
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.71k
9.01k
| golden_diff
stringlengths 151
4.94k
| verification_info
stringlengths 465
11.3k
| num_tokens_prompt
int64 557
2.05k
| num_tokens_diff
int64 48
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_4756
|
rasdani/github-patches
|
git_diff
|
keras-team__keras-core-579
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Using torch backend
Using PyTorch backend.
Epoch 1/3
32/32 ━━━━━━━━━━━━━━━━━━━━ 1s 4ms/step - mean_absolute_error: 0.4083 - loss: 0.2566
Epoch 2/3
32/32 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - mean_absolute_error: 0.3805 - loss: 0.2151
Epoch 3/3
32/32 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - mean_absolute_error: 0.3704 - loss: 0.2056
Epoch 1/5
32/32 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - loss: 0.2699 - mae: 0.4200
Epoch 2/5
32/32 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - loss: 0.2409 - mae: 0.3940
Epoch 3/5
32/32 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - loss: 0.2271 - mae: 0.3856
Epoch 4/5
32/32 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - loss: 0.2174 - mae: 0.3785
Epoch 5/5
32/32 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - loss: 0.2120 - mae: 0.3699
Epoch 1/3
32/32 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - mean_absolute_error: 0.7020 - loss: 0.3334
Epoch 2/3
32/32 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - mean_absolute_error: 0.4075 - loss: 0.1271
Epoch 3/3
32/32 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - mean_absolute_error: 0.3776 - loss: 0.1010
32/32 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - mean_absolute_error: 0.8608 - loss: 0.9672
Traceback (most recent call last):
File "E:\custom_train_step_in_torch.py", line 483, in <module>
gan.fit(dataloader, epochs=1)
File "C:\Python_310\lib\site-packages\keras_core\src\utils\traceback_utils.py", line 123, in error_handler
raise e.with_traceback(filtered_tb) from None
File "C:\Python_310\lib\site-packages\keras_core\src\utils\module_utils.py", line 26, in initialize
raise ImportError(
ImportError: This requires the tensorflow module. You can install it via `pip install tensorflow`
</issue>
<code>
[start of keras_core/utils/module_utils.py]
1 import importlib
2
3
4 class LazyModule:
5 def __init__(self, name, pip_name=None):
6 self.name = name
7 pip_name = pip_name or name
8 self.pip_name = pip_name
9 self.module = None
10 self._available = None
11
12 @property
13 def available(self):
14 if self._available is None:
15 try:
16 self.initialize()
17 except ImportError:
18 self._available = False
19 self._available = True
20 return self._available
21
22 def initialize(self):
23 try:
24 self.module = importlib.import_module(self.name)
25 except ImportError:
26 raise ImportError(
27 f"This requires the {self.name} module. "
28 f"You can install it via `pip install {self.pip_name}`"
29 )
30
31 def __getattr__(self, name):
32 if self.module is None:
33 self.initialize()
34 return getattr(self.module, name)
35
36
37 tensorflow = LazyModule("tensorflow")
38 gfile = LazyModule("tensorflow.io.gfile")
39
[end of keras_core/utils/module_utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/keras_core/utils/module_utils.py b/keras_core/utils/module_utils.py
--- a/keras_core/utils/module_utils.py
+++ b/keras_core/utils/module_utils.py
@@ -14,9 +14,9 @@
if self._available is None:
try:
self.initialize()
+ self._available = True
except ImportError:
self._available = False
- self._available = True
return self._available
def initialize(self):
|
{"golden_diff": "diff --git a/keras_core/utils/module_utils.py b/keras_core/utils/module_utils.py\n--- a/keras_core/utils/module_utils.py\n+++ b/keras_core/utils/module_utils.py\n@@ -14,9 +14,9 @@\n if self._available is None:\n try:\n self.initialize()\n+ self._available = True\n except ImportError:\n self._available = False\n- self._available = True\n return self._available\n \n def initialize(self):\n", "issue": "Using torch backend\nUsing PyTorch backend.\r\nEpoch 1/3\r\n32/32 \u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501 1s 4ms/step - mean_absolute_error: 0.4083 - loss: 0.2566\r\nEpoch 2/3\r\n32/32 \u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501 0s 4ms/step - mean_absolute_error: 0.3805 - loss: 0.2151\r\nEpoch 3/3\r\n32/32 \u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501 0s 4ms/step - mean_absolute_error: 0.3704 - loss: 0.2056\r\nEpoch 1/5\r\n32/32 \u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501 0s 4ms/step - loss: 0.2699 - mae: 0.4200\r\nEpoch 2/5\r\n32/32 \u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501 0s 4ms/step - loss: 0.2409 - mae: 0.3940\r\nEpoch 3/5\r\n32/32 \u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501 0s 4ms/step - loss: 0.2271 - mae: 0.3856\r\nEpoch 4/5\r\n32/32 \u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501 0s 4ms/step - loss: 0.2174 - mae: 0.3785\r\nEpoch 5/5\r\n32/32 \u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501 0s 4ms/step - loss: 0.2120 - mae: 0.3699\r\nEpoch 1/3\r\n32/32 \u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501 0s 4ms/step - mean_absolute_error: 0.7020 - loss: 0.3334\r\nEpoch 2/3\r\n32/32 \u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501 0s 4ms/step - mean_absolute_error: 0.4075 - loss: 0.1271\r\nEpoch 3/3\r\n32/32 \u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501 0s 4ms/step - mean_absolute_error: 0.3776 - loss: 0.1010\r\n32/32 \u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501 0s 2ms/step - mean_absolute_error: 0.8608 - loss: 0.9672\r\nTraceback (most recent call last):\r\n File \"E:\\custom_train_step_in_torch.py\", line 483, in <module>\r\n gan.fit(dataloader, epochs=1)\r\n File \"C:\\Python_310\\lib\\site-packages\\keras_core\\src\\utils\\traceback_utils.py\", line 123, in error_handler\r\n raise e.with_traceback(filtered_tb) from None\r\n File \"C:\\Python_310\\lib\\site-packages\\keras_core\\src\\utils\\module_utils.py\", line 26, in initialize\r\n raise ImportError(\r\nImportError: This requires the tensorflow module. You can install it via `pip install tensorflow`\n", "before_files": [{"content": "import importlib\n\n\nclass LazyModule:\n def __init__(self, name, pip_name=None):\n self.name = name\n pip_name = pip_name or name\n self.pip_name = pip_name\n self.module = None\n self._available = None\n\n @property\n def available(self):\n if self._available is None:\n try:\n self.initialize()\n except ImportError:\n self._available = False\n self._available = True\n return self._available\n\n def initialize(self):\n try:\n self.module = importlib.import_module(self.name)\n except ImportError:\n raise ImportError(\n f\"This requires the {self.name} module. \"\n f\"You can install it via `pip install {self.pip_name}`\"\n )\n\n def __getattr__(self, name):\n if self.module is None:\n self.initialize()\n return getattr(self.module, name)\n\n\ntensorflow = LazyModule(\"tensorflow\")\ngfile = LazyModule(\"tensorflow.io.gfile\")\n", "path": "keras_core/utils/module_utils.py"}]}
| 1,622 | 110 |
gh_patches_debug_1251
|
rasdani/github-patches
|
git_diff
|
chainer__chainer-987
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix the shape of return value of F.det
Currently, return value of `det` is `xp.array` whose shape is `(1, )`, not a scalar.
```
In [16]: a = chainer.Variable(numpy.random.uniform(-1, 1, (3, 3)).astype(numpy.float32))
In [17]: chainer.functions.det(a).data
Out[17]: array([-0.80874199], dtype=float32)
```
But the document says the return value should be `chainer.Variable` whose data have the shape `()`.
</issue>
<code>
[start of chainer/functions/math/det.py]
1 import numpy
2
3 from chainer import cuda
4 from chainer import function
5 from chainer.functions.array import reshape
6 from chainer.functions.math import inv
7 from chainer.functions.math import matmul
8 from chainer import utils
9 from chainer.utils import type_check
10
11
12 def _det_gpu(b):
13 # We do a batched LU decomposition on the GPU to compute
14 # and compute the determinant by multiplying the diagonal.
15 # Change the shape of the array to be size=1 minibatch if necessary.
16 # Also copy the matrix as the elments will be modified in-place.
17 a = matmul._as_batch_mat(b).copy()
18 n = a.shape[1]
19 n_matrices = len(a)
20 # Pivot array
21 p = cuda.cupy.zeros((n_matrices, n), dtype='int32')
22 # Output array
23 # These arrays hold information on the execution success
24 # or if the matrix was singular.
25 info1 = cuda.cupy.zeros(n_matrices, dtype=numpy.intp)
26 ap = matmul._mat_ptrs(a)
27 _, lda = matmul._get_ld(a)
28 cuda.cublas.sgetrfBatched(cuda.Device().cublas_handle, n, ap.data.ptr, lda,
29 p.data.ptr, info1.data.ptr, n_matrices)
30 det = cuda.cupy.prod(a.diagonal(axis1=1, axis2=2), axis=1)
31 # The determinant is equal to the product of the diagonal entries
32 # of `a` where the sign of `a` is flipped depending on whether
33 # the pivot array is equal to its index.
34 rng = cuda.cupy.arange(1, n + 1, dtype='int32')
35 parity = cuda.cupy.sum(p != rng, axis=1) % 2
36 sign = 1. - 2. * parity.astype('float32')
37 success = cuda.cupy.all(info1 == 0)
38 return det * sign, success
39
40
41 class BatchDet(function.Function):
42
43 @property
44 def label(self):
45 return 'det'
46
47 def check_type_forward(self, in_types):
48 type_check.expect(in_types.size() == 1)
49 a_type, = in_types
50 a_type = matmul._convert_type(a_type)
51 type_check.expect(a_type.dtype.kind == 'f')
52 # Only a minibatch of 2D array shapes allowed.
53 type_check.expect(a_type.ndim == 3)
54 # Matrix inversion only allowed for square matrices
55 # so assert the last two dimensions are equal.
56 type_check.expect(a_type.shape[-1] == a_type.shape[-2])
57
58 def forward_cpu(self, x):
59 self.detx = utils.force_array(numpy.linalg.det(x[0]))
60 return self.detx,
61
62 def forward_gpu(self, x):
63 self.detx, success = _det_gpu(x[0])
64 if not success:
65 raise ValueError('Singular Matrix')
66 return self.detx,
67
68 def backward_cpu(self, x, gy):
69 x, = x
70 gy, = gy
71 grad = (gy[:, None, None] * self.detx[:, None, None] *
72 numpy.linalg.inv(x.transpose((0, 2, 1))))
73 return utils.force_array(grad),
74
75 def backward_gpu(self, x, gy):
76 x, = x
77 gy, = gy
78 grad = (gy[:, None, None] * self.detx[:, None, None] *
79 inv._inv_gpu(x.transpose((0, 2, 1))))
80 return utils.force_array(grad),
81
82
83 def batch_det(a):
84 """Computes the determinant of a batch of square matrices.
85
86 Args:
87 a (Variable): Input array to compute the determinant for.
88 The first dimension should iterate over each matrix and be
89 of the batchsize.
90
91 Returns:
92 ~chainer.Variable: vector of determinants for every matrix
93 in the batch.
94
95 """
96 return BatchDet()(a)
97
98
99 def det(a):
100 """Computes the determinant of a single square matrix.
101
102 Args:
103 a (Variable): Input array to compute the determinant for.
104
105 Returns:
106 ~chainer.Variable: Scalar determinant of the matrix a.
107
108 """
109 shape = (1, len(a.data), a.data.shape[1])
110 batched_a = reshape.Reshape(shape)(a)
111 batched_det = BatchDet()(batched_a)
112 return reshape.Reshape((1, ))(batched_det)
113
[end of chainer/functions/math/det.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/chainer/functions/math/det.py b/chainer/functions/math/det.py
--- a/chainer/functions/math/det.py
+++ b/chainer/functions/math/det.py
@@ -109,4 +109,4 @@
shape = (1, len(a.data), a.data.shape[1])
batched_a = reshape.Reshape(shape)(a)
batched_det = BatchDet()(batched_a)
- return reshape.Reshape((1, ))(batched_det)
+ return reshape.Reshape(())(batched_det)
|
{"golden_diff": "diff --git a/chainer/functions/math/det.py b/chainer/functions/math/det.py\n--- a/chainer/functions/math/det.py\n+++ b/chainer/functions/math/det.py\n@@ -109,4 +109,4 @@\n shape = (1, len(a.data), a.data.shape[1])\n batched_a = reshape.Reshape(shape)(a)\n batched_det = BatchDet()(batched_a)\n- return reshape.Reshape((1, ))(batched_det)\n+ return reshape.Reshape(())(batched_det)\n", "issue": "Fix the shape of return value of F.det\nCurrently, return value of `det` is `xp.array` whose shape is `(1, )`, not a scalar.\n\n```\nIn [16]: a = chainer.Variable(numpy.random.uniform(-1, 1, (3, 3)).astype(numpy.float32))\nIn [17]: chainer.functions.det(a).data\nOut[17]: array([-0.80874199], dtype=float32)\n```\n\nBut the document says the return value should be `chainer.Variable` whose data have the shape `()`.\n\n", "before_files": [{"content": "import numpy\n\nfrom chainer import cuda\nfrom chainer import function\nfrom chainer.functions.array import reshape\nfrom chainer.functions.math import inv\nfrom chainer.functions.math import matmul\nfrom chainer import utils\nfrom chainer.utils import type_check\n\n\ndef _det_gpu(b):\n # We do a batched LU decomposition on the GPU to compute\n # and compute the determinant by multiplying the diagonal.\n # Change the shape of the array to be size=1 minibatch if necessary.\n # Also copy the matrix as the elments will be modified in-place.\n a = matmul._as_batch_mat(b).copy()\n n = a.shape[1]\n n_matrices = len(a)\n # Pivot array\n p = cuda.cupy.zeros((n_matrices, n), dtype='int32')\n # Output array\n # These arrays hold information on the execution success\n # or if the matrix was singular.\n info1 = cuda.cupy.zeros(n_matrices, dtype=numpy.intp)\n ap = matmul._mat_ptrs(a)\n _, lda = matmul._get_ld(a)\n cuda.cublas.sgetrfBatched(cuda.Device().cublas_handle, n, ap.data.ptr, lda,\n p.data.ptr, info1.data.ptr, n_matrices)\n det = cuda.cupy.prod(a.diagonal(axis1=1, axis2=2), axis=1)\n # The determinant is equal to the product of the diagonal entries\n # of `a` where the sign of `a` is flipped depending on whether\n # the pivot array is equal to its index.\n rng = cuda.cupy.arange(1, n + 1, dtype='int32')\n parity = cuda.cupy.sum(p != rng, axis=1) % 2\n sign = 1. - 2. * parity.astype('float32')\n success = cuda.cupy.all(info1 == 0)\n return det * sign, success\n\n\nclass BatchDet(function.Function):\n\n @property\n def label(self):\n return 'det'\n\n def check_type_forward(self, in_types):\n type_check.expect(in_types.size() == 1)\n a_type, = in_types\n a_type = matmul._convert_type(a_type)\n type_check.expect(a_type.dtype.kind == 'f')\n # Only a minibatch of 2D array shapes allowed.\n type_check.expect(a_type.ndim == 3)\n # Matrix inversion only allowed for square matrices\n # so assert the last two dimensions are equal.\n type_check.expect(a_type.shape[-1] == a_type.shape[-2])\n\n def forward_cpu(self, x):\n self.detx = utils.force_array(numpy.linalg.det(x[0]))\n return self.detx,\n\n def forward_gpu(self, x):\n self.detx, success = _det_gpu(x[0])\n if not success:\n raise ValueError('Singular Matrix')\n return self.detx,\n\n def backward_cpu(self, x, gy):\n x, = x\n gy, = gy\n grad = (gy[:, None, None] * self.detx[:, None, None] *\n numpy.linalg.inv(x.transpose((0, 2, 1))))\n return utils.force_array(grad),\n\n def backward_gpu(self, x, gy):\n x, = x\n gy, = gy\n grad = (gy[:, None, None] * self.detx[:, None, None] *\n inv._inv_gpu(x.transpose((0, 2, 1))))\n return utils.force_array(grad),\n\n\ndef batch_det(a):\n \"\"\"Computes the determinant of a batch of square matrices.\n\n Args:\n a (Variable): Input array to compute the determinant for.\n The first dimension should iterate over each matrix and be\n of the batchsize.\n\n Returns:\n ~chainer.Variable: vector of determinants for every matrix\n in the batch.\n\n \"\"\"\n return BatchDet()(a)\n\n\ndef det(a):\n \"\"\"Computes the determinant of a single square matrix.\n\n Args:\n a (Variable): Input array to compute the determinant for.\n\n Returns:\n ~chainer.Variable: Scalar determinant of the matrix a.\n\n \"\"\"\n shape = (1, len(a.data), a.data.shape[1])\n batched_a = reshape.Reshape(shape)(a)\n batched_det = BatchDet()(batched_a)\n return reshape.Reshape((1, ))(batched_det)\n", "path": "chainer/functions/math/det.py"}]}
| 1,864 | 123 |
gh_patches_debug_1484
|
rasdani/github-patches
|
git_diff
|
PyGithub__PyGithub-1891
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
allow PyJWT 2+
other libraries are moving to PyJWT2+ as requirement, is it possible to update pygithub as well? currently we can't use for example pygithub together with django-social-core
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2
3 ############################ Copyrights and license ############################
4 # #
5 # Copyright 2012 Vincent Jacques <[email protected]> #
6 # Copyright 2012 Zearin <[email protected]> #
7 # Copyright 2013 Vincent Jacques <[email protected]> #
8 # Copyright 2014 Tomas Radej <[email protected]> #
9 # Copyright 2014 Vincent Jacques <[email protected]> #
10 # Copyright 2015 Jimmy Zelinskie <[email protected]> #
11 # Copyright 2016 Felix Yan <[email protected]> #
12 # Copyright 2016 Jakub Wilk <[email protected]> #
13 # Copyright 2016 Jannis Gebauer <[email protected]> #
14 # Copyright 2016 Peter Buckley <[email protected]> #
15 # Copyright 2017 Hugo <[email protected]> #
16 # Copyright 2017 Jannis Gebauer <[email protected]> #
17 # Copyright 2017 Jannis Gebauer <[email protected]> #
18 # Copyright 2017 Nhomar Hernandez <[email protected]> #
19 # Copyright 2017 Paul Ortman <[email protected]> #
20 # Copyright 2018 Jason White <[email protected]> #
21 # Copyright 2018 Mike Miller <[email protected]> #
22 # Copyright 2018 Wan Liuyang <[email protected]> #
23 # Copyright 2018 sfdye <[email protected]> #
24 # #
25 # This file is part of PyGithub. #
26 # http://pygithub.readthedocs.io/ #
27 # #
28 # PyGithub is free software: you can redistribute it and/or modify it under #
29 # the terms of the GNU Lesser General Public License as published by the Free #
30 # Software Foundation, either version 3 of the License, or (at your option) #
31 # any later version. #
32 # #
33 # PyGithub is distributed in the hope that it will be useful, but WITHOUT ANY #
34 # WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS #
35 # FOR A PARTICULAR PURPOSE. See the GNU Lesser General Public License for more #
36 # details. #
37 # #
38 # You should have received a copy of the GNU Lesser General Public License #
39 # along with PyGithub. If not, see <http://www.gnu.org/licenses/>. #
40 # #
41 ################################################################################
42
43 import textwrap
44
45 import setuptools
46
47 version = "1.54.1"
48
49
50 if __name__ == "__main__":
51 setuptools.setup(
52 name="PyGithub",
53 version=version,
54 description="Use the full Github API v3",
55 author="Vincent Jacques",
56 author_email="[email protected]",
57 url="https://github.com/pygithub/pygithub",
58 project_urls={
59 "Documentation": "http://pygithub.readthedocs.io/en/latest/",
60 "Source": "https://github.com/pygithub/pygithub",
61 "Tracker": "https://github.com/pygithub/pygithub/issues",
62 },
63 long_description=textwrap.dedent(
64 """\
65 (Very short) Tutorial
66 =====================
67
68 First create a Github instance::
69
70 from github import Github
71
72 # using username and password
73 g = Github("user", "password")
74
75 # or using an access token
76 g = Github("access_token")
77
78 Then play with your Github objects::
79
80 for repo in g.get_user().get_repos():
81 print(repo.name)
82 repo.edit(has_wiki=False)
83
84 Reference documentation
85 =======================
86
87 See http://pygithub.readthedocs.io/en/latest/"""
88 ),
89 packages=["github"],
90 package_data={"github": ["py.typed", "*.pyi"]},
91 classifiers=[
92 "Development Status :: 5 - Production/Stable",
93 "Environment :: Web Environment",
94 "Intended Audience :: Developers",
95 "License :: OSI Approved :: GNU Library or Lesser General Public License (LGPL)",
96 "Operating System :: OS Independent",
97 "Programming Language :: Python",
98 "Programming Language :: Python :: 3",
99 "Programming Language :: Python :: 3.6",
100 "Programming Language :: Python :: 3.7",
101 "Programming Language :: Python :: 3.8",
102 "Programming Language :: Python :: 3.9",
103 "Topic :: Software Development",
104 ],
105 python_requires=">=3.6",
106 install_requires=[
107 "deprecated",
108 "pyjwt<2.0",
109 "pynacl>=1.4.0",
110 "requests>=2.14.0",
111 ],
112 extras_require={"integrations": ["cryptography"]},
113 tests_require=["cryptography", "httpretty>=1.0.3"],
114 )
115
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -105,7 +105,7 @@
python_requires=">=3.6",
install_requires=[
"deprecated",
- "pyjwt<2.0",
+ "pyjwt>=2.0",
"pynacl>=1.4.0",
"requests>=2.14.0",
],
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -105,7 +105,7 @@\n python_requires=\">=3.6\",\n install_requires=[\n \"deprecated\",\n- \"pyjwt<2.0\",\n+ \"pyjwt>=2.0\",\n \"pynacl>=1.4.0\",\n \"requests>=2.14.0\",\n ],\n", "issue": "allow PyJWT 2+\nother libraries are moving to PyJWT2+ as requirement, is it possible to update pygithub as well? currently we can't use for example pygithub together with django-social-core\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\n\n############################ Copyrights and license ############################\n# #\n# Copyright 2012 Vincent Jacques <[email protected]> #\n# Copyright 2012 Zearin <[email protected]> #\n# Copyright 2013 Vincent Jacques <[email protected]> #\n# Copyright 2014 Tomas Radej <[email protected]> #\n# Copyright 2014 Vincent Jacques <[email protected]> #\n# Copyright 2015 Jimmy Zelinskie <[email protected]> #\n# Copyright 2016 Felix Yan <[email protected]> #\n# Copyright 2016 Jakub Wilk <[email protected]> #\n# Copyright 2016 Jannis Gebauer <[email protected]> #\n# Copyright 2016 Peter Buckley <[email protected]> #\n# Copyright 2017 Hugo <[email protected]> #\n# Copyright 2017 Jannis Gebauer <[email protected]> #\n# Copyright 2017 Jannis Gebauer <[email protected]> #\n# Copyright 2017 Nhomar Hernandez <[email protected]> #\n# Copyright 2017 Paul Ortman <[email protected]> #\n# Copyright 2018 Jason White <[email protected]> #\n# Copyright 2018 Mike Miller <[email protected]> #\n# Copyright 2018 Wan Liuyang <[email protected]> #\n# Copyright 2018 sfdye <[email protected]> #\n# #\n# This file is part of PyGithub. #\n# http://pygithub.readthedocs.io/ #\n# #\n# PyGithub is free software: you can redistribute it and/or modify it under #\n# the terms of the GNU Lesser General Public License as published by the Free #\n# Software Foundation, either version 3 of the License, or (at your option) #\n# any later version. #\n# #\n# PyGithub is distributed in the hope that it will be useful, but WITHOUT ANY #\n# WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS #\n# FOR A PARTICULAR PURPOSE. See the GNU Lesser General Public License for more #\n# details. #\n# #\n# You should have received a copy of the GNU Lesser General Public License #\n# along with PyGithub. If not, see <http://www.gnu.org/licenses/>. #\n# #\n################################################################################\n\nimport textwrap\n\nimport setuptools\n\nversion = \"1.54.1\"\n\n\nif __name__ == \"__main__\":\n setuptools.setup(\n name=\"PyGithub\",\n version=version,\n description=\"Use the full Github API v3\",\n author=\"Vincent Jacques\",\n author_email=\"[email protected]\",\n url=\"https://github.com/pygithub/pygithub\",\n project_urls={\n \"Documentation\": \"http://pygithub.readthedocs.io/en/latest/\",\n \"Source\": \"https://github.com/pygithub/pygithub\",\n \"Tracker\": \"https://github.com/pygithub/pygithub/issues\",\n },\n long_description=textwrap.dedent(\n \"\"\"\\\n (Very short) Tutorial\n =====================\n\n First create a Github instance::\n\n from github import Github\n\n # using username and password\n g = Github(\"user\", \"password\")\n\n # or using an access token\n g = Github(\"access_token\")\n\n Then play with your Github objects::\n\n for repo in g.get_user().get_repos():\n print(repo.name)\n repo.edit(has_wiki=False)\n\n Reference documentation\n =======================\n\n See http://pygithub.readthedocs.io/en/latest/\"\"\"\n ),\n packages=[\"github\"],\n package_data={\"github\": [\"py.typed\", \"*.pyi\"]},\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Environment :: Web Environment\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: GNU Library or Lesser General Public License (LGPL)\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Topic :: Software Development\",\n ],\n python_requires=\">=3.6\",\n install_requires=[\n \"deprecated\",\n \"pyjwt<2.0\",\n \"pynacl>=1.4.0\",\n \"requests>=2.14.0\",\n ],\n extras_require={\"integrations\": [\"cryptography\"]},\n tests_require=[\"cryptography\", \"httpretty>=1.0.3\"],\n )\n", "path": "setup.py"}]}
| 1,937 | 97 |
gh_patches_debug_14714
|
rasdani/github-patches
|
git_diff
|
bokeh__bokeh-8466
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
"CustomJS for Selections" Example in Docs Broken
In the latest version of the docs, it appears [this example]( https://bokeh.pydata.org/en/latest/docs/user_guide/interaction/callbacks.html#customjs-for-selections ) is broken. This is also true of the example in the Bokeh 1.0.0 docs. Selecting points in the plot on the left does not result in points being shown in the right plot. Compare this to [the same plot using Bokeh 0.13.0]( https://bokeh.pydata.org/en/0.13.0/docs/user_guide/interaction/callbacks.html#customjs-for-selections ), which seems to work without issues.
</issue>
<code>
[start of sphinx/source/docs/user_guide/examples/interaction_callbacks_for_selections.py]
1 from random import random
2
3 from bokeh.layouts import row
4 from bokeh.models import CustomJS, ColumnDataSource
5 from bokeh.plotting import figure, output_file, show
6
7 output_file("callback.html")
8
9 x = [random() for x in range(500)]
10 y = [random() for y in range(500)]
11
12 s1 = ColumnDataSource(data=dict(x=x, y=y))
13 p1 = figure(plot_width=400, plot_height=400, tools="lasso_select", title="Select Here")
14 p1.circle('x', 'y', source=s1, alpha=0.6)
15
16 s2 = ColumnDataSource(data=dict(x=[], y=[]))
17 p2 = figure(plot_width=400, plot_height=400, x_range=(0, 1), y_range=(0, 1),
18 tools="", title="Watch Here")
19 p2.circle('x', 'y', source=s2, alpha=0.6)
20
21 s1.callback = CustomJS(args=dict(s2=s2), code="""
22 var inds = cb_obj.selected.indices;
23 var d1 = cb_obj.data;
24 var d2 = s2.data;
25 d2['x'] = []
26 d2['y'] = []
27 for (var i = 0; i < inds.length; i++) {
28 d2['x'].push(d1['x'][inds[i]])
29 d2['y'].push(d1['y'][inds[i]])
30 }
31 s2.change.emit();
32 """)
33
34 layout = row(p1, p2)
35
36 show(layout)
37
[end of sphinx/source/docs/user_guide/examples/interaction_callbacks_for_selections.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sphinx/source/docs/user_guide/examples/interaction_callbacks_for_selections.py b/sphinx/source/docs/user_guide/examples/interaction_callbacks_for_selections.py
--- a/sphinx/source/docs/user_guide/examples/interaction_callbacks_for_selections.py
+++ b/sphinx/source/docs/user_guide/examples/interaction_callbacks_for_selections.py
@@ -18,9 +18,9 @@
tools="", title="Watch Here")
p2.circle('x', 'y', source=s2, alpha=0.6)
-s1.callback = CustomJS(args=dict(s2=s2), code="""
- var inds = cb_obj.selected.indices;
- var d1 = cb_obj.data;
+s1.selected.js_on_change('indices', CustomJS(args=dict(s1=s1, s2=s2), code="""
+ var inds = cb_obj.indices;
+ var d1 = s1.data;
var d2 = s2.data;
d2['x'] = []
d2['y'] = []
@@ -30,6 +30,7 @@
}
s2.change.emit();
""")
+)
layout = row(p1, p2)
|
{"golden_diff": "diff --git a/sphinx/source/docs/user_guide/examples/interaction_callbacks_for_selections.py b/sphinx/source/docs/user_guide/examples/interaction_callbacks_for_selections.py\n--- a/sphinx/source/docs/user_guide/examples/interaction_callbacks_for_selections.py\n+++ b/sphinx/source/docs/user_guide/examples/interaction_callbacks_for_selections.py\n@@ -18,9 +18,9 @@\n tools=\"\", title=\"Watch Here\")\n p2.circle('x', 'y', source=s2, alpha=0.6)\n \n-s1.callback = CustomJS(args=dict(s2=s2), code=\"\"\"\n- var inds = cb_obj.selected.indices;\n- var d1 = cb_obj.data;\n+s1.selected.js_on_change('indices', CustomJS(args=dict(s1=s1, s2=s2), code=\"\"\"\n+ var inds = cb_obj.indices;\n+ var d1 = s1.data;\n var d2 = s2.data;\n d2['x'] = []\n d2['y'] = []\n@@ -30,6 +30,7 @@\n }\n s2.change.emit();\n \"\"\")\n+)\n \n layout = row(p1, p2)\n", "issue": "\"CustomJS for Selections\" Example in Docs Broken\nIn the latest version of the docs, it appears [this example]( https://bokeh.pydata.org/en/latest/docs/user_guide/interaction/callbacks.html#customjs-for-selections ) is broken. This is also true of the example in the Bokeh 1.0.0 docs. Selecting points in the plot on the left does not result in points being shown in the right plot. Compare this to [the same plot using Bokeh 0.13.0]( https://bokeh.pydata.org/en/0.13.0/docs/user_guide/interaction/callbacks.html#customjs-for-selections ), which seems to work without issues.\n", "before_files": [{"content": "from random import random\n\nfrom bokeh.layouts import row\nfrom bokeh.models import CustomJS, ColumnDataSource\nfrom bokeh.plotting import figure, output_file, show\n\noutput_file(\"callback.html\")\n\nx = [random() for x in range(500)]\ny = [random() for y in range(500)]\n\ns1 = ColumnDataSource(data=dict(x=x, y=y))\np1 = figure(plot_width=400, plot_height=400, tools=\"lasso_select\", title=\"Select Here\")\np1.circle('x', 'y', source=s1, alpha=0.6)\n\ns2 = ColumnDataSource(data=dict(x=[], y=[]))\np2 = figure(plot_width=400, plot_height=400, x_range=(0, 1), y_range=(0, 1),\n tools=\"\", title=\"Watch Here\")\np2.circle('x', 'y', source=s2, alpha=0.6)\n\ns1.callback = CustomJS(args=dict(s2=s2), code=\"\"\"\n var inds = cb_obj.selected.indices;\n var d1 = cb_obj.data;\n var d2 = s2.data;\n d2['x'] = []\n d2['y'] = []\n for (var i = 0; i < inds.length; i++) {\n d2['x'].push(d1['x'][inds[i]])\n d2['y'].push(d1['y'][inds[i]])\n }\n s2.change.emit();\n \"\"\")\n\nlayout = row(p1, p2)\n\nshow(layout)\n", "path": "sphinx/source/docs/user_guide/examples/interaction_callbacks_for_selections.py"}]}
| 1,108 | 250 |
gh_patches_debug_41073
|
rasdani/github-patches
|
git_diff
|
PaddlePaddle__PaddleSeg-1747
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
paddleseg/models/hrnet_contrast.py 中没有执行 init_weight
paddleseg/models/hrnet_contrast.py 中__init__()没有执行 init_weight,导致hrnet_w48_contrast 没法加载完整的模型
</issue>
<code>
[start of paddleseg/models/hrnet_contrast.py]
1 # Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import paddle
16 import paddle.nn as nn
17 import paddle.nn.functional as F
18
19 from paddleseg.cvlibs import manager
20 from paddleseg.models import layers
21 from paddleseg.utils import utils
22
23
24 @manager.MODELS.add_component
25 class HRNetW48Contrast(nn.Layer):
26 """
27 The HRNetW48Contrast implementation based on PaddlePaddle.
28
29 The original article refers to
30 Wenguan Wang, Tianfei Zhou, et al. "Exploring Cross-Image Pixel Contrast for Semantic Segmentation"
31 (https://arxiv.org/abs/2101.11939).
32
33 Args:
34 in_channels (int): The output dimensions of backbone.
35 num_classes (int): The unique number of target classes.
36 backbone (Paddle.nn.Layer): Backbone network, currently support HRNet_W48.
37 drop_prob (float): The probability of dropout.
38 proj_dim (int): The projection dimensions.
39 align_corners (bool, optional): An argument of F.interpolate. It should be set to False when the feature size is even,
40 e.g. 1024x512, otherwise it is True, e.g. 769x769. Default: False.
41 pretrained (str, optional): The path or url of pretrained model. Default: None.
42 """
43 def __init__(self,
44 in_channels,
45 num_classes,
46 backbone,
47 drop_prob,
48 proj_dim,
49 align_corners=False,
50 pretrained=None):
51 super().__init__()
52 self.in_channels = in_channels
53 self.backbone = backbone
54 self.num_classes = num_classes
55 self.proj_dim = proj_dim
56 self.align_corners = align_corners
57 self.pretrained = pretrained
58
59 self.cls_head = nn.Sequential(
60 layers.ConvBNReLU(in_channels,
61 in_channels,
62 kernel_size=3,
63 stride=1,
64 padding=1),
65 nn.Dropout2D(drop_prob),
66 nn.Conv2D(in_channels,
67 num_classes,
68 kernel_size=1,
69 stride=1,
70 bias_attr=False),
71 )
72 self.proj_head = ProjectionHead(dim_in=in_channels,
73 proj_dim=self.proj_dim)
74
75 def init_weight(self):
76 if self.pretrained is not None:
77 utils.load_entire_model(self, self.pretrained)
78
79 def forward(self, x):
80 feats = self.backbone(x)[0]
81 out = self.cls_head(feats)
82 logit_list = []
83 if self.training:
84 emb = self.proj_head(feats)
85 logit_list.append(
86 F.interpolate(out,
87 paddle.shape(x)[2:],
88 mode='bilinear',
89 align_corners=self.align_corners))
90 logit_list.append({'seg': out, 'embed': emb})
91 else:
92 logit_list.append(
93 F.interpolate(out,
94 paddle.shape(x)[2:],
95 mode='bilinear',
96 align_corners=self.align_corners))
97 return logit_list
98
99
100 class ProjectionHead(nn.Layer):
101 """
102 The projection head used by contrast learning.
103 Args:
104 dim_in (int): The dimensions of input features.
105 proj_dim (int, optional): The output dimensions of projection head. Default: 256.
106 proj (str, optional): The type of projection head, only support 'linear' and 'convmlp'. Default: 'convmlp'.
107 """
108 def __init__(self, dim_in, proj_dim=256, proj='convmlp'):
109 super(ProjectionHead, self).__init__()
110 if proj == 'linear':
111 self.proj = nn.Conv2D(dim_in, proj_dim, kernel_size=1)
112 elif proj == 'convmlp':
113 self.proj = nn.Sequential(
114 layers.ConvBNReLU(dim_in, dim_in, kernel_size=1),
115 nn.Conv2D(dim_in, proj_dim, kernel_size=1),
116 )
117 else:
118 raise ValueError(
119 "The type of project head only support 'linear' and 'convmlp', but got {}."
120 .format(proj))
121
122 def forward(self, x):
123 return F.normalize(self.proj(x), p=2, axis=1)
124
[end of paddleseg/models/hrnet_contrast.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/paddleseg/models/hrnet_contrast.py b/paddleseg/models/hrnet_contrast.py
--- a/paddleseg/models/hrnet_contrast.py
+++ b/paddleseg/models/hrnet_contrast.py
@@ -40,6 +40,7 @@
e.g. 1024x512, otherwise it is True, e.g. 769x769. Default: False.
pretrained (str, optional): The path or url of pretrained model. Default: None.
"""
+
def __init__(self,
in_channels,
num_classes,
@@ -54,23 +55,23 @@
self.num_classes = num_classes
self.proj_dim = proj_dim
self.align_corners = align_corners
- self.pretrained = pretrained
self.cls_head = nn.Sequential(
- layers.ConvBNReLU(in_channels,
- in_channels,
- kernel_size=3,
- stride=1,
- padding=1),
+ layers.ConvBNReLU(
+ in_channels, in_channels, kernel_size=3, stride=1, padding=1),
nn.Dropout2D(drop_prob),
- nn.Conv2D(in_channels,
- num_classes,
- kernel_size=1,
- stride=1,
- bias_attr=False),
+ nn.Conv2D(
+ in_channels,
+ num_classes,
+ kernel_size=1,
+ stride=1,
+ bias_attr=False),
)
- self.proj_head = ProjectionHead(dim_in=in_channels,
- proj_dim=self.proj_dim)
+ self.proj_head = ProjectionHead(
+ dim_in=in_channels, proj_dim=self.proj_dim)
+
+ self.pretrained = pretrained
+ self.init_weight()
def init_weight(self):
if self.pretrained is not None:
@@ -83,17 +84,19 @@
if self.training:
emb = self.proj_head(feats)
logit_list.append(
- F.interpolate(out,
- paddle.shape(x)[2:],
- mode='bilinear',
- align_corners=self.align_corners))
+ F.interpolate(
+ out,
+ paddle.shape(x)[2:],
+ mode='bilinear',
+ align_corners=self.align_corners))
logit_list.append({'seg': out, 'embed': emb})
else:
logit_list.append(
- F.interpolate(out,
- paddle.shape(x)[2:],
- mode='bilinear',
- align_corners=self.align_corners))
+ F.interpolate(
+ out,
+ paddle.shape(x)[2:],
+ mode='bilinear',
+ align_corners=self.align_corners))
return logit_list
@@ -105,6 +108,7 @@
proj_dim (int, optional): The output dimensions of projection head. Default: 256.
proj (str, optional): The type of projection head, only support 'linear' and 'convmlp'. Default: 'convmlp'.
"""
+
def __init__(self, dim_in, proj_dim=256, proj='convmlp'):
super(ProjectionHead, self).__init__()
if proj == 'linear':
|
{"golden_diff": "diff --git a/paddleseg/models/hrnet_contrast.py b/paddleseg/models/hrnet_contrast.py\n--- a/paddleseg/models/hrnet_contrast.py\n+++ b/paddleseg/models/hrnet_contrast.py\n@@ -40,6 +40,7 @@\n e.g. 1024x512, otherwise it is True, e.g. 769x769. Default: False.\n pretrained (str, optional): The path or url of pretrained model. Default: None.\n \"\"\"\n+\n def __init__(self,\n in_channels,\n num_classes,\n@@ -54,23 +55,23 @@\n self.num_classes = num_classes\n self.proj_dim = proj_dim\n self.align_corners = align_corners\n- self.pretrained = pretrained\n \n self.cls_head = nn.Sequential(\n- layers.ConvBNReLU(in_channels,\n- in_channels,\n- kernel_size=3,\n- stride=1,\n- padding=1),\n+ layers.ConvBNReLU(\n+ in_channels, in_channels, kernel_size=3, stride=1, padding=1),\n nn.Dropout2D(drop_prob),\n- nn.Conv2D(in_channels,\n- num_classes,\n- kernel_size=1,\n- stride=1,\n- bias_attr=False),\n+ nn.Conv2D(\n+ in_channels,\n+ num_classes,\n+ kernel_size=1,\n+ stride=1,\n+ bias_attr=False),\n )\n- self.proj_head = ProjectionHead(dim_in=in_channels,\n- proj_dim=self.proj_dim)\n+ self.proj_head = ProjectionHead(\n+ dim_in=in_channels, proj_dim=self.proj_dim)\n+\n+ self.pretrained = pretrained\n+ self.init_weight()\n \n def init_weight(self):\n if self.pretrained is not None:\n@@ -83,17 +84,19 @@\n if self.training:\n emb = self.proj_head(feats)\n logit_list.append(\n- F.interpolate(out,\n- paddle.shape(x)[2:],\n- mode='bilinear',\n- align_corners=self.align_corners))\n+ F.interpolate(\n+ out,\n+ paddle.shape(x)[2:],\n+ mode='bilinear',\n+ align_corners=self.align_corners))\n logit_list.append({'seg': out, 'embed': emb})\n else:\n logit_list.append(\n- F.interpolate(out,\n- paddle.shape(x)[2:],\n- mode='bilinear',\n- align_corners=self.align_corners))\n+ F.interpolate(\n+ out,\n+ paddle.shape(x)[2:],\n+ mode='bilinear',\n+ align_corners=self.align_corners))\n return logit_list\n \n \n@@ -105,6 +108,7 @@\n proj_dim (int, optional): The output dimensions of projection head. Default: 256.\n proj (str, optional): The type of projection head, only support 'linear' and 'convmlp'. Default: 'convmlp'.\n \"\"\"\n+\n def __init__(self, dim_in, proj_dim=256, proj='convmlp'):\n super(ProjectionHead, self).__init__()\n if proj == 'linear':\n", "issue": "paddleseg/models/hrnet_contrast.py \u4e2d\u6ca1\u6709\u6267\u884c init_weight\npaddleseg/models/hrnet_contrast.py \u4e2d__init__()\u6ca1\u6709\u6267\u884c init_weight\uff0c\u5bfc\u81f4hrnet_w48_contrast \u6ca1\u6cd5\u52a0\u8f7d\u5b8c\u6574\u7684\u6a21\u578b\n", "before_files": [{"content": "# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport paddle\nimport paddle.nn as nn\nimport paddle.nn.functional as F\n\nfrom paddleseg.cvlibs import manager\nfrom paddleseg.models import layers\nfrom paddleseg.utils import utils\n\n\[email protected]_component\nclass HRNetW48Contrast(nn.Layer):\n \"\"\"\n The HRNetW48Contrast implementation based on PaddlePaddle.\n\n The original article refers to\n Wenguan Wang, Tianfei Zhou, et al. \"Exploring Cross-Image Pixel Contrast for Semantic Segmentation\"\n (https://arxiv.org/abs/2101.11939).\n\n Args:\n in_channels (int): The output dimensions of backbone.\n num_classes (int): The unique number of target classes.\n backbone (Paddle.nn.Layer): Backbone network, currently support HRNet_W48.\n drop_prob (float): The probability of dropout.\n proj_dim (int): The projection dimensions.\n align_corners (bool, optional): An argument of F.interpolate. It should be set to False when the feature size is even,\n e.g. 1024x512, otherwise it is True, e.g. 769x769. Default: False.\n pretrained (str, optional): The path or url of pretrained model. Default: None.\n \"\"\"\n def __init__(self,\n in_channels,\n num_classes,\n backbone,\n drop_prob,\n proj_dim,\n align_corners=False,\n pretrained=None):\n super().__init__()\n self.in_channels = in_channels\n self.backbone = backbone\n self.num_classes = num_classes\n self.proj_dim = proj_dim\n self.align_corners = align_corners\n self.pretrained = pretrained\n\n self.cls_head = nn.Sequential(\n layers.ConvBNReLU(in_channels,\n in_channels,\n kernel_size=3,\n stride=1,\n padding=1),\n nn.Dropout2D(drop_prob),\n nn.Conv2D(in_channels,\n num_classes,\n kernel_size=1,\n stride=1,\n bias_attr=False),\n )\n self.proj_head = ProjectionHead(dim_in=in_channels,\n proj_dim=self.proj_dim)\n\n def init_weight(self):\n if self.pretrained is not None:\n utils.load_entire_model(self, self.pretrained)\n\n def forward(self, x):\n feats = self.backbone(x)[0]\n out = self.cls_head(feats)\n logit_list = []\n if self.training:\n emb = self.proj_head(feats)\n logit_list.append(\n F.interpolate(out,\n paddle.shape(x)[2:],\n mode='bilinear',\n align_corners=self.align_corners))\n logit_list.append({'seg': out, 'embed': emb})\n else:\n logit_list.append(\n F.interpolate(out,\n paddle.shape(x)[2:],\n mode='bilinear',\n align_corners=self.align_corners))\n return logit_list\n\n\nclass ProjectionHead(nn.Layer):\n \"\"\"\n The projection head used by contrast learning.\n Args:\n dim_in (int): The dimensions of input features.\n proj_dim (int, optional): The output dimensions of projection head. Default: 256.\n proj (str, optional): The type of projection head, only support 'linear' and 'convmlp'. Default: 'convmlp'.\n \"\"\"\n def __init__(self, dim_in, proj_dim=256, proj='convmlp'):\n super(ProjectionHead, self).__init__()\n if proj == 'linear':\n self.proj = nn.Conv2D(dim_in, proj_dim, kernel_size=1)\n elif proj == 'convmlp':\n self.proj = nn.Sequential(\n layers.ConvBNReLU(dim_in, dim_in, kernel_size=1),\n nn.Conv2D(dim_in, proj_dim, kernel_size=1),\n )\n else:\n raise ValueError(\n \"The type of project head only support 'linear' and 'convmlp', but got {}.\"\n .format(proj))\n\n def forward(self, x):\n return F.normalize(self.proj(x), p=2, axis=1)\n", "path": "paddleseg/models/hrnet_contrast.py"}]}
| 1,881 | 702 |
gh_patches_debug_6236
|
rasdani/github-patches
|
git_diff
|
engnadeau__pybotics-18
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Update examples
Examples are now out of sync with current codebase. Potential use for iPython?
</issue>
<code>
[start of examples/example_robot.py]
1 import copy
2
3 import pybotics as py
4 import numpy as np
5
6 # set numpy print options
7 np.set_printoptions(precision=3)
8 np.set_printoptions(suppress=True)
9
10 # create robot
11 model = np.loadtxt('ur10-mdh.csv', delimiter=',')
12 robot = py.Robot(model)
13
14 print('Robot Model:\n{}\n'.format(robot.robot_model))
15
16 # demonstrate forward kinematics
17 joints = [0] * robot.num_dof()
18 pose = robot.fk(joints)
19
20 print('Pose:\n{}\n'.format(pose))
21
22 # demonstrate inverse kinematics
23 new_joints = robot.ik(pose)
24 print('Solved Joints:\n{}\n'.format(new_joints))
25
[end of examples/example_robot.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/example_robot.py b/examples/example_robot.py
deleted file mode 100644
--- a/examples/example_robot.py
+++ /dev/null
@@ -1,24 +0,0 @@
-import copy
-
-import pybotics as py
-import numpy as np
-
-# set numpy print options
-np.set_printoptions(precision=3)
-np.set_printoptions(suppress=True)
-
-# create robot
-model = np.loadtxt('ur10-mdh.csv', delimiter=',')
-robot = py.Robot(model)
-
-print('Robot Model:\n{}\n'.format(robot.robot_model))
-
-# demonstrate forward kinematics
-joints = [0] * robot.num_dof()
-pose = robot.fk(joints)
-
-print('Pose:\n{}\n'.format(pose))
-
-# demonstrate inverse kinematics
-new_joints = robot.ik(pose)
-print('Solved Joints:\n{}\n'.format(new_joints))
|
{"golden_diff": "diff --git a/examples/example_robot.py b/examples/example_robot.py\ndeleted file mode 100644\n--- a/examples/example_robot.py\n+++ /dev/null\n@@ -1,24 +0,0 @@\n-import copy\n-\n-import pybotics as py\n-import numpy as np\n-\n-# set numpy print options\n-np.set_printoptions(precision=3)\n-np.set_printoptions(suppress=True)\n-\n-# create robot\n-model = np.loadtxt('ur10-mdh.csv', delimiter=',')\n-robot = py.Robot(model)\n-\n-print('Robot Model:\\n{}\\n'.format(robot.robot_model))\n-\n-# demonstrate forward kinematics\n-joints = [0] * robot.num_dof()\n-pose = robot.fk(joints)\n-\n-print('Pose:\\n{}\\n'.format(pose))\n-\n-# demonstrate inverse kinematics\n-new_joints = robot.ik(pose)\n-print('Solved Joints:\\n{}\\n'.format(new_joints))\n", "issue": "Update examples\nExamples are now out of sync with current codebase. Potential use for iPython?\n", "before_files": [{"content": "import copy\n\nimport pybotics as py\nimport numpy as np\n\n# set numpy print options\nnp.set_printoptions(precision=3)\nnp.set_printoptions(suppress=True)\n\n# create robot\nmodel = np.loadtxt('ur10-mdh.csv', delimiter=',')\nrobot = py.Robot(model)\n\nprint('Robot Model:\\n{}\\n'.format(robot.robot_model))\n\n# demonstrate forward kinematics\njoints = [0] * robot.num_dof()\npose = robot.fk(joints)\n\nprint('Pose:\\n{}\\n'.format(pose))\n\n# demonstrate inverse kinematics\nnew_joints = robot.ik(pose)\nprint('Solved Joints:\\n{}\\n'.format(new_joints))\n", "path": "examples/example_robot.py"}]}
| 750 | 213 |
gh_patches_debug_31739
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-1863
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Remove 9anime.to
As discussed over here: https://github.com/streamlink/streamlink/issues/1110#issuecomment-400687075 9anime.to isn't worth supporting at this point and is broken so I'm proposing we remove it.
</issue>
<code>
[start of src/streamlink/plugins/nineanime.py]
1 import re
2 from streamlink.plugin import Plugin
3 from streamlink.plugin.api import http
4 from streamlink.plugin.api import useragents
5 from streamlink.plugin.api import validate
6 from streamlink.stream import HTTPStream
7 from streamlink.compat import urlparse
8
9
10 class NineAnime(Plugin):
11 _episode_info_url = "//9anime.to/ajax/episode/info"
12
13 _info_schema = validate.Schema({
14 "grabber": validate.url(),
15 "params": {
16 "id": validate.text,
17 "token": validate.text,
18 "options": validate.text,
19 }
20 })
21
22 _streams_schema = validate.Schema({
23 "token": validate.text,
24 "error": None,
25 "data": [{
26 "label": validate.text,
27 "file": validate.url(),
28 "type": "mp4"
29 }]
30 })
31
32 _url_re = re.compile(r"https?://9anime.to/watch/(?:[^.]+?\.)(\w+)/(\w+)")
33
34 @classmethod
35 def can_handle_url(cls, url):
36 return cls._url_re.match(url) is not None
37
38 def add_scheme(self, url):
39 # update the scheme for the grabber url if required
40 if url.startswith("//"):
41 url = "{0}:{1}".format(urlparse(self.url).scheme, url)
42 return url
43
44 @Plugin.broken(1110)
45 def _get_streams(self):
46 match = self._url_re.match(self.url)
47 film_id, episode_id = match.groups()
48
49 headers = {
50 "Referer": self.url,
51 "User-Agent": useragents.FIREFOX
52 }
53
54 # Get the info about the Episode, including the Grabber API URL
55 info_res = http.get(self.add_scheme(self._episode_info_url),
56 params=dict(update=0, film=film_id, id=episode_id),
57 headers=headers)
58 info = http.json(info_res, schema=self._info_schema)
59
60 # Get the data about the streams from the Grabber API
61 grabber_url = self.add_scheme(info["grabber"])
62 stream_list_res = http.get(grabber_url, params=info["params"], headers=headers)
63 stream_data = http.json(stream_list_res, schema=self._streams_schema)
64
65 for stream in stream_data["data"]:
66 yield stream["label"], HTTPStream(self.session, stream["file"])
67
68
69 __plugin__ = NineAnime
70
[end of src/streamlink/plugins/nineanime.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/streamlink/plugins/nineanime.py b/src/streamlink/plugins/nineanime.py
--- a/src/streamlink/plugins/nineanime.py
+++ b/src/streamlink/plugins/nineanime.py
@@ -1,69 +1 @@
-import re
-from streamlink.plugin import Plugin
-from streamlink.plugin.api import http
-from streamlink.plugin.api import useragents
-from streamlink.plugin.api import validate
-from streamlink.stream import HTTPStream
-from streamlink.compat import urlparse
-
-
-class NineAnime(Plugin):
- _episode_info_url = "//9anime.to/ajax/episode/info"
-
- _info_schema = validate.Schema({
- "grabber": validate.url(),
- "params": {
- "id": validate.text,
- "token": validate.text,
- "options": validate.text,
- }
- })
-
- _streams_schema = validate.Schema({
- "token": validate.text,
- "error": None,
- "data": [{
- "label": validate.text,
- "file": validate.url(),
- "type": "mp4"
- }]
- })
-
- _url_re = re.compile(r"https?://9anime.to/watch/(?:[^.]+?\.)(\w+)/(\w+)")
-
- @classmethod
- def can_handle_url(cls, url):
- return cls._url_re.match(url) is not None
-
- def add_scheme(self, url):
- # update the scheme for the grabber url if required
- if url.startswith("//"):
- url = "{0}:{1}".format(urlparse(self.url).scheme, url)
- return url
-
- @Plugin.broken(1110)
- def _get_streams(self):
- match = self._url_re.match(self.url)
- film_id, episode_id = match.groups()
-
- headers = {
- "Referer": self.url,
- "User-Agent": useragents.FIREFOX
- }
-
- # Get the info about the Episode, including the Grabber API URL
- info_res = http.get(self.add_scheme(self._episode_info_url),
- params=dict(update=0, film=film_id, id=episode_id),
- headers=headers)
- info = http.json(info_res, schema=self._info_schema)
-
- # Get the data about the streams from the Grabber API
- grabber_url = self.add_scheme(info["grabber"])
- stream_list_res = http.get(grabber_url, params=info["params"], headers=headers)
- stream_data = http.json(stream_list_res, schema=self._streams_schema)
-
- for stream in stream_data["data"]:
- yield stream["label"], HTTPStream(self.session, stream["file"])
-
-
-__plugin__ = NineAnime
+# Plugin removed - https://github.com/streamlink/streamlink/issues/1862
|
{"golden_diff": "diff --git a/src/streamlink/plugins/nineanime.py b/src/streamlink/plugins/nineanime.py\n--- a/src/streamlink/plugins/nineanime.py\n+++ b/src/streamlink/plugins/nineanime.py\n@@ -1,69 +1 @@\n-import re\n-from streamlink.plugin import Plugin\n-from streamlink.plugin.api import http\n-from streamlink.plugin.api import useragents\n-from streamlink.plugin.api import validate\n-from streamlink.stream import HTTPStream\n-from streamlink.compat import urlparse\n-\n-\n-class NineAnime(Plugin):\n- _episode_info_url = \"//9anime.to/ajax/episode/info\"\n-\n- _info_schema = validate.Schema({\n- \"grabber\": validate.url(),\n- \"params\": {\n- \"id\": validate.text,\n- \"token\": validate.text,\n- \"options\": validate.text,\n- }\n- })\n-\n- _streams_schema = validate.Schema({\n- \"token\": validate.text,\n- \"error\": None,\n- \"data\": [{\n- \"label\": validate.text,\n- \"file\": validate.url(),\n- \"type\": \"mp4\"\n- }]\n- })\n-\n- _url_re = re.compile(r\"https?://9anime.to/watch/(?:[^.]+?\\.)(\\w+)/(\\w+)\")\n-\n- @classmethod\n- def can_handle_url(cls, url):\n- return cls._url_re.match(url) is not None\n-\n- def add_scheme(self, url):\n- # update the scheme for the grabber url if required\n- if url.startswith(\"//\"):\n- url = \"{0}:{1}\".format(urlparse(self.url).scheme, url)\n- return url\n-\n- @Plugin.broken(1110)\n- def _get_streams(self):\n- match = self._url_re.match(self.url)\n- film_id, episode_id = match.groups()\n-\n- headers = {\n- \"Referer\": self.url,\n- \"User-Agent\": useragents.FIREFOX\n- }\n-\n- # Get the info about the Episode, including the Grabber API URL\n- info_res = http.get(self.add_scheme(self._episode_info_url),\n- params=dict(update=0, film=film_id, id=episode_id),\n- headers=headers)\n- info = http.json(info_res, schema=self._info_schema)\n-\n- # Get the data about the streams from the Grabber API\n- grabber_url = self.add_scheme(info[\"grabber\"])\n- stream_list_res = http.get(grabber_url, params=info[\"params\"], headers=headers)\n- stream_data = http.json(stream_list_res, schema=self._streams_schema)\n-\n- for stream in stream_data[\"data\"]:\n- yield stream[\"label\"], HTTPStream(self.session, stream[\"file\"])\n-\n-\n-__plugin__ = NineAnime\n+# Plugin removed - https://github.com/streamlink/streamlink/issues/1862\n", "issue": "Remove 9anime.to\nAs discussed over here: https://github.com/streamlink/streamlink/issues/1110#issuecomment-400687075 9anime.to isn't worth supporting at this point and is broken so I'm proposing we remove it.\r\n\n", "before_files": [{"content": "import re\nfrom streamlink.plugin import Plugin\nfrom streamlink.plugin.api import http\nfrom streamlink.plugin.api import useragents\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream import HTTPStream\nfrom streamlink.compat import urlparse\n\n\nclass NineAnime(Plugin):\n _episode_info_url = \"//9anime.to/ajax/episode/info\"\n\n _info_schema = validate.Schema({\n \"grabber\": validate.url(),\n \"params\": {\n \"id\": validate.text,\n \"token\": validate.text,\n \"options\": validate.text,\n }\n })\n\n _streams_schema = validate.Schema({\n \"token\": validate.text,\n \"error\": None,\n \"data\": [{\n \"label\": validate.text,\n \"file\": validate.url(),\n \"type\": \"mp4\"\n }]\n })\n\n _url_re = re.compile(r\"https?://9anime.to/watch/(?:[^.]+?\\.)(\\w+)/(\\w+)\")\n\n @classmethod\n def can_handle_url(cls, url):\n return cls._url_re.match(url) is not None\n\n def add_scheme(self, url):\n # update the scheme for the grabber url if required\n if url.startswith(\"//\"):\n url = \"{0}:{1}\".format(urlparse(self.url).scheme, url)\n return url\n\n @Plugin.broken(1110)\n def _get_streams(self):\n match = self._url_re.match(self.url)\n film_id, episode_id = match.groups()\n\n headers = {\n \"Referer\": self.url,\n \"User-Agent\": useragents.FIREFOX\n }\n\n # Get the info about the Episode, including the Grabber API URL\n info_res = http.get(self.add_scheme(self._episode_info_url),\n params=dict(update=0, film=film_id, id=episode_id),\n headers=headers)\n info = http.json(info_res, schema=self._info_schema)\n\n # Get the data about the streams from the Grabber API\n grabber_url = self.add_scheme(info[\"grabber\"])\n stream_list_res = http.get(grabber_url, params=info[\"params\"], headers=headers)\n stream_data = http.json(stream_list_res, schema=self._streams_schema)\n\n for stream in stream_data[\"data\"]:\n yield stream[\"label\"], HTTPStream(self.session, stream[\"file\"])\n\n\n__plugin__ = NineAnime\n", "path": "src/streamlink/plugins/nineanime.py"}]}
| 1,248 | 633 |
gh_patches_debug_5172
|
rasdani/github-patches
|
git_diff
|
yt-project__yt-4776
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
BUG: modifications through matplotlib engine cannot be properly displayed
<!--To help us understand and resolve your issue, please fill out the form to
the best of your ability.-->
<!--You can feel free to delete the sections that do not apply.-->
### Bug report
**Bug summary**
The Modifications through Matplotlib engine cannot be properly displayed.
Taking the following code for example, the expected modifications can only be shown by the containing matplotlib figure object like `fig.savefig("sloshing.png")`.
**Code for reproduction**
adapted from [docs](https://yt-project.org/docs/dev/cookbook/simple_plots.html#accessing-and-modifying-plots-directly) (also broken there)
```python
import numpy as np
import yt
# Load the dataset.
ds = yt.load("GasSloshing/sloshing_nomag2_hdf5_plt_cnt_0150")
# Create a slice object
slc = yt.SlicePlot(ds, "x", ("gas", "density"), width=(800.0, "kpc"))
# Get a reference to the matplotlib axes object for the plot
ax = slc.plots[("gas", "density")].axes
# Let's adjust the x axis tick labels
for label in ax.xaxis.get_ticklabels():
label.set_color("red")
label.set_fontsize(16)
# Get a reference to the matplotlib figure object for the plot
fig = slc.plots[("gas", "density")].figure
# And create a mini-panel of a gaussian histogram inside the plot
rect = (0.2, 0.2, 0.2, 0.2)
new_ax = fig.add_axes(rect)
n, bins, patches = new_ax.hist(
np.random.randn(1000) + 20, 50, facecolor="black", edgecolor="black"
)
# Make sure its visible
new_ax.tick_params(colors="white")
# And label it
la = new_ax.set_xlabel("Dinosaurs per furlong")
la.set_color("white")
slc.save()
```
**Actual outcome**

**Expected outcome**
The changes of the x-axis tick labels

**Version Information**
* Operating System: MacOS 14.1.1 and Red Hat Enterprise Linux Server release 7.8 (Maipo)
* Python Version: 3.9
* yt version: 4.2.1 and 4.3.0
<!--Please tell us how you installed yt and python e.g., from source,
pip, conda. If you installed from conda, please specify which channel you used
if not the default-->
</issue>
<code>
[start of doc/source/cookbook/simple_slice_matplotlib_example.py]
1 import numpy as np
2
3 import yt
4
5 # Load the dataset.
6 ds = yt.load("GasSloshing/sloshing_nomag2_hdf5_plt_cnt_0150")
7
8 # Create a slice object
9 slc = yt.SlicePlot(ds, "x", ("gas", "density"), width=(800.0, "kpc"))
10
11 # Get a reference to the matplotlib axes object for the plot
12 ax = slc.plots[("gas", "density")].axes
13
14 # Let's adjust the x axis tick labels
15 for label in ax.xaxis.get_ticklabels():
16 label.set_color("red")
17 label.set_fontsize(16)
18
19 # Get a reference to the matplotlib figure object for the plot
20 fig = slc.plots[("gas", "density")].figure
21
22 # And create a mini-panel of a gaussian histogram inside the plot
23 rect = (0.2, 0.2, 0.2, 0.2)
24 new_ax = fig.add_axes(rect)
25
26 n, bins, patches = new_ax.hist(
27 np.random.randn(1000) + 20, 50, facecolor="black", edgecolor="black"
28 )
29
30 # Make sure its visible
31 new_ax.tick_params(colors="white")
32
33 # And label it
34 la = new_ax.set_xlabel("Dinosaurs per furlong")
35 la.set_color("white")
36
37 slc.save()
38
[end of doc/source/cookbook/simple_slice_matplotlib_example.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/doc/source/cookbook/simple_slice_matplotlib_example.py b/doc/source/cookbook/simple_slice_matplotlib_example.py
--- a/doc/source/cookbook/simple_slice_matplotlib_example.py
+++ b/doc/source/cookbook/simple_slice_matplotlib_example.py
@@ -8,6 +8,10 @@
# Create a slice object
slc = yt.SlicePlot(ds, "x", ("gas", "density"), width=(800.0, "kpc"))
+# Rendering should be performed explicitly *before* any modification is
+# performed directly with matplotlib.
+slc.render()
+
# Get a reference to the matplotlib axes object for the plot
ax = slc.plots[("gas", "density")].axes
|
{"golden_diff": "diff --git a/doc/source/cookbook/simple_slice_matplotlib_example.py b/doc/source/cookbook/simple_slice_matplotlib_example.py\n--- a/doc/source/cookbook/simple_slice_matplotlib_example.py\n+++ b/doc/source/cookbook/simple_slice_matplotlib_example.py\n@@ -8,6 +8,10 @@\n # Create a slice object\n slc = yt.SlicePlot(ds, \"x\", (\"gas\", \"density\"), width=(800.0, \"kpc\"))\n \n+# Rendering should be performed explicitly *before* any modification is\n+# performed directly with matplotlib.\n+slc.render()\n+\n # Get a reference to the matplotlib axes object for the plot\n ax = slc.plots[(\"gas\", \"density\")].axes\n", "issue": "BUG: modifications through matplotlib engine cannot be properly displayed\n<!--To help us understand and resolve your issue, please fill out the form to\r\nthe best of your ability.-->\r\n<!--You can feel free to delete the sections that do not apply.-->\r\n\r\n### Bug report\r\n\r\n**Bug summary**\r\n\r\nThe Modifications through Matplotlib engine cannot be properly displayed. \r\n\r\nTaking the following code for example, the expected modifications can only be shown by the containing matplotlib figure object like `fig.savefig(\"sloshing.png\")`. \r\n\r\n**Code for reproduction**\r\n\r\nadapted from [docs](https://yt-project.org/docs/dev/cookbook/simple_plots.html#accessing-and-modifying-plots-directly) (also broken there)\r\n\r\n```python\r\nimport numpy as np\r\n\r\nimport yt\r\n\r\n# Load the dataset.\r\nds = yt.load(\"GasSloshing/sloshing_nomag2_hdf5_plt_cnt_0150\")\r\n\r\n# Create a slice object\r\nslc = yt.SlicePlot(ds, \"x\", (\"gas\", \"density\"), width=(800.0, \"kpc\"))\r\n\r\n# Get a reference to the matplotlib axes object for the plot\r\nax = slc.plots[(\"gas\", \"density\")].axes\r\n\r\n# Let's adjust the x axis tick labels\r\nfor label in ax.xaxis.get_ticklabels():\r\n label.set_color(\"red\")\r\n label.set_fontsize(16)\r\n\r\n# Get a reference to the matplotlib figure object for the plot\r\nfig = slc.plots[(\"gas\", \"density\")].figure\r\n\r\n# And create a mini-panel of a gaussian histogram inside the plot\r\nrect = (0.2, 0.2, 0.2, 0.2)\r\nnew_ax = fig.add_axes(rect)\r\n\r\nn, bins, patches = new_ax.hist(\r\n np.random.randn(1000) + 20, 50, facecolor=\"black\", edgecolor=\"black\"\r\n)\r\n\r\n# Make sure its visible\r\nnew_ax.tick_params(colors=\"white\")\r\n\r\n# And label it\r\nla = new_ax.set_xlabel(\"Dinosaurs per furlong\")\r\nla.set_color(\"white\")\r\n\r\nslc.save()\r\n```\r\n\r\n**Actual outcome**\r\n\r\n\r\n\r\n**Expected outcome**\r\n\r\nThe changes of the x-axis tick labels\r\n\r\n\r\n**Version Information**\r\n * Operating System: MacOS 14.1.1 and Red Hat Enterprise Linux Server release 7.8 (Maipo)\r\n * Python Version: 3.9\r\n * yt version: 4.2.1 and 4.3.0\r\n\r\n<!--Please tell us how you installed yt and python e.g., from source,\r\npip, conda. If you installed from conda, please specify which channel you used\r\nif not the default-->\r\n\n", "before_files": [{"content": "import numpy as np\n\nimport yt\n\n# Load the dataset.\nds = yt.load(\"GasSloshing/sloshing_nomag2_hdf5_plt_cnt_0150\")\n\n# Create a slice object\nslc = yt.SlicePlot(ds, \"x\", (\"gas\", \"density\"), width=(800.0, \"kpc\"))\n\n# Get a reference to the matplotlib axes object for the plot\nax = slc.plots[(\"gas\", \"density\")].axes\n\n# Let's adjust the x axis tick labels\nfor label in ax.xaxis.get_ticklabels():\n label.set_color(\"red\")\n label.set_fontsize(16)\n\n# Get a reference to the matplotlib figure object for the plot\nfig = slc.plots[(\"gas\", \"density\")].figure\n\n# And create a mini-panel of a gaussian histogram inside the plot\nrect = (0.2, 0.2, 0.2, 0.2)\nnew_ax = fig.add_axes(rect)\n\nn, bins, patches = new_ax.hist(\n np.random.randn(1000) + 20, 50, facecolor=\"black\", edgecolor=\"black\"\n)\n\n# Make sure its visible\nnew_ax.tick_params(colors=\"white\")\n\n# And label it\nla = new_ax.set_xlabel(\"Dinosaurs per furlong\")\nla.set_color(\"white\")\n\nslc.save()\n", "path": "doc/source/cookbook/simple_slice_matplotlib_example.py"}]}
| 1,643 | 158 |
gh_patches_debug_12157
|
rasdani/github-patches
|
git_diff
|
pyro-ppl__pyro-198
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
pytorch broadcasting
in various places in the codebase we have tensor ops like `expand_as()`. given the extended broadcasting functionality in the latest version of pytorch, some of these may be unnecessary and/or clunky. more generally, we should investigate and deal with any pytorch warnings that popped once once we switched pytorch versions. for example:
_UserWarning: other is not broadcastable to self, but they have the same number of elements. Falling back to deprecated pointwise behavior._
</issue>
<code>
[start of examples/categorical_bmm.py]
1 import argparse
2
3 import numpy as np
4 import torch
5 import torchvision.datasets as dset
6 import torchvision.transforms as transforms
7 import visdom
8 from torch.autograd import Variable
9 from torch.nn import Softmax
10
11 import pyro
12 from pyro.distributions import Bernoulli, Categorical
13 from pyro.infer.kl_qp import KL_QP
14
15 mnist = dset.MNIST(
16 root='./data',
17 train=True,
18 transform=None,
19 target_transform=None,
20 download=True)
21 print('dataset loaded')
22
23 softmax = Softmax()
24
25 train_loader = torch.utils.data.DataLoader(
26 dset.MNIST('../data', train=True, download=True,
27 transform=transforms.Compose([
28 transforms.ToTensor(),
29 transforms.Normalize((0.1307,), (0.3081,))
30 ])),
31 batch_size=128, shuffle=True)
32 test_loader = torch.utils.data.DataLoader(
33 dset.MNIST('../data', train=False, transform=transforms.Compose([
34 transforms.ToTensor(),
35 transforms.Normalize((0.1307,), (0.3081,))
36 ])),
37 batch_size=128, shuffle=True)
38
39
40 def local_model(i, datum):
41 beta = Variable(torch.ones(1, 10)) * 0.1
42 cll = pyro.sample("class_of_datum_" + str(i), Categorical(beta))
43 mean_param = Variable(torch.zeros(1, 784), requires_grad=True)
44 # do MLE for class means
45 mu = pyro.param("mean_of_class_" + str(cll[0]), mean_param)
46 mu_param = softmax(mu)
47 pyro.observe("obs_" + str(i), Bernoulli(mu_param), datum)
48 return cll
49
50
51 def local_guide(i, datum):
52 alpha = torch.ones(1, 10) * 0.1
53 beta_q = Variable(alpha, requires_grad=True)
54 beta_param = pyro.param("class_posterior_", beta_q)
55 guide_params = softmax(beta_param)
56 cll = pyro.sample("class_of_datum_" + str(i), Categorical(guide_params))
57 return cll
58
59
60 def inspect_posterior_samples(i):
61 cll = local_guide(i, None)
62 mean_param = Variable(torch.zeros(1, 784), requires_grad=True)
63 # do MLE for class means
64 mu = pyro.param("mean_of_class_" + str(cll[0]), mean_param)
65 dat = pyro.sample("obs_" + str(i), Bernoulli(mu))
66 return dat
67
68
69 optim_fct = pyro.optim(torch.optim.Adam, {'lr': .0001})
70
71 inference = KL_QP(local_model, local_guide, optim_fct)
72
73 vis = visdom.Visdom()
74
75 nr_epochs = 50
76 # apply it to minibatches of data by hand:
77
78 mnist_data = Variable(train_loader.dataset.train_data.float() / 255.)
79 mnist_labels = Variable(train_loader.dataset.train_labels)
80 mnist_size = mnist_data.size(0)
81 batch_size = 1 # 64
82
83 all_batches = np.arange(0, mnist_size, batch_size)
84
85 if all_batches[-1] != mnist_size:
86 all_batches = list(all_batches) + [mnist_size]
87
88
89 def main():
90 parser = argparse.ArgumentParser(description="parse args")
91 parser.add_argument('-n', '--num-epochs', nargs='?', default=1000, type=int)
92 args = parser.parse_args()
93 for i in range(args.num_epochs):
94 epoch_loss = 0.
95 for ix, batch_start in enumerate(all_batches[:-1]):
96 batch_end = all_batches[ix + 1]
97 batch_data = mnist_data[batch_start:batch_end]
98 bs_size = batch_data.size(0)
99 batch_class_raw = mnist_labels[batch_start:batch_end]
100 batch_class = torch.zeros(bs_size, 10) # maybe it needs a FloatTensor
101 batch_class.scatter_(1, batch_class_raw.data.view(-1, 1), 1)
102 batch_class = Variable(batch_class)
103 epoch_loss += inference.step(ix, batch_data)
104
105 # optional visualization!
106 # vis.image(batch_data[0].view(28, 28).data.numpy())
107 # vis.image(sample[0].view(28, 28).data.numpy())
108 # vis.image(sample_mu[0].view(28, 28).data.numpy())
109 print("epoch avg loss {}".format(epoch_loss / float(mnist_size)))
110
111
112 if __name__ == '__main__':
113 main()
114
[end of examples/categorical_bmm.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/categorical_bmm.py b/examples/categorical_bmm.py
--- a/examples/categorical_bmm.py
+++ b/examples/categorical_bmm.py
@@ -12,6 +12,7 @@
from pyro.distributions import Bernoulli, Categorical
from pyro.infer.kl_qp import KL_QP
+
mnist = dset.MNIST(
root='./data',
train=True,
@@ -44,7 +45,7 @@
# do MLE for class means
mu = pyro.param("mean_of_class_" + str(cll[0]), mean_param)
mu_param = softmax(mu)
- pyro.observe("obs_" + str(i), Bernoulli(mu_param), datum)
+ pyro.observe("obs_" + str(i), Bernoulli(mu_param), datum.view(1, -1))
return cll
|
{"golden_diff": "diff --git a/examples/categorical_bmm.py b/examples/categorical_bmm.py\n--- a/examples/categorical_bmm.py\n+++ b/examples/categorical_bmm.py\n@@ -12,6 +12,7 @@\n from pyro.distributions import Bernoulli, Categorical\n from pyro.infer.kl_qp import KL_QP\n \n+\n mnist = dset.MNIST(\n root='./data',\n train=True,\n@@ -44,7 +45,7 @@\n # do MLE for class means\n mu = pyro.param(\"mean_of_class_\" + str(cll[0]), mean_param)\n mu_param = softmax(mu)\n- pyro.observe(\"obs_\" + str(i), Bernoulli(mu_param), datum)\n+ pyro.observe(\"obs_\" + str(i), Bernoulli(mu_param), datum.view(1, -1))\n return cll\n", "issue": "pytorch broadcasting\nin various places in the codebase we have tensor ops like `expand_as()`. given the extended broadcasting functionality in the latest version of pytorch, some of these may be unnecessary and/or clunky. more generally, we should investigate and deal with any pytorch warnings that popped once once we switched pytorch versions. for example: \r\n\r\n_UserWarning: other is not broadcastable to self, but they have the same number of elements. Falling back to deprecated pointwise behavior._\n", "before_files": [{"content": "import argparse\n\nimport numpy as np\nimport torch\nimport torchvision.datasets as dset\nimport torchvision.transforms as transforms\nimport visdom\nfrom torch.autograd import Variable\nfrom torch.nn import Softmax\n\nimport pyro\nfrom pyro.distributions import Bernoulli, Categorical\nfrom pyro.infer.kl_qp import KL_QP\n\nmnist = dset.MNIST(\n root='./data',\n train=True,\n transform=None,\n target_transform=None,\n download=True)\nprint('dataset loaded')\n\nsoftmax = Softmax()\n\ntrain_loader = torch.utils.data.DataLoader(\n dset.MNIST('../data', train=True, download=True,\n transform=transforms.Compose([\n transforms.ToTensor(),\n transforms.Normalize((0.1307,), (0.3081,))\n ])),\n batch_size=128, shuffle=True)\ntest_loader = torch.utils.data.DataLoader(\n dset.MNIST('../data', train=False, transform=transforms.Compose([\n transforms.ToTensor(),\n transforms.Normalize((0.1307,), (0.3081,))\n ])),\n batch_size=128, shuffle=True)\n\n\ndef local_model(i, datum):\n beta = Variable(torch.ones(1, 10)) * 0.1\n cll = pyro.sample(\"class_of_datum_\" + str(i), Categorical(beta))\n mean_param = Variable(torch.zeros(1, 784), requires_grad=True)\n # do MLE for class means\n mu = pyro.param(\"mean_of_class_\" + str(cll[0]), mean_param)\n mu_param = softmax(mu)\n pyro.observe(\"obs_\" + str(i), Bernoulli(mu_param), datum)\n return cll\n\n\ndef local_guide(i, datum):\n alpha = torch.ones(1, 10) * 0.1\n beta_q = Variable(alpha, requires_grad=True)\n beta_param = pyro.param(\"class_posterior_\", beta_q)\n guide_params = softmax(beta_param)\n cll = pyro.sample(\"class_of_datum_\" + str(i), Categorical(guide_params))\n return cll\n\n\ndef inspect_posterior_samples(i):\n cll = local_guide(i, None)\n mean_param = Variable(torch.zeros(1, 784), requires_grad=True)\n # do MLE for class means\n mu = pyro.param(\"mean_of_class_\" + str(cll[0]), mean_param)\n dat = pyro.sample(\"obs_\" + str(i), Bernoulli(mu))\n return dat\n\n\noptim_fct = pyro.optim(torch.optim.Adam, {'lr': .0001})\n\ninference = KL_QP(local_model, local_guide, optim_fct)\n\nvis = visdom.Visdom()\n\nnr_epochs = 50\n# apply it to minibatches of data by hand:\n\nmnist_data = Variable(train_loader.dataset.train_data.float() / 255.)\nmnist_labels = Variable(train_loader.dataset.train_labels)\nmnist_size = mnist_data.size(0)\nbatch_size = 1 # 64\n\nall_batches = np.arange(0, mnist_size, batch_size)\n\nif all_batches[-1] != mnist_size:\n all_batches = list(all_batches) + [mnist_size]\n\n\ndef main():\n parser = argparse.ArgumentParser(description=\"parse args\")\n parser.add_argument('-n', '--num-epochs', nargs='?', default=1000, type=int)\n args = parser.parse_args()\n for i in range(args.num_epochs):\n epoch_loss = 0.\n for ix, batch_start in enumerate(all_batches[:-1]):\n batch_end = all_batches[ix + 1]\n batch_data = mnist_data[batch_start:batch_end]\n bs_size = batch_data.size(0)\n batch_class_raw = mnist_labels[batch_start:batch_end]\n batch_class = torch.zeros(bs_size, 10) # maybe it needs a FloatTensor\n batch_class.scatter_(1, batch_class_raw.data.view(-1, 1), 1)\n batch_class = Variable(batch_class)\n epoch_loss += inference.step(ix, batch_data)\n\n # optional visualization!\n # vis.image(batch_data[0].view(28, 28).data.numpy())\n # vis.image(sample[0].view(28, 28).data.numpy())\n # vis.image(sample_mu[0].view(28, 28).data.numpy())\n print(\"epoch avg loss {}\".format(epoch_loss / float(mnist_size)))\n\n\nif __name__ == '__main__':\n main()\n", "path": "examples/categorical_bmm.py"}]}
| 1,871 | 193 |
gh_patches_debug_22576
|
rasdani/github-patches
|
git_diff
|
google__mobly-799
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Mobly Release 1.11.1
</issue>
<code>
[start of setup.py]
1 # Copyright 2016 Google Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import platform
16 import setuptools
17 from setuptools.command import test
18 import sys
19
20 install_requires = [
21 'portpicker', 'pyserial', 'pyyaml', 'timeout_decorator', 'typing_extensions'
22 ]
23
24 if platform.system() == 'Windows':
25 install_requires.append('pywin32')
26
27
28 class PyTest(test.test):
29 """Class used to execute unit tests using PyTest. This allows us to execute
30 unit tests without having to install the package.
31 """
32
33 def finalize_options(self):
34 test.test.finalize_options(self)
35 self.test_args = ['-x', "tests/mobly"]
36 self.test_suite = True
37
38 def run_tests(self):
39 import pytest
40 errno = pytest.main(self.test_args)
41 sys.exit(errno)
42
43
44 def main():
45 setuptools.setup(
46 name='mobly',
47 version='1.11',
48 maintainer='Ang Li',
49 maintainer_email='[email protected]',
50 description='Automation framework for special end-to-end test cases',
51 license='Apache2.0',
52 url='https://github.com/google/mobly',
53 download_url='https://github.com/google/mobly/tarball/1.11',
54 packages=setuptools.find_packages(exclude=['tests']),
55 include_package_data=False,
56 scripts=['tools/sl4a_shell.py', 'tools/snippet_shell.py'],
57 tests_require=[
58 'mock',
59 'pytest',
60 'pytz',
61 ],
62 install_requires=install_requires,
63 cmdclass={'test': PyTest},
64 )
65
66
67 if __name__ == '__main__':
68 main()
69
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -18,7 +18,7 @@
import sys
install_requires = [
- 'portpicker', 'pyserial', 'pyyaml', 'timeout_decorator', 'typing_extensions'
+ 'portpicker', 'pyserial', 'pyyaml', 'timeout_decorator', 'typing_extensions>=4.1.1'
]
if platform.system() == 'Windows':
@@ -44,13 +44,13 @@
def main():
setuptools.setup(
name='mobly',
- version='1.11',
+ version='1.11.1',
maintainer='Ang Li',
maintainer_email='[email protected]',
description='Automation framework for special end-to-end test cases',
license='Apache2.0',
url='https://github.com/google/mobly',
- download_url='https://github.com/google/mobly/tarball/1.11',
+ download_url='https://github.com/google/mobly/tarball/1.11.1',
packages=setuptools.find_packages(exclude=['tests']),
include_package_data=False,
scripts=['tools/sl4a_shell.py', 'tools/snippet_shell.py'],
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -18,7 +18,7 @@\n import sys\n \n install_requires = [\n- 'portpicker', 'pyserial', 'pyyaml', 'timeout_decorator', 'typing_extensions'\n+ 'portpicker', 'pyserial', 'pyyaml', 'timeout_decorator', 'typing_extensions>=4.1.1'\n ]\n \n if platform.system() == 'Windows':\n@@ -44,13 +44,13 @@\n def main():\n setuptools.setup(\n name='mobly',\n- version='1.11',\n+ version='1.11.1',\n maintainer='Ang Li',\n maintainer_email='[email protected]',\n description='Automation framework for special end-to-end test cases',\n license='Apache2.0',\n url='https://github.com/google/mobly',\n- download_url='https://github.com/google/mobly/tarball/1.11',\n+ download_url='https://github.com/google/mobly/tarball/1.11.1',\n packages=setuptools.find_packages(exclude=['tests']),\n include_package_data=False,\n scripts=['tools/sl4a_shell.py', 'tools/snippet_shell.py'],\n", "issue": "Mobly Release 1.11.1\n\n", "before_files": [{"content": "# Copyright 2016 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport platform\nimport setuptools\nfrom setuptools.command import test\nimport sys\n\ninstall_requires = [\n 'portpicker', 'pyserial', 'pyyaml', 'timeout_decorator', 'typing_extensions'\n]\n\nif platform.system() == 'Windows':\n install_requires.append('pywin32')\n\n\nclass PyTest(test.test):\n \"\"\"Class used to execute unit tests using PyTest. This allows us to execute\n unit tests without having to install the package.\n \"\"\"\n\n def finalize_options(self):\n test.test.finalize_options(self)\n self.test_args = ['-x', \"tests/mobly\"]\n self.test_suite = True\n\n def run_tests(self):\n import pytest\n errno = pytest.main(self.test_args)\n sys.exit(errno)\n\n\ndef main():\n setuptools.setup(\n name='mobly',\n version='1.11',\n maintainer='Ang Li',\n maintainer_email='[email protected]',\n description='Automation framework for special end-to-end test cases',\n license='Apache2.0',\n url='https://github.com/google/mobly',\n download_url='https://github.com/google/mobly/tarball/1.11',\n packages=setuptools.find_packages(exclude=['tests']),\n include_package_data=False,\n scripts=['tools/sl4a_shell.py', 'tools/snippet_shell.py'],\n tests_require=[\n 'mock',\n 'pytest',\n 'pytz',\n ],\n install_requires=install_requires,\n cmdclass={'test': PyTest},\n )\n\n\nif __name__ == '__main__':\n main()\n", "path": "setup.py"}]}
| 1,144 | 282 |
gh_patches_debug_22271
|
rasdani/github-patches
|
git_diff
|
pydantic__pydantic-299
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Сreating a child model causes a RecursionError exception
<!-- Questions, Feature Requests, and Bug Reports are all welcome -->
<!-- delete as applicable: -->
# Bug
* OS: **Ubuntu 14.04**
* Python version `import sys; print(sys.version)`: **3.6.7**
* Pydantic version `import pydantic; print(pydantic.VERSION)`: **0.14**
I'm expecting, that I can use a classic inheritance for dataclass models:
```py
import pydantic.dataclasses
@pydantic.dataclasses.dataclass
class A:
a: str = None
@pydantic.dataclasses.dataclass
class B(A):
b: str = None
B(a='a', b='b')
```
But as a result I'm receiving this:
```
Traceback (most recent call last):
File "/usr/local/pyenv/versions/3.6.7/lib/python3.6/site-packages/IPython/core/interactiveshell.py", line 2881, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-9-10a7116ca691>", line 12, in <module>
B(a='a', b='b')
File "<string>", line 4, in __init__
File "/usr/local/pyenv/versions/3.6.7/lib/python3.6/site-packages/pydantic/dataclasses.py", line 13, in post_init
self.__post_init_original__()
File "/usr/local/pyenv/versions/3.6.7/lib/python3.6/site-packages/pydantic/dataclasses.py", line 13, in post_init
self.__post_init_original__()
File "/usr/local/pyenv/versions/3.6.7/lib/python3.6/site-packages/pydantic/dataclasses.py", line 13, in post_init
self.__post_init_original__()
[Previous line repeated 952 more times]
File "/usr/local/pyenv/versions/3.6.7/lib/python3.6/site-packages/pydantic/dataclasses.py", line 9, in post_init
d = validate_model(self.__pydantic_model__, self.__dict__)
File "/usr/local/pyenv/versions/3.6.7/lib/python3.6/site-packages/pydantic/main.py", line 484, in validate_model
v_, errors_ = field.validate(value, values, loc=field.alias, cls=model.__class__)
File "/usr/local/pyenv/versions/3.6.7/lib/python3.6/site-packages/pydantic/fields.py", line 303, in validate
v, errors = self._validate_singleton(v, values, loc, cls)
File "/usr/local/pyenv/versions/3.6.7/lib/python3.6/site-packages/pydantic/fields.py", line 406, in _validate_singleton
return self._apply_validators(v, values, loc, cls, self.validators)
File "/usr/local/pyenv/versions/3.6.7/lib/python3.6/site-packages/pydantic/fields.py", line 412, in _apply_validators
v = validator(v)
File "/usr/local/pyenv/versions/3.6.7/lib/python3.6/site-packages/pydantic/validators.py", line 23, in str_validator
if isinstance(v, (str, NoneType)):
RecursionError: maximum recursion depth exceeded in __instancecheck__
```
This line below causes this problem:
https://github.com/samuelcolvin/pydantic/blob/master/pydantic/dataclasses.py#L13
UPD: defining `__post_init__` in child model fixes the problem, but this is workaround.
```py
import pydantic.dataclasses
@pydantic.dataclasses.dataclass
class A:
a: str = None
@pydantic.dataclasses.dataclass
class B(A):
b: str = None
def __post_init__():
pass
B(a='a', b='b')
```
</issue>
<code>
[start of pydantic/dataclasses.py]
1 import dataclasses
2
3 from pydantic import ValidationError
4
5 from .main import create_model, validate_model
6
7
8 def post_init(self):
9 d = validate_model(self.__pydantic_model__, self.__dict__)
10 object.__setattr__(self, '__dict__', d)
11 object.__setattr__(self, '__initialised__', True)
12 if self.__post_init_original__:
13 self.__post_init_original__()
14
15
16 def setattr_validate_assignment(self, name, value):
17 if self.__initialised__:
18 d = dict(self.__dict__)
19 d.pop(name)
20 value, error_ = self.__pydantic_model__.__fields__[name].validate(value, d, loc=name)
21 if error_:
22 raise ValidationError([error_])
23
24 object.__setattr__(self, name, value)
25
26
27 def _process_class(_cls, init, repr, eq, order, unsafe_hash, frozen, validate_assignment):
28 post_init_original = getattr(_cls, '__post_init__', None)
29 _cls.__post_init__ = post_init
30 cls = dataclasses._process_class(_cls, init, repr, eq, order, unsafe_hash, frozen)
31
32 fields = {name: (field.type, field.default) for name, field in cls.__dataclass_fields__.items()}
33 cls.__post_init_original__ = post_init_original
34 cls.__pydantic_model__ = create_model(cls.__name__, **fields)
35 cls.__initialised__ = False
36
37 if validate_assignment and not frozen:
38 cls.__setattr__ = setattr_validate_assignment
39 return cls
40
41
42 def dataclass(
43 _cls=None, *, init=True, repr=True, eq=True, order=False, unsafe_hash=False, frozen=False, validate_assignment=False
44 ):
45 """
46 Like the python standard lib dataclasses but with type validation.
47
48 Arguments are the same as for standard dataclasses, except for validate_assignment which has the same meaning
49 as Config.validate_assignment.
50 """
51
52 def wrap(cls):
53 return _process_class(cls, init, repr, eq, order, unsafe_hash, frozen, validate_assignment)
54
55 if _cls is None:
56 return wrap
57
58 return wrap(_cls)
59
[end of pydantic/dataclasses.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pydantic/dataclasses.py b/pydantic/dataclasses.py
--- a/pydantic/dataclasses.py
+++ b/pydantic/dataclasses.py
@@ -5,7 +5,7 @@
from .main import create_model, validate_model
-def post_init(self):
+def _pydantic_post_init(self):
d = validate_model(self.__pydantic_model__, self.__dict__)
object.__setattr__(self, '__dict__', d)
object.__setattr__(self, '__initialised__', True)
@@ -26,7 +26,9 @@
def _process_class(_cls, init, repr, eq, order, unsafe_hash, frozen, validate_assignment):
post_init_original = getattr(_cls, '__post_init__', None)
- _cls.__post_init__ = post_init
+ if post_init_original and post_init_original.__name__ == '_pydantic_post_init':
+ post_init_original = None
+ _cls.__post_init__ = _pydantic_post_init
cls = dataclasses._process_class(_cls, init, repr, eq, order, unsafe_hash, frozen)
fields = {name: (field.type, field.default) for name, field in cls.__dataclass_fields__.items()}
|
{"golden_diff": "diff --git a/pydantic/dataclasses.py b/pydantic/dataclasses.py\n--- a/pydantic/dataclasses.py\n+++ b/pydantic/dataclasses.py\n@@ -5,7 +5,7 @@\n from .main import create_model, validate_model\n \n \n-def post_init(self):\n+def _pydantic_post_init(self):\n d = validate_model(self.__pydantic_model__, self.__dict__)\n object.__setattr__(self, '__dict__', d)\n object.__setattr__(self, '__initialised__', True)\n@@ -26,7 +26,9 @@\n \n def _process_class(_cls, init, repr, eq, order, unsafe_hash, frozen, validate_assignment):\n post_init_original = getattr(_cls, '__post_init__', None)\n- _cls.__post_init__ = post_init\n+ if post_init_original and post_init_original.__name__ == '_pydantic_post_init':\n+ post_init_original = None\n+ _cls.__post_init__ = _pydantic_post_init\n cls = dataclasses._process_class(_cls, init, repr, eq, order, unsafe_hash, frozen)\n \n fields = {name: (field.type, field.default) for name, field in cls.__dataclass_fields__.items()}\n", "issue": "\u0421reating a child model causes a RecursionError exception\n<!-- Questions, Feature Requests, and Bug Reports are all welcome -->\r\n<!-- delete as applicable: -->\r\n# Bug\r\n\r\n* OS: **Ubuntu 14.04**\r\n* Python version `import sys; print(sys.version)`: **3.6.7**\r\n* Pydantic version `import pydantic; print(pydantic.VERSION)`: **0.14**\r\n\r\nI'm expecting, that I can use a classic inheritance for dataclass models:\r\n```py\r\nimport pydantic.dataclasses\r\n\r\[email protected]\r\nclass A:\r\n a: str = None\r\n\r\[email protected]\r\nclass B(A):\r\n b: str = None\r\n\r\nB(a='a', b='b')\r\n```\r\n\r\nBut as a result I'm receiving this:\r\n```\r\nTraceback (most recent call last):\r\n File \"/usr/local/pyenv/versions/3.6.7/lib/python3.6/site-packages/IPython/core/interactiveshell.py\", line 2881, in run_code\r\n exec(code_obj, self.user_global_ns, self.user_ns)\r\n File \"<ipython-input-9-10a7116ca691>\", line 12, in <module>\r\n B(a='a', b='b')\r\n File \"<string>\", line 4, in __init__\r\n File \"/usr/local/pyenv/versions/3.6.7/lib/python3.6/site-packages/pydantic/dataclasses.py\", line 13, in post_init\r\n self.__post_init_original__()\r\n File \"/usr/local/pyenv/versions/3.6.7/lib/python3.6/site-packages/pydantic/dataclasses.py\", line 13, in post_init\r\n self.__post_init_original__()\r\n File \"/usr/local/pyenv/versions/3.6.7/lib/python3.6/site-packages/pydantic/dataclasses.py\", line 13, in post_init\r\n self.__post_init_original__()\r\n [Previous line repeated 952 more times]\r\n File \"/usr/local/pyenv/versions/3.6.7/lib/python3.6/site-packages/pydantic/dataclasses.py\", line 9, in post_init\r\n d = validate_model(self.__pydantic_model__, self.__dict__)\r\n File \"/usr/local/pyenv/versions/3.6.7/lib/python3.6/site-packages/pydantic/main.py\", line 484, in validate_model\r\n v_, errors_ = field.validate(value, values, loc=field.alias, cls=model.__class__)\r\n File \"/usr/local/pyenv/versions/3.6.7/lib/python3.6/site-packages/pydantic/fields.py\", line 303, in validate\r\n v, errors = self._validate_singleton(v, values, loc, cls)\r\n File \"/usr/local/pyenv/versions/3.6.7/lib/python3.6/site-packages/pydantic/fields.py\", line 406, in _validate_singleton\r\n return self._apply_validators(v, values, loc, cls, self.validators)\r\n File \"/usr/local/pyenv/versions/3.6.7/lib/python3.6/site-packages/pydantic/fields.py\", line 412, in _apply_validators\r\n v = validator(v)\r\n File \"/usr/local/pyenv/versions/3.6.7/lib/python3.6/site-packages/pydantic/validators.py\", line 23, in str_validator\r\n if isinstance(v, (str, NoneType)):\r\nRecursionError: maximum recursion depth exceeded in __instancecheck__\r\n```\r\nThis line below causes this problem:\r\nhttps://github.com/samuelcolvin/pydantic/blob/master/pydantic/dataclasses.py#L13\r\n\r\nUPD: defining `__post_init__` in child model fixes the problem, but this is workaround.\r\n```py\r\nimport pydantic.dataclasses\r\n\r\[email protected]\r\nclass A:\r\n a: str = None\r\n\r\[email protected]\r\nclass B(A):\r\n b: str = None\r\n\r\n def __post_init__():\r\n pass\r\n\r\nB(a='a', b='b')\r\n```\n", "before_files": [{"content": "import dataclasses\n\nfrom pydantic import ValidationError\n\nfrom .main import create_model, validate_model\n\n\ndef post_init(self):\n d = validate_model(self.__pydantic_model__, self.__dict__)\n object.__setattr__(self, '__dict__', d)\n object.__setattr__(self, '__initialised__', True)\n if self.__post_init_original__:\n self.__post_init_original__()\n\n\ndef setattr_validate_assignment(self, name, value):\n if self.__initialised__:\n d = dict(self.__dict__)\n d.pop(name)\n value, error_ = self.__pydantic_model__.__fields__[name].validate(value, d, loc=name)\n if error_:\n raise ValidationError([error_])\n\n object.__setattr__(self, name, value)\n\n\ndef _process_class(_cls, init, repr, eq, order, unsafe_hash, frozen, validate_assignment):\n post_init_original = getattr(_cls, '__post_init__', None)\n _cls.__post_init__ = post_init\n cls = dataclasses._process_class(_cls, init, repr, eq, order, unsafe_hash, frozen)\n\n fields = {name: (field.type, field.default) for name, field in cls.__dataclass_fields__.items()}\n cls.__post_init_original__ = post_init_original\n cls.__pydantic_model__ = create_model(cls.__name__, **fields)\n cls.__initialised__ = False\n\n if validate_assignment and not frozen:\n cls.__setattr__ = setattr_validate_assignment\n return cls\n\n\ndef dataclass(\n _cls=None, *, init=True, repr=True, eq=True, order=False, unsafe_hash=False, frozen=False, validate_assignment=False\n):\n \"\"\"\n Like the python standard lib dataclasses but with type validation.\n\n Arguments are the same as for standard dataclasses, except for validate_assignment which has the same meaning\n as Config.validate_assignment.\n \"\"\"\n\n def wrap(cls):\n return _process_class(cls, init, repr, eq, order, unsafe_hash, frozen, validate_assignment)\n\n if _cls is None:\n return wrap\n\n return wrap(_cls)\n", "path": "pydantic/dataclasses.py"}]}
| 2,017 | 273 |
gh_patches_debug_18778
|
rasdani/github-patches
|
git_diff
|
vacanza__python-holidays-1782
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
The calculation of the lunar start date throws a TypeError exception for Thailand and Cambodia
version: 0.47
stack trace:
"python39\lib\site-packages\holidays\calendars\thai.py", line 233, in _get_start_date
return _ThaiLunisolar.START_DATE + td(days=delta_days)
TypeError: unsupported type for timedelta days component: numpy.int32
</issue>
<code>
[start of holidays/helpers.py]
1 # holidays
2 # --------
3 # A fast, efficient Python library for generating country, province and state
4 # specific sets of holidays on the fly. It aims to make determining whether a
5 # specific date is a holiday as fast and flexible as possible.
6 #
7 # Authors: Vacanza Team and individual contributors (see AUTHORS file)
8 # dr-prodigy <[email protected]> (c) 2017-2023
9 # ryanss <[email protected]> (c) 2014-2017
10 # Website: https://github.com/vacanza/python-holidays
11 # License: MIT (see LICENSE file)
12
13
14 def _normalize_arguments(cls, value):
15 """Normalize arguments.
16
17 :param cls:
18 A type of arguments to normalize.
19
20 :param value:
21 Either a single item or an iterable of `cls` type.
22
23 :return:
24 A set created from `value` argument.
25
26 """
27 if isinstance(value, cls):
28 return {value}
29
30 return set(value) if value is not None else set()
31
32
33 def _normalize_tuple(data):
34 """Normalize tuple.
35
36 :param data:
37 Either a tuple or a tuple of tuples.
38
39 :return:
40 An unchanged object for tuple of tuples, e.g., ((JAN, 10), (DEC, 31)).
41 An object put into a tuple otherwise, e.g., ((JAN, 10),).
42 """
43 return data if not data or isinstance(data[0], tuple) else (data,)
44
[end of holidays/helpers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/holidays/helpers.py b/holidays/helpers.py
--- a/holidays/helpers.py
+++ b/holidays/helpers.py
@@ -24,13 +24,19 @@
A set created from `value` argument.
"""
+ if value is None:
+ return set()
+
if isinstance(value, cls):
return {value}
- return set(value) if value is not None else set()
+ try:
+ return {v if isinstance(v, cls) else cls(v) for v in value}
+ except TypeError: # non-iterable
+ return {value if isinstance(value, cls) else cls(value)}
-def _normalize_tuple(data):
+def _normalize_tuple(value):
"""Normalize tuple.
:param data:
@@ -40,4 +46,4 @@
An unchanged object for tuple of tuples, e.g., ((JAN, 10), (DEC, 31)).
An object put into a tuple otherwise, e.g., ((JAN, 10),).
"""
- return data if not data or isinstance(data[0], tuple) else (data,)
+ return value if not value or isinstance(value[0], tuple) else (value,)
|
{"golden_diff": "diff --git a/holidays/helpers.py b/holidays/helpers.py\n--- a/holidays/helpers.py\n+++ b/holidays/helpers.py\n@@ -24,13 +24,19 @@\n A set created from `value` argument.\n \n \"\"\"\n+ if value is None:\n+ return set()\n+\n if isinstance(value, cls):\n return {value}\n \n- return set(value) if value is not None else set()\n+ try:\n+ return {v if isinstance(v, cls) else cls(v) for v in value}\n+ except TypeError: # non-iterable\n+ return {value if isinstance(value, cls) else cls(value)}\n \n \n-def _normalize_tuple(data):\n+def _normalize_tuple(value):\n \"\"\"Normalize tuple.\n \n :param data:\n@@ -40,4 +46,4 @@\n An unchanged object for tuple of tuples, e.g., ((JAN, 10), (DEC, 31)).\n An object put into a tuple otherwise, e.g., ((JAN, 10),).\n \"\"\"\n- return data if not data or isinstance(data[0], tuple) else (data,)\n+ return value if not value or isinstance(value[0], tuple) else (value,)\n", "issue": "The calculation of the lunar start date throws a TypeError exception for Thailand and Cambodia\nversion: 0.47\r\nstack trace:\r\n\"python39\\lib\\site-packages\\holidays\\calendars\\thai.py\", line 233, in _get_start_date\r\n return _ThaiLunisolar.START_DATE + td(days=delta_days)\r\nTypeError: unsupported type for timedelta days component: numpy.int32\n", "before_files": [{"content": "# holidays\n# --------\n# A fast, efficient Python library for generating country, province and state\n# specific sets of holidays on the fly. It aims to make determining whether a\n# specific date is a holiday as fast and flexible as possible.\n#\n# Authors: Vacanza Team and individual contributors (see AUTHORS file)\n# dr-prodigy <[email protected]> (c) 2017-2023\n# ryanss <[email protected]> (c) 2014-2017\n# Website: https://github.com/vacanza/python-holidays\n# License: MIT (see LICENSE file)\n\n\ndef _normalize_arguments(cls, value):\n \"\"\"Normalize arguments.\n\n :param cls:\n A type of arguments to normalize.\n\n :param value:\n Either a single item or an iterable of `cls` type.\n\n :return:\n A set created from `value` argument.\n\n \"\"\"\n if isinstance(value, cls):\n return {value}\n\n return set(value) if value is not None else set()\n\n\ndef _normalize_tuple(data):\n \"\"\"Normalize tuple.\n\n :param data:\n Either a tuple or a tuple of tuples.\n\n :return:\n An unchanged object for tuple of tuples, e.g., ((JAN, 10), (DEC, 31)).\n An object put into a tuple otherwise, e.g., ((JAN, 10),).\n \"\"\"\n return data if not data or isinstance(data[0], tuple) else (data,)\n", "path": "holidays/helpers.py"}]}
| 1,050 | 272 |
gh_patches_debug_13296
|
rasdani/github-patches
|
git_diff
|
qtile__qtile-1687
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Ampersands need to be escaped in WindowName widget
# Issue description
Ampersands in window names need to be changed in WindowName widget to "&" before being passed to Pango/Cairo
# Qtile version
0.15.1
# Stack traces
Exception: parse_markup() failed for b'Seth Lakeman - King & Country'
2020-04-27 19:12:00,744 ERROR libqtile hook.py:fire():L373 Error in hook focus_change
Traceback (most recent call last):
File "/usr/lib/python3.8/site-packages/libqtile/hook.py", line 371, in fire
i(*args, **kwargs)
File "/usr/lib/python3.8/site-packages/libqtile/widget/windowname.py", line 67, in update
self.text = "%s%s" % (state, w.name if w and w.name else " ")
File "/usr/lib/python3.8/site-packages/libqtile/widget/base.py", line 323, in text
self.layout.text = self.formatted_text
File "/usr/lib/python3.8/site-packages/libqtile/drawer.py", line 70, in text
attrlist, value, accel_char = pangocffi.parse_markup(value)
File "/usr/lib/python3.8/site-packages/libqtile/pangocffi.py", line 173, in parse_markup
raise Exception("parse_markup() failed for %s" % value)
Exception: parse_markup() failed for b'Seth Lakeman - King & Country'
# Configuration
N/A
</issue>
<code>
[start of libqtile/widget/windowname.py]
1 # Copyright (c) 2008, 2010 Aldo Cortesi
2 # Copyright (c) 2010 matt
3 # Copyright (c) 2011 Mounier Florian
4 # Copyright (c) 2012 Tim Neumann
5 # Copyright (c) 2013 Craig Barnes
6 # Copyright (c) 2014 Sean Vig
7 # Copyright (c) 2014 Tycho Andersen
8 #
9 # Permission is hereby granted, free of charge, to any person obtaining a copy
10 # of this software and associated documentation files (the "Software"), to deal
11 # in the Software without restriction, including without limitation the rights
12 # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
13 # copies of the Software, and to permit persons to whom the Software is
14 # furnished to do so, subject to the following conditions:
15 #
16 # The above copyright notice and this permission notice shall be included in
17 # all copies or substantial portions of the Software.
18 #
19 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
20 # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
21 # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
22 # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
23 # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
24 # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
25 # SOFTWARE.
26
27 from libqtile import bar, hook
28 from libqtile.widget import base
29
30
31 class WindowName(base._TextBox):
32 """Displays the name of the window that currently has focus"""
33 orientations = base.ORIENTATION_HORIZONTAL
34 defaults = [
35 ('show_state', True, 'show window status before window name'),
36 ('for_current_screen', False, 'instead of this bars screen use currently active screen')
37 ]
38
39 def __init__(self, width=bar.STRETCH, **config):
40 base._TextBox.__init__(self, width=width, **config)
41 self.add_defaults(WindowName.defaults)
42
43 def _configure(self, qtile, bar):
44 base._TextBox._configure(self, qtile, bar)
45 hook.subscribe.client_name_updated(self.update)
46 hook.subscribe.focus_change(self.update)
47 hook.subscribe.float_change(self.update)
48
49 @hook.subscribe.current_screen_change
50 def on_screen_changed():
51 if self.for_current_screen:
52 self.update()
53
54 def update(self, *args):
55 if self.for_current_screen:
56 w = self.qtile.current_screen.group.current_window
57 else:
58 w = self.bar.screen.group.current_window
59 state = ''
60 if self.show_state and w is not None:
61 if w.maximized:
62 state = '[] '
63 elif w.minimized:
64 state = '_ '
65 elif w.floating:
66 state = 'V '
67 self.text = "%s%s" % (state, w.name if w and w.name else " ")
68 self.bar.draw()
69
[end of libqtile/widget/windowname.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/libqtile/widget/windowname.py b/libqtile/widget/windowname.py
--- a/libqtile/widget/windowname.py
+++ b/libqtile/widget/windowname.py
@@ -24,7 +24,7 @@
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
# SOFTWARE.
-from libqtile import bar, hook
+from libqtile import bar, hook, pangocffi
from libqtile.widget import base
@@ -64,5 +64,6 @@
state = '_ '
elif w.floating:
state = 'V '
- self.text = "%s%s" % (state, w.name if w and w.name else " ")
+ unescaped = "%s%s" % (state, w.name if w and w.name else " ")
+ self.text = pangocffi.markup_escape_text(unescaped)
self.bar.draw()
|
{"golden_diff": "diff --git a/libqtile/widget/windowname.py b/libqtile/widget/windowname.py\n--- a/libqtile/widget/windowname.py\n+++ b/libqtile/widget/windowname.py\n@@ -24,7 +24,7 @@\n # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n # SOFTWARE.\n \n-from libqtile import bar, hook\n+from libqtile import bar, hook, pangocffi\n from libqtile.widget import base\n \n \n@@ -64,5 +64,6 @@\n state = '_ '\n elif w.floating:\n state = 'V '\n- self.text = \"%s%s\" % (state, w.name if w and w.name else \" \")\n+ unescaped = \"%s%s\" % (state, w.name if w and w.name else \" \")\n+ self.text = pangocffi.markup_escape_text(unescaped)\n self.bar.draw()\n", "issue": "Ampersands need to be escaped in WindowName widget\n# Issue description\r\nAmpersands in window names need to be changed in WindowName widget to \"&\" before being passed to Pango/Cairo\r\n\r\n# Qtile version\r\n0.15.1\r\n\r\n# Stack traces\r\nException: parse_markup() failed for b'Seth Lakeman - King & Country'\r\n2020-04-27 19:12:00,744 ERROR libqtile hook.py:fire():L373 Error in hook focus_change\r\nTraceback (most recent call last):\r\n File \"/usr/lib/python3.8/site-packages/libqtile/hook.py\", line 371, in fire\r\n i(*args, **kwargs)\r\n File \"/usr/lib/python3.8/site-packages/libqtile/widget/windowname.py\", line 67, in update\r\n self.text = \"%s%s\" % (state, w.name if w and w.name else \" \")\r\n File \"/usr/lib/python3.8/site-packages/libqtile/widget/base.py\", line 323, in text\r\n self.layout.text = self.formatted_text\r\n File \"/usr/lib/python3.8/site-packages/libqtile/drawer.py\", line 70, in text\r\n attrlist, value, accel_char = pangocffi.parse_markup(value)\r\n File \"/usr/lib/python3.8/site-packages/libqtile/pangocffi.py\", line 173, in parse_markup\r\n raise Exception(\"parse_markup() failed for %s\" % value)\r\nException: parse_markup() failed for b'Seth Lakeman - King & Country'\r\n\r\n# Configuration\r\nN/A\n", "before_files": [{"content": "# Copyright (c) 2008, 2010 Aldo Cortesi\n# Copyright (c) 2010 matt\n# Copyright (c) 2011 Mounier Florian\n# Copyright (c) 2012 Tim Neumann\n# Copyright (c) 2013 Craig Barnes\n# Copyright (c) 2014 Sean Vig\n# Copyright (c) 2014 Tycho Andersen\n#\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n# SOFTWARE.\n\nfrom libqtile import bar, hook\nfrom libqtile.widget import base\n\n\nclass WindowName(base._TextBox):\n \"\"\"Displays the name of the window that currently has focus\"\"\"\n orientations = base.ORIENTATION_HORIZONTAL\n defaults = [\n ('show_state', True, 'show window status before window name'),\n ('for_current_screen', False, 'instead of this bars screen use currently active screen')\n ]\n\n def __init__(self, width=bar.STRETCH, **config):\n base._TextBox.__init__(self, width=width, **config)\n self.add_defaults(WindowName.defaults)\n\n def _configure(self, qtile, bar):\n base._TextBox._configure(self, qtile, bar)\n hook.subscribe.client_name_updated(self.update)\n hook.subscribe.focus_change(self.update)\n hook.subscribe.float_change(self.update)\n\n @hook.subscribe.current_screen_change\n def on_screen_changed():\n if self.for_current_screen:\n self.update()\n\n def update(self, *args):\n if self.for_current_screen:\n w = self.qtile.current_screen.group.current_window\n else:\n w = self.bar.screen.group.current_window\n state = ''\n if self.show_state and w is not None:\n if w.maximized:\n state = '[] '\n elif w.minimized:\n state = '_ '\n elif w.floating:\n state = 'V '\n self.text = \"%s%s\" % (state, w.name if w and w.name else \" \")\n self.bar.draw()\n", "path": "libqtile/widget/windowname.py"}]}
| 1,674 | 202 |
gh_patches_debug_15825
|
rasdani/github-patches
|
git_diff
|
zulip__zulip-13771
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Creation of temporary files in requirements/ can cause provision to fail
An example to trigger this for me is was as follows:
* `cd requirements/`
* edit file using editor which creates temporary file in this location (eg vim, depending on configuration)
* `tools/provision`
* provision fails with an error like
```
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xcd in position 17: invalid continuation byte
```
This appears to be due to the venv management script not being able to handle the unexpected file produced by eg. vim.
This is not a major issue, but is a bit of a strange issue to debug if you are not expecting it or are new, and potentially could be easy to fix.
</issue>
<code>
[start of scripts/lib/clean_venv_cache.py]
1 #!/usr/bin/env python3
2 import argparse
3 import os
4 import sys
5
6 from typing import Set
7
8 ZULIP_PATH = os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
9 sys.path.append(ZULIP_PATH)
10 from scripts.lib.hash_reqs import expand_reqs, hash_deps
11 from scripts.lib.zulip_tools import \
12 get_environment, get_recent_deployments, parse_cache_script_args, \
13 purge_unused_caches
14
15 ENV = get_environment()
16 VENV_CACHE_DIR = '/srv/zulip-venv-cache'
17 if ENV == "travis":
18 VENV_CACHE_DIR = os.path.join(os.environ["HOME"], "zulip-venv-cache")
19
20 def get_caches_in_use(threshold_days):
21 # type: (int) -> Set[str]
22 setups_to_check = set([ZULIP_PATH, ])
23 caches_in_use = set()
24
25 def add_current_venv_cache(venv_name: str) -> None:
26 CACHE_SYMLINK = os.path.join(os.path.dirname(ZULIP_PATH), venv_name)
27 CURRENT_CACHE = os.path.dirname(os.path.realpath(CACHE_SYMLINK))
28 caches_in_use.add(CURRENT_CACHE)
29
30 if ENV == "prod":
31 setups_to_check |= get_recent_deployments(threshold_days)
32 if ENV == "dev":
33 add_current_venv_cache("zulip-py3-venv")
34 add_current_venv_cache("zulip-thumbor-venv")
35
36 for path in setups_to_check:
37 reqs_dir = os.path.join(path, "requirements")
38 # If the target directory doesn't contain a requirements
39 # directory, skip it to avoid throwing an exception trying to
40 # list its requirements subdirectory.
41 if not os.path.exists(reqs_dir):
42 continue
43 for filename in os.listdir(reqs_dir):
44 requirements_file = os.path.join(reqs_dir, filename)
45 deps = expand_reqs(requirements_file)
46 hash_val = hash_deps(deps)
47 caches_in_use.add(os.path.join(VENV_CACHE_DIR, hash_val))
48
49 return caches_in_use
50
51 def main(args: argparse.Namespace) -> None:
52 caches_in_use = get_caches_in_use(args.threshold_days)
53 purge_unused_caches(
54 VENV_CACHE_DIR, caches_in_use, "venv cache", args)
55
56 if __name__ == "__main__":
57 args = parse_cache_script_args("This script cleans unused zulip venv caches.")
58 main(args)
59
[end of scripts/lib/clean_venv_cache.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scripts/lib/clean_venv_cache.py b/scripts/lib/clean_venv_cache.py
--- a/scripts/lib/clean_venv_cache.py
+++ b/scripts/lib/clean_venv_cache.py
@@ -1,5 +1,6 @@
#!/usr/bin/env python3
import argparse
+import glob
import os
import sys
@@ -40,8 +41,8 @@
# list its requirements subdirectory.
if not os.path.exists(reqs_dir):
continue
- for filename in os.listdir(reqs_dir):
- requirements_file = os.path.join(reqs_dir, filename)
+ requirements_files = glob.glob(os.path.join(reqs_dir, "*.txt"))
+ for requirements_file in requirements_files:
deps = expand_reqs(requirements_file)
hash_val = hash_deps(deps)
caches_in_use.add(os.path.join(VENV_CACHE_DIR, hash_val))
|
{"golden_diff": "diff --git a/scripts/lib/clean_venv_cache.py b/scripts/lib/clean_venv_cache.py\n--- a/scripts/lib/clean_venv_cache.py\n+++ b/scripts/lib/clean_venv_cache.py\n@@ -1,5 +1,6 @@\n #!/usr/bin/env python3\n import argparse\n+import glob\n import os\n import sys\n \n@@ -40,8 +41,8 @@\n # list its requirements subdirectory.\n if not os.path.exists(reqs_dir):\n continue\n- for filename in os.listdir(reqs_dir):\n- requirements_file = os.path.join(reqs_dir, filename)\n+ requirements_files = glob.glob(os.path.join(reqs_dir, \"*.txt\"))\n+ for requirements_file in requirements_files:\n deps = expand_reqs(requirements_file)\n hash_val = hash_deps(deps)\n caches_in_use.add(os.path.join(VENV_CACHE_DIR, hash_val))\n", "issue": "Creation of temporary files in requirements/ can cause provision to fail\nAn example to trigger this for me is was as follows:\r\n* `cd requirements/`\r\n* edit file using editor which creates temporary file in this location (eg vim, depending on configuration)\r\n* `tools/provision`\r\n* provision fails with an error like\r\n```\r\nUnicodeDecodeError: 'utf-8' codec can't decode byte 0xcd in position 17: invalid continuation byte\r\n```\r\n\r\nThis appears to be due to the venv management script not being able to handle the unexpected file produced by eg. vim.\r\n\r\nThis is not a major issue, but is a bit of a strange issue to debug if you are not expecting it or are new, and potentially could be easy to fix.\n", "before_files": [{"content": "#!/usr/bin/env python3\nimport argparse\nimport os\nimport sys\n\nfrom typing import Set\n\nZULIP_PATH = os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))\nsys.path.append(ZULIP_PATH)\nfrom scripts.lib.hash_reqs import expand_reqs, hash_deps\nfrom scripts.lib.zulip_tools import \\\n get_environment, get_recent_deployments, parse_cache_script_args, \\\n purge_unused_caches\n\nENV = get_environment()\nVENV_CACHE_DIR = '/srv/zulip-venv-cache'\nif ENV == \"travis\":\n VENV_CACHE_DIR = os.path.join(os.environ[\"HOME\"], \"zulip-venv-cache\")\n\ndef get_caches_in_use(threshold_days):\n # type: (int) -> Set[str]\n setups_to_check = set([ZULIP_PATH, ])\n caches_in_use = set()\n\n def add_current_venv_cache(venv_name: str) -> None:\n CACHE_SYMLINK = os.path.join(os.path.dirname(ZULIP_PATH), venv_name)\n CURRENT_CACHE = os.path.dirname(os.path.realpath(CACHE_SYMLINK))\n caches_in_use.add(CURRENT_CACHE)\n\n if ENV == \"prod\":\n setups_to_check |= get_recent_deployments(threshold_days)\n if ENV == \"dev\":\n add_current_venv_cache(\"zulip-py3-venv\")\n add_current_venv_cache(\"zulip-thumbor-venv\")\n\n for path in setups_to_check:\n reqs_dir = os.path.join(path, \"requirements\")\n # If the target directory doesn't contain a requirements\n # directory, skip it to avoid throwing an exception trying to\n # list its requirements subdirectory.\n if not os.path.exists(reqs_dir):\n continue\n for filename in os.listdir(reqs_dir):\n requirements_file = os.path.join(reqs_dir, filename)\n deps = expand_reqs(requirements_file)\n hash_val = hash_deps(deps)\n caches_in_use.add(os.path.join(VENV_CACHE_DIR, hash_val))\n\n return caches_in_use\n\ndef main(args: argparse.Namespace) -> None:\n caches_in_use = get_caches_in_use(args.threshold_days)\n purge_unused_caches(\n VENV_CACHE_DIR, caches_in_use, \"venv cache\", args)\n\nif __name__ == \"__main__\":\n args = parse_cache_script_args(\"This script cleans unused zulip venv caches.\")\n main(args)\n", "path": "scripts/lib/clean_venv_cache.py"}]}
| 1,341 | 199 |
gh_patches_debug_15375
|
rasdani/github-patches
|
git_diff
|
openstates__openstates-scrapers-1221
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Make `LXMLMixin.lxmlize` use scraper's `session`, rather than a raw `request.get()`
Otherwise it slows down `--fast` scrapes because it doesn't use cached responses.
</issue>
<code>
[start of openstates/utils/lxmlize.py]
1 import requests
2 import lxml.html
3
4
5 class LXMLMixin(object):
6 """Mixin for adding LXML helper functions to Open States code."""
7
8 def lxmlize(self, url, raise_exceptions=False):
9 """Parses document into an LXML object and makes links absolute.
10
11 Args:
12 url (str): URL of the document to parse.
13 Returns:
14 Element: Document node representing the page.
15 """
16 try:
17 response = requests.get(url)
18 except requests.exceptions.SSLError:
19 self.warning('`self.lxmlize()` failed due to SSL error, trying'\
20 'an unverified `requests.get()`')
21 response = requests.get(url, verify=False)
22
23 if raise_exceptions:
24 response.raise_for_status()
25
26 page = lxml.html.fromstring(response.text)
27 page.make_links_absolute(url)
28
29 return page
30
31 def get_node(self, base_node, xpath_query):
32 """Searches for node in an element tree.
33
34 Attempts to return only the first node found for an xpath query. Meant
35 to cut down on exception handling boilerplate.
36
37 Args:
38 base_node (Element): Document node to begin querying from.
39 xpath_query (str): XPath query to define nodes to search for.
40 Returns:
41 Element: First node found that matches the query.
42 """
43 try:
44 node = base_node.xpath(xpath_query)[0]
45 except IndexError:
46 node = None
47
48 return node
49
50 def get_nodes(self, base_node, xpath_query):
51 """Searches for nodes in an element tree.
52
53 Attempts to return all nodes found for an xpath query. Meant to cut
54 down on exception handling boilerplate.
55
56 Args:
57 base_node (Element): Document node to begin querying from.
58 xpath_query (str): Xpath query to define nodes to search for.
59 Returns:
60 List[Element]: All nodes found that match the query.
61 """
62 return base_node.xpath(xpath_query)
63
[end of openstates/utils/lxmlize.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/openstates/utils/lxmlize.py b/openstates/utils/lxmlize.py
--- a/openstates/utils/lxmlize.py
+++ b/openstates/utils/lxmlize.py
@@ -14,11 +14,13 @@
Element: Document node representing the page.
"""
try:
- response = requests.get(url)
+ # This class is always mixed into subclasses of `billy.Scraper`,
+ # which have a `get` method defined.
+ response = self.get(url)
except requests.exceptions.SSLError:
self.warning('`self.lxmlize()` failed due to SSL error, trying'\
- 'an unverified `requests.get()`')
- response = requests.get(url, verify=False)
+ 'an unverified `self.get()` (i.e. `requests.get()`)')
+ response = self.get(url, verify=False)
if raise_exceptions:
response.raise_for_status()
|
{"golden_diff": "diff --git a/openstates/utils/lxmlize.py b/openstates/utils/lxmlize.py\n--- a/openstates/utils/lxmlize.py\n+++ b/openstates/utils/lxmlize.py\n@@ -14,11 +14,13 @@\n Element: Document node representing the page.\n \"\"\"\n try:\n- response = requests.get(url)\n+ # This class is always mixed into subclasses of `billy.Scraper`,\n+ # which have a `get` method defined.\n+ response = self.get(url)\n except requests.exceptions.SSLError:\n self.warning('`self.lxmlize()` failed due to SSL error, trying'\\\n- 'an unverified `requests.get()`')\n- response = requests.get(url, verify=False)\n+ 'an unverified `self.get()` (i.e. `requests.get()`)')\n+ response = self.get(url, verify=False)\n \n if raise_exceptions:\n response.raise_for_status()\n", "issue": "Make `LXMLMixin.lxmlize` use scraper's `session`, rather than a raw `request.get()`\nOtherwise it slows down `--fast` scrapes because it doesn't use cached responses.\n", "before_files": [{"content": "import requests\nimport lxml.html\n\n\nclass LXMLMixin(object):\n \"\"\"Mixin for adding LXML helper functions to Open States code.\"\"\"\n\n def lxmlize(self, url, raise_exceptions=False):\n \"\"\"Parses document into an LXML object and makes links absolute.\n\n Args:\n url (str): URL of the document to parse.\n Returns:\n Element: Document node representing the page.\n \"\"\"\n try:\n response = requests.get(url)\n except requests.exceptions.SSLError:\n self.warning('`self.lxmlize()` failed due to SSL error, trying'\\\n 'an unverified `requests.get()`')\n response = requests.get(url, verify=False)\n\n if raise_exceptions:\n response.raise_for_status()\n\n page = lxml.html.fromstring(response.text)\n page.make_links_absolute(url)\n\n return page\n\n def get_node(self, base_node, xpath_query):\n \"\"\"Searches for node in an element tree.\n\n Attempts to return only the first node found for an xpath query. Meant\n to cut down on exception handling boilerplate.\n\n Args:\n base_node (Element): Document node to begin querying from.\n xpath_query (str): XPath query to define nodes to search for.\n Returns:\n Element: First node found that matches the query.\n \"\"\"\n try:\n node = base_node.xpath(xpath_query)[0]\n except IndexError:\n node = None\n\n return node\n\n def get_nodes(self, base_node, xpath_query):\n \"\"\"Searches for nodes in an element tree.\n\n Attempts to return all nodes found for an xpath query. Meant to cut\n down on exception handling boilerplate.\n\n Args:\n base_node (Element): Document node to begin querying from.\n xpath_query (str): Xpath query to define nodes to search for.\n Returns:\n List[Element]: All nodes found that match the query.\n \"\"\"\n return base_node.xpath(xpath_query)\n", "path": "openstates/utils/lxmlize.py"}]}
| 1,116 | 206 |
gh_patches_debug_5394
|
rasdani/github-patches
|
git_diff
|
cupy__cupy-1717
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`cupy.nextafter` is wrong on a=0
`test_nextafter_combination` is failing.
`{'dtype_b': <type 'numpy.float32'>, 'dtype_a': <type 'numpy.bool_'>}`
```
x = array([[1.1754944e-38, 1.0000001e+00, 1.1754944e-38],
[1.0000001e+00, 1.1754944e-38, 1.0000000e+00]], dtype=float32)
y = array([[1.4012985e-45, 1.0000001e+00, 1.4012985e-45],
[1.0000001e+00, 1.4012985e-45, 1.0000000e+00]], dtype=float32)
```
</issue>
<code>
[start of cupy/math/floating.py]
1 from cupy import core
2 from cupy.math import ufunc
3
4
5 signbit = core.create_ufunc(
6 'cupy_signbit',
7 ('e->?', 'f->?', 'd->?'),
8 'out0 = signbit(in0)',
9 doc='''Tests elementwise if the sign bit is set (i.e. less than zero).
10
11 .. seealso:: :data:`numpy.signbit`
12
13 ''')
14
15
16 copysign = ufunc.create_math_ufunc(
17 'copysign', 2, 'cupy_copysign',
18 '''Returns the first argument with the sign bit of the second elementwise.
19
20 .. seealso:: :data:`numpy.copysign`
21
22 ''')
23
24
25 ldexp = core.create_ufunc(
26 'cupy_ldexp',
27 ('ei->e', 'fi->f', 'el->e', 'fl->f', 'di->d', 'dq->d'),
28 'out0 = ldexp(in0, in1)',
29 doc='''Computes ``x1 * 2 ** x2`` elementwise.
30
31 .. seealso:: :data:`numpy.ldexp`
32
33 ''')
34
35
36 frexp = core.create_ufunc(
37 'cupy_frexp',
38 ('e->ei', 'f->fi', 'd->di'),
39 'int nptr; out0 = frexp(in0, &nptr); out1 = nptr',
40 doc='''Decomposes each element to mantissa and two's exponent.
41
42 This ufunc outputs two arrays of the input dtype and the ``int`` dtype.
43
44 .. seealso:: :data:`numpy.frexp`
45
46 ''')
47
48
49 nextafter = ufunc.create_math_ufunc(
50 'nextafter', 2, 'cupy_nextafter',
51 '''Computes the nearest neighbor float values towards the second argument.
52
53 .. seealso:: :data:`numpy.nextafter`
54
55 ''')
56
[end of cupy/math/floating.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/cupy/math/floating.py b/cupy/math/floating.py
--- a/cupy/math/floating.py
+++ b/cupy/math/floating.py
@@ -50,6 +50,11 @@
'nextafter', 2, 'cupy_nextafter',
'''Computes the nearest neighbor float values towards the second argument.
+ .. note::
+ For values that are close to zero (or denormal numbers),
+ results of :func:`cupy.nextafter` may be different from those of
+ :func:`numpy.nextafter`, because CuPy sets ``-ftz=true``.
+
.. seealso:: :data:`numpy.nextafter`
''')
|
{"golden_diff": "diff --git a/cupy/math/floating.py b/cupy/math/floating.py\n--- a/cupy/math/floating.py\n+++ b/cupy/math/floating.py\n@@ -50,6 +50,11 @@\n 'nextafter', 2, 'cupy_nextafter',\n '''Computes the nearest neighbor float values towards the second argument.\n \n+ .. note::\n+ For values that are close to zero (or denormal numbers),\n+ results of :func:`cupy.nextafter` may be different from those of\n+ :func:`numpy.nextafter`, because CuPy sets ``-ftz=true``.\n+\n .. seealso:: :data:`numpy.nextafter`\n \n ''')\n", "issue": "`cupy.nextafter` is wrong on a=0\n`test_nextafter_combination` is failing.\r\n\r\n`{'dtype_b': <type 'numpy.float32'>, 'dtype_a': <type 'numpy.bool_'>}`\r\n```\r\nx = array([[1.1754944e-38, 1.0000001e+00, 1.1754944e-38],\r\n [1.0000001e+00, 1.1754944e-38, 1.0000000e+00]], dtype=float32)\r\ny = array([[1.4012985e-45, 1.0000001e+00, 1.4012985e-45],\r\n [1.0000001e+00, 1.4012985e-45, 1.0000000e+00]], dtype=float32)\r\n```\n", "before_files": [{"content": "from cupy import core\nfrom cupy.math import ufunc\n\n\nsignbit = core.create_ufunc(\n 'cupy_signbit',\n ('e->?', 'f->?', 'd->?'),\n 'out0 = signbit(in0)',\n doc='''Tests elementwise if the sign bit is set (i.e. less than zero).\n\n .. seealso:: :data:`numpy.signbit`\n\n ''')\n\n\ncopysign = ufunc.create_math_ufunc(\n 'copysign', 2, 'cupy_copysign',\n '''Returns the first argument with the sign bit of the second elementwise.\n\n .. seealso:: :data:`numpy.copysign`\n\n ''')\n\n\nldexp = core.create_ufunc(\n 'cupy_ldexp',\n ('ei->e', 'fi->f', 'el->e', 'fl->f', 'di->d', 'dq->d'),\n 'out0 = ldexp(in0, in1)',\n doc='''Computes ``x1 * 2 ** x2`` elementwise.\n\n .. seealso:: :data:`numpy.ldexp`\n\n ''')\n\n\nfrexp = core.create_ufunc(\n 'cupy_frexp',\n ('e->ei', 'f->fi', 'd->di'),\n 'int nptr; out0 = frexp(in0, &nptr); out1 = nptr',\n doc='''Decomposes each element to mantissa and two's exponent.\n\n This ufunc outputs two arrays of the input dtype and the ``int`` dtype.\n\n .. seealso:: :data:`numpy.frexp`\n\n ''')\n\n\nnextafter = ufunc.create_math_ufunc(\n 'nextafter', 2, 'cupy_nextafter',\n '''Computes the nearest neighbor float values towards the second argument.\n\n .. seealso:: :data:`numpy.nextafter`\n\n ''')\n", "path": "cupy/math/floating.py"}]}
| 1,322 | 155 |
gh_patches_debug_34472
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-3951
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Spider dominos_pizza_jp is broken
During the global build at 2021-06-30-14-42-26, spider **dominos_pizza_jp** failed with **0 features** and **0 errors**.
Here's [the log](https://data.alltheplaces.xyz/runs/2021-06-30-14-42-26/logs/dominos_pizza_jp.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-06-30-14-42-26/output/dominos_pizza_jp.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-06-30-14-42-26/output/dominos_pizza_jp.geojson))
</issue>
<code>
[start of locations/spiders/dominos_pizza_jp.py]
1 # -*- coding: utf-8 -*-
2 import re
3
4 import scrapy
5
6 from locations.items import GeojsonPointItem
7
8
9 class DominosPizzaJPSpider(scrapy.Spider):
10 name = "dominos_pizza_jp"
11 item_attributes = {"brand": "Domino's", "brand_wikidata": "Q839466"}
12 allowed_domains = ["dominos.jp"]
13 start_urls = [
14 "https://www.dominos.jp/sitemap.aspx",
15 ]
16 download_delay = 0.3
17
18 def parse(self, response):
19 response.selector.remove_namespaces()
20 store_urls = response.xpath('//url/loc/text()[contains(.,"/store/")]').extract()
21 for url in store_urls:
22 yield scrapy.Request(url, callback=self.parse_store)
23
24 def parse_store(self, response):
25 ref = re.search(r".+/(.+?)/?(?:\.html|$)", response.url).group(1)
26
27 properties = {
28 "ref": ref,
29 "name": response.xpath(
30 'normalize-space(//div[@class="storetitle"][1]/text())'
31 ).extract_first(),
32 "addr_full": response.xpath(
33 'normalize-space(//span[@id="store-address-info"]/p/a/text())'
34 ).extract_first(),
35 "postcode": re.search(
36 r"([\d-]*)$",
37 response.xpath(
38 'normalize-space(//div[@class="store-details-text"][1]/p/text())'
39 ).extract_first(),
40 ).group(1),
41 "country": "JP",
42 "lat": response.xpath(
43 'normalize-space(//input[@id="store-lat"]/@value)'
44 ).extract_first(),
45 "lon": response.xpath(
46 'normalize-space(//input[@id="store-lon"]/@value)'
47 ).extract_first(),
48 "phone": re.search(
49 r"\s([\d-]*)$",
50 response.xpath('//div[@id="store-tel"]/a/text()').extract_first(),
51 ).group(1),
52 "website": response.url,
53 }
54
55 yield GeojsonPointItem(**properties)
56
[end of locations/spiders/dominos_pizza_jp.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/locations/spiders/dominos_pizza_jp.py b/locations/spiders/dominos_pizza_jp.py
--- a/locations/spiders/dominos_pizza_jp.py
+++ b/locations/spiders/dominos_pizza_jp.py
@@ -8,7 +8,11 @@
class DominosPizzaJPSpider(scrapy.Spider):
name = "dominos_pizza_jp"
- item_attributes = {"brand": "Domino's", "brand_wikidata": "Q839466"}
+ item_attributes = {
+ "brand": "Domino's",
+ "brand_wikidata": "Q839466",
+ "country": "JP",
+ }
allowed_domains = ["dominos.jp"]
start_urls = [
"https://www.dominos.jp/sitemap.aspx",
@@ -27,28 +31,24 @@
properties = {
"ref": ref,
"name": response.xpath(
- 'normalize-space(//div[@class="storetitle"][1]/text())'
+ 'normalize-space(//h1[@class="storetitle"][1]/text())'
).extract_first(),
"addr_full": response.xpath(
- 'normalize-space(//span[@id="store-address-info"]/p/a/text())'
+ 'normalize-space(//span[@id="store-address-info"]/p/text()[4])'
).extract_first(),
"postcode": re.search(
r"([\d-]*)$",
response.xpath(
- 'normalize-space(//div[@class="store-details-text"][1]/p/text())'
+ 'normalize-space(//div[@class="store-details-text"]/span/p/text()[2])'
).extract_first(),
).group(1),
- "country": "JP",
"lat": response.xpath(
'normalize-space(//input[@id="store-lat"]/@value)'
).extract_first(),
"lon": response.xpath(
'normalize-space(//input[@id="store-lon"]/@value)'
).extract_first(),
- "phone": re.search(
- r"\s([\d-]*)$",
- response.xpath('//div[@id="store-tel"]/a/text()').extract_first(),
- ).group(1),
+ "phone": response.xpath('//div[@id="store-tel"]/a/text()').extract_first(),
"website": response.url,
}
|
{"golden_diff": "diff --git a/locations/spiders/dominos_pizza_jp.py b/locations/spiders/dominos_pizza_jp.py\n--- a/locations/spiders/dominos_pizza_jp.py\n+++ b/locations/spiders/dominos_pizza_jp.py\n@@ -8,7 +8,11 @@\n \n class DominosPizzaJPSpider(scrapy.Spider):\n name = \"dominos_pizza_jp\"\n- item_attributes = {\"brand\": \"Domino's\", \"brand_wikidata\": \"Q839466\"}\n+ item_attributes = {\n+ \"brand\": \"Domino's\",\n+ \"brand_wikidata\": \"Q839466\",\n+ \"country\": \"JP\",\n+ }\n allowed_domains = [\"dominos.jp\"]\n start_urls = [\n \"https://www.dominos.jp/sitemap.aspx\",\n@@ -27,28 +31,24 @@\n properties = {\n \"ref\": ref,\n \"name\": response.xpath(\n- 'normalize-space(//div[@class=\"storetitle\"][1]/text())'\n+ 'normalize-space(//h1[@class=\"storetitle\"][1]/text())'\n ).extract_first(),\n \"addr_full\": response.xpath(\n- 'normalize-space(//span[@id=\"store-address-info\"]/p/a/text())'\n+ 'normalize-space(//span[@id=\"store-address-info\"]/p/text()[4])'\n ).extract_first(),\n \"postcode\": re.search(\n r\"([\\d-]*)$\",\n response.xpath(\n- 'normalize-space(//div[@class=\"store-details-text\"][1]/p/text())'\n+ 'normalize-space(//div[@class=\"store-details-text\"]/span/p/text()[2])'\n ).extract_first(),\n ).group(1),\n- \"country\": \"JP\",\n \"lat\": response.xpath(\n 'normalize-space(//input[@id=\"store-lat\"]/@value)'\n ).extract_first(),\n \"lon\": response.xpath(\n 'normalize-space(//input[@id=\"store-lon\"]/@value)'\n ).extract_first(),\n- \"phone\": re.search(\n- r\"\\s([\\d-]*)$\",\n- response.xpath('//div[@id=\"store-tel\"]/a/text()').extract_first(),\n- ).group(1),\n+ \"phone\": response.xpath('//div[@id=\"store-tel\"]/a/text()').extract_first(),\n \"website\": response.url,\n }\n", "issue": "Spider dominos_pizza_jp is broken\nDuring the global build at 2021-06-30-14-42-26, spider **dominos_pizza_jp** failed with **0 features** and **0 errors**.\n\nHere's [the log](https://data.alltheplaces.xyz/runs/2021-06-30-14-42-26/logs/dominos_pizza_jp.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-06-30-14-42-26/output/dominos_pizza_jp.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-06-30-14-42-26/output/dominos_pizza_jp.geojson))\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nimport re\n\nimport scrapy\n\nfrom locations.items import GeojsonPointItem\n\n\nclass DominosPizzaJPSpider(scrapy.Spider):\n name = \"dominos_pizza_jp\"\n item_attributes = {\"brand\": \"Domino's\", \"brand_wikidata\": \"Q839466\"}\n allowed_domains = [\"dominos.jp\"]\n start_urls = [\n \"https://www.dominos.jp/sitemap.aspx\",\n ]\n download_delay = 0.3\n\n def parse(self, response):\n response.selector.remove_namespaces()\n store_urls = response.xpath('//url/loc/text()[contains(.,\"/store/\")]').extract()\n for url in store_urls:\n yield scrapy.Request(url, callback=self.parse_store)\n\n def parse_store(self, response):\n ref = re.search(r\".+/(.+?)/?(?:\\.html|$)\", response.url).group(1)\n\n properties = {\n \"ref\": ref,\n \"name\": response.xpath(\n 'normalize-space(//div[@class=\"storetitle\"][1]/text())'\n ).extract_first(),\n \"addr_full\": response.xpath(\n 'normalize-space(//span[@id=\"store-address-info\"]/p/a/text())'\n ).extract_first(),\n \"postcode\": re.search(\n r\"([\\d-]*)$\",\n response.xpath(\n 'normalize-space(//div[@class=\"store-details-text\"][1]/p/text())'\n ).extract_first(),\n ).group(1),\n \"country\": \"JP\",\n \"lat\": response.xpath(\n 'normalize-space(//input[@id=\"store-lat\"]/@value)'\n ).extract_first(),\n \"lon\": response.xpath(\n 'normalize-space(//input[@id=\"store-lon\"]/@value)'\n ).extract_first(),\n \"phone\": re.search(\n r\"\\s([\\d-]*)$\",\n response.xpath('//div[@id=\"store-tel\"]/a/text()').extract_first(),\n ).group(1),\n \"website\": response.url,\n }\n\n yield GeojsonPointItem(**properties)\n", "path": "locations/spiders/dominos_pizza_jp.py"}]}
| 1,308 | 542 |
gh_patches_debug_23323
|
rasdani/github-patches
|
git_diff
|
facebookresearch__xformers-326
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Rotary embeddings convert queries and keys to float32 when using mixed precision training
Not sure, if this is expected behaviour. The problem is that the cos_sin table in the RotaryEmbedding class is stored in float32 format, thus the returned queries and keys get converted to float32 aswell.
</issue>
<code>
[start of xformers/components/positional_embedding/rotary.py]
1 # Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
2 #
3 # This source code is licensed under the BSD license found in the
4 # LICENSE file in the root directory of this source tree.
5
6
7 # CREDITS: This implementation is inspired by GPT-NeoX https://github.com/EleutherAI/gpt-neox
8 # NOTE: Almost the same right now, moving parts to Triton is the next step
9
10 from typing import Tuple
11
12 import torch
13
14
15 def rotate_half(x):
16 x1, x2 = x.chunk(2, dim=-1)
17 return torch.cat((-x2, x1), dim=-1)
18
19
20 @torch.jit.script
21 def apply_rotary_pos_emb(x, cos, sin):
22 # NOTE: This could probably be moved to Triton
23
24 # Handle a possible sequence length mismatch in between q and k
25 cos = cos[:, :, : x.shape[-2], :]
26 sin = sin[:, :, : x.shape[-2], :]
27
28 return (x * cos) + (rotate_half(x) * sin)
29
30
31 class RotaryEmbedding(torch.nn.Module):
32 """
33 The rotary position embeddings from RoFormer_ (Su et. al).
34 A crucial insight from the method is that the query and keys are
35 transformed by rotation matrices which depend on the relative positions.
36
37 Other implementations are available in the Rotary Transformer repo_ and in
38 GPT-NeoX_, GPT-NeoX was an inspiration
39
40 .. _RoFormer: https://arxiv.org/abs/2104.09864
41 .. _repo: https://github.com/ZhuiyiTechnology/roformer
42 .. _GPT-NeoX: https://github.com/EleutherAI/gpt-neox
43
44
45 .. warning: Please note that this embedding is not registered on purpose, as it is transformative
46 (it does not create the embedding dimension) and will likely be picked up (imported) on a ad-hoc basis
47 """
48
49 def __init__(self, dim_model: int, *_, **__):
50 super().__init__()
51 # Generate and save the inverse frequency buffer (non trainable)
52 inv_freq = 1.0 / (10000 ** (torch.arange(0, dim_model, 2).float() / dim_model))
53 self.register_buffer("inv_freq", inv_freq)
54
55 self._seq_len_cached = None
56 self._cos_cached = None
57 self._sin_cached = None
58
59 def _update_cos_sin_tables(self, x, seq_dimension=1):
60 seq_len = x.shape[seq_dimension]
61
62 # Reset the tables if the sequence length has changed,
63 # or if we're on a new device (possibly due to tracing for instance)
64 if seq_len != self._seq_len_cached or self._cos_cached.device != x.device:
65 self._seq_len_cached = seq_len
66 t = torch.arange(x.shape[seq_dimension], device=x.device).type_as(
67 self.inv_freq
68 )
69 freqs = torch.einsum("i,j->ij", t, self.inv_freq)
70 emb = torch.cat((freqs, freqs), dim=-1).to(x.device)
71
72 self._cos_cached = emb.cos()[None, None, :, :]
73 self._sin_cached = emb.sin()[None, None, :, :]
74
75 return self._cos_cached, self._sin_cached
76
77 def forward(
78 self, q: torch.Tensor, k: torch.Tensor
79 ) -> Tuple[torch.Tensor, torch.Tensor]:
80 self._cos_cached, self._sin_cached = self._update_cos_sin_tables(
81 k, seq_dimension=-2
82 )
83
84 return (
85 apply_rotary_pos_emb(q, self._cos_cached, self._sin_cached),
86 apply_rotary_pos_emb(k, self._cos_cached, self._sin_cached),
87 )
88
[end of xformers/components/positional_embedding/rotary.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/xformers/components/positional_embedding/rotary.py b/xformers/components/positional_embedding/rotary.py
--- a/xformers/components/positional_embedding/rotary.py
+++ b/xformers/components/positional_embedding/rotary.py
@@ -61,16 +61,20 @@
# Reset the tables if the sequence length has changed,
# or if we're on a new device (possibly due to tracing for instance)
- if seq_len != self._seq_len_cached or self._cos_cached.device != x.device:
+ if (
+ seq_len != self._seq_len_cached
+ or self._cos_cached.device != x.device
+ or self._cos_cached.dtype != x.dtype
+ ):
self._seq_len_cached = seq_len
- t = torch.arange(x.shape[seq_dimension], device=x.device).type_as(
- self.inv_freq
+ t = torch.arange(
+ x.shape[seq_dimension], device=x.device, dtype=torch.float32
)
- freqs = torch.einsum("i,j->ij", t, self.inv_freq)
+ freqs = torch.einsum("i,j->ij", t, self.inv_freq.to(x.dtype))
emb = torch.cat((freqs, freqs), dim=-1).to(x.device)
- self._cos_cached = emb.cos()[None, None, :, :]
- self._sin_cached = emb.sin()[None, None, :, :]
+ self._cos_cached = emb.cos()[None, None, :, :].to(x.dtype)
+ self._sin_cached = emb.sin()[None, None, :, :].to(x.dtype)
return self._cos_cached, self._sin_cached
|
{"golden_diff": "diff --git a/xformers/components/positional_embedding/rotary.py b/xformers/components/positional_embedding/rotary.py\n--- a/xformers/components/positional_embedding/rotary.py\n+++ b/xformers/components/positional_embedding/rotary.py\n@@ -61,16 +61,20 @@\n \n # Reset the tables if the sequence length has changed,\n # or if we're on a new device (possibly due to tracing for instance)\n- if seq_len != self._seq_len_cached or self._cos_cached.device != x.device:\n+ if (\n+ seq_len != self._seq_len_cached\n+ or self._cos_cached.device != x.device\n+ or self._cos_cached.dtype != x.dtype\n+ ):\n self._seq_len_cached = seq_len\n- t = torch.arange(x.shape[seq_dimension], device=x.device).type_as(\n- self.inv_freq\n+ t = torch.arange(\n+ x.shape[seq_dimension], device=x.device, dtype=torch.float32\n )\n- freqs = torch.einsum(\"i,j->ij\", t, self.inv_freq)\n+ freqs = torch.einsum(\"i,j->ij\", t, self.inv_freq.to(x.dtype))\n emb = torch.cat((freqs, freqs), dim=-1).to(x.device)\n \n- self._cos_cached = emb.cos()[None, None, :, :]\n- self._sin_cached = emb.sin()[None, None, :, :]\n+ self._cos_cached = emb.cos()[None, None, :, :].to(x.dtype)\n+ self._sin_cached = emb.sin()[None, None, :, :].to(x.dtype)\n \n return self._cos_cached, self._sin_cached\n", "issue": "Rotary embeddings convert queries and keys to float32 when using mixed precision training\nNot sure, if this is expected behaviour. The problem is that the cos_sin table in the RotaryEmbedding class is stored in float32 format, thus the returned queries and keys get converted to float32 aswell.\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.\n#\n# This source code is licensed under the BSD license found in the\n# LICENSE file in the root directory of this source tree.\n\n\n# CREDITS: This implementation is inspired by GPT-NeoX https://github.com/EleutherAI/gpt-neox\n# NOTE: Almost the same right now, moving parts to Triton is the next step\n\nfrom typing import Tuple\n\nimport torch\n\n\ndef rotate_half(x):\n x1, x2 = x.chunk(2, dim=-1)\n return torch.cat((-x2, x1), dim=-1)\n\n\[email protected]\ndef apply_rotary_pos_emb(x, cos, sin):\n # NOTE: This could probably be moved to Triton\n\n # Handle a possible sequence length mismatch in between q and k\n cos = cos[:, :, : x.shape[-2], :]\n sin = sin[:, :, : x.shape[-2], :]\n\n return (x * cos) + (rotate_half(x) * sin)\n\n\nclass RotaryEmbedding(torch.nn.Module):\n \"\"\"\n The rotary position embeddings from RoFormer_ (Su et. al).\n A crucial insight from the method is that the query and keys are\n transformed by rotation matrices which depend on the relative positions.\n\n Other implementations are available in the Rotary Transformer repo_ and in\n GPT-NeoX_, GPT-NeoX was an inspiration\n\n .. _RoFormer: https://arxiv.org/abs/2104.09864\n .. _repo: https://github.com/ZhuiyiTechnology/roformer\n .. _GPT-NeoX: https://github.com/EleutherAI/gpt-neox\n\n\n .. warning: Please note that this embedding is not registered on purpose, as it is transformative\n (it does not create the embedding dimension) and will likely be picked up (imported) on a ad-hoc basis\n \"\"\"\n\n def __init__(self, dim_model: int, *_, **__):\n super().__init__()\n # Generate and save the inverse frequency buffer (non trainable)\n inv_freq = 1.0 / (10000 ** (torch.arange(0, dim_model, 2).float() / dim_model))\n self.register_buffer(\"inv_freq\", inv_freq)\n\n self._seq_len_cached = None\n self._cos_cached = None\n self._sin_cached = None\n\n def _update_cos_sin_tables(self, x, seq_dimension=1):\n seq_len = x.shape[seq_dimension]\n\n # Reset the tables if the sequence length has changed,\n # or if we're on a new device (possibly due to tracing for instance)\n if seq_len != self._seq_len_cached or self._cos_cached.device != x.device:\n self._seq_len_cached = seq_len\n t = torch.arange(x.shape[seq_dimension], device=x.device).type_as(\n self.inv_freq\n )\n freqs = torch.einsum(\"i,j->ij\", t, self.inv_freq)\n emb = torch.cat((freqs, freqs), dim=-1).to(x.device)\n\n self._cos_cached = emb.cos()[None, None, :, :]\n self._sin_cached = emb.sin()[None, None, :, :]\n\n return self._cos_cached, self._sin_cached\n\n def forward(\n self, q: torch.Tensor, k: torch.Tensor\n ) -> Tuple[torch.Tensor, torch.Tensor]:\n self._cos_cached, self._sin_cached = self._update_cos_sin_tables(\n k, seq_dimension=-2\n )\n\n return (\n apply_rotary_pos_emb(q, self._cos_cached, self._sin_cached),\n apply_rotary_pos_emb(k, self._cos_cached, self._sin_cached),\n )\n", "path": "xformers/components/positional_embedding/rotary.py"}]}
| 1,617 | 384 |
gh_patches_debug_60855
|
rasdani/github-patches
|
git_diff
|
airctic__icevision-500
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add tutorial with hard negative samples
## 📓 Documentation Update
"how to use an image as background annotation" is a common question. We can provide a tutorial showing how to do that
### Racoon and dogs
If you train a model on the racoon dataset and show the model a picture of a dog it will classify it as a racoon. We can add images of dogs to the dataset (without any annotations) and show how the difference of model performance in both scenarios.
</issue>
<code>
[start of icevision/models/base_show_results.py]
1 __all__ = ["base_show_results"]
2
3 from icevision.imports import *
4 from icevision.utils import *
5 from icevision.core import *
6 from icevision.visualize import *
7 from icevision.data import *
8
9
10 def base_show_results(
11 predict_fn: callable,
12 build_infer_batch_fn: callable,
13 model: nn.Module,
14 dataset: Dataset,
15 class_map: Optional[ClassMap] = None,
16 num_samples: int = 6,
17 ncols: int = 3,
18 denormalize_fn: Optional[callable] = denormalize_imagenet,
19 show: bool = True,
20 ) -> None:
21 samples = [dataset[i] for i in range(num_samples)]
22 batch, samples = build_infer_batch_fn(samples)
23 preds = predict_fn(model, batch)
24
25 imgs = [sample["img"] for sample in samples]
26 show_preds(
27 imgs,
28 preds,
29 class_map=class_map,
30 denormalize_fn=denormalize_fn,
31 ncols=ncols,
32 show=show,
33 )
34
[end of icevision/models/base_show_results.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/icevision/models/base_show_results.py b/icevision/models/base_show_results.py
--- a/icevision/models/base_show_results.py
+++ b/icevision/models/base_show_results.py
@@ -18,7 +18,7 @@
denormalize_fn: Optional[callable] = denormalize_imagenet,
show: bool = True,
) -> None:
- samples = [dataset[i] for i in range(num_samples)]
+ samples = random.choices(dataset, k=num_samples)
batch, samples = build_infer_batch_fn(samples)
preds = predict_fn(model, batch)
|
{"golden_diff": "diff --git a/icevision/models/base_show_results.py b/icevision/models/base_show_results.py\n--- a/icevision/models/base_show_results.py\n+++ b/icevision/models/base_show_results.py\n@@ -18,7 +18,7 @@\n denormalize_fn: Optional[callable] = denormalize_imagenet,\n show: bool = True,\n ) -> None:\n- samples = [dataset[i] for i in range(num_samples)]\n+ samples = random.choices(dataset, k=num_samples)\n batch, samples = build_infer_batch_fn(samples)\n preds = predict_fn(model, batch)\n", "issue": "Add tutorial with hard negative samples\n## \ud83d\udcd3 Documentation Update\r\n\"how to use an image as background annotation\" is a common question. We can provide a tutorial showing how to do that\r\n\r\n### Racoon and dogs\r\nIf you train a model on the racoon dataset and show the model a picture of a dog it will classify it as a racoon. We can add images of dogs to the dataset (without any annotations) and show how the difference of model performance in both scenarios.\n", "before_files": [{"content": "__all__ = [\"base_show_results\"]\n\nfrom icevision.imports import *\nfrom icevision.utils import *\nfrom icevision.core import *\nfrom icevision.visualize import *\nfrom icevision.data import *\n\n\ndef base_show_results(\n predict_fn: callable,\n build_infer_batch_fn: callable,\n model: nn.Module,\n dataset: Dataset,\n class_map: Optional[ClassMap] = None,\n num_samples: int = 6,\n ncols: int = 3,\n denormalize_fn: Optional[callable] = denormalize_imagenet,\n show: bool = True,\n) -> None:\n samples = [dataset[i] for i in range(num_samples)]\n batch, samples = build_infer_batch_fn(samples)\n preds = predict_fn(model, batch)\n\n imgs = [sample[\"img\"] for sample in samples]\n show_preds(\n imgs,\n preds,\n class_map=class_map,\n denormalize_fn=denormalize_fn,\n ncols=ncols,\n show=show,\n )\n", "path": "icevision/models/base_show_results.py"}]}
| 922 | 134 |
gh_patches_debug_15676
|
rasdani/github-patches
|
git_diff
|
WeblateOrg__weblate-7984
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Translation Memory Maintenance - Delete Entries
It would be good to be able to maintain the TM in one way or the other.
Perhaps
- [ ] Search & Replace in TM
- [ ] Search & Delete entries in TM
Or perhpas, as a "simple" (?) starting point, giving the translator the option to delete single entries from the TM when they see the result list in **Automatic Suggestions**. Like perhaps:
- [ ] Delete single entry in **Automatic Suggestions** view:

</issue>
<code>
[start of weblate/memory/machine.py]
1 #
2 # Copyright © 2012–2022 Michal Čihař <[email protected]>
3 #
4 # This file is part of Weblate <https://weblate.org/>
5 #
6 # This program is free software: you can redistribute it and/or modify
7 # it under the terms of the GNU General Public License as published by
8 # the Free Software Foundation, either version 3 of the License, or
9 # (at your option) any later version.
10 #
11 # This program is distributed in the hope that it will be useful,
12 # but WITHOUT ANY WARRANTY; without even the implied warranty of
13 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
14 # GNU General Public License for more details.
15 #
16 # You should have received a copy of the GNU General Public License
17 # along with this program. If not, see <https://www.gnu.org/licenses/>.
18 #
19
20 from weblate.machinery.base import MachineTranslation, get_machinery_language
21 from weblate.memory.models import Memory
22
23
24 class WeblateMemory(MachineTranslation):
25 """Translation service using strings already translated in Weblate."""
26
27 name = "Weblate Translation Memory"
28 rank_boost = 2
29 cache_translations = False
30 same_languages = True
31 accounting_key = "internal"
32 do_cleanup = False
33
34 def convert_language(self, language):
35 """No conversion of language object."""
36 return get_machinery_language(language)
37
38 def is_supported(self, source, language):
39 """Any language is supported."""
40 return True
41
42 def is_rate_limited(self):
43 """This service has no rate limiting."""
44 return False
45
46 def download_translations(
47 self,
48 source,
49 language,
50 text: str,
51 unit,
52 user,
53 search: bool,
54 threshold: int = 75,
55 ):
56 """Download list of possible translations from a service."""
57 for result in Memory.objects.lookup(
58 source,
59 language,
60 text,
61 user,
62 unit.translation.component.project,
63 unit.translation.component.project.use_shared_tm,
64 ).iterator():
65 quality = self.comparer.similarity(text, result.source)
66 if quality < 10 or (quality < threshold and not search):
67 continue
68 yield {
69 "text": result.target,
70 "quality": quality,
71 "service": self.name,
72 "origin": result.get_origin_display(),
73 "source": result.source,
74 "show_quality": True,
75 }
76
[end of weblate/memory/machine.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/weblate/memory/machine.py b/weblate/memory/machine.py
--- a/weblate/memory/machine.py
+++ b/weblate/memory/machine.py
@@ -17,6 +17,8 @@
# along with this program. If not, see <https://www.gnu.org/licenses/>.
#
+from django.urls import reverse
+
from weblate.machinery.base import MachineTranslation, get_machinery_language
from weblate.memory.models import Memory
@@ -72,4 +74,7 @@
"origin": result.get_origin_display(),
"source": result.source,
"show_quality": True,
+ "delete_url": reverse("api:memory-detail", kwargs={"pk": result.id})
+ if user is not None and user.has_perm("memory.delete", result)
+ else None,
}
|
{"golden_diff": "diff --git a/weblate/memory/machine.py b/weblate/memory/machine.py\n--- a/weblate/memory/machine.py\n+++ b/weblate/memory/machine.py\n@@ -17,6 +17,8 @@\n # along with this program. If not, see <https://www.gnu.org/licenses/>.\n #\n \n+from django.urls import reverse\n+\n from weblate.machinery.base import MachineTranslation, get_machinery_language\n from weblate.memory.models import Memory\n \n@@ -72,4 +74,7 @@\n \"origin\": result.get_origin_display(),\n \"source\": result.source,\n \"show_quality\": True,\n+ \"delete_url\": reverse(\"api:memory-detail\", kwargs={\"pk\": result.id})\n+ if user is not None and user.has_perm(\"memory.delete\", result)\n+ else None,\n }\n", "issue": "Translation Memory Maintenance - Delete Entries\nIt would be good to be able to maintain the TM in one way or the other.\r\n\r\nPerhaps \r\n- [ ] Search & Replace in TM\r\n- [ ] Search & Delete entries in TM\r\n\r\nOr perhpas, as a \"simple\" (?) starting point, giving the translator the option to delete single entries from the TM when they see the result list in **Automatic Suggestions**. Like perhaps:\r\n\r\n- [ ] Delete single entry in **Automatic Suggestions** view:\r\n\r\n\r\n\n", "before_files": [{"content": "#\n# Copyright \u00a9 2012\u20132022 Michal \u010ciha\u0159 <[email protected]>\n#\n# This file is part of Weblate <https://weblate.org/>\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this program. If not, see <https://www.gnu.org/licenses/>.\n#\n\nfrom weblate.machinery.base import MachineTranslation, get_machinery_language\nfrom weblate.memory.models import Memory\n\n\nclass WeblateMemory(MachineTranslation):\n \"\"\"Translation service using strings already translated in Weblate.\"\"\"\n\n name = \"Weblate Translation Memory\"\n rank_boost = 2\n cache_translations = False\n same_languages = True\n accounting_key = \"internal\"\n do_cleanup = False\n\n def convert_language(self, language):\n \"\"\"No conversion of language object.\"\"\"\n return get_machinery_language(language)\n\n def is_supported(self, source, language):\n \"\"\"Any language is supported.\"\"\"\n return True\n\n def is_rate_limited(self):\n \"\"\"This service has no rate limiting.\"\"\"\n return False\n\n def download_translations(\n self,\n source,\n language,\n text: str,\n unit,\n user,\n search: bool,\n threshold: int = 75,\n ):\n \"\"\"Download list of possible translations from a service.\"\"\"\n for result in Memory.objects.lookup(\n source,\n language,\n text,\n user,\n unit.translation.component.project,\n unit.translation.component.project.use_shared_tm,\n ).iterator():\n quality = self.comparer.similarity(text, result.source)\n if quality < 10 or (quality < threshold and not search):\n continue\n yield {\n \"text\": result.target,\n \"quality\": quality,\n \"service\": self.name,\n \"origin\": result.get_origin_display(),\n \"source\": result.source,\n \"show_quality\": True,\n }\n", "path": "weblate/memory/machine.py"}]}
| 1,373 | 186 |
gh_patches_debug_39639
|
rasdani/github-patches
|
git_diff
|
DataDog__dd-trace-py-959
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Stuck in "Waiting for GIL"
Hi,
We found a thread that seems blocked forever:
```
gdb python 30107
```
Here's the single thread:
```
(gdb) info threads
Id Target Id Frame
* 1 Thread 0x7f1dd852e4c0 (LWP 30107) "/opt/simon/rele" 0x00007f1dd7d2e146 in do_futex_wait.constprop () from /lib64/libpthread.so.0
```
Here's the backtrace:
```
raceback (most recent call first):
Waiting for the GIL
File "/opt/simon/releases/b038662ce7d140609b1e4883a3ea0edf77851537/venv/lib/python2.7/site-packages/ddtrace/sampler.py", line 88, in sample
with self._lock:
File "/opt/simon/releases/b038662ce7d140609b1e4883a3ea0edf77851537/venv/lib/python2.7/site-packages/ddtrace/tracer.py", line 251, in start_span
if self.priority_sampler.sample(span):
File "/opt/simon/releases/b038662ce7d140609b1e4883a3ea0edf77851537/venv/lib/python2.7/site-packages/ddtrace/tracer.py", line 376, in trace
span_type=span_type,
File "/opt/simon/releases/b038662ce7d140609b1e4883a3ea0edf77851537/venv/lib/python2.7/site-packages/ddtrace/contrib/django/cache.py", line 56, in wrapped
with tracer.trace('django.cache', span_type=TYPE, service=cache_service_name) as span:
```
I'm not sure how to troubleshoot from here. Have you seen this before, or have any suggestions on what I could look at? It's the only thread in process so nothing should be holding the GIL.
</issue>
<code>
[start of ddtrace/sampler.py]
1 """Samplers manage the client-side trace sampling
2
3 Any `sampled = False` trace won't be written, and can be ignored by the instrumentation.
4 """
5 from threading import Lock
6
7 from .compat import iteritems
8 from .internal.logger import get_logger
9
10 log = get_logger(__name__)
11
12 MAX_TRACE_ID = 2 ** 64
13
14 # Has to be the same factor and key as the Agent to allow chained sampling
15 KNUTH_FACTOR = 1111111111111111111
16
17
18 class AllSampler(object):
19 """Sampler sampling all the traces"""
20
21 def sample(self, span):
22 return True
23
24
25 class RateSampler(object):
26 """Sampler based on a rate
27
28 Keep (100 * `sample_rate`)% of the traces.
29 It samples randomly, its main purpose is to reduce the instrumentation footprint.
30 """
31
32 def __init__(self, sample_rate=1):
33 if sample_rate <= 0:
34 log.error('sample_rate is negative or null, disable the Sampler')
35 sample_rate = 1
36 elif sample_rate > 1:
37 sample_rate = 1
38
39 self.set_sample_rate(sample_rate)
40
41 log.debug('initialized RateSampler, sample %s%% of traces', 100 * sample_rate)
42
43 def set_sample_rate(self, sample_rate):
44 self.sample_rate = sample_rate
45 self.sampling_id_threshold = sample_rate * MAX_TRACE_ID
46
47 def sample(self, span):
48 sampled = ((span.trace_id * KNUTH_FACTOR) % MAX_TRACE_ID) <= self.sampling_id_threshold
49
50 return sampled
51
52
53 def _key(service=None, env=None):
54 service = service or ''
55 env = env or ''
56 return 'service:' + service + ',env:' + env
57
58
59 _default_key = _key()
60
61
62 class RateByServiceSampler(object):
63 """Sampler based on a rate, by service
64
65 Keep (100 * `sample_rate`)% of the traces.
66 The sample rate is kept independently for each service/env tuple.
67 """
68
69 def __init__(self, sample_rate=1):
70 self._lock = Lock()
71 self._by_service_samplers = {}
72 self._by_service_samplers[_default_key] = RateSampler(sample_rate)
73
74 def _set_sample_rate_by_key(self, sample_rate, key):
75 with self._lock:
76 if key in self._by_service_samplers:
77 self._by_service_samplers[key].set_sample_rate(sample_rate)
78 else:
79 self._by_service_samplers[key] = RateSampler(sample_rate)
80
81 def set_sample_rate(self, sample_rate, service='', env=''):
82 self._set_sample_rate_by_key(sample_rate, _key(service, env))
83
84 def sample(self, span):
85 tags = span.tracer().tags
86 env = tags['env'] if 'env' in tags else None
87 key = _key(span.service, env)
88 with self._lock:
89 if key in self._by_service_samplers:
90 return self._by_service_samplers[key].sample(span)
91 return self._by_service_samplers[_default_key].sample(span)
92
93 def set_sample_rate_by_service(self, rate_by_service):
94 for key, sample_rate in iteritems(rate_by_service):
95 self._set_sample_rate_by_key(sample_rate, key)
96 with self._lock:
97 for key in list(self._by_service_samplers):
98 if key not in rate_by_service and key != _default_key:
99 del self._by_service_samplers[key]
100
[end of ddtrace/sampler.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ddtrace/sampler.py b/ddtrace/sampler.py
--- a/ddtrace/sampler.py
+++ b/ddtrace/sampler.py
@@ -2,8 +2,6 @@
Any `sampled = False` trace won't be written, and can be ignored by the instrumentation.
"""
-from threading import Lock
-
from .compat import iteritems
from .internal.logger import get_logger
@@ -50,15 +48,6 @@
return sampled
-def _key(service=None, env=None):
- service = service or ''
- env = env or ''
- return 'service:' + service + ',env:' + env
-
-
-_default_key = _key()
-
-
class RateByServiceSampler(object):
"""Sampler based on a rate, by service
@@ -66,34 +55,40 @@
The sample rate is kept independently for each service/env tuple.
"""
+ @staticmethod
+ def _key(service=None, env=None):
+ """Compute a key with the same format used by the Datadog agent API."""
+ service = service or ''
+ env = env or ''
+ return 'service:' + service + ',env:' + env
+
def __init__(self, sample_rate=1):
- self._lock = Lock()
- self._by_service_samplers = {}
- self._by_service_samplers[_default_key] = RateSampler(sample_rate)
+ self.sample_rate = sample_rate
+ self._by_service_samplers = self._get_new_by_service_sampler()
- def _set_sample_rate_by_key(self, sample_rate, key):
- with self._lock:
- if key in self._by_service_samplers:
- self._by_service_samplers[key].set_sample_rate(sample_rate)
- else:
- self._by_service_samplers[key] = RateSampler(sample_rate)
+ def _get_new_by_service_sampler(self):
+ return {
+ self._default_key: RateSampler(self.sample_rate)
+ }
def set_sample_rate(self, sample_rate, service='', env=''):
- self._set_sample_rate_by_key(sample_rate, _key(service, env))
+ self._by_service_samplers[self._key(service, env)] = RateSampler(sample_rate)
def sample(self, span):
tags = span.tracer().tags
env = tags['env'] if 'env' in tags else None
- key = _key(span.service, env)
- with self._lock:
- if key in self._by_service_samplers:
- return self._by_service_samplers[key].sample(span)
- return self._by_service_samplers[_default_key].sample(span)
+ key = self._key(span.service, env)
+ return self._by_service_samplers.get(
+ key, self._by_service_samplers[self._default_key]
+ ).sample(span)
def set_sample_rate_by_service(self, rate_by_service):
+ new_by_service_samplers = self._get_new_by_service_sampler()
for key, sample_rate in iteritems(rate_by_service):
- self._set_sample_rate_by_key(sample_rate, key)
- with self._lock:
- for key in list(self._by_service_samplers):
- if key not in rate_by_service and key != _default_key:
- del self._by_service_samplers[key]
+ new_by_service_samplers[key] = RateSampler(sample_rate)
+
+ self._by_service_samplers = new_by_service_samplers
+
+
+# Default key for service with no specific rate
+RateByServiceSampler._default_key = RateByServiceSampler._key()
|
{"golden_diff": "diff --git a/ddtrace/sampler.py b/ddtrace/sampler.py\n--- a/ddtrace/sampler.py\n+++ b/ddtrace/sampler.py\n@@ -2,8 +2,6 @@\n \n Any `sampled = False` trace won't be written, and can be ignored by the instrumentation.\n \"\"\"\n-from threading import Lock\n-\n from .compat import iteritems\n from .internal.logger import get_logger\n \n@@ -50,15 +48,6 @@\n return sampled\n \n \n-def _key(service=None, env=None):\n- service = service or ''\n- env = env or ''\n- return 'service:' + service + ',env:' + env\n-\n-\n-_default_key = _key()\n-\n-\n class RateByServiceSampler(object):\n \"\"\"Sampler based on a rate, by service\n \n@@ -66,34 +55,40 @@\n The sample rate is kept independently for each service/env tuple.\n \"\"\"\n \n+ @staticmethod\n+ def _key(service=None, env=None):\n+ \"\"\"Compute a key with the same format used by the Datadog agent API.\"\"\"\n+ service = service or ''\n+ env = env or ''\n+ return 'service:' + service + ',env:' + env\n+\n def __init__(self, sample_rate=1):\n- self._lock = Lock()\n- self._by_service_samplers = {}\n- self._by_service_samplers[_default_key] = RateSampler(sample_rate)\n+ self.sample_rate = sample_rate\n+ self._by_service_samplers = self._get_new_by_service_sampler()\n \n- def _set_sample_rate_by_key(self, sample_rate, key):\n- with self._lock:\n- if key in self._by_service_samplers:\n- self._by_service_samplers[key].set_sample_rate(sample_rate)\n- else:\n- self._by_service_samplers[key] = RateSampler(sample_rate)\n+ def _get_new_by_service_sampler(self):\n+ return {\n+ self._default_key: RateSampler(self.sample_rate)\n+ }\n \n def set_sample_rate(self, sample_rate, service='', env=''):\n- self._set_sample_rate_by_key(sample_rate, _key(service, env))\n+ self._by_service_samplers[self._key(service, env)] = RateSampler(sample_rate)\n \n def sample(self, span):\n tags = span.tracer().tags\n env = tags['env'] if 'env' in tags else None\n- key = _key(span.service, env)\n- with self._lock:\n- if key in self._by_service_samplers:\n- return self._by_service_samplers[key].sample(span)\n- return self._by_service_samplers[_default_key].sample(span)\n+ key = self._key(span.service, env)\n+ return self._by_service_samplers.get(\n+ key, self._by_service_samplers[self._default_key]\n+ ).sample(span)\n \n def set_sample_rate_by_service(self, rate_by_service):\n+ new_by_service_samplers = self._get_new_by_service_sampler()\n for key, sample_rate in iteritems(rate_by_service):\n- self._set_sample_rate_by_key(sample_rate, key)\n- with self._lock:\n- for key in list(self._by_service_samplers):\n- if key not in rate_by_service and key != _default_key:\n- del self._by_service_samplers[key]\n+ new_by_service_samplers[key] = RateSampler(sample_rate)\n+\n+ self._by_service_samplers = new_by_service_samplers\n+\n+\n+# Default key for service with no specific rate\n+RateByServiceSampler._default_key = RateByServiceSampler._key()\n", "issue": "Stuck in \"Waiting for GIL\"\nHi,\r\n\r\nWe found a thread that seems blocked forever:\r\n\r\n```\r\ngdb python 30107\r\n```\r\n\r\nHere's the single thread:\r\n\r\n```\r\n(gdb) info threads\r\n Id Target Id Frame\r\n* 1 Thread 0x7f1dd852e4c0 (LWP 30107) \"/opt/simon/rele\" 0x00007f1dd7d2e146 in do_futex_wait.constprop () from /lib64/libpthread.so.0\r\n```\r\n\r\nHere's the backtrace:\r\n\r\n```\r\nraceback (most recent call first):\r\n Waiting for the GIL\r\n File \"/opt/simon/releases/b038662ce7d140609b1e4883a3ea0edf77851537/venv/lib/python2.7/site-packages/ddtrace/sampler.py\", line 88, in sample\r\n with self._lock:\r\n File \"/opt/simon/releases/b038662ce7d140609b1e4883a3ea0edf77851537/venv/lib/python2.7/site-packages/ddtrace/tracer.py\", line 251, in start_span\r\n if self.priority_sampler.sample(span):\r\n File \"/opt/simon/releases/b038662ce7d140609b1e4883a3ea0edf77851537/venv/lib/python2.7/site-packages/ddtrace/tracer.py\", line 376, in trace\r\n span_type=span_type,\r\n File \"/opt/simon/releases/b038662ce7d140609b1e4883a3ea0edf77851537/venv/lib/python2.7/site-packages/ddtrace/contrib/django/cache.py\", line 56, in wrapped\r\n with tracer.trace('django.cache', span_type=TYPE, service=cache_service_name) as span:\r\n```\r\n\r\nI'm not sure how to troubleshoot from here. Have you seen this before, or have any suggestions on what I could look at? It's the only thread in process so nothing should be holding the GIL.\n", "before_files": [{"content": "\"\"\"Samplers manage the client-side trace sampling\n\nAny `sampled = False` trace won't be written, and can be ignored by the instrumentation.\n\"\"\"\nfrom threading import Lock\n\nfrom .compat import iteritems\nfrom .internal.logger import get_logger\n\nlog = get_logger(__name__)\n\nMAX_TRACE_ID = 2 ** 64\n\n# Has to be the same factor and key as the Agent to allow chained sampling\nKNUTH_FACTOR = 1111111111111111111\n\n\nclass AllSampler(object):\n \"\"\"Sampler sampling all the traces\"\"\"\n\n def sample(self, span):\n return True\n\n\nclass RateSampler(object):\n \"\"\"Sampler based on a rate\n\n Keep (100 * `sample_rate`)% of the traces.\n It samples randomly, its main purpose is to reduce the instrumentation footprint.\n \"\"\"\n\n def __init__(self, sample_rate=1):\n if sample_rate <= 0:\n log.error('sample_rate is negative or null, disable the Sampler')\n sample_rate = 1\n elif sample_rate > 1:\n sample_rate = 1\n\n self.set_sample_rate(sample_rate)\n\n log.debug('initialized RateSampler, sample %s%% of traces', 100 * sample_rate)\n\n def set_sample_rate(self, sample_rate):\n self.sample_rate = sample_rate\n self.sampling_id_threshold = sample_rate * MAX_TRACE_ID\n\n def sample(self, span):\n sampled = ((span.trace_id * KNUTH_FACTOR) % MAX_TRACE_ID) <= self.sampling_id_threshold\n\n return sampled\n\n\ndef _key(service=None, env=None):\n service = service or ''\n env = env or ''\n return 'service:' + service + ',env:' + env\n\n\n_default_key = _key()\n\n\nclass RateByServiceSampler(object):\n \"\"\"Sampler based on a rate, by service\n\n Keep (100 * `sample_rate`)% of the traces.\n The sample rate is kept independently for each service/env tuple.\n \"\"\"\n\n def __init__(self, sample_rate=1):\n self._lock = Lock()\n self._by_service_samplers = {}\n self._by_service_samplers[_default_key] = RateSampler(sample_rate)\n\n def _set_sample_rate_by_key(self, sample_rate, key):\n with self._lock:\n if key in self._by_service_samplers:\n self._by_service_samplers[key].set_sample_rate(sample_rate)\n else:\n self._by_service_samplers[key] = RateSampler(sample_rate)\n\n def set_sample_rate(self, sample_rate, service='', env=''):\n self._set_sample_rate_by_key(sample_rate, _key(service, env))\n\n def sample(self, span):\n tags = span.tracer().tags\n env = tags['env'] if 'env' in tags else None\n key = _key(span.service, env)\n with self._lock:\n if key in self._by_service_samplers:\n return self._by_service_samplers[key].sample(span)\n return self._by_service_samplers[_default_key].sample(span)\n\n def set_sample_rate_by_service(self, rate_by_service):\n for key, sample_rate in iteritems(rate_by_service):\n self._set_sample_rate_by_key(sample_rate, key)\n with self._lock:\n for key in list(self._by_service_samplers):\n if key not in rate_by_service and key != _default_key:\n del self._by_service_samplers[key]\n", "path": "ddtrace/sampler.py"}]}
| 2,028 | 816 |
gh_patches_debug_38850
|
rasdani/github-patches
|
git_diff
|
sanic-org__sanic-2170
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
deprecate CompositionView ?
Currently sanic offers a class called `CompositionView`
I really am struggling to find any utility in this class, since
```python
from sanic.views import CompositionView
def get_handler(request):
return text("I am a get method")
view = CompositionView()
view.add(["GET"], get_handler)
view.add(["POST", "PUT"], lambda request: text("I am a post/put method"))
# Use the new view to handle requests to the base URL
app.add_route(view, "/")
```
Seems much more confusing to me than
```python
def get_handler(request):
return text("I am a get method")
app.route("/", methods=["GET"])(get_handler)
app.route("/", methods=["POST", "PUT"])(lambda request: text("I am a post/put method"))
```
Can anyone offer a compelling use case for CompositionView?
If not, I would suggest to deprecate it
https://github.com/sanic-org/sanic/blob/master/sanic/views.py
</issue>
<code>
[start of sanic/views.py]
1 from typing import Any, Callable, List
2
3 from sanic.constants import HTTP_METHODS
4 from sanic.exceptions import InvalidUsage
5
6
7 class HTTPMethodView:
8 """Simple class based implementation of view for the sanic.
9 You should implement methods (get, post, put, patch, delete) for the class
10 to every HTTP method you want to support.
11
12 For example:
13
14 .. code-block:: python
15
16 class DummyView(HTTPMethodView):
17 def get(self, request, *args, **kwargs):
18 return text('I am get method')
19 def put(self, request, *args, **kwargs):
20 return text('I am put method')
21
22 If someone tries to use a non-implemented method, there will be a
23 405 response.
24
25 If you need any url params just mention them in method definition:
26
27 .. code-block:: python
28
29 class DummyView(HTTPMethodView):
30 def get(self, request, my_param_here, *args, **kwargs):
31 return text('I am get method with %s' % my_param_here)
32
33 To add the view into the routing you could use
34
35 1) ``app.add_route(DummyView.as_view(), '/')``, OR
36 2) ``app.route('/')(DummyView.as_view())``
37
38 To add any decorator you could set it into decorators variable
39 """
40
41 decorators: List[Callable[[Callable[..., Any]], Callable[..., Any]]] = []
42
43 def dispatch_request(self, request, *args, **kwargs):
44 handler = getattr(self, request.method.lower(), None)
45 return handler(request, *args, **kwargs)
46
47 @classmethod
48 def as_view(cls, *class_args, **class_kwargs):
49 """Return view function for use with the routing system, that
50 dispatches request to appropriate handler method.
51 """
52
53 def view(*args, **kwargs):
54 self = view.view_class(*class_args, **class_kwargs)
55 return self.dispatch_request(*args, **kwargs)
56
57 if cls.decorators:
58 view.__module__ = cls.__module__
59 for decorator in cls.decorators:
60 view = decorator(view)
61
62 view.view_class = cls
63 view.__doc__ = cls.__doc__
64 view.__module__ = cls.__module__
65 view.__name__ = cls.__name__
66 return view
67
68
69 def stream(func):
70 func.is_stream = True
71 return func
72
73
74 class CompositionView:
75 """Simple method-function mapped view for the sanic.
76 You can add handler functions to methods (get, post, put, patch, delete)
77 for every HTTP method you want to support.
78
79 For example:
80
81 .. code-block:: python
82
83 view = CompositionView()
84 view.add(['GET'], lambda request: text('I am get method'))
85 view.add(['POST', 'PUT'], lambda request: text('I am post/put method'))
86
87 If someone tries to use a non-implemented method, there will be a
88 405 response.
89 """
90
91 def __init__(self):
92 self.handlers = {}
93 self.name = self.__class__.__name__
94
95 def __name__(self):
96 return self.name
97
98 def add(self, methods, handler, stream=False):
99 if stream:
100 handler.is_stream = stream
101 for method in methods:
102 if method not in HTTP_METHODS:
103 raise InvalidUsage(f"{method} is not a valid HTTP method.")
104
105 if method in self.handlers:
106 raise InvalidUsage(f"Method {method} is already registered.")
107 self.handlers[method] = handler
108
109 def __call__(self, request, *args, **kwargs):
110 handler = self.handlers[request.method.upper()]
111 return handler(request, *args, **kwargs)
112
[end of sanic/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sanic/views.py b/sanic/views.py
--- a/sanic/views.py
+++ b/sanic/views.py
@@ -1,9 +1,25 @@
-from typing import Any, Callable, List
+from __future__ import annotations
+
+from typing import (
+ TYPE_CHECKING,
+ Any,
+ Callable,
+ Iterable,
+ List,
+ Optional,
+ Union,
+)
+from warnings import warn
from sanic.constants import HTTP_METHODS
from sanic.exceptions import InvalidUsage
+if TYPE_CHECKING:
+ from sanic import Sanic
+ from sanic.blueprints import Blueprint
+
+
class HTTPMethodView:
"""Simple class based implementation of view for the sanic.
You should implement methods (get, post, put, patch, delete) for the class
@@ -40,6 +56,31 @@
decorators: List[Callable[[Callable[..., Any]], Callable[..., Any]]] = []
+ def __init_subclass__(
+ cls,
+ attach: Optional[Union[Sanic, Blueprint]] = None,
+ uri: str = "",
+ methods: Iterable[str] = frozenset({"GET"}),
+ host: Optional[str] = None,
+ strict_slashes: Optional[bool] = None,
+ version: Optional[int] = None,
+ name: Optional[str] = None,
+ stream: bool = False,
+ version_prefix: str = "/v",
+ ) -> None:
+ if attach:
+ cls.attach(
+ attach,
+ uri=uri,
+ methods=methods,
+ host=host,
+ strict_slashes=strict_slashes,
+ version=version,
+ name=name,
+ stream=stream,
+ version_prefix=version_prefix,
+ )
+
def dispatch_request(self, request, *args, **kwargs):
handler = getattr(self, request.method.lower(), None)
return handler(request, *args, **kwargs)
@@ -65,6 +106,31 @@
view.__name__ = cls.__name__
return view
+ @classmethod
+ def attach(
+ cls,
+ to: Union[Sanic, Blueprint],
+ uri: str,
+ methods: Iterable[str] = frozenset({"GET"}),
+ host: Optional[str] = None,
+ strict_slashes: Optional[bool] = None,
+ version: Optional[int] = None,
+ name: Optional[str] = None,
+ stream: bool = False,
+ version_prefix: str = "/v",
+ ) -> None:
+ to.add_route(
+ cls.as_view(),
+ uri=uri,
+ methods=methods,
+ host=host,
+ strict_slashes=strict_slashes,
+ version=version,
+ name=name,
+ stream=stream,
+ version_prefix=version_prefix,
+ )
+
def stream(func):
func.is_stream = True
@@ -91,6 +157,11 @@
def __init__(self):
self.handlers = {}
self.name = self.__class__.__name__
+ warn(
+ "CompositionView has been deprecated and will be removed in "
+ "v21.12. Please update your view to HTTPMethodView.",
+ DeprecationWarning,
+ )
def __name__(self):
return self.name
|
{"golden_diff": "diff --git a/sanic/views.py b/sanic/views.py\n--- a/sanic/views.py\n+++ b/sanic/views.py\n@@ -1,9 +1,25 @@\n-from typing import Any, Callable, List\n+from __future__ import annotations\n+\n+from typing import (\n+ TYPE_CHECKING,\n+ Any,\n+ Callable,\n+ Iterable,\n+ List,\n+ Optional,\n+ Union,\n+)\n+from warnings import warn\n \n from sanic.constants import HTTP_METHODS\n from sanic.exceptions import InvalidUsage\n \n \n+if TYPE_CHECKING:\n+ from sanic import Sanic\n+ from sanic.blueprints import Blueprint\n+\n+\n class HTTPMethodView:\n \"\"\"Simple class based implementation of view for the sanic.\n You should implement methods (get, post, put, patch, delete) for the class\n@@ -40,6 +56,31 @@\n \n decorators: List[Callable[[Callable[..., Any]], Callable[..., Any]]] = []\n \n+ def __init_subclass__(\n+ cls,\n+ attach: Optional[Union[Sanic, Blueprint]] = None,\n+ uri: str = \"\",\n+ methods: Iterable[str] = frozenset({\"GET\"}),\n+ host: Optional[str] = None,\n+ strict_slashes: Optional[bool] = None,\n+ version: Optional[int] = None,\n+ name: Optional[str] = None,\n+ stream: bool = False,\n+ version_prefix: str = \"/v\",\n+ ) -> None:\n+ if attach:\n+ cls.attach(\n+ attach,\n+ uri=uri,\n+ methods=methods,\n+ host=host,\n+ strict_slashes=strict_slashes,\n+ version=version,\n+ name=name,\n+ stream=stream,\n+ version_prefix=version_prefix,\n+ )\n+\n def dispatch_request(self, request, *args, **kwargs):\n handler = getattr(self, request.method.lower(), None)\n return handler(request, *args, **kwargs)\n@@ -65,6 +106,31 @@\n view.__name__ = cls.__name__\n return view\n \n+ @classmethod\n+ def attach(\n+ cls,\n+ to: Union[Sanic, Blueprint],\n+ uri: str,\n+ methods: Iterable[str] = frozenset({\"GET\"}),\n+ host: Optional[str] = None,\n+ strict_slashes: Optional[bool] = None,\n+ version: Optional[int] = None,\n+ name: Optional[str] = None,\n+ stream: bool = False,\n+ version_prefix: str = \"/v\",\n+ ) -> None:\n+ to.add_route(\n+ cls.as_view(),\n+ uri=uri,\n+ methods=methods,\n+ host=host,\n+ strict_slashes=strict_slashes,\n+ version=version,\n+ name=name,\n+ stream=stream,\n+ version_prefix=version_prefix,\n+ )\n+\n \n def stream(func):\n func.is_stream = True\n@@ -91,6 +157,11 @@\n def __init__(self):\n self.handlers = {}\n self.name = self.__class__.__name__\n+ warn(\n+ \"CompositionView has been deprecated and will be removed in \"\n+ \"v21.12. Please update your view to HTTPMethodView.\",\n+ DeprecationWarning,\n+ )\n \n def __name__(self):\n return self.name\n", "issue": "deprecate CompositionView ? \nCurrently sanic offers a class called `CompositionView`\r\n\r\nI really am struggling to find any utility in this class, since \r\n\r\n```python\r\nfrom sanic.views import CompositionView\r\n\r\ndef get_handler(request):\r\n return text(\"I am a get method\")\r\n\r\nview = CompositionView()\r\nview.add([\"GET\"], get_handler)\r\nview.add([\"POST\", \"PUT\"], lambda request: text(\"I am a post/put method\"))\r\n\r\n# Use the new view to handle requests to the base URL\r\napp.add_route(view, \"/\")\r\n```\r\n\r\n\r\nSeems much more confusing to me than\r\n\r\n```python\r\ndef get_handler(request):\r\n return text(\"I am a get method\")\r\n\r\napp.route(\"/\", methods=[\"GET\"])(get_handler)\r\napp.route(\"/\", methods=[\"POST\", \"PUT\"])(lambda request: text(\"I am a post/put method\"))\r\n```\r\n\r\nCan anyone offer a compelling use case for CompositionView?\r\n\r\nIf not, I would suggest to deprecate it \r\n\r\n\r\nhttps://github.com/sanic-org/sanic/blob/master/sanic/views.py\n", "before_files": [{"content": "from typing import Any, Callable, List\n\nfrom sanic.constants import HTTP_METHODS\nfrom sanic.exceptions import InvalidUsage\n\n\nclass HTTPMethodView:\n \"\"\"Simple class based implementation of view for the sanic.\n You should implement methods (get, post, put, patch, delete) for the class\n to every HTTP method you want to support.\n\n For example:\n\n .. code-block:: python\n\n class DummyView(HTTPMethodView):\n def get(self, request, *args, **kwargs):\n return text('I am get method')\n def put(self, request, *args, **kwargs):\n return text('I am put method')\n\n If someone tries to use a non-implemented method, there will be a\n 405 response.\n\n If you need any url params just mention them in method definition:\n\n .. code-block:: python\n\n class DummyView(HTTPMethodView):\n def get(self, request, my_param_here, *args, **kwargs):\n return text('I am get method with %s' % my_param_here)\n\n To add the view into the routing you could use\n\n 1) ``app.add_route(DummyView.as_view(), '/')``, OR\n 2) ``app.route('/')(DummyView.as_view())``\n\n To add any decorator you could set it into decorators variable\n \"\"\"\n\n decorators: List[Callable[[Callable[..., Any]], Callable[..., Any]]] = []\n\n def dispatch_request(self, request, *args, **kwargs):\n handler = getattr(self, request.method.lower(), None)\n return handler(request, *args, **kwargs)\n\n @classmethod\n def as_view(cls, *class_args, **class_kwargs):\n \"\"\"Return view function for use with the routing system, that\n dispatches request to appropriate handler method.\n \"\"\"\n\n def view(*args, **kwargs):\n self = view.view_class(*class_args, **class_kwargs)\n return self.dispatch_request(*args, **kwargs)\n\n if cls.decorators:\n view.__module__ = cls.__module__\n for decorator in cls.decorators:\n view = decorator(view)\n\n view.view_class = cls\n view.__doc__ = cls.__doc__\n view.__module__ = cls.__module__\n view.__name__ = cls.__name__\n return view\n\n\ndef stream(func):\n func.is_stream = True\n return func\n\n\nclass CompositionView:\n \"\"\"Simple method-function mapped view for the sanic.\n You can add handler functions to methods (get, post, put, patch, delete)\n for every HTTP method you want to support.\n\n For example:\n\n .. code-block:: python\n\n view = CompositionView()\n view.add(['GET'], lambda request: text('I am get method'))\n view.add(['POST', 'PUT'], lambda request: text('I am post/put method'))\n\n If someone tries to use a non-implemented method, there will be a\n 405 response.\n \"\"\"\n\n def __init__(self):\n self.handlers = {}\n self.name = self.__class__.__name__\n\n def __name__(self):\n return self.name\n\n def add(self, methods, handler, stream=False):\n if stream:\n handler.is_stream = stream\n for method in methods:\n if method not in HTTP_METHODS:\n raise InvalidUsage(f\"{method} is not a valid HTTP method.\")\n\n if method in self.handlers:\n raise InvalidUsage(f\"Method {method} is already registered.\")\n self.handlers[method] = handler\n\n def __call__(self, request, *args, **kwargs):\n handler = self.handlers[request.method.upper()]\n return handler(request, *args, **kwargs)\n", "path": "sanic/views.py"}]}
| 1,792 | 758 |
gh_patches_debug_43430
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-3346
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Spider jackinthebox is broken
During the global build at 2021-06-23-14-42-18, spider **jackinthebox** failed with **0 features** and **1 errors**.
Here's [the log](https://data.alltheplaces.xyz/runs/2021-06-23-14-42-18/logs/jackinthebox.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-06-23-14-42-18/output/jackinthebox.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-06-23-14-42-18/output/jackinthebox.geojson))
</issue>
<code>
[start of locations/spiders/jackinthebox.py]
1 import json
2 import re
3 import scrapy
4 from locations.items import GeojsonPointItem
5
6 class JackInTheBoxSpider(scrapy.Spider):
7 name = "jackinthebox"
8 item_attributes = { 'brand': "Jack In The Box" }
9 allowed_domains = ["jackinthebox.com"]
10 start_urls = (
11 "https://www.jackinthebox.com/api/locations",
12 )
13 dayMap = {
14 'monday': 'Mo',
15 'tuesday': 'Tu',
16 'wednesday': 'We',
17 'thursday': 'Th',
18 'friday': 'Fr',
19 'saturday': 'Sa',
20 'sunday': 'Su'
21 }
22 def opening_hours(self, days_hours):
23 day_groups = []
24 this_day_group = None
25 for day_hours in days_hours:
26 day = day_hours[0]
27 hours = day_hours[1]
28 match = re.search(r'^(\d{1,2}):(\d{2})\w*(a|p)m-(\d{1,2}):(\d{2})\w*(a|p)m?$', hours)
29 (f_hr, f_min, f_ampm, t_hr, t_min, t_ampm) = match.groups()
30
31 f_hr = int(f_hr)
32 if f_ampm == 'p':
33 f_hr += 12
34 elif f_ampm == 'a' and f_hr == 12:
35 f_hr = 0
36 t_hr = int(t_hr)
37 if t_ampm == 'p':
38 t_hr += 12
39 elif t_ampm == 'a' and t_hr == 12:
40 t_hr = 0
41
42 hours = '{:02d}:{}-{:02d}:{}'.format(
43 f_hr,
44 f_min,
45 t_hr,
46 t_min,
47 )
48
49 if not this_day_group:
50 this_day_group = {
51 'from_day': day,
52 'to_day': day,
53 'hours': hours
54 }
55 elif this_day_group['hours'] != hours:
56 day_groups.append(this_day_group)
57 this_day_group = {
58 'from_day': day,
59 'to_day': day,
60 'hours': hours
61 }
62 elif this_day_group['hours'] == hours:
63 this_day_group['to_day'] = day
64
65 day_groups.append(this_day_group)
66
67 opening_hours = ""
68 if len(day_groups) == 1 and day_groups[0]['hours'] in ('00:00-23:59', '00:00-00:00'):
69 opening_hours = '24/7'
70 else:
71 for day_group in day_groups:
72 if day_group['from_day'] == day_group['to_day']:
73 opening_hours += '{from_day} {hours}; '.format(**day_group)
74 elif day_group['from_day'] == 'Su' and day_group['to_day'] == 'Sa':
75 opening_hours += '{hours}; '.format(**day_group)
76 else:
77 opening_hours += '{from_day}-{to_day} {hours}; '.format(**day_group)
78 opening_hours = opening_hours[:-2]
79
80 return opening_hours
81
82 def parse(self, response):
83 stores = json.loads(response.body_as_unicode())
84 for store in stores:
85 properties = {
86 'ref': store['id'],
87 'addr_full': store['address'],
88 'city': store['city'],
89 'state': store['state'],
90 'postcode': store['postal'],
91 'lat': store['lat'],
92 'lon': store['lng'],
93 'phone': store['phone'],
94 }
95
96 if store['twentyfourhours']:
97 properties['opening_hours'] = '24/7'
98 elif 'hours' in store:
99 hours = store['hours']
100 if not all(hours[d] == '' for d in hours):
101 days_hours = []
102 for day in ['monday', 'tuesday', 'wednesday', 'thursday', 'friday', 'saturday', 'sunday']:
103 days_hours.append([
104 self.dayMap[day],
105 hours[day].lower().replace(' ', '')
106 ])
107 properties['opening_hours'] = self.opening_hours(days_hours)
108
109 yield GeojsonPointItem(**properties)
110
111
112
[end of locations/spiders/jackinthebox.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/locations/spiders/jackinthebox.py b/locations/spiders/jackinthebox.py
--- a/locations/spiders/jackinthebox.py
+++ b/locations/spiders/jackinthebox.py
@@ -11,13 +11,13 @@
"https://www.jackinthebox.com/api/locations",
)
dayMap = {
- 'monday': 'Mo',
- 'tuesday': 'Tu',
- 'wednesday': 'We',
- 'thursday': 'Th',
- 'friday': 'Fr',
- 'saturday': 'Sa',
- 'sunday': 'Su'
+ 'Monday': 'Mo',
+ 'Tuesday': 'Tu',
+ 'Wednesday': 'We',
+ 'Thursday': 'Th',
+ 'Friday': 'Fr',
+ 'Saturday': 'Sa',
+ 'Sunday': 'Su'
}
def opening_hours(self, days_hours):
day_groups = []
@@ -25,6 +25,9 @@
for day_hours in days_hours:
day = day_hours[0]
hours = day_hours[1]
+ if not hours:
+ continue
+
match = re.search(r'^(\d{1,2}):(\d{2})\w*(a|p)m-(\d{1,2}):(\d{2})\w*(a|p)m?$', hours)
(f_hr, f_min, f_ampm, t_hr, t_min, t_ampm) = match.groups()
@@ -62,7 +65,8 @@
elif this_day_group['hours'] == hours:
this_day_group['to_day'] = day
- day_groups.append(this_day_group)
+ if this_day_group:
+ day_groups.append(this_day_group)
opening_hours = ""
if len(day_groups) == 1 and day_groups[0]['hours'] in ('00:00-23:59', '00:00-00:00'):
@@ -80,31 +84,32 @@
return opening_hours
def parse(self, response):
- stores = json.loads(response.body_as_unicode())
- for store in stores:
+ stores = json.loads(response.body_as_unicode())['Locations']
+ for store in stores:
+ address = store['Address']
properties = {
- 'ref': store['id'],
- 'addr_full': store['address'],
- 'city': store['city'],
- 'state': store['state'],
- 'postcode': store['postal'],
- 'lat': store['lat'],
- 'lon': store['lng'],
- 'phone': store['phone'],
+ 'ref': store['LocationId'],
+ 'addr_full': ", ".join([address['StreetLine1'], address['StreetLine2']]),
+ 'city': address['City'],
+ 'state': address['State'],
+ 'postcode': address['Zipcode'],
+ 'lat': store['Coordinates']['Lat'],
+ 'lon': store['Coordinates']['Lon'],
+ 'phone': store['OperationsData']['BusinessPhoneNumber'],
}
- if store['twentyfourhours']:
+ hours = store['OperatingHours']
+ if all (hours['DineInAllDay'][day] == True for day in hours['DineInAllDay']):
properties['opening_hours'] = '24/7'
- elif 'hours' in store:
- hours = store['hours']
- if not all(hours[d] == '' for d in hours):
- days_hours = []
- for day in ['monday', 'tuesday', 'wednesday', 'thursday', 'friday', 'saturday', 'sunday']:
- days_hours.append([
- self.dayMap[day],
- hours[day].lower().replace(' ', '')
- ])
- properties['opening_hours'] = self.opening_hours(days_hours)
+
+ else:
+ days_hours = []
+ for day in ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']:
+ days_hours.append([
+ self.dayMap[day],
+ hours['DineIn'][day].lower().replace(' ', '')
+ ])
+ properties['opening_hours'] = self.opening_hours(days_hours)
yield GeojsonPointItem(**properties)
|
{"golden_diff": "diff --git a/locations/spiders/jackinthebox.py b/locations/spiders/jackinthebox.py\n--- a/locations/spiders/jackinthebox.py\n+++ b/locations/spiders/jackinthebox.py\n@@ -11,13 +11,13 @@\n \"https://www.jackinthebox.com/api/locations\",\n )\n dayMap = {\n- 'monday': 'Mo',\n- 'tuesday': 'Tu',\n- 'wednesday': 'We',\n- 'thursday': 'Th',\n- 'friday': 'Fr',\n- 'saturday': 'Sa',\n- 'sunday': 'Su'\n+ 'Monday': 'Mo',\n+ 'Tuesday': 'Tu',\n+ 'Wednesday': 'We',\n+ 'Thursday': 'Th',\n+ 'Friday': 'Fr',\n+ 'Saturday': 'Sa',\n+ 'Sunday': 'Su'\n }\n def opening_hours(self, days_hours):\n day_groups = []\n@@ -25,6 +25,9 @@\n for day_hours in days_hours:\n day = day_hours[0]\n hours = day_hours[1]\n+ if not hours:\n+ continue\n+\n match = re.search(r'^(\\d{1,2}):(\\d{2})\\w*(a|p)m-(\\d{1,2}):(\\d{2})\\w*(a|p)m?$', hours)\n (f_hr, f_min, f_ampm, t_hr, t_min, t_ampm) = match.groups()\n \n@@ -62,7 +65,8 @@\n elif this_day_group['hours'] == hours:\n this_day_group['to_day'] = day\n \n- day_groups.append(this_day_group)\n+ if this_day_group:\n+ day_groups.append(this_day_group)\n \n opening_hours = \"\"\n if len(day_groups) == 1 and day_groups[0]['hours'] in ('00:00-23:59', '00:00-00:00'):\n@@ -80,31 +84,32 @@\n return opening_hours\n \n def parse(self, response):\n- stores = json.loads(response.body_as_unicode())\n- for store in stores: \n+ stores = json.loads(response.body_as_unicode())['Locations']\n+ for store in stores:\n+ address = store['Address']\n properties = { \n- 'ref': store['id'], \n- 'addr_full': store['address'],\n- 'city': store['city'], \n- 'state': store['state'], \n- 'postcode': store['postal'], \n- 'lat': store['lat'], \n- 'lon': store['lng'], \n- 'phone': store['phone'],\n+ 'ref': store['LocationId'],\n+ 'addr_full': \", \".join([address['StreetLine1'], address['StreetLine2']]),\n+ 'city': address['City'],\n+ 'state': address['State'],\n+ 'postcode': address['Zipcode'],\n+ 'lat': store['Coordinates']['Lat'],\n+ 'lon': store['Coordinates']['Lon'],\n+ 'phone': store['OperationsData']['BusinessPhoneNumber'],\n } \n \n- if store['twentyfourhours']:\n+ hours = store['OperatingHours']\n+ if all (hours['DineInAllDay'][day] == True for day in hours['DineInAllDay']):\n properties['opening_hours'] = '24/7'\n- elif 'hours' in store:\n- hours = store['hours']\n- if not all(hours[d] == '' for d in hours):\n- days_hours = []\n- for day in ['monday', 'tuesday', 'wednesday', 'thursday', 'friday', 'saturday', 'sunday']:\n- days_hours.append([\n- self.dayMap[day],\n- hours[day].lower().replace(' ', '')\n- ])\n- properties['opening_hours'] = self.opening_hours(days_hours)\n+\n+ else:\n+ days_hours = []\n+ for day in ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']:\n+ days_hours.append([\n+ self.dayMap[day],\n+ hours['DineIn'][day].lower().replace(' ', '')\n+ ])\n+ properties['opening_hours'] = self.opening_hours(days_hours)\n \n yield GeojsonPointItem(**properties)\n", "issue": "Spider jackinthebox is broken\nDuring the global build at 2021-06-23-14-42-18, spider **jackinthebox** failed with **0 features** and **1 errors**.\n\nHere's [the log](https://data.alltheplaces.xyz/runs/2021-06-23-14-42-18/logs/jackinthebox.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-06-23-14-42-18/output/jackinthebox.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-06-23-14-42-18/output/jackinthebox.geojson))\n", "before_files": [{"content": "import json\nimport re\nimport scrapy\nfrom locations.items import GeojsonPointItem\n\nclass JackInTheBoxSpider(scrapy.Spider):\n name = \"jackinthebox\"\n item_attributes = { 'brand': \"Jack In The Box\" }\n allowed_domains = [\"jackinthebox.com\"]\n start_urls = (\n \"https://www.jackinthebox.com/api/locations\",\n )\n dayMap = {\n 'monday': 'Mo',\n 'tuesday': 'Tu',\n 'wednesday': 'We',\n 'thursday': 'Th',\n 'friday': 'Fr',\n 'saturday': 'Sa',\n 'sunday': 'Su'\n }\n def opening_hours(self, days_hours):\n day_groups = []\n this_day_group = None\n for day_hours in days_hours:\n day = day_hours[0]\n hours = day_hours[1]\n match = re.search(r'^(\\d{1,2}):(\\d{2})\\w*(a|p)m-(\\d{1,2}):(\\d{2})\\w*(a|p)m?$', hours)\n (f_hr, f_min, f_ampm, t_hr, t_min, t_ampm) = match.groups()\n\n f_hr = int(f_hr)\n if f_ampm == 'p':\n f_hr += 12\n elif f_ampm == 'a' and f_hr == 12:\n f_hr = 0\n t_hr = int(t_hr)\n if t_ampm == 'p':\n t_hr += 12\n elif t_ampm == 'a' and t_hr == 12:\n t_hr = 0\n\n hours = '{:02d}:{}-{:02d}:{}'.format(\n f_hr,\n f_min,\n t_hr,\n t_min,\n )\n\n if not this_day_group:\n this_day_group = {\n 'from_day': day,\n 'to_day': day,\n 'hours': hours\n }\n elif this_day_group['hours'] != hours:\n day_groups.append(this_day_group)\n this_day_group = {\n 'from_day': day,\n 'to_day': day,\n 'hours': hours\n }\n elif this_day_group['hours'] == hours:\n this_day_group['to_day'] = day\n\n day_groups.append(this_day_group)\n\n opening_hours = \"\"\n if len(day_groups) == 1 and day_groups[0]['hours'] in ('00:00-23:59', '00:00-00:00'):\n opening_hours = '24/7'\n else:\n for day_group in day_groups:\n if day_group['from_day'] == day_group['to_day']:\n opening_hours += '{from_day} {hours}; '.format(**day_group)\n elif day_group['from_day'] == 'Su' and day_group['to_day'] == 'Sa':\n opening_hours += '{hours}; '.format(**day_group)\n else:\n opening_hours += '{from_day}-{to_day} {hours}; '.format(**day_group)\n opening_hours = opening_hours[:-2]\n\n return opening_hours\n\n def parse(self, response):\n stores = json.loads(response.body_as_unicode())\n for store in stores: \n properties = { \n 'ref': store['id'], \n 'addr_full': store['address'],\n 'city': store['city'], \n 'state': store['state'], \n 'postcode': store['postal'], \n 'lat': store['lat'], \n 'lon': store['lng'], \n 'phone': store['phone'],\n } \n \n if store['twentyfourhours']:\n properties['opening_hours'] = '24/7'\n elif 'hours' in store:\n hours = store['hours']\n if not all(hours[d] == '' for d in hours):\n days_hours = []\n for day in ['monday', 'tuesday', 'wednesday', 'thursday', 'friday', 'saturday', 'sunday']:\n days_hours.append([\n self.dayMap[day],\n hours[day].lower().replace(' ', '')\n ])\n properties['opening_hours'] = self.opening_hours(days_hours)\n \n yield GeojsonPointItem(**properties) \n\n\n", "path": "locations/spiders/jackinthebox.py"}]}
| 1,910 | 987 |
gh_patches_debug_5360
|
rasdani/github-patches
|
git_diff
|
ibis-project__ibis-2884
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
BUG: File pseudo-backends failing for missing pandas option
The next code is failing in master since #2833:
```python
>>> import ibis
>>> con = ibis.csv.connect('/home/mgarcia/src/ibis/ci/ibis-testing-data/')
>>> expr = con.table('functional_alltypes')['double_col'] * 2
>>> print(expr.execute())
OptionError: "No such keys(s): 'pandas.enable_trace'"
```
The problem is when the `csv` backend (or other file backends) are loaded, but the pandas backend is not. This is because `ibis.pandas` loads the pandas options, which looks like they are needed by the file pseudo-backends.
The CI is not failing, I guess because we test pandas and the file backends are tested together, and pandas is loaded when the file backends are tested.
</issue>
<code>
[start of ibis/backends/base/file/__init__.py]
1 from pathlib import Path
2
3 import ibis.expr.types as ir
4 from ibis.backends.base import BaseBackend, Client, Database
5 from ibis.backends.pandas.core import execute_and_reset
6
7
8 class FileClient(Client):
9 def __init__(self, backend, root):
10 self.backend = backend
11 self.extension = backend.extension
12 self.table_class = backend.table_class
13 self.root = Path(str(root))
14 self.dictionary = {}
15
16 def insert(self, path, expr, **kwargs):
17 raise NotImplementedError
18
19 def table(self, name, path):
20 raise NotImplementedError
21
22 def database(self, name=None, path=None):
23 if name is None:
24 return FileDatabase('root', self, path=path)
25
26 if name not in self.list_databases(path):
27 raise AttributeError(name)
28 if path is None:
29 path = self.root
30
31 new_name = "{}.{}".format(name, self.extension)
32 if (self.root / name).is_dir():
33 path /= name
34 elif not str(path).endswith(new_name):
35 path /= new_name
36
37 return FileDatabase(name, self, path=path)
38
39 def execute(self, expr, params=None, **kwargs): # noqa
40 assert isinstance(expr, ir.Expr)
41 return execute_and_reset(expr, params=params, **kwargs)
42
43 def list_tables(self, path=None):
44 raise NotImplementedError
45
46 def _list_tables_files(self, path=None):
47 # tables are files in a dir
48 if path is None:
49 path = self.root
50
51 tables = []
52 if path.is_dir():
53 for d in path.iterdir():
54 if d.is_file():
55 if str(d).endswith(self.extension):
56 tables.append(d.stem)
57 elif path.is_file():
58 if str(path).endswith(self.extension):
59 tables.append(path.stem)
60 return tables
61
62 def list_databases(self, path=None):
63 raise NotImplementedError
64
65 def _list_databases_dirs(self, path=None):
66 # databases are dir
67 if path is None:
68 path = self.root
69
70 tables = []
71 if path.is_dir():
72 for d in path.iterdir():
73 if d.is_dir():
74 tables.append(d.name)
75 return tables
76
77 def _list_databases_dirs_or_files(self, path=None):
78 # databases are dir & file
79 if path is None:
80 path = self.root
81
82 tables = []
83 if path.is_dir():
84 for d in path.iterdir():
85 if d.is_dir():
86 tables.append(d.name)
87 elif d.is_file():
88 if str(d).endswith(self.extension):
89 tables.append(d.stem)
90 elif path.is_file():
91 # by definition we are at the db level at this point
92 pass
93
94 return tables
95
96
97 class FileDatabase(Database):
98 def __init__(self, name, client, path=None):
99 super().__init__(name, client)
100 self.path = path
101
102 def __str__(self):
103 return '{0.__class__.__name__}({0.name})'.format(self)
104
105 def __dir__(self):
106 dbs = self.list_databases(path=self.path)
107 tables = self.list_tables(path=self.path)
108 return sorted(set(dbs).union(set(tables)))
109
110 def __getattr__(self, name):
111 try:
112 return self.table(name, path=self.path)
113 except AttributeError:
114 return self.database(name, path=self.path)
115
116 def table(self, name, path):
117 return self.client.table(name, path=path)
118
119 def database(self, name=None, path=None):
120 return self.client.database(name=name, path=path)
121
122 def list_databases(self, path=None):
123 if path is None:
124 path = self.path
125 return sorted(self.client.list_databases(path=path))
126
127 def list_tables(self, path=None):
128 if path is None:
129 path = self.path
130 return sorted(self.client.list_tables(path=path))
131
132
133 class BaseFileBackend(BaseBackend):
134 """
135 Base backend class for pandas pseudo-backends for file formats.
136 """
137
138 def connect(self, path):
139 """Create a Client for use with Ibis
140
141 Parameters
142 ----------
143 path : str or pathlib.Path
144
145 Returns
146 -------
147 Client
148 """
149 return self.client_class(backend=self, root=path)
150
[end of ibis/backends/base/file/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ibis/backends/base/file/__init__.py b/ibis/backends/base/file/__init__.py
--- a/ibis/backends/base/file/__init__.py
+++ b/ibis/backends/base/file/__init__.py
@@ -1,9 +1,13 @@
from pathlib import Path
+import ibis
import ibis.expr.types as ir
from ibis.backends.base import BaseBackend, Client, Database
from ibis.backends.pandas.core import execute_and_reset
+# Load options of pandas backend
+ibis.pandas
+
class FileClient(Client):
def __init__(self, backend, root):
|
{"golden_diff": "diff --git a/ibis/backends/base/file/__init__.py b/ibis/backends/base/file/__init__.py\n--- a/ibis/backends/base/file/__init__.py\n+++ b/ibis/backends/base/file/__init__.py\n@@ -1,9 +1,13 @@\n from pathlib import Path\n \n+import ibis\n import ibis.expr.types as ir\n from ibis.backends.base import BaseBackend, Client, Database\n from ibis.backends.pandas.core import execute_and_reset\n \n+# Load options of pandas backend\n+ibis.pandas\n+\n \n class FileClient(Client):\n def __init__(self, backend, root):\n", "issue": "BUG: File pseudo-backends failing for missing pandas option\nThe next code is failing in master since #2833:\r\n\r\n```python\r\n>>> import ibis\r\n>>> con = ibis.csv.connect('/home/mgarcia/src/ibis/ci/ibis-testing-data/')\r\n>>> expr = con.table('functional_alltypes')['double_col'] * 2\r\n>>> print(expr.execute())\r\nOptionError: \"No such keys(s): 'pandas.enable_trace'\"\r\n```\r\n\r\nThe problem is when the `csv` backend (or other file backends) are loaded, but the pandas backend is not. This is because `ibis.pandas` loads the pandas options, which looks like they are needed by the file pseudo-backends.\r\n\r\nThe CI is not failing, I guess because we test pandas and the file backends are tested together, and pandas is loaded when the file backends are tested.\n", "before_files": [{"content": "from pathlib import Path\n\nimport ibis.expr.types as ir\nfrom ibis.backends.base import BaseBackend, Client, Database\nfrom ibis.backends.pandas.core import execute_and_reset\n\n\nclass FileClient(Client):\n def __init__(self, backend, root):\n self.backend = backend\n self.extension = backend.extension\n self.table_class = backend.table_class\n self.root = Path(str(root))\n self.dictionary = {}\n\n def insert(self, path, expr, **kwargs):\n raise NotImplementedError\n\n def table(self, name, path):\n raise NotImplementedError\n\n def database(self, name=None, path=None):\n if name is None:\n return FileDatabase('root', self, path=path)\n\n if name not in self.list_databases(path):\n raise AttributeError(name)\n if path is None:\n path = self.root\n\n new_name = \"{}.{}\".format(name, self.extension)\n if (self.root / name).is_dir():\n path /= name\n elif not str(path).endswith(new_name):\n path /= new_name\n\n return FileDatabase(name, self, path=path)\n\n def execute(self, expr, params=None, **kwargs): # noqa\n assert isinstance(expr, ir.Expr)\n return execute_and_reset(expr, params=params, **kwargs)\n\n def list_tables(self, path=None):\n raise NotImplementedError\n\n def _list_tables_files(self, path=None):\n # tables are files in a dir\n if path is None:\n path = self.root\n\n tables = []\n if path.is_dir():\n for d in path.iterdir():\n if d.is_file():\n if str(d).endswith(self.extension):\n tables.append(d.stem)\n elif path.is_file():\n if str(path).endswith(self.extension):\n tables.append(path.stem)\n return tables\n\n def list_databases(self, path=None):\n raise NotImplementedError\n\n def _list_databases_dirs(self, path=None):\n # databases are dir\n if path is None:\n path = self.root\n\n tables = []\n if path.is_dir():\n for d in path.iterdir():\n if d.is_dir():\n tables.append(d.name)\n return tables\n\n def _list_databases_dirs_or_files(self, path=None):\n # databases are dir & file\n if path is None:\n path = self.root\n\n tables = []\n if path.is_dir():\n for d in path.iterdir():\n if d.is_dir():\n tables.append(d.name)\n elif d.is_file():\n if str(d).endswith(self.extension):\n tables.append(d.stem)\n elif path.is_file():\n # by definition we are at the db level at this point\n pass\n\n return tables\n\n\nclass FileDatabase(Database):\n def __init__(self, name, client, path=None):\n super().__init__(name, client)\n self.path = path\n\n def __str__(self):\n return '{0.__class__.__name__}({0.name})'.format(self)\n\n def __dir__(self):\n dbs = self.list_databases(path=self.path)\n tables = self.list_tables(path=self.path)\n return sorted(set(dbs).union(set(tables)))\n\n def __getattr__(self, name):\n try:\n return self.table(name, path=self.path)\n except AttributeError:\n return self.database(name, path=self.path)\n\n def table(self, name, path):\n return self.client.table(name, path=path)\n\n def database(self, name=None, path=None):\n return self.client.database(name=name, path=path)\n\n def list_databases(self, path=None):\n if path is None:\n path = self.path\n return sorted(self.client.list_databases(path=path))\n\n def list_tables(self, path=None):\n if path is None:\n path = self.path\n return sorted(self.client.list_tables(path=path))\n\n\nclass BaseFileBackend(BaseBackend):\n \"\"\"\n Base backend class for pandas pseudo-backends for file formats.\n \"\"\"\n\n def connect(self, path):\n \"\"\"Create a Client for use with Ibis\n\n Parameters\n ----------\n path : str or pathlib.Path\n\n Returns\n -------\n Client\n \"\"\"\n return self.client_class(backend=self, root=path)\n", "path": "ibis/backends/base/file/__init__.py"}]}
| 1,997 | 142 |
gh_patches_debug_35728
|
rasdani/github-patches
|
git_diff
|
mindsdb__lightwood-518
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Lightwood.api.ensemble is not necessary
This script is deprecated, as the ensemble module has moved to `lw.ensemble` with a base abstraction. A quick inspection of the code (ex: grep for this call) and I don't see any references. Please double check if this file is required, as I think it should be removed.
The culprit link is [here](https://github.com/mindsdb/lightwood/blob/0372d292796a6d1f91ac9df9b8658ad2f128b7c9/lightwood/api/ensemble.py)
</issue>
<code>
[start of lightwood/api/ensemble.py]
1 from lightwood import Predictor
2 from lightwood.constants.lightwood import ColumnDataTypes
3 from collections import Counter
4 import numpy as np
5 import pickle
6 import os
7
8
9 class LightwoodEnsemble:
10 def __init__(self, predictors=None, load_from_path=None):
11 self.path_list = None
12 if load_from_path is not None:
13 with open(os.path.join(load_from_path, 'lightwood_data'), 'rb') as pickle_in:
14 obj = pickle.load(pickle_in)
15 self.path = load_from_path
16 self.path_list = obj.path_list
17 self.ensemble = [Predictor(load_from_path=path) for path in self.path_list]
18 elif isinstance(predictors, Predictor):
19 self.ensemble = [predictors]
20 elif isinstance(predictors, list):
21 self.ensemble = predictors
22
23 def append(self, predictor):
24 if isinstance(self.ensemble, list):
25 self.ensemble.append(predictor)
26 else:
27 self.ensemble = [predictor]
28
29 def __iter__(self):
30 yield self.ensemble
31
32 def predict(self, when_data):
33 predictions = [p.predict(when_data=when_data) for p in self.ensemble]
34 formatted_predictions = {}
35 for target in self.ensemble[0].config['output_features']:
36 target_name = target['name']
37 formatted_predictions[target_name] = {}
38 pred_arr = np.array([p[target_name]['predictions'] for p in predictions])
39 if target['type'] == ColumnDataTypes.NUMERIC:
40 final_preds = np.mean(pred_arr, axis=0).tolist()
41 elif target['type'] == ColumnDataTypes.CATEGORICAL:
42 final_preds = [max(Counter(pred_arr[:, idx])) for idx in range(pred_arr.shape[1])]
43
44 # @TODO: implement class distribution for ensembles
45 # NOTE: label set *could* grow when adding predictors, which complicates belief score computation
46 formatted_predictions[target_name]['class_distribution'] = np.ones(shape=(len(final_preds), 1))
47 else:
48 raise Exception('Only numeric and categorical datatypes are supported for ensembles')
49
50 formatted_predictions[target_name]['predictions'] = final_preds
51
52 return formatted_predictions
53
54 def save(self, path_to):
55 # TODO: potentially save predictors inside ensemble pickle, though there's the issue of nonpersistent stuff with torch.save() # noqa
56 path_list = []
57 for i, model in enumerate(self.ensemble):
58 path = os.path.join(path_to, f'lightwood_predictor_{i}')
59 path_list.append(path)
60 model.save(path_to=path)
61
62 self.path_list = path_list
63
64 # TODO: in the future, save preds inside this data struct
65 self.ensemble = None # we deref predictors for now
66 with open(os.path.join(path_to, 'lightwood_data'), 'wb') as file:
67 pickle.dump(self, file, pickle.HIGHEST_PROTOCOL)
68
[end of lightwood/api/ensemble.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lightwood/api/ensemble.py b/lightwood/api/ensemble.py
deleted file mode 100644
--- a/lightwood/api/ensemble.py
+++ /dev/null
@@ -1,67 +0,0 @@
-from lightwood import Predictor
-from lightwood.constants.lightwood import ColumnDataTypes
-from collections import Counter
-import numpy as np
-import pickle
-import os
-
-
-class LightwoodEnsemble:
- def __init__(self, predictors=None, load_from_path=None):
- self.path_list = None
- if load_from_path is not None:
- with open(os.path.join(load_from_path, 'lightwood_data'), 'rb') as pickle_in:
- obj = pickle.load(pickle_in)
- self.path = load_from_path
- self.path_list = obj.path_list
- self.ensemble = [Predictor(load_from_path=path) for path in self.path_list]
- elif isinstance(predictors, Predictor):
- self.ensemble = [predictors]
- elif isinstance(predictors, list):
- self.ensemble = predictors
-
- def append(self, predictor):
- if isinstance(self.ensemble, list):
- self.ensemble.append(predictor)
- else:
- self.ensemble = [predictor]
-
- def __iter__(self):
- yield self.ensemble
-
- def predict(self, when_data):
- predictions = [p.predict(when_data=when_data) for p in self.ensemble]
- formatted_predictions = {}
- for target in self.ensemble[0].config['output_features']:
- target_name = target['name']
- formatted_predictions[target_name] = {}
- pred_arr = np.array([p[target_name]['predictions'] for p in predictions])
- if target['type'] == ColumnDataTypes.NUMERIC:
- final_preds = np.mean(pred_arr, axis=0).tolist()
- elif target['type'] == ColumnDataTypes.CATEGORICAL:
- final_preds = [max(Counter(pred_arr[:, idx])) for idx in range(pred_arr.shape[1])]
-
- # @TODO: implement class distribution for ensembles
- # NOTE: label set *could* grow when adding predictors, which complicates belief score computation
- formatted_predictions[target_name]['class_distribution'] = np.ones(shape=(len(final_preds), 1))
- else:
- raise Exception('Only numeric and categorical datatypes are supported for ensembles')
-
- formatted_predictions[target_name]['predictions'] = final_preds
-
- return formatted_predictions
-
- def save(self, path_to):
- # TODO: potentially save predictors inside ensemble pickle, though there's the issue of nonpersistent stuff with torch.save() # noqa
- path_list = []
- for i, model in enumerate(self.ensemble):
- path = os.path.join(path_to, f'lightwood_predictor_{i}')
- path_list.append(path)
- model.save(path_to=path)
-
- self.path_list = path_list
-
- # TODO: in the future, save preds inside this data struct
- self.ensemble = None # we deref predictors for now
- with open(os.path.join(path_to, 'lightwood_data'), 'wb') as file:
- pickle.dump(self, file, pickle.HIGHEST_PROTOCOL)
|
{"golden_diff": "diff --git a/lightwood/api/ensemble.py b/lightwood/api/ensemble.py\ndeleted file mode 100644\n--- a/lightwood/api/ensemble.py\n+++ /dev/null\n@@ -1,67 +0,0 @@\n-from lightwood import Predictor\n-from lightwood.constants.lightwood import ColumnDataTypes\n-from collections import Counter\n-import numpy as np\n-import pickle\n-import os\n-\n-\n-class LightwoodEnsemble:\n- def __init__(self, predictors=None, load_from_path=None):\n- self.path_list = None\n- if load_from_path is not None:\n- with open(os.path.join(load_from_path, 'lightwood_data'), 'rb') as pickle_in:\n- obj = pickle.load(pickle_in)\n- self.path = load_from_path\n- self.path_list = obj.path_list\n- self.ensemble = [Predictor(load_from_path=path) for path in self.path_list]\n- elif isinstance(predictors, Predictor):\n- self.ensemble = [predictors]\n- elif isinstance(predictors, list):\n- self.ensemble = predictors\n-\n- def append(self, predictor):\n- if isinstance(self.ensemble, list):\n- self.ensemble.append(predictor)\n- else:\n- self.ensemble = [predictor]\n-\n- def __iter__(self):\n- yield self.ensemble\n-\n- def predict(self, when_data):\n- predictions = [p.predict(when_data=when_data) for p in self.ensemble]\n- formatted_predictions = {}\n- for target in self.ensemble[0].config['output_features']:\n- target_name = target['name']\n- formatted_predictions[target_name] = {}\n- pred_arr = np.array([p[target_name]['predictions'] for p in predictions])\n- if target['type'] == ColumnDataTypes.NUMERIC:\n- final_preds = np.mean(pred_arr, axis=0).tolist()\n- elif target['type'] == ColumnDataTypes.CATEGORICAL:\n- final_preds = [max(Counter(pred_arr[:, idx])) for idx in range(pred_arr.shape[1])]\n-\n- # @TODO: implement class distribution for ensembles\n- # NOTE: label set *could* grow when adding predictors, which complicates belief score computation\n- formatted_predictions[target_name]['class_distribution'] = np.ones(shape=(len(final_preds), 1))\n- else:\n- raise Exception('Only numeric and categorical datatypes are supported for ensembles')\n-\n- formatted_predictions[target_name]['predictions'] = final_preds\n-\n- return formatted_predictions\n-\n- def save(self, path_to):\n- # TODO: potentially save predictors inside ensemble pickle, though there's the issue of nonpersistent stuff with torch.save() # noqa\n- path_list = []\n- for i, model in enumerate(self.ensemble):\n- path = os.path.join(path_to, f'lightwood_predictor_{i}')\n- path_list.append(path)\n- model.save(path_to=path)\n-\n- self.path_list = path_list\n-\n- # TODO: in the future, save preds inside this data struct\n- self.ensemble = None # we deref predictors for now\n- with open(os.path.join(path_to, 'lightwood_data'), 'wb') as file:\n- pickle.dump(self, file, pickle.HIGHEST_PROTOCOL)\n", "issue": "Lightwood.api.ensemble is not necessary\nThis script is deprecated, as the ensemble module has moved to `lw.ensemble` with a base abstraction. A quick inspection of the code (ex: grep for this call) and I don't see any references. Please double check if this file is required, as I think it should be removed.\r\n\r\nThe culprit link is [here](https://github.com/mindsdb/lightwood/blob/0372d292796a6d1f91ac9df9b8658ad2f128b7c9/lightwood/api/ensemble.py)\n", "before_files": [{"content": "from lightwood import Predictor\nfrom lightwood.constants.lightwood import ColumnDataTypes\nfrom collections import Counter\nimport numpy as np\nimport pickle\nimport os\n\n\nclass LightwoodEnsemble:\n def __init__(self, predictors=None, load_from_path=None):\n self.path_list = None\n if load_from_path is not None:\n with open(os.path.join(load_from_path, 'lightwood_data'), 'rb') as pickle_in:\n obj = pickle.load(pickle_in)\n self.path = load_from_path\n self.path_list = obj.path_list\n self.ensemble = [Predictor(load_from_path=path) for path in self.path_list]\n elif isinstance(predictors, Predictor):\n self.ensemble = [predictors]\n elif isinstance(predictors, list):\n self.ensemble = predictors\n\n def append(self, predictor):\n if isinstance(self.ensemble, list):\n self.ensemble.append(predictor)\n else:\n self.ensemble = [predictor]\n\n def __iter__(self):\n yield self.ensemble\n\n def predict(self, when_data):\n predictions = [p.predict(when_data=when_data) for p in self.ensemble]\n formatted_predictions = {}\n for target in self.ensemble[0].config['output_features']:\n target_name = target['name']\n formatted_predictions[target_name] = {}\n pred_arr = np.array([p[target_name]['predictions'] for p in predictions])\n if target['type'] == ColumnDataTypes.NUMERIC:\n final_preds = np.mean(pred_arr, axis=0).tolist()\n elif target['type'] == ColumnDataTypes.CATEGORICAL:\n final_preds = [max(Counter(pred_arr[:, idx])) for idx in range(pred_arr.shape[1])]\n\n # @TODO: implement class distribution for ensembles\n # NOTE: label set *could* grow when adding predictors, which complicates belief score computation\n formatted_predictions[target_name]['class_distribution'] = np.ones(shape=(len(final_preds), 1))\n else:\n raise Exception('Only numeric and categorical datatypes are supported for ensembles')\n\n formatted_predictions[target_name]['predictions'] = final_preds\n\n return formatted_predictions\n\n def save(self, path_to):\n # TODO: potentially save predictors inside ensemble pickle, though there's the issue of nonpersistent stuff with torch.save() # noqa\n path_list = []\n for i, model in enumerate(self.ensemble):\n path = os.path.join(path_to, f'lightwood_predictor_{i}')\n path_list.append(path)\n model.save(path_to=path)\n\n self.path_list = path_list\n\n # TODO: in the future, save preds inside this data struct\n self.ensemble = None # we deref predictors for now\n with open(os.path.join(path_to, 'lightwood_data'), 'wb') as file:\n pickle.dump(self, file, pickle.HIGHEST_PROTOCOL)\n", "path": "lightwood/api/ensemble.py"}]}
| 1,418 | 725 |
gh_patches_debug_1352
|
rasdani/github-patches
|
git_diff
|
pwr-Solaar__Solaar-1826
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Release 1.1.7
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python3
2
3 from glob import glob as _glob
4
5 try:
6 from setuptools import setup
7 except ImportError:
8 from distutils.core import setup
9
10 # from solaar import NAME, __version__
11 __version__ = '1.1.7'
12 NAME = 'Solaar'
13
14
15 def _data_files():
16 from os.path import dirname as _dirname
17
18 yield 'share/solaar/icons', _glob('share/solaar/icons/solaar*.svg')
19 yield 'share/solaar/icons', _glob('share/solaar/icons/light_*.png')
20 yield 'share/icons/hicolor/scalable/apps', ['share/solaar/icons/solaar.svg']
21
22 for mo in _glob('share/locale/*/LC_MESSAGES/solaar.mo'):
23 yield _dirname(mo), [mo]
24
25 yield 'share/applications', ['share/applications/solaar.desktop']
26 yield 'share/solaar/udev-rules.d', ['rules.d/42-logitech-unify-permissions.rules']
27 yield 'share/metainfo', ['share/solaar/io.github.pwr_solaar.solaar.metainfo.xml']
28
29 del _dirname
30
31
32 setup(
33 name=NAME.lower(),
34 version=__version__,
35 description='Linux device manager for Logitech receivers, keyboards, mice, and tablets.',
36 long_description='''
37 Solaar is a Linux device manager for many Logitech peripherals that connect through
38 Unifying and other receivers or via USB or Bluetooth.
39 Solaar is able to pair/unpair devices with receivers and show and modify some of the
40 modifiable features of devices.
41 For instructions on installing Solaar see https://pwr-solaar.github.io/Solaar/installation'''.strip(),
42 author='Daniel Pavel',
43 license='GPLv2',
44 url='http://pwr-solaar.github.io/Solaar/',
45 classifiers=[
46 'Development Status :: 4 - Beta',
47 'Environment :: X11 Applications :: GTK',
48 'Environment :: Console',
49 'Intended Audience :: End Users/Desktop',
50 'License :: DFSG approved',
51 'License :: OSI Approved :: GNU General Public License v2 (GPLv2)',
52 'Natural Language :: English',
53 'Programming Language :: Python :: 3 :: Only',
54 'Operating System :: POSIX :: Linux',
55 'Topic :: Utilities',
56 ],
57 platforms=['linux'],
58
59 # sudo apt install python-gi python3-gi \
60 # gir1.2-gtk-3.0 gir1.2-notify-0.7 gir1.2-ayatanaappindicator3-0.1
61 # os_requires=['gi.repository.GObject (>= 2.0)', 'gi.repository.Gtk (>= 3.0)'],
62 python_requires='>=3.7',
63 install_requires=[
64 'evdev (>= 1.1.2)',
65 'pyudev (>= 0.13)',
66 'PyYAML (>= 3.12)',
67 'python-xlib (>= 0.27)',
68 'psutil (>= 5.4.3)',
69 'typing_extensions (>=4.0.0)',
70 ],
71 extras_require={
72 'report-descriptor': ['hid-parser'],
73 'desktop-notifications': ['Notify (>= 0.7)'],
74 },
75 package_dir={'': 'lib'},
76 packages=['keysyms', 'hidapi', 'logitech_receiver', 'solaar', 'solaar.ui', 'solaar.cli'],
77 data_files=list(_data_files()),
78 scripts=_glob('bin/*'),
79 )
80
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -66,7 +66,6 @@
'PyYAML (>= 3.12)',
'python-xlib (>= 0.27)',
'psutil (>= 5.4.3)',
- 'typing_extensions (>=4.0.0)',
],
extras_require={
'report-descriptor': ['hid-parser'],
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -66,7 +66,6 @@\n 'PyYAML (>= 3.12)',\n 'python-xlib (>= 0.27)',\n 'psutil (>= 5.4.3)',\n- 'typing_extensions (>=4.0.0)',\n ],\n extras_require={\n 'report-descriptor': ['hid-parser'],\n", "issue": "Release 1.1.7\n\n", "before_files": [{"content": "#!/usr/bin/env python3\n\nfrom glob import glob as _glob\n\ntry:\n from setuptools import setup\nexcept ImportError:\n from distutils.core import setup\n\n# from solaar import NAME, __version__\n__version__ = '1.1.7'\nNAME = 'Solaar'\n\n\ndef _data_files():\n from os.path import dirname as _dirname\n\n yield 'share/solaar/icons', _glob('share/solaar/icons/solaar*.svg')\n yield 'share/solaar/icons', _glob('share/solaar/icons/light_*.png')\n yield 'share/icons/hicolor/scalable/apps', ['share/solaar/icons/solaar.svg']\n\n for mo in _glob('share/locale/*/LC_MESSAGES/solaar.mo'):\n yield _dirname(mo), [mo]\n\n yield 'share/applications', ['share/applications/solaar.desktop']\n yield 'share/solaar/udev-rules.d', ['rules.d/42-logitech-unify-permissions.rules']\n yield 'share/metainfo', ['share/solaar/io.github.pwr_solaar.solaar.metainfo.xml']\n\n del _dirname\n\n\nsetup(\n name=NAME.lower(),\n version=__version__,\n description='Linux device manager for Logitech receivers, keyboards, mice, and tablets.',\n long_description='''\nSolaar is a Linux device manager for many Logitech peripherals that connect through\nUnifying and other receivers or via USB or Bluetooth.\nSolaar is able to pair/unpair devices with receivers and show and modify some of the\nmodifiable features of devices.\nFor instructions on installing Solaar see https://pwr-solaar.github.io/Solaar/installation'''.strip(),\n author='Daniel Pavel',\n license='GPLv2',\n url='http://pwr-solaar.github.io/Solaar/',\n classifiers=[\n 'Development Status :: 4 - Beta',\n 'Environment :: X11 Applications :: GTK',\n 'Environment :: Console',\n 'Intended Audience :: End Users/Desktop',\n 'License :: DFSG approved',\n 'License :: OSI Approved :: GNU General Public License v2 (GPLv2)',\n 'Natural Language :: English',\n 'Programming Language :: Python :: 3 :: Only',\n 'Operating System :: POSIX :: Linux',\n 'Topic :: Utilities',\n ],\n platforms=['linux'],\n\n # sudo apt install python-gi python3-gi \\\n # gir1.2-gtk-3.0 gir1.2-notify-0.7 gir1.2-ayatanaappindicator3-0.1\n # os_requires=['gi.repository.GObject (>= 2.0)', 'gi.repository.Gtk (>= 3.0)'],\n python_requires='>=3.7',\n install_requires=[\n 'evdev (>= 1.1.2)',\n 'pyudev (>= 0.13)',\n 'PyYAML (>= 3.12)',\n 'python-xlib (>= 0.27)',\n 'psutil (>= 5.4.3)',\n 'typing_extensions (>=4.0.0)',\n ],\n extras_require={\n 'report-descriptor': ['hid-parser'],\n 'desktop-notifications': ['Notify (>= 0.7)'],\n },\n package_dir={'': 'lib'},\n packages=['keysyms', 'hidapi', 'logitech_receiver', 'solaar', 'solaar.ui', 'solaar.cli'],\n data_files=list(_data_files()),\n scripts=_glob('bin/*'),\n)\n", "path": "setup.py"}]}
| 1,461 | 101 |
gh_patches_debug_6252
|
rasdani/github-patches
|
git_diff
|
google__turbinia-809
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
GrepTask issue
```
2021-04-28 17:13:25 [ERROR] GrepTask Task failed with exception: [a bytes-like object is required, not 'str']
2021-04-28 17:13:25 [ERROR] Traceback (most recent call last):
File "/usr/local/lib/python3.6/dist-packages/turbinia-20210330-py3.6.egg/turbinia/workers/__init__.py", line 893, in run_wrapper
self.result = self.run(evidence, self.result)
File "/usr/local/lib/python3.6/dist-packages/turbinia-20210330-py3.6.egg/turbinia/workers/grep.py", line 49, in run
fh.write('\n'.join(patterns))
File "/usr/lib/python3.6/tempfile.py", line 624, in func_wrapper
return func(*args, **kwargs)
TypeError: a bytes-like object is required, not 'str'
2021-04-28 17:13:26 [ERROR] GrepTask Task failed with exception: [a bytes-like object is required, not 'str']
2021-04-28 17:13:26 [INFO] Traceback (most recent call last):
File "/usr/local/lib/python3.6/dist-packages/turbinia-20210330-py3.6.egg/turbinia/workers/__init__.py", line 893, in run_wrapper
self.result = self.run(evidence, self.result)
File "/usr/local/lib/python3.6/dist-packages/turbinia-20210330-py3.6.egg/turbinia/workers/grep.py", line 49, in run
fh.write('\n'.join(patterns))
File "/usr/lib/python3.6/tempfile.py", line 624, in func_wrapper
return func(*args, **kwargs)
TypeError: a bytes-like object is required, not 'str'
```
</issue>
<code>
[start of turbinia/workers/grep.py]
1 # -*- coding: utf-8 -*-
2 # Copyright 2015 Google Inc.
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15 """Task to filter a text file using extended regular expression patterns."""
16
17 from __future__ import unicode_literals
18
19 import os
20 from tempfile import NamedTemporaryFile
21
22 from turbinia.evidence import FilteredTextFile
23 from turbinia.workers import TurbiniaTask
24
25
26 class GrepTask(TurbiniaTask):
27 """Filter input based on extended regular expression patterns."""
28
29 def run(self, evidence, result):
30 """Run grep binary.
31
32 Args:
33 evidence (Evidence object): The evidence we will process
34 result (TurbiniaTaskResult): The object to place task results into.
35
36 Returns:
37 TurbiniaTaskResult object.
38 """
39
40 patterns = evidence.config.get('filter_patterns')
41 if not patterns:
42 result.close(self, success=True, status='No patterns supplied, exit task')
43 return result
44
45 # Create temporary file to write patterns to.
46 # Used as input to grep (-f).
47 with NamedTemporaryFile(dir=self.output_dir, delete=False) as fh:
48 patterns_file_path = fh.name
49 fh.write('\n'.join(patterns))
50
51 # Create a path that we can write the new file to.
52 base_name = os.path.basename(evidence.local_path)
53 output_file_path = os.path.join(
54 self.output_dir, '{0:s}.filtered'.format(base_name))
55
56 output_evidence = FilteredTextFile(source_path=output_file_path)
57 cmd = 'grep -E -b -n -f {0:s} {1:s} > {2:s}'.format(
58 patterns_file_path, evidence.local_path, output_file_path)
59
60 result.log('Running [{0:s}]'.format(cmd))
61 ret, result = self.execute(
62 cmd, result, new_evidence=[output_evidence], shell=True,
63 success_codes=[0, 1])
64
65 # Grep returns 0 on success and 1 if no results are found.
66 if ret == 0:
67 status = 'Grep Task found results in {0:s}'.format(evidence.name)
68 result.close(self, success=True, status=status)
69 elif ret == 1:
70 status = 'Grep Task did not find any results in {0:s}'.format(
71 evidence.name)
72 result.close(self, success=True, status=status)
73 else:
74 result.close(self, success=False)
75
76 return result
77
[end of turbinia/workers/grep.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/turbinia/workers/grep.py b/turbinia/workers/grep.py
--- a/turbinia/workers/grep.py
+++ b/turbinia/workers/grep.py
@@ -46,7 +46,7 @@
# Used as input to grep (-f).
with NamedTemporaryFile(dir=self.output_dir, delete=False) as fh:
patterns_file_path = fh.name
- fh.write('\n'.join(patterns))
+ fh.write('\n'.join(patterns.encode('utf-8')))
# Create a path that we can write the new file to.
base_name = os.path.basename(evidence.local_path)
|
{"golden_diff": "diff --git a/turbinia/workers/grep.py b/turbinia/workers/grep.py\n--- a/turbinia/workers/grep.py\n+++ b/turbinia/workers/grep.py\n@@ -46,7 +46,7 @@\n # Used as input to grep (-f).\n with NamedTemporaryFile(dir=self.output_dir, delete=False) as fh:\n patterns_file_path = fh.name\n- fh.write('\\n'.join(patterns))\n+ fh.write('\\n'.join(patterns.encode('utf-8')))\n \n # Create a path that we can write the new file to.\n base_name = os.path.basename(evidence.local_path)\n", "issue": "GrepTask issue\n```\r\n2021-04-28 17:13:25 [ERROR] GrepTask Task failed with exception: [a bytes-like object is required, not 'str']\r\n2021-04-28 17:13:25 [ERROR] Traceback (most recent call last):\r\n File \"/usr/local/lib/python3.6/dist-packages/turbinia-20210330-py3.6.egg/turbinia/workers/__init__.py\", line 893, in run_wrapper\r\n self.result = self.run(evidence, self.result)\r\n File \"/usr/local/lib/python3.6/dist-packages/turbinia-20210330-py3.6.egg/turbinia/workers/grep.py\", line 49, in run\r\n fh.write('\\n'.join(patterns))\r\n File \"/usr/lib/python3.6/tempfile.py\", line 624, in func_wrapper\r\n return func(*args, **kwargs)\r\nTypeError: a bytes-like object is required, not 'str'\r\n\r\n2021-04-28 17:13:26 [ERROR] GrepTask Task failed with exception: [a bytes-like object is required, not 'str']\r\n2021-04-28 17:13:26 [INFO] Traceback (most recent call last):\r\n File \"/usr/local/lib/python3.6/dist-packages/turbinia-20210330-py3.6.egg/turbinia/workers/__init__.py\", line 893, in run_wrapper\r\n self.result = self.run(evidence, self.result)\r\n File \"/usr/local/lib/python3.6/dist-packages/turbinia-20210330-py3.6.egg/turbinia/workers/grep.py\", line 49, in run\r\n fh.write('\\n'.join(patterns))\r\n File \"/usr/lib/python3.6/tempfile.py\", line 624, in func_wrapper\r\n return func(*args, **kwargs)\r\nTypeError: a bytes-like object is required, not 'str'\r\n```\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright 2015 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Task to filter a text file using extended regular expression patterns.\"\"\"\n\nfrom __future__ import unicode_literals\n\nimport os\nfrom tempfile import NamedTemporaryFile\n\nfrom turbinia.evidence import FilteredTextFile\nfrom turbinia.workers import TurbiniaTask\n\n\nclass GrepTask(TurbiniaTask):\n \"\"\"Filter input based on extended regular expression patterns.\"\"\"\n\n def run(self, evidence, result):\n \"\"\"Run grep binary.\n\n Args:\n evidence (Evidence object): The evidence we will process\n result (TurbiniaTaskResult): The object to place task results into.\n\n Returns:\n TurbiniaTaskResult object.\n \"\"\"\n\n patterns = evidence.config.get('filter_patterns')\n if not patterns:\n result.close(self, success=True, status='No patterns supplied, exit task')\n return result\n\n # Create temporary file to write patterns to.\n # Used as input to grep (-f).\n with NamedTemporaryFile(dir=self.output_dir, delete=False) as fh:\n patterns_file_path = fh.name\n fh.write('\\n'.join(patterns))\n\n # Create a path that we can write the new file to.\n base_name = os.path.basename(evidence.local_path)\n output_file_path = os.path.join(\n self.output_dir, '{0:s}.filtered'.format(base_name))\n\n output_evidence = FilteredTextFile(source_path=output_file_path)\n cmd = 'grep -E -b -n -f {0:s} {1:s} > {2:s}'.format(\n patterns_file_path, evidence.local_path, output_file_path)\n\n result.log('Running [{0:s}]'.format(cmd))\n ret, result = self.execute(\n cmd, result, new_evidence=[output_evidence], shell=True,\n success_codes=[0, 1])\n\n # Grep returns 0 on success and 1 if no results are found.\n if ret == 0:\n status = 'Grep Task found results in {0:s}'.format(evidence.name)\n result.close(self, success=True, status=status)\n elif ret == 1:\n status = 'Grep Task did not find any results in {0:s}'.format(\n evidence.name)\n result.close(self, success=True, status=status)\n else:\n result.close(self, success=False)\n\n return result\n", "path": "turbinia/workers/grep.py"}]}
| 1,823 | 149 |
gh_patches_debug_37596
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-4550
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
plugins.useetv: log if no link has been found
<!--
Thanks for opening a pull request!
Before you continue, please make sure that you have read and understood the contribution guidelines, otherwise your changes may be rejected:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
If possible, run the tests, perform code linting and build the documentation locally on your system first to avoid unnecessary build failures:
https://streamlink.github.io/latest/developing.html#validating-changes
Also don't forget to add a meaningful description of your changes, so that the reviewing process is as simple as possible for the maintainers.
Thank you very much!
-->
**Why this PR ?**
This PR has been made to verify if no link has been found. Indeed, USeeTV doesn't provide all his channels worldwide. Some channels are blocked for Indonesian people only, and some others need a subscription to work (see beIN Asia as an example). Some channels like SeaToday would work, but channels like this one :

will only show a Geo-restriction message above the player, telling the end-user he has no access to the stream.
This also reflects inside the player, meaning no link can be scraped.
</issue>
<code>
[start of src/streamlink/plugins/useetv.py]
1 """
2 $description Live TV channels and video on-demand service from UseeTV, owned by Telkom Indonesia.
3 $url useetv.com
4 $type live, vod
5 """
6
7 import re
8
9 from streamlink.plugin import Plugin, pluginmatcher
10 from streamlink.plugin.api import validate
11 from streamlink.stream.dash import DASHStream
12 from streamlink.stream.hls import HLSStream
13
14
15 @pluginmatcher(re.compile(r"https?://(?:www\.)?useetv\.com/"))
16 class UseeTV(Plugin):
17 def find_url(self):
18 url_re = re.compile(r"""['"](https://.*?/(?:[Pp]laylist\.m3u8|manifest\.mpd)[^'"]+)['"]""")
19
20 return self.session.http.get(self.url, schema=validate.Schema(
21 validate.parse_html(),
22 validate.any(
23 validate.all(
24 validate.xml_xpath_string("""
25 .//script[contains(text(), 'laylist.m3u8') or contains(text(), 'manifest.mpd')][1]/text()
26 """),
27 str,
28 validate.transform(url_re.search),
29 validate.any(None, validate.all(validate.get(1), validate.url())),
30 ),
31 validate.all(
32 validate.xml_xpath_string(".//video[@id='video-player']/source/@src"),
33 validate.any(None, validate.url()),
34 ),
35 ),
36 ))
37
38 def _get_streams(self):
39 url = self.find_url()
40
41 if url and ".m3u8" in url:
42 return HLSStream.parse_variant_playlist(self.session, url)
43 elif url and ".mpd" in url:
44 return DASHStream.parse_manifest(self.session, url)
45
46
47 __plugin__ = UseeTV
48
[end of src/streamlink/plugins/useetv.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/streamlink/plugins/useetv.py b/src/streamlink/plugins/useetv.py
--- a/src/streamlink/plugins/useetv.py
+++ b/src/streamlink/plugins/useetv.py
@@ -4,6 +4,7 @@
$type live, vod
"""
+import logging
import re
from streamlink.plugin import Plugin, pluginmatcher
@@ -11,32 +12,46 @@
from streamlink.stream.dash import DASHStream
from streamlink.stream.hls import HLSStream
+log = logging.getLogger(__name__)
+
@pluginmatcher(re.compile(r"https?://(?:www\.)?useetv\.com/"))
class UseeTV(Plugin):
- def find_url(self):
- url_re = re.compile(r"""['"](https://.*?/(?:[Pp]laylist\.m3u8|manifest\.mpd)[^'"]+)['"]""")
+ def _get_streams(self):
+ root = self.session.http.get(self.url, schema=validate.Schema(validate.parse_html()))
+
+ for needle, errormsg in (
+ (
+ "This service is not available in your Country",
+ "The content is not available in your region",
+ ),
+ (
+ "Silahkan login Menggunakan akun MyIndihome dan berlangganan minipack",
+ "The content is not available without a subscription",
+ ),
+ ):
+ if validate.Schema(validate.xml_xpath(f""".//script[contains(text(), '"{needle}"')]""")).validate(root):
+ log.error(errormsg)
+ return
- return self.session.http.get(self.url, schema=validate.Schema(
- validate.parse_html(),
+ url = validate.Schema(
validate.any(
validate.all(
validate.xml_xpath_string("""
.//script[contains(text(), 'laylist.m3u8') or contains(text(), 'manifest.mpd')][1]/text()
"""),
str,
- validate.transform(url_re.search),
- validate.any(None, validate.all(validate.get(1), validate.url())),
+ validate.transform(
+ re.compile(r"""(?P<q>['"])(?P<url>https://.*?/(?:[Pp]laylist\.m3u8|manifest\.mpd).+?)(?P=q)""").search
+ ),
+ validate.any(None, validate.all(validate.get("url"), validate.url())),
),
validate.all(
validate.xml_xpath_string(".//video[@id='video-player']/source/@src"),
validate.any(None, validate.url()),
),
- ),
- ))
-
- def _get_streams(self):
- url = self.find_url()
+ )
+ ).validate(root)
if url and ".m3u8" in url:
return HLSStream.parse_variant_playlist(self.session, url)
|
{"golden_diff": "diff --git a/src/streamlink/plugins/useetv.py b/src/streamlink/plugins/useetv.py\n--- a/src/streamlink/plugins/useetv.py\n+++ b/src/streamlink/plugins/useetv.py\n@@ -4,6 +4,7 @@\n $type live, vod\n \"\"\"\n \n+import logging\n import re\n \n from streamlink.plugin import Plugin, pluginmatcher\n@@ -11,32 +12,46 @@\n from streamlink.stream.dash import DASHStream\n from streamlink.stream.hls import HLSStream\n \n+log = logging.getLogger(__name__)\n+\n \n @pluginmatcher(re.compile(r\"https?://(?:www\\.)?useetv\\.com/\"))\n class UseeTV(Plugin):\n- def find_url(self):\n- url_re = re.compile(r\"\"\"['\"](https://.*?/(?:[Pp]laylist\\.m3u8|manifest\\.mpd)[^'\"]+)['\"]\"\"\")\n+ def _get_streams(self):\n+ root = self.session.http.get(self.url, schema=validate.Schema(validate.parse_html()))\n+\n+ for needle, errormsg in (\n+ (\n+ \"This service is not available in your Country\",\n+ \"The content is not available in your region\",\n+ ),\n+ (\n+ \"Silahkan login Menggunakan akun MyIndihome dan berlangganan minipack\",\n+ \"The content is not available without a subscription\",\n+ ),\n+ ):\n+ if validate.Schema(validate.xml_xpath(f\"\"\".//script[contains(text(), '\"{needle}\"')]\"\"\")).validate(root):\n+ log.error(errormsg)\n+ return\n \n- return self.session.http.get(self.url, schema=validate.Schema(\n- validate.parse_html(),\n+ url = validate.Schema(\n validate.any(\n validate.all(\n validate.xml_xpath_string(\"\"\"\n .//script[contains(text(), 'laylist.m3u8') or contains(text(), 'manifest.mpd')][1]/text()\n \"\"\"),\n str,\n- validate.transform(url_re.search),\n- validate.any(None, validate.all(validate.get(1), validate.url())),\n+ validate.transform(\n+ re.compile(r\"\"\"(?P<q>['\"])(?P<url>https://.*?/(?:[Pp]laylist\\.m3u8|manifest\\.mpd).+?)(?P=q)\"\"\").search\n+ ),\n+ validate.any(None, validate.all(validate.get(\"url\"), validate.url())),\n ),\n validate.all(\n validate.xml_xpath_string(\".//video[@id='video-player']/source/@src\"),\n validate.any(None, validate.url()),\n ),\n- ),\n- ))\n-\n- def _get_streams(self):\n- url = self.find_url()\n+ )\n+ ).validate(root)\n \n if url and \".m3u8\" in url:\n return HLSStream.parse_variant_playlist(self.session, url)\n", "issue": "plugins.useetv: log if no link has been found\n<!--\r\nThanks for opening a pull request!\r\n\r\nBefore you continue, please make sure that you have read and understood the contribution guidelines, otherwise your changes may be rejected:\r\nhttps://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink\r\n\r\nIf possible, run the tests, perform code linting and build the documentation locally on your system first to avoid unnecessary build failures:\r\nhttps://streamlink.github.io/latest/developing.html#validating-changes\r\n\r\nAlso don't forget to add a meaningful description of your changes, so that the reviewing process is as simple as possible for the maintainers.\r\n\r\nThank you very much!\r\n-->\r\n\r\n**Why this PR ?**\r\n\r\nThis PR has been made to verify if no link has been found. Indeed, USeeTV doesn't provide all his channels worldwide. Some channels are blocked for Indonesian people only, and some others need a subscription to work (see beIN Asia as an example). Some channels like SeaToday would work, but channels like this one : \r\n\r\nwill only show a Geo-restriction message above the player, telling the end-user he has no access to the stream. \r\n\r\nThis also reflects inside the player, meaning no link can be scraped.\r\n\n", "before_files": [{"content": "\"\"\"\n$description Live TV channels and video on-demand service from UseeTV, owned by Telkom Indonesia.\n$url useetv.com\n$type live, vod\n\"\"\"\n\nimport re\n\nfrom streamlink.plugin import Plugin, pluginmatcher\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream.dash import DASHStream\nfrom streamlink.stream.hls import HLSStream\n\n\n@pluginmatcher(re.compile(r\"https?://(?:www\\.)?useetv\\.com/\"))\nclass UseeTV(Plugin):\n def find_url(self):\n url_re = re.compile(r\"\"\"['\"](https://.*?/(?:[Pp]laylist\\.m3u8|manifest\\.mpd)[^'\"]+)['\"]\"\"\")\n\n return self.session.http.get(self.url, schema=validate.Schema(\n validate.parse_html(),\n validate.any(\n validate.all(\n validate.xml_xpath_string(\"\"\"\n .//script[contains(text(), 'laylist.m3u8') or contains(text(), 'manifest.mpd')][1]/text()\n \"\"\"),\n str,\n validate.transform(url_re.search),\n validate.any(None, validate.all(validate.get(1), validate.url())),\n ),\n validate.all(\n validate.xml_xpath_string(\".//video[@id='video-player']/source/@src\"),\n validate.any(None, validate.url()),\n ),\n ),\n ))\n\n def _get_streams(self):\n url = self.find_url()\n\n if url and \".m3u8\" in url:\n return HLSStream.parse_variant_playlist(self.session, url)\n elif url and \".mpd\" in url:\n return DASHStream.parse_manifest(self.session, url)\n\n\n__plugin__ = UseeTV\n", "path": "src/streamlink/plugins/useetv.py"}]}
| 1,317 | 619 |
gh_patches_debug_12345
|
rasdani/github-patches
|
git_diff
|
meltano__meltano-7636
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
bug: When meltano.yml is empty, no error message is printed. Rather, it just mentions to reach out to community
### Meltano Version
2.19.0
### Python Version
3.9
### Bug scope
CLI (options, error messages, logging, etc.)
### Operating System
Windows - WSL(Ubuntu)
### Description
when `meltano.yml` is empty, `cli`(`meltano.cli.__init__.py: 105`) raises `EmptyMeltanoFileException` exception whenever we try to run any command such as `meltano add` or `meltano ui`. But, since there's no exception message, it just prints the troubleshooting message and blank lines as follows
```
Need help fixing this problem? Visit http://melta.no/ for troubleshooting steps, or to
join our friendly Slack community.
```
### Code
_No response_
</issue>
<code>
[start of src/meltano/core/error.py]
1 """Base Error classes."""
2
3 from __future__ import annotations
4
5 import typing as t
6 from asyncio.streams import StreamReader
7 from asyncio.subprocess import Process
8 from enum import Enum
9
10 if t.TYPE_CHECKING:
11 from meltano.core.project import Project
12
13
14 class ExitCode(int, Enum): # noqa: D101
15 OK = 0
16 FAIL = 1
17 NO_RETRY = 2
18
19
20 class MeltanoError(Exception):
21 """Base class for all user-facing errors."""
22
23 def __init__(
24 self,
25 reason: str,
26 instruction: str | None = None,
27 *args: t.Any,
28 **kwargs: t.Any,
29 ) -> None:
30 """Initialize a MeltanoError.
31
32 Args:
33 reason: A short explanation of the error.
34 instruction: A short instruction on how to fix the error.
35 args: Additional arguments to pass to the base exception class.
36 kwargs: Keyword arguments to pass to the base exception class.
37 """
38 self.reason = reason
39 self.instruction = instruction
40 super().__init__(reason, instruction, *args, **kwargs)
41
42 def __str__(self) -> str:
43 """Return a string representation of the error.
44
45 Returns:
46 A string representation of the error.
47 """
48 return (
49 f"{self.reason}. {self.instruction}."
50 if self.instruction
51 else f"{self.reason}."
52 )
53
54
55 class Error(Exception):
56 """Base exception for ELT errors."""
57
58 def exit_code(self): # noqa: D102
59 return ExitCode.FAIL
60
61
62 class ExtractError(Error):
63 """Error in the extraction process, like API errors."""
64
65 def exit_code(self): # noqa: D102
66 return ExitCode.NO_RETRY
67
68
69 class AsyncSubprocessError(Exception):
70 """Happens when an async subprocess exits with a resultcode != 0."""
71
72 def __init__(
73 self,
74 message: str,
75 process: Process,
76 stderr: str | None = None,
77 ): # noqa: DAR101
78 """Initialize AsyncSubprocessError."""
79 self.process = process
80 self._stderr: str | StreamReader | None = stderr or process.stderr
81 super().__init__(message)
82
83 @property
84 async def stderr(self) -> str | None:
85 """Return the output of the process to stderr."""
86 if not self._stderr: # noqa: DAR201
87 return None
88 elif not isinstance(self._stderr, str):
89 stream = await self._stderr.read()
90 self._stderr = stream.decode("utf-8")
91
92 return self._stderr
93
94
95 class PluginInstallError(Exception):
96 """Exception for when a plugin fails to install."""
97
98
99 class PluginInstallWarning(Exception):
100 """Exception for when a plugin optional optional step fails to install."""
101
102
103 class EmptyMeltanoFileException(Exception):
104 """Exception for empty meltano.yml file."""
105
106
107 class MeltanoConfigurationError(MeltanoError):
108 """Exception for when Meltano is inproperly configured."""
109
110
111 class ProjectNotFound(Error):
112 """A Project is instantiated outside of a meltano project structure."""
113
114 def __init__(self, project: Project):
115 """Instantiate the error.
116
117 Args:
118 project: the name of the project which cannot be found
119 """
120 super().__init__(
121 f"Cannot find `{project.meltanofile}`. Are you in a meltano project?",
122 )
123
124
125 class ProjectReadonly(Error):
126 """Attempting to update a readonly project."""
127
128 def __init__(self):
129 """Instantiate the error."""
130 super().__init__("This Meltano project is deployed as read-only")
131
[end of src/meltano/core/error.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/meltano/core/error.py b/src/meltano/core/error.py
--- a/src/meltano/core/error.py
+++ b/src/meltano/core/error.py
@@ -100,9 +100,15 @@
"""Exception for when a plugin optional optional step fails to install."""
-class EmptyMeltanoFileException(Exception):
+class EmptyMeltanoFileException(MeltanoError):
"""Exception for empty meltano.yml file."""
+ def __init__(self) -> None:
+ """Instantiate the error."""
+ reason = "Your meltano.yml file is empty"
+ instruction = "Please update your meltano file with a valid configuration"
+ super().__init__(reason, instruction)
+
class MeltanoConfigurationError(MeltanoError):
"""Exception for when Meltano is inproperly configured."""
|
{"golden_diff": "diff --git a/src/meltano/core/error.py b/src/meltano/core/error.py\n--- a/src/meltano/core/error.py\n+++ b/src/meltano/core/error.py\n@@ -100,9 +100,15 @@\n \"\"\"Exception for when a plugin optional optional step fails to install.\"\"\"\n \n \n-class EmptyMeltanoFileException(Exception):\n+class EmptyMeltanoFileException(MeltanoError):\n \"\"\"Exception for empty meltano.yml file.\"\"\"\n \n+ def __init__(self) -> None:\n+ \"\"\"Instantiate the error.\"\"\"\n+ reason = \"Your meltano.yml file is empty\"\n+ instruction = \"Please update your meltano file with a valid configuration\"\n+ super().__init__(reason, instruction)\n+\n \n class MeltanoConfigurationError(MeltanoError):\n \"\"\"Exception for when Meltano is inproperly configured.\"\"\"\n", "issue": "bug: When meltano.yml is empty, no error message is printed. Rather, it just mentions to reach out to community\n### Meltano Version\r\n\r\n2.19.0\r\n\r\n### Python Version\r\n\r\n3.9\r\n\r\n### Bug scope\r\n\r\nCLI (options, error messages, logging, etc.)\r\n\r\n### Operating System\r\n\r\nWindows - WSL(Ubuntu)\r\n\r\n### Description\r\n\r\nwhen `meltano.yml` is empty, `cli`(`meltano.cli.__init__.py: 105`) raises `EmptyMeltanoFileException` exception whenever we try to run any command such as `meltano add` or `meltano ui`. But, since there's no exception message, it just prints the troubleshooting message and blank lines as follows\r\n\r\n```\r\nNeed help fixing this problem? Visit http://melta.no/ for troubleshooting steps, or to\r\njoin our friendly Slack community.\r\n\r\n```\r\n\r\n\r\n### Code\r\n\r\n_No response_\n", "before_files": [{"content": "\"\"\"Base Error classes.\"\"\"\n\nfrom __future__ import annotations\n\nimport typing as t\nfrom asyncio.streams import StreamReader\nfrom asyncio.subprocess import Process\nfrom enum import Enum\n\nif t.TYPE_CHECKING:\n from meltano.core.project import Project\n\n\nclass ExitCode(int, Enum): # noqa: D101\n OK = 0\n FAIL = 1\n NO_RETRY = 2\n\n\nclass MeltanoError(Exception):\n \"\"\"Base class for all user-facing errors.\"\"\"\n\n def __init__(\n self,\n reason: str,\n instruction: str | None = None,\n *args: t.Any,\n **kwargs: t.Any,\n ) -> None:\n \"\"\"Initialize a MeltanoError.\n\n Args:\n reason: A short explanation of the error.\n instruction: A short instruction on how to fix the error.\n args: Additional arguments to pass to the base exception class.\n kwargs: Keyword arguments to pass to the base exception class.\n \"\"\"\n self.reason = reason\n self.instruction = instruction\n super().__init__(reason, instruction, *args, **kwargs)\n\n def __str__(self) -> str:\n \"\"\"Return a string representation of the error.\n\n Returns:\n A string representation of the error.\n \"\"\"\n return (\n f\"{self.reason}. {self.instruction}.\"\n if self.instruction\n else f\"{self.reason}.\"\n )\n\n\nclass Error(Exception):\n \"\"\"Base exception for ELT errors.\"\"\"\n\n def exit_code(self): # noqa: D102\n return ExitCode.FAIL\n\n\nclass ExtractError(Error):\n \"\"\"Error in the extraction process, like API errors.\"\"\"\n\n def exit_code(self): # noqa: D102\n return ExitCode.NO_RETRY\n\n\nclass AsyncSubprocessError(Exception):\n \"\"\"Happens when an async subprocess exits with a resultcode != 0.\"\"\"\n\n def __init__(\n self,\n message: str,\n process: Process,\n stderr: str | None = None,\n ): # noqa: DAR101\n \"\"\"Initialize AsyncSubprocessError.\"\"\"\n self.process = process\n self._stderr: str | StreamReader | None = stderr or process.stderr\n super().__init__(message)\n\n @property\n async def stderr(self) -> str | None:\n \"\"\"Return the output of the process to stderr.\"\"\"\n if not self._stderr: # noqa: DAR201\n return None\n elif not isinstance(self._stderr, str):\n stream = await self._stderr.read()\n self._stderr = stream.decode(\"utf-8\")\n\n return self._stderr\n\n\nclass PluginInstallError(Exception):\n \"\"\"Exception for when a plugin fails to install.\"\"\"\n\n\nclass PluginInstallWarning(Exception):\n \"\"\"Exception for when a plugin optional optional step fails to install.\"\"\"\n\n\nclass EmptyMeltanoFileException(Exception):\n \"\"\"Exception for empty meltano.yml file.\"\"\"\n\n\nclass MeltanoConfigurationError(MeltanoError):\n \"\"\"Exception for when Meltano is inproperly configured.\"\"\"\n\n\nclass ProjectNotFound(Error):\n \"\"\"A Project is instantiated outside of a meltano project structure.\"\"\"\n\n def __init__(self, project: Project):\n \"\"\"Instantiate the error.\n\n Args:\n project: the name of the project which cannot be found\n \"\"\"\n super().__init__(\n f\"Cannot find `{project.meltanofile}`. Are you in a meltano project?\",\n )\n\n\nclass ProjectReadonly(Error):\n \"\"\"Attempting to update a readonly project.\"\"\"\n\n def __init__(self):\n \"\"\"Instantiate the error.\"\"\"\n super().__init__(\"This Meltano project is deployed as read-only\")\n", "path": "src/meltano/core/error.py"}]}
| 1,819 | 188 |
gh_patches_debug_19026
|
rasdani/github-patches
|
git_diff
|
Kinto__kinto-135
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Missing CORS header on /v1/buckets/default/collections/tasks/records
> 09:19:55,733 Blocage d'une requête multi-origines (Cross-Origin Request) : la politique « Same Origin » ne permet pas de consulter la ressource distante située sur http://0.0.0.0:8888/v1/buckets/default/collections/tasks/records?_since=1436512795672. Raison : l'en-tête CORS « Access-Control-Allow-Origin » est manquant.1 <inconnu>
</issue>
<code>
[start of kinto/views/buckets.py]
1 from six import text_type
2 from uuid import UUID
3
4 from pyramid.httpexceptions import HTTPForbidden, HTTPPreconditionFailed
5 from pyramid.security import NO_PERMISSION_REQUIRED
6 from pyramid.view import view_config
7
8 from cliquet import resource
9 from cliquet.utils import hmac_digest, build_request
10
11 from kinto.views import NameGenerator
12
13
14 def create_bucket(request, bucket_id):
15 """Create a bucket if it doesn't exists."""
16 bucket_put = (request.method.lower() == 'put' and
17 request.path.endswith('buckets/default'))
18
19 if not bucket_put:
20 subrequest = build_request(request, {
21 'method': 'PUT',
22 'path': '/buckets/%s' % bucket_id,
23 'body': {"data": {}},
24 'headers': {'If-None-Match': '*'.encode('utf-8')}
25 })
26
27 try:
28 request.invoke_subrequest(subrequest)
29 except HTTPPreconditionFailed:
30 # The bucket already exists
31 pass
32
33
34 def create_collection(request, bucket_id):
35 subpath = request.matchdict['subpath']
36 if subpath.startswith('/collections/'):
37 collection_id = subpath.split('/')[2]
38 collection_put = (request.method.lower() == 'put' and
39 request.path.endswith(collection_id))
40 if not collection_put:
41 subrequest = build_request(request, {
42 'method': 'PUT',
43 'path': '/buckets/%s/collections/%s' % (
44 bucket_id, collection_id),
45 'body': {"data": {}},
46 'headers': {'If-None-Match': '*'.encode('utf-8')}
47 })
48 try:
49 request.invoke_subrequest(subrequest)
50 except HTTPPreconditionFailed:
51 # The collection already exists
52 pass
53
54
55 @view_config(route_name='default_bucket', permission=NO_PERMISSION_REQUIRED)
56 def default_bucket(request):
57 if request.method.lower() == 'options':
58 path = request.path.replace('default', 'unknown')
59 subrequest = build_request(request, {
60 'method': 'OPTIONS',
61 'path': path
62 })
63 return request.invoke_subrequest(subrequest)
64
65 if getattr(request, 'prefixed_userid', None) is None:
66 raise HTTPForbidden # Pass through the forbidden_view_config
67
68 settings = request.registry.settings
69 hmac_secret = settings['cliquet.userid_hmac_secret']
70 # Build the user unguessable bucket_id UUID from its user_id
71 digest = hmac_digest(hmac_secret, request.prefixed_userid)
72 bucket_id = text_type(UUID(digest[:32]))
73 path = request.path.replace('default', bucket_id)
74 querystring = request.url[(request.url.index(request.path) +
75 len(request.path)):]
76
77 # Make sure bucket exists
78 create_bucket(request, bucket_id)
79
80 # Make sure the collection exists
81 create_collection(request, bucket_id)
82
83 subrequest = build_request(request, {
84 'method': request.method,
85 'path': path + querystring,
86 'body': request.body
87 })
88
89 return request.invoke_subrequest(subrequest)
90
91
92 @resource.register(name='bucket',
93 collection_methods=('GET',),
94 collection_path='/buckets',
95 record_path='/buckets/{{id}}')
96 class Bucket(resource.ProtectedResource):
97 permissions = ('read', 'write', 'collection:create', 'group:create')
98
99 def __init__(self, *args, **kwargs):
100 super(Bucket, self).__init__(*args, **kwargs)
101 self.collection.id_generator = NameGenerator()
102
103 def get_parent_id(self, request):
104 # Buckets are not isolated by user, unlike Cliquet resources.
105 return ''
106
107 def delete(self):
108 result = super(Bucket, self).delete()
109
110 # Delete groups.
111 storage = self.collection.storage
112 parent_id = '/buckets/%s' % self.record_id
113 storage.delete_all(collection_id='group', parent_id=parent_id)
114
115 # Delete collections.
116 deleted = storage.delete_all(collection_id='collection',
117 parent_id=parent_id)
118
119 # Delete records.
120 id_field = self.collection.id_field
121 for collection in deleted:
122 parent_id = '/buckets/%s/collections/%s' % (self.record_id,
123 collection[id_field])
124 storage.delete_all(collection_id='record', parent_id=parent_id)
125
126 return result
127
[end of kinto/views/buckets.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kinto/views/buckets.py b/kinto/views/buckets.py
--- a/kinto/views/buckets.py
+++ b/kinto/views/buckets.py
@@ -1,12 +1,13 @@
from six import text_type
from uuid import UUID
-from pyramid.httpexceptions import HTTPForbidden, HTTPPreconditionFailed
+from pyramid.httpexceptions import (HTTPForbidden, HTTPPreconditionFailed,
+ HTTPException)
from pyramid.security import NO_PERMISSION_REQUIRED
from pyramid.view import view_config
from cliquet import resource
-from cliquet.utils import hmac_digest, build_request
+from cliquet.utils import hmac_digest, build_request, reapply_cors
from kinto.views import NameGenerator
@@ -86,7 +87,11 @@
'body': request.body
})
- return request.invoke_subrequest(subrequest)
+ try:
+ response = request.invoke_subrequest(subrequest)
+ except HTTPException as error:
+ response = reapply_cors(subrequest, error)
+ return response
@resource.register(name='bucket',
|
{"golden_diff": "diff --git a/kinto/views/buckets.py b/kinto/views/buckets.py\n--- a/kinto/views/buckets.py\n+++ b/kinto/views/buckets.py\n@@ -1,12 +1,13 @@\n from six import text_type\n from uuid import UUID\n \n-from pyramid.httpexceptions import HTTPForbidden, HTTPPreconditionFailed\n+from pyramid.httpexceptions import (HTTPForbidden, HTTPPreconditionFailed,\n+ HTTPException)\n from pyramid.security import NO_PERMISSION_REQUIRED\n from pyramid.view import view_config\n \n from cliquet import resource\n-from cliquet.utils import hmac_digest, build_request\n+from cliquet.utils import hmac_digest, build_request, reapply_cors\n \n from kinto.views import NameGenerator\n \n@@ -86,7 +87,11 @@\n 'body': request.body\n })\n \n- return request.invoke_subrequest(subrequest)\n+ try:\n+ response = request.invoke_subrequest(subrequest)\n+ except HTTPException as error:\n+ response = reapply_cors(subrequest, error)\n+ return response\n \n \n @resource.register(name='bucket',\n", "issue": "Missing CORS header on /v1/buckets/default/collections/tasks/records\n> 09:19:55,733 Blocage d'une requ\u00eate multi-origines (Cross-Origin Request)\u00a0: la politique \u00ab\u00a0Same Origin\u00a0\u00bb ne permet pas de consulter la ressource distante situ\u00e9e sur http://0.0.0.0:8888/v1/buckets/default/collections/tasks/records?_since=1436512795672. Raison\u00a0: l'en-t\u00eate CORS \u00ab\u00a0Access-Control-Allow-Origin\u00a0\u00bb est manquant.1 <inconnu>\n\n", "before_files": [{"content": "from six import text_type\nfrom uuid import UUID\n\nfrom pyramid.httpexceptions import HTTPForbidden, HTTPPreconditionFailed\nfrom pyramid.security import NO_PERMISSION_REQUIRED\nfrom pyramid.view import view_config\n\nfrom cliquet import resource\nfrom cliquet.utils import hmac_digest, build_request\n\nfrom kinto.views import NameGenerator\n\n\ndef create_bucket(request, bucket_id):\n \"\"\"Create a bucket if it doesn't exists.\"\"\"\n bucket_put = (request.method.lower() == 'put' and\n request.path.endswith('buckets/default'))\n\n if not bucket_put:\n subrequest = build_request(request, {\n 'method': 'PUT',\n 'path': '/buckets/%s' % bucket_id,\n 'body': {\"data\": {}},\n 'headers': {'If-None-Match': '*'.encode('utf-8')}\n })\n\n try:\n request.invoke_subrequest(subrequest)\n except HTTPPreconditionFailed:\n # The bucket already exists\n pass\n\n\ndef create_collection(request, bucket_id):\n subpath = request.matchdict['subpath']\n if subpath.startswith('/collections/'):\n collection_id = subpath.split('/')[2]\n collection_put = (request.method.lower() == 'put' and\n request.path.endswith(collection_id))\n if not collection_put:\n subrequest = build_request(request, {\n 'method': 'PUT',\n 'path': '/buckets/%s/collections/%s' % (\n bucket_id, collection_id),\n 'body': {\"data\": {}},\n 'headers': {'If-None-Match': '*'.encode('utf-8')}\n })\n try:\n request.invoke_subrequest(subrequest)\n except HTTPPreconditionFailed:\n # The collection already exists\n pass\n\n\n@view_config(route_name='default_bucket', permission=NO_PERMISSION_REQUIRED)\ndef default_bucket(request):\n if request.method.lower() == 'options':\n path = request.path.replace('default', 'unknown')\n subrequest = build_request(request, {\n 'method': 'OPTIONS',\n 'path': path\n })\n return request.invoke_subrequest(subrequest)\n\n if getattr(request, 'prefixed_userid', None) is None:\n raise HTTPForbidden # Pass through the forbidden_view_config\n\n settings = request.registry.settings\n hmac_secret = settings['cliquet.userid_hmac_secret']\n # Build the user unguessable bucket_id UUID from its user_id\n digest = hmac_digest(hmac_secret, request.prefixed_userid)\n bucket_id = text_type(UUID(digest[:32]))\n path = request.path.replace('default', bucket_id)\n querystring = request.url[(request.url.index(request.path) +\n len(request.path)):]\n\n # Make sure bucket exists\n create_bucket(request, bucket_id)\n\n # Make sure the collection exists\n create_collection(request, bucket_id)\n\n subrequest = build_request(request, {\n 'method': request.method,\n 'path': path + querystring,\n 'body': request.body\n })\n\n return request.invoke_subrequest(subrequest)\n\n\[email protected](name='bucket',\n collection_methods=('GET',),\n collection_path='/buckets',\n record_path='/buckets/{{id}}')\nclass Bucket(resource.ProtectedResource):\n permissions = ('read', 'write', 'collection:create', 'group:create')\n\n def __init__(self, *args, **kwargs):\n super(Bucket, self).__init__(*args, **kwargs)\n self.collection.id_generator = NameGenerator()\n\n def get_parent_id(self, request):\n # Buckets are not isolated by user, unlike Cliquet resources.\n return ''\n\n def delete(self):\n result = super(Bucket, self).delete()\n\n # Delete groups.\n storage = self.collection.storage\n parent_id = '/buckets/%s' % self.record_id\n storage.delete_all(collection_id='group', parent_id=parent_id)\n\n # Delete collections.\n deleted = storage.delete_all(collection_id='collection',\n parent_id=parent_id)\n\n # Delete records.\n id_field = self.collection.id_field\n for collection in deleted:\n parent_id = '/buckets/%s/collections/%s' % (self.record_id,\n collection[id_field])\n storage.delete_all(collection_id='record', parent_id=parent_id)\n\n return result\n", "path": "kinto/views/buckets.py"}]}
| 1,868 | 232 |
gh_patches_debug_25220
|
rasdani/github-patches
|
git_diff
|
pytorch__examples-189
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[super_resolution]
def _get_orthogonal_init_weights(weights):
fan_out = weights.size(0)
fan_in = weights.size(1) * weights.size(2) * weights.size(3)
u, _, v = svd(normal(0.0, 1.0, (fan_out, fan_in)), full_matrices=False)
if u.shape == (fan_out, fan_in):
return torch.Tensor(u.reshape(weights.size()))
else:
return torch.Tensor(v.reshape(weights.size()))
Why do the above operation?
</issue>
<code>
[start of super_resolution/model.py]
1 import torch
2 import torch.nn as nn
3 from numpy.random import normal
4 from numpy.linalg import svd
5 from math import sqrt
6
7
8 def _get_orthogonal_init_weights(weights):
9 fan_out = weights.size(0)
10 fan_in = weights.size(1) * weights.size(2) * weights.size(3)
11
12 u, _, v = svd(normal(0.0, 1.0, (fan_out, fan_in)), full_matrices=False)
13
14 if u.shape == (fan_out, fan_in):
15 return torch.Tensor(u.reshape(weights.size()))
16 else:
17 return torch.Tensor(v.reshape(weights.size()))
18
19
20 class Net(nn.Module):
21 def __init__(self, upscale_factor):
22 super(Net, self).__init__()
23
24 self.relu = nn.ReLU()
25 self.conv1 = nn.Conv2d(1, 64, (5, 5), (1, 1), (2, 2))
26 self.conv2 = nn.Conv2d(64, 64, (3, 3), (1, 1), (1, 1))
27 self.conv3 = nn.Conv2d(64, 32, (3, 3), (1, 1), (1, 1))
28 self.conv4 = nn.Conv2d(32, upscale_factor ** 2, (3, 3), (1, 1), (1, 1))
29 self.pixel_shuffle = nn.PixelShuffle(upscale_factor)
30
31 self._initialize_weights()
32
33 def forward(self, x):
34 x = self.relu(self.conv1(x))
35 x = self.relu(self.conv2(x))
36 x = self.relu(self.conv3(x))
37 x = self.pixel_shuffle(self.conv4(x))
38 return x
39
40 def _initialize_weights(self):
41 self.conv1.weight.data.copy_(_get_orthogonal_init_weights(self.conv1.weight) * sqrt(2))
42 self.conv2.weight.data.copy_(_get_orthogonal_init_weights(self.conv2.weight) * sqrt(2))
43 self.conv3.weight.data.copy_(_get_orthogonal_init_weights(self.conv3.weight) * sqrt(2))
44 self.conv4.weight.data.copy_(_get_orthogonal_init_weights(self.conv4.weight))
45
[end of super_resolution/model.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/super_resolution/model.py b/super_resolution/model.py
--- a/super_resolution/model.py
+++ b/super_resolution/model.py
@@ -1,22 +1,11 @@
import torch
import torch.nn as nn
+import torch.nn.init as init
from numpy.random import normal
from numpy.linalg import svd
from math import sqrt
-def _get_orthogonal_init_weights(weights):
- fan_out = weights.size(0)
- fan_in = weights.size(1) * weights.size(2) * weights.size(3)
-
- u, _, v = svd(normal(0.0, 1.0, (fan_out, fan_in)), full_matrices=False)
-
- if u.shape == (fan_out, fan_in):
- return torch.Tensor(u.reshape(weights.size()))
- else:
- return torch.Tensor(v.reshape(weights.size()))
-
-
class Net(nn.Module):
def __init__(self, upscale_factor):
super(Net, self).__init__()
@@ -38,7 +27,7 @@
return x
def _initialize_weights(self):
- self.conv1.weight.data.copy_(_get_orthogonal_init_weights(self.conv1.weight) * sqrt(2))
- self.conv2.weight.data.copy_(_get_orthogonal_init_weights(self.conv2.weight) * sqrt(2))
- self.conv3.weight.data.copy_(_get_orthogonal_init_weights(self.conv3.weight) * sqrt(2))
- self.conv4.weight.data.copy_(_get_orthogonal_init_weights(self.conv4.weight))
+ init.orthogonal(self.conv1.weight, init.gain('relu'))
+ init.orthogonal(self.conv2.weight, init.gain('relu'))
+ init.orthogonal(self.conv3.weight, init.gain('relu'))
+ init.orthogonal(self.conv4.weight)
|
{"golden_diff": "diff --git a/super_resolution/model.py b/super_resolution/model.py\n--- a/super_resolution/model.py\n+++ b/super_resolution/model.py\n@@ -1,22 +1,11 @@\n import torch\n import torch.nn as nn\n+import torch.nn.init as init\n from numpy.random import normal\n from numpy.linalg import svd\n from math import sqrt\n \n \n-def _get_orthogonal_init_weights(weights):\n- fan_out = weights.size(0)\n- fan_in = weights.size(1) * weights.size(2) * weights.size(3)\n-\n- u, _, v = svd(normal(0.0, 1.0, (fan_out, fan_in)), full_matrices=False)\n-\n- if u.shape == (fan_out, fan_in):\n- return torch.Tensor(u.reshape(weights.size()))\n- else:\n- return torch.Tensor(v.reshape(weights.size()))\n-\n-\n class Net(nn.Module):\n def __init__(self, upscale_factor):\n super(Net, self).__init__()\n@@ -38,7 +27,7 @@\n return x\n \n def _initialize_weights(self):\n- self.conv1.weight.data.copy_(_get_orthogonal_init_weights(self.conv1.weight) * sqrt(2))\n- self.conv2.weight.data.copy_(_get_orthogonal_init_weights(self.conv2.weight) * sqrt(2))\n- self.conv3.weight.data.copy_(_get_orthogonal_init_weights(self.conv3.weight) * sqrt(2))\n- self.conv4.weight.data.copy_(_get_orthogonal_init_weights(self.conv4.weight))\n+ init.orthogonal(self.conv1.weight, init.gain('relu'))\n+ init.orthogonal(self.conv2.weight, init.gain('relu'))\n+ init.orthogonal(self.conv3.weight, init.gain('relu'))\n+ init.orthogonal(self.conv4.weight)\n", "issue": "[super_resolution]\ndef _get_orthogonal_init_weights(weights):\r\n fan_out = weights.size(0)\r\n fan_in = weights.size(1) * weights.size(2) * weights.size(3)\r\n u, _, v = svd(normal(0.0, 1.0, (fan_out, fan_in)), full_matrices=False)\r\n if u.shape == (fan_out, fan_in):\r\n return torch.Tensor(u.reshape(weights.size()))\r\n else:\r\n return torch.Tensor(v.reshape(weights.size()))\r\n\r\nWhy do the above operation\uff1f\n", "before_files": [{"content": "import torch\nimport torch.nn as nn\nfrom numpy.random import normal\nfrom numpy.linalg import svd\nfrom math import sqrt\n\n\ndef _get_orthogonal_init_weights(weights):\n fan_out = weights.size(0)\n fan_in = weights.size(1) * weights.size(2) * weights.size(3)\n\n u, _, v = svd(normal(0.0, 1.0, (fan_out, fan_in)), full_matrices=False)\n\n if u.shape == (fan_out, fan_in):\n return torch.Tensor(u.reshape(weights.size()))\n else:\n return torch.Tensor(v.reshape(weights.size()))\n\n\nclass Net(nn.Module):\n def __init__(self, upscale_factor):\n super(Net, self).__init__()\n\n self.relu = nn.ReLU()\n self.conv1 = nn.Conv2d(1, 64, (5, 5), (1, 1), (2, 2))\n self.conv2 = nn.Conv2d(64, 64, (3, 3), (1, 1), (1, 1))\n self.conv3 = nn.Conv2d(64, 32, (3, 3), (1, 1), (1, 1))\n self.conv4 = nn.Conv2d(32, upscale_factor ** 2, (3, 3), (1, 1), (1, 1))\n self.pixel_shuffle = nn.PixelShuffle(upscale_factor)\n\n self._initialize_weights()\n\n def forward(self, x):\n x = self.relu(self.conv1(x))\n x = self.relu(self.conv2(x))\n x = self.relu(self.conv3(x))\n x = self.pixel_shuffle(self.conv4(x))\n return x\n\n def _initialize_weights(self):\n self.conv1.weight.data.copy_(_get_orthogonal_init_weights(self.conv1.weight) * sqrt(2))\n self.conv2.weight.data.copy_(_get_orthogonal_init_weights(self.conv2.weight) * sqrt(2))\n self.conv3.weight.data.copy_(_get_orthogonal_init_weights(self.conv3.weight) * sqrt(2))\n self.conv4.weight.data.copy_(_get_orthogonal_init_weights(self.conv4.weight))\n", "path": "super_resolution/model.py"}]}
| 1,215 | 403 |
gh_patches_debug_10562
|
rasdani/github-patches
|
git_diff
|
plotly__plotly.py-2132
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
plotly.express import raises ModuleNotFound in environment without pandas.
Importing plotly.express when pandas is not available raises `ModuleNotFoundError: No module named 'pandas'`, instead of the intended `ImportError: Plotly express requires pandas to be installed.`
This happens on `from ._imshow import imshow`.
Perhaps this import should be moved below the code that will output a more helpful message?
</issue>
<code>
[start of packages/python/plotly/plotly/express/__init__.py]
1 """
2 `plotly.express` is a terse, consistent, high-level wrapper around `plotly.graph_objects`
3 for rapid data exploration and figure generation. Learn more at https://plotly.express/
4 """
5 from __future__ import absolute_import
6 from plotly import optional_imports
7 from ._imshow import imshow
8
9 pd = optional_imports.get_module("pandas")
10 if pd is None:
11 raise ImportError(
12 """\
13 Plotly express requires pandas to be installed."""
14 )
15
16 from ._chart_types import ( # noqa: F401
17 scatter,
18 scatter_3d,
19 scatter_polar,
20 scatter_ternary,
21 scatter_mapbox,
22 scatter_geo,
23 line,
24 line_3d,
25 line_polar,
26 line_ternary,
27 line_mapbox,
28 line_geo,
29 area,
30 bar,
31 bar_polar,
32 violin,
33 box,
34 strip,
35 histogram,
36 scatter_matrix,
37 parallel_coordinates,
38 parallel_categories,
39 choropleth,
40 density_contour,
41 density_heatmap,
42 pie,
43 sunburst,
44 treemap,
45 funnel,
46 funnel_area,
47 choropleth_mapbox,
48 density_mapbox,
49 )
50
51
52 from ._core import ( # noqa: F401
53 set_mapbox_access_token,
54 defaults,
55 get_trendline_results,
56 )
57
58 from . import data, colors # noqa: F401
59
60 __all__ = [
61 "scatter",
62 "scatter_3d",
63 "scatter_polar",
64 "scatter_ternary",
65 "scatter_mapbox",
66 "scatter_geo",
67 "scatter_matrix",
68 "density_contour",
69 "density_heatmap",
70 "density_mapbox",
71 "line",
72 "line_3d",
73 "line_polar",
74 "line_ternary",
75 "line_mapbox",
76 "line_geo",
77 "parallel_coordinates",
78 "parallel_categories",
79 "area",
80 "bar",
81 "bar_polar",
82 "violin",
83 "box",
84 "strip",
85 "histogram",
86 "choropleth",
87 "choropleth_mapbox",
88 "pie",
89 "sunburst",
90 "treemap",
91 "funnel",
92 "funnel_area",
93 "imshow",
94 "data",
95 "colors",
96 "set_mapbox_access_token",
97 "get_trendline_results",
98 ]
99
[end of packages/python/plotly/plotly/express/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/packages/python/plotly/plotly/express/__init__.py b/packages/python/plotly/plotly/express/__init__.py
--- a/packages/python/plotly/plotly/express/__init__.py
+++ b/packages/python/plotly/plotly/express/__init__.py
@@ -4,7 +4,6 @@
"""
from __future__ import absolute_import
from plotly import optional_imports
-from ._imshow import imshow
pd = optional_imports.get_module("pandas")
if pd is None:
@@ -13,6 +12,7 @@
Plotly express requires pandas to be installed."""
)
+from ._imshow import imshow
from ._chart_types import ( # noqa: F401
scatter,
scatter_3d,
|
{"golden_diff": "diff --git a/packages/python/plotly/plotly/express/__init__.py b/packages/python/plotly/plotly/express/__init__.py\n--- a/packages/python/plotly/plotly/express/__init__.py\n+++ b/packages/python/plotly/plotly/express/__init__.py\n@@ -4,7 +4,6 @@\n \"\"\"\n from __future__ import absolute_import\n from plotly import optional_imports\n-from ._imshow import imshow\n \n pd = optional_imports.get_module(\"pandas\")\n if pd is None:\n@@ -13,6 +12,7 @@\n Plotly express requires pandas to be installed.\"\"\"\n )\n \n+from ._imshow import imshow\n from ._chart_types import ( # noqa: F401\n scatter,\n scatter_3d,\n", "issue": "plotly.express import raises ModuleNotFound in environment without pandas.\nImporting plotly.express when pandas is not available raises `ModuleNotFoundError: No module named 'pandas'`, instead of the intended `ImportError: Plotly express requires pandas to be installed.`\r\nThis happens on `from ._imshow import imshow`.\r\nPerhaps this import should be moved below the code that will output a more helpful message?\n", "before_files": [{"content": "\"\"\"\n`plotly.express` is a terse, consistent, high-level wrapper around `plotly.graph_objects`\nfor rapid data exploration and figure generation. Learn more at https://plotly.express/\n\"\"\"\nfrom __future__ import absolute_import\nfrom plotly import optional_imports\nfrom ._imshow import imshow\n\npd = optional_imports.get_module(\"pandas\")\nif pd is None:\n raise ImportError(\n \"\"\"\\\nPlotly express requires pandas to be installed.\"\"\"\n )\n\nfrom ._chart_types import ( # noqa: F401\n scatter,\n scatter_3d,\n scatter_polar,\n scatter_ternary,\n scatter_mapbox,\n scatter_geo,\n line,\n line_3d,\n line_polar,\n line_ternary,\n line_mapbox,\n line_geo,\n area,\n bar,\n bar_polar,\n violin,\n box,\n strip,\n histogram,\n scatter_matrix,\n parallel_coordinates,\n parallel_categories,\n choropleth,\n density_contour,\n density_heatmap,\n pie,\n sunburst,\n treemap,\n funnel,\n funnel_area,\n choropleth_mapbox,\n density_mapbox,\n)\n\n\nfrom ._core import ( # noqa: F401\n set_mapbox_access_token,\n defaults,\n get_trendline_results,\n)\n\nfrom . import data, colors # noqa: F401\n\n__all__ = [\n \"scatter\",\n \"scatter_3d\",\n \"scatter_polar\",\n \"scatter_ternary\",\n \"scatter_mapbox\",\n \"scatter_geo\",\n \"scatter_matrix\",\n \"density_contour\",\n \"density_heatmap\",\n \"density_mapbox\",\n \"line\",\n \"line_3d\",\n \"line_polar\",\n \"line_ternary\",\n \"line_mapbox\",\n \"line_geo\",\n \"parallel_coordinates\",\n \"parallel_categories\",\n \"area\",\n \"bar\",\n \"bar_polar\",\n \"violin\",\n \"box\",\n \"strip\",\n \"histogram\",\n \"choropleth\",\n \"choropleth_mapbox\",\n \"pie\",\n \"sunburst\",\n \"treemap\",\n \"funnel\",\n \"funnel_area\",\n \"imshow\",\n \"data\",\n \"colors\",\n \"set_mapbox_access_token\",\n \"get_trendline_results\",\n]\n", "path": "packages/python/plotly/plotly/express/__init__.py"}]}
| 1,339 | 173 |
gh_patches_debug_9121
|
rasdani/github-patches
|
git_diff
|
OCHA-DAP__hdx-ckan-1053
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Org Admin: Dataset management page is broken
Log in as a sysadmin user.
Go to:
http://data.hdx.rwlabs.org/organization/bulk_process/ocha-fiss-geneva
</issue>
<code>
[start of ckanext-hdx_orgs/ckanext/hdx_orgs/plugin.py]
1 import logging
2 import ckan.plugins as plugins
3 import ckan.plugins.toolkit as tk
4 import ckan.lib.plugins as lib_plugins
5
6 class HDXOrgFormPlugin(plugins.SingletonPlugin, lib_plugins.DefaultOrganizationForm):
7 plugins.implements(plugins.IConfigurer, inherit=False)
8 plugins.implements(plugins.IRoutes, inherit=True)
9 plugins.implements(plugins.IGroupForm, inherit=False)
10 plugins.implements(plugins.ITemplateHelpers, inherit=False)
11
12 num_times_new_template_called = 0
13 num_times_read_template_called = 0
14 num_times_edit_template_called = 0
15 num_times_search_template_called = 0
16 num_times_history_template_called = 0
17 num_times_package_form_called = 0
18 num_times_check_data_dict_called = 0
19 num_times_setup_template_variables_called = 0
20
21 def update_config(self, config):
22 tk.add_template_directory(config, 'templates')
23
24 def get_helpers(self):
25 return {}
26
27 def is_fallback(self):
28 return False
29
30 def group_types(self):
31 return ['organization']
32
33 def _modify_group_schema(self, schema):
34 schema.update({
35 'description':[tk.get_validator('not_empty')],
36 'org_url':[tk.get_validator('not_missing'), tk.get_converter('convert_to_extras')],
37 })
38 return schema
39
40 def form_to_db_schema(self):
41 schema = super(HDXOrgFormPlugin, self).form_to_db_schema()
42 schema = self._modify_group_schema(schema)
43 return schema
44
45 # def check_data_dict(self, data_dict):
46 # return super(HDXOrgFormPlugin, self).check_data_dict(self, data_dict)
47
48 def db_to_form_schema(self):
49 # There's a bug in dictionary validation when form isn't present
50 if tk.request.urlvars['action'] == 'index' or tk.request.urlvars['action'] == 'edit' or tk.request.urlvars['action'] == 'new':
51 schema = super(HDXOrgFormPlugin, self).form_to_db_schema()
52 schema.update({'description':[tk.get_validator('not_empty')] })
53 schema.update({'org_url':[tk.get_validator('not_missing'), tk.get_converter('convert_to_extras')]})
54 return schema
55 else:
56 return None
57
58 def before_map(self, map):
59 map.connect('user_dashboard', '/dashboard', controller='ckanext.hdx_orgs.dashboard:DashboardController', action='dashboard',
60 ckan_icon='list')
61 return map
62
[end of ckanext-hdx_orgs/ckanext/hdx_orgs/plugin.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ckanext-hdx_orgs/ckanext/hdx_orgs/plugin.py b/ckanext-hdx_orgs/ckanext/hdx_orgs/plugin.py
--- a/ckanext-hdx_orgs/ckanext/hdx_orgs/plugin.py
+++ b/ckanext-hdx_orgs/ckanext/hdx_orgs/plugin.py
@@ -58,4 +58,6 @@
def before_map(self, map):
map.connect('user_dashboard', '/dashboard', controller='ckanext.hdx_orgs.dashboard:DashboardController', action='dashboard',
ckan_icon='list')
+ map.connect('organization_bulk_process', '/organization/bulk_process/{org_id}', controller='organization', action='index')
+ map.connect('organization_bulk_process_no_id', '/organization/bulk_process', controller='organization', action='index')
return map
|
{"golden_diff": "diff --git a/ckanext-hdx_orgs/ckanext/hdx_orgs/plugin.py b/ckanext-hdx_orgs/ckanext/hdx_orgs/plugin.py\n--- a/ckanext-hdx_orgs/ckanext/hdx_orgs/plugin.py\n+++ b/ckanext-hdx_orgs/ckanext/hdx_orgs/plugin.py\n@@ -58,4 +58,6 @@\n def before_map(self, map):\n map.connect('user_dashboard', '/dashboard', controller='ckanext.hdx_orgs.dashboard:DashboardController', action='dashboard',\n ckan_icon='list')\n+ map.connect('organization_bulk_process', '/organization/bulk_process/{org_id}', controller='organization', action='index')\n+ map.connect('organization_bulk_process_no_id', '/organization/bulk_process', controller='organization', action='index')\n return map\n", "issue": "Org Admin: Dataset management page is broken\nLog in as a sysadmin user.\nGo to:\nhttp://data.hdx.rwlabs.org/organization/bulk_process/ocha-fiss-geneva\n\n", "before_files": [{"content": "import logging\nimport ckan.plugins as plugins\nimport ckan.plugins.toolkit as tk\nimport ckan.lib.plugins as lib_plugins\n\nclass HDXOrgFormPlugin(plugins.SingletonPlugin, lib_plugins.DefaultOrganizationForm):\n plugins.implements(plugins.IConfigurer, inherit=False)\n plugins.implements(plugins.IRoutes, inherit=True)\n plugins.implements(plugins.IGroupForm, inherit=False)\n plugins.implements(plugins.ITemplateHelpers, inherit=False)\n\n num_times_new_template_called = 0\n num_times_read_template_called = 0\n num_times_edit_template_called = 0\n num_times_search_template_called = 0\n num_times_history_template_called = 0\n num_times_package_form_called = 0\n num_times_check_data_dict_called = 0\n num_times_setup_template_variables_called = 0\n\n def update_config(self, config):\n tk.add_template_directory(config, 'templates')\n\n def get_helpers(self):\n return {}\n\n def is_fallback(self):\n return False\n\n def group_types(self):\n return ['organization']\n\n def _modify_group_schema(self, schema):\n schema.update({\n 'description':[tk.get_validator('not_empty')],\n 'org_url':[tk.get_validator('not_missing'), tk.get_converter('convert_to_extras')],\n })\n return schema\n\n def form_to_db_schema(self):\n schema = super(HDXOrgFormPlugin, self).form_to_db_schema()\n schema = self._modify_group_schema(schema)\n return schema\n \n# def check_data_dict(self, data_dict):\n# return super(HDXOrgFormPlugin, self).check_data_dict(self, data_dict)\n \n def db_to_form_schema(self):\n # There's a bug in dictionary validation when form isn't present\n if tk.request.urlvars['action'] == 'index' or tk.request.urlvars['action'] == 'edit' or tk.request.urlvars['action'] == 'new':\n schema = super(HDXOrgFormPlugin, self).form_to_db_schema()\n schema.update({'description':[tk.get_validator('not_empty')] })\n schema.update({'org_url':[tk.get_validator('not_missing'), tk.get_converter('convert_to_extras')]})\n return schema\n else:\n return None\n\n def before_map(self, map):\n map.connect('user_dashboard', '/dashboard', controller='ckanext.hdx_orgs.dashboard:DashboardController', action='dashboard',\n ckan_icon='list')\n return map\n", "path": "ckanext-hdx_orgs/ckanext/hdx_orgs/plugin.py"}]}
| 1,251 | 195 |
gh_patches_debug_30606
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-5444
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
plugins.lrt: stream is reported Forbidden (though plays if opened manually)
### Checklist
- [X] This is a plugin issue and not a different kind of issue
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)
- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)
### Streamlink version
Latest stable release
### Description
When trying to open https://www.lrt.lt/mediateka/tiesiogiai/lrt-televizija or https://www.lrt.lt/mediateka/tiesiogiai/lrt-plius, an error is reported (see the log below).
However, if I try to manually pass the m3u8 URL mentioned in the error to `mpv`, like this (the URL taken from the log below, note the absence of the `%0A` at the end of it):
mpv https://af5dcb595ac445ab94d7da3af2ebb360.dlvr1.net/lrt_hd/master.m3u8?RxKc3mPWTMxjM1SuDkHZeW1Fw3jEx0oqyryrSQODiHo-Bs31UZVEBEPkLtrdbPKVKrlorJgTLUnSwqks_5Y1QrSQRYfbtlWddOuLrpnY9-kuyM_3QE_yBbqwzhre
...then, after a few ffmpeg errors and warnings, it does open.
The error started to appear a few days ago, worked perfectly before that (so, probably, they changed something at their side).
Thanks.
### Debug log
```text
[cli][debug] OS: Linux-5.15.0-76-generic-x86_64-with-glibc2.35
[cli][debug] Python: 3.11.3
[cli][debug] Streamlink: 5.5.1
[cli][debug] Dependencies:
[cli][debug] certifi: 2023.5.7
[cli][debug] isodate: 0.6.1
[cli][debug] lxml: 4.9.2
[cli][debug] pycountry: 22.3.5
[cli][debug] pycryptodome: 3.18.0
[cli][debug] PySocks: 1.7.1
[cli][debug] requests: 2.31.0
[cli][debug] urllib3: 2.0.2
[cli][debug] websocket-client: 1.5.2
[cli][debug] Arguments:
[cli][debug] url=https://www.lrt.lt/mediateka/tiesiogiai/lrt-televizija
[cli][debug] --loglevel=debug
[cli][info] Found matching plugin lrt for URL https://www.lrt.lt/mediateka/tiesiogiai/lrt-televizija
[utils.l10n][debug] Language code: en_US
error: Unable to open URL: https://af5dcb595ac445ab94d7da3af2ebb360.dlvr1.net/lrt_hd/master.m3u8?RxKc3mPWTMxjM1SuDkHZeW1Fw3jEx0oqyryrSQODiHo-Bs31UZVEBEPkLtrdbPKVKrlorJgTLUnSwqks_5Y1QrSQRYfbtlWddOuLrpnY9-kuyM_3QE_yBbqwzhre
(403 Client Error: Forbidden for url: https://af5dcb595ac445ab94d7da3af2ebb360.dlvr1.net/lrt_hd/master.m3u8?RxKc3mPWTMxjM1SuDkHZeW1Fw3jEx0oqyryrSQODiHo-Bs31UZVEBEPkLtrdbPKVKrlorJgTLUnSwqks_5Y1QrSQRYfbtlWddOuLrpnY9-kuyM_3QE_yBbqwzhre%0A)
```
</issue>
<code>
[start of src/streamlink/plugins/lrt.py]
1 """
2 $description Live TV channels from LRT, a Lithuanian public, state-owned broadcaster.
3 $url lrt.lt
4 $type live
5 """
6
7 import logging
8 import re
9
10 from streamlink.plugin import Plugin, pluginmatcher
11 from streamlink.stream.hls import HLSStream
12
13
14 log = logging.getLogger(__name__)
15
16
17 @pluginmatcher(re.compile(
18 r"https?://(?:www\.)?lrt\.lt/mediateka/tiesiogiai/",
19 ))
20 class LRT(Plugin):
21 _video_id_re = re.compile(r"""var\svideo_id\s*=\s*["'](?P<video_id>\w+)["']""")
22 API_URL = "https://www.lrt.lt/servisai/stream_url/live/get_live_url.php?channel={0}"
23
24 def _get_streams(self):
25 page = self.session.http.get(self.url)
26 m = self._video_id_re.search(page.text)
27 if m:
28 video_id = m.group("video_id")
29 data = self.session.http.get(self.API_URL.format(video_id)).json()
30 hls_url = data["response"]["data"]["content"]
31
32 yield from HLSStream.parse_variant_playlist(self.session, hls_url).items()
33 else:
34 log.debug("No match for video_id regex")
35
36
37 __plugin__ = LRT
38
[end of src/streamlink/plugins/lrt.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/streamlink/plugins/lrt.py b/src/streamlink/plugins/lrt.py
--- a/src/streamlink/plugins/lrt.py
+++ b/src/streamlink/plugins/lrt.py
@@ -4,34 +4,42 @@
$type live
"""
-import logging
import re
from streamlink.plugin import Plugin, pluginmatcher
+from streamlink.plugin.api import validate
from streamlink.stream.hls import HLSStream
-log = logging.getLogger(__name__)
-
-
@pluginmatcher(re.compile(
r"https?://(?:www\.)?lrt\.lt/mediateka/tiesiogiai/",
))
class LRT(Plugin):
- _video_id_re = re.compile(r"""var\svideo_id\s*=\s*["'](?P<video_id>\w+)["']""")
- API_URL = "https://www.lrt.lt/servisai/stream_url/live/get_live_url.php?channel={0}"
-
def _get_streams(self):
- page = self.session.http.get(self.url)
- m = self._video_id_re.search(page.text)
- if m:
- video_id = m.group("video_id")
- data = self.session.http.get(self.API_URL.format(video_id)).json()
- hls_url = data["response"]["data"]["content"]
-
- yield from HLSStream.parse_variant_playlist(self.session, hls_url).items()
- else:
- log.debug("No match for video_id regex")
+ token_url = self.session.http.get(self.url, schema=validate.Schema(
+ re.compile(r"""var\s+tokenURL\s*=\s*(?P<q>["'])(?P<url>https://\S+)(?P=q)"""),
+ validate.none_or_all(validate.get("url")),
+ ))
+ if not token_url:
+ return
+
+ hls_url = self.session.http.get(token_url, schema=validate.Schema(
+ validate.parse_json(),
+ {
+ "response": {
+ "data": {
+ "content": validate.all(
+ str,
+ validate.transform(lambda url: url.strip()),
+ validate.url(path=validate.endswith(".m3u8")),
+ ),
+ },
+ },
+ },
+ validate.get(("response", "data", "content")),
+ ))
+
+ return HLSStream.parse_variant_playlist(self.session, hls_url)
__plugin__ = LRT
|
{"golden_diff": "diff --git a/src/streamlink/plugins/lrt.py b/src/streamlink/plugins/lrt.py\n--- a/src/streamlink/plugins/lrt.py\n+++ b/src/streamlink/plugins/lrt.py\n@@ -4,34 +4,42 @@\n $type live\n \"\"\"\n \n-import logging\n import re\n \n from streamlink.plugin import Plugin, pluginmatcher\n+from streamlink.plugin.api import validate\n from streamlink.stream.hls import HLSStream\n \n \n-log = logging.getLogger(__name__)\n-\n-\n @pluginmatcher(re.compile(\n r\"https?://(?:www\\.)?lrt\\.lt/mediateka/tiesiogiai/\",\n ))\n class LRT(Plugin):\n- _video_id_re = re.compile(r\"\"\"var\\svideo_id\\s*=\\s*[\"'](?P<video_id>\\w+)[\"']\"\"\")\n- API_URL = \"https://www.lrt.lt/servisai/stream_url/live/get_live_url.php?channel={0}\"\n-\n def _get_streams(self):\n- page = self.session.http.get(self.url)\n- m = self._video_id_re.search(page.text)\n- if m:\n- video_id = m.group(\"video_id\")\n- data = self.session.http.get(self.API_URL.format(video_id)).json()\n- hls_url = data[\"response\"][\"data\"][\"content\"]\n-\n- yield from HLSStream.parse_variant_playlist(self.session, hls_url).items()\n- else:\n- log.debug(\"No match for video_id regex\")\n+ token_url = self.session.http.get(self.url, schema=validate.Schema(\n+ re.compile(r\"\"\"var\\s+tokenURL\\s*=\\s*(?P<q>[\"'])(?P<url>https://\\S+)(?P=q)\"\"\"),\n+ validate.none_or_all(validate.get(\"url\")),\n+ ))\n+ if not token_url:\n+ return\n+\n+ hls_url = self.session.http.get(token_url, schema=validate.Schema(\n+ validate.parse_json(),\n+ {\n+ \"response\": {\n+ \"data\": {\n+ \"content\": validate.all(\n+ str,\n+ validate.transform(lambda url: url.strip()),\n+ validate.url(path=validate.endswith(\".m3u8\")),\n+ ),\n+ },\n+ },\n+ },\n+ validate.get((\"response\", \"data\", \"content\")),\n+ ))\n+\n+ return HLSStream.parse_variant_playlist(self.session, hls_url)\n \n \n __plugin__ = LRT\n", "issue": "plugins.lrt: stream is reported Forbidden (though plays if opened manually)\n### Checklist\n\n- [X] This is a plugin issue and not a different kind of issue\n- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)\n- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)\n- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)\n\n### Streamlink version\n\nLatest stable release\n\n### Description\n\nWhen trying to open https://www.lrt.lt/mediateka/tiesiogiai/lrt-televizija or https://www.lrt.lt/mediateka/tiesiogiai/lrt-plius, an error is reported (see the log below).\r\n\r\nHowever, if I try to manually pass the m3u8 URL mentioned in the error to `mpv`, like this (the URL taken from the log below, note the absence of the `%0A` at the end of it):\r\n\r\n mpv https://af5dcb595ac445ab94d7da3af2ebb360.dlvr1.net/lrt_hd/master.m3u8?RxKc3mPWTMxjM1SuDkHZeW1Fw3jEx0oqyryrSQODiHo-Bs31UZVEBEPkLtrdbPKVKrlorJgTLUnSwqks_5Y1QrSQRYfbtlWddOuLrpnY9-kuyM_3QE_yBbqwzhre\r\n\r\n...then, after a few ffmpeg errors and warnings, it does open.\r\n\r\nThe error started to appear a few days ago, worked perfectly before that (so, probably, they changed something at their side).\r\n\r\nThanks.\n\n### Debug log\n\n```text\n[cli][debug] OS: Linux-5.15.0-76-generic-x86_64-with-glibc2.35\r\n[cli][debug] Python: 3.11.3\r\n[cli][debug] Streamlink: 5.5.1\r\n[cli][debug] Dependencies:\r\n[cli][debug] certifi: 2023.5.7\r\n[cli][debug] isodate: 0.6.1\r\n[cli][debug] lxml: 4.9.2\r\n[cli][debug] pycountry: 22.3.5\r\n[cli][debug] pycryptodome: 3.18.0\r\n[cli][debug] PySocks: 1.7.1\r\n[cli][debug] requests: 2.31.0\r\n[cli][debug] urllib3: 2.0.2\r\n[cli][debug] websocket-client: 1.5.2\r\n[cli][debug] Arguments:\r\n[cli][debug] url=https://www.lrt.lt/mediateka/tiesiogiai/lrt-televizija\r\n[cli][debug] --loglevel=debug\r\n[cli][info] Found matching plugin lrt for URL https://www.lrt.lt/mediateka/tiesiogiai/lrt-televizija\r\n[utils.l10n][debug] Language code: en_US\r\nerror: Unable to open URL: https://af5dcb595ac445ab94d7da3af2ebb360.dlvr1.net/lrt_hd/master.m3u8?RxKc3mPWTMxjM1SuDkHZeW1Fw3jEx0oqyryrSQODiHo-Bs31UZVEBEPkLtrdbPKVKrlorJgTLUnSwqks_5Y1QrSQRYfbtlWddOuLrpnY9-kuyM_3QE_yBbqwzhre\r\n (403 Client Error: Forbidden for url: https://af5dcb595ac445ab94d7da3af2ebb360.dlvr1.net/lrt_hd/master.m3u8?RxKc3mPWTMxjM1SuDkHZeW1Fw3jEx0oqyryrSQODiHo-Bs31UZVEBEPkLtrdbPKVKrlorJgTLUnSwqks_5Y1QrSQRYfbtlWddOuLrpnY9-kuyM_3QE_yBbqwzhre%0A)\n```\n\n", "before_files": [{"content": "\"\"\"\n$description Live TV channels from LRT, a Lithuanian public, state-owned broadcaster.\n$url lrt.lt\n$type live\n\"\"\"\n\nimport logging\nimport re\n\nfrom streamlink.plugin import Plugin, pluginmatcher\nfrom streamlink.stream.hls import HLSStream\n\n\nlog = logging.getLogger(__name__)\n\n\n@pluginmatcher(re.compile(\n r\"https?://(?:www\\.)?lrt\\.lt/mediateka/tiesiogiai/\",\n))\nclass LRT(Plugin):\n _video_id_re = re.compile(r\"\"\"var\\svideo_id\\s*=\\s*[\"'](?P<video_id>\\w+)[\"']\"\"\")\n API_URL = \"https://www.lrt.lt/servisai/stream_url/live/get_live_url.php?channel={0}\"\n\n def _get_streams(self):\n page = self.session.http.get(self.url)\n m = self._video_id_re.search(page.text)\n if m:\n video_id = m.group(\"video_id\")\n data = self.session.http.get(self.API_URL.format(video_id)).json()\n hls_url = data[\"response\"][\"data\"][\"content\"]\n\n yield from HLSStream.parse_variant_playlist(self.session, hls_url).items()\n else:\n log.debug(\"No match for video_id regex\")\n\n\n__plugin__ = LRT\n", "path": "src/streamlink/plugins/lrt.py"}]}
| 1,941 | 526 |
gh_patches_debug_39191
|
rasdani/github-patches
|
git_diff
|
wandb__wandb-516
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
use six for configparser for py2 compat
</issue>
<code>
[start of wandb/settings.py]
1 import os
2 import configparser
3
4 import wandb.util as util
5 from wandb import core, env, wandb_dir
6
7
8 class Settings(object):
9 """Global W&B settings stored under $WANDB_CONFIG_DIR/settings.
10 """
11
12 DEFAULT_SECTION = "default"
13
14 def __init__(self, load_settings=True):
15 config_dir = os.environ.get(env.CONFIG_DIR, os.path.join(os.path.expanduser("~"), ".config", "wandb"))
16
17 # Ensure the config directory and settings file both exist.
18 util.mkdir_exists_ok(config_dir)
19 util.mkdir_exists_ok(wandb_dir())
20
21 self._global_settings_path = os.path.join(config_dir, 'settings')
22 self._global_settings = Settings._settings_wth_defaults({})
23
24 self._local_settings_path = os.path.join(wandb_dir(), 'settings')
25 self._local_settings = Settings._settings_wth_defaults({})
26
27 if load_settings:
28 self._global_settings.read([self._global_settings_path])
29 self._local_settings.read([self._local_settings_path])
30
31 def get(self, section, key, fallback=configparser._UNSET):
32 # Try the local settings first. If we can't find the key, then try the global settings.
33 # If a fallback is provided, return it if we can't find the key in either the local or global
34 # settings.
35 try:
36 return self._local_settings.get(section, key)
37 except configparser.NoOptionError:
38 return self._global_settings.get(section, key, fallback=fallback)
39
40 def set(self, section, key, value, globally=False):
41 def write_setting(settings, settings_path):
42 if not settings.has_section(section):
43 settings.add_section(section)
44 settings.set(section, key, str(value))
45 with open(settings_path, "w+") as f:
46 settings.write(f)
47
48 if globally:
49 write_setting(self._global_settings, self._global_settings_path)
50 else:
51 write_setting(self._local_settings, self._local_settings_path)
52
53 def clear(self, section, key, globally=False):
54 def clear_setting(settings, settings_path):
55 settings.remove_option(section, key)
56 with open(settings_path, "w+") as f:
57 settings.write(f)
58
59 if globally:
60 clear_setting(self._global_settings, self._global_settings_path)
61 else:
62 clear_setting(self._local_settings, self._local_settings_path)
63
64 def items(self, section=None):
65 section = section if section is not None else Settings.DEFAULT_SECTION
66
67 result = {'section': section}
68
69 try:
70 if section in self._global_settings.sections():
71 for option in self._global_settings.options(section):
72 result[option] = self._global_settings.get(section, option)
73 if section in self._local_settings.sections():
74 for option in self._local_settings.options(section):
75 result[option] = self._local_settings.get(section, option)
76 except configparser.InterpolationSyntaxError:
77 core.termwarn("Unable to parse settings file")
78
79 return result
80
81 @staticmethod
82 def _settings_wth_defaults(default_settings):
83 config = configparser.ConfigParser()
84 config.add_section(Settings.DEFAULT_SECTION)
85 for key, value in default_settings.items():
86 config.set(Settings.DEFAULT_SECTION, key, str(value))
87 return config
88
[end of wandb/settings.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/wandb/settings.py b/wandb/settings.py
--- a/wandb/settings.py
+++ b/wandb/settings.py
@@ -1,5 +1,6 @@
import os
-import configparser
+
+from six.moves import configparser
import wandb.util as util
from wandb import core, env, wandb_dir
@@ -9,7 +10,9 @@
"""Global W&B settings stored under $WANDB_CONFIG_DIR/settings.
"""
- DEFAULT_SECTION = "default"
+ DEFAULT_SECTION = "client"
+
+ _UNSET = object()
def __init__(self, load_settings=True):
config_dir = os.environ.get(env.CONFIG_DIR, os.path.join(os.path.expanduser("~"), ".config", "wandb"))
@@ -19,23 +22,29 @@
util.mkdir_exists_ok(wandb_dir())
self._global_settings_path = os.path.join(config_dir, 'settings')
- self._global_settings = Settings._settings_wth_defaults({})
+ self._global_settings = Settings._settings()
self._local_settings_path = os.path.join(wandb_dir(), 'settings')
- self._local_settings = Settings._settings_wth_defaults({})
+ self._local_settings = Settings._settings()
if load_settings:
self._global_settings.read([self._global_settings_path])
self._local_settings.read([self._local_settings_path])
- def get(self, section, key, fallback=configparser._UNSET):
+ def get(self, section, key, fallback=_UNSET):
# Try the local settings first. If we can't find the key, then try the global settings.
# If a fallback is provided, return it if we can't find the key in either the local or global
# settings.
try:
return self._local_settings.get(section, key)
except configparser.NoOptionError:
- return self._global_settings.get(section, key, fallback=fallback)
+ try:
+ return self._global_settings.get(section, key)
+ except configparser.NoOptionError:
+ if fallback is not Settings._UNSET:
+ return fallback
+ else:
+ raise
def set(self, section, key, value, globally=False):
def write_setting(settings, settings_path):
@@ -79,7 +88,7 @@
return result
@staticmethod
- def _settings_wth_defaults(default_settings):
+ def _settings(default_settings={}):
config = configparser.ConfigParser()
config.add_section(Settings.DEFAULT_SECTION)
for key, value in default_settings.items():
|
{"golden_diff": "diff --git a/wandb/settings.py b/wandb/settings.py\n--- a/wandb/settings.py\n+++ b/wandb/settings.py\n@@ -1,5 +1,6 @@\n import os\n-import configparser\n+\n+from six.moves import configparser\n \n import wandb.util as util\n from wandb import core, env, wandb_dir\n@@ -9,7 +10,9 @@\n \"\"\"Global W&B settings stored under $WANDB_CONFIG_DIR/settings.\n \"\"\"\n \n- DEFAULT_SECTION = \"default\"\n+ DEFAULT_SECTION = \"client\"\n+\n+ _UNSET = object()\n \n def __init__(self, load_settings=True):\n config_dir = os.environ.get(env.CONFIG_DIR, os.path.join(os.path.expanduser(\"~\"), \".config\", \"wandb\"))\n@@ -19,23 +22,29 @@\n util.mkdir_exists_ok(wandb_dir())\n \n self._global_settings_path = os.path.join(config_dir, 'settings')\n- self._global_settings = Settings._settings_wth_defaults({})\n+ self._global_settings = Settings._settings()\n \n self._local_settings_path = os.path.join(wandb_dir(), 'settings')\n- self._local_settings = Settings._settings_wth_defaults({})\n+ self._local_settings = Settings._settings()\n \n if load_settings:\n self._global_settings.read([self._global_settings_path])\n self._local_settings.read([self._local_settings_path])\n \n- def get(self, section, key, fallback=configparser._UNSET):\n+ def get(self, section, key, fallback=_UNSET):\n # Try the local settings first. If we can't find the key, then try the global settings.\n # If a fallback is provided, return it if we can't find the key in either the local or global\n # settings.\n try:\n return self._local_settings.get(section, key)\n except configparser.NoOptionError:\n- return self._global_settings.get(section, key, fallback=fallback)\n+ try:\n+ return self._global_settings.get(section, key)\n+ except configparser.NoOptionError:\n+ if fallback is not Settings._UNSET:\n+ return fallback\n+ else:\n+ raise\n \n def set(self, section, key, value, globally=False):\n def write_setting(settings, settings_path):\n@@ -79,7 +88,7 @@\n return result\n \n @staticmethod\n- def _settings_wth_defaults(default_settings):\n+ def _settings(default_settings={}):\n config = configparser.ConfigParser()\n config.add_section(Settings.DEFAULT_SECTION)\n for key, value in default_settings.items():\n", "issue": "use six for configparser for py2 compat\n\n", "before_files": [{"content": "import os\nimport configparser\n\nimport wandb.util as util\nfrom wandb import core, env, wandb_dir\n\n\nclass Settings(object):\n \"\"\"Global W&B settings stored under $WANDB_CONFIG_DIR/settings.\n \"\"\"\n\n DEFAULT_SECTION = \"default\"\n\n def __init__(self, load_settings=True):\n config_dir = os.environ.get(env.CONFIG_DIR, os.path.join(os.path.expanduser(\"~\"), \".config\", \"wandb\"))\n\n # Ensure the config directory and settings file both exist.\n util.mkdir_exists_ok(config_dir)\n util.mkdir_exists_ok(wandb_dir())\n\n self._global_settings_path = os.path.join(config_dir, 'settings')\n self._global_settings = Settings._settings_wth_defaults({})\n\n self._local_settings_path = os.path.join(wandb_dir(), 'settings')\n self._local_settings = Settings._settings_wth_defaults({})\n\n if load_settings:\n self._global_settings.read([self._global_settings_path])\n self._local_settings.read([self._local_settings_path])\n\n def get(self, section, key, fallback=configparser._UNSET):\n # Try the local settings first. If we can't find the key, then try the global settings.\n # If a fallback is provided, return it if we can't find the key in either the local or global\n # settings.\n try:\n return self._local_settings.get(section, key)\n except configparser.NoOptionError:\n return self._global_settings.get(section, key, fallback=fallback)\n\n def set(self, section, key, value, globally=False):\n def write_setting(settings, settings_path):\n if not settings.has_section(section):\n settings.add_section(section)\n settings.set(section, key, str(value))\n with open(settings_path, \"w+\") as f:\n settings.write(f)\n\n if globally:\n write_setting(self._global_settings, self._global_settings_path)\n else:\n write_setting(self._local_settings, self._local_settings_path)\n\n def clear(self, section, key, globally=False):\n def clear_setting(settings, settings_path):\n settings.remove_option(section, key)\n with open(settings_path, \"w+\") as f:\n settings.write(f)\n\n if globally:\n clear_setting(self._global_settings, self._global_settings_path)\n else:\n clear_setting(self._local_settings, self._local_settings_path)\n\n def items(self, section=None):\n section = section if section is not None else Settings.DEFAULT_SECTION\n\n result = {'section': section}\n\n try:\n if section in self._global_settings.sections():\n for option in self._global_settings.options(section):\n result[option] = self._global_settings.get(section, option)\n if section in self._local_settings.sections():\n for option in self._local_settings.options(section):\n result[option] = self._local_settings.get(section, option)\n except configparser.InterpolationSyntaxError:\n core.termwarn(\"Unable to parse settings file\")\n\n return result\n\n @staticmethod\n def _settings_wth_defaults(default_settings):\n config = configparser.ConfigParser()\n config.add_section(Settings.DEFAULT_SECTION)\n for key, value in default_settings.items():\n config.set(Settings.DEFAULT_SECTION, key, str(value))\n return config\n", "path": "wandb/settings.py"}]}
| 1,407 | 568 |
gh_patches_debug_24433
|
rasdani/github-patches
|
git_diff
|
opensearch-project__opensearch-build-1652
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[BUG] Only send `-d` to core components, instead of everything.
As of now, build workflow will not send `-d` if user does not specify `--distribution`.
However, if user specify things such as `--distribution rpm` and try to build core+all plugins,
`-d` will be sent to plugins as well.
The plugin build script does not know how to interpret `-d` thus fail.
```
+ echo 'Invalid option: -?'
Invalid option: -?
+ exit 1
2022-02-17 23:58:36 ERROR Error building common-utils, retry with: ./build.sh manifests/1.3.0/opensearch-1.3.0.yml --component common-utils
Traceback (most recent call last):
File "./src/run_build.py", line 79, in <module>
sys.exit(main())
File "./src/run_build.py", line 67, in main
builder.build(build_recorder)
File "/local/home/zhujiaxi/opensearch-build-peterzhuamazon/src/build_workflow/builder_from_source.py", line 49, in build
self.git_repo.execute(build_command)
File "/local/home/zhujiaxi/opensearch-build-peterzhuamazon/src/git/git_repository.py", line 83, in execute
subprocess.check_call(command, cwd=cwd, shell=True)
File "/usr/lib64/python3.7/subprocess.py", line 363, in check_call
raise CalledProcessError(retcode, cmd)
subprocess.CalledProcessError: Command 'bash /local/home/zhujiaxi/opensearch-build-peterzhuamazon/scripts/components/common-utils/build.sh -v 1.3.0 -p linux -a x64 -d rpm -s false -o builds' returned non-zero exit status 1.
```
Need to add a condition where if component != OpenSearch/OpenSearch-Dashboards, then `-d` will not be sent even if not None.
</issue>
<code>
[start of src/build_workflow/builder_from_source.py]
1 # SPDX-License-Identifier: Apache-2.0
2 #
3 # The OpenSearch Contributors require contributions made to
4 # this file be licensed under the Apache-2.0 license or a
5 # compatible open source license.
6
7 import os
8
9 from build_workflow.build_recorder import BuildRecorder
10 from build_workflow.builder import Builder
11 from git.git_repository import GitRepository
12 from paths.script_finder import ScriptFinder
13
14 """
15 This class is responsible for executing the build for a component and passing the results to a build recorder.
16 It will notify the build recorder of build information such as repository and git ref, and any artifacts generated by the build.
17 Artifacts found in "<build root>/artifacts/<maven|plugins|libs|dist|core-plugins>" will be recognized and recorded.
18 """
19
20
21 class BuilderFromSource(Builder):
22 def checkout(self, work_dir: str) -> None:
23 self.git_repo = GitRepository(
24 self.component.repository,
25 self.component.ref,
26 os.path.join(work_dir, self.component.name),
27 self.component.working_directory,
28 )
29
30 def build(self, build_recorder: BuildRecorder) -> None:
31 build_script = ScriptFinder.find_build_script(self.target.name, self.component.name, self.git_repo.working_directory)
32
33 build_command = " ".join(
34 filter(
35 None,
36 [
37 "bash",
38 build_script,
39 f"-v {self.target.version}",
40 f"-p {self.target.platform}",
41 f"-a {self.target.architecture}",
42 f"-d {self.target.distribution}" if self.target.distribution else None,
43 f"-s {str(self.target.snapshot).lower()}",
44 f"-o {self.output_path}",
45 ]
46 )
47 )
48
49 self.git_repo.execute(build_command)
50 build_recorder.record_component(self.component.name, self.git_repo)
51
52 def export_artifacts(self, build_recorder: BuildRecorder) -> None:
53 artifacts_path = os.path.join(self.git_repo.working_directory, self.output_path)
54 for artifact_type in ["maven", "dist", "plugins", "libs", "core-plugins"]:
55 for dir, _, files in os.walk(os.path.join(artifacts_path, artifact_type)):
56 for file_name in files:
57 absolute_path = os.path.join(dir, file_name)
58 relative_path = os.path.relpath(absolute_path, artifacts_path)
59 build_recorder.record_artifact(self.component.name, artifact_type, relative_path, absolute_path)
60
[end of src/build_workflow/builder_from_source.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/build_workflow/builder_from_source.py b/src/build_workflow/builder_from_source.py
--- a/src/build_workflow/builder_from_source.py
+++ b/src/build_workflow/builder_from_source.py
@@ -28,6 +28,11 @@
)
def build(self, build_recorder: BuildRecorder) -> None:
+
+ # List of components whose build scripts support `-d` parameter
+ # Bundled plugins do not need `-d` as they are java based zips
+ DISTRIBUTION_SUPPORTED_COMPONENTS = ["OpenSearch", "OpenSearch-Dashboards"]
+
build_script = ScriptFinder.find_build_script(self.target.name, self.component.name, self.git_repo.working_directory)
build_command = " ".join(
@@ -39,7 +44,7 @@
f"-v {self.target.version}",
f"-p {self.target.platform}",
f"-a {self.target.architecture}",
- f"-d {self.target.distribution}" if self.target.distribution else None,
+ f"-d {self.target.distribution}" if self.target.distribution and (self.component.name in DISTRIBUTION_SUPPORTED_COMPONENTS) else None,
f"-s {str(self.target.snapshot).lower()}",
f"-o {self.output_path}",
]
|
{"golden_diff": "diff --git a/src/build_workflow/builder_from_source.py b/src/build_workflow/builder_from_source.py\n--- a/src/build_workflow/builder_from_source.py\n+++ b/src/build_workflow/builder_from_source.py\n@@ -28,6 +28,11 @@\n )\n \n def build(self, build_recorder: BuildRecorder) -> None:\n+\n+ # List of components whose build scripts support `-d` parameter\n+ # Bundled plugins do not need `-d` as they are java based zips\n+ DISTRIBUTION_SUPPORTED_COMPONENTS = [\"OpenSearch\", \"OpenSearch-Dashboards\"]\n+\n build_script = ScriptFinder.find_build_script(self.target.name, self.component.name, self.git_repo.working_directory)\n \n build_command = \" \".join(\n@@ -39,7 +44,7 @@\n f\"-v {self.target.version}\",\n f\"-p {self.target.platform}\",\n f\"-a {self.target.architecture}\",\n- f\"-d {self.target.distribution}\" if self.target.distribution else None,\n+ f\"-d {self.target.distribution}\" if self.target.distribution and (self.component.name in DISTRIBUTION_SUPPORTED_COMPONENTS) else None,\n f\"-s {str(self.target.snapshot).lower()}\",\n f\"-o {self.output_path}\",\n ]\n", "issue": "[BUG] Only send `-d` to core components, instead of everything.\nAs of now, build workflow will not send `-d` if user does not specify `--distribution`.\r\nHowever, if user specify things such as `--distribution rpm` and try to build core+all plugins,\r\n`-d` will be sent to plugins as well.\r\n\r\nThe plugin build script does not know how to interpret `-d` thus fail.\r\n```\r\n+ echo 'Invalid option: -?'\r\nInvalid option: -?\r\n+ exit 1\r\n2022-02-17 23:58:36 ERROR Error building common-utils, retry with: ./build.sh manifests/1.3.0/opensearch-1.3.0.yml --component common-utils\r\nTraceback (most recent call last):\r\n File \"./src/run_build.py\", line 79, in <module>\r\n sys.exit(main())\r\n File \"./src/run_build.py\", line 67, in main\r\n builder.build(build_recorder)\r\n File \"/local/home/zhujiaxi/opensearch-build-peterzhuamazon/src/build_workflow/builder_from_source.py\", line 49, in build\r\n self.git_repo.execute(build_command)\r\n File \"/local/home/zhujiaxi/opensearch-build-peterzhuamazon/src/git/git_repository.py\", line 83, in execute\r\n subprocess.check_call(command, cwd=cwd, shell=True)\r\n File \"/usr/lib64/python3.7/subprocess.py\", line 363, in check_call\r\n raise CalledProcessError(retcode, cmd)\r\nsubprocess.CalledProcessError: Command 'bash /local/home/zhujiaxi/opensearch-build-peterzhuamazon/scripts/components/common-utils/build.sh -v 1.3.0 -p linux -a x64 -d rpm -s false -o builds' returned non-zero exit status 1.\r\n```\r\n\r\nNeed to add a condition where if component != OpenSearch/OpenSearch-Dashboards, then `-d` will not be sent even if not None.\n", "before_files": [{"content": "# SPDX-License-Identifier: Apache-2.0\n#\n# The OpenSearch Contributors require contributions made to\n# this file be licensed under the Apache-2.0 license or a\n# compatible open source license.\n\nimport os\n\nfrom build_workflow.build_recorder import BuildRecorder\nfrom build_workflow.builder import Builder\nfrom git.git_repository import GitRepository\nfrom paths.script_finder import ScriptFinder\n\n\"\"\"\nThis class is responsible for executing the build for a component and passing the results to a build recorder.\nIt will notify the build recorder of build information such as repository and git ref, and any artifacts generated by the build.\nArtifacts found in \"<build root>/artifacts/<maven|plugins|libs|dist|core-plugins>\" will be recognized and recorded.\n\"\"\"\n\n\nclass BuilderFromSource(Builder):\n def checkout(self, work_dir: str) -> None:\n self.git_repo = GitRepository(\n self.component.repository,\n self.component.ref,\n os.path.join(work_dir, self.component.name),\n self.component.working_directory,\n )\n\n def build(self, build_recorder: BuildRecorder) -> None:\n build_script = ScriptFinder.find_build_script(self.target.name, self.component.name, self.git_repo.working_directory)\n\n build_command = \" \".join(\n filter(\n None,\n [\n \"bash\",\n build_script,\n f\"-v {self.target.version}\",\n f\"-p {self.target.platform}\",\n f\"-a {self.target.architecture}\",\n f\"-d {self.target.distribution}\" if self.target.distribution else None,\n f\"-s {str(self.target.snapshot).lower()}\",\n f\"-o {self.output_path}\",\n ]\n )\n )\n\n self.git_repo.execute(build_command)\n build_recorder.record_component(self.component.name, self.git_repo)\n\n def export_artifacts(self, build_recorder: BuildRecorder) -> None:\n artifacts_path = os.path.join(self.git_repo.working_directory, self.output_path)\n for artifact_type in [\"maven\", \"dist\", \"plugins\", \"libs\", \"core-plugins\"]:\n for dir, _, files in os.walk(os.path.join(artifacts_path, artifact_type)):\n for file_name in files:\n absolute_path = os.path.join(dir, file_name)\n relative_path = os.path.relpath(absolute_path, artifacts_path)\n build_recorder.record_artifact(self.component.name, artifact_type, relative_path, absolute_path)\n", "path": "src/build_workflow/builder_from_source.py"}]}
| 1,605 | 279 |
gh_patches_debug_18245
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-338
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
TVCatchup addon not working anymore
root@ovh2:/data# streamlink http://tvcatchup.com/watch/channel4
[cli][info] streamlink is running as root! Be careful!
[cli][info] Found matching plugin tvcatchup for URL http://tvcatchup.com/watch/channel4
error: No streams found on this URL: http://tvcatchup.com/watch/channel4
root@ovh2:/data# streamlink --plugins
[cli][info] streamlink is running as root! Be careful!
Loaded plugins: adultswim, afreeca, afreecatv, aftonbladet, alieztv, antenna, ard_live, ard_mediathek, artetv, atresplayer, azubutv, bambuser, beam, beattv, bigo, bilibili, bliptv, chaturbate, cinergroup, connectcast, crunchyroll, cybergame, dailymotion, dingittv, disney_de, dmcloud, dmcloud_embed, dogan, dogus, dommune, douyutv, dplay, drdk, euronews, expressen, filmon, filmon_us, foxtr, furstream, gaminglive, gomexp, goodgame, hitbox, itvplayer, kanal7, letontv, livecodingtv, livestation, livestream, media_ccc_de, mediaklikk, meerkat, mips, mlgtv, nhkworld, nineanime, nos, npo, nrk, oldlivestream, openrectv, orf_tvthek, pandatv, periscope, picarto, piczel, powerapp, rtlxl, rtve, ruv, seemeplay, servustv, speedrunslive, sportschau, ssh101, stream, streamboat, streamingvideoprovider, streamlive, streamme, streamupcom, svtplay, tga, tigerdile, trt, turkuvaz, tv360, tv3cat, tv4play, tv8, tvcatchup, tvplayer, twitch, ustreamtv, vaughnlive, veetle, vgtv, viagame, viasat, viasat_embed, vidio, wattv, webtv, weeb, younow, youtube, zdf_mediathek
</issue>
<code>
[start of src/streamlink/plugins/tvcatchup.py]
1 import re
2
3 from streamlink.plugin import Plugin
4 from streamlink.plugin.api import http
5 from streamlink.stream import HLSStream
6
7 USER_AGENT = "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36"
8 _url_re = re.compile("http://(?:www\.)?tvcatchup.com/watch/\w+")
9 _stream_re = re.compile(r"\"(?P<stream_url>https?://.*m3u8\?.*clientKey=[^\"]*)\";")
10
11
12 class TVCatchup(Plugin):
13 @classmethod
14 def can_handle_url(cls, url):
15 return _url_re.match(url)
16
17 def _get_streams(self):
18 """
19 Finds the streams from tvcatchup.com.
20 """
21 http.headers.update({"User-Agent": USER_AGENT})
22 res = http.get(self.url)
23
24 match = _stream_re.search(res.text, re.IGNORECASE | re.MULTILINE)
25
26 if match:
27 stream_url = match.groupdict()["stream_url"]
28
29 if stream_url:
30 if "_adp" in stream_url:
31 return HLSStream.parse_variant_playlist(self.session, stream_url)
32 else:
33 return {'576p': HLSStream(self.session, stream_url)}
34
35
36 __plugin__ = TVCatchup
37
[end of src/streamlink/plugins/tvcatchup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/streamlink/plugins/tvcatchup.py b/src/streamlink/plugins/tvcatchup.py
--- a/src/streamlink/plugins/tvcatchup.py
+++ b/src/streamlink/plugins/tvcatchup.py
@@ -6,7 +6,7 @@
USER_AGENT = "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36"
_url_re = re.compile("http://(?:www\.)?tvcatchup.com/watch/\w+")
-_stream_re = re.compile(r"\"(?P<stream_url>https?://.*m3u8\?.*clientKey=[^\"]*)\";")
+_stream_re = re.compile(r'''(?P<q>["'])(?P<stream_url>https?://.*m3u8\?.*clientKey=.*?)(?P=q)''')
class TVCatchup(Plugin):
@@ -24,7 +24,7 @@
match = _stream_re.search(res.text, re.IGNORECASE | re.MULTILINE)
if match:
- stream_url = match.groupdict()["stream_url"]
+ stream_url = match.group("stream_url")
if stream_url:
if "_adp" in stream_url:
|
{"golden_diff": "diff --git a/src/streamlink/plugins/tvcatchup.py b/src/streamlink/plugins/tvcatchup.py\n--- a/src/streamlink/plugins/tvcatchup.py\n+++ b/src/streamlink/plugins/tvcatchup.py\n@@ -6,7 +6,7 @@\n \n USER_AGENT = \"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36\"\n _url_re = re.compile(\"http://(?:www\\.)?tvcatchup.com/watch/\\w+\")\n-_stream_re = re.compile(r\"\\\"(?P<stream_url>https?://.*m3u8\\?.*clientKey=[^\\\"]*)\\\";\")\n+_stream_re = re.compile(r'''(?P<q>[\"'])(?P<stream_url>https?://.*m3u8\\?.*clientKey=.*?)(?P=q)''')\n \n \n class TVCatchup(Plugin):\n@@ -24,7 +24,7 @@\n match = _stream_re.search(res.text, re.IGNORECASE | re.MULTILINE)\n \n if match:\n- stream_url = match.groupdict()[\"stream_url\"]\n+ stream_url = match.group(\"stream_url\")\n \n if stream_url:\n if \"_adp\" in stream_url:\n", "issue": "TVCatchup addon not working anymore\nroot@ovh2:/data# streamlink http://tvcatchup.com/watch/channel4\r\n[cli][info] streamlink is running as root! Be careful!\r\n[cli][info] Found matching plugin tvcatchup for URL http://tvcatchup.com/watch/channel4\r\nerror: No streams found on this URL: http://tvcatchup.com/watch/channel4\r\nroot@ovh2:/data# streamlink --plugins\r\n[cli][info] streamlink is running as root! Be careful!\r\nLoaded plugins: adultswim, afreeca, afreecatv, aftonbladet, alieztv, antenna, ard_live, ard_mediathek, artetv, atresplayer, azubutv, bambuser, beam, beattv, bigo, bilibili, bliptv, chaturbate, cinergroup, connectcast, crunchyroll, cybergame, dailymotion, dingittv, disney_de, dmcloud, dmcloud_embed, dogan, dogus, dommune, douyutv, dplay, drdk, euronews, expressen, filmon, filmon_us, foxtr, furstream, gaminglive, gomexp, goodgame, hitbox, itvplayer, kanal7, letontv, livecodingtv, livestation, livestream, media_ccc_de, mediaklikk, meerkat, mips, mlgtv, nhkworld, nineanime, nos, npo, nrk, oldlivestream, openrectv, orf_tvthek, pandatv, periscope, picarto, piczel, powerapp, rtlxl, rtve, ruv, seemeplay, servustv, speedrunslive, sportschau, ssh101, stream, streamboat, streamingvideoprovider, streamlive, streamme, streamupcom, svtplay, tga, tigerdile, trt, turkuvaz, tv360, tv3cat, tv4play, tv8, tvcatchup, tvplayer, twitch, ustreamtv, vaughnlive, veetle, vgtv, viagame, viasat, viasat_embed, vidio, wattv, webtv, weeb, younow, youtube, zdf_mediathek\r\n\n", "before_files": [{"content": "import re\n\nfrom streamlink.plugin import Plugin\nfrom streamlink.plugin.api import http\nfrom streamlink.stream import HLSStream\n\nUSER_AGENT = \"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36\"\n_url_re = re.compile(\"http://(?:www\\.)?tvcatchup.com/watch/\\w+\")\n_stream_re = re.compile(r\"\\\"(?P<stream_url>https?://.*m3u8\\?.*clientKey=[^\\\"]*)\\\";\")\n\n\nclass TVCatchup(Plugin):\n @classmethod\n def can_handle_url(cls, url):\n return _url_re.match(url)\n\n def _get_streams(self):\n \"\"\"\n Finds the streams from tvcatchup.com.\n \"\"\"\n http.headers.update({\"User-Agent\": USER_AGENT})\n res = http.get(self.url)\n\n match = _stream_re.search(res.text, re.IGNORECASE | re.MULTILINE)\n\n if match:\n stream_url = match.groupdict()[\"stream_url\"]\n\n if stream_url:\n if \"_adp\" in stream_url:\n return HLSStream.parse_variant_playlist(self.session, stream_url)\n else:\n return {'576p': HLSStream(self.session, stream_url)}\n\n\n__plugin__ = TVCatchup\n", "path": "src/streamlink/plugins/tvcatchup.py"}]}
| 1,425 | 297 |
gh_patches_debug_4935
|
rasdani/github-patches
|
git_diff
|
quantumlib__Cirq-4249
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Push to PyPi failing
```
error in cirq setup command: 'extras_require' must be a dictionary whose values are strings or lists of strings containing valid project/version requirement specifiers.
```
See https://github.com/quantumlib/Cirq/runs/2851981344
</issue>
<code>
[start of setup.py]
1 # Copyright 2018 The Cirq Developers
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import io
16 import os
17 from setuptools import setup
18
19 # This reads the __version__ variable from cirq/_version.py
20 __version__ = ''
21
22 from dev_tools import modules
23 from dev_tools.requirements import explode
24
25 exec(open('cirq-core/cirq/_version.py').read())
26
27 name = 'cirq'
28
29 description = (
30 'A framework for creating, editing, and invoking '
31 'Noisy Intermediate Scale Quantum (NISQ) circuits.'
32 )
33
34 # README file as long_description.
35 long_description = io.open('README.rst', encoding='utf-8').read()
36
37 # If CIRQ_PRE_RELEASE_VERSION is set then we update the version to this value.
38 # It is assumed that it ends with one of `.devN`, `.aN`, `.bN`, `.rcN` and hence
39 # it will be a pre-release version on PyPi. See
40 # https://packaging.python.org/guides/distributing-packages-using-setuptools/#pre-release-versioning
41 # for more details.
42 if 'CIRQ_PRE_RELEASE_VERSION' in os.environ:
43 __version__ = os.environ['CIRQ_PRE_RELEASE_VERSION']
44 long_description = (
45 "**This is a development version of Cirq and may be "
46 "unstable.**\n\n**For the latest stable release of Cirq "
47 "see**\n`here <https://pypi.org/project/cirq>`__.\n\n" + long_description
48 )
49
50 # Sanity check
51 assert __version__, 'Version string cannot be empty'
52
53 # This is a pure metapackage that installs all our packages
54 requirements = [f'{p.name}=={p.version}' for p in modules.list_modules()]
55
56 dev_requirements = explode('dev_tools/requirements/deps/dev-tools.txt')
57 dev_requirements = [r.strip() for r in dev_requirements]
58
59 setup(
60 name=name,
61 version=__version__,
62 url='http://github.com/quantumlib/cirq',
63 author='The Cirq Developers',
64 author_email='[email protected]',
65 python_requires='>=3.6.0',
66 install_requires=requirements,
67 extras_require={
68 'dev_env': dev_requirements,
69 },
70 license='Apache 2',
71 description=description,
72 long_description=long_description,
73 )
74
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -54,7 +54,9 @@
requirements = [f'{p.name}=={p.version}' for p in modules.list_modules()]
dev_requirements = explode('dev_tools/requirements/deps/dev-tools.txt')
-dev_requirements = [r.strip() for r in dev_requirements]
+
+# filter out direct urls (https://github.com/pypa/pip/issues/6301)
+dev_requirements = [r.strip() for r in dev_requirements if "git+http" not in r]
setup(
name=name,
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -54,7 +54,9 @@\n requirements = [f'{p.name}=={p.version}' for p in modules.list_modules()]\n \n dev_requirements = explode('dev_tools/requirements/deps/dev-tools.txt')\n-dev_requirements = [r.strip() for r in dev_requirements]\n+\n+# filter out direct urls (https://github.com/pypa/pip/issues/6301)\n+dev_requirements = [r.strip() for r in dev_requirements if \"git+http\" not in r]\n \n setup(\n name=name,\n", "issue": "Push to PyPi failing\n```\r\nerror in cirq setup command: 'extras_require' must be a dictionary whose values are strings or lists of strings containing valid project/version requirement specifiers.\r\n```\r\n\r\nSee https://github.com/quantumlib/Cirq/runs/2851981344\r\n\n", "before_files": [{"content": "# Copyright 2018 The Cirq Developers\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport io\nimport os\nfrom setuptools import setup\n\n# This reads the __version__ variable from cirq/_version.py\n__version__ = ''\n\nfrom dev_tools import modules\nfrom dev_tools.requirements import explode\n\nexec(open('cirq-core/cirq/_version.py').read())\n\nname = 'cirq'\n\ndescription = (\n 'A framework for creating, editing, and invoking '\n 'Noisy Intermediate Scale Quantum (NISQ) circuits.'\n)\n\n# README file as long_description.\nlong_description = io.open('README.rst', encoding='utf-8').read()\n\n# If CIRQ_PRE_RELEASE_VERSION is set then we update the version to this value.\n# It is assumed that it ends with one of `.devN`, `.aN`, `.bN`, `.rcN` and hence\n# it will be a pre-release version on PyPi. See\n# https://packaging.python.org/guides/distributing-packages-using-setuptools/#pre-release-versioning\n# for more details.\nif 'CIRQ_PRE_RELEASE_VERSION' in os.environ:\n __version__ = os.environ['CIRQ_PRE_RELEASE_VERSION']\n long_description = (\n \"**This is a development version of Cirq and may be \"\n \"unstable.**\\n\\n**For the latest stable release of Cirq \"\n \"see**\\n`here <https://pypi.org/project/cirq>`__.\\n\\n\" + long_description\n )\n\n# Sanity check\nassert __version__, 'Version string cannot be empty'\n\n# This is a pure metapackage that installs all our packages\nrequirements = [f'{p.name}=={p.version}' for p in modules.list_modules()]\n\ndev_requirements = explode('dev_tools/requirements/deps/dev-tools.txt')\ndev_requirements = [r.strip() for r in dev_requirements]\n\nsetup(\n name=name,\n version=__version__,\n url='http://github.com/quantumlib/cirq',\n author='The Cirq Developers',\n author_email='[email protected]',\n python_requires='>=3.6.0',\n install_requires=requirements,\n extras_require={\n 'dev_env': dev_requirements,\n },\n license='Apache 2',\n description=description,\n long_description=long_description,\n)\n", "path": "setup.py"}]}
| 1,355 | 135 |
gh_patches_debug_3669
|
rasdani/github-patches
|
git_diff
|
ocadotechnology__codeforlife-portal-783
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
portal API not working anymore
**Describe the bug**
When trying to access the following URLs:
/api/lastconnectedsince/YYYY/MM/DD
.../registered/YYYY/MM/DD
.../userspercountry/CC
On any of our servers, we get a 500 error.
Google console says:
> TemplateSyntaxError: 'url' is not a valid tag or filter in tag library 'future'
It happens even with the right to access them.
**To Reproduce**
If you have an authorised google account, go to https://www.codeforlife.education/api/lastconnectedsince/2018/07/20/ and you will see a 500 error
**Expected behaviour**
This page to display a number when your google account is autorised
**Desktop (please complete the following information):**
- OS:Ubuntu 16.04
- Browser:Chrome
**Additional context**
The urls.py file has been reworked for forward compatibility
</issue>
<code>
[start of setup.py]
1 # -*- coding: utf-8 -*-
2 from setuptools import find_packages, setup
3 import versioneer
4 setup(name='codeforlife-portal',
5 cmdclass=versioneer.get_cmdclass(),
6 version=versioneer.get_version(),
7 packages=find_packages(),
8 include_package_data=True,
9 install_requires=[
10 'django==1.9.13',
11 'django-appconf==1.0.1',
12 'django-countries==3.4.1',
13 'djangorestframework==3.1.3',
14 'django-jquery==1.9.1',
15 'django-autoconfig==0.8.0',
16 'django-pipeline==1.5.4',
17 'django-recaptcha==1.3.1', # 1.4 dropped support for < 1.11
18
19 'pyyaml==3.10',
20 'rapid-router >= 1.0.0.post.dev1',
21 'six==1.11.0',
22 'aimmo',
23 'docutils==0.12',
24 'reportlab==3.2.0',
25 'postcodes==0.1',
26 'django-formtools==1.0',
27 'django-two-factor-auth==1.5.0',
28 'urllib3==1.22',
29 'requests==2.18.4',
30
31 'django-classy-tags==0.6.1',
32 'django-treebeard==4.3',
33 'django-sekizai==0.10.0',
34
35 'django-online-status==0.1.0',
36
37 'Pillow==3.3.2',
38 'django-reversion==2.0.0',
39 'sqlparse',
40 'libsass',
41 'django-forms-bootstrap'
42 ],
43 tests_require=[
44 'django-setuptest==0.2.1',
45 'django-selenium-clean==0.3.0',
46 'responses==0.4.0',
47 'selenium==2.48.0',
48 ],
49 test_suite='setuptest.setuptest.SetupTestSuite',
50 zip_safe=False,
51 )
52
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -10,7 +10,7 @@
'django==1.9.13',
'django-appconf==1.0.1',
'django-countries==3.4.1',
- 'djangorestframework==3.1.3',
+ 'djangorestframework==3.2.3',
'django-jquery==1.9.1',
'django-autoconfig==0.8.0',
'django-pipeline==1.5.4',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -10,7 +10,7 @@\n 'django==1.9.13',\n 'django-appconf==1.0.1',\n 'django-countries==3.4.1',\n- 'djangorestframework==3.1.3',\n+ 'djangorestframework==3.2.3',\n 'django-jquery==1.9.1',\n 'django-autoconfig==0.8.0',\n 'django-pipeline==1.5.4',\n", "issue": "portal API not working anymore\n**Describe the bug**\r\nWhen trying to access the following URLs:\r\n/api/lastconnectedsince/YYYY/MM/DD\r\n.../registered/YYYY/MM/DD\r\n.../userspercountry/CC\r\nOn any of our servers, we get a 500 error.\r\nGoogle console says: \r\n\r\n> TemplateSyntaxError: 'url' is not a valid tag or filter in tag library 'future'\r\n\r\nIt happens even with the right to access them.\r\n\r\n**To Reproduce**\r\nIf you have an authorised google account, go to https://www.codeforlife.education/api/lastconnectedsince/2018/07/20/ and you will see a 500 error\r\n\r\n**Expected behaviour**\r\nThis page to display a number when your google account is autorised\r\n\r\n**Desktop (please complete the following information):**\r\n\r\n- OS:Ubuntu 16.04\r\n- Browser:Chrome\r\n \r\n**Additional context**\r\nThe urls.py file has been reworked for forward compatibility\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom setuptools import find_packages, setup\nimport versioneer\nsetup(name='codeforlife-portal',\n cmdclass=versioneer.get_cmdclass(),\n version=versioneer.get_version(),\n packages=find_packages(),\n include_package_data=True,\n install_requires=[\n 'django==1.9.13',\n 'django-appconf==1.0.1',\n 'django-countries==3.4.1',\n 'djangorestframework==3.1.3',\n 'django-jquery==1.9.1',\n 'django-autoconfig==0.8.0',\n 'django-pipeline==1.5.4',\n 'django-recaptcha==1.3.1', # 1.4 dropped support for < 1.11\n\n 'pyyaml==3.10',\n 'rapid-router >= 1.0.0.post.dev1',\n 'six==1.11.0',\n 'aimmo',\n 'docutils==0.12',\n 'reportlab==3.2.0',\n 'postcodes==0.1',\n 'django-formtools==1.0',\n 'django-two-factor-auth==1.5.0',\n 'urllib3==1.22',\n 'requests==2.18.4',\n\n 'django-classy-tags==0.6.1',\n 'django-treebeard==4.3',\n 'django-sekizai==0.10.0',\n\n 'django-online-status==0.1.0',\n\n 'Pillow==3.3.2',\n 'django-reversion==2.0.0',\n 'sqlparse',\n 'libsass',\n 'django-forms-bootstrap'\n ],\n tests_require=[\n 'django-setuptest==0.2.1',\n 'django-selenium-clean==0.3.0',\n 'responses==0.4.0',\n 'selenium==2.48.0',\n ],\n test_suite='setuptest.setuptest.SetupTestSuite',\n zip_safe=False,\n )\n", "path": "setup.py"}]}
| 1,295 | 132 |
gh_patches_debug_59
|
rasdani/github-patches
|
git_diff
|
Anselmoo__spectrafit-662
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Docs]: Using mike for versioning docs
### Is there an existing issue for this?
- [X] I have searched the existing issues
### Current Missing Information in the Docs
https://squidfunk.github.io/mkdocs-material/setup/setting-up-versioning/
### Anything else?
_No response_
### Code of Conduct
- [X] I agree to follow this project's Code of Conduct
</issue>
<code>
[start of spectrafit/__init__.py]
1 """SpectraFit, fast command line tool for fitting data."""
2 __version__ = "1.0.0a2"
3
[end of spectrafit/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/spectrafit/__init__.py b/spectrafit/__init__.py
--- a/spectrafit/__init__.py
+++ b/spectrafit/__init__.py
@@ -1,2 +1,2 @@
"""SpectraFit, fast command line tool for fitting data."""
-__version__ = "1.0.0a2"
+__version__ = "1.0.0a3"
|
{"golden_diff": "diff --git a/spectrafit/__init__.py b/spectrafit/__init__.py\n--- a/spectrafit/__init__.py\n+++ b/spectrafit/__init__.py\n@@ -1,2 +1,2 @@\n \"\"\"SpectraFit, fast command line tool for fitting data.\"\"\"\n-__version__ = \"1.0.0a2\"\n+__version__ = \"1.0.0a3\"\n", "issue": "[Docs]: Using mike for versioning docs\n### Is there an existing issue for this?\n\n- [X] I have searched the existing issues\n\n### Current Missing Information in the Docs\n\nhttps://squidfunk.github.io/mkdocs-material/setup/setting-up-versioning/\n\n### Anything else?\n\n_No response_\n\n### Code of Conduct\n\n- [X] I agree to follow this project's Code of Conduct\n", "before_files": [{"content": "\"\"\"SpectraFit, fast command line tool for fitting data.\"\"\"\n__version__ = \"1.0.0a2\"\n", "path": "spectrafit/__init__.py"}]}
| 651 | 97 |
gh_patches_debug_12265
|
rasdani/github-patches
|
git_diff
|
DDMAL__CantusDB-273
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Sources should automatically have segments
From #257:
> A source should always have a segment. It is either "Cantus Database" or "Sequence Database". It's a foreign key field. In cases where a source doesn't have a segment, it is probably a test source that we created.
> Desired behaviour: when creating a source, assign it to "Cantus Database" by default.
</issue>
<code>
[start of django/cantusdb_project/main_app/models/source.py]
1 from django.db import models
2 from main_app.models import BaseModel
3 from django.contrib.auth import get_user_model
4
5
6 class Source(BaseModel):
7 cursus_choices = [("Monastic", "Monastic"), ("Secular", "Secular")]
8 source_status_choices = [
9 (
10 "Editing process (not all the fields have been proofread)",
11 "Editing process (not all the fields have been proofread)",
12 ),
13 ("Published / Complete", "Published / Complete"),
14 ("Published / Proofread pending", "Published / Proofread pending"),
15 ("Unpublished / Editing process", "Unpublished / Editing process"),
16 ("Unpublished / Indexing process", "Unpublished / Indexing process"),
17 ("Unpublished / Proofread pending", "Unpublished / Proofread pending"),
18 ("Unpublished / Proofreading process", "Unpublished / Proofreading process"),
19 ]
20
21 # sources with public=False cannot be accessed by its url (access denied) and do not appear in source list
22 public = models.BooleanField(blank=True, null=True)
23 # sources with visible=False can be accessed by typing in the url, but do not appear in source list
24 visible = models.BooleanField(blank=True, null=True)
25 title = models.CharField(
26 max_length=255,
27 help_text="Full Manuscript Identification (City, Archive, Shelf-mark)",
28 )
29 # the siglum field as implemented on the old Cantus is composed of both the RISM siglum and the shelfmark
30 # it is a human-readable ID for a source
31 siglum = models.CharField(
32 max_length=63,
33 null=True,
34 blank=True,
35 help_text="RISM-style siglum + Shelf-mark (e.g. GB-Ob 202).",
36 )
37 # the RISM siglum uniquely identifies a library or holding institution
38 rism_siglum = models.ForeignKey(
39 "RismSiglum", on_delete=models.PROTECT, null=True, blank=True,
40 )
41 provenance = models.ForeignKey(
42 "Provenance",
43 on_delete=models.PROTECT,
44 help_text="If the origin is unknown, select a location where the source was "
45 "used later in its lifetime and provide details in the "
46 '"Provenance notes" field.',
47 null=True,
48 blank=True,
49 )
50 provenance_notes = models.TextField(
51 blank=True,
52 null=True,
53 help_text="More exact indication of the provenance (if necessary)",
54 )
55 full_source = models.BooleanField(blank=True, null=True)
56 date = models.CharField(
57 blank=True,
58 null=True,
59 max_length=63,
60 help_text='Date of the manuscript (e.g. "1200s", "1300-1350", etc.)',
61 )
62 century = models.ManyToManyField("Century", related_name="sources")
63 notation = models.ManyToManyField("Notation", related_name="sources")
64 cursus = models.CharField(
65 blank=True, null=True, choices=cursus_choices, max_length=63
66 )
67 # TODO: Fill this field up with JSON info when I have access to the Users
68 current_editors = models.ManyToManyField(get_user_model(), related_name="sources_user_can_edit")
69 inventoried_by = models.ManyToManyField(
70 "Indexer", related_name="sources_inventoried"
71 )
72 full_text_entered_by = models.ManyToManyField(
73 "Indexer", related_name="entered_full_text_for_sources"
74 )
75 melodies_entered_by = models.ManyToManyField(
76 "Indexer", related_name="entered_melody_for_sources"
77 )
78 proofreaders = models.ManyToManyField("Indexer", related_name="proofread_sources")
79 other_editors = models.ManyToManyField("Indexer", related_name="edited_sources")
80 segment = models.ForeignKey(
81 "Segment", on_delete=models.PROTECT, blank=True, null=True
82 )
83 source_status = models.CharField(blank=True, null=True, max_length=255)
84 complete_inventory = models.BooleanField(blank=True, null=True)
85 summary = models.TextField(blank=True, null=True)
86 liturgical_occasions = models.TextField(blank=True, null=True)
87 description = models.TextField(blank=True, null=True)
88 selected_bibliography = models.TextField(blank=True, null=True)
89 image_link = models.URLField(
90 blank=True,
91 null=True,
92 help_text='HTTP link to the image gallery of the source.',
93 )
94 indexing_notes = models.TextField(blank=True, null=True)
95 indexing_date = models.TextField(blank=True, null=True)
96 json_info = models.JSONField(blank=True, null=True)
97 fragmentarium_id = models.CharField(max_length=15, blank=True, null=True)
98 dact_id = models.CharField(max_length=15, blank=True, null=True)
99
100 def number_of_chants(self) -> int:
101 """Returns the number of Chants and Sequences in this Source."""
102 return self.chant_set.count() + self.sequence_set.count()
103
104 def number_of_melodies(self) -> int:
105 """Returns the number of Chants in this Source that have melodies."""
106 return self.chant_set.filter(volpiano__isnull=False).count()
107
108 def __str__(self):
109 string = '{t} ({i})'.format(t=self.title, i=self.id)
110 return string
111
112
[end of django/cantusdb_project/main_app/models/source.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/django/cantusdb_project/main_app/models/source.py b/django/cantusdb_project/main_app/models/source.py
--- a/django/cantusdb_project/main_app/models/source.py
+++ b/django/cantusdb_project/main_app/models/source.py
@@ -1,5 +1,5 @@
from django.db import models
-from main_app.models import BaseModel
+from main_app.models import BaseModel, Segment
from django.contrib.auth import get_user_model
@@ -109,4 +109,8 @@
string = '{t} ({i})'.format(t=self.title, i=self.id)
return string
-
\ No newline at end of file
+ def save(self, *args, **kwargs):
+ # when creating a source, assign it to "Cantus Database" by default
+ cantus_db_segment = Segment.objects.get(name="CANTUS Database")
+ self.segment = cantus_db_segment
+ super().save(*args, **kwargs)
|
{"golden_diff": "diff --git a/django/cantusdb_project/main_app/models/source.py b/django/cantusdb_project/main_app/models/source.py\n--- a/django/cantusdb_project/main_app/models/source.py\n+++ b/django/cantusdb_project/main_app/models/source.py\n@@ -1,5 +1,5 @@\n from django.db import models\n-from main_app.models import BaseModel\n+from main_app.models import BaseModel, Segment\n from django.contrib.auth import get_user_model\n \n \n@@ -109,4 +109,8 @@\n string = '{t} ({i})'.format(t=self.title, i=self.id)\n return string\n \n- \n\\ No newline at end of file\n+ def save(self, *args, **kwargs):\n+ # when creating a source, assign it to \"Cantus Database\" by default\n+ cantus_db_segment = Segment.objects.get(name=\"CANTUS Database\")\n+ self.segment = cantus_db_segment\n+ super().save(*args, **kwargs)\n", "issue": "Sources should automatically have segments\nFrom #257:\r\n\r\n> A source should always have a segment. It is either \"Cantus Database\" or \"Sequence Database\". It's a foreign key field. In cases where a source doesn't have a segment, it is probably a test source that we created.\r\n> Desired behaviour: when creating a source, assign it to \"Cantus Database\" by default.\n", "before_files": [{"content": "from django.db import models\nfrom main_app.models import BaseModel\nfrom django.contrib.auth import get_user_model\n\n\nclass Source(BaseModel):\n cursus_choices = [(\"Monastic\", \"Monastic\"), (\"Secular\", \"Secular\")]\n source_status_choices = [\n (\n \"Editing process (not all the fields have been proofread)\",\n \"Editing process (not all the fields have been proofread)\",\n ),\n (\"Published / Complete\", \"Published / Complete\"),\n (\"Published / Proofread pending\", \"Published / Proofread pending\"),\n (\"Unpublished / Editing process\", \"Unpublished / Editing process\"),\n (\"Unpublished / Indexing process\", \"Unpublished / Indexing process\"),\n (\"Unpublished / Proofread pending\", \"Unpublished / Proofread pending\"),\n (\"Unpublished / Proofreading process\", \"Unpublished / Proofreading process\"),\n ]\n\n # sources with public=False cannot be accessed by its url (access denied) and do not appear in source list\n public = models.BooleanField(blank=True, null=True)\n # sources with visible=False can be accessed by typing in the url, but do not appear in source list\n visible = models.BooleanField(blank=True, null=True)\n title = models.CharField(\n max_length=255,\n help_text=\"Full Manuscript Identification (City, Archive, Shelf-mark)\",\n )\n # the siglum field as implemented on the old Cantus is composed of both the RISM siglum and the shelfmark\n # it is a human-readable ID for a source\n siglum = models.CharField(\n max_length=63, \n null=True, \n blank=True,\n help_text=\"RISM-style siglum + Shelf-mark (e.g. GB-Ob 202).\",\n )\n # the RISM siglum uniquely identifies a library or holding institution\n rism_siglum = models.ForeignKey(\n \"RismSiglum\", on_delete=models.PROTECT, null=True, blank=True,\n )\n provenance = models.ForeignKey(\n \"Provenance\",\n on_delete=models.PROTECT,\n help_text=\"If the origin is unknown, select a location where the source was \"\n \"used later in its lifetime and provide details in the \"\n '\"Provenance notes\" field.',\n null=True,\n blank=True,\n )\n provenance_notes = models.TextField(\n blank=True,\n null=True,\n help_text=\"More exact indication of the provenance (if necessary)\",\n )\n full_source = models.BooleanField(blank=True, null=True)\n date = models.CharField(\n blank=True,\n null=True,\n max_length=63,\n help_text='Date of the manuscript (e.g. \"1200s\", \"1300-1350\", etc.)',\n )\n century = models.ManyToManyField(\"Century\", related_name=\"sources\")\n notation = models.ManyToManyField(\"Notation\", related_name=\"sources\")\n cursus = models.CharField(\n blank=True, null=True, choices=cursus_choices, max_length=63\n )\n # TODO: Fill this field up with JSON info when I have access to the Users\n current_editors = models.ManyToManyField(get_user_model(), related_name=\"sources_user_can_edit\")\n inventoried_by = models.ManyToManyField(\n \"Indexer\", related_name=\"sources_inventoried\"\n )\n full_text_entered_by = models.ManyToManyField(\n \"Indexer\", related_name=\"entered_full_text_for_sources\"\n )\n melodies_entered_by = models.ManyToManyField(\n \"Indexer\", related_name=\"entered_melody_for_sources\"\n )\n proofreaders = models.ManyToManyField(\"Indexer\", related_name=\"proofread_sources\")\n other_editors = models.ManyToManyField(\"Indexer\", related_name=\"edited_sources\")\n segment = models.ForeignKey(\n \"Segment\", on_delete=models.PROTECT, blank=True, null=True\n )\n source_status = models.CharField(blank=True, null=True, max_length=255)\n complete_inventory = models.BooleanField(blank=True, null=True)\n summary = models.TextField(blank=True, null=True)\n liturgical_occasions = models.TextField(blank=True, null=True)\n description = models.TextField(blank=True, null=True)\n selected_bibliography = models.TextField(blank=True, null=True)\n image_link = models.URLField(\n blank=True, \n null=True,\n help_text='HTTP link to the image gallery of the source.',\n )\n indexing_notes = models.TextField(blank=True, null=True)\n indexing_date = models.TextField(blank=True, null=True)\n json_info = models.JSONField(blank=True, null=True)\n fragmentarium_id = models.CharField(max_length=15, blank=True, null=True)\n dact_id = models.CharField(max_length=15, blank=True, null=True)\n\n def number_of_chants(self) -> int:\n \"\"\"Returns the number of Chants and Sequences in this Source.\"\"\"\n return self.chant_set.count() + self.sequence_set.count()\n\n def number_of_melodies(self) -> int:\n \"\"\"Returns the number of Chants in this Source that have melodies.\"\"\"\n return self.chant_set.filter(volpiano__isnull=False).count()\n\n def __str__(self):\n string = '{t} ({i})'.format(t=self.title, i=self.id)\n return string\n\n ", "path": "django/cantusdb_project/main_app/models/source.py"}]}
| 1,992 | 221 |
gh_patches_debug_7058
|
rasdani/github-patches
|
git_diff
|
Kinto__kinto-1139
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Consistency on PUT with mandatory schema fields
While working on #790 I realize that there is something not clear in our specifications.
Currently, if a resource has a mandatory field (eg. groups `members`), then we cannot do a `PUT` with just the `permissions` values. This is because a PUT can lead to a creation, and the `members` fields has to be provided.
On other resources, which have no mandatory field, it is perfectly possible to only provide `permissions`.
But, I believe we should make every resources behave the same way.
For example, when we'll implement the edition of permissions in Kinto-admin, we don't want to have to pass the `data` if it was not changed.
Two solutions:
- Add a default value (`[]`) for the groups members attribute (_my prefered one, trivial and not absurd_)
- Allow `data` to be omitted only when the `PUT` replaces an existing object (_more complex to implement, but would work for any resource with mandatory fields_)
Consistency on PUT with mandatory schema fields
While working on #790 I realize that there is something not clear in our specifications.
Currently, if a resource has a mandatory field (eg. groups `members`), then we cannot do a `PUT` with just the `permissions` values. This is because a PUT can lead to a creation, and the `members` fields has to be provided.
On other resources, which have no mandatory field, it is perfectly possible to only provide `permissions`.
But, I believe we should make every resources behave the same way.
For example, when we'll implement the edition of permissions in Kinto-admin, we don't want to have to pass the `data` if it was not changed.
Two solutions:
- Add a default value (`[]`) for the groups members attribute (_my prefered one, trivial and not absurd_)
- Allow `data` to be omitted only when the `PUT` replaces an existing object (_more complex to implement, but would work for any resource with mandatory fields_)
</issue>
<code>
[start of kinto/views/groups.py]
1 import colander
2
3 from kinto.core import resource, utils
4 from kinto.core.events import ResourceChanged, ACTIONS
5 from pyramid.events import subscriber
6
7
8 def validate_member(node, member):
9 if member.startswith('/buckets/') or member == 'system.Everyone':
10 raise colander.Invalid(node, "'{}' is not a valid user ID.".format(member))
11
12
13 class GroupSchema(resource.ResourceSchema):
14 members = colander.SchemaNode(colander.Sequence(),
15 colander.SchemaNode(colander.String(),
16 validator=validate_member))
17
18
19 @resource.register(name='group',
20 collection_path='/buckets/{{bucket_id}}/groups',
21 record_path='/buckets/{{bucket_id}}/groups/{{id}}')
22 class Group(resource.ShareableResource):
23 schema = GroupSchema
24
25 def get_parent_id(self, request):
26 bucket_id = request.matchdict['bucket_id']
27 parent_id = utils.instance_uri(request, 'bucket', id=bucket_id)
28 return parent_id
29
30
31 @subscriber(ResourceChanged,
32 for_resources=('group',),
33 for_actions=(ACTIONS.DELETE,))
34 def on_groups_deleted(event):
35 """Some groups were deleted, remove them from users principals.
36 """
37 permission_backend = event.request.registry.permission
38
39 for change in event.impacted_records:
40 group = change['old']
41 bucket_id = event.payload['bucket_id']
42 group_uri = utils.instance_uri(event.request, 'group',
43 bucket_id=bucket_id,
44 id=group['id'])
45
46 permission_backend.remove_principal(group_uri)
47
48
49 @subscriber(ResourceChanged,
50 for_resources=('group',),
51 for_actions=(ACTIONS.CREATE, ACTIONS.UPDATE))
52 def on_groups_changed(event):
53 """Some groups were changed, update users principals.
54 """
55 permission_backend = event.request.registry.permission
56
57 for change in event.impacted_records:
58 if 'old' in change:
59 existing_record_members = set(change['old'].get('members', []))
60 else:
61 existing_record_members = set()
62
63 group = change['new']
64 group_uri = '/buckets/{bucket_id}/groups/{id}'.format(id=group['id'],
65 **event.payload)
66 new_record_members = set(group.get('members', []))
67 new_members = new_record_members - existing_record_members
68 removed_members = existing_record_members - new_record_members
69
70 for member in new_members:
71 # Add the group to the member principal.
72 permission_backend.add_user_principal(member, group_uri)
73
74 for member in removed_members:
75 # Remove the group from the member principal.
76 permission_backend.remove_user_principal(member, group_uri)
77
[end of kinto/views/groups.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kinto/views/groups.py b/kinto/views/groups.py
--- a/kinto/views/groups.py
+++ b/kinto/views/groups.py
@@ -13,7 +13,8 @@
class GroupSchema(resource.ResourceSchema):
members = colander.SchemaNode(colander.Sequence(),
colander.SchemaNode(colander.String(),
- validator=validate_member))
+ validator=validate_member),
+ missing=[])
@resource.register(name='group',
|
{"golden_diff": "diff --git a/kinto/views/groups.py b/kinto/views/groups.py\n--- a/kinto/views/groups.py\n+++ b/kinto/views/groups.py\n@@ -13,7 +13,8 @@\n class GroupSchema(resource.ResourceSchema):\n members = colander.SchemaNode(colander.Sequence(),\n colander.SchemaNode(colander.String(),\n- validator=validate_member))\n+ validator=validate_member),\n+ missing=[])\n \n \n @resource.register(name='group',\n", "issue": "Consistency on PUT with mandatory schema fields\nWhile working on #790 I realize that there is something not clear in our specifications.\n\nCurrently, if a resource has a mandatory field (eg. groups `members`), then we cannot do a `PUT` with just the `permissions` values. This is because a PUT can lead to a creation, and the `members` fields has to be provided.\n\nOn other resources, which have no mandatory field, it is perfectly possible to only provide `permissions`.\n\nBut, I believe we should make every resources behave the same way.\n\nFor example, when we'll implement the edition of permissions in Kinto-admin, we don't want to have to pass the `data` if it was not changed.\n\nTwo solutions:\n- Add a default value (`[]`) for the groups members attribute (_my prefered one, trivial and not absurd_)\n- Allow `data` to be omitted only when the `PUT` replaces an existing object (_more complex to implement, but would work for any resource with mandatory fields_)\n\nConsistency on PUT with mandatory schema fields\nWhile working on #790 I realize that there is something not clear in our specifications.\n\nCurrently, if a resource has a mandatory field (eg. groups `members`), then we cannot do a `PUT` with just the `permissions` values. This is because a PUT can lead to a creation, and the `members` fields has to be provided.\n\nOn other resources, which have no mandatory field, it is perfectly possible to only provide `permissions`.\n\nBut, I believe we should make every resources behave the same way.\n\nFor example, when we'll implement the edition of permissions in Kinto-admin, we don't want to have to pass the `data` if it was not changed.\n\nTwo solutions:\n- Add a default value (`[]`) for the groups members attribute (_my prefered one, trivial and not absurd_)\n- Allow `data` to be omitted only when the `PUT` replaces an existing object (_more complex to implement, but would work for any resource with mandatory fields_)\n\n", "before_files": [{"content": "import colander\n\nfrom kinto.core import resource, utils\nfrom kinto.core.events import ResourceChanged, ACTIONS\nfrom pyramid.events import subscriber\n\n\ndef validate_member(node, member):\n if member.startswith('/buckets/') or member == 'system.Everyone':\n raise colander.Invalid(node, \"'{}' is not a valid user ID.\".format(member))\n\n\nclass GroupSchema(resource.ResourceSchema):\n members = colander.SchemaNode(colander.Sequence(),\n colander.SchemaNode(colander.String(),\n validator=validate_member))\n\n\[email protected](name='group',\n collection_path='/buckets/{{bucket_id}}/groups',\n record_path='/buckets/{{bucket_id}}/groups/{{id}}')\nclass Group(resource.ShareableResource):\n schema = GroupSchema\n\n def get_parent_id(self, request):\n bucket_id = request.matchdict['bucket_id']\n parent_id = utils.instance_uri(request, 'bucket', id=bucket_id)\n return parent_id\n\n\n@subscriber(ResourceChanged,\n for_resources=('group',),\n for_actions=(ACTIONS.DELETE,))\ndef on_groups_deleted(event):\n \"\"\"Some groups were deleted, remove them from users principals.\n \"\"\"\n permission_backend = event.request.registry.permission\n\n for change in event.impacted_records:\n group = change['old']\n bucket_id = event.payload['bucket_id']\n group_uri = utils.instance_uri(event.request, 'group',\n bucket_id=bucket_id,\n id=group['id'])\n\n permission_backend.remove_principal(group_uri)\n\n\n@subscriber(ResourceChanged,\n for_resources=('group',),\n for_actions=(ACTIONS.CREATE, ACTIONS.UPDATE))\ndef on_groups_changed(event):\n \"\"\"Some groups were changed, update users principals.\n \"\"\"\n permission_backend = event.request.registry.permission\n\n for change in event.impacted_records:\n if 'old' in change:\n existing_record_members = set(change['old'].get('members', []))\n else:\n existing_record_members = set()\n\n group = change['new']\n group_uri = '/buckets/{bucket_id}/groups/{id}'.format(id=group['id'],\n **event.payload)\n new_record_members = set(group.get('members', []))\n new_members = new_record_members - existing_record_members\n removed_members = existing_record_members - new_record_members\n\n for member in new_members:\n # Add the group to the member principal.\n permission_backend.add_user_principal(member, group_uri)\n\n for member in removed_members:\n # Remove the group from the member principal.\n permission_backend.remove_user_principal(member, group_uri)\n", "path": "kinto/views/groups.py"}]}
| 1,652 | 99 |
gh_patches_debug_15873
|
rasdani/github-patches
|
git_diff
|
frappe__frappe-13917
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Review: Connected App: Difficult to see how Token Cache get_expires_in could be any more wrong
https://github.com/frappe/frappe/blob/86e512452d77f3e61405fd33ecd1bf881790ae18/frappe/integrations/doctype/token_cache/token_cache.py#L53
PR to follow
</issue>
<code>
[start of frappe/integrations/doctype/token_cache/token_cache.py]
1 # -*- coding: utf-8 -*-
2 # Copyright (c) 2019, Frappe Technologies and contributors
3 # For license information, please see license.txt
4
5 from __future__ import unicode_literals
6 from datetime import datetime, timedelta
7
8 import frappe
9 from frappe import _
10 from frappe.utils import cstr, cint
11 from frappe.model.document import Document
12
13 class TokenCache(Document):
14
15 def get_auth_header(self):
16 if self.access_token:
17 headers = {'Authorization': 'Bearer ' + self.get_password('access_token')}
18 return headers
19
20 raise frappe.exceptions.DoesNotExistError
21
22 def update_data(self, data):
23 """
24 Store data returned by authorization flow.
25
26 Params:
27 data - Dict with access_token, refresh_token, expires_in and scope.
28 """
29 token_type = cstr(data.get('token_type', '')).lower()
30 if token_type not in ['bearer', 'mac']:
31 frappe.throw(_('Received an invalid token type.'))
32 # 'Bearer' or 'MAC'
33 token_type = token_type.title() if token_type == 'bearer' else token_type.upper()
34
35 self.token_type = token_type
36 self.access_token = cstr(data.get('access_token', ''))
37 self.refresh_token = cstr(data.get('refresh_token', ''))
38 self.expires_in = cint(data.get('expires_in', 0))
39
40 new_scopes = data.get('scope')
41 if new_scopes:
42 if isinstance(new_scopes, str):
43 new_scopes = new_scopes.split(' ')
44 if isinstance(new_scopes, list):
45 self.scopes = None
46 for scope in new_scopes:
47 self.append('scopes', {'scope': scope})
48
49 self.state = None
50 self.save(ignore_permissions=True)
51 frappe.db.commit()
52 return self
53
54 def get_expires_in(self):
55 expiry_time = frappe.utils.get_datetime(self.modified) + timedelta(self.expires_in)
56 return (datetime.now() - expiry_time).total_seconds()
57
58 def is_expired(self):
59 return self.get_expires_in() < 0
60
61 def get_json(self):
62 return {
63 'access_token': self.get_password('access_token', ''),
64 'refresh_token': self.get_password('refresh_token', ''),
65 'expires_in': self.get_expires_in(),
66 'token_type': self.token_type
67 }
68
[end of frappe/integrations/doctype/token_cache/token_cache.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/frappe/integrations/doctype/token_cache/token_cache.py b/frappe/integrations/doctype/token_cache/token_cache.py
--- a/frappe/integrations/doctype/token_cache/token_cache.py
+++ b/frappe/integrations/doctype/token_cache/token_cache.py
@@ -3,7 +3,7 @@
# For license information, please see license.txt
from __future__ import unicode_literals
-from datetime import datetime, timedelta
+from datetime import timedelta
import frappe
from frappe import _
@@ -52,8 +52,8 @@
return self
def get_expires_in(self):
- expiry_time = frappe.utils.get_datetime(self.modified) + timedelta(self.expires_in)
- return (datetime.now() - expiry_time).total_seconds()
+ expiry_time = frappe.utils.get_datetime(self.modified) + timedelta(seconds=self.expires_in)
+ return (expiry_time - frappe.utils.now_datetime()).total_seconds()
def is_expired(self):
return self.get_expires_in() < 0
|
{"golden_diff": "diff --git a/frappe/integrations/doctype/token_cache/token_cache.py b/frappe/integrations/doctype/token_cache/token_cache.py\n--- a/frappe/integrations/doctype/token_cache/token_cache.py\n+++ b/frappe/integrations/doctype/token_cache/token_cache.py\n@@ -3,7 +3,7 @@\n # For license information, please see license.txt\n \n from __future__ import unicode_literals\n-from datetime import datetime, timedelta\n+from datetime import timedelta\n \n import frappe\n from frappe import _\n@@ -52,8 +52,8 @@\n \t\treturn self\n \n \tdef get_expires_in(self):\n-\t\texpiry_time = frappe.utils.get_datetime(self.modified) + timedelta(self.expires_in)\n-\t\treturn (datetime.now() - expiry_time).total_seconds()\n+\t\texpiry_time = frappe.utils.get_datetime(self.modified) + timedelta(seconds=self.expires_in)\n+\t\treturn (expiry_time - frappe.utils.now_datetime()).total_seconds()\n \n \tdef is_expired(self):\n \t\treturn self.get_expires_in() < 0\n", "issue": "Review: Connected App: Difficult to see how Token Cache get_expires_in could be any more wrong\nhttps://github.com/frappe/frappe/blob/86e512452d77f3e61405fd33ecd1bf881790ae18/frappe/integrations/doctype/token_cache/token_cache.py#L53\r\n\r\nPR to follow\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright (c) 2019, Frappe Technologies and contributors\n# For license information, please see license.txt\n\nfrom __future__ import unicode_literals\nfrom datetime import datetime, timedelta\n\nimport frappe\nfrom frappe import _\nfrom frappe.utils import cstr, cint\nfrom frappe.model.document import Document\n\nclass TokenCache(Document):\n\n\tdef get_auth_header(self):\n\t\tif self.access_token:\n\t\t\theaders = {'Authorization': 'Bearer ' + self.get_password('access_token')}\n\t\t\treturn headers\n\n\t\traise frappe.exceptions.DoesNotExistError\n\n\tdef update_data(self, data):\n\t\t\"\"\"\n\t\tStore data returned by authorization flow.\n\n\t\tParams:\n\t\tdata - Dict with access_token, refresh_token, expires_in and scope.\n\t\t\"\"\"\n\t\ttoken_type = cstr(data.get('token_type', '')).lower()\n\t\tif token_type not in ['bearer', 'mac']:\n\t\t\tfrappe.throw(_('Received an invalid token type.'))\n\t\t# 'Bearer' or 'MAC'\n\t\ttoken_type = token_type.title() if token_type == 'bearer' else token_type.upper()\n\n\t\tself.token_type = token_type\n\t\tself.access_token = cstr(data.get('access_token', ''))\n\t\tself.refresh_token = cstr(data.get('refresh_token', ''))\n\t\tself.expires_in = cint(data.get('expires_in', 0))\n\n\t\tnew_scopes = data.get('scope')\n\t\tif new_scopes:\n\t\t\tif isinstance(new_scopes, str):\n\t\t\t\tnew_scopes = new_scopes.split(' ')\n\t\t\tif isinstance(new_scopes, list):\n\t\t\t\tself.scopes = None\n\t\t\t\tfor scope in new_scopes:\n\t\t\t\t\tself.append('scopes', {'scope': scope})\n\n\t\tself.state = None\n\t\tself.save(ignore_permissions=True)\n\t\tfrappe.db.commit()\n\t\treturn self\n\n\tdef get_expires_in(self):\n\t\texpiry_time = frappe.utils.get_datetime(self.modified) + timedelta(self.expires_in)\n\t\treturn (datetime.now() - expiry_time).total_seconds()\n\n\tdef is_expired(self):\n\t\treturn self.get_expires_in() < 0\n\n\tdef get_json(self):\n\t\treturn {\n\t\t\t'access_token': self.get_password('access_token', ''),\n\t\t\t'refresh_token': self.get_password('refresh_token', ''),\n\t\t\t'expires_in': self.get_expires_in(),\n\t\t\t'token_type': self.token_type\n\t\t}\n", "path": "frappe/integrations/doctype/token_cache/token_cache.py"}]}
| 1,286 | 225 |
gh_patches_debug_24555
|
rasdani/github-patches
|
git_diff
|
pyg-team__pytorch_geometric-5051
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Data Batch problem in PyG
### 🐛 Describe the bug
Hi. I am a computational physics researcher and was using PyG very well.
my pyg code was working well a few weeks ago, but now that I run my code, it is not working anymore without any changes.
the problem is like below.
I have many material structures and in my "custom_dataset" class, these are preprocessed and all graph informations (node features, edge features, edge index etc) are inserted into "Data" object in PyTorch geometric.
You can see that each preprocessed sample with index $i$ was printed normal "Data" object in pyg
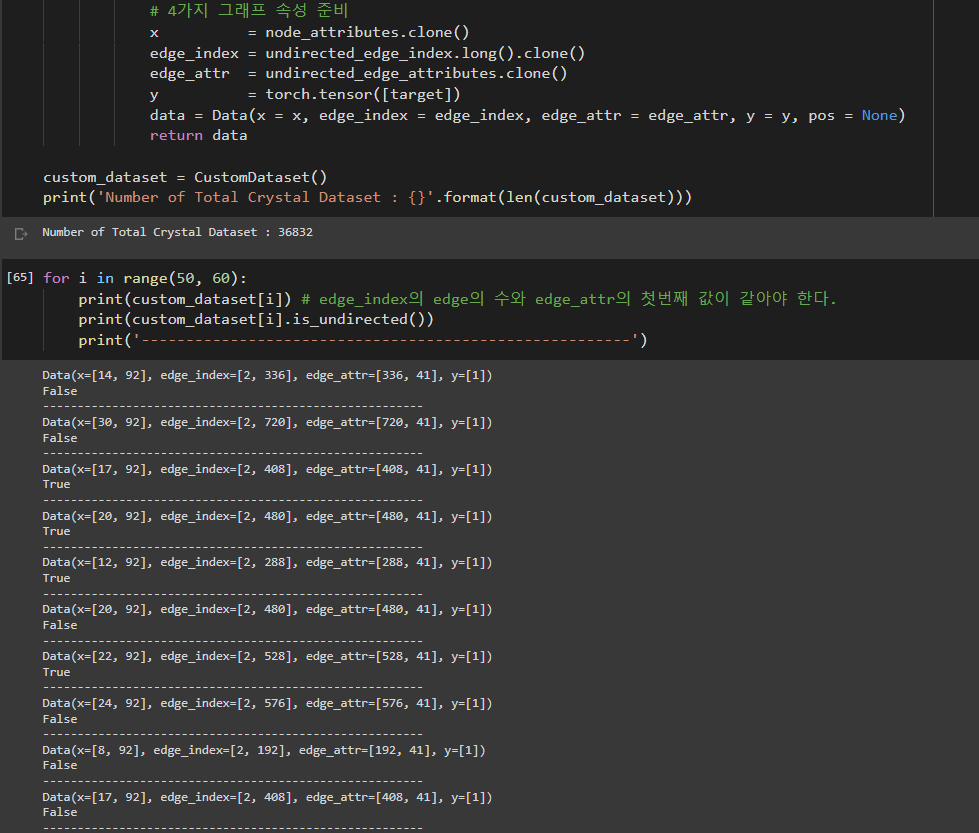
But When I insert my custom dataset class into pyg DataLoader and I did like below,
``` Python
sample = next(iter(train_loader)) # batch sample
```
batch sample is denoted by "DataDataBatch". I didn't see this kind of object name.
and i can't use "sample.x' or "sample.edge_index" command. Instead I need to do like this
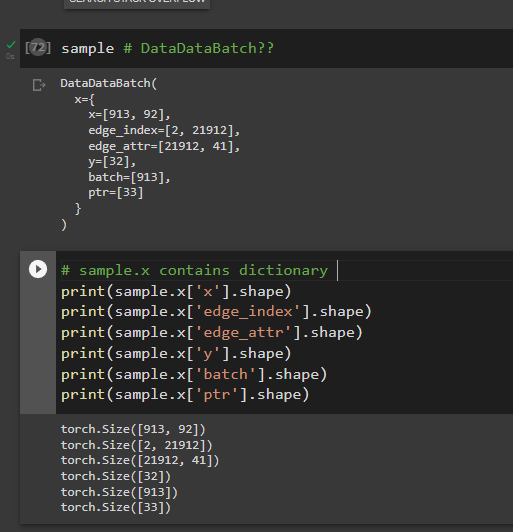
I want to use expressions like "sample.x", "sample.edge_index" or "sample.edge_attr" as like before.
I expect your kind explanations. Thank you.
### Environment
* PyG version: `2.0.5`
* PyTorch version: `1.11.0+cu113`
* OS: `GoogleColab Pro Plus`
* Python version: `Python 3.7.13 in colab`
* CUDA/cuDNN version:
* How you installed PyTorch and PyG (`conda`, `pip`, source):
``` python
# Install required packages.
import os
import torch
os.environ['TORCH'] = torch.__version__
print(torch.__version__)
!pip install -q torch-scatter -f https://data.pyg.org/whl/torch-${TORCH}.html
!pip install -q torch-sparse -f https://data.pyg.org/whl/torch-${TORCH}.html
!pip install -q git+https://github.com/pyg-team/pytorch_geometric.git
!pip install -q pymatgen==2020.11.11
```
* Any other relevant information (*e.g.*, version of `torch-scatter`):
</issue>
<code>
[start of torch_geometric/loader/dataloader.py]
1 from collections.abc import Mapping, Sequence
2 from typing import List, Optional, Union
3
4 import torch.utils.data
5 from torch.utils.data.dataloader import default_collate
6
7 from torch_geometric.data import Batch, Dataset
8 from torch_geometric.data.data import BaseData
9
10
11 class Collater:
12 def __init__(self, follow_batch, exclude_keys):
13 self.follow_batch = follow_batch
14 self.exclude_keys = exclude_keys
15
16 def __call__(self, batch):
17 elem = batch[0]
18 if isinstance(elem, BaseData):
19 return Batch.from_data_list(batch, self.follow_batch,
20 self.exclude_keys)
21 elif isinstance(elem, torch.Tensor):
22 return default_collate(batch)
23 elif isinstance(elem, float):
24 return torch.tensor(batch, dtype=torch.float)
25 elif isinstance(elem, int):
26 return torch.tensor(batch)
27 elif isinstance(elem, str):
28 return batch
29 elif isinstance(elem, Mapping):
30 return {key: self([data[key] for data in batch]) for key in elem}
31 elif isinstance(elem, tuple) and hasattr(elem, '_fields'):
32 return type(elem)(*(self(s) for s in zip(*batch)))
33 elif isinstance(elem, Sequence) and not isinstance(elem, str):
34 return [self(s) for s in zip(*batch)]
35
36 raise TypeError(f'DataLoader found invalid type: {type(elem)}')
37
38 def collate(self, batch): # Deprecated...
39 return self(batch)
40
41
42 class DataLoader(torch.utils.data.DataLoader):
43 r"""A data loader which merges data objects from a
44 :class:`torch_geometric.data.Dataset` to a mini-batch.
45 Data objects can be either of type :class:`~torch_geometric.data.Data` or
46 :class:`~torch_geometric.data.HeteroData`.
47
48 Args:
49 dataset (Dataset): The dataset from which to load the data.
50 batch_size (int, optional): How many samples per batch to load.
51 (default: :obj:`1`)
52 shuffle (bool, optional): If set to :obj:`True`, the data will be
53 reshuffled at every epoch. (default: :obj:`False`)
54 follow_batch (List[str], optional): Creates assignment batch
55 vectors for each key in the list. (default: :obj:`None`)
56 exclude_keys (List[str], optional): Will exclude each key in the
57 list. (default: :obj:`None`)
58 **kwargs (optional): Additional arguments of
59 :class:`torch.utils.data.DataLoader`.
60 """
61 def __init__(
62 self,
63 dataset: Union[Dataset, List[BaseData]],
64 batch_size: int = 1,
65 shuffle: bool = False,
66 follow_batch: Optional[List[str]] = None,
67 exclude_keys: Optional[List[str]] = None,
68 **kwargs,
69 ):
70
71 if 'collate_fn' in kwargs:
72 del kwargs['collate_fn']
73
74 # Save for PyTorch Lightning < 1.6:
75 self.follow_batch = follow_batch
76 self.exclude_keys = exclude_keys
77
78 super().__init__(
79 dataset,
80 batch_size,
81 shuffle,
82 collate_fn=Collater(follow_batch, exclude_keys),
83 **kwargs,
84 )
85
[end of torch_geometric/loader/dataloader.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/torch_geometric/loader/dataloader.py b/torch_geometric/loader/dataloader.py
--- a/torch_geometric/loader/dataloader.py
+++ b/torch_geometric/loader/dataloader.py
@@ -1,4 +1,5 @@
from collections.abc import Mapping, Sequence
+from inspect import signature
from typing import List, Optional, Union
import torch.utils.data
@@ -39,6 +40,28 @@
return self(batch)
+# PyG 'Data' objects are subclasses of MutableMapping, which is an
+# instance of collections.abc.Mapping. Currently, PyTorch pin_memory
+# for DataLoaders treats the returned batches as Mapping objects and
+# calls `pin_memory` on each element in `Data.__dict__`, which is not
+# desired behavior if 'Data' has a `pin_memory` function. We patch
+# this behavior here by monkeypatching `pin_memory`, but can hopefully patch
+# this in PyTorch in the future:
+__torch_pin_memory = torch.utils.data._utils.pin_memory.pin_memory
+__torch_pin_memory_params = signature(__torch_pin_memory).parameters
+
+
+def pin_memory(data, device=None):
+ if hasattr(data, "pin_memory"):
+ return data.pin_memory()
+ if len(__torch_pin_memory_params) > 1:
+ return __torch_pin_memory(data, device)
+ return __torch_pin_memory(data)
+
+
+torch.utils.data._utils.pin_memory.pin_memory = pin_memory
+
+
class DataLoader(torch.utils.data.DataLoader):
r"""A data loader which merges data objects from a
:class:`torch_geometric.data.Dataset` to a mini-batch.
|
{"golden_diff": "diff --git a/torch_geometric/loader/dataloader.py b/torch_geometric/loader/dataloader.py\n--- a/torch_geometric/loader/dataloader.py\n+++ b/torch_geometric/loader/dataloader.py\n@@ -1,4 +1,5 @@\n from collections.abc import Mapping, Sequence\n+from inspect import signature\n from typing import List, Optional, Union\n \n import torch.utils.data\n@@ -39,6 +40,28 @@\n return self(batch)\n \n \n+# PyG 'Data' objects are subclasses of MutableMapping, which is an\n+# instance of collections.abc.Mapping. Currently, PyTorch pin_memory\n+# for DataLoaders treats the returned batches as Mapping objects and\n+# calls `pin_memory` on each element in `Data.__dict__`, which is not\n+# desired behavior if 'Data' has a `pin_memory` function. We patch\n+# this behavior here by monkeypatching `pin_memory`, but can hopefully patch\n+# this in PyTorch in the future:\n+__torch_pin_memory = torch.utils.data._utils.pin_memory.pin_memory\n+__torch_pin_memory_params = signature(__torch_pin_memory).parameters\n+\n+\n+def pin_memory(data, device=None):\n+ if hasattr(data, \"pin_memory\"):\n+ return data.pin_memory()\n+ if len(__torch_pin_memory_params) > 1:\n+ return __torch_pin_memory(data, device)\n+ return __torch_pin_memory(data)\n+\n+\n+torch.utils.data._utils.pin_memory.pin_memory = pin_memory\n+\n+\n class DataLoader(torch.utils.data.DataLoader):\n r\"\"\"A data loader which merges data objects from a\n :class:`torch_geometric.data.Dataset` to a mini-batch.\n", "issue": "Data Batch problem in PyG\n### \ud83d\udc1b Describe the bug\n\nHi. I am a computational physics researcher and was using PyG very well.\r\nmy pyg code was working well a few weeks ago, but now that I run my code, it is not working anymore without any changes.\r\n\r\nthe problem is like below.\r\nI have many material structures and in my \"custom_dataset\" class, these are preprocessed and all graph informations (node features, edge features, edge index etc) are inserted into \"Data\" object in PyTorch geometric.\r\nYou can see that each preprocessed sample with index $i$ was printed normal \"Data\" object in pyg\r\n\r\n\r\n\r\nBut When I insert my custom dataset class into pyg DataLoader and I did like below,\r\n\r\n``` Python\r\nsample = next(iter(train_loader)) # batch sample\r\n```\r\n\r\nbatch sample is denoted by \"DataDataBatch\". I didn't see this kind of object name.\r\nand i can't use \"sample.x' or \"sample.edge_index\" command. Instead I need to do like this\r\n\r\n\r\n\r\nI want to use expressions like \"sample.x\", \"sample.edge_index\" or \"sample.edge_attr\" as like before. \r\nI expect your kind explanations. Thank you.\r\n\n\n### Environment\n\n* PyG version: `2.0.5`\r\n* PyTorch version: `1.11.0+cu113`\r\n* OS: `GoogleColab Pro Plus`\r\n* Python version: `Python 3.7.13 in colab`\r\n* CUDA/cuDNN version:\r\n* How you installed PyTorch and PyG (`conda`, `pip`, source): \r\n``` python\r\n# Install required packages.\r\nimport os\r\nimport torch\r\nos.environ['TORCH'] = torch.__version__\r\nprint(torch.__version__)\r\n!pip install -q torch-scatter -f https://data.pyg.org/whl/torch-${TORCH}.html\r\n!pip install -q torch-sparse -f https://data.pyg.org/whl/torch-${TORCH}.html\r\n!pip install -q git+https://github.com/pyg-team/pytorch_geometric.git\r\n!pip install -q pymatgen==2020.11.11 \r\n```\r\n* Any other relevant information (*e.g.*, version of `torch-scatter`):\r\n\n", "before_files": [{"content": "from collections.abc import Mapping, Sequence\nfrom typing import List, Optional, Union\n\nimport torch.utils.data\nfrom torch.utils.data.dataloader import default_collate\n\nfrom torch_geometric.data import Batch, Dataset\nfrom torch_geometric.data.data import BaseData\n\n\nclass Collater:\n def __init__(self, follow_batch, exclude_keys):\n self.follow_batch = follow_batch\n self.exclude_keys = exclude_keys\n\n def __call__(self, batch):\n elem = batch[0]\n if isinstance(elem, BaseData):\n return Batch.from_data_list(batch, self.follow_batch,\n self.exclude_keys)\n elif isinstance(elem, torch.Tensor):\n return default_collate(batch)\n elif isinstance(elem, float):\n return torch.tensor(batch, dtype=torch.float)\n elif isinstance(elem, int):\n return torch.tensor(batch)\n elif isinstance(elem, str):\n return batch\n elif isinstance(elem, Mapping):\n return {key: self([data[key] for data in batch]) for key in elem}\n elif isinstance(elem, tuple) and hasattr(elem, '_fields'):\n return type(elem)(*(self(s) for s in zip(*batch)))\n elif isinstance(elem, Sequence) and not isinstance(elem, str):\n return [self(s) for s in zip(*batch)]\n\n raise TypeError(f'DataLoader found invalid type: {type(elem)}')\n\n def collate(self, batch): # Deprecated...\n return self(batch)\n\n\nclass DataLoader(torch.utils.data.DataLoader):\n r\"\"\"A data loader which merges data objects from a\n :class:`torch_geometric.data.Dataset` to a mini-batch.\n Data objects can be either of type :class:`~torch_geometric.data.Data` or\n :class:`~torch_geometric.data.HeteroData`.\n\n Args:\n dataset (Dataset): The dataset from which to load the data.\n batch_size (int, optional): How many samples per batch to load.\n (default: :obj:`1`)\n shuffle (bool, optional): If set to :obj:`True`, the data will be\n reshuffled at every epoch. (default: :obj:`False`)\n follow_batch (List[str], optional): Creates assignment batch\n vectors for each key in the list. (default: :obj:`None`)\n exclude_keys (List[str], optional): Will exclude each key in the\n list. (default: :obj:`None`)\n **kwargs (optional): Additional arguments of\n :class:`torch.utils.data.DataLoader`.\n \"\"\"\n def __init__(\n self,\n dataset: Union[Dataset, List[BaseData]],\n batch_size: int = 1,\n shuffle: bool = False,\n follow_batch: Optional[List[str]] = None,\n exclude_keys: Optional[List[str]] = None,\n **kwargs,\n ):\n\n if 'collate_fn' in kwargs:\n del kwargs['collate_fn']\n\n # Save for PyTorch Lightning < 1.6:\n self.follow_batch = follow_batch\n self.exclude_keys = exclude_keys\n\n super().__init__(\n dataset,\n batch_size,\n shuffle,\n collate_fn=Collater(follow_batch, exclude_keys),\n **kwargs,\n )\n", "path": "torch_geometric/loader/dataloader.py"}]}
| 2,006 | 363 |
gh_patches_debug_3074
|
rasdani/github-patches
|
git_diff
|
bookwyrm-social__bookwyrm-1341
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Cannot make other users admin on the website
**Describe the bug**
For the moment, there is no way to promote an user to be an admin. One has to do it in the "./bw-dev shell"
**To Reproduce**
Steps to reproduce the behavior:
1. Go to 'Admin' and then the page of the user you want to promote
2. Promote the user and save
3. The "promoted user" logins in
4. Nope, not promoted
**Expected behavior**
The logged in promoted user should see the admin panel.
</issue>
<code>
[start of bookwyrm/views/user_admin.py]
1 """ manage user """
2 from django.contrib.auth.decorators import login_required, permission_required
3 from django.core.paginator import Paginator
4 from django.shortcuts import get_object_or_404
5 from django.template.response import TemplateResponse
6 from django.utils.decorators import method_decorator
7 from django.views import View
8
9 from bookwyrm import forms, models
10 from bookwyrm.settings import PAGE_LENGTH
11
12
13 # pylint: disable= no-self-use
14 @method_decorator(login_required, name="dispatch")
15 @method_decorator(
16 permission_required("bookwyrm.moderate_users", raise_exception=True),
17 name="dispatch",
18 )
19 class UserAdminList(View):
20 """admin view of users on this server"""
21
22 def get(self, request):
23 """list of users"""
24 filters = {}
25 server = request.GET.get("server")
26 if server:
27 server = models.FederatedServer.objects.filter(server_name=server).first()
28 filters["federated_server"] = server
29 filters["federated_server__isnull"] = False
30 username = request.GET.get("username")
31 if username:
32 filters["username__icontains"] = username
33 scope = request.GET.get("scope")
34 if scope:
35 filters["local"] = scope == "local"
36
37 users = models.User.objects.filter(**filters)
38
39 sort = request.GET.get("sort", "-created_date")
40 sort_fields = [
41 "created_date",
42 "last_active_date",
43 "username",
44 "federated_server__server_name",
45 "is_active",
46 ]
47 if sort in sort_fields + ["-{:s}".format(f) for f in sort_fields]:
48 users = users.order_by(sort)
49
50 paginated = Paginator(users, PAGE_LENGTH)
51 data = {
52 "users": paginated.get_page(request.GET.get("page")),
53 "sort": sort,
54 "server": server,
55 }
56 return TemplateResponse(request, "user_admin/user_admin.html", data)
57
58
59 @method_decorator(login_required, name="dispatch")
60 @method_decorator(
61 permission_required("bookwyrm.moderate_users", raise_exception=True),
62 name="dispatch",
63 )
64 class UserAdmin(View):
65 """moderate an individual user"""
66
67 def get(self, request, user):
68 """user view"""
69 user = get_object_or_404(models.User, id=user)
70 data = {"user": user, "group_form": forms.UserGroupForm()}
71 return TemplateResponse(request, "user_admin/user.html", data)
72
73 def post(self, request, user):
74 """update user group"""
75 user = get_object_or_404(models.User, id=user)
76 form = forms.UserGroupForm(request.POST, instance=user)
77 if form.is_valid():
78 form.save()
79 data = {"user": user, "group_form": form}
80 return TemplateResponse(request, "user_admin/user.html", data)
81
[end of bookwyrm/views/user_admin.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bookwyrm/views/user_admin.py b/bookwyrm/views/user_admin.py
--- a/bookwyrm/views/user_admin.py
+++ b/bookwyrm/views/user_admin.py
@@ -13,7 +13,7 @@
# pylint: disable= no-self-use
@method_decorator(login_required, name="dispatch")
@method_decorator(
- permission_required("bookwyrm.moderate_users", raise_exception=True),
+ permission_required("bookwyrm.moderate_user", raise_exception=True),
name="dispatch",
)
class UserAdminList(View):
|
{"golden_diff": "diff --git a/bookwyrm/views/user_admin.py b/bookwyrm/views/user_admin.py\n--- a/bookwyrm/views/user_admin.py\n+++ b/bookwyrm/views/user_admin.py\n@@ -13,7 +13,7 @@\n # pylint: disable= no-self-use\n @method_decorator(login_required, name=\"dispatch\")\n @method_decorator(\n- permission_required(\"bookwyrm.moderate_users\", raise_exception=True),\n+ permission_required(\"bookwyrm.moderate_user\", raise_exception=True),\n name=\"dispatch\",\n )\n class UserAdminList(View):\n", "issue": "Cannot make other users admin on the website\n**Describe the bug**\r\nFor the moment, there is no way to promote an user to be an admin. One has to do it in the \"./bw-dev shell\"\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Go to 'Admin' and then the page of the user you want to promote\r\n2. Promote the user and save\r\n3. The \"promoted user\" logins in\r\n4. Nope, not promoted\r\n\r\n**Expected behavior**\r\nThe logged in promoted user should see the admin panel.\r\n\n", "before_files": [{"content": "\"\"\" manage user \"\"\"\nfrom django.contrib.auth.decorators import login_required, permission_required\nfrom django.core.paginator import Paginator\nfrom django.shortcuts import get_object_or_404\nfrom django.template.response import TemplateResponse\nfrom django.utils.decorators import method_decorator\nfrom django.views import View\n\nfrom bookwyrm import forms, models\nfrom bookwyrm.settings import PAGE_LENGTH\n\n\n# pylint: disable= no-self-use\n@method_decorator(login_required, name=\"dispatch\")\n@method_decorator(\n permission_required(\"bookwyrm.moderate_users\", raise_exception=True),\n name=\"dispatch\",\n)\nclass UserAdminList(View):\n \"\"\"admin view of users on this server\"\"\"\n\n def get(self, request):\n \"\"\"list of users\"\"\"\n filters = {}\n server = request.GET.get(\"server\")\n if server:\n server = models.FederatedServer.objects.filter(server_name=server).first()\n filters[\"federated_server\"] = server\n filters[\"federated_server__isnull\"] = False\n username = request.GET.get(\"username\")\n if username:\n filters[\"username__icontains\"] = username\n scope = request.GET.get(\"scope\")\n if scope:\n filters[\"local\"] = scope == \"local\"\n\n users = models.User.objects.filter(**filters)\n\n sort = request.GET.get(\"sort\", \"-created_date\")\n sort_fields = [\n \"created_date\",\n \"last_active_date\",\n \"username\",\n \"federated_server__server_name\",\n \"is_active\",\n ]\n if sort in sort_fields + [\"-{:s}\".format(f) for f in sort_fields]:\n users = users.order_by(sort)\n\n paginated = Paginator(users, PAGE_LENGTH)\n data = {\n \"users\": paginated.get_page(request.GET.get(\"page\")),\n \"sort\": sort,\n \"server\": server,\n }\n return TemplateResponse(request, \"user_admin/user_admin.html\", data)\n\n\n@method_decorator(login_required, name=\"dispatch\")\n@method_decorator(\n permission_required(\"bookwyrm.moderate_users\", raise_exception=True),\n name=\"dispatch\",\n)\nclass UserAdmin(View):\n \"\"\"moderate an individual user\"\"\"\n\n def get(self, request, user):\n \"\"\"user view\"\"\"\n user = get_object_or_404(models.User, id=user)\n data = {\"user\": user, \"group_form\": forms.UserGroupForm()}\n return TemplateResponse(request, \"user_admin/user.html\", data)\n\n def post(self, request, user):\n \"\"\"update user group\"\"\"\n user = get_object_or_404(models.User, id=user)\n form = forms.UserGroupForm(request.POST, instance=user)\n if form.is_valid():\n form.save()\n data = {\"user\": user, \"group_form\": form}\n return TemplateResponse(request, \"user_admin/user.html\", data)\n", "path": "bookwyrm/views/user_admin.py"}]}
| 1,415 | 122 |
gh_patches_debug_557
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-743
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Release 1.6.8
On the docket:
+ [x] Fixup pex re-exec during bootstrap. #741
+ [x] Pex should not re-exec when the current interpreter satifies constraints #709
+ [x] Pex should not lose PEX_PYTHON or PEX_PYTHON_PATH when re-exec-ing #710
+ [x] Fix resolution of `setup.py` project extras. #739
Deferred:
+ [ ] Remove PEX_HTTP_RETRIES and push into a flag for the pex tool #94
+ [ ] Sdist resolution is not always reproducible #735
</issue>
<code>
[start of pex/version.py]
1 # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 __version__ = '1.6.7'
5
[end of pex/version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pex/version.py b/pex/version.py
--- a/pex/version.py
+++ b/pex/version.py
@@ -1,4 +1,4 @@
# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
# Licensed under the Apache License, Version 2.0 (see LICENSE).
-__version__ = '1.6.7'
+__version__ = '1.6.8'
|
{"golden_diff": "diff --git a/pex/version.py b/pex/version.py\n--- a/pex/version.py\n+++ b/pex/version.py\n@@ -1,4 +1,4 @@\n # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n # Licensed under the Apache License, Version 2.0 (see LICENSE).\n \n-__version__ = '1.6.7'\n+__version__ = '1.6.8'\n", "issue": "Release 1.6.8\nOn the docket:\r\n\r\n+ [x] Fixup pex re-exec during bootstrap. #741 \r\n + [x] Pex should not re-exec when the current interpreter satifies constraints #709\r\n + [x] Pex should not lose PEX_PYTHON or PEX_PYTHON_PATH when re-exec-ing #710\r\n+ [x] Fix resolution of `setup.py` project extras. #739\r\n\r\nDeferred:\r\n\r\n+ [ ] Remove PEX_HTTP_RETRIES and push into a flag for the pex tool #94\r\n+ [ ] Sdist resolution is not always reproducible #735\n", "before_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = '1.6.7'\n", "path": "pex/version.py"}]}
| 725 | 95 |
gh_patches_debug_36499
|
rasdani/github-patches
|
git_diff
|
pytorch__ignite-380
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Issue with metric arithmetics
I'm trying to define my metric as
```python
from ignite.metrics import Accuracy
accuracy = Accuracy()
error_metric = 1.0 - accuracy
```
and I got the following error:
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-70-c4c69e70a6d5> in <module>()
2
3 accuracy = Accuracy()
----> 4 error_metric = 1.0 - accuracy
TypeError: unsupported operand type(s) for -: 'float' and 'Accuracy'
```
But I can define
```python
from ignite.metrics import Accuracy
accuracy = Accuracy()
error_metric = (accuracy - 1.0) * -1.0
```
cc @zasdfgbnm
Issue with metric arithmetics
I'm trying to define my metric as
```python
from ignite.metrics import Accuracy
accuracy = Accuracy()
error_metric = 1.0 - accuracy
```
and I got the following error:
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-70-c4c69e70a6d5> in <module>()
2
3 accuracy = Accuracy()
----> 4 error_metric = 1.0 - accuracy
TypeError: unsupported operand type(s) for -: 'float' and 'Accuracy'
```
But I can define
```python
from ignite.metrics import Accuracy
accuracy = Accuracy()
error_metric = (accuracy - 1.0) * -1.0
```
cc @zasdfgbnm
</issue>
<code>
[start of ignite/metrics/metric.py]
1 from abc import ABCMeta, abstractmethod
2 from ignite._six import with_metaclass
3 from ignite.engine import Events
4 import torch
5
6
7 class Metric(with_metaclass(ABCMeta, object)):
8 """
9 Base class for all Metrics.
10
11 Args:
12 output_transform (callable, optional): a callable that is used to transform the
13 :class:`ignite.engine.Engine`'s `process_function`'s output into the
14 form expected by the metric. This can be useful if, for example, you have a multi-output model and
15 you want to compute the metric with respect to one of the outputs.
16
17 """
18
19 def __init__(self, output_transform=lambda x: x):
20 self._output_transform = output_transform
21 self.reset()
22
23 @abstractmethod
24 def reset(self):
25 """
26 Resets the metric to to it's initial state.
27
28 This is called at the start of each epoch.
29 """
30 pass
31
32 @abstractmethod
33 def update(self, output):
34 """
35 Updates the metric's state using the passed batch output.
36
37 This is called once for each batch.
38
39 Args:
40 output: the is the output from the engine's process function
41 """
42 pass
43
44 @abstractmethod
45 def compute(self):
46 """
47 Computes the metric based on it's accumulated state.
48
49 This is called at the end of each epoch.
50
51 Returns:
52 Any: the actual quantity of interest
53
54 Raises:
55 NotComputableError: raised when the metric cannot be computed
56 """
57 pass
58
59 def started(self, engine):
60 self.reset()
61
62 @torch.no_grad()
63 def iteration_completed(self, engine):
64 output = self._output_transform(engine.state.output)
65 self.update(output)
66
67 def completed(self, engine, name):
68 engine.state.metrics[name] = self.compute()
69
70 def attach(self, engine, name):
71 engine.add_event_handler(Events.EPOCH_COMPLETED, self.completed, name)
72 if not engine.has_event_handler(self.started, Events.EPOCH_STARTED):
73 engine.add_event_handler(Events.EPOCH_STARTED, self.started)
74 if not engine.has_event_handler(self.iteration_completed, Events.ITERATION_COMPLETED):
75 engine.add_event_handler(Events.ITERATION_COMPLETED, self.iteration_completed)
76
77 def __add__(self, other):
78 from ignite.metrics import MetricsLambda
79 return MetricsLambda(lambda x, y: x + y, self, other)
80
81 def __sub__(self, other):
82 from ignite.metrics import MetricsLambda
83 return MetricsLambda(lambda x, y: x - y, self, other)
84
85 def __mul__(self, other):
86 from ignite.metrics import MetricsLambda
87 return MetricsLambda(lambda x, y: x * y, self, other)
88
89 def __pow__(self, other):
90 from ignite.metrics import MetricsLambda
91 return MetricsLambda(lambda x, y: x ** y, self, other)
92
93 def __mod__(self, other):
94 from ignite.metrics import MetricsLambda
95 return MetricsLambda(lambda x, y: x % y, self, other)
96
97 def __div__(self, other):
98 from ignite.metrics import MetricsLambda
99 return MetricsLambda(lambda x, y: x.__div__(y), self, other)
100
101 def __truediv__(self, other):
102 from ignite.metrics import MetricsLambda
103 return MetricsLambda(lambda x, y: x.__truediv__(y), self, other)
104
105 def __floordiv__(self, other):
106 from ignite.metrics import MetricsLambda
107 return MetricsLambda(lambda x, y: x // y, self, other)
108
[end of ignite/metrics/metric.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ignite/metrics/metric.py b/ignite/metrics/metric.py
--- a/ignite/metrics/metric.py
+++ b/ignite/metrics/metric.py
@@ -78,18 +78,34 @@
from ignite.metrics import MetricsLambda
return MetricsLambda(lambda x, y: x + y, self, other)
+ def __radd__(self, other):
+ from ignite.metrics import MetricsLambda
+ return MetricsLambda(lambda x, y: x + y, other, self)
+
def __sub__(self, other):
from ignite.metrics import MetricsLambda
return MetricsLambda(lambda x, y: x - y, self, other)
+ def __rsub__(self, other):
+ from ignite.metrics import MetricsLambda
+ return MetricsLambda(lambda x, y: x - y, other, self)
+
def __mul__(self, other):
from ignite.metrics import MetricsLambda
return MetricsLambda(lambda x, y: x * y, self, other)
+ def __rmul__(self, other):
+ from ignite.metrics import MetricsLambda
+ return MetricsLambda(lambda x, y: x * y, other, self)
+
def __pow__(self, other):
from ignite.metrics import MetricsLambda
return MetricsLambda(lambda x, y: x ** y, self, other)
+ def __rpow__(self, other):
+ from ignite.metrics import MetricsLambda
+ return MetricsLambda(lambda x, y: x ** y, other, self)
+
def __mod__(self, other):
from ignite.metrics import MetricsLambda
return MetricsLambda(lambda x, y: x % y, self, other)
@@ -98,10 +114,18 @@
from ignite.metrics import MetricsLambda
return MetricsLambda(lambda x, y: x.__div__(y), self, other)
+ def __rdiv__(self, other):
+ from ignite.metrics import MetricsLambda
+ return MetricsLambda(lambda x, y: x.__div__(y), other, self)
+
def __truediv__(self, other):
from ignite.metrics import MetricsLambda
return MetricsLambda(lambda x, y: x.__truediv__(y), self, other)
+ def __rtruediv__(self, other):
+ from ignite.metrics import MetricsLambda
+ return MetricsLambda(lambda x, y: x.__truediv__(y), other, self)
+
def __floordiv__(self, other):
from ignite.metrics import MetricsLambda
return MetricsLambda(lambda x, y: x // y, self, other)
|
{"golden_diff": "diff --git a/ignite/metrics/metric.py b/ignite/metrics/metric.py\n--- a/ignite/metrics/metric.py\n+++ b/ignite/metrics/metric.py\n@@ -78,18 +78,34 @@\n from ignite.metrics import MetricsLambda\n return MetricsLambda(lambda x, y: x + y, self, other)\n \n+ def __radd__(self, other):\n+ from ignite.metrics import MetricsLambda\n+ return MetricsLambda(lambda x, y: x + y, other, self)\n+\n def __sub__(self, other):\n from ignite.metrics import MetricsLambda\n return MetricsLambda(lambda x, y: x - y, self, other)\n \n+ def __rsub__(self, other):\n+ from ignite.metrics import MetricsLambda\n+ return MetricsLambda(lambda x, y: x - y, other, self)\n+\n def __mul__(self, other):\n from ignite.metrics import MetricsLambda\n return MetricsLambda(lambda x, y: x * y, self, other)\n \n+ def __rmul__(self, other):\n+ from ignite.metrics import MetricsLambda\n+ return MetricsLambda(lambda x, y: x * y, other, self)\n+\n def __pow__(self, other):\n from ignite.metrics import MetricsLambda\n return MetricsLambda(lambda x, y: x ** y, self, other)\n \n+ def __rpow__(self, other):\n+ from ignite.metrics import MetricsLambda\n+ return MetricsLambda(lambda x, y: x ** y, other, self)\n+\n def __mod__(self, other):\n from ignite.metrics import MetricsLambda\n return MetricsLambda(lambda x, y: x % y, self, other)\n@@ -98,10 +114,18 @@\n from ignite.metrics import MetricsLambda\n return MetricsLambda(lambda x, y: x.__div__(y), self, other)\n \n+ def __rdiv__(self, other):\n+ from ignite.metrics import MetricsLambda\n+ return MetricsLambda(lambda x, y: x.__div__(y), other, self)\n+\n def __truediv__(self, other):\n from ignite.metrics import MetricsLambda\n return MetricsLambda(lambda x, y: x.__truediv__(y), self, other)\n \n+ def __rtruediv__(self, other):\n+ from ignite.metrics import MetricsLambda\n+ return MetricsLambda(lambda x, y: x.__truediv__(y), other, self)\n+\n def __floordiv__(self, other):\n from ignite.metrics import MetricsLambda\n return MetricsLambda(lambda x, y: x // y, self, other)\n", "issue": "Issue with metric arithmetics\nI'm trying to define my metric as \r\n```python\r\nfrom ignite.metrics import Accuracy\r\n\r\naccuracy = Accuracy()\r\nerror_metric = 1.0 - accuracy\r\n```\r\nand I got the following error:\r\n```\r\n---------------------------------------------------------------------------\r\nTypeError Traceback (most recent call last)\r\n<ipython-input-70-c4c69e70a6d5> in <module>()\r\n 2 \r\n 3 accuracy = Accuracy()\r\n----> 4 error_metric = 1.0 - accuracy\r\n\r\nTypeError: unsupported operand type(s) for -: 'float' and 'Accuracy'\r\n```\r\nBut I can define \r\n```python\r\nfrom ignite.metrics import Accuracy\r\n\r\naccuracy = Accuracy()\r\nerror_metric = (accuracy - 1.0) * -1.0\r\n```\r\n\r\ncc @zasdfgbnm \nIssue with metric arithmetics\nI'm trying to define my metric as \r\n```python\r\nfrom ignite.metrics import Accuracy\r\n\r\naccuracy = Accuracy()\r\nerror_metric = 1.0 - accuracy\r\n```\r\nand I got the following error:\r\n```\r\n---------------------------------------------------------------------------\r\nTypeError Traceback (most recent call last)\r\n<ipython-input-70-c4c69e70a6d5> in <module>()\r\n 2 \r\n 3 accuracy = Accuracy()\r\n----> 4 error_metric = 1.0 - accuracy\r\n\r\nTypeError: unsupported operand type(s) for -: 'float' and 'Accuracy'\r\n```\r\nBut I can define \r\n```python\r\nfrom ignite.metrics import Accuracy\r\n\r\naccuracy = Accuracy()\r\nerror_metric = (accuracy - 1.0) * -1.0\r\n```\r\n\r\ncc @zasdfgbnm \n", "before_files": [{"content": "from abc import ABCMeta, abstractmethod\nfrom ignite._six import with_metaclass\nfrom ignite.engine import Events\nimport torch\n\n\nclass Metric(with_metaclass(ABCMeta, object)):\n \"\"\"\n Base class for all Metrics.\n\n Args:\n output_transform (callable, optional): a callable that is used to transform the\n :class:`ignite.engine.Engine`'s `process_function`'s output into the\n form expected by the metric. This can be useful if, for example, you have a multi-output model and\n you want to compute the metric with respect to one of the outputs.\n\n \"\"\"\n\n def __init__(self, output_transform=lambda x: x):\n self._output_transform = output_transform\n self.reset()\n\n @abstractmethod\n def reset(self):\n \"\"\"\n Resets the metric to to it's initial state.\n\n This is called at the start of each epoch.\n \"\"\"\n pass\n\n @abstractmethod\n def update(self, output):\n \"\"\"\n Updates the metric's state using the passed batch output.\n\n This is called once for each batch.\n\n Args:\n output: the is the output from the engine's process function\n \"\"\"\n pass\n\n @abstractmethod\n def compute(self):\n \"\"\"\n Computes the metric based on it's accumulated state.\n\n This is called at the end of each epoch.\n\n Returns:\n Any: the actual quantity of interest\n\n Raises:\n NotComputableError: raised when the metric cannot be computed\n \"\"\"\n pass\n\n def started(self, engine):\n self.reset()\n\n @torch.no_grad()\n def iteration_completed(self, engine):\n output = self._output_transform(engine.state.output)\n self.update(output)\n\n def completed(self, engine, name):\n engine.state.metrics[name] = self.compute()\n\n def attach(self, engine, name):\n engine.add_event_handler(Events.EPOCH_COMPLETED, self.completed, name)\n if not engine.has_event_handler(self.started, Events.EPOCH_STARTED):\n engine.add_event_handler(Events.EPOCH_STARTED, self.started)\n if not engine.has_event_handler(self.iteration_completed, Events.ITERATION_COMPLETED):\n engine.add_event_handler(Events.ITERATION_COMPLETED, self.iteration_completed)\n\n def __add__(self, other):\n from ignite.metrics import MetricsLambda\n return MetricsLambda(lambda x, y: x + y, self, other)\n\n def __sub__(self, other):\n from ignite.metrics import MetricsLambda\n return MetricsLambda(lambda x, y: x - y, self, other)\n\n def __mul__(self, other):\n from ignite.metrics import MetricsLambda\n return MetricsLambda(lambda x, y: x * y, self, other)\n\n def __pow__(self, other):\n from ignite.metrics import MetricsLambda\n return MetricsLambda(lambda x, y: x ** y, self, other)\n\n def __mod__(self, other):\n from ignite.metrics import MetricsLambda\n return MetricsLambda(lambda x, y: x % y, self, other)\n\n def __div__(self, other):\n from ignite.metrics import MetricsLambda\n return MetricsLambda(lambda x, y: x.__div__(y), self, other)\n\n def __truediv__(self, other):\n from ignite.metrics import MetricsLambda\n return MetricsLambda(lambda x, y: x.__truediv__(y), self, other)\n\n def __floordiv__(self, other):\n from ignite.metrics import MetricsLambda\n return MetricsLambda(lambda x, y: x // y, self, other)\n", "path": "ignite/metrics/metric.py"}]}
| 1,876 | 582 |
gh_patches_debug_11137
|
rasdani/github-patches
|
git_diff
|
DataDog__dd-trace-py-3035
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
tuple index out of range of threading.py
After upgrading from ddtrace==0.46.0 to version ddtrace==0.55.4 my service crash with IndexError.
```
Traceback (most recent call last):
File "/my_service/services/base_service.py", line 105, in run
futures.append(executor.submit(fn=self._single_entry_point_run, entry_point=entry_point))
File "/my_service/venv/lib/python3.7/site-packages/ddtrace/contrib/futures/threading.py", line 26, in _wrap_submit
fn = args[0]
IndexError: tuple index out of range
```
I'm facing this issue even when setting futures=False.
`patch_all(celery=True, django=True, psycopg2=True, redis=True, futures=True)`
</issue>
<code>
[start of ddtrace/contrib/futures/threading.py]
1 import ddtrace
2
3
4 def _wrap_submit(func, instance, args, kwargs):
5 """
6 Wrap `Executor` method used to submit a work executed in another
7 thread. This wrapper ensures that a new `Context` is created and
8 properly propagated using an intermediate function.
9 """
10 # If there isn't a currently active context, then do not create one
11 # DEV: Calling `.active()` when there isn't an active context will create a new context
12 # DEV: We need to do this in case they are either:
13 # - Starting nested futures
14 # - Starting futures from outside of an existing context
15 #
16 # In either of these cases we essentially will propagate the wrong context between futures
17 #
18 # The resolution is to not create/propagate a new context if one does not exist, but let the
19 # future's thread create the context instead.
20 current_ctx = None
21 if ddtrace.tracer.context_provider._has_active_context():
22 current_ctx = ddtrace.tracer.context_provider.active()
23
24 # extract the target function that must be executed in
25 # a new thread and the `target` arguments
26 fn = args[0]
27 fn_args = args[1:]
28 return func(_wrap_execution, current_ctx, fn, fn_args, kwargs)
29
30
31 def _wrap_execution(ctx, fn, args, kwargs):
32 """
33 Intermediate target function that is executed in a new thread;
34 it receives the original function with arguments and keyword
35 arguments, including our tracing `Context`. The current context
36 provider sets the Active context in a thread local storage
37 variable because it's outside the asynchronous loop.
38 """
39 if ctx is not None:
40 ddtrace.tracer.context_provider.activate(ctx)
41 return fn(*args, **kwargs)
42
[end of ddtrace/contrib/futures/threading.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ddtrace/contrib/futures/threading.py b/ddtrace/contrib/futures/threading.py
--- a/ddtrace/contrib/futures/threading.py
+++ b/ddtrace/contrib/futures/threading.py
@@ -21,10 +21,12 @@
if ddtrace.tracer.context_provider._has_active_context():
current_ctx = ddtrace.tracer.context_provider.active()
- # extract the target function that must be executed in
- # a new thread and the `target` arguments
- fn = args[0]
- fn_args = args[1:]
+ # The target function can be provided as a kwarg argument "fn" or the first positional argument
+ if "fn" in kwargs:
+ fn = kwargs.pop("fn")
+ fn_args = args
+ else:
+ fn, fn_args = args[0], args[1:]
return func(_wrap_execution, current_ctx, fn, fn_args, kwargs)
|
{"golden_diff": "diff --git a/ddtrace/contrib/futures/threading.py b/ddtrace/contrib/futures/threading.py\n--- a/ddtrace/contrib/futures/threading.py\n+++ b/ddtrace/contrib/futures/threading.py\n@@ -21,10 +21,12 @@\n if ddtrace.tracer.context_provider._has_active_context():\n current_ctx = ddtrace.tracer.context_provider.active()\n \n- # extract the target function that must be executed in\n- # a new thread and the `target` arguments\n- fn = args[0]\n- fn_args = args[1:]\n+ # The target function can be provided as a kwarg argument \"fn\" or the first positional argument\n+ if \"fn\" in kwargs:\n+ fn = kwargs.pop(\"fn\")\n+ fn_args = args\n+ else:\n+ fn, fn_args = args[0], args[1:]\n return func(_wrap_execution, current_ctx, fn, fn_args, kwargs)\n", "issue": "tuple index out of range of threading.py\nAfter upgrading from ddtrace==0.46.0 to version ddtrace==0.55.4 my service crash with IndexError.\r\n```\r\nTraceback (most recent call last):\r\n File \"/my_service/services/base_service.py\", line 105, in run\r\n futures.append(executor.submit(fn=self._single_entry_point_run, entry_point=entry_point))\r\n File \"/my_service/venv/lib/python3.7/site-packages/ddtrace/contrib/futures/threading.py\", line 26, in _wrap_submit\r\n fn = args[0]\r\nIndexError: tuple index out of range\r\n```\r\n\r\nI'm facing this issue even when setting futures=False.\r\n`patch_all(celery=True, django=True, psycopg2=True, redis=True, futures=True)`\r\n\n", "before_files": [{"content": "import ddtrace\n\n\ndef _wrap_submit(func, instance, args, kwargs):\n \"\"\"\n Wrap `Executor` method used to submit a work executed in another\n thread. This wrapper ensures that a new `Context` is created and\n properly propagated using an intermediate function.\n \"\"\"\n # If there isn't a currently active context, then do not create one\n # DEV: Calling `.active()` when there isn't an active context will create a new context\n # DEV: We need to do this in case they are either:\n # - Starting nested futures\n # - Starting futures from outside of an existing context\n #\n # In either of these cases we essentially will propagate the wrong context between futures\n #\n # The resolution is to not create/propagate a new context if one does not exist, but let the\n # future's thread create the context instead.\n current_ctx = None\n if ddtrace.tracer.context_provider._has_active_context():\n current_ctx = ddtrace.tracer.context_provider.active()\n\n # extract the target function that must be executed in\n # a new thread and the `target` arguments\n fn = args[0]\n fn_args = args[1:]\n return func(_wrap_execution, current_ctx, fn, fn_args, kwargs)\n\n\ndef _wrap_execution(ctx, fn, args, kwargs):\n \"\"\"\n Intermediate target function that is executed in a new thread;\n it receives the original function with arguments and keyword\n arguments, including our tracing `Context`. The current context\n provider sets the Active context in a thread local storage\n variable because it's outside the asynchronous loop.\n \"\"\"\n if ctx is not None:\n ddtrace.tracer.context_provider.activate(ctx)\n return fn(*args, **kwargs)\n", "path": "ddtrace/contrib/futures/threading.py"}]}
| 1,176 | 216 |
gh_patches_debug_20162
|
rasdani/github-patches
|
git_diff
|
Kinto__kinto-120
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Default bucket UUID doesn't have dashes
I've seen that default record ID's have got dashes whereas default bucket id doesn't.
Does it makes sense to try to be consistent here?
```
$ http GET http://localhost:8888/v1/buckets/e93a0bb5b7d16d4f9bfd81b6d737271c -v --auth 'mary:marypassword'
{
"data": {
"id": "e93a0bb5b7d16d4f9bfd81b6d737271c",
"last_modified": 1436191171386
},
[...]
}
```
</issue>
<code>
[start of kinto/views/buckets.py]
1 from pyramid.httpexceptions import HTTPForbidden, HTTPPreconditionFailed
2 from pyramid.security import NO_PERMISSION_REQUIRED
3 from pyramid.view import view_config
4
5 from cliquet import resource
6 from cliquet.utils import hmac_digest, build_request
7
8 from kinto.views import NameGenerator
9
10
11 def create_bucket(request, bucket_id):
12 """Create a bucket if it doesn't exists."""
13 bucket_put = (request.method.lower() == 'put' and
14 request.path.endswith('buckets/default'))
15
16 if not bucket_put:
17 subrequest = build_request(request, {
18 'method': 'PUT',
19 'path': '/buckets/%s' % bucket_id,
20 'body': {"data": {}},
21 'headers': {'If-None-Match': '*'.encode('utf-8')}
22 })
23
24 try:
25 request.invoke_subrequest(subrequest)
26 except HTTPPreconditionFailed:
27 # The bucket already exists
28 pass
29
30
31 def create_collection(request, bucket_id):
32 subpath = request.matchdict['subpath']
33 if subpath.startswith('/collections/'):
34 collection_id = subpath.split('/')[2]
35 collection_put = (request.method.lower() == 'put' and
36 request.path.endswith(collection_id))
37 if not collection_put:
38 subrequest = build_request(request, {
39 'method': 'PUT',
40 'path': '/buckets/%s/collections/%s' % (
41 bucket_id, collection_id),
42 'body': {"data": {}},
43 'headers': {'If-None-Match': '*'.encode('utf-8')}
44 })
45 try:
46 request.invoke_subrequest(subrequest)
47 except HTTPPreconditionFailed:
48 # The collection already exists
49 pass
50
51
52 @view_config(route_name='default_bucket', permission=NO_PERMISSION_REQUIRED)
53 def default_bucket(request):
54 if getattr(request, 'prefixed_userid', None) is None:
55 raise HTTPForbidden # Pass through the forbidden_view_config
56
57 settings = request.registry.settings
58 hmac_secret = settings['cliquet.userid_hmac_secret']
59 # Build the user unguessable bucket_id UUID from its user_id
60 bucket_id = hmac_digest(hmac_secret, request.prefixed_userid)[:32]
61 path = request.path.replace('default', bucket_id)
62 querystring = request.url[(request.url.index(request.path) +
63 len(request.path)):]
64
65 # Make sure bucket exists
66 create_bucket(request, bucket_id)
67
68 # Make sure the collection exists
69 create_collection(request, bucket_id)
70
71 subrequest = build_request(request, {
72 'method': request.method,
73 'path': path + querystring,
74 'body': request.body
75 })
76
77 return request.invoke_subrequest(subrequest)
78
79
80 @resource.register(name='bucket',
81 collection_methods=('GET',),
82 collection_path='/buckets',
83 record_path='/buckets/{{id}}')
84 class Bucket(resource.ProtectedResource):
85 permissions = ('read', 'write', 'collection:create', 'group:create')
86
87 def __init__(self, *args, **kwargs):
88 super(Bucket, self).__init__(*args, **kwargs)
89 self.collection.id_generator = NameGenerator()
90
91 def get_parent_id(self, request):
92 # Buckets are not isolated by user, unlike Cliquet resources.
93 return ''
94
95 def delete(self):
96 result = super(Bucket, self).delete()
97
98 # Delete groups.
99 storage = self.collection.storage
100 parent_id = '/buckets/%s' % self.record_id
101 storage.delete_all(collection_id='group', parent_id=parent_id)
102
103 # Delete collections.
104 deleted = storage.delete_all(collection_id='collection',
105 parent_id=parent_id)
106
107 # Delete records.
108 id_field = self.collection.id_field
109 for collection in deleted:
110 parent_id = '/buckets/%s/collections/%s' % (self.record_id,
111 collection[id_field])
112 storage.delete_all(collection_id='record', parent_id=parent_id)
113
114 return result
115
[end of kinto/views/buckets.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kinto/views/buckets.py b/kinto/views/buckets.py
--- a/kinto/views/buckets.py
+++ b/kinto/views/buckets.py
@@ -1,3 +1,6 @@
+from six import text_type
+from uuid import UUID
+
from pyramid.httpexceptions import HTTPForbidden, HTTPPreconditionFailed
from pyramid.security import NO_PERMISSION_REQUIRED
from pyramid.view import view_config
@@ -57,7 +60,8 @@
settings = request.registry.settings
hmac_secret = settings['cliquet.userid_hmac_secret']
# Build the user unguessable bucket_id UUID from its user_id
- bucket_id = hmac_digest(hmac_secret, request.prefixed_userid)[:32]
+ digest = hmac_digest(hmac_secret, request.prefixed_userid)
+ bucket_id = text_type(UUID(digest[:32]))
path = request.path.replace('default', bucket_id)
querystring = request.url[(request.url.index(request.path) +
len(request.path)):]
|
{"golden_diff": "diff --git a/kinto/views/buckets.py b/kinto/views/buckets.py\n--- a/kinto/views/buckets.py\n+++ b/kinto/views/buckets.py\n@@ -1,3 +1,6 @@\n+from six import text_type\n+from uuid import UUID\n+\n from pyramid.httpexceptions import HTTPForbidden, HTTPPreconditionFailed\n from pyramid.security import NO_PERMISSION_REQUIRED\n from pyramid.view import view_config\n@@ -57,7 +60,8 @@\n settings = request.registry.settings\n hmac_secret = settings['cliquet.userid_hmac_secret']\n # Build the user unguessable bucket_id UUID from its user_id\n- bucket_id = hmac_digest(hmac_secret, request.prefixed_userid)[:32]\n+ digest = hmac_digest(hmac_secret, request.prefixed_userid)\n+ bucket_id = text_type(UUID(digest[:32]))\n path = request.path.replace('default', bucket_id)\n querystring = request.url[(request.url.index(request.path) +\n len(request.path)):]\n", "issue": "Default bucket UUID doesn't have dashes\nI've seen that default record ID's have got dashes whereas default bucket id doesn't.\n\nDoes it makes sense to try to be consistent here?\n\n```\n$ http GET http://localhost:8888/v1/buckets/e93a0bb5b7d16d4f9bfd81b6d737271c -v --auth 'mary:marypassword'\n{\n \"data\": {\n \"id\": \"e93a0bb5b7d16d4f9bfd81b6d737271c\", \n \"last_modified\": 1436191171386\n }, \n [...]\n}\n```\n\n", "before_files": [{"content": "from pyramid.httpexceptions import HTTPForbidden, HTTPPreconditionFailed\nfrom pyramid.security import NO_PERMISSION_REQUIRED\nfrom pyramid.view import view_config\n\nfrom cliquet import resource\nfrom cliquet.utils import hmac_digest, build_request\n\nfrom kinto.views import NameGenerator\n\n\ndef create_bucket(request, bucket_id):\n \"\"\"Create a bucket if it doesn't exists.\"\"\"\n bucket_put = (request.method.lower() == 'put' and\n request.path.endswith('buckets/default'))\n\n if not bucket_put:\n subrequest = build_request(request, {\n 'method': 'PUT',\n 'path': '/buckets/%s' % bucket_id,\n 'body': {\"data\": {}},\n 'headers': {'If-None-Match': '*'.encode('utf-8')}\n })\n\n try:\n request.invoke_subrequest(subrequest)\n except HTTPPreconditionFailed:\n # The bucket already exists\n pass\n\n\ndef create_collection(request, bucket_id):\n subpath = request.matchdict['subpath']\n if subpath.startswith('/collections/'):\n collection_id = subpath.split('/')[2]\n collection_put = (request.method.lower() == 'put' and\n request.path.endswith(collection_id))\n if not collection_put:\n subrequest = build_request(request, {\n 'method': 'PUT',\n 'path': '/buckets/%s/collections/%s' % (\n bucket_id, collection_id),\n 'body': {\"data\": {}},\n 'headers': {'If-None-Match': '*'.encode('utf-8')}\n })\n try:\n request.invoke_subrequest(subrequest)\n except HTTPPreconditionFailed:\n # The collection already exists\n pass\n\n\n@view_config(route_name='default_bucket', permission=NO_PERMISSION_REQUIRED)\ndef default_bucket(request):\n if getattr(request, 'prefixed_userid', None) is None:\n raise HTTPForbidden # Pass through the forbidden_view_config\n\n settings = request.registry.settings\n hmac_secret = settings['cliquet.userid_hmac_secret']\n # Build the user unguessable bucket_id UUID from its user_id\n bucket_id = hmac_digest(hmac_secret, request.prefixed_userid)[:32]\n path = request.path.replace('default', bucket_id)\n querystring = request.url[(request.url.index(request.path) +\n len(request.path)):]\n\n # Make sure bucket exists\n create_bucket(request, bucket_id)\n\n # Make sure the collection exists\n create_collection(request, bucket_id)\n\n subrequest = build_request(request, {\n 'method': request.method,\n 'path': path + querystring,\n 'body': request.body\n })\n\n return request.invoke_subrequest(subrequest)\n\n\[email protected](name='bucket',\n collection_methods=('GET',),\n collection_path='/buckets',\n record_path='/buckets/{{id}}')\nclass Bucket(resource.ProtectedResource):\n permissions = ('read', 'write', 'collection:create', 'group:create')\n\n def __init__(self, *args, **kwargs):\n super(Bucket, self).__init__(*args, **kwargs)\n self.collection.id_generator = NameGenerator()\n\n def get_parent_id(self, request):\n # Buckets are not isolated by user, unlike Cliquet resources.\n return ''\n\n def delete(self):\n result = super(Bucket, self).delete()\n\n # Delete groups.\n storage = self.collection.storage\n parent_id = '/buckets/%s' % self.record_id\n storage.delete_all(collection_id='group', parent_id=parent_id)\n\n # Delete collections.\n deleted = storage.delete_all(collection_id='collection',\n parent_id=parent_id)\n\n # Delete records.\n id_field = self.collection.id_field\n for collection in deleted:\n parent_id = '/buckets/%s/collections/%s' % (self.record_id,\n collection[id_field])\n storage.delete_all(collection_id='record', parent_id=parent_id)\n\n return result\n", "path": "kinto/views/buckets.py"}]}
| 1,781 | 218 |
gh_patches_debug_16866
|
rasdani/github-patches
|
git_diff
|
plone__Products.CMFPlone-1528
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CSS bundles generation breaks background images relative urls
This is a bug related to PR #1300.
</issue>
<code>
[start of Products/CMFPlone/resources/browser/combine.py]
1 import re
2 from zExceptions import NotFound
3 from Acquisition import aq_base
4 from datetime import datetime
5 from plone.registry.interfaces import IRegistry
6 from plone.resource.file import FilesystemFile
7 from plone.resource.interfaces import IResourceDirectory
8 from Products.CMFPlone.interfaces import IBundleRegistry
9 from Products.CMFPlone.interfaces.resources import (
10 OVERRIDE_RESOURCE_DIRECTORY_NAME,
11 )
12 from StringIO import StringIO
13 from zope.component import getUtility
14 from zope.component import queryUtility
15
16 PRODUCTION_RESOURCE_DIRECTORY = "production"
17
18
19 def get_production_resource_directory():
20 persistent_directory = queryUtility(IResourceDirectory, name="persistent")
21 if persistent_directory is None:
22 return ''
23 container = persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]
24 try:
25 production_folder = container[PRODUCTION_RESOURCE_DIRECTORY]
26 except NotFound:
27 return "%s/++unique++1" % PRODUCTION_RESOURCE_DIRECTORY
28 timestamp = production_folder.readFile('timestamp.txt')
29 return "%s/++unique++%s" % (
30 PRODUCTION_RESOURCE_DIRECTORY, timestamp)
31
32
33 def get_resource(context, path):
34 if path.startswith('++plone++'):
35 # ++plone++ resources can be customized, we return their override
36 # value if any
37 overrides = get_override_directory(context)
38 filepath = path[9:]
39 if overrides.isFile(filepath):
40 return overrides.readFile(filepath)
41
42 resource = context.unrestrictedTraverse(path)
43 if isinstance(resource, FilesystemFile):
44 (directory, sep, filename) = path.rpartition('/')
45 return context.unrestrictedTraverse(directory).readFile(filename)
46 else:
47 if hasattr(aq_base(resource), 'GET'):
48 # for FileResource
49 return resource.GET()
50 else:
51 # any BrowserView
52 return resource()
53
54
55 def write_js(context, folder, meta_bundle):
56 registry = getUtility(IRegistry)
57 resources = []
58
59 # default resources
60 if meta_bundle == 'default' and registry.records.get(
61 'plone.resources/jquery.js'
62 ):
63 resources.append(get_resource(context,
64 registry.records['plone.resources/jquery.js'].value))
65 resources.append(get_resource(context,
66 registry.records['plone.resources.requirejs'].value))
67 resources.append(get_resource(context,
68 registry.records['plone.resources.configjs'].value))
69
70 # bundles
71 bundles = registry.collectionOfInterface(
72 IBundleRegistry, prefix="plone.bundles", check=False)
73 for bundle in bundles.values():
74 if bundle.merge_with == meta_bundle and bundle.jscompilation:
75 resources.append(get_resource(context, bundle.jscompilation))
76
77 fi = StringIO()
78 for script in resources:
79 fi.write(script + '\n')
80 folder.writeFile(meta_bundle + ".js", fi)
81
82
83 def write_css(context, folder, meta_bundle):
84 registry = getUtility(IRegistry)
85 resources = []
86
87 bundles = registry.collectionOfInterface(
88 IBundleRegistry, prefix="plone.bundles", check=False)
89 for bundle in bundles.values():
90 if bundle.merge_with == meta_bundle and bundle.csscompilation:
91 css = get_resource(context, bundle.csscompilation)
92 # Preserve relative urls:
93 # we prefix with '../'' any url not starting with '/'
94 # or http: or data:
95 css = re.sub(
96 r"""(url\(['"]?(?!['"]?([a-z]+:|\/)))""",
97 r'\1../',
98 css)
99 resources.append(css)
100
101 fi = StringIO()
102 for script in resources:
103 fi.write(script + '\n')
104 folder.writeFile(meta_bundle + ".css", fi)
105
106
107 def get_override_directory(context):
108 persistent_directory = queryUtility(IResourceDirectory, name="persistent")
109 if persistent_directory is None:
110 return
111 if OVERRIDE_RESOURCE_DIRECTORY_NAME not in persistent_directory:
112 persistent_directory.makeDirectory(OVERRIDE_RESOURCE_DIRECTORY_NAME)
113 return persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]
114
115
116 def combine_bundles(context):
117 container = get_override_directory(context)
118 if PRODUCTION_RESOURCE_DIRECTORY not in container:
119 container.makeDirectory(PRODUCTION_RESOURCE_DIRECTORY)
120 production_folder = container[PRODUCTION_RESOURCE_DIRECTORY]
121
122 # store timestamp
123 fi = StringIO()
124 fi.write(datetime.now().isoformat())
125 production_folder.writeFile("timestamp.txt", fi)
126
127 # generate new combined bundles
128 write_js(context, production_folder, 'default')
129 write_js(context, production_folder, 'logged-in')
130 write_css(context, production_folder, 'default')
131 write_css(context, production_folder, 'logged-in')
132
[end of Products/CMFPlone/resources/browser/combine.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/Products/CMFPlone/resources/browser/combine.py b/Products/CMFPlone/resources/browser/combine.py
--- a/Products/CMFPlone/resources/browser/combine.py
+++ b/Products/CMFPlone/resources/browser/combine.py
@@ -89,12 +89,13 @@
for bundle in bundles.values():
if bundle.merge_with == meta_bundle and bundle.csscompilation:
css = get_resource(context, bundle.csscompilation)
- # Preserve relative urls:
- # we prefix with '../'' any url not starting with '/'
- # or http: or data:
+ (path, sep, filename) = bundle.csscompilation.rpartition('/')
+ # Process relative urls:
+ # we prefix with current resource path any url not starting with
+ # '/' or http: or data:
css = re.sub(
r"""(url\(['"]?(?!['"]?([a-z]+:|\/)))""",
- r'\1../',
+ r'\1%s/' % path,
css)
resources.append(css)
|
{"golden_diff": "diff --git a/Products/CMFPlone/resources/browser/combine.py b/Products/CMFPlone/resources/browser/combine.py\n--- a/Products/CMFPlone/resources/browser/combine.py\n+++ b/Products/CMFPlone/resources/browser/combine.py\n@@ -89,12 +89,13 @@\n for bundle in bundles.values():\n if bundle.merge_with == meta_bundle and bundle.csscompilation:\n css = get_resource(context, bundle.csscompilation)\n- # Preserve relative urls:\n- # we prefix with '../'' any url not starting with '/'\n- # or http: or data:\n+ (path, sep, filename) = bundle.csscompilation.rpartition('/')\n+ # Process relative urls:\n+ # we prefix with current resource path any url not starting with\n+ # '/' or http: or data:\n css = re.sub(\n r\"\"\"(url\\(['\"]?(?!['\"]?([a-z]+:|\\/)))\"\"\",\n- r'\\1../',\n+ r'\\1%s/' % path,\n css)\n resources.append(css)\n", "issue": "CSS bundles generation breaks background images relative urls\nThis is a bug related to PR #1300.\n\n", "before_files": [{"content": "import re\nfrom zExceptions import NotFound\nfrom Acquisition import aq_base\nfrom datetime import datetime\nfrom plone.registry.interfaces import IRegistry\nfrom plone.resource.file import FilesystemFile\nfrom plone.resource.interfaces import IResourceDirectory\nfrom Products.CMFPlone.interfaces import IBundleRegistry\nfrom Products.CMFPlone.interfaces.resources import (\n OVERRIDE_RESOURCE_DIRECTORY_NAME,\n)\nfrom StringIO import StringIO\nfrom zope.component import getUtility\nfrom zope.component import queryUtility\n\nPRODUCTION_RESOURCE_DIRECTORY = \"production\"\n\n\ndef get_production_resource_directory():\n persistent_directory = queryUtility(IResourceDirectory, name=\"persistent\")\n if persistent_directory is None:\n return ''\n container = persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]\n try:\n production_folder = container[PRODUCTION_RESOURCE_DIRECTORY]\n except NotFound:\n return \"%s/++unique++1\" % PRODUCTION_RESOURCE_DIRECTORY\n timestamp = production_folder.readFile('timestamp.txt')\n return \"%s/++unique++%s\" % (\n PRODUCTION_RESOURCE_DIRECTORY, timestamp)\n\n\ndef get_resource(context, path):\n if path.startswith('++plone++'):\n # ++plone++ resources can be customized, we return their override\n # value if any\n overrides = get_override_directory(context)\n filepath = path[9:]\n if overrides.isFile(filepath):\n return overrides.readFile(filepath)\n\n resource = context.unrestrictedTraverse(path)\n if isinstance(resource, FilesystemFile):\n (directory, sep, filename) = path.rpartition('/')\n return context.unrestrictedTraverse(directory).readFile(filename)\n else:\n if hasattr(aq_base(resource), 'GET'):\n # for FileResource\n return resource.GET()\n else:\n # any BrowserView\n return resource()\n\n\ndef write_js(context, folder, meta_bundle):\n registry = getUtility(IRegistry)\n resources = []\n\n # default resources\n if meta_bundle == 'default' and registry.records.get(\n 'plone.resources/jquery.js'\n ):\n resources.append(get_resource(context,\n registry.records['plone.resources/jquery.js'].value))\n resources.append(get_resource(context,\n registry.records['plone.resources.requirejs'].value))\n resources.append(get_resource(context,\n registry.records['plone.resources.configjs'].value))\n\n # bundles\n bundles = registry.collectionOfInterface(\n IBundleRegistry, prefix=\"plone.bundles\", check=False)\n for bundle in bundles.values():\n if bundle.merge_with == meta_bundle and bundle.jscompilation:\n resources.append(get_resource(context, bundle.jscompilation))\n\n fi = StringIO()\n for script in resources:\n fi.write(script + '\\n')\n folder.writeFile(meta_bundle + \".js\", fi)\n\n\ndef write_css(context, folder, meta_bundle):\n registry = getUtility(IRegistry)\n resources = []\n\n bundles = registry.collectionOfInterface(\n IBundleRegistry, prefix=\"plone.bundles\", check=False)\n for bundle in bundles.values():\n if bundle.merge_with == meta_bundle and bundle.csscompilation:\n css = get_resource(context, bundle.csscompilation)\n # Preserve relative urls:\n # we prefix with '../'' any url not starting with '/'\n # or http: or data:\n css = re.sub(\n r\"\"\"(url\\(['\"]?(?!['\"]?([a-z]+:|\\/)))\"\"\",\n r'\\1../',\n css)\n resources.append(css)\n\n fi = StringIO()\n for script in resources:\n fi.write(script + '\\n')\n folder.writeFile(meta_bundle + \".css\", fi)\n\n\ndef get_override_directory(context):\n persistent_directory = queryUtility(IResourceDirectory, name=\"persistent\")\n if persistent_directory is None:\n return\n if OVERRIDE_RESOURCE_DIRECTORY_NAME not in persistent_directory:\n persistent_directory.makeDirectory(OVERRIDE_RESOURCE_DIRECTORY_NAME)\n return persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]\n\n\ndef combine_bundles(context):\n container = get_override_directory(context)\n if PRODUCTION_RESOURCE_DIRECTORY not in container:\n container.makeDirectory(PRODUCTION_RESOURCE_DIRECTORY)\n production_folder = container[PRODUCTION_RESOURCE_DIRECTORY]\n\n # store timestamp\n fi = StringIO()\n fi.write(datetime.now().isoformat())\n production_folder.writeFile(\"timestamp.txt\", fi)\n\n # generate new combined bundles\n write_js(context, production_folder, 'default')\n write_js(context, production_folder, 'logged-in')\n write_css(context, production_folder, 'default')\n write_css(context, production_folder, 'logged-in')\n", "path": "Products/CMFPlone/resources/browser/combine.py"}]}
| 1,806 | 240 |
gh_patches_debug_8379
|
rasdani/github-patches
|
git_diff
|
kedro-org__kedro-3013
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Document the LIFO order in which hooks are executed in `settings.py`
### Description
We mention that hook implementations registered in `settings.py` run in LIFO order and that auto discovered hooks run before hooks in `settings.py`.
- [ ] We need to also document what the order is in which auto-discovered hooks run. Add this to: https://kedro.readthedocs.io/en/stable/hooks/introduction.html To verify the run order, create a project and install several plugins with hooks to test.
- [ ] Add a comment in the `settings.py` template file to explain the run order of hooks
</issue>
<code>
[start of kedro/templates/project/{{ cookiecutter.repo_name }}/src/{{ cookiecutter.python_package }}/settings.py]
1 """Project settings. There is no need to edit this file unless you want to change values
2 from the Kedro defaults. For further information, including these default values, see
3 https://kedro.readthedocs.io/en/stable/kedro_project_setup/settings.html."""
4
5 # Instantiated project hooks.
6 # For example, after creating a hooks.py and defining a ProjectHooks class there, do
7 # from {{cookiecutter.python_package}}.hooks import ProjectHooks
8 # HOOKS = (ProjectHooks(),)
9
10 # Installed plugins for which to disable hook auto-registration.
11 # DISABLE_HOOKS_FOR_PLUGINS = ("kedro-viz",)
12
13 # Class that manages storing KedroSession data.
14 # from kedro.framework.session.store import BaseSessionStore
15 # SESSION_STORE_CLASS = BaseSessionStore
16 # Keyword arguments to pass to the `SESSION_STORE_CLASS` constructor.
17 # SESSION_STORE_ARGS = {
18 # "path": "./sessions"
19 # }
20
21 # Directory that holds configuration.
22 # CONF_SOURCE = "conf"
23
24 # Class that manages how configuration is loaded.
25 from kedro.config import OmegaConfigLoader # noqa: import-outside-toplevel
26
27 CONFIG_LOADER_CLASS = OmegaConfigLoader
28 # Keyword arguments to pass to the `CONFIG_LOADER_CLASS` constructor.
29 # CONFIG_LOADER_ARGS = {
30 # "config_patterns": {
31 # "spark" : ["spark*/"],
32 # "parameters": ["parameters*", "parameters*/**", "**/parameters*"],
33 # }
34 # }
35
36 # Class that manages Kedro's library components.
37 # from kedro.framework.context import KedroContext
38 # CONTEXT_CLASS = KedroContext
39
40 # Class that manages the Data Catalog.
41 # from kedro.io import DataCatalog
42 # DATA_CATALOG_CLASS = DataCatalog
43
[end of kedro/templates/project/{{ cookiecutter.repo_name }}/src/{{ cookiecutter.python_package }}/settings.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kedro/templates/project/{{ cookiecutter.repo_name }}/src/{{ cookiecutter.python_package }}/settings.py b/kedro/templates/project/{{ cookiecutter.repo_name }}/src/{{ cookiecutter.python_package }}/settings.py
--- a/kedro/templates/project/{{ cookiecutter.repo_name }}/src/{{ cookiecutter.python_package }}/settings.py
+++ b/kedro/templates/project/{{ cookiecutter.repo_name }}/src/{{ cookiecutter.python_package }}/settings.py
@@ -5,6 +5,7 @@
# Instantiated project hooks.
# For example, after creating a hooks.py and defining a ProjectHooks class there, do
# from {{cookiecutter.python_package}}.hooks import ProjectHooks
+# Hooks are executed in a Last-In-First-Out (LIFO) order.
# HOOKS = (ProjectHooks(),)
# Installed plugins for which to disable hook auto-registration.
|
{"golden_diff": "diff --git a/kedro/templates/project/{{ cookiecutter.repo_name }}/src/{{ cookiecutter.python_package }}/settings.py b/kedro/templates/project/{{ cookiecutter.repo_name }}/src/{{ cookiecutter.python_package }}/settings.py\n--- a/kedro/templates/project/{{ cookiecutter.repo_name }}/src/{{ cookiecutter.python_package }}/settings.py\t\n+++ b/kedro/templates/project/{{ cookiecutter.repo_name }}/src/{{ cookiecutter.python_package }}/settings.py\t\n@@ -5,6 +5,7 @@\n # Instantiated project hooks.\n # For example, after creating a hooks.py and defining a ProjectHooks class there, do\n # from {{cookiecutter.python_package}}.hooks import ProjectHooks\n+# Hooks are executed in a Last-In-First-Out (LIFO) order.\n # HOOKS = (ProjectHooks(),)\n \n # Installed plugins for which to disable hook auto-registration.\n", "issue": "Document the LIFO order in which hooks are executed in `settings.py`\n### Description\r\n\r\nWe mention that hook implementations registered in `settings.py` run in LIFO order and that auto discovered hooks run before hooks in `settings.py`. \r\n\r\n- [ ] We need to also document what the order is in which auto-discovered hooks run. Add this to: https://kedro.readthedocs.io/en/stable/hooks/introduction.html To verify the run order, create a project and install several plugins with hooks to test.\r\n- [ ] Add a comment in the `settings.py` template file to explain the run order of hooks\n", "before_files": [{"content": "\"\"\"Project settings. There is no need to edit this file unless you want to change values\nfrom the Kedro defaults. For further information, including these default values, see\nhttps://kedro.readthedocs.io/en/stable/kedro_project_setup/settings.html.\"\"\"\n\n# Instantiated project hooks.\n# For example, after creating a hooks.py and defining a ProjectHooks class there, do\n# from {{cookiecutter.python_package}}.hooks import ProjectHooks\n# HOOKS = (ProjectHooks(),)\n\n# Installed plugins for which to disable hook auto-registration.\n# DISABLE_HOOKS_FOR_PLUGINS = (\"kedro-viz\",)\n\n# Class that manages storing KedroSession data.\n# from kedro.framework.session.store import BaseSessionStore\n# SESSION_STORE_CLASS = BaseSessionStore\n# Keyword arguments to pass to the `SESSION_STORE_CLASS` constructor.\n# SESSION_STORE_ARGS = {\n# \"path\": \"./sessions\"\n# }\n\n# Directory that holds configuration.\n# CONF_SOURCE = \"conf\"\n\n# Class that manages how configuration is loaded.\nfrom kedro.config import OmegaConfigLoader # noqa: import-outside-toplevel\n\nCONFIG_LOADER_CLASS = OmegaConfigLoader\n# Keyword arguments to pass to the `CONFIG_LOADER_CLASS` constructor.\n# CONFIG_LOADER_ARGS = {\n# \"config_patterns\": {\n# \"spark\" : [\"spark*/\"],\n# \"parameters\": [\"parameters*\", \"parameters*/**\", \"**/parameters*\"],\n# }\n# }\n\n# Class that manages Kedro's library components.\n# from kedro.framework.context import KedroContext\n# CONTEXT_CLASS = KedroContext\n\n# Class that manages the Data Catalog.\n# from kedro.io import DataCatalog\n# DATA_CATALOG_CLASS = DataCatalog\n", "path": "kedro/templates/project/{{ cookiecutter.repo_name }}/src/{{ cookiecutter.python_package }}/settings.py"}]}
| 1,143 | 190 |
gh_patches_debug_35493
|
rasdani/github-patches
|
git_diff
|
rasterio__rasterio-287
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Reprojection Example/Documentation
I was having some trouble following the [reprojection](https://github.com/mapbox/rasterio/blob/master/examples/reproject.py) example; the Affine parameters for `dst_transform` aren't referenced anywhere before they are applied:
https://github.com/mapbox/rasterio/blob/master/examples/reproject.py#L29
</issue>
<code>
[start of rasterio/transform.py]
1 import warnings
2
3 from affine import Affine
4
5 IDENTITY = Affine.identity()
6
7
8 def tastes_like_gdal(seq):
9 """Return True if `seq` matches the GDAL geotransform pattern."""
10 return seq[2] == seq[4] == 0.0 and seq[1] > 0 and seq[5] < 0
11
12
13 def guard_transform(transform):
14 """Return an Affine transformation instance"""
15 if not isinstance(transform, Affine):
16 if tastes_like_gdal(transform):
17 warnings.warn(
18 "GDAL-style transforms are deprecated and will not "
19 "be supported in Rasterio 1.0.",
20 FutureWarning,
21 stacklevel=2)
22 transform = Affine.from_gdal(*transform)
23 else:
24 transform = Affine(*transform)
25 return transform
26
[end of rasterio/transform.py]
[start of examples/reproject.py]
1 import os
2 import shutil
3 import subprocess
4 import tempfile
5
6 import numpy
7 import rasterio
8 from rasterio import Affine as A
9 from rasterio.warp import reproject, RESAMPLING
10
11 tempdir = '/tmp'
12 tiffname = os.path.join(tempdir, 'example.tif')
13
14 with rasterio.drivers():
15
16 # Consider a 512 x 512 raster centered on 0 degrees E and 0 degrees N
17 # with each pixel covering 15".
18 rows, cols = src_shape = (512, 512)
19 dpp = 1.0/240 # decimal degrees per pixel
20 # The following is equivalent to
21 # A(dpp, 0, -cols*dpp/2, 0, -dpp, rows*dpp/2).
22 src_transform = A.translation(-cols*dpp/2, rows*dpp/2) * A.scale(dpp, -dpp)
23 src_crs = {'init': 'EPSG:4326'}
24 source = numpy.ones(src_shape, numpy.uint8)*255
25
26 # Prepare to reproject this rasters to a 1024 x 1024 dataset in
27 # Web Mercator (EPSG:3857) with origin at -8928592, 2999585.
28 dst_shape = (1024, 1024)
29 dst_transform = A.from_gdal(-237481.5, 425.0, 0.0, 237536.4, 0.0, -425.0)
30 dst_transform = dst_transform.to_gdal()
31 dst_crs = {'init': 'EPSG:3857'}
32 destination = numpy.zeros(dst_shape, numpy.uint8)
33
34 reproject(
35 source,
36 destination,
37 src_transform=src_transform,
38 src_crs=src_crs,
39 dst_transform=dst_transform,
40 dst_crs=dst_crs,
41 resampling=RESAMPLING.nearest)
42
43 # Assert that the destination is only partly filled.
44 assert destination.any()
45 assert not destination.all()
46
47 # Write it out to a file.
48 with rasterio.open(
49 tiffname,
50 'w',
51 driver='GTiff',
52 width=dst_shape[1],
53 height=dst_shape[0],
54 count=1,
55 dtype=numpy.uint8,
56 nodata=0,
57 transform=dst_transform,
58 crs=dst_crs) as dst:
59 dst.write_band(1, destination)
60
61 info = subprocess.call(['open', tiffname])
62
63
[end of examples/reproject.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/reproject.py b/examples/reproject.py
--- a/examples/reproject.py
+++ b/examples/reproject.py
@@ -5,7 +5,7 @@
import numpy
import rasterio
-from rasterio import Affine as A
+from rasterio import transform
from rasterio.warp import reproject, RESAMPLING
tempdir = '/tmp'
@@ -17,17 +17,15 @@
# with each pixel covering 15".
rows, cols = src_shape = (512, 512)
dpp = 1.0/240 # decimal degrees per pixel
- # The following is equivalent to
- # A(dpp, 0, -cols*dpp/2, 0, -dpp, rows*dpp/2).
- src_transform = A.translation(-cols*dpp/2, rows*dpp/2) * A.scale(dpp, -dpp)
+ west, south, east, north = -cols*dpp/2, -rows*dpp/2, cols*dpp/2, rows*dpp/2
+ src_transform = transform.from_bounds(west, south, east, north, cols, rows)
src_crs = {'init': 'EPSG:4326'}
source = numpy.ones(src_shape, numpy.uint8)*255
# Prepare to reproject this rasters to a 1024 x 1024 dataset in
- # Web Mercator (EPSG:3857) with origin at -8928592, 2999585.
+ # Web Mercator (EPSG:3857) with origin at -237481.5, 237536.4.
dst_shape = (1024, 1024)
- dst_transform = A.from_gdal(-237481.5, 425.0, 0.0, 237536.4, 0.0, -425.0)
- dst_transform = dst_transform.to_gdal()
+ dst_transform = transform.from_origin(-237481.5, 237536.4, 425.0, 425.0)
dst_crs = {'init': 'EPSG:3857'}
destination = numpy.zeros(dst_shape, numpy.uint8)
@@ -59,4 +57,3 @@
dst.write_band(1, destination)
info = subprocess.call(['open', tiffname])
-
diff --git a/rasterio/transform.py b/rasterio/transform.py
--- a/rasterio/transform.py
+++ b/rasterio/transform.py
@@ -23,3 +23,18 @@
else:
transform = Affine(*transform)
return transform
+
+
+def from_origin(west, north, xsize, ysize):
+ """Return an Affine transformation for a georeferenced raster given
+ the coordinates of its upper left corner `west`, `north` and pixel
+ sizes `xsize`, `ysize`."""
+ return Affine.translation(west, north) * Affine.scale(xsize, -ysize)
+
+
+def from_bounds(west, south, east, north, width, height):
+ """Return an Affine transformation for a georeferenced raster given
+ its bounds `west`, `south`, `east`, `north` and its `width` and
+ `height` in number of pixels."""
+ return Affine.translation(west, north) * Affine.scale(
+ (east - west)/width, (south - north)/height)
|
{"golden_diff": "diff --git a/examples/reproject.py b/examples/reproject.py\n--- a/examples/reproject.py\n+++ b/examples/reproject.py\n@@ -5,7 +5,7 @@\n \n import numpy\n import rasterio\n-from rasterio import Affine as A\n+from rasterio import transform\n from rasterio.warp import reproject, RESAMPLING\n \n tempdir = '/tmp'\n@@ -17,17 +17,15 @@\n # with each pixel covering 15\".\n rows, cols = src_shape = (512, 512)\n dpp = 1.0/240 # decimal degrees per pixel\n- # The following is equivalent to \n- # A(dpp, 0, -cols*dpp/2, 0, -dpp, rows*dpp/2).\n- src_transform = A.translation(-cols*dpp/2, rows*dpp/2) * A.scale(dpp, -dpp)\n+ west, south, east, north = -cols*dpp/2, -rows*dpp/2, cols*dpp/2, rows*dpp/2\n+ src_transform = transform.from_bounds(west, south, east, north, cols, rows)\n src_crs = {'init': 'EPSG:4326'}\n source = numpy.ones(src_shape, numpy.uint8)*255\n \n # Prepare to reproject this rasters to a 1024 x 1024 dataset in\n- # Web Mercator (EPSG:3857) with origin at -8928592, 2999585.\n+ # Web Mercator (EPSG:3857) with origin at -237481.5, 237536.4.\n dst_shape = (1024, 1024)\n- dst_transform = A.from_gdal(-237481.5, 425.0, 0.0, 237536.4, 0.0, -425.0)\n- dst_transform = dst_transform.to_gdal()\n+ dst_transform = transform.from_origin(-237481.5, 237536.4, 425.0, 425.0)\n dst_crs = {'init': 'EPSG:3857'}\n destination = numpy.zeros(dst_shape, numpy.uint8)\n \n@@ -59,4 +57,3 @@\n dst.write_band(1, destination)\n \n info = subprocess.call(['open', tiffname])\n-\ndiff --git a/rasterio/transform.py b/rasterio/transform.py\n--- a/rasterio/transform.py\n+++ b/rasterio/transform.py\n@@ -23,3 +23,18 @@\n else:\n transform = Affine(*transform)\n return transform\n+\n+\n+def from_origin(west, north, xsize, ysize):\n+ \"\"\"Return an Affine transformation for a georeferenced raster given\n+ the coordinates of its upper left corner `west`, `north` and pixel\n+ sizes `xsize`, `ysize`.\"\"\"\n+ return Affine.translation(west, north) * Affine.scale(xsize, -ysize)\n+\n+\n+def from_bounds(west, south, east, north, width, height):\n+ \"\"\"Return an Affine transformation for a georeferenced raster given\n+ its bounds `west`, `south`, `east`, `north` and its `width` and\n+ `height` in number of pixels.\"\"\"\n+ return Affine.translation(west, north) * Affine.scale(\n+ (east - west)/width, (south - north)/height)\n", "issue": "Reprojection Example/Documentation\nI was having some trouble following the [reprojection](https://github.com/mapbox/rasterio/blob/master/examples/reproject.py) example; the Affine parameters for `dst_transform` aren't referenced anywhere before they are applied:\n\nhttps://github.com/mapbox/rasterio/blob/master/examples/reproject.py#L29\n\n", "before_files": [{"content": "import warnings\n\nfrom affine import Affine\n\nIDENTITY = Affine.identity()\n\n\ndef tastes_like_gdal(seq):\n \"\"\"Return True if `seq` matches the GDAL geotransform pattern.\"\"\"\n return seq[2] == seq[4] == 0.0 and seq[1] > 0 and seq[5] < 0\n\n\ndef guard_transform(transform):\n \"\"\"Return an Affine transformation instance\"\"\"\n if not isinstance(transform, Affine):\n if tastes_like_gdal(transform):\n warnings.warn(\n \"GDAL-style transforms are deprecated and will not \"\n \"be supported in Rasterio 1.0.\",\n FutureWarning,\n stacklevel=2)\n transform = Affine.from_gdal(*transform)\n else:\n transform = Affine(*transform)\n return transform\n", "path": "rasterio/transform.py"}, {"content": "import os\nimport shutil\nimport subprocess\nimport tempfile\n\nimport numpy\nimport rasterio\nfrom rasterio import Affine as A\nfrom rasterio.warp import reproject, RESAMPLING\n\ntempdir = '/tmp'\ntiffname = os.path.join(tempdir, 'example.tif')\n\nwith rasterio.drivers():\n\n # Consider a 512 x 512 raster centered on 0 degrees E and 0 degrees N\n # with each pixel covering 15\".\n rows, cols = src_shape = (512, 512)\n dpp = 1.0/240 # decimal degrees per pixel\n # The following is equivalent to \n # A(dpp, 0, -cols*dpp/2, 0, -dpp, rows*dpp/2).\n src_transform = A.translation(-cols*dpp/2, rows*dpp/2) * A.scale(dpp, -dpp)\n src_crs = {'init': 'EPSG:4326'}\n source = numpy.ones(src_shape, numpy.uint8)*255\n\n # Prepare to reproject this rasters to a 1024 x 1024 dataset in\n # Web Mercator (EPSG:3857) with origin at -8928592, 2999585.\n dst_shape = (1024, 1024)\n dst_transform = A.from_gdal(-237481.5, 425.0, 0.0, 237536.4, 0.0, -425.0)\n dst_transform = dst_transform.to_gdal()\n dst_crs = {'init': 'EPSG:3857'}\n destination = numpy.zeros(dst_shape, numpy.uint8)\n\n reproject(\n source, \n destination, \n src_transform=src_transform,\n src_crs=src_crs,\n dst_transform=dst_transform,\n dst_crs=dst_crs,\n resampling=RESAMPLING.nearest)\n\n # Assert that the destination is only partly filled.\n assert destination.any()\n assert not destination.all()\n\n # Write it out to a file.\n with rasterio.open(\n tiffname, \n 'w',\n driver='GTiff',\n width=dst_shape[1],\n height=dst_shape[0],\n count=1,\n dtype=numpy.uint8,\n nodata=0,\n transform=dst_transform,\n crs=dst_crs) as dst:\n dst.write_band(1, destination)\n\ninfo = subprocess.call(['open', tiffname])\n\n", "path": "examples/reproject.py"}]}
| 1,553 | 835 |
gh_patches_debug_1604
|
rasdani/github-patches
|
git_diff
|
swcarpentry__python-novice-inflammation-946
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Code provided for students contain python code not compatible with python 3
At least one file in the `code` directory, e.g., `gen_inflammation.py` fails when running it with python 3. The [problem is the "division" not giving an integer](https://github.com/swcarpentry/python-novice-inflammation/blob/11643f14d31726f2f60873c4ca1230fff0bbf108/code/gen_inflammation.py#L19). It needs to be changed to
```diff
- upper / 4
+ upper // 4
```
This was spotted by a student trying to check their installation and running different files.
Other files may have similar errors. I'd suggest running and testing via CI everything we provide to the students.
</issue>
<code>
[start of code/gen_inflammation.py]
1 #!/usr/bin/env python
2
3 """
4 Generate pseudo-random patient inflammation data for use in Python lessons.
5 """
6
7 import random
8
9 n_patients = 60
10 n_days = 40
11 n_range = 20
12
13 middle = n_days / 2
14
15 for p in range(n_patients):
16 vals = []
17 for d in range(n_days):
18 upper = max(n_range - abs(d - middle), 0)
19 vals.append(random.randint(upper/4, upper))
20 print(','.join([str(v) for v in vals]))
21
[end of code/gen_inflammation.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/code/gen_inflammation.py b/code/gen_inflammation.py
--- a/code/gen_inflammation.py
+++ b/code/gen_inflammation.py
@@ -16,5 +16,5 @@
vals = []
for d in range(n_days):
upper = max(n_range - abs(d - middle), 0)
- vals.append(random.randint(upper/4, upper))
+ vals.append(random.randint(upper//4, upper))
print(','.join([str(v) for v in vals]))
|
{"golden_diff": "diff --git a/code/gen_inflammation.py b/code/gen_inflammation.py\n--- a/code/gen_inflammation.py\n+++ b/code/gen_inflammation.py\n@@ -16,5 +16,5 @@\n vals = []\n for d in range(n_days):\n upper = max(n_range - abs(d - middle), 0)\n- vals.append(random.randint(upper/4, upper))\n+ vals.append(random.randint(upper//4, upper))\n print(','.join([str(v) for v in vals]))\n", "issue": "Code provided for students contain python code not compatible with python 3\nAt least one file in the `code` directory, e.g., `gen_inflammation.py` fails when running it with python 3. The [problem is the \"division\" not giving an integer](https://github.com/swcarpentry/python-novice-inflammation/blob/11643f14d31726f2f60873c4ca1230fff0bbf108/code/gen_inflammation.py#L19). It needs to be changed to\r\n```diff\r\n- upper / 4\r\n+ upper // 4\r\n```\r\n\r\nThis was spotted by a student trying to check their installation and running different files.\r\nOther files may have similar errors. I'd suggest running and testing via CI everything we provide to the students.\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\n\n\"\"\"\nGenerate pseudo-random patient inflammation data for use in Python lessons.\n\"\"\"\n\nimport random\n\nn_patients = 60\nn_days = 40\nn_range = 20\n\nmiddle = n_days / 2\n\nfor p in range(n_patients):\n vals = []\n for d in range(n_days):\n upper = max(n_range - abs(d - middle), 0)\n vals.append(random.randint(upper/4, upper))\n print(','.join([str(v) for v in vals]))\n", "path": "code/gen_inflammation.py"}]}
| 876 | 116 |
gh_patches_debug_24699
|
rasdani/github-patches
|
git_diff
|
HypothesisWorks__hypothesis-285
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
django_polymorphic breaks model generation
`django_polymorphic` adds mandatory fields (named `*_ptr`) to models, but gives them values when the model is created. Hypothesis sees these as normal non-nullable fields, which trigger the relevant health check. However, explicitly providing a value for one of these fields causes an exception to be thrown in the model's constructor.
</issue>
<code>
[start of src/hypothesis/extra/django/models.py]
1 # coding=utf-8
2 #
3 # This file is part of Hypothesis (https://github.com/DRMacIver/hypothesis)
4 #
5 # Most of this work is copyright (C) 2013-2015 David R. MacIver
6 # ([email protected]), but it contains contributions by others. See
7 # https://github.com/DRMacIver/hypothesis/blob/master/CONTRIBUTING.rst for a
8 # full list of people who may hold copyright, and consult the git log if you
9 # need to determine who owns an individual contribution.
10 #
11 # This Source Code Form is subject to the terms of the Mozilla Public License,
12 # v. 2.0. If a copy of the MPL was not distributed with this file, You can
13 # obtain one at http://mozilla.org/MPL/2.0/.
14 #
15 # END HEADER
16
17 from __future__ import division, print_function, absolute_import
18
19 import django.db.models as dm
20 from django.db import IntegrityError
21
22 import hypothesis.strategies as st
23 import hypothesis.extra.fakefactory as ff
24 from hypothesis.errors import InvalidArgument
25 from hypothesis.extra.datetime import datetimes
26 from hypothesis.searchstrategy.strategies import SearchStrategy
27
28
29 class ModelNotSupported(Exception):
30 pass
31
32
33 def referenced_models(model, seen=None):
34 if seen is None:
35 seen = set()
36 for f in model._meta.concrete_fields:
37 if isinstance(f, dm.ForeignKey):
38 t = f.rel.to
39 if t not in seen:
40 seen.add(t)
41 referenced_models(t, seen)
42 return seen
43
44
45 __default_field_mappings = None
46
47
48 def field_mappings():
49 global __default_field_mappings
50
51 if __default_field_mappings is None:
52 __default_field_mappings = {
53 dm.SmallIntegerField: st.integers(-32768, 32767),
54 dm.IntegerField: st.integers(-2147483648, 2147483647),
55 dm.BigIntegerField:
56 st.integers(-9223372036854775808, 9223372036854775807),
57 dm.PositiveIntegerField: st.integers(0, 2147483647),
58 dm.PositiveSmallIntegerField: st.integers(0, 32767),
59 dm.BinaryField: st.binary(),
60 dm.BooleanField: st.booleans(),
61 dm.CharField: st.text(),
62 dm.TextField: st.text(),
63 dm.DateTimeField: datetimes(allow_naive=False),
64 dm.EmailField: ff.fake_factory(u'email'),
65 dm.FloatField: st.floats(),
66 dm.NullBooleanField: st.one_of(st.none(), st.booleans()),
67 }
68 return __default_field_mappings
69
70
71 def add_default_field_mapping(field_type, strategy):
72 field_mappings()[field_type] = strategy
73
74
75 def models(model, **extra):
76 result = {}
77 mappings = field_mappings()
78 mandatory = set()
79 for f in model._meta.concrete_fields:
80 if isinstance(f, dm.AutoField):
81 continue
82 try:
83 mapped = mappings[type(f)]
84 except KeyError:
85 if not f.null:
86 mandatory.add(f.name)
87 continue
88 if f.null:
89 mapped = st.one_of(st.none(), mapped)
90 result[f.name] = mapped
91 missed = {x for x in mandatory if x not in extra}
92 if missed:
93 raise InvalidArgument((
94 u'Missing arguments for mandatory field%s %s for model %s' % (
95 u's' if len(missed) > 1 else u'',
96 u', '.join(missed),
97 model.__name__,
98 )))
99 for k, v in extra.items():
100 if isinstance(v, SearchStrategy):
101 result[k] = v
102 else:
103 result[k] = st.just(v)
104 result.update(extra)
105 return ModelStrategy(model, result)
106
107
108 class ModelStrategy(SearchStrategy):
109
110 def __init__(self, model, mappings):
111 super(ModelStrategy, self).__init__()
112 self.model = model
113 self.arg_strategy = st.fixed_dictionaries(mappings)
114
115 def __repr__(self):
116 return u'ModelStrategy(%s)' % (self.model.__name__,)
117
118 def do_draw(self, data):
119 try:
120 result, _ = self.model.objects.get_or_create(
121 **self.arg_strategy.do_draw(data)
122 )
123 return result
124 except IntegrityError:
125 data.mark_invalid()
126
[end of src/hypothesis/extra/django/models.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/hypothesis/extra/django/models.py b/src/hypothesis/extra/django/models.py
--- a/src/hypothesis/extra/django/models.py
+++ b/src/hypothesis/extra/django/models.py
@@ -23,6 +23,7 @@
import hypothesis.extra.fakefactory as ff
from hypothesis.errors import InvalidArgument
from hypothesis.extra.datetime import datetimes
+from hypothesis.utils.conventions import UniqueIdentifier
from hypothesis.searchstrategy.strategies import SearchStrategy
@@ -72,6 +73,9 @@
field_mappings()[field_type] = strategy
+default_value = UniqueIdentifier(u'default_value')
+
+
def models(model, **extra):
result = {}
mappings = field_mappings()
@@ -96,12 +100,9 @@
u', '.join(missed),
model.__name__,
)))
- for k, v in extra.items():
- if isinstance(v, SearchStrategy):
- result[k] = v
- else:
- result[k] = st.just(v)
result.update(extra)
+ # Remove default_values so we don't try to generate anything for those.
+ result = {k: v for k, v in result.items() if v is not default_value}
return ModelStrategy(model, result)
|
{"golden_diff": "diff --git a/src/hypothesis/extra/django/models.py b/src/hypothesis/extra/django/models.py\n--- a/src/hypothesis/extra/django/models.py\n+++ b/src/hypothesis/extra/django/models.py\n@@ -23,6 +23,7 @@\n import hypothesis.extra.fakefactory as ff\n from hypothesis.errors import InvalidArgument\n from hypothesis.extra.datetime import datetimes\n+from hypothesis.utils.conventions import UniqueIdentifier\n from hypothesis.searchstrategy.strategies import SearchStrategy\n \n \n@@ -72,6 +73,9 @@\n field_mappings()[field_type] = strategy\n \n \n+default_value = UniqueIdentifier(u'default_value')\n+\n+\n def models(model, **extra):\n result = {}\n mappings = field_mappings()\n@@ -96,12 +100,9 @@\n u', '.join(missed),\n model.__name__,\n )))\n- for k, v in extra.items():\n- if isinstance(v, SearchStrategy):\n- result[k] = v\n- else:\n- result[k] = st.just(v)\n result.update(extra)\n+ # Remove default_values so we don't try to generate anything for those.\n+ result = {k: v for k, v in result.items() if v is not default_value}\n return ModelStrategy(model, result)\n", "issue": "django_polymorphic breaks model generation\n`django_polymorphic` adds mandatory fields (named `*_ptr`) to models, but gives them values when the model is created. Hypothesis sees these as normal non-nullable fields, which trigger the relevant health check. However, explicitly providing a value for one of these fields causes an exception to be thrown in the model's constructor.\n\n", "before_files": [{"content": "# coding=utf-8\n#\n# This file is part of Hypothesis (https://github.com/DRMacIver/hypothesis)\n#\n# Most of this work is copyright (C) 2013-2015 David R. MacIver\n# ([email protected]), but it contains contributions by others. See\n# https://github.com/DRMacIver/hypothesis/blob/master/CONTRIBUTING.rst for a\n# full list of people who may hold copyright, and consult the git log if you\n# need to determine who owns an individual contribution.\n#\n# This Source Code Form is subject to the terms of the Mozilla Public License,\n# v. 2.0. If a copy of the MPL was not distributed with this file, You can\n# obtain one at http://mozilla.org/MPL/2.0/.\n#\n# END HEADER\n\nfrom __future__ import division, print_function, absolute_import\n\nimport django.db.models as dm\nfrom django.db import IntegrityError\n\nimport hypothesis.strategies as st\nimport hypothesis.extra.fakefactory as ff\nfrom hypothesis.errors import InvalidArgument\nfrom hypothesis.extra.datetime import datetimes\nfrom hypothesis.searchstrategy.strategies import SearchStrategy\n\n\nclass ModelNotSupported(Exception):\n pass\n\n\ndef referenced_models(model, seen=None):\n if seen is None:\n seen = set()\n for f in model._meta.concrete_fields:\n if isinstance(f, dm.ForeignKey):\n t = f.rel.to\n if t not in seen:\n seen.add(t)\n referenced_models(t, seen)\n return seen\n\n\n__default_field_mappings = None\n\n\ndef field_mappings():\n global __default_field_mappings\n\n if __default_field_mappings is None:\n __default_field_mappings = {\n dm.SmallIntegerField: st.integers(-32768, 32767),\n dm.IntegerField: st.integers(-2147483648, 2147483647),\n dm.BigIntegerField:\n st.integers(-9223372036854775808, 9223372036854775807),\n dm.PositiveIntegerField: st.integers(0, 2147483647),\n dm.PositiveSmallIntegerField: st.integers(0, 32767),\n dm.BinaryField: st.binary(),\n dm.BooleanField: st.booleans(),\n dm.CharField: st.text(),\n dm.TextField: st.text(),\n dm.DateTimeField: datetimes(allow_naive=False),\n dm.EmailField: ff.fake_factory(u'email'),\n dm.FloatField: st.floats(),\n dm.NullBooleanField: st.one_of(st.none(), st.booleans()),\n }\n return __default_field_mappings\n\n\ndef add_default_field_mapping(field_type, strategy):\n field_mappings()[field_type] = strategy\n\n\ndef models(model, **extra):\n result = {}\n mappings = field_mappings()\n mandatory = set()\n for f in model._meta.concrete_fields:\n if isinstance(f, dm.AutoField):\n continue\n try:\n mapped = mappings[type(f)]\n except KeyError:\n if not f.null:\n mandatory.add(f.name)\n continue\n if f.null:\n mapped = st.one_of(st.none(), mapped)\n result[f.name] = mapped\n missed = {x for x in mandatory if x not in extra}\n if missed:\n raise InvalidArgument((\n u'Missing arguments for mandatory field%s %s for model %s' % (\n u's' if len(missed) > 1 else u'',\n u', '.join(missed),\n model.__name__,\n )))\n for k, v in extra.items():\n if isinstance(v, SearchStrategy):\n result[k] = v\n else:\n result[k] = st.just(v)\n result.update(extra)\n return ModelStrategy(model, result)\n\n\nclass ModelStrategy(SearchStrategy):\n\n def __init__(self, model, mappings):\n super(ModelStrategy, self).__init__()\n self.model = model\n self.arg_strategy = st.fixed_dictionaries(mappings)\n\n def __repr__(self):\n return u'ModelStrategy(%s)' % (self.model.__name__,)\n\n def do_draw(self, data):\n try:\n result, _ = self.model.objects.get_or_create(\n **self.arg_strategy.do_draw(data)\n )\n return result\n except IntegrityError:\n data.mark_invalid()\n", "path": "src/hypothesis/extra/django/models.py"}]}
| 1,873 | 287 |
gh_patches_debug_1180
|
rasdani/github-patches
|
git_diff
|
encode__httpx-1054
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Type-checking our tests
I know this is not a standard thing to do across Encode projects, but I've been wondering if it would be worth starting to type-hint our tests.
I've seen at least two instances of this recently:
- In HTTPX: https://github.com/encode/httpx/pull/648#discussion_r359862603
- In Starlette: https://github.com/encode/starlette/issues/722
My rationale is based on two aspects:
- It improves our upfront knowledge about how users will actually use HTTPX — currently their usage of type hints in the wild is not reflected anywhere.
- It helps us catch type hint inconsistencies we wouldn't see in the core package.
The main counter-argument, I suppose, is that type hinting tests is tedious. I think that's fair, but I believe the two pro's above make it compelling.
Thoughts?
</issue>
<code>
[start of httpx/_types.py]
1 """
2 Type definitions for type checking purposes.
3 """
4
5 import ssl
6 from http.cookiejar import CookieJar
7 from typing import (
8 IO,
9 TYPE_CHECKING,
10 AsyncIterator,
11 Callable,
12 Dict,
13 Iterator,
14 List,
15 Mapping,
16 Optional,
17 Sequence,
18 Tuple,
19 Union,
20 )
21
22 if TYPE_CHECKING: # pragma: no cover
23 from ._auth import Auth # noqa: F401
24 from ._config import Proxy, Timeout # noqa: F401
25 from ._models import URL, Cookies, Headers, QueryParams, Request # noqa: F401
26
27
28 PrimitiveData = Optional[Union[str, int, float, bool]]
29
30 URLTypes = Union["URL", str]
31
32 QueryParamTypes = Union[
33 "QueryParams",
34 Mapping[str, Union[PrimitiveData, Sequence[PrimitiveData]]],
35 List[Tuple[str, PrimitiveData]],
36 str,
37 ]
38
39 HeaderTypes = Union[
40 "Headers",
41 Dict[str, str],
42 Dict[bytes, bytes],
43 Sequence[Tuple[str, str]],
44 Sequence[Tuple[bytes, bytes]],
45 ]
46
47 CookieTypes = Union["Cookies", CookieJar, Dict[str, str]]
48
49 CertTypes = Union[str, Tuple[str, str], Tuple[str, str, str]]
50 VerifyTypes = Union[str, bool, ssl.SSLContext]
51 TimeoutTypes = Union[
52 Optional[float],
53 Tuple[Optional[float], Optional[float], Optional[float], Optional[float]],
54 "Timeout",
55 ]
56 ProxiesTypes = Union[URLTypes, "Proxy", Dict[URLTypes, Union[URLTypes, "Proxy"]]]
57
58 AuthTypes = Union[
59 Tuple[Union[str, bytes], Union[str, bytes]],
60 Callable[["Request"], "Request"],
61 "Auth",
62 ]
63
64 RequestData = Union[dict, str, bytes, Iterator[bytes], AsyncIterator[bytes]]
65
66 FileContent = Union[IO[str], IO[bytes], str, bytes]
67 FileTypes = Union[
68 # file (or text)
69 FileContent,
70 # (filename, file (or text))
71 Tuple[Optional[str], FileContent],
72 # (filename, file (or text), content_type)
73 Tuple[Optional[str], FileContent, Optional[str]],
74 ]
75 RequestFiles = Union[Mapping[str, FileTypes], List[Tuple[str, FileTypes]]]
76
[end of httpx/_types.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/httpx/_types.py b/httpx/_types.py
--- a/httpx/_types.py
+++ b/httpx/_types.py
@@ -72,4 +72,4 @@
# (filename, file (or text), content_type)
Tuple[Optional[str], FileContent, Optional[str]],
]
-RequestFiles = Union[Mapping[str, FileTypes], List[Tuple[str, FileTypes]]]
+RequestFiles = Union[Mapping[str, FileTypes], Sequence[Tuple[str, FileTypes]]]
|
{"golden_diff": "diff --git a/httpx/_types.py b/httpx/_types.py\n--- a/httpx/_types.py\n+++ b/httpx/_types.py\n@@ -72,4 +72,4 @@\n # (filename, file (or text), content_type)\n Tuple[Optional[str], FileContent, Optional[str]],\n ]\n-RequestFiles = Union[Mapping[str, FileTypes], List[Tuple[str, FileTypes]]]\n+RequestFiles = Union[Mapping[str, FileTypes], Sequence[Tuple[str, FileTypes]]]\n", "issue": "Type-checking our tests\nI know this is not a standard thing to do across Encode projects, but I've been wondering if it would be worth starting to type-hint our tests.\r\n\r\nI've seen at least two instances of this recently:\r\n\r\n- In HTTPX: https://github.com/encode/httpx/pull/648#discussion_r359862603\r\n- In Starlette: https://github.com/encode/starlette/issues/722\r\n\r\nMy rationale is based on two aspects:\r\n\r\n- It improves our upfront knowledge about how users will actually use HTTPX \u2014 currently their usage of type hints in the wild is not reflected anywhere.\r\n- It helps us catch type hint inconsistencies we wouldn't see in the core package.\r\n\r\nThe main counter-argument, I suppose, is that type hinting tests is tedious. I think that's fair, but I believe the two pro's above make it compelling.\r\n\r\nThoughts?\n", "before_files": [{"content": "\"\"\"\nType definitions for type checking purposes.\n\"\"\"\n\nimport ssl\nfrom http.cookiejar import CookieJar\nfrom typing import (\n IO,\n TYPE_CHECKING,\n AsyncIterator,\n Callable,\n Dict,\n Iterator,\n List,\n Mapping,\n Optional,\n Sequence,\n Tuple,\n Union,\n)\n\nif TYPE_CHECKING: # pragma: no cover\n from ._auth import Auth # noqa: F401\n from ._config import Proxy, Timeout # noqa: F401\n from ._models import URL, Cookies, Headers, QueryParams, Request # noqa: F401\n\n\nPrimitiveData = Optional[Union[str, int, float, bool]]\n\nURLTypes = Union[\"URL\", str]\n\nQueryParamTypes = Union[\n \"QueryParams\",\n Mapping[str, Union[PrimitiveData, Sequence[PrimitiveData]]],\n List[Tuple[str, PrimitiveData]],\n str,\n]\n\nHeaderTypes = Union[\n \"Headers\",\n Dict[str, str],\n Dict[bytes, bytes],\n Sequence[Tuple[str, str]],\n Sequence[Tuple[bytes, bytes]],\n]\n\nCookieTypes = Union[\"Cookies\", CookieJar, Dict[str, str]]\n\nCertTypes = Union[str, Tuple[str, str], Tuple[str, str, str]]\nVerifyTypes = Union[str, bool, ssl.SSLContext]\nTimeoutTypes = Union[\n Optional[float],\n Tuple[Optional[float], Optional[float], Optional[float], Optional[float]],\n \"Timeout\",\n]\nProxiesTypes = Union[URLTypes, \"Proxy\", Dict[URLTypes, Union[URLTypes, \"Proxy\"]]]\n\nAuthTypes = Union[\n Tuple[Union[str, bytes], Union[str, bytes]],\n Callable[[\"Request\"], \"Request\"],\n \"Auth\",\n]\n\nRequestData = Union[dict, str, bytes, Iterator[bytes], AsyncIterator[bytes]]\n\nFileContent = Union[IO[str], IO[bytes], str, bytes]\nFileTypes = Union[\n # file (or text)\n FileContent,\n # (filename, file (or text))\n Tuple[Optional[str], FileContent],\n # (filename, file (or text), content_type)\n Tuple[Optional[str], FileContent, Optional[str]],\n]\nRequestFiles = Union[Mapping[str, FileTypes], List[Tuple[str, FileTypes]]]\n", "path": "httpx/_types.py"}]}
| 1,368 | 113 |
gh_patches_debug_10160
|
rasdani/github-patches
|
git_diff
|
comic__grand-challenge.org-581
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CKEditor Image upload makes the GUI undismissable
The browser keeps the changed fields state after the image is uploaded, and for some reason we're unable to dismiss the gui.
</issue>
<code>
[start of app/config/urls.py]
1 from django.conf import settings
2 from django.conf.urls import include
3 from django.contrib import admin
4 from django.template.response import TemplateResponse
5 from django.urls import re_path, path
6 from django.views.generic import TemplateView, RedirectView
7
8 from grandchallenge.core.views import comicmain
9 from grandchallenge.pages.views import FaviconView
10
11 admin.autodiscover()
12
13
14 def handler500(request):
15 context = {"request": request}
16 template_name = "500.html"
17 return TemplateResponse(request, template_name, context, status=500)
18
19
20 urlpatterns = [
21 path("", comicmain, name="home"),
22 path(
23 "robots.txt/",
24 TemplateView.as_view(
25 template_name="robots.txt", content_type="text/plain"
26 ),
27 ),
28 # Favicons
29 path(
30 "favicon.ico/",
31 FaviconView.as_view(rel="shortcut icon"),
32 name="favicon",
33 ),
34 path(
35 "apple-touch-icon.png/",
36 FaviconView.as_view(rel="apple-touch-icon"),
37 name="apple-touch-icon",
38 ),
39 path(
40 "apple-touch-icon-precomposed.png/",
41 FaviconView.as_view(rel="apple-touch-icon-precomposed"),
42 name="apple-touch-icon-precomposed",
43 ),
44 path(
45 "apple-touch-icon-<int:size>x<int>.png/",
46 FaviconView.as_view(rel="apple-touch-icon"),
47 name="apple-touch-icon-sized",
48 ),
49 path(
50 "apple-touch-icon-<int:size>x<int>-precomposed.png/",
51 FaviconView.as_view(rel="apple-touch-icon-precomposed"),
52 name="apple-touch-icon-precomposed-sized",
53 ),
54 path(settings.ADMIN_URL, admin.site.urls),
55 path(
56 "site/<slug:challenge_short_name>/",
57 include("grandchallenge.core.urls"),
58 name="site",
59 ),
60 path(
61 "stats/",
62 include("grandchallenge.statistics.urls", namespace="statistics"),
63 ),
64 # Do not change the api namespace without updating the view names in
65 # all of the serializers
66 path("api/", include("grandchallenge.api.urls", namespace="api")),
67 # Used for logging in and managing grandchallenge.profiles. This is done on
68 # the framework level because it is too hard to get this all under each
69 # project
70 path("accounts/", include("grandchallenge.profiles.urls")),
71 path("socialauth/", include("social_django.urls", namespace="social")),
72 path(
73 "challenges/",
74 include("grandchallenge.challenges.urls", namespace="challenges"),
75 ),
76 re_path(
77 r"^(?i)all_challenges/$",
78 RedirectView.as_view(pattern_name="challenges:list", permanent=False),
79 ),
80 path("cases/", include("grandchallenge.cases.urls", namespace="cases")),
81 path(
82 "algorithms/",
83 include("grandchallenge.algorithms.urls", namespace="algorithms"),
84 ),
85 # ========== catch all ====================
86 # when all other urls have been checked, try to load page from main project
87 # keep this url at the bottom of this list, because urls are checked in
88 # order
89 path("<slug:page_title>/", comicmain, name="mainproject-home"),
90 path(
91 "media/", include("grandchallenge.serving.urls", namespace="serving")
92 ),
93 ]
94 if settings.DEBUG and settings.ENABLE_DEBUG_TOOLBAR:
95 import debug_toolbar
96
97 urlpatterns = [
98 path("__debug__/", include(debug_toolbar.urls))
99 ] + urlpatterns
100
[end of app/config/urls.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/app/config/urls.py b/app/config/urls.py
--- a/app/config/urls.py
+++ b/app/config/urls.py
@@ -73,8 +73,12 @@
"challenges/",
include("grandchallenge.challenges.urls", namespace="challenges"),
),
- re_path(
- r"^(?i)all_challenges/$",
+ path(
+ "all_challenges/",
+ RedirectView.as_view(pattern_name="challenges:list", permanent=False),
+ ),
+ path(
+ "All_Challenges/",
RedirectView.as_view(pattern_name="challenges:list", permanent=False),
),
path("cases/", include("grandchallenge.cases.urls", namespace="cases")),
|
{"golden_diff": "diff --git a/app/config/urls.py b/app/config/urls.py\n--- a/app/config/urls.py\n+++ b/app/config/urls.py\n@@ -73,8 +73,12 @@\n \"challenges/\",\n include(\"grandchallenge.challenges.urls\", namespace=\"challenges\"),\n ),\n- re_path(\n- r\"^(?i)all_challenges/$\",\n+ path(\n+ \"all_challenges/\",\n+ RedirectView.as_view(pattern_name=\"challenges:list\", permanent=False),\n+ ),\n+ path(\n+ \"All_Challenges/\",\n RedirectView.as_view(pattern_name=\"challenges:list\", permanent=False),\n ),\n path(\"cases/\", include(\"grandchallenge.cases.urls\", namespace=\"cases\")),\n", "issue": "CKEditor Image upload makes the GUI undismissable\nThe browser keeps the changed fields state after the image is uploaded, and for some reason we're unable to dismiss the gui.\n", "before_files": [{"content": "from django.conf import settings\nfrom django.conf.urls import include\nfrom django.contrib import admin\nfrom django.template.response import TemplateResponse\nfrom django.urls import re_path, path\nfrom django.views.generic import TemplateView, RedirectView\n\nfrom grandchallenge.core.views import comicmain\nfrom grandchallenge.pages.views import FaviconView\n\nadmin.autodiscover()\n\n\ndef handler500(request):\n context = {\"request\": request}\n template_name = \"500.html\"\n return TemplateResponse(request, template_name, context, status=500)\n\n\nurlpatterns = [\n path(\"\", comicmain, name=\"home\"),\n path(\n \"robots.txt/\",\n TemplateView.as_view(\n template_name=\"robots.txt\", content_type=\"text/plain\"\n ),\n ),\n # Favicons\n path(\n \"favicon.ico/\",\n FaviconView.as_view(rel=\"shortcut icon\"),\n name=\"favicon\",\n ),\n path(\n \"apple-touch-icon.png/\",\n FaviconView.as_view(rel=\"apple-touch-icon\"),\n name=\"apple-touch-icon\",\n ),\n path(\n \"apple-touch-icon-precomposed.png/\",\n FaviconView.as_view(rel=\"apple-touch-icon-precomposed\"),\n name=\"apple-touch-icon-precomposed\",\n ),\n path(\n \"apple-touch-icon-<int:size>x<int>.png/\",\n FaviconView.as_view(rel=\"apple-touch-icon\"),\n name=\"apple-touch-icon-sized\",\n ),\n path(\n \"apple-touch-icon-<int:size>x<int>-precomposed.png/\",\n FaviconView.as_view(rel=\"apple-touch-icon-precomposed\"),\n name=\"apple-touch-icon-precomposed-sized\",\n ),\n path(settings.ADMIN_URL, admin.site.urls),\n path(\n \"site/<slug:challenge_short_name>/\",\n include(\"grandchallenge.core.urls\"),\n name=\"site\",\n ),\n path(\n \"stats/\",\n include(\"grandchallenge.statistics.urls\", namespace=\"statistics\"),\n ),\n # Do not change the api namespace without updating the view names in\n # all of the serializers\n path(\"api/\", include(\"grandchallenge.api.urls\", namespace=\"api\")),\n # Used for logging in and managing grandchallenge.profiles. This is done on\n # the framework level because it is too hard to get this all under each\n # project\n path(\"accounts/\", include(\"grandchallenge.profiles.urls\")),\n path(\"socialauth/\", include(\"social_django.urls\", namespace=\"social\")),\n path(\n \"challenges/\",\n include(\"grandchallenge.challenges.urls\", namespace=\"challenges\"),\n ),\n re_path(\n r\"^(?i)all_challenges/$\",\n RedirectView.as_view(pattern_name=\"challenges:list\", permanent=False),\n ),\n path(\"cases/\", include(\"grandchallenge.cases.urls\", namespace=\"cases\")),\n path(\n \"algorithms/\",\n include(\"grandchallenge.algorithms.urls\", namespace=\"algorithms\"),\n ),\n # ========== catch all ====================\n # when all other urls have been checked, try to load page from main project\n # keep this url at the bottom of this list, because urls are checked in\n # order\n path(\"<slug:page_title>/\", comicmain, name=\"mainproject-home\"),\n path(\n \"media/\", include(\"grandchallenge.serving.urls\", namespace=\"serving\")\n ),\n]\nif settings.DEBUG and settings.ENABLE_DEBUG_TOOLBAR:\n import debug_toolbar\n\n urlpatterns = [\n path(\"__debug__/\", include(debug_toolbar.urls))\n ] + urlpatterns\n", "path": "app/config/urls.py"}]}
| 1,501 | 160 |
gh_patches_debug_57471
|
rasdani/github-patches
|
git_diff
|
d2l-ai__d2l-en-2279
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ModuleNotFoundError when running the official pytorch colab notebook

I can replicate the error at multiple official pytorch colab notebooks, e.g.
https://colab.research.google.com/github/d2l-ai/d2l-pytorch-colab/blob/master/chapter_linear-classification/image-classification-dataset.ipynb#scrollTo=ee445cce
</issue>
<code>
[start of setup.py]
1 from setuptools import setup, find_packages
2 import d2l
3
4 requirements = [
5 'ipython>=7.23',
6 'jupyter',
7 'numpy',
8 'matplotlib',
9 'requests',
10 'pandas',
11 'gym'
12 ]
13
14 setup(
15 name='d2l',
16 version=d2l.__version__,
17 python_requires='>=3.5',
18 author='D2L Developers',
19 author_email='[email protected]',
20 url='https://d2l.ai',
21 description='Dive into Deep Learning',
22 license='MIT-0',
23 packages=find_packages(),
24 zip_safe=True,
25 install_requires=requirements,
26 )
27
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -2,10 +2,10 @@
import d2l
requirements = [
- 'ipython>=7.23',
'jupyter',
'numpy',
'matplotlib',
+ 'matplotlib-inline',
'requests',
'pandas',
'gym'
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -2,10 +2,10 @@\n import d2l\n \n requirements = [\n- 'ipython>=7.23',\n 'jupyter',\n 'numpy',\n 'matplotlib',\n+ 'matplotlib-inline',\n 'requests',\n 'pandas',\n 'gym'\n", "issue": "ModuleNotFoundError when running the official pytorch colab notebook\n\r\n\r\nI can replicate the error at multiple official pytorch colab notebooks, e.g. \r\n\r\nhttps://colab.research.google.com/github/d2l-ai/d2l-pytorch-colab/blob/master/chapter_linear-classification/image-classification-dataset.ipynb#scrollTo=ee445cce\r\n\r\n\r\n\n", "before_files": [{"content": "from setuptools import setup, find_packages\nimport d2l\n\nrequirements = [\n 'ipython>=7.23',\n 'jupyter',\n 'numpy',\n 'matplotlib',\n 'requests',\n 'pandas',\n 'gym'\n]\n\nsetup(\n name='d2l',\n version=d2l.__version__,\n python_requires='>=3.5',\n author='D2L Developers',\n author_email='[email protected]',\n url='https://d2l.ai',\n description='Dive into Deep Learning',\n license='MIT-0',\n packages=find_packages(),\n zip_safe=True,\n install_requires=requirements,\n)\n", "path": "setup.py"}]}
| 865 | 85 |
gh_patches_debug_892
|
rasdani/github-patches
|
git_diff
|
rasterio__rasterio-437
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Check for "ndarray-like" instead of ndarray in _warp; other places
I want to use `rasterio.warp.reproject` on an `xray.Dataset` with `xray.Dataset.apply` (http://xray.readthedocs.org/en/stable/). xray has a feature to turn the dataset into a `np.ndarray`, but that means losing all my metadata.
At https://github.com/mapbox/rasterio/blob/master/rasterio/_warp.pyx#L249, _warp checks that the source is an `np.ndarray` (whereas the source in my case is an `xray.DataArray` - satisfying the same interfaces as `np.ndarray`), so I get an invalid source error.
It could be a good idea to check for something like
```
def is_ndarray_like(source):
return hasattr(source, '__array__')
```
instead of
```
isinstance(source, np.ndarray)
```
so other numpy-like arrays can be used.
</issue>
<code>
[start of rasterio/dtypes.py]
1 # Mapping of GDAL to Numpy data types.
2 #
3 # Since 0.13 we are not importing numpy here and data types are strings.
4 # Happily strings can be used throughout Numpy and so existing code will
5 # break.
6 #
7 # Within Rasterio, to test data types, we use Numpy's dtype() factory to
8 # do something like this:
9 #
10 # if np.dtype(destination.dtype) == np.dtype(rasterio.uint8): ...
11 #
12
13 bool_ = 'bool'
14 ubyte = uint8 = 'uint8'
15 uint16 = 'uint16'
16 int16 = 'int16'
17 uint32 = 'uint32'
18 int32 = 'int32'
19 float32 = 'float32'
20 float64 = 'float64'
21 complex_ = 'complex'
22 complex64 = 'complex64'
23 complex128 = 'complex128'
24
25 # Not supported:
26 # GDT_CInt16 = 8, GDT_CInt32 = 9, GDT_CFloat32 = 10, GDT_CFloat64 = 11
27
28 dtype_fwd = {
29 0: None, # GDT_Unknown
30 1: ubyte, # GDT_Byte
31 2: uint16, # GDT_UInt16
32 3: int16, # GDT_Int16
33 4: uint32, # GDT_UInt32
34 5: int32, # GDT_Int32
35 6: float32, # GDT_Float32
36 7: float64, # GDT_Float64
37 8: complex_, # GDT_CInt16
38 9: complex_, # GDT_CInt32
39 10: complex64, # GDT_CFloat32
40 11: complex128 } # GDT_CFloat64
41
42 dtype_rev = dict((v, k) for k, v in dtype_fwd.items())
43 dtype_rev['uint8'] = 1
44
45 typename_fwd = {
46 0: 'Unknown',
47 1: 'Byte',
48 2: 'UInt16',
49 3: 'Int16',
50 4: 'UInt32',
51 5: 'Int32',
52 6: 'Float32',
53 7: 'Float64',
54 8: 'CInt16',
55 9: 'CInt32',
56 10: 'CFloat32',
57 11: 'CFloat64' }
58
59 typename_rev = dict((v, k) for k, v in typename_fwd.items())
60
61 def _gdal_typename(dt):
62 try:
63 return typename_fwd[dtype_rev[dt]]
64 except KeyError:
65 return typename_fwd[dtype_rev[dt().dtype.name]]
66
67 def check_dtype(dt):
68 if dt not in dtype_rev:
69 try:
70 return dt().dtype.name in dtype_rev
71 except:
72 return False
73 return True
74
75
76 def get_minimum_int_dtype(values):
77 """
78 Uses range checking to determine the minimum integer data type required
79 to represent values.
80
81 :param values: numpy array
82 :return: named data type that can be later used to create a numpy dtype
83 """
84
85 min_value = values.min()
86 max_value = values.max()
87
88 if min_value >= 0:
89 if max_value <= 255:
90 return uint8
91 elif max_value <= 65535:
92 return uint16
93 elif max_value <= 4294967295:
94 return uint32
95 elif min_value >= -32768 and max_value <= 32767:
96 return int16
97 elif min_value >= -2147483648 and max_value <= 2147483647:
98 return int32
99
[end of rasterio/dtypes.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/rasterio/dtypes.py b/rasterio/dtypes.py
--- a/rasterio/dtypes.py
+++ b/rasterio/dtypes.py
@@ -96,3 +96,9 @@
return int16
elif min_value >= -2147483648 and max_value <= 2147483647:
return int32
+
+
+def is_ndarray(array):
+ import numpy
+
+ return isinstance(array, numpy.ndarray) or hasattr(array, '__array__')
|
{"golden_diff": "diff --git a/rasterio/dtypes.py b/rasterio/dtypes.py\n--- a/rasterio/dtypes.py\n+++ b/rasterio/dtypes.py\n@@ -96,3 +96,9 @@\n return int16\n elif min_value >= -2147483648 and max_value <= 2147483647:\n return int32\n+\n+\n+def is_ndarray(array):\n+ import numpy\n+\n+ return isinstance(array, numpy.ndarray) or hasattr(array, '__array__')\n", "issue": "Check for \"ndarray-like\" instead of ndarray in _warp; other places\nI want to use `rasterio.warp.reproject` on an `xray.Dataset` with `xray.Dataset.apply` (http://xray.readthedocs.org/en/stable/). xray has a feature to turn the dataset into a `np.ndarray`, but that means losing all my metadata.\n\nAt https://github.com/mapbox/rasterio/blob/master/rasterio/_warp.pyx#L249, _warp checks that the source is an `np.ndarray` (whereas the source in my case is an `xray.DataArray` - satisfying the same interfaces as `np.ndarray`), so I get an invalid source error.\n\nIt could be a good idea to check for something like\n\n```\ndef is_ndarray_like(source):\n return hasattr(source, '__array__')\n```\n\ninstead of\n\n```\nisinstance(source, np.ndarray)\n```\n\nso other numpy-like arrays can be used.\n\n", "before_files": [{"content": "# Mapping of GDAL to Numpy data types.\n#\n# Since 0.13 we are not importing numpy here and data types are strings.\n# Happily strings can be used throughout Numpy and so existing code will\n# break.\n#\n# Within Rasterio, to test data types, we use Numpy's dtype() factory to \n# do something like this:\n#\n# if np.dtype(destination.dtype) == np.dtype(rasterio.uint8): ...\n#\n\nbool_ = 'bool'\nubyte = uint8 = 'uint8'\nuint16 = 'uint16'\nint16 = 'int16'\nuint32 = 'uint32'\nint32 = 'int32'\nfloat32 = 'float32'\nfloat64 = 'float64'\ncomplex_ = 'complex'\ncomplex64 = 'complex64'\ncomplex128 = 'complex128'\n\n# Not supported:\n# GDT_CInt16 = 8, GDT_CInt32 = 9, GDT_CFloat32 = 10, GDT_CFloat64 = 11\n\ndtype_fwd = {\n 0: None, # GDT_Unknown\n 1: ubyte, # GDT_Byte\n 2: uint16, # GDT_UInt16\n 3: int16, # GDT_Int16\n 4: uint32, # GDT_UInt32\n 5: int32, # GDT_Int32\n 6: float32, # GDT_Float32\n 7: float64, # GDT_Float64\n 8: complex_, # GDT_CInt16\n 9: complex_, # GDT_CInt32\n 10: complex64, # GDT_CFloat32\n 11: complex128 } # GDT_CFloat64\n\ndtype_rev = dict((v, k) for k, v in dtype_fwd.items())\ndtype_rev['uint8'] = 1\n\ntypename_fwd = {\n 0: 'Unknown',\n 1: 'Byte',\n 2: 'UInt16',\n 3: 'Int16',\n 4: 'UInt32',\n 5: 'Int32',\n 6: 'Float32',\n 7: 'Float64',\n 8: 'CInt16',\n 9: 'CInt32',\n 10: 'CFloat32',\n 11: 'CFloat64' }\n\ntypename_rev = dict((v, k) for k, v in typename_fwd.items())\n\ndef _gdal_typename(dt):\n try:\n return typename_fwd[dtype_rev[dt]]\n except KeyError:\n return typename_fwd[dtype_rev[dt().dtype.name]]\n\ndef check_dtype(dt):\n if dt not in dtype_rev:\n try:\n return dt().dtype.name in dtype_rev\n except:\n return False\n return True\n\n\ndef get_minimum_int_dtype(values):\n \"\"\"\n Uses range checking to determine the minimum integer data type required\n to represent values.\n\n :param values: numpy array\n :return: named data type that can be later used to create a numpy dtype\n \"\"\"\n\n min_value = values.min()\n max_value = values.max()\n \n if min_value >= 0:\n if max_value <= 255:\n return uint8\n elif max_value <= 65535:\n return uint16\n elif max_value <= 4294967295:\n return uint32\n elif min_value >= -32768 and max_value <= 32767:\n return int16\n elif min_value >= -2147483648 and max_value <= 2147483647:\n return int32\n", "path": "rasterio/dtypes.py"}]}
| 1,822 | 125 |
gh_patches_debug_63370
|
rasdani/github-patches
|
git_diff
|
mkdocs__mkdocs-130
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Update requirements
While working with Markdown extensions (c.f. #74), I noticed that mkdocs' setup.py has its dependencies [pinned to specific patch versions](https://github.com/tomchristie/mkdocs/blob/master/setup.py#L18):
```
install_requires = [
'Jinja2==2.7.1',
'Markdown==2.3.1',
'PyYAML==3.10',
'watchdog==0.7.0',
'ghp-import==0.4.1'
]
```
Since these dependencies are slightly out of date (e.g., [Jinja2 is at 2.7.3](https://pypi.python.org/pypi/Jinja2) and [Markdown is at 2.4.1](https://pypi.python.org/pypi/Markdown)), it's hard to use mkdocs on a system with other software. Perhaps it's a shame that Python doesn't have npm-like dependency management, but that's the way it is—you'll get a setuptools when trying to run mkdocs error if any other package upgrades Jinja to a bugfix release.
How would the developers feel about loosening these version requirements? An idiomatic approach is to [just use `>=`](https://github.com/mitsuhiko/flask/blob/master/setup.py#L99).
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3
4 from __future__ import print_function
5 from setuptools import setup
6 import re
7 import os
8 import sys
9
10
11 name = 'mkdocs'
12 package = 'mkdocs'
13 description = 'In progress.'
14 url = 'http://www.mkdocs.org'
15 author = 'Tom Christie'
16 author_email = '[email protected]'
17 license = 'BSD'
18 install_requires = [
19 'Jinja2==2.7.1',
20 'Markdown==2.3.1',
21 'PyYAML==3.10',
22 'watchdog==0.7.0',
23 'ghp-import==0.4.1'
24 ]
25
26 long_description = """Work in progress."""
27
28
29 def get_version(package):
30 """
31 Return package version as listed in `__version__` in `init.py`.
32 """
33 init_py = open(os.path.join(package, '__init__.py')).read()
34 return re.search("^__version__ = ['\"]([^'\"]+)['\"]", init_py, re.MULTILINE).group(1)
35
36
37 def get_packages(package):
38 """
39 Return root package and all sub-packages.
40 """
41 return [dirpath
42 for dirpath, dirnames, filenames in os.walk(package)
43 if os.path.exists(os.path.join(dirpath, '__init__.py'))]
44
45
46 def get_package_data(package):
47 """
48 Return all files under the root package, that are not in a
49 package themselves.
50 """
51 walk = [(dirpath.replace(package + os.sep, '', 1), filenames)
52 for dirpath, dirnames, filenames in os.walk(package)
53 if not os.path.exists(os.path.join(dirpath, '__init__.py'))]
54
55 filepaths = []
56 for base, filenames in walk:
57 filepaths.extend([os.path.join(base, filename)
58 for filename in filenames])
59 return {package: filepaths}
60
61
62 if sys.argv[-1] == 'publish':
63 os.system("python setup.py sdist upload")
64 args = {'version': get_version(package)}
65 print("You probably want to also tag the version now:")
66 print(" git tag -a %(version)s -m 'version %(version)s'" % args)
67 print(" git push --tags")
68 sys.exit()
69
70
71 setup(
72 name=name,
73 version=get_version(package),
74 url=url,
75 license=license,
76 description=description,
77 long_description=long_description,
78 author=author,
79 author_email=author_email,
80 packages=get_packages(package),
81 package_data=get_package_data(package),
82 install_requires=install_requires,
83 entry_points={
84 'console_scripts': [
85 'mkdocs = mkdocs.main:run_main',
86 ],
87 },
88 classifiers=[
89 'Development Status :: 5 - Production/Stable',
90 'Environment :: Console',
91 'Environment :: Web Environment',
92 'Intended Audience :: Developers',
93 'License :: OSI Approved :: BSD License',
94 'Operating System :: OS Independent',
95 'Programming Language :: Python',
96 'Programming Language :: Python :: 2',
97 'Programming Language :: Python :: 2.6',
98 'Programming Language :: Python :: 2.7',
99 'Programming Language :: Python :: 3',
100 'Programming Language :: Python :: 3.3',
101 'Programming Language :: Python :: 3.4',
102 'Topic :: Documentation',
103 'Topic :: Text Processing',
104 ]
105 )
106
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -16,11 +16,11 @@
author_email = '[email protected]'
license = 'BSD'
install_requires = [
- 'Jinja2==2.7.1',
- 'Markdown==2.3.1',
- 'PyYAML==3.10',
- 'watchdog==0.7.0',
- 'ghp-import==0.4.1'
+ 'Jinja2>=2.7.1',
+ 'Markdown>=2.3.1,<2.5',
+ 'PyYAML>=3.10',
+ 'watchdog>=0.7.0',
+ 'ghp-import>=0.4.1'
]
long_description = """Work in progress."""
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -16,11 +16,11 @@\n author_email = '[email protected]'\n license = 'BSD'\n install_requires = [\n- 'Jinja2==2.7.1',\n- 'Markdown==2.3.1',\n- 'PyYAML==3.10',\n- 'watchdog==0.7.0',\n- 'ghp-import==0.4.1'\n+ 'Jinja2>=2.7.1',\n+ 'Markdown>=2.3.1,<2.5',\n+ 'PyYAML>=3.10',\n+ 'watchdog>=0.7.0',\n+ 'ghp-import>=0.4.1'\n ]\n \n long_description = \"\"\"Work in progress.\"\"\"\n", "issue": "Update requirements\nWhile working with Markdown extensions (c.f. #74), I noticed that mkdocs' setup.py has its dependencies [pinned to specific patch versions](https://github.com/tomchristie/mkdocs/blob/master/setup.py#L18):\n\n```\ninstall_requires = [\n 'Jinja2==2.7.1',\n 'Markdown==2.3.1',\n 'PyYAML==3.10',\n 'watchdog==0.7.0',\n 'ghp-import==0.4.1'\n]\n```\n\nSince these dependencies are slightly out of date (e.g., [Jinja2 is at 2.7.3](https://pypi.python.org/pypi/Jinja2) and [Markdown is at 2.4.1](https://pypi.python.org/pypi/Markdown)), it's hard to use mkdocs on a system with other software. Perhaps it's a shame that Python doesn't have npm-like dependency management, but that's the way it is\u2014you'll get a setuptools when trying to run mkdocs error if any other package upgrades Jinja to a bugfix release.\n\nHow would the developers feel about loosening these version requirements? An idiomatic approach is to [just use `>=`](https://github.com/mitsuhiko/flask/blob/master/setup.py#L99).\n\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom __future__ import print_function\nfrom setuptools import setup\nimport re\nimport os\nimport sys\n\n\nname = 'mkdocs'\npackage = 'mkdocs'\ndescription = 'In progress.'\nurl = 'http://www.mkdocs.org'\nauthor = 'Tom Christie'\nauthor_email = '[email protected]'\nlicense = 'BSD'\ninstall_requires = [\n 'Jinja2==2.7.1',\n 'Markdown==2.3.1',\n 'PyYAML==3.10',\n 'watchdog==0.7.0',\n 'ghp-import==0.4.1'\n]\n\nlong_description = \"\"\"Work in progress.\"\"\"\n\n\ndef get_version(package):\n \"\"\"\n Return package version as listed in `__version__` in `init.py`.\n \"\"\"\n init_py = open(os.path.join(package, '__init__.py')).read()\n return re.search(\"^__version__ = ['\\\"]([^'\\\"]+)['\\\"]\", init_py, re.MULTILINE).group(1)\n\n\ndef get_packages(package):\n \"\"\"\n Return root package and all sub-packages.\n \"\"\"\n return [dirpath\n for dirpath, dirnames, filenames in os.walk(package)\n if os.path.exists(os.path.join(dirpath, '__init__.py'))]\n\n\ndef get_package_data(package):\n \"\"\"\n Return all files under the root package, that are not in a\n package themselves.\n \"\"\"\n walk = [(dirpath.replace(package + os.sep, '', 1), filenames)\n for dirpath, dirnames, filenames in os.walk(package)\n if not os.path.exists(os.path.join(dirpath, '__init__.py'))]\n\n filepaths = []\n for base, filenames in walk:\n filepaths.extend([os.path.join(base, filename)\n for filename in filenames])\n return {package: filepaths}\n\n\nif sys.argv[-1] == 'publish':\n os.system(\"python setup.py sdist upload\")\n args = {'version': get_version(package)}\n print(\"You probably want to also tag the version now:\")\n print(\" git tag -a %(version)s -m 'version %(version)s'\" % args)\n print(\" git push --tags\")\n sys.exit()\n\n\nsetup(\n name=name,\n version=get_version(package),\n url=url,\n license=license,\n description=description,\n long_description=long_description,\n author=author,\n author_email=author_email,\n packages=get_packages(package),\n package_data=get_package_data(package),\n install_requires=install_requires,\n entry_points={\n 'console_scripts': [\n 'mkdocs = mkdocs.main:run_main',\n ],\n },\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Console',\n 'Environment :: Web Environment',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: BSD License',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.6',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Topic :: Documentation',\n 'Topic :: Text Processing',\n ]\n)\n", "path": "setup.py"}]}
| 1,756 | 191 |
gh_patches_debug_49
|
rasdani/github-patches
|
git_diff
|
cookiecutter__cookiecutter-1712
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CI/CD: Verify .pre-commit-config.yaml use latest hooks versions
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 """cookiecutter distutils configuration."""
3 from setuptools import setup
4
5 version = "2.1.2.dev0"
6
7 with open('README.md', encoding='utf-8') as readme_file:
8 readme = readme_file.read()
9
10 requirements = [
11 'binaryornot>=0.4.4',
12 'Jinja2>=2.7,<4.0.0',
13 'click>=7.0,<9.0.0',
14 'pyyaml>=5.3.1',
15 'jinja2-time>=0.2.0',
16 'python-slugify>=4.0.0',
17 'requests>=2.23.0',
18 ]
19
20 setup(
21 name='cookiecutter',
22 version=version,
23 description=(
24 'A command-line utility that creates projects from project '
25 'templates, e.g. creating a Python package project from a '
26 'Python package project template.'
27 ),
28 long_description=readme,
29 long_description_content_type='text/markdown',
30 author='Audrey Feldroy',
31 author_email='[email protected]',
32 url='https://github.com/cookiecutter/cookiecutter',
33 packages=['cookiecutter'],
34 package_dir={'cookiecutter': 'cookiecutter'},
35 entry_points={'console_scripts': ['cookiecutter = cookiecutter.__main__:main']},
36 include_package_data=True,
37 python_requires='>=3.7',
38 install_requires=requirements,
39 license='BSD',
40 zip_safe=False,
41 classifiers=[
42 "Development Status :: 5 - Production/Stable",
43 "Environment :: Console",
44 "Intended Audience :: Developers",
45 "Natural Language :: English",
46 "License :: OSI Approved :: BSD License",
47 "Programming Language :: Python :: 3 :: Only",
48 "Programming Language :: Python :: 3",
49 "Programming Language :: Python :: 3.7",
50 "Programming Language :: Python :: 3.8",
51 "Programming Language :: Python :: 3.9",
52 "Programming Language :: Python :: 3.10",
53 "Programming Language :: Python :: Implementation :: CPython",
54 "Programming Language :: Python :: Implementation :: PyPy",
55 "Programming Language :: Python",
56 "Topic :: Software Development",
57 ],
58 keywords=[
59 "cookiecutter",
60 "Python",
61 "projects",
62 "project templates",
63 "Jinja2",
64 "skeleton",
65 "scaffolding",
66 "project directory",
67 "package",
68 "packaging",
69 ],
70 )
71
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -1,4 +1,3 @@
-#!/usr/bin/env python
"""cookiecutter distutils configuration."""
from setuptools import setup
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -1,4 +1,3 @@\n-#!/usr/bin/env python\n \"\"\"cookiecutter distutils configuration.\"\"\"\n from setuptools import setup\n", "issue": "CI/CD: Verify .pre-commit-config.yaml use latest hooks versions\n\n", "before_files": [{"content": "#!/usr/bin/env python\n\"\"\"cookiecutter distutils configuration.\"\"\"\nfrom setuptools import setup\n\nversion = \"2.1.2.dev0\"\n\nwith open('README.md', encoding='utf-8') as readme_file:\n readme = readme_file.read()\n\nrequirements = [\n 'binaryornot>=0.4.4',\n 'Jinja2>=2.7,<4.0.0',\n 'click>=7.0,<9.0.0',\n 'pyyaml>=5.3.1',\n 'jinja2-time>=0.2.0',\n 'python-slugify>=4.0.0',\n 'requests>=2.23.0',\n]\n\nsetup(\n name='cookiecutter',\n version=version,\n description=(\n 'A command-line utility that creates projects from project '\n 'templates, e.g. creating a Python package project from a '\n 'Python package project template.'\n ),\n long_description=readme,\n long_description_content_type='text/markdown',\n author='Audrey Feldroy',\n author_email='[email protected]',\n url='https://github.com/cookiecutter/cookiecutter',\n packages=['cookiecutter'],\n package_dir={'cookiecutter': 'cookiecutter'},\n entry_points={'console_scripts': ['cookiecutter = cookiecutter.__main__:main']},\n include_package_data=True,\n python_requires='>=3.7',\n install_requires=requirements,\n license='BSD',\n zip_safe=False,\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Environment :: Console\",\n \"Intended Audience :: Developers\",\n \"Natural Language :: English\",\n \"License :: OSI Approved :: BSD License\",\n \"Programming Language :: Python :: 3 :: Only\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n \"Programming Language :: Python\",\n \"Topic :: Software Development\",\n ],\n keywords=[\n \"cookiecutter\",\n \"Python\",\n \"projects\",\n \"project templates\",\n \"Jinja2\",\n \"skeleton\",\n \"scaffolding\",\n \"project directory\",\n \"package\",\n \"packaging\",\n ],\n)\n", "path": "setup.py"}]}
| 1,217 | 51 |
gh_patches_debug_35130
|
rasdani/github-patches
|
git_diff
|
mlflow__mlflow-6206
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Timeout value too small: when downloading large model files, timeout is reached
https://github.com/mlflow/mlflow/blob/d40780be361f4bd2741c2e8fcbd428c1d693edcf/mlflow/store/artifact/http_artifact_repo.py#L63
</issue>
<code>
[start of mlflow/store/artifact/http_artifact_repo.py]
1 import os
2 import posixpath
3
4 from mlflow.entities import FileInfo
5 from mlflow.store.artifact.artifact_repo import ArtifactRepository, verify_artifact_path
6 from mlflow.tracking._tracking_service.utils import _get_default_host_creds
7 from mlflow.utils.file_utils import relative_path_to_artifact_path
8 from mlflow.utils.rest_utils import augmented_raise_for_status, http_request
9
10
11 class HttpArtifactRepository(ArtifactRepository):
12 """Stores artifacts in a remote artifact storage using HTTP requests"""
13
14 @property
15 def _host_creds(self):
16 return _get_default_host_creds(self.artifact_uri)
17
18 def log_artifact(self, local_file, artifact_path=None):
19 verify_artifact_path(artifact_path)
20
21 file_name = os.path.basename(local_file)
22 paths = (artifact_path, file_name) if artifact_path else (file_name,)
23 endpoint = posixpath.join("/", *paths)
24 with open(local_file, "rb") as f:
25 resp = http_request(self._host_creds, endpoint, "PUT", data=f, timeout=600)
26 augmented_raise_for_status(resp)
27
28 def log_artifacts(self, local_dir, artifact_path=None):
29 local_dir = os.path.abspath(local_dir)
30 for root, _, filenames in os.walk(local_dir):
31 if root == local_dir:
32 artifact_dir = artifact_path
33 else:
34 rel_path = os.path.relpath(root, local_dir)
35 rel_path = relative_path_to_artifact_path(rel_path)
36 artifact_dir = (
37 posixpath.join(artifact_path, rel_path) if artifact_path else rel_path
38 )
39 for f in filenames:
40 self.log_artifact(os.path.join(root, f), artifact_dir)
41
42 def list_artifacts(self, path=None):
43 endpoint = "/mlflow-artifacts/artifacts"
44 url, tail = self.artifact_uri.split(endpoint, maxsplit=1)
45 root = tail.lstrip("/")
46 params = {"path": posixpath.join(root, path) if path else root}
47 host_creds = _get_default_host_creds(url)
48 resp = http_request(host_creds, endpoint, "GET", params=params, timeout=10)
49 augmented_raise_for_status(resp)
50 file_infos = []
51 for f in resp.json().get("files", []):
52 file_info = FileInfo(
53 posixpath.join(path, f["path"]) if path else f["path"],
54 f["is_dir"],
55 int(f["file_size"]) if ("file_size" in f) else None,
56 )
57 file_infos.append(file_info)
58
59 return sorted(file_infos, key=lambda f: f.path)
60
61 def _download_file(self, remote_file_path, local_path):
62 endpoint = posixpath.join("/", remote_file_path)
63 resp = http_request(self._host_creds, endpoint, "GET", stream=True, timeout=10)
64 augmented_raise_for_status(resp)
65 with open(local_path, "wb") as f:
66 chunk_size = 1024 * 1024 # 1 MB
67 for chunk in resp.iter_content(chunk_size=chunk_size):
68 f.write(chunk)
69
70 def delete_artifacts(self, artifact_path=None):
71 endpoint = posixpath.join("/", artifact_path) if artifact_path else "/"
72 resp = http_request(self._host_creds, endpoint, "DELETE", stream=True, timeout=10)
73 augmented_raise_for_status(resp)
74
[end of mlflow/store/artifact/http_artifact_repo.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mlflow/store/artifact/http_artifact_repo.py b/mlflow/store/artifact/http_artifact_repo.py
--- a/mlflow/store/artifact/http_artifact_repo.py
+++ b/mlflow/store/artifact/http_artifact_repo.py
@@ -22,7 +22,7 @@
paths = (artifact_path, file_name) if artifact_path else (file_name,)
endpoint = posixpath.join("/", *paths)
with open(local_file, "rb") as f:
- resp = http_request(self._host_creds, endpoint, "PUT", data=f, timeout=600)
+ resp = http_request(self._host_creds, endpoint, "PUT", data=f)
augmented_raise_for_status(resp)
def log_artifacts(self, local_dir, artifact_path=None):
@@ -45,7 +45,7 @@
root = tail.lstrip("/")
params = {"path": posixpath.join(root, path) if path else root}
host_creds = _get_default_host_creds(url)
- resp = http_request(host_creds, endpoint, "GET", params=params, timeout=10)
+ resp = http_request(host_creds, endpoint, "GET", params=params)
augmented_raise_for_status(resp)
file_infos = []
for f in resp.json().get("files", []):
@@ -60,7 +60,7 @@
def _download_file(self, remote_file_path, local_path):
endpoint = posixpath.join("/", remote_file_path)
- resp = http_request(self._host_creds, endpoint, "GET", stream=True, timeout=10)
+ resp = http_request(self._host_creds, endpoint, "GET", stream=True)
augmented_raise_for_status(resp)
with open(local_path, "wb") as f:
chunk_size = 1024 * 1024 # 1 MB
@@ -69,5 +69,5 @@
def delete_artifacts(self, artifact_path=None):
endpoint = posixpath.join("/", artifact_path) if artifact_path else "/"
- resp = http_request(self._host_creds, endpoint, "DELETE", stream=True, timeout=10)
+ resp = http_request(self._host_creds, endpoint, "DELETE", stream=True)
augmented_raise_for_status(resp)
|
{"golden_diff": "diff --git a/mlflow/store/artifact/http_artifact_repo.py b/mlflow/store/artifact/http_artifact_repo.py\n--- a/mlflow/store/artifact/http_artifact_repo.py\n+++ b/mlflow/store/artifact/http_artifact_repo.py\n@@ -22,7 +22,7 @@\n paths = (artifact_path, file_name) if artifact_path else (file_name,)\n endpoint = posixpath.join(\"/\", *paths)\n with open(local_file, \"rb\") as f:\n- resp = http_request(self._host_creds, endpoint, \"PUT\", data=f, timeout=600)\n+ resp = http_request(self._host_creds, endpoint, \"PUT\", data=f)\n augmented_raise_for_status(resp)\n \n def log_artifacts(self, local_dir, artifact_path=None):\n@@ -45,7 +45,7 @@\n root = tail.lstrip(\"/\")\n params = {\"path\": posixpath.join(root, path) if path else root}\n host_creds = _get_default_host_creds(url)\n- resp = http_request(host_creds, endpoint, \"GET\", params=params, timeout=10)\n+ resp = http_request(host_creds, endpoint, \"GET\", params=params)\n augmented_raise_for_status(resp)\n file_infos = []\n for f in resp.json().get(\"files\", []):\n@@ -60,7 +60,7 @@\n \n def _download_file(self, remote_file_path, local_path):\n endpoint = posixpath.join(\"/\", remote_file_path)\n- resp = http_request(self._host_creds, endpoint, \"GET\", stream=True, timeout=10)\n+ resp = http_request(self._host_creds, endpoint, \"GET\", stream=True)\n augmented_raise_for_status(resp)\n with open(local_path, \"wb\") as f:\n chunk_size = 1024 * 1024 # 1 MB\n@@ -69,5 +69,5 @@\n \n def delete_artifacts(self, artifact_path=None):\n endpoint = posixpath.join(\"/\", artifact_path) if artifact_path else \"/\"\n- resp = http_request(self._host_creds, endpoint, \"DELETE\", stream=True, timeout=10)\n+ resp = http_request(self._host_creds, endpoint, \"DELETE\", stream=True)\n augmented_raise_for_status(resp)\n", "issue": "Timeout value too small: when downloading large model files, timeout is reached\nhttps://github.com/mlflow/mlflow/blob/d40780be361f4bd2741c2e8fcbd428c1d693edcf/mlflow/store/artifact/http_artifact_repo.py#L63\n", "before_files": [{"content": "import os\nimport posixpath\n\nfrom mlflow.entities import FileInfo\nfrom mlflow.store.artifact.artifact_repo import ArtifactRepository, verify_artifact_path\nfrom mlflow.tracking._tracking_service.utils import _get_default_host_creds\nfrom mlflow.utils.file_utils import relative_path_to_artifact_path\nfrom mlflow.utils.rest_utils import augmented_raise_for_status, http_request\n\n\nclass HttpArtifactRepository(ArtifactRepository):\n \"\"\"Stores artifacts in a remote artifact storage using HTTP requests\"\"\"\n\n @property\n def _host_creds(self):\n return _get_default_host_creds(self.artifact_uri)\n\n def log_artifact(self, local_file, artifact_path=None):\n verify_artifact_path(artifact_path)\n\n file_name = os.path.basename(local_file)\n paths = (artifact_path, file_name) if artifact_path else (file_name,)\n endpoint = posixpath.join(\"/\", *paths)\n with open(local_file, \"rb\") as f:\n resp = http_request(self._host_creds, endpoint, \"PUT\", data=f, timeout=600)\n augmented_raise_for_status(resp)\n\n def log_artifacts(self, local_dir, artifact_path=None):\n local_dir = os.path.abspath(local_dir)\n for root, _, filenames in os.walk(local_dir):\n if root == local_dir:\n artifact_dir = artifact_path\n else:\n rel_path = os.path.relpath(root, local_dir)\n rel_path = relative_path_to_artifact_path(rel_path)\n artifact_dir = (\n posixpath.join(artifact_path, rel_path) if artifact_path else rel_path\n )\n for f in filenames:\n self.log_artifact(os.path.join(root, f), artifact_dir)\n\n def list_artifacts(self, path=None):\n endpoint = \"/mlflow-artifacts/artifacts\"\n url, tail = self.artifact_uri.split(endpoint, maxsplit=1)\n root = tail.lstrip(\"/\")\n params = {\"path\": posixpath.join(root, path) if path else root}\n host_creds = _get_default_host_creds(url)\n resp = http_request(host_creds, endpoint, \"GET\", params=params, timeout=10)\n augmented_raise_for_status(resp)\n file_infos = []\n for f in resp.json().get(\"files\", []):\n file_info = FileInfo(\n posixpath.join(path, f[\"path\"]) if path else f[\"path\"],\n f[\"is_dir\"],\n int(f[\"file_size\"]) if (\"file_size\" in f) else None,\n )\n file_infos.append(file_info)\n\n return sorted(file_infos, key=lambda f: f.path)\n\n def _download_file(self, remote_file_path, local_path):\n endpoint = posixpath.join(\"/\", remote_file_path)\n resp = http_request(self._host_creds, endpoint, \"GET\", stream=True, timeout=10)\n augmented_raise_for_status(resp)\n with open(local_path, \"wb\") as f:\n chunk_size = 1024 * 1024 # 1 MB\n for chunk in resp.iter_content(chunk_size=chunk_size):\n f.write(chunk)\n\n def delete_artifacts(self, artifact_path=None):\n endpoint = posixpath.join(\"/\", artifact_path) if artifact_path else \"/\"\n resp = http_request(self._host_creds, endpoint, \"DELETE\", stream=True, timeout=10)\n augmented_raise_for_status(resp)\n", "path": "mlflow/store/artifact/http_artifact_repo.py"}]}
| 1,479 | 503 |
gh_patches_debug_33750
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-4349
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix experimental make generator CONAN_CPPFLAGS and CONAN_INCLUDE_PATHS
Following the conversation here https://github.com/conan-io/conan/issues/4286#issuecomment-454194188
We have finally reached the conclusion of having ``cpp_info.cppflags`` converted to ``CONAN_CXXFLAGS`` in the ``make`` generator to be consistent with orhter generators such as ``cmake``.
Also the flag ``CONAN_INCLUDE_PATHS`` should be renamed to ``CONAN_INCLUDE_DIRS`` for the same reason.
In another issue we would probably introduce a ``cpp_info.cxxflags`` that would be an internal alias of ``cpp_info.cppflags`` to avoid this confusion without breaking.
cc/ @solvingj
</issue>
<code>
[start of conans/client/generators/make.py]
1 from conans.model import Generator
2 from conans.paths import BUILD_INFO_MAKE
3
4
5 class MakeGenerator(Generator):
6
7 def __init__(self, conanfile):
8 Generator.__init__(self, conanfile)
9 self.makefile_newline = "\n"
10 self.makefile_line_continuation = " \\\n"
11 self.assignment_if_absent = " ?= "
12 self.assignment_append = " += "
13
14 @property
15 def filename(self):
16 return BUILD_INFO_MAKE
17
18 @property
19 def content(self):
20
21 content = [
22 "#-------------------------------------------------------------------#",
23 "# Makefile variables from Conan Dependencies #",
24 "#-------------------------------------------------------------------#",
25 "",
26 ]
27
28 for line_as_list in self.create_deps_content():
29 content.append("".join(line_as_list))
30
31 content.append("#-------------------------------------------------------------------#")
32 content.append(self.makefile_newline)
33 return self.makefile_newline.join(content)
34
35 def create_deps_content(self):
36 deps_content = self.create_content_from_deps()
37 deps_content.extend(self.create_combined_content())
38 return deps_content
39
40 def create_content_from_deps(self):
41 content = []
42 for pkg_name, cpp_info in self.deps_build_info.dependencies:
43 content.extend(self.create_content_from_dep(pkg_name, cpp_info))
44 return content
45
46 def create_content_from_dep(self, pkg_name, cpp_info):
47
48 vars_info = [("ROOT", self.assignment_if_absent, [cpp_info.rootpath]),
49 ("SYSROOT", self.assignment_if_absent, [cpp_info.sysroot]),
50 ("INCLUDE_PATHS", self.assignment_append, cpp_info.include_paths),
51 ("LIB_PATHS", self.assignment_append, cpp_info.lib_paths),
52 ("BIN_PATHS", self.assignment_append, cpp_info.bin_paths),
53 ("BUILD_PATHS", self.assignment_append, cpp_info.build_paths),
54 ("RES_PATHS", self.assignment_append, cpp_info.res_paths),
55 ("LIBS", self.assignment_append, cpp_info.libs),
56 ("DEFINES", self.assignment_append, cpp_info.defines),
57 ("CFLAGS", self.assignment_append, cpp_info.cflags),
58 ("CPPFLAGS", self.assignment_append, cpp_info.cppflags),
59 ("SHAREDLINKFLAGS", self.assignment_append, cpp_info.sharedlinkflags),
60 ("EXELINKFLAGS", self.assignment_append, cpp_info.exelinkflags)]
61
62 return [self.create_makefile_var_pkg(var_name, pkg_name, operator, info)
63 for var_name, operator, info in vars_info]
64
65 def create_combined_content(self):
66 content = []
67 for var_name in self.all_dep_vars():
68 content.append(self.create_makefile_var_global(var_name, self.assignment_append,
69 self.create_combined_var_list(var_name)))
70 return content
71
72 def create_combined_var_list(self, var_name):
73 make_vars = []
74 for pkg_name, _ in self.deps_build_info.dependencies:
75 pkg_var = self.create_makefile_var_name_pkg(var_name, pkg_name)
76 make_vars.append("$({pkg_var})".format(pkg_var=pkg_var))
77 return make_vars
78
79 def create_makefile_var_global(self, var_name, operator, values):
80 make_var = [self.create_makefile_var_name_global(var_name)]
81 make_var.extend(self.create_makefile_var_common(operator, values))
82 return make_var
83
84 def create_makefile_var_pkg(self, var_name, pkg_name, operator, values):
85 make_var = [self.create_makefile_var_name_pkg(var_name, pkg_name)]
86 make_var.extend(self.create_makefile_var_common(operator, values))
87 return make_var
88
89 def create_makefile_var_common(self, operator, values):
90 return [operator, self.makefile_line_continuation, self.create_makefile_var_value(values),
91 self.makefile_newline]
92
93 @staticmethod
94 def create_makefile_var_name_global(var_name):
95 return "CONAN_{var}".format(var=var_name).upper()
96
97 @staticmethod
98 def create_makefile_var_name_pkg(var_name, pkg_name):
99 return "CONAN_{var}_{lib}".format(var=var_name, lib=pkg_name).upper()
100
101 def create_makefile_var_value(self, values):
102 formatted_values = [value.replace("\\", "/") for value in values]
103 return self.makefile_line_continuation.join(formatted_values)
104
105 @staticmethod
106 def all_dep_vars():
107 return ["rootpath", "sysroot", "include_paths", "lib_paths", "bin_paths", "build_paths",
108 "res_paths", "libs", "defines", "cflags", "cppflags", "sharedlinkflags",
109 "exelinkflags"]
110
[end of conans/client/generators/make.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/conans/client/generators/make.py b/conans/client/generators/make.py
--- a/conans/client/generators/make.py
+++ b/conans/client/generators/make.py
@@ -47,15 +47,15 @@
vars_info = [("ROOT", self.assignment_if_absent, [cpp_info.rootpath]),
("SYSROOT", self.assignment_if_absent, [cpp_info.sysroot]),
- ("INCLUDE_PATHS", self.assignment_append, cpp_info.include_paths),
- ("LIB_PATHS", self.assignment_append, cpp_info.lib_paths),
- ("BIN_PATHS", self.assignment_append, cpp_info.bin_paths),
- ("BUILD_PATHS", self.assignment_append, cpp_info.build_paths),
- ("RES_PATHS", self.assignment_append, cpp_info.res_paths),
+ ("INCLUDE_DIRS", self.assignment_append, cpp_info.include_paths),
+ ("LIB_DIRS", self.assignment_append, cpp_info.lib_paths),
+ ("BIN_DIRS", self.assignment_append, cpp_info.bin_paths),
+ ("BUILD_DIRS", self.assignment_append, cpp_info.build_paths),
+ ("RES_DIRS", self.assignment_append, cpp_info.res_paths),
("LIBS", self.assignment_append, cpp_info.libs),
("DEFINES", self.assignment_append, cpp_info.defines),
("CFLAGS", self.assignment_append, cpp_info.cflags),
- ("CPPFLAGS", self.assignment_append, cpp_info.cppflags),
+ ("CXXFLAGS", self.assignment_append, cpp_info.cppflags),
("SHAREDLINKFLAGS", self.assignment_append, cpp_info.sharedlinkflags),
("EXELINKFLAGS", self.assignment_append, cpp_info.exelinkflags)]
@@ -104,6 +104,6 @@
@staticmethod
def all_dep_vars():
- return ["rootpath", "sysroot", "include_paths", "lib_paths", "bin_paths", "build_paths",
- "res_paths", "libs", "defines", "cflags", "cppflags", "sharedlinkflags",
+ return ["rootpath", "sysroot", "include_dirs", "lib_dirs", "bin_dirs", "build_dirs",
+ "res_dirs", "libs", "defines", "cflags", "cxxflags", "sharedlinkflags",
"exelinkflags"]
|
{"golden_diff": "diff --git a/conans/client/generators/make.py b/conans/client/generators/make.py\n--- a/conans/client/generators/make.py\n+++ b/conans/client/generators/make.py\n@@ -47,15 +47,15 @@\n \n vars_info = [(\"ROOT\", self.assignment_if_absent, [cpp_info.rootpath]),\n (\"SYSROOT\", self.assignment_if_absent, [cpp_info.sysroot]),\n- (\"INCLUDE_PATHS\", self.assignment_append, cpp_info.include_paths),\n- (\"LIB_PATHS\", self.assignment_append, cpp_info.lib_paths),\n- (\"BIN_PATHS\", self.assignment_append, cpp_info.bin_paths),\n- (\"BUILD_PATHS\", self.assignment_append, cpp_info.build_paths),\n- (\"RES_PATHS\", self.assignment_append, cpp_info.res_paths),\n+ (\"INCLUDE_DIRS\", self.assignment_append, cpp_info.include_paths),\n+ (\"LIB_DIRS\", self.assignment_append, cpp_info.lib_paths),\n+ (\"BIN_DIRS\", self.assignment_append, cpp_info.bin_paths),\n+ (\"BUILD_DIRS\", self.assignment_append, cpp_info.build_paths),\n+ (\"RES_DIRS\", self.assignment_append, cpp_info.res_paths),\n (\"LIBS\", self.assignment_append, cpp_info.libs),\n (\"DEFINES\", self.assignment_append, cpp_info.defines),\n (\"CFLAGS\", self.assignment_append, cpp_info.cflags),\n- (\"CPPFLAGS\", self.assignment_append, cpp_info.cppflags),\n+ (\"CXXFLAGS\", self.assignment_append, cpp_info.cppflags),\n (\"SHAREDLINKFLAGS\", self.assignment_append, cpp_info.sharedlinkflags),\n (\"EXELINKFLAGS\", self.assignment_append, cpp_info.exelinkflags)]\n \n@@ -104,6 +104,6 @@\n \n @staticmethod\n def all_dep_vars():\n- return [\"rootpath\", \"sysroot\", \"include_paths\", \"lib_paths\", \"bin_paths\", \"build_paths\",\n- \"res_paths\", \"libs\", \"defines\", \"cflags\", \"cppflags\", \"sharedlinkflags\",\n+ return [\"rootpath\", \"sysroot\", \"include_dirs\", \"lib_dirs\", \"bin_dirs\", \"build_dirs\",\n+ \"res_dirs\", \"libs\", \"defines\", \"cflags\", \"cxxflags\", \"sharedlinkflags\",\n \"exelinkflags\"]\n", "issue": "Fix experimental make generator CONAN_CPPFLAGS and CONAN_INCLUDE_PATHS\nFollowing the conversation here https://github.com/conan-io/conan/issues/4286#issuecomment-454194188\r\n\r\nWe have finally reached the conclusion of having ``cpp_info.cppflags`` converted to ``CONAN_CXXFLAGS`` in the ``make`` generator to be consistent with orhter generators such as ``cmake``.\r\n\r\nAlso the flag ``CONAN_INCLUDE_PATHS`` should be renamed to ``CONAN_INCLUDE_DIRS`` for the same reason.\r\n\r\nIn another issue we would probably introduce a ``cpp_info.cxxflags`` that would be an internal alias of ``cpp_info.cppflags`` to avoid this confusion without breaking.\r\n\r\ncc/ @solvingj \n", "before_files": [{"content": "from conans.model import Generator\nfrom conans.paths import BUILD_INFO_MAKE\n\n\nclass MakeGenerator(Generator):\n\n def __init__(self, conanfile):\n Generator.__init__(self, conanfile)\n self.makefile_newline = \"\\n\"\n self.makefile_line_continuation = \" \\\\\\n\"\n self.assignment_if_absent = \" ?= \"\n self.assignment_append = \" += \"\n\n @property\n def filename(self):\n return BUILD_INFO_MAKE\n\n @property\n def content(self):\n\n content = [\n \"#-------------------------------------------------------------------#\",\n \"# Makefile variables from Conan Dependencies #\",\n \"#-------------------------------------------------------------------#\",\n \"\",\n ]\n\n for line_as_list in self.create_deps_content():\n content.append(\"\".join(line_as_list))\n\n content.append(\"#-------------------------------------------------------------------#\")\n content.append(self.makefile_newline)\n return self.makefile_newline.join(content)\n\n def create_deps_content(self):\n deps_content = self.create_content_from_deps()\n deps_content.extend(self.create_combined_content())\n return deps_content\n\n def create_content_from_deps(self):\n content = []\n for pkg_name, cpp_info in self.deps_build_info.dependencies:\n content.extend(self.create_content_from_dep(pkg_name, cpp_info))\n return content\n\n def create_content_from_dep(self, pkg_name, cpp_info):\n\n vars_info = [(\"ROOT\", self.assignment_if_absent, [cpp_info.rootpath]),\n (\"SYSROOT\", self.assignment_if_absent, [cpp_info.sysroot]),\n (\"INCLUDE_PATHS\", self.assignment_append, cpp_info.include_paths),\n (\"LIB_PATHS\", self.assignment_append, cpp_info.lib_paths),\n (\"BIN_PATHS\", self.assignment_append, cpp_info.bin_paths),\n (\"BUILD_PATHS\", self.assignment_append, cpp_info.build_paths),\n (\"RES_PATHS\", self.assignment_append, cpp_info.res_paths),\n (\"LIBS\", self.assignment_append, cpp_info.libs),\n (\"DEFINES\", self.assignment_append, cpp_info.defines),\n (\"CFLAGS\", self.assignment_append, cpp_info.cflags),\n (\"CPPFLAGS\", self.assignment_append, cpp_info.cppflags),\n (\"SHAREDLINKFLAGS\", self.assignment_append, cpp_info.sharedlinkflags),\n (\"EXELINKFLAGS\", self.assignment_append, cpp_info.exelinkflags)]\n\n return [self.create_makefile_var_pkg(var_name, pkg_name, operator, info)\n for var_name, operator, info in vars_info]\n\n def create_combined_content(self):\n content = []\n for var_name in self.all_dep_vars():\n content.append(self.create_makefile_var_global(var_name, self.assignment_append,\n self.create_combined_var_list(var_name)))\n return content\n\n def create_combined_var_list(self, var_name):\n make_vars = []\n for pkg_name, _ in self.deps_build_info.dependencies:\n pkg_var = self.create_makefile_var_name_pkg(var_name, pkg_name)\n make_vars.append(\"$({pkg_var})\".format(pkg_var=pkg_var))\n return make_vars\n\n def create_makefile_var_global(self, var_name, operator, values):\n make_var = [self.create_makefile_var_name_global(var_name)]\n make_var.extend(self.create_makefile_var_common(operator, values))\n return make_var\n\n def create_makefile_var_pkg(self, var_name, pkg_name, operator, values):\n make_var = [self.create_makefile_var_name_pkg(var_name, pkg_name)]\n make_var.extend(self.create_makefile_var_common(operator, values))\n return make_var\n\n def create_makefile_var_common(self, operator, values):\n return [operator, self.makefile_line_continuation, self.create_makefile_var_value(values),\n self.makefile_newline]\n\n @staticmethod\n def create_makefile_var_name_global(var_name):\n return \"CONAN_{var}\".format(var=var_name).upper()\n\n @staticmethod\n def create_makefile_var_name_pkg(var_name, pkg_name):\n return \"CONAN_{var}_{lib}\".format(var=var_name, lib=pkg_name).upper()\n\n def create_makefile_var_value(self, values):\n formatted_values = [value.replace(\"\\\\\", \"/\") for value in values]\n return self.makefile_line_continuation.join(formatted_values)\n\n @staticmethod\n def all_dep_vars():\n return [\"rootpath\", \"sysroot\", \"include_paths\", \"lib_paths\", \"bin_paths\", \"build_paths\",\n \"res_paths\", \"libs\", \"defines\", \"cflags\", \"cppflags\", \"sharedlinkflags\",\n \"exelinkflags\"]\n", "path": "conans/client/generators/make.py"}]}
| 1,903 | 499 |
gh_patches_debug_13502
|
rasdani/github-patches
|
git_diff
|
mne-tools__mne-bids-111
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
prune dependencies that we do not really depend on
As became apparent in a discussion with @agramfort and @jasmainak, we probably do not need the `environment.yml` and instead should rely on minimal dependencies such as numpy, scipy, and matplotlib.
if we decide to keep the `environment.yml` for convenience during installation, we should at least prune it.
</issue>
<code>
[start of mne_bids/datasets.py]
1 """Helper functions to fetch data to work with."""
2 # Authors: Mainak Jas <[email protected]>
3 # Alexandre Gramfort <[email protected]>
4 # Teon Brooks <[email protected]>
5 # Stefan Appelhoff <[email protected]>
6 #
7 # License: BSD (3-clause)
8
9 import os
10 import os.path as op
11 import shutil
12 import tarfile
13 import requests
14
15 from mne.utils import _fetch_file
16
17
18 def fetch_faces_data(data_path=None, repo='ds000117', subject_ids=[1]):
19 """Dataset fetcher for OpenfMRI dataset ds000117.
20
21 Parameters
22 ----------
23 data_path : str | None
24 Path to the folder where data is stored. Defaults to
25 '~/mne_data/mne_bids_examples'
26 repo : str
27 The folder name. Defaults to 'ds000117'.
28 subject_ids : list of int
29 The subjects to fetch. Defaults to [1], downloading subject 1.
30
31 Returns
32 -------
33 data_path : str
34 Path to the folder where data is stored.
35
36 """
37 if not data_path:
38 home = os.path.expanduser('~')
39 data_path = os.path.join(home, 'mne_data', 'mne_bids_examples')
40 if not os.path.exists(data_path):
41 os.makedirs(data_path)
42
43 for subject_id in subject_ids:
44 src_url = ('http://openfmri.s3.amazonaws.com/tarballs/'
45 'ds117_R0.1.1_sub%03d_raw.tgz' % subject_id)
46 tar_fname = op.join(data_path, repo + '.tgz')
47 target_dir = op.join(data_path, repo)
48 if not op.exists(target_dir):
49 if not op.exists(tar_fname):
50 _fetch_file(url=src_url, file_name=tar_fname,
51 print_destination=True, resume=True, timeout=10.)
52 tf = tarfile.open(tar_fname)
53 print('Extracting files. This may take a while ...')
54 tf.extractall(path=data_path)
55 shutil.move(op.join(data_path, 'ds117'), target_dir)
56 os.remove(tar_fname)
57
58 return data_path
59
60
61 def fetch_brainvision_testing_data(data_path=None):
62 """Download the MNE-Python testing data for the BrainVision format.
63
64 Parameters
65 ----------
66 data_path : str | None
67 Path to the folder where data is stored. Defaults to
68 '~/mne_data/mne_bids_examples'
69
70 Returns
71 -------
72 data_path : str
73 Path to the folder where data is stored.
74
75 """
76 if not data_path:
77 home = os.path.expanduser('~')
78 data_path = os.path.join(home, 'mne_data', 'mne_bids_examples')
79 if not os.path.exists(data_path):
80 os.makedirs(data_path)
81
82 base_url = 'https://github.com/mne-tools/mne-python/'
83 base_url += 'raw/master/mne/io/brainvision/tests/data/test'
84 file_endings = ['.vhdr', '.vmrk', '.eeg', ]
85
86 for f_ending in file_endings:
87 url = base_url + f_ending
88 response = requests.get(url)
89
90 fname = os.path.join(data_path, 'test' + f_ending)
91 with open(fname, 'wb') as fout:
92 fout.write(response.content)
93
94 return data_path
95
[end of mne_bids/datasets.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mne_bids/datasets.py b/mne_bids/datasets.py
--- a/mne_bids/datasets.py
+++ b/mne_bids/datasets.py
@@ -10,7 +10,7 @@
import os.path as op
import shutil
import tarfile
-import requests
+from six.moves import urllib
from mne.utils import _fetch_file
@@ -85,10 +85,10 @@
for f_ending in file_endings:
url = base_url + f_ending
- response = requests.get(url)
+ response = urllib.request.urlopen(url)
fname = os.path.join(data_path, 'test' + f_ending)
with open(fname, 'wb') as fout:
- fout.write(response.content)
+ fout.write(response.read())
return data_path
|
{"golden_diff": "diff --git a/mne_bids/datasets.py b/mne_bids/datasets.py\n--- a/mne_bids/datasets.py\n+++ b/mne_bids/datasets.py\n@@ -10,7 +10,7 @@\n import os.path as op\n import shutil\n import tarfile\n-import requests\n+from six.moves import urllib\n \n from mne.utils import _fetch_file\n \n@@ -85,10 +85,10 @@\n \n for f_ending in file_endings:\n url = base_url + f_ending\n- response = requests.get(url)\n+ response = urllib.request.urlopen(url)\n \n fname = os.path.join(data_path, 'test' + f_ending)\n with open(fname, 'wb') as fout:\n- fout.write(response.content)\n+ fout.write(response.read())\n \n return data_path\n", "issue": "prune dependencies that we do not really depend on\nAs became apparent in a discussion with @agramfort and @jasmainak, we probably do not need the `environment.yml` and instead should rely on minimal dependencies such as numpy, scipy, and matplotlib.\r\n\r\nif we decide to keep the `environment.yml` for convenience during installation, we should at least prune it.\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "\"\"\"Helper functions to fetch data to work with.\"\"\"\n# Authors: Mainak Jas <[email protected]>\n# Alexandre Gramfort <[email protected]>\n# Teon Brooks <[email protected]>\n# Stefan Appelhoff <[email protected]>\n#\n# License: BSD (3-clause)\n\nimport os\nimport os.path as op\nimport shutil\nimport tarfile\nimport requests\n\nfrom mne.utils import _fetch_file\n\n\ndef fetch_faces_data(data_path=None, repo='ds000117', subject_ids=[1]):\n \"\"\"Dataset fetcher for OpenfMRI dataset ds000117.\n\n Parameters\n ----------\n data_path : str | None\n Path to the folder where data is stored. Defaults to\n '~/mne_data/mne_bids_examples'\n repo : str\n The folder name. Defaults to 'ds000117'.\n subject_ids : list of int\n The subjects to fetch. Defaults to [1], downloading subject 1.\n\n Returns\n -------\n data_path : str\n Path to the folder where data is stored.\n\n \"\"\"\n if not data_path:\n home = os.path.expanduser('~')\n data_path = os.path.join(home, 'mne_data', 'mne_bids_examples')\n if not os.path.exists(data_path):\n os.makedirs(data_path)\n\n for subject_id in subject_ids:\n src_url = ('http://openfmri.s3.amazonaws.com/tarballs/'\n 'ds117_R0.1.1_sub%03d_raw.tgz' % subject_id)\n tar_fname = op.join(data_path, repo + '.tgz')\n target_dir = op.join(data_path, repo)\n if not op.exists(target_dir):\n if not op.exists(tar_fname):\n _fetch_file(url=src_url, file_name=tar_fname,\n print_destination=True, resume=True, timeout=10.)\n tf = tarfile.open(tar_fname)\n print('Extracting files. This may take a while ...')\n tf.extractall(path=data_path)\n shutil.move(op.join(data_path, 'ds117'), target_dir)\n os.remove(tar_fname)\n\n return data_path\n\n\ndef fetch_brainvision_testing_data(data_path=None):\n \"\"\"Download the MNE-Python testing data for the BrainVision format.\n\n Parameters\n ----------\n data_path : str | None\n Path to the folder where data is stored. Defaults to\n '~/mne_data/mne_bids_examples'\n\n Returns\n -------\n data_path : str\n Path to the folder where data is stored.\n\n \"\"\"\n if not data_path:\n home = os.path.expanduser('~')\n data_path = os.path.join(home, 'mne_data', 'mne_bids_examples')\n if not os.path.exists(data_path):\n os.makedirs(data_path)\n\n base_url = 'https://github.com/mne-tools/mne-python/'\n base_url += 'raw/master/mne/io/brainvision/tests/data/test'\n file_endings = ['.vhdr', '.vmrk', '.eeg', ]\n\n for f_ending in file_endings:\n url = base_url + f_ending\n response = requests.get(url)\n\n fname = os.path.join(data_path, 'test' + f_ending)\n with open(fname, 'wb') as fout:\n fout.write(response.content)\n\n return data_path\n", "path": "mne_bids/datasets.py"}]}
| 1,569 | 186 |
gh_patches_debug_17256
|
rasdani/github-patches
|
git_diff
|
apluslms__a-plus-1352
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Login should not take the user to the front page
Common scenario: the user is browsing a particular course module. They aren’t logged in. They decide to log in, but doing so takes them to the A+ front page, from which they have to navigate back to where they were. Inconvenient.
</issue>
<code>
[start of course/templatetags/base.py]
1 from datetime import datetime
2
3 from django import template
4 from django.conf import settings
5 from django.utils.safestring import mark_safe
6 from django.utils.text import format_lazy
7 from django.utils.translation import get_language, gettext_lazy as _
8 from lib.helpers import remove_query_param_from_url, settings_text, update_url_params
9 from exercise.submission_models import PendingSubmission
10 from site_alert.models import SiteAlert
11
12
13 register = template.Library()
14
15
16 def pick_localized(message):
17 if message and isinstance(message, dict):
18 return (message.get(get_language()) or
19 message.get(settings.LANGUAGE_CODE[:2]) or
20 list(message.values())[0])
21 return message
22
23
24 def get_date(cont, key):
25 data = cont.get(key)
26 if data and not isinstance(data, datetime):
27 data = datetime.strptime(data, '%Y-%m-%d')
28 cont[key] = data
29 return data
30
31
32 @register.simple_tag
33 def brand_name():
34 return mark_safe(settings.BRAND_NAME)
35
36
37 @register.simple_tag
38 def brand_name_long():
39 return mark_safe(settings.BRAND_NAME_LONG)
40
41
42 @register.simple_tag
43 def brand_institution_name():
44 return mark_safe(settings_text('BRAND_INSTITUTION_NAME'))
45
46
47 @register.simple_tag
48 def course_alert(instance):
49 exercises = PendingSubmission.objects.get_exercise_names_if_grader_is_unstable(instance)
50 if exercises:
51 message = format_lazy(
52 _('GRADER_PROBLEMS_ALERT -- {exercises}'),
53 exercises=exercises,
54 )
55 return mark_safe(format_lazy('<div class="alert alert-danger sticky-alert">{message}</div>', message=message))
56 return ''
57
58
59 @register.simple_tag
60 def site_alert():
61 alerts = SiteAlert.objects.filter(status=SiteAlert.STATUS.ACTIVE)
62 return mark_safe(
63 ''.join(
64 '<div class="alert alert-danger">{}</div>'.format(pick_localized(alert.alert))
65 for alert in alerts
66 )
67 )
68
69
70 @register.simple_tag
71 def site_advert(): # pylint: disable=inconsistent-return-statements
72 advert = settings.SITEWIDE_ADVERT
73 if not advert or not isinstance(advert, dict):
74 return
75 not_before = get_date(advert, 'not-before')
76 not_after = get_date(advert, 'not-after')
77 if not_before or not_after:
78 now = datetime.now()
79 if not_before and not_before > now:
80 return
81 if not_after and not_after < now:
82 return
83 return {k: pick_localized(advert.get(k))
84 for k in ('title', 'text', 'href', 'image')}
85
86
87 @register.simple_tag
88 def tracking_html():
89 return mark_safe(settings.TRACKING_HTML)
90
91
92 @register.filter
93 def localized_url(path, language=None):
94 base_url = settings.BASE_URL
95 if base_url.endswith('/'):
96 base_url = base_url[:-1]
97 path = remove_query_param_from_url(path, 'hl')
98 if not language:
99 language = settings.LANGUAGE_CODE.split('-')[0]
100 path = update_url_params(path, { 'hl': language })
101 return base_url + path
102
[end of course/templatetags/base.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/course/templatetags/base.py b/course/templatetags/base.py
--- a/course/templatetags/base.py
+++ b/course/templatetags/base.py
@@ -2,6 +2,8 @@
from django import template
from django.conf import settings
+from django.urls import resolve
+from django.urls.exceptions import Resolver404
from django.utils.safestring import mark_safe
from django.utils.text import format_lazy
from django.utils.translation import get_language, gettext_lazy as _
@@ -28,6 +30,15 @@
cont[key] = data
return data
[email protected]_tag(takes_context=True)
+def login_next(context):
+ request = context["request"]
+ try:
+ matched_url_name = resolve(request.path).url_name
+ next_path = f"?next={request.path}" if matched_url_name != 'logout' else ""
+ return next_path
+ except Resolver404:
+ return ""
@register.simple_tag
def brand_name():
|
{"golden_diff": "diff --git a/course/templatetags/base.py b/course/templatetags/base.py\n--- a/course/templatetags/base.py\n+++ b/course/templatetags/base.py\n@@ -2,6 +2,8 @@\n \n from django import template\n from django.conf import settings\n+from django.urls import resolve\n+from django.urls.exceptions import Resolver404\n from django.utils.safestring import mark_safe\n from django.utils.text import format_lazy\n from django.utils.translation import get_language, gettext_lazy as _\n@@ -28,6 +30,15 @@\n cont[key] = data\n return data\n \[email protected]_tag(takes_context=True)\n+def login_next(context):\n+ request = context[\"request\"]\n+ try:\n+ matched_url_name = resolve(request.path).url_name\n+ next_path = f\"?next={request.path}\" if matched_url_name != 'logout' else \"\"\n+ return next_path\n+ except Resolver404:\n+ return \"\"\n \n @register.simple_tag\n def brand_name():\n", "issue": "Login should not take the user to the front page\nCommon scenario: the user is browsing a particular course module. They aren\u2019t logged in. They decide to log in, but doing so takes them to the A+ front page, from which they have to navigate back to where they were. Inconvenient.\n", "before_files": [{"content": "from datetime import datetime\n\nfrom django import template\nfrom django.conf import settings\nfrom django.utils.safestring import mark_safe\nfrom django.utils.text import format_lazy\nfrom django.utils.translation import get_language, gettext_lazy as _\nfrom lib.helpers import remove_query_param_from_url, settings_text, update_url_params\nfrom exercise.submission_models import PendingSubmission\nfrom site_alert.models import SiteAlert\n\n\nregister = template.Library()\n\n\ndef pick_localized(message):\n if message and isinstance(message, dict):\n return (message.get(get_language()) or\n message.get(settings.LANGUAGE_CODE[:2]) or\n list(message.values())[0])\n return message\n\n\ndef get_date(cont, key):\n data = cont.get(key)\n if data and not isinstance(data, datetime):\n data = datetime.strptime(data, '%Y-%m-%d')\n cont[key] = data\n return data\n\n\[email protected]_tag\ndef brand_name():\n return mark_safe(settings.BRAND_NAME)\n\n\[email protected]_tag\ndef brand_name_long():\n return mark_safe(settings.BRAND_NAME_LONG)\n\n\[email protected]_tag\ndef brand_institution_name():\n return mark_safe(settings_text('BRAND_INSTITUTION_NAME'))\n\n\[email protected]_tag\ndef course_alert(instance):\n exercises = PendingSubmission.objects.get_exercise_names_if_grader_is_unstable(instance)\n if exercises:\n message = format_lazy(\n _('GRADER_PROBLEMS_ALERT -- {exercises}'),\n exercises=exercises,\n )\n return mark_safe(format_lazy('<div class=\"alert alert-danger sticky-alert\">{message}</div>', message=message))\n return ''\n\n\[email protected]_tag\ndef site_alert():\n alerts = SiteAlert.objects.filter(status=SiteAlert.STATUS.ACTIVE)\n return mark_safe(\n ''.join(\n '<div class=\"alert alert-danger\">{}</div>'.format(pick_localized(alert.alert))\n for alert in alerts\n )\n )\n\n\[email protected]_tag\ndef site_advert(): # pylint: disable=inconsistent-return-statements\n advert = settings.SITEWIDE_ADVERT\n if not advert or not isinstance(advert, dict):\n return\n not_before = get_date(advert, 'not-before')\n not_after = get_date(advert, 'not-after')\n if not_before or not_after:\n now = datetime.now()\n if not_before and not_before > now:\n return\n if not_after and not_after < now:\n return\n return {k: pick_localized(advert.get(k))\n for k in ('title', 'text', 'href', 'image')}\n\n\[email protected]_tag\ndef tracking_html():\n return mark_safe(settings.TRACKING_HTML)\n\n\[email protected]\ndef localized_url(path, language=None):\n base_url = settings.BASE_URL\n if base_url.endswith('/'):\n base_url = base_url[:-1]\n path = remove_query_param_from_url(path, 'hl')\n if not language:\n language = settings.LANGUAGE_CODE.split('-')[0]\n path = update_url_params(path, { 'hl': language })\n return base_url + path\n", "path": "course/templatetags/base.py"}]}
| 1,467 | 230 |
gh_patches_debug_1790
|
rasdani/github-patches
|
git_diff
|
scikit-hep__pyhf-933
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Docs build broken with Sphinx v3.1.1
# Description
After the new Sphinx patch release [`v3.1.1`](https://github.com/sphinx-doc/sphinx/releases/tag/v3.1.1) was released there is an error with building the docs due to `autodocumenting`:
```
WARNING: don't know which module to import for autodocumenting 'optimize.opt_jax.jax_optimizer' (try placing a "module" or "currentmodule" directive in the document, or giving an explicit module name)
WARNING: don't know which module to import for autodocumenting 'optimize.opt_minuit.minuit_optimizer' (try placing a "module" or "currentmodule" directive in the document, or giving an explicit module name)
WARNING: don't know which module to import for autodocumenting 'optimize.opt_pytorch.pytorch_optimizer' (try placing a "module" or "currentmodule" directive in the document, or giving an explicit module name)
WARNING: don't know which module to import for autodocumenting 'optimize.opt_scipy.scipy_optimizer' (try placing a "module" or "currentmodule" directive in the document, or giving an explicit module name)
WARNING: don't know which module to import for autodocumenting 'optimize.opt_tflow.tflow_optimizer' (try placing a "module" or "currentmodule" directive in the document, or giving an explicit module name)
WARNING: don't know which module to import for autodocumenting 'tensor.jax_backend.jax_backend' (try placing a "module" or "currentmodule" directive in the document, or giving an explicit module name)
WARNING: don't know which module to import for autodocumenting 'tensor.numpy_backend.numpy_backend' (try placing a "module" or "currentmodule" directive in the document, or giving an explicit module name)
WARNING: don't know which module to import for autodocumenting 'tensor.pytorch_backend.pytorch_backend' (try placing a "module" or "currentmodule" directive in the document, or giving an explicit module name)
WARNING: don't know which module to import for autodocumenting 'tensor.tensorflow_backend.tensorflow_backend' (try placing a "module" or "currentmodule" directive in the document, or giving an explicit module name)
```
</issue>
<code>
[start of setup.py]
1 from setuptools import setup
2
3 extras_require = {
4 'tensorflow': [
5 'tensorflow~=2.0',
6 'tensorflow-probability~=0.10', # TODO: Temp patch until tfp v0.11
7 ],
8 'torch': ['torch~=1.2'],
9 'jax': ['jax~=0.1,>0.1.51', 'jaxlib~=0.1,>0.1.33'],
10 'xmlio': ['uproot~=3.6'], # Future proof against uproot4 API changes
11 'minuit': ['iminuit'],
12 }
13 extras_require['backends'] = sorted(
14 set(
15 extras_require['tensorflow']
16 + extras_require['torch']
17 + extras_require['jax']
18 + extras_require['minuit']
19 )
20 )
21 extras_require['contrib'] = sorted(set(['matplotlib']))
22 extras_require['lint'] = sorted(set(['pyflakes', 'black']))
23
24 extras_require['test'] = sorted(
25 set(
26 extras_require['backends']
27 + extras_require['xmlio']
28 + extras_require['contrib']
29 + [
30 'pytest~=3.5',
31 'pytest-cov>=2.5.1',
32 'pytest-mock',
33 'pytest-benchmark[histogram]',
34 'pytest-console-scripts',
35 'pytest-mpl',
36 'pydocstyle',
37 'coverage>=4.0', # coveralls
38 'papermill~=2.0',
39 'nteract-scrapbook~=0.2',
40 'jupyter',
41 'uproot~=3.3',
42 'graphviz',
43 'jsonpatch',
44 ]
45 )
46 )
47 extras_require['docs'] = sorted(
48 set(
49 [
50 'sphinx~=3.0.0', # Sphinx v3.1.X regressions break docs
51 'sphinxcontrib-bibtex',
52 'sphinx-click',
53 'sphinx_rtd_theme',
54 'nbsphinx',
55 'ipywidgets',
56 'sphinx-issues',
57 'sphinx-copybutton>0.2.9',
58 ]
59 )
60 )
61 extras_require['develop'] = sorted(
62 set(
63 extras_require['docs']
64 + extras_require['lint']
65 + extras_require['test']
66 + ['nbdime', 'bumpversion', 'ipython', 'pre-commit', 'check-manifest', 'twine']
67 )
68 )
69 extras_require['complete'] = sorted(set(sum(extras_require.values(), [])))
70
71
72 setup(
73 extras_require=extras_require,
74 use_scm_version=lambda: {'local_scheme': lambda version: ''},
75 )
76
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -47,7 +47,7 @@
extras_require['docs'] = sorted(
set(
[
- 'sphinx~=3.0.0', # Sphinx v3.1.X regressions break docs
+ 'sphinx>=3.1.2',
'sphinxcontrib-bibtex',
'sphinx-click',
'sphinx_rtd_theme',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -47,7 +47,7 @@\n extras_require['docs'] = sorted(\n set(\n [\n- 'sphinx~=3.0.0', # Sphinx v3.1.X regressions break docs\n+ 'sphinx>=3.1.2',\n 'sphinxcontrib-bibtex',\n 'sphinx-click',\n 'sphinx_rtd_theme',\n", "issue": "Docs build broken with Sphinx v3.1.1\n# Description\r\n\r\nAfter the new Sphinx patch release [`v3.1.1`](https://github.com/sphinx-doc/sphinx/releases/tag/v3.1.1) was released there is an error with building the docs due to `autodocumenting`:\r\n\r\n```\r\n\r\nWARNING: don't know which module to import for autodocumenting 'optimize.opt_jax.jax_optimizer' (try placing a \"module\" or \"currentmodule\" directive in the document, or giving an explicit module name)\r\nWARNING: don't know which module to import for autodocumenting 'optimize.opt_minuit.minuit_optimizer' (try placing a \"module\" or \"currentmodule\" directive in the document, or giving an explicit module name)\r\nWARNING: don't know which module to import for autodocumenting 'optimize.opt_pytorch.pytorch_optimizer' (try placing a \"module\" or \"currentmodule\" directive in the document, or giving an explicit module name)\r\nWARNING: don't know which module to import for autodocumenting 'optimize.opt_scipy.scipy_optimizer' (try placing a \"module\" or \"currentmodule\" directive in the document, or giving an explicit module name)\r\nWARNING: don't know which module to import for autodocumenting 'optimize.opt_tflow.tflow_optimizer' (try placing a \"module\" or \"currentmodule\" directive in the document, or giving an explicit module name)\r\nWARNING: don't know which module to import for autodocumenting 'tensor.jax_backend.jax_backend' (try placing a \"module\" or \"currentmodule\" directive in the document, or giving an explicit module name)\r\nWARNING: don't know which module to import for autodocumenting 'tensor.numpy_backend.numpy_backend' (try placing a \"module\" or \"currentmodule\" directive in the document, or giving an explicit module name)\r\nWARNING: don't know which module to import for autodocumenting 'tensor.pytorch_backend.pytorch_backend' (try placing a \"module\" or \"currentmodule\" directive in the document, or giving an explicit module name)\r\nWARNING: don't know which module to import for autodocumenting 'tensor.tensorflow_backend.tensorflow_backend' (try placing a \"module\" or \"currentmodule\" directive in the document, or giving an explicit module name)\r\n```\n", "before_files": [{"content": "from setuptools import setup\n\nextras_require = {\n 'tensorflow': [\n 'tensorflow~=2.0',\n 'tensorflow-probability~=0.10', # TODO: Temp patch until tfp v0.11\n ],\n 'torch': ['torch~=1.2'],\n 'jax': ['jax~=0.1,>0.1.51', 'jaxlib~=0.1,>0.1.33'],\n 'xmlio': ['uproot~=3.6'], # Future proof against uproot4 API changes\n 'minuit': ['iminuit'],\n}\nextras_require['backends'] = sorted(\n set(\n extras_require['tensorflow']\n + extras_require['torch']\n + extras_require['jax']\n + extras_require['minuit']\n )\n)\nextras_require['contrib'] = sorted(set(['matplotlib']))\nextras_require['lint'] = sorted(set(['pyflakes', 'black']))\n\nextras_require['test'] = sorted(\n set(\n extras_require['backends']\n + extras_require['xmlio']\n + extras_require['contrib']\n + [\n 'pytest~=3.5',\n 'pytest-cov>=2.5.1',\n 'pytest-mock',\n 'pytest-benchmark[histogram]',\n 'pytest-console-scripts',\n 'pytest-mpl',\n 'pydocstyle',\n 'coverage>=4.0', # coveralls\n 'papermill~=2.0',\n 'nteract-scrapbook~=0.2',\n 'jupyter',\n 'uproot~=3.3',\n 'graphviz',\n 'jsonpatch',\n ]\n )\n)\nextras_require['docs'] = sorted(\n set(\n [\n 'sphinx~=3.0.0', # Sphinx v3.1.X regressions break docs\n 'sphinxcontrib-bibtex',\n 'sphinx-click',\n 'sphinx_rtd_theme',\n 'nbsphinx',\n 'ipywidgets',\n 'sphinx-issues',\n 'sphinx-copybutton>0.2.9',\n ]\n )\n)\nextras_require['develop'] = sorted(\n set(\n extras_require['docs']\n + extras_require['lint']\n + extras_require['test']\n + ['nbdime', 'bumpversion', 'ipython', 'pre-commit', 'check-manifest', 'twine']\n )\n)\nextras_require['complete'] = sorted(set(sum(extras_require.values(), [])))\n\n\nsetup(\n extras_require=extras_require,\n use_scm_version=lambda: {'local_scheme': lambda version: ''},\n)\n", "path": "setup.py"}]}
| 1,723 | 106 |
gh_patches_debug_9087
|
rasdani/github-patches
|
git_diff
|
wagtail__wagtail-2585
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
RoutablePage throws a TypeError if index route is not set
RoutablePage should not raise TypeError if index route is not set.
[route method](https://github.com/torchbox/wagtail/blob/master/wagtail/contrib/wagtailroutablepage/models.py#L97) properly calls parent class method if route is not found, but `serve` method has different signature, so it fails.
There is also a discussion of similar issue on Google groups:
https://groups.google.com/forum/#!msg/wagtail/Q9FymA-MOxM/1UkQ0hRGAAAJ
</issue>
<code>
[start of wagtail/contrib/wagtailroutablepage/models.py]
1 from __future__ import absolute_import, unicode_literals
2
3 from django.conf.urls import url
4 from django.core.urlresolvers import RegexURLResolver
5 from django.http import Http404
6
7 from wagtail.wagtailcore.models import Page
8 from wagtail.wagtailcore.url_routing import RouteResult
9
10 _creation_counter = 0
11
12
13 def route(pattern, name=None):
14 def decorator(view_func):
15 global _creation_counter
16 _creation_counter += 1
17
18 # Make sure page has _routablepage_routes attribute
19 if not hasattr(view_func, '_routablepage_routes'):
20 view_func._routablepage_routes = []
21
22 # Add new route to view
23 view_func._routablepage_routes.append((
24 url(pattern, view_func, name=(name or view_func.__name__)),
25 _creation_counter,
26 ))
27
28 return view_func
29
30 return decorator
31
32
33 class RoutablePageMixin(object):
34 """
35 This class can be mixed in to a Page model, allowing extra routes to be
36 added to it.
37 """
38 #: Set this to a tuple of ``django.conf.urls.url`` objects.
39 subpage_urls = None
40
41 @classmethod
42 def get_subpage_urls(cls):
43 routes = []
44 for attr in dir(cls):
45 val = getattr(cls, attr)
46 if hasattr(val, '_routablepage_routes'):
47 routes.extend(val._routablepage_routes)
48
49 return tuple([
50 route[0]
51 for route in sorted(routes, key=lambda route: route[1])
52 ])
53
54 @classmethod
55 def get_resolver(cls):
56 if '_routablepage_urlresolver' not in cls.__dict__:
57 subpage_urls = cls.get_subpage_urls()
58 cls._routablepage_urlresolver = RegexURLResolver(r'^/', subpage_urls)
59
60 return cls._routablepage_urlresolver
61
62 def reverse_subpage(self, name, args=None, kwargs=None):
63 """
64 This method takes a route name/arguments and returns a URL path.
65 """
66 args = args or []
67 kwargs = kwargs or {}
68
69 return self.get_resolver().reverse(name, *args, **kwargs)
70
71 def resolve_subpage(self, path):
72 """
73 This method takes a URL path and finds the view to call.
74 """
75 view, args, kwargs = self.get_resolver().resolve(path)
76
77 # Bind the method
78 view = view.__get__(self, type(self))
79
80 return view, args, kwargs
81
82 def route(self, request, path_components):
83 """
84 This hooks the subpage URLs into Wagtail's routing.
85 """
86 if self.live:
87 try:
88 path = '/'
89 if path_components:
90 path += '/'.join(path_components) + '/'
91
92 view, args, kwargs = self.resolve_subpage(path)
93 return RouteResult(self, args=(view, args, kwargs))
94 except Http404:
95 pass
96
97 return super(RoutablePageMixin, self).route(request, path_components)
98
99 def serve(self, request, view, args, kwargs):
100 return view(request, *args, **kwargs)
101
102 def serve_preview(self, request, mode_name):
103 view, args, kwargs = self.resolve_subpage('/')
104 return view(request, *args, **kwargs)
105
106
107 class RoutablePage(RoutablePageMixin, Page):
108 """
109 This class extends Page by adding methods which allows extra routes to be
110 added to it.
111 """
112
113 class Meta:
114 abstract = True
115
[end of wagtail/contrib/wagtailroutablepage/models.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/wagtail/contrib/wagtailroutablepage/models.py b/wagtail/contrib/wagtailroutablepage/models.py
--- a/wagtail/contrib/wagtailroutablepage/models.py
+++ b/wagtail/contrib/wagtailroutablepage/models.py
@@ -96,7 +96,13 @@
return super(RoutablePageMixin, self).route(request, path_components)
- def serve(self, request, view, args, kwargs):
+ def serve(self, request, view=None, args=None, kwargs=None):
+ if args is None:
+ args = []
+ if kwargs is None:
+ kwargs = {}
+ if view is None:
+ return super(RoutablePageMixin, self).serve(request, *args, **kwargs)
return view(request, *args, **kwargs)
def serve_preview(self, request, mode_name):
|
{"golden_diff": "diff --git a/wagtail/contrib/wagtailroutablepage/models.py b/wagtail/contrib/wagtailroutablepage/models.py\n--- a/wagtail/contrib/wagtailroutablepage/models.py\n+++ b/wagtail/contrib/wagtailroutablepage/models.py\n@@ -96,7 +96,13 @@\n \n return super(RoutablePageMixin, self).route(request, path_components)\n \n- def serve(self, request, view, args, kwargs):\n+ def serve(self, request, view=None, args=None, kwargs=None):\n+ if args is None:\n+ args = []\n+ if kwargs is None:\n+ kwargs = {}\n+ if view is None:\n+ return super(RoutablePageMixin, self).serve(request, *args, **kwargs)\n return view(request, *args, **kwargs)\n \n def serve_preview(self, request, mode_name):\n", "issue": "RoutablePage throws a TypeError if index route is not set\nRoutablePage should not raise TypeError if index route is not set. \n\n[route method](https://github.com/torchbox/wagtail/blob/master/wagtail/contrib/wagtailroutablepage/models.py#L97) properly calls parent class method if route is not found, but `serve` method has different signature, so it fails.\n\nThere is also a discussion of similar issue on Google groups:\nhttps://groups.google.com/forum/#!msg/wagtail/Q9FymA-MOxM/1UkQ0hRGAAAJ\n\n", "before_files": [{"content": "from __future__ import absolute_import, unicode_literals\n\nfrom django.conf.urls import url\nfrom django.core.urlresolvers import RegexURLResolver\nfrom django.http import Http404\n\nfrom wagtail.wagtailcore.models import Page\nfrom wagtail.wagtailcore.url_routing import RouteResult\n\n_creation_counter = 0\n\n\ndef route(pattern, name=None):\n def decorator(view_func):\n global _creation_counter\n _creation_counter += 1\n\n # Make sure page has _routablepage_routes attribute\n if not hasattr(view_func, '_routablepage_routes'):\n view_func._routablepage_routes = []\n\n # Add new route to view\n view_func._routablepage_routes.append((\n url(pattern, view_func, name=(name or view_func.__name__)),\n _creation_counter,\n ))\n\n return view_func\n\n return decorator\n\n\nclass RoutablePageMixin(object):\n \"\"\"\n This class can be mixed in to a Page model, allowing extra routes to be\n added to it.\n \"\"\"\n #: Set this to a tuple of ``django.conf.urls.url`` objects.\n subpage_urls = None\n\n @classmethod\n def get_subpage_urls(cls):\n routes = []\n for attr in dir(cls):\n val = getattr(cls, attr)\n if hasattr(val, '_routablepage_routes'):\n routes.extend(val._routablepage_routes)\n\n return tuple([\n route[0]\n for route in sorted(routes, key=lambda route: route[1])\n ])\n\n @classmethod\n def get_resolver(cls):\n if '_routablepage_urlresolver' not in cls.__dict__:\n subpage_urls = cls.get_subpage_urls()\n cls._routablepage_urlresolver = RegexURLResolver(r'^/', subpage_urls)\n\n return cls._routablepage_urlresolver\n\n def reverse_subpage(self, name, args=None, kwargs=None):\n \"\"\"\n This method takes a route name/arguments and returns a URL path.\n \"\"\"\n args = args or []\n kwargs = kwargs or {}\n\n return self.get_resolver().reverse(name, *args, **kwargs)\n\n def resolve_subpage(self, path):\n \"\"\"\n This method takes a URL path and finds the view to call.\n \"\"\"\n view, args, kwargs = self.get_resolver().resolve(path)\n\n # Bind the method\n view = view.__get__(self, type(self))\n\n return view, args, kwargs\n\n def route(self, request, path_components):\n \"\"\"\n This hooks the subpage URLs into Wagtail's routing.\n \"\"\"\n if self.live:\n try:\n path = '/'\n if path_components:\n path += '/'.join(path_components) + '/'\n\n view, args, kwargs = self.resolve_subpage(path)\n return RouteResult(self, args=(view, args, kwargs))\n except Http404:\n pass\n\n return super(RoutablePageMixin, self).route(request, path_components)\n\n def serve(self, request, view, args, kwargs):\n return view(request, *args, **kwargs)\n\n def serve_preview(self, request, mode_name):\n view, args, kwargs = self.resolve_subpage('/')\n return view(request, *args, **kwargs)\n\n\nclass RoutablePage(RoutablePageMixin, Page):\n \"\"\"\n This class extends Page by adding methods which allows extra routes to be\n added to it.\n \"\"\"\n\n class Meta:\n abstract = True\n", "path": "wagtail/contrib/wagtailroutablepage/models.py"}]}
| 1,683 | 207 |
gh_patches_debug_9881
|
rasdani/github-patches
|
git_diff
|
Kinto__kinto-1862
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Updated Error on Version File Missing
4XX errors are client errors. In that case, if the file is not on the server, the client is not guilty
Raise error instead of returning 404 on __version__ if version file is missing
https://github.com/Kinto/kinto/blame/master/kinto/core/views/version.py#L49
suggested by @peterbe
4XX errors are client errors. In that case, if the file is not on the server, the client is not guilty ;)
</issue>
<code>
[start of kinto/core/views/version.py]
1 import json
2 import os
3
4 import colander
5 from pyramid import httpexceptions
6 from pyramid.security import NO_PERMISSION_REQUIRED
7 from kinto.core import Service
8
9 HERE = os.path.dirname(__file__)
10 ORIGIN = os.path.dirname(HERE)
11
12
13 class VersionResponseSchema(colander.MappingSchema):
14 body = colander.SchemaNode(colander.Mapping(unknown="preserve"))
15
16
17 version_response_schemas = {
18 "200": VersionResponseSchema(description="Return the running Instance version information.")
19 }
20
21
22 version = Service(name="version", path="/__version__", description="Version")
23
24
25 @version.get(
26 permission=NO_PERMISSION_REQUIRED,
27 tags=["Utilities"],
28 operation_id="__version__",
29 response_schemas=version_response_schemas,
30 )
31 def version_view(request):
32 try:
33 return version_view.__json__
34 except AttributeError:
35 pass
36
37 location = request.registry.settings["version_json_path"]
38 files = [
39 location, # Default is current working dir.
40 os.path.join(ORIGIN, "version.json"), # Relative to the package root.
41 os.path.join(HERE, "version.json"), # Relative to this file.
42 ]
43 for version_file in files:
44 if os.path.exists(version_file):
45 with open(version_file) as f:
46 version_view.__json__ = json.load(f)
47 return version_view.__json__ # First one wins.
48
49 raise httpexceptions.HTTPNotFound()
50
[end of kinto/core/views/version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kinto/core/views/version.py b/kinto/core/views/version.py
--- a/kinto/core/views/version.py
+++ b/kinto/core/views/version.py
@@ -2,7 +2,6 @@
import os
import colander
-from pyramid import httpexceptions
from pyramid.security import NO_PERMISSION_REQUIRED
from kinto.core import Service
@@ -46,4 +45,4 @@
version_view.__json__ = json.load(f)
return version_view.__json__ # First one wins.
- raise httpexceptions.HTTPNotFound()
+ raise FileNotFoundError("Version file missing from {}".format(files.join(",")))
|
{"golden_diff": "diff --git a/kinto/core/views/version.py b/kinto/core/views/version.py\n--- a/kinto/core/views/version.py\n+++ b/kinto/core/views/version.py\n@@ -2,7 +2,6 @@\n import os\n \n import colander\n-from pyramid import httpexceptions\n from pyramid.security import NO_PERMISSION_REQUIRED\n from kinto.core import Service\n \n@@ -46,4 +45,4 @@\n version_view.__json__ = json.load(f)\n return version_view.__json__ # First one wins.\n \n- raise httpexceptions.HTTPNotFound()\n+ raise FileNotFoundError(\"Version file missing from {}\".format(files.join(\",\")))\n", "issue": "Updated Error on Version File Missing\n4XX errors are client errors. In that case, if the file is not on the server, the client is not guilty\nRaise error instead of returning 404 on __version__ if version file is missing\nhttps://github.com/Kinto/kinto/blame/master/kinto/core/views/version.py#L49\r\n\r\nsuggested by @peterbe \r\n\r\n4XX errors are client errors. In that case, if the file is not on the server, the client is not guilty ;)\n", "before_files": [{"content": "import json\nimport os\n\nimport colander\nfrom pyramid import httpexceptions\nfrom pyramid.security import NO_PERMISSION_REQUIRED\nfrom kinto.core import Service\n\nHERE = os.path.dirname(__file__)\nORIGIN = os.path.dirname(HERE)\n\n\nclass VersionResponseSchema(colander.MappingSchema):\n body = colander.SchemaNode(colander.Mapping(unknown=\"preserve\"))\n\n\nversion_response_schemas = {\n \"200\": VersionResponseSchema(description=\"Return the running Instance version information.\")\n}\n\n\nversion = Service(name=\"version\", path=\"/__version__\", description=\"Version\")\n\n\[email protected](\n permission=NO_PERMISSION_REQUIRED,\n tags=[\"Utilities\"],\n operation_id=\"__version__\",\n response_schemas=version_response_schemas,\n)\ndef version_view(request):\n try:\n return version_view.__json__\n except AttributeError:\n pass\n\n location = request.registry.settings[\"version_json_path\"]\n files = [\n location, # Default is current working dir.\n os.path.join(ORIGIN, \"version.json\"), # Relative to the package root.\n os.path.join(HERE, \"version.json\"), # Relative to this file.\n ]\n for version_file in files:\n if os.path.exists(version_file):\n with open(version_file) as f:\n version_view.__json__ = json.load(f)\n return version_view.__json__ # First one wins.\n\n raise httpexceptions.HTTPNotFound()\n", "path": "kinto/core/views/version.py"}]}
| 1,040 | 135 |
gh_patches_debug_31495
|
rasdani/github-patches
|
git_diff
|
modin-project__modin-2784
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[ASV] add read_csv benchmark with dtype/names/parse_dates parameters
</issue>
<code>
[start of asv_bench/benchmarks/io/csv.py]
1 # Licensed to Modin Development Team under one or more contributor license agreements.
2 # See the NOTICE file distributed with this work for additional information regarding
3 # copyright ownership. The Modin Development Team licenses this file to you under the
4 # Apache License, Version 2.0 (the "License"); you may not use this file except in
5 # compliance with the License. You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software distributed under
10 # the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF
11 # ANY KIND, either express or implied. See the License for the specific language
12 # governing permissions and limitations under the License.
13
14 import modin.pandas as pd
15 import numpy as np
16
17 from ..utils import (
18 generate_dataframe,
19 RAND_LOW,
20 RAND_HIGH,
21 ASV_USE_IMPL,
22 ASV_DATASET_SIZE,
23 UNARY_OP_DATA_SIZE,
24 IMPL,
25 execute,
26 get_shape_id,
27 )
28
29 # ray init
30 if ASV_USE_IMPL == "modin":
31 pd.DataFrame([])
32
33
34 class BaseReadCsv:
35 # test data file can de created only once
36 def setup_cache(self, test_filename="io_test_file"):
37 test_filenames = {}
38 for shape in UNARY_OP_DATA_SIZE[ASV_DATASET_SIZE]:
39 shape_id = get_shape_id(shape)
40 test_filenames[shape_id] = f"{test_filename}_{shape_id}.csv"
41 df = generate_dataframe("pandas", "str_int", *shape, RAND_LOW, RAND_HIGH)
42 df.to_csv(test_filenames[shape_id], index=False)
43
44 return test_filenames
45
46 def setup(self, test_filenames, shape, *args, **kwargs):
47 self.shape_id = get_shape_id(shape)
48
49
50 class TimeReadCsvSkiprows(BaseReadCsv):
51 param_names = ["shape", "skiprows"]
52 params = [
53 UNARY_OP_DATA_SIZE[ASV_DATASET_SIZE],
54 [
55 None,
56 lambda x: x % 2,
57 np.arange(1, UNARY_OP_DATA_SIZE[ASV_DATASET_SIZE][0][0] // 10),
58 np.arange(1, UNARY_OP_DATA_SIZE[ASV_DATASET_SIZE][0][0], 2),
59 ],
60 ]
61
62 def time_skiprows(self, test_filenames, shape, skiprows):
63 execute(
64 IMPL[ASV_USE_IMPL].read_csv(
65 test_filenames[self.shape_id], skiprows=skiprows
66 )
67 )
68
[end of asv_bench/benchmarks/io/csv.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/asv_bench/benchmarks/io/csv.py b/asv_bench/benchmarks/io/csv.py
--- a/asv_bench/benchmarks/io/csv.py
+++ b/asv_bench/benchmarks/io/csv.py
@@ -65,3 +65,70 @@
test_filenames[self.shape_id], skiprows=skiprows
)
)
+
+
+class TimeReadCsvNamesDtype:
+ _dtypes_params = ["Int64", "Int64_Timestamp"]
+ _timestamp_columns = ["col1", "col2"]
+
+ param_names = ["shape", "names", "dtype"]
+ params = [
+ UNARY_OP_DATA_SIZE[ASV_DATASET_SIZE],
+ ["array-like"],
+ _dtypes_params,
+ ]
+
+ def _get_file_id(self, shape, dtype):
+ return get_shape_id(shape) + dtype
+
+ def _add_timestamp_columns(self, df):
+ df = df.copy()
+ date_column = IMPL["pandas"].date_range(
+ "2000",
+ periods=df.shape[0],
+ freq="ms",
+ )
+ for col in self._timestamp_columns:
+ df[col] = date_column
+ return df
+
+ def setup_cache(self, test_filename="io_test_file_csv_names_dtype"):
+ # filenames with a metadata of saved dataframes
+ cache = {}
+ for shape in UNARY_OP_DATA_SIZE[ASV_DATASET_SIZE]:
+ for dtype in self._dtypes_params:
+ df = generate_dataframe("pandas", "int", *shape, RAND_LOW, RAND_HIGH)
+ if dtype == "Int64_Timestamp":
+ df = self._add_timestamp_columns(df)
+
+ file_id = self._get_file_id(shape, dtype)
+ cache[file_id] = (
+ f"{test_filename}_{file_id}.csv",
+ df.columns.to_list(),
+ df.dtypes.to_dict(),
+ )
+ df.to_csv(cache[file_id][0], index=False)
+ return cache
+
+ def setup(self, cache, shape, names, dtype):
+ file_id = self._get_file_id(shape, dtype)
+ self.filename, self.names, self.dtype = cache[file_id]
+
+ self.parse_dates = None
+ if dtype == "Int64_Timestamp":
+ # cached version of dtype should not change
+ self.dtype = self.dtype.copy()
+ for col in self._timestamp_columns:
+ del self.dtype[col]
+ self.parse_dates = self._timestamp_columns
+
+ def time_read_csv_names_dtype(self, cache, shape, names, dtype):
+ execute(
+ IMPL[ASV_USE_IMPL].read_csv(
+ self.filename,
+ names=self.names,
+ header=0,
+ dtype=self.dtype,
+ parse_dates=self.parse_dates,
+ )
+ )
|
{"golden_diff": "diff --git a/asv_bench/benchmarks/io/csv.py b/asv_bench/benchmarks/io/csv.py\n--- a/asv_bench/benchmarks/io/csv.py\n+++ b/asv_bench/benchmarks/io/csv.py\n@@ -65,3 +65,70 @@\n test_filenames[self.shape_id], skiprows=skiprows\n )\n )\n+\n+\n+class TimeReadCsvNamesDtype:\n+ _dtypes_params = [\"Int64\", \"Int64_Timestamp\"]\n+ _timestamp_columns = [\"col1\", \"col2\"]\n+\n+ param_names = [\"shape\", \"names\", \"dtype\"]\n+ params = [\n+ UNARY_OP_DATA_SIZE[ASV_DATASET_SIZE],\n+ [\"array-like\"],\n+ _dtypes_params,\n+ ]\n+\n+ def _get_file_id(self, shape, dtype):\n+ return get_shape_id(shape) + dtype\n+\n+ def _add_timestamp_columns(self, df):\n+ df = df.copy()\n+ date_column = IMPL[\"pandas\"].date_range(\n+ \"2000\",\n+ periods=df.shape[0],\n+ freq=\"ms\",\n+ )\n+ for col in self._timestamp_columns:\n+ df[col] = date_column\n+ return df\n+\n+ def setup_cache(self, test_filename=\"io_test_file_csv_names_dtype\"):\n+ # filenames with a metadata of saved dataframes\n+ cache = {}\n+ for shape in UNARY_OP_DATA_SIZE[ASV_DATASET_SIZE]:\n+ for dtype in self._dtypes_params:\n+ df = generate_dataframe(\"pandas\", \"int\", *shape, RAND_LOW, RAND_HIGH)\n+ if dtype == \"Int64_Timestamp\":\n+ df = self._add_timestamp_columns(df)\n+\n+ file_id = self._get_file_id(shape, dtype)\n+ cache[file_id] = (\n+ f\"{test_filename}_{file_id}.csv\",\n+ df.columns.to_list(),\n+ df.dtypes.to_dict(),\n+ )\n+ df.to_csv(cache[file_id][0], index=False)\n+ return cache\n+\n+ def setup(self, cache, shape, names, dtype):\n+ file_id = self._get_file_id(shape, dtype)\n+ self.filename, self.names, self.dtype = cache[file_id]\n+\n+ self.parse_dates = None\n+ if dtype == \"Int64_Timestamp\":\n+ # cached version of dtype should not change\n+ self.dtype = self.dtype.copy()\n+ for col in self._timestamp_columns:\n+ del self.dtype[col]\n+ self.parse_dates = self._timestamp_columns\n+\n+ def time_read_csv_names_dtype(self, cache, shape, names, dtype):\n+ execute(\n+ IMPL[ASV_USE_IMPL].read_csv(\n+ self.filename,\n+ names=self.names,\n+ header=0,\n+ dtype=self.dtype,\n+ parse_dates=self.parse_dates,\n+ )\n+ )\n", "issue": "[ASV] add read_csv benchmark with dtype/names/parse_dates parameters\n\n", "before_files": [{"content": "# Licensed to Modin Development Team under one or more contributor license agreements.\n# See the NOTICE file distributed with this work for additional information regarding\n# copyright ownership. The Modin Development Team licenses this file to you under the\n# Apache License, Version 2.0 (the \"License\"); you may not use this file except in\n# compliance with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software distributed under\n# the License is distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF\n# ANY KIND, either express or implied. See the License for the specific language\n# governing permissions and limitations under the License.\n\nimport modin.pandas as pd\nimport numpy as np\n\nfrom ..utils import (\n generate_dataframe,\n RAND_LOW,\n RAND_HIGH,\n ASV_USE_IMPL,\n ASV_DATASET_SIZE,\n UNARY_OP_DATA_SIZE,\n IMPL,\n execute,\n get_shape_id,\n)\n\n# ray init\nif ASV_USE_IMPL == \"modin\":\n pd.DataFrame([])\n\n\nclass BaseReadCsv:\n # test data file can de created only once\n def setup_cache(self, test_filename=\"io_test_file\"):\n test_filenames = {}\n for shape in UNARY_OP_DATA_SIZE[ASV_DATASET_SIZE]:\n shape_id = get_shape_id(shape)\n test_filenames[shape_id] = f\"{test_filename}_{shape_id}.csv\"\n df = generate_dataframe(\"pandas\", \"str_int\", *shape, RAND_LOW, RAND_HIGH)\n df.to_csv(test_filenames[shape_id], index=False)\n\n return test_filenames\n\n def setup(self, test_filenames, shape, *args, **kwargs):\n self.shape_id = get_shape_id(shape)\n\n\nclass TimeReadCsvSkiprows(BaseReadCsv):\n param_names = [\"shape\", \"skiprows\"]\n params = [\n UNARY_OP_DATA_SIZE[ASV_DATASET_SIZE],\n [\n None,\n lambda x: x % 2,\n np.arange(1, UNARY_OP_DATA_SIZE[ASV_DATASET_SIZE][0][0] // 10),\n np.arange(1, UNARY_OP_DATA_SIZE[ASV_DATASET_SIZE][0][0], 2),\n ],\n ]\n\n def time_skiprows(self, test_filenames, shape, skiprows):\n execute(\n IMPL[ASV_USE_IMPL].read_csv(\n test_filenames[self.shape_id], skiprows=skiprows\n )\n )\n", "path": "asv_bench/benchmarks/io/csv.py"}]}
| 1,243 | 650 |
gh_patches_debug_1317
|
rasdani/github-patches
|
git_diff
|
sopel-irc__sopel-1325
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bugzilla] Error calling shutdown method for module bugzilla:None
Noticed this in my logs. Bugzilla shutdown throwing none. On Sopel 6.5.3, Python 3.5.3.
```
Ping timeout reached after 120 seconds, closing connection
Calling shutdown for 2 modules.
calling reddit.shutdown
calling bugzilla.shutdown
Error calling shutdown method for module bugzilla:None
Closed!
Warning: Disconnected. Reconnecting in 20 seconds...
Welcome to Sopel. Loading modules...
```
</issue>
<code>
[start of sopel/modules/bugzilla.py]
1 # coding=utf-8
2 """Bugzilla issue reporting module
3
4 Copyright 2013-2015, Embolalia, embolalia.com
5 Licensed under the Eiffel Forum License 2.
6 """
7 from __future__ import unicode_literals, absolute_import, print_function, division
8
9 import re
10
11 import xmltodict
12
13 from sopel import web, tools
14 from sopel.config.types import StaticSection, ListAttribute
15 from sopel.logger import get_logger
16 from sopel.module import rule
17
18
19 regex = None
20 LOGGER = get_logger(__name__)
21
22
23 class BugzillaSection(StaticSection):
24 domains = ListAttribute('domains')
25 """The domains of the Bugzilla instances from which to get information."""
26
27
28 def configure(config):
29 config.define_section('bugzilla', BugzillaSection)
30 config.bugzilla.configure_setting(
31 'domains',
32 'Enter the domains of the Bugzillas you want extra information '
33 'from (e.g. bugzilla.gnome.org)'
34 )
35
36
37 def setup(bot):
38 global regex
39 bot.config.define_section('bugzilla', BugzillaSection)
40
41 if not bot.config.bugzilla.domains:
42 return
43 if not bot.memory.contains('url_callbacks'):
44 bot.memory['url_callbacks'] = tools.SopelMemory()
45
46 domains = '|'.join(bot.config.bugzilla.domains)
47 regex = re.compile((r'https?://(%s)'
48 '(/show_bug.cgi\?\S*?)'
49 '(id=\d+)')
50 % domains)
51 bot.memory['url_callbacks'][regex] = show_bug
52
53
54 def shutdown(bot):
55 del bot.memory['url_callbacks'][regex]
56
57
58 @rule(r'.*https?://(\S+?)'
59 '(/show_bug.cgi\?\S*?)'
60 '(id=\d+).*')
61 def show_bug(bot, trigger, match=None):
62 """Show information about a Bugzilla bug."""
63 match = match or trigger
64 domain = match.group(1)
65 if domain not in bot.config.bugzilla.domains:
66 return
67 url = 'https://%s%sctype=xml&%s' % match.groups()
68 data = web.get(url, dont_decode=True)
69 bug = xmltodict.parse(data).get('bugzilla').get('bug')
70 error = bug.get('@error', None) # error="NotPermitted"
71
72 if error:
73 LOGGER.warning('Bugzilla error: %s' % error)
74 bot.say('[BUGZILLA] Unable to get infomation for '
75 'linked bug (%s)' % error)
76 return
77
78 message = ('[BUGZILLA] %s | Product: %s | Component: %s | Version: %s | ' +
79 'Importance: %s | Status: %s | Assigned to: %s | ' +
80 'Reported: %s | Modified: %s')
81
82 resolution = bug.get('resolution')
83 if resolution is not None:
84 status = bug.get('bug_status') + ' ' + resolution
85 else:
86 status = bug.get('bug_status')
87
88 assigned_to = bug.get('assigned_to')
89 if isinstance(assigned_to, dict):
90 assigned_to = assigned_to.get('@name')
91
92 message = message % (
93 bug.get('short_desc'), bug.get('product'),
94 bug.get('component'), bug.get('version'),
95 (bug.get('priority') + ' ' + bug.get('bug_severity')),
96 status, assigned_to, bug.get('creation_ts'),
97 bug.get('delta_ts'))
98 bot.say(message)
99
[end of sopel/modules/bugzilla.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sopel/modules/bugzilla.py b/sopel/modules/bugzilla.py
--- a/sopel/modules/bugzilla.py
+++ b/sopel/modules/bugzilla.py
@@ -52,7 +52,12 @@
def shutdown(bot):
- del bot.memory['url_callbacks'][regex]
+ try:
+ del bot.memory['url_callbacks'][regex]
+ except KeyError:
+ # bot.config.bugzilla.domains was probably just empty on startup
+ # everything's daijoubu
+ pass
@rule(r'.*https?://(\S+?)'
|
{"golden_diff": "diff --git a/sopel/modules/bugzilla.py b/sopel/modules/bugzilla.py\n--- a/sopel/modules/bugzilla.py\n+++ b/sopel/modules/bugzilla.py\n@@ -52,7 +52,12 @@\n \n \n def shutdown(bot):\n- del bot.memory['url_callbacks'][regex]\n+ try:\n+ del bot.memory['url_callbacks'][regex]\n+ except KeyError:\n+ # bot.config.bugzilla.domains was probably just empty on startup\n+ # everything's daijoubu\n+ pass\n \n \n @rule(r'.*https?://(\\S+?)'\n", "issue": "[Bugzilla] Error calling shutdown method for module bugzilla:None\nNoticed this in my logs. Bugzilla shutdown throwing none. On Sopel 6.5.3, Python 3.5.3.\r\n\r\n```\r\nPing timeout reached after 120 seconds, closing connection\r\nCalling shutdown for 2 modules.\r\ncalling reddit.shutdown\r\ncalling bugzilla.shutdown\r\nError calling shutdown method for module bugzilla:None\r\nClosed!\r\nWarning: Disconnected. Reconnecting in 20 seconds...\r\n \r\nWelcome to Sopel. Loading modules...\r\n```\n", "before_files": [{"content": "# coding=utf-8\n\"\"\"Bugzilla issue reporting module\n\nCopyright 2013-2015, Embolalia, embolalia.com\nLicensed under the Eiffel Forum License 2.\n\"\"\"\nfrom __future__ import unicode_literals, absolute_import, print_function, division\n\nimport re\n\nimport xmltodict\n\nfrom sopel import web, tools\nfrom sopel.config.types import StaticSection, ListAttribute\nfrom sopel.logger import get_logger\nfrom sopel.module import rule\n\n\nregex = None\nLOGGER = get_logger(__name__)\n\n\nclass BugzillaSection(StaticSection):\n domains = ListAttribute('domains')\n \"\"\"The domains of the Bugzilla instances from which to get information.\"\"\"\n\n\ndef configure(config):\n config.define_section('bugzilla', BugzillaSection)\n config.bugzilla.configure_setting(\n 'domains',\n 'Enter the domains of the Bugzillas you want extra information '\n 'from (e.g. bugzilla.gnome.org)'\n )\n\n\ndef setup(bot):\n global regex\n bot.config.define_section('bugzilla', BugzillaSection)\n\n if not bot.config.bugzilla.domains:\n return\n if not bot.memory.contains('url_callbacks'):\n bot.memory['url_callbacks'] = tools.SopelMemory()\n\n domains = '|'.join(bot.config.bugzilla.domains)\n regex = re.compile((r'https?://(%s)'\n '(/show_bug.cgi\\?\\S*?)'\n '(id=\\d+)')\n % domains)\n bot.memory['url_callbacks'][regex] = show_bug\n\n\ndef shutdown(bot):\n del bot.memory['url_callbacks'][regex]\n\n\n@rule(r'.*https?://(\\S+?)'\n '(/show_bug.cgi\\?\\S*?)'\n '(id=\\d+).*')\ndef show_bug(bot, trigger, match=None):\n \"\"\"Show information about a Bugzilla bug.\"\"\"\n match = match or trigger\n domain = match.group(1)\n if domain not in bot.config.bugzilla.domains:\n return\n url = 'https://%s%sctype=xml&%s' % match.groups()\n data = web.get(url, dont_decode=True)\n bug = xmltodict.parse(data).get('bugzilla').get('bug')\n error = bug.get('@error', None) # error=\"NotPermitted\"\n\n if error:\n LOGGER.warning('Bugzilla error: %s' % error)\n bot.say('[BUGZILLA] Unable to get infomation for '\n 'linked bug (%s)' % error)\n return\n\n message = ('[BUGZILLA] %s | Product: %s | Component: %s | Version: %s | ' +\n 'Importance: %s | Status: %s | Assigned to: %s | ' +\n 'Reported: %s | Modified: %s')\n\n resolution = bug.get('resolution')\n if resolution is not None:\n status = bug.get('bug_status') + ' ' + resolution\n else:\n status = bug.get('bug_status')\n\n assigned_to = bug.get('assigned_to')\n if isinstance(assigned_to, dict):\n assigned_to = assigned_to.get('@name')\n\n message = message % (\n bug.get('short_desc'), bug.get('product'),\n bug.get('component'), bug.get('version'),\n (bug.get('priority') + ' ' + bug.get('bug_severity')),\n status, assigned_to, bug.get('creation_ts'),\n bug.get('delta_ts'))\n bot.say(message)\n", "path": "sopel/modules/bugzilla.py"}]}
| 1,612 | 139 |
gh_patches_debug_50359
|
rasdani/github-patches
|
git_diff
|
pyinstaller__pyinstaller-5239
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
gevent hook unnecessarily bundles ~17MB of "stuff"
## Description of the issue
The included `gevent` hook bundles about 17MB of unnecessary files.
These include:
- HTML documentation
- `__pycache__` folders
- tests
- Generated `.c` and `.h` files
## Context information (for bug reports)
* Output of `pyinstaller --version`: `3.6`
* Version of Python: `3.7.7`
* Platform: macOS 10.15.4 / Ubuntu 18.04
### A minimal example program which shows the error
`test.py`:
```
import gevent
```
Commands
```shell
$ pip install gevent pyinstaller
[...]
$ pyinstaller -D test.py
[...]
$ find dist/test/gevent -name "*.c" -or -name "*.h" -or -name "*.html" -or -path "*/__pycache__/*" -or -path "*/tests/*" | xargs du -shc
[...]
17M total
```
</issue>
<code>
[start of PyInstaller/hooks/hook-gevent.py]
1 #-----------------------------------------------------------------------------
2 # Copyright (c) 2015-2020, PyInstaller Development Team.
3 #
4 # Distributed under the terms of the GNU General Public License (version 2
5 # or later) with exception for distributing the bootloader.
6 #
7 # The full license is in the file COPYING.txt, distributed with this software.
8 #
9 # SPDX-License-Identifier: (GPL-2.0-or-later WITH Bootloader-exception)
10 #-----------------------------------------------------------------------------
11
12 from PyInstaller.utils.hooks import collect_all
13
14 excludedimports = ["gevent.testing", "gevent.tests"]
15
16 datas, binaries, hiddenimports = collect_all(
17 'gevent',
18 filter_submodules=lambda name: (
19 "gevent.testing" not in name or "gevent.tests" not in name))
20
[end of PyInstaller/hooks/hook-gevent.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/PyInstaller/hooks/hook-gevent.py b/PyInstaller/hooks/hook-gevent.py
--- a/PyInstaller/hooks/hook-gevent.py
+++ b/PyInstaller/hooks/hook-gevent.py
@@ -16,4 +16,6 @@
datas, binaries, hiddenimports = collect_all(
'gevent',
filter_submodules=lambda name: (
- "gevent.testing" not in name or "gevent.tests" not in name))
+ "gevent.testing" not in name or "gevent.tests" not in name),
+ include_py_files=False,
+ exclude_datas=["**/tests"])
|
{"golden_diff": "diff --git a/PyInstaller/hooks/hook-gevent.py b/PyInstaller/hooks/hook-gevent.py\n--- a/PyInstaller/hooks/hook-gevent.py\n+++ b/PyInstaller/hooks/hook-gevent.py\n@@ -16,4 +16,6 @@\n datas, binaries, hiddenimports = collect_all(\n 'gevent',\n filter_submodules=lambda name: (\n- \"gevent.testing\" not in name or \"gevent.tests\" not in name))\n+ \"gevent.testing\" not in name or \"gevent.tests\" not in name),\n+ include_py_files=False,\n+ exclude_datas=[\"**/tests\"])\n", "issue": "gevent hook unnecessarily bundles ~17MB of \"stuff\"\n## Description of the issue\r\n\r\nThe included `gevent` hook bundles about 17MB of unnecessary files.\r\nThese include:\r\n- HTML documentation\r\n- `__pycache__` folders\r\n- tests\r\n- Generated `.c` and `.h` files\r\n\r\n## Context information (for bug reports)\r\n\r\n* Output of `pyinstaller --version`: `3.6`\r\n* Version of Python: `3.7.7`\r\n* Platform: macOS 10.15.4 / Ubuntu 18.04\r\n\r\n### A minimal example program which shows the error\r\n\r\n`test.py`:\r\n```\r\nimport gevent\r\n```\r\n\r\nCommands\r\n```shell\r\n$ pip install gevent pyinstaller\r\n[...]\r\n$ pyinstaller -D test.py\r\n[...]\r\n$ find dist/test/gevent -name \"*.c\" -or -name \"*.h\" -or -name \"*.html\" -or -path \"*/__pycache__/*\" -or -path \"*/tests/*\" | xargs du -shc\r\n[...]\r\n 17M\ttotal\r\n```\r\n\n", "before_files": [{"content": "#-----------------------------------------------------------------------------\n# Copyright (c) 2015-2020, PyInstaller Development Team.\n#\n# Distributed under the terms of the GNU General Public License (version 2\n# or later) with exception for distributing the bootloader.\n#\n# The full license is in the file COPYING.txt, distributed with this software.\n#\n# SPDX-License-Identifier: (GPL-2.0-or-later WITH Bootloader-exception)\n#-----------------------------------------------------------------------------\n\nfrom PyInstaller.utils.hooks import collect_all\n\nexcludedimports = [\"gevent.testing\", \"gevent.tests\"]\n\ndatas, binaries, hiddenimports = collect_all(\n 'gevent',\n filter_submodules=lambda name: (\n \"gevent.testing\" not in name or \"gevent.tests\" not in name))\n", "path": "PyInstaller/hooks/hook-gevent.py"}]}
| 973 | 144 |
gh_patches_debug_17518
|
rasdani/github-patches
|
git_diff
|
PaddlePaddle__PaddleSpeech-1644
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[vec][search] update to paddlespeech model
</issue>
<code>
[start of demos/audio_searching/src/encode.py]
1 # Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 import numpy as np
15 from logs import LOGGER
16
17 from paddlespeech.cli import VectorExecutor
18
19 vector_executor = VectorExecutor()
20
21
22 def get_audio_embedding(path):
23 """
24 Use vpr_inference to generate embedding of audio
25 """
26 try:
27 embedding = vector_executor(audio_file=path)
28 embedding = embedding / np.linalg.norm(embedding)
29 embedding = embedding.tolist()
30 return embedding
31 except Exception as e:
32 LOGGER.error(f"Error with embedding:{e}")
33 return None
34
[end of demos/audio_searching/src/encode.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/demos/audio_searching/src/encode.py b/demos/audio_searching/src/encode.py
--- a/demos/audio_searching/src/encode.py
+++ b/demos/audio_searching/src/encode.py
@@ -12,8 +12,8 @@
# See the License for the specific language governing permissions and
# limitations under the License.
import numpy as np
-from logs import LOGGER
+from logs import LOGGER
from paddlespeech.cli import VectorExecutor
vector_executor = VectorExecutor()
@@ -24,7 +24,8 @@
Use vpr_inference to generate embedding of audio
"""
try:
- embedding = vector_executor(audio_file=path)
+ embedding = vector_executor(
+ audio_file=path, model='ecapatdnn_voxceleb12')
embedding = embedding / np.linalg.norm(embedding)
embedding = embedding.tolist()
return embedding
|
{"golden_diff": "diff --git a/demos/audio_searching/src/encode.py b/demos/audio_searching/src/encode.py\n--- a/demos/audio_searching/src/encode.py\n+++ b/demos/audio_searching/src/encode.py\n@@ -12,8 +12,8 @@\n # See the License for the specific language governing permissions and\n # limitations under the License.\n import numpy as np\n-from logs import LOGGER\n \n+from logs import LOGGER\n from paddlespeech.cli import VectorExecutor\n \n vector_executor = VectorExecutor()\n@@ -24,7 +24,8 @@\n Use vpr_inference to generate embedding of audio\n \"\"\"\n try:\n- embedding = vector_executor(audio_file=path)\n+ embedding = vector_executor(\n+ audio_file=path, model='ecapatdnn_voxceleb12')\n embedding = embedding / np.linalg.norm(embedding)\n embedding = embedding.tolist()\n return embedding\n", "issue": "[vec][search] update to paddlespeech model\n\n", "before_files": [{"content": "# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport numpy as np\nfrom logs import LOGGER\n\nfrom paddlespeech.cli import VectorExecutor\n\nvector_executor = VectorExecutor()\n\n\ndef get_audio_embedding(path):\n \"\"\"\n Use vpr_inference to generate embedding of audio\n \"\"\"\n try:\n embedding = vector_executor(audio_file=path)\n embedding = embedding / np.linalg.norm(embedding)\n embedding = embedding.tolist()\n return embedding\n except Exception as e:\n LOGGER.error(f\"Error with embedding:{e}\")\n return None\n", "path": "demos/audio_searching/src/encode.py"}]}
| 858 | 196 |
gh_patches_debug_17425
|
rasdani/github-patches
|
git_diff
|
python-discord__site-716
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ValueError: Unknown format code 'X' for object of type 'str'
Sentry Issue: [SITE-25](https://sentry.io/organizations/python-discord/issues/3211854811/?referrer=github_integration)
```
ValueError: Unknown format code 'X' for object of type 'str'
(16 additional frame(s) were not displayed)
...
File "django/template/defaulttags.py", line 211, in render
nodelist.append(node.render_annotated(context))
File "django/template/base.py", line 905, in render_annotated
return self.render(context)
File "django/template/base.py", line 988, in render
output = self.filter_expression.resolve(context)
File "django/template/base.py", line 698, in resolve
new_obj = func(obj, *arg_vals)
File "pydis_site/apps/staff/templatetags/deletedmessage_filters.py", line 15, in hex_colour
colour = f"#{color:0>6X}"
```
</issue>
<code>
[start of pydis_site/apps/staff/templatetags/deletedmessage_filters.py]
1 from datetime import datetime
2
3 from django import template
4
5 register = template.Library()
6
7
8 @register.filter
9 def hex_colour(color: int) -> str:
10 """
11 Converts an integer representation of a colour to the RGB hex value.
12
13 As we are using a Discord dark theme analogue, black colours are returned as white instead.
14 """
15 colour = f"#{color:0>6X}"
16 return colour if colour != "#000000" else "#FFFFFF"
17
18
19 @register.filter
20 def footer_datetime(timestamp: str) -> datetime:
21 """Takes an embed timestamp and returns a timezone-aware datetime object."""
22 return datetime.fromisoformat(timestamp)
23
24
25 @register.filter
26 def visible_newlines(text: str) -> str:
27 """Takes an embed timestamp and returns a timezone-aware datetime object."""
28 return text.replace("\n", " <span class='has-text-grey'>↵</span><br>")
29
[end of pydis_site/apps/staff/templatetags/deletedmessage_filters.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pydis_site/apps/staff/templatetags/deletedmessage_filters.py b/pydis_site/apps/staff/templatetags/deletedmessage_filters.py
--- a/pydis_site/apps/staff/templatetags/deletedmessage_filters.py
+++ b/pydis_site/apps/staff/templatetags/deletedmessage_filters.py
@@ -1,4 +1,5 @@
from datetime import datetime
+from typing import Union
from django import template
@@ -6,13 +7,16 @@
@register.filter
-def hex_colour(color: int) -> str:
+def hex_colour(colour: Union[str, int]) -> str:
"""
- Converts an integer representation of a colour to the RGB hex value.
+ Converts the given representation of a colour to its RGB hex string.
As we are using a Discord dark theme analogue, black colours are returned as white instead.
"""
- colour = f"#{color:0>6X}"
+ if isinstance(colour, str):
+ colour = colour if colour.startswith("#") else f"#{colour}"
+ else:
+ colour = f"#{colour:0>6X}"
return colour if colour != "#000000" else "#FFFFFF"
|
{"golden_diff": "diff --git a/pydis_site/apps/staff/templatetags/deletedmessage_filters.py b/pydis_site/apps/staff/templatetags/deletedmessage_filters.py\n--- a/pydis_site/apps/staff/templatetags/deletedmessage_filters.py\n+++ b/pydis_site/apps/staff/templatetags/deletedmessage_filters.py\n@@ -1,4 +1,5 @@\n from datetime import datetime\n+from typing import Union\n \n from django import template\n \n@@ -6,13 +7,16 @@\n \n \n @register.filter\n-def hex_colour(color: int) -> str:\n+def hex_colour(colour: Union[str, int]) -> str:\n \"\"\"\n- Converts an integer representation of a colour to the RGB hex value.\n+ Converts the given representation of a colour to its RGB hex string.\n \n As we are using a Discord dark theme analogue, black colours are returned as white instead.\n \"\"\"\n- colour = f\"#{color:0>6X}\"\n+ if isinstance(colour, str):\n+ colour = colour if colour.startswith(\"#\") else f\"#{colour}\"\n+ else:\n+ colour = f\"#{colour:0>6X}\"\n return colour if colour != \"#000000\" else \"#FFFFFF\"\n", "issue": "ValueError: Unknown format code 'X' for object of type 'str'\nSentry Issue: [SITE-25](https://sentry.io/organizations/python-discord/issues/3211854811/?referrer=github_integration)\n\n```\nValueError: Unknown format code 'X' for object of type 'str'\n(16 additional frame(s) were not displayed)\n...\n File \"django/template/defaulttags.py\", line 211, in render\n nodelist.append(node.render_annotated(context))\n File \"django/template/base.py\", line 905, in render_annotated\n return self.render(context)\n File \"django/template/base.py\", line 988, in render\n output = self.filter_expression.resolve(context)\n File \"django/template/base.py\", line 698, in resolve\n new_obj = func(obj, *arg_vals)\n File \"pydis_site/apps/staff/templatetags/deletedmessage_filters.py\", line 15, in hex_colour\n colour = f\"#{color:0>6X}\"\n```\n", "before_files": [{"content": "from datetime import datetime\n\nfrom django import template\n\nregister = template.Library()\n\n\[email protected]\ndef hex_colour(color: int) -> str:\n \"\"\"\n Converts an integer representation of a colour to the RGB hex value.\n\n As we are using a Discord dark theme analogue, black colours are returned as white instead.\n \"\"\"\n colour = f\"#{color:0>6X}\"\n return colour if colour != \"#000000\" else \"#FFFFFF\"\n\n\[email protected]\ndef footer_datetime(timestamp: str) -> datetime:\n \"\"\"Takes an embed timestamp and returns a timezone-aware datetime object.\"\"\"\n return datetime.fromisoformat(timestamp)\n\n\[email protected]\ndef visible_newlines(text: str) -> str:\n \"\"\"Takes an embed timestamp and returns a timezone-aware datetime object.\"\"\"\n return text.replace(\"\\n\", \" <span class='has-text-grey'>\u21b5</span><br>\")\n", "path": "pydis_site/apps/staff/templatetags/deletedmessage_filters.py"}]}
| 1,039 | 274 |
gh_patches_debug_30245
|
rasdani/github-patches
|
git_diff
|
pyinstaller__pyinstaller-6569
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Setuptools 60.7.0 breaks the executable
Building with setuptools==60.7.0 I get this error.
There is no `jaraco` module (seems like this is the author of `setuptools)
```
(simulator_venv) ➜ agent git:(feature/SB-22361-improve-socket-error-handling) ✗ dist/sbsimulator/sbsimulator
Traceback (most recent call last):
File "PyInstaller/hooks/rthooks/pyi_rth_pkgres.py", line 16, in <module>
File "/Users/arossert/Shared/Bitbucket/agent/simulator_venv/lib/python3.8/site-packages/pkg_resources/__init__.py", line 74, in <module>
from pkg_resources.extern.jaraco.text import (
File "/Users/arossert/Shared/Bitbucket/agent/simulator_venv/lib/python3.8/site-packages/pkg_resources/extern/__init__.py", line 52, in create_module
return self.load_module(spec.name)
File "/Users/arossert/Shared/Bitbucket/agent/simulator_venv/lib/python3.8/site-packages/pkg_resources/extern/__init__.py", line 44, in load_module
raise ImportError(
ImportError: The 'jaraco' package is required; normally this is bundled with this package so if you get this warning, consult the packager of your distribution.
[23421] Failed to execute script 'pyi_rth_pkgres' due to unhandled exception!
```
PyInstaller: 4.8
OS: Linux/Mac (not tested on Windows)
Python: 3.8.10
</issue>
<code>
[start of PyInstaller/hooks/hook-pkg_resources.py]
1 #-----------------------------------------------------------------------------
2 # Copyright (c) 2005-2021, PyInstaller Development Team.
3 #
4 # Distributed under the terms of the GNU General Public License (version 2
5 # or later) with exception for distributing the bootloader.
6 #
7 # The full license is in the file COPYING.txt, distributed with this software.
8 #
9 # SPDX-License-Identifier: (GPL-2.0-or-later WITH Bootloader-exception)
10 #-----------------------------------------------------------------------------
11
12 from PyInstaller.utils.hooks import collect_submodules
13
14 # pkg_resources keeps vendored modules in its _vendor subpackage, and does sys.meta_path based import magic to expose
15 # them as pkg_resources.extern.*
16 hiddenimports = collect_submodules('pkg_resources._vendor')
17
18 # pkg_resources v45.0 dropped support for Python 2 and added this module printing a warning. We could save some bytes if
19 # we would replace this by a fake module.
20 hiddenimports.append('pkg_resources.py2_warn')
21
22 excludedimports = ['__main__']
23
24 # Some more hidden imports. See:
25 # https://github.com/pyinstaller/pyinstaller-hooks-contrib/issues/15#issuecomment-663699288 `packaging` can either be
26 # its own package, or embedded in `pkg_resources._vendor.packaging`, or both. Assume the worst and include both if
27 # present.
28 hiddenimports += collect_submodules('packaging')
29
30 hiddenimports += ['pkg_resources.markers']
31
[end of PyInstaller/hooks/hook-pkg_resources.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/PyInstaller/hooks/hook-pkg_resources.py b/PyInstaller/hooks/hook-pkg_resources.py
--- a/PyInstaller/hooks/hook-pkg_resources.py
+++ b/PyInstaller/hooks/hook-pkg_resources.py
@@ -9,7 +9,7 @@
# SPDX-License-Identifier: (GPL-2.0-or-later WITH Bootloader-exception)
#-----------------------------------------------------------------------------
-from PyInstaller.utils.hooks import collect_submodules
+from PyInstaller.utils.hooks import collect_submodules, is_module_satisfies
# pkg_resources keeps vendored modules in its _vendor subpackage, and does sys.meta_path based import magic to expose
# them as pkg_resources.extern.*
@@ -28,3 +28,24 @@
hiddenimports += collect_submodules('packaging')
hiddenimports += ['pkg_resources.markers']
+
+# As of v60.7, setuptools vendored jaraco and has pkg_resources use it. Currently, the pkg_resources._vendor.jaraco
+# namespace package cannot be automatically scanned due to limited support for pure namespace packages in our hook
+# utilities.
+#
+# In setuptools 60.7.0, the vendored jaraco.text package included "Lorem Ipsum.txt" data file, which also has to be
+# collected. However, the presence of the data file (and the resulting directory hierarchy) confuses the importer's
+# redirection logic; instead of trying to work-around that, tell user to upgrade or downgrade their setuptools.
+if is_module_satisfies("setuptools == 60.7.0"):
+ raise SystemExit(
+ "ERROR: Setuptools 60.7.0 is incompatible with PyInstaller. "
+ "Downgrade to an earlier version or upgrade to a later version."
+ )
+# In setuptools 60.7.1, the "Lorem Ipsum.txt" data file was dropped from the vendored jaraco.text package, so we can
+# accommodate it with couple of hidden imports.
+elif is_module_satisfies("setuptools >= 60.7.1"):
+ hiddenimports += [
+ 'pkg_resources._vendor.jaraco.functools',
+ 'pkg_resources._vendor.jaraco.context',
+ 'pkg_resources._vendor.jaraco.text',
+ ]
|
{"golden_diff": "diff --git a/PyInstaller/hooks/hook-pkg_resources.py b/PyInstaller/hooks/hook-pkg_resources.py\n--- a/PyInstaller/hooks/hook-pkg_resources.py\n+++ b/PyInstaller/hooks/hook-pkg_resources.py\n@@ -9,7 +9,7 @@\n # SPDX-License-Identifier: (GPL-2.0-or-later WITH Bootloader-exception)\n #-----------------------------------------------------------------------------\n \n-from PyInstaller.utils.hooks import collect_submodules\n+from PyInstaller.utils.hooks import collect_submodules, is_module_satisfies\n \n # pkg_resources keeps vendored modules in its _vendor subpackage, and does sys.meta_path based import magic to expose\n # them as pkg_resources.extern.*\n@@ -28,3 +28,24 @@\n hiddenimports += collect_submodules('packaging')\n \n hiddenimports += ['pkg_resources.markers']\n+\n+# As of v60.7, setuptools vendored jaraco and has pkg_resources use it. Currently, the pkg_resources._vendor.jaraco\n+# namespace package cannot be automatically scanned due to limited support for pure namespace packages in our hook\n+# utilities.\n+#\n+# In setuptools 60.7.0, the vendored jaraco.text package included \"Lorem Ipsum.txt\" data file, which also has to be\n+# collected. However, the presence of the data file (and the resulting directory hierarchy) confuses the importer's\n+# redirection logic; instead of trying to work-around that, tell user to upgrade or downgrade their setuptools.\n+if is_module_satisfies(\"setuptools == 60.7.0\"):\n+ raise SystemExit(\n+ \"ERROR: Setuptools 60.7.0 is incompatible with PyInstaller. \"\n+ \"Downgrade to an earlier version or upgrade to a later version.\"\n+ )\n+# In setuptools 60.7.1, the \"Lorem Ipsum.txt\" data file was dropped from the vendored jaraco.text package, so we can\n+# accommodate it with couple of hidden imports.\n+elif is_module_satisfies(\"setuptools >= 60.7.1\"):\n+ hiddenimports += [\n+ 'pkg_resources._vendor.jaraco.functools',\n+ 'pkg_resources._vendor.jaraco.context',\n+ 'pkg_resources._vendor.jaraco.text',\n+ ]\n", "issue": "Setuptools 60.7.0 breaks the executable\nBuilding with setuptools==60.7.0 I get this error.\r\nThere is no `jaraco` module (seems like this is the author of `setuptools)\r\n```\r\n(simulator_venv) \u279c agent git:(feature/SB-22361-improve-socket-error-handling) \u2717 dist/sbsimulator/sbsimulator\r\nTraceback (most recent call last):\r\n File \"PyInstaller/hooks/rthooks/pyi_rth_pkgres.py\", line 16, in <module>\r\n File \"/Users/arossert/Shared/Bitbucket/agent/simulator_venv/lib/python3.8/site-packages/pkg_resources/__init__.py\", line 74, in <module>\r\n from pkg_resources.extern.jaraco.text import (\r\n File \"/Users/arossert/Shared/Bitbucket/agent/simulator_venv/lib/python3.8/site-packages/pkg_resources/extern/__init__.py\", line 52, in create_module\r\n return self.load_module(spec.name)\r\n File \"/Users/arossert/Shared/Bitbucket/agent/simulator_venv/lib/python3.8/site-packages/pkg_resources/extern/__init__.py\", line 44, in load_module\r\n raise ImportError(\r\nImportError: The 'jaraco' package is required; normally this is bundled with this package so if you get this warning, consult the packager of your distribution.\r\n[23421] Failed to execute script 'pyi_rth_pkgres' due to unhandled exception!\r\n```\r\n\r\nPyInstaller: 4.8\r\nOS: Linux/Mac (not tested on Windows)\r\nPython: 3.8.10\n", "before_files": [{"content": "#-----------------------------------------------------------------------------\n# Copyright (c) 2005-2021, PyInstaller Development Team.\n#\n# Distributed under the terms of the GNU General Public License (version 2\n# or later) with exception for distributing the bootloader.\n#\n# The full license is in the file COPYING.txt, distributed with this software.\n#\n# SPDX-License-Identifier: (GPL-2.0-or-later WITH Bootloader-exception)\n#-----------------------------------------------------------------------------\n\nfrom PyInstaller.utils.hooks import collect_submodules\n\n# pkg_resources keeps vendored modules in its _vendor subpackage, and does sys.meta_path based import magic to expose\n# them as pkg_resources.extern.*\nhiddenimports = collect_submodules('pkg_resources._vendor')\n\n# pkg_resources v45.0 dropped support for Python 2 and added this module printing a warning. We could save some bytes if\n# we would replace this by a fake module.\nhiddenimports.append('pkg_resources.py2_warn')\n\nexcludedimports = ['__main__']\n\n# Some more hidden imports. See:\n# https://github.com/pyinstaller/pyinstaller-hooks-contrib/issues/15#issuecomment-663699288 `packaging` can either be\n# its own package, or embedded in `pkg_resources._vendor.packaging`, or both. Assume the worst and include both if\n# present.\nhiddenimports += collect_submodules('packaging')\n\nhiddenimports += ['pkg_resources.markers']\n", "path": "PyInstaller/hooks/hook-pkg_resources.py"}]}
| 1,267 | 486 |
gh_patches_debug_24447
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-4316
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CKV_AWS_157 False Positive on Aurora
**Describe the issue**
CKV_AWS_157 fails on Aurora instances even though the `MultiAZ` property is not applicable to Aurora
**Examples**
```
RDSinstance:
Type: AWS::RDS::DBInstance
Properties:
DBClusterIdentifier: !Ref DBCluster
DBInstanceClass: !Ref DbType
DBInstanceIdentifier: !Sub ${AppName}-${EnvironmentName}
DBParameterGroupName: !Ref DbParameterGroup
DBSubnetGroupName: !Ref DBSubnetGroup
Engine: aurora-mysql
MonitoringInterval: "60"
MonitoringRoleArn: !GetAtt RdsMonitoringRole.Arn
PubliclyAccessible: 'false'
```
**Version (please complete the following information):**
- Checkov Version 2.2.270
**Additional context**
- AWS docs: https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-rds-dbinstance.html#cfn-rds-dbinstance-multiaz
<img width="1377" alt="Screenshot 2023-01-19 at 1 25 49 PM" src="https://user-images.githubusercontent.com/1328683/213552592-4736b84a-3926-44b2-9dad-196b68f28daa.png">
</issue>
<code>
[start of checkov/cloudformation/checks/resource/aws/RDSMultiAZEnabled.py]
1 from checkov.cloudformation.checks.resource.base_resource_value_check import BaseResourceValueCheck
2 from checkov.common.models.enums import CheckCategories
3
4
5 class RDSMultiAZEnabled(BaseResourceValueCheck):
6 def __init__(self):
7 name = "Ensure that RDS instances have Multi-AZ enabled"
8 id = "CKV_AWS_157"
9 supported_resources = ['AWS::RDS::DBInstance']
10 categories = [CheckCategories.NETWORKING]
11 super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
12
13 def get_inspected_key(self):
14 return 'Properties/MultiAZ'
15
16
17 check = RDSMultiAZEnabled()
18
[end of checkov/cloudformation/checks/resource/aws/RDSMultiAZEnabled.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/checkov/cloudformation/checks/resource/aws/RDSMultiAZEnabled.py b/checkov/cloudformation/checks/resource/aws/RDSMultiAZEnabled.py
--- a/checkov/cloudformation/checks/resource/aws/RDSMultiAZEnabled.py
+++ b/checkov/cloudformation/checks/resource/aws/RDSMultiAZEnabled.py
@@ -1,5 +1,5 @@
+from checkov.common.models.enums import CheckResult, CheckCategories
from checkov.cloudformation.checks.resource.base_resource_value_check import BaseResourceValueCheck
-from checkov.common.models.enums import CheckCategories
class RDSMultiAZEnabled(BaseResourceValueCheck):
@@ -10,6 +10,16 @@
categories = [CheckCategories.NETWORKING]
super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
+ def scan_resource_conf(self, conf):
+ # Aurora is replicated across all AZs and doesn't require MultiAZ to be set
+ # https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-rds-dbinstance.html#cfn-rds-dbinstance-multiaz
+ if 'Properties' in conf.keys():
+ if 'Engine' in conf['Properties'].keys():
+ if 'aurora' in conf['Properties']['Engine']:
+ return CheckResult.UNKNOWN
+ # Database is not Aurora; Use base class implementation
+ return super().scan_resource_conf(conf)
+
def get_inspected_key(self):
return 'Properties/MultiAZ'
|
{"golden_diff": "diff --git a/checkov/cloudformation/checks/resource/aws/RDSMultiAZEnabled.py b/checkov/cloudformation/checks/resource/aws/RDSMultiAZEnabled.py\n--- a/checkov/cloudformation/checks/resource/aws/RDSMultiAZEnabled.py\n+++ b/checkov/cloudformation/checks/resource/aws/RDSMultiAZEnabled.py\n@@ -1,5 +1,5 @@\n+from checkov.common.models.enums import CheckResult, CheckCategories\n from checkov.cloudformation.checks.resource.base_resource_value_check import BaseResourceValueCheck\n-from checkov.common.models.enums import CheckCategories\n \n \n class RDSMultiAZEnabled(BaseResourceValueCheck):\n@@ -10,6 +10,16 @@\n categories = [CheckCategories.NETWORKING]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n \n+ def scan_resource_conf(self, conf):\n+ # Aurora is replicated across all AZs and doesn't require MultiAZ to be set\n+ # https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-rds-dbinstance.html#cfn-rds-dbinstance-multiaz\n+ if 'Properties' in conf.keys():\n+ if 'Engine' in conf['Properties'].keys():\n+ if 'aurora' in conf['Properties']['Engine']:\n+ return CheckResult.UNKNOWN\n+ # Database is not Aurora; Use base class implementation\n+ return super().scan_resource_conf(conf)\n+ \n def get_inspected_key(self):\n return 'Properties/MultiAZ'\n", "issue": "CKV_AWS_157 False Positive on Aurora\n**Describe the issue**\r\nCKV_AWS_157 fails on Aurora instances even though the `MultiAZ` property is not applicable to Aurora\r\n\r\n**Examples**\r\n```\r\nRDSinstance:\r\n Type: AWS::RDS::DBInstance\r\n Properties:\r\n DBClusterIdentifier: !Ref DBCluster\r\n DBInstanceClass: !Ref DbType\r\n DBInstanceIdentifier: !Sub ${AppName}-${EnvironmentName}\r\n DBParameterGroupName: !Ref DbParameterGroup\r\n DBSubnetGroupName: !Ref DBSubnetGroup\r\n Engine: aurora-mysql\r\n MonitoringInterval: \"60\"\r\n MonitoringRoleArn: !GetAtt RdsMonitoringRole.Arn\r\n PubliclyAccessible: 'false'\r\n```\r\n\r\n**Version (please complete the following information):**\r\n - Checkov Version 2.2.270\r\n\r\n**Additional context**\r\n- AWS docs: https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-rds-dbinstance.html#cfn-rds-dbinstance-multiaz\r\n\r\n<img width=\"1377\" alt=\"Screenshot 2023-01-19 at 1 25 49 PM\" src=\"https://user-images.githubusercontent.com/1328683/213552592-4736b84a-3926-44b2-9dad-196b68f28daa.png\">\r\n\n", "before_files": [{"content": "from checkov.cloudformation.checks.resource.base_resource_value_check import BaseResourceValueCheck\nfrom checkov.common.models.enums import CheckCategories\n\n\nclass RDSMultiAZEnabled(BaseResourceValueCheck):\n def __init__(self):\n name = \"Ensure that RDS instances have Multi-AZ enabled\"\n id = \"CKV_AWS_157\"\n supported_resources = ['AWS::RDS::DBInstance']\n categories = [CheckCategories.NETWORKING]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def get_inspected_key(self):\n return 'Properties/MultiAZ'\n\n\ncheck = RDSMultiAZEnabled()\n", "path": "checkov/cloudformation/checks/resource/aws/RDSMultiAZEnabled.py"}]}
| 1,053 | 325 |
gh_patches_debug_32293
|
rasdani/github-patches
|
git_diff
|
translate__pootle-5675
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Move session data into session
atm there is data like sidebar stuff that is stored in the actual cookie.
apart from slowing down normal users (they send all that data in *every* request), bots are acumulating cookie cruft and needlessly posting that at our sites.
if the cookie cruft gets too long it gets truncated and errors out
</issue>
<code>
[start of pootle/core/helpers.py]
1 # -*- coding: utf-8 -*-
2 #
3 # Copyright (C) Pootle contributors.
4 #
5 # This file is a part of the Pootle project. It is distributed under the GPL3
6 # or later license. See the LICENSE file for a copy of the license and the
7 # AUTHORS file for copyright and authorship information.
8
9 import json
10 from urllib import quote, unquote
11
12 from django.utils import dateformat
13
14
15 SIDEBAR_COOKIE_NAME = 'pootle-browser-sidebar'
16
17
18 def get_sidebar_announcements_context(request, objects):
19 """Return the announcements context for the browser pages sidebar.
20
21 :param request: a :cls:`django.http.HttpRequest` object.
22 :param objects: a tuple of Project, Language and TranslationProject to
23 retrieve the announcements for. Any of those can be
24 missing, but it is recommended for them to be in that exact
25 order.
26 """
27 announcements = []
28 new_cookie_data = {}
29 cookie_data = {}
30
31 if SIDEBAR_COOKIE_NAME in request.COOKIES:
32 json_str = unquote(request.COOKIES[SIDEBAR_COOKIE_NAME])
33 cookie_data = json.loads(json_str)
34
35 is_sidebar_open = cookie_data.get('isOpen', True)
36
37 for item in objects:
38 announcement = item.get_announcement(request.user)
39
40 if announcement is None:
41 continue
42
43 announcements.append(announcement)
44 # The virtual_path cannot be used as is for JSON.
45 ann_key = announcement.virtual_path.replace('/', '_')
46 ann_mtime = dateformat.format(announcement.modified_on, 'U')
47 stored_mtime = cookie_data.get(ann_key, None)
48
49 if ann_mtime != stored_mtime:
50 new_cookie_data[ann_key] = ann_mtime
51
52 if new_cookie_data:
53 # Some announcement has been changed or was never displayed before, so
54 # display sidebar and save the changed mtimes in the cookie to not
55 # display it next time unless it is necessary.
56 is_sidebar_open = True
57 cookie_data.update(new_cookie_data)
58 new_cookie_data = quote(json.dumps(cookie_data))
59
60 ctx = {
61 'announcements': announcements,
62 'is_sidebar_open': is_sidebar_open,
63 'has_sidebar': len(announcements) > 0,
64 }
65
66 return ctx, new_cookie_data
67
[end of pootle/core/helpers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pootle/core/helpers.py b/pootle/core/helpers.py
--- a/pootle/core/helpers.py
+++ b/pootle/core/helpers.py
@@ -12,7 +12,7 @@
from django.utils import dateformat
-SIDEBAR_COOKIE_NAME = 'pootle-browser-sidebar'
+SIDEBAR_COOKIE_NAME = 'pootle-browser-open-sidebar'
def get_sidebar_announcements_context(request, objects):
@@ -24,6 +24,7 @@
missing, but it is recommended for them to be in that exact
order.
"""
+ must_show_announcement = False
announcements = []
new_cookie_data = {}
cookie_data = {}
@@ -41,20 +42,20 @@
continue
announcements.append(announcement)
- # The virtual_path cannot be used as is for JSON.
- ann_key = announcement.virtual_path.replace('/', '_')
+
ann_mtime = dateformat.format(announcement.modified_on, 'U')
- stored_mtime = cookie_data.get(ann_key, None)
+ stored_mtime = request.session.get(announcement.virtual_path, None)
if ann_mtime != stored_mtime:
- new_cookie_data[ann_key] = ann_mtime
+ # Some announcement has been changed or was never displayed before,
+ # so display sidebar and save the changed mtimes in the session to
+ # not display it next time unless it is necessary.
+ must_show_announcement = True
+ request.session[announcement.virtual_path] = ann_mtime
- if new_cookie_data:
- # Some announcement has been changed or was never displayed before, so
- # display sidebar and save the changed mtimes in the cookie to not
- # display it next time unless it is necessary.
+ if must_show_announcement and not is_sidebar_open:
is_sidebar_open = True
- cookie_data.update(new_cookie_data)
+ cookie_data['isOpen'] = is_sidebar_open
new_cookie_data = quote(json.dumps(cookie_data))
ctx = {
|
{"golden_diff": "diff --git a/pootle/core/helpers.py b/pootle/core/helpers.py\n--- a/pootle/core/helpers.py\n+++ b/pootle/core/helpers.py\n@@ -12,7 +12,7 @@\n from django.utils import dateformat\n \n \n-SIDEBAR_COOKIE_NAME = 'pootle-browser-sidebar'\n+SIDEBAR_COOKIE_NAME = 'pootle-browser-open-sidebar'\n \n \n def get_sidebar_announcements_context(request, objects):\n@@ -24,6 +24,7 @@\n missing, but it is recommended for them to be in that exact\n order.\n \"\"\"\n+ must_show_announcement = False\n announcements = []\n new_cookie_data = {}\n cookie_data = {}\n@@ -41,20 +42,20 @@\n continue\n \n announcements.append(announcement)\n- # The virtual_path cannot be used as is for JSON.\n- ann_key = announcement.virtual_path.replace('/', '_')\n+\n ann_mtime = dateformat.format(announcement.modified_on, 'U')\n- stored_mtime = cookie_data.get(ann_key, None)\n+ stored_mtime = request.session.get(announcement.virtual_path, None)\n \n if ann_mtime != stored_mtime:\n- new_cookie_data[ann_key] = ann_mtime\n+ # Some announcement has been changed or was never displayed before,\n+ # so display sidebar and save the changed mtimes in the session to\n+ # not display it next time unless it is necessary.\n+ must_show_announcement = True\n+ request.session[announcement.virtual_path] = ann_mtime\n \n- if new_cookie_data:\n- # Some announcement has been changed or was never displayed before, so\n- # display sidebar and save the changed mtimes in the cookie to not\n- # display it next time unless it is necessary.\n+ if must_show_announcement and not is_sidebar_open:\n is_sidebar_open = True\n- cookie_data.update(new_cookie_data)\n+ cookie_data['isOpen'] = is_sidebar_open\n new_cookie_data = quote(json.dumps(cookie_data))\n \n ctx = {\n", "issue": "Move session data into session\natm there is data like sidebar stuff that is stored in the actual cookie.\r\n\r\napart from slowing down normal users (they send all that data in *every* request), bots are acumulating cookie cruft and needlessly posting that at our sites.\r\n\r\nif the cookie cruft gets too long it gets truncated and errors out\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Copyright (C) Pootle contributors.\n#\n# This file is a part of the Pootle project. It is distributed under the GPL3\n# or later license. See the LICENSE file for a copy of the license and the\n# AUTHORS file for copyright and authorship information.\n\nimport json\nfrom urllib import quote, unquote\n\nfrom django.utils import dateformat\n\n\nSIDEBAR_COOKIE_NAME = 'pootle-browser-sidebar'\n\n\ndef get_sidebar_announcements_context(request, objects):\n \"\"\"Return the announcements context for the browser pages sidebar.\n\n :param request: a :cls:`django.http.HttpRequest` object.\n :param objects: a tuple of Project, Language and TranslationProject to\n retrieve the announcements for. Any of those can be\n missing, but it is recommended for them to be in that exact\n order.\n \"\"\"\n announcements = []\n new_cookie_data = {}\n cookie_data = {}\n\n if SIDEBAR_COOKIE_NAME in request.COOKIES:\n json_str = unquote(request.COOKIES[SIDEBAR_COOKIE_NAME])\n cookie_data = json.loads(json_str)\n\n is_sidebar_open = cookie_data.get('isOpen', True)\n\n for item in objects:\n announcement = item.get_announcement(request.user)\n\n if announcement is None:\n continue\n\n announcements.append(announcement)\n # The virtual_path cannot be used as is for JSON.\n ann_key = announcement.virtual_path.replace('/', '_')\n ann_mtime = dateformat.format(announcement.modified_on, 'U')\n stored_mtime = cookie_data.get(ann_key, None)\n\n if ann_mtime != stored_mtime:\n new_cookie_data[ann_key] = ann_mtime\n\n if new_cookie_data:\n # Some announcement has been changed or was never displayed before, so\n # display sidebar and save the changed mtimes in the cookie to not\n # display it next time unless it is necessary.\n is_sidebar_open = True\n cookie_data.update(new_cookie_data)\n new_cookie_data = quote(json.dumps(cookie_data))\n\n ctx = {\n 'announcements': announcements,\n 'is_sidebar_open': is_sidebar_open,\n 'has_sidebar': len(announcements) > 0,\n }\n\n return ctx, new_cookie_data\n", "path": "pootle/core/helpers.py"}]}
| 1,226 | 444 |
gh_patches_debug_30619
|
rasdani/github-patches
|
git_diff
|
ipython__ipython-8859
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Wrong Tooltip with shift-tab
@andram opened jupyter/notebook#520 at 2015-10-01 10:09:29 UTC
If a notebook cell starts with a multiline string, then shift-tab gets confused and shows the wrong tooltips for following lines. For example consider a cell containing the following 5 lines:
```
"""
Docstring
"""
max()
min()
```
now position the cursor inside the brackets of max(). Expected behaviour is that the docstring for `max` is shown. Actual behaviour is that the docstring for min is shown. (see attached screenshot for current github version of jupyter notebook)

</issue>
<code>
[start of IPython/utils/tokenutil.py]
1 """Token-related utilities"""
2
3 # Copyright (c) IPython Development Team.
4 # Distributed under the terms of the Modified BSD License.
5
6 from __future__ import absolute_import, print_function
7
8 from collections import namedtuple
9 from io import StringIO
10 from keyword import iskeyword
11
12 from . import tokenize2
13 from .py3compat import cast_unicode_py2
14
15 Token = namedtuple('Token', ['token', 'text', 'start', 'end', 'line'])
16
17 def generate_tokens(readline):
18 """wrap generate_tokens to catch EOF errors"""
19 try:
20 for token in tokenize2.generate_tokens(readline):
21 yield token
22 except tokenize2.TokenError:
23 # catch EOF error
24 return
25
26 def line_at_cursor(cell, cursor_pos=0):
27 """Return the line in a cell at a given cursor position
28
29 Used for calling line-based APIs that don't support multi-line input, yet.
30
31 Parameters
32 ----------
33
34 cell: text
35 multiline block of text
36 cursor_pos: integer
37 the cursor position
38
39 Returns
40 -------
41
42 (line, offset): (text, integer)
43 The line with the current cursor, and the character offset of the start of the line.
44 """
45 offset = 0
46 lines = cell.splitlines(True)
47 for line in lines:
48 next_offset = offset + len(line)
49 if next_offset >= cursor_pos:
50 break
51 offset = next_offset
52 else:
53 line = ""
54 return (line, offset)
55
56 def token_at_cursor(cell, cursor_pos=0):
57 """Get the token at a given cursor
58
59 Used for introspection.
60
61 Function calls are prioritized, so the token for the callable will be returned
62 if the cursor is anywhere inside the call.
63
64 Parameters
65 ----------
66
67 cell : unicode
68 A block of Python code
69 cursor_pos : int
70 The location of the cursor in the block where the token should be found
71 """
72 cell = cast_unicode_py2(cell)
73 names = []
74 tokens = []
75 offset = 0
76 call_names = []
77 for tup in generate_tokens(StringIO(cell).readline):
78
79 tok = Token(*tup)
80
81 # token, text, start, end, line = tup
82 start_col = tok.start[1]
83 end_col = tok.end[1]
84 # allow '|foo' to find 'foo' at the beginning of a line
85 boundary = cursor_pos + 1 if start_col == 0 else cursor_pos
86 if offset + start_col >= boundary:
87 # current token starts after the cursor,
88 # don't consume it
89 break
90
91 if tok.token == tokenize2.NAME and not iskeyword(tok.text):
92 if names and tokens and tokens[-1].token == tokenize2.OP and tokens[-1].text == '.':
93 names[-1] = "%s.%s" % (names[-1], tok.text)
94 else:
95 names.append(tok.text)
96 elif tok.token == tokenize2.OP:
97 if tok.text == '=' and names:
98 # don't inspect the lhs of an assignment
99 names.pop(-1)
100 if tok.text == '(' and names:
101 # if we are inside a function call, inspect the function
102 call_names.append(names[-1])
103 elif tok.text == ')' and call_names:
104 call_names.pop(-1)
105
106 if offset + end_col > cursor_pos:
107 # we found the cursor, stop reading
108 break
109
110 tokens.append(tok)
111 if tok.token in (tokenize2.NEWLINE, tokenize2.NL):
112 offset += len(tok.line)
113
114 if call_names:
115 return call_names[-1]
116 elif names:
117 return names[-1]
118 else:
119 return ''
120
121
122
[end of IPython/utils/tokenutil.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/IPython/utils/tokenutil.py b/IPython/utils/tokenutil.py
--- a/IPython/utils/tokenutil.py
+++ b/IPython/utils/tokenutil.py
@@ -72,15 +72,24 @@
cell = cast_unicode_py2(cell)
names = []
tokens = []
- offset = 0
call_names = []
+
+ offsets = {1: 0} # lines start at 1
for tup in generate_tokens(StringIO(cell).readline):
tok = Token(*tup)
# token, text, start, end, line = tup
- start_col = tok.start[1]
- end_col = tok.end[1]
+ start_line, start_col = tok.start
+ end_line, end_col = tok.end
+ if end_line + 1 not in offsets:
+ # keep track of offsets for each line
+ lines = tok.line.splitlines(True)
+ for lineno, line in zip(range(start_line + 1, end_line + 2), lines):
+ if lineno not in offsets:
+ offsets[lineno] = offsets[lineno-1] + len(line)
+
+ offset = offsets[start_line]
# allow '|foo' to find 'foo' at the beginning of a line
boundary = cursor_pos + 1 if start_col == 0 else cursor_pos
if offset + start_col >= boundary:
@@ -103,14 +112,12 @@
elif tok.text == ')' and call_names:
call_names.pop(-1)
- if offset + end_col > cursor_pos:
+ tokens.append(tok)
+
+ if offsets[end_line] + end_col > cursor_pos:
# we found the cursor, stop reading
break
- tokens.append(tok)
- if tok.token in (tokenize2.NEWLINE, tokenize2.NL):
- offset += len(tok.line)
-
if call_names:
return call_names[-1]
elif names:
|
{"golden_diff": "diff --git a/IPython/utils/tokenutil.py b/IPython/utils/tokenutil.py\n--- a/IPython/utils/tokenutil.py\n+++ b/IPython/utils/tokenutil.py\n@@ -72,15 +72,24 @@\n cell = cast_unicode_py2(cell)\n names = []\n tokens = []\n- offset = 0\n call_names = []\n+ \n+ offsets = {1: 0} # lines start at 1\n for tup in generate_tokens(StringIO(cell).readline):\n \n tok = Token(*tup)\n \n # token, text, start, end, line = tup\n- start_col = tok.start[1]\n- end_col = tok.end[1]\n+ start_line, start_col = tok.start\n+ end_line, end_col = tok.end\n+ if end_line + 1 not in offsets:\n+ # keep track of offsets for each line\n+ lines = tok.line.splitlines(True)\n+ for lineno, line in zip(range(start_line + 1, end_line + 2), lines):\n+ if lineno not in offsets:\n+ offsets[lineno] = offsets[lineno-1] + len(line)\n+ \n+ offset = offsets[start_line]\n # allow '|foo' to find 'foo' at the beginning of a line\n boundary = cursor_pos + 1 if start_col == 0 else cursor_pos\n if offset + start_col >= boundary:\n@@ -103,14 +112,12 @@\n elif tok.text == ')' and call_names:\n call_names.pop(-1)\n \n- if offset + end_col > cursor_pos:\n+ tokens.append(tok)\n+ \n+ if offsets[end_line] + end_col > cursor_pos:\n # we found the cursor, stop reading\n break\n \n- tokens.append(tok)\n- if tok.token in (tokenize2.NEWLINE, tokenize2.NL):\n- offset += len(tok.line)\n- \n if call_names:\n return call_names[-1]\n elif names:\n", "issue": "Wrong Tooltip with shift-tab\n@andram opened jupyter/notebook#520 at 2015-10-01 10:09:29 UTC\n\nIf a notebook cell starts with a multiline string, then shift-tab gets confused and shows the wrong tooltips for following lines. For example consider a cell containing the following 5 lines:\n\n```\n\"\"\"\nDocstring\n\"\"\"\nmax()\nmin()\n```\n\nnow position the cursor inside the brackets of max(). Expected behaviour is that the docstring for `max` is shown. Actual behaviour is that the docstring for min is shown. (see attached screenshot for current github version of jupyter notebook)\n\n\n\n", "before_files": [{"content": "\"\"\"Token-related utilities\"\"\"\n\n# Copyright (c) IPython Development Team.\n# Distributed under the terms of the Modified BSD License.\n\nfrom __future__ import absolute_import, print_function\n\nfrom collections import namedtuple\nfrom io import StringIO\nfrom keyword import iskeyword\n\nfrom . import tokenize2\nfrom .py3compat import cast_unicode_py2\n\nToken = namedtuple('Token', ['token', 'text', 'start', 'end', 'line'])\n\ndef generate_tokens(readline):\n \"\"\"wrap generate_tokens to catch EOF errors\"\"\"\n try:\n for token in tokenize2.generate_tokens(readline):\n yield token\n except tokenize2.TokenError:\n # catch EOF error\n return\n\ndef line_at_cursor(cell, cursor_pos=0):\n \"\"\"Return the line in a cell at a given cursor position\n \n Used for calling line-based APIs that don't support multi-line input, yet.\n \n Parameters\n ----------\n \n cell: text\n multiline block of text\n cursor_pos: integer\n the cursor position\n \n Returns\n -------\n \n (line, offset): (text, integer)\n The line with the current cursor, and the character offset of the start of the line.\n \"\"\"\n offset = 0\n lines = cell.splitlines(True)\n for line in lines:\n next_offset = offset + len(line)\n if next_offset >= cursor_pos:\n break\n offset = next_offset\n else:\n line = \"\"\n return (line, offset)\n\ndef token_at_cursor(cell, cursor_pos=0):\n \"\"\"Get the token at a given cursor\n \n Used for introspection.\n \n Function calls are prioritized, so the token for the callable will be returned\n if the cursor is anywhere inside the call.\n \n Parameters\n ----------\n \n cell : unicode\n A block of Python code\n cursor_pos : int\n The location of the cursor in the block where the token should be found\n \"\"\"\n cell = cast_unicode_py2(cell)\n names = []\n tokens = []\n offset = 0\n call_names = []\n for tup in generate_tokens(StringIO(cell).readline):\n \n tok = Token(*tup)\n \n # token, text, start, end, line = tup\n start_col = tok.start[1]\n end_col = tok.end[1]\n # allow '|foo' to find 'foo' at the beginning of a line\n boundary = cursor_pos + 1 if start_col == 0 else cursor_pos\n if offset + start_col >= boundary:\n # current token starts after the cursor,\n # don't consume it\n break\n \n if tok.token == tokenize2.NAME and not iskeyword(tok.text):\n if names and tokens and tokens[-1].token == tokenize2.OP and tokens[-1].text == '.':\n names[-1] = \"%s.%s\" % (names[-1], tok.text)\n else:\n names.append(tok.text)\n elif tok.token == tokenize2.OP:\n if tok.text == '=' and names:\n # don't inspect the lhs of an assignment\n names.pop(-1)\n if tok.text == '(' and names:\n # if we are inside a function call, inspect the function\n call_names.append(names[-1])\n elif tok.text == ')' and call_names:\n call_names.pop(-1)\n \n if offset + end_col > cursor_pos:\n # we found the cursor, stop reading\n break\n \n tokens.append(tok)\n if tok.token in (tokenize2.NEWLINE, tokenize2.NL):\n offset += len(tok.line)\n \n if call_names:\n return call_names[-1]\n elif names:\n return names[-1]\n else:\n return ''\n \n\n", "path": "IPython/utils/tokenutil.py"}]}
| 1,804 | 445 |
gh_patches_debug_21233
|
rasdani/github-patches
|
git_diff
|
liqd__a4-meinberlin-4048
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
(react list) proposal-list-item should show created/modified date
**URL:** proposal-list
**user:** any
**expected behaviour:** list items (tiles) in react list should show `created on/modified on` in front of date (see django list)
**behaviour:** list items do not indicate created on or modified on, but shows only the date
**important screensize:** any
**device & browser:** any
**Comment/Question:**
Screenshot?
Note: This will only affect where this particular react list is used (currently only used for budgeting/proposal-list)
</issue>
<code>
[start of meinberlin/apps/budgeting/serializers.py]
1 from django.utils import translation
2 from rest_framework import serializers
3
4 from adhocracy4.categories.models import Category
5
6 from .models import Proposal
7
8
9 class CategoryField(serializers.Field):
10
11 def to_internal_value(self, category):
12 if category:
13 return Category.objects.get(pk=category)
14 else:
15 return None
16
17 def to_representation(self, category):
18 return {'id': category.pk, 'name': category.name}
19
20
21 class ProposalSerializer(serializers.ModelSerializer):
22
23 creator = serializers.SerializerMethodField()
24 comment_count = serializers.SerializerMethodField()
25 positive_rating_count = serializers.SerializerMethodField()
26 negative_rating_count = serializers.SerializerMethodField()
27 category = CategoryField()
28 url = serializers.SerializerMethodField()
29 locale = serializers.SerializerMethodField()
30
31 class Meta:
32 model = Proposal
33 fields = ('budget', 'category', 'comment_count', 'created', 'creator',
34 'is_archived', 'name', 'negative_rating_count',
35 'positive_rating_count', 'url', 'pk', 'moderator_feedback',
36 'moderator_feedback_choices', 'locale')
37 read_only_fields = ('budget', 'category', 'comment_count', 'created',
38 'creator', 'is_archived', 'name',
39 'negative_rating_count', 'positive_rating_count',
40 'url', 'pk', 'moderator_feedback',
41 'moderator_feedback_choices', 'locale')
42
43 def get_creator(self, proposal):
44 return proposal.creator.username
45
46 def get_comment_count(self, proposal):
47 if hasattr(proposal, 'comment_count'):
48 return proposal.comment_count
49 else:
50 return 0
51
52 def get_positive_rating_count(self, proposal):
53 if hasattr(proposal, 'positive_rating_count'):
54 return proposal.positive_rating_count
55 else:
56 return 0
57
58 def get_negative_rating_count(self, proposal):
59 if hasattr(proposal, 'negative_rating_count'):
60 return proposal.negative_rating_count
61 else:
62 return 0
63
64 def get_url(self, proposal):
65 return proposal.get_absolute_url()
66
67 def get_moderator_feedback(self, proposal):
68 if hasattr(proposal, 'moderator_feedback'):
69 return proposal.moderator_feedback
70 else:
71 return None
72
73 def get_moderator_feedback_choices(self, proposal):
74 if hasattr(proposal, 'moderator_feedback_choices'):
75 return proposal.moderator_feedback_choices
76 else:
77 return None
78
79 def get_locale(self, proposal):
80 return translation.get_language()
81
[end of meinberlin/apps/budgeting/serializers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/meinberlin/apps/budgeting/serializers.py b/meinberlin/apps/budgeting/serializers.py
--- a/meinberlin/apps/budgeting/serializers.py
+++ b/meinberlin/apps/budgeting/serializers.py
@@ -30,12 +30,12 @@
class Meta:
model = Proposal
- fields = ('budget', 'category', 'comment_count', 'created', 'creator',
- 'is_archived', 'name', 'negative_rating_count',
+ fields = ('budget', 'category', 'comment_count', 'created', 'modified',
+ 'creator', 'is_archived', 'name', 'negative_rating_count',
'positive_rating_count', 'url', 'pk', 'moderator_feedback',
'moderator_feedback_choices', 'locale')
read_only_fields = ('budget', 'category', 'comment_count', 'created',
- 'creator', 'is_archived', 'name',
+ 'modified', 'creator', 'is_archived', 'name',
'negative_rating_count', 'positive_rating_count',
'url', 'pk', 'moderator_feedback',
'moderator_feedback_choices', 'locale')
|
{"golden_diff": "diff --git a/meinberlin/apps/budgeting/serializers.py b/meinberlin/apps/budgeting/serializers.py\n--- a/meinberlin/apps/budgeting/serializers.py\n+++ b/meinberlin/apps/budgeting/serializers.py\n@@ -30,12 +30,12 @@\n \n class Meta:\n model = Proposal\n- fields = ('budget', 'category', 'comment_count', 'created', 'creator',\n- 'is_archived', 'name', 'negative_rating_count',\n+ fields = ('budget', 'category', 'comment_count', 'created', 'modified',\n+ 'creator', 'is_archived', 'name', 'negative_rating_count',\n 'positive_rating_count', 'url', 'pk', 'moderator_feedback',\n 'moderator_feedback_choices', 'locale')\n read_only_fields = ('budget', 'category', 'comment_count', 'created',\n- 'creator', 'is_archived', 'name',\n+ 'modified', 'creator', 'is_archived', 'name',\n 'negative_rating_count', 'positive_rating_count',\n 'url', 'pk', 'moderator_feedback',\n 'moderator_feedback_choices', 'locale')\n", "issue": "(react list) proposal-list-item should show created/modified date\n**URL:** proposal-list\r\n**user:** any\r\n**expected behaviour:** list items (tiles) in react list should show `created on/modified on` in front of date (see django list)\r\n**behaviour:** list items do not indicate created on or modified on, but shows only the date\r\n**important screensize:** any\r\n**device & browser:** any\r\n**Comment/Question:** \r\n\r\nScreenshot?\r\n\r\nNote: This will only affect where this particular react list is used (currently only used for budgeting/proposal-list)\n", "before_files": [{"content": "from django.utils import translation\nfrom rest_framework import serializers\n\nfrom adhocracy4.categories.models import Category\n\nfrom .models import Proposal\n\n\nclass CategoryField(serializers.Field):\n\n def to_internal_value(self, category):\n if category:\n return Category.objects.get(pk=category)\n else:\n return None\n\n def to_representation(self, category):\n return {'id': category.pk, 'name': category.name}\n\n\nclass ProposalSerializer(serializers.ModelSerializer):\n\n creator = serializers.SerializerMethodField()\n comment_count = serializers.SerializerMethodField()\n positive_rating_count = serializers.SerializerMethodField()\n negative_rating_count = serializers.SerializerMethodField()\n category = CategoryField()\n url = serializers.SerializerMethodField()\n locale = serializers.SerializerMethodField()\n\n class Meta:\n model = Proposal\n fields = ('budget', 'category', 'comment_count', 'created', 'creator',\n 'is_archived', 'name', 'negative_rating_count',\n 'positive_rating_count', 'url', 'pk', 'moderator_feedback',\n 'moderator_feedback_choices', 'locale')\n read_only_fields = ('budget', 'category', 'comment_count', 'created',\n 'creator', 'is_archived', 'name',\n 'negative_rating_count', 'positive_rating_count',\n 'url', 'pk', 'moderator_feedback',\n 'moderator_feedback_choices', 'locale')\n\n def get_creator(self, proposal):\n return proposal.creator.username\n\n def get_comment_count(self, proposal):\n if hasattr(proposal, 'comment_count'):\n return proposal.comment_count\n else:\n return 0\n\n def get_positive_rating_count(self, proposal):\n if hasattr(proposal, 'positive_rating_count'):\n return proposal.positive_rating_count\n else:\n return 0\n\n def get_negative_rating_count(self, proposal):\n if hasattr(proposal, 'negative_rating_count'):\n return proposal.negative_rating_count\n else:\n return 0\n\n def get_url(self, proposal):\n return proposal.get_absolute_url()\n\n def get_moderator_feedback(self, proposal):\n if hasattr(proposal, 'moderator_feedback'):\n return proposal.moderator_feedback\n else:\n return None\n\n def get_moderator_feedback_choices(self, proposal):\n if hasattr(proposal, 'moderator_feedback_choices'):\n return proposal.moderator_feedback_choices\n else:\n return None\n\n def get_locale(self, proposal):\n return translation.get_language()\n", "path": "meinberlin/apps/budgeting/serializers.py"}]}
| 1,351 | 265 |
gh_patches_debug_5471
|
rasdani/github-patches
|
git_diff
|
archlinux__archinstall-565
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Exit code 256 in networking.py
While doing PR #562 I noticed that we check if exit code is 256. I thought for any process it was an 8 bit value and could be 0 through 255, so I'm not sure about this logic. I'd like to figure out why it was written in this manner and it probably should be fixed. Maybe drop the exit code check entirely?
</issue>
<code>
[start of archinstall/lib/networking.py]
1 import fcntl
2 import logging
3 import os
4 import socket
5 import struct
6 from collections import OrderedDict
7
8 from .exceptions import *
9 from .general import SysCommand
10 from .output import log
11 from .storage import storage
12
13
14 def get_hw_addr(ifname):
15 s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
16 info = fcntl.ioctl(s.fileno(), 0x8927, struct.pack('256s', bytes(ifname, 'utf-8')[:15]))
17 return ':'.join('%02x' % b for b in info[18:24])
18
19
20 def list_interfaces(skip_loopback=True):
21 interfaces = OrderedDict()
22 for index, iface in socket.if_nameindex():
23 if skip_loopback and iface == "lo":
24 continue
25
26 mac = get_hw_addr(iface).replace(':', '-').lower()
27 interfaces[mac] = iface
28 return interfaces
29
30
31 def check_mirror_reachable():
32 if (exit_code := SysCommand("pacman -Sy").exit_code) == 0:
33 return True
34 elif exit_code == 256:
35 if os.geteuid() != 0:
36 log("check_mirror_reachable() uses 'pacman -Sy' which requires root.", level=logging.ERROR, fg="red")
37
38 return False
39
40
41 def enrich_iface_types(interfaces: dict):
42 result = {}
43 for iface in interfaces:
44 if os.path.isdir(f"/sys/class/net/{iface}/bridge/"):
45 result[iface] = 'BRIDGE'
46 elif os.path.isfile(f"/sys/class/net/{iface}/tun_flags"):
47 # ethtool -i {iface}
48 result[iface] = 'TUN/TAP'
49 elif os.path.isdir(f"/sys/class/net/{iface}/device"):
50 if os.path.isdir(f"/sys/class/net/{iface}/wireless/"):
51 result[iface] = 'WIRELESS'
52 else:
53 result[iface] = 'PHYSICAL'
54 else:
55 result[iface] = 'UNKNOWN'
56 return result
57
58
59 def get_interface_from_mac(mac):
60 return list_interfaces().get(mac.lower(), None)
61
62
63 def wireless_scan(interface):
64 interfaces = enrich_iface_types(list_interfaces().values())
65 if interfaces[interface] != 'WIRELESS':
66 raise HardwareIncompatibilityError(f"Interface {interface} is not a wireless interface: {interfaces}")
67
68 SysCommand(f"iwctl station {interface} scan")
69
70 if '_WIFI' not in storage:
71 storage['_WIFI'] = {}
72 if interface not in storage['_WIFI']:
73 storage['_WIFI'][interface] = {}
74
75 storage['_WIFI'][interface]['scanning'] = True
76
77
78 # TODO: Full WiFi experience might get evolved in the future, pausing for now 2021-01-25
79 def get_wireless_networks(interface):
80 # TODO: Make this oneliner pritter to check if the interface is scanning or not.
81 if '_WIFI' not in storage or interface not in storage['_WIFI'] or storage['_WIFI'][interface].get('scanning', False) is False:
82 import time
83
84 wireless_scan(interface)
85 time.sleep(5)
86
87 for line in SysCommand(f"iwctl station {interface} get-networks"):
88 print(line)
89
[end of archinstall/lib/networking.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/archinstall/lib/networking.py b/archinstall/lib/networking.py
--- a/archinstall/lib/networking.py
+++ b/archinstall/lib/networking.py
@@ -31,9 +31,8 @@
def check_mirror_reachable():
if (exit_code := SysCommand("pacman -Sy").exit_code) == 0:
return True
- elif exit_code == 256:
- if os.geteuid() != 0:
- log("check_mirror_reachable() uses 'pacman -Sy' which requires root.", level=logging.ERROR, fg="red")
+ elif os.geteuid() != 0:
+ log("check_mirror_reachable() uses 'pacman -Sy' which requires root.", level=logging.ERROR, fg="red")
return False
|
{"golden_diff": "diff --git a/archinstall/lib/networking.py b/archinstall/lib/networking.py\n--- a/archinstall/lib/networking.py\n+++ b/archinstall/lib/networking.py\n@@ -31,9 +31,8 @@\n def check_mirror_reachable():\n \tif (exit_code := SysCommand(\"pacman -Sy\").exit_code) == 0:\n \t\treturn True\n-\telif exit_code == 256:\n-\t\tif os.geteuid() != 0:\n-\t\t\tlog(\"check_mirror_reachable() uses 'pacman -Sy' which requires root.\", level=logging.ERROR, fg=\"red\")\n+\telif os.geteuid() != 0:\n+\t\tlog(\"check_mirror_reachable() uses 'pacman -Sy' which requires root.\", level=logging.ERROR, fg=\"red\")\n \n \treturn False\n", "issue": "Exit code 256 in networking.py\nWhile doing PR #562 I noticed that we check if exit code is 256. I thought for any process it was an 8 bit value and could be 0 through 255, so I'm not sure about this logic. I'd like to figure out why it was written in this manner and it probably should be fixed. Maybe drop the exit code check entirely? \n", "before_files": [{"content": "import fcntl\nimport logging\nimport os\nimport socket\nimport struct\nfrom collections import OrderedDict\n\nfrom .exceptions import *\nfrom .general import SysCommand\nfrom .output import log\nfrom .storage import storage\n\n\ndef get_hw_addr(ifname):\n\ts = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)\n\tinfo = fcntl.ioctl(s.fileno(), 0x8927, struct.pack('256s', bytes(ifname, 'utf-8')[:15]))\n\treturn ':'.join('%02x' % b for b in info[18:24])\n\n\ndef list_interfaces(skip_loopback=True):\n\tinterfaces = OrderedDict()\n\tfor index, iface in socket.if_nameindex():\n\t\tif skip_loopback and iface == \"lo\":\n\t\t\tcontinue\n\n\t\tmac = get_hw_addr(iface).replace(':', '-').lower()\n\t\tinterfaces[mac] = iface\n\treturn interfaces\n\n\ndef check_mirror_reachable():\n\tif (exit_code := SysCommand(\"pacman -Sy\").exit_code) == 0:\n\t\treturn True\n\telif exit_code == 256:\n\t\tif os.geteuid() != 0:\n\t\t\tlog(\"check_mirror_reachable() uses 'pacman -Sy' which requires root.\", level=logging.ERROR, fg=\"red\")\n\n\treturn False\n\n\ndef enrich_iface_types(interfaces: dict):\n\tresult = {}\n\tfor iface in interfaces:\n\t\tif os.path.isdir(f\"/sys/class/net/{iface}/bridge/\"):\n\t\t\tresult[iface] = 'BRIDGE'\n\t\telif os.path.isfile(f\"/sys/class/net/{iface}/tun_flags\"):\n\t\t\t# ethtool -i {iface}\n\t\t\tresult[iface] = 'TUN/TAP'\n\t\telif os.path.isdir(f\"/sys/class/net/{iface}/device\"):\n\t\t\tif os.path.isdir(f\"/sys/class/net/{iface}/wireless/\"):\n\t\t\t\tresult[iface] = 'WIRELESS'\n\t\t\telse:\n\t\t\t\tresult[iface] = 'PHYSICAL'\n\t\telse:\n\t\t\tresult[iface] = 'UNKNOWN'\n\treturn result\n\n\ndef get_interface_from_mac(mac):\n\treturn list_interfaces().get(mac.lower(), None)\n\n\ndef wireless_scan(interface):\n\tinterfaces = enrich_iface_types(list_interfaces().values())\n\tif interfaces[interface] != 'WIRELESS':\n\t\traise HardwareIncompatibilityError(f\"Interface {interface} is not a wireless interface: {interfaces}\")\n\n\tSysCommand(f\"iwctl station {interface} scan\")\n\n\tif '_WIFI' not in storage:\n\t\tstorage['_WIFI'] = {}\n\tif interface not in storage['_WIFI']:\n\t\tstorage['_WIFI'][interface] = {}\n\n\tstorage['_WIFI'][interface]['scanning'] = True\n\n\n# TODO: Full WiFi experience might get evolved in the future, pausing for now 2021-01-25\ndef get_wireless_networks(interface):\n\t# TODO: Make this oneliner pritter to check if the interface is scanning or not.\n\tif '_WIFI' not in storage or interface not in storage['_WIFI'] or storage['_WIFI'][interface].get('scanning', False) is False:\n\t\timport time\n\n\t\twireless_scan(interface)\n\t\ttime.sleep(5)\n\n\tfor line in SysCommand(f\"iwctl station {interface} get-networks\"):\n\t\tprint(line)\n", "path": "archinstall/lib/networking.py"}]}
| 1,530 | 174 |
gh_patches_debug_3036
|
rasdani/github-patches
|
git_diff
|
archlinux__archinstall-184
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
gnome-extra provides WAY too much bloatware
I can't imagine most people wanting all the packages this installs on a new installation. Most of these applications are things like games and advanced tools like dconf-editor that your average user should not be touching. Some of them are nice to have but can be installed later manually instead of during initial installation.
</issue>
<code>
[start of profiles/applications/gnome.py]
1 import archinstall
2
3 installation.add_additional_packages("gnome gnome-extra gdm") # We'll create a gnome-minimal later, but for now, we'll avoid issues by giving more than we need.
4 # Note: gdm should be part of the gnome group, but adding it here for clarity
[end of profiles/applications/gnome.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/profiles/applications/gnome.py b/profiles/applications/gnome.py
--- a/profiles/applications/gnome.py
+++ b/profiles/applications/gnome.py
@@ -1,4 +1,4 @@
import archinstall
-installation.add_additional_packages("gnome gnome-extra gdm") # We'll create a gnome-minimal later, but for now, we'll avoid issues by giving more than we need.
-# Note: gdm should be part of the gnome group, but adding it here for clarity
\ No newline at end of file
+installation.add_additional_packages("gnome gnome-tweaks gnome-todo gnome-sound-recorder evolution gdm")
+# Note: gdm should be part of the gnome group, but adding it here for clarity
|
{"golden_diff": "diff --git a/profiles/applications/gnome.py b/profiles/applications/gnome.py\n--- a/profiles/applications/gnome.py\n+++ b/profiles/applications/gnome.py\n@@ -1,4 +1,4 @@\n import archinstall\n \n-installation.add_additional_packages(\"gnome gnome-extra gdm\") # We'll create a gnome-minimal later, but for now, we'll avoid issues by giving more than we need.\n-# Note: gdm should be part of the gnome group, but adding it here for clarity\n\\ No newline at end of file\n+installation.add_additional_packages(\"gnome gnome-tweaks gnome-todo gnome-sound-recorder evolution gdm\")\n+# Note: gdm should be part of the gnome group, but adding it here for clarity\n", "issue": "gnome-extra provides WAY too much bloatware\nI can't imagine most people wanting all the packages this installs on a new installation. Most of these applications are things like games and advanced tools like dconf-editor that your average user should not be touching. Some of them are nice to have but can be installed later manually instead of during initial installation.\n", "before_files": [{"content": "import archinstall\n\ninstallation.add_additional_packages(\"gnome gnome-extra gdm\") # We'll create a gnome-minimal later, but for now, we'll avoid issues by giving more than we need.\n# Note: gdm should be part of the gnome group, but adding it here for clarity", "path": "profiles/applications/gnome.py"}]}
| 674 | 166 |
gh_patches_debug_5503
|
rasdani/github-patches
|
git_diff
|
getsentry__sentry-3604
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
New Auth Tokens cannot pass sudo check
The new auth token based API access never passes sudo:
``` python
def is_considered_sudo(request):
return request.is_sudo() or \
isinstance(request.auth, ApiKey)
```
</issue>
<code>
[start of src/sentry/api/decorators.py]
1 from __future__ import absolute_import
2
3 import json
4
5 from django.http import HttpResponse
6 from functools import wraps
7
8 from sentry.models import ApiKey
9
10
11 def is_considered_sudo(request):
12 return request.is_sudo() or \
13 isinstance(request.auth, ApiKey)
14
15
16 def sudo_required(func):
17 @wraps(func)
18 def wrapped(self, request, *args, **kwargs):
19 # If we are already authenticated through an API key we do not
20 # care about the sudo flag.
21 if not is_considered_sudo(request):
22 # TODO(dcramer): support some kind of auth flow to allow this
23 # externally
24 data = {
25 "error": "Account verification required.",
26 "sudoRequired": True,
27 "username": request.user.username,
28 }
29 return HttpResponse(json.dumps(data), status=401)
30 return func(self, request, *args, **kwargs)
31 return wrapped
32
[end of src/sentry/api/decorators.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/sentry/api/decorators.py b/src/sentry/api/decorators.py
--- a/src/sentry/api/decorators.py
+++ b/src/sentry/api/decorators.py
@@ -5,12 +5,13 @@
from django.http import HttpResponse
from functools import wraps
-from sentry.models import ApiKey
+from sentry.models import ApiKey, ApiToken
def is_considered_sudo(request):
return request.is_sudo() or \
- isinstance(request.auth, ApiKey)
+ isinstance(request.auth, ApiKey) or \
+ isinstance(request.auth, ApiToken)
def sudo_required(func):
|
{"golden_diff": "diff --git a/src/sentry/api/decorators.py b/src/sentry/api/decorators.py\n--- a/src/sentry/api/decorators.py\n+++ b/src/sentry/api/decorators.py\n@@ -5,12 +5,13 @@\n from django.http import HttpResponse\n from functools import wraps\n \n-from sentry.models import ApiKey\n+from sentry.models import ApiKey, ApiToken\n \n \n def is_considered_sudo(request):\n return request.is_sudo() or \\\n- isinstance(request.auth, ApiKey)\n+ isinstance(request.auth, ApiKey) or \\\n+ isinstance(request.auth, ApiToken)\n \n \n def sudo_required(func):\n", "issue": "New Auth Tokens cannot pass sudo check\nThe new auth token based API access never passes sudo:\n\n``` python\ndef is_considered_sudo(request):\n return request.is_sudo() or \\\n isinstance(request.auth, ApiKey)\n```\n\n", "before_files": [{"content": "from __future__ import absolute_import\n\nimport json\n\nfrom django.http import HttpResponse\nfrom functools import wraps\n\nfrom sentry.models import ApiKey\n\n\ndef is_considered_sudo(request):\n return request.is_sudo() or \\\n isinstance(request.auth, ApiKey)\n\n\ndef sudo_required(func):\n @wraps(func)\n def wrapped(self, request, *args, **kwargs):\n # If we are already authenticated through an API key we do not\n # care about the sudo flag.\n if not is_considered_sudo(request):\n # TODO(dcramer): support some kind of auth flow to allow this\n # externally\n data = {\n \"error\": \"Account verification required.\",\n \"sudoRequired\": True,\n \"username\": request.user.username,\n }\n return HttpResponse(json.dumps(data), status=401)\n return func(self, request, *args, **kwargs)\n return wrapped\n", "path": "src/sentry/api/decorators.py"}]}
| 848 | 142 |
gh_patches_debug_18519
|
rasdani/github-patches
|
git_diff
|
quantumlib__Cirq-3527
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Prevent installing both cirq and cirq-unstable.
**Is your feature request related to a use case or problem? Please describe.**
If `cirq-unstable` is installed in a virtualenv and you `pip install cirq`, the virtualenv gets into a bad state. This is because they are different packages with separate metadata, but they put the python code in the same location in a `cirq` folder in site-packages. So pip thinks both are installed but in fact only the most-recently installed package is "active".
If you try to fix such a situation by uninstalling one package, the code gets removed but pip still thinks the other package is installed. The other package is now in a broken state (can't be imported, etc.). The only way to recover is to uninstall _both_ packages and then install one of them again.
**Describe the solution you'd like**
I'd like `pip install cirq` to fail if `cirq-unstable` is installed, and vice-versa. I did a quick glance at setuptools docs to see if there is some way to specify packages that _must not_ be present, but I couldn't see anything. It also doesn't seem to work to add a package requirement like `cirq != *`. I'm not sure if there's any other mechanism we can use to accomplish this.
**What is the urgency from your perspective for this issue? Is it blocking important work?**
P3 - I'm not really blocked by it, it is an idea I'd like to discuss / suggestion based on principle
We have internal workarounds for this to try to keep people's virtualenvs in a good state if they accidentally install both versions, but it'd be great if we could prevent the problem from happening at all.
</issue>
<code>
[start of setup.py]
1 # Copyright 2018 The Cirq Developers
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import io
16 import os
17 from setuptools import find_packages, setup
18
19 # This reads the __version__ variable from cirq/_version.py
20 __version__ = ''
21 exec(open('cirq/_version.py').read())
22
23 name = 'cirq'
24
25 description = (
26 'A framework for creating, editing, and invoking '
27 'Noisy Intermediate Scale Quantum (NISQ) circuits.'
28 )
29
30 # README file as long_description.
31 long_description = io.open('README.rst', encoding='utf-8').read()
32
33 # If CIRQ_UNSTABLE_VERSION is set then we use cirq-unstable as the name of the package
34 # and update the version to this value.
35 if 'CIRQ_UNSTABLE_VERSION' in os.environ:
36 name = 'cirq-unstable'
37 __version__ = os.environ['CIRQ_UNSTABLE_VERSION']
38 long_description = (
39 "**This is a development version of Cirq and may be "
40 "unstable.**\n\n**For the latest stable release of Cirq "
41 "see**\n`here <https://pypi.org/project/cirq>`__.\n\n" + long_description
42 )
43
44 # Read in requirements
45 requirements = open('requirements.txt').readlines()
46 requirements = [r.strip() for r in requirements]
47 contrib_requirements = open('cirq/contrib/contrib-requirements.txt').readlines()
48 contrib_requirements = [r.strip() for r in contrib_requirements]
49 dev_requirements = open('dev_tools/conf/pip-list-dev-tools.txt').readlines()
50 dev_requirements = [r.strip() for r in dev_requirements]
51
52 cirq_packages = ['cirq'] + ['cirq.' + package for package in find_packages(where='cirq')]
53
54 # Sanity check
55 assert __version__, 'Version string cannot be empty'
56
57 setup(
58 name=name,
59 version=__version__,
60 url='http://github.com/quantumlib/cirq',
61 author='The Cirq Developers',
62 author_email='[email protected]',
63 python_requires=('>=3.6.0'),
64 install_requires=requirements,
65 extras_require={
66 'contrib': contrib_requirements,
67 'dev_env': dev_requirements + contrib_requirements,
68 },
69 license='Apache 2',
70 description=description,
71 long_description=long_description,
72 packages=cirq_packages,
73 package_data={
74 'cirq': ['py.typed'],
75 'cirq.google.api.v1': ['*.proto', '*.pyi'],
76 'cirq.google.api.v2': ['*.proto', '*.pyi'],
77 'cirq.protocols.json_test_data': ['*'],
78 },
79 )
80
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -30,11 +30,13 @@
# README file as long_description.
long_description = io.open('README.rst', encoding='utf-8').read()
-# If CIRQ_UNSTABLE_VERSION is set then we use cirq-unstable as the name of the package
-# and update the version to this value.
-if 'CIRQ_UNSTABLE_VERSION' in os.environ:
- name = 'cirq-unstable'
- __version__ = os.environ['CIRQ_UNSTABLE_VERSION']
+# If CIRQ_PRE_RELEASE_VERSION is set then we update the version to this value.
+# It is assumed that it ends with one of `.devN`, `.aN`, `.bN`, `.rcN` and hence
+# it will be a pre-release version on PyPi. See
+# https://packaging.python.org/guides/distributing-packages-using-setuptools/#pre-release-versioning
+# for more details.
+if 'CIRQ_PRE_RELEASE_VERSION' in os.environ:
+ __version__ = os.environ['CIRQ_PRE_RELEASE_VERSION']
long_description = (
"**This is a development version of Cirq and may be "
"unstable.**\n\n**For the latest stable release of Cirq "
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -30,11 +30,13 @@\n # README file as long_description.\n long_description = io.open('README.rst', encoding='utf-8').read()\n \n-# If CIRQ_UNSTABLE_VERSION is set then we use cirq-unstable as the name of the package\n-# and update the version to this value.\n-if 'CIRQ_UNSTABLE_VERSION' in os.environ:\n- name = 'cirq-unstable'\n- __version__ = os.environ['CIRQ_UNSTABLE_VERSION']\n+# If CIRQ_PRE_RELEASE_VERSION is set then we update the version to this value.\n+# It is assumed that it ends with one of `.devN`, `.aN`, `.bN`, `.rcN` and hence\n+# it will be a pre-release version on PyPi. See\n+# https://packaging.python.org/guides/distributing-packages-using-setuptools/#pre-release-versioning\n+# for more details.\n+if 'CIRQ_PRE_RELEASE_VERSION' in os.environ:\n+ __version__ = os.environ['CIRQ_PRE_RELEASE_VERSION']\n long_description = (\n \"**This is a development version of Cirq and may be \"\n \"unstable.**\\n\\n**For the latest stable release of Cirq \"\n", "issue": "Prevent installing both cirq and cirq-unstable.\n**Is your feature request related to a use case or problem? Please describe.**\r\n\r\nIf `cirq-unstable` is installed in a virtualenv and you `pip install cirq`, the virtualenv gets into a bad state. This is because they are different packages with separate metadata, but they put the python code in the same location in a `cirq` folder in site-packages. So pip thinks both are installed but in fact only the most-recently installed package is \"active\".\r\n\r\nIf you try to fix such a situation by uninstalling one package, the code gets removed but pip still thinks the other package is installed. The other package is now in a broken state (can't be imported, etc.). The only way to recover is to uninstall _both_ packages and then install one of them again.\r\n\r\n**Describe the solution you'd like**\r\n\r\nI'd like `pip install cirq` to fail if `cirq-unstable` is installed, and vice-versa. I did a quick glance at setuptools docs to see if there is some way to specify packages that _must not_ be present, but I couldn't see anything. It also doesn't seem to work to add a package requirement like `cirq != *`. I'm not sure if there's any other mechanism we can use to accomplish this.\r\n\r\n**What is the urgency from your perspective for this issue? Is it blocking important work?**\r\n\r\nP3 - I'm not really blocked by it, it is an idea I'd like to discuss / suggestion based on principle \r\n\r\nWe have internal workarounds for this to try to keep people's virtualenvs in a good state if they accidentally install both versions, but it'd be great if we could prevent the problem from happening at all.\n", "before_files": [{"content": "# Copyright 2018 The Cirq Developers\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport io\nimport os\nfrom setuptools import find_packages, setup\n\n# This reads the __version__ variable from cirq/_version.py\n__version__ = ''\nexec(open('cirq/_version.py').read())\n\nname = 'cirq'\n\ndescription = (\n 'A framework for creating, editing, and invoking '\n 'Noisy Intermediate Scale Quantum (NISQ) circuits.'\n)\n\n# README file as long_description.\nlong_description = io.open('README.rst', encoding='utf-8').read()\n\n# If CIRQ_UNSTABLE_VERSION is set then we use cirq-unstable as the name of the package\n# and update the version to this value.\nif 'CIRQ_UNSTABLE_VERSION' in os.environ:\n name = 'cirq-unstable'\n __version__ = os.environ['CIRQ_UNSTABLE_VERSION']\n long_description = (\n \"**This is a development version of Cirq and may be \"\n \"unstable.**\\n\\n**For the latest stable release of Cirq \"\n \"see**\\n`here <https://pypi.org/project/cirq>`__.\\n\\n\" + long_description\n )\n\n# Read in requirements\nrequirements = open('requirements.txt').readlines()\nrequirements = [r.strip() for r in requirements]\ncontrib_requirements = open('cirq/contrib/contrib-requirements.txt').readlines()\ncontrib_requirements = [r.strip() for r in contrib_requirements]\ndev_requirements = open('dev_tools/conf/pip-list-dev-tools.txt').readlines()\ndev_requirements = [r.strip() for r in dev_requirements]\n\ncirq_packages = ['cirq'] + ['cirq.' + package for package in find_packages(where='cirq')]\n\n# Sanity check\nassert __version__, 'Version string cannot be empty'\n\nsetup(\n name=name,\n version=__version__,\n url='http://github.com/quantumlib/cirq',\n author='The Cirq Developers',\n author_email='[email protected]',\n python_requires=('>=3.6.0'),\n install_requires=requirements,\n extras_require={\n 'contrib': contrib_requirements,\n 'dev_env': dev_requirements + contrib_requirements,\n },\n license='Apache 2',\n description=description,\n long_description=long_description,\n packages=cirq_packages,\n package_data={\n 'cirq': ['py.typed'],\n 'cirq.google.api.v1': ['*.proto', '*.pyi'],\n 'cirq.google.api.v2': ['*.proto', '*.pyi'],\n 'cirq.protocols.json_test_data': ['*'],\n },\n)\n", "path": "setup.py"}]}
| 1,742 | 289 |
gh_patches_debug_9804
|
rasdani/github-patches
|
git_diff
|
bokeh__bokeh-9604
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[FEATURE] BokehJS embed_item should return a reference to the plot.
Bokeh.embed.embed_item currently returns nothing. I propose it should return a reference to the plot object so I don't have to go fishing (Bokeh.index[plotData.root_id]) in Bokeh.index to do things like call resize_layout() manually.
Honestly any sort of 'official' method for doing this would be super useful.
</issue>
<code>
[start of examples/embed/json_item.py]
1 import json
2
3 from flask import Flask
4 from jinja2 import Template
5
6 from bokeh.embed import json_item
7 from bokeh.plotting import figure
8 from bokeh.resources import CDN
9 from bokeh.sampledata.iris import flowers
10
11 app = Flask(__name__)
12
13 page = Template("""
14 <!DOCTYPE html>
15 <html lang="en">
16 <head>
17 {{ resources }}
18 </head>
19
20 <body>
21 <div id="myplot"></div>
22 <div id="myplot2"></div>
23 <script>
24 fetch('/plot')
25 .then(function(response) { return response.json(); })
26 .then(function(item) { Bokeh.embed.embed_item(item); })
27 </script>
28 <script>
29 fetch('/plot2')
30 .then(function(response) { return response.json(); })
31 .then(function(item) { Bokeh.embed.embed_item(item, "myplot2"); })
32 </script>
33 </body>
34 """)
35
36 colormap = {'setosa': 'red', 'versicolor': 'green', 'virginica': 'blue'}
37 colors = [colormap[x] for x in flowers['species']]
38
39 def make_plot(x, y):
40 p = figure(title = "Iris Morphology", sizing_mode="fixed", plot_width=400, plot_height=400)
41 p.xaxis.axis_label = x
42 p.yaxis.axis_label = y
43 p.circle(flowers[x], flowers[y], color=colors, fill_alpha=0.2, size=10)
44 return p
45
46 @app.route('/')
47 def root():
48 return page.render(resources=CDN.render())
49
50 @app.route('/plot')
51 def plot():
52 p = make_plot('petal_width', 'petal_length')
53 return json.dumps(json_item(p, "myplot"))
54
55 @app.route('/plot2')
56 def plot2():
57 p = make_plot('sepal_width', 'sepal_length')
58 return json.dumps(json_item(p))
59
60 if __name__ == '__main__':
61 app.run()
62
[end of examples/embed/json_item.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/embed/json_item.py b/examples/embed/json_item.py
--- a/examples/embed/json_item.py
+++ b/examples/embed/json_item.py
@@ -23,12 +23,12 @@
<script>
fetch('/plot')
.then(function(response) { return response.json(); })
- .then(function(item) { Bokeh.embed.embed_item(item); })
+ .then(function(item) { return Bokeh.embed.embed_item(item); })
</script>
<script>
fetch('/plot2')
.then(function(response) { return response.json(); })
- .then(function(item) { Bokeh.embed.embed_item(item, "myplot2"); })
+ .then(function(item) { return Bokeh.embed.embed_item(item, "myplot2"); })
</script>
</body>
""")
|
{"golden_diff": "diff --git a/examples/embed/json_item.py b/examples/embed/json_item.py\n--- a/examples/embed/json_item.py\n+++ b/examples/embed/json_item.py\n@@ -23,12 +23,12 @@\n <script>\n fetch('/plot')\n .then(function(response) { return response.json(); })\n- .then(function(item) { Bokeh.embed.embed_item(item); })\n+ .then(function(item) { return Bokeh.embed.embed_item(item); })\n </script>\n <script>\n fetch('/plot2')\n .then(function(response) { return response.json(); })\n- .then(function(item) { Bokeh.embed.embed_item(item, \"myplot2\"); })\n+ .then(function(item) { return Bokeh.embed.embed_item(item, \"myplot2\"); })\n </script>\n </body>\n \"\"\")\n", "issue": "[FEATURE] BokehJS embed_item should return a reference to the plot. \nBokeh.embed.embed_item currently returns nothing. I propose it should return a reference to the plot object so I don't have to go fishing (Bokeh.index[plotData.root_id]) in Bokeh.index to do things like call resize_layout() manually.\r\n\r\nHonestly any sort of 'official' method for doing this would be super useful.\r\n\n", "before_files": [{"content": "import json\n\nfrom flask import Flask\nfrom jinja2 import Template\n\nfrom bokeh.embed import json_item\nfrom bokeh.plotting import figure\nfrom bokeh.resources import CDN\nfrom bokeh.sampledata.iris import flowers\n\napp = Flask(__name__)\n\npage = Template(\"\"\"\n<!DOCTYPE html>\n<html lang=\"en\">\n<head>\n {{ resources }}\n</head>\n\n<body>\n <div id=\"myplot\"></div>\n <div id=\"myplot2\"></div>\n <script>\n fetch('/plot')\n .then(function(response) { return response.json(); })\n .then(function(item) { Bokeh.embed.embed_item(item); })\n </script>\n <script>\n fetch('/plot2')\n .then(function(response) { return response.json(); })\n .then(function(item) { Bokeh.embed.embed_item(item, \"myplot2\"); })\n </script>\n</body>\n\"\"\")\n\ncolormap = {'setosa': 'red', 'versicolor': 'green', 'virginica': 'blue'}\ncolors = [colormap[x] for x in flowers['species']]\n\ndef make_plot(x, y):\n p = figure(title = \"Iris Morphology\", sizing_mode=\"fixed\", plot_width=400, plot_height=400)\n p.xaxis.axis_label = x\n p.yaxis.axis_label = y\n p.circle(flowers[x], flowers[y], color=colors, fill_alpha=0.2, size=10)\n return p\n\[email protected]('/')\ndef root():\n return page.render(resources=CDN.render())\n\[email protected]('/plot')\ndef plot():\n p = make_plot('petal_width', 'petal_length')\n return json.dumps(json_item(p, \"myplot\"))\n\[email protected]('/plot2')\ndef plot2():\n p = make_plot('sepal_width', 'sepal_length')\n return json.dumps(json_item(p))\n\nif __name__ == '__main__':\n app.run()\n", "path": "examples/embed/json_item.py"}]}
| 1,164 | 179 |
gh_patches_debug_16323
|
rasdani/github-patches
|
git_diff
|
litestar-org__litestar-2602
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
docs: update TODO app w/ sqlalchemy tutorial to use autocommitting before send handler.
> @AgarwalPragy You are correct. By default, the plugin session handler does not automatically commit on a successful response. You can easily change it by using the following `before_send` handler:
>
> ```python
> from advanced_alchemy.extensions.litestar.plugins.init.config.asyncio import autocommit_before_send_handler
>
> db_url = "sqlite+aiosqlite:///:memory:"
> app = Litestar(
> route_handlers=[hello],
> plugins=[
> SQLAlchemyPlugin(
> config=SQLAlchemyAsyncConfig(
> connection_string=db_url,
> session_dependency_key="transaction",
> create_all=True,
> alembic_config=AlembicAsyncConfig(target_metadata=orm_registry.metadata),
> before_send_handler=autocommit_before_send_handler,
> ),
> ),
> ],
> )
> ```
I'd say this is a documentation bug on our side now.
We should update https://docs.litestar.dev/latest/tutorials/sqlalchemy/3-init-plugin.html to do the same as this (it was written before the autocommit handler was a part of the plugin, IIRC).
_Originally posted by @peterschutt in https://github.com/litestar-org/litestar/issues/2556#issuecomment-1786287414_
<!-- POLAR PLEDGE BADGE START -->
---
> [!NOTE]
> While we are open for sponsoring on [GitHub Sponsors](https://github.com/sponsors/litestar-org/) and
> [OpenCollective](https://opencollective.com/litestar), we also utilize [Polar.sh](https://polar.sh/) to engage in pledge-based sponsorship.
>
> Check out all issues funded or available for funding [on our Polar.sh Litestar dashboard](https://polar.sh/litestar-org)
> * If you would like to see an issue prioritized, make a pledge towards it!
> * We receive the pledge once the issue is completed & verified
> * This, along with engagement in the community, helps us know which features are a priority to our users.
<a href="https://polar.sh/litestar-org/litestar/issues/2569">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://polar.sh/api/github/litestar-org/litestar/issues/2569/pledge.svg?darkmode=1">
<img alt="Fund with Polar" src="https://polar.sh/api/github/litestar-org/litestar/issues/2569/pledge.svg">
</picture>
</a>
<!-- POLAR PLEDGE BADGE END -->
</issue>
<code>
[start of docs/examples/contrib/sqlalchemy/plugins/tutorial/full_app_with_plugin.py]
1 from typing import AsyncGenerator, List, Optional
2
3 from sqlalchemy import select
4 from sqlalchemy.exc import IntegrityError, NoResultFound
5 from sqlalchemy.ext.asyncio import AsyncSession
6 from sqlalchemy.orm import DeclarativeBase, Mapped, mapped_column
7
8 from litestar import Litestar, get, post, put
9 from litestar.contrib.sqlalchemy.plugins import SQLAlchemyAsyncConfig, SQLAlchemyPlugin
10 from litestar.exceptions import ClientException, NotFoundException
11 from litestar.status_codes import HTTP_409_CONFLICT
12
13
14 class Base(DeclarativeBase):
15 ...
16
17
18 class TodoItem(Base):
19 __tablename__ = "todo_items"
20
21 title: Mapped[str] = mapped_column(primary_key=True)
22 done: Mapped[bool]
23
24
25 async def provide_transaction(db_session: AsyncSession) -> AsyncGenerator[AsyncSession, None]:
26 try:
27 async with db_session.begin():
28 yield db_session
29 except IntegrityError as exc:
30 raise ClientException(
31 status_code=HTTP_409_CONFLICT,
32 detail=str(exc),
33 ) from exc
34
35
36 async def get_todo_by_title(todo_name, session: AsyncSession) -> TodoItem:
37 query = select(TodoItem).where(TodoItem.title == todo_name)
38 result = await session.execute(query)
39 try:
40 return result.scalar_one()
41 except NoResultFound as e:
42 raise NotFoundException(detail=f"TODO {todo_name!r} not found") from e
43
44
45 async def get_todo_list(done: Optional[bool], session: AsyncSession) -> List[TodoItem]:
46 query = select(TodoItem)
47 if done is not None:
48 query = query.where(TodoItem.done.is_(done))
49
50 result = await session.execute(query)
51 return result.scalars().all()
52
53
54 @get("/")
55 async def get_list(transaction: AsyncSession, done: Optional[bool] = None) -> List[TodoItem]:
56 return await get_todo_list(done, transaction)
57
58
59 @post("/")
60 async def add_item(data: TodoItem, transaction: AsyncSession) -> TodoItem:
61 transaction.add(data)
62 return data
63
64
65 @put("/{item_title:str}")
66 async def update_item(item_title: str, data: TodoItem, transaction: AsyncSession) -> TodoItem:
67 todo_item = await get_todo_by_title(item_title, transaction)
68 todo_item.title = data.title
69 todo_item.done = data.done
70 return todo_item
71
72
73 db_config = SQLAlchemyAsyncConfig(
74 connection_string="sqlite+aiosqlite:///todo.sqlite", metadata=Base.metadata, create_all=True
75 )
76
77 app = Litestar(
78 [get_list, add_item, update_item],
79 dependencies={"transaction": provide_transaction},
80 plugins=[SQLAlchemyPlugin(db_config)],
81 )
82
[end of docs/examples/contrib/sqlalchemy/plugins/tutorial/full_app_with_plugin.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/examples/contrib/sqlalchemy/plugins/tutorial/full_app_with_plugin.py b/docs/examples/contrib/sqlalchemy/plugins/tutorial/full_app_with_plugin.py
--- a/docs/examples/contrib/sqlalchemy/plugins/tutorial/full_app_with_plugin.py
+++ b/docs/examples/contrib/sqlalchemy/plugins/tutorial/full_app_with_plugin.py
@@ -1,5 +1,6 @@
from typing import AsyncGenerator, List, Optional
+from advanced_alchemy.extensions.litestar.plugins.init.config.asyncio import autocommit_before_send_handler
from sqlalchemy import select
from sqlalchemy.exc import IntegrityError, NoResultFound
from sqlalchemy.ext.asyncio import AsyncSession
@@ -71,7 +72,10 @@
db_config = SQLAlchemyAsyncConfig(
- connection_string="sqlite+aiosqlite:///todo.sqlite", metadata=Base.metadata, create_all=True
+ connection_string="sqlite+aiosqlite:///todo.sqlite",
+ metadata=Base.metadata,
+ create_all=True,
+ before_send_handler=autocommit_before_send_handler,
)
app = Litestar(
|
{"golden_diff": "diff --git a/docs/examples/contrib/sqlalchemy/plugins/tutorial/full_app_with_plugin.py b/docs/examples/contrib/sqlalchemy/plugins/tutorial/full_app_with_plugin.py\n--- a/docs/examples/contrib/sqlalchemy/plugins/tutorial/full_app_with_plugin.py\n+++ b/docs/examples/contrib/sqlalchemy/plugins/tutorial/full_app_with_plugin.py\n@@ -1,5 +1,6 @@\n from typing import AsyncGenerator, List, Optional\n \n+from advanced_alchemy.extensions.litestar.plugins.init.config.asyncio import autocommit_before_send_handler\n from sqlalchemy import select\n from sqlalchemy.exc import IntegrityError, NoResultFound\n from sqlalchemy.ext.asyncio import AsyncSession\n@@ -71,7 +72,10 @@\n \n \n db_config = SQLAlchemyAsyncConfig(\n- connection_string=\"sqlite+aiosqlite:///todo.sqlite\", metadata=Base.metadata, create_all=True\n+ connection_string=\"sqlite+aiosqlite:///todo.sqlite\",\n+ metadata=Base.metadata,\n+ create_all=True,\n+ before_send_handler=autocommit_before_send_handler,\n )\n \n app = Litestar(\n", "issue": "docs: update TODO app w/ sqlalchemy tutorial to use autocommitting before send handler.\n > @AgarwalPragy You are correct. By default, the plugin session handler does not automatically commit on a successful response. You can easily change it by using the following `before_send` handler:\r\n> \r\n> ```python\r\n> from advanced_alchemy.extensions.litestar.plugins.init.config.asyncio import autocommit_before_send_handler\r\n> \r\n> db_url = \"sqlite+aiosqlite:///:memory:\"\r\n> app = Litestar(\r\n> route_handlers=[hello],\r\n> plugins=[\r\n> SQLAlchemyPlugin(\r\n> config=SQLAlchemyAsyncConfig(\r\n> connection_string=db_url,\r\n> session_dependency_key=\"transaction\",\r\n> create_all=True,\r\n> alembic_config=AlembicAsyncConfig(target_metadata=orm_registry.metadata),\r\n> before_send_handler=autocommit_before_send_handler,\r\n> ),\r\n> ),\r\n> ],\r\n> )\r\n> ```\r\n\r\nI'd say this is a documentation bug on our side now.\r\n\r\nWe should update https://docs.litestar.dev/latest/tutorials/sqlalchemy/3-init-plugin.html to do the same as this (it was written before the autocommit handler was a part of the plugin, IIRC).\r\n\r\n_Originally posted by @peterschutt in https://github.com/litestar-org/litestar/issues/2556#issuecomment-1786287414_\r\n \n\n<!-- POLAR PLEDGE BADGE START -->\n---\n> [!NOTE] \n> While we are open for sponsoring on [GitHub Sponsors](https://github.com/sponsors/litestar-org/) and \n> [OpenCollective](https://opencollective.com/litestar), we also utilize [Polar.sh](https://polar.sh/) to engage in pledge-based sponsorship.\n>\n> Check out all issues funded or available for funding [on our Polar.sh Litestar dashboard](https://polar.sh/litestar-org)\n> * If you would like to see an issue prioritized, make a pledge towards it!\n> * We receive the pledge once the issue is completed & verified\n> * This, along with engagement in the community, helps us know which features are a priority to our users.\n\n<a href=\"https://polar.sh/litestar-org/litestar/issues/2569\">\n<picture>\n <source media=\"(prefers-color-scheme: dark)\" srcset=\"https://polar.sh/api/github/litestar-org/litestar/issues/2569/pledge.svg?darkmode=1\">\n <img alt=\"Fund with Polar\" src=\"https://polar.sh/api/github/litestar-org/litestar/issues/2569/pledge.svg\">\n</picture>\n</a>\n<!-- POLAR PLEDGE BADGE END -->\n\n", "before_files": [{"content": "from typing import AsyncGenerator, List, Optional\n\nfrom sqlalchemy import select\nfrom sqlalchemy.exc import IntegrityError, NoResultFound\nfrom sqlalchemy.ext.asyncio import AsyncSession\nfrom sqlalchemy.orm import DeclarativeBase, Mapped, mapped_column\n\nfrom litestar import Litestar, get, post, put\nfrom litestar.contrib.sqlalchemy.plugins import SQLAlchemyAsyncConfig, SQLAlchemyPlugin\nfrom litestar.exceptions import ClientException, NotFoundException\nfrom litestar.status_codes import HTTP_409_CONFLICT\n\n\nclass Base(DeclarativeBase):\n ...\n\n\nclass TodoItem(Base):\n __tablename__ = \"todo_items\"\n\n title: Mapped[str] = mapped_column(primary_key=True)\n done: Mapped[bool]\n\n\nasync def provide_transaction(db_session: AsyncSession) -> AsyncGenerator[AsyncSession, None]:\n try:\n async with db_session.begin():\n yield db_session\n except IntegrityError as exc:\n raise ClientException(\n status_code=HTTP_409_CONFLICT,\n detail=str(exc),\n ) from exc\n\n\nasync def get_todo_by_title(todo_name, session: AsyncSession) -> TodoItem:\n query = select(TodoItem).where(TodoItem.title == todo_name)\n result = await session.execute(query)\n try:\n return result.scalar_one()\n except NoResultFound as e:\n raise NotFoundException(detail=f\"TODO {todo_name!r} not found\") from e\n\n\nasync def get_todo_list(done: Optional[bool], session: AsyncSession) -> List[TodoItem]:\n query = select(TodoItem)\n if done is not None:\n query = query.where(TodoItem.done.is_(done))\n\n result = await session.execute(query)\n return result.scalars().all()\n\n\n@get(\"/\")\nasync def get_list(transaction: AsyncSession, done: Optional[bool] = None) -> List[TodoItem]:\n return await get_todo_list(done, transaction)\n\n\n@post(\"/\")\nasync def add_item(data: TodoItem, transaction: AsyncSession) -> TodoItem:\n transaction.add(data)\n return data\n\n\n@put(\"/{item_title:str}\")\nasync def update_item(item_title: str, data: TodoItem, transaction: AsyncSession) -> TodoItem:\n todo_item = await get_todo_by_title(item_title, transaction)\n todo_item.title = data.title\n todo_item.done = data.done\n return todo_item\n\n\ndb_config = SQLAlchemyAsyncConfig(\n connection_string=\"sqlite+aiosqlite:///todo.sqlite\", metadata=Base.metadata, create_all=True\n)\n\napp = Litestar(\n [get_list, add_item, update_item],\n dependencies={\"transaction\": provide_transaction},\n plugins=[SQLAlchemyPlugin(db_config)],\n)\n", "path": "docs/examples/contrib/sqlalchemy/plugins/tutorial/full_app_with_plugin.py"}]}
| 1,888 | 225 |
gh_patches_debug_29329
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-2326
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Streamlink no longer provides streamlink-script.py
As of version 0.14.0 streamlink does not install the streamlink-script.py script,
because of this streamlink-twitch-gui does not work as it cannot load the script.
This may an issue in streamlink, as there is no mention of its removal in the changelog.
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 import codecs
3 from os import environ
4 from os import path
5 from sys import path as sys_path
6
7 from setuptools import setup, find_packages
8
9 import versioneer
10
11 deps = [
12 # Require backport of concurrent.futures on Python 2
13 'futures;python_version<"3.0"',
14 # Require singledispatch on Python <3.4
15 'singledispatch;python_version<"3.4"',
16 "requests>=2.21.0,<3.0",
17 'urllib3[secure]>=1.23;python_version<"3.0"',
18 "isodate",
19 "websocket-client",
20 # Support for SOCKS proxies
21 "PySocks!=1.5.7,>=1.5.6",
22 # win-inet-pton is missing a dependency in PySocks, this has been fixed but not released yet
23 # Required due to missing socket.inet_ntop & socket.inet_pton method in Windows Python 2.x
24 'win-inet-pton;python_version<"3.0" and platform_system=="Windows"',
25 # shutil.get_terminal_size and which were added in Python 3.3
26 'backports.shutil_which;python_version<"3.3"',
27 'backports.shutil_get_terminal_size;python_version<"3.3"'
28 ]
29
30 # for encrypted streams
31 if environ.get("STREAMLINK_USE_PYCRYPTO"):
32 deps.append("pycrypto")
33 else:
34 # this version of pycryptodome is known to work and has a Windows wheel for py2.7, py3.3-3.6
35 deps.append("pycryptodome>=3.4.3,<4")
36
37 # for localization
38 if environ.get("STREAMLINK_USE_PYCOUNTRY"):
39 deps.append("pycountry")
40 else:
41 deps.append("iso-639")
42 deps.append("iso3166")
43
44 # When we build an egg for the Win32 bootstrap we don"t want dependency
45 # information built into it.
46 if environ.get("NO_DEPS"):
47 deps = []
48
49 this_directory = path.abspath(path.dirname(__file__))
50 srcdir = path.join(this_directory, "src/")
51 sys_path.insert(0, srcdir)
52
53 with codecs.open(path.join(this_directory, "README.md"), 'r', "utf8") as f:
54 long_description = f.read()
55
56 setup(name="streamlink",
57 version=versioneer.get_version(),
58 cmdclass=versioneer.get_cmdclass(),
59 description="Streamlink is command-line utility that extracts streams "
60 "from various services and pipes them into a video player of "
61 "choice.",
62 long_description=long_description,
63 long_description_content_type="text/markdown",
64 url="https://github.com/streamlink/streamlink",
65 project_urls={
66 "Documentation": "https://streamlink.github.io/",
67 "Tracker": "https://github.com/streamlink/streamlink/issues",
68 "Source": "https://github.com/streamlink/streamlink",
69 "Funding": "https://opencollective.com/streamlink"
70 },
71 author="Streamlink",
72 # temp until we have a mailing list / global email
73 author_email="[email protected]",
74 license="Simplified BSD",
75 packages=find_packages("src"),
76 package_dir={"": "src"},
77 entry_points={
78 "console_scripts": ["streamlink=streamlink_cli.main:main"]
79 },
80 install_requires=deps,
81 test_suite="tests",
82 python_requires=">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, <4",
83 classifiers=["Development Status :: 5 - Production/Stable",
84 "License :: OSI Approved :: BSD License",
85 "Environment :: Console",
86 "Intended Audience :: End Users/Desktop",
87 "Operating System :: POSIX",
88 "Operating System :: Microsoft :: Windows",
89 "Operating System :: MacOS",
90 "Programming Language :: Python :: 2.7",
91 "Programming Language :: Python :: 3.4",
92 "Programming Language :: Python :: 3.5",
93 "Programming Language :: Python :: 3.6",
94 "Programming Language :: Python :: 3.7",
95 "Topic :: Internet :: WWW/HTTP",
96 "Topic :: Multimedia :: Sound/Audio",
97 "Topic :: Multimedia :: Video",
98 "Topic :: Utilities"])
99
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -1,8 +1,7 @@
#!/usr/bin/env python
import codecs
-from os import environ
-from os import path
-from sys import path as sys_path
+from os import environ, path
+from sys import argv, path as sys_path
from setuptools import setup, find_packages
@@ -53,6 +52,27 @@
with codecs.open(path.join(this_directory, "README.md"), 'r', "utf8") as f:
long_description = f.read()
+
+def is_wheel_for_windows():
+ if "bdist_wheel" in argv:
+ names = ["win32", "win-amd64", "cygwin"]
+ length = len(argv)
+ for pos in range(argv.index("bdist_wheel") + 1, length):
+ if argv[pos] == "--plat-name" and pos + 1 < length:
+ return argv[pos + 1] in names
+ elif argv[pos][:12] == "--plat-name=":
+ return argv[pos][12:] in names
+ return False
+
+
+entry_points = {
+ "console_scripts": ["streamlink=streamlink_cli.main:main"]
+}
+
+if is_wheel_for_windows():
+ entry_points["gui_scripts"] = ["streamlinkw=streamlink_cli.main:main"]
+
+
setup(name="streamlink",
version=versioneer.get_version(),
cmdclass=versioneer.get_cmdclass(),
@@ -74,9 +94,7 @@
license="Simplified BSD",
packages=find_packages("src"),
package_dir={"": "src"},
- entry_points={
- "console_scripts": ["streamlink=streamlink_cli.main:main"]
- },
+ entry_points=entry_points,
install_requires=deps,
test_suite="tests",
python_requires=">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, <4",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -1,8 +1,7 @@\n #!/usr/bin/env python\n import codecs\n-from os import environ\n-from os import path\n-from sys import path as sys_path\n+from os import environ, path\n+from sys import argv, path as sys_path\n \n from setuptools import setup, find_packages\n \n@@ -53,6 +52,27 @@\n with codecs.open(path.join(this_directory, \"README.md\"), 'r', \"utf8\") as f:\n long_description = f.read()\n \n+\n+def is_wheel_for_windows():\n+ if \"bdist_wheel\" in argv:\n+ names = [\"win32\", \"win-amd64\", \"cygwin\"]\n+ length = len(argv)\n+ for pos in range(argv.index(\"bdist_wheel\") + 1, length):\n+ if argv[pos] == \"--plat-name\" and pos + 1 < length:\n+ return argv[pos + 1] in names\n+ elif argv[pos][:12] == \"--plat-name=\":\n+ return argv[pos][12:] in names\n+ return False\n+\n+\n+entry_points = {\n+ \"console_scripts\": [\"streamlink=streamlink_cli.main:main\"]\n+}\n+\n+if is_wheel_for_windows():\n+ entry_points[\"gui_scripts\"] = [\"streamlinkw=streamlink_cli.main:main\"]\n+\n+\n setup(name=\"streamlink\",\n version=versioneer.get_version(),\n cmdclass=versioneer.get_cmdclass(),\n@@ -74,9 +94,7 @@\n license=\"Simplified BSD\",\n packages=find_packages(\"src\"),\n package_dir={\"\": \"src\"},\n- entry_points={\n- \"console_scripts\": [\"streamlink=streamlink_cli.main:main\"]\n- },\n+ entry_points=entry_points,\n install_requires=deps,\n test_suite=\"tests\",\n python_requires=\">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, <4\",\n", "issue": "Streamlink no longer provides streamlink-script.py\nAs of version 0.14.0 streamlink does not install the streamlink-script.py script,\r\nbecause of this streamlink-twitch-gui does not work as it cannot load the script.\r\nThis may an issue in streamlink, as there is no mention of its removal in the changelog.\n", "before_files": [{"content": "#!/usr/bin/env python\nimport codecs\nfrom os import environ\nfrom os import path\nfrom sys import path as sys_path\n\nfrom setuptools import setup, find_packages\n\nimport versioneer\n\ndeps = [\n # Require backport of concurrent.futures on Python 2\n 'futures;python_version<\"3.0\"',\n # Require singledispatch on Python <3.4\n 'singledispatch;python_version<\"3.4\"',\n \"requests>=2.21.0,<3.0\",\n 'urllib3[secure]>=1.23;python_version<\"3.0\"',\n \"isodate\",\n \"websocket-client\",\n # Support for SOCKS proxies\n \"PySocks!=1.5.7,>=1.5.6\",\n # win-inet-pton is missing a dependency in PySocks, this has been fixed but not released yet\n # Required due to missing socket.inet_ntop & socket.inet_pton method in Windows Python 2.x\n 'win-inet-pton;python_version<\"3.0\" and platform_system==\"Windows\"',\n # shutil.get_terminal_size and which were added in Python 3.3\n 'backports.shutil_which;python_version<\"3.3\"',\n 'backports.shutil_get_terminal_size;python_version<\"3.3\"'\n]\n\n# for encrypted streams\nif environ.get(\"STREAMLINK_USE_PYCRYPTO\"):\n deps.append(\"pycrypto\")\nelse:\n # this version of pycryptodome is known to work and has a Windows wheel for py2.7, py3.3-3.6\n deps.append(\"pycryptodome>=3.4.3,<4\")\n\n# for localization\nif environ.get(\"STREAMLINK_USE_PYCOUNTRY\"):\n deps.append(\"pycountry\")\nelse:\n deps.append(\"iso-639\")\n deps.append(\"iso3166\")\n\n# When we build an egg for the Win32 bootstrap we don\"t want dependency\n# information built into it.\nif environ.get(\"NO_DEPS\"):\n deps = []\n\nthis_directory = path.abspath(path.dirname(__file__))\nsrcdir = path.join(this_directory, \"src/\")\nsys_path.insert(0, srcdir)\n\nwith codecs.open(path.join(this_directory, \"README.md\"), 'r', \"utf8\") as f:\n long_description = f.read()\n\nsetup(name=\"streamlink\",\n version=versioneer.get_version(),\n cmdclass=versioneer.get_cmdclass(),\n description=\"Streamlink is command-line utility that extracts streams \"\n \"from various services and pipes them into a video player of \"\n \"choice.\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n url=\"https://github.com/streamlink/streamlink\",\n project_urls={\n \"Documentation\": \"https://streamlink.github.io/\",\n \"Tracker\": \"https://github.com/streamlink/streamlink/issues\",\n \"Source\": \"https://github.com/streamlink/streamlink\",\n \"Funding\": \"https://opencollective.com/streamlink\"\n },\n author=\"Streamlink\",\n # temp until we have a mailing list / global email\n author_email=\"[email protected]\",\n license=\"Simplified BSD\",\n packages=find_packages(\"src\"),\n package_dir={\"\": \"src\"},\n entry_points={\n \"console_scripts\": [\"streamlink=streamlink_cli.main:main\"]\n },\n install_requires=deps,\n test_suite=\"tests\",\n python_requires=\">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, <4\",\n classifiers=[\"Development Status :: 5 - Production/Stable\",\n \"License :: OSI Approved :: BSD License\",\n \"Environment :: Console\",\n \"Intended Audience :: End Users/Desktop\",\n \"Operating System :: POSIX\",\n \"Operating System :: Microsoft :: Windows\",\n \"Operating System :: MacOS\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3.4\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Topic :: Internet :: WWW/HTTP\",\n \"Topic :: Multimedia :: Sound/Audio\",\n \"Topic :: Multimedia :: Video\",\n \"Topic :: Utilities\"])\n", "path": "setup.py"}]}
| 1,729 | 450 |
gh_patches_debug_29106
|
rasdani/github-patches
|
git_diff
|
apache__airflow-34931
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Airflow 2.7.1 can not start Scheduler & trigger
### Apache Airflow version
2.7.1
### What happened
After upgrade from 2.6.0 to 2.7.1 (try pip uninstall apache-airflow, and clear dir airflow - remove airflow.cfg), I can start scheduler & trigger with daemon.
I try start with command, it can start, but logout console it killed.
I try: airflow scheduler or airflow triggerer :done but kill when logout console
airflow scheduler --daemon && airflow triggerer --daemon: fail, can not start scheduler & triggerer (2.6.0 run ok). but start deamon with webserver & celery worker is fine
Help me
### What you think should happen instead
_No response_
### How to reproduce
1. run airflow 2.6.0 fine on ubuntu server 22.04.3 lts
2. install airflow 2.7.1
3. can not start daemon triggerer & scheduler
### Operating System
ubuntu server 22.04.3 LTS
### Versions of Apache Airflow Providers
_No response_
### Deployment
Virtualenv installation
### Deployment details
_No response_
### Anything else
_No response_
### Are you willing to submit PR?
- [X] Yes I am willing to submit a PR!
### Code of Conduct
- [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md)
</issue>
<code>
[start of airflow/cli/commands/triggerer_command.py]
1 # Licensed to the Apache Software Foundation (ASF) under one
2 # or more contributor license agreements. See the NOTICE file
3 # distributed with this work for additional information
4 # regarding copyright ownership. The ASF licenses this file
5 # to you under the Apache License, Version 2.0 (the
6 # "License"); you may not use this file except in compliance
7 # with the License. You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing,
12 # software distributed under the License is distributed on an
13 # "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
14 # KIND, either express or implied. See the License for the
15 # specific language governing permissions and limitations
16 # under the License.
17 """Triggerer command."""
18 from __future__ import annotations
19
20 import signal
21 from contextlib import contextmanager
22 from functools import partial
23 from multiprocessing import Process
24 from typing import Generator
25
26 import daemon
27 from daemon.pidfile import TimeoutPIDLockFile
28
29 from airflow import settings
30 from airflow.configuration import conf
31 from airflow.jobs.job import Job, run_job
32 from airflow.jobs.triggerer_job_runner import TriggererJobRunner
33 from airflow.utils import cli as cli_utils
34 from airflow.utils.cli import setup_locations, setup_logging, sigint_handler, sigquit_handler
35 from airflow.utils.providers_configuration_loader import providers_configuration_loaded
36 from airflow.utils.serve_logs import serve_logs
37
38
39 @contextmanager
40 def _serve_logs(skip_serve_logs: bool = False) -> Generator[None, None, None]:
41 """Start serve_logs sub-process."""
42 sub_proc = None
43 if skip_serve_logs is False:
44 port = conf.getint("logging", "trigger_log_server_port", fallback=8794)
45 sub_proc = Process(target=partial(serve_logs, port=port))
46 sub_proc.start()
47 try:
48 yield
49 finally:
50 if sub_proc:
51 sub_proc.terminate()
52
53
54 @cli_utils.action_cli
55 @providers_configuration_loaded
56 def triggerer(args):
57 """Start Airflow Triggerer."""
58 settings.MASK_SECRETS_IN_LOGS = True
59 print(settings.HEADER)
60 triggerer_heartrate = conf.getfloat("triggerer", "JOB_HEARTBEAT_SEC")
61 triggerer_job_runner = TriggererJobRunner(job=Job(heartrate=triggerer_heartrate), capacity=args.capacity)
62
63 if args.daemon:
64 pid, stdout, stderr, log_file = setup_locations(
65 "triggerer", args.pid, args.stdout, args.stderr, args.log_file
66 )
67 handle = setup_logging(log_file)
68 with open(stdout, "a") as stdout_handle, open(stderr, "a") as stderr_handle:
69 stdout_handle.truncate(0)
70 stderr_handle.truncate(0)
71
72 daemon_context = daemon.DaemonContext(
73 pidfile=TimeoutPIDLockFile(pid, -1),
74 files_preserve=[handle],
75 stdout=stdout_handle,
76 stderr=stderr_handle,
77 umask=int(settings.DAEMON_UMASK, 8),
78 )
79 with daemon_context, _serve_logs(args.skip_serve_logs):
80 run_job(job=triggerer_job_runner.job, execute_callable=triggerer_job_runner._execute)
81 else:
82 signal.signal(signal.SIGINT, sigint_handler)
83 signal.signal(signal.SIGTERM, sigint_handler)
84 signal.signal(signal.SIGQUIT, sigquit_handler)
85 with _serve_logs(args.skip_serve_logs):
86 run_job(job=triggerer_job_runner.job, execute_callable=triggerer_job_runner._execute)
87
[end of airflow/cli/commands/triggerer_command.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/airflow/cli/commands/triggerer_command.py b/airflow/cli/commands/triggerer_command.py
--- a/airflow/cli/commands/triggerer_command.py
+++ b/airflow/cli/commands/triggerer_command.py
@@ -58,7 +58,6 @@
settings.MASK_SECRETS_IN_LOGS = True
print(settings.HEADER)
triggerer_heartrate = conf.getfloat("triggerer", "JOB_HEARTBEAT_SEC")
- triggerer_job_runner = TriggererJobRunner(job=Job(heartrate=triggerer_heartrate), capacity=args.capacity)
if args.daemon:
pid, stdout, stderr, log_file = setup_locations(
@@ -77,10 +76,16 @@
umask=int(settings.DAEMON_UMASK, 8),
)
with daemon_context, _serve_logs(args.skip_serve_logs):
+ triggerer_job_runner = TriggererJobRunner(
+ job=Job(heartrate=triggerer_heartrate), capacity=args.capacity
+ )
run_job(job=triggerer_job_runner.job, execute_callable=triggerer_job_runner._execute)
else:
signal.signal(signal.SIGINT, sigint_handler)
signal.signal(signal.SIGTERM, sigint_handler)
signal.signal(signal.SIGQUIT, sigquit_handler)
with _serve_logs(args.skip_serve_logs):
+ triggerer_job_runner = TriggererJobRunner(
+ job=Job(heartrate=triggerer_heartrate), capacity=args.capacity
+ )
run_job(job=triggerer_job_runner.job, execute_callable=triggerer_job_runner._execute)
|
{"golden_diff": "diff --git a/airflow/cli/commands/triggerer_command.py b/airflow/cli/commands/triggerer_command.py\n--- a/airflow/cli/commands/triggerer_command.py\n+++ b/airflow/cli/commands/triggerer_command.py\n@@ -58,7 +58,6 @@\n settings.MASK_SECRETS_IN_LOGS = True\n print(settings.HEADER)\n triggerer_heartrate = conf.getfloat(\"triggerer\", \"JOB_HEARTBEAT_SEC\")\n- triggerer_job_runner = TriggererJobRunner(job=Job(heartrate=triggerer_heartrate), capacity=args.capacity)\n \n if args.daemon:\n pid, stdout, stderr, log_file = setup_locations(\n@@ -77,10 +76,16 @@\n umask=int(settings.DAEMON_UMASK, 8),\n )\n with daemon_context, _serve_logs(args.skip_serve_logs):\n+ triggerer_job_runner = TriggererJobRunner(\n+ job=Job(heartrate=triggerer_heartrate), capacity=args.capacity\n+ )\n run_job(job=triggerer_job_runner.job, execute_callable=triggerer_job_runner._execute)\n else:\n signal.signal(signal.SIGINT, sigint_handler)\n signal.signal(signal.SIGTERM, sigint_handler)\n signal.signal(signal.SIGQUIT, sigquit_handler)\n with _serve_logs(args.skip_serve_logs):\n+ triggerer_job_runner = TriggererJobRunner(\n+ job=Job(heartrate=triggerer_heartrate), capacity=args.capacity\n+ )\n run_job(job=triggerer_job_runner.job, execute_callable=triggerer_job_runner._execute)\n", "issue": "Airflow 2.7.1 can not start Scheduler & trigger\n### Apache Airflow version\n\n2.7.1\n\n### What happened\n\nAfter upgrade from 2.6.0 to 2.7.1 (try pip uninstall apache-airflow, and clear dir airflow - remove airflow.cfg), I can start scheduler & trigger with daemon. \r\nI try start with command, it can start, but logout console it killed.\r\nI try: airflow scheduler or airflow triggerer :done but kill when logout console\r\nairflow scheduler --daemon && airflow triggerer --daemon: fail, can not start scheduler & triggerer (2.6.0 run ok). but start deamon with webserver & celery worker is fine\r\n\r\nHelp me\n\n### What you think should happen instead\n\n_No response_\n\n### How to reproduce\n\n1. run airflow 2.6.0 fine on ubuntu server 22.04.3 lts\r\n2. install airflow 2.7.1 \r\n3. can not start daemon triggerer & scheduler\n\n### Operating System\n\nubuntu server 22.04.3 LTS\n\n### Versions of Apache Airflow Providers\n\n_No response_\n\n### Deployment\n\nVirtualenv installation\n\n### Deployment details\n\n_No response_\n\n### Anything else\n\n_No response_\n\n### Are you willing to submit PR?\n\n- [X] Yes I am willing to submit a PR!\n\n### Code of Conduct\n\n- [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md)\n\n", "before_files": [{"content": "# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\n\"\"\"Triggerer command.\"\"\"\nfrom __future__ import annotations\n\nimport signal\nfrom contextlib import contextmanager\nfrom functools import partial\nfrom multiprocessing import Process\nfrom typing import Generator\n\nimport daemon\nfrom daemon.pidfile import TimeoutPIDLockFile\n\nfrom airflow import settings\nfrom airflow.configuration import conf\nfrom airflow.jobs.job import Job, run_job\nfrom airflow.jobs.triggerer_job_runner import TriggererJobRunner\nfrom airflow.utils import cli as cli_utils\nfrom airflow.utils.cli import setup_locations, setup_logging, sigint_handler, sigquit_handler\nfrom airflow.utils.providers_configuration_loader import providers_configuration_loaded\nfrom airflow.utils.serve_logs import serve_logs\n\n\n@contextmanager\ndef _serve_logs(skip_serve_logs: bool = False) -> Generator[None, None, None]:\n \"\"\"Start serve_logs sub-process.\"\"\"\n sub_proc = None\n if skip_serve_logs is False:\n port = conf.getint(\"logging\", \"trigger_log_server_port\", fallback=8794)\n sub_proc = Process(target=partial(serve_logs, port=port))\n sub_proc.start()\n try:\n yield\n finally:\n if sub_proc:\n sub_proc.terminate()\n\n\n@cli_utils.action_cli\n@providers_configuration_loaded\ndef triggerer(args):\n \"\"\"Start Airflow Triggerer.\"\"\"\n settings.MASK_SECRETS_IN_LOGS = True\n print(settings.HEADER)\n triggerer_heartrate = conf.getfloat(\"triggerer\", \"JOB_HEARTBEAT_SEC\")\n triggerer_job_runner = TriggererJobRunner(job=Job(heartrate=triggerer_heartrate), capacity=args.capacity)\n\n if args.daemon:\n pid, stdout, stderr, log_file = setup_locations(\n \"triggerer\", args.pid, args.stdout, args.stderr, args.log_file\n )\n handle = setup_logging(log_file)\n with open(stdout, \"a\") as stdout_handle, open(stderr, \"a\") as stderr_handle:\n stdout_handle.truncate(0)\n stderr_handle.truncate(0)\n\n daemon_context = daemon.DaemonContext(\n pidfile=TimeoutPIDLockFile(pid, -1),\n files_preserve=[handle],\n stdout=stdout_handle,\n stderr=stderr_handle,\n umask=int(settings.DAEMON_UMASK, 8),\n )\n with daemon_context, _serve_logs(args.skip_serve_logs):\n run_job(job=triggerer_job_runner.job, execute_callable=triggerer_job_runner._execute)\n else:\n signal.signal(signal.SIGINT, sigint_handler)\n signal.signal(signal.SIGTERM, sigint_handler)\n signal.signal(signal.SIGQUIT, sigquit_handler)\n with _serve_logs(args.skip_serve_logs):\n run_job(job=triggerer_job_runner.job, execute_callable=triggerer_job_runner._execute)\n", "path": "airflow/cli/commands/triggerer_command.py"}]}
| 1,801 | 367 |
gh_patches_debug_5667
|
rasdani/github-patches
|
git_diff
|
ivy-llc__ivy-16244
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
softshrink
</issue>
<code>
[start of ivy/functional/frontends/paddle/nn/functional/activation.py]
1 # local
2 import ivy
3 from ivy.func_wrapper import with_supported_dtypes
4 from ivy.functional.frontends.paddle.func_wrapper import to_ivy_arrays_and_back
5 from ivy.functional.frontends.paddle.tensor.math import tanh as paddle_tanh
6 from ivy.functional.frontends.paddle.tensor.math import (
7 log_softmax as paddle_log_softmax,
8 )
9
10
11 @with_supported_dtypes({"2.4.2 and below": ("float32", "float64")}, "paddle")
12 @to_ivy_arrays_and_back
13 def selu(
14 x,
15 /,
16 *,
17 alpha=1.6732632423543772848170429916717,
18 scale=1.0507009873554804934193349852946,
19 name=None,
20 ):
21 if scale <= 1.0:
22 raise ValueError(f"The scale must be greater than 1.0. Received: {scale}.")
23
24 if alpha < 0:
25 raise ValueError(f"The alpha must be no less than zero. Received: {alpha}.")
26
27 ret = ivy.where(x > 0, x, alpha * ivy.expm1(x))
28 arr = scale * ret
29 return ivy.astype(arr, x.dtype)
30
31
32 tanh = paddle_tanh
33 log_softmax = paddle_log_softmax
34
35
36 @with_supported_dtypes({"2.4.2 and below": ("float32", "float64")}, "paddle")
37 @to_ivy_arrays_and_back
38 def hardshrink(x, threshold=0.5, name=None):
39 mask = ivy.logical_or(ivy.greater(x, threshold), ivy.less(x, -threshold))
40 return ivy.where(mask, x, 0.0)
41
42
43 @with_supported_dtypes({"2.4.2 and below": ("float32", "float64")}, "paddle")
44 @to_ivy_arrays_and_back
45 def hardtanh(
46 x,
47 /,
48 *,
49 min=-1.0,
50 max=1.0,
51 name=None,
52 ):
53 less = ivy.where(ivy.less(x, min), min, x)
54 ret = ivy.where(ivy.greater(x, max), max, less).astype(x.dtype)
55 return ret
56
57
58 @with_supported_dtypes({"2.4.2 and below": ("float32", "float64")}, "paddle")
59 @to_ivy_arrays_and_back
60 def gelu(x, approximate=False, name=None):
61 return ivy.gelu(x, approximate=approximate)
62
63
64 @with_supported_dtypes({"2.4.2 and below": ("float32", "float64")}, "paddle")
65 @to_ivy_arrays_and_back
66 def hardsigmoid(x, slope=0.1666667, offset=0.5, name=None):
67 ret = ivy.minimum(ivy.maximum(ivy.add(ivy.multiply(x, slope), offset), 0), 1)
68 return ret
69
70
71 @with_supported_dtypes({"2.4.2 and below": ("float32", "float64")}, "paddle")
72 @to_ivy_arrays_and_back
73 def relu6(x, name=None):
74 return ivy.relu6(x)
75
[end of ivy/functional/frontends/paddle/nn/functional/activation.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ivy/functional/frontends/paddle/nn/functional/activation.py b/ivy/functional/frontends/paddle/nn/functional/activation.py
--- a/ivy/functional/frontends/paddle/nn/functional/activation.py
+++ b/ivy/functional/frontends/paddle/nn/functional/activation.py
@@ -72,3 +72,18 @@
@to_ivy_arrays_and_back
def relu6(x, name=None):
return ivy.relu6(x)
+
+
+@with_supported_dtypes({"2.4.2 and below": ("float32", "float64")}, "paddle")
+@to_ivy_arrays_and_back
+def softshrink(
+ x,
+ /,
+ *,
+ threshold=0.5,
+ name=None,
+):
+ low = ivy.where(ivy.less(x, -threshold), ivy.add(x, threshold), 0)
+ up = ivy.where(ivy.greater(x, threshold), ivy.subtract(x, threshold), 0)
+ add = ivy.add(low, up)
+ return ivy.astype(add, x.dtype)
|
{"golden_diff": "diff --git a/ivy/functional/frontends/paddle/nn/functional/activation.py b/ivy/functional/frontends/paddle/nn/functional/activation.py\n--- a/ivy/functional/frontends/paddle/nn/functional/activation.py\n+++ b/ivy/functional/frontends/paddle/nn/functional/activation.py\n@@ -72,3 +72,18 @@\n @to_ivy_arrays_and_back\n def relu6(x, name=None):\n return ivy.relu6(x)\n+\n+\n+@with_supported_dtypes({\"2.4.2 and below\": (\"float32\", \"float64\")}, \"paddle\")\n+@to_ivy_arrays_and_back\n+def softshrink(\n+ x,\n+ /,\n+ *,\n+ threshold=0.5,\n+ name=None,\n+):\n+ low = ivy.where(ivy.less(x, -threshold), ivy.add(x, threshold), 0)\n+ up = ivy.where(ivy.greater(x, threshold), ivy.subtract(x, threshold), 0)\n+ add = ivy.add(low, up)\n+ return ivy.astype(add, x.dtype)\n", "issue": "softshrink\n\n", "before_files": [{"content": "# local\nimport ivy\nfrom ivy.func_wrapper import with_supported_dtypes\nfrom ivy.functional.frontends.paddle.func_wrapper import to_ivy_arrays_and_back\nfrom ivy.functional.frontends.paddle.tensor.math import tanh as paddle_tanh\nfrom ivy.functional.frontends.paddle.tensor.math import (\n log_softmax as paddle_log_softmax,\n)\n\n\n@with_supported_dtypes({\"2.4.2 and below\": (\"float32\", \"float64\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef selu(\n x,\n /,\n *,\n alpha=1.6732632423543772848170429916717,\n scale=1.0507009873554804934193349852946,\n name=None,\n):\n if scale <= 1.0:\n raise ValueError(f\"The scale must be greater than 1.0. Received: {scale}.\")\n\n if alpha < 0:\n raise ValueError(f\"The alpha must be no less than zero. Received: {alpha}.\")\n\n ret = ivy.where(x > 0, x, alpha * ivy.expm1(x))\n arr = scale * ret\n return ivy.astype(arr, x.dtype)\n\n\ntanh = paddle_tanh\nlog_softmax = paddle_log_softmax\n\n\n@with_supported_dtypes({\"2.4.2 and below\": (\"float32\", \"float64\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef hardshrink(x, threshold=0.5, name=None):\n mask = ivy.logical_or(ivy.greater(x, threshold), ivy.less(x, -threshold))\n return ivy.where(mask, x, 0.0)\n\n\n@with_supported_dtypes({\"2.4.2 and below\": (\"float32\", \"float64\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef hardtanh(\n x,\n /,\n *,\n min=-1.0,\n max=1.0,\n name=None,\n):\n less = ivy.where(ivy.less(x, min), min, x)\n ret = ivy.where(ivy.greater(x, max), max, less).astype(x.dtype)\n return ret\n\n\n@with_supported_dtypes({\"2.4.2 and below\": (\"float32\", \"float64\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef gelu(x, approximate=False, name=None):\n return ivy.gelu(x, approximate=approximate)\n\n\n@with_supported_dtypes({\"2.4.2 and below\": (\"float32\", \"float64\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef hardsigmoid(x, slope=0.1666667, offset=0.5, name=None):\n ret = ivy.minimum(ivy.maximum(ivy.add(ivy.multiply(x, slope), offset), 0), 1)\n return ret\n\n\n@with_supported_dtypes({\"2.4.2 and below\": (\"float32\", \"float64\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef relu6(x, name=None):\n return ivy.relu6(x)\n", "path": "ivy/functional/frontends/paddle/nn/functional/activation.py"}]}
| 1,439 | 255 |
gh_patches_debug_59317
|
rasdani/github-patches
|
git_diff
|
chainer__chainer-1178
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
HuberLoss's backward() should not ignore gy
`HuberLoss`'s `backward()` ignores `gy`, so any computation after `HuberLoss` has no effect for gradients backpropagated by `HuberLoss`. I think such a behavior is not correct.
``` python
>>> x = chainer.Variable(np.zeros((1,1), dtype=np.float32))
>>> t = chainer.Variable(np.ones((1,1), dtype=np.float32))
>>> F.huber_loss(x, t, 1.0).backward()
>>> x.grad
array([[-1.]], dtype=float32)
```
``` python
>>> x = chainer.Variable(np.zeros((1,1), dtype=np.float32))
>>> t = chainer.Variable(np.ones((1,1), dtype=np.float32))
>>> (F.huber_loss(x, t, 1.0) * 0).backward() # Multiply the loss by zero
>>> x.grad
array([[-1.]], dtype=float32)
```
</issue>
<code>
[start of chainer/functions/loss/huber_loss.py]
1 import numpy
2
3 from chainer import cuda
4 from chainer import function
5 from chainer.utils import type_check
6
7
8 class HuberLoss(function.Function):
9
10 def __init__(self, delta):
11 self.delta = delta
12
13 def check_type_forward(self, in_types):
14 type_check.expect(in_types.size() == 2)
15 type_check.expect(
16 in_types[0].dtype == numpy.float32,
17 in_types[1].dtype == numpy.float32,
18 in_types[0].shape == in_types[1].shape
19 )
20
21 def forward(self, inputs):
22 xp = cuda.get_array_module(*inputs)
23 x0, x1 = inputs
24 self.diff = x0 - x1
25 y = xp.square(self.diff)
26 mask = y > (self.delta ** 2)
27 y -= mask * xp.square(abs(self.diff) - self.delta)
28 y *= 0.5
29 return y.sum(axis=1),
30
31 def backward(self, inputs, gy):
32 xp = cuda.get_array_module(*inputs)
33 mask = xp.abs(self.diff) <= self.delta
34 gx = xp.where(mask, self.diff, self.delta * xp.sign(self.diff))
35 return gx, -gx
36
37
38 def huber_loss(x, t, delta):
39 """Loss function which is less sensitive to outliers in data than MSE.
40
41 .. math::
42 a = x - t
43
44 and
45
46 .. math::
47 L_{\\delta}(a) = \\left \\{ \\begin{array}{cc}
48 \\frac{1}{2} a^2 & {\\rm if~|a| \\leq \\delta} \\\\
49 \\delta (|a| - \\frac{1}{2} \\delta) & {\\rm otherwise,}
50 \\end{array} \\right.
51
52 Args:
53 x (~chainer.Variable): Input variable.
54 The shape of ``x`` should be (:math:`N`, :math:`K`).
55 t (~chainer.Variable): Target variable for regression.
56 The shape of ``t`` should be (:math:`N`, :math:`K`).
57 delta (float): Constant variable for huber loss function
58 as used in definition.
59
60 Returns:
61 ~chainer.Variable: A variable object holding a scalar array of the
62 huber loss :math:`L_{\\delta}`.
63
64 See:
65 `Huber loss - Wikipedia <https://en.wikipedia.org/wiki/Huber_loss>`_.
66
67 """
68 return HuberLoss(delta=delta)(x, t)
69
[end of chainer/functions/loss/huber_loss.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/chainer/functions/loss/huber_loss.py b/chainer/functions/loss/huber_loss.py
--- a/chainer/functions/loss/huber_loss.py
+++ b/chainer/functions/loss/huber_loss.py
@@ -31,7 +31,8 @@
def backward(self, inputs, gy):
xp = cuda.get_array_module(*inputs)
mask = xp.abs(self.diff) <= self.delta
- gx = xp.where(mask, self.diff, self.delta * xp.sign(self.diff))
+ gx = gy[0].reshape(gy[0].shape + (1,) * (self.diff.ndim - 1)) * \
+ xp.where(mask, self.diff, self.delta * xp.sign(self.diff))
return gx, -gx
|
{"golden_diff": "diff --git a/chainer/functions/loss/huber_loss.py b/chainer/functions/loss/huber_loss.py\n--- a/chainer/functions/loss/huber_loss.py\n+++ b/chainer/functions/loss/huber_loss.py\n@@ -31,7 +31,8 @@\n def backward(self, inputs, gy):\n xp = cuda.get_array_module(*inputs)\n mask = xp.abs(self.diff) <= self.delta\n- gx = xp.where(mask, self.diff, self.delta * xp.sign(self.diff))\n+ gx = gy[0].reshape(gy[0].shape + (1,) * (self.diff.ndim - 1)) * \\\n+ xp.where(mask, self.diff, self.delta * xp.sign(self.diff))\n return gx, -gx\n", "issue": "HuberLoss's backward() should not ignore gy\n`HuberLoss`'s `backward()` ignores `gy`, so any computation after `HuberLoss` has no effect for gradients backpropagated by `HuberLoss`. I think such a behavior is not correct.\n\n``` python\n>>> x = chainer.Variable(np.zeros((1,1), dtype=np.float32))\n>>> t = chainer.Variable(np.ones((1,1), dtype=np.float32))\n>>> F.huber_loss(x, t, 1.0).backward()\n>>> x.grad\narray([[-1.]], dtype=float32)\n```\n\n``` python\n>>> x = chainer.Variable(np.zeros((1,1), dtype=np.float32))\n>>> t = chainer.Variable(np.ones((1,1), dtype=np.float32))\n>>> (F.huber_loss(x, t, 1.0) * 0).backward() # Multiply the loss by zero\n>>> x.grad\narray([[-1.]], dtype=float32)\n```\n\n", "before_files": [{"content": "import numpy\n\nfrom chainer import cuda\nfrom chainer import function\nfrom chainer.utils import type_check\n\n\nclass HuberLoss(function.Function):\n\n def __init__(self, delta):\n self.delta = delta\n\n def check_type_forward(self, in_types):\n type_check.expect(in_types.size() == 2)\n type_check.expect(\n in_types[0].dtype == numpy.float32,\n in_types[1].dtype == numpy.float32,\n in_types[0].shape == in_types[1].shape\n )\n\n def forward(self, inputs):\n xp = cuda.get_array_module(*inputs)\n x0, x1 = inputs\n self.diff = x0 - x1\n y = xp.square(self.diff)\n mask = y > (self.delta ** 2)\n y -= mask * xp.square(abs(self.diff) - self.delta)\n y *= 0.5\n return y.sum(axis=1),\n\n def backward(self, inputs, gy):\n xp = cuda.get_array_module(*inputs)\n mask = xp.abs(self.diff) <= self.delta\n gx = xp.where(mask, self.diff, self.delta * xp.sign(self.diff))\n return gx, -gx\n\n\ndef huber_loss(x, t, delta):\n \"\"\"Loss function which is less sensitive to outliers in data than MSE.\n\n .. math::\n a = x - t\n\n and\n\n .. math::\n L_{\\\\delta}(a) = \\\\left \\\\{ \\\\begin{array}{cc}\n \\\\frac{1}{2} a^2 & {\\\\rm if~|a| \\\\leq \\\\delta} \\\\\\\\\n \\\\delta (|a| - \\\\frac{1}{2} \\\\delta) & {\\\\rm otherwise,}\n \\\\end{array} \\\\right.\n\n Args:\n x (~chainer.Variable): Input variable.\n The shape of ``x`` should be (:math:`N`, :math:`K`).\n t (~chainer.Variable): Target variable for regression.\n The shape of ``t`` should be (:math:`N`, :math:`K`).\n delta (float): Constant variable for huber loss function\n as used in definition.\n\n Returns:\n ~chainer.Variable: A variable object holding a scalar array of the\n huber loss :math:`L_{\\\\delta}`.\n\n See:\n `Huber loss - Wikipedia <https://en.wikipedia.org/wiki/Huber_loss>`_.\n\n \"\"\"\n return HuberLoss(delta=delta)(x, t)\n", "path": "chainer/functions/loss/huber_loss.py"}]}
| 1,447 | 165 |
gh_patches_debug_36731
|
rasdani/github-patches
|
git_diff
|
google__flax-3385
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Improve Early Stopping API
See discussion in #2090
</issue>
<code>
[start of flax/training/early_stopping.py]
1 # Copyright 2023 The Flax Authors.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Early stopping."""
16
17 import math
18 from flax import struct
19
20
21 class EarlyStopping(struct.PyTreeNode):
22 """Early stopping to avoid overfitting during training.
23
24 The following example stops training early if the difference between losses
25 recorded in the current epoch and previous epoch is less than 1e-3
26 consecutively for 2 times::
27
28 early_stop = EarlyStopping(min_delta=1e-3, patience=2)
29 for epoch in range(1, num_epochs+1):
30 rng, input_rng = jax.random.split(rng)
31 optimizer, train_metrics = train_epoch(
32 optimizer, train_ds, config.batch_size, epoch, input_rng)
33 _, early_stop = early_stop.update(train_metrics['loss'])
34 if early_stop.should_stop:
35 print('Met early stopping criteria, breaking...')
36 break
37
38 Attributes:
39 min_delta: Minimum delta between updates to be considered an
40 improvement.
41 patience: Number of steps of no improvement before stopping.
42 best_metric: Current best metric value.
43 patience_count: Number of steps since last improving update.
44 should_stop: Whether the training loop should stop to avoid
45 overfitting.
46 """
47
48 min_delta: float = 0
49 patience: int = 0
50 best_metric: float = float('inf')
51 patience_count: int = 0
52 should_stop: bool = False
53
54 def reset(self):
55 return self.replace(
56 best_metric=float('inf'), patience_count=0, should_stop=False
57 )
58
59 def update(self, metric):
60 """Update the state based on metric.
61
62 Returns:
63 A pair (has_improved, early_stop), where `has_improved` is True when there
64 was an improvement greater than `min_delta` from the previous
65 `best_metric` and `early_stop` is the updated `EarlyStop` object.
66 """
67
68 if (
69 math.isinf(self.best_metric)
70 or self.best_metric - metric > self.min_delta
71 ):
72 return True, self.replace(best_metric=metric, patience_count=0)
73 else:
74 should_stop = self.patience_count >= self.patience or self.should_stop
75 return False, self.replace(
76 patience_count=self.patience_count + 1, should_stop=should_stop
77 )
78
[end of flax/training/early_stopping.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/flax/training/early_stopping.py b/flax/training/early_stopping.py
--- a/flax/training/early_stopping.py
+++ b/flax/training/early_stopping.py
@@ -30,7 +30,7 @@
rng, input_rng = jax.random.split(rng)
optimizer, train_metrics = train_epoch(
optimizer, train_ds, config.batch_size, epoch, input_rng)
- _, early_stop = early_stop.update(train_metrics['loss'])
+ early_stop = early_stop.update(train_metrics['loss'])
if early_stop.should_stop:
print('Met early stopping criteria, breaking...')
break
@@ -43,6 +43,8 @@
patience_count: Number of steps since last improving update.
should_stop: Whether the training loop should stop to avoid
overfitting.
+ has_improved: Whether the metric has improved greater or
+ equal to the min_delta in the last `.update` call.
"""
min_delta: float = 0
@@ -50,28 +52,29 @@
best_metric: float = float('inf')
patience_count: int = 0
should_stop: bool = False
+ has_improved: bool = False
def reset(self):
return self.replace(
- best_metric=float('inf'), patience_count=0, should_stop=False
+ best_metric=float('inf'), patience_count=0, should_stop=False, has_improved=False
)
def update(self, metric):
"""Update the state based on metric.
Returns:
- A pair (has_improved, early_stop), where `has_improved` is True when there
- was an improvement greater than `min_delta` from the previous
- `best_metric` and `early_stop` is the updated `EarlyStop` object.
+ The updated EarlyStopping class. The `.has_improved` attribute is True
+ when there was an improvement greater than `min_delta` from the previous
+ `best_metric`.
"""
if (
math.isinf(self.best_metric)
or self.best_metric - metric > self.min_delta
):
- return True, self.replace(best_metric=metric, patience_count=0)
+ return self.replace(best_metric=metric, patience_count=0, has_improved=True)
else:
should_stop = self.patience_count >= self.patience or self.should_stop
- return False, self.replace(
- patience_count=self.patience_count + 1, should_stop=should_stop
+ return self.replace(
+ patience_count=self.patience_count + 1, should_stop=should_stop, has_improved=False
)
|
{"golden_diff": "diff --git a/flax/training/early_stopping.py b/flax/training/early_stopping.py\n--- a/flax/training/early_stopping.py\n+++ b/flax/training/early_stopping.py\n@@ -30,7 +30,7 @@\n rng, input_rng = jax.random.split(rng)\n optimizer, train_metrics = train_epoch(\n optimizer, train_ds, config.batch_size, epoch, input_rng)\n- _, early_stop = early_stop.update(train_metrics['loss'])\n+ early_stop = early_stop.update(train_metrics['loss'])\n if early_stop.should_stop:\n print('Met early stopping criteria, breaking...')\n break\n@@ -43,6 +43,8 @@\n patience_count: Number of steps since last improving update.\n should_stop: Whether the training loop should stop to avoid\n overfitting.\n+ has_improved: Whether the metric has improved greater or\n+ equal to the min_delta in the last `.update` call.\n \"\"\"\n \n min_delta: float = 0\n@@ -50,28 +52,29 @@\n best_metric: float = float('inf')\n patience_count: int = 0\n should_stop: bool = False\n+ has_improved: bool = False\n \n def reset(self):\n return self.replace(\n- best_metric=float('inf'), patience_count=0, should_stop=False\n+ best_metric=float('inf'), patience_count=0, should_stop=False, has_improved=False\n )\n \n def update(self, metric):\n \"\"\"Update the state based on metric.\n \n Returns:\n- A pair (has_improved, early_stop), where `has_improved` is True when there\n- was an improvement greater than `min_delta` from the previous\n- `best_metric` and `early_stop` is the updated `EarlyStop` object.\n+ The updated EarlyStopping class. The `.has_improved` attribute is True\n+ when there was an improvement greater than `min_delta` from the previous\n+ `best_metric`.\n \"\"\"\n \n if (\n math.isinf(self.best_metric)\n or self.best_metric - metric > self.min_delta\n ):\n- return True, self.replace(best_metric=metric, patience_count=0)\n+ return self.replace(best_metric=metric, patience_count=0, has_improved=True)\n else:\n should_stop = self.patience_count >= self.patience or self.should_stop\n- return False, self.replace(\n- patience_count=self.patience_count + 1, should_stop=should_stop\n+ return self.replace(\n+ patience_count=self.patience_count + 1, should_stop=should_stop, has_improved=False\n )\n", "issue": "Improve Early Stopping API\nSee discussion in #2090\n", "before_files": [{"content": "# Copyright 2023 The Flax Authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Early stopping.\"\"\"\n\nimport math\nfrom flax import struct\n\n\nclass EarlyStopping(struct.PyTreeNode):\n \"\"\"Early stopping to avoid overfitting during training.\n\n The following example stops training early if the difference between losses\n recorded in the current epoch and previous epoch is less than 1e-3\n consecutively for 2 times::\n\n early_stop = EarlyStopping(min_delta=1e-3, patience=2)\n for epoch in range(1, num_epochs+1):\n rng, input_rng = jax.random.split(rng)\n optimizer, train_metrics = train_epoch(\n optimizer, train_ds, config.batch_size, epoch, input_rng)\n _, early_stop = early_stop.update(train_metrics['loss'])\n if early_stop.should_stop:\n print('Met early stopping criteria, breaking...')\n break\n\n Attributes:\n min_delta: Minimum delta between updates to be considered an\n improvement.\n patience: Number of steps of no improvement before stopping.\n best_metric: Current best metric value.\n patience_count: Number of steps since last improving update.\n should_stop: Whether the training loop should stop to avoid\n overfitting.\n \"\"\"\n\n min_delta: float = 0\n patience: int = 0\n best_metric: float = float('inf')\n patience_count: int = 0\n should_stop: bool = False\n\n def reset(self):\n return self.replace(\n best_metric=float('inf'), patience_count=0, should_stop=False\n )\n\n def update(self, metric):\n \"\"\"Update the state based on metric.\n\n Returns:\n A pair (has_improved, early_stop), where `has_improved` is True when there\n was an improvement greater than `min_delta` from the previous\n `best_metric` and `early_stop` is the updated `EarlyStop` object.\n \"\"\"\n\n if (\n math.isinf(self.best_metric)\n or self.best_metric - metric > self.min_delta\n ):\n return True, self.replace(best_metric=metric, patience_count=0)\n else:\n should_stop = self.patience_count >= self.patience or self.should_stop\n return False, self.replace(\n patience_count=self.patience_count + 1, should_stop=should_stop\n )\n", "path": "flax/training/early_stopping.py"}]}
| 1,331 | 591 |
gh_patches_debug_30
|
rasdani/github-patches
|
git_diff
|
aws-cloudformation__cfn-lint-2249
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
E3002 Invalid Property Lambda/Properties/EphemeralStorage
*cfn-lint version: (`cfn-lint --version`)*
`cfn-lint 0.58.4`
*Description of issue.*
Looks like it does not yet recognize `EphemeralStorage` as a valid property for lambdas
```yml
Lambda:
Type: AWS::Lambda::Function
Properties:
Role: !GetAtt Role.Arn
Timeout: 600
MemorySize: 2048
EphemeralStorage:
Size: 1024
```
Link to the [**docs**](https://aws.amazon.com/blogs/compute/using-larger-ephemeral-storage-for-aws-lambda/) where it shows the new feature
Cfn-lint uses the [CloudFormation Resource Specifications](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/cfn-resource-specification.html) as the base to do validation. These files are included as part of the application version. Please update to the latest version of `cfn-lint` or update the spec files manually (`cfn-lint -u`)
</issue>
<code>
[start of src/cfnlint/version.py]
1 """
2 Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
3 SPDX-License-Identifier: MIT-0
4 """
5
6 __version__ = '0.58.4'
7
[end of src/cfnlint/version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/cfnlint/version.py b/src/cfnlint/version.py
--- a/src/cfnlint/version.py
+++ b/src/cfnlint/version.py
@@ -3,4 +3,4 @@
SPDX-License-Identifier: MIT-0
"""
-__version__ = '0.58.4'
+__version__ = '0.59.0'
|
{"golden_diff": "diff --git a/src/cfnlint/version.py b/src/cfnlint/version.py\n--- a/src/cfnlint/version.py\n+++ b/src/cfnlint/version.py\n@@ -3,4 +3,4 @@\n SPDX-License-Identifier: MIT-0\n \"\"\"\n \n-__version__ = '0.58.4'\n+__version__ = '0.59.0'\n", "issue": "E3002 Invalid Property Lambda/Properties/EphemeralStorage\n*cfn-lint version: (`cfn-lint --version`)*\r\n\r\n`cfn-lint 0.58.4`\r\n\r\n*Description of issue.*\r\nLooks like it does not yet recognize `EphemeralStorage` as a valid property for lambdas\r\n```yml\r\nLambda:\r\n Type: AWS::Lambda::Function\r\n Properties:\r\n Role: !GetAtt Role.Arn\r\n Timeout: 600\r\n MemorySize: 2048\r\n EphemeralStorage:\r\n Size: 1024\r\n```\r\n\r\nLink to the [**docs**](https://aws.amazon.com/blogs/compute/using-larger-ephemeral-storage-for-aws-lambda/) where it shows the new feature\r\n\r\nCfn-lint uses the [CloudFormation Resource Specifications](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/cfn-resource-specification.html) as the base to do validation. These files are included as part of the application version. Please update to the latest version of `cfn-lint` or update the spec files manually (`cfn-lint -u`)\r\n\n", "before_files": [{"content": "\"\"\"\nCopyright Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\n\n__version__ = '0.58.4'\n", "path": "src/cfnlint/version.py"}]}
| 835 | 83 |
gh_patches_debug_37629
|
rasdani/github-patches
|
git_diff
|
medtagger__MedTagger-202
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
User personal information cannot be changed
## Expected Behavior
User can change its personal information at any time using Settings page.
User should only be able to change their first and last name. The E-mail field should be grayed out.
## Actual Behavior
Form fields are filled with user data but there is no way to change them. User cannot modify these fields and there is no "Save" button available.
## Steps to Reproduce the Problem
1. Go to Settings page.
2. Open "User data" section.
3. Done.
## Additional comment
Consider changing the name of the section from "User data" to something else.
</issue>
<code>
[start of backend/medtagger/api/users/service.py]
1 """Module responsible for defining endpoints for users administration."""
2 from typing import Any
3
4 from flask import request
5 from flask_restplus import Resource
6
7 from medtagger.api import api
8 from medtagger.api.users import serializers
9 from medtagger.api.users.business import get_all_users, set_user_role
10 from medtagger.api.utils import get_current_user
11 from medtagger.api.security import login_required, role_required
12
13 users_ns = api.namespace('users', 'Users management')
14
15
16 @users_ns.route('/')
17 class GetUsers(Resource):
18 """Get all users endpoint."""
19
20 @staticmethod
21 @login_required
22 @role_required('admin')
23 @users_ns.marshal_with(serializers.users_list)
24 @users_ns.doc(security='token')
25 def get() -> Any:
26 """Get all users endpoint."""
27 users = get_all_users()
28 return {'users': users}, 200
29
30
31 @users_ns.route('/<int:user_id>/role')
32 class SetRole(Resource):
33 """Set user's role."""
34
35 @staticmethod
36 @login_required
37 @role_required('admin')
38 @users_ns.doc(security='token')
39 def put(user_id: int) -> Any:
40 """Set user's role."""
41 set_user_role(user_id, request.json['role'])
42 return {}, 204
43
44
45 @users_ns.route('/info')
46 class GetUserInfo(Resource):
47 """Get current user information."""
48
49 @staticmethod
50 @login_required
51 @users_ns.marshal_with(serializers.user)
52 @users_ns.doc(security='token')
53 @users_ns.doc(responses={200: 'Successfully retrieved data.'})
54 def get() -> Any:
55 """Get user info."""
56 user = get_current_user()
57 return user, 200
58
[end of backend/medtagger/api/users/service.py]
[start of backend/medtagger/repositories/users.py]
1 """Module responsible for definition of Users' Repository."""
2 from typing import List, Optional
3
4 from medtagger.database import db_session
5 from medtagger.database.models import User
6
7
8 class UsersRepository(object):
9 """Repository for Users."""
10
11 @staticmethod
12 def add_new_user(new_user: User) -> int:
13 """Add new user.
14
15 :return: id of the new user
16 """
17 with db_session() as session:
18 session.add(new_user)
19 return new_user.id
20
21 @staticmethod
22 def get_all_users() -> List[User]:
23 """Return list of all users."""
24 return User.query.order_by(User.id).all()
25
26 @staticmethod
27 def get_user_by_email(user_email: str) -> Optional[User]:
28 """Get user with given email.
29
30 :return Optional of User
31 """
32 return User.query.filter(User.email == user_email).first()
33
34 @staticmethod
35 def get_user_by_id(user_id: int) -> User:
36 """Get user with given id."""
37 return User.query.filter(User.id == user_id).one()
38
[end of backend/medtagger/repositories/users.py]
[start of backend/medtagger/api/users/business.py]
1 """Module responsible for business logic for users administration."""
2 from typing import List
3
4 from medtagger.database.models import User
5 from medtagger.repositories.users import UsersRepository
6 from medtagger.repositories.roles import RolesRepository
7
8
9 def get_all_users() -> List[User]:
10 """Return list of all users."""
11 return UsersRepository.get_all_users()
12
13
14 def set_user_role(user_id: int, role_name: str) -> None:
15 """Set user's role. Old role is being replaced."""
16 RolesRepository.set_user_role(user_id, role_name)
17
[end of backend/medtagger/api/users/business.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/backend/medtagger/api/users/business.py b/backend/medtagger/api/users/business.py
--- a/backend/medtagger/api/users/business.py
+++ b/backend/medtagger/api/users/business.py
@@ -1,6 +1,9 @@
"""Module responsible for business logic for users administration."""
from typing import List
+from sqlalchemy.orm.exc import NoResultFound
+
+from medtagger.api import InvalidArgumentsException
from medtagger.database.models import User
from medtagger.repositories.users import UsersRepository
from medtagger.repositories.roles import RolesRepository
@@ -14,3 +17,12 @@
def set_user_role(user_id: int, role_name: str) -> None:
"""Set user's role. Old role is being replaced."""
RolesRepository.set_user_role(user_id, role_name)
+
+
+def set_user_info(user_id: int, firstName: str, lastName: str) -> None:
+ """Set user's information."""
+ try:
+ user = UsersRepository.get_user_by_id(user_id)
+ UsersRepository.set_user_info(user, firstName, lastName)
+ except NoResultFound:
+ raise InvalidArgumentsException('User with this id does not exist.')
diff --git a/backend/medtagger/api/users/service.py b/backend/medtagger/api/users/service.py
--- a/backend/medtagger/api/users/service.py
+++ b/backend/medtagger/api/users/service.py
@@ -6,7 +6,7 @@
from medtagger.api import api
from medtagger.api.users import serializers
-from medtagger.api.users.business import get_all_users, set_user_role
+from medtagger.api.users.business import get_all_users, set_user_role, set_user_info
from medtagger.api.utils import get_current_user
from medtagger.api.security import login_required, role_required
@@ -55,3 +55,18 @@
"""Get user info."""
user = get_current_user()
return user, 200
+
+
+@users_ns.route('/<int:user_id>')
+class SetUserInfo(Resource):
+ """Set user's information (first name and last name)."""
+
+ @staticmethod
+ @login_required
+ @users_ns.doc(security='token')
+ def put(user_id: int) -> Any:
+ """Set user info."""
+ if get_current_user().id != user_id:
+ return {}, 403
+ set_user_info(user_id, request.json['firstName'], request.json['lastName'])
+ return {}, 204
diff --git a/backend/medtagger/repositories/users.py b/backend/medtagger/repositories/users.py
--- a/backend/medtagger/repositories/users.py
+++ b/backend/medtagger/repositories/users.py
@@ -35,3 +35,11 @@
def get_user_by_id(user_id: int) -> User:
"""Get user with given id."""
return User.query.filter(User.id == user_id).one()
+
+ @staticmethod
+ def set_user_info(user: User, firstName: str, lastName: str) -> None:
+ """Set user's info."""
+ with db_session() as session:
+ user.first_name = firstName
+ user.last_name = lastName
+ session.add(user)
|
{"golden_diff": "diff --git a/backend/medtagger/api/users/business.py b/backend/medtagger/api/users/business.py\n--- a/backend/medtagger/api/users/business.py\n+++ b/backend/medtagger/api/users/business.py\n@@ -1,6 +1,9 @@\n \"\"\"Module responsible for business logic for users administration.\"\"\"\n from typing import List\n \n+from sqlalchemy.orm.exc import NoResultFound\n+\n+from medtagger.api import InvalidArgumentsException\n from medtagger.database.models import User\n from medtagger.repositories.users import UsersRepository\n from medtagger.repositories.roles import RolesRepository\n@@ -14,3 +17,12 @@\n def set_user_role(user_id: int, role_name: str) -> None:\n \"\"\"Set user's role. Old role is being replaced.\"\"\"\n RolesRepository.set_user_role(user_id, role_name)\n+\n+\n+def set_user_info(user_id: int, firstName: str, lastName: str) -> None:\n+ \"\"\"Set user's information.\"\"\"\n+ try:\n+ user = UsersRepository.get_user_by_id(user_id)\n+ UsersRepository.set_user_info(user, firstName, lastName)\n+ except NoResultFound:\n+ raise InvalidArgumentsException('User with this id does not exist.')\ndiff --git a/backend/medtagger/api/users/service.py b/backend/medtagger/api/users/service.py\n--- a/backend/medtagger/api/users/service.py\n+++ b/backend/medtagger/api/users/service.py\n@@ -6,7 +6,7 @@\n \n from medtagger.api import api\n from medtagger.api.users import serializers\n-from medtagger.api.users.business import get_all_users, set_user_role\n+from medtagger.api.users.business import get_all_users, set_user_role, set_user_info\n from medtagger.api.utils import get_current_user\n from medtagger.api.security import login_required, role_required\n \n@@ -55,3 +55,18 @@\n \"\"\"Get user info.\"\"\"\n user = get_current_user()\n return user, 200\n+\n+\n+@users_ns.route('/<int:user_id>')\n+class SetUserInfo(Resource):\n+ \"\"\"Set user's information (first name and last name).\"\"\"\n+\n+ @staticmethod\n+ @login_required\n+ @users_ns.doc(security='token')\n+ def put(user_id: int) -> Any:\n+ \"\"\"Set user info.\"\"\"\n+ if get_current_user().id != user_id:\n+ return {}, 403\n+ set_user_info(user_id, request.json['firstName'], request.json['lastName'])\n+ return {}, 204\ndiff --git a/backend/medtagger/repositories/users.py b/backend/medtagger/repositories/users.py\n--- a/backend/medtagger/repositories/users.py\n+++ b/backend/medtagger/repositories/users.py\n@@ -35,3 +35,11 @@\n def get_user_by_id(user_id: int) -> User:\n \"\"\"Get user with given id.\"\"\"\n return User.query.filter(User.id == user_id).one()\n+\n+ @staticmethod\n+ def set_user_info(user: User, firstName: str, lastName: str) -> None:\n+ \"\"\"Set user's info.\"\"\"\n+ with db_session() as session:\n+ user.first_name = firstName\n+ user.last_name = lastName\n+ session.add(user)\n", "issue": "User personal information cannot be changed\n## Expected Behavior\r\n\r\nUser can change its personal information at any time using Settings page.\r\n\r\nUser should only be able to change their first and last name. The E-mail field should be grayed out.\r\n\r\n## Actual Behavior\r\n\r\nForm fields are filled with user data but there is no way to change them. User cannot modify these fields and there is no \"Save\" button available.\r\n\r\n## Steps to Reproduce the Problem\r\n\r\n 1. Go to Settings page.\r\n 2. Open \"User data\" section.\r\n 3. Done.\r\n\r\n## Additional comment\r\n\r\nConsider changing the name of the section from \"User data\" to something else.\r\n\n", "before_files": [{"content": "\"\"\"Module responsible for defining endpoints for users administration.\"\"\"\nfrom typing import Any\n\nfrom flask import request\nfrom flask_restplus import Resource\n\nfrom medtagger.api import api\nfrom medtagger.api.users import serializers\nfrom medtagger.api.users.business import get_all_users, set_user_role\nfrom medtagger.api.utils import get_current_user\nfrom medtagger.api.security import login_required, role_required\n\nusers_ns = api.namespace('users', 'Users management')\n\n\n@users_ns.route('/')\nclass GetUsers(Resource):\n \"\"\"Get all users endpoint.\"\"\"\n\n @staticmethod\n @login_required\n @role_required('admin')\n @users_ns.marshal_with(serializers.users_list)\n @users_ns.doc(security='token')\n def get() -> Any:\n \"\"\"Get all users endpoint.\"\"\"\n users = get_all_users()\n return {'users': users}, 200\n\n\n@users_ns.route('/<int:user_id>/role')\nclass SetRole(Resource):\n \"\"\"Set user's role.\"\"\"\n\n @staticmethod\n @login_required\n @role_required('admin')\n @users_ns.doc(security='token')\n def put(user_id: int) -> Any:\n \"\"\"Set user's role.\"\"\"\n set_user_role(user_id, request.json['role'])\n return {}, 204\n\n\n@users_ns.route('/info')\nclass GetUserInfo(Resource):\n \"\"\"Get current user information.\"\"\"\n\n @staticmethod\n @login_required\n @users_ns.marshal_with(serializers.user)\n @users_ns.doc(security='token')\n @users_ns.doc(responses={200: 'Successfully retrieved data.'})\n def get() -> Any:\n \"\"\"Get user info.\"\"\"\n user = get_current_user()\n return user, 200\n", "path": "backend/medtagger/api/users/service.py"}, {"content": "\"\"\"Module responsible for definition of Users' Repository.\"\"\"\nfrom typing import List, Optional\n\nfrom medtagger.database import db_session\nfrom medtagger.database.models import User\n\n\nclass UsersRepository(object):\n \"\"\"Repository for Users.\"\"\"\n\n @staticmethod\n def add_new_user(new_user: User) -> int:\n \"\"\"Add new user.\n\n :return: id of the new user\n \"\"\"\n with db_session() as session:\n session.add(new_user)\n return new_user.id\n\n @staticmethod\n def get_all_users() -> List[User]:\n \"\"\"Return list of all users.\"\"\"\n return User.query.order_by(User.id).all()\n\n @staticmethod\n def get_user_by_email(user_email: str) -> Optional[User]:\n \"\"\"Get user with given email.\n\n :return Optional of User\n \"\"\"\n return User.query.filter(User.email == user_email).first()\n\n @staticmethod\n def get_user_by_id(user_id: int) -> User:\n \"\"\"Get user with given id.\"\"\"\n return User.query.filter(User.id == user_id).one()\n", "path": "backend/medtagger/repositories/users.py"}, {"content": "\"\"\"Module responsible for business logic for users administration.\"\"\"\nfrom typing import List\n\nfrom medtagger.database.models import User\nfrom medtagger.repositories.users import UsersRepository\nfrom medtagger.repositories.roles import RolesRepository\n\n\ndef get_all_users() -> List[User]:\n \"\"\"Return list of all users.\"\"\"\n return UsersRepository.get_all_users()\n\n\ndef set_user_role(user_id: int, role_name: str) -> None:\n \"\"\"Set user's role. Old role is being replaced.\"\"\"\n RolesRepository.set_user_role(user_id, role_name)\n", "path": "backend/medtagger/api/users/business.py"}]}
| 1,659 | 721 |
gh_patches_debug_43873
|
rasdani/github-patches
|
git_diff
|
Flexget__Flexget-2224
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Issue 2.7.2: Form plugin
### Expected behaviour:
No error while using 2.5.2 version
### Actual behaviour:
Got an error while running task that using form plugin
### Steps to reproduce:
Running task with form plugin
#### Config:
```yaml
avistaz_subs:
form:
url: https://avistaz.to/auth/login
username: "{{secrets.avistaz.usr}}"
password: "{{secrets.avistaz.pwd}}"
userfield: email_username
passfield: password
html:
url: "https://avistaz.to/subtitles?type=2&search=720p&language=0&subtitle=45&page={{i}}"
title_from: url
links_re:
- '\.(rar|r0+[01](/01)|zip|srt)'
increment:
from: 0
to: 1
#dump: result.html
regexp:
accept:
- someregex
#disable: builtins
download: yes
decompress: true
template: [notify_me]
```
#### Log:
Generated new crash log
### Additional information:
- Flexget Version: 2.7.2
- Python Version: 2.7.9
- Installation method: easy_install upgrade flexget
- OS and version: osmc raspberry pi
- Link to crash log: http://pastebin.com/XHL3dzQH
</issue>
<code>
[start of flexget/plugins/operate/formlogin.py]
1 from __future__ import unicode_literals, division, absolute_import
2 from builtins import * # noqa pylint: disable=unused-import, redefined-builtin
3
4 import logging
5 import io
6 import os
7 import socket
8
9 try:
10 import mechanize
11 except ImportError:
12 mechanize = None
13
14 from flexget import plugin
15 from flexget.event import event
16 from flexget.utils.soup import get_soup
17
18 log = logging.getLogger('formlogin')
19
20
21 if mechanize:
22 class SanitizeHandler(mechanize.BaseHandler):
23 def http_response(self, request, response):
24 if not hasattr(response, "seek"):
25 response = mechanize.response_seek_wrapper(response)
26 # Run HTML through BeautifulSoup for sanitizing
27 if 'html' in response.info().get('content-type', ''):
28 soup = get_soup(response.get_data())
29 response.set_data(soup.prettify(encoding=soup.original_encoding))
30 return response
31
32
33 class FormLogin(object):
34 """
35 Login on form
36 """
37
38 schema = {
39 'type': 'object',
40 'properties': {
41 'url': {'type': 'string', 'format': 'url'},
42 'username': {'type': 'string'},
43 'password': {'type': 'string'},
44 'userfield': {'type': 'string'},
45 'passfield': {'type': 'string'}
46 },
47 'required': ['url', 'username', 'password'],
48 'additionalProperties': False
49 }
50
51 def on_task_start(self, task, config):
52 if not mechanize:
53 raise plugin.PluginError('mechanize required (python module), please install it.', log)
54
55 userfield = config.get('userfield', 'username')
56 passfield = config.get('passfield', 'password')
57
58 url = config['url']
59 username = config['username']
60 password = config['password']
61
62 br = mechanize.Browser()
63 br.add_handler(SanitizeHandler())
64 br.set_handle_robots(False)
65 try:
66 br.open(url)
67 except Exception:
68 # TODO: improve error handling
69 log.debug('Exception posting login form.', exc_info=True)
70 raise plugin.PluginError('Unable to post login form', log)
71
72 # br.set_debug_redirects(True)
73 # br.set_debug_responses(True)
74 # br.set_debug_http(True)
75
76 try:
77 for form in br.forms():
78 loginform = form
79
80 try:
81 loginform[userfield] = username
82 loginform[passfield] = password
83 break
84 except Exception:
85 pass
86 else:
87 received = os.path.join(task.manager.config_base, 'received')
88 if not os.path.isdir(received):
89 os.mkdir(received)
90 filename = os.path.join(received, '%s.formlogin.html' % task.name)
91 with io.open(filename, 'wb') as f:
92 f.write(br.response().get_data())
93 log.critical('I have saved the login page content to %s for you to view', filename)
94 raise plugin.PluginError('Unable to find login fields', log)
95 except socket.timeout:
96 raise plugin.PluginError('Timed out on url %s' % url)
97
98 br.form = loginform
99
100 br.submit()
101
102 cookiejar = br._ua_handlers["_cookies"].cookiejar
103
104 # Add cookiejar to our requests session
105 task.requests.add_cookiejar(cookiejar)
106
107
108 @event('plugin.register')
109 def register_plugin():
110 plugin.register(FormLogin, 'form', api_ver=2)
111
[end of flexget/plugins/operate/formlogin.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/flexget/plugins/operate/formlogin.py b/flexget/plugins/operate/formlogin.py
--- a/flexget/plugins/operate/formlogin.py
+++ b/flexget/plugins/operate/formlogin.py
@@ -7,29 +7,17 @@
import socket
try:
- import mechanize
+ import mechanicalsoup
except ImportError:
- mechanize = None
+ mechanicalsoup = None
+import requests
from flexget import plugin
from flexget.event import event
-from flexget.utils.soup import get_soup
log = logging.getLogger('formlogin')
-if mechanize:
- class SanitizeHandler(mechanize.BaseHandler):
- def http_response(self, request, response):
- if not hasattr(response, "seek"):
- response = mechanize.response_seek_wrapper(response)
- # Run HTML through BeautifulSoup for sanitizing
- if 'html' in response.info().get('content-type', ''):
- soup = get_soup(response.get_data())
- response.set_data(soup.prettify(encoding=soup.original_encoding))
- return response
-
-
class FormLogin(object):
"""
Login on form
@@ -49,8 +37,8 @@
}
def on_task_start(self, task, config):
- if not mechanize:
- raise plugin.PluginError('mechanize required (python module), please install it.', log)
+ if not mechanicalsoup:
+ raise plugin.PluginError('mechanicalsoup required (python module), please install it.', log)
userfield = config.get('userfield', 'username')
passfield = config.get('passfield', 'password')
@@ -59,29 +47,28 @@
username = config['username']
password = config['password']
- br = mechanize.Browser()
- br.add_handler(SanitizeHandler())
- br.set_handle_robots(False)
+ br = mechanicalsoup.StatefulBrowser(session=task.requests)
+
try:
- br.open(url)
- except Exception:
+ response = br.open(url)
+ except requests.RequestException:
# TODO: improve error handling
- log.debug('Exception posting login form.', exc_info=True)
- raise plugin.PluginError('Unable to post login form', log)
+ log.debug('Exception getting login page.', exc_info=True)
+ raise plugin.PluginError('Unable to get login page', log)
- # br.set_debug_redirects(True)
- # br.set_debug_responses(True)
- # br.set_debug_http(True)
+ # br.set_debug(True)
+ num_forms = len(br.get_current_page().find_all('form'))
+ if not num_forms:
+ raise plugin.PluginError('Unable to find any forms on {}'.format(url), log)
try:
- for form in br.forms():
- loginform = form
-
+ for form_num in range(num_forms):
+ br.select_form(nr=form_num)
try:
- loginform[userfield] = username
- loginform[passfield] = password
+ br[userfield] = username
+ br[passfield] = password
break
- except Exception:
+ except mechanicalsoup.LinkNotFoundError:
pass
else:
received = os.path.join(task.manager.config_base, 'received')
@@ -89,20 +76,17 @@
os.mkdir(received)
filename = os.path.join(received, '%s.formlogin.html' % task.name)
with io.open(filename, 'wb') as f:
- f.write(br.response().get_data())
+ f.write(response.content)
log.critical('I have saved the login page content to %s for you to view', filename)
raise plugin.PluginError('Unable to find login fields', log)
except socket.timeout:
raise plugin.PluginError('Timed out on url %s' % url)
- br.form = loginform
-
- br.submit()
-
- cookiejar = br._ua_handlers["_cookies"].cookiejar
-
- # Add cookiejar to our requests session
- task.requests.add_cookiejar(cookiejar)
+ try:
+ br.submit_selected()
+ except requests.RequestException:
+ log.debug('Exception submitting login form.', exc_info=True)
+ raise plugin.PluginError('Unable to post login form', log)
@event('plugin.register')
|
{"golden_diff": "diff --git a/flexget/plugins/operate/formlogin.py b/flexget/plugins/operate/formlogin.py\n--- a/flexget/plugins/operate/formlogin.py\n+++ b/flexget/plugins/operate/formlogin.py\n@@ -7,29 +7,17 @@\n import socket\n \n try:\n- import mechanize\n+ import mechanicalsoup\n except ImportError:\n- mechanize = None\n+ mechanicalsoup = None\n+import requests\n \n from flexget import plugin\n from flexget.event import event\n-from flexget.utils.soup import get_soup\n \n log = logging.getLogger('formlogin')\n \n \n-if mechanize:\n- class SanitizeHandler(mechanize.BaseHandler):\n- def http_response(self, request, response):\n- if not hasattr(response, \"seek\"):\n- response = mechanize.response_seek_wrapper(response)\n- # Run HTML through BeautifulSoup for sanitizing\n- if 'html' in response.info().get('content-type', ''):\n- soup = get_soup(response.get_data())\n- response.set_data(soup.prettify(encoding=soup.original_encoding))\n- return response\n-\n-\n class FormLogin(object):\n \"\"\"\n Login on form\n@@ -49,8 +37,8 @@\n }\n \n def on_task_start(self, task, config):\n- if not mechanize:\n- raise plugin.PluginError('mechanize required (python module), please install it.', log)\n+ if not mechanicalsoup:\n+ raise plugin.PluginError('mechanicalsoup required (python module), please install it.', log)\n \n userfield = config.get('userfield', 'username')\n passfield = config.get('passfield', 'password')\n@@ -59,29 +47,28 @@\n username = config['username']\n password = config['password']\n \n- br = mechanize.Browser()\n- br.add_handler(SanitizeHandler())\n- br.set_handle_robots(False)\n+ br = mechanicalsoup.StatefulBrowser(session=task.requests)\n+\n try:\n- br.open(url)\n- except Exception:\n+ response = br.open(url)\n+ except requests.RequestException:\n # TODO: improve error handling\n- log.debug('Exception posting login form.', exc_info=True)\n- raise plugin.PluginError('Unable to post login form', log)\n+ log.debug('Exception getting login page.', exc_info=True)\n+ raise plugin.PluginError('Unable to get login page', log)\n \n- # br.set_debug_redirects(True)\n- # br.set_debug_responses(True)\n- # br.set_debug_http(True)\n+ # br.set_debug(True)\n \n+ num_forms = len(br.get_current_page().find_all('form'))\n+ if not num_forms:\n+ raise plugin.PluginError('Unable to find any forms on {}'.format(url), log)\n try:\n- for form in br.forms():\n- loginform = form\n-\n+ for form_num in range(num_forms):\n+ br.select_form(nr=form_num)\n try:\n- loginform[userfield] = username\n- loginform[passfield] = password\n+ br[userfield] = username\n+ br[passfield] = password\n break\n- except Exception:\n+ except mechanicalsoup.LinkNotFoundError:\n pass\n else:\n received = os.path.join(task.manager.config_base, 'received')\n@@ -89,20 +76,17 @@\n os.mkdir(received)\n filename = os.path.join(received, '%s.formlogin.html' % task.name)\n with io.open(filename, 'wb') as f:\n- f.write(br.response().get_data())\n+ f.write(response.content)\n log.critical('I have saved the login page content to %s for you to view', filename)\n raise plugin.PluginError('Unable to find login fields', log)\n except socket.timeout:\n raise plugin.PluginError('Timed out on url %s' % url)\n \n- br.form = loginform\n-\n- br.submit()\n-\n- cookiejar = br._ua_handlers[\"_cookies\"].cookiejar\n-\n- # Add cookiejar to our requests session\n- task.requests.add_cookiejar(cookiejar)\n+ try:\n+ br.submit_selected()\n+ except requests.RequestException:\n+ log.debug('Exception submitting login form.', exc_info=True)\n+ raise plugin.PluginError('Unable to post login form', log)\n \n \n @event('plugin.register')\n", "issue": "Issue 2.7.2: Form plugin\n### Expected behaviour:\r\nNo error while using 2.5.2 version\r\n### Actual behaviour:\r\nGot an error while running task that using form plugin\r\n### Steps to reproduce:\r\nRunning task with form plugin\r\n\r\n#### Config:\r\n```yaml\r\n avistaz_subs:\r\n form:\r\n url: https://avistaz.to/auth/login\r\n username: \"{{secrets.avistaz.usr}}\"\r\n password: \"{{secrets.avistaz.pwd}}\"\r\n userfield: email_username\r\n passfield: password\r\n html:\r\n url: \"https://avistaz.to/subtitles?type=2&search=720p&language=0&subtitle=45&page={{i}}\"\r\n title_from: url\r\n links_re:\r\n - '\\.(rar|r0+[01](/01)|zip|srt)'\r\n increment:\r\n from: 0\r\n to: 1\r\n #dump: result.html\r\n regexp:\r\n accept:\r\n - someregex\r\n #disable: builtins\r\n download: yes\r\n decompress: true\r\n template: [notify_me]\r\n```\r\n#### Log:\r\nGenerated new crash log\r\n\r\n### Additional information:\r\n\r\n- Flexget Version: 2.7.2\r\n- Python Version: 2.7.9\r\n- Installation method: easy_install upgrade flexget\r\n- OS and version: osmc raspberry pi\r\n- Link to crash log: http://pastebin.com/XHL3dzQH\n", "before_files": [{"content": "from __future__ import unicode_literals, division, absolute_import\nfrom builtins import * # noqa pylint: disable=unused-import, redefined-builtin\n\nimport logging\nimport io\nimport os\nimport socket\n\ntry:\n import mechanize\nexcept ImportError:\n mechanize = None\n\nfrom flexget import plugin\nfrom flexget.event import event\nfrom flexget.utils.soup import get_soup\n\nlog = logging.getLogger('formlogin')\n\n\nif mechanize:\n class SanitizeHandler(mechanize.BaseHandler):\n def http_response(self, request, response):\n if not hasattr(response, \"seek\"):\n response = mechanize.response_seek_wrapper(response)\n # Run HTML through BeautifulSoup for sanitizing\n if 'html' in response.info().get('content-type', ''):\n soup = get_soup(response.get_data())\n response.set_data(soup.prettify(encoding=soup.original_encoding))\n return response\n\n\nclass FormLogin(object):\n \"\"\"\n Login on form\n \"\"\"\n\n schema = {\n 'type': 'object',\n 'properties': {\n 'url': {'type': 'string', 'format': 'url'},\n 'username': {'type': 'string'},\n 'password': {'type': 'string'},\n 'userfield': {'type': 'string'},\n 'passfield': {'type': 'string'}\n },\n 'required': ['url', 'username', 'password'],\n 'additionalProperties': False\n }\n\n def on_task_start(self, task, config):\n if not mechanize:\n raise plugin.PluginError('mechanize required (python module), please install it.', log)\n\n userfield = config.get('userfield', 'username')\n passfield = config.get('passfield', 'password')\n\n url = config['url']\n username = config['username']\n password = config['password']\n\n br = mechanize.Browser()\n br.add_handler(SanitizeHandler())\n br.set_handle_robots(False)\n try:\n br.open(url)\n except Exception:\n # TODO: improve error handling\n log.debug('Exception posting login form.', exc_info=True)\n raise plugin.PluginError('Unable to post login form', log)\n\n # br.set_debug_redirects(True)\n # br.set_debug_responses(True)\n # br.set_debug_http(True)\n\n try:\n for form in br.forms():\n loginform = form\n\n try:\n loginform[userfield] = username\n loginform[passfield] = password\n break\n except Exception:\n pass\n else:\n received = os.path.join(task.manager.config_base, 'received')\n if not os.path.isdir(received):\n os.mkdir(received)\n filename = os.path.join(received, '%s.formlogin.html' % task.name)\n with io.open(filename, 'wb') as f:\n f.write(br.response().get_data())\n log.critical('I have saved the login page content to %s for you to view', filename)\n raise plugin.PluginError('Unable to find login fields', log)\n except socket.timeout:\n raise plugin.PluginError('Timed out on url %s' % url)\n\n br.form = loginform\n\n br.submit()\n\n cookiejar = br._ua_handlers[\"_cookies\"].cookiejar\n\n # Add cookiejar to our requests session\n task.requests.add_cookiejar(cookiejar)\n\n\n@event('plugin.register')\ndef register_plugin():\n plugin.register(FormLogin, 'form', api_ver=2)\n", "path": "flexget/plugins/operate/formlogin.py"}]}
| 1,840 | 958 |
gh_patches_debug_3597
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-489
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Checkov crashes when evaluating a Terraform dynamic block in NSGRulePortAccessRestricted.py
**Describe the bug**
When checking azure_security_group_rule, azurerm_network_security_rule or azurerm_network_security_group Terraform resource types, NSGRulePortAccessRestricted.py throws a "TypeError: string indices must be integers" error whenever there's a dynamic block.
**To Reproduce**
Steps to reproduce the behavior:
1. Create a resource in terraform, containing a dynamic security rule -
```
resource "azurerm_network_security_group" "snet_nsgs" {
count = "${length(local.subnets)}"
name = "${local.root}-snet-${lookup(local.subnets[count.index], "name")}-nsg"
location = "${azurerm_resource_group.net_rg.location}"
resource_group_name = "${azurerm_resource_group.net_rg.name}"
tags = "${local.tags}"
dynamic "security_rule" {
for_each = [for s in local.subnets[count.index].nsg_rules : {
name = s.name
priority = s.priority
direction = s.direction
access = s.access
protocol = s.protocol
source_port_range = s.source_port_range
destination_port_range = s.destination_port_range
source_address_prefix = s.source_address_prefix
destination_address_prefix = s.destination_address_prefix
description = s.description
}]
content {
name = security_rule.value.name
priority = security_rule.value.priority
direction = security_rule.value.direction
access = security_rule.value.access
protocol = security_rule.value.protocol
source_port_range = security_rule.value.source_port_range
destination_port_range = security_rule.value.destination_port_range
source_address_prefix = security_rule.value.source_address_prefix
destination_address_prefix = security_rule.value.destination_address_prefix
description = security_rule.value.description
}
}
}
```
2. Run checkov
3. Error!
**Expected behavior**
As checkov cannot evaluate the dynamic block, I expect the check to be skipped without throwing an error.
**Desktop (please complete the following information):**
- OS: Ubuntu
- Checkov Version 1.0.479
</issue>
<code>
[start of checkov/terraform/checks/resource/azure/NSGRulePortAccessRestricted.py]
1 from checkov.common.models.enums import CheckResult, CheckCategories
2 from checkov.terraform.checks.resource.base_resource_value_check import BaseResourceCheck
3 from checkov.common.util.type_forcers import force_list
4 import re
5
6 INTERNET_ADDRESSES = ["*", "0.0.0.0", "<nw>/0", "/0", "internet", "any"]
7 PORT_RANGE = re.compile('\d+-\d+')
8
9
10 class NSGRulePortAccessRestricted(BaseResourceCheck):
11 def __init__(self, name, check_id, port):
12 supported_resources = ['azure_security_group_rule', 'azurerm_network_security_rule', 'azurerm_network_security_group']
13 categories = [CheckCategories.NETWORKING]
14 super().__init__(name=name, id=check_id, categories=categories, supported_resources=supported_resources)
15 self.port = port
16
17 def is_port_in_range(self, conf):
18 ports = force_list(conf['destination_port_range'][0])
19 for range in ports:
20 if re.match(PORT_RANGE, range):
21 start, end = int(range.split('-')[0]), int(range.split('-')[1])
22 if start <= self.port <= end:
23 return True
24 if range in [str(self.port), '*']:
25 return True
26 return False
27
28 def scan_resource_conf(self, conf):
29 rule_confs = [conf]
30 if 'security_rule' in conf:
31 rule_confs = conf['security_rule']
32
33 for rule_conf in rule_confs:
34 if 'access' in rule_conf and rule_conf['access'][0] == "Allow":
35 if 'direction' in rule_conf and rule_conf['direction'][0] == "Inbound":
36 if 'protocol' in rule_conf and rule_conf['protocol'][0] == 'TCP':
37 if 'destination_port_range' in rule_conf and self.is_port_in_range(rule_conf):
38 if 'source_address_prefix' in rule_conf and rule_conf['source_address_prefix'][0] in INTERNET_ADDRESSES:
39 return CheckResult.FAILED
40 return CheckResult.PASSED
41
42
[end of checkov/terraform/checks/resource/azure/NSGRulePortAccessRestricted.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/checkov/terraform/checks/resource/azure/NSGRulePortAccessRestricted.py b/checkov/terraform/checks/resource/azure/NSGRulePortAccessRestricted.py
--- a/checkov/terraform/checks/resource/azure/NSGRulePortAccessRestricted.py
+++ b/checkov/terraform/checks/resource/azure/NSGRulePortAccessRestricted.py
@@ -26,6 +26,9 @@
return False
def scan_resource_conf(self, conf):
+ if "dynamic" in conf:
+ return CheckResult.UNKNOWN
+
rule_confs = [conf]
if 'security_rule' in conf:
rule_confs = conf['security_rule']
|
{"golden_diff": "diff --git a/checkov/terraform/checks/resource/azure/NSGRulePortAccessRestricted.py b/checkov/terraform/checks/resource/azure/NSGRulePortAccessRestricted.py\n--- a/checkov/terraform/checks/resource/azure/NSGRulePortAccessRestricted.py\n+++ b/checkov/terraform/checks/resource/azure/NSGRulePortAccessRestricted.py\n@@ -26,6 +26,9 @@\n return False\n \n def scan_resource_conf(self, conf):\n+ if \"dynamic\" in conf:\n+ return CheckResult.UNKNOWN\n+ \n rule_confs = [conf]\n if 'security_rule' in conf:\n rule_confs = conf['security_rule']\n", "issue": "Checkov crashes when evaluating a Terraform dynamic block in NSGRulePortAccessRestricted.py\n**Describe the bug**\r\nWhen checking azure_security_group_rule, azurerm_network_security_rule or azurerm_network_security_group Terraform resource types, NSGRulePortAccessRestricted.py throws a \"TypeError: string indices must be integers\" error whenever there's a dynamic block.\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Create a resource in terraform, containing a dynamic security rule -\r\n```\r\nresource \"azurerm_network_security_group\" \"snet_nsgs\" {\r\n count = \"${length(local.subnets)}\"\r\n name = \"${local.root}-snet-${lookup(local.subnets[count.index], \"name\")}-nsg\"\r\n location = \"${azurerm_resource_group.net_rg.location}\"\r\n resource_group_name = \"${azurerm_resource_group.net_rg.name}\"\r\n tags = \"${local.tags}\"\r\n\r\n\r\n dynamic \"security_rule\" {\r\n for_each = [for s in local.subnets[count.index].nsg_rules : {\r\n name = s.name\r\n priority = s.priority\r\n direction = s.direction\r\n access = s.access\r\n protocol = s.protocol\r\n source_port_range = s.source_port_range\r\n destination_port_range = s.destination_port_range\r\n source_address_prefix = s.source_address_prefix\r\n destination_address_prefix = s.destination_address_prefix\r\n description = s.description\r\n }]\r\n content {\r\n name = security_rule.value.name\r\n priority = security_rule.value.priority\r\n direction = security_rule.value.direction\r\n access = security_rule.value.access\r\n protocol = security_rule.value.protocol\r\n source_port_range = security_rule.value.source_port_range\r\n destination_port_range = security_rule.value.destination_port_range\r\n source_address_prefix = security_rule.value.source_address_prefix\r\n destination_address_prefix = security_rule.value.destination_address_prefix\r\n description = security_rule.value.description\r\n }\r\n }\r\n}\r\n```\r\n2. Run checkov\r\n3. Error!\r\n\r\n**Expected behavior**\r\nAs checkov cannot evaluate the dynamic block, I expect the check to be skipped without throwing an error.\r\n\r\n**Desktop (please complete the following information):**\r\n - OS: Ubuntu\r\n - Checkov Version 1.0.479\r\n\n", "before_files": [{"content": "from checkov.common.models.enums import CheckResult, CheckCategories\nfrom checkov.terraform.checks.resource.base_resource_value_check import BaseResourceCheck\nfrom checkov.common.util.type_forcers import force_list\nimport re\n\nINTERNET_ADDRESSES = [\"*\", \"0.0.0.0\", \"<nw>/0\", \"/0\", \"internet\", \"any\"]\nPORT_RANGE = re.compile('\\d+-\\d+')\n\n\nclass NSGRulePortAccessRestricted(BaseResourceCheck):\n def __init__(self, name, check_id, port):\n supported_resources = ['azure_security_group_rule', 'azurerm_network_security_rule', 'azurerm_network_security_group']\n categories = [CheckCategories.NETWORKING]\n super().__init__(name=name, id=check_id, categories=categories, supported_resources=supported_resources)\n self.port = port\n\n def is_port_in_range(self, conf):\n ports = force_list(conf['destination_port_range'][0])\n for range in ports:\n if re.match(PORT_RANGE, range):\n start, end = int(range.split('-')[0]), int(range.split('-')[1])\n if start <= self.port <= end:\n return True\n if range in [str(self.port), '*']:\n return True\n return False\n\n def scan_resource_conf(self, conf):\n rule_confs = [conf]\n if 'security_rule' in conf:\n rule_confs = conf['security_rule']\n\n for rule_conf in rule_confs:\n if 'access' in rule_conf and rule_conf['access'][0] == \"Allow\":\n if 'direction' in rule_conf and rule_conf['direction'][0] == \"Inbound\":\n if 'protocol' in rule_conf and rule_conf['protocol'][0] == 'TCP':\n if 'destination_port_range' in rule_conf and self.is_port_in_range(rule_conf):\n if 'source_address_prefix' in rule_conf and rule_conf['source_address_prefix'][0] in INTERNET_ADDRESSES:\n return CheckResult.FAILED\n return CheckResult.PASSED\n\n", "path": "checkov/terraform/checks/resource/azure/NSGRulePortAccessRestricted.py"}]}
| 1,568 | 151 |
gh_patches_debug_37404
|
rasdani/github-patches
|
git_diff
|
svthalia__concrexit-1135
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix "identical-code" issue in website/education/admin.py
Identical blocks of code found in 2 locations. Consider refactoring.
https://codeclimate.com/github/svthalia/concrexit/website/education/admin.py#issue_5ecfbb80e8d0fa00010003f6
</issue>
<code>
[start of website/education/admin.py]
1 """
2 This module registers admin pages for the models
3 """
4 import csv
5
6 from django.contrib import admin
7 from django.http import HttpResponse
8 from django.utils.translation import gettext_lazy as _
9
10 from utils.translation import TranslatedModelAdmin
11 from . import models
12 from .forms import SummaryAdminForm
13
14 admin.site.register(models.Category)
15
16
17 @admin.register(models.Course)
18 class CourseAdmin(TranslatedModelAdmin):
19 fields = (
20 "name",
21 "course_code",
22 "ec",
23 "since",
24 "until",
25 "categories",
26 "old_courses",
27 )
28 list_filter = ("categories", "ec")
29 search_fields = ("name", "course_code")
30
31
32 @admin.register(models.Exam)
33 class ExamAdmin(TranslatedModelAdmin):
34 list_display = (
35 "type",
36 "course",
37 "exam_date",
38 "uploader",
39 "accepted",
40 "language",
41 "download_count",
42 )
43 readonly_fields = ("download_count",)
44 list_filter = ("accepted", "exam_date", "type", "language")
45 search_fields = (
46 "name",
47 "uploader__first_name",
48 "uploader__last_name",
49 "course__name_nl",
50 "course__name_en",
51 )
52 actions = ["accept", "reject", "reset_download_count", "download_csv"]
53
54 def accept(self, request, queryset):
55 queryset.update(accepted=True)
56
57 accept.short_description = _("Mark exams as accepted")
58
59 def reject(self, request, queryset):
60 queryset.update(accepted=False)
61
62 reject.short_description = _("Mark exams as rejected")
63
64 def reset_download_count(self, request, queryset):
65 queryset.update(download_count=0)
66
67 reset_download_count.short_description = _("Reset the marked exams download count")
68
69 def download_csv(self, request, queryset):
70 opts = queryset.model._meta
71 response = HttpResponse(content_type="text/csv")
72 # force download.
73 response["Content-Disposition"] = "attachment;filename=export.csv"
74 # the csv writer
75 writer = csv.writer(response)
76 field_names = [field.name for field in opts.fields]
77 # Write a first row with header information
78 writer.writerow(field_names)
79 # Write data rows
80 for obj in queryset:
81 writer.writerow([getattr(obj, field) for field in field_names])
82 return response
83
84 download_csv.short_description = _("Download marked as csv")
85
86
87 @admin.register(models.Summary)
88 class SummaryAdmin(TranslatedModelAdmin):
89 list_display = (
90 "name",
91 "course",
92 "uploader",
93 "accepted",
94 "language",
95 "download_count",
96 )
97 readonly_fields = ("download_count",)
98 list_filter = ("accepted", "language")
99 search_fields = (
100 "name",
101 "uploader__first_name",
102 "uploader__last_name",
103 "course__name_nl",
104 "course__name_en",
105 )
106 actions = ["accept", "reject", "reset_download_count", "download_csv"]
107 form = SummaryAdminForm
108
109 def accept(self, request, queryset):
110 queryset.update(accepted=True)
111
112 accept.short_description = _("Mark summaries as accepted")
113
114 def reject(self, request, queryset):
115 queryset.update(accepted=False)
116
117 reject.short_description = _("Mark summaries as rejected")
118
119 def reset_download_count(self, request, queryset):
120 queryset.update(download_count=0)
121
122 reset_download_count.short_description = _(
123 "Reset the marked summaries download count"
124 )
125
126 def download_csv(self, request, queryset):
127 opts = queryset.model._meta
128 response = HttpResponse(content_type="text/csv")
129 # force download.
130 response["Content-Disposition"] = "attachment;filename=export.csv"
131 # the csv writer
132 writer = csv.writer(response)
133 field_names = [field.name for field in opts.fields]
134 # Write a first row with header information
135 writer.writerow(field_names)
136 # Write data rows
137 for obj in queryset:
138 writer.writerow([getattr(obj, field) for field in field_names])
139 return response
140
141 download_csv.short_description = _("Download marked as csv")
142
[end of website/education/admin.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/website/education/admin.py b/website/education/admin.py
--- a/website/education/admin.py
+++ b/website/education/admin.py
@@ -29,8 +29,27 @@
search_fields = ("name", "course_code")
+class WithDownloadCsv:
+ def download_csv(self, request, queryset):
+ opts = queryset.model._meta
+ response = HttpResponse(content_type="text/csv")
+ # force download.
+ response["Content-Disposition"] = "attachment;filename=export.csv"
+ # the csv writer
+ writer = csv.writer(response)
+ field_names = [field.name for field in opts.fields]
+ # Write a first row with header information
+ writer.writerow(field_names)
+ # Write data rows
+ for obj in queryset:
+ writer.writerow([getattr(obj, field) for field in field_names])
+ return response
+
+ download_csv.short_description = _("Download marked as csv")
+
+
@admin.register(models.Exam)
-class ExamAdmin(TranslatedModelAdmin):
+class ExamAdmin(TranslatedModelAdmin, WithDownloadCsv):
list_display = (
"type",
"course",
@@ -66,26 +85,9 @@
reset_download_count.short_description = _("Reset the marked exams download count")
- def download_csv(self, request, queryset):
- opts = queryset.model._meta
- response = HttpResponse(content_type="text/csv")
- # force download.
- response["Content-Disposition"] = "attachment;filename=export.csv"
- # the csv writer
- writer = csv.writer(response)
- field_names = [field.name for field in opts.fields]
- # Write a first row with header information
- writer.writerow(field_names)
- # Write data rows
- for obj in queryset:
- writer.writerow([getattr(obj, field) for field in field_names])
- return response
-
- download_csv.short_description = _("Download marked as csv")
-
@admin.register(models.Summary)
-class SummaryAdmin(TranslatedModelAdmin):
+class SummaryAdmin(TranslatedModelAdmin, WithDownloadCsv):
list_display = (
"name",
"course",
@@ -122,20 +124,3 @@
reset_download_count.short_description = _(
"Reset the marked summaries download count"
)
-
- def download_csv(self, request, queryset):
- opts = queryset.model._meta
- response = HttpResponse(content_type="text/csv")
- # force download.
- response["Content-Disposition"] = "attachment;filename=export.csv"
- # the csv writer
- writer = csv.writer(response)
- field_names = [field.name for field in opts.fields]
- # Write a first row with header information
- writer.writerow(field_names)
- # Write data rows
- for obj in queryset:
- writer.writerow([getattr(obj, field) for field in field_names])
- return response
-
- download_csv.short_description = _("Download marked as csv")
|
{"golden_diff": "diff --git a/website/education/admin.py b/website/education/admin.py\n--- a/website/education/admin.py\n+++ b/website/education/admin.py\n@@ -29,8 +29,27 @@\n search_fields = (\"name\", \"course_code\")\n \n \n+class WithDownloadCsv:\n+ def download_csv(self, request, queryset):\n+ opts = queryset.model._meta\n+ response = HttpResponse(content_type=\"text/csv\")\n+ # force download.\n+ response[\"Content-Disposition\"] = \"attachment;filename=export.csv\"\n+ # the csv writer\n+ writer = csv.writer(response)\n+ field_names = [field.name for field in opts.fields]\n+ # Write a first row with header information\n+ writer.writerow(field_names)\n+ # Write data rows\n+ for obj in queryset:\n+ writer.writerow([getattr(obj, field) for field in field_names])\n+ return response\n+\n+ download_csv.short_description = _(\"Download marked as csv\")\n+\n+\n @admin.register(models.Exam)\n-class ExamAdmin(TranslatedModelAdmin):\n+class ExamAdmin(TranslatedModelAdmin, WithDownloadCsv):\n list_display = (\n \"type\",\n \"course\",\n@@ -66,26 +85,9 @@\n \n reset_download_count.short_description = _(\"Reset the marked exams download count\")\n \n- def download_csv(self, request, queryset):\n- opts = queryset.model._meta\n- response = HttpResponse(content_type=\"text/csv\")\n- # force download.\n- response[\"Content-Disposition\"] = \"attachment;filename=export.csv\"\n- # the csv writer\n- writer = csv.writer(response)\n- field_names = [field.name for field in opts.fields]\n- # Write a first row with header information\n- writer.writerow(field_names)\n- # Write data rows\n- for obj in queryset:\n- writer.writerow([getattr(obj, field) for field in field_names])\n- return response\n-\n- download_csv.short_description = _(\"Download marked as csv\")\n-\n \n @admin.register(models.Summary)\n-class SummaryAdmin(TranslatedModelAdmin):\n+class SummaryAdmin(TranslatedModelAdmin, WithDownloadCsv):\n list_display = (\n \"name\",\n \"course\",\n@@ -122,20 +124,3 @@\n reset_download_count.short_description = _(\n \"Reset the marked summaries download count\"\n )\n-\n- def download_csv(self, request, queryset):\n- opts = queryset.model._meta\n- response = HttpResponse(content_type=\"text/csv\")\n- # force download.\n- response[\"Content-Disposition\"] = \"attachment;filename=export.csv\"\n- # the csv writer\n- writer = csv.writer(response)\n- field_names = [field.name for field in opts.fields]\n- # Write a first row with header information\n- writer.writerow(field_names)\n- # Write data rows\n- for obj in queryset:\n- writer.writerow([getattr(obj, field) for field in field_names])\n- return response\n-\n- download_csv.short_description = _(\"Download marked as csv\")\n", "issue": "Fix \"identical-code\" issue in website/education/admin.py\nIdentical blocks of code found in 2 locations. Consider refactoring.\n\nhttps://codeclimate.com/github/svthalia/concrexit/website/education/admin.py#issue_5ecfbb80e8d0fa00010003f6\n", "before_files": [{"content": "\"\"\"\nThis module registers admin pages for the models\n\"\"\"\nimport csv\n\nfrom django.contrib import admin\nfrom django.http import HttpResponse\nfrom django.utils.translation import gettext_lazy as _\n\nfrom utils.translation import TranslatedModelAdmin\nfrom . import models\nfrom .forms import SummaryAdminForm\n\nadmin.site.register(models.Category)\n\n\[email protected](models.Course)\nclass CourseAdmin(TranslatedModelAdmin):\n fields = (\n \"name\",\n \"course_code\",\n \"ec\",\n \"since\",\n \"until\",\n \"categories\",\n \"old_courses\",\n )\n list_filter = (\"categories\", \"ec\")\n search_fields = (\"name\", \"course_code\")\n\n\[email protected](models.Exam)\nclass ExamAdmin(TranslatedModelAdmin):\n list_display = (\n \"type\",\n \"course\",\n \"exam_date\",\n \"uploader\",\n \"accepted\",\n \"language\",\n \"download_count\",\n )\n readonly_fields = (\"download_count\",)\n list_filter = (\"accepted\", \"exam_date\", \"type\", \"language\")\n search_fields = (\n \"name\",\n \"uploader__first_name\",\n \"uploader__last_name\",\n \"course__name_nl\",\n \"course__name_en\",\n )\n actions = [\"accept\", \"reject\", \"reset_download_count\", \"download_csv\"]\n\n def accept(self, request, queryset):\n queryset.update(accepted=True)\n\n accept.short_description = _(\"Mark exams as accepted\")\n\n def reject(self, request, queryset):\n queryset.update(accepted=False)\n\n reject.short_description = _(\"Mark exams as rejected\")\n\n def reset_download_count(self, request, queryset):\n queryset.update(download_count=0)\n\n reset_download_count.short_description = _(\"Reset the marked exams download count\")\n\n def download_csv(self, request, queryset):\n opts = queryset.model._meta\n response = HttpResponse(content_type=\"text/csv\")\n # force download.\n response[\"Content-Disposition\"] = \"attachment;filename=export.csv\"\n # the csv writer\n writer = csv.writer(response)\n field_names = [field.name for field in opts.fields]\n # Write a first row with header information\n writer.writerow(field_names)\n # Write data rows\n for obj in queryset:\n writer.writerow([getattr(obj, field) for field in field_names])\n return response\n\n download_csv.short_description = _(\"Download marked as csv\")\n\n\[email protected](models.Summary)\nclass SummaryAdmin(TranslatedModelAdmin):\n list_display = (\n \"name\",\n \"course\",\n \"uploader\",\n \"accepted\",\n \"language\",\n \"download_count\",\n )\n readonly_fields = (\"download_count\",)\n list_filter = (\"accepted\", \"language\")\n search_fields = (\n \"name\",\n \"uploader__first_name\",\n \"uploader__last_name\",\n \"course__name_nl\",\n \"course__name_en\",\n )\n actions = [\"accept\", \"reject\", \"reset_download_count\", \"download_csv\"]\n form = SummaryAdminForm\n\n def accept(self, request, queryset):\n queryset.update(accepted=True)\n\n accept.short_description = _(\"Mark summaries as accepted\")\n\n def reject(self, request, queryset):\n queryset.update(accepted=False)\n\n reject.short_description = _(\"Mark summaries as rejected\")\n\n def reset_download_count(self, request, queryset):\n queryset.update(download_count=0)\n\n reset_download_count.short_description = _(\n \"Reset the marked summaries download count\"\n )\n\n def download_csv(self, request, queryset):\n opts = queryset.model._meta\n response = HttpResponse(content_type=\"text/csv\")\n # force download.\n response[\"Content-Disposition\"] = \"attachment;filename=export.csv\"\n # the csv writer\n writer = csv.writer(response)\n field_names = [field.name for field in opts.fields]\n # Write a first row with header information\n writer.writerow(field_names)\n # Write data rows\n for obj in queryset:\n writer.writerow([getattr(obj, field) for field in field_names])\n return response\n\n download_csv.short_description = _(\"Download marked as csv\")\n", "path": "website/education/admin.py"}]}
| 1,797 | 666 |
gh_patches_debug_5654
|
rasdani/github-patches
|
git_diff
|
Nitrate__Nitrate-360
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Ensure to work with Python 3.7
</issue>
<code>
[start of setup.py]
1 # -*- coding: utf-8 -*-
2
3 import sys
4
5 from setuptools import setup, find_packages
6
7
8 with open('VERSION.txt', 'r') as f:
9 pkg_version = f.read().strip()
10
11
12 def get_long_description():
13 with open('README.rst', 'r') as f:
14 return f.read()
15
16
17 install_requires = [
18 'PyMySQL == 0.7.11',
19 'beautifulsoup4 >= 4.1.1',
20 'django >= 1.11,<2.0',
21 'django-contrib-comments == 1.8.0',
22 'django-tinymce == 2.7.0',
23 'django-uuslug == 1.1.8',
24 'html2text',
25 'kobo == 0.7.0',
26 'odfpy >= 0.9.6',
27 'python-bugzilla',
28 'six',
29 'xmltodict',
30 ]
31
32 if sys.version_info.major < 3:
33 install_requires += [
34 'enum34',
35 ]
36
37 extras_require = {
38 # Required for tcms.core.contrib.auth.backends.KerberosBackend
39 'krbauth': [
40 'kerberos == 1.2.5'
41 ],
42
43 # Packages for building documentation
44 'docs': [
45 'Sphinx >= 1.1.2',
46 'sphinx_rtd_theme',
47 ],
48
49 # Necessary packages for running tests
50 'tests': [
51 'coverage',
52 'factory_boy',
53 'flake8',
54 'mock',
55 'pytest',
56 'pytest-cov',
57 'pytest-django',
58 ],
59
60 # Contain tools that assists the development
61 'devtools': [
62 'django-debug-toolbar == 1.7',
63 'tox',
64 'django-extensions',
65 'pygraphviz',
66 'future-breakpoint',
67 ],
68
69 # Required packages required to run async tasks
70 'async': [
71 'celery == 4.1.0',
72 ]
73 }
74
75
76 setup(
77 name='Nitrate',
78 version=pkg_version,
79 description='Test Case Management System',
80 long_description=get_long_description(),
81 author='Nitrate Team',
82 maintainer='Chenxiong Qi',
83 maintainer_email='[email protected]',
84 url='https://github.com/Nitrate/Nitrate/',
85 license='GPLv2+',
86 keywords='test case',
87 install_requires=install_requires,
88 extras_require=extras_require,
89 packages=find_packages(),
90 include_package_data=True,
91 classifiers=[
92 'Framework :: Django',
93 'Framework :: Django :: 1.11',
94 'Intended Audience :: Developers',
95 'License :: OSI Approved :: GNU General Public License v2 or later (GPLv2+)',
96 'Programming Language :: Python :: 2',
97 'Programming Language :: Python :: 2.7',
98 'Programming Language :: Python :: 3',
99 'Programming Language :: Python :: 3.6',
100 'Topic :: Software Development :: Quality Assurance',
101 'Topic :: Software Development :: Testing',
102 ],
103 )
104
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -97,6 +97,7 @@
'Programming Language :: Python :: 2.7',
'Programming Language :: Python :: 3',
'Programming Language :: Python :: 3.6',
+ 'Programming Language :: Python :: 3.7',
'Topic :: Software Development :: Quality Assurance',
'Topic :: Software Development :: Testing',
],
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -97,6 +97,7 @@\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.6',\n+ 'Programming Language :: Python :: 3.7',\n 'Topic :: Software Development :: Quality Assurance',\n 'Topic :: Software Development :: Testing',\n ],\n", "issue": "Ensure to work with Python 3.7\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\nimport sys\n\nfrom setuptools import setup, find_packages\n\n\nwith open('VERSION.txt', 'r') as f:\n pkg_version = f.read().strip()\n\n\ndef get_long_description():\n with open('README.rst', 'r') as f:\n return f.read()\n\n\ninstall_requires = [\n 'PyMySQL == 0.7.11',\n 'beautifulsoup4 >= 4.1.1',\n 'django >= 1.11,<2.0',\n 'django-contrib-comments == 1.8.0',\n 'django-tinymce == 2.7.0',\n 'django-uuslug == 1.1.8',\n 'html2text',\n 'kobo == 0.7.0',\n 'odfpy >= 0.9.6',\n 'python-bugzilla',\n 'six',\n 'xmltodict',\n]\n\nif sys.version_info.major < 3:\n install_requires += [\n 'enum34',\n ]\n\nextras_require = {\n # Required for tcms.core.contrib.auth.backends.KerberosBackend\n 'krbauth': [\n 'kerberos == 1.2.5'\n ],\n\n # Packages for building documentation\n 'docs': [\n 'Sphinx >= 1.1.2',\n 'sphinx_rtd_theme',\n ],\n\n # Necessary packages for running tests\n 'tests': [\n 'coverage',\n 'factory_boy',\n 'flake8',\n 'mock',\n 'pytest',\n 'pytest-cov',\n 'pytest-django',\n ],\n\n # Contain tools that assists the development\n 'devtools': [\n 'django-debug-toolbar == 1.7',\n 'tox',\n 'django-extensions',\n 'pygraphviz',\n 'future-breakpoint',\n ],\n\n # Required packages required to run async tasks\n 'async': [\n 'celery == 4.1.0',\n ]\n}\n\n\nsetup(\n name='Nitrate',\n version=pkg_version,\n description='Test Case Management System',\n long_description=get_long_description(),\n author='Nitrate Team',\n maintainer='Chenxiong Qi',\n maintainer_email='[email protected]',\n url='https://github.com/Nitrate/Nitrate/',\n license='GPLv2+',\n keywords='test case',\n install_requires=install_requires,\n extras_require=extras_require,\n packages=find_packages(),\n include_package_data=True,\n classifiers=[\n 'Framework :: Django',\n 'Framework :: Django :: 1.11',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: GNU General Public License v2 or later (GPLv2+)',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.6',\n 'Topic :: Software Development :: Quality Assurance',\n 'Topic :: Software Development :: Testing',\n ],\n)\n", "path": "setup.py"}]}
| 1,413 | 101 |
gh_patches_debug_7678
|
rasdani/github-patches
|
git_diff
|
xonsh__xonsh-490
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add 'edit and execute command` function
bash and zsh (and I'm sure others) have an edit and execute command that is invoked with Ctrl-e + Ctrl-x which opens the current contents of the command prompt in the system editor. Edits made to the command are then run on save and quit.
It could be this functionality is already baked in and I'm missing it? In any case, it's especially handy for longer commands -- and given xonsh's multi-line input capabilities this seems like a good fit.
Thoughts?
</issue>
<code>
[start of xonsh/prompt_toolkit_shell.py]
1 """The prompt_toolkit based xonsh shell"""
2 import os
3 import builtins
4 from warnings import warn
5
6 from prompt_toolkit.shortcuts import get_input
7 from prompt_toolkit.key_binding.manager import KeyBindingManager
8 from prompt_toolkit.auto_suggest import AutoSuggestFromHistory
9 from pygments.token import Token
10 from pygments.style import Style
11
12 from xonsh.base_shell import BaseShell
13 from xonsh.tools import format_prompt_for_prompt_toolkit
14 from xonsh.prompt_toolkit_completer import PromptToolkitCompleter
15 from xonsh.prompt_toolkit_history import LimitedFileHistory
16 from xonsh.prompt_toolkit_key_bindings import load_xonsh_bindings
17
18
19 def setup_history():
20 """Creates history object."""
21 env = builtins.__xonsh_env__
22 hfile = env.get('XONSH_HISTORY_FILE')
23 history = LimitedFileHistory()
24 try:
25 history.read_history_file(hfile)
26 except PermissionError:
27 warn('do not have read permissions for ' + hfile, RuntimeWarning)
28 return history
29
30
31 def teardown_history(history):
32 """Tears down the history object."""
33 env = builtins.__xonsh_env__
34 hsize = env.get('XONSH_HISTORY_SIZE')[0]
35 hfile = env.get('XONSH_HISTORY_FILE')
36 try:
37 history.save_history_to_file(hfile, hsize)
38 except PermissionError:
39 warn('do not have write permissions for ' + hfile, RuntimeWarning)
40
41
42 class PromptToolkitShell(BaseShell):
43 """The xonsh shell."""
44
45 def __init__(self, **kwargs):
46 super().__init__(**kwargs)
47 self.history = setup_history()
48 self.pt_completer = PromptToolkitCompleter(self.completer, self.ctx)
49 self.key_bindings_manager = KeyBindingManager(
50 enable_auto_suggest_bindings=True,
51 enable_search=True, enable_abort_and_exit_bindings=True)
52 load_xonsh_bindings(self.key_bindings_manager)
53
54 def __del__(self):
55 if self.history is not None:
56 teardown_history(self.history)
57
58 def cmdloop(self, intro=None):
59 """Enters a loop that reads and execute input from user."""
60 if intro:
61 print(intro)
62 _auto_suggest = AutoSuggestFromHistory()
63 while not builtins.__xonsh_exit__:
64 try:
65 token_func, style_cls = self._get_prompt_tokens_and_style()
66 mouse_support = builtins.__xonsh_env__.get('MOUSE_SUPPORT')
67 if builtins.__xonsh_env__.get('AUTO_SUGGEST'):
68 auto_suggest = _auto_suggest
69 else:
70 auto_suggest = None
71 completions_display = builtins.__xonsh_env__.get('COMPLETIONS_DISPLAY')
72 multicolumn = (completions_display == 'multi')
73 completer = None if completions_display == 'none' else self.pt_completer
74 line = get_input(
75 mouse_support=mouse_support,
76 auto_suggest=auto_suggest,
77 get_prompt_tokens=token_func,
78 style=style_cls,
79 completer=completer,
80 history=self.history,
81 key_bindings_registry=self.key_bindings_manager.registry,
82 display_completions_in_columns=multicolumn)
83 if not line:
84 self.emptyline()
85 else:
86 line = self.precmd(line)
87 self.default(line)
88 except KeyboardInterrupt:
89 self.reset_buffer()
90 except EOFError:
91 break
92
93 def _get_prompt_tokens_and_style(self):
94 """Returns function to pass as prompt to prompt_toolkit."""
95 token_names, cstyles, strings = format_prompt_for_prompt_toolkit(self.prompt)
96 tokens = [getattr(Token, n) for n in token_names]
97
98 def get_tokens(cli):
99 return list(zip(tokens, strings))
100
101 class CustomStyle(Style):
102 styles = {
103 Token.Menu.Completions.Completion.Current: 'bg:#00aaaa #000000',
104 Token.Menu.Completions.Completion: 'bg:#008888 #ffffff',
105 Token.Menu.Completions.ProgressButton: 'bg:#003333',
106 Token.Menu.Completions.ProgressBar: 'bg:#00aaaa',
107 Token.AutoSuggestion: '#666666',
108 Token.Aborted: '#888888',
109 }
110 # update with the prompt styles
111 styles.update({t: s for (t, s) in zip(tokens, cstyles)})
112 # Update with with any user styles
113 userstyle = builtins.__xonsh_env__.get('PROMPT_TOOLKIT_STYLES')
114 if userstyle is not None:
115 styles.update(userstyle)
116
117 return get_tokens, CustomStyle
118
[end of xonsh/prompt_toolkit_shell.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/xonsh/prompt_toolkit_shell.py b/xonsh/prompt_toolkit_shell.py
--- a/xonsh/prompt_toolkit_shell.py
+++ b/xonsh/prompt_toolkit_shell.py
@@ -48,6 +48,7 @@
self.pt_completer = PromptToolkitCompleter(self.completer, self.ctx)
self.key_bindings_manager = KeyBindingManager(
enable_auto_suggest_bindings=True,
+ enable_open_in_editor=True,
enable_search=True, enable_abort_and_exit_bindings=True)
load_xonsh_bindings(self.key_bindings_manager)
|
{"golden_diff": "diff --git a/xonsh/prompt_toolkit_shell.py b/xonsh/prompt_toolkit_shell.py\n--- a/xonsh/prompt_toolkit_shell.py\n+++ b/xonsh/prompt_toolkit_shell.py\n@@ -48,6 +48,7 @@\n self.pt_completer = PromptToolkitCompleter(self.completer, self.ctx)\n self.key_bindings_manager = KeyBindingManager(\n enable_auto_suggest_bindings=True,\n+ enable_open_in_editor=True,\n enable_search=True, enable_abort_and_exit_bindings=True)\n load_xonsh_bindings(self.key_bindings_manager)\n", "issue": "Add 'edit and execute command` function\nbash and zsh (and I'm sure others) have an edit and execute command that is invoked with Ctrl-e + Ctrl-x which opens the current contents of the command prompt in the system editor. Edits made to the command are then run on save and quit. \n\nIt could be this functionality is already baked in and I'm missing it? In any case, it's especially handy for longer commands -- and given xonsh's multi-line input capabilities this seems like a good fit.\n\nThoughts?\n\n", "before_files": [{"content": "\"\"\"The prompt_toolkit based xonsh shell\"\"\"\nimport os\nimport builtins\nfrom warnings import warn\n\nfrom prompt_toolkit.shortcuts import get_input\nfrom prompt_toolkit.key_binding.manager import KeyBindingManager\nfrom prompt_toolkit.auto_suggest import AutoSuggestFromHistory\nfrom pygments.token import Token\nfrom pygments.style import Style\n\nfrom xonsh.base_shell import BaseShell\nfrom xonsh.tools import format_prompt_for_prompt_toolkit\nfrom xonsh.prompt_toolkit_completer import PromptToolkitCompleter\nfrom xonsh.prompt_toolkit_history import LimitedFileHistory\nfrom xonsh.prompt_toolkit_key_bindings import load_xonsh_bindings\n\n\ndef setup_history():\n \"\"\"Creates history object.\"\"\"\n env = builtins.__xonsh_env__\n hfile = env.get('XONSH_HISTORY_FILE')\n history = LimitedFileHistory()\n try:\n history.read_history_file(hfile)\n except PermissionError:\n warn('do not have read permissions for ' + hfile, RuntimeWarning)\n return history\n\n\ndef teardown_history(history):\n \"\"\"Tears down the history object.\"\"\"\n env = builtins.__xonsh_env__\n hsize = env.get('XONSH_HISTORY_SIZE')[0]\n hfile = env.get('XONSH_HISTORY_FILE')\n try:\n history.save_history_to_file(hfile, hsize)\n except PermissionError:\n warn('do not have write permissions for ' + hfile, RuntimeWarning)\n\n\nclass PromptToolkitShell(BaseShell):\n \"\"\"The xonsh shell.\"\"\"\n\n def __init__(self, **kwargs):\n super().__init__(**kwargs)\n self.history = setup_history()\n self.pt_completer = PromptToolkitCompleter(self.completer, self.ctx)\n self.key_bindings_manager = KeyBindingManager(\n enable_auto_suggest_bindings=True,\n enable_search=True, enable_abort_and_exit_bindings=True)\n load_xonsh_bindings(self.key_bindings_manager)\n\n def __del__(self):\n if self.history is not None:\n teardown_history(self.history)\n\n def cmdloop(self, intro=None):\n \"\"\"Enters a loop that reads and execute input from user.\"\"\"\n if intro:\n print(intro)\n _auto_suggest = AutoSuggestFromHistory()\n while not builtins.__xonsh_exit__:\n try:\n token_func, style_cls = self._get_prompt_tokens_and_style()\n mouse_support = builtins.__xonsh_env__.get('MOUSE_SUPPORT')\n if builtins.__xonsh_env__.get('AUTO_SUGGEST'):\n auto_suggest = _auto_suggest\n else:\n auto_suggest = None\n completions_display = builtins.__xonsh_env__.get('COMPLETIONS_DISPLAY')\n multicolumn = (completions_display == 'multi')\n completer = None if completions_display == 'none' else self.pt_completer\n line = get_input(\n mouse_support=mouse_support,\n auto_suggest=auto_suggest,\n get_prompt_tokens=token_func,\n style=style_cls,\n completer=completer,\n history=self.history,\n key_bindings_registry=self.key_bindings_manager.registry,\n display_completions_in_columns=multicolumn)\n if not line:\n self.emptyline()\n else:\n line = self.precmd(line)\n self.default(line)\n except KeyboardInterrupt:\n self.reset_buffer()\n except EOFError:\n break\n\n def _get_prompt_tokens_and_style(self):\n \"\"\"Returns function to pass as prompt to prompt_toolkit.\"\"\"\n token_names, cstyles, strings = format_prompt_for_prompt_toolkit(self.prompt)\n tokens = [getattr(Token, n) for n in token_names]\n\n def get_tokens(cli):\n return list(zip(tokens, strings))\n\n class CustomStyle(Style):\n styles = {\n Token.Menu.Completions.Completion.Current: 'bg:#00aaaa #000000',\n Token.Menu.Completions.Completion: 'bg:#008888 #ffffff',\n Token.Menu.Completions.ProgressButton: 'bg:#003333',\n Token.Menu.Completions.ProgressBar: 'bg:#00aaaa',\n Token.AutoSuggestion: '#666666',\n Token.Aborted: '#888888',\n }\n # update with the prompt styles\n styles.update({t: s for (t, s) in zip(tokens, cstyles)})\n # Update with with any user styles\n userstyle = builtins.__xonsh_env__.get('PROMPT_TOOLKIT_STYLES')\n if userstyle is not None:\n styles.update(userstyle)\n\n return get_tokens, CustomStyle\n", "path": "xonsh/prompt_toolkit_shell.py"}]}
| 1,907 | 129 |
gh_patches_debug_6573
|
rasdani/github-patches
|
git_diff
|
OCA__bank-payment-44
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Code error in account_payment_sale
I'm reporting a bug in my own code : in the 7.0 branch, in account_payment_sale/model/sale.py line 41, we have the following code:
partner.customer_payment_mode.id or False,
We should NOT have a coma at the end of this line. When we run the module in Odoo 8.0, it will crash when creating a sale order via a call to create because addons/sale/sale.py in odoo 8.0 silently plays the on_change and then it will try to create {"payment_mode_id: (False,)}, when leads to a crash
</issue>
<code>
[start of account_payment_sale/model/sale.py]
1 # -*- encoding: utf-8 -*-
2 ##############################################################################
3 #
4 # Account Payment Sale module for OpenERP
5 # Copyright (C) 2014 Akretion (http://www.akretion.com)
6 # @author Alexis de Lattre <[email protected]>
7 #
8 # This program is free software: you can redistribute it and/or modify
9 # it under the terms of the GNU Affero General Public License as
10 # published by the Free Software Foundation, either version 3 of the
11 # License, or (at your option) any later version.
12 #
13 # This program is distributed in the hope that it will be useful,
14 # but WITHOUT ANY WARRANTY; without even the implied warranty of
15 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
16 # GNU Affero General Public License for more details.
17 #
18 # You should have received a copy of the GNU Affero General Public License
19 # along with this program. If not, see <http://www.gnu.org/licenses/>.
20 #
21 ##############################################################################
22
23 from openerp.osv import orm, fields
24
25
26 class sale_order(orm.Model):
27 _inherit = "sale.order"
28
29 _columns = {
30 'payment_mode_id': fields.many2one(
31 'payment.mode', 'Payment Mode'),
32 }
33
34 def onchange_partner_id(self, cr, uid, ids, part, context=None):
35 res = super(sale_order, self).onchange_partner_id(
36 cr, uid, ids, part, context=context)
37 if part:
38 partner = self.pool['res.partner'].browse(
39 cr, uid, part, context=context)
40 res['value']['payment_mode_id'] = \
41 partner.customer_payment_mode.id or False,
42 else:
43 res['value']['payment_mode_id'] = False
44 return res
45
46 def _prepare_invoice(self, cr, uid, order, lines, context=None):
47 """Copy bank partner from sale order to invoice"""
48 invoice_vals = super(sale_order, self)._prepare_invoice(
49 cr, uid, order, lines, context=context)
50 invoice_vals.update({
51 'payment_mode_id': order.payment_mode_id.id or False,
52 'partner_bank_id': order.payment_mode_id and
53 order.payment_mode_id.bank_id.id or False,
54 })
55 return invoice_vals
56
[end of account_payment_sale/model/sale.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/account_payment_sale/model/sale.py b/account_payment_sale/model/sale.py
--- a/account_payment_sale/model/sale.py
+++ b/account_payment_sale/model/sale.py
@@ -38,7 +38,7 @@
partner = self.pool['res.partner'].browse(
cr, uid, part, context=context)
res['value']['payment_mode_id'] = \
- partner.customer_payment_mode.id or False,
+ partner.customer_payment_mode.id or False
else:
res['value']['payment_mode_id'] = False
return res
|
{"golden_diff": "diff --git a/account_payment_sale/model/sale.py b/account_payment_sale/model/sale.py\n--- a/account_payment_sale/model/sale.py\n+++ b/account_payment_sale/model/sale.py\n@@ -38,7 +38,7 @@\n partner = self.pool['res.partner'].browse(\n cr, uid, part, context=context)\n res['value']['payment_mode_id'] = \\\n- partner.customer_payment_mode.id or False,\n+ partner.customer_payment_mode.id or False\n else:\n res['value']['payment_mode_id'] = False\n return res\n", "issue": "Code error in account_payment_sale\nI'm reporting a bug in my own code : in the 7.0 branch, in account_payment_sale/model/sale.py line 41, we have the following code:\n\n partner.customer_payment_mode.id or False,\n\nWe should NOT have a coma at the end of this line. When we run the module in Odoo 8.0, it will crash when creating a sale order via a call to create because addons/sale/sale.py in odoo 8.0 silently plays the on_change and then it will try to create {\"payment_mode_id: (False,)}, when leads to a crash\n\n", "before_files": [{"content": "# -*- encoding: utf-8 -*-\n##############################################################################\n#\n# Account Payment Sale module for OpenERP\n# Copyright (C) 2014 Akretion (http://www.akretion.com)\n# @author Alexis de Lattre <[email protected]>\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU Affero General Public License as\n# published by the Free Software Foundation, either version 3 of the\n# License, or (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU Affero General Public License for more details.\n#\n# You should have received a copy of the GNU Affero General Public License\n# along with this program. If not, see <http://www.gnu.org/licenses/>.\n#\n##############################################################################\n\nfrom openerp.osv import orm, fields\n\n\nclass sale_order(orm.Model):\n _inherit = \"sale.order\"\n\n _columns = {\n 'payment_mode_id': fields.many2one(\n 'payment.mode', 'Payment Mode'),\n }\n\n def onchange_partner_id(self, cr, uid, ids, part, context=None):\n res = super(sale_order, self).onchange_partner_id(\n cr, uid, ids, part, context=context)\n if part:\n partner = self.pool['res.partner'].browse(\n cr, uid, part, context=context)\n res['value']['payment_mode_id'] = \\\n partner.customer_payment_mode.id or False,\n else:\n res['value']['payment_mode_id'] = False\n return res\n\n def _prepare_invoice(self, cr, uid, order, lines, context=None):\n \"\"\"Copy bank partner from sale order to invoice\"\"\"\n invoice_vals = super(sale_order, self)._prepare_invoice(\n cr, uid, order, lines, context=context)\n invoice_vals.update({\n 'payment_mode_id': order.payment_mode_id.id or False,\n 'partner_bank_id': order.payment_mode_id and\n order.payment_mode_id.bank_id.id or False,\n })\n return invoice_vals\n", "path": "account_payment_sale/model/sale.py"}]}
| 1,269 | 124 |
gh_patches_debug_5448
|
rasdani/github-patches
|
git_diff
|
kserve__kserve-704
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
storage-initialiser fails to copy model from S3
Upon using a Secret and Service account that look like this:
```
apiVersion: v1
metadata:
name: kfserving-aws-secret
namespace: {namespace}
annotations:
serving.kubeflow.org/s3-endpoint: s3.eu-east-1.amazonaws.com
serving.kubeflow.org/s3-usehttps: "1"
serving.kubeflow.org/s3-verifyssl: "1"
serving.kubeflow.org/s3-region: eu-east-1
data:
AWS_ACCESS_KEY_ID: {access_key_base64}
AWS_SECRET_ACCESS_KEY: {secret_key_base64}
kind: Secret
type: Opaque
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: kfserving-sa
namespace: {namespace}
secrets:
- name: kfserving-aws-secret
```
...and an InferenceService like this:
```
apiVersion: "serving.kubeflow.org/v1alpha2"
kind: "InferenceService"
metadata:
name: {model_name}
namespace: {namespace}
spec:
default:
predictor:
serviceAccountName: kfserving-sa
tensorflow:
storageUri: {model_base_path}
```
...the model fails to serve, with the `storage-initialiser` pod throwing the following error:
```
[I 200226 14:09:42 initializer-entrypoint:13] Initializing, args: src_uri [s3://at-kubeflow-training/tf-job/ksc-ebce76a1] dest_path[ [/mnt/models]
[I 200226 14:09:42 storage:35] Copying contents of s3://at-kubeflow-training/tf-job/ksc-ebce76a1 to local
Traceback (most recent call last):
File "/storage-initializer/scripts/initializer-entrypoint", line 14, in <module>
kfserving.Storage.download(src_uri, dest_path)
File "/usr/local/lib/python3.7/site-packages/kfserving/storage.py", line 50, in download
Storage._download_s3(uri, out_dir)
File "/usr/local/lib/python3.7/site-packages/kfserving/storage.py", line 65, in _download_s3
client = Storage._create_minio_client()
File "/usr/local/lib/python3.7/site-packages/kfserving/storage.py", line 217, in _create_minio_client
secure=use_ssl)
File "/usr/local/lib/python3.7/site-packages/minio/api.py", line 150, in __init__
is_valid_endpoint(endpoint)
File "/usr/local/lib/python3.7/site-packages/minio/helpers.py", line 301, in is_valid_endpoint
if hostname[-1] == '.':
IndexError: string index out of range
```
This was using Kubeflow 1.0.0RC4, KFServing 0.2.2 and KNative 0.11.1
</issue>
<code>
[start of python/kfserving/kfserving/constants/constants.py]
1 # Copyright 2020 kubeflow.org.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import os
16
17 # KFServing K8S constants
18 KFSERVING_GROUP = 'serving.kubeflow.org'
19 KFSERVING_KIND = 'InferenceService'
20 KFSERVING_PLURAL = 'inferenceservices'
21 KFSERVING_VERSION = os.environ.get('KFSERVING_VERSION', 'v1alpha2')
22 KFSERVING_API_VERSION = KFSERVING_GROUP + '/' + KFSERVING_VERSION
23
24 KFSERVING_LOGLEVEL = os.environ.get('KFSERVING_LOGLEVEL', 'INFO').upper()
25
26 # INFERENCESERVICE credentials common constants
27 INFERENCESERVICE_CONFIG_MAP_NAME = 'inferenceservice-config'
28 INFERENCESERVICE_SYSTEM_NAMESPACE = 'kfserving-system'
29 DEFAULT_SECRET_NAME = "kfserving-secret-"
30 DEFAULT_SA_NAME = "kfserving-service-credentials"
31
32 # S3 credentials constants
33 S3_ACCESS_KEY_ID_DEFAULT_NAME = "awsAccessKeyID"
34 S3_SECRET_ACCESS_KEY_DEFAULT_NAME = "awsSecretAccessKey"
35 S3_DEFAULT_CREDS_FILE = '~/.aws/credentials'
36
37 # GCS credentials constants
38 GCS_CREDS_FILE_DEFAULT_NAME = 'gcloud-application-credentials.json'
39 GCS_DEFAULT_CREDS_FILE = '~/.config/gcloud/application_default_credentials.json'
40
41 # Azure credentials constants
42 AZ_DEFAULT_CREDS_FILE = '~/.azure/azure_credentials.json'
43
[end of python/kfserving/kfserving/constants/constants.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/python/kfserving/kfserving/constants/constants.py b/python/kfserving/kfserving/constants/constants.py
--- a/python/kfserving/kfserving/constants/constants.py
+++ b/python/kfserving/kfserving/constants/constants.py
@@ -30,8 +30,8 @@
DEFAULT_SA_NAME = "kfserving-service-credentials"
# S3 credentials constants
-S3_ACCESS_KEY_ID_DEFAULT_NAME = "awsAccessKeyID"
-S3_SECRET_ACCESS_KEY_DEFAULT_NAME = "awsSecretAccessKey"
+S3_ACCESS_KEY_ID_DEFAULT_NAME = "AWS_ACCESS_KEY_ID"
+S3_SECRET_ACCESS_KEY_DEFAULT_NAME = "AWS_SECRET_ACCESS_KEY"
S3_DEFAULT_CREDS_FILE = '~/.aws/credentials'
# GCS credentials constants
|
{"golden_diff": "diff --git a/python/kfserving/kfserving/constants/constants.py b/python/kfserving/kfserving/constants/constants.py\n--- a/python/kfserving/kfserving/constants/constants.py\n+++ b/python/kfserving/kfserving/constants/constants.py\n@@ -30,8 +30,8 @@\n DEFAULT_SA_NAME = \"kfserving-service-credentials\"\n \n # S3 credentials constants\n-S3_ACCESS_KEY_ID_DEFAULT_NAME = \"awsAccessKeyID\"\n-S3_SECRET_ACCESS_KEY_DEFAULT_NAME = \"awsSecretAccessKey\"\n+S3_ACCESS_KEY_ID_DEFAULT_NAME = \"AWS_ACCESS_KEY_ID\"\n+S3_SECRET_ACCESS_KEY_DEFAULT_NAME = \"AWS_SECRET_ACCESS_KEY\"\n S3_DEFAULT_CREDS_FILE = '~/.aws/credentials'\n \n # GCS credentials constants\n", "issue": "storage-initialiser fails to copy model from S3\nUpon using a Secret and Service account that look like this:\r\n\r\n```\r\napiVersion: v1\r\nmetadata:\r\n name: kfserving-aws-secret\r\n namespace: {namespace}\r\n annotations:\r\n serving.kubeflow.org/s3-endpoint: s3.eu-east-1.amazonaws.com\r\n serving.kubeflow.org/s3-usehttps: \"1\"\r\n serving.kubeflow.org/s3-verifyssl: \"1\"\r\n serving.kubeflow.org/s3-region: eu-east-1\r\ndata:\r\n AWS_ACCESS_KEY_ID: {access_key_base64}\r\n AWS_SECRET_ACCESS_KEY: {secret_key_base64}\r\nkind: Secret\r\ntype: Opaque\r\n---\r\napiVersion: v1\r\nkind: ServiceAccount\r\nmetadata:\r\n name: kfserving-sa\r\n namespace: {namespace}\r\nsecrets:\r\n - name: kfserving-aws-secret \r\n```\r\n...and an InferenceService like this:\r\n\r\n```\r\napiVersion: \"serving.kubeflow.org/v1alpha2\"\r\nkind: \"InferenceService\"\r\nmetadata:\r\n name: {model_name}\r\n namespace: {namespace}\r\nspec:\r\n default:\r\n predictor:\r\n serviceAccountName: kfserving-sa\r\n tensorflow:\r\n storageUri: {model_base_path} \r\n```\r\n\r\n...the model fails to serve, with the `storage-initialiser` pod throwing the following error:\r\n\r\n```\r\n[I 200226 14:09:42 initializer-entrypoint:13] Initializing, args: src_uri [s3://at-kubeflow-training/tf-job/ksc-ebce76a1] dest_path[ [/mnt/models]\r\n[I 200226 14:09:42 storage:35] Copying contents of s3://at-kubeflow-training/tf-job/ksc-ebce76a1 to local\r\nTraceback (most recent call last):\r\n File \"/storage-initializer/scripts/initializer-entrypoint\", line 14, in <module>\r\n kfserving.Storage.download(src_uri, dest_path)\r\n File \"/usr/local/lib/python3.7/site-packages/kfserving/storage.py\", line 50, in download\r\n Storage._download_s3(uri, out_dir)\r\n File \"/usr/local/lib/python3.7/site-packages/kfserving/storage.py\", line 65, in _download_s3\r\n client = Storage._create_minio_client()\r\n File \"/usr/local/lib/python3.7/site-packages/kfserving/storage.py\", line 217, in _create_minio_client\r\n secure=use_ssl)\r\n File \"/usr/local/lib/python3.7/site-packages/minio/api.py\", line 150, in __init__\r\n is_valid_endpoint(endpoint)\r\n File \"/usr/local/lib/python3.7/site-packages/minio/helpers.py\", line 301, in is_valid_endpoint\r\n if hostname[-1] == '.':\r\nIndexError: string index out of range\r\n```\r\n\r\nThis was using Kubeflow 1.0.0RC4, KFServing 0.2.2 and KNative 0.11.1\n", "before_files": [{"content": "# Copyright 2020 kubeflow.org.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\n\n# KFServing K8S constants\nKFSERVING_GROUP = 'serving.kubeflow.org'\nKFSERVING_KIND = 'InferenceService'\nKFSERVING_PLURAL = 'inferenceservices'\nKFSERVING_VERSION = os.environ.get('KFSERVING_VERSION', 'v1alpha2')\nKFSERVING_API_VERSION = KFSERVING_GROUP + '/' + KFSERVING_VERSION\n\nKFSERVING_LOGLEVEL = os.environ.get('KFSERVING_LOGLEVEL', 'INFO').upper()\n\n# INFERENCESERVICE credentials common constants\nINFERENCESERVICE_CONFIG_MAP_NAME = 'inferenceservice-config'\nINFERENCESERVICE_SYSTEM_NAMESPACE = 'kfserving-system'\nDEFAULT_SECRET_NAME = \"kfserving-secret-\"\nDEFAULT_SA_NAME = \"kfserving-service-credentials\"\n\n# S3 credentials constants\nS3_ACCESS_KEY_ID_DEFAULT_NAME = \"awsAccessKeyID\"\nS3_SECRET_ACCESS_KEY_DEFAULT_NAME = \"awsSecretAccessKey\"\nS3_DEFAULT_CREDS_FILE = '~/.aws/credentials'\n\n# GCS credentials constants\nGCS_CREDS_FILE_DEFAULT_NAME = 'gcloud-application-credentials.json'\nGCS_DEFAULT_CREDS_FILE = '~/.config/gcloud/application_default_credentials.json'\n\n# Azure credentials constants\nAZ_DEFAULT_CREDS_FILE = '~/.azure/azure_credentials.json'\n", "path": "python/kfserving/kfserving/constants/constants.py"}]}
| 1,730 | 160 |
gh_patches_debug_11237
|
rasdani/github-patches
|
git_diff
|
Mailu__Mailu-1183
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Mailu 1.7 : Issue when moving mail to the Junk folder
When I move a mail to the Junk Folder, i see the following in the logs:
imap_1 | Sep 22 16:51:26 imap: Error: cannot stat file mailu
imap_1 | Sep 22 16:51:26 imap: Error: cannot stat file mailu
imap_1 | Sep 22 16:51:26 imap: Error: tee: /dev/fd/63: I/O error
imap_1 | Sep 22 16:51:26 imap([email protected])<27629><hn93GCeTsresEgAC>: Info: program exec:/conf/bin/spam (27655): Terminated with non-zero exit code 1
imap_1 | Sep 22 16:51:26 imap([email protected])<27629><hn93GCeTsresEgAC>: Info: sieve: left message in mailbox 'Junk'
</issue>
<code>
[start of core/dovecot/start.py]
1 #!/usr/bin/python3
2
3 import os
4 import glob
5 import multiprocessing
6 import logging as log
7 import sys
8
9 from podop import run_server
10 from socrate import system, conf
11
12 log.basicConfig(stream=sys.stderr, level=os.environ.get("LOG_LEVEL", "WARNING"))
13
14 def start_podop():
15 os.setuid(8)
16 url = "http://" + os.environ["ADMIN_ADDRESS"] + "/internal/dovecot/§"
17 run_server(0, "dovecot", "/tmp/podop.socket", [
18 ("quota", "url", url ),
19 ("auth", "url", url),
20 ("sieve", "url", url),
21 ])
22
23 # Actual startup script
24
25 os.environ["FRONT_ADDRESS"] = system.get_host_address_from_environment("FRONT", "front")
26 os.environ["REDIS_ADDRESS"] = system.get_host_address_from_environment("REDIS", "redis")
27 os.environ["ADMIN_ADDRESS"] = system.get_host_address_from_environment("ADMIN", "admin")
28 os.environ["ANTISPAM_ADDRESS"] = system.get_host_address_from_environment("ANTISPAM", "antispam:11334")
29 if os.environ["WEBMAIL"] != "none":
30 os.environ["WEBMAIL_ADDRESS"] = system.get_host_address_from_environment("WEBMAIL", "webmail")
31
32 for dovecot_file in glob.glob("/conf/*.conf"):
33 conf.jinja(dovecot_file, os.environ, os.path.join("/etc/dovecot", os.path.basename(dovecot_file)))
34
35 # Run Podop, then postfix
36 multiprocessing.Process(target=start_podop).start()
37 os.system("chown mail:mail /mail")
38 os.system("chown -R mail:mail /var/lib/dovecot /conf")
39 os.execv("/usr/sbin/dovecot", ["dovecot", "-c", "/etc/dovecot/dovecot.conf", "-F"])
40
[end of core/dovecot/start.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/core/dovecot/start.py b/core/dovecot/start.py
--- a/core/dovecot/start.py
+++ b/core/dovecot/start.py
@@ -32,6 +32,12 @@
for dovecot_file in glob.glob("/conf/*.conf"):
conf.jinja(dovecot_file, os.environ, os.path.join("/etc/dovecot", os.path.basename(dovecot_file)))
+os.makedirs("/conf/bin", exist_ok=True)
+for script_file in glob.glob("/conf/*.script"):
+ out_file = os.path.join("/conf/bin/", os.path.basename(script_file).replace('.script',''))
+ conf.jinja(script_file, os.environ, out_file)
+ os.chmod(out_file, 0o555)
+
# Run Podop, then postfix
multiprocessing.Process(target=start_podop).start()
os.system("chown mail:mail /mail")
|
{"golden_diff": "diff --git a/core/dovecot/start.py b/core/dovecot/start.py\n--- a/core/dovecot/start.py\n+++ b/core/dovecot/start.py\n@@ -32,6 +32,12 @@\n for dovecot_file in glob.glob(\"/conf/*.conf\"):\n conf.jinja(dovecot_file, os.environ, os.path.join(\"/etc/dovecot\", os.path.basename(dovecot_file)))\n \n+os.makedirs(\"/conf/bin\", exist_ok=True)\n+for script_file in glob.glob(\"/conf/*.script\"):\n+ out_file = os.path.join(\"/conf/bin/\", os.path.basename(script_file).replace('.script',''))\n+ conf.jinja(script_file, os.environ, out_file)\n+ os.chmod(out_file, 0o555)\n+\n # Run Podop, then postfix\n multiprocessing.Process(target=start_podop).start()\n os.system(\"chown mail:mail /mail\")\n", "issue": "Mailu 1.7 : Issue when moving mail to the Junk folder\nWhen I move a mail to the Junk Folder, i see the following in the logs:\r\nimap_1 | Sep 22 16:51:26 imap: Error: cannot stat file mailu\r\nimap_1 | Sep 22 16:51:26 imap: Error: cannot stat file mailu\r\nimap_1 | Sep 22 16:51:26 imap: Error: tee: /dev/fd/63: I/O error\r\nimap_1 | Sep 22 16:51:26 imap([email protected])<27629><hn93GCeTsresEgAC>: Info: program exec:/conf/bin/spam (27655): Terminated with non-zero exit code 1\r\nimap_1 | Sep 22 16:51:26 imap([email protected])<27629><hn93GCeTsresEgAC>: Info: sieve: left message in mailbox 'Junk'\n", "before_files": [{"content": "#!/usr/bin/python3\n\nimport os\nimport glob\nimport multiprocessing\nimport logging as log\nimport sys\n\nfrom podop import run_server\nfrom socrate import system, conf\n\nlog.basicConfig(stream=sys.stderr, level=os.environ.get(\"LOG_LEVEL\", \"WARNING\"))\n\ndef start_podop():\n os.setuid(8)\n url = \"http://\" + os.environ[\"ADMIN_ADDRESS\"] + \"/internal/dovecot/\u00a7\"\n run_server(0, \"dovecot\", \"/tmp/podop.socket\", [\n\t\t(\"quota\", \"url\", url ),\n\t\t(\"auth\", \"url\", url),\n\t\t(\"sieve\", \"url\", url),\n ])\n\n# Actual startup script\n\nos.environ[\"FRONT_ADDRESS\"] = system.get_host_address_from_environment(\"FRONT\", \"front\")\nos.environ[\"REDIS_ADDRESS\"] = system.get_host_address_from_environment(\"REDIS\", \"redis\")\nos.environ[\"ADMIN_ADDRESS\"] = system.get_host_address_from_environment(\"ADMIN\", \"admin\")\nos.environ[\"ANTISPAM_ADDRESS\"] = system.get_host_address_from_environment(\"ANTISPAM\", \"antispam:11334\")\nif os.environ[\"WEBMAIL\"] != \"none\":\n os.environ[\"WEBMAIL_ADDRESS\"] = system.get_host_address_from_environment(\"WEBMAIL\", \"webmail\")\n\nfor dovecot_file in glob.glob(\"/conf/*.conf\"):\n conf.jinja(dovecot_file, os.environ, os.path.join(\"/etc/dovecot\", os.path.basename(dovecot_file)))\n\n# Run Podop, then postfix\nmultiprocessing.Process(target=start_podop).start()\nos.system(\"chown mail:mail /mail\")\nos.system(\"chown -R mail:mail /var/lib/dovecot /conf\")\nos.execv(\"/usr/sbin/dovecot\", [\"dovecot\", \"-c\", \"/etc/dovecot/dovecot.conf\", \"-F\"])\n", "path": "core/dovecot/start.py"}]}
| 1,258 | 197 |
gh_patches_debug_36986
|
rasdani/github-patches
|
git_diff
|
encode__httpx-167
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
non-ASCII characters filename in multipart/form-data
I tried to send a file with russian letters in the file name, and `httpx` escaped all non-ASCII characters (as I understood it the way specified in [RFC 7578](https://tools.ietf.org/html/rfc7578)). But this is different from `requests` [behavior](https://github.com/psf/requests/blob/589a82256759018a7e5e289302898dae32544949/requests/models.py#L110), where the file name is simply written as is (using [`RequestField.make_multipart`](https://github.com/urllib3/urllib3/blob/f0d9ebc41e51c4c4c9990b1eed02d297fd1b20d8/src/urllib3/fields.py#L248) from `urllib3`). Maybe `httpx` should just change [`FileField.render_headers`](https://github.com/encode/httpx/blob/3ba2e8c328f05b07ee06ae40f99dce7fe1e8292c/httpx/multipart.py#L57), so as not to escape the file name and instead just put it as bytes?
```diff
def render_headers(self) -> bytes:
- name = quote(self.name, encoding="utf-8").encode("ascii")
- filename = quote(self.filename, encoding="utf-8").encode("ascii")
- content_type = self.content_type.encode("ascii")
return b"".join(
[
b'Content-Disposition: form-data; name="',
- name,
+ self.name.encode(),
b'"; filename="',
- filename,
+ self.filename.encode(),
b'"\r\n',
b"Content-Type: ",
- content_type,
+ self.content_type.encode(),
b"\r\n",
]
)
```
</issue>
<code>
[start of httpx/multipart.py]
1 import binascii
2 import mimetypes
3 import os
4 import typing
5 from io import BytesIO
6 from urllib.parse import quote
7
8
9 class Field:
10 def render_headers(self) -> bytes:
11 raise NotImplementedError() # pragma: nocover
12
13 def render_data(self) -> bytes:
14 raise NotImplementedError() # pragma: nocover
15
16
17 class DataField(Field):
18 def __init__(self, name: str, value: typing.Union[str, bytes]) -> None:
19 if not isinstance(name, str):
20 raise TypeError("Invalid type for name. Expected str.")
21 if not isinstance(value, (str, bytes)):
22 raise TypeError("Invalid type for value. Expected str or bytes.")
23 self.name = name
24 self.value = value
25
26 def render_headers(self) -> bytes:
27 name = quote(self.name, encoding="utf-8").encode("ascii")
28 return b"".join(
29 [b'Content-Disposition: form-data; name="', name, b'"\r\n' b"\r\n"]
30 )
31
32 def render_data(self) -> bytes:
33 return (
34 self.value if isinstance(self.value, bytes) else self.value.encode("utf-8")
35 )
36
37
38 class FileField(Field):
39 def __init__(
40 self, name: str, value: typing.Union[typing.IO[typing.AnyStr], tuple]
41 ) -> None:
42 self.name = name
43 if not isinstance(value, tuple):
44 self.filename = os.path.basename(getattr(value, "name", "upload"))
45 self.file = value # type: typing.Union[typing.IO[str], typing.IO[bytes]]
46 self.content_type = self.guess_content_type()
47 else:
48 self.filename = value[0]
49 self.file = value[1]
50 self.content_type = (
51 value[2] if len(value) > 2 else self.guess_content_type()
52 )
53
54 def guess_content_type(self) -> str:
55 return mimetypes.guess_type(self.filename)[0] or "application/octet-stream"
56
57 def render_headers(self) -> bytes:
58 name = quote(self.name, encoding="utf-8").encode("ascii")
59 filename = quote(self.filename, encoding="utf-8").encode("ascii")
60 content_type = self.content_type.encode("ascii")
61 return b"".join(
62 [
63 b'Content-Disposition: form-data; name="',
64 name,
65 b'"; filename="',
66 filename,
67 b'"\r\n',
68 b"Content-Type: ",
69 content_type,
70 b"\r\n",
71 b"\r\n",
72 ]
73 )
74
75 def render_data(self) -> bytes:
76 content = self.file.read()
77 return content.encode("utf-8") if isinstance(content, str) else content
78
79
80 def iter_fields(data: dict, files: dict) -> typing.Iterator[Field]:
81 for name, value in data.items():
82 if isinstance(value, (list, dict)):
83 for item in value:
84 yield DataField(name=name, value=item)
85 else:
86 yield DataField(name=name, value=value)
87
88 for name, value in files.items():
89 yield FileField(name=name, value=value)
90
91
92 def multipart_encode(data: dict, files: dict) -> typing.Tuple[bytes, str]:
93 body = BytesIO()
94 boundary = binascii.hexlify(os.urandom(16))
95
96 for field in iter_fields(data, files):
97 body.write(b"--%s\r\n" % boundary)
98 body.write(field.render_headers())
99 body.write(field.render_data())
100 body.write(b"\r\n")
101
102 body.write(b"--%s--\r\n" % boundary)
103
104 content_type = "multipart/form-data; boundary=%s" % boundary.decode("ascii")
105
106 return body.getvalue(), content_type
107
[end of httpx/multipart.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/httpx/multipart.py b/httpx/multipart.py
--- a/httpx/multipart.py
+++ b/httpx/multipart.py
@@ -1,9 +1,17 @@
import binascii
import mimetypes
import os
+import re
import typing
from io import BytesIO
-from urllib.parse import quote
+
+_HTML5_FORM_ENCODING_REPLACEMENTS = {'"': "%22", "\\": "\\\\"}
+_HTML5_FORM_ENCODING_REPLACEMENTS.update(
+ {chr(c): "%{:02X}".format(c) for c in range(0x00, 0x1F + 1) if c != 0x1B}
+)
+_HTML5_FORM_ENCODING_RE = re.compile(
+ r"|".join([re.escape(c) for c in _HTML5_FORM_ENCODING_REPLACEMENTS.keys()])
+)
class Field:
@@ -24,10 +32,8 @@
self.value = value
def render_headers(self) -> bytes:
- name = quote(self.name, encoding="utf-8").encode("ascii")
- return b"".join(
- [b'Content-Disposition: form-data; name="', name, b'"\r\n' b"\r\n"]
- )
+ name = _format_param("name", self.name)
+ return b"".join([b"Content-Disposition: form-data; ", name, b"\r\n\r\n"])
def render_data(self) -> bytes:
return (
@@ -55,20 +61,18 @@
return mimetypes.guess_type(self.filename)[0] or "application/octet-stream"
def render_headers(self) -> bytes:
- name = quote(self.name, encoding="utf-8").encode("ascii")
- filename = quote(self.filename, encoding="utf-8").encode("ascii")
- content_type = self.content_type.encode("ascii")
+ name = _format_param("name", self.name)
+ filename = _format_param("filename", self.filename)
+ content_type = self.content_type.encode()
return b"".join(
[
- b'Content-Disposition: form-data; name="',
+ b"Content-Disposition: form-data; ",
name,
- b'"; filename="',
+ b"; ",
filename,
- b'"\r\n',
- b"Content-Type: ",
+ b"\r\nContent-Type: ",
content_type,
- b"\r\n",
- b"\r\n",
+ b"\r\n\r\n",
]
)
@@ -104,3 +108,14 @@
content_type = "multipart/form-data; boundary=%s" % boundary.decode("ascii")
return body.getvalue(), content_type
+
+
+def _format_param(name: str, value: typing.Union[str, bytes]) -> bytes:
+ if isinstance(value, bytes):
+ value = value.decode()
+
+ def replacer(match: typing.Match[str]) -> str:
+ return _HTML5_FORM_ENCODING_REPLACEMENTS[match.group(0)]
+
+ value = _HTML5_FORM_ENCODING_RE.sub(replacer, value)
+ return f'{name}="{value}"'.encode()
|
{"golden_diff": "diff --git a/httpx/multipart.py b/httpx/multipart.py\n--- a/httpx/multipart.py\n+++ b/httpx/multipart.py\n@@ -1,9 +1,17 @@\n import binascii\n import mimetypes\n import os\n+import re\n import typing\n from io import BytesIO\n-from urllib.parse import quote\n+\n+_HTML5_FORM_ENCODING_REPLACEMENTS = {'\"': \"%22\", \"\\\\\": \"\\\\\\\\\"}\n+_HTML5_FORM_ENCODING_REPLACEMENTS.update(\n+ {chr(c): \"%{:02X}\".format(c) for c in range(0x00, 0x1F + 1) if c != 0x1B}\n+)\n+_HTML5_FORM_ENCODING_RE = re.compile(\n+ r\"|\".join([re.escape(c) for c in _HTML5_FORM_ENCODING_REPLACEMENTS.keys()])\n+)\n \n \n class Field:\n@@ -24,10 +32,8 @@\n self.value = value\n \n def render_headers(self) -> bytes:\n- name = quote(self.name, encoding=\"utf-8\").encode(\"ascii\")\n- return b\"\".join(\n- [b'Content-Disposition: form-data; name=\"', name, b'\"\\r\\n' b\"\\r\\n\"]\n- )\n+ name = _format_param(\"name\", self.name)\n+ return b\"\".join([b\"Content-Disposition: form-data; \", name, b\"\\r\\n\\r\\n\"])\n \n def render_data(self) -> bytes:\n return (\n@@ -55,20 +61,18 @@\n return mimetypes.guess_type(self.filename)[0] or \"application/octet-stream\"\n \n def render_headers(self) -> bytes:\n- name = quote(self.name, encoding=\"utf-8\").encode(\"ascii\")\n- filename = quote(self.filename, encoding=\"utf-8\").encode(\"ascii\")\n- content_type = self.content_type.encode(\"ascii\")\n+ name = _format_param(\"name\", self.name)\n+ filename = _format_param(\"filename\", self.filename)\n+ content_type = self.content_type.encode()\n return b\"\".join(\n [\n- b'Content-Disposition: form-data; name=\"',\n+ b\"Content-Disposition: form-data; \",\n name,\n- b'\"; filename=\"',\n+ b\"; \",\n filename,\n- b'\"\\r\\n',\n- b\"Content-Type: \",\n+ b\"\\r\\nContent-Type: \",\n content_type,\n- b\"\\r\\n\",\n- b\"\\r\\n\",\n+ b\"\\r\\n\\r\\n\",\n ]\n )\n \n@@ -104,3 +108,14 @@\n content_type = \"multipart/form-data; boundary=%s\" % boundary.decode(\"ascii\")\n \n return body.getvalue(), content_type\n+\n+\n+def _format_param(name: str, value: typing.Union[str, bytes]) -> bytes:\n+ if isinstance(value, bytes):\n+ value = value.decode()\n+ \n+ def replacer(match: typing.Match[str]) -> str:\n+ return _HTML5_FORM_ENCODING_REPLACEMENTS[match.group(0)]\n+\n+ value = _HTML5_FORM_ENCODING_RE.sub(replacer, value)\n+ return f'{name}=\"{value}\"'.encode()\n", "issue": "non-ASCII characters filename in multipart/form-data\nI tried to send a file with russian letters in the file name, and `httpx` escaped all non-ASCII characters (as I understood it the way specified in [RFC 7578](https://tools.ietf.org/html/rfc7578)). But this is different from `requests` [behavior](https://github.com/psf/requests/blob/589a82256759018a7e5e289302898dae32544949/requests/models.py#L110), where the file name is simply written as is (using [`RequestField.make_multipart`](https://github.com/urllib3/urllib3/blob/f0d9ebc41e51c4c4c9990b1eed02d297fd1b20d8/src/urllib3/fields.py#L248) from `urllib3`). Maybe `httpx` should just change [`FileField.render_headers`](https://github.com/encode/httpx/blob/3ba2e8c328f05b07ee06ae40f99dce7fe1e8292c/httpx/multipart.py#L57), so as not to escape the file name and instead just put it as bytes?\r\n\r\n```diff\r\ndef render_headers(self) -> bytes:\r\n- name = quote(self.name, encoding=\"utf-8\").encode(\"ascii\")\r\n- filename = quote(self.filename, encoding=\"utf-8\").encode(\"ascii\")\r\n- content_type = self.content_type.encode(\"ascii\")\r\n return b\"\".join(\r\n [\r\n b'Content-Disposition: form-data; name=\"',\r\n- name,\r\n+ self.name.encode(),\r\n b'\"; filename=\"',\r\n- filename,\r\n+ self.filename.encode(),\r\n b'\"\\r\\n',\r\n b\"Content-Type: \",\r\n- content_type,\r\n+ self.content_type.encode(),\r\n b\"\\r\\n\",\r\n ]\r\n )\r\n```\n", "before_files": [{"content": "import binascii\nimport mimetypes\nimport os\nimport typing\nfrom io import BytesIO\nfrom urllib.parse import quote\n\n\nclass Field:\n def render_headers(self) -> bytes:\n raise NotImplementedError() # pragma: nocover\n\n def render_data(self) -> bytes:\n raise NotImplementedError() # pragma: nocover\n\n\nclass DataField(Field):\n def __init__(self, name: str, value: typing.Union[str, bytes]) -> None:\n if not isinstance(name, str):\n raise TypeError(\"Invalid type for name. Expected str.\")\n if not isinstance(value, (str, bytes)):\n raise TypeError(\"Invalid type for value. Expected str or bytes.\")\n self.name = name\n self.value = value\n\n def render_headers(self) -> bytes:\n name = quote(self.name, encoding=\"utf-8\").encode(\"ascii\")\n return b\"\".join(\n [b'Content-Disposition: form-data; name=\"', name, b'\"\\r\\n' b\"\\r\\n\"]\n )\n\n def render_data(self) -> bytes:\n return (\n self.value if isinstance(self.value, bytes) else self.value.encode(\"utf-8\")\n )\n\n\nclass FileField(Field):\n def __init__(\n self, name: str, value: typing.Union[typing.IO[typing.AnyStr], tuple]\n ) -> None:\n self.name = name\n if not isinstance(value, tuple):\n self.filename = os.path.basename(getattr(value, \"name\", \"upload\"))\n self.file = value # type: typing.Union[typing.IO[str], typing.IO[bytes]]\n self.content_type = self.guess_content_type()\n else:\n self.filename = value[0]\n self.file = value[1]\n self.content_type = (\n value[2] if len(value) > 2 else self.guess_content_type()\n )\n\n def guess_content_type(self) -> str:\n return mimetypes.guess_type(self.filename)[0] or \"application/octet-stream\"\n\n def render_headers(self) -> bytes:\n name = quote(self.name, encoding=\"utf-8\").encode(\"ascii\")\n filename = quote(self.filename, encoding=\"utf-8\").encode(\"ascii\")\n content_type = self.content_type.encode(\"ascii\")\n return b\"\".join(\n [\n b'Content-Disposition: form-data; name=\"',\n name,\n b'\"; filename=\"',\n filename,\n b'\"\\r\\n',\n b\"Content-Type: \",\n content_type,\n b\"\\r\\n\",\n b\"\\r\\n\",\n ]\n )\n\n def render_data(self) -> bytes:\n content = self.file.read()\n return content.encode(\"utf-8\") if isinstance(content, str) else content\n\n\ndef iter_fields(data: dict, files: dict) -> typing.Iterator[Field]:\n for name, value in data.items():\n if isinstance(value, (list, dict)):\n for item in value:\n yield DataField(name=name, value=item)\n else:\n yield DataField(name=name, value=value)\n\n for name, value in files.items():\n yield FileField(name=name, value=value)\n\n\ndef multipart_encode(data: dict, files: dict) -> typing.Tuple[bytes, str]:\n body = BytesIO()\n boundary = binascii.hexlify(os.urandom(16))\n\n for field in iter_fields(data, files):\n body.write(b\"--%s\\r\\n\" % boundary)\n body.write(field.render_headers())\n body.write(field.render_data())\n body.write(b\"\\r\\n\")\n\n body.write(b\"--%s--\\r\\n\" % boundary)\n\n content_type = \"multipart/form-data; boundary=%s\" % boundary.decode(\"ascii\")\n\n return body.getvalue(), content_type\n", "path": "httpx/multipart.py"}]}
| 2,010 | 709 |
gh_patches_debug_20601
|
rasdani/github-patches
|
git_diff
|
LibraryOfCongress__concordia-396
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Refine Contact Us page
**What behavior did you observe? Please describe the bug**
- The language is very direct. Need to make it more user friendly.
- Add content to get to History Hub
- Begin with options to self-service in Help Center or History Hub
**What is the expected behavior?**
As a user, I want to contact a community manager with a pressing question via the Contact Us form so that I can get a swift reply. It should also include:
- Friendlier language for the different fields
- Contact Us form would autopopulate my email and tell CM what page they are referring to
- I should be able to categorize my question in the Contact Us form to best route the question.
- Some information telling me about History Hub
**Got screenshots? This helps us identify the issue**

**Additional context**
Add any other context about the problem here.
</issue>
<code>
[start of concordia/forms.py]
1 from logging import getLogger
2
3 from captcha.fields import CaptchaField
4 from django import forms
5 from django.contrib.auth import get_user_model
6 from django_registration.forms import RegistrationForm
7
8 from .models import TranscriptionStatus
9
10 User = get_user_model()
11 logger = getLogger(__name__)
12
13
14 class UserRegistrationForm(RegistrationForm):
15 newsletterOptIn = forms.BooleanField(
16 label="Newsletter",
17 required=False,
18 help_text="Email me about campaign updates, upcoming events, and new features.",
19 )
20
21
22 class UserProfileForm(forms.Form):
23 email = forms.CharField(
24 label="Email address", required=True, widget=forms.EmailInput()
25 )
26
27 def __init__(self, *, request, **kwargs):
28 self.request = request
29 return super().__init__(**kwargs)
30
31 def clean_email(self):
32 data = self.cleaned_data["email"]
33 if (
34 User.objects.exclude(pk=self.request.user.pk)
35 .filter(email__iexact=data)
36 .exists()
37 ):
38 raise forms.ValidationError("That email address is not available")
39 return data
40
41
42 class ContactUsForm(forms.Form):
43 referrer = forms.CharField(label="Referring Page", widget=forms.HiddenInput())
44
45 email = forms.EmailField(label="Your email", required=True)
46 subject = forms.CharField(label="Subject", required=False)
47
48 category = forms.CharField(
49 label="Category",
50 required=True,
51 widget=forms.Select(
52 choices=(
53 ("General", "General"),
54 ("Campaign", "Question about campaign"),
55 ("Problem", "Something is not working"),
56 )
57 ),
58 )
59
60 link = forms.URLField(
61 label="Link to the page you need support with", required=False
62 )
63
64 story = forms.CharField(
65 label="Why are you contacting us", required=True, widget=forms.Textarea
66 )
67
68
69 class CaptchaEmbedForm(forms.Form):
70 captcha = CaptchaField()
71
72
73 class AssetFilteringForm(forms.Form):
74 transcription_status = forms.ChoiceField(
75 choices=TranscriptionStatus.CHOICES,
76 required=False,
77 label="Image Status",
78 widget=forms.Select(attrs={"class": "form-control"}),
79 )
80
81 def __init__(self, status_counts, *args, **kwargs):
82 super().__init__(*args, **kwargs)
83
84 asset_statuses = {
85 status: "%s (%d)" % (TranscriptionStatus.CHOICE_MAP[status], count)
86 for status, count in status_counts.items()
87 }
88
89 filtered_choices = [("", f"All Images ({sum(status_counts.values())})")]
90 for val, label in self.fields["transcription_status"].choices:
91 if val in asset_statuses:
92 filtered_choices.append((val, asset_statuses[val]))
93
94 self.fields["transcription_status"].choices = filtered_choices
95
96
97 class AdminItemImportForm(forms.Form):
98 import_url = forms.URLField(
99 required=True, label="URL of the item/collection/search page to import"
100 )
101
102
103 class AdminProjectBulkImportForm(forms.Form):
104 spreadsheet_file = forms.FileField(
105 required=True,
106 label="Spreadsheet containing the campaigns, projects, and items to import",
107 )
108
[end of concordia/forms.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/concordia/forms.py b/concordia/forms.py
--- a/concordia/forms.py
+++ b/concordia/forms.py
@@ -42,27 +42,16 @@
class ContactUsForm(forms.Form):
referrer = forms.CharField(label="Referring Page", widget=forms.HiddenInput())
- email = forms.EmailField(label="Your email", required=True)
- subject = forms.CharField(label="Subject", required=False)
+ email = forms.EmailField(label="Your email:", required=True)
+ subject = forms.CharField(label="Subject:", required=False)
- category = forms.CharField(
- label="Category",
- required=True,
- widget=forms.Select(
- choices=(
- ("General", "General"),
- ("Campaign", "Question about campaign"),
- ("Problem", "Something is not working"),
- )
- ),
- )
link = forms.URLField(
- label="Link to the page you need support with", required=False
+ label="Have a specific page you need help with? Add the link below:", required=False
)
story = forms.CharField(
- label="Why are you contacting us", required=True, widget=forms.Textarea
+ label="Let us know how we can help:", required=True, widget=forms.Textarea
)
|
{"golden_diff": "diff --git a/concordia/forms.py b/concordia/forms.py\n--- a/concordia/forms.py\n+++ b/concordia/forms.py\n@@ -42,27 +42,16 @@\n class ContactUsForm(forms.Form):\n referrer = forms.CharField(label=\"Referring Page\", widget=forms.HiddenInput())\n \n- email = forms.EmailField(label=\"Your email\", required=True)\n- subject = forms.CharField(label=\"Subject\", required=False)\n+ email = forms.EmailField(label=\"Your email:\", required=True)\n+ subject = forms.CharField(label=\"Subject:\", required=False)\n \n- category = forms.CharField(\n- label=\"Category\",\n- required=True,\n- widget=forms.Select(\n- choices=(\n- (\"General\", \"General\"),\n- (\"Campaign\", \"Question about campaign\"),\n- (\"Problem\", \"Something is not working\"),\n- )\n- ),\n- )\n \n link = forms.URLField(\n- label=\"Link to the page you need support with\", required=False\n+ label=\"Have a specific page you need help with? Add the link below:\", required=False\n )\n \n story = forms.CharField(\n- label=\"Why are you contacting us\", required=True, widget=forms.Textarea\n+ label=\"Let us know how we can help:\", required=True, widget=forms.Textarea\n )\n", "issue": "Refine Contact Us page\n**What behavior did you observe? Please describe the bug**\r\n- The language is very direct. Need to make it more user friendly. \r\n- Add content to get to History Hub\r\n- Begin with options to self-service in Help Center or History Hub\r\n\r\n**What is the expected behavior?**\r\nAs a user, I want to contact a community manager with a pressing question via the Contact Us form so that I can get a swift reply. It should also include: \r\n- Friendlier language for the different fields\r\n- Contact Us form would autopopulate my email and tell CM what page they are referring to\r\n- I should be able to categorize my question in the Contact Us form to best route the question.\r\n- Some information telling me about History Hub\r\n\r\n**Got screenshots? This helps us identify the issue**\r\n\r\n\r\n\r\n\r\n**Additional context**\r\nAdd any other context about the problem here.\r\n\n", "before_files": [{"content": "from logging import getLogger\n\nfrom captcha.fields import CaptchaField\nfrom django import forms\nfrom django.contrib.auth import get_user_model\nfrom django_registration.forms import RegistrationForm\n\nfrom .models import TranscriptionStatus\n\nUser = get_user_model()\nlogger = getLogger(__name__)\n\n\nclass UserRegistrationForm(RegistrationForm):\n newsletterOptIn = forms.BooleanField(\n label=\"Newsletter\",\n required=False,\n help_text=\"Email me about campaign updates, upcoming events, and new features.\",\n )\n\n\nclass UserProfileForm(forms.Form):\n email = forms.CharField(\n label=\"Email address\", required=True, widget=forms.EmailInput()\n )\n\n def __init__(self, *, request, **kwargs):\n self.request = request\n return super().__init__(**kwargs)\n\n def clean_email(self):\n data = self.cleaned_data[\"email\"]\n if (\n User.objects.exclude(pk=self.request.user.pk)\n .filter(email__iexact=data)\n .exists()\n ):\n raise forms.ValidationError(\"That email address is not available\")\n return data\n\n\nclass ContactUsForm(forms.Form):\n referrer = forms.CharField(label=\"Referring Page\", widget=forms.HiddenInput())\n\n email = forms.EmailField(label=\"Your email\", required=True)\n subject = forms.CharField(label=\"Subject\", required=False)\n\n category = forms.CharField(\n label=\"Category\",\n required=True,\n widget=forms.Select(\n choices=(\n (\"General\", \"General\"),\n (\"Campaign\", \"Question about campaign\"),\n (\"Problem\", \"Something is not working\"),\n )\n ),\n )\n\n link = forms.URLField(\n label=\"Link to the page you need support with\", required=False\n )\n\n story = forms.CharField(\n label=\"Why are you contacting us\", required=True, widget=forms.Textarea\n )\n\n\nclass CaptchaEmbedForm(forms.Form):\n captcha = CaptchaField()\n\n\nclass AssetFilteringForm(forms.Form):\n transcription_status = forms.ChoiceField(\n choices=TranscriptionStatus.CHOICES,\n required=False,\n label=\"Image Status\",\n widget=forms.Select(attrs={\"class\": \"form-control\"}),\n )\n\n def __init__(self, status_counts, *args, **kwargs):\n super().__init__(*args, **kwargs)\n\n asset_statuses = {\n status: \"%s (%d)\" % (TranscriptionStatus.CHOICE_MAP[status], count)\n for status, count in status_counts.items()\n }\n\n filtered_choices = [(\"\", f\"All Images ({sum(status_counts.values())})\")]\n for val, label in self.fields[\"transcription_status\"].choices:\n if val in asset_statuses:\n filtered_choices.append((val, asset_statuses[val]))\n\n self.fields[\"transcription_status\"].choices = filtered_choices\n\n\nclass AdminItemImportForm(forms.Form):\n import_url = forms.URLField(\n required=True, label=\"URL of the item/collection/search page to import\"\n )\n\n\nclass AdminProjectBulkImportForm(forms.Form):\n spreadsheet_file = forms.FileField(\n required=True,\n label=\"Spreadsheet containing the campaigns, projects, and items to import\",\n )\n", "path": "concordia/forms.py"}]}
| 1,663 | 289 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.