampler,
+ EnvPoolSampler,
+ SetTaskSampler,
+ TaskSampler)
+
+# yapf: enable
__all__ = [
'LocalRunner',
@@ -12,4 +18,7 @@
'Snapshotter',
'SnapshotConfig',
'TaskSampler',
+ 'ConstructEnvsSampler',
+ 'EnvPoolSampler',
+ 'SetTaskSampler',
]
|
{"golden_diff": "diff --git a/src/garage/experiment/__init__.py b/src/garage/experiment/__init__.py\n--- a/src/garage/experiment/__init__.py\n+++ b/src/garage/experiment/__init__.py\n@@ -1,9 +1,15 @@\n \"\"\"Experiment functions.\"\"\"\n+# yapf: disable\n from garage.experiment.local_runner import LocalRunner\n from garage.experiment.local_tf_runner import LocalTFRunner\n from garage.experiment.meta_evaluator import MetaEvaluator\n from garage.experiment.snapshotter import SnapshotConfig, Snapshotter\n-from garage.experiment.task_sampler import TaskSampler\n+from garage.experiment.task_sampler import (ConstructEnvsSampler,\n+ EnvPoolSampler,\n+ SetTaskSampler,\n+ TaskSampler)\n+\n+# yapf: enable\n \n __all__ = [\n 'LocalRunner',\n@@ -12,4 +18,7 @@\n 'Snapshotter',\n 'SnapshotConfig',\n 'TaskSampler',\n+ 'ConstructEnvsSampler',\n+ 'EnvPoolSampler',\n+ 'SetTaskSampler',\n ]\n", "issue": "Export TaskSamplers in __init__\nThis will put them in the public API and make them visible in the API docs\n", "before_files": [{"content": "\"\"\"Experiment functions.\"\"\"\nfrom garage.experiment.local_runner import LocalRunner\nfrom garage.experiment.local_tf_runner import LocalTFRunner\nfrom garage.experiment.meta_evaluator import MetaEvaluator\nfrom garage.experiment.snapshotter import SnapshotConfig, Snapshotter\nfrom garage.experiment.task_sampler import TaskSampler\n\n__all__ = [\n 'LocalRunner',\n 'LocalTFRunner',\n 'MetaEvaluator',\n 'Snapshotter',\n 'SnapshotConfig',\n 'TaskSampler',\n]\n", "path": "src/garage/experiment/__init__.py"}], "after_files": [{"content": "\"\"\"Experiment functions.\"\"\"\n# yapf: disable\nfrom garage.experiment.local_runner import LocalRunner\nfrom garage.experiment.local_tf_runner import LocalTFRunner\nfrom garage.experiment.meta_evaluator import MetaEvaluator\nfrom garage.experiment.snapshotter import SnapshotConfig, Snapshotter\nfrom garage.experiment.task_sampler import (ConstructEnvsSampler,\n EnvPoolSampler,\n SetTaskSampler,\n TaskSampler)\n\n# yapf: enable\n\n__all__ = [\n 'LocalRunner',\n 'LocalTFRunner',\n 'MetaEvaluator',\n 'Snapshotter',\n 'SnapshotConfig',\n 'TaskSampler',\n 'ConstructEnvsSampler',\n 'EnvPoolSampler',\n 'SetTaskSampler',\n]\n", "path": "src/garage/experiment/__init__.py"}]}
| 410 | 227 |
gh_patches_debug_26652
|
rasdani/github-patches
|
git_diff
|
easybuilders__easybuild-framework-2786
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Issue running tests
```
[mboisson@build-node easybuild-framework]$ python -O -m test.framework.suite test_update
INFO: This is (based on) vsc.install.shared_setup 0.10.17
Traceback (most recent call last):
File "/cvmfs/soft.computecanada.ca/nix/store/4x0hqnpd0hfh62m3apkxmz8hz3hlsikx-python-2.7.13-env/lib/python2.7/runpy.py", line 174, in _run_module_as_main
"__main__", fname, loader, pkg_name)
File "/cvmfs/soft.computecanada.ca/nix/store/4x0hqnpd0hfh62m3apkxmz8hz3hlsikx-python-2.7.13-env/lib/python2.7/runpy.py", line 72, in _run_code
exec code in run_globals
File "/home/mboisson/git/easybuild-framework/test/framework/suite.py", line 44, in <module>
import test.framework.asyncprocess as a
File "/home/mboisson/git/easybuild-framework/test/framework/asyncprocess.py", line 34, in <module>
from test.framework.utilities import EnhancedTestCase
File "/home/mboisson/git/easybuild-framework/test/framework/utilities.py", line 71, in <module>
go = EasyBuildOptions(go_useconfigfiles=False)
File "easybuild/tools/options.py", line 246, in __init__
super(EasyBuildOptions, self).__init__(*args, **kwargs)
File "/cvmfs/soft.computecanada.ca/nix/store/4x0hqnpd0hfh62m3apkxmz8hz3hlsikx-python-2.7.13-env/lib/python2.7/site-packages/vsc/utils/generaloption.py", line 982, in __init__
self.main_options()
File "/cvmfs/soft.computecanada.ca/nix/store/4x0hqnpd0hfh62m3apkxmz8hz3hlsikx-python-2.7.13-env/lib/python2.7/site-packages/vsc/utils/generaloption.py", line 1058, in main_options
fn()
File "easybuild/tools/options.py", line 493, in config_options
'choice', 'store', DEFAULT_REPOSITORY, sorted(avail_repositories().keys())),
File "easybuild/tools/repository/repository.py", line 152, in avail_repositories
raise EasyBuildError("avail_repositories: FileRepository missing from list of repositories")
easybuild.tools.build_log.EasyBuildError: 'avail_repositories: FileRepository missing from list of repositories'
```
Opening an issue for @boegel
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `easybuild/tools/utilities.py`
Content:
```
1 # #
2 # Copyright 2012-2019 Ghent University
3 #
4 # This file is part of EasyBuild,
5 # originally created by the HPC team of Ghent University (http://ugent.be/hpc/en),
6 # with support of Ghent University (http://ugent.be/hpc),
7 # the Flemish Supercomputer Centre (VSC) (https://www.vscentrum.be),
8 # Flemish Research Foundation (FWO) (http://www.fwo.be/en)
9 # and the Department of Economy, Science and Innovation (EWI) (http://www.ewi-vlaanderen.be/en).
10 #
11 # https://github.com/easybuilders/easybuild
12 #
13 # EasyBuild is free software: you can redistribute it and/or modify
14 # it under the terms of the GNU General Public License as published by
15 # the Free Software Foundation v2.
16 #
17 # EasyBuild is distributed in the hope that it will be useful,
18 # but WITHOUT ANY WARRANTY; without even the implied warranty of
19 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
20 # GNU General Public License for more details.
21 #
22 # You should have received a copy of the GNU General Public License
23 # along with EasyBuild. If not, see <http://www.gnu.org/licenses/>.
24 # #
25 """
26 Module with various utility functions
27
28 :author: Kenneth Hoste (Ghent University)
29 """
30 import glob
31 import os
32 import string
33 import sys
34 from vsc.utils import fancylogger
35
36 from easybuild.tools.build_log import EasyBuildError, print_msg
37 from easybuild.tools.config import build_option
38
39
40 _log = fancylogger.getLogger('tools.utilities')
41
42
43 # a list of all ascii characters
44 ASCII_CHARS = string.maketrans('', '')
45 # a list of all unwanted ascii characters (we only want to keep digits, letters and _)
46 UNWANTED_CHARS = ASCII_CHARS.translate(ASCII_CHARS, string.digits + string.ascii_letters + "_")
47
48
49 def read_environment(env_vars, strict=False):
50 """NO LONGER SUPPORTED: use read_environment from easybuild.tools.environment instead"""
51 _log.nosupport("read_environment has been moved to easybuild.tools.environment", '2.0')
52
53
54 def flatten(lst):
55 """Flatten a list of lists."""
56 res = []
57 for x in lst:
58 res.extend(x)
59 return res
60
61
62 def quote_str(val, escape_newline=False, prefer_single_quotes=False):
63 """
64 Obtain a new value to be used in string replacement context.
65
66 For non-string values, it just returns the exact same value.
67
68 For string values, it tries to escape the string in quotes, e.g.,
69 foo becomes 'foo', foo'bar becomes "foo'bar",
70 foo'bar"baz becomes \"\"\"foo'bar"baz\"\"\", etc.
71
72 :param escape_newline: wrap strings that include a newline in triple quotes
73 """
74
75 if isinstance(val, basestring):
76 # forced triple double quotes
77 if ("'" in val and '"' in val) or (escape_newline and '\n' in val):
78 return '"""%s"""' % val
79 # single quotes to escape double quote used in strings
80 elif '"' in val:
81 return "'%s'" % val
82 # if single quotes are preferred, use single quotes;
83 # unless a space or a single quote are in the string
84 elif prefer_single_quotes and "'" not in val and ' ' not in val:
85 return "'%s'" % val
86 # fallback on double quotes (required in tcl syntax)
87 else:
88 return '"%s"' % val
89 else:
90 return val
91
92
93 def quote_py_str(val):
94 """Version of quote_str specific for generating use in Python context (e.g., easyconfig parameters)."""
95 return quote_str(val, escape_newline=True, prefer_single_quotes=True)
96
97
98 def remove_unwanted_chars(inputstring):
99 """Remove unwanted characters from the given string and return a copy
100
101 All non-letter and non-numeral characters are considered unwanted except for underscore ('_'), see UNWANTED_CHARS.
102 """
103 return inputstring.translate(ASCII_CHARS, UNWANTED_CHARS)
104
105
106 def import_available_modules(namespace):
107 """
108 Import all available module in the specified namespace.
109
110 :param namespace: The namespace to import modules from.
111 """
112 modules = []
113 for path in sys.path:
114 for module in sorted(glob.glob(os.path.sep.join([path] + namespace.split('.') + ['*.py']))):
115 if not module.endswith('__init__.py'):
116 mod_name = module.split(os.path.sep)[-1].split('.')[0]
117 modpath = '.'.join([namespace, mod_name])
118 _log.debug("importing module %s", modpath)
119 try:
120 mod = __import__(modpath, globals(), locals(), [''])
121 except ImportError as err:
122 raise EasyBuildError("import_available_modules: Failed to import %s: %s", modpath, err)
123 modules.append(mod)
124 return modules
125
126
127 def only_if_module_is_available(modnames, pkgname=None, url=None):
128 """Decorator to guard functions/methods against missing required module with specified name."""
129 if pkgname and url is None:
130 url = 'https://pypi.python.org/pypi/%s' % pkgname
131
132 if isinstance(modnames, basestring):
133 modnames = (modnames,)
134
135 def wrap(orig):
136 """Decorated function, raises ImportError if specified module is not available."""
137 try:
138 imported = None
139 for modname in modnames:
140 try:
141 __import__(modname)
142 imported = modname
143 break
144 except ImportError:
145 pass
146
147 if imported is None:
148 raise ImportError("None of the specified modules %s is available" % ', '.join(modnames))
149 else:
150 return orig
151
152 except ImportError as err:
153 def error(*args, **kwargs):
154 msg = "%s; required module '%s' is not available" % (err, modname)
155 if pkgname:
156 msg += " (provided by Python package %s, available from %s)" % (pkgname, url)
157 elif url:
158 msg += " (available from %s)" % url
159 raise EasyBuildError("ImportError: %s", msg)
160 return error
161
162 return wrap
163
164
165 def trace_msg(message, silent=False):
166 """Print trace message."""
167 if build_option('trace'):
168 print_msg(' >> ' + message, prefix=False)
169
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/easybuild/tools/utilities.py b/easybuild/tools/utilities.py
--- a/easybuild/tools/utilities.py
+++ b/easybuild/tools/utilities.py
@@ -111,7 +111,16 @@
"""
modules = []
for path in sys.path:
- for module in sorted(glob.glob(os.path.sep.join([path] + namespace.split('.') + ['*.py']))):
+
+ cand_modpath_glob = os.path.sep.join([path] + namespace.split('.') + ['*.py'])
+
+ # if sys.path entry being considered is the empty string
+ # (which corresponds to Python packages/modules in current working directory being considered),
+ # we need to strip off / from the start of the path
+ if path == '' and cand_modpath_glob.startswith(os.path.sep):
+ cand_modpath_glob = cand_modpath_glob.lstrip(os.path.sep)
+
+ for module in sorted(glob.glob(cand_modpath_glob)):
if not module.endswith('__init__.py'):
mod_name = module.split(os.path.sep)[-1].split('.')[0]
modpath = '.'.join([namespace, mod_name])
@@ -120,7 +129,10 @@
mod = __import__(modpath, globals(), locals(), [''])
except ImportError as err:
raise EasyBuildError("import_available_modules: Failed to import %s: %s", modpath, err)
- modules.append(mod)
+
+ if mod not in modules:
+ modules.append(mod)
+
return modules
|
{"golden_diff": "diff --git a/easybuild/tools/utilities.py b/easybuild/tools/utilities.py\n--- a/easybuild/tools/utilities.py\n+++ b/easybuild/tools/utilities.py\n@@ -111,7 +111,16 @@\n \"\"\"\n modules = []\n for path in sys.path:\n- for module in sorted(glob.glob(os.path.sep.join([path] + namespace.split('.') + ['*.py']))):\n+\n+ cand_modpath_glob = os.path.sep.join([path] + namespace.split('.') + ['*.py'])\n+\n+ # if sys.path entry being considered is the empty string\n+ # (which corresponds to Python packages/modules in current working directory being considered),\n+ # we need to strip off / from the start of the path\n+ if path == '' and cand_modpath_glob.startswith(os.path.sep):\n+ cand_modpath_glob = cand_modpath_glob.lstrip(os.path.sep)\n+\n+ for module in sorted(glob.glob(cand_modpath_glob)):\n if not module.endswith('__init__.py'):\n mod_name = module.split(os.path.sep)[-1].split('.')[0]\n modpath = '.'.join([namespace, mod_name])\n@@ -120,7 +129,10 @@\n mod = __import__(modpath, globals(), locals(), [''])\n except ImportError as err:\n raise EasyBuildError(\"import_available_modules: Failed to import %s: %s\", modpath, err)\n- modules.append(mod)\n+\n+ if mod not in modules:\n+ modules.append(mod)\n+\n return modules\n", "issue": "Issue running tests\n```\r\n[mboisson@build-node easybuild-framework]$ python -O -m test.framework.suite test_update\r\nINFO: This is (based on) vsc.install.shared_setup 0.10.17\r\nTraceback (most recent call last):\r\n File \"/cvmfs/soft.computecanada.ca/nix/store/4x0hqnpd0hfh62m3apkxmz8hz3hlsikx-python-2.7.13-env/lib/python2.7/runpy.py\", line 174, in _run_module_as_main\r\n \"__main__\", fname, loader, pkg_name)\r\n File \"/cvmfs/soft.computecanada.ca/nix/store/4x0hqnpd0hfh62m3apkxmz8hz3hlsikx-python-2.7.13-env/lib/python2.7/runpy.py\", line 72, in _run_code\r\n exec code in run_globals\r\n File \"/home/mboisson/git/easybuild-framework/test/framework/suite.py\", line 44, in <module>\r\n import test.framework.asyncprocess as a\r\n File \"/home/mboisson/git/easybuild-framework/test/framework/asyncprocess.py\", line 34, in <module>\r\n from test.framework.utilities import EnhancedTestCase\r\n File \"/home/mboisson/git/easybuild-framework/test/framework/utilities.py\", line 71, in <module>\r\n go = EasyBuildOptions(go_useconfigfiles=False)\r\n File \"easybuild/tools/options.py\", line 246, in __init__\r\n super(EasyBuildOptions, self).__init__(*args, **kwargs)\r\n File \"/cvmfs/soft.computecanada.ca/nix/store/4x0hqnpd0hfh62m3apkxmz8hz3hlsikx-python-2.7.13-env/lib/python2.7/site-packages/vsc/utils/generaloption.py\", line 982, in __init__\r\n self.main_options()\r\n File \"/cvmfs/soft.computecanada.ca/nix/store/4x0hqnpd0hfh62m3apkxmz8hz3hlsikx-python-2.7.13-env/lib/python2.7/site-packages/vsc/utils/generaloption.py\", line 1058, in main_options\r\n fn()\r\n File \"easybuild/tools/options.py\", line 493, in config_options\r\n 'choice', 'store', DEFAULT_REPOSITORY, sorted(avail_repositories().keys())),\r\n File \"easybuild/tools/repository/repository.py\", line 152, in avail_repositories\r\n raise EasyBuildError(\"avail_repositories: FileRepository missing from list of repositories\")\r\neasybuild.tools.build_log.EasyBuildError: 'avail_repositories: FileRepository missing from list of repositories'\r\n``` \r\n\r\nOpening an issue for @boegel \n", "before_files": [{"content": "# #\n# Copyright 2012-2019 Ghent University\n#\n# This file is part of EasyBuild,\n# originally created by the HPC team of Ghent University (http://ugent.be/hpc/en),\n# with support of Ghent University (http://ugent.be/hpc),\n# the Flemish Supercomputer Centre (VSC) (https://www.vscentrum.be),\n# Flemish Research Foundation (FWO) (http://www.fwo.be/en)\n# and the Department of Economy, Science and Innovation (EWI) (http://www.ewi-vlaanderen.be/en).\n#\n# https://github.com/easybuilders/easybuild\n#\n# EasyBuild is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation v2.\n#\n# EasyBuild is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with EasyBuild. If not, see <http://www.gnu.org/licenses/>.\n# #\n\"\"\"\nModule with various utility functions\n\n:author: Kenneth Hoste (Ghent University)\n\"\"\"\nimport glob\nimport os\nimport string\nimport sys\nfrom vsc.utils import fancylogger\n\nfrom easybuild.tools.build_log import EasyBuildError, print_msg\nfrom easybuild.tools.config import build_option\n\n\n_log = fancylogger.getLogger('tools.utilities')\n\n\n# a list of all ascii characters\nASCII_CHARS = string.maketrans('', '')\n# a list of all unwanted ascii characters (we only want to keep digits, letters and _)\nUNWANTED_CHARS = ASCII_CHARS.translate(ASCII_CHARS, string.digits + string.ascii_letters + \"_\")\n\n\ndef read_environment(env_vars, strict=False):\n \"\"\"NO LONGER SUPPORTED: use read_environment from easybuild.tools.environment instead\"\"\"\n _log.nosupport(\"read_environment has been moved to easybuild.tools.environment\", '2.0')\n\n\ndef flatten(lst):\n \"\"\"Flatten a list of lists.\"\"\"\n res = []\n for x in lst:\n res.extend(x)\n return res\n\n\ndef quote_str(val, escape_newline=False, prefer_single_quotes=False):\n \"\"\"\n Obtain a new value to be used in string replacement context.\n\n For non-string values, it just returns the exact same value.\n\n For string values, it tries to escape the string in quotes, e.g.,\n foo becomes 'foo', foo'bar becomes \"foo'bar\",\n foo'bar\"baz becomes \\\"\\\"\\\"foo'bar\"baz\\\"\\\"\\\", etc.\n\n :param escape_newline: wrap strings that include a newline in triple quotes\n \"\"\"\n\n if isinstance(val, basestring):\n # forced triple double quotes\n if (\"'\" in val and '\"' in val) or (escape_newline and '\\n' in val):\n return '\"\"\"%s\"\"\"' % val\n # single quotes to escape double quote used in strings\n elif '\"' in val:\n return \"'%s'\" % val\n # if single quotes are preferred, use single quotes;\n # unless a space or a single quote are in the string\n elif prefer_single_quotes and \"'\" not in val and ' ' not in val:\n return \"'%s'\" % val\n # fallback on double quotes (required in tcl syntax)\n else:\n return '\"%s\"' % val\n else:\n return val\n\n\ndef quote_py_str(val):\n \"\"\"Version of quote_str specific for generating use in Python context (e.g., easyconfig parameters).\"\"\"\n return quote_str(val, escape_newline=True, prefer_single_quotes=True)\n\n\ndef remove_unwanted_chars(inputstring):\n \"\"\"Remove unwanted characters from the given string and return a copy\n\n All non-letter and non-numeral characters are considered unwanted except for underscore ('_'), see UNWANTED_CHARS.\n \"\"\"\n return inputstring.translate(ASCII_CHARS, UNWANTED_CHARS)\n\n\ndef import_available_modules(namespace):\n \"\"\"\n Import all available module in the specified namespace.\n\n :param namespace: The namespace to import modules from.\n \"\"\"\n modules = []\n for path in sys.path:\n for module in sorted(glob.glob(os.path.sep.join([path] + namespace.split('.') + ['*.py']))):\n if not module.endswith('__init__.py'):\n mod_name = module.split(os.path.sep)[-1].split('.')[0]\n modpath = '.'.join([namespace, mod_name])\n _log.debug(\"importing module %s\", modpath)\n try:\n mod = __import__(modpath, globals(), locals(), [''])\n except ImportError as err:\n raise EasyBuildError(\"import_available_modules: Failed to import %s: %s\", modpath, err)\n modules.append(mod)\n return modules\n\n\ndef only_if_module_is_available(modnames, pkgname=None, url=None):\n \"\"\"Decorator to guard functions/methods against missing required module with specified name.\"\"\"\n if pkgname and url is None:\n url = 'https://pypi.python.org/pypi/%s' % pkgname\n\n if isinstance(modnames, basestring):\n modnames = (modnames,)\n\n def wrap(orig):\n \"\"\"Decorated function, raises ImportError if specified module is not available.\"\"\"\n try:\n imported = None\n for modname in modnames:\n try:\n __import__(modname)\n imported = modname\n break\n except ImportError:\n pass\n\n if imported is None:\n raise ImportError(\"None of the specified modules %s is available\" % ', '.join(modnames))\n else:\n return orig\n\n except ImportError as err:\n def error(*args, **kwargs):\n msg = \"%s; required module '%s' is not available\" % (err, modname)\n if pkgname:\n msg += \" (provided by Python package %s, available from %s)\" % (pkgname, url)\n elif url:\n msg += \" (available from %s)\" % url\n raise EasyBuildError(\"ImportError: %s\", msg)\n return error\n\n return wrap\n\n\ndef trace_msg(message, silent=False):\n \"\"\"Print trace message.\"\"\"\n if build_option('trace'):\n print_msg(' >> ' + message, prefix=False)\n", "path": "easybuild/tools/utilities.py"}], "after_files": [{"content": "# #\n# Copyright 2012-2019 Ghent University\n#\n# This file is part of EasyBuild,\n# originally created by the HPC team of Ghent University (http://ugent.be/hpc/en),\n# with support of Ghent University (http://ugent.be/hpc),\n# the Flemish Supercomputer Centre (VSC) (https://www.vscentrum.be),\n# Flemish Research Foundation (FWO) (http://www.fwo.be/en)\n# and the Department of Economy, Science and Innovation (EWI) (http://www.ewi-vlaanderen.be/en).\n#\n# https://github.com/easybuilders/easybuild\n#\n# EasyBuild is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation v2.\n#\n# EasyBuild is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with EasyBuild. If not, see <http://www.gnu.org/licenses/>.\n# #\n\"\"\"\nModule with various utility functions\n\n:author: Kenneth Hoste (Ghent University)\n\"\"\"\nimport glob\nimport os\nimport string\nimport sys\nfrom vsc.utils import fancylogger\n\nfrom easybuild.tools.build_log import EasyBuildError, print_msg\nfrom easybuild.tools.config import build_option\n\n\n_log = fancylogger.getLogger('tools.utilities')\n\n\n# a list of all ascii characters\nASCII_CHARS = string.maketrans('', '')\n# a list of all unwanted ascii characters (we only want to keep digits, letters and _)\nUNWANTED_CHARS = ASCII_CHARS.translate(ASCII_CHARS, string.digits + string.ascii_letters + \"_\")\n\n\ndef read_environment(env_vars, strict=False):\n \"\"\"NO LONGER SUPPORTED: use read_environment from easybuild.tools.environment instead\"\"\"\n _log.nosupport(\"read_environment has been moved to easybuild.tools.environment\", '2.0')\n\n\ndef flatten(lst):\n \"\"\"Flatten a list of lists.\"\"\"\n res = []\n for x in lst:\n res.extend(x)\n return res\n\n\ndef quote_str(val, escape_newline=False, prefer_single_quotes=False):\n \"\"\"\n Obtain a new value to be used in string replacement context.\n\n For non-string values, it just returns the exact same value.\n\n For string values, it tries to escape the string in quotes, e.g.,\n foo becomes 'foo', foo'bar becomes \"foo'bar\",\n foo'bar\"baz becomes \\\"\\\"\\\"foo'bar\"baz\\\"\\\"\\\", etc.\n\n :param escape_newline: wrap strings that include a newline in triple quotes\n \"\"\"\n\n if isinstance(val, basestring):\n # forced triple double quotes\n if (\"'\" in val and '\"' in val) or (escape_newline and '\\n' in val):\n return '\"\"\"%s\"\"\"' % val\n # single quotes to escape double quote used in strings\n elif '\"' in val:\n return \"'%s'\" % val\n # if single quotes are preferred, use single quotes;\n # unless a space or a single quote are in the string\n elif prefer_single_quotes and \"'\" not in val and ' ' not in val:\n return \"'%s'\" % val\n # fallback on double quotes (required in tcl syntax)\n else:\n return '\"%s\"' % val\n else:\n return val\n\n\ndef quote_py_str(val):\n \"\"\"Version of quote_str specific for generating use in Python context (e.g., easyconfig parameters).\"\"\"\n return quote_str(val, escape_newline=True, prefer_single_quotes=True)\n\n\ndef remove_unwanted_chars(inputstring):\n \"\"\"Remove unwanted characters from the given string and return a copy\n\n All non-letter and non-numeral characters are considered unwanted except for underscore ('_'), see UNWANTED_CHARS.\n \"\"\"\n return inputstring.translate(ASCII_CHARS, UNWANTED_CHARS)\n\n\ndef import_available_modules(namespace):\n \"\"\"\n Import all available module in the specified namespace.\n\n :param namespace: The namespace to import modules from.\n \"\"\"\n modules = []\n for path in sys.path:\n\n cand_modpath_glob = os.path.sep.join([path] + namespace.split('.') + ['*.py'])\n\n # if sys.path entry being considered is the empty string\n # (which corresponds to Python packages/modules in current working directory being considered),\n # we need to strip off / from the start of the path\n if path == '' and cand_modpath_glob.startswith(os.path.sep):\n cand_modpath_glob = cand_modpath_glob.lstrip(os.path.sep)\n\n for module in sorted(glob.glob(cand_modpath_glob)):\n if not module.endswith('__init__.py'):\n mod_name = module.split(os.path.sep)[-1].split('.')[0]\n modpath = '.'.join([namespace, mod_name])\n _log.debug(\"importing module %s\", modpath)\n try:\n mod = __import__(modpath, globals(), locals(), [''])\n except ImportError as err:\n raise EasyBuildError(\"import_available_modules: Failed to import %s: %s\", modpath, err)\n\n if mod not in modules:\n modules.append(mod)\n\n return modules\n\n\ndef only_if_module_is_available(modnames, pkgname=None, url=None):\n \"\"\"Decorator to guard functions/methods against missing required module with specified name.\"\"\"\n if pkgname and url is None:\n url = 'https://pypi.python.org/pypi/%s' % pkgname\n\n if isinstance(modnames, basestring):\n modnames = (modnames,)\n\n def wrap(orig):\n \"\"\"Decorated function, raises ImportError if specified module is not available.\"\"\"\n try:\n imported = None\n for modname in modnames:\n try:\n __import__(modname)\n imported = modname\n break\n except ImportError:\n pass\n\n if imported is None:\n raise ImportError(\"None of the specified modules %s is available\" % ', '.join(modnames))\n else:\n return orig\n\n except ImportError as err:\n def error(*args, **kwargs):\n msg = \"%s; required module '%s' is not available\" % (err, modname)\n if pkgname:\n msg += \" (provided by Python package %s, available from %s)\" % (pkgname, url)\n elif url:\n msg += \" (available from %s)\" % url\n raise EasyBuildError(\"ImportError: %s\", msg)\n return error\n\n return wrap\n\n\ndef trace_msg(message, silent=False):\n \"\"\"Print trace message.\"\"\"\n if build_option('trace'):\n print_msg(' >> ' + message, prefix=False)\n", "path": "easybuild/tools/utilities.py"}]}
| 2,682 | 340 |
gh_patches_debug_2540
|
rasdani/github-patches
|
git_diff
|
ivy-llc__ivy-23070
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
exponential_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ivy/functional/frontends/paddle/tensor/random.py`
Content:
```
1 # global
2 import ivy
3 from ivy.func_wrapper import with_supported_dtypes
4 from ivy.func_wrapper import with_supported_device_and_dtypes, with_unsupported_dtypes
5 from ivy.functional.frontends.paddle.func_wrapper import (
6 to_ivy_arrays_and_back,
7 )
8
9
10 @with_supported_dtypes(
11 {"2.5.1 and below": ("float32", "float64")},
12 "paddle",
13 )
14 @to_ivy_arrays_and_back
15 def normal(mean=0.0, std=1.0, shape=None, name=None):
16 return ivy.random_normal(mean=mean, std=std, shape=shape)
17
18
19 @with_supported_dtypes(
20 {"2.5.1 and below": ("float32", "float64")},
21 "paddle",
22 )
23 @to_ivy_arrays_and_back
24 def poisson(x, name=None):
25 return ivy.poisson(x, shape=None, device=None, dtype=None, seed=None, out=None)
26
27
28 @with_supported_device_and_dtypes(
29 {
30 "2.5.1 and above": {
31 "cpu": (
32 "bfloat16",
33 "float32",
34 "float64",
35 ),
36 "gpu": (
37 "bfloat16",
38 "float16",
39 "float32",
40 "float64",
41 ),
42 },
43 "2.4.2 and below": {
44 "cpu": (
45 "float32",
46 "float64",
47 ),
48 "gpu": (
49 "float16",
50 "float32",
51 "float64",
52 ),
53 },
54 },
55 "paddle",
56 )
57 @to_ivy_arrays_and_back
58 def rand(shape, dtype=None, name=None):
59 return ivy.random_uniform(low=0.0, high=1.0, shape=shape, dtype=dtype, seed=None)
60
61
62 @to_ivy_arrays_and_back
63 def randint(low=0, high=None, shape=[1], dtype=None, name=None):
64 return ivy.randint(low, high, shape=shape, dtype=dtype)
65
66
67 @with_unsupported_dtypes(
68 {"2.5.1 and below": ("int16", "float16", "bfloat16", "uint8")},
69 "paddle",
70 )
71 @to_ivy_arrays_and_back
72 def randint_like(x, low=0, high=None, dtype=None, name=None):
73 if high is None:
74 high = low
75 low = 0
76 if high <= 0:
77 raise ivy.exceptions.IvyError(
78 "If high is None, low must be greater than 0, but received low = 0."
79 )
80 return ivy.randint(low, high, shape=x.shape, dtype=dtype, seed=None)
81
82
83 def randn(shape, dtype=None, name=None):
84 if dtype not in ["float32", "float64"]:
85 raise ivy.exceptions.IvyError(
86 "Unsupported dtype for randn, only float32 and float64 are supported, "
87 )
88 return ivy.random_normal(shape=shape, dtype=dtype, seed=None)
89
90
91 @with_supported_dtypes(
92 {"2.5.1 and below": ("float32", "float64")},
93 "paddle",
94 )
95 @to_ivy_arrays_and_back
96 def standard_normal(shape, dtype=None, name=None):
97 return ivy.random_normal(mean=0, std=1, shape=shape, dtype=dtype)
98
99
100 @with_supported_dtypes(
101 {"2.5.1 and below": ("float32", "float64")},
102 "paddle",
103 )
104 @to_ivy_arrays_and_back
105 def uniform(shape, dtype=None, min=-1.0, max=1.0, seed=0, name=None):
106 return ivy.random_uniform(low=min, high=max, shape=shape, dtype=dtype, seed=seed)
107
108
109 @with_supported_dtypes(
110 {"2.5.1 and below": ("float32", "float64")},
111 "paddle",
112 )
113 @to_ivy_arrays_and_back
114 def uniform_(x, min=-1.0, max=1.0, seed=0, name=None):
115 x = ivy.array(x)
116 return ivy.random_uniform(
117 low=min, high=max, shape=x.shape, dtype=x.dtype, seed=seed
118 )
119
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ivy/functional/frontends/paddle/tensor/random.py b/ivy/functional/frontends/paddle/tensor/random.py
--- a/ivy/functional/frontends/paddle/tensor/random.py
+++ b/ivy/functional/frontends/paddle/tensor/random.py
@@ -7,6 +7,15 @@
)
+@with_supported_dtypes(
+ {"2.5.1 and below": ("float32", "float64")},
+ "paddle",
+)
+@to_ivy_arrays_and_back
+def exponential_(x, lam=1.0, name=None):
+ return ivy.multiply(lam, ivy.exp(ivy.multiply(-lam, x)))
+
+
@with_supported_dtypes(
{"2.5.1 and below": ("float32", "float64")},
"paddle",
|
{"golden_diff": "diff --git a/ivy/functional/frontends/paddle/tensor/random.py b/ivy/functional/frontends/paddle/tensor/random.py\n--- a/ivy/functional/frontends/paddle/tensor/random.py\n+++ b/ivy/functional/frontends/paddle/tensor/random.py\n@@ -7,6 +7,15 @@\n )\n \n \n+@with_supported_dtypes(\n+ {\"2.5.1 and below\": (\"float32\", \"float64\")},\n+ \"paddle\",\n+)\n+@to_ivy_arrays_and_back\n+def exponential_(x, lam=1.0, name=None):\n+ return ivy.multiply(lam, ivy.exp(ivy.multiply(-lam, x)))\n+\n+\n @with_supported_dtypes(\n {\"2.5.1 and below\": (\"float32\", \"float64\")},\n \"paddle\",\n", "issue": "exponential_\n\n", "before_files": [{"content": "# global\nimport ivy\nfrom ivy.func_wrapper import with_supported_dtypes\nfrom ivy.func_wrapper import with_supported_device_and_dtypes, with_unsupported_dtypes\nfrom ivy.functional.frontends.paddle.func_wrapper import (\n to_ivy_arrays_and_back,\n)\n\n\n@with_supported_dtypes(\n {\"2.5.1 and below\": (\"float32\", \"float64\")},\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef normal(mean=0.0, std=1.0, shape=None, name=None):\n return ivy.random_normal(mean=mean, std=std, shape=shape)\n\n\n@with_supported_dtypes(\n {\"2.5.1 and below\": (\"float32\", \"float64\")},\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef poisson(x, name=None):\n return ivy.poisson(x, shape=None, device=None, dtype=None, seed=None, out=None)\n\n\n@with_supported_device_and_dtypes(\n {\n \"2.5.1 and above\": {\n \"cpu\": (\n \"bfloat16\",\n \"float32\",\n \"float64\",\n ),\n \"gpu\": (\n \"bfloat16\",\n \"float16\",\n \"float32\",\n \"float64\",\n ),\n },\n \"2.4.2 and below\": {\n \"cpu\": (\n \"float32\",\n \"float64\",\n ),\n \"gpu\": (\n \"float16\",\n \"float32\",\n \"float64\",\n ),\n },\n },\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef rand(shape, dtype=None, name=None):\n return ivy.random_uniform(low=0.0, high=1.0, shape=shape, dtype=dtype, seed=None)\n\n\n@to_ivy_arrays_and_back\ndef randint(low=0, high=None, shape=[1], dtype=None, name=None):\n return ivy.randint(low, high, shape=shape, dtype=dtype)\n\n\n@with_unsupported_dtypes(\n {\"2.5.1 and below\": (\"int16\", \"float16\", \"bfloat16\", \"uint8\")},\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef randint_like(x, low=0, high=None, dtype=None, name=None):\n if high is None:\n high = low\n low = 0\n if high <= 0:\n raise ivy.exceptions.IvyError(\n \"If high is None, low must be greater than 0, but received low = 0.\"\n )\n return ivy.randint(low, high, shape=x.shape, dtype=dtype, seed=None)\n\n\ndef randn(shape, dtype=None, name=None):\n if dtype not in [\"float32\", \"float64\"]:\n raise ivy.exceptions.IvyError(\n \"Unsupported dtype for randn, only float32 and float64 are supported, \"\n )\n return ivy.random_normal(shape=shape, dtype=dtype, seed=None)\n\n\n@with_supported_dtypes(\n {\"2.5.1 and below\": (\"float32\", \"float64\")},\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef standard_normal(shape, dtype=None, name=None):\n return ivy.random_normal(mean=0, std=1, shape=shape, dtype=dtype)\n\n\n@with_supported_dtypes(\n {\"2.5.1 and below\": (\"float32\", \"float64\")},\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef uniform(shape, dtype=None, min=-1.0, max=1.0, seed=0, name=None):\n return ivy.random_uniform(low=min, high=max, shape=shape, dtype=dtype, seed=seed)\n\n\n@with_supported_dtypes(\n {\"2.5.1 and below\": (\"float32\", \"float64\")},\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef uniform_(x, min=-1.0, max=1.0, seed=0, name=None):\n x = ivy.array(x)\n return ivy.random_uniform(\n low=min, high=max, shape=x.shape, dtype=x.dtype, seed=seed\n )\n", "path": "ivy/functional/frontends/paddle/tensor/random.py"}], "after_files": [{"content": "# global\nimport ivy\nfrom ivy.func_wrapper import with_supported_dtypes\nfrom ivy.func_wrapper import with_supported_device_and_dtypes, with_unsupported_dtypes\nfrom ivy.functional.frontends.paddle.func_wrapper import (\n to_ivy_arrays_and_back,\n)\n\n\n@with_supported_dtypes(\n {\"2.5.1 and below\": (\"float32\", \"float64\")},\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef exponential_(x, lam=1.0, name=None):\n return ivy.multiply(lam, ivy.exp(ivy.multiply(-lam, x)))\n\n\n@with_supported_dtypes(\n {\"2.5.1 and below\": (\"float32\", \"float64\")},\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef normal(mean=0.0, std=1.0, shape=None, name=None):\n return ivy.random_normal(mean=mean, std=std, shape=shape)\n\n\n@with_supported_dtypes(\n {\"2.5.1 and below\": (\"float32\", \"float64\")},\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef poisson(x, name=None):\n return ivy.poisson(x, shape=None, device=None, dtype=None, seed=None, out=None)\n\n\n@with_supported_device_and_dtypes(\n {\n \"2.5.1 and above\": {\n \"cpu\": (\n \"bfloat16\",\n \"float32\",\n \"float64\",\n ),\n \"gpu\": (\n \"bfloat16\",\n \"float16\",\n \"float32\",\n \"float64\",\n ),\n },\n \"2.4.2 and below\": {\n \"cpu\": (\n \"float32\",\n \"float64\",\n ),\n \"gpu\": (\n \"float16\",\n \"float32\",\n \"float64\",\n ),\n },\n },\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef rand(shape, dtype=None, name=None):\n return ivy.random_uniform(low=0.0, high=1.0, shape=shape, dtype=dtype, seed=None)\n\n\n@to_ivy_arrays_and_back\ndef randint(low=0, high=None, shape=[1], dtype=None, name=None):\n return ivy.randint(low, high, shape=shape, dtype=dtype)\n\n\n@with_unsupported_dtypes(\n {\"2.5.1 and below\": (\"int16\", \"float16\", \"bfloat16\", \"uint8\")},\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef randint_like(x, low=0, high=None, dtype=None, name=None):\n if high is None:\n high = low\n low = 0\n if high <= 0:\n raise ivy.exceptions.IvyError(\n \"If high is None, low must be greater than 0, but received low = 0.\"\n )\n return ivy.randint(low, high, shape=x.shape, dtype=dtype, seed=None)\n\n\ndef randn(shape, dtype=None, name=None):\n if dtype not in [\"float32\", \"float64\"]:\n raise ivy.exceptions.IvyError(\n \"Unsupported dtype for randn, only float32 and float64 are supported, \"\n )\n return ivy.random_normal(shape=shape, dtype=dtype, seed=None)\n\n\n@with_supported_dtypes(\n {\"2.5.1 and below\": (\"float32\", \"float64\")},\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef standard_normal(shape, dtype=None, name=None):\n return ivy.random_normal(mean=0, std=1, shape=shape, dtype=dtype)\n\n\n@with_supported_dtypes(\n {\"2.5.1 and below\": (\"float32\", \"float64\")},\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef uniform(shape, dtype=None, min=-1.0, max=1.0, seed=0, name=None):\n return ivy.random_uniform(low=min, high=max, shape=shape, dtype=dtype, seed=seed)\n\n\n@with_supported_dtypes(\n {\"2.5.1 and below\": (\"float32\", \"float64\")},\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef uniform_(x, min=-1.0, max=1.0, seed=0, name=None):\n x = ivy.array(x)\n return ivy.random_uniform(\n low=min, high=max, shape=x.shape, dtype=x.dtype, seed=seed\n )\n", "path": "ivy/functional/frontends/paddle/tensor/random.py"}]}
| 1,464 | 186 |
gh_patches_debug_341
|
rasdani/github-patches
|
git_diff
|
Kinto__kinto-981
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
JSON Merge Patch deserialization is broken
Merge-patch operations are broken. It looks like a deserialization problem, which may have been introduced with #790. Also, we should definitely include some view tests for this content-type. My bad :/
```
echo '{"data": {"aaa": "bbb"}}' | http patch localhost:8888/v1/buckets/b1 Content-Type:application/merge-patch+json -a aaa:
HTTP/1.1 400 Bad Request
Access-Control-Expose-Headers: Retry-After, Content-Length, Alert, Backoff
Content-Length: 331
Content-Type: application/json; charset=UTF-8
Date: Sun, 11 Dec 2016 23:47:26 GMT
Server: waitress
{
"code": 400,
"details": [
{
"description": "\"{\"data\": {\"aaa\": \"bbb\"}}\n\" is not a mapping type: Does not implement dict-like functionality.",
"location": "body",
"name": ""
}
],
"errno": 107,
"error": "Invalid parameters",
"message": "\"{\"data\": {\"aaa\": \"bbb\"}}\n\" is not a mapping type: Does not implement dict-like functionality."
}
```
JSON Merge Patch deserialization is broken
Merge-patch operations are broken. It looks like a deserialization problem, which may have been introduced with #790. Also, we should definitely include some view tests for this content-type. My bad :/
```
echo '{"data": {"aaa": "bbb"}}' | http patch localhost:8888/v1/buckets/b1 Content-Type:application/merge-patch+json -a aaa:
HTTP/1.1 400 Bad Request
Access-Control-Expose-Headers: Retry-After, Content-Length, Alert, Backoff
Content-Length: 331
Content-Type: application/json; charset=UTF-8
Date: Sun, 11 Dec 2016 23:47:26 GMT
Server: waitress
{
"code": 400,
"details": [
{
"description": "\"{\"data\": {\"aaa\": \"bbb\"}}\n\" is not a mapping type: Does not implement dict-like functionality.",
"location": "body",
"name": ""
}
],
"errno": 107,
"error": "Invalid parameters",
"message": "\"{\"data\": {\"aaa\": \"bbb\"}}\n\" is not a mapping type: Does not implement dict-like functionality."
}
```
JSON Merge Patch deserialization is broken
Merge-patch operations are broken. It looks like a deserialization problem, which may have been introduced with #790. Also, we should definitely include some view tests for this content-type. My bad :/
```
echo '{"data": {"aaa": "bbb"}}' | http patch localhost:8888/v1/buckets/b1 Content-Type:application/merge-patch+json -a aaa:
HTTP/1.1 400 Bad Request
Access-Control-Expose-Headers: Retry-After, Content-Length, Alert, Backoff
Content-Length: 331
Content-Type: application/json; charset=UTF-8
Date: Sun, 11 Dec 2016 23:47:26 GMT
Server: waitress
{
"code": 400,
"details": [
{
"description": "\"{\"data\": {\"aaa\": \"bbb\"}}\n\" is not a mapping type: Does not implement dict-like functionality.",
"location": "body",
"name": ""
}
],
"errno": 107,
"error": "Invalid parameters",
"message": "\"{\"data\": {\"aaa\": \"bbb\"}}\n\" is not a mapping type: Does not implement dict-like functionality."
}
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 import platform
2 import codecs
3 import os
4 from setuptools import setup, find_packages
5
6 here = os.path.abspath(os.path.dirname(__file__))
7
8
9 def read_file(filename):
10 """Open a related file and return its content."""
11 with codecs.open(os.path.join(here, filename), encoding='utf-8') as f:
12 content = f.read()
13 return content
14
15 README = read_file('README.rst')
16 CHANGELOG = read_file('CHANGELOG.rst')
17 CONTRIBUTORS = read_file('CONTRIBUTORS.rst')
18
19 installed_with_pypy = platform.python_implementation() == 'PyPy'
20
21 REQUIREMENTS = [
22 'colander',
23 'colorama',
24 'cornice >= 2.1',
25 'jsonschema',
26 'jsonpatch',
27 'python-dateutil',
28 'pyramid_multiauth >= 0.8', # User on policy selected event.
29 'transaction',
30 'pyramid_tm',
31 'requests',
32 'six',
33 'structlog >= 16.1.0',
34 'enum34',
35 'waitress',
36 ]
37
38 if installed_with_pypy:
39 # We install psycopg2cffi instead of psycopg2 when dealing with pypy
40 # Note: JSONB support landed after psycopg2cffi 2.7.0
41 POSTGRESQL_REQUIRES = [
42 'SQLAlchemy',
43 'psycopg2cffi>2.7.0',
44 'zope.sqlalchemy',
45 ]
46 else:
47 # ujson is not pypy compliant, as it uses the CPython C API
48 REQUIREMENTS.append('ujson >= 1.35')
49 POSTGRESQL_REQUIRES = [
50 'SQLAlchemy',
51 'psycopg2>2.5',
52 'zope.sqlalchemy',
53 ]
54
55 REDIS_REQUIRES = [
56 'kinto_redis'
57 ]
58
59 SETUP_REQUIRES = [
60 'pytest-runner'
61 ]
62
63 TEST_REQUIREMENTS = [
64 'pytest',
65 'WebTest'
66 ]
67
68 DEPENDENCY_LINKS = [
69 ]
70
71 MONITORING_REQUIRES = [
72 'raven',
73 'statsd',
74 'newrelic',
75 'werkzeug',
76 ]
77
78 ENTRY_POINTS = {
79 'paste.app_factory': [
80 'main = kinto:main',
81 ],
82 'console_scripts': [
83 'kinto = kinto.__main__:main'
84 ],
85 }
86
87
88 setup(name='kinto',
89 version='5.0.1.dev0',
90 description='Kinto Web Service - Store, Sync, Share, and Self-Host.',
91 long_description=README + "\n\n" + CHANGELOG + "\n\n" + CONTRIBUTORS,
92 license='Apache License (2.0)',
93 classifiers=[
94 "Programming Language :: Python",
95 "Programming Language :: Python :: 2",
96 "Programming Language :: Python :: 2.7",
97 "Programming Language :: Python :: 3",
98 "Programming Language :: Python :: 3.4",
99 "Programming Language :: Python :: 3.5",
100 "Programming Language :: Python :: Implementation :: CPython",
101 "Programming Language :: Python :: Implementation :: PyPy",
102 "Topic :: Internet :: WWW/HTTP",
103 "Topic :: Internet :: WWW/HTTP :: WSGI :: Application",
104 "License :: OSI Approved :: Apache Software License"
105 ],
106 keywords="web sync json storage services",
107 author='Mozilla Services',
108 author_email='[email protected]',
109 url='https://github.com/Kinto/kinto',
110 packages=find_packages(),
111 package_data={'': ['*.rst', '*.py']},
112 include_package_data=True,
113 zip_safe=False,
114 setup_requires=SETUP_REQUIRES,
115 tests_require=TEST_REQUIREMENTS,
116 install_requires=REQUIREMENTS,
117 extras_require={
118 'redis': REDIS_REQUIRES,
119 'postgresql': POSTGRESQL_REQUIRES,
120 'monitoring': MONITORING_REQUIRES,
121 ":python_version=='2.7'": ["functools32", "futures"],
122 },
123 test_suite="tests",
124 dependency_links=DEPENDENCY_LINKS,
125 entry_points=ENTRY_POINTS)
126
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -21,7 +21,7 @@
REQUIREMENTS = [
'colander',
'colorama',
- 'cornice >= 2.1',
+ 'cornice >= 2.3',
'jsonschema',
'jsonpatch',
'python-dateutil',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -21,7 +21,7 @@\n REQUIREMENTS = [\n 'colander',\n 'colorama',\n- 'cornice >= 2.1',\n+ 'cornice >= 2.3',\n 'jsonschema',\n 'jsonpatch',\n 'python-dateutil',\n", "issue": "JSON Merge Patch deserialization is broken \nMerge-patch operations are broken. It looks like a deserialization problem, which may have been introduced with #790. Also, we should definitely include some view tests for this content-type. My bad :/ \r\n \r\n```\r\necho '{\"data\": {\"aaa\": \"bbb\"}}' | http patch localhost:8888/v1/buckets/b1 Content-Type:application/merge-patch+json -a aaa:\r\nHTTP/1.1 400 Bad Request\r\nAccess-Control-Expose-Headers: Retry-After, Content-Length, Alert, Backoff\r\nContent-Length: 331\r\nContent-Type: application/json; charset=UTF-8\r\nDate: Sun, 11 Dec 2016 23:47:26 GMT\r\nServer: waitress\r\n\r\n{\r\n \"code\": 400,\r\n \"details\": [\r\n {\r\n \"description\": \"\\\"{\\\"data\\\": {\\\"aaa\\\": \\\"bbb\\\"}}\\n\\\" is not a mapping type: Does not implement dict-like functionality.\",\r\n \"location\": \"body\",\r\n \"name\": \"\"\r\n }\r\n ],\r\n \"errno\": 107,\r\n \"error\": \"Invalid parameters\",\r\n \"message\": \"\\\"{\\\"data\\\": {\\\"aaa\\\": \\\"bbb\\\"}}\\n\\\" is not a mapping type: Does not implement dict-like functionality.\"\r\n}\r\n```\nJSON Merge Patch deserialization is broken \nMerge-patch operations are broken. It looks like a deserialization problem, which may have been introduced with #790. Also, we should definitely include some view tests for this content-type. My bad :/ \r\n \r\n```\r\necho '{\"data\": {\"aaa\": \"bbb\"}}' | http patch localhost:8888/v1/buckets/b1 Content-Type:application/merge-patch+json -a aaa:\r\nHTTP/1.1 400 Bad Request\r\nAccess-Control-Expose-Headers: Retry-After, Content-Length, Alert, Backoff\r\nContent-Length: 331\r\nContent-Type: application/json; charset=UTF-8\r\nDate: Sun, 11 Dec 2016 23:47:26 GMT\r\nServer: waitress\r\n\r\n{\r\n \"code\": 400,\r\n \"details\": [\r\n {\r\n \"description\": \"\\\"{\\\"data\\\": {\\\"aaa\\\": \\\"bbb\\\"}}\\n\\\" is not a mapping type: Does not implement dict-like functionality.\",\r\n \"location\": \"body\",\r\n \"name\": \"\"\r\n }\r\n ],\r\n \"errno\": 107,\r\n \"error\": \"Invalid parameters\",\r\n \"message\": \"\\\"{\\\"data\\\": {\\\"aaa\\\": \\\"bbb\\\"}}\\n\\\" is not a mapping type: Does not implement dict-like functionality.\"\r\n}\r\n```\nJSON Merge Patch deserialization is broken \nMerge-patch operations are broken. It looks like a deserialization problem, which may have been introduced with #790. Also, we should definitely include some view tests for this content-type. My bad :/ \r\n \r\n```\r\necho '{\"data\": {\"aaa\": \"bbb\"}}' | http patch localhost:8888/v1/buckets/b1 Content-Type:application/merge-patch+json -a aaa:\r\nHTTP/1.1 400 Bad Request\r\nAccess-Control-Expose-Headers: Retry-After, Content-Length, Alert, Backoff\r\nContent-Length: 331\r\nContent-Type: application/json; charset=UTF-8\r\nDate: Sun, 11 Dec 2016 23:47:26 GMT\r\nServer: waitress\r\n\r\n{\r\n \"code\": 400,\r\n \"details\": [\r\n {\r\n \"description\": \"\\\"{\\\"data\\\": {\\\"aaa\\\": \\\"bbb\\\"}}\\n\\\" is not a mapping type: Does not implement dict-like functionality.\",\r\n \"location\": \"body\",\r\n \"name\": \"\"\r\n }\r\n ],\r\n \"errno\": 107,\r\n \"error\": \"Invalid parameters\",\r\n \"message\": \"\\\"{\\\"data\\\": {\\\"aaa\\\": \\\"bbb\\\"}}\\n\\\" is not a mapping type: Does not implement dict-like functionality.\"\r\n}\r\n```\n", "before_files": [{"content": "import platform\nimport codecs\nimport os\nfrom setuptools import setup, find_packages\n\nhere = os.path.abspath(os.path.dirname(__file__))\n\n\ndef read_file(filename):\n \"\"\"Open a related file and return its content.\"\"\"\n with codecs.open(os.path.join(here, filename), encoding='utf-8') as f:\n content = f.read()\n return content\n\nREADME = read_file('README.rst')\nCHANGELOG = read_file('CHANGELOG.rst')\nCONTRIBUTORS = read_file('CONTRIBUTORS.rst')\n\ninstalled_with_pypy = platform.python_implementation() == 'PyPy'\n\nREQUIREMENTS = [\n 'colander',\n 'colorama',\n 'cornice >= 2.1',\n 'jsonschema',\n 'jsonpatch',\n 'python-dateutil',\n 'pyramid_multiauth >= 0.8', # User on policy selected event.\n 'transaction',\n 'pyramid_tm',\n 'requests',\n 'six',\n 'structlog >= 16.1.0',\n 'enum34',\n 'waitress',\n]\n\nif installed_with_pypy:\n # We install psycopg2cffi instead of psycopg2 when dealing with pypy\n # Note: JSONB support landed after psycopg2cffi 2.7.0\n POSTGRESQL_REQUIRES = [\n 'SQLAlchemy',\n 'psycopg2cffi>2.7.0',\n 'zope.sqlalchemy',\n ]\nelse:\n # ujson is not pypy compliant, as it uses the CPython C API\n REQUIREMENTS.append('ujson >= 1.35')\n POSTGRESQL_REQUIRES = [\n 'SQLAlchemy',\n 'psycopg2>2.5',\n 'zope.sqlalchemy',\n ]\n\nREDIS_REQUIRES = [\n 'kinto_redis'\n]\n\nSETUP_REQUIRES = [\n 'pytest-runner'\n]\n\nTEST_REQUIREMENTS = [\n 'pytest',\n 'WebTest'\n]\n\nDEPENDENCY_LINKS = [\n]\n\nMONITORING_REQUIRES = [\n 'raven',\n 'statsd',\n 'newrelic',\n 'werkzeug',\n]\n\nENTRY_POINTS = {\n 'paste.app_factory': [\n 'main = kinto:main',\n ],\n 'console_scripts': [\n 'kinto = kinto.__main__:main'\n ],\n}\n\n\nsetup(name='kinto',\n version='5.0.1.dev0',\n description='Kinto Web Service - Store, Sync, Share, and Self-Host.',\n long_description=README + \"\\n\\n\" + CHANGELOG + \"\\n\\n\" + CONTRIBUTORS,\n license='Apache License (2.0)',\n classifiers=[\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.4\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n \"Topic :: Internet :: WWW/HTTP\",\n \"Topic :: Internet :: WWW/HTTP :: WSGI :: Application\",\n \"License :: OSI Approved :: Apache Software License\"\n ],\n keywords=\"web sync json storage services\",\n author='Mozilla Services',\n author_email='[email protected]',\n url='https://github.com/Kinto/kinto',\n packages=find_packages(),\n package_data={'': ['*.rst', '*.py']},\n include_package_data=True,\n zip_safe=False,\n setup_requires=SETUP_REQUIRES,\n tests_require=TEST_REQUIREMENTS,\n install_requires=REQUIREMENTS,\n extras_require={\n 'redis': REDIS_REQUIRES,\n 'postgresql': POSTGRESQL_REQUIRES,\n 'monitoring': MONITORING_REQUIRES,\n \":python_version=='2.7'\": [\"functools32\", \"futures\"],\n },\n test_suite=\"tests\",\n dependency_links=DEPENDENCY_LINKS,\n entry_points=ENTRY_POINTS)\n", "path": "setup.py"}], "after_files": [{"content": "import platform\nimport codecs\nimport os\nfrom setuptools import setup, find_packages\n\nhere = os.path.abspath(os.path.dirname(__file__))\n\n\ndef read_file(filename):\n \"\"\"Open a related file and return its content.\"\"\"\n with codecs.open(os.path.join(here, filename), encoding='utf-8') as f:\n content = f.read()\n return content\n\nREADME = read_file('README.rst')\nCHANGELOG = read_file('CHANGELOG.rst')\nCONTRIBUTORS = read_file('CONTRIBUTORS.rst')\n\ninstalled_with_pypy = platform.python_implementation() == 'PyPy'\n\nREQUIREMENTS = [\n 'colander',\n 'colorama',\n 'cornice >= 2.3',\n 'jsonschema',\n 'jsonpatch',\n 'python-dateutil',\n 'pyramid_multiauth >= 0.8', # User on policy selected event.\n 'transaction',\n 'pyramid_tm',\n 'requests',\n 'six',\n 'structlog >= 16.1.0',\n 'enum34',\n 'waitress',\n]\n\nif installed_with_pypy:\n # We install psycopg2cffi instead of psycopg2 when dealing with pypy\n # Note: JSONB support landed after psycopg2cffi 2.7.0\n POSTGRESQL_REQUIRES = [\n 'SQLAlchemy',\n 'psycopg2cffi>2.7.0',\n 'zope.sqlalchemy',\n ]\nelse:\n # ujson is not pypy compliant, as it uses the CPython C API\n REQUIREMENTS.append('ujson >= 1.35')\n POSTGRESQL_REQUIRES = [\n 'SQLAlchemy',\n 'psycopg2>2.5',\n 'zope.sqlalchemy',\n ]\n\nREDIS_REQUIRES = [\n 'kinto_redis'\n]\n\nSETUP_REQUIRES = [\n 'pytest-runner'\n]\n\nTEST_REQUIREMENTS = [\n 'pytest',\n 'WebTest'\n]\n\nDEPENDENCY_LINKS = [\n]\n\nMONITORING_REQUIRES = [\n 'raven',\n 'statsd',\n 'newrelic',\n 'werkzeug',\n]\n\nENTRY_POINTS = {\n 'paste.app_factory': [\n 'main = kinto:main',\n ],\n 'console_scripts': [\n 'kinto = kinto.__main__:main'\n ],\n}\n\n\nsetup(name='kinto',\n version='5.0.1.dev0',\n description='Kinto Web Service - Store, Sync, Share, and Self-Host.',\n long_description=README + \"\\n\\n\" + CHANGELOG + \"\\n\\n\" + CONTRIBUTORS,\n license='Apache License (2.0)',\n classifiers=[\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.4\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n \"Topic :: Internet :: WWW/HTTP\",\n \"Topic :: Internet :: WWW/HTTP :: WSGI :: Application\",\n \"License :: OSI Approved :: Apache Software License\"\n ],\n keywords=\"web sync json storage services\",\n author='Mozilla Services',\n author_email='[email protected]',\n url='https://github.com/Kinto/kinto',\n packages=find_packages(),\n package_data={'': ['*.rst', '*.py']},\n include_package_data=True,\n zip_safe=False,\n setup_requires=SETUP_REQUIRES,\n tests_require=TEST_REQUIREMENTS,\n install_requires=REQUIREMENTS,\n extras_require={\n 'redis': REDIS_REQUIRES,\n 'postgresql': POSTGRESQL_REQUIRES,\n 'monitoring': MONITORING_REQUIRES,\n \":python_version=='2.7'\": [\"functools32\", \"futures\"],\n },\n test_suite=\"tests\",\n dependency_links=DEPENDENCY_LINKS,\n entry_points=ENTRY_POINTS)\n", "path": "setup.py"}]}
| 2,274 | 84 |
gh_patches_debug_59753
|
rasdani/github-patches
|
git_diff
|
pyca__cryptography-3273
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add tests for ec.derive_private_key with negative secret value
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/cryptography/hazmat/primitives/asymmetric/ec.py`
Content:
```
1 # This file is dual licensed under the terms of the Apache License, Version
2 # 2.0, and the BSD License. See the LICENSE file in the root of this repository
3 # for complete details.
4
5 from __future__ import absolute_import, division, print_function
6
7 import abc
8
9 import six
10
11 from cryptography import utils
12
13
14 @six.add_metaclass(abc.ABCMeta)
15 class EllipticCurve(object):
16 @abc.abstractproperty
17 def name(self):
18 """
19 The name of the curve. e.g. secp256r1.
20 """
21
22 @abc.abstractproperty
23 def key_size(self):
24 """
25 The bit length of the base point of the curve.
26 """
27
28
29 @six.add_metaclass(abc.ABCMeta)
30 class EllipticCurveSignatureAlgorithm(object):
31 @abc.abstractproperty
32 def algorithm(self):
33 """
34 The digest algorithm used with this signature.
35 """
36
37
38 @six.add_metaclass(abc.ABCMeta)
39 class EllipticCurvePrivateKey(object):
40 @abc.abstractmethod
41 def signer(self, signature_algorithm):
42 """
43 Returns an AsymmetricSignatureContext used for signing data.
44 """
45
46 @abc.abstractmethod
47 def exchange(self, algorithm, peer_public_key):
48 """
49 Performs a key exchange operation using the provided algorithm with the
50 provided peer's public key.
51 """
52
53 @abc.abstractmethod
54 def public_key(self):
55 """
56 The EllipticCurvePublicKey for this private key.
57 """
58
59 @abc.abstractproperty
60 def curve(self):
61 """
62 The EllipticCurve that this key is on.
63 """
64
65 @abc.abstractproperty
66 def sign(self, data, signature_algorithm):
67 """
68 Signs the data
69 """
70
71
72 @six.add_metaclass(abc.ABCMeta)
73 class EllipticCurvePrivateKeyWithSerialization(EllipticCurvePrivateKey):
74 @abc.abstractmethod
75 def private_numbers(self):
76 """
77 Returns an EllipticCurvePrivateNumbers.
78 """
79
80 @abc.abstractmethod
81 def private_bytes(self, encoding, format, encryption_algorithm):
82 """
83 Returns the key serialized as bytes.
84 """
85
86
87 @six.add_metaclass(abc.ABCMeta)
88 class EllipticCurvePublicKey(object):
89 @abc.abstractmethod
90 def verifier(self, signature, signature_algorithm):
91 """
92 Returns an AsymmetricVerificationContext used for signing data.
93 """
94
95 @abc.abstractproperty
96 def curve(self):
97 """
98 The EllipticCurve that this key is on.
99 """
100
101 @abc.abstractmethod
102 def public_numbers(self):
103 """
104 Returns an EllipticCurvePublicNumbers.
105 """
106
107 @abc.abstractmethod
108 def public_bytes(self, encoding, format):
109 """
110 Returns the key serialized as bytes.
111 """
112
113 @abc.abstractmethod
114 def verify(self, signature, data, signature_algorithm):
115 """
116 Verifies the signature of the data.
117 """
118
119
120 EllipticCurvePublicKeyWithSerialization = EllipticCurvePublicKey
121
122
123 @utils.register_interface(EllipticCurve)
124 class SECT571R1(object):
125 name = "sect571r1"
126 key_size = 571
127
128
129 @utils.register_interface(EllipticCurve)
130 class SECT409R1(object):
131 name = "sect409r1"
132 key_size = 409
133
134
135 @utils.register_interface(EllipticCurve)
136 class SECT283R1(object):
137 name = "sect283r1"
138 key_size = 283
139
140
141 @utils.register_interface(EllipticCurve)
142 class SECT233R1(object):
143 name = "sect233r1"
144 key_size = 233
145
146
147 @utils.register_interface(EllipticCurve)
148 class SECT163R2(object):
149 name = "sect163r2"
150 key_size = 163
151
152
153 @utils.register_interface(EllipticCurve)
154 class SECT571K1(object):
155 name = "sect571k1"
156 key_size = 571
157
158
159 @utils.register_interface(EllipticCurve)
160 class SECT409K1(object):
161 name = "sect409k1"
162 key_size = 409
163
164
165 @utils.register_interface(EllipticCurve)
166 class SECT283K1(object):
167 name = "sect283k1"
168 key_size = 283
169
170
171 @utils.register_interface(EllipticCurve)
172 class SECT233K1(object):
173 name = "sect233k1"
174 key_size = 233
175
176
177 @utils.register_interface(EllipticCurve)
178 class SECT163K1(object):
179 name = "sect163k1"
180 key_size = 163
181
182
183 @utils.register_interface(EllipticCurve)
184 class SECP521R1(object):
185 name = "secp521r1"
186 key_size = 521
187
188
189 @utils.register_interface(EllipticCurve)
190 class SECP384R1(object):
191 name = "secp384r1"
192 key_size = 384
193
194
195 @utils.register_interface(EllipticCurve)
196 class SECP256R1(object):
197 name = "secp256r1"
198 key_size = 256
199
200
201 @utils.register_interface(EllipticCurve)
202 class SECP256K1(object):
203 name = "secp256k1"
204 key_size = 256
205
206
207 @utils.register_interface(EllipticCurve)
208 class SECP224R1(object):
209 name = "secp224r1"
210 key_size = 224
211
212
213 @utils.register_interface(EllipticCurve)
214 class SECP192R1(object):
215 name = "secp192r1"
216 key_size = 192
217
218
219 _CURVE_TYPES = {
220 "prime192v1": SECP192R1,
221 "prime256v1": SECP256R1,
222
223 "secp192r1": SECP192R1,
224 "secp224r1": SECP224R1,
225 "secp256r1": SECP256R1,
226 "secp384r1": SECP384R1,
227 "secp521r1": SECP521R1,
228 "secp256k1": SECP256K1,
229
230 "sect163k1": SECT163K1,
231 "sect233k1": SECT233K1,
232 "sect283k1": SECT283K1,
233 "sect409k1": SECT409K1,
234 "sect571k1": SECT571K1,
235
236 "sect163r2": SECT163R2,
237 "sect233r1": SECT233R1,
238 "sect283r1": SECT283R1,
239 "sect409r1": SECT409R1,
240 "sect571r1": SECT571R1,
241 }
242
243
244 @utils.register_interface(EllipticCurveSignatureAlgorithm)
245 class ECDSA(object):
246 def __init__(self, algorithm):
247 self._algorithm = algorithm
248
249 algorithm = utils.read_only_property("_algorithm")
250
251
252 def generate_private_key(curve, backend):
253 return backend.generate_elliptic_curve_private_key(curve)
254
255
256 def derive_private_key(private_value, curve, backend):
257 if not isinstance(private_value, six.integer_types):
258 raise TypeError("private_value must be an integer type.")
259
260 if not isinstance(curve, EllipticCurve):
261 raise TypeError("curve must provide the EllipticCurve interface.")
262
263 return backend.derive_elliptic_curve_private_key(private_value, curve)
264
265
266 class EllipticCurvePublicNumbers(object):
267 def __init__(self, x, y, curve):
268 if (
269 not isinstance(x, six.integer_types) or
270 not isinstance(y, six.integer_types)
271 ):
272 raise TypeError("x and y must be integers.")
273
274 if not isinstance(curve, EllipticCurve):
275 raise TypeError("curve must provide the EllipticCurve interface.")
276
277 self._y = y
278 self._x = x
279 self._curve = curve
280
281 def public_key(self, backend):
282 return backend.load_elliptic_curve_public_numbers(self)
283
284 def encode_point(self):
285 # key_size is in bits. Convert to bytes and round up
286 byte_length = (self.curve.key_size + 7) // 8
287 return (
288 b'\x04' + utils.int_to_bytes(self.x, byte_length) +
289 utils.int_to_bytes(self.y, byte_length)
290 )
291
292 @classmethod
293 def from_encoded_point(cls, curve, data):
294 if not isinstance(curve, EllipticCurve):
295 raise TypeError("curve must be an EllipticCurve instance")
296
297 if data.startswith(b'\x04'):
298 # key_size is in bits. Convert to bytes and round up
299 byte_length = (curve.key_size + 7) // 8
300 if len(data) == 2 * byte_length + 1:
301 x = utils.int_from_bytes(data[1:byte_length + 1], 'big')
302 y = utils.int_from_bytes(data[byte_length + 1:], 'big')
303 return cls(x, y, curve)
304 else:
305 raise ValueError('Invalid elliptic curve point data length')
306 else:
307 raise ValueError('Unsupported elliptic curve point type')
308
309 curve = utils.read_only_property("_curve")
310 x = utils.read_only_property("_x")
311 y = utils.read_only_property("_y")
312
313 def __eq__(self, other):
314 if not isinstance(other, EllipticCurvePublicNumbers):
315 return NotImplemented
316
317 return (
318 self.x == other.x and
319 self.y == other.y and
320 self.curve.name == other.curve.name and
321 self.curve.key_size == other.curve.key_size
322 )
323
324 def __ne__(self, other):
325 return not self == other
326
327 def __hash__(self):
328 return hash((self.x, self.y, self.curve.name, self.curve.key_size))
329
330 def __repr__(self):
331 return (
332 "<EllipticCurvePublicNumbers(curve={0.curve.name}, x={0.x}, "
333 "y={0.y}>".format(self)
334 )
335
336
337 class EllipticCurvePrivateNumbers(object):
338 def __init__(self, private_value, public_numbers):
339 if not isinstance(private_value, six.integer_types):
340 raise TypeError("private_value must be an integer.")
341
342 if not isinstance(public_numbers, EllipticCurvePublicNumbers):
343 raise TypeError(
344 "public_numbers must be an EllipticCurvePublicNumbers "
345 "instance."
346 )
347
348 self._private_value = private_value
349 self._public_numbers = public_numbers
350
351 def private_key(self, backend):
352 return backend.load_elliptic_curve_private_numbers(self)
353
354 private_value = utils.read_only_property("_private_value")
355 public_numbers = utils.read_only_property("_public_numbers")
356
357 def __eq__(self, other):
358 if not isinstance(other, EllipticCurvePrivateNumbers):
359 return NotImplemented
360
361 return (
362 self.private_value == other.private_value and
363 self.public_numbers == other.public_numbers
364 )
365
366 def __ne__(self, other):
367 return not self == other
368
369 def __hash__(self):
370 return hash((self.private_value, self.public_numbers))
371
372
373 class ECDH(object):
374 pass
375
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/cryptography/hazmat/primitives/asymmetric/ec.py b/src/cryptography/hazmat/primitives/asymmetric/ec.py
--- a/src/cryptography/hazmat/primitives/asymmetric/ec.py
+++ b/src/cryptography/hazmat/primitives/asymmetric/ec.py
@@ -257,6 +257,9 @@
if not isinstance(private_value, six.integer_types):
raise TypeError("private_value must be an integer type.")
+ if private_value <= 0:
+ raise ValueError("private_value must be a positive integer.")
+
if not isinstance(curve, EllipticCurve):
raise TypeError("curve must provide the EllipticCurve interface.")
|
{"golden_diff": "diff --git a/src/cryptography/hazmat/primitives/asymmetric/ec.py b/src/cryptography/hazmat/primitives/asymmetric/ec.py\n--- a/src/cryptography/hazmat/primitives/asymmetric/ec.py\n+++ b/src/cryptography/hazmat/primitives/asymmetric/ec.py\n@@ -257,6 +257,9 @@\n if not isinstance(private_value, six.integer_types):\n raise TypeError(\"private_value must be an integer type.\")\n \n+ if private_value <= 0:\n+ raise ValueError(\"private_value must be a positive integer.\")\n+\n if not isinstance(curve, EllipticCurve):\n raise TypeError(\"curve must provide the EllipticCurve interface.\")\n", "issue": "Add tests for ec.derive_private_key with negative secret value\n\n", "before_files": [{"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\nfrom __future__ import absolute_import, division, print_function\n\nimport abc\n\nimport six\n\nfrom cryptography import utils\n\n\[email protected]_metaclass(abc.ABCMeta)\nclass EllipticCurve(object):\n @abc.abstractproperty\n def name(self):\n \"\"\"\n The name of the curve. e.g. secp256r1.\n \"\"\"\n\n @abc.abstractproperty\n def key_size(self):\n \"\"\"\n The bit length of the base point of the curve.\n \"\"\"\n\n\[email protected]_metaclass(abc.ABCMeta)\nclass EllipticCurveSignatureAlgorithm(object):\n @abc.abstractproperty\n def algorithm(self):\n \"\"\"\n The digest algorithm used with this signature.\n \"\"\"\n\n\[email protected]_metaclass(abc.ABCMeta)\nclass EllipticCurvePrivateKey(object):\n @abc.abstractmethod\n def signer(self, signature_algorithm):\n \"\"\"\n Returns an AsymmetricSignatureContext used for signing data.\n \"\"\"\n\n @abc.abstractmethod\n def exchange(self, algorithm, peer_public_key):\n \"\"\"\n Performs a key exchange operation using the provided algorithm with the\n provided peer's public key.\n \"\"\"\n\n @abc.abstractmethod\n def public_key(self):\n \"\"\"\n The EllipticCurvePublicKey for this private key.\n \"\"\"\n\n @abc.abstractproperty\n def curve(self):\n \"\"\"\n The EllipticCurve that this key is on.\n \"\"\"\n\n @abc.abstractproperty\n def sign(self, data, signature_algorithm):\n \"\"\"\n Signs the data\n \"\"\"\n\n\[email protected]_metaclass(abc.ABCMeta)\nclass EllipticCurvePrivateKeyWithSerialization(EllipticCurvePrivateKey):\n @abc.abstractmethod\n def private_numbers(self):\n \"\"\"\n Returns an EllipticCurvePrivateNumbers.\n \"\"\"\n\n @abc.abstractmethod\n def private_bytes(self, encoding, format, encryption_algorithm):\n \"\"\"\n Returns the key serialized as bytes.\n \"\"\"\n\n\[email protected]_metaclass(abc.ABCMeta)\nclass EllipticCurvePublicKey(object):\n @abc.abstractmethod\n def verifier(self, signature, signature_algorithm):\n \"\"\"\n Returns an AsymmetricVerificationContext used for signing data.\n \"\"\"\n\n @abc.abstractproperty\n def curve(self):\n \"\"\"\n The EllipticCurve that this key is on.\n \"\"\"\n\n @abc.abstractmethod\n def public_numbers(self):\n \"\"\"\n Returns an EllipticCurvePublicNumbers.\n \"\"\"\n\n @abc.abstractmethod\n def public_bytes(self, encoding, format):\n \"\"\"\n Returns the key serialized as bytes.\n \"\"\"\n\n @abc.abstractmethod\n def verify(self, signature, data, signature_algorithm):\n \"\"\"\n Verifies the signature of the data.\n \"\"\"\n\n\nEllipticCurvePublicKeyWithSerialization = EllipticCurvePublicKey\n\n\[email protected]_interface(EllipticCurve)\nclass SECT571R1(object):\n name = \"sect571r1\"\n key_size = 571\n\n\[email protected]_interface(EllipticCurve)\nclass SECT409R1(object):\n name = \"sect409r1\"\n key_size = 409\n\n\[email protected]_interface(EllipticCurve)\nclass SECT283R1(object):\n name = \"sect283r1\"\n key_size = 283\n\n\[email protected]_interface(EllipticCurve)\nclass SECT233R1(object):\n name = \"sect233r1\"\n key_size = 233\n\n\[email protected]_interface(EllipticCurve)\nclass SECT163R2(object):\n name = \"sect163r2\"\n key_size = 163\n\n\[email protected]_interface(EllipticCurve)\nclass SECT571K1(object):\n name = \"sect571k1\"\n key_size = 571\n\n\[email protected]_interface(EllipticCurve)\nclass SECT409K1(object):\n name = \"sect409k1\"\n key_size = 409\n\n\[email protected]_interface(EllipticCurve)\nclass SECT283K1(object):\n name = \"sect283k1\"\n key_size = 283\n\n\[email protected]_interface(EllipticCurve)\nclass SECT233K1(object):\n name = \"sect233k1\"\n key_size = 233\n\n\[email protected]_interface(EllipticCurve)\nclass SECT163K1(object):\n name = \"sect163k1\"\n key_size = 163\n\n\[email protected]_interface(EllipticCurve)\nclass SECP521R1(object):\n name = \"secp521r1\"\n key_size = 521\n\n\[email protected]_interface(EllipticCurve)\nclass SECP384R1(object):\n name = \"secp384r1\"\n key_size = 384\n\n\[email protected]_interface(EllipticCurve)\nclass SECP256R1(object):\n name = \"secp256r1\"\n key_size = 256\n\n\[email protected]_interface(EllipticCurve)\nclass SECP256K1(object):\n name = \"secp256k1\"\n key_size = 256\n\n\[email protected]_interface(EllipticCurve)\nclass SECP224R1(object):\n name = \"secp224r1\"\n key_size = 224\n\n\[email protected]_interface(EllipticCurve)\nclass SECP192R1(object):\n name = \"secp192r1\"\n key_size = 192\n\n\n_CURVE_TYPES = {\n \"prime192v1\": SECP192R1,\n \"prime256v1\": SECP256R1,\n\n \"secp192r1\": SECP192R1,\n \"secp224r1\": SECP224R1,\n \"secp256r1\": SECP256R1,\n \"secp384r1\": SECP384R1,\n \"secp521r1\": SECP521R1,\n \"secp256k1\": SECP256K1,\n\n \"sect163k1\": SECT163K1,\n \"sect233k1\": SECT233K1,\n \"sect283k1\": SECT283K1,\n \"sect409k1\": SECT409K1,\n \"sect571k1\": SECT571K1,\n\n \"sect163r2\": SECT163R2,\n \"sect233r1\": SECT233R1,\n \"sect283r1\": SECT283R1,\n \"sect409r1\": SECT409R1,\n \"sect571r1\": SECT571R1,\n}\n\n\[email protected]_interface(EllipticCurveSignatureAlgorithm)\nclass ECDSA(object):\n def __init__(self, algorithm):\n self._algorithm = algorithm\n\n algorithm = utils.read_only_property(\"_algorithm\")\n\n\ndef generate_private_key(curve, backend):\n return backend.generate_elliptic_curve_private_key(curve)\n\n\ndef derive_private_key(private_value, curve, backend):\n if not isinstance(private_value, six.integer_types):\n raise TypeError(\"private_value must be an integer type.\")\n\n if not isinstance(curve, EllipticCurve):\n raise TypeError(\"curve must provide the EllipticCurve interface.\")\n\n return backend.derive_elliptic_curve_private_key(private_value, curve)\n\n\nclass EllipticCurvePublicNumbers(object):\n def __init__(self, x, y, curve):\n if (\n not isinstance(x, six.integer_types) or\n not isinstance(y, six.integer_types)\n ):\n raise TypeError(\"x and y must be integers.\")\n\n if not isinstance(curve, EllipticCurve):\n raise TypeError(\"curve must provide the EllipticCurve interface.\")\n\n self._y = y\n self._x = x\n self._curve = curve\n\n def public_key(self, backend):\n return backend.load_elliptic_curve_public_numbers(self)\n\n def encode_point(self):\n # key_size is in bits. Convert to bytes and round up\n byte_length = (self.curve.key_size + 7) // 8\n return (\n b'\\x04' + utils.int_to_bytes(self.x, byte_length) +\n utils.int_to_bytes(self.y, byte_length)\n )\n\n @classmethod\n def from_encoded_point(cls, curve, data):\n if not isinstance(curve, EllipticCurve):\n raise TypeError(\"curve must be an EllipticCurve instance\")\n\n if data.startswith(b'\\x04'):\n # key_size is in bits. Convert to bytes and round up\n byte_length = (curve.key_size + 7) // 8\n if len(data) == 2 * byte_length + 1:\n x = utils.int_from_bytes(data[1:byte_length + 1], 'big')\n y = utils.int_from_bytes(data[byte_length + 1:], 'big')\n return cls(x, y, curve)\n else:\n raise ValueError('Invalid elliptic curve point data length')\n else:\n raise ValueError('Unsupported elliptic curve point type')\n\n curve = utils.read_only_property(\"_curve\")\n x = utils.read_only_property(\"_x\")\n y = utils.read_only_property(\"_y\")\n\n def __eq__(self, other):\n if not isinstance(other, EllipticCurvePublicNumbers):\n return NotImplemented\n\n return (\n self.x == other.x and\n self.y == other.y and\n self.curve.name == other.curve.name and\n self.curve.key_size == other.curve.key_size\n )\n\n def __ne__(self, other):\n return not self == other\n\n def __hash__(self):\n return hash((self.x, self.y, self.curve.name, self.curve.key_size))\n\n def __repr__(self):\n return (\n \"<EllipticCurvePublicNumbers(curve={0.curve.name}, x={0.x}, \"\n \"y={0.y}>\".format(self)\n )\n\n\nclass EllipticCurvePrivateNumbers(object):\n def __init__(self, private_value, public_numbers):\n if not isinstance(private_value, six.integer_types):\n raise TypeError(\"private_value must be an integer.\")\n\n if not isinstance(public_numbers, EllipticCurvePublicNumbers):\n raise TypeError(\n \"public_numbers must be an EllipticCurvePublicNumbers \"\n \"instance.\"\n )\n\n self._private_value = private_value\n self._public_numbers = public_numbers\n\n def private_key(self, backend):\n return backend.load_elliptic_curve_private_numbers(self)\n\n private_value = utils.read_only_property(\"_private_value\")\n public_numbers = utils.read_only_property(\"_public_numbers\")\n\n def __eq__(self, other):\n if not isinstance(other, EllipticCurvePrivateNumbers):\n return NotImplemented\n\n return (\n self.private_value == other.private_value and\n self.public_numbers == other.public_numbers\n )\n\n def __ne__(self, other):\n return not self == other\n\n def __hash__(self):\n return hash((self.private_value, self.public_numbers))\n\n\nclass ECDH(object):\n pass\n", "path": "src/cryptography/hazmat/primitives/asymmetric/ec.py"}], "after_files": [{"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\nfrom __future__ import absolute_import, division, print_function\n\nimport abc\n\nimport six\n\nfrom cryptography import utils\n\n\[email protected]_metaclass(abc.ABCMeta)\nclass EllipticCurve(object):\n @abc.abstractproperty\n def name(self):\n \"\"\"\n The name of the curve. e.g. secp256r1.\n \"\"\"\n\n @abc.abstractproperty\n def key_size(self):\n \"\"\"\n The bit length of the base point of the curve.\n \"\"\"\n\n\[email protected]_metaclass(abc.ABCMeta)\nclass EllipticCurveSignatureAlgorithm(object):\n @abc.abstractproperty\n def algorithm(self):\n \"\"\"\n The digest algorithm used with this signature.\n \"\"\"\n\n\[email protected]_metaclass(abc.ABCMeta)\nclass EllipticCurvePrivateKey(object):\n @abc.abstractmethod\n def signer(self, signature_algorithm):\n \"\"\"\n Returns an AsymmetricSignatureContext used for signing data.\n \"\"\"\n\n @abc.abstractmethod\n def exchange(self, algorithm, peer_public_key):\n \"\"\"\n Performs a key exchange operation using the provided algorithm with the\n provided peer's public key.\n \"\"\"\n\n @abc.abstractmethod\n def public_key(self):\n \"\"\"\n The EllipticCurvePublicKey for this private key.\n \"\"\"\n\n @abc.abstractproperty\n def curve(self):\n \"\"\"\n The EllipticCurve that this key is on.\n \"\"\"\n\n @abc.abstractproperty\n def sign(self, data, signature_algorithm):\n \"\"\"\n Signs the data\n \"\"\"\n\n\[email protected]_metaclass(abc.ABCMeta)\nclass EllipticCurvePrivateKeyWithSerialization(EllipticCurvePrivateKey):\n @abc.abstractmethod\n def private_numbers(self):\n \"\"\"\n Returns an EllipticCurvePrivateNumbers.\n \"\"\"\n\n @abc.abstractmethod\n def private_bytes(self, encoding, format, encryption_algorithm):\n \"\"\"\n Returns the key serialized as bytes.\n \"\"\"\n\n\[email protected]_metaclass(abc.ABCMeta)\nclass EllipticCurvePublicKey(object):\n @abc.abstractmethod\n def verifier(self, signature, signature_algorithm):\n \"\"\"\n Returns an AsymmetricVerificationContext used for signing data.\n \"\"\"\n\n @abc.abstractproperty\n def curve(self):\n \"\"\"\n The EllipticCurve that this key is on.\n \"\"\"\n\n @abc.abstractmethod\n def public_numbers(self):\n \"\"\"\n Returns an EllipticCurvePublicNumbers.\n \"\"\"\n\n @abc.abstractmethod\n def public_bytes(self, encoding, format):\n \"\"\"\n Returns the key serialized as bytes.\n \"\"\"\n\n @abc.abstractmethod\n def verify(self, signature, data, signature_algorithm):\n \"\"\"\n Verifies the signature of the data.\n \"\"\"\n\n\nEllipticCurvePublicKeyWithSerialization = EllipticCurvePublicKey\n\n\[email protected]_interface(EllipticCurve)\nclass SECT571R1(object):\n name = \"sect571r1\"\n key_size = 571\n\n\[email protected]_interface(EllipticCurve)\nclass SECT409R1(object):\n name = \"sect409r1\"\n key_size = 409\n\n\[email protected]_interface(EllipticCurve)\nclass SECT283R1(object):\n name = \"sect283r1\"\n key_size = 283\n\n\[email protected]_interface(EllipticCurve)\nclass SECT233R1(object):\n name = \"sect233r1\"\n key_size = 233\n\n\[email protected]_interface(EllipticCurve)\nclass SECT163R2(object):\n name = \"sect163r2\"\n key_size = 163\n\n\[email protected]_interface(EllipticCurve)\nclass SECT571K1(object):\n name = \"sect571k1\"\n key_size = 571\n\n\[email protected]_interface(EllipticCurve)\nclass SECT409K1(object):\n name = \"sect409k1\"\n key_size = 409\n\n\[email protected]_interface(EllipticCurve)\nclass SECT283K1(object):\n name = \"sect283k1\"\n key_size = 283\n\n\[email protected]_interface(EllipticCurve)\nclass SECT233K1(object):\n name = \"sect233k1\"\n key_size = 233\n\n\[email protected]_interface(EllipticCurve)\nclass SECT163K1(object):\n name = \"sect163k1\"\n key_size = 163\n\n\[email protected]_interface(EllipticCurve)\nclass SECP521R1(object):\n name = \"secp521r1\"\n key_size = 521\n\n\[email protected]_interface(EllipticCurve)\nclass SECP384R1(object):\n name = \"secp384r1\"\n key_size = 384\n\n\[email protected]_interface(EllipticCurve)\nclass SECP256R1(object):\n name = \"secp256r1\"\n key_size = 256\n\n\[email protected]_interface(EllipticCurve)\nclass SECP256K1(object):\n name = \"secp256k1\"\n key_size = 256\n\n\[email protected]_interface(EllipticCurve)\nclass SECP224R1(object):\n name = \"secp224r1\"\n key_size = 224\n\n\[email protected]_interface(EllipticCurve)\nclass SECP192R1(object):\n name = \"secp192r1\"\n key_size = 192\n\n\n_CURVE_TYPES = {\n \"prime192v1\": SECP192R1,\n \"prime256v1\": SECP256R1,\n\n \"secp192r1\": SECP192R1,\n \"secp224r1\": SECP224R1,\n \"secp256r1\": SECP256R1,\n \"secp384r1\": SECP384R1,\n \"secp521r1\": SECP521R1,\n \"secp256k1\": SECP256K1,\n\n \"sect163k1\": SECT163K1,\n \"sect233k1\": SECT233K1,\n \"sect283k1\": SECT283K1,\n \"sect409k1\": SECT409K1,\n \"sect571k1\": SECT571K1,\n\n \"sect163r2\": SECT163R2,\n \"sect233r1\": SECT233R1,\n \"sect283r1\": SECT283R1,\n \"sect409r1\": SECT409R1,\n \"sect571r1\": SECT571R1,\n}\n\n\[email protected]_interface(EllipticCurveSignatureAlgorithm)\nclass ECDSA(object):\n def __init__(self, algorithm):\n self._algorithm = algorithm\n\n algorithm = utils.read_only_property(\"_algorithm\")\n\n\ndef generate_private_key(curve, backend):\n return backend.generate_elliptic_curve_private_key(curve)\n\n\ndef derive_private_key(private_value, curve, backend):\n if not isinstance(private_value, six.integer_types):\n raise TypeError(\"private_value must be an integer type.\")\n\n if private_value <= 0:\n raise ValueError(\"private_value must be a positive integer.\")\n\n if not isinstance(curve, EllipticCurve):\n raise TypeError(\"curve must provide the EllipticCurve interface.\")\n\n return backend.derive_elliptic_curve_private_key(private_value, curve)\n\n\nclass EllipticCurvePublicNumbers(object):\n def __init__(self, x, y, curve):\n if (\n not isinstance(x, six.integer_types) or\n not isinstance(y, six.integer_types)\n ):\n raise TypeError(\"x and y must be integers.\")\n\n if not isinstance(curve, EllipticCurve):\n raise TypeError(\"curve must provide the EllipticCurve interface.\")\n\n self._y = y\n self._x = x\n self._curve = curve\n\n def public_key(self, backend):\n return backend.load_elliptic_curve_public_numbers(self)\n\n def encode_point(self):\n # key_size is in bits. Convert to bytes and round up\n byte_length = (self.curve.key_size + 7) // 8\n return (\n b'\\x04' + utils.int_to_bytes(self.x, byte_length) +\n utils.int_to_bytes(self.y, byte_length)\n )\n\n @classmethod\n def from_encoded_point(cls, curve, data):\n if not isinstance(curve, EllipticCurve):\n raise TypeError(\"curve must be an EllipticCurve instance\")\n\n if data.startswith(b'\\x04'):\n # key_size is in bits. Convert to bytes and round up\n byte_length = (curve.key_size + 7) // 8\n if len(data) == 2 * byte_length + 1:\n x = utils.int_from_bytes(data[1:byte_length + 1], 'big')\n y = utils.int_from_bytes(data[byte_length + 1:], 'big')\n return cls(x, y, curve)\n else:\n raise ValueError('Invalid elliptic curve point data length')\n else:\n raise ValueError('Unsupported elliptic curve point type')\n\n curve = utils.read_only_property(\"_curve\")\n x = utils.read_only_property(\"_x\")\n y = utils.read_only_property(\"_y\")\n\n def __eq__(self, other):\n if not isinstance(other, EllipticCurvePublicNumbers):\n return NotImplemented\n\n return (\n self.x == other.x and\n self.y == other.y and\n self.curve.name == other.curve.name and\n self.curve.key_size == other.curve.key_size\n )\n\n def __ne__(self, other):\n return not self == other\n\n def __hash__(self):\n return hash((self.x, self.y, self.curve.name, self.curve.key_size))\n\n def __repr__(self):\n return (\n \"<EllipticCurvePublicNumbers(curve={0.curve.name}, x={0.x}, \"\n \"y={0.y}>\".format(self)\n )\n\n\nclass EllipticCurvePrivateNumbers(object):\n def __init__(self, private_value, public_numbers):\n if not isinstance(private_value, six.integer_types):\n raise TypeError(\"private_value must be an integer.\")\n\n if not isinstance(public_numbers, EllipticCurvePublicNumbers):\n raise TypeError(\n \"public_numbers must be an EllipticCurvePublicNumbers \"\n \"instance.\"\n )\n\n self._private_value = private_value\n self._public_numbers = public_numbers\n\n def private_key(self, backend):\n return backend.load_elliptic_curve_private_numbers(self)\n\n private_value = utils.read_only_property(\"_private_value\")\n public_numbers = utils.read_only_property(\"_public_numbers\")\n\n def __eq__(self, other):\n if not isinstance(other, EllipticCurvePrivateNumbers):\n return NotImplemented\n\n return (\n self.private_value == other.private_value and\n self.public_numbers == other.public_numbers\n )\n\n def __ne__(self, other):\n return not self == other\n\n def __hash__(self):\n return hash((self.private_value, self.public_numbers))\n\n\nclass ECDH(object):\n pass\n", "path": "src/cryptography/hazmat/primitives/asymmetric/ec.py"}]}
| 3,917 | 147 |
gh_patches_debug_6006
|
rasdani/github-patches
|
git_diff
|
getsentry__sentry-6091
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
After upgrading to 8.21, Sentry upgrade wizard hangs on auth.allow-registration
When upgrading my onpremise installation form 8.20 to 8.21 (using docker-compose), the wizard prompted me to set the “Anonymize Beacon” option. When clicking “Continue”, the following error message pops up:
> An invalid value for (auth.allow-registration) was passed to the server.
There was no such option `auth.allow-registration` set in either `sentry.conf.py` or `config.yml`.
The call to `https://sentry.example.com/api/0/internal/options/` returned a 400, with the following params:
```
system.admin-email: [email protected]
system.url-prefix | https://sentry.example.com
auth.allow-registration | 0
beacon.anonymous | true
```
I worked around that by resending the request, changing 0 for False. My install is now fine
Running `sentry config get auth.allow-registration`, whether before the fix or after, returns:
```
type: BOOLEAN
from config: <not set>
current: 0
```
This looks somehow similar to #5699.
Hope that helps!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/sentry/utils/types.py`
Content:
```
1 """
2 sentry.utils.types
3 ~~~~~~~~~~~~~~~~~~
4
5 :copyright: (c) 2010-2016 by the Sentry Team, see AUTHORS for more details.
6 :license: BSD, see LICENSE for more details.
7 """
8 from __future__ import absolute_import, print_function
9
10 import six
11
12 from yaml.parser import ParserError
13 from yaml.scanner import ScannerError
14
15 from sentry.utils.yaml import safe_load
16
17 __all__ = ('InvalidTypeError', 'Any', 'Bool', 'Int', 'Float', 'String', 'Dict', 'Sequence', )
18
19
20 class InvalidTypeError(TypeError):
21 pass
22
23
24 class Type(object):
25 """Base Type that provides type coersion"""
26 name = ''
27 # Default value to be returned when initializing
28 default = None
29 # Types that do not need to be coerced
30 expected_types = ()
31 # Types that are acceptable for coersion
32 compatible_types = six.string_types
33
34 def __call__(self, value=None):
35 if value is None:
36 return self._default()
37 if self.test(value):
38 return value
39 if isinstance(value, self.compatible_types):
40 rv = self.convert(value)
41 # Make sure convert was able to do the right thing
42 # and give us the type we were expecting
43 if self.test(rv):
44 return rv
45 raise InvalidTypeError('{!r} is not a valid {}'.format(value, repr(self)))
46
47 def convert(self, value):
48 return value
49
50 def _default(self):
51 return self.default
52
53 def test(self, value):
54 """Check if the value is the correct type or not"""
55 return isinstance(value, self.expected_types)
56
57 def __repr__(self):
58 return self.name
59
60
61 class AnyType(Type):
62 """A type that accepts any value and does no coersion"""
63 name = 'any'
64 expected_types = (object, )
65 compatible_types = (object, )
66
67
68 class BoolType(Type):
69 "Coerce a boolean from a string"
70 name = 'boolean'
71 default = False
72 expected_types = (bool, )
73
74 def convert(self, value):
75 value = value.lower()
76 if value in ('y', 'yes', 't', 'true', '1', 'on'):
77 return True
78 if value in ('n', 'no', 'f', 'false', '0', 'off'):
79 return False
80
81
82 class IntType(Type):
83 """Coerce an integer from a string"""
84 name = 'integer'
85 default = 0
86 expected_types = six.integer_types
87
88 def convert(self, value):
89 try:
90 return int(value)
91 except ValueError:
92 return
93
94
95 class FloatType(Type):
96 """Coerce a float from a string or integer"""
97 name = 'float'
98 default = 0.0
99 expected_types = (float, )
100 compatible_types = six.string_types + six.integer_types + (float, )
101
102 def convert(self, value):
103 try:
104 return float(value)
105 except ValueError:
106 return
107
108
109 class StringType(Type):
110 """String type without any coersion, must be a string"""
111 name = 'string'
112 default = u''
113 expected_types = six.string_types
114 compatible_types = six.string_types
115
116
117 class DictType(Type):
118 """Coerce a dict out of a json/yaml string"""
119 name = 'dictionary'
120 expected_types = (dict, )
121
122 def _default(self):
123 # make sure we create a fresh dict each time
124 return {}
125
126 def convert(self, value):
127 try:
128 return safe_load(value)
129 except (AttributeError, ParserError, ScannerError):
130 return
131
132
133 class SequenceType(Type):
134 """Coerce a tuple out of a json/yaml string or a list"""
135 name = 'sequence'
136 default = ()
137 expected_types = (tuple, list)
138 compatible_types = six.string_types + (tuple, list)
139
140 def convert(self, value):
141 if isinstance(value, six.string_types):
142 try:
143 value = safe_load(value)
144 except (AttributeError, ParserError, ScannerError):
145 return
146 if isinstance(value, list):
147 value = tuple(value)
148 return value
149
150
151 # Initialize singletons of each type for easy reuse
152 Any = AnyType()
153 Bool = BoolType()
154 Int = IntType()
155 Float = FloatType()
156 String = StringType()
157 Dict = DictType()
158 Sequence = SequenceType()
159
160 # Mapping for basic types into what their Type is
161 _type_mapping = {
162 bool: Bool,
163 int: Int,
164 float: Float,
165 six.binary_type: String,
166 six.text_type: String,
167 dict: Dict,
168 tuple: Sequence,
169 list: Sequence,
170 }
171
172
173 def type_from_value(value):
174 """Fetch Type based on a primitive value"""
175 return _type_mapping[type(value)]
176
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/sentry/utils/types.py b/src/sentry/utils/types.py
--- a/src/sentry/utils/types.py
+++ b/src/sentry/utils/types.py
@@ -70,8 +70,11 @@
name = 'boolean'
default = False
expected_types = (bool, )
+ compatible_types = six.string_types + six.integer_types
def convert(self, value):
+ if isinstance(value, six.integer_types):
+ return bool(value)
value = value.lower()
if value in ('y', 'yes', 't', 'true', '1', 'on'):
return True
|
{"golden_diff": "diff --git a/src/sentry/utils/types.py b/src/sentry/utils/types.py\n--- a/src/sentry/utils/types.py\n+++ b/src/sentry/utils/types.py\n@@ -70,8 +70,11 @@\n name = 'boolean'\n default = False\n expected_types = (bool, )\n+ compatible_types = six.string_types + six.integer_types\n \n def convert(self, value):\n+ if isinstance(value, six.integer_types):\n+ return bool(value)\n value = value.lower()\n if value in ('y', 'yes', 't', 'true', '1', 'on'):\n return True\n", "issue": "After upgrading to 8.21, Sentry upgrade wizard hangs on auth.allow-registration\nWhen upgrading my onpremise installation form 8.20 to 8.21 (using docker-compose), the wizard prompted me to set the \u201cAnonymize Beacon\u201d option. When clicking \u201cContinue\u201d, the following error message pops up:\r\n> An invalid value for (auth.allow-registration) was passed to the server.\r\n\r\nThere was no such option `auth.allow-registration` set in either `sentry.conf.py` or `config.yml`.\r\n\r\nThe call to `https://sentry.example.com/api/0/internal/options/` returned a 400, with the following params:\r\n```\r\nsystem.admin-email: [email protected]\r\nsystem.url-prefix | https://sentry.example.com\r\nauth.allow-registration | 0\r\nbeacon.anonymous | true\r\n```\r\nI worked around that by resending the request, changing 0 for False. My install is now fine\r\n\r\nRunning `sentry config get auth.allow-registration`, whether before the fix or after, returns:\r\n```\r\n type: BOOLEAN\r\n from config: <not set>\r\n current: 0\r\n```\r\nThis looks somehow similar to #5699.\r\n\r\nHope that helps!\n", "before_files": [{"content": "\"\"\"\nsentry.utils.types\n~~~~~~~~~~~~~~~~~~\n\n:copyright: (c) 2010-2016 by the Sentry Team, see AUTHORS for more details.\n:license: BSD, see LICENSE for more details.\n\"\"\"\nfrom __future__ import absolute_import, print_function\n\nimport six\n\nfrom yaml.parser import ParserError\nfrom yaml.scanner import ScannerError\n\nfrom sentry.utils.yaml import safe_load\n\n__all__ = ('InvalidTypeError', 'Any', 'Bool', 'Int', 'Float', 'String', 'Dict', 'Sequence', )\n\n\nclass InvalidTypeError(TypeError):\n pass\n\n\nclass Type(object):\n \"\"\"Base Type that provides type coersion\"\"\"\n name = ''\n # Default value to be returned when initializing\n default = None\n # Types that do not need to be coerced\n expected_types = ()\n # Types that are acceptable for coersion\n compatible_types = six.string_types\n\n def __call__(self, value=None):\n if value is None:\n return self._default()\n if self.test(value):\n return value\n if isinstance(value, self.compatible_types):\n rv = self.convert(value)\n # Make sure convert was able to do the right thing\n # and give us the type we were expecting\n if self.test(rv):\n return rv\n raise InvalidTypeError('{!r} is not a valid {}'.format(value, repr(self)))\n\n def convert(self, value):\n return value\n\n def _default(self):\n return self.default\n\n def test(self, value):\n \"\"\"Check if the value is the correct type or not\"\"\"\n return isinstance(value, self.expected_types)\n\n def __repr__(self):\n return self.name\n\n\nclass AnyType(Type):\n \"\"\"A type that accepts any value and does no coersion\"\"\"\n name = 'any'\n expected_types = (object, )\n compatible_types = (object, )\n\n\nclass BoolType(Type):\n \"Coerce a boolean from a string\"\n name = 'boolean'\n default = False\n expected_types = (bool, )\n\n def convert(self, value):\n value = value.lower()\n if value in ('y', 'yes', 't', 'true', '1', 'on'):\n return True\n if value in ('n', 'no', 'f', 'false', '0', 'off'):\n return False\n\n\nclass IntType(Type):\n \"\"\"Coerce an integer from a string\"\"\"\n name = 'integer'\n default = 0\n expected_types = six.integer_types\n\n def convert(self, value):\n try:\n return int(value)\n except ValueError:\n return\n\n\nclass FloatType(Type):\n \"\"\"Coerce a float from a string or integer\"\"\"\n name = 'float'\n default = 0.0\n expected_types = (float, )\n compatible_types = six.string_types + six.integer_types + (float, )\n\n def convert(self, value):\n try:\n return float(value)\n except ValueError:\n return\n\n\nclass StringType(Type):\n \"\"\"String type without any coersion, must be a string\"\"\"\n name = 'string'\n default = u''\n expected_types = six.string_types\n compatible_types = six.string_types\n\n\nclass DictType(Type):\n \"\"\"Coerce a dict out of a json/yaml string\"\"\"\n name = 'dictionary'\n expected_types = (dict, )\n\n def _default(self):\n # make sure we create a fresh dict each time\n return {}\n\n def convert(self, value):\n try:\n return safe_load(value)\n except (AttributeError, ParserError, ScannerError):\n return\n\n\nclass SequenceType(Type):\n \"\"\"Coerce a tuple out of a json/yaml string or a list\"\"\"\n name = 'sequence'\n default = ()\n expected_types = (tuple, list)\n compatible_types = six.string_types + (tuple, list)\n\n def convert(self, value):\n if isinstance(value, six.string_types):\n try:\n value = safe_load(value)\n except (AttributeError, ParserError, ScannerError):\n return\n if isinstance(value, list):\n value = tuple(value)\n return value\n\n\n# Initialize singletons of each type for easy reuse\nAny = AnyType()\nBool = BoolType()\nInt = IntType()\nFloat = FloatType()\nString = StringType()\nDict = DictType()\nSequence = SequenceType()\n\n# Mapping for basic types into what their Type is\n_type_mapping = {\n bool: Bool,\n int: Int,\n float: Float,\n six.binary_type: String,\n six.text_type: String,\n dict: Dict,\n tuple: Sequence,\n list: Sequence,\n}\n\n\ndef type_from_value(value):\n \"\"\"Fetch Type based on a primitive value\"\"\"\n return _type_mapping[type(value)]\n", "path": "src/sentry/utils/types.py"}], "after_files": [{"content": "\"\"\"\nsentry.utils.types\n~~~~~~~~~~~~~~~~~~\n\n:copyright: (c) 2010-2016 by the Sentry Team, see AUTHORS for more details.\n:license: BSD, see LICENSE for more details.\n\"\"\"\nfrom __future__ import absolute_import, print_function\n\nimport six\n\nfrom yaml.parser import ParserError\nfrom yaml.scanner import ScannerError\n\nfrom sentry.utils.yaml import safe_load\n\n__all__ = ('InvalidTypeError', 'Any', 'Bool', 'Int', 'Float', 'String', 'Dict', 'Sequence', )\n\n\nclass InvalidTypeError(TypeError):\n pass\n\n\nclass Type(object):\n \"\"\"Base Type that provides type coersion\"\"\"\n name = ''\n # Default value to be returned when initializing\n default = None\n # Types that do not need to be coerced\n expected_types = ()\n # Types that are acceptable for coersion\n compatible_types = six.string_types\n\n def __call__(self, value=None):\n if value is None:\n return self._default()\n if self.test(value):\n return value\n if isinstance(value, self.compatible_types):\n rv = self.convert(value)\n # Make sure convert was able to do the right thing\n # and give us the type we were expecting\n if self.test(rv):\n return rv\n raise InvalidTypeError('{!r} is not a valid {}'.format(value, repr(self)))\n\n def convert(self, value):\n return value\n\n def _default(self):\n return self.default\n\n def test(self, value):\n \"\"\"Check if the value is the correct type or not\"\"\"\n return isinstance(value, self.expected_types)\n\n def __repr__(self):\n return self.name\n\n\nclass AnyType(Type):\n \"\"\"A type that accepts any value and does no coersion\"\"\"\n name = 'any'\n expected_types = (object, )\n compatible_types = (object, )\n\n\nclass BoolType(Type):\n \"Coerce a boolean from a string\"\n name = 'boolean'\n default = False\n expected_types = (bool, )\n compatible_types = six.string_types + six.integer_types\n\n def convert(self, value):\n if isinstance(value, six.integer_types):\n return bool(value)\n value = value.lower()\n if value in ('y', 'yes', 't', 'true', '1', 'on'):\n return True\n if value in ('n', 'no', 'f', 'false', '0', 'off'):\n return False\n\n\nclass IntType(Type):\n \"\"\"Coerce an integer from a string\"\"\"\n name = 'integer'\n default = 0\n expected_types = six.integer_types\n\n def convert(self, value):\n try:\n return int(value)\n except ValueError:\n return\n\n\nclass FloatType(Type):\n \"\"\"Coerce a float from a string or integer\"\"\"\n name = 'float'\n default = 0.0\n expected_types = (float, )\n compatible_types = six.string_types + six.integer_types + (float, )\n\n def convert(self, value):\n try:\n return float(value)\n except ValueError:\n return\n\n\nclass StringType(Type):\n \"\"\"String type without any coersion, must be a string\"\"\"\n name = 'string'\n default = u''\n expected_types = six.string_types\n compatible_types = six.string_types\n\n\nclass DictType(Type):\n \"\"\"Coerce a dict out of a json/yaml string\"\"\"\n name = 'dictionary'\n expected_types = (dict, )\n\n def _default(self):\n # make sure we create a fresh dict each time\n return {}\n\n def convert(self, value):\n try:\n return safe_load(value)\n except (AttributeError, ParserError, ScannerError):\n return\n\n\nclass SequenceType(Type):\n \"\"\"Coerce a tuple out of a json/yaml string or a list\"\"\"\n name = 'sequence'\n default = ()\n expected_types = (tuple, list)\n compatible_types = six.string_types + (tuple, list)\n\n def convert(self, value):\n if isinstance(value, six.string_types):\n try:\n value = safe_load(value)\n except (AttributeError, ParserError, ScannerError):\n return\n if isinstance(value, list):\n value = tuple(value)\n return value\n\n\n# Initialize singletons of each type for easy reuse\nAny = AnyType()\nBool = BoolType()\nInt = IntType()\nFloat = FloatType()\nString = StringType()\nDict = DictType()\nSequence = SequenceType()\n\n# Mapping for basic types into what their Type is\n_type_mapping = {\n bool: Bool,\n int: Int,\n float: Float,\n six.binary_type: String,\n six.text_type: String,\n dict: Dict,\n tuple: Sequence,\n list: Sequence,\n}\n\n\ndef type_from_value(value):\n \"\"\"Fetch Type based on a primitive value\"\"\"\n return _type_mapping[type(value)]\n", "path": "src/sentry/utils/types.py"}]}
| 1,976 | 136 |
gh_patches_debug_27774
|
rasdani/github-patches
|
git_diff
|
open-mmlab__mmpose-946
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
a dataset bug causing topdown training very slow, wasting 3 min every epoch
i found a dataset bug, i test it on several server(including 8 a100 with 96 core cpu), it all happened. for every epoch, this bug cause about 3min time wasting. i jsut can locat the bug, but i don't known why it happen. it seems only happen when distribution launching.
bug loaction: when you lauch a topdown method, eg, topdown_heatmap/coco/res50_coco_256x192.py, go to /mmcv/runner/epoch_based_runner.py, about line 48. there is such func
self.call_hook('before_train_epoch')
time.sleep(2) # Prevent possible deadlock during epoch transition
for i, data_batch in enumerate(self.data_loader):
self._inner_iter = i
at the every epoch begining, the ( for i, data_batch in enumerate(self.data_loader): ) takes about 3min, it make the training very slow.
you can modify the ori code to the code below to reproduce this issue, this only happen at very epoch begining.
self.call_hook('before_train_epoch')
time.sleep(2) # Prevent possible deadlock during epoch transition
print('before_train_epoch, time:{}'.format(time.time()-start_time))
start_time = time.time()
for i, data_batch in enumerate(self.data_loader):
self._inner_iter = i
print('before_train_iter_load_data, time:{}'.format(time.time()-start_time))
here is my sys information
Python: 3.7.10 | packaged by conda-forge | (default, Feb 19 2021, 16:07:37) [GCC 9.3.0]
CUDA available: True GPU 0,1,2,3,4,5,6,7: A100-SXM4-40GB
CUDA_HOME: /usr/local/cuda-11.1
NVCC: Build cuda_11.1.TC455_06.29190527_0 GCC: gcc (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
PyTorch: 1.8.1+cu111
PyTorch compiling details: PyTorch built with:
- GCC 7.3
- C++ Version: 201402
- Intel(R) Math Kernel Library Version 2020.0.0 Product Build 20191122 for Intel(R) 64 architecture applications
- Intel(R) MKL-DNN v1.7.0 (Git Hash 7aed236906b1f7a05c0917e5257a1af05e9ff683)
- OpenMP 201511 (a.k.a. OpenMP 4.5)
- NNPACK is enabled
- CPU capability usage: AVX2
- CUDA Runtime 11.1
- NVCC architecture flags: -gencode;arch=compute_37,code=sm_37;-gencode;arch=compute_50,code=sm_50;-gencode;arch=compute_60,code=sm_60;-gencode;arch=compute_70,code=sm_70;-
gencode;arch=compute_75,code=sm_75;-gencode;arch=compute_80,code=sm_80;-gencode;arch=compute_86,code=sm_86
- CuDNN 8.0.5
- Magma 2.5.2
- Build settings: BLAS_INFO=mkl, BUILD_TYPE=Release, CUDA_VERSION=11.1, CUDNN_VERSION=8.0.5, CXX_COMPILER=/opt/rh/devtoolset-7/root/usr/bin/c++, CXX_FLAGS= -Wno-deprecated
-fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -O2 -fPIC -Wno-narrowing -Wall -We
xtra -Werror=return-type -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wno-sign-compare -Wno-unused-parameter -Wno-unused-variable
-Wno-unused-function -Wno-unused-result -Wno-unused-local-typedefs -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-ps
abi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -f
no-math-errno -fno-trapping-math -Werror=format -Wno-stringop-overflow, LAPACK_INFO=mkl, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, TORCH_VERSION=1.8.1, USE_CUDA=
ON, USE_CUDNN=ON, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=ON, USE_MKLDNN=ON, USE_MPI=OFF, USE_NCCL=ON, USE_NNPACK=ON, USE_OPENMP=ON,
TorchVision: 0.9.1+cu111
OpenCV: 4.5.3
MMCV: 1.3.8
MMCV Compiler: GCC 7.5
MMCV CUDA Compiler: 11.1
MMPose: 0.15.0+51b4b45
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mmpose/apis/train.py`
Content:
```
1 # Copyright (c) OpenMMLab. All rights reserved.
2 import warnings
3
4 import torch
5 from mmcv.parallel import MMDataParallel, MMDistributedDataParallel
6 from mmcv.runner import DistSamplerSeedHook, EpochBasedRunner, OptimizerHook
7
8 from mmpose.core import DistEvalHook, EvalHook, build_optimizers
9 from mmpose.core.distributed_wrapper import DistributedDataParallelWrapper
10 from mmpose.datasets import build_dataloader, build_dataset
11 from mmpose.utils import get_root_logger
12
13 try:
14 from mmcv.runner import Fp16OptimizerHook
15 except ImportError:
16 warnings.warn(
17 'Fp16OptimizerHook from mmpose will be deprecated from '
18 'v0.15.0. Please install mmcv>=1.1.4', DeprecationWarning)
19 from mmpose.core import Fp16OptimizerHook
20
21
22 def train_model(model,
23 dataset,
24 cfg,
25 distributed=False,
26 validate=False,
27 timestamp=None,
28 meta=None):
29 """Train model entry function.
30
31 Args:
32 model (nn.Module): The model to be trained.
33 dataset (Dataset): Train dataset.
34 cfg (dict): The config dict for training.
35 distributed (bool): Whether to use distributed training.
36 Default: False.
37 validate (bool): Whether to do evaluation. Default: False.
38 timestamp (str | None): Local time for runner. Default: None.
39 meta (dict | None): Meta dict to record some important information.
40 Default: None
41 """
42 logger = get_root_logger(cfg.log_level)
43
44 # prepare data loaders
45 dataset = dataset if isinstance(dataset, (list, tuple)) else [dataset]
46 dataloader_setting = dict(
47 samples_per_gpu=cfg.data.get('samples_per_gpu', {}),
48 workers_per_gpu=cfg.data.get('workers_per_gpu', {}),
49 # cfg.gpus will be ignored if distributed
50 num_gpus=len(cfg.gpu_ids),
51 dist=distributed,
52 seed=cfg.seed)
53 dataloader_setting = dict(dataloader_setting,
54 **cfg.data.get('train_dataloader', {}))
55
56 data_loaders = [
57 build_dataloader(ds, **dataloader_setting) for ds in dataset
58 ]
59
60 # determine wether use adversarial training precess or not
61 use_adverserial_train = cfg.get('use_adversarial_train', False)
62
63 # put model on gpus
64 if distributed:
65 find_unused_parameters = cfg.get('find_unused_parameters', True)
66 # Sets the `find_unused_parameters` parameter in
67 # torch.nn.parallel.DistributedDataParallel
68
69 if use_adverserial_train:
70 # Use DistributedDataParallelWrapper for adversarial training
71 model = DistributedDataParallelWrapper(
72 model,
73 device_ids=[torch.cuda.current_device()],
74 broadcast_buffers=False,
75 find_unused_parameters=find_unused_parameters)
76 else:
77 model = MMDistributedDataParallel(
78 model.cuda(),
79 device_ids=[torch.cuda.current_device()],
80 broadcast_buffers=False,
81 find_unused_parameters=find_unused_parameters)
82 else:
83 model = MMDataParallel(
84 model.cuda(cfg.gpu_ids[0]), device_ids=cfg.gpu_ids)
85
86 # build runner
87 optimizer = build_optimizers(model, cfg.optimizer)
88
89 runner = EpochBasedRunner(
90 model,
91 optimizer=optimizer,
92 work_dir=cfg.work_dir,
93 logger=logger,
94 meta=meta)
95 # an ugly workaround to make .log and .log.json filenames the same
96 runner.timestamp = timestamp
97
98 if use_adverserial_train:
99 # The optimizer step process is included in the train_step function
100 # of the model, so the runner should NOT include optimizer hook.
101 optimizer_config = None
102 else:
103 # fp16 setting
104 fp16_cfg = cfg.get('fp16', None)
105 if fp16_cfg is not None:
106 optimizer_config = Fp16OptimizerHook(
107 **cfg.optimizer_config, **fp16_cfg, distributed=distributed)
108 elif distributed and 'type' not in cfg.optimizer_config:
109 optimizer_config = OptimizerHook(**cfg.optimizer_config)
110 else:
111 optimizer_config = cfg.optimizer_config
112
113 # register hooks
114 runner.register_training_hooks(cfg.lr_config, optimizer_config,
115 cfg.checkpoint_config, cfg.log_config,
116 cfg.get('momentum_config', None))
117 if distributed:
118 runner.register_hook(DistSamplerSeedHook())
119
120 # register eval hooks
121 if validate:
122 eval_cfg = cfg.get('evaluation', {})
123 val_dataset = build_dataset(cfg.data.val, dict(test_mode=True))
124 dataloader_setting = dict(
125 samples_per_gpu=1,
126 workers_per_gpu=cfg.data.get('workers_per_gpu', {}),
127 # cfg.gpus will be ignored if distributed
128 num_gpus=len(cfg.gpu_ids),
129 dist=distributed,
130 drop_last=False,
131 shuffle=False)
132 dataloader_setting = dict(dataloader_setting,
133 **cfg.data.get('val_dataloader', {}))
134 val_dataloader = build_dataloader(val_dataset, **dataloader_setting)
135 eval_hook = DistEvalHook if distributed else EvalHook
136 runner.register_hook(eval_hook(val_dataloader, **eval_cfg))
137
138 if cfg.resume_from:
139 runner.resume(cfg.resume_from)
140 elif cfg.load_from:
141 runner.load_checkpoint(cfg.load_from)
142 runner.run(data_loaders, cfg.workflow, cfg.total_epochs)
143
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mmpose/apis/train.py b/mmpose/apis/train.py
--- a/mmpose/apis/train.py
+++ b/mmpose/apis/train.py
@@ -43,19 +43,33 @@
# prepare data loaders
dataset = dataset if isinstance(dataset, (list, tuple)) else [dataset]
- dataloader_setting = dict(
- samples_per_gpu=cfg.data.get('samples_per_gpu', {}),
- workers_per_gpu=cfg.data.get('workers_per_gpu', {}),
- # cfg.gpus will be ignored if distributed
- num_gpus=len(cfg.gpu_ids),
- dist=distributed,
- seed=cfg.seed)
- dataloader_setting = dict(dataloader_setting,
- **cfg.data.get('train_dataloader', {}))
-
- data_loaders = [
- build_dataloader(ds, **dataloader_setting) for ds in dataset
- ]
+ # step 1: give default values and override (if exist) from cfg.data
+ loader_cfg = {
+ **dict(
+ seed=cfg.get('seed'),
+ drop_last=False,
+ dist=distributed,
+ num_gpus=len(cfg.gpu_ids)),
+ **({} if torch.__version__ != 'parrots' else dict(
+ prefetch_num=2,
+ pin_memory=False,
+ )),
+ **dict((k, cfg.data[k]) for k in [
+ 'samples_per_gpu',
+ 'workers_per_gpu',
+ 'shuffle',
+ 'seed',
+ 'drop_last',
+ 'prefetch_num',
+ 'pin_memory',
+ 'persistent_workers',
+ ] if k in cfg.data)
+ }
+
+ # step 2: cfg.data.train_dataloader has highest priority
+ train_loader_cfg = dict(loader_cfg, **cfg.data.get('train_dataloader', {}))
+
+ data_loaders = [build_dataloader(ds, **train_loader_cfg) for ds in dataset]
# determine wether use adversarial training precess or not
use_adverserial_train = cfg.get('use_adversarial_train', False)
|
{"golden_diff": "diff --git a/mmpose/apis/train.py b/mmpose/apis/train.py\n--- a/mmpose/apis/train.py\n+++ b/mmpose/apis/train.py\n@@ -43,19 +43,33 @@\n \n # prepare data loaders\n dataset = dataset if isinstance(dataset, (list, tuple)) else [dataset]\n- dataloader_setting = dict(\n- samples_per_gpu=cfg.data.get('samples_per_gpu', {}),\n- workers_per_gpu=cfg.data.get('workers_per_gpu', {}),\n- # cfg.gpus will be ignored if distributed\n- num_gpus=len(cfg.gpu_ids),\n- dist=distributed,\n- seed=cfg.seed)\n- dataloader_setting = dict(dataloader_setting,\n- **cfg.data.get('train_dataloader', {}))\n-\n- data_loaders = [\n- build_dataloader(ds, **dataloader_setting) for ds in dataset\n- ]\n+ # step 1: give default values and override (if exist) from cfg.data\n+ loader_cfg = {\n+ **dict(\n+ seed=cfg.get('seed'),\n+ drop_last=False,\n+ dist=distributed,\n+ num_gpus=len(cfg.gpu_ids)),\n+ **({} if torch.__version__ != 'parrots' else dict(\n+ prefetch_num=2,\n+ pin_memory=False,\n+ )),\n+ **dict((k, cfg.data[k]) for k in [\n+ 'samples_per_gpu',\n+ 'workers_per_gpu',\n+ 'shuffle',\n+ 'seed',\n+ 'drop_last',\n+ 'prefetch_num',\n+ 'pin_memory',\n+ 'persistent_workers',\n+ ] if k in cfg.data)\n+ }\n+\n+ # step 2: cfg.data.train_dataloader has highest priority\n+ train_loader_cfg = dict(loader_cfg, **cfg.data.get('train_dataloader', {}))\n+\n+ data_loaders = [build_dataloader(ds, **train_loader_cfg) for ds in dataset]\n \n # determine wether use adversarial training precess or not\n use_adverserial_train = cfg.get('use_adversarial_train', False)\n", "issue": "a dataset bug causing topdown training very slow, wasting 3 min every epoch\ni found a dataset bug, i test it on several server(including 8 a100 with 96 core cpu), it all happened. for every epoch, this bug cause about 3min time wasting. i jsut can locat the bug, but i don't known why it happen. it seems only happen when distribution launching.\r\n\r\nbug loaction: when you lauch a topdown method, eg, topdown_heatmap/coco/res50_coco_256x192.py, go to /mmcv/runner/epoch_based_runner.py, about line 48. there is such func\r\n\r\n self.call_hook('before_train_epoch')\r\n time.sleep(2) # Prevent possible deadlock during epoch transition\r\n for i, data_batch in enumerate(self.data_loader):\r\n self._inner_iter = i\r\n\r\nat the every epoch begining, the ( for i, data_batch in enumerate(self.data_loader): ) takes about 3min, it make the training very slow.\r\n\r\nyou can modify the ori code to the code below to reproduce this issue, this only happen at very epoch begining.\r\n\r\n self.call_hook('before_train_epoch')\r\n time.sleep(2) # Prevent possible deadlock during epoch transition\r\n print('before_train_epoch, time:{}'.format(time.time()-start_time))\r\n start_time = time.time()\r\n for i, data_batch in enumerate(self.data_loader):\r\n self._inner_iter = i\r\n print('before_train_iter_load_data, time:{}'.format(time.time()-start_time))\r\n\r\nhere is my sys information\r\nPython: 3.7.10 | packaged by conda-forge | (default, Feb 19 2021, 16:07:37) [GCC 9.3.0] \r\nCUDA available: True GPU 0,1,2,3,4,5,6,7: A100-SXM4-40GB \r\nCUDA_HOME: /usr/local/cuda-11.1 \r\nNVCC: Build cuda_11.1.TC455_06.29190527_0 GCC: gcc (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0 \r\nPyTorch: 1.8.1+cu111 \r\nPyTorch compiling details: PyTorch built with: \r\n - GCC 7.3 \r\n - C++ Version: 201402 \r\n - Intel(R) Math Kernel Library Version 2020.0.0 Product Build 20191122 for Intel(R) 64 architecture applications\r\n - Intel(R) MKL-DNN v1.7.0 (Git Hash 7aed236906b1f7a05c0917e5257a1af05e9ff683)\r\n - OpenMP 201511 (a.k.a. OpenMP 4.5)\r\n - NNPACK is enabled \r\n - CPU capability usage: AVX2 \r\n - CUDA Runtime 11.1\r\n - NVCC architecture flags: -gencode;arch=compute_37,code=sm_37;-gencode;arch=compute_50,code=sm_50;-gencode;arch=compute_60,code=sm_60;-gencode;arch=compute_70,code=sm_70;-\r\ngencode;arch=compute_75,code=sm_75;-gencode;arch=compute_80,code=sm_80;-gencode;arch=compute_86,code=sm_86\r\n - CuDNN 8.0.5 \r\n - Magma 2.5.2 \r\n - Build settings: BLAS_INFO=mkl, BUILD_TYPE=Release, CUDA_VERSION=11.1, CUDNN_VERSION=8.0.5, CXX_COMPILER=/opt/rh/devtoolset-7/root/usr/bin/c++, CXX_FLAGS= -Wno-deprecated\r\n-fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -O2 -fPIC -Wno-narrowing -Wall -We\r\nxtra -Werror=return-type -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wno-sign-compare -Wno-unused-parameter -Wno-unused-variable\r\n-Wno-unused-function -Wno-unused-result -Wno-unused-local-typedefs -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-ps\r\nabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -f\r\nno-math-errno -fno-trapping-math -Werror=format -Wno-stringop-overflow, LAPACK_INFO=mkl, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, TORCH_VERSION=1.8.1, USE_CUDA=\r\nON, USE_CUDNN=ON, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=ON, USE_MKLDNN=ON, USE_MPI=OFF, USE_NCCL=ON, USE_NNPACK=ON, USE_OPENMP=ON,\r\n \r\nTorchVision: 0.9.1+cu111 \r\nOpenCV: 4.5.3 \r\nMMCV: 1.3.8 \r\nMMCV Compiler: GCC 7.5\r\nMMCV CUDA Compiler: 11.1\r\nMMPose: 0.15.0+51b4b45\n", "before_files": [{"content": "# Copyright (c) OpenMMLab. All rights reserved.\nimport warnings\n\nimport torch\nfrom mmcv.parallel import MMDataParallel, MMDistributedDataParallel\nfrom mmcv.runner import DistSamplerSeedHook, EpochBasedRunner, OptimizerHook\n\nfrom mmpose.core import DistEvalHook, EvalHook, build_optimizers\nfrom mmpose.core.distributed_wrapper import DistributedDataParallelWrapper\nfrom mmpose.datasets import build_dataloader, build_dataset\nfrom mmpose.utils import get_root_logger\n\ntry:\n from mmcv.runner import Fp16OptimizerHook\nexcept ImportError:\n warnings.warn(\n 'Fp16OptimizerHook from mmpose will be deprecated from '\n 'v0.15.0. Please install mmcv>=1.1.4', DeprecationWarning)\n from mmpose.core import Fp16OptimizerHook\n\n\ndef train_model(model,\n dataset,\n cfg,\n distributed=False,\n validate=False,\n timestamp=None,\n meta=None):\n \"\"\"Train model entry function.\n\n Args:\n model (nn.Module): The model to be trained.\n dataset (Dataset): Train dataset.\n cfg (dict): The config dict for training.\n distributed (bool): Whether to use distributed training.\n Default: False.\n validate (bool): Whether to do evaluation. Default: False.\n timestamp (str | None): Local time for runner. Default: None.\n meta (dict | None): Meta dict to record some important information.\n Default: None\n \"\"\"\n logger = get_root_logger(cfg.log_level)\n\n # prepare data loaders\n dataset = dataset if isinstance(dataset, (list, tuple)) else [dataset]\n dataloader_setting = dict(\n samples_per_gpu=cfg.data.get('samples_per_gpu', {}),\n workers_per_gpu=cfg.data.get('workers_per_gpu', {}),\n # cfg.gpus will be ignored if distributed\n num_gpus=len(cfg.gpu_ids),\n dist=distributed,\n seed=cfg.seed)\n dataloader_setting = dict(dataloader_setting,\n **cfg.data.get('train_dataloader', {}))\n\n data_loaders = [\n build_dataloader(ds, **dataloader_setting) for ds in dataset\n ]\n\n # determine wether use adversarial training precess or not\n use_adverserial_train = cfg.get('use_adversarial_train', False)\n\n # put model on gpus\n if distributed:\n find_unused_parameters = cfg.get('find_unused_parameters', True)\n # Sets the `find_unused_parameters` parameter in\n # torch.nn.parallel.DistributedDataParallel\n\n if use_adverserial_train:\n # Use DistributedDataParallelWrapper for adversarial training\n model = DistributedDataParallelWrapper(\n model,\n device_ids=[torch.cuda.current_device()],\n broadcast_buffers=False,\n find_unused_parameters=find_unused_parameters)\n else:\n model = MMDistributedDataParallel(\n model.cuda(),\n device_ids=[torch.cuda.current_device()],\n broadcast_buffers=False,\n find_unused_parameters=find_unused_parameters)\n else:\n model = MMDataParallel(\n model.cuda(cfg.gpu_ids[0]), device_ids=cfg.gpu_ids)\n\n # build runner\n optimizer = build_optimizers(model, cfg.optimizer)\n\n runner = EpochBasedRunner(\n model,\n optimizer=optimizer,\n work_dir=cfg.work_dir,\n logger=logger,\n meta=meta)\n # an ugly workaround to make .log and .log.json filenames the same\n runner.timestamp = timestamp\n\n if use_adverserial_train:\n # The optimizer step process is included in the train_step function\n # of the model, so the runner should NOT include optimizer hook.\n optimizer_config = None\n else:\n # fp16 setting\n fp16_cfg = cfg.get('fp16', None)\n if fp16_cfg is not None:\n optimizer_config = Fp16OptimizerHook(\n **cfg.optimizer_config, **fp16_cfg, distributed=distributed)\n elif distributed and 'type' not in cfg.optimizer_config:\n optimizer_config = OptimizerHook(**cfg.optimizer_config)\n else:\n optimizer_config = cfg.optimizer_config\n\n # register hooks\n runner.register_training_hooks(cfg.lr_config, optimizer_config,\n cfg.checkpoint_config, cfg.log_config,\n cfg.get('momentum_config', None))\n if distributed:\n runner.register_hook(DistSamplerSeedHook())\n\n # register eval hooks\n if validate:\n eval_cfg = cfg.get('evaluation', {})\n val_dataset = build_dataset(cfg.data.val, dict(test_mode=True))\n dataloader_setting = dict(\n samples_per_gpu=1,\n workers_per_gpu=cfg.data.get('workers_per_gpu', {}),\n # cfg.gpus will be ignored if distributed\n num_gpus=len(cfg.gpu_ids),\n dist=distributed,\n drop_last=False,\n shuffle=False)\n dataloader_setting = dict(dataloader_setting,\n **cfg.data.get('val_dataloader', {}))\n val_dataloader = build_dataloader(val_dataset, **dataloader_setting)\n eval_hook = DistEvalHook if distributed else EvalHook\n runner.register_hook(eval_hook(val_dataloader, **eval_cfg))\n\n if cfg.resume_from:\n runner.resume(cfg.resume_from)\n elif cfg.load_from:\n runner.load_checkpoint(cfg.load_from)\n runner.run(data_loaders, cfg.workflow, cfg.total_epochs)\n", "path": "mmpose/apis/train.py"}], "after_files": [{"content": "# Copyright (c) OpenMMLab. All rights reserved.\nimport warnings\n\nimport torch\nfrom mmcv.parallel import MMDataParallel, MMDistributedDataParallel\nfrom mmcv.runner import DistSamplerSeedHook, EpochBasedRunner, OptimizerHook\n\nfrom mmpose.core import DistEvalHook, EvalHook, build_optimizers\nfrom mmpose.core.distributed_wrapper import DistributedDataParallelWrapper\nfrom mmpose.datasets import build_dataloader, build_dataset\nfrom mmpose.utils import get_root_logger\n\ntry:\n from mmcv.runner import Fp16OptimizerHook\nexcept ImportError:\n warnings.warn(\n 'Fp16OptimizerHook from mmpose will be deprecated from '\n 'v0.15.0. Please install mmcv>=1.1.4', DeprecationWarning)\n from mmpose.core import Fp16OptimizerHook\n\n\ndef train_model(model,\n dataset,\n cfg,\n distributed=False,\n validate=False,\n timestamp=None,\n meta=None):\n \"\"\"Train model entry function.\n\n Args:\n model (nn.Module): The model to be trained.\n dataset (Dataset): Train dataset.\n cfg (dict): The config dict for training.\n distributed (bool): Whether to use distributed training.\n Default: False.\n validate (bool): Whether to do evaluation. Default: False.\n timestamp (str | None): Local time for runner. Default: None.\n meta (dict | None): Meta dict to record some important information.\n Default: None\n \"\"\"\n logger = get_root_logger(cfg.log_level)\n\n # prepare data loaders\n dataset = dataset if isinstance(dataset, (list, tuple)) else [dataset]\n # step 1: give default values and override (if exist) from cfg.data\n loader_cfg = {\n **dict(\n seed=cfg.get('seed'),\n drop_last=False,\n dist=distributed,\n num_gpus=len(cfg.gpu_ids)),\n **({} if torch.__version__ != 'parrots' else dict(\n prefetch_num=2,\n pin_memory=False,\n )),\n **dict((k, cfg.data[k]) for k in [\n 'samples_per_gpu',\n 'workers_per_gpu',\n 'shuffle',\n 'seed',\n 'drop_last',\n 'prefetch_num',\n 'pin_memory',\n 'persistent_workers',\n ] if k in cfg.data)\n }\n\n # step 2: cfg.data.train_dataloader has highest priority\n train_loader_cfg = dict(loader_cfg, **cfg.data.get('train_dataloader', {}))\n\n data_loaders = [build_dataloader(ds, **train_loader_cfg) for ds in dataset]\n\n # determine wether use adversarial training precess or not\n use_adverserial_train = cfg.get('use_adversarial_train', False)\n\n # put model on gpus\n if distributed:\n find_unused_parameters = cfg.get('find_unused_parameters', True)\n # Sets the `find_unused_parameters` parameter in\n # torch.nn.parallel.DistributedDataParallel\n\n if use_adverserial_train:\n # Use DistributedDataParallelWrapper for adversarial training\n model = DistributedDataParallelWrapper(\n model,\n device_ids=[torch.cuda.current_device()],\n broadcast_buffers=False,\n find_unused_parameters=find_unused_parameters)\n else:\n model = MMDistributedDataParallel(\n model.cuda(),\n device_ids=[torch.cuda.current_device()],\n broadcast_buffers=False,\n find_unused_parameters=find_unused_parameters)\n else:\n model = MMDataParallel(\n model.cuda(cfg.gpu_ids[0]), device_ids=cfg.gpu_ids)\n\n # build runner\n optimizer = build_optimizers(model, cfg.optimizer)\n\n runner = EpochBasedRunner(\n model,\n optimizer=optimizer,\n work_dir=cfg.work_dir,\n logger=logger,\n meta=meta)\n # an ugly workaround to make .log and .log.json filenames the same\n runner.timestamp = timestamp\n\n if use_adverserial_train:\n # The optimizer step process is included in the train_step function\n # of the model, so the runner should NOT include optimizer hook.\n optimizer_config = None\n else:\n # fp16 setting\n fp16_cfg = cfg.get('fp16', None)\n if fp16_cfg is not None:\n optimizer_config = Fp16OptimizerHook(\n **cfg.optimizer_config, **fp16_cfg, distributed=distributed)\n elif distributed and 'type' not in cfg.optimizer_config:\n optimizer_config = OptimizerHook(**cfg.optimizer_config)\n else:\n optimizer_config = cfg.optimizer_config\n\n # register hooks\n runner.register_training_hooks(cfg.lr_config, optimizer_config,\n cfg.checkpoint_config, cfg.log_config,\n cfg.get('momentum_config', None))\n if distributed:\n runner.register_hook(DistSamplerSeedHook())\n\n # register eval hooks\n if validate:\n eval_cfg = cfg.get('evaluation', {})\n val_dataset = build_dataset(cfg.data.val, dict(test_mode=True))\n dataloader_setting = dict(\n samples_per_gpu=1,\n workers_per_gpu=cfg.data.get('workers_per_gpu', {}),\n # cfg.gpus will be ignored if distributed\n num_gpus=len(cfg.gpu_ids),\n dist=distributed,\n drop_last=False,\n shuffle=False)\n dataloader_setting = dict(dataloader_setting,\n **cfg.data.get('val_dataloader', {}))\n val_dataloader = build_dataloader(val_dataset, **dataloader_setting)\n eval_hook = DistEvalHook if distributed else EvalHook\n runner.register_hook(eval_hook(val_dataloader, **eval_cfg))\n\n if cfg.resume_from:\n runner.resume(cfg.resume_from)\n elif cfg.load_from:\n runner.load_checkpoint(cfg.load_from)\n runner.run(data_loaders, cfg.workflow, cfg.total_epochs)\n", "path": "mmpose/apis/train.py"}]}
| 3,103 | 467 |
gh_patches_debug_9805
|
rasdani/github-patches
|
git_diff
|
qutebrowser__qutebrowser-3175
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
UnicodeEncodeError with os.path.isdir in NetworkManager.createRequest
Report with `LC_ALL=C`:
```
10:56:42 DEBUG init app:process_pos_args:275 Startup URL file:///tmp/people.inf.elte.hu/mersaai/helpvizsgahoz/cpp%20vizsg%ED%B3%83%ED%B2%A1ra/index.html
[...]
10:56:42 ERROR misc utils:wrapper:616 Error in qutebrowser.browser.network.networkmanager.NetworkManager.createRequest
Traceback (most recent call last):
File "/usr/lib/python3.5/site-packages/qutebrowser/utils/utils.py", line 614, in wrapper
return func(*args, **kwargs)
File "/usr/lib/python3.5/site-packages/qutebrowser/browser/network/networkmanager.py", line 365, in createRequest
op, req, outgoing_data)
File "/usr/lib/python3.5/site-packages/qutebrowser/browser/network/filescheme.py", line 116, in createRequest
if os.path.isdir(path):
File "/usr/lib/python3.5/genericpath.py", line 42, in isdir
st = os.stat(s)
UnicodeEncodeError: 'ascii' codec can't encode characters in position 55-60: ordinal not in range(128)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `qutebrowser/browser/webkit/network/filescheme.py`
Content:
```
1 # vim: ft=python fileencoding=utf-8 sts=4 sw=4 et:
2
3 # Copyright 2014-2017 Florian Bruhin (The Compiler) <[email protected]>
4 # Copyright 2015-2017 Antoni Boucher (antoyo) <[email protected]>
5 #
6 # This file is part of qutebrowser.
7 #
8 # qutebrowser is free software: you can redistribute it and/or modify
9 # it under the terms of the GNU General Public License as published by
10 # the Free Software Foundation, either version 3 of the License, or
11 # (at your option) any later version.
12 #
13 # qutebrowser is distributed in the hope that it will be useful,
14 # but WITHOUT ANY WARRANTY; without even the implied warranty of
15 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
16 # GNU General Public License for more details.
17 #
18 # You should have received a copy of the GNU General Public License
19 # along with qutebrowser. If not, see <http://www.gnu.org/licenses/>.
20 #
21 # pylint complains when using .render() on jinja templates, so we make it shut
22 # up for this whole module.
23
24 """Handler functions for file:... pages."""
25
26 import os
27
28 from qutebrowser.browser.webkit.network import schemehandler, networkreply
29 from qutebrowser.utils import jinja
30
31
32 def get_file_list(basedir, all_files, filterfunc):
33 """Get a list of files filtered by a filter function and sorted by name.
34
35 Args:
36 basedir: The parent directory of all files.
37 all_files: The list of files to filter and sort.
38 filterfunc: The filter function.
39
40 Return:
41 A list of dicts. Each dict contains the name and absname keys.
42 """
43 items = []
44 for filename in all_files:
45 absname = os.path.join(basedir, filename)
46 if filterfunc(absname):
47 items.append({'name': filename, 'absname': absname})
48 return sorted(items, key=lambda v: v['name'].lower())
49
50
51 def is_root(directory):
52 """Check if the directory is the root directory.
53
54 Args:
55 directory: The directory to check.
56
57 Return:
58 Whether the directory is a root directory or not.
59 """
60 # If you're curious as why this works:
61 # dirname('/') = '/'
62 # dirname('/home') = '/'
63 # dirname('/home/') = '/home'
64 # dirname('/home/foo') = '/home'
65 # basically, for files (no trailing slash) it removes the file part, and
66 # for directories, it removes the trailing slash, so the only way for this
67 # to be equal is if the directory is the root directory.
68 return os.path.dirname(directory) == directory
69
70
71 def parent_dir(directory):
72 """Return the parent directory for the given directory.
73
74 Args:
75 directory: The path to the directory.
76
77 Return:
78 The path to the parent directory.
79 """
80 return os.path.normpath(os.path.join(directory, os.pardir))
81
82
83 def dirbrowser_html(path):
84 """Get the directory browser web page.
85
86 Args:
87 path: The directory path.
88
89 Return:
90 The HTML of the web page.
91 """
92 title = "Browse directory: {}".format(path)
93
94 if is_root(path):
95 parent = None
96 else:
97 parent = parent_dir(path)
98
99 try:
100 all_files = os.listdir(path)
101 except OSError as e:
102 html = jinja.render('error.html',
103 title="Error while reading directory",
104 url='file:///{}'.format(path), error=str(e))
105 return html.encode('UTF-8', errors='xmlcharrefreplace')
106
107 files = get_file_list(path, all_files, os.path.isfile)
108 directories = get_file_list(path, all_files, os.path.isdir)
109 html = jinja.render('dirbrowser.html', title=title, url=path,
110 parent=parent, files=files, directories=directories)
111 return html.encode('UTF-8', errors='xmlcharrefreplace')
112
113
114 class FileSchemeHandler(schemehandler.SchemeHandler):
115
116 """Scheme handler for file: URLs."""
117
118 def createRequest(self, _op, request, _outgoing_data):
119 """Create a new request.
120
121 Args:
122 request: const QNetworkRequest & req
123 _op: Operation op
124 _outgoing_data: QIODevice * outgoingData
125
126 Return:
127 A QNetworkReply for directories, None for files.
128 """
129 path = request.url().toLocalFile()
130 if os.path.isdir(path):
131 data = dirbrowser_html(path)
132 return networkreply.FixedDataNetworkReply(
133 request, data, 'text/html', self.parent())
134
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/qutebrowser/browser/webkit/network/filescheme.py b/qutebrowser/browser/webkit/network/filescheme.py
--- a/qutebrowser/browser/webkit/network/filescheme.py
+++ b/qutebrowser/browser/webkit/network/filescheme.py
@@ -127,7 +127,10 @@
A QNetworkReply for directories, None for files.
"""
path = request.url().toLocalFile()
- if os.path.isdir(path):
- data = dirbrowser_html(path)
- return networkreply.FixedDataNetworkReply(
- request, data, 'text/html', self.parent())
+ try:
+ if os.path.isdir(path):
+ data = dirbrowser_html(path)
+ return networkreply.FixedDataNetworkReply(
+ request, data, 'text/html', self.parent())
+ except UnicodeEncodeError:
+ return None
|
{"golden_diff": "diff --git a/qutebrowser/browser/webkit/network/filescheme.py b/qutebrowser/browser/webkit/network/filescheme.py\n--- a/qutebrowser/browser/webkit/network/filescheme.py\n+++ b/qutebrowser/browser/webkit/network/filescheme.py\n@@ -127,7 +127,10 @@\n A QNetworkReply for directories, None for files.\n \"\"\"\n path = request.url().toLocalFile()\n- if os.path.isdir(path):\n- data = dirbrowser_html(path)\n- return networkreply.FixedDataNetworkReply(\n- request, data, 'text/html', self.parent())\n+ try:\n+ if os.path.isdir(path):\n+ data = dirbrowser_html(path)\n+ return networkreply.FixedDataNetworkReply(\n+ request, data, 'text/html', self.parent())\n+ except UnicodeEncodeError:\n+ return None\n", "issue": "UnicodeEncodeError with os.path.isdir in NetworkManager.createRequest\nReport with `LC_ALL=C`:\n\n```\n10:56:42 DEBUG init app:process_pos_args:275 Startup URL file:///tmp/people.inf.elte.hu/mersaai/helpvizsgahoz/cpp%20vizsg%ED%B3%83%ED%B2%A1ra/index.html\n[...]\n10:56:42 ERROR misc utils:wrapper:616 Error in qutebrowser.browser.network.networkmanager.NetworkManager.createRequest\nTraceback (most recent call last):\n File \"/usr/lib/python3.5/site-packages/qutebrowser/utils/utils.py\", line 614, in wrapper\n return func(*args, **kwargs)\n File \"/usr/lib/python3.5/site-packages/qutebrowser/browser/network/networkmanager.py\", line 365, in createRequest\n op, req, outgoing_data)\n File \"/usr/lib/python3.5/site-packages/qutebrowser/browser/network/filescheme.py\", line 116, in createRequest\n if os.path.isdir(path):\n File \"/usr/lib/python3.5/genericpath.py\", line 42, in isdir\n st = os.stat(s)\nUnicodeEncodeError: 'ascii' codec can't encode characters in position 55-60: ordinal not in range(128)\n```\n\n", "before_files": [{"content": "# vim: ft=python fileencoding=utf-8 sts=4 sw=4 et:\n\n# Copyright 2014-2017 Florian Bruhin (The Compiler) <[email protected]>\n# Copyright 2015-2017 Antoni Boucher (antoyo) <[email protected]>\n#\n# This file is part of qutebrowser.\n#\n# qutebrowser is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# qutebrowser is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with qutebrowser. If not, see <http://www.gnu.org/licenses/>.\n#\n# pylint complains when using .render() on jinja templates, so we make it shut\n# up for this whole module.\n\n\"\"\"Handler functions for file:... pages.\"\"\"\n\nimport os\n\nfrom qutebrowser.browser.webkit.network import schemehandler, networkreply\nfrom qutebrowser.utils import jinja\n\n\ndef get_file_list(basedir, all_files, filterfunc):\n \"\"\"Get a list of files filtered by a filter function and sorted by name.\n\n Args:\n basedir: The parent directory of all files.\n all_files: The list of files to filter and sort.\n filterfunc: The filter function.\n\n Return:\n A list of dicts. Each dict contains the name and absname keys.\n \"\"\"\n items = []\n for filename in all_files:\n absname = os.path.join(basedir, filename)\n if filterfunc(absname):\n items.append({'name': filename, 'absname': absname})\n return sorted(items, key=lambda v: v['name'].lower())\n\n\ndef is_root(directory):\n \"\"\"Check if the directory is the root directory.\n\n Args:\n directory: The directory to check.\n\n Return:\n Whether the directory is a root directory or not.\n \"\"\"\n # If you're curious as why this works:\n # dirname('/') = '/'\n # dirname('/home') = '/'\n # dirname('/home/') = '/home'\n # dirname('/home/foo') = '/home'\n # basically, for files (no trailing slash) it removes the file part, and\n # for directories, it removes the trailing slash, so the only way for this\n # to be equal is if the directory is the root directory.\n return os.path.dirname(directory) == directory\n\n\ndef parent_dir(directory):\n \"\"\"Return the parent directory for the given directory.\n\n Args:\n directory: The path to the directory.\n\n Return:\n The path to the parent directory.\n \"\"\"\n return os.path.normpath(os.path.join(directory, os.pardir))\n\n\ndef dirbrowser_html(path):\n \"\"\"Get the directory browser web page.\n\n Args:\n path: The directory path.\n\n Return:\n The HTML of the web page.\n \"\"\"\n title = \"Browse directory: {}\".format(path)\n\n if is_root(path):\n parent = None\n else:\n parent = parent_dir(path)\n\n try:\n all_files = os.listdir(path)\n except OSError as e:\n html = jinja.render('error.html',\n title=\"Error while reading directory\",\n url='file:///{}'.format(path), error=str(e))\n return html.encode('UTF-8', errors='xmlcharrefreplace')\n\n files = get_file_list(path, all_files, os.path.isfile)\n directories = get_file_list(path, all_files, os.path.isdir)\n html = jinja.render('dirbrowser.html', title=title, url=path,\n parent=parent, files=files, directories=directories)\n return html.encode('UTF-8', errors='xmlcharrefreplace')\n\n\nclass FileSchemeHandler(schemehandler.SchemeHandler):\n\n \"\"\"Scheme handler for file: URLs.\"\"\"\n\n def createRequest(self, _op, request, _outgoing_data):\n \"\"\"Create a new request.\n\n Args:\n request: const QNetworkRequest & req\n _op: Operation op\n _outgoing_data: QIODevice * outgoingData\n\n Return:\n A QNetworkReply for directories, None for files.\n \"\"\"\n path = request.url().toLocalFile()\n if os.path.isdir(path):\n data = dirbrowser_html(path)\n return networkreply.FixedDataNetworkReply(\n request, data, 'text/html', self.parent())\n", "path": "qutebrowser/browser/webkit/network/filescheme.py"}], "after_files": [{"content": "# vim: ft=python fileencoding=utf-8 sts=4 sw=4 et:\n\n# Copyright 2014-2017 Florian Bruhin (The Compiler) <[email protected]>\n# Copyright 2015-2017 Antoni Boucher (antoyo) <[email protected]>\n#\n# This file is part of qutebrowser.\n#\n# qutebrowser is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# qutebrowser is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with qutebrowser. If not, see <http://www.gnu.org/licenses/>.\n#\n# pylint complains when using .render() on jinja templates, so we make it shut\n# up for this whole module.\n\n\"\"\"Handler functions for file:... pages.\"\"\"\n\nimport os\n\nfrom qutebrowser.browser.webkit.network import schemehandler, networkreply\nfrom qutebrowser.utils import jinja\n\n\ndef get_file_list(basedir, all_files, filterfunc):\n \"\"\"Get a list of files filtered by a filter function and sorted by name.\n\n Args:\n basedir: The parent directory of all files.\n all_files: The list of files to filter and sort.\n filterfunc: The filter function.\n\n Return:\n A list of dicts. Each dict contains the name and absname keys.\n \"\"\"\n items = []\n for filename in all_files:\n absname = os.path.join(basedir, filename)\n if filterfunc(absname):\n items.append({'name': filename, 'absname': absname})\n return sorted(items, key=lambda v: v['name'].lower())\n\n\ndef is_root(directory):\n \"\"\"Check if the directory is the root directory.\n\n Args:\n directory: The directory to check.\n\n Return:\n Whether the directory is a root directory or not.\n \"\"\"\n # If you're curious as why this works:\n # dirname('/') = '/'\n # dirname('/home') = '/'\n # dirname('/home/') = '/home'\n # dirname('/home/foo') = '/home'\n # basically, for files (no trailing slash) it removes the file part, and\n # for directories, it removes the trailing slash, so the only way for this\n # to be equal is if the directory is the root directory.\n return os.path.dirname(directory) == directory\n\n\ndef parent_dir(directory):\n \"\"\"Return the parent directory for the given directory.\n\n Args:\n directory: The path to the directory.\n\n Return:\n The path to the parent directory.\n \"\"\"\n return os.path.normpath(os.path.join(directory, os.pardir))\n\n\ndef dirbrowser_html(path):\n \"\"\"Get the directory browser web page.\n\n Args:\n path: The directory path.\n\n Return:\n The HTML of the web page.\n \"\"\"\n title = \"Browse directory: {}\".format(path)\n\n if is_root(path):\n parent = None\n else:\n parent = parent_dir(path)\n\n try:\n all_files = os.listdir(path)\n except OSError as e:\n html = jinja.render('error.html',\n title=\"Error while reading directory\",\n url='file:///{}'.format(path), error=str(e))\n return html.encode('UTF-8', errors='xmlcharrefreplace')\n\n files = get_file_list(path, all_files, os.path.isfile)\n directories = get_file_list(path, all_files, os.path.isdir)\n html = jinja.render('dirbrowser.html', title=title, url=path,\n parent=parent, files=files, directories=directories)\n return html.encode('UTF-8', errors='xmlcharrefreplace')\n\n\nclass FileSchemeHandler(schemehandler.SchemeHandler):\n\n \"\"\"Scheme handler for file: URLs.\"\"\"\n\n def createRequest(self, _op, request, _outgoing_data):\n \"\"\"Create a new request.\n\n Args:\n request: const QNetworkRequest & req\n _op: Operation op\n _outgoing_data: QIODevice * outgoingData\n\n Return:\n A QNetworkReply for directories, None for files.\n \"\"\"\n path = request.url().toLocalFile()\n try:\n if os.path.isdir(path):\n data = dirbrowser_html(path)\n return networkreply.FixedDataNetworkReply(\n request, data, 'text/html', self.parent())\n except UnicodeEncodeError:\n return None\n", "path": "qutebrowser/browser/webkit/network/filescheme.py"}]}
| 1,886 | 187 |
gh_patches_debug_41370
|
rasdani/github-patches
|
git_diff
|
mathesar-foundation__mathesar-2520
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Do not include unconfirmed tables for users with viewer & editor access
## Description
1. GET requests to `/api/db/v0/tables/`, `/api/db/v0/tables/<table_id>` and `common_data.tables` currently include unconfirmed tables for all users.
2. Request to `/api/db/v0/schemas/` and `/api/db/v0/schemas/<schema_id>/` have count for `num_tables` which contains count of all tables including ones that are not confirmed.
Confirmation can currently only be performed by a schema manager or a db manager. Users with viewer and editor access cannot should not be able to see tables that aren't confirmed yet.
The UI currently hides unconfirmed tables for case (1), but this should happen at an API level. The count issue mentioned in (2) however, is currently visible on the UI leading to inconsistent count being shown between DB page and schema page.
## Expected behavior
* Endpoints and common_data that contains tables should not include unconfirmed tables for users with viewer and editor access. i.e. Permission check should take `import_verified` into account. This includes:
- Table list
- Table get
- common_data.tables
* `schema.num_tables` should also take this into account.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mathesar/api/db/permissions/table.py`
Content:
```
1 from django.db.models import Q
2 from rest_access_policy import AccessPolicy
3
4 from mathesar.models.users import DatabaseRole, Role, SchemaRole
5
6
7 class TableAccessPolicy(AccessPolicy):
8 """
9 Anyone can view Table as long as they have
10 at least a Viewer access to the schema or its database
11 Create Access is restricted to superusers or managers of the schema or the database the table is part of.
12 Only superuser or schema/database manager can delete/modify/update the Table
13 """
14
15 statements = [
16 {
17 # Restrictions for the create method is done by the Serializers when creating the schema,
18 # As the permissions depend on the database object.
19 'action': [
20 'list',
21 'retrieve',
22 'create',
23 'type_suggestions',
24 'dependents',
25 'ui_dependents',
26 'joinable_tables',
27 ],
28 'principal': 'authenticated',
29 'effect': 'allow',
30 },
31
32 {
33 'action': [
34 'destroy',
35 'update',
36 'partial_update',
37 'split_table',
38 'move_columns',
39 'previews',
40 'existing_import',
41 'map_imported_columns'
42 ],
43 'principal': 'authenticated',
44 'effect': 'allow',
45 'condition_expression': ['(is_superuser or is_table_manager)']
46 },
47 ]
48
49 @classmethod
50 def _scope_queryset(cls, request, qs, allowed_roles):
51 if not (request.user.is_superuser or request.user.is_anonymous):
52 permissible_database_role_filter = (
53 Q(schema__database__database_role__role__in=allowed_roles)
54 & Q(schema__database__database_role__user=request.user)
55 )
56 permissible_schema_roles_filter = (
57 Q(schema__schema_role__role__in=allowed_roles) & Q(schema__schema_role__user=request.user)
58 )
59 qs = qs.filter(permissible_database_role_filter | permissible_schema_roles_filter)
60 return qs
61
62 @classmethod
63 def scope_queryset(cls, request, qs):
64 """
65 Used for scoping the queryset of Serializer RelatedField which reference a Table
66 """
67 allowed_roles = (Role.MANAGER.value,)
68
69 if request.method.lower() == 'get':
70 allowed_roles = allowed_roles + (Role.EDITOR.value, Role.VIEWER.value)
71 return TableAccessPolicy._scope_queryset(request, qs, allowed_roles)
72
73 @classmethod
74 def scope_viewset_queryset(cls, request, qs):
75 """
76 Used for scoping queryset of the TableViewSet.
77 It is used for listing all the table the user has Viewer access.
78 Restrictions are then applied based on the request method using the Policy statements.
79 This helps us to throw correct error status code instead of a 404 error code
80 """
81 allowed_roles = (Role.MANAGER.value, Role.EDITOR.value, Role.VIEWER.value)
82 return TableAccessPolicy._scope_queryset(request, qs, allowed_roles)
83
84 def is_table_manager(self, request, view, action):
85 # Table access control is based on Schema and Database Roles as of now
86 # TODO Include Table Role based access when Table Roles are introduced
87 table = view.get_object()
88 is_schema_manager = SchemaRole.objects.filter(
89 user=request.user,
90 schema=table.schema,
91 role=Role.MANAGER.value
92 ).exists()
93 is_db_manager = DatabaseRole.objects.filter(
94 user=request.user,
95 database=table.schema.database,
96 role=Role.MANAGER.value
97 ).exists()
98 return is_db_manager or is_schema_manager
99
```
Path: `mathesar/api/serializers/schemas.py`
Content:
```
1 from rest_access_policy import PermittedSlugRelatedField
2 from rest_framework import serializers
3
4 from mathesar.api.db.permissions.database import DatabaseAccessPolicy
5 from mathesar.api.exceptions.mixins import MathesarErrorMessageMixin
6 from mathesar.models.base import Database, Schema
7
8
9 class SchemaSerializer(MathesarErrorMessageMixin, serializers.HyperlinkedModelSerializer):
10 name = serializers.CharField()
11 # Restrict access to databases with create access.
12 # Unlike PermittedPkRelatedField this field uses a slug instead of an id
13 # Refer https://rsinger86.github.io/drf-access-policy/policy_reuse/
14 database = PermittedSlugRelatedField(
15 access_policy=DatabaseAccessPolicy,
16 slug_field='name',
17 queryset=Database.current_objects.all()
18 )
19 description = serializers.CharField(
20 required=False, allow_blank=True, default=None, allow_null=True
21 )
22 num_tables = serializers.SerializerMethodField()
23 num_queries = serializers.SerializerMethodField()
24
25 class Meta:
26 model = Schema
27 fields = [
28 'id', 'name', 'database', 'has_dependents', 'description',
29 'num_tables', 'num_queries'
30 ]
31
32 def get_num_tables(self, obj):
33 return obj.tables.count()
34
35 def get_num_queries(self, obj):
36 return sum(t.queries.count() for t in obj.tables.all())
37
```
Path: `mathesar/api/db/viewsets/schemas.py`
Content:
```
1 from django_filters import rest_framework as filters
2 from rest_access_policy import AccessViewSetMixin
3 from rest_framework import status, viewsets
4 from rest_framework.decorators import action
5 from rest_framework.mixins import ListModelMixin, RetrieveModelMixin
6 from rest_framework.response import Response
7
8 from mathesar.api.db.permissions.schema import SchemaAccessPolicy
9 from mathesar.api.dj_filters import SchemaFilter
10 from mathesar.api.pagination import DefaultLimitOffsetPagination
11 from mathesar.api.serializers.dependents import DependentSerializer, DependentFilterSerializer
12 from mathesar.api.serializers.schemas import SchemaSerializer
13 from mathesar.models.base import Schema
14 from mathesar.utils.schemas import create_schema_and_object
15 from mathesar.api.exceptions.validation_exceptions.exceptions import EditingPublicSchemaIsDisallowed
16
17
18 class SchemaViewSet(AccessViewSetMixin, viewsets.GenericViewSet, ListModelMixin, RetrieveModelMixin):
19 serializer_class = SchemaSerializer
20 pagination_class = DefaultLimitOffsetPagination
21 filter_backends = (filters.DjangoFilterBackend,)
22 filterset_class = SchemaFilter
23 access_policy = SchemaAccessPolicy
24
25 def get_queryset(self):
26 qs = Schema.objects.all().order_by('-created_at')
27 return self.access_policy.scope_viewset_queryset(self.request, qs)
28
29 def create(self, request):
30 serializer = SchemaSerializer(data=request.data, context={'request': request})
31 serializer.is_valid(raise_exception=True)
32 database_name = serializer.validated_data['database'].name
33 schema = create_schema_and_object(
34 serializer.validated_data['name'],
35 database_name,
36 comment=serializer.validated_data.get('description')
37 )
38 serializer = SchemaSerializer(schema)
39 return Response(serializer.data, status=status.HTTP_201_CREATED)
40
41 def partial_update(self, request, pk=None):
42 serializer = SchemaSerializer(
43 data=request.data, context={'request': request}, partial=True
44 )
45 serializer.is_valid(raise_exception=True)
46
47 schema = self.get_object()
48
49 # We forbid editing the public schema
50 if schema.name == "public":
51 raise EditingPublicSchemaIsDisallowed()
52
53 schema.update_sa_schema(serializer.validated_data)
54
55 # Reload the schema to avoid cached properties
56 schema = self.get_object()
57 schema.clear_name_cache()
58 serializer = SchemaSerializer(schema, context={'request': request})
59 return Response(serializer.data)
60
61 def destroy(self, request, pk=None):
62 schema = self.get_object()
63 schema.delete_sa_schema()
64 return Response(status=status.HTTP_204_NO_CONTENT)
65
66 @action(methods=['get'], detail=True)
67 def dependents(self, request, pk=None):
68 serializer = DependentFilterSerializer(data=request.GET)
69 serializer.is_valid(raise_exception=True)
70 types_exclude = serializer.validated_data['exclude']
71
72 schema = self.get_object()
73 serializer = DependentSerializer(schema.get_dependents(types_exclude), many=True, context={'request': request})
74 return Response(serializer.data)
75
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mathesar/api/db/permissions/table.py b/mathesar/api/db/permissions/table.py
--- a/mathesar/api/db/permissions/table.py
+++ b/mathesar/api/db/permissions/table.py
@@ -49,13 +49,38 @@
@classmethod
def _scope_queryset(cls, request, qs, allowed_roles):
if not (request.user.is_superuser or request.user.is_anonymous):
- permissible_database_role_filter = (
+ db_role_access_filter = (
Q(schema__database__database_role__role__in=allowed_roles)
& Q(schema__database__database_role__user=request.user)
)
+ schema_role_access_filter = (
+ Q(schema__schema_role__role__in=allowed_roles)
+ & Q(schema__schema_role__user=request.user)
+ )
+
+ # Filters to check whether user is a db/schema manager
+ is_database_manager = (
+ Q(schema__database__database_role__role='manager')
+ & Q(schema__database__database_role__user=request.user)
+ )
+ is_schema_manager = (
+ Q(schema__schema_role__role='manager')
+ & Q(schema__schema_role__user=request.user)
+ )
+
+ # Filter for confirmed tables
+ cnf_table_filter = (Q(import_verified=True) | Q(import_verified__isnull=True))
+
+ # Filters for the purpose of including/removing unconfirmed tables based on user's role
+ permissible_database_role_filter = (
+ is_database_manager & Q(import_verified=False)
+ | cnf_table_filter & db_role_access_filter
+ )
permissible_schema_roles_filter = (
- Q(schema__schema_role__role__in=allowed_roles) & Q(schema__schema_role__user=request.user)
+ is_schema_manager & Q(import_verified=False)
+ | cnf_table_filter & schema_role_access_filter
)
+
qs = qs.filter(permissible_database_role_filter | permissible_schema_roles_filter)
return qs
diff --git a/mathesar/api/db/viewsets/schemas.py b/mathesar/api/db/viewsets/schemas.py
--- a/mathesar/api/db/viewsets/schemas.py
+++ b/mathesar/api/db/viewsets/schemas.py
@@ -35,7 +35,7 @@
database_name,
comment=serializer.validated_data.get('description')
)
- serializer = SchemaSerializer(schema)
+ serializer = SchemaSerializer(schema, context={'request': request})
return Response(serializer.data, status=status.HTTP_201_CREATED)
def partial_update(self, request, pk=None):
diff --git a/mathesar/api/serializers/schemas.py b/mathesar/api/serializers/schemas.py
--- a/mathesar/api/serializers/schemas.py
+++ b/mathesar/api/serializers/schemas.py
@@ -1,9 +1,11 @@
from rest_access_policy import PermittedSlugRelatedField
from rest_framework import serializers
+from mathesar.api.db.permissions.table import TableAccessPolicy
+
from mathesar.api.db.permissions.database import DatabaseAccessPolicy
from mathesar.api.exceptions.mixins import MathesarErrorMessageMixin
-from mathesar.models.base import Database, Schema
+from mathesar.models.base import Database, Schema, Table
class SchemaSerializer(MathesarErrorMessageMixin, serializers.HyperlinkedModelSerializer):
@@ -30,7 +32,9 @@
]
def get_num_tables(self, obj):
- return obj.tables.count()
+ qs = Table.objects.filter(schema=obj)
+ count = TableAccessPolicy.scope_queryset(self.context['request'], qs).count()
+ return count
def get_num_queries(self, obj):
return sum(t.queries.count() for t in obj.tables.all())
|
{"golden_diff": "diff --git a/mathesar/api/db/permissions/table.py b/mathesar/api/db/permissions/table.py\n--- a/mathesar/api/db/permissions/table.py\n+++ b/mathesar/api/db/permissions/table.py\n@@ -49,13 +49,38 @@\n @classmethod\n def _scope_queryset(cls, request, qs, allowed_roles):\n if not (request.user.is_superuser or request.user.is_anonymous):\n- permissible_database_role_filter = (\n+ db_role_access_filter = (\n Q(schema__database__database_role__role__in=allowed_roles)\n & Q(schema__database__database_role__user=request.user)\n )\n+ schema_role_access_filter = (\n+ Q(schema__schema_role__role__in=allowed_roles)\n+ & Q(schema__schema_role__user=request.user)\n+ )\n+\n+ # Filters to check whether user is a db/schema manager\n+ is_database_manager = (\n+ Q(schema__database__database_role__role='manager')\n+ & Q(schema__database__database_role__user=request.user)\n+ )\n+ is_schema_manager = (\n+ Q(schema__schema_role__role='manager')\n+ & Q(schema__schema_role__user=request.user)\n+ )\n+\n+ # Filter for confirmed tables\n+ cnf_table_filter = (Q(import_verified=True) | Q(import_verified__isnull=True))\n+\n+ # Filters for the purpose of including/removing unconfirmed tables based on user's role\n+ permissible_database_role_filter = (\n+ is_database_manager & Q(import_verified=False)\n+ | cnf_table_filter & db_role_access_filter\n+ )\n permissible_schema_roles_filter = (\n- Q(schema__schema_role__role__in=allowed_roles) & Q(schema__schema_role__user=request.user)\n+ is_schema_manager & Q(import_verified=False)\n+ | cnf_table_filter & schema_role_access_filter\n )\n+\n qs = qs.filter(permissible_database_role_filter | permissible_schema_roles_filter)\n return qs\n \ndiff --git a/mathesar/api/db/viewsets/schemas.py b/mathesar/api/db/viewsets/schemas.py\n--- a/mathesar/api/db/viewsets/schemas.py\n+++ b/mathesar/api/db/viewsets/schemas.py\n@@ -35,7 +35,7 @@\n database_name,\n comment=serializer.validated_data.get('description')\n )\n- serializer = SchemaSerializer(schema)\n+ serializer = SchemaSerializer(schema, context={'request': request})\n return Response(serializer.data, status=status.HTTP_201_CREATED)\n \n def partial_update(self, request, pk=None):\ndiff --git a/mathesar/api/serializers/schemas.py b/mathesar/api/serializers/schemas.py\n--- a/mathesar/api/serializers/schemas.py\n+++ b/mathesar/api/serializers/schemas.py\n@@ -1,9 +1,11 @@\n from rest_access_policy import PermittedSlugRelatedField\n from rest_framework import serializers\n \n+from mathesar.api.db.permissions.table import TableAccessPolicy\n+\n from mathesar.api.db.permissions.database import DatabaseAccessPolicy\n from mathesar.api.exceptions.mixins import MathesarErrorMessageMixin\n-from mathesar.models.base import Database, Schema\n+from mathesar.models.base import Database, Schema, Table\n \n \n class SchemaSerializer(MathesarErrorMessageMixin, serializers.HyperlinkedModelSerializer):\n@@ -30,7 +32,9 @@\n ]\n \n def get_num_tables(self, obj):\n- return obj.tables.count()\n+ qs = Table.objects.filter(schema=obj)\n+ count = TableAccessPolicy.scope_queryset(self.context['request'], qs).count()\n+ return count\n \n def get_num_queries(self, obj):\n return sum(t.queries.count() for t in obj.tables.all())\n", "issue": "Do not include unconfirmed tables for users with viewer & editor access\n## Description\r\n1. GET requests to `/api/db/v0/tables/`, `/api/db/v0/tables/<table_id>` and `common_data.tables` currently include unconfirmed tables for all users.\r\n2. Request to `/api/db/v0/schemas/` and `/api/db/v0/schemas/<schema_id>/` have count for `num_tables` which contains count of all tables including ones that are not confirmed.\r\n\r\nConfirmation can currently only be performed by a schema manager or a db manager. Users with viewer and editor access cannot should not be able to see tables that aren't confirmed yet.\r\n\r\nThe UI currently hides unconfirmed tables for case (1), but this should happen at an API level. The count issue mentioned in (2) however, is currently visible on the UI leading to inconsistent count being shown between DB page and schema page.\r\n\r\n## Expected behavior\r\n* Endpoints and common_data that contains tables should not include unconfirmed tables for users with viewer and editor access. i.e. Permission check should take `import_verified` into account. This includes:\r\n - Table list\r\n - Table get\r\n - common_data.tables\r\n* `schema.num_tables` should also take this into account.\n", "before_files": [{"content": "from django.db.models import Q\nfrom rest_access_policy import AccessPolicy\n\nfrom mathesar.models.users import DatabaseRole, Role, SchemaRole\n\n\nclass TableAccessPolicy(AccessPolicy):\n \"\"\"\n Anyone can view Table as long as they have\n at least a Viewer access to the schema or its database\n Create Access is restricted to superusers or managers of the schema or the database the table is part of.\n Only superuser or schema/database manager can delete/modify/update the Table\n \"\"\"\n\n statements = [\n {\n # Restrictions for the create method is done by the Serializers when creating the schema,\n # As the permissions depend on the database object.\n 'action': [\n 'list',\n 'retrieve',\n 'create',\n 'type_suggestions',\n 'dependents',\n 'ui_dependents',\n 'joinable_tables',\n ],\n 'principal': 'authenticated',\n 'effect': 'allow',\n },\n\n {\n 'action': [\n 'destroy',\n 'update',\n 'partial_update',\n 'split_table',\n 'move_columns',\n 'previews',\n 'existing_import',\n 'map_imported_columns'\n ],\n 'principal': 'authenticated',\n 'effect': 'allow',\n 'condition_expression': ['(is_superuser or is_table_manager)']\n },\n ]\n\n @classmethod\n def _scope_queryset(cls, request, qs, allowed_roles):\n if not (request.user.is_superuser or request.user.is_anonymous):\n permissible_database_role_filter = (\n Q(schema__database__database_role__role__in=allowed_roles)\n & Q(schema__database__database_role__user=request.user)\n )\n permissible_schema_roles_filter = (\n Q(schema__schema_role__role__in=allowed_roles) & Q(schema__schema_role__user=request.user)\n )\n qs = qs.filter(permissible_database_role_filter | permissible_schema_roles_filter)\n return qs\n\n @classmethod\n def scope_queryset(cls, request, qs):\n \"\"\"\n Used for scoping the queryset of Serializer RelatedField which reference a Table\n \"\"\"\n allowed_roles = (Role.MANAGER.value,)\n\n if request.method.lower() == 'get':\n allowed_roles = allowed_roles + (Role.EDITOR.value, Role.VIEWER.value)\n return TableAccessPolicy._scope_queryset(request, qs, allowed_roles)\n\n @classmethod\n def scope_viewset_queryset(cls, request, qs):\n \"\"\"\n Used for scoping queryset of the TableViewSet.\n It is used for listing all the table the user has Viewer access.\n Restrictions are then applied based on the request method using the Policy statements.\n This helps us to throw correct error status code instead of a 404 error code\n \"\"\"\n allowed_roles = (Role.MANAGER.value, Role.EDITOR.value, Role.VIEWER.value)\n return TableAccessPolicy._scope_queryset(request, qs, allowed_roles)\n\n def is_table_manager(self, request, view, action):\n # Table access control is based on Schema and Database Roles as of now\n # TODO Include Table Role based access when Table Roles are introduced\n table = view.get_object()\n is_schema_manager = SchemaRole.objects.filter(\n user=request.user,\n schema=table.schema,\n role=Role.MANAGER.value\n ).exists()\n is_db_manager = DatabaseRole.objects.filter(\n user=request.user,\n database=table.schema.database,\n role=Role.MANAGER.value\n ).exists()\n return is_db_manager or is_schema_manager\n", "path": "mathesar/api/db/permissions/table.py"}, {"content": "from rest_access_policy import PermittedSlugRelatedField\nfrom rest_framework import serializers\n\nfrom mathesar.api.db.permissions.database import DatabaseAccessPolicy\nfrom mathesar.api.exceptions.mixins import MathesarErrorMessageMixin\nfrom mathesar.models.base import Database, Schema\n\n\nclass SchemaSerializer(MathesarErrorMessageMixin, serializers.HyperlinkedModelSerializer):\n name = serializers.CharField()\n # Restrict access to databases with create access.\n # Unlike PermittedPkRelatedField this field uses a slug instead of an id\n # Refer https://rsinger86.github.io/drf-access-policy/policy_reuse/\n database = PermittedSlugRelatedField(\n access_policy=DatabaseAccessPolicy,\n slug_field='name',\n queryset=Database.current_objects.all()\n )\n description = serializers.CharField(\n required=False, allow_blank=True, default=None, allow_null=True\n )\n num_tables = serializers.SerializerMethodField()\n num_queries = serializers.SerializerMethodField()\n\n class Meta:\n model = Schema\n fields = [\n 'id', 'name', 'database', 'has_dependents', 'description',\n 'num_tables', 'num_queries'\n ]\n\n def get_num_tables(self, obj):\n return obj.tables.count()\n\n def get_num_queries(self, obj):\n return sum(t.queries.count() for t in obj.tables.all())\n", "path": "mathesar/api/serializers/schemas.py"}, {"content": "from django_filters import rest_framework as filters\nfrom rest_access_policy import AccessViewSetMixin\nfrom rest_framework import status, viewsets\nfrom rest_framework.decorators import action\nfrom rest_framework.mixins import ListModelMixin, RetrieveModelMixin\nfrom rest_framework.response import Response\n\nfrom mathesar.api.db.permissions.schema import SchemaAccessPolicy\nfrom mathesar.api.dj_filters import SchemaFilter\nfrom mathesar.api.pagination import DefaultLimitOffsetPagination\nfrom mathesar.api.serializers.dependents import DependentSerializer, DependentFilterSerializer\nfrom mathesar.api.serializers.schemas import SchemaSerializer\nfrom mathesar.models.base import Schema\nfrom mathesar.utils.schemas import create_schema_and_object\nfrom mathesar.api.exceptions.validation_exceptions.exceptions import EditingPublicSchemaIsDisallowed\n\n\nclass SchemaViewSet(AccessViewSetMixin, viewsets.GenericViewSet, ListModelMixin, RetrieveModelMixin):\n serializer_class = SchemaSerializer\n pagination_class = DefaultLimitOffsetPagination\n filter_backends = (filters.DjangoFilterBackend,)\n filterset_class = SchemaFilter\n access_policy = SchemaAccessPolicy\n\n def get_queryset(self):\n qs = Schema.objects.all().order_by('-created_at')\n return self.access_policy.scope_viewset_queryset(self.request, qs)\n\n def create(self, request):\n serializer = SchemaSerializer(data=request.data, context={'request': request})\n serializer.is_valid(raise_exception=True)\n database_name = serializer.validated_data['database'].name\n schema = create_schema_and_object(\n serializer.validated_data['name'],\n database_name,\n comment=serializer.validated_data.get('description')\n )\n serializer = SchemaSerializer(schema)\n return Response(serializer.data, status=status.HTTP_201_CREATED)\n\n def partial_update(self, request, pk=None):\n serializer = SchemaSerializer(\n data=request.data, context={'request': request}, partial=True\n )\n serializer.is_valid(raise_exception=True)\n\n schema = self.get_object()\n\n # We forbid editing the public schema\n if schema.name == \"public\":\n raise EditingPublicSchemaIsDisallowed()\n\n schema.update_sa_schema(serializer.validated_data)\n\n # Reload the schema to avoid cached properties\n schema = self.get_object()\n schema.clear_name_cache()\n serializer = SchemaSerializer(schema, context={'request': request})\n return Response(serializer.data)\n\n def destroy(self, request, pk=None):\n schema = self.get_object()\n schema.delete_sa_schema()\n return Response(status=status.HTTP_204_NO_CONTENT)\n\n @action(methods=['get'], detail=True)\n def dependents(self, request, pk=None):\n serializer = DependentFilterSerializer(data=request.GET)\n serializer.is_valid(raise_exception=True)\n types_exclude = serializer.validated_data['exclude']\n\n schema = self.get_object()\n serializer = DependentSerializer(schema.get_dependents(types_exclude), many=True, context={'request': request})\n return Response(serializer.data)\n", "path": "mathesar/api/db/viewsets/schemas.py"}], "after_files": [{"content": "from django.db.models import Q\nfrom rest_access_policy import AccessPolicy\n\nfrom mathesar.models.users import DatabaseRole, Role, SchemaRole\n\n\nclass TableAccessPolicy(AccessPolicy):\n \"\"\"\n Anyone can view Table as long as they have\n at least a Viewer access to the schema or its database\n Create Access is restricted to superusers or managers of the schema or the database the table is part of.\n Only superuser or schema/database manager can delete/modify/update the Table\n \"\"\"\n\n statements = [\n {\n # Restrictions for the create method is done by the Serializers when creating the schema,\n # As the permissions depend on the database object.\n 'action': [\n 'list',\n 'retrieve',\n 'create',\n 'type_suggestions',\n 'dependents',\n 'ui_dependents',\n 'joinable_tables',\n ],\n 'principal': 'authenticated',\n 'effect': 'allow',\n },\n\n {\n 'action': [\n 'destroy',\n 'update',\n 'partial_update',\n 'split_table',\n 'move_columns',\n 'previews',\n 'existing_import',\n 'map_imported_columns'\n ],\n 'principal': 'authenticated',\n 'effect': 'allow',\n 'condition_expression': ['(is_superuser or is_table_manager)']\n },\n ]\n\n @classmethod\n def _scope_queryset(cls, request, qs, allowed_roles):\n if not (request.user.is_superuser or request.user.is_anonymous):\n db_role_access_filter = (\n Q(schema__database__database_role__role__in=allowed_roles)\n & Q(schema__database__database_role__user=request.user)\n )\n schema_role_access_filter = (\n Q(schema__schema_role__role__in=allowed_roles)\n & Q(schema__schema_role__user=request.user)\n )\n\n # Filters to check whether user is a db/schema manager\n is_database_manager = (\n Q(schema__database__database_role__role='manager')\n & Q(schema__database__database_role__user=request.user)\n )\n is_schema_manager = (\n Q(schema__schema_role__role='manager')\n & Q(schema__schema_role__user=request.user)\n )\n\n # Filter for confirmed tables\n cnf_table_filter = (Q(import_verified=True) | Q(import_verified__isnull=True))\n\n # Filters for the purpose of including/removing unconfirmed tables based on user's role\n permissible_database_role_filter = (\n is_database_manager & Q(import_verified=False)\n | cnf_table_filter & db_role_access_filter\n )\n permissible_schema_roles_filter = (\n is_schema_manager & Q(import_verified=False)\n | cnf_table_filter & schema_role_access_filter\n )\n\n qs = qs.filter(permissible_database_role_filter | permissible_schema_roles_filter)\n return qs\n\n @classmethod\n def scope_queryset(cls, request, qs):\n \"\"\"\n Used for scoping the queryset of Serializer RelatedField which reference a Table\n \"\"\"\n allowed_roles = (Role.MANAGER.value,)\n\n if request.method.lower() == 'get':\n allowed_roles = allowed_roles + (Role.EDITOR.value, Role.VIEWER.value)\n return TableAccessPolicy._scope_queryset(request, qs, allowed_roles)\n\n @classmethod\n def scope_viewset_queryset(cls, request, qs):\n \"\"\"\n Used for scoping queryset of the TableViewSet.\n It is used for listing all the table the user has Viewer access.\n Restrictions are then applied based on the request method using the Policy statements.\n This helps us to throw correct error status code instead of a 404 error code\n \"\"\"\n allowed_roles = (Role.MANAGER.value, Role.EDITOR.value, Role.VIEWER.value)\n return TableAccessPolicy._scope_queryset(request, qs, allowed_roles)\n\n def is_table_manager(self, request, view, action):\n # Table access control is based on Schema and Database Roles as of now\n # TODO Include Table Role based access when Table Roles are introduced\n table = view.get_object()\n is_schema_manager = SchemaRole.objects.filter(\n user=request.user,\n schema=table.schema,\n role=Role.MANAGER.value\n ).exists()\n is_db_manager = DatabaseRole.objects.filter(\n user=request.user,\n database=table.schema.database,\n role=Role.MANAGER.value\n ).exists()\n return is_db_manager or is_schema_manager\n", "path": "mathesar/api/db/permissions/table.py"}, {"content": "from rest_access_policy import PermittedSlugRelatedField\nfrom rest_framework import serializers\n\nfrom mathesar.api.db.permissions.table import TableAccessPolicy\n\nfrom mathesar.api.db.permissions.database import DatabaseAccessPolicy\nfrom mathesar.api.exceptions.mixins import MathesarErrorMessageMixin\nfrom mathesar.models.base import Database, Schema, Table\n\n\nclass SchemaSerializer(MathesarErrorMessageMixin, serializers.HyperlinkedModelSerializer):\n name = serializers.CharField()\n # Restrict access to databases with create access.\n # Unlike PermittedPkRelatedField this field uses a slug instead of an id\n # Refer https://rsinger86.github.io/drf-access-policy/policy_reuse/\n database = PermittedSlugRelatedField(\n access_policy=DatabaseAccessPolicy,\n slug_field='name',\n queryset=Database.current_objects.all()\n )\n description = serializers.CharField(\n required=False, allow_blank=True, default=None, allow_null=True\n )\n num_tables = serializers.SerializerMethodField()\n num_queries = serializers.SerializerMethodField()\n\n class Meta:\n model = Schema\n fields = [\n 'id', 'name', 'database', 'has_dependents', 'description',\n 'num_tables', 'num_queries'\n ]\n\n def get_num_tables(self, obj):\n qs = Table.objects.filter(schema=obj)\n count = TableAccessPolicy.scope_queryset(self.context['request'], qs).count()\n return count\n\n def get_num_queries(self, obj):\n return sum(t.queries.count() for t in obj.tables.all())\n", "path": "mathesar/api/serializers/schemas.py"}, {"content": "from django_filters import rest_framework as filters\nfrom rest_access_policy import AccessViewSetMixin\nfrom rest_framework import status, viewsets\nfrom rest_framework.decorators import action\nfrom rest_framework.mixins import ListModelMixin, RetrieveModelMixin\nfrom rest_framework.response import Response\n\nfrom mathesar.api.db.permissions.schema import SchemaAccessPolicy\nfrom mathesar.api.dj_filters import SchemaFilter\nfrom mathesar.api.pagination import DefaultLimitOffsetPagination\nfrom mathesar.api.serializers.dependents import DependentSerializer, DependentFilterSerializer\nfrom mathesar.api.serializers.schemas import SchemaSerializer\nfrom mathesar.models.base import Schema\nfrom mathesar.utils.schemas import create_schema_and_object\nfrom mathesar.api.exceptions.validation_exceptions.exceptions import EditingPublicSchemaIsDisallowed\n\n\nclass SchemaViewSet(AccessViewSetMixin, viewsets.GenericViewSet, ListModelMixin, RetrieveModelMixin):\n serializer_class = SchemaSerializer\n pagination_class = DefaultLimitOffsetPagination\n filter_backends = (filters.DjangoFilterBackend,)\n filterset_class = SchemaFilter\n access_policy = SchemaAccessPolicy\n\n def get_queryset(self):\n qs = Schema.objects.all().order_by('-created_at')\n return self.access_policy.scope_viewset_queryset(self.request, qs)\n\n def create(self, request):\n serializer = SchemaSerializer(data=request.data, context={'request': request})\n serializer.is_valid(raise_exception=True)\n database_name = serializer.validated_data['database'].name\n schema = create_schema_and_object(\n serializer.validated_data['name'],\n database_name,\n comment=serializer.validated_data.get('description')\n )\n serializer = SchemaSerializer(schema, context={'request': request})\n return Response(serializer.data, status=status.HTTP_201_CREATED)\n\n def partial_update(self, request, pk=None):\n serializer = SchemaSerializer(\n data=request.data, context={'request': request}, partial=True\n )\n serializer.is_valid(raise_exception=True)\n\n schema = self.get_object()\n\n # We forbid editing the public schema\n if schema.name == \"public\":\n raise EditingPublicSchemaIsDisallowed()\n\n schema.update_sa_schema(serializer.validated_data)\n\n # Reload the schema to avoid cached properties\n schema = self.get_object()\n schema.clear_name_cache()\n serializer = SchemaSerializer(schema, context={'request': request})\n return Response(serializer.data)\n\n def destroy(self, request, pk=None):\n schema = self.get_object()\n schema.delete_sa_schema()\n return Response(status=status.HTTP_204_NO_CONTENT)\n\n @action(methods=['get'], detail=True)\n def dependents(self, request, pk=None):\n serializer = DependentFilterSerializer(data=request.GET)\n serializer.is_valid(raise_exception=True)\n types_exclude = serializer.validated_data['exclude']\n\n schema = self.get_object()\n serializer = DependentSerializer(schema.get_dependents(types_exclude), many=True, context={'request': request})\n return Response(serializer.data)\n", "path": "mathesar/api/db/viewsets/schemas.py"}]}
| 2,607 | 802 |
gh_patches_debug_22884
|
rasdani/github-patches
|
git_diff
|
HypothesisWorks__hypothesis-601
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Changelog doesn't check for date for *this* release
https://github.com/HypothesisWorks/hypothesis-python/pull/580 is currently passing its build but shouldn't be because its date in the changelog says TBD. However the current date was present for *another* release.
The changelog check should check for the current date occurring on the same line as the current version number.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `scripts/check-changelog.py`
Content:
```
1 #!/usr/bin/env python
2
3 # coding=utf-8
4 #
5 # This file is part of Hypothesis, which may be found at
6 # https://github.com/HypothesisWorks/hypothesis-python
7 #
8 # Most of this work is copyright (C) 2013-2017 David R. MacIver
9 # ([email protected]), but it contains contributions by others. See
10 # CONTRIBUTING.rst for a full list of people who may hold copyright, and
11 # consult the git log if you need to determine who owns an individual
12 # contribution.
13 #
14 # This Source Code Form is subject to the terms of the Mozilla Public License,
15 # v. 2.0. If a copy of the MPL was not distributed with this file, You can
16 # obtain one at http://mozilla.org/MPL/2.0/.
17 #
18 # END HEADER
19
20 from __future__ import division, print_function, absolute_import
21
22 import os
23 import sys
24 from datetime import datetime, timedelta
25
26 import hypothesistooling as tools
27
28 sys.path.append(os.path.dirname(__file__)) # noqa
29
30
31 if __name__ == '__main__':
32
33 if not tools.has_source_changes():
34 print('No source changes found')
35 sys.exit(0)
36
37 changelog = tools.changelog()
38
39 if '\n%s - ' % (tools.__version__,) not in changelog:
40 print(
41 'The current version (%s) isn\'t mentioned in the changelog' % (
42 tools.__version__,))
43 sys.exit(1)
44
45 now = datetime.utcnow()
46
47 hour = timedelta(hours=1)
48
49 acceptable_dates = {
50 d.strftime('%Y-%m-%d')
51 for d in (now, now + hour, now - hour)
52 }
53
54 when = ' or '.join(sorted(acceptable_dates))
55
56 if not any(d in changelog for d in acceptable_dates):
57 print((
58 'The current date (%s) isn\'t mentioned in the changelog. '
59 'Remember this will be released as soon as you merge to master!'
60 ) % (when,))
61 sys.exit(1)
62
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/scripts/check-changelog.py b/scripts/check-changelog.py
--- a/scripts/check-changelog.py
+++ b/scripts/check-changelog.py
@@ -34,28 +34,18 @@
print('No source changes found')
sys.exit(0)
- changelog = tools.changelog()
-
- if '\n%s - ' % (tools.__version__,) not in changelog:
- print(
- 'The current version (%s) isn\'t mentioned in the changelog' % (
- tools.__version__,))
- sys.exit(1)
-
now = datetime.utcnow()
-
hour = timedelta(hours=1)
-
- acceptable_dates = {
- d.strftime('%Y-%m-%d')
+ acceptable_lines = sorted(set(
+ '{} - {}'.format(tools.__version__, d.strftime('%Y-%m-%d'))
for d in (now, now + hour, now - hour)
- }
-
- when = ' or '.join(sorted(acceptable_dates))
-
- if not any(d in changelog for d in acceptable_dates):
- print((
- 'The current date (%s) isn\'t mentioned in the changelog. '
- 'Remember this will be released as soon as you merge to master!'
- ) % (when,))
+ ))
+
+ for line in tools.changelog().split('\n'):
+ if line.strip() in acceptable_lines:
+ break
+ else:
+ print('No line with version and current date (%s) in the changelog. '
+ 'Remember this will be released as soon as you merge to master!'
+ % ' or '.join(repr(line) for line in acceptable_lines))
sys.exit(1)
|
{"golden_diff": "diff --git a/scripts/check-changelog.py b/scripts/check-changelog.py\n--- a/scripts/check-changelog.py\n+++ b/scripts/check-changelog.py\n@@ -34,28 +34,18 @@\n print('No source changes found')\n sys.exit(0)\n \n- changelog = tools.changelog()\n-\n- if '\\n%s - ' % (tools.__version__,) not in changelog:\n- print(\n- 'The current version (%s) isn\\'t mentioned in the changelog' % (\n- tools.__version__,))\n- sys.exit(1)\n-\n now = datetime.utcnow()\n-\n hour = timedelta(hours=1)\n-\n- acceptable_dates = {\n- d.strftime('%Y-%m-%d')\n+ acceptable_lines = sorted(set(\n+ '{} - {}'.format(tools.__version__, d.strftime('%Y-%m-%d'))\n for d in (now, now + hour, now - hour)\n- }\n-\n- when = ' or '.join(sorted(acceptable_dates))\n-\n- if not any(d in changelog for d in acceptable_dates):\n- print((\n- 'The current date (%s) isn\\'t mentioned in the changelog. '\n- 'Remember this will be released as soon as you merge to master!'\n- ) % (when,))\n+ ))\n+\n+ for line in tools.changelog().split('\\n'):\n+ if line.strip() in acceptable_lines:\n+ break\n+ else:\n+ print('No line with version and current date (%s) in the changelog. '\n+ 'Remember this will be released as soon as you merge to master!'\n+ % ' or '.join(repr(line) for line in acceptable_lines))\n sys.exit(1)\n", "issue": "Changelog doesn't check for date for *this* release\nhttps://github.com/HypothesisWorks/hypothesis-python/pull/580 is currently passing its build but shouldn't be because its date in the changelog says TBD. However the current date was present for *another* release.\r\n\r\nThe changelog check should check for the current date occurring on the same line as the current version number.\n", "before_files": [{"content": "#!/usr/bin/env python\n\n# coding=utf-8\n#\n# This file is part of Hypothesis, which may be found at\n# https://github.com/HypothesisWorks/hypothesis-python\n#\n# Most of this work is copyright (C) 2013-2017 David R. MacIver\n# ([email protected]), but it contains contributions by others. See\n# CONTRIBUTING.rst for a full list of people who may hold copyright, and\n# consult the git log if you need to determine who owns an individual\n# contribution.\n#\n# This Source Code Form is subject to the terms of the Mozilla Public License,\n# v. 2.0. If a copy of the MPL was not distributed with this file, You can\n# obtain one at http://mozilla.org/MPL/2.0/.\n#\n# END HEADER\n\nfrom __future__ import division, print_function, absolute_import\n\nimport os\nimport sys\nfrom datetime import datetime, timedelta\n\nimport hypothesistooling as tools\n\nsys.path.append(os.path.dirname(__file__)) # noqa\n\n\nif __name__ == '__main__':\n\n if not tools.has_source_changes():\n print('No source changes found')\n sys.exit(0)\n\n changelog = tools.changelog()\n\n if '\\n%s - ' % (tools.__version__,) not in changelog:\n print(\n 'The current version (%s) isn\\'t mentioned in the changelog' % (\n tools.__version__,))\n sys.exit(1)\n\n now = datetime.utcnow()\n\n hour = timedelta(hours=1)\n\n acceptable_dates = {\n d.strftime('%Y-%m-%d')\n for d in (now, now + hour, now - hour)\n }\n\n when = ' or '.join(sorted(acceptable_dates))\n\n if not any(d in changelog for d in acceptable_dates):\n print((\n 'The current date (%s) isn\\'t mentioned in the changelog. '\n 'Remember this will be released as soon as you merge to master!'\n ) % (when,))\n sys.exit(1)\n", "path": "scripts/check-changelog.py"}], "after_files": [{"content": "#!/usr/bin/env python\n\n# coding=utf-8\n#\n# This file is part of Hypothesis, which may be found at\n# https://github.com/HypothesisWorks/hypothesis-python\n#\n# Most of this work is copyright (C) 2013-2017 David R. MacIver\n# ([email protected]), but it contains contributions by others. See\n# CONTRIBUTING.rst for a full list of people who may hold copyright, and\n# consult the git log if you need to determine who owns an individual\n# contribution.\n#\n# This Source Code Form is subject to the terms of the Mozilla Public License,\n# v. 2.0. If a copy of the MPL was not distributed with this file, You can\n# obtain one at http://mozilla.org/MPL/2.0/.\n#\n# END HEADER\n\nfrom __future__ import division, print_function, absolute_import\n\nimport os\nimport sys\nfrom datetime import datetime, timedelta\n\nimport hypothesistooling as tools\n\nsys.path.append(os.path.dirname(__file__)) # noqa\n\n\nif __name__ == '__main__':\n\n if not tools.has_source_changes():\n print('No source changes found')\n sys.exit(0)\n\n now = datetime.utcnow()\n hour = timedelta(hours=1)\n acceptable_lines = sorted(set(\n '{} - {}'.format(tools.__version__, d.strftime('%Y-%m-%d'))\n for d in (now, now + hour, now - hour)\n ))\n\n for line in tools.changelog().split('\\n'):\n if line.strip() in acceptable_lines:\n break\n else:\n print('No line with version and current date (%s) in the changelog. '\n 'Remember this will be released as soon as you merge to master!'\n % ' or '.join(repr(line) for line in acceptable_lines))\n sys.exit(1)\n", "path": "scripts/check-changelog.py"}]}
| 919 | 379 |
gh_patches_debug_1746
|
rasdani/github-patches
|
git_diff
|
beeware__toga-998
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Have tutorial 3 open up pybee.org by default
**Is your feature request related to a problem? Please describe.**
https://toga.readthedocs.io/en/latest/tutorial/tutorial-3.html shows a screenshot of pybee.org being opened, but the code defaults to github.com.
**Describe the solution you'd like**
Have the code direct to pybee.org by default.
**Describe alternatives you've considered**
An updated screenshot of the tutorial to show github.com.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/tutorial3/tutorial/app.py`
Content:
```
1 import toga
2 from toga.style.pack import CENTER, COLUMN, ROW, Pack
3
4
5 class Graze(toga.App):
6 def startup(self):
7 self.main_window = toga.MainWindow(title=self.name)
8
9 self.webview = toga.WebView(style=Pack(flex=1))
10 self.url_input = toga.TextInput(
11 initial='https://github.com/',
12 style=Pack(flex=1)
13 )
14
15 box = toga.Box(
16 children=[
17 toga.Box(
18 children=[
19 self.url_input,
20 toga.Button('Go', on_press=self.load_page, style=Pack(width=50, padding_left=5)),
21 ],
22 style=Pack(
23 direction=ROW,
24 alignment=CENTER,
25 padding=5,
26 )
27 ),
28 self.webview,
29 ],
30 style=Pack(
31 direction=COLUMN
32 )
33 )
34
35 self.main_window.content = box
36 self.webview.url = self.url_input.value
37
38 # Show the main window
39 self.main_window.show()
40
41 def load_page(self, widget):
42 self.webview.url = self.url_input.value
43
44
45 def main():
46 return Graze('Graze', 'org.beeware.graze')
47
48
49 if __name__ == '__main__':
50 main().main_loop()
51
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/tutorial3/tutorial/app.py b/examples/tutorial3/tutorial/app.py
--- a/examples/tutorial3/tutorial/app.py
+++ b/examples/tutorial3/tutorial/app.py
@@ -8,7 +8,7 @@
self.webview = toga.WebView(style=Pack(flex=1))
self.url_input = toga.TextInput(
- initial='https://github.com/',
+ initial='https://beeware.org/',
style=Pack(flex=1)
)
|
{"golden_diff": "diff --git a/examples/tutorial3/tutorial/app.py b/examples/tutorial3/tutorial/app.py\n--- a/examples/tutorial3/tutorial/app.py\n+++ b/examples/tutorial3/tutorial/app.py\n@@ -8,7 +8,7 @@\n \n self.webview = toga.WebView(style=Pack(flex=1))\n self.url_input = toga.TextInput(\n- initial='https://github.com/',\n+ initial='https://beeware.org/',\n style=Pack(flex=1)\n )\n", "issue": "Have tutorial 3 open up pybee.org by default\n**Is your feature request related to a problem? Please describe.**\r\nhttps://toga.readthedocs.io/en/latest/tutorial/tutorial-3.html shows a screenshot of pybee.org being opened, but the code defaults to github.com.\r\n\r\n**Describe the solution you'd like**\r\nHave the code direct to pybee.org by default.\r\n\r\n**Describe alternatives you've considered**\r\nAn updated screenshot of the tutorial to show github.com.\r\n\n", "before_files": [{"content": "import toga\nfrom toga.style.pack import CENTER, COLUMN, ROW, Pack\n\n\nclass Graze(toga.App):\n def startup(self):\n self.main_window = toga.MainWindow(title=self.name)\n\n self.webview = toga.WebView(style=Pack(flex=1))\n self.url_input = toga.TextInput(\n initial='https://github.com/',\n style=Pack(flex=1)\n )\n\n box = toga.Box(\n children=[\n toga.Box(\n children=[\n self.url_input,\n toga.Button('Go', on_press=self.load_page, style=Pack(width=50, padding_left=5)),\n ],\n style=Pack(\n direction=ROW,\n alignment=CENTER,\n padding=5,\n )\n ),\n self.webview,\n ],\n style=Pack(\n direction=COLUMN\n )\n )\n\n self.main_window.content = box\n self.webview.url = self.url_input.value\n\n # Show the main window\n self.main_window.show()\n\n def load_page(self, widget):\n self.webview.url = self.url_input.value\n\n\ndef main():\n return Graze('Graze', 'org.beeware.graze')\n\n\nif __name__ == '__main__':\n main().main_loop()\n", "path": "examples/tutorial3/tutorial/app.py"}], "after_files": [{"content": "import toga\nfrom toga.style.pack import CENTER, COLUMN, ROW, Pack\n\n\nclass Graze(toga.App):\n def startup(self):\n self.main_window = toga.MainWindow(title=self.name)\n\n self.webview = toga.WebView(style=Pack(flex=1))\n self.url_input = toga.TextInput(\n initial='https://beeware.org/',\n style=Pack(flex=1)\n )\n\n box = toga.Box(\n children=[\n toga.Box(\n children=[\n self.url_input,\n toga.Button('Go', on_press=self.load_page, style=Pack(width=50, padding_left=5)),\n ],\n style=Pack(\n direction=ROW,\n alignment=CENTER,\n padding=5,\n )\n ),\n self.webview,\n ],\n style=Pack(\n direction=COLUMN\n )\n )\n\n self.main_window.content = box\n self.webview.url = self.url_input.value\n\n # Show the main window\n self.main_window.show()\n\n def load_page(self, widget):\n self.webview.url = self.url_input.value\n\n\ndef main():\n return Graze('Graze', 'org.beeware.graze')\n\n\nif __name__ == '__main__':\n main().main_loop()\n", "path": "examples/tutorial3/tutorial/app.py"}]}
| 730 | 103 |
gh_patches_debug_27046
|
rasdani/github-patches
|
git_diff
|
CTFd__CTFd-410
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Move plugin focused functions to the plugins folder
`override_template`
`register_plugin_script`
`register_plugin_stylesheet`
These should move to the plugins directory.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `CTFd/plugins/__init__.py`
Content:
```
1 import glob
2 import importlib
3 import os
4
5 from flask.helpers import safe_join
6 from flask import send_file, send_from_directory, abort
7 from CTFd.utils import admins_only as admins_only_wrapper
8
9
10 def register_plugin_assets_directory(app, base_path, admins_only=False):
11 """
12 Registers a directory to serve assets
13
14 :param app: A CTFd application
15 :param string base_path: The path to the directory
16 :param boolean admins_only: Whether or not the assets served out of the directory should be accessible to the public
17 :return:
18 """
19 base_path = base_path.strip('/')
20
21 def assets_handler(path):
22 return send_from_directory(base_path, path)
23
24 if admins_only:
25 asset_handler = admins_only_wrapper(assets_handler)
26
27 rule = '/' + base_path + '/<path:path>'
28 app.add_url_rule(rule=rule, endpoint=base_path, view_func=assets_handler)
29
30
31 def register_plugin_asset(app, asset_path, admins_only=False):
32 """
33 Registers an file path to be served by CTFd
34
35 :param app: A CTFd application
36 :param string asset_path: The path to the asset file
37 :param boolean admins_only: Whether or not this file should be accessible to the public
38 :return:
39 """
40 asset_path = asset_path.strip('/')
41
42 def asset_handler():
43 return send_file(asset_path)
44
45 if admins_only:
46 asset_handler = admins_only_wrapper(asset_handler)
47 rule = '/' + asset_path
48 app.add_url_rule(rule=rule, endpoint=asset_path, view_func=asset_handler)
49
50
51 def init_plugins(app):
52 """
53 Searches for the load function in modules in the CTFd/plugins folder. This function is called with the current CTFd
54 app as a parameter. This allows CTFd plugins to modify CTFd's behavior.
55
56 :param app: A CTFd application
57 :return:
58 """
59 modules = glob.glob(os.path.dirname(__file__) + "/*")
60 blacklist = {'__pycache__'}
61 for module in modules:
62 module_name = os.path.basename(module)
63 if os.path.isdir(module) and module_name not in blacklist:
64 module = '.' + module_name
65 module = importlib.import_module(module, package='CTFd.plugins')
66 module.load(app)
67 print(" * Loaded module, %s" % module)
68
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/CTFd/plugins/__init__.py b/CTFd/plugins/__init__.py
--- a/CTFd/plugins/__init__.py
+++ b/CTFd/plugins/__init__.py
@@ -3,8 +3,13 @@
import os
from flask.helpers import safe_join
-from flask import send_file, send_from_directory, abort
-from CTFd.utils import admins_only as admins_only_wrapper
+from flask import current_app as app, send_file, send_from_directory, abort
+from CTFd.utils import (
+ admins_only as admins_only_wrapper,
+ override_template as utils_override_template,
+ register_plugin_script as utils_register_plugin_script,
+ register_plugin_stylesheet as utils_register_plugin_stylesheet
+)
def register_plugin_assets_directory(app, base_path, admins_only=False):
@@ -48,6 +53,29 @@
app.add_url_rule(rule=rule, endpoint=asset_path, view_func=asset_handler)
+def override_template(*args, **kwargs):
+ """
+ Overrides a template with the provided html content.
+
+ e.g. override_template('scoreboard.html', '<h1>scores</h1>')
+ """
+ utils_override_template(*args, **kwargs)
+
+
+def register_plugin_script(*args, **kwargs):
+ """
+ Adds a given script to the base.html template which all pages inherit from
+ """
+ utils_register_plugin_script(*args, **kwargs)
+
+
+def register_plugin_stylesheet(*args, **kwargs):
+ """
+ Adds a given stylesheet to the base.html template which all pages inherit from.
+ """
+ utils_register_plugin_stylesheet(*args, **kwargs)
+
+
def init_plugins(app):
"""
Searches for the load function in modules in the CTFd/plugins folder. This function is called with the current CTFd
|
{"golden_diff": "diff --git a/CTFd/plugins/__init__.py b/CTFd/plugins/__init__.py\n--- a/CTFd/plugins/__init__.py\n+++ b/CTFd/plugins/__init__.py\n@@ -3,8 +3,13 @@\n import os\n \n from flask.helpers import safe_join\n-from flask import send_file, send_from_directory, abort\n-from CTFd.utils import admins_only as admins_only_wrapper\n+from flask import current_app as app, send_file, send_from_directory, abort\n+from CTFd.utils import (\n+ admins_only as admins_only_wrapper,\n+ override_template as utils_override_template,\n+ register_plugin_script as utils_register_plugin_script,\n+ register_plugin_stylesheet as utils_register_plugin_stylesheet\n+)\n \n \n def register_plugin_assets_directory(app, base_path, admins_only=False):\n@@ -48,6 +53,29 @@\n app.add_url_rule(rule=rule, endpoint=asset_path, view_func=asset_handler)\n \n \n+def override_template(*args, **kwargs):\n+ \"\"\"\n+ Overrides a template with the provided html content.\n+\n+ e.g. override_template('scoreboard.html', '<h1>scores</h1>')\n+ \"\"\"\n+ utils_override_template(*args, **kwargs)\n+\n+\n+def register_plugin_script(*args, **kwargs):\n+ \"\"\"\n+ Adds a given script to the base.html template which all pages inherit from\n+ \"\"\"\n+ utils_register_plugin_script(*args, **kwargs)\n+\n+\n+def register_plugin_stylesheet(*args, **kwargs):\n+ \"\"\"\n+ Adds a given stylesheet to the base.html template which all pages inherit from.\n+ \"\"\"\n+ utils_register_plugin_stylesheet(*args, **kwargs)\n+\n+\n def init_plugins(app):\n \"\"\"\n Searches for the load function in modules in the CTFd/plugins folder. This function is called with the current CTFd\n", "issue": "Move plugin focused functions to the plugins folder\n`override_template`\r\n`register_plugin_script`\r\n`register_plugin_stylesheet`\r\n\r\nThese should move to the plugins directory.\n", "before_files": [{"content": "import glob\nimport importlib\nimport os\n\nfrom flask.helpers import safe_join\nfrom flask import send_file, send_from_directory, abort\nfrom CTFd.utils import admins_only as admins_only_wrapper\n\n\ndef register_plugin_assets_directory(app, base_path, admins_only=False):\n \"\"\"\n Registers a directory to serve assets\n\n :param app: A CTFd application\n :param string base_path: The path to the directory\n :param boolean admins_only: Whether or not the assets served out of the directory should be accessible to the public\n :return:\n \"\"\"\n base_path = base_path.strip('/')\n\n def assets_handler(path):\n return send_from_directory(base_path, path)\n\n if admins_only:\n asset_handler = admins_only_wrapper(assets_handler)\n\n rule = '/' + base_path + '/<path:path>'\n app.add_url_rule(rule=rule, endpoint=base_path, view_func=assets_handler)\n\n\ndef register_plugin_asset(app, asset_path, admins_only=False):\n \"\"\"\n Registers an file path to be served by CTFd\n\n :param app: A CTFd application\n :param string asset_path: The path to the asset file\n :param boolean admins_only: Whether or not this file should be accessible to the public\n :return:\n \"\"\"\n asset_path = asset_path.strip('/')\n\n def asset_handler():\n return send_file(asset_path)\n\n if admins_only:\n asset_handler = admins_only_wrapper(asset_handler)\n rule = '/' + asset_path\n app.add_url_rule(rule=rule, endpoint=asset_path, view_func=asset_handler)\n\n\ndef init_plugins(app):\n \"\"\"\n Searches for the load function in modules in the CTFd/plugins folder. This function is called with the current CTFd\n app as a parameter. This allows CTFd plugins to modify CTFd's behavior.\n\n :param app: A CTFd application\n :return:\n \"\"\"\n modules = glob.glob(os.path.dirname(__file__) + \"/*\")\n blacklist = {'__pycache__'}\n for module in modules:\n module_name = os.path.basename(module)\n if os.path.isdir(module) and module_name not in blacklist:\n module = '.' + module_name\n module = importlib.import_module(module, package='CTFd.plugins')\n module.load(app)\n print(\" * Loaded module, %s\" % module)\n", "path": "CTFd/plugins/__init__.py"}], "after_files": [{"content": "import glob\nimport importlib\nimport os\n\nfrom flask.helpers import safe_join\nfrom flask import current_app as app, send_file, send_from_directory, abort\nfrom CTFd.utils import (\n admins_only as admins_only_wrapper,\n override_template as utils_override_template,\n register_plugin_script as utils_register_plugin_script,\n register_plugin_stylesheet as utils_register_plugin_stylesheet\n)\n\n\ndef register_plugin_assets_directory(app, base_path, admins_only=False):\n \"\"\"\n Registers a directory to serve assets\n\n :param app: A CTFd application\n :param string base_path: The path to the directory\n :param boolean admins_only: Whether or not the assets served out of the directory should be accessible to the public\n :return:\n \"\"\"\n base_path = base_path.strip('/')\n\n def assets_handler(path):\n return send_from_directory(base_path, path)\n\n if admins_only:\n asset_handler = admins_only_wrapper(assets_handler)\n\n rule = '/' + base_path + '/<path:path>'\n app.add_url_rule(rule=rule, endpoint=base_path, view_func=assets_handler)\n\n\ndef register_plugin_asset(app, asset_path, admins_only=False):\n \"\"\"\n Registers an file path to be served by CTFd\n\n :param app: A CTFd application\n :param string asset_path: The path to the asset file\n :param boolean admins_only: Whether or not this file should be accessible to the public\n :return:\n \"\"\"\n asset_path = asset_path.strip('/')\n\n def asset_handler():\n return send_file(asset_path)\n\n if admins_only:\n asset_handler = admins_only_wrapper(asset_handler)\n rule = '/' + asset_path\n app.add_url_rule(rule=rule, endpoint=asset_path, view_func=asset_handler)\n\n\ndef override_template(*args, **kwargs):\n \"\"\"\n Overrides a template with the provided html content.\n\n e.g. override_template('scoreboard.html', '<h1>scores</h1>')\n \"\"\"\n utils_override_template(*args, **kwargs)\n\n\ndef register_plugin_script(*args, **kwargs):\n \"\"\"\n Adds a given script to the base.html template which all pages inherit from\n \"\"\"\n utils_register_plugin_script(*args, **kwargs)\n\n\ndef register_plugin_stylesheet(*args, **kwargs):\n \"\"\"\n Adds a given stylesheet to the base.html template which all pages inherit from.\n \"\"\"\n utils_register_plugin_stylesheet(*args, **kwargs)\n\n\ndef init_plugins(app):\n \"\"\"\n Searches for the load function in modules in the CTFd/plugins folder. This function is called with the current CTFd\n app as a parameter. This allows CTFd plugins to modify CTFd's behavior.\n\n :param app: A CTFd application\n :return:\n \"\"\"\n modules = glob.glob(os.path.dirname(__file__) + \"/*\")\n blacklist = {'__pycache__'}\n for module in modules:\n module_name = os.path.basename(module)\n if os.path.isdir(module) and module_name not in blacklist:\n module = '.' + module_name\n module = importlib.import_module(module, package='CTFd.plugins')\n module.load(app)\n print(\" * Loaded module, %s\" % module)\n", "path": "CTFd/plugins/__init__.py"}]}
| 934 | 399 |
gh_patches_debug_33168
|
rasdani/github-patches
|
git_diff
|
tensorflow__addons-2265
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Drop GELU for 0.13 release
https://www.tensorflow.org/api_docs/python/tf/keras/activations/gelu will be available in TF2.4. Deprecation warning is already set for our upcming 0.12 release
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `tensorflow_addons/activations/gelu.py`
Content:
```
1 # Copyright 2019 The TensorFlow Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ==============================================================================
15
16 import tensorflow as tf
17 import math
18 import warnings
19
20 from tensorflow_addons.utils import types
21
22
23 @tf.keras.utils.register_keras_serializable(package="Addons")
24 def gelu(x: types.TensorLike, approximate: bool = True) -> tf.Tensor:
25 r"""Gaussian Error Linear Unit.
26
27 Computes gaussian error linear:
28
29 $$
30 \mathrm{gelu}(x) = x \Phi(x),
31 $$
32
33 where
34
35 $$
36 \Phi(x) = \frac{1}{2} \left[ 1 + \mathrm{erf}(\frac{x}{\sqrt{2}}) \right]$
37 $$
38
39 when `approximate` is `False`; or
40
41 $$
42 \Phi(x) = \frac{x}{2} \left[ 1 + \tanh(\sqrt{\frac{2}{\pi}} \cdot (x + 0.044715 \cdot x^3)) \right]
43 $$
44
45 when `approximate` is `True`.
46
47 See [Gaussian Error Linear Units (GELUs)](https://arxiv.org/abs/1606.08415)
48 and [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805).
49
50 Usage:
51
52 >>> tfa.options.TF_ADDONS_PY_OPS = True
53 >>> x = tf.constant([-1.0, 0.0, 1.0])
54 >>> tfa.activations.gelu(x, approximate=False)
55 <tf.Tensor: shape=(3,), dtype=float32, numpy=array([-0.15865529, 0. , 0.8413447 ], dtype=float32)>
56 >>> tfa.activations.gelu(x, approximate=True)
57 <tf.Tensor: shape=(3,), dtype=float32, numpy=array([-0.158808, 0. , 0.841192], dtype=float32)>
58
59 Args:
60 x: A `Tensor`. Must be one of the following types:
61 `float16`, `float32`, `float64`.
62 approximate: bool, whether to enable approximation.
63 Returns:
64 A `Tensor`. Has the same type as `x`.
65 """
66 warnings.warn(
67 "gelu activation has been migrated to core TensorFlow, "
68 "and will be deprecated in Addons 0.13.",
69 DeprecationWarning,
70 )
71
72 x = tf.convert_to_tensor(x)
73
74 return _gelu_py(x, approximate)
75
76
77 def _gelu_py(x: types.TensorLike, approximate: bool = True) -> tf.Tensor:
78 x = tf.convert_to_tensor(x)
79 if approximate:
80 pi = tf.cast(math.pi, x.dtype)
81 coeff = tf.cast(0.044715, x.dtype)
82 return 0.5 * x * (1.0 + tf.tanh(tf.sqrt(2.0 / pi) * (x + coeff * tf.pow(x, 3))))
83 else:
84 return 0.5 * x * (1.0 + tf.math.erf(x / tf.cast(tf.sqrt(2.0), x.dtype)))
85
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/tensorflow_addons/activations/gelu.py b/tensorflow_addons/activations/gelu.py
--- a/tensorflow_addons/activations/gelu.py
+++ b/tensorflow_addons/activations/gelu.py
@@ -18,6 +18,7 @@
import warnings
from tensorflow_addons.utils import types
+from distutils.version import LooseVersion
@tf.keras.utils.register_keras_serializable(package="Addons")
@@ -47,6 +48,9 @@
See [Gaussian Error Linear Units (GELUs)](https://arxiv.org/abs/1606.08415)
and [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805).
+ Note that `approximate` will default to `False` from TensorFlow version 2.4 onwards.
+ Consider using `tf.nn.gelu` instead.
+
Usage:
>>> tfa.options.TF_ADDONS_PY_OPS = True
@@ -54,7 +58,7 @@
>>> tfa.activations.gelu(x, approximate=False)
<tf.Tensor: shape=(3,), dtype=float32, numpy=array([-0.15865529, 0. , 0.8413447 ], dtype=float32)>
>>> tfa.activations.gelu(x, approximate=True)
- <tf.Tensor: shape=(3,), dtype=float32, numpy=array([-0.158808, 0. , 0.841192], dtype=float32)>
+ <tf.Tensor: shape=(3,), dtype=float32, numpy=array([-0.15880796, 0. , 0.841192 ], dtype=float32)>
Args:
x: A `Tensor`. Must be one of the following types:
@@ -71,7 +75,15 @@
x = tf.convert_to_tensor(x)
- return _gelu_py(x, approximate)
+ if LooseVersion(tf.__version__) >= "2.4":
+ gelu_op = tf.nn.gelu
+ warnings.warn(
+ "Default value of `approximate` is changed from `True` to `False`"
+ )
+ else:
+ gelu_op = _gelu_py
+
+ return gelu_op(x, approximate)
def _gelu_py(x: types.TensorLike, approximate: bool = True) -> tf.Tensor:
|
{"golden_diff": "diff --git a/tensorflow_addons/activations/gelu.py b/tensorflow_addons/activations/gelu.py\n--- a/tensorflow_addons/activations/gelu.py\n+++ b/tensorflow_addons/activations/gelu.py\n@@ -18,6 +18,7 @@\n import warnings\n \n from tensorflow_addons.utils import types\n+from distutils.version import LooseVersion\n \n \n @tf.keras.utils.register_keras_serializable(package=\"Addons\")\n@@ -47,6 +48,9 @@\n See [Gaussian Error Linear Units (GELUs)](https://arxiv.org/abs/1606.08415)\n and [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805).\n \n+ Note that `approximate` will default to `False` from TensorFlow version 2.4 onwards.\n+ Consider using `tf.nn.gelu` instead.\n+\n Usage:\n \n >>> tfa.options.TF_ADDONS_PY_OPS = True\n@@ -54,7 +58,7 @@\n >>> tfa.activations.gelu(x, approximate=False)\n <tf.Tensor: shape=(3,), dtype=float32, numpy=array([-0.15865529, 0. , 0.8413447 ], dtype=float32)>\n >>> tfa.activations.gelu(x, approximate=True)\n- <tf.Tensor: shape=(3,), dtype=float32, numpy=array([-0.158808, 0. , 0.841192], dtype=float32)>\n+ <tf.Tensor: shape=(3,), dtype=float32, numpy=array([-0.15880796, 0. , 0.841192 ], dtype=float32)>\n \n Args:\n x: A `Tensor`. Must be one of the following types:\n@@ -71,7 +75,15 @@\n \n x = tf.convert_to_tensor(x)\n \n- return _gelu_py(x, approximate)\n+ if LooseVersion(tf.__version__) >= \"2.4\":\n+ gelu_op = tf.nn.gelu\n+ warnings.warn(\n+ \"Default value of `approximate` is changed from `True` to `False`\"\n+ )\n+ else:\n+ gelu_op = _gelu_py\n+\n+ return gelu_op(x, approximate)\n \n \n def _gelu_py(x: types.TensorLike, approximate: bool = True) -> tf.Tensor:\n", "issue": "Drop GELU for 0.13 release\nhttps://www.tensorflow.org/api_docs/python/tf/keras/activations/gelu will be available in TF2.4. Deprecation warning is already set for our upcming 0.12 release\n", "before_files": [{"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\nimport tensorflow as tf\nimport math\nimport warnings\n\nfrom tensorflow_addons.utils import types\n\n\[email protected]_keras_serializable(package=\"Addons\")\ndef gelu(x: types.TensorLike, approximate: bool = True) -> tf.Tensor:\n r\"\"\"Gaussian Error Linear Unit.\n\n Computes gaussian error linear:\n\n $$\n \\mathrm{gelu}(x) = x \\Phi(x),\n $$\n\n where\n\n $$\n \\Phi(x) = \\frac{1}{2} \\left[ 1 + \\mathrm{erf}(\\frac{x}{\\sqrt{2}}) \\right]$\n $$\n\n when `approximate` is `False`; or\n\n $$\n \\Phi(x) = \\frac{x}{2} \\left[ 1 + \\tanh(\\sqrt{\\frac{2}{\\pi}} \\cdot (x + 0.044715 \\cdot x^3)) \\right]\n $$\n\n when `approximate` is `True`.\n\n See [Gaussian Error Linear Units (GELUs)](https://arxiv.org/abs/1606.08415)\n and [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805).\n\n Usage:\n\n >>> tfa.options.TF_ADDONS_PY_OPS = True\n >>> x = tf.constant([-1.0, 0.0, 1.0])\n >>> tfa.activations.gelu(x, approximate=False)\n <tf.Tensor: shape=(3,), dtype=float32, numpy=array([-0.15865529, 0. , 0.8413447 ], dtype=float32)>\n >>> tfa.activations.gelu(x, approximate=True)\n <tf.Tensor: shape=(3,), dtype=float32, numpy=array([-0.158808, 0. , 0.841192], dtype=float32)>\n\n Args:\n x: A `Tensor`. Must be one of the following types:\n `float16`, `float32`, `float64`.\n approximate: bool, whether to enable approximation.\n Returns:\n A `Tensor`. Has the same type as `x`.\n \"\"\"\n warnings.warn(\n \"gelu activation has been migrated to core TensorFlow, \"\n \"and will be deprecated in Addons 0.13.\",\n DeprecationWarning,\n )\n\n x = tf.convert_to_tensor(x)\n\n return _gelu_py(x, approximate)\n\n\ndef _gelu_py(x: types.TensorLike, approximate: bool = True) -> tf.Tensor:\n x = tf.convert_to_tensor(x)\n if approximate:\n pi = tf.cast(math.pi, x.dtype)\n coeff = tf.cast(0.044715, x.dtype)\n return 0.5 * x * (1.0 + tf.tanh(tf.sqrt(2.0 / pi) * (x + coeff * tf.pow(x, 3))))\n else:\n return 0.5 * x * (1.0 + tf.math.erf(x / tf.cast(tf.sqrt(2.0), x.dtype)))\n", "path": "tensorflow_addons/activations/gelu.py"}], "after_files": [{"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\nimport tensorflow as tf\nimport math\nimport warnings\n\nfrom tensorflow_addons.utils import types\nfrom distutils.version import LooseVersion\n\n\[email protected]_keras_serializable(package=\"Addons\")\ndef gelu(x: types.TensorLike, approximate: bool = True) -> tf.Tensor:\n r\"\"\"Gaussian Error Linear Unit.\n\n Computes gaussian error linear:\n\n $$\n \\mathrm{gelu}(x) = x \\Phi(x),\n $$\n\n where\n\n $$\n \\Phi(x) = \\frac{1}{2} \\left[ 1 + \\mathrm{erf}(\\frac{x}{\\sqrt{2}}) \\right]$\n $$\n\n when `approximate` is `False`; or\n\n $$\n \\Phi(x) = \\frac{x}{2} \\left[ 1 + \\tanh(\\sqrt{\\frac{2}{\\pi}} \\cdot (x + 0.044715 \\cdot x^3)) \\right]\n $$\n\n when `approximate` is `True`.\n\n See [Gaussian Error Linear Units (GELUs)](https://arxiv.org/abs/1606.08415)\n and [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805).\n\n Note that `approximate` will default to `False` from TensorFlow version 2.4 onwards.\n Consider using `tf.nn.gelu` instead.\n\n Usage:\n\n >>> tfa.options.TF_ADDONS_PY_OPS = True\n >>> x = tf.constant([-1.0, 0.0, 1.0])\n >>> tfa.activations.gelu(x, approximate=False)\n <tf.Tensor: shape=(3,), dtype=float32, numpy=array([-0.15865529, 0. , 0.8413447 ], dtype=float32)>\n >>> tfa.activations.gelu(x, approximate=True)\n <tf.Tensor: shape=(3,), dtype=float32, numpy=array([-0.15880796, 0. , 0.841192 ], dtype=float32)>\n\n Args:\n x: A `Tensor`. Must be one of the following types:\n `float16`, `float32`, `float64`.\n approximate: bool, whether to enable approximation.\n Returns:\n A `Tensor`. Has the same type as `x`.\n \"\"\"\n warnings.warn(\n \"gelu activation has been migrated to core TensorFlow, \"\n \"and will be deprecated in Addons 0.13.\",\n DeprecationWarning,\n )\n\n x = tf.convert_to_tensor(x)\n\n if LooseVersion(tf.__version__) >= \"2.4\":\n gelu_op = tf.nn.gelu\n warnings.warn(\n \"Default value of `approximate` is changed from `True` to `False`\"\n )\n else:\n gelu_op = _gelu_py\n\n return gelu_op(x, approximate)\n\n\ndef _gelu_py(x: types.TensorLike, approximate: bool = True) -> tf.Tensor:\n x = tf.convert_to_tensor(x)\n if approximate:\n pi = tf.cast(math.pi, x.dtype)\n coeff = tf.cast(0.044715, x.dtype)\n return 0.5 * x * (1.0 + tf.tanh(tf.sqrt(2.0 / pi) * (x + coeff * tf.pow(x, 3))))\n else:\n return 0.5 * x * (1.0 + tf.math.erf(x / tf.cast(tf.sqrt(2.0), x.dtype)))\n", "path": "tensorflow_addons/activations/gelu.py"}]}
| 1,348 | 586 |
gh_patches_debug_5095
|
rasdani/github-patches
|
git_diff
|
kivy__kivy-3104
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Issues with popup on py3
When running the following code in py3 on windows I get the following error:
``` py
from kivy.uix.widget import Widget
from kivy.uix.popup import Popup
w1 = Widget()
w2 = Widget()
p1 = Popup(content=w1)
p2 = Popup(content=w2)
```
```
Traceback (most recent call last):
File "playground8.py", line 7, in <module>
p2 = Popup(content=w2)
File "C:\Users\Matthew Einhorn\Desktop\Kivy-1.8.0-py3.3-win32\kivy\kivy\uix\modalview.py", line 152, in __init__
super(ModalView, self).__init__(**kwargs)
File "C:\Users\Matthew Einhorn\Desktop\Kivy-1.8.0-py3.3-win32\kivy\kivy\uix\anchorlayout.py", line 68, in __init__
super(AnchorLayout, self).__init__(**kwargs)
File "C:\Users\Matthew Einhorn\Desktop\Kivy-1.8.0-py3.3-win32\kivy\kivy\uix\layout.py", line 66, in __init__
super(Layout, self).__init__(**kwargs)
File "C:\Users\Matthew Einhorn\Desktop\Kivy-1.8.0-py3.3-win32\kivy\kivy\uix\widget.py", line 261, in __init__
super(Widget, self).__init__(**kwargs)
File "kivy\_event.pyx", line 271, in kivy._event.EventDispatcher.__init__ (kivy\_event.c:4933)
File "kivy\properties.pyx", line 397, in kivy.properties.Property.__set__ (kivy\properties.c:4680)
File "kivy\properties.pyx", line 429, in kivy.properties.Property.set (kivy\properties.c:5203)
File "kivy\properties.pyx", line 480, in kivy.properties.Property.dispatch (kivy\properties.c:5779)
File "kivy\_event.pyx", line 1168, in kivy._event.EventObservers.dispatch (kivy\_event.c:12154)
File "kivy\_event.pyx", line 1074, in kivy._event.EventObservers._dispatch (kivy\_event.c:11451)
File "C:\Users\Matthew Einhorn\Desktop\Kivy-1.8.0-py3.3-win32\kivy\kivy\uix\popup.py", line 188, in on_content
if not hasattr(value, 'popup'):
File "kivy\properties.pyx", line 402, in kivy.properties.Property.__get__ (kivy\properties.c:4776)
File "kivy\properties.pyx", line 435, in kivy.properties.Property.get (kivy\properties.c:5416)
KeyError: 'popup'
```
The reason is because of https://github.com/kivy/kivy/blob/master/kivy/uix/popup.py#L188. Both Widgets are created first. Then upon creation of first Popup its `on_content` is executed and a property in that widget as well in Widget class is created. However, it's only initialized for w1, w2 `__storage` has not been initialized for w2. So when hasattr is called on widget 2 and in python 3 it causes obj.__storage['popup']` to be executed from get, because storage has not been initialized for 'popup' in this widget it crashes.
The question is, why does the Popup code do this `create_property` stuff?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kivy/uix/popup.py`
Content:
```
1 '''
2 Popup
3 =====
4
5 .. versionadded:: 1.0.7
6
7 .. image:: images/popup.jpg
8 :align: right
9
10 The :class:`Popup` widget is used to create modal popups. By default, the popup
11 will cover the whole "parent" window. When you are creating a popup, you
12 must at least set a :attr:`Popup.title` and :attr:`Popup.content`.
13
14 Remember that the default size of a Widget is size_hint=(1, 1). If you don't
15 want your popup to be fullscreen, either use size hints with values less than 1
16 (for instance size_hint=(.8, .8)) or deactivate the size_hint and use
17 fixed size attributes.
18
19
20 .. versionchanged:: 1.4.0
21 The :class:`Popup` class now inherits from
22 :class:`~kivy.uix.modalview.ModalView`. The :class:`Popup` offers a default
23 layout with a title and a separation bar.
24
25 Examples
26 --------
27
28 Example of a simple 400x400 Hello world popup::
29
30 popup = Popup(title='Test popup',
31 content=Label(text='Hello world'),
32 size_hint=(None, None), size=(400, 400))
33
34 By default, any click outside the popup will dismiss/close it. If you don't
35 want that, you can set
36 :attr:`~kivy.uix.modalview.ModalView.auto_dismiss` to False::
37
38 popup = Popup(title='Test popup', content=Label(text='Hello world'),
39 auto_dismiss=False)
40 popup.open()
41
42 To manually dismiss/close the popup, use
43 :attr:`~kivy.uix.modalview.ModalView.dismiss`::
44
45 popup.dismiss()
46
47 Both :meth:`~kivy.uix.modalview.ModalView.open` and
48 :meth:`~kivy.uix.modalview.ModalView.dismiss` are bindable. That means you
49 can directly bind the function to an action, e.g. to a button's on_press::
50
51 # create content and add to the popup
52 content = Button(text='Close me!')
53 popup = Popup(content=content, auto_dismiss=False)
54
55 # bind the on_press event of the button to the dismiss function
56 content.bind(on_press=popup.dismiss)
57
58 # open the popup
59 popup.open()
60
61
62 Popup Events
63 ------------
64
65 There are two events available: `on_open` which is raised when the popup is
66 opening, and `on_dismiss` which is raised when the popup is closed.
67 For `on_dismiss`, you can prevent the
68 popup from closing by explictly returning True from your callback::
69
70 def my_callback(instance):
71 print('Popup', instance, 'is being dismissed but is prevented!')
72 return True
73 popup = Popup(content=Label(text='Hello world'))
74 popup.bind(on_dismiss=my_callback)
75 popup.open()
76
77 '''
78
79 __all__ = ('Popup', 'PopupException')
80
81 from kivy.uix.modalview import ModalView
82 from kivy.properties import (StringProperty, ObjectProperty, OptionProperty,
83 NumericProperty, ListProperty)
84
85
86 class PopupException(Exception):
87 '''Popup exception, fired when multiple content widgets are added to the
88 popup.
89
90 .. versionadded:: 1.4.0
91 '''
92
93
94 class Popup(ModalView):
95 '''Popup class. See module documentation for more information.
96
97 :Events:
98 `on_open`:
99 Fired when the Popup is opened.
100 `on_dismiss`:
101 Fired when the Popup is closed. If the callback returns True, the
102 dismiss will be canceled.
103 '''
104
105 title = StringProperty('No title')
106 '''String that represents the title of the popup.
107
108 :attr:`title` is a :class:`~kivy.properties.StringProperty` and defaults to
109 'No title'.
110 '''
111
112 title_size = NumericProperty('14sp')
113 '''Represents the font size of the popup title.
114
115 .. versionadded:: 1.6.0
116
117 :attr:`title_size` is a :class:`~kivy.properties.NumericProperty` and
118 defaults to '14sp'.
119 '''
120
121 title_align = OptionProperty('left',
122 options=['left', 'center', 'right', 'justify'])
123 '''Horizontal alignment of the title.
124
125 .. versionadded:: 1.9.0
126
127 :attr:`title_align` is a :class:`~kivy.properties.OptionProperty` and
128 defaults to 'left'. Available options are left, middle, right and justify.
129 '''
130
131 title_font = StringProperty('DroidSans')
132 '''Font used to render the title text.
133
134 .. versionadded:: 1.9.0
135
136 :attr:`title_font` is a :class:`~kivy.properties.StringProperty` and
137 defaults to 'DroidSans'.
138 '''
139
140 content = ObjectProperty(None)
141 '''Content of the popup that is displayed just under the title.
142
143 :attr:`content` is an :class:`~kivy.properties.ObjectProperty` and defaults
144 to None.
145 '''
146
147 title_color = ListProperty([1, 1, 1, 1])
148 '''Color used by the Title.
149
150 .. versionadded:: 1.8.0
151
152 :attr:`title_color` is a :class:`~kivy.properties.ListProperty` and
153 defaults to [1, 1, 1, 1].
154 '''
155
156 separator_color = ListProperty([47 / 255., 167 / 255., 212 / 255., 1.])
157 '''Color used by the separator between title and content.
158
159 .. versionadded:: 1.1.0
160
161 :attr:`separator_color` is a :class:`~kivy.properties.ListProperty` and
162 defaults to [47 / 255., 167 / 255., 212 / 255., 1.]
163 '''
164
165 separator_height = NumericProperty('2dp')
166 '''Height of the separator.
167
168 .. versionadded:: 1.1.0
169
170 :attr:`separator_height` is a :class:`~kivy.properties.NumericProperty` and
171 defaults to 2dp.
172 '''
173
174 # Internal properties used for graphical representation.
175
176 _container = ObjectProperty(None)
177
178 def add_widget(self, widget):
179 if self._container:
180 if self.content:
181 raise PopupException(
182 'Popup can have only one widget as content')
183 self.content = widget
184 else:
185 super(Popup, self).add_widget(widget)
186
187 def on_content(self, instance, value):
188 if not hasattr(value, 'popup'):
189 value.create_property('popup')
190 value.popup = self
191 if self._container:
192 self._container.clear_widgets()
193 self._container.add_widget(value)
194
195 def on__container(self, instance, value):
196 if value is None or self.content is None:
197 return
198 self._container.clear_widgets()
199 self._container.add_widget(self.content)
200
201 def on_touch_down(self, touch):
202 if self.disabled and self.collide_point(*touch.pos):
203 return True
204 return super(Popup, self).on_touch_down(touch)
205
206
207 if __name__ == '__main__':
208 from kivy.base import runTouchApp
209 from kivy.uix.button import Button
210 from kivy.uix.label import Label
211 from kivy.uix.gridlayout import GridLayout
212 from kivy.core.window import Window
213
214 # add popup
215 content = GridLayout(cols=1)
216 content_cancel = Button(text='Cancel', size_hint_y=None, height=40)
217 content.add_widget(Label(text='This is a hello world'))
218 content.add_widget(content_cancel)
219 popup = Popup(title='Test popup',
220 size_hint=(None, None), size=(256, 256),
221 content=content, disabled=True)
222 content_cancel.bind(on_release=popup.dismiss)
223
224 layout = GridLayout(cols=3)
225 for x in range(9):
226 btn = Button(text=str(x))
227 btn.bind(on_release=popup.open)
228 layout.add_widget(btn)
229
230 Window.add_widget(layout)
231
232 popup.open()
233
234 runTouchApp()
235
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kivy/uix/popup.py b/kivy/uix/popup.py
--- a/kivy/uix/popup.py
+++ b/kivy/uix/popup.py
@@ -185,9 +185,6 @@
super(Popup, self).add_widget(widget)
def on_content(self, instance, value):
- if not hasattr(value, 'popup'):
- value.create_property('popup')
- value.popup = self
if self._container:
self._container.clear_widgets()
self._container.add_widget(value)
|
{"golden_diff": "diff --git a/kivy/uix/popup.py b/kivy/uix/popup.py\n--- a/kivy/uix/popup.py\n+++ b/kivy/uix/popup.py\n@@ -185,9 +185,6 @@\n super(Popup, self).add_widget(widget)\n \n def on_content(self, instance, value):\n- if not hasattr(value, 'popup'):\n- value.create_property('popup')\n- value.popup = self\n if self._container:\n self._container.clear_widgets()\n self._container.add_widget(value)\n", "issue": "Issues with popup on py3\nWhen running the following code in py3 on windows I get the following error:\n\n``` py\nfrom kivy.uix.widget import Widget\nfrom kivy.uix.popup import Popup\n\nw1 = Widget()\nw2 = Widget()\np1 = Popup(content=w1)\np2 = Popup(content=w2)\n```\n\n```\n Traceback (most recent call last):\n File \"playground8.py\", line 7, in <module>\n p2 = Popup(content=w2)\n File \"C:\\Users\\Matthew Einhorn\\Desktop\\Kivy-1.8.0-py3.3-win32\\kivy\\kivy\\uix\\modalview.py\", line 152, in __init__\n super(ModalView, self).__init__(**kwargs)\n File \"C:\\Users\\Matthew Einhorn\\Desktop\\Kivy-1.8.0-py3.3-win32\\kivy\\kivy\\uix\\anchorlayout.py\", line 68, in __init__\n super(AnchorLayout, self).__init__(**kwargs)\n File \"C:\\Users\\Matthew Einhorn\\Desktop\\Kivy-1.8.0-py3.3-win32\\kivy\\kivy\\uix\\layout.py\", line 66, in __init__\n super(Layout, self).__init__(**kwargs)\n File \"C:\\Users\\Matthew Einhorn\\Desktop\\Kivy-1.8.0-py3.3-win32\\kivy\\kivy\\uix\\widget.py\", line 261, in __init__\n super(Widget, self).__init__(**kwargs)\n File \"kivy\\_event.pyx\", line 271, in kivy._event.EventDispatcher.__init__ (kivy\\_event.c:4933)\n File \"kivy\\properties.pyx\", line 397, in kivy.properties.Property.__set__ (kivy\\properties.c:4680)\n File \"kivy\\properties.pyx\", line 429, in kivy.properties.Property.set (kivy\\properties.c:5203)\n File \"kivy\\properties.pyx\", line 480, in kivy.properties.Property.dispatch (kivy\\properties.c:5779)\n File \"kivy\\_event.pyx\", line 1168, in kivy._event.EventObservers.dispatch (kivy\\_event.c:12154)\n File \"kivy\\_event.pyx\", line 1074, in kivy._event.EventObservers._dispatch (kivy\\_event.c:11451)\n File \"C:\\Users\\Matthew Einhorn\\Desktop\\Kivy-1.8.0-py3.3-win32\\kivy\\kivy\\uix\\popup.py\", line 188, in on_content\n if not hasattr(value, 'popup'):\n File \"kivy\\properties.pyx\", line 402, in kivy.properties.Property.__get__ (kivy\\properties.c:4776)\n File \"kivy\\properties.pyx\", line 435, in kivy.properties.Property.get (kivy\\properties.c:5416)\n KeyError: 'popup'\n```\n\nThe reason is because of https://github.com/kivy/kivy/blob/master/kivy/uix/popup.py#L188. Both Widgets are created first. Then upon creation of first Popup its `on_content` is executed and a property in that widget as well in Widget class is created. However, it's only initialized for w1, w2 `__storage` has not been initialized for w2. So when hasattr is called on widget 2 and in python 3 it causes obj.__storage['popup']` to be executed from get, because storage has not been initialized for 'popup' in this widget it crashes.\n\nThe question is, why does the Popup code do this `create_property` stuff?\n\n", "before_files": [{"content": "'''\nPopup\n=====\n\n.. versionadded:: 1.0.7\n\n.. image:: images/popup.jpg\n :align: right\n\nThe :class:`Popup` widget is used to create modal popups. By default, the popup\nwill cover the whole \"parent\" window. When you are creating a popup, you\nmust at least set a :attr:`Popup.title` and :attr:`Popup.content`.\n\nRemember that the default size of a Widget is size_hint=(1, 1). If you don't\nwant your popup to be fullscreen, either use size hints with values less than 1\n(for instance size_hint=(.8, .8)) or deactivate the size_hint and use\nfixed size attributes.\n\n\n.. versionchanged:: 1.4.0\n The :class:`Popup` class now inherits from\n :class:`~kivy.uix.modalview.ModalView`. The :class:`Popup` offers a default\n layout with a title and a separation bar.\n\nExamples\n--------\n\nExample of a simple 400x400 Hello world popup::\n\n popup = Popup(title='Test popup',\n content=Label(text='Hello world'),\n size_hint=(None, None), size=(400, 400))\n\nBy default, any click outside the popup will dismiss/close it. If you don't\nwant that, you can set\n:attr:`~kivy.uix.modalview.ModalView.auto_dismiss` to False::\n\n popup = Popup(title='Test popup', content=Label(text='Hello world'),\n auto_dismiss=False)\n popup.open()\n\nTo manually dismiss/close the popup, use\n:attr:`~kivy.uix.modalview.ModalView.dismiss`::\n\n popup.dismiss()\n\nBoth :meth:`~kivy.uix.modalview.ModalView.open` and\n:meth:`~kivy.uix.modalview.ModalView.dismiss` are bindable. That means you\ncan directly bind the function to an action, e.g. to a button's on_press::\n\n # create content and add to the popup\n content = Button(text='Close me!')\n popup = Popup(content=content, auto_dismiss=False)\n\n # bind the on_press event of the button to the dismiss function\n content.bind(on_press=popup.dismiss)\n\n # open the popup\n popup.open()\n\n\nPopup Events\n------------\n\nThere are two events available: `on_open` which is raised when the popup is\nopening, and `on_dismiss` which is raised when the popup is closed.\nFor `on_dismiss`, you can prevent the\npopup from closing by explictly returning True from your callback::\n\n def my_callback(instance):\n print('Popup', instance, 'is being dismissed but is prevented!')\n return True\n popup = Popup(content=Label(text='Hello world'))\n popup.bind(on_dismiss=my_callback)\n popup.open()\n\n'''\n\n__all__ = ('Popup', 'PopupException')\n\nfrom kivy.uix.modalview import ModalView\nfrom kivy.properties import (StringProperty, ObjectProperty, OptionProperty,\n NumericProperty, ListProperty)\n\n\nclass PopupException(Exception):\n '''Popup exception, fired when multiple content widgets are added to the\n popup.\n\n .. versionadded:: 1.4.0\n '''\n\n\nclass Popup(ModalView):\n '''Popup class. See module documentation for more information.\n\n :Events:\n `on_open`:\n Fired when the Popup is opened.\n `on_dismiss`:\n Fired when the Popup is closed. If the callback returns True, the\n dismiss will be canceled.\n '''\n\n title = StringProperty('No title')\n '''String that represents the title of the popup.\n\n :attr:`title` is a :class:`~kivy.properties.StringProperty` and defaults to\n 'No title'.\n '''\n\n title_size = NumericProperty('14sp')\n '''Represents the font size of the popup title.\n\n .. versionadded:: 1.6.0\n\n :attr:`title_size` is a :class:`~kivy.properties.NumericProperty` and\n defaults to '14sp'.\n '''\n\n title_align = OptionProperty('left',\n options=['left', 'center', 'right', 'justify'])\n '''Horizontal alignment of the title.\n\n .. versionadded:: 1.9.0\n\n :attr:`title_align` is a :class:`~kivy.properties.OptionProperty` and\n defaults to 'left'. Available options are left, middle, right and justify.\n '''\n\n title_font = StringProperty('DroidSans')\n '''Font used to render the title text.\n\n .. versionadded:: 1.9.0\n\n :attr:`title_font` is a :class:`~kivy.properties.StringProperty` and\n defaults to 'DroidSans'.\n '''\n\n content = ObjectProperty(None)\n '''Content of the popup that is displayed just under the title.\n\n :attr:`content` is an :class:`~kivy.properties.ObjectProperty` and defaults\n to None.\n '''\n\n title_color = ListProperty([1, 1, 1, 1])\n '''Color used by the Title.\n\n .. versionadded:: 1.8.0\n\n :attr:`title_color` is a :class:`~kivy.properties.ListProperty` and\n defaults to [1, 1, 1, 1].\n '''\n\n separator_color = ListProperty([47 / 255., 167 / 255., 212 / 255., 1.])\n '''Color used by the separator between title and content.\n\n .. versionadded:: 1.1.0\n\n :attr:`separator_color` is a :class:`~kivy.properties.ListProperty` and\n defaults to [47 / 255., 167 / 255., 212 / 255., 1.]\n '''\n\n separator_height = NumericProperty('2dp')\n '''Height of the separator.\n\n .. versionadded:: 1.1.0\n\n :attr:`separator_height` is a :class:`~kivy.properties.NumericProperty` and\n defaults to 2dp.\n '''\n\n # Internal properties used for graphical representation.\n\n _container = ObjectProperty(None)\n\n def add_widget(self, widget):\n if self._container:\n if self.content:\n raise PopupException(\n 'Popup can have only one widget as content')\n self.content = widget\n else:\n super(Popup, self).add_widget(widget)\n\n def on_content(self, instance, value):\n if not hasattr(value, 'popup'):\n value.create_property('popup')\n value.popup = self\n if self._container:\n self._container.clear_widgets()\n self._container.add_widget(value)\n\n def on__container(self, instance, value):\n if value is None or self.content is None:\n return\n self._container.clear_widgets()\n self._container.add_widget(self.content)\n\n def on_touch_down(self, touch):\n if self.disabled and self.collide_point(*touch.pos):\n return True\n return super(Popup, self).on_touch_down(touch)\n\n\nif __name__ == '__main__':\n from kivy.base import runTouchApp\n from kivy.uix.button import Button\n from kivy.uix.label import Label\n from kivy.uix.gridlayout import GridLayout\n from kivy.core.window import Window\n\n # add popup\n content = GridLayout(cols=1)\n content_cancel = Button(text='Cancel', size_hint_y=None, height=40)\n content.add_widget(Label(text='This is a hello world'))\n content.add_widget(content_cancel)\n popup = Popup(title='Test popup',\n size_hint=(None, None), size=(256, 256),\n content=content, disabled=True)\n content_cancel.bind(on_release=popup.dismiss)\n\n layout = GridLayout(cols=3)\n for x in range(9):\n btn = Button(text=str(x))\n btn.bind(on_release=popup.open)\n layout.add_widget(btn)\n\n Window.add_widget(layout)\n\n popup.open()\n\n runTouchApp()\n", "path": "kivy/uix/popup.py"}], "after_files": [{"content": "'''\nPopup\n=====\n\n.. versionadded:: 1.0.7\n\n.. image:: images/popup.jpg\n :align: right\n\nThe :class:`Popup` widget is used to create modal popups. By default, the popup\nwill cover the whole \"parent\" window. When you are creating a popup, you\nmust at least set a :attr:`Popup.title` and :attr:`Popup.content`.\n\nRemember that the default size of a Widget is size_hint=(1, 1). If you don't\nwant your popup to be fullscreen, either use size hints with values less than 1\n(for instance size_hint=(.8, .8)) or deactivate the size_hint and use\nfixed size attributes.\n\n\n.. versionchanged:: 1.4.0\n The :class:`Popup` class now inherits from\n :class:`~kivy.uix.modalview.ModalView`. The :class:`Popup` offers a default\n layout with a title and a separation bar.\n\nExamples\n--------\n\nExample of a simple 400x400 Hello world popup::\n\n popup = Popup(title='Test popup',\n content=Label(text='Hello world'),\n size_hint=(None, None), size=(400, 400))\n\nBy default, any click outside the popup will dismiss/close it. If you don't\nwant that, you can set\n:attr:`~kivy.uix.modalview.ModalView.auto_dismiss` to False::\n\n popup = Popup(title='Test popup', content=Label(text='Hello world'),\n auto_dismiss=False)\n popup.open()\n\nTo manually dismiss/close the popup, use\n:attr:`~kivy.uix.modalview.ModalView.dismiss`::\n\n popup.dismiss()\n\nBoth :meth:`~kivy.uix.modalview.ModalView.open` and\n:meth:`~kivy.uix.modalview.ModalView.dismiss` are bindable. That means you\ncan directly bind the function to an action, e.g. to a button's on_press::\n\n # create content and add to the popup\n content = Button(text='Close me!')\n popup = Popup(content=content, auto_dismiss=False)\n\n # bind the on_press event of the button to the dismiss function\n content.bind(on_press=popup.dismiss)\n\n # open the popup\n popup.open()\n\n\nPopup Events\n------------\n\nThere are two events available: `on_open` which is raised when the popup is\nopening, and `on_dismiss` which is raised when the popup is closed.\nFor `on_dismiss`, you can prevent the\npopup from closing by explictly returning True from your callback::\n\n def my_callback(instance):\n print('Popup', instance, 'is being dismissed but is prevented!')\n return True\n popup = Popup(content=Label(text='Hello world'))\n popup.bind(on_dismiss=my_callback)\n popup.open()\n\n'''\n\n__all__ = ('Popup', 'PopupException')\n\nfrom kivy.uix.modalview import ModalView\nfrom kivy.properties import (StringProperty, ObjectProperty, OptionProperty,\n NumericProperty, ListProperty)\n\n\nclass PopupException(Exception):\n '''Popup exception, fired when multiple content widgets are added to the\n popup.\n\n .. versionadded:: 1.4.0\n '''\n\n\nclass Popup(ModalView):\n '''Popup class. See module documentation for more information.\n\n :Events:\n `on_open`:\n Fired when the Popup is opened.\n `on_dismiss`:\n Fired when the Popup is closed. If the callback returns True, the\n dismiss will be canceled.\n '''\n\n title = StringProperty('No title')\n '''String that represents the title of the popup.\n\n :attr:`title` is a :class:`~kivy.properties.StringProperty` and defaults to\n 'No title'.\n '''\n\n title_size = NumericProperty('14sp')\n '''Represents the font size of the popup title.\n\n .. versionadded:: 1.6.0\n\n :attr:`title_size` is a :class:`~kivy.properties.NumericProperty` and\n defaults to '14sp'.\n '''\n\n title_align = OptionProperty('left',\n options=['left', 'center', 'right', 'justify'])\n '''Horizontal alignment of the title.\n\n .. versionadded:: 1.9.0\n\n :attr:`title_align` is a :class:`~kivy.properties.OptionProperty` and\n defaults to 'left'. Available options are left, middle, right and justify.\n '''\n\n title_font = StringProperty('DroidSans')\n '''Font used to render the title text.\n\n .. versionadded:: 1.9.0\n\n :attr:`title_font` is a :class:`~kivy.properties.StringProperty` and\n defaults to 'DroidSans'.\n '''\n\n content = ObjectProperty(None)\n '''Content of the popup that is displayed just under the title.\n\n :attr:`content` is an :class:`~kivy.properties.ObjectProperty` and defaults\n to None.\n '''\n\n title_color = ListProperty([1, 1, 1, 1])\n '''Color used by the Title.\n\n .. versionadded:: 1.8.0\n\n :attr:`title_color` is a :class:`~kivy.properties.ListProperty` and\n defaults to [1, 1, 1, 1].\n '''\n\n separator_color = ListProperty([47 / 255., 167 / 255., 212 / 255., 1.])\n '''Color used by the separator between title and content.\n\n .. versionadded:: 1.1.0\n\n :attr:`separator_color` is a :class:`~kivy.properties.ListProperty` and\n defaults to [47 / 255., 167 / 255., 212 / 255., 1.]\n '''\n\n separator_height = NumericProperty('2dp')\n '''Height of the separator.\n\n .. versionadded:: 1.1.0\n\n :attr:`separator_height` is a :class:`~kivy.properties.NumericProperty` and\n defaults to 2dp.\n '''\n\n # Internal properties used for graphical representation.\n\n _container = ObjectProperty(None)\n\n def add_widget(self, widget):\n if self._container:\n if self.content:\n raise PopupException(\n 'Popup can have only one widget as content')\n self.content = widget\n else:\n super(Popup, self).add_widget(widget)\n\n def on_content(self, instance, value):\n if self._container:\n self._container.clear_widgets()\n self._container.add_widget(value)\n\n def on__container(self, instance, value):\n if value is None or self.content is None:\n return\n self._container.clear_widgets()\n self._container.add_widget(self.content)\n\n def on_touch_down(self, touch):\n if self.disabled and self.collide_point(*touch.pos):\n return True\n return super(Popup, self).on_touch_down(touch)\n\n\nif __name__ == '__main__':\n from kivy.base import runTouchApp\n from kivy.uix.button import Button\n from kivy.uix.label import Label\n from kivy.uix.gridlayout import GridLayout\n from kivy.core.window import Window\n\n # add popup\n content = GridLayout(cols=1)\n content_cancel = Button(text='Cancel', size_hint_y=None, height=40)\n content.add_widget(Label(text='This is a hello world'))\n content.add_widget(content_cancel)\n popup = Popup(title='Test popup',\n size_hint=(None, None), size=(256, 256),\n content=content, disabled=True)\n content_cancel.bind(on_release=popup.dismiss)\n\n layout = GridLayout(cols=3)\n for x in range(9):\n btn = Button(text=str(x))\n btn.bind(on_release=popup.open)\n layout.add_widget(btn)\n\n Window.add_widget(layout)\n\n popup.open()\n\n runTouchApp()\n", "path": "kivy/uix/popup.py"}]}
| 3,507 | 122 |
gh_patches_debug_1812
|
rasdani/github-patches
|
git_diff
|
pytorch__vision-6883
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
deepcopying retinanet fails
### 🐛 Describe the bug
Deepcoping retinanet fails
```py
from torchvision.models.detection.retinanet import retinanet_resnet50_fpn
from torchvision.models.resnet import ResNet50_Weights
from copy import deepcopy
from torch import nn
class RetinaNet(nn.Module):
def __init__(self):
super().__init__()
self.weights_backbone = ResNet50_Weights.IMAGENET1K_V1
self.model = retinanet_resnet50_fpn(weights=None, weights_backbone=self.weights_backbone)
if __name__ == '__main__':
deepcopy(RetinaNet())
```
Error:
```console
le "/Users/goku/Desktop/work/repos/lightning-bolts/build/tmp2.py", line 15, in <module>
deepcopy(RetinaNet())
File "/Users/goku/miniconda3/envs/lit_bolts/lib/python3.9/copy.py", line 172, in deepcopy
y = _reconstruct(x, memo, *rv)
File "/Users/goku/miniconda3/envs/lit_bolts/lib/python3.9/copy.py", line 270, in _reconstruct
state = deepcopy(state, memo)
File "/Users/goku/miniconda3/envs/lit_bolts/lib/python3.9/copy.py", line 146, in deepcopy
y = copier(x, memo)
File "/Users/goku/miniconda3/envs/lit_bolts/lib/python3.9/copy.py", line 230, in _deepcopy_dict
y[deepcopy(key, memo)] = deepcopy(value, memo)
File "/Users/goku/miniconda3/envs/lit_bolts/lib/python3.9/copy.py", line 172, in deepcopy
y = _reconstruct(x, memo, *rv)
File "/Users/goku/miniconda3/envs/lit_bolts/lib/python3.9/copy.py", line 264, in _reconstruct
y = func(*args)
File "/Users/goku/miniconda3/envs/lit_bolts/lib/python3.9/enum.py", line 384, in __call__
return cls.__new__(cls, value)
File "/Users/goku/miniconda3/envs/lit_bolts/lib/python3.9/enum.py", line 702, in __new__
raise ve_exc
ValueError: Weights(url='https://download.pytorch.org/models/resnet50-0676ba61.pth', transforms=functools.partial(<class 'torchvision.transforms._presets.ImageClassification'>, crop_size=224), meta={'min_size': (1, 1), 'categories': ['tench', 'goldfish', 'great white shark', ...}}, '_docs': 'These weights reproduce closely the results of the paper using a simple training recipe.'}) is not a valid ResNet50_Weights
```
In short this fails:
```python
from copy import deepcopy
from torchvision.models.resnet import ResNet50_Weights
deepcopy(ResNet50_Weights.IMAGENET1K_V1)
```
### Versions
```console
Collecting environment information...
PyTorch version: 1.13.0
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 11.6 (x86_64)
GCC version: Could not collect
Clang version: 13.0.0 (clang-1300.0.29.3)
CMake version: version 3.21.3
Libc version: N/A
Python version: 3.9.13 (main, Oct 13 2022, 16:12:30) [Clang 12.0.0 ] (64-
Python platform: macOS-10.16-x86_64-i386-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.4
[pip3] pytorch-lightning==1.8.0rc1
[pip3] torch==1.13.0
[pip3] torchmetrics==0.10.1
[pip3] torchvision==0.14.0
[conda] numpy 1.23.4 pypi_0 pypi
[conda] pytorch-lightning 1.8.0rc1 pypi_0 pypi
[conda] torch 1.13.0 pypi_0 pypi
[conda] torchmetrics 0.10.1 pypi_0 pypi
[conda] torchvision 0.14.0 pypi_0 pypi
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `torchvision/models/_api.py`
Content:
```
1 import importlib
2 import inspect
3 import sys
4 from dataclasses import dataclass, fields
5 from inspect import signature
6 from types import ModuleType
7 from typing import Any, Callable, cast, Dict, List, Mapping, Optional, TypeVar, Union
8
9 from torch import nn
10
11 from torchvision._utils import StrEnum
12
13 from .._internally_replaced_utils import load_state_dict_from_url
14
15
16 __all__ = ["WeightsEnum", "Weights", "get_model", "get_model_builder", "get_model_weights", "get_weight", "list_models"]
17
18
19 @dataclass
20 class Weights:
21 """
22 This class is used to group important attributes associated with the pre-trained weights.
23
24 Args:
25 url (str): The location where we find the weights.
26 transforms (Callable): A callable that constructs the preprocessing method (or validation preset transforms)
27 needed to use the model. The reason we attach a constructor method rather than an already constructed
28 object is because the specific object might have memory and thus we want to delay initialization until
29 needed.
30 meta (Dict[str, Any]): Stores meta-data related to the weights of the model and its configuration. These can be
31 informative attributes (for example the number of parameters/flops, recipe link/methods used in training
32 etc), configuration parameters (for example the `num_classes`) needed to construct the model or important
33 meta-data (for example the `classes` of a classification model) needed to use the model.
34 """
35
36 url: str
37 transforms: Callable
38 meta: Dict[str, Any]
39
40
41 class WeightsEnum(StrEnum):
42 """
43 This class is the parent class of all model weights. Each model building method receives an optional `weights`
44 parameter with its associated pre-trained weights. It inherits from `Enum` and its values should be of type
45 `Weights`.
46
47 Args:
48 value (Weights): The data class entry with the weight information.
49 """
50
51 def __init__(self, value: Weights):
52 self._value_ = value
53
54 @classmethod
55 def verify(cls, obj: Any) -> Any:
56 if obj is not None:
57 if type(obj) is str:
58 obj = cls.from_str(obj.replace(cls.__name__ + ".", ""))
59 elif not isinstance(obj, cls):
60 raise TypeError(
61 f"Invalid Weight class provided; expected {cls.__name__} but received {obj.__class__.__name__}."
62 )
63 return obj
64
65 def get_state_dict(self, progress: bool) -> Mapping[str, Any]:
66 return load_state_dict_from_url(self.url, progress=progress)
67
68 def __repr__(self) -> str:
69 return f"{self.__class__.__name__}.{self._name_}"
70
71 def __getattr__(self, name):
72 # Be able to fetch Weights attributes directly
73 for f in fields(Weights):
74 if f.name == name:
75 return object.__getattribute__(self.value, name)
76 return super().__getattr__(name)
77
78
79 def get_weight(name: str) -> WeightsEnum:
80 """
81 Gets the weights enum value by its full name. Example: "ResNet50_Weights.IMAGENET1K_V1"
82
83 .. betastatus:: function
84
85 Args:
86 name (str): The name of the weight enum entry.
87
88 Returns:
89 WeightsEnum: The requested weight enum.
90 """
91 try:
92 enum_name, value_name = name.split(".")
93 except ValueError:
94 raise ValueError(f"Invalid weight name provided: '{name}'.")
95
96 base_module_name = ".".join(sys.modules[__name__].__name__.split(".")[:-1])
97 base_module = importlib.import_module(base_module_name)
98 model_modules = [base_module] + [
99 x[1] for x in inspect.getmembers(base_module, inspect.ismodule) if x[1].__file__.endswith("__init__.py")
100 ]
101
102 weights_enum = None
103 for m in model_modules:
104 potential_class = m.__dict__.get(enum_name, None)
105 if potential_class is not None and issubclass(potential_class, WeightsEnum):
106 weights_enum = potential_class
107 break
108
109 if weights_enum is None:
110 raise ValueError(f"The weight enum '{enum_name}' for the specific method couldn't be retrieved.")
111
112 return weights_enum.from_str(value_name)
113
114
115 def get_model_weights(name: Union[Callable, str]) -> WeightsEnum:
116 """
117 Retuns the weights enum class associated to the given model.
118
119 .. betastatus:: function
120
121 Args:
122 name (callable or str): The model builder function or the name under which it is registered.
123
124 Returns:
125 weights_enum (WeightsEnum): The weights enum class associated with the model.
126 """
127 model = get_model_builder(name) if isinstance(name, str) else name
128 return _get_enum_from_fn(model)
129
130
131 def _get_enum_from_fn(fn: Callable) -> WeightsEnum:
132 """
133 Internal method that gets the weight enum of a specific model builder method.
134
135 Args:
136 fn (Callable): The builder method used to create the model.
137 weight_name (str): The name of the weight enum entry of the specific model.
138 Returns:
139 WeightsEnum: The requested weight enum.
140 """
141 sig = signature(fn)
142 if "weights" not in sig.parameters:
143 raise ValueError("The method is missing the 'weights' argument.")
144
145 ann = signature(fn).parameters["weights"].annotation
146 weights_enum = None
147 if isinstance(ann, type) and issubclass(ann, WeightsEnum):
148 weights_enum = ann
149 else:
150 # handle cases like Union[Optional, T]
151 # TODO: Replace ann.__args__ with typing.get_args(ann) after python >= 3.8
152 for t in ann.__args__: # type: ignore[union-attr]
153 if isinstance(t, type) and issubclass(t, WeightsEnum):
154 weights_enum = t
155 break
156
157 if weights_enum is None:
158 raise ValueError(
159 "The WeightsEnum class for the specific method couldn't be retrieved. Make sure the typing info is correct."
160 )
161
162 return cast(WeightsEnum, weights_enum)
163
164
165 M = TypeVar("M", bound=nn.Module)
166
167 BUILTIN_MODELS = {}
168
169
170 def register_model(name: Optional[str] = None) -> Callable[[Callable[..., M]], Callable[..., M]]:
171 def wrapper(fn: Callable[..., M]) -> Callable[..., M]:
172 key = name if name is not None else fn.__name__
173 if key in BUILTIN_MODELS:
174 raise ValueError(f"An entry is already registered under the name '{key}'.")
175 BUILTIN_MODELS[key] = fn
176 return fn
177
178 return wrapper
179
180
181 def list_models(module: Optional[ModuleType] = None) -> List[str]:
182 """
183 Returns a list with the names of registered models.
184
185 .. betastatus:: function
186
187 Args:
188 module (ModuleType, optional): The module from which we want to extract the available models.
189
190 Returns:
191 models (list): A list with the names of available models.
192 """
193 models = [
194 k for k, v in BUILTIN_MODELS.items() if module is None or v.__module__.rsplit(".", 1)[0] == module.__name__
195 ]
196 return sorted(models)
197
198
199 def get_model_builder(name: str) -> Callable[..., nn.Module]:
200 """
201 Gets the model name and returns the model builder method.
202
203 .. betastatus:: function
204
205 Args:
206 name (str): The name under which the model is registered.
207
208 Returns:
209 fn (Callable): The model builder method.
210 """
211 name = name.lower()
212 try:
213 fn = BUILTIN_MODELS[name]
214 except KeyError:
215 raise ValueError(f"Unknown model {name}")
216 return fn
217
218
219 def get_model(name: str, **config: Any) -> nn.Module:
220 """
221 Gets the model name and configuration and returns an instantiated model.
222
223 .. betastatus:: function
224
225 Args:
226 name (str): The name under which the model is registered.
227 **config (Any): parameters passed to the model builder method.
228
229 Returns:
230 model (nn.Module): The initialized model.
231 """
232 fn = get_model_builder(name)
233 return fn(**config)
234
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/torchvision/models/_api.py b/torchvision/models/_api.py
--- a/torchvision/models/_api.py
+++ b/torchvision/models/_api.py
@@ -75,6 +75,9 @@
return object.__getattribute__(self.value, name)
return super().__getattr__(name)
+ def __deepcopy__(self, memodict=None):
+ return self
+
def get_weight(name: str) -> WeightsEnum:
"""
|
{"golden_diff": "diff --git a/torchvision/models/_api.py b/torchvision/models/_api.py\n--- a/torchvision/models/_api.py\n+++ b/torchvision/models/_api.py\n@@ -75,6 +75,9 @@\n return object.__getattribute__(self.value, name)\n return super().__getattr__(name)\n \n+ def __deepcopy__(self, memodict=None):\n+ return self\n+\n \n def get_weight(name: str) -> WeightsEnum:\n \"\"\"\n", "issue": "deepcopying retinanet fails\n### \ud83d\udc1b Describe the bug\n\nDeepcoping retinanet fails\r\n\r\n```py\r\nfrom torchvision.models.detection.retinanet import retinanet_resnet50_fpn\r\nfrom torchvision.models.resnet import ResNet50_Weights\r\nfrom copy import deepcopy\r\nfrom torch import nn\r\n\r\n\r\nclass RetinaNet(nn.Module):\r\n def __init__(self):\r\n super().__init__()\r\n self.weights_backbone = ResNet50_Weights.IMAGENET1K_V1\r\n self.model = retinanet_resnet50_fpn(weights=None, weights_backbone=self.weights_backbone)\r\n\r\nif __name__ == '__main__':\r\n deepcopy(RetinaNet())\r\n```\r\n\r\nError:\r\n```console\r\nle \"/Users/goku/Desktop/work/repos/lightning-bolts/build/tmp2.py\", line 15, in <module>\r\n deepcopy(RetinaNet())\r\n File \"/Users/goku/miniconda3/envs/lit_bolts/lib/python3.9/copy.py\", line 172, in deepcopy\r\n y = _reconstruct(x, memo, *rv)\r\n File \"/Users/goku/miniconda3/envs/lit_bolts/lib/python3.9/copy.py\", line 270, in _reconstruct\r\n state = deepcopy(state, memo)\r\n File \"/Users/goku/miniconda3/envs/lit_bolts/lib/python3.9/copy.py\", line 146, in deepcopy\r\n y = copier(x, memo)\r\n File \"/Users/goku/miniconda3/envs/lit_bolts/lib/python3.9/copy.py\", line 230, in _deepcopy_dict\r\n y[deepcopy(key, memo)] = deepcopy(value, memo)\r\n File \"/Users/goku/miniconda3/envs/lit_bolts/lib/python3.9/copy.py\", line 172, in deepcopy\r\n y = _reconstruct(x, memo, *rv)\r\n File \"/Users/goku/miniconda3/envs/lit_bolts/lib/python3.9/copy.py\", line 264, in _reconstruct\r\n y = func(*args)\r\n File \"/Users/goku/miniconda3/envs/lit_bolts/lib/python3.9/enum.py\", line 384, in __call__\r\n return cls.__new__(cls, value)\r\n File \"/Users/goku/miniconda3/envs/lit_bolts/lib/python3.9/enum.py\", line 702, in __new__\r\n raise ve_exc\r\nValueError: Weights(url='https://download.pytorch.org/models/resnet50-0676ba61.pth', transforms=functools.partial(<class 'torchvision.transforms._presets.ImageClassification'>, crop_size=224), meta={'min_size': (1, 1), 'categories': ['tench', 'goldfish', 'great white shark', ...}}, '_docs': 'These weights reproduce closely the results of the paper using a simple training recipe.'}) is not a valid ResNet50_Weights\r\n```\r\n\r\nIn short this fails:\r\n```python\r\nfrom copy import deepcopy\r\nfrom torchvision.models.resnet import ResNet50_Weights\r\n\r\ndeepcopy(ResNet50_Weights.IMAGENET1K_V1)\r\n```\n\n### Versions\n\n```console\r\nCollecting environment information...\r\nPyTorch version: 1.13.0\r\nIs debug build: False\r\nCUDA used to build PyTorch: None\r\nROCM used to build PyTorch: N/A\r\n\r\nOS: macOS 11.6 (x86_64)\r\nGCC version: Could not collect\r\nClang version: 13.0.0 (clang-1300.0.29.3)\r\nCMake version: version 3.21.3\r\nLibc version: N/A\r\n\r\nPython version: 3.9.13 (main, Oct 13 2022, 16:12:30) [Clang 12.0.0 ] (64-\r\nPython platform: macOS-10.16-x86_64-i386-64bit\r\nIs CUDA available: False\r\nCUDA runtime version: No CUDA\r\nCUDA_MODULE_LOADING set to: N/A\r\nGPU models and configuration: No CUDA\r\nNvidia driver version: No CUDA\r\ncuDNN version: No CUDA\r\nHIP runtime version: N/A\r\nMIOpen runtime version: N/A\r\nIs XNNPACK available: True\r\n\r\nVersions of relevant libraries:\r\n[pip3] numpy==1.23.4\r\n[pip3] pytorch-lightning==1.8.0rc1\r\n[pip3] torch==1.13.0\r\n[pip3] torchmetrics==0.10.1\r\n[pip3] torchvision==0.14.0\r\n[conda] numpy 1.23.4 pypi_0 pypi\r\n[conda] pytorch-lightning 1.8.0rc1 pypi_0 pypi\r\n[conda] torch 1.13.0 pypi_0 pypi\r\n[conda] torchmetrics 0.10.1 pypi_0 pypi\r\n[conda] torchvision 0.14.0 pypi_0 pypi\r\n```\n", "before_files": [{"content": "import importlib\nimport inspect\nimport sys\nfrom dataclasses import dataclass, fields\nfrom inspect import signature\nfrom types import ModuleType\nfrom typing import Any, Callable, cast, Dict, List, Mapping, Optional, TypeVar, Union\n\nfrom torch import nn\n\nfrom torchvision._utils import StrEnum\n\nfrom .._internally_replaced_utils import load_state_dict_from_url\n\n\n__all__ = [\"WeightsEnum\", \"Weights\", \"get_model\", \"get_model_builder\", \"get_model_weights\", \"get_weight\", \"list_models\"]\n\n\n@dataclass\nclass Weights:\n \"\"\"\n This class is used to group important attributes associated with the pre-trained weights.\n\n Args:\n url (str): The location where we find the weights.\n transforms (Callable): A callable that constructs the preprocessing method (or validation preset transforms)\n needed to use the model. The reason we attach a constructor method rather than an already constructed\n object is because the specific object might have memory and thus we want to delay initialization until\n needed.\n meta (Dict[str, Any]): Stores meta-data related to the weights of the model and its configuration. These can be\n informative attributes (for example the number of parameters/flops, recipe link/methods used in training\n etc), configuration parameters (for example the `num_classes`) needed to construct the model or important\n meta-data (for example the `classes` of a classification model) needed to use the model.\n \"\"\"\n\n url: str\n transforms: Callable\n meta: Dict[str, Any]\n\n\nclass WeightsEnum(StrEnum):\n \"\"\"\n This class is the parent class of all model weights. Each model building method receives an optional `weights`\n parameter with its associated pre-trained weights. It inherits from `Enum` and its values should be of type\n `Weights`.\n\n Args:\n value (Weights): The data class entry with the weight information.\n \"\"\"\n\n def __init__(self, value: Weights):\n self._value_ = value\n\n @classmethod\n def verify(cls, obj: Any) -> Any:\n if obj is not None:\n if type(obj) is str:\n obj = cls.from_str(obj.replace(cls.__name__ + \".\", \"\"))\n elif not isinstance(obj, cls):\n raise TypeError(\n f\"Invalid Weight class provided; expected {cls.__name__} but received {obj.__class__.__name__}.\"\n )\n return obj\n\n def get_state_dict(self, progress: bool) -> Mapping[str, Any]:\n return load_state_dict_from_url(self.url, progress=progress)\n\n def __repr__(self) -> str:\n return f\"{self.__class__.__name__}.{self._name_}\"\n\n def __getattr__(self, name):\n # Be able to fetch Weights attributes directly\n for f in fields(Weights):\n if f.name == name:\n return object.__getattribute__(self.value, name)\n return super().__getattr__(name)\n\n\ndef get_weight(name: str) -> WeightsEnum:\n \"\"\"\n Gets the weights enum value by its full name. Example: \"ResNet50_Weights.IMAGENET1K_V1\"\n\n .. betastatus:: function\n\n Args:\n name (str): The name of the weight enum entry.\n\n Returns:\n WeightsEnum: The requested weight enum.\n \"\"\"\n try:\n enum_name, value_name = name.split(\".\")\n except ValueError:\n raise ValueError(f\"Invalid weight name provided: '{name}'.\")\n\n base_module_name = \".\".join(sys.modules[__name__].__name__.split(\".\")[:-1])\n base_module = importlib.import_module(base_module_name)\n model_modules = [base_module] + [\n x[1] for x in inspect.getmembers(base_module, inspect.ismodule) if x[1].__file__.endswith(\"__init__.py\")\n ]\n\n weights_enum = None\n for m in model_modules:\n potential_class = m.__dict__.get(enum_name, None)\n if potential_class is not None and issubclass(potential_class, WeightsEnum):\n weights_enum = potential_class\n break\n\n if weights_enum is None:\n raise ValueError(f\"The weight enum '{enum_name}' for the specific method couldn't be retrieved.\")\n\n return weights_enum.from_str(value_name)\n\n\ndef get_model_weights(name: Union[Callable, str]) -> WeightsEnum:\n \"\"\"\n Retuns the weights enum class associated to the given model.\n\n .. betastatus:: function\n\n Args:\n name (callable or str): The model builder function or the name under which it is registered.\n\n Returns:\n weights_enum (WeightsEnum): The weights enum class associated with the model.\n \"\"\"\n model = get_model_builder(name) if isinstance(name, str) else name\n return _get_enum_from_fn(model)\n\n\ndef _get_enum_from_fn(fn: Callable) -> WeightsEnum:\n \"\"\"\n Internal method that gets the weight enum of a specific model builder method.\n\n Args:\n fn (Callable): The builder method used to create the model.\n weight_name (str): The name of the weight enum entry of the specific model.\n Returns:\n WeightsEnum: The requested weight enum.\n \"\"\"\n sig = signature(fn)\n if \"weights\" not in sig.parameters:\n raise ValueError(\"The method is missing the 'weights' argument.\")\n\n ann = signature(fn).parameters[\"weights\"].annotation\n weights_enum = None\n if isinstance(ann, type) and issubclass(ann, WeightsEnum):\n weights_enum = ann\n else:\n # handle cases like Union[Optional, T]\n # TODO: Replace ann.__args__ with typing.get_args(ann) after python >= 3.8\n for t in ann.__args__: # type: ignore[union-attr]\n if isinstance(t, type) and issubclass(t, WeightsEnum):\n weights_enum = t\n break\n\n if weights_enum is None:\n raise ValueError(\n \"The WeightsEnum class for the specific method couldn't be retrieved. Make sure the typing info is correct.\"\n )\n\n return cast(WeightsEnum, weights_enum)\n\n\nM = TypeVar(\"M\", bound=nn.Module)\n\nBUILTIN_MODELS = {}\n\n\ndef register_model(name: Optional[str] = None) -> Callable[[Callable[..., M]], Callable[..., M]]:\n def wrapper(fn: Callable[..., M]) -> Callable[..., M]:\n key = name if name is not None else fn.__name__\n if key in BUILTIN_MODELS:\n raise ValueError(f\"An entry is already registered under the name '{key}'.\")\n BUILTIN_MODELS[key] = fn\n return fn\n\n return wrapper\n\n\ndef list_models(module: Optional[ModuleType] = None) -> List[str]:\n \"\"\"\n Returns a list with the names of registered models.\n\n .. betastatus:: function\n\n Args:\n module (ModuleType, optional): The module from which we want to extract the available models.\n\n Returns:\n models (list): A list with the names of available models.\n \"\"\"\n models = [\n k for k, v in BUILTIN_MODELS.items() if module is None or v.__module__.rsplit(\".\", 1)[0] == module.__name__\n ]\n return sorted(models)\n\n\ndef get_model_builder(name: str) -> Callable[..., nn.Module]:\n \"\"\"\n Gets the model name and returns the model builder method.\n\n .. betastatus:: function\n\n Args:\n name (str): The name under which the model is registered.\n\n Returns:\n fn (Callable): The model builder method.\n \"\"\"\n name = name.lower()\n try:\n fn = BUILTIN_MODELS[name]\n except KeyError:\n raise ValueError(f\"Unknown model {name}\")\n return fn\n\n\ndef get_model(name: str, **config: Any) -> nn.Module:\n \"\"\"\n Gets the model name and configuration and returns an instantiated model.\n\n .. betastatus:: function\n\n Args:\n name (str): The name under which the model is registered.\n **config (Any): parameters passed to the model builder method.\n\n Returns:\n model (nn.Module): The initialized model.\n \"\"\"\n fn = get_model_builder(name)\n return fn(**config)\n", "path": "torchvision/models/_api.py"}], "after_files": [{"content": "import importlib\nimport inspect\nimport sys\nfrom dataclasses import dataclass, fields\nfrom inspect import signature\nfrom types import ModuleType\nfrom typing import Any, Callable, cast, Dict, List, Mapping, Optional, TypeVar, Union\n\nfrom torch import nn\n\nfrom torchvision._utils import StrEnum\n\nfrom .._internally_replaced_utils import load_state_dict_from_url\n\n\n__all__ = [\"WeightsEnum\", \"Weights\", \"get_model\", \"get_model_builder\", \"get_model_weights\", \"get_weight\", \"list_models\"]\n\n\n@dataclass\nclass Weights:\n \"\"\"\n This class is used to group important attributes associated with the pre-trained weights.\n\n Args:\n url (str): The location where we find the weights.\n transforms (Callable): A callable that constructs the preprocessing method (or validation preset transforms)\n needed to use the model. The reason we attach a constructor method rather than an already constructed\n object is because the specific object might have memory and thus we want to delay initialization until\n needed.\n meta (Dict[str, Any]): Stores meta-data related to the weights of the model and its configuration. These can be\n informative attributes (for example the number of parameters/flops, recipe link/methods used in training\n etc), configuration parameters (for example the `num_classes`) needed to construct the model or important\n meta-data (for example the `classes` of a classification model) needed to use the model.\n \"\"\"\n\n url: str\n transforms: Callable\n meta: Dict[str, Any]\n\n\nclass WeightsEnum(StrEnum):\n \"\"\"\n This class is the parent class of all model weights. Each model building method receives an optional `weights`\n parameter with its associated pre-trained weights. It inherits from `Enum` and its values should be of type\n `Weights`.\n\n Args:\n value (Weights): The data class entry with the weight information.\n \"\"\"\n\n def __init__(self, value: Weights):\n self._value_ = value\n\n @classmethod\n def verify(cls, obj: Any) -> Any:\n if obj is not None:\n if type(obj) is str:\n obj = cls.from_str(obj.replace(cls.__name__ + \".\", \"\"))\n elif not isinstance(obj, cls):\n raise TypeError(\n f\"Invalid Weight class provided; expected {cls.__name__} but received {obj.__class__.__name__}.\"\n )\n return obj\n\n def get_state_dict(self, progress: bool) -> Mapping[str, Any]:\n return load_state_dict_from_url(self.url, progress=progress)\n\n def __repr__(self) -> str:\n return f\"{self.__class__.__name__}.{self._name_}\"\n\n def __getattr__(self, name):\n # Be able to fetch Weights attributes directly\n for f in fields(Weights):\n if f.name == name:\n return object.__getattribute__(self.value, name)\n return super().__getattr__(name)\n\n def __deepcopy__(self, memodict=None):\n return self\n\n\ndef get_weight(name: str) -> WeightsEnum:\n \"\"\"\n Gets the weights enum value by its full name. Example: \"ResNet50_Weights.IMAGENET1K_V1\"\n\n .. betastatus:: function\n\n Args:\n name (str): The name of the weight enum entry.\n\n Returns:\n WeightsEnum: The requested weight enum.\n \"\"\"\n try:\n enum_name, value_name = name.split(\".\")\n except ValueError:\n raise ValueError(f\"Invalid weight name provided: '{name}'.\")\n\n base_module_name = \".\".join(sys.modules[__name__].__name__.split(\".\")[:-1])\n base_module = importlib.import_module(base_module_name)\n model_modules = [base_module] + [\n x[1] for x in inspect.getmembers(base_module, inspect.ismodule) if x[1].__file__.endswith(\"__init__.py\")\n ]\n\n weights_enum = None\n for m in model_modules:\n potential_class = m.__dict__.get(enum_name, None)\n if potential_class is not None and issubclass(potential_class, WeightsEnum):\n weights_enum = potential_class\n break\n\n if weights_enum is None:\n raise ValueError(f\"The weight enum '{enum_name}' for the specific method couldn't be retrieved.\")\n\n return weights_enum.from_str(value_name)\n\n\ndef get_model_weights(name: Union[Callable, str]) -> WeightsEnum:\n \"\"\"\n Retuns the weights enum class associated to the given model.\n\n .. betastatus:: function\n\n Args:\n name (callable or str): The model builder function or the name under which it is registered.\n\n Returns:\n weights_enum (WeightsEnum): The weights enum class associated with the model.\n \"\"\"\n model = get_model_builder(name) if isinstance(name, str) else name\n return _get_enum_from_fn(model)\n\n\ndef _get_enum_from_fn(fn: Callable) -> WeightsEnum:\n \"\"\"\n Internal method that gets the weight enum of a specific model builder method.\n\n Args:\n fn (Callable): The builder method used to create the model.\n weight_name (str): The name of the weight enum entry of the specific model.\n Returns:\n WeightsEnum: The requested weight enum.\n \"\"\"\n sig = signature(fn)\n if \"weights\" not in sig.parameters:\n raise ValueError(\"The method is missing the 'weights' argument.\")\n\n ann = signature(fn).parameters[\"weights\"].annotation\n weights_enum = None\n if isinstance(ann, type) and issubclass(ann, WeightsEnum):\n weights_enum = ann\n else:\n # handle cases like Union[Optional, T]\n # TODO: Replace ann.__args__ with typing.get_args(ann) after python >= 3.8\n for t in ann.__args__: # type: ignore[union-attr]\n if isinstance(t, type) and issubclass(t, WeightsEnum):\n weights_enum = t\n break\n\n if weights_enum is None:\n raise ValueError(\n \"The WeightsEnum class for the specific method couldn't be retrieved. Make sure the typing info is correct.\"\n )\n\n return cast(WeightsEnum, weights_enum)\n\n\nM = TypeVar(\"M\", bound=nn.Module)\n\nBUILTIN_MODELS = {}\n\n\ndef register_model(name: Optional[str] = None) -> Callable[[Callable[..., M]], Callable[..., M]]:\n def wrapper(fn: Callable[..., M]) -> Callable[..., M]:\n key = name if name is not None else fn.__name__\n if key in BUILTIN_MODELS:\n raise ValueError(f\"An entry is already registered under the name '{key}'.\")\n BUILTIN_MODELS[key] = fn\n return fn\n\n return wrapper\n\n\ndef list_models(module: Optional[ModuleType] = None) -> List[str]:\n \"\"\"\n Returns a list with the names of registered models.\n\n .. betastatus:: function\n\n Args:\n module (ModuleType, optional): The module from which we want to extract the available models.\n\n Returns:\n models (list): A list with the names of available models.\n \"\"\"\n models = [\n k for k, v in BUILTIN_MODELS.items() if module is None or v.__module__.rsplit(\".\", 1)[0] == module.__name__\n ]\n return sorted(models)\n\n\ndef get_model_builder(name: str) -> Callable[..., nn.Module]:\n \"\"\"\n Gets the model name and returns the model builder method.\n\n .. betastatus:: function\n\n Args:\n name (str): The name under which the model is registered.\n\n Returns:\n fn (Callable): The model builder method.\n \"\"\"\n name = name.lower()\n try:\n fn = BUILTIN_MODELS[name]\n except KeyError:\n raise ValueError(f\"Unknown model {name}\")\n return fn\n\n\ndef get_model(name: str, **config: Any) -> nn.Module:\n \"\"\"\n Gets the model name and configuration and returns an instantiated model.\n\n .. betastatus:: function\n\n Args:\n name (str): The name under which the model is registered.\n **config (Any): parameters passed to the model builder method.\n\n Returns:\n model (nn.Module): The initialized model.\n \"\"\"\n fn = get_model_builder(name)\n return fn(**config)\n", "path": "torchvision/models/_api.py"}]}
| 3,827 | 108 |
gh_patches_debug_50119
|
rasdani/github-patches
|
git_diff
|
scrapy__scrapy-3039
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Line-ends (unnecessary blank lines) problem in CSV export on Windows
CSV export on Windows create unnecessary blank lines after each line.
You can fix the problem just by adding
newline=''
as parameter to io.TextIOWrapper in the __init__ method of the CsvItemExporter class in scrapy.exporters
Details are over here:
https://stackoverflow.com/questions/39477662/scrapy-csv-file-has-uniform-empty-rows/43394566#43394566
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `scrapy/exporters.py`
Content:
```
1 """
2 Item Exporters are used to export/serialize items into different formats.
3 """
4
5 import csv
6 import io
7 import sys
8 import pprint
9 import marshal
10 import six
11 from six.moves import cPickle as pickle
12 from xml.sax.saxutils import XMLGenerator
13
14 from scrapy.utils.serialize import ScrapyJSONEncoder
15 from scrapy.utils.python import to_bytes, to_unicode, to_native_str, is_listlike
16 from scrapy.item import BaseItem
17 from scrapy.exceptions import ScrapyDeprecationWarning
18 import warnings
19
20
21 __all__ = ['BaseItemExporter', 'PprintItemExporter', 'PickleItemExporter',
22 'CsvItemExporter', 'XmlItemExporter', 'JsonLinesItemExporter',
23 'JsonItemExporter', 'MarshalItemExporter']
24
25
26 class BaseItemExporter(object):
27
28 def __init__(self, **kwargs):
29 self._configure(kwargs)
30
31 def _configure(self, options, dont_fail=False):
32 """Configure the exporter by poping options from the ``options`` dict.
33 If dont_fail is set, it won't raise an exception on unexpected options
34 (useful for using with keyword arguments in subclasses constructors)
35 """
36 self.encoding = options.pop('encoding', None)
37 self.fields_to_export = options.pop('fields_to_export', None)
38 self.export_empty_fields = options.pop('export_empty_fields', False)
39 self.indent = options.pop('indent', None)
40 if not dont_fail and options:
41 raise TypeError("Unexpected options: %s" % ', '.join(options.keys()))
42
43 def export_item(self, item):
44 raise NotImplementedError
45
46 def serialize_field(self, field, name, value):
47 serializer = field.get('serializer', lambda x: x)
48 return serializer(value)
49
50 def start_exporting(self):
51 pass
52
53 def finish_exporting(self):
54 pass
55
56 def _get_serialized_fields(self, item, default_value=None, include_empty=None):
57 """Return the fields to export as an iterable of tuples
58 (name, serialized_value)
59 """
60 if include_empty is None:
61 include_empty = self.export_empty_fields
62 if self.fields_to_export is None:
63 if include_empty and not isinstance(item, dict):
64 field_iter = six.iterkeys(item.fields)
65 else:
66 field_iter = six.iterkeys(item)
67 else:
68 if include_empty:
69 field_iter = self.fields_to_export
70 else:
71 field_iter = (x for x in self.fields_to_export if x in item)
72
73 for field_name in field_iter:
74 if field_name in item:
75 field = {} if isinstance(item, dict) else item.fields[field_name]
76 value = self.serialize_field(field, field_name, item[field_name])
77 else:
78 value = default_value
79
80 yield field_name, value
81
82
83 class JsonLinesItemExporter(BaseItemExporter):
84
85 def __init__(self, file, **kwargs):
86 self._configure(kwargs, dont_fail=True)
87 self.file = file
88 kwargs.setdefault('ensure_ascii', not self.encoding)
89 self.encoder = ScrapyJSONEncoder(**kwargs)
90
91 def export_item(self, item):
92 itemdict = dict(self._get_serialized_fields(item))
93 data = self.encoder.encode(itemdict) + '\n'
94 self.file.write(to_bytes(data, self.encoding))
95
96
97 class JsonItemExporter(BaseItemExporter):
98
99 def __init__(self, file, **kwargs):
100 self._configure(kwargs, dont_fail=True)
101 self.file = file
102 # there is a small difference between the behaviour or JsonItemExporter.indent
103 # and ScrapyJSONEncoder.indent. ScrapyJSONEncoder.indent=None is needed to prevent
104 # the addition of newlines everywhere
105 json_indent = self.indent if self.indent is not None and self.indent > 0 else None
106 kwargs.setdefault('indent', json_indent)
107 kwargs.setdefault('ensure_ascii', not self.encoding)
108 self.encoder = ScrapyJSONEncoder(**kwargs)
109 self.first_item = True
110
111 def _beautify_newline(self):
112 if self.indent is not None:
113 self.file.write(b'\n')
114
115 def start_exporting(self):
116 self.file.write(b"[")
117 self._beautify_newline()
118
119 def finish_exporting(self):
120 self._beautify_newline()
121 self.file.write(b"]")
122
123 def export_item(self, item):
124 if self.first_item:
125 self.first_item = False
126 else:
127 self.file.write(b',')
128 self._beautify_newline()
129 itemdict = dict(self._get_serialized_fields(item))
130 data = self.encoder.encode(itemdict)
131 self.file.write(to_bytes(data, self.encoding))
132
133
134 class XmlItemExporter(BaseItemExporter):
135
136 def __init__(self, file, **kwargs):
137 self.item_element = kwargs.pop('item_element', 'item')
138 self.root_element = kwargs.pop('root_element', 'items')
139 self._configure(kwargs)
140 if not self.encoding:
141 self.encoding = 'utf-8'
142 self.xg = XMLGenerator(file, encoding=self.encoding)
143
144 def _beautify_newline(self, new_item=False):
145 if self.indent is not None and (self.indent > 0 or new_item):
146 self._xg_characters('\n')
147
148 def _beautify_indent(self, depth=1):
149 if self.indent:
150 self._xg_characters(' ' * self.indent * depth)
151
152 def start_exporting(self):
153 self.xg.startDocument()
154 self.xg.startElement(self.root_element, {})
155 self._beautify_newline(new_item=True)
156
157 def export_item(self, item):
158 self._beautify_indent(depth=1)
159 self.xg.startElement(self.item_element, {})
160 self._beautify_newline()
161 for name, value in self._get_serialized_fields(item, default_value=''):
162 self._export_xml_field(name, value, depth=2)
163 self._beautify_indent(depth=1)
164 self.xg.endElement(self.item_element)
165 self._beautify_newline(new_item=True)
166
167 def finish_exporting(self):
168 self.xg.endElement(self.root_element)
169 self.xg.endDocument()
170
171 def _export_xml_field(self, name, serialized_value, depth):
172 self._beautify_indent(depth=depth)
173 self.xg.startElement(name, {})
174 if hasattr(serialized_value, 'items'):
175 self._beautify_newline()
176 for subname, value in serialized_value.items():
177 self._export_xml_field(subname, value, depth=depth+1)
178 self._beautify_indent(depth=depth)
179 elif is_listlike(serialized_value):
180 self._beautify_newline()
181 for value in serialized_value:
182 self._export_xml_field('value', value, depth=depth+1)
183 self._beautify_indent(depth=depth)
184 elif isinstance(serialized_value, six.text_type):
185 self._xg_characters(serialized_value)
186 else:
187 self._xg_characters(str(serialized_value))
188 self.xg.endElement(name)
189 self._beautify_newline()
190
191 # Workaround for https://bugs.python.org/issue17606
192 # Before Python 2.7.4 xml.sax.saxutils required bytes;
193 # since 2.7.4 it requires unicode. The bug is likely to be
194 # fixed in 2.7.6, but 2.7.6 will still support unicode,
195 # and Python 3.x will require unicode, so ">= 2.7.4" should be fine.
196 if sys.version_info[:3] >= (2, 7, 4):
197 def _xg_characters(self, serialized_value):
198 if not isinstance(serialized_value, six.text_type):
199 serialized_value = serialized_value.decode(self.encoding)
200 return self.xg.characters(serialized_value)
201 else: # pragma: no cover
202 def _xg_characters(self, serialized_value):
203 return self.xg.characters(serialized_value)
204
205
206 class CsvItemExporter(BaseItemExporter):
207
208 def __init__(self, file, include_headers_line=True, join_multivalued=',', **kwargs):
209 self._configure(kwargs, dont_fail=True)
210 if not self.encoding:
211 self.encoding = 'utf-8'
212 self.include_headers_line = include_headers_line
213 self.stream = io.TextIOWrapper(
214 file,
215 line_buffering=False,
216 write_through=True,
217 encoding=self.encoding
218 ) if six.PY3 else file
219 self.csv_writer = csv.writer(self.stream, **kwargs)
220 self._headers_not_written = True
221 self._join_multivalued = join_multivalued
222
223 def serialize_field(self, field, name, value):
224 serializer = field.get('serializer', self._join_if_needed)
225 return serializer(value)
226
227 def _join_if_needed(self, value):
228 if isinstance(value, (list, tuple)):
229 try:
230 return self._join_multivalued.join(value)
231 except TypeError: # list in value may not contain strings
232 pass
233 return value
234
235 def export_item(self, item):
236 if self._headers_not_written:
237 self._headers_not_written = False
238 self._write_headers_and_set_fields_to_export(item)
239
240 fields = self._get_serialized_fields(item, default_value='',
241 include_empty=True)
242 values = list(self._build_row(x for _, x in fields))
243 self.csv_writer.writerow(values)
244
245 def _build_row(self, values):
246 for s in values:
247 try:
248 yield to_native_str(s, self.encoding)
249 except TypeError:
250 yield s
251
252 def _write_headers_and_set_fields_to_export(self, item):
253 if self.include_headers_line:
254 if not self.fields_to_export:
255 if isinstance(item, dict):
256 # for dicts try using fields of the first item
257 self.fields_to_export = list(item.keys())
258 else:
259 # use fields declared in Item
260 self.fields_to_export = list(item.fields.keys())
261 row = list(self._build_row(self.fields_to_export))
262 self.csv_writer.writerow(row)
263
264
265 class PickleItemExporter(BaseItemExporter):
266
267 def __init__(self, file, protocol=2, **kwargs):
268 self._configure(kwargs)
269 self.file = file
270 self.protocol = protocol
271
272 def export_item(self, item):
273 d = dict(self._get_serialized_fields(item))
274 pickle.dump(d, self.file, self.protocol)
275
276
277 class MarshalItemExporter(BaseItemExporter):
278
279 def __init__(self, file, **kwargs):
280 self._configure(kwargs)
281 self.file = file
282
283 def export_item(self, item):
284 marshal.dump(dict(self._get_serialized_fields(item)), self.file)
285
286
287 class PprintItemExporter(BaseItemExporter):
288
289 def __init__(self, file, **kwargs):
290 self._configure(kwargs)
291 self.file = file
292
293 def export_item(self, item):
294 itemdict = dict(self._get_serialized_fields(item))
295 self.file.write(to_bytes(pprint.pformat(itemdict) + '\n'))
296
297
298 class PythonItemExporter(BaseItemExporter):
299 """The idea behind this exporter is to have a mechanism to serialize items
300 to built-in python types so any serialization library (like
301 json, msgpack, binc, etc) can be used on top of it. Its main goal is to
302 seamless support what BaseItemExporter does plus nested items.
303 """
304 def _configure(self, options, dont_fail=False):
305 self.binary = options.pop('binary', True)
306 super(PythonItemExporter, self)._configure(options, dont_fail)
307 if self.binary:
308 warnings.warn(
309 "PythonItemExporter will drop support for binary export in the future",
310 ScrapyDeprecationWarning)
311 if not self.encoding:
312 self.encoding = 'utf-8'
313
314 def serialize_field(self, field, name, value):
315 serializer = field.get('serializer', self._serialize_value)
316 return serializer(value)
317
318 def _serialize_value(self, value):
319 if isinstance(value, BaseItem):
320 return self.export_item(value)
321 if isinstance(value, dict):
322 return dict(self._serialize_dict(value))
323 if is_listlike(value):
324 return [self._serialize_value(v) for v in value]
325 encode_func = to_bytes if self.binary else to_unicode
326 if isinstance(value, (six.text_type, bytes)):
327 return encode_func(value, encoding=self.encoding)
328 return value
329
330 def _serialize_dict(self, value):
331 for key, val in six.iteritems(value):
332 key = to_bytes(key) if self.binary else key
333 yield key, self._serialize_value(val)
334
335 def export_item(self, item):
336 result = dict(self._get_serialized_fields(item))
337 if self.binary:
338 result = dict(self._serialize_dict(result))
339 return result
340
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/scrapy/exporters.py b/scrapy/exporters.py
--- a/scrapy/exporters.py
+++ b/scrapy/exporters.py
@@ -214,7 +214,8 @@
file,
line_buffering=False,
write_through=True,
- encoding=self.encoding
+ encoding=self.encoding,
+ newline='' # Windows needs this https://github.com/scrapy/scrapy/issues/3034
) if six.PY3 else file
self.csv_writer = csv.writer(self.stream, **kwargs)
self._headers_not_written = True
|
{"golden_diff": "diff --git a/scrapy/exporters.py b/scrapy/exporters.py\n--- a/scrapy/exporters.py\n+++ b/scrapy/exporters.py\n@@ -214,7 +214,8 @@\n file,\n line_buffering=False,\n write_through=True,\n- encoding=self.encoding\n+ encoding=self.encoding,\n+ newline='' # Windows needs this https://github.com/scrapy/scrapy/issues/3034\n ) if six.PY3 else file\n self.csv_writer = csv.writer(self.stream, **kwargs)\n self._headers_not_written = True\n", "issue": "Line-ends (unnecessary blank lines) problem in CSV export on Windows \nCSV export on Windows create unnecessary blank lines after each line.\r\n\r\nYou can fix the problem just by adding \r\nnewline='' \r\nas parameter to io.TextIOWrapper in the __init__ method of the CsvItemExporter class in scrapy.exporters\r\n\r\nDetails are over here:\r\nhttps://stackoverflow.com/questions/39477662/scrapy-csv-file-has-uniform-empty-rows/43394566#43394566\n", "before_files": [{"content": "\"\"\"\nItem Exporters are used to export/serialize items into different formats.\n\"\"\"\n\nimport csv\nimport io\nimport sys\nimport pprint\nimport marshal\nimport six\nfrom six.moves import cPickle as pickle\nfrom xml.sax.saxutils import XMLGenerator\n\nfrom scrapy.utils.serialize import ScrapyJSONEncoder\nfrom scrapy.utils.python import to_bytes, to_unicode, to_native_str, is_listlike\nfrom scrapy.item import BaseItem\nfrom scrapy.exceptions import ScrapyDeprecationWarning\nimport warnings\n\n\n__all__ = ['BaseItemExporter', 'PprintItemExporter', 'PickleItemExporter',\n 'CsvItemExporter', 'XmlItemExporter', 'JsonLinesItemExporter',\n 'JsonItemExporter', 'MarshalItemExporter']\n\n\nclass BaseItemExporter(object):\n\n def __init__(self, **kwargs):\n self._configure(kwargs)\n\n def _configure(self, options, dont_fail=False):\n \"\"\"Configure the exporter by poping options from the ``options`` dict.\n If dont_fail is set, it won't raise an exception on unexpected options\n (useful for using with keyword arguments in subclasses constructors)\n \"\"\"\n self.encoding = options.pop('encoding', None)\n self.fields_to_export = options.pop('fields_to_export', None)\n self.export_empty_fields = options.pop('export_empty_fields', False)\n self.indent = options.pop('indent', None)\n if not dont_fail and options:\n raise TypeError(\"Unexpected options: %s\" % ', '.join(options.keys()))\n\n def export_item(self, item):\n raise NotImplementedError\n\n def serialize_field(self, field, name, value):\n serializer = field.get('serializer', lambda x: x)\n return serializer(value)\n\n def start_exporting(self):\n pass\n\n def finish_exporting(self):\n pass\n\n def _get_serialized_fields(self, item, default_value=None, include_empty=None):\n \"\"\"Return the fields to export as an iterable of tuples\n (name, serialized_value)\n \"\"\"\n if include_empty is None:\n include_empty = self.export_empty_fields\n if self.fields_to_export is None:\n if include_empty and not isinstance(item, dict):\n field_iter = six.iterkeys(item.fields)\n else:\n field_iter = six.iterkeys(item)\n else:\n if include_empty:\n field_iter = self.fields_to_export\n else:\n field_iter = (x for x in self.fields_to_export if x in item)\n\n for field_name in field_iter:\n if field_name in item:\n field = {} if isinstance(item, dict) else item.fields[field_name]\n value = self.serialize_field(field, field_name, item[field_name])\n else:\n value = default_value\n\n yield field_name, value\n\n\nclass JsonLinesItemExporter(BaseItemExporter):\n\n def __init__(self, file, **kwargs):\n self._configure(kwargs, dont_fail=True)\n self.file = file\n kwargs.setdefault('ensure_ascii', not self.encoding)\n self.encoder = ScrapyJSONEncoder(**kwargs)\n\n def export_item(self, item):\n itemdict = dict(self._get_serialized_fields(item))\n data = self.encoder.encode(itemdict) + '\\n'\n self.file.write(to_bytes(data, self.encoding))\n\n\nclass JsonItemExporter(BaseItemExporter):\n\n def __init__(self, file, **kwargs):\n self._configure(kwargs, dont_fail=True)\n self.file = file\n # there is a small difference between the behaviour or JsonItemExporter.indent\n # and ScrapyJSONEncoder.indent. ScrapyJSONEncoder.indent=None is needed to prevent\n # the addition of newlines everywhere\n json_indent = self.indent if self.indent is not None and self.indent > 0 else None\n kwargs.setdefault('indent', json_indent)\n kwargs.setdefault('ensure_ascii', not self.encoding)\n self.encoder = ScrapyJSONEncoder(**kwargs)\n self.first_item = True\n\n def _beautify_newline(self):\n if self.indent is not None:\n self.file.write(b'\\n')\n\n def start_exporting(self):\n self.file.write(b\"[\")\n self._beautify_newline()\n\n def finish_exporting(self):\n self._beautify_newline()\n self.file.write(b\"]\")\n\n def export_item(self, item):\n if self.first_item:\n self.first_item = False\n else:\n self.file.write(b',')\n self._beautify_newline()\n itemdict = dict(self._get_serialized_fields(item))\n data = self.encoder.encode(itemdict)\n self.file.write(to_bytes(data, self.encoding))\n\n\nclass XmlItemExporter(BaseItemExporter):\n\n def __init__(self, file, **kwargs):\n self.item_element = kwargs.pop('item_element', 'item')\n self.root_element = kwargs.pop('root_element', 'items')\n self._configure(kwargs)\n if not self.encoding:\n self.encoding = 'utf-8'\n self.xg = XMLGenerator(file, encoding=self.encoding)\n\n def _beautify_newline(self, new_item=False):\n if self.indent is not None and (self.indent > 0 or new_item):\n self._xg_characters('\\n')\n\n def _beautify_indent(self, depth=1):\n if self.indent:\n self._xg_characters(' ' * self.indent * depth)\n\n def start_exporting(self):\n self.xg.startDocument()\n self.xg.startElement(self.root_element, {})\n self._beautify_newline(new_item=True)\n\n def export_item(self, item):\n self._beautify_indent(depth=1)\n self.xg.startElement(self.item_element, {})\n self._beautify_newline()\n for name, value in self._get_serialized_fields(item, default_value=''):\n self._export_xml_field(name, value, depth=2)\n self._beautify_indent(depth=1)\n self.xg.endElement(self.item_element)\n self._beautify_newline(new_item=True)\n\n def finish_exporting(self):\n self.xg.endElement(self.root_element)\n self.xg.endDocument()\n\n def _export_xml_field(self, name, serialized_value, depth):\n self._beautify_indent(depth=depth)\n self.xg.startElement(name, {})\n if hasattr(serialized_value, 'items'):\n self._beautify_newline()\n for subname, value in serialized_value.items():\n self._export_xml_field(subname, value, depth=depth+1)\n self._beautify_indent(depth=depth)\n elif is_listlike(serialized_value):\n self._beautify_newline()\n for value in serialized_value:\n self._export_xml_field('value', value, depth=depth+1)\n self._beautify_indent(depth=depth)\n elif isinstance(serialized_value, six.text_type):\n self._xg_characters(serialized_value)\n else:\n self._xg_characters(str(serialized_value))\n self.xg.endElement(name)\n self._beautify_newline()\n\n # Workaround for https://bugs.python.org/issue17606\n # Before Python 2.7.4 xml.sax.saxutils required bytes;\n # since 2.7.4 it requires unicode. The bug is likely to be\n # fixed in 2.7.6, but 2.7.6 will still support unicode,\n # and Python 3.x will require unicode, so \">= 2.7.4\" should be fine.\n if sys.version_info[:3] >= (2, 7, 4):\n def _xg_characters(self, serialized_value):\n if not isinstance(serialized_value, six.text_type):\n serialized_value = serialized_value.decode(self.encoding)\n return self.xg.characters(serialized_value)\n else: # pragma: no cover\n def _xg_characters(self, serialized_value):\n return self.xg.characters(serialized_value)\n\n\nclass CsvItemExporter(BaseItemExporter):\n\n def __init__(self, file, include_headers_line=True, join_multivalued=',', **kwargs):\n self._configure(kwargs, dont_fail=True)\n if not self.encoding:\n self.encoding = 'utf-8'\n self.include_headers_line = include_headers_line\n self.stream = io.TextIOWrapper(\n file,\n line_buffering=False,\n write_through=True,\n encoding=self.encoding\n ) if six.PY3 else file\n self.csv_writer = csv.writer(self.stream, **kwargs)\n self._headers_not_written = True\n self._join_multivalued = join_multivalued\n\n def serialize_field(self, field, name, value):\n serializer = field.get('serializer', self._join_if_needed)\n return serializer(value)\n\n def _join_if_needed(self, value):\n if isinstance(value, (list, tuple)):\n try:\n return self._join_multivalued.join(value)\n except TypeError: # list in value may not contain strings\n pass\n return value\n\n def export_item(self, item):\n if self._headers_not_written:\n self._headers_not_written = False\n self._write_headers_and_set_fields_to_export(item)\n\n fields = self._get_serialized_fields(item, default_value='',\n include_empty=True)\n values = list(self._build_row(x for _, x in fields))\n self.csv_writer.writerow(values)\n\n def _build_row(self, values):\n for s in values:\n try:\n yield to_native_str(s, self.encoding)\n except TypeError:\n yield s\n\n def _write_headers_and_set_fields_to_export(self, item):\n if self.include_headers_line:\n if not self.fields_to_export:\n if isinstance(item, dict):\n # for dicts try using fields of the first item\n self.fields_to_export = list(item.keys())\n else:\n # use fields declared in Item\n self.fields_to_export = list(item.fields.keys())\n row = list(self._build_row(self.fields_to_export))\n self.csv_writer.writerow(row)\n\n\nclass PickleItemExporter(BaseItemExporter):\n\n def __init__(self, file, protocol=2, **kwargs):\n self._configure(kwargs)\n self.file = file\n self.protocol = protocol\n\n def export_item(self, item):\n d = dict(self._get_serialized_fields(item))\n pickle.dump(d, self.file, self.protocol)\n\n\nclass MarshalItemExporter(BaseItemExporter):\n\n def __init__(self, file, **kwargs):\n self._configure(kwargs)\n self.file = file\n\n def export_item(self, item):\n marshal.dump(dict(self._get_serialized_fields(item)), self.file)\n\n\nclass PprintItemExporter(BaseItemExporter):\n\n def __init__(self, file, **kwargs):\n self._configure(kwargs)\n self.file = file\n\n def export_item(self, item):\n itemdict = dict(self._get_serialized_fields(item))\n self.file.write(to_bytes(pprint.pformat(itemdict) + '\\n'))\n\n\nclass PythonItemExporter(BaseItemExporter):\n \"\"\"The idea behind this exporter is to have a mechanism to serialize items\n to built-in python types so any serialization library (like\n json, msgpack, binc, etc) can be used on top of it. Its main goal is to\n seamless support what BaseItemExporter does plus nested items.\n \"\"\"\n def _configure(self, options, dont_fail=False):\n self.binary = options.pop('binary', True)\n super(PythonItemExporter, self)._configure(options, dont_fail)\n if self.binary:\n warnings.warn(\n \"PythonItemExporter will drop support for binary export in the future\",\n ScrapyDeprecationWarning)\n if not self.encoding:\n self.encoding = 'utf-8'\n\n def serialize_field(self, field, name, value):\n serializer = field.get('serializer', self._serialize_value)\n return serializer(value)\n\n def _serialize_value(self, value):\n if isinstance(value, BaseItem):\n return self.export_item(value)\n if isinstance(value, dict):\n return dict(self._serialize_dict(value))\n if is_listlike(value):\n return [self._serialize_value(v) for v in value]\n encode_func = to_bytes if self.binary else to_unicode\n if isinstance(value, (six.text_type, bytes)):\n return encode_func(value, encoding=self.encoding)\n return value\n\n def _serialize_dict(self, value):\n for key, val in six.iteritems(value):\n key = to_bytes(key) if self.binary else key\n yield key, self._serialize_value(val)\n\n def export_item(self, item):\n result = dict(self._get_serialized_fields(item))\n if self.binary:\n result = dict(self._serialize_dict(result))\n return result\n", "path": "scrapy/exporters.py"}], "after_files": [{"content": "\"\"\"\nItem Exporters are used to export/serialize items into different formats.\n\"\"\"\n\nimport csv\nimport io\nimport sys\nimport pprint\nimport marshal\nimport six\nfrom six.moves import cPickle as pickle\nfrom xml.sax.saxutils import XMLGenerator\n\nfrom scrapy.utils.serialize import ScrapyJSONEncoder\nfrom scrapy.utils.python import to_bytes, to_unicode, to_native_str, is_listlike\nfrom scrapy.item import BaseItem\nfrom scrapy.exceptions import ScrapyDeprecationWarning\nimport warnings\n\n\n__all__ = ['BaseItemExporter', 'PprintItemExporter', 'PickleItemExporter',\n 'CsvItemExporter', 'XmlItemExporter', 'JsonLinesItemExporter',\n 'JsonItemExporter', 'MarshalItemExporter']\n\n\nclass BaseItemExporter(object):\n\n def __init__(self, **kwargs):\n self._configure(kwargs)\n\n def _configure(self, options, dont_fail=False):\n \"\"\"Configure the exporter by poping options from the ``options`` dict.\n If dont_fail is set, it won't raise an exception on unexpected options\n (useful for using with keyword arguments in subclasses constructors)\n \"\"\"\n self.encoding = options.pop('encoding', None)\n self.fields_to_export = options.pop('fields_to_export', None)\n self.export_empty_fields = options.pop('export_empty_fields', False)\n self.indent = options.pop('indent', None)\n if not dont_fail and options:\n raise TypeError(\"Unexpected options: %s\" % ', '.join(options.keys()))\n\n def export_item(self, item):\n raise NotImplementedError\n\n def serialize_field(self, field, name, value):\n serializer = field.get('serializer', lambda x: x)\n return serializer(value)\n\n def start_exporting(self):\n pass\n\n def finish_exporting(self):\n pass\n\n def _get_serialized_fields(self, item, default_value=None, include_empty=None):\n \"\"\"Return the fields to export as an iterable of tuples\n (name, serialized_value)\n \"\"\"\n if include_empty is None:\n include_empty = self.export_empty_fields\n if self.fields_to_export is None:\n if include_empty and not isinstance(item, dict):\n field_iter = six.iterkeys(item.fields)\n else:\n field_iter = six.iterkeys(item)\n else:\n if include_empty:\n field_iter = self.fields_to_export\n else:\n field_iter = (x for x in self.fields_to_export if x in item)\n\n for field_name in field_iter:\n if field_name in item:\n field = {} if isinstance(item, dict) else item.fields[field_name]\n value = self.serialize_field(field, field_name, item[field_name])\n else:\n value = default_value\n\n yield field_name, value\n\n\nclass JsonLinesItemExporter(BaseItemExporter):\n\n def __init__(self, file, **kwargs):\n self._configure(kwargs, dont_fail=True)\n self.file = file\n kwargs.setdefault('ensure_ascii', not self.encoding)\n self.encoder = ScrapyJSONEncoder(**kwargs)\n\n def export_item(self, item):\n itemdict = dict(self._get_serialized_fields(item))\n data = self.encoder.encode(itemdict) + '\\n'\n self.file.write(to_bytes(data, self.encoding))\n\n\nclass JsonItemExporter(BaseItemExporter):\n\n def __init__(self, file, **kwargs):\n self._configure(kwargs, dont_fail=True)\n self.file = file\n # there is a small difference between the behaviour or JsonItemExporter.indent\n # and ScrapyJSONEncoder.indent. ScrapyJSONEncoder.indent=None is needed to prevent\n # the addition of newlines everywhere\n json_indent = self.indent if self.indent is not None and self.indent > 0 else None\n kwargs.setdefault('indent', json_indent)\n kwargs.setdefault('ensure_ascii', not self.encoding)\n self.encoder = ScrapyJSONEncoder(**kwargs)\n self.first_item = True\n\n def _beautify_newline(self):\n if self.indent is not None:\n self.file.write(b'\\n')\n\n def start_exporting(self):\n self.file.write(b\"[\")\n self._beautify_newline()\n\n def finish_exporting(self):\n self._beautify_newline()\n self.file.write(b\"]\")\n\n def export_item(self, item):\n if self.first_item:\n self.first_item = False\n else:\n self.file.write(b',')\n self._beautify_newline()\n itemdict = dict(self._get_serialized_fields(item))\n data = self.encoder.encode(itemdict)\n self.file.write(to_bytes(data, self.encoding))\n\n\nclass XmlItemExporter(BaseItemExporter):\n\n def __init__(self, file, **kwargs):\n self.item_element = kwargs.pop('item_element', 'item')\n self.root_element = kwargs.pop('root_element', 'items')\n self._configure(kwargs)\n if not self.encoding:\n self.encoding = 'utf-8'\n self.xg = XMLGenerator(file, encoding=self.encoding)\n\n def _beautify_newline(self, new_item=False):\n if self.indent is not None and (self.indent > 0 or new_item):\n self._xg_characters('\\n')\n\n def _beautify_indent(self, depth=1):\n if self.indent:\n self._xg_characters(' ' * self.indent * depth)\n\n def start_exporting(self):\n self.xg.startDocument()\n self.xg.startElement(self.root_element, {})\n self._beautify_newline(new_item=True)\n\n def export_item(self, item):\n self._beautify_indent(depth=1)\n self.xg.startElement(self.item_element, {})\n self._beautify_newline()\n for name, value in self._get_serialized_fields(item, default_value=''):\n self._export_xml_field(name, value, depth=2)\n self._beautify_indent(depth=1)\n self.xg.endElement(self.item_element)\n self._beautify_newline(new_item=True)\n\n def finish_exporting(self):\n self.xg.endElement(self.root_element)\n self.xg.endDocument()\n\n def _export_xml_field(self, name, serialized_value, depth):\n self._beautify_indent(depth=depth)\n self.xg.startElement(name, {})\n if hasattr(serialized_value, 'items'):\n self._beautify_newline()\n for subname, value in serialized_value.items():\n self._export_xml_field(subname, value, depth=depth+1)\n self._beautify_indent(depth=depth)\n elif is_listlike(serialized_value):\n self._beautify_newline()\n for value in serialized_value:\n self._export_xml_field('value', value, depth=depth+1)\n self._beautify_indent(depth=depth)\n elif isinstance(serialized_value, six.text_type):\n self._xg_characters(serialized_value)\n else:\n self._xg_characters(str(serialized_value))\n self.xg.endElement(name)\n self._beautify_newline()\n\n # Workaround for https://bugs.python.org/issue17606\n # Before Python 2.7.4 xml.sax.saxutils required bytes;\n # since 2.7.4 it requires unicode. The bug is likely to be\n # fixed in 2.7.6, but 2.7.6 will still support unicode,\n # and Python 3.x will require unicode, so \">= 2.7.4\" should be fine.\n if sys.version_info[:3] >= (2, 7, 4):\n def _xg_characters(self, serialized_value):\n if not isinstance(serialized_value, six.text_type):\n serialized_value = serialized_value.decode(self.encoding)\n return self.xg.characters(serialized_value)\n else: # pragma: no cover\n def _xg_characters(self, serialized_value):\n return self.xg.characters(serialized_value)\n\n\nclass CsvItemExporter(BaseItemExporter):\n\n def __init__(self, file, include_headers_line=True, join_multivalued=',', **kwargs):\n self._configure(kwargs, dont_fail=True)\n if not self.encoding:\n self.encoding = 'utf-8'\n self.include_headers_line = include_headers_line\n self.stream = io.TextIOWrapper(\n file,\n line_buffering=False,\n write_through=True,\n encoding=self.encoding,\n newline='' # Windows needs this https://github.com/scrapy/scrapy/issues/3034\n ) if six.PY3 else file\n self.csv_writer = csv.writer(self.stream, **kwargs)\n self._headers_not_written = True\n self._join_multivalued = join_multivalued\n\n def serialize_field(self, field, name, value):\n serializer = field.get('serializer', self._join_if_needed)\n return serializer(value)\n\n def _join_if_needed(self, value):\n if isinstance(value, (list, tuple)):\n try:\n return self._join_multivalued.join(value)\n except TypeError: # list in value may not contain strings\n pass\n return value\n\n def export_item(self, item):\n if self._headers_not_written:\n self._headers_not_written = False\n self._write_headers_and_set_fields_to_export(item)\n\n fields = self._get_serialized_fields(item, default_value='',\n include_empty=True)\n values = list(self._build_row(x for _, x in fields))\n self.csv_writer.writerow(values)\n\n def _build_row(self, values):\n for s in values:\n try:\n yield to_native_str(s, self.encoding)\n except TypeError:\n yield s\n\n def _write_headers_and_set_fields_to_export(self, item):\n if self.include_headers_line:\n if not self.fields_to_export:\n if isinstance(item, dict):\n # for dicts try using fields of the first item\n self.fields_to_export = list(item.keys())\n else:\n # use fields declared in Item\n self.fields_to_export = list(item.fields.keys())\n row = list(self._build_row(self.fields_to_export))\n self.csv_writer.writerow(row)\n\n\nclass PickleItemExporter(BaseItemExporter):\n\n def __init__(self, file, protocol=2, **kwargs):\n self._configure(kwargs)\n self.file = file\n self.protocol = protocol\n\n def export_item(self, item):\n d = dict(self._get_serialized_fields(item))\n pickle.dump(d, self.file, self.protocol)\n\n\nclass MarshalItemExporter(BaseItemExporter):\n\n def __init__(self, file, **kwargs):\n self._configure(kwargs)\n self.file = file\n\n def export_item(self, item):\n marshal.dump(dict(self._get_serialized_fields(item)), self.file)\n\n\nclass PprintItemExporter(BaseItemExporter):\n\n def __init__(self, file, **kwargs):\n self._configure(kwargs)\n self.file = file\n\n def export_item(self, item):\n itemdict = dict(self._get_serialized_fields(item))\n self.file.write(to_bytes(pprint.pformat(itemdict) + '\\n'))\n\n\nclass PythonItemExporter(BaseItemExporter):\n \"\"\"The idea behind this exporter is to have a mechanism to serialize items\n to built-in python types so any serialization library (like\n json, msgpack, binc, etc) can be used on top of it. Its main goal is to\n seamless support what BaseItemExporter does plus nested items.\n \"\"\"\n def _configure(self, options, dont_fail=False):\n self.binary = options.pop('binary', True)\n super(PythonItemExporter, self)._configure(options, dont_fail)\n if self.binary:\n warnings.warn(\n \"PythonItemExporter will drop support for binary export in the future\",\n ScrapyDeprecationWarning)\n if not self.encoding:\n self.encoding = 'utf-8'\n\n def serialize_field(self, field, name, value):\n serializer = field.get('serializer', self._serialize_value)\n return serializer(value)\n\n def _serialize_value(self, value):\n if isinstance(value, BaseItem):\n return self.export_item(value)\n if isinstance(value, dict):\n return dict(self._serialize_dict(value))\n if is_listlike(value):\n return [self._serialize_value(v) for v in value]\n encode_func = to_bytes if self.binary else to_unicode\n if isinstance(value, (six.text_type, bytes)):\n return encode_func(value, encoding=self.encoding)\n return value\n\n def _serialize_dict(self, value):\n for key, val in six.iteritems(value):\n key = to_bytes(key) if self.binary else key\n yield key, self._serialize_value(val)\n\n def export_item(self, item):\n result = dict(self._get_serialized_fields(item))\n if self.binary:\n result = dict(self._serialize_dict(result))\n return result\n", "path": "scrapy/exporters.py"}]}
| 4,033 | 127 |
gh_patches_debug_60845
|
rasdani/github-patches
|
git_diff
|
uclapi__uclapi-226
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
timetable/data/departments endpoint returns 500 error
The timetable/data/departments endpoint is currently returning a 500 error on any request.
I know it's not a documented endpoint, but it would be nice if it worked :)
It looks to me like the problem is line 85 below - `rate_limiting_data` is being passed as an argument to `append`.
https://github.com/uclapi/uclapi/blob/cfd6753ae3d979bbe53573dad68babc2de19e04d/backend/uclapi/timetable/views.py#L82-L85
Removing that and replacing with this:
```python
depts["departments"].append({
"department_id": dept.deptid,
"name": dept.name})
```
should fix it, though I don't have the whole API setup installed, so I can't be sure.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `backend/uclapi/timetable/views.py`
Content:
```
1 from django.conf import settings
2
3 from rest_framework.decorators import api_view
4
5 from common.helpers import PrettyJsonResponse as JsonResponse
6
7 from .models import Lock, Course, Depts, ModuleA, ModuleB
8
9 from .app_helpers import get_student_timetable, get_custom_timetable
10
11 from common.decorators import uclapi_protected_endpoint
12
13 _SETID = settings.ROOMBOOKINGS_SETID
14
15
16 @api_view(["GET"])
17 @uclapi_protected_endpoint(personal_data=True, required_scopes=['timetable'])
18 def get_personal_timetable(request, *args, **kwargs):
19 token = kwargs['token']
20 user = token.user
21 try:
22 date_filter = request.GET["date_filter"]
23 timetable = get_student_timetable(user.employee_id, date_filter)
24 except KeyError:
25 timetable = get_student_timetable(user.employee_id)
26
27 response = {
28 "ok": True,
29 "timetable": timetable
30 }
31 return JsonResponse(response, rate_limiting_data=kwargs)
32
33
34 @api_view(["GET"])
35 @uclapi_protected_endpoint()
36 def get_modules_timetable(request, *args, **kwargs):
37 module_ids = request.GET.get("modules")
38 if module_ids is None:
39 return JsonResponse({
40 "ok": False,
41 "error": "No module IDs provided."
42 }, rate_limiting_data=kwargs)
43
44 try:
45 modules = module_ids.split(',')
46 except ValueError:
47 return JsonResponse({
48 "ok": False,
49 "error": "Invalid module IDs provided."
50 }, rate_limiting_data=kwargs)
51
52 try:
53 date_filter = request.GET["date_filter"]
54 custom_timetable = get_custom_timetable(modules, date_filter)
55 except KeyError:
56 custom_timetable = get_custom_timetable(modules)
57
58 if custom_timetable:
59 response_json = {
60 "ok": True,
61 "timetable": custom_timetable
62 }
63 return JsonResponse(response_json, rate_limiting_data=kwargs)
64 else:
65 response_json = {
66 "ok": False,
67 "error": "One or more invalid Module IDs supplied."
68 }
69 response = JsonResponse(response_json, rate_limiting_data=kwargs)
70 response.status_code = 400
71 return response
72
73
74 @api_view(["GET"])
75 @uclapi_protected_endpoint()
76 def get_departments(request, *args, **kwargs):
77 """
78 Returns all departments at UCL
79 """
80 depts = {"ok": True, "departments": []}
81 for dept in Depts.objects.all():
82 depts["departments"].append({
83 "department_id": dept.deptid,
84 "name": dept.name
85 }, rate_limiting_data=kwargs)
86 return JsonResponse(depts, rate_limiting_data=kwargs)
87
88
89 @api_view(["GET"])
90 @uclapi_protected_endpoint()
91 def get_department_courses(request, *args, **kwargs):
92 """
93 Returns all the courses in UCL with relevant ID
94 """
95 try:
96 department_id = request.GET["department"]
97 except KeyError:
98 response = JsonResponse({
99 "ok": False,
100 "error": "Supply a Department ID using the department parameter."
101 }, rate_limiting_data=kwargs)
102 response.status_code = 400
103 return response
104
105 courses = {"ok": True, "courses": []}
106 for course in Course.objects.filter(owner=department_id, setid=_SETID):
107 courses["courses"].append({
108 "course_name": course.name,
109 "course_id": course.courseid,
110 "years": course.numyears
111 })
112 return JsonResponse(courses, rate_limiting_data=kwargs)
113
114
115 @api_view(["GET"])
116 @uclapi_protected_endpoint()
117 def get_department_modules(request, *args, **kwargs):
118 """
119 Returns all modules taught by a particular department.
120 """
121 try:
122 department_id = request.GET["department"]
123 except KeyError:
124 response = JsonResponse({
125 "ok": False,
126 "error": "Supply a Department ID using the department parameter."
127 }, rate_limiting_data=kwargs)
128 response.status_code = 400
129 return response
130
131 modules = {"ok": True, "modules": []}
132 lock = Lock.objects.all()[0]
133 m = ModuleA if lock.a else ModuleB
134 for module in m.objects.filter(owner=department_id, setid=_SETID):
135 modules["modules"].append({
136 "module_id": module.moduleid,
137 "name": module.name,
138 "module_code": module.linkcode,
139 "class_size": module.csize
140 })
141
142 return JsonResponse(modules, rate_limiting_data=kwargs)
143
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/backend/uclapi/timetable/views.py b/backend/uclapi/timetable/views.py
--- a/backend/uclapi/timetable/views.py
+++ b/backend/uclapi/timetable/views.py
@@ -82,7 +82,7 @@
depts["departments"].append({
"department_id": dept.deptid,
"name": dept.name
- }, rate_limiting_data=kwargs)
+ })
return JsonResponse(depts, rate_limiting_data=kwargs)
|
{"golden_diff": "diff --git a/backend/uclapi/timetable/views.py b/backend/uclapi/timetable/views.py\n--- a/backend/uclapi/timetable/views.py\n+++ b/backend/uclapi/timetable/views.py\n@@ -82,7 +82,7 @@\n depts[\"departments\"].append({\n \"department_id\": dept.deptid,\n \"name\": dept.name\n- }, rate_limiting_data=kwargs)\n+ })\n return JsonResponse(depts, rate_limiting_data=kwargs)\n", "issue": "timetable/data/departments endpoint returns 500 error\nThe timetable/data/departments endpoint is currently returning a 500 error on any request.\r\n\r\nI know it's not a documented endpoint, but it would be nice if it worked :)\r\n\r\nIt looks to me like the problem is line 85 below - `rate_limiting_data` is being passed as an argument to `append`. \r\n\r\nhttps://github.com/uclapi/uclapi/blob/cfd6753ae3d979bbe53573dad68babc2de19e04d/backend/uclapi/timetable/views.py#L82-L85\r\n\r\nRemoving that and replacing with this:\r\n```python\r\ndepts[\"departments\"].append({ \r\n\"department_id\": dept.deptid, \r\n\"name\": dept.name}) \r\n```\r\nshould fix it, though I don't have the whole API setup installed, so I can't be sure.\n", "before_files": [{"content": "from django.conf import settings\n\nfrom rest_framework.decorators import api_view\n\nfrom common.helpers import PrettyJsonResponse as JsonResponse\n\nfrom .models import Lock, Course, Depts, ModuleA, ModuleB\n\nfrom .app_helpers import get_student_timetable, get_custom_timetable\n\nfrom common.decorators import uclapi_protected_endpoint\n\n_SETID = settings.ROOMBOOKINGS_SETID\n\n\n@api_view([\"GET\"])\n@uclapi_protected_endpoint(personal_data=True, required_scopes=['timetable'])\ndef get_personal_timetable(request, *args, **kwargs):\n token = kwargs['token']\n user = token.user\n try:\n date_filter = request.GET[\"date_filter\"]\n timetable = get_student_timetable(user.employee_id, date_filter)\n except KeyError:\n timetable = get_student_timetable(user.employee_id)\n\n response = {\n \"ok\": True,\n \"timetable\": timetable\n }\n return JsonResponse(response, rate_limiting_data=kwargs)\n\n\n@api_view([\"GET\"])\n@uclapi_protected_endpoint()\ndef get_modules_timetable(request, *args, **kwargs):\n module_ids = request.GET.get(\"modules\")\n if module_ids is None:\n return JsonResponse({\n \"ok\": False,\n \"error\": \"No module IDs provided.\"\n }, rate_limiting_data=kwargs)\n\n try:\n modules = module_ids.split(',')\n except ValueError:\n return JsonResponse({\n \"ok\": False,\n \"error\": \"Invalid module IDs provided.\"\n }, rate_limiting_data=kwargs)\n\n try:\n date_filter = request.GET[\"date_filter\"]\n custom_timetable = get_custom_timetable(modules, date_filter)\n except KeyError:\n custom_timetable = get_custom_timetable(modules)\n\n if custom_timetable:\n response_json = {\n \"ok\": True,\n \"timetable\": custom_timetable\n }\n return JsonResponse(response_json, rate_limiting_data=kwargs)\n else:\n response_json = {\n \"ok\": False,\n \"error\": \"One or more invalid Module IDs supplied.\"\n }\n response = JsonResponse(response_json, rate_limiting_data=kwargs)\n response.status_code = 400\n return response\n\n\n@api_view([\"GET\"])\n@uclapi_protected_endpoint()\ndef get_departments(request, *args, **kwargs):\n \"\"\"\n Returns all departments at UCL\n \"\"\"\n depts = {\"ok\": True, \"departments\": []}\n for dept in Depts.objects.all():\n depts[\"departments\"].append({\n \"department_id\": dept.deptid,\n \"name\": dept.name\n }, rate_limiting_data=kwargs)\n return JsonResponse(depts, rate_limiting_data=kwargs)\n\n\n@api_view([\"GET\"])\n@uclapi_protected_endpoint()\ndef get_department_courses(request, *args, **kwargs):\n \"\"\"\n Returns all the courses in UCL with relevant ID\n \"\"\"\n try:\n department_id = request.GET[\"department\"]\n except KeyError:\n response = JsonResponse({\n \"ok\": False,\n \"error\": \"Supply a Department ID using the department parameter.\"\n }, rate_limiting_data=kwargs)\n response.status_code = 400\n return response\n\n courses = {\"ok\": True, \"courses\": []}\n for course in Course.objects.filter(owner=department_id, setid=_SETID):\n courses[\"courses\"].append({\n \"course_name\": course.name,\n \"course_id\": course.courseid,\n \"years\": course.numyears\n })\n return JsonResponse(courses, rate_limiting_data=kwargs)\n\n\n@api_view([\"GET\"])\n@uclapi_protected_endpoint()\ndef get_department_modules(request, *args, **kwargs):\n \"\"\"\n Returns all modules taught by a particular department.\n \"\"\"\n try:\n department_id = request.GET[\"department\"]\n except KeyError:\n response = JsonResponse({\n \"ok\": False,\n \"error\": \"Supply a Department ID using the department parameter.\"\n }, rate_limiting_data=kwargs)\n response.status_code = 400\n return response\n\n modules = {\"ok\": True, \"modules\": []}\n lock = Lock.objects.all()[0]\n m = ModuleA if lock.a else ModuleB\n for module in m.objects.filter(owner=department_id, setid=_SETID):\n modules[\"modules\"].append({\n \"module_id\": module.moduleid,\n \"name\": module.name,\n \"module_code\": module.linkcode,\n \"class_size\": module.csize\n })\n\n return JsonResponse(modules, rate_limiting_data=kwargs)\n", "path": "backend/uclapi/timetable/views.py"}], "after_files": [{"content": "from django.conf import settings\n\nfrom rest_framework.decorators import api_view\n\nfrom common.helpers import PrettyJsonResponse as JsonResponse\n\nfrom .models import Lock, Course, Depts, ModuleA, ModuleB\n\nfrom .app_helpers import get_student_timetable, get_custom_timetable\n\nfrom common.decorators import uclapi_protected_endpoint\n\n_SETID = settings.ROOMBOOKINGS_SETID\n\n\n@api_view([\"GET\"])\n@uclapi_protected_endpoint(personal_data=True, required_scopes=['timetable'])\ndef get_personal_timetable(request, *args, **kwargs):\n token = kwargs['token']\n user = token.user\n try:\n date_filter = request.GET[\"date_filter\"]\n timetable = get_student_timetable(user.employee_id, date_filter)\n except KeyError:\n timetable = get_student_timetable(user.employee_id)\n\n response = {\n \"ok\": True,\n \"timetable\": timetable\n }\n return JsonResponse(response, rate_limiting_data=kwargs)\n\n\n@api_view([\"GET\"])\n@uclapi_protected_endpoint()\ndef get_modules_timetable(request, *args, **kwargs):\n module_ids = request.GET.get(\"modules\")\n if module_ids is None:\n return JsonResponse({\n \"ok\": False,\n \"error\": \"No module IDs provided.\"\n }, rate_limiting_data=kwargs)\n\n try:\n modules = module_ids.split(',')\n except ValueError:\n return JsonResponse({\n \"ok\": False,\n \"error\": \"Invalid module IDs provided.\"\n }, rate_limiting_data=kwargs)\n\n try:\n date_filter = request.GET[\"date_filter\"]\n custom_timetable = get_custom_timetable(modules, date_filter)\n except KeyError:\n custom_timetable = get_custom_timetable(modules)\n\n if custom_timetable:\n response_json = {\n \"ok\": True,\n \"timetable\": custom_timetable\n }\n return JsonResponse(response_json, rate_limiting_data=kwargs)\n else:\n response_json = {\n \"ok\": False,\n \"error\": \"One or more invalid Module IDs supplied.\"\n }\n response = JsonResponse(response_json, rate_limiting_data=kwargs)\n response.status_code = 400\n return response\n\n\n@api_view([\"GET\"])\n@uclapi_protected_endpoint()\ndef get_departments(request, *args, **kwargs):\n \"\"\"\n Returns all departments at UCL\n \"\"\"\n depts = {\"ok\": True, \"departments\": []}\n for dept in Depts.objects.all():\n depts[\"departments\"].append({\n \"department_id\": dept.deptid,\n \"name\": dept.name\n })\n return JsonResponse(depts, rate_limiting_data=kwargs)\n\n\n@api_view([\"GET\"])\n@uclapi_protected_endpoint()\ndef get_department_courses(request, *args, **kwargs):\n \"\"\"\n Returns all the courses in UCL with relevant ID\n \"\"\"\n try:\n department_id = request.GET[\"department\"]\n except KeyError:\n response = JsonResponse({\n \"ok\": False,\n \"error\": \"Supply a Department ID using the department parameter.\"\n }, rate_limiting_data=kwargs)\n response.status_code = 400\n return response\n\n courses = {\"ok\": True, \"courses\": []}\n for course in Course.objects.filter(owner=department_id, setid=_SETID):\n courses[\"courses\"].append({\n \"course_name\": course.name,\n \"course_id\": course.courseid,\n \"years\": course.numyears\n })\n return JsonResponse(courses, rate_limiting_data=kwargs)\n\n\n@api_view([\"GET\"])\n@uclapi_protected_endpoint()\ndef get_department_modules(request, *args, **kwargs):\n \"\"\"\n Returns all modules taught by a particular department.\n \"\"\"\n try:\n department_id = request.GET[\"department\"]\n except KeyError:\n response = JsonResponse({\n \"ok\": False,\n \"error\": \"Supply a Department ID using the department parameter.\"\n }, rate_limiting_data=kwargs)\n response.status_code = 400\n return response\n\n modules = {\"ok\": True, \"modules\": []}\n lock = Lock.objects.all()[0]\n m = ModuleA if lock.a else ModuleB\n for module in m.objects.filter(owner=department_id, setid=_SETID):\n modules[\"modules\"].append({\n \"module_id\": module.moduleid,\n \"name\": module.name,\n \"module_code\": module.linkcode,\n \"class_size\": module.csize\n })\n\n return JsonResponse(modules, rate_limiting_data=kwargs)\n", "path": "backend/uclapi/timetable/views.py"}]}
| 1,773 | 111 |
gh_patches_debug_21817
|
rasdani/github-patches
|
git_diff
|
pantsbuild__pants-18258
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`shfmt` assumes downloaded executable will be named `shfmt_{version}_{platform}`, and breaks if it isn't
**Describe the bug**
To reduce network transfer & flakiness during CI, we've pre-cached all the "external" tools used by Pants in our executor container. As part of this I've overridden the `url_template` for each tool to use a `file://` URL. The URL-paths I ended up using in the image were "simplified" from the defaults - for example, I have:
```toml
[shfmt]
url_template = "file:///opt/pants-tools/shfmt/{version}/shfmt"
```
When CI runs with this config, it fails with:
```
Error launching process: Os { code: 2, kind: NotFound, message: "No such file or directory" }
```
I `ssh`'d into one of the executors that hit this failure, and looked inside the failing sandbox. There I saw:
1. The `shfmt` binary _was_ in the sandbox, and runnable
2. According to `__run.sh`, Pants was trying to invoke `./shfmt_v3.2.4_linux_amd64` instead of plain `./shfmt`
I believe this is happening because the `shfmt` subsystem defines `generate_exe` to hard-code the same naming pattern as is used in the default `url_pattern`: https://github.com/pantsbuild/pants/blob/ac9e27b142b14f079089522c1175a9e380291100/src/python/pants/backend/shell/lint/shfmt/subsystem.py#L56-L58
I think things would operate as expected if we deleted that `generate_exe` override, since the `shfmt` download is the executable itself.
**Pants version**
2.15.0rc4
**OS**
Observed on Linux
**Additional info**
https://app.toolchain.com/organizations/color/repos/color/builds/pants_run_2023_02_15_12_48_26_897_660d20c55cc041fbb63374c79a4402b0/
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/python/pants/backend/shell/lint/shfmt/subsystem.py`
Content:
```
1 # Copyright 2021 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 from __future__ import annotations
5
6 import os.path
7 from typing import Iterable
8
9 from pants.core.util_rules.config_files import ConfigFilesRequest
10 from pants.core.util_rules.external_tool import TemplatedExternalTool
11 from pants.engine.platform import Platform
12 from pants.option.option_types import ArgsListOption, BoolOption, SkipOption
13 from pants.util.strutil import softwrap
14
15
16 class Shfmt(TemplatedExternalTool):
17 options_scope = "shfmt"
18 name = "shfmt"
19 help = "An autoformatter for shell scripts (https://github.com/mvdan/sh)."
20
21 default_version = "v3.6.0"
22 default_known_versions = [
23 "v3.2.4|macos_arm64 |e70fc42e69debe3e400347d4f918630cdf4bf2537277d672bbc43490387508ec|2998546",
24 "v3.2.4|macos_x86_64|43a0461a1b54070ddc04fbbf1b78f7861ee39a65a61f5466d15a39c4aba4f917|2980208",
25 "v3.2.4|linux_arm64 |6474d9cc08a1c9fe2ef4be7a004951998e3067d46cf55a011ddd5ff7bfab3de6|2752512",
26 "v3.2.4|linux_x86_64|3f5a47f8fec27fae3e06d611559a2063f5d27e4b9501171dde9959b8c60a3538|2797568",
27 "v3.6.0|macos_arm64 |633f242246ee0a866c5f5df25cbf61b6af0d5e143555aca32950059cf13d91e0|3065202",
28 "v3.6.0|macos_x86_64|b8c9c025b498e2816b62f0b717f6032e9ab49e725a45b8205f52f66318f17185|3047552",
29 "v3.6.0|linux_arm64 |fb1cf0af3dbe9aac7d98e38e3c7426765208ecfe23cb2da51037bb234776fd70|2818048",
30 "v3.6.0|linux_x86_64|5741a02a641de7e56b8da170e71a97e58050d66a3cf485fb268d6a5a8bb74afb|2850816",
31 ]
32
33 default_url_template = (
34 "https://github.com/mvdan/sh/releases/download/{version}/shfmt_{version}_{platform}"
35 )
36 default_url_platform_mapping = {
37 "macos_arm64": "darwin_arm64",
38 "macos_x86_64": "darwin_amd64",
39 "linux_arm64": "linux_arm64",
40 "linux_x86_64": "linux_amd64",
41 }
42
43 skip = SkipOption("fmt", "lint")
44 args = ArgsListOption(example="-i 2")
45 config_discovery = BoolOption(
46 default=True,
47 advanced=True,
48 help=softwrap(
49 """
50 If true, Pants will include all relevant `.editorconfig` files during runs.
51 See https://editorconfig.org.
52 """
53 ),
54 )
55
56 def generate_exe(self, plat: Platform) -> str:
57 plat_str = self.default_url_platform_mapping[plat.value]
58 return f"./shfmt_{self.version}_{plat_str}"
59
60 def config_request(self, dirs: Iterable[str]) -> ConfigFilesRequest:
61 # Refer to https://editorconfig.org/#file-location for how config files are discovered.
62 candidates = (os.path.join(d, ".editorconfig") for d in ("", *dirs))
63 return ConfigFilesRequest(
64 discovery=self.config_discovery,
65 check_content={fp: b"[*.sh]" for fp in candidates},
66 )
67
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/python/pants/backend/shell/lint/shfmt/subsystem.py b/src/python/pants/backend/shell/lint/shfmt/subsystem.py
--- a/src/python/pants/backend/shell/lint/shfmt/subsystem.py
+++ b/src/python/pants/backend/shell/lint/shfmt/subsystem.py
@@ -8,7 +8,6 @@
from pants.core.util_rules.config_files import ConfigFilesRequest
from pants.core.util_rules.external_tool import TemplatedExternalTool
-from pants.engine.platform import Platform
from pants.option.option_types import ArgsListOption, BoolOption, SkipOption
from pants.util.strutil import softwrap
@@ -53,10 +52,6 @@
),
)
- def generate_exe(self, plat: Platform) -> str:
- plat_str = self.default_url_platform_mapping[plat.value]
- return f"./shfmt_{self.version}_{plat_str}"
-
def config_request(self, dirs: Iterable[str]) -> ConfigFilesRequest:
# Refer to https://editorconfig.org/#file-location for how config files are discovered.
candidates = (os.path.join(d, ".editorconfig") for d in ("", *dirs))
|
{"golden_diff": "diff --git a/src/python/pants/backend/shell/lint/shfmt/subsystem.py b/src/python/pants/backend/shell/lint/shfmt/subsystem.py\n--- a/src/python/pants/backend/shell/lint/shfmt/subsystem.py\n+++ b/src/python/pants/backend/shell/lint/shfmt/subsystem.py\n@@ -8,7 +8,6 @@\n \n from pants.core.util_rules.config_files import ConfigFilesRequest\n from pants.core.util_rules.external_tool import TemplatedExternalTool\n-from pants.engine.platform import Platform\n from pants.option.option_types import ArgsListOption, BoolOption, SkipOption\n from pants.util.strutil import softwrap\n \n@@ -53,10 +52,6 @@\n ),\n )\n \n- def generate_exe(self, plat: Platform) -> str:\n- plat_str = self.default_url_platform_mapping[plat.value]\n- return f\"./shfmt_{self.version}_{plat_str}\"\n-\n def config_request(self, dirs: Iterable[str]) -> ConfigFilesRequest:\n # Refer to https://editorconfig.org/#file-location for how config files are discovered.\n candidates = (os.path.join(d, \".editorconfig\") for d in (\"\", *dirs))\n", "issue": "`shfmt` assumes downloaded executable will be named `shfmt_{version}_{platform}`, and breaks if it isn't\n**Describe the bug**\r\n\r\nTo reduce network transfer & flakiness during CI, we've pre-cached all the \"external\" tools used by Pants in our executor container. As part of this I've overridden the `url_template` for each tool to use a `file://` URL. The URL-paths I ended up using in the image were \"simplified\" from the defaults - for example, I have:\r\n```toml\r\n[shfmt]\r\nurl_template = \"file:///opt/pants-tools/shfmt/{version}/shfmt\"\r\n```\r\n\r\nWhen CI runs with this config, it fails with:\r\n```\r\nError launching process: Os { code: 2, kind: NotFound, message: \"No such file or directory\" }\r\n```\r\n\r\nI `ssh`'d into one of the executors that hit this failure, and looked inside the failing sandbox. There I saw:\r\n1. The `shfmt` binary _was_ in the sandbox, and runnable\r\n2. According to `__run.sh`, Pants was trying to invoke `./shfmt_v3.2.4_linux_amd64` instead of plain `./shfmt`\r\n\r\nI believe this is happening because the `shfmt` subsystem defines `generate_exe` to hard-code the same naming pattern as is used in the default `url_pattern`: https://github.com/pantsbuild/pants/blob/ac9e27b142b14f079089522c1175a9e380291100/src/python/pants/backend/shell/lint/shfmt/subsystem.py#L56-L58\r\n\r\nI think things would operate as expected if we deleted that `generate_exe` override, since the `shfmt` download is the executable itself.\r\n\r\n**Pants version**\r\n\r\n2.15.0rc4\r\n\r\n**OS**\r\n\r\nObserved on Linux\r\n\r\n**Additional info**\r\n\r\nhttps://app.toolchain.com/organizations/color/repos/color/builds/pants_run_2023_02_15_12_48_26_897_660d20c55cc041fbb63374c79a4402b0/\r\n\n", "before_files": [{"content": "# Copyright 2021 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\nfrom __future__ import annotations\n\nimport os.path\nfrom typing import Iterable\n\nfrom pants.core.util_rules.config_files import ConfigFilesRequest\nfrom pants.core.util_rules.external_tool import TemplatedExternalTool\nfrom pants.engine.platform import Platform\nfrom pants.option.option_types import ArgsListOption, BoolOption, SkipOption\nfrom pants.util.strutil import softwrap\n\n\nclass Shfmt(TemplatedExternalTool):\n options_scope = \"shfmt\"\n name = \"shfmt\"\n help = \"An autoformatter for shell scripts (https://github.com/mvdan/sh).\"\n\n default_version = \"v3.6.0\"\n default_known_versions = [\n \"v3.2.4|macos_arm64 |e70fc42e69debe3e400347d4f918630cdf4bf2537277d672bbc43490387508ec|2998546\",\n \"v3.2.4|macos_x86_64|43a0461a1b54070ddc04fbbf1b78f7861ee39a65a61f5466d15a39c4aba4f917|2980208\",\n \"v3.2.4|linux_arm64 |6474d9cc08a1c9fe2ef4be7a004951998e3067d46cf55a011ddd5ff7bfab3de6|2752512\",\n \"v3.2.4|linux_x86_64|3f5a47f8fec27fae3e06d611559a2063f5d27e4b9501171dde9959b8c60a3538|2797568\",\n \"v3.6.0|macos_arm64 |633f242246ee0a866c5f5df25cbf61b6af0d5e143555aca32950059cf13d91e0|3065202\",\n \"v3.6.0|macos_x86_64|b8c9c025b498e2816b62f0b717f6032e9ab49e725a45b8205f52f66318f17185|3047552\",\n \"v3.6.0|linux_arm64 |fb1cf0af3dbe9aac7d98e38e3c7426765208ecfe23cb2da51037bb234776fd70|2818048\",\n \"v3.6.0|linux_x86_64|5741a02a641de7e56b8da170e71a97e58050d66a3cf485fb268d6a5a8bb74afb|2850816\",\n ]\n\n default_url_template = (\n \"https://github.com/mvdan/sh/releases/download/{version}/shfmt_{version}_{platform}\"\n )\n default_url_platform_mapping = {\n \"macos_arm64\": \"darwin_arm64\",\n \"macos_x86_64\": \"darwin_amd64\",\n \"linux_arm64\": \"linux_arm64\",\n \"linux_x86_64\": \"linux_amd64\",\n }\n\n skip = SkipOption(\"fmt\", \"lint\")\n args = ArgsListOption(example=\"-i 2\")\n config_discovery = BoolOption(\n default=True,\n advanced=True,\n help=softwrap(\n \"\"\"\n If true, Pants will include all relevant `.editorconfig` files during runs.\n See https://editorconfig.org.\n \"\"\"\n ),\n )\n\n def generate_exe(self, plat: Platform) -> str:\n plat_str = self.default_url_platform_mapping[plat.value]\n return f\"./shfmt_{self.version}_{plat_str}\"\n\n def config_request(self, dirs: Iterable[str]) -> ConfigFilesRequest:\n # Refer to https://editorconfig.org/#file-location for how config files are discovered.\n candidates = (os.path.join(d, \".editorconfig\") for d in (\"\", *dirs))\n return ConfigFilesRequest(\n discovery=self.config_discovery,\n check_content={fp: b\"[*.sh]\" for fp in candidates},\n )\n", "path": "src/python/pants/backend/shell/lint/shfmt/subsystem.py"}], "after_files": [{"content": "# Copyright 2021 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\nfrom __future__ import annotations\n\nimport os.path\nfrom typing import Iterable\n\nfrom pants.core.util_rules.config_files import ConfigFilesRequest\nfrom pants.core.util_rules.external_tool import TemplatedExternalTool\nfrom pants.option.option_types import ArgsListOption, BoolOption, SkipOption\nfrom pants.util.strutil import softwrap\n\n\nclass Shfmt(TemplatedExternalTool):\n options_scope = \"shfmt\"\n name = \"shfmt\"\n help = \"An autoformatter for shell scripts (https://github.com/mvdan/sh).\"\n\n default_version = \"v3.6.0\"\n default_known_versions = [\n \"v3.2.4|macos_arm64 |e70fc42e69debe3e400347d4f918630cdf4bf2537277d672bbc43490387508ec|2998546\",\n \"v3.2.4|macos_x86_64|43a0461a1b54070ddc04fbbf1b78f7861ee39a65a61f5466d15a39c4aba4f917|2980208\",\n \"v3.2.4|linux_arm64 |6474d9cc08a1c9fe2ef4be7a004951998e3067d46cf55a011ddd5ff7bfab3de6|2752512\",\n \"v3.2.4|linux_x86_64|3f5a47f8fec27fae3e06d611559a2063f5d27e4b9501171dde9959b8c60a3538|2797568\",\n \"v3.6.0|macos_arm64 |633f242246ee0a866c5f5df25cbf61b6af0d5e143555aca32950059cf13d91e0|3065202\",\n \"v3.6.0|macos_x86_64|b8c9c025b498e2816b62f0b717f6032e9ab49e725a45b8205f52f66318f17185|3047552\",\n \"v3.6.0|linux_arm64 |fb1cf0af3dbe9aac7d98e38e3c7426765208ecfe23cb2da51037bb234776fd70|2818048\",\n \"v3.6.0|linux_x86_64|5741a02a641de7e56b8da170e71a97e58050d66a3cf485fb268d6a5a8bb74afb|2850816\",\n ]\n\n default_url_template = (\n \"https://github.com/mvdan/sh/releases/download/{version}/shfmt_{version}_{platform}\"\n )\n default_url_platform_mapping = {\n \"macos_arm64\": \"darwin_arm64\",\n \"macos_x86_64\": \"darwin_amd64\",\n \"linux_arm64\": \"linux_arm64\",\n \"linux_x86_64\": \"linux_amd64\",\n }\n\n skip = SkipOption(\"fmt\", \"lint\")\n args = ArgsListOption(example=\"-i 2\")\n config_discovery = BoolOption(\n default=True,\n advanced=True,\n help=softwrap(\n \"\"\"\n If true, Pants will include all relevant `.editorconfig` files during runs.\n See https://editorconfig.org.\n \"\"\"\n ),\n )\n\n def config_request(self, dirs: Iterable[str]) -> ConfigFilesRequest:\n # Refer to https://editorconfig.org/#file-location for how config files are discovered.\n candidates = (os.path.join(d, \".editorconfig\") for d in (\"\", *dirs))\n return ConfigFilesRequest(\n discovery=self.config_discovery,\n check_content={fp: b\"[*.sh]\" for fp in candidates},\n )\n", "path": "src/python/pants/backend/shell/lint/shfmt/subsystem.py"}]}
| 2,032 | 253 |
gh_patches_debug_3045
|
rasdani/github-patches
|
git_diff
|
ethereum__web3.py-1095
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Dissallow python 3.5.1
### What was wrong?
It looks like `typing.NewType` may not be available in python 3.5.1
https://github.com/ethereum/web3.py/issues/1091
### How can it be fixed?
Check what version `NewType` was added and restrict our python versions as declared in `setup.py` to be `>=` that version
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 from setuptools import (
4 find_packages,
5 setup,
6 )
7
8 extras_require = {
9 'tester': [
10 "eth-tester[py-evm]==0.1.0-beta.32",
11 "py-geth>=2.0.1,<3.0.0",
12 ],
13 'testrpc': ["eth-testrpc>=1.3.3,<2.0.0"],
14 'linter': [
15 "flake8==3.4.1",
16 "isort>=4.2.15,<5",
17 ],
18 'docs': [
19 "mock",
20 "sphinx-better-theme>=0.1.4",
21 "click>=5.1",
22 "configparser==3.5.0",
23 "contextlib2>=0.5.4",
24 #"eth-testrpc>=0.8.0",
25 #"ethereum-tester-client>=1.1.0",
26 "ethtoken",
27 "py-geth>=1.4.0",
28 "py-solc>=0.4.0",
29 "pytest>=2.7.2",
30 "sphinx",
31 "sphinx_rtd_theme>=0.1.9",
32 "toposort>=1.4",
33 "urllib3",
34 "web3>=2.1.0",
35 "wheel"
36 ],
37 'dev': [
38 "bumpversion",
39 "flaky>=3.3.0",
40 "hypothesis>=3.31.2",
41 "pytest>=3.5.0,<4",
42 "pytest-mock==1.*",
43 "pytest-pythonpath>=0.3",
44 "pytest-watch==4.*",
45 "pytest-xdist==1.*",
46 "setuptools>=36.2.0",
47 "tox>=1.8.0",
48 "tqdm",
49 "when-changed"
50 ]
51 }
52
53 extras_require['dev'] = (
54 extras_require['tester'] +
55 extras_require['linter'] +
56 extras_require['docs'] +
57 extras_require['dev']
58 )
59
60 setup(
61 name='web3',
62 # *IMPORTANT*: Don't manually change the version here. Use the 'bumpversion' utility.
63 version='4.7.1',
64 description="""Web3.py""",
65 long_description_markdown_filename='README.md',
66 author='Piper Merriam',
67 author_email='[email protected]',
68 url='https://github.com/ethereum/web3.py',
69 include_package_data=True,
70 install_requires=[
71 "toolz>=0.9.0,<1.0.0;implementation_name=='pypy'",
72 "cytoolz>=0.9.0,<1.0.0;implementation_name=='cpython'",
73 "eth-abi>=1.2.0,<2.0.0",
74 "eth-account>=0.2.1,<0.4.0",
75 "eth-utils>=1.0.1,<2.0.0",
76 "hexbytes>=0.1.0,<1.0.0",
77 "lru-dict>=1.1.6,<2.0.0",
78 "eth-hash[pycryptodome]>=0.2.0,<1.0.0",
79 "requests>=2.16.0,<3.0.0",
80 "websockets>=6.0.0,<7.0.0",
81 "pypiwin32>=223;platform_system=='Windows'",
82 ],
83 setup_requires=['setuptools-markdown'],
84 python_requires='>=3.5, <4',
85 extras_require=extras_require,
86 py_modules=['web3', 'ens'],
87 license="MIT",
88 zip_safe=False,
89 keywords='ethereum',
90 packages=find_packages(exclude=["tests", "tests.*"]),
91 classifiers=[
92 'Development Status :: 5 - Production/Stable',
93 'Intended Audience :: Developers',
94 'License :: OSI Approved :: MIT License',
95 'Natural Language :: English',
96 'Programming Language :: Python :: 3',
97 'Programming Language :: Python :: 3.5',
98 'Programming Language :: Python :: 3.6',
99 ],
100 )
101
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -81,7 +81,7 @@
"pypiwin32>=223;platform_system=='Windows'",
],
setup_requires=['setuptools-markdown'],
- python_requires='>=3.5, <4',
+ python_requires='>=3.5.2, <4',
extras_require=extras_require,
py_modules=['web3', 'ens'],
license="MIT",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -81,7 +81,7 @@\n \"pypiwin32>=223;platform_system=='Windows'\",\n ],\n setup_requires=['setuptools-markdown'],\n- python_requires='>=3.5, <4',\n+ python_requires='>=3.5.2, <4',\n extras_require=extras_require,\n py_modules=['web3', 'ens'],\n license=\"MIT\",\n", "issue": "Dissallow python 3.5.1\n### What was wrong?\r\n\r\nIt looks like `typing.NewType` may not be available in python 3.5.1\r\n\r\nhttps://github.com/ethereum/web3.py/issues/1091\r\n\r\n### How can it be fixed?\r\n\r\nCheck what version `NewType` was added and restrict our python versions as declared in `setup.py` to be `>=` that version\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nfrom setuptools import (\n find_packages,\n setup,\n)\n\nextras_require = {\n 'tester': [\n \"eth-tester[py-evm]==0.1.0-beta.32\",\n \"py-geth>=2.0.1,<3.0.0\",\n ],\n 'testrpc': [\"eth-testrpc>=1.3.3,<2.0.0\"],\n 'linter': [\n \"flake8==3.4.1\",\n \"isort>=4.2.15,<5\",\n ],\n 'docs': [\n \"mock\",\n \"sphinx-better-theme>=0.1.4\",\n \"click>=5.1\",\n \"configparser==3.5.0\",\n \"contextlib2>=0.5.4\",\n #\"eth-testrpc>=0.8.0\",\n #\"ethereum-tester-client>=1.1.0\",\n \"ethtoken\",\n \"py-geth>=1.4.0\",\n \"py-solc>=0.4.0\",\n \"pytest>=2.7.2\",\n \"sphinx\",\n \"sphinx_rtd_theme>=0.1.9\",\n \"toposort>=1.4\",\n \"urllib3\",\n \"web3>=2.1.0\",\n \"wheel\"\n ],\n 'dev': [\n \"bumpversion\",\n \"flaky>=3.3.0\",\n \"hypothesis>=3.31.2\",\n \"pytest>=3.5.0,<4\",\n \"pytest-mock==1.*\",\n \"pytest-pythonpath>=0.3\",\n \"pytest-watch==4.*\",\n \"pytest-xdist==1.*\",\n \"setuptools>=36.2.0\",\n \"tox>=1.8.0\",\n \"tqdm\",\n \"when-changed\"\n ]\n}\n\nextras_require['dev'] = (\n extras_require['tester'] +\n extras_require['linter'] +\n extras_require['docs'] +\n extras_require['dev']\n)\n\nsetup(\n name='web3',\n # *IMPORTANT*: Don't manually change the version here. Use the 'bumpversion' utility.\n version='4.7.1',\n description=\"\"\"Web3.py\"\"\",\n long_description_markdown_filename='README.md',\n author='Piper Merriam',\n author_email='[email protected]',\n url='https://github.com/ethereum/web3.py',\n include_package_data=True,\n install_requires=[\n \"toolz>=0.9.0,<1.0.0;implementation_name=='pypy'\",\n \"cytoolz>=0.9.0,<1.0.0;implementation_name=='cpython'\",\n \"eth-abi>=1.2.0,<2.0.0\",\n \"eth-account>=0.2.1,<0.4.0\",\n \"eth-utils>=1.0.1,<2.0.0\",\n \"hexbytes>=0.1.0,<1.0.0\",\n \"lru-dict>=1.1.6,<2.0.0\",\n \"eth-hash[pycryptodome]>=0.2.0,<1.0.0\",\n \"requests>=2.16.0,<3.0.0\",\n \"websockets>=6.0.0,<7.0.0\",\n \"pypiwin32>=223;platform_system=='Windows'\",\n ],\n setup_requires=['setuptools-markdown'],\n python_requires='>=3.5, <4',\n extras_require=extras_require,\n py_modules=['web3', 'ens'],\n license=\"MIT\",\n zip_safe=False,\n keywords='ethereum',\n packages=find_packages(exclude=[\"tests\", \"tests.*\"]),\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: MIT License',\n 'Natural Language :: English',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n ],\n)\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nfrom setuptools import (\n find_packages,\n setup,\n)\n\nextras_require = {\n 'tester': [\n \"eth-tester[py-evm]==0.1.0-beta.32\",\n \"py-geth>=2.0.1,<3.0.0\",\n ],\n 'testrpc': [\"eth-testrpc>=1.3.3,<2.0.0\"],\n 'linter': [\n \"flake8==3.4.1\",\n \"isort>=4.2.15,<5\",\n ],\n 'docs': [\n \"mock\",\n \"sphinx-better-theme>=0.1.4\",\n \"click>=5.1\",\n \"configparser==3.5.0\",\n \"contextlib2>=0.5.4\",\n #\"eth-testrpc>=0.8.0\",\n #\"ethereum-tester-client>=1.1.0\",\n \"ethtoken\",\n \"py-geth>=1.4.0\",\n \"py-solc>=0.4.0\",\n \"pytest>=2.7.2\",\n \"sphinx\",\n \"sphinx_rtd_theme>=0.1.9\",\n \"toposort>=1.4\",\n \"urllib3\",\n \"web3>=2.1.0\",\n \"wheel\"\n ],\n 'dev': [\n \"bumpversion\",\n \"flaky>=3.3.0\",\n \"hypothesis>=3.31.2\",\n \"pytest>=3.5.0,<4\",\n \"pytest-mock==1.*\",\n \"pytest-pythonpath>=0.3\",\n \"pytest-watch==4.*\",\n \"pytest-xdist==1.*\",\n \"setuptools>=36.2.0\",\n \"tox>=1.8.0\",\n \"tqdm\",\n \"when-changed\"\n ]\n}\n\nextras_require['dev'] = (\n extras_require['tester'] +\n extras_require['linter'] +\n extras_require['docs'] +\n extras_require['dev']\n)\n\nsetup(\n name='web3',\n # *IMPORTANT*: Don't manually change the version here. Use the 'bumpversion' utility.\n version='4.7.1',\n description=\"\"\"Web3.py\"\"\",\n long_description_markdown_filename='README.md',\n author='Piper Merriam',\n author_email='[email protected]',\n url='https://github.com/ethereum/web3.py',\n include_package_data=True,\n install_requires=[\n \"toolz>=0.9.0,<1.0.0;implementation_name=='pypy'\",\n \"cytoolz>=0.9.0,<1.0.0;implementation_name=='cpython'\",\n \"eth-abi>=1.2.0,<2.0.0\",\n \"eth-account>=0.2.1,<0.4.0\",\n \"eth-utils>=1.0.1,<2.0.0\",\n \"hexbytes>=0.1.0,<1.0.0\",\n \"lru-dict>=1.1.6,<2.0.0\",\n \"eth-hash[pycryptodome]>=0.2.0,<1.0.0\",\n \"requests>=2.16.0,<3.0.0\",\n \"websockets>=6.0.0,<7.0.0\",\n \"pypiwin32>=223;platform_system=='Windows'\",\n ],\n setup_requires=['setuptools-markdown'],\n python_requires='>=3.5.2, <4',\n extras_require=extras_require,\n py_modules=['web3', 'ens'],\n license=\"MIT\",\n zip_safe=False,\n keywords='ethereum',\n packages=find_packages(exclude=[\"tests\", \"tests.*\"]),\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: MIT License',\n 'Natural Language :: English',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n ],\n)\n", "path": "setup.py"}]}
| 1,458 | 110 |
gh_patches_debug_1632
|
rasdani/github-patches
|
git_diff
|
ansible__ansible-modules-extras-1291
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
pam_limits - documentation is not updated
`limit_type` choices are `hard`, `soft` in the [documentation](http://docs.ansible.com/ansible/pam_limits_module.html) but in the [code](https://github.com/ansible/ansible-modules-extras/blob/devel/system/pam_limits.py#L95) `-` is supported.
pam_limits - documentation is not updated
`limit_type` choices are `hard`, `soft` in the [documentation](http://docs.ansible.com/ansible/pam_limits_module.html) but in the [code](https://github.com/ansible/ansible-modules-extras/blob/devel/system/pam_limits.py#L95) `-` is supported.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `system/pam_limits.py`
Content:
```
1 #!/usr/bin/python
2 # -*- coding: utf-8 -*-
3
4 # (c) 2014, Sebastien Rohaut <[email protected]>
5 #
6 # This file is part of Ansible
7 #
8 # Ansible is free software: you can redistribute it and/or modify
9 # it under the terms of the GNU General Public License as published by
10 # the Free Software Foundation, either version 3 of the License, or
11 # (at your option) any later version.
12 #
13 # Ansible is distributed in the hope that it will be useful,
14 # but WITHOUT ANY WARRANTY; without even the implied warranty of
15 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
16 # GNU General Public License for more details.
17 #
18 # You should have received a copy of the GNU General Public License
19 # along with Ansible. If not, see <http://www.gnu.org/licenses/>.
20
21 import os
22 import os.path
23 import shutil
24 import re
25
26 DOCUMENTATION = '''
27 ---
28 module: pam_limits
29 version_added: "2.0"
30 short_description: Modify Linux PAM limits
31 description:
32 - The M(pam_limits) module modify PAM limits, default in /etc/security/limits.conf.
33 For the full documentation, see man limits.conf(5).
34 options:
35 domain:
36 description:
37 - A username, @groupname, wildcard, uid/gid range.
38 required: true
39 limit_type:
40 description:
41 - Limit type, see C(man limits) for an explanation
42 required: true
43 choices: [ "hard", "soft" ]
44 limit_item:
45 description:
46 - The limit to be set
47 required: true
48 choices: [ "core", "data", "fsize", "memlock", "nofile", "rss", "stack", "cpu", "nproc", "as", "maxlogins", "maxsyslogins", "priority", "locks", "sigpending", "msgqueue", "nice", "rtprio", "chroot" ]
49 value:
50 description:
51 - The value of the limit.
52 required: true
53 backup:
54 description:
55 - Create a backup file including the timestamp information so you can get
56 the original file back if you somehow clobbered it incorrectly.
57 required: false
58 choices: [ "yes", "no" ]
59 default: "no"
60 use_min:
61 description:
62 - If set to C(yes), the minimal value will be used or conserved.
63 If the specified value is inferior to the value in the file, file content is replaced with the new value,
64 else content is not modified.
65 required: false
66 choices: [ "yes", "no" ]
67 default: "no"
68 use_max:
69 description:
70 - If set to C(yes), the maximal value will be used or conserved.
71 If the specified value is superior to the value in the file, file content is replaced with the new value,
72 else content is not modified.
73 required: false
74 choices: [ "yes", "no" ]
75 default: "no"
76 dest:
77 description:
78 - Modify the limits.conf path.
79 required: false
80 default: "/etc/security/limits.conf"
81 '''
82
83 EXAMPLES = '''
84 # Add or modify limits for the user joe
85 - pam_limits: domain=joe limit_type=soft limit_item=nofile value=64000
86
87 # Add or modify limits for the user joe. Keep or set the maximal value
88 - pam_limits: domain=joe limit_type=soft limit_item=nofile value=1000000
89 '''
90
91 def main():
92
93 pam_items = [ 'core', 'data', 'fsize', 'memlock', 'nofile', 'rss', 'stack', 'cpu', 'nproc', 'as', 'maxlogins', 'maxsyslogins', 'priority', 'locks', 'sigpending', 'msgqueue', 'nice', 'rtprio', 'chroot' ]
94
95 pam_types = [ 'soft', 'hard', '-' ]
96
97 limits_conf = '/etc/security/limits.conf'
98
99 module = AnsibleModule(
100 # not checking because of daisy chain to file module
101 argument_spec = dict(
102 domain = dict(required=True, type='str'),
103 limit_type = dict(required=True, type='str', choices=pam_types),
104 limit_item = dict(required=True, type='str', choices=pam_items),
105 value = dict(required=True, type='str'),
106 use_max = dict(default=False, type='bool'),
107 use_min = dict(default=False, type='bool'),
108 backup = dict(default=False, type='bool'),
109 dest = dict(default=limits_conf, type='str'),
110 comment = dict(required=False, default='', type='str')
111 )
112 )
113
114 domain = module.params['domain']
115 limit_type = module.params['limit_type']
116 limit_item = module.params['limit_item']
117 value = module.params['value']
118 use_max = module.params['use_max']
119 use_min = module.params['use_min']
120 backup = module.params['backup']
121 limits_conf = module.params['dest']
122 new_comment = module.params['comment']
123
124 changed = False
125
126 if os.path.isfile(limits_conf):
127 if not os.access(limits_conf, os.W_OK):
128 module.fail_json(msg="%s is not writable. Use sudo" % (limits_conf) )
129 else:
130 module.fail_json(msg="%s is not visible (check presence, access rights, use sudo)" % (limits_conf) )
131
132 if use_max and use_min:
133 module.fail_json(msg="Cannot use use_min and use_max at the same time." )
134
135 if not (value in ['unlimited', 'infinity', '-1'] or value.isdigit()):
136 module.fail_json(msg="Argument 'value' can be one of 'unlimited', 'infinity', '-1' or positive number. Refer to manual pages for more details.")
137
138 # Backup
139 if backup:
140 backup_file = module.backup_local(limits_conf)
141
142 space_pattern = re.compile(r'\s+')
143
144 message = ''
145 f = open (limits_conf, 'r')
146 # Tempfile
147 nf = tempfile.NamedTemporaryFile(delete = False)
148
149 found = False
150 new_value = value
151
152 for line in f:
153
154 if line.startswith('#'):
155 nf.write(line)
156 continue
157
158 newline = re.sub(space_pattern, ' ', line).strip()
159 if not newline:
160 nf.write(line)
161 continue
162
163 # Remove comment in line
164 newline = newline.split('#',1)[0]
165 try:
166 old_comment = line.split('#',1)[1]
167 except:
168 old_comment = ''
169
170 newline = newline.rstrip()
171
172 if not new_comment:
173 new_comment = old_comment
174
175 if new_comment:
176 new_comment = "\t#"+new_comment
177
178 line_fields = newline.split(' ')
179
180 if len(line_fields) != 4:
181 nf.write(line)
182 continue
183
184 line_domain = line_fields[0]
185 line_type = line_fields[1]
186 line_item = line_fields[2]
187 actual_value = line_fields[3]
188
189 if not (actual_value in ['unlimited', 'infinity', '-1'] or actual_value.isdigit()):
190 module.fail_json(msg="Invalid configuration of '%s'. Current value of %s is unsupported." % (limits_conf, line_item))
191
192 # Found the line
193 if line_domain == domain and line_type == limit_type and line_item == limit_item:
194 found = True
195 if value == actual_value:
196 message = line
197 nf.write(line)
198 continue
199
200 actual_value_unlimited = actual_value in ['unlimited', 'infinity', '-1']
201 value_unlimited = value in ['unlimited', 'infinity', '-1']
202
203 if use_max:
204 if value.isdigit() and actual_value.isdigit():
205 new_value = max(int(value), int(actual_value))
206 elif actual_value_unlimited:
207 new_value = actual_value
208 else:
209 new_value = value
210
211 if use_min:
212 if value.isdigit() and actual_value.isdigit():
213 new_value = min(int(value), int(actual_value))
214 elif value_unlimited:
215 new_value = actual_value
216 else:
217 new_value = value
218
219 # Change line only if value has changed
220 if new_value != actual_value:
221 changed = True
222 new_limit = domain + "\t" + limit_type + "\t" + limit_item + "\t" + str(new_value) + new_comment + "\n"
223 message = new_limit
224 nf.write(new_limit)
225 else:
226 message = line
227 nf.write(line)
228 else:
229 nf.write(line)
230
231 if not found:
232 changed = True
233 new_limit = domain + "\t" + limit_type + "\t" + limit_item + "\t" + str(new_value) + new_comment + "\n"
234 message = new_limit
235 nf.write(new_limit)
236
237 f.close()
238 nf.close()
239
240 # Copy tempfile to newfile
241 module.atomic_move(nf.name, f.name)
242
243 res_args = dict(
244 changed = changed, msg = message
245 )
246
247 if backup:
248 res_args['backup_file'] = backup_file
249
250 module.exit_json(**res_args)
251
252
253 # import module snippets
254 from ansible.module_utils.basic import *
255 main()
256
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/system/pam_limits.py b/system/pam_limits.py
--- a/system/pam_limits.py
+++ b/system/pam_limits.py
@@ -40,7 +40,7 @@
description:
- Limit type, see C(man limits) for an explanation
required: true
- choices: [ "hard", "soft" ]
+ choices: [ "hard", "soft", "-" ]
limit_item:
description:
- The limit to be set
|
{"golden_diff": "diff --git a/system/pam_limits.py b/system/pam_limits.py\n--- a/system/pam_limits.py\n+++ b/system/pam_limits.py\n@@ -40,7 +40,7 @@\n description:\n - Limit type, see C(man limits) for an explanation\n required: true\n- choices: [ \"hard\", \"soft\" ]\n+ choices: [ \"hard\", \"soft\", \"-\" ]\n limit_item:\n description:\n - The limit to be set\n", "issue": "pam_limits - documentation is not updated \n`limit_type` choices are `hard`, `soft` in the [documentation](http://docs.ansible.com/ansible/pam_limits_module.html) but in the [code](https://github.com/ansible/ansible-modules-extras/blob/devel/system/pam_limits.py#L95) `-` is supported.\n\npam_limits - documentation is not updated \n`limit_type` choices are `hard`, `soft` in the [documentation](http://docs.ansible.com/ansible/pam_limits_module.html) but in the [code](https://github.com/ansible/ansible-modules-extras/blob/devel/system/pam_limits.py#L95) `-` is supported.\n\n", "before_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# (c) 2014, Sebastien Rohaut <[email protected]>\n#\n# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Ansible is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Ansible. If not, see <http://www.gnu.org/licenses/>.\n\nimport os\nimport os.path\nimport shutil\nimport re\n\nDOCUMENTATION = '''\n---\nmodule: pam_limits\nversion_added: \"2.0\"\nshort_description: Modify Linux PAM limits\ndescription:\n - The M(pam_limits) module modify PAM limits, default in /etc/security/limits.conf.\n For the full documentation, see man limits.conf(5).\noptions:\n domain:\n description:\n - A username, @groupname, wildcard, uid/gid range.\n required: true\n limit_type:\n description:\n - Limit type, see C(man limits) for an explanation\n required: true\n choices: [ \"hard\", \"soft\" ]\n limit_item:\n description:\n - The limit to be set\n required: true\n choices: [ \"core\", \"data\", \"fsize\", \"memlock\", \"nofile\", \"rss\", \"stack\", \"cpu\", \"nproc\", \"as\", \"maxlogins\", \"maxsyslogins\", \"priority\", \"locks\", \"sigpending\", \"msgqueue\", \"nice\", \"rtprio\", \"chroot\" ]\n value:\n description:\n - The value of the limit.\n required: true\n backup:\n description:\n - Create a backup file including the timestamp information so you can get\n the original file back if you somehow clobbered it incorrectly.\n required: false\n choices: [ \"yes\", \"no\" ]\n default: \"no\"\n use_min:\n description:\n - If set to C(yes), the minimal value will be used or conserved.\n If the specified value is inferior to the value in the file, file content is replaced with the new value,\n else content is not modified.\n required: false\n choices: [ \"yes\", \"no\" ]\n default: \"no\"\n use_max:\n description:\n - If set to C(yes), the maximal value will be used or conserved.\n If the specified value is superior to the value in the file, file content is replaced with the new value,\n else content is not modified.\n required: false\n choices: [ \"yes\", \"no\" ]\n default: \"no\"\n dest:\n description:\n - Modify the limits.conf path.\n required: false\n default: \"/etc/security/limits.conf\"\n'''\n\nEXAMPLES = '''\n# Add or modify limits for the user joe\n- pam_limits: domain=joe limit_type=soft limit_item=nofile value=64000\n\n# Add or modify limits for the user joe. Keep or set the maximal value\n- pam_limits: domain=joe limit_type=soft limit_item=nofile value=1000000\n'''\n\ndef main():\n\n pam_items = [ 'core', 'data', 'fsize', 'memlock', 'nofile', 'rss', 'stack', 'cpu', 'nproc', 'as', 'maxlogins', 'maxsyslogins', 'priority', 'locks', 'sigpending', 'msgqueue', 'nice', 'rtprio', 'chroot' ]\n\n pam_types = [ 'soft', 'hard', '-' ]\n\n limits_conf = '/etc/security/limits.conf'\n\n module = AnsibleModule(\n # not checking because of daisy chain to file module\n argument_spec = dict(\n domain = dict(required=True, type='str'),\n limit_type = dict(required=True, type='str', choices=pam_types),\n limit_item = dict(required=True, type='str', choices=pam_items),\n value = dict(required=True, type='str'),\n use_max = dict(default=False, type='bool'),\n use_min = dict(default=False, type='bool'),\n backup = dict(default=False, type='bool'),\n dest = dict(default=limits_conf, type='str'),\n comment = dict(required=False, default='', type='str')\n )\n )\n\n domain = module.params['domain']\n limit_type = module.params['limit_type']\n limit_item = module.params['limit_item']\n value = module.params['value']\n use_max = module.params['use_max']\n use_min = module.params['use_min']\n backup = module.params['backup']\n limits_conf = module.params['dest']\n new_comment = module.params['comment']\n\n changed = False\n\n if os.path.isfile(limits_conf):\n if not os.access(limits_conf, os.W_OK):\n module.fail_json(msg=\"%s is not writable. Use sudo\" % (limits_conf) )\n else:\n module.fail_json(msg=\"%s is not visible (check presence, access rights, use sudo)\" % (limits_conf) )\n\n if use_max and use_min:\n module.fail_json(msg=\"Cannot use use_min and use_max at the same time.\" )\n\n if not (value in ['unlimited', 'infinity', '-1'] or value.isdigit()):\n module.fail_json(msg=\"Argument 'value' can be one of 'unlimited', 'infinity', '-1' or positive number. Refer to manual pages for more details.\")\n\n # Backup\n if backup:\n backup_file = module.backup_local(limits_conf)\n\n space_pattern = re.compile(r'\\s+')\n\n message = ''\n f = open (limits_conf, 'r')\n # Tempfile\n nf = tempfile.NamedTemporaryFile(delete = False)\n\n found = False\n new_value = value\n\n for line in f:\n\n if line.startswith('#'):\n nf.write(line)\n continue\n\n newline = re.sub(space_pattern, ' ', line).strip()\n if not newline:\n nf.write(line)\n continue\n\n # Remove comment in line\n newline = newline.split('#',1)[0]\n try:\n old_comment = line.split('#',1)[1]\n except:\n old_comment = ''\n\n newline = newline.rstrip()\n\n if not new_comment:\n new_comment = old_comment\n\n if new_comment:\n new_comment = \"\\t#\"+new_comment\n\n line_fields = newline.split(' ')\n\n if len(line_fields) != 4:\n nf.write(line)\n continue\n\n line_domain = line_fields[0]\n line_type = line_fields[1]\n line_item = line_fields[2]\n actual_value = line_fields[3]\n\n if not (actual_value in ['unlimited', 'infinity', '-1'] or actual_value.isdigit()):\n module.fail_json(msg=\"Invalid configuration of '%s'. Current value of %s is unsupported.\" % (limits_conf, line_item))\n\n # Found the line\n if line_domain == domain and line_type == limit_type and line_item == limit_item:\n found = True\n if value == actual_value:\n message = line\n nf.write(line)\n continue\n\n actual_value_unlimited = actual_value in ['unlimited', 'infinity', '-1']\n value_unlimited = value in ['unlimited', 'infinity', '-1']\n\n if use_max:\n if value.isdigit() and actual_value.isdigit():\n new_value = max(int(value), int(actual_value))\n elif actual_value_unlimited:\n new_value = actual_value\n else:\n new_value = value\n\n if use_min:\n if value.isdigit() and actual_value.isdigit():\n new_value = min(int(value), int(actual_value))\n elif value_unlimited:\n new_value = actual_value\n else:\n new_value = value\n\n # Change line only if value has changed\n if new_value != actual_value:\n changed = True\n new_limit = domain + \"\\t\" + limit_type + \"\\t\" + limit_item + \"\\t\" + str(new_value) + new_comment + \"\\n\"\n message = new_limit\n nf.write(new_limit)\n else:\n message = line\n nf.write(line)\n else:\n nf.write(line)\n\n if not found:\n changed = True\n new_limit = domain + \"\\t\" + limit_type + \"\\t\" + limit_item + \"\\t\" + str(new_value) + new_comment + \"\\n\"\n message = new_limit\n nf.write(new_limit)\n\n f.close()\n nf.close()\n\n # Copy tempfile to newfile\n module.atomic_move(nf.name, f.name)\n\n res_args = dict(\n changed = changed, msg = message\n )\n\n if backup:\n res_args['backup_file'] = backup_file\n\n module.exit_json(**res_args)\n\n\n# import module snippets\nfrom ansible.module_utils.basic import *\nmain()\n", "path": "system/pam_limits.py"}], "after_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# (c) 2014, Sebastien Rohaut <[email protected]>\n#\n# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Ansible is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Ansible. If not, see <http://www.gnu.org/licenses/>.\n\nimport os\nimport os.path\nimport shutil\nimport re\n\nDOCUMENTATION = '''\n---\nmodule: pam_limits\nversion_added: \"2.0\"\nshort_description: Modify Linux PAM limits\ndescription:\n - The M(pam_limits) module modify PAM limits, default in /etc/security/limits.conf.\n For the full documentation, see man limits.conf(5).\noptions:\n domain:\n description:\n - A username, @groupname, wildcard, uid/gid range.\n required: true\n limit_type:\n description:\n - Limit type, see C(man limits) for an explanation\n required: true\n choices: [ \"hard\", \"soft\", \"-\" ]\n limit_item:\n description:\n - The limit to be set\n required: true\n choices: [ \"core\", \"data\", \"fsize\", \"memlock\", \"nofile\", \"rss\", \"stack\", \"cpu\", \"nproc\", \"as\", \"maxlogins\", \"maxsyslogins\", \"priority\", \"locks\", \"sigpending\", \"msgqueue\", \"nice\", \"rtprio\", \"chroot\" ]\n value:\n description:\n - The value of the limit.\n required: true\n backup:\n description:\n - Create a backup file including the timestamp information so you can get\n the original file back if you somehow clobbered it incorrectly.\n required: false\n choices: [ \"yes\", \"no\" ]\n default: \"no\"\n use_min:\n description:\n - If set to C(yes), the minimal value will be used or conserved.\n If the specified value is inferior to the value in the file, file content is replaced with the new value,\n else content is not modified.\n required: false\n choices: [ \"yes\", \"no\" ]\n default: \"no\"\n use_max:\n description:\n - If set to C(yes), the maximal value will be used or conserved.\n If the specified value is superior to the value in the file, file content is replaced with the new value,\n else content is not modified.\n required: false\n choices: [ \"yes\", \"no\" ]\n default: \"no\"\n dest:\n description:\n - Modify the limits.conf path.\n required: false\n default: \"/etc/security/limits.conf\"\n'''\n\nEXAMPLES = '''\n# Add or modify limits for the user joe\n- pam_limits: domain=joe limit_type=soft limit_item=nofile value=64000\n\n# Add or modify limits for the user joe. Keep or set the maximal value\n- pam_limits: domain=joe limit_type=soft limit_item=nofile value=1000000\n'''\n\ndef main():\n\n pam_items = [ 'core', 'data', 'fsize', 'memlock', 'nofile', 'rss', 'stack', 'cpu', 'nproc', 'as', 'maxlogins', 'maxsyslogins', 'priority', 'locks', 'sigpending', 'msgqueue', 'nice', 'rtprio', 'chroot' ]\n\n pam_types = [ 'soft', 'hard', '-' ]\n\n limits_conf = '/etc/security/limits.conf'\n\n module = AnsibleModule(\n # not checking because of daisy chain to file module\n argument_spec = dict(\n domain = dict(required=True, type='str'),\n limit_type = dict(required=True, type='str', choices=pam_types),\n limit_item = dict(required=True, type='str', choices=pam_items),\n value = dict(required=True, type='str'),\n use_max = dict(default=False, type='bool'),\n use_min = dict(default=False, type='bool'),\n backup = dict(default=False, type='bool'),\n dest = dict(default=limits_conf, type='str'),\n comment = dict(required=False, default='', type='str')\n )\n )\n\n domain = module.params['domain']\n limit_type = module.params['limit_type']\n limit_item = module.params['limit_item']\n value = module.params['value']\n use_max = module.params['use_max']\n use_min = module.params['use_min']\n backup = module.params['backup']\n limits_conf = module.params['dest']\n new_comment = module.params['comment']\n\n changed = False\n\n if os.path.isfile(limits_conf):\n if not os.access(limits_conf, os.W_OK):\n module.fail_json(msg=\"%s is not writable. Use sudo\" % (limits_conf) )\n else:\n module.fail_json(msg=\"%s is not visible (check presence, access rights, use sudo)\" % (limits_conf) )\n\n if use_max and use_min:\n module.fail_json(msg=\"Cannot use use_min and use_max at the same time.\" )\n\n if not (value in ['unlimited', 'infinity', '-1'] or value.isdigit()):\n module.fail_json(msg=\"Argument 'value' can be one of 'unlimited', 'infinity', '-1' or positive number. Refer to manual pages for more details.\")\n\n # Backup\n if backup:\n backup_file = module.backup_local(limits_conf)\n\n space_pattern = re.compile(r'\\s+')\n\n message = ''\n f = open (limits_conf, 'r')\n # Tempfile\n nf = tempfile.NamedTemporaryFile(delete = False)\n\n found = False\n new_value = value\n\n for line in f:\n\n if line.startswith('#'):\n nf.write(line)\n continue\n\n newline = re.sub(space_pattern, ' ', line).strip()\n if not newline:\n nf.write(line)\n continue\n\n # Remove comment in line\n newline = newline.split('#',1)[0]\n try:\n old_comment = line.split('#',1)[1]\n except:\n old_comment = ''\n\n newline = newline.rstrip()\n\n if not new_comment:\n new_comment = old_comment\n\n if new_comment:\n new_comment = \"\\t#\"+new_comment\n\n line_fields = newline.split(' ')\n\n if len(line_fields) != 4:\n nf.write(line)\n continue\n\n line_domain = line_fields[0]\n line_type = line_fields[1]\n line_item = line_fields[2]\n actual_value = line_fields[3]\n\n if not (actual_value in ['unlimited', 'infinity', '-1'] or actual_value.isdigit()):\n module.fail_json(msg=\"Invalid configuration of '%s'. Current value of %s is unsupported.\" % (limits_conf, line_item))\n\n # Found the line\n if line_domain == domain and line_type == limit_type and line_item == limit_item:\n found = True\n if value == actual_value:\n message = line\n nf.write(line)\n continue\n\n actual_value_unlimited = actual_value in ['unlimited', 'infinity', '-1']\n value_unlimited = value in ['unlimited', 'infinity', '-1']\n\n if use_max:\n if value.isdigit() and actual_value.isdigit():\n new_value = max(int(value), int(actual_value))\n elif actual_value_unlimited:\n new_value = actual_value\n else:\n new_value = value\n\n if use_min:\n if value.isdigit() and actual_value.isdigit():\n new_value = min(int(value), int(actual_value))\n elif value_unlimited:\n new_value = actual_value\n else:\n new_value = value\n\n # Change line only if value has changed\n if new_value != actual_value:\n changed = True\n new_limit = domain + \"\\t\" + limit_type + \"\\t\" + limit_item + \"\\t\" + str(new_value) + new_comment + \"\\n\"\n message = new_limit\n nf.write(new_limit)\n else:\n message = line\n nf.write(line)\n else:\n nf.write(line)\n\n if not found:\n changed = True\n new_limit = domain + \"\\t\" + limit_type + \"\\t\" + limit_item + \"\\t\" + str(new_value) + new_comment + \"\\n\"\n message = new_limit\n nf.write(new_limit)\n\n f.close()\n nf.close()\n\n # Copy tempfile to newfile\n module.atomic_move(nf.name, f.name)\n\n res_args = dict(\n changed = changed, msg = message\n )\n\n if backup:\n res_args['backup_file'] = backup_file\n\n module.exit_json(**res_args)\n\n\n# import module snippets\nfrom ansible.module_utils.basic import *\nmain()\n", "path": "system/pam_limits.py"}]}
| 3,125 | 106 |
gh_patches_debug_22163
|
rasdani/github-patches
|
git_diff
|
learningequality__kolibri-5797
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
add support for OIDC in account creation flow
### Observed behavior
currently SSO works for sign in but not account creation
### Expected behavior
the 'next' parameter needs to be passed from the sign in page to the account creation page and handled there
### User-facing consequences
The following flow is not supported:
> 1. User comes to SCE portal and click on login for one server, system would redirect to Kolibri portal.
> 2. On Kolibri portal, user decides to not login but register and clicks on register.
> 3. After registration, user is redirecting to Kolibri portal instead of returning back to SCE portal.
### Context
0.12.5
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kolibri/core/theme_hook.py`
Content:
```
1 from __future__ import absolute_import
2 from __future__ import print_function
3 from __future__ import unicode_literals
4
5 import logging
6
7 from kolibri.plugins import hooks
8 import kolibri
9 from django.utils.six.moves.urllib import parse
10 from django.conf import settings
11 import os
12
13 logger = logging.getLogger(__name__)
14
15
16 # Important for cache busting
17 THEME_NAME = "themeName"
18 THEME_VERSION = "themeVersion"
19
20 # These constants are used by theme.js and the $theme mixin on the front-end
21 TOKEN_MAPPING = "tokenMapping"
22 BRAND_COLORS = "brandColors"
23 PRIMARY = "primary"
24 SECONDARY = "secondary"
25 COLOR_V50 = "v_50"
26 COLOR_V100 = "v_100"
27 COLOR_V200 = "v_200"
28 COLOR_V300 = "v_300"
29 COLOR_V400 = "v_400"
30 COLOR_V500 = "v_500"
31 COLOR_V600 = "v_600"
32 COLOR_V700 = "v_700"
33 COLOR_V800 = "v_800"
34 COLOR_V900 = "v_900"
35 SIGN_IN = "signIn"
36 SIDE_NAV = "sideNav"
37 APP_BAR = "appBar"
38 BACKGROUND = "background"
39 TITLE = "title"
40 TITLE_STYLE = "titleStyle"
41 TOP_LOGO = "topLogo"
42 IMG_SRC = "src"
43 IMG_STYLE = "style"
44 IMG_ALT = "alt"
45 SHOW_K_FOOTER_LOGO = "showKolibriFooterLogo"
46
47 # This is the image file name that will be used when customizing the sign-in background
48 # image using the 'kolibri manage background' command. It does not attempt to use a file
49 # extension (like .jpg) because we don't know if it's a JPG, SVG, PNG, etc...
50 DEFAULT_BG_IMAGE_FILE = "background_image"
51 DEFAULT_BG_MD5_FILE = "background_image_md5"
52
53
54 def _isSet(theme, keys):
55 """
56 Given a theme dict, recursively check that all the keys are populated
57 and that the associated value is truthy
58 """
59 obj = theme
60 for key in keys:
61 if not obj or key not in obj:
62 return False
63 obj = obj[key]
64 return bool(obj)
65
66
67 def _validateMetadata(theme):
68 if THEME_NAME not in theme:
69 logger.error("a theme name must be set")
70 if THEME_VERSION not in theme:
71 logger.error("a theme version must be set")
72
73
74 def _validateBrandColors(theme):
75 if BRAND_COLORS not in theme:
76 logger.error("brand colors not defined by theme")
77 return
78
79 required_colors = [PRIMARY, SECONDARY]
80 color_names = [
81 COLOR_V50,
82 COLOR_V100,
83 COLOR_V200,
84 COLOR_V300,
85 COLOR_V400,
86 COLOR_V500,
87 COLOR_V600,
88 COLOR_V700,
89 COLOR_V800,
90 COLOR_V900,
91 ]
92 for color in required_colors:
93 if color not in theme[BRAND_COLORS]:
94 logger.error("'{}' not defined by theme".format(color))
95 for name in color_names:
96 if name not in theme[BRAND_COLORS][color]:
97 logger.error("{} '{}' not defined by theme".format(color, name))
98
99
100 def _initFields(theme):
101 """
102 set up top-level dicts if they don't exist
103 """
104 if SIGN_IN not in theme:
105 theme[SIGN_IN] = {}
106 if TOKEN_MAPPING not in theme:
107 theme[TOKEN_MAPPING] = {}
108 if SIDE_NAV not in theme:
109 theme[SIDE_NAV] = {}
110 if APP_BAR not in theme:
111 theme[APP_BAR] = {}
112
113
114 class ThemeHook(hooks.KolibriHook):
115 """
116 A hook to allow custom theming of Kolibri
117 Use this tool to help generate your brand colors: https://materialpalettes.com/
118 """
119
120 class Meta:
121 abstract = True
122
123 @property
124 @hooks.only_one_registered
125 def cacheKey(self):
126 theme = list(self.registered_hooks)[0].theme
127 return parse.quote(
128 "{}-{}-{}".format(
129 kolibri.__version__, theme[THEME_NAME], theme[THEME_VERSION]
130 )
131 )
132
133 @property
134 @hooks.only_one_registered
135 def theme(self):
136 theme = list(self.registered_hooks)[0].theme
137
138 # some validation and initialization
139 _initFields(theme)
140 _validateMetadata(theme)
141 _validateBrandColors(theme)
142
143 # set up cache busting
144 bust = "?" + self.cacheKey
145 if _isSet(theme, [SIGN_IN, BACKGROUND]):
146 theme[SIGN_IN][BACKGROUND] += bust
147 if _isSet(theme, [SIGN_IN, TOP_LOGO, IMG_SRC]):
148 theme[SIGN_IN][TOP_LOGO][IMG_SRC] += bust
149 if _isSet(theme, [SIDE_NAV, TOP_LOGO, IMG_SRC]):
150 theme[SIDE_NAV][TOP_LOGO][IMG_SRC] += bust
151 if _isSet(theme, [APP_BAR, TOP_LOGO, IMG_SRC]):
152 theme[APP_BAR][TOP_LOGO][IMG_SRC] += bust
153
154 # if a background image has been locally set using the `manage background` command, use it
155 bg_img = os.path.join(settings.MEDIA_ROOT, DEFAULT_BG_IMAGE_FILE)
156 if os.path.exists(bg_img):
157 theme[SIGN_IN][BACKGROUND] = parse.urljoin(
158 settings.MEDIA_URL, DEFAULT_BG_IMAGE_FILE
159 )
160 # add cache busting
161 md5_file = os.path.join(settings.MEDIA_ROOT, DEFAULT_BG_MD5_FILE)
162 if os.path.exists(md5_file):
163 with open(md5_file) as f:
164 theme[SIGN_IN][BACKGROUND] += "?{}".format(f.read())
165
166 return theme
167
```
Path: `kolibri/plugins/default_theme/kolibri_plugin.py`
Content:
```
1 from __future__ import absolute_import
2 from __future__ import print_function
3 from __future__ import unicode_literals
4
5 from django.contrib.staticfiles.templatetags.staticfiles import static
6
7 from kolibri.plugins.base import KolibriPluginBase
8
9 from kolibri.core import theme_hook
10
11
12 class DefaultThemePlugin(KolibriPluginBase):
13 pass
14
15
16 class DefaultThemeHook(theme_hook.ThemeHook):
17 @property
18 def theme(self):
19 return {
20 # metadata
21 theme_hook.THEME_NAME: "Default theme",
22 theme_hook.THEME_VERSION: 1, # increment when changes are made
23 # specify primary and secondary brand colors
24 theme_hook.BRAND_COLORS: {
25 theme_hook.PRIMARY: {
26 theme_hook.COLOR_V50: "#f0e7ed",
27 theme_hook.COLOR_V100: "#dbc3d4",
28 theme_hook.COLOR_V200: "#c59db9",
29 theme_hook.COLOR_V300: "#ac799d",
30 theme_hook.COLOR_V400: "#996189",
31 theme_hook.COLOR_V500: "#874e77",
32 theme_hook.COLOR_V600: "#7c4870",
33 theme_hook.COLOR_V700: "#6e4167",
34 theme_hook.COLOR_V800: "#5f3b5c",
35 theme_hook.COLOR_V900: "#4b2e4d",
36 },
37 theme_hook.SECONDARY: {
38 theme_hook.COLOR_V50: "#e3f0ed",
39 theme_hook.COLOR_V100: "#badbd2",
40 theme_hook.COLOR_V200: "#8dc5b6",
41 theme_hook.COLOR_V300: "#62af9a",
42 theme_hook.COLOR_V400: "#479e86",
43 theme_hook.COLOR_V500: "#368d74",
44 theme_hook.COLOR_V600: "#328168",
45 theme_hook.COLOR_V700: "#2c715a",
46 theme_hook.COLOR_V800: "#26614d",
47 theme_hook.COLOR_V900: "#1b4634",
48 },
49 },
50 # sign-in page config
51 theme_hook.SIGN_IN: {
52 theme_hook.BACKGROUND: static("background.jpg"),
53 theme_hook.TITLE: None, # use default: "Kolibri"
54 theme_hook.TOP_LOGO: {
55 theme_hook.IMG_SRC: None, # use default Kolibri bird
56 theme_hook.IMG_STYLE: "padding-left: 64px; padding-right: 64px; margin-bottom: 8px; margin-top: 8px",
57 theme_hook.IMG_ALT: None,
58 },
59 theme_hook.SHOW_K_FOOTER_LOGO: False,
60 },
61 # side-nav config
62 theme_hook.SIDE_NAV: {theme_hook.SHOW_K_FOOTER_LOGO: True},
63 # app bar config
64 theme_hook.APP_BAR: {theme_hook.TOP_LOGO: None},
65 }
66
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kolibri/core/theme_hook.py b/kolibri/core/theme_hook.py
--- a/kolibri/core/theme_hook.py
+++ b/kolibri/core/theme_hook.py
@@ -42,7 +42,10 @@
IMG_SRC = "src"
IMG_STYLE = "style"
IMG_ALT = "alt"
+SHOW_TITLE = "showTitle"
SHOW_K_FOOTER_LOGO = "showKolibriFooterLogo"
+SHOW_POWERED_BY = "showPoweredBy"
+POWERED_BY_STYLE = "poweredByStyle"
# This is the image file name that will be used when customizing the sign-in background
# image using the 'kolibri manage background' command. It does not attempt to use a file
diff --git a/kolibri/plugins/default_theme/kolibri_plugin.py b/kolibri/plugins/default_theme/kolibri_plugin.py
--- a/kolibri/plugins/default_theme/kolibri_plugin.py
+++ b/kolibri/plugins/default_theme/kolibri_plugin.py
@@ -56,6 +56,8 @@
theme_hook.IMG_STYLE: "padding-left: 64px; padding-right: 64px; margin-bottom: 8px; margin-top: 8px",
theme_hook.IMG_ALT: None,
},
+ theme_hook.SHOW_POWERED_BY: False,
+ theme_hook.SHOW_TITLE: True,
theme_hook.SHOW_K_FOOTER_LOGO: False,
},
# side-nav config
|
{"golden_diff": "diff --git a/kolibri/core/theme_hook.py b/kolibri/core/theme_hook.py\n--- a/kolibri/core/theme_hook.py\n+++ b/kolibri/core/theme_hook.py\n@@ -42,7 +42,10 @@\n IMG_SRC = \"src\"\n IMG_STYLE = \"style\"\n IMG_ALT = \"alt\"\n+SHOW_TITLE = \"showTitle\"\n SHOW_K_FOOTER_LOGO = \"showKolibriFooterLogo\"\n+SHOW_POWERED_BY = \"showPoweredBy\"\n+POWERED_BY_STYLE = \"poweredByStyle\"\n \n # This is the image file name that will be used when customizing the sign-in background\n # image using the 'kolibri manage background' command. It does not attempt to use a file\ndiff --git a/kolibri/plugins/default_theme/kolibri_plugin.py b/kolibri/plugins/default_theme/kolibri_plugin.py\n--- a/kolibri/plugins/default_theme/kolibri_plugin.py\n+++ b/kolibri/plugins/default_theme/kolibri_plugin.py\n@@ -56,6 +56,8 @@\n theme_hook.IMG_STYLE: \"padding-left: 64px; padding-right: 64px; margin-bottom: 8px; margin-top: 8px\",\n theme_hook.IMG_ALT: None,\n },\n+ theme_hook.SHOW_POWERED_BY: False,\n+ theme_hook.SHOW_TITLE: True,\n theme_hook.SHOW_K_FOOTER_LOGO: False,\n },\n # side-nav config\n", "issue": "add support for OIDC in account creation flow\n\r\n### Observed behavior\r\n\r\ncurrently SSO works for sign in but not account creation\r\n\r\n### Expected behavior\r\n\r\nthe 'next' parameter needs to be passed from the sign in page to the account creation page and handled there\r\n\r\n### User-facing consequences\r\n\r\nThe following flow is not supported:\r\n\r\n> 1. User comes to SCE portal and click on login for one server, system would redirect to Kolibri portal.\r\n> 2. On Kolibri portal, user decides to not login but register and clicks on register.\r\n> 3. After registration, user is redirecting to Kolibri portal instead of returning back to SCE portal.\r\n\r\n\r\n\r\n### Context\r\n\r\n0.12.5\n", "before_files": [{"content": "from __future__ import absolute_import\nfrom __future__ import print_function\nfrom __future__ import unicode_literals\n\nimport logging\n\nfrom kolibri.plugins import hooks\nimport kolibri\nfrom django.utils.six.moves.urllib import parse\nfrom django.conf import settings\nimport os\n\nlogger = logging.getLogger(__name__)\n\n\n# Important for cache busting\nTHEME_NAME = \"themeName\"\nTHEME_VERSION = \"themeVersion\"\n\n# These constants are used by theme.js and the $theme mixin on the front-end\nTOKEN_MAPPING = \"tokenMapping\"\nBRAND_COLORS = \"brandColors\"\nPRIMARY = \"primary\"\nSECONDARY = \"secondary\"\nCOLOR_V50 = \"v_50\"\nCOLOR_V100 = \"v_100\"\nCOLOR_V200 = \"v_200\"\nCOLOR_V300 = \"v_300\"\nCOLOR_V400 = \"v_400\"\nCOLOR_V500 = \"v_500\"\nCOLOR_V600 = \"v_600\"\nCOLOR_V700 = \"v_700\"\nCOLOR_V800 = \"v_800\"\nCOLOR_V900 = \"v_900\"\nSIGN_IN = \"signIn\"\nSIDE_NAV = \"sideNav\"\nAPP_BAR = \"appBar\"\nBACKGROUND = \"background\"\nTITLE = \"title\"\nTITLE_STYLE = \"titleStyle\"\nTOP_LOGO = \"topLogo\"\nIMG_SRC = \"src\"\nIMG_STYLE = \"style\"\nIMG_ALT = \"alt\"\nSHOW_K_FOOTER_LOGO = \"showKolibriFooterLogo\"\n\n# This is the image file name that will be used when customizing the sign-in background\n# image using the 'kolibri manage background' command. It does not attempt to use a file\n# extension (like .jpg) because we don't know if it's a JPG, SVG, PNG, etc...\nDEFAULT_BG_IMAGE_FILE = \"background_image\"\nDEFAULT_BG_MD5_FILE = \"background_image_md5\"\n\n\ndef _isSet(theme, keys):\n \"\"\"\n Given a theme dict, recursively check that all the keys are populated\n and that the associated value is truthy\n \"\"\"\n obj = theme\n for key in keys:\n if not obj or key not in obj:\n return False\n obj = obj[key]\n return bool(obj)\n\n\ndef _validateMetadata(theme):\n if THEME_NAME not in theme:\n logger.error(\"a theme name must be set\")\n if THEME_VERSION not in theme:\n logger.error(\"a theme version must be set\")\n\n\ndef _validateBrandColors(theme):\n if BRAND_COLORS not in theme:\n logger.error(\"brand colors not defined by theme\")\n return\n\n required_colors = [PRIMARY, SECONDARY]\n color_names = [\n COLOR_V50,\n COLOR_V100,\n COLOR_V200,\n COLOR_V300,\n COLOR_V400,\n COLOR_V500,\n COLOR_V600,\n COLOR_V700,\n COLOR_V800,\n COLOR_V900,\n ]\n for color in required_colors:\n if color not in theme[BRAND_COLORS]:\n logger.error(\"'{}' not defined by theme\".format(color))\n for name in color_names:\n if name not in theme[BRAND_COLORS][color]:\n logger.error(\"{} '{}' not defined by theme\".format(color, name))\n\n\ndef _initFields(theme):\n \"\"\"\n set up top-level dicts if they don't exist\n \"\"\"\n if SIGN_IN not in theme:\n theme[SIGN_IN] = {}\n if TOKEN_MAPPING not in theme:\n theme[TOKEN_MAPPING] = {}\n if SIDE_NAV not in theme:\n theme[SIDE_NAV] = {}\n if APP_BAR not in theme:\n theme[APP_BAR] = {}\n\n\nclass ThemeHook(hooks.KolibriHook):\n \"\"\"\n A hook to allow custom theming of Kolibri\n Use this tool to help generate your brand colors: https://materialpalettes.com/\n \"\"\"\n\n class Meta:\n abstract = True\n\n @property\n @hooks.only_one_registered\n def cacheKey(self):\n theme = list(self.registered_hooks)[0].theme\n return parse.quote(\n \"{}-{}-{}\".format(\n kolibri.__version__, theme[THEME_NAME], theme[THEME_VERSION]\n )\n )\n\n @property\n @hooks.only_one_registered\n def theme(self):\n theme = list(self.registered_hooks)[0].theme\n\n # some validation and initialization\n _initFields(theme)\n _validateMetadata(theme)\n _validateBrandColors(theme)\n\n # set up cache busting\n bust = \"?\" + self.cacheKey\n if _isSet(theme, [SIGN_IN, BACKGROUND]):\n theme[SIGN_IN][BACKGROUND] += bust\n if _isSet(theme, [SIGN_IN, TOP_LOGO, IMG_SRC]):\n theme[SIGN_IN][TOP_LOGO][IMG_SRC] += bust\n if _isSet(theme, [SIDE_NAV, TOP_LOGO, IMG_SRC]):\n theme[SIDE_NAV][TOP_LOGO][IMG_SRC] += bust\n if _isSet(theme, [APP_BAR, TOP_LOGO, IMG_SRC]):\n theme[APP_BAR][TOP_LOGO][IMG_SRC] += bust\n\n # if a background image has been locally set using the `manage background` command, use it\n bg_img = os.path.join(settings.MEDIA_ROOT, DEFAULT_BG_IMAGE_FILE)\n if os.path.exists(bg_img):\n theme[SIGN_IN][BACKGROUND] = parse.urljoin(\n settings.MEDIA_URL, DEFAULT_BG_IMAGE_FILE\n )\n # add cache busting\n md5_file = os.path.join(settings.MEDIA_ROOT, DEFAULT_BG_MD5_FILE)\n if os.path.exists(md5_file):\n with open(md5_file) as f:\n theme[SIGN_IN][BACKGROUND] += \"?{}\".format(f.read())\n\n return theme\n", "path": "kolibri/core/theme_hook.py"}, {"content": "from __future__ import absolute_import\nfrom __future__ import print_function\nfrom __future__ import unicode_literals\n\nfrom django.contrib.staticfiles.templatetags.staticfiles import static\n\nfrom kolibri.plugins.base import KolibriPluginBase\n\nfrom kolibri.core import theme_hook\n\n\nclass DefaultThemePlugin(KolibriPluginBase):\n pass\n\n\nclass DefaultThemeHook(theme_hook.ThemeHook):\n @property\n def theme(self):\n return {\n # metadata\n theme_hook.THEME_NAME: \"Default theme\",\n theme_hook.THEME_VERSION: 1, # increment when changes are made\n # specify primary and secondary brand colors\n theme_hook.BRAND_COLORS: {\n theme_hook.PRIMARY: {\n theme_hook.COLOR_V50: \"#f0e7ed\",\n theme_hook.COLOR_V100: \"#dbc3d4\",\n theme_hook.COLOR_V200: \"#c59db9\",\n theme_hook.COLOR_V300: \"#ac799d\",\n theme_hook.COLOR_V400: \"#996189\",\n theme_hook.COLOR_V500: \"#874e77\",\n theme_hook.COLOR_V600: \"#7c4870\",\n theme_hook.COLOR_V700: \"#6e4167\",\n theme_hook.COLOR_V800: \"#5f3b5c\",\n theme_hook.COLOR_V900: \"#4b2e4d\",\n },\n theme_hook.SECONDARY: {\n theme_hook.COLOR_V50: \"#e3f0ed\",\n theme_hook.COLOR_V100: \"#badbd2\",\n theme_hook.COLOR_V200: \"#8dc5b6\",\n theme_hook.COLOR_V300: \"#62af9a\",\n theme_hook.COLOR_V400: \"#479e86\",\n theme_hook.COLOR_V500: \"#368d74\",\n theme_hook.COLOR_V600: \"#328168\",\n theme_hook.COLOR_V700: \"#2c715a\",\n theme_hook.COLOR_V800: \"#26614d\",\n theme_hook.COLOR_V900: \"#1b4634\",\n },\n },\n # sign-in page config\n theme_hook.SIGN_IN: {\n theme_hook.BACKGROUND: static(\"background.jpg\"),\n theme_hook.TITLE: None, # use default: \"Kolibri\"\n theme_hook.TOP_LOGO: {\n theme_hook.IMG_SRC: None, # use default Kolibri bird\n theme_hook.IMG_STYLE: \"padding-left: 64px; padding-right: 64px; margin-bottom: 8px; margin-top: 8px\",\n theme_hook.IMG_ALT: None,\n },\n theme_hook.SHOW_K_FOOTER_LOGO: False,\n },\n # side-nav config\n theme_hook.SIDE_NAV: {theme_hook.SHOW_K_FOOTER_LOGO: True},\n # app bar config\n theme_hook.APP_BAR: {theme_hook.TOP_LOGO: None},\n }\n", "path": "kolibri/plugins/default_theme/kolibri_plugin.py"}], "after_files": [{"content": "from __future__ import absolute_import\nfrom __future__ import print_function\nfrom __future__ import unicode_literals\n\nimport logging\n\nfrom kolibri.plugins import hooks\nimport kolibri\nfrom django.utils.six.moves.urllib import parse\nfrom django.conf import settings\nimport os\n\nlogger = logging.getLogger(__name__)\n\n\n# Important for cache busting\nTHEME_NAME = \"themeName\"\nTHEME_VERSION = \"themeVersion\"\n\n# These constants are used by theme.js and the $theme mixin on the front-end\nTOKEN_MAPPING = \"tokenMapping\"\nBRAND_COLORS = \"brandColors\"\nPRIMARY = \"primary\"\nSECONDARY = \"secondary\"\nCOLOR_V50 = \"v_50\"\nCOLOR_V100 = \"v_100\"\nCOLOR_V200 = \"v_200\"\nCOLOR_V300 = \"v_300\"\nCOLOR_V400 = \"v_400\"\nCOLOR_V500 = \"v_500\"\nCOLOR_V600 = \"v_600\"\nCOLOR_V700 = \"v_700\"\nCOLOR_V800 = \"v_800\"\nCOLOR_V900 = \"v_900\"\nSIGN_IN = \"signIn\"\nSIDE_NAV = \"sideNav\"\nAPP_BAR = \"appBar\"\nBACKGROUND = \"background\"\nTITLE = \"title\"\nTITLE_STYLE = \"titleStyle\"\nTOP_LOGO = \"topLogo\"\nIMG_SRC = \"src\"\nIMG_STYLE = \"style\"\nIMG_ALT = \"alt\"\nSHOW_TITLE = \"showTitle\"\nSHOW_K_FOOTER_LOGO = \"showKolibriFooterLogo\"\nSHOW_POWERED_BY = \"showPoweredBy\"\nPOWERED_BY_STYLE = \"poweredByStyle\"\n\n# This is the image file name that will be used when customizing the sign-in background\n# image using the 'kolibri manage background' command. It does not attempt to use a file\n# extension (like .jpg) because we don't know if it's a JPG, SVG, PNG, etc...\nDEFAULT_BG_IMAGE_FILE = \"background_image\"\nDEFAULT_BG_MD5_FILE = \"background_image_md5\"\n\n\ndef _isSet(theme, keys):\n \"\"\"\n Given a theme dict, recursively check that all the keys are populated\n and that the associated value is truthy\n \"\"\"\n obj = theme\n for key in keys:\n if not obj or key not in obj:\n return False\n obj = obj[key]\n return bool(obj)\n\n\ndef _validateMetadata(theme):\n if THEME_NAME not in theme:\n logger.error(\"a theme name must be set\")\n if THEME_VERSION not in theme:\n logger.error(\"a theme version must be set\")\n\n\ndef _validateBrandColors(theme):\n if BRAND_COLORS not in theme:\n logger.error(\"brand colors not defined by theme\")\n return\n\n required_colors = [PRIMARY, SECONDARY]\n color_names = [\n COLOR_V50,\n COLOR_V100,\n COLOR_V200,\n COLOR_V300,\n COLOR_V400,\n COLOR_V500,\n COLOR_V600,\n COLOR_V700,\n COLOR_V800,\n COLOR_V900,\n ]\n for color in required_colors:\n if color not in theme[BRAND_COLORS]:\n logger.error(\"'{}' not defined by theme\".format(color))\n for name in color_names:\n if name not in theme[BRAND_COLORS][color]:\n logger.error(\"{} '{}' not defined by theme\".format(color, name))\n\n\ndef _initFields(theme):\n \"\"\"\n set up top-level dicts if they don't exist\n \"\"\"\n if SIGN_IN not in theme:\n theme[SIGN_IN] = {}\n if TOKEN_MAPPING not in theme:\n theme[TOKEN_MAPPING] = {}\n if SIDE_NAV not in theme:\n theme[SIDE_NAV] = {}\n if APP_BAR not in theme:\n theme[APP_BAR] = {}\n\n\nclass ThemeHook(hooks.KolibriHook):\n \"\"\"\n A hook to allow custom theming of Kolibri\n Use this tool to help generate your brand colors: https://materialpalettes.com/\n \"\"\"\n\n class Meta:\n abstract = True\n\n @property\n @hooks.only_one_registered\n def cacheKey(self):\n theme = list(self.registered_hooks)[0].theme\n return parse.quote(\n \"{}-{}-{}\".format(\n kolibri.__version__, theme[THEME_NAME], theme[THEME_VERSION]\n )\n )\n\n @property\n @hooks.only_one_registered\n def theme(self):\n theme = list(self.registered_hooks)[0].theme\n\n # some validation and initialization\n _initFields(theme)\n _validateMetadata(theme)\n _validateBrandColors(theme)\n\n # set up cache busting\n bust = \"?\" + self.cacheKey\n if _isSet(theme, [SIGN_IN, BACKGROUND]):\n theme[SIGN_IN][BACKGROUND] += bust\n if _isSet(theme, [SIGN_IN, TOP_LOGO, IMG_SRC]):\n theme[SIGN_IN][TOP_LOGO][IMG_SRC] += bust\n if _isSet(theme, [SIDE_NAV, TOP_LOGO, IMG_SRC]):\n theme[SIDE_NAV][TOP_LOGO][IMG_SRC] += bust\n if _isSet(theme, [APP_BAR, TOP_LOGO, IMG_SRC]):\n theme[APP_BAR][TOP_LOGO][IMG_SRC] += bust\n\n # if a background image has been locally set using the `manage background` command, use it\n bg_img = os.path.join(settings.MEDIA_ROOT, DEFAULT_BG_IMAGE_FILE)\n if os.path.exists(bg_img):\n theme[SIGN_IN][BACKGROUND] = parse.urljoin(\n settings.MEDIA_URL, DEFAULT_BG_IMAGE_FILE\n )\n # add cache busting\n md5_file = os.path.join(settings.MEDIA_ROOT, DEFAULT_BG_MD5_FILE)\n if os.path.exists(md5_file):\n with open(md5_file) as f:\n theme[SIGN_IN][BACKGROUND] += \"?{}\".format(f.read())\n\n return theme\n", "path": "kolibri/core/theme_hook.py"}, {"content": "from __future__ import absolute_import\nfrom __future__ import print_function\nfrom __future__ import unicode_literals\n\nfrom django.contrib.staticfiles.templatetags.staticfiles import static\n\nfrom kolibri.plugins.base import KolibriPluginBase\n\nfrom kolibri.core import theme_hook\n\n\nclass DefaultThemePlugin(KolibriPluginBase):\n pass\n\n\nclass DefaultThemeHook(theme_hook.ThemeHook):\n @property\n def theme(self):\n return {\n # metadata\n theme_hook.THEME_NAME: \"Default theme\",\n theme_hook.THEME_VERSION: 1, # increment when changes are made\n # specify primary and secondary brand colors\n theme_hook.BRAND_COLORS: {\n theme_hook.PRIMARY: {\n theme_hook.COLOR_V50: \"#f0e7ed\",\n theme_hook.COLOR_V100: \"#dbc3d4\",\n theme_hook.COLOR_V200: \"#c59db9\",\n theme_hook.COLOR_V300: \"#ac799d\",\n theme_hook.COLOR_V400: \"#996189\",\n theme_hook.COLOR_V500: \"#874e77\",\n theme_hook.COLOR_V600: \"#7c4870\",\n theme_hook.COLOR_V700: \"#6e4167\",\n theme_hook.COLOR_V800: \"#5f3b5c\",\n theme_hook.COLOR_V900: \"#4b2e4d\",\n },\n theme_hook.SECONDARY: {\n theme_hook.COLOR_V50: \"#e3f0ed\",\n theme_hook.COLOR_V100: \"#badbd2\",\n theme_hook.COLOR_V200: \"#8dc5b6\",\n theme_hook.COLOR_V300: \"#62af9a\",\n theme_hook.COLOR_V400: \"#479e86\",\n theme_hook.COLOR_V500: \"#368d74\",\n theme_hook.COLOR_V600: \"#328168\",\n theme_hook.COLOR_V700: \"#2c715a\",\n theme_hook.COLOR_V800: \"#26614d\",\n theme_hook.COLOR_V900: \"#1b4634\",\n },\n },\n # sign-in page config\n theme_hook.SIGN_IN: {\n theme_hook.BACKGROUND: static(\"background.jpg\"),\n theme_hook.TITLE: None, # use default: \"Kolibri\"\n theme_hook.TOP_LOGO: {\n theme_hook.IMG_SRC: None, # use default Kolibri bird\n theme_hook.IMG_STYLE: \"padding-left: 64px; padding-right: 64px; margin-bottom: 8px; margin-top: 8px\",\n theme_hook.IMG_ALT: None,\n },\n theme_hook.SHOW_POWERED_BY: False,\n theme_hook.SHOW_TITLE: True,\n theme_hook.SHOW_K_FOOTER_LOGO: False,\n },\n # side-nav config\n theme_hook.SIDE_NAV: {theme_hook.SHOW_K_FOOTER_LOGO: True},\n # app bar config\n theme_hook.APP_BAR: {theme_hook.TOP_LOGO: None},\n }\n", "path": "kolibri/plugins/default_theme/kolibri_plugin.py"}]}
| 2,905 | 319 |
gh_patches_debug_66259
|
rasdani/github-patches
|
git_diff
|
qtile__qtile-1432
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
docs: Missing deps when building widget docs gives "alias to ImportErrorWidget"
See http://docs.qtile.org/en/latest/manual/ref/widgets.html#memory for example.
I guess the widget dependencies are not installed while building the docs, resulting in Sphinx telling the widget is an alias to `libqtile.widget.import_error.make_error.<locals>.ImportErrorWidget`.
EDIT: okay I see where the deps are listed: in `docs/conf.py`. Indeed `mpd` is present but `psutil` is not, so the `Memory` widget's docs do not build.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/conf.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 #
3 # Qtile documentation build configuration file, created by
4 # sphinx-quickstart on Sat Feb 11 15:20:21 2012.
5 #
6 # This file is execfile()d with the current directory set to its containing dir.
7 #
8 # Note that not all possible configuration values are present in this
9 # autogenerated file.
10 #
11 # All configuration values have a default; values that are commented out
12 # serve to show the default.
13
14 import os
15 import sys
16 from unittest.mock import MagicMock
17
18
19 class Mock(MagicMock):
20 # xcbq does a dir() on objects and pull stuff out of them and tries to sort
21 # the result. MagicMock has a bunch of stuff that can't be sorted, so let's
22 # like about dir().
23 def __dir__(self):
24 return []
25
26 MOCK_MODULES = [
27 'libqtile._ffi_pango',
28 'libqtile.core._ffi_xcursors',
29 'cairocffi',
30 'cairocffi.pixbuf',
31 'cffi',
32 'dateutil',
33 'dateutil.parser',
34 'dbus',
35 'dbus.mainloop.glib',
36 'iwlib',
37 'keyring',
38 'mpd',
39 'trollius',
40 'xcffib',
41 'xcffib.randr',
42 'xcffib.xfixes',
43 'xcffib.xinerama',
44 'xcffib.xproto',
45 'xdg.IconTheme',
46 ]
47 sys.modules.update((mod_name, Mock()) for mod_name in MOCK_MODULES)
48
49 # If extensions (or modules to document with autodoc) are in another directory,
50 # add these directories to sys.path here. If the directory is relative to the
51 # documentation root, use os.path.abspath to make it absolute, like shown here.
52 sys.path.insert(0, os.path.abspath('.'))
53 sys.path.insert(0, os.path.abspath('../'))
54
55 # -- General configuration -----------------------------------------------------
56
57 # If your documentation needs a minimal Sphinx version, state it here.
58 #needs_sphinx = '1.0'
59
60 # Add any Sphinx extension module names here, as strings. They can be extensions
61 # coming with Sphinx (named 'sphinx.ext.*') or your custom ones.
62 extensions = [
63 'sphinx.ext.autodoc',
64 'sphinx.ext.autosummary',
65 'sphinx.ext.coverage',
66 'sphinx.ext.graphviz',
67 'sphinx.ext.todo',
68 'sphinx.ext.viewcode',
69 'sphinxcontrib.seqdiag',
70 'sphinx_qtile',
71 'numpydoc',
72 ]
73
74 numpydoc_show_class_members = False
75
76 # Add any paths that contain templates here, relative to this directory.
77 templates_path = []
78
79 # The suffix of source filenames.
80 source_suffix = '.rst'
81
82 # The encoding of source files.
83 #source_encoding = 'utf-8-sig'
84
85 # The master toctree document.
86 master_doc = 'index'
87
88 # General information about the project.
89 project = u'Qtile'
90 copyright = u'2008-2019, Aldo Cortesi and contributers'
91
92 # The version info for the project you're documenting, acts as replacement for
93 # |version| and |release|, also used in various other places throughout the
94 # built documents.
95 #
96 # The short X.Y version.
97 version = '0.14.2'
98 # The full version, including alpha/beta/rc tags.
99 release = version
100
101 # The language for content autogenerated by Sphinx. Refer to documentation
102 # for a list of supported languages.
103 #language = None
104
105 # There are two options for replacing |today|: either, you set today to some
106 # non-false value, then it is used:
107 #today = ''
108 # Else, today_fmt is used as the format for a strftime call.
109 #today_fmt = '%B %d, %Y'
110
111 # List of patterns, relative to source directory, that match files and
112 # directories to ignore when looking for source files.
113 exclude_patterns = ['_build', 'man']
114
115 # The reST default role (used for this markup: `text`) to use for all documents.
116 #default_role = None
117
118 # If true, '()' will be appended to :func: etc. cross-reference text.
119 #add_function_parentheses = True
120
121 # If true, the current module name will be prepended to all description
122 # unit titles (such as .. function::).
123 #add_module_names = True
124
125 # If true, sectionauthor and moduleauthor directives will be shown in the
126 # output. They are ignored by default.
127 #show_authors = False
128
129 # The name of the Pygments (syntax highlighting) style to use.
130 pygments_style = 'sphinx'
131
132 # A list of ignored prefixes for module index sorting.
133 #modindex_common_prefix = []
134
135 # If true, `todo` and `todoList` produce output, else they produce nothing.
136 todo_include_todos = True
137
138
139 # -- Options for HTML output --------fautod-------------------------------------------
140
141 # The theme to use for HTML and HTML Help pages. See the documentation for
142 # a list of builtin themes.
143 #html_theme = 'default'
144
145 # Theme options are theme-specific and customize the look and feel of a theme
146 # further. For a list of options available for each theme, see the
147 # documentation.
148 #html_theme_options = {}
149
150 # Add any paths that contain custom themes here, relative to this directory.
151 #html_theme_path = []
152
153 # The name for this set of Sphinx documents. If None, it defaults to
154 # "<project> v<release> documentation".
155 #html_title = None
156
157 # A shorter title for the navigation bar. Default is the same as html_title.
158 #html_short_title = None
159
160 # The name of an image file (relative to this directory) to place at the top
161 # of the sidebar.
162 #html_logo = None
163
164 # The name of an image file (within the static path) to use as favicon of the
165 # docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32
166 # pixels large.
167 html_favicon = '_static/favicon.ico'
168
169 # Add any paths that contain custom static files (such as style sheets) here,
170 # relative to this directory. They are copied after the builtin static files,
171 # so a file named "default.css" will overwrite the builtin "default.css".
172 html_static_path = ['_static']
173
174 # If not '', a 'Last updated on:' timestamp is inserted at every page bottom,
175 # using the given strftime format.
176 #html_last_updated_fmt = '%b %d, %Y'
177
178 # If true, SmartyPants will be used to convert quotes and dashes to
179 # typographically correct entities.
180 #html_use_smartypants = True
181
182 # Custom sidebar templates, maps document names to template names.
183 #html_sidebars = {}
184
185 # Additional templates that should be rendered to pages, maps page names to
186 # template names.
187 #html_additional_pages = {'index': 'index.html'}
188
189 # If false, no module index is generated.
190 #html_domain_indices = True
191
192 # If false, no index is generated.
193 html_use_index = True
194
195 # If true, the index is split into individual pages for each letter.
196 #html_split_index = False
197
198 # If true, links to the reST sources are added to the pages.
199 #html_show_sourcelink = True
200
201 # If true, "Created using Sphinx" is shown in the HTML footer. Default is True.
202 #html_show_sphinx = True
203
204 # If true, "(C) Copyright ..." is shown in the HTML footer. Default is True.
205 #html_show_copyright = True
206
207 # If true, an OpenSearch description file will be output, and all pages will
208 # contain a <link> tag referring to it. The value of this option must be the
209 # base URL from which the finished HTML is served.
210 #html_use_opensearch = ''
211
212 # This is the file name suffix for HTML files (e.g. ".xhtml").
213 #html_file_suffix = None
214
215 # Output file base name for HTML help builder.
216 htmlhelp_basename = 'Qtiledoc'
217
218
219 # -- Options for LaTeX output --------------------------------------------------
220
221 latex_elements = {
222 # The paper size ('letterpaper' or 'a4paper').
223 #'papersize': 'letterpaper',
224
225 # The font size ('10pt', '11pt' or '12pt').
226 #'pointsize': '10pt',
227
228 # Additional stuff for the LaTeX preamble.
229 #'preamble': '',
230 }
231
232 # Grouping the document tree into LaTeX files. List of tuples
233 # (source start file, target name, title, author, documentclass [howto/manual]).
234 latex_documents = [
235 ('index', 'Qtile.tex', u'Qtile Documentation',
236 u'Aldo Cortesi', 'manual'),
237 ]
238
239 # The name of an image file (relative to this directory) to place at the top of
240 # the title page.
241 #latex_logo = None
242
243 # For "manual" documents, if this is true, then toplevel headings are parts,
244 # not chapters.
245 #latex_use_parts = False
246
247 # If true, show page references after internal links.
248 #latex_show_pagerefs = False
249
250 # If true, show URL addresses after external links.
251 #latex_show_urls = False
252
253 # Documents to append as an appendix to all manuals.
254 #latex_appendices = []
255
256 # If false, no module index is generated.
257 #latex_domain_indices = True
258
259
260 # -- Options for manual page output --------------------------------------------
261
262 # One entry per manual page. List of tuples
263 # (source start file, name, description, authors, manual section).
264 man_pages = [
265 ('man/qtile', 'qtile', u'Qtile Documentation',
266 [u'Tycho Andersen'], 1),
267 ('man/qshell', 'qshell', u'Qtile Documentation',
268 [u'Tycho Andersen'], 1),
269 ]
270
271 # If true, show URL addresses after external links.
272 #man_show_urls = False
273
274
275 # -- Options for Texinfo output ------------------------------------------------
276
277 # Grouping the document tree into Texinfo files. List of tuples
278 # (source start file, target name, title, author,
279 # dir menu entry, description, category)
280 texinfo_documents = [
281 ('index', 'Qtile', u'Qtile Documentation',
282 u'Aldo Cortesi', 'Qtile', 'A hackable tiling window manager.',
283 'Miscellaneous'),
284 ]
285
286 # Documents to append as an appendix to all manuals.
287 #texinfo_appendices = []
288
289 # If false, no module index is generated.
290 #texinfo_domain_indices = True
291
292 # How to display URL addresses: 'footnote', 'no', or 'inline'.
293 #texinfo_show_urls = 'footnote'
294
295 # only import and set the theme if we're building docs locally
296 if not os.environ.get('READTHEDOCS'):
297 import sphinx_rtd_theme
298 html_theme = 'sphinx_rtd_theme'
299 html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]
300
301
302 graphviz_dot_args = ['-Lg']
303
304 # A workaround for the responsive tables always having annoying scrollbars.
305 def setup(app):
306 app.add_stylesheet("no_scrollbars.css")
307
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -36,6 +36,7 @@
'iwlib',
'keyring',
'mpd',
+ 'psutil',
'trollius',
'xcffib',
'xcffib.randr',
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -36,6 +36,7 @@\n 'iwlib',\n 'keyring',\n 'mpd',\n+ 'psutil',\n 'trollius',\n 'xcffib',\n 'xcffib.randr',\n", "issue": "docs: Missing deps when building widget docs gives \"alias to ImportErrorWidget\"\nSee http://docs.qtile.org/en/latest/manual/ref/widgets.html#memory for example.\r\n\r\nI guess the widget dependencies are not installed while building the docs, resulting in Sphinx telling the widget is an alias to `libqtile.widget.import_error.make_error.<locals>.ImportErrorWidget`.\r\n\r\nEDIT: okay I see where the deps are listed: in `docs/conf.py`. Indeed `mpd` is present but `psutil` is not, so the `Memory` widget's docs do not build.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Qtile documentation build configuration file, created by\n# sphinx-quickstart on Sat Feb 11 15:20:21 2012.\n#\n# This file is execfile()d with the current directory set to its containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\nimport os\nimport sys\nfrom unittest.mock import MagicMock\n\n\nclass Mock(MagicMock):\n # xcbq does a dir() on objects and pull stuff out of them and tries to sort\n # the result. MagicMock has a bunch of stuff that can't be sorted, so let's\n # like about dir().\n def __dir__(self):\n return []\n\nMOCK_MODULES = [\n 'libqtile._ffi_pango',\n 'libqtile.core._ffi_xcursors',\n 'cairocffi',\n 'cairocffi.pixbuf',\n 'cffi',\n 'dateutil',\n 'dateutil.parser',\n 'dbus',\n 'dbus.mainloop.glib',\n 'iwlib',\n 'keyring',\n 'mpd',\n 'trollius',\n 'xcffib',\n 'xcffib.randr',\n 'xcffib.xfixes',\n 'xcffib.xinerama',\n 'xcffib.xproto',\n 'xdg.IconTheme',\n]\nsys.modules.update((mod_name, Mock()) for mod_name in MOCK_MODULES)\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\nsys.path.insert(0, os.path.abspath('.'))\nsys.path.insert(0, os.path.abspath('../'))\n\n# -- General configuration -----------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be extensions\n# coming with Sphinx (named 'sphinx.ext.*') or your custom ones.\nextensions = [\n 'sphinx.ext.autodoc',\n 'sphinx.ext.autosummary',\n 'sphinx.ext.coverage',\n 'sphinx.ext.graphviz',\n 'sphinx.ext.todo',\n 'sphinx.ext.viewcode',\n 'sphinxcontrib.seqdiag',\n 'sphinx_qtile',\n 'numpydoc',\n]\n\nnumpydoc_show_class_members = False\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = []\n\n# The suffix of source filenames.\nsource_suffix = '.rst'\n\n# The encoding of source files.\n#source_encoding = 'utf-8-sig'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = u'Qtile'\ncopyright = u'2008-2019, Aldo Cortesi and contributers'\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = '0.14.2'\n# The full version, including alpha/beta/rc tags.\nrelease = version\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#language = None\n\n# There are two options for replacing |today|: either, you set today to some\n# non-false value, then it is used:\n#today = ''\n# Else, today_fmt is used as the format for a strftime call.\n#today_fmt = '%B %d, %Y'\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\nexclude_patterns = ['_build', 'man']\n\n# The reST default role (used for this markup: `text`) to use for all documents.\n#default_role = None\n\n# If true, '()' will be appended to :func: etc. cross-reference text.\n#add_function_parentheses = True\n\n# If true, the current module name will be prepended to all description\n# unit titles (such as .. function::).\n#add_module_names = True\n\n# If true, sectionauthor and moduleauthor directives will be shown in the\n# output. They are ignored by default.\n#show_authors = False\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# A list of ignored prefixes for module index sorting.\n#modindex_common_prefix = []\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = True\n\n\n# -- Options for HTML output --------fautod-------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#html_theme = 'default'\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#html_theme_options = {}\n\n# Add any paths that contain custom themes here, relative to this directory.\n#html_theme_path = []\n\n# The name for this set of Sphinx documents. If None, it defaults to\n# \"<project> v<release> documentation\".\n#html_title = None\n\n# A shorter title for the navigation bar. Default is the same as html_title.\n#html_short_title = None\n\n# The name of an image file (relative to this directory) to place at the top\n# of the sidebar.\n#html_logo = None\n\n# The name of an image file (within the static path) to use as favicon of the\n# docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32\n# pixels large.\nhtml_favicon = '_static/favicon.ico'\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n\n# If not '', a 'Last updated on:' timestamp is inserted at every page bottom,\n# using the given strftime format.\n#html_last_updated_fmt = '%b %d, %Y'\n\n# If true, SmartyPants will be used to convert quotes and dashes to\n# typographically correct entities.\n#html_use_smartypants = True\n\n# Custom sidebar templates, maps document names to template names.\n#html_sidebars = {}\n\n# Additional templates that should be rendered to pages, maps page names to\n# template names.\n#html_additional_pages = {'index': 'index.html'}\n\n# If false, no module index is generated.\n#html_domain_indices = True\n\n# If false, no index is generated.\nhtml_use_index = True\n\n# If true, the index is split into individual pages for each letter.\n#html_split_index = False\n\n# If true, links to the reST sources are added to the pages.\n#html_show_sourcelink = True\n\n# If true, \"Created using Sphinx\" is shown in the HTML footer. Default is True.\n#html_show_sphinx = True\n\n# If true, \"(C) Copyright ...\" is shown in the HTML footer. Default is True.\n#html_show_copyright = True\n\n# If true, an OpenSearch description file will be output, and all pages will\n# contain a <link> tag referring to it. The value of this option must be the\n# base URL from which the finished HTML is served.\n#html_use_opensearch = ''\n\n# This is the file name suffix for HTML files (e.g. \".xhtml\").\n#html_file_suffix = None\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'Qtiledoc'\n\n\n# -- Options for LaTeX output --------------------------------------------------\n\nlatex_elements = {\n# The paper size ('letterpaper' or 'a4paper').\n#'papersize': 'letterpaper',\n\n# The font size ('10pt', '11pt' or '12pt').\n#'pointsize': '10pt',\n\n# Additional stuff for the LaTeX preamble.\n#'preamble': '',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title, author, documentclass [howto/manual]).\nlatex_documents = [\n ('index', 'Qtile.tex', u'Qtile Documentation',\n u'Aldo Cortesi', 'manual'),\n]\n\n# The name of an image file (relative to this directory) to place at the top of\n# the title page.\n#latex_logo = None\n\n# For \"manual\" documents, if this is true, then toplevel headings are parts,\n# not chapters.\n#latex_use_parts = False\n\n# If true, show page references after internal links.\n#latex_show_pagerefs = False\n\n# If true, show URL addresses after external links.\n#latex_show_urls = False\n\n# Documents to append as an appendix to all manuals.\n#latex_appendices = []\n\n# If false, no module index is generated.\n#latex_domain_indices = True\n\n\n# -- Options for manual page output --------------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n ('man/qtile', 'qtile', u'Qtile Documentation',\n [u'Tycho Andersen'], 1),\n ('man/qshell', 'qshell', u'Qtile Documentation',\n [u'Tycho Andersen'], 1),\n]\n\n# If true, show URL addresses after external links.\n#man_show_urls = False\n\n\n# -- Options for Texinfo output ------------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n ('index', 'Qtile', u'Qtile Documentation',\n u'Aldo Cortesi', 'Qtile', 'A hackable tiling window manager.',\n 'Miscellaneous'),\n]\n\n# Documents to append as an appendix to all manuals.\n#texinfo_appendices = []\n\n# If false, no module index is generated.\n#texinfo_domain_indices = True\n\n# How to display URL addresses: 'footnote', 'no', or 'inline'.\n#texinfo_show_urls = 'footnote'\n\n# only import and set the theme if we're building docs locally\nif not os.environ.get('READTHEDOCS'):\n import sphinx_rtd_theme\n html_theme = 'sphinx_rtd_theme'\n html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]\n\n\ngraphviz_dot_args = ['-Lg']\n\n# A workaround for the responsive tables always having annoying scrollbars.\ndef setup(app):\n app.add_stylesheet(\"no_scrollbars.css\")\n", "path": "docs/conf.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Qtile documentation build configuration file, created by\n# sphinx-quickstart on Sat Feb 11 15:20:21 2012.\n#\n# This file is execfile()d with the current directory set to its containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\nimport os\nimport sys\nfrom unittest.mock import MagicMock\n\n\nclass Mock(MagicMock):\n # xcbq does a dir() on objects and pull stuff out of them and tries to sort\n # the result. MagicMock has a bunch of stuff that can't be sorted, so let's\n # like about dir().\n def __dir__(self):\n return []\n\nMOCK_MODULES = [\n 'libqtile._ffi_pango',\n 'libqtile.core._ffi_xcursors',\n 'cairocffi',\n 'cairocffi.pixbuf',\n 'cffi',\n 'dateutil',\n 'dateutil.parser',\n 'dbus',\n 'dbus.mainloop.glib',\n 'iwlib',\n 'keyring',\n 'mpd',\n 'psutil',\n 'trollius',\n 'xcffib',\n 'xcffib.randr',\n 'xcffib.xfixes',\n 'xcffib.xinerama',\n 'xcffib.xproto',\n 'xdg.IconTheme',\n]\nsys.modules.update((mod_name, Mock()) for mod_name in MOCK_MODULES)\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\nsys.path.insert(0, os.path.abspath('.'))\nsys.path.insert(0, os.path.abspath('../'))\n\n# -- General configuration -----------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be extensions\n# coming with Sphinx (named 'sphinx.ext.*') or your custom ones.\nextensions = [\n 'sphinx.ext.autodoc',\n 'sphinx.ext.autosummary',\n 'sphinx.ext.coverage',\n 'sphinx.ext.graphviz',\n 'sphinx.ext.todo',\n 'sphinx.ext.viewcode',\n 'sphinxcontrib.seqdiag',\n 'sphinx_qtile',\n 'numpydoc',\n]\n\nnumpydoc_show_class_members = False\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = []\n\n# The suffix of source filenames.\nsource_suffix = '.rst'\n\n# The encoding of source files.\n#source_encoding = 'utf-8-sig'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = u'Qtile'\ncopyright = u'2008-2019, Aldo Cortesi and contributers'\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = '0.14.2'\n# The full version, including alpha/beta/rc tags.\nrelease = version\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#language = None\n\n# There are two options for replacing |today|: either, you set today to some\n# non-false value, then it is used:\n#today = ''\n# Else, today_fmt is used as the format for a strftime call.\n#today_fmt = '%B %d, %Y'\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\nexclude_patterns = ['_build', 'man']\n\n# The reST default role (used for this markup: `text`) to use for all documents.\n#default_role = None\n\n# If true, '()' will be appended to :func: etc. cross-reference text.\n#add_function_parentheses = True\n\n# If true, the current module name will be prepended to all description\n# unit titles (such as .. function::).\n#add_module_names = True\n\n# If true, sectionauthor and moduleauthor directives will be shown in the\n# output. They are ignored by default.\n#show_authors = False\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# A list of ignored prefixes for module index sorting.\n#modindex_common_prefix = []\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = True\n\n\n# -- Options for HTML output --------fautod-------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#html_theme = 'default'\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#html_theme_options = {}\n\n# Add any paths that contain custom themes here, relative to this directory.\n#html_theme_path = []\n\n# The name for this set of Sphinx documents. If None, it defaults to\n# \"<project> v<release> documentation\".\n#html_title = None\n\n# A shorter title for the navigation bar. Default is the same as html_title.\n#html_short_title = None\n\n# The name of an image file (relative to this directory) to place at the top\n# of the sidebar.\n#html_logo = None\n\n# The name of an image file (within the static path) to use as favicon of the\n# docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32\n# pixels large.\nhtml_favicon = '_static/favicon.ico'\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n\n# If not '', a 'Last updated on:' timestamp is inserted at every page bottom,\n# using the given strftime format.\n#html_last_updated_fmt = '%b %d, %Y'\n\n# If true, SmartyPants will be used to convert quotes and dashes to\n# typographically correct entities.\n#html_use_smartypants = True\n\n# Custom sidebar templates, maps document names to template names.\n#html_sidebars = {}\n\n# Additional templates that should be rendered to pages, maps page names to\n# template names.\n#html_additional_pages = {'index': 'index.html'}\n\n# If false, no module index is generated.\n#html_domain_indices = True\n\n# If false, no index is generated.\nhtml_use_index = True\n\n# If true, the index is split into individual pages for each letter.\n#html_split_index = False\n\n# If true, links to the reST sources are added to the pages.\n#html_show_sourcelink = True\n\n# If true, \"Created using Sphinx\" is shown in the HTML footer. Default is True.\n#html_show_sphinx = True\n\n# If true, \"(C) Copyright ...\" is shown in the HTML footer. Default is True.\n#html_show_copyright = True\n\n# If true, an OpenSearch description file will be output, and all pages will\n# contain a <link> tag referring to it. The value of this option must be the\n# base URL from which the finished HTML is served.\n#html_use_opensearch = ''\n\n# This is the file name suffix for HTML files (e.g. \".xhtml\").\n#html_file_suffix = None\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'Qtiledoc'\n\n\n# -- Options for LaTeX output --------------------------------------------------\n\nlatex_elements = {\n# The paper size ('letterpaper' or 'a4paper').\n#'papersize': 'letterpaper',\n\n# The font size ('10pt', '11pt' or '12pt').\n#'pointsize': '10pt',\n\n# Additional stuff for the LaTeX preamble.\n#'preamble': '',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title, author, documentclass [howto/manual]).\nlatex_documents = [\n ('index', 'Qtile.tex', u'Qtile Documentation',\n u'Aldo Cortesi', 'manual'),\n]\n\n# The name of an image file (relative to this directory) to place at the top of\n# the title page.\n#latex_logo = None\n\n# For \"manual\" documents, if this is true, then toplevel headings are parts,\n# not chapters.\n#latex_use_parts = False\n\n# If true, show page references after internal links.\n#latex_show_pagerefs = False\n\n# If true, show URL addresses after external links.\n#latex_show_urls = False\n\n# Documents to append as an appendix to all manuals.\n#latex_appendices = []\n\n# If false, no module index is generated.\n#latex_domain_indices = True\n\n\n# -- Options for manual page output --------------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n ('man/qtile', 'qtile', u'Qtile Documentation',\n [u'Tycho Andersen'], 1),\n ('man/qshell', 'qshell', u'Qtile Documentation',\n [u'Tycho Andersen'], 1),\n]\n\n# If true, show URL addresses after external links.\n#man_show_urls = False\n\n\n# -- Options for Texinfo output ------------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n ('index', 'Qtile', u'Qtile Documentation',\n u'Aldo Cortesi', 'Qtile', 'A hackable tiling window manager.',\n 'Miscellaneous'),\n]\n\n# Documents to append as an appendix to all manuals.\n#texinfo_appendices = []\n\n# If false, no module index is generated.\n#texinfo_domain_indices = True\n\n# How to display URL addresses: 'footnote', 'no', or 'inline'.\n#texinfo_show_urls = 'footnote'\n\n# only import and set the theme if we're building docs locally\nif not os.environ.get('READTHEDOCS'):\n import sphinx_rtd_theme\n html_theme = 'sphinx_rtd_theme'\n html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]\n\n\ngraphviz_dot_args = ['-Lg']\n\n# A workaround for the responsive tables always having annoying scrollbars.\ndef setup(app):\n app.add_stylesheet(\"no_scrollbars.css\")\n", "path": "docs/conf.py"}]}
| 3,611 | 77 |
gh_patches_debug_42121
|
rasdani/github-patches
|
git_diff
|
MongoEngine__mongoengine-1871
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Flaky test in test suite makes CI randomly failing due to query_counter context manager
The test `def test_no_cached_queryset(self):` Is failing from time to time which is not handy as it makes the CI failing for unrelated reasons in PRs (e.g: #1766). https://github.com/MongoEngine/mongoengine/blob/42bbe6392729ee12ee4461452ac3614814933dcd/tests/queryset/queryset.py#L4709-L4719
The issue occurs because the query_counter() context was catching queries that aren't related to this particular test.
I managed to reproduce the issue after adding some debugging code and running travis in my fork (https://travis-ci.com/bagerard/mongoengine/jobs/143421029). The additional query being counted is actually a 'killcursors' query, probably being issued after the garbage collector closes another pymongo cursors.
The query_counter context manager is very handy for debugging but since it is not only counting the queries being issued within the context (other threads or processes can pollute it), it is not very robust.
I'll push a PR that makes the query_counter context ignoring 'killcursors' queries to fix this (and add a parameter `ignore_query` to the query_counter to let users customize the behavior if needed). Let me know if you have other ideas
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mongoengine/context_managers.py`
Content:
```
1 from contextlib import contextmanager
2 from pymongo.write_concern import WriteConcern
3 from mongoengine.common import _import_class
4 from mongoengine.connection import DEFAULT_CONNECTION_NAME, get_db
5
6
7 __all__ = ('switch_db', 'switch_collection', 'no_dereference',
8 'no_sub_classes', 'query_counter', 'set_write_concern')
9
10
11 class switch_db(object):
12 """switch_db alias context manager.
13
14 Example ::
15
16 # Register connections
17 register_connection('default', 'mongoenginetest')
18 register_connection('testdb-1', 'mongoenginetest2')
19
20 class Group(Document):
21 name = StringField()
22
23 Group(name='test').save() # Saves in the default db
24
25 with switch_db(Group, 'testdb-1') as Group:
26 Group(name='hello testdb!').save() # Saves in testdb-1
27 """
28
29 def __init__(self, cls, db_alias):
30 """Construct the switch_db context manager
31
32 :param cls: the class to change the registered db
33 :param db_alias: the name of the specific database to use
34 """
35 self.cls = cls
36 self.collection = cls._get_collection()
37 self.db_alias = db_alias
38 self.ori_db_alias = cls._meta.get('db_alias', DEFAULT_CONNECTION_NAME)
39
40 def __enter__(self):
41 """Change the db_alias and clear the cached collection."""
42 self.cls._meta['db_alias'] = self.db_alias
43 self.cls._collection = None
44 return self.cls
45
46 def __exit__(self, t, value, traceback):
47 """Reset the db_alias and collection."""
48 self.cls._meta['db_alias'] = self.ori_db_alias
49 self.cls._collection = self.collection
50
51
52 class switch_collection(object):
53 """switch_collection alias context manager.
54
55 Example ::
56
57 class Group(Document):
58 name = StringField()
59
60 Group(name='test').save() # Saves in the default db
61
62 with switch_collection(Group, 'group1') as Group:
63 Group(name='hello testdb!').save() # Saves in group1 collection
64 """
65
66 def __init__(self, cls, collection_name):
67 """Construct the switch_collection context manager.
68
69 :param cls: the class to change the registered db
70 :param collection_name: the name of the collection to use
71 """
72 self.cls = cls
73 self.ori_collection = cls._get_collection()
74 self.ori_get_collection_name = cls._get_collection_name
75 self.collection_name = collection_name
76
77 def __enter__(self):
78 """Change the _get_collection_name and clear the cached collection."""
79
80 @classmethod
81 def _get_collection_name(cls):
82 return self.collection_name
83
84 self.cls._get_collection_name = _get_collection_name
85 self.cls._collection = None
86 return self.cls
87
88 def __exit__(self, t, value, traceback):
89 """Reset the collection."""
90 self.cls._collection = self.ori_collection
91 self.cls._get_collection_name = self.ori_get_collection_name
92
93
94 class no_dereference(object):
95 """no_dereference context manager.
96
97 Turns off all dereferencing in Documents for the duration of the context
98 manager::
99
100 with no_dereference(Group) as Group:
101 Group.objects.find()
102 """
103
104 def __init__(self, cls):
105 """Construct the no_dereference context manager.
106
107 :param cls: the class to turn dereferencing off on
108 """
109 self.cls = cls
110
111 ReferenceField = _import_class('ReferenceField')
112 GenericReferenceField = _import_class('GenericReferenceField')
113 ComplexBaseField = _import_class('ComplexBaseField')
114
115 self.deref_fields = [k for k, v in self.cls._fields.iteritems()
116 if isinstance(v, (ReferenceField,
117 GenericReferenceField,
118 ComplexBaseField))]
119
120 def __enter__(self):
121 """Change the objects default and _auto_dereference values."""
122 for field in self.deref_fields:
123 self.cls._fields[field]._auto_dereference = False
124 return self.cls
125
126 def __exit__(self, t, value, traceback):
127 """Reset the default and _auto_dereference values."""
128 for field in self.deref_fields:
129 self.cls._fields[field]._auto_dereference = True
130 return self.cls
131
132
133 class no_sub_classes(object):
134 """no_sub_classes context manager.
135
136 Only returns instances of this class and no sub (inherited) classes::
137
138 with no_sub_classes(Group) as Group:
139 Group.objects.find()
140 """
141
142 def __init__(self, cls):
143 """Construct the no_sub_classes context manager.
144
145 :param cls: the class to turn querying sub classes on
146 """
147 self.cls = cls
148 self.cls_initial_subclasses = None
149
150 def __enter__(self):
151 """Change the objects default and _auto_dereference values."""
152 self.cls_initial_subclasses = self.cls._subclasses
153 self.cls._subclasses = (self.cls._class_name,)
154 return self.cls
155
156 def __exit__(self, t, value, traceback):
157 """Reset the default and _auto_dereference values."""
158 self.cls._subclasses = self.cls_initial_subclasses
159
160
161 class query_counter(object):
162 """Query_counter context manager to get the number of queries."""
163
164 def __init__(self):
165 """Construct the query_counter."""
166 self.counter = 0
167 self.db = get_db()
168
169 def __enter__(self):
170 """On every with block we need to drop the profile collection."""
171 self.db.set_profiling_level(0)
172 self.db.system.profile.drop()
173 self.db.set_profiling_level(2)
174 return self
175
176 def __exit__(self, t, value, traceback):
177 """Reset the profiling level."""
178 self.db.set_profiling_level(0)
179
180 def __eq__(self, value):
181 """== Compare querycounter."""
182 counter = self._get_count()
183 return value == counter
184
185 def __ne__(self, value):
186 """!= Compare querycounter."""
187 return not self.__eq__(value)
188
189 def __lt__(self, value):
190 """< Compare querycounter."""
191 return self._get_count() < value
192
193 def __le__(self, value):
194 """<= Compare querycounter."""
195 return self._get_count() <= value
196
197 def __gt__(self, value):
198 """> Compare querycounter."""
199 return self._get_count() > value
200
201 def __ge__(self, value):
202 """>= Compare querycounter."""
203 return self._get_count() >= value
204
205 def __int__(self):
206 """int representation."""
207 return self._get_count()
208
209 def __repr__(self):
210 """repr query_counter as the number of queries."""
211 return u"%s" % self._get_count()
212
213 def _get_count(self):
214 """Get the number of queries."""
215 ignore_query = {'ns': {'$ne': '%s.system.indexes' % self.db.name}}
216 count = self.db.system.profile.find(ignore_query).count() - self.counter
217 self.counter += 1 # Account for the query we just fired
218 return count
219
220
221 @contextmanager
222 def set_write_concern(collection, write_concerns):
223 combined_concerns = dict(collection.write_concern.document.items())
224 combined_concerns.update(write_concerns)
225 yield collection.with_options(write_concern=WriteConcern(**combined_concerns))
226
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mongoengine/context_managers.py b/mongoengine/context_managers.py
--- a/mongoengine/context_managers.py
+++ b/mongoengine/context_managers.py
@@ -159,51 +159,69 @@
class query_counter(object):
- """Query_counter context manager to get the number of queries."""
+ """Query_counter context manager to get the number of queries.
+ This works by updating the `profiling_level` of the database so that all queries get logged,
+ resetting the db.system.profile collection at the beginnig of the context and counting the new entries.
+
+ This was designed for debugging purpose. In fact it is a global counter so queries issued by other threads/processes
+ can interfere with it
+
+ Be aware that:
+ - Iterating over large amount of documents (>101) makes pymongo issue `getmore` queries to fetch the next batch of
+ documents (https://docs.mongodb.com/manual/tutorial/iterate-a-cursor/#cursor-batches)
+ - Some queries are ignored by default by the counter (killcursors, db.system.indexes)
+ """
def __init__(self):
- """Construct the query_counter."""
- self.counter = 0
+ """Construct the query_counter
+ """
self.db = get_db()
-
- def __enter__(self):
- """On every with block we need to drop the profile collection."""
+ self.initial_profiling_level = None
+ self._ctx_query_counter = 0 # number of queries issued by the context
+
+ self._ignored_query = {
+ 'ns':
+ {'$ne': '%s.system.indexes' % self.db.name},
+ 'op':
+ {'$ne': 'killcursors'}
+ }
+
+ def _turn_on_profiling(self):
+ self.initial_profiling_level = self.db.profiling_level()
self.db.set_profiling_level(0)
self.db.system.profile.drop()
self.db.set_profiling_level(2)
+
+ def _resets_profiling(self):
+ self.db.set_profiling_level(self.initial_profiling_level)
+
+ def __enter__(self):
+ self._turn_on_profiling()
return self
def __exit__(self, t, value, traceback):
- """Reset the profiling level."""
- self.db.set_profiling_level(0)
+ self._resets_profiling()
def __eq__(self, value):
- """== Compare querycounter."""
counter = self._get_count()
return value == counter
def __ne__(self, value):
- """!= Compare querycounter."""
return not self.__eq__(value)
def __lt__(self, value):
- """< Compare querycounter."""
return self._get_count() < value
def __le__(self, value):
- """<= Compare querycounter."""
return self._get_count() <= value
def __gt__(self, value):
- """> Compare querycounter."""
return self._get_count() > value
def __ge__(self, value):
- """>= Compare querycounter."""
return self._get_count() >= value
def __int__(self):
- """int representation."""
return self._get_count()
def __repr__(self):
@@ -211,10 +229,12 @@
return u"%s" % self._get_count()
def _get_count(self):
- """Get the number of queries."""
- ignore_query = {'ns': {'$ne': '%s.system.indexes' % self.db.name}}
- count = self.db.system.profile.find(ignore_query).count() - self.counter
- self.counter += 1 # Account for the query we just fired
+ """Get the number of queries by counting the current number of entries in db.system.profile
+ and substracting the queries issued by this context. In fact everytime this is called, 1 query is
+ issued so we need to balance that
+ """
+ count = self.db.system.profile.find(self._ignored_query).count() - self._ctx_query_counter
+ self._ctx_query_counter += 1 # Account for the query we just issued to gather the information
return count
|
{"golden_diff": "diff --git a/mongoengine/context_managers.py b/mongoengine/context_managers.py\n--- a/mongoengine/context_managers.py\n+++ b/mongoengine/context_managers.py\n@@ -159,51 +159,69 @@\n \n \n class query_counter(object):\n- \"\"\"Query_counter context manager to get the number of queries.\"\"\"\n+ \"\"\"Query_counter context manager to get the number of queries.\n+ This works by updating the `profiling_level` of the database so that all queries get logged,\n+ resetting the db.system.profile collection at the beginnig of the context and counting the new entries.\n+\n+ This was designed for debugging purpose. In fact it is a global counter so queries issued by other threads/processes\n+ can interfere with it\n+\n+ Be aware that:\n+ - Iterating over large amount of documents (>101) makes pymongo issue `getmore` queries to fetch the next batch of\n+ documents (https://docs.mongodb.com/manual/tutorial/iterate-a-cursor/#cursor-batches)\n+ - Some queries are ignored by default by the counter (killcursors, db.system.indexes)\n+ \"\"\"\n \n def __init__(self):\n- \"\"\"Construct the query_counter.\"\"\"\n- self.counter = 0\n+ \"\"\"Construct the query_counter\n+ \"\"\"\n self.db = get_db()\n-\n- def __enter__(self):\n- \"\"\"On every with block we need to drop the profile collection.\"\"\"\n+ self.initial_profiling_level = None\n+ self._ctx_query_counter = 0 # number of queries issued by the context\n+\n+ self._ignored_query = {\n+ 'ns':\n+ {'$ne': '%s.system.indexes' % self.db.name},\n+ 'op':\n+ {'$ne': 'killcursors'}\n+ }\n+\n+ def _turn_on_profiling(self):\n+ self.initial_profiling_level = self.db.profiling_level()\n self.db.set_profiling_level(0)\n self.db.system.profile.drop()\n self.db.set_profiling_level(2)\n+\n+ def _resets_profiling(self):\n+ self.db.set_profiling_level(self.initial_profiling_level)\n+\n+ def __enter__(self):\n+ self._turn_on_profiling()\n return self\n \n def __exit__(self, t, value, traceback):\n- \"\"\"Reset the profiling level.\"\"\"\n- self.db.set_profiling_level(0)\n+ self._resets_profiling()\n \n def __eq__(self, value):\n- \"\"\"== Compare querycounter.\"\"\"\n counter = self._get_count()\n return value == counter\n \n def __ne__(self, value):\n- \"\"\"!= Compare querycounter.\"\"\"\n return not self.__eq__(value)\n \n def __lt__(self, value):\n- \"\"\"< Compare querycounter.\"\"\"\n return self._get_count() < value\n \n def __le__(self, value):\n- \"\"\"<= Compare querycounter.\"\"\"\n return self._get_count() <= value\n \n def __gt__(self, value):\n- \"\"\"> Compare querycounter.\"\"\"\n return self._get_count() > value\n \n def __ge__(self, value):\n- \"\"\">= Compare querycounter.\"\"\"\n return self._get_count() >= value\n \n def __int__(self):\n- \"\"\"int representation.\"\"\"\n return self._get_count()\n \n def __repr__(self):\n@@ -211,10 +229,12 @@\n return u\"%s\" % self._get_count()\n \n def _get_count(self):\n- \"\"\"Get the number of queries.\"\"\"\n- ignore_query = {'ns': {'$ne': '%s.system.indexes' % self.db.name}}\n- count = self.db.system.profile.find(ignore_query).count() - self.counter\n- self.counter += 1 # Account for the query we just fired\n+ \"\"\"Get the number of queries by counting the current number of entries in db.system.profile\n+ and substracting the queries issued by this context. In fact everytime this is called, 1 query is\n+ issued so we need to balance that\n+ \"\"\"\n+ count = self.db.system.profile.find(self._ignored_query).count() - self._ctx_query_counter\n+ self._ctx_query_counter += 1 # Account for the query we just issued to gather the information\n return count\n", "issue": "Flaky test in test suite makes CI randomly failing due to query_counter context manager\nThe test `def test_no_cached_queryset(self):` Is failing from time to time which is not handy as it makes the CI failing for unrelated reasons in PRs (e.g: #1766). https://github.com/MongoEngine/mongoengine/blob/42bbe6392729ee12ee4461452ac3614814933dcd/tests/queryset/queryset.py#L4709-L4719\r\n\r\nThe issue occurs because the query_counter() context was catching queries that aren't related to this particular test.\r\n\r\nI managed to reproduce the issue after adding some debugging code and running travis in my fork (https://travis-ci.com/bagerard/mongoengine/jobs/143421029). The additional query being counted is actually a 'killcursors' query, probably being issued after the garbage collector closes another pymongo cursors.\r\n\r\nThe query_counter context manager is very handy for debugging but since it is not only counting the queries being issued within the context (other threads or processes can pollute it), it is not very robust.\r\n\r\nI'll push a PR that makes the query_counter context ignoring 'killcursors' queries to fix this (and add a parameter `ignore_query` to the query_counter to let users customize the behavior if needed). Let me know if you have other ideas\n", "before_files": [{"content": "from contextlib import contextmanager\nfrom pymongo.write_concern import WriteConcern\nfrom mongoengine.common import _import_class\nfrom mongoengine.connection import DEFAULT_CONNECTION_NAME, get_db\n\n\n__all__ = ('switch_db', 'switch_collection', 'no_dereference',\n 'no_sub_classes', 'query_counter', 'set_write_concern')\n\n\nclass switch_db(object):\n \"\"\"switch_db alias context manager.\n\n Example ::\n\n # Register connections\n register_connection('default', 'mongoenginetest')\n register_connection('testdb-1', 'mongoenginetest2')\n\n class Group(Document):\n name = StringField()\n\n Group(name='test').save() # Saves in the default db\n\n with switch_db(Group, 'testdb-1') as Group:\n Group(name='hello testdb!').save() # Saves in testdb-1\n \"\"\"\n\n def __init__(self, cls, db_alias):\n \"\"\"Construct the switch_db context manager\n\n :param cls: the class to change the registered db\n :param db_alias: the name of the specific database to use\n \"\"\"\n self.cls = cls\n self.collection = cls._get_collection()\n self.db_alias = db_alias\n self.ori_db_alias = cls._meta.get('db_alias', DEFAULT_CONNECTION_NAME)\n\n def __enter__(self):\n \"\"\"Change the db_alias and clear the cached collection.\"\"\"\n self.cls._meta['db_alias'] = self.db_alias\n self.cls._collection = None\n return self.cls\n\n def __exit__(self, t, value, traceback):\n \"\"\"Reset the db_alias and collection.\"\"\"\n self.cls._meta['db_alias'] = self.ori_db_alias\n self.cls._collection = self.collection\n\n\nclass switch_collection(object):\n \"\"\"switch_collection alias context manager.\n\n Example ::\n\n class Group(Document):\n name = StringField()\n\n Group(name='test').save() # Saves in the default db\n\n with switch_collection(Group, 'group1') as Group:\n Group(name='hello testdb!').save() # Saves in group1 collection\n \"\"\"\n\n def __init__(self, cls, collection_name):\n \"\"\"Construct the switch_collection context manager.\n\n :param cls: the class to change the registered db\n :param collection_name: the name of the collection to use\n \"\"\"\n self.cls = cls\n self.ori_collection = cls._get_collection()\n self.ori_get_collection_name = cls._get_collection_name\n self.collection_name = collection_name\n\n def __enter__(self):\n \"\"\"Change the _get_collection_name and clear the cached collection.\"\"\"\n\n @classmethod\n def _get_collection_name(cls):\n return self.collection_name\n\n self.cls._get_collection_name = _get_collection_name\n self.cls._collection = None\n return self.cls\n\n def __exit__(self, t, value, traceback):\n \"\"\"Reset the collection.\"\"\"\n self.cls._collection = self.ori_collection\n self.cls._get_collection_name = self.ori_get_collection_name\n\n\nclass no_dereference(object):\n \"\"\"no_dereference context manager.\n\n Turns off all dereferencing in Documents for the duration of the context\n manager::\n\n with no_dereference(Group) as Group:\n Group.objects.find()\n \"\"\"\n\n def __init__(self, cls):\n \"\"\"Construct the no_dereference context manager.\n\n :param cls: the class to turn dereferencing off on\n \"\"\"\n self.cls = cls\n\n ReferenceField = _import_class('ReferenceField')\n GenericReferenceField = _import_class('GenericReferenceField')\n ComplexBaseField = _import_class('ComplexBaseField')\n\n self.deref_fields = [k for k, v in self.cls._fields.iteritems()\n if isinstance(v, (ReferenceField,\n GenericReferenceField,\n ComplexBaseField))]\n\n def __enter__(self):\n \"\"\"Change the objects default and _auto_dereference values.\"\"\"\n for field in self.deref_fields:\n self.cls._fields[field]._auto_dereference = False\n return self.cls\n\n def __exit__(self, t, value, traceback):\n \"\"\"Reset the default and _auto_dereference values.\"\"\"\n for field in self.deref_fields:\n self.cls._fields[field]._auto_dereference = True\n return self.cls\n\n\nclass no_sub_classes(object):\n \"\"\"no_sub_classes context manager.\n\n Only returns instances of this class and no sub (inherited) classes::\n\n with no_sub_classes(Group) as Group:\n Group.objects.find()\n \"\"\"\n\n def __init__(self, cls):\n \"\"\"Construct the no_sub_classes context manager.\n\n :param cls: the class to turn querying sub classes on\n \"\"\"\n self.cls = cls\n self.cls_initial_subclasses = None\n\n def __enter__(self):\n \"\"\"Change the objects default and _auto_dereference values.\"\"\"\n self.cls_initial_subclasses = self.cls._subclasses\n self.cls._subclasses = (self.cls._class_name,)\n return self.cls\n\n def __exit__(self, t, value, traceback):\n \"\"\"Reset the default and _auto_dereference values.\"\"\"\n self.cls._subclasses = self.cls_initial_subclasses\n\n\nclass query_counter(object):\n \"\"\"Query_counter context manager to get the number of queries.\"\"\"\n\n def __init__(self):\n \"\"\"Construct the query_counter.\"\"\"\n self.counter = 0\n self.db = get_db()\n\n def __enter__(self):\n \"\"\"On every with block we need to drop the profile collection.\"\"\"\n self.db.set_profiling_level(0)\n self.db.system.profile.drop()\n self.db.set_profiling_level(2)\n return self\n\n def __exit__(self, t, value, traceback):\n \"\"\"Reset the profiling level.\"\"\"\n self.db.set_profiling_level(0)\n\n def __eq__(self, value):\n \"\"\"== Compare querycounter.\"\"\"\n counter = self._get_count()\n return value == counter\n\n def __ne__(self, value):\n \"\"\"!= Compare querycounter.\"\"\"\n return not self.__eq__(value)\n\n def __lt__(self, value):\n \"\"\"< Compare querycounter.\"\"\"\n return self._get_count() < value\n\n def __le__(self, value):\n \"\"\"<= Compare querycounter.\"\"\"\n return self._get_count() <= value\n\n def __gt__(self, value):\n \"\"\"> Compare querycounter.\"\"\"\n return self._get_count() > value\n\n def __ge__(self, value):\n \"\"\">= Compare querycounter.\"\"\"\n return self._get_count() >= value\n\n def __int__(self):\n \"\"\"int representation.\"\"\"\n return self._get_count()\n\n def __repr__(self):\n \"\"\"repr query_counter as the number of queries.\"\"\"\n return u\"%s\" % self._get_count()\n\n def _get_count(self):\n \"\"\"Get the number of queries.\"\"\"\n ignore_query = {'ns': {'$ne': '%s.system.indexes' % self.db.name}}\n count = self.db.system.profile.find(ignore_query).count() - self.counter\n self.counter += 1 # Account for the query we just fired\n return count\n\n\n@contextmanager\ndef set_write_concern(collection, write_concerns):\n combined_concerns = dict(collection.write_concern.document.items())\n combined_concerns.update(write_concerns)\n yield collection.with_options(write_concern=WriteConcern(**combined_concerns))\n", "path": "mongoengine/context_managers.py"}], "after_files": [{"content": "from contextlib import contextmanager\nfrom pymongo.write_concern import WriteConcern\nfrom mongoengine.common import _import_class\nfrom mongoengine.connection import DEFAULT_CONNECTION_NAME, get_db\n\n\n__all__ = ('switch_db', 'switch_collection', 'no_dereference',\n 'no_sub_classes', 'query_counter', 'set_write_concern')\n\n\nclass switch_db(object):\n \"\"\"switch_db alias context manager.\n\n Example ::\n\n # Register connections\n register_connection('default', 'mongoenginetest')\n register_connection('testdb-1', 'mongoenginetest2')\n\n class Group(Document):\n name = StringField()\n\n Group(name='test').save() # Saves in the default db\n\n with switch_db(Group, 'testdb-1') as Group:\n Group(name='hello testdb!').save() # Saves in testdb-1\n \"\"\"\n\n def __init__(self, cls, db_alias):\n \"\"\"Construct the switch_db context manager\n\n :param cls: the class to change the registered db\n :param db_alias: the name of the specific database to use\n \"\"\"\n self.cls = cls\n self.collection = cls._get_collection()\n self.db_alias = db_alias\n self.ori_db_alias = cls._meta.get('db_alias', DEFAULT_CONNECTION_NAME)\n\n def __enter__(self):\n \"\"\"Change the db_alias and clear the cached collection.\"\"\"\n self.cls._meta['db_alias'] = self.db_alias\n self.cls._collection = None\n return self.cls\n\n def __exit__(self, t, value, traceback):\n \"\"\"Reset the db_alias and collection.\"\"\"\n self.cls._meta['db_alias'] = self.ori_db_alias\n self.cls._collection = self.collection\n\n\nclass switch_collection(object):\n \"\"\"switch_collection alias context manager.\n\n Example ::\n\n class Group(Document):\n name = StringField()\n\n Group(name='test').save() # Saves in the default db\n\n with switch_collection(Group, 'group1') as Group:\n Group(name='hello testdb!').save() # Saves in group1 collection\n \"\"\"\n\n def __init__(self, cls, collection_name):\n \"\"\"Construct the switch_collection context manager.\n\n :param cls: the class to change the registered db\n :param collection_name: the name of the collection to use\n \"\"\"\n self.cls = cls\n self.ori_collection = cls._get_collection()\n self.ori_get_collection_name = cls._get_collection_name\n self.collection_name = collection_name\n\n def __enter__(self):\n \"\"\"Change the _get_collection_name and clear the cached collection.\"\"\"\n\n @classmethod\n def _get_collection_name(cls):\n return self.collection_name\n\n self.cls._get_collection_name = _get_collection_name\n self.cls._collection = None\n return self.cls\n\n def __exit__(self, t, value, traceback):\n \"\"\"Reset the collection.\"\"\"\n self.cls._collection = self.ori_collection\n self.cls._get_collection_name = self.ori_get_collection_name\n\n\nclass no_dereference(object):\n \"\"\"no_dereference context manager.\n\n Turns off all dereferencing in Documents for the duration of the context\n manager::\n\n with no_dereference(Group) as Group:\n Group.objects.find()\n \"\"\"\n\n def __init__(self, cls):\n \"\"\"Construct the no_dereference context manager.\n\n :param cls: the class to turn dereferencing off on\n \"\"\"\n self.cls = cls\n\n ReferenceField = _import_class('ReferenceField')\n GenericReferenceField = _import_class('GenericReferenceField')\n ComplexBaseField = _import_class('ComplexBaseField')\n\n self.deref_fields = [k for k, v in self.cls._fields.iteritems()\n if isinstance(v, (ReferenceField,\n GenericReferenceField,\n ComplexBaseField))]\n\n def __enter__(self):\n \"\"\"Change the objects default and _auto_dereference values.\"\"\"\n for field in self.deref_fields:\n self.cls._fields[field]._auto_dereference = False\n return self.cls\n\n def __exit__(self, t, value, traceback):\n \"\"\"Reset the default and _auto_dereference values.\"\"\"\n for field in self.deref_fields:\n self.cls._fields[field]._auto_dereference = True\n return self.cls\n\n\nclass no_sub_classes(object):\n \"\"\"no_sub_classes context manager.\n\n Only returns instances of this class and no sub (inherited) classes::\n\n with no_sub_classes(Group) as Group:\n Group.objects.find()\n \"\"\"\n\n def __init__(self, cls):\n \"\"\"Construct the no_sub_classes context manager.\n\n :param cls: the class to turn querying sub classes on\n \"\"\"\n self.cls = cls\n self.cls_initial_subclasses = None\n\n def __enter__(self):\n \"\"\"Change the objects default and _auto_dereference values.\"\"\"\n self.cls_initial_subclasses = self.cls._subclasses\n self.cls._subclasses = (self.cls._class_name,)\n return self.cls\n\n def __exit__(self, t, value, traceback):\n \"\"\"Reset the default and _auto_dereference values.\"\"\"\n self.cls._subclasses = self.cls_initial_subclasses\n\n\nclass query_counter(object):\n \"\"\"Query_counter context manager to get the number of queries.\n This works by updating the `profiling_level` of the database so that all queries get logged,\n resetting the db.system.profile collection at the beginnig of the context and counting the new entries.\n\n This was designed for debugging purpose. In fact it is a global counter so queries issued by other threads/processes\n can interfere with it\n\n Be aware that:\n - Iterating over large amount of documents (>101) makes pymongo issue `getmore` queries to fetch the next batch of\n documents (https://docs.mongodb.com/manual/tutorial/iterate-a-cursor/#cursor-batches)\n - Some queries are ignored by default by the counter (killcursors, db.system.indexes)\n \"\"\"\n\n def __init__(self):\n \"\"\"Construct the query_counter\n \"\"\"\n self.db = get_db()\n self.initial_profiling_level = None\n self._ctx_query_counter = 0 # number of queries issued by the context\n\n self._ignored_query = {\n 'ns':\n {'$ne': '%s.system.indexes' % self.db.name},\n 'op':\n {'$ne': 'killcursors'}\n }\n\n def _turn_on_profiling(self):\n self.initial_profiling_level = self.db.profiling_level()\n self.db.set_profiling_level(0)\n self.db.system.profile.drop()\n self.db.set_profiling_level(2)\n\n def _resets_profiling(self):\n self.db.set_profiling_level(self.initial_profiling_level)\n\n def __enter__(self):\n self._turn_on_profiling()\n return self\n\n def __exit__(self, t, value, traceback):\n self._resets_profiling()\n\n def __eq__(self, value):\n counter = self._get_count()\n return value == counter\n\n def __ne__(self, value):\n return not self.__eq__(value)\n\n def __lt__(self, value):\n return self._get_count() < value\n\n def __le__(self, value):\n return self._get_count() <= value\n\n def __gt__(self, value):\n return self._get_count() > value\n\n def __ge__(self, value):\n return self._get_count() >= value\n\n def __int__(self):\n return self._get_count()\n\n def __repr__(self):\n \"\"\"repr query_counter as the number of queries.\"\"\"\n return u\"%s\" % self._get_count()\n\n def _get_count(self):\n \"\"\"Get the number of queries by counting the current number of entries in db.system.profile\n and substracting the queries issued by this context. In fact everytime this is called, 1 query is\n issued so we need to balance that\n \"\"\"\n count = self.db.system.profile.find(self._ignored_query).count() - self._ctx_query_counter\n self._ctx_query_counter += 1 # Account for the query we just issued to gather the information\n return count\n\n\n@contextmanager\ndef set_write_concern(collection, write_concerns):\n combined_concerns = dict(collection.write_concern.document.items())\n combined_concerns.update(write_concerns)\n yield collection.with_options(write_concern=WriteConcern(**combined_concerns))\n", "path": "mongoengine/context_managers.py"}]}
| 2,774 | 944 |
gh_patches_debug_25412
|
rasdani/github-patches
|
git_diff
|
keras-team__keras-18926
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Implement `binomial` and `beta` distribution functions in `keras.random`
Following up on the issue https://github.com/keras-team/keras/issues/18918
- Implement `binomial` and `beta` distribution functions in all backends currently supported by Keras namely TensorFlow, Jax, PyTorch and Numpy.
- Add unit tests for each of these functions
Importantly,
As tensorflow doesn't offer a built-in method for beta function so I've implemented a workaround using a statistical formula to use gamma distributed random variables to derive beta distributed random variable.
Specifically, $U(a, b) = X(a) / (X(a) + Y(b))$ where $U(a,b)$ is the beta distributed random variable using parameters $a$ and $b$ and $X(a)$ and $Y(b)$ are gamma-distributed random variables using parameter $a$ and $b$ respectively.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `keras/backend/torch/random.py`
Content:
```
1 import torch
2 import torch._dynamo as dynamo
3 import torch.nn.functional as tnn
4
5 from keras.backend.config import floatx
6 from keras.backend.torch.core import convert_to_tensor
7 from keras.backend.torch.core import get_device
8 from keras.backend.torch.core import to_torch_dtype
9 from keras.random.seed_generator import SeedGenerator
10 from keras.random.seed_generator import draw_seed
11 from keras.random.seed_generator import make_default_seed
12
13
14 # torch.Generator not supported with dynamo
15 # see: https://github.com/pytorch/pytorch/issues/88576
16 @dynamo.disable()
17 def torch_seed_generator(seed):
18 first_seed, second_seed = draw_seed(seed)
19 device = get_device()
20 if device == "meta":
21 # Generator is not supported by the meta device.
22 return None
23 generator = torch.Generator(device=get_device())
24 generator.manual_seed(int(first_seed + second_seed))
25 return generator
26
27
28 def normal(shape, mean=0.0, stddev=1.0, dtype=None, seed=None):
29 dtype = dtype or floatx()
30 dtype = to_torch_dtype(dtype)
31 # Do not use generator during symbolic execution.
32 if get_device() == "meta":
33 return torch.normal(
34 mean, stddev, size=shape, dtype=dtype, device=get_device()
35 )
36 generator = torch_seed_generator(seed)
37 return torch.normal(
38 mean,
39 stddev,
40 size=shape,
41 generator=generator,
42 dtype=dtype,
43 device=get_device(),
44 )
45
46
47 def categorical(logits, num_samples, dtype="int32", seed=None):
48 logits = convert_to_tensor(logits)
49 dtype = to_torch_dtype(dtype)
50 probs = torch.softmax(logits, dim=-1)
51 # Do not use generator during symbolic execution.
52 if get_device() == "meta":
53 return torch.multinomial(
54 probs,
55 num_samples,
56 replacement=True,
57 ).type(dtype)
58 generator = torch_seed_generator(seed)
59 return torch.multinomial(
60 probs,
61 num_samples,
62 replacement=True,
63 generator=generator,
64 ).type(dtype)
65
66
67 def uniform(shape, minval=0.0, maxval=1.0, dtype=None, seed=None):
68 dtype = dtype or floatx()
69 dtype = to_torch_dtype(dtype)
70 requested_shape = shape
71 if len(requested_shape) == 0:
72 shape = (1,)
73 # Do not use generator during symbolic execution.
74 if get_device() == "meta":
75 rand_tensor = torch.rand(size=shape, dtype=dtype, device=get_device())
76 else:
77 generator = torch_seed_generator(seed)
78 rand_tensor = torch.rand(
79 size=shape, generator=generator, dtype=dtype, device=get_device()
80 )
81
82 output = (maxval - minval) * rand_tensor + minval
83
84 if len(requested_shape) == 0:
85 return output[0]
86 return output
87
88
89 def randint(shape, minval, maxval, dtype="int32", seed=None):
90 dtype = to_torch_dtype(dtype)
91 # Do not use generator during symbolic execution.
92 if get_device() == "meta":
93 return torch.randint(
94 low=minval,
95 high=maxval,
96 size=shape,
97 dtype=dtype,
98 device=get_device(),
99 )
100 generator = torch_seed_generator(seed)
101 return torch.randint(
102 low=minval,
103 high=maxval,
104 size=shape,
105 generator=generator,
106 dtype=dtype,
107 device=get_device(),
108 )
109
110
111 def truncated_normal(shape, mean=0.0, stddev=1.0, dtype=None, seed=None):
112 # Take a larger standard normal dist, discard values outside 2 * stddev
113 # Offset by mean and stddev
114 x = normal(tuple(shape) + (4,), mean=0, stddev=1, dtype=dtype, seed=seed)
115 valid = (x > -2) & (x < 2)
116 indexes = valid.max(-1, keepdim=True)[1]
117 trunc_x = torch.empty(shape, device=get_device())
118 trunc_x.data.copy_(x.gather(-1, indexes).squeeze(-1))
119 trunc_x.data.mul_(stddev).add_(mean)
120 return trunc_x
121
122
123 def _get_concrete_noise_shape(inputs, noise_shape):
124 if noise_shape is None:
125 return inputs.shape
126
127 concrete_inputs_shape = inputs.shape
128 concrete_noise_shape = []
129 for i, value in enumerate(noise_shape):
130 concrete_noise_shape.append(
131 concrete_inputs_shape[i] if value is None else value
132 )
133 return concrete_noise_shape
134
135
136 def dropout(inputs, rate, noise_shape=None, seed=None):
137 if (
138 seed is not None
139 and not (isinstance(seed, SeedGenerator) and seed._initial_seed is None)
140 or noise_shape is not None
141 ):
142 keep_prob = 1.0 - rate
143 noise_shape = _get_concrete_noise_shape(inputs, noise_shape)
144 keep_prob_matrix = torch.full(
145 noise_shape, keep_prob, device=get_device()
146 )
147 generator = torch_seed_generator(seed)
148
149 # Do not use generator during symbolic execution.
150 if get_device() == "meta":
151 mask = torch.bernoulli(keep_prob_matrix)
152 else:
153 mask = torch.bernoulli(keep_prob_matrix, generator=generator)
154
155 mask = mask.bool()
156 mask = torch.broadcast_to(mask, inputs.shape)
157 return torch.where(
158 mask,
159 inputs / keep_prob,
160 torch.zeros_like(inputs, dtype=inputs.dtype),
161 )
162 # Fast path, unseeded (since torch doesn't support seeding dropout!!!!)
163 # Using the above implementation is possible, but much slower.
164 return torch.nn.functional.dropout(
165 inputs, p=rate, training=True, inplace=False
166 )
167
168
169 def shuffle(x, axis=0, seed=None):
170 # Ref: https://github.com/pytorch/pytorch/issues/71409
171 x = convert_to_tensor(x)
172
173 # Get permutation indices
174 # Do not use generator during symbolic execution.
175 if get_device() == "meta":
176 row_perm = torch.rand(x.shape[: axis + 1], device=get_device()).argsort(
177 axis
178 )
179 else:
180 generator = torch_seed_generator(seed)
181 row_perm = torch.rand(
182 x.shape[: axis + 1], generator=generator, device=get_device()
183 ).argsort(axis)
184 for _ in range(x.ndim - axis - 1):
185 row_perm.unsqueeze_(-1)
186
187 # Reformat this for the gather operation
188 row_perm = row_perm.repeat(
189 *[1 for _ in range(axis + 1)], *(x.shape[axis + 1 :])
190 )
191 return x.gather(axis, row_perm)
192
193
194 def gamma(shape, alpha, dtype=None, seed=None):
195 dtype = dtype or floatx()
196 dtype = to_torch_dtype(dtype)
197 alpha = torch.ones(shape) * torch.tensor(alpha)
198 beta = torch.ones(shape)
199 prev_rng_state = torch.random.get_rng_state()
200 first_seed, second_seed = draw_seed(seed)
201 torch.manual_seed(first_seed + second_seed)
202 gamma_distribution = torch.distributions.gamma.Gamma(alpha, beta)
203 sample = gamma_distribution.sample().type(dtype)
204 torch.random.set_rng_state(prev_rng_state)
205 return sample
206
207
208 def binomial(shape, counts, probabilities, dtype=None, seed=None):
209 dtype = dtype or floatx()
210 dtype = to_torch_dtype(dtype)
211 counts = torch.ones(shape) * convert_to_tensor(counts)
212 probabilities = torch.ones(shape) * convert_to_tensor(probabilities)
213 prev_rng_state = torch.random.get_rng_state()
214 first_seed, second_seed = draw_seed(seed)
215 torch.manual_seed(first_seed + second_seed)
216 binomial_distribution = torch.distributions.binomial.Binomial(
217 total_count=counts, probs=probabilities
218 )
219 sample = binomial_distribution.sample().type(dtype)
220 torch.random.set_rng_state(prev_rng_state)
221 return sample
222
223
224 def beta(shape, alpha, beta, dtype=None, seed=None):
225 dtype = dtype or floatx()
226 dtype = to_torch_dtype(dtype)
227 alpha = torch.ones(shape) * convert_to_tensor(alpha)
228 beta = torch.ones(shape) * convert_to_tensor(beta)
229 prev_rng_state = torch.random.get_rng_state()
230 first_seed, second_seed = draw_seed(seed)
231 torch.manual_seed(first_seed + second_seed)
232 beta_distribution = torch.distributions.beta.Beta(
233 concentration1=alpha, concentration0=beta
234 )
235 sample = beta_distribution.sample().type(dtype)
236 torch.random.set_rng_state(prev_rng_state)
237 return sample
238
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/keras/backend/torch/random.py b/keras/backend/torch/random.py
--- a/keras/backend/torch/random.py
+++ b/keras/backend/torch/random.py
@@ -208,8 +208,8 @@
def binomial(shape, counts, probabilities, dtype=None, seed=None):
dtype = dtype or floatx()
dtype = to_torch_dtype(dtype)
- counts = torch.ones(shape) * convert_to_tensor(counts)
- probabilities = torch.ones(shape) * convert_to_tensor(probabilities)
+ counts = torch.broadcast_to(convert_to_tensor(counts), shape)
+ probabilities = torch.broadcast_to(convert_to_tensor(probabilities), shape)
prev_rng_state = torch.random.get_rng_state()
first_seed, second_seed = draw_seed(seed)
torch.manual_seed(first_seed + second_seed)
@@ -224,8 +224,8 @@
def beta(shape, alpha, beta, dtype=None, seed=None):
dtype = dtype or floatx()
dtype = to_torch_dtype(dtype)
- alpha = torch.ones(shape) * convert_to_tensor(alpha)
- beta = torch.ones(shape) * convert_to_tensor(beta)
+ alpha = torch.broadcast_to(convert_to_tensor(alpha), shape)
+ beta = torch.broadcast_to(convert_to_tensor(beta), shape)
prev_rng_state = torch.random.get_rng_state()
first_seed, second_seed = draw_seed(seed)
torch.manual_seed(first_seed + second_seed)
|
{"golden_diff": "diff --git a/keras/backend/torch/random.py b/keras/backend/torch/random.py\n--- a/keras/backend/torch/random.py\n+++ b/keras/backend/torch/random.py\n@@ -208,8 +208,8 @@\n def binomial(shape, counts, probabilities, dtype=None, seed=None):\n dtype = dtype or floatx()\n dtype = to_torch_dtype(dtype)\n- counts = torch.ones(shape) * convert_to_tensor(counts)\n- probabilities = torch.ones(shape) * convert_to_tensor(probabilities)\n+ counts = torch.broadcast_to(convert_to_tensor(counts), shape)\n+ probabilities = torch.broadcast_to(convert_to_tensor(probabilities), shape)\n prev_rng_state = torch.random.get_rng_state()\n first_seed, second_seed = draw_seed(seed)\n torch.manual_seed(first_seed + second_seed)\n@@ -224,8 +224,8 @@\n def beta(shape, alpha, beta, dtype=None, seed=None):\n dtype = dtype or floatx()\n dtype = to_torch_dtype(dtype)\n- alpha = torch.ones(shape) * convert_to_tensor(alpha)\n- beta = torch.ones(shape) * convert_to_tensor(beta)\n+ alpha = torch.broadcast_to(convert_to_tensor(alpha), shape)\n+ beta = torch.broadcast_to(convert_to_tensor(beta), shape)\n prev_rng_state = torch.random.get_rng_state()\n first_seed, second_seed = draw_seed(seed)\n torch.manual_seed(first_seed + second_seed)\n", "issue": "Implement `binomial` and `beta` distribution functions in `keras.random`\nFollowing up on the issue https://github.com/keras-team/keras/issues/18918\r\n\r\n- Implement `binomial` and `beta` distribution functions in all backends currently supported by Keras namely TensorFlow, Jax, PyTorch and Numpy.\r\n- Add unit tests for each of these functions\r\n\r\nImportantly,\r\nAs tensorflow doesn't offer a built-in method for beta function so I've implemented a workaround using a statistical formula to use gamma distributed random variables to derive beta distributed random variable.\r\nSpecifically, $U(a, b) = X(a) / (X(a) + Y(b))$ where $U(a,b)$ is the beta distributed random variable using parameters $a$ and $b$ and $X(a)$ and $Y(b)$ are gamma-distributed random variables using parameter $a$ and $b$ respectively.\n", "before_files": [{"content": "import torch\nimport torch._dynamo as dynamo\nimport torch.nn.functional as tnn\n\nfrom keras.backend.config import floatx\nfrom keras.backend.torch.core import convert_to_tensor\nfrom keras.backend.torch.core import get_device\nfrom keras.backend.torch.core import to_torch_dtype\nfrom keras.random.seed_generator import SeedGenerator\nfrom keras.random.seed_generator import draw_seed\nfrom keras.random.seed_generator import make_default_seed\n\n\n# torch.Generator not supported with dynamo\n# see: https://github.com/pytorch/pytorch/issues/88576\[email protected]()\ndef torch_seed_generator(seed):\n first_seed, second_seed = draw_seed(seed)\n device = get_device()\n if device == \"meta\":\n # Generator is not supported by the meta device.\n return None\n generator = torch.Generator(device=get_device())\n generator.manual_seed(int(first_seed + second_seed))\n return generator\n\n\ndef normal(shape, mean=0.0, stddev=1.0, dtype=None, seed=None):\n dtype = dtype or floatx()\n dtype = to_torch_dtype(dtype)\n # Do not use generator during symbolic execution.\n if get_device() == \"meta\":\n return torch.normal(\n mean, stddev, size=shape, dtype=dtype, device=get_device()\n )\n generator = torch_seed_generator(seed)\n return torch.normal(\n mean,\n stddev,\n size=shape,\n generator=generator,\n dtype=dtype,\n device=get_device(),\n )\n\n\ndef categorical(logits, num_samples, dtype=\"int32\", seed=None):\n logits = convert_to_tensor(logits)\n dtype = to_torch_dtype(dtype)\n probs = torch.softmax(logits, dim=-1)\n # Do not use generator during symbolic execution.\n if get_device() == \"meta\":\n return torch.multinomial(\n probs,\n num_samples,\n replacement=True,\n ).type(dtype)\n generator = torch_seed_generator(seed)\n return torch.multinomial(\n probs,\n num_samples,\n replacement=True,\n generator=generator,\n ).type(dtype)\n\n\ndef uniform(shape, minval=0.0, maxval=1.0, dtype=None, seed=None):\n dtype = dtype or floatx()\n dtype = to_torch_dtype(dtype)\n requested_shape = shape\n if len(requested_shape) == 0:\n shape = (1,)\n # Do not use generator during symbolic execution.\n if get_device() == \"meta\":\n rand_tensor = torch.rand(size=shape, dtype=dtype, device=get_device())\n else:\n generator = torch_seed_generator(seed)\n rand_tensor = torch.rand(\n size=shape, generator=generator, dtype=dtype, device=get_device()\n )\n\n output = (maxval - minval) * rand_tensor + minval\n\n if len(requested_shape) == 0:\n return output[0]\n return output\n\n\ndef randint(shape, minval, maxval, dtype=\"int32\", seed=None):\n dtype = to_torch_dtype(dtype)\n # Do not use generator during symbolic execution.\n if get_device() == \"meta\":\n return torch.randint(\n low=minval,\n high=maxval,\n size=shape,\n dtype=dtype,\n device=get_device(),\n )\n generator = torch_seed_generator(seed)\n return torch.randint(\n low=minval,\n high=maxval,\n size=shape,\n generator=generator,\n dtype=dtype,\n device=get_device(),\n )\n\n\ndef truncated_normal(shape, mean=0.0, stddev=1.0, dtype=None, seed=None):\n # Take a larger standard normal dist, discard values outside 2 * stddev\n # Offset by mean and stddev\n x = normal(tuple(shape) + (4,), mean=0, stddev=1, dtype=dtype, seed=seed)\n valid = (x > -2) & (x < 2)\n indexes = valid.max(-1, keepdim=True)[1]\n trunc_x = torch.empty(shape, device=get_device())\n trunc_x.data.copy_(x.gather(-1, indexes).squeeze(-1))\n trunc_x.data.mul_(stddev).add_(mean)\n return trunc_x\n\n\ndef _get_concrete_noise_shape(inputs, noise_shape):\n if noise_shape is None:\n return inputs.shape\n\n concrete_inputs_shape = inputs.shape\n concrete_noise_shape = []\n for i, value in enumerate(noise_shape):\n concrete_noise_shape.append(\n concrete_inputs_shape[i] if value is None else value\n )\n return concrete_noise_shape\n\n\ndef dropout(inputs, rate, noise_shape=None, seed=None):\n if (\n seed is not None\n and not (isinstance(seed, SeedGenerator) and seed._initial_seed is None)\n or noise_shape is not None\n ):\n keep_prob = 1.0 - rate\n noise_shape = _get_concrete_noise_shape(inputs, noise_shape)\n keep_prob_matrix = torch.full(\n noise_shape, keep_prob, device=get_device()\n )\n generator = torch_seed_generator(seed)\n\n # Do not use generator during symbolic execution.\n if get_device() == \"meta\":\n mask = torch.bernoulli(keep_prob_matrix)\n else:\n mask = torch.bernoulli(keep_prob_matrix, generator=generator)\n\n mask = mask.bool()\n mask = torch.broadcast_to(mask, inputs.shape)\n return torch.where(\n mask,\n inputs / keep_prob,\n torch.zeros_like(inputs, dtype=inputs.dtype),\n )\n # Fast path, unseeded (since torch doesn't support seeding dropout!!!!)\n # Using the above implementation is possible, but much slower.\n return torch.nn.functional.dropout(\n inputs, p=rate, training=True, inplace=False\n )\n\n\ndef shuffle(x, axis=0, seed=None):\n # Ref: https://github.com/pytorch/pytorch/issues/71409\n x = convert_to_tensor(x)\n\n # Get permutation indices\n # Do not use generator during symbolic execution.\n if get_device() == \"meta\":\n row_perm = torch.rand(x.shape[: axis + 1], device=get_device()).argsort(\n axis\n )\n else:\n generator = torch_seed_generator(seed)\n row_perm = torch.rand(\n x.shape[: axis + 1], generator=generator, device=get_device()\n ).argsort(axis)\n for _ in range(x.ndim - axis - 1):\n row_perm.unsqueeze_(-1)\n\n # Reformat this for the gather operation\n row_perm = row_perm.repeat(\n *[1 for _ in range(axis + 1)], *(x.shape[axis + 1 :])\n )\n return x.gather(axis, row_perm)\n\n\ndef gamma(shape, alpha, dtype=None, seed=None):\n dtype = dtype or floatx()\n dtype = to_torch_dtype(dtype)\n alpha = torch.ones(shape) * torch.tensor(alpha)\n beta = torch.ones(shape)\n prev_rng_state = torch.random.get_rng_state()\n first_seed, second_seed = draw_seed(seed)\n torch.manual_seed(first_seed + second_seed)\n gamma_distribution = torch.distributions.gamma.Gamma(alpha, beta)\n sample = gamma_distribution.sample().type(dtype)\n torch.random.set_rng_state(prev_rng_state)\n return sample\n\n\ndef binomial(shape, counts, probabilities, dtype=None, seed=None):\n dtype = dtype or floatx()\n dtype = to_torch_dtype(dtype)\n counts = torch.ones(shape) * convert_to_tensor(counts)\n probabilities = torch.ones(shape) * convert_to_tensor(probabilities)\n prev_rng_state = torch.random.get_rng_state()\n first_seed, second_seed = draw_seed(seed)\n torch.manual_seed(first_seed + second_seed)\n binomial_distribution = torch.distributions.binomial.Binomial(\n total_count=counts, probs=probabilities\n )\n sample = binomial_distribution.sample().type(dtype)\n torch.random.set_rng_state(prev_rng_state)\n return sample\n\n\ndef beta(shape, alpha, beta, dtype=None, seed=None):\n dtype = dtype or floatx()\n dtype = to_torch_dtype(dtype)\n alpha = torch.ones(shape) * convert_to_tensor(alpha)\n beta = torch.ones(shape) * convert_to_tensor(beta)\n prev_rng_state = torch.random.get_rng_state()\n first_seed, second_seed = draw_seed(seed)\n torch.manual_seed(first_seed + second_seed)\n beta_distribution = torch.distributions.beta.Beta(\n concentration1=alpha, concentration0=beta\n )\n sample = beta_distribution.sample().type(dtype)\n torch.random.set_rng_state(prev_rng_state)\n return sample\n", "path": "keras/backend/torch/random.py"}], "after_files": [{"content": "import torch\nimport torch._dynamo as dynamo\nimport torch.nn.functional as tnn\n\nfrom keras.backend.config import floatx\nfrom keras.backend.torch.core import convert_to_tensor\nfrom keras.backend.torch.core import get_device\nfrom keras.backend.torch.core import to_torch_dtype\nfrom keras.random.seed_generator import SeedGenerator\nfrom keras.random.seed_generator import draw_seed\nfrom keras.random.seed_generator import make_default_seed\n\n\n# torch.Generator not supported with dynamo\n# see: https://github.com/pytorch/pytorch/issues/88576\[email protected]()\ndef torch_seed_generator(seed):\n first_seed, second_seed = draw_seed(seed)\n device = get_device()\n if device == \"meta\":\n # Generator is not supported by the meta device.\n return None\n generator = torch.Generator(device=get_device())\n generator.manual_seed(int(first_seed + second_seed))\n return generator\n\n\ndef normal(shape, mean=0.0, stddev=1.0, dtype=None, seed=None):\n dtype = dtype or floatx()\n dtype = to_torch_dtype(dtype)\n # Do not use generator during symbolic execution.\n if get_device() == \"meta\":\n return torch.normal(\n mean, stddev, size=shape, dtype=dtype, device=get_device()\n )\n generator = torch_seed_generator(seed)\n return torch.normal(\n mean,\n stddev,\n size=shape,\n generator=generator,\n dtype=dtype,\n device=get_device(),\n )\n\n\ndef categorical(logits, num_samples, dtype=\"int32\", seed=None):\n logits = convert_to_tensor(logits)\n dtype = to_torch_dtype(dtype)\n probs = torch.softmax(logits, dim=-1)\n # Do not use generator during symbolic execution.\n if get_device() == \"meta\":\n return torch.multinomial(\n probs,\n num_samples,\n replacement=True,\n ).type(dtype)\n generator = torch_seed_generator(seed)\n return torch.multinomial(\n probs,\n num_samples,\n replacement=True,\n generator=generator,\n ).type(dtype)\n\n\ndef uniform(shape, minval=0.0, maxval=1.0, dtype=None, seed=None):\n dtype = dtype or floatx()\n dtype = to_torch_dtype(dtype)\n requested_shape = shape\n if len(requested_shape) == 0:\n shape = (1,)\n # Do not use generator during symbolic execution.\n if get_device() == \"meta\":\n rand_tensor = torch.rand(size=shape, dtype=dtype, device=get_device())\n else:\n generator = torch_seed_generator(seed)\n rand_tensor = torch.rand(\n size=shape, generator=generator, dtype=dtype, device=get_device()\n )\n\n output = (maxval - minval) * rand_tensor + minval\n\n if len(requested_shape) == 0:\n return output[0]\n return output\n\n\ndef randint(shape, minval, maxval, dtype=\"int32\", seed=None):\n dtype = to_torch_dtype(dtype)\n # Do not use generator during symbolic execution.\n if get_device() == \"meta\":\n return torch.randint(\n low=minval,\n high=maxval,\n size=shape,\n dtype=dtype,\n device=get_device(),\n )\n generator = torch_seed_generator(seed)\n return torch.randint(\n low=minval,\n high=maxval,\n size=shape,\n generator=generator,\n dtype=dtype,\n device=get_device(),\n )\n\n\ndef truncated_normal(shape, mean=0.0, stddev=1.0, dtype=None, seed=None):\n # Take a larger standard normal dist, discard values outside 2 * stddev\n # Offset by mean and stddev\n x = normal(tuple(shape) + (4,), mean=0, stddev=1, dtype=dtype, seed=seed)\n valid = (x > -2) & (x < 2)\n indexes = valid.max(-1, keepdim=True)[1]\n trunc_x = torch.empty(shape, device=get_device())\n trunc_x.data.copy_(x.gather(-1, indexes).squeeze(-1))\n trunc_x.data.mul_(stddev).add_(mean)\n return trunc_x\n\n\ndef _get_concrete_noise_shape(inputs, noise_shape):\n if noise_shape is None:\n return inputs.shape\n\n concrete_inputs_shape = inputs.shape\n concrete_noise_shape = []\n for i, value in enumerate(noise_shape):\n concrete_noise_shape.append(\n concrete_inputs_shape[i] if value is None else value\n )\n return concrete_noise_shape\n\n\ndef dropout(inputs, rate, noise_shape=None, seed=None):\n if (\n seed is not None\n and not (isinstance(seed, SeedGenerator) and seed._initial_seed is None)\n or noise_shape is not None\n ):\n keep_prob = 1.0 - rate\n noise_shape = _get_concrete_noise_shape(inputs, noise_shape)\n keep_prob_matrix = torch.full(\n noise_shape, keep_prob, device=get_device()\n )\n generator = torch_seed_generator(seed)\n\n # Do not use generator during symbolic execution.\n if get_device() == \"meta\":\n mask = torch.bernoulli(keep_prob_matrix)\n else:\n mask = torch.bernoulli(keep_prob_matrix, generator=generator)\n\n mask = mask.bool()\n mask = torch.broadcast_to(mask, inputs.shape)\n return torch.where(\n mask,\n inputs / keep_prob,\n torch.zeros_like(inputs, dtype=inputs.dtype),\n )\n # Fast path, unseeded (since torch doesn't support seeding dropout!!!!)\n # Using the above implementation is possible, but much slower.\n return torch.nn.functional.dropout(\n inputs, p=rate, training=True, inplace=False\n )\n\n\ndef shuffle(x, axis=0, seed=None):\n # Ref: https://github.com/pytorch/pytorch/issues/71409\n x = convert_to_tensor(x)\n\n # Get permutation indices\n # Do not use generator during symbolic execution.\n if get_device() == \"meta\":\n row_perm = torch.rand(x.shape[: axis + 1], device=get_device()).argsort(\n axis\n )\n else:\n generator = torch_seed_generator(seed)\n row_perm = torch.rand(\n x.shape[: axis + 1], generator=generator, device=get_device()\n ).argsort(axis)\n for _ in range(x.ndim - axis - 1):\n row_perm.unsqueeze_(-1)\n\n # Reformat this for the gather operation\n row_perm = row_perm.repeat(\n *[1 for _ in range(axis + 1)], *(x.shape[axis + 1 :])\n )\n return x.gather(axis, row_perm)\n\n\ndef gamma(shape, alpha, dtype=None, seed=None):\n dtype = dtype or floatx()\n dtype = to_torch_dtype(dtype)\n alpha = torch.ones(shape) * torch.tensor(alpha)\n beta = torch.ones(shape)\n prev_rng_state = torch.random.get_rng_state()\n first_seed, second_seed = draw_seed(seed)\n torch.manual_seed(first_seed + second_seed)\n gamma_distribution = torch.distributions.gamma.Gamma(alpha, beta)\n sample = gamma_distribution.sample().type(dtype)\n torch.random.set_rng_state(prev_rng_state)\n return sample\n\n\ndef binomial(shape, counts, probabilities, dtype=None, seed=None):\n dtype = dtype or floatx()\n dtype = to_torch_dtype(dtype)\n counts = torch.broadcast_to(convert_to_tensor(counts), shape)\n probabilities = torch.broadcast_to(convert_to_tensor(probabilities), shape)\n prev_rng_state = torch.random.get_rng_state()\n first_seed, second_seed = draw_seed(seed)\n torch.manual_seed(first_seed + second_seed)\n binomial_distribution = torch.distributions.binomial.Binomial(\n total_count=counts, probs=probabilities\n )\n sample = binomial_distribution.sample().type(dtype)\n torch.random.set_rng_state(prev_rng_state)\n return sample\n\n\ndef beta(shape, alpha, beta, dtype=None, seed=None):\n dtype = dtype or floatx()\n dtype = to_torch_dtype(dtype)\n alpha = torch.broadcast_to(convert_to_tensor(alpha), shape)\n beta = torch.broadcast_to(convert_to_tensor(beta), shape)\n prev_rng_state = torch.random.get_rng_state()\n first_seed, second_seed = draw_seed(seed)\n torch.manual_seed(first_seed + second_seed)\n beta_distribution = torch.distributions.beta.Beta(\n concentration1=alpha, concentration0=beta\n )\n sample = beta_distribution.sample().type(dtype)\n torch.random.set_rng_state(prev_rng_state)\n return sample\n", "path": "keras/backend/torch/random.py"}]}
| 2,917 | 315 |
gh_patches_debug_29233
|
rasdani/github-patches
|
git_diff
|
spack__spack-5268
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Spack provides wrong path for include library
I am trying to setup my own package for Spack using a very simple C++ program:
```
// in test.cpp
#include <iostream>
#include <armadillo>
using namespace std;
using namespace arma;
int main()
{
mat A = randu<mat>(4,5);
mat B = randu<mat>(4,5);
cout << A*B.t() << endl;
return 0;
}
```
The program depends on the library Armadillo. I compile the program using CMake; here is my CMakeLists.txt file:
```
project(test)
# -----------------------------------------------------------------------------
# Require CMake 2.8.
cmake_minimum_required(VERSION 2.8)
# -----------------------------------------------------------------------------
# CMake policies.
# VERSION not allowed in project() unless CMP0048 is set to NEW.
cmake_policy(SET CMP0048 NEW)
# Allow creating targets with reserved names
# or which do not match the validity pattern.
cmake_policy(SET CMP0037 OLD)
# -----------------------------------------------------------------------------
find_package(Armadillo)
if(ARMADILLO_FOUND)
list(APPEND OLIVE_DEFINITIONS "-DHAVE_ARMA")
list(APPEND OLIVE_INCLUDE_DIRS "${ARMADILLO_INCLUDE_DIRS}")
else()
MESSAGE(FATAL_ERROR "A library with Armadillo API is not found.")
endif()
# -----------------------------------------------------------------------------
find_package(BLAS REQUIRED)
find_package(LAPACK REQUIRED)
if(LAPACK_FOUND)
list(APPEND OLIVE_LIBRARIES ${LAPACK_LIBRARIES})
else()
MESSAGE(FATAL_ERROR "A library with LAPACK API is not found.")
endif()
# -----------------------------------------------------------------------------
# Preprocessor definitions.
foreach(OLIVE_DEFINITION ${OLIVE_DEFINITIONS})
add_definitions(${OLIVE_DEFINITION})
endforeach()
# Include directories.
foreach(OLIVE_INCLUDE_DIR ${OLIVE_INCLUDE_DIRS})
include_directories(${OLIVE_INCLUDE_DIR})
endforeach()
# Linker directories.
foreach(OLIVE_LIBRARY_DIR ${OLIVE_LIBRARY_DIRS})
link_directories(${OLIVE_LIBRARY_DIR})
endforeach()
# Executable.
add_executable (test test.cpp)
target_link_libraries(test ${OLIVE_LIBRARIES})
```
Then I create a package using the `spack create` command:
```
from spack import *
class Olive(CMakePackage):
homepage = "http://www.example.com"
url = "file:///home/chvillanuevap/Workspace/olive-1.0.0.tar.gz"
version('1.0.0', '4d594401468e9a7766c2c2e0f1c0c4e2')
depends_on('cmake', type='build')
depends_on('armadillo')
def cmake_args(self):
args = []
return args
```
When I run `spack install olive`, I get the following error:
```
Building CXX object CMakeFiles/test.dir/test.cpp.o
/home/chvillanuevap/Workspace/spack/lib/spack/env/gcc/g++ -DHAVE_ARMA -I/home/chvillanuevap/Workspace/spack/opt/spack/linux-ubuntu16-x86_64/gcc-5.4.0/armadillo-7.500.0-k7fwnukwvvyzgfxhyhhwwxjhaohmdmit/include -O2 -g -DNDEBUG -o CMakeFiles/test.dir/test.cpp.o -c /home/chvillanuevap/Workspace/spack/var/spack/stage/olive-1.0.0-io6llpqdxqohx457argmnsjqtq4fpmhr/olive/test.cpp
In file included from /home/chvillanuevap/Workspace/spack/opt/spack/linux-ubuntu16-x86_64/gcc-5.4.0/armadillo-7.500.0-k7fwnukwvvyzgfxhyhhwwxjhaohmdmit/include/armadillo:83:0,
from /home/chvillanuevap/Workspace/spack/var/spack/stage/olive-1.0.0-io6llpqdxqohx457argmnsjqtq4fpmhr/olive/test.cpp:2:
/home/chvillanuevap/Workspace/spack/opt/spack/linux-ubuntu16-x86_64/gcc-5.4.0/armadillo-7.500.0-k7fwnukwvvyzgfxhyhhwwxjhaohmdmit/include/armadillo_bits/include_superlu.hpp:91:53: fatal error: /home/chvillanuevap/Workspace/spack/opt/spack/1-ubuntu16-x86_64/gcc-5.4.0/superlu-5.2.1-lrqbalx6k6q6btuxmszymj7p5dal65d2/include/supermatrix.h: No such file or directory
```
Notice how the path for SuperLU (a dependency of Armadillo) says `1-ubuntu16-x86_64` for the architecture instead of the correct `linux-ubuntu16-x86_64`. Why does this happen?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `var/spack/repos/builtin/packages/armadillo/package.py`
Content:
```
1 ##############################################################################
2 # Copyright (c) 2013-2016, Lawrence Livermore National Security, LLC.
3 # Produced at the Lawrence Livermore National Laboratory.
4 #
5 # This file is part of Spack.
6 # Created by Todd Gamblin, [email protected], All rights reserved.
7 # LLNL-CODE-647188
8 #
9 # For details, see https://github.com/llnl/spack
10 # Please also see the NOTICE and LICENSE files for our notice and the LGPL.
11 #
12 # This program is free software; you can redistribute it and/or modify
13 # it under the terms of the GNU Lesser General Public License (as
14 # published by the Free Software Foundation) version 2.1, February 1999.
15 #
16 # This program is distributed in the hope that it will be useful, but
17 # WITHOUT ANY WARRANTY; without even the IMPLIED WARRANTY OF
18 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the terms and
19 # conditions of the GNU Lesser General Public License for more details.
20 #
21 # You should have received a copy of the GNU Lesser General Public
22 # License along with this program; if not, write to the Free Software
23 # Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA
24 ##############################################################################
25 from spack import *
26
27
28 class Armadillo(CMakePackage):
29 """Armadillo is a high quality linear algebra library (matrix maths)
30 for the C++ language, aiming towards a good balance between speed and
31 ease of use."""
32
33 homepage = "http://arma.sourceforge.net/"
34 url = "http://sourceforge.net/projects/arma/files/armadillo-7.200.1.tar.xz"
35
36 version('7.900.1', '5ef71763bd429a3d481499878351f3be')
37 version('7.500.0', '7d316fdf3c3c7ea92b64704180ae315d')
38 version('7.200.2', 'b21585372d67a8876117fd515d8cf0a2')
39 version('7.200.1', 'ed86d6df0058979e107502e1fe3e469e')
40
41 variant('hdf5', default=False, description='Include HDF5 support')
42
43 depends_on('[email protected]:', type='build')
44 depends_on('arpack-ng') # old arpack causes undefined symbols
45 depends_on('blas')
46 depends_on('lapack')
47 depends_on('[email protected]:')
48 depends_on('hdf5', when='+hdf5')
49
50 def cmake_args(self):
51 spec = self.spec
52
53 arpack = find_libraries('libarpack', root=spec[
54 'arpack-ng'].prefix.lib, shared=True)
55 superlu = find_libraries('libsuperlu', root=spec[
56 'superlu'].prefix, shared=False, recurse=True)
57 return [
58 # ARPACK support
59 '-DARPACK_LIBRARY={0}'.format(arpack.joined()),
60 # BLAS support
61 '-DBLAS_LIBRARY={0}'.format(spec['blas'].libs.joined()),
62 # LAPACK support
63 '-DLAPACK_LIBRARY={0}'.format(spec['lapack'].libs.joined()),
64 # SuperLU support
65 '-DSuperLU_INCLUDE_DIR={0}'.format(spec['superlu'].prefix.include),
66 '-DSuperLU_LIBRARY={0}'.format(superlu.joined()),
67 # HDF5 support
68 '-DDETECT_HDF5={0}'.format('ON' if '+hdf5' in spec else 'OFF')
69 ]
70
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/var/spack/repos/builtin/packages/armadillo/package.py b/var/spack/repos/builtin/packages/armadillo/package.py
--- a/var/spack/repos/builtin/packages/armadillo/package.py
+++ b/var/spack/repos/builtin/packages/armadillo/package.py
@@ -33,6 +33,9 @@
homepage = "http://arma.sourceforge.net/"
url = "http://sourceforge.net/projects/arma/files/armadillo-7.200.1.tar.xz"
+ version('8.100.1', 'd9762d6f097e0451d0cfadfbda295e7c')
+ version('7.950.1', 'c06eb38b12cae49cab0ce05f96147147')
+ # NOTE: v7.900.1 download url seems broken is no v7.950.1?
version('7.900.1', '5ef71763bd429a3d481499878351f3be')
version('7.500.0', '7d316fdf3c3c7ea92b64704180ae315d')
version('7.200.2', 'b21585372d67a8876117fd515d8cf0a2')
@@ -47,11 +50,17 @@
depends_on('[email protected]:')
depends_on('hdf5', when='+hdf5')
+ # Adds an `#undef linux` to prevent preprocessor expansion of include
+ # directories with `linux` in them getting transformed into a 1.
+ # E.g. `/path/linux-x86_64/dir` -> `/path/1-x86_64/dir` if/when a linux
+ # platform's compiler is adding `#define linux 1`.
+ patch('undef_linux.patch', when='platform=linux')
+
def cmake_args(self):
spec = self.spec
arpack = find_libraries('libarpack', root=spec[
- 'arpack-ng'].prefix.lib, shared=True)
+ 'arpack-ng'].prefix.lib64, shared=True)
superlu = find_libraries('libsuperlu', root=spec[
'superlu'].prefix, shared=False, recurse=True)
return [
|
{"golden_diff": "diff --git a/var/spack/repos/builtin/packages/armadillo/package.py b/var/spack/repos/builtin/packages/armadillo/package.py\n--- a/var/spack/repos/builtin/packages/armadillo/package.py\n+++ b/var/spack/repos/builtin/packages/armadillo/package.py\n@@ -33,6 +33,9 @@\n homepage = \"http://arma.sourceforge.net/\"\n url = \"http://sourceforge.net/projects/arma/files/armadillo-7.200.1.tar.xz\"\n \n+ version('8.100.1', 'd9762d6f097e0451d0cfadfbda295e7c')\n+ version('7.950.1', 'c06eb38b12cae49cab0ce05f96147147')\n+ # NOTE: v7.900.1 download url seems broken is no v7.950.1?\n version('7.900.1', '5ef71763bd429a3d481499878351f3be')\n version('7.500.0', '7d316fdf3c3c7ea92b64704180ae315d')\n version('7.200.2', 'b21585372d67a8876117fd515d8cf0a2')\n@@ -47,11 +50,17 @@\n depends_on('[email protected]:')\n depends_on('hdf5', when='+hdf5')\n \n+ # Adds an `#undef linux` to prevent preprocessor expansion of include\n+ # directories with `linux` in them getting transformed into a 1.\n+ # E.g. `/path/linux-x86_64/dir` -> `/path/1-x86_64/dir` if/when a linux\n+ # platform's compiler is adding `#define linux 1`.\n+ patch('undef_linux.patch', when='platform=linux')\n+\n def cmake_args(self):\n spec = self.spec\n \n arpack = find_libraries('libarpack', root=spec[\n- 'arpack-ng'].prefix.lib, shared=True)\n+ 'arpack-ng'].prefix.lib64, shared=True)\n superlu = find_libraries('libsuperlu', root=spec[\n 'superlu'].prefix, shared=False, recurse=True)\n return [\n", "issue": "Spack provides wrong path for include library\nI am trying to setup my own package for Spack using a very simple C++ program:\r\n\r\n```\r\n// in test.cpp\r\n#include <iostream>\r\n#include <armadillo>\r\n\r\nusing namespace std;\r\nusing namespace arma;\r\n\r\nint main()\r\n{\r\n\tmat A = randu<mat>(4,5);\r\n\tmat B = randu<mat>(4,5);\r\n\r\n\tcout << A*B.t() << endl;\r\n\r\n\treturn 0;\r\n}\r\n```\r\n\r\nThe program depends on the library Armadillo. I compile the program using CMake; here is my CMakeLists.txt file:\r\n\r\n```\r\nproject(test)\r\n\r\n# -----------------------------------------------------------------------------\r\n\r\n# Require CMake 2.8.\r\ncmake_minimum_required(VERSION 2.8)\r\n\r\n# -----------------------------------------------------------------------------\r\n# CMake policies.\r\n\r\n# VERSION not allowed in project() unless CMP0048 is set to NEW.\r\ncmake_policy(SET CMP0048 NEW)\r\n\r\n# Allow creating targets with reserved names\r\n# or which do not match the validity pattern.\r\ncmake_policy(SET CMP0037 OLD)\r\n\r\n# -----------------------------------------------------------------------------\r\n\r\nfind_package(Armadillo)\r\n\r\nif(ARMADILLO_FOUND)\r\n list(APPEND OLIVE_DEFINITIONS \"-DHAVE_ARMA\")\r\n list(APPEND OLIVE_INCLUDE_DIRS \"${ARMADILLO_INCLUDE_DIRS}\")\r\nelse()\r\n MESSAGE(FATAL_ERROR \"A library with Armadillo API is not found.\")\r\nendif()\r\n\r\n# ----------------------------------------------------------------------------- \r\n\r\nfind_package(BLAS REQUIRED)\r\n\r\nfind_package(LAPACK REQUIRED)\r\n\r\nif(LAPACK_FOUND)\r\n list(APPEND OLIVE_LIBRARIES ${LAPACK_LIBRARIES})\r\nelse()\r\n MESSAGE(FATAL_ERROR \"A library with LAPACK API is not found.\")\r\nendif()\r\n \r\n# ----------------------------------------------------------------------------- \r\n\r\n# Preprocessor definitions.\r\nforeach(OLIVE_DEFINITION ${OLIVE_DEFINITIONS})\r\n add_definitions(${OLIVE_DEFINITION})\r\nendforeach()\r\n\r\n# Include directories.\r\nforeach(OLIVE_INCLUDE_DIR ${OLIVE_INCLUDE_DIRS})\r\n include_directories(${OLIVE_INCLUDE_DIR})\r\nendforeach()\r\n\r\n# Linker directories.\r\nforeach(OLIVE_LIBRARY_DIR ${OLIVE_LIBRARY_DIRS})\r\n link_directories(${OLIVE_LIBRARY_DIR})\r\nendforeach()\r\n\r\n# Executable.\r\nadd_executable (test test.cpp)\r\ntarget_link_libraries(test ${OLIVE_LIBRARIES})\r\n```\r\n\r\nThen I create a package using the `spack create` command:\r\n\r\n```\r\nfrom spack import *\r\n\r\nclass Olive(CMakePackage):\r\n\r\n homepage = \"http://www.example.com\"\r\n url = \"file:///home/chvillanuevap/Workspace/olive-1.0.0.tar.gz\"\r\n\r\n version('1.0.0', '4d594401468e9a7766c2c2e0f1c0c4e2')\r\n\r\n depends_on('cmake', type='build')\r\n depends_on('armadillo')\r\n\r\n def cmake_args(self):\r\n args = []\r\n return args\r\n```\r\n\r\nWhen I run `spack install olive`, I get the following error:\r\n\r\n```\r\nBuilding CXX object CMakeFiles/test.dir/test.cpp.o\r\n/home/chvillanuevap/Workspace/spack/lib/spack/env/gcc/g++ -DHAVE_ARMA -I/home/chvillanuevap/Workspace/spack/opt/spack/linux-ubuntu16-x86_64/gcc-5.4.0/armadillo-7.500.0-k7fwnukwvvyzgfxhyhhwwxjhaohmdmit/include -O2 -g -DNDEBUG -o CMakeFiles/test.dir/test.cpp.o -c /home/chvillanuevap/Workspace/spack/var/spack/stage/olive-1.0.0-io6llpqdxqohx457argmnsjqtq4fpmhr/olive/test.cpp\r\nIn file included from /home/chvillanuevap/Workspace/spack/opt/spack/linux-ubuntu16-x86_64/gcc-5.4.0/armadillo-7.500.0-k7fwnukwvvyzgfxhyhhwwxjhaohmdmit/include/armadillo:83:0,\r\n from /home/chvillanuevap/Workspace/spack/var/spack/stage/olive-1.0.0-io6llpqdxqohx457argmnsjqtq4fpmhr/olive/test.cpp:2:\r\n/home/chvillanuevap/Workspace/spack/opt/spack/linux-ubuntu16-x86_64/gcc-5.4.0/armadillo-7.500.0-k7fwnukwvvyzgfxhyhhwwxjhaohmdmit/include/armadillo_bits/include_superlu.hpp:91:53: fatal error: /home/chvillanuevap/Workspace/spack/opt/spack/1-ubuntu16-x86_64/gcc-5.4.0/superlu-5.2.1-lrqbalx6k6q6btuxmszymj7p5dal65d2/include/supermatrix.h: No such file or directory\r\n```\r\n\r\nNotice how the path for SuperLU (a dependency of Armadillo) says `1-ubuntu16-x86_64` for the architecture instead of the correct `linux-ubuntu16-x86_64`. Why does this happen?\n", "before_files": [{"content": "##############################################################################\n# Copyright (c) 2013-2016, Lawrence Livermore National Security, LLC.\n# Produced at the Lawrence Livermore National Laboratory.\n#\n# This file is part of Spack.\n# Created by Todd Gamblin, [email protected], All rights reserved.\n# LLNL-CODE-647188\n#\n# For details, see https://github.com/llnl/spack\n# Please also see the NOTICE and LICENSE files for our notice and the LGPL.\n#\n# This program is free software; you can redistribute it and/or modify\n# it under the terms of the GNU Lesser General Public License (as\n# published by the Free Software Foundation) version 2.1, February 1999.\n#\n# This program is distributed in the hope that it will be useful, but\n# WITHOUT ANY WARRANTY; without even the IMPLIED WARRANTY OF\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the terms and\n# conditions of the GNU Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this program; if not, write to the Free Software\n# Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA\n##############################################################################\nfrom spack import *\n\n\nclass Armadillo(CMakePackage):\n \"\"\"Armadillo is a high quality linear algebra library (matrix maths)\n for the C++ language, aiming towards a good balance between speed and\n ease of use.\"\"\"\n\n homepage = \"http://arma.sourceforge.net/\"\n url = \"http://sourceforge.net/projects/arma/files/armadillo-7.200.1.tar.xz\"\n\n version('7.900.1', '5ef71763bd429a3d481499878351f3be')\n version('7.500.0', '7d316fdf3c3c7ea92b64704180ae315d')\n version('7.200.2', 'b21585372d67a8876117fd515d8cf0a2')\n version('7.200.1', 'ed86d6df0058979e107502e1fe3e469e')\n\n variant('hdf5', default=False, description='Include HDF5 support')\n\n depends_on('[email protected]:', type='build')\n depends_on('arpack-ng') # old arpack causes undefined symbols\n depends_on('blas')\n depends_on('lapack')\n depends_on('[email protected]:')\n depends_on('hdf5', when='+hdf5')\n\n def cmake_args(self):\n spec = self.spec\n\n arpack = find_libraries('libarpack', root=spec[\n 'arpack-ng'].prefix.lib, shared=True)\n superlu = find_libraries('libsuperlu', root=spec[\n 'superlu'].prefix, shared=False, recurse=True)\n return [\n # ARPACK support\n '-DARPACK_LIBRARY={0}'.format(arpack.joined()),\n # BLAS support\n '-DBLAS_LIBRARY={0}'.format(spec['blas'].libs.joined()),\n # LAPACK support\n '-DLAPACK_LIBRARY={0}'.format(spec['lapack'].libs.joined()),\n # SuperLU support\n '-DSuperLU_INCLUDE_DIR={0}'.format(spec['superlu'].prefix.include),\n '-DSuperLU_LIBRARY={0}'.format(superlu.joined()),\n # HDF5 support\n '-DDETECT_HDF5={0}'.format('ON' if '+hdf5' in spec else 'OFF')\n ]\n", "path": "var/spack/repos/builtin/packages/armadillo/package.py"}], "after_files": [{"content": "##############################################################################\n# Copyright (c) 2013-2016, Lawrence Livermore National Security, LLC.\n# Produced at the Lawrence Livermore National Laboratory.\n#\n# This file is part of Spack.\n# Created by Todd Gamblin, [email protected], All rights reserved.\n# LLNL-CODE-647188\n#\n# For details, see https://github.com/llnl/spack\n# Please also see the NOTICE and LICENSE files for our notice and the LGPL.\n#\n# This program is free software; you can redistribute it and/or modify\n# it under the terms of the GNU Lesser General Public License (as\n# published by the Free Software Foundation) version 2.1, February 1999.\n#\n# This program is distributed in the hope that it will be useful, but\n# WITHOUT ANY WARRANTY; without even the IMPLIED WARRANTY OF\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the terms and\n# conditions of the GNU Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this program; if not, write to the Free Software\n# Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA\n##############################################################################\nfrom spack import *\n\n\nclass Armadillo(CMakePackage):\n \"\"\"Armadillo is a high quality linear algebra library (matrix maths)\n for the C++ language, aiming towards a good balance between speed and\n ease of use.\"\"\"\n\n homepage = \"http://arma.sourceforge.net/\"\n url = \"http://sourceforge.net/projects/arma/files/armadillo-7.200.1.tar.xz\"\n\n version('8.100.1', 'd9762d6f097e0451d0cfadfbda295e7c')\n version('7.950.1', 'c06eb38b12cae49cab0ce05f96147147')\n # NOTE: v7.900.1 download url seems broken is no v7.950.1?\n version('7.900.1', '5ef71763bd429a3d481499878351f3be')\n version('7.500.0', '7d316fdf3c3c7ea92b64704180ae315d')\n version('7.200.2', 'b21585372d67a8876117fd515d8cf0a2')\n version('7.200.1', 'ed86d6df0058979e107502e1fe3e469e')\n\n variant('hdf5', default=False, description='Include HDF5 support')\n\n depends_on('[email protected]:', type='build')\n depends_on('arpack-ng') # old arpack causes undefined symbols\n depends_on('blas')\n depends_on('lapack')\n depends_on('[email protected]:')\n depends_on('hdf5', when='+hdf5')\n\n # Adds an `#undef linux` to prevent preprocessor expansion of include\n # directories with `linux` in them getting transformed into a 1.\n # E.g. `/path/linux-x86_64/dir` -> `/path/1-x86_64/dir` if/when a linux\n # platform's compiler is adding `#define linux 1`.\n patch('undef_linux.patch', when='platform=linux')\n\n def cmake_args(self):\n spec = self.spec\n\n arpack = find_libraries('libarpack', root=spec[\n 'arpack-ng'].prefix.lib64, shared=True)\n superlu = find_libraries('libsuperlu', root=spec[\n 'superlu'].prefix, shared=False, recurse=True)\n return [\n # ARPACK support\n '-DARPACK_LIBRARY={0}'.format(arpack.joined()),\n # BLAS support\n '-DBLAS_LIBRARY={0}'.format(spec['blas'].libs.joined()),\n # LAPACK support\n '-DLAPACK_LIBRARY={0}'.format(spec['lapack'].libs.joined()),\n # SuperLU support\n '-DSuperLU_INCLUDE_DIR={0}'.format(spec['superlu'].prefix.include),\n '-DSuperLU_LIBRARY={0}'.format(superlu.joined()),\n # HDF5 support\n '-DDETECT_HDF5={0}'.format('ON' if '+hdf5' in spec else 'OFF')\n ]\n", "path": "var/spack/repos/builtin/packages/armadillo/package.py"}]}
| 2,413 | 576 |
gh_patches_debug_6538
|
rasdani/github-patches
|
git_diff
|
microsoft__torchgeo-91
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Samplers don't work in parallel
When I try to use RandomGeoSampler with `num_workers` >= 1, I get the following error:
```
Traceback (most recent call last):
File "/anaconda/envs/azureml_py38/lib/python3.9/multiprocessing/process.py", line 315, in _bootstrap
self.run()
File "/anaconda/envs/azureml_py38/lib/python3.9/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/anaconda/envs/azureml_py38/lib/python3.9/site-packages/torch/utils/data/_utils/worker.py", line 260, in _worker_loop
r = index_queue.get(timeout=MP_STATUS_CHECK_INTERVAL)
File "/anaconda/envs/azureml_py38/lib/python3.9/multiprocessing/queues.py", line 122, in get
return _ForkingPickler.loads(res)
TypeError: __new__() missing 5 required positional arguments: 'maxx', 'miny', 'maxy', 'mint', and 'maxt'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `torchgeo/datasets/utils.py`
Content:
```
1 """Common dataset utilities."""
2
3 import bz2
4 import contextlib
5 import gzip
6 import lzma
7 import os
8 import tarfile
9 import zipfile
10 from typing import Any, Dict, Iterator, List, Optional, Tuple, Union
11
12 import torch
13 from torch import Tensor
14 from torchvision.datasets.utils import check_integrity, download_url
15
16 __all__ = (
17 "check_integrity",
18 "download_url",
19 "download_and_extract_archive",
20 "extract_archive",
21 "BoundingBox",
22 "working_dir",
23 "collate_dict",
24 )
25
26
27 class _rarfile:
28 class RarFile:
29 def __init__(self, *args: Any, **kwargs: Any) -> None:
30 self.args = args
31 self.kwargs = kwargs
32
33 def __enter__(self) -> Any:
34 try:
35 import rarfile
36 except ImportError:
37 raise ImportError(
38 "rarfile is not installed and is required to extract this dataset"
39 )
40
41 # TODO: catch exception for when rarfile is installed but not
42 # unrar/unar/bsdtar
43 return rarfile.RarFile(*self.args, **self.kwargs)
44
45 def __exit__(self, exc_type: None, exc_value: None, traceback: None) -> None:
46 pass
47
48
49 def extract_archive(src: str, dst: Optional[str] = None) -> None:
50 """Extract an archive.
51
52 Args:
53 src: file to be extracted
54 dst: directory to extract to (defaults to dirname of ``src``)
55
56 Raises:
57 RuntimeError: if src file has unknown archival/compression scheme
58 """
59 if dst is None:
60 dst = os.path.dirname(src)
61
62 suffix_and_extractor: List[Tuple[Union[str, Tuple[str, ...]], Any]] = [
63 (".rar", _rarfile.RarFile),
64 (
65 (".tar", ".tar.gz", ".tar.bz2", ".tar.xz", ".tgz", ".tbz2", ".tbz", ".txz"),
66 tarfile.open,
67 ),
68 (".zip", zipfile.ZipFile),
69 ]
70
71 for suffix, extractor in suffix_and_extractor:
72 if src.endswith(suffix):
73 with extractor(src, "r") as f:
74 f.extractall(dst)
75 return
76
77 suffix_and_decompressor: List[Tuple[str, Any]] = [
78 (".bz2", bz2.open),
79 (".gz", gzip.open),
80 (".xz", lzma.open),
81 ]
82
83 for suffix, decompressor in suffix_and_decompressor:
84 if src.endswith(suffix):
85 dst = os.path.join(dst, os.path.basename(src).replace(suffix, ""))
86 with decompressor(src, "rb") as sf, open(dst, "wb") as df:
87 df.write(sf.read())
88 return
89
90 raise RuntimeError("src file has unknown archival/compression scheme")
91
92
93 def download_and_extract_archive(
94 url: str,
95 download_root: str,
96 extract_root: Optional[str] = None,
97 filename: Optional[str] = None,
98 md5: Optional[str] = None,
99 ) -> None:
100 """Download and extract an archive.
101
102 Args:
103 url: URL to download
104 download_root: directory to download to
105 extract_root: directory to extract to (defaults to ``download_root``)
106 filename: download filename (defaults to basename of ``url``)
107 md5: checksum for download verification
108 """
109 download_root = os.path.expanduser(download_root)
110 if extract_root is None:
111 extract_root = download_root
112 if not filename:
113 filename = os.path.basename(url)
114
115 download_url(url, download_root, filename, md5)
116
117 archive = os.path.join(download_root, filename)
118 print("Extracting {} to {}".format(archive, extract_root))
119 extract_archive(archive, extract_root)
120
121
122 def download_radiant_mlhub(
123 dataset_id: str, download_root: str, api_key: Optional[str] = None
124 ) -> None:
125 """Download a dataset from Radiant Earth.
126
127 Args:
128 dataset_id: the ID of the dataset to fetch
129 download_root: directory to download to
130 api_key: the API key to use for all requests from the session. Can also be
131 passed in via the ``MLHUB_API_KEY`` environment variable, or configured in
132 ``~/.mlhub/profiles``.
133 """
134 try:
135 import radiant_mlhub
136 except ImportError:
137 raise ImportError(
138 "radiant_mlhub is not installed and is required to download this dataset"
139 )
140
141 dataset = radiant_mlhub.Dataset.fetch(dataset_id, api_key=api_key)
142 dataset.download(output_dir=download_root, api_key=api_key)
143
144
145 class BoundingBox(Tuple[float, float, float, float, float, float]):
146 """Data class for indexing spatiotemporal data.
147
148 Attributes:
149 minx (float): western boundary
150 maxx (float): eastern boundary
151 miny (float): southern boundary
152 maxy (float): northern boundary
153 mint (float): earliest boundary
154 maxt (float): latest boundary
155 """
156
157 def __new__(
158 cls,
159 minx: float,
160 maxx: float,
161 miny: float,
162 maxy: float,
163 mint: float,
164 maxt: float,
165 ) -> "BoundingBox":
166 """Create a new instance of BoundingBox.
167
168 Args:
169 minx: western boundary
170 maxx: eastern boundary
171 miny: southern boundary
172 maxy: northern boundary
173 mint: earliest boundary
174 maxt: latest boundary
175
176 Raises:
177 ValueError: if bounding box is invalid
178 (minx > maxx, miny > maxy, or mint > maxt)
179 """
180 if minx > maxx:
181 raise ValueError(f"Bounding box is invalid: 'minx={minx}' > 'maxx={maxx}'")
182 if miny > maxy:
183 raise ValueError(f"Bounding box is invalid: 'miny={miny}' > 'maxy={maxy}'")
184 if mint > maxt:
185 raise ValueError(f"Bounding box is invalid: 'mint={mint}' > 'maxt={maxt}'")
186
187 # Using super() doesn't work with mypy, see:
188 # https://stackoverflow.com/q/60611012/5828163
189 return tuple.__new__(cls, [minx, maxx, miny, maxy, mint, maxt])
190
191 def __init__(
192 self,
193 minx: float,
194 maxx: float,
195 miny: float,
196 maxy: float,
197 mint: float,
198 maxt: float,
199 ) -> None:
200 """Initialize a new instance of BoundingBox.
201
202 Args:
203 minx: western boundary
204 maxx: eastern boundary
205 miny: southern boundary
206 maxy: northern boundary
207 mint: earliest boundary
208 maxt: latest boundary
209 """
210 self.minx = minx
211 self.maxx = maxx
212 self.miny = miny
213 self.maxy = maxy
214 self.mint = mint
215 self.maxt = maxt
216
217 def __repr__(self) -> str:
218 """Return the formal string representation of the object.
219
220 Returns:
221 formal string representation
222 """
223 return (
224 f"{self.__class__.__name__}(minx={self.minx}, maxx={self.maxx}, "
225 f"miny={self.miny}, maxy={self.maxy}, mint={self.mint}, maxt={self.maxt})"
226 )
227
228 def intersects(self, other: "BoundingBox") -> bool:
229 """Whether or not two bounding boxes intersect.
230
231 Args:
232 other: another bounding box
233
234 Returns:
235 True if bounding boxes intersect, else False
236 """
237 return (
238 self.minx <= other.maxx
239 and self.maxx >= other.minx
240 and self.miny <= other.maxy
241 and self.maxy >= other.miny
242 and self.mint <= other.maxt
243 and self.maxt >= other.mint
244 )
245
246
247 @contextlib.contextmanager
248 def working_dir(dirname: str, create: bool = False) -> Iterator[None]:
249 """Context manager for changing directories.
250
251 Args:
252 dirname: directory to temporarily change to
253 create: if True, create the destination directory
254 """
255 if create:
256 os.makedirs(dirname, exist_ok=True)
257
258 cwd = os.getcwd()
259 os.chdir(dirname)
260
261 try:
262 yield
263 finally:
264 os.chdir(cwd)
265
266
267 def collate_dict(samples: List[Dict[str, Any]]) -> Dict[str, Any]:
268 """Merge a list of samples to form a mini-batch of Tensors.
269
270 Args:
271 samples: list of samples
272
273 Returns:
274 a single sample
275 """
276 collated = {}
277 for key, value in samples[0].items():
278 if isinstance(value, Tensor):
279 collated[key] = torch.stack([sample[key] for sample in samples])
280 else:
281 collated[key] = [
282 sample[key] for sample in samples
283 ] # type: ignore[assignment]
284 return collated
285
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/torchgeo/datasets/utils.py b/torchgeo/datasets/utils.py
--- a/torchgeo/datasets/utils.py
+++ b/torchgeo/datasets/utils.py
@@ -214,6 +214,14 @@
self.mint = mint
self.maxt = maxt
+ def __getnewargs__(self) -> Tuple[float, float, float, float, float, float]:
+ """Values passed to the ``__new__()`` method upon unpickling.
+
+ Returns:
+ tuple of bounds
+ """
+ return self.minx, self.maxx, self.miny, self.maxy, self.mint, self.maxt
+
def __repr__(self) -> str:
"""Return the formal string representation of the object.
|
{"golden_diff": "diff --git a/torchgeo/datasets/utils.py b/torchgeo/datasets/utils.py\n--- a/torchgeo/datasets/utils.py\n+++ b/torchgeo/datasets/utils.py\n@@ -214,6 +214,14 @@\n self.mint = mint\n self.maxt = maxt\n \n+ def __getnewargs__(self) -> Tuple[float, float, float, float, float, float]:\n+ \"\"\"Values passed to the ``__new__()`` method upon unpickling.\n+\n+ Returns:\n+ tuple of bounds\n+ \"\"\"\n+ return self.minx, self.maxx, self.miny, self.maxy, self.mint, self.maxt\n+\n def __repr__(self) -> str:\n \"\"\"Return the formal string representation of the object.\n", "issue": "Samplers don't work in parallel\nWhen I try to use RandomGeoSampler with `num_workers` >= 1, I get the following error:\r\n```\r\nTraceback (most recent call last):\r\n File \"/anaconda/envs/azureml_py38/lib/python3.9/multiprocessing/process.py\", line 315, in _bootstrap\r\n self.run()\r\n File \"/anaconda/envs/azureml_py38/lib/python3.9/multiprocessing/process.py\", line 108, in run\r\n self._target(*self._args, **self._kwargs)\r\n File \"/anaconda/envs/azureml_py38/lib/python3.9/site-packages/torch/utils/data/_utils/worker.py\", line 260, in _worker_loop\r\n r = index_queue.get(timeout=MP_STATUS_CHECK_INTERVAL)\r\n File \"/anaconda/envs/azureml_py38/lib/python3.9/multiprocessing/queues.py\", line 122, in get\r\n return _ForkingPickler.loads(res)\r\nTypeError: __new__() missing 5 required positional arguments: 'maxx', 'miny', 'maxy', 'mint', and 'maxt'\r\n```\n", "before_files": [{"content": "\"\"\"Common dataset utilities.\"\"\"\n\nimport bz2\nimport contextlib\nimport gzip\nimport lzma\nimport os\nimport tarfile\nimport zipfile\nfrom typing import Any, Dict, Iterator, List, Optional, Tuple, Union\n\nimport torch\nfrom torch import Tensor\nfrom torchvision.datasets.utils import check_integrity, download_url\n\n__all__ = (\n \"check_integrity\",\n \"download_url\",\n \"download_and_extract_archive\",\n \"extract_archive\",\n \"BoundingBox\",\n \"working_dir\",\n \"collate_dict\",\n)\n\n\nclass _rarfile:\n class RarFile:\n def __init__(self, *args: Any, **kwargs: Any) -> None:\n self.args = args\n self.kwargs = kwargs\n\n def __enter__(self) -> Any:\n try:\n import rarfile\n except ImportError:\n raise ImportError(\n \"rarfile is not installed and is required to extract this dataset\"\n )\n\n # TODO: catch exception for when rarfile is installed but not\n # unrar/unar/bsdtar\n return rarfile.RarFile(*self.args, **self.kwargs)\n\n def __exit__(self, exc_type: None, exc_value: None, traceback: None) -> None:\n pass\n\n\ndef extract_archive(src: str, dst: Optional[str] = None) -> None:\n \"\"\"Extract an archive.\n\n Args:\n src: file to be extracted\n dst: directory to extract to (defaults to dirname of ``src``)\n\n Raises:\n RuntimeError: if src file has unknown archival/compression scheme\n \"\"\"\n if dst is None:\n dst = os.path.dirname(src)\n\n suffix_and_extractor: List[Tuple[Union[str, Tuple[str, ...]], Any]] = [\n (\".rar\", _rarfile.RarFile),\n (\n (\".tar\", \".tar.gz\", \".tar.bz2\", \".tar.xz\", \".tgz\", \".tbz2\", \".tbz\", \".txz\"),\n tarfile.open,\n ),\n (\".zip\", zipfile.ZipFile),\n ]\n\n for suffix, extractor in suffix_and_extractor:\n if src.endswith(suffix):\n with extractor(src, \"r\") as f:\n f.extractall(dst)\n return\n\n suffix_and_decompressor: List[Tuple[str, Any]] = [\n (\".bz2\", bz2.open),\n (\".gz\", gzip.open),\n (\".xz\", lzma.open),\n ]\n\n for suffix, decompressor in suffix_and_decompressor:\n if src.endswith(suffix):\n dst = os.path.join(dst, os.path.basename(src).replace(suffix, \"\"))\n with decompressor(src, \"rb\") as sf, open(dst, \"wb\") as df:\n df.write(sf.read())\n return\n\n raise RuntimeError(\"src file has unknown archival/compression scheme\")\n\n\ndef download_and_extract_archive(\n url: str,\n download_root: str,\n extract_root: Optional[str] = None,\n filename: Optional[str] = None,\n md5: Optional[str] = None,\n) -> None:\n \"\"\"Download and extract an archive.\n\n Args:\n url: URL to download\n download_root: directory to download to\n extract_root: directory to extract to (defaults to ``download_root``)\n filename: download filename (defaults to basename of ``url``)\n md5: checksum for download verification\n \"\"\"\n download_root = os.path.expanduser(download_root)\n if extract_root is None:\n extract_root = download_root\n if not filename:\n filename = os.path.basename(url)\n\n download_url(url, download_root, filename, md5)\n\n archive = os.path.join(download_root, filename)\n print(\"Extracting {} to {}\".format(archive, extract_root))\n extract_archive(archive, extract_root)\n\n\ndef download_radiant_mlhub(\n dataset_id: str, download_root: str, api_key: Optional[str] = None\n) -> None:\n \"\"\"Download a dataset from Radiant Earth.\n\n Args:\n dataset_id: the ID of the dataset to fetch\n download_root: directory to download to\n api_key: the API key to use for all requests from the session. Can also be\n passed in via the ``MLHUB_API_KEY`` environment variable, or configured in\n ``~/.mlhub/profiles``.\n \"\"\"\n try:\n import radiant_mlhub\n except ImportError:\n raise ImportError(\n \"radiant_mlhub is not installed and is required to download this dataset\"\n )\n\n dataset = radiant_mlhub.Dataset.fetch(dataset_id, api_key=api_key)\n dataset.download(output_dir=download_root, api_key=api_key)\n\n\nclass BoundingBox(Tuple[float, float, float, float, float, float]):\n \"\"\"Data class for indexing spatiotemporal data.\n\n Attributes:\n minx (float): western boundary\n maxx (float): eastern boundary\n miny (float): southern boundary\n maxy (float): northern boundary\n mint (float): earliest boundary\n maxt (float): latest boundary\n \"\"\"\n\n def __new__(\n cls,\n minx: float,\n maxx: float,\n miny: float,\n maxy: float,\n mint: float,\n maxt: float,\n ) -> \"BoundingBox\":\n \"\"\"Create a new instance of BoundingBox.\n\n Args:\n minx: western boundary\n maxx: eastern boundary\n miny: southern boundary\n maxy: northern boundary\n mint: earliest boundary\n maxt: latest boundary\n\n Raises:\n ValueError: if bounding box is invalid\n (minx > maxx, miny > maxy, or mint > maxt)\n \"\"\"\n if minx > maxx:\n raise ValueError(f\"Bounding box is invalid: 'minx={minx}' > 'maxx={maxx}'\")\n if miny > maxy:\n raise ValueError(f\"Bounding box is invalid: 'miny={miny}' > 'maxy={maxy}'\")\n if mint > maxt:\n raise ValueError(f\"Bounding box is invalid: 'mint={mint}' > 'maxt={maxt}'\")\n\n # Using super() doesn't work with mypy, see:\n # https://stackoverflow.com/q/60611012/5828163\n return tuple.__new__(cls, [minx, maxx, miny, maxy, mint, maxt])\n\n def __init__(\n self,\n minx: float,\n maxx: float,\n miny: float,\n maxy: float,\n mint: float,\n maxt: float,\n ) -> None:\n \"\"\"Initialize a new instance of BoundingBox.\n\n Args:\n minx: western boundary\n maxx: eastern boundary\n miny: southern boundary\n maxy: northern boundary\n mint: earliest boundary\n maxt: latest boundary\n \"\"\"\n self.minx = minx\n self.maxx = maxx\n self.miny = miny\n self.maxy = maxy\n self.mint = mint\n self.maxt = maxt\n\n def __repr__(self) -> str:\n \"\"\"Return the formal string representation of the object.\n\n Returns:\n formal string representation\n \"\"\"\n return (\n f\"{self.__class__.__name__}(minx={self.minx}, maxx={self.maxx}, \"\n f\"miny={self.miny}, maxy={self.maxy}, mint={self.mint}, maxt={self.maxt})\"\n )\n\n def intersects(self, other: \"BoundingBox\") -> bool:\n \"\"\"Whether or not two bounding boxes intersect.\n\n Args:\n other: another bounding box\n\n Returns:\n True if bounding boxes intersect, else False\n \"\"\"\n return (\n self.minx <= other.maxx\n and self.maxx >= other.minx\n and self.miny <= other.maxy\n and self.maxy >= other.miny\n and self.mint <= other.maxt\n and self.maxt >= other.mint\n )\n\n\[email protected]\ndef working_dir(dirname: str, create: bool = False) -> Iterator[None]:\n \"\"\"Context manager for changing directories.\n\n Args:\n dirname: directory to temporarily change to\n create: if True, create the destination directory\n \"\"\"\n if create:\n os.makedirs(dirname, exist_ok=True)\n\n cwd = os.getcwd()\n os.chdir(dirname)\n\n try:\n yield\n finally:\n os.chdir(cwd)\n\n\ndef collate_dict(samples: List[Dict[str, Any]]) -> Dict[str, Any]:\n \"\"\"Merge a list of samples to form a mini-batch of Tensors.\n\n Args:\n samples: list of samples\n\n Returns:\n a single sample\n \"\"\"\n collated = {}\n for key, value in samples[0].items():\n if isinstance(value, Tensor):\n collated[key] = torch.stack([sample[key] for sample in samples])\n else:\n collated[key] = [\n sample[key] for sample in samples\n ] # type: ignore[assignment]\n return collated\n", "path": "torchgeo/datasets/utils.py"}], "after_files": [{"content": "\"\"\"Common dataset utilities.\"\"\"\n\nimport bz2\nimport contextlib\nimport gzip\nimport lzma\nimport os\nimport tarfile\nimport zipfile\nfrom typing import Any, Dict, Iterator, List, Optional, Tuple, Union\n\nimport torch\nfrom torch import Tensor\nfrom torchvision.datasets.utils import check_integrity, download_url\n\n__all__ = (\n \"check_integrity\",\n \"download_url\",\n \"download_and_extract_archive\",\n \"extract_archive\",\n \"BoundingBox\",\n \"working_dir\",\n \"collate_dict\",\n)\n\n\nclass _rarfile:\n class RarFile:\n def __init__(self, *args: Any, **kwargs: Any) -> None:\n self.args = args\n self.kwargs = kwargs\n\n def __enter__(self) -> Any:\n try:\n import rarfile\n except ImportError:\n raise ImportError(\n \"rarfile is not installed and is required to extract this dataset\"\n )\n\n # TODO: catch exception for when rarfile is installed but not\n # unrar/unar/bsdtar\n return rarfile.RarFile(*self.args, **self.kwargs)\n\n def __exit__(self, exc_type: None, exc_value: None, traceback: None) -> None:\n pass\n\n\ndef extract_archive(src: str, dst: Optional[str] = None) -> None:\n \"\"\"Extract an archive.\n\n Args:\n src: file to be extracted\n dst: directory to extract to (defaults to dirname of ``src``)\n\n Raises:\n RuntimeError: if src file has unknown archival/compression scheme\n \"\"\"\n if dst is None:\n dst = os.path.dirname(src)\n\n suffix_and_extractor: List[Tuple[Union[str, Tuple[str, ...]], Any]] = [\n (\".rar\", _rarfile.RarFile),\n (\n (\".tar\", \".tar.gz\", \".tar.bz2\", \".tar.xz\", \".tgz\", \".tbz2\", \".tbz\", \".txz\"),\n tarfile.open,\n ),\n (\".zip\", zipfile.ZipFile),\n ]\n\n for suffix, extractor in suffix_and_extractor:\n if src.endswith(suffix):\n with extractor(src, \"r\") as f:\n f.extractall(dst)\n return\n\n suffix_and_decompressor: List[Tuple[str, Any]] = [\n (\".bz2\", bz2.open),\n (\".gz\", gzip.open),\n (\".xz\", lzma.open),\n ]\n\n for suffix, decompressor in suffix_and_decompressor:\n if src.endswith(suffix):\n dst = os.path.join(dst, os.path.basename(src).replace(suffix, \"\"))\n with decompressor(src, \"rb\") as sf, open(dst, \"wb\") as df:\n df.write(sf.read())\n return\n\n raise RuntimeError(\"src file has unknown archival/compression scheme\")\n\n\ndef download_and_extract_archive(\n url: str,\n download_root: str,\n extract_root: Optional[str] = None,\n filename: Optional[str] = None,\n md5: Optional[str] = None,\n) -> None:\n \"\"\"Download and extract an archive.\n\n Args:\n url: URL to download\n download_root: directory to download to\n extract_root: directory to extract to (defaults to ``download_root``)\n filename: download filename (defaults to basename of ``url``)\n md5: checksum for download verification\n \"\"\"\n download_root = os.path.expanduser(download_root)\n if extract_root is None:\n extract_root = download_root\n if not filename:\n filename = os.path.basename(url)\n\n download_url(url, download_root, filename, md5)\n\n archive = os.path.join(download_root, filename)\n print(\"Extracting {} to {}\".format(archive, extract_root))\n extract_archive(archive, extract_root)\n\n\ndef download_radiant_mlhub(\n dataset_id: str, download_root: str, api_key: Optional[str] = None\n) -> None:\n \"\"\"Download a dataset from Radiant Earth.\n\n Args:\n dataset_id: the ID of the dataset to fetch\n download_root: directory to download to\n api_key: the API key to use for all requests from the session. Can also be\n passed in via the ``MLHUB_API_KEY`` environment variable, or configured in\n ``~/.mlhub/profiles``.\n \"\"\"\n try:\n import radiant_mlhub\n except ImportError:\n raise ImportError(\n \"radiant_mlhub is not installed and is required to download this dataset\"\n )\n\n dataset = radiant_mlhub.Dataset.fetch(dataset_id, api_key=api_key)\n dataset.download(output_dir=download_root, api_key=api_key)\n\n\nclass BoundingBox(Tuple[float, float, float, float, float, float]):\n \"\"\"Data class for indexing spatiotemporal data.\n\n Attributes:\n minx (float): western boundary\n maxx (float): eastern boundary\n miny (float): southern boundary\n maxy (float): northern boundary\n mint (float): earliest boundary\n maxt (float): latest boundary\n \"\"\"\n\n def __new__(\n cls,\n minx: float,\n maxx: float,\n miny: float,\n maxy: float,\n mint: float,\n maxt: float,\n ) -> \"BoundingBox\":\n \"\"\"Create a new instance of BoundingBox.\n\n Args:\n minx: western boundary\n maxx: eastern boundary\n miny: southern boundary\n maxy: northern boundary\n mint: earliest boundary\n maxt: latest boundary\n\n Raises:\n ValueError: if bounding box is invalid\n (minx > maxx, miny > maxy, or mint > maxt)\n \"\"\"\n if minx > maxx:\n raise ValueError(f\"Bounding box is invalid: 'minx={minx}' > 'maxx={maxx}'\")\n if miny > maxy:\n raise ValueError(f\"Bounding box is invalid: 'miny={miny}' > 'maxy={maxy}'\")\n if mint > maxt:\n raise ValueError(f\"Bounding box is invalid: 'mint={mint}' > 'maxt={maxt}'\")\n\n # Using super() doesn't work with mypy, see:\n # https://stackoverflow.com/q/60611012/5828163\n return tuple.__new__(cls, [minx, maxx, miny, maxy, mint, maxt])\n\n def __init__(\n self,\n minx: float,\n maxx: float,\n miny: float,\n maxy: float,\n mint: float,\n maxt: float,\n ) -> None:\n \"\"\"Initialize a new instance of BoundingBox.\n\n Args:\n minx: western boundary\n maxx: eastern boundary\n miny: southern boundary\n maxy: northern boundary\n mint: earliest boundary\n maxt: latest boundary\n \"\"\"\n self.minx = minx\n self.maxx = maxx\n self.miny = miny\n self.maxy = maxy\n self.mint = mint\n self.maxt = maxt\n\n def __getnewargs__(self) -> Tuple[float, float, float, float, float, float]:\n \"\"\"Values passed to the ``__new__()`` method upon unpickling.\n\n Returns:\n tuple of bounds\n \"\"\"\n return self.minx, self.maxx, self.miny, self.maxy, self.mint, self.maxt\n\n def __repr__(self) -> str:\n \"\"\"Return the formal string representation of the object.\n\n Returns:\n formal string representation\n \"\"\"\n return (\n f\"{self.__class__.__name__}(minx={self.minx}, maxx={self.maxx}, \"\n f\"miny={self.miny}, maxy={self.maxy}, mint={self.mint}, maxt={self.maxt})\"\n )\n\n def intersects(self, other: \"BoundingBox\") -> bool:\n \"\"\"Whether or not two bounding boxes intersect.\n\n Args:\n other: another bounding box\n\n Returns:\n True if bounding boxes intersect, else False\n \"\"\"\n return (\n self.minx <= other.maxx\n and self.maxx >= other.minx\n and self.miny <= other.maxy\n and self.maxy >= other.miny\n and self.mint <= other.maxt\n and self.maxt >= other.mint\n )\n\n\[email protected]\ndef working_dir(dirname: str, create: bool = False) -> Iterator[None]:\n \"\"\"Context manager for changing directories.\n\n Args:\n dirname: directory to temporarily change to\n create: if True, create the destination directory\n \"\"\"\n if create:\n os.makedirs(dirname, exist_ok=True)\n\n cwd = os.getcwd()\n os.chdir(dirname)\n\n try:\n yield\n finally:\n os.chdir(cwd)\n\n\ndef collate_dict(samples: List[Dict[str, Any]]) -> Dict[str, Any]:\n \"\"\"Merge a list of samples to form a mini-batch of Tensors.\n\n Args:\n samples: list of samples\n\n Returns:\n a single sample\n \"\"\"\n collated = {}\n for key, value in samples[0].items():\n if isinstance(value, Tensor):\n collated[key] = torch.stack([sample[key] for sample in samples])\n else:\n collated[key] = [\n sample[key] for sample in samples\n ] # type: ignore[assignment]\n return collated\n", "path": "torchgeo/datasets/utils.py"}]}
| 3,260 | 175 |
gh_patches_debug_5688
|
rasdani/github-patches
|
git_diff
|
facebookresearch__CompilerGym-735
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Running autotuning fails with `Primary config directory not found.`
## 🐛 Bug
When I tried running the auto tuning script, I get an error saying `Primary config directory not found`. See details below.
## To Reproduce
Steps to reproduce the behavior:
1. Run `make install` from base directory to install from source
2. Run `python setup.py install` from `examples/` to install scripts.
3. Run the following command to run the script
```
HYDRA_FULL_ERROR=1 python -m llvm_autotuning.tune -m \
experiment=my-exp \
outputs=/tmp/logs \
executor.cpus=32 \
num_replicas=1 \
autotuner=nevergrad \
autotuner.optimization_target=runtime \
autotuner.search_time_seconds=600
```
The full error message is:
```
Traceback (most recent call last):
File "/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/runpy.py", line 194, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/compiler_gym_examples-0.2.4-py3.8.egg/llvm_autotuning/tune.py", line 37, in <module>
main()
File "/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/main.py", line 49, in decorated_main
_run_hydra(
File "/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/utils.py", line 375, in _run_hydra
run_and_report(
File "/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/utils.py", line 214, in run_and_report
raise ex
File "/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/utils.py", line 211, in run_and_report
return func()
File "/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/utils.py", line 376, in <lambda>
lambda: hydra.multirun(
File "/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/hydra.py", line 121, in multirun
cfg = self.compose_config(
File "/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/hydra.py", line 564, in compose_config
cfg = self.config_loader.load_configuration(
File "/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/config_loader_impl.py", line 146, in load_configuration
return self._load_configuration_impl(
File "/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/config_loader_impl.py", line 227, in _load_configuration_impl
self.ensure_main_config_source_available()
File "/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/config_loader_impl.py", line 134, in ensure_main_config_source_available
self._missing_config_error(
File "/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/config_loader_impl.py", line 108, in _missing_config_error
raise MissingConfigException(
hydra.errors.MissingConfigException: Primary config directory not found.
Check that the config directory '/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/compiler_gym_examples-0.2.4-py3.8.egg/llvm_autotuning/config' exists and readable
```
## Expected behavior
The script shouldn't fail.
## Environment
Please fill in this checklist:
- CompilerGym: latest development branch
- How you installed CompilerGym (pip, source): source
- OS: MacOS
- Python version: 3.7
- Build command you used (if compiling from source): make install
- GCC/clang version (if compiling from source):
- Versions of any other relevant libraries:
You may use the
[environment collection script](https://raw.githubusercontent.com/facebookresearch/CompilerGym/stable/build_tools/collect_env.py)
to generate most of this information. You can get the script and run it with:
```sh
wget https://raw.githubusercontent.com/facebookresearch/CompilerGym/stable/build_tools/collect_env.py
# For security purposes, please check the contents of collect_env.py before running it.
python collect_env.py
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/setup.py`
Content:
```
1 #!/usr/bin/env python3
2 #
3 # Copyright (c) Facebook, Inc. and its affiliates.
4 #
5 # This source code is licensed under the MIT license found in the
6 # LICENSE file in the root directory of this source tree.
7
8 import distutils.util
9
10 import setuptools
11
12 with open("../VERSION") as f:
13 version = f.read().strip()
14 with open("requirements.txt") as f:
15 requirements = [ln.split("#")[0].rstrip() for ln in f.readlines()]
16 with open("../tests/requirements.txt") as f:
17 requirements += [ln.split("#")[0].rstrip() for ln in f.readlines()]
18
19 setuptools.setup(
20 name="compiler_gym_examples",
21 version=version,
22 description="Example code for CompilerGym",
23 author="Facebook AI Research",
24 url="https://github.com/facebookresearch/CompilerGym",
25 license="MIT",
26 install_requires=requirements,
27 packages=[
28 "llvm_autotuning",
29 "llvm_autotuning.autotuners",
30 "llvm_rl",
31 "llvm_rl.model",
32 ],
33 package_data={
34 "llvm_rl": [
35 "config/*.yaml",
36 "config/**/*.yaml",
37 ]
38 },
39 python_requires=">=3.8",
40 platforms=[distutils.util.get_platform()],
41 zip_safe=False,
42 )
43
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/setup.py b/examples/setup.py
--- a/examples/setup.py
+++ b/examples/setup.py
@@ -31,10 +31,14 @@
"llvm_rl.model",
],
package_data={
+ "llvm_autotuning": [
+ "config/*.yaml",
+ "config/**/*.yaml",
+ ],
"llvm_rl": [
"config/*.yaml",
"config/**/*.yaml",
- ]
+ ],
},
python_requires=">=3.8",
platforms=[distutils.util.get_platform()],
|
{"golden_diff": "diff --git a/examples/setup.py b/examples/setup.py\n--- a/examples/setup.py\n+++ b/examples/setup.py\n@@ -31,10 +31,14 @@\n \"llvm_rl.model\",\n ],\n package_data={\n+ \"llvm_autotuning\": [\n+ \"config/*.yaml\",\n+ \"config/**/*.yaml\",\n+ ],\n \"llvm_rl\": [\n \"config/*.yaml\",\n \"config/**/*.yaml\",\n- ]\n+ ],\n },\n python_requires=\">=3.8\",\n platforms=[distutils.util.get_platform()],\n", "issue": "Running autotuning fails with `Primary config directory not found.`\n## \ud83d\udc1b Bug\r\n\r\nWhen I tried running the auto tuning script, I get an error saying `Primary config directory not found`. See details below.\r\n\r\n## To Reproduce\r\n\r\nSteps to reproduce the behavior:\r\n\r\n1. Run `make install` from base directory to install from source\r\n2. Run `python setup.py install` from `examples/` to install scripts.\r\n3. Run the following command to run the script\r\n\r\n```\r\nHYDRA_FULL_ERROR=1 python -m llvm_autotuning.tune -m \\\r\n experiment=my-exp \\\r\n outputs=/tmp/logs \\\r\n executor.cpus=32 \\\r\n num_replicas=1 \\\r\n autotuner=nevergrad \\\r\n autotuner.optimization_target=runtime \\ \r\n autotuner.search_time_seconds=600\r\n```\r\n\r\nThe full error message is:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/runpy.py\", line 194, in _run_module_as_main\r\n return _run_code(code, main_globals, None,\r\n File \"/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/runpy.py\", line 87, in _run_code\r\n exec(code, run_globals)\r\n File \"/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/compiler_gym_examples-0.2.4-py3.8.egg/llvm_autotuning/tune.py\", line 37, in <module>\r\n main()\r\n File \"/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/main.py\", line 49, in decorated_main\r\n _run_hydra(\r\n File \"/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/utils.py\", line 375, in _run_hydra\r\n run_and_report(\r\n File \"/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/utils.py\", line 214, in run_and_report\r\n raise ex\r\n File \"/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/utils.py\", line 211, in run_and_report\r\n return func()\r\n File \"/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/utils.py\", line 376, in <lambda>\r\n lambda: hydra.multirun(\r\n File \"/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/hydra.py\", line 121, in multirun\r\n cfg = self.compose_config(\r\n File \"/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/hydra.py\", line 564, in compose_config\r\n cfg = self.config_loader.load_configuration(\r\n File \"/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/config_loader_impl.py\", line 146, in load_configuration\r\n return self._load_configuration_impl(\r\n File \"/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/config_loader_impl.py\", line 227, in _load_configuration_impl\r\n self.ensure_main_config_source_available()\r\n File \"/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/config_loader_impl.py\", line 134, in ensure_main_config_source_available\r\n self._missing_config_error(\r\n File \"/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/config_loader_impl.py\", line 108, in _missing_config_error\r\n raise MissingConfigException(\r\nhydra.errors.MissingConfigException: Primary config directory not found.\r\nCheck that the config directory '/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/compiler_gym_examples-0.2.4-py3.8.egg/llvm_autotuning/config' exists and readable\r\n```\r\n\r\n## Expected behavior\r\n\r\nThe script shouldn't fail.\r\n\r\n## Environment\r\n\r\nPlease fill in this checklist:\r\n\r\n- CompilerGym: latest development branch\r\n- How you installed CompilerGym (pip, source): source\r\n- OS: MacOS\r\n- Python version: 3.7\r\n- Build command you used (if compiling from source): make install\r\n- GCC/clang version (if compiling from source):\r\n- Versions of any other relevant libraries:\r\n\r\nYou may use the\r\n[environment collection script](https://raw.githubusercontent.com/facebookresearch/CompilerGym/stable/build_tools/collect_env.py)\r\nto generate most of this information. You can get the script and run it with:\r\n\r\n```sh\r\nwget https://raw.githubusercontent.com/facebookresearch/CompilerGym/stable/build_tools/collect_env.py\r\n# For security purposes, please check the contents of collect_env.py before running it.\r\npython collect_env.py\r\n```\r\n\n", "before_files": [{"content": "#!/usr/bin/env python3\n#\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\nimport distutils.util\n\nimport setuptools\n\nwith open(\"../VERSION\") as f:\n version = f.read().strip()\nwith open(\"requirements.txt\") as f:\n requirements = [ln.split(\"#\")[0].rstrip() for ln in f.readlines()]\nwith open(\"../tests/requirements.txt\") as f:\n requirements += [ln.split(\"#\")[0].rstrip() for ln in f.readlines()]\n\nsetuptools.setup(\n name=\"compiler_gym_examples\",\n version=version,\n description=\"Example code for CompilerGym\",\n author=\"Facebook AI Research\",\n url=\"https://github.com/facebookresearch/CompilerGym\",\n license=\"MIT\",\n install_requires=requirements,\n packages=[\n \"llvm_autotuning\",\n \"llvm_autotuning.autotuners\",\n \"llvm_rl\",\n \"llvm_rl.model\",\n ],\n package_data={\n \"llvm_rl\": [\n \"config/*.yaml\",\n \"config/**/*.yaml\",\n ]\n },\n python_requires=\">=3.8\",\n platforms=[distutils.util.get_platform()],\n zip_safe=False,\n)\n", "path": "examples/setup.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n#\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\nimport distutils.util\n\nimport setuptools\n\nwith open(\"../VERSION\") as f:\n version = f.read().strip()\nwith open(\"requirements.txt\") as f:\n requirements = [ln.split(\"#\")[0].rstrip() for ln in f.readlines()]\nwith open(\"../tests/requirements.txt\") as f:\n requirements += [ln.split(\"#\")[0].rstrip() for ln in f.readlines()]\n\nsetuptools.setup(\n name=\"compiler_gym_examples\",\n version=version,\n description=\"Example code for CompilerGym\",\n author=\"Facebook AI Research\",\n url=\"https://github.com/facebookresearch/CompilerGym\",\n license=\"MIT\",\n install_requires=requirements,\n packages=[\n \"llvm_autotuning\",\n \"llvm_autotuning.autotuners\",\n \"llvm_rl\",\n \"llvm_rl.model\",\n ],\n package_data={\n \"llvm_autotuning\": [\n \"config/*.yaml\",\n \"config/**/*.yaml\",\n ],\n \"llvm_rl\": [\n \"config/*.yaml\",\n \"config/**/*.yaml\",\n ],\n },\n python_requires=\">=3.8\",\n platforms=[distutils.util.get_platform()],\n zip_safe=False,\n)\n", "path": "examples/setup.py"}]}
| 1,775 | 120 |
gh_patches_debug_16686
|
rasdani/github-patches
|
git_diff
|
open-mmlab__mmcv-1138
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
SyncBatchNorm breaks after PyTorch 1.9.0
**Describe the Issue**
`torch.nn.SyncBatchNorm` has been updated since PyTorch 1.9.0 and `_specify_ddp_gpu_num()` is no longer available, breaking the following code snippet: https://github.com/open-mmlab/mmcv/blob/eb08835fa246ea81263eb25fbe2caa54ef11271c/mmcv/utils/parrots_wrapper.py#L83-L87
More details: https://github.com/open-mmlab/mmocr/issues/325
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mmcv/utils/parrots_wrapper.py`
Content:
```
1 from functools import partial
2
3 import torch
4
5 TORCH_VERSION = torch.__version__
6
7
8 def _get_cuda_home():
9 if TORCH_VERSION == 'parrots':
10 from parrots.utils.build_extension import CUDA_HOME
11 else:
12 from torch.utils.cpp_extension import CUDA_HOME
13 return CUDA_HOME
14
15
16 def get_build_config():
17 if TORCH_VERSION == 'parrots':
18 from parrots.config import get_build_info
19 return get_build_info()
20 else:
21 return torch.__config__.show()
22
23
24 def _get_conv():
25 if TORCH_VERSION == 'parrots':
26 from parrots.nn.modules.conv import _ConvNd, _ConvTransposeMixin
27 else:
28 from torch.nn.modules.conv import _ConvNd, _ConvTransposeMixin
29 return _ConvNd, _ConvTransposeMixin
30
31
32 def _get_dataloader():
33 if TORCH_VERSION == 'parrots':
34 from torch.utils.data import DataLoader, PoolDataLoader
35 else:
36 from torch.utils.data import DataLoader
37 PoolDataLoader = DataLoader
38 return DataLoader, PoolDataLoader
39
40
41 def _get_extension():
42 if TORCH_VERSION == 'parrots':
43 from parrots.utils.build_extension import BuildExtension, Extension
44 CppExtension = partial(Extension, cuda=False)
45 CUDAExtension = partial(Extension, cuda=True)
46 else:
47 from torch.utils.cpp_extension import (BuildExtension, CppExtension,
48 CUDAExtension)
49 return BuildExtension, CppExtension, CUDAExtension
50
51
52 def _get_pool():
53 if TORCH_VERSION == 'parrots':
54 from parrots.nn.modules.pool import (_AdaptiveAvgPoolNd,
55 _AdaptiveMaxPoolNd, _AvgPoolNd,
56 _MaxPoolNd)
57 else:
58 from torch.nn.modules.pooling import (_AdaptiveAvgPoolNd,
59 _AdaptiveMaxPoolNd, _AvgPoolNd,
60 _MaxPoolNd)
61 return _AdaptiveAvgPoolNd, _AdaptiveMaxPoolNd, _AvgPoolNd, _MaxPoolNd
62
63
64 def _get_norm():
65 if TORCH_VERSION == 'parrots':
66 from parrots.nn.modules.batchnorm import _BatchNorm, _InstanceNorm
67 SyncBatchNorm_ = torch.nn.SyncBatchNorm2d
68 else:
69 from torch.nn.modules.instancenorm import _InstanceNorm
70 from torch.nn.modules.batchnorm import _BatchNorm
71 SyncBatchNorm_ = torch.nn.SyncBatchNorm
72 return _BatchNorm, _InstanceNorm, SyncBatchNorm_
73
74
75 CUDA_HOME = _get_cuda_home()
76 _ConvNd, _ConvTransposeMixin = _get_conv()
77 DataLoader, PoolDataLoader = _get_dataloader()
78 BuildExtension, CppExtension, CUDAExtension = _get_extension()
79 _BatchNorm, _InstanceNorm, SyncBatchNorm_ = _get_norm()
80 _AdaptiveAvgPoolNd, _AdaptiveMaxPoolNd, _AvgPoolNd, _MaxPoolNd = _get_pool()
81
82
83 class SyncBatchNorm(SyncBatchNorm_):
84
85 def _specify_ddp_gpu_num(self, gpu_size):
86 if TORCH_VERSION != 'parrots':
87 super()._specify_ddp_gpu_num(gpu_size)
88
89 def _check_input_dim(self, input):
90 if TORCH_VERSION == 'parrots':
91 if input.dim() < 2:
92 raise ValueError(
93 f'expected at least 2D input (got {input.dim()}D input)')
94 else:
95 super()._check_input_dim(input)
96
```
Path: `mmcv/cnn/bricks/norm.py`
Content:
```
1 import inspect
2
3 import torch.nn as nn
4
5 from mmcv.utils import is_tuple_of
6 from mmcv.utils.parrots_wrapper import SyncBatchNorm, _BatchNorm, _InstanceNorm
7 from .registry import NORM_LAYERS
8
9 NORM_LAYERS.register_module('BN', module=nn.BatchNorm2d)
10 NORM_LAYERS.register_module('BN1d', module=nn.BatchNorm1d)
11 NORM_LAYERS.register_module('BN2d', module=nn.BatchNorm2d)
12 NORM_LAYERS.register_module('BN3d', module=nn.BatchNorm3d)
13 NORM_LAYERS.register_module('SyncBN', module=SyncBatchNorm)
14 NORM_LAYERS.register_module('GN', module=nn.GroupNorm)
15 NORM_LAYERS.register_module('LN', module=nn.LayerNorm)
16 NORM_LAYERS.register_module('IN', module=nn.InstanceNorm2d)
17 NORM_LAYERS.register_module('IN1d', module=nn.InstanceNorm1d)
18 NORM_LAYERS.register_module('IN2d', module=nn.InstanceNorm2d)
19 NORM_LAYERS.register_module('IN3d', module=nn.InstanceNorm3d)
20
21
22 def infer_abbr(class_type):
23 """Infer abbreviation from the class name.
24
25 When we build a norm layer with `build_norm_layer()`, we want to preserve
26 the norm type in variable names, e.g, self.bn1, self.gn. This method will
27 infer the abbreviation to map class types to abbreviations.
28
29 Rule 1: If the class has the property "_abbr_", return the property.
30 Rule 2: If the parent class is _BatchNorm, GroupNorm, LayerNorm or
31 InstanceNorm, the abbreviation of this layer will be "bn", "gn", "ln" and
32 "in" respectively.
33 Rule 3: If the class name contains "batch", "group", "layer" or "instance",
34 the abbreviation of this layer will be "bn", "gn", "ln" and "in"
35 respectively.
36 Rule 4: Otherwise, the abbreviation falls back to "norm".
37
38 Args:
39 class_type (type): The norm layer type.
40
41 Returns:
42 str: The inferred abbreviation.
43 """
44 if not inspect.isclass(class_type):
45 raise TypeError(
46 f'class_type must be a type, but got {type(class_type)}')
47 if hasattr(class_type, '_abbr_'):
48 return class_type._abbr_
49 if issubclass(class_type, _InstanceNorm): # IN is a subclass of BN
50 return 'in'
51 elif issubclass(class_type, _BatchNorm):
52 return 'bn'
53 elif issubclass(class_type, nn.GroupNorm):
54 return 'gn'
55 elif issubclass(class_type, nn.LayerNorm):
56 return 'ln'
57 else:
58 class_name = class_type.__name__.lower()
59 if 'batch' in class_name:
60 return 'bn'
61 elif 'group' in class_name:
62 return 'gn'
63 elif 'layer' in class_name:
64 return 'ln'
65 elif 'instance' in class_name:
66 return 'in'
67 else:
68 return 'norm_layer'
69
70
71 def build_norm_layer(cfg, num_features, postfix=''):
72 """Build normalization layer.
73
74 Args:
75 cfg (dict): The norm layer config, which should contain:
76
77 - type (str): Layer type.
78 - layer args: Args needed to instantiate a norm layer.
79 - requires_grad (bool, optional): Whether stop gradient updates.
80 num_features (int): Number of input channels.
81 postfix (int | str): The postfix to be appended into norm abbreviation
82 to create named layer.
83
84 Returns:
85 (str, nn.Module): The first element is the layer name consisting of
86 abbreviation and postfix, e.g., bn1, gn. The second element is the
87 created norm layer.
88 """
89 if not isinstance(cfg, dict):
90 raise TypeError('cfg must be a dict')
91 if 'type' not in cfg:
92 raise KeyError('the cfg dict must contain the key "type"')
93 cfg_ = cfg.copy()
94
95 layer_type = cfg_.pop('type')
96 if layer_type not in NORM_LAYERS:
97 raise KeyError(f'Unrecognized norm type {layer_type}')
98
99 norm_layer = NORM_LAYERS.get(layer_type)
100 abbr = infer_abbr(norm_layer)
101
102 assert isinstance(postfix, (int, str))
103 name = abbr + str(postfix)
104
105 requires_grad = cfg_.pop('requires_grad', True)
106 cfg_.setdefault('eps', 1e-5)
107 if layer_type != 'GN':
108 layer = norm_layer(num_features, **cfg_)
109 if layer_type == 'SyncBN':
110 layer._specify_ddp_gpu_num(1)
111 else:
112 assert 'num_groups' in cfg_
113 layer = norm_layer(num_channels=num_features, **cfg_)
114
115 for param in layer.parameters():
116 param.requires_grad = requires_grad
117
118 return name, layer
119
120
121 def is_norm(layer, exclude=None):
122 """Check if a layer is a normalization layer.
123
124 Args:
125 layer (nn.Module): The layer to be checked.
126 exclude (type | tuple[type]): Types to be excluded.
127
128 Returns:
129 bool: Whether the layer is a norm layer.
130 """
131 if exclude is not None:
132 if not isinstance(exclude, tuple):
133 exclude = (exclude, )
134 if not is_tuple_of(exclude, type):
135 raise TypeError(
136 f'"exclude" must be either None or type or a tuple of types, '
137 f'but got {type(exclude)}: {exclude}')
138
139 if exclude and isinstance(layer, exclude):
140 return False
141
142 all_norm_bases = (_BatchNorm, _InstanceNorm, nn.GroupNorm, nn.LayerNorm)
143 return isinstance(layer, all_norm_bases)
144
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mmcv/cnn/bricks/norm.py b/mmcv/cnn/bricks/norm.py
--- a/mmcv/cnn/bricks/norm.py
+++ b/mmcv/cnn/bricks/norm.py
@@ -106,7 +106,7 @@
cfg_.setdefault('eps', 1e-5)
if layer_type != 'GN':
layer = norm_layer(num_features, **cfg_)
- if layer_type == 'SyncBN':
+ if layer_type == 'SyncBN' and hasattr(layer, '_specify_ddp_gpu_num'):
layer._specify_ddp_gpu_num(1)
else:
assert 'num_groups' in cfg_
diff --git a/mmcv/utils/parrots_wrapper.py b/mmcv/utils/parrots_wrapper.py
--- a/mmcv/utils/parrots_wrapper.py
+++ b/mmcv/utils/parrots_wrapper.py
@@ -82,10 +82,6 @@
class SyncBatchNorm(SyncBatchNorm_):
- def _specify_ddp_gpu_num(self, gpu_size):
- if TORCH_VERSION != 'parrots':
- super()._specify_ddp_gpu_num(gpu_size)
-
def _check_input_dim(self, input):
if TORCH_VERSION == 'parrots':
if input.dim() < 2:
|
{"golden_diff": "diff --git a/mmcv/cnn/bricks/norm.py b/mmcv/cnn/bricks/norm.py\n--- a/mmcv/cnn/bricks/norm.py\n+++ b/mmcv/cnn/bricks/norm.py\n@@ -106,7 +106,7 @@\n cfg_.setdefault('eps', 1e-5)\n if layer_type != 'GN':\n layer = norm_layer(num_features, **cfg_)\n- if layer_type == 'SyncBN':\n+ if layer_type == 'SyncBN' and hasattr(layer, '_specify_ddp_gpu_num'):\n layer._specify_ddp_gpu_num(1)\n else:\n assert 'num_groups' in cfg_\ndiff --git a/mmcv/utils/parrots_wrapper.py b/mmcv/utils/parrots_wrapper.py\n--- a/mmcv/utils/parrots_wrapper.py\n+++ b/mmcv/utils/parrots_wrapper.py\n@@ -82,10 +82,6 @@\n \n class SyncBatchNorm(SyncBatchNorm_):\n \n- def _specify_ddp_gpu_num(self, gpu_size):\n- if TORCH_VERSION != 'parrots':\n- super()._specify_ddp_gpu_num(gpu_size)\n-\n def _check_input_dim(self, input):\n if TORCH_VERSION == 'parrots':\n if input.dim() < 2:\n", "issue": "SyncBatchNorm breaks after PyTorch 1.9.0\n**Describe the Issue**\r\n`torch.nn.SyncBatchNorm` has been updated since PyTorch 1.9.0 and `_specify_ddp_gpu_num()` is no longer available, breaking the following code snippet: https://github.com/open-mmlab/mmcv/blob/eb08835fa246ea81263eb25fbe2caa54ef11271c/mmcv/utils/parrots_wrapper.py#L83-L87\r\n\r\nMore details: https://github.com/open-mmlab/mmocr/issues/325\n", "before_files": [{"content": "from functools import partial\n\nimport torch\n\nTORCH_VERSION = torch.__version__\n\n\ndef _get_cuda_home():\n if TORCH_VERSION == 'parrots':\n from parrots.utils.build_extension import CUDA_HOME\n else:\n from torch.utils.cpp_extension import CUDA_HOME\n return CUDA_HOME\n\n\ndef get_build_config():\n if TORCH_VERSION == 'parrots':\n from parrots.config import get_build_info\n return get_build_info()\n else:\n return torch.__config__.show()\n\n\ndef _get_conv():\n if TORCH_VERSION == 'parrots':\n from parrots.nn.modules.conv import _ConvNd, _ConvTransposeMixin\n else:\n from torch.nn.modules.conv import _ConvNd, _ConvTransposeMixin\n return _ConvNd, _ConvTransposeMixin\n\n\ndef _get_dataloader():\n if TORCH_VERSION == 'parrots':\n from torch.utils.data import DataLoader, PoolDataLoader\n else:\n from torch.utils.data import DataLoader\n PoolDataLoader = DataLoader\n return DataLoader, PoolDataLoader\n\n\ndef _get_extension():\n if TORCH_VERSION == 'parrots':\n from parrots.utils.build_extension import BuildExtension, Extension\n CppExtension = partial(Extension, cuda=False)\n CUDAExtension = partial(Extension, cuda=True)\n else:\n from torch.utils.cpp_extension import (BuildExtension, CppExtension,\n CUDAExtension)\n return BuildExtension, CppExtension, CUDAExtension\n\n\ndef _get_pool():\n if TORCH_VERSION == 'parrots':\n from parrots.nn.modules.pool import (_AdaptiveAvgPoolNd,\n _AdaptiveMaxPoolNd, _AvgPoolNd,\n _MaxPoolNd)\n else:\n from torch.nn.modules.pooling import (_AdaptiveAvgPoolNd,\n _AdaptiveMaxPoolNd, _AvgPoolNd,\n _MaxPoolNd)\n return _AdaptiveAvgPoolNd, _AdaptiveMaxPoolNd, _AvgPoolNd, _MaxPoolNd\n\n\ndef _get_norm():\n if TORCH_VERSION == 'parrots':\n from parrots.nn.modules.batchnorm import _BatchNorm, _InstanceNorm\n SyncBatchNorm_ = torch.nn.SyncBatchNorm2d\n else:\n from torch.nn.modules.instancenorm import _InstanceNorm\n from torch.nn.modules.batchnorm import _BatchNorm\n SyncBatchNorm_ = torch.nn.SyncBatchNorm\n return _BatchNorm, _InstanceNorm, SyncBatchNorm_\n\n\nCUDA_HOME = _get_cuda_home()\n_ConvNd, _ConvTransposeMixin = _get_conv()\nDataLoader, PoolDataLoader = _get_dataloader()\nBuildExtension, CppExtension, CUDAExtension = _get_extension()\n_BatchNorm, _InstanceNorm, SyncBatchNorm_ = _get_norm()\n_AdaptiveAvgPoolNd, _AdaptiveMaxPoolNd, _AvgPoolNd, _MaxPoolNd = _get_pool()\n\n\nclass SyncBatchNorm(SyncBatchNorm_):\n\n def _specify_ddp_gpu_num(self, gpu_size):\n if TORCH_VERSION != 'parrots':\n super()._specify_ddp_gpu_num(gpu_size)\n\n def _check_input_dim(self, input):\n if TORCH_VERSION == 'parrots':\n if input.dim() < 2:\n raise ValueError(\n f'expected at least 2D input (got {input.dim()}D input)')\n else:\n super()._check_input_dim(input)\n", "path": "mmcv/utils/parrots_wrapper.py"}, {"content": "import inspect\n\nimport torch.nn as nn\n\nfrom mmcv.utils import is_tuple_of\nfrom mmcv.utils.parrots_wrapper import SyncBatchNorm, _BatchNorm, _InstanceNorm\nfrom .registry import NORM_LAYERS\n\nNORM_LAYERS.register_module('BN', module=nn.BatchNorm2d)\nNORM_LAYERS.register_module('BN1d', module=nn.BatchNorm1d)\nNORM_LAYERS.register_module('BN2d', module=nn.BatchNorm2d)\nNORM_LAYERS.register_module('BN3d', module=nn.BatchNorm3d)\nNORM_LAYERS.register_module('SyncBN', module=SyncBatchNorm)\nNORM_LAYERS.register_module('GN', module=nn.GroupNorm)\nNORM_LAYERS.register_module('LN', module=nn.LayerNorm)\nNORM_LAYERS.register_module('IN', module=nn.InstanceNorm2d)\nNORM_LAYERS.register_module('IN1d', module=nn.InstanceNorm1d)\nNORM_LAYERS.register_module('IN2d', module=nn.InstanceNorm2d)\nNORM_LAYERS.register_module('IN3d', module=nn.InstanceNorm3d)\n\n\ndef infer_abbr(class_type):\n \"\"\"Infer abbreviation from the class name.\n\n When we build a norm layer with `build_norm_layer()`, we want to preserve\n the norm type in variable names, e.g, self.bn1, self.gn. This method will\n infer the abbreviation to map class types to abbreviations.\n\n Rule 1: If the class has the property \"_abbr_\", return the property.\n Rule 2: If the parent class is _BatchNorm, GroupNorm, LayerNorm or\n InstanceNorm, the abbreviation of this layer will be \"bn\", \"gn\", \"ln\" and\n \"in\" respectively.\n Rule 3: If the class name contains \"batch\", \"group\", \"layer\" or \"instance\",\n the abbreviation of this layer will be \"bn\", \"gn\", \"ln\" and \"in\"\n respectively.\n Rule 4: Otherwise, the abbreviation falls back to \"norm\".\n\n Args:\n class_type (type): The norm layer type.\n\n Returns:\n str: The inferred abbreviation.\n \"\"\"\n if not inspect.isclass(class_type):\n raise TypeError(\n f'class_type must be a type, but got {type(class_type)}')\n if hasattr(class_type, '_abbr_'):\n return class_type._abbr_\n if issubclass(class_type, _InstanceNorm): # IN is a subclass of BN\n return 'in'\n elif issubclass(class_type, _BatchNorm):\n return 'bn'\n elif issubclass(class_type, nn.GroupNorm):\n return 'gn'\n elif issubclass(class_type, nn.LayerNorm):\n return 'ln'\n else:\n class_name = class_type.__name__.lower()\n if 'batch' in class_name:\n return 'bn'\n elif 'group' in class_name:\n return 'gn'\n elif 'layer' in class_name:\n return 'ln'\n elif 'instance' in class_name:\n return 'in'\n else:\n return 'norm_layer'\n\n\ndef build_norm_layer(cfg, num_features, postfix=''):\n \"\"\"Build normalization layer.\n\n Args:\n cfg (dict): The norm layer config, which should contain:\n\n - type (str): Layer type.\n - layer args: Args needed to instantiate a norm layer.\n - requires_grad (bool, optional): Whether stop gradient updates.\n num_features (int): Number of input channels.\n postfix (int | str): The postfix to be appended into norm abbreviation\n to create named layer.\n\n Returns:\n (str, nn.Module): The first element is the layer name consisting of\n abbreviation and postfix, e.g., bn1, gn. The second element is the\n created norm layer.\n \"\"\"\n if not isinstance(cfg, dict):\n raise TypeError('cfg must be a dict')\n if 'type' not in cfg:\n raise KeyError('the cfg dict must contain the key \"type\"')\n cfg_ = cfg.copy()\n\n layer_type = cfg_.pop('type')\n if layer_type not in NORM_LAYERS:\n raise KeyError(f'Unrecognized norm type {layer_type}')\n\n norm_layer = NORM_LAYERS.get(layer_type)\n abbr = infer_abbr(norm_layer)\n\n assert isinstance(postfix, (int, str))\n name = abbr + str(postfix)\n\n requires_grad = cfg_.pop('requires_grad', True)\n cfg_.setdefault('eps', 1e-5)\n if layer_type != 'GN':\n layer = norm_layer(num_features, **cfg_)\n if layer_type == 'SyncBN':\n layer._specify_ddp_gpu_num(1)\n else:\n assert 'num_groups' in cfg_\n layer = norm_layer(num_channels=num_features, **cfg_)\n\n for param in layer.parameters():\n param.requires_grad = requires_grad\n\n return name, layer\n\n\ndef is_norm(layer, exclude=None):\n \"\"\"Check if a layer is a normalization layer.\n\n Args:\n layer (nn.Module): The layer to be checked.\n exclude (type | tuple[type]): Types to be excluded.\n\n Returns:\n bool: Whether the layer is a norm layer.\n \"\"\"\n if exclude is not None:\n if not isinstance(exclude, tuple):\n exclude = (exclude, )\n if not is_tuple_of(exclude, type):\n raise TypeError(\n f'\"exclude\" must be either None or type or a tuple of types, '\n f'but got {type(exclude)}: {exclude}')\n\n if exclude and isinstance(layer, exclude):\n return False\n\n all_norm_bases = (_BatchNorm, _InstanceNorm, nn.GroupNorm, nn.LayerNorm)\n return isinstance(layer, all_norm_bases)\n", "path": "mmcv/cnn/bricks/norm.py"}], "after_files": [{"content": "from functools import partial\n\nimport torch\n\nTORCH_VERSION = torch.__version__\n\n\ndef _get_cuda_home():\n if TORCH_VERSION == 'parrots':\n from parrots.utils.build_extension import CUDA_HOME\n else:\n from torch.utils.cpp_extension import CUDA_HOME\n return CUDA_HOME\n\n\ndef get_build_config():\n if TORCH_VERSION == 'parrots':\n from parrots.config import get_build_info\n return get_build_info()\n else:\n return torch.__config__.show()\n\n\ndef _get_conv():\n if TORCH_VERSION == 'parrots':\n from parrots.nn.modules.conv import _ConvNd, _ConvTransposeMixin\n else:\n from torch.nn.modules.conv import _ConvNd, _ConvTransposeMixin\n return _ConvNd, _ConvTransposeMixin\n\n\ndef _get_dataloader():\n if TORCH_VERSION == 'parrots':\n from torch.utils.data import DataLoader, PoolDataLoader\n else:\n from torch.utils.data import DataLoader\n PoolDataLoader = DataLoader\n return DataLoader, PoolDataLoader\n\n\ndef _get_extension():\n if TORCH_VERSION == 'parrots':\n from parrots.utils.build_extension import BuildExtension, Extension\n CppExtension = partial(Extension, cuda=False)\n CUDAExtension = partial(Extension, cuda=True)\n else:\n from torch.utils.cpp_extension import (BuildExtension, CppExtension,\n CUDAExtension)\n return BuildExtension, CppExtension, CUDAExtension\n\n\ndef _get_pool():\n if TORCH_VERSION == 'parrots':\n from parrots.nn.modules.pool import (_AdaptiveAvgPoolNd,\n _AdaptiveMaxPoolNd, _AvgPoolNd,\n _MaxPoolNd)\n else:\n from torch.nn.modules.pooling import (_AdaptiveAvgPoolNd,\n _AdaptiveMaxPoolNd, _AvgPoolNd,\n _MaxPoolNd)\n return _AdaptiveAvgPoolNd, _AdaptiveMaxPoolNd, _AvgPoolNd, _MaxPoolNd\n\n\ndef _get_norm():\n if TORCH_VERSION == 'parrots':\n from parrots.nn.modules.batchnorm import _BatchNorm, _InstanceNorm\n SyncBatchNorm_ = torch.nn.SyncBatchNorm2d\n else:\n from torch.nn.modules.instancenorm import _InstanceNorm\n from torch.nn.modules.batchnorm import _BatchNorm\n SyncBatchNorm_ = torch.nn.SyncBatchNorm\n return _BatchNorm, _InstanceNorm, SyncBatchNorm_\n\n\nCUDA_HOME = _get_cuda_home()\n_ConvNd, _ConvTransposeMixin = _get_conv()\nDataLoader, PoolDataLoader = _get_dataloader()\nBuildExtension, CppExtension, CUDAExtension = _get_extension()\n_BatchNorm, _InstanceNorm, SyncBatchNorm_ = _get_norm()\n_AdaptiveAvgPoolNd, _AdaptiveMaxPoolNd, _AvgPoolNd, _MaxPoolNd = _get_pool()\n\n\nclass SyncBatchNorm(SyncBatchNorm_):\n\n def _check_input_dim(self, input):\n if TORCH_VERSION == 'parrots':\n if input.dim() < 2:\n raise ValueError(\n f'expected at least 2D input (got {input.dim()}D input)')\n else:\n super()._check_input_dim(input)\n", "path": "mmcv/utils/parrots_wrapper.py"}, {"content": "import inspect\n\nimport torch.nn as nn\n\nfrom mmcv.utils import is_tuple_of\nfrom mmcv.utils.parrots_wrapper import SyncBatchNorm, _BatchNorm, _InstanceNorm\nfrom .registry import NORM_LAYERS\n\nNORM_LAYERS.register_module('BN', module=nn.BatchNorm2d)\nNORM_LAYERS.register_module('BN1d', module=nn.BatchNorm1d)\nNORM_LAYERS.register_module('BN2d', module=nn.BatchNorm2d)\nNORM_LAYERS.register_module('BN3d', module=nn.BatchNorm3d)\nNORM_LAYERS.register_module('SyncBN', module=SyncBatchNorm)\nNORM_LAYERS.register_module('GN', module=nn.GroupNorm)\nNORM_LAYERS.register_module('LN', module=nn.LayerNorm)\nNORM_LAYERS.register_module('IN', module=nn.InstanceNorm2d)\nNORM_LAYERS.register_module('IN1d', module=nn.InstanceNorm1d)\nNORM_LAYERS.register_module('IN2d', module=nn.InstanceNorm2d)\nNORM_LAYERS.register_module('IN3d', module=nn.InstanceNorm3d)\n\n\ndef infer_abbr(class_type):\n \"\"\"Infer abbreviation from the class name.\n\n When we build a norm layer with `build_norm_layer()`, we want to preserve\n the norm type in variable names, e.g, self.bn1, self.gn. This method will\n infer the abbreviation to map class types to abbreviations.\n\n Rule 1: If the class has the property \"_abbr_\", return the property.\n Rule 2: If the parent class is _BatchNorm, GroupNorm, LayerNorm or\n InstanceNorm, the abbreviation of this layer will be \"bn\", \"gn\", \"ln\" and\n \"in\" respectively.\n Rule 3: If the class name contains \"batch\", \"group\", \"layer\" or \"instance\",\n the abbreviation of this layer will be \"bn\", \"gn\", \"ln\" and \"in\"\n respectively.\n Rule 4: Otherwise, the abbreviation falls back to \"norm\".\n\n Args:\n class_type (type): The norm layer type.\n\n Returns:\n str: The inferred abbreviation.\n \"\"\"\n if not inspect.isclass(class_type):\n raise TypeError(\n f'class_type must be a type, but got {type(class_type)}')\n if hasattr(class_type, '_abbr_'):\n return class_type._abbr_\n if issubclass(class_type, _InstanceNorm): # IN is a subclass of BN\n return 'in'\n elif issubclass(class_type, _BatchNorm):\n return 'bn'\n elif issubclass(class_type, nn.GroupNorm):\n return 'gn'\n elif issubclass(class_type, nn.LayerNorm):\n return 'ln'\n else:\n class_name = class_type.__name__.lower()\n if 'batch' in class_name:\n return 'bn'\n elif 'group' in class_name:\n return 'gn'\n elif 'layer' in class_name:\n return 'ln'\n elif 'instance' in class_name:\n return 'in'\n else:\n return 'norm_layer'\n\n\ndef build_norm_layer(cfg, num_features, postfix=''):\n \"\"\"Build normalization layer.\n\n Args:\n cfg (dict): The norm layer config, which should contain:\n\n - type (str): Layer type.\n - layer args: Args needed to instantiate a norm layer.\n - requires_grad (bool, optional): Whether stop gradient updates.\n num_features (int): Number of input channels.\n postfix (int | str): The postfix to be appended into norm abbreviation\n to create named layer.\n\n Returns:\n (str, nn.Module): The first element is the layer name consisting of\n abbreviation and postfix, e.g., bn1, gn. The second element is the\n created norm layer.\n \"\"\"\n if not isinstance(cfg, dict):\n raise TypeError('cfg must be a dict')\n if 'type' not in cfg:\n raise KeyError('the cfg dict must contain the key \"type\"')\n cfg_ = cfg.copy()\n\n layer_type = cfg_.pop('type')\n if layer_type not in NORM_LAYERS:\n raise KeyError(f'Unrecognized norm type {layer_type}')\n\n norm_layer = NORM_LAYERS.get(layer_type)\n abbr = infer_abbr(norm_layer)\n\n assert isinstance(postfix, (int, str))\n name = abbr + str(postfix)\n\n requires_grad = cfg_.pop('requires_grad', True)\n cfg_.setdefault('eps', 1e-5)\n if layer_type != 'GN':\n layer = norm_layer(num_features, **cfg_)\n if layer_type == 'SyncBN' and hasattr(layer, '_specify_ddp_gpu_num'):\n layer._specify_ddp_gpu_num(1)\n else:\n assert 'num_groups' in cfg_\n layer = norm_layer(num_channels=num_features, **cfg_)\n\n for param in layer.parameters():\n param.requires_grad = requires_grad\n\n return name, layer\n\n\ndef is_norm(layer, exclude=None):\n \"\"\"Check if a layer is a normalization layer.\n\n Args:\n layer (nn.Module): The layer to be checked.\n exclude (type | tuple[type]): Types to be excluded.\n\n Returns:\n bool: Whether the layer is a norm layer.\n \"\"\"\n if exclude is not None:\n if not isinstance(exclude, tuple):\n exclude = (exclude, )\n if not is_tuple_of(exclude, type):\n raise TypeError(\n f'\"exclude\" must be either None or type or a tuple of types, '\n f'but got {type(exclude)}: {exclude}')\n\n if exclude and isinstance(layer, exclude):\n return False\n\n all_norm_bases = (_BatchNorm, _InstanceNorm, nn.GroupNorm, nn.LayerNorm)\n return isinstance(layer, all_norm_bases)\n", "path": "mmcv/cnn/bricks/norm.py"}]}
| 2,936 | 302 |
gh_patches_debug_35789
|
rasdani/github-patches
|
git_diff
|
saulpw__visidata-1188
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[save-selected] default save filename is not valid
**Small description**
When doing a `save-selected` the default sheet name is invalid, see the screenshot below
**Expected result**
For the suggested file name to be valid and useable. Maybe something like '`sheet1_sheet2_.csv`'.
**Actual result with screenshot**
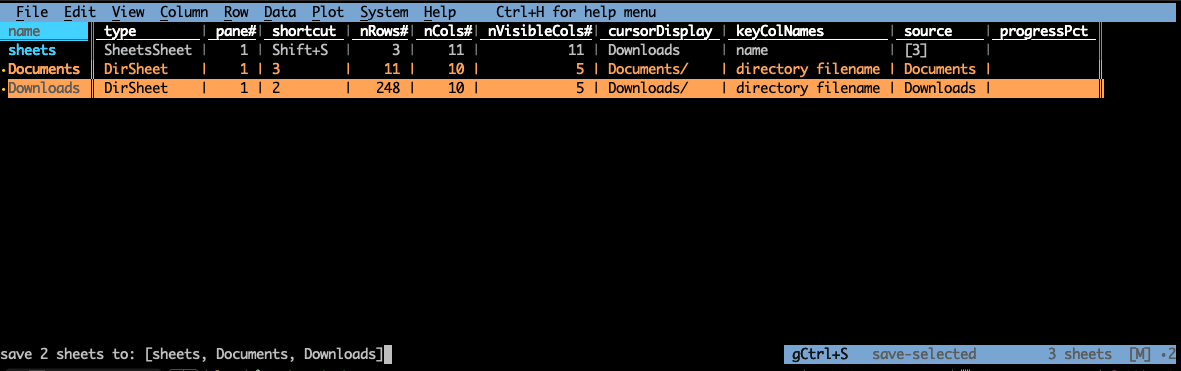
**Steps to reproduce with sample data and a .vd**
Open a number of sheets, go to `sheets-stack` select a few and do `save-selected`. This gives a stringified list rather than a proper name.
**Additional context**
Commit: https://github.com/saulpw/visidata/commit/9ce048d0378de0211e53f1591d79c8fbed39dff1
This seems to work:
`IndexSheet.addCommand('g^S', 'save-selected', 'vd.saveSheets(inputPath("save %d sheets to: " % nSelectedRows, value="_".join(vs.name or "blank" for vs in source)), *selectedRows, confirm_overwrite=options.confirm_overwrite)', 'save all selected sheets to given file or directory')`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `visidata/textsheet.py`
Content:
```
1 import textwrap
2
3 from visidata import vd, BaseSheet, options, Sheet, ColumnItem, asyncthread
4 from visidata import Column, ColumnItem, vlen
5 from visidata import globalCommand, VisiData
6 import visidata
7
8
9 vd.option('wrap', False, 'wrap text to fit window width on TextSheet')
10 vd.option('save_filetype', '', 'specify default file type to save as', replay=True)
11
12
13 ## text viewer
14 # rowdef: (linenum, str)
15 class TextSheet(Sheet):
16 'Displays any iterable source, with linewrap if ``options.wrap`` is set.'
17 rowtype = 'lines' # rowdef: [linenum, text]
18 filetype = 'txt'
19 columns = [
20 ColumnItem('linenum', 0, type=int, width=0),
21 ColumnItem('text', 1),
22 ]
23
24 def iterload(self):
25 yield from self.readlines(self.source)
26
27 def readlines(self, source):
28 winWidth = min(self.columns[1].width or 78, self.windowWidth-2)
29 wrap = self.options.wrap
30 for startingLine, text in enumerate(source):
31 if wrap and text:
32 for i, L in enumerate(textwrap.wrap(str(text), width=winWidth)):
33 yield [startingLine+i+1, L]
34 else:
35 yield [startingLine+1, text]
36
37 def sysopen(sheet, linenum=0):
38 @asyncthread
39 def writelines(sheet, fn):
40 with open(fn, 'w') as fp:
41 for row in sheet.rows:
42 fp.write(row[1])
43 fp.write('\n')
44
45 import tempfile
46 with tempfile.NamedTemporaryFile() as temp:
47 writelines(sheet, temp.name)
48 vd.launchEditor(temp.name, '+%s' % linenum)
49 sheet.rows = []
50 for r in sheet.readlines(visidata.Path(temp.name)):
51 sheet.addRow(r)
52
53
54 # .source is list of source text lines to 'load'
55 # .sourceSheet is Sheet error came from
56 class ErrorSheet(TextSheet):
57 precious = False
58
59
60 class ErrorsSheet(Sheet):
61 columns = [
62 Column('nlines', type=vlen),
63 ColumnItem('lastline', -1)
64 ]
65 def reload(self):
66 self.rows = self.source
67
68 def openRow(self, row):
69 return ErrorSheet(source=self.cursorRow)
70
71 @VisiData.property
72 def allErrorsSheet(self):
73 return ErrorsSheet("errors_all", source=vd.lastErrors)
74
75 @VisiData.property
76 def recentErrorsSheet(self):
77 error = vd.lastErrors[-1] if vd.lastErrors else ''
78 return ErrorSheet("errors_recent", source=error)
79
80
81
82 BaseSheet.addCommand('^E', 'error-recent', 'vd.lastErrors and vd.push(recentErrorsSheet) or status("no error")', 'view traceback for most recent error')
83 BaseSheet.addCommand('g^E', 'errors-all', 'vd.push(vd.allErrorsSheet)', 'view traceback for most recent errors')
84
85 Sheet.addCommand(None, 'view-cell', 'vd.push(ErrorSheet("%s[%s].%s" % (name, cursorRowIndex, cursorCol.name), sourceSheet=sheet, source=cursorDisplay.splitlines()))', 'view contents of current cell in a new sheet'),
86 Sheet.addCommand('z^E', 'error-cell', 'vd.push(ErrorSheet(sheet.name+"_cell_error", sourceSheet=sheet, source=getattr(cursorCell, "error", None) or fail("no error this cell")))', 'view traceback for error in current cell')
87
88 TextSheet.addCommand('^O', 'sysopen-sheet', 'sheet.sysopen(sheet.cursorRowIndex)', 'open copy of text sheet in $EDITOR and reload on exit')
89
90
91 TextSheet.class_options.save_filetype = 'txt'
92
93 vd.addGlobals({'TextSheet': TextSheet, 'ErrorSheet': ErrorSheet})
94
```
Path: `visidata/save.py`
Content:
```
1 from visidata import *
2
3
4 vd.option('confirm_overwrite', True, 'whether to prompt for overwrite confirmation on save')
5 vd.option('safe_error', '#ERR', 'error string to use while saving', replay=True)
6
7 @Sheet.api
8 def safe_trdict(vs):
9 'returns string.translate dictionary for replacing tabs and newlines'
10 if options.safety_first:
11 delim = vs.options.delimiter
12 return {
13 0: '', # strip NUL completely
14 ord(delim): vs.options.tsv_safe_tab, # \t
15 10: vs.options.tsv_safe_newline, # \n
16 13: vs.options.tsv_safe_newline, # \r
17 }
18 return {}
19
20
21 @Sheet.api
22 def iterdispvals(sheet, *cols, format=False):
23 'For each row in sheet, yield OrderedDict of values for given cols. Values are typed if format=False, or a formatted display string if format=True.'
24 if not cols:
25 cols = sheet.visibleCols
26
27 transformers = collections.OrderedDict() # list of transformers for each column in order
28 for col in cols:
29 transformers[col] = [ col.type ]
30 if format:
31 transformers[col].append(col.format)
32 trdict = sheet.safe_trdict()
33 if trdict:
34 transformers[col].append(lambda v,trdict=trdict: v.translate(trdict))
35
36 options_safe_error = options.safe_error
37 for r in Progress(sheet.rows):
38 dispvals = collections.OrderedDict() # [col] -> value
39 for col, transforms in transformers.items():
40 try:
41 dispval = col.getValue(r)
42
43 except Exception as e:
44 vd.exceptionCaught(e)
45 dispval = options_safe_error or str(e)
46
47 try:
48 for t in transforms:
49 if dispval is None:
50 break
51 elif isinstance(dispval, TypedExceptionWrapper):
52 dispval = options_safe_error or str(dispval)
53 break
54 else:
55 dispval = t(dispval)
56
57 if dispval is None and format:
58 dispval = ''
59 except Exception as e:
60 dispval = str(dispval)
61
62 dispvals[col] = dispval
63
64 yield dispvals
65
66
67 @Sheet.api
68 def itervals(sheet, *cols, format=False):
69 for row in sheet.iterdispvals(*cols, format=format):
70 yield [row[c] for c in cols]
71
72 @BaseSheet.api
73 def getDefaultSaveName(sheet):
74 src = getattr(sheet, 'source', None)
75 if hasattr(src, 'scheme') and src.scheme:
76 return src.name + src.suffix
77 if isinstance(src, Path):
78 if sheet.options.is_set('save_filetype', sheet):
79 # if save_filetype is over-ridden from default, use it as the extension
80 return str(src.with_suffix('')) + '.' + sheet.options.save_filetype
81 return str(src)
82 else:
83 return sheet.name+'.'+getattr(sheet, 'filetype', options.save_filetype)
84
85
86 @VisiData.api
87 def save_cols(vd, cols):
88 sheet = cols[0].sheet
89 vs = copy(sheet)
90 vs.columns = list(cols)
91 vs.rows = sheet.rows
92 if len(cols) == 1:
93 savedcoltxt = cols[0].name + ' column'
94 else:
95 savedcoltxt = '%s columns' % len(cols)
96 path = vd.inputPath('save %s to: ' % savedcoltxt, value=vs.getDefaultSaveName())
97 vd.saveSheets(path, vs, confirm_overwrite=options.confirm_overwrite)
98
99
100 @VisiData.api
101 def saveSheets(vd, givenpath, *vsheets, confirm_overwrite=False):
102 'Save all *vsheets* to *givenpath*.'
103
104 filetype = givenpath.ext or options.save_filetype
105
106 vd.clearCaches()
107
108 savefunc = getattr(vsheets[0], 'save_' + filetype, None) or getattr(vd, 'save_' + filetype, None)
109
110 if savefunc is None:
111 savefunc = getattr(vd, 'save_' + options.save_filetype, None) or vd.fail('no function to save as type %s, set options.save_filetype' % filetype)
112 vd.warning(f'save for {filetype} unavailable, using {options.save_filetype}')
113
114 if givenpath.exists() and confirm_overwrite:
115 vd.confirm("%s already exists. overwrite? " % givenpath.given)
116
117 vd.status('saving %s sheets to %s as %s' % (len(vsheets), givenpath.given, filetype))
118
119 if not givenpath.given.endswith('/'): # forcibly specify save individual files into directory by ending path with /
120 for vs in vsheets:
121 vs.hasBeenModified = False
122 return vd.execAsync(savefunc, givenpath, *vsheets)
123
124 # more than one sheet; either no specific multisave for save filetype, or path ends with /
125
126 # save as individual files in the givenpath directory
127 try:
128 os.makedirs(givenpath, exist_ok=True)
129 except FileExistsError:
130 pass
131
132 if not givenpath.is_dir():
133 vd.fail(f'cannot save multiple {filetype} sheets to non-dir')
134
135 def _savefiles(vsheets, givenpath, savefunc, filetype):
136 for vs in vsheets:
137 p = Path((givenpath / vs.name).with_suffix('.'+filetype))
138 savefunc(p, vs)
139 vs.hasBeenModified = False
140 return vd.execAsync(_savefiles, vsheets, givenpath, savefunc, filetype)
141
142
143 @VisiData.api
144 def save_txt(vd, p, *vsheets):
145 with p.open_text(mode='w', encoding=vsheets[0].options.encoding) as fp:
146 for vs in vsheets:
147 unitsep = vs.options.delimiter
148 rowsep = vs.options.row_delimiter
149 for dispvals in vs.iterdispvals(*vs.visibleCols, format=True):
150 fp.write(unitsep.join(dispvals.values()))
151 fp.write(rowsep)
152 vd.status('%s save finished' % p)
153
154
155 BaseSheet.addCommand('^S', 'save-sheet', 'vd.saveSheets(inputPath("save to: ", value=getDefaultSaveName()), sheet, confirm_overwrite=options.confirm_overwrite)', 'save current sheet to filename in format determined by extension (default .tsv)')
156 BaseSheet.addCommand('g^S', 'save-all', 'vd.saveSheets(inputPath("save all sheets to: "), *vd.stackedSheets, confirm_overwrite=options.confirm_overwrite)', 'save all sheets to given file or directory)')
157 IndexSheet.addCommand('g^S', 'save-selected', 'vd.saveSheets(inputPath("save %d sheets to: " % nSelectedRows, value=str(source)), *selectedRows, confirm_overwrite=options.confirm_overwrite)', 'save all selected sheets to given file or directory')
158 Sheet.addCommand('', 'save-col', 'save_cols([cursorCol])', 'save current column only to filename in format determined by extension (default .tsv)')
159 Sheet.addCommand('', 'save-col-keys', 'save_cols(keyCols + [cursorCol])', 'save key columns and current column to filename in format determined by extension (default .tsv)')
160
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/visidata/save.py b/visidata/save.py
--- a/visidata/save.py
+++ b/visidata/save.py
@@ -107,11 +107,16 @@
savefunc = getattr(vsheets[0], 'save_' + filetype, None) or getattr(vd, 'save_' + filetype, None)
+ using_save_filetype = False
+
if savefunc is None:
savefunc = getattr(vd, 'save_' + options.save_filetype, None) or vd.fail('no function to save as type %s, set options.save_filetype' % filetype)
vd.warning(f'save for {filetype} unavailable, using {options.save_filetype}')
+ using_save_filetype = True
- if givenpath.exists() and confirm_overwrite:
+ if using_save_filetype and givenpath.exists() and confirm_overwrite:
+ vd.confirm("%s already exists. overwrite with %s? " % (givenpath.given, options.save_filetype))
+ elif givenpath.exists() and confirm_overwrite:
vd.confirm("%s already exists. overwrite? " % givenpath.given)
vd.status('saving %s sheets to %s as %s' % (len(vsheets), givenpath.given, filetype))
@@ -119,9 +124,13 @@
if not givenpath.given.endswith('/'): # forcibly specify save individual files into directory by ending path with /
for vs in vsheets:
vs.hasBeenModified = False
+ # savefuncs(vd, p, *vsheets) will have 2 argcount (*vsheets does not get counted as an arg)
+ # savefuncs(vd, p, vs) will have 3 argcount (vs counts as an arg, along with vd, path)
+ if savefunc.__code__.co_argcount == 3 and len(vsheets) > 1:
+ vd.fail(f'cannot save multiple {filetype} sheets to non-dir')
return vd.execAsync(savefunc, givenpath, *vsheets)
- # more than one sheet; either no specific multisave for save filetype, or path ends with /
+ # path is a dir
# save as individual files in the givenpath directory
try:
diff --git a/visidata/textsheet.py b/visidata/textsheet.py
--- a/visidata/textsheet.py
+++ b/visidata/textsheet.py
@@ -7,7 +7,7 @@
vd.option('wrap', False, 'wrap text to fit window width on TextSheet')
-vd.option('save_filetype', '', 'specify default file type to save as', replay=True)
+vd.option('save_filetype', 'tsv', 'specify default file type to save as', replay=True)
## text viewer
|
{"golden_diff": "diff --git a/visidata/save.py b/visidata/save.py\n--- a/visidata/save.py\n+++ b/visidata/save.py\n@@ -107,11 +107,16 @@\n \n savefunc = getattr(vsheets[0], 'save_' + filetype, None) or getattr(vd, 'save_' + filetype, None)\n \n+ using_save_filetype = False\n+\n if savefunc is None:\n savefunc = getattr(vd, 'save_' + options.save_filetype, None) or vd.fail('no function to save as type %s, set options.save_filetype' % filetype)\n vd.warning(f'save for {filetype} unavailable, using {options.save_filetype}')\n+ using_save_filetype = True\n \n- if givenpath.exists() and confirm_overwrite:\n+ if using_save_filetype and givenpath.exists() and confirm_overwrite:\n+ vd.confirm(\"%s already exists. overwrite with %s? \" % (givenpath.given, options.save_filetype))\n+ elif givenpath.exists() and confirm_overwrite:\n vd.confirm(\"%s already exists. overwrite? \" % givenpath.given)\n \n vd.status('saving %s sheets to %s as %s' % (len(vsheets), givenpath.given, filetype))\n@@ -119,9 +124,13 @@\n if not givenpath.given.endswith('/'): # forcibly specify save individual files into directory by ending path with /\n for vs in vsheets:\n vs.hasBeenModified = False\n+ # savefuncs(vd, p, *vsheets) will have 2 argcount (*vsheets does not get counted as an arg)\n+ # savefuncs(vd, p, vs) will have 3 argcount (vs counts as an arg, along with vd, path)\n+ if savefunc.__code__.co_argcount == 3 and len(vsheets) > 1:\n+ vd.fail(f'cannot save multiple {filetype} sheets to non-dir')\n return vd.execAsync(savefunc, givenpath, *vsheets)\n \n- # more than one sheet; either no specific multisave for save filetype, or path ends with /\n+ # path is a dir\n \n # save as individual files in the givenpath directory\n try:\ndiff --git a/visidata/textsheet.py b/visidata/textsheet.py\n--- a/visidata/textsheet.py\n+++ b/visidata/textsheet.py\n@@ -7,7 +7,7 @@\n \n \n vd.option('wrap', False, 'wrap text to fit window width on TextSheet')\n-vd.option('save_filetype', '', 'specify default file type to save as', replay=True)\n+vd.option('save_filetype', 'tsv', 'specify default file type to save as', replay=True)\n \n \n ## text viewer\n", "issue": "[save-selected] default save filename is not valid\n**Small description**\r\nWhen doing a `save-selected` the default sheet name is invalid, see the screenshot below\r\n\r\n**Expected result**\r\nFor the suggested file name to be valid and useable. Maybe something like '`sheet1_sheet2_.csv`'.\r\n\r\n**Actual result with screenshot**\r\n\r\n\r\n**Steps to reproduce with sample data and a .vd**\r\nOpen a number of sheets, go to `sheets-stack` select a few and do `save-selected`. This gives a stringified list rather than a proper name.\r\n\r\n**Additional context**\r\nCommit: https://github.com/saulpw/visidata/commit/9ce048d0378de0211e53f1591d79c8fbed39dff1\r\n\r\nThis seems to work:\r\n`IndexSheet.addCommand('g^S', 'save-selected', 'vd.saveSheets(inputPath(\"save %d sheets to: \" % nSelectedRows, value=\"_\".join(vs.name or \"blank\" for vs in source)), *selectedRows, confirm_overwrite=options.confirm_overwrite)', 'save all selected sheets to given file or directory')`\r\n\n", "before_files": [{"content": "import textwrap\n\nfrom visidata import vd, BaseSheet, options, Sheet, ColumnItem, asyncthread\nfrom visidata import Column, ColumnItem, vlen\nfrom visidata import globalCommand, VisiData\nimport visidata\n\n\nvd.option('wrap', False, 'wrap text to fit window width on TextSheet')\nvd.option('save_filetype', '', 'specify default file type to save as', replay=True)\n\n\n## text viewer\n# rowdef: (linenum, str)\nclass TextSheet(Sheet):\n 'Displays any iterable source, with linewrap if ``options.wrap`` is set.'\n rowtype = 'lines' # rowdef: [linenum, text]\n filetype = 'txt'\n columns = [\n ColumnItem('linenum', 0, type=int, width=0),\n ColumnItem('text', 1),\n ]\n\n def iterload(self):\n yield from self.readlines(self.source)\n\n def readlines(self, source):\n winWidth = min(self.columns[1].width or 78, self.windowWidth-2)\n wrap = self.options.wrap\n for startingLine, text in enumerate(source):\n if wrap and text:\n for i, L in enumerate(textwrap.wrap(str(text), width=winWidth)):\n yield [startingLine+i+1, L]\n else:\n yield [startingLine+1, text]\n\n def sysopen(sheet, linenum=0):\n @asyncthread\n def writelines(sheet, fn):\n with open(fn, 'w') as fp:\n for row in sheet.rows:\n fp.write(row[1])\n fp.write('\\n')\n\n import tempfile\n with tempfile.NamedTemporaryFile() as temp:\n writelines(sheet, temp.name)\n vd.launchEditor(temp.name, '+%s' % linenum)\n sheet.rows = []\n for r in sheet.readlines(visidata.Path(temp.name)):\n sheet.addRow(r)\n\n\n# .source is list of source text lines to 'load'\n# .sourceSheet is Sheet error came from\nclass ErrorSheet(TextSheet):\n precious = False\n\n\nclass ErrorsSheet(Sheet):\n columns = [\n Column('nlines', type=vlen),\n ColumnItem('lastline', -1)\n ]\n def reload(self):\n self.rows = self.source\n\n def openRow(self, row):\n return ErrorSheet(source=self.cursorRow)\n\[email protected]\ndef allErrorsSheet(self):\n return ErrorsSheet(\"errors_all\", source=vd.lastErrors)\n\[email protected]\ndef recentErrorsSheet(self):\n error = vd.lastErrors[-1] if vd.lastErrors else ''\n return ErrorSheet(\"errors_recent\", source=error)\n\n\n\nBaseSheet.addCommand('^E', 'error-recent', 'vd.lastErrors and vd.push(recentErrorsSheet) or status(\"no error\")', 'view traceback for most recent error')\nBaseSheet.addCommand('g^E', 'errors-all', 'vd.push(vd.allErrorsSheet)', 'view traceback for most recent errors')\n\nSheet.addCommand(None, 'view-cell', 'vd.push(ErrorSheet(\"%s[%s].%s\" % (name, cursorRowIndex, cursorCol.name), sourceSheet=sheet, source=cursorDisplay.splitlines()))', 'view contents of current cell in a new sheet'),\nSheet.addCommand('z^E', 'error-cell', 'vd.push(ErrorSheet(sheet.name+\"_cell_error\", sourceSheet=sheet, source=getattr(cursorCell, \"error\", None) or fail(\"no error this cell\")))', 'view traceback for error in current cell')\n\nTextSheet.addCommand('^O', 'sysopen-sheet', 'sheet.sysopen(sheet.cursorRowIndex)', 'open copy of text sheet in $EDITOR and reload on exit')\n\n\nTextSheet.class_options.save_filetype = 'txt'\n\nvd.addGlobals({'TextSheet': TextSheet, 'ErrorSheet': ErrorSheet})\n", "path": "visidata/textsheet.py"}, {"content": "from visidata import *\n\n\nvd.option('confirm_overwrite', True, 'whether to prompt for overwrite confirmation on save')\nvd.option('safe_error', '#ERR', 'error string to use while saving', replay=True)\n\[email protected]\ndef safe_trdict(vs):\n 'returns string.translate dictionary for replacing tabs and newlines'\n if options.safety_first:\n delim = vs.options.delimiter\n return {\n 0: '', # strip NUL completely\n ord(delim): vs.options.tsv_safe_tab, # \\t\n 10: vs.options.tsv_safe_newline, # \\n\n 13: vs.options.tsv_safe_newline, # \\r\n }\n return {}\n\n\[email protected]\ndef iterdispvals(sheet, *cols, format=False):\n 'For each row in sheet, yield OrderedDict of values for given cols. Values are typed if format=False, or a formatted display string if format=True.'\n if not cols:\n cols = sheet.visibleCols\n\n transformers = collections.OrderedDict() # list of transformers for each column in order\n for col in cols:\n transformers[col] = [ col.type ]\n if format:\n transformers[col].append(col.format)\n trdict = sheet.safe_trdict()\n if trdict:\n transformers[col].append(lambda v,trdict=trdict: v.translate(trdict))\n\n options_safe_error = options.safe_error\n for r in Progress(sheet.rows):\n dispvals = collections.OrderedDict() # [col] -> value\n for col, transforms in transformers.items():\n try:\n dispval = col.getValue(r)\n\n except Exception as e:\n vd.exceptionCaught(e)\n dispval = options_safe_error or str(e)\n\n try:\n for t in transforms:\n if dispval is None:\n break\n elif isinstance(dispval, TypedExceptionWrapper):\n dispval = options_safe_error or str(dispval)\n break\n else:\n dispval = t(dispval)\n\n if dispval is None and format:\n dispval = ''\n except Exception as e:\n dispval = str(dispval)\n\n dispvals[col] = dispval\n\n yield dispvals\n\n\[email protected]\ndef itervals(sheet, *cols, format=False):\n for row in sheet.iterdispvals(*cols, format=format):\n yield [row[c] for c in cols]\n\[email protected]\ndef getDefaultSaveName(sheet):\n src = getattr(sheet, 'source', None)\n if hasattr(src, 'scheme') and src.scheme:\n return src.name + src.suffix\n if isinstance(src, Path):\n if sheet.options.is_set('save_filetype', sheet):\n # if save_filetype is over-ridden from default, use it as the extension\n return str(src.with_suffix('')) + '.' + sheet.options.save_filetype\n return str(src)\n else:\n return sheet.name+'.'+getattr(sheet, 'filetype', options.save_filetype)\n\n\[email protected]\ndef save_cols(vd, cols):\n sheet = cols[0].sheet\n vs = copy(sheet)\n vs.columns = list(cols)\n vs.rows = sheet.rows\n if len(cols) == 1:\n savedcoltxt = cols[0].name + ' column'\n else:\n savedcoltxt = '%s columns' % len(cols)\n path = vd.inputPath('save %s to: ' % savedcoltxt, value=vs.getDefaultSaveName())\n vd.saveSheets(path, vs, confirm_overwrite=options.confirm_overwrite)\n\n\[email protected]\ndef saveSheets(vd, givenpath, *vsheets, confirm_overwrite=False):\n 'Save all *vsheets* to *givenpath*.'\n\n filetype = givenpath.ext or options.save_filetype\n\n vd.clearCaches()\n\n savefunc = getattr(vsheets[0], 'save_' + filetype, None) or getattr(vd, 'save_' + filetype, None)\n\n if savefunc is None:\n savefunc = getattr(vd, 'save_' + options.save_filetype, None) or vd.fail('no function to save as type %s, set options.save_filetype' % filetype)\n vd.warning(f'save for {filetype} unavailable, using {options.save_filetype}')\n\n if givenpath.exists() and confirm_overwrite:\n vd.confirm(\"%s already exists. overwrite? \" % givenpath.given)\n\n vd.status('saving %s sheets to %s as %s' % (len(vsheets), givenpath.given, filetype))\n\n if not givenpath.given.endswith('/'): # forcibly specify save individual files into directory by ending path with /\n for vs in vsheets:\n vs.hasBeenModified = False\n return vd.execAsync(savefunc, givenpath, *vsheets)\n\n # more than one sheet; either no specific multisave for save filetype, or path ends with /\n\n # save as individual files in the givenpath directory\n try:\n os.makedirs(givenpath, exist_ok=True)\n except FileExistsError:\n pass\n\n if not givenpath.is_dir():\n vd.fail(f'cannot save multiple {filetype} sheets to non-dir')\n\n def _savefiles(vsheets, givenpath, savefunc, filetype):\n for vs in vsheets:\n p = Path((givenpath / vs.name).with_suffix('.'+filetype))\n savefunc(p, vs)\n vs.hasBeenModified = False\n return vd.execAsync(_savefiles, vsheets, givenpath, savefunc, filetype)\n\n\[email protected]\ndef save_txt(vd, p, *vsheets):\n with p.open_text(mode='w', encoding=vsheets[0].options.encoding) as fp:\n for vs in vsheets:\n unitsep = vs.options.delimiter\n rowsep = vs.options.row_delimiter\n for dispvals in vs.iterdispvals(*vs.visibleCols, format=True):\n fp.write(unitsep.join(dispvals.values()))\n fp.write(rowsep)\n vd.status('%s save finished' % p)\n\n\nBaseSheet.addCommand('^S', 'save-sheet', 'vd.saveSheets(inputPath(\"save to: \", value=getDefaultSaveName()), sheet, confirm_overwrite=options.confirm_overwrite)', 'save current sheet to filename in format determined by extension (default .tsv)')\nBaseSheet.addCommand('g^S', 'save-all', 'vd.saveSheets(inputPath(\"save all sheets to: \"), *vd.stackedSheets, confirm_overwrite=options.confirm_overwrite)', 'save all sheets to given file or directory)')\nIndexSheet.addCommand('g^S', 'save-selected', 'vd.saveSheets(inputPath(\"save %d sheets to: \" % nSelectedRows, value=str(source)), *selectedRows, confirm_overwrite=options.confirm_overwrite)', 'save all selected sheets to given file or directory')\nSheet.addCommand('', 'save-col', 'save_cols([cursorCol])', 'save current column only to filename in format determined by extension (default .tsv)')\nSheet.addCommand('', 'save-col-keys', 'save_cols(keyCols + [cursorCol])', 'save key columns and current column to filename in format determined by extension (default .tsv)')\n", "path": "visidata/save.py"}], "after_files": [{"content": "import textwrap\n\nfrom visidata import vd, BaseSheet, options, Sheet, ColumnItem, asyncthread\nfrom visidata import Column, ColumnItem, vlen\nfrom visidata import globalCommand, VisiData\nimport visidata\n\n\nvd.option('wrap', False, 'wrap text to fit window width on TextSheet')\nvd.option('save_filetype', 'tsv', 'specify default file type to save as', replay=True)\n\n\n## text viewer\n# rowdef: (linenum, str)\nclass TextSheet(Sheet):\n 'Displays any iterable source, with linewrap if ``options.wrap`` is set.'\n rowtype = 'lines' # rowdef: [linenum, text]\n filetype = 'txt'\n columns = [\n ColumnItem('linenum', 0, type=int, width=0),\n ColumnItem('text', 1),\n ]\n\n def iterload(self):\n yield from self.readlines(self.source)\n\n def readlines(self, source):\n winWidth = min(self.columns[1].width or 78, self.windowWidth-2)\n wrap = self.options.wrap\n for startingLine, text in enumerate(source):\n if wrap and text:\n for i, L in enumerate(textwrap.wrap(str(text), width=winWidth)):\n yield [startingLine+i+1, L]\n else:\n yield [startingLine+1, text]\n\n def sysopen(sheet, linenum=0):\n @asyncthread\n def writelines(sheet, fn):\n with open(fn, 'w') as fp:\n for row in sheet.rows:\n fp.write(row[1])\n fp.write('\\n')\n\n import tempfile\n with tempfile.NamedTemporaryFile() as temp:\n writelines(sheet, temp.name)\n vd.launchEditor(temp.name, '+%s' % linenum)\n sheet.rows = []\n for r in sheet.readlines(visidata.Path(temp.name)):\n sheet.addRow(r)\n\n\n# .source is list of source text lines to 'load'\n# .sourceSheet is Sheet error came from\nclass ErrorSheet(TextSheet):\n precious = False\n\n\nclass ErrorsSheet(Sheet):\n columns = [\n Column('nlines', type=vlen),\n ColumnItem('lastline', -1)\n ]\n def reload(self):\n self.rows = self.source\n\n def openRow(self, row):\n return ErrorSheet(source=self.cursorRow)\n\[email protected]\ndef allErrorsSheet(self):\n return ErrorsSheet(\"errors_all\", source=vd.lastErrors)\n\[email protected]\ndef recentErrorsSheet(self):\n error = vd.lastErrors[-1] if vd.lastErrors else ''\n return ErrorSheet(\"errors_recent\", source=error)\n\n\n\nBaseSheet.addCommand('^E', 'error-recent', 'vd.lastErrors and vd.push(recentErrorsSheet) or status(\"no error\")', 'view traceback for most recent error')\nBaseSheet.addCommand('g^E', 'errors-all', 'vd.push(vd.allErrorsSheet)', 'view traceback for most recent errors')\n\nSheet.addCommand(None, 'view-cell', 'vd.push(ErrorSheet(\"%s[%s].%s\" % (name, cursorRowIndex, cursorCol.name), sourceSheet=sheet, source=cursorDisplay.splitlines()))', 'view contents of current cell in a new sheet'),\nSheet.addCommand('z^E', 'error-cell', 'vd.push(ErrorSheet(sheet.name+\"_cell_error\", sourceSheet=sheet, source=getattr(cursorCell, \"error\", None) or fail(\"no error this cell\")))', 'view traceback for error in current cell')\n\nTextSheet.addCommand('^O', 'sysopen-sheet', 'sheet.sysopen(sheet.cursorRowIndex)', 'open copy of text sheet in $EDITOR and reload on exit')\n\n\nTextSheet.class_options.save_filetype = 'txt'\n\nvd.addGlobals({'TextSheet': TextSheet, 'ErrorSheet': ErrorSheet})\n", "path": "visidata/textsheet.py"}, {"content": "from visidata import *\n\n\nvd.option('confirm_overwrite', True, 'whether to prompt for overwrite confirmation on save')\nvd.option('safe_error', '#ERR', 'error string to use while saving', replay=True)\n\[email protected]\ndef safe_trdict(vs):\n 'returns string.translate dictionary for replacing tabs and newlines'\n if options.safety_first:\n delim = vs.options.delimiter\n return {\n 0: '', # strip NUL completely\n ord(delim): vs.options.tsv_safe_tab, # \\t\n 10: vs.options.tsv_safe_newline, # \\n\n 13: vs.options.tsv_safe_newline, # \\r\n }\n return {}\n\n\[email protected]\ndef iterdispvals(sheet, *cols, format=False):\n 'For each row in sheet, yield OrderedDict of values for given cols. Values are typed if format=False, or a formatted display string if format=True.'\n if not cols:\n cols = sheet.visibleCols\n\n transformers = collections.OrderedDict() # list of transformers for each column in order\n for col in cols:\n transformers[col] = [ col.type ]\n if format:\n transformers[col].append(col.format)\n trdict = sheet.safe_trdict()\n if trdict:\n transformers[col].append(lambda v,trdict=trdict: v.translate(trdict))\n\n options_safe_error = options.safe_error\n for r in Progress(sheet.rows):\n dispvals = collections.OrderedDict() # [col] -> value\n for col, transforms in transformers.items():\n try:\n dispval = col.getValue(r)\n\n except Exception as e:\n vd.exceptionCaught(e)\n dispval = options_safe_error or str(e)\n\n try:\n for t in transforms:\n if dispval is None:\n break\n elif isinstance(dispval, TypedExceptionWrapper):\n dispval = options_safe_error or str(dispval)\n break\n else:\n dispval = t(dispval)\n\n if dispval is None and format:\n dispval = ''\n except Exception as e:\n dispval = str(dispval)\n\n dispvals[col] = dispval\n\n yield dispvals\n\n\[email protected]\ndef itervals(sheet, *cols, format=False):\n for row in sheet.iterdispvals(*cols, format=format):\n yield [row[c] for c in cols]\n\[email protected]\ndef getDefaultSaveName(sheet):\n src = getattr(sheet, 'source', None)\n if hasattr(src, 'scheme') and src.scheme:\n return src.name + src.suffix\n if isinstance(src, Path):\n if sheet.options.is_set('save_filetype', sheet):\n # if save_filetype is over-ridden from default, use it as the extension\n return str(src.with_suffix('')) + '.' + sheet.options.save_filetype\n return str(src)\n else:\n return sheet.name+'.'+getattr(sheet, 'filetype', options.save_filetype)\n\n\[email protected]\ndef save_cols(vd, cols):\n sheet = cols[0].sheet\n vs = copy(sheet)\n vs.columns = list(cols)\n vs.rows = sheet.rows\n if len(cols) == 1:\n savedcoltxt = cols[0].name + ' column'\n else:\n savedcoltxt = '%s columns' % len(cols)\n path = vd.inputPath('save %s to: ' % savedcoltxt, value=vs.getDefaultSaveName())\n vd.saveSheets(path, vs, confirm_overwrite=options.confirm_overwrite)\n\n\[email protected]\ndef saveSheets(vd, givenpath, *vsheets, confirm_overwrite=False):\n 'Save all *vsheets* to *givenpath*.'\n\n filetype = givenpath.ext or options.save_filetype\n\n vd.clearCaches()\n\n savefunc = getattr(vsheets[0], 'save_' + filetype, None) or getattr(vd, 'save_' + filetype, None)\n\n using_save_filetype = False\n\n if savefunc is None:\n savefunc = getattr(vd, 'save_' + options.save_filetype, None) or vd.fail('no function to save as type %s, set options.save_filetype' % filetype)\n vd.warning(f'save for {filetype} unavailable, using {options.save_filetype}')\n using_save_filetype = True\n\n if using_save_filetype and givenpath.exists() and confirm_overwrite:\n vd.confirm(\"%s already exists. overwrite with %s? \" % (givenpath.given, options.save_filetype))\n elif givenpath.exists() and confirm_overwrite:\n vd.confirm(\"%s already exists. overwrite? \" % givenpath.given)\n\n vd.status('saving %s sheets to %s as %s' % (len(vsheets), givenpath.given, filetype))\n\n if not givenpath.given.endswith('/'): # forcibly specify save individual files into directory by ending path with /\n for vs in vsheets:\n vs.hasBeenModified = False\n # savefuncs(vd, p, *vsheets) will have 2 argcount (*vsheets does not get counted as an arg)\n # savefuncs(vd, p, vs) will have 3 argcount (vs counts as an arg, along with vd, path)\n if savefunc.__code__.co_argcount == 3 and len(vsheets) > 1:\n vd.fail(f'cannot save multiple {filetype} sheets to non-dir')\n return vd.execAsync(savefunc, givenpath, *vsheets)\n\n # path is a dir\n\n # save as individual files in the givenpath directory\n try:\n os.makedirs(givenpath, exist_ok=True)\n except FileExistsError:\n pass\n\n if not givenpath.is_dir():\n vd.fail(f'cannot save multiple {filetype} sheets to non-dir')\n\n def _savefiles(vsheets, givenpath, savefunc, filetype):\n for vs in vsheets:\n p = Path((givenpath / vs.name).with_suffix('.'+filetype))\n savefunc(p, vs)\n vs.hasBeenModified = False\n return vd.execAsync(_savefiles, vsheets, givenpath, savefunc, filetype)\n\n\[email protected]\ndef save_txt(vd, p, *vsheets):\n with p.open_text(mode='w', encoding=vsheets[0].options.encoding) as fp:\n for vs in vsheets:\n unitsep = vs.options.delimiter\n rowsep = vs.options.row_delimiter\n for dispvals in vs.iterdispvals(*vs.visibleCols, format=True):\n fp.write(unitsep.join(dispvals.values()))\n fp.write(rowsep)\n vd.status('%s save finished' % p)\n\n\nBaseSheet.addCommand('^S', 'save-sheet', 'vd.saveSheets(inputPath(\"save to: \", value=getDefaultSaveName()), sheet, confirm_overwrite=options.confirm_overwrite)', 'save current sheet to filename in format determined by extension (default .tsv)')\nBaseSheet.addCommand('g^S', 'save-all', 'vd.saveSheets(inputPath(\"save all sheets to: \"), *vd.stackedSheets, confirm_overwrite=options.confirm_overwrite)', 'save all sheets to given file or directory)')\nIndexSheet.addCommand('g^S', 'save-selected', 'vd.saveSheets(inputPath(\"save %d sheets to: \" % nSelectedRows, value=str(source)), *selectedRows, confirm_overwrite=options.confirm_overwrite)', 'save all selected sheets to given file or directory')\nSheet.addCommand('', 'save-col', 'save_cols([cursorCol])', 'save current column only to filename in format determined by extension (default .tsv)')\nSheet.addCommand('', 'save-col-keys', 'save_cols(keyCols + [cursorCol])', 'save key columns and current column to filename in format determined by extension (default .tsv)')\n", "path": "visidata/save.py"}]}
| 3,541 | 617 |
gh_patches_debug_21989
|
rasdani/github-patches
|
git_diff
|
cloudtools__troposphere-2156
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
When using ec2.VpnTunnelOptionsSpecification, report error:compile() missing required argument 'filename' (pos 2)
I am using troposphere version 4.3.2
The issue occurs in this code section:
```
vpn_tunnel_option_props = self.filter_parameters(
vpn_option.items(), ec2.VpnTunnelOptionsSpecification
)
```
after I ran it an error occured: compile() missing required argument 'filename' (pos 2)
But it works in troposphere version 3.2.2
I find that troposphere uses re.complile() in the old versions(v3), but the Python system function compile() is used in the new versions(v4), which caused this problem. Is this a bug?
```
def vpn_tunnel_inside_cidr(cidr):
"""
Property: VpnTunnelOptionsSpecification.TunnelInsideCidr
"""
cidr_match_re = compile(
r"^169\.254\.(?:25[0-5]|2[0-4]\d|[01]?\d\d?)"
r"\.(?:25[0-5]|2[0-4]\d|[01]?\d\d?)\/30$"
)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `troposphere/validators/ec2.py`
Content:
```
1 # Copyright (c) 2012-2022, Mark Peek <[email protected]>
2 # All rights reserved.
3 #
4 # See LICENSE file for full license.
5
6
7 from .. import AWSProperty
8 from ..compat import validate_policytype
9 from ..type_defs.compat import Final
10 from . import exactly_one, integer_range, network_port, tags_or_list
11
12 PERMISSION_INSTANCE_ATTACH: Final = "INSTANCE-ATTACH"
13 PERMISSION_EIP_ASSOCIATE: Final = "EIP-ASSOCIATE"
14
15 NO_DEVICE: Final = {}
16
17
18 def Ipv6Addresses(ipv6_address):
19 """
20 Export:
21 """
22 from ..ec2 import InstanceIpv6Address
23
24 return InstanceIpv6Address(Ipv6Address=ipv6_address)
25
26
27 class Tag(AWSProperty):
28 """
29 Export:
30 """
31
32 props = {
33 "Key": (str, True),
34 "Value": (str, True),
35 }
36
37 def __init__(self, key=None, value=None, **kwargs):
38 # provided for backward compatibility
39 if key is not None:
40 kwargs["Key"] = key
41 if value is not None:
42 kwargs["Value"] = value
43 super().__init__(**kwargs)
44
45
46 def validate_int_to_str(x):
47 """
48 Backward compatibility - field was int and now str.
49 Property: NetworkInterfaceProperty.DeviceIndex
50 Property: NetworkInterfaceAttachment.DeviceIndex
51 """
52
53 if isinstance(x, int):
54 return str(x)
55 if isinstance(x, str):
56 return str(int(x))
57
58 raise TypeError(f"Value {x} of type {type(x)} must be either int or str")
59
60
61 def policytypes(policy):
62 """
63 Property: VPCEndpoint.PolicyDocument
64 """
65 return validate_policytype(policy)
66
67
68 def validate_networkaclentry_rulenumber(x):
69 """
70 Property: NetworkAclEntry.RuleNumber
71 """
72 return integer_range(1, 32766)(x)
73
74
75 def validate_network_port(x):
76 """
77 Property: NetworkAclEntry.Protocol
78 Property: PortRange.From
79 Property: PortRange.To
80 Property: SecurityGroupRule.FromPort
81 Property: SecurityGroupRule.ToPort
82 Property: SecurityGroupEgress.FromPort
83 Property: SecurityGroupEgress.ToPort
84 Property: SecurityGroupIngress.FromPort
85 Property: SecurityGroupIngress.ToPort
86 """
87 return network_port(x)
88
89
90 def validate_tags_or_list(x):
91 """
92 Property: TagSpecifications.Tags
93 Property: CustomerGateway.Tags
94 Property: DHCPOptions.Tags
95 Property: Instance.Tags
96 Property: InternetGateway.Tags
97 Property: LocalGatewayRouteTableVPCAssociation.Tags
98 Property: NatGateway.Tags
99 Property: NetworkAcl.Tags
100 Property: NetworkInterface.Tags
101 Property: RouteTable.Tags
102 Property: SecurityGroup.Tags
103 Property: SpotFleetTagSpecification.Tags
104 Property: Subnet.Tags
105 Property: TransitGateway.Tags
106 Property: TransitGatewayAttachment.Tags
107 Property: TransitGatewayRouteTable.Tags
108 Property: VPC.Tags
109 Property: VPCPeeringConnection.Tags
110 Property: VPNConnection.Tags
111 Property: VPNGateway.Tags
112 Property: Volume.Tags
113 Property: VPNGateway.Tags
114 Property: VPNGateway.Tags
115 """
116 return tags_or_list(x)
117
118
119 def instance_tenancy(value):
120 """
121 Property: VPC.InstanceTenancy
122 """
123 valid = ["default", "dedicated"]
124 if value not in valid:
125 raise ValueError("InstanceTenancy needs to be one of %r" % valid)
126 return value
127
128
129 def check_ports(props):
130 # IpProtocol is a required field but not all values allowed require
131 # ToPort and FromPort. The ones that don't need these ports are:
132 ports_optional = [
133 "-1", # all protocols
134 "58", # ICMPv6
135 ]
136 proto = props["IpProtocol"]
137
138 if proto not in ports_optional:
139 if not ("ToPort" in props and "FromPort" in props):
140 raise ValueError("ToPort/FromPort must be specified for proto %s" % proto)
141
142
143 def validate_elasticinferenceaccelerator_type(elasticinferenceaccelerator_type):
144 """
145 Validate ElasticInferenceAccelerator for Instance
146 Property: ElasticInferenceAccelerator.Type
147 Property: LaunchTemplateElasticInferenceAccelerator.Type
148 """
149
150 VALID_ELASTICINFERENCEACCELERATOR_TYPES = (
151 "eia1.medium",
152 "eia1.large",
153 "eia1.xlarge",
154 )
155 if elasticinferenceaccelerator_type not in VALID_ELASTICINFERENCEACCELERATOR_TYPES:
156 raise ValueError(
157 "Elastic Inference Accelerator Type must be one of: %s"
158 % ", ".join(VALID_ELASTICINFERENCEACCELERATOR_TYPES)
159 )
160 return elasticinferenceaccelerator_type
161
162
163 def validate_clientvpnendpoint_selfserviceportal(value):
164 """
165 Validate SelfServicePortal for ClientVpnEndpoint.
166 Property: ClientVpnEndpoint.SelfServicePortal
167 """
168
169 VALID_CLIENTVPNENDPOINT_SELFSERVICEPORTAL = ("disabled", "enabled")
170
171 if value not in VALID_CLIENTVPNENDPOINT_SELFSERVICEPORTAL:
172 raise ValueError(
173 "ClientVpnEndpoint.SelfServicePortal must be one of: {}".format(
174 ", ".join(VALID_CLIENTVPNENDPOINT_SELFSERVICEPORTAL)
175 )
176 )
177 return value
178
179
180 def validate_clientvpnendpoint_vpnport(vpnport):
181 """
182 Validate VpnPort for ClientVpnEndpoint
183 Property: ClientVpnEndpoint.VpnPort
184 """
185
186 VALID_CLIENTVPNENDPOINT_VPNPORT = (443, 1194)
187 if vpnport not in VALID_CLIENTVPNENDPOINT_VPNPORT:
188 raise ValueError(
189 "ClientVpnEndpoint VpnPort must be one of: %s"
190 % ", ".join(VALID_CLIENTVPNENDPOINT_VPNPORT)
191 )
192 return vpnport
193
194
195 def vpn_pre_shared_key(key):
196 """
197 Property: VpnTunnelOptionsSpecification.PreSharedKey
198 """
199 pre_shared_key_match_re = compile(r"^(?!0)([A-Za-z0-9]|\_|\.){8,64}$")
200 if not pre_shared_key_match_re.match(key):
201 raise ValueError(
202 "%s is not a valid key."
203 " Allowed characters are alphanumeric characters and ._. Must"
204 " be between 8 and 64 characters in length and cannot"
205 " start with zero (0)." % key
206 )
207 return key
208
209
210 def vpn_tunnel_inside_cidr(cidr):
211 """
212 Property: VpnTunnelOptionsSpecification.TunnelInsideCidr
213 """
214 reserved_cidrs = [
215 "169.254.0.0/30",
216 "169.254.1.0/30",
217 "169.254.2.0/30",
218 "169.254.3.0/30",
219 "169.254.4.0/30",
220 "169.254.5.0/30",
221 "169.254.169.252/30",
222 ]
223 cidr_match_re = compile(
224 r"^169\.254\.(?:25[0-5]|2[0-4]\d|[01]?\d\d?)"
225 r"\.(?:25[0-5]|2[0-4]\d|[01]?\d\d?)\/30$"
226 )
227 if cidr in reserved_cidrs:
228 raise ValueError(
229 'The following CIDR blocks are reserved and cannot be used: "%s"'
230 % (", ".join(reserved_cidrs))
231 )
232 elif not cidr_match_re.match(cidr):
233 raise ValueError(
234 "%s is not a valid CIDR."
235 " A size /30 CIDR block from the 169.254.0.0/16 must be specified." % cidr
236 )
237 return cidr
238
239
240 def vpc_endpoint_type(endpoint_type):
241 """
242 Property: VPCEndpoint.VpcEndpointType
243 """
244 valid_types = ["Interface", "Gateway", "GatewayLoadBalancer"]
245 if endpoint_type not in valid_types:
246 raise ValueError(
247 'VpcEndpointType must be one of: "%s"' % (", ".join(valid_types))
248 )
249 return endpoint_type
250
251
252 def validate_network_acl_entry(self):
253 """
254 Class: NetworkAclEntry
255 """
256 conds = [
257 "CidrBlock",
258 "Ipv6CidrBlock",
259 ]
260 exactly_one(self.__class__.__name__, self.properties, conds)
261
262
263 def validate_route(self):
264 """
265 Class: Route
266 """
267 cidr_conds = [
268 "DestinationCidrBlock",
269 "DestinationIpv6CidrBlock",
270 ]
271 gateway_conds = [
272 "CarrierGatewayId",
273 "EgressOnlyInternetGatewayId",
274 "GatewayId",
275 "InstanceId",
276 "LocalGatewayId",
277 "NatGatewayId",
278 "NetworkInterfaceId",
279 "TransitGatewayId",
280 "VpcEndpointId",
281 "VpcPeeringConnectionId",
282 ]
283 exactly_one(self.__class__.__name__, self.properties, cidr_conds)
284 exactly_one(self.__class__.__name__, self.properties, gateway_conds)
285
286
287 def validate_security_group_egress(self):
288 """
289 Class: SecurityGroupEgress
290 """
291 conds = [
292 "CidrIp",
293 "CidrIpv6",
294 "DestinationPrefixListId",
295 "DestinationSecurityGroupId",
296 ]
297 exactly_one(self.__class__.__name__, self.properties, conds)
298 check_ports(self.properties)
299
300
301 def validate_security_group_ingress(self):
302 """
303 Class: SecurityGroupIngress
304 """
305 conds = [
306 "CidrIp",
307 "CidrIpv6",
308 "SourcePrefixListId",
309 "SourceSecurityGroupName",
310 "SourceSecurityGroupId",
311 ]
312 exactly_one(self.__class__.__name__, self.properties, conds)
313 check_ports(self.properties)
314
315
316 def validate_spot_fleet_request_config_data(self):
317 """
318 Class: SpotFleetRequestConfigData
319 """
320 conds = ["LaunchSpecifications", "LaunchTemplateConfigs"]
321 exactly_one(self.__class__.__name__, self.properties, conds)
322
323
324 def validate_subnet(self):
325 """
326 Class: Subnet
327 """
328 if "Ipv6CidrBlock" in self.properties:
329 if not self.properties.get("AssignIpv6AddressOnCreation"):
330 raise ValueError(
331 "If Ipv6CidrBlock is present, "
332 "AssignIpv6AddressOnCreation must be set to True"
333 )
334
335
336 def validate_vpn_connection(self):
337 """
338 Class: VPNConnection
339 """
340 conds = [
341 "VpnGatewayId",
342 "TransitGatewayId",
343 ]
344 exactly_one(self.__class__.__name__, self.properties, conds)
345
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/troposphere/validators/ec2.py b/troposphere/validators/ec2.py
--- a/troposphere/validators/ec2.py
+++ b/troposphere/validators/ec2.py
@@ -3,6 +3,7 @@
#
# See LICENSE file for full license.
+import re
from .. import AWSProperty
from ..compat import validate_policytype
@@ -196,7 +197,7 @@
"""
Property: VpnTunnelOptionsSpecification.PreSharedKey
"""
- pre_shared_key_match_re = compile(r"^(?!0)([A-Za-z0-9]|\_|\.){8,64}$")
+ pre_shared_key_match_re = re.compile(r"^(?!0)([A-Za-z0-9]|\_|\.){8,64}$")
if not pre_shared_key_match_re.match(key):
raise ValueError(
"%s is not a valid key."
@@ -220,7 +221,7 @@
"169.254.5.0/30",
"169.254.169.252/30",
]
- cidr_match_re = compile(
+ cidr_match_re = re.compile(
r"^169\.254\.(?:25[0-5]|2[0-4]\d|[01]?\d\d?)"
r"\.(?:25[0-5]|2[0-4]\d|[01]?\d\d?)\/30$"
)
|
{"golden_diff": "diff --git a/troposphere/validators/ec2.py b/troposphere/validators/ec2.py\n--- a/troposphere/validators/ec2.py\n+++ b/troposphere/validators/ec2.py\n@@ -3,6 +3,7 @@\n #\n # See LICENSE file for full license.\n \n+import re\n \n from .. import AWSProperty\n from ..compat import validate_policytype\n@@ -196,7 +197,7 @@\n \"\"\"\n Property: VpnTunnelOptionsSpecification.PreSharedKey\n \"\"\"\n- pre_shared_key_match_re = compile(r\"^(?!0)([A-Za-z0-9]|\\_|\\.){8,64}$\")\n+ pre_shared_key_match_re = re.compile(r\"^(?!0)([A-Za-z0-9]|\\_|\\.){8,64}$\")\n if not pre_shared_key_match_re.match(key):\n raise ValueError(\n \"%s is not a valid key.\"\n@@ -220,7 +221,7 @@\n \"169.254.5.0/30\",\n \"169.254.169.252/30\",\n ]\n- cidr_match_re = compile(\n+ cidr_match_re = re.compile(\n r\"^169\\.254\\.(?:25[0-5]|2[0-4]\\d|[01]?\\d\\d?)\"\n r\"\\.(?:25[0-5]|2[0-4]\\d|[01]?\\d\\d?)\\/30$\"\n )\n", "issue": "When using ec2.VpnTunnelOptionsSpecification, report error:compile() missing required argument 'filename' (pos 2)\nI am using troposphere version 4.3.2\r\nThe issue occurs in this code section:\r\n```\r\n vpn_tunnel_option_props = self.filter_parameters(\r\n vpn_option.items(), ec2.VpnTunnelOptionsSpecification\r\n )\r\n```\r\nafter I ran it an error occured: compile() missing required argument 'filename' (pos 2)\r\nBut it works in troposphere version 3.2.2\r\nI find that troposphere uses re.complile() in the old versions(v3), but the Python system function compile() is used in the new versions(v4), which caused this problem. Is this a bug?\r\n```\r\ndef vpn_tunnel_inside_cidr(cidr):\r\n \"\"\"\r\n Property: VpnTunnelOptionsSpecification.TunnelInsideCidr\r\n \"\"\"\r\n cidr_match_re = compile(\r\n r\"^169\\.254\\.(?:25[0-5]|2[0-4]\\d|[01]?\\d\\d?)\"\r\n r\"\\.(?:25[0-5]|2[0-4]\\d|[01]?\\d\\d?)\\/30$\"\r\n )\r\n```\n", "before_files": [{"content": "# Copyright (c) 2012-2022, Mark Peek <[email protected]>\n# All rights reserved.\n#\n# See LICENSE file for full license.\n\n\nfrom .. import AWSProperty\nfrom ..compat import validate_policytype\nfrom ..type_defs.compat import Final\nfrom . import exactly_one, integer_range, network_port, tags_or_list\n\nPERMISSION_INSTANCE_ATTACH: Final = \"INSTANCE-ATTACH\"\nPERMISSION_EIP_ASSOCIATE: Final = \"EIP-ASSOCIATE\"\n\nNO_DEVICE: Final = {}\n\n\ndef Ipv6Addresses(ipv6_address):\n \"\"\"\n Export:\n \"\"\"\n from ..ec2 import InstanceIpv6Address\n\n return InstanceIpv6Address(Ipv6Address=ipv6_address)\n\n\nclass Tag(AWSProperty):\n \"\"\"\n Export:\n \"\"\"\n\n props = {\n \"Key\": (str, True),\n \"Value\": (str, True),\n }\n\n def __init__(self, key=None, value=None, **kwargs):\n # provided for backward compatibility\n if key is not None:\n kwargs[\"Key\"] = key\n if value is not None:\n kwargs[\"Value\"] = value\n super().__init__(**kwargs)\n\n\ndef validate_int_to_str(x):\n \"\"\"\n Backward compatibility - field was int and now str.\n Property: NetworkInterfaceProperty.DeviceIndex\n Property: NetworkInterfaceAttachment.DeviceIndex\n \"\"\"\n\n if isinstance(x, int):\n return str(x)\n if isinstance(x, str):\n return str(int(x))\n\n raise TypeError(f\"Value {x} of type {type(x)} must be either int or str\")\n\n\ndef policytypes(policy):\n \"\"\"\n Property: VPCEndpoint.PolicyDocument\n \"\"\"\n return validate_policytype(policy)\n\n\ndef validate_networkaclentry_rulenumber(x):\n \"\"\"\n Property: NetworkAclEntry.RuleNumber\n \"\"\"\n return integer_range(1, 32766)(x)\n\n\ndef validate_network_port(x):\n \"\"\"\n Property: NetworkAclEntry.Protocol\n Property: PortRange.From\n Property: PortRange.To\n Property: SecurityGroupRule.FromPort\n Property: SecurityGroupRule.ToPort\n Property: SecurityGroupEgress.FromPort\n Property: SecurityGroupEgress.ToPort\n Property: SecurityGroupIngress.FromPort\n Property: SecurityGroupIngress.ToPort\n \"\"\"\n return network_port(x)\n\n\ndef validate_tags_or_list(x):\n \"\"\"\n Property: TagSpecifications.Tags\n Property: CustomerGateway.Tags\n Property: DHCPOptions.Tags\n Property: Instance.Tags\n Property: InternetGateway.Tags\n Property: LocalGatewayRouteTableVPCAssociation.Tags\n Property: NatGateway.Tags\n Property: NetworkAcl.Tags\n Property: NetworkInterface.Tags\n Property: RouteTable.Tags\n Property: SecurityGroup.Tags\n Property: SpotFleetTagSpecification.Tags\n Property: Subnet.Tags\n Property: TransitGateway.Tags\n Property: TransitGatewayAttachment.Tags\n Property: TransitGatewayRouteTable.Tags\n Property: VPC.Tags\n Property: VPCPeeringConnection.Tags\n Property: VPNConnection.Tags\n Property: VPNGateway.Tags\n Property: Volume.Tags\n Property: VPNGateway.Tags\n Property: VPNGateway.Tags\n \"\"\"\n return tags_or_list(x)\n\n\ndef instance_tenancy(value):\n \"\"\"\n Property: VPC.InstanceTenancy\n \"\"\"\n valid = [\"default\", \"dedicated\"]\n if value not in valid:\n raise ValueError(\"InstanceTenancy needs to be one of %r\" % valid)\n return value\n\n\ndef check_ports(props):\n # IpProtocol is a required field but not all values allowed require\n # ToPort and FromPort. The ones that don't need these ports are:\n ports_optional = [\n \"-1\", # all protocols\n \"58\", # ICMPv6\n ]\n proto = props[\"IpProtocol\"]\n\n if proto not in ports_optional:\n if not (\"ToPort\" in props and \"FromPort\" in props):\n raise ValueError(\"ToPort/FromPort must be specified for proto %s\" % proto)\n\n\ndef validate_elasticinferenceaccelerator_type(elasticinferenceaccelerator_type):\n \"\"\"\n Validate ElasticInferenceAccelerator for Instance\n Property: ElasticInferenceAccelerator.Type\n Property: LaunchTemplateElasticInferenceAccelerator.Type\n \"\"\"\n\n VALID_ELASTICINFERENCEACCELERATOR_TYPES = (\n \"eia1.medium\",\n \"eia1.large\",\n \"eia1.xlarge\",\n )\n if elasticinferenceaccelerator_type not in VALID_ELASTICINFERENCEACCELERATOR_TYPES:\n raise ValueError(\n \"Elastic Inference Accelerator Type must be one of: %s\"\n % \", \".join(VALID_ELASTICINFERENCEACCELERATOR_TYPES)\n )\n return elasticinferenceaccelerator_type\n\n\ndef validate_clientvpnendpoint_selfserviceportal(value):\n \"\"\"\n Validate SelfServicePortal for ClientVpnEndpoint.\n Property: ClientVpnEndpoint.SelfServicePortal\n \"\"\"\n\n VALID_CLIENTVPNENDPOINT_SELFSERVICEPORTAL = (\"disabled\", \"enabled\")\n\n if value not in VALID_CLIENTVPNENDPOINT_SELFSERVICEPORTAL:\n raise ValueError(\n \"ClientVpnEndpoint.SelfServicePortal must be one of: {}\".format(\n \", \".join(VALID_CLIENTVPNENDPOINT_SELFSERVICEPORTAL)\n )\n )\n return value\n\n\ndef validate_clientvpnendpoint_vpnport(vpnport):\n \"\"\"\n Validate VpnPort for ClientVpnEndpoint\n Property: ClientVpnEndpoint.VpnPort\n \"\"\"\n\n VALID_CLIENTVPNENDPOINT_VPNPORT = (443, 1194)\n if vpnport not in VALID_CLIENTVPNENDPOINT_VPNPORT:\n raise ValueError(\n \"ClientVpnEndpoint VpnPort must be one of: %s\"\n % \", \".join(VALID_CLIENTVPNENDPOINT_VPNPORT)\n )\n return vpnport\n\n\ndef vpn_pre_shared_key(key):\n \"\"\"\n Property: VpnTunnelOptionsSpecification.PreSharedKey\n \"\"\"\n pre_shared_key_match_re = compile(r\"^(?!0)([A-Za-z0-9]|\\_|\\.){8,64}$\")\n if not pre_shared_key_match_re.match(key):\n raise ValueError(\n \"%s is not a valid key.\"\n \" Allowed characters are alphanumeric characters and ._. Must\"\n \" be between 8 and 64 characters in length and cannot\"\n \" start with zero (0).\" % key\n )\n return key\n\n\ndef vpn_tunnel_inside_cidr(cidr):\n \"\"\"\n Property: VpnTunnelOptionsSpecification.TunnelInsideCidr\n \"\"\"\n reserved_cidrs = [\n \"169.254.0.0/30\",\n \"169.254.1.0/30\",\n \"169.254.2.0/30\",\n \"169.254.3.0/30\",\n \"169.254.4.0/30\",\n \"169.254.5.0/30\",\n \"169.254.169.252/30\",\n ]\n cidr_match_re = compile(\n r\"^169\\.254\\.(?:25[0-5]|2[0-4]\\d|[01]?\\d\\d?)\"\n r\"\\.(?:25[0-5]|2[0-4]\\d|[01]?\\d\\d?)\\/30$\"\n )\n if cidr in reserved_cidrs:\n raise ValueError(\n 'The following CIDR blocks are reserved and cannot be used: \"%s\"'\n % (\", \".join(reserved_cidrs))\n )\n elif not cidr_match_re.match(cidr):\n raise ValueError(\n \"%s is not a valid CIDR.\"\n \" A size /30 CIDR block from the 169.254.0.0/16 must be specified.\" % cidr\n )\n return cidr\n\n\ndef vpc_endpoint_type(endpoint_type):\n \"\"\"\n Property: VPCEndpoint.VpcEndpointType\n \"\"\"\n valid_types = [\"Interface\", \"Gateway\", \"GatewayLoadBalancer\"]\n if endpoint_type not in valid_types:\n raise ValueError(\n 'VpcEndpointType must be one of: \"%s\"' % (\", \".join(valid_types))\n )\n return endpoint_type\n\n\ndef validate_network_acl_entry(self):\n \"\"\"\n Class: NetworkAclEntry\n \"\"\"\n conds = [\n \"CidrBlock\",\n \"Ipv6CidrBlock\",\n ]\n exactly_one(self.__class__.__name__, self.properties, conds)\n\n\ndef validate_route(self):\n \"\"\"\n Class: Route\n \"\"\"\n cidr_conds = [\n \"DestinationCidrBlock\",\n \"DestinationIpv6CidrBlock\",\n ]\n gateway_conds = [\n \"CarrierGatewayId\",\n \"EgressOnlyInternetGatewayId\",\n \"GatewayId\",\n \"InstanceId\",\n \"LocalGatewayId\",\n \"NatGatewayId\",\n \"NetworkInterfaceId\",\n \"TransitGatewayId\",\n \"VpcEndpointId\",\n \"VpcPeeringConnectionId\",\n ]\n exactly_one(self.__class__.__name__, self.properties, cidr_conds)\n exactly_one(self.__class__.__name__, self.properties, gateway_conds)\n\n\ndef validate_security_group_egress(self):\n \"\"\"\n Class: SecurityGroupEgress\n \"\"\"\n conds = [\n \"CidrIp\",\n \"CidrIpv6\",\n \"DestinationPrefixListId\",\n \"DestinationSecurityGroupId\",\n ]\n exactly_one(self.__class__.__name__, self.properties, conds)\n check_ports(self.properties)\n\n\ndef validate_security_group_ingress(self):\n \"\"\"\n Class: SecurityGroupIngress\n \"\"\"\n conds = [\n \"CidrIp\",\n \"CidrIpv6\",\n \"SourcePrefixListId\",\n \"SourceSecurityGroupName\",\n \"SourceSecurityGroupId\",\n ]\n exactly_one(self.__class__.__name__, self.properties, conds)\n check_ports(self.properties)\n\n\ndef validate_spot_fleet_request_config_data(self):\n \"\"\"\n Class: SpotFleetRequestConfigData\n \"\"\"\n conds = [\"LaunchSpecifications\", \"LaunchTemplateConfigs\"]\n exactly_one(self.__class__.__name__, self.properties, conds)\n\n\ndef validate_subnet(self):\n \"\"\"\n Class: Subnet\n \"\"\"\n if \"Ipv6CidrBlock\" in self.properties:\n if not self.properties.get(\"AssignIpv6AddressOnCreation\"):\n raise ValueError(\n \"If Ipv6CidrBlock is present, \"\n \"AssignIpv6AddressOnCreation must be set to True\"\n )\n\n\ndef validate_vpn_connection(self):\n \"\"\"\n Class: VPNConnection\n \"\"\"\n conds = [\n \"VpnGatewayId\",\n \"TransitGatewayId\",\n ]\n exactly_one(self.__class__.__name__, self.properties, conds)\n", "path": "troposphere/validators/ec2.py"}], "after_files": [{"content": "# Copyright (c) 2012-2022, Mark Peek <[email protected]>\n# All rights reserved.\n#\n# See LICENSE file for full license.\n\nimport re\n\nfrom .. import AWSProperty\nfrom ..compat import validate_policytype\nfrom ..type_defs.compat import Final\nfrom . import exactly_one, integer_range, network_port, tags_or_list\n\nPERMISSION_INSTANCE_ATTACH: Final = \"INSTANCE-ATTACH\"\nPERMISSION_EIP_ASSOCIATE: Final = \"EIP-ASSOCIATE\"\n\nNO_DEVICE: Final = {}\n\n\ndef Ipv6Addresses(ipv6_address):\n \"\"\"\n Export:\n \"\"\"\n from ..ec2 import InstanceIpv6Address\n\n return InstanceIpv6Address(Ipv6Address=ipv6_address)\n\n\nclass Tag(AWSProperty):\n \"\"\"\n Export:\n \"\"\"\n\n props = {\n \"Key\": (str, True),\n \"Value\": (str, True),\n }\n\n def __init__(self, key=None, value=None, **kwargs):\n # provided for backward compatibility\n if key is not None:\n kwargs[\"Key\"] = key\n if value is not None:\n kwargs[\"Value\"] = value\n super().__init__(**kwargs)\n\n\ndef validate_int_to_str(x):\n \"\"\"\n Backward compatibility - field was int and now str.\n Property: NetworkInterfaceProperty.DeviceIndex\n Property: NetworkInterfaceAttachment.DeviceIndex\n \"\"\"\n\n if isinstance(x, int):\n return str(x)\n if isinstance(x, str):\n return str(int(x))\n\n raise TypeError(f\"Value {x} of type {type(x)} must be either int or str\")\n\n\ndef policytypes(policy):\n \"\"\"\n Property: VPCEndpoint.PolicyDocument\n \"\"\"\n return validate_policytype(policy)\n\n\ndef validate_networkaclentry_rulenumber(x):\n \"\"\"\n Property: NetworkAclEntry.RuleNumber\n \"\"\"\n return integer_range(1, 32766)(x)\n\n\ndef validate_network_port(x):\n \"\"\"\n Property: NetworkAclEntry.Protocol\n Property: PortRange.From\n Property: PortRange.To\n Property: SecurityGroupRule.FromPort\n Property: SecurityGroupRule.ToPort\n Property: SecurityGroupEgress.FromPort\n Property: SecurityGroupEgress.ToPort\n Property: SecurityGroupIngress.FromPort\n Property: SecurityGroupIngress.ToPort\n \"\"\"\n return network_port(x)\n\n\ndef validate_tags_or_list(x):\n \"\"\"\n Property: TagSpecifications.Tags\n Property: CustomerGateway.Tags\n Property: DHCPOptions.Tags\n Property: Instance.Tags\n Property: InternetGateway.Tags\n Property: LocalGatewayRouteTableVPCAssociation.Tags\n Property: NatGateway.Tags\n Property: NetworkAcl.Tags\n Property: NetworkInterface.Tags\n Property: RouteTable.Tags\n Property: SecurityGroup.Tags\n Property: SpotFleetTagSpecification.Tags\n Property: Subnet.Tags\n Property: TransitGateway.Tags\n Property: TransitGatewayAttachment.Tags\n Property: TransitGatewayRouteTable.Tags\n Property: VPC.Tags\n Property: VPCPeeringConnection.Tags\n Property: VPNConnection.Tags\n Property: VPNGateway.Tags\n Property: Volume.Tags\n Property: VPNGateway.Tags\n Property: VPNGateway.Tags\n \"\"\"\n return tags_or_list(x)\n\n\ndef instance_tenancy(value):\n \"\"\"\n Property: VPC.InstanceTenancy\n \"\"\"\n valid = [\"default\", \"dedicated\"]\n if value not in valid:\n raise ValueError(\"InstanceTenancy needs to be one of %r\" % valid)\n return value\n\n\ndef check_ports(props):\n # IpProtocol is a required field but not all values allowed require\n # ToPort and FromPort. The ones that don't need these ports are:\n ports_optional = [\n \"-1\", # all protocols\n \"58\", # ICMPv6\n ]\n proto = props[\"IpProtocol\"]\n\n if proto not in ports_optional:\n if not (\"ToPort\" in props and \"FromPort\" in props):\n raise ValueError(\"ToPort/FromPort must be specified for proto %s\" % proto)\n\n\ndef validate_elasticinferenceaccelerator_type(elasticinferenceaccelerator_type):\n \"\"\"\n Validate ElasticInferenceAccelerator for Instance\n Property: ElasticInferenceAccelerator.Type\n Property: LaunchTemplateElasticInferenceAccelerator.Type\n \"\"\"\n\n VALID_ELASTICINFERENCEACCELERATOR_TYPES = (\n \"eia1.medium\",\n \"eia1.large\",\n \"eia1.xlarge\",\n )\n if elasticinferenceaccelerator_type not in VALID_ELASTICINFERENCEACCELERATOR_TYPES:\n raise ValueError(\n \"Elastic Inference Accelerator Type must be one of: %s\"\n % \", \".join(VALID_ELASTICINFERENCEACCELERATOR_TYPES)\n )\n return elasticinferenceaccelerator_type\n\n\ndef validate_clientvpnendpoint_selfserviceportal(value):\n \"\"\"\n Validate SelfServicePortal for ClientVpnEndpoint.\n Property: ClientVpnEndpoint.SelfServicePortal\n \"\"\"\n\n VALID_CLIENTVPNENDPOINT_SELFSERVICEPORTAL = (\"disabled\", \"enabled\")\n\n if value not in VALID_CLIENTVPNENDPOINT_SELFSERVICEPORTAL:\n raise ValueError(\n \"ClientVpnEndpoint.SelfServicePortal must be one of: {}\".format(\n \", \".join(VALID_CLIENTVPNENDPOINT_SELFSERVICEPORTAL)\n )\n )\n return value\n\n\ndef validate_clientvpnendpoint_vpnport(vpnport):\n \"\"\"\n Validate VpnPort for ClientVpnEndpoint\n Property: ClientVpnEndpoint.VpnPort\n \"\"\"\n\n VALID_CLIENTVPNENDPOINT_VPNPORT = (443, 1194)\n if vpnport not in VALID_CLIENTVPNENDPOINT_VPNPORT:\n raise ValueError(\n \"ClientVpnEndpoint VpnPort must be one of: %s\"\n % \", \".join(VALID_CLIENTVPNENDPOINT_VPNPORT)\n )\n return vpnport\n\n\ndef vpn_pre_shared_key(key):\n \"\"\"\n Property: VpnTunnelOptionsSpecification.PreSharedKey\n \"\"\"\n pre_shared_key_match_re = re.compile(r\"^(?!0)([A-Za-z0-9]|\\_|\\.){8,64}$\")\n if not pre_shared_key_match_re.match(key):\n raise ValueError(\n \"%s is not a valid key.\"\n \" Allowed characters are alphanumeric characters and ._. Must\"\n \" be between 8 and 64 characters in length and cannot\"\n \" start with zero (0).\" % key\n )\n return key\n\n\ndef vpn_tunnel_inside_cidr(cidr):\n \"\"\"\n Property: VpnTunnelOptionsSpecification.TunnelInsideCidr\n \"\"\"\n reserved_cidrs = [\n \"169.254.0.0/30\",\n \"169.254.1.0/30\",\n \"169.254.2.0/30\",\n \"169.254.3.0/30\",\n \"169.254.4.0/30\",\n \"169.254.5.0/30\",\n \"169.254.169.252/30\",\n ]\n cidr_match_re = re.compile(\n r\"^169\\.254\\.(?:25[0-5]|2[0-4]\\d|[01]?\\d\\d?)\"\n r\"\\.(?:25[0-5]|2[0-4]\\d|[01]?\\d\\d?)\\/30$\"\n )\n if cidr in reserved_cidrs:\n raise ValueError(\n 'The following CIDR blocks are reserved and cannot be used: \"%s\"'\n % (\", \".join(reserved_cidrs))\n )\n elif not cidr_match_re.match(cidr):\n raise ValueError(\n \"%s is not a valid CIDR.\"\n \" A size /30 CIDR block from the 169.254.0.0/16 must be specified.\" % cidr\n )\n return cidr\n\n\ndef vpc_endpoint_type(endpoint_type):\n \"\"\"\n Property: VPCEndpoint.VpcEndpointType\n \"\"\"\n valid_types = [\"Interface\", \"Gateway\", \"GatewayLoadBalancer\"]\n if endpoint_type not in valid_types:\n raise ValueError(\n 'VpcEndpointType must be one of: \"%s\"' % (\", \".join(valid_types))\n )\n return endpoint_type\n\n\ndef validate_network_acl_entry(self):\n \"\"\"\n Class: NetworkAclEntry\n \"\"\"\n conds = [\n \"CidrBlock\",\n \"Ipv6CidrBlock\",\n ]\n exactly_one(self.__class__.__name__, self.properties, conds)\n\n\ndef validate_route(self):\n \"\"\"\n Class: Route\n \"\"\"\n cidr_conds = [\n \"DestinationCidrBlock\",\n \"DestinationIpv6CidrBlock\",\n ]\n gateway_conds = [\n \"CarrierGatewayId\",\n \"EgressOnlyInternetGatewayId\",\n \"GatewayId\",\n \"InstanceId\",\n \"LocalGatewayId\",\n \"NatGatewayId\",\n \"NetworkInterfaceId\",\n \"TransitGatewayId\",\n \"VpcEndpointId\",\n \"VpcPeeringConnectionId\",\n ]\n exactly_one(self.__class__.__name__, self.properties, cidr_conds)\n exactly_one(self.__class__.__name__, self.properties, gateway_conds)\n\n\ndef validate_security_group_egress(self):\n \"\"\"\n Class: SecurityGroupEgress\n \"\"\"\n conds = [\n \"CidrIp\",\n \"CidrIpv6\",\n \"DestinationPrefixListId\",\n \"DestinationSecurityGroupId\",\n ]\n exactly_one(self.__class__.__name__, self.properties, conds)\n check_ports(self.properties)\n\n\ndef validate_security_group_ingress(self):\n \"\"\"\n Class: SecurityGroupIngress\n \"\"\"\n conds = [\n \"CidrIp\",\n \"CidrIpv6\",\n \"SourcePrefixListId\",\n \"SourceSecurityGroupName\",\n \"SourceSecurityGroupId\",\n ]\n exactly_one(self.__class__.__name__, self.properties, conds)\n check_ports(self.properties)\n\n\ndef validate_spot_fleet_request_config_data(self):\n \"\"\"\n Class: SpotFleetRequestConfigData\n \"\"\"\n conds = [\"LaunchSpecifications\", \"LaunchTemplateConfigs\"]\n exactly_one(self.__class__.__name__, self.properties, conds)\n\n\ndef validate_subnet(self):\n \"\"\"\n Class: Subnet\n \"\"\"\n if \"Ipv6CidrBlock\" in self.properties:\n if not self.properties.get(\"AssignIpv6AddressOnCreation\"):\n raise ValueError(\n \"If Ipv6CidrBlock is present, \"\n \"AssignIpv6AddressOnCreation must be set to True\"\n )\n\n\ndef validate_vpn_connection(self):\n \"\"\"\n Class: VPNConnection\n \"\"\"\n conds = [\n \"VpnGatewayId\",\n \"TransitGatewayId\",\n ]\n exactly_one(self.__class__.__name__, self.properties, conds)\n", "path": "troposphere/validators/ec2.py"}]}
| 3,885 | 347 |
gh_patches_debug_29122
|
rasdani/github-patches
|
git_diff
|
PrefectHQ__prefect-5237
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add proxies to slack_notifier
## Current behavior
`prefect.utilities.notifications.slack_notifier` sends requests to the Slack webhook using `requests.post` without allowing `proxies={"http": "0.123.456.789"}` to be passed, which is problematic when Internet access must be done through a proxy.
It is possible to go around this by setting HTTP_PROXY / HTTPS_PROXY environment variables, but this is not ideal / possible when running on private infrastructure which by default does not access the Internet and should not have these variables set.
## Proposed behavior
Add an optional `proxies` argument to `prefect.utilities.notifications.slack_notifier` which gets passed to `requests.post`.
## Example
To use Slack notifications from Prefect running on private infrastructure.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/prefect/utilities/notifications/notifications.py`
Content:
```
1 """
2 Tools and utilities for notifications and callbacks.
3
4 For an in-depth guide to setting up your system for using Slack notifications, [please see our
5 tutorial](/core/advanced_tutorials/slack-notifications.html).
6 """
7 import smtplib
8 from email.header import Header
9 from email.mime.multipart import MIMEMultipart
10 from email.mime.text import MIMEText
11 from typing import TYPE_CHECKING, Any, Callable, Union, cast
12
13 from toolz import curry
14
15 import prefect
16
17 if TYPE_CHECKING:
18 import prefect.engine.state
19 import prefect.client
20 from prefect import Flow, Task # noqa
21
22 TrackedObjectType = Union["Flow", "Task"]
23
24 __all__ = ["callback_factory", "gmail_notifier", "slack_notifier"]
25
26
27 def callback_factory(
28 fn: Callable[[Any, "prefect.engine.state.State"], Any],
29 check: Callable[["prefect.engine.state.State"], bool],
30 ) -> Callable:
31 """
32 Utility for generating state handlers that serve as callbacks, under arbitrary
33 state-based checks.
34
35 Args:
36 - fn (Callable): a function with signature `fn(obj, state: State) -> None`
37 that will be called anytime the associated state-check passes; in general, it is
38 expected that this function will have side effects (e.g., sends an email). The
39 first argument to this function is the `Task` or `Flow` it is attached to.
40 - check (Callable): a function with signature `check(state: State) -> bool`
41 that is used for determining when the callback function should be called
42
43 Returns:
44 - state_handler (Callable): a state handler function that can be attached to both Tasks
45 and Flows
46
47 Example:
48 ```python
49 from prefect import Task, Flow
50 from prefect.utilities.notifications import callback_factory
51
52 fn = lambda obj, state: print(state)
53 check = lambda state: state.is_successful()
54 callback = callback_factory(fn, check)
55
56 t = Task(state_handlers=[callback])
57 f = Flow("My Example Flow", tasks=[t], state_handlers=[callback])
58 f.run()
59 # prints:
60 # Success("Task run succeeded.")
61 # Success("All reference tasks succeeded.")
62 ```
63 """
64
65 def state_handler(
66 obj: Any,
67 old_state: "prefect.engine.state.State",
68 new_state: "prefect.engine.state.State",
69 ) -> "prefect.engine.state.State":
70 if check(new_state) is True:
71 fn(obj, new_state)
72 return new_state
73
74 return state_handler
75
76
77 def email_message_formatter(
78 tracked_obj: TrackedObjectType, state: "prefect.engine.state.State", email_to: str
79 ) -> str:
80 if isinstance(state.result, Exception):
81 msg = "<pre>{}</pre>".format(repr(state.result))
82 else:
83 msg = '"{}"'.format(state.message)
84
85 html = """
86 <html>
87 <head></head>
88 <body>
89 <table align="left" border="0" cellpadding="2px" cellspacing="2px">
90 <tr>
91 <td style="border-left: 2px solid {color};">
92 <img src="https://emoji.slack-edge.com/TAN3D79AL/prefect/2497370f58500a5a.png">
93 </td>
94 <td style="border-left: 2px solid {color}; padding-left: 6px;">
95 {text}
96 </td>
97 </tr>
98 </table>
99 </body>
100 </html>
101 """
102 color = state.color
103 text = """
104 <pre>{name}</pre> is now in a <font color="{color}"><b>{state}</b></font> state
105 <br><br>
106 Message: {msg}
107 """.format(
108 name=tracked_obj.name, color=state.color, state=type(state).__name__, msg=msg
109 )
110
111 contents = MIMEMultipart("alternative")
112 contents.attach(MIMEText(text, "plain"))
113 contents.attach(MIMEText(html.format(color=color, text=text), "html"))
114
115 contents["Subject"] = Header(
116 "Prefect state change notification for {}".format(tracked_obj.name), "UTF-8"
117 )
118 contents["From"] = "[email protected]"
119 contents["To"] = email_to
120
121 return contents.as_string()
122
123
124 def slack_message_formatter(
125 tracked_obj: TrackedObjectType,
126 state: "prefect.engine.state.State",
127 backend_info: bool = True,
128 ) -> dict:
129 # see https://api.slack.com/docs/message-attachments
130 fields = []
131 if isinstance(state.result, Exception):
132 value = "```{}```".format(repr(state.result))
133 else:
134 value = cast(str, state.message)
135 if value is not None:
136 fields.append({"title": "Message", "value": value, "short": False})
137
138 notification_payload = {
139 "fallback": "State change notification",
140 "color": state.color,
141 "author_name": "Prefect",
142 "author_link": "https://www.prefect.io/",
143 "author_icon": "https://emoji.slack-edge.com/TAN3D79AL/prefect/2497370f58500a5a.png",
144 "title": type(state).__name__,
145 "fields": fields,
146 # "title_link": "https://www.prefect.io/",
147 "text": "{0} is now in a {1} state".format(
148 tracked_obj.name, type(state).__name__
149 ),
150 "footer": "Prefect notification",
151 }
152
153 if backend_info and prefect.context.get("flow_run_id"):
154 url = None
155
156 if isinstance(tracked_obj, prefect.Flow):
157 url = prefect.client.Client().get_cloud_url(
158 "flow-run", prefect.context["flow_run_id"], as_user=False
159 )
160 elif isinstance(tracked_obj, prefect.Task):
161 url = prefect.client.Client().get_cloud_url(
162 "task-run", prefect.context.get("task_run_id", ""), as_user=False
163 )
164
165 if url:
166 notification_payload.update(title_link=url)
167
168 data = {"attachments": [notification_payload]}
169 return data
170
171
172 @curry
173 def gmail_notifier(
174 tracked_obj: TrackedObjectType,
175 old_state: "prefect.engine.state.State",
176 new_state: "prefect.engine.state.State",
177 ignore_states: list = None,
178 only_states: list = None,
179 ) -> "prefect.engine.state.State":
180 """
181 Email state change handler - configured to work solely with Gmail; works as a standalone
182 state handler, or can be called from within a custom state handler. This function is
183 curried meaning that it can be called multiple times to partially bind any keyword
184 arguments (see example below).
185
186 The username and password Gmail credentials will be taken from your `"EMAIL_USERNAME"` and
187 `"EMAIL_PASSWORD"` secrets, respectively; note the username will also serve as the
188 destination email address for the notification.
189
190 Args:
191 - tracked_obj (Task or Flow): Task or Flow object the handler is registered with
192 - old_state (State): previous state of tracked object
193 - new_state (State): new state of tracked object
194 - ignore_states ([State], optional): list of `State` classes to ignore, e.g.,
195 `[Running, Scheduled]`. If `new_state` is an instance of one of the passed states,
196 no notification will occur.
197 - only_states ([State], optional): similar to `ignore_states`, but instead _only_
198 notifies you if the Task / Flow is in a state from the provided list of `State`
199 classes
200
201 Returns:
202 - State: the `new_state` object that was provided
203
204 Raises:
205 - ValueError: if the email notification fails for any reason
206
207 Example:
208 ```python
209 from prefect import task
210 from prefect.utilities.notifications import gmail_notifier
211
212 @task(state_handlers=[gmail_notifier(ignore_states=[Running])]) # uses currying
213 def add(x, y):
214 return x + y
215 ```
216 """
217 username = cast(str, prefect.client.Secret("EMAIL_USERNAME").get())
218 password = cast(str, prefect.client.Secret("EMAIL_PASSWORD").get())
219 ignore_states = ignore_states or []
220 only_states = only_states or []
221
222 if any(isinstance(new_state, ignored) for ignored in ignore_states):
223 return new_state
224
225 if only_states and not any(
226 [isinstance(new_state, included) for included in only_states]
227 ):
228 return new_state
229
230 body = email_message_formatter(tracked_obj, new_state, username)
231
232 server = smtplib.SMTP_SSL("smtp.gmail.com", 465)
233 server.login(username, password)
234 try:
235 server.sendmail("[email protected]", username, body)
236 except Exception as exc:
237 raise ValueError(
238 "Email notification for {} failed".format(tracked_obj)
239 ) from exc
240 finally:
241 server.quit()
242
243 return new_state
244
245
246 @curry
247 def slack_notifier(
248 tracked_obj: TrackedObjectType,
249 old_state: "prefect.engine.state.State",
250 new_state: "prefect.engine.state.State",
251 ignore_states: list = None,
252 only_states: list = None,
253 webhook_secret: str = None,
254 backend_info: bool = True,
255 ) -> "prefect.engine.state.State":
256 """
257 Slack state change handler; requires having the Prefect slack app installed. Works as a
258 standalone state handler, or can be called from within a custom state handler. This
259 function is curried meaning that it can be called multiple times to partially bind any
260 keyword arguments (see example below).
261
262 Args:
263 - tracked_obj (Task or Flow): Task or Flow object the handler is
264 registered with
265 - old_state (State): previous state of tracked object
266 - new_state (State): new state of tracked object
267 - ignore_states ([State], optional): list of `State` classes to ignore, e.g.,
268 `[Running, Scheduled]`. If `new_state` is an instance of one of the passed states,
269 no notification will occur.
270 - only_states ([State], optional): similar to `ignore_states`, but instead _only_
271 notifies you if the Task / Flow is in a state from the provided list of `State`
272 classes
273 - webhook_secret (str, optional): the name of the Prefect Secret that stores your slack
274 webhook URL; defaults to `"SLACK_WEBHOOK_URL"`
275 - backend_info (bool, optional): Whether to supply slack notification with urls
276 pointing to backend pages; defaults to True
277
278 Returns:
279 - State: the `new_state` object that was provided
280
281 Raises:
282 - ValueError: if the slack notification fails for any reason
283
284 Example:
285 ```python
286 from prefect import task
287 from prefect.utilities.notifications import slack_notifier
288
289 @task(state_handlers=[slack_notifier(ignore_states=[Running])]) # uses currying
290 def add(x, y):
291 return x + y
292 ```
293 """
294 webhook_url = cast(
295 str, prefect.client.Secret(webhook_secret or "SLACK_WEBHOOK_URL").get()
296 )
297 ignore_states = ignore_states or []
298 only_states = only_states or []
299
300 if any(isinstance(new_state, ignored) for ignored in ignore_states):
301 return new_state
302
303 if only_states and not any(
304 [isinstance(new_state, included) for included in only_states]
305 ):
306 return new_state
307
308 # 'import requests' is expensive time-wise, we should do this just-in-time to keep
309 # the 'import prefect' time low
310 import requests
311
312 form_data = slack_message_formatter(tracked_obj, new_state, backend_info)
313 r = requests.post(webhook_url, json=form_data)
314 if not r.ok:
315 raise ValueError("Slack notification for {} failed".format(tracked_obj))
316 return new_state
317
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/prefect/utilities/notifications/notifications.py b/src/prefect/utilities/notifications/notifications.py
--- a/src/prefect/utilities/notifications/notifications.py
+++ b/src/prefect/utilities/notifications/notifications.py
@@ -252,6 +252,7 @@
only_states: list = None,
webhook_secret: str = None,
backend_info: bool = True,
+ proxies: dict = None,
) -> "prefect.engine.state.State":
"""
Slack state change handler; requires having the Prefect slack app installed. Works as a
@@ -274,6 +275,9 @@
webhook URL; defaults to `"SLACK_WEBHOOK_URL"`
- backend_info (bool, optional): Whether to supply slack notification with urls
pointing to backend pages; defaults to True
+ - proxies (dict), optional): `dict` with "http" and/or "https" keys, passed to
+ `requests.post` - for situations where a proxy is required to send requests to the
+ Slack webhook
Returns:
- State: the `new_state` object that was provided
@@ -310,7 +314,7 @@
import requests
form_data = slack_message_formatter(tracked_obj, new_state, backend_info)
- r = requests.post(webhook_url, json=form_data)
+ r = requests.post(webhook_url, json=form_data, proxies=proxies)
if not r.ok:
raise ValueError("Slack notification for {} failed".format(tracked_obj))
return new_state
|
{"golden_diff": "diff --git a/src/prefect/utilities/notifications/notifications.py b/src/prefect/utilities/notifications/notifications.py\n--- a/src/prefect/utilities/notifications/notifications.py\n+++ b/src/prefect/utilities/notifications/notifications.py\n@@ -252,6 +252,7 @@\n only_states: list = None,\n webhook_secret: str = None,\n backend_info: bool = True,\n+ proxies: dict = None,\n ) -> \"prefect.engine.state.State\":\n \"\"\"\n Slack state change handler; requires having the Prefect slack app installed. Works as a\n@@ -274,6 +275,9 @@\n webhook URL; defaults to `\"SLACK_WEBHOOK_URL\"`\n - backend_info (bool, optional): Whether to supply slack notification with urls\n pointing to backend pages; defaults to True\n+ - proxies (dict), optional): `dict` with \"http\" and/or \"https\" keys, passed to\n+ `requests.post` - for situations where a proxy is required to send requests to the\n+ Slack webhook\n \n Returns:\n - State: the `new_state` object that was provided\n@@ -310,7 +314,7 @@\n import requests\n \n form_data = slack_message_formatter(tracked_obj, new_state, backend_info)\n- r = requests.post(webhook_url, json=form_data)\n+ r = requests.post(webhook_url, json=form_data, proxies=proxies)\n if not r.ok:\n raise ValueError(\"Slack notification for {} failed\".format(tracked_obj))\n return new_state\n", "issue": "Add proxies to slack_notifier\n## Current behavior\r\n`prefect.utilities.notifications.slack_notifier` sends requests to the Slack webhook using `requests.post` without allowing `proxies={\"http\": \"0.123.456.789\"}` to be passed, which is problematic when Internet access must be done through a proxy.\r\n\r\n It is possible to go around this by setting HTTP_PROXY / HTTPS_PROXY environment variables, but this is not ideal / possible when running on private infrastructure which by default does not access the Internet and should not have these variables set.\r\n\r\n\r\n\r\n## Proposed behavior\r\nAdd an optional `proxies` argument to `prefect.utilities.notifications.slack_notifier` which gets passed to `requests.post`.\r\n\r\n\r\n\r\n## Example\r\nTo use Slack notifications from Prefect running on private infrastructure.\n", "before_files": [{"content": "\"\"\"\nTools and utilities for notifications and callbacks.\n\nFor an in-depth guide to setting up your system for using Slack notifications, [please see our\ntutorial](/core/advanced_tutorials/slack-notifications.html).\n\"\"\"\nimport smtplib\nfrom email.header import Header\nfrom email.mime.multipart import MIMEMultipart\nfrom email.mime.text import MIMEText\nfrom typing import TYPE_CHECKING, Any, Callable, Union, cast\n\nfrom toolz import curry\n\nimport prefect\n\nif TYPE_CHECKING:\n import prefect.engine.state\n import prefect.client\n from prefect import Flow, Task # noqa\n\nTrackedObjectType = Union[\"Flow\", \"Task\"]\n\n__all__ = [\"callback_factory\", \"gmail_notifier\", \"slack_notifier\"]\n\n\ndef callback_factory(\n fn: Callable[[Any, \"prefect.engine.state.State\"], Any],\n check: Callable[[\"prefect.engine.state.State\"], bool],\n) -> Callable:\n \"\"\"\n Utility for generating state handlers that serve as callbacks, under arbitrary\n state-based checks.\n\n Args:\n - fn (Callable): a function with signature `fn(obj, state: State) -> None`\n that will be called anytime the associated state-check passes; in general, it is\n expected that this function will have side effects (e.g., sends an email). The\n first argument to this function is the `Task` or `Flow` it is attached to.\n - check (Callable): a function with signature `check(state: State) -> bool`\n that is used for determining when the callback function should be called\n\n Returns:\n - state_handler (Callable): a state handler function that can be attached to both Tasks\n and Flows\n\n Example:\n ```python\n from prefect import Task, Flow\n from prefect.utilities.notifications import callback_factory\n\n fn = lambda obj, state: print(state)\n check = lambda state: state.is_successful()\n callback = callback_factory(fn, check)\n\n t = Task(state_handlers=[callback])\n f = Flow(\"My Example Flow\", tasks=[t], state_handlers=[callback])\n f.run()\n # prints:\n # Success(\"Task run succeeded.\")\n # Success(\"All reference tasks succeeded.\")\n ```\n \"\"\"\n\n def state_handler(\n obj: Any,\n old_state: \"prefect.engine.state.State\",\n new_state: \"prefect.engine.state.State\",\n ) -> \"prefect.engine.state.State\":\n if check(new_state) is True:\n fn(obj, new_state)\n return new_state\n\n return state_handler\n\n\ndef email_message_formatter(\n tracked_obj: TrackedObjectType, state: \"prefect.engine.state.State\", email_to: str\n) -> str:\n if isinstance(state.result, Exception):\n msg = \"<pre>{}</pre>\".format(repr(state.result))\n else:\n msg = '\"{}\"'.format(state.message)\n\n html = \"\"\"\n <html>\n <head></head>\n <body>\n <table align=\"left\" border=\"0\" cellpadding=\"2px\" cellspacing=\"2px\">\n <tr>\n <td style=\"border-left: 2px solid {color};\">\n <img src=\"https://emoji.slack-edge.com/TAN3D79AL/prefect/2497370f58500a5a.png\">\n </td>\n <td style=\"border-left: 2px solid {color}; padding-left: 6px;\">\n {text}\n </td>\n </tr>\n </table>\n </body>\n </html>\n \"\"\"\n color = state.color\n text = \"\"\"\n <pre>{name}</pre> is now in a <font color=\"{color}\"><b>{state}</b></font> state\n <br><br>\n Message: {msg}\n \"\"\".format(\n name=tracked_obj.name, color=state.color, state=type(state).__name__, msg=msg\n )\n\n contents = MIMEMultipart(\"alternative\")\n contents.attach(MIMEText(text, \"plain\"))\n contents.attach(MIMEText(html.format(color=color, text=text), \"html\"))\n\n contents[\"Subject\"] = Header(\n \"Prefect state change notification for {}\".format(tracked_obj.name), \"UTF-8\"\n )\n contents[\"From\"] = \"[email protected]\"\n contents[\"To\"] = email_to\n\n return contents.as_string()\n\n\ndef slack_message_formatter(\n tracked_obj: TrackedObjectType,\n state: \"prefect.engine.state.State\",\n backend_info: bool = True,\n) -> dict:\n # see https://api.slack.com/docs/message-attachments\n fields = []\n if isinstance(state.result, Exception):\n value = \"```{}```\".format(repr(state.result))\n else:\n value = cast(str, state.message)\n if value is not None:\n fields.append({\"title\": \"Message\", \"value\": value, \"short\": False})\n\n notification_payload = {\n \"fallback\": \"State change notification\",\n \"color\": state.color,\n \"author_name\": \"Prefect\",\n \"author_link\": \"https://www.prefect.io/\",\n \"author_icon\": \"https://emoji.slack-edge.com/TAN3D79AL/prefect/2497370f58500a5a.png\",\n \"title\": type(state).__name__,\n \"fields\": fields,\n # \"title_link\": \"https://www.prefect.io/\",\n \"text\": \"{0} is now in a {1} state\".format(\n tracked_obj.name, type(state).__name__\n ),\n \"footer\": \"Prefect notification\",\n }\n\n if backend_info and prefect.context.get(\"flow_run_id\"):\n url = None\n\n if isinstance(tracked_obj, prefect.Flow):\n url = prefect.client.Client().get_cloud_url(\n \"flow-run\", prefect.context[\"flow_run_id\"], as_user=False\n )\n elif isinstance(tracked_obj, prefect.Task):\n url = prefect.client.Client().get_cloud_url(\n \"task-run\", prefect.context.get(\"task_run_id\", \"\"), as_user=False\n )\n\n if url:\n notification_payload.update(title_link=url)\n\n data = {\"attachments\": [notification_payload]}\n return data\n\n\n@curry\ndef gmail_notifier(\n tracked_obj: TrackedObjectType,\n old_state: \"prefect.engine.state.State\",\n new_state: \"prefect.engine.state.State\",\n ignore_states: list = None,\n only_states: list = None,\n) -> \"prefect.engine.state.State\":\n \"\"\"\n Email state change handler - configured to work solely with Gmail; works as a standalone\n state handler, or can be called from within a custom state handler. This function is\n curried meaning that it can be called multiple times to partially bind any keyword\n arguments (see example below).\n\n The username and password Gmail credentials will be taken from your `\"EMAIL_USERNAME\"` and\n `\"EMAIL_PASSWORD\"` secrets, respectively; note the username will also serve as the\n destination email address for the notification.\n\n Args:\n - tracked_obj (Task or Flow): Task or Flow object the handler is registered with\n - old_state (State): previous state of tracked object\n - new_state (State): new state of tracked object\n - ignore_states ([State], optional): list of `State` classes to ignore, e.g.,\n `[Running, Scheduled]`. If `new_state` is an instance of one of the passed states,\n no notification will occur.\n - only_states ([State], optional): similar to `ignore_states`, but instead _only_\n notifies you if the Task / Flow is in a state from the provided list of `State`\n classes\n\n Returns:\n - State: the `new_state` object that was provided\n\n Raises:\n - ValueError: if the email notification fails for any reason\n\n Example:\n ```python\n from prefect import task\n from prefect.utilities.notifications import gmail_notifier\n\n @task(state_handlers=[gmail_notifier(ignore_states=[Running])]) # uses currying\n def add(x, y):\n return x + y\n ```\n \"\"\"\n username = cast(str, prefect.client.Secret(\"EMAIL_USERNAME\").get())\n password = cast(str, prefect.client.Secret(\"EMAIL_PASSWORD\").get())\n ignore_states = ignore_states or []\n only_states = only_states or []\n\n if any(isinstance(new_state, ignored) for ignored in ignore_states):\n return new_state\n\n if only_states and not any(\n [isinstance(new_state, included) for included in only_states]\n ):\n return new_state\n\n body = email_message_formatter(tracked_obj, new_state, username)\n\n server = smtplib.SMTP_SSL(\"smtp.gmail.com\", 465)\n server.login(username, password)\n try:\n server.sendmail(\"[email protected]\", username, body)\n except Exception as exc:\n raise ValueError(\n \"Email notification for {} failed\".format(tracked_obj)\n ) from exc\n finally:\n server.quit()\n\n return new_state\n\n\n@curry\ndef slack_notifier(\n tracked_obj: TrackedObjectType,\n old_state: \"prefect.engine.state.State\",\n new_state: \"prefect.engine.state.State\",\n ignore_states: list = None,\n only_states: list = None,\n webhook_secret: str = None,\n backend_info: bool = True,\n) -> \"prefect.engine.state.State\":\n \"\"\"\n Slack state change handler; requires having the Prefect slack app installed. Works as a\n standalone state handler, or can be called from within a custom state handler. This\n function is curried meaning that it can be called multiple times to partially bind any\n keyword arguments (see example below).\n\n Args:\n - tracked_obj (Task or Flow): Task or Flow object the handler is\n registered with\n - old_state (State): previous state of tracked object\n - new_state (State): new state of tracked object\n - ignore_states ([State], optional): list of `State` classes to ignore, e.g.,\n `[Running, Scheduled]`. If `new_state` is an instance of one of the passed states,\n no notification will occur.\n - only_states ([State], optional): similar to `ignore_states`, but instead _only_\n notifies you if the Task / Flow is in a state from the provided list of `State`\n classes\n - webhook_secret (str, optional): the name of the Prefect Secret that stores your slack\n webhook URL; defaults to `\"SLACK_WEBHOOK_URL\"`\n - backend_info (bool, optional): Whether to supply slack notification with urls\n pointing to backend pages; defaults to True\n\n Returns:\n - State: the `new_state` object that was provided\n\n Raises:\n - ValueError: if the slack notification fails for any reason\n\n Example:\n ```python\n from prefect import task\n from prefect.utilities.notifications import slack_notifier\n\n @task(state_handlers=[slack_notifier(ignore_states=[Running])]) # uses currying\n def add(x, y):\n return x + y\n ```\n \"\"\"\n webhook_url = cast(\n str, prefect.client.Secret(webhook_secret or \"SLACK_WEBHOOK_URL\").get()\n )\n ignore_states = ignore_states or []\n only_states = only_states or []\n\n if any(isinstance(new_state, ignored) for ignored in ignore_states):\n return new_state\n\n if only_states and not any(\n [isinstance(new_state, included) for included in only_states]\n ):\n return new_state\n\n # 'import requests' is expensive time-wise, we should do this just-in-time to keep\n # the 'import prefect' time low\n import requests\n\n form_data = slack_message_formatter(tracked_obj, new_state, backend_info)\n r = requests.post(webhook_url, json=form_data)\n if not r.ok:\n raise ValueError(\"Slack notification for {} failed\".format(tracked_obj))\n return new_state\n", "path": "src/prefect/utilities/notifications/notifications.py"}], "after_files": [{"content": "\"\"\"\nTools and utilities for notifications and callbacks.\n\nFor an in-depth guide to setting up your system for using Slack notifications, [please see our\ntutorial](/core/advanced_tutorials/slack-notifications.html).\n\"\"\"\nimport smtplib\nfrom email.header import Header\nfrom email.mime.multipart import MIMEMultipart\nfrom email.mime.text import MIMEText\nfrom typing import TYPE_CHECKING, Any, Callable, Union, cast\n\nfrom toolz import curry\n\nimport prefect\n\nif TYPE_CHECKING:\n import prefect.engine.state\n import prefect.client\n from prefect import Flow, Task # noqa\n\nTrackedObjectType = Union[\"Flow\", \"Task\"]\n\n__all__ = [\"callback_factory\", \"gmail_notifier\", \"slack_notifier\"]\n\n\ndef callback_factory(\n fn: Callable[[Any, \"prefect.engine.state.State\"], Any],\n check: Callable[[\"prefect.engine.state.State\"], bool],\n) -> Callable:\n \"\"\"\n Utility for generating state handlers that serve as callbacks, under arbitrary\n state-based checks.\n\n Args:\n - fn (Callable): a function with signature `fn(obj, state: State) -> None`\n that will be called anytime the associated state-check passes; in general, it is\n expected that this function will have side effects (e.g., sends an email). The\n first argument to this function is the `Task` or `Flow` it is attached to.\n - check (Callable): a function with signature `check(state: State) -> bool`\n that is used for determining when the callback function should be called\n\n Returns:\n - state_handler (Callable): a state handler function that can be attached to both Tasks\n and Flows\n\n Example:\n ```python\n from prefect import Task, Flow\n from prefect.utilities.notifications import callback_factory\n\n fn = lambda obj, state: print(state)\n check = lambda state: state.is_successful()\n callback = callback_factory(fn, check)\n\n t = Task(state_handlers=[callback])\n f = Flow(\"My Example Flow\", tasks=[t], state_handlers=[callback])\n f.run()\n # prints:\n # Success(\"Task run succeeded.\")\n # Success(\"All reference tasks succeeded.\")\n ```\n \"\"\"\n\n def state_handler(\n obj: Any,\n old_state: \"prefect.engine.state.State\",\n new_state: \"prefect.engine.state.State\",\n ) -> \"prefect.engine.state.State\":\n if check(new_state) is True:\n fn(obj, new_state)\n return new_state\n\n return state_handler\n\n\ndef email_message_formatter(\n tracked_obj: TrackedObjectType, state: \"prefect.engine.state.State\", email_to: str\n) -> str:\n if isinstance(state.result, Exception):\n msg = \"<pre>{}</pre>\".format(repr(state.result))\n else:\n msg = '\"{}\"'.format(state.message)\n\n html = \"\"\"\n <html>\n <head></head>\n <body>\n <table align=\"left\" border=\"0\" cellpadding=\"2px\" cellspacing=\"2px\">\n <tr>\n <td style=\"border-left: 2px solid {color};\">\n <img src=\"https://emoji.slack-edge.com/TAN3D79AL/prefect/2497370f58500a5a.png\">\n </td>\n <td style=\"border-left: 2px solid {color}; padding-left: 6px;\">\n {text}\n </td>\n </tr>\n </table>\n </body>\n </html>\n \"\"\"\n color = state.color\n text = \"\"\"\n <pre>{name}</pre> is now in a <font color=\"{color}\"><b>{state}</b></font> state\n <br><br>\n Message: {msg}\n \"\"\".format(\n name=tracked_obj.name, color=state.color, state=type(state).__name__, msg=msg\n )\n\n contents = MIMEMultipart(\"alternative\")\n contents.attach(MIMEText(text, \"plain\"))\n contents.attach(MIMEText(html.format(color=color, text=text), \"html\"))\n\n contents[\"Subject\"] = Header(\n \"Prefect state change notification for {}\".format(tracked_obj.name), \"UTF-8\"\n )\n contents[\"From\"] = \"[email protected]\"\n contents[\"To\"] = email_to\n\n return contents.as_string()\n\n\ndef slack_message_formatter(\n tracked_obj: TrackedObjectType,\n state: \"prefect.engine.state.State\",\n backend_info: bool = True,\n) -> dict:\n # see https://api.slack.com/docs/message-attachments\n fields = []\n if isinstance(state.result, Exception):\n value = \"```{}```\".format(repr(state.result))\n else:\n value = cast(str, state.message)\n if value is not None:\n fields.append({\"title\": \"Message\", \"value\": value, \"short\": False})\n\n notification_payload = {\n \"fallback\": \"State change notification\",\n \"color\": state.color,\n \"author_name\": \"Prefect\",\n \"author_link\": \"https://www.prefect.io/\",\n \"author_icon\": \"https://emoji.slack-edge.com/TAN3D79AL/prefect/2497370f58500a5a.png\",\n \"title\": type(state).__name__,\n \"fields\": fields,\n # \"title_link\": \"https://www.prefect.io/\",\n \"text\": \"{0} is now in a {1} state\".format(\n tracked_obj.name, type(state).__name__\n ),\n \"footer\": \"Prefect notification\",\n }\n\n if backend_info and prefect.context.get(\"flow_run_id\"):\n url = None\n\n if isinstance(tracked_obj, prefect.Flow):\n url = prefect.client.Client().get_cloud_url(\n \"flow-run\", prefect.context[\"flow_run_id\"], as_user=False\n )\n elif isinstance(tracked_obj, prefect.Task):\n url = prefect.client.Client().get_cloud_url(\n \"task-run\", prefect.context.get(\"task_run_id\", \"\"), as_user=False\n )\n\n if url:\n notification_payload.update(title_link=url)\n\n data = {\"attachments\": [notification_payload]}\n return data\n\n\n@curry\ndef gmail_notifier(\n tracked_obj: TrackedObjectType,\n old_state: \"prefect.engine.state.State\",\n new_state: \"prefect.engine.state.State\",\n ignore_states: list = None,\n only_states: list = None,\n) -> \"prefect.engine.state.State\":\n \"\"\"\n Email state change handler - configured to work solely with Gmail; works as a standalone\n state handler, or can be called from within a custom state handler. This function is\n curried meaning that it can be called multiple times to partially bind any keyword\n arguments (see example below).\n\n The username and password Gmail credentials will be taken from your `\"EMAIL_USERNAME\"` and\n `\"EMAIL_PASSWORD\"` secrets, respectively; note the username will also serve as the\n destination email address for the notification.\n\n Args:\n - tracked_obj (Task or Flow): Task or Flow object the handler is registered with\n - old_state (State): previous state of tracked object\n - new_state (State): new state of tracked object\n - ignore_states ([State], optional): list of `State` classes to ignore, e.g.,\n `[Running, Scheduled]`. If `new_state` is an instance of one of the passed states,\n no notification will occur.\n - only_states ([State], optional): similar to `ignore_states`, but instead _only_\n notifies you if the Task / Flow is in a state from the provided list of `State`\n classes\n\n Returns:\n - State: the `new_state` object that was provided\n\n Raises:\n - ValueError: if the email notification fails for any reason\n\n Example:\n ```python\n from prefect import task\n from prefect.utilities.notifications import gmail_notifier\n\n @task(state_handlers=[gmail_notifier(ignore_states=[Running])]) # uses currying\n def add(x, y):\n return x + y\n ```\n \"\"\"\n username = cast(str, prefect.client.Secret(\"EMAIL_USERNAME\").get())\n password = cast(str, prefect.client.Secret(\"EMAIL_PASSWORD\").get())\n ignore_states = ignore_states or []\n only_states = only_states or []\n\n if any(isinstance(new_state, ignored) for ignored in ignore_states):\n return new_state\n\n if only_states and not any(\n [isinstance(new_state, included) for included in only_states]\n ):\n return new_state\n\n body = email_message_formatter(tracked_obj, new_state, username)\n\n server = smtplib.SMTP_SSL(\"smtp.gmail.com\", 465)\n server.login(username, password)\n try:\n server.sendmail(\"[email protected]\", username, body)\n except Exception as exc:\n raise ValueError(\n \"Email notification for {} failed\".format(tracked_obj)\n ) from exc\n finally:\n server.quit()\n\n return new_state\n\n\n@curry\ndef slack_notifier(\n tracked_obj: TrackedObjectType,\n old_state: \"prefect.engine.state.State\",\n new_state: \"prefect.engine.state.State\",\n ignore_states: list = None,\n only_states: list = None,\n webhook_secret: str = None,\n backend_info: bool = True,\n proxies: dict = None,\n) -> \"prefect.engine.state.State\":\n \"\"\"\n Slack state change handler; requires having the Prefect slack app installed. Works as a\n standalone state handler, or can be called from within a custom state handler. This\n function is curried meaning that it can be called multiple times to partially bind any\n keyword arguments (see example below).\n\n Args:\n - tracked_obj (Task or Flow): Task or Flow object the handler is\n registered with\n - old_state (State): previous state of tracked object\n - new_state (State): new state of tracked object\n - ignore_states ([State], optional): list of `State` classes to ignore, e.g.,\n `[Running, Scheduled]`. If `new_state` is an instance of one of the passed states,\n no notification will occur.\n - only_states ([State], optional): similar to `ignore_states`, but instead _only_\n notifies you if the Task / Flow is in a state from the provided list of `State`\n classes\n - webhook_secret (str, optional): the name of the Prefect Secret that stores your slack\n webhook URL; defaults to `\"SLACK_WEBHOOK_URL\"`\n - backend_info (bool, optional): Whether to supply slack notification with urls\n pointing to backend pages; defaults to True\n - proxies (dict), optional): `dict` with \"http\" and/or \"https\" keys, passed to\n `requests.post` - for situations where a proxy is required to send requests to the\n Slack webhook\n\n Returns:\n - State: the `new_state` object that was provided\n\n Raises:\n - ValueError: if the slack notification fails for any reason\n\n Example:\n ```python\n from prefect import task\n from prefect.utilities.notifications import slack_notifier\n\n @task(state_handlers=[slack_notifier(ignore_states=[Running])]) # uses currying\n def add(x, y):\n return x + y\n ```\n \"\"\"\n webhook_url = cast(\n str, prefect.client.Secret(webhook_secret or \"SLACK_WEBHOOK_URL\").get()\n )\n ignore_states = ignore_states or []\n only_states = only_states or []\n\n if any(isinstance(new_state, ignored) for ignored in ignore_states):\n return new_state\n\n if only_states and not any(\n [isinstance(new_state, included) for included in only_states]\n ):\n return new_state\n\n # 'import requests' is expensive time-wise, we should do this just-in-time to keep\n # the 'import prefect' time low\n import requests\n\n form_data = slack_message_formatter(tracked_obj, new_state, backend_info)\n r = requests.post(webhook_url, json=form_data, proxies=proxies)\n if not r.ok:\n raise ValueError(\"Slack notification for {} failed\".format(tracked_obj))\n return new_state\n", "path": "src/prefect/utilities/notifications/notifications.py"}]}
| 3,864 | 350 |
gh_patches_debug_21295
|
rasdani/github-patches
|
git_diff
|
sublimelsp__LSP-1512
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Recursive variable expansion in lsp_execute command
**Is your feature request related to a problem? Please describe.**
The documentation states ...
```js
[
// ...
{
"caption": "Thread First",
"command": "lsp_execute",
"args": {
"command_name": "thread-first",
"command_args": ["${file_uri}", 0, 0]
}
}
]
```
Note: `command_args` is optional depending on the `workspace/executeCommand` that are supported by the LSP server.
The following **variables will be expanded, but only if they are top-level array items** and not within nested arrays or objects:
The **LemMinX** language server provides a validation command which expects [textDocumentIdentifie](https://microsoft.github.io/language-server-protocol/specification#textDocumentIdentifier) as first parameter.
see: https://github.com/eclipse/lemminx/pull/938
The proper command definition in ST would look like
```
[
{
"caption": "XML: Validate File",
"command": "lsp_execute",
"args": {
"command_name": "xml.validation.current.file",
"command_args": [{"uri": "${file_uri}"}]
}
}
]
```
Unfortunatelly `${file_uri}` is not expanded as it is not in the top-level array.
**Describe the solution you'd like**
The most flexible and straight forward solution would probably be to support recursive variable expansions in all nested arrays and objects.
**Describe alternatives you've considered**
An `$document_id` variable which is expanded to `{"uri": "file:///path/to/file.xml"}` would do the job as well. The command definition would look as follows then.
```
[
{
"caption": "XML: Validate File",
"command": "lsp_execute",
"args": {
"command_name": "xml.validation.current.file",
"command_args": ["$document_id"]
}
}
]
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `plugin/execute_command.py`
Content:
```
1 import sublime
2 from .core.protocol import Error
3 from .core.protocol import ExecuteCommandParams
4 from .core.registry import LspTextCommand
5 from .core.typing import List, Optional, Any
6 from .core.views import uri_from_view, offset_to_point, region_to_range
7
8
9 class LspExecuteCommand(LspTextCommand):
10
11 capability = 'executeCommandProvider'
12
13 def run(self,
14 edit: sublime.Edit,
15 command_name: Optional[str] = None,
16 command_args: Optional[List[Any]] = None,
17 session_name: Optional[str] = None,
18 event: Optional[dict] = None) -> None:
19 session = self.session_by_name(session_name) if session_name else self.best_session(self.capability)
20 if session and command_name:
21 if command_args:
22 self._expand_variables(command_args)
23 params = {"command": command_name} # type: ExecuteCommandParams
24 if command_args:
25 params["arguments"] = command_args
26
27 def handle_response(response: Any) -> None:
28 assert command_name
29 if isinstance(response, Error):
30 sublime.message_dialog("command {} failed. Reason: {}".format(command_name, str(response)))
31 return
32 msg = "command {} completed".format(command_name)
33 if response:
34 msg += "with response: {}".format(response)
35 window = self.view.window()
36 if window:
37 window.status_message(msg)
38
39 session.execute_command(params).then(handle_response)
40
41 def _expand_variables(self, command_args: List[Any]) -> None:
42 region = self.view.sel()[0]
43 for i, arg in enumerate(command_args):
44 if arg in ["$file_uri", "${file_uri}"]:
45 command_args[i] = uri_from_view(self.view)
46 elif arg in ["$selection", "${selection}"]:
47 command_args[i] = self.view.substr(region)
48 elif arg in ["$offset", "${offset}"]:
49 command_args[i] = region.b
50 elif arg in ["$selection_begin", "${selection_begin}"]:
51 command_args[i] = region.begin()
52 elif arg in ["$selection_end", "${selection_end}"]:
53 command_args[i] = region.end()
54 elif arg in ["$position", "${position}"]:
55 command_args[i] = offset_to_point(self.view, region.b).to_lsp()
56 elif arg in ["$range", "${range}"]:
57 command_args[i] = region_to_range(self.view, region).to_lsp()
58
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/plugin/execute_command.py b/plugin/execute_command.py
--- a/plugin/execute_command.py
+++ b/plugin/execute_command.py
@@ -3,7 +3,7 @@
from .core.protocol import ExecuteCommandParams
from .core.registry import LspTextCommand
from .core.typing import List, Optional, Any
-from .core.views import uri_from_view, offset_to_point, region_to_range
+from .core.views import uri_from_view, offset_to_point, region_to_range, text_document_identifier
class LspExecuteCommand(LspTextCommand):
@@ -41,6 +41,8 @@
def _expand_variables(self, command_args: List[Any]) -> None:
region = self.view.sel()[0]
for i, arg in enumerate(command_args):
+ if arg in ["$document_id", "${document_id}"]:
+ command_args[i] = text_document_identifier(self.view)
if arg in ["$file_uri", "${file_uri}"]:
command_args[i] = uri_from_view(self.view)
elif arg in ["$selection", "${selection}"]:
|
{"golden_diff": "diff --git a/plugin/execute_command.py b/plugin/execute_command.py\n--- a/plugin/execute_command.py\n+++ b/plugin/execute_command.py\n@@ -3,7 +3,7 @@\n from .core.protocol import ExecuteCommandParams\n from .core.registry import LspTextCommand\n from .core.typing import List, Optional, Any\n-from .core.views import uri_from_view, offset_to_point, region_to_range\n+from .core.views import uri_from_view, offset_to_point, region_to_range, text_document_identifier\n \n \n class LspExecuteCommand(LspTextCommand):\n@@ -41,6 +41,8 @@\n def _expand_variables(self, command_args: List[Any]) -> None:\n region = self.view.sel()[0]\n for i, arg in enumerate(command_args):\n+ if arg in [\"$document_id\", \"${document_id}\"]:\n+ command_args[i] = text_document_identifier(self.view)\n if arg in [\"$file_uri\", \"${file_uri}\"]:\n command_args[i] = uri_from_view(self.view)\n elif arg in [\"$selection\", \"${selection}\"]:\n", "issue": "Recursive variable expansion in lsp_execute command\n**Is your feature request related to a problem? Please describe.**\r\n\r\nThe documentation states ...\r\n\r\n```js\r\n[\r\n // ...\r\n {\r\n \"caption\": \"Thread First\",\r\n \"command\": \"lsp_execute\",\r\n \"args\": {\r\n \"command_name\": \"thread-first\",\r\n \"command_args\": [\"${file_uri}\", 0, 0]\r\n }\r\n }\r\n]\r\n```\r\n\r\nNote: `command_args` is optional depending on the `workspace/executeCommand` that are supported by the LSP server.\r\nThe following **variables will be expanded, but only if they are top-level array items** and not within nested arrays or objects:\r\n\r\nThe **LemMinX** language server provides a validation command which expects [textDocumentIdentifie](https://microsoft.github.io/language-server-protocol/specification#textDocumentIdentifier) as first parameter.\r\n\r\nsee: https://github.com/eclipse/lemminx/pull/938\r\n\r\nThe proper command definition in ST would look like\r\n\r\n```\r\n[\r\n\t{\r\n\t\t\"caption\": \"XML: Validate File\",\r\n\t\t\"command\": \"lsp_execute\",\r\n\t\t\"args\": {\r\n\t\t\t\"command_name\": \"xml.validation.current.file\",\r\n\t\t\t\"command_args\": [{\"uri\": \"${file_uri}\"}]\r\n\t\t}\r\n\t}\r\n]\r\n```\r\n\r\nUnfortunatelly `${file_uri}` is not expanded as it is not in the top-level array.\r\n\r\n**Describe the solution you'd like**\r\n\r\nThe most flexible and straight forward solution would probably be to support recursive variable expansions in all nested arrays and objects.\r\n\r\n**Describe alternatives you've considered**\r\n\r\nAn `$document_id` variable which is expanded to `{\"uri\": \"file:///path/to/file.xml\"}` would do the job as well. The command definition would look as follows then.\r\n\r\n```\r\n[\r\n\t{\r\n\t\t\"caption\": \"XML: Validate File\",\r\n\t\t\"command\": \"lsp_execute\",\r\n\t\t\"args\": {\r\n\t\t\t\"command_name\": \"xml.validation.current.file\",\r\n\t\t\t\"command_args\": [\"$document_id\"]\r\n\t\t}\r\n\t}\r\n]\r\n```\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "import sublime\nfrom .core.protocol import Error\nfrom .core.protocol import ExecuteCommandParams\nfrom .core.registry import LspTextCommand\nfrom .core.typing import List, Optional, Any\nfrom .core.views import uri_from_view, offset_to_point, region_to_range\n\n\nclass LspExecuteCommand(LspTextCommand):\n\n capability = 'executeCommandProvider'\n\n def run(self,\n edit: sublime.Edit,\n command_name: Optional[str] = None,\n command_args: Optional[List[Any]] = None,\n session_name: Optional[str] = None,\n event: Optional[dict] = None) -> None:\n session = self.session_by_name(session_name) if session_name else self.best_session(self.capability)\n if session and command_name:\n if command_args:\n self._expand_variables(command_args)\n params = {\"command\": command_name} # type: ExecuteCommandParams\n if command_args:\n params[\"arguments\"] = command_args\n\n def handle_response(response: Any) -> None:\n assert command_name\n if isinstance(response, Error):\n sublime.message_dialog(\"command {} failed. Reason: {}\".format(command_name, str(response)))\n return\n msg = \"command {} completed\".format(command_name)\n if response:\n msg += \"with response: {}\".format(response)\n window = self.view.window()\n if window:\n window.status_message(msg)\n\n session.execute_command(params).then(handle_response)\n\n def _expand_variables(self, command_args: List[Any]) -> None:\n region = self.view.sel()[0]\n for i, arg in enumerate(command_args):\n if arg in [\"$file_uri\", \"${file_uri}\"]:\n command_args[i] = uri_from_view(self.view)\n elif arg in [\"$selection\", \"${selection}\"]:\n command_args[i] = self.view.substr(region)\n elif arg in [\"$offset\", \"${offset}\"]:\n command_args[i] = region.b\n elif arg in [\"$selection_begin\", \"${selection_begin}\"]:\n command_args[i] = region.begin()\n elif arg in [\"$selection_end\", \"${selection_end}\"]:\n command_args[i] = region.end()\n elif arg in [\"$position\", \"${position}\"]:\n command_args[i] = offset_to_point(self.view, region.b).to_lsp()\n elif arg in [\"$range\", \"${range}\"]:\n command_args[i] = region_to_range(self.view, region).to_lsp()\n", "path": "plugin/execute_command.py"}], "after_files": [{"content": "import sublime\nfrom .core.protocol import Error\nfrom .core.protocol import ExecuteCommandParams\nfrom .core.registry import LspTextCommand\nfrom .core.typing import List, Optional, Any\nfrom .core.views import uri_from_view, offset_to_point, region_to_range, text_document_identifier\n\n\nclass LspExecuteCommand(LspTextCommand):\n\n capability = 'executeCommandProvider'\n\n def run(self,\n edit: sublime.Edit,\n command_name: Optional[str] = None,\n command_args: Optional[List[Any]] = None,\n session_name: Optional[str] = None,\n event: Optional[dict] = None) -> None:\n session = self.session_by_name(session_name) if session_name else self.best_session(self.capability)\n if session and command_name:\n if command_args:\n self._expand_variables(command_args)\n params = {\"command\": command_name} # type: ExecuteCommandParams\n if command_args:\n params[\"arguments\"] = command_args\n\n def handle_response(response: Any) -> None:\n assert command_name\n if isinstance(response, Error):\n sublime.message_dialog(\"command {} failed. Reason: {}\".format(command_name, str(response)))\n return\n msg = \"command {} completed\".format(command_name)\n if response:\n msg += \"with response: {}\".format(response)\n window = self.view.window()\n if window:\n window.status_message(msg)\n\n session.execute_command(params).then(handle_response)\n\n def _expand_variables(self, command_args: List[Any]) -> None:\n region = self.view.sel()[0]\n for i, arg in enumerate(command_args):\n if arg in [\"$document_id\", \"${document_id}\"]:\n command_args[i] = text_document_identifier(self.view)\n if arg in [\"$file_uri\", \"${file_uri}\"]:\n command_args[i] = uri_from_view(self.view)\n elif arg in [\"$selection\", \"${selection}\"]:\n command_args[i] = self.view.substr(region)\n elif arg in [\"$offset\", \"${offset}\"]:\n command_args[i] = region.b\n elif arg in [\"$selection_begin\", \"${selection_begin}\"]:\n command_args[i] = region.begin()\n elif arg in [\"$selection_end\", \"${selection_end}\"]:\n command_args[i] = region.end()\n elif arg in [\"$position\", \"${position}\"]:\n command_args[i] = offset_to_point(self.view, region.b).to_lsp()\n elif arg in [\"$range\", \"${range}\"]:\n command_args[i] = region_to_range(self.view, region).to_lsp()\n", "path": "plugin/execute_command.py"}]}
| 1,336 | 236 |
gh_patches_debug_28886
|
rasdani/github-patches
|
git_diff
|
nltk__nltk-2787
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Remove outdated names in init.py
Cf #2508
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nltk/__init__.py`
Content:
```
1 # Natural Language Toolkit (NLTK)
2 #
3 # Copyright (C) 2001-2021 NLTK Project
4 # Authors: Steven Bird <[email protected]>
5 # Edward Loper <[email protected]>
6 # URL: <http://nltk.org/>
7 # For license information, see LICENSE.TXT
8
9 """
10 The Natural Language Toolkit (NLTK) is an open source Python library
11 for Natural Language Processing. A free online book is available.
12 (If you use the library for academic research, please cite the book.)
13
14 Steven Bird, Ewan Klein, and Edward Loper (2009).
15 Natural Language Processing with Python. O'Reilly Media Inc.
16 http://nltk.org/book
17
18 isort:skip_file
19 """
20
21 import os
22
23 # //////////////////////////////////////////////////////
24 # Metadata
25 # //////////////////////////////////////////////////////
26
27 # Version. For each new release, the version number should be updated
28 # in the file VERSION.
29 try:
30 # If a VERSION file exists, use it!
31 version_file = os.path.join(os.path.dirname(__file__), "VERSION")
32 with open(version_file) as infile:
33 __version__ = infile.read().strip()
34 except NameError:
35 __version__ = "unknown (running code interactively?)"
36 except OSError as ex:
37 __version__ = "unknown (%s)" % ex
38
39 if __doc__ is not None: # fix for the ``python -OO``
40 __doc__ += "\n@version: " + __version__
41
42
43 # Copyright notice
44 __copyright__ = """\
45 Copyright (C) 2001-2021 NLTK Project.
46
47 Distributed and Licensed under the Apache License, Version 2.0,
48 which is included by reference.
49 """
50
51 __license__ = "Apache License, Version 2.0"
52 # Description of the toolkit, keywords, and the project's primary URL.
53 __longdescr__ = """\
54 The Natural Language Toolkit (NLTK) is a Python package for
55 natural language processing. NLTK requires Python 2.6 or higher."""
56 __keywords__ = [
57 "NLP",
58 "CL",
59 "natural language processing",
60 "computational linguistics",
61 "parsing",
62 "tagging",
63 "tokenizing",
64 "syntax",
65 "linguistics",
66 "language",
67 "natural language",
68 "text analytics",
69 ]
70 __url__ = "http://nltk.org/"
71
72 # Maintainer, contributors, etc.
73 __maintainer__ = "Steven Bird, Edward Loper, Ewan Klein"
74 __maintainer_email__ = "[email protected]"
75 __author__ = __maintainer__
76 __author_email__ = __maintainer_email__
77
78 # "Trove" classifiers for Python Package Index.
79 __classifiers__ = [
80 "Development Status :: 5 - Production/Stable",
81 "Intended Audience :: Developers",
82 "Intended Audience :: Education",
83 "Intended Audience :: Information Technology",
84 "Intended Audience :: Science/Research",
85 "License :: OSI Approved :: Apache Software License",
86 "Operating System :: OS Independent",
87 "Programming Language :: Python :: 2.6",
88 "Programming Language :: Python :: 2.7",
89 "Topic :: Scientific/Engineering",
90 "Topic :: Scientific/Engineering :: Artificial Intelligence",
91 "Topic :: Scientific/Engineering :: Human Machine Interfaces",
92 "Topic :: Scientific/Engineering :: Information Analysis",
93 "Topic :: Text Processing",
94 "Topic :: Text Processing :: Filters",
95 "Topic :: Text Processing :: General",
96 "Topic :: Text Processing :: Indexing",
97 "Topic :: Text Processing :: Linguistic",
98 ]
99
100 from nltk.internals import config_java
101
102 # support numpy from pypy
103 try:
104 import numpypy
105 except ImportError:
106 pass
107
108 # Override missing methods on environments where it cannot be used like GAE.
109 import subprocess
110
111 if not hasattr(subprocess, "PIPE"):
112
113 def _fake_PIPE(*args, **kwargs):
114 raise NotImplementedError("subprocess.PIPE is not supported.")
115
116 subprocess.PIPE = _fake_PIPE
117 if not hasattr(subprocess, "Popen"):
118
119 def _fake_Popen(*args, **kwargs):
120 raise NotImplementedError("subprocess.Popen is not supported.")
121
122 subprocess.Popen = _fake_Popen
123
124 ###########################################################
125 # TOP-LEVEL MODULES
126 ###########################################################
127
128 # Import top-level functionality into top-level namespace
129
130 from nltk.collocations import *
131 from nltk.decorators import decorator, memoize
132 from nltk.featstruct import *
133 from nltk.grammar import *
134 from nltk.probability import *
135 from nltk.text import *
136 from nltk.tree import *
137 from nltk.util import *
138 from nltk.jsontags import *
139
140 ###########################################################
141 # PACKAGES
142 ###########################################################
143
144 from nltk.chunk import *
145 from nltk.classify import *
146 from nltk.inference import *
147 from nltk.metrics import *
148 from nltk.parse import *
149 from nltk.tag import *
150 from nltk.tokenize import *
151 from nltk.translate import *
152 from nltk.sem import *
153 from nltk.stem import *
154
155 # Packages which can be lazily imported
156 # (a) we don't import *
157 # (b) they're slow to import or have run-time dependencies
158 # that can safely fail at run time
159
160 from nltk import lazyimport
161
162 app = lazyimport.LazyModule("nltk.app", locals(), globals())
163 chat = lazyimport.LazyModule("nltk.chat", locals(), globals())
164 corpus = lazyimport.LazyModule("nltk.corpus", locals(), globals())
165 draw = lazyimport.LazyModule("nltk.draw", locals(), globals())
166 toolbox = lazyimport.LazyModule("nltk.toolbox", locals(), globals())
167
168 # Optional loading
169
170 try:
171 import numpy
172 except ImportError:
173 pass
174 else:
175 from nltk import cluster
176
177 from nltk.downloader import download, download_shell
178
179 try:
180 import tkinter
181 except ImportError:
182 pass
183 else:
184 try:
185 from nltk.downloader import download_gui
186 except RuntimeError as e:
187 import warnings
188
189 warnings.warn(
190 "Corpus downloader GUI not loaded "
191 "(RuntimeError during import: %s)" % str(e)
192 )
193
194 # explicitly import all top-level modules (ensuring
195 # they override the same names inadvertently imported
196 # from a subpackage)
197
198 from nltk import ccg, chunk, classify, collocations
199 from nltk import data, featstruct, grammar, help, inference, metrics
200 from nltk import misc, parse, probability, sem, stem, wsd
201 from nltk import tag, tbl, text, tokenize, translate, tree, treetransforms, util
202
203
204 # FIXME: override any accidentally imported demo, see https://github.com/nltk/nltk/issues/2116
205 def demo():
206 print("To run the demo code for a module, type nltk.module.demo()")
207
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nltk/__init__.py b/nltk/__init__.py
--- a/nltk/__init__.py
+++ b/nltk/__init__.py
@@ -52,7 +52,7 @@
# Description of the toolkit, keywords, and the project's primary URL.
__longdescr__ = """\
The Natural Language Toolkit (NLTK) is a Python package for
-natural language processing. NLTK requires Python 2.6 or higher."""
+natural language processing. NLTK requires Python 3.6, 3.7, 3.8, or 3.9."""
__keywords__ = [
"NLP",
"CL",
@@ -70,7 +70,7 @@
__url__ = "http://nltk.org/"
# Maintainer, contributors, etc.
-__maintainer__ = "Steven Bird, Edward Loper, Ewan Klein"
+__maintainer__ = "Steven Bird"
__maintainer_email__ = "[email protected]"
__author__ = __maintainer__
__author_email__ = __maintainer_email__
@@ -84,8 +84,10 @@
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
- "Programming Language :: Python :: 2.6",
- "Programming Language :: Python :: 2.7",
+ "Programming Language :: Python :: 3.6",
+ "Programming Language :: Python :: 3.7",
+ "Programming Language :: Python :: 3.8",
+ "Programming Language :: Python :: 3.9",
"Topic :: Scientific/Engineering",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Topic :: Scientific/Engineering :: Human Machine Interfaces",
|
{"golden_diff": "diff --git a/nltk/__init__.py b/nltk/__init__.py\n--- a/nltk/__init__.py\n+++ b/nltk/__init__.py\n@@ -52,7 +52,7 @@\n # Description of the toolkit, keywords, and the project's primary URL.\n __longdescr__ = \"\"\"\\\n The Natural Language Toolkit (NLTK) is a Python package for\n-natural language processing. NLTK requires Python 2.6 or higher.\"\"\"\n+natural language processing. NLTK requires Python 3.6, 3.7, 3.8, or 3.9.\"\"\"\n __keywords__ = [\n \"NLP\",\n \"CL\",\n@@ -70,7 +70,7 @@\n __url__ = \"http://nltk.org/\"\n \n # Maintainer, contributors, etc.\n-__maintainer__ = \"Steven Bird, Edward Loper, Ewan Klein\"\n+__maintainer__ = \"Steven Bird\"\n __maintainer_email__ = \"[email protected]\"\n __author__ = __maintainer__\n __author_email__ = __maintainer_email__\n@@ -84,8 +84,10 @@\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: OS Independent\",\n- \"Programming Language :: Python :: 2.6\",\n- \"Programming Language :: Python :: 2.7\",\n+ \"Programming Language :: Python :: 3.6\",\n+ \"Programming Language :: Python :: 3.7\",\n+ \"Programming Language :: Python :: 3.8\",\n+ \"Programming Language :: Python :: 3.9\",\n \"Topic :: Scientific/Engineering\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n \"Topic :: Scientific/Engineering :: Human Machine Interfaces\",\n", "issue": "Remove outdated names in init.py\nCf #2508 \r\n\n", "before_files": [{"content": "# Natural Language Toolkit (NLTK)\n#\n# Copyright (C) 2001-2021 NLTK Project\n# Authors: Steven Bird <[email protected]>\n# Edward Loper <[email protected]>\n# URL: <http://nltk.org/>\n# For license information, see LICENSE.TXT\n\n\"\"\"\nThe Natural Language Toolkit (NLTK) is an open source Python library\nfor Natural Language Processing. A free online book is available.\n(If you use the library for academic research, please cite the book.)\n\nSteven Bird, Ewan Klein, and Edward Loper (2009).\nNatural Language Processing with Python. O'Reilly Media Inc.\nhttp://nltk.org/book\n\nisort:skip_file\n\"\"\"\n\nimport os\n\n# //////////////////////////////////////////////////////\n# Metadata\n# //////////////////////////////////////////////////////\n\n# Version. For each new release, the version number should be updated\n# in the file VERSION.\ntry:\n # If a VERSION file exists, use it!\n version_file = os.path.join(os.path.dirname(__file__), \"VERSION\")\n with open(version_file) as infile:\n __version__ = infile.read().strip()\nexcept NameError:\n __version__ = \"unknown (running code interactively?)\"\nexcept OSError as ex:\n __version__ = \"unknown (%s)\" % ex\n\nif __doc__ is not None: # fix for the ``python -OO``\n __doc__ += \"\\n@version: \" + __version__\n\n\n# Copyright notice\n__copyright__ = \"\"\"\\\nCopyright (C) 2001-2021 NLTK Project.\n\nDistributed and Licensed under the Apache License, Version 2.0,\nwhich is included by reference.\n\"\"\"\n\n__license__ = \"Apache License, Version 2.0\"\n# Description of the toolkit, keywords, and the project's primary URL.\n__longdescr__ = \"\"\"\\\nThe Natural Language Toolkit (NLTK) is a Python package for\nnatural language processing. NLTK requires Python 2.6 or higher.\"\"\"\n__keywords__ = [\n \"NLP\",\n \"CL\",\n \"natural language processing\",\n \"computational linguistics\",\n \"parsing\",\n \"tagging\",\n \"tokenizing\",\n \"syntax\",\n \"linguistics\",\n \"language\",\n \"natural language\",\n \"text analytics\",\n]\n__url__ = \"http://nltk.org/\"\n\n# Maintainer, contributors, etc.\n__maintainer__ = \"Steven Bird, Edward Loper, Ewan Klein\"\n__maintainer_email__ = \"[email protected]\"\n__author__ = __maintainer__\n__author_email__ = __maintainer_email__\n\n# \"Trove\" classifiers for Python Package Index.\n__classifiers__ = [\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Information Technology\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 2.6\",\n \"Programming Language :: Python :: 2.7\",\n \"Topic :: Scientific/Engineering\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n \"Topic :: Scientific/Engineering :: Human Machine Interfaces\",\n \"Topic :: Scientific/Engineering :: Information Analysis\",\n \"Topic :: Text Processing\",\n \"Topic :: Text Processing :: Filters\",\n \"Topic :: Text Processing :: General\",\n \"Topic :: Text Processing :: Indexing\",\n \"Topic :: Text Processing :: Linguistic\",\n]\n\nfrom nltk.internals import config_java\n\n# support numpy from pypy\ntry:\n import numpypy\nexcept ImportError:\n pass\n\n# Override missing methods on environments where it cannot be used like GAE.\nimport subprocess\n\nif not hasattr(subprocess, \"PIPE\"):\n\n def _fake_PIPE(*args, **kwargs):\n raise NotImplementedError(\"subprocess.PIPE is not supported.\")\n\n subprocess.PIPE = _fake_PIPE\nif not hasattr(subprocess, \"Popen\"):\n\n def _fake_Popen(*args, **kwargs):\n raise NotImplementedError(\"subprocess.Popen is not supported.\")\n\n subprocess.Popen = _fake_Popen\n\n###########################################################\n# TOP-LEVEL MODULES\n###########################################################\n\n# Import top-level functionality into top-level namespace\n\nfrom nltk.collocations import *\nfrom nltk.decorators import decorator, memoize\nfrom nltk.featstruct import *\nfrom nltk.grammar import *\nfrom nltk.probability import *\nfrom nltk.text import *\nfrom nltk.tree import *\nfrom nltk.util import *\nfrom nltk.jsontags import *\n\n###########################################################\n# PACKAGES\n###########################################################\n\nfrom nltk.chunk import *\nfrom nltk.classify import *\nfrom nltk.inference import *\nfrom nltk.metrics import *\nfrom nltk.parse import *\nfrom nltk.tag import *\nfrom nltk.tokenize import *\nfrom nltk.translate import *\nfrom nltk.sem import *\nfrom nltk.stem import *\n\n# Packages which can be lazily imported\n# (a) we don't import *\n# (b) they're slow to import or have run-time dependencies\n# that can safely fail at run time\n\nfrom nltk import lazyimport\n\napp = lazyimport.LazyModule(\"nltk.app\", locals(), globals())\nchat = lazyimport.LazyModule(\"nltk.chat\", locals(), globals())\ncorpus = lazyimport.LazyModule(\"nltk.corpus\", locals(), globals())\ndraw = lazyimport.LazyModule(\"nltk.draw\", locals(), globals())\ntoolbox = lazyimport.LazyModule(\"nltk.toolbox\", locals(), globals())\n\n# Optional loading\n\ntry:\n import numpy\nexcept ImportError:\n pass\nelse:\n from nltk import cluster\n\nfrom nltk.downloader import download, download_shell\n\ntry:\n import tkinter\nexcept ImportError:\n pass\nelse:\n try:\n from nltk.downloader import download_gui\n except RuntimeError as e:\n import warnings\n\n warnings.warn(\n \"Corpus downloader GUI not loaded \"\n \"(RuntimeError during import: %s)\" % str(e)\n )\n\n# explicitly import all top-level modules (ensuring\n# they override the same names inadvertently imported\n# from a subpackage)\n\nfrom nltk import ccg, chunk, classify, collocations\nfrom nltk import data, featstruct, grammar, help, inference, metrics\nfrom nltk import misc, parse, probability, sem, stem, wsd\nfrom nltk import tag, tbl, text, tokenize, translate, tree, treetransforms, util\n\n\n# FIXME: override any accidentally imported demo, see https://github.com/nltk/nltk/issues/2116\ndef demo():\n print(\"To run the demo code for a module, type nltk.module.demo()\")\n", "path": "nltk/__init__.py"}], "after_files": [{"content": "# Natural Language Toolkit (NLTK)\n#\n# Copyright (C) 2001-2021 NLTK Project\n# Authors: Steven Bird <[email protected]>\n# Edward Loper <[email protected]>\n# URL: <http://nltk.org/>\n# For license information, see LICENSE.TXT\n\n\"\"\"\nThe Natural Language Toolkit (NLTK) is an open source Python library\nfor Natural Language Processing. A free online book is available.\n(If you use the library for academic research, please cite the book.)\n\nSteven Bird, Ewan Klein, and Edward Loper (2009).\nNatural Language Processing with Python. O'Reilly Media Inc.\nhttp://nltk.org/book\n\nisort:skip_file\n\"\"\"\n\nimport os\n\n# //////////////////////////////////////////////////////\n# Metadata\n# //////////////////////////////////////////////////////\n\n# Version. For each new release, the version number should be updated\n# in the file VERSION.\ntry:\n # If a VERSION file exists, use it!\n version_file = os.path.join(os.path.dirname(__file__), \"VERSION\")\n with open(version_file) as infile:\n __version__ = infile.read().strip()\nexcept NameError:\n __version__ = \"unknown (running code interactively?)\"\nexcept OSError as ex:\n __version__ = \"unknown (%s)\" % ex\n\nif __doc__ is not None: # fix for the ``python -OO``\n __doc__ += \"\\n@version: \" + __version__\n\n\n# Copyright notice\n__copyright__ = \"\"\"\\\nCopyright (C) 2001-2021 NLTK Project.\n\nDistributed and Licensed under the Apache License, Version 2.0,\nwhich is included by reference.\n\"\"\"\n\n__license__ = \"Apache License, Version 2.0\"\n# Description of the toolkit, keywords, and the project's primary URL.\n__longdescr__ = \"\"\"\\\nThe Natural Language Toolkit (NLTK) is a Python package for\nnatural language processing. NLTK requires Python 3.6, 3.7, 3.8, or 3.9.\"\"\"\n__keywords__ = [\n \"NLP\",\n \"CL\",\n \"natural language processing\",\n \"computational linguistics\",\n \"parsing\",\n \"tagging\",\n \"tokenizing\",\n \"syntax\",\n \"linguistics\",\n \"language\",\n \"natural language\",\n \"text analytics\",\n]\n__url__ = \"http://nltk.org/\"\n\n# Maintainer, contributors, etc.\n__maintainer__ = \"Steven Bird\"\n__maintainer_email__ = \"[email protected]\"\n__author__ = __maintainer__\n__author_email__ = __maintainer_email__\n\n# \"Trove\" classifiers for Python Package Index.\n__classifiers__ = [\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Information Technology\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Topic :: Scientific/Engineering\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n \"Topic :: Scientific/Engineering :: Human Machine Interfaces\",\n \"Topic :: Scientific/Engineering :: Information Analysis\",\n \"Topic :: Text Processing\",\n \"Topic :: Text Processing :: Filters\",\n \"Topic :: Text Processing :: General\",\n \"Topic :: Text Processing :: Indexing\",\n \"Topic :: Text Processing :: Linguistic\",\n]\n\nfrom nltk.internals import config_java\n\n# support numpy from pypy\ntry:\n import numpypy\nexcept ImportError:\n pass\n\n# Override missing methods on environments where it cannot be used like GAE.\nimport subprocess\n\nif not hasattr(subprocess, \"PIPE\"):\n\n def _fake_PIPE(*args, **kwargs):\n raise NotImplementedError(\"subprocess.PIPE is not supported.\")\n\n subprocess.PIPE = _fake_PIPE\nif not hasattr(subprocess, \"Popen\"):\n\n def _fake_Popen(*args, **kwargs):\n raise NotImplementedError(\"subprocess.Popen is not supported.\")\n\n subprocess.Popen = _fake_Popen\n\n###########################################################\n# TOP-LEVEL MODULES\n###########################################################\n\n# Import top-level functionality into top-level namespace\n\nfrom nltk.collocations import *\nfrom nltk.decorators import decorator, memoize\nfrom nltk.featstruct import *\nfrom nltk.grammar import *\nfrom nltk.probability import *\nfrom nltk.text import *\nfrom nltk.tree import *\nfrom nltk.util import *\nfrom nltk.jsontags import *\n\n###########################################################\n# PACKAGES\n###########################################################\n\nfrom nltk.chunk import *\nfrom nltk.classify import *\nfrom nltk.inference import *\nfrom nltk.metrics import *\nfrom nltk.parse import *\nfrom nltk.tag import *\nfrom nltk.tokenize import *\nfrom nltk.translate import *\nfrom nltk.sem import *\nfrom nltk.stem import *\n\n# Packages which can be lazily imported\n# (a) we don't import *\n# (b) they're slow to import or have run-time dependencies\n# that can safely fail at run time\n\nfrom nltk import lazyimport\n\napp = lazyimport.LazyModule(\"nltk.app\", locals(), globals())\nchat = lazyimport.LazyModule(\"nltk.chat\", locals(), globals())\ncorpus = lazyimport.LazyModule(\"nltk.corpus\", locals(), globals())\ndraw = lazyimport.LazyModule(\"nltk.draw\", locals(), globals())\ntoolbox = lazyimport.LazyModule(\"nltk.toolbox\", locals(), globals())\n\n# Optional loading\n\ntry:\n import numpy\nexcept ImportError:\n pass\nelse:\n from nltk import cluster\n\nfrom nltk.downloader import download, download_shell\n\ntry:\n import tkinter\nexcept ImportError:\n pass\nelse:\n try:\n from nltk.downloader import download_gui\n except RuntimeError as e:\n import warnings\n\n warnings.warn(\n \"Corpus downloader GUI not loaded \"\n \"(RuntimeError during import: %s)\" % str(e)\n )\n\n# explicitly import all top-level modules (ensuring\n# they override the same names inadvertently imported\n# from a subpackage)\n\nfrom nltk import ccg, chunk, classify, collocations\nfrom nltk import data, featstruct, grammar, help, inference, metrics\nfrom nltk import misc, parse, probability, sem, stem, wsd\nfrom nltk import tag, tbl, text, tokenize, translate, tree, treetransforms, util\n\n\n# FIXME: override any accidentally imported demo, see https://github.com/nltk/nltk/issues/2116\ndef demo():\n print(\"To run the demo code for a module, type nltk.module.demo()\")\n", "path": "nltk/__init__.py"}]}
| 2,223 | 389 |
gh_patches_debug_25760
|
rasdani/github-patches
|
git_diff
|
kedro-org__kedro-2891
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add `kedro catalog resolve` CLI command
## Description
Child of #2603
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kedro/framework/cli/catalog.py`
Content:
```
1 """A collection of CLI commands for working with Kedro catalog."""
2 from collections import defaultdict
3 from itertools import chain
4
5 import click
6 import yaml
7 from click import secho
8
9 from kedro.framework.cli.utils import KedroCliError, env_option, split_string
10 from kedro.framework.project import pipelines, settings
11 from kedro.framework.session import KedroSession
12 from kedro.framework.startup import ProjectMetadata
13
14
15 def _create_session(package_name: str, **kwargs):
16 kwargs.setdefault("save_on_close", False)
17 try:
18 return KedroSession.create(package_name, **kwargs)
19 except Exception as exc:
20 raise KedroCliError(
21 f"Unable to instantiate Kedro session.\nError: {exc}"
22 ) from exc
23
24
25 # noqa: missing-function-docstring
26 @click.group(name="Kedro")
27 def catalog_cli(): # pragma: no cover
28 pass
29
30
31 @catalog_cli.group()
32 def catalog():
33 """Commands for working with catalog."""
34
35
36 # noqa: too-many-locals,protected-access
37 @catalog.command("list")
38 @env_option
39 @click.option(
40 "--pipeline",
41 "-p",
42 type=str,
43 default="",
44 help="Name of the modular pipeline to run. If not set, "
45 "the project pipeline is run by default.",
46 callback=split_string,
47 )
48 @click.pass_obj
49 def list_datasets(metadata: ProjectMetadata, pipeline, env):
50 """Show datasets per type."""
51 title = "Datasets in '{}' pipeline"
52 not_mentioned = "Datasets not mentioned in pipeline"
53 mentioned = "Datasets mentioned in pipeline"
54 factories = "Datasets generated from factories"
55
56 session = _create_session(metadata.package_name, env=env)
57 context = session.load_context()
58
59 data_catalog = context.catalog
60 datasets_meta = data_catalog._data_sets
61 catalog_ds = set(data_catalog.list())
62
63 target_pipelines = pipeline or pipelines.keys()
64
65 result = {}
66 for pipe in target_pipelines:
67 pl_obj = pipelines.get(pipe)
68 if pl_obj:
69 pipeline_ds = pl_obj.data_sets()
70 else:
71 existing_pls = ", ".join(sorted(pipelines.keys()))
72 raise KedroCliError(
73 f"'{pipe}' pipeline not found! Existing pipelines: {existing_pls}"
74 )
75
76 unused_ds = catalog_ds - pipeline_ds
77 default_ds = pipeline_ds - catalog_ds
78 used_ds = catalog_ds - unused_ds
79
80 # resolve any factory datasets in the pipeline
81 factory_ds_by_type = defaultdict(list)
82 for ds_name in default_ds:
83 matched_pattern = data_catalog._match_pattern(
84 data_catalog._dataset_patterns, ds_name
85 )
86 if matched_pattern:
87 ds_config = data_catalog._resolve_config(ds_name, matched_pattern)
88 factory_ds_by_type[ds_config["type"]].append(ds_name)
89
90 default_ds = default_ds - set(chain.from_iterable(factory_ds_by_type.values()))
91
92 unused_by_type = _map_type_to_datasets(unused_ds, datasets_meta)
93 used_by_type = _map_type_to_datasets(used_ds, datasets_meta)
94
95 if default_ds:
96 used_by_type["DefaultDataset"].extend(default_ds)
97
98 data = (
99 (mentioned, dict(used_by_type)),
100 (factories, dict(factory_ds_by_type)),
101 (not_mentioned, dict(unused_by_type)),
102 )
103 result[title.format(pipe)] = {key: value for key, value in data if value}
104 secho(yaml.dump(result))
105
106
107 def _map_type_to_datasets(datasets, datasets_meta):
108 """Build dictionary with a dataset type as a key and list of
109 datasets of the specific type as a value.
110 """
111 mapping = defaultdict(list)
112 for dataset in datasets:
113 is_param = dataset.startswith("params:") or dataset == "parameters"
114 if not is_param:
115 ds_type = datasets_meta[dataset].__class__.__name__
116 if dataset not in mapping[ds_type]:
117 mapping[ds_type].append(dataset)
118 return mapping
119
120
121 @catalog.command("create")
122 @env_option(help="Environment to create Data Catalog YAML file in. Defaults to `base`.")
123 @click.option(
124 "--pipeline",
125 "-p",
126 "pipeline_name",
127 type=str,
128 required=True,
129 help="Name of a pipeline.",
130 )
131 @click.pass_obj
132 def create_catalog(metadata: ProjectMetadata, pipeline_name, env):
133 """Create Data Catalog YAML configuration with missing datasets.
134
135 Add ``MemoryDataset`` datasets to Data Catalog YAML configuration
136 file for each dataset in a registered pipeline if it is missing from
137 the ``DataCatalog``.
138
139 The catalog configuration will be saved to
140 `<conf_source>/<env>/catalog/<pipeline_name>.yml` file.
141 """
142 env = env or "base"
143 session = _create_session(metadata.package_name, env=env)
144 context = session.load_context()
145
146 pipeline = pipelines.get(pipeline_name)
147
148 if not pipeline:
149 existing_pipelines = ", ".join(sorted(pipelines.keys()))
150 raise KedroCliError(
151 f"'{pipeline_name}' pipeline not found! Existing pipelines: {existing_pipelines}"
152 )
153
154 pipe_datasets = {
155 ds_name
156 for ds_name in pipeline.data_sets()
157 if not ds_name.startswith("params:") and ds_name != "parameters"
158 }
159
160 catalog_datasets = {
161 ds_name
162 for ds_name in context.catalog._data_sets.keys() # noqa: protected-access
163 if not ds_name.startswith("params:") and ds_name != "parameters"
164 }
165
166 # Datasets that are missing in Data Catalog
167 missing_ds = sorted(pipe_datasets - catalog_datasets)
168 if missing_ds:
169 catalog_path = (
170 context.project_path
171 / settings.CONF_SOURCE
172 / env
173 / f"catalog_{pipeline_name}.yml"
174 )
175 _add_missing_datasets_to_catalog(missing_ds, catalog_path)
176 click.echo(f"Data Catalog YAML configuration was created: {catalog_path}")
177 else:
178 click.echo("All datasets are already configured.")
179
180
181 def _add_missing_datasets_to_catalog(missing_ds, catalog_path):
182 if catalog_path.is_file():
183 catalog_config = yaml.safe_load(catalog_path.read_text()) or {}
184 else:
185 catalog_config = {}
186
187 for ds_name in missing_ds:
188 catalog_config[ds_name] = {"type": "MemoryDataset"}
189
190 # Create only `catalog` folder under existing environment
191 # (all parent folders must exist).
192 catalog_path.parent.mkdir(exist_ok=True)
193 with catalog_path.open(mode="w") as catalog_file:
194 yaml.safe_dump(catalog_config, catalog_file, default_flow_style=False)
195
196
197 @catalog.command("rank")
198 @env_option
199 @click.pass_obj
200 def rank_catalog_factories(metadata: ProjectMetadata, env):
201 """List all dataset factories in the catalog, ranked by priority by which they are matched."""
202 session = _create_session(metadata.package_name, env=env)
203 context = session.load_context()
204
205 catalog_factories = context.catalog._dataset_patterns
206 if catalog_factories:
207 click.echo(yaml.dump(list(catalog_factories.keys())))
208 else:
209 click.echo("There are no dataset factories in the catalog.")
210
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kedro/framework/cli/catalog.py b/kedro/framework/cli/catalog.py
--- a/kedro/framework/cli/catalog.py
+++ b/kedro/framework/cli/catalog.py
@@ -207,3 +207,51 @@
click.echo(yaml.dump(list(catalog_factories.keys())))
else:
click.echo("There are no dataset factories in the catalog.")
+
+
[email protected]("resolve")
+@env_option
[email protected]_obj
+def resolve_patterns(metadata: ProjectMetadata, env):
+ """Resolve catalog factories against pipeline datasets"""
+
+ session = _create_session(metadata.package_name, env=env)
+ context = session.load_context()
+
+ data_catalog = context.catalog
+ catalog_config = context.config_loader["catalog"]
+
+ explicit_datasets = {
+ ds_name: ds_config
+ for ds_name, ds_config in catalog_config.items()
+ if not data_catalog._is_pattern(ds_name)
+ }
+
+ target_pipelines = pipelines.keys()
+ datasets = set()
+
+ for pipe in target_pipelines:
+ pl_obj = pipelines.get(pipe)
+ if pl_obj:
+ datasets.update(pl_obj.data_sets())
+
+ for ds_name in datasets:
+ is_param = ds_name.startswith("params:") or ds_name == "parameters"
+ if ds_name in explicit_datasets or is_param:
+ continue
+
+ matched_pattern = data_catalog._match_pattern(
+ data_catalog._dataset_patterns, ds_name
+ )
+ if matched_pattern:
+ ds_config = data_catalog._resolve_config(ds_name, matched_pattern)
+ ds_config["filepath"] = _trim_filepath(
+ str(context.project_path) + "/", ds_config["filepath"]
+ )
+ explicit_datasets[ds_name] = ds_config
+
+ secho(yaml.dump(explicit_datasets))
+
+
+def _trim_filepath(project_path: str, file_path: str):
+ return file_path.replace(project_path, "", 1)
|
{"golden_diff": "diff --git a/kedro/framework/cli/catalog.py b/kedro/framework/cli/catalog.py\n--- a/kedro/framework/cli/catalog.py\n+++ b/kedro/framework/cli/catalog.py\n@@ -207,3 +207,51 @@\n click.echo(yaml.dump(list(catalog_factories.keys())))\n else:\n click.echo(\"There are no dataset factories in the catalog.\")\n+\n+\[email protected](\"resolve\")\n+@env_option\[email protected]_obj\n+def resolve_patterns(metadata: ProjectMetadata, env):\n+ \"\"\"Resolve catalog factories against pipeline datasets\"\"\"\n+\n+ session = _create_session(metadata.package_name, env=env)\n+ context = session.load_context()\n+\n+ data_catalog = context.catalog\n+ catalog_config = context.config_loader[\"catalog\"]\n+\n+ explicit_datasets = {\n+ ds_name: ds_config\n+ for ds_name, ds_config in catalog_config.items()\n+ if not data_catalog._is_pattern(ds_name)\n+ }\n+\n+ target_pipelines = pipelines.keys()\n+ datasets = set()\n+\n+ for pipe in target_pipelines:\n+ pl_obj = pipelines.get(pipe)\n+ if pl_obj:\n+ datasets.update(pl_obj.data_sets())\n+\n+ for ds_name in datasets:\n+ is_param = ds_name.startswith(\"params:\") or ds_name == \"parameters\"\n+ if ds_name in explicit_datasets or is_param:\n+ continue\n+\n+ matched_pattern = data_catalog._match_pattern(\n+ data_catalog._dataset_patterns, ds_name\n+ )\n+ if matched_pattern:\n+ ds_config = data_catalog._resolve_config(ds_name, matched_pattern)\n+ ds_config[\"filepath\"] = _trim_filepath(\n+ str(context.project_path) + \"/\", ds_config[\"filepath\"]\n+ )\n+ explicit_datasets[ds_name] = ds_config\n+\n+ secho(yaml.dump(explicit_datasets))\n+\n+\n+def _trim_filepath(project_path: str, file_path: str):\n+ return file_path.replace(project_path, \"\", 1)\n", "issue": "Add `kedro catalog resolve` CLI command\n## Description\r\nChild of #2603 \n", "before_files": [{"content": "\"\"\"A collection of CLI commands for working with Kedro catalog.\"\"\"\nfrom collections import defaultdict\nfrom itertools import chain\n\nimport click\nimport yaml\nfrom click import secho\n\nfrom kedro.framework.cli.utils import KedroCliError, env_option, split_string\nfrom kedro.framework.project import pipelines, settings\nfrom kedro.framework.session import KedroSession\nfrom kedro.framework.startup import ProjectMetadata\n\n\ndef _create_session(package_name: str, **kwargs):\n kwargs.setdefault(\"save_on_close\", False)\n try:\n return KedroSession.create(package_name, **kwargs)\n except Exception as exc:\n raise KedroCliError(\n f\"Unable to instantiate Kedro session.\\nError: {exc}\"\n ) from exc\n\n\n# noqa: missing-function-docstring\[email protected](name=\"Kedro\")\ndef catalog_cli(): # pragma: no cover\n pass\n\n\n@catalog_cli.group()\ndef catalog():\n \"\"\"Commands for working with catalog.\"\"\"\n\n\n# noqa: too-many-locals,protected-access\[email protected](\"list\")\n@env_option\[email protected](\n \"--pipeline\",\n \"-p\",\n type=str,\n default=\"\",\n help=\"Name of the modular pipeline to run. If not set, \"\n \"the project pipeline is run by default.\",\n callback=split_string,\n)\[email protected]_obj\ndef list_datasets(metadata: ProjectMetadata, pipeline, env):\n \"\"\"Show datasets per type.\"\"\"\n title = \"Datasets in '{}' pipeline\"\n not_mentioned = \"Datasets not mentioned in pipeline\"\n mentioned = \"Datasets mentioned in pipeline\"\n factories = \"Datasets generated from factories\"\n\n session = _create_session(metadata.package_name, env=env)\n context = session.load_context()\n\n data_catalog = context.catalog\n datasets_meta = data_catalog._data_sets\n catalog_ds = set(data_catalog.list())\n\n target_pipelines = pipeline or pipelines.keys()\n\n result = {}\n for pipe in target_pipelines:\n pl_obj = pipelines.get(pipe)\n if pl_obj:\n pipeline_ds = pl_obj.data_sets()\n else:\n existing_pls = \", \".join(sorted(pipelines.keys()))\n raise KedroCliError(\n f\"'{pipe}' pipeline not found! Existing pipelines: {existing_pls}\"\n )\n\n unused_ds = catalog_ds - pipeline_ds\n default_ds = pipeline_ds - catalog_ds\n used_ds = catalog_ds - unused_ds\n\n # resolve any factory datasets in the pipeline\n factory_ds_by_type = defaultdict(list)\n for ds_name in default_ds:\n matched_pattern = data_catalog._match_pattern(\n data_catalog._dataset_patterns, ds_name\n )\n if matched_pattern:\n ds_config = data_catalog._resolve_config(ds_name, matched_pattern)\n factory_ds_by_type[ds_config[\"type\"]].append(ds_name)\n\n default_ds = default_ds - set(chain.from_iterable(factory_ds_by_type.values()))\n\n unused_by_type = _map_type_to_datasets(unused_ds, datasets_meta)\n used_by_type = _map_type_to_datasets(used_ds, datasets_meta)\n\n if default_ds:\n used_by_type[\"DefaultDataset\"].extend(default_ds)\n\n data = (\n (mentioned, dict(used_by_type)),\n (factories, dict(factory_ds_by_type)),\n (not_mentioned, dict(unused_by_type)),\n )\n result[title.format(pipe)] = {key: value for key, value in data if value}\n secho(yaml.dump(result))\n\n\ndef _map_type_to_datasets(datasets, datasets_meta):\n \"\"\"Build dictionary with a dataset type as a key and list of\n datasets of the specific type as a value.\n \"\"\"\n mapping = defaultdict(list)\n for dataset in datasets:\n is_param = dataset.startswith(\"params:\") or dataset == \"parameters\"\n if not is_param:\n ds_type = datasets_meta[dataset].__class__.__name__\n if dataset not in mapping[ds_type]:\n mapping[ds_type].append(dataset)\n return mapping\n\n\[email protected](\"create\")\n@env_option(help=\"Environment to create Data Catalog YAML file in. Defaults to `base`.\")\[email protected](\n \"--pipeline\",\n \"-p\",\n \"pipeline_name\",\n type=str,\n required=True,\n help=\"Name of a pipeline.\",\n)\[email protected]_obj\ndef create_catalog(metadata: ProjectMetadata, pipeline_name, env):\n \"\"\"Create Data Catalog YAML configuration with missing datasets.\n\n Add ``MemoryDataset`` datasets to Data Catalog YAML configuration\n file for each dataset in a registered pipeline if it is missing from\n the ``DataCatalog``.\n\n The catalog configuration will be saved to\n `<conf_source>/<env>/catalog/<pipeline_name>.yml` file.\n \"\"\"\n env = env or \"base\"\n session = _create_session(metadata.package_name, env=env)\n context = session.load_context()\n\n pipeline = pipelines.get(pipeline_name)\n\n if not pipeline:\n existing_pipelines = \", \".join(sorted(pipelines.keys()))\n raise KedroCliError(\n f\"'{pipeline_name}' pipeline not found! Existing pipelines: {existing_pipelines}\"\n )\n\n pipe_datasets = {\n ds_name\n for ds_name in pipeline.data_sets()\n if not ds_name.startswith(\"params:\") and ds_name != \"parameters\"\n }\n\n catalog_datasets = {\n ds_name\n for ds_name in context.catalog._data_sets.keys() # noqa: protected-access\n if not ds_name.startswith(\"params:\") and ds_name != \"parameters\"\n }\n\n # Datasets that are missing in Data Catalog\n missing_ds = sorted(pipe_datasets - catalog_datasets)\n if missing_ds:\n catalog_path = (\n context.project_path\n / settings.CONF_SOURCE\n / env\n / f\"catalog_{pipeline_name}.yml\"\n )\n _add_missing_datasets_to_catalog(missing_ds, catalog_path)\n click.echo(f\"Data Catalog YAML configuration was created: {catalog_path}\")\n else:\n click.echo(\"All datasets are already configured.\")\n\n\ndef _add_missing_datasets_to_catalog(missing_ds, catalog_path):\n if catalog_path.is_file():\n catalog_config = yaml.safe_load(catalog_path.read_text()) or {}\n else:\n catalog_config = {}\n\n for ds_name in missing_ds:\n catalog_config[ds_name] = {\"type\": \"MemoryDataset\"}\n\n # Create only `catalog` folder under existing environment\n # (all parent folders must exist).\n catalog_path.parent.mkdir(exist_ok=True)\n with catalog_path.open(mode=\"w\") as catalog_file:\n yaml.safe_dump(catalog_config, catalog_file, default_flow_style=False)\n\n\[email protected](\"rank\")\n@env_option\[email protected]_obj\ndef rank_catalog_factories(metadata: ProjectMetadata, env):\n \"\"\"List all dataset factories in the catalog, ranked by priority by which they are matched.\"\"\"\n session = _create_session(metadata.package_name, env=env)\n context = session.load_context()\n\n catalog_factories = context.catalog._dataset_patterns\n if catalog_factories:\n click.echo(yaml.dump(list(catalog_factories.keys())))\n else:\n click.echo(\"There are no dataset factories in the catalog.\")\n", "path": "kedro/framework/cli/catalog.py"}], "after_files": [{"content": "\"\"\"A collection of CLI commands for working with Kedro catalog.\"\"\"\nfrom collections import defaultdict\nfrom itertools import chain\n\nimport click\nimport yaml\nfrom click import secho\n\nfrom kedro.framework.cli.utils import KedroCliError, env_option, split_string\nfrom kedro.framework.project import pipelines, settings\nfrom kedro.framework.session import KedroSession\nfrom kedro.framework.startup import ProjectMetadata\n\n\ndef _create_session(package_name: str, **kwargs):\n kwargs.setdefault(\"save_on_close\", False)\n try:\n return KedroSession.create(package_name, **kwargs)\n except Exception as exc:\n raise KedroCliError(\n f\"Unable to instantiate Kedro session.\\nError: {exc}\"\n ) from exc\n\n\n# noqa: missing-function-docstring\[email protected](name=\"Kedro\")\ndef catalog_cli(): # pragma: no cover\n pass\n\n\n@catalog_cli.group()\ndef catalog():\n \"\"\"Commands for working with catalog.\"\"\"\n\n\n# noqa: too-many-locals,protected-access\[email protected](\"list\")\n@env_option\[email protected](\n \"--pipeline\",\n \"-p\",\n type=str,\n default=\"\",\n help=\"Name of the modular pipeline to run. If not set, \"\n \"the project pipeline is run by default.\",\n callback=split_string,\n)\[email protected]_obj\ndef list_datasets(metadata: ProjectMetadata, pipeline, env):\n \"\"\"Show datasets per type.\"\"\"\n title = \"Datasets in '{}' pipeline\"\n not_mentioned = \"Datasets not mentioned in pipeline\"\n mentioned = \"Datasets mentioned in pipeline\"\n factories = \"Datasets generated from factories\"\n\n session = _create_session(metadata.package_name, env=env)\n context = session.load_context()\n\n data_catalog = context.catalog\n datasets_meta = data_catalog._data_sets\n catalog_ds = set(data_catalog.list())\n\n target_pipelines = pipeline or pipelines.keys()\n\n result = {}\n for pipe in target_pipelines:\n pl_obj = pipelines.get(pipe)\n if pl_obj:\n pipeline_ds = pl_obj.data_sets()\n else:\n existing_pls = \", \".join(sorted(pipelines.keys()))\n raise KedroCliError(\n f\"'{pipe}' pipeline not found! Existing pipelines: {existing_pls}\"\n )\n\n unused_ds = catalog_ds - pipeline_ds\n default_ds = pipeline_ds - catalog_ds\n used_ds = catalog_ds - unused_ds\n\n # resolve any factory datasets in the pipeline\n factory_ds_by_type = defaultdict(list)\n for ds_name in default_ds:\n matched_pattern = data_catalog._match_pattern(\n data_catalog._dataset_patterns, ds_name\n )\n if matched_pattern:\n ds_config = data_catalog._resolve_config(ds_name, matched_pattern)\n factory_ds_by_type[ds_config[\"type\"]].append(ds_name)\n\n default_ds = default_ds - set(chain.from_iterable(factory_ds_by_type.values()))\n\n unused_by_type = _map_type_to_datasets(unused_ds, datasets_meta)\n used_by_type = _map_type_to_datasets(used_ds, datasets_meta)\n\n if default_ds:\n used_by_type[\"DefaultDataset\"].extend(default_ds)\n\n data = (\n (mentioned, dict(used_by_type)),\n (factories, dict(factory_ds_by_type)),\n (not_mentioned, dict(unused_by_type)),\n )\n result[title.format(pipe)] = {key: value for key, value in data if value}\n secho(yaml.dump(result))\n\n\ndef _map_type_to_datasets(datasets, datasets_meta):\n \"\"\"Build dictionary with a dataset type as a key and list of\n datasets of the specific type as a value.\n \"\"\"\n mapping = defaultdict(list)\n for dataset in datasets:\n is_param = dataset.startswith(\"params:\") or dataset == \"parameters\"\n if not is_param:\n ds_type = datasets_meta[dataset].__class__.__name__\n if dataset not in mapping[ds_type]:\n mapping[ds_type].append(dataset)\n return mapping\n\n\[email protected](\"create\")\n@env_option(help=\"Environment to create Data Catalog YAML file in. Defaults to `base`.\")\[email protected](\n \"--pipeline\",\n \"-p\",\n \"pipeline_name\",\n type=str,\n required=True,\n help=\"Name of a pipeline.\",\n)\[email protected]_obj\ndef create_catalog(metadata: ProjectMetadata, pipeline_name, env):\n \"\"\"Create Data Catalog YAML configuration with missing datasets.\n\n Add ``MemoryDataset`` datasets to Data Catalog YAML configuration\n file for each dataset in a registered pipeline if it is missing from\n the ``DataCatalog``.\n\n The catalog configuration will be saved to\n `<conf_source>/<env>/catalog/<pipeline_name>.yml` file.\n \"\"\"\n env = env or \"base\"\n session = _create_session(metadata.package_name, env=env)\n context = session.load_context()\n\n pipeline = pipelines.get(pipeline_name)\n\n if not pipeline:\n existing_pipelines = \", \".join(sorted(pipelines.keys()))\n raise KedroCliError(\n f\"'{pipeline_name}' pipeline not found! Existing pipelines: {existing_pipelines}\"\n )\n\n pipe_datasets = {\n ds_name\n for ds_name in pipeline.data_sets()\n if not ds_name.startswith(\"params:\") and ds_name != \"parameters\"\n }\n\n catalog_datasets = {\n ds_name\n for ds_name in context.catalog._data_sets.keys() # noqa: protected-access\n if not ds_name.startswith(\"params:\") and ds_name != \"parameters\"\n }\n\n # Datasets that are missing in Data Catalog\n missing_ds = sorted(pipe_datasets - catalog_datasets)\n if missing_ds:\n catalog_path = (\n context.project_path\n / settings.CONF_SOURCE\n / env\n / f\"catalog_{pipeline_name}.yml\"\n )\n _add_missing_datasets_to_catalog(missing_ds, catalog_path)\n click.echo(f\"Data Catalog YAML configuration was created: {catalog_path}\")\n else:\n click.echo(\"All datasets are already configured.\")\n\n\ndef _add_missing_datasets_to_catalog(missing_ds, catalog_path):\n if catalog_path.is_file():\n catalog_config = yaml.safe_load(catalog_path.read_text()) or {}\n else:\n catalog_config = {}\n\n for ds_name in missing_ds:\n catalog_config[ds_name] = {\"type\": \"MemoryDataset\"}\n\n # Create only `catalog` folder under existing environment\n # (all parent folders must exist).\n catalog_path.parent.mkdir(exist_ok=True)\n with catalog_path.open(mode=\"w\") as catalog_file:\n yaml.safe_dump(catalog_config, catalog_file, default_flow_style=False)\n\n\[email protected](\"rank\")\n@env_option\[email protected]_obj\ndef rank_catalog_factories(metadata: ProjectMetadata, env):\n \"\"\"List all dataset factories in the catalog, ranked by priority by which they are matched.\"\"\"\n session = _create_session(metadata.package_name, env=env)\n context = session.load_context()\n\n catalog_factories = context.catalog._dataset_patterns\n if catalog_factories:\n click.echo(yaml.dump(list(catalog_factories.keys())))\n else:\n click.echo(\"There are no dataset factories in the catalog.\")\n\n\[email protected](\"resolve\")\n@env_option\[email protected]_obj\ndef resolve_patterns(metadata: ProjectMetadata, env):\n \"\"\"Resolve catalog factories against pipeline datasets\"\"\"\n\n session = _create_session(metadata.package_name, env=env)\n context = session.load_context()\n\n data_catalog = context.catalog\n catalog_config = context.config_loader[\"catalog\"]\n\n explicit_datasets = {\n ds_name: ds_config\n for ds_name, ds_config in catalog_config.items()\n if not data_catalog._is_pattern(ds_name)\n }\n\n target_pipelines = pipelines.keys()\n datasets = set()\n\n for pipe in target_pipelines:\n pl_obj = pipelines.get(pipe)\n if pl_obj:\n datasets.update(pl_obj.data_sets())\n\n for ds_name in datasets:\n is_param = ds_name.startswith(\"params:\") or ds_name == \"parameters\"\n if ds_name in explicit_datasets or is_param:\n continue\n\n matched_pattern = data_catalog._match_pattern(\n data_catalog._dataset_patterns, ds_name\n )\n if matched_pattern:\n ds_config = data_catalog._resolve_config(ds_name, matched_pattern)\n ds_config[\"filepath\"] = _trim_filepath(\n str(context.project_path) + \"/\", ds_config[\"filepath\"]\n )\n explicit_datasets[ds_name] = ds_config\n\n secho(yaml.dump(explicit_datasets))\n\n\ndef _trim_filepath(project_path: str, file_path: str):\n return file_path.replace(project_path, \"\", 1)\n", "path": "kedro/framework/cli/catalog.py"}]}
| 2,349 | 436 |
gh_patches_debug_8499
|
rasdani/github-patches
|
git_diff
|
openai__gym-994
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
MuJoCo env Box initialization causes warnings
In gym/gym/envs/mujoco/mujoco_env.py on line 46, Box object initialization is missing dtype=np.float32 parameter which causes autodetect warning spam.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `gym/envs/mujoco/mujoco_env.py`
Content:
```
1 import os
2
3 from gym import error, spaces
4 from gym.utils import seeding
5 import numpy as np
6 from os import path
7 import gym
8 import six
9
10 try:
11 import mujoco_py
12 except ImportError as e:
13 raise error.DependencyNotInstalled("{}. (HINT: you need to install mujoco_py, and also perform the setup instructions here: https://github.com/openai/mujoco-py/.)".format(e))
14
15 class MujocoEnv(gym.Env):
16 """Superclass for all MuJoCo environments.
17 """
18
19 def __init__(self, model_path, frame_skip):
20 if model_path.startswith("/"):
21 fullpath = model_path
22 else:
23 fullpath = os.path.join(os.path.dirname(__file__), "assets", model_path)
24 if not path.exists(fullpath):
25 raise IOError("File %s does not exist" % fullpath)
26 self.frame_skip = frame_skip
27 self.model = mujoco_py.load_model_from_path(fullpath)
28 self.sim = mujoco_py.MjSim(self.model)
29 self.data = self.sim.data
30 self.viewer = None
31
32 self.metadata = {
33 'render.modes': ['human', 'rgb_array'],
34 'video.frames_per_second': int(np.round(1.0 / self.dt))
35 }
36
37 self.init_qpos = self.sim.data.qpos.ravel().copy()
38 self.init_qvel = self.sim.data.qvel.ravel().copy()
39 observation, _reward, done, _info = self.step(np.zeros(self.model.nu))
40 assert not done
41 self.obs_dim = observation.size
42
43 bounds = self.model.actuator_ctrlrange.copy()
44 low = bounds[:, 0]
45 high = bounds[:, 1]
46 self.action_space = spaces.Box(low=low, high=high)
47
48 high = np.inf*np.ones(self.obs_dim)
49 low = -high
50 self.observation_space = spaces.Box(low, high)
51
52 self.seed()
53
54 def seed(self, seed=None):
55 self.np_random, seed = seeding.np_random(seed)
56 return [seed]
57
58 # methods to override:
59 # ----------------------------
60
61 def reset_model(self):
62 """
63 Reset the robot degrees of freedom (qpos and qvel).
64 Implement this in each subclass.
65 """
66 raise NotImplementedError
67
68 def viewer_setup(self):
69 """
70 This method is called when the viewer is initialized and after every reset
71 Optionally implement this method, if you need to tinker with camera position
72 and so forth.
73 """
74 pass
75
76 # -----------------------------
77
78 def reset(self):
79 self.sim.reset()
80 ob = self.reset_model()
81 if self.viewer is not None:
82 self.viewer_setup()
83 return ob
84
85 def set_state(self, qpos, qvel):
86 assert qpos.shape == (self.model.nq,) and qvel.shape == (self.model.nv,)
87 old_state = self.sim.get_state()
88 new_state = mujoco_py.MjSimState(old_state.time, qpos, qvel,
89 old_state.act, old_state.udd_state)
90 self.sim.set_state(new_state)
91 self.sim.forward()
92
93 @property
94 def dt(self):
95 return self.model.opt.timestep * self.frame_skip
96
97 def do_simulation(self, ctrl, n_frames):
98 self.sim.data.ctrl[:] = ctrl
99 for _ in range(n_frames):
100 self.sim.step()
101
102 def render(self, mode='human'):
103 if mode == 'rgb_array':
104 self._get_viewer().render()
105 # window size used for old mujoco-py:
106 width, height = 500, 500
107 data = self._get_viewer().read_pixels(width, height, depth=False)
108 # original image is upside-down, so flip it
109 return data[::-1, :, :]
110 elif mode == 'human':
111 self._get_viewer().render()
112
113 def close(self):
114 if self.viewer is not None:
115 self.viewer.finish()
116 self.viewer = None
117
118 def _get_viewer(self):
119 if self.viewer is None:
120 self.viewer = mujoco_py.MjViewer(self.sim)
121 self.viewer_setup()
122 return self.viewer
123
124 def get_body_com(self, body_name):
125 return self.data.get_body_xpos(body_name)
126
127 def state_vector(self):
128 return np.concatenate([
129 self.sim.data.qpos.flat,
130 self.sim.data.qvel.flat
131 ])
132
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/gym/envs/mujoco/mujoco_env.py b/gym/envs/mujoco/mujoco_env.py
--- a/gym/envs/mujoco/mujoco_env.py
+++ b/gym/envs/mujoco/mujoco_env.py
@@ -43,11 +43,11 @@
bounds = self.model.actuator_ctrlrange.copy()
low = bounds[:, 0]
high = bounds[:, 1]
- self.action_space = spaces.Box(low=low, high=high)
+ self.action_space = spaces.Box(low=low, high=high, dtype=np.float32)
high = np.inf*np.ones(self.obs_dim)
low = -high
- self.observation_space = spaces.Box(low, high)
+ self.observation_space = spaces.Box(low, high, dtype=np.float32)
self.seed()
|
{"golden_diff": "diff --git a/gym/envs/mujoco/mujoco_env.py b/gym/envs/mujoco/mujoco_env.py\n--- a/gym/envs/mujoco/mujoco_env.py\n+++ b/gym/envs/mujoco/mujoco_env.py\n@@ -43,11 +43,11 @@\n bounds = self.model.actuator_ctrlrange.copy()\n low = bounds[:, 0]\n high = bounds[:, 1]\n- self.action_space = spaces.Box(low=low, high=high)\n+ self.action_space = spaces.Box(low=low, high=high, dtype=np.float32)\n \n high = np.inf*np.ones(self.obs_dim)\n low = -high\n- self.observation_space = spaces.Box(low, high)\n+ self.observation_space = spaces.Box(low, high, dtype=np.float32)\n \n self.seed()\n", "issue": "MuJoCo env Box initialization causes warnings\nIn gym/gym/envs/mujoco/mujoco_env.py on line 46, Box object initialization is missing dtype=np.float32 parameter which causes autodetect warning spam.\n", "before_files": [{"content": "import os\n\nfrom gym import error, spaces\nfrom gym.utils import seeding\nimport numpy as np\nfrom os import path\nimport gym\nimport six\n\ntry:\n import mujoco_py\nexcept ImportError as e:\n raise error.DependencyNotInstalled(\"{}. (HINT: you need to install mujoco_py, and also perform the setup instructions here: https://github.com/openai/mujoco-py/.)\".format(e))\n\nclass MujocoEnv(gym.Env):\n \"\"\"Superclass for all MuJoCo environments.\n \"\"\"\n\n def __init__(self, model_path, frame_skip):\n if model_path.startswith(\"/\"):\n fullpath = model_path\n else:\n fullpath = os.path.join(os.path.dirname(__file__), \"assets\", model_path)\n if not path.exists(fullpath):\n raise IOError(\"File %s does not exist\" % fullpath)\n self.frame_skip = frame_skip\n self.model = mujoco_py.load_model_from_path(fullpath)\n self.sim = mujoco_py.MjSim(self.model)\n self.data = self.sim.data\n self.viewer = None\n\n self.metadata = {\n 'render.modes': ['human', 'rgb_array'],\n 'video.frames_per_second': int(np.round(1.0 / self.dt))\n }\n\n self.init_qpos = self.sim.data.qpos.ravel().copy()\n self.init_qvel = self.sim.data.qvel.ravel().copy()\n observation, _reward, done, _info = self.step(np.zeros(self.model.nu))\n assert not done\n self.obs_dim = observation.size\n\n bounds = self.model.actuator_ctrlrange.copy()\n low = bounds[:, 0]\n high = bounds[:, 1]\n self.action_space = spaces.Box(low=low, high=high)\n\n high = np.inf*np.ones(self.obs_dim)\n low = -high\n self.observation_space = spaces.Box(low, high)\n\n self.seed()\n\n def seed(self, seed=None):\n self.np_random, seed = seeding.np_random(seed)\n return [seed]\n\n # methods to override:\n # ----------------------------\n\n def reset_model(self):\n \"\"\"\n Reset the robot degrees of freedom (qpos and qvel).\n Implement this in each subclass.\n \"\"\"\n raise NotImplementedError\n\n def viewer_setup(self):\n \"\"\"\n This method is called when the viewer is initialized and after every reset\n Optionally implement this method, if you need to tinker with camera position\n and so forth.\n \"\"\"\n pass\n\n # -----------------------------\n\n def reset(self):\n self.sim.reset()\n ob = self.reset_model()\n if self.viewer is not None:\n self.viewer_setup()\n return ob\n\n def set_state(self, qpos, qvel):\n assert qpos.shape == (self.model.nq,) and qvel.shape == (self.model.nv,)\n old_state = self.sim.get_state()\n new_state = mujoco_py.MjSimState(old_state.time, qpos, qvel,\n old_state.act, old_state.udd_state)\n self.sim.set_state(new_state)\n self.sim.forward()\n\n @property\n def dt(self):\n return self.model.opt.timestep * self.frame_skip\n\n def do_simulation(self, ctrl, n_frames):\n self.sim.data.ctrl[:] = ctrl\n for _ in range(n_frames):\n self.sim.step()\n\n def render(self, mode='human'):\n if mode == 'rgb_array':\n self._get_viewer().render()\n # window size used for old mujoco-py:\n width, height = 500, 500\n data = self._get_viewer().read_pixels(width, height, depth=False)\n # original image is upside-down, so flip it\n return data[::-1, :, :]\n elif mode == 'human':\n self._get_viewer().render()\n\n def close(self):\n if self.viewer is not None:\n self.viewer.finish()\n self.viewer = None\n\n def _get_viewer(self):\n if self.viewer is None:\n self.viewer = mujoco_py.MjViewer(self.sim)\n self.viewer_setup()\n return self.viewer\n\n def get_body_com(self, body_name):\n return self.data.get_body_xpos(body_name)\n\n def state_vector(self):\n return np.concatenate([\n self.sim.data.qpos.flat,\n self.sim.data.qvel.flat\n ])\n", "path": "gym/envs/mujoco/mujoco_env.py"}], "after_files": [{"content": "import os\n\nfrom gym import error, spaces\nfrom gym.utils import seeding\nimport numpy as np\nfrom os import path\nimport gym\nimport six\n\ntry:\n import mujoco_py\nexcept ImportError as e:\n raise error.DependencyNotInstalled(\"{}. (HINT: you need to install mujoco_py, and also perform the setup instructions here: https://github.com/openai/mujoco-py/.)\".format(e))\n\nclass MujocoEnv(gym.Env):\n \"\"\"Superclass for all MuJoCo environments.\n \"\"\"\n\n def __init__(self, model_path, frame_skip):\n if model_path.startswith(\"/\"):\n fullpath = model_path\n else:\n fullpath = os.path.join(os.path.dirname(__file__), \"assets\", model_path)\n if not path.exists(fullpath):\n raise IOError(\"File %s does not exist\" % fullpath)\n self.frame_skip = frame_skip\n self.model = mujoco_py.load_model_from_path(fullpath)\n self.sim = mujoco_py.MjSim(self.model)\n self.data = self.sim.data\n self.viewer = None\n\n self.metadata = {\n 'render.modes': ['human', 'rgb_array'],\n 'video.frames_per_second': int(np.round(1.0 / self.dt))\n }\n\n self.init_qpos = self.sim.data.qpos.ravel().copy()\n self.init_qvel = self.sim.data.qvel.ravel().copy()\n observation, _reward, done, _info = self.step(np.zeros(self.model.nu))\n assert not done\n self.obs_dim = observation.size\n\n bounds = self.model.actuator_ctrlrange.copy()\n low = bounds[:, 0]\n high = bounds[:, 1]\n self.action_space = spaces.Box(low=low, high=high, dtype=np.float32)\n\n high = np.inf*np.ones(self.obs_dim)\n low = -high\n self.observation_space = spaces.Box(low, high, dtype=np.float32)\n\n self.seed()\n\n def seed(self, seed=None):\n self.np_random, seed = seeding.np_random(seed)\n return [seed]\n\n # methods to override:\n # ----------------------------\n\n def reset_model(self):\n \"\"\"\n Reset the robot degrees of freedom (qpos and qvel).\n Implement this in each subclass.\n \"\"\"\n raise NotImplementedError\n\n def viewer_setup(self):\n \"\"\"\n This method is called when the viewer is initialized and after every reset\n Optionally implement this method, if you need to tinker with camera position\n and so forth.\n \"\"\"\n pass\n\n # -----------------------------\n\n def reset(self):\n self.sim.reset()\n ob = self.reset_model()\n if self.viewer is not None:\n self.viewer_setup()\n return ob\n\n def set_state(self, qpos, qvel):\n assert qpos.shape == (self.model.nq,) and qvel.shape == (self.model.nv,)\n old_state = self.sim.get_state()\n new_state = mujoco_py.MjSimState(old_state.time, qpos, qvel,\n old_state.act, old_state.udd_state)\n self.sim.set_state(new_state)\n self.sim.forward()\n\n @property\n def dt(self):\n return self.model.opt.timestep * self.frame_skip\n\n def do_simulation(self, ctrl, n_frames):\n self.sim.data.ctrl[:] = ctrl\n for _ in range(n_frames):\n self.sim.step()\n\n def render(self, mode='human'):\n if mode == 'rgb_array':\n self._get_viewer().render()\n # window size used for old mujoco-py:\n width, height = 500, 500\n data = self._get_viewer().read_pixels(width, height, depth=False)\n # original image is upside-down, so flip it\n return data[::-1, :, :]\n elif mode == 'human':\n self._get_viewer().render()\n\n def close(self):\n if self.viewer is not None:\n self.viewer.finish()\n self.viewer = None\n\n def _get_viewer(self):\n if self.viewer is None:\n self.viewer = mujoco_py.MjViewer(self.sim)\n self.viewer_setup()\n return self.viewer\n\n def get_body_com(self, body_name):\n return self.data.get_body_xpos(body_name)\n\n def state_vector(self):\n return np.concatenate([\n self.sim.data.qpos.flat,\n self.sim.data.qvel.flat\n ])\n", "path": "gym/envs/mujoco/mujoco_env.py"}]}
| 1,550 | 194 |
gh_patches_debug_32864
|
rasdani/github-patches
|
git_diff
|
mathesar-foundation__mathesar-3612
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Implement `tables.get` RPC method
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mathesar/rpc/tables.py`
Content:
```
1 from typing import Optional, TypedDict
2
3 from modernrpc.core import rpc_method, REQUEST_KEY
4 from modernrpc.auth.basic import http_basic_auth_login_required
5
6 from db.tables.operations.select import get_table_info
7 from db.tables.operations.drop import drop_table_from_database
8 from mathesar.rpc.exceptions.handlers import handle_rpc_exceptions
9 from mathesar.rpc.utils import connect
10
11
12 class TableInfo(TypedDict):
13 """
14 Information about a table.
15
16 Attributes:
17 oid: The `oid` of the table in the schema.
18 name: The name of the table.
19 schema: The `oid` of the schema where the table lives.
20 description: The description of the table.
21 """
22 oid: int
23 name: str
24 schema: int
25 description: Optional[str]
26
27
28 @rpc_method(name="tables.list")
29 @http_basic_auth_login_required
30 @handle_rpc_exceptions
31 def list_(*, schema_oid: int, database_id: int, **kwargs) -> list[TableInfo]:
32 """
33 List information about tables for a schema. Exposed as `list`.
34
35 Args:
36 schema_oid: Identity of the schema in the user's database.
37 database_id: The Django id of the database containing the table.
38
39 Returns:
40 A list of table details.
41 """
42 user = kwargs.get(REQUEST_KEY).user
43 with connect(database_id, user) as conn:
44 raw_table_info = get_table_info(schema_oid, conn)
45 return [
46 TableInfo(tab) for tab in raw_table_info
47 ]
48
49
50 @rpc_method(name="tables.delete")
51 @http_basic_auth_login_required
52 @handle_rpc_exceptions
53 def delete(
54 *, table_oid: int, database_id: int, cascade: bool = False, **kwargs
55 ) -> str:
56 """
57 Delete a table from a schema.
58
59 Args:
60 table_oid: Identity of the table in the user's database.
61 database_id: The Django id of the database containing the table.
62 cascade: Whether to drop the dependent objects.
63
64 Returns:
65 The name of the dropped table.
66 """
67 user = kwargs.get(REQUEST_KEY).user
68 with connect(database_id, user) as conn:
69 return drop_table_from_database(table_oid, conn, cascade)
70
```
Path: `db/tables/operations/select.py`
Content:
```
1 from sqlalchemy import (
2 Table, select, join, inspect, and_, cast, func, Integer, literal, or_,
3 )
4 from sqlalchemy.dialects.postgresql import JSONB
5
6 from db.connection import exec_msar_func
7 from db.utils import execute_statement, get_pg_catalog_table
8
9 BASE = 'base'
10 DEPTH = 'depth'
11 JP_PATH = 'jp_path'
12 FK_PATH = 'fk_path'
13 REVERSE = 'reverse'
14 TARGET = 'target'
15 MULTIPLE_RESULTS = 'multiple_results'
16
17
18 def get_table_info(schema, conn):
19 """
20 Return a list of dictionaries describing the tables of a schema.
21
22 The `schema` can be given as either a "qualified name", or an OID.
23 The OID is the preferred identifier, since it's much more robust.
24
25 The returned list contains dictionaries of the following form:
26
27 {
28 "oid": <int>,
29 "name": <str>,
30 "schema": <int>,
31 "description": <str>
32 }
33
34 Args:
35 schema: The schema for which we want table info.
36 """
37 return exec_msar_func(conn, 'get_table_info', schema).fetchone()[0]
38
39
40 def reflect_table(name, schema, engine, metadata, connection_to_use=None, keep_existing=False):
41 extend_existing = not keep_existing
42 autoload_with = engine if connection_to_use is None else connection_to_use
43 return Table(
44 name,
45 metadata,
46 schema=schema,
47 autoload_with=autoload_with,
48 extend_existing=extend_existing,
49 keep_existing=keep_existing
50 )
51
52
53 def reflect_table_from_oid(oid, engine, metadata, connection_to_use=None, keep_existing=False):
54 tables = reflect_tables_from_oids(
55 [oid],
56 engine,
57 metadata=metadata,
58 connection_to_use=connection_to_use,
59 keep_existing=keep_existing
60 )
61 return tables.get(oid, None)
62
63
64 def reflect_tables_from_oids(oids, engine, metadata, connection_to_use=None, keep_existing=False):
65 oids_to_schema_and_table_names = (
66 get_map_of_table_oid_to_schema_name_and_table_name(
67 oids,
68 engine,
69 metadata=metadata,
70 connection_to_use=connection_to_use,
71 )
72 )
73 table_oids_to_sa_tables = {}
74 for table_oid, (schema_name, table_name) in oids_to_schema_and_table_names.items():
75 table_oids_to_sa_tables[table_oid] = reflect_table(
76 table_name,
77 schema_name,
78 engine,
79 metadata=metadata,
80 connection_to_use=connection_to_use,
81 keep_existing=keep_existing
82 )
83 return table_oids_to_sa_tables
84
85
86 def get_map_of_table_oid_to_schema_name_and_table_name(
87 table_oids,
88 engine,
89 metadata,
90 connection_to_use=None,
91 ):
92 if len(table_oids) == 0:
93 return {}
94 pg_class = get_pg_catalog_table("pg_class", engine, metadata=metadata)
95 pg_namespace = get_pg_catalog_table("pg_namespace", engine, metadata=metadata)
96 sel = (
97 select(pg_namespace.c.nspname, pg_class.c.relname, pg_class.c.oid)
98 .select_from(
99 join(
100 pg_class,
101 pg_namespace,
102 pg_class.c.relnamespace == pg_namespace.c.oid
103 )
104 )
105 .where(pg_class.c.oid.in_(table_oids))
106 )
107 result_rows = execute_statement(engine, sel, connection_to_use).fetchall()
108 table_oids_to_schema_names_and_table_names = {
109 table_oid: (schema_name, table_name)
110 for schema_name, table_name, table_oid
111 in result_rows
112 }
113 return table_oids_to_schema_names_and_table_names
114
115
116 def get_table_oids_from_schemas(schema_oids, engine, metadata):
117 pg_class = get_pg_catalog_table("pg_class", engine, metadata)
118 sel = (
119 select(pg_class.c.oid, pg_class.c.relnamespace.label('schema_oid'))
120 .where(
121 and_(pg_class.c.relkind == 'r', pg_class.c.relnamespace.in_(schema_oids))
122 )
123 )
124 with engine.begin() as conn:
125 table_oids = conn.execute(sel).fetchall()
126 return table_oids
127
128
129 def get_oid_from_table(name, schema, engine):
130 inspector = inspect(engine)
131 return inspector.get_table_oid(name, schema=schema)
132
133
134 def get_table_description(oid, engine):
135 with engine.begin() as conn:
136 res = conn.execute(select(func.obj_description(oid, 'pg_class')))
137 return res.fetchone()[0]
138
139
140 def get_joinable_tables(
141 engine, metadata, base_table_oid=None, max_depth=3, limit=None, offset=None
142 ):
143 """
144 Output is a collection of `sqlalchemy.engine.Row`[0]. `Row` "seeks to act as much like a
145 Python named tuple as possible". Look ups can be done via integer indexes, string indexes or
146 attributes (e.g. `joinable_table[TARGET]. Inspect code to know what the exact keys are, but
147 their order and semantics is: `(base table oid, target table oid, join parameter path,
148 foreign key path, depth, multiple results boolean flag).
149
150 [0] https://docs.sqlalchemy.org/en/14/core/connections.html#sqlalchemy.engine.Row
151 """
152 FK_OID = 'fk_oid'
153 LEFT_REL = 'left_rel'
154 RIGHT_REL = 'right_rel'
155 LEFT_COL = 'left_col'
156 RIGHT_COL = 'right_col'
157
158 SYMMETRIC_FKEYS = 'symmetric_fkeys'
159 SEARCH_FKEY_GRAPH = 'search_fkey_graph'
160 OUTPUT_CTE = 'output_cte'
161
162 jba = func.jsonb_build_array
163
164 pg_constraint = get_pg_catalog_table("pg_constraint", engine, metadata=metadata)
165
166 symmetric_fkeys = select(
167 cast(pg_constraint.c.oid, Integer).label(FK_OID),
168 cast(pg_constraint.c.conrelid, Integer).label(LEFT_REL),
169 cast(pg_constraint.c.confrelid, Integer).label(RIGHT_REL),
170 cast(pg_constraint.c.conkey[1], Integer).label(LEFT_COL),
171 cast(pg_constraint.c.confkey[1], Integer).label(RIGHT_COL),
172 literal(False).label(MULTIPLE_RESULTS),
173 literal(False).label(REVERSE),
174 ).where(
175 and_(
176 pg_constraint.c.contype == 'f',
177 func.array_length(pg_constraint.c.conkey, 1) == 1
178 )
179 ).union_all(
180 select(
181 cast(pg_constraint.c.oid, Integer).label(FK_OID),
182 cast(pg_constraint.c.confrelid, Integer).label(LEFT_REL),
183 cast(pg_constraint.c.conrelid, Integer).label(RIGHT_REL),
184 cast(pg_constraint.c.confkey[1], Integer).label(LEFT_COL),
185 cast(pg_constraint.c.conkey[1], Integer).label(RIGHT_COL),
186 literal(True).label(MULTIPLE_RESULTS),
187 literal(True).label(REVERSE),
188 ).where(
189 and_(
190 pg_constraint.c.contype == 'f',
191 func.array_length(pg_constraint.c.conkey, 1) == 1
192 )
193 )
194 ).cte(name=SYMMETRIC_FKEYS)
195
196 search_fkey_graph = select(
197 symmetric_fkeys.columns[LEFT_REL],
198 symmetric_fkeys.columns[RIGHT_REL],
199 symmetric_fkeys.columns[LEFT_COL],
200 symmetric_fkeys.columns[RIGHT_COL],
201 literal(1).label(DEPTH),
202 cast(
203 jba(
204 jba(
205 jba(
206 symmetric_fkeys.columns[LEFT_REL],
207 symmetric_fkeys.columns[LEFT_COL]
208 ),
209 jba(
210 symmetric_fkeys.columns[RIGHT_REL],
211 symmetric_fkeys.columns[RIGHT_COL]
212 ),
213 )
214 ),
215 JSONB
216 ).label(JP_PATH),
217 cast(
218 jba(
219 jba(
220 symmetric_fkeys.columns[FK_OID],
221 symmetric_fkeys.columns[REVERSE],
222 )
223 ),
224 JSONB
225 ).label(FK_PATH),
226 symmetric_fkeys.columns[MULTIPLE_RESULTS],
227 ).cte(name=SEARCH_FKEY_GRAPH, recursive=True)
228
229 search_fkey_graph = search_fkey_graph.union_all(
230 select(
231 symmetric_fkeys.columns[LEFT_REL],
232 symmetric_fkeys.columns[RIGHT_REL],
233 symmetric_fkeys.columns[LEFT_COL],
234 symmetric_fkeys.columns[RIGHT_COL],
235 search_fkey_graph.columns[DEPTH] + 1,
236 search_fkey_graph.columns[JP_PATH] + cast(
237 jba(
238 jba(
239 jba(
240 symmetric_fkeys.columns[LEFT_REL],
241 symmetric_fkeys.columns[LEFT_COL]
242 ),
243 jba(
244 symmetric_fkeys.columns[RIGHT_REL],
245 symmetric_fkeys.columns[RIGHT_COL]
246 ),
247 )
248 ),
249 JSONB
250 ),
251 search_fkey_graph.columns[FK_PATH] + cast(
252 jba(
253 jba(
254 symmetric_fkeys.columns[FK_OID],
255 symmetric_fkeys.columns[REVERSE],
256 )
257 ),
258 JSONB
259 ),
260 or_(
261 search_fkey_graph.columns[MULTIPLE_RESULTS],
262 symmetric_fkeys.columns[MULTIPLE_RESULTS]
263 )
264 ).where(
265 and_(
266 symmetric_fkeys.columns[LEFT_REL] == search_fkey_graph.columns[RIGHT_REL],
267 search_fkey_graph.columns[DEPTH] < max_depth,
268 search_fkey_graph.columns[JP_PATH][-1] != jba(
269 jba(
270 symmetric_fkeys.columns[RIGHT_REL],
271 symmetric_fkeys.columns[RIGHT_COL]
272 ),
273 jba(
274 symmetric_fkeys.columns[LEFT_REL],
275 symmetric_fkeys.columns[LEFT_COL]
276 ),
277 )
278 )
279 )
280 )
281
282 output_cte = select(
283 cast(search_fkey_graph.columns[JP_PATH][0][0][0], Integer).label(BASE),
284 cast(search_fkey_graph.columns[JP_PATH][-1][-1][0], Integer).label(TARGET),
285 search_fkey_graph.columns[JP_PATH].label(JP_PATH),
286 search_fkey_graph.columns[FK_PATH].label(FK_PATH),
287 search_fkey_graph.columns[DEPTH].label(DEPTH),
288 search_fkey_graph.columns[MULTIPLE_RESULTS].label(MULTIPLE_RESULTS)
289 ).cte(name=OUTPUT_CTE)
290
291 if base_table_oid is not None:
292 final_sel = select(output_cte).where(
293 output_cte.columns[BASE] == base_table_oid
294 )
295 else:
296 final_sel = select(output_cte)
297
298 with engine.begin() as conn:
299 results = conn.execute(final_sel.limit(limit).offset(offset)).fetchall()
300
301 return results
302
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/db/tables/operations/select.py b/db/tables/operations/select.py
--- a/db/tables/operations/select.py
+++ b/db/tables/operations/select.py
@@ -15,6 +15,28 @@
MULTIPLE_RESULTS = 'multiple_results'
+def get_table(table, conn):
+ """
+ Return a dictionary describing a table of a schema.
+
+ The `table` can be given as either a "qualified name", or an OID.
+ The OID is the preferred identifier, since it's much more robust.
+
+ The returned dictionary is of the following form:
+
+ {
+ "oid": <int>,
+ "name": <str>,
+ "schema": <int>,
+ "description": <str>
+ }
+
+ Args:
+ table: The table for which we want table info.
+ """
+ return exec_msar_func(conn, 'get_table', table).fetchone()[0]
+
+
def get_table_info(schema, conn):
"""
Return a list of dictionaries describing the tables of a schema.
diff --git a/mathesar/rpc/tables.py b/mathesar/rpc/tables.py
--- a/mathesar/rpc/tables.py
+++ b/mathesar/rpc/tables.py
@@ -3,7 +3,7 @@
from modernrpc.core import rpc_method, REQUEST_KEY
from modernrpc.auth.basic import http_basic_auth_login_required
-from db.tables.operations.select import get_table_info
+from db.tables.operations.select import get_table_info, get_table
from db.tables.operations.drop import drop_table_from_database
from mathesar.rpc.exceptions.handlers import handle_rpc_exceptions
from mathesar.rpc.utils import connect
@@ -47,6 +47,26 @@
]
+@rpc_method(name="tables.get")
+@http_basic_auth_login_required
+@handle_rpc_exceptions
+def get(*, table_oid: int, database_id: int, **kwargs) -> TableInfo:
+ """
+ List information about a table for a schema.
+
+ Args:
+ table_oid: Identity of the table in the user's database.
+ database_id: The Django id of the database containing the table.
+
+ Returns:
+ Table details for a given table oid.
+ """
+ user = kwargs.get(REQUEST_KEY).user
+ with connect(database_id, user) as conn:
+ raw_table_info = get_table(table_oid, conn)
+ return TableInfo(raw_table_info)
+
+
@rpc_method(name="tables.delete")
@http_basic_auth_login_required
@handle_rpc_exceptions
|
{"golden_diff": "diff --git a/db/tables/operations/select.py b/db/tables/operations/select.py\n--- a/db/tables/operations/select.py\n+++ b/db/tables/operations/select.py\n@@ -15,6 +15,28 @@\n MULTIPLE_RESULTS = 'multiple_results'\n \n \n+def get_table(table, conn):\n+ \"\"\"\n+ Return a dictionary describing a table of a schema.\n+\n+ The `table` can be given as either a \"qualified name\", or an OID.\n+ The OID is the preferred identifier, since it's much more robust.\n+\n+ The returned dictionary is of the following form:\n+\n+ {\n+ \"oid\": <int>,\n+ \"name\": <str>,\n+ \"schema\": <int>,\n+ \"description\": <str>\n+ }\n+\n+ Args:\n+ table: The table for which we want table info.\n+ \"\"\"\n+ return exec_msar_func(conn, 'get_table', table).fetchone()[0]\n+\n+\n def get_table_info(schema, conn):\n \"\"\"\n Return a list of dictionaries describing the tables of a schema.\ndiff --git a/mathesar/rpc/tables.py b/mathesar/rpc/tables.py\n--- a/mathesar/rpc/tables.py\n+++ b/mathesar/rpc/tables.py\n@@ -3,7 +3,7 @@\n from modernrpc.core import rpc_method, REQUEST_KEY\n from modernrpc.auth.basic import http_basic_auth_login_required\n \n-from db.tables.operations.select import get_table_info\n+from db.tables.operations.select import get_table_info, get_table\n from db.tables.operations.drop import drop_table_from_database\n from mathesar.rpc.exceptions.handlers import handle_rpc_exceptions\n from mathesar.rpc.utils import connect\n@@ -47,6 +47,26 @@\n ]\n \n \n+@rpc_method(name=\"tables.get\")\n+@http_basic_auth_login_required\n+@handle_rpc_exceptions\n+def get(*, table_oid: int, database_id: int, **kwargs) -> TableInfo:\n+ \"\"\"\n+ List information about a table for a schema.\n+\n+ Args:\n+ table_oid: Identity of the table in the user's database.\n+ database_id: The Django id of the database containing the table.\n+\n+ Returns:\n+ Table details for a given table oid.\n+ \"\"\"\n+ user = kwargs.get(REQUEST_KEY).user\n+ with connect(database_id, user) as conn:\n+ raw_table_info = get_table(table_oid, conn)\n+ return TableInfo(raw_table_info)\n+\n+\n @rpc_method(name=\"tables.delete\")\n @http_basic_auth_login_required\n @handle_rpc_exceptions\n", "issue": "Implement `tables.get` RPC method\n\n", "before_files": [{"content": "from typing import Optional, TypedDict\n\nfrom modernrpc.core import rpc_method, REQUEST_KEY\nfrom modernrpc.auth.basic import http_basic_auth_login_required\n\nfrom db.tables.operations.select import get_table_info\nfrom db.tables.operations.drop import drop_table_from_database\nfrom mathesar.rpc.exceptions.handlers import handle_rpc_exceptions\nfrom mathesar.rpc.utils import connect\n\n\nclass TableInfo(TypedDict):\n \"\"\"\n Information about a table.\n\n Attributes:\n oid: The `oid` of the table in the schema.\n name: The name of the table.\n schema: The `oid` of the schema where the table lives.\n description: The description of the table.\n \"\"\"\n oid: int\n name: str\n schema: int\n description: Optional[str]\n\n\n@rpc_method(name=\"tables.list\")\n@http_basic_auth_login_required\n@handle_rpc_exceptions\ndef list_(*, schema_oid: int, database_id: int, **kwargs) -> list[TableInfo]:\n \"\"\"\n List information about tables for a schema. Exposed as `list`.\n\n Args:\n schema_oid: Identity of the schema in the user's database.\n database_id: The Django id of the database containing the table.\n\n Returns:\n A list of table details.\n \"\"\"\n user = kwargs.get(REQUEST_KEY).user\n with connect(database_id, user) as conn:\n raw_table_info = get_table_info(schema_oid, conn)\n return [\n TableInfo(tab) for tab in raw_table_info\n ]\n\n\n@rpc_method(name=\"tables.delete\")\n@http_basic_auth_login_required\n@handle_rpc_exceptions\ndef delete(\n *, table_oid: int, database_id: int, cascade: bool = False, **kwargs\n) -> str:\n \"\"\"\n Delete a table from a schema.\n\n Args:\n table_oid: Identity of the table in the user's database.\n database_id: The Django id of the database containing the table.\n cascade: Whether to drop the dependent objects.\n\n Returns:\n The name of the dropped table.\n \"\"\"\n user = kwargs.get(REQUEST_KEY).user\n with connect(database_id, user) as conn:\n return drop_table_from_database(table_oid, conn, cascade)\n", "path": "mathesar/rpc/tables.py"}, {"content": "from sqlalchemy import (\n Table, select, join, inspect, and_, cast, func, Integer, literal, or_,\n)\nfrom sqlalchemy.dialects.postgresql import JSONB\n\nfrom db.connection import exec_msar_func\nfrom db.utils import execute_statement, get_pg_catalog_table\n\nBASE = 'base'\nDEPTH = 'depth'\nJP_PATH = 'jp_path'\nFK_PATH = 'fk_path'\nREVERSE = 'reverse'\nTARGET = 'target'\nMULTIPLE_RESULTS = 'multiple_results'\n\n\ndef get_table_info(schema, conn):\n \"\"\"\n Return a list of dictionaries describing the tables of a schema.\n\n The `schema` can be given as either a \"qualified name\", or an OID.\n The OID is the preferred identifier, since it's much more robust.\n\n The returned list contains dictionaries of the following form:\n\n {\n \"oid\": <int>,\n \"name\": <str>,\n \"schema\": <int>,\n \"description\": <str>\n }\n\n Args:\n schema: The schema for which we want table info.\n \"\"\"\n return exec_msar_func(conn, 'get_table_info', schema).fetchone()[0]\n\n\ndef reflect_table(name, schema, engine, metadata, connection_to_use=None, keep_existing=False):\n extend_existing = not keep_existing\n autoload_with = engine if connection_to_use is None else connection_to_use\n return Table(\n name,\n metadata,\n schema=schema,\n autoload_with=autoload_with,\n extend_existing=extend_existing,\n keep_existing=keep_existing\n )\n\n\ndef reflect_table_from_oid(oid, engine, metadata, connection_to_use=None, keep_existing=False):\n tables = reflect_tables_from_oids(\n [oid],\n engine,\n metadata=metadata,\n connection_to_use=connection_to_use,\n keep_existing=keep_existing\n )\n return tables.get(oid, None)\n\n\ndef reflect_tables_from_oids(oids, engine, metadata, connection_to_use=None, keep_existing=False):\n oids_to_schema_and_table_names = (\n get_map_of_table_oid_to_schema_name_and_table_name(\n oids,\n engine,\n metadata=metadata,\n connection_to_use=connection_to_use,\n )\n )\n table_oids_to_sa_tables = {}\n for table_oid, (schema_name, table_name) in oids_to_schema_and_table_names.items():\n table_oids_to_sa_tables[table_oid] = reflect_table(\n table_name,\n schema_name,\n engine,\n metadata=metadata,\n connection_to_use=connection_to_use,\n keep_existing=keep_existing\n )\n return table_oids_to_sa_tables\n\n\ndef get_map_of_table_oid_to_schema_name_and_table_name(\n table_oids,\n engine,\n metadata,\n connection_to_use=None,\n):\n if len(table_oids) == 0:\n return {}\n pg_class = get_pg_catalog_table(\"pg_class\", engine, metadata=metadata)\n pg_namespace = get_pg_catalog_table(\"pg_namespace\", engine, metadata=metadata)\n sel = (\n select(pg_namespace.c.nspname, pg_class.c.relname, pg_class.c.oid)\n .select_from(\n join(\n pg_class,\n pg_namespace,\n pg_class.c.relnamespace == pg_namespace.c.oid\n )\n )\n .where(pg_class.c.oid.in_(table_oids))\n )\n result_rows = execute_statement(engine, sel, connection_to_use).fetchall()\n table_oids_to_schema_names_and_table_names = {\n table_oid: (schema_name, table_name)\n for schema_name, table_name, table_oid\n in result_rows\n }\n return table_oids_to_schema_names_and_table_names\n\n\ndef get_table_oids_from_schemas(schema_oids, engine, metadata):\n pg_class = get_pg_catalog_table(\"pg_class\", engine, metadata)\n sel = (\n select(pg_class.c.oid, pg_class.c.relnamespace.label('schema_oid'))\n .where(\n and_(pg_class.c.relkind == 'r', pg_class.c.relnamespace.in_(schema_oids))\n )\n )\n with engine.begin() as conn:\n table_oids = conn.execute(sel).fetchall()\n return table_oids\n\n\ndef get_oid_from_table(name, schema, engine):\n inspector = inspect(engine)\n return inspector.get_table_oid(name, schema=schema)\n\n\ndef get_table_description(oid, engine):\n with engine.begin() as conn:\n res = conn.execute(select(func.obj_description(oid, 'pg_class')))\n return res.fetchone()[0]\n\n\ndef get_joinable_tables(\n engine, metadata, base_table_oid=None, max_depth=3, limit=None, offset=None\n):\n \"\"\"\n Output is a collection of `sqlalchemy.engine.Row`[0]. `Row` \"seeks to act as much like a\n Python named tuple as possible\". Look ups can be done via integer indexes, string indexes or\n attributes (e.g. `joinable_table[TARGET]. Inspect code to know what the exact keys are, but\n their order and semantics is: `(base table oid, target table oid, join parameter path,\n foreign key path, depth, multiple results boolean flag).\n\n [0] https://docs.sqlalchemy.org/en/14/core/connections.html#sqlalchemy.engine.Row\n \"\"\"\n FK_OID = 'fk_oid'\n LEFT_REL = 'left_rel'\n RIGHT_REL = 'right_rel'\n LEFT_COL = 'left_col'\n RIGHT_COL = 'right_col'\n\n SYMMETRIC_FKEYS = 'symmetric_fkeys'\n SEARCH_FKEY_GRAPH = 'search_fkey_graph'\n OUTPUT_CTE = 'output_cte'\n\n jba = func.jsonb_build_array\n\n pg_constraint = get_pg_catalog_table(\"pg_constraint\", engine, metadata=metadata)\n\n symmetric_fkeys = select(\n cast(pg_constraint.c.oid, Integer).label(FK_OID),\n cast(pg_constraint.c.conrelid, Integer).label(LEFT_REL),\n cast(pg_constraint.c.confrelid, Integer).label(RIGHT_REL),\n cast(pg_constraint.c.conkey[1], Integer).label(LEFT_COL),\n cast(pg_constraint.c.confkey[1], Integer).label(RIGHT_COL),\n literal(False).label(MULTIPLE_RESULTS),\n literal(False).label(REVERSE),\n ).where(\n and_(\n pg_constraint.c.contype == 'f',\n func.array_length(pg_constraint.c.conkey, 1) == 1\n )\n ).union_all(\n select(\n cast(pg_constraint.c.oid, Integer).label(FK_OID),\n cast(pg_constraint.c.confrelid, Integer).label(LEFT_REL),\n cast(pg_constraint.c.conrelid, Integer).label(RIGHT_REL),\n cast(pg_constraint.c.confkey[1], Integer).label(LEFT_COL),\n cast(pg_constraint.c.conkey[1], Integer).label(RIGHT_COL),\n literal(True).label(MULTIPLE_RESULTS),\n literal(True).label(REVERSE),\n ).where(\n and_(\n pg_constraint.c.contype == 'f',\n func.array_length(pg_constraint.c.conkey, 1) == 1\n )\n )\n ).cte(name=SYMMETRIC_FKEYS)\n\n search_fkey_graph = select(\n symmetric_fkeys.columns[LEFT_REL],\n symmetric_fkeys.columns[RIGHT_REL],\n symmetric_fkeys.columns[LEFT_COL],\n symmetric_fkeys.columns[RIGHT_COL],\n literal(1).label(DEPTH),\n cast(\n jba(\n jba(\n jba(\n symmetric_fkeys.columns[LEFT_REL],\n symmetric_fkeys.columns[LEFT_COL]\n ),\n jba(\n symmetric_fkeys.columns[RIGHT_REL],\n symmetric_fkeys.columns[RIGHT_COL]\n ),\n )\n ),\n JSONB\n ).label(JP_PATH),\n cast(\n jba(\n jba(\n symmetric_fkeys.columns[FK_OID],\n symmetric_fkeys.columns[REVERSE],\n )\n ),\n JSONB\n ).label(FK_PATH),\n symmetric_fkeys.columns[MULTIPLE_RESULTS],\n ).cte(name=SEARCH_FKEY_GRAPH, recursive=True)\n\n search_fkey_graph = search_fkey_graph.union_all(\n select(\n symmetric_fkeys.columns[LEFT_REL],\n symmetric_fkeys.columns[RIGHT_REL],\n symmetric_fkeys.columns[LEFT_COL],\n symmetric_fkeys.columns[RIGHT_COL],\n search_fkey_graph.columns[DEPTH] + 1,\n search_fkey_graph.columns[JP_PATH] + cast(\n jba(\n jba(\n jba(\n symmetric_fkeys.columns[LEFT_REL],\n symmetric_fkeys.columns[LEFT_COL]\n ),\n jba(\n symmetric_fkeys.columns[RIGHT_REL],\n symmetric_fkeys.columns[RIGHT_COL]\n ),\n )\n ),\n JSONB\n ),\n search_fkey_graph.columns[FK_PATH] + cast(\n jba(\n jba(\n symmetric_fkeys.columns[FK_OID],\n symmetric_fkeys.columns[REVERSE],\n )\n ),\n JSONB\n ),\n or_(\n search_fkey_graph.columns[MULTIPLE_RESULTS],\n symmetric_fkeys.columns[MULTIPLE_RESULTS]\n )\n ).where(\n and_(\n symmetric_fkeys.columns[LEFT_REL] == search_fkey_graph.columns[RIGHT_REL],\n search_fkey_graph.columns[DEPTH] < max_depth,\n search_fkey_graph.columns[JP_PATH][-1] != jba(\n jba(\n symmetric_fkeys.columns[RIGHT_REL],\n symmetric_fkeys.columns[RIGHT_COL]\n ),\n jba(\n symmetric_fkeys.columns[LEFT_REL],\n symmetric_fkeys.columns[LEFT_COL]\n ),\n )\n )\n )\n )\n\n output_cte = select(\n cast(search_fkey_graph.columns[JP_PATH][0][0][0], Integer).label(BASE),\n cast(search_fkey_graph.columns[JP_PATH][-1][-1][0], Integer).label(TARGET),\n search_fkey_graph.columns[JP_PATH].label(JP_PATH),\n search_fkey_graph.columns[FK_PATH].label(FK_PATH),\n search_fkey_graph.columns[DEPTH].label(DEPTH),\n search_fkey_graph.columns[MULTIPLE_RESULTS].label(MULTIPLE_RESULTS)\n ).cte(name=OUTPUT_CTE)\n\n if base_table_oid is not None:\n final_sel = select(output_cte).where(\n output_cte.columns[BASE] == base_table_oid\n )\n else:\n final_sel = select(output_cte)\n\n with engine.begin() as conn:\n results = conn.execute(final_sel.limit(limit).offset(offset)).fetchall()\n\n return results\n", "path": "db/tables/operations/select.py"}], "after_files": [{"content": "from typing import Optional, TypedDict\n\nfrom modernrpc.core import rpc_method, REQUEST_KEY\nfrom modernrpc.auth.basic import http_basic_auth_login_required\n\nfrom db.tables.operations.select import get_table_info, get_table\nfrom db.tables.operations.drop import drop_table_from_database\nfrom mathesar.rpc.exceptions.handlers import handle_rpc_exceptions\nfrom mathesar.rpc.utils import connect\n\n\nclass TableInfo(TypedDict):\n \"\"\"\n Information about a table.\n\n Attributes:\n oid: The `oid` of the table in the schema.\n name: The name of the table.\n schema: The `oid` of the schema where the table lives.\n description: The description of the table.\n \"\"\"\n oid: int\n name: str\n schema: int\n description: Optional[str]\n\n\n@rpc_method(name=\"tables.list\")\n@http_basic_auth_login_required\n@handle_rpc_exceptions\ndef list_(*, schema_oid: int, database_id: int, **kwargs) -> list[TableInfo]:\n \"\"\"\n List information about tables for a schema. Exposed as `list`.\n\n Args:\n schema_oid: Identity of the schema in the user's database.\n database_id: The Django id of the database containing the table.\n\n Returns:\n A list of table details.\n \"\"\"\n user = kwargs.get(REQUEST_KEY).user\n with connect(database_id, user) as conn:\n raw_table_info = get_table_info(schema_oid, conn)\n return [\n TableInfo(tab) for tab in raw_table_info\n ]\n\n\n@rpc_method(name=\"tables.get\")\n@http_basic_auth_login_required\n@handle_rpc_exceptions\ndef get(*, table_oid: int, database_id: int, **kwargs) -> TableInfo:\n \"\"\"\n List information about a table for a schema.\n\n Args:\n table_oid: Identity of the table in the user's database.\n database_id: The Django id of the database containing the table.\n\n Returns:\n Table details for a given table oid.\n \"\"\"\n user = kwargs.get(REQUEST_KEY).user\n with connect(database_id, user) as conn:\n raw_table_info = get_table(table_oid, conn)\n return TableInfo(raw_table_info)\n\n\n@rpc_method(name=\"tables.delete\")\n@http_basic_auth_login_required\n@handle_rpc_exceptions\ndef delete(\n *, table_oid: int, database_id: int, cascade: bool = False, **kwargs\n) -> str:\n \"\"\"\n Delete a table from a schema.\n\n Args:\n table_oid: Identity of the table in the user's database.\n database_id: The Django id of the database containing the table.\n cascade: Whether to drop the dependent objects.\n\n Returns:\n The name of the dropped table.\n \"\"\"\n user = kwargs.get(REQUEST_KEY).user\n with connect(database_id, user) as conn:\n return drop_table_from_database(table_oid, conn, cascade)\n", "path": "mathesar/rpc/tables.py"}, {"content": "from sqlalchemy import (\n Table, select, join, inspect, and_, cast, func, Integer, literal, or_,\n)\nfrom sqlalchemy.dialects.postgresql import JSONB\n\nfrom db.connection import exec_msar_func\nfrom db.utils import execute_statement, get_pg_catalog_table\n\nBASE = 'base'\nDEPTH = 'depth'\nJP_PATH = 'jp_path'\nFK_PATH = 'fk_path'\nREVERSE = 'reverse'\nTARGET = 'target'\nMULTIPLE_RESULTS = 'multiple_results'\n\n\ndef get_table(table, conn):\n \"\"\"\n Return a dictionary describing a table of a schema.\n\n The `table` can be given as either a \"qualified name\", or an OID.\n The OID is the preferred identifier, since it's much more robust.\n\n The returned dictionary is of the following form:\n\n {\n \"oid\": <int>,\n \"name\": <str>,\n \"schema\": <int>,\n \"description\": <str>\n }\n\n Args:\n table: The table for which we want table info.\n \"\"\"\n return exec_msar_func(conn, 'get_table', table).fetchone()[0]\n\n\ndef get_table_info(schema, conn):\n \"\"\"\n Return a list of dictionaries describing the tables of a schema.\n\n The `schema` can be given as either a \"qualified name\", or an OID.\n The OID is the preferred identifier, since it's much more robust.\n\n The returned list contains dictionaries of the following form:\n\n {\n \"oid\": <int>,\n \"name\": <str>,\n \"schema\": <int>,\n \"description\": <str>\n }\n\n Args:\n schema: The schema for which we want table info.\n \"\"\"\n return exec_msar_func(conn, 'get_table_info', schema).fetchone()[0]\n\n\ndef reflect_table(name, schema, engine, metadata, connection_to_use=None, keep_existing=False):\n extend_existing = not keep_existing\n autoload_with = engine if connection_to_use is None else connection_to_use\n return Table(\n name,\n metadata,\n schema=schema,\n autoload_with=autoload_with,\n extend_existing=extend_existing,\n keep_existing=keep_existing\n )\n\n\ndef reflect_table_from_oid(oid, engine, metadata, connection_to_use=None, keep_existing=False):\n tables = reflect_tables_from_oids(\n [oid],\n engine,\n metadata=metadata,\n connection_to_use=connection_to_use,\n keep_existing=keep_existing\n )\n return tables.get(oid, None)\n\n\ndef reflect_tables_from_oids(oids, engine, metadata, connection_to_use=None, keep_existing=False):\n oids_to_schema_and_table_names = (\n get_map_of_table_oid_to_schema_name_and_table_name(\n oids,\n engine,\n metadata=metadata,\n connection_to_use=connection_to_use,\n )\n )\n table_oids_to_sa_tables = {}\n for table_oid, (schema_name, table_name) in oids_to_schema_and_table_names.items():\n table_oids_to_sa_tables[table_oid] = reflect_table(\n table_name,\n schema_name,\n engine,\n metadata=metadata,\n connection_to_use=connection_to_use,\n keep_existing=keep_existing\n )\n return table_oids_to_sa_tables\n\n\ndef get_map_of_table_oid_to_schema_name_and_table_name(\n table_oids,\n engine,\n metadata,\n connection_to_use=None,\n):\n if len(table_oids) == 0:\n return {}\n pg_class = get_pg_catalog_table(\"pg_class\", engine, metadata=metadata)\n pg_namespace = get_pg_catalog_table(\"pg_namespace\", engine, metadata=metadata)\n sel = (\n select(pg_namespace.c.nspname, pg_class.c.relname, pg_class.c.oid)\n .select_from(\n join(\n pg_class,\n pg_namespace,\n pg_class.c.relnamespace == pg_namespace.c.oid\n )\n )\n .where(pg_class.c.oid.in_(table_oids))\n )\n result_rows = execute_statement(engine, sel, connection_to_use).fetchall()\n table_oids_to_schema_names_and_table_names = {\n table_oid: (schema_name, table_name)\n for schema_name, table_name, table_oid\n in result_rows\n }\n return table_oids_to_schema_names_and_table_names\n\n\ndef get_table_oids_from_schemas(schema_oids, engine, metadata):\n pg_class = get_pg_catalog_table(\"pg_class\", engine, metadata)\n sel = (\n select(pg_class.c.oid, pg_class.c.relnamespace.label('schema_oid'))\n .where(\n and_(pg_class.c.relkind == 'r', pg_class.c.relnamespace.in_(schema_oids))\n )\n )\n with engine.begin() as conn:\n table_oids = conn.execute(sel).fetchall()\n return table_oids\n\n\ndef get_oid_from_table(name, schema, engine):\n inspector = inspect(engine)\n return inspector.get_table_oid(name, schema=schema)\n\n\ndef get_table_description(oid, engine):\n with engine.begin() as conn:\n res = conn.execute(select(func.obj_description(oid, 'pg_class')))\n return res.fetchone()[0]\n\n\ndef get_joinable_tables(\n engine, metadata, base_table_oid=None, max_depth=3, limit=None, offset=None\n):\n \"\"\"\n Output is a collection of `sqlalchemy.engine.Row`[0]. `Row` \"seeks to act as much like a\n Python named tuple as possible\". Look ups can be done via integer indexes, string indexes or\n attributes (e.g. `joinable_table[TARGET]. Inspect code to know what the exact keys are, but\n their order and semantics is: `(base table oid, target table oid, join parameter path,\n foreign key path, depth, multiple results boolean flag).\n\n [0] https://docs.sqlalchemy.org/en/14/core/connections.html#sqlalchemy.engine.Row\n \"\"\"\n FK_OID = 'fk_oid'\n LEFT_REL = 'left_rel'\n RIGHT_REL = 'right_rel'\n LEFT_COL = 'left_col'\n RIGHT_COL = 'right_col'\n\n SYMMETRIC_FKEYS = 'symmetric_fkeys'\n SEARCH_FKEY_GRAPH = 'search_fkey_graph'\n OUTPUT_CTE = 'output_cte'\n\n jba = func.jsonb_build_array\n\n pg_constraint = get_pg_catalog_table(\"pg_constraint\", engine, metadata=metadata)\n\n symmetric_fkeys = select(\n cast(pg_constraint.c.oid, Integer).label(FK_OID),\n cast(pg_constraint.c.conrelid, Integer).label(LEFT_REL),\n cast(pg_constraint.c.confrelid, Integer).label(RIGHT_REL),\n cast(pg_constraint.c.conkey[1], Integer).label(LEFT_COL),\n cast(pg_constraint.c.confkey[1], Integer).label(RIGHT_COL),\n literal(False).label(MULTIPLE_RESULTS),\n literal(False).label(REVERSE),\n ).where(\n and_(\n pg_constraint.c.contype == 'f',\n func.array_length(pg_constraint.c.conkey, 1) == 1\n )\n ).union_all(\n select(\n cast(pg_constraint.c.oid, Integer).label(FK_OID),\n cast(pg_constraint.c.confrelid, Integer).label(LEFT_REL),\n cast(pg_constraint.c.conrelid, Integer).label(RIGHT_REL),\n cast(pg_constraint.c.confkey[1], Integer).label(LEFT_COL),\n cast(pg_constraint.c.conkey[1], Integer).label(RIGHT_COL),\n literal(True).label(MULTIPLE_RESULTS),\n literal(True).label(REVERSE),\n ).where(\n and_(\n pg_constraint.c.contype == 'f',\n func.array_length(pg_constraint.c.conkey, 1) == 1\n )\n )\n ).cte(name=SYMMETRIC_FKEYS)\n\n search_fkey_graph = select(\n symmetric_fkeys.columns[LEFT_REL],\n symmetric_fkeys.columns[RIGHT_REL],\n symmetric_fkeys.columns[LEFT_COL],\n symmetric_fkeys.columns[RIGHT_COL],\n literal(1).label(DEPTH),\n cast(\n jba(\n jba(\n jba(\n symmetric_fkeys.columns[LEFT_REL],\n symmetric_fkeys.columns[LEFT_COL]\n ),\n jba(\n symmetric_fkeys.columns[RIGHT_REL],\n symmetric_fkeys.columns[RIGHT_COL]\n ),\n )\n ),\n JSONB\n ).label(JP_PATH),\n cast(\n jba(\n jba(\n symmetric_fkeys.columns[FK_OID],\n symmetric_fkeys.columns[REVERSE],\n )\n ),\n JSONB\n ).label(FK_PATH),\n symmetric_fkeys.columns[MULTIPLE_RESULTS],\n ).cte(name=SEARCH_FKEY_GRAPH, recursive=True)\n\n search_fkey_graph = search_fkey_graph.union_all(\n select(\n symmetric_fkeys.columns[LEFT_REL],\n symmetric_fkeys.columns[RIGHT_REL],\n symmetric_fkeys.columns[LEFT_COL],\n symmetric_fkeys.columns[RIGHT_COL],\n search_fkey_graph.columns[DEPTH] + 1,\n search_fkey_graph.columns[JP_PATH] + cast(\n jba(\n jba(\n jba(\n symmetric_fkeys.columns[LEFT_REL],\n symmetric_fkeys.columns[LEFT_COL]\n ),\n jba(\n symmetric_fkeys.columns[RIGHT_REL],\n symmetric_fkeys.columns[RIGHT_COL]\n ),\n )\n ),\n JSONB\n ),\n search_fkey_graph.columns[FK_PATH] + cast(\n jba(\n jba(\n symmetric_fkeys.columns[FK_OID],\n symmetric_fkeys.columns[REVERSE],\n )\n ),\n JSONB\n ),\n or_(\n search_fkey_graph.columns[MULTIPLE_RESULTS],\n symmetric_fkeys.columns[MULTIPLE_RESULTS]\n )\n ).where(\n and_(\n symmetric_fkeys.columns[LEFT_REL] == search_fkey_graph.columns[RIGHT_REL],\n search_fkey_graph.columns[DEPTH] < max_depth,\n search_fkey_graph.columns[JP_PATH][-1] != jba(\n jba(\n symmetric_fkeys.columns[RIGHT_REL],\n symmetric_fkeys.columns[RIGHT_COL]\n ),\n jba(\n symmetric_fkeys.columns[LEFT_REL],\n symmetric_fkeys.columns[LEFT_COL]\n ),\n )\n )\n )\n )\n\n output_cte = select(\n cast(search_fkey_graph.columns[JP_PATH][0][0][0], Integer).label(BASE),\n cast(search_fkey_graph.columns[JP_PATH][-1][-1][0], Integer).label(TARGET),\n search_fkey_graph.columns[JP_PATH].label(JP_PATH),\n search_fkey_graph.columns[FK_PATH].label(FK_PATH),\n search_fkey_graph.columns[DEPTH].label(DEPTH),\n search_fkey_graph.columns[MULTIPLE_RESULTS].label(MULTIPLE_RESULTS)\n ).cte(name=OUTPUT_CTE)\n\n if base_table_oid is not None:\n final_sel = select(output_cte).where(\n output_cte.columns[BASE] == base_table_oid\n )\n else:\n final_sel = select(output_cte)\n\n with engine.begin() as conn:\n results = conn.execute(final_sel.limit(limit).offset(offset)).fetchall()\n\n return results\n", "path": "db/tables/operations/select.py"}]}
| 3,973 | 562 |
gh_patches_debug_1868
|
rasdani/github-patches
|
git_diff
|
cloud-custodian__cloud-custodian-3075
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
GCP: Firewalls resource policy fails with no resource attribute 'Firewall'
When running this policy custodian fails:
- policies:
- name: firewall-test
resource: gcp.firewall
The error returned is:
AttributeError: 'Resource' object has no attribute 'firewall'
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `tools/c7n_gcp/c7n_gcp/resources/network.py`
Content:
```
1 # Copyright 2018 Capital One Services, LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 from c7n_gcp.query import QueryResourceManager, TypeInfo
15
16 from c7n_gcp.provider import resources
17
18
19 @resources.register('vpc')
20 class Network(QueryResourceManager):
21
22 class resource_type(TypeInfo):
23 service = 'compute'
24 version = 'v1'
25 component = 'networks'
26 scope_template = "projects/{}/global/networks"
27
28
29 @resources.register('subnet')
30 class Subnet(QueryResourceManager):
31
32 class resource_type(TypeInfo):
33 service = 'compute'
34 version = 'v1'
35 component = 'networks'
36 enum_spec = ('aggregatedList', 'items.*.subnetworks[]', None)
37 scope_template = "projects/{}/aggregated/subnetworks"
38
39
40 @resources.register('firewall')
41 class Firewall(QueryResourceManager):
42
43 class resource_type(TypeInfo):
44 service = 'compute'
45 version = 'v1'
46 component = 'firewall'
47 scope_template = "projects/{}/global/firewalls"
48
49
50 @resources.register('router')
51 class Router(QueryResourceManager):
52
53 class resource_type(TypeInfo):
54 service = 'compute'
55 version = 'v1'
56 component = 'routers'
57 enum_spec = ('aggregatedList', 'items.*.routers[]', None)
58 scope_template = "projects/{}/aggregated/routers"
59
60
61 @resources.register('route')
62 class Route(QueryResourceManager):
63
64 class resource_type(TypeInfo):
65 service = 'compute'
66 version = 'v1'
67 component = 'routes'
68 scope_template = "projects/{}/global/routes"
69
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/tools/c7n_gcp/c7n_gcp/resources/network.py b/tools/c7n_gcp/c7n_gcp/resources/network.py
--- a/tools/c7n_gcp/c7n_gcp/resources/network.py
+++ b/tools/c7n_gcp/c7n_gcp/resources/network.py
@@ -43,8 +43,7 @@
class resource_type(TypeInfo):
service = 'compute'
version = 'v1'
- component = 'firewall'
- scope_template = "projects/{}/global/firewalls"
+ component = 'firewalls'
@resources.register('router')
|
{"golden_diff": "diff --git a/tools/c7n_gcp/c7n_gcp/resources/network.py b/tools/c7n_gcp/c7n_gcp/resources/network.py\n--- a/tools/c7n_gcp/c7n_gcp/resources/network.py\n+++ b/tools/c7n_gcp/c7n_gcp/resources/network.py\n@@ -43,8 +43,7 @@\n class resource_type(TypeInfo):\n service = 'compute'\n version = 'v1'\n- component = 'firewall'\n- scope_template = \"projects/{}/global/firewalls\"\n+ component = 'firewalls'\n \n \n @resources.register('router')\n", "issue": "GCP: Firewalls resource policy fails with no resource attribute 'Firewall'\nWhen running this policy custodian fails: \r\n\r\n- policies:\r\n - name: firewall-test\r\n resource: gcp.firewall\r\n\r\nThe error returned is:\r\nAttributeError: 'Resource' object has no attribute 'firewall'\n", "before_files": [{"content": "# Copyright 2018 Capital One Services, LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom c7n_gcp.query import QueryResourceManager, TypeInfo\n\nfrom c7n_gcp.provider import resources\n\n\[email protected]('vpc')\nclass Network(QueryResourceManager):\n\n class resource_type(TypeInfo):\n service = 'compute'\n version = 'v1'\n component = 'networks'\n scope_template = \"projects/{}/global/networks\"\n\n\[email protected]('subnet')\nclass Subnet(QueryResourceManager):\n\n class resource_type(TypeInfo):\n service = 'compute'\n version = 'v1'\n component = 'networks'\n enum_spec = ('aggregatedList', 'items.*.subnetworks[]', None)\n scope_template = \"projects/{}/aggregated/subnetworks\"\n\n\[email protected]('firewall')\nclass Firewall(QueryResourceManager):\n\n class resource_type(TypeInfo):\n service = 'compute'\n version = 'v1'\n component = 'firewall'\n scope_template = \"projects/{}/global/firewalls\"\n\n\[email protected]('router')\nclass Router(QueryResourceManager):\n\n class resource_type(TypeInfo):\n service = 'compute'\n version = 'v1'\n component = 'routers'\n enum_spec = ('aggregatedList', 'items.*.routers[]', None)\n scope_template = \"projects/{}/aggregated/routers\"\n\n\[email protected]('route')\nclass Route(QueryResourceManager):\n\n class resource_type(TypeInfo):\n service = 'compute'\n version = 'v1'\n component = 'routes'\n scope_template = \"projects/{}/global/routes\"\n", "path": "tools/c7n_gcp/c7n_gcp/resources/network.py"}], "after_files": [{"content": "# Copyright 2018 Capital One Services, LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom c7n_gcp.query import QueryResourceManager, TypeInfo\n\nfrom c7n_gcp.provider import resources\n\n\[email protected]('vpc')\nclass Network(QueryResourceManager):\n\n class resource_type(TypeInfo):\n service = 'compute'\n version = 'v1'\n component = 'networks'\n scope_template = \"projects/{}/global/networks\"\n\n\[email protected]('subnet')\nclass Subnet(QueryResourceManager):\n\n class resource_type(TypeInfo):\n service = 'compute'\n version = 'v1'\n component = 'networks'\n enum_spec = ('aggregatedList', 'items.*.subnetworks[]', None)\n scope_template = \"projects/{}/aggregated/subnetworks\"\n\n\[email protected]('firewall')\nclass Firewall(QueryResourceManager):\n\n class resource_type(TypeInfo):\n service = 'compute'\n version = 'v1'\n component = 'firewalls'\n\n\[email protected]('router')\nclass Router(QueryResourceManager):\n\n class resource_type(TypeInfo):\n service = 'compute'\n version = 'v1'\n component = 'routers'\n enum_spec = ('aggregatedList', 'items.*.routers[]', None)\n scope_template = \"projects/{}/aggregated/routers\"\n\n\[email protected]('route')\nclass Route(QueryResourceManager):\n\n class resource_type(TypeInfo):\n service = 'compute'\n version = 'v1'\n component = 'routes'\n scope_template = \"projects/{}/global/routes\"\n", "path": "tools/c7n_gcp/c7n_gcp/resources/network.py"}]}
| 918 | 135 |
gh_patches_debug_32966
|
rasdani/github-patches
|
git_diff
|
rotki__rotki-160
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Providing a non-existing argument should fail gracefully
## Problem Definition
When a non-existing argument is provided to rotkehlchen at the moment an exception is thrown.
```
__main__.py: error: unrecognized arguments: --lol
CRITICAL:root:Traceback (most recent call last):
File "/home/lefteris/w/rotkehlchen/rotkehlchen/__main__.py", line 12, in main
rotkehlchen_server = RotkehlchenServer()
File "/home/lefteris/w/rotkehlchen/rotkehlchen/server.py", line 25, in __init__
self.args = app_args()
File "/home/lefteris/w/rotkehlchen/rotkehlchen/args.py", line 91, in app_args
args = p.parse_args()
File "/usr/lib64/python3.7/argparse.py", line 1752, in parse_args
self.error(msg % ' '.join(argv))
File "/usr/lib64/python3.7/argparse.py", line 2501, in error
self.exit(2, _('%(prog)s: error: %(message)s\n') % args)
File "/usr/lib64/python3.7/argparse.py", line 2488, in exit
_sys.exit(status)
SystemExit: 2
```
## Task
Instead of throwing an exception, an error message should be displayed and the program should exit gracefully.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `rotkehlchen/__main__.py`
Content:
```
1 from gevent import monkey
2 monkey.patch_all()
3 import logging
4 logger = logging.getLogger(__name__)
5
6
7 def main():
8 import traceback
9 import sys
10 from rotkehlchen.server import RotkehlchenServer
11 try:
12 rotkehlchen_server = RotkehlchenServer()
13 except SystemExit as e:
14 if e.code is None or e.code == 0:
15 sys.exit(0)
16 else:
17 tb = traceback.format_exc()
18 logging.critical(tb)
19 print("Failed to start rotkehlchen backend:\n{}".format(tb))
20 sys.exit(1)
21 except: # noqa
22 tb = traceback.format_exc()
23 logging.critical(tb)
24 print("Failed to start rotkehlchen backend:\n{}".format(tb))
25 sys.exit(1)
26
27 rotkehlchen_server.main()
28
29
30 if __name__ == '__main__':
31 main()
32
```
Path: `rotkehlchen/args.py`
Content:
```
1 #!/usr/bin/env python
2 import argparse
3 from rotkehlchen.config import default_data_directory
4
5
6 def app_args() -> argparse.Namespace:
7 """ Parse the arguments and create and return the arguments object"""
8 p = argparse.ArgumentParser(description='Rotkehlchen Crypto Portfolio Management')
9
10 p.add_argument(
11 '--output',
12 help=(
13 'A path to a file for logging all output. If nothing is given'
14 'stdout is used'
15 )
16 )
17 p.add_argument(
18 '--sleep-secs',
19 type=int,
20 default=20,
21 help="Seconds to sleep during the main loop"
22 )
23 p.add_argument(
24 '--notify',
25 action='store_true',
26 help=(
27 'If given then the tool will send notifications via '
28 'notify-send.'
29 )
30 )
31 p.add_argument(
32 '--data-dir',
33 help='The directory where all data and configs are placed',
34 default=default_data_directory()
35 )
36 p.add_argument(
37 '--zerorpc-port',
38 help='The port on which to open a zerorpc server for communication with the UI',
39 default=4242
40 )
41 p.add_argument(
42 '--ethrpc-port',
43 help="The port on which to communicate with an ethereum client's RPC.",
44 default=8545,
45 )
46 p.add_argument(
47 '--logfile',
48 help='The name of the file to write log entries to',
49 default='rotkehlchen.log',
50 )
51 p.add_argument(
52 '--logtarget',
53 help='Choose where logging entries will be sent. Valid values are "file and "stdout"',
54 choices=['stdout', 'file'],
55 default='file',
56 )
57 p.add_argument(
58 '--loglevel',
59 help='Choose the logging level',
60 choices=['debug', 'info', 'warn', 'error', 'critical'],
61 default='debug'
62 )
63 p.add_argument(
64 '--logfromothermodules',
65 help=(
66 'If given then logs from all imported modules that use the '
67 'logging system will also be visible.'
68 ),
69 action='store_true',
70 )
71
72 args = p.parse_args()
73
74 return args
75
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/rotkehlchen/__main__.py b/rotkehlchen/__main__.py
--- a/rotkehlchen/__main__.py
+++ b/rotkehlchen/__main__.py
@@ -1,6 +1,8 @@
+import logging
+
from gevent import monkey
+
monkey.patch_all()
-import logging
logger = logging.getLogger(__name__)
@@ -11,8 +13,10 @@
try:
rotkehlchen_server = RotkehlchenServer()
except SystemExit as e:
- if e.code is None or e.code == 0:
- sys.exit(0)
+ if e.code is None or e.code == 0 or e.code == 2:
+ # exit_code 2 is for invalid arguments
+ exit_code = 0 if e.code is None else e.code
+ sys.exit(exit_code)
else:
tb = traceback.format_exc()
logging.critical(tb)
diff --git a/rotkehlchen/args.py b/rotkehlchen/args.py
--- a/rotkehlchen/args.py
+++ b/rotkehlchen/args.py
@@ -1,11 +1,28 @@
#!/usr/bin/env python
import argparse
+import sys
+
from rotkehlchen.config import default_data_directory
+from rotkehlchen.utils import get_system_spec
+
+
+class VersionAction(argparse.Action):
+ def __init__(self, option_strings, dest, nargs=None, required=False, **kwargs):
+ if nargs is not None:
+ raise ValueError("nargs not allowed")
+ super().__init__(option_strings, dest, **kwargs)
+
+ def __call__(self, parser, namespace, values, option_string=None):
+ print(get_system_spec()['rotkehlchen'])
+ sys.exit(0)
def app_args() -> argparse.Namespace:
""" Parse the arguments and create and return the arguments object"""
- p = argparse.ArgumentParser(description='Rotkehlchen Crypto Portfolio Management')
+ p = argparse.ArgumentParser(
+ prog='rotkehlchen',
+ description='Rotkehlchen Crypto Portfolio Management',
+ )
p.add_argument(
'--output',
@@ -68,6 +85,11 @@
),
action='store_true',
)
+ p.add_argument(
+ 'version',
+ help='Shows the rotkehlchen version',
+ action=VersionAction,
+ )
args = p.parse_args()
|
{"golden_diff": "diff --git a/rotkehlchen/__main__.py b/rotkehlchen/__main__.py\n--- a/rotkehlchen/__main__.py\n+++ b/rotkehlchen/__main__.py\n@@ -1,6 +1,8 @@\n+import logging\n+\n from gevent import monkey\n+\n monkey.patch_all()\n-import logging\n logger = logging.getLogger(__name__)\n \n \n@@ -11,8 +13,10 @@\n try:\n rotkehlchen_server = RotkehlchenServer()\n except SystemExit as e:\n- if e.code is None or e.code == 0:\n- sys.exit(0)\n+ if e.code is None or e.code == 0 or e.code == 2:\n+ # exit_code 2 is for invalid arguments\n+ exit_code = 0 if e.code is None else e.code\n+ sys.exit(exit_code)\n else:\n tb = traceback.format_exc()\n logging.critical(tb)\ndiff --git a/rotkehlchen/args.py b/rotkehlchen/args.py\n--- a/rotkehlchen/args.py\n+++ b/rotkehlchen/args.py\n@@ -1,11 +1,28 @@\n #!/usr/bin/env python\n import argparse\n+import sys\n+\n from rotkehlchen.config import default_data_directory\n+from rotkehlchen.utils import get_system_spec\n+\n+\n+class VersionAction(argparse.Action):\n+ def __init__(self, option_strings, dest, nargs=None, required=False, **kwargs):\n+ if nargs is not None:\n+ raise ValueError(\"nargs not allowed\")\n+ super().__init__(option_strings, dest, **kwargs)\n+\n+ def __call__(self, parser, namespace, values, option_string=None):\n+ print(get_system_spec()['rotkehlchen'])\n+ sys.exit(0)\n \n \n def app_args() -> argparse.Namespace:\n \"\"\" Parse the arguments and create and return the arguments object\"\"\"\n- p = argparse.ArgumentParser(description='Rotkehlchen Crypto Portfolio Management')\n+ p = argparse.ArgumentParser(\n+ prog='rotkehlchen',\n+ description='Rotkehlchen Crypto Portfolio Management',\n+ )\n \n p.add_argument(\n '--output',\n@@ -68,6 +85,11 @@\n ),\n action='store_true',\n )\n+ p.add_argument(\n+ 'version',\n+ help='Shows the rotkehlchen version',\n+ action=VersionAction,\n+ )\n \n args = p.parse_args()\n", "issue": "Providing a non-existing argument should fail gracefully\n## Problem Definition\r\n\r\nWhen a non-existing argument is provided to rotkehlchen at the moment an exception is thrown.\r\n\r\n```\r\n__main__.py: error: unrecognized arguments: --lol \r\nCRITICAL:root:Traceback (most recent call last): \r\n File \"/home/lefteris/w/rotkehlchen/rotkehlchen/__main__.py\", line 12, in main\r\n rotkehlchen_server = RotkehlchenServer()\r\n File \"/home/lefteris/w/rotkehlchen/rotkehlchen/server.py\", line 25, in __init__\r\n self.args = app_args()\r\n File \"/home/lefteris/w/rotkehlchen/rotkehlchen/args.py\", line 91, in app_args\r\n args = p.parse_args()\r\n File \"/usr/lib64/python3.7/argparse.py\", line 1752, in parse_args\r\n self.error(msg % ' '.join(argv))\r\n File \"/usr/lib64/python3.7/argparse.py\", line 2501, in error\r\n self.exit(2, _('%(prog)s: error: %(message)s\\n') % args)\r\n File \"/usr/lib64/python3.7/argparse.py\", line 2488, in exit\r\n _sys.exit(status)\r\nSystemExit: 2\r\n```\r\n\r\n\r\n\r\n## Task\r\n\r\nInstead of throwing an exception, an error message should be displayed and the program should exit gracefully.\n", "before_files": [{"content": "from gevent import monkey\nmonkey.patch_all()\nimport logging\nlogger = logging.getLogger(__name__)\n\n\ndef main():\n import traceback\n import sys\n from rotkehlchen.server import RotkehlchenServer\n try:\n rotkehlchen_server = RotkehlchenServer()\n except SystemExit as e:\n if e.code is None or e.code == 0:\n sys.exit(0)\n else:\n tb = traceback.format_exc()\n logging.critical(tb)\n print(\"Failed to start rotkehlchen backend:\\n{}\".format(tb))\n sys.exit(1)\n except: # noqa\n tb = traceback.format_exc()\n logging.critical(tb)\n print(\"Failed to start rotkehlchen backend:\\n{}\".format(tb))\n sys.exit(1)\n\n rotkehlchen_server.main()\n\n\nif __name__ == '__main__':\n main()\n", "path": "rotkehlchen/__main__.py"}, {"content": "#!/usr/bin/env python\nimport argparse\nfrom rotkehlchen.config import default_data_directory\n\n\ndef app_args() -> argparse.Namespace:\n \"\"\" Parse the arguments and create and return the arguments object\"\"\"\n p = argparse.ArgumentParser(description='Rotkehlchen Crypto Portfolio Management')\n\n p.add_argument(\n '--output',\n help=(\n 'A path to a file for logging all output. If nothing is given'\n 'stdout is used'\n )\n )\n p.add_argument(\n '--sleep-secs',\n type=int,\n default=20,\n help=\"Seconds to sleep during the main loop\"\n )\n p.add_argument(\n '--notify',\n action='store_true',\n help=(\n 'If given then the tool will send notifications via '\n 'notify-send.'\n )\n )\n p.add_argument(\n '--data-dir',\n help='The directory where all data and configs are placed',\n default=default_data_directory()\n )\n p.add_argument(\n '--zerorpc-port',\n help='The port on which to open a zerorpc server for communication with the UI',\n default=4242\n )\n p.add_argument(\n '--ethrpc-port',\n help=\"The port on which to communicate with an ethereum client's RPC.\",\n default=8545,\n )\n p.add_argument(\n '--logfile',\n help='The name of the file to write log entries to',\n default='rotkehlchen.log',\n )\n p.add_argument(\n '--logtarget',\n help='Choose where logging entries will be sent. Valid values are \"file and \"stdout\"',\n choices=['stdout', 'file'],\n default='file',\n )\n p.add_argument(\n '--loglevel',\n help='Choose the logging level',\n choices=['debug', 'info', 'warn', 'error', 'critical'],\n default='debug'\n )\n p.add_argument(\n '--logfromothermodules',\n help=(\n 'If given then logs from all imported modules that use the '\n 'logging system will also be visible.'\n ),\n action='store_true',\n )\n\n args = p.parse_args()\n\n return args\n", "path": "rotkehlchen/args.py"}], "after_files": [{"content": "import logging\n\nfrom gevent import monkey\n\nmonkey.patch_all()\nlogger = logging.getLogger(__name__)\n\n\ndef main():\n import traceback\n import sys\n from rotkehlchen.server import RotkehlchenServer\n try:\n rotkehlchen_server = RotkehlchenServer()\n except SystemExit as e:\n if e.code is None or e.code == 0 or e.code == 2:\n # exit_code 2 is for invalid arguments\n exit_code = 0 if e.code is None else e.code\n sys.exit(exit_code)\n else:\n tb = traceback.format_exc()\n logging.critical(tb)\n print(\"Failed to start rotkehlchen backend:\\n{}\".format(tb))\n sys.exit(1)\n except: # noqa\n tb = traceback.format_exc()\n logging.critical(tb)\n print(\"Failed to start rotkehlchen backend:\\n{}\".format(tb))\n sys.exit(1)\n\n rotkehlchen_server.main()\n\n\nif __name__ == '__main__':\n main()\n", "path": "rotkehlchen/__main__.py"}, {"content": "#!/usr/bin/env python\nimport argparse\nimport sys\n\nfrom rotkehlchen.config import default_data_directory\nfrom rotkehlchen.utils import get_system_spec\n\n\nclass VersionAction(argparse.Action):\n def __init__(self, option_strings, dest, nargs=None, required=False, **kwargs):\n if nargs is not None:\n raise ValueError(\"nargs not allowed\")\n super().__init__(option_strings, dest, **kwargs)\n\n def __call__(self, parser, namespace, values, option_string=None):\n print(get_system_spec()['rotkehlchen'])\n sys.exit(0)\n\n\ndef app_args() -> argparse.Namespace:\n \"\"\" Parse the arguments and create and return the arguments object\"\"\"\n p = argparse.ArgumentParser(\n prog='rotkehlchen',\n description='Rotkehlchen Crypto Portfolio Management',\n )\n\n p.add_argument(\n '--output',\n help=(\n 'A path to a file for logging all output. If nothing is given'\n 'stdout is used'\n )\n )\n p.add_argument(\n '--sleep-secs',\n type=int,\n default=20,\n help=\"Seconds to sleep during the main loop\"\n )\n p.add_argument(\n '--notify',\n action='store_true',\n help=(\n 'If given then the tool will send notifications via '\n 'notify-send.'\n )\n )\n p.add_argument(\n '--data-dir',\n help='The directory where all data and configs are placed',\n default=default_data_directory()\n )\n p.add_argument(\n '--zerorpc-port',\n help='The port on which to open a zerorpc server for communication with the UI',\n default=4242\n )\n p.add_argument(\n '--ethrpc-port',\n help=\"The port on which to communicate with an ethereum client's RPC.\",\n default=8545,\n )\n p.add_argument(\n '--logfile',\n help='The name of the file to write log entries to',\n default='rotkehlchen.log',\n )\n p.add_argument(\n '--logtarget',\n help='Choose where logging entries will be sent. Valid values are \"file and \"stdout\"',\n choices=['stdout', 'file'],\n default='file',\n )\n p.add_argument(\n '--loglevel',\n help='Choose the logging level',\n choices=['debug', 'info', 'warn', 'error', 'critical'],\n default='debug'\n )\n p.add_argument(\n '--logfromothermodules',\n help=(\n 'If given then logs from all imported modules that use the '\n 'logging system will also be visible.'\n ),\n action='store_true',\n )\n p.add_argument(\n 'version',\n help='Shows the rotkehlchen version',\n action=VersionAction,\n )\n\n args = p.parse_args()\n\n return args\n", "path": "rotkehlchen/args.py"}]}
| 1,470 | 552 |
gh_patches_debug_8577
|
rasdani/github-patches
|
git_diff
|
mitmproxy__mitmproxy-2642
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug in expected_http_body_size
##### Steps to reproduce the problem:
1. Any response with more than one content-length header
##### Any other comments? What have you tried so far?
headers is MultiDict so this:
size = int(headers["content-length"])
can be change to:
size = int(headers.get_all("content-length")[0])
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mitmproxy/net/http/http1/read.py`
Content:
```
1 import time
2 import sys
3 import re
4
5 from mitmproxy.net.http import request
6 from mitmproxy.net.http import response
7 from mitmproxy.net.http import headers
8 from mitmproxy.net.http import url
9 from mitmproxy.net import check
10 from mitmproxy import exceptions
11
12
13 def get_header_tokens(headers, key):
14 """
15 Retrieve all tokens for a header key. A number of different headers
16 follow a pattern where each header line can containe comma-separated
17 tokens, and headers can be set multiple times.
18 """
19 if key not in headers:
20 return []
21 tokens = headers[key].split(",")
22 return [token.strip() for token in tokens]
23
24
25 def read_request(rfile, body_size_limit=None):
26 request = read_request_head(rfile)
27 expected_body_size = expected_http_body_size(request)
28 request.data.content = b"".join(read_body(rfile, expected_body_size, limit=body_size_limit))
29 request.timestamp_end = time.time()
30 return request
31
32
33 def read_request_head(rfile):
34 """
35 Parse an HTTP request head (request line + headers) from an input stream
36
37 Args:
38 rfile: The input stream
39
40 Returns:
41 The HTTP request object (without body)
42
43 Raises:
44 exceptions.HttpReadDisconnect: No bytes can be read from rfile.
45 exceptions.HttpSyntaxException: The input is malformed HTTP.
46 exceptions.HttpException: Any other error occured.
47 """
48 timestamp_start = time.time()
49 if hasattr(rfile, "reset_timestamps"):
50 rfile.reset_timestamps()
51
52 form, method, scheme, host, port, path, http_version = _read_request_line(rfile)
53 headers = _read_headers(rfile)
54
55 if hasattr(rfile, "first_byte_timestamp"):
56 # more accurate timestamp_start
57 timestamp_start = rfile.first_byte_timestamp
58
59 return request.Request(
60 form, method, scheme, host, port, path, http_version, headers, None, timestamp_start
61 )
62
63
64 def read_response(rfile, request, body_size_limit=None):
65 response = read_response_head(rfile)
66 expected_body_size = expected_http_body_size(request, response)
67 response.data.content = b"".join(read_body(rfile, expected_body_size, body_size_limit))
68 response.timestamp_end = time.time()
69 return response
70
71
72 def read_response_head(rfile):
73 """
74 Parse an HTTP response head (response line + headers) from an input stream
75
76 Args:
77 rfile: The input stream
78
79 Returns:
80 The HTTP request object (without body)
81
82 Raises:
83 exceptions.HttpReadDisconnect: No bytes can be read from rfile.
84 exceptions.HttpSyntaxException: The input is malformed HTTP.
85 exceptions.HttpException: Any other error occured.
86 """
87
88 timestamp_start = time.time()
89 if hasattr(rfile, "reset_timestamps"):
90 rfile.reset_timestamps()
91
92 http_version, status_code, message = _read_response_line(rfile)
93 headers = _read_headers(rfile)
94
95 if hasattr(rfile, "first_byte_timestamp"):
96 # more accurate timestamp_start
97 timestamp_start = rfile.first_byte_timestamp
98
99 return response.Response(http_version, status_code, message, headers, None, timestamp_start)
100
101
102 def read_body(rfile, expected_size, limit=None, max_chunk_size=4096):
103 """
104 Read an HTTP message body
105
106 Args:
107 rfile: The input stream
108 expected_size: The expected body size (see :py:meth:`expected_body_size`)
109 limit: Maximum body size
110 max_chunk_size: Maximium chunk size that gets yielded
111
112 Returns:
113 A generator that yields byte chunks of the content.
114
115 Raises:
116 exceptions.HttpException, if an error occurs
117
118 Caveats:
119 max_chunk_size is not considered if the transfer encoding is chunked.
120 """
121 if not limit or limit < 0:
122 limit = sys.maxsize
123 if not max_chunk_size:
124 max_chunk_size = limit
125
126 if expected_size is None:
127 for x in _read_chunked(rfile, limit):
128 yield x
129 elif expected_size >= 0:
130 if limit is not None and expected_size > limit:
131 raise exceptions.HttpException(
132 "HTTP Body too large. "
133 "Limit is {}, content length was advertised as {}".format(limit, expected_size)
134 )
135 bytes_left = expected_size
136 while bytes_left:
137 chunk_size = min(bytes_left, max_chunk_size)
138 content = rfile.read(chunk_size)
139 if len(content) < chunk_size:
140 raise exceptions.HttpException("Unexpected EOF")
141 yield content
142 bytes_left -= chunk_size
143 else:
144 bytes_left = limit
145 while bytes_left:
146 chunk_size = min(bytes_left, max_chunk_size)
147 content = rfile.read(chunk_size)
148 if not content:
149 return
150 yield content
151 bytes_left -= chunk_size
152 not_done = rfile.read(1)
153 if not_done:
154 raise exceptions.HttpException("HTTP body too large. Limit is {}.".format(limit))
155
156
157 def connection_close(http_version, headers):
158 """
159 Checks the message to see if the client connection should be closed
160 according to RFC 2616 Section 8.1.
161 If we don't have a Connection header, HTTP 1.1 connections are assumed
162 to be persistent.
163 """
164 if "connection" in headers:
165 tokens = get_header_tokens(headers, "connection")
166 if "close" in tokens:
167 return True
168 elif "keep-alive" in tokens:
169 return False
170
171 return http_version != "HTTP/1.1" and http_version != b"HTTP/1.1"
172
173
174 def expected_http_body_size(request, response=None):
175 """
176 Returns:
177 The expected body length:
178 - a positive integer, if the size is known in advance
179 - None, if the size in unknown in advance (chunked encoding)
180 - -1, if all data should be read until end of stream.
181
182 Raises:
183 exceptions.HttpSyntaxException, if the content length header is invalid
184 """
185 # Determine response size according to
186 # http://tools.ietf.org/html/rfc7230#section-3.3
187 if not response:
188 headers = request.headers
189 response_code = None
190 is_request = True
191 else:
192 headers = response.headers
193 response_code = response.status_code
194 is_request = False
195
196 if is_request:
197 if headers.get("expect", "").lower() == "100-continue":
198 return 0
199 else:
200 if request.method.upper() == "HEAD":
201 return 0
202 if 100 <= response_code <= 199:
203 return 0
204 if response_code == 200 and request.method.upper() == "CONNECT":
205 return 0
206 if response_code in (204, 304):
207 return 0
208
209 if "chunked" in headers.get("transfer-encoding", "").lower():
210 return None
211 if "content-length" in headers:
212 try:
213 size = int(headers["content-length"])
214 if size < 0:
215 raise ValueError()
216 return size
217 except ValueError:
218 raise exceptions.HttpSyntaxException("Unparseable Content Length")
219 if is_request:
220 return 0
221 return -1
222
223
224 def _get_first_line(rfile):
225 try:
226 line = rfile.readline()
227 if line == b"\r\n" or line == b"\n":
228 # Possible leftover from previous message
229 line = rfile.readline()
230 except (exceptions.TcpDisconnect, exceptions.TlsException):
231 raise exceptions.HttpReadDisconnect("Remote disconnected")
232 if not line:
233 raise exceptions.HttpReadDisconnect("Remote disconnected")
234 return line.strip()
235
236
237 def _read_request_line(rfile):
238 try:
239 line = _get_first_line(rfile)
240 except exceptions.HttpReadDisconnect:
241 # We want to provide a better error message.
242 raise exceptions.HttpReadDisconnect("Client disconnected")
243
244 try:
245 method, path, http_version = line.split()
246
247 if path == b"*" or path.startswith(b"/"):
248 form = "relative"
249 scheme, host, port = None, None, None
250 elif method == b"CONNECT":
251 form = "authority"
252 host, port = _parse_authority_form(path)
253 scheme, path = None, None
254 else:
255 form = "absolute"
256 scheme, host, port, path = url.parse(path)
257
258 _check_http_version(http_version)
259 except ValueError:
260 raise exceptions.HttpSyntaxException("Bad HTTP request line: {}".format(line))
261
262 return form, method, scheme, host, port, path, http_version
263
264
265 def _parse_authority_form(hostport):
266 """
267 Returns (host, port) if hostport is a valid authority-form host specification.
268 http://tools.ietf.org/html/draft-luotonen-web-proxy-tunneling-01 section 3.1
269
270 Raises:
271 ValueError, if the input is malformed
272 """
273 try:
274 host, port = hostport.rsplit(b":", 1)
275 if host.startswith(b"[") and host.endswith(b"]"):
276 host = host[1:-1]
277 port = int(port)
278 if not check.is_valid_host(host) or not check.is_valid_port(port):
279 raise ValueError()
280 except ValueError:
281 raise exceptions.HttpSyntaxException("Invalid host specification: {}".format(hostport))
282
283 return host, port
284
285
286 def _read_response_line(rfile):
287 try:
288 line = _get_first_line(rfile)
289 except exceptions.HttpReadDisconnect:
290 # We want to provide a better error message.
291 raise exceptions.HttpReadDisconnect("Server disconnected")
292
293 try:
294 parts = line.split(None, 2)
295 if len(parts) == 2: # handle missing message gracefully
296 parts.append(b"")
297
298 http_version, status_code, message = parts
299 status_code = int(status_code)
300 _check_http_version(http_version)
301
302 except ValueError:
303 raise exceptions.HttpSyntaxException("Bad HTTP response line: {}".format(line))
304
305 return http_version, status_code, message
306
307
308 def _check_http_version(http_version):
309 if not re.match(br"^HTTP/\d\.\d$", http_version):
310 raise exceptions.HttpSyntaxException("Unknown HTTP version: {}".format(http_version))
311
312
313 def _read_headers(rfile):
314 """
315 Read a set of headers.
316 Stop once a blank line is reached.
317
318 Returns:
319 A headers object
320
321 Raises:
322 exceptions.HttpSyntaxException
323 """
324 ret = []
325 while True:
326 line = rfile.readline()
327 if not line or line == b"\r\n" or line == b"\n":
328 break
329 if line[0] in b" \t":
330 if not ret:
331 raise exceptions.HttpSyntaxException("Invalid headers")
332 # continued header
333 ret[-1] = (ret[-1][0], ret[-1][1] + b'\r\n ' + line.strip())
334 else:
335 try:
336 name, value = line.split(b":", 1)
337 value = value.strip()
338 if not name:
339 raise ValueError()
340 ret.append((name, value))
341 except ValueError:
342 raise exceptions.HttpSyntaxException(
343 "Invalid header line: %s" % repr(line)
344 )
345 return headers.Headers(ret)
346
347
348 def _read_chunked(rfile, limit=sys.maxsize):
349 """
350 Read a HTTP body with chunked transfer encoding.
351
352 Args:
353 rfile: the input file
354 limit: A positive integer
355 """
356 total = 0
357 while True:
358 line = rfile.readline(128)
359 if line == b"":
360 raise exceptions.HttpException("Connection closed prematurely")
361 if line != b"\r\n" and line != b"\n":
362 try:
363 length = int(line, 16)
364 except ValueError:
365 raise exceptions.HttpSyntaxException("Invalid chunked encoding length: {}".format(line))
366 total += length
367 if total > limit:
368 raise exceptions.HttpException(
369 "HTTP Body too large. Limit is {}, "
370 "chunked content longer than {}".format(limit, total)
371 )
372 chunk = rfile.read(length)
373 suffix = rfile.readline(5)
374 if suffix != b"\r\n":
375 raise exceptions.HttpSyntaxException("Malformed chunked body")
376 if length == 0:
377 return
378 yield chunk
379
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mitmproxy/net/http/http1/read.py b/mitmproxy/net/http/http1/read.py
--- a/mitmproxy/net/http/http1/read.py
+++ b/mitmproxy/net/http/http1/read.py
@@ -210,7 +210,11 @@
return None
if "content-length" in headers:
try:
- size = int(headers["content-length"])
+ sizes = headers.get_all("content-length")
+ different_content_length_headers = any(x != sizes[0] for x in sizes)
+ if different_content_length_headers:
+ raise exceptions.HttpSyntaxException("Conflicting Content Length Headers")
+ size = int(sizes[0])
if size < 0:
raise ValueError()
return size
|
{"golden_diff": "diff --git a/mitmproxy/net/http/http1/read.py b/mitmproxy/net/http/http1/read.py\n--- a/mitmproxy/net/http/http1/read.py\n+++ b/mitmproxy/net/http/http1/read.py\n@@ -210,7 +210,11 @@\n return None\n if \"content-length\" in headers:\n try:\n- size = int(headers[\"content-length\"])\n+ sizes = headers.get_all(\"content-length\")\n+ different_content_length_headers = any(x != sizes[0] for x in sizes)\n+ if different_content_length_headers:\n+ raise exceptions.HttpSyntaxException(\"Conflicting Content Length Headers\")\n+ size = int(sizes[0])\n if size < 0:\n raise ValueError()\n return size\n", "issue": "Bug in expected_http_body_size\n##### Steps to reproduce the problem:\r\n\r\n1. Any response with more than one content-length header\r\n\r\n\r\n##### Any other comments? What have you tried so far?\r\n\r\nheaders is MultiDict so this:\r\nsize = int(headers[\"content-length\"])\r\ncan be change to:\r\nsize = int(headers.get_all(\"content-length\")[0])\n", "before_files": [{"content": "import time\nimport sys\nimport re\n\nfrom mitmproxy.net.http import request\nfrom mitmproxy.net.http import response\nfrom mitmproxy.net.http import headers\nfrom mitmproxy.net.http import url\nfrom mitmproxy.net import check\nfrom mitmproxy import exceptions\n\n\ndef get_header_tokens(headers, key):\n \"\"\"\n Retrieve all tokens for a header key. A number of different headers\n follow a pattern where each header line can containe comma-separated\n tokens, and headers can be set multiple times.\n \"\"\"\n if key not in headers:\n return []\n tokens = headers[key].split(\",\")\n return [token.strip() for token in tokens]\n\n\ndef read_request(rfile, body_size_limit=None):\n request = read_request_head(rfile)\n expected_body_size = expected_http_body_size(request)\n request.data.content = b\"\".join(read_body(rfile, expected_body_size, limit=body_size_limit))\n request.timestamp_end = time.time()\n return request\n\n\ndef read_request_head(rfile):\n \"\"\"\n Parse an HTTP request head (request line + headers) from an input stream\n\n Args:\n rfile: The input stream\n\n Returns:\n The HTTP request object (without body)\n\n Raises:\n exceptions.HttpReadDisconnect: No bytes can be read from rfile.\n exceptions.HttpSyntaxException: The input is malformed HTTP.\n exceptions.HttpException: Any other error occured.\n \"\"\"\n timestamp_start = time.time()\n if hasattr(rfile, \"reset_timestamps\"):\n rfile.reset_timestamps()\n\n form, method, scheme, host, port, path, http_version = _read_request_line(rfile)\n headers = _read_headers(rfile)\n\n if hasattr(rfile, \"first_byte_timestamp\"):\n # more accurate timestamp_start\n timestamp_start = rfile.first_byte_timestamp\n\n return request.Request(\n form, method, scheme, host, port, path, http_version, headers, None, timestamp_start\n )\n\n\ndef read_response(rfile, request, body_size_limit=None):\n response = read_response_head(rfile)\n expected_body_size = expected_http_body_size(request, response)\n response.data.content = b\"\".join(read_body(rfile, expected_body_size, body_size_limit))\n response.timestamp_end = time.time()\n return response\n\n\ndef read_response_head(rfile):\n \"\"\"\n Parse an HTTP response head (response line + headers) from an input stream\n\n Args:\n rfile: The input stream\n\n Returns:\n The HTTP request object (without body)\n\n Raises:\n exceptions.HttpReadDisconnect: No bytes can be read from rfile.\n exceptions.HttpSyntaxException: The input is malformed HTTP.\n exceptions.HttpException: Any other error occured.\n \"\"\"\n\n timestamp_start = time.time()\n if hasattr(rfile, \"reset_timestamps\"):\n rfile.reset_timestamps()\n\n http_version, status_code, message = _read_response_line(rfile)\n headers = _read_headers(rfile)\n\n if hasattr(rfile, \"first_byte_timestamp\"):\n # more accurate timestamp_start\n timestamp_start = rfile.first_byte_timestamp\n\n return response.Response(http_version, status_code, message, headers, None, timestamp_start)\n\n\ndef read_body(rfile, expected_size, limit=None, max_chunk_size=4096):\n \"\"\"\n Read an HTTP message body\n\n Args:\n rfile: The input stream\n expected_size: The expected body size (see :py:meth:`expected_body_size`)\n limit: Maximum body size\n max_chunk_size: Maximium chunk size that gets yielded\n\n Returns:\n A generator that yields byte chunks of the content.\n\n Raises:\n exceptions.HttpException, if an error occurs\n\n Caveats:\n max_chunk_size is not considered if the transfer encoding is chunked.\n \"\"\"\n if not limit or limit < 0:\n limit = sys.maxsize\n if not max_chunk_size:\n max_chunk_size = limit\n\n if expected_size is None:\n for x in _read_chunked(rfile, limit):\n yield x\n elif expected_size >= 0:\n if limit is not None and expected_size > limit:\n raise exceptions.HttpException(\n \"HTTP Body too large. \"\n \"Limit is {}, content length was advertised as {}\".format(limit, expected_size)\n )\n bytes_left = expected_size\n while bytes_left:\n chunk_size = min(bytes_left, max_chunk_size)\n content = rfile.read(chunk_size)\n if len(content) < chunk_size:\n raise exceptions.HttpException(\"Unexpected EOF\")\n yield content\n bytes_left -= chunk_size\n else:\n bytes_left = limit\n while bytes_left:\n chunk_size = min(bytes_left, max_chunk_size)\n content = rfile.read(chunk_size)\n if not content:\n return\n yield content\n bytes_left -= chunk_size\n not_done = rfile.read(1)\n if not_done:\n raise exceptions.HttpException(\"HTTP body too large. Limit is {}.\".format(limit))\n\n\ndef connection_close(http_version, headers):\n \"\"\"\n Checks the message to see if the client connection should be closed\n according to RFC 2616 Section 8.1.\n If we don't have a Connection header, HTTP 1.1 connections are assumed\n to be persistent.\n \"\"\"\n if \"connection\" in headers:\n tokens = get_header_tokens(headers, \"connection\")\n if \"close\" in tokens:\n return True\n elif \"keep-alive\" in tokens:\n return False\n\n return http_version != \"HTTP/1.1\" and http_version != b\"HTTP/1.1\"\n\n\ndef expected_http_body_size(request, response=None):\n \"\"\"\n Returns:\n The expected body length:\n - a positive integer, if the size is known in advance\n - None, if the size in unknown in advance (chunked encoding)\n - -1, if all data should be read until end of stream.\n\n Raises:\n exceptions.HttpSyntaxException, if the content length header is invalid\n \"\"\"\n # Determine response size according to\n # http://tools.ietf.org/html/rfc7230#section-3.3\n if not response:\n headers = request.headers\n response_code = None\n is_request = True\n else:\n headers = response.headers\n response_code = response.status_code\n is_request = False\n\n if is_request:\n if headers.get(\"expect\", \"\").lower() == \"100-continue\":\n return 0\n else:\n if request.method.upper() == \"HEAD\":\n return 0\n if 100 <= response_code <= 199:\n return 0\n if response_code == 200 and request.method.upper() == \"CONNECT\":\n return 0\n if response_code in (204, 304):\n return 0\n\n if \"chunked\" in headers.get(\"transfer-encoding\", \"\").lower():\n return None\n if \"content-length\" in headers:\n try:\n size = int(headers[\"content-length\"])\n if size < 0:\n raise ValueError()\n return size\n except ValueError:\n raise exceptions.HttpSyntaxException(\"Unparseable Content Length\")\n if is_request:\n return 0\n return -1\n\n\ndef _get_first_line(rfile):\n try:\n line = rfile.readline()\n if line == b\"\\r\\n\" or line == b\"\\n\":\n # Possible leftover from previous message\n line = rfile.readline()\n except (exceptions.TcpDisconnect, exceptions.TlsException):\n raise exceptions.HttpReadDisconnect(\"Remote disconnected\")\n if not line:\n raise exceptions.HttpReadDisconnect(\"Remote disconnected\")\n return line.strip()\n\n\ndef _read_request_line(rfile):\n try:\n line = _get_first_line(rfile)\n except exceptions.HttpReadDisconnect:\n # We want to provide a better error message.\n raise exceptions.HttpReadDisconnect(\"Client disconnected\")\n\n try:\n method, path, http_version = line.split()\n\n if path == b\"*\" or path.startswith(b\"/\"):\n form = \"relative\"\n scheme, host, port = None, None, None\n elif method == b\"CONNECT\":\n form = \"authority\"\n host, port = _parse_authority_form(path)\n scheme, path = None, None\n else:\n form = \"absolute\"\n scheme, host, port, path = url.parse(path)\n\n _check_http_version(http_version)\n except ValueError:\n raise exceptions.HttpSyntaxException(\"Bad HTTP request line: {}\".format(line))\n\n return form, method, scheme, host, port, path, http_version\n\n\ndef _parse_authority_form(hostport):\n \"\"\"\n Returns (host, port) if hostport is a valid authority-form host specification.\n http://tools.ietf.org/html/draft-luotonen-web-proxy-tunneling-01 section 3.1\n\n Raises:\n ValueError, if the input is malformed\n \"\"\"\n try:\n host, port = hostport.rsplit(b\":\", 1)\n if host.startswith(b\"[\") and host.endswith(b\"]\"):\n host = host[1:-1]\n port = int(port)\n if not check.is_valid_host(host) or not check.is_valid_port(port):\n raise ValueError()\n except ValueError:\n raise exceptions.HttpSyntaxException(\"Invalid host specification: {}\".format(hostport))\n\n return host, port\n\n\ndef _read_response_line(rfile):\n try:\n line = _get_first_line(rfile)\n except exceptions.HttpReadDisconnect:\n # We want to provide a better error message.\n raise exceptions.HttpReadDisconnect(\"Server disconnected\")\n\n try:\n parts = line.split(None, 2)\n if len(parts) == 2: # handle missing message gracefully\n parts.append(b\"\")\n\n http_version, status_code, message = parts\n status_code = int(status_code)\n _check_http_version(http_version)\n\n except ValueError:\n raise exceptions.HttpSyntaxException(\"Bad HTTP response line: {}\".format(line))\n\n return http_version, status_code, message\n\n\ndef _check_http_version(http_version):\n if not re.match(br\"^HTTP/\\d\\.\\d$\", http_version):\n raise exceptions.HttpSyntaxException(\"Unknown HTTP version: {}\".format(http_version))\n\n\ndef _read_headers(rfile):\n \"\"\"\n Read a set of headers.\n Stop once a blank line is reached.\n\n Returns:\n A headers object\n\n Raises:\n exceptions.HttpSyntaxException\n \"\"\"\n ret = []\n while True:\n line = rfile.readline()\n if not line or line == b\"\\r\\n\" or line == b\"\\n\":\n break\n if line[0] in b\" \\t\":\n if not ret:\n raise exceptions.HttpSyntaxException(\"Invalid headers\")\n # continued header\n ret[-1] = (ret[-1][0], ret[-1][1] + b'\\r\\n ' + line.strip())\n else:\n try:\n name, value = line.split(b\":\", 1)\n value = value.strip()\n if not name:\n raise ValueError()\n ret.append((name, value))\n except ValueError:\n raise exceptions.HttpSyntaxException(\n \"Invalid header line: %s\" % repr(line)\n )\n return headers.Headers(ret)\n\n\ndef _read_chunked(rfile, limit=sys.maxsize):\n \"\"\"\n Read a HTTP body with chunked transfer encoding.\n\n Args:\n rfile: the input file\n limit: A positive integer\n \"\"\"\n total = 0\n while True:\n line = rfile.readline(128)\n if line == b\"\":\n raise exceptions.HttpException(\"Connection closed prematurely\")\n if line != b\"\\r\\n\" and line != b\"\\n\":\n try:\n length = int(line, 16)\n except ValueError:\n raise exceptions.HttpSyntaxException(\"Invalid chunked encoding length: {}\".format(line))\n total += length\n if total > limit:\n raise exceptions.HttpException(\n \"HTTP Body too large. Limit is {}, \"\n \"chunked content longer than {}\".format(limit, total)\n )\n chunk = rfile.read(length)\n suffix = rfile.readline(5)\n if suffix != b\"\\r\\n\":\n raise exceptions.HttpSyntaxException(\"Malformed chunked body\")\n if length == 0:\n return\n yield chunk\n", "path": "mitmproxy/net/http/http1/read.py"}], "after_files": [{"content": "import time\nimport sys\nimport re\n\nfrom mitmproxy.net.http import request\nfrom mitmproxy.net.http import response\nfrom mitmproxy.net.http import headers\nfrom mitmproxy.net.http import url\nfrom mitmproxy.net import check\nfrom mitmproxy import exceptions\n\n\ndef get_header_tokens(headers, key):\n \"\"\"\n Retrieve all tokens for a header key. A number of different headers\n follow a pattern where each header line can containe comma-separated\n tokens, and headers can be set multiple times.\n \"\"\"\n if key not in headers:\n return []\n tokens = headers[key].split(\",\")\n return [token.strip() for token in tokens]\n\n\ndef read_request(rfile, body_size_limit=None):\n request = read_request_head(rfile)\n expected_body_size = expected_http_body_size(request)\n request.data.content = b\"\".join(read_body(rfile, expected_body_size, limit=body_size_limit))\n request.timestamp_end = time.time()\n return request\n\n\ndef read_request_head(rfile):\n \"\"\"\n Parse an HTTP request head (request line + headers) from an input stream\n\n Args:\n rfile: The input stream\n\n Returns:\n The HTTP request object (without body)\n\n Raises:\n exceptions.HttpReadDisconnect: No bytes can be read from rfile.\n exceptions.HttpSyntaxException: The input is malformed HTTP.\n exceptions.HttpException: Any other error occured.\n \"\"\"\n timestamp_start = time.time()\n if hasattr(rfile, \"reset_timestamps\"):\n rfile.reset_timestamps()\n\n form, method, scheme, host, port, path, http_version = _read_request_line(rfile)\n headers = _read_headers(rfile)\n\n if hasattr(rfile, \"first_byte_timestamp\"):\n # more accurate timestamp_start\n timestamp_start = rfile.first_byte_timestamp\n\n return request.Request(\n form, method, scheme, host, port, path, http_version, headers, None, timestamp_start\n )\n\n\ndef read_response(rfile, request, body_size_limit=None):\n response = read_response_head(rfile)\n expected_body_size = expected_http_body_size(request, response)\n response.data.content = b\"\".join(read_body(rfile, expected_body_size, body_size_limit))\n response.timestamp_end = time.time()\n return response\n\n\ndef read_response_head(rfile):\n \"\"\"\n Parse an HTTP response head (response line + headers) from an input stream\n\n Args:\n rfile: The input stream\n\n Returns:\n The HTTP request object (without body)\n\n Raises:\n exceptions.HttpReadDisconnect: No bytes can be read from rfile.\n exceptions.HttpSyntaxException: The input is malformed HTTP.\n exceptions.HttpException: Any other error occured.\n \"\"\"\n\n timestamp_start = time.time()\n if hasattr(rfile, \"reset_timestamps\"):\n rfile.reset_timestamps()\n\n http_version, status_code, message = _read_response_line(rfile)\n headers = _read_headers(rfile)\n\n if hasattr(rfile, \"first_byte_timestamp\"):\n # more accurate timestamp_start\n timestamp_start = rfile.first_byte_timestamp\n\n return response.Response(http_version, status_code, message, headers, None, timestamp_start)\n\n\ndef read_body(rfile, expected_size, limit=None, max_chunk_size=4096):\n \"\"\"\n Read an HTTP message body\n\n Args:\n rfile: The input stream\n expected_size: The expected body size (see :py:meth:`expected_body_size`)\n limit: Maximum body size\n max_chunk_size: Maximium chunk size that gets yielded\n\n Returns:\n A generator that yields byte chunks of the content.\n\n Raises:\n exceptions.HttpException, if an error occurs\n\n Caveats:\n max_chunk_size is not considered if the transfer encoding is chunked.\n \"\"\"\n if not limit or limit < 0:\n limit = sys.maxsize\n if not max_chunk_size:\n max_chunk_size = limit\n\n if expected_size is None:\n for x in _read_chunked(rfile, limit):\n yield x\n elif expected_size >= 0:\n if limit is not None and expected_size > limit:\n raise exceptions.HttpException(\n \"HTTP Body too large. \"\n \"Limit is {}, content length was advertised as {}\".format(limit, expected_size)\n )\n bytes_left = expected_size\n while bytes_left:\n chunk_size = min(bytes_left, max_chunk_size)\n content = rfile.read(chunk_size)\n if len(content) < chunk_size:\n raise exceptions.HttpException(\"Unexpected EOF\")\n yield content\n bytes_left -= chunk_size\n else:\n bytes_left = limit\n while bytes_left:\n chunk_size = min(bytes_left, max_chunk_size)\n content = rfile.read(chunk_size)\n if not content:\n return\n yield content\n bytes_left -= chunk_size\n not_done = rfile.read(1)\n if not_done:\n raise exceptions.HttpException(\"HTTP body too large. Limit is {}.\".format(limit))\n\n\ndef connection_close(http_version, headers):\n \"\"\"\n Checks the message to see if the client connection should be closed\n according to RFC 2616 Section 8.1.\n If we don't have a Connection header, HTTP 1.1 connections are assumed\n to be persistent.\n \"\"\"\n if \"connection\" in headers:\n tokens = get_header_tokens(headers, \"connection\")\n if \"close\" in tokens:\n return True\n elif \"keep-alive\" in tokens:\n return False\n\n return http_version != \"HTTP/1.1\" and http_version != b\"HTTP/1.1\"\n\n\ndef expected_http_body_size(request, response=None):\n \"\"\"\n Returns:\n The expected body length:\n - a positive integer, if the size is known in advance\n - None, if the size in unknown in advance (chunked encoding)\n - -1, if all data should be read until end of stream.\n\n Raises:\n exceptions.HttpSyntaxException, if the content length header is invalid\n \"\"\"\n # Determine response size according to\n # http://tools.ietf.org/html/rfc7230#section-3.3\n if not response:\n headers = request.headers\n response_code = None\n is_request = True\n else:\n headers = response.headers\n response_code = response.status_code\n is_request = False\n\n if is_request:\n if headers.get(\"expect\", \"\").lower() == \"100-continue\":\n return 0\n else:\n if request.method.upper() == \"HEAD\":\n return 0\n if 100 <= response_code <= 199:\n return 0\n if response_code == 200 and request.method.upper() == \"CONNECT\":\n return 0\n if response_code in (204, 304):\n return 0\n\n if \"chunked\" in headers.get(\"transfer-encoding\", \"\").lower():\n return None\n if \"content-length\" in headers:\n try:\n sizes = headers.get_all(\"content-length\")\n different_content_length_headers = any(x != sizes[0] for x in sizes)\n if different_content_length_headers:\n raise exceptions.HttpSyntaxException(\"Conflicting Content Length Headers\")\n size = int(sizes[0])\n if size < 0:\n raise ValueError()\n return size\n except ValueError:\n raise exceptions.HttpSyntaxException(\"Unparseable Content Length\")\n if is_request:\n return 0\n return -1\n\n\ndef _get_first_line(rfile):\n try:\n line = rfile.readline()\n if line == b\"\\r\\n\" or line == b\"\\n\":\n # Possible leftover from previous message\n line = rfile.readline()\n except (exceptions.TcpDisconnect, exceptions.TlsException):\n raise exceptions.HttpReadDisconnect(\"Remote disconnected\")\n if not line:\n raise exceptions.HttpReadDisconnect(\"Remote disconnected\")\n return line.strip()\n\n\ndef _read_request_line(rfile):\n try:\n line = _get_first_line(rfile)\n except exceptions.HttpReadDisconnect:\n # We want to provide a better error message.\n raise exceptions.HttpReadDisconnect(\"Client disconnected\")\n\n try:\n method, path, http_version = line.split()\n\n if path == b\"*\" or path.startswith(b\"/\"):\n form = \"relative\"\n scheme, host, port = None, None, None\n elif method == b\"CONNECT\":\n form = \"authority\"\n host, port = _parse_authority_form(path)\n scheme, path = None, None\n else:\n form = \"absolute\"\n scheme, host, port, path = url.parse(path)\n\n _check_http_version(http_version)\n except ValueError:\n raise exceptions.HttpSyntaxException(\"Bad HTTP request line: {}\".format(line))\n\n return form, method, scheme, host, port, path, http_version\n\n\ndef _parse_authority_form(hostport):\n \"\"\"\n Returns (host, port) if hostport is a valid authority-form host specification.\n http://tools.ietf.org/html/draft-luotonen-web-proxy-tunneling-01 section 3.1\n\n Raises:\n ValueError, if the input is malformed\n \"\"\"\n try:\n host, port = hostport.rsplit(b\":\", 1)\n if host.startswith(b\"[\") and host.endswith(b\"]\"):\n host = host[1:-1]\n port = int(port)\n if not check.is_valid_host(host) or not check.is_valid_port(port):\n raise ValueError()\n except ValueError:\n raise exceptions.HttpSyntaxException(\"Invalid host specification: {}\".format(hostport))\n\n return host, port\n\n\ndef _read_response_line(rfile):\n try:\n line = _get_first_line(rfile)\n except exceptions.HttpReadDisconnect:\n # We want to provide a better error message.\n raise exceptions.HttpReadDisconnect(\"Server disconnected\")\n\n try:\n parts = line.split(None, 2)\n if len(parts) == 2: # handle missing message gracefully\n parts.append(b\"\")\n\n http_version, status_code, message = parts\n status_code = int(status_code)\n _check_http_version(http_version)\n\n except ValueError:\n raise exceptions.HttpSyntaxException(\"Bad HTTP response line: {}\".format(line))\n\n return http_version, status_code, message\n\n\ndef _check_http_version(http_version):\n if not re.match(br\"^HTTP/\\d\\.\\d$\", http_version):\n raise exceptions.HttpSyntaxException(\"Unknown HTTP version: {}\".format(http_version))\n\n\ndef _read_headers(rfile):\n \"\"\"\n Read a set of headers.\n Stop once a blank line is reached.\n\n Returns:\n A headers object\n\n Raises:\n exceptions.HttpSyntaxException\n \"\"\"\n ret = []\n while True:\n line = rfile.readline()\n if not line or line == b\"\\r\\n\" or line == b\"\\n\":\n break\n if line[0] in b\" \\t\":\n if not ret:\n raise exceptions.HttpSyntaxException(\"Invalid headers\")\n # continued header\n ret[-1] = (ret[-1][0], ret[-1][1] + b'\\r\\n ' + line.strip())\n else:\n try:\n name, value = line.split(b\":\", 1)\n value = value.strip()\n if not name:\n raise ValueError()\n ret.append((name, value))\n except ValueError:\n raise exceptions.HttpSyntaxException(\n \"Invalid header line: %s\" % repr(line)\n )\n return headers.Headers(ret)\n\n\ndef _read_chunked(rfile, limit=sys.maxsize):\n \"\"\"\n Read a HTTP body with chunked transfer encoding.\n\n Args:\n rfile: the input file\n limit: A positive integer\n \"\"\"\n total = 0\n while True:\n line = rfile.readline(128)\n if line == b\"\":\n raise exceptions.HttpException(\"Connection closed prematurely\")\n if line != b\"\\r\\n\" and line != b\"\\n\":\n try:\n length = int(line, 16)\n except ValueError:\n raise exceptions.HttpSyntaxException(\"Invalid chunked encoding length: {}\".format(line))\n total += length\n if total > limit:\n raise exceptions.HttpException(\n \"HTTP Body too large. Limit is {}, \"\n \"chunked content longer than {}\".format(limit, total)\n )\n chunk = rfile.read(length)\n suffix = rfile.readline(5)\n if suffix != b\"\\r\\n\":\n raise exceptions.HttpSyntaxException(\"Malformed chunked body\")\n if length == 0:\n return\n yield chunk\n", "path": "mitmproxy/net/http/http1/read.py"}]}
| 4,057 | 166 |
gh_patches_debug_11041
|
rasdani/github-patches
|
git_diff
|
cloud-custodian__cloud-custodian-4913
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
c7n-mailer - azure functions error when using SendGrid
Using a simple policy to queue a notification from the example [here](https://cloudcustodian.io/docs/tools/c7n-mailer.html#using-on-azure).
I see the following two errors:
1. Default Template
```
Invalid template reference default.j2
default.j2
```
2. Fetching contents of an object
```
local variable 'bpayload' referenced before assignment
Traceback (most recent call last):
File "/home/site/wwwroot/c7n_mailer/azure_mailer/sendgrid_delivery.py", line 129, in _sendgrid_mail_from_email_message
body = message.get_content()
AttributeError: 'MIMEText' object has no attribute 'get_content'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/site/wwwroot/c7n_mailer/azure_mailer/azure_queue_processor.py", line 137, in _deliver_email
return sendgrid_delivery.sendgrid_handler(queue_message, email_messages)
File "/home/site/wwwroot/c7n_mailer/azure_mailer/sendgrid_delivery.py", line 92, in sendgrid_handler
mail = SendGridDelivery._sendgrid_mail_from_email_message(message)
File "/home/site/wwwroot/c7n_mailer/azure_mailer/sendgrid_delivery.py", line 132, in _sendgrid_mail_from_email_message
body = message.get_payload(decode=True).decode('utf-8')
File "/usr/local/lib/python3.6/email/message.py", line 286, in get_payload
value, defects = decode_b(b''.join(bpayload.splitlines()))
UnboundLocalError: local variable 'bpayload' referenced before assignment
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `tools/c7n_mailer/c7n_mailer/azure_mailer/deploy.py`
Content:
```
1 # Copyright 2016-2017 Capital One Services, LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 from __future__ import (absolute_import, division, print_function,
15 unicode_literals)
16
17 import copy
18 import json
19 import logging
20 import os
21
22 try:
23 from c7n_azure.function_package import FunctionPackage
24 from c7n_azure.functionapp_utils import FunctionAppUtilities
25 from c7n_azure.policy import AzureFunctionMode
26 from c7n_azure.session import Session
27 from c7n_azure.utils import StringUtils
28 from c7n.utils import local_session
29 except ImportError:
30 FunctionPackage = None
31 pass
32
33
34 def cache_path():
35 return os.path.join(os.path.dirname(__file__), 'cache')
36
37
38 def build_function_package(config, function_name, sub_id):
39 schedule = config.get('function_schedule', '0 */10 * * * *')
40
41 cache_override_path = cache_path()
42
43 function_path = function_name + "_" + sub_id
44
45 # Build package
46 package = FunctionPackage(
47 function_name,
48 os.path.join(os.path.dirname(__file__), 'function.py'),
49 target_sub_ids=[sub_id],
50 cache_override_path=cache_override_path)
51
52 package.build(None,
53 modules=['c7n', 'c7n-azure', 'c7n-mailer'],
54 non_binary_packages=['pyyaml', 'pycparser', 'tabulate', 'jmespath',
55 'datadog', 'MarkupSafe', 'simplejson', 'pyrsistent'],
56 excluded_packages=['azure-cli-core', 'distlib', 'future', 'futures'])
57
58 package.pkg.add_contents(
59 function_path + '/function.json',
60 contents=package.get_function_config({'mode':
61 {'type': 'azure-periodic',
62 'schedule': schedule}}))
63
64 # Add mail templates
65 for d in set(config['templates_folders']):
66 if not os.path.exists(d):
67 continue
68 for t in [f for f in os.listdir(d) if os.path.splitext(f)[1] == '.j2']:
69 with open(os.path.join(d, t)) as fh:
70 package.pkg.add_contents(function_path + '/msg-templates/%s' % t, fh.read())
71
72 function_config = copy.deepcopy(config)
73 function_config['templates_folders'] = [function_path + '/msg-templates/']
74 package.pkg.add_contents(
75 function_path + '/config.json',
76 contents=json.dumps(function_config))
77
78 package.close()
79 return package
80
81
82 def provision(config):
83 log = logging.getLogger('c7n_mailer.azure.deploy')
84
85 function_name = config.get('function_name', 'mailer')
86 function_properties = config.get('function_properties', {})
87
88 # service plan is parse first, because its location might be shared with storage & insights
89 service_plan = AzureFunctionMode.extract_properties(function_properties,
90 'servicePlan',
91 {
92 'name': 'cloud-custodian',
93 'location': 'eastus',
94 'resource_group_name': 'cloud-custodian',
95 'sku_tier': 'Dynamic', # consumption plan
96 'sku_name': 'Y1'
97 })
98
99 location = service_plan.get('location', 'eastus')
100 rg_name = service_plan['resource_group_name']
101
102 sub_id = local_session(Session).get_subscription_id()
103 suffix = StringUtils.naming_hash(rg_name + sub_id)
104
105 storage_account = AzureFunctionMode.extract_properties(function_properties,
106 'storageAccount',
107 {'name': 'mailerstorage' + suffix,
108 'location': location,
109 'resource_group_name': rg_name})
110
111 app_insights = AzureFunctionMode.extract_properties(function_properties,
112 'appInsights',
113 {'name': service_plan['name'],
114 'location': location,
115 'resource_group_name': rg_name})
116
117 function_app_name = FunctionAppUtilities.get_function_name(
118 '-'.join([service_plan['name'], function_name]), suffix)
119 FunctionAppUtilities.validate_function_name(function_app_name)
120
121 params = FunctionAppUtilities.FunctionAppInfrastructureParameters(
122 app_insights=app_insights,
123 service_plan=service_plan,
124 storage_account=storage_account,
125 function_app_resource_group_name=service_plan['resource_group_name'],
126 function_app_name=function_app_name)
127
128 FunctionAppUtilities.deploy_function_app(params)
129
130 log.info("Building function package for %s" % function_app_name)
131 package = build_function_package(config, function_name, sub_id)
132
133 log.info("Function package built, size is %dMB" % (package.pkg.size / (1024 * 1024)))
134
135 FunctionAppUtilities.publish_functions_package(params, package)
136
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/tools/c7n_mailer/c7n_mailer/azure_mailer/deploy.py b/tools/c7n_mailer/c7n_mailer/azure_mailer/deploy.py
--- a/tools/c7n_mailer/c7n_mailer/azure_mailer/deploy.py
+++ b/tools/c7n_mailer/c7n_mailer/azure_mailer/deploy.py
@@ -70,7 +70,10 @@
package.pkg.add_contents(function_path + '/msg-templates/%s' % t, fh.read())
function_config = copy.deepcopy(config)
- function_config['templates_folders'] = [function_path + '/msg-templates/']
+
+ functions_full_template_path = '/home/site/wwwroot/' + function_path + '/msg-templates/'
+ function_config['templates_folders'] = [functions_full_template_path]
+
package.pkg.add_contents(
function_path + '/config.json',
contents=json.dumps(function_config))
|
{"golden_diff": "diff --git a/tools/c7n_mailer/c7n_mailer/azure_mailer/deploy.py b/tools/c7n_mailer/c7n_mailer/azure_mailer/deploy.py\n--- a/tools/c7n_mailer/c7n_mailer/azure_mailer/deploy.py\n+++ b/tools/c7n_mailer/c7n_mailer/azure_mailer/deploy.py\n@@ -70,7 +70,10 @@\n package.pkg.add_contents(function_path + '/msg-templates/%s' % t, fh.read())\n \n function_config = copy.deepcopy(config)\n- function_config['templates_folders'] = [function_path + '/msg-templates/']\n+\n+ functions_full_template_path = '/home/site/wwwroot/' + function_path + '/msg-templates/'\n+ function_config['templates_folders'] = [functions_full_template_path]\n+\n package.pkg.add_contents(\n function_path + '/config.json',\n contents=json.dumps(function_config))\n", "issue": "c7n-mailer - azure functions error when using SendGrid\nUsing a simple policy to queue a notification from the example [here](https://cloudcustodian.io/docs/tools/c7n-mailer.html#using-on-azure).\r\n\r\nI see the following two errors:\r\n\r\n1. Default Template\r\n```\r\nInvalid template reference default.j2\r\ndefault.j2\r\n```\r\n\r\n2. Fetching contents of an object\r\n```\r\nlocal variable 'bpayload' referenced before assignment\r\nTraceback (most recent call last):\r\n File \"/home/site/wwwroot/c7n_mailer/azure_mailer/sendgrid_delivery.py\", line 129, in _sendgrid_mail_from_email_message\r\n body = message.get_content()\r\nAttributeError: 'MIMEText' object has no attribute 'get_content'\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/home/site/wwwroot/c7n_mailer/azure_mailer/azure_queue_processor.py\", line 137, in _deliver_email\r\n return sendgrid_delivery.sendgrid_handler(queue_message, email_messages)\r\n File \"/home/site/wwwroot/c7n_mailer/azure_mailer/sendgrid_delivery.py\", line 92, in sendgrid_handler\r\n mail = SendGridDelivery._sendgrid_mail_from_email_message(message)\r\n File \"/home/site/wwwroot/c7n_mailer/azure_mailer/sendgrid_delivery.py\", line 132, in _sendgrid_mail_from_email_message\r\n body = message.get_payload(decode=True).decode('utf-8')\r\n File \"/usr/local/lib/python3.6/email/message.py\", line 286, in get_payload\r\n value, defects = decode_b(b''.join(bpayload.splitlines()))\r\nUnboundLocalError: local variable 'bpayload' referenced before assignment\r\n```\n", "before_files": [{"content": "# Copyright 2016-2017 Capital One Services, LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom __future__ import (absolute_import, division, print_function,\n unicode_literals)\n\nimport copy\nimport json\nimport logging\nimport os\n\ntry:\n from c7n_azure.function_package import FunctionPackage\n from c7n_azure.functionapp_utils import FunctionAppUtilities\n from c7n_azure.policy import AzureFunctionMode\n from c7n_azure.session import Session\n from c7n_azure.utils import StringUtils\n from c7n.utils import local_session\nexcept ImportError:\n FunctionPackage = None\n pass\n\n\ndef cache_path():\n return os.path.join(os.path.dirname(__file__), 'cache')\n\n\ndef build_function_package(config, function_name, sub_id):\n schedule = config.get('function_schedule', '0 */10 * * * *')\n\n cache_override_path = cache_path()\n\n function_path = function_name + \"_\" + sub_id\n\n # Build package\n package = FunctionPackage(\n function_name,\n os.path.join(os.path.dirname(__file__), 'function.py'),\n target_sub_ids=[sub_id],\n cache_override_path=cache_override_path)\n\n package.build(None,\n modules=['c7n', 'c7n-azure', 'c7n-mailer'],\n non_binary_packages=['pyyaml', 'pycparser', 'tabulate', 'jmespath',\n 'datadog', 'MarkupSafe', 'simplejson', 'pyrsistent'],\n excluded_packages=['azure-cli-core', 'distlib', 'future', 'futures'])\n\n package.pkg.add_contents(\n function_path + '/function.json',\n contents=package.get_function_config({'mode':\n {'type': 'azure-periodic',\n 'schedule': schedule}}))\n\n # Add mail templates\n for d in set(config['templates_folders']):\n if not os.path.exists(d):\n continue\n for t in [f for f in os.listdir(d) if os.path.splitext(f)[1] == '.j2']:\n with open(os.path.join(d, t)) as fh:\n package.pkg.add_contents(function_path + '/msg-templates/%s' % t, fh.read())\n\n function_config = copy.deepcopy(config)\n function_config['templates_folders'] = [function_path + '/msg-templates/']\n package.pkg.add_contents(\n function_path + '/config.json',\n contents=json.dumps(function_config))\n\n package.close()\n return package\n\n\ndef provision(config):\n log = logging.getLogger('c7n_mailer.azure.deploy')\n\n function_name = config.get('function_name', 'mailer')\n function_properties = config.get('function_properties', {})\n\n # service plan is parse first, because its location might be shared with storage & insights\n service_plan = AzureFunctionMode.extract_properties(function_properties,\n 'servicePlan',\n {\n 'name': 'cloud-custodian',\n 'location': 'eastus',\n 'resource_group_name': 'cloud-custodian',\n 'sku_tier': 'Dynamic', # consumption plan\n 'sku_name': 'Y1'\n })\n\n location = service_plan.get('location', 'eastus')\n rg_name = service_plan['resource_group_name']\n\n sub_id = local_session(Session).get_subscription_id()\n suffix = StringUtils.naming_hash(rg_name + sub_id)\n\n storage_account = AzureFunctionMode.extract_properties(function_properties,\n 'storageAccount',\n {'name': 'mailerstorage' + suffix,\n 'location': location,\n 'resource_group_name': rg_name})\n\n app_insights = AzureFunctionMode.extract_properties(function_properties,\n 'appInsights',\n {'name': service_plan['name'],\n 'location': location,\n 'resource_group_name': rg_name})\n\n function_app_name = FunctionAppUtilities.get_function_name(\n '-'.join([service_plan['name'], function_name]), suffix)\n FunctionAppUtilities.validate_function_name(function_app_name)\n\n params = FunctionAppUtilities.FunctionAppInfrastructureParameters(\n app_insights=app_insights,\n service_plan=service_plan,\n storage_account=storage_account,\n function_app_resource_group_name=service_plan['resource_group_name'],\n function_app_name=function_app_name)\n\n FunctionAppUtilities.deploy_function_app(params)\n\n log.info(\"Building function package for %s\" % function_app_name)\n package = build_function_package(config, function_name, sub_id)\n\n log.info(\"Function package built, size is %dMB\" % (package.pkg.size / (1024 * 1024)))\n\n FunctionAppUtilities.publish_functions_package(params, package)\n", "path": "tools/c7n_mailer/c7n_mailer/azure_mailer/deploy.py"}], "after_files": [{"content": "# Copyright 2016-2017 Capital One Services, LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom __future__ import (absolute_import, division, print_function,\n unicode_literals)\n\nimport copy\nimport json\nimport logging\nimport os\n\ntry:\n from c7n_azure.function_package import FunctionPackage\n from c7n_azure.functionapp_utils import FunctionAppUtilities\n from c7n_azure.policy import AzureFunctionMode\n from c7n_azure.session import Session\n from c7n_azure.utils import StringUtils\n from c7n.utils import local_session\nexcept ImportError:\n FunctionPackage = None\n pass\n\n\ndef cache_path():\n return os.path.join(os.path.dirname(__file__), 'cache')\n\n\ndef build_function_package(config, function_name, sub_id):\n schedule = config.get('function_schedule', '0 */10 * * * *')\n\n cache_override_path = cache_path()\n\n function_path = function_name + \"_\" + sub_id\n\n # Build package\n package = FunctionPackage(\n function_name,\n os.path.join(os.path.dirname(__file__), 'function.py'),\n target_sub_ids=[sub_id],\n cache_override_path=cache_override_path)\n\n package.build(None,\n modules=['c7n', 'c7n-azure', 'c7n-mailer'],\n non_binary_packages=['pyyaml', 'pycparser', 'tabulate', 'jmespath',\n 'datadog', 'MarkupSafe', 'simplejson', 'pyrsistent'],\n excluded_packages=['azure-cli-core', 'distlib', 'future', 'futures'])\n\n package.pkg.add_contents(\n function_path + '/function.json',\n contents=package.get_function_config({'mode':\n {'type': 'azure-periodic',\n 'schedule': schedule}}))\n\n # Add mail templates\n for d in set(config['templates_folders']):\n if not os.path.exists(d):\n continue\n for t in [f for f in os.listdir(d) if os.path.splitext(f)[1] == '.j2']:\n with open(os.path.join(d, t)) as fh:\n package.pkg.add_contents(function_path + '/msg-templates/%s' % t, fh.read())\n\n function_config = copy.deepcopy(config)\n\n functions_full_template_path = '/home/site/wwwroot/' + function_path + '/msg-templates/'\n function_config['templates_folders'] = [functions_full_template_path]\n\n package.pkg.add_contents(\n function_path + '/config.json',\n contents=json.dumps(function_config))\n\n package.close()\n return package\n\n\ndef provision(config):\n log = logging.getLogger('c7n_mailer.azure.deploy')\n\n function_name = config.get('function_name', 'mailer')\n function_properties = config.get('function_properties', {})\n\n # service plan is parse first, because its location might be shared with storage & insights\n service_plan = AzureFunctionMode.extract_properties(function_properties,\n 'servicePlan',\n {\n 'name': 'cloud-custodian',\n 'location': 'eastus',\n 'resource_group_name': 'cloud-custodian',\n 'sku_tier': 'Dynamic', # consumption plan\n 'sku_name': 'Y1'\n })\n\n location = service_plan.get('location', 'eastus')\n rg_name = service_plan['resource_group_name']\n\n sub_id = local_session(Session).get_subscription_id()\n suffix = StringUtils.naming_hash(rg_name + sub_id)\n\n storage_account = AzureFunctionMode.extract_properties(function_properties,\n 'storageAccount',\n {'name': 'mailerstorage' + suffix,\n 'location': location,\n 'resource_group_name': rg_name})\n\n app_insights = AzureFunctionMode.extract_properties(function_properties,\n 'appInsights',\n {'name': service_plan['name'],\n 'location': location,\n 'resource_group_name': rg_name})\n\n function_app_name = FunctionAppUtilities.get_function_name(\n '-'.join([service_plan['name'], function_name]), suffix)\n FunctionAppUtilities.validate_function_name(function_app_name)\n\n params = FunctionAppUtilities.FunctionAppInfrastructureParameters(\n app_insights=app_insights,\n service_plan=service_plan,\n storage_account=storage_account,\n function_app_resource_group_name=service_plan['resource_group_name'],\n function_app_name=function_app_name)\n\n FunctionAppUtilities.deploy_function_app(params)\n\n log.info(\"Building function package for %s\" % function_app_name)\n package = build_function_package(config, function_name, sub_id)\n\n log.info(\"Function package built, size is %dMB\" % (package.pkg.size / (1024 * 1024)))\n\n FunctionAppUtilities.publish_functions_package(params, package)\n", "path": "tools/c7n_mailer/c7n_mailer/azure_mailer/deploy.py"}]}
| 2,068 | 206 |
gh_patches_debug_12206
|
rasdani/github-patches
|
git_diff
|
praw-dev__praw-1145
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`reddit.user.moderator_subreddits()` has a limit of 100 subreddits that is not documented.
## Issue Description
`reddit.user.moderator_subreddits()` is a method for `reddit.user` that [returns a ListingGenerator of the subreddits that the currently authenticated user is a moderator of](https://praw.readthedocs.io/en/latest/code_overview/reddit/user.html). It works fine, but there is actually a **hard limit of 100 subreddits returned** through this method, and that limit is currently not documented for the method. I tested this with my bot u/AssistantBOT, which is currently moderating 600+ public and private subreddits, and the method only returns the top 100 subreddits it's a mod of, sorted by most subscribers to least subscribers.
I believe this limit should be documented in the method. It's true that the vast majority of users are unlikely to encounter this issue, but it is something that could dramatically affect what a user is expecting in their results.
I would make a pull request, but I already have one PR #1137 that's awaiting review for a feature addition and I don't want to add something unrelated to that PR directly. The new method I proposed, `.moderated()`, can actually overcome the limitations of `moderator_subreddits()`, however, so if it's a good idea to add this documentation to that PR, then I'll do so.
**Edit:** I'll make a new Documentation PR once ##1137 gets merged.
## System Information
- PRAW Version: 6.4.0
- Python Version: 3.5.1
- Operating System: Windows 10 Pro
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `praw/models/user.py`
Content:
```
1 """Provides the User class."""
2 from ..const import API_PATH
3 from ..models import Preferences
4 from ..util.cache import cachedproperty
5 from .base import PRAWBase
6 from .listing.generator import ListingGenerator
7 from .reddit.redditor import Redditor
8 from .reddit.subreddit import Subreddit
9
10
11 class User(PRAWBase):
12 """The user class provides methods for the currently authenticated user."""
13
14 @cachedproperty
15 def preferences(self):
16 """Get an instance of :class:`.Preferences`.
17
18 The preferences can be accessed as a ``dict`` like so:
19
20 .. code-block:: python
21
22 preferences = reddit.user.preferences()
23 print(preferences['show_link_flair'])
24
25 Preferences can be updated via:
26
27 .. code-block:: python
28
29 reddit.user.preferences.update(show_link_flair=True)
30
31 The :meth:`.Preferences.update` method returns the new state of the
32 preferences as a ``dict``, which can be used to check whether a
33 change went through. Changes with invalid types or parameter names
34 fail silently.
35
36 .. code-block:: python
37
38 original_preferences = reddit.user.preferences()
39 new_preferences = reddit.user.preferences.update(invalid_param=123)
40 print(original_preferences == new_preferences) # True, no change
41
42
43 """
44 return Preferences(self._reddit)
45
46 def __init__(self, reddit):
47 """Initialize a User instance.
48
49 This class is intended to be interfaced with through ``reddit.user``.
50
51 """
52 super(User, self).__init__(reddit, _data=None)
53
54 def blocked(self):
55 """Return a RedditorList of blocked Redditors."""
56 return self._reddit.get(API_PATH["blocked"])
57
58 def contributor_subreddits(self, **generator_kwargs):
59 """Return a ListingGenerator of subreddits user is a contributor of.
60
61 Additional keyword arguments are passed in the initialization of
62 :class:`.ListingGenerator`.
63
64 """
65 return ListingGenerator(
66 self._reddit, API_PATH["my_contributor"], **generator_kwargs
67 )
68
69 def friends(self):
70 """Return a RedditorList of friends."""
71 return self._reddit.get(API_PATH["friends"])
72
73 def karma(self):
74 """Return a dictionary mapping subreddits to their karma."""
75 karma_map = {}
76 for row in self._reddit.get(API_PATH["karma"])["data"]:
77 subreddit = Subreddit(self._reddit, row["sr"])
78 del row["sr"]
79 karma_map[subreddit] = row
80 return karma_map
81
82 def me(self, use_cache=True): # pylint: disable=invalid-name
83 """Return a :class:`.Redditor` instance for the authenticated user.
84
85 In :attr:`~praw.Reddit.read_only` mode, this method returns ``None``.
86
87 :param use_cache: When true, and if this function has been previously
88 called, returned the cached version (default: True).
89
90 .. note:: If you change the Reddit instance's authorization, you might
91 want to refresh the cached value. Prefer using separate Reddit
92 instances, however, for distinct authorizations.
93
94 """
95 if self._reddit.read_only:
96 return None
97 if "_me" not in self.__dict__ or not use_cache:
98 user_data = self._reddit.get(API_PATH["me"])
99 self._me = Redditor(self._reddit, _data=user_data)
100 return self._me
101
102 def moderator_subreddits(self, **generator_kwargs):
103 """Return a ListingGenerator of subreddits the user is a moderator of.
104
105 Additional keyword arguments are passed in the initialization of
106 :class:`.ListingGenerator`.
107
108 """
109 return ListingGenerator(
110 self._reddit, API_PATH["my_moderator"], **generator_kwargs
111 )
112
113 def multireddits(self):
114 """Return a list of multireddits belonging to the user."""
115 return self._reddit.get(API_PATH["my_multireddits"])
116
117 def subreddits(self, **generator_kwargs):
118 """Return a ListingGenerator of subreddits the user is subscribed to.
119
120 Additional keyword arguments are passed in the initialization of
121 :class:`.ListingGenerator`.
122
123 """
124 return ListingGenerator(
125 self._reddit, API_PATH["my_subreddits"], **generator_kwargs
126 )
127
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/praw/models/user.py b/praw/models/user.py
--- a/praw/models/user.py
+++ b/praw/models/user.py
@@ -105,6 +105,18 @@
Additional keyword arguments are passed in the initialization of
:class:`.ListingGenerator`.
+ .. note:: This method will return a maximum of 100 moderated
+ subreddits, ordered by subscriber count. To retrieve more than
+ 100 moderated subreddits, please see :meth:`.Redditor.moderated`.
+
+ Usage:
+
+ .. code-block:: python
+
+ for subreddit in reddit.user.moderator_subreddits():
+ print(subreddit.display_name)
+
+
"""
return ListingGenerator(
self._reddit, API_PATH["my_moderator"], **generator_kwargs
|
{"golden_diff": "diff --git a/praw/models/user.py b/praw/models/user.py\n--- a/praw/models/user.py\n+++ b/praw/models/user.py\n@@ -105,6 +105,18 @@\n Additional keyword arguments are passed in the initialization of\n :class:`.ListingGenerator`.\n \n+ .. note:: This method will return a maximum of 100 moderated\n+ subreddits, ordered by subscriber count. To retrieve more than\n+ 100 moderated subreddits, please see :meth:`.Redditor.moderated`.\n+\n+ Usage:\n+\n+ .. code-block:: python\n+\n+ for subreddit in reddit.user.moderator_subreddits():\n+ print(subreddit.display_name)\n+\n+\n \"\"\"\n return ListingGenerator(\n self._reddit, API_PATH[\"my_moderator\"], **generator_kwargs\n", "issue": "`reddit.user.moderator_subreddits()` has a limit of 100 subreddits that is not documented.\n## Issue Description\r\n\r\n`reddit.user.moderator_subreddits()` is a method for `reddit.user` that [returns a ListingGenerator of the subreddits that the currently authenticated user is a moderator of](https://praw.readthedocs.io/en/latest/code_overview/reddit/user.html). It works fine, but there is actually a **hard limit of 100 subreddits returned** through this method, and that limit is currently not documented for the method. I tested this with my bot u/AssistantBOT, which is currently moderating 600+ public and private subreddits, and the method only returns the top 100 subreddits it's a mod of, sorted by most subscribers to least subscribers. \r\n\r\nI believe this limit should be documented in the method. It's true that the vast majority of users are unlikely to encounter this issue, but it is something that could dramatically affect what a user is expecting in their results.\r\n\r\nI would make a pull request, but I already have one PR #1137 that's awaiting review for a feature addition and I don't want to add something unrelated to that PR directly. The new method I proposed, `.moderated()`, can actually overcome the limitations of `moderator_subreddits()`, however, so if it's a good idea to add this documentation to that PR, then I'll do so. \r\n\r\n\r\n**Edit:** I'll make a new Documentation PR once ##1137 gets merged.\r\n\r\n## System Information\r\n\r\n- PRAW Version: 6.4.0\r\n- Python Version: 3.5.1\r\n- Operating System: Windows 10 Pro\r\n\n", "before_files": [{"content": "\"\"\"Provides the User class.\"\"\"\nfrom ..const import API_PATH\nfrom ..models import Preferences\nfrom ..util.cache import cachedproperty\nfrom .base import PRAWBase\nfrom .listing.generator import ListingGenerator\nfrom .reddit.redditor import Redditor\nfrom .reddit.subreddit import Subreddit\n\n\nclass User(PRAWBase):\n \"\"\"The user class provides methods for the currently authenticated user.\"\"\"\n\n @cachedproperty\n def preferences(self):\n \"\"\"Get an instance of :class:`.Preferences`.\n\n The preferences can be accessed as a ``dict`` like so:\n\n .. code-block:: python\n\n preferences = reddit.user.preferences()\n print(preferences['show_link_flair'])\n\n Preferences can be updated via:\n\n .. code-block:: python\n\n reddit.user.preferences.update(show_link_flair=True)\n\n The :meth:`.Preferences.update` method returns the new state of the\n preferences as a ``dict``, which can be used to check whether a\n change went through. Changes with invalid types or parameter names\n fail silently.\n\n .. code-block:: python\n\n original_preferences = reddit.user.preferences()\n new_preferences = reddit.user.preferences.update(invalid_param=123)\n print(original_preferences == new_preferences) # True, no change\n\n\n \"\"\"\n return Preferences(self._reddit)\n\n def __init__(self, reddit):\n \"\"\"Initialize a User instance.\n\n This class is intended to be interfaced with through ``reddit.user``.\n\n \"\"\"\n super(User, self).__init__(reddit, _data=None)\n\n def blocked(self):\n \"\"\"Return a RedditorList of blocked Redditors.\"\"\"\n return self._reddit.get(API_PATH[\"blocked\"])\n\n def contributor_subreddits(self, **generator_kwargs):\n \"\"\"Return a ListingGenerator of subreddits user is a contributor of.\n\n Additional keyword arguments are passed in the initialization of\n :class:`.ListingGenerator`.\n\n \"\"\"\n return ListingGenerator(\n self._reddit, API_PATH[\"my_contributor\"], **generator_kwargs\n )\n\n def friends(self):\n \"\"\"Return a RedditorList of friends.\"\"\"\n return self._reddit.get(API_PATH[\"friends\"])\n\n def karma(self):\n \"\"\"Return a dictionary mapping subreddits to their karma.\"\"\"\n karma_map = {}\n for row in self._reddit.get(API_PATH[\"karma\"])[\"data\"]:\n subreddit = Subreddit(self._reddit, row[\"sr\"])\n del row[\"sr\"]\n karma_map[subreddit] = row\n return karma_map\n\n def me(self, use_cache=True): # pylint: disable=invalid-name\n \"\"\"Return a :class:`.Redditor` instance for the authenticated user.\n\n In :attr:`~praw.Reddit.read_only` mode, this method returns ``None``.\n\n :param use_cache: When true, and if this function has been previously\n called, returned the cached version (default: True).\n\n .. note:: If you change the Reddit instance's authorization, you might\n want to refresh the cached value. Prefer using separate Reddit\n instances, however, for distinct authorizations.\n\n \"\"\"\n if self._reddit.read_only:\n return None\n if \"_me\" not in self.__dict__ or not use_cache:\n user_data = self._reddit.get(API_PATH[\"me\"])\n self._me = Redditor(self._reddit, _data=user_data)\n return self._me\n\n def moderator_subreddits(self, **generator_kwargs):\n \"\"\"Return a ListingGenerator of subreddits the user is a moderator of.\n\n Additional keyword arguments are passed in the initialization of\n :class:`.ListingGenerator`.\n\n \"\"\"\n return ListingGenerator(\n self._reddit, API_PATH[\"my_moderator\"], **generator_kwargs\n )\n\n def multireddits(self):\n \"\"\"Return a list of multireddits belonging to the user.\"\"\"\n return self._reddit.get(API_PATH[\"my_multireddits\"])\n\n def subreddits(self, **generator_kwargs):\n \"\"\"Return a ListingGenerator of subreddits the user is subscribed to.\n\n Additional keyword arguments are passed in the initialization of\n :class:`.ListingGenerator`.\n\n \"\"\"\n return ListingGenerator(\n self._reddit, API_PATH[\"my_subreddits\"], **generator_kwargs\n )\n", "path": "praw/models/user.py"}], "after_files": [{"content": "\"\"\"Provides the User class.\"\"\"\nfrom ..const import API_PATH\nfrom ..models import Preferences\nfrom ..util.cache import cachedproperty\nfrom .base import PRAWBase\nfrom .listing.generator import ListingGenerator\nfrom .reddit.redditor import Redditor\nfrom .reddit.subreddit import Subreddit\n\n\nclass User(PRAWBase):\n \"\"\"The user class provides methods for the currently authenticated user.\"\"\"\n\n @cachedproperty\n def preferences(self):\n \"\"\"Get an instance of :class:`.Preferences`.\n\n The preferences can be accessed as a ``dict`` like so:\n\n .. code-block:: python\n\n preferences = reddit.user.preferences()\n print(preferences['show_link_flair'])\n\n Preferences can be updated via:\n\n .. code-block:: python\n\n reddit.user.preferences.update(show_link_flair=True)\n\n The :meth:`.Preferences.update` method returns the new state of the\n preferences as a ``dict``, which can be used to check whether a\n change went through. Changes with invalid types or parameter names\n fail silently.\n\n .. code-block:: python\n\n original_preferences = reddit.user.preferences()\n new_preferences = reddit.user.preferences.update(invalid_param=123)\n print(original_preferences == new_preferences) # True, no change\n\n\n \"\"\"\n return Preferences(self._reddit)\n\n def __init__(self, reddit):\n \"\"\"Initialize a User instance.\n\n This class is intended to be interfaced with through ``reddit.user``.\n\n \"\"\"\n super(User, self).__init__(reddit, _data=None)\n\n def blocked(self):\n \"\"\"Return a RedditorList of blocked Redditors.\"\"\"\n return self._reddit.get(API_PATH[\"blocked\"])\n\n def contributor_subreddits(self, **generator_kwargs):\n \"\"\"Return a ListingGenerator of subreddits user is a contributor of.\n\n Additional keyword arguments are passed in the initialization of\n :class:`.ListingGenerator`.\n\n \"\"\"\n return ListingGenerator(\n self._reddit, API_PATH[\"my_contributor\"], **generator_kwargs\n )\n\n def friends(self):\n \"\"\"Return a RedditorList of friends.\"\"\"\n return self._reddit.get(API_PATH[\"friends\"])\n\n def karma(self):\n \"\"\"Return a dictionary mapping subreddits to their karma.\"\"\"\n karma_map = {}\n for row in self._reddit.get(API_PATH[\"karma\"])[\"data\"]:\n subreddit = Subreddit(self._reddit, row[\"sr\"])\n del row[\"sr\"]\n karma_map[subreddit] = row\n return karma_map\n\n def me(self, use_cache=True): # pylint: disable=invalid-name\n \"\"\"Return a :class:`.Redditor` instance for the authenticated user.\n\n In :attr:`~praw.Reddit.read_only` mode, this method returns ``None``.\n\n :param use_cache: When true, and if this function has been previously\n called, returned the cached version (default: True).\n\n .. note:: If you change the Reddit instance's authorization, you might\n want to refresh the cached value. Prefer using separate Reddit\n instances, however, for distinct authorizations.\n\n \"\"\"\n if self._reddit.read_only:\n return None\n if \"_me\" not in self.__dict__ or not use_cache:\n user_data = self._reddit.get(API_PATH[\"me\"])\n self._me = Redditor(self._reddit, _data=user_data)\n return self._me\n\n def moderator_subreddits(self, **generator_kwargs):\n \"\"\"Return a ListingGenerator of subreddits the user is a moderator of.\n\n Additional keyword arguments are passed in the initialization of\n :class:`.ListingGenerator`.\n\n .. note:: This method will return a maximum of 100 moderated\n subreddits, ordered by subscriber count. To retrieve more than\n 100 moderated subreddits, please see :meth:`.Redditor.moderated`.\n\n Usage:\n\n .. code-block:: python\n\n for subreddit in reddit.user.moderator_subreddits():\n print(subreddit.display_name)\n\n\n \"\"\"\n return ListingGenerator(\n self._reddit, API_PATH[\"my_moderator\"], **generator_kwargs\n )\n\n def multireddits(self):\n \"\"\"Return a list of multireddits belonging to the user.\"\"\"\n return self._reddit.get(API_PATH[\"my_multireddits\"])\n\n def subreddits(self, **generator_kwargs):\n \"\"\"Return a ListingGenerator of subreddits the user is subscribed to.\n\n Additional keyword arguments are passed in the initialization of\n :class:`.ListingGenerator`.\n\n \"\"\"\n return ListingGenerator(\n self._reddit, API_PATH[\"my_subreddits\"], **generator_kwargs\n )\n", "path": "praw/models/user.py"}]}
| 1,833 | 187 |
gh_patches_debug_15242
|
rasdani/github-patches
|
git_diff
|
openstates__openstates-scrapers-2513
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
PR failing since at least 2018-09-06
PR has been failing since 2018-09-06
Based on automated runs it appears that PR has not run successfully in 6 days (2018-09-06).
```
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "Ram\u00f3n L. Cruz Burgos"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "Angel Buler\u00edn Ramos"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "\u00c1ngel Mart\u00ednez Santiago"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "Manuel A. Natal Albelo"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "Eduardo Bhatia Gautier"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "Zoe Laboy Alvarado"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "An\u00edbal Jos\u00e9 Torres Torres"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "Carmelo J. R\u00edos Santiago"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "Itzamar Pe\u00f1a Ram\u00edrez"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "Carlos A. Bianchi Angler\u00f3"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "Jos\u00e9 Vargas Vidot"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "Angel Mart\u00ednez Santiago"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "Eduardo Bhatia Gauthier"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "Miguel Romero Lugo"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "Margarita Nolasco Santiago"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "Luis R. Ortiz Lugo"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "Urayo\u00e1n Hern\u00e1ndez Alvarado"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "Jos\u00e9 M. Varela Fern\u00e1ndez"}
loaded Open States pupa settings...
pr (scrape, import)
people: {}
committees: {}
bills: {}
import jurisdictions...
import organizations...
import people...
import posts...
import memberships...
Traceback (most recent call last):
File "/opt/openstates/venv-pupa//bin/pupa", line 11, in <module>
load_entry_point('pupa', 'console_scripts', 'pupa')()
File "/opt/openstates/venv-pupa/src/pupa/pupa/cli/__main__.py", line 68, in main
subcommands[args.subcommand].handle(args, other)
File "/opt/openstates/venv-pupa/src/pupa/pupa/cli/commands/update.py", line 260, in handle
return self.do_handle(args, other, juris)
File "/opt/openstates/venv-pupa/src/pupa/pupa/cli/commands/update.py", line 307, in do_handle
report['import'] = self.do_import(juris, args)
File "/opt/openstates/venv-pupa/src/pupa/pupa/cli/commands/update.py", line 211, in do_import
report.update(membership_importer.import_directory(datadir))
File "/opt/openstates/venv-pupa/src/pupa/pupa/importers/base.py", line 196, in import_directory
return self.import_data(json_stream())
File "/opt/openstates/venv-pupa/src/pupa/pupa/importers/base.py", line 233, in import_data
obj_id, what = self.import_item(data)
File "/opt/openstates/venv-pupa/src/pupa/pupa/importers/base.py", line 254, in import_item
data = self.prepare_for_db(data)
File "/opt/openstates/venv-pupa/src/pupa/pupa/importers/memberships.py", line 47, in prepare_for_db
data['organization_id'] = self.org_importer.resolve_json_id(data['organization_id'])
File "/opt/openstates/venv-pupa/src/pupa/pupa/importers/base.py", line 171, in resolve_json_id
raise UnresolvedIdError(errmsg)
pupa.exceptions.UnresolvedIdError: cannot resolve pseudo id to Organization: ~{"classification": "party", "name": "Independiente"}
```
Visit http://bobsled.openstates.org for more info.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `openstates/pr/people.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 import re
3 from pupa.scrape import Person, Scraper
4 from openstates.utils import LXMLMixin, validate_phone_number
5
6
7 class PRPersonScraper(Scraper, LXMLMixin):
8 def scrape(self, chamber=None):
9 term = self.jurisdiction.legislative_sessions[-1]['identifier']
10 chambers = [chamber] if chamber is not None else ['upper', 'lower']
11 for chamber in chambers:
12 yield from getattr(self, 'scrape_' + chamber + '_chamber')(term)
13
14 def scrape_upper_chamber(self, term):
15 url = 'https://senado.pr.gov/Pages/Senadores.aspx'
16
17 doc = self.lxmlize(url)
18 links = self.get_nodes(doc, '//ul[@class="senadores-list"]/li/a/@href')
19
20 for link in links:
21 senator_page = self.lxmlize(link)
22 profile_links = self.get_nodes(senator_page, '//ul[@class="profiles-links"]/li')
23
24 name_text = self.get_node(senator_page, '//span[@class="name"]').text_content().strip()
25 name = re.sub(r'^Hon\.', '', name_text, flags=re.IGNORECASE).strip()
26 party = profile_links[0].text_content().strip()
27 photo_url = self.get_node(senator_page, '//div[@class="avatar"]//img/@src')
28
29 if profile_links[1].text_content().strip() == "Senador por Distrito":
30 district_text = self.get_node(
31 senator_page,
32 '//div[@class="module-distrito"]//span[@class="headline"]').text_content()
33 district = district_text.replace('DISTRITO', '', 1).replace('\u200b', '').strip()
34 elif profile_links[1].text_content().strip() == "Senador por Acumulación":
35 district = "At-Large"
36
37 phone_node = self.get_node(senator_page, '//a[@class="contact-data tel"]')
38 phone = phone_node.text_content().strip()
39 email_node = self.get_node(senator_page, '//a[@class="contact-data email"]')
40 email = email_node.text_content().replace('\u200b', '').strip()
41
42 person = Person(primary_org='upper',
43 district=district,
44 name=name,
45 party=party,
46 image=photo_url)
47 person.add_contact_detail(type='email',
48 value=email,
49 note='Capitol Office')
50 person.add_contact_detail(type='voice',
51 value=phone,
52 note='Capitol Office')
53 person.add_link(link)
54 person.add_source(link)
55
56 yield person
57
58 def scrape_lower_chamber(self, term):
59 # E-mail contact is now hidden behind webforms. Sadness.
60
61 party_map = {'PNP': 'Partido Nuevo Progresista',
62 'PPD': u'Partido Popular Democr\xe1tico',
63 'PIP': u'Partido Independentista Puertorrique\u00F1o',
64 }
65
66 url = 'http://www.tucamarapr.org/dnncamara/ComposiciondelaCamara/Biografia.aspx'
67 page = self.lxmlize(url)
68
69 member_nodes = self.get_nodes(page, '//li[@class="selectionRep"]')
70 for member_node in member_nodes:
71 member_info = member_node.text_content().strip().split("\n")
72
73 name = re.sub(r'^Hon\.', '', member_info[0]).strip()
74 district_text = member_info[-1].strip()
75 if district_text == 'Representante por Acumulación':
76 district = 'At-Large'
77 else:
78 district = district_text.replace("Representante del Distrito ", "").strip()
79 photo_url = self.get_node(member_node, './/img/@src')
80
81 rep_link = self.get_node(member_node, ".//a/@href")
82 rep_page = self.lxmlize(rep_link)
83
84 party_node = self.get_node(rep_page, '//span[@class="partyBio"]')
85 party_text = party_node.text_content().strip()
86 party = party_map[party_text]
87
88 address = self.get_node(rep_page, '//h6').text.strip().split("\n")[0].strip()
89
90 # Only grabs the first validated phone number found.
91 # Typically, representatives have multiple phone numbers.
92 phone_node = self.get_node(
93 rep_page,
94 '//span[@class="data-type" and contains(text(), "Tel.")]')
95 phone = None
96 possible_phones = phone_node.text.strip().split("\n")
97 for phone_attempt in possible_phones:
98 # Don't keep searching phone numbers if a good one is found.
99 if phone:
100 break
101
102 phone_text = re.sub(r'^Tel\.[\s]*', '', phone_attempt).strip()
103 if validate_phone_number(phone_text):
104 phone = phone_text
105
106 fax_node = self.get_node(
107 rep_page,
108 '//span[@class="data-type" and contains(text(), "Fax.")]')
109 fax = None
110 if fax_node:
111 fax_text = fax_node.text.strip()
112 fax_text = re.sub(r'^Fax\.[\s]*', '', fax_text).strip()
113 if validate_phone_number(fax_text):
114 fax = fax_text
115
116 person = Person(primary_org='lower',
117 district=district,
118 name=name,
119 party=party,
120 image=photo_url)
121
122 person.add_link(rep_link)
123 person.add_source(rep_link)
124 person.add_source(url)
125
126 if address:
127 person.add_contact_detail(type='address',
128 value=address,
129 note='Capitol Office')
130 if phone:
131 person.add_contact_detail(type='voice',
132 value=phone,
133 note='Capitol Office')
134 if fax:
135 person.add_contact_detail(type='fax',
136 value=fax,
137 note='Capitol Office')
138
139 yield person
140
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/openstates/pr/people.py b/openstates/pr/people.py
--- a/openstates/pr/people.py
+++ b/openstates/pr/people.py
@@ -24,6 +24,10 @@
name_text = self.get_node(senator_page, '//span[@class="name"]').text_content().strip()
name = re.sub(r'^Hon\.', '', name_text, flags=re.IGNORECASE).strip()
party = profile_links[0].text_content().strip()
+ # Translate to English since being an Independent is a universal construct
+ if party == "Independiente":
+ party = "Independent"
+
photo_url = self.get_node(senator_page, '//div[@class="avatar"]//img/@src')
if profile_links[1].text_content().strip() == "Senador por Distrito":
|
{"golden_diff": "diff --git a/openstates/pr/people.py b/openstates/pr/people.py\n--- a/openstates/pr/people.py\n+++ b/openstates/pr/people.py\n@@ -24,6 +24,10 @@\n name_text = self.get_node(senator_page, '//span[@class=\"name\"]').text_content().strip()\n name = re.sub(r'^Hon\\.', '', name_text, flags=re.IGNORECASE).strip()\n party = profile_links[0].text_content().strip()\n+ # Translate to English since being an Independent is a universal construct\n+ if party == \"Independiente\":\n+ party = \"Independent\"\n+\n photo_url = self.get_node(senator_page, '//div[@class=\"avatar\"]//img/@src')\n \n if profile_links[1].text_content().strip() == \"Senador por Distrito\":\n", "issue": "PR failing since at least 2018-09-06\nPR has been failing since 2018-09-06\n\nBased on automated runs it appears that PR has not run successfully in 6 days (2018-09-06).\n\n\n```\n 00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"Ram\\u00f3n L. Cruz Burgos\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"Angel Buler\\u00edn Ramos\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"\\u00c1ngel Mart\\u00ednez Santiago\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"Manuel A. Natal Albelo\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"Eduardo Bhatia Gautier\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"Zoe Laboy Alvarado\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"An\\u00edbal Jos\\u00e9 Torres Torres\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"Carmelo J. R\\u00edos Santiago\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"Itzamar Pe\\u00f1a Ram\\u00edrez\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"Carlos A. Bianchi Angler\\u00f3\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"Jos\\u00e9 Vargas Vidot\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"Angel Mart\\u00ednez Santiago\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"Eduardo Bhatia Gauthier\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"Miguel Romero Lugo\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"Margarita Nolasco Santiago\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"Luis R. Ortiz Lugo\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"Urayo\\u00e1n Hern\\u00e1ndez Alvarado\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"Jos\\u00e9 M. Varela Fern\\u00e1ndez\"}\nloaded Open States pupa settings...\npr (scrape, import)\n people: {}\n committees: {}\n bills: {}\nimport jurisdictions...\nimport organizations...\nimport people...\nimport posts...\nimport memberships...\nTraceback (most recent call last):\n File \"/opt/openstates/venv-pupa//bin/pupa\", line 11, in <module>\n load_entry_point('pupa', 'console_scripts', 'pupa')()\n File \"/opt/openstates/venv-pupa/src/pupa/pupa/cli/__main__.py\", line 68, in main\n subcommands[args.subcommand].handle(args, other)\n File \"/opt/openstates/venv-pupa/src/pupa/pupa/cli/commands/update.py\", line 260, in handle\n return self.do_handle(args, other, juris)\n File \"/opt/openstates/venv-pupa/src/pupa/pupa/cli/commands/update.py\", line 307, in do_handle\n report['import'] = self.do_import(juris, args)\n File \"/opt/openstates/venv-pupa/src/pupa/pupa/cli/commands/update.py\", line 211, in do_import\n report.update(membership_importer.import_directory(datadir))\n File \"/opt/openstates/venv-pupa/src/pupa/pupa/importers/base.py\", line 196, in import_directory\n return self.import_data(json_stream())\n File \"/opt/openstates/venv-pupa/src/pupa/pupa/importers/base.py\", line 233, in import_data\n obj_id, what = self.import_item(data)\n File \"/opt/openstates/venv-pupa/src/pupa/pupa/importers/base.py\", line 254, in import_item\n data = self.prepare_for_db(data)\n File \"/opt/openstates/venv-pupa/src/pupa/pupa/importers/memberships.py\", line 47, in prepare_for_db\n data['organization_id'] = self.org_importer.resolve_json_id(data['organization_id'])\n File \"/opt/openstates/venv-pupa/src/pupa/pupa/importers/base.py\", line 171, in resolve_json_id\n raise UnresolvedIdError(errmsg)\npupa.exceptions.UnresolvedIdError: cannot resolve pseudo id to Organization: ~{\"classification\": \"party\", \"name\": \"Independiente\"}\n```\n\nVisit http://bobsled.openstates.org for more info.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nimport re\nfrom pupa.scrape import Person, Scraper\nfrom openstates.utils import LXMLMixin, validate_phone_number\n\n\nclass PRPersonScraper(Scraper, LXMLMixin):\n def scrape(self, chamber=None):\n term = self.jurisdiction.legislative_sessions[-1]['identifier']\n chambers = [chamber] if chamber is not None else ['upper', 'lower']\n for chamber in chambers:\n yield from getattr(self, 'scrape_' + chamber + '_chamber')(term)\n\n def scrape_upper_chamber(self, term):\n url = 'https://senado.pr.gov/Pages/Senadores.aspx'\n\n doc = self.lxmlize(url)\n links = self.get_nodes(doc, '//ul[@class=\"senadores-list\"]/li/a/@href')\n\n for link in links:\n senator_page = self.lxmlize(link)\n profile_links = self.get_nodes(senator_page, '//ul[@class=\"profiles-links\"]/li')\n\n name_text = self.get_node(senator_page, '//span[@class=\"name\"]').text_content().strip()\n name = re.sub(r'^Hon\\.', '', name_text, flags=re.IGNORECASE).strip()\n party = profile_links[0].text_content().strip()\n photo_url = self.get_node(senator_page, '//div[@class=\"avatar\"]//img/@src')\n\n if profile_links[1].text_content().strip() == \"Senador por Distrito\":\n district_text = self.get_node(\n senator_page,\n '//div[@class=\"module-distrito\"]//span[@class=\"headline\"]').text_content()\n district = district_text.replace('DISTRITO', '', 1).replace('\\u200b', '').strip()\n elif profile_links[1].text_content().strip() == \"Senador por Acumulaci\u00f3n\":\n district = \"At-Large\"\n\n phone_node = self.get_node(senator_page, '//a[@class=\"contact-data tel\"]')\n phone = phone_node.text_content().strip()\n email_node = self.get_node(senator_page, '//a[@class=\"contact-data email\"]')\n email = email_node.text_content().replace('\\u200b', '').strip()\n\n person = Person(primary_org='upper',\n district=district,\n name=name,\n party=party,\n image=photo_url)\n person.add_contact_detail(type='email',\n value=email,\n note='Capitol Office')\n person.add_contact_detail(type='voice',\n value=phone,\n note='Capitol Office')\n person.add_link(link)\n person.add_source(link)\n\n yield person\n\n def scrape_lower_chamber(self, term):\n # E-mail contact is now hidden behind webforms. Sadness.\n\n party_map = {'PNP': 'Partido Nuevo Progresista',\n 'PPD': u'Partido Popular Democr\\xe1tico',\n 'PIP': u'Partido Independentista Puertorrique\\u00F1o',\n }\n\n url = 'http://www.tucamarapr.org/dnncamara/ComposiciondelaCamara/Biografia.aspx'\n page = self.lxmlize(url)\n\n member_nodes = self.get_nodes(page, '//li[@class=\"selectionRep\"]')\n for member_node in member_nodes:\n member_info = member_node.text_content().strip().split(\"\\n\")\n\n name = re.sub(r'^Hon\\.', '', member_info[0]).strip()\n district_text = member_info[-1].strip()\n if district_text == 'Representante por Acumulaci\u00f3n':\n district = 'At-Large'\n else:\n district = district_text.replace(\"Representante del Distrito \", \"\").strip()\n photo_url = self.get_node(member_node, './/img/@src')\n\n rep_link = self.get_node(member_node, \".//a/@href\")\n rep_page = self.lxmlize(rep_link)\n\n party_node = self.get_node(rep_page, '//span[@class=\"partyBio\"]')\n party_text = party_node.text_content().strip()\n party = party_map[party_text]\n\n address = self.get_node(rep_page, '//h6').text.strip().split(\"\\n\")[0].strip()\n\n # Only grabs the first validated phone number found.\n # Typically, representatives have multiple phone numbers.\n phone_node = self.get_node(\n rep_page,\n '//span[@class=\"data-type\" and contains(text(), \"Tel.\")]')\n phone = None\n possible_phones = phone_node.text.strip().split(\"\\n\")\n for phone_attempt in possible_phones:\n # Don't keep searching phone numbers if a good one is found.\n if phone:\n break\n\n phone_text = re.sub(r'^Tel\\.[\\s]*', '', phone_attempt).strip()\n if validate_phone_number(phone_text):\n phone = phone_text\n\n fax_node = self.get_node(\n rep_page,\n '//span[@class=\"data-type\" and contains(text(), \"Fax.\")]')\n fax = None\n if fax_node:\n fax_text = fax_node.text.strip()\n fax_text = re.sub(r'^Fax\\.[\\s]*', '', fax_text).strip()\n if validate_phone_number(fax_text):\n fax = fax_text\n\n person = Person(primary_org='lower',\n district=district,\n name=name,\n party=party,\n image=photo_url)\n\n person.add_link(rep_link)\n person.add_source(rep_link)\n person.add_source(url)\n\n if address:\n person.add_contact_detail(type='address',\n value=address,\n note='Capitol Office')\n if phone:\n person.add_contact_detail(type='voice',\n value=phone,\n note='Capitol Office')\n if fax:\n person.add_contact_detail(type='fax',\n value=fax,\n note='Capitol Office')\n\n yield person\n", "path": "openstates/pr/people.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\nimport re\nfrom pupa.scrape import Person, Scraper\nfrom openstates.utils import LXMLMixin, validate_phone_number\n\n\nclass PRPersonScraper(Scraper, LXMLMixin):\n def scrape(self, chamber=None):\n term = self.jurisdiction.legislative_sessions[-1]['identifier']\n chambers = [chamber] if chamber is not None else ['upper', 'lower']\n for chamber in chambers:\n yield from getattr(self, 'scrape_' + chamber + '_chamber')(term)\n\n def scrape_upper_chamber(self, term):\n url = 'https://senado.pr.gov/Pages/Senadores.aspx'\n\n doc = self.lxmlize(url)\n links = self.get_nodes(doc, '//ul[@class=\"senadores-list\"]/li/a/@href')\n\n for link in links:\n senator_page = self.lxmlize(link)\n profile_links = self.get_nodes(senator_page, '//ul[@class=\"profiles-links\"]/li')\n\n name_text = self.get_node(senator_page, '//span[@class=\"name\"]').text_content().strip()\n name = re.sub(r'^Hon\\.', '', name_text, flags=re.IGNORECASE).strip()\n party = profile_links[0].text_content().strip()\n # Translate to English since being an Independent is a universal construct\n if party == \"Independiente\":\n party = \"Independent\"\n\n photo_url = self.get_node(senator_page, '//div[@class=\"avatar\"]//img/@src')\n\n if profile_links[1].text_content().strip() == \"Senador por Distrito\":\n district_text = self.get_node(\n senator_page,\n '//div[@class=\"module-distrito\"]//span[@class=\"headline\"]').text_content()\n district = district_text.replace('DISTRITO', '', 1).replace('\\u200b', '').strip()\n elif profile_links[1].text_content().strip() == \"Senador por Acumulaci\u00f3n\":\n district = \"At-Large\"\n\n phone_node = self.get_node(senator_page, '//a[@class=\"contact-data tel\"]')\n phone = phone_node.text_content().strip()\n email_node = self.get_node(senator_page, '//a[@class=\"contact-data email\"]')\n email = email_node.text_content().replace('\\u200b', '').strip()\n\n person = Person(primary_org='upper',\n district=district,\n name=name,\n party=party,\n image=photo_url)\n person.add_contact_detail(type='email',\n value=email,\n note='Capitol Office')\n person.add_contact_detail(type='voice',\n value=phone,\n note='Capitol Office')\n person.add_link(link)\n person.add_source(link)\n\n yield person\n\n def scrape_lower_chamber(self, term):\n # E-mail contact is now hidden behind webforms. Sadness.\n\n party_map = {'PNP': 'Partido Nuevo Progresista',\n 'PPD': u'Partido Popular Democr\\xe1tico',\n 'PIP': u'Partido Independentista Puertorrique\\u00F1o',\n }\n\n url = 'http://www.tucamarapr.org/dnncamara/ComposiciondelaCamara/Biografia.aspx'\n page = self.lxmlize(url)\n\n member_nodes = self.get_nodes(page, '//li[@class=\"selectionRep\"]')\n for member_node in member_nodes:\n member_info = member_node.text_content().strip().split(\"\\n\")\n\n name = re.sub(r'^Hon\\.', '', member_info[0]).strip()\n district_text = member_info[-1].strip()\n if district_text == 'Representante por Acumulaci\u00f3n':\n district = 'At-Large'\n else:\n district = district_text.replace(\"Representante del Distrito \", \"\").strip()\n photo_url = self.get_node(member_node, './/img/@src')\n\n rep_link = self.get_node(member_node, \".//a/@href\")\n rep_page = self.lxmlize(rep_link)\n\n party_node = self.get_node(rep_page, '//span[@class=\"partyBio\"]')\n party_text = party_node.text_content().strip()\n party = party_map[party_text]\n\n address = self.get_node(rep_page, '//h6').text.strip().split(\"\\n\")[0].strip()\n\n # Only grabs the first validated phone number found.\n # Typically, representatives have multiple phone numbers.\n phone_node = self.get_node(\n rep_page,\n '//span[@class=\"data-type\" and contains(text(), \"Tel.\")]')\n phone = None\n possible_phones = phone_node.text.strip().split(\"\\n\")\n for phone_attempt in possible_phones:\n # Don't keep searching phone numbers if a good one is found.\n if phone:\n break\n\n phone_text = re.sub(r'^Tel\\.[\\s]*', '', phone_attempt).strip()\n if validate_phone_number(phone_text):\n phone = phone_text\n\n fax_node = self.get_node(\n rep_page,\n '//span[@class=\"data-type\" and contains(text(), \"Fax.\")]')\n fax = None\n if fax_node:\n fax_text = fax_node.text.strip()\n fax_text = re.sub(r'^Fax\\.[\\s]*', '', fax_text).strip()\n if validate_phone_number(fax_text):\n fax = fax_text\n\n person = Person(primary_org='lower',\n district=district,\n name=name,\n party=party,\n image=photo_url)\n\n person.add_link(rep_link)\n person.add_source(rep_link)\n person.add_source(url)\n\n if address:\n person.add_contact_detail(type='address',\n value=address,\n note='Capitol Office')\n if phone:\n person.add_contact_detail(type='voice',\n value=phone,\n note='Capitol Office')\n if fax:\n person.add_contact_detail(type='fax',\n value=fax,\n note='Capitol Office')\n\n yield person\n", "path": "openstates/pr/people.py"}]}
| 3,082 | 180 |
gh_patches_debug_35975
|
rasdani/github-patches
|
git_diff
|
ckan__ckan-7933
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Some patch actions raise `ckan.logic.NotAuthorized` even though `context['ignore_auth'] = True`
## CKAN version
2.9+
## Describe the bug
The patch action functions in [ckan/logic/action/patch.py](https://github.com/ckan/ckan/tree/master/ckan/logic/action/patch.py) create a separate `show_context: Context` object that is used with a show action to retrieve the resource that is being patched. For almost all of these patch functions, the `'ignore_auth'` value from the patch action's input `context: Context` argument is not propagated to the `show_context` object. As a result, patching some resource types with `'ignore_auth': True` in the patch action's `Context` unexpectedly fails with a `ckan.logic.NotAuthorized` error.
Only [`package_patch()`](https://github.com/ckan/ckan/blob/master/ckan/logic/action/patch.py#L14) correctly propagates this value. The other four patch action functions are affected:
* [`resource_patch()`](https://github.com/ckan/ckan/blob/master/ckan/logic/action/patch.py#L57)
* [`group_patch()`](https://github.com/ckan/ckan/blob/master/ckan/logic/action/patch.py#L88)
* [`organization_patch()`](https://github.com/ckan/ckan/blob/master/ckan/logic/action/patch.py#L122)
* [`user_patch()`](https://github.com/ckan/ckan/blob/master/ckan/logic/action/patch.py#L157)
## Example
The following code snippet uses the Plugin Toolkit to access the [`user_patch()` function](https://github.com/ckan/ckan/blob/master/ckan/logic/action/patch.py#L157). This will fail if `user` is not authorized to perform `'user_show'`, because `'ignore_auth'` [is not propagated to `show_context`](https://github.com/ckan/ckan/blob/master/ckan/logic/action/patch.py#L171) in `user_patch()`.
```python
toolkit.get_action('user_patch')(
context={
'user': user,
'ignore_auth': True,
},
)
```
A problem like this showed up while I was modifying some code in the `ckanext-ldap` plugin. I believe the reason is that at the time this is being called, a currently not-logged-in user is being passed, and such a user cannot perform `'user_show'`. Regardless, I would have expected that with `'ignore_auth'` being passed into the patch function, the action would succeed, or at least would not return an authorization error.
## Suggested fix
### Easy
The easiest thing to do is just add `'ignore_auth': context.get('ignore_auth', False)` to each of the `show_context` definitions that are missing them.
### Robust
A more robust fix would be to introduce a helper function, `_create_show_context()` (defined below), that each function can call to create the `show_context` object. That way, future changes to the `show_context` will be propagated to all of the patch functions.
It is worth noting that I have absolutely no clue what the `'for_update'` key does. I couldn't find any documentation about it. It seems to be used in the database interaction code, but I'm not really familiar with working with databases. In any case: this key is not set consistently in the `show_context` objects across the various patch functions, so in the code below, it is an optional parameter that can be passed into the new function.
```python
def _create_show_context(context: Context, for_update: bool = False) -> Context:
'''Create a Context that can be used with a user_show action call.
This method is internal. It is meant to be used by the patch action
functions to generate a Context that can be used with a show action
corresponding to the type of the patch action. The show action is
used to retrieve the item that will be patched.
The ``show_context`` is derived from the original patch Context,
which is the ``context`` input argument. Certain values are propagated
from the input ``context`` to the returned ``show_context``.
:param context: Context from the original patch request
:type context: Context
:param for_update: if ``True``, then ``show_context['for_update'] = True``.
If ``False`` (the default), then ``'for_update'`` will not be
explicitly set in ``show_context``.
:type for_update: bool
:returns: A Context, ``show_context``, with the appropriate settings.
'''
show_context: Context = {
'model': context['model'],
'session': context['session'],
'user': context['user'],
'auth_user_obj': context['auth_user_obj'],
'ignore_auth': context.get('ignore_auth', False),
}
if for_update:
show_context['for_update'] = True
return show_context
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ckan/logic/action/patch.py`
Content:
```
1 # encoding: utf-8
2
3 '''API functions for partial updates of existing data in CKAN'''
4
5 from ckan.logic import (
6 get_action as _get_action,
7 check_access as _check_access,
8 get_or_bust as _get_or_bust,
9 )
10 from ckan.types import Context, DataDict
11 from ckan.types.logic import ActionResult
12
13
14 def package_patch(
15 context: Context, data_dict: DataDict) -> ActionResult.PackagePatch:
16 '''Patch a dataset (package).
17
18 :param id: the id or name of the dataset
19 :type id: string
20
21 The difference between the update and patch methods is that the patch will
22 perform an update of the provided parameters, while leaving all other
23 parameters unchanged, whereas the update methods deletes all parameters
24 not explicitly provided in the data_dict.
25
26 You are able to partially update and/or create resources with
27 package_patch. If you are updating existing resources be sure to provide
28 the resource id. Existing resources excluded from the package_patch
29 data_dict will be removed. Resources in the package data_dict without
30 an id will be treated as new resources and will be added. New resources
31 added with the patch method do not create the default views.
32
33 You must be authorized to edit the dataset and the groups that it belongs
34 to.
35 '''
36 _check_access('package_patch', context, data_dict)
37
38 show_context: Context = {
39 'model': context['model'],
40 'session': context['session'],
41 'user': context['user'],
42 'auth_user_obj': context['auth_user_obj'],
43 'ignore_auth': context.get('ignore_auth', False),
44 'for_update': True
45 }
46
47 package_dict = _get_action('package_show')(
48 show_context,
49 {'id': _get_or_bust(data_dict, 'id')})
50
51 patched = dict(package_dict)
52 patched.update(data_dict)
53 patched['id'] = package_dict['id']
54 return _get_action('package_update')(context, patched)
55
56
57 def resource_patch(context: Context,
58 data_dict: DataDict) -> ActionResult.ResourcePatch:
59 '''Patch a resource
60
61 :param id: the id of the resource
62 :type id: string
63
64 The difference between the update and patch methods is that the patch will
65 perform an update of the provided parameters, while leaving all other
66 parameters unchanged, whereas the update methods deletes all parameters
67 not explicitly provided in the data_dict
68 '''
69 _check_access('resource_patch', context, data_dict)
70
71 show_context: Context = {
72 'model': context['model'],
73 'session': context['session'],
74 'user': context['user'],
75 'auth_user_obj': context['auth_user_obj'],
76 'for_update': True
77 }
78
79 resource_dict = _get_action('resource_show')(
80 show_context,
81 {'id': _get_or_bust(data_dict, 'id')})
82
83 patched = dict(resource_dict)
84 patched.update(data_dict)
85 return _get_action('resource_update')(context, patched)
86
87
88 def group_patch(context: Context,
89 data_dict: DataDict) -> ActionResult.GroupPatch:
90 '''Patch a group
91
92 :param id: the id or name of the group
93 :type id: string
94
95 The difference between the update and patch methods is that the patch will
96 perform an update of the provided parameters, while leaving all other
97 parameters unchanged, whereas the update methods deletes all parameters
98 not explicitly provided in the data_dict
99 '''
100 _check_access('group_patch', context, data_dict)
101
102 show_context: Context = {
103 'model': context['model'],
104 'session': context['session'],
105 'user': context['user'],
106 'auth_user_obj': context['auth_user_obj'],
107 }
108
109 group_dict = _get_action('group_show')(
110 show_context,
111 {'id': _get_or_bust(data_dict, 'id')})
112
113 patched = dict(group_dict)
114 patched.pop('display_name', None)
115 patched.update(data_dict)
116
117 patch_context = context.copy()
118 patch_context['allow_partial_update'] = True
119 return _get_action('group_update')(patch_context, patched)
120
121
122 def organization_patch(
123 context: Context,
124 data_dict: DataDict) -> ActionResult.OrganizationPatch:
125 '''Patch an organization
126
127 :param id: the id or name of the organization
128 :type id: string
129
130 The difference between the update and patch methods is that the patch will
131 perform an update of the provided parameters, while leaving all other
132 parameters unchanged, whereas the update methods deletes all parameters
133 not explicitly provided in the data_dict
134 '''
135 _check_access('organization_patch', context, data_dict)
136
137 show_context: Context = {
138 'model': context['model'],
139 'session': context['session'],
140 'user': context['user'],
141 'auth_user_obj': context['auth_user_obj'],
142 }
143
144 organization_dict = _get_action('organization_show')(
145 show_context,
146 {'id': _get_or_bust(data_dict, 'id')})
147
148 patched = dict(organization_dict)
149 patched.pop('display_name', None)
150 patched.update(data_dict)
151
152 patch_context = context.copy()
153 patch_context['allow_partial_update'] = True
154 return _get_action('organization_update')(patch_context, patched)
155
156
157 def user_patch(context: Context,
158 data_dict: DataDict) -> ActionResult.UserPatch:
159 '''Patch a user
160
161 :param id: the id or name of the user
162 :type id: string
163
164 The difference between the update and patch methods is that the patch will
165 perform an update of the provided parameters, while leaving all other
166 parameters unchanged, whereas the update methods deletes all parameters
167 not explicitly provided in the data_dict
168 '''
169 _check_access('user_patch', context, data_dict)
170
171 show_context: Context = {
172 'model': context['model'],
173 'session': context['session'],
174 'user': context['user'],
175 'auth_user_obj': context['auth_user_obj'],
176 }
177
178 user_dict = _get_action('user_show')(
179 show_context,
180 {'id': _get_or_bust(data_dict, 'id')})
181
182 patched = dict(user_dict)
183 patched.pop('display_name', None)
184 patched.update(data_dict)
185 return _get_action('user_update')(context, patched)
186
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ckan/logic/action/patch.py b/ckan/logic/action/patch.py
--- a/ckan/logic/action/patch.py
+++ b/ckan/logic/action/patch.py
@@ -6,6 +6,7 @@
get_action as _get_action,
check_access as _check_access,
get_or_bust as _get_or_bust,
+ fresh_context as _fresh_context
)
from ckan.types import Context, DataDict
from ckan.types.logic import ActionResult
@@ -68,13 +69,8 @@
'''
_check_access('resource_patch', context, data_dict)
- show_context: Context = {
- 'model': context['model'],
- 'session': context['session'],
- 'user': context['user'],
- 'auth_user_obj': context['auth_user_obj'],
- 'for_update': True
- }
+ show_context: Context = _fresh_context(context)
+ show_context.update({'for_update': True})
resource_dict = _get_action('resource_show')(
show_context,
@@ -99,12 +95,7 @@
'''
_check_access('group_patch', context, data_dict)
- show_context: Context = {
- 'model': context['model'],
- 'session': context['session'],
- 'user': context['user'],
- 'auth_user_obj': context['auth_user_obj'],
- }
+ show_context: Context = _fresh_context(context)
group_dict = _get_action('group_show')(
show_context,
@@ -134,12 +125,7 @@
'''
_check_access('organization_patch', context, data_dict)
- show_context: Context = {
- 'model': context['model'],
- 'session': context['session'],
- 'user': context['user'],
- 'auth_user_obj': context['auth_user_obj'],
- }
+ show_context: Context = _fresh_context(context)
organization_dict = _get_action('organization_show')(
show_context,
@@ -168,12 +154,7 @@
'''
_check_access('user_patch', context, data_dict)
- show_context: Context = {
- 'model': context['model'],
- 'session': context['session'],
- 'user': context['user'],
- 'auth_user_obj': context['auth_user_obj'],
- }
+ show_context: Context = _fresh_context(context)
user_dict = _get_action('user_show')(
show_context,
|
{"golden_diff": "diff --git a/ckan/logic/action/patch.py b/ckan/logic/action/patch.py\n--- a/ckan/logic/action/patch.py\n+++ b/ckan/logic/action/patch.py\n@@ -6,6 +6,7 @@\n get_action as _get_action,\n check_access as _check_access,\n get_or_bust as _get_or_bust,\n+ fresh_context as _fresh_context\n )\n from ckan.types import Context, DataDict\n from ckan.types.logic import ActionResult\n@@ -68,13 +69,8 @@\n '''\n _check_access('resource_patch', context, data_dict)\n \n- show_context: Context = {\n- 'model': context['model'],\n- 'session': context['session'],\n- 'user': context['user'],\n- 'auth_user_obj': context['auth_user_obj'],\n- 'for_update': True\n- }\n+ show_context: Context = _fresh_context(context)\n+ show_context.update({'for_update': True})\n \n resource_dict = _get_action('resource_show')(\n show_context,\n@@ -99,12 +95,7 @@\n '''\n _check_access('group_patch', context, data_dict)\n \n- show_context: Context = {\n- 'model': context['model'],\n- 'session': context['session'],\n- 'user': context['user'],\n- 'auth_user_obj': context['auth_user_obj'],\n- }\n+ show_context: Context = _fresh_context(context)\n \n group_dict = _get_action('group_show')(\n show_context,\n@@ -134,12 +125,7 @@\n '''\n _check_access('organization_patch', context, data_dict)\n \n- show_context: Context = {\n- 'model': context['model'],\n- 'session': context['session'],\n- 'user': context['user'],\n- 'auth_user_obj': context['auth_user_obj'],\n- }\n+ show_context: Context = _fresh_context(context)\n \n organization_dict = _get_action('organization_show')(\n show_context,\n@@ -168,12 +154,7 @@\n '''\n _check_access('user_patch', context, data_dict)\n \n- show_context: Context = {\n- 'model': context['model'],\n- 'session': context['session'],\n- 'user': context['user'],\n- 'auth_user_obj': context['auth_user_obj'],\n- }\n+ show_context: Context = _fresh_context(context)\n \n user_dict = _get_action('user_show')(\n show_context,\n", "issue": "Some patch actions raise `ckan.logic.NotAuthorized` even though `context['ignore_auth'] = True`\n## CKAN version\r\n\r\n2.9+\r\n\r\n## Describe the bug\r\n\r\nThe patch action functions in [ckan/logic/action/patch.py](https://github.com/ckan/ckan/tree/master/ckan/logic/action/patch.py) create a separate `show_context: Context` object that is used with a show action to retrieve the resource that is being patched. For almost all of these patch functions, the `'ignore_auth'` value from the patch action's input `context: Context` argument is not propagated to the `show_context` object. As a result, patching some resource types with `'ignore_auth': True` in the patch action's `Context` unexpectedly fails with a `ckan.logic.NotAuthorized` error.\r\n\r\nOnly [`package_patch()`](https://github.com/ckan/ckan/blob/master/ckan/logic/action/patch.py#L14) correctly propagates this value. The other four patch action functions are affected:\r\n\r\n* [`resource_patch()`](https://github.com/ckan/ckan/blob/master/ckan/logic/action/patch.py#L57)\r\n* [`group_patch()`](https://github.com/ckan/ckan/blob/master/ckan/logic/action/patch.py#L88)\r\n* [`organization_patch()`](https://github.com/ckan/ckan/blob/master/ckan/logic/action/patch.py#L122)\r\n* [`user_patch()`](https://github.com/ckan/ckan/blob/master/ckan/logic/action/patch.py#L157)\r\n\r\n## Example\r\n\r\nThe following code snippet uses the Plugin Toolkit to access the [`user_patch()` function](https://github.com/ckan/ckan/blob/master/ckan/logic/action/patch.py#L157). This will fail if `user` is not authorized to perform `'user_show'`, because `'ignore_auth'` [is not propagated to `show_context`](https://github.com/ckan/ckan/blob/master/ckan/logic/action/patch.py#L171) in `user_patch()`.\r\n\r\n```python\r\ntoolkit.get_action('user_patch')(\r\n context={\r\n 'user': user,\r\n 'ignore_auth': True,\r\n },\r\n)\r\n```\r\n\r\nA problem like this showed up while I was modifying some code in the `ckanext-ldap` plugin. I believe the reason is that at the time this is being called, a currently not-logged-in user is being passed, and such a user cannot perform `'user_show'`. Regardless, I would have expected that with `'ignore_auth'` being passed into the patch function, the action would succeed, or at least would not return an authorization error.\r\n\r\n## Suggested fix\r\n\r\n### Easy\r\n\r\nThe easiest thing to do is just add `'ignore_auth': context.get('ignore_auth', False)` to each of the `show_context` definitions that are missing them.\r\n\r\n### Robust\r\n\r\nA more robust fix would be to introduce a helper function, `_create_show_context()` (defined below), that each function can call to create the `show_context` object. That way, future changes to the `show_context` will be propagated to all of the patch functions.\r\n\r\nIt is worth noting that I have absolutely no clue what the `'for_update'` key does. I couldn't find any documentation about it. It seems to be used in the database interaction code, but I'm not really familiar with working with databases. In any case: this key is not set consistently in the `show_context` objects across the various patch functions, so in the code below, it is an optional parameter that can be passed into the new function.\r\n\r\n```python\r\ndef _create_show_context(context: Context, for_update: bool = False) -> Context:\r\n '''Create a Context that can be used with a user_show action call.\r\n\r\n This method is internal. It is meant to be used by the patch action\r\n functions to generate a Context that can be used with a show action\r\n corresponding to the type of the patch action. The show action is\r\n used to retrieve the item that will be patched.\r\n\r\n The ``show_context`` is derived from the original patch Context,\r\n which is the ``context`` input argument. Certain values are propagated\r\n from the input ``context`` to the returned ``show_context``.\r\n\r\n :param context: Context from the original patch request\r\n :type context: Context\r\n\r\n :param for_update: if ``True``, then ``show_context['for_update'] = True``.\r\n If ``False`` (the default), then ``'for_update'`` will not be\r\n explicitly set in ``show_context``.\r\n :type for_update: bool\r\n\r\n :returns: A Context, ``show_context``, with the appropriate settings.\r\n '''\r\n show_context: Context = {\r\n 'model': context['model'],\r\n 'session': context['session'],\r\n 'user': context['user'],\r\n 'auth_user_obj': context['auth_user_obj'],\r\n 'ignore_auth': context.get('ignore_auth', False),\r\n }\r\n\r\n if for_update:\r\n show_context['for_update'] = True\r\n\r\n return show_context\r\n```\n", "before_files": [{"content": "# encoding: utf-8\n\n'''API functions for partial updates of existing data in CKAN'''\n\nfrom ckan.logic import (\n get_action as _get_action,\n check_access as _check_access,\n get_or_bust as _get_or_bust,\n)\nfrom ckan.types import Context, DataDict\nfrom ckan.types.logic import ActionResult\n\n\ndef package_patch(\n context: Context, data_dict: DataDict) -> ActionResult.PackagePatch:\n '''Patch a dataset (package).\n\n :param id: the id or name of the dataset\n :type id: string\n\n The difference between the update and patch methods is that the patch will\n perform an update of the provided parameters, while leaving all other\n parameters unchanged, whereas the update methods deletes all parameters\n not explicitly provided in the data_dict.\n\n You are able to partially update and/or create resources with\n package_patch. If you are updating existing resources be sure to provide\n the resource id. Existing resources excluded from the package_patch\n data_dict will be removed. Resources in the package data_dict without\n an id will be treated as new resources and will be added. New resources\n added with the patch method do not create the default views.\n\n You must be authorized to edit the dataset and the groups that it belongs\n to.\n '''\n _check_access('package_patch', context, data_dict)\n\n show_context: Context = {\n 'model': context['model'],\n 'session': context['session'],\n 'user': context['user'],\n 'auth_user_obj': context['auth_user_obj'],\n 'ignore_auth': context.get('ignore_auth', False),\n 'for_update': True\n }\n\n package_dict = _get_action('package_show')(\n show_context,\n {'id': _get_or_bust(data_dict, 'id')})\n\n patched = dict(package_dict)\n patched.update(data_dict)\n patched['id'] = package_dict['id']\n return _get_action('package_update')(context, patched)\n\n\ndef resource_patch(context: Context,\n data_dict: DataDict) -> ActionResult.ResourcePatch:\n '''Patch a resource\n\n :param id: the id of the resource\n :type id: string\n\n The difference between the update and patch methods is that the patch will\n perform an update of the provided parameters, while leaving all other\n parameters unchanged, whereas the update methods deletes all parameters\n not explicitly provided in the data_dict\n '''\n _check_access('resource_patch', context, data_dict)\n\n show_context: Context = {\n 'model': context['model'],\n 'session': context['session'],\n 'user': context['user'],\n 'auth_user_obj': context['auth_user_obj'],\n 'for_update': True\n }\n\n resource_dict = _get_action('resource_show')(\n show_context,\n {'id': _get_or_bust(data_dict, 'id')})\n\n patched = dict(resource_dict)\n patched.update(data_dict)\n return _get_action('resource_update')(context, patched)\n\n\ndef group_patch(context: Context,\n data_dict: DataDict) -> ActionResult.GroupPatch:\n '''Patch a group\n\n :param id: the id or name of the group\n :type id: string\n\n The difference between the update and patch methods is that the patch will\n perform an update of the provided parameters, while leaving all other\n parameters unchanged, whereas the update methods deletes all parameters\n not explicitly provided in the data_dict\n '''\n _check_access('group_patch', context, data_dict)\n\n show_context: Context = {\n 'model': context['model'],\n 'session': context['session'],\n 'user': context['user'],\n 'auth_user_obj': context['auth_user_obj'],\n }\n\n group_dict = _get_action('group_show')(\n show_context,\n {'id': _get_or_bust(data_dict, 'id')})\n\n patched = dict(group_dict)\n patched.pop('display_name', None)\n patched.update(data_dict)\n\n patch_context = context.copy()\n patch_context['allow_partial_update'] = True\n return _get_action('group_update')(patch_context, patched)\n\n\ndef organization_patch(\n context: Context,\n data_dict: DataDict) -> ActionResult.OrganizationPatch:\n '''Patch an organization\n\n :param id: the id or name of the organization\n :type id: string\n\n The difference between the update and patch methods is that the patch will\n perform an update of the provided parameters, while leaving all other\n parameters unchanged, whereas the update methods deletes all parameters\n not explicitly provided in the data_dict\n '''\n _check_access('organization_patch', context, data_dict)\n\n show_context: Context = {\n 'model': context['model'],\n 'session': context['session'],\n 'user': context['user'],\n 'auth_user_obj': context['auth_user_obj'],\n }\n\n organization_dict = _get_action('organization_show')(\n show_context,\n {'id': _get_or_bust(data_dict, 'id')})\n\n patched = dict(organization_dict)\n patched.pop('display_name', None)\n patched.update(data_dict)\n\n patch_context = context.copy()\n patch_context['allow_partial_update'] = True\n return _get_action('organization_update')(patch_context, patched)\n\n\ndef user_patch(context: Context,\n data_dict: DataDict) -> ActionResult.UserPatch:\n '''Patch a user\n\n :param id: the id or name of the user\n :type id: string\n\n The difference between the update and patch methods is that the patch will\n perform an update of the provided parameters, while leaving all other\n parameters unchanged, whereas the update methods deletes all parameters\n not explicitly provided in the data_dict\n '''\n _check_access('user_patch', context, data_dict)\n\n show_context: Context = {\n 'model': context['model'],\n 'session': context['session'],\n 'user': context['user'],\n 'auth_user_obj': context['auth_user_obj'],\n }\n\n user_dict = _get_action('user_show')(\n show_context,\n {'id': _get_or_bust(data_dict, 'id')})\n\n patched = dict(user_dict)\n patched.pop('display_name', None)\n patched.update(data_dict)\n return _get_action('user_update')(context, patched)\n", "path": "ckan/logic/action/patch.py"}], "after_files": [{"content": "# encoding: utf-8\n\n'''API functions for partial updates of existing data in CKAN'''\n\nfrom ckan.logic import (\n get_action as _get_action,\n check_access as _check_access,\n get_or_bust as _get_or_bust,\n fresh_context as _fresh_context\n)\nfrom ckan.types import Context, DataDict\nfrom ckan.types.logic import ActionResult\n\n\ndef package_patch(\n context: Context, data_dict: DataDict) -> ActionResult.PackagePatch:\n '''Patch a dataset (package).\n\n :param id: the id or name of the dataset\n :type id: string\n\n The difference between the update and patch methods is that the patch will\n perform an update of the provided parameters, while leaving all other\n parameters unchanged, whereas the update methods deletes all parameters\n not explicitly provided in the data_dict.\n\n You are able to partially update and/or create resources with\n package_patch. If you are updating existing resources be sure to provide\n the resource id. Existing resources excluded from the package_patch\n data_dict will be removed. Resources in the package data_dict without\n an id will be treated as new resources and will be added. New resources\n added with the patch method do not create the default views.\n\n You must be authorized to edit the dataset and the groups that it belongs\n to.\n '''\n _check_access('package_patch', context, data_dict)\n\n show_context: Context = {\n 'model': context['model'],\n 'session': context['session'],\n 'user': context['user'],\n 'auth_user_obj': context['auth_user_obj'],\n 'ignore_auth': context.get('ignore_auth', False),\n 'for_update': True\n }\n\n package_dict = _get_action('package_show')(\n show_context,\n {'id': _get_or_bust(data_dict, 'id')})\n\n patched = dict(package_dict)\n patched.update(data_dict)\n patched['id'] = package_dict['id']\n return _get_action('package_update')(context, patched)\n\n\ndef resource_patch(context: Context,\n data_dict: DataDict) -> ActionResult.ResourcePatch:\n '''Patch a resource\n\n :param id: the id of the resource\n :type id: string\n\n The difference between the update and patch methods is that the patch will\n perform an update of the provided parameters, while leaving all other\n parameters unchanged, whereas the update methods deletes all parameters\n not explicitly provided in the data_dict\n '''\n _check_access('resource_patch', context, data_dict)\n\n show_context: Context = _fresh_context(context)\n show_context.update({'for_update': True})\n\n resource_dict = _get_action('resource_show')(\n show_context,\n {'id': _get_or_bust(data_dict, 'id')})\n\n patched = dict(resource_dict)\n patched.update(data_dict)\n return _get_action('resource_update')(context, patched)\n\n\ndef group_patch(context: Context,\n data_dict: DataDict) -> ActionResult.GroupPatch:\n '''Patch a group\n\n :param id: the id or name of the group\n :type id: string\n\n The difference between the update and patch methods is that the patch will\n perform an update of the provided parameters, while leaving all other\n parameters unchanged, whereas the update methods deletes all parameters\n not explicitly provided in the data_dict\n '''\n _check_access('group_patch', context, data_dict)\n\n show_context: Context = _fresh_context(context)\n\n group_dict = _get_action('group_show')(\n show_context,\n {'id': _get_or_bust(data_dict, 'id')})\n\n patched = dict(group_dict)\n patched.pop('display_name', None)\n patched.update(data_dict)\n\n patch_context = context.copy()\n patch_context['allow_partial_update'] = True\n return _get_action('group_update')(patch_context, patched)\n\n\ndef organization_patch(\n context: Context,\n data_dict: DataDict) -> ActionResult.OrganizationPatch:\n '''Patch an organization\n\n :param id: the id or name of the organization\n :type id: string\n\n The difference between the update and patch methods is that the patch will\n perform an update of the provided parameters, while leaving all other\n parameters unchanged, whereas the update methods deletes all parameters\n not explicitly provided in the data_dict\n '''\n _check_access('organization_patch', context, data_dict)\n\n show_context: Context = _fresh_context(context)\n\n organization_dict = _get_action('organization_show')(\n show_context,\n {'id': _get_or_bust(data_dict, 'id')})\n\n patched = dict(organization_dict)\n patched.pop('display_name', None)\n patched.update(data_dict)\n\n patch_context = context.copy()\n patch_context['allow_partial_update'] = True\n return _get_action('organization_update')(patch_context, patched)\n\n\ndef user_patch(context: Context,\n data_dict: DataDict) -> ActionResult.UserPatch:\n '''Patch a user\n\n :param id: the id or name of the user\n :type id: string\n\n The difference between the update and patch methods is that the patch will\n perform an update of the provided parameters, while leaving all other\n parameters unchanged, whereas the update methods deletes all parameters\n not explicitly provided in the data_dict\n '''\n _check_access('user_patch', context, data_dict)\n\n show_context: Context = _fresh_context(context)\n\n user_dict = _get_action('user_show')(\n show_context,\n {'id': _get_or_bust(data_dict, 'id')})\n\n patched = dict(user_dict)\n patched.pop('display_name', None)\n patched.update(data_dict)\n return _get_action('user_update')(context, patched)\n", "path": "ckan/logic/action/patch.py"}]}
| 3,207 | 573 |
gh_patches_debug_7401
|
rasdani/github-patches
|
git_diff
|
kubeflow__pipelines-1399
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug: Dataset not found in US
I'm getting an error while running the BigQuery kfp component to export some data from BQ to GCS. It says: `google.api_core.exceptions.NotFound: 404 Not found: xxx was not found in location US` which is correct, because the dataset is in EU, but I couldn't find any way to change the default behaviour of looking for datasets in the US.
On our regular codebase we specify the location on the BigQuery client initialisation, but the code here just uses the default: https://github.com/danicat/pipelines/blob/master/component_sdk/python/kfp_component/google/bigquery/_query.py
It is a one line change in the code, but I don't know how to rebuild the ml-pipeline container. The developer guide doesn't mention how to do it (but it does explain how to build containers for other components of the solution).
Please help! :)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `component_sdk/python/kfp_component/google/bigquery/_query.py`
Content:
```
1 # Copyright 2018 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import json
16 import logging
17
18 from google.cloud import bigquery
19 from google.api_core import exceptions
20
21 from kfp_component.core import KfpExecutionContext, display
22 from .. import common as gcp_common
23
24 # TODO(hongyes): make this path configurable as a environment variable
25 KFP_OUTPUT_PATH = '/tmp/kfp/output/'
26
27 def query(query, project_id, dataset_id=None, table_id=None,
28 output_gcs_path=None, dataset_location='US', job_config=None):
29 """Submit a query to Bigquery service and dump outputs to Bigquery table or
30 a GCS blob.
31
32 Args:
33 query (str): The query used by Bigquery service to fetch the results.
34 project_id (str): The project to execute the query job.
35 dataset_id (str): The ID of the persistent dataset to keep the results
36 of the query. If the dataset does not exist, the operation will
37 create a new one.
38 table_id (str): The ID of the table to keep the results of the query. If
39 absent, the operation will generate a random id for the table.
40 output_gcs_path (str): The GCS blob path to dump the query results to.
41 dataset_location (str): The location to create the dataset. Defaults to `US`.
42 job_config (dict): The full config spec for the query job.
43 Returns:
44 The API representation of the completed query job.
45 """
46 client = bigquery.Client(project=project_id)
47 if not job_config:
48 job_config = bigquery.QueryJobConfig()
49 job_config.create_disposition = bigquery.job.CreateDisposition.CREATE_IF_NEEDED
50 job_config.write_disposition = bigquery.job.WriteDisposition.WRITE_TRUNCATE
51 job_id = None
52 def cancel():
53 if job_id:
54 client.cancel_job(job_id)
55 with KfpExecutionContext(on_cancel=cancel) as ctx:
56 job_id = 'query_' + ctx.context_id()
57 query_job = _get_job(client, job_id)
58 table_ref = None
59 if not query_job:
60 dataset_ref = _prepare_dataset_ref(client, dataset_id, output_gcs_path,
61 dataset_location)
62 if dataset_ref:
63 if not table_id:
64 table_id = job_id
65 table_ref = dataset_ref.table(table_id)
66 job_config.destination = table_ref
67 query_job = client.query(query, job_config, job_id=job_id)
68 _display_job_link(project_id, job_id)
69 query_job.result() # Wait for query to finish
70 if output_gcs_path:
71 job_id = 'extract_' + ctx.context_id()
72 extract_job = _get_job(client, job_id)
73 logging.info('Extracting data from table {} to {}.'.format(str(table_ref), output_gcs_path))
74 if not extract_job:
75 extract_job = client.extract_table(table_ref, output_gcs_path)
76 extract_job.result() # Wait for export to finish
77 _dump_outputs(query_job, output_gcs_path, table_ref)
78 return query_job.to_api_repr()
79
80 def _get_job(client, job_id):
81 try:
82 return client.get_job(job_id)
83 except exceptions.NotFound:
84 return None
85
86 def _prepare_dataset_ref(client, dataset_id, output_gcs_path, dataset_location):
87 if not output_gcs_path and not dataset_id:
88 return None
89
90 if not dataset_id:
91 dataset_id = 'kfp_tmp_dataset'
92 dataset_ref = client.dataset(dataset_id)
93 dataset = _get_dataset(client, dataset_ref)
94 if not dataset:
95 logging.info('Creating dataset {}'.format(dataset_id))
96 dataset = _create_dataset(client, dataset_ref, dataset_location)
97 return dataset_ref
98
99 def _get_dataset(client, dataset_ref):
100 try:
101 return client.get_dataset(dataset_ref)
102 except exceptions.NotFound:
103 return None
104
105 def _create_dataset(client, dataset_ref, location):
106 dataset = bigquery.Dataset(dataset_ref)
107 dataset.location = location
108 return client.create_dataset(dataset)
109
110 def _display_job_link(project_id, job_id):
111 display.display(display.Link(
112 href= 'https://console.cloud.google.com/bigquery?project={}'
113 '&j={}&page=queryresults'.format(project_id, job_id),
114 text='Query Details'
115 ))
116
117 def _dump_outputs(job, output_path, table_ref):
118 gcp_common.dump_file(KFP_OUTPUT_PATH + 'bigquery/query-job.json',
119 json.dumps(job.to_api_repr()))
120 if not output_path:
121 output_path = ''
122 gcp_common.dump_file(KFP_OUTPUT_PATH + 'bigquery/query-output-path.txt',
123 output_path)
124 (dataset_id, table_id) = (table_ref.dataset_id, table_ref.table_id) if table_ref else ('', '')
125 gcp_common.dump_file(KFP_OUTPUT_PATH + 'bigquery/query-dataset-id.txt',
126 dataset_id)
127 gcp_common.dump_file(KFP_OUTPUT_PATH + 'bigquery/query-table-id.txt',
128 table_id)
129
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/component_sdk/python/kfp_component/google/bigquery/_query.py b/component_sdk/python/kfp_component/google/bigquery/_query.py
--- a/component_sdk/python/kfp_component/google/bigquery/_query.py
+++ b/component_sdk/python/kfp_component/google/bigquery/_query.py
@@ -43,7 +43,7 @@
Returns:
The API representation of the completed query job.
"""
- client = bigquery.Client(project=project_id)
+ client = bigquery.Client(project=project_id, location=dataset_location)
if not job_config:
job_config = bigquery.QueryJobConfig()
job_config.create_disposition = bigquery.job.CreateDisposition.CREATE_IF_NEEDED
|
{"golden_diff": "diff --git a/component_sdk/python/kfp_component/google/bigquery/_query.py b/component_sdk/python/kfp_component/google/bigquery/_query.py\n--- a/component_sdk/python/kfp_component/google/bigquery/_query.py\n+++ b/component_sdk/python/kfp_component/google/bigquery/_query.py\n@@ -43,7 +43,7 @@\n Returns:\n The API representation of the completed query job.\n \"\"\"\n- client = bigquery.Client(project=project_id)\n+ client = bigquery.Client(project=project_id, location=dataset_location)\n if not job_config:\n job_config = bigquery.QueryJobConfig()\n job_config.create_disposition = bigquery.job.CreateDisposition.CREATE_IF_NEEDED\n", "issue": "Bug: Dataset not found in US\nI'm getting an error while running the BigQuery kfp component to export some data from BQ to GCS. It says: `google.api_core.exceptions.NotFound: 404 Not found: xxx was not found in location US` which is correct, because the dataset is in EU, but I couldn't find any way to change the default behaviour of looking for datasets in the US.\r\n\r\nOn our regular codebase we specify the location on the BigQuery client initialisation, but the code here just uses the default: https://github.com/danicat/pipelines/blob/master/component_sdk/python/kfp_component/google/bigquery/_query.py\r\n\r\nIt is a one line change in the code, but I don't know how to rebuild the ml-pipeline container. The developer guide doesn't mention how to do it (but it does explain how to build containers for other components of the solution).\r\n\r\nPlease help! :)\n", "before_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport json\nimport logging\n\nfrom google.cloud import bigquery\nfrom google.api_core import exceptions\n\nfrom kfp_component.core import KfpExecutionContext, display\nfrom .. import common as gcp_common\n\n# TODO(hongyes): make this path configurable as a environment variable\nKFP_OUTPUT_PATH = '/tmp/kfp/output/'\n\ndef query(query, project_id, dataset_id=None, table_id=None, \n output_gcs_path=None, dataset_location='US', job_config=None):\n \"\"\"Submit a query to Bigquery service and dump outputs to Bigquery table or \n a GCS blob.\n \n Args:\n query (str): The query used by Bigquery service to fetch the results.\n project_id (str): The project to execute the query job.\n dataset_id (str): The ID of the persistent dataset to keep the results\n of the query. If the dataset does not exist, the operation will \n create a new one.\n table_id (str): The ID of the table to keep the results of the query. If\n absent, the operation will generate a random id for the table.\n output_gcs_path (str): The GCS blob path to dump the query results to.\n dataset_location (str): The location to create the dataset. Defaults to `US`.\n job_config (dict): The full config spec for the query job.\n Returns:\n The API representation of the completed query job.\n \"\"\"\n client = bigquery.Client(project=project_id)\n if not job_config:\n job_config = bigquery.QueryJobConfig()\n job_config.create_disposition = bigquery.job.CreateDisposition.CREATE_IF_NEEDED\n job_config.write_disposition = bigquery.job.WriteDisposition.WRITE_TRUNCATE\n job_id = None\n def cancel():\n if job_id:\n client.cancel_job(job_id)\n with KfpExecutionContext(on_cancel=cancel) as ctx:\n job_id = 'query_' + ctx.context_id()\n query_job = _get_job(client, job_id)\n table_ref = None\n if not query_job:\n dataset_ref = _prepare_dataset_ref(client, dataset_id, output_gcs_path, \n dataset_location)\n if dataset_ref:\n if not table_id:\n table_id = job_id\n table_ref = dataset_ref.table(table_id)\n job_config.destination = table_ref\n query_job = client.query(query, job_config, job_id=job_id)\n _display_job_link(project_id, job_id)\n query_job.result() # Wait for query to finish\n if output_gcs_path:\n job_id = 'extract_' + ctx.context_id()\n extract_job = _get_job(client, job_id)\n logging.info('Extracting data from table {} to {}.'.format(str(table_ref), output_gcs_path))\n if not extract_job:\n extract_job = client.extract_table(table_ref, output_gcs_path)\n extract_job.result() # Wait for export to finish\n _dump_outputs(query_job, output_gcs_path, table_ref)\n return query_job.to_api_repr()\n\ndef _get_job(client, job_id):\n try:\n return client.get_job(job_id)\n except exceptions.NotFound:\n return None\n\ndef _prepare_dataset_ref(client, dataset_id, output_gcs_path, dataset_location):\n if not output_gcs_path and not dataset_id:\n return None\n \n if not dataset_id:\n dataset_id = 'kfp_tmp_dataset'\n dataset_ref = client.dataset(dataset_id)\n dataset = _get_dataset(client, dataset_ref)\n if not dataset:\n logging.info('Creating dataset {}'.format(dataset_id))\n dataset = _create_dataset(client, dataset_ref, dataset_location)\n return dataset_ref\n\ndef _get_dataset(client, dataset_ref):\n try:\n return client.get_dataset(dataset_ref)\n except exceptions.NotFound:\n return None\n\ndef _create_dataset(client, dataset_ref, location):\n dataset = bigquery.Dataset(dataset_ref)\n dataset.location = location\n return client.create_dataset(dataset)\n\ndef _display_job_link(project_id, job_id):\n display.display(display.Link(\n href= 'https://console.cloud.google.com/bigquery?project={}'\n '&j={}&page=queryresults'.format(project_id, job_id),\n text='Query Details'\n ))\n\ndef _dump_outputs(job, output_path, table_ref):\n gcp_common.dump_file(KFP_OUTPUT_PATH + 'bigquery/query-job.json', \n json.dumps(job.to_api_repr()))\n if not output_path:\n output_path = ''\n gcp_common.dump_file(KFP_OUTPUT_PATH + 'bigquery/query-output-path.txt', \n output_path)\n (dataset_id, table_id) = (table_ref.dataset_id, table_ref.table_id) if table_ref else ('', '')\n gcp_common.dump_file(KFP_OUTPUT_PATH + 'bigquery/query-dataset-id.txt', \n dataset_id)\n gcp_common.dump_file(KFP_OUTPUT_PATH + 'bigquery/query-table-id.txt', \n table_id)\n", "path": "component_sdk/python/kfp_component/google/bigquery/_query.py"}], "after_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport json\nimport logging\n\nfrom google.cloud import bigquery\nfrom google.api_core import exceptions\n\nfrom kfp_component.core import KfpExecutionContext, display\nfrom .. import common as gcp_common\n\n# TODO(hongyes): make this path configurable as a environment variable\nKFP_OUTPUT_PATH = '/tmp/kfp/output/'\n\ndef query(query, project_id, dataset_id=None, table_id=None, \n output_gcs_path=None, dataset_location='US', job_config=None):\n \"\"\"Submit a query to Bigquery service and dump outputs to Bigquery table or \n a GCS blob.\n \n Args:\n query (str): The query used by Bigquery service to fetch the results.\n project_id (str): The project to execute the query job.\n dataset_id (str): The ID of the persistent dataset to keep the results\n of the query. If the dataset does not exist, the operation will \n create a new one.\n table_id (str): The ID of the table to keep the results of the query. If\n absent, the operation will generate a random id for the table.\n output_gcs_path (str): The GCS blob path to dump the query results to.\n dataset_location (str): The location to create the dataset. Defaults to `US`.\n job_config (dict): The full config spec for the query job.\n Returns:\n The API representation of the completed query job.\n \"\"\"\n client = bigquery.Client(project=project_id, location=dataset_location)\n if not job_config:\n job_config = bigquery.QueryJobConfig()\n job_config.create_disposition = bigquery.job.CreateDisposition.CREATE_IF_NEEDED\n job_config.write_disposition = bigquery.job.WriteDisposition.WRITE_TRUNCATE\n job_id = None\n def cancel():\n if job_id:\n client.cancel_job(job_id)\n with KfpExecutionContext(on_cancel=cancel) as ctx:\n job_id = 'query_' + ctx.context_id()\n query_job = _get_job(client, job_id)\n table_ref = None\n if not query_job:\n dataset_ref = _prepare_dataset_ref(client, dataset_id, output_gcs_path, \n dataset_location)\n if dataset_ref:\n if not table_id:\n table_id = job_id\n table_ref = dataset_ref.table(table_id)\n job_config.destination = table_ref\n query_job = client.query(query, job_config, job_id=job_id)\n _display_job_link(project_id, job_id)\n query_job.result() # Wait for query to finish\n if output_gcs_path:\n job_id = 'extract_' + ctx.context_id()\n extract_job = _get_job(client, job_id)\n logging.info('Extracting data from table {} to {}.'.format(str(table_ref), output_gcs_path))\n if not extract_job:\n extract_job = client.extract_table(table_ref, output_gcs_path)\n extract_job.result() # Wait for export to finish\n _dump_outputs(query_job, output_gcs_path, table_ref)\n return query_job.to_api_repr()\n\ndef _get_job(client, job_id):\n try:\n return client.get_job(job_id)\n except exceptions.NotFound:\n return None\n\ndef _prepare_dataset_ref(client, dataset_id, output_gcs_path, dataset_location):\n if not output_gcs_path and not dataset_id:\n return None\n \n if not dataset_id:\n dataset_id = 'kfp_tmp_dataset'\n dataset_ref = client.dataset(dataset_id)\n dataset = _get_dataset(client, dataset_ref)\n if not dataset:\n logging.info('Creating dataset {}'.format(dataset_id))\n dataset = _create_dataset(client, dataset_ref, dataset_location)\n return dataset_ref\n\ndef _get_dataset(client, dataset_ref):\n try:\n return client.get_dataset(dataset_ref)\n except exceptions.NotFound:\n return None\n\ndef _create_dataset(client, dataset_ref, location):\n dataset = bigquery.Dataset(dataset_ref)\n dataset.location = location\n return client.create_dataset(dataset)\n\ndef _display_job_link(project_id, job_id):\n display.display(display.Link(\n href= 'https://console.cloud.google.com/bigquery?project={}'\n '&j={}&page=queryresults'.format(project_id, job_id),\n text='Query Details'\n ))\n\ndef _dump_outputs(job, output_path, table_ref):\n gcp_common.dump_file(KFP_OUTPUT_PATH + 'bigquery/query-job.json', \n json.dumps(job.to_api_repr()))\n if not output_path:\n output_path = ''\n gcp_common.dump_file(KFP_OUTPUT_PATH + 'bigquery/query-output-path.txt', \n output_path)\n (dataset_id, table_id) = (table_ref.dataset_id, table_ref.table_id) if table_ref else ('', '')\n gcp_common.dump_file(KFP_OUTPUT_PATH + 'bigquery/query-dataset-id.txt', \n dataset_id)\n gcp_common.dump_file(KFP_OUTPUT_PATH + 'bigquery/query-table-id.txt', \n table_id)\n", "path": "component_sdk/python/kfp_component/google/bigquery/_query.py"}]}
| 1,924 | 149 |
gh_patches_debug_28389
|
rasdani/github-patches
|
git_diff
|
freedomofpress__securedrop-5575
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Test result combination scripts can be removed
## Description
We have a couple of scripts for combining test results in CI that are no longer being used and can be deleted:
```
devops/scripts/combine-junit.py
devops/scripts/combine-junit-test-results.sh
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `devops/scripts/combine-junit.py`
Content:
```
1 #!/usr/bin/env python
2 #
3 # Corey Goldberg, Dec 2012
4 # Original source from gist.github.com/cgoldberg/4320815
5
6 import os
7 import sys
8 import xml.etree.ElementTree as ET
9
10
11 """Merge multiple JUnit XML files into a single results file.
12
13 Output dumps to sdtdout.
14
15 example usage:
16 $ python merge_junit_results.py results1.xml results2.xml > results.xml
17 """
18
19
20 def main():
21 args = sys.argv[1:]
22 if not args:
23 usage()
24 sys.exit(2)
25 if '-h' in args or '--help' in args:
26 usage()
27 sys.exit(2)
28 merge_results(args[:])
29
30
31 def merge_results(xml_files):
32 failures = 0
33 tests = 0
34 errors = 0
35 time = 0.0
36 cases = []
37
38 for file_name in xml_files:
39 # We disable bandit checking to permit B314, which recommends use
40 # of defusedxml to protect against malicious XML files. This code
41 # path only runs in CI, not on developer workstations, and the XML
42 # output is generated by testinfra on staging machines.
43 tree = ET.parse(file_name) # nosec
44 test_suite = tree.getroot()
45 failures += int(test_suite.attrib['failures'])
46 tests += int(test_suite.attrib['tests'])
47 errors += int(test_suite.attrib['errors'])
48 time += float(test_suite.attrib['time'])
49 cases.append(test_suite.getchildren())
50
51 new_root = ET.Element('testsuite')
52 new_root.attrib['failures'] = '%s' % failures
53 new_root.attrib['tests'] = '%s' % tests
54 new_root.attrib['errors'] = '%s' % errors
55 new_root.attrib['time'] = '%s' % time
56 for case in cases:
57 new_root.extend(case)
58 new_tree = ET.ElementTree(new_root)
59 ET.dump(new_tree)
60
61
62 def usage():
63 this_file = os.path.basename(__file__)
64 print('Usage: %s results1.xml results2.xml' % this_file)
65
66
67 if __name__ == '__main__':
68 main()
69
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/devops/scripts/combine-junit.py b/devops/scripts/combine-junit.py
deleted file mode 100755
--- a/devops/scripts/combine-junit.py
+++ /dev/null
@@ -1,68 +0,0 @@
-#!/usr/bin/env python
-#
-# Corey Goldberg, Dec 2012
-# Original source from gist.github.com/cgoldberg/4320815
-
-import os
-import sys
-import xml.etree.ElementTree as ET
-
-
-"""Merge multiple JUnit XML files into a single results file.
-
-Output dumps to sdtdout.
-
-example usage:
- $ python merge_junit_results.py results1.xml results2.xml > results.xml
-"""
-
-
-def main():
- args = sys.argv[1:]
- if not args:
- usage()
- sys.exit(2)
- if '-h' in args or '--help' in args:
- usage()
- sys.exit(2)
- merge_results(args[:])
-
-
-def merge_results(xml_files):
- failures = 0
- tests = 0
- errors = 0
- time = 0.0
- cases = []
-
- for file_name in xml_files:
- # We disable bandit checking to permit B314, which recommends use
- # of defusedxml to protect against malicious XML files. This code
- # path only runs in CI, not on developer workstations, and the XML
- # output is generated by testinfra on staging machines.
- tree = ET.parse(file_name) # nosec
- test_suite = tree.getroot()
- failures += int(test_suite.attrib['failures'])
- tests += int(test_suite.attrib['tests'])
- errors += int(test_suite.attrib['errors'])
- time += float(test_suite.attrib['time'])
- cases.append(test_suite.getchildren())
-
- new_root = ET.Element('testsuite')
- new_root.attrib['failures'] = '%s' % failures
- new_root.attrib['tests'] = '%s' % tests
- new_root.attrib['errors'] = '%s' % errors
- new_root.attrib['time'] = '%s' % time
- for case in cases:
- new_root.extend(case)
- new_tree = ET.ElementTree(new_root)
- ET.dump(new_tree)
-
-
-def usage():
- this_file = os.path.basename(__file__)
- print('Usage: %s results1.xml results2.xml' % this_file)
-
-
-if __name__ == '__main__':
- main()
|
{"golden_diff": "diff --git a/devops/scripts/combine-junit.py b/devops/scripts/combine-junit.py\ndeleted file mode 100755\n--- a/devops/scripts/combine-junit.py\n+++ /dev/null\n@@ -1,68 +0,0 @@\n-#!/usr/bin/env python\n-#\n-# Corey Goldberg, Dec 2012\n-# Original source from gist.github.com/cgoldberg/4320815\n-\n-import os\n-import sys\n-import xml.etree.ElementTree as ET\n-\n-\n-\"\"\"Merge multiple JUnit XML files into a single results file.\n-\n-Output dumps to sdtdout.\n-\n-example usage:\n- $ python merge_junit_results.py results1.xml results2.xml > results.xml\n-\"\"\"\n-\n-\n-def main():\n- args = sys.argv[1:]\n- if not args:\n- usage()\n- sys.exit(2)\n- if '-h' in args or '--help' in args:\n- usage()\n- sys.exit(2)\n- merge_results(args[:])\n-\n-\n-def merge_results(xml_files):\n- failures = 0\n- tests = 0\n- errors = 0\n- time = 0.0\n- cases = []\n-\n- for file_name in xml_files:\n- # We disable bandit checking to permit B314, which recommends use\n- # of defusedxml to protect against malicious XML files. This code\n- # path only runs in CI, not on developer workstations, and the XML\n- # output is generated by testinfra on staging machines.\n- tree = ET.parse(file_name) # nosec\n- test_suite = tree.getroot()\n- failures += int(test_suite.attrib['failures'])\n- tests += int(test_suite.attrib['tests'])\n- errors += int(test_suite.attrib['errors'])\n- time += float(test_suite.attrib['time'])\n- cases.append(test_suite.getchildren())\n-\n- new_root = ET.Element('testsuite')\n- new_root.attrib['failures'] = '%s' % failures\n- new_root.attrib['tests'] = '%s' % tests\n- new_root.attrib['errors'] = '%s' % errors\n- new_root.attrib['time'] = '%s' % time\n- for case in cases:\n- new_root.extend(case)\n- new_tree = ET.ElementTree(new_root)\n- ET.dump(new_tree)\n-\n-\n-def usage():\n- this_file = os.path.basename(__file__)\n- print('Usage: %s results1.xml results2.xml' % this_file)\n-\n-\n-if __name__ == '__main__':\n- main()\n", "issue": "Test result combination scripts can be removed\n## Description\r\n\r\nWe have a couple of scripts for combining test results in CI that are no longer being used and can be deleted:\r\n```\r\ndevops/scripts/combine-junit.py\r\ndevops/scripts/combine-junit-test-results.sh\r\n```\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\n#\n# Corey Goldberg, Dec 2012\n# Original source from gist.github.com/cgoldberg/4320815\n\nimport os\nimport sys\nimport xml.etree.ElementTree as ET\n\n\n\"\"\"Merge multiple JUnit XML files into a single results file.\n\nOutput dumps to sdtdout.\n\nexample usage:\n $ python merge_junit_results.py results1.xml results2.xml > results.xml\n\"\"\"\n\n\ndef main():\n args = sys.argv[1:]\n if not args:\n usage()\n sys.exit(2)\n if '-h' in args or '--help' in args:\n usage()\n sys.exit(2)\n merge_results(args[:])\n\n\ndef merge_results(xml_files):\n failures = 0\n tests = 0\n errors = 0\n time = 0.0\n cases = []\n\n for file_name in xml_files:\n # We disable bandit checking to permit B314, which recommends use\n # of defusedxml to protect against malicious XML files. This code\n # path only runs in CI, not on developer workstations, and the XML\n # output is generated by testinfra on staging machines.\n tree = ET.parse(file_name) # nosec\n test_suite = tree.getroot()\n failures += int(test_suite.attrib['failures'])\n tests += int(test_suite.attrib['tests'])\n errors += int(test_suite.attrib['errors'])\n time += float(test_suite.attrib['time'])\n cases.append(test_suite.getchildren())\n\n new_root = ET.Element('testsuite')\n new_root.attrib['failures'] = '%s' % failures\n new_root.attrib['tests'] = '%s' % tests\n new_root.attrib['errors'] = '%s' % errors\n new_root.attrib['time'] = '%s' % time\n for case in cases:\n new_root.extend(case)\n new_tree = ET.ElementTree(new_root)\n ET.dump(new_tree)\n\n\ndef usage():\n this_file = os.path.basename(__file__)\n print('Usage: %s results1.xml results2.xml' % this_file)\n\n\nif __name__ == '__main__':\n main()\n", "path": "devops/scripts/combine-junit.py"}], "after_files": [{"content": null, "path": "devops/scripts/combine-junit.py"}]}
| 932 | 586 |
gh_patches_debug_8914
|
rasdani/github-patches
|
git_diff
|
microsoft__knossos-ksc-629
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Calls to "main"
In merging #550 I find I need ``ks::main``.
Looking at this comment in
https://github.com/microsoft/knossos-ksc/blob/18f654086f349cceb59c30dcbc8de2c534dcb5ec/src/ksc/Cgen.hs#L801
I wonder is it time to look at removing that?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/python/ksc/utils.py`
Content:
```
1 from dataclasses import dataclass
2 from typing import Tuple, Union
3 from collections import namedtuple
4 import itertools
5
6 import importlib.util
7 import os
8 import numpy as np
9 import subprocess
10 import sysconfig
11 import sys
12 from tempfile import NamedTemporaryFile
13
14 from ksc.type import Type, tangent_type, make_tuple_if_many
15
16 class KRecord:
17 """
18 A smoother namedtuple -- like https://pythonhosted.org/pyrecord but using the existing class syntax.
19 Like a 3.7 dataclass, but don't need to decorate each derived class
20
21 Derive a class from KRecord, declare its fields, and use keyword args in __init__
22
23 def MyClass(KRecord):
24 cost: float
25 names: List[String]
26
27 def __init__(cost, names):
28 super().__init__(cost=cost, names=names)
29
30 And now you have a nice little record class.
31
32 Construct a MyClass:
33 a = MyClass(1.3, ["fred", "conor", "una"])
34
35 Compare two MyClasses
36 if a == b: ...
37
38 Etc
39 """
40
41 def __init__(self, **args):
42 for (nt,v) in args.items():
43 # assert nt in self.__annotations__ # <- This check will fail for chains of derived classes -- only the deepest has __annotations__ ready yet.
44 setattr(self, nt, v)
45
46 def __eq__(self, that):
47 if type(self) != type(that):
48 return False
49
50 for nt in self.__annotations__:
51 if getattr(self, nt) != getattr(that,nt):
52 return False
53 return True
54
55
56
57
58 def ensure_list_of_lists(l):
59 """return input, wrapped in a singleton list if its first element is not a list
60
61 ensure_list_of_lists([]) = []
62 ensure_list_of_lists([1]) = [[1]]
63 ensure_list_of_lists([[1]]) = [[1]]
64 ensure_list_of_lists([[1,2]]) = [[1, 2]]
65 ensure_list_of_lists([[1,2], [3,4]]) = [[1, 2], [3, 4]]
66 """
67
68 if not isinstance(l, list):
69 raise ValueError("Expect a list")
70 if len(l) < 1: # Empty list is empty list
71 return l
72 if not isinstance(l[0], list):
73 return [l]
74 else:
75 return l
76
77 def paren(s):
78 return "(" + s + ")"
79
80 PYTHON_MODULE_NAME = "ks_mod"
81
82 def import_module_from_path(module_name, path):
83 # These three lines are for loading a module from a file in Python 3.5+
84 # https://bugs.python.org/issue21436
85 spec = importlib.util.spec_from_file_location(module_name, path)
86 py_out = importlib.util.module_from_spec(spec)
87 spec.loader.exec_module(py_out)
88 return py_out
89
90 def translate_and_import(source_file_name, *args):
91 from ksc.translate import translate
92 py_out = translate(*args, source_file_name, with_main=False)
93 with NamedTemporaryFile(mode="w", suffix=".py", delete=False) as f:
94 f.write(f"# AUTOGEN from {source_file_name} via ksc.utils.translate_and_import")
95 f.write(py_out)
96
97 print(f.name)
98 return import_module_from_path(PYTHON_MODULE_NAME, f.name)
99
100 def subprocess_run(cmd, env=None):
101 return subprocess.run(cmd, stdout=subprocess.PIPE, env=env).stdout.decode().strip("\n")
102
103 def get_ksc_paths():
104 if "KSC_RUNTIME_DIR" in os.environ:
105 ksc_runtime_dir = os.environ["KSC_RUNTIME_DIR"]
106 else:
107 ksc_runtime_dir = "./src/runtime"
108
109 if "KSC_PATH" in os.environ:
110 ksc_path = os.environ["KSC_PATH"]
111 else:
112 ksc_path = "./build/bin/ksc"
113
114 return ksc_path,ksc_runtime_dir
115
116
117 def generate_cpp_from_ks(ks_str, generate_derivatives = False, use_aten = False):
118 ksc_path,_ksc_runtime_dir = get_ksc_paths()
119
120 with NamedTemporaryFile(mode="w", suffix=".ks", delete=False) as fks:
121 fks.write(ks_str)
122 try:
123 with NamedTemporaryFile(mode="w", suffix=".kso", delete=False) as fkso:
124 with NamedTemporaryFile(mode="w", suffix=".cpp", delete=False) as fcpp:
125 print("generate_cpp_from_ks:", ksc_path, fks.name)
126 e = subprocess.run([
127 ksc_path,
128 "--generate-cpp" if generate_derivatives else "--generate-cpp-without-diffs",
129 "--ks-source-file", "src/runtime/prelude.ks",
130 *(("--ks-source-file", "src/runtime/prelude-aten.ks") if use_aten else ()),
131 "--ks-source-file", fks.name,
132 "--ks-output-file", fkso.name,
133 "--cpp-output-file", fcpp.name
134 ], capture_output=True, check=True)
135 print(e.stdout.decode('ascii'))
136 print(e.stderr.decode('ascii'))
137 except subprocess.CalledProcessError as e:
138 print(f"files {fks.name} {fkso.name} {fcpp.name}")
139 print(f"ks_str=\n{ks_str}")
140 print(e.output.decode('ascii'))
141 print(e.stderr.decode('ascii'))
142 raise
143
144
145 # Read from CPP back to string
146 with open(fcpp.name) as f:
147 out = f.read()
148
149 # only delete these file if no error
150 os.unlink(fks.name)
151 os.unlink(fcpp.name)
152 os.unlink(fkso.name)
153
154 return out
155
156 def build_py_module_from_cpp(cpp_str, pybind11_path, use_aten=False):
157 _ksc_path,ksc_runtime_dir = get_ksc_paths()
158
159 with NamedTemporaryFile(mode="w", suffix=".cpp", delete=False) as fcpp:
160 fcpp.write(cpp_str)
161
162 extension_suffix = sysconfig.get_config_var('EXT_SUFFIX')
163 if extension_suffix is None:
164 extension_suffix = sysconfig.get_config_var('SO')
165
166 with NamedTemporaryFile(mode="w", suffix=extension_suffix, delete=False) as fpymod:
167 pass
168 module_path = fpymod.name
169 module_name = os.path.basename(module_path).split(".")[0]
170 python_includes = subprocess_run(
171 [sys.executable, "-m", "pybind11", "--includes"],
172 env={"PYTHONPATH": "extern/pybind11"}
173 )
174 try:
175 cmd = (f"g++ -I{ksc_runtime_dir} -I{pybind11_path}/include "
176 + python_includes
177 + " -Wall -Wno-unused-variable -Wno-unused-but-set-variable"
178 " -fmax-errors=1"
179 " -std=c++17"
180 " -O3"
181 " -fPIC"
182 " -shared"
183 + (" -DKS_INCLUDE_ATEN" if use_aten else "")
184 + f" -DPYTHON_MODULE_NAME={module_name}"
185 f" -o {module_path} "
186 + fcpp.name)
187 print(cmd)
188 subprocess.run(cmd, shell=True, capture_output=True, check=True)
189 except subprocess.CalledProcessError as e:
190 print(f"cpp_file={fcpp.name}")
191 print(cmd)
192 print(e.output.decode('utf-8'))
193 print(e.stderr.decode('utf-8'))
194
195 raise
196
197 os.unlink(fcpp.name)
198 return module_name, module_path
199
200 def mangleType(ty):
201 return ty.shortstr()
202
203 def mangleTypes(tys):
204 return "".join(mangleType(ty) for ty in tys)
205
206
207 def encode_name(s : str) -> str:
208 # TODO: this could be faster
209 return s.\
210 replace('@',"$a").\
211 replace(',',"$_").\
212 replace('.',"$o").\
213 replace('[',"$6").\
214 replace(']',"$9").\
215 replace('<',"$d").\
216 replace('>',"$b").\
217 replace('*',"$x").\
218 replace(':',"$8")
219
220 def generate_and_compile_cpp_from_ks(ks_str, name_to_call, arg_types, return_type=None, generate_derivatives=False, use_aten=False, pybind11_path="extern/pybind11"):
221
222 generated_cpp_source = generate_cpp_from_ks(ks_str, generate_derivatives=generate_derivatives, use_aten=use_aten)
223
224 cpp_str = """
225 #include "knossos-pybind.h"
226
227 """ + generated_cpp_source + """
228
229 int ks::main(ks::allocator *) { return 0; };
230
231 """
232
233 args_str = mangleTypes(arg_types)
234 name_str = encode_name(f"{name_to_call}@{args_str}")
235 declarations = f"""
236 m.def("entry", with_ks_allocator(&ks::{name_str}));
237 """
238
239 if generate_derivatives:
240 darg_types = [tangent_type(ty) for ty in arg_types]
241 args_tuple_str = mangleType(make_tuple_if_many(arg_types))
242 dargs_tuple_str = mangleType(make_tuple_if_many(darg_types))
243 dreturn_type_str = mangleType(tangent_type(return_type))
244
245 fwd_name = encode_name(f"fwd${name_to_call}@{args_tuple_str}")
246 declarations += f"""
247 m.def("fwd_entry", with_ks_allocator(&ks::{fwd_name}));
248 """
249
250 rev_name = encode_name(f"rev${name_to_call}@{args_tuple_str}")
251 declarations += f"""
252 m.def("rev_entry", with_ks_allocator(&ks::{rev_name}));
253 """
254
255 cpp_str += """
256 PYBIND11_MODULE(PYTHON_MODULE_NAME, m) {
257 m.def("reset_allocator", []{g_alloc.reset();});
258 m.def("allocator_top", []{ return g_alloc.mark();});
259 m.def("allocator_peak", []{ return g_alloc.peak();});
260
261 declare_tensor_2<double>(m, "Tensor_2_Float");
262 declare_tensor_2<int>(m, "Tensor_2_Integer");
263
264 """ + declarations + """
265 }
266 """
267 pybindcpppath = "obj/pybind.cpp"
268 print(f"Saving to {pybindcpppath}")
269 os.makedirs(os.path.dirname(pybindcpppath), exist_ok=True)
270 with open(pybindcpppath, "w") as fcpp:
271 fcpp.write(cpp_str)
272
273 module_name, module_path = build_py_module_from_cpp(cpp_str, pybind11_path, use_aten=use_aten)
274 return import_module_from_path(module_name, module_path)
275
276 def ndgrid_inds(sz):
277 """
278 Return a sequnce of tuples of indices as if generated by nested comprehensions.
279 Example:
280 ndgrid_inds((ni,nj))
281 Returns the same sequence as
282 [(i,j) for i in range(ni) for j in range(nj)]
283
284 The iterates are always tuples so
285 ndgrid_inds(4)
286 returns
287 [(0,), (1,), (2,), (3,)]
288
289 """
290
291 return itertools.product(*map(range, sz))
292
293
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/python/ksc/utils.py b/src/python/ksc/utils.py
--- a/src/python/ksc/utils.py
+++ b/src/python/ksc/utils.py
@@ -221,14 +221,11 @@
generated_cpp_source = generate_cpp_from_ks(ks_str, generate_derivatives=generate_derivatives, use_aten=use_aten)
- cpp_str = """
-#include "knossos-pybind.h"
+ cpp_str = f"""
+ #include "knossos-pybind.h"
+ {generated_cpp_source}
-""" + generated_cpp_source + """
-
-int ks::main(ks::allocator *) { return 0; };
-
-"""
+ """
args_str = mangleTypes(arg_types)
name_str = encode_name(f"{name_to_call}@{args_str}")
|
{"golden_diff": "diff --git a/src/python/ksc/utils.py b/src/python/ksc/utils.py\n--- a/src/python/ksc/utils.py\n+++ b/src/python/ksc/utils.py\n@@ -221,14 +221,11 @@\n \n generated_cpp_source = generate_cpp_from_ks(ks_str, generate_derivatives=generate_derivatives, use_aten=use_aten)\n \n- cpp_str = \"\"\"\n-#include \"knossos-pybind.h\"\n+ cpp_str = f\"\"\"\n+ #include \"knossos-pybind.h\"\n+ {generated_cpp_source}\n \n-\"\"\" + generated_cpp_source + \"\"\"\n-\n-int ks::main(ks::allocator *) { return 0; };\n-\n-\"\"\"\n+ \"\"\"\n \n args_str = mangleTypes(arg_types)\n name_str = encode_name(f\"{name_to_call}@{args_str}\")\n", "issue": "Calls to \"main\"\nIn merging #550 I find I need ``ks::main``. \r\nLooking at this comment in \r\nhttps://github.com/microsoft/knossos-ksc/blob/18f654086f349cceb59c30dcbc8de2c534dcb5ec/src/ksc/Cgen.hs#L801\r\n\r\nI wonder is it time to look at removing that?\n", "before_files": [{"content": "from dataclasses import dataclass\nfrom typing import Tuple, Union\nfrom collections import namedtuple\nimport itertools\n\nimport importlib.util\nimport os\nimport numpy as np\nimport subprocess\nimport sysconfig\nimport sys\nfrom tempfile import NamedTemporaryFile\n\nfrom ksc.type import Type, tangent_type, make_tuple_if_many\n\nclass KRecord:\n \"\"\"\n A smoother namedtuple -- like https://pythonhosted.org/pyrecord but using the existing class syntax.\n Like a 3.7 dataclass, but don't need to decorate each derived class\n\n Derive a class from KRecord, declare its fields, and use keyword args in __init__\n\n def MyClass(KRecord):\n cost: float\n names: List[String]\n\n def __init__(cost, names):\n super().__init__(cost=cost, names=names)\n\n And now you have a nice little record class.\n\n Construct a MyClass:\n a = MyClass(1.3, [\"fred\", \"conor\", \"una\"])\n\n Compare two MyClasses\n if a == b: ...\n \n Etc\n \"\"\"\n\n def __init__(self, **args):\n for (nt,v) in args.items():\n # assert nt in self.__annotations__ # <- This check will fail for chains of derived classes -- only the deepest has __annotations__ ready yet.\n setattr(self, nt, v)\n\n def __eq__(self, that):\n if type(self) != type(that):\n return False\n\n for nt in self.__annotations__:\n if getattr(self, nt) != getattr(that,nt):\n return False\n return True\n\n\n\n\ndef ensure_list_of_lists(l):\n \"\"\"return input, wrapped in a singleton list if its first element is not a list\n\n ensure_list_of_lists([]) = []\n ensure_list_of_lists([1]) = [[1]]\n ensure_list_of_lists([[1]]) = [[1]]\n ensure_list_of_lists([[1,2]]) = [[1, 2]]\n ensure_list_of_lists([[1,2], [3,4]]) = [[1, 2], [3, 4]]\n \"\"\"\n\n if not isinstance(l, list):\n raise ValueError(\"Expect a list\")\n if len(l) < 1: # Empty list is empty list\n return l\n if not isinstance(l[0], list):\n return [l]\n else:\n return l\n\ndef paren(s):\n return \"(\" + s + \")\"\n\nPYTHON_MODULE_NAME = \"ks_mod\"\n\ndef import_module_from_path(module_name, path):\n # These three lines are for loading a module from a file in Python 3.5+\n # https://bugs.python.org/issue21436\n spec = importlib.util.spec_from_file_location(module_name, path)\n py_out = importlib.util.module_from_spec(spec)\n spec.loader.exec_module(py_out)\n return py_out\n\ndef translate_and_import(source_file_name, *args):\n from ksc.translate import translate\n py_out = translate(*args, source_file_name, with_main=False)\n with NamedTemporaryFile(mode=\"w\", suffix=\".py\", delete=False) as f:\n f.write(f\"# AUTOGEN from {source_file_name} via ksc.utils.translate_and_import\")\n f.write(py_out)\n\n print(f.name)\n return import_module_from_path(PYTHON_MODULE_NAME, f.name)\n\ndef subprocess_run(cmd, env=None):\n return subprocess.run(cmd, stdout=subprocess.PIPE, env=env).stdout.decode().strip(\"\\n\")\n\ndef get_ksc_paths():\n if \"KSC_RUNTIME_DIR\" in os.environ:\n ksc_runtime_dir = os.environ[\"KSC_RUNTIME_DIR\"]\n else:\n ksc_runtime_dir = \"./src/runtime\"\n\n if \"KSC_PATH\" in os.environ:\n ksc_path = os.environ[\"KSC_PATH\"]\n else:\n ksc_path = \"./build/bin/ksc\"\n \n return ksc_path,ksc_runtime_dir\n\n\ndef generate_cpp_from_ks(ks_str, generate_derivatives = False, use_aten = False):\n ksc_path,_ksc_runtime_dir = get_ksc_paths()\n\n with NamedTemporaryFile(mode=\"w\", suffix=\".ks\", delete=False) as fks:\n fks.write(ks_str)\n try:\n with NamedTemporaryFile(mode=\"w\", suffix=\".kso\", delete=False) as fkso:\n with NamedTemporaryFile(mode=\"w\", suffix=\".cpp\", delete=False) as fcpp:\n print(\"generate_cpp_from_ks:\", ksc_path, fks.name)\n e = subprocess.run([\n ksc_path,\n \"--generate-cpp\" if generate_derivatives else \"--generate-cpp-without-diffs\",\n \"--ks-source-file\", \"src/runtime/prelude.ks\",\n *((\"--ks-source-file\", \"src/runtime/prelude-aten.ks\") if use_aten else ()),\n \"--ks-source-file\", fks.name,\n \"--ks-output-file\", fkso.name,\n \"--cpp-output-file\", fcpp.name\n ], capture_output=True, check=True)\n print(e.stdout.decode('ascii'))\n print(e.stderr.decode('ascii'))\n except subprocess.CalledProcessError as e:\n print(f\"files {fks.name} {fkso.name} {fcpp.name}\")\n print(f\"ks_str=\\n{ks_str}\")\n print(e.output.decode('ascii'))\n print(e.stderr.decode('ascii'))\n raise\n\n\n # Read from CPP back to string\n with open(fcpp.name) as f:\n out = f.read()\n\n # only delete these file if no error\n os.unlink(fks.name)\n os.unlink(fcpp.name)\n os.unlink(fkso.name)\n\n return out\n\ndef build_py_module_from_cpp(cpp_str, pybind11_path, use_aten=False):\n _ksc_path,ksc_runtime_dir = get_ksc_paths()\n\n with NamedTemporaryFile(mode=\"w\", suffix=\".cpp\", delete=False) as fcpp:\n fcpp.write(cpp_str)\n\n extension_suffix = sysconfig.get_config_var('EXT_SUFFIX')\n if extension_suffix is None:\n extension_suffix = sysconfig.get_config_var('SO')\n\n with NamedTemporaryFile(mode=\"w\", suffix=extension_suffix, delete=False) as fpymod:\n pass\n module_path = fpymod.name\n module_name = os.path.basename(module_path).split(\".\")[0]\n python_includes = subprocess_run(\n [sys.executable, \"-m\", \"pybind11\", \"--includes\"],\n env={\"PYTHONPATH\": \"extern/pybind11\"}\n )\n try:\n cmd = (f\"g++ -I{ksc_runtime_dir} -I{pybind11_path}/include \"\n + python_includes\n + \" -Wall -Wno-unused-variable -Wno-unused-but-set-variable\"\n \" -fmax-errors=1\"\n \" -std=c++17\"\n \" -O3\"\n \" -fPIC\"\n \" -shared\"\n + (\" -DKS_INCLUDE_ATEN\" if use_aten else \"\")\n + f\" -DPYTHON_MODULE_NAME={module_name}\"\n f\" -o {module_path} \"\n + fcpp.name)\n print(cmd)\n subprocess.run(cmd, shell=True, capture_output=True, check=True)\n except subprocess.CalledProcessError as e:\n print(f\"cpp_file={fcpp.name}\")\n print(cmd)\n print(e.output.decode('utf-8'))\n print(e.stderr.decode('utf-8'))\n\n raise\n \n os.unlink(fcpp.name)\n return module_name, module_path\n\ndef mangleType(ty):\n return ty.shortstr()\n\ndef mangleTypes(tys):\n return \"\".join(mangleType(ty) for ty in tys)\n\n\ndef encode_name(s : str) -> str:\n # TODO: this could be faster\n return s.\\\n replace('@',\"$a\").\\\n replace(',',\"$_\").\\\n replace('.',\"$o\").\\\n replace('[',\"$6\").\\\n replace(']',\"$9\").\\\n replace('<',\"$d\").\\\n replace('>',\"$b\").\\\n replace('*',\"$x\").\\\n replace(':',\"$8\")\n\ndef generate_and_compile_cpp_from_ks(ks_str, name_to_call, arg_types, return_type=None, generate_derivatives=False, use_aten=False, pybind11_path=\"extern/pybind11\"):\n\n generated_cpp_source = generate_cpp_from_ks(ks_str, generate_derivatives=generate_derivatives, use_aten=use_aten)\n\n cpp_str = \"\"\"\n#include \"knossos-pybind.h\"\n\n\"\"\" + generated_cpp_source + \"\"\"\n\nint ks::main(ks::allocator *) { return 0; };\n\n\"\"\"\n\n args_str = mangleTypes(arg_types)\n name_str = encode_name(f\"{name_to_call}@{args_str}\")\n declarations = f\"\"\"\n m.def(\"entry\", with_ks_allocator(&ks::{name_str}));\n \"\"\"\n\n if generate_derivatives:\n darg_types = [tangent_type(ty) for ty in arg_types]\n args_tuple_str = mangleType(make_tuple_if_many(arg_types))\n dargs_tuple_str = mangleType(make_tuple_if_many(darg_types))\n dreturn_type_str = mangleType(tangent_type(return_type))\n\n fwd_name = encode_name(f\"fwd${name_to_call}@{args_tuple_str}\")\n declarations += f\"\"\"\n m.def(\"fwd_entry\", with_ks_allocator(&ks::{fwd_name}));\n \"\"\"\n\n rev_name = encode_name(f\"rev${name_to_call}@{args_tuple_str}\")\n declarations += f\"\"\"\n m.def(\"rev_entry\", with_ks_allocator(&ks::{rev_name}));\n \"\"\"\n\n cpp_str += \"\"\"\nPYBIND11_MODULE(PYTHON_MODULE_NAME, m) {\n m.def(\"reset_allocator\", []{g_alloc.reset();});\n m.def(\"allocator_top\", []{ return g_alloc.mark();});\n m.def(\"allocator_peak\", []{ return g_alloc.peak();});\n\n declare_tensor_2<double>(m, \"Tensor_2_Float\");\n declare_tensor_2<int>(m, \"Tensor_2_Integer\");\n\n\"\"\" + declarations + \"\"\"\n}\n\"\"\"\n pybindcpppath = \"obj/pybind.cpp\"\n print(f\"Saving to {pybindcpppath}\") \n os.makedirs(os.path.dirname(pybindcpppath), exist_ok=True)\n with open(pybindcpppath, \"w\") as fcpp:\n fcpp.write(cpp_str)\n\n module_name, module_path = build_py_module_from_cpp(cpp_str, pybind11_path, use_aten=use_aten)\n return import_module_from_path(module_name, module_path)\n\ndef ndgrid_inds(sz):\n \"\"\"\n Return a sequnce of tuples of indices as if generated by nested comprehensions.\n Example:\n ndgrid_inds((ni,nj))\n Returns the same sequence as\n [(i,j) for i in range(ni) for j in range(nj)]\n\n The iterates are always tuples so\n ndgrid_inds(4)\n returns\n [(0,), (1,), (2,), (3,)] \n\n \"\"\"\n\n return itertools.product(*map(range, sz))\n\n", "path": "src/python/ksc/utils.py"}], "after_files": [{"content": "from dataclasses import dataclass\nfrom typing import Tuple, Union\nfrom collections import namedtuple\nimport itertools\n\nimport importlib.util\nimport os\nimport numpy as np\nimport subprocess\nimport sysconfig\nimport sys\nfrom tempfile import NamedTemporaryFile\n\nfrom ksc.type import Type, tangent_type, make_tuple_if_many\n\nclass KRecord:\n \"\"\"\n A smoother namedtuple -- like https://pythonhosted.org/pyrecord but using the existing class syntax.\n Like a 3.7 dataclass, but don't need to decorate each derived class\n\n Derive a class from KRecord, declare its fields, and use keyword args in __init__\n\n def MyClass(KRecord):\n cost: float\n names: List[String]\n\n def __init__(cost, names):\n super().__init__(cost=cost, names=names)\n\n And now you have a nice little record class.\n\n Construct a MyClass:\n a = MyClass(1.3, [\"fred\", \"conor\", \"una\"])\n\n Compare two MyClasses\n if a == b: ...\n \n Etc\n \"\"\"\n\n def __init__(self, **args):\n for (nt,v) in args.items():\n # assert nt in self.__annotations__ # <- This check will fail for chains of derived classes -- only the deepest has __annotations__ ready yet.\n setattr(self, nt, v)\n\n def __eq__(self, that):\n if type(self) != type(that):\n return False\n\n for nt in self.__annotations__:\n if getattr(self, nt) != getattr(that,nt):\n return False\n return True\n\n\n\n\ndef ensure_list_of_lists(l):\n \"\"\"return input, wrapped in a singleton list if its first element is not a list\n\n ensure_list_of_lists([]) = []\n ensure_list_of_lists([1]) = [[1]]\n ensure_list_of_lists([[1]]) = [[1]]\n ensure_list_of_lists([[1,2]]) = [[1, 2]]\n ensure_list_of_lists([[1,2], [3,4]]) = [[1, 2], [3, 4]]\n \"\"\"\n\n if not isinstance(l, list):\n raise ValueError(\"Expect a list\")\n if len(l) < 1: # Empty list is empty list\n return l\n if not isinstance(l[0], list):\n return [l]\n else:\n return l\n\ndef paren(s):\n return \"(\" + s + \")\"\n\nPYTHON_MODULE_NAME = \"ks_mod\"\n\ndef import_module_from_path(module_name, path):\n # These three lines are for loading a module from a file in Python 3.5+\n # https://bugs.python.org/issue21436\n spec = importlib.util.spec_from_file_location(module_name, path)\n py_out = importlib.util.module_from_spec(spec)\n spec.loader.exec_module(py_out)\n return py_out\n\ndef translate_and_import(source_file_name, *args):\n from ksc.translate import translate\n py_out = translate(*args, source_file_name, with_main=False)\n with NamedTemporaryFile(mode=\"w\", suffix=\".py\", delete=False) as f:\n f.write(f\"# AUTOGEN from {source_file_name} via ksc.utils.translate_and_import\")\n f.write(py_out)\n\n print(f.name)\n return import_module_from_path(PYTHON_MODULE_NAME, f.name)\n\ndef subprocess_run(cmd, env=None):\n return subprocess.run(cmd, stdout=subprocess.PIPE, env=env).stdout.decode().strip(\"\\n\")\n\ndef get_ksc_paths():\n if \"KSC_RUNTIME_DIR\" in os.environ:\n ksc_runtime_dir = os.environ[\"KSC_RUNTIME_DIR\"]\n else:\n ksc_runtime_dir = \"./src/runtime\"\n\n if \"KSC_PATH\" in os.environ:\n ksc_path = os.environ[\"KSC_PATH\"]\n else:\n ksc_path = \"./build/bin/ksc\"\n \n return ksc_path,ksc_runtime_dir\n\n\ndef generate_cpp_from_ks(ks_str, generate_derivatives = False, use_aten = False):\n ksc_path,_ksc_runtime_dir = get_ksc_paths()\n\n with NamedTemporaryFile(mode=\"w\", suffix=\".ks\", delete=False) as fks:\n fks.write(ks_str)\n try:\n with NamedTemporaryFile(mode=\"w\", suffix=\".kso\", delete=False) as fkso:\n with NamedTemporaryFile(mode=\"w\", suffix=\".cpp\", delete=False) as fcpp:\n print(\"generate_cpp_from_ks:\", ksc_path, fks.name)\n e = subprocess.run([\n ksc_path,\n \"--generate-cpp\" if generate_derivatives else \"--generate-cpp-without-diffs\",\n \"--ks-source-file\", \"src/runtime/prelude.ks\",\n *((\"--ks-source-file\", \"src/runtime/prelude-aten.ks\") if use_aten else ()),\n \"--ks-source-file\", fks.name,\n \"--ks-output-file\", fkso.name,\n \"--cpp-output-file\", fcpp.name\n ], capture_output=True, check=True)\n print(e.stdout.decode('ascii'))\n print(e.stderr.decode('ascii'))\n except subprocess.CalledProcessError as e:\n print(f\"files {fks.name} {fkso.name} {fcpp.name}\")\n print(f\"ks_str=\\n{ks_str}\")\n print(e.output.decode('ascii'))\n print(e.stderr.decode('ascii'))\n raise\n\n\n # Read from CPP back to string\n with open(fcpp.name) as f:\n out = f.read()\n\n # only delete these file if no error\n os.unlink(fks.name)\n os.unlink(fcpp.name)\n os.unlink(fkso.name)\n\n return out\n\ndef build_py_module_from_cpp(cpp_str, pybind11_path, use_aten=False):\n _ksc_path,ksc_runtime_dir = get_ksc_paths()\n\n with NamedTemporaryFile(mode=\"w\", suffix=\".cpp\", delete=False) as fcpp:\n fcpp.write(cpp_str)\n\n extension_suffix = sysconfig.get_config_var('EXT_SUFFIX')\n if extension_suffix is None:\n extension_suffix = sysconfig.get_config_var('SO')\n\n with NamedTemporaryFile(mode=\"w\", suffix=extension_suffix, delete=False) as fpymod:\n pass\n module_path = fpymod.name\n module_name = os.path.basename(module_path).split(\".\")[0]\n python_includes = subprocess_run(\n [sys.executable, \"-m\", \"pybind11\", \"--includes\"],\n env={\"PYTHONPATH\": \"extern/pybind11\"}\n )\n try:\n cmd = (f\"g++ -I{ksc_runtime_dir} -I{pybind11_path}/include \"\n + python_includes\n + \" -Wall -Wno-unused-variable -Wno-unused-but-set-variable\"\n \" -fmax-errors=1\"\n \" -std=c++17\"\n \" -O3\"\n \" -fPIC\"\n \" -shared\"\n + (\" -DKS_INCLUDE_ATEN\" if use_aten else \"\")\n + f\" -DPYTHON_MODULE_NAME={module_name}\"\n f\" -o {module_path} \"\n + fcpp.name)\n print(cmd)\n subprocess.run(cmd, shell=True, capture_output=True, check=True)\n except subprocess.CalledProcessError as e:\n print(f\"cpp_file={fcpp.name}\")\n print(cmd)\n print(e.output.decode('utf-8'))\n print(e.stderr.decode('utf-8'))\n\n raise\n \n os.unlink(fcpp.name)\n return module_name, module_path\n\ndef mangleType(ty):\n return ty.shortstr()\n\ndef mangleTypes(tys):\n return \"\".join(mangleType(ty) for ty in tys)\n\n\ndef encode_name(s : str) -> str:\n # TODO: this could be faster\n return s.\\\n replace('@',\"$a\").\\\n replace(',',\"$_\").\\\n replace('.',\"$o\").\\\n replace('[',\"$6\").\\\n replace(']',\"$9\").\\\n replace('<',\"$d\").\\\n replace('>',\"$b\").\\\n replace('*',\"$x\").\\\n replace(':',\"$8\")\n\ndef generate_and_compile_cpp_from_ks(ks_str, name_to_call, arg_types, return_type=None, generate_derivatives=False, use_aten=False, pybind11_path=\"extern/pybind11\"):\n\n generated_cpp_source = generate_cpp_from_ks(ks_str, generate_derivatives=generate_derivatives, use_aten=use_aten)\n\n cpp_str = f\"\"\"\n #include \"knossos-pybind.h\"\n {generated_cpp_source}\n\n \"\"\"\n\n args_str = mangleTypes(arg_types)\n name_str = encode_name(f\"{name_to_call}@{args_str}\")\n declarations = f\"\"\"\n m.def(\"entry\", with_ks_allocator(&ks::{name_str}));\n \"\"\"\n\n if generate_derivatives:\n darg_types = [tangent_type(ty) for ty in arg_types]\n args_tuple_str = mangleType(make_tuple_if_many(arg_types))\n dargs_tuple_str = mangleType(make_tuple_if_many(darg_types))\n dreturn_type_str = mangleType(tangent_type(return_type))\n\n fwd_name = encode_name(f\"fwd${name_to_call}@{args_tuple_str}\")\n declarations += f\"\"\"\n m.def(\"fwd_entry\", with_ks_allocator(&ks::{fwd_name}));\n \"\"\"\n\n rev_name = encode_name(f\"rev${name_to_call}@{args_tuple_str}\")\n declarations += f\"\"\"\n m.def(\"rev_entry\", with_ks_allocator(&ks::{rev_name}));\n \"\"\"\n\n cpp_str += \"\"\"\nPYBIND11_MODULE(PYTHON_MODULE_NAME, m) {\n m.def(\"reset_allocator\", []{g_alloc.reset();});\n m.def(\"allocator_top\", []{ return g_alloc.mark();});\n m.def(\"allocator_peak\", []{ return g_alloc.peak();});\n\n declare_tensor_2<double>(m, \"Tensor_2_Float\");\n declare_tensor_2<int>(m, \"Tensor_2_Integer\");\n\n\"\"\" + declarations + \"\"\"\n}\n\"\"\"\n pybindcpppath = \"obj/pybind.cpp\"\n print(f\"Saving to {pybindcpppath}\") \n os.makedirs(os.path.dirname(pybindcpppath), exist_ok=True)\n with open(pybindcpppath, \"w\") as fcpp:\n fcpp.write(cpp_str)\n\n module_name, module_path = build_py_module_from_cpp(cpp_str, pybind11_path, use_aten=use_aten)\n return import_module_from_path(module_name, module_path)\n\ndef ndgrid_inds(sz):\n \"\"\"\n Return a sequnce of tuples of indices as if generated by nested comprehensions.\n Example:\n ndgrid_inds((ni,nj))\n Returns the same sequence as\n [(i,j) for i in range(ni) for j in range(nj)]\n\n The iterates are always tuples so\n ndgrid_inds(4)\n returns\n [(0,), (1,), (2,), (3,)] \n\n \"\"\"\n\n return itertools.product(*map(range, sz))\n\n", "path": "src/python/ksc/utils.py"}]}
| 3,563 | 187 |
gh_patches_debug_9288
|
rasdani/github-patches
|
git_diff
|
microsoft__nni-2375
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
BUG in spos evolution part
I trained the spos from scratch with supernet.py, but failed to load the checkpoints. It turned out there was a mismatch between load and save part.
In the save part https://github.com/microsoft/nni/blob/69dfbf5e976cf75e89949af4764928dde631a3f6/src/sdk/pynni/nni/nas/pytorch/callbacks.py#L136, no dict was used. But in the load part, https://github.com/microsoft/nni/blob/69dfbf5e976cf75e89949af4764928dde631a3f6/examples/nas/spos/network.py#L151, key 'state_dict' was used. It failed to load the checkpoint. After removing 'state_dict', checkpoint could be loaded and problem was solved.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/nas/spos/network.py`
Content:
```
1 # Copyright (c) Microsoft Corporation.
2 # Licensed under the MIT license.
3
4 import os
5 import pickle
6 import re
7
8 import torch
9 import torch.nn as nn
10 from nni.nas.pytorch import mutables
11
12 from blocks import ShuffleNetBlock, ShuffleXceptionBlock
13
14
15 class ShuffleNetV2OneShot(nn.Module):
16 block_keys = [
17 'shufflenet_3x3',
18 'shufflenet_5x5',
19 'shufflenet_7x7',
20 'xception_3x3',
21 ]
22
23 def __init__(self, input_size=224, first_conv_channels=16, last_conv_channels=1024, n_classes=1000,
24 op_flops_path="./data/op_flops_dict.pkl"):
25 super().__init__()
26
27 assert input_size % 32 == 0
28 with open(os.path.join(os.path.dirname(__file__), op_flops_path), "rb") as fp:
29 self._op_flops_dict = pickle.load(fp)
30
31 self.stage_blocks = [4, 4, 8, 4]
32 self.stage_channels = [64, 160, 320, 640]
33 self._parsed_flops = dict()
34 self._input_size = input_size
35 self._feature_map_size = input_size
36 self._first_conv_channels = first_conv_channels
37 self._last_conv_channels = last_conv_channels
38 self._n_classes = n_classes
39
40 # building first layer
41 self.first_conv = nn.Sequential(
42 nn.Conv2d(3, first_conv_channels, 3, 2, 1, bias=False),
43 nn.BatchNorm2d(first_conv_channels, affine=False),
44 nn.ReLU(inplace=True),
45 )
46 self._feature_map_size //= 2
47
48 p_channels = first_conv_channels
49 features = []
50 for num_blocks, channels in zip(self.stage_blocks, self.stage_channels):
51 features.extend(self._make_blocks(num_blocks, p_channels, channels))
52 p_channels = channels
53 self.features = nn.Sequential(*features)
54
55 self.conv_last = nn.Sequential(
56 nn.Conv2d(p_channels, last_conv_channels, 1, 1, 0, bias=False),
57 nn.BatchNorm2d(last_conv_channels, affine=False),
58 nn.ReLU(inplace=True),
59 )
60 self.globalpool = nn.AvgPool2d(self._feature_map_size)
61 self.dropout = nn.Dropout(0.1)
62 self.classifier = nn.Sequential(
63 nn.Linear(last_conv_channels, n_classes, bias=False),
64 )
65
66 self._initialize_weights()
67
68 def _make_blocks(self, blocks, in_channels, channels):
69 result = []
70 for i in range(blocks):
71 stride = 2 if i == 0 else 1
72 inp = in_channels if i == 0 else channels
73 oup = channels
74
75 base_mid_channels = channels // 2
76 mid_channels = int(base_mid_channels) # prepare for scale
77 choice_block = mutables.LayerChoice([
78 ShuffleNetBlock(inp, oup, mid_channels=mid_channels, ksize=3, stride=stride),
79 ShuffleNetBlock(inp, oup, mid_channels=mid_channels, ksize=5, stride=stride),
80 ShuffleNetBlock(inp, oup, mid_channels=mid_channels, ksize=7, stride=stride),
81 ShuffleXceptionBlock(inp, oup, mid_channels=mid_channels, stride=stride)
82 ])
83 result.append(choice_block)
84
85 # find the corresponding flops
86 flop_key = (inp, oup, mid_channels, self._feature_map_size, self._feature_map_size, stride)
87 self._parsed_flops[choice_block.key] = [
88 self._op_flops_dict["{}_stride_{}".format(k, stride)][flop_key] for k in self.block_keys
89 ]
90 if stride == 2:
91 self._feature_map_size //= 2
92 return result
93
94 def forward(self, x):
95 bs = x.size(0)
96 x = self.first_conv(x)
97 x = self.features(x)
98 x = self.conv_last(x)
99 x = self.globalpool(x)
100
101 x = self.dropout(x)
102 x = x.contiguous().view(bs, -1)
103 x = self.classifier(x)
104 return x
105
106 def get_candidate_flops(self, candidate):
107 conv1_flops = self._op_flops_dict["conv1"][(3, self._first_conv_channels,
108 self._input_size, self._input_size, 2)]
109 # Should use `last_conv_channels` here, but megvii insists that it's `n_classes`. Keeping it.
110 # https://github.com/megvii-model/SinglePathOneShot/blob/36eed6cf083497ffa9cfe7b8da25bb0b6ba5a452/src/Supernet/flops.py#L313
111 rest_flops = self._op_flops_dict["rest_operation"][(self.stage_channels[-1], self._n_classes,
112 self._feature_map_size, self._feature_map_size, 1)]
113 total_flops = conv1_flops + rest_flops
114 for k, m in candidate.items():
115 parsed_flops_dict = self._parsed_flops[k]
116 if isinstance(m, dict): # to be compatible with classical nas format
117 total_flops += parsed_flops_dict[m["_idx"]]
118 else:
119 total_flops += parsed_flops_dict[torch.max(m, 0)[1]]
120 return total_flops
121
122 def _initialize_weights(self):
123 for name, m in self.named_modules():
124 if isinstance(m, nn.Conv2d):
125 if 'first' in name:
126 nn.init.normal_(m.weight, 0, 0.01)
127 else:
128 nn.init.normal_(m.weight, 0, 1.0 / m.weight.shape[1])
129 if m.bias is not None:
130 nn.init.constant_(m.bias, 0)
131 elif isinstance(m, nn.BatchNorm2d):
132 if m.weight is not None:
133 nn.init.constant_(m.weight, 1)
134 if m.bias is not None:
135 nn.init.constant_(m.bias, 0.0001)
136 nn.init.constant_(m.running_mean, 0)
137 elif isinstance(m, nn.BatchNorm1d):
138 nn.init.constant_(m.weight, 1)
139 if m.bias is not None:
140 nn.init.constant_(m.bias, 0.0001)
141 nn.init.constant_(m.running_mean, 0)
142 elif isinstance(m, nn.Linear):
143 nn.init.normal_(m.weight, 0, 0.01)
144 if m.bias is not None:
145 nn.init.constant_(m.bias, 0)
146
147
148 def load_and_parse_state_dict(filepath="./data/checkpoint-150000.pth.tar"):
149 checkpoint = torch.load(filepath, map_location=torch.device("cpu"))
150 result = dict()
151 for k, v in checkpoint["state_dict"].items():
152 if k.startswith("module."):
153 k = k[len("module."):]
154 result[k] = v
155 return result
156
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/nas/spos/network.py b/examples/nas/spos/network.py
--- a/examples/nas/spos/network.py
+++ b/examples/nas/spos/network.py
@@ -147,8 +147,10 @@
def load_and_parse_state_dict(filepath="./data/checkpoint-150000.pth.tar"):
checkpoint = torch.load(filepath, map_location=torch.device("cpu"))
+ if "state_dict" in checkpoint:
+ checkpoint = checkpoint["state_dict"]
result = dict()
- for k, v in checkpoint["state_dict"].items():
+ for k, v in checkpoint.items():
if k.startswith("module."):
k = k[len("module."):]
result[k] = v
|
{"golden_diff": "diff --git a/examples/nas/spos/network.py b/examples/nas/spos/network.py\n--- a/examples/nas/spos/network.py\n+++ b/examples/nas/spos/network.py\n@@ -147,8 +147,10 @@\n \n def load_and_parse_state_dict(filepath=\"./data/checkpoint-150000.pth.tar\"):\n checkpoint = torch.load(filepath, map_location=torch.device(\"cpu\"))\n+ if \"state_dict\" in checkpoint:\n+ checkpoint = checkpoint[\"state_dict\"]\n result = dict()\n- for k, v in checkpoint[\"state_dict\"].items():\n+ for k, v in checkpoint.items():\n if k.startswith(\"module.\"):\n k = k[len(\"module.\"):]\n result[k] = v\n", "issue": "BUG in spos evolution part\nI trained the spos from scratch with supernet.py, but failed to load the checkpoints. It turned out there was a mismatch between load and save part. \r\n\r\nIn the save part https://github.com/microsoft/nni/blob/69dfbf5e976cf75e89949af4764928dde631a3f6/src/sdk/pynni/nni/nas/pytorch/callbacks.py#L136, no dict was used. But in the load part, https://github.com/microsoft/nni/blob/69dfbf5e976cf75e89949af4764928dde631a3f6/examples/nas/spos/network.py#L151, key 'state_dict' was used. It failed to load the checkpoint. After removing 'state_dict', checkpoint could be loaded and problem was solved.\r\n\r\n\n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation.\n# Licensed under the MIT license.\n\nimport os\nimport pickle\nimport re\n\nimport torch\nimport torch.nn as nn\nfrom nni.nas.pytorch import mutables\n\nfrom blocks import ShuffleNetBlock, ShuffleXceptionBlock\n\n\nclass ShuffleNetV2OneShot(nn.Module):\n block_keys = [\n 'shufflenet_3x3',\n 'shufflenet_5x5',\n 'shufflenet_7x7',\n 'xception_3x3',\n ]\n\n def __init__(self, input_size=224, first_conv_channels=16, last_conv_channels=1024, n_classes=1000,\n op_flops_path=\"./data/op_flops_dict.pkl\"):\n super().__init__()\n\n assert input_size % 32 == 0\n with open(os.path.join(os.path.dirname(__file__), op_flops_path), \"rb\") as fp:\n self._op_flops_dict = pickle.load(fp)\n\n self.stage_blocks = [4, 4, 8, 4]\n self.stage_channels = [64, 160, 320, 640]\n self._parsed_flops = dict()\n self._input_size = input_size\n self._feature_map_size = input_size\n self._first_conv_channels = first_conv_channels\n self._last_conv_channels = last_conv_channels\n self._n_classes = n_classes\n\n # building first layer\n self.first_conv = nn.Sequential(\n nn.Conv2d(3, first_conv_channels, 3, 2, 1, bias=False),\n nn.BatchNorm2d(first_conv_channels, affine=False),\n nn.ReLU(inplace=True),\n )\n self._feature_map_size //= 2\n\n p_channels = first_conv_channels\n features = []\n for num_blocks, channels in zip(self.stage_blocks, self.stage_channels):\n features.extend(self._make_blocks(num_blocks, p_channels, channels))\n p_channels = channels\n self.features = nn.Sequential(*features)\n\n self.conv_last = nn.Sequential(\n nn.Conv2d(p_channels, last_conv_channels, 1, 1, 0, bias=False),\n nn.BatchNorm2d(last_conv_channels, affine=False),\n nn.ReLU(inplace=True),\n )\n self.globalpool = nn.AvgPool2d(self._feature_map_size)\n self.dropout = nn.Dropout(0.1)\n self.classifier = nn.Sequential(\n nn.Linear(last_conv_channels, n_classes, bias=False),\n )\n\n self._initialize_weights()\n\n def _make_blocks(self, blocks, in_channels, channels):\n result = []\n for i in range(blocks):\n stride = 2 if i == 0 else 1\n inp = in_channels if i == 0 else channels\n oup = channels\n\n base_mid_channels = channels // 2\n mid_channels = int(base_mid_channels) # prepare for scale\n choice_block = mutables.LayerChoice([\n ShuffleNetBlock(inp, oup, mid_channels=mid_channels, ksize=3, stride=stride),\n ShuffleNetBlock(inp, oup, mid_channels=mid_channels, ksize=5, stride=stride),\n ShuffleNetBlock(inp, oup, mid_channels=mid_channels, ksize=7, stride=stride),\n ShuffleXceptionBlock(inp, oup, mid_channels=mid_channels, stride=stride)\n ])\n result.append(choice_block)\n\n # find the corresponding flops\n flop_key = (inp, oup, mid_channels, self._feature_map_size, self._feature_map_size, stride)\n self._parsed_flops[choice_block.key] = [\n self._op_flops_dict[\"{}_stride_{}\".format(k, stride)][flop_key] for k in self.block_keys\n ]\n if stride == 2:\n self._feature_map_size //= 2\n return result\n\n def forward(self, x):\n bs = x.size(0)\n x = self.first_conv(x)\n x = self.features(x)\n x = self.conv_last(x)\n x = self.globalpool(x)\n\n x = self.dropout(x)\n x = x.contiguous().view(bs, -1)\n x = self.classifier(x)\n return x\n\n def get_candidate_flops(self, candidate):\n conv1_flops = self._op_flops_dict[\"conv1\"][(3, self._first_conv_channels,\n self._input_size, self._input_size, 2)]\n # Should use `last_conv_channels` here, but megvii insists that it's `n_classes`. Keeping it.\n # https://github.com/megvii-model/SinglePathOneShot/blob/36eed6cf083497ffa9cfe7b8da25bb0b6ba5a452/src/Supernet/flops.py#L313\n rest_flops = self._op_flops_dict[\"rest_operation\"][(self.stage_channels[-1], self._n_classes,\n self._feature_map_size, self._feature_map_size, 1)]\n total_flops = conv1_flops + rest_flops\n for k, m in candidate.items():\n parsed_flops_dict = self._parsed_flops[k]\n if isinstance(m, dict): # to be compatible with classical nas format\n total_flops += parsed_flops_dict[m[\"_idx\"]]\n else:\n total_flops += parsed_flops_dict[torch.max(m, 0)[1]]\n return total_flops\n\n def _initialize_weights(self):\n for name, m in self.named_modules():\n if isinstance(m, nn.Conv2d):\n if 'first' in name:\n nn.init.normal_(m.weight, 0, 0.01)\n else:\n nn.init.normal_(m.weight, 0, 1.0 / m.weight.shape[1])\n if m.bias is not None:\n nn.init.constant_(m.bias, 0)\n elif isinstance(m, nn.BatchNorm2d):\n if m.weight is not None:\n nn.init.constant_(m.weight, 1)\n if m.bias is not None:\n nn.init.constant_(m.bias, 0.0001)\n nn.init.constant_(m.running_mean, 0)\n elif isinstance(m, nn.BatchNorm1d):\n nn.init.constant_(m.weight, 1)\n if m.bias is not None:\n nn.init.constant_(m.bias, 0.0001)\n nn.init.constant_(m.running_mean, 0)\n elif isinstance(m, nn.Linear):\n nn.init.normal_(m.weight, 0, 0.01)\n if m.bias is not None:\n nn.init.constant_(m.bias, 0)\n\n\ndef load_and_parse_state_dict(filepath=\"./data/checkpoint-150000.pth.tar\"):\n checkpoint = torch.load(filepath, map_location=torch.device(\"cpu\"))\n result = dict()\n for k, v in checkpoint[\"state_dict\"].items():\n if k.startswith(\"module.\"):\n k = k[len(\"module.\"):]\n result[k] = v\n return result\n", "path": "examples/nas/spos/network.py"}], "after_files": [{"content": "# Copyright (c) Microsoft Corporation.\n# Licensed under the MIT license.\n\nimport os\nimport pickle\nimport re\n\nimport torch\nimport torch.nn as nn\nfrom nni.nas.pytorch import mutables\n\nfrom blocks import ShuffleNetBlock, ShuffleXceptionBlock\n\n\nclass ShuffleNetV2OneShot(nn.Module):\n block_keys = [\n 'shufflenet_3x3',\n 'shufflenet_5x5',\n 'shufflenet_7x7',\n 'xception_3x3',\n ]\n\n def __init__(self, input_size=224, first_conv_channels=16, last_conv_channels=1024, n_classes=1000,\n op_flops_path=\"./data/op_flops_dict.pkl\"):\n super().__init__()\n\n assert input_size % 32 == 0\n with open(os.path.join(os.path.dirname(__file__), op_flops_path), \"rb\") as fp:\n self._op_flops_dict = pickle.load(fp)\n\n self.stage_blocks = [4, 4, 8, 4]\n self.stage_channels = [64, 160, 320, 640]\n self._parsed_flops = dict()\n self._input_size = input_size\n self._feature_map_size = input_size\n self._first_conv_channels = first_conv_channels\n self._last_conv_channels = last_conv_channels\n self._n_classes = n_classes\n\n # building first layer\n self.first_conv = nn.Sequential(\n nn.Conv2d(3, first_conv_channels, 3, 2, 1, bias=False),\n nn.BatchNorm2d(first_conv_channels, affine=False),\n nn.ReLU(inplace=True),\n )\n self._feature_map_size //= 2\n\n p_channels = first_conv_channels\n features = []\n for num_blocks, channels in zip(self.stage_blocks, self.stage_channels):\n features.extend(self._make_blocks(num_blocks, p_channels, channels))\n p_channels = channels\n self.features = nn.Sequential(*features)\n\n self.conv_last = nn.Sequential(\n nn.Conv2d(p_channels, last_conv_channels, 1, 1, 0, bias=False),\n nn.BatchNorm2d(last_conv_channels, affine=False),\n nn.ReLU(inplace=True),\n )\n self.globalpool = nn.AvgPool2d(self._feature_map_size)\n self.dropout = nn.Dropout(0.1)\n self.classifier = nn.Sequential(\n nn.Linear(last_conv_channels, n_classes, bias=False),\n )\n\n self._initialize_weights()\n\n def _make_blocks(self, blocks, in_channels, channels):\n result = []\n for i in range(blocks):\n stride = 2 if i == 0 else 1\n inp = in_channels if i == 0 else channels\n oup = channels\n\n base_mid_channels = channels // 2\n mid_channels = int(base_mid_channels) # prepare for scale\n choice_block = mutables.LayerChoice([\n ShuffleNetBlock(inp, oup, mid_channels=mid_channels, ksize=3, stride=stride),\n ShuffleNetBlock(inp, oup, mid_channels=mid_channels, ksize=5, stride=stride),\n ShuffleNetBlock(inp, oup, mid_channels=mid_channels, ksize=7, stride=stride),\n ShuffleXceptionBlock(inp, oup, mid_channels=mid_channels, stride=stride)\n ])\n result.append(choice_block)\n\n # find the corresponding flops\n flop_key = (inp, oup, mid_channels, self._feature_map_size, self._feature_map_size, stride)\n self._parsed_flops[choice_block.key] = [\n self._op_flops_dict[\"{}_stride_{}\".format(k, stride)][flop_key] for k in self.block_keys\n ]\n if stride == 2:\n self._feature_map_size //= 2\n return result\n\n def forward(self, x):\n bs = x.size(0)\n x = self.first_conv(x)\n x = self.features(x)\n x = self.conv_last(x)\n x = self.globalpool(x)\n\n x = self.dropout(x)\n x = x.contiguous().view(bs, -1)\n x = self.classifier(x)\n return x\n\n def get_candidate_flops(self, candidate):\n conv1_flops = self._op_flops_dict[\"conv1\"][(3, self._first_conv_channels,\n self._input_size, self._input_size, 2)]\n # Should use `last_conv_channels` here, but megvii insists that it's `n_classes`. Keeping it.\n # https://github.com/megvii-model/SinglePathOneShot/blob/36eed6cf083497ffa9cfe7b8da25bb0b6ba5a452/src/Supernet/flops.py#L313\n rest_flops = self._op_flops_dict[\"rest_operation\"][(self.stage_channels[-1], self._n_classes,\n self._feature_map_size, self._feature_map_size, 1)]\n total_flops = conv1_flops + rest_flops\n for k, m in candidate.items():\n parsed_flops_dict = self._parsed_flops[k]\n if isinstance(m, dict): # to be compatible with classical nas format\n total_flops += parsed_flops_dict[m[\"_idx\"]]\n else:\n total_flops += parsed_flops_dict[torch.max(m, 0)[1]]\n return total_flops\n\n def _initialize_weights(self):\n for name, m in self.named_modules():\n if isinstance(m, nn.Conv2d):\n if 'first' in name:\n nn.init.normal_(m.weight, 0, 0.01)\n else:\n nn.init.normal_(m.weight, 0, 1.0 / m.weight.shape[1])\n if m.bias is not None:\n nn.init.constant_(m.bias, 0)\n elif isinstance(m, nn.BatchNorm2d):\n if m.weight is not None:\n nn.init.constant_(m.weight, 1)\n if m.bias is not None:\n nn.init.constant_(m.bias, 0.0001)\n nn.init.constant_(m.running_mean, 0)\n elif isinstance(m, nn.BatchNorm1d):\n nn.init.constant_(m.weight, 1)\n if m.bias is not None:\n nn.init.constant_(m.bias, 0.0001)\n nn.init.constant_(m.running_mean, 0)\n elif isinstance(m, nn.Linear):\n nn.init.normal_(m.weight, 0, 0.01)\n if m.bias is not None:\n nn.init.constant_(m.bias, 0)\n\n\ndef load_and_parse_state_dict(filepath=\"./data/checkpoint-150000.pth.tar\"):\n checkpoint = torch.load(filepath, map_location=torch.device(\"cpu\"))\n if \"state_dict\" in checkpoint:\n checkpoint = checkpoint[\"state_dict\"]\n result = dict()\n for k, v in checkpoint.items():\n if k.startswith(\"module.\"):\n k = k[len(\"module.\"):]\n result[k] = v\n return result\n", "path": "examples/nas/spos/network.py"}]}
| 2,395 | 163 |
gh_patches_debug_14255
|
rasdani/github-patches
|
git_diff
|
pyca__cryptography-513
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
KDF Interfaces
Who has opinions? This is relevant for HKDF in #490 and upcoming PBKDF2.
Here's a straw man to knock down:
``` python
# This API is a bit challenging since each KDF has different features
# (salt/no salt, maximum time, output length, iteration count, etc)
kdf = PBKDF2(iterations, digest, backend)
key = kdf.derive("key/password", "salt")
kdf.verify("key/password", salt="salt", key)
kdf = HKDF(algorithm, key_length, info, backend)
key = kdf.derive("key/password", "salt")
kdf.verify("key/password", salt="salt", key)
kdf = BCrypt(work_factor=100, backend)
key = kdf.derive("key/password")
kdf.verify("key/password", key)
kdf = SCrypt(key_length, salt_size=16, max_time=0.1, max_mem=4, backend)
key = kdf.derive("key/password") # really need to get key/salt out since auto-generated
kdf.verify("key/password", key)
```
There are also calibration routines available for some of these KDFs. (scrypt has one as well as CommonCrypto's `CCCalibratePBKDF` for PBKDF2).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cryptography/hazmat/primitives/interfaces.py`
Content:
```
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
10 # implied.
11 # See the License for the specific language governing permissions and
12 # limitations under the License.
13
14 from __future__ import absolute_import, division, print_function
15
16 import abc
17
18 import six
19
20
21 class CipherAlgorithm(six.with_metaclass(abc.ABCMeta)):
22 @abc.abstractproperty
23 def name(self):
24 """
25 A string naming this mode (e.g. "AES", "Camellia").
26 """
27
28 @abc.abstractproperty
29 def key_size(self):
30 """
31 The size of the key being used as an integer in bits (e.g. 128, 256).
32 """
33
34
35 class BlockCipherAlgorithm(six.with_metaclass(abc.ABCMeta)):
36 @abc.abstractproperty
37 def block_size(self):
38 """
39 The size of a block as an integer in bits (e.g. 64, 128).
40 """
41
42
43 class Mode(six.with_metaclass(abc.ABCMeta)):
44 @abc.abstractproperty
45 def name(self):
46 """
47 A string naming this mode (e.g. "ECB", "CBC").
48 """
49
50 @abc.abstractmethod
51 def validate_for_algorithm(self, algorithm):
52 """
53 Checks that all the necessary invariants of this (mode, algorithm)
54 combination are met.
55 """
56
57
58 class ModeWithInitializationVector(six.with_metaclass(abc.ABCMeta)):
59 @abc.abstractproperty
60 def initialization_vector(self):
61 """
62 The value of the initialization vector for this mode as bytes.
63 """
64
65
66 class ModeWithNonce(six.with_metaclass(abc.ABCMeta)):
67 @abc.abstractproperty
68 def nonce(self):
69 """
70 The value of the nonce for this mode as bytes.
71 """
72
73
74 class ModeWithAuthenticationTag(six.with_metaclass(abc.ABCMeta)):
75 @abc.abstractproperty
76 def tag(self):
77 """
78 The value of the tag supplied to the constructor of this mode.
79 """
80
81
82 class CipherContext(six.with_metaclass(abc.ABCMeta)):
83 @abc.abstractmethod
84 def update(self, data):
85 """
86 Processes the provided bytes through the cipher and returns the results
87 as bytes.
88 """
89
90 @abc.abstractmethod
91 def finalize(self):
92 """
93 Returns the results of processing the final block as bytes.
94 """
95
96
97 class AEADCipherContext(six.with_metaclass(abc.ABCMeta)):
98 @abc.abstractmethod
99 def authenticate_additional_data(self, data):
100 """
101 Authenticates the provided bytes.
102 """
103
104
105 class AEADEncryptionContext(six.with_metaclass(abc.ABCMeta)):
106 @abc.abstractproperty
107 def tag(self):
108 """
109 Returns tag bytes. This is only available after encryption is
110 finalized.
111 """
112
113
114 class PaddingContext(six.with_metaclass(abc.ABCMeta)):
115 @abc.abstractmethod
116 def update(self, data):
117 """
118 Pads the provided bytes and returns any available data as bytes.
119 """
120
121 @abc.abstractmethod
122 def finalize(self):
123 """
124 Finalize the padding, returns bytes.
125 """
126
127
128 class HashAlgorithm(six.with_metaclass(abc.ABCMeta)):
129 @abc.abstractproperty
130 def name(self):
131 """
132 A string naming this algorithm (e.g. "sha256", "md5").
133 """
134
135 @abc.abstractproperty
136 def digest_size(self):
137 """
138 The size of the resulting digest in bytes.
139 """
140
141 @abc.abstractproperty
142 def block_size(self):
143 """
144 The internal block size of the hash algorithm in bytes.
145 """
146
147
148 class HashContext(six.with_metaclass(abc.ABCMeta)):
149 @abc.abstractproperty
150 def algorithm(self):
151 """
152 A HashAlgorithm that will be used by this context.
153 """
154
155 @abc.abstractmethod
156 def update(self, data):
157 """
158 Processes the provided bytes through the hash.
159 """
160
161 @abc.abstractmethod
162 def finalize(self):
163 """
164 Finalizes the hash context and returns the hash digest as bytes.
165 """
166
167 @abc.abstractmethod
168 def copy(self):
169 """
170 Return a HashContext that is a copy of the current context.
171 """
172
173
174 class RSAPrivateKey(six.with_metaclass(abc.ABCMeta)):
175 @abc.abstractproperty
176 def modulus(self):
177 """
178 The public modulus of the RSA key.
179 """
180
181 @abc.abstractproperty
182 def public_exponent(self):
183 """
184 The public exponent of the RSA key.
185 """
186
187 @abc.abstractproperty
188 def key_length(self):
189 """
190 The bit length of the public modulus.
191 """
192
193 @abc.abstractmethod
194 def public_key(self):
195 """
196 The RSAPublicKey associated with this private key.
197 """
198
199 @abc.abstractproperty
200 def n(self):
201 """
202 The public modulus of the RSA key. Alias for modulus.
203 """
204
205 @abc.abstractproperty
206 def p(self):
207 """
208 One of the two primes used to generate d.
209 """
210
211 @abc.abstractproperty
212 def q(self):
213 """
214 One of the two primes used to generate d.
215 """
216
217 @abc.abstractproperty
218 def d(self):
219 """
220 The private exponent. This can be calculated using p and q.
221 """
222
223 @abc.abstractproperty
224 def e(self):
225 """
226 The public exponent of the RSA key. Alias for public_exponent.
227 """
228
229
230 class RSAPublicKey(six.with_metaclass(abc.ABCMeta)):
231 @abc.abstractproperty
232 def modulus(self):
233 """
234 The public modulus of the RSA key.
235 """
236
237 @abc.abstractproperty
238 def public_exponent(self):
239 """
240 The public exponent of the RSA key.
241 """
242
243 @abc.abstractproperty
244 def key_length(self):
245 """
246 The bit length of the public modulus.
247 """
248
249 @abc.abstractproperty
250 def n(self):
251 """
252 The public modulus of the RSA key. Alias for modulus.
253 """
254
255 @abc.abstractproperty
256 def e(self):
257 """
258 The public exponent of the RSA key. Alias for public_exponent.
259 """
260
```
Path: `cryptography/exceptions.py`
Content:
```
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
10 # implied.
11 # See the License for the specific language governing permissions and
12 # limitations under the License.
13
14
15 class UnsupportedAlgorithm(Exception):
16 pass
17
18
19 class AlreadyFinalized(Exception):
20 pass
21
22
23 class AlreadyUpdated(Exception):
24 pass
25
26
27 class NotYetFinalized(Exception):
28 pass
29
30
31 class InvalidTag(Exception):
32 pass
33
34
35 class InvalidSignature(Exception):
36 pass
37
38
39 class InternalError(Exception):
40 pass
41
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/cryptography/exceptions.py b/cryptography/exceptions.py
--- a/cryptography/exceptions.py
+++ b/cryptography/exceptions.py
@@ -38,3 +38,7 @@
class InternalError(Exception):
pass
+
+
+class InvalidKey(Exception):
+ pass
diff --git a/cryptography/hazmat/primitives/interfaces.py b/cryptography/hazmat/primitives/interfaces.py
--- a/cryptography/hazmat/primitives/interfaces.py
+++ b/cryptography/hazmat/primitives/interfaces.py
@@ -257,3 +257,19 @@
"""
The public exponent of the RSA key. Alias for public_exponent.
"""
+
+
+class KeyDerivationFunction(six.with_metaclass(abc.ABCMeta)):
+ @abc.abstractmethod
+ def derive(self, key_material):
+ """
+ Deterministically generates and returns a new key based on the existing
+ key material.
+ """
+
+ @abc.abstractmethod
+ def verify(self, key_material, expected_key):
+ """
+ Checks whether the key generated by the key material matches the
+ expected derived key. Raises an exception if they do not match.
+ """
|
{"golden_diff": "diff --git a/cryptography/exceptions.py b/cryptography/exceptions.py\n--- a/cryptography/exceptions.py\n+++ b/cryptography/exceptions.py\n@@ -38,3 +38,7 @@\n \n class InternalError(Exception):\n pass\n+\n+\n+class InvalidKey(Exception):\n+ pass\ndiff --git a/cryptography/hazmat/primitives/interfaces.py b/cryptography/hazmat/primitives/interfaces.py\n--- a/cryptography/hazmat/primitives/interfaces.py\n+++ b/cryptography/hazmat/primitives/interfaces.py\n@@ -257,3 +257,19 @@\n \"\"\"\n The public exponent of the RSA key. Alias for public_exponent.\n \"\"\"\n+\n+\n+class KeyDerivationFunction(six.with_metaclass(abc.ABCMeta)):\n+ @abc.abstractmethod\n+ def derive(self, key_material):\n+ \"\"\"\n+ Deterministically generates and returns a new key based on the existing\n+ key material.\n+ \"\"\"\n+\n+ @abc.abstractmethod\n+ def verify(self, key_material, expected_key):\n+ \"\"\"\n+ Checks whether the key generated by the key material matches the\n+ expected derived key. Raises an exception if they do not match.\n+ \"\"\"\n", "issue": "KDF Interfaces\nWho has opinions? This is relevant for HKDF in #490 and upcoming PBKDF2.\n\nHere's a straw man to knock down:\n\n``` python\n# This API is a bit challenging since each KDF has different features \n# (salt/no salt, maximum time, output length, iteration count, etc)\n\nkdf = PBKDF2(iterations, digest, backend)\nkey = kdf.derive(\"key/password\", \"salt\")\nkdf.verify(\"key/password\", salt=\"salt\", key)\n\nkdf = HKDF(algorithm, key_length, info, backend)\nkey = kdf.derive(\"key/password\", \"salt\")\nkdf.verify(\"key/password\", salt=\"salt\", key)\n\nkdf = BCrypt(work_factor=100, backend)\nkey = kdf.derive(\"key/password\")\nkdf.verify(\"key/password\", key)\n\nkdf = SCrypt(key_length, salt_size=16, max_time=0.1, max_mem=4, backend)\nkey = kdf.derive(\"key/password\") # really need to get key/salt out since auto-generated\nkdf.verify(\"key/password\", key)\n```\n\nThere are also calibration routines available for some of these KDFs. (scrypt has one as well as CommonCrypto's `CCCalibratePBKDF` for PBKDF2).\n\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or\n# implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom __future__ import absolute_import, division, print_function\n\nimport abc\n\nimport six\n\n\nclass CipherAlgorithm(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractproperty\n def name(self):\n \"\"\"\n A string naming this mode (e.g. \"AES\", \"Camellia\").\n \"\"\"\n\n @abc.abstractproperty\n def key_size(self):\n \"\"\"\n The size of the key being used as an integer in bits (e.g. 128, 256).\n \"\"\"\n\n\nclass BlockCipherAlgorithm(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractproperty\n def block_size(self):\n \"\"\"\n The size of a block as an integer in bits (e.g. 64, 128).\n \"\"\"\n\n\nclass Mode(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractproperty\n def name(self):\n \"\"\"\n A string naming this mode (e.g. \"ECB\", \"CBC\").\n \"\"\"\n\n @abc.abstractmethod\n def validate_for_algorithm(self, algorithm):\n \"\"\"\n Checks that all the necessary invariants of this (mode, algorithm)\n combination are met.\n \"\"\"\n\n\nclass ModeWithInitializationVector(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractproperty\n def initialization_vector(self):\n \"\"\"\n The value of the initialization vector for this mode as bytes.\n \"\"\"\n\n\nclass ModeWithNonce(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractproperty\n def nonce(self):\n \"\"\"\n The value of the nonce for this mode as bytes.\n \"\"\"\n\n\nclass ModeWithAuthenticationTag(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractproperty\n def tag(self):\n \"\"\"\n The value of the tag supplied to the constructor of this mode.\n \"\"\"\n\n\nclass CipherContext(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractmethod\n def update(self, data):\n \"\"\"\n Processes the provided bytes through the cipher and returns the results\n as bytes.\n \"\"\"\n\n @abc.abstractmethod\n def finalize(self):\n \"\"\"\n Returns the results of processing the final block as bytes.\n \"\"\"\n\n\nclass AEADCipherContext(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractmethod\n def authenticate_additional_data(self, data):\n \"\"\"\n Authenticates the provided bytes.\n \"\"\"\n\n\nclass AEADEncryptionContext(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractproperty\n def tag(self):\n \"\"\"\n Returns tag bytes. This is only available after encryption is\n finalized.\n \"\"\"\n\n\nclass PaddingContext(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractmethod\n def update(self, data):\n \"\"\"\n Pads the provided bytes and returns any available data as bytes.\n \"\"\"\n\n @abc.abstractmethod\n def finalize(self):\n \"\"\"\n Finalize the padding, returns bytes.\n \"\"\"\n\n\nclass HashAlgorithm(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractproperty\n def name(self):\n \"\"\"\n A string naming this algorithm (e.g. \"sha256\", \"md5\").\n \"\"\"\n\n @abc.abstractproperty\n def digest_size(self):\n \"\"\"\n The size of the resulting digest in bytes.\n \"\"\"\n\n @abc.abstractproperty\n def block_size(self):\n \"\"\"\n The internal block size of the hash algorithm in bytes.\n \"\"\"\n\n\nclass HashContext(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractproperty\n def algorithm(self):\n \"\"\"\n A HashAlgorithm that will be used by this context.\n \"\"\"\n\n @abc.abstractmethod\n def update(self, data):\n \"\"\"\n Processes the provided bytes through the hash.\n \"\"\"\n\n @abc.abstractmethod\n def finalize(self):\n \"\"\"\n Finalizes the hash context and returns the hash digest as bytes.\n \"\"\"\n\n @abc.abstractmethod\n def copy(self):\n \"\"\"\n Return a HashContext that is a copy of the current context.\n \"\"\"\n\n\nclass RSAPrivateKey(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractproperty\n def modulus(self):\n \"\"\"\n The public modulus of the RSA key.\n \"\"\"\n\n @abc.abstractproperty\n def public_exponent(self):\n \"\"\"\n The public exponent of the RSA key.\n \"\"\"\n\n @abc.abstractproperty\n def key_length(self):\n \"\"\"\n The bit length of the public modulus.\n \"\"\"\n\n @abc.abstractmethod\n def public_key(self):\n \"\"\"\n The RSAPublicKey associated with this private key.\n \"\"\"\n\n @abc.abstractproperty\n def n(self):\n \"\"\"\n The public modulus of the RSA key. Alias for modulus.\n \"\"\"\n\n @abc.abstractproperty\n def p(self):\n \"\"\"\n One of the two primes used to generate d.\n \"\"\"\n\n @abc.abstractproperty\n def q(self):\n \"\"\"\n One of the two primes used to generate d.\n \"\"\"\n\n @abc.abstractproperty\n def d(self):\n \"\"\"\n The private exponent. This can be calculated using p and q.\n \"\"\"\n\n @abc.abstractproperty\n def e(self):\n \"\"\"\n The public exponent of the RSA key. Alias for public_exponent.\n \"\"\"\n\n\nclass RSAPublicKey(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractproperty\n def modulus(self):\n \"\"\"\n The public modulus of the RSA key.\n \"\"\"\n\n @abc.abstractproperty\n def public_exponent(self):\n \"\"\"\n The public exponent of the RSA key.\n \"\"\"\n\n @abc.abstractproperty\n def key_length(self):\n \"\"\"\n The bit length of the public modulus.\n \"\"\"\n\n @abc.abstractproperty\n def n(self):\n \"\"\"\n The public modulus of the RSA key. Alias for modulus.\n \"\"\"\n\n @abc.abstractproperty\n def e(self):\n \"\"\"\n The public exponent of the RSA key. Alias for public_exponent.\n \"\"\"\n", "path": "cryptography/hazmat/primitives/interfaces.py"}, {"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or\n# implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\nclass UnsupportedAlgorithm(Exception):\n pass\n\n\nclass AlreadyFinalized(Exception):\n pass\n\n\nclass AlreadyUpdated(Exception):\n pass\n\n\nclass NotYetFinalized(Exception):\n pass\n\n\nclass InvalidTag(Exception):\n pass\n\n\nclass InvalidSignature(Exception):\n pass\n\n\nclass InternalError(Exception):\n pass\n", "path": "cryptography/exceptions.py"}], "after_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or\n# implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom __future__ import absolute_import, division, print_function\n\nimport abc\n\nimport six\n\n\nclass CipherAlgorithm(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractproperty\n def name(self):\n \"\"\"\n A string naming this mode (e.g. \"AES\", \"Camellia\").\n \"\"\"\n\n @abc.abstractproperty\n def key_size(self):\n \"\"\"\n The size of the key being used as an integer in bits (e.g. 128, 256).\n \"\"\"\n\n\nclass BlockCipherAlgorithm(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractproperty\n def block_size(self):\n \"\"\"\n The size of a block as an integer in bits (e.g. 64, 128).\n \"\"\"\n\n\nclass Mode(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractproperty\n def name(self):\n \"\"\"\n A string naming this mode (e.g. \"ECB\", \"CBC\").\n \"\"\"\n\n @abc.abstractmethod\n def validate_for_algorithm(self, algorithm):\n \"\"\"\n Checks that all the necessary invariants of this (mode, algorithm)\n combination are met.\n \"\"\"\n\n\nclass ModeWithInitializationVector(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractproperty\n def initialization_vector(self):\n \"\"\"\n The value of the initialization vector for this mode as bytes.\n \"\"\"\n\n\nclass ModeWithNonce(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractproperty\n def nonce(self):\n \"\"\"\n The value of the nonce for this mode as bytes.\n \"\"\"\n\n\nclass ModeWithAuthenticationTag(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractproperty\n def tag(self):\n \"\"\"\n The value of the tag supplied to the constructor of this mode.\n \"\"\"\n\n\nclass CipherContext(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractmethod\n def update(self, data):\n \"\"\"\n Processes the provided bytes through the cipher and returns the results\n as bytes.\n \"\"\"\n\n @abc.abstractmethod\n def finalize(self):\n \"\"\"\n Returns the results of processing the final block as bytes.\n \"\"\"\n\n\nclass AEADCipherContext(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractmethod\n def authenticate_additional_data(self, data):\n \"\"\"\n Authenticates the provided bytes.\n \"\"\"\n\n\nclass AEADEncryptionContext(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractproperty\n def tag(self):\n \"\"\"\n Returns tag bytes. This is only available after encryption is\n finalized.\n \"\"\"\n\n\nclass PaddingContext(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractmethod\n def update(self, data):\n \"\"\"\n Pads the provided bytes and returns any available data as bytes.\n \"\"\"\n\n @abc.abstractmethod\n def finalize(self):\n \"\"\"\n Finalize the padding, returns bytes.\n \"\"\"\n\n\nclass HashAlgorithm(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractproperty\n def name(self):\n \"\"\"\n A string naming this algorithm (e.g. \"sha256\", \"md5\").\n \"\"\"\n\n @abc.abstractproperty\n def digest_size(self):\n \"\"\"\n The size of the resulting digest in bytes.\n \"\"\"\n\n @abc.abstractproperty\n def block_size(self):\n \"\"\"\n The internal block size of the hash algorithm in bytes.\n \"\"\"\n\n\nclass HashContext(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractproperty\n def algorithm(self):\n \"\"\"\n A HashAlgorithm that will be used by this context.\n \"\"\"\n\n @abc.abstractmethod\n def update(self, data):\n \"\"\"\n Processes the provided bytes through the hash.\n \"\"\"\n\n @abc.abstractmethod\n def finalize(self):\n \"\"\"\n Finalizes the hash context and returns the hash digest as bytes.\n \"\"\"\n\n @abc.abstractmethod\n def copy(self):\n \"\"\"\n Return a HashContext that is a copy of the current context.\n \"\"\"\n\n\nclass RSAPrivateKey(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractproperty\n def modulus(self):\n \"\"\"\n The public modulus of the RSA key.\n \"\"\"\n\n @abc.abstractproperty\n def public_exponent(self):\n \"\"\"\n The public exponent of the RSA key.\n \"\"\"\n\n @abc.abstractproperty\n def key_length(self):\n \"\"\"\n The bit length of the public modulus.\n \"\"\"\n\n @abc.abstractmethod\n def public_key(self):\n \"\"\"\n The RSAPublicKey associated with this private key.\n \"\"\"\n\n @abc.abstractproperty\n def n(self):\n \"\"\"\n The public modulus of the RSA key. Alias for modulus.\n \"\"\"\n\n @abc.abstractproperty\n def p(self):\n \"\"\"\n One of the two primes used to generate d.\n \"\"\"\n\n @abc.abstractproperty\n def q(self):\n \"\"\"\n One of the two primes used to generate d.\n \"\"\"\n\n @abc.abstractproperty\n def d(self):\n \"\"\"\n The private exponent. This can be calculated using p and q.\n \"\"\"\n\n @abc.abstractproperty\n def e(self):\n \"\"\"\n The public exponent of the RSA key. Alias for public_exponent.\n \"\"\"\n\n\nclass RSAPublicKey(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractproperty\n def modulus(self):\n \"\"\"\n The public modulus of the RSA key.\n \"\"\"\n\n @abc.abstractproperty\n def public_exponent(self):\n \"\"\"\n The public exponent of the RSA key.\n \"\"\"\n\n @abc.abstractproperty\n def key_length(self):\n \"\"\"\n The bit length of the public modulus.\n \"\"\"\n\n @abc.abstractproperty\n def n(self):\n \"\"\"\n The public modulus of the RSA key. Alias for modulus.\n \"\"\"\n\n @abc.abstractproperty\n def e(self):\n \"\"\"\n The public exponent of the RSA key. Alias for public_exponent.\n \"\"\"\n\n\nclass KeyDerivationFunction(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractmethod\n def derive(self, key_material):\n \"\"\"\n Deterministically generates and returns a new key based on the existing\n key material.\n \"\"\"\n\n @abc.abstractmethod\n def verify(self, key_material, expected_key):\n \"\"\"\n Checks whether the key generated by the key material matches the\n expected derived key. Raises an exception if they do not match.\n \"\"\"\n", "path": "cryptography/hazmat/primitives/interfaces.py"}, {"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or\n# implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\nclass UnsupportedAlgorithm(Exception):\n pass\n\n\nclass AlreadyFinalized(Exception):\n pass\n\n\nclass AlreadyUpdated(Exception):\n pass\n\n\nclass NotYetFinalized(Exception):\n pass\n\n\nclass InvalidTag(Exception):\n pass\n\n\nclass InvalidSignature(Exception):\n pass\n\n\nclass InternalError(Exception):\n pass\n\n\nclass InvalidKey(Exception):\n pass\n", "path": "cryptography/exceptions.py"}]}
| 2,927 | 263 |
gh_patches_debug_29418
|
rasdani/github-patches
|
git_diff
|
litestar-org__litestar-1731
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug: Premature instantiation of nested models
### Description
Assume two dataclasses `Person `and `Address`. `Person `contains an `address` (see MCVE).
Using `DataDTO[Person]` in a route handler results in a `TypeError(\"Address.__init__() missing 1 required positional argument: 'id'\")` because it tries to initialize the nested `Address` (which fails because the `address.id` is excluded from the `WriteDTO`).
### URL to code causing the issue
https://discord.com/channels/919193495116337154/1110854577575698463
### MCVE
```python
from dataclasses import dataclass
import uuid
from litestar import Litestar, post
from litestar.dto.factory import DTOConfig, DTOData
from litestar.dto.factory.stdlib import DataclassDTO
@dataclass
class Address:
id: uuid.UUID
street: str
city: str
@dataclass
class Person:
id: uuid.UUID
name: str
email: str
address: Address
class WriteDTO(DataclassDTO[Person]):
config = DTOConfig(exclude={"id", "address.id"})
@post("/person", dto=WriteDTO, return_dto=None, sync_to_thread=False)
def create_person(data: DTOData[Person]) -> str:
return "Success"
app = Litestar([create_person])
```
### Steps to reproduce
```bash
curl -X 'POST' \
'http://127.0.0.1:8000/person' \
-H 'accept: text/plain' \
-H 'Content-Type: application/json' \
-d '{
"name": "test",
"email": "test",
"address": {
"street": "test",
"city": "test"
}
}'
```
### Screenshots
```bash
""
```
### Logs
```bash
INFO: 127.0.0.1:36960 - "POST /person HTTP/1.1" 500 Internal Server Error
```
### Litestar Version
2.0.0a7
### Platform
- [X] Linux
- [X] Mac
- [X] Windows
- [ ] Other (Please specify in the description above)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `litestar/dto/factory/_backends/utils.py`
Content:
```
1 from __future__ import annotations
2
3 from typing import TYPE_CHECKING, Collection, Mapping, TypeVar, cast
4
5 from msgspec import UNSET
6 from typing_extensions import get_origin
7
8 from litestar.dto.factory import Mark
9
10 from .types import (
11 CollectionType,
12 CompositeType,
13 MappingType,
14 NestedFieldInfo,
15 SimpleType,
16 TransferType,
17 TupleType,
18 UnionType,
19 )
20
21 if TYPE_CHECKING:
22 from typing import AbstractSet, Any, Iterable
23
24 from litestar.dto.factory.types import FieldDefinition, RenameStrategy
25 from litestar.dto.types import ForType
26
27 from .types import FieldDefinitionsType
28
29 __all__ = (
30 "RenameStrategies",
31 "build_annotation_for_backend",
32 "create_transfer_model_type_annotation",
33 "should_exclude_field",
34 "transfer_data",
35 )
36
37 T = TypeVar("T")
38
39
40 def build_annotation_for_backend(annotation: Any, model: type[T]) -> type[T] | type[Iterable[T]]:
41 """A helper to re-build a generic outer type with new inner type.
42
43 Args:
44 annotation: The original annotation on the handler signature
45 model: The data container type
46
47 Returns:
48 Annotation with new inner type if applicable.
49 """
50 origin = get_origin(annotation)
51 if not origin:
52 return model
53 try:
54 return origin[model] # type:ignore[no-any-return]
55 except TypeError: # pragma: no cover
56 return annotation.copy_with((model,)) # type:ignore[no-any-return]
57
58
59 def should_exclude_field(field_definition: FieldDefinition, exclude: AbstractSet[str], dto_for: ForType) -> bool:
60 """Returns ``True`` where a field should be excluded from data transfer.
61
62 Args:
63 field_definition: defined DTO field
64 exclude: names of fields to exclude
65 dto_for: indicates whether the DTO is for the request body or response.
66
67 Returns:
68 ``True`` if the field should not be included in any data transfer.
69 """
70 field_name = field_definition.name
71 dto_field = field_definition.dto_field
72 excluded = field_name in exclude
73 private = dto_field and dto_field.mark is Mark.PRIVATE
74 read_only_for_write = dto_for == "data" and dto_field and dto_field.mark is Mark.READ_ONLY
75 return bool(excluded or private or read_only_for_write)
76
77
78 class RenameStrategies:
79 """Useful renaming strategies than be used with :class:`DTOConfig`"""
80
81 def __init__(self, renaming_strategy: RenameStrategy) -> None:
82 self.renaming_strategy = renaming_strategy
83
84 def __call__(self, field_name: str) -> str:
85 if not isinstance(self.renaming_strategy, str):
86 return self.renaming_strategy(field_name)
87
88 return cast(str, getattr(self, self.renaming_strategy)(field_name))
89
90 @staticmethod
91 def upper(field_name: str) -> str:
92 return field_name.upper()
93
94 @staticmethod
95 def lower(field_name: str) -> str:
96 return field_name.lower()
97
98 @staticmethod
99 def camel(field_name: str) -> str:
100 return RenameStrategies._camelize(field_name)
101
102 @staticmethod
103 def pascal(field_name: str) -> str:
104 return RenameStrategies._camelize(field_name, capitalize_first_letter=True)
105
106 @staticmethod
107 def _camelize(string: str, capitalize_first_letter: bool = False) -> str:
108 """Convert a string to camel case.
109
110 Args:
111 string (str): The string to convert
112 capitalize_first_letter (bool): Default is False, a True value will convert to PascalCase
113 Returns:
114 str: The string converted to camel case or Pascal case
115 """
116 return "".join(
117 word if index == 0 and not capitalize_first_letter else word.capitalize()
118 for index, word in enumerate(string.split("_"))
119 )
120
121
122 def transfer_data(
123 destination_type: type[T],
124 source_data: Any | Collection[Any],
125 field_definitions: FieldDefinitionsType,
126 dto_for: ForType = "data",
127 ) -> T | Collection[T]:
128 """Create instance or iterable of instances of ``destination_type``.
129
130 Args:
131 destination_type: the model type received by the DTO on type narrowing.
132 source_data: data that has been parsed and validated via the backend.
133 field_definitions: model field definitions.
134 dto_for: indicates whether the DTO is for the request body or response.
135
136 Returns:
137 Data parsed into ``destination_type``.
138 """
139 if not isinstance(source_data, Mapping) and isinstance(source_data, Collection):
140 return type(source_data)(
141 transfer_data(destination_type, item, field_definitions, dto_for) # type:ignore[call-arg]
142 for item in source_data
143 )
144 return transfer_instance_data(destination_type, source_data, field_definitions, dto_for)
145
146
147 def transfer_instance_data(
148 destination_type: type[T], source_instance: Any, field_definitions: FieldDefinitionsType, dto_for: ForType
149 ) -> T:
150 """Create instance of ``destination_type`` with data from ``source_instance``.
151
152 Args:
153 destination_type: the model type received by the DTO on type narrowing.
154 source_instance: primitive data that has been parsed and validated via the backend.
155 field_definitions: model field definitions.
156 dto_for: indicates whether the DTO is for the request body or response.
157
158 Returns:
159 Data parsed into ``model_type``.
160 """
161 unstructured_data = {}
162 source_is_mapping = isinstance(source_instance, Mapping)
163
164 def filter_missing(value: Any) -> bool:
165 return value is UNSET
166
167 for field_definition in field_definitions:
168 transfer_type = field_definition.transfer_type
169 source_name = field_definition.serialization_name if dto_for == "data" else field_definition.name
170 destination_name = field_definition.name if dto_for == "data" else field_definition.serialization_name
171 source_value = source_instance[source_name] if source_is_mapping else getattr(source_instance, source_name)
172 if field_definition.is_partial and dto_for == "data" and filter_missing(source_value):
173 continue
174 unstructured_data[destination_name] = transfer_type_data(source_value, transfer_type, dto_for)
175 return destination_type(**unstructured_data)
176
177
178 def transfer_type_data(source_value: Any, transfer_type: TransferType, dto_for: ForType) -> Any:
179 if isinstance(transfer_type, SimpleType) and transfer_type.nested_field_info:
180 dest_type = transfer_type.parsed_type.annotation if dto_for == "data" else transfer_type.nested_field_info.model
181 return transfer_nested_simple_type_data(dest_type, transfer_type.nested_field_info, dto_for, source_value)
182 if isinstance(transfer_type, UnionType) and transfer_type.has_nested:
183 return transfer_nested_union_type_data(transfer_type, dto_for, source_value)
184 if isinstance(transfer_type, CollectionType) and transfer_type.has_nested:
185 return transfer_nested_collection_type_data(
186 transfer_type.parsed_type.origin, transfer_type, dto_for, source_value
187 )
188 return source_value
189
190
191 def transfer_nested_collection_type_data(
192 origin_type: type[Any], transfer_type: CollectionType, dto_for: ForType, source_value: Any
193 ) -> Any:
194 return origin_type(transfer_type_data(item, transfer_type.inner_type, dto_for) for item in source_value)
195
196
197 def transfer_nested_simple_type_data(
198 destination_type: type[Any], nested_field_info: NestedFieldInfo, dto_for: ForType, source_value: Any
199 ) -> Any:
200 return transfer_instance_data(
201 destination_type,
202 source_value,
203 nested_field_info.field_definitions,
204 dto_for,
205 )
206
207
208 def transfer_nested_union_type_data(transfer_type: UnionType, dto_for: ForType, source_value: Any) -> Any:
209 for inner_type in transfer_type.inner_types:
210 if isinstance(inner_type, CompositeType):
211 raise RuntimeError("Composite inner types not (yet) supported for nested unions.")
212
213 if inner_type.nested_field_info and isinstance(
214 source_value,
215 inner_type.nested_field_info.model if dto_for == "data" else inner_type.parsed_type.annotation,
216 ):
217 return transfer_instance_data(
218 inner_type.parsed_type.annotation if dto_for == "data" else inner_type.nested_field_info.model,
219 source_value,
220 inner_type.nested_field_info.field_definitions,
221 dto_for,
222 )
223 return source_value
224
225
226 def create_transfer_model_type_annotation(transfer_type: TransferType) -> Any:
227 """Create a type annotation for a transfer model.
228
229 Uses the parsed type that originates from the data model and the transfer model generated to represent a nested
230 type to reconstruct the type annotation for the transfer model.
231 """
232 if isinstance(transfer_type, SimpleType):
233 if transfer_type.nested_field_info:
234 return transfer_type.nested_field_info.model
235 return transfer_type.parsed_type.annotation
236
237 if isinstance(transfer_type, CollectionType):
238 return create_transfer_model_collection_type(transfer_type)
239
240 if isinstance(transfer_type, MappingType):
241 return create_transfer_model_mapping_type(transfer_type)
242
243 if isinstance(transfer_type, TupleType):
244 return create_transfer_model_tuple_type(transfer_type)
245
246 if isinstance(transfer_type, UnionType):
247 return create_transfer_model_union_type(transfer_type)
248
249 raise RuntimeError(f"Unexpected transfer type: {type(transfer_type)}")
250
251
252 def create_transfer_model_collection_type(transfer_type: CollectionType) -> Any:
253 generic_collection_type = transfer_type.parsed_type.safe_generic_origin
254 inner_type = create_transfer_model_type_annotation(transfer_type.inner_type)
255 if transfer_type.parsed_type.origin is tuple:
256 return generic_collection_type[inner_type, ...]
257 return generic_collection_type[inner_type]
258
259
260 def create_transfer_model_tuple_type(transfer_type: TupleType) -> Any:
261 inner_types = tuple(create_transfer_model_type_annotation(t) for t in transfer_type.inner_types)
262 return transfer_type.parsed_type.safe_generic_origin[inner_types]
263
264
265 def create_transfer_model_union_type(transfer_type: UnionType) -> Any:
266 inner_types = tuple(create_transfer_model_type_annotation(t) for t in transfer_type.inner_types)
267 return transfer_type.parsed_type.safe_generic_origin[inner_types]
268
269
270 def create_transfer_model_mapping_type(transfer_type: MappingType) -> Any:
271 key_type = create_transfer_model_type_annotation(transfer_type.key_type)
272 value_type = create_transfer_model_type_annotation(transfer_type.value_type)
273 return transfer_type.parsed_type.safe_generic_origin[key_type, value_type]
274
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/litestar/dto/factory/_backends/utils.py b/litestar/dto/factory/_backends/utils.py
--- a/litestar/dto/factory/_backends/utils.py
+++ b/litestar/dto/factory/_backends/utils.py
@@ -171,13 +171,23 @@
source_value = source_instance[source_name] if source_is_mapping else getattr(source_instance, source_name)
if field_definition.is_partial and dto_for == "data" and filter_missing(source_value):
continue
- unstructured_data[destination_name] = transfer_type_data(source_value, transfer_type, dto_for)
+ unstructured_data[destination_name] = transfer_type_data(
+ source_value, transfer_type, dto_for, nested_as_dict=destination_type is dict
+ )
return destination_type(**unstructured_data)
-def transfer_type_data(source_value: Any, transfer_type: TransferType, dto_for: ForType) -> Any:
+def transfer_type_data(
+ source_value: Any, transfer_type: TransferType, dto_for: ForType, nested_as_dict: bool = False
+) -> Any:
if isinstance(transfer_type, SimpleType) and transfer_type.nested_field_info:
- dest_type = transfer_type.parsed_type.annotation if dto_for == "data" else transfer_type.nested_field_info.model
+ if nested_as_dict:
+ dest_type = dict
+ else:
+ dest_type = (
+ transfer_type.parsed_type.annotation if dto_for == "data" else transfer_type.nested_field_info.model
+ )
+
return transfer_nested_simple_type_data(dest_type, transfer_type.nested_field_info, dto_for, source_value)
if isinstance(transfer_type, UnionType) and transfer_type.has_nested:
return transfer_nested_union_type_data(transfer_type, dto_for, source_value)
|
{"golden_diff": "diff --git a/litestar/dto/factory/_backends/utils.py b/litestar/dto/factory/_backends/utils.py\n--- a/litestar/dto/factory/_backends/utils.py\n+++ b/litestar/dto/factory/_backends/utils.py\n@@ -171,13 +171,23 @@\n source_value = source_instance[source_name] if source_is_mapping else getattr(source_instance, source_name)\n if field_definition.is_partial and dto_for == \"data\" and filter_missing(source_value):\n continue\n- unstructured_data[destination_name] = transfer_type_data(source_value, transfer_type, dto_for)\n+ unstructured_data[destination_name] = transfer_type_data(\n+ source_value, transfer_type, dto_for, nested_as_dict=destination_type is dict\n+ )\n return destination_type(**unstructured_data)\n \n \n-def transfer_type_data(source_value: Any, transfer_type: TransferType, dto_for: ForType) -> Any:\n+def transfer_type_data(\n+ source_value: Any, transfer_type: TransferType, dto_for: ForType, nested_as_dict: bool = False\n+) -> Any:\n if isinstance(transfer_type, SimpleType) and transfer_type.nested_field_info:\n- dest_type = transfer_type.parsed_type.annotation if dto_for == \"data\" else transfer_type.nested_field_info.model\n+ if nested_as_dict:\n+ dest_type = dict\n+ else:\n+ dest_type = (\n+ transfer_type.parsed_type.annotation if dto_for == \"data\" else transfer_type.nested_field_info.model\n+ )\n+\n return transfer_nested_simple_type_data(dest_type, transfer_type.nested_field_info, dto_for, source_value)\n if isinstance(transfer_type, UnionType) and transfer_type.has_nested:\n return transfer_nested_union_type_data(transfer_type, dto_for, source_value)\n", "issue": "Bug: Premature instantiation of nested models\n### Description\n\nAssume two dataclasses `Person `and `Address`. `Person `contains an `address` (see MCVE).\r\nUsing `DataDTO[Person]` in a route handler results in a `TypeError(\\\"Address.__init__() missing 1 required positional argument: 'id'\\\")` because it tries to initialize the nested `Address` (which fails because the `address.id` is excluded from the `WriteDTO`).\n\n### URL to code causing the issue\n\nhttps://discord.com/channels/919193495116337154/1110854577575698463\n\n### MCVE\n\n```python\nfrom dataclasses import dataclass\r\nimport uuid\r\n\r\nfrom litestar import Litestar, post\r\nfrom litestar.dto.factory import DTOConfig, DTOData\r\nfrom litestar.dto.factory.stdlib import DataclassDTO\r\n\r\n@dataclass\r\nclass Address:\r\n id: uuid.UUID\r\n street: str\r\n city: str\r\n\r\n@dataclass\r\nclass Person:\r\n id: uuid.UUID\r\n name: str\r\n email: str\r\n address: Address\r\n\r\nclass WriteDTO(DataclassDTO[Person]):\r\n config = DTOConfig(exclude={\"id\", \"address.id\"})\r\n\r\n@post(\"/person\", dto=WriteDTO, return_dto=None, sync_to_thread=False)\r\ndef create_person(data: DTOData[Person]) -> str:\r\n return \"Success\"\r\n\r\napp = Litestar([create_person])\n```\n\n\n### Steps to reproduce\n\n```bash\ncurl -X 'POST' \\\r\n 'http://127.0.0.1:8000/person' \\\r\n -H 'accept: text/plain' \\\r\n -H 'Content-Type: application/json' \\\r\n -d '{\r\n \"name\": \"test\",\r\n \"email\": \"test\",\r\n \"address\": {\r\n \"street\": \"test\",\r\n \"city\": \"test\"\r\n }\r\n}'\n```\n\n\n### Screenshots\n\n```bash\n\"\"\n```\n\n\n### Logs\n\n```bash\nINFO: 127.0.0.1:36960 - \"POST /person HTTP/1.1\" 500 Internal Server Error\n```\n\n\n### Litestar Version\n\n2.0.0a7\n\n### Platform\n\n- [X] Linux\n- [X] Mac\n- [X] Windows\n- [ ] Other (Please specify in the description above)\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom typing import TYPE_CHECKING, Collection, Mapping, TypeVar, cast\n\nfrom msgspec import UNSET\nfrom typing_extensions import get_origin\n\nfrom litestar.dto.factory import Mark\n\nfrom .types import (\n CollectionType,\n CompositeType,\n MappingType,\n NestedFieldInfo,\n SimpleType,\n TransferType,\n TupleType,\n UnionType,\n)\n\nif TYPE_CHECKING:\n from typing import AbstractSet, Any, Iterable\n\n from litestar.dto.factory.types import FieldDefinition, RenameStrategy\n from litestar.dto.types import ForType\n\n from .types import FieldDefinitionsType\n\n__all__ = (\n \"RenameStrategies\",\n \"build_annotation_for_backend\",\n \"create_transfer_model_type_annotation\",\n \"should_exclude_field\",\n \"transfer_data\",\n)\n\nT = TypeVar(\"T\")\n\n\ndef build_annotation_for_backend(annotation: Any, model: type[T]) -> type[T] | type[Iterable[T]]:\n \"\"\"A helper to re-build a generic outer type with new inner type.\n\n Args:\n annotation: The original annotation on the handler signature\n model: The data container type\n\n Returns:\n Annotation with new inner type if applicable.\n \"\"\"\n origin = get_origin(annotation)\n if not origin:\n return model\n try:\n return origin[model] # type:ignore[no-any-return]\n except TypeError: # pragma: no cover\n return annotation.copy_with((model,)) # type:ignore[no-any-return]\n\n\ndef should_exclude_field(field_definition: FieldDefinition, exclude: AbstractSet[str], dto_for: ForType) -> bool:\n \"\"\"Returns ``True`` where a field should be excluded from data transfer.\n\n Args:\n field_definition: defined DTO field\n exclude: names of fields to exclude\n dto_for: indicates whether the DTO is for the request body or response.\n\n Returns:\n ``True`` if the field should not be included in any data transfer.\n \"\"\"\n field_name = field_definition.name\n dto_field = field_definition.dto_field\n excluded = field_name in exclude\n private = dto_field and dto_field.mark is Mark.PRIVATE\n read_only_for_write = dto_for == \"data\" and dto_field and dto_field.mark is Mark.READ_ONLY\n return bool(excluded or private or read_only_for_write)\n\n\nclass RenameStrategies:\n \"\"\"Useful renaming strategies than be used with :class:`DTOConfig`\"\"\"\n\n def __init__(self, renaming_strategy: RenameStrategy) -> None:\n self.renaming_strategy = renaming_strategy\n\n def __call__(self, field_name: str) -> str:\n if not isinstance(self.renaming_strategy, str):\n return self.renaming_strategy(field_name)\n\n return cast(str, getattr(self, self.renaming_strategy)(field_name))\n\n @staticmethod\n def upper(field_name: str) -> str:\n return field_name.upper()\n\n @staticmethod\n def lower(field_name: str) -> str:\n return field_name.lower()\n\n @staticmethod\n def camel(field_name: str) -> str:\n return RenameStrategies._camelize(field_name)\n\n @staticmethod\n def pascal(field_name: str) -> str:\n return RenameStrategies._camelize(field_name, capitalize_first_letter=True)\n\n @staticmethod\n def _camelize(string: str, capitalize_first_letter: bool = False) -> str:\n \"\"\"Convert a string to camel case.\n\n Args:\n string (str): The string to convert\n capitalize_first_letter (bool): Default is False, a True value will convert to PascalCase\n Returns:\n str: The string converted to camel case or Pascal case\n \"\"\"\n return \"\".join(\n word if index == 0 and not capitalize_first_letter else word.capitalize()\n for index, word in enumerate(string.split(\"_\"))\n )\n\n\ndef transfer_data(\n destination_type: type[T],\n source_data: Any | Collection[Any],\n field_definitions: FieldDefinitionsType,\n dto_for: ForType = \"data\",\n) -> T | Collection[T]:\n \"\"\"Create instance or iterable of instances of ``destination_type``.\n\n Args:\n destination_type: the model type received by the DTO on type narrowing.\n source_data: data that has been parsed and validated via the backend.\n field_definitions: model field definitions.\n dto_for: indicates whether the DTO is for the request body or response.\n\n Returns:\n Data parsed into ``destination_type``.\n \"\"\"\n if not isinstance(source_data, Mapping) and isinstance(source_data, Collection):\n return type(source_data)(\n transfer_data(destination_type, item, field_definitions, dto_for) # type:ignore[call-arg]\n for item in source_data\n )\n return transfer_instance_data(destination_type, source_data, field_definitions, dto_for)\n\n\ndef transfer_instance_data(\n destination_type: type[T], source_instance: Any, field_definitions: FieldDefinitionsType, dto_for: ForType\n) -> T:\n \"\"\"Create instance of ``destination_type`` with data from ``source_instance``.\n\n Args:\n destination_type: the model type received by the DTO on type narrowing.\n source_instance: primitive data that has been parsed and validated via the backend.\n field_definitions: model field definitions.\n dto_for: indicates whether the DTO is for the request body or response.\n\n Returns:\n Data parsed into ``model_type``.\n \"\"\"\n unstructured_data = {}\n source_is_mapping = isinstance(source_instance, Mapping)\n\n def filter_missing(value: Any) -> bool:\n return value is UNSET\n\n for field_definition in field_definitions:\n transfer_type = field_definition.transfer_type\n source_name = field_definition.serialization_name if dto_for == \"data\" else field_definition.name\n destination_name = field_definition.name if dto_for == \"data\" else field_definition.serialization_name\n source_value = source_instance[source_name] if source_is_mapping else getattr(source_instance, source_name)\n if field_definition.is_partial and dto_for == \"data\" and filter_missing(source_value):\n continue\n unstructured_data[destination_name] = transfer_type_data(source_value, transfer_type, dto_for)\n return destination_type(**unstructured_data)\n\n\ndef transfer_type_data(source_value: Any, transfer_type: TransferType, dto_for: ForType) -> Any:\n if isinstance(transfer_type, SimpleType) and transfer_type.nested_field_info:\n dest_type = transfer_type.parsed_type.annotation if dto_for == \"data\" else transfer_type.nested_field_info.model\n return transfer_nested_simple_type_data(dest_type, transfer_type.nested_field_info, dto_for, source_value)\n if isinstance(transfer_type, UnionType) and transfer_type.has_nested:\n return transfer_nested_union_type_data(transfer_type, dto_for, source_value)\n if isinstance(transfer_type, CollectionType) and transfer_type.has_nested:\n return transfer_nested_collection_type_data(\n transfer_type.parsed_type.origin, transfer_type, dto_for, source_value\n )\n return source_value\n\n\ndef transfer_nested_collection_type_data(\n origin_type: type[Any], transfer_type: CollectionType, dto_for: ForType, source_value: Any\n) -> Any:\n return origin_type(transfer_type_data(item, transfer_type.inner_type, dto_for) for item in source_value)\n\n\ndef transfer_nested_simple_type_data(\n destination_type: type[Any], nested_field_info: NestedFieldInfo, dto_for: ForType, source_value: Any\n) -> Any:\n return transfer_instance_data(\n destination_type,\n source_value,\n nested_field_info.field_definitions,\n dto_for,\n )\n\n\ndef transfer_nested_union_type_data(transfer_type: UnionType, dto_for: ForType, source_value: Any) -> Any:\n for inner_type in transfer_type.inner_types:\n if isinstance(inner_type, CompositeType):\n raise RuntimeError(\"Composite inner types not (yet) supported for nested unions.\")\n\n if inner_type.nested_field_info and isinstance(\n source_value,\n inner_type.nested_field_info.model if dto_for == \"data\" else inner_type.parsed_type.annotation,\n ):\n return transfer_instance_data(\n inner_type.parsed_type.annotation if dto_for == \"data\" else inner_type.nested_field_info.model,\n source_value,\n inner_type.nested_field_info.field_definitions,\n dto_for,\n )\n return source_value\n\n\ndef create_transfer_model_type_annotation(transfer_type: TransferType) -> Any:\n \"\"\"Create a type annotation for a transfer model.\n\n Uses the parsed type that originates from the data model and the transfer model generated to represent a nested\n type to reconstruct the type annotation for the transfer model.\n \"\"\"\n if isinstance(transfer_type, SimpleType):\n if transfer_type.nested_field_info:\n return transfer_type.nested_field_info.model\n return transfer_type.parsed_type.annotation\n\n if isinstance(transfer_type, CollectionType):\n return create_transfer_model_collection_type(transfer_type)\n\n if isinstance(transfer_type, MappingType):\n return create_transfer_model_mapping_type(transfer_type)\n\n if isinstance(transfer_type, TupleType):\n return create_transfer_model_tuple_type(transfer_type)\n\n if isinstance(transfer_type, UnionType):\n return create_transfer_model_union_type(transfer_type)\n\n raise RuntimeError(f\"Unexpected transfer type: {type(transfer_type)}\")\n\n\ndef create_transfer_model_collection_type(transfer_type: CollectionType) -> Any:\n generic_collection_type = transfer_type.parsed_type.safe_generic_origin\n inner_type = create_transfer_model_type_annotation(transfer_type.inner_type)\n if transfer_type.parsed_type.origin is tuple:\n return generic_collection_type[inner_type, ...]\n return generic_collection_type[inner_type]\n\n\ndef create_transfer_model_tuple_type(transfer_type: TupleType) -> Any:\n inner_types = tuple(create_transfer_model_type_annotation(t) for t in transfer_type.inner_types)\n return transfer_type.parsed_type.safe_generic_origin[inner_types]\n\n\ndef create_transfer_model_union_type(transfer_type: UnionType) -> Any:\n inner_types = tuple(create_transfer_model_type_annotation(t) for t in transfer_type.inner_types)\n return transfer_type.parsed_type.safe_generic_origin[inner_types]\n\n\ndef create_transfer_model_mapping_type(transfer_type: MappingType) -> Any:\n key_type = create_transfer_model_type_annotation(transfer_type.key_type)\n value_type = create_transfer_model_type_annotation(transfer_type.value_type)\n return transfer_type.parsed_type.safe_generic_origin[key_type, value_type]\n", "path": "litestar/dto/factory/_backends/utils.py"}], "after_files": [{"content": "from __future__ import annotations\n\nfrom typing import TYPE_CHECKING, Collection, Mapping, TypeVar, cast\n\nfrom msgspec import UNSET\nfrom typing_extensions import get_origin\n\nfrom litestar.dto.factory import Mark\n\nfrom .types import (\n CollectionType,\n CompositeType,\n MappingType,\n NestedFieldInfo,\n SimpleType,\n TransferType,\n TupleType,\n UnionType,\n)\n\nif TYPE_CHECKING:\n from typing import AbstractSet, Any, Iterable\n\n from litestar.dto.factory.types import FieldDefinition, RenameStrategy\n from litestar.dto.types import ForType\n\n from .types import FieldDefinitionsType\n\n__all__ = (\n \"RenameStrategies\",\n \"build_annotation_for_backend\",\n \"create_transfer_model_type_annotation\",\n \"should_exclude_field\",\n \"transfer_data\",\n)\n\nT = TypeVar(\"T\")\n\n\ndef build_annotation_for_backend(annotation: Any, model: type[T]) -> type[T] | type[Iterable[T]]:\n \"\"\"A helper to re-build a generic outer type with new inner type.\n\n Args:\n annotation: The original annotation on the handler signature\n model: The data container type\n\n Returns:\n Annotation with new inner type if applicable.\n \"\"\"\n origin = get_origin(annotation)\n if not origin:\n return model\n try:\n return origin[model] # type:ignore[no-any-return]\n except TypeError: # pragma: no cover\n return annotation.copy_with((model,)) # type:ignore[no-any-return]\n\n\ndef should_exclude_field(field_definition: FieldDefinition, exclude: AbstractSet[str], dto_for: ForType) -> bool:\n \"\"\"Returns ``True`` where a field should be excluded from data transfer.\n\n Args:\n field_definition: defined DTO field\n exclude: names of fields to exclude\n dto_for: indicates whether the DTO is for the request body or response.\n\n Returns:\n ``True`` if the field should not be included in any data transfer.\n \"\"\"\n field_name = field_definition.name\n dto_field = field_definition.dto_field\n excluded = field_name in exclude\n private = dto_field and dto_field.mark is Mark.PRIVATE\n read_only_for_write = dto_for == \"data\" and dto_field and dto_field.mark is Mark.READ_ONLY\n return bool(excluded or private or read_only_for_write)\n\n\nclass RenameStrategies:\n \"\"\"Useful renaming strategies than be used with :class:`DTOConfig`\"\"\"\n\n def __init__(self, renaming_strategy: RenameStrategy) -> None:\n self.renaming_strategy = renaming_strategy\n\n def __call__(self, field_name: str) -> str:\n if not isinstance(self.renaming_strategy, str):\n return self.renaming_strategy(field_name)\n\n return cast(str, getattr(self, self.renaming_strategy)(field_name))\n\n @staticmethod\n def upper(field_name: str) -> str:\n return field_name.upper()\n\n @staticmethod\n def lower(field_name: str) -> str:\n return field_name.lower()\n\n @staticmethod\n def camel(field_name: str) -> str:\n return RenameStrategies._camelize(field_name)\n\n @staticmethod\n def pascal(field_name: str) -> str:\n return RenameStrategies._camelize(field_name, capitalize_first_letter=True)\n\n @staticmethod\n def _camelize(string: str, capitalize_first_letter: bool = False) -> str:\n \"\"\"Convert a string to camel case.\n\n Args:\n string (str): The string to convert\n capitalize_first_letter (bool): Default is False, a True value will convert to PascalCase\n Returns:\n str: The string converted to camel case or Pascal case\n \"\"\"\n return \"\".join(\n word if index == 0 and not capitalize_first_letter else word.capitalize()\n for index, word in enumerate(string.split(\"_\"))\n )\n\n\ndef transfer_data(\n destination_type: type[T],\n source_data: Any | Collection[Any],\n field_definitions: FieldDefinitionsType,\n dto_for: ForType = \"data\",\n) -> T | Collection[T]:\n \"\"\"Create instance or iterable of instances of ``destination_type``.\n\n Args:\n destination_type: the model type received by the DTO on type narrowing.\n source_data: data that has been parsed and validated via the backend.\n field_definitions: model field definitions.\n dto_for: indicates whether the DTO is for the request body or response.\n\n Returns:\n Data parsed into ``destination_type``.\n \"\"\"\n if not isinstance(source_data, Mapping) and isinstance(source_data, Collection):\n return type(source_data)(\n transfer_data(destination_type, item, field_definitions, dto_for) # type:ignore[call-arg]\n for item in source_data\n )\n return transfer_instance_data(destination_type, source_data, field_definitions, dto_for)\n\n\ndef transfer_instance_data(\n destination_type: type[T], source_instance: Any, field_definitions: FieldDefinitionsType, dto_for: ForType\n) -> T:\n \"\"\"Create instance of ``destination_type`` with data from ``source_instance``.\n\n Args:\n destination_type: the model type received by the DTO on type narrowing.\n source_instance: primitive data that has been parsed and validated via the backend.\n field_definitions: model field definitions.\n dto_for: indicates whether the DTO is for the request body or response.\n\n Returns:\n Data parsed into ``model_type``.\n \"\"\"\n unstructured_data = {}\n source_is_mapping = isinstance(source_instance, Mapping)\n\n def filter_missing(value: Any) -> bool:\n return value is UNSET\n\n for field_definition in field_definitions:\n transfer_type = field_definition.transfer_type\n source_name = field_definition.serialization_name if dto_for == \"data\" else field_definition.name\n destination_name = field_definition.name if dto_for == \"data\" else field_definition.serialization_name\n source_value = source_instance[source_name] if source_is_mapping else getattr(source_instance, source_name)\n if field_definition.is_partial and dto_for == \"data\" and filter_missing(source_value):\n continue\n unstructured_data[destination_name] = transfer_type_data(\n source_value, transfer_type, dto_for, nested_as_dict=destination_type is dict\n )\n return destination_type(**unstructured_data)\n\n\ndef transfer_type_data(\n source_value: Any, transfer_type: TransferType, dto_for: ForType, nested_as_dict: bool = False\n) -> Any:\n if isinstance(transfer_type, SimpleType) and transfer_type.nested_field_info:\n if nested_as_dict:\n dest_type = dict\n else:\n dest_type = (\n transfer_type.parsed_type.annotation if dto_for == \"data\" else transfer_type.nested_field_info.model\n )\n\n return transfer_nested_simple_type_data(dest_type, transfer_type.nested_field_info, dto_for, source_value)\n if isinstance(transfer_type, UnionType) and transfer_type.has_nested:\n return transfer_nested_union_type_data(transfer_type, dto_for, source_value)\n if isinstance(transfer_type, CollectionType) and transfer_type.has_nested:\n return transfer_nested_collection_type_data(\n transfer_type.parsed_type.origin, transfer_type, dto_for, source_value\n )\n return source_value\n\n\ndef transfer_nested_collection_type_data(\n origin_type: type[Any], transfer_type: CollectionType, dto_for: ForType, source_value: Any\n) -> Any:\n return origin_type(transfer_type_data(item, transfer_type.inner_type, dto_for) for item in source_value)\n\n\ndef transfer_nested_simple_type_data(\n destination_type: type[Any], nested_field_info: NestedFieldInfo, dto_for: ForType, source_value: Any\n) -> Any:\n return transfer_instance_data(\n destination_type,\n source_value,\n nested_field_info.field_definitions,\n dto_for,\n )\n\n\ndef transfer_nested_union_type_data(transfer_type: UnionType, dto_for: ForType, source_value: Any) -> Any:\n for inner_type in transfer_type.inner_types:\n if isinstance(inner_type, CompositeType):\n raise RuntimeError(\"Composite inner types not (yet) supported for nested unions.\")\n\n if inner_type.nested_field_info and isinstance(\n source_value,\n inner_type.nested_field_info.model if dto_for == \"data\" else inner_type.parsed_type.annotation,\n ):\n return transfer_instance_data(\n inner_type.parsed_type.annotation if dto_for == \"data\" else inner_type.nested_field_info.model,\n source_value,\n inner_type.nested_field_info.field_definitions,\n dto_for,\n )\n return source_value\n\n\ndef create_transfer_model_type_annotation(transfer_type: TransferType) -> Any:\n \"\"\"Create a type annotation for a transfer model.\n\n Uses the parsed type that originates from the data model and the transfer model generated to represent a nested\n type to reconstruct the type annotation for the transfer model.\n \"\"\"\n if isinstance(transfer_type, SimpleType):\n if transfer_type.nested_field_info:\n return transfer_type.nested_field_info.model\n return transfer_type.parsed_type.annotation\n\n if isinstance(transfer_type, CollectionType):\n return create_transfer_model_collection_type(transfer_type)\n\n if isinstance(transfer_type, MappingType):\n return create_transfer_model_mapping_type(transfer_type)\n\n if isinstance(transfer_type, TupleType):\n return create_transfer_model_tuple_type(transfer_type)\n\n if isinstance(transfer_type, UnionType):\n return create_transfer_model_union_type(transfer_type)\n\n raise RuntimeError(f\"Unexpected transfer type: {type(transfer_type)}\")\n\n\ndef create_transfer_model_collection_type(transfer_type: CollectionType) -> Any:\n generic_collection_type = transfer_type.parsed_type.safe_generic_origin\n inner_type = create_transfer_model_type_annotation(transfer_type.inner_type)\n if transfer_type.parsed_type.origin is tuple:\n return generic_collection_type[inner_type, ...]\n return generic_collection_type[inner_type]\n\n\ndef create_transfer_model_tuple_type(transfer_type: TupleType) -> Any:\n inner_types = tuple(create_transfer_model_type_annotation(t) for t in transfer_type.inner_types)\n return transfer_type.parsed_type.safe_generic_origin[inner_types]\n\n\ndef create_transfer_model_union_type(transfer_type: UnionType) -> Any:\n inner_types = tuple(create_transfer_model_type_annotation(t) for t in transfer_type.inner_types)\n return transfer_type.parsed_type.safe_generic_origin[inner_types]\n\n\ndef create_transfer_model_mapping_type(transfer_type: MappingType) -> Any:\n key_type = create_transfer_model_type_annotation(transfer_type.key_type)\n value_type = create_transfer_model_type_annotation(transfer_type.value_type)\n return transfer_type.parsed_type.safe_generic_origin[key_type, value_type]\n", "path": "litestar/dto/factory/_backends/utils.py"}]}
| 3,771 | 402 |
gh_patches_debug_35326
|
rasdani/github-patches
|
git_diff
|
internetarchive__openlibrary-8575
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bad matches in works Mass tagging system
I was trying to add subject "Comedy" to the works and these are the first matches I get

And when I try to manually search for the exact match there are many more subjects with word "coming" that have less works than the actual "Comedy". I think the exact matches should be the first one in the list or at least be boosted.
### Evidence / Screenshot (if possible)
### Relevant url?
<!-- `https://openlibrary.org/...` -->
### Steps to Reproduce
<!-- What steps caused you to find the bug? -->
1. Go to ...
2. Do ...
<!-- What actually happened after these steps? What did you expect to happen? -->
* Actual:
* Expected:
### Details
- **Logged in (Y/N)?**
- **Browser type/version?**
- **Operating system?**
- **Environment (prod/dev/local)?** prod
<!-- If not sure, put prod -->
### Proposal & Constraints
<!-- What is the proposed solution / implementation? Is there a precedent of this approach succeeding elsewhere? -->
### Related files
<!-- Files related to this issue; this is super useful for new contributors who might want to help! If you're not sure, leave this blank; a maintainer will add them. -->
### Stakeholders
<!-- @ tag stakeholders of this bug -->
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `openlibrary/plugins/openlibrary/bulk_tag.py`
Content:
```
1 from infogami.utils import delegate
2 from infogami.utils.view import render_template, public
3 from openlibrary.utils import uniq
4 import web
5 import json
6
7
8 class tags_partials(delegate.page):
9 path = "/tags/partials"
10 encoding = "json"
11
12 def GET(self):
13 i = web.input(key=None)
14
15 works = i.work_ids
16
17 tagging_menu = render_template('subjects/tagging_menu', works)
18
19 partials = {
20 'tagging_menu': str(tagging_menu),
21 }
22
23 return delegate.RawText(json.dumps(partials))
24
25
26 class bulk_tag_works(delegate.page):
27 path = "/tags/bulk_tag_works"
28
29 def POST(self):
30 i = web.input(work_ids='', tag_subjects='{}')
31 works = i.work_ids.split(',')
32 incoming_subjects = json.loads(i.tag_subjects)
33 docs_to_update = []
34
35 for work in works:
36 w = web.ctx.site.get(f"/works/{work}")
37 current_subjects = {
38 'subjects': uniq(w.get('subjects', '')),
39 'subject_people': uniq(w.get('subject_people', '')),
40 'subject_places': uniq(w.get('subject_places', '')),
41 'subject_times': uniq(w.get('subject_times', '')),
42 }
43 for subject_type, subject_list in incoming_subjects.items():
44 if subject_list:
45 current_subjects[subject_type] = uniq( # dedupe incoming subjects
46 current_subjects[subject_type] + subject_list
47 )
48 w[subject_type] = current_subjects[subject_type]
49
50 docs_to_update.append(
51 w.dict()
52 ) # need to convert class to raw dict in order for save_many to work
53
54 web.ctx.site.save_many(docs_to_update, comment="Bulk tagging works")
55
56 def response(msg, status="success"):
57 return delegate.RawText(
58 json.dumps({status: msg}), content_type="application/json"
59 )
60
61 return response('Tagged works successfully')
62
63
64 def setup():
65 pass
66
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/openlibrary/plugins/openlibrary/bulk_tag.py b/openlibrary/plugins/openlibrary/bulk_tag.py
--- a/openlibrary/plugins/openlibrary/bulk_tag.py
+++ b/openlibrary/plugins/openlibrary/bulk_tag.py
@@ -5,31 +5,16 @@
import json
-class tags_partials(delegate.page):
- path = "/tags/partials"
- encoding = "json"
-
- def GET(self):
- i = web.input(key=None)
-
- works = i.work_ids
-
- tagging_menu = render_template('subjects/tagging_menu', works)
-
- partials = {
- 'tagging_menu': str(tagging_menu),
- }
-
- return delegate.RawText(json.dumps(partials))
-
-
class bulk_tag_works(delegate.page):
path = "/tags/bulk_tag_works"
def POST(self):
- i = web.input(work_ids='', tag_subjects='{}')
+ i = web.input(work_ids='', tags_to_add='', tags_to_remove='')
+
works = i.work_ids.split(',')
- incoming_subjects = json.loads(i.tag_subjects)
+ tags_to_add = json.loads(i.tags_to_add or '{}')
+ tags_to_remove = json.loads(i.tags_to_remove or '{}')
+
docs_to_update = []
for work in works:
@@ -40,13 +25,22 @@
'subject_places': uniq(w.get('subject_places', '')),
'subject_times': uniq(w.get('subject_times', '')),
}
- for subject_type, subject_list in incoming_subjects.items():
- if subject_list:
+ for subject_type, add_list in tags_to_add.items():
+ if add_list:
current_subjects[subject_type] = uniq( # dedupe incoming subjects
- current_subjects[subject_type] + subject_list
+ current_subjects[subject_type] + add_list
)
w[subject_type] = current_subjects[subject_type]
+ for subject_type, remove_list in tags_to_remove.items():
+ if remove_list:
+ current_subjects[subject_type] = [
+ item
+ for item in current_subjects[subject_type]
+ if item not in remove_list
+ ]
+ w[subject_type] = current_subjects[subject_type]
+
docs_to_update.append(
w.dict()
) # need to convert class to raw dict in order for save_many to work
|
{"golden_diff": "diff --git a/openlibrary/plugins/openlibrary/bulk_tag.py b/openlibrary/plugins/openlibrary/bulk_tag.py\n--- a/openlibrary/plugins/openlibrary/bulk_tag.py\n+++ b/openlibrary/plugins/openlibrary/bulk_tag.py\n@@ -5,31 +5,16 @@\n import json\n \n \n-class tags_partials(delegate.page):\n- path = \"/tags/partials\"\n- encoding = \"json\"\n-\n- def GET(self):\n- i = web.input(key=None)\n-\n- works = i.work_ids\n-\n- tagging_menu = render_template('subjects/tagging_menu', works)\n-\n- partials = {\n- 'tagging_menu': str(tagging_menu),\n- }\n-\n- return delegate.RawText(json.dumps(partials))\n-\n-\n class bulk_tag_works(delegate.page):\n path = \"/tags/bulk_tag_works\"\n \n def POST(self):\n- i = web.input(work_ids='', tag_subjects='{}')\n+ i = web.input(work_ids='', tags_to_add='', tags_to_remove='')\n+\n works = i.work_ids.split(',')\n- incoming_subjects = json.loads(i.tag_subjects)\n+ tags_to_add = json.loads(i.tags_to_add or '{}')\n+ tags_to_remove = json.loads(i.tags_to_remove or '{}')\n+\n docs_to_update = []\n \n for work in works:\n@@ -40,13 +25,22 @@\n 'subject_places': uniq(w.get('subject_places', '')),\n 'subject_times': uniq(w.get('subject_times', '')),\n }\n- for subject_type, subject_list in incoming_subjects.items():\n- if subject_list:\n+ for subject_type, add_list in tags_to_add.items():\n+ if add_list:\n current_subjects[subject_type] = uniq( # dedupe incoming subjects\n- current_subjects[subject_type] + subject_list\n+ current_subjects[subject_type] + add_list\n )\n w[subject_type] = current_subjects[subject_type]\n \n+ for subject_type, remove_list in tags_to_remove.items():\n+ if remove_list:\n+ current_subjects[subject_type] = [\n+ item\n+ for item in current_subjects[subject_type]\n+ if item not in remove_list\n+ ]\n+ w[subject_type] = current_subjects[subject_type]\n+\n docs_to_update.append(\n w.dict()\n ) # need to convert class to raw dict in order for save_many to work\n", "issue": "Bad matches in works Mass tagging system\nI was trying to add subject \"Comedy\" to the works and these are the first matches I get \r\n\r\nAnd when I try to manually search for the exact match there are many more subjects with word \"coming\" that have less works than the actual \"Comedy\". I think the exact matches should be the first one in the list or at least be boosted.\r\n\r\n### Evidence / Screenshot (if possible)\r\n\r\n### Relevant url?\r\n<!-- `https://openlibrary.org/...` -->\r\n\r\n### Steps to Reproduce\r\n<!-- What steps caused you to find the bug? -->\r\n1. Go to ...\r\n2. Do ...\r\n\r\n<!-- What actually happened after these steps? What did you expect to happen? -->\r\n* Actual:\r\n* Expected:\r\n\r\n### Details\r\n\r\n- **Logged in (Y/N)?**\r\n- **Browser type/version?**\r\n- **Operating system?**\r\n- **Environment (prod/dev/local)?** prod\r\n<!-- If not sure, put prod -->\r\n\r\n### Proposal & Constraints\r\n<!-- What is the proposed solution / implementation? Is there a precedent of this approach succeeding elsewhere? -->\r\n\r\n### Related files\r\n<!-- Files related to this issue; this is super useful for new contributors who might want to help! If you're not sure, leave this blank; a maintainer will add them. -->\r\n\r\n### Stakeholders\r\n<!-- @ tag stakeholders of this bug -->\r\n\n", "before_files": [{"content": "from infogami.utils import delegate\nfrom infogami.utils.view import render_template, public\nfrom openlibrary.utils import uniq\nimport web\nimport json\n\n\nclass tags_partials(delegate.page):\n path = \"/tags/partials\"\n encoding = \"json\"\n\n def GET(self):\n i = web.input(key=None)\n\n works = i.work_ids\n\n tagging_menu = render_template('subjects/tagging_menu', works)\n\n partials = {\n 'tagging_menu': str(tagging_menu),\n }\n\n return delegate.RawText(json.dumps(partials))\n\n\nclass bulk_tag_works(delegate.page):\n path = \"/tags/bulk_tag_works\"\n\n def POST(self):\n i = web.input(work_ids='', tag_subjects='{}')\n works = i.work_ids.split(',')\n incoming_subjects = json.loads(i.tag_subjects)\n docs_to_update = []\n\n for work in works:\n w = web.ctx.site.get(f\"/works/{work}\")\n current_subjects = {\n 'subjects': uniq(w.get('subjects', '')),\n 'subject_people': uniq(w.get('subject_people', '')),\n 'subject_places': uniq(w.get('subject_places', '')),\n 'subject_times': uniq(w.get('subject_times', '')),\n }\n for subject_type, subject_list in incoming_subjects.items():\n if subject_list:\n current_subjects[subject_type] = uniq( # dedupe incoming subjects\n current_subjects[subject_type] + subject_list\n )\n w[subject_type] = current_subjects[subject_type]\n\n docs_to_update.append(\n w.dict()\n ) # need to convert class to raw dict in order for save_many to work\n\n web.ctx.site.save_many(docs_to_update, comment=\"Bulk tagging works\")\n\n def response(msg, status=\"success\"):\n return delegate.RawText(\n json.dumps({status: msg}), content_type=\"application/json\"\n )\n\n return response('Tagged works successfully')\n\n\ndef setup():\n pass\n", "path": "openlibrary/plugins/openlibrary/bulk_tag.py"}], "after_files": [{"content": "from infogami.utils import delegate\nfrom infogami.utils.view import render_template, public\nfrom openlibrary.utils import uniq\nimport web\nimport json\n\n\nclass bulk_tag_works(delegate.page):\n path = \"/tags/bulk_tag_works\"\n\n def POST(self):\n i = web.input(work_ids='', tags_to_add='', tags_to_remove='')\n\n works = i.work_ids.split(',')\n tags_to_add = json.loads(i.tags_to_add or '{}')\n tags_to_remove = json.loads(i.tags_to_remove or '{}')\n\n docs_to_update = []\n\n for work in works:\n w = web.ctx.site.get(f\"/works/{work}\")\n current_subjects = {\n 'subjects': uniq(w.get('subjects', '')),\n 'subject_people': uniq(w.get('subject_people', '')),\n 'subject_places': uniq(w.get('subject_places', '')),\n 'subject_times': uniq(w.get('subject_times', '')),\n }\n for subject_type, add_list in tags_to_add.items():\n if add_list:\n current_subjects[subject_type] = uniq( # dedupe incoming subjects\n current_subjects[subject_type] + add_list\n )\n w[subject_type] = current_subjects[subject_type]\n\n for subject_type, remove_list in tags_to_remove.items():\n if remove_list:\n current_subjects[subject_type] = [\n item\n for item in current_subjects[subject_type]\n if item not in remove_list\n ]\n w[subject_type] = current_subjects[subject_type]\n\n docs_to_update.append(\n w.dict()\n ) # need to convert class to raw dict in order for save_many to work\n\n web.ctx.site.save_many(docs_to_update, comment=\"Bulk tagging works\")\n\n def response(msg, status=\"success\"):\n return delegate.RawText(\n json.dumps({status: msg}), content_type=\"application/json\"\n )\n\n return response('Tagged works successfully')\n\n\ndef setup():\n pass\n", "path": "openlibrary/plugins/openlibrary/bulk_tag.py"}]}
| 1,156 | 536 |
gh_patches_debug_6109
|
rasdani/github-patches
|
git_diff
|
facebookresearch__ParlAI-2281
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
projects/convai2/interactive.py not using new message force_set feature
**Bug description**
The code hasn't been updated for the force_set.
**Reproduction steps**
python projects/convai2/interactive.py -mf models:convai2/seq2seq/convai2_self_seq2seq_model -m legacy:seq2seq:0 --no_cuda
**Expected behavior**
to just chat
**Logs**
```
Traceback (most recent call last):
File "projects/convai2/interactive.py", line 126, in <module>
interactive(parser.parse_args(print_args=False), print_parser=parser)
File "projects/convai2/interactive.py", line 105, in interactive
acts[0]['text'] = bot_persona + acts[0].get('text', 'hi')
File "/home/ubuntu/anaconda3/envs/pytorch_p36/lib/python3.6/site-packages/parlai-0.1.0-py3.6.egg/parlai/core/message.py", line 26, in __setitem__
'please use the function `force_set(key, value)`.'.format(key)
RuntimeError: Message already contains key `text`. If this was intentional, please use the function `force_set(key, value)`.
```
**Additional context**
possible fix
```
index 61ead742..9d478d75 100644
--- a/projects/convai2/interactive.py
+++ b/projects/convai2/interactive.py
@@ -102,7 +102,8 @@ def interactive(opt, print_parser=None):
acts[0] = agents[0].act()
# add the persona on to the first message
if cnt == 0:
- acts[0]['text'] = bot_persona + acts[0].get('text', 'hi')
+ #acts[0]['text'] = bot_persona + acts[0].get('text', 'hi')
+ acts[0].force_set('text',bot_persona + acts[0].get('text', 'hi'))
agents[1].observe(acts[0])
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `projects/convai2/interactive.py`
Content:
```
1 #!/usr/bin/env python3
2
3 # Copyright (c) Facebook, Inc. and its affiliates.
4 # This source code is licensed under the MIT license found in the
5 # LICENSE file in the root directory of this source tree.
6 """
7 Basic script which allows local human keyboard input to talk to a trained model.
8
9 Examples
10 --------
11
12 .. code-block:: shell
13
14 python projects/convai2/interactive.py -mf models:convai2/kvmemnn/model
15
16 When prompted, chat with the both, you will both be assigned personalities!
17 Use "[DONE]" to indicate you are done with that chat partner, and want a new one.
18 """
19 from parlai.core.params import ParlaiParser
20 from parlai.core.agents import create_agent
21 from parlai.core.worlds import create_task
22 from parlai.agents.repeat_label.repeat_label import RepeatLabelAgent
23 from parlai.agents.local_human.local_human import LocalHumanAgent
24
25 import random
26
27
28 def setup_args(parser=None):
29 if parser is None:
30 parser = ParlaiParser(True, True, 'Interactive chat with a model')
31 parser.add_argument('-d', '--display-examples', type='bool', default=False)
32 parser.add_argument(
33 '--display-prettify',
34 type='bool',
35 default=False,
36 help='Set to use a prettytable when displaying '
37 'examples with text candidates',
38 )
39 parser.add_argument(
40 '--display-ignore-fields',
41 type=str,
42 default='label_candidates,text_candidates',
43 help='Do not display these fields',
44 )
45 parser.set_defaults(model_file='models:convai2/kvmemnn/model')
46 LocalHumanAgent.add_cmdline_args(parser)
47 return parser
48
49
50 def interactive(opt, print_parser=None):
51 if print_parser is not None:
52 if print_parser is True and isinstance(opt, ParlaiParser):
53 print_parser = opt
54 elif print_parser is False:
55 print_parser = None
56 if isinstance(opt, ParlaiParser):
57 print('[ Deprecated Warning: interactive should be passed opt not Parser ]')
58 opt = opt.parse_args()
59 opt['task'] = 'parlai.agents.local_human.local_human:LocalHumanAgent'
60 # Create model and assign it to the specified task
61 agent = create_agent(opt, requireModelExists=True)
62 world = create_task(opt, agent)
63 if print_parser:
64 # Show arguments after loading model
65 print_parser.opt = agent.opt
66 print_parser.print_args()
67
68 # Create ConvAI2 data so we can assign personas.
69 convai2_opt = opt.copy()
70 convai2_opt['task'] = 'convai2:both'
71 convai2_agent = RepeatLabelAgent(convai2_opt)
72 convai2_world = create_task(convai2_opt, convai2_agent)
73
74 def get_new_personas():
75 # Find a new episode
76 while True:
77 convai2_world.parley()
78 msg = convai2_world.get_acts()[0]
79 if msg['episode_done']:
80 convai2_world.parley()
81 msg = convai2_world.get_acts()[0]
82 break
83 txt = msg.get('text', '').split('\n')
84 bot_persona = ""
85 for t in txt:
86 if t.startswith("partner's persona:"):
87 print(t.replace("partner's ", 'your '))
88 if t.startswith('your persona:'):
89 bot_persona += t + '\n'
90 print("Enter [DONE] if you want a new partner at any time.")
91 return bot_persona
92
93 # Now run interactive mode, chatting with personas!
94 cnt = 0
95 while True:
96 if cnt == 0:
97 bot_persona = get_new_personas()
98 # Run the parts of world.parley() in turn,
99 # but insert persona into user message.
100 acts = world.acts
101 agents = world.agents
102 acts[0] = agents[0].act()
103 # add the persona on to the first message
104 if cnt == 0:
105 acts[0]['text'] = bot_persona + acts[0].get('text', 'hi')
106 agents[1].observe(acts[0])
107 acts[1] = agents[1].act()
108 agents[0].observe(acts[1])
109 world.update_counters()
110 cnt = cnt + 1
111
112 if opt.get('display_examples'):
113 print("---")
114 print(world.display())
115 if world.episode_done():
116 print("CHAT DONE ")
117 print("In case you were curious you were talking to this bot:")
118 print(bot_persona.split('\n'))
119 print("\n... preparing new chat... \n")
120 cnt = 0
121
122
123 if __name__ == '__main__':
124 random.seed(42)
125 parser = setup_args()
126 interactive(parser.parse_args(print_args=False), print_parser=parser)
127
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/projects/convai2/interactive.py b/projects/convai2/interactive.py
--- a/projects/convai2/interactive.py
+++ b/projects/convai2/interactive.py
@@ -102,7 +102,7 @@
acts[0] = agents[0].act()
# add the persona on to the first message
if cnt == 0:
- acts[0]['text'] = bot_persona + acts[0].get('text', 'hi')
+ acts[0].force_set('text', bot_persona + acts[0].get('text', 'hi'))
agents[1].observe(acts[0])
acts[1] = agents[1].act()
agents[0].observe(acts[1])
|
{"golden_diff": "diff --git a/projects/convai2/interactive.py b/projects/convai2/interactive.py\n--- a/projects/convai2/interactive.py\n+++ b/projects/convai2/interactive.py\n@@ -102,7 +102,7 @@\n acts[0] = agents[0].act()\n # add the persona on to the first message\n if cnt == 0:\n- acts[0]['text'] = bot_persona + acts[0].get('text', 'hi')\n+ acts[0].force_set('text', bot_persona + acts[0].get('text', 'hi'))\n agents[1].observe(acts[0])\n acts[1] = agents[1].act()\n agents[0].observe(acts[1])\n", "issue": "projects/convai2/interactive.py not using new message force_set feature\n**Bug description**\r\nThe code hasn't been updated for the force_set.\r\n\r\n**Reproduction steps**\r\npython projects/convai2/interactive.py -mf models:convai2/seq2seq/convai2_self_seq2seq_model -m legacy:seq2seq:0 --no_cuda\r\n\r\n**Expected behavior**\r\nto just chat\r\n\r\n**Logs**\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"projects/convai2/interactive.py\", line 126, in <module>\r\n interactive(parser.parse_args(print_args=False), print_parser=parser)\r\n File \"projects/convai2/interactive.py\", line 105, in interactive\r\n acts[0]['text'] = bot_persona + acts[0].get('text', 'hi')\r\n File \"/home/ubuntu/anaconda3/envs/pytorch_p36/lib/python3.6/site-packages/parlai-0.1.0-py3.6.egg/parlai/core/message.py\", line 26, in __setitem__\r\n 'please use the function `force_set(key, value)`.'.format(key)\r\nRuntimeError: Message already contains key `text`. If this was intentional, please use the function `force_set(key, value)`.\r\n```\r\n\r\n**Additional context**\r\npossible fix\r\n```\r\nindex 61ead742..9d478d75 100644\r\n--- a/projects/convai2/interactive.py\r\n+++ b/projects/convai2/interactive.py\r\n@@ -102,7 +102,8 @@ def interactive(opt, print_parser=None):\r\n acts[0] = agents[0].act()\r\n # add the persona on to the first message\r\n if cnt == 0:\r\n- acts[0]['text'] = bot_persona + acts[0].get('text', 'hi')\r\n+ #acts[0]['text'] = bot_persona + acts[0].get('text', 'hi')\r\n+ acts[0].force_set('text',bot_persona + acts[0].get('text', 'hi'))\r\n agents[1].observe(acts[0])\r\n\r\n```\r\n\n", "before_files": [{"content": "#!/usr/bin/env python3\n\n# Copyright (c) Facebook, Inc. and its affiliates.\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\"\"\"\nBasic script which allows local human keyboard input to talk to a trained model.\n\nExamples\n--------\n\n.. code-block:: shell\n\n python projects/convai2/interactive.py -mf models:convai2/kvmemnn/model\n\nWhen prompted, chat with the both, you will both be assigned personalities!\nUse \"[DONE]\" to indicate you are done with that chat partner, and want a new one.\n\"\"\"\nfrom parlai.core.params import ParlaiParser\nfrom parlai.core.agents import create_agent\nfrom parlai.core.worlds import create_task\nfrom parlai.agents.repeat_label.repeat_label import RepeatLabelAgent\nfrom parlai.agents.local_human.local_human import LocalHumanAgent\n\nimport random\n\n\ndef setup_args(parser=None):\n if parser is None:\n parser = ParlaiParser(True, True, 'Interactive chat with a model')\n parser.add_argument('-d', '--display-examples', type='bool', default=False)\n parser.add_argument(\n '--display-prettify',\n type='bool',\n default=False,\n help='Set to use a prettytable when displaying '\n 'examples with text candidates',\n )\n parser.add_argument(\n '--display-ignore-fields',\n type=str,\n default='label_candidates,text_candidates',\n help='Do not display these fields',\n )\n parser.set_defaults(model_file='models:convai2/kvmemnn/model')\n LocalHumanAgent.add_cmdline_args(parser)\n return parser\n\n\ndef interactive(opt, print_parser=None):\n if print_parser is not None:\n if print_parser is True and isinstance(opt, ParlaiParser):\n print_parser = opt\n elif print_parser is False:\n print_parser = None\n if isinstance(opt, ParlaiParser):\n print('[ Deprecated Warning: interactive should be passed opt not Parser ]')\n opt = opt.parse_args()\n opt['task'] = 'parlai.agents.local_human.local_human:LocalHumanAgent'\n # Create model and assign it to the specified task\n agent = create_agent(opt, requireModelExists=True)\n world = create_task(opt, agent)\n if print_parser:\n # Show arguments after loading model\n print_parser.opt = agent.opt\n print_parser.print_args()\n\n # Create ConvAI2 data so we can assign personas.\n convai2_opt = opt.copy()\n convai2_opt['task'] = 'convai2:both'\n convai2_agent = RepeatLabelAgent(convai2_opt)\n convai2_world = create_task(convai2_opt, convai2_agent)\n\n def get_new_personas():\n # Find a new episode\n while True:\n convai2_world.parley()\n msg = convai2_world.get_acts()[0]\n if msg['episode_done']:\n convai2_world.parley()\n msg = convai2_world.get_acts()[0]\n break\n txt = msg.get('text', '').split('\\n')\n bot_persona = \"\"\n for t in txt:\n if t.startswith(\"partner's persona:\"):\n print(t.replace(\"partner's \", 'your '))\n if t.startswith('your persona:'):\n bot_persona += t + '\\n'\n print(\"Enter [DONE] if you want a new partner at any time.\")\n return bot_persona\n\n # Now run interactive mode, chatting with personas!\n cnt = 0\n while True:\n if cnt == 0:\n bot_persona = get_new_personas()\n # Run the parts of world.parley() in turn,\n # but insert persona into user message.\n acts = world.acts\n agents = world.agents\n acts[0] = agents[0].act()\n # add the persona on to the first message\n if cnt == 0:\n acts[0]['text'] = bot_persona + acts[0].get('text', 'hi')\n agents[1].observe(acts[0])\n acts[1] = agents[1].act()\n agents[0].observe(acts[1])\n world.update_counters()\n cnt = cnt + 1\n\n if opt.get('display_examples'):\n print(\"---\")\n print(world.display())\n if world.episode_done():\n print(\"CHAT DONE \")\n print(\"In case you were curious you were talking to this bot:\")\n print(bot_persona.split('\\n'))\n print(\"\\n... preparing new chat... \\n\")\n cnt = 0\n\n\nif __name__ == '__main__':\n random.seed(42)\n parser = setup_args()\n interactive(parser.parse_args(print_args=False), print_parser=parser)\n", "path": "projects/convai2/interactive.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n\n# Copyright (c) Facebook, Inc. and its affiliates.\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\"\"\"\nBasic script which allows local human keyboard input to talk to a trained model.\n\nExamples\n--------\n\n.. code-block:: shell\n\n python projects/convai2/interactive.py -mf models:convai2/kvmemnn/model\n\nWhen prompted, chat with the both, you will both be assigned personalities!\nUse \"[DONE]\" to indicate you are done with that chat partner, and want a new one.\n\"\"\"\nfrom parlai.core.params import ParlaiParser\nfrom parlai.core.agents import create_agent\nfrom parlai.core.worlds import create_task\nfrom parlai.agents.repeat_label.repeat_label import RepeatLabelAgent\nfrom parlai.agents.local_human.local_human import LocalHumanAgent\n\nimport random\n\n\ndef setup_args(parser=None):\n if parser is None:\n parser = ParlaiParser(True, True, 'Interactive chat with a model')\n parser.add_argument('-d', '--display-examples', type='bool', default=False)\n parser.add_argument(\n '--display-prettify',\n type='bool',\n default=False,\n help='Set to use a prettytable when displaying '\n 'examples with text candidates',\n )\n parser.add_argument(\n '--display-ignore-fields',\n type=str,\n default='label_candidates,text_candidates',\n help='Do not display these fields',\n )\n parser.set_defaults(model_file='models:convai2/kvmemnn/model')\n LocalHumanAgent.add_cmdline_args(parser)\n return parser\n\n\ndef interactive(opt, print_parser=None):\n if print_parser is not None:\n if print_parser is True and isinstance(opt, ParlaiParser):\n print_parser = opt\n elif print_parser is False:\n print_parser = None\n if isinstance(opt, ParlaiParser):\n print('[ Deprecated Warning: interactive should be passed opt not Parser ]')\n opt = opt.parse_args()\n opt['task'] = 'parlai.agents.local_human.local_human:LocalHumanAgent'\n # Create model and assign it to the specified task\n agent = create_agent(opt, requireModelExists=True)\n world = create_task(opt, agent)\n if print_parser:\n # Show arguments after loading model\n print_parser.opt = agent.opt\n print_parser.print_args()\n\n # Create ConvAI2 data so we can assign personas.\n convai2_opt = opt.copy()\n convai2_opt['task'] = 'convai2:both'\n convai2_agent = RepeatLabelAgent(convai2_opt)\n convai2_world = create_task(convai2_opt, convai2_agent)\n\n def get_new_personas():\n # Find a new episode\n while True:\n convai2_world.parley()\n msg = convai2_world.get_acts()[0]\n if msg['episode_done']:\n convai2_world.parley()\n msg = convai2_world.get_acts()[0]\n break\n txt = msg.get('text', '').split('\\n')\n bot_persona = \"\"\n for t in txt:\n if t.startswith(\"partner's persona:\"):\n print(t.replace(\"partner's \", 'your '))\n if t.startswith('your persona:'):\n bot_persona += t + '\\n'\n print(\"Enter [DONE] if you want a new partner at any time.\")\n return bot_persona\n\n # Now run interactive mode, chatting with personas!\n cnt = 0\n while True:\n if cnt == 0:\n bot_persona = get_new_personas()\n # Run the parts of world.parley() in turn,\n # but insert persona into user message.\n acts = world.acts\n agents = world.agents\n acts[0] = agents[0].act()\n # add the persona on to the first message\n if cnt == 0:\n acts[0].force_set('text', bot_persona + acts[0].get('text', 'hi'))\n agents[1].observe(acts[0])\n acts[1] = agents[1].act()\n agents[0].observe(acts[1])\n world.update_counters()\n cnt = cnt + 1\n\n if opt.get('display_examples'):\n print(\"---\")\n print(world.display())\n if world.episode_done():\n print(\"CHAT DONE \")\n print(\"In case you were curious you were talking to this bot:\")\n print(bot_persona.split('\\n'))\n print(\"\\n... preparing new chat... \\n\")\n cnt = 0\n\n\nif __name__ == '__main__':\n random.seed(42)\n parser = setup_args()\n interactive(parser.parse_args(print_args=False), print_parser=parser)\n", "path": "projects/convai2/interactive.py"}]}
| 2,039 | 170 |
gh_patches_debug_4267
|
rasdani/github-patches
|
git_diff
|
web2py__web2py-1381
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
XML helper and incorrect HTML
XML crashes while trying to sanitize some sorts of incorrect html.
For example:
```
a = '</em></em>' # wrong html
b = XML(a, sanitize=True)
```
Result:
`<type 'exceptions.IndexError'> pop from empty list`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `gluon/sanitizer.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 """
4 | From http://aspn.activestate.com/ASPN/Cookbook/Python/Recipe/496942
5 | Submitter: Josh Goldfoot (other recipes)
6 | Last Updated: 2006/08/05
7 | Version: 1.0
8
9 Cross-site scripting (XSS) defense
10 -----------------------------------
11 """
12
13 from ._compat import HTMLParser, urlparse, entitydefs, basestring
14 from cgi import escape
15 from formatter import AbstractFormatter
16 from xml.sax.saxutils import quoteattr
17
18 __all__ = ['sanitize']
19
20
21 def xssescape(text):
22 """Gets rid of < and > and & and, for good measure, :"""
23
24 return escape(text, quote=True).replace(':', ':')
25
26
27 class XssCleaner(HTMLParser):
28
29 def __init__(
30 self,
31 permitted_tags=[
32 'a',
33 'b',
34 'blockquote',
35 'br/',
36 'i',
37 'li',
38 'ol',
39 'ul',
40 'p',
41 'cite',
42 'code',
43 'pre',
44 'img/',
45 ],
46 allowed_attributes={'a': ['href', 'title'], 'img': ['src', 'alt'
47 ], 'blockquote': ['type']},
48 strip_disallowed=False
49 ):
50
51 HTMLParser.__init__(self)
52 self.result = ''
53 self.open_tags = []
54 self.permitted_tags = [i for i in permitted_tags if i[-1] != '/']
55 self.requires_no_close = [i[:-1] for i in permitted_tags
56 if i[-1] == '/']
57 self.permitted_tags += self.requires_no_close
58 self.allowed_attributes = allowed_attributes
59
60 # The only schemes allowed in URLs (for href and src attributes).
61 # Adding "javascript" or "vbscript" to this list would not be smart.
62
63 self.allowed_schemes = ['http', 'https', 'ftp', 'mailto']
64
65 #to strip or escape disallowed tags?
66 self.strip_disallowed = strip_disallowed
67 # there might be data after final closing tag, that is to be ignored
68 self.in_disallowed = [False]
69
70 def handle_data(self, data):
71 if data and not self.in_disallowed[-1]:
72 self.result += xssescape(data)
73
74 def handle_charref(self, ref):
75 if self.in_disallowed[-1]:
76 return
77 elif len(ref) < 7 and (ref.isdigit() or ref == 'x27'): # x27 is a special case for apostrophe
78 self.result += '&#%s;' % ref
79 else:
80 self.result += xssescape('&#%s' % ref)
81
82 def handle_entityref(self, ref):
83 if self.in_disallowed[-1]:
84 return
85 elif ref in entitydefs:
86 self.result += '&%s;' % ref
87 else:
88 self.result += xssescape('&%s' % ref)
89
90 def handle_comment(self, comment):
91 if self.in_disallowed[-1]:
92 return
93 elif comment:
94 self.result += xssescape('<!--%s-->' % comment)
95
96 def handle_starttag(
97 self,
98 tag,
99 attrs
100 ):
101 if tag not in self.permitted_tags:
102 self.in_disallowed.append(True)
103 if (not self.strip_disallowed):
104 self.result += xssescape('<%s>' % tag)
105 else:
106 self.in_disallowed.append(False)
107 bt = '<' + tag
108 if tag in self.allowed_attributes:
109 attrs = dict(attrs)
110 self.allowed_attributes_here = [x for x in
111 self.allowed_attributes[tag] if x in attrs
112 and len(attrs[x]) > 0]
113 for attribute in self.allowed_attributes_here:
114 if attribute in ['href', 'src', 'background']:
115 if self.url_is_acceptable(attrs[attribute]):
116 bt += ' %s="%s"' % (attribute,
117 attrs[attribute])
118 else:
119 bt += ' %s=%s' % (xssescape(attribute),
120 quoteattr(attrs[attribute]))
121 # deal with <a> without href and <img> without src
122 if bt == '<a' or bt == '<img':
123 return
124 if tag in self.requires_no_close:
125 bt += ' /'
126 bt += '>'
127 self.result += bt
128 if tag not in self.requires_no_close: self.open_tags.insert(0, tag)
129
130 def handle_endtag(self, tag):
131 bracketed = '</%s>' % tag
132 self.in_disallowed.pop()
133 if tag not in self.permitted_tags:
134 if (not self.strip_disallowed):
135 self.result += xssescape(bracketed)
136 elif tag in self.open_tags:
137 self.result += bracketed
138 self.open_tags.remove(tag)
139
140 def url_is_acceptable(self, url):
141 """
142 Accepts relative, absolute, and mailto urls
143 """
144
145 if url.startswith('#'):
146 return True
147 else:
148 parsed = urlparse(url)
149 return ((parsed[0] in self.allowed_schemes and '.' in parsed[1]) or
150 (parsed[0] in self.allowed_schemes and '@' in parsed[2]) or
151 (parsed[0] == '' and parsed[2].startswith('/')))
152
153 def strip(self, rawstring, escape=True):
154 """
155 Returns the argument stripped of potentially harmful
156 HTML or Javascript code
157
158 @type escape: boolean
159 @param escape: If True (default) it escapes the potentially harmful
160 content, otherwise remove it
161 """
162
163 if not isinstance(rawstring, str):
164 return str(rawstring)
165 for tag in self.requires_no_close:
166 rawstring = rawstring.replace("<%s/>" % tag, "<%s />" % tag)
167 if not escape:
168 self.strip_disallowed = True
169 self.result = ''
170 self.feed(rawstring)
171 for endtag in self.open_tags:
172 if endtag not in self.requires_no_close:
173 self.result += '</%s>' % endtag
174 return self.result
175
176 def xtags(self):
177 """
178 Returns a printable string informing the user which tags are allowed
179 """
180
181 tg = ''
182 for x in sorted(self.permitted_tags):
183 tg += '<' + x
184 if x in self.allowed_attributes:
185 for y in self.allowed_attributes[x]:
186 tg += ' %s=""' % y
187 tg += '> '
188 return xssescape(tg.strip())
189
190
191 def sanitize(text, permitted_tags=[
192 'a',
193 'b',
194 'blockquote',
195 'br/',
196 'i',
197 'li',
198 'ol',
199 'ul',
200 'p',
201 'cite',
202 'code',
203 'pre',
204 'img/',
205 'h1', 'h2', 'h3', 'h4', 'h5', 'h6',
206 'table', 'tbody', 'thead', 'tfoot', 'tr', 'td', 'div',
207 'strong', 'span',
208 ],
209 allowed_attributes={
210 'a': ['href', 'title'],
211 'img': ['src', 'alt'],
212 'blockquote': ['type'],
213 'td': ['colspan'],
214 },
215 escape=True):
216 if not isinstance(text, basestring):
217 return str(text)
218 return XssCleaner(permitted_tags=permitted_tags,
219 allowed_attributes=allowed_attributes).strip(text, escape)
220
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/gluon/sanitizer.py b/gluon/sanitizer.py
--- a/gluon/sanitizer.py
+++ b/gluon/sanitizer.py
@@ -129,7 +129,7 @@
def handle_endtag(self, tag):
bracketed = '</%s>' % tag
- self.in_disallowed.pop()
+ self.in_disallowed and self.in_disallowed.pop()
if tag not in self.permitted_tags:
if (not self.strip_disallowed):
self.result += xssescape(bracketed)
|
{"golden_diff": "diff --git a/gluon/sanitizer.py b/gluon/sanitizer.py\n--- a/gluon/sanitizer.py\n+++ b/gluon/sanitizer.py\n@@ -129,7 +129,7 @@\n \n def handle_endtag(self, tag):\n bracketed = '</%s>' % tag\n- self.in_disallowed.pop()\n+ self.in_disallowed and self.in_disallowed.pop()\n if tag not in self.permitted_tags:\n if (not self.strip_disallowed):\n self.result += xssescape(bracketed)\n", "issue": "XML helper and incorrect HTML\nXML crashes while trying to sanitize some sorts of incorrect html.\n\nFor example:\n\n```\na = '</em></em>' # wrong html\nb = XML(a, sanitize=True)\n```\n\nResult:\n`<type 'exceptions.IndexError'> pop from empty list`\n\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"\n| From http://aspn.activestate.com/ASPN/Cookbook/Python/Recipe/496942\n| Submitter: Josh Goldfoot (other recipes)\n| Last Updated: 2006/08/05\n| Version: 1.0\n\nCross-site scripting (XSS) defense\n-----------------------------------\n\"\"\"\n\nfrom ._compat import HTMLParser, urlparse, entitydefs, basestring\nfrom cgi import escape\nfrom formatter import AbstractFormatter\nfrom xml.sax.saxutils import quoteattr\n\n__all__ = ['sanitize']\n\n\ndef xssescape(text):\n \"\"\"Gets rid of < and > and & and, for good measure, :\"\"\"\n\n return escape(text, quote=True).replace(':', ':')\n\n\nclass XssCleaner(HTMLParser):\n\n def __init__(\n self,\n permitted_tags=[\n 'a',\n 'b',\n 'blockquote',\n 'br/',\n 'i',\n 'li',\n 'ol',\n 'ul',\n 'p',\n 'cite',\n 'code',\n 'pre',\n 'img/',\n ],\n allowed_attributes={'a': ['href', 'title'], 'img': ['src', 'alt'\n ], 'blockquote': ['type']},\n strip_disallowed=False\n ):\n\n HTMLParser.__init__(self)\n self.result = ''\n self.open_tags = []\n self.permitted_tags = [i for i in permitted_tags if i[-1] != '/']\n self.requires_no_close = [i[:-1] for i in permitted_tags\n if i[-1] == '/']\n self.permitted_tags += self.requires_no_close\n self.allowed_attributes = allowed_attributes\n\n # The only schemes allowed in URLs (for href and src attributes).\n # Adding \"javascript\" or \"vbscript\" to this list would not be smart.\n\n self.allowed_schemes = ['http', 'https', 'ftp', 'mailto']\n\n #to strip or escape disallowed tags?\n self.strip_disallowed = strip_disallowed\n # there might be data after final closing tag, that is to be ignored\n self.in_disallowed = [False]\n\n def handle_data(self, data):\n if data and not self.in_disallowed[-1]:\n self.result += xssescape(data)\n\n def handle_charref(self, ref):\n if self.in_disallowed[-1]:\n return\n elif len(ref) < 7 and (ref.isdigit() or ref == 'x27'): # x27 is a special case for apostrophe\n self.result += '&#%s;' % ref\n else:\n self.result += xssescape('&#%s' % ref)\n\n def handle_entityref(self, ref):\n if self.in_disallowed[-1]:\n return\n elif ref in entitydefs:\n self.result += '&%s;' % ref\n else:\n self.result += xssescape('&%s' % ref)\n\n def handle_comment(self, comment):\n if self.in_disallowed[-1]:\n return\n elif comment:\n self.result += xssescape('<!--%s-->' % comment)\n\n def handle_starttag(\n self,\n tag,\n attrs\n ):\n if tag not in self.permitted_tags:\n self.in_disallowed.append(True)\n if (not self.strip_disallowed):\n self.result += xssescape('<%s>' % tag)\n else:\n self.in_disallowed.append(False)\n bt = '<' + tag\n if tag in self.allowed_attributes:\n attrs = dict(attrs)\n self.allowed_attributes_here = [x for x in\n self.allowed_attributes[tag] if x in attrs\n and len(attrs[x]) > 0]\n for attribute in self.allowed_attributes_here:\n if attribute in ['href', 'src', 'background']:\n if self.url_is_acceptable(attrs[attribute]):\n bt += ' %s=\"%s\"' % (attribute,\n attrs[attribute])\n else:\n bt += ' %s=%s' % (xssescape(attribute),\n quoteattr(attrs[attribute]))\n # deal with <a> without href and <img> without src\n if bt == '<a' or bt == '<img':\n return\n if tag in self.requires_no_close:\n bt += ' /'\n bt += '>'\n self.result += bt\n if tag not in self.requires_no_close: self.open_tags.insert(0, tag)\n\n def handle_endtag(self, tag):\n bracketed = '</%s>' % tag\n self.in_disallowed.pop()\n if tag not in self.permitted_tags:\n if (not self.strip_disallowed):\n self.result += xssescape(bracketed)\n elif tag in self.open_tags:\n self.result += bracketed\n self.open_tags.remove(tag)\n\n def url_is_acceptable(self, url):\n \"\"\"\n Accepts relative, absolute, and mailto urls\n \"\"\"\n\n if url.startswith('#'):\n return True\n else:\n parsed = urlparse(url)\n return ((parsed[0] in self.allowed_schemes and '.' in parsed[1]) or\n (parsed[0] in self.allowed_schemes and '@' in parsed[2]) or\n (parsed[0] == '' and parsed[2].startswith('/')))\n\n def strip(self, rawstring, escape=True):\n \"\"\"\n Returns the argument stripped of potentially harmful\n HTML or Javascript code\n\n @type escape: boolean\n @param escape: If True (default) it escapes the potentially harmful\n content, otherwise remove it\n \"\"\"\n\n if not isinstance(rawstring, str):\n return str(rawstring)\n for tag in self.requires_no_close:\n rawstring = rawstring.replace(\"<%s/>\" % tag, \"<%s />\" % tag)\n if not escape:\n self.strip_disallowed = True\n self.result = ''\n self.feed(rawstring)\n for endtag in self.open_tags:\n if endtag not in self.requires_no_close:\n self.result += '</%s>' % endtag\n return self.result\n\n def xtags(self):\n \"\"\"\n Returns a printable string informing the user which tags are allowed\n \"\"\"\n\n tg = ''\n for x in sorted(self.permitted_tags):\n tg += '<' + x\n if x in self.allowed_attributes:\n for y in self.allowed_attributes[x]:\n tg += ' %s=\"\"' % y\n tg += '> '\n return xssescape(tg.strip())\n\n\ndef sanitize(text, permitted_tags=[\n 'a',\n 'b',\n 'blockquote',\n 'br/',\n 'i',\n 'li',\n 'ol',\n 'ul',\n 'p',\n 'cite',\n 'code',\n 'pre',\n 'img/',\n 'h1', 'h2', 'h3', 'h4', 'h5', 'h6',\n 'table', 'tbody', 'thead', 'tfoot', 'tr', 'td', 'div',\n 'strong', 'span',\n],\n allowed_attributes={\n 'a': ['href', 'title'],\n 'img': ['src', 'alt'],\n 'blockquote': ['type'],\n 'td': ['colspan'],\n },\n escape=True):\n if not isinstance(text, basestring):\n return str(text)\n return XssCleaner(permitted_tags=permitted_tags,\n allowed_attributes=allowed_attributes).strip(text, escape)\n", "path": "gluon/sanitizer.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"\n| From http://aspn.activestate.com/ASPN/Cookbook/Python/Recipe/496942\n| Submitter: Josh Goldfoot (other recipes)\n| Last Updated: 2006/08/05\n| Version: 1.0\n\nCross-site scripting (XSS) defense\n-----------------------------------\n\"\"\"\n\nfrom ._compat import HTMLParser, urlparse, entitydefs, basestring\nfrom cgi import escape\nfrom formatter import AbstractFormatter\nfrom xml.sax.saxutils import quoteattr\n\n__all__ = ['sanitize']\n\n\ndef xssescape(text):\n \"\"\"Gets rid of < and > and & and, for good measure, :\"\"\"\n\n return escape(text, quote=True).replace(':', ':')\n\n\nclass XssCleaner(HTMLParser):\n\n def __init__(\n self,\n permitted_tags=[\n 'a',\n 'b',\n 'blockquote',\n 'br/',\n 'i',\n 'li',\n 'ol',\n 'ul',\n 'p',\n 'cite',\n 'code',\n 'pre',\n 'img/',\n ],\n allowed_attributes={'a': ['href', 'title'], 'img': ['src', 'alt'\n ], 'blockquote': ['type']},\n strip_disallowed=False\n ):\n\n HTMLParser.__init__(self)\n self.result = ''\n self.open_tags = []\n self.permitted_tags = [i for i in permitted_tags if i[-1] != '/']\n self.requires_no_close = [i[:-1] for i in permitted_tags\n if i[-1] == '/']\n self.permitted_tags += self.requires_no_close\n self.allowed_attributes = allowed_attributes\n\n # The only schemes allowed in URLs (for href and src attributes).\n # Adding \"javascript\" or \"vbscript\" to this list would not be smart.\n\n self.allowed_schemes = ['http', 'https', 'ftp', 'mailto']\n\n #to strip or escape disallowed tags?\n self.strip_disallowed = strip_disallowed\n # there might be data after final closing tag, that is to be ignored\n self.in_disallowed = [False]\n\n def handle_data(self, data):\n if data and not self.in_disallowed[-1]:\n self.result += xssescape(data)\n\n def handle_charref(self, ref):\n if self.in_disallowed[-1]:\n return\n elif len(ref) < 7 and (ref.isdigit() or ref == 'x27'): # x27 is a special case for apostrophe\n self.result += '&#%s;' % ref\n else:\n self.result += xssescape('&#%s' % ref)\n\n def handle_entityref(self, ref):\n if self.in_disallowed[-1]:\n return\n elif ref in entitydefs:\n self.result += '&%s;' % ref\n else:\n self.result += xssescape('&%s' % ref)\n\n def handle_comment(self, comment):\n if self.in_disallowed[-1]:\n return\n elif comment:\n self.result += xssescape('<!--%s-->' % comment)\n\n def handle_starttag(\n self,\n tag,\n attrs\n ):\n if tag not in self.permitted_tags:\n self.in_disallowed.append(True)\n if (not self.strip_disallowed):\n self.result += xssescape('<%s>' % tag)\n else:\n self.in_disallowed.append(False)\n bt = '<' + tag\n if tag in self.allowed_attributes:\n attrs = dict(attrs)\n self.allowed_attributes_here = [x for x in\n self.allowed_attributes[tag] if x in attrs\n and len(attrs[x]) > 0]\n for attribute in self.allowed_attributes_here:\n if attribute in ['href', 'src', 'background']:\n if self.url_is_acceptable(attrs[attribute]):\n bt += ' %s=\"%s\"' % (attribute,\n attrs[attribute])\n else:\n bt += ' %s=%s' % (xssescape(attribute),\n quoteattr(attrs[attribute]))\n # deal with <a> without href and <img> without src\n if bt == '<a' or bt == '<img':\n return\n if tag in self.requires_no_close:\n bt += ' /'\n bt += '>'\n self.result += bt\n if tag not in self.requires_no_close: self.open_tags.insert(0, tag)\n\n def handle_endtag(self, tag):\n bracketed = '</%s>' % tag\n self.in_disallowed and self.in_disallowed.pop()\n if tag not in self.permitted_tags:\n if (not self.strip_disallowed):\n self.result += xssescape(bracketed)\n elif tag in self.open_tags:\n self.result += bracketed\n self.open_tags.remove(tag)\n\n def url_is_acceptable(self, url):\n \"\"\"\n Accepts relative, absolute, and mailto urls\n \"\"\"\n\n if url.startswith('#'):\n return True\n else:\n parsed = urlparse(url)\n return ((parsed[0] in self.allowed_schemes and '.' in parsed[1]) or\n (parsed[0] in self.allowed_schemes and '@' in parsed[2]) or\n (parsed[0] == '' and parsed[2].startswith('/')))\n\n def strip(self, rawstring, escape=True):\n \"\"\"\n Returns the argument stripped of potentially harmful\n HTML or Javascript code\n\n @type escape: boolean\n @param escape: If True (default) it escapes the potentially harmful\n content, otherwise remove it\n \"\"\"\n\n if not isinstance(rawstring, str):\n return str(rawstring)\n for tag in self.requires_no_close:\n rawstring = rawstring.replace(\"<%s/>\" % tag, \"<%s />\" % tag)\n if not escape:\n self.strip_disallowed = True\n self.result = ''\n self.feed(rawstring)\n for endtag in self.open_tags:\n if endtag not in self.requires_no_close:\n self.result += '</%s>' % endtag\n return self.result\n\n def xtags(self):\n \"\"\"\n Returns a printable string informing the user which tags are allowed\n \"\"\"\n\n tg = ''\n for x in sorted(self.permitted_tags):\n tg += '<' + x\n if x in self.allowed_attributes:\n for y in self.allowed_attributes[x]:\n tg += ' %s=\"\"' % y\n tg += '> '\n return xssescape(tg.strip())\n\n\ndef sanitize(text, permitted_tags=[\n 'a',\n 'b',\n 'blockquote',\n 'br/',\n 'i',\n 'li',\n 'ol',\n 'ul',\n 'p',\n 'cite',\n 'code',\n 'pre',\n 'img/',\n 'h1', 'h2', 'h3', 'h4', 'h5', 'h6',\n 'table', 'tbody', 'thead', 'tfoot', 'tr', 'td', 'div',\n 'strong', 'span',\n],\n allowed_attributes={\n 'a': ['href', 'title'],\n 'img': ['src', 'alt'],\n 'blockquote': ['type'],\n 'td': ['colspan'],\n },\n escape=True):\n if not isinstance(text, basestring):\n return str(text)\n return XssCleaner(permitted_tags=permitted_tags,\n allowed_attributes=allowed_attributes).strip(text, escape)\n", "path": "gluon/sanitizer.py"}]}
| 2,490 | 126 |
gh_patches_debug_15888
|
rasdani/github-patches
|
git_diff
|
AnalogJ__lexicon-795
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Plesk provider assumes `site_name` equals `domain` (which is not always true)
The plesk provider assumes that the `site_name` is always the same as the `domain`: https://github.com/AnalogJ/lexicon/blob/master/lexicon/providers/plesk.py#L52
That creates problems if one wants to create a record for a subdomain (e.g. `test.example.com`) for which there is no matching plesk site. It could be the case that the record for `test.example.com` (and even all records `*.test.example.com`) are part of the site `example.com`.
Example (source for the certbot plugin [here](https://gitlab.com/spike77453/certbot-dns-plesk/)):
```
# certbot certonly --authenticator dns-plesk --dns-plesk-credentials plesk.ini -d test.example.com
Saving debug log to /var/log/letsencrypt/letsencrypt.log
Plugins selected: Authenticator dns-plesk, Installer None
Simulating a certificate request for test.example.com
Performing the following challenges:
dns-01 challenge for test.example.com
Cleaning up challenges
Unexpected error determining zone identifier for test.example.com: API returned error: 1013 (Site does not exist)
```
One could fix this by doing something similar to the `Client` class and strip the subdomain part https://github.com/AnalogJ/lexicon/blob/master/lexicon/client.py#L36. The `Provider` constructor could do something like:
```
try:
domain_extractor = tldextract.TLDExtract(
cache_dir=_get_tldextract_cache_path(), include_psl_private_domains=True
)
except TypeError:
domain_extractor = tldextract.TLDExtract(
cache_file=_get_tldextract_cache_path(), include_psl_private_domains=True # type: ignore
)
domain_parts = domain_extractor(self.domain)
#self.site_name = self.domain
self.site_name = f"{domain_parts.domain}.{domain_parts.suffix}"
assert self.site_name is not None
```
And then instead of stripping the domain from `host`, one would strip the `site_name` here: https://github.com/AnalogJ/lexicon/blob/master/lexicon/providers/plesk.py#L179
That however doesn't work any more if there actually is a site for a particular subdomain.
How about adding an optional `site-id` provider option so the user can specify the site manually in the configuration file?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lexicon/providers/plesk.py`
Content:
```
1 """
2 Lexicon Plesk Provider
3
4 Author: Jens Reimann, 2018
5
6 API Docs: https://docs.plesk.com/en-US/onyx/api-rpc
7 """
8 import logging
9 from collections import defaultdict
10 from typing import Dict, List, Optional
11 from xml.etree import cElementTree
12 from xml.etree.ElementTree import Element
13
14 import requests
15
16 from lexicon.providers.base import Provider as BaseProvider
17
18 LOGGER = logging.getLogger(__name__)
19
20 PLEX_URL_SUFFIX = "/enterprise/control/agent.php"
21
22 NAMESERVER_DOMAINS: List[str] = []
23
24
25 def provider_parser(subparser):
26 """Configure provider parser for Plesk"""
27 subparser.add_argument(
28 "--auth-username", help="specify username for authentication"
29 )
30 subparser.add_argument(
31 "--auth-password", help="specify password for authentication"
32 )
33 subparser.add_argument(
34 "--plesk-server", help="specify URL to the Plesk Web UI, including the port"
35 )
36
37
38 class Provider(BaseProvider):
39 """Provider class for Plesk"""
40
41 def __init__(self, config):
42 super(Provider, self).__init__(config)
43
44 self.api_endpoint = self._get_provider_option("plesk_server")
45
46 if self.api_endpoint.endswith("/"):
47 self.api_endpoint = self.api_endpoint[:-1]
48
49 if not self.api_endpoint.endswith(PLEX_URL_SUFFIX):
50 self.api_endpoint += PLEX_URL_SUFFIX
51
52 self.site_name = self.domain
53 assert self.site_name is not None
54
55 self.domain_id = None
56
57 self.username = self._get_provider_option("auth_username")
58 assert self.username is not None
59
60 self.password = self._get_provider_option("auth_password")
61 assert self.password is not None
62
63 def __simple_request(self, rtype, operation, req):
64
65 response = self.__plesk_request({rtype: {operation: req}})[rtype][operation]
66
67 result = response["result"]
68
69 if isinstance(result, list):
70 for record in result:
71 if record["status"] == "error":
72 raise Exception(
73 f"API returned at least one error: {record['errtext']}"
74 )
75 elif response["result"]["status"] == "error":
76 errcode = response["result"]["errcode"]
77 errtext = response["result"]["errtext"]
78 raise Exception(f"API returned error: {errcode} ({errtext})")
79
80 return response
81
82 def __plesk_request(self, request):
83
84 headers = {
85 "Content-type": "text/xml",
86 "HTTP_PRETTY_PRINT": "TRUE",
87 "HTTP_AUTH_LOGIN": self.username,
88 "HTTP_AUTH_PASSWD": self.password,
89 }
90
91 xml = f"""\
92 <?xml version="1.0" encoding="utf-8"?>
93 {cElementTree.tostring(_dict_to_etree({"packet": request}), encoding="unicode")}\
94 """
95
96 LOGGER.debug("Request: %s", xml)
97
98 response = requests.post(
99 self.api_endpoint,
100 headers=headers,
101 data=xml,
102 auth=(self.username, self.password),
103 )
104
105 data = response.text
106
107 LOGGER.debug("Response: %s", data)
108 result = _etree_to_dict(cElementTree.XML(data))
109 return result["packet"]
110
111 def __find_site(self):
112 return self.__simple_request(
113 "site", "get", {"filter": {"name": self.site_name, "dataset": {}}}
114 )["result"]["id"]
115
116 def _authenticate(self):
117 self.domain_id = self.__find_site()
118
119 if self.domain_id is None:
120 raise Exception("Domain not found")
121
122 def _create_record(self, rtype, name, content):
123 return self.__create_entry(rtype, name, content, None)
124
125 def _list_records(self, rtype=None, name=None, content=None):
126 entries = self.__find_dns_entries(rtype, name, content)
127 LOGGER.debug("list_records: %s", entries)
128 return entries
129
130 def _update_record(self, identifier, rtype=None, name=None, content=None):
131 if identifier is None:
132 entries = self.__find_dns_entries(rtype, name, None)
133 LOGGER.debug("Entries found: %s", entries)
134
135 if not entries:
136 raise Exception("No entry found for updating")
137
138 identifier = entries[0]["id"]
139 entry = self.__get_dns_entry(identifier)
140
141 ids = []
142 for an_entry in entries:
143 ids.append(an_entry["id"])
144
145 self.__delete_dns_records_by_id(ids)
146
147 else:
148
149 entry = self.__get_dns_entry(identifier)
150 self.__delete_dns_records_by_id([identifier])
151
152 assert entry is not None
153
154 LOGGER.debug("Updating: %s", entry)
155
156 if rtype:
157 entry["type"] = rtype
158 if name:
159 entry["host"] = name
160 if content:
161 entry["value"] = content
162
163 return self.__create_entry(
164 entry["type"], entry["host"], entry["value"], entry["opt"]
165 )
166
167 def __create_entry(self, rtype, host, value, opt):
168 entries = self.__find_dns_entries(rtype, self._fqdn_name(host), value)
169
170 if entries:
171 return True # already exists
172
173 self.__simple_request(
174 "dns",
175 "add_rec",
176 {
177 "site-id": self.domain_id,
178 "type": rtype,
179 "host": self._relative_name(host),
180 "value": value,
181 "opt": opt,
182 },
183 )
184
185 return True
186
187 def _delete_record(self, identifier=None, rtype=None, name=None, content=None):
188 if identifier:
189 self.__delete_dns_records_by_id([identifier])
190 return True
191 entries = self.__find_dns_entries(rtype, self._fqdn_name(name), content)
192 ids = []
193
194 for entry in entries:
195 ids.append(entry["id"])
196
197 self.__delete_dns_records_by_id(ids)
198 return bool(ids)
199
200 def __get_dns_entry(self, identifier):
201 return self.__simple_request("dns", "get_rec", {"filter": {"id": identifier}})[
202 "result"
203 ]["data"]
204
205 def __find_dns_entries(self, rtype=None, host=None, value=None):
206 LOGGER.debug("Searching for: %s, %s, %s", rtype, host, value)
207
208 if value and rtype and rtype in ["CNAME"]:
209 LOGGER.debug("CNAME transformation")
210 value = value.rstrip(".") + "."
211
212 if host:
213 host = self._fqdn_name(host)
214
215 result = self.__simple_request(
216 "dns", "get_rec", {"filter": {"site-id": self.domain_id}}
217 )
218
219 entries = []
220
221 for record in result["result"]:
222
223 LOGGER.debug("Record: %s", record)
224
225 if (rtype is not None) and (record["data"]["type"] != rtype):
226 LOGGER.debug(
227 "\tType doesn't match - expected: '%s', found: '%s'",
228 rtype,
229 record["data"]["type"],
230 )
231 continue
232
233 if (host is not None) and (record["data"]["host"] != host):
234 LOGGER.debug(
235 "\tHost doesn't match - expected: '%s', found: '%s'",
236 host,
237 record["data"]["host"],
238 )
239 continue
240
241 if (value is not None) and (record["data"]["value"] != value):
242 LOGGER.debug(
243 "\tValue doesn't match - expected: '%s', found: '%s'",
244 value,
245 record["data"]["value"],
246 )
247 continue
248
249 entry = {
250 "id": record["id"],
251 "type": record["data"]["type"],
252 "name": self._full_name(record["data"]["host"]),
253 "ttl": None,
254 "options": {},
255 }
256
257 if record["data"]["type"] in ["CNAME"]:
258 entry["content"] = record["data"]["value"].rstrip(".")
259 else:
260 entry["content"] = record["data"]["value"]
261
262 if record["data"]["type"] == "MX":
263 entry["options"]["mx"] = {"priority": int(record["data"]["opt"])}
264
265 entries.append(entry)
266
267 return entries
268
269 def __delete_dns_records_by_id(self, ids):
270 if not ids:
271 return
272
273 req = []
274 for i in ids:
275 req.append({"del_rec": {"filter": {"id": i}}})
276
277 self.__plesk_request({"dns": req})
278
279 def _request(self, action="GET", url="/", data=None, query_params=None):
280 # Helper _request is not used for Plesk provider
281 pass
282
283
284 def _etree_to_dict(t: Element) -> Optional[Dict]:
285 d: Optional[Dict] = {t.tag: {} if t.attrib else None}
286 children = list(t)
287 if children:
288 dd = defaultdict(list)
289 for dc in map(_etree_to_dict, children):
290 if dc:
291 for k, v in dc.items():
292 dd[k].append(v)
293 d = {t.tag: {k: v[0] if len(v) == 1 else v for k, v in dd.items()}}
294 if t.attrib and d:
295 d[t.tag].update(("@" + k, v) for k, v in t.attrib.items())
296 if t.text and d:
297 text = t.text.strip()
298 if children or t.attrib:
299 if text:
300 d[t.tag]["#text"] = text
301 else:
302 d[t.tag] = text
303 return d
304
305
306 def _dict_to_etree(d: Dict) -> Element:
307 def _to_etree(d1, root):
308 if not d1:
309 pass
310 elif isinstance(d1, str):
311 root.text = d1
312 elif isinstance(d1, dict):
313 for k, v in d1.items():
314 assert isinstance(k, str)
315 if k.startswith("#"):
316 assert k == "#text" and isinstance(v, str)
317 root.text = v
318 elif k.startswith("@"):
319 assert isinstance(v, str)
320 root.set(k[1:], v)
321 elif isinstance(v, list):
322 for e in v:
323 _to_etree(e, cElementTree.SubElement(root, k))
324 else:
325 _to_etree(v, cElementTree.SubElement(root, k))
326 else:
327 raise TypeError("invalid type: " + str(type(d1)))
328
329 assert isinstance(d, dict) and len(d) == 1
330 tag, body = next(iter(d.items()))
331 node = cElementTree.Element(tag)
332 _to_etree(body, node)
333 return node
334
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lexicon/providers/plesk.py b/lexicon/providers/plesk.py
--- a/lexicon/providers/plesk.py
+++ b/lexicon/providers/plesk.py
@@ -49,9 +49,6 @@
if not self.api_endpoint.endswith(PLEX_URL_SUFFIX):
self.api_endpoint += PLEX_URL_SUFFIX
- self.site_name = self.domain
- assert self.site_name is not None
-
self.domain_id = None
self.username = self._get_provider_option("auth_username")
@@ -110,7 +107,7 @@
def __find_site(self):
return self.__simple_request(
- "site", "get", {"filter": {"name": self.site_name, "dataset": {}}}
+ "site", "get", {"filter": {"name": self.domain, "dataset": {}}}
)["result"]["id"]
def _authenticate(self):
|
{"golden_diff": "diff --git a/lexicon/providers/plesk.py b/lexicon/providers/plesk.py\n--- a/lexicon/providers/plesk.py\n+++ b/lexicon/providers/plesk.py\n@@ -49,9 +49,6 @@\n if not self.api_endpoint.endswith(PLEX_URL_SUFFIX):\n self.api_endpoint += PLEX_URL_SUFFIX\n \n- self.site_name = self.domain\n- assert self.site_name is not None\n-\n self.domain_id = None\n \n self.username = self._get_provider_option(\"auth_username\")\n@@ -110,7 +107,7 @@\n \n def __find_site(self):\n return self.__simple_request(\n- \"site\", \"get\", {\"filter\": {\"name\": self.site_name, \"dataset\": {}}}\n+ \"site\", \"get\", {\"filter\": {\"name\": self.domain, \"dataset\": {}}}\n )[\"result\"][\"id\"]\n \n def _authenticate(self):\n", "issue": "Plesk provider assumes `site_name` equals `domain` (which is not always true)\nThe plesk provider assumes that the `site_name` is always the same as the `domain`: https://github.com/AnalogJ/lexicon/blob/master/lexicon/providers/plesk.py#L52\r\n\r\nThat creates problems if one wants to create a record for a subdomain (e.g. `test.example.com`) for which there is no matching plesk site. It could be the case that the record for `test.example.com` (and even all records `*.test.example.com`) are part of the site `example.com`.\r\n\r\nExample (source for the certbot plugin [here](https://gitlab.com/spike77453/certbot-dns-plesk/)):\r\n```\r\n# certbot certonly --authenticator dns-plesk --dns-plesk-credentials plesk.ini -d test.example.com\r\nSaving debug log to /var/log/letsencrypt/letsencrypt.log\r\nPlugins selected: Authenticator dns-plesk, Installer None\r\nSimulating a certificate request for test.example.com\r\nPerforming the following challenges:\r\ndns-01 challenge for test.example.com\r\nCleaning up challenges\r\nUnexpected error determining zone identifier for test.example.com: API returned error: 1013 (Site does not exist)\r\n```\r\n\r\nOne could fix this by doing something similar to the `Client` class and strip the subdomain part https://github.com/AnalogJ/lexicon/blob/master/lexicon/client.py#L36. The `Provider` constructor could do something like:\r\n\r\n```\r\n try:\r\n domain_extractor = tldextract.TLDExtract(\r\n cache_dir=_get_tldextract_cache_path(), include_psl_private_domains=True\r\n )\r\n except TypeError:\r\n domain_extractor = tldextract.TLDExtract(\r\n cache_file=_get_tldextract_cache_path(), include_psl_private_domains=True # type: ignore\r\n )\r\n domain_parts = domain_extractor(self.domain)\r\n\r\n #self.site_name = self.domain\r\n self.site_name = f\"{domain_parts.domain}.{domain_parts.suffix}\"\r\n assert self.site_name is not None\r\n```\r\n\r\nAnd then instead of stripping the domain from `host`, one would strip the `site_name` here: https://github.com/AnalogJ/lexicon/blob/master/lexicon/providers/plesk.py#L179 \r\nThat however doesn't work any more if there actually is a site for a particular subdomain.\r\n\r\nHow about adding an optional `site-id` provider option so the user can specify the site manually in the configuration file?\r\n\n", "before_files": [{"content": "\"\"\"\nLexicon Plesk Provider\n\nAuthor: Jens Reimann, 2018\n\nAPI Docs: https://docs.plesk.com/en-US/onyx/api-rpc\n\"\"\"\nimport logging\nfrom collections import defaultdict\nfrom typing import Dict, List, Optional\nfrom xml.etree import cElementTree\nfrom xml.etree.ElementTree import Element\n\nimport requests\n\nfrom lexicon.providers.base import Provider as BaseProvider\n\nLOGGER = logging.getLogger(__name__)\n\nPLEX_URL_SUFFIX = \"/enterprise/control/agent.php\"\n\nNAMESERVER_DOMAINS: List[str] = []\n\n\ndef provider_parser(subparser):\n \"\"\"Configure provider parser for Plesk\"\"\"\n subparser.add_argument(\n \"--auth-username\", help=\"specify username for authentication\"\n )\n subparser.add_argument(\n \"--auth-password\", help=\"specify password for authentication\"\n )\n subparser.add_argument(\n \"--plesk-server\", help=\"specify URL to the Plesk Web UI, including the port\"\n )\n\n\nclass Provider(BaseProvider):\n \"\"\"Provider class for Plesk\"\"\"\n\n def __init__(self, config):\n super(Provider, self).__init__(config)\n\n self.api_endpoint = self._get_provider_option(\"plesk_server\")\n\n if self.api_endpoint.endswith(\"/\"):\n self.api_endpoint = self.api_endpoint[:-1]\n\n if not self.api_endpoint.endswith(PLEX_URL_SUFFIX):\n self.api_endpoint += PLEX_URL_SUFFIX\n\n self.site_name = self.domain\n assert self.site_name is not None\n\n self.domain_id = None\n\n self.username = self._get_provider_option(\"auth_username\")\n assert self.username is not None\n\n self.password = self._get_provider_option(\"auth_password\")\n assert self.password is not None\n\n def __simple_request(self, rtype, operation, req):\n\n response = self.__plesk_request({rtype: {operation: req}})[rtype][operation]\n\n result = response[\"result\"]\n\n if isinstance(result, list):\n for record in result:\n if record[\"status\"] == \"error\":\n raise Exception(\n f\"API returned at least one error: {record['errtext']}\"\n )\n elif response[\"result\"][\"status\"] == \"error\":\n errcode = response[\"result\"][\"errcode\"]\n errtext = response[\"result\"][\"errtext\"]\n raise Exception(f\"API returned error: {errcode} ({errtext})\")\n\n return response\n\n def __plesk_request(self, request):\n\n headers = {\n \"Content-type\": \"text/xml\",\n \"HTTP_PRETTY_PRINT\": \"TRUE\",\n \"HTTP_AUTH_LOGIN\": self.username,\n \"HTTP_AUTH_PASSWD\": self.password,\n }\n\n xml = f\"\"\"\\\n<?xml version=\"1.0\" encoding=\"utf-8\"?>\n{cElementTree.tostring(_dict_to_etree({\"packet\": request}), encoding=\"unicode\")}\\\n\"\"\"\n\n LOGGER.debug(\"Request: %s\", xml)\n\n response = requests.post(\n self.api_endpoint,\n headers=headers,\n data=xml,\n auth=(self.username, self.password),\n )\n\n data = response.text\n\n LOGGER.debug(\"Response: %s\", data)\n result = _etree_to_dict(cElementTree.XML(data))\n return result[\"packet\"]\n\n def __find_site(self):\n return self.__simple_request(\n \"site\", \"get\", {\"filter\": {\"name\": self.site_name, \"dataset\": {}}}\n )[\"result\"][\"id\"]\n\n def _authenticate(self):\n self.domain_id = self.__find_site()\n\n if self.domain_id is None:\n raise Exception(\"Domain not found\")\n\n def _create_record(self, rtype, name, content):\n return self.__create_entry(rtype, name, content, None)\n\n def _list_records(self, rtype=None, name=None, content=None):\n entries = self.__find_dns_entries(rtype, name, content)\n LOGGER.debug(\"list_records: %s\", entries)\n return entries\n\n def _update_record(self, identifier, rtype=None, name=None, content=None):\n if identifier is None:\n entries = self.__find_dns_entries(rtype, name, None)\n LOGGER.debug(\"Entries found: %s\", entries)\n\n if not entries:\n raise Exception(\"No entry found for updating\")\n\n identifier = entries[0][\"id\"]\n entry = self.__get_dns_entry(identifier)\n\n ids = []\n for an_entry in entries:\n ids.append(an_entry[\"id\"])\n\n self.__delete_dns_records_by_id(ids)\n\n else:\n\n entry = self.__get_dns_entry(identifier)\n self.__delete_dns_records_by_id([identifier])\n\n assert entry is not None\n\n LOGGER.debug(\"Updating: %s\", entry)\n\n if rtype:\n entry[\"type\"] = rtype\n if name:\n entry[\"host\"] = name\n if content:\n entry[\"value\"] = content\n\n return self.__create_entry(\n entry[\"type\"], entry[\"host\"], entry[\"value\"], entry[\"opt\"]\n )\n\n def __create_entry(self, rtype, host, value, opt):\n entries = self.__find_dns_entries(rtype, self._fqdn_name(host), value)\n\n if entries:\n return True # already exists\n\n self.__simple_request(\n \"dns\",\n \"add_rec\",\n {\n \"site-id\": self.domain_id,\n \"type\": rtype,\n \"host\": self._relative_name(host),\n \"value\": value,\n \"opt\": opt,\n },\n )\n\n return True\n\n def _delete_record(self, identifier=None, rtype=None, name=None, content=None):\n if identifier:\n self.__delete_dns_records_by_id([identifier])\n return True\n entries = self.__find_dns_entries(rtype, self._fqdn_name(name), content)\n ids = []\n\n for entry in entries:\n ids.append(entry[\"id\"])\n\n self.__delete_dns_records_by_id(ids)\n return bool(ids)\n\n def __get_dns_entry(self, identifier):\n return self.__simple_request(\"dns\", \"get_rec\", {\"filter\": {\"id\": identifier}})[\n \"result\"\n ][\"data\"]\n\n def __find_dns_entries(self, rtype=None, host=None, value=None):\n LOGGER.debug(\"Searching for: %s, %s, %s\", rtype, host, value)\n\n if value and rtype and rtype in [\"CNAME\"]:\n LOGGER.debug(\"CNAME transformation\")\n value = value.rstrip(\".\") + \".\"\n\n if host:\n host = self._fqdn_name(host)\n\n result = self.__simple_request(\n \"dns\", \"get_rec\", {\"filter\": {\"site-id\": self.domain_id}}\n )\n\n entries = []\n\n for record in result[\"result\"]:\n\n LOGGER.debug(\"Record: %s\", record)\n\n if (rtype is not None) and (record[\"data\"][\"type\"] != rtype):\n LOGGER.debug(\n \"\\tType doesn't match - expected: '%s', found: '%s'\",\n rtype,\n record[\"data\"][\"type\"],\n )\n continue\n\n if (host is not None) and (record[\"data\"][\"host\"] != host):\n LOGGER.debug(\n \"\\tHost doesn't match - expected: '%s', found: '%s'\",\n host,\n record[\"data\"][\"host\"],\n )\n continue\n\n if (value is not None) and (record[\"data\"][\"value\"] != value):\n LOGGER.debug(\n \"\\tValue doesn't match - expected: '%s', found: '%s'\",\n value,\n record[\"data\"][\"value\"],\n )\n continue\n\n entry = {\n \"id\": record[\"id\"],\n \"type\": record[\"data\"][\"type\"],\n \"name\": self._full_name(record[\"data\"][\"host\"]),\n \"ttl\": None,\n \"options\": {},\n }\n\n if record[\"data\"][\"type\"] in [\"CNAME\"]:\n entry[\"content\"] = record[\"data\"][\"value\"].rstrip(\".\")\n else:\n entry[\"content\"] = record[\"data\"][\"value\"]\n\n if record[\"data\"][\"type\"] == \"MX\":\n entry[\"options\"][\"mx\"] = {\"priority\": int(record[\"data\"][\"opt\"])}\n\n entries.append(entry)\n\n return entries\n\n def __delete_dns_records_by_id(self, ids):\n if not ids:\n return\n\n req = []\n for i in ids:\n req.append({\"del_rec\": {\"filter\": {\"id\": i}}})\n\n self.__plesk_request({\"dns\": req})\n\n def _request(self, action=\"GET\", url=\"/\", data=None, query_params=None):\n # Helper _request is not used for Plesk provider\n pass\n\n\ndef _etree_to_dict(t: Element) -> Optional[Dict]:\n d: Optional[Dict] = {t.tag: {} if t.attrib else None}\n children = list(t)\n if children:\n dd = defaultdict(list)\n for dc in map(_etree_to_dict, children):\n if dc:\n for k, v in dc.items():\n dd[k].append(v)\n d = {t.tag: {k: v[0] if len(v) == 1 else v for k, v in dd.items()}}\n if t.attrib and d:\n d[t.tag].update((\"@\" + k, v) for k, v in t.attrib.items())\n if t.text and d:\n text = t.text.strip()\n if children or t.attrib:\n if text:\n d[t.tag][\"#text\"] = text\n else:\n d[t.tag] = text\n return d\n\n\ndef _dict_to_etree(d: Dict) -> Element:\n def _to_etree(d1, root):\n if not d1:\n pass\n elif isinstance(d1, str):\n root.text = d1\n elif isinstance(d1, dict):\n for k, v in d1.items():\n assert isinstance(k, str)\n if k.startswith(\"#\"):\n assert k == \"#text\" and isinstance(v, str)\n root.text = v\n elif k.startswith(\"@\"):\n assert isinstance(v, str)\n root.set(k[1:], v)\n elif isinstance(v, list):\n for e in v:\n _to_etree(e, cElementTree.SubElement(root, k))\n else:\n _to_etree(v, cElementTree.SubElement(root, k))\n else:\n raise TypeError(\"invalid type: \" + str(type(d1)))\n\n assert isinstance(d, dict) and len(d) == 1\n tag, body = next(iter(d.items()))\n node = cElementTree.Element(tag)\n _to_etree(body, node)\n return node\n", "path": "lexicon/providers/plesk.py"}], "after_files": [{"content": "\"\"\"\nLexicon Plesk Provider\n\nAuthor: Jens Reimann, 2018\n\nAPI Docs: https://docs.plesk.com/en-US/onyx/api-rpc\n\"\"\"\nimport logging\nfrom collections import defaultdict\nfrom typing import Dict, List, Optional\nfrom xml.etree import cElementTree\nfrom xml.etree.ElementTree import Element\n\nimport requests\n\nfrom lexicon.providers.base import Provider as BaseProvider\n\nLOGGER = logging.getLogger(__name__)\n\nPLEX_URL_SUFFIX = \"/enterprise/control/agent.php\"\n\nNAMESERVER_DOMAINS: List[str] = []\n\n\ndef provider_parser(subparser):\n \"\"\"Configure provider parser for Plesk\"\"\"\n subparser.add_argument(\n \"--auth-username\", help=\"specify username for authentication\"\n )\n subparser.add_argument(\n \"--auth-password\", help=\"specify password for authentication\"\n )\n subparser.add_argument(\n \"--plesk-server\", help=\"specify URL to the Plesk Web UI, including the port\"\n )\n\n\nclass Provider(BaseProvider):\n \"\"\"Provider class for Plesk\"\"\"\n\n def __init__(self, config):\n super(Provider, self).__init__(config)\n\n self.api_endpoint = self._get_provider_option(\"plesk_server\")\n\n if self.api_endpoint.endswith(\"/\"):\n self.api_endpoint = self.api_endpoint[:-1]\n\n if not self.api_endpoint.endswith(PLEX_URL_SUFFIX):\n self.api_endpoint += PLEX_URL_SUFFIX\n\n self.domain_id = None\n\n self.username = self._get_provider_option(\"auth_username\")\n assert self.username is not None\n\n self.password = self._get_provider_option(\"auth_password\")\n assert self.password is not None\n\n def __simple_request(self, rtype, operation, req):\n\n response = self.__plesk_request({rtype: {operation: req}})[rtype][operation]\n\n result = response[\"result\"]\n\n if isinstance(result, list):\n for record in result:\n if record[\"status\"] == \"error\":\n raise Exception(\n f\"API returned at least one error: {record['errtext']}\"\n )\n elif response[\"result\"][\"status\"] == \"error\":\n errcode = response[\"result\"][\"errcode\"]\n errtext = response[\"result\"][\"errtext\"]\n raise Exception(f\"API returned error: {errcode} ({errtext})\")\n\n return response\n\n def __plesk_request(self, request):\n\n headers = {\n \"Content-type\": \"text/xml\",\n \"HTTP_PRETTY_PRINT\": \"TRUE\",\n \"HTTP_AUTH_LOGIN\": self.username,\n \"HTTP_AUTH_PASSWD\": self.password,\n }\n\n xml = f\"\"\"\\\n<?xml version=\"1.0\" encoding=\"utf-8\"?>\n{cElementTree.tostring(_dict_to_etree({\"packet\": request}), encoding=\"unicode\")}\\\n\"\"\"\n\n LOGGER.debug(\"Request: %s\", xml)\n\n response = requests.post(\n self.api_endpoint,\n headers=headers,\n data=xml,\n auth=(self.username, self.password),\n )\n\n data = response.text\n\n LOGGER.debug(\"Response: %s\", data)\n result = _etree_to_dict(cElementTree.XML(data))\n return result[\"packet\"]\n\n def __find_site(self):\n return self.__simple_request(\n \"site\", \"get\", {\"filter\": {\"name\": self.domain, \"dataset\": {}}}\n )[\"result\"][\"id\"]\n\n def _authenticate(self):\n self.domain_id = self.__find_site()\n\n if self.domain_id is None:\n raise Exception(\"Domain not found\")\n\n def _create_record(self, rtype, name, content):\n return self.__create_entry(rtype, name, content, None)\n\n def _list_records(self, rtype=None, name=None, content=None):\n entries = self.__find_dns_entries(rtype, name, content)\n LOGGER.debug(\"list_records: %s\", entries)\n return entries\n\n def _update_record(self, identifier, rtype=None, name=None, content=None):\n if identifier is None:\n entries = self.__find_dns_entries(rtype, name, None)\n LOGGER.debug(\"Entries found: %s\", entries)\n\n if not entries:\n raise Exception(\"No entry found for updating\")\n\n identifier = entries[0][\"id\"]\n entry = self.__get_dns_entry(identifier)\n\n ids = []\n for an_entry in entries:\n ids.append(an_entry[\"id\"])\n\n self.__delete_dns_records_by_id(ids)\n\n else:\n\n entry = self.__get_dns_entry(identifier)\n self.__delete_dns_records_by_id([identifier])\n\n assert entry is not None\n\n LOGGER.debug(\"Updating: %s\", entry)\n\n if rtype:\n entry[\"type\"] = rtype\n if name:\n entry[\"host\"] = name\n if content:\n entry[\"value\"] = content\n\n return self.__create_entry(\n entry[\"type\"], entry[\"host\"], entry[\"value\"], entry[\"opt\"]\n )\n\n def __create_entry(self, rtype, host, value, opt):\n entries = self.__find_dns_entries(rtype, self._fqdn_name(host), value)\n\n if entries:\n return True # already exists\n\n self.__simple_request(\n \"dns\",\n \"add_rec\",\n {\n \"site-id\": self.domain_id,\n \"type\": rtype,\n \"host\": self._relative_name(host),\n \"value\": value,\n \"opt\": opt,\n },\n )\n\n return True\n\n def _delete_record(self, identifier=None, rtype=None, name=None, content=None):\n if identifier:\n self.__delete_dns_records_by_id([identifier])\n return True\n entries = self.__find_dns_entries(rtype, self._fqdn_name(name), content)\n ids = []\n\n for entry in entries:\n ids.append(entry[\"id\"])\n\n self.__delete_dns_records_by_id(ids)\n return bool(ids)\n\n def __get_dns_entry(self, identifier):\n return self.__simple_request(\"dns\", \"get_rec\", {\"filter\": {\"id\": identifier}})[\n \"result\"\n ][\"data\"]\n\n def __find_dns_entries(self, rtype=None, host=None, value=None):\n LOGGER.debug(\"Searching for: %s, %s, %s\", rtype, host, value)\n\n if value and rtype and rtype in [\"CNAME\"]:\n LOGGER.debug(\"CNAME transformation\")\n value = value.rstrip(\".\") + \".\"\n\n if host:\n host = self._fqdn_name(host)\n\n result = self.__simple_request(\n \"dns\", \"get_rec\", {\"filter\": {\"site-id\": self.domain_id}}\n )\n\n entries = []\n\n for record in result[\"result\"]:\n\n LOGGER.debug(\"Record: %s\", record)\n\n if (rtype is not None) and (record[\"data\"][\"type\"] != rtype):\n LOGGER.debug(\n \"\\tType doesn't match - expected: '%s', found: '%s'\",\n rtype,\n record[\"data\"][\"type\"],\n )\n continue\n\n if (host is not None) and (record[\"data\"][\"host\"] != host):\n LOGGER.debug(\n \"\\tHost doesn't match - expected: '%s', found: '%s'\",\n host,\n record[\"data\"][\"host\"],\n )\n continue\n\n if (value is not None) and (record[\"data\"][\"value\"] != value):\n LOGGER.debug(\n \"\\tValue doesn't match - expected: '%s', found: '%s'\",\n value,\n record[\"data\"][\"value\"],\n )\n continue\n\n entry = {\n \"id\": record[\"id\"],\n \"type\": record[\"data\"][\"type\"],\n \"name\": self._full_name(record[\"data\"][\"host\"]),\n \"ttl\": None,\n \"options\": {},\n }\n\n if record[\"data\"][\"type\"] in [\"CNAME\"]:\n entry[\"content\"] = record[\"data\"][\"value\"].rstrip(\".\")\n else:\n entry[\"content\"] = record[\"data\"][\"value\"]\n\n if record[\"data\"][\"type\"] == \"MX\":\n entry[\"options\"][\"mx\"] = {\"priority\": int(record[\"data\"][\"opt\"])}\n\n entries.append(entry)\n\n return entries\n\n def __delete_dns_records_by_id(self, ids):\n if not ids:\n return\n\n req = []\n for i in ids:\n req.append({\"del_rec\": {\"filter\": {\"id\": i}}})\n\n self.__plesk_request({\"dns\": req})\n\n def _request(self, action=\"GET\", url=\"/\", data=None, query_params=None):\n # Helper _request is not used for Plesk provider\n pass\n\n\ndef _etree_to_dict(t: Element) -> Optional[Dict]:\n d: Optional[Dict] = {t.tag: {} if t.attrib else None}\n children = list(t)\n if children:\n dd = defaultdict(list)\n for dc in map(_etree_to_dict, children):\n if dc:\n for k, v in dc.items():\n dd[k].append(v)\n d = {t.tag: {k: v[0] if len(v) == 1 else v for k, v in dd.items()}}\n if t.attrib and d:\n d[t.tag].update((\"@\" + k, v) for k, v in t.attrib.items())\n if t.text and d:\n text = t.text.strip()\n if children or t.attrib:\n if text:\n d[t.tag][\"#text\"] = text\n else:\n d[t.tag] = text\n return d\n\n\ndef _dict_to_etree(d: Dict) -> Element:\n def _to_etree(d1, root):\n if not d1:\n pass\n elif isinstance(d1, str):\n root.text = d1\n elif isinstance(d1, dict):\n for k, v in d1.items():\n assert isinstance(k, str)\n if k.startswith(\"#\"):\n assert k == \"#text\" and isinstance(v, str)\n root.text = v\n elif k.startswith(\"@\"):\n assert isinstance(v, str)\n root.set(k[1:], v)\n elif isinstance(v, list):\n for e in v:\n _to_etree(e, cElementTree.SubElement(root, k))\n else:\n _to_etree(v, cElementTree.SubElement(root, k))\n else:\n raise TypeError(\"invalid type: \" + str(type(d1)))\n\n assert isinstance(d, dict) and len(d) == 1\n tag, body = next(iter(d.items()))\n node = cElementTree.Element(tag)\n _to_etree(body, node)\n return node\n", "path": "lexicon/providers/plesk.py"}]}
| 4,052 | 208 |
gh_patches_debug_43718
|
rasdani/github-patches
|
git_diff
|
python-telegram-bot__python-telegram-bot-608
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
add ability to handle only edited messages updates
Actually if you want to develop a bot where when a user edits his message it replies "you edited this message" or a bot that in groups kicks users that edit their messages (let's imagine a strange rule), there is not a handler to handle only edited messages.
messagehandler just handles any messages and not only those edited. So a handler or a filter to handle only edited messages is needed. Thanks
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `telegram/ext/messagehandler.py`
Content:
```
1 #!/usr/bin/env python
2 #
3 # A library that provides a Python interface to the Telegram Bot API
4 # Copyright (C) 2015-2017
5 # Leandro Toledo de Souza <[email protected]>
6 #
7 # This program is free software: you can redistribute it and/or modify
8 # it under the terms of the GNU Lesser Public License as published by
9 # the Free Software Foundation, either version 3 of the License, or
10 # (at your option) any later version.
11 #
12 # This program is distributed in the hope that it will be useful,
13 # but WITHOUT ANY WARRANTY; without even the implied warranty of
14 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
15 # GNU Lesser Public License for more details.
16 #
17 # You should have received a copy of the GNU Lesser Public License
18 # along with this program. If not, see [http://www.gnu.org/licenses/].
19 """ This module contains the MessageHandler class """
20 import warnings
21
22 from .handler import Handler
23 from telegram import Update
24
25
26 class MessageHandler(Handler):
27 """
28 Handler class to handle telegram messages. Messages are Telegram Updates
29 that do not contain a command. They might contain text, media or status
30 updates.
31
32 Args:
33 filters (telegram.ext.BaseFilter): A filter inheriting from
34 :class:`telegram.ext.filters.BaseFilter`. Standard filters can be found in
35 :class:`telegram.ext.filters.Filters`. Filters can be combined using bitwise
36 operators (& for and, | for or).
37 callback (function): A function that takes ``bot, update`` as
38 positional arguments. It will be called when the ``check_update``
39 has determined that an update should be processed by this handler.
40 allow_edited (Optional[bool]): If the handler should also accept edited messages.
41 Default is ``False``
42 pass_update_queue (optional[bool]): If the handler should be passed the
43 update queue as a keyword argument called ``update_queue``. It can
44 be used to insert updates. Default is ``False``
45 pass_user_data (optional[bool]): If set to ``True``, a keyword argument called
46 ``user_data`` will be passed to the callback function. It will be a ``dict`` you
47 can use to keep any data related to the user that sent the update. For each update of
48 the same user, it will be the same ``dict``. Default is ``False``.
49 pass_chat_data (optional[bool]): If set to ``True``, a keyword argument called
50 ``chat_data`` will be passed to the callback function. It will be a ``dict`` you
51 can use to keep any data related to the chat that the update was sent in.
52 For each update in the same chat, it will be the same ``dict``. Default is ``False``.
53 message_updates (Optional[bool]): Should "normal" message updates be handled? Default is
54 ``True``.
55 channel_post_updates (Optional[bool]): Should channel posts updates be handled? Default is
56 ``True``.
57
58 """
59
60 def __init__(self,
61 filters,
62 callback,
63 allow_edited=False,
64 pass_update_queue=False,
65 pass_job_queue=False,
66 pass_user_data=False,
67 pass_chat_data=False,
68 message_updates=True,
69 channel_post_updates=True):
70 if not message_updates and not channel_post_updates:
71 raise ValueError('Both message_updates & channel_post_updates are False')
72
73 super(MessageHandler, self).__init__(
74 callback,
75 pass_update_queue=pass_update_queue,
76 pass_job_queue=pass_job_queue,
77 pass_user_data=pass_user_data,
78 pass_chat_data=pass_chat_data)
79 self.filters = filters
80 self.allow_edited = allow_edited
81 self.message_updates = message_updates
82 self.channel_post_updates = channel_post_updates
83
84 # We put this up here instead of with the rest of checking code
85 # in check_update since we don't wanna spam a ton
86 if isinstance(self.filters, list):
87 warnings.warn('Using a list of filters in MessageHandler is getting '
88 'deprecated, please use bitwise operators (& and |) '
89 'instead. More info: https://git.io/vPTbc.')
90
91 def _is_allowed_message(self, update):
92 return (self.message_updates
93 and (update.message or (update.edited_message and self.allow_edited)))
94
95 def _is_allowed_channel_post(self, update):
96 return (self.channel_post_updates
97 and (update.channel_post or (update.edited_channel_post and self.allow_edited)))
98
99 def check_update(self, update):
100 if (isinstance(update, Update)
101 and (self._is_allowed_message(update) or self._is_allowed_channel_post(update))):
102
103 if not self.filters:
104 res = True
105
106 else:
107 message = update.effective_message
108 if isinstance(self.filters, list):
109 res = any(func(message) for func in self.filters)
110 else:
111 res = self.filters(message)
112
113 else:
114 res = False
115
116 return res
117
118 def handle_update(self, update, dispatcher):
119 optional_args = self.collect_optional_args(dispatcher, update)
120
121 return self.callback(dispatcher.bot, update, **optional_args)
122
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/telegram/ext/messagehandler.py b/telegram/ext/messagehandler.py
--- a/telegram/ext/messagehandler.py
+++ b/telegram/ext/messagehandler.py
@@ -37,8 +37,6 @@
callback (function): A function that takes ``bot, update`` as
positional arguments. It will be called when the ``check_update``
has determined that an update should be processed by this handler.
- allow_edited (Optional[bool]): If the handler should also accept edited messages.
- Default is ``False``
pass_update_queue (optional[bool]): If the handler should be passed the
update queue as a keyword argument called ``update_queue``. It can
be used to insert updates. Default is ``False``
@@ -52,8 +50,12 @@
For each update in the same chat, it will be the same ``dict``. Default is ``False``.
message_updates (Optional[bool]): Should "normal" message updates be handled? Default is
``True``.
+ allow_edited (Optional[bool]): If the handler should also accept edited messages.
+ Default is ``False`` - Deprecated. use edited updates instead.
channel_post_updates (Optional[bool]): Should channel posts updates be handled? Default is
``True``.
+ edited_updates (Optional[bool]): Should "edited" message updates be handled? Default is
+ ``False``.
"""
@@ -66,9 +68,14 @@
pass_user_data=False,
pass_chat_data=False,
message_updates=True,
- channel_post_updates=True):
- if not message_updates and not channel_post_updates:
- raise ValueError('Both message_updates & channel_post_updates are False')
+ channel_post_updates=True,
+ edited_updates=False):
+ if not message_updates and not channel_post_updates and not edited_updates:
+ raise ValueError(
+ 'message_updates, channel_post_updates and edited_updates are all False')
+ if allow_edited:
+ warnings.warn('allow_edited is getting deprecated, please use edited_updates instead')
+ edited_updates = allow_edited
super(MessageHandler, self).__init__(
callback,
@@ -77,9 +84,9 @@
pass_user_data=pass_user_data,
pass_chat_data=pass_chat_data)
self.filters = filters
- self.allow_edited = allow_edited
self.message_updates = message_updates
self.channel_post_updates = channel_post_updates
+ self.edited_updates = edited_updates
# We put this up here instead of with the rest of checking code
# in check_update since we don't wanna spam a ton
@@ -88,17 +95,13 @@
'deprecated, please use bitwise operators (& and |) '
'instead. More info: https://git.io/vPTbc.')
- def _is_allowed_message(self, update):
- return (self.message_updates
- and (update.message or (update.edited_message and self.allow_edited)))
-
- def _is_allowed_channel_post(self, update):
- return (self.channel_post_updates
- and (update.channel_post or (update.edited_channel_post and self.allow_edited)))
+ def _is_allowed_update(self, update):
+ return any([(self.message_updates and update.message),
+ (self.edited_updates and update.edited_message),
+ (self.channel_post_updates and update.channel_post)])
def check_update(self, update):
- if (isinstance(update, Update)
- and (self._is_allowed_message(update) or self._is_allowed_channel_post(update))):
+ if isinstance(update, Update) and self._is_allowed_update(update):
if not self.filters:
res = True
|
{"golden_diff": "diff --git a/telegram/ext/messagehandler.py b/telegram/ext/messagehandler.py\n--- a/telegram/ext/messagehandler.py\n+++ b/telegram/ext/messagehandler.py\n@@ -37,8 +37,6 @@\n callback (function): A function that takes ``bot, update`` as\n positional arguments. It will be called when the ``check_update``\n has determined that an update should be processed by this handler.\n- allow_edited (Optional[bool]): If the handler should also accept edited messages.\n- Default is ``False``\n pass_update_queue (optional[bool]): If the handler should be passed the\n update queue as a keyword argument called ``update_queue``. It can\n be used to insert updates. Default is ``False``\n@@ -52,8 +50,12 @@\n For each update in the same chat, it will be the same ``dict``. Default is ``False``.\n message_updates (Optional[bool]): Should \"normal\" message updates be handled? Default is\n ``True``.\n+ allow_edited (Optional[bool]): If the handler should also accept edited messages.\n+ Default is ``False`` - Deprecated. use edited updates instead.\n channel_post_updates (Optional[bool]): Should channel posts updates be handled? Default is\n ``True``.\n+ edited_updates (Optional[bool]): Should \"edited\" message updates be handled? Default is\n+ ``False``.\n \n \"\"\"\n \n@@ -66,9 +68,14 @@\n pass_user_data=False,\n pass_chat_data=False,\n message_updates=True,\n- channel_post_updates=True):\n- if not message_updates and not channel_post_updates:\n- raise ValueError('Both message_updates & channel_post_updates are False')\n+ channel_post_updates=True,\n+ edited_updates=False):\n+ if not message_updates and not channel_post_updates and not edited_updates:\n+ raise ValueError(\n+ 'message_updates, channel_post_updates and edited_updates are all False')\n+ if allow_edited:\n+ warnings.warn('allow_edited is getting deprecated, please use edited_updates instead')\n+ edited_updates = allow_edited\n \n super(MessageHandler, self).__init__(\n callback,\n@@ -77,9 +84,9 @@\n pass_user_data=pass_user_data,\n pass_chat_data=pass_chat_data)\n self.filters = filters\n- self.allow_edited = allow_edited\n self.message_updates = message_updates\n self.channel_post_updates = channel_post_updates\n+ self.edited_updates = edited_updates\n \n # We put this up here instead of with the rest of checking code\n # in check_update since we don't wanna spam a ton\n@@ -88,17 +95,13 @@\n 'deprecated, please use bitwise operators (& and |) '\n 'instead. More info: https://git.io/vPTbc.')\n \n- def _is_allowed_message(self, update):\n- return (self.message_updates\n- and (update.message or (update.edited_message and self.allow_edited)))\n-\n- def _is_allowed_channel_post(self, update):\n- return (self.channel_post_updates\n- and (update.channel_post or (update.edited_channel_post and self.allow_edited)))\n+ def _is_allowed_update(self, update):\n+ return any([(self.message_updates and update.message),\n+ (self.edited_updates and update.edited_message),\n+ (self.channel_post_updates and update.channel_post)])\n \n def check_update(self, update):\n- if (isinstance(update, Update)\n- and (self._is_allowed_message(update) or self._is_allowed_channel_post(update))):\n+ if isinstance(update, Update) and self._is_allowed_update(update):\n \n if not self.filters:\n res = True\n", "issue": "add ability to handle only edited messages updates\nActually if you want to develop a bot where when a user edits his message it replies \"you edited this message\" or a bot that in groups kicks users that edit their messages (let's imagine a strange rule), there is not a handler to handle only edited messages.\r\n\r\nmessagehandler just handles any messages and not only those edited. So a handler or a filter to handle only edited messages is needed. Thanks\r\n\r\n\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\n#\n# A library that provides a Python interface to the Telegram Bot API\n# Copyright (C) 2015-2017\n# Leandro Toledo de Souza <[email protected]>\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU Lesser Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU Lesser Public License for more details.\n#\n# You should have received a copy of the GNU Lesser Public License\n# along with this program. If not, see [http://www.gnu.org/licenses/].\n\"\"\" This module contains the MessageHandler class \"\"\"\nimport warnings\n\nfrom .handler import Handler\nfrom telegram import Update\n\n\nclass MessageHandler(Handler):\n \"\"\"\n Handler class to handle telegram messages. Messages are Telegram Updates\n that do not contain a command. They might contain text, media or status\n updates.\n\n Args:\n filters (telegram.ext.BaseFilter): A filter inheriting from\n :class:`telegram.ext.filters.BaseFilter`. Standard filters can be found in\n :class:`telegram.ext.filters.Filters`. Filters can be combined using bitwise\n operators (& for and, | for or).\n callback (function): A function that takes ``bot, update`` as\n positional arguments. It will be called when the ``check_update``\n has determined that an update should be processed by this handler.\n allow_edited (Optional[bool]): If the handler should also accept edited messages.\n Default is ``False``\n pass_update_queue (optional[bool]): If the handler should be passed the\n update queue as a keyword argument called ``update_queue``. It can\n be used to insert updates. Default is ``False``\n pass_user_data (optional[bool]): If set to ``True``, a keyword argument called\n ``user_data`` will be passed to the callback function. It will be a ``dict`` you\n can use to keep any data related to the user that sent the update. For each update of\n the same user, it will be the same ``dict``. Default is ``False``.\n pass_chat_data (optional[bool]): If set to ``True``, a keyword argument called\n ``chat_data`` will be passed to the callback function. It will be a ``dict`` you\n can use to keep any data related to the chat that the update was sent in.\n For each update in the same chat, it will be the same ``dict``. Default is ``False``.\n message_updates (Optional[bool]): Should \"normal\" message updates be handled? Default is\n ``True``.\n channel_post_updates (Optional[bool]): Should channel posts updates be handled? Default is\n ``True``.\n\n \"\"\"\n\n def __init__(self,\n filters,\n callback,\n allow_edited=False,\n pass_update_queue=False,\n pass_job_queue=False,\n pass_user_data=False,\n pass_chat_data=False,\n message_updates=True,\n channel_post_updates=True):\n if not message_updates and not channel_post_updates:\n raise ValueError('Both message_updates & channel_post_updates are False')\n\n super(MessageHandler, self).__init__(\n callback,\n pass_update_queue=pass_update_queue,\n pass_job_queue=pass_job_queue,\n pass_user_data=pass_user_data,\n pass_chat_data=pass_chat_data)\n self.filters = filters\n self.allow_edited = allow_edited\n self.message_updates = message_updates\n self.channel_post_updates = channel_post_updates\n\n # We put this up here instead of with the rest of checking code\n # in check_update since we don't wanna spam a ton\n if isinstance(self.filters, list):\n warnings.warn('Using a list of filters in MessageHandler is getting '\n 'deprecated, please use bitwise operators (& and |) '\n 'instead. More info: https://git.io/vPTbc.')\n\n def _is_allowed_message(self, update):\n return (self.message_updates\n and (update.message or (update.edited_message and self.allow_edited)))\n\n def _is_allowed_channel_post(self, update):\n return (self.channel_post_updates\n and (update.channel_post or (update.edited_channel_post and self.allow_edited)))\n\n def check_update(self, update):\n if (isinstance(update, Update)\n and (self._is_allowed_message(update) or self._is_allowed_channel_post(update))):\n\n if not self.filters:\n res = True\n\n else:\n message = update.effective_message\n if isinstance(self.filters, list):\n res = any(func(message) for func in self.filters)\n else:\n res = self.filters(message)\n\n else:\n res = False\n\n return res\n\n def handle_update(self, update, dispatcher):\n optional_args = self.collect_optional_args(dispatcher, update)\n\n return self.callback(dispatcher.bot, update, **optional_args)\n", "path": "telegram/ext/messagehandler.py"}], "after_files": [{"content": "#!/usr/bin/env python\n#\n# A library that provides a Python interface to the Telegram Bot API\n# Copyright (C) 2015-2017\n# Leandro Toledo de Souza <[email protected]>\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU Lesser Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU Lesser Public License for more details.\n#\n# You should have received a copy of the GNU Lesser Public License\n# along with this program. If not, see [http://www.gnu.org/licenses/].\n\"\"\" This module contains the MessageHandler class \"\"\"\nimport warnings\n\nfrom .handler import Handler\nfrom telegram import Update\n\n\nclass MessageHandler(Handler):\n \"\"\"\n Handler class to handle telegram messages. Messages are Telegram Updates\n that do not contain a command. They might contain text, media or status\n updates.\n\n Args:\n filters (telegram.ext.BaseFilter): A filter inheriting from\n :class:`telegram.ext.filters.BaseFilter`. Standard filters can be found in\n :class:`telegram.ext.filters.Filters`. Filters can be combined using bitwise\n operators (& for and, | for or).\n callback (function): A function that takes ``bot, update`` as\n positional arguments. It will be called when the ``check_update``\n has determined that an update should be processed by this handler.\n pass_update_queue (optional[bool]): If the handler should be passed the\n update queue as a keyword argument called ``update_queue``. It can\n be used to insert updates. Default is ``False``\n pass_user_data (optional[bool]): If set to ``True``, a keyword argument called\n ``user_data`` will be passed to the callback function. It will be a ``dict`` you\n can use to keep any data related to the user that sent the update. For each update of\n the same user, it will be the same ``dict``. Default is ``False``.\n pass_chat_data (optional[bool]): If set to ``True``, a keyword argument called\n ``chat_data`` will be passed to the callback function. It will be a ``dict`` you\n can use to keep any data related to the chat that the update was sent in.\n For each update in the same chat, it will be the same ``dict``. Default is ``False``.\n message_updates (Optional[bool]): Should \"normal\" message updates be handled? Default is\n ``True``.\n allow_edited (Optional[bool]): If the handler should also accept edited messages.\n Default is ``False`` - Deprecated. use edited updates instead.\n channel_post_updates (Optional[bool]): Should channel posts updates be handled? Default is\n ``True``.\n edited_updates (Optional[bool]): Should \"edited\" message updates be handled? Default is\n ``False``.\n\n \"\"\"\n\n def __init__(self,\n filters,\n callback,\n allow_edited=False,\n pass_update_queue=False,\n pass_job_queue=False,\n pass_user_data=False,\n pass_chat_data=False,\n message_updates=True,\n channel_post_updates=True,\n edited_updates=False):\n if not message_updates and not channel_post_updates and not edited_updates:\n raise ValueError(\n 'message_updates, channel_post_updates and edited_updates are all False')\n if allow_edited:\n warnings.warn('allow_edited is getting deprecated, please use edited_updates instead')\n edited_updates = allow_edited\n\n super(MessageHandler, self).__init__(\n callback,\n pass_update_queue=pass_update_queue,\n pass_job_queue=pass_job_queue,\n pass_user_data=pass_user_data,\n pass_chat_data=pass_chat_data)\n self.filters = filters\n self.message_updates = message_updates\n self.channel_post_updates = channel_post_updates\n self.edited_updates = edited_updates\n\n # We put this up here instead of with the rest of checking code\n # in check_update since we don't wanna spam a ton\n if isinstance(self.filters, list):\n warnings.warn('Using a list of filters in MessageHandler is getting '\n 'deprecated, please use bitwise operators (& and |) '\n 'instead. More info: https://git.io/vPTbc.')\n\n def _is_allowed_update(self, update):\n return any([(self.message_updates and update.message),\n (self.edited_updates and update.edited_message),\n (self.channel_post_updates and update.channel_post)])\n\n def check_update(self, update):\n if isinstance(update, Update) and self._is_allowed_update(update):\n\n if not self.filters:\n res = True\n\n else:\n message = update.effective_message\n if isinstance(self.filters, list):\n res = any(func(message) for func in self.filters)\n else:\n res = self.filters(message)\n\n else:\n res = False\n\n return res\n\n def handle_update(self, update, dispatcher):\n optional_args = self.collect_optional_args(dispatcher, update)\n\n return self.callback(dispatcher.bot, update, **optional_args)\n", "path": "telegram/ext/messagehandler.py"}]}
| 1,730 | 815 |
gh_patches_debug_4579
|
rasdani/github-patches
|
git_diff
|
zigpy__zha-device-handlers-289
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Hue dimmer (rwl020) off short press
Hi,
I have Hue Dimmer controller integrated in Hass Core via ZHA and Bellows (zigpy). The quirk is set to a [long press of the Off button as show here](https://github.com/dmulcahey/zha-device-handlers/blob/5c726a717a4d1dc3930b177f346e852bede9ee63/zhaquirks/philips/rwl021.py#L117). However it seems device is sending this on the short press and not sending any long press for the Off button. The event on Hass is:
```
{
"event_type": "zha_event",
"data": {
"unique_id": "xx:xx:xx:xx:xx:1:0x0006",
"device_ieee": "xx:xx:xx:xx",
"endpoint_id": 1,
"cluster_id": 6,
"command": "off_with_effect",
"args": [
0,
0
]
},
"origin": "LOCAL",
"time_fired": "2020-03-05T05:49:25.119524+00:00",
"context": {
"id": "xxxxxxxxxxxx",
"parent_id": null,
"user_id": null
}
}
```
Based on quirk code, it should be `long press` with no args but it is `short press` with `args [0,0]`.
This hue dimmer is with latest firmware (upgraded using Hue bridge before paring dimmer with ZHA).
Thanks.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `zhaquirks/philips/rwl021.py`
Content:
```
1 """Phillips RWL021 device."""
2 from zigpy.profiles import zha, zll
3 from zigpy.quirks import CustomCluster, CustomDevice
4 import zigpy.types as t
5 from zigpy.zcl.clusters.general import (
6 Basic,
7 BinaryInput,
8 Groups,
9 Identify,
10 LevelControl,
11 OnOff,
12 Ota,
13 PowerConfiguration,
14 Scenes,
15 )
16
17 from ..const import (
18 ARGS,
19 CLUSTER_ID,
20 COMMAND,
21 COMMAND_OFF_WITH_EFFECT,
22 COMMAND_ON,
23 COMMAND_STEP,
24 DEVICE_TYPE,
25 DIM_DOWN,
26 DIM_UP,
27 ENDPOINT_ID,
28 ENDPOINTS,
29 INPUT_CLUSTERS,
30 LONG_PRESS,
31 OUTPUT_CLUSTERS,
32 PROFILE_ID,
33 SHORT_PRESS,
34 TURN_OFF,
35 TURN_ON,
36 )
37
38 DIAGNOSTICS_CLUSTER_ID = 0x0B05 # decimal = 2821
39
40
41 class BasicCluster(CustomCluster, Basic):
42 """Centralite acceleration cluster."""
43
44 attributes = Basic.attributes.copy()
45 attributes.update({0x0031: ("phillips", t.bitmap16)})
46
47
48 class PhilipsRWL021(CustomDevice):
49 """Phillips RWL021 device."""
50
51 signature = {
52 # <SimpleDescriptor endpoint=1 profile=49246 device_type=2096
53 # device_version=2
54 # input_clusters=[0]
55 # output_clusters=[0, 3, 4, 6, 8, 5]>
56 ENDPOINTS: {
57 1: {
58 PROFILE_ID: zll.PROFILE_ID,
59 DEVICE_TYPE: zll.DeviceType.SCENE_CONTROLLER,
60 INPUT_CLUSTERS: [Basic.cluster_id],
61 OUTPUT_CLUSTERS: [
62 Basic.cluster_id,
63 Identify.cluster_id,
64 Groups.cluster_id,
65 OnOff.cluster_id,
66 LevelControl.cluster_id,
67 Scenes.cluster_id,
68 ],
69 },
70 # <SimpleDescriptor endpoint=2 profile=260 device_type=12
71 # device_version=0
72 # input_clusters=[0, 1, 3, 15, 64512]
73 # output_clusters=[25]>
74 2: {
75 PROFILE_ID: zha.PROFILE_ID,
76 DEVICE_TYPE: zha.DeviceType.SIMPLE_SENSOR,
77 INPUT_CLUSTERS: [
78 Basic.cluster_id,
79 PowerConfiguration.cluster_id,
80 Identify.cluster_id,
81 BinaryInput.cluster_id,
82 64512,
83 ],
84 OUTPUT_CLUSTERS: [Ota.cluster_id],
85 },
86 }
87 }
88
89 replacement = {
90 ENDPOINTS: {
91 1: {
92 INPUT_CLUSTERS: [Basic.cluster_id],
93 OUTPUT_CLUSTERS: [
94 Basic.cluster_id,
95 Identify.cluster_id,
96 Groups.cluster_id,
97 OnOff.cluster_id,
98 LevelControl.cluster_id,
99 Scenes.cluster_id,
100 ],
101 },
102 2: {
103 INPUT_CLUSTERS: [
104 BasicCluster,
105 PowerConfiguration.cluster_id,
106 Identify.cluster_id,
107 BinaryInput.cluster_id,
108 64512,
109 ],
110 OUTPUT_CLUSTERS: [Ota.cluster_id],
111 },
112 }
113 }
114
115 device_automation_triggers = {
116 (SHORT_PRESS, TURN_ON): {COMMAND: COMMAND_ON},
117 (LONG_PRESS, TURN_OFF): {COMMAND: COMMAND_OFF_WITH_EFFECT},
118 (SHORT_PRESS, DIM_UP): {
119 COMMAND: COMMAND_STEP,
120 CLUSTER_ID: 8,
121 ENDPOINT_ID: 1,
122 ARGS: [0, 30, 9],
123 },
124 (LONG_PRESS, DIM_UP): {
125 COMMAND: COMMAND_STEP,
126 CLUSTER_ID: 8,
127 ENDPOINT_ID: 1,
128 ARGS: [0, 56, 9],
129 },
130 (SHORT_PRESS, DIM_DOWN): {
131 COMMAND: COMMAND_STEP,
132 CLUSTER_ID: 8,
133 ENDPOINT_ID: 1,
134 ARGS: [1, 30, 9],
135 },
136 (LONG_PRESS, DIM_DOWN): {
137 COMMAND: COMMAND_STEP,
138 CLUSTER_ID: 8,
139 ENDPOINT_ID: 1,
140 ARGS: [1, 56, 9],
141 },
142 }
143
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/zhaquirks/philips/rwl021.py b/zhaquirks/philips/rwl021.py
--- a/zhaquirks/philips/rwl021.py
+++ b/zhaquirks/philips/rwl021.py
@@ -114,7 +114,7 @@
device_automation_triggers = {
(SHORT_PRESS, TURN_ON): {COMMAND: COMMAND_ON},
- (LONG_PRESS, TURN_OFF): {COMMAND: COMMAND_OFF_WITH_EFFECT},
+ (SHORT_PRESS, TURN_OFF): {COMMAND: COMMAND_OFF_WITH_EFFECT},
(SHORT_PRESS, DIM_UP): {
COMMAND: COMMAND_STEP,
CLUSTER_ID: 8,
|
{"golden_diff": "diff --git a/zhaquirks/philips/rwl021.py b/zhaquirks/philips/rwl021.py\n--- a/zhaquirks/philips/rwl021.py\n+++ b/zhaquirks/philips/rwl021.py\n@@ -114,7 +114,7 @@\n \n device_automation_triggers = {\n (SHORT_PRESS, TURN_ON): {COMMAND: COMMAND_ON},\n- (LONG_PRESS, TURN_OFF): {COMMAND: COMMAND_OFF_WITH_EFFECT},\n+ (SHORT_PRESS, TURN_OFF): {COMMAND: COMMAND_OFF_WITH_EFFECT},\n (SHORT_PRESS, DIM_UP): {\n COMMAND: COMMAND_STEP,\n CLUSTER_ID: 8,\n", "issue": "Hue dimmer (rwl020) off short press\nHi,\r\n\r\nI have Hue Dimmer controller integrated in Hass Core via ZHA and Bellows (zigpy). The quirk is set to a [long press of the Off button as show here](https://github.com/dmulcahey/zha-device-handlers/blob/5c726a717a4d1dc3930b177f346e852bede9ee63/zhaquirks/philips/rwl021.py#L117). However it seems device is sending this on the short press and not sending any long press for the Off button. The event on Hass is:\r\n\r\n```\r\n{\r\n \"event_type\": \"zha_event\",\r\n \"data\": {\r\n \"unique_id\": \"xx:xx:xx:xx:xx:1:0x0006\",\r\n \"device_ieee\": \"xx:xx:xx:xx\",\r\n \"endpoint_id\": 1,\r\n \"cluster_id\": 6,\r\n \"command\": \"off_with_effect\",\r\n \"args\": [\r\n 0,\r\n 0\r\n ]\r\n },\r\n \"origin\": \"LOCAL\",\r\n \"time_fired\": \"2020-03-05T05:49:25.119524+00:00\",\r\n \"context\": {\r\n \"id\": \"xxxxxxxxxxxx\",\r\n \"parent_id\": null,\r\n \"user_id\": null\r\n }\r\n}\r\n```\r\nBased on quirk code, it should be `long press` with no args but it is `short press` with `args [0,0]`.\r\n\r\nThis hue dimmer is with latest firmware (upgraded using Hue bridge before paring dimmer with ZHA).\r\n\r\nThanks.\n", "before_files": [{"content": "\"\"\"Phillips RWL021 device.\"\"\"\nfrom zigpy.profiles import zha, zll\nfrom zigpy.quirks import CustomCluster, CustomDevice\nimport zigpy.types as t\nfrom zigpy.zcl.clusters.general import (\n Basic,\n BinaryInput,\n Groups,\n Identify,\n LevelControl,\n OnOff,\n Ota,\n PowerConfiguration,\n Scenes,\n)\n\nfrom ..const import (\n ARGS,\n CLUSTER_ID,\n COMMAND,\n COMMAND_OFF_WITH_EFFECT,\n COMMAND_ON,\n COMMAND_STEP,\n DEVICE_TYPE,\n DIM_DOWN,\n DIM_UP,\n ENDPOINT_ID,\n ENDPOINTS,\n INPUT_CLUSTERS,\n LONG_PRESS,\n OUTPUT_CLUSTERS,\n PROFILE_ID,\n SHORT_PRESS,\n TURN_OFF,\n TURN_ON,\n)\n\nDIAGNOSTICS_CLUSTER_ID = 0x0B05 # decimal = 2821\n\n\nclass BasicCluster(CustomCluster, Basic):\n \"\"\"Centralite acceleration cluster.\"\"\"\n\n attributes = Basic.attributes.copy()\n attributes.update({0x0031: (\"phillips\", t.bitmap16)})\n\n\nclass PhilipsRWL021(CustomDevice):\n \"\"\"Phillips RWL021 device.\"\"\"\n\n signature = {\n # <SimpleDescriptor endpoint=1 profile=49246 device_type=2096\n # device_version=2\n # input_clusters=[0]\n # output_clusters=[0, 3, 4, 6, 8, 5]>\n ENDPOINTS: {\n 1: {\n PROFILE_ID: zll.PROFILE_ID,\n DEVICE_TYPE: zll.DeviceType.SCENE_CONTROLLER,\n INPUT_CLUSTERS: [Basic.cluster_id],\n OUTPUT_CLUSTERS: [\n Basic.cluster_id,\n Identify.cluster_id,\n Groups.cluster_id,\n OnOff.cluster_id,\n LevelControl.cluster_id,\n Scenes.cluster_id,\n ],\n },\n # <SimpleDescriptor endpoint=2 profile=260 device_type=12\n # device_version=0\n # input_clusters=[0, 1, 3, 15, 64512]\n # output_clusters=[25]>\n 2: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.SIMPLE_SENSOR,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n PowerConfiguration.cluster_id,\n Identify.cluster_id,\n BinaryInput.cluster_id,\n 64512,\n ],\n OUTPUT_CLUSTERS: [Ota.cluster_id],\n },\n }\n }\n\n replacement = {\n ENDPOINTS: {\n 1: {\n INPUT_CLUSTERS: [Basic.cluster_id],\n OUTPUT_CLUSTERS: [\n Basic.cluster_id,\n Identify.cluster_id,\n Groups.cluster_id,\n OnOff.cluster_id,\n LevelControl.cluster_id,\n Scenes.cluster_id,\n ],\n },\n 2: {\n INPUT_CLUSTERS: [\n BasicCluster,\n PowerConfiguration.cluster_id,\n Identify.cluster_id,\n BinaryInput.cluster_id,\n 64512,\n ],\n OUTPUT_CLUSTERS: [Ota.cluster_id],\n },\n }\n }\n\n device_automation_triggers = {\n (SHORT_PRESS, TURN_ON): {COMMAND: COMMAND_ON},\n (LONG_PRESS, TURN_OFF): {COMMAND: COMMAND_OFF_WITH_EFFECT},\n (SHORT_PRESS, DIM_UP): {\n COMMAND: COMMAND_STEP,\n CLUSTER_ID: 8,\n ENDPOINT_ID: 1,\n ARGS: [0, 30, 9],\n },\n (LONG_PRESS, DIM_UP): {\n COMMAND: COMMAND_STEP,\n CLUSTER_ID: 8,\n ENDPOINT_ID: 1,\n ARGS: [0, 56, 9],\n },\n (SHORT_PRESS, DIM_DOWN): {\n COMMAND: COMMAND_STEP,\n CLUSTER_ID: 8,\n ENDPOINT_ID: 1,\n ARGS: [1, 30, 9],\n },\n (LONG_PRESS, DIM_DOWN): {\n COMMAND: COMMAND_STEP,\n CLUSTER_ID: 8,\n ENDPOINT_ID: 1,\n ARGS: [1, 56, 9],\n },\n }\n", "path": "zhaquirks/philips/rwl021.py"}], "after_files": [{"content": "\"\"\"Phillips RWL021 device.\"\"\"\nfrom zigpy.profiles import zha, zll\nfrom zigpy.quirks import CustomCluster, CustomDevice\nimport zigpy.types as t\nfrom zigpy.zcl.clusters.general import (\n Basic,\n BinaryInput,\n Groups,\n Identify,\n LevelControl,\n OnOff,\n Ota,\n PowerConfiguration,\n Scenes,\n)\n\nfrom ..const import (\n ARGS,\n CLUSTER_ID,\n COMMAND,\n COMMAND_OFF_WITH_EFFECT,\n COMMAND_ON,\n COMMAND_STEP,\n DEVICE_TYPE,\n DIM_DOWN,\n DIM_UP,\n ENDPOINT_ID,\n ENDPOINTS,\n INPUT_CLUSTERS,\n LONG_PRESS,\n OUTPUT_CLUSTERS,\n PROFILE_ID,\n SHORT_PRESS,\n TURN_OFF,\n TURN_ON,\n)\n\nDIAGNOSTICS_CLUSTER_ID = 0x0B05 # decimal = 2821\n\n\nclass BasicCluster(CustomCluster, Basic):\n \"\"\"Centralite acceleration cluster.\"\"\"\n\n attributes = Basic.attributes.copy()\n attributes.update({0x0031: (\"phillips\", t.bitmap16)})\n\n\nclass PhilipsRWL021(CustomDevice):\n \"\"\"Phillips RWL021 device.\"\"\"\n\n signature = {\n # <SimpleDescriptor endpoint=1 profile=49246 device_type=2096\n # device_version=2\n # input_clusters=[0]\n # output_clusters=[0, 3, 4, 6, 8, 5]>\n ENDPOINTS: {\n 1: {\n PROFILE_ID: zll.PROFILE_ID,\n DEVICE_TYPE: zll.DeviceType.SCENE_CONTROLLER,\n INPUT_CLUSTERS: [Basic.cluster_id],\n OUTPUT_CLUSTERS: [\n Basic.cluster_id,\n Identify.cluster_id,\n Groups.cluster_id,\n OnOff.cluster_id,\n LevelControl.cluster_id,\n Scenes.cluster_id,\n ],\n },\n # <SimpleDescriptor endpoint=2 profile=260 device_type=12\n # device_version=0\n # input_clusters=[0, 1, 3, 15, 64512]\n # output_clusters=[25]>\n 2: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.SIMPLE_SENSOR,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n PowerConfiguration.cluster_id,\n Identify.cluster_id,\n BinaryInput.cluster_id,\n 64512,\n ],\n OUTPUT_CLUSTERS: [Ota.cluster_id],\n },\n }\n }\n\n replacement = {\n ENDPOINTS: {\n 1: {\n INPUT_CLUSTERS: [Basic.cluster_id],\n OUTPUT_CLUSTERS: [\n Basic.cluster_id,\n Identify.cluster_id,\n Groups.cluster_id,\n OnOff.cluster_id,\n LevelControl.cluster_id,\n Scenes.cluster_id,\n ],\n },\n 2: {\n INPUT_CLUSTERS: [\n BasicCluster,\n PowerConfiguration.cluster_id,\n Identify.cluster_id,\n BinaryInput.cluster_id,\n 64512,\n ],\n OUTPUT_CLUSTERS: [Ota.cluster_id],\n },\n }\n }\n\n device_automation_triggers = {\n (SHORT_PRESS, TURN_ON): {COMMAND: COMMAND_ON},\n (SHORT_PRESS, TURN_OFF): {COMMAND: COMMAND_OFF_WITH_EFFECT},\n (SHORT_PRESS, DIM_UP): {\n COMMAND: COMMAND_STEP,\n CLUSTER_ID: 8,\n ENDPOINT_ID: 1,\n ARGS: [0, 30, 9],\n },\n (LONG_PRESS, DIM_UP): {\n COMMAND: COMMAND_STEP,\n CLUSTER_ID: 8,\n ENDPOINT_ID: 1,\n ARGS: [0, 56, 9],\n },\n (SHORT_PRESS, DIM_DOWN): {\n COMMAND: COMMAND_STEP,\n CLUSTER_ID: 8,\n ENDPOINT_ID: 1,\n ARGS: [1, 30, 9],\n },\n (LONG_PRESS, DIM_DOWN): {\n COMMAND: COMMAND_STEP,\n CLUSTER_ID: 8,\n ENDPOINT_ID: 1,\n ARGS: [1, 56, 9],\n },\n }\n", "path": "zhaquirks/philips/rwl021.py"}]}
| 1,901 | 158 |
gh_patches_debug_7076
|
rasdani/github-patches
|
git_diff
|
ipython__ipython-6586
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
notebook.start_kernel is undefined
Hi, in notificationarea.js, when we need to restart a kernel we call `notebook.start_kernel` which doesn't exist. Not sure how you guys were planning to handle this, but I took a stab at it.
thanks!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `IPython/html/services/sessions/handlers.py`
Content:
```
1 """Tornado handlers for the sessions web service."""
2
3 # Copyright (c) IPython Development Team.
4 # Distributed under the terms of the Modified BSD License.
5
6 import json
7
8 from tornado import web
9
10 from ...base.handlers import IPythonHandler, json_errors
11 from IPython.utils.jsonutil import date_default
12 from IPython.html.utils import url_path_join, url_escape
13 from IPython.kernel.kernelspec import NoSuchKernel
14
15
16 class SessionRootHandler(IPythonHandler):
17
18 @web.authenticated
19 @json_errors
20 def get(self):
21 # Return a list of running sessions
22 sm = self.session_manager
23 sessions = sm.list_sessions()
24 self.finish(json.dumps(sessions, default=date_default))
25
26 @web.authenticated
27 @json_errors
28 def post(self):
29 # Creates a new session
30 #(unless a session already exists for the named nb)
31 sm = self.session_manager
32 cm = self.contents_manager
33 km = self.kernel_manager
34
35 model = self.get_json_body()
36 if model is None:
37 raise web.HTTPError(400, "No JSON data provided")
38 try:
39 name = model['notebook']['name']
40 except KeyError:
41 raise web.HTTPError(400, "Missing field in JSON data: notebook.name")
42 try:
43 path = model['notebook']['path']
44 except KeyError:
45 raise web.HTTPError(400, "Missing field in JSON data: notebook.path")
46 try:
47 kernel_name = model['kernel']['name']
48 except KeyError:
49 self.log.debug("No kernel name specified, using default kernel")
50 kernel_name = None
51
52 # Check to see if session exists
53 if sm.session_exists(name=name, path=path):
54 model = sm.get_session(name=name, path=path)
55 else:
56 try:
57 model = sm.create_session(name=name, path=path, kernel_name=kernel_name)
58 except NoSuchKernel:
59 msg = ("The '%s' kernel is not available. Please pick another "
60 "suitable kernel instead, or install that kernel." % kernel_name)
61 status_msg = '%s not found' % kernel_name
62 self.log.warn('Kernel not found: %s' % kernel_name)
63 self.set_status(501)
64 self.finish(json.dumps(dict(message=msg, short_message=status_msg)))
65 return
66
67 location = url_path_join(self.base_url, 'api', 'sessions', model['id'])
68 self.set_header('Location', url_escape(location))
69 self.set_status(201)
70 self.finish(json.dumps(model, default=date_default))
71
72 class SessionHandler(IPythonHandler):
73
74 SUPPORTED_METHODS = ('GET', 'PATCH', 'DELETE')
75
76 @web.authenticated
77 @json_errors
78 def get(self, session_id):
79 # Returns the JSON model for a single session
80 sm = self.session_manager
81 model = sm.get_session(session_id=session_id)
82 self.finish(json.dumps(model, default=date_default))
83
84 @web.authenticated
85 @json_errors
86 def patch(self, session_id):
87 # Currently, this handler is strictly for renaming notebooks
88 sm = self.session_manager
89 model = self.get_json_body()
90 if model is None:
91 raise web.HTTPError(400, "No JSON data provided")
92 changes = {}
93 if 'notebook' in model:
94 notebook = model['notebook']
95 if 'name' in notebook:
96 changes['name'] = notebook['name']
97 if 'path' in notebook:
98 changes['path'] = notebook['path']
99
100 sm.update_session(session_id, **changes)
101 model = sm.get_session(session_id=session_id)
102 self.finish(json.dumps(model, default=date_default))
103
104 @web.authenticated
105 @json_errors
106 def delete(self, session_id):
107 # Deletes the session with given session_id
108 sm = self.session_manager
109 sm.delete_session(session_id)
110 self.set_status(204)
111 self.finish()
112
113
114 #-----------------------------------------------------------------------------
115 # URL to handler mappings
116 #-----------------------------------------------------------------------------
117
118 _session_id_regex = r"(?P<session_id>\w+-\w+-\w+-\w+-\w+)"
119
120 default_handlers = [
121 (r"/api/sessions/%s" % _session_id_regex, SessionHandler),
122 (r"/api/sessions", SessionRootHandler)
123 ]
124
125
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/IPython/html/services/sessions/handlers.py b/IPython/html/services/sessions/handlers.py
--- a/IPython/html/services/sessions/handlers.py
+++ b/IPython/html/services/sessions/handlers.py
@@ -106,7 +106,11 @@
def delete(self, session_id):
# Deletes the session with given session_id
sm = self.session_manager
- sm.delete_session(session_id)
+ try:
+ sm.delete_session(session_id)
+ except KeyError:
+ # the kernel was deleted but the session wasn't!
+ raise web.HTTPError(410, "Kernel deleted before session")
self.set_status(204)
self.finish()
|
{"golden_diff": "diff --git a/IPython/html/services/sessions/handlers.py b/IPython/html/services/sessions/handlers.py\n--- a/IPython/html/services/sessions/handlers.py\n+++ b/IPython/html/services/sessions/handlers.py\n@@ -106,7 +106,11 @@\n def delete(self, session_id):\n # Deletes the session with given session_id\n sm = self.session_manager\n- sm.delete_session(session_id)\n+ try:\n+ sm.delete_session(session_id)\n+ except KeyError:\n+ # the kernel was deleted but the session wasn't!\n+ raise web.HTTPError(410, \"Kernel deleted before session\")\n self.set_status(204)\n self.finish()\n", "issue": "notebook.start_kernel is undefined\nHi, in notificationarea.js, when we need to restart a kernel we call `notebook.start_kernel` which doesn't exist. Not sure how you guys were planning to handle this, but I took a stab at it.\n\nthanks!\n\n", "before_files": [{"content": "\"\"\"Tornado handlers for the sessions web service.\"\"\"\n\n# Copyright (c) IPython Development Team.\n# Distributed under the terms of the Modified BSD License.\n\nimport json\n\nfrom tornado import web\n\nfrom ...base.handlers import IPythonHandler, json_errors\nfrom IPython.utils.jsonutil import date_default\nfrom IPython.html.utils import url_path_join, url_escape\nfrom IPython.kernel.kernelspec import NoSuchKernel\n\n\nclass SessionRootHandler(IPythonHandler):\n\n @web.authenticated\n @json_errors\n def get(self):\n # Return a list of running sessions\n sm = self.session_manager\n sessions = sm.list_sessions()\n self.finish(json.dumps(sessions, default=date_default))\n\n @web.authenticated\n @json_errors\n def post(self):\n # Creates a new session\n #(unless a session already exists for the named nb)\n sm = self.session_manager\n cm = self.contents_manager\n km = self.kernel_manager\n\n model = self.get_json_body()\n if model is None:\n raise web.HTTPError(400, \"No JSON data provided\")\n try:\n name = model['notebook']['name']\n except KeyError:\n raise web.HTTPError(400, \"Missing field in JSON data: notebook.name\")\n try:\n path = model['notebook']['path']\n except KeyError:\n raise web.HTTPError(400, \"Missing field in JSON data: notebook.path\")\n try:\n kernel_name = model['kernel']['name']\n except KeyError:\n self.log.debug(\"No kernel name specified, using default kernel\")\n kernel_name = None\n\n # Check to see if session exists\n if sm.session_exists(name=name, path=path):\n model = sm.get_session(name=name, path=path)\n else:\n try:\n model = sm.create_session(name=name, path=path, kernel_name=kernel_name)\n except NoSuchKernel:\n msg = (\"The '%s' kernel is not available. Please pick another \"\n \"suitable kernel instead, or install that kernel.\" % kernel_name)\n status_msg = '%s not found' % kernel_name\n self.log.warn('Kernel not found: %s' % kernel_name)\n self.set_status(501)\n self.finish(json.dumps(dict(message=msg, short_message=status_msg)))\n return\n\n location = url_path_join(self.base_url, 'api', 'sessions', model['id'])\n self.set_header('Location', url_escape(location))\n self.set_status(201)\n self.finish(json.dumps(model, default=date_default))\n\nclass SessionHandler(IPythonHandler):\n\n SUPPORTED_METHODS = ('GET', 'PATCH', 'DELETE')\n\n @web.authenticated\n @json_errors\n def get(self, session_id):\n # Returns the JSON model for a single session\n sm = self.session_manager\n model = sm.get_session(session_id=session_id)\n self.finish(json.dumps(model, default=date_default))\n\n @web.authenticated\n @json_errors\n def patch(self, session_id):\n # Currently, this handler is strictly for renaming notebooks\n sm = self.session_manager\n model = self.get_json_body()\n if model is None:\n raise web.HTTPError(400, \"No JSON data provided\")\n changes = {}\n if 'notebook' in model:\n notebook = model['notebook']\n if 'name' in notebook:\n changes['name'] = notebook['name']\n if 'path' in notebook:\n changes['path'] = notebook['path']\n\n sm.update_session(session_id, **changes)\n model = sm.get_session(session_id=session_id)\n self.finish(json.dumps(model, default=date_default))\n\n @web.authenticated\n @json_errors\n def delete(self, session_id):\n # Deletes the session with given session_id\n sm = self.session_manager\n sm.delete_session(session_id)\n self.set_status(204)\n self.finish()\n\n\n#-----------------------------------------------------------------------------\n# URL to handler mappings\n#-----------------------------------------------------------------------------\n\n_session_id_regex = r\"(?P<session_id>\\w+-\\w+-\\w+-\\w+-\\w+)\"\n\ndefault_handlers = [\n (r\"/api/sessions/%s\" % _session_id_regex, SessionHandler),\n (r\"/api/sessions\", SessionRootHandler)\n]\n\n", "path": "IPython/html/services/sessions/handlers.py"}], "after_files": [{"content": "\"\"\"Tornado handlers for the sessions web service.\"\"\"\n\n# Copyright (c) IPython Development Team.\n# Distributed under the terms of the Modified BSD License.\n\nimport json\n\nfrom tornado import web\n\nfrom ...base.handlers import IPythonHandler, json_errors\nfrom IPython.utils.jsonutil import date_default\nfrom IPython.html.utils import url_path_join, url_escape\nfrom IPython.kernel.kernelspec import NoSuchKernel\n\n\nclass SessionRootHandler(IPythonHandler):\n\n @web.authenticated\n @json_errors\n def get(self):\n # Return a list of running sessions\n sm = self.session_manager\n sessions = sm.list_sessions()\n self.finish(json.dumps(sessions, default=date_default))\n\n @web.authenticated\n @json_errors\n def post(self):\n # Creates a new session\n #(unless a session already exists for the named nb)\n sm = self.session_manager\n cm = self.contents_manager\n km = self.kernel_manager\n\n model = self.get_json_body()\n if model is None:\n raise web.HTTPError(400, \"No JSON data provided\")\n try:\n name = model['notebook']['name']\n except KeyError:\n raise web.HTTPError(400, \"Missing field in JSON data: notebook.name\")\n try:\n path = model['notebook']['path']\n except KeyError:\n raise web.HTTPError(400, \"Missing field in JSON data: notebook.path\")\n try:\n kernel_name = model['kernel']['name']\n except KeyError:\n self.log.debug(\"No kernel name specified, using default kernel\")\n kernel_name = None\n\n # Check to see if session exists\n if sm.session_exists(name=name, path=path):\n model = sm.get_session(name=name, path=path)\n else:\n try:\n model = sm.create_session(name=name, path=path, kernel_name=kernel_name)\n except NoSuchKernel:\n msg = (\"The '%s' kernel is not available. Please pick another \"\n \"suitable kernel instead, or install that kernel.\" % kernel_name)\n status_msg = '%s not found' % kernel_name\n self.log.warn('Kernel not found: %s' % kernel_name)\n self.set_status(501)\n self.finish(json.dumps(dict(message=msg, short_message=status_msg)))\n return\n\n location = url_path_join(self.base_url, 'api', 'sessions', model['id'])\n self.set_header('Location', url_escape(location))\n self.set_status(201)\n self.finish(json.dumps(model, default=date_default))\n\nclass SessionHandler(IPythonHandler):\n\n SUPPORTED_METHODS = ('GET', 'PATCH', 'DELETE')\n\n @web.authenticated\n @json_errors\n def get(self, session_id):\n # Returns the JSON model for a single session\n sm = self.session_manager\n model = sm.get_session(session_id=session_id)\n self.finish(json.dumps(model, default=date_default))\n\n @web.authenticated\n @json_errors\n def patch(self, session_id):\n # Currently, this handler is strictly for renaming notebooks\n sm = self.session_manager\n model = self.get_json_body()\n if model is None:\n raise web.HTTPError(400, \"No JSON data provided\")\n changes = {}\n if 'notebook' in model:\n notebook = model['notebook']\n if 'name' in notebook:\n changes['name'] = notebook['name']\n if 'path' in notebook:\n changes['path'] = notebook['path']\n\n sm.update_session(session_id, **changes)\n model = sm.get_session(session_id=session_id)\n self.finish(json.dumps(model, default=date_default))\n\n @web.authenticated\n @json_errors\n def delete(self, session_id):\n # Deletes the session with given session_id\n sm = self.session_manager\n try:\n sm.delete_session(session_id)\n except KeyError:\n # the kernel was deleted but the session wasn't!\n raise web.HTTPError(410, \"Kernel deleted before session\")\n self.set_status(204)\n self.finish()\n\n\n#-----------------------------------------------------------------------------\n# URL to handler mappings\n#-----------------------------------------------------------------------------\n\n_session_id_regex = r\"(?P<session_id>\\w+-\\w+-\\w+-\\w+-\\w+)\"\n\ndefault_handlers = [\n (r\"/api/sessions/%s\" % _session_id_regex, SessionHandler),\n (r\"/api/sessions\", SessionRootHandler)\n]\n\n", "path": "IPython/html/services/sessions/handlers.py"}]}
| 1,521 | 160 |
gh_patches_debug_16104
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-5687
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
CKV_AZURE_153 - Not available for linux_web_app_slot & azurerm_windows_web_app_slot
**Describe the issue**
It seems that the best practice CKV_AZURE_153 is not being checked against the following Terraform resources:
- azurerm_linux_web_app_slot
- azurerm_windows_web_app_slot
CKV_AZURE_153 is used to "Ensure web app redirects all HTTP traffic to HTTPS in Azure App Service"
**Examples**
Same as with "azurerm_app_service_slot"
**Version (please complete the following information):**
N/A
**Additional context**
It seems that the check needs to be adjusted cc https://registry.terraform.io/providers/hashicorp/azurerm/latest/docs/resources/app_service_slot

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `checkov/terraform/checks/resource/azure/AppServiceSlotHTTPSOnly.py`
Content:
```
1 from checkov.common.models.enums import CheckCategories
2 from checkov.terraform.checks.resource.base_resource_value_check import BaseResourceValueCheck
3
4
5 class AppServiceSlotHTTPSOnly(BaseResourceValueCheck):
6 def __init__(self):
7 name = "Ensure web app redirects all HTTP traffic to HTTPS in Azure App Service Slot"
8 id = "CKV_AZURE_153"
9 supported_resources = ['azurerm_app_service_slot']
10 categories = [CheckCategories.NETWORKING]
11 super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
12
13 def get_inspected_key(self):
14 return 'https_only/[0]'
15
16
17 check = AppServiceSlotHTTPSOnly()
18
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/checkov/terraform/checks/resource/azure/AppServiceSlotHTTPSOnly.py b/checkov/terraform/checks/resource/azure/AppServiceSlotHTTPSOnly.py
--- a/checkov/terraform/checks/resource/azure/AppServiceSlotHTTPSOnly.py
+++ b/checkov/terraform/checks/resource/azure/AppServiceSlotHTTPSOnly.py
@@ -6,12 +6,12 @@
def __init__(self):
name = "Ensure web app redirects all HTTP traffic to HTTPS in Azure App Service Slot"
id = "CKV_AZURE_153"
- supported_resources = ['azurerm_app_service_slot']
+ supported_resources = ["azurerm_app_service_slot", "azurerm_linux_web_app_slot", "azurerm_windows_web_app_slot"]
categories = [CheckCategories.NETWORKING]
super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
def get_inspected_key(self):
- return 'https_only/[0]'
+ return "https_only/[0]"
check = AppServiceSlotHTTPSOnly()
|
{"golden_diff": "diff --git a/checkov/terraform/checks/resource/azure/AppServiceSlotHTTPSOnly.py b/checkov/terraform/checks/resource/azure/AppServiceSlotHTTPSOnly.py\n--- a/checkov/terraform/checks/resource/azure/AppServiceSlotHTTPSOnly.py\n+++ b/checkov/terraform/checks/resource/azure/AppServiceSlotHTTPSOnly.py\n@@ -6,12 +6,12 @@\n def __init__(self):\n name = \"Ensure web app redirects all HTTP traffic to HTTPS in Azure App Service Slot\"\n id = \"CKV_AZURE_153\"\n- supported_resources = ['azurerm_app_service_slot']\n+ supported_resources = [\"azurerm_app_service_slot\", \"azurerm_linux_web_app_slot\", \"azurerm_windows_web_app_slot\"]\n categories = [CheckCategories.NETWORKING]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n \n def get_inspected_key(self):\n- return 'https_only/[0]'\n+ return \"https_only/[0]\"\n \n \n check = AppServiceSlotHTTPSOnly()\n", "issue": "CKV_AZURE_153 - Not available for linux_web_app_slot & azurerm_windows_web_app_slot\n**Describe the issue**\r\nIt seems that the best practice CKV_AZURE_153 is not being checked against the following Terraform resources:\r\n\r\n- azurerm_linux_web_app_slot\r\n- azurerm_windows_web_app_slot\r\n\r\nCKV_AZURE_153 is used to \"Ensure web app redirects all HTTP traffic to HTTPS in Azure App Service\"\r\n\r\n**Examples**\r\n\r\nSame as with \"azurerm_app_service_slot\"\r\n\r\n**Version (please complete the following information):**\r\nN/A\r\n\r\n**Additional context**\r\n\r\nIt seems that the check needs to be adjusted cc https://registry.terraform.io/providers/hashicorp/azurerm/latest/docs/resources/app_service_slot\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "from checkov.common.models.enums import CheckCategories\nfrom checkov.terraform.checks.resource.base_resource_value_check import BaseResourceValueCheck\n\n\nclass AppServiceSlotHTTPSOnly(BaseResourceValueCheck):\n def __init__(self):\n name = \"Ensure web app redirects all HTTP traffic to HTTPS in Azure App Service Slot\"\n id = \"CKV_AZURE_153\"\n supported_resources = ['azurerm_app_service_slot']\n categories = [CheckCategories.NETWORKING]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def get_inspected_key(self):\n return 'https_only/[0]'\n\n\ncheck = AppServiceSlotHTTPSOnly()\n", "path": "checkov/terraform/checks/resource/azure/AppServiceSlotHTTPSOnly.py"}], "after_files": [{"content": "from checkov.common.models.enums import CheckCategories\nfrom checkov.terraform.checks.resource.base_resource_value_check import BaseResourceValueCheck\n\n\nclass AppServiceSlotHTTPSOnly(BaseResourceValueCheck):\n def __init__(self):\n name = \"Ensure web app redirects all HTTP traffic to HTTPS in Azure App Service Slot\"\n id = \"CKV_AZURE_153\"\n supported_resources = [\"azurerm_app_service_slot\", \"azurerm_linux_web_app_slot\", \"azurerm_windows_web_app_slot\"]\n categories = [CheckCategories.NETWORKING]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def get_inspected_key(self):\n return \"https_only/[0]\"\n\n\ncheck = AppServiceSlotHTTPSOnly()\n", "path": "checkov/terraform/checks/resource/azure/AppServiceSlotHTTPSOnly.py"}]}
| 674 | 235 |
gh_patches_debug_51247
|
rasdani/github-patches
|
git_diff
|
conda__conda-4729
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
cannot import conda.fetch.cache_fn_url
I'm using conda 4.3.2, and the function `conda.fetch.cache_fn_url` does not exist anymore. What to do?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conda/exports.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 from __future__ import absolute_import, division, print_function, unicode_literals
3
4 from functools import partial
5 from logging import getLogger
6 from warnings import warn
7
8 log = getLogger(__name__)
9
10 from . import CondaError # NOQA
11 CondaError = CondaError
12
13 from . import compat, plan # NOQA
14 compat, plan = compat, plan
15
16 from .api import get_index # NOQA
17 get_index = get_index
18
19 from .cli.common import (Completer, InstalledPackages, add_parser_channels, add_parser_prefix, # NOQA
20 specs_from_args, spec_from_line, specs_from_url) # NOQA
21 Completer, InstalledPackages = Completer, InstalledPackages
22 add_parser_channels, add_parser_prefix = add_parser_channels, add_parser_prefix
23 specs_from_args, spec_from_line = specs_from_args, spec_from_line
24 specs_from_url = specs_from_url
25
26 from .cli.conda_argparse import ArgumentParser # NOQA
27 ArgumentParser = ArgumentParser
28
29 from .common.compat import PY3, StringIO, input, iteritems, string_types, text_type # NOQA
30 PY3, StringIO, input, iteritems, string_types, text_type = PY3, StringIO, input, iteritems, string_types, text_type # NOQA
31 from .connection import CondaSession # NOQA
32 CondaSession = CondaSession
33
34 from .gateways.disk.link import lchmod # NOQA
35 lchmod = lchmod
36
37 from .fetch import TmpDownload # NOQA
38 TmpDownload = TmpDownload
39 handle_proxy_407 = lambda x, y: warn("handle_proxy_407 is deprecated. "
40 "Now handled by CondaSession.")
41 from .core.index import dist_str_in_index, fetch_index # NOQA
42 dist_str_in_index, fetch_index = dist_str_in_index, fetch_index
43 from .core.package_cache import download, rm_fetched # NOQA
44 download, rm_fetched = download, rm_fetched
45
46 from .install import package_cache, prefix_placeholder, rm_rf, symlink_conda # NOQA
47 package_cache, prefix_placeholder, rm_rf, symlink_conda = package_cache, prefix_placeholder, rm_rf, symlink_conda # NOQA
48
49 from .gateways.disk.delete import delete_trash, move_to_trash # NOQA
50 delete_trash, move_to_trash = delete_trash, move_to_trash
51
52 from .core.linked_data import is_linked, linked, linked_data # NOQA
53 is_linked, linked, linked_data = is_linked, linked, linked_data
54
55 from .misc import untracked, walk_prefix # NOQA
56 untracked, walk_prefix = untracked, walk_prefix
57
58 from .resolve import MatchSpec, NoPackagesFound, Resolve, Unsatisfiable, normalized_version # NOQA
59 MatchSpec, NoPackagesFound, Resolve = MatchSpec, NoPackagesFound, Resolve
60 Unsatisfiable, normalized_version = Unsatisfiable, normalized_version
61
62 from .signature import KEYS, KEYS_DIR, hash_file, verify # NOQA
63 KEYS, KEYS_DIR = KEYS, KEYS_DIR
64 hash_file, verify = hash_file, verify
65
66 from .utils import (human_bytes, hashsum_file, md5_file, memoized, unix_path_to_win, # NOQA
67 win_path_to_unix, url_path) # NOQA
68 human_bytes, hashsum_file, md5_file = human_bytes, hashsum_file, md5_file
69 memoized, unix_path_to_win = memoized, unix_path_to_win
70 win_path_to_unix, url_path = win_path_to_unix, url_path
71
72 from .config import sys_rc_path # NOQA
73 sys_rc_path = sys_rc_path
74
75 from .version import VersionOrder # NOQA
76 VersionOrder = VersionOrder
77
78
79 import conda.base.context # NOQA
80 from conda.base.context import get_prefix as context_get_prefix, non_x86_linux_machines # NOQA
81 non_x86_linux_machines = non_x86_linux_machines
82
83 from ._vendor.auxlib.entity import EntityEncoder # NOQA
84 EntityEncoder = EntityEncoder
85 from .base.constants import DEFAULT_CHANNELS, DEFAULT_CHANNELS_WIN, DEFAULT_CHANNELS_UNIX # NOQA
86 DEFAULT_CHANNELS, DEFAULT_CHANNELS_WIN, DEFAULT_CHANNELS_UNIX = DEFAULT_CHANNELS, DEFAULT_CHANNELS_WIN, DEFAULT_CHANNELS_UNIX # NOQA
87 get_prefix = partial(context_get_prefix, conda.base.context.context)
88 get_default_urls = lambda: DEFAULT_CHANNELS
89
90 arch_name = conda.base.context.context.arch_name
91 binstar_upload = conda.base.context.context.binstar_upload
92 bits = conda.base.context.context.bits
93 default_prefix = conda.base.context.context.default_prefix
94 default_python = conda.base.context.context.default_python
95 envs_dirs = conda.base.context.context.envs_dirs
96 pkgs_dirs = conda.base.context.context.pkgs_dirs
97 platform = conda.base.context.context.platform
98 root_dir = conda.base.context.context.root_prefix
99 root_writable = conda.base.context.context.root_writable
100 subdir = conda.base.context.context.subdir
101 from .models.channel import get_conda_build_local_url # NOQA
102 get_rc_urls = lambda: list(conda.base.context.context.channels)
103 get_local_urls = lambda: list(get_conda_build_local_url()) or []
104 load_condarc = lambda fn: conda.base.context.reset_context([fn])
105 from .exceptions import PaddingError # NOQA
106 PaddingError = PaddingError
107 from .gateways.disk.link import CrossPlatformStLink # NOQA
108 CrossPlatformStLink = CrossPlatformStLink
109
110 from .models.enums import FileMode # NOQA
111 FileMode = FileMode
112 from .models.enums import PathType # NOQA
113 PathType = PathType
114
115
116 if PY3:
117 import configparser # NOQA # pragma: py2 no cover
118 else:
119 import ConfigParser as configparser # NOQA # pragma: py3 no cover
120 configparser = configparser
121
122
123 from .compat import TemporaryDirectory # NOQA
124 TemporaryDirectory = TemporaryDirectory
125
126 from .gateways.subprocess import ACTIVE_SUBPROCESSES, subprocess_call # NOQA
127 ACTIVE_SUBPROCESSES, subprocess_call = ACTIVE_SUBPROCESSES, subprocess_call
128
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/conda/exports.py b/conda/exports.py
--- a/conda/exports.py
+++ b/conda/exports.py
@@ -125,3 +125,6 @@
from .gateways.subprocess import ACTIVE_SUBPROCESSES, subprocess_call # NOQA
ACTIVE_SUBPROCESSES, subprocess_call = ACTIVE_SUBPROCESSES, subprocess_call
+
+from .core.repodata import cache_fn_url # NOQA
+cache_fn_url = cache_fn_url
|
{"golden_diff": "diff --git a/conda/exports.py b/conda/exports.py\n--- a/conda/exports.py\n+++ b/conda/exports.py\n@@ -125,3 +125,6 @@\n \n from .gateways.subprocess import ACTIVE_SUBPROCESSES, subprocess_call # NOQA\n ACTIVE_SUBPROCESSES, subprocess_call = ACTIVE_SUBPROCESSES, subprocess_call\n+\n+from .core.repodata import cache_fn_url # NOQA\n+cache_fn_url = cache_fn_url\n", "issue": "cannot import conda.fetch.cache_fn_url\nI'm using conda 4.3.2, and the function `conda.fetch.cache_fn_url` does not exist anymore. What to do?\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nfrom functools import partial\nfrom logging import getLogger\nfrom warnings import warn\n\nlog = getLogger(__name__)\n\nfrom . import CondaError # NOQA\nCondaError = CondaError\n\nfrom . import compat, plan # NOQA\ncompat, plan = compat, plan\n\nfrom .api import get_index # NOQA\nget_index = get_index\n\nfrom .cli.common import (Completer, InstalledPackages, add_parser_channels, add_parser_prefix, # NOQA\n specs_from_args, spec_from_line, specs_from_url) # NOQA\nCompleter, InstalledPackages = Completer, InstalledPackages\nadd_parser_channels, add_parser_prefix = add_parser_channels, add_parser_prefix\nspecs_from_args, spec_from_line = specs_from_args, spec_from_line\nspecs_from_url = specs_from_url\n\nfrom .cli.conda_argparse import ArgumentParser # NOQA\nArgumentParser = ArgumentParser\n\nfrom .common.compat import PY3, StringIO, input, iteritems, string_types, text_type # NOQA\nPY3, StringIO, input, iteritems, string_types, text_type = PY3, StringIO, input, iteritems, string_types, text_type # NOQA\nfrom .connection import CondaSession # NOQA\nCondaSession = CondaSession\n\nfrom .gateways.disk.link import lchmod # NOQA\nlchmod = lchmod\n\nfrom .fetch import TmpDownload # NOQA\nTmpDownload = TmpDownload\nhandle_proxy_407 = lambda x, y: warn(\"handle_proxy_407 is deprecated. \"\n \"Now handled by CondaSession.\")\nfrom .core.index import dist_str_in_index, fetch_index # NOQA\ndist_str_in_index, fetch_index = dist_str_in_index, fetch_index\nfrom .core.package_cache import download, rm_fetched # NOQA\ndownload, rm_fetched = download, rm_fetched\n\nfrom .install import package_cache, prefix_placeholder, rm_rf, symlink_conda # NOQA\npackage_cache, prefix_placeholder, rm_rf, symlink_conda = package_cache, prefix_placeholder, rm_rf, symlink_conda # NOQA\n\nfrom .gateways.disk.delete import delete_trash, move_to_trash # NOQA\ndelete_trash, move_to_trash = delete_trash, move_to_trash\n\nfrom .core.linked_data import is_linked, linked, linked_data # NOQA\nis_linked, linked, linked_data = is_linked, linked, linked_data\n\nfrom .misc import untracked, walk_prefix # NOQA\nuntracked, walk_prefix = untracked, walk_prefix\n\nfrom .resolve import MatchSpec, NoPackagesFound, Resolve, Unsatisfiable, normalized_version # NOQA\nMatchSpec, NoPackagesFound, Resolve = MatchSpec, NoPackagesFound, Resolve\nUnsatisfiable, normalized_version = Unsatisfiable, normalized_version\n\nfrom .signature import KEYS, KEYS_DIR, hash_file, verify # NOQA\nKEYS, KEYS_DIR = KEYS, KEYS_DIR\nhash_file, verify = hash_file, verify\n\nfrom .utils import (human_bytes, hashsum_file, md5_file, memoized, unix_path_to_win, # NOQA\n win_path_to_unix, url_path) # NOQA\nhuman_bytes, hashsum_file, md5_file = human_bytes, hashsum_file, md5_file\nmemoized, unix_path_to_win = memoized, unix_path_to_win\nwin_path_to_unix, url_path = win_path_to_unix, url_path\n\nfrom .config import sys_rc_path # NOQA\nsys_rc_path = sys_rc_path\n\nfrom .version import VersionOrder # NOQA\nVersionOrder = VersionOrder\n\n\nimport conda.base.context # NOQA\nfrom conda.base.context import get_prefix as context_get_prefix, non_x86_linux_machines # NOQA\nnon_x86_linux_machines = non_x86_linux_machines\n\nfrom ._vendor.auxlib.entity import EntityEncoder # NOQA\nEntityEncoder = EntityEncoder\nfrom .base.constants import DEFAULT_CHANNELS, DEFAULT_CHANNELS_WIN, DEFAULT_CHANNELS_UNIX # NOQA\nDEFAULT_CHANNELS, DEFAULT_CHANNELS_WIN, DEFAULT_CHANNELS_UNIX = DEFAULT_CHANNELS, DEFAULT_CHANNELS_WIN, DEFAULT_CHANNELS_UNIX # NOQA\nget_prefix = partial(context_get_prefix, conda.base.context.context)\nget_default_urls = lambda: DEFAULT_CHANNELS\n\narch_name = conda.base.context.context.arch_name\nbinstar_upload = conda.base.context.context.binstar_upload\nbits = conda.base.context.context.bits\ndefault_prefix = conda.base.context.context.default_prefix\ndefault_python = conda.base.context.context.default_python\nenvs_dirs = conda.base.context.context.envs_dirs\npkgs_dirs = conda.base.context.context.pkgs_dirs\nplatform = conda.base.context.context.platform\nroot_dir = conda.base.context.context.root_prefix\nroot_writable = conda.base.context.context.root_writable\nsubdir = conda.base.context.context.subdir\nfrom .models.channel import get_conda_build_local_url # NOQA\nget_rc_urls = lambda: list(conda.base.context.context.channels)\nget_local_urls = lambda: list(get_conda_build_local_url()) or []\nload_condarc = lambda fn: conda.base.context.reset_context([fn])\nfrom .exceptions import PaddingError # NOQA\nPaddingError = PaddingError\nfrom .gateways.disk.link import CrossPlatformStLink # NOQA\nCrossPlatformStLink = CrossPlatformStLink\n\nfrom .models.enums import FileMode # NOQA\nFileMode = FileMode\nfrom .models.enums import PathType # NOQA\nPathType = PathType\n\n\nif PY3:\n import configparser # NOQA # pragma: py2 no cover\nelse:\n import ConfigParser as configparser # NOQA # pragma: py3 no cover\nconfigparser = configparser\n\n\nfrom .compat import TemporaryDirectory # NOQA\nTemporaryDirectory = TemporaryDirectory\n\nfrom .gateways.subprocess import ACTIVE_SUBPROCESSES, subprocess_call # NOQA\nACTIVE_SUBPROCESSES, subprocess_call = ACTIVE_SUBPROCESSES, subprocess_call\n", "path": "conda/exports.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nfrom functools import partial\nfrom logging import getLogger\nfrom warnings import warn\n\nlog = getLogger(__name__)\n\nfrom . import CondaError # NOQA\nCondaError = CondaError\n\nfrom . import compat, plan # NOQA\ncompat, plan = compat, plan\n\nfrom .api import get_index # NOQA\nget_index = get_index\n\nfrom .cli.common import (Completer, InstalledPackages, add_parser_channels, add_parser_prefix, # NOQA\n specs_from_args, spec_from_line, specs_from_url) # NOQA\nCompleter, InstalledPackages = Completer, InstalledPackages\nadd_parser_channels, add_parser_prefix = add_parser_channels, add_parser_prefix\nspecs_from_args, spec_from_line = specs_from_args, spec_from_line\nspecs_from_url = specs_from_url\n\nfrom .cli.conda_argparse import ArgumentParser # NOQA\nArgumentParser = ArgumentParser\n\nfrom .common.compat import PY3, StringIO, input, iteritems, string_types, text_type # NOQA\nPY3, StringIO, input, iteritems, string_types, text_type = PY3, StringIO, input, iteritems, string_types, text_type # NOQA\nfrom .connection import CondaSession # NOQA\nCondaSession = CondaSession\n\nfrom .gateways.disk.link import lchmod # NOQA\nlchmod = lchmod\n\nfrom .fetch import TmpDownload # NOQA\nTmpDownload = TmpDownload\nhandle_proxy_407 = lambda x, y: warn(\"handle_proxy_407 is deprecated. \"\n \"Now handled by CondaSession.\")\nfrom .core.index import dist_str_in_index, fetch_index # NOQA\ndist_str_in_index, fetch_index = dist_str_in_index, fetch_index\nfrom .core.package_cache import download, rm_fetched # NOQA\ndownload, rm_fetched = download, rm_fetched\n\nfrom .install import package_cache, prefix_placeholder, rm_rf, symlink_conda # NOQA\npackage_cache, prefix_placeholder, rm_rf, symlink_conda = package_cache, prefix_placeholder, rm_rf, symlink_conda # NOQA\n\nfrom .gateways.disk.delete import delete_trash, move_to_trash # NOQA\ndelete_trash, move_to_trash = delete_trash, move_to_trash\n\nfrom .core.linked_data import is_linked, linked, linked_data # NOQA\nis_linked, linked, linked_data = is_linked, linked, linked_data\n\nfrom .misc import untracked, walk_prefix # NOQA\nuntracked, walk_prefix = untracked, walk_prefix\n\nfrom .resolve import MatchSpec, NoPackagesFound, Resolve, Unsatisfiable, normalized_version # NOQA\nMatchSpec, NoPackagesFound, Resolve = MatchSpec, NoPackagesFound, Resolve\nUnsatisfiable, normalized_version = Unsatisfiable, normalized_version\n\nfrom .signature import KEYS, KEYS_DIR, hash_file, verify # NOQA\nKEYS, KEYS_DIR = KEYS, KEYS_DIR\nhash_file, verify = hash_file, verify\n\nfrom .utils import (human_bytes, hashsum_file, md5_file, memoized, unix_path_to_win, # NOQA\n win_path_to_unix, url_path) # NOQA\nhuman_bytes, hashsum_file, md5_file = human_bytes, hashsum_file, md5_file\nmemoized, unix_path_to_win = memoized, unix_path_to_win\nwin_path_to_unix, url_path = win_path_to_unix, url_path\n\nfrom .config import sys_rc_path # NOQA\nsys_rc_path = sys_rc_path\n\nfrom .version import VersionOrder # NOQA\nVersionOrder = VersionOrder\n\n\nimport conda.base.context # NOQA\nfrom conda.base.context import get_prefix as context_get_prefix, non_x86_linux_machines # NOQA\nnon_x86_linux_machines = non_x86_linux_machines\n\nfrom ._vendor.auxlib.entity import EntityEncoder # NOQA\nEntityEncoder = EntityEncoder\nfrom .base.constants import DEFAULT_CHANNELS, DEFAULT_CHANNELS_WIN, DEFAULT_CHANNELS_UNIX # NOQA\nDEFAULT_CHANNELS, DEFAULT_CHANNELS_WIN, DEFAULT_CHANNELS_UNIX = DEFAULT_CHANNELS, DEFAULT_CHANNELS_WIN, DEFAULT_CHANNELS_UNIX # NOQA\nget_prefix = partial(context_get_prefix, conda.base.context.context)\nget_default_urls = lambda: DEFAULT_CHANNELS\n\narch_name = conda.base.context.context.arch_name\nbinstar_upload = conda.base.context.context.binstar_upload\nbits = conda.base.context.context.bits\ndefault_prefix = conda.base.context.context.default_prefix\ndefault_python = conda.base.context.context.default_python\nenvs_dirs = conda.base.context.context.envs_dirs\npkgs_dirs = conda.base.context.context.pkgs_dirs\nplatform = conda.base.context.context.platform\nroot_dir = conda.base.context.context.root_prefix\nroot_writable = conda.base.context.context.root_writable\nsubdir = conda.base.context.context.subdir\nfrom .models.channel import get_conda_build_local_url # NOQA\nget_rc_urls = lambda: list(conda.base.context.context.channels)\nget_local_urls = lambda: list(get_conda_build_local_url()) or []\nload_condarc = lambda fn: conda.base.context.reset_context([fn])\nfrom .exceptions import PaddingError # NOQA\nPaddingError = PaddingError\nfrom .gateways.disk.link import CrossPlatformStLink # NOQA\nCrossPlatformStLink = CrossPlatformStLink\n\nfrom .models.enums import FileMode # NOQA\nFileMode = FileMode\nfrom .models.enums import PathType # NOQA\nPathType = PathType\n\n\nif PY3:\n import configparser # NOQA # pragma: py2 no cover\nelse:\n import ConfigParser as configparser # NOQA # pragma: py3 no cover\nconfigparser = configparser\n\n\nfrom .compat import TemporaryDirectory # NOQA\nTemporaryDirectory = TemporaryDirectory\n\nfrom .gateways.subprocess import ACTIVE_SUBPROCESSES, subprocess_call # NOQA\nACTIVE_SUBPROCESSES, subprocess_call = ACTIVE_SUBPROCESSES, subprocess_call\n\nfrom .core.repodata import cache_fn_url # NOQA\ncache_fn_url = cache_fn_url\n", "path": "conda/exports.py"}]}
| 1,927 | 111 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.