
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.71k
9.01k
| golden_diff
stringlengths 151
4.94k
| verification_info
stringlengths 465
11.3k
| num_tokens_prompt
int64 557
2.05k
| num_tokens_diff
int64 48
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_35351
|
rasdani/github-patches
|
git_diff
|
microsoft__onnxscript-392
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ghpage: use the Furo theme
https://pradyunsg.me/furo/. It’s pretty and more modern. Used by black https://black.readthedocs.io/en/stable/#
</issue>
<code>
[start of docs/conf.py]
1 # Configuration file for the Sphinx documentation builder.
2 # To run the documentation: python -m sphinx docs dist/html
3
4 import os
5 import re
6 import sys
7
8 import sphinx_gallery.sorting
9
10 import onnxscript
11
12 # -- Project information -----------------------------------------------------
13
14 project = "onnx-script"
15 copyright = "2022, onnx"
16 author = "onnx"
17 version = onnxscript.__version__
18 release = version
19
20 # -- General configuration ---------------------------------------------------
21
22 extensions = [
23 "sphinx.ext.intersphinx",
24 "sphinx.ext.imgmath",
25 "sphinx.ext.ifconfig",
26 "sphinx.ext.viewcode",
27 "sphinx.ext.autodoc",
28 "sphinx.ext.githubpages",
29 "sphinx_gallery.gen_gallery",
30 "sphinx.ext.autodoc",
31 "sphinx.ext.graphviz",
32 "sphinx.ext.doctest",
33 "sphinx.ext.napoleon",
34 ]
35
36 templates_path = ["_templates"]
37 source_suffix = [".rst"]
38
39 master_doc = "index"
40 language = "en"
41 exclude_patterns = []
42 pygments_style = "default"
43
44 # -- Options for HTML output -------------------------------------------------
45
46 html_static_path = ["_static"]
47 html_theme = "pydata_sphinx_theme"
48 html_theme_path = ["_static"]
49 html_theme_options = {
50 "logo": {
51 "image_light": "logo-light.png",
52 "image_dark": "logo-dark.png",
53 }
54 }
55 html_css_files = ["css/custom.css"]
56
57 # -- Options for graphviz ----------------------------------------------------
58
59 graphviz_output_format = "svg"
60
61 # -- Options for intersphinx extension ---------------------------------------
62
63 # Example configuration for intersphinx: refer to the Python standard library.
64 intersphinx_mapping = {"https://docs.python.org/": None}
65
66 # -- Options for Sphinx Gallery ----------------------------------------------
67
68 intersphinx_mapping = {
69 "python": (f"https://docs.python.org/{sys.version_info.major}", None),
70 "matplotlib": ("https://matplotlib.org/", None),
71 "numpy": ("https://docs.scipy.org/doc/numpy/", None),
72 "onnxruntime": ("https://onnxruntime.ai/docs/api/python/", None),
73 }
74
75 sphinx_gallery_conf = {
76 "examples_dirs": ["examples"],
77 "gallery_dirs": ["auto_examples"],
78 "capture_repr": ("_repr_html_", "__repr__"),
79 "ignore_repr_types": r"matplotlib.text|matplotlib.axes",
80 "filename_pattern": f"{re.escape(os.sep)}[0-9]*_?plot_",
81 "within_subsection_order": sphinx_gallery.sorting.FileNameSortKey,
82 }
83
[end of docs/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -12,7 +12,7 @@
# -- Project information -----------------------------------------------------
project = "onnx-script"
-copyright = "2022, onnx"
+copyright = "2023, onnx"
author = "onnx"
version = onnxscript.__version__
release = version
@@ -31,10 +31,11 @@
"sphinx.ext.graphviz",
"sphinx.ext.doctest",
"sphinx.ext.napoleon",
+ "sphinx_copybutton",
]
templates_path = ["_templates"]
-source_suffix = [".rst"]
+source_suffix = [".rst", ".md"]
master_doc = "index"
language = "en"
@@ -44,13 +45,12 @@
# -- Options for HTML output -------------------------------------------------
html_static_path = ["_static"]
-html_theme = "pydata_sphinx_theme"
+html_theme = "furo"
html_theme_path = ["_static"]
html_theme_options = {
- "logo": {
- "image_light": "logo-light.png",
- "image_dark": "logo-dark.png",
- }
+ "light_logo": "logo-light.png",
+ "dark_logo": "logo-dark.png",
+ "sidebar_hide_name": True,
}
html_css_files = ["css/custom.css"]
@@ -60,11 +60,6 @@
# -- Options for intersphinx extension ---------------------------------------
-# Example configuration for intersphinx: refer to the Python standard library.
-intersphinx_mapping = {"https://docs.python.org/": None}
-
-# -- Options for Sphinx Gallery ----------------------------------------------
-
intersphinx_mapping = {
"python": (f"https://docs.python.org/{sys.version_info.major}", None),
"matplotlib": ("https://matplotlib.org/", None),
@@ -72,6 +67,8 @@
"onnxruntime": ("https://onnxruntime.ai/docs/api/python/", None),
}
+# -- Options for Sphinx Gallery ----------------------------------------------
+
sphinx_gallery_conf = {
"examples_dirs": ["examples"],
"gallery_dirs": ["auto_examples"],
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -12,7 +12,7 @@\n # -- Project information -----------------------------------------------------\n \n project = \"onnx-script\"\n-copyright = \"2022, onnx\"\n+copyright = \"2023, onnx\"\n author = \"onnx\"\n version = onnxscript.__version__\n release = version\n@@ -31,10 +31,11 @@\n \"sphinx.ext.graphviz\",\n \"sphinx.ext.doctest\",\n \"sphinx.ext.napoleon\",\n+ \"sphinx_copybutton\",\n ]\n \n templates_path = [\"_templates\"]\n-source_suffix = [\".rst\"]\n+source_suffix = [\".rst\", \".md\"]\n \n master_doc = \"index\"\n language = \"en\"\n@@ -44,13 +45,12 @@\n # -- Options for HTML output -------------------------------------------------\n \n html_static_path = [\"_static\"]\n-html_theme = \"pydata_sphinx_theme\"\n+html_theme = \"furo\"\n html_theme_path = [\"_static\"]\n html_theme_options = {\n- \"logo\": {\n- \"image_light\": \"logo-light.png\",\n- \"image_dark\": \"logo-dark.png\",\n- }\n+ \"light_logo\": \"logo-light.png\",\n+ \"dark_logo\": \"logo-dark.png\",\n+ \"sidebar_hide_name\": True,\n }\n html_css_files = [\"css/custom.css\"]\n \n@@ -60,11 +60,6 @@\n \n # -- Options for intersphinx extension ---------------------------------------\n \n-# Example configuration for intersphinx: refer to the Python standard library.\n-intersphinx_mapping = {\"https://docs.python.org/\": None}\n-\n-# -- Options for Sphinx Gallery ----------------------------------------------\n-\n intersphinx_mapping = {\n \"python\": (f\"https://docs.python.org/{sys.version_info.major}\", None),\n \"matplotlib\": (\"https://matplotlib.org/\", None),\n@@ -72,6 +67,8 @@\n \"onnxruntime\": (\"https://onnxruntime.ai/docs/api/python/\", None),\n }\n \n+# -- Options for Sphinx Gallery ----------------------------------------------\n+\n sphinx_gallery_conf = {\n \"examples_dirs\": [\"examples\"],\n \"gallery_dirs\": [\"auto_examples\"],\n", "issue": "ghpage: use the Furo theme\nhttps://pradyunsg.me/furo/. It\u2019s pretty and more modern. Used by black https://black.readthedocs.io/en/stable/#\n", "before_files": [{"content": "# Configuration file for the Sphinx documentation builder.\n# To run the documentation: python -m sphinx docs dist/html\n\nimport os\nimport re\nimport sys\n\nimport sphinx_gallery.sorting\n\nimport onnxscript\n\n# -- Project information -----------------------------------------------------\n\nproject = \"onnx-script\"\ncopyright = \"2022, onnx\"\nauthor = \"onnx\"\nversion = onnxscript.__version__\nrelease = version\n\n# -- General configuration ---------------------------------------------------\n\nextensions = [\n \"sphinx.ext.intersphinx\",\n \"sphinx.ext.imgmath\",\n \"sphinx.ext.ifconfig\",\n \"sphinx.ext.viewcode\",\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.githubpages\",\n \"sphinx_gallery.gen_gallery\",\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.graphviz\",\n \"sphinx.ext.doctest\",\n \"sphinx.ext.napoleon\",\n]\n\ntemplates_path = [\"_templates\"]\nsource_suffix = [\".rst\"]\n\nmaster_doc = \"index\"\nlanguage = \"en\"\nexclude_patterns = []\npygments_style = \"default\"\n\n# -- Options for HTML output -------------------------------------------------\n\nhtml_static_path = [\"_static\"]\nhtml_theme = \"pydata_sphinx_theme\"\nhtml_theme_path = [\"_static\"]\nhtml_theme_options = {\n \"logo\": {\n \"image_light\": \"logo-light.png\",\n \"image_dark\": \"logo-dark.png\",\n }\n}\nhtml_css_files = [\"css/custom.css\"]\n\n# -- Options for graphviz ----------------------------------------------------\n\ngraphviz_output_format = \"svg\"\n\n# -- Options for intersphinx extension ---------------------------------------\n\n# Example configuration for intersphinx: refer to the Python standard library.\nintersphinx_mapping = {\"https://docs.python.org/\": None}\n\n# -- Options for Sphinx Gallery ----------------------------------------------\n\nintersphinx_mapping = {\n \"python\": (f\"https://docs.python.org/{sys.version_info.major}\", None),\n \"matplotlib\": (\"https://matplotlib.org/\", None),\n \"numpy\": (\"https://docs.scipy.org/doc/numpy/\", None),\n \"onnxruntime\": (\"https://onnxruntime.ai/docs/api/python/\", None),\n}\n\nsphinx_gallery_conf = {\n \"examples_dirs\": [\"examples\"],\n \"gallery_dirs\": [\"auto_examples\"],\n \"capture_repr\": (\"_repr_html_\", \"__repr__\"),\n \"ignore_repr_types\": r\"matplotlib.text|matplotlib.axes\",\n \"filename_pattern\": f\"{re.escape(os.sep)}[0-9]*_?plot_\",\n \"within_subsection_order\": sphinx_gallery.sorting.FileNameSortKey,\n}\n", "path": "docs/conf.py"}]}
| 1,273 | 480 |
gh_patches_debug_49854
|
rasdani/github-patches
|
git_diff
|
urllib3__urllib3-678
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
setup.py extra_require for certifi, pyopenssl, other?
Try to setup as many of https://urllib3.readthedocs.org/en/latest/security.html#security's recommended dependencies as possible.
Maybe something like `pip install urllib3[secure]`
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2
3 from distutils.core import setup
4
5 import os
6 import re
7
8 try:
9 import setuptools
10 except ImportError:
11 pass # No 'develop' command, oh well.
12
13 base_path = os.path.dirname(__file__)
14
15 # Get the version (borrowed from SQLAlchemy)
16 fp = open(os.path.join(base_path, 'urllib3', '__init__.py'))
17 VERSION = re.compile(r".*__version__ = '(.*?)'",
18 re.S).match(fp.read()).group(1)
19 fp.close()
20
21
22 version = VERSION
23
24 setup(name='urllib3',
25 version=version,
26 description="HTTP library with thread-safe connection pooling, file post, and more.",
27 long_description=open('README.rst').read() + '\n\n' + open('CHANGES.rst').read(),
28 classifiers=[
29 'Environment :: Web Environment',
30 'Intended Audience :: Developers',
31 'License :: OSI Approved :: MIT License',
32 'Operating System :: OS Independent',
33 'Programming Language :: Python',
34 'Programming Language :: Python :: 2',
35 'Programming Language :: Python :: 3',
36 'Topic :: Internet :: WWW/HTTP',
37 'Topic :: Software Development :: Libraries',
38 ],
39 keywords='urllib httplib threadsafe filepost http https ssl pooling',
40 author='Andrey Petrov',
41 author_email='[email protected]',
42 url='http://urllib3.readthedocs.org/',
43 license='MIT',
44 packages=['urllib3',
45 'urllib3.packages', 'urllib3.packages.ssl_match_hostname',
46 'urllib3.contrib', 'urllib3.util',
47 ],
48 requires=[],
49 tests_require=[
50 # These are a less-specific subset of dev-requirements.txt, for the
51 # convenience of distro package maintainers.
52 'nose',
53 'mock',
54 'tornado',
55 ],
56 test_suite='test',
57 )
58
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -54,4 +54,15 @@
'tornado',
],
test_suite='test',
+ extras_require={
+ 'secure;python_version<="2.7"': [
+ 'pyOpenSSL',
+ 'ndg-httpsclient',
+ 'pyasn1',
+ 'certifi',
+ ],
+ 'secure;python_version>"2.7"': [
+ 'certifi',
+ ],
+ },
)
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -54,4 +54,15 @@\n 'tornado',\n ],\n test_suite='test',\n+ extras_require={\n+ 'secure;python_version<=\"2.7\"': [\n+ 'pyOpenSSL',\n+ 'ndg-httpsclient',\n+ 'pyasn1',\n+ 'certifi',\n+ ],\n+ 'secure;python_version>\"2.7\"': [\n+ 'certifi',\n+ ],\n+ },\n )\n", "issue": "setup.py extra_require for certifi, pyopenssl, other?\nTry to setup as many of https://urllib3.readthedocs.org/en/latest/security.html#security's recommended dependencies as possible.\n\nMaybe something like `pip install urllib3[secure]`\n\n", "before_files": [{"content": "#!/usr/bin/env python\n\nfrom distutils.core import setup\n\nimport os\nimport re\n\ntry:\n import setuptools\nexcept ImportError:\n pass # No 'develop' command, oh well.\n\nbase_path = os.path.dirname(__file__)\n\n# Get the version (borrowed from SQLAlchemy)\nfp = open(os.path.join(base_path, 'urllib3', '__init__.py'))\nVERSION = re.compile(r\".*__version__ = '(.*?)'\",\n re.S).match(fp.read()).group(1)\nfp.close()\n\n\nversion = VERSION\n\nsetup(name='urllib3',\n version=version,\n description=\"HTTP library with thread-safe connection pooling, file post, and more.\",\n long_description=open('README.rst').read() + '\\n\\n' + open('CHANGES.rst').read(),\n classifiers=[\n 'Environment :: Web Environment',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: MIT License',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 3',\n 'Topic :: Internet :: WWW/HTTP',\n 'Topic :: Software Development :: Libraries',\n ],\n keywords='urllib httplib threadsafe filepost http https ssl pooling',\n author='Andrey Petrov',\n author_email='[email protected]',\n url='http://urllib3.readthedocs.org/',\n license='MIT',\n packages=['urllib3',\n 'urllib3.packages', 'urllib3.packages.ssl_match_hostname',\n 'urllib3.contrib', 'urllib3.util',\n ],\n requires=[],\n tests_require=[\n # These are a less-specific subset of dev-requirements.txt, for the\n # convenience of distro package maintainers.\n 'nose',\n 'mock',\n 'tornado',\n ],\n test_suite='test',\n )\n", "path": "setup.py"}]}
| 1,105 | 127 |
gh_patches_debug_2284
|
rasdani/github-patches
|
git_diff
|
OCA__social-91
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Unable to send email on new template
module: mail_notification_email_template
version: 8.0
**Steps to reproduce**
- Install Sales module and activate technical settings
-configure and test one outgoing server
- Create a new template for Quotation sent ( can keep most values the same as per the Discussions example) , although my final goal is to utilize fields from the sales Quotation
- Create a new draft quotation , add new followers (internal users and one customer)
- make sure that followers is part of the Quotation sent sub type (eg they will receive emails)
- Print the quotation
**Current behavior**
- Emails fails most of the time to all followers, although i have had cases where it succeeds in sending to one.
-remainder of emails is stuck showing failed status.
Log file shows :
**odoo attributeerror: 'mail.notification' object has no attribute '_get_access_link'**
**Expected behavior**
-All emails are supposed to go out using the configured template.
(i have had success where i manually configure the to Email field with email addresses, thus the issue is possibly with the formatting of the to(partners) field, which is currently
${object.partner_id.ids|join(',')}
I currently don't have access to my server logs, but will attach clean logs asap.
Is there any verbose mode i might need to activate? (there is debugging on the outgoing servers, but it doesn't seem to generate more data)
</issue>
<code>
[start of mail_notification_email_template/models/mail_notification.py]
1 # -*- coding: utf-8 -*-
2 # © 2016 Therp BV <http://therp.nl>
3 # License AGPL-3.0 or later (http://www.gnu.org/licenses/agpl.html).
4 from lxml import etree
5 from openerp import api, fields, models
6
7
8 class MailNotification(models.Model):
9 _inherit = 'mail.notification'
10
11 record = fields.Reference(
12 selection=lambda self: [
13 (m.model, m.name) for m in self.env['ir.model'].search([])
14 ],
15 compute='_compute_record')
16 record_access_link = fields.Char(compute='_compute_record')
17
18 @api.multi
19 def _notify_email(self, message_id, force_send=False, user_signature=True):
20 if not self.mapped('message_id.subtype_id.template_id'):
21 return super(MailNotification, self)._notify_email(
22 message_id, force_send=force_send,
23 user_signature=user_signature)
24 message_ids = []
25 for this in self:
26 if not this.mapped('message_id.subtype_id.template_id'):
27 super(MailNotification, this)._notify_email(
28 message_id, force_send=force_send,
29 user_signature=user_signature)
30 continue
31 message = this.message_id
32 if not this.get_partners_to_email(message):
33 continue
34 custom_values = {
35 'references': message.parent_id.message_id,
36 }
37 if message.res_id and hasattr(
38 self.env[message.model], 'message_get_email_values'
39 ):
40 message_values = self.env[message.model].browse(
41 message.res_id
42 ).message_get_email_values(message)
43 # message_get_email_values is guessed to @api.one
44 if message_values and isinstance(message_values, list):
45 message_values = message_values[0]
46 custom_values.update(message_values)
47 message_id = message.subtype_id.template_id.send_mail(this.id)
48 if 'mail_message_id' in custom_values:
49 custom_values.pop('mail_message_id')
50 self.env['mail.mail'].browse(message_id).write(custom_values)
51 message_ids.append(message_id)
52 return message_ids or True
53
54 @api.multi
55 def _compute_record(self):
56 for this in self:
57 if not this.message_id.model or not this.message_id.res_id:
58 continue
59 this.record = self.env[this.message_id.model].browse(
60 this.message_id.res_id)
61 link_html = self.env['mail.mail']._get_partner_access_link(
62 self.env['mail.mail'].new({
63 'notification': True,
64 'mail_message_id': this.message_id.id,
65 }),
66 this.partner_id
67 )
68 for a in etree.HTML(link_html).xpath('//a[@href]'):
69 this.record_access_link = a.get('href')
70
[end of mail_notification_email_template/models/mail_notification.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mail_notification_email_template/models/mail_notification.py b/mail_notification_email_template/models/mail_notification.py
--- a/mail_notification_email_template/models/mail_notification.py
+++ b/mail_notification_email_template/models/mail_notification.py
@@ -65,5 +65,5 @@
}),
this.partner_id
)
- for a in etree.HTML(link_html).xpath('//a[@href]'):
+ for a in etree.HTML(link_html or '<html/>').xpath('//a[@href]'):
this.record_access_link = a.get('href')
|
{"golden_diff": "diff --git a/mail_notification_email_template/models/mail_notification.py b/mail_notification_email_template/models/mail_notification.py\n--- a/mail_notification_email_template/models/mail_notification.py\n+++ b/mail_notification_email_template/models/mail_notification.py\n@@ -65,5 +65,5 @@\n }),\n this.partner_id\n )\n- for a in etree.HTML(link_html).xpath('//a[@href]'):\n+ for a in etree.HTML(link_html or '<html/>').xpath('//a[@href]'):\n this.record_access_link = a.get('href')\n", "issue": "Unable to send email on new template\nmodule: mail_notification_email_template\nversion: 8.0\n\n**Steps to reproduce**\n- Install Sales module and activate technical settings\n -configure and test one outgoing server\n- Create a new template for Quotation sent ( can keep most values the same as per the Discussions example) , although my final goal is to utilize fields from the sales Quotation\n- Create a new draft quotation , add new followers (internal users and one customer)\n- make sure that followers is part of the Quotation sent sub type (eg they will receive emails)\n- Print the quotation\n\n**Current behavior**\n- Emails fails most of the time to all followers, although i have had cases where it succeeds in sending to one.\n -remainder of emails is stuck showing failed status.\n Log file shows :\n **odoo attributeerror: 'mail.notification' object has no attribute '_get_access_link'**\n\n**Expected behavior**\n-All emails are supposed to go out using the configured template.\n\n(i have had success where i manually configure the to Email field with email addresses, thus the issue is possibly with the formatting of the to(partners) field, which is currently\n${object.partner_id.ids|join(',')}\n\nI currently don't have access to my server logs, but will attach clean logs asap. \nIs there any verbose mode i might need to activate? (there is debugging on the outgoing servers, but it doesn't seem to generate more data)\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# \u00a9 2016 Therp BV <http://therp.nl>\n# License AGPL-3.0 or later (http://www.gnu.org/licenses/agpl.html).\nfrom lxml import etree\nfrom openerp import api, fields, models\n\n\nclass MailNotification(models.Model):\n _inherit = 'mail.notification'\n\n record = fields.Reference(\n selection=lambda self: [\n (m.model, m.name) for m in self.env['ir.model'].search([])\n ],\n compute='_compute_record')\n record_access_link = fields.Char(compute='_compute_record')\n\n @api.multi\n def _notify_email(self, message_id, force_send=False, user_signature=True):\n if not self.mapped('message_id.subtype_id.template_id'):\n return super(MailNotification, self)._notify_email(\n message_id, force_send=force_send,\n user_signature=user_signature)\n message_ids = []\n for this in self:\n if not this.mapped('message_id.subtype_id.template_id'):\n super(MailNotification, this)._notify_email(\n message_id, force_send=force_send,\n user_signature=user_signature)\n continue\n message = this.message_id\n if not this.get_partners_to_email(message):\n continue\n custom_values = {\n 'references': message.parent_id.message_id,\n }\n if message.res_id and hasattr(\n self.env[message.model], 'message_get_email_values'\n ):\n message_values = self.env[message.model].browse(\n message.res_id\n ).message_get_email_values(message)\n # message_get_email_values is guessed to @api.one\n if message_values and isinstance(message_values, list):\n message_values = message_values[0]\n custom_values.update(message_values)\n message_id = message.subtype_id.template_id.send_mail(this.id)\n if 'mail_message_id' in custom_values:\n custom_values.pop('mail_message_id')\n self.env['mail.mail'].browse(message_id).write(custom_values)\n message_ids.append(message_id)\n return message_ids or True\n\n @api.multi\n def _compute_record(self):\n for this in self:\n if not this.message_id.model or not this.message_id.res_id:\n continue\n this.record = self.env[this.message_id.model].browse(\n this.message_id.res_id)\n link_html = self.env['mail.mail']._get_partner_access_link(\n self.env['mail.mail'].new({\n 'notification': True,\n 'mail_message_id': this.message_id.id,\n }),\n this.partner_id\n )\n for a in etree.HTML(link_html).xpath('//a[@href]'):\n this.record_access_link = a.get('href')\n", "path": "mail_notification_email_template/models/mail_notification.py"}]}
| 1,554 | 115 |
gh_patches_debug_22969
|
rasdani/github-patches
|
git_diff
|
TencentBlueKing__bk-user-935
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
【安全】安全漏洞扫描,生产环境下能访问后台swagger
**用文字描述你遇到的问题**
生产环境,swagger未屏蔽可访问
**重现方法**

对应源码未屏蔽
https://github.com/TencentBlueKing/bk-user/blob/40ee56ed90d47b214274819394aa21ec7459b970/src/api/bkuser_core/apis/urls.py#L45
**预期行为**
预期的正常行为
**版本**
- 2.5.2
- 是否是企业版问题?
是
**如果是 SaaS 页面问题,请提供使用的操作系统和浏览器信息**
- OS: [e.g. iOS]
- Browser [e.g. chrome, safari]
- Version [e.g. 22]
**额外信息**
任何你觉得有助于问题解决的内容
</issue>
<code>
[start of src/api/bkuser_core/apis/urls.py]
1 # -*- coding: utf-8 -*-
2 """
3 TencentBlueKing is pleased to support the open source community by making 蓝鲸智云-用户管理(Bk-User) available.
4 Copyright (C) 2017-2021 THL A29 Limited, a Tencent company. All rights reserved.
5 Licensed under the MIT License (the "License"); you may not use this file except in compliance with the License.
6 You may obtain a copy of the License at http://opensource.org/licenses/MIT
7 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
8 an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
9 specific language governing permissions and limitations under the License.
10 """
11 from django.conf.urls import include, url
12 from drf_yasg import openapi
13 from drf_yasg.generators import OpenAPISchemaGenerator
14 from drf_yasg.views import get_schema_view
15 from rest_framework import permissions
16
17
18 class CustomOpenAPISchemaGenerator(OpenAPISchemaGenerator):
19 def get_schema(self, request=None, public=False):
20 schema = super().get_schema(request, public)
21 return schema
22
23
24 schema_view = get_schema_view(
25 openapi.Info(
26 title="蓝鲸用户管理 API",
27 default_version="v2",
28 description="蓝鲸用户管理后台服务 API",
29 license=openapi.License(name="MIT License"),
30 ),
31 public=True,
32 permission_classes=(permissions.AllowAny,),
33 generator_class=CustomOpenAPISchemaGenerator,
34 patterns=[
35 url(r"^", include("bkuser_core.monitoring.urls")),
36 url(r"^", include("bkuser_core.departments.urls")),
37 url(r"^", include("bkuser_core.profiles.urls")),
38 url(r"^", include("bkuser_core.categories.urls")),
39 # url(r"^", include("bkuser_core.user_settings.urls")),
40 # url(r"^", include("bkuser_core.audit.urls")),
41 ],
42 )
43
44
45 urlpatterns = [
46 url(r"^swagger(?P<format>\.json|\.yaml)$", schema_view.without_ui(cache_timeout=0), name="schema-json"),
47 url(r"^swagger/$", schema_view.with_ui("swagger", cache_timeout=0), name="schema-swagger-ui"),
48 url(r"^redoc/$", schema_view.with_ui("redoc", cache_timeout=0), name="schema-redoc"),
49 ]
50
[end of src/api/bkuser_core/apis/urls.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/api/bkuser_core/apis/urls.py b/src/api/bkuser_core/apis/urls.py
--- a/src/api/bkuser_core/apis/urls.py
+++ b/src/api/bkuser_core/apis/urls.py
@@ -8,6 +8,7 @@
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
"""
+from django.conf import settings
from django.conf.urls import include, url
from drf_yasg import openapi
from drf_yasg.generators import OpenAPISchemaGenerator
@@ -41,9 +42,10 @@
],
)
-
-urlpatterns = [
- url(r"^swagger(?P<format>\.json|\.yaml)$", schema_view.without_ui(cache_timeout=0), name="schema-json"),
- url(r"^swagger/$", schema_view.with_ui("swagger", cache_timeout=0), name="schema-swagger-ui"),
- url(r"^redoc/$", schema_view.with_ui("redoc", cache_timeout=0), name="schema-redoc"),
-]
+urlpatterns = []
+if settings.DEBUG:
+ urlpatterns += [
+ url(r"^swagger(?P<format>\.json|\.yaml)$", schema_view.without_ui(cache_timeout=0), name="schema-json"),
+ url(r"^swagger/$", schema_view.with_ui("swagger", cache_timeout=0), name="schema-swagger-ui"),
+ url(r"^redoc/$", schema_view.with_ui("redoc", cache_timeout=0), name="schema-redoc"),
+ ]
|
{"golden_diff": "diff --git a/src/api/bkuser_core/apis/urls.py b/src/api/bkuser_core/apis/urls.py\n--- a/src/api/bkuser_core/apis/urls.py\n+++ b/src/api/bkuser_core/apis/urls.py\n@@ -8,6 +8,7 @@\n an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the\n specific language governing permissions and limitations under the License.\n \"\"\"\n+from django.conf import settings\n from django.conf.urls import include, url\n from drf_yasg import openapi\n from drf_yasg.generators import OpenAPISchemaGenerator\n@@ -41,9 +42,10 @@\n ],\n )\n \n-\n-urlpatterns = [\n- url(r\"^swagger(?P<format>\\.json|\\.yaml)$\", schema_view.without_ui(cache_timeout=0), name=\"schema-json\"),\n- url(r\"^swagger/$\", schema_view.with_ui(\"swagger\", cache_timeout=0), name=\"schema-swagger-ui\"),\n- url(r\"^redoc/$\", schema_view.with_ui(\"redoc\", cache_timeout=0), name=\"schema-redoc\"),\n-]\n+urlpatterns = []\n+if settings.DEBUG:\n+ urlpatterns += [\n+ url(r\"^swagger(?P<format>\\.json|\\.yaml)$\", schema_view.without_ui(cache_timeout=0), name=\"schema-json\"),\n+ url(r\"^swagger/$\", schema_view.with_ui(\"swagger\", cache_timeout=0), name=\"schema-swagger-ui\"),\n+ url(r\"^redoc/$\", schema_view.with_ui(\"redoc\", cache_timeout=0), name=\"schema-redoc\"),\n+ ]\n", "issue": "\u3010\u5b89\u5168\u3011\u5b89\u5168\u6f0f\u6d1e\u626b\u63cf\uff0c\u751f\u4ea7\u73af\u5883\u4e0b\u80fd\u8bbf\u95ee\u540e\u53f0swagger\n**\u7528\u6587\u5b57\u63cf\u8ff0\u4f60\u9047\u5230\u7684\u95ee\u9898**\r\n\r\n\u751f\u4ea7\u73af\u5883\uff0cswagger\u672a\u5c4f\u853d\u53ef\u8bbf\u95ee\r\n\r\n**\u91cd\u73b0\u65b9\u6cd5**\r\n\r\n\r\n\u5bf9\u5e94\u6e90\u7801\u672a\u5c4f\u853d\r\nhttps://github.com/TencentBlueKing/bk-user/blob/40ee56ed90d47b214274819394aa21ec7459b970/src/api/bkuser_core/apis/urls.py#L45\r\n\r\n**\u9884\u671f\u884c\u4e3a**\r\n\r\n\u9884\u671f\u7684\u6b63\u5e38\u884c\u4e3a\r\n\r\n**\u7248\u672c**\r\n- 2.5.2\r\n- \u662f\u5426\u662f\u4f01\u4e1a\u7248\u95ee\u9898\uff1f\r\n\u662f\r\n\r\n**\u5982\u679c\u662f SaaS \u9875\u9762\u95ee\u9898\uff0c\u8bf7\u63d0\u4f9b\u4f7f\u7528\u7684\u64cd\u4f5c\u7cfb\u7edf\u548c\u6d4f\u89c8\u5668\u4fe1\u606f**\r\n - OS: [e.g. iOS]\r\n - Browser [e.g. chrome, safari]\r\n - Version [e.g. 22]\r\n\r\n**\u989d\u5916\u4fe1\u606f**\r\n\r\n\u4efb\u4f55\u4f60\u89c9\u5f97\u6709\u52a9\u4e8e\u95ee\u9898\u89e3\u51b3\u7684\u5185\u5bb9\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\nTencentBlueKing is pleased to support the open source community by making \u84dd\u9cb8\u667a\u4e91-\u7528\u6237\u7ba1\u7406(Bk-User) available.\nCopyright (C) 2017-2021 THL A29 Limited, a Tencent company. All rights reserved.\nLicensed under the MIT License (the \"License\"); you may not use this file except in compliance with the License.\nYou may obtain a copy of the License at http://opensource.org/licenses/MIT\nUnless required by applicable law or agreed to in writing, software distributed under the License is distributed on\nan \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the\nspecific language governing permissions and limitations under the License.\n\"\"\"\nfrom django.conf.urls import include, url\nfrom drf_yasg import openapi\nfrom drf_yasg.generators import OpenAPISchemaGenerator\nfrom drf_yasg.views import get_schema_view\nfrom rest_framework import permissions\n\n\nclass CustomOpenAPISchemaGenerator(OpenAPISchemaGenerator):\n def get_schema(self, request=None, public=False):\n schema = super().get_schema(request, public)\n return schema\n\n\nschema_view = get_schema_view(\n openapi.Info(\n title=\"\u84dd\u9cb8\u7528\u6237\u7ba1\u7406 API\",\n default_version=\"v2\",\n description=\"\u84dd\u9cb8\u7528\u6237\u7ba1\u7406\u540e\u53f0\u670d\u52a1 API\",\n license=openapi.License(name=\"MIT License\"),\n ),\n public=True,\n permission_classes=(permissions.AllowAny,),\n generator_class=CustomOpenAPISchemaGenerator,\n patterns=[\n url(r\"^\", include(\"bkuser_core.monitoring.urls\")),\n url(r\"^\", include(\"bkuser_core.departments.urls\")),\n url(r\"^\", include(\"bkuser_core.profiles.urls\")),\n url(r\"^\", include(\"bkuser_core.categories.urls\")),\n # url(r\"^\", include(\"bkuser_core.user_settings.urls\")),\n # url(r\"^\", include(\"bkuser_core.audit.urls\")),\n ],\n)\n\n\nurlpatterns = [\n url(r\"^swagger(?P<format>\\.json|\\.yaml)$\", schema_view.without_ui(cache_timeout=0), name=\"schema-json\"),\n url(r\"^swagger/$\", schema_view.with_ui(\"swagger\", cache_timeout=0), name=\"schema-swagger-ui\"),\n url(r\"^redoc/$\", schema_view.with_ui(\"redoc\", cache_timeout=0), name=\"schema-redoc\"),\n]\n", "path": "src/api/bkuser_core/apis/urls.py"}]}
| 1,409 | 358 |
gh_patches_debug_4072
|
rasdani/github-patches
|
git_diff
|
mathesar-foundation__mathesar-3127
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Implement frontend flow: User sharing an entity
I've not added a description, since I'll be implementing this.
Refer [Product spec](https://wiki.mathesar.org/en/product/specs/publicly-shareable-links) for detailed info.
</issue>
<code>
[start of mathesar/api/ui/permissions/shares.py]
1 from rest_access_policy import AccessPolicy
2
3 from mathesar.api.utils import get_query_or_404
4 from mathesar.api.permission_utils import QueryAccessInspector
5
6
7 class SharedTableAccessPolicy(AccessPolicy):
8 statements = [
9 {
10 'action': ['list', 'retrieve'],
11 'principal': 'authenticated',
12 'effect': 'allow',
13 'condition_expression': 'is_atleast_viewer_nested_table_resource'
14 },
15 {
16 'action': ['create', 'destroy', 'update', 'partial_update'],
17 'principal': 'authenticated',
18 'effect': 'allow',
19 'condition_expression': 'is_atleast_manager_nested_table_resource'
20 },
21 ]
22
23
24 class SharedQueryAccessPolicy(AccessPolicy):
25 statements = [
26 {
27 'action': ['list', 'retrieve'],
28 'principal': 'authenticated',
29 'effect': 'allow',
30 'condition_expression': 'is_atleast_query_viewer'
31 },
32 {
33 'action': ['create', 'destroy', 'update', 'partial_update'],
34 'principal': 'authenticated',
35 'effect': 'allow',
36 'condition_expression': 'is_atleast_query_editor'
37 },
38 ]
39
40 def is_atleast_query_viewer(self, request, view, action):
41 query = get_query_or_404(view.kwargs['query_pk'])
42 return QueryAccessInspector(request.user, query).is_atleast_viewer()
43
44 def is_atleast_query_editor(self, request, view, action):
45 query = get_query_or_404(view.kwargs['query_pk'])
46 return QueryAccessInspector(request.user, query).is_atleast_editor()
47
[end of mathesar/api/ui/permissions/shares.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mathesar/api/ui/permissions/shares.py b/mathesar/api/ui/permissions/shares.py
--- a/mathesar/api/ui/permissions/shares.py
+++ b/mathesar/api/ui/permissions/shares.py
@@ -16,7 +16,7 @@
'action': ['create', 'destroy', 'update', 'partial_update'],
'principal': 'authenticated',
'effect': 'allow',
- 'condition_expression': 'is_atleast_manager_nested_table_resource'
+ 'condition_expression': 'is_atleast_editor_nested_table_resource'
},
]
|
{"golden_diff": "diff --git a/mathesar/api/ui/permissions/shares.py b/mathesar/api/ui/permissions/shares.py\n--- a/mathesar/api/ui/permissions/shares.py\n+++ b/mathesar/api/ui/permissions/shares.py\n@@ -16,7 +16,7 @@\n 'action': ['create', 'destroy', 'update', 'partial_update'],\n 'principal': 'authenticated',\n 'effect': 'allow',\n- 'condition_expression': 'is_atleast_manager_nested_table_resource'\n+ 'condition_expression': 'is_atleast_editor_nested_table_resource'\n },\n ]\n", "issue": "Implement frontend flow: User sharing an entity\nI've not added a description, since I'll be implementing this.\r\n\r\nRefer [Product spec](https://wiki.mathesar.org/en/product/specs/publicly-shareable-links) for detailed info.\n", "before_files": [{"content": "from rest_access_policy import AccessPolicy\n\nfrom mathesar.api.utils import get_query_or_404\nfrom mathesar.api.permission_utils import QueryAccessInspector\n\n\nclass SharedTableAccessPolicy(AccessPolicy):\n statements = [\n {\n 'action': ['list', 'retrieve'],\n 'principal': 'authenticated',\n 'effect': 'allow',\n 'condition_expression': 'is_atleast_viewer_nested_table_resource'\n },\n {\n 'action': ['create', 'destroy', 'update', 'partial_update'],\n 'principal': 'authenticated',\n 'effect': 'allow',\n 'condition_expression': 'is_atleast_manager_nested_table_resource'\n },\n ]\n\n\nclass SharedQueryAccessPolicy(AccessPolicy):\n statements = [\n {\n 'action': ['list', 'retrieve'],\n 'principal': 'authenticated',\n 'effect': 'allow',\n 'condition_expression': 'is_atleast_query_viewer'\n },\n {\n 'action': ['create', 'destroy', 'update', 'partial_update'],\n 'principal': 'authenticated',\n 'effect': 'allow',\n 'condition_expression': 'is_atleast_query_editor'\n },\n ]\n\n def is_atleast_query_viewer(self, request, view, action):\n query = get_query_or_404(view.kwargs['query_pk'])\n return QueryAccessInspector(request.user, query).is_atleast_viewer()\n\n def is_atleast_query_editor(self, request, view, action):\n query = get_query_or_404(view.kwargs['query_pk'])\n return QueryAccessInspector(request.user, query).is_atleast_editor()\n", "path": "mathesar/api/ui/permissions/shares.py"}]}
| 1,017 | 126 |
gh_patches_debug_24804
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-7262
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
NewspowerAUSpider - can this be rewritten as a WPStoreLocator spider?
```
import re
from html import unescape
from chompjs import parse_js_object
from scrapy.spiders import SitemapSpider
from locations.hours import OpeningHours
from locations.items import Feature
class NewspowerAUSpider(SitemapSpider):
name = "newspower_au"
item_attributes = {"brand": "Newspower", "brand_wikidata": "Q120670137"}
allowed_domains = ["newspower.com.au"]
sitemap_urls = [
"https://newspower.com.au/wpsl_stores-sitemap1.xml",
"https://newspower.com.au/wpsl_stores-sitemap2.xml",
]
sitemap_rules = [("/stores/", "parse")]
def parse(self, response):
map_marker_js_blob = response.xpath('//script[contains(text(), "var wpslMap_0 = ")]/text()').get()
map_marker_js_blob = map_marker_js_blob.split("var wpslMap_0 = ", 1)[1].split("]};", 1)[0] + "]}"
map_marker_dict = parse_js_object(map_marker_js_blob)["locations"][0]
properties = {
"ref": map_marker_dict["id"],
"name": response.xpath('//div[@class="wpsl-locations-details"]/span/strong/text()').get().strip(),
"addr_full": unescape(
re.sub(
r"\s+",
" ",
", ".join(filter(None, response.xpath('//div[@class="wpsl-location-address"]//text()').getall())),
)
)
.replace(" ,", ",")
.strip(),
"street_address": ", ".join(filter(None, [map_marker_dict["address"], map_marker_dict["address2"]])),
"city": map_marker_dict["city"],
"state": map_marker_dict["state"],
"postcode": map_marker_dict["zip"],
"lat": map_marker_dict["lat"],
"lon": map_marker_dict["lng"],
"phone": response.xpath('//div[@class="wpsl-contact-details"]//a[contains(@href, "tel:")]/@href').get(),
"website": response.url,
"facebook": response.xpath(
'//div[@class="entry-content"]//a[contains(@href, "https://www.facebook.com/")]/@href'
).get(),
}
if properties.get("phone") and "tel:" in properties.get("phone"):
properties["phone"] = properties["phone"].replace("tel:", "")
hours_string = " ".join(filter(None, response.xpath('//table[@class="wpsl-opening-hours"]//text()').getall()))
properties["opening_hours"] = OpeningHours()
properties["opening_hours"].add_ranges_from_string(hours_string)
yield Feature(**properties)
```
</issue>
<code>
[start of locations/spiders/newspower_au.py]
1 import re
2 from html import unescape
3
4 from chompjs import parse_js_object
5 from scrapy.spiders import SitemapSpider
6
7 from locations.hours import OpeningHours
8 from locations.items import Feature
9
10
11 class NewspowerAUSpider(SitemapSpider):
12 name = "newspower_au"
13 item_attributes = {"brand": "Newspower", "brand_wikidata": "Q120670137"}
14 allowed_domains = ["newspower.com.au"]
15 sitemap_urls = [
16 "https://newspower.com.au/wpsl_stores-sitemap1.xml",
17 "https://newspower.com.au/wpsl_stores-sitemap2.xml",
18 ]
19 sitemap_rules = [("/stores/", "parse")]
20
21 def parse(self, response):
22 map_marker_js_blob = response.xpath('//script[contains(text(), "var wpslMap_0 = ")]/text()').get()
23 map_marker_js_blob = map_marker_js_blob.split("var wpslMap_0 = ", 1)[1].split("]};", 1)[0] + "]}"
24 map_marker_dict = parse_js_object(map_marker_js_blob)["locations"][0]
25 properties = {
26 "ref": map_marker_dict["id"],
27 "name": response.xpath('//div[@class="wpsl-locations-details"]/span/strong/text()').get().strip(),
28 "addr_full": unescape(
29 re.sub(
30 r"\s+",
31 " ",
32 ", ".join(filter(None, response.xpath('//div[@class="wpsl-location-address"]//text()').getall())),
33 )
34 )
35 .replace(" ,", ",")
36 .strip(),
37 "street_address": ", ".join(filter(None, [map_marker_dict["address"], map_marker_dict["address2"]])),
38 "city": map_marker_dict["city"],
39 "state": map_marker_dict["state"],
40 "postcode": map_marker_dict["zip"],
41 "lat": map_marker_dict["lat"],
42 "lon": map_marker_dict["lng"],
43 "phone": response.xpath('//div[@class="wpsl-contact-details"]//a[contains(@href, "tel:")]/@href').get(),
44 "website": response.url,
45 "facebook": response.xpath(
46 '//div[@class="entry-content"]//a[contains(@href, "https://www.facebook.com/")]/@href'
47 ).get(),
48 }
49 if properties.get("phone") and "tel:" in properties.get("phone"):
50 properties["phone"] = properties["phone"].replace("tel:", "")
51 hours_string = " ".join(filter(None, response.xpath('//table[@class="wpsl-opening-hours"]//text()').getall()))
52 properties["opening_hours"] = OpeningHours()
53 properties["opening_hours"].add_ranges_from_string(hours_string)
54 yield Feature(**properties)
55
[end of locations/spiders/newspower_au.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/locations/spiders/newspower_au.py b/locations/spiders/newspower_au.py
--- a/locations/spiders/newspower_au.py
+++ b/locations/spiders/newspower_au.py
@@ -9,6 +9,11 @@
class NewspowerAUSpider(SitemapSpider):
+ # Whilst WP Store Locator is used for this brand, it is set to
+ # return at most the 5 closest points to a provided search
+ # coordinate. There is an impractical number of search requests
+ # thus required to use the WP Store Locator store finder API.
+ # A Sitemap spider is used instead.
name = "newspower_au"
item_attributes = {"brand": "Newspower", "brand_wikidata": "Q120670137"}
allowed_domains = ["newspower.com.au"]
@@ -16,7 +21,11 @@
"https://newspower.com.au/wpsl_stores-sitemap1.xml",
"https://newspower.com.au/wpsl_stores-sitemap2.xml",
]
- sitemap_rules = [("/stores/", "parse")]
+ sitemap_rules = [(r"^https:\/\/newspower\.com\.au\/stores/[^/]+\/$", "parse")]
+ # Server will redirect wpsl_stores-sitemap2.xml to
+ # https://newspower.com.au/store-locator/ if it doesn't like
+ # the country/netblock requesting the page.
+ requires_proxy = True
def parse(self, response):
map_marker_js_blob = response.xpath('//script[contains(text(), "var wpslMap_0 = ")]/text()').get()
|
{"golden_diff": "diff --git a/locations/spiders/newspower_au.py b/locations/spiders/newspower_au.py\n--- a/locations/spiders/newspower_au.py\n+++ b/locations/spiders/newspower_au.py\n@@ -9,6 +9,11 @@\n \n \n class NewspowerAUSpider(SitemapSpider):\n+ # Whilst WP Store Locator is used for this brand, it is set to\n+ # return at most the 5 closest points to a provided search\n+ # coordinate. There is an impractical number of search requests\n+ # thus required to use the WP Store Locator store finder API.\n+ # A Sitemap spider is used instead.\n name = \"newspower_au\"\n item_attributes = {\"brand\": \"Newspower\", \"brand_wikidata\": \"Q120670137\"}\n allowed_domains = [\"newspower.com.au\"]\n@@ -16,7 +21,11 @@\n \"https://newspower.com.au/wpsl_stores-sitemap1.xml\",\n \"https://newspower.com.au/wpsl_stores-sitemap2.xml\",\n ]\n- sitemap_rules = [(\"/stores/\", \"parse\")]\n+ sitemap_rules = [(r\"^https:\\/\\/newspower\\.com\\.au\\/stores/[^/]+\\/$\", \"parse\")]\n+ # Server will redirect wpsl_stores-sitemap2.xml to\n+ # https://newspower.com.au/store-locator/ if it doesn't like\n+ # the country/netblock requesting the page.\n+ requires_proxy = True\n \n def parse(self, response):\n map_marker_js_blob = response.xpath('//script[contains(text(), \"var wpslMap_0 = \")]/text()').get()\n", "issue": "NewspowerAUSpider - can this be rewritten as a WPStoreLocator spider?\n```\r\nimport re\r\nfrom html import unescape\r\n\r\nfrom chompjs import parse_js_object\r\nfrom scrapy.spiders import SitemapSpider\r\n\r\nfrom locations.hours import OpeningHours\r\nfrom locations.items import Feature\r\n\r\n\r\nclass NewspowerAUSpider(SitemapSpider):\r\n name = \"newspower_au\"\r\n item_attributes = {\"brand\": \"Newspower\", \"brand_wikidata\": \"Q120670137\"}\r\n allowed_domains = [\"newspower.com.au\"]\r\n sitemap_urls = [\r\n \"https://newspower.com.au/wpsl_stores-sitemap1.xml\",\r\n \"https://newspower.com.au/wpsl_stores-sitemap2.xml\",\r\n ]\r\n sitemap_rules = [(\"/stores/\", \"parse\")]\r\n\r\n def parse(self, response):\r\n map_marker_js_blob = response.xpath('//script[contains(text(), \"var wpslMap_0 = \")]/text()').get()\r\n map_marker_js_blob = map_marker_js_blob.split(\"var wpslMap_0 = \", 1)[1].split(\"]};\", 1)[0] + \"]}\"\r\n map_marker_dict = parse_js_object(map_marker_js_blob)[\"locations\"][0]\r\n properties = {\r\n \"ref\": map_marker_dict[\"id\"],\r\n \"name\": response.xpath('//div[@class=\"wpsl-locations-details\"]/span/strong/text()').get().strip(),\r\n \"addr_full\": unescape(\r\n re.sub(\r\n r\"\\s+\",\r\n \" \",\r\n \", \".join(filter(None, response.xpath('//div[@class=\"wpsl-location-address\"]//text()').getall())),\r\n )\r\n )\r\n .replace(\" ,\", \",\")\r\n .strip(),\r\n \"street_address\": \", \".join(filter(None, [map_marker_dict[\"address\"], map_marker_dict[\"address2\"]])),\r\n \"city\": map_marker_dict[\"city\"],\r\n \"state\": map_marker_dict[\"state\"],\r\n \"postcode\": map_marker_dict[\"zip\"],\r\n \"lat\": map_marker_dict[\"lat\"],\r\n \"lon\": map_marker_dict[\"lng\"],\r\n \"phone\": response.xpath('//div[@class=\"wpsl-contact-details\"]//a[contains(@href, \"tel:\")]/@href').get(),\r\n \"website\": response.url,\r\n \"facebook\": response.xpath(\r\n '//div[@class=\"entry-content\"]//a[contains(@href, \"https://www.facebook.com/\")]/@href'\r\n ).get(),\r\n }\r\n if properties.get(\"phone\") and \"tel:\" in properties.get(\"phone\"):\r\n properties[\"phone\"] = properties[\"phone\"].replace(\"tel:\", \"\")\r\n hours_string = \" \".join(filter(None, response.xpath('//table[@class=\"wpsl-opening-hours\"]//text()').getall()))\r\n properties[\"opening_hours\"] = OpeningHours()\r\n properties[\"opening_hours\"].add_ranges_from_string(hours_string)\r\n yield Feature(**properties)\r\n```\n", "before_files": [{"content": "import re\nfrom html import unescape\n\nfrom chompjs import parse_js_object\nfrom scrapy.spiders import SitemapSpider\n\nfrom locations.hours import OpeningHours\nfrom locations.items import Feature\n\n\nclass NewspowerAUSpider(SitemapSpider):\n name = \"newspower_au\"\n item_attributes = {\"brand\": \"Newspower\", \"brand_wikidata\": \"Q120670137\"}\n allowed_domains = [\"newspower.com.au\"]\n sitemap_urls = [\n \"https://newspower.com.au/wpsl_stores-sitemap1.xml\",\n \"https://newspower.com.au/wpsl_stores-sitemap2.xml\",\n ]\n sitemap_rules = [(\"/stores/\", \"parse\")]\n\n def parse(self, response):\n map_marker_js_blob = response.xpath('//script[contains(text(), \"var wpslMap_0 = \")]/text()').get()\n map_marker_js_blob = map_marker_js_blob.split(\"var wpslMap_0 = \", 1)[1].split(\"]};\", 1)[0] + \"]}\"\n map_marker_dict = parse_js_object(map_marker_js_blob)[\"locations\"][0]\n properties = {\n \"ref\": map_marker_dict[\"id\"],\n \"name\": response.xpath('//div[@class=\"wpsl-locations-details\"]/span/strong/text()').get().strip(),\n \"addr_full\": unescape(\n re.sub(\n r\"\\s+\",\n \" \",\n \", \".join(filter(None, response.xpath('//div[@class=\"wpsl-location-address\"]//text()').getall())),\n )\n )\n .replace(\" ,\", \",\")\n .strip(),\n \"street_address\": \", \".join(filter(None, [map_marker_dict[\"address\"], map_marker_dict[\"address2\"]])),\n \"city\": map_marker_dict[\"city\"],\n \"state\": map_marker_dict[\"state\"],\n \"postcode\": map_marker_dict[\"zip\"],\n \"lat\": map_marker_dict[\"lat\"],\n \"lon\": map_marker_dict[\"lng\"],\n \"phone\": response.xpath('//div[@class=\"wpsl-contact-details\"]//a[contains(@href, \"tel:\")]/@href').get(),\n \"website\": response.url,\n \"facebook\": response.xpath(\n '//div[@class=\"entry-content\"]//a[contains(@href, \"https://www.facebook.com/\")]/@href'\n ).get(),\n }\n if properties.get(\"phone\") and \"tel:\" in properties.get(\"phone\"):\n properties[\"phone\"] = properties[\"phone\"].replace(\"tel:\", \"\")\n hours_string = \" \".join(filter(None, response.xpath('//table[@class=\"wpsl-opening-hours\"]//text()').getall()))\n properties[\"opening_hours\"] = OpeningHours()\n properties[\"opening_hours\"].add_ranges_from_string(hours_string)\n yield Feature(**properties)\n", "path": "locations/spiders/newspower_au.py"}]}
| 1,886 | 389 |
gh_patches_debug_8250
|
rasdani/github-patches
|
git_diff
|
saleor__saleor-4824
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Users can create the same address multiple times
### Steps to reproduce the problem
1. Start checkout
1. Set a shipping address A
1. Set a billing address B
1. Place the order
1. Go to your account details
1. Edit the address B to have the same information than A
1. Checkout with A or B (or re-create it through a new address input?)
1. Place the order
1. The order should have failed because the same address exist two times: `get() returned more than one object`
### What I expected to happen
Have an error when updating the address, saying I already have that address.
</issue>
<code>
[start of saleor/account/utils.py]
1 import os
2 import os.path
3 import random
4
5 from django.conf import settings
6 from django.core.files import File
7
8 from ..checkout import AddressType
9
10 AVATARS_PATH = os.path.join(
11 settings.PROJECT_ROOT, "saleor", "static", "images", "avatars"
12 )
13
14
15 def store_user_address(user, address, address_type):
16 """Add address to user address book and set as default one."""
17 address, _ = user.addresses.get_or_create(**address.as_data())
18
19 if address_type == AddressType.BILLING:
20 if not user.default_billing_address:
21 set_user_default_billing_address(user, address)
22 elif address_type == AddressType.SHIPPING:
23 if not user.default_shipping_address:
24 set_user_default_shipping_address(user, address)
25
26
27 def set_user_default_billing_address(user, address):
28 user.default_billing_address = address
29 user.save(update_fields=["default_billing_address"])
30
31
32 def set_user_default_shipping_address(user, address):
33 user.default_shipping_address = address
34 user.save(update_fields=["default_shipping_address"])
35
36
37 def change_user_default_address(user, address, address_type):
38 if address_type == AddressType.BILLING:
39 if user.default_billing_address:
40 user.addresses.add(user.default_billing_address)
41 set_user_default_billing_address(user, address)
42 elif address_type == AddressType.SHIPPING:
43 if user.default_shipping_address:
44 user.addresses.add(user.default_shipping_address)
45 set_user_default_shipping_address(user, address)
46
47
48 def get_user_first_name(user):
49 """Return a user's first name from their default belling address.
50
51 Return nothing if none where found.
52 """
53 if user.first_name:
54 return user.first_name
55 if user.default_billing_address:
56 return user.default_billing_address.first_name
57 return None
58
59
60 def get_user_last_name(user):
61 """Return a user's last name from their default belling address.
62
63 Return nothing if none where found.
64 """
65 if user.last_name:
66 return user.last_name
67 if user.default_billing_address:
68 return user.default_billing_address.last_name
69 return None
70
71
72 def get_random_avatar():
73 """Return random avatar picked from a pool of static avatars."""
74 avatar_name = random.choice(os.listdir(AVATARS_PATH))
75 avatar_path = os.path.join(AVATARS_PATH, avatar_name)
76 return File(open(avatar_path, "rb"), name=avatar_name)
77
[end of saleor/account/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/saleor/account/utils.py b/saleor/account/utils.py
--- a/saleor/account/utils.py
+++ b/saleor/account/utils.py
@@ -14,7 +14,11 @@
def store_user_address(user, address, address_type):
"""Add address to user address book and set as default one."""
- address, _ = user.addresses.get_or_create(**address.as_data())
+ address_data = address.as_data()
+
+ address = user.addresses.filter(**address_data).first()
+ if address is None:
+ address = user.addresses.create(**address_data)
if address_type == AddressType.BILLING:
if not user.default_billing_address:
|
{"golden_diff": "diff --git a/saleor/account/utils.py b/saleor/account/utils.py\n--- a/saleor/account/utils.py\n+++ b/saleor/account/utils.py\n@@ -14,7 +14,11 @@\n \n def store_user_address(user, address, address_type):\n \"\"\"Add address to user address book and set as default one.\"\"\"\n- address, _ = user.addresses.get_or_create(**address.as_data())\n+ address_data = address.as_data()\n+\n+ address = user.addresses.filter(**address_data).first()\n+ if address is None:\n+ address = user.addresses.create(**address_data)\n \n if address_type == AddressType.BILLING:\n if not user.default_billing_address:\n", "issue": "Users can create the same address multiple times\n### Steps to reproduce the problem\r\n1. Start checkout\r\n1. Set a shipping address A\r\n1. Set a billing address B\r\n1. Place the order\r\n1. Go to your account details\r\n1. Edit the address B to have the same information than A\r\n1. Checkout with A or B (or re-create it through a new address input?)\r\n1. Place the order\r\n1. The order should have failed because the same address exist two times: `get() returned more than one object`\r\n\r\n\r\n### What I expected to happen\r\nHave an error when updating the address, saying I already have that address.\r\n\n", "before_files": [{"content": "import os\nimport os.path\nimport random\n\nfrom django.conf import settings\nfrom django.core.files import File\n\nfrom ..checkout import AddressType\n\nAVATARS_PATH = os.path.join(\n settings.PROJECT_ROOT, \"saleor\", \"static\", \"images\", \"avatars\"\n)\n\n\ndef store_user_address(user, address, address_type):\n \"\"\"Add address to user address book and set as default one.\"\"\"\n address, _ = user.addresses.get_or_create(**address.as_data())\n\n if address_type == AddressType.BILLING:\n if not user.default_billing_address:\n set_user_default_billing_address(user, address)\n elif address_type == AddressType.SHIPPING:\n if not user.default_shipping_address:\n set_user_default_shipping_address(user, address)\n\n\ndef set_user_default_billing_address(user, address):\n user.default_billing_address = address\n user.save(update_fields=[\"default_billing_address\"])\n\n\ndef set_user_default_shipping_address(user, address):\n user.default_shipping_address = address\n user.save(update_fields=[\"default_shipping_address\"])\n\n\ndef change_user_default_address(user, address, address_type):\n if address_type == AddressType.BILLING:\n if user.default_billing_address:\n user.addresses.add(user.default_billing_address)\n set_user_default_billing_address(user, address)\n elif address_type == AddressType.SHIPPING:\n if user.default_shipping_address:\n user.addresses.add(user.default_shipping_address)\n set_user_default_shipping_address(user, address)\n\n\ndef get_user_first_name(user):\n \"\"\"Return a user's first name from their default belling address.\n\n Return nothing if none where found.\n \"\"\"\n if user.first_name:\n return user.first_name\n if user.default_billing_address:\n return user.default_billing_address.first_name\n return None\n\n\ndef get_user_last_name(user):\n \"\"\"Return a user's last name from their default belling address.\n\n Return nothing if none where found.\n \"\"\"\n if user.last_name:\n return user.last_name\n if user.default_billing_address:\n return user.default_billing_address.last_name\n return None\n\n\ndef get_random_avatar():\n \"\"\"Return random avatar picked from a pool of static avatars.\"\"\"\n avatar_name = random.choice(os.listdir(AVATARS_PATH))\n avatar_path = os.path.join(AVATARS_PATH, avatar_name)\n return File(open(avatar_path, \"rb\"), name=avatar_name)\n", "path": "saleor/account/utils.py"}]}
| 1,333 | 156 |
gh_patches_debug_12244
|
rasdani/github-patches
|
git_diff
|
vega__altair-2106
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Options of `point` argument
Documentation of `point` argument in marks isn't very easily discoverable.
Recently I tried to create a chart with colored line and points. My first try was with `mark_line(color="red", point=True)`, similarly to [this example](https://altair-viz.github.io/gallery/line_chart_with_points.html), but it produced red line with blue points. This turned out to be current default behavior of Vega-lite (found in [this issue](https://github.com/vega/vega-lite/issues/6111)).
After some digging, I found that `point` can be "an object defining the properties of the overlayed points." (which seems to imply `OverlayMarkDef`, but simple dictionary showed to be enough). I think it would be really helpful to have this slightly easier to find. A "Line chart with points" example seems like a good place.
So, what do you think about adding some sort of variation of the following code snippet in that example?
```python
import altair as alt
import numpy as np
import pandas as pd
x = np.arange(100)
source = pd.DataFrame({"x": x, "f(x)": np.sin(x / 5)})
# Only this part will be added
alt.Chart(source).mark_line(
color="red", point={"color": "red"}
).encode(
x="x",
y="f(x)"
)
```

If this is OK, I would like to help with PR. Thanks.
</issue>
<code>
[start of altair/examples/line_chart_with_points.py]
1 """
2 Line Chart with Points
3 ----------------------
4 This chart shows a simple line chart with points marking each value.
5 """
6 # category: line charts
7 import altair as alt
8 import numpy as np
9 import pandas as pd
10
11 x = np.arange(100)
12 source = pd.DataFrame({
13 'x': x,
14 'f(x)': np.sin(x / 5)
15 })
16
17 alt.Chart(source).mark_line(point=True).encode(
18 x='x',
19 y='f(x)'
20 )
21
[end of altair/examples/line_chart_with_points.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/altair/examples/line_chart_with_points.py b/altair/examples/line_chart_with_points.py
--- a/altair/examples/line_chart_with_points.py
+++ b/altair/examples/line_chart_with_points.py
@@ -1,7 +1,9 @@
"""
Line Chart with Points
----------------------
-This chart shows a simple line chart with points marking each value.
+This chart shows a simple line chart with points marking each value. Use
+``point=True`` for points with default appearance or customize it with
+``OverlayMarkDef()``.
"""
# category: line charts
import altair as alt
@@ -14,7 +16,9 @@
'f(x)': np.sin(x / 5)
})
-alt.Chart(source).mark_line(point=True).encode(
+alt.Chart(source).mark_line(
+ point=alt.OverlayMarkDef(color="red")
+).encode(
x='x',
y='f(x)'
)
|
{"golden_diff": "diff --git a/altair/examples/line_chart_with_points.py b/altair/examples/line_chart_with_points.py\n--- a/altair/examples/line_chart_with_points.py\n+++ b/altair/examples/line_chart_with_points.py\n@@ -1,7 +1,9 @@\n \"\"\"\n Line Chart with Points\n ----------------------\n-This chart shows a simple line chart with points marking each value.\n+This chart shows a simple line chart with points marking each value. Use\n+``point=True`` for points with default appearance or customize it with\n+``OverlayMarkDef()``.\n \"\"\"\n # category: line charts\n import altair as alt\n@@ -14,7 +16,9 @@\n 'f(x)': np.sin(x / 5)\n })\n \n-alt.Chart(source).mark_line(point=True).encode(\n+alt.Chart(source).mark_line(\n+ point=alt.OverlayMarkDef(color=\"red\")\n+).encode(\n x='x',\n y='f(x)'\n )\n", "issue": "Options of `point` argument\nDocumentation of `point` argument in marks isn't very easily discoverable.\r\n\r\nRecently I tried to create a chart with colored line and points. My first try was with `mark_line(color=\"red\", point=True)`, similarly to [this example](https://altair-viz.github.io/gallery/line_chart_with_points.html), but it produced red line with blue points. This turned out to be current default behavior of Vega-lite (found in [this issue](https://github.com/vega/vega-lite/issues/6111)).\r\n\r\nAfter some digging, I found that `point` can be \"an object defining the properties of the overlayed points.\" (which seems to imply `OverlayMarkDef`, but simple dictionary showed to be enough). I think it would be really helpful to have this slightly easier to find. A \"Line chart with points\" example seems like a good place.\r\n\r\nSo, what do you think about adding some sort of variation of the following code snippet in that example?\r\n```python\r\nimport altair as alt\r\nimport numpy as np\r\nimport pandas as pd\r\n\r\nx = np.arange(100)\r\nsource = pd.DataFrame({\"x\": x, \"f(x)\": np.sin(x / 5)})\r\n\r\n# Only this part will be added\r\nalt.Chart(source).mark_line(\r\n color=\"red\", point={\"color\": \"red\"}\r\n).encode(\r\n x=\"x\",\r\n y=\"f(x)\"\r\n)\r\n```\r\n\r\n\r\nIf this is OK, I would like to help with PR. Thanks.\n", "before_files": [{"content": "\"\"\"\nLine Chart with Points\n----------------------\nThis chart shows a simple line chart with points marking each value.\n\"\"\"\n# category: line charts\nimport altair as alt\nimport numpy as np\nimport pandas as pd\n\nx = np.arange(100)\nsource = pd.DataFrame({\n 'x': x,\n 'f(x)': np.sin(x / 5)\n})\n\nalt.Chart(source).mark_line(point=True).encode(\n x='x',\n y='f(x)'\n)\n", "path": "altair/examples/line_chart_with_points.py"}]}
| 1,068 | 211 |
gh_patches_debug_16051
|
rasdani/github-patches
|
git_diff
|
docker__docker-py-812
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
requests 2.8.0 re-introduces bug #647
</issue>
<code>
[start of docker/unixconn/unixconn.py]
1 # Copyright 2013 dotCloud inc.
2
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6
7 # http://www.apache.org/licenses/LICENSE-2.0
8
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 import six
15 import requests.adapters
16 import socket
17
18 if six.PY3:
19 import http.client as httplib
20 else:
21 import httplib
22
23 try:
24 import requests.packages.urllib3 as urllib3
25 except ImportError:
26 import urllib3
27
28 RecentlyUsedContainer = urllib3._collections.RecentlyUsedContainer
29
30
31 class UnixHTTPConnection(httplib.HTTPConnection, object):
32 def __init__(self, base_url, unix_socket, timeout=60):
33 httplib.HTTPConnection.__init__(self, 'localhost', timeout=timeout)
34 self.base_url = base_url
35 self.unix_socket = unix_socket
36 self.timeout = timeout
37
38 def connect(self):
39 sock = socket.socket(socket.AF_UNIX, socket.SOCK_STREAM)
40 sock.settimeout(self.timeout)
41 sock.connect(self.unix_socket)
42 self.sock = sock
43
44
45 class UnixHTTPConnectionPool(urllib3.connectionpool.HTTPConnectionPool):
46 def __init__(self, base_url, socket_path, timeout=60):
47 urllib3.connectionpool.HTTPConnectionPool.__init__(
48 self, 'localhost', timeout=timeout
49 )
50 self.base_url = base_url
51 self.socket_path = socket_path
52 self.timeout = timeout
53
54 def _new_conn(self):
55 return UnixHTTPConnection(self.base_url, self.socket_path,
56 self.timeout)
57
58
59 class UnixAdapter(requests.adapters.HTTPAdapter):
60 def __init__(self, socket_url, timeout=60):
61 socket_path = socket_url.replace('http+unix://', '')
62 if not socket_path.startswith('/'):
63 socket_path = '/' + socket_path
64 self.socket_path = socket_path
65 self.timeout = timeout
66 self.pools = RecentlyUsedContainer(10,
67 dispose_func=lambda p: p.close())
68 super(UnixAdapter, self).__init__()
69
70 def get_connection(self, url, proxies=None):
71 with self.pools.lock:
72 pool = self.pools.get(url)
73 if pool:
74 return pool
75
76 pool = UnixHTTPConnectionPool(url,
77 self.socket_path,
78 self.timeout)
79 self.pools[url] = pool
80
81 return pool
82
83 def close(self):
84 self.pools.clear()
85
[end of docker/unixconn/unixconn.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docker/unixconn/unixconn.py b/docker/unixconn/unixconn.py
--- a/docker/unixconn/unixconn.py
+++ b/docker/unixconn/unixconn.py
@@ -73,12 +73,20 @@
if pool:
return pool
- pool = UnixHTTPConnectionPool(url,
- self.socket_path,
- self.timeout)
+ pool = UnixHTTPConnectionPool(
+ url, self.socket_path, self.timeout
+ )
self.pools[url] = pool
return pool
+ def request_url(self, request, proxies):
+ # The select_proxy utility in requests errors out when the provided URL
+ # doesn't have a hostname, like is the case when using a UNIX socket.
+ # Since proxies are an irrelevant notion in the case of UNIX sockets
+ # anyway, we simply return the path URL directly.
+ # See also: https://github.com/docker/docker-py/issues/811
+ return request.path_url
+
def close(self):
self.pools.clear()
|
{"golden_diff": "diff --git a/docker/unixconn/unixconn.py b/docker/unixconn/unixconn.py\n--- a/docker/unixconn/unixconn.py\n+++ b/docker/unixconn/unixconn.py\n@@ -73,12 +73,20 @@\n if pool:\n return pool\n \n- pool = UnixHTTPConnectionPool(url,\n- self.socket_path,\n- self.timeout)\n+ pool = UnixHTTPConnectionPool(\n+ url, self.socket_path, self.timeout\n+ )\n self.pools[url] = pool\n \n return pool\n \n+ def request_url(self, request, proxies):\n+ # The select_proxy utility in requests errors out when the provided URL\n+ # doesn't have a hostname, like is the case when using a UNIX socket.\n+ # Since proxies are an irrelevant notion in the case of UNIX sockets\n+ # anyway, we simply return the path URL directly.\n+ # See also: https://github.com/docker/docker-py/issues/811\n+ return request.path_url\n+\n def close(self):\n self.pools.clear()\n", "issue": "requests 2.8.0 re-introduces bug #647\n\n", "before_files": [{"content": "# Copyright 2013 dotCloud inc.\n\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n\n# http://www.apache.org/licenses/LICENSE-2.0\n\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport six\nimport requests.adapters\nimport socket\n\nif six.PY3:\n import http.client as httplib\nelse:\n import httplib\n\ntry:\n import requests.packages.urllib3 as urllib3\nexcept ImportError:\n import urllib3\n\nRecentlyUsedContainer = urllib3._collections.RecentlyUsedContainer\n\n\nclass UnixHTTPConnection(httplib.HTTPConnection, object):\n def __init__(self, base_url, unix_socket, timeout=60):\n httplib.HTTPConnection.__init__(self, 'localhost', timeout=timeout)\n self.base_url = base_url\n self.unix_socket = unix_socket\n self.timeout = timeout\n\n def connect(self):\n sock = socket.socket(socket.AF_UNIX, socket.SOCK_STREAM)\n sock.settimeout(self.timeout)\n sock.connect(self.unix_socket)\n self.sock = sock\n\n\nclass UnixHTTPConnectionPool(urllib3.connectionpool.HTTPConnectionPool):\n def __init__(self, base_url, socket_path, timeout=60):\n urllib3.connectionpool.HTTPConnectionPool.__init__(\n self, 'localhost', timeout=timeout\n )\n self.base_url = base_url\n self.socket_path = socket_path\n self.timeout = timeout\n\n def _new_conn(self):\n return UnixHTTPConnection(self.base_url, self.socket_path,\n self.timeout)\n\n\nclass UnixAdapter(requests.adapters.HTTPAdapter):\n def __init__(self, socket_url, timeout=60):\n socket_path = socket_url.replace('http+unix://', '')\n if not socket_path.startswith('/'):\n socket_path = '/' + socket_path\n self.socket_path = socket_path\n self.timeout = timeout\n self.pools = RecentlyUsedContainer(10,\n dispose_func=lambda p: p.close())\n super(UnixAdapter, self).__init__()\n\n def get_connection(self, url, proxies=None):\n with self.pools.lock:\n pool = self.pools.get(url)\n if pool:\n return pool\n\n pool = UnixHTTPConnectionPool(url,\n self.socket_path,\n self.timeout)\n self.pools[url] = pool\n\n return pool\n\n def close(self):\n self.pools.clear()\n", "path": "docker/unixconn/unixconn.py"}]}
| 1,327 | 238 |
gh_patches_debug_13689
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-2592
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
conan search gives AttributeError: 'UserIO' object has no attribute 'warn'
Version: 1.1.1
OS: Linux Ubuntu 14.04
conda: v4.2.7
Repro steps:
* `conda create -n conan python=2.7`
* `source activate conan`
* `pip install conan`
* `conan search zlib/1.2.11@conan/stable -r=conan-center`
Gives the following python stack:
```
(conan) ~ $ conan search zlib/1.2.11@conan/stable -r=conan-center
Traceback (most recent call last):
File "/home/mgodbolt/apps/miniconda/envs/conan/lib/python2.7/site-packages/conans/client/command.py", line 1131, in run
method(args[0][1:])
File "/home/mgodbolt/apps/miniconda/envs/conan/lib/python2.7/site-packages/conans/client/command.py", line 814, in search
outdated=args.outdated)
File "/home/mgodbolt/apps/miniconda/envs/conan/lib/python2.7/site-packages/conans/client/conan_api.py", line 64, in wrapper
return f(*args, **kwargs)
File "/home/mgodbolt/apps/miniconda/envs/conan/lib/python2.7/site-packages/conans/client/conan_api.py", line 595, in search_packages
outdated=outdated)
File "/home/mgodbolt/apps/miniconda/envs/conan/lib/python2.7/site-packages/conans/client/cmd/search.py", line 44, in search_packages
remote = RemoteRegistry(self._client_cache.registry, self._user_io).remote(remote)
File "/home/mgodbolt/apps/miniconda/envs/conan/lib/python2.7/site-packages/conans/client/remote_registry.py", line 95, in remote
remotes, _ = self._load()
File "/home/mgodbolt/apps/miniconda/envs/conan/lib/python2.7/site-packages/conans/client/remote_registry.py", line 65, in _load
self._output.warn("Remotes registry file missing, creating default one in %s"
AttributeError: 'UserIO' object has no attribute 'warn'
ERROR: 'UserIO' object has no attribute 'warn'
```
</issue>
<code>
[start of conans/client/cmd/search.py]
1 from conans.search.search import DiskSearchManager, filter_outdated
2 from collections import OrderedDict
3 from conans.client.remote_registry import RemoteRegistry
4
5
6 class Search(object):
7 def __init__(self, client_cache, remote_manager, user_io):
8 self._client_cache = client_cache
9 self._remote_manager = remote_manager
10 self._user_io = user_io
11
12 def search_recipes(self, pattern, remote=None, case_sensitive=False):
13 ignorecase = not case_sensitive
14 if not remote:
15 return DiskSearchManager(self._client_cache).search_recipes(pattern, ignorecase)
16
17 registry = RemoteRegistry(self._client_cache.registry, self._user_io.out)
18 if remote == 'all':
19 remotes = registry.remotes
20 # We have to check if there is a remote called "all"
21 # Deprecate: 2.0 can remove this check
22 if 'all' not in (r.name for r in remotes):
23 references = {}
24 for remote in remotes:
25 result = self._remote_manager.search_recipes(remote, pattern, ignorecase)
26 if result:
27 references[remote.name] = result
28 return references
29 # single remote
30 remote = registry.remote(remote)
31 return self._remote_manager.search_recipes(remote, pattern, ignorecase)
32
33 def search_packages(self, reference=None, remote=None, query=None, outdated=False):
34 """ Return the single information saved in conan.vars about all the packages
35 or the packages which match with a pattern
36
37 Attributes:
38 pattern = string to match packages
39 remote = search on another origin to get packages info
40 packages_pattern = String query with binary
41 packages properties: "arch=x86 AND os=Windows"
42 """
43 if remote:
44 remote = RemoteRegistry(self._client_cache.registry, self._user_io).remote(remote)
45 packages_props = self._remote_manager.search_packages(remote, reference, query)
46 ordered_packages = OrderedDict(sorted(packages_props.items()))
47 manifest = self._remote_manager.get_conan_digest(reference, remote)
48 recipe_hash = manifest.summary_hash
49 else:
50 searcher = DiskSearchManager(self._client_cache)
51 packages_props = searcher.search_packages(reference, query)
52 ordered_packages = OrderedDict(sorted(packages_props.items()))
53 try:
54 recipe_hash = self._client_cache.load_manifest(reference).summary_hash
55 except IOError: # It could not exist in local
56 recipe_hash = None
57 if outdated and recipe_hash:
58 ordered_packages = filter_outdated(ordered_packages, recipe_hash)
59 return ordered_packages, reference, recipe_hash, query
60
[end of conans/client/cmd/search.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/conans/client/cmd/search.py b/conans/client/cmd/search.py
--- a/conans/client/cmd/search.py
+++ b/conans/client/cmd/search.py
@@ -41,7 +41,7 @@
packages properties: "arch=x86 AND os=Windows"
"""
if remote:
- remote = RemoteRegistry(self._client_cache.registry, self._user_io).remote(remote)
+ remote = RemoteRegistry(self._client_cache.registry, self._user_io.out).remote(remote)
packages_props = self._remote_manager.search_packages(remote, reference, query)
ordered_packages = OrderedDict(sorted(packages_props.items()))
manifest = self._remote_manager.get_conan_digest(reference, remote)
|
{"golden_diff": "diff --git a/conans/client/cmd/search.py b/conans/client/cmd/search.py\n--- a/conans/client/cmd/search.py\n+++ b/conans/client/cmd/search.py\n@@ -41,7 +41,7 @@\n packages properties: \"arch=x86 AND os=Windows\"\n \"\"\"\n if remote:\n- remote = RemoteRegistry(self._client_cache.registry, self._user_io).remote(remote)\n+ remote = RemoteRegistry(self._client_cache.registry, self._user_io.out).remote(remote)\n packages_props = self._remote_manager.search_packages(remote, reference, query)\n ordered_packages = OrderedDict(sorted(packages_props.items()))\n manifest = self._remote_manager.get_conan_digest(reference, remote)\n", "issue": "conan search gives AttributeError: 'UserIO' object has no attribute 'warn'\nVersion: 1.1.1\r\nOS: Linux Ubuntu 14.04 \r\nconda: v4.2.7\r\n\r\nRepro steps:\r\n* `conda create -n conan python=2.7`\r\n* `source activate conan`\r\n* `pip install conan`\r\n* `conan search zlib/1.2.11@conan/stable -r=conan-center`\r\n\r\nGives the following python stack:\r\n\r\n```\r\n(conan) ~ $ conan search zlib/1.2.11@conan/stable -r=conan-center\r\nTraceback (most recent call last):\r\n File \"/home/mgodbolt/apps/miniconda/envs/conan/lib/python2.7/site-packages/conans/client/command.py\", line 1131, in run\r\n method(args[0][1:])\r\n File \"/home/mgodbolt/apps/miniconda/envs/conan/lib/python2.7/site-packages/conans/client/command.py\", line 814, in search\r\n outdated=args.outdated)\r\n File \"/home/mgodbolt/apps/miniconda/envs/conan/lib/python2.7/site-packages/conans/client/conan_api.py\", line 64, in wrapper\r\n return f(*args, **kwargs)\r\n File \"/home/mgodbolt/apps/miniconda/envs/conan/lib/python2.7/site-packages/conans/client/conan_api.py\", line 595, in search_packages\r\n outdated=outdated)\r\n File \"/home/mgodbolt/apps/miniconda/envs/conan/lib/python2.7/site-packages/conans/client/cmd/search.py\", line 44, in search_packages\r\n remote = RemoteRegistry(self._client_cache.registry, self._user_io).remote(remote)\r\n File \"/home/mgodbolt/apps/miniconda/envs/conan/lib/python2.7/site-packages/conans/client/remote_registry.py\", line 95, in remote\r\n remotes, _ = self._load()\r\n File \"/home/mgodbolt/apps/miniconda/envs/conan/lib/python2.7/site-packages/conans/client/remote_registry.py\", line 65, in _load\r\n self._output.warn(\"Remotes registry file missing, creating default one in %s\"\r\nAttributeError: 'UserIO' object has no attribute 'warn'\r\n\r\nERROR: 'UserIO' object has no attribute 'warn'\r\n```\r\n\n", "before_files": [{"content": "from conans.search.search import DiskSearchManager, filter_outdated\nfrom collections import OrderedDict\nfrom conans.client.remote_registry import RemoteRegistry\n\n\nclass Search(object):\n def __init__(self, client_cache, remote_manager, user_io):\n self._client_cache = client_cache\n self._remote_manager = remote_manager\n self._user_io = user_io\n\n def search_recipes(self, pattern, remote=None, case_sensitive=False):\n ignorecase = not case_sensitive\n if not remote:\n return DiskSearchManager(self._client_cache).search_recipes(pattern, ignorecase)\n\n registry = RemoteRegistry(self._client_cache.registry, self._user_io.out)\n if remote == 'all':\n remotes = registry.remotes\n # We have to check if there is a remote called \"all\"\n # Deprecate: 2.0 can remove this check\n if 'all' not in (r.name for r in remotes):\n references = {}\n for remote in remotes:\n result = self._remote_manager.search_recipes(remote, pattern, ignorecase)\n if result:\n references[remote.name] = result\n return references\n # single remote\n remote = registry.remote(remote)\n return self._remote_manager.search_recipes(remote, pattern, ignorecase)\n\n def search_packages(self, reference=None, remote=None, query=None, outdated=False):\n \"\"\" Return the single information saved in conan.vars about all the packages\n or the packages which match with a pattern\n\n Attributes:\n pattern = string to match packages\n remote = search on another origin to get packages info\n packages_pattern = String query with binary\n packages properties: \"arch=x86 AND os=Windows\"\n \"\"\"\n if remote:\n remote = RemoteRegistry(self._client_cache.registry, self._user_io).remote(remote)\n packages_props = self._remote_manager.search_packages(remote, reference, query)\n ordered_packages = OrderedDict(sorted(packages_props.items()))\n manifest = self._remote_manager.get_conan_digest(reference, remote)\n recipe_hash = manifest.summary_hash\n else:\n searcher = DiskSearchManager(self._client_cache)\n packages_props = searcher.search_packages(reference, query)\n ordered_packages = OrderedDict(sorted(packages_props.items()))\n try:\n recipe_hash = self._client_cache.load_manifest(reference).summary_hash\n except IOError: # It could not exist in local\n recipe_hash = None\n if outdated and recipe_hash:\n ordered_packages = filter_outdated(ordered_packages, recipe_hash)\n return ordered_packages, reference, recipe_hash, query\n", "path": "conans/client/cmd/search.py"}]}
| 1,731 | 152 |
gh_patches_debug_38054
|
rasdani/github-patches
|
git_diff
|
translate__pootle-4613
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
TP creation email should use BCC
Let's BCC by default when Pootle is communicating to lists of people. When you create a TP all relevant people are listed in the To field.
</issue>
<code>
[start of pootle/core/mail.py]
1 # -*- coding: utf-8 -*-
2 #
3 # Copyright (C) Pootle contributors.
4 #
5 # This file is a part of the Pootle project. It is distributed under the GPL3
6 # or later license. See the LICENSE file for a copy of the license and the
7 # AUTHORS file for copyright and authorship information.
8
9 from django.core.mail import EmailMultiAlternatives, get_connection
10
11
12 def send_mail(subject, message, from_email, recipient_list,
13 fail_silently=False, auth_user=None, auth_password=None,
14 connection=None, html_message=None, headers=None):
15 """Override django send_mail function to allow use of custom email headers.
16 """
17
18 connection = connection or get_connection(username=auth_user,
19 password=auth_password,
20 fail_silently=fail_silently)
21
22 mail = EmailMultiAlternatives(subject, message,
23 from_email, recipient_list,
24 connection=connection, headers=headers)
25
26 if html_message:
27 mail.attach_alternative(html_message, 'text/html')
28
29 return mail.send()
30
[end of pootle/core/mail.py]
[start of pootle/apps/pootle_translationproject/receivers.py]
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 #
4 # Copyright (C) Pootle contributors.
5 #
6 # This file is a part of the Pootle project. It is distributed under the GPL3
7 # or later license. See the LICENSE file for a copy of the license and the
8 # AUTHORS file for copyright and authorship information.
9
10 from django.contrib.auth import get_user_model
11 from django.core.mail import send_mail
12 from django.db.models import Q
13 from django.dispatch import receiver
14 from django.template.loader import render_to_string
15 from django.utils.translation import ugettext_lazy as _
16
17 from pootle.core.url_helpers import urljoin
18
19 from .models import TranslationProject
20 from .signals import tp_init_failed_async, tp_inited_async
21
22
23 def get_recipients(project):
24 User = get_user_model()
25 return list(set(User.objects.filter(
26 Q(permissionset__positive_permissions__codename="administrate",
27 permissionset__directory__pootle_path=project.pootle_path) |
28 Q(is_superuser=True)).values_list("email", flat=True)))
29
30
31 @receiver(tp_inited_async, sender=TranslationProject)
32 def tp_inited_async(instance, response_url, **kwargs):
33 ctx = {"tp": instance,
34 "url": urljoin(response_url, instance.get_absolute_url())}
35 message = render_to_string(
36 'projects/admin/email/translation_project_created.txt', ctx)
37 subject = _(u"Translation project (%s) created" % instance)
38 recipients = get_recipients(instance.project)
39 send_mail(subject, message, from_email=None,
40 recipient_list=recipients, fail_silently=True)
41
42
43 @receiver(tp_init_failed_async, sender=TranslationProject)
44 def tp_init_failed_async(instance, **kwargs):
45 ctx = {"tp": instance}
46 message = render_to_string(
47 'projects/admin/email/translation_project_creation_failed.txt', ctx)
48 subject = _(u"Translation project (%s) creation failed" % instance)
49 recipients = get_recipients(instance.project)
50 send_mail(subject, message, from_email=None,
51 recipient_list=recipients, fail_silently=True)
52
[end of pootle/apps/pootle_translationproject/receivers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pootle/apps/pootle_translationproject/receivers.py b/pootle/apps/pootle_translationproject/receivers.py
--- a/pootle/apps/pootle_translationproject/receivers.py
+++ b/pootle/apps/pootle_translationproject/receivers.py
@@ -8,12 +8,12 @@
# AUTHORS file for copyright and authorship information.
from django.contrib.auth import get_user_model
-from django.core.mail import send_mail
from django.db.models import Q
from django.dispatch import receiver
from django.template.loader import render_to_string
from django.utils.translation import ugettext_lazy as _
+from pootle.core.mail import send_mail
from pootle.core.url_helpers import urljoin
from .models import TranslationProject
@@ -37,7 +37,7 @@
subject = _(u"Translation project (%s) created" % instance)
recipients = get_recipients(instance.project)
send_mail(subject, message, from_email=None,
- recipient_list=recipients, fail_silently=True)
+ recipient_list=[], fail_silently=True, bcc=recipients)
@receiver(tp_init_failed_async, sender=TranslationProject)
@@ -48,4 +48,4 @@
subject = _(u"Translation project (%s) creation failed" % instance)
recipients = get_recipients(instance.project)
send_mail(subject, message, from_email=None,
- recipient_list=recipients, fail_silently=True)
+ recipient_list=[], fail_silently=True, bcc=recipients)
diff --git a/pootle/core/mail.py b/pootle/core/mail.py
--- a/pootle/core/mail.py
+++ b/pootle/core/mail.py
@@ -11,7 +11,8 @@
def send_mail(subject, message, from_email, recipient_list,
fail_silently=False, auth_user=None, auth_password=None,
- connection=None, html_message=None, headers=None):
+ connection=None, html_message=None, headers=None,
+ cc=None, bcc=None):
"""Override django send_mail function to allow use of custom email headers.
"""
@@ -21,7 +22,8 @@
mail = EmailMultiAlternatives(subject, message,
from_email, recipient_list,
- connection=connection, headers=headers)
+ connection=connection, headers=headers,
+ cc=cc, bcc=bcc)
if html_message:
mail.attach_alternative(html_message, 'text/html')
|
{"golden_diff": "diff --git a/pootle/apps/pootle_translationproject/receivers.py b/pootle/apps/pootle_translationproject/receivers.py\n--- a/pootle/apps/pootle_translationproject/receivers.py\n+++ b/pootle/apps/pootle_translationproject/receivers.py\n@@ -8,12 +8,12 @@\n # AUTHORS file for copyright and authorship information.\n \n from django.contrib.auth import get_user_model\n-from django.core.mail import send_mail\n from django.db.models import Q\n from django.dispatch import receiver\n from django.template.loader import render_to_string\n from django.utils.translation import ugettext_lazy as _\n \n+from pootle.core.mail import send_mail\n from pootle.core.url_helpers import urljoin\n \n from .models import TranslationProject\n@@ -37,7 +37,7 @@\n subject = _(u\"Translation project (%s) created\" % instance)\n recipients = get_recipients(instance.project)\n send_mail(subject, message, from_email=None,\n- recipient_list=recipients, fail_silently=True)\n+ recipient_list=[], fail_silently=True, bcc=recipients)\n \n \n @receiver(tp_init_failed_async, sender=TranslationProject)\n@@ -48,4 +48,4 @@\n subject = _(u\"Translation project (%s) creation failed\" % instance)\n recipients = get_recipients(instance.project)\n send_mail(subject, message, from_email=None,\n- recipient_list=recipients, fail_silently=True)\n+ recipient_list=[], fail_silently=True, bcc=recipients)\ndiff --git a/pootle/core/mail.py b/pootle/core/mail.py\n--- a/pootle/core/mail.py\n+++ b/pootle/core/mail.py\n@@ -11,7 +11,8 @@\n \n def send_mail(subject, message, from_email, recipient_list,\n fail_silently=False, auth_user=None, auth_password=None,\n- connection=None, html_message=None, headers=None):\n+ connection=None, html_message=None, headers=None,\n+ cc=None, bcc=None):\n \"\"\"Override django send_mail function to allow use of custom email headers.\n \"\"\"\n \n@@ -21,7 +22,8 @@\n \n mail = EmailMultiAlternatives(subject, message,\n from_email, recipient_list,\n- connection=connection, headers=headers)\n+ connection=connection, headers=headers,\n+ cc=cc, bcc=bcc)\n \n if html_message:\n mail.attach_alternative(html_message, 'text/html')\n", "issue": "TP creation email should use BCC\nLet's BCC by default when Pootle is communicating to lists of people. When you create a TP all relevant people are listed in the To field.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Copyright (C) Pootle contributors.\n#\n# This file is a part of the Pootle project. It is distributed under the GPL3\n# or later license. See the LICENSE file for a copy of the license and the\n# AUTHORS file for copyright and authorship information.\n\nfrom django.core.mail import EmailMultiAlternatives, get_connection\n\n\ndef send_mail(subject, message, from_email, recipient_list,\n fail_silently=False, auth_user=None, auth_password=None,\n connection=None, html_message=None, headers=None):\n \"\"\"Override django send_mail function to allow use of custom email headers.\n \"\"\"\n\n connection = connection or get_connection(username=auth_user,\n password=auth_password,\n fail_silently=fail_silently)\n\n mail = EmailMultiAlternatives(subject, message,\n from_email, recipient_list,\n connection=connection, headers=headers)\n\n if html_message:\n mail.attach_alternative(html_message, 'text/html')\n\n return mail.send()\n", "path": "pootle/core/mail.py"}, {"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n#\n# Copyright (C) Pootle contributors.\n#\n# This file is a part of the Pootle project. It is distributed under the GPL3\n# or later license. See the LICENSE file for a copy of the license and the\n# AUTHORS file for copyright and authorship information.\n\nfrom django.contrib.auth import get_user_model\nfrom django.core.mail import send_mail\nfrom django.db.models import Q\nfrom django.dispatch import receiver\nfrom django.template.loader import render_to_string\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom pootle.core.url_helpers import urljoin\n\nfrom .models import TranslationProject\nfrom .signals import tp_init_failed_async, tp_inited_async\n\n\ndef get_recipients(project):\n User = get_user_model()\n return list(set(User.objects.filter(\n Q(permissionset__positive_permissions__codename=\"administrate\",\n permissionset__directory__pootle_path=project.pootle_path) |\n Q(is_superuser=True)).values_list(\"email\", flat=True)))\n\n\n@receiver(tp_inited_async, sender=TranslationProject)\ndef tp_inited_async(instance, response_url, **kwargs):\n ctx = {\"tp\": instance,\n \"url\": urljoin(response_url, instance.get_absolute_url())}\n message = render_to_string(\n 'projects/admin/email/translation_project_created.txt', ctx)\n subject = _(u\"Translation project (%s) created\" % instance)\n recipients = get_recipients(instance.project)\n send_mail(subject, message, from_email=None,\n recipient_list=recipients, fail_silently=True)\n\n\n@receiver(tp_init_failed_async, sender=TranslationProject)\ndef tp_init_failed_async(instance, **kwargs):\n ctx = {\"tp\": instance}\n message = render_to_string(\n 'projects/admin/email/translation_project_creation_failed.txt', ctx)\n subject = _(u\"Translation project (%s) creation failed\" % instance)\n recipients = get_recipients(instance.project)\n send_mail(subject, message, from_email=None,\n recipient_list=recipients, fail_silently=True)\n", "path": "pootle/apps/pootle_translationproject/receivers.py"}]}
| 1,431 | 545 |
gh_patches_debug_8480
|
rasdani/github-patches
|
git_diff
|
elastic__apm-agent-python-580
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
DB interactions not traced when using context manager with psycopg2 connections or cursors
When using a context manager with psycopg2 connections or cursors, db interactions are not captured in spans.
The code below generates a span for `psycopg2.connect`, but not the query:
```
with psycopg2.connect(DSN) as conn:
with conn.cursor() as curs:
curs.execute("SELECT * FROM data.portfolio;")
portfolios = curs.fetchall()
```
whereas the following captures both spans as expected:
```
conn = psycopg2.connect(DSN)
curs = conn.cursor()
curs.execute("SELECT * FROM data.portfolio;")
portfolios = curs.fetchall()
curs.close()
conn.close()
```
</issue>
<code>
[start of elasticapm/instrumentation/packages/psycopg2.py]
1 # BSD 3-Clause License
2 #
3 # Copyright (c) 2019, Elasticsearch BV
4 # All rights reserved.
5 #
6 # Redistribution and use in source and binary forms, with or without
7 # modification, are permitted provided that the following conditions are met:
8 #
9 # * Redistributions of source code must retain the above copyright notice, this
10 # list of conditions and the following disclaimer.
11 #
12 # * Redistributions in binary form must reproduce the above copyright notice,
13 # this list of conditions and the following disclaimer in the documentation
14 # and/or other materials provided with the distribution.
15 #
16 # * Neither the name of the copyright holder nor the names of its
17 # contributors may be used to endorse or promote products derived from
18 # this software without specific prior written permission.
19 #
20 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
21 # AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
22 # IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
23 # DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
24 # FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
25 # DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
26 # SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
27 # CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
28 # OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
29 # OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
30
31 from elasticapm.instrumentation.packages.dbapi2 import (
32 ConnectionProxy,
33 CursorProxy,
34 DbApi2Instrumentation,
35 extract_signature,
36 )
37 from elasticapm.traces import capture_span
38 from elasticapm.utils import default_ports
39
40
41 class PGCursorProxy(CursorProxy):
42 provider_name = "postgresql"
43
44 def _bake_sql(self, sql):
45 # if this is a Composable object, use its `as_string` method
46 # see http://initd.org/psycopg/docs/sql.html
47 if hasattr(sql, "as_string"):
48 return sql.as_string(self.__wrapped__)
49 return sql
50
51 def extract_signature(self, sql):
52 return extract_signature(sql)
53
54
55 class PGConnectionProxy(ConnectionProxy):
56 cursor_proxy = PGCursorProxy
57
58
59 class Psycopg2Instrumentation(DbApi2Instrumentation):
60 name = "psycopg2"
61
62 instrument_list = [("psycopg2", "connect")]
63
64 def call(self, module, method, wrapped, instance, args, kwargs):
65 signature = "psycopg2.connect"
66
67 host = kwargs.get("host")
68 if host:
69 signature += " " + str(host)
70
71 port = kwargs.get("port")
72 if port:
73 port = str(port)
74 if int(port) != default_ports.get("postgresql"):
75 signature += ":" + port
76 else:
77 # Parse connection string and extract host/port
78 pass
79
80 with capture_span(signature, span_type="db", span_subtype="postgresql", span_action="connect"):
81 return PGConnectionProxy(wrapped(*args, **kwargs))
82
83
84 class Psycopg2RegisterTypeInstrumentation(DbApi2Instrumentation):
85 name = "psycopg2-register-type"
86
87 instrument_list = [
88 ("psycopg2.extensions", "register_type"),
89 # specifically instrument `register_json` as it bypasses `register_type`
90 ("psycopg2._json", "register_json"),
91 ]
92
93 def call(self, module, method, wrapped, instance, args, kwargs):
94 if "conn_or_curs" in kwargs and hasattr(kwargs["conn_or_curs"], "__wrapped__"):
95 kwargs["conn_or_curs"] = kwargs["conn_or_curs"].__wrapped__
96 # register_type takes the connection as second argument
97 elif len(args) == 2 and hasattr(args[1], "__wrapped__"):
98 args = (args[0], args[1].__wrapped__)
99 # register_json takes the connection as first argument, and can have
100 # several more arguments
101 elif method == "register_json":
102 if args and hasattr(args[0], "__wrapped__"):
103 args = (args[0].__wrapped__,) + args[1:]
104
105 return wrapped(*args, **kwargs)
106
[end of elasticapm/instrumentation/packages/psycopg2.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/elasticapm/instrumentation/packages/psycopg2.py b/elasticapm/instrumentation/packages/psycopg2.py
--- a/elasticapm/instrumentation/packages/psycopg2.py
+++ b/elasticapm/instrumentation/packages/psycopg2.py
@@ -51,10 +51,16 @@
def extract_signature(self, sql):
return extract_signature(sql)
+ def __enter__(self):
+ return PGCursorProxy(self.__wrapped__.__enter__())
+
class PGConnectionProxy(ConnectionProxy):
cursor_proxy = PGCursorProxy
+ def __enter__(self):
+ return PGConnectionProxy(self.__wrapped__.__enter__())
+
class Psycopg2Instrumentation(DbApi2Instrumentation):
name = "psycopg2"
|
{"golden_diff": "diff --git a/elasticapm/instrumentation/packages/psycopg2.py b/elasticapm/instrumentation/packages/psycopg2.py\n--- a/elasticapm/instrumentation/packages/psycopg2.py\n+++ b/elasticapm/instrumentation/packages/psycopg2.py\n@@ -51,10 +51,16 @@\n def extract_signature(self, sql):\n return extract_signature(sql)\n \n+ def __enter__(self):\n+ return PGCursorProxy(self.__wrapped__.__enter__())\n+\n \n class PGConnectionProxy(ConnectionProxy):\n cursor_proxy = PGCursorProxy\n \n+ def __enter__(self):\n+ return PGConnectionProxy(self.__wrapped__.__enter__())\n+\n \n class Psycopg2Instrumentation(DbApi2Instrumentation):\n name = \"psycopg2\"\n", "issue": "DB interactions not traced when using context manager with psycopg2 connections or cursors\nWhen using a context manager with psycopg2 connections or cursors, db interactions are not captured in spans.\r\n\r\nThe code below generates a span for `psycopg2.connect`, but not the query:\r\n```\r\nwith psycopg2.connect(DSN) as conn:\r\n with conn.cursor() as curs:\r\n curs.execute(\"SELECT * FROM data.portfolio;\")\r\n portfolios = curs.fetchall()\r\n```\r\n\r\nwhereas the following captures both spans as expected:\r\n```\r\nconn = psycopg2.connect(DSN)\r\ncurs = conn.cursor()\r\ncurs.execute(\"SELECT * FROM data.portfolio;\")\r\nportfolios = curs.fetchall()\r\ncurs.close()\r\nconn.close()\r\n```\n", "before_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2019, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n\nfrom elasticapm.instrumentation.packages.dbapi2 import (\n ConnectionProxy,\n CursorProxy,\n DbApi2Instrumentation,\n extract_signature,\n)\nfrom elasticapm.traces import capture_span\nfrom elasticapm.utils import default_ports\n\n\nclass PGCursorProxy(CursorProxy):\n provider_name = \"postgresql\"\n\n def _bake_sql(self, sql):\n # if this is a Composable object, use its `as_string` method\n # see http://initd.org/psycopg/docs/sql.html\n if hasattr(sql, \"as_string\"):\n return sql.as_string(self.__wrapped__)\n return sql\n\n def extract_signature(self, sql):\n return extract_signature(sql)\n\n\nclass PGConnectionProxy(ConnectionProxy):\n cursor_proxy = PGCursorProxy\n\n\nclass Psycopg2Instrumentation(DbApi2Instrumentation):\n name = \"psycopg2\"\n\n instrument_list = [(\"psycopg2\", \"connect\")]\n\n def call(self, module, method, wrapped, instance, args, kwargs):\n signature = \"psycopg2.connect\"\n\n host = kwargs.get(\"host\")\n if host:\n signature += \" \" + str(host)\n\n port = kwargs.get(\"port\")\n if port:\n port = str(port)\n if int(port) != default_ports.get(\"postgresql\"):\n signature += \":\" + port\n else:\n # Parse connection string and extract host/port\n pass\n\n with capture_span(signature, span_type=\"db\", span_subtype=\"postgresql\", span_action=\"connect\"):\n return PGConnectionProxy(wrapped(*args, **kwargs))\n\n\nclass Psycopg2RegisterTypeInstrumentation(DbApi2Instrumentation):\n name = \"psycopg2-register-type\"\n\n instrument_list = [\n (\"psycopg2.extensions\", \"register_type\"),\n # specifically instrument `register_json` as it bypasses `register_type`\n (\"psycopg2._json\", \"register_json\"),\n ]\n\n def call(self, module, method, wrapped, instance, args, kwargs):\n if \"conn_or_curs\" in kwargs and hasattr(kwargs[\"conn_or_curs\"], \"__wrapped__\"):\n kwargs[\"conn_or_curs\"] = kwargs[\"conn_or_curs\"].__wrapped__\n # register_type takes the connection as second argument\n elif len(args) == 2 and hasattr(args[1], \"__wrapped__\"):\n args = (args[0], args[1].__wrapped__)\n # register_json takes the connection as first argument, and can have\n # several more arguments\n elif method == \"register_json\":\n if args and hasattr(args[0], \"__wrapped__\"):\n args = (args[0].__wrapped__,) + args[1:]\n\n return wrapped(*args, **kwargs)\n", "path": "elasticapm/instrumentation/packages/psycopg2.py"}]}
| 1,833 | 175 |
gh_patches_debug_143
|
rasdani/github-patches
|
git_diff
|
ManimCommunity__manim-126
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Remove argparse from setup.py
https://github.com/ManimCommunity/manim/blob/cf8c5b9938abafba9f6c2c1aeff9e15c8edbfdd1/setup.py#L17
Remove `argparse` from setup.py as it is a default library and need not be mentioned in `requirements.txt` and `setup.py`.
</issue>
<code>
[start of setup.py]
1 from setuptools import setup, find_namespace_packages
2
3 setup(
4 name="manimlib",
5 version="0.2.0",
6 description="Animation engine for explanatory math videos",
7 license="MIT",
8 packages=find_namespace_packages(),
9 package_data={ "manim": ["*.tex"] },
10 entry_points={
11 "console_scripts": [
12 "manim=manim.__main__:main",
13 "manimcm=manim.__main__:main",
14 ]
15 },
16 install_requires=[
17 "argparse",
18 "colour",
19 "numpy",
20 "Pillow",
21 "progressbar",
22 "scipy",
23 "tqdm",
24 "pycairo",
25 "pydub",
26 "pygments",
27 "pyreadline; sys_platform == 'win32'",
28 "rich",
29 ],
30 )
31
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -14,7 +14,6 @@
]
},
install_requires=[
- "argparse",
"colour",
"numpy",
"Pillow",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -14,7 +14,6 @@\n ]\n },\n install_requires=[\n- \"argparse\",\n \"colour\",\n \"numpy\",\n \"Pillow\",\n", "issue": "Remove argparse from setup.py\nhttps://github.com/ManimCommunity/manim/blob/cf8c5b9938abafba9f6c2c1aeff9e15c8edbfdd1/setup.py#L17\r\nRemove `argparse` from setup.py as it is a default library and need not be mentioned in `requirements.txt` and `setup.py`.\n", "before_files": [{"content": "from setuptools import setup, find_namespace_packages\n\nsetup(\n name=\"manimlib\",\n version=\"0.2.0\",\n description=\"Animation engine for explanatory math videos\",\n license=\"MIT\",\n packages=find_namespace_packages(),\n package_data={ \"manim\": [\"*.tex\"] },\n entry_points={\n \"console_scripts\": [\n \"manim=manim.__main__:main\",\n \"manimcm=manim.__main__:main\",\n ]\n },\n install_requires=[\n \"argparse\",\n \"colour\",\n \"numpy\",\n \"Pillow\",\n \"progressbar\",\n \"scipy\",\n \"tqdm\",\n \"pycairo\",\n \"pydub\",\n \"pygments\",\n \"pyreadline; sys_platform == 'win32'\",\n \"rich\",\n ],\n)\n", "path": "setup.py"}]}
| 843 | 60 |
gh_patches_debug_9582
|
rasdani/github-patches
|
git_diff
|
mampfes__hacs_waste_collection_schedule-596
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Error with Service Provider Stadtreinigung Leipzig / stadtreinigung-leipzig.de
Hi everyone,
Since 03.01.2023 (this is where I noticed it), WCS can no longer retrieve data from Stadtwerke Leipzig.
The following error is displayed:
fetch failed for source Stadtreinigung Leipzig: Traceback (most recent call last): File "/config/custom_components/waste_collection_schedule/waste_collection_schedule/source_shell.py", line 134, in fetch entries = self._source.fetch() File "/config/custom_components/waste_collection_schedule/waste_collection_schedule/source/stadtreinigung_leipzig_de.py", line 34, in fetch raise Exception(f"street not found: {self._street}") Exception: street not found: Pflugkstraße
My configuration.yaml:
waste_collection_schedule:
sources:
- name: stadtreinigung_leipzig_de
args:
street: Pflugkstraße
house_number: 1
calendar_title: Abfallkalender
I've been trying around here for a few days, but I can't find a solution to the problem. Is it possible that the API has been changed/defective?
Thanks for your help...
</issue>
<code>
[start of custom_components/waste_collection_schedule/waste_collection_schedule/source/stadtreinigung_leipzig_de.py]
1 import json
2 import logging
3
4 import requests
5 from waste_collection_schedule import Collection # type: ignore[attr-defined]
6 from waste_collection_schedule.service.ICS import ICS
7
8 _LOGGER = logging.getLogger(__name__)
9
10 TITLE = "Stadtreinigung Leipzig"
11 DESCRIPTION = "Source for Stadtreinigung Leipzig."
12 URL = "https://stadtreinigung-leipzig.de"
13 TEST_CASES = {"Bahnhofsallee": {"street": "Bahnhofsallee", "house_number": 7}}
14
15
16 class Source:
17 def __init__(self, street, house_number):
18 self._street = street
19 self._house_number = house_number
20 self._ics = ICS()
21
22 def fetch(self):
23 params = {
24 "name": self._street,
25 }
26
27 # get list of streets and house numbers
28 r = requests.get(
29 "https://stadtreinigung-leipzig.de/rest/wastecalendarstreets", params=params
30 )
31
32 data = json.loads(r.text)
33 if len(data["results"]) == 0:
34 raise Exception(f"street not found: {self._street}")
35 street_entry = data["results"].get(self._street)
36 if street_entry is None:
37 raise Exception(f"street not found: {self._street}")
38
39 id = street_entry.get(str(self._house_number))
40 if id is None:
41 raise Exception(f"house_number not found: {self._house_number}")
42
43 # get ics file
44 params = {
45 "position_nos": id,
46 }
47 r = requests.get(
48 "https://stadtreinigung-leipzig.de/wir-kommen-zu-ihnen/abfallkalender/ical.ics",
49 params=params,
50 )
51 dates = self._ics.convert(r.text)
52
53 entries = []
54 for d in dates:
55 entries.append(Collection(d[0], d[1].removesuffix(", ")))
56 return entries
57
[end of custom_components/waste_collection_schedule/waste_collection_schedule/source/stadtreinigung_leipzig_de.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/custom_components/waste_collection_schedule/waste_collection_schedule/source/stadtreinigung_leipzig_de.py b/custom_components/waste_collection_schedule/waste_collection_schedule/source/stadtreinigung_leipzig_de.py
--- a/custom_components/waste_collection_schedule/waste_collection_schedule/source/stadtreinigung_leipzig_de.py
+++ b/custom_components/waste_collection_schedule/waste_collection_schedule/source/stadtreinigung_leipzig_de.py
@@ -21,12 +21,13 @@
def fetch(self):
params = {
- "name": self._street,
+ "old_format": 1,
+ "search": self._street,
}
# get list of streets and house numbers
r = requests.get(
- "https://stadtreinigung-leipzig.de/rest/wastecalendarstreets", params=params
+ "https://stadtreinigung-leipzig.de/rest/Navision/Streets", params=params
)
data = json.loads(r.text)
|
{"golden_diff": "diff --git a/custom_components/waste_collection_schedule/waste_collection_schedule/source/stadtreinigung_leipzig_de.py b/custom_components/waste_collection_schedule/waste_collection_schedule/source/stadtreinigung_leipzig_de.py\n--- a/custom_components/waste_collection_schedule/waste_collection_schedule/source/stadtreinigung_leipzig_de.py\n+++ b/custom_components/waste_collection_schedule/waste_collection_schedule/source/stadtreinigung_leipzig_de.py\n@@ -21,12 +21,13 @@\n \n def fetch(self):\n params = {\n- \"name\": self._street,\n+ \"old_format\": 1,\n+ \"search\": self._street,\n }\n \n # get list of streets and house numbers\n r = requests.get(\n- \"https://stadtreinigung-leipzig.de/rest/wastecalendarstreets\", params=params\n+ \"https://stadtreinigung-leipzig.de/rest/Navision/Streets\", params=params\n )\n \n data = json.loads(r.text)\n", "issue": "Error with Service Provider Stadtreinigung Leipzig / stadtreinigung-leipzig.de\nHi everyone,\r\nSince 03.01.2023 (this is where I noticed it), WCS can no longer retrieve data from Stadtwerke Leipzig.\r\nThe following error is displayed:\r\n\r\nfetch failed for source Stadtreinigung Leipzig: Traceback (most recent call last): File \"/config/custom_components/waste_collection_schedule/waste_collection_schedule/source_shell.py\", line 134, in fetch entries = self._source.fetch() File \"/config/custom_components/waste_collection_schedule/waste_collection_schedule/source/stadtreinigung_leipzig_de.py\", line 34, in fetch raise Exception(f\"street not found: {self._street}\") Exception: street not found: Pflugkstra\u00dfe\r\n\r\nMy configuration.yaml:\r\nwaste_collection_schedule:\r\n sources:\r\n - name: stadtreinigung_leipzig_de\r\n args:\r\n street: Pflugkstra\u00dfe\r\n house_number: 1\r\n calendar_title: Abfallkalender\r\n\r\nI've been trying around here for a few days, but I can't find a solution to the problem. Is it possible that the API has been changed/defective?\r\nThanks for your help...\n", "before_files": [{"content": "import json\nimport logging\n\nimport requests\nfrom waste_collection_schedule import Collection # type: ignore[attr-defined]\nfrom waste_collection_schedule.service.ICS import ICS\n\n_LOGGER = logging.getLogger(__name__)\n\nTITLE = \"Stadtreinigung Leipzig\"\nDESCRIPTION = \"Source for Stadtreinigung Leipzig.\"\nURL = \"https://stadtreinigung-leipzig.de\"\nTEST_CASES = {\"Bahnhofsallee\": {\"street\": \"Bahnhofsallee\", \"house_number\": 7}}\n\n\nclass Source:\n def __init__(self, street, house_number):\n self._street = street\n self._house_number = house_number\n self._ics = ICS()\n\n def fetch(self):\n params = {\n \"name\": self._street,\n }\n\n # get list of streets and house numbers\n r = requests.get(\n \"https://stadtreinigung-leipzig.de/rest/wastecalendarstreets\", params=params\n )\n\n data = json.loads(r.text)\n if len(data[\"results\"]) == 0:\n raise Exception(f\"street not found: {self._street}\")\n street_entry = data[\"results\"].get(self._street)\n if street_entry is None:\n raise Exception(f\"street not found: {self._street}\")\n\n id = street_entry.get(str(self._house_number))\n if id is None:\n raise Exception(f\"house_number not found: {self._house_number}\")\n\n # get ics file\n params = {\n \"position_nos\": id,\n }\n r = requests.get(\n \"https://stadtreinigung-leipzig.de/wir-kommen-zu-ihnen/abfallkalender/ical.ics\",\n params=params,\n )\n dates = self._ics.convert(r.text)\n\n entries = []\n for d in dates:\n entries.append(Collection(d[0], d[1].removesuffix(\", \")))\n return entries\n", "path": "custom_components/waste_collection_schedule/waste_collection_schedule/source/stadtreinigung_leipzig_de.py"}]}
| 1,348 | 220 |
gh_patches_debug_37670
|
rasdani/github-patches
|
git_diff
|
biolab__orange3-3842
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Replicability in Neural networks and Random forests
Follow up from #3715: Neural networks and Random forests should have a checkbox `Replicable training` or something like this, which would decide whether random seed is fixed (to 0) or "random".
In Neural networks: add the check box.
In Random forest: remove the spin box.
</issue>
<code>
[start of Orange/widgets/model/owrandomforest.py]
1 from AnyQt.QtCore import Qt
2
3 from Orange.data import Table
4 from Orange.modelling import RandomForestLearner
5 from Orange.widgets import settings, gui
6 from Orange.widgets.utils.owlearnerwidget import OWBaseLearner
7 from Orange.widgets.utils.widgetpreview import WidgetPreview
8 from Orange.widgets.widget import Msg
9
10
11 class OWRandomForest(OWBaseLearner):
12 name = "Random Forest"
13 description = "Predict using an ensemble of decision trees."
14 icon = "icons/RandomForest.svg"
15 replaces = [
16 "Orange.widgets.classify.owrandomforest.OWRandomForest",
17 "Orange.widgets.regression.owrandomforestregression.OWRandomForestRegression",
18 ]
19 priority = 40
20 keywords = []
21
22 LEARNER = RandomForestLearner
23
24 n_estimators = settings.Setting(10)
25 max_features = settings.Setting(5)
26 use_max_features = settings.Setting(False)
27 random_state = settings.Setting(0)
28 use_random_state = settings.Setting(False)
29 max_depth = settings.Setting(3)
30 use_max_depth = settings.Setting(False)
31 min_samples_split = settings.Setting(5)
32 use_min_samples_split = settings.Setting(True)
33 index_output = settings.Setting(0)
34
35 class Error(OWBaseLearner.Error):
36 not_enough_features = Msg("Insufficient number of attributes ({})")
37
38 def add_main_layout(self):
39 box = gui.vBox(self.controlArea, 'Basic Properties')
40 self.n_estimators_spin = gui.spin(
41 box, self, "n_estimators", minv=1, maxv=10000, controlWidth=80,
42 alignment=Qt.AlignRight, label="Number of trees: ",
43 callback=self.settings_changed)
44 self.max_features_spin = gui.spin(
45 box, self, "max_features", 2, 50, controlWidth=80,
46 label="Number of attributes considered at each split: ",
47 callback=self.settings_changed, checked="use_max_features",
48 checkCallback=self.settings_changed, alignment=Qt.AlignRight,)
49 self.random_state_spin = gui.spin(
50 box, self, "random_state", 0, 2 ** 31 - 1, controlWidth=80,
51 label="Fixed seed for random generator: ", alignment=Qt.AlignRight,
52 callback=self.settings_changed, checked="use_random_state",
53 checkCallback=self.settings_changed)
54
55 box = gui.vBox(self.controlArea, "Growth Control")
56 self.max_depth_spin = gui.spin(
57 box, self, "max_depth", 1, 50, controlWidth=80,
58 label="Limit depth of individual trees: ", alignment=Qt.AlignRight,
59 callback=self.settings_changed, checked="use_max_depth",
60 checkCallback=self.settings_changed)
61 self.min_samples_split_spin = gui.spin(
62 box, self, "min_samples_split", 2, 1000, controlWidth=80,
63 label="Do not split subsets smaller than: ",
64 callback=self.settings_changed, checked="use_min_samples_split",
65 checkCallback=self.settings_changed, alignment=Qt.AlignRight)
66
67 def create_learner(self):
68 common_args = {"n_estimators": self.n_estimators}
69 if self.use_max_features:
70 common_args["max_features"] = self.max_features
71 if self.use_random_state:
72 common_args["random_state"] = self.random_state
73 if self.use_max_depth:
74 common_args["max_depth"] = self.max_depth
75 if self.use_min_samples_split:
76 common_args["min_samples_split"] = self.min_samples_split
77
78 return self.LEARNER(preprocessors=self.preprocessors, **common_args)
79
80 def check_data(self):
81 self.Error.not_enough_features.clear()
82 if super().check_data():
83 n_features = len(self.data.domain.attributes)
84 if self.use_max_features and self.max_features > n_features:
85 self.Error.not_enough_features(n_features)
86 self.valid_data = False
87 return self.valid_data
88
89 def get_learner_parameters(self):
90 """Called by send report to list the parameters of the learner."""
91 return (
92 ("Number of trees", self.n_estimators),
93 ("Maximal number of considered features",
94 self.max_features if self.use_max_features else "unlimited"),
95 ("Fixed random seed", self.use_random_state and self.random_state),
96 ("Maximal tree depth",
97 self.max_depth if self.use_max_depth else "unlimited"),
98 ("Stop splitting nodes with maximum instances",
99 self.min_samples_split if self.use_min_samples_split else "unlimited")
100 )
101
102
103 if __name__ == "__main__": # pragma: no cover
104 WidgetPreview(OWRandomForest).run(Table("iris"))
105
[end of Orange/widgets/model/owrandomforest.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/Orange/widgets/model/owrandomforest.py b/Orange/widgets/model/owrandomforest.py
--- a/Orange/widgets/model/owrandomforest.py
+++ b/Orange/widgets/model/owrandomforest.py
@@ -24,7 +24,6 @@
n_estimators = settings.Setting(10)
max_features = settings.Setting(5)
use_max_features = settings.Setting(False)
- random_state = settings.Setting(0)
use_random_state = settings.Setting(False)
max_depth = settings.Setting(3)
use_max_depth = settings.Setting(False)
@@ -46,11 +45,9 @@
label="Number of attributes considered at each split: ",
callback=self.settings_changed, checked="use_max_features",
checkCallback=self.settings_changed, alignment=Qt.AlignRight,)
- self.random_state_spin = gui.spin(
- box, self, "random_state", 0, 2 ** 31 - 1, controlWidth=80,
- label="Fixed seed for random generator: ", alignment=Qt.AlignRight,
- callback=self.settings_changed, checked="use_random_state",
- checkCallback=self.settings_changed)
+ self.random_state = gui.checkBox(
+ box, self, "use_random_state", label="Replicable training",
+ callback=self.settings_changed)
box = gui.vBox(self.controlArea, "Growth Control")
self.max_depth_spin = gui.spin(
@@ -69,7 +66,7 @@
if self.use_max_features:
common_args["max_features"] = self.max_features
if self.use_random_state:
- common_args["random_state"] = self.random_state
+ common_args["random_state"] = 0
if self.use_max_depth:
common_args["max_depth"] = self.max_depth
if self.use_min_samples_split:
@@ -92,7 +89,7 @@
("Number of trees", self.n_estimators),
("Maximal number of considered features",
self.max_features if self.use_max_features else "unlimited"),
- ("Fixed random seed", self.use_random_state and self.random_state),
+ ("Replicable training", ["No", "Yes"][self.use_random_state]),
("Maximal tree depth",
self.max_depth if self.use_max_depth else "unlimited"),
("Stop splitting nodes with maximum instances",
|
{"golden_diff": "diff --git a/Orange/widgets/model/owrandomforest.py b/Orange/widgets/model/owrandomforest.py\n--- a/Orange/widgets/model/owrandomforest.py\n+++ b/Orange/widgets/model/owrandomforest.py\n@@ -24,7 +24,6 @@\n n_estimators = settings.Setting(10)\n max_features = settings.Setting(5)\n use_max_features = settings.Setting(False)\n- random_state = settings.Setting(0)\n use_random_state = settings.Setting(False)\n max_depth = settings.Setting(3)\n use_max_depth = settings.Setting(False)\n@@ -46,11 +45,9 @@\n label=\"Number of attributes considered at each split: \",\n callback=self.settings_changed, checked=\"use_max_features\",\n checkCallback=self.settings_changed, alignment=Qt.AlignRight,)\n- self.random_state_spin = gui.spin(\n- box, self, \"random_state\", 0, 2 ** 31 - 1, controlWidth=80,\n- label=\"Fixed seed for random generator: \", alignment=Qt.AlignRight,\n- callback=self.settings_changed, checked=\"use_random_state\",\n- checkCallback=self.settings_changed)\n+ self.random_state = gui.checkBox(\n+ box, self, \"use_random_state\", label=\"Replicable training\",\n+ callback=self.settings_changed)\n \n box = gui.vBox(self.controlArea, \"Growth Control\")\n self.max_depth_spin = gui.spin(\n@@ -69,7 +66,7 @@\n if self.use_max_features:\n common_args[\"max_features\"] = self.max_features\n if self.use_random_state:\n- common_args[\"random_state\"] = self.random_state\n+ common_args[\"random_state\"] = 0\n if self.use_max_depth:\n common_args[\"max_depth\"] = self.max_depth\n if self.use_min_samples_split:\n@@ -92,7 +89,7 @@\n (\"Number of trees\", self.n_estimators),\n (\"Maximal number of considered features\",\n self.max_features if self.use_max_features else \"unlimited\"),\n- (\"Fixed random seed\", self.use_random_state and self.random_state),\n+ (\"Replicable training\", [\"No\", \"Yes\"][self.use_random_state]),\n (\"Maximal tree depth\",\n self.max_depth if self.use_max_depth else \"unlimited\"),\n (\"Stop splitting nodes with maximum instances\",\n", "issue": "Replicability in Neural networks and Random forests\nFollow up from #3715: Neural networks and Random forests should have a checkbox `Replicable training` or something like this, which would decide whether random seed is fixed (to 0) or \"random\".\r\n\r\nIn Neural networks: add the check box.\r\n\r\nIn Random forest: remove the spin box.\n", "before_files": [{"content": "from AnyQt.QtCore import Qt\n\nfrom Orange.data import Table\nfrom Orange.modelling import RandomForestLearner\nfrom Orange.widgets import settings, gui\nfrom Orange.widgets.utils.owlearnerwidget import OWBaseLearner\nfrom Orange.widgets.utils.widgetpreview import WidgetPreview\nfrom Orange.widgets.widget import Msg\n\n\nclass OWRandomForest(OWBaseLearner):\n name = \"Random Forest\"\n description = \"Predict using an ensemble of decision trees.\"\n icon = \"icons/RandomForest.svg\"\n replaces = [\n \"Orange.widgets.classify.owrandomforest.OWRandomForest\",\n \"Orange.widgets.regression.owrandomforestregression.OWRandomForestRegression\",\n ]\n priority = 40\n keywords = []\n\n LEARNER = RandomForestLearner\n\n n_estimators = settings.Setting(10)\n max_features = settings.Setting(5)\n use_max_features = settings.Setting(False)\n random_state = settings.Setting(0)\n use_random_state = settings.Setting(False)\n max_depth = settings.Setting(3)\n use_max_depth = settings.Setting(False)\n min_samples_split = settings.Setting(5)\n use_min_samples_split = settings.Setting(True)\n index_output = settings.Setting(0)\n\n class Error(OWBaseLearner.Error):\n not_enough_features = Msg(\"Insufficient number of attributes ({})\")\n\n def add_main_layout(self):\n box = gui.vBox(self.controlArea, 'Basic Properties')\n self.n_estimators_spin = gui.spin(\n box, self, \"n_estimators\", minv=1, maxv=10000, controlWidth=80,\n alignment=Qt.AlignRight, label=\"Number of trees: \",\n callback=self.settings_changed)\n self.max_features_spin = gui.spin(\n box, self, \"max_features\", 2, 50, controlWidth=80,\n label=\"Number of attributes considered at each split: \",\n callback=self.settings_changed, checked=\"use_max_features\",\n checkCallback=self.settings_changed, alignment=Qt.AlignRight,)\n self.random_state_spin = gui.spin(\n box, self, \"random_state\", 0, 2 ** 31 - 1, controlWidth=80,\n label=\"Fixed seed for random generator: \", alignment=Qt.AlignRight,\n callback=self.settings_changed, checked=\"use_random_state\",\n checkCallback=self.settings_changed)\n\n box = gui.vBox(self.controlArea, \"Growth Control\")\n self.max_depth_spin = gui.spin(\n box, self, \"max_depth\", 1, 50, controlWidth=80,\n label=\"Limit depth of individual trees: \", alignment=Qt.AlignRight,\n callback=self.settings_changed, checked=\"use_max_depth\",\n checkCallback=self.settings_changed)\n self.min_samples_split_spin = gui.spin(\n box, self, \"min_samples_split\", 2, 1000, controlWidth=80,\n label=\"Do not split subsets smaller than: \",\n callback=self.settings_changed, checked=\"use_min_samples_split\",\n checkCallback=self.settings_changed, alignment=Qt.AlignRight)\n\n def create_learner(self):\n common_args = {\"n_estimators\": self.n_estimators}\n if self.use_max_features:\n common_args[\"max_features\"] = self.max_features\n if self.use_random_state:\n common_args[\"random_state\"] = self.random_state\n if self.use_max_depth:\n common_args[\"max_depth\"] = self.max_depth\n if self.use_min_samples_split:\n common_args[\"min_samples_split\"] = self.min_samples_split\n\n return self.LEARNER(preprocessors=self.preprocessors, **common_args)\n\n def check_data(self):\n self.Error.not_enough_features.clear()\n if super().check_data():\n n_features = len(self.data.domain.attributes)\n if self.use_max_features and self.max_features > n_features:\n self.Error.not_enough_features(n_features)\n self.valid_data = False\n return self.valid_data\n\n def get_learner_parameters(self):\n \"\"\"Called by send report to list the parameters of the learner.\"\"\"\n return (\n (\"Number of trees\", self.n_estimators),\n (\"Maximal number of considered features\",\n self.max_features if self.use_max_features else \"unlimited\"),\n (\"Fixed random seed\", self.use_random_state and self.random_state),\n (\"Maximal tree depth\",\n self.max_depth if self.use_max_depth else \"unlimited\"),\n (\"Stop splitting nodes with maximum instances\",\n self.min_samples_split if self.use_min_samples_split else \"unlimited\")\n )\n\n\nif __name__ == \"__main__\": # pragma: no cover\n WidgetPreview(OWRandomForest).run(Table(\"iris\"))\n", "path": "Orange/widgets/model/owrandomforest.py"}]}
| 1,836 | 517 |
gh_patches_debug_15202
|
rasdani/github-patches
|
git_diff
|
vega__altair-1265
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
line_percent.py does not work offline
We need all examples to work offline. Currently ``line_percent.py`` uses ``pd.read_json`` from a URL.
The example should probably use a URL plus a filter.
</issue>
<code>
[start of altair/examples/boxplot_max_min.py]
1 """
2 Box Plot with Min/Max Whiskers
3 ------------------------------
4 This example shows how to make a basic box plot using US Population data from 2000.
5 """
6 # category: other charts
7 import altair as alt
8 from vega_datasets import data
9
10 source = data.population()
11
12 base = alt.Chart(source)
13
14 # Define aggregate fields
15 lower_box = 'q1(people):Q'
16 lower_whisker = 'min(people):Q'
17 upper_box = 'q3(people):Q'
18 upper_whisker = 'max(people):Q'
19
20 # Compose each layer individually
21 lower_plot = base.mark_rule().encode(
22 y=alt.Y(lower_whisker, title="population"),
23 y2=lower_box,
24 x='age:O'
25 )
26
27 middle_plot = base.mark_bar(size=5.0).encode(
28 y=lower_box,
29 y2=upper_box,
30 x='age:O'
31 )
32
33 upper_plot = base.mark_rule().encode(
34 y=upper_whisker,
35 y2=upper_box,
36 x='age:O'
37 )
38
39 middle_tick = base.mark_tick(
40 color='white',
41 size=5.0
42 ).encode(
43 y='median(people):Q',
44 x='age:O',
45 )
46
47 lower_plot + middle_plot + upper_plot + middle_tick
48
[end of altair/examples/boxplot_max_min.py]
[start of altair/examples/line_percent.py]
1 """
2 Line Chart with Percent axis
3 ----------------------------
4 This example shows how to format the tick labels of the y-axis of a chart as percentages.
5 """
6 # category: line charts
7 import altair as alt
8 import pandas as pd
9 from vega_datasets import data
10
11 source = pd.read_json(data.jobs.url)
12 welders = source[source.job == 'Welder']
13
14 alt.Chart(welders).mark_line().encode(
15 alt.X('year:O'),
16 alt.Y('perc:Q', axis=alt.Axis(format='%')),
17 color='sex:N'
18 )
19
[end of altair/examples/line_percent.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/altair/examples/boxplot_max_min.py b/altair/examples/boxplot_max_min.py
--- a/altair/examples/boxplot_max_min.py
+++ b/altair/examples/boxplot_max_min.py
@@ -7,7 +7,7 @@
import altair as alt
from vega_datasets import data
-source = data.population()
+source = data.population.url
base = alt.Chart(source)
diff --git a/altair/examples/line_percent.py b/altair/examples/line_percent.py
--- a/altair/examples/line_percent.py
+++ b/altair/examples/line_percent.py
@@ -5,14 +5,14 @@
"""
# category: line charts
import altair as alt
-import pandas as pd
from vega_datasets import data
-source = pd.read_json(data.jobs.url)
-welders = source[source.job == 'Welder']
+source = data.jobs.url
-alt.Chart(welders).mark_line().encode(
+alt.Chart(source).mark_line().encode(
alt.X('year:O'),
alt.Y('perc:Q', axis=alt.Axis(format='%')),
color='sex:N'
+).transform_filter(
+ alt.datum.job == 'Welder'
)
|
{"golden_diff": "diff --git a/altair/examples/boxplot_max_min.py b/altair/examples/boxplot_max_min.py\n--- a/altair/examples/boxplot_max_min.py\n+++ b/altair/examples/boxplot_max_min.py\n@@ -7,7 +7,7 @@\n import altair as alt\n from vega_datasets import data\n \n-source = data.population()\n+source = data.population.url\n \n base = alt.Chart(source)\n \ndiff --git a/altair/examples/line_percent.py b/altair/examples/line_percent.py\n--- a/altair/examples/line_percent.py\n+++ b/altair/examples/line_percent.py\n@@ -5,14 +5,14 @@\n \"\"\"\n # category: line charts\n import altair as alt\n-import pandas as pd\n from vega_datasets import data\n \n-source = pd.read_json(data.jobs.url)\n-welders = source[source.job == 'Welder']\n+source = data.jobs.url\n \n-alt.Chart(welders).mark_line().encode(\n+alt.Chart(source).mark_line().encode(\n alt.X('year:O'),\n alt.Y('perc:Q', axis=alt.Axis(format='%')),\n color='sex:N'\n+).transform_filter(\n+ alt.datum.job == 'Welder'\n )\n", "issue": "line_percent.py does not work offline\nWe need all examples to work offline. Currently ``line_percent.py`` uses ``pd.read_json`` from a URL.\r\n\r\nThe example should probably use a URL plus a filter.\n", "before_files": [{"content": "\"\"\"\nBox Plot with Min/Max Whiskers\n------------------------------\nThis example shows how to make a basic box plot using US Population data from 2000.\n\"\"\"\n# category: other charts\nimport altair as alt\nfrom vega_datasets import data\n\nsource = data.population()\n\nbase = alt.Chart(source)\n\n# Define aggregate fields\nlower_box = 'q1(people):Q'\nlower_whisker = 'min(people):Q'\nupper_box = 'q3(people):Q'\nupper_whisker = 'max(people):Q'\n\n# Compose each layer individually\nlower_plot = base.mark_rule().encode(\n y=alt.Y(lower_whisker, title=\"population\"),\n y2=lower_box,\n x='age:O'\n)\n\nmiddle_plot = base.mark_bar(size=5.0).encode(\n y=lower_box,\n y2=upper_box,\n x='age:O'\n)\n\nupper_plot = base.mark_rule().encode(\n y=upper_whisker,\n y2=upper_box,\n x='age:O'\n)\n\nmiddle_tick = base.mark_tick(\n color='white',\n size=5.0\n).encode(\n y='median(people):Q',\n x='age:O',\n)\n\nlower_plot + middle_plot + upper_plot + middle_tick\n", "path": "altair/examples/boxplot_max_min.py"}, {"content": "\"\"\"\nLine Chart with Percent axis\n----------------------------\nThis example shows how to format the tick labels of the y-axis of a chart as percentages.\n\"\"\"\n# category: line charts\nimport altair as alt\nimport pandas as pd\nfrom vega_datasets import data\n\nsource = pd.read_json(data.jobs.url)\nwelders = source[source.job == 'Welder']\n\nalt.Chart(welders).mark_line().encode(\n alt.X('year:O'),\n alt.Y('perc:Q', axis=alt.Axis(format='%')),\n color='sex:N'\n)\n", "path": "altair/examples/line_percent.py"}]}
| 1,127 | 271 |
gh_patches_debug_12654
|
rasdani/github-patches
|
git_diff
|
ocadotechnology__aimmo-499
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Game Creator RC initialised with wrong game API URL
The `REPLACE_ME` change in one of the latest PR's has broken the game on minikube level in `minikube.py`. The URL is incorrect so minikube does not work and prohibits testing.
</issue>
<code>
[start of setup.py]
1 # -*- coding: utf-8 -*-
2 from setuptools import find_packages, setup
3
4 import versioneer
5
6 setup(
7 name='aimmo',
8 cmdclass=versioneer.get_cmdclass(),
9 packages=find_packages(),
10 include_package_data=True,
11 install_requires=[
12 'django >= 1.8.3, < 1.9.0',
13 'django-autoconfig >= 0.3.6, < 1.0.0',
14 'django-forms-bootstrap',
15 'django-js-reverse',
16 'eventlet',
17 'flask',
18 'flask-socketio',
19 'requests',
20 'six',
21 'pykube',
22 'hypothesis',
23 'flask-cors >= 3.0, < 3.1',
24 'psutil >= 5.4, < 5.5',
25 ],
26 tests_require=[
27 'django-setuptest',
28 'httmock',
29 ],
30 test_suite='setuptest.setuptest.SetupTestSuite',
31 version=versioneer.get_version(),
32 zip_safe=False,
33 )
34
[end of setup.py]
[start of aimmo_runner/shell_api.py]
1 import subprocess
2 import sys
3 import os
4 import stat
5 import errno
6 import platform
7 from subprocess import CalledProcessError
8 from urllib import urlretrieve, urlopen
9
10 BASE_DIR = os.path.abspath(os.path.dirname(os.path.dirname(__file__)))
11 TEST_BIN = os.path.join(BASE_DIR, 'test-bin')
12 OS = platform.system().lower()
13 FILE_SUFFIX = '.exe' if OS == 'windows' else ''
14 KUBECTL = os.path.join(TEST_BIN, 'kubectl%s' % FILE_SUFFIX)
15 MINIKUBE = os.path.join(TEST_BIN, 'minikube%s' % FILE_SUFFIX)
16 FNULL = open(os.devnull, 'w')
17
18 def log(message):
19 sys.stderr.write(message + "\n")
20
21
22 def run_command(args, capture_output=False):
23 try:
24 if capture_output:
25 return subprocess.check_output(args)
26 else:
27 subprocess.check_call(args)
28 except CalledProcessError as e:
29 log('Command failed with exit status %d: %s' % (e.returncode, ' '.join(args)))
30 raise
31
32
33 def run_command_async(args, capture_output=False):
34 if capture_output is True:
35 p = subprocess.Popen(args, stdout=FNULL, stderr=subprocess.STDOUT)
36 else:
37 p = subprocess.Popen(args)
38 return p
39
40
41 def create_test_bin():
42 try:
43 os.makedirs(TEST_BIN)
44 except OSError as err:
45 if err.errno != errno.EEXIST:
46 raise
47
48
49 def binary_exists(filename):
50 # Check if binary is callable on our path
51 try:
52 run_command([filename], True)
53 return True
54 except OSError:
55 return False
56
57
58 def download_exec(url, dest):
59 dest = urlretrieve(url, dest)[0]
60 make_exec(dest)
61
62
63 def make_exec(file):
64 current_stat = os.stat(file)
65 os.chmod(file, current_stat.st_mode | stat.S_IEXEC)
66
67
68 def get_latest_github_version(repo):
69 result = urlopen('https://github.com/%s/releases/latest' % repo)
70 return result.geturl().split('/')[-1]
71
72
[end of aimmo_runner/shell_api.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/aimmo_runner/shell_api.py b/aimmo_runner/shell_api.py
--- a/aimmo_runner/shell_api.py
+++ b/aimmo_runner/shell_api.py
@@ -15,6 +15,7 @@
MINIKUBE = os.path.join(TEST_BIN, 'minikube%s' % FILE_SUFFIX)
FNULL = open(os.devnull, 'w')
+
def log(message):
sys.stderr.write(message + "\n")
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -26,6 +26,10 @@
tests_require=[
'django-setuptest',
'httmock',
+ 'mock == 2.0.0',
+ 'docker == 2.7.0',
+ 'kubernetes == 4.0.0',
+ 'PyYAML == 3.12',
],
test_suite='setuptest.setuptest.SetupTestSuite',
version=versioneer.get_version(),
|
{"golden_diff": "diff --git a/aimmo_runner/shell_api.py b/aimmo_runner/shell_api.py\n--- a/aimmo_runner/shell_api.py\n+++ b/aimmo_runner/shell_api.py\n@@ -15,6 +15,7 @@\n MINIKUBE = os.path.join(TEST_BIN, 'minikube%s' % FILE_SUFFIX)\n FNULL = open(os.devnull, 'w')\n \n+\n def log(message):\n sys.stderr.write(message + \"\\n\")\n \ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -26,6 +26,10 @@\n tests_require=[\n 'django-setuptest',\n 'httmock',\n+ 'mock == 2.0.0',\n+ 'docker == 2.7.0',\n+ 'kubernetes == 4.0.0',\n+ 'PyYAML == 3.12',\n ],\n test_suite='setuptest.setuptest.SetupTestSuite',\n version=versioneer.get_version(),\n", "issue": "Game Creator RC initialised with wrong game API URL\nThe `REPLACE_ME` change in one of the latest PR's has broken the game on minikube level in `minikube.py`. The URL is incorrect so minikube does not work and prohibits testing. \r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom setuptools import find_packages, setup\n\nimport versioneer\n\nsetup(\n name='aimmo',\n cmdclass=versioneer.get_cmdclass(),\n packages=find_packages(),\n include_package_data=True,\n install_requires=[\n 'django >= 1.8.3, < 1.9.0',\n 'django-autoconfig >= 0.3.6, < 1.0.0',\n 'django-forms-bootstrap',\n 'django-js-reverse',\n 'eventlet',\n 'flask',\n 'flask-socketio',\n 'requests',\n 'six',\n 'pykube',\n 'hypothesis',\n 'flask-cors >= 3.0, < 3.1',\n 'psutil >= 5.4, < 5.5',\n ],\n tests_require=[\n 'django-setuptest',\n 'httmock',\n ],\n test_suite='setuptest.setuptest.SetupTestSuite',\n version=versioneer.get_version(),\n zip_safe=False,\n)\n", "path": "setup.py"}, {"content": "import subprocess\nimport sys\nimport os\nimport stat\nimport errno\nimport platform\nfrom subprocess import CalledProcessError\nfrom urllib import urlretrieve, urlopen\n\nBASE_DIR = os.path.abspath(os.path.dirname(os.path.dirname(__file__)))\nTEST_BIN = os.path.join(BASE_DIR, 'test-bin')\nOS = platform.system().lower()\nFILE_SUFFIX = '.exe' if OS == 'windows' else ''\nKUBECTL = os.path.join(TEST_BIN, 'kubectl%s' % FILE_SUFFIX)\nMINIKUBE = os.path.join(TEST_BIN, 'minikube%s' % FILE_SUFFIX)\nFNULL = open(os.devnull, 'w')\n\ndef log(message):\n sys.stderr.write(message + \"\\n\")\n\n\ndef run_command(args, capture_output=False):\n try:\n if capture_output:\n return subprocess.check_output(args)\n else:\n subprocess.check_call(args)\n except CalledProcessError as e:\n log('Command failed with exit status %d: %s' % (e.returncode, ' '.join(args)))\n raise\n\n\ndef run_command_async(args, capture_output=False):\n if capture_output is True:\n p = subprocess.Popen(args, stdout=FNULL, stderr=subprocess.STDOUT)\n else:\n p = subprocess.Popen(args)\n return p\n\n\ndef create_test_bin():\n try:\n os.makedirs(TEST_BIN)\n except OSError as err:\n if err.errno != errno.EEXIST:\n raise\n\n\ndef binary_exists(filename):\n # Check if binary is callable on our path\n try:\n run_command([filename], True)\n return True\n except OSError:\n return False\n\n\ndef download_exec(url, dest):\n dest = urlretrieve(url, dest)[0]\n make_exec(dest)\n\n\ndef make_exec(file):\n current_stat = os.stat(file)\n os.chmod(file, current_stat.st_mode | stat.S_IEXEC)\n\n\ndef get_latest_github_version(repo):\n result = urlopen('https://github.com/%s/releases/latest' % repo)\n return result.geturl().split('/')[-1]\n\n", "path": "aimmo_runner/shell_api.py"}]}
| 1,474 | 228 |
gh_patches_debug_2784
|
rasdani/github-patches
|
git_diff
|
archlinux__archinstall-1954
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[master] awesome (desktops in general?) don't install packages?
It appears when choosing awesome, install is called: https://github.com/archlinux/archinstall/blob/7326d51161bf6fd7f1c683cf1d7ce09338efe4b7/archinstall/default_profiles/desktops/awesome.py#L23-L24
And super being `XorgProfile`: https://github.com/archlinux/archinstall/blob/7326d51161bf6fd7f1c683cf1d7ce09338efe4b7/archinstall/default_profiles/xorg.py#L1-L21
That class does not have an install so it calls `Profile.install()` which contains: https://github.com/archlinux/archinstall/blob/7326d51161bf6fd7f1c683cf1d7ce09338efe4b7/archinstall/default_profiles/profile.py#L101-L104
Which is just a placeholder?

I haven't ran through all the profiles yet, but have we overlooked something here?
What happened to all the packages per profile when we moved them to the dataclass structure? :)
I obviously missed something in a PR some where hehe
</issue>
<code>
[start of archinstall/default_profiles/desktops/awesome.py]
1 from typing import List, Optional, Any, TYPE_CHECKING
2
3 from archinstall.default_profiles.profile import ProfileType
4 from archinstall.default_profiles.xorg import XorgProfile
5
6 if TYPE_CHECKING:
7 from archinstall.lib.installer import Installer
8 _: Any
9
10
11 class AwesomeProfile(XorgProfile):
12 def __init__(self):
13 super().__init__('Awesome', ProfileType.WindowMgr, description='')
14
15 @property
16 def packages(self) -> List[str]:
17 return ['alacritty']
18
19 def preview_text(self) -> Optional[str]:
20 text = str(_('Environment type: {}')).format(self.profile_type.value)
21 return text + '\n' + self.packages_text()
22
23 def install(self, install_session: 'Installer'):
24 super().install(install_session)
25
26 # TODO: Copy a full configuration to ~/.config/awesome/rc.lua instead.
27 with open(f"{install_session.target}/etc/xdg/awesome/rc.lua", 'r') as fh:
28 awesome_lua = fh.read()
29
30 # Replace xterm with alacritty for a smoother experience.
31 awesome_lua = awesome_lua.replace('"xterm"', '"alacritty"')
32
33 with open(f"{install_session.target}/etc/xdg/awesome/rc.lua", 'w') as fh:
34 fh.write(awesome_lua)
35
36 # TODO: Configure the right-click-menu to contain the above packages that were installed. (as a user config)
37
[end of archinstall/default_profiles/desktops/awesome.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/archinstall/default_profiles/desktops/awesome.py b/archinstall/default_profiles/desktops/awesome.py
--- a/archinstall/default_profiles/desktops/awesome.py
+++ b/archinstall/default_profiles/desktops/awesome.py
@@ -14,7 +14,10 @@
@property
def packages(self) -> List[str]:
- return ['alacritty']
+ return [
+ 'awesome',
+ 'alacritty'
+ ]
def preview_text(self) -> Optional[str]:
text = str(_('Environment type: {}')).format(self.profile_type.value)
|
{"golden_diff": "diff --git a/archinstall/default_profiles/desktops/awesome.py b/archinstall/default_profiles/desktops/awesome.py\n--- a/archinstall/default_profiles/desktops/awesome.py\n+++ b/archinstall/default_profiles/desktops/awesome.py\n@@ -14,7 +14,10 @@\n \n \t@property\n \tdef packages(self) -> List[str]:\n-\t\treturn ['alacritty']\n+\t\treturn [\n+\t\t\t'awesome',\n+\t\t\t'alacritty'\n+\t\t]\n \n \tdef preview_text(self) -> Optional[str]:\n \t\ttext = str(_('Environment type: {}')).format(self.profile_type.value)\n", "issue": "[master] awesome (desktops in general?) don't install packages?\nIt appears when choosing awesome, install is called: https://github.com/archlinux/archinstall/blob/7326d51161bf6fd7f1c683cf1d7ce09338efe4b7/archinstall/default_profiles/desktops/awesome.py#L23-L24\r\n\r\nAnd super being `XorgProfile`: https://github.com/archlinux/archinstall/blob/7326d51161bf6fd7f1c683cf1d7ce09338efe4b7/archinstall/default_profiles/xorg.py#L1-L21\r\n\r\nThat class does not have an install so it calls `Profile.install()` which contains: https://github.com/archlinux/archinstall/blob/7326d51161bf6fd7f1c683cf1d7ce09338efe4b7/archinstall/default_profiles/profile.py#L101-L104\r\nWhich is just a placeholder?\r\n\r\n\r\n\r\nI haven't ran through all the profiles yet, but have we overlooked something here?\r\nWhat happened to all the packages per profile when we moved them to the dataclass structure? :)\r\n\r\nI obviously missed something in a PR some where hehe\n", "before_files": [{"content": "from typing import List, Optional, Any, TYPE_CHECKING\n\nfrom archinstall.default_profiles.profile import ProfileType\nfrom archinstall.default_profiles.xorg import XorgProfile\n\nif TYPE_CHECKING:\n\tfrom archinstall.lib.installer import Installer\n\t_: Any\n\n\nclass AwesomeProfile(XorgProfile):\n\tdef __init__(self):\n\t\tsuper().__init__('Awesome', ProfileType.WindowMgr, description='')\n\n\t@property\n\tdef packages(self) -> List[str]:\n\t\treturn ['alacritty']\n\n\tdef preview_text(self) -> Optional[str]:\n\t\ttext = str(_('Environment type: {}')).format(self.profile_type.value)\n\t\treturn text + '\\n' + self.packages_text()\n\n\tdef install(self, install_session: 'Installer'):\n\t\tsuper().install(install_session)\n\n\t\t# TODO: Copy a full configuration to ~/.config/awesome/rc.lua instead.\n\t\twith open(f\"{install_session.target}/etc/xdg/awesome/rc.lua\", 'r') as fh:\n\t\t\tawesome_lua = fh.read()\n\n\t\t# Replace xterm with alacritty for a smoother experience.\n\t\tawesome_lua = awesome_lua.replace('\"xterm\"', '\"alacritty\"')\n\n\t\twith open(f\"{install_session.target}/etc/xdg/awesome/rc.lua\", 'w') as fh:\n\t\t\tfh.write(awesome_lua)\n\n\t\t# TODO: Configure the right-click-menu to contain the above packages that were installed. (as a user config)\n", "path": "archinstall/default_profiles/desktops/awesome.py"}]}
| 1,265 | 134 |
gh_patches_debug_24635
|
rasdani/github-patches
|
git_diff
|
plone__Products.CMFPlone-1438
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
plone-upgrade to 5.0.3 shows plain text as result
This is caused by https://github.com/plone/plone.app.upgrade/pull/67 by @vangheem, though this change looks fine to me.
With the above change, when running `@@plone-upgrade`, even with dry-run selected, the result page is shown as text: you see plain html. Very strange. Reported here: https://community.plone.org/t/plone-5-0-3-soft-released/1699/4
When I empty the registry.xml, keeping only the main `registry` tags for safety, it all works fine. Keeping one of the two changed records, it again shows as text.
To check it:
- Use current coredev 5.0
- Create a Plone Site.
- Simulate a Plone 5.0.2 site: in portal_setup, Upgrades, select Products.CMFPlone:plone, and run the to502 upgrade profile.
- Go to @@plone-upgrade, optionally select dry-run, and run the upgrade.
Result: it will show as plain text.
BTW, afterwards, all is fine: the migration has succeeded and it looks like all pages show up fine.
Any idea?
</issue>
<code>
[start of Products/CMFPlone/resources/exportimport/bundles.py]
1 from plone.registry.interfaces import IRegistry
2 from zope.component import queryUtility
3
4 from ..browser.combine import combine_bundles
5
6
7 def combine(context):
8
9 logger = context.getLogger('bundles')
10 registry = queryUtility(IRegistry)
11
12 if registry is None:
13 logger.info("Cannot find registry")
14 return
15
16 body = context.readDataFile('registry.xml')
17 if body and "IBundleRegistry" in body:
18 site = context.getSite()
19 combine_bundles(site)
20
[end of Products/CMFPlone/resources/exportimport/bundles.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/Products/CMFPlone/resources/exportimport/bundles.py b/Products/CMFPlone/resources/exportimport/bundles.py
--- a/Products/CMFPlone/resources/exportimport/bundles.py
+++ b/Products/CMFPlone/resources/exportimport/bundles.py
@@ -1,5 +1,6 @@
from plone.registry.interfaces import IRegistry
from zope.component import queryUtility
+from zope.globalrequest import getRequest
from ..browser.combine import combine_bundles
@@ -16,4 +17,20 @@
body = context.readDataFile('registry.xml')
if body and "IBundleRegistry" in body:
site = context.getSite()
+ # Calling combine_bundles will have as side effect that the
+ # Content-Type header of the response is set to application/javascript,
+ # which we do not want. So we reset it to the original at the end.
+ site = context.getSite()
+ request = getattr(site, 'REQUEST', getRequest())
+ if request is not None:
+ # Easily happens in tests.
+ orig_header = request.response.getHeader('Content-Type')
combine_bundles(site)
+ if request is not None:
+ new_header = request.response.getHeader('Content-Type')
+ if new_header != orig_header:
+ if orig_header is None:
+ # Setting it to None would result in the string 'None'.
+ # So pick a saner one.
+ orig_header = 'text/html'
+ request.response.setHeader('Content-Type', orig_header)
|
{"golden_diff": "diff --git a/Products/CMFPlone/resources/exportimport/bundles.py b/Products/CMFPlone/resources/exportimport/bundles.py\n--- a/Products/CMFPlone/resources/exportimport/bundles.py\n+++ b/Products/CMFPlone/resources/exportimport/bundles.py\n@@ -1,5 +1,6 @@\n from plone.registry.interfaces import IRegistry\n from zope.component import queryUtility\n+from zope.globalrequest import getRequest\n \n from ..browser.combine import combine_bundles\n \n@@ -16,4 +17,20 @@\n body = context.readDataFile('registry.xml')\n if body and \"IBundleRegistry\" in body:\n site = context.getSite()\n+ # Calling combine_bundles will have as side effect that the\n+ # Content-Type header of the response is set to application/javascript,\n+ # which we do not want. So we reset it to the original at the end.\n+ site = context.getSite()\n+ request = getattr(site, 'REQUEST', getRequest())\n+ if request is not None:\n+ # Easily happens in tests.\n+ orig_header = request.response.getHeader('Content-Type')\n combine_bundles(site)\n+ if request is not None:\n+ new_header = request.response.getHeader('Content-Type')\n+ if new_header != orig_header:\n+ if orig_header is None:\n+ # Setting it to None would result in the string 'None'.\n+ # So pick a saner one.\n+ orig_header = 'text/html'\n+ request.response.setHeader('Content-Type', orig_header)\n", "issue": "plone-upgrade to 5.0.3 shows plain text as result\nThis is caused by https://github.com/plone/plone.app.upgrade/pull/67 by @vangheem, though this change looks fine to me.\n\nWith the above change, when running `@@plone-upgrade`, even with dry-run selected, the result page is shown as text: you see plain html. Very strange. Reported here: https://community.plone.org/t/plone-5-0-3-soft-released/1699/4\nWhen I empty the registry.xml, keeping only the main `registry` tags for safety, it all works fine. Keeping one of the two changed records, it again shows as text.\n\nTo check it:\n- Use current coredev 5.0\n- Create a Plone Site.\n- Simulate a Plone 5.0.2 site: in portal_setup, Upgrades, select Products.CMFPlone:plone, and run the to502 upgrade profile.\n- Go to @@plone-upgrade, optionally select dry-run, and run the upgrade.\n\nResult: it will show as plain text.\nBTW, afterwards, all is fine: the migration has succeeded and it looks like all pages show up fine.\n\nAny idea?\n\n", "before_files": [{"content": "from plone.registry.interfaces import IRegistry\nfrom zope.component import queryUtility\n\nfrom ..browser.combine import combine_bundles\n\n\ndef combine(context):\n\n logger = context.getLogger('bundles')\n registry = queryUtility(IRegistry)\n\n if registry is None:\n logger.info(\"Cannot find registry\")\n return\n\n body = context.readDataFile('registry.xml')\n if body and \"IBundleRegistry\" in body:\n site = context.getSite()\n combine_bundles(site)\n", "path": "Products/CMFPlone/resources/exportimport/bundles.py"}]}
| 956 | 341 |
gh_patches_debug_9715
|
rasdani/github-patches
|
git_diff
|
OCA__server-tools-74
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[7.0] [base_optional_quick_create] AttributeError: 'NoneType' object has no attribute 'name_create'
Error at starting before a migration if a model has been removed
</issue>
<code>
[start of base_optional_quick_create/model.py]
1 # -*- coding: utf-8 -*-
2 ##############################################################################
3 #
4 # Copyright (C) 2013 Agile Business Group sagl (<http://www.agilebg.com>)
5 #
6 # This program is free software: you can redistribute it and/or modify
7 # it under the terms of the GNU Affero General Public License as published
8 # by the Free Software Foundation, either version 3 of the License, or
9 # (at your option) any later version.
10 #
11 # This program is distributed in the hope that it will be useful,
12 # but WITHOUT ANY WARRANTY; without even the implied warranty of
13 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
14 # GNU Affero General Public License for more details.
15 #
16 # You should have received a copy of the GNU Affero General Public License
17 # along with this program. If not, see <http://www.gnu.org/licenses/>.
18 #
19 ##############################################################################
20
21 from openerp.osv import orm, fields
22 from openerp import SUPERUSER_ID
23 from openerp.tools.translate import _
24
25
26 class ir_model(orm.Model):
27
28 _inherit = 'ir.model'
29
30 _columns = {
31 'avoid_quick_create': fields.boolean('Avoid quick create'),
32 }
33
34 def _wrap_name_create(self, old_create, model):
35 def wrapper(cr, uid, name, context=None):
36 raise orm.except_orm(_('Error'),
37 _("Can't create quickly. "
38 "Opening create form"))
39 return wrapper
40
41 def _register_hook(self, cr, ids=None):
42 if ids is None:
43 ids = self.search(cr, SUPERUSER_ID, [])
44 for model in self.browse(cr, SUPERUSER_ID, ids):
45 if model.avoid_quick_create:
46 model_name = model.model
47 model_obj = self.pool.get(model_name)
48 if not hasattr(model_obj, 'check_quick_create'):
49 model_obj.name_create = self._wrap_name_create(
50 model_obj.name_create,
51 model_name)
52 model_obj.check_quick_create = True
53 return True
54
55 def create(self, cr, uid, vals, context=None):
56 res_id = super(ir_model, self).create(cr, uid, vals, context=context)
57 self._register_hook(cr, [res_id])
58 return res_id
59
60 def write(self, cr, uid, ids, vals, context=None):
61 if isinstance(ids, (int, long)):
62 ids = [ids]
63 super(ir_model, self).write(cr, uid, ids, vals, context=context)
64 self._register_hook(cr, ids)
65 return True
66
[end of base_optional_quick_create/model.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/base_optional_quick_create/model.py b/base_optional_quick_create/model.py
--- a/base_optional_quick_create/model.py
+++ b/base_optional_quick_create/model.py
@@ -45,7 +45,7 @@
if model.avoid_quick_create:
model_name = model.model
model_obj = self.pool.get(model_name)
- if not hasattr(model_obj, 'check_quick_create'):
+ if model_obj and not hasattr(model_obj, 'check_quick_create'):
model_obj.name_create = self._wrap_name_create(
model_obj.name_create,
model_name)
|
{"golden_diff": "diff --git a/base_optional_quick_create/model.py b/base_optional_quick_create/model.py\n--- a/base_optional_quick_create/model.py\n+++ b/base_optional_quick_create/model.py\n@@ -45,7 +45,7 @@\n if model.avoid_quick_create:\n model_name = model.model\n model_obj = self.pool.get(model_name)\n- if not hasattr(model_obj, 'check_quick_create'):\n+ if model_obj and not hasattr(model_obj, 'check_quick_create'):\n model_obj.name_create = self._wrap_name_create(\n model_obj.name_create,\n model_name)\n", "issue": "[7.0] [base_optional_quick_create] AttributeError: 'NoneType' object has no attribute 'name_create'\nError at starting before a migration if a model has been removed\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n##############################################################################\n#\n# Copyright (C) 2013 Agile Business Group sagl (<http://www.agilebg.com>)\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU Affero General Public License as published\n# by the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU Affero General Public License for more details.\n#\n# You should have received a copy of the GNU Affero General Public License\n# along with this program. If not, see <http://www.gnu.org/licenses/>.\n#\n##############################################################################\n\nfrom openerp.osv import orm, fields\nfrom openerp import SUPERUSER_ID\nfrom openerp.tools.translate import _\n\n\nclass ir_model(orm.Model):\n\n _inherit = 'ir.model'\n\n _columns = {\n 'avoid_quick_create': fields.boolean('Avoid quick create'),\n }\n\n def _wrap_name_create(self, old_create, model):\n def wrapper(cr, uid, name, context=None):\n raise orm.except_orm(_('Error'),\n _(\"Can't create quickly. \"\n \"Opening create form\"))\n return wrapper\n\n def _register_hook(self, cr, ids=None):\n if ids is None:\n ids = self.search(cr, SUPERUSER_ID, [])\n for model in self.browse(cr, SUPERUSER_ID, ids):\n if model.avoid_quick_create:\n model_name = model.model\n model_obj = self.pool.get(model_name)\n if not hasattr(model_obj, 'check_quick_create'):\n model_obj.name_create = self._wrap_name_create(\n model_obj.name_create,\n model_name)\n model_obj.check_quick_create = True\n return True\n\n def create(self, cr, uid, vals, context=None):\n res_id = super(ir_model, self).create(cr, uid, vals, context=context)\n self._register_hook(cr, [res_id])\n return res_id\n\n def write(self, cr, uid, ids, vals, context=None):\n if isinstance(ids, (int, long)):\n ids = [ids]\n super(ir_model, self).write(cr, uid, ids, vals, context=context)\n self._register_hook(cr, ids)\n return True\n", "path": "base_optional_quick_create/model.py"}]}
| 1,245 | 125 |
gh_patches_debug_27735
|
rasdani/github-patches
|
git_diff
|
e-valuation__EvaP-1263
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Remove ViewTest where possible
Right now we have a `class ViewTest`, for which there is one subclass for each view that we have.
For views that we have tested properly, it provides no additional value and I I propose to replace it with the original `WebTest`.
Originally I proposed to remove it altogether and copypaste its test to all the test cases that wouldn't have any valuable test otherwise. @janno42 convinced me to leave it there and rename it to `WebTestWith200Check` instead.
</issue>
<code>
[start of evap/evaluation/migrations/0002_initial_data.py]
1 from django.db import migrations
2 from django.contrib.auth.models import Group
3
4
5 def insert_emailtemplates(apps, _schema_editor):
6 emailtemplates = [
7 ("Lecturer Review Notice", "[EvaP] New Course ready for approval"),
8 ("Student Reminder", "[EvaP] Evaluation period is ending"),
9 ("Publishing Notice", "[EvaP] A course has been published"),
10 ("Login Key Created", "[EvaP] A login key was created"),
11 ]
12
13 EmailTemplate = apps.get_model("evaluation", "EmailTemplate")
14
15 for name, subject in emailtemplates:
16 if not EmailTemplate.objects.filter(name=name).exists():
17 EmailTemplate.objects.create(name=name, subject=subject, body="")
18
19 Group.objects.create(name="Staff")
20
21
22 class Migration(migrations.Migration):
23
24 dependencies = [
25 ('evaluation', '0001_initial'),
26 ]
27
28 operations = [
29 migrations.RunPython(insert_emailtemplates),
30 ]
31
[end of evap/evaluation/migrations/0002_initial_data.py]
[start of evap/grades/migrations/0002_initial_data.py]
1 from django.db import migrations
2 from django.contrib.auth.models import Group
3
4
5 def add_group(_apps, _schema_editor):
6 Group.objects.create(name="Grade publisher")
7
8
9 class Migration(migrations.Migration):
10
11 dependencies = [
12 ('grades', '0001_initial'),
13 ]
14
15 operations = [
16 migrations.RunPython(add_group),
17 ]
18
[end of evap/grades/migrations/0002_initial_data.py]
[start of evap/evaluation/migrations/0055_reviewer_group.py]
1 from django.contrib.auth.models import Group
2 from django.db import migrations
3
4
5 def add_group(_apps, _schema_editor):
6 Group.objects.create(name="Reviewer")
7
8
9 def delete_group(_apps, _schema_editor):
10 Group.objects.get(name="Reviewer").delete()
11
12
13 class Migration(migrations.Migration):
14
15 dependencies = [
16 ('evaluation', '0054_userprofile_language'),
17 ]
18
19 operations = [
20 migrations.RunPython(add_group, reverse_code=delete_group),
21 ]
22
[end of evap/evaluation/migrations/0055_reviewer_group.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/evap/evaluation/migrations/0002_initial_data.py b/evap/evaluation/migrations/0002_initial_data.py
--- a/evap/evaluation/migrations/0002_initial_data.py
+++ b/evap/evaluation/migrations/0002_initial_data.py
@@ -1,5 +1,4 @@
from django.db import migrations
-from django.contrib.auth.models import Group
def insert_emailtemplates(apps, _schema_editor):
@@ -16,6 +15,7 @@
if not EmailTemplate.objects.filter(name=name).exists():
EmailTemplate.objects.create(name=name, subject=subject, body="")
+ Group = apps.get_model("auth", "Group")
Group.objects.create(name="Staff")
diff --git a/evap/evaluation/migrations/0055_reviewer_group.py b/evap/evaluation/migrations/0055_reviewer_group.py
--- a/evap/evaluation/migrations/0055_reviewer_group.py
+++ b/evap/evaluation/migrations/0055_reviewer_group.py
@@ -1,12 +1,13 @@
-from django.contrib.auth.models import Group
from django.db import migrations
-def add_group(_apps, _schema_editor):
+def add_group(apps, _schema_editor):
+ Group = apps.get_model("auth", "Group")
Group.objects.create(name="Reviewer")
-def delete_group(_apps, _schema_editor):
+def delete_group(apps, _schema_editor):
+ Group = apps.get_model("auth", "Group")
Group.objects.get(name="Reviewer").delete()
diff --git a/evap/grades/migrations/0002_initial_data.py b/evap/grades/migrations/0002_initial_data.py
--- a/evap/grades/migrations/0002_initial_data.py
+++ b/evap/grades/migrations/0002_initial_data.py
@@ -1,8 +1,8 @@
from django.db import migrations
-from django.contrib.auth.models import Group
-def add_group(_apps, _schema_editor):
+def add_group(apps, _schema_editor):
+ Group = apps.get_model("auth", "Group")
Group.objects.create(name="Grade publisher")
|
{"golden_diff": "diff --git a/evap/evaluation/migrations/0002_initial_data.py b/evap/evaluation/migrations/0002_initial_data.py\n--- a/evap/evaluation/migrations/0002_initial_data.py\n+++ b/evap/evaluation/migrations/0002_initial_data.py\n@@ -1,5 +1,4 @@\n from django.db import migrations\n-from django.contrib.auth.models import Group\n \n \n def insert_emailtemplates(apps, _schema_editor):\n@@ -16,6 +15,7 @@\n if not EmailTemplate.objects.filter(name=name).exists():\n EmailTemplate.objects.create(name=name, subject=subject, body=\"\")\n \n+ Group = apps.get_model(\"auth\", \"Group\")\n Group.objects.create(name=\"Staff\")\n \n \ndiff --git a/evap/evaluation/migrations/0055_reviewer_group.py b/evap/evaluation/migrations/0055_reviewer_group.py\n--- a/evap/evaluation/migrations/0055_reviewer_group.py\n+++ b/evap/evaluation/migrations/0055_reviewer_group.py\n@@ -1,12 +1,13 @@\n-from django.contrib.auth.models import Group\n from django.db import migrations\n \n \n-def add_group(_apps, _schema_editor):\n+def add_group(apps, _schema_editor):\n+ Group = apps.get_model(\"auth\", \"Group\")\n Group.objects.create(name=\"Reviewer\")\n \n \n-def delete_group(_apps, _schema_editor):\n+def delete_group(apps, _schema_editor):\n+ Group = apps.get_model(\"auth\", \"Group\")\n Group.objects.get(name=\"Reviewer\").delete()\n \n \ndiff --git a/evap/grades/migrations/0002_initial_data.py b/evap/grades/migrations/0002_initial_data.py\n--- a/evap/grades/migrations/0002_initial_data.py\n+++ b/evap/grades/migrations/0002_initial_data.py\n@@ -1,8 +1,8 @@\n from django.db import migrations\n-from django.contrib.auth.models import Group\n \n \n-def add_group(_apps, _schema_editor):\n+def add_group(apps, _schema_editor):\n+ Group = apps.get_model(\"auth\", \"Group\")\n Group.objects.create(name=\"Grade publisher\")\n", "issue": "Remove ViewTest where possible\nRight now we have a `class ViewTest`, for which there is one subclass for each view that we have.\r\n\r\nFor views that we have tested properly, it provides no additional value and I I propose to replace it with the original `WebTest`. \r\n\r\nOriginally I proposed to remove it altogether and copypaste its test to all the test cases that wouldn't have any valuable test otherwise. @janno42 convinced me to leave it there and rename it to `WebTestWith200Check` instead.\n", "before_files": [{"content": "from django.db import migrations\nfrom django.contrib.auth.models import Group\n\n\ndef insert_emailtemplates(apps, _schema_editor):\n emailtemplates = [\n (\"Lecturer Review Notice\", \"[EvaP] New Course ready for approval\"),\n (\"Student Reminder\", \"[EvaP] Evaluation period is ending\"),\n (\"Publishing Notice\", \"[EvaP] A course has been published\"),\n (\"Login Key Created\", \"[EvaP] A login key was created\"),\n ]\n\n EmailTemplate = apps.get_model(\"evaluation\", \"EmailTemplate\")\n\n for name, subject in emailtemplates:\n if not EmailTemplate.objects.filter(name=name).exists():\n EmailTemplate.objects.create(name=name, subject=subject, body=\"\")\n\n Group.objects.create(name=\"Staff\")\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('evaluation', '0001_initial'),\n ]\n\n operations = [\n migrations.RunPython(insert_emailtemplates),\n ]\n", "path": "evap/evaluation/migrations/0002_initial_data.py"}, {"content": "from django.db import migrations\nfrom django.contrib.auth.models import Group\n\n\ndef add_group(_apps, _schema_editor):\n Group.objects.create(name=\"Grade publisher\")\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('grades', '0001_initial'),\n ]\n\n operations = [\n migrations.RunPython(add_group),\n ]\n", "path": "evap/grades/migrations/0002_initial_data.py"}, {"content": "from django.contrib.auth.models import Group\nfrom django.db import migrations\n\n\ndef add_group(_apps, _schema_editor):\n Group.objects.create(name=\"Reviewer\")\n\n\ndef delete_group(_apps, _schema_editor):\n Group.objects.get(name=\"Reviewer\").delete()\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('evaluation', '0054_userprofile_language'),\n ]\n\n operations = [\n migrations.RunPython(add_group, reverse_code=delete_group),\n ]\n", "path": "evap/evaluation/migrations/0055_reviewer_group.py"}]}
| 1,236 | 501 |
gh_patches_debug_8092
|
rasdani/github-patches
|
git_diff
|
vega__altair-1907
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Interval Selection Example Bug
I am having trouble with the the [Interval Selection Example](https://altair-viz.github.io/gallery/interval_selection.html).

```python
import altair as alt
from vega_datasets import data
source = data.sp500.url
brush = alt.selection(type='interval', encodings=['x'])
upper = alt.Chart(source).mark_area().encode(
alt.X('date:T', scale=alt.Scale(domain=brush)),
y='price:Q'
).properties(
width=600,
height=200
)
lower = upper.properties(
height=60
).add_selection(brush)
upper & lower
```
The example looks correct so I am unsure what is causing this behavior.
</issue>
<code>
[start of altair/examples/interval_selection.py]
1 """
2 Interval Selection Example
3 ==========================
4
5 This is an example of creating a stacked chart for which the domain of the
6 top chart can be selected by interacting with the bottom chart.
7 """
8 # category: area charts
9 import altair as alt
10 from vega_datasets import data
11
12 source = data.sp500.url
13
14 brush = alt.selection(type='interval', encodings=['x'])
15
16 upper = alt.Chart(source).mark_area().encode(
17 alt.X('date:T', scale=alt.Scale(domain=brush)),
18 y='price:Q'
19 ).properties(
20 width=600,
21 height=200
22 )
23
24 lower = upper.properties(
25 height=60
26 ).add_selection(brush)
27
28 upper & lower
29
[end of altair/examples/interval_selection.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/altair/examples/interval_selection.py b/altair/examples/interval_selection.py
--- a/altair/examples/interval_selection.py
+++ b/altair/examples/interval_selection.py
@@ -13,15 +13,19 @@
brush = alt.selection(type='interval', encodings=['x'])
-upper = alt.Chart(source).mark_area().encode(
- alt.X('date:T', scale=alt.Scale(domain=brush)),
- y='price:Q'
+base = alt.Chart(source).mark_area().encode(
+ x = 'date:T',
+ y = 'price:Q'
).properties(
width=600,
height=200
)
-lower = upper.properties(
+upper = base.encode(
+ alt.X('date:T', scale=alt.Scale(domain=brush))
+)
+
+lower = base.properties(
height=60
).add_selection(brush)
|
{"golden_diff": "diff --git a/altair/examples/interval_selection.py b/altair/examples/interval_selection.py\n--- a/altair/examples/interval_selection.py\n+++ b/altair/examples/interval_selection.py\n@@ -13,15 +13,19 @@\n \n brush = alt.selection(type='interval', encodings=['x'])\n \n-upper = alt.Chart(source).mark_area().encode(\n- alt.X('date:T', scale=alt.Scale(domain=brush)),\n- y='price:Q'\n+base = alt.Chart(source).mark_area().encode(\n+ x = 'date:T',\n+ y = 'price:Q'\n ).properties(\n width=600,\n height=200\n )\n \n-lower = upper.properties(\n+upper = base.encode(\n+ alt.X('date:T', scale=alt.Scale(domain=brush))\n+)\n+\n+lower = base.properties(\n height=60\n ).add_selection(brush)\n", "issue": "Interval Selection Example Bug\nI am having trouble with the the [Interval Selection Example](https://altair-viz.github.io/gallery/interval_selection.html). \r\n\r\n\r\n```python\r\nimport altair as alt\r\nfrom vega_datasets import data\r\n\r\nsource = data.sp500.url\r\n\r\nbrush = alt.selection(type='interval', encodings=['x'])\r\n\r\nupper = alt.Chart(source).mark_area().encode(\r\n alt.X('date:T', scale=alt.Scale(domain=brush)),\r\n y='price:Q'\r\n).properties(\r\n width=600,\r\n height=200\r\n)\r\n\r\nlower = upper.properties(\r\n height=60\r\n).add_selection(brush)\r\n\r\nupper & lower\r\n```\r\n\r\nThe example looks correct so I am unsure what is causing this behavior. \n", "before_files": [{"content": "\"\"\"\nInterval Selection Example\n==========================\n\nThis is an example of creating a stacked chart for which the domain of the\ntop chart can be selected by interacting with the bottom chart.\n\"\"\"\n# category: area charts\nimport altair as alt\nfrom vega_datasets import data\n\nsource = data.sp500.url\n\nbrush = alt.selection(type='interval', encodings=['x'])\n\nupper = alt.Chart(source).mark_area().encode(\n alt.X('date:T', scale=alt.Scale(domain=brush)),\n y='price:Q'\n).properties(\n width=600,\n height=200\n)\n\nlower = upper.properties(\n height=60\n).add_selection(brush)\n\nupper & lower\n", "path": "altair/examples/interval_selection.py"}]}
| 966 | 206 |
gh_patches_debug_34681
|
rasdani/github-patches
|
git_diff
|
sql-machine-learning__elasticdl-323
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
submit master pod using k8s python client instead of kubectl
use k8s python client to submit master pod instead of using the command below
`os.system('kubectl run ...')`
</issue>
<code>
[start of elasticdl/client/client.py]
1 import os
2 import inspect
3 import shutil
4 import time
5 import getpass
6 from string import Template
7 import docker
8
9
10 def run(model_class, train_data_dir=None,
11 num_epoch=1, minibatch_size=10,
12 record_per_task=100, num_worker=1, grads_to_wait=2):
13 m_path, m_file = _getModelFile()
14 m_file_in_docker = "/model/" + m_file
15 timestamp = int(round(time.time() * 1000))
16 _build_docker_image(m_path, m_file, m_file_in_docker, timestamp)
17 yaml_file = _generate_yaml(m_file_in_docker, model_class.__name__, train_data_dir=train_data_dir,
18 num_epoch=num_epoch, minibatch_size=minibatch_size,
19 record_per_task=record_per_task, num_worker=num_worker,
20 grads_to_wait=grads_to_wait, timestamp=timestamp)
21 _submit(yaml_file)
22
23 def _getModelFile():
24 m_file = inspect.currentframe().f_back.f_back.f_code.co_filename
25 m_path = os.path.abspath(os.path.dirname(m_file))
26 return m_path, m_file
27
28 def _build_docker_image(m_path, m_file, m_file_in_docker, timestamp):
29 d_path = os.path.abspath(os.path.dirname(
30 inspect.currentframe().f_back.f_code.co_filename))
31 new_dfile = m_path + "/Dockerfile"
32 shutil.copyfile(d_path + "/../Dockerfile.dev", new_dfile)
33
34 with open(new_dfile, 'a') as df:
35 df.write("COPY " + m_file + " " + m_file_in_docker)
36 client = docker.APIClient(base_url='unix://var/run/docker.sock')
37 for line in client.build(dockerfile='Dockerfile', path='.', tag='elasticdl:dev_' + str(timestamp)):
38 print(str(line, encoding = "utf-8"))
39
40 # TODO: upload docker image to docker hub.
41
42 def _generate_yaml(m_file, m_class,
43 train_data_dir=None, num_epoch=1,
44 minibatch_size=10, record_per_task=100,
45 num_worker=1, grads_to_wait=2, timestamp=1):
46 YAML_TEMPLATE = """
47 apiVersion: v1
48 kind: Pod
49 metadata:
50 name: elasticdl-master-$timestamp
51 labels:
52 purpose: test-command
53 spec:
54 containers:
55 - name: elasticdl-master-$timestamp
56 image: elasticdl:dev_$timestamp
57 command: ["python"]
58 args: ["-m", "elasticdl.master.main",
59 "--model-file", "$m_file",
60 "--num_worker", "$num_worker",
61 "--worker_image", "elasticdl:dev_$timestamp",
62 "--job_name", "elasticdl-$timestamp",
63 "--model-class", "$m_class",
64 "--train_data_dir", "$train_data_dir",
65 "--num_epoch", "$num_epoch",
66 "--grads_to_wait", "$grads_to_wait",
67 "--minibatch_size", "$minibatch_size",
68 "--record_per_task", "$record_per_task"]
69 imagePullPolicy: Never
70 env:
71 - name: MY_POD_IP
72 valueFrom:
73 fieldRef:
74 fieldPath: status.podIP
75 restartPolicy: Never
76 """
77 t = Template(YAML_TEMPLATE)
78 yaml_file = 'job_desc.yaml'
79 with open(yaml_file, "w") as yaml:
80 yaml.write(t.substitute(m_file=m_file, m_class=m_class,
81 train_data_dir=train_data_dir,
82 timestamp=timestamp, num_worker=num_worker, num_epoch=num_epoch,
83 minibatch_size=minibatch_size, record_per_task=record_per_task,
84 user=getpass.getuser(), grads_to_wait=grads_to_wait))
85 return yaml_file
86
87 def _submit(yaml_file):
88 os.system('kubectl create -f ' + yaml_file)
89
[end of elasticdl/client/client.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/elasticdl/client/client.py b/elasticdl/client/client.py
--- a/elasticdl/client/client.py
+++ b/elasticdl/client/client.py
@@ -5,6 +5,9 @@
import getpass
from string import Template
import docker
+import yaml
+from kubernetes.client.apis import core_v1_api
+from kubernetes import config
def run(model_class, train_data_dir=None,
@@ -14,11 +17,11 @@
m_file_in_docker = "/model/" + m_file
timestamp = int(round(time.time() * 1000))
_build_docker_image(m_path, m_file, m_file_in_docker, timestamp)
- yaml_file = _generate_yaml(m_file_in_docker, model_class.__name__, train_data_dir=train_data_dir,
+ yaml_content = _generate_yaml(m_file_in_docker, model_class.__name__, train_data_dir=train_data_dir,
num_epoch=num_epoch, minibatch_size=minibatch_size,
record_per_task=record_per_task, num_worker=num_worker,
grads_to_wait=grads_to_wait, timestamp=timestamp)
- _submit(yaml_file)
+ _submit(yaml_content)
def _getModelFile():
m_file = inspect.currentframe().f_back.f_back.f_code.co_filename
@@ -75,14 +78,15 @@
restartPolicy: Never
"""
t = Template(YAML_TEMPLATE)
- yaml_file = 'job_desc.yaml'
- with open(yaml_file, "w") as yaml:
- yaml.write(t.substitute(m_file=m_file, m_class=m_class,
- train_data_dir=train_data_dir,
- timestamp=timestamp, num_worker=num_worker, num_epoch=num_epoch,
- minibatch_size=minibatch_size, record_per_task=record_per_task,
- user=getpass.getuser(), grads_to_wait=grads_to_wait))
- return yaml_file
+ return t.substitute(m_file=m_file, m_class=m_class,
+ train_data_dir=train_data_dir,
+ timestamp=timestamp, num_worker=num_worker, num_epoch=num_epoch,
+ minibatch_size=minibatch_size, record_per_task=record_per_task,
+ user=getpass.getuser(), grads_to_wait=grads_to_wait)
-def _submit(yaml_file):
- os.system('kubectl create -f ' + yaml_file)
+def _submit(yaml_content):
+ config.load_kube_config()
+ pod_desc = yaml.safe_load(yaml_content)
+ api = core_v1_api.CoreV1Api()
+ resp = api.create_namespaced_pod(body=pod_desc, namespace='default')
+ print("Pod created. status='%s'" % str(resp.status))
|
{"golden_diff": "diff --git a/elasticdl/client/client.py b/elasticdl/client/client.py\n--- a/elasticdl/client/client.py\n+++ b/elasticdl/client/client.py\n@@ -5,6 +5,9 @@\n import getpass\n from string import Template\n import docker\n+import yaml\n+from kubernetes.client.apis import core_v1_api\n+from kubernetes import config\n \n \n def run(model_class, train_data_dir=None, \n@@ -14,11 +17,11 @@\n m_file_in_docker = \"/model/\" + m_file \n timestamp = int(round(time.time() * 1000))\n _build_docker_image(m_path, m_file, m_file_in_docker, timestamp)\n- yaml_file = _generate_yaml(m_file_in_docker, model_class.__name__, train_data_dir=train_data_dir, \n+ yaml_content = _generate_yaml(m_file_in_docker, model_class.__name__, train_data_dir=train_data_dir, \n num_epoch=num_epoch, minibatch_size=minibatch_size, \n record_per_task=record_per_task, num_worker=num_worker, \n grads_to_wait=grads_to_wait, timestamp=timestamp)\n- _submit(yaml_file)\n+ _submit(yaml_content)\n \n def _getModelFile():\n m_file = inspect.currentframe().f_back.f_back.f_code.co_filename\n@@ -75,14 +78,15 @@\n restartPolicy: Never\n \"\"\"\n t = Template(YAML_TEMPLATE)\n- yaml_file = 'job_desc.yaml'\n- with open(yaml_file, \"w\") as yaml:\n- yaml.write(t.substitute(m_file=m_file, m_class=m_class, \n- train_data_dir=train_data_dir, \n- timestamp=timestamp, num_worker=num_worker, num_epoch=num_epoch,\n- minibatch_size=minibatch_size, record_per_task=record_per_task,\n- user=getpass.getuser(), grads_to_wait=grads_to_wait))\n- return yaml_file\n+ return t.substitute(m_file=m_file, m_class=m_class, \n+ train_data_dir=train_data_dir, \n+ timestamp=timestamp, num_worker=num_worker, num_epoch=num_epoch,\n+ minibatch_size=minibatch_size, record_per_task=record_per_task,\n+ user=getpass.getuser(), grads_to_wait=grads_to_wait)\n \n-def _submit(yaml_file):\n- os.system('kubectl create -f ' + yaml_file)\n+def _submit(yaml_content):\n+ config.load_kube_config()\n+ pod_desc = yaml.safe_load(yaml_content)\n+ api = core_v1_api.CoreV1Api()\n+ resp = api.create_namespaced_pod(body=pod_desc, namespace='default')\n+ print(\"Pod created. status='%s'\" % str(resp.status))\n", "issue": "submit master pod using k8s python client instead of kubectl \nuse k8s python client to submit master pod instead of using the command below\r\n`os.system('kubectl run ...')`\n", "before_files": [{"content": "import os\nimport inspect\nimport shutil\nimport time\nimport getpass\nfrom string import Template\nimport docker\n\n\ndef run(model_class, train_data_dir=None, \n num_epoch=1, minibatch_size=10, \n record_per_task=100, num_worker=1, grads_to_wait=2):\n m_path, m_file = _getModelFile()\n m_file_in_docker = \"/model/\" + m_file \n timestamp = int(round(time.time() * 1000))\n _build_docker_image(m_path, m_file, m_file_in_docker, timestamp)\n yaml_file = _generate_yaml(m_file_in_docker, model_class.__name__, train_data_dir=train_data_dir, \n num_epoch=num_epoch, minibatch_size=minibatch_size, \n record_per_task=record_per_task, num_worker=num_worker, \n grads_to_wait=grads_to_wait, timestamp=timestamp)\n _submit(yaml_file)\n\ndef _getModelFile():\n m_file = inspect.currentframe().f_back.f_back.f_code.co_filename\n m_path = os.path.abspath(os.path.dirname(m_file))\n return m_path, m_file\n\ndef _build_docker_image(m_path, m_file, m_file_in_docker, timestamp):\n d_path = os.path.abspath(os.path.dirname(\n inspect.currentframe().f_back.f_code.co_filename))\n new_dfile = m_path + \"/Dockerfile\"\n shutil.copyfile(d_path + \"/../Dockerfile.dev\", new_dfile)\n\n with open(new_dfile, 'a') as df:\n df.write(\"COPY \" + m_file + \" \" + m_file_in_docker)\n client = docker.APIClient(base_url='unix://var/run/docker.sock') \n for line in client.build(dockerfile='Dockerfile', path='.', tag='elasticdl:dev_' + str(timestamp)):\n print(str(line, encoding = \"utf-8\"))\n\n # TODO: upload docker image to docker hub.\n\ndef _generate_yaml(m_file, m_class,\n train_data_dir=None, num_epoch=1,\n minibatch_size=10, record_per_task=100, \n num_worker=1, grads_to_wait=2, timestamp=1):\n YAML_TEMPLATE = \"\"\"\n apiVersion: v1\n kind: Pod\n metadata:\n name: elasticdl-master-$timestamp\n labels:\n purpose: test-command\n spec:\n containers:\n - name: elasticdl-master-$timestamp\n image: elasticdl:dev_$timestamp\n command: [\"python\"]\n args: [\"-m\", \"elasticdl.master.main\",\n \"--model-file\", \"$m_file\",\n \"--num_worker\", \"$num_worker\",\n \"--worker_image\", \"elasticdl:dev_$timestamp\",\n \"--job_name\", \"elasticdl-$timestamp\",\n \"--model-class\", \"$m_class\",\n \"--train_data_dir\", \"$train_data_dir\",\n \"--num_epoch\", \"$num_epoch\",\n \"--grads_to_wait\", \"$grads_to_wait\",\n \"--minibatch_size\", \"$minibatch_size\",\n \"--record_per_task\", \"$record_per_task\"]\n imagePullPolicy: Never\n env:\n - name: MY_POD_IP\n valueFrom:\n fieldRef:\n fieldPath: status.podIP\n restartPolicy: Never\n \"\"\"\n t = Template(YAML_TEMPLATE)\n yaml_file = 'job_desc.yaml'\n with open(yaml_file, \"w\") as yaml:\n yaml.write(t.substitute(m_file=m_file, m_class=m_class, \n train_data_dir=train_data_dir, \n timestamp=timestamp, num_worker=num_worker, num_epoch=num_epoch,\n minibatch_size=minibatch_size, record_per_task=record_per_task,\n user=getpass.getuser(), grads_to_wait=grads_to_wait))\n return yaml_file\n\ndef _submit(yaml_file):\n os.system('kubectl create -f ' + yaml_file)\n", "path": "elasticdl/client/client.py"}]}
| 1,594 | 609 |
gh_patches_debug_27572
|
rasdani/github-patches
|
git_diff
|
cookiecutter__cookiecutter-1358
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add log message to get_user_config function
there should be debug message for cases when default config overwrites user_config.
Currently, it is done silently.
</issue>
<code>
[start of cookiecutter/config.py]
1 # -*- coding: utf-8 -*-
2
3 """Global configuration handling."""
4
5 from __future__ import unicode_literals
6 import copy
7 import logging
8 import os
9 import io
10 import collections
11
12 import poyo
13
14 from cookiecutter.exceptions import ConfigDoesNotExistException
15 from cookiecutter.exceptions import InvalidConfiguration
16
17
18 logger = logging.getLogger(__name__)
19
20 USER_CONFIG_PATH = os.path.expanduser('~/.cookiecutterrc')
21
22 BUILTIN_ABBREVIATIONS = {
23 'gh': 'https://github.com/{0}.git',
24 'gl': 'https://gitlab.com/{0}.git',
25 'bb': 'https://bitbucket.org/{0}',
26 }
27
28 DEFAULT_CONFIG = {
29 'cookiecutters_dir': os.path.expanduser('~/.cookiecutters/'),
30 'replay_dir': os.path.expanduser('~/.cookiecutter_replay/'),
31 'default_context': collections.OrderedDict([]),
32 'abbreviations': BUILTIN_ABBREVIATIONS,
33 }
34
35
36 def _expand_path(path):
37 """Expand both environment variables and user home in the given path."""
38 path = os.path.expandvars(path)
39 path = os.path.expanduser(path)
40 return path
41
42
43 def merge_configs(default, overwrite):
44 """Recursively update a dict with the key/value pair of another.
45
46 Dict values that are dictionaries themselves will be updated, whilst
47 preserving existing keys.
48 """
49 new_config = copy.deepcopy(default)
50
51 for k, v in overwrite.items():
52 # Make sure to preserve existing items in
53 # nested dicts, for example `abbreviations`
54 if isinstance(v, dict):
55 new_config[k] = merge_configs(default[k], v)
56 else:
57 new_config[k] = v
58
59 return new_config
60
61
62 def get_config(config_path):
63 """Retrieve the config from the specified path, returning a config dict."""
64 if not os.path.exists(config_path):
65 raise ConfigDoesNotExistException
66
67 logger.debug('config_path is %s', config_path)
68 with io.open(config_path, encoding='utf-8') as file_handle:
69 try:
70 yaml_dict = poyo.parse_string(file_handle.read())
71 except poyo.exceptions.PoyoException as e:
72 raise InvalidConfiguration(
73 'Unable to parse YAML file {}. Error: {}'
74 ''.format(config_path, e)
75 )
76
77 config_dict = merge_configs(DEFAULT_CONFIG, yaml_dict)
78
79 raw_replay_dir = config_dict['replay_dir']
80 config_dict['replay_dir'] = _expand_path(raw_replay_dir)
81
82 raw_cookies_dir = config_dict['cookiecutters_dir']
83 config_dict['cookiecutters_dir'] = _expand_path(raw_cookies_dir)
84
85 return config_dict
86
87
88 def get_user_config(config_file=None, default_config=False):
89 """Return the user config as a dict.
90
91 If ``default_config`` is True, ignore ``config_file`` and return default
92 values for the config parameters.
93
94 If a path to a ``config_file`` is given, that is different from the default
95 location, load the user config from that.
96
97 Otherwise look up the config file path in the ``COOKIECUTTER_CONFIG``
98 environment variable. If set, load the config from this path. This will
99 raise an error if the specified path is not valid.
100
101 If the environment variable is not set, try the default config file path
102 before falling back to the default config values.
103 """
104 # Do NOT load a config. Return defaults instead.
105 if default_config:
106 return copy.copy(DEFAULT_CONFIG)
107
108 # Load the given config file
109 if config_file and config_file is not USER_CONFIG_PATH:
110 return get_config(config_file)
111
112 try:
113 # Does the user set up a config environment variable?
114 env_config_file = os.environ['COOKIECUTTER_CONFIG']
115 except KeyError:
116 # Load an optional user config if it exists
117 # otherwise return the defaults
118 if os.path.exists(USER_CONFIG_PATH):
119 return get_config(USER_CONFIG_PATH)
120 else:
121 return copy.copy(DEFAULT_CONFIG)
122 else:
123 # There is a config environment variable. Try to load it.
124 # Do not check for existence, so invalid file paths raise an error.
125 return get_config(env_config_file)
126
[end of cookiecutter/config.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/cookiecutter/config.py b/cookiecutter/config.py
--- a/cookiecutter/config.py
+++ b/cookiecutter/config.py
@@ -103,10 +103,12 @@
"""
# Do NOT load a config. Return defaults instead.
if default_config:
+ logger.debug("Force ignoring user config with default_config switch.")
return copy.copy(DEFAULT_CONFIG)
# Load the given config file
if config_file and config_file is not USER_CONFIG_PATH:
+ logger.debug("Loading custom config from %s.", config_file)
return get_config(config_file)
try:
@@ -116,10 +118,13 @@
# Load an optional user config if it exists
# otherwise return the defaults
if os.path.exists(USER_CONFIG_PATH):
+ logger.debug("Loading config from %s.", USER_CONFIG_PATH)
return get_config(USER_CONFIG_PATH)
else:
+ logger.debug("User config not found. Loading default config.")
return copy.copy(DEFAULT_CONFIG)
else:
# There is a config environment variable. Try to load it.
# Do not check for existence, so invalid file paths raise an error.
+ logger.debug("User config not found or not specified. Loading default config.")
return get_config(env_config_file)
|
{"golden_diff": "diff --git a/cookiecutter/config.py b/cookiecutter/config.py\n--- a/cookiecutter/config.py\n+++ b/cookiecutter/config.py\n@@ -103,10 +103,12 @@\n \"\"\"\n # Do NOT load a config. Return defaults instead.\n if default_config:\n+ logger.debug(\"Force ignoring user config with default_config switch.\")\n return copy.copy(DEFAULT_CONFIG)\n \n # Load the given config file\n if config_file and config_file is not USER_CONFIG_PATH:\n+ logger.debug(\"Loading custom config from %s.\", config_file)\n return get_config(config_file)\n \n try:\n@@ -116,10 +118,13 @@\n # Load an optional user config if it exists\n # otherwise return the defaults\n if os.path.exists(USER_CONFIG_PATH):\n+ logger.debug(\"Loading config from %s.\", USER_CONFIG_PATH)\n return get_config(USER_CONFIG_PATH)\n else:\n+ logger.debug(\"User config not found. Loading default config.\")\n return copy.copy(DEFAULT_CONFIG)\n else:\n # There is a config environment variable. Try to load it.\n # Do not check for existence, so invalid file paths raise an error.\n+ logger.debug(\"User config not found or not specified. Loading default config.\")\n return get_config(env_config_file)\n", "issue": "Add log message to get_user_config function\nthere should be debug message for cases when default config overwrites user_config. \r\nCurrently, it is done silently.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"Global configuration handling.\"\"\"\n\nfrom __future__ import unicode_literals\nimport copy\nimport logging\nimport os\nimport io\nimport collections\n\nimport poyo\n\nfrom cookiecutter.exceptions import ConfigDoesNotExistException\nfrom cookiecutter.exceptions import InvalidConfiguration\n\n\nlogger = logging.getLogger(__name__)\n\nUSER_CONFIG_PATH = os.path.expanduser('~/.cookiecutterrc')\n\nBUILTIN_ABBREVIATIONS = {\n 'gh': 'https://github.com/{0}.git',\n 'gl': 'https://gitlab.com/{0}.git',\n 'bb': 'https://bitbucket.org/{0}',\n}\n\nDEFAULT_CONFIG = {\n 'cookiecutters_dir': os.path.expanduser('~/.cookiecutters/'),\n 'replay_dir': os.path.expanduser('~/.cookiecutter_replay/'),\n 'default_context': collections.OrderedDict([]),\n 'abbreviations': BUILTIN_ABBREVIATIONS,\n}\n\n\ndef _expand_path(path):\n \"\"\"Expand both environment variables and user home in the given path.\"\"\"\n path = os.path.expandvars(path)\n path = os.path.expanduser(path)\n return path\n\n\ndef merge_configs(default, overwrite):\n \"\"\"Recursively update a dict with the key/value pair of another.\n\n Dict values that are dictionaries themselves will be updated, whilst\n preserving existing keys.\n \"\"\"\n new_config = copy.deepcopy(default)\n\n for k, v in overwrite.items():\n # Make sure to preserve existing items in\n # nested dicts, for example `abbreviations`\n if isinstance(v, dict):\n new_config[k] = merge_configs(default[k], v)\n else:\n new_config[k] = v\n\n return new_config\n\n\ndef get_config(config_path):\n \"\"\"Retrieve the config from the specified path, returning a config dict.\"\"\"\n if not os.path.exists(config_path):\n raise ConfigDoesNotExistException\n\n logger.debug('config_path is %s', config_path)\n with io.open(config_path, encoding='utf-8') as file_handle:\n try:\n yaml_dict = poyo.parse_string(file_handle.read())\n except poyo.exceptions.PoyoException as e:\n raise InvalidConfiguration(\n 'Unable to parse YAML file {}. Error: {}'\n ''.format(config_path, e)\n )\n\n config_dict = merge_configs(DEFAULT_CONFIG, yaml_dict)\n\n raw_replay_dir = config_dict['replay_dir']\n config_dict['replay_dir'] = _expand_path(raw_replay_dir)\n\n raw_cookies_dir = config_dict['cookiecutters_dir']\n config_dict['cookiecutters_dir'] = _expand_path(raw_cookies_dir)\n\n return config_dict\n\n\ndef get_user_config(config_file=None, default_config=False):\n \"\"\"Return the user config as a dict.\n\n If ``default_config`` is True, ignore ``config_file`` and return default\n values for the config parameters.\n\n If a path to a ``config_file`` is given, that is different from the default\n location, load the user config from that.\n\n Otherwise look up the config file path in the ``COOKIECUTTER_CONFIG``\n environment variable. If set, load the config from this path. This will\n raise an error if the specified path is not valid.\n\n If the environment variable is not set, try the default config file path\n before falling back to the default config values.\n \"\"\"\n # Do NOT load a config. Return defaults instead.\n if default_config:\n return copy.copy(DEFAULT_CONFIG)\n\n # Load the given config file\n if config_file and config_file is not USER_CONFIG_PATH:\n return get_config(config_file)\n\n try:\n # Does the user set up a config environment variable?\n env_config_file = os.environ['COOKIECUTTER_CONFIG']\n except KeyError:\n # Load an optional user config if it exists\n # otherwise return the defaults\n if os.path.exists(USER_CONFIG_PATH):\n return get_config(USER_CONFIG_PATH)\n else:\n return copy.copy(DEFAULT_CONFIG)\n else:\n # There is a config environment variable. Try to load it.\n # Do not check for existence, so invalid file paths raise an error.\n return get_config(env_config_file)\n", "path": "cookiecutter/config.py"}]}
| 1,746 | 289 |
gh_patches_debug_14365
|
rasdani/github-patches
|
git_diff
|
comic__grand-challenge.org-1084
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Create a simple interface for fetching datatypes schemas on grand-challenge
**Problem**
The grand-challenge datatypes are currently only stored in the [gc-api](https://github.com/DIAGNijmegen/rse-gcapi/tree/master/gcapi/schemas) repository. However, the information is required by other libraries as well. Duplication of this information seems bad.
**Solution**
* [x] It would be nice to have this information in a central location like grand-challenge and provide a simple GET interface to allow the libraries /comic/evalutils and /DIAGNijmegen/rse-gcapi/ to fetch and cache this information (only a few kbs) from grand-challenge.
* [x] The answer type schemas should be added to the generated schema
</issue>
<code>
[start of app/grandchallenge/reader_studies/serializers.py]
1 from rest_framework.exceptions import ValidationError
2 from rest_framework.fields import CharField
3 from rest_framework.relations import HyperlinkedRelatedField, SlugRelatedField
4 from rest_framework.serializers import (
5 HyperlinkedModelSerializer,
6 SerializerMethodField,
7 )
8
9 from grandchallenge.api.swagger import swagger_schema_fields_for_charfield
10 from grandchallenge.cases.models import Image
11 from grandchallenge.reader_studies.models import Answer, Question, ReaderStudy
12
13
14 class QuestionSerializer(HyperlinkedModelSerializer):
15 answer_type = CharField(source="get_answer_type_display")
16 reader_study = HyperlinkedRelatedField(
17 view_name="api:reader-study-detail", read_only=True
18 )
19 form_direction = CharField(source="get_direction_display")
20 image_port = CharField(source="get_image_port_display")
21
22 class Meta:
23 model = Question
24 fields = (
25 "answer_type",
26 "api_url",
27 "form_direction",
28 "help_text",
29 "image_port",
30 "pk",
31 "question_text",
32 "reader_study",
33 "required",
34 )
35 swagger_schema_fields = swagger_schema_fields_for_charfield(
36 answer_type=model._meta.get_field("answer_type"),
37 form_direction=model._meta.get_field(
38 "direction"
39 ), # model.direction gets remapped
40 image_port=model._meta.get_field("image_port"),
41 )
42
43
44 class ReaderStudySerializer(HyperlinkedModelSerializer):
45 questions = QuestionSerializer(many=True, read_only=True)
46 hanging_list_images = SerializerMethodField()
47
48 class Meta:
49 model = ReaderStudy
50 fields = (
51 "api_url",
52 "description",
53 "hanging_list_images",
54 "is_valid",
55 "pk",
56 "questions",
57 "title",
58 )
59
60 def get_hanging_list_images(self, obj: ReaderStudy):
61 """Used by hanging_list_images serializer field."""
62 return obj.get_hanging_list_images_for_user(
63 user=self.context["request"].user
64 )
65
66
67 class AnswerSerializer(HyperlinkedModelSerializer):
68 creator = SlugRelatedField(read_only=True, slug_field="username")
69 question = HyperlinkedRelatedField(
70 view_name="api:reader-studies-question-detail",
71 queryset=Question.objects.all(),
72 )
73 images = HyperlinkedRelatedField(
74 many=True, queryset=Image.objects.all(), view_name="api:image-detail"
75 )
76
77 def validate(self, attrs):
78 question = attrs["question"]
79 images = attrs["images"]
80 answer = attrs["answer"]
81 creator = self.context.get("request").user
82
83 if not question.reader_study.is_reader(user=creator):
84 raise ValidationError("This user is not a reader for this study.")
85
86 if not question.is_answer_valid(answer=answer):
87 raise ValidationError(
88 f"You answer is not the correct type. "
89 f"{question.get_answer_type_display()} expected, "
90 f"{type(answer)} found."
91 )
92
93 if len(images) == 0:
94 raise ValidationError(
95 "You must specify the images that this answer corresponds to."
96 )
97
98 reader_study_images = question.reader_study.images.all()
99 for im in images:
100 if im not in reader_study_images:
101 raise ValidationError(
102 f"Image {im} does not belong to this reader study."
103 )
104
105 if Answer.objects.filter(
106 creator=creator, question=question, images__in=images
107 ).exists():
108 raise ValidationError(
109 f"User {creator} has already answered this question "
110 f"for at least 1 of these images."
111 )
112
113 return attrs
114
115 class Meta:
116 model = Answer
117 fields = (
118 "answer",
119 "api_url",
120 "created",
121 "creator",
122 "images",
123 "pk",
124 "question",
125 )
126
[end of app/grandchallenge/reader_studies/serializers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/app/grandchallenge/reader_studies/serializers.py b/app/grandchallenge/reader_studies/serializers.py
--- a/app/grandchallenge/reader_studies/serializers.py
+++ b/app/grandchallenge/reader_studies/serializers.py
@@ -8,7 +8,12 @@
from grandchallenge.api.swagger import swagger_schema_fields_for_charfield
from grandchallenge.cases.models import Image
-from grandchallenge.reader_studies.models import Answer, Question, ReaderStudy
+from grandchallenge.reader_studies.models import (
+ ANSWER_TYPE_SCHEMA,
+ Answer,
+ Question,
+ ReaderStudy,
+)
class QuestionSerializer(HyperlinkedModelSerializer):
@@ -123,3 +128,6 @@
"pk",
"question",
)
+ swagger_schema_fields = {
+ "properties": {"answer": {"title": "Answer", **ANSWER_TYPE_SCHEMA}}
+ }
|
{"golden_diff": "diff --git a/app/grandchallenge/reader_studies/serializers.py b/app/grandchallenge/reader_studies/serializers.py\n--- a/app/grandchallenge/reader_studies/serializers.py\n+++ b/app/grandchallenge/reader_studies/serializers.py\n@@ -8,7 +8,12 @@\n \n from grandchallenge.api.swagger import swagger_schema_fields_for_charfield\n from grandchallenge.cases.models import Image\n-from grandchallenge.reader_studies.models import Answer, Question, ReaderStudy\n+from grandchallenge.reader_studies.models import (\n+ ANSWER_TYPE_SCHEMA,\n+ Answer,\n+ Question,\n+ ReaderStudy,\n+)\n \n \n class QuestionSerializer(HyperlinkedModelSerializer):\n@@ -123,3 +128,6 @@\n \"pk\",\n \"question\",\n )\n+ swagger_schema_fields = {\n+ \"properties\": {\"answer\": {\"title\": \"Answer\", **ANSWER_TYPE_SCHEMA}}\n+ }\n", "issue": "Create a simple interface for fetching datatypes schemas on grand-challenge \n**Problem**\r\nThe grand-challenge datatypes are currently only stored in the [gc-api](https://github.com/DIAGNijmegen/rse-gcapi/tree/master/gcapi/schemas) repository. However, the information is required by other libraries as well. Duplication of this information seems bad.\r\n\r\n**Solution**\r\n* [x] It would be nice to have this information in a central location like grand-challenge and provide a simple GET interface to allow the libraries /comic/evalutils and /DIAGNijmegen/rse-gcapi/ to fetch and cache this information (only a few kbs) from grand-challenge.\r\n* [x] The answer type schemas should be added to the generated schema\r\n\n", "before_files": [{"content": "from rest_framework.exceptions import ValidationError\nfrom rest_framework.fields import CharField\nfrom rest_framework.relations import HyperlinkedRelatedField, SlugRelatedField\nfrom rest_framework.serializers import (\n HyperlinkedModelSerializer,\n SerializerMethodField,\n)\n\nfrom grandchallenge.api.swagger import swagger_schema_fields_for_charfield\nfrom grandchallenge.cases.models import Image\nfrom grandchallenge.reader_studies.models import Answer, Question, ReaderStudy\n\n\nclass QuestionSerializer(HyperlinkedModelSerializer):\n answer_type = CharField(source=\"get_answer_type_display\")\n reader_study = HyperlinkedRelatedField(\n view_name=\"api:reader-study-detail\", read_only=True\n )\n form_direction = CharField(source=\"get_direction_display\")\n image_port = CharField(source=\"get_image_port_display\")\n\n class Meta:\n model = Question\n fields = (\n \"answer_type\",\n \"api_url\",\n \"form_direction\",\n \"help_text\",\n \"image_port\",\n \"pk\",\n \"question_text\",\n \"reader_study\",\n \"required\",\n )\n swagger_schema_fields = swagger_schema_fields_for_charfield(\n answer_type=model._meta.get_field(\"answer_type\"),\n form_direction=model._meta.get_field(\n \"direction\"\n ), # model.direction gets remapped\n image_port=model._meta.get_field(\"image_port\"),\n )\n\n\nclass ReaderStudySerializer(HyperlinkedModelSerializer):\n questions = QuestionSerializer(many=True, read_only=True)\n hanging_list_images = SerializerMethodField()\n\n class Meta:\n model = ReaderStudy\n fields = (\n \"api_url\",\n \"description\",\n \"hanging_list_images\",\n \"is_valid\",\n \"pk\",\n \"questions\",\n \"title\",\n )\n\n def get_hanging_list_images(self, obj: ReaderStudy):\n \"\"\"Used by hanging_list_images serializer field.\"\"\"\n return obj.get_hanging_list_images_for_user(\n user=self.context[\"request\"].user\n )\n\n\nclass AnswerSerializer(HyperlinkedModelSerializer):\n creator = SlugRelatedField(read_only=True, slug_field=\"username\")\n question = HyperlinkedRelatedField(\n view_name=\"api:reader-studies-question-detail\",\n queryset=Question.objects.all(),\n )\n images = HyperlinkedRelatedField(\n many=True, queryset=Image.objects.all(), view_name=\"api:image-detail\"\n )\n\n def validate(self, attrs):\n question = attrs[\"question\"]\n images = attrs[\"images\"]\n answer = attrs[\"answer\"]\n creator = self.context.get(\"request\").user\n\n if not question.reader_study.is_reader(user=creator):\n raise ValidationError(\"This user is not a reader for this study.\")\n\n if not question.is_answer_valid(answer=answer):\n raise ValidationError(\n f\"You answer is not the correct type. \"\n f\"{question.get_answer_type_display()} expected, \"\n f\"{type(answer)} found.\"\n )\n\n if len(images) == 0:\n raise ValidationError(\n \"You must specify the images that this answer corresponds to.\"\n )\n\n reader_study_images = question.reader_study.images.all()\n for im in images:\n if im not in reader_study_images:\n raise ValidationError(\n f\"Image {im} does not belong to this reader study.\"\n )\n\n if Answer.objects.filter(\n creator=creator, question=question, images__in=images\n ).exists():\n raise ValidationError(\n f\"User {creator} has already answered this question \"\n f\"for at least 1 of these images.\"\n )\n\n return attrs\n\n class Meta:\n model = Answer\n fields = (\n \"answer\",\n \"api_url\",\n \"created\",\n \"creator\",\n \"images\",\n \"pk\",\n \"question\",\n )\n", "path": "app/grandchallenge/reader_studies/serializers.py"}]}
| 1,781 | 206 |
gh_patches_debug_21733
|
rasdani/github-patches
|
git_diff
|
getredash__redash-3619
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Support for Presto username and password
Currently the Presto query runner supports username only. We should support password as well.
This probably requires upgrading the PyHive library.
</issue>
<code>
[start of redash/query_runner/presto.py]
1 from redash.query_runner import *
2 from redash.utils import json_dumps, json_loads
3
4 import logging
5 logger = logging.getLogger(__name__)
6
7 from collections import defaultdict
8
9 try:
10 from pyhive import presto
11 from pyhive.exc import DatabaseError
12 enabled = True
13
14 except ImportError:
15 enabled = False
16
17 PRESTO_TYPES_MAPPING = {
18 "integer": TYPE_INTEGER,
19 "tinyint": TYPE_INTEGER,
20 "smallint": TYPE_INTEGER,
21 "long": TYPE_INTEGER,
22 "bigint": TYPE_INTEGER,
23 "float": TYPE_FLOAT,
24 "double": TYPE_FLOAT,
25 "boolean": TYPE_BOOLEAN,
26 "string": TYPE_STRING,
27 "varchar": TYPE_STRING,
28 "date": TYPE_DATE,
29 }
30
31
32 class Presto(BaseQueryRunner):
33 noop_query = 'SHOW TABLES'
34
35 @classmethod
36 def configuration_schema(cls):
37 return {
38 'type': 'object',
39 'properties': {
40 'host': {
41 'type': 'string'
42 },
43 'protocol': {
44 'type': 'string',
45 'default': 'http'
46 },
47 'port': {
48 'type': 'number'
49 },
50 'schema': {
51 'type': 'string'
52 },
53 'catalog': {
54 'type': 'string'
55 },
56 'username': {
57 'type': 'string'
58 },
59 },
60 'order': ['host', 'protocol', 'port', 'username', 'schema', 'catalog'],
61 'required': ['host']
62 }
63
64 @classmethod
65 def enabled(cls):
66 return enabled
67
68 @classmethod
69 def type(cls):
70 return "presto"
71
72 def get_schema(self, get_stats=False):
73 schema = {}
74 query = """
75 SELECT table_schema, table_name, column_name
76 FROM information_schema.columns
77 WHERE table_schema NOT IN ('pg_catalog', 'information_schema')
78 """
79
80 results, error = self.run_query(query, None)
81
82 if error is not None:
83 raise Exception("Failed getting schema.")
84
85 results = json_loads(results)
86
87 for row in results['rows']:
88 table_name = '{}.{}'.format(row['table_schema'], row['table_name'])
89
90 if table_name not in schema:
91 schema[table_name] = {'name': table_name, 'columns': []}
92
93 schema[table_name]['columns'].append(row['column_name'])
94
95 return schema.values()
96
97 def run_query(self, query, user):
98 connection = presto.connect(
99 host=self.configuration.get('host', ''),
100 port=self.configuration.get('port', 8080),
101 protocol=self.configuration.get('protocol', 'http'),
102 username=self.configuration.get('username', 'redash'),
103 catalog=self.configuration.get('catalog', 'hive'),
104 schema=self.configuration.get('schema', 'default'))
105
106 cursor = connection.cursor()
107
108
109 try:
110 cursor.execute(query)
111 column_tuples = [(i[0], PRESTO_TYPES_MAPPING.get(i[1], None)) for i in cursor.description]
112 columns = self.fetch_columns(column_tuples)
113 rows = [dict(zip(([c['name'] for c in columns]), r)) for i, r in enumerate(cursor.fetchall())]
114 data = {'columns': columns, 'rows': rows}
115 json_data = json_dumps(data)
116 error = None
117 except DatabaseError as db:
118 json_data = None
119 default_message = 'Unspecified DatabaseError: {0}'.format(db.message)
120 if isinstance(db.message, dict):
121 message = db.message.get('failureInfo', {'message', None}).get('message')
122 else:
123 message = None
124 error = default_message if message is None else message
125 except (KeyboardInterrupt, InterruptException) as e:
126 cursor.cancel()
127 error = "Query cancelled by user."
128 json_data = None
129 except Exception as ex:
130 json_data = None
131 error = ex.message
132 if not isinstance(error, basestring):
133 error = unicode(error)
134
135 return json_data, error
136
137 register(Presto)
138
[end of redash/query_runner/presto.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/redash/query_runner/presto.py b/redash/query_runner/presto.py
--- a/redash/query_runner/presto.py
+++ b/redash/query_runner/presto.py
@@ -56,8 +56,11 @@
'username': {
'type': 'string'
},
+ 'password': {
+ 'type': 'string'
+ },
},
- 'order': ['host', 'protocol', 'port', 'username', 'schema', 'catalog'],
+ 'order': ['host', 'protocol', 'port', 'username', 'password', 'schema', 'catalog'],
'required': ['host']
}
@@ -100,6 +103,7 @@
port=self.configuration.get('port', 8080),
protocol=self.configuration.get('protocol', 'http'),
username=self.configuration.get('username', 'redash'),
+ password=self.configuration.get('password', ''),
catalog=self.configuration.get('catalog', 'hive'),
schema=self.configuration.get('schema', 'default'))
|
{"golden_diff": "diff --git a/redash/query_runner/presto.py b/redash/query_runner/presto.py\n--- a/redash/query_runner/presto.py\n+++ b/redash/query_runner/presto.py\n@@ -56,8 +56,11 @@\n 'username': {\n 'type': 'string'\n },\n+ 'password': {\n+ 'type': 'string'\n+ },\n },\n- 'order': ['host', 'protocol', 'port', 'username', 'schema', 'catalog'],\n+ 'order': ['host', 'protocol', 'port', 'username', 'password', 'schema', 'catalog'],\n 'required': ['host']\n }\n \n@@ -100,6 +103,7 @@\n port=self.configuration.get('port', 8080),\n protocol=self.configuration.get('protocol', 'http'),\n username=self.configuration.get('username', 'redash'),\n+ password=self.configuration.get('password', ''),\n catalog=self.configuration.get('catalog', 'hive'),\n schema=self.configuration.get('schema', 'default'))\n", "issue": "Support for Presto username and password\nCurrently the Presto query runner supports username only. We should support password as well.\r\n\r\nThis probably requires upgrading the PyHive library.\n", "before_files": [{"content": "from redash.query_runner import *\nfrom redash.utils import json_dumps, json_loads\n\nimport logging\nlogger = logging.getLogger(__name__)\n\nfrom collections import defaultdict\n\ntry:\n from pyhive import presto\n from pyhive.exc import DatabaseError\n enabled = True\n\nexcept ImportError:\n enabled = False\n\nPRESTO_TYPES_MAPPING = {\n \"integer\": TYPE_INTEGER,\n \"tinyint\": TYPE_INTEGER,\n \"smallint\": TYPE_INTEGER,\n \"long\": TYPE_INTEGER,\n \"bigint\": TYPE_INTEGER,\n \"float\": TYPE_FLOAT,\n \"double\": TYPE_FLOAT,\n \"boolean\": TYPE_BOOLEAN,\n \"string\": TYPE_STRING,\n \"varchar\": TYPE_STRING,\n \"date\": TYPE_DATE,\n}\n\n\nclass Presto(BaseQueryRunner):\n noop_query = 'SHOW TABLES'\n\n @classmethod\n def configuration_schema(cls):\n return {\n 'type': 'object',\n 'properties': {\n 'host': {\n 'type': 'string'\n },\n 'protocol': {\n 'type': 'string',\n 'default': 'http'\n },\n 'port': {\n 'type': 'number'\n },\n 'schema': {\n 'type': 'string'\n },\n 'catalog': {\n 'type': 'string'\n },\n 'username': {\n 'type': 'string'\n },\n },\n 'order': ['host', 'protocol', 'port', 'username', 'schema', 'catalog'],\n 'required': ['host']\n }\n\n @classmethod\n def enabled(cls):\n return enabled\n\n @classmethod\n def type(cls):\n return \"presto\"\n\n def get_schema(self, get_stats=False):\n schema = {}\n query = \"\"\"\n SELECT table_schema, table_name, column_name\n FROM information_schema.columns\n WHERE table_schema NOT IN ('pg_catalog', 'information_schema')\n \"\"\"\n\n results, error = self.run_query(query, None)\n\n if error is not None:\n raise Exception(\"Failed getting schema.\")\n\n results = json_loads(results)\n\n for row in results['rows']:\n table_name = '{}.{}'.format(row['table_schema'], row['table_name'])\n\n if table_name not in schema:\n schema[table_name] = {'name': table_name, 'columns': []}\n\n schema[table_name]['columns'].append(row['column_name'])\n\n return schema.values()\n\n def run_query(self, query, user):\n connection = presto.connect(\n host=self.configuration.get('host', ''),\n port=self.configuration.get('port', 8080),\n protocol=self.configuration.get('protocol', 'http'),\n username=self.configuration.get('username', 'redash'),\n catalog=self.configuration.get('catalog', 'hive'),\n schema=self.configuration.get('schema', 'default'))\n\n cursor = connection.cursor()\n\n\n try:\n cursor.execute(query)\n column_tuples = [(i[0], PRESTO_TYPES_MAPPING.get(i[1], None)) for i in cursor.description]\n columns = self.fetch_columns(column_tuples)\n rows = [dict(zip(([c['name'] for c in columns]), r)) for i, r in enumerate(cursor.fetchall())]\n data = {'columns': columns, 'rows': rows}\n json_data = json_dumps(data)\n error = None\n except DatabaseError as db:\n json_data = None\n default_message = 'Unspecified DatabaseError: {0}'.format(db.message)\n if isinstance(db.message, dict):\n message = db.message.get('failureInfo', {'message', None}).get('message')\n else:\n message = None\n error = default_message if message is None else message\n except (KeyboardInterrupt, InterruptException) as e:\n cursor.cancel()\n error = \"Query cancelled by user.\"\n json_data = None\n except Exception as ex:\n json_data = None\n error = ex.message\n if not isinstance(error, basestring):\n error = unicode(error)\n\n return json_data, error\n\nregister(Presto)\n", "path": "redash/query_runner/presto.py"}]}
| 1,750 | 229 |
gh_patches_debug_24151
|
rasdani/github-patches
|
git_diff
|
gammapy__gammapy-4924
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Remove deprecated features
This is a reminder issue to remove the features deprecated since 1.1 before the next release
</issue>
<code>
[start of gammapy/utils/table.py]
1 # Licensed under a 3-clause BSD style license - see LICENSE.rst
2 """Table helper utilities."""
3 import numpy as np
4 from astropy.table import Table
5 from astropy.units import Quantity
6 from .deprecation import deprecated
7 from .units import standardise_unit
8
9 __all__ = [
10 "hstack_columns",
11 "table_from_row_data",
12 "table_row_to_dict",
13 "table_standardise_units_copy",
14 "table_standardise_units_inplace",
15 ]
16
17
18 def hstack_columns(table, table_other):
19 """Stack the column data horizontally.
20
21 Parameters
22 ----------
23 table : `~astropy.table.Table`
24 Input table.
25 table_other : `~astropy.table.Table`
26 Other input table.
27
28 Returns
29 -------
30 stacked : `~astropy.table.Table`
31 Stacked table.
32 """
33 stacked = Table()
34
35 for column in table.colnames:
36 data = np.hstack([table[column].data[0], table_other[column].data[0]])
37 stacked[column] = data[np.newaxis, :]
38 return stacked
39
40
41 def table_standardise_units_copy(table):
42 """Standardise units for all columns in a table in a copy.
43
44 Calls `~gammapy.utils.units.standardise_unit`.
45
46 Parameters
47 ----------
48 table : `~astropy.table.Table`
49 Input table (won't be modified).
50
51 Returns
52 -------
53 table : `~astropy.table.Table`
54 Copy of the input table with standardised column units.
55 """
56 # Note: we could add an `inplace` option (or variant of this function)
57 # See https://github.com/astropy/astropy/issues/6098
58 table = Table(table)
59 return table_standardise_units_inplace(table)
60
61
62 def table_standardise_units_inplace(table):
63 """Standardise units for all columns in a table in place."""
64 for column in table.columns.values():
65 if column.unit:
66 column.unit = standardise_unit(column.unit)
67
68 return table
69
70
71 def table_row_to_dict(row, make_quantity=True):
72 """Make one source data dictionary.
73
74 Parameters
75 ----------
76 row : `~astropy.table.Row`
77 Row.
78 make_quantity : bool, optional
79 Make quantity values for columns with units.
80 Default is True.
81
82 Returns
83 -------
84 data : dict
85 Row data.
86 """
87 data = {}
88 for name, col in row.columns.items():
89 val = row[name]
90
91 if make_quantity and col.unit:
92 val = Quantity(val, unit=col.unit)
93 data[name] = val
94 return data
95
96
97 @deprecated("v1.1", alternative="astropy.table.Table")
98 def table_from_row_data(rows, **kwargs):
99 """Helper function to create table objects from row data.
100
101 Works with quantities.
102
103 Parameters
104 ----------
105 rows : list
106 List of row data (each row a dictionary).
107 """
108 table = Table(**kwargs)
109
110 if len(rows) == 0:
111 return table
112
113 colnames = list(rows[0].keys())
114
115 for name in colnames:
116 coldata = [_[name] for _ in rows]
117 if isinstance(rows[0][name], Quantity):
118 coldata = Quantity(coldata, unit=rows[0][name].unit)
119 table[name] = coldata
120
121 return table
122
[end of gammapy/utils/table.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/gammapy/utils/table.py b/gammapy/utils/table.py
--- a/gammapy/utils/table.py
+++ b/gammapy/utils/table.py
@@ -3,12 +3,10 @@
import numpy as np
from astropy.table import Table
from astropy.units import Quantity
-from .deprecation import deprecated
from .units import standardise_unit
__all__ = [
"hstack_columns",
- "table_from_row_data",
"table_row_to_dict",
"table_standardise_units_copy",
"table_standardise_units_inplace",
@@ -92,30 +90,3 @@
val = Quantity(val, unit=col.unit)
data[name] = val
return data
-
-
-@deprecated("v1.1", alternative="astropy.table.Table")
-def table_from_row_data(rows, **kwargs):
- """Helper function to create table objects from row data.
-
- Works with quantities.
-
- Parameters
- ----------
- rows : list
- List of row data (each row a dictionary).
- """
- table = Table(**kwargs)
-
- if len(rows) == 0:
- return table
-
- colnames = list(rows[0].keys())
-
- for name in colnames:
- coldata = [_[name] for _ in rows]
- if isinstance(rows[0][name], Quantity):
- coldata = Quantity(coldata, unit=rows[0][name].unit)
- table[name] = coldata
-
- return table
|
{"golden_diff": "diff --git a/gammapy/utils/table.py b/gammapy/utils/table.py\n--- a/gammapy/utils/table.py\n+++ b/gammapy/utils/table.py\n@@ -3,12 +3,10 @@\n import numpy as np\n from astropy.table import Table\n from astropy.units import Quantity\n-from .deprecation import deprecated\n from .units import standardise_unit\n \n __all__ = [\n \"hstack_columns\",\n- \"table_from_row_data\",\n \"table_row_to_dict\",\n \"table_standardise_units_copy\",\n \"table_standardise_units_inplace\",\n@@ -92,30 +90,3 @@\n val = Quantity(val, unit=col.unit)\n data[name] = val\n return data\n-\n-\n-@deprecated(\"v1.1\", alternative=\"astropy.table.Table\")\n-def table_from_row_data(rows, **kwargs):\n- \"\"\"Helper function to create table objects from row data.\n-\n- Works with quantities.\n-\n- Parameters\n- ----------\n- rows : list\n- List of row data (each row a dictionary).\n- \"\"\"\n- table = Table(**kwargs)\n-\n- if len(rows) == 0:\n- return table\n-\n- colnames = list(rows[0].keys())\n-\n- for name in colnames:\n- coldata = [_[name] for _ in rows]\n- if isinstance(rows[0][name], Quantity):\n- coldata = Quantity(coldata, unit=rows[0][name].unit)\n- table[name] = coldata\n-\n- return table\n", "issue": "Remove deprecated features\nThis is a reminder issue to remove the features deprecated since 1.1 before the next release\n", "before_files": [{"content": "# Licensed under a 3-clause BSD style license - see LICENSE.rst\n\"\"\"Table helper utilities.\"\"\"\nimport numpy as np\nfrom astropy.table import Table\nfrom astropy.units import Quantity\nfrom .deprecation import deprecated\nfrom .units import standardise_unit\n\n__all__ = [\n \"hstack_columns\",\n \"table_from_row_data\",\n \"table_row_to_dict\",\n \"table_standardise_units_copy\",\n \"table_standardise_units_inplace\",\n]\n\n\ndef hstack_columns(table, table_other):\n \"\"\"Stack the column data horizontally.\n\n Parameters\n ----------\n table : `~astropy.table.Table`\n Input table.\n table_other : `~astropy.table.Table`\n Other input table.\n\n Returns\n -------\n stacked : `~astropy.table.Table`\n Stacked table.\n \"\"\"\n stacked = Table()\n\n for column in table.colnames:\n data = np.hstack([table[column].data[0], table_other[column].data[0]])\n stacked[column] = data[np.newaxis, :]\n return stacked\n\n\ndef table_standardise_units_copy(table):\n \"\"\"Standardise units for all columns in a table in a copy.\n\n Calls `~gammapy.utils.units.standardise_unit`.\n\n Parameters\n ----------\n table : `~astropy.table.Table`\n Input table (won't be modified).\n\n Returns\n -------\n table : `~astropy.table.Table`\n Copy of the input table with standardised column units.\n \"\"\"\n # Note: we could add an `inplace` option (or variant of this function)\n # See https://github.com/astropy/astropy/issues/6098\n table = Table(table)\n return table_standardise_units_inplace(table)\n\n\ndef table_standardise_units_inplace(table):\n \"\"\"Standardise units for all columns in a table in place.\"\"\"\n for column in table.columns.values():\n if column.unit:\n column.unit = standardise_unit(column.unit)\n\n return table\n\n\ndef table_row_to_dict(row, make_quantity=True):\n \"\"\"Make one source data dictionary.\n\n Parameters\n ----------\n row : `~astropy.table.Row`\n Row.\n make_quantity : bool, optional\n Make quantity values for columns with units.\n Default is True.\n\n Returns\n -------\n data : dict\n Row data.\n \"\"\"\n data = {}\n for name, col in row.columns.items():\n val = row[name]\n\n if make_quantity and col.unit:\n val = Quantity(val, unit=col.unit)\n data[name] = val\n return data\n\n\n@deprecated(\"v1.1\", alternative=\"astropy.table.Table\")\ndef table_from_row_data(rows, **kwargs):\n \"\"\"Helper function to create table objects from row data.\n\n Works with quantities.\n\n Parameters\n ----------\n rows : list\n List of row data (each row a dictionary).\n \"\"\"\n table = Table(**kwargs)\n\n if len(rows) == 0:\n return table\n\n colnames = list(rows[0].keys())\n\n for name in colnames:\n coldata = [_[name] for _ in rows]\n if isinstance(rows[0][name], Quantity):\n coldata = Quantity(coldata, unit=rows[0][name].unit)\n table[name] = coldata\n\n return table\n", "path": "gammapy/utils/table.py"}]}
| 1,545 | 348 |
gh_patches_debug_476
|
rasdani/github-patches
|
git_diff
|
rlworkgroup__garage-2133
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Unpin cloudpickle instead of pinning it to 1.3
Currently, #1879 pins cloudpickle to 1.3 because tensorflow-probability 0.11 does so. When tfp unpins cloudpickle, we should unpin it too.
</issue>
<code>
[start of setup.py]
1 """setuptools based setup module."""
2 import os
3
4 from setuptools import find_packages, setup
5
6 GARAGE_GH_TOKEN = os.environ.get('GARAGE_GH_TOKEN') or 'git'
7 GYM_VERSION = '0.17.2'
8
9 # Required dependencies
10 REQUIRED = [
11 # Please keep alphabetized
12 'akro',
13 'click>=2.0',
14 'cloudpickle==1.3',
15 'cma==2.7.0',
16 'dowel==0.0.3',
17 'numpy>=1.14.5',
18 'psutil',
19 'python-dateutil',
20 'ray',
21 'scikit-image',
22 'scipy',
23 'setproctitle>=1.0',
24 'tensorflow>=1.14',
25 'tensorflow-probability>=0.11.0',
26 'torch>=1.0.0,!=1.5.0',
27 'torchvision>=0.2.1',
28 ]
29
30 # Dependencies for optional features
31 EXTRAS = {}
32
33 EXTRAS['gym'] = [
34 f'gym[atari,box2d,classic_control]=={GYM_VERSION}',
35 ]
36
37 EXTRAS['mujoco'] = [
38 'mujoco-py>=2.0,<=2.0.2.8',
39 f'gym[all]=={GYM_VERSION}',
40 ]
41
42 EXTRAS['dm_control'] = [
43 # dm_control throws an error during install about not being able to
44 # find a build dependency (absl-py). Later pip executes the `install`
45 # command again and the install succeeds because absl-py has been
46 # installed. This is stupid, but harmless.
47 'dm_control',
48 ]
49
50 EXTRAS['bullet'] = ['mpi4py', 'pybullet>=2.8.7']
51
52 EXTRAS['all'] = list(set(sum(EXTRAS.values(), [])))
53
54 # Development dependencies (*not* included in 'all')
55 EXTRAS['dev'] = [
56 # Please keep alphabetized
57 'flake8',
58 'flake8-docstrings>=1.5.0',
59 'flake8-import-order',
60 f'metaworld @ https://{GARAGE_GH_TOKEN}@api.github.com/repos/rlworkgroup/metaworld/tarball/0875192baaa91c43523708f55866d98eaf3facaf', # noqa: E501
61 'isort>=4.3.21,<5.0.0',
62 'pep8-naming==0.7.0',
63 'pre-commit',
64 'pycodestyle>=2.5.0',
65 'pydocstyle>=4.0.0',
66 'pylint>=2.5.3',
67 'pytest>=4.5.0', # Required for strict-markers
68 'pytest-cov',
69 'pytest-rerunfailures',
70 'pytest-timeout',
71 'pytest-xdist',
72 'recommonmark',
73 'sphinx',
74 'sphinx-autoapi>=1.4.0',
75 'sphinx_rtd_theme',
76 'sphinxcontrib-bibtex',
77 'yapf==0.30.0',
78 ] # yapf: disable
79
80 with open('README.md') as f:
81 README = f.read()
82
83 # Get the package version dynamically
84 with open('VERSION') as v:
85 VERSION = v.read().strip()
86
87 setup(
88 name='garage',
89 version=VERSION,
90 author='Reinforcement Learning Working Group',
91 description='A toolkit for reproducible reinforcement learning research',
92 url='https://github.com/rlworkgroup/garage',
93 packages=find_packages(where='src'),
94 package_dir={'': 'src'},
95 scripts=['scripts/garage'],
96 python_requires='>=3.6',
97 install_requires=REQUIRED,
98 extras_require=EXTRAS,
99 license='MIT',
100 long_description=README,
101 long_description_content_type='text/markdown',
102 classifiers=[
103 'Development Status :: 4 - Beta',
104 'Intended Audience :: Developers',
105 'Intended Audience :: Education',
106 'Intended Audience :: Science/Research',
107 'License :: OSI Approved :: MIT License',
108 'Programming Language :: Python :: 3.6',
109 'Programming Language :: Python :: 3.7',
110 'Programming Language :: Python :: 3 :: Only',
111 'Topic :: Scientific/Engineering :: Artificial Intelligence',
112 'Topic :: Scientific/Engineering :: Mathematics',
113 'Topic :: Software Development :: Libraries',
114 ],
115 )
116
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -11,7 +11,7 @@
# Please keep alphabetized
'akro',
'click>=2.0',
- 'cloudpickle==1.3',
+ 'cloudpickle',
'cma==2.7.0',
'dowel==0.0.3',
'numpy>=1.14.5',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -11,7 +11,7 @@\n # Please keep alphabetized\n 'akro',\n 'click>=2.0',\n- 'cloudpickle==1.3',\n+ 'cloudpickle',\n 'cma==2.7.0',\n 'dowel==0.0.3',\n 'numpy>=1.14.5',\n", "issue": "Unpin cloudpickle instead of pinning it to 1.3\nCurrently, #1879 pins cloudpickle to 1.3 because tensorflow-probability 0.11 does so. When tfp unpins cloudpickle, we should unpin it too.\n", "before_files": [{"content": "\"\"\"setuptools based setup module.\"\"\"\nimport os\n\nfrom setuptools import find_packages, setup\n\nGARAGE_GH_TOKEN = os.environ.get('GARAGE_GH_TOKEN') or 'git'\nGYM_VERSION = '0.17.2'\n\n# Required dependencies\nREQUIRED = [\n # Please keep alphabetized\n 'akro',\n 'click>=2.0',\n 'cloudpickle==1.3',\n 'cma==2.7.0',\n 'dowel==0.0.3',\n 'numpy>=1.14.5',\n 'psutil',\n 'python-dateutil',\n 'ray',\n 'scikit-image',\n 'scipy',\n 'setproctitle>=1.0',\n 'tensorflow>=1.14',\n 'tensorflow-probability>=0.11.0',\n 'torch>=1.0.0,!=1.5.0',\n 'torchvision>=0.2.1',\n]\n\n# Dependencies for optional features\nEXTRAS = {}\n\nEXTRAS['gym'] = [\n f'gym[atari,box2d,classic_control]=={GYM_VERSION}',\n]\n\nEXTRAS['mujoco'] = [\n 'mujoco-py>=2.0,<=2.0.2.8',\n f'gym[all]=={GYM_VERSION}',\n]\n\nEXTRAS['dm_control'] = [\n # dm_control throws an error during install about not being able to\n # find a build dependency (absl-py). Later pip executes the `install`\n # command again and the install succeeds because absl-py has been\n # installed. This is stupid, but harmless.\n 'dm_control',\n]\n\nEXTRAS['bullet'] = ['mpi4py', 'pybullet>=2.8.7']\n\nEXTRAS['all'] = list(set(sum(EXTRAS.values(), [])))\n\n# Development dependencies (*not* included in 'all')\nEXTRAS['dev'] = [\n # Please keep alphabetized\n 'flake8',\n 'flake8-docstrings>=1.5.0',\n 'flake8-import-order',\n f'metaworld @ https://{GARAGE_GH_TOKEN}@api.github.com/repos/rlworkgroup/metaworld/tarball/0875192baaa91c43523708f55866d98eaf3facaf', # noqa: E501\n 'isort>=4.3.21,<5.0.0',\n 'pep8-naming==0.7.0',\n 'pre-commit',\n 'pycodestyle>=2.5.0',\n 'pydocstyle>=4.0.0',\n 'pylint>=2.5.3',\n 'pytest>=4.5.0', # Required for strict-markers\n 'pytest-cov',\n 'pytest-rerunfailures',\n 'pytest-timeout',\n 'pytest-xdist',\n 'recommonmark',\n 'sphinx',\n 'sphinx-autoapi>=1.4.0',\n 'sphinx_rtd_theme',\n 'sphinxcontrib-bibtex',\n 'yapf==0.30.0',\n] # yapf: disable\n\nwith open('README.md') as f:\n README = f.read()\n\n# Get the package version dynamically\nwith open('VERSION') as v:\n VERSION = v.read().strip()\n\nsetup(\n name='garage',\n version=VERSION,\n author='Reinforcement Learning Working Group',\n description='A toolkit for reproducible reinforcement learning research',\n url='https://github.com/rlworkgroup/garage',\n packages=find_packages(where='src'),\n package_dir={'': 'src'},\n scripts=['scripts/garage'],\n python_requires='>=3.6',\n install_requires=REQUIRED,\n extras_require=EXTRAS,\n license='MIT',\n long_description=README,\n long_description_content_type='text/markdown',\n classifiers=[\n 'Development Status :: 4 - Beta',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Education',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: MIT License',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3 :: Only',\n 'Topic :: Scientific/Engineering :: Artificial Intelligence',\n 'Topic :: Scientific/Engineering :: Mathematics',\n 'Topic :: Software Development :: Libraries',\n ],\n)\n", "path": "setup.py"}]}
| 1,829 | 102 |
gh_patches_debug_18827
|
rasdani/github-patches
|
git_diff
|
DataDog__dd-trace-py-1879
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Sanic resource names gets grouped incorrectly
Hi!
The Endpoints gets grouped incorrectly in the UI when using the Sanic integration because the path parameter values are used in the resource name instead of the parameter names and thus creating one unique Endpoint for every unique method + request path.
Example:

Is this by design? Other integrations (node express for example) groups them by the paramater names which imo seems to be the proper way to do it.
I have created a PR to solve this: #1879
</issue>
<code>
[start of ddtrace/contrib/sanic/patch.py]
1 import asyncio
2 import ddtrace
3 import sanic
4 from ddtrace import config
5 from ddtrace.constants import ANALYTICS_SAMPLE_RATE_KEY
6 from ddtrace.ext import SpanTypes
7 from ddtrace.propagation.http import HTTPPropagator
8 from ddtrace.utils.wrappers import unwrap as _u
9 from ddtrace.vendor import wrapt
10 from ddtrace.vendor.wrapt import wrap_function_wrapper as _w
11
12 from .. import trace_utils
13 from ...internal.logger import get_logger
14
15 log = get_logger(__name__)
16
17 config._add("sanic", dict(_default_service="sanic", distributed_tracing=True))
18
19
20 def _wrap_response_callback(span, callback):
21 # wrap response callbacks (either sync or async function) to set span tags
22 # based on response and finish span before returning response
23
24 def update_span(response):
25 if isinstance(response, sanic.response.BaseHTTPResponse):
26 status_code = response.status
27 response_headers = response.headers
28 else:
29 # invalid response causes ServerError exception which must be handled
30 status_code = 500
31 response_headers = None
32 trace_utils.set_http_meta(span, config.sanic, status_code=status_code, response_headers=response_headers)
33 span.finish()
34
35 @wrapt.function_wrapper
36 def wrap_sync(wrapped, instance, args, kwargs):
37 r = wrapped(*args, **kwargs)
38 response = args[0]
39 update_span(response)
40 return r
41
42 @wrapt.function_wrapper
43 async def wrap_async(wrapped, instance, args, kwargs):
44 r = await wrapped(*args, **kwargs)
45 response = args[0]
46 update_span(response)
47 return r
48
49 if asyncio.iscoroutinefunction(callback):
50 return wrap_async(callback)
51
52 return wrap_sync(callback)
53
54
55 def patch():
56 """Patch the instrumented methods."""
57 if getattr(sanic, "__datadog_patch", False):
58 return
59 setattr(sanic, "__datadog_patch", True)
60 _w("sanic", "Sanic.handle_request", patch_handle_request)
61
62
63 def unpatch():
64 """Unpatch the instrumented methods."""
65 _u(sanic.Sanic, "handle_request")
66 if not getattr(sanic, "__datadog_patch", False):
67 return
68 setattr(sanic, "__datadog_patch", False)
69
70
71 async def patch_handle_request(wrapped, instance, args, kwargs):
72 """Wrapper for Sanic.handle_request"""
73 request = kwargs.get("request", args[0])
74 write_callback = kwargs.get("write_callback", args[1])
75 stream_callback = kwargs.get("stream_callback", args[2])
76
77 if request.scheme not in ("http", "https"):
78 return await wrapped(request, write_callback, stream_callback, **kwargs)
79
80 resource = "{} {}".format(request.method, request.path)
81
82 headers = request.headers.copy()
83
84 if config.sanic.distributed_tracing:
85 propagator = HTTPPropagator()
86 context = propagator.extract(headers)
87 if context.trace_id:
88 ddtrace.tracer.context_provider.activate(context)
89
90 span = ddtrace.tracer.trace(
91 "sanic.request",
92 service=trace_utils.int_service(None, config.sanic),
93 resource=resource,
94 span_type=SpanTypes.WEB,
95 )
96 sample_rate = config.sanic.get_analytics_sample_rate(use_global_config=True)
97 if sample_rate is not None:
98 span.set_tag(ANALYTICS_SAMPLE_RATE_KEY, sample_rate)
99
100 method = request.method
101 url = "{scheme}://{host}{path}".format(scheme=request.scheme, host=request.host, path=request.path)
102 query_string = request.query_string
103 if isinstance(query_string, bytes):
104 query_string = query_string.decode()
105 trace_utils.set_http_meta(span, config.sanic, method=method, url=url, query=query_string, request_headers=headers)
106
107 if write_callback is not None:
108 write_callback = _wrap_response_callback(span, write_callback)
109 if stream_callback is not None:
110 stream_callback = _wrap_response_callback(span, stream_callback)
111
112 return await wrapped(request, write_callback, stream_callback, **kwargs)
113
[end of ddtrace/contrib/sanic/patch.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ddtrace/contrib/sanic/patch.py b/ddtrace/contrib/sanic/patch.py
--- a/ddtrace/contrib/sanic/patch.py
+++ b/ddtrace/contrib/sanic/patch.py
@@ -52,6 +52,18 @@
return wrap_sync(callback)
+def _get_path(request):
+ """Get path and replace path parameter values with names if route exists."""
+ path = request.path
+ try:
+ match_info = request.match_info
+ except sanic.exceptions.SanicException:
+ return path
+ for key, value in match_info.items():
+ path = path.replace(value, f"<{key}>")
+ return path
+
+
def patch():
"""Patch the instrumented methods."""
if getattr(sanic, "__datadog_patch", False):
@@ -77,7 +89,7 @@
if request.scheme not in ("http", "https"):
return await wrapped(request, write_callback, stream_callback, **kwargs)
- resource = "{} {}".format(request.method, request.path)
+ resource = "{} {}".format(request.method, _get_path(request))
headers = request.headers.copy()
|
{"golden_diff": "diff --git a/ddtrace/contrib/sanic/patch.py b/ddtrace/contrib/sanic/patch.py\n--- a/ddtrace/contrib/sanic/patch.py\n+++ b/ddtrace/contrib/sanic/patch.py\n@@ -52,6 +52,18 @@\n return wrap_sync(callback)\n \n \n+def _get_path(request):\n+ \"\"\"Get path and replace path parameter values with names if route exists.\"\"\"\n+ path = request.path\n+ try:\n+ match_info = request.match_info\n+ except sanic.exceptions.SanicException:\n+ return path\n+ for key, value in match_info.items():\n+ path = path.replace(value, f\"<{key}>\")\n+ return path\n+\n+\n def patch():\n \"\"\"Patch the instrumented methods.\"\"\"\n if getattr(sanic, \"__datadog_patch\", False):\n@@ -77,7 +89,7 @@\n if request.scheme not in (\"http\", \"https\"):\n return await wrapped(request, write_callback, stream_callback, **kwargs)\n \n- resource = \"{} {}\".format(request.method, request.path)\n+ resource = \"{} {}\".format(request.method, _get_path(request))\n \n headers = request.headers.copy()\n", "issue": "Sanic resource names gets grouped incorrectly\nHi!\r\n\r\nThe Endpoints gets grouped incorrectly in the UI when using the Sanic integration because the path parameter values are used in the resource name instead of the parameter names and thus creating one unique Endpoint for every unique method + request path.\r\n\r\nExample:\r\n\r\n\r\nIs this by design? Other integrations (node express for example) groups them by the paramater names which imo seems to be the proper way to do it.\r\n\r\nI have created a PR to solve this: #1879\n", "before_files": [{"content": "import asyncio\nimport ddtrace\nimport sanic\nfrom ddtrace import config\nfrom ddtrace.constants import ANALYTICS_SAMPLE_RATE_KEY\nfrom ddtrace.ext import SpanTypes\nfrom ddtrace.propagation.http import HTTPPropagator\nfrom ddtrace.utils.wrappers import unwrap as _u\nfrom ddtrace.vendor import wrapt\nfrom ddtrace.vendor.wrapt import wrap_function_wrapper as _w\n\nfrom .. import trace_utils\nfrom ...internal.logger import get_logger\n\nlog = get_logger(__name__)\n\nconfig._add(\"sanic\", dict(_default_service=\"sanic\", distributed_tracing=True))\n\n\ndef _wrap_response_callback(span, callback):\n # wrap response callbacks (either sync or async function) to set span tags\n # based on response and finish span before returning response\n\n def update_span(response):\n if isinstance(response, sanic.response.BaseHTTPResponse):\n status_code = response.status\n response_headers = response.headers\n else:\n # invalid response causes ServerError exception which must be handled\n status_code = 500\n response_headers = None\n trace_utils.set_http_meta(span, config.sanic, status_code=status_code, response_headers=response_headers)\n span.finish()\n\n @wrapt.function_wrapper\n def wrap_sync(wrapped, instance, args, kwargs):\n r = wrapped(*args, **kwargs)\n response = args[0]\n update_span(response)\n return r\n\n @wrapt.function_wrapper\n async def wrap_async(wrapped, instance, args, kwargs):\n r = await wrapped(*args, **kwargs)\n response = args[0]\n update_span(response)\n return r\n\n if asyncio.iscoroutinefunction(callback):\n return wrap_async(callback)\n\n return wrap_sync(callback)\n\n\ndef patch():\n \"\"\"Patch the instrumented methods.\"\"\"\n if getattr(sanic, \"__datadog_patch\", False):\n return\n setattr(sanic, \"__datadog_patch\", True)\n _w(\"sanic\", \"Sanic.handle_request\", patch_handle_request)\n\n\ndef unpatch():\n \"\"\"Unpatch the instrumented methods.\"\"\"\n _u(sanic.Sanic, \"handle_request\")\n if not getattr(sanic, \"__datadog_patch\", False):\n return\n setattr(sanic, \"__datadog_patch\", False)\n\n\nasync def patch_handle_request(wrapped, instance, args, kwargs):\n \"\"\"Wrapper for Sanic.handle_request\"\"\"\n request = kwargs.get(\"request\", args[0])\n write_callback = kwargs.get(\"write_callback\", args[1])\n stream_callback = kwargs.get(\"stream_callback\", args[2])\n\n if request.scheme not in (\"http\", \"https\"):\n return await wrapped(request, write_callback, stream_callback, **kwargs)\n\n resource = \"{} {}\".format(request.method, request.path)\n\n headers = request.headers.copy()\n\n if config.sanic.distributed_tracing:\n propagator = HTTPPropagator()\n context = propagator.extract(headers)\n if context.trace_id:\n ddtrace.tracer.context_provider.activate(context)\n\n span = ddtrace.tracer.trace(\n \"sanic.request\",\n service=trace_utils.int_service(None, config.sanic),\n resource=resource,\n span_type=SpanTypes.WEB,\n )\n sample_rate = config.sanic.get_analytics_sample_rate(use_global_config=True)\n if sample_rate is not None:\n span.set_tag(ANALYTICS_SAMPLE_RATE_KEY, sample_rate)\n\n method = request.method\n url = \"{scheme}://{host}{path}\".format(scheme=request.scheme, host=request.host, path=request.path)\n query_string = request.query_string\n if isinstance(query_string, bytes):\n query_string = query_string.decode()\n trace_utils.set_http_meta(span, config.sanic, method=method, url=url, query=query_string, request_headers=headers)\n\n if write_callback is not None:\n write_callback = _wrap_response_callback(span, write_callback)\n if stream_callback is not None:\n stream_callback = _wrap_response_callback(span, stream_callback)\n\n return await wrapped(request, write_callback, stream_callback, **kwargs)\n", "path": "ddtrace/contrib/sanic/patch.py"}]}
| 1,821 | 260 |
gh_patches_debug_28758
|
rasdani/github-patches
|
git_diff
|
microsoft__botbuilder-python-1402
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[PORT] Add EndOfConversationCodes to EndOfConversation activity from Skill
> Port this change from botbuilder-dotnet/master branch:
https://github.com/microsoft/botbuilder-dotnet/pull/4235
Fixes https://github.com/microsoft/botframework-sdk/issues/5852
# Changed projects
* Microsoft.Bot.Builder.Dialogs
* Microsoft.Bot.Builder.Dialogs.Tests
</issue>
<code>
[start of libraries/botbuilder-dialogs/botbuilder/dialogs/dialog_extensions.py]
1 # Copyright (c) Microsoft Corporation. All rights reserved.
2 # Licensed under the MIT License.
3
4 from botbuilder.core import BotAdapter, StatePropertyAccessor, TurnContext
5 from botbuilder.core.skills import SkillHandler, SkillConversationReference
6
7 from botbuilder.dialogs import (
8 Dialog,
9 DialogEvents,
10 DialogSet,
11 DialogTurnStatus,
12 )
13 from botbuilder.schema import Activity, ActivityTypes
14 from botframework.connector.auth import (
15 ClaimsIdentity,
16 SkillValidation,
17 AuthenticationConstants,
18 GovernmentConstants,
19 )
20
21
22 class DialogExtensions:
23 @staticmethod
24 async def run_dialog(
25 dialog: Dialog, turn_context: TurnContext, accessor: StatePropertyAccessor
26 ):
27 """
28 Creates a dialog stack and starts a dialog, pushing it onto the stack.
29 """
30
31 dialog_set = DialogSet(accessor)
32 dialog_set.add(dialog)
33
34 dialog_context = await dialog_set.create_context(turn_context)
35
36 # Handle EoC and Reprompt event from a parent bot (can be root bot to skill or skill to skill)
37 if DialogExtensions.__is_from_parent_to_skill(turn_context):
38 # Handle remote cancellation request from parent.
39 if turn_context.activity.type == ActivityTypes.end_of_conversation:
40 if not dialog_context.stack:
41 # No dialogs to cancel, just return.
42 return
43
44 remote_cancel_text = "Skill was canceled through an EndOfConversation activity from the parent."
45 await turn_context.send_trace_activity(
46 f"Extension {Dialog.__name__}.run_dialog", label=remote_cancel_text,
47 )
48
49 # Send cancellation message to the dialog to ensure all the parents are canceled
50 # in the right order.
51 await dialog_context.cancel_all_dialogs()
52 return
53
54 # Handle a reprompt event sent from the parent.
55 if (
56 turn_context.activity.type == ActivityTypes.event
57 and turn_context.activity.name == DialogEvents.reprompt_dialog
58 ):
59 if not dialog_context.stack:
60 # No dialogs to reprompt, just return.
61 return
62
63 await dialog_context.reprompt_dialog()
64 return
65
66 # Continue or start the dialog.
67 result = await dialog_context.continue_dialog()
68 if result.status == DialogTurnStatus.Empty:
69 result = await dialog_context.begin_dialog(dialog.id)
70
71 # Skills should send EoC when the dialog completes.
72 if (
73 result.status == DialogTurnStatus.Complete
74 or result.status == DialogTurnStatus.Cancelled
75 ):
76 if DialogExtensions.__send_eoc_to_parent(turn_context):
77 end_message_text = (
78 f"Dialog {dialog.id} has **completed**. Sending EndOfConversation."
79 )
80 await turn_context.send_trace_activity(
81 f"Extension {Dialog.__name__}.run_dialog",
82 label=end_message_text,
83 value=result.result,
84 )
85
86 activity = Activity(
87 type=ActivityTypes.end_of_conversation,
88 value=result.result,
89 locale=turn_context.activity.locale,
90 )
91 await turn_context.send_activity(activity)
92
93 @staticmethod
94 def __is_from_parent_to_skill(turn_context: TurnContext) -> bool:
95 if turn_context.turn_state.get(SkillHandler.SKILL_CONVERSATION_REFERENCE_KEY):
96 return False
97
98 claims_identity = turn_context.turn_state.get(BotAdapter.BOT_IDENTITY_KEY)
99 return isinstance(
100 claims_identity, ClaimsIdentity
101 ) and SkillValidation.is_skill_claim(claims_identity.claims)
102
103 @staticmethod
104 def __send_eoc_to_parent(turn_context: TurnContext) -> bool:
105 claims_identity = turn_context.turn_state.get(BotAdapter.BOT_IDENTITY_KEY)
106 if isinstance(
107 claims_identity, ClaimsIdentity
108 ) and SkillValidation.is_skill_claim(claims_identity.claims):
109 # EoC Activities returned by skills are bounced back to the bot by SkillHandler.
110 # In those cases we will have a SkillConversationReference instance in state.
111 skill_conversation_reference: SkillConversationReference = turn_context.turn_state.get(
112 SkillHandler.SKILL_CONVERSATION_REFERENCE_KEY
113 )
114 if skill_conversation_reference:
115 # If the skillConversationReference.OAuthScope is for one of the supported channels,
116 # we are at the root and we should not send an EoC.
117 return (
118 skill_conversation_reference.oauth_scope
119 != AuthenticationConstants.TO_CHANNEL_FROM_BOT_OAUTH_SCOPE
120 and skill_conversation_reference.oauth_scope
121 != GovernmentConstants.TO_CHANNEL_FROM_BOT_OAUTH_SCOPE
122 )
123 return True
124
125 return False
126
[end of libraries/botbuilder-dialogs/botbuilder/dialogs/dialog_extensions.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/libraries/botbuilder-dialogs/botbuilder/dialogs/dialog_extensions.py b/libraries/botbuilder-dialogs/botbuilder/dialogs/dialog_extensions.py
--- a/libraries/botbuilder-dialogs/botbuilder/dialogs/dialog_extensions.py
+++ b/libraries/botbuilder-dialogs/botbuilder/dialogs/dialog_extensions.py
@@ -1,22 +1,21 @@
# Copyright (c) Microsoft Corporation. All rights reserved.
# Licensed under the MIT License.
+from botframework.connector.auth import (
+ ClaimsIdentity,
+ SkillValidation,
+ AuthenticationConstants,
+ GovernmentConstants,
+)
from botbuilder.core import BotAdapter, StatePropertyAccessor, TurnContext
from botbuilder.core.skills import SkillHandler, SkillConversationReference
-
from botbuilder.dialogs import (
Dialog,
DialogEvents,
DialogSet,
DialogTurnStatus,
)
-from botbuilder.schema import Activity, ActivityTypes
-from botframework.connector.auth import (
- ClaimsIdentity,
- SkillValidation,
- AuthenticationConstants,
- GovernmentConstants,
-)
+from botbuilder.schema import Activity, ActivityTypes, EndOfConversationCodes
class DialogExtensions:
@@ -87,6 +86,9 @@
type=ActivityTypes.end_of_conversation,
value=result.result,
locale=turn_context.activity.locale,
+ code=EndOfConversationCodes.completed_successfully
+ if result.status == DialogTurnStatus.Complete
+ else EndOfConversationCodes.user_cancelled,
)
await turn_context.send_activity(activity)
|
{"golden_diff": "diff --git a/libraries/botbuilder-dialogs/botbuilder/dialogs/dialog_extensions.py b/libraries/botbuilder-dialogs/botbuilder/dialogs/dialog_extensions.py\n--- a/libraries/botbuilder-dialogs/botbuilder/dialogs/dialog_extensions.py\n+++ b/libraries/botbuilder-dialogs/botbuilder/dialogs/dialog_extensions.py\n@@ -1,22 +1,21 @@\n # Copyright (c) Microsoft Corporation. All rights reserved.\n # Licensed under the MIT License.\n \n+from botframework.connector.auth import (\n+ ClaimsIdentity,\n+ SkillValidation,\n+ AuthenticationConstants,\n+ GovernmentConstants,\n+)\n from botbuilder.core import BotAdapter, StatePropertyAccessor, TurnContext\n from botbuilder.core.skills import SkillHandler, SkillConversationReference\n-\n from botbuilder.dialogs import (\n Dialog,\n DialogEvents,\n DialogSet,\n DialogTurnStatus,\n )\n-from botbuilder.schema import Activity, ActivityTypes\n-from botframework.connector.auth import (\n- ClaimsIdentity,\n- SkillValidation,\n- AuthenticationConstants,\n- GovernmentConstants,\n-)\n+from botbuilder.schema import Activity, ActivityTypes, EndOfConversationCodes\n \n \n class DialogExtensions:\n@@ -87,6 +86,9 @@\n type=ActivityTypes.end_of_conversation,\n value=result.result,\n locale=turn_context.activity.locale,\n+ code=EndOfConversationCodes.completed_successfully\n+ if result.status == DialogTurnStatus.Complete\n+ else EndOfConversationCodes.user_cancelled,\n )\n await turn_context.send_activity(activity)\n", "issue": "[PORT] Add EndOfConversationCodes to EndOfConversation activity from Skill\n> Port this change from botbuilder-dotnet/master branch:\nhttps://github.com/microsoft/botbuilder-dotnet/pull/4235\n\nFixes https://github.com/microsoft/botframework-sdk/issues/5852\n\n\r\n# Changed projects\r\n* Microsoft.Bot.Builder.Dialogs\r\n* Microsoft.Bot.Builder.Dialogs.Tests\r\n\r\n\r\n\n\n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License.\n\nfrom botbuilder.core import BotAdapter, StatePropertyAccessor, TurnContext\nfrom botbuilder.core.skills import SkillHandler, SkillConversationReference\n\nfrom botbuilder.dialogs import (\n Dialog,\n DialogEvents,\n DialogSet,\n DialogTurnStatus,\n)\nfrom botbuilder.schema import Activity, ActivityTypes\nfrom botframework.connector.auth import (\n ClaimsIdentity,\n SkillValidation,\n AuthenticationConstants,\n GovernmentConstants,\n)\n\n\nclass DialogExtensions:\n @staticmethod\n async def run_dialog(\n dialog: Dialog, turn_context: TurnContext, accessor: StatePropertyAccessor\n ):\n \"\"\"\n Creates a dialog stack and starts a dialog, pushing it onto the stack.\n \"\"\"\n\n dialog_set = DialogSet(accessor)\n dialog_set.add(dialog)\n\n dialog_context = await dialog_set.create_context(turn_context)\n\n # Handle EoC and Reprompt event from a parent bot (can be root bot to skill or skill to skill)\n if DialogExtensions.__is_from_parent_to_skill(turn_context):\n # Handle remote cancellation request from parent.\n if turn_context.activity.type == ActivityTypes.end_of_conversation:\n if not dialog_context.stack:\n # No dialogs to cancel, just return.\n return\n\n remote_cancel_text = \"Skill was canceled through an EndOfConversation activity from the parent.\"\n await turn_context.send_trace_activity(\n f\"Extension {Dialog.__name__}.run_dialog\", label=remote_cancel_text,\n )\n\n # Send cancellation message to the dialog to ensure all the parents are canceled\n # in the right order.\n await dialog_context.cancel_all_dialogs()\n return\n\n # Handle a reprompt event sent from the parent.\n if (\n turn_context.activity.type == ActivityTypes.event\n and turn_context.activity.name == DialogEvents.reprompt_dialog\n ):\n if not dialog_context.stack:\n # No dialogs to reprompt, just return.\n return\n\n await dialog_context.reprompt_dialog()\n return\n\n # Continue or start the dialog.\n result = await dialog_context.continue_dialog()\n if result.status == DialogTurnStatus.Empty:\n result = await dialog_context.begin_dialog(dialog.id)\n\n # Skills should send EoC when the dialog completes.\n if (\n result.status == DialogTurnStatus.Complete\n or result.status == DialogTurnStatus.Cancelled\n ):\n if DialogExtensions.__send_eoc_to_parent(turn_context):\n end_message_text = (\n f\"Dialog {dialog.id} has **completed**. Sending EndOfConversation.\"\n )\n await turn_context.send_trace_activity(\n f\"Extension {Dialog.__name__}.run_dialog\",\n label=end_message_text,\n value=result.result,\n )\n\n activity = Activity(\n type=ActivityTypes.end_of_conversation,\n value=result.result,\n locale=turn_context.activity.locale,\n )\n await turn_context.send_activity(activity)\n\n @staticmethod\n def __is_from_parent_to_skill(turn_context: TurnContext) -> bool:\n if turn_context.turn_state.get(SkillHandler.SKILL_CONVERSATION_REFERENCE_KEY):\n return False\n\n claims_identity = turn_context.turn_state.get(BotAdapter.BOT_IDENTITY_KEY)\n return isinstance(\n claims_identity, ClaimsIdentity\n ) and SkillValidation.is_skill_claim(claims_identity.claims)\n\n @staticmethod\n def __send_eoc_to_parent(turn_context: TurnContext) -> bool:\n claims_identity = turn_context.turn_state.get(BotAdapter.BOT_IDENTITY_KEY)\n if isinstance(\n claims_identity, ClaimsIdentity\n ) and SkillValidation.is_skill_claim(claims_identity.claims):\n # EoC Activities returned by skills are bounced back to the bot by SkillHandler.\n # In those cases we will have a SkillConversationReference instance in state.\n skill_conversation_reference: SkillConversationReference = turn_context.turn_state.get(\n SkillHandler.SKILL_CONVERSATION_REFERENCE_KEY\n )\n if skill_conversation_reference:\n # If the skillConversationReference.OAuthScope is for one of the supported channels,\n # we are at the root and we should not send an EoC.\n return (\n skill_conversation_reference.oauth_scope\n != AuthenticationConstants.TO_CHANNEL_FROM_BOT_OAUTH_SCOPE\n and skill_conversation_reference.oauth_scope\n != GovernmentConstants.TO_CHANNEL_FROM_BOT_OAUTH_SCOPE\n )\n return True\n\n return False\n", "path": "libraries/botbuilder-dialogs/botbuilder/dialogs/dialog_extensions.py"}]}
| 1,852 | 327 |
gh_patches_debug_41475
|
rasdani/github-patches
|
git_diff
|
automl__auto-sklearn-1407
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
run_wrapper() got an unexpected keyword argument 'pure'
While running a fitting on a classifier (*output[0]* with data *output[1]* to *output[4]*), I get the following error; I think it's packages issue;
> output[0].fit(output[1], output[2], output[3], output[4])
> File "/usr/local/lib/python3.8/dist-packages/autosklearn/estimators.py", line 1045, in fit
super().fit(
> File "/usr/local/lib/python3.8/dist-packages/autosklearn/estimators.py", line 375, in fit
self.automl_.fit(load_models=self.load_models, **kwargs)
> File "/usr/local/lib/python3.8/dist-packages/autosklearn/automl.py", line 2056, in fit
return super().fit(
> File "/usr/local/lib/python3.8/dist-packages/autosklearn/automl.py", line 931, in fit
_proc_smac.run_smbo()
> File "/usr/local/lib/python3.8/dist-packages/autosklearn/smbo.py", line 498, in run_smbo
smac.optimize()
> File "/usr/local/lib/python3.8/dist-packages/smac/facade/smac_ac_facade.py", line 720, in optimize
incumbent = self.solver.run()
> File "/usr/local/lib/python3.8/dist-packages/smac/optimizer/smbo.py", line 287, in run
self.tae_runner.submit_run(run_info=run_info)
> File "/usr/local/lib/python3.8/dist-packages/smac/tae/dask_runner.py", line 166, in submit_run
self.client.submit(
> File "/usr/local/lib/python3.8/dist-packages/autosklearn/util/single_thread_client.py", line 59, in submit
return DummyFuture(func(*args, **kwargs))
> **TypeError: run_wrapper() got an unexpected keyword argument 'pure'**
It seems like it's an error with Dask. Here are the installed packages on ubuntu 18.04
pandas==1.3.0
scikit-learn==0.24
dask==2021.12.0
auto-sklearn==0.14.5 #AutoML
tensorflow==2.8.0
I've tried all versions of dask from 2021.12.0 to 2022.02.0 (Current) and nothing seems to work. Downgrading to auto-sklearn 0.14.4 and lower didn't solve the problem.
</issue>
<code>
[start of autosklearn/util/single_thread_client.py]
1 import typing
2 from pathlib import Path
3
4 import dask.distributed
5
6
7 class DummyFuture(dask.distributed.Future):
8 """
9 A class that mimics a distributed Future, the outcome of
10 performing submit on a distributed client.
11 """
12 def __init__(self, result: typing.Any) -> None:
13 self._result = result # type: typing.Any
14
15 def result(self, timeout: typing.Optional[int] = None) -> typing.Any:
16 return self._result
17
18 def cancel(self) -> None:
19 pass
20
21 def done(self) -> bool:
22 return True
23
24 def __repr__(self) -> str:
25 return "DummyFuture: {}".format(self._result)
26
27 def __del__(self) -> None:
28 pass
29
30
31 class SingleThreadedClient(dask.distributed.Client):
32 """
33 A class to Mock the Distributed Client class, in case
34 Auto-Sklearn is meant to run in the current Thread.
35 """
36 def __init__(self) -> None:
37
38 # Raise a not implemented error if using a method from Client
39 implemented_methods = ['submit', 'close', 'shutdown', 'write_scheduler_file',
40 '_get_scheduler_info', 'nthreads']
41 method_list = [func for func in dir(dask.distributed.Client) if callable(
42 getattr(dask.distributed.Client, func)) and not func.startswith('__')]
43 for method in method_list:
44 if method in implemented_methods:
45 continue
46 setattr(self, method, self._unsupported_method)
47 pass
48
49 def _unsupported_method(self) -> None:
50 raise NotImplementedError()
51
52 def submit(
53 self,
54 func: typing.Callable,
55 *args: typing.List,
56 priority: int = 0,
57 **kwargs: typing.Dict,
58 ) -> typing.Any:
59 return DummyFuture(func(*args, **kwargs))
60
61 def close(self) -> None:
62 pass
63
64 def shutdown(self) -> None:
65 pass
66
67 def write_scheduler_file(self, scheduler_file: str) -> None:
68 Path(scheduler_file).touch()
69 return
70
71 def _get_scheduler_info(self) -> typing.Dict:
72 return {
73 'workers': ['127.0.0.1'],
74 'type': 'Scheduler',
75 }
76
77 def nthreads(self) -> typing.Dict:
78 return {
79 '127.0.0.1': 1,
80 }
81
82 def __repr__(self) -> str:
83 return 'SingleThreadedClient()'
84
85 def __del__(self) -> None:
86 pass
87
[end of autosklearn/util/single_thread_client.py]
[start of autosklearn/__version__.py]
1 """Version information."""
2
3 # The following line *must* be the last in the module, exactly as formatted:
4 __version__ = "0.14.4"
5
[end of autosklearn/__version__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/autosklearn/__version__.py b/autosklearn/__version__.py
--- a/autosklearn/__version__.py
+++ b/autosklearn/__version__.py
@@ -1,4 +1,4 @@
"""Version information."""
# The following line *must* be the last in the module, exactly as formatted:
-__version__ = "0.14.4"
+__version__ = "0.14.6"
diff --git a/autosklearn/util/single_thread_client.py b/autosklearn/util/single_thread_client.py
--- a/autosklearn/util/single_thread_client.py
+++ b/autosklearn/util/single_thread_client.py
@@ -1,5 +1,6 @@
import typing
from pathlib import Path
+from typing import Any
import dask.distributed
@@ -9,6 +10,7 @@
A class that mimics a distributed Future, the outcome of
performing submit on a distributed client.
"""
+
def __init__(self, result: typing.Any) -> None:
self._result = result # type: typing.Any
@@ -33,13 +35,24 @@
A class to Mock the Distributed Client class, in case
Auto-Sklearn is meant to run in the current Thread.
"""
+
def __init__(self) -> None:
# Raise a not implemented error if using a method from Client
- implemented_methods = ['submit', 'close', 'shutdown', 'write_scheduler_file',
- '_get_scheduler_info', 'nthreads']
- method_list = [func for func in dir(dask.distributed.Client) if callable(
- getattr(dask.distributed.Client, func)) and not func.startswith('__')]
+ implemented_methods = [
+ "submit",
+ "close",
+ "shutdown",
+ "write_scheduler_file",
+ "_get_scheduler_info",
+ "nthreads",
+ ]
+ method_list = [
+ func
+ for func in dir(dask.distributed.Client)
+ if callable(getattr(dask.distributed.Client, func))
+ and not func.startswith("__")
+ ]
for method in method_list:
if method in implemented_methods:
continue
@@ -54,8 +67,24 @@
func: typing.Callable,
*args: typing.List,
priority: int = 0,
- **kwargs: typing.Dict,
+ key: Any = None,
+ workers: Any = None,
+ resources: Any = None,
+ retries: Any = None,
+ fifo_timeout: Any = "100 ms",
+ allow_other_workers: Any = False,
+ actor: Any = False,
+ actors: Any = False,
+ pure: Any = None,
+ **kwargs: Any,
) -> typing.Any:
+ """
+ Note
+ ----
+ The keyword arguments caught in `dask.distributed.Client` need to
+ be specified here so they don't get passed in as ``**kwargs`` to the
+ ``func``.
+ """
return DummyFuture(func(*args, **kwargs))
def close(self) -> None:
@@ -70,17 +99,17 @@
def _get_scheduler_info(self) -> typing.Dict:
return {
- 'workers': ['127.0.0.1'],
- 'type': 'Scheduler',
+ "workers": ["127.0.0.1"],
+ "type": "Scheduler",
}
def nthreads(self) -> typing.Dict:
return {
- '127.0.0.1': 1,
+ "127.0.0.1": 1,
}
def __repr__(self) -> str:
- return 'SingleThreadedClient()'
+ return "SingleThreadedClient()"
def __del__(self) -> None:
pass
|
{"golden_diff": "diff --git a/autosklearn/__version__.py b/autosklearn/__version__.py\n--- a/autosklearn/__version__.py\n+++ b/autosklearn/__version__.py\n@@ -1,4 +1,4 @@\n \"\"\"Version information.\"\"\"\n \n # The following line *must* be the last in the module, exactly as formatted:\n-__version__ = \"0.14.4\"\n+__version__ = \"0.14.6\"\ndiff --git a/autosklearn/util/single_thread_client.py b/autosklearn/util/single_thread_client.py\n--- a/autosklearn/util/single_thread_client.py\n+++ b/autosklearn/util/single_thread_client.py\n@@ -1,5 +1,6 @@\n import typing\n from pathlib import Path\n+from typing import Any\n \n import dask.distributed\n \n@@ -9,6 +10,7 @@\n A class that mimics a distributed Future, the outcome of\n performing submit on a distributed client.\n \"\"\"\n+\n def __init__(self, result: typing.Any) -> None:\n self._result = result # type: typing.Any\n \n@@ -33,13 +35,24 @@\n A class to Mock the Distributed Client class, in case\n Auto-Sklearn is meant to run in the current Thread.\n \"\"\"\n+\n def __init__(self) -> None:\n \n # Raise a not implemented error if using a method from Client\n- implemented_methods = ['submit', 'close', 'shutdown', 'write_scheduler_file',\n- '_get_scheduler_info', 'nthreads']\n- method_list = [func for func in dir(dask.distributed.Client) if callable(\n- getattr(dask.distributed.Client, func)) and not func.startswith('__')]\n+ implemented_methods = [\n+ \"submit\",\n+ \"close\",\n+ \"shutdown\",\n+ \"write_scheduler_file\",\n+ \"_get_scheduler_info\",\n+ \"nthreads\",\n+ ]\n+ method_list = [\n+ func\n+ for func in dir(dask.distributed.Client)\n+ if callable(getattr(dask.distributed.Client, func))\n+ and not func.startswith(\"__\")\n+ ]\n for method in method_list:\n if method in implemented_methods:\n continue\n@@ -54,8 +67,24 @@\n func: typing.Callable,\n *args: typing.List,\n priority: int = 0,\n- **kwargs: typing.Dict,\n+ key: Any = None,\n+ workers: Any = None,\n+ resources: Any = None,\n+ retries: Any = None,\n+ fifo_timeout: Any = \"100 ms\",\n+ allow_other_workers: Any = False,\n+ actor: Any = False,\n+ actors: Any = False,\n+ pure: Any = None,\n+ **kwargs: Any,\n ) -> typing.Any:\n+ \"\"\"\n+ Note\n+ ----\n+ The keyword arguments caught in `dask.distributed.Client` need to\n+ be specified here so they don't get passed in as ``**kwargs`` to the\n+ ``func``.\n+ \"\"\"\n return DummyFuture(func(*args, **kwargs))\n \n def close(self) -> None:\n@@ -70,17 +99,17 @@\n \n def _get_scheduler_info(self) -> typing.Dict:\n return {\n- 'workers': ['127.0.0.1'],\n- 'type': 'Scheduler',\n+ \"workers\": [\"127.0.0.1\"],\n+ \"type\": \"Scheduler\",\n }\n \n def nthreads(self) -> typing.Dict:\n return {\n- '127.0.0.1': 1,\n+ \"127.0.0.1\": 1,\n }\n \n def __repr__(self) -> str:\n- return 'SingleThreadedClient()'\n+ return \"SingleThreadedClient()\"\n \n def __del__(self) -> None:\n pass\n", "issue": "run_wrapper() got an unexpected keyword argument 'pure'\nWhile running a fitting on a classifier (*output[0]* with data *output[1]* to *output[4]*), I get the following error; I think it's packages issue;\r\n\r\n > output[0].fit(output[1], output[2], output[3], output[4])\r\n > File \"/usr/local/lib/python3.8/dist-packages/autosklearn/estimators.py\", line 1045, in fit\r\n super().fit(\r\n > File \"/usr/local/lib/python3.8/dist-packages/autosklearn/estimators.py\", line 375, in fit\r\n self.automl_.fit(load_models=self.load_models, **kwargs)\r\n > File \"/usr/local/lib/python3.8/dist-packages/autosklearn/automl.py\", line 2056, in fit\r\n return super().fit(\r\n > File \"/usr/local/lib/python3.8/dist-packages/autosklearn/automl.py\", line 931, in fit\r\n _proc_smac.run_smbo()\r\n > File \"/usr/local/lib/python3.8/dist-packages/autosklearn/smbo.py\", line 498, in run_smbo\r\n smac.optimize()\r\n > File \"/usr/local/lib/python3.8/dist-packages/smac/facade/smac_ac_facade.py\", line 720, in optimize\r\n incumbent = self.solver.run()\r\n > File \"/usr/local/lib/python3.8/dist-packages/smac/optimizer/smbo.py\", line 287, in run\r\n self.tae_runner.submit_run(run_info=run_info)\r\n > File \"/usr/local/lib/python3.8/dist-packages/smac/tae/dask_runner.py\", line 166, in submit_run\r\n self.client.submit(\r\n > File \"/usr/local/lib/python3.8/dist-packages/autosklearn/util/single_thread_client.py\", line 59, in submit\r\n return DummyFuture(func(*args, **kwargs))\r\n > **TypeError: run_wrapper() got an unexpected keyword argument 'pure'**\r\n\r\nIt seems like it's an error with Dask. Here are the installed packages on ubuntu 18.04\r\n\r\npandas==1.3.0\r\nscikit-learn==0.24\r\ndask==2021.12.0\r\nauto-sklearn==0.14.5 #AutoML\r\ntensorflow==2.8.0\r\n\r\nI've tried all versions of dask from 2021.12.0 to 2022.02.0 (Current) and nothing seems to work. Downgrading to auto-sklearn 0.14.4 and lower didn't solve the problem.\n", "before_files": [{"content": "import typing\nfrom pathlib import Path\n\nimport dask.distributed\n\n\nclass DummyFuture(dask.distributed.Future):\n \"\"\"\n A class that mimics a distributed Future, the outcome of\n performing submit on a distributed client.\n \"\"\"\n def __init__(self, result: typing.Any) -> None:\n self._result = result # type: typing.Any\n\n def result(self, timeout: typing.Optional[int] = None) -> typing.Any:\n return self._result\n\n def cancel(self) -> None:\n pass\n\n def done(self) -> bool:\n return True\n\n def __repr__(self) -> str:\n return \"DummyFuture: {}\".format(self._result)\n\n def __del__(self) -> None:\n pass\n\n\nclass SingleThreadedClient(dask.distributed.Client):\n \"\"\"\n A class to Mock the Distributed Client class, in case\n Auto-Sklearn is meant to run in the current Thread.\n \"\"\"\n def __init__(self) -> None:\n\n # Raise a not implemented error if using a method from Client\n implemented_methods = ['submit', 'close', 'shutdown', 'write_scheduler_file',\n '_get_scheduler_info', 'nthreads']\n method_list = [func for func in dir(dask.distributed.Client) if callable(\n getattr(dask.distributed.Client, func)) and not func.startswith('__')]\n for method in method_list:\n if method in implemented_methods:\n continue\n setattr(self, method, self._unsupported_method)\n pass\n\n def _unsupported_method(self) -> None:\n raise NotImplementedError()\n\n def submit(\n self,\n func: typing.Callable,\n *args: typing.List,\n priority: int = 0,\n **kwargs: typing.Dict,\n ) -> typing.Any:\n return DummyFuture(func(*args, **kwargs))\n\n def close(self) -> None:\n pass\n\n def shutdown(self) -> None:\n pass\n\n def write_scheduler_file(self, scheduler_file: str) -> None:\n Path(scheduler_file).touch()\n return\n\n def _get_scheduler_info(self) -> typing.Dict:\n return {\n 'workers': ['127.0.0.1'],\n 'type': 'Scheduler',\n }\n\n def nthreads(self) -> typing.Dict:\n return {\n '127.0.0.1': 1,\n }\n\n def __repr__(self) -> str:\n return 'SingleThreadedClient()'\n\n def __del__(self) -> None:\n pass\n", "path": "autosklearn/util/single_thread_client.py"}, {"content": "\"\"\"Version information.\"\"\"\n\n# The following line *must* be the last in the module, exactly as formatted:\n__version__ = \"0.14.4\"\n", "path": "autosklearn/__version__.py"}]}
| 1,917 | 874 |
gh_patches_debug_10877
|
rasdani/github-patches
|
git_diff
|
ivy-llc__ivy-20857
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
fftshift
This subtask is to add the `fftshift` function to the Jax frontend
</issue>
<code>
[start of ivy/functional/frontends/jax/numpy/fft.py]
1 # local
2 import ivy
3 from ivy.functional.frontends.jax.func_wrapper import to_ivy_arrays_and_back
4
5
6 @to_ivy_arrays_and_back
7 def fft(a, n=None, axis=-1, norm=None):
8 if norm is None:
9 norm = "backward"
10 return ivy.fft(a, axis, norm=norm, n=n)
11
[end of ivy/functional/frontends/jax/numpy/fft.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ivy/functional/frontends/jax/numpy/fft.py b/ivy/functional/frontends/jax/numpy/fft.py
--- a/ivy/functional/frontends/jax/numpy/fft.py
+++ b/ivy/functional/frontends/jax/numpy/fft.py
@@ -1,6 +1,25 @@
# local
import ivy
from ivy.functional.frontends.jax.func_wrapper import to_ivy_arrays_and_back
+from ivy.func_wrapper import with_unsupported_dtypes
+
+
+@to_ivy_arrays_and_back
+@with_unsupported_dtypes({"2.4.2 and below": ("float16", "bfloat16")}, "paddle")
+def fftshift(x, axes=None, name=None):
+ shape = x.shape
+
+ if axes is None:
+ axes = tuple(range(x.ndim))
+ shifts = [(dim // 2) for dim in shape]
+ elif isinstance(axes, int):
+ shifts = shape[axes] // 2
+ else:
+ shifts = [shape[ax] // 2 for ax in axes]
+
+ roll = ivy.roll(x, shifts, axis=axes)
+
+ return roll
@to_ivy_arrays_and_back
|
{"golden_diff": "diff --git a/ivy/functional/frontends/jax/numpy/fft.py b/ivy/functional/frontends/jax/numpy/fft.py\n--- a/ivy/functional/frontends/jax/numpy/fft.py\n+++ b/ivy/functional/frontends/jax/numpy/fft.py\n@@ -1,6 +1,25 @@\n # local\n import ivy\n from ivy.functional.frontends.jax.func_wrapper import to_ivy_arrays_and_back\n+from ivy.func_wrapper import with_unsupported_dtypes\n+\n+\n+@to_ivy_arrays_and_back\n+@with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n+def fftshift(x, axes=None, name=None):\n+ shape = x.shape\n+\n+ if axes is None:\n+ axes = tuple(range(x.ndim))\n+ shifts = [(dim // 2) for dim in shape]\n+ elif isinstance(axes, int):\n+ shifts = shape[axes] // 2\n+ else:\n+ shifts = [shape[ax] // 2 for ax in axes]\n+\n+ roll = ivy.roll(x, shifts, axis=axes)\n+\n+ return roll\n \n \n @to_ivy_arrays_and_back\n", "issue": "fftshift\nThis subtask is to add the `fftshift` function to the Jax frontend\n", "before_files": [{"content": "# local\nimport ivy\nfrom ivy.functional.frontends.jax.func_wrapper import to_ivy_arrays_and_back\n\n\n@to_ivy_arrays_and_back\ndef fft(a, n=None, axis=-1, norm=None):\n if norm is None:\n norm = \"backward\"\n return ivy.fft(a, axis, norm=norm, n=n)\n", "path": "ivy/functional/frontends/jax/numpy/fft.py"}]}
| 663 | 281 |
gh_patches_debug_20482
|
rasdani/github-patches
|
git_diff
|
crytic__slither-546
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
function-id not zero-padding function signature
```
ERC20:
+---------------------------------------+------------+
| Name | ID |
+---------------------------------------+------------+
| totalSupply() | 0x18160ddd |
| balanceOf(address) | 0x70a08231 |
| allowance(address,address) | 0xdd62ed3e |
| transfer(address,uint256) | 0xa9059cbb |
| transferFrom(address,address,uint256) | 0x23b872dd |
| approve(address,uint256) | 0x95ea7b3 |
+---------------------------------------+------------+
```
It's a minor annoyance, but for approve it outputs `0x95ea7b3` instead of `0x095ea7b3`. It is the same numerically, of course, but the function signature is more of an opaque 4-byte identifier than something numerically quantified.
function-id not zero-padding function signature
```
ERC20:
+---------------------------------------+------------+
| Name | ID |
+---------------------------------------+------------+
| totalSupply() | 0x18160ddd |
| balanceOf(address) | 0x70a08231 |
| allowance(address,address) | 0xdd62ed3e |
| transfer(address,uint256) | 0xa9059cbb |
| transferFrom(address,address,uint256) | 0x23b872dd |
| approve(address,uint256) | 0x95ea7b3 |
+---------------------------------------+------------+
```
It's a minor annoyance, but for approve it outputs `0x95ea7b3` instead of `0x095ea7b3`. It is the same numerically, of course, but the function signature is more of an opaque 4-byte identifier than something numerically quantified.
</issue>
<code>
[start of slither/printers/summary/function_ids.py]
1 """
2 Module printing summary of the contract
3 """
4 from slither.printers.abstract_printer import AbstractPrinter
5 from slither.utils.function import get_function_id
6 from slither.utils.myprettytable import MyPrettyTable
7
8
9 class FunctionIds(AbstractPrinter):
10
11 ARGUMENT = 'function-id'
12 HELP = 'Print the keccack256 signature of the functions'
13
14 WIKI = 'https://github.com/trailofbits/slither/wiki/Printer-documentation#function-id'
15
16 def output(self, _filename):
17 """
18 _filename is not used
19 Args:
20 _filename(string)
21 """
22
23 txt = ''
24 all_tables = []
25 for contract in self.slither.contracts_derived:
26 txt += '\n{}:\n'.format(contract.name)
27 table = MyPrettyTable(['Name', 'ID'])
28 for function in contract.functions:
29 if function.visibility in ['public', 'external']:
30 table.add_row([function.solidity_signature, hex(get_function_id(function.solidity_signature))])
31 for variable in contract.state_variables:
32 if variable.visibility in ['public']:
33 sig = variable.function_name
34 table.add_row([sig, hex(get_function_id(sig))])
35 txt += str(table) + '\n'
36 all_tables.append((contract.name, table))
37
38 self.info(txt)
39
40 res = self.generate_output(txt)
41 for name, table in all_tables:
42 res.add_pretty_table(table, name)
43
44 return res
[end of slither/printers/summary/function_ids.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/slither/printers/summary/function_ids.py b/slither/printers/summary/function_ids.py
--- a/slither/printers/summary/function_ids.py
+++ b/slither/printers/summary/function_ids.py
@@ -27,11 +27,13 @@
table = MyPrettyTable(['Name', 'ID'])
for function in contract.functions:
if function.visibility in ['public', 'external']:
- table.add_row([function.solidity_signature, hex(get_function_id(function.solidity_signature))])
+ function_id = get_function_id(function.solidity_signature)
+ table.add_row([function.solidity_signature, f"{function_id:#0{10}x}"])
for variable in contract.state_variables:
if variable.visibility in ['public']:
sig = variable.function_name
- table.add_row([sig, hex(get_function_id(sig))])
+ function_id = get_function_id(sig)
+ table.add_row([sig, f"{function_id:#0{10}x}"])
txt += str(table) + '\n'
all_tables.append((contract.name, table))
|
{"golden_diff": "diff --git a/slither/printers/summary/function_ids.py b/slither/printers/summary/function_ids.py\n--- a/slither/printers/summary/function_ids.py\n+++ b/slither/printers/summary/function_ids.py\n@@ -27,11 +27,13 @@\n table = MyPrettyTable(['Name', 'ID'])\n for function in contract.functions:\n if function.visibility in ['public', 'external']:\n- table.add_row([function.solidity_signature, hex(get_function_id(function.solidity_signature))])\n+ function_id = get_function_id(function.solidity_signature)\n+ table.add_row([function.solidity_signature, f\"{function_id:#0{10}x}\"])\n for variable in contract.state_variables:\n if variable.visibility in ['public']:\n sig = variable.function_name\n- table.add_row([sig, hex(get_function_id(sig))])\n+ function_id = get_function_id(sig)\n+ table.add_row([sig, f\"{function_id:#0{10}x}\"])\n txt += str(table) + '\\n'\n all_tables.append((contract.name, table))\n", "issue": "function-id not zero-padding function signature \n```\r\nERC20:\r\n+---------------------------------------+------------+\r\n| Name | ID |\r\n+---------------------------------------+------------+\r\n| totalSupply() | 0x18160ddd |\r\n| balanceOf(address) | 0x70a08231 |\r\n| allowance(address,address) | 0xdd62ed3e |\r\n| transfer(address,uint256) | 0xa9059cbb |\r\n| transferFrom(address,address,uint256) | 0x23b872dd |\r\n| approve(address,uint256) | 0x95ea7b3 |\r\n+---------------------------------------+------------+\r\n\r\n```\r\n\r\nIt's a minor annoyance, but for approve it outputs `0x95ea7b3` instead of `0x095ea7b3`. It is the same numerically, of course, but the function signature is more of an opaque 4-byte identifier than something numerically quantified.\r\n\r\n\nfunction-id not zero-padding function signature \n```\r\nERC20:\r\n+---------------------------------------+------------+\r\n| Name | ID |\r\n+---------------------------------------+------------+\r\n| totalSupply() | 0x18160ddd |\r\n| balanceOf(address) | 0x70a08231 |\r\n| allowance(address,address) | 0xdd62ed3e |\r\n| transfer(address,uint256) | 0xa9059cbb |\r\n| transferFrom(address,address,uint256) | 0x23b872dd |\r\n| approve(address,uint256) | 0x95ea7b3 |\r\n+---------------------------------------+------------+\r\n\r\n```\r\n\r\nIt's a minor annoyance, but for approve it outputs `0x95ea7b3` instead of `0x095ea7b3`. It is the same numerically, of course, but the function signature is more of an opaque 4-byte identifier than something numerically quantified.\r\n\r\n\n", "before_files": [{"content": "\"\"\"\n Module printing summary of the contract\n\"\"\"\nfrom slither.printers.abstract_printer import AbstractPrinter\nfrom slither.utils.function import get_function_id\nfrom slither.utils.myprettytable import MyPrettyTable\n\n\nclass FunctionIds(AbstractPrinter):\n\n ARGUMENT = 'function-id'\n HELP = 'Print the keccack256 signature of the functions'\n\n WIKI = 'https://github.com/trailofbits/slither/wiki/Printer-documentation#function-id'\n\n def output(self, _filename):\n \"\"\"\n _filename is not used\n Args:\n _filename(string)\n \"\"\"\n\n txt = ''\n all_tables = []\n for contract in self.slither.contracts_derived:\n txt += '\\n{}:\\n'.format(contract.name)\n table = MyPrettyTable(['Name', 'ID'])\n for function in contract.functions:\n if function.visibility in ['public', 'external']:\n table.add_row([function.solidity_signature, hex(get_function_id(function.solidity_signature))])\n for variable in contract.state_variables:\n if variable.visibility in ['public']:\n sig = variable.function_name\n table.add_row([sig, hex(get_function_id(sig))])\n txt += str(table) + '\\n'\n all_tables.append((contract.name, table))\n\n self.info(txt)\n\n res = self.generate_output(txt)\n for name, table in all_tables:\n res.add_pretty_table(table, name)\n\n return res", "path": "slither/printers/summary/function_ids.py"}]}
| 1,398 | 244 |
gh_patches_debug_64987
|
rasdani/github-patches
|
git_diff
|
googleapis__google-auth-library-python-937
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
new cachetools version (5.0.0+) can't work with google-auth
`cachetools` has released a new version (5.0.0) which conflicts with google-auth requirements of it being <5, this prevents updates to the `cachetools` package and pose a potential security concern (as updates are no longer possible to it)
```
The conflict is caused by:
The user requested cachetools==5.0.0
google-auth 2.3.3 depends on cachetools<5.0 and >=2.0.0
```
issue seems in https://github.com/googleapis/google-auth-library-python/blob/3c3fbf40b07e090f2be7fac5b304dbf438b5cd6c/setup.py#L23
#### Environment details
- OS: alpine3.11
- Python version: python:3.8.6
- pip version: 20.3.3
- `google-auth` version: 2.3.3 (latest at time of writing)
#### Steps to reproduce
1. try pip install using latest `cachetools` with latest `google-auth`
2. pip fails
</issue>
<code>
[start of setup.py]
1 # Copyright 2014 Google Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import io
16 import os
17
18 from setuptools import find_packages
19 from setuptools import setup
20
21
22 DEPENDENCIES = (
23 "cachetools>=2.0.0,<5.0",
24 "pyasn1-modules>=0.2.1",
25 # rsa==4.5 is the last version to support 2.7
26 # https://github.com/sybrenstuvel/python-rsa/issues/152#issuecomment-643470233
27 'rsa<4.6; python_version < "3.6"',
28 'rsa>=3.1.4,<5; python_version >= "3.6"',
29 # install enum34 to support 2.7. enum34 only works up to python version 3.3.
30 'enum34>=1.1.10; python_version < "3.4"',
31 "six>=1.9.0",
32 )
33
34 extras = {
35 "aiohttp": [
36 "aiohttp >= 3.6.2, < 4.0.0dev; python_version>='3.6'",
37 "requests >= 2.20.0, < 3.0.0dev",
38 ],
39 "pyopenssl": "pyopenssl>=20.0.0",
40 "reauth": "pyu2f>=0.1.5",
41 }
42
43 with io.open("README.rst", "r") as fh:
44 long_description = fh.read()
45
46 package_root = os.path.abspath(os.path.dirname(__file__))
47
48 version = {}
49 with open(os.path.join(package_root, "google/auth/version.py")) as fp:
50 exec(fp.read(), version)
51 version = version["__version__"]
52
53 setup(
54 name="google-auth",
55 version=version,
56 author="Google Cloud Platform",
57 author_email="[email protected]",
58 description="Google Authentication Library",
59 long_description=long_description,
60 url="https://github.com/googleapis/google-auth-library-python",
61 packages=find_packages(exclude=("tests*", "system_tests*")),
62 namespace_packages=("google",),
63 install_requires=DEPENDENCIES,
64 extras_require=extras,
65 python_requires=">=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*,!=3.4.*,!=3.5.*",
66 license="Apache 2.0",
67 keywords="google auth oauth client",
68 classifiers=[
69 "Programming Language :: Python :: 3",
70 "Programming Language :: Python :: 3.6",
71 "Programming Language :: Python :: 3.7",
72 "Programming Language :: Python :: 3.8",
73 "Programming Language :: Python :: 3.9",
74 "Programming Language :: Python :: 3.10",
75 "Development Status :: 5 - Production/Stable",
76 "Intended Audience :: Developers",
77 "License :: OSI Approved :: Apache Software License",
78 "Operating System :: POSIX",
79 "Operating System :: Microsoft :: Windows",
80 "Operating System :: MacOS :: MacOS X",
81 "Operating System :: OS Independent",
82 "Topic :: Internet :: WWW/HTTP",
83 ],
84 )
85
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -20,7 +20,7 @@
DEPENDENCIES = (
- "cachetools>=2.0.0,<5.0",
+ "cachetools>=2.0.0,<6.0",
"pyasn1-modules>=0.2.1",
# rsa==4.5 is the last version to support 2.7
# https://github.com/sybrenstuvel/python-rsa/issues/152#issuecomment-643470233
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -20,7 +20,7 @@\n \n \n DEPENDENCIES = (\n- \"cachetools>=2.0.0,<5.0\",\n+ \"cachetools>=2.0.0,<6.0\",\n \"pyasn1-modules>=0.2.1\",\n # rsa==4.5 is the last version to support 2.7\n # https://github.com/sybrenstuvel/python-rsa/issues/152#issuecomment-643470233\n", "issue": "new cachetools version (5.0.0+) can't work with google-auth\n`cachetools` has released a new version (5.0.0) which conflicts with google-auth requirements of it being <5, this prevents updates to the `cachetools` package and pose a potential security concern (as updates are no longer possible to it)\r\n\r\n```\r\nThe conflict is caused by:\r\n The user requested cachetools==5.0.0\r\n google-auth 2.3.3 depends on cachetools<5.0 and >=2.0.0\r\n```\r\n\r\nissue seems in https://github.com/googleapis/google-auth-library-python/blob/3c3fbf40b07e090f2be7fac5b304dbf438b5cd6c/setup.py#L23 \r\n\r\n#### Environment details\r\n\r\n - OS: alpine3.11\r\n - Python version: python:3.8.6\r\n - pip version: 20.3.3\r\n - `google-auth` version: 2.3.3 (latest at time of writing)\r\n\r\n#### Steps to reproduce\r\n\r\n 1. try pip install using latest `cachetools` with latest `google-auth`\r\n 2. pip fails\r\n\n", "before_files": [{"content": "# Copyright 2014 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport io\nimport os\n\nfrom setuptools import find_packages\nfrom setuptools import setup\n\n\nDEPENDENCIES = (\n \"cachetools>=2.0.0,<5.0\",\n \"pyasn1-modules>=0.2.1\",\n # rsa==4.5 is the last version to support 2.7\n # https://github.com/sybrenstuvel/python-rsa/issues/152#issuecomment-643470233\n 'rsa<4.6; python_version < \"3.6\"',\n 'rsa>=3.1.4,<5; python_version >= \"3.6\"',\n # install enum34 to support 2.7. enum34 only works up to python version 3.3.\n 'enum34>=1.1.10; python_version < \"3.4\"',\n \"six>=1.9.0\",\n)\n\nextras = {\n \"aiohttp\": [\n \"aiohttp >= 3.6.2, < 4.0.0dev; python_version>='3.6'\",\n \"requests >= 2.20.0, < 3.0.0dev\",\n ],\n \"pyopenssl\": \"pyopenssl>=20.0.0\",\n \"reauth\": \"pyu2f>=0.1.5\",\n}\n\nwith io.open(\"README.rst\", \"r\") as fh:\n long_description = fh.read()\n\npackage_root = os.path.abspath(os.path.dirname(__file__))\n\nversion = {}\nwith open(os.path.join(package_root, \"google/auth/version.py\")) as fp:\n exec(fp.read(), version)\nversion = version[\"__version__\"]\n\nsetup(\n name=\"google-auth\",\n version=version,\n author=\"Google Cloud Platform\",\n author_email=\"[email protected]\",\n description=\"Google Authentication Library\",\n long_description=long_description,\n url=\"https://github.com/googleapis/google-auth-library-python\",\n packages=find_packages(exclude=(\"tests*\", \"system_tests*\")),\n namespace_packages=(\"google\",),\n install_requires=DEPENDENCIES,\n extras_require=extras,\n python_requires=\">=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*,!=3.4.*,!=3.5.*\",\n license=\"Apache 2.0\",\n keywords=\"google auth oauth client\",\n classifiers=[\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: POSIX\",\n \"Operating System :: Microsoft :: Windows\",\n \"Operating System :: MacOS :: MacOS X\",\n \"Operating System :: OS Independent\",\n \"Topic :: Internet :: WWW/HTTP\",\n ],\n)\n", "path": "setup.py"}]}
| 1,774 | 139 |
gh_patches_debug_20415
|
rasdani/github-patches
|
git_diff
|
ansible__awx-12803
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Token and Session Expiration never run after the first time
### Please confirm the following
- [X] I agree to follow this project's [code of conduct](https://docs.ansible.com/ansible/latest/community/code_of_conduct.html).
- [X] I have checked the [current issues](https://github.com/ansible/awx/issues) for duplicates.
- [X] I understand that AWX is open source software provided for free and that I might not receive a timely response.
### Bug Summary
Looks like when we implemented token and session cleanup way back in https://github.com/ansible/awx/pull/3856
We populated the recurrence rule incorrectly:
https://github.com/ansible/awx/blob/8a06ffbe15c9f8e68b1da86e5ca7daf5ecfd6da4/awx/main/migrations/_create_system_jobs.py#L39
This schedule will only ever run once due to `COUNT=1`.... we should omit that so that it will periodically run.
### AWX version
latest
### Select the relevant components
- [ ] UI
- [X] API
- [ ] Docs
- [ ] Collection
- [ ] CLI
- [ ] Other
### Installation method
minishift
### Modifications
no
### Ansible version
_No response_
### Operating system
_No response_
### Web browser
_No response_
### Steps to reproduce
install awx
### Expected results
periodic running of these management jobs
### Actual results
the jobs only run once
### Additional information
_No response_
</issue>
<code>
[start of awx/main/migrations/_create_system_jobs.py]
1 import logging
2
3 from django.utils.timezone import now
4
5 logger = logging.getLogger('awx.main.migrations')
6
7 __all__ = ['create_collection_jt', 'create_clearsessions_jt', 'create_cleartokens_jt']
8
9 '''
10 These methods are called by migrations to create various system job templates
11
12 Create default system job templates if not present. Create default schedules
13 only if new system job templates were created (i.e. new database).
14 '''
15
16
17 def create_clearsessions_jt(apps, schema_editor):
18
19 SystemJobTemplate = apps.get_model('main', 'SystemJobTemplate')
20 Schedule = apps.get_model('main', 'Schedule')
21 ContentType = apps.get_model('contenttypes', 'ContentType')
22 sjt_ct = ContentType.objects.get_for_model(SystemJobTemplate)
23 now_dt = now()
24 schedule_time = now_dt.strftime('%Y%m%dT%H%M%SZ')
25
26 sjt, created = SystemJobTemplate.objects.get_or_create(
27 job_type='cleanup_sessions',
28 defaults=dict(
29 name='Cleanup Expired Sessions',
30 description='Cleans out expired browser sessions',
31 polymorphic_ctype=sjt_ct,
32 created=now_dt,
33 modified=now_dt,
34 ),
35 )
36 if created:
37 sched = Schedule(
38 name='Cleanup Expired Sessions',
39 rrule='DTSTART:%s RRULE:FREQ=WEEKLY;INTERVAL=1;COUNT=1' % schedule_time,
40 description='Cleans out expired browser sessions',
41 enabled=True,
42 created=now_dt,
43 modified=now_dt,
44 extra_data={},
45 )
46 sched.unified_job_template = sjt
47 sched.save()
48
49
50 def create_cleartokens_jt(apps, schema_editor):
51
52 SystemJobTemplate = apps.get_model('main', 'SystemJobTemplate')
53 Schedule = apps.get_model('main', 'Schedule')
54 ContentType = apps.get_model('contenttypes', 'ContentType')
55 sjt_ct = ContentType.objects.get_for_model(SystemJobTemplate)
56 now_dt = now()
57 schedule_time = now_dt.strftime('%Y%m%dT%H%M%SZ')
58
59 sjt, created = SystemJobTemplate.objects.get_or_create(
60 job_type='cleanup_tokens',
61 defaults=dict(
62 name='Cleanup Expired OAuth 2 Tokens',
63 description='Cleanup expired OAuth 2 access and refresh tokens',
64 polymorphic_ctype=sjt_ct,
65 created=now_dt,
66 modified=now_dt,
67 ),
68 )
69 if created:
70 sched = Schedule(
71 name='Cleanup Expired OAuth 2 Tokens',
72 rrule='DTSTART:%s RRULE:FREQ=WEEKLY;INTERVAL=1;COUNT=1' % schedule_time,
73 description='Removes expired OAuth 2 access and refresh tokens',
74 enabled=True,
75 created=now_dt,
76 modified=now_dt,
77 extra_data={},
78 )
79 sched.unified_job_template = sjt
80 sched.save()
81
[end of awx/main/migrations/_create_system_jobs.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/awx/main/migrations/_create_system_jobs.py b/awx/main/migrations/_create_system_jobs.py
--- a/awx/main/migrations/_create_system_jobs.py
+++ b/awx/main/migrations/_create_system_jobs.py
@@ -36,7 +36,7 @@
if created:
sched = Schedule(
name='Cleanup Expired Sessions',
- rrule='DTSTART:%s RRULE:FREQ=WEEKLY;INTERVAL=1;COUNT=1' % schedule_time,
+ rrule='DTSTART:%s RRULE:FREQ=WEEKLY;INTERVAL=1' % schedule_time,
description='Cleans out expired browser sessions',
enabled=True,
created=now_dt,
@@ -69,7 +69,7 @@
if created:
sched = Schedule(
name='Cleanup Expired OAuth 2 Tokens',
- rrule='DTSTART:%s RRULE:FREQ=WEEKLY;INTERVAL=1;COUNT=1' % schedule_time,
+ rrule='DTSTART:%s RRULE:FREQ=WEEKLY;INTERVAL=1' % schedule_time,
description='Removes expired OAuth 2 access and refresh tokens',
enabled=True,
created=now_dt,
|
{"golden_diff": "diff --git a/awx/main/migrations/_create_system_jobs.py b/awx/main/migrations/_create_system_jobs.py\n--- a/awx/main/migrations/_create_system_jobs.py\n+++ b/awx/main/migrations/_create_system_jobs.py\n@@ -36,7 +36,7 @@\n if created:\n sched = Schedule(\n name='Cleanup Expired Sessions',\n- rrule='DTSTART:%s RRULE:FREQ=WEEKLY;INTERVAL=1;COUNT=1' % schedule_time,\n+ rrule='DTSTART:%s RRULE:FREQ=WEEKLY;INTERVAL=1' % schedule_time,\n description='Cleans out expired browser sessions',\n enabled=True,\n created=now_dt,\n@@ -69,7 +69,7 @@\n if created:\n sched = Schedule(\n name='Cleanup Expired OAuth 2 Tokens',\n- rrule='DTSTART:%s RRULE:FREQ=WEEKLY;INTERVAL=1;COUNT=1' % schedule_time,\n+ rrule='DTSTART:%s RRULE:FREQ=WEEKLY;INTERVAL=1' % schedule_time,\n description='Removes expired OAuth 2 access and refresh tokens',\n enabled=True,\n created=now_dt,\n", "issue": "Token and Session Expiration never run after the first time\n### Please confirm the following\n\n- [X] I agree to follow this project's [code of conduct](https://docs.ansible.com/ansible/latest/community/code_of_conduct.html).\n- [X] I have checked the [current issues](https://github.com/ansible/awx/issues) for duplicates.\n- [X] I understand that AWX is open source software provided for free and that I might not receive a timely response.\n\n### Bug Summary\n\nLooks like when we implemented token and session cleanup way back in https://github.com/ansible/awx/pull/3856\r\n\r\nWe populated the recurrence rule incorrectly:\r\n\r\nhttps://github.com/ansible/awx/blob/8a06ffbe15c9f8e68b1da86e5ca7daf5ecfd6da4/awx/main/migrations/_create_system_jobs.py#L39\r\n\r\nThis schedule will only ever run once due to `COUNT=1`.... we should omit that so that it will periodically run.\n\n### AWX version\n\nlatest\n\n### Select the relevant components\n\n- [ ] UI\n- [X] API\n- [ ] Docs\n- [ ] Collection\n- [ ] CLI\n- [ ] Other\n\n### Installation method\n\nminishift\n\n### Modifications\n\nno\n\n### Ansible version\n\n_No response_\n\n### Operating system\n\n_No response_\n\n### Web browser\n\n_No response_\n\n### Steps to reproduce\n\ninstall awx\n\n### Expected results\n\nperiodic running of these management jobs\n\n### Actual results\n\nthe jobs only run once\n\n### Additional information\n\n_No response_\n", "before_files": [{"content": "import logging\n\nfrom django.utils.timezone import now\n\nlogger = logging.getLogger('awx.main.migrations')\n\n__all__ = ['create_collection_jt', 'create_clearsessions_jt', 'create_cleartokens_jt']\n\n'''\nThese methods are called by migrations to create various system job templates\n\nCreate default system job templates if not present. Create default schedules\nonly if new system job templates were created (i.e. new database).\n'''\n\n\ndef create_clearsessions_jt(apps, schema_editor):\n\n SystemJobTemplate = apps.get_model('main', 'SystemJobTemplate')\n Schedule = apps.get_model('main', 'Schedule')\n ContentType = apps.get_model('contenttypes', 'ContentType')\n sjt_ct = ContentType.objects.get_for_model(SystemJobTemplate)\n now_dt = now()\n schedule_time = now_dt.strftime('%Y%m%dT%H%M%SZ')\n\n sjt, created = SystemJobTemplate.objects.get_or_create(\n job_type='cleanup_sessions',\n defaults=dict(\n name='Cleanup Expired Sessions',\n description='Cleans out expired browser sessions',\n polymorphic_ctype=sjt_ct,\n created=now_dt,\n modified=now_dt,\n ),\n )\n if created:\n sched = Schedule(\n name='Cleanup Expired Sessions',\n rrule='DTSTART:%s RRULE:FREQ=WEEKLY;INTERVAL=1;COUNT=1' % schedule_time,\n description='Cleans out expired browser sessions',\n enabled=True,\n created=now_dt,\n modified=now_dt,\n extra_data={},\n )\n sched.unified_job_template = sjt\n sched.save()\n\n\ndef create_cleartokens_jt(apps, schema_editor):\n\n SystemJobTemplate = apps.get_model('main', 'SystemJobTemplate')\n Schedule = apps.get_model('main', 'Schedule')\n ContentType = apps.get_model('contenttypes', 'ContentType')\n sjt_ct = ContentType.objects.get_for_model(SystemJobTemplate)\n now_dt = now()\n schedule_time = now_dt.strftime('%Y%m%dT%H%M%SZ')\n\n sjt, created = SystemJobTemplate.objects.get_or_create(\n job_type='cleanup_tokens',\n defaults=dict(\n name='Cleanup Expired OAuth 2 Tokens',\n description='Cleanup expired OAuth 2 access and refresh tokens',\n polymorphic_ctype=sjt_ct,\n created=now_dt,\n modified=now_dt,\n ),\n )\n if created:\n sched = Schedule(\n name='Cleanup Expired OAuth 2 Tokens',\n rrule='DTSTART:%s RRULE:FREQ=WEEKLY;INTERVAL=1;COUNT=1' % schedule_time,\n description='Removes expired OAuth 2 access and refresh tokens',\n enabled=True,\n created=now_dt,\n modified=now_dt,\n extra_data={},\n )\n sched.unified_job_template = sjt\n sched.save()\n", "path": "awx/main/migrations/_create_system_jobs.py"}]}
| 1,662 | 274 |
gh_patches_debug_3959
|
rasdani/github-patches
|
git_diff
|
great-expectations__great_expectations-5468
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Use cleaner solution for non-truncating division in python 2
Prefer `from __future__ import division` to `1.*x/y`
</issue>
<code>
[start of contrib/capitalone_dataprofiler_expectations/capitalone_dataprofiler_expectations/expectations/__init__.py]
1 # Make sure to include any Expectations your want exported below!
2
3 from .expect_column_values_confidence_for_data_label_to_be_greater_than_or_equal_to_threshold import (
4 ExpectColumnValuesConfidenceForDataLabelToBeGreaterThanOrEqualToThreshold,
5 )
6 from .expect_column_values_confidence_for_data_label_to_be_less_than_or_equal_to_threshold import (
7 ExpectColumnValuesConfidenceForDataLabelToBeLessThanOrEqualToThreshold,
8 )
9 from .expect_column_values_to_be_equal_to_or_greater_than_profile_min import (
10 ExpectColumnValuesToBeEqualToOrGreaterThanProfileMin,
11 )
12 from .expect_column_values_to_be_equal_to_or_less_than_profile_max import (
13 ExpectColumnValuesToBeEqualToOrLessThanProfileMax,
14 )
15 from .expect_column_values_to_be_probabilistically_greater_than_or_equal_to_threshold import (
16 ExpectColumnValuesToBeProbabilisticallyGreaterThanOrEqualToThreshold,
17 )
18 from .expect_profile_numeric_columns_diff_between_threshold_range import (
19 ExpectProfileNumericColumnsDiffBetweenThresholdRange
20 )
21
[end of contrib/capitalone_dataprofiler_expectations/capitalone_dataprofiler_expectations/expectations/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/contrib/capitalone_dataprofiler_expectations/capitalone_dataprofiler_expectations/expectations/__init__.py b/contrib/capitalone_dataprofiler_expectations/capitalone_dataprofiler_expectations/expectations/__init__.py
--- a/contrib/capitalone_dataprofiler_expectations/capitalone_dataprofiler_expectations/expectations/__init__.py
+++ b/contrib/capitalone_dataprofiler_expectations/capitalone_dataprofiler_expectations/expectations/__init__.py
@@ -16,5 +16,5 @@
ExpectColumnValuesToBeProbabilisticallyGreaterThanOrEqualToThreshold,
)
from .expect_profile_numeric_columns_diff_between_threshold_range import (
- ExpectProfileNumericColumnsDiffBetweenThresholdRange
+ ExpectProfileNumericColumnsDiffBetweenThresholdRange,
)
|
{"golden_diff": "diff --git a/contrib/capitalone_dataprofiler_expectations/capitalone_dataprofiler_expectations/expectations/__init__.py b/contrib/capitalone_dataprofiler_expectations/capitalone_dataprofiler_expectations/expectations/__init__.py\n--- a/contrib/capitalone_dataprofiler_expectations/capitalone_dataprofiler_expectations/expectations/__init__.py\n+++ b/contrib/capitalone_dataprofiler_expectations/capitalone_dataprofiler_expectations/expectations/__init__.py\n@@ -16,5 +16,5 @@\n ExpectColumnValuesToBeProbabilisticallyGreaterThanOrEqualToThreshold,\n )\n from .expect_profile_numeric_columns_diff_between_threshold_range import (\n- ExpectProfileNumericColumnsDiffBetweenThresholdRange\n+ ExpectProfileNumericColumnsDiffBetweenThresholdRange,\n )\n", "issue": "Use cleaner solution for non-truncating division in python 2\nPrefer `from __future__ import division` to `1.*x/y`\n", "before_files": [{"content": "# Make sure to include any Expectations your want exported below!\n\nfrom .expect_column_values_confidence_for_data_label_to_be_greater_than_or_equal_to_threshold import (\n ExpectColumnValuesConfidenceForDataLabelToBeGreaterThanOrEqualToThreshold,\n)\nfrom .expect_column_values_confidence_for_data_label_to_be_less_than_or_equal_to_threshold import (\n ExpectColumnValuesConfidenceForDataLabelToBeLessThanOrEqualToThreshold,\n)\nfrom .expect_column_values_to_be_equal_to_or_greater_than_profile_min import (\n ExpectColumnValuesToBeEqualToOrGreaterThanProfileMin,\n)\nfrom .expect_column_values_to_be_equal_to_or_less_than_profile_max import (\n ExpectColumnValuesToBeEqualToOrLessThanProfileMax,\n)\nfrom .expect_column_values_to_be_probabilistically_greater_than_or_equal_to_threshold import (\n ExpectColumnValuesToBeProbabilisticallyGreaterThanOrEqualToThreshold,\n)\nfrom .expect_profile_numeric_columns_diff_between_threshold_range import (\n ExpectProfileNumericColumnsDiffBetweenThresholdRange\n)\n", "path": "contrib/capitalone_dataprofiler_expectations/capitalone_dataprofiler_expectations/expectations/__init__.py"}]}
| 842 | 182 |
gh_patches_debug_5751
|
rasdani/github-patches
|
git_diff
|
ansible__ansible-lint-1128
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[701] No 'galaxy_info' found results in meta/requirements.yml file
### Summary
ansible-lint reporting `[701] No 'galaxy_info' found` in my `meta/requirements.yml`, a file that unlike `meta/main.yml` does not (to my knowledge) support a `galaxy_info` field.
##### Issue Type
- Bug Report
##### Ansible and Ansible Lint details
<!--- Paste verbatim output between tripple backticks -->
```console (paste below)
$ ansible --version
ansible 2.10.1
$ ansible-lint --version
ansible-lint 4.3.5
```
- ansible installation method: pipenv (pip)
- ansible-lint installation method: pipenv (pip)
##### OS / ENVIRONMENT
MacOS 10.15.7 (Catalina Latest)
##### STEPS TO REPRODUCE
Using this `meta/requirements.yml`
```bash
---
# insert third party deps here. download with:
# ansible-galaxy install -r requirements.yml
# https://docs.ansible.com/ansible/galaxy.html
- name: singleplatform-eng.users
version: v1.2.6
- name: weareinteractive.sudo
version: 1.14.1
- name: geerlingguy.fluentd
version: 1.1.0
```
Note that `meta/main.yml` does include `galaxy_info`, but does not include as dependencies, the roles listed in requirements.yml. This is purposeful because I'm choosing `meta/requirements.yml` instead of `meta/main.yml` because I prefer the workflow and do not want the roles running first, as they do when in `meta/main.yml`. I'm following the previously linked user-guide on this topic.
To reproduce, I simply run ansible-lint directly or via molecule.
##### Desired Behaviour
I would expect ansible-lint not to flag these as issues... unless I'm completely misunderstanding the finding and misreading the documentation associated with this rule.
##### Actual Behaviour
Below are the ansible-lint results when run on my role.
```bash
$ ansible-lint
[701] No 'galaxy_info' found
meta/requirements.yml:7
{'meta/main.yml': {'name': 'singleplatform-eng.users', 'version': 'v1.2.6', '__line__': 7, '__file__': '/Users/tmichael/orgs/tmb/ansible_roles/base/meta/requirements.yml', 'skipped_rules': []}}
[701] No 'galaxy_info' found
meta/requirements.yml:10
{'meta/main.yml': {'name': 'weareinteractive.sudo', 'version': '1.14.1', '__line__': 10, '__file__': '/Users/tmichael/orgs/tmb/ansible_roles/base/meta/requirements.yml'}}
[701] No 'galaxy_info' found
meta/requirements.yml:13
{'meta/main.yml': {'name': 'geerlingguy.fluentd', 'version': '1.1.0', '__line__': 13, '__file__': '/Users/tmichael/orgs/tmb/ansible_roles/base/meta/requirements.yml'}}
```
</issue>
<code>
[start of lib/ansiblelint/rules/MetaMainHasInfoRule.py]
1 # Copyright (c) 2016, Will Thames and contributors
2 # Copyright (c) 2018, Ansible Project
3
4 from ansiblelint.rules import AnsibleLintRule
5
6 META_STR_INFO = (
7 'author',
8 'description'
9 )
10 META_INFO = tuple(list(META_STR_INFO) + [
11 'license',
12 'min_ansible_version',
13 'platforms',
14 ])
15
16
17 def _platform_info_errors_itr(platforms):
18 if not isinstance(platforms, list):
19 yield 'Platforms should be a list of dictionaries'
20 return
21
22 for platform in platforms:
23 if not isinstance(platform, dict):
24 yield 'Platforms should be a list of dictionaries'
25 elif 'name' not in platform:
26 yield 'Platform should contain name'
27
28
29 def _galaxy_info_errors_itr(galaxy_info,
30 info_list=META_INFO,
31 str_info_list=META_STR_INFO):
32 for info in info_list:
33 ginfo = galaxy_info.get(info, False)
34 if ginfo:
35 if info in str_info_list and not isinstance(ginfo, str):
36 yield '{info} should be a string'.format(info=info)
37 elif info == 'platforms':
38 for err in _platform_info_errors_itr(ginfo):
39 yield err
40 else:
41 yield 'Role info should contain {info}'.format(info=info)
42
43
44 class MetaMainHasInfoRule(AnsibleLintRule):
45 id = '701'
46 shortdesc = 'meta/main.yml should contain relevant info'
47 str_info = META_STR_INFO
48 info = META_INFO
49 description = (
50 'meta/main.yml should contain: ``{}``'.format(', '.join(info))
51 )
52 severity = 'HIGH'
53 tags = ['metadata']
54 version_added = 'v4.0.0'
55
56 def matchplay(self, file, data):
57 if file['type'] != 'meta':
58 return False
59
60 meta = {'meta/main.yml': data}
61 galaxy_info = data.get('galaxy_info', False)
62 if galaxy_info:
63 return [(meta, err) for err
64 in _galaxy_info_errors_itr(galaxy_info)]
65
66 return [(meta, "No 'galaxy_info' found")]
67
[end of lib/ansiblelint/rules/MetaMainHasInfoRule.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lib/ansiblelint/rules/MetaMainHasInfoRule.py b/lib/ansiblelint/rules/MetaMainHasInfoRule.py
--- a/lib/ansiblelint/rules/MetaMainHasInfoRule.py
+++ b/lib/ansiblelint/rules/MetaMainHasInfoRule.py
@@ -57,6 +57,11 @@
if file['type'] != 'meta':
return False
+ # since Ansible 2.10 we can add a meta/requirements.yml but
+ # we only want to match on meta/main.yml
+ if not file['path'].endswith('/main.yml'):
+ return False
+
meta = {'meta/main.yml': data}
galaxy_info = data.get('galaxy_info', False)
if galaxy_info:
|
{"golden_diff": "diff --git a/lib/ansiblelint/rules/MetaMainHasInfoRule.py b/lib/ansiblelint/rules/MetaMainHasInfoRule.py\n--- a/lib/ansiblelint/rules/MetaMainHasInfoRule.py\n+++ b/lib/ansiblelint/rules/MetaMainHasInfoRule.py\n@@ -57,6 +57,11 @@\n if file['type'] != 'meta':\n return False\n \n+ # since Ansible 2.10 we can add a meta/requirements.yml but\n+ # we only want to match on meta/main.yml\n+ if not file['path'].endswith('/main.yml'):\n+ return False\n+\n meta = {'meta/main.yml': data}\n galaxy_info = data.get('galaxy_info', False)\n if galaxy_info:\n", "issue": "[701] No 'galaxy_info' found results in meta/requirements.yml file\n### Summary\r\n\r\nansible-lint reporting `[701] No 'galaxy_info' found` in my `meta/requirements.yml`, a file that unlike `meta/main.yml` does not (to my knowledge) support a `galaxy_info` field.\r\n\r\n##### Issue Type\r\n\r\n- Bug Report\r\n\r\n##### Ansible and Ansible Lint details\r\n<!--- Paste verbatim output between tripple backticks -->\r\n```console (paste below)\r\n$ ansible --version\r\nansible 2.10.1\r\n\r\n$ ansible-lint --version\r\nansible-lint 4.3.5\r\n```\r\n\r\n- ansible installation method: pipenv (pip)\r\n- ansible-lint installation method: pipenv (pip)\r\n\r\n##### OS / ENVIRONMENT\r\nMacOS 10.15.7 (Catalina Latest)\r\n\r\n##### STEPS TO REPRODUCE\r\n\r\nUsing this `meta/requirements.yml`\r\n```bash\r\n---\r\n\r\n# insert third party deps here. download with:\r\n# ansible-galaxy install -r requirements.yml\r\n# https://docs.ansible.com/ansible/galaxy.html\r\n\r\n- name: singleplatform-eng.users\r\n version: v1.2.6\r\n\r\n- name: weareinteractive.sudo\r\n version: 1.14.1\r\n\r\n- name: geerlingguy.fluentd\r\n version: 1.1.0\r\n```\r\n\r\nNote that `meta/main.yml` does include `galaxy_info`, but does not include as dependencies, the roles listed in requirements.yml. This is purposeful because I'm choosing `meta/requirements.yml` instead of `meta/main.yml` because I prefer the workflow and do not want the roles running first, as they do when in `meta/main.yml`. I'm following the previously linked user-guide on this topic.\r\n\r\nTo reproduce, I simply run ansible-lint directly or via molecule.\r\n\r\n##### Desired Behaviour\r\n\r\nI would expect ansible-lint not to flag these as issues... unless I'm completely misunderstanding the finding and misreading the documentation associated with this rule.\r\n\r\n##### Actual Behaviour\r\n\r\n\r\nBelow are the ansible-lint results when run on my role.\r\n```bash\r\n$ ansible-lint\r\n[701] No 'galaxy_info' found\r\nmeta/requirements.yml:7\r\n{'meta/main.yml': {'name': 'singleplatform-eng.users', 'version': 'v1.2.6', '__line__': 7, '__file__': '/Users/tmichael/orgs/tmb/ansible_roles/base/meta/requirements.yml', 'skipped_rules': []}}\r\n\r\n[701] No 'galaxy_info' found\r\nmeta/requirements.yml:10\r\n{'meta/main.yml': {'name': 'weareinteractive.sudo', 'version': '1.14.1', '__line__': 10, '__file__': '/Users/tmichael/orgs/tmb/ansible_roles/base/meta/requirements.yml'}}\r\n\r\n[701] No 'galaxy_info' found\r\nmeta/requirements.yml:13\r\n{'meta/main.yml': {'name': 'geerlingguy.fluentd', 'version': '1.1.0', '__line__': 13, '__file__': '/Users/tmichael/orgs/tmb/ansible_roles/base/meta/requirements.yml'}}\r\n```\n", "before_files": [{"content": "# Copyright (c) 2016, Will Thames and contributors\n# Copyright (c) 2018, Ansible Project\n\nfrom ansiblelint.rules import AnsibleLintRule\n\nMETA_STR_INFO = (\n 'author',\n 'description'\n)\nMETA_INFO = tuple(list(META_STR_INFO) + [\n 'license',\n 'min_ansible_version',\n 'platforms',\n])\n\n\ndef _platform_info_errors_itr(platforms):\n if not isinstance(platforms, list):\n yield 'Platforms should be a list of dictionaries'\n return\n\n for platform in platforms:\n if not isinstance(platform, dict):\n yield 'Platforms should be a list of dictionaries'\n elif 'name' not in platform:\n yield 'Platform should contain name'\n\n\ndef _galaxy_info_errors_itr(galaxy_info,\n info_list=META_INFO,\n str_info_list=META_STR_INFO):\n for info in info_list:\n ginfo = galaxy_info.get(info, False)\n if ginfo:\n if info in str_info_list and not isinstance(ginfo, str):\n yield '{info} should be a string'.format(info=info)\n elif info == 'platforms':\n for err in _platform_info_errors_itr(ginfo):\n yield err\n else:\n yield 'Role info should contain {info}'.format(info=info)\n\n\nclass MetaMainHasInfoRule(AnsibleLintRule):\n id = '701'\n shortdesc = 'meta/main.yml should contain relevant info'\n str_info = META_STR_INFO\n info = META_INFO\n description = (\n 'meta/main.yml should contain: ``{}``'.format(', '.join(info))\n )\n severity = 'HIGH'\n tags = ['metadata']\n version_added = 'v4.0.0'\n\n def matchplay(self, file, data):\n if file['type'] != 'meta':\n return False\n\n meta = {'meta/main.yml': data}\n galaxy_info = data.get('galaxy_info', False)\n if galaxy_info:\n return [(meta, err) for err\n in _galaxy_info_errors_itr(galaxy_info)]\n\n return [(meta, \"No 'galaxy_info' found\")]\n", "path": "lib/ansiblelint/rules/MetaMainHasInfoRule.py"}]}
| 1,860 | 170 |
gh_patches_debug_32180
|
rasdani/github-patches
|
git_diff
|
mathesar-foundation__mathesar-3459
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Demo mode results in 5XX
## Description
<!-- A clear and concise description of what the bug is. -->
Mathesar is broken (as of 0.1.4) for Demo Mode. It doesn't load, and just says "Server Error (500)" instead.
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
Demo mode should work.
## To Reproduce
<!-- How can we recreate this bug? Please try to provide a Minimal, Complete, and Verifiable (http://stackoverflow.com/help/mcve) example if code-related. -->
Change the `.env` file according to the comment to use the demo mode settings, try to build and start mathesar (dev environment is fine)
</issue>
<code>
[start of mathesar/install.py]
1 """
2 This script installs functions and types for Mathesar onto the configured DB.
3 """
4 import getopt
5 import os
6 import sys
7
8 import django
9 from django.core import management
10 from decouple import config as decouple_config
11 from django.conf import settings
12 from django.db.utils import IntegrityError
13 from sqlalchemy.exc import OperationalError
14 from db import install
15
16
17 def main(skip_static_collection=False):
18 # skip_confirm is temporarily enabled by default as we don't have any use
19 # for interactive prompts with docker only deployments
20 skip_confirm = True
21 (opts, _) = getopt.getopt(sys.argv[1:], ":s", ["skip-confirm"])
22 for (opt, value) in opts:
23 if (opt == "-s") or (opt == "--skip-confirm"):
24 skip_confirm = True
25 os.environ.setdefault("DJANGO_SETTINGS_MODULE", "config.settings.production")
26 django.setup()
27 management.call_command('migrate')
28 debug_mode = decouple_config('DEBUG', default=False, cast=bool)
29 #
30 if not debug_mode and not skip_static_collection:
31 management.call_command('collectstatic', '--noinput', '--clear')
32 print("------------Setting up User Databases------------")
33 django_db_key = decouple_config('DJANGO_DATABASE_KEY', default="default")
34 user_databases = [key for key in settings.DATABASES if key != django_db_key]
35 for database_key in user_databases:
36 try:
37 install_on_db_with_key(database_key, skip_confirm)
38 except IntegrityError:
39 continue
40
41
42 def install_on_db_with_key(database_key, skip_confirm):
43 from mathesar.models.base import Database
44 db_model = Database.create_from_settings_key(database_key)
45 db_model.save()
46 try:
47 install.install_mathesar(
48 database_name=db_model.db_name,
49 hostname=db_model.host,
50 username=db_model.username,
51 password=db_model.password,
52 port=db_model.port,
53 skip_confirm=skip_confirm
54 )
55 except OperationalError as e:
56 db_model.delete()
57 raise e
58
59
60 if __name__ == "__main__":
61 main()
62
[end of mathesar/install.py]
[start of demo/settings.py]
1 from config.settings.production import * # noqa
2 from config.settings import * # noqa
3 from decouple import config as decouple_config
4
5 INSTALLED_APPS += [ # noqa
6 "demo"
7 ]
8
9 MIDDLEWARE += [ # noqa
10 "demo.middleware.LiveDemoModeMiddleware",
11 ]
12
13 MATHESAR_LIVE_DEMO = True
14 MATHESAR_LIVE_DEMO_USERNAME = decouple_config('MATHESAR_LIVE_DEMO_USERNAME', default=None)
15 MATHESAR_LIVE_DEMO_PASSWORD = decouple_config('MATHESAR_LIVE_DEMO_PASSWORD', default=None)
16
17 MATHESAR_DEMO_TEMPLATE = 'mathesar_demo_template'
18 MATHESAR_DEMO_ARXIV_LOG_PATH = decouple_config(
19 'MATHESAR_DEMO_ARXIV_LOG_PATH',
20 default='/var/lib/mathesar/demo/arxiv_db_schema_log'
21 )
22 BASE_TEMPLATE_ADDITIONAL_SCRIPT_TEMPLATES += ['demo/analytics.html'] # noqa
23 ROOT_URLCONF = "demo.urls"
24
[end of demo/settings.py]
[start of demo/management/commands/setup_demo_template_db.py]
1 from sqlalchemy import text
2 from sqlalchemy.exc import OperationalError
3 from django.conf import settings
4 from django.core.management import BaseCommand
5
6 from db.install import install_mathesar
7 from demo.install.datasets import load_datasets
8 from mathesar.database.base import create_mathesar_engine
9 from mathesar.models.base import Database
10
11
12 class Command(BaseCommand):
13 help = 'Initialize the demo template database.'
14
15 def handle(self, *args, **options):
16 _setup_demo_template_db()
17
18
19 def _setup_demo_template_db():
20 print("Initializing demo template database...")
21
22 template_db_name = settings.MATHESAR_DEMO_TEMPLATE
23 django_model = Database.current_objects.get(name=settings.DATABASES["default"]["NAME"])
24 root_engine = create_mathesar_engine(django_model)
25 with root_engine.connect() as conn:
26 conn.execution_options(isolation_level="AUTOCOMMIT")
27 conn.execute(text(f"DROP DATABASE IF EXISTS {template_db_name} WITH (FORCE)"))
28 root_engine.dispose()
29 db_model, _ = Database.current_objects.get_or_create(
30 name=template_db_name,
31 defaults={
32 'db_name': template_db_name,
33 'username': django_model.username,
34 'password': django_model.password,
35 'host': django_model.host,
36 'port': django_model.port
37 }
38 )
39 try:
40 install_mathesar(
41 database_name=template_db_name,
42 hostname=db_model.host,
43 username=db_model.username,
44 password=db_model.password,
45 port=db_model.port,
46 skip_confirm=True
47 )
48 except OperationalError as e:
49 db_model.delete()
50 raise e
51 user_engine = create_mathesar_engine(db_model)
52 load_datasets(user_engine)
53 user_engine.dispose()
54
[end of demo/management/commands/setup_demo_template_db.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/demo/management/commands/setup_demo_template_db.py b/demo/management/commands/setup_demo_template_db.py
--- a/demo/management/commands/setup_demo_template_db.py
+++ b/demo/management/commands/setup_demo_template_db.py
@@ -20,7 +20,7 @@
print("Initializing demo template database...")
template_db_name = settings.MATHESAR_DEMO_TEMPLATE
- django_model = Database.current_objects.get(name=settings.DATABASES["default"]["NAME"])
+ django_model = Database.create_from_settings_key("default")
root_engine = create_mathesar_engine(django_model)
with root_engine.connect() as conn:
conn.execution_options(isolation_level="AUTOCOMMIT")
diff --git a/demo/settings.py b/demo/settings.py
--- a/demo/settings.py
+++ b/demo/settings.py
@@ -1,5 +1,4 @@
-from config.settings.production import * # noqa
-from config.settings import * # noqa
+from config.settings.common_settings import * # noqa
from decouple import config as decouple_config
INSTALLED_APPS += [ # noqa
@@ -10,6 +9,7 @@
"demo.middleware.LiveDemoModeMiddleware",
]
+MATHESAR_MODE = 'PRODUCTION'
MATHESAR_LIVE_DEMO = True
MATHESAR_LIVE_DEMO_USERNAME = decouple_config('MATHESAR_LIVE_DEMO_USERNAME', default=None)
MATHESAR_LIVE_DEMO_PASSWORD = decouple_config('MATHESAR_LIVE_DEMO_PASSWORD', default=None)
diff --git a/mathesar/install.py b/mathesar/install.py
--- a/mathesar/install.py
+++ b/mathesar/install.py
@@ -37,6 +37,14 @@
install_on_db_with_key(database_key, skip_confirm)
except IntegrityError:
continue
+ if getattr(settings, 'MATHESAR_LIVE_DEMO', False) is True:
+ management.call_command(
+ 'createsuperuser',
+ '--no-input',
+ '--username', 'demo',
+ '--email', '[email protected]',
+ )
+ management.call_command('setup_demo_template_db')
def install_on_db_with_key(database_key, skip_confirm):
|
{"golden_diff": "diff --git a/demo/management/commands/setup_demo_template_db.py b/demo/management/commands/setup_demo_template_db.py\n--- a/demo/management/commands/setup_demo_template_db.py\n+++ b/demo/management/commands/setup_demo_template_db.py\n@@ -20,7 +20,7 @@\n print(\"Initializing demo template database...\")\n \n template_db_name = settings.MATHESAR_DEMO_TEMPLATE\n- django_model = Database.current_objects.get(name=settings.DATABASES[\"default\"][\"NAME\"])\n+ django_model = Database.create_from_settings_key(\"default\")\n root_engine = create_mathesar_engine(django_model)\n with root_engine.connect() as conn:\n conn.execution_options(isolation_level=\"AUTOCOMMIT\")\ndiff --git a/demo/settings.py b/demo/settings.py\n--- a/demo/settings.py\n+++ b/demo/settings.py\n@@ -1,5 +1,4 @@\n-from config.settings.production import * # noqa\n-from config.settings import * # noqa\n+from config.settings.common_settings import * # noqa\n from decouple import config as decouple_config\n \n INSTALLED_APPS += [ # noqa\n@@ -10,6 +9,7 @@\n \"demo.middleware.LiveDemoModeMiddleware\",\n ]\n \n+MATHESAR_MODE = 'PRODUCTION'\n MATHESAR_LIVE_DEMO = True\n MATHESAR_LIVE_DEMO_USERNAME = decouple_config('MATHESAR_LIVE_DEMO_USERNAME', default=None)\n MATHESAR_LIVE_DEMO_PASSWORD = decouple_config('MATHESAR_LIVE_DEMO_PASSWORD', default=None)\ndiff --git a/mathesar/install.py b/mathesar/install.py\n--- a/mathesar/install.py\n+++ b/mathesar/install.py\n@@ -37,6 +37,14 @@\n install_on_db_with_key(database_key, skip_confirm)\n except IntegrityError:\n continue\n+ if getattr(settings, 'MATHESAR_LIVE_DEMO', False) is True:\n+ management.call_command(\n+ 'createsuperuser',\n+ '--no-input',\n+ '--username', 'demo',\n+ '--email', '[email protected]',\n+ )\n+ management.call_command('setup_demo_template_db')\n \n \n def install_on_db_with_key(database_key, skip_confirm):\n", "issue": "Demo mode results in 5XX\n## Description\r\n<!-- A clear and concise description of what the bug is. -->\r\n\r\nMathesar is broken (as of 0.1.4) for Demo Mode. It doesn't load, and just says \"Server Error (500)\" instead.\r\n\r\n## Expected behavior\r\n<!-- A clear and concise description of what you expected to happen. -->\r\n\r\nDemo mode should work.\r\n\r\n## To Reproduce\r\n<!-- How can we recreate this bug? Please try to provide a Minimal, Complete, and Verifiable (http://stackoverflow.com/help/mcve) example if code-related. -->\r\n\r\nChange the `.env` file according to the comment to use the demo mode settings, try to build and start mathesar (dev environment is fine)\n", "before_files": [{"content": "\"\"\"\nThis script installs functions and types for Mathesar onto the configured DB.\n\"\"\"\nimport getopt\nimport os\nimport sys\n\nimport django\nfrom django.core import management\nfrom decouple import config as decouple_config\nfrom django.conf import settings\nfrom django.db.utils import IntegrityError\nfrom sqlalchemy.exc import OperationalError\nfrom db import install\n\n\ndef main(skip_static_collection=False):\n # skip_confirm is temporarily enabled by default as we don't have any use\n # for interactive prompts with docker only deployments\n skip_confirm = True\n (opts, _) = getopt.getopt(sys.argv[1:], \":s\", [\"skip-confirm\"])\n for (opt, value) in opts:\n if (opt == \"-s\") or (opt == \"--skip-confirm\"):\n skip_confirm = True\n os.environ.setdefault(\"DJANGO_SETTINGS_MODULE\", \"config.settings.production\")\n django.setup()\n management.call_command('migrate')\n debug_mode = decouple_config('DEBUG', default=False, cast=bool)\n #\n if not debug_mode and not skip_static_collection:\n management.call_command('collectstatic', '--noinput', '--clear')\n print(\"------------Setting up User Databases------------\")\n django_db_key = decouple_config('DJANGO_DATABASE_KEY', default=\"default\")\n user_databases = [key for key in settings.DATABASES if key != django_db_key]\n for database_key in user_databases:\n try:\n install_on_db_with_key(database_key, skip_confirm)\n except IntegrityError:\n continue\n\n\ndef install_on_db_with_key(database_key, skip_confirm):\n from mathesar.models.base import Database\n db_model = Database.create_from_settings_key(database_key)\n db_model.save()\n try:\n install.install_mathesar(\n database_name=db_model.db_name,\n hostname=db_model.host,\n username=db_model.username,\n password=db_model.password,\n port=db_model.port,\n skip_confirm=skip_confirm\n )\n except OperationalError as e:\n db_model.delete()\n raise e\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "mathesar/install.py"}, {"content": "from config.settings.production import * # noqa\nfrom config.settings import * # noqa\nfrom decouple import config as decouple_config\n\nINSTALLED_APPS += [ # noqa\n \"demo\"\n]\n\nMIDDLEWARE += [ # noqa\n \"demo.middleware.LiveDemoModeMiddleware\",\n]\n\nMATHESAR_LIVE_DEMO = True\nMATHESAR_LIVE_DEMO_USERNAME = decouple_config('MATHESAR_LIVE_DEMO_USERNAME', default=None)\nMATHESAR_LIVE_DEMO_PASSWORD = decouple_config('MATHESAR_LIVE_DEMO_PASSWORD', default=None)\n\nMATHESAR_DEMO_TEMPLATE = 'mathesar_demo_template'\nMATHESAR_DEMO_ARXIV_LOG_PATH = decouple_config(\n 'MATHESAR_DEMO_ARXIV_LOG_PATH',\n default='/var/lib/mathesar/demo/arxiv_db_schema_log'\n)\nBASE_TEMPLATE_ADDITIONAL_SCRIPT_TEMPLATES += ['demo/analytics.html'] # noqa\nROOT_URLCONF = \"demo.urls\"\n", "path": "demo/settings.py"}, {"content": "from sqlalchemy import text\nfrom sqlalchemy.exc import OperationalError\nfrom django.conf import settings\nfrom django.core.management import BaseCommand\n\nfrom db.install import install_mathesar\nfrom demo.install.datasets import load_datasets\nfrom mathesar.database.base import create_mathesar_engine\nfrom mathesar.models.base import Database\n\n\nclass Command(BaseCommand):\n help = 'Initialize the demo template database.'\n\n def handle(self, *args, **options):\n _setup_demo_template_db()\n\n\ndef _setup_demo_template_db():\n print(\"Initializing demo template database...\")\n\n template_db_name = settings.MATHESAR_DEMO_TEMPLATE\n django_model = Database.current_objects.get(name=settings.DATABASES[\"default\"][\"NAME\"])\n root_engine = create_mathesar_engine(django_model)\n with root_engine.connect() as conn:\n conn.execution_options(isolation_level=\"AUTOCOMMIT\")\n conn.execute(text(f\"DROP DATABASE IF EXISTS {template_db_name} WITH (FORCE)\"))\n root_engine.dispose()\n db_model, _ = Database.current_objects.get_or_create(\n name=template_db_name,\n defaults={\n 'db_name': template_db_name,\n 'username': django_model.username,\n 'password': django_model.password,\n 'host': django_model.host,\n 'port': django_model.port\n }\n )\n try:\n install_mathesar(\n database_name=template_db_name,\n hostname=db_model.host,\n username=db_model.username,\n password=db_model.password,\n port=db_model.port,\n skip_confirm=True\n )\n except OperationalError as e:\n db_model.delete()\n raise e\n user_engine = create_mathesar_engine(db_model)\n load_datasets(user_engine)\n user_engine.dispose()\n", "path": "demo/management/commands/setup_demo_template_db.py"}]}
| 1,995 | 482 |
gh_patches_debug_38209
|
rasdani/github-patches
|
git_diff
|
digitalfabrik__integreat-cms-445
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Improve documentation of cms rules
Explain the rules module and how it interacts with our permission management. Add docstrings of the following format:
```
"""
[Summary]
:param [ParamName]: [ParamDescription], defaults to [DefaultParamVal]
:type [ParamName]: [ParamType](, optional)
...
:raises [ErrorType]: [ErrorDescription]
...
:return: [ReturnDescription]
:rtype: [ReturnType]
"""
```
Improve documentation of cms rules
Explain the rules module and how it interacts with our permission management. Add docstrings of the following format:
```
"""
[Summary]
:param [ParamName]: [ParamDescription], defaults to [DefaultParamVal]
:type [ParamName]: [ParamType](, optional)
...
:raises [ErrorType]: [ErrorDescription]
...
:return: [ReturnDescription]
:rtype: [ReturnType]
"""
```
</issue>
<code>
[start of src/cms/rules.py]
1 from rules import add_perm, predicate
2
3
4 # Predicates
5
6 @predicate
7 def is_page_editor(user, page):
8 if not page:
9 return False
10 return user in page.editors.all()
11
12 @predicate
13 def is_page_publisher(user, page):
14 if not page:
15 return False
16 return user in page.publishers.all()
17
18 @predicate
19 # pylint: disable=unused-argument
20 def can_edit_all_pages(user, page):
21 return user.has_perm('cms.edit_pages')
22
23 @predicate
24 # pylint: disable=unused-argument
25 def can_publish_all_pages(user, page):
26 return user.has_perm('cms.publish_pages')
27
28
29 # Permissions
30
31 add_perm('cms.edit_page', can_edit_all_pages | is_page_editor | can_publish_all_pages | is_page_publisher)
32 add_perm('cms.publish_page', can_publish_all_pages | is_page_publisher)
33
[end of src/cms/rules.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/cms/rules.py b/src/cms/rules.py
--- a/src/cms/rules.py
+++ b/src/cms/rules.py
@@ -1,3 +1,22 @@
+"""
+We use `django-rules <https://pypi.org/project/rules/>`_ to add custom permissions for specific pages.
+
+For a given user and page, the following permissions are added:
+
+* ``cms.edit_page`` if one of the following predicates return true:
+
+ * :func:`~cms.rules.can_edit_all_pages`
+ * :func:`~cms.rules.is_page_editor`
+ * :func:`~cms.rules.can_publish_all_pages`
+ * :func:`~cms.rules.is_page_publisher`
+
+* ``cms.publish_page`` if one of the following predicates return true:
+
+ * :func:`~cms.rules.can_publish_all_pages`
+ * :func:`~cms.rules.is_page_publisher`
+
+See the project's `README <https://github.com/dfunckt/django-rules/blob/master/README.rst>`_ to learn more.
+"""
from rules import add_perm, predicate
@@ -5,12 +24,36 @@
@predicate
def is_page_editor(user, page):
+ """
+ This predicate checks whether the given user is one of the editors of the given page.
+
+ :param user: The user who's permission should be checked
+ :type user: ~django.contrib.auth.models.User
+
+ :param page: The requested page
+ :type page: ~cms.models.pages.page.Page
+
+ :return: Whether or not ``user`` is an editor of ``page``
+ :rtype: bool
+ """
if not page:
return False
return user in page.editors.all()
@predicate
def is_page_publisher(user, page):
+ """
+ This predicate checks whether the given user is one of the publishers of the given page.
+
+ :param user: The user who's permission should be checked
+ :type user: ~django.contrib.auth.models.User
+
+ :param page: The requested page
+ :type page: ~cms.models.pages.page.Page
+
+ :return: Whether or not ``user`` is a publisher of ``page``
+ :rtype: bool
+ """
if not page:
return False
return user in page.publishers.all()
@@ -18,11 +61,35 @@
@predicate
# pylint: disable=unused-argument
def can_edit_all_pages(user, page):
+ """
+ This predicate checks whether the given user can edit all pages.
+
+ :param user: The user who's permission should be checked
+ :type user: ~django.contrib.auth.models.User
+
+ :param page: Unused page parameter (the function signature must match the other predicates)
+ :type page: ~cms.models.pages.page.Page
+
+ :return: Whether or not ``user`` can edit all pages
+ :rtype: bool
+ """
return user.has_perm('cms.edit_pages')
@predicate
# pylint: disable=unused-argument
def can_publish_all_pages(user, page):
+ """
+ This predicate checks whether the given user can publish all pages.
+
+ :param user: The user who's permission should be checked
+ :type user: ~django.contrib.auth.models.User
+
+ :param page: Unused page parameter (the function signature must match the other predicates)
+ :type page: ~cms.models.pages.page.Page
+
+ :return: Whether or not ``user`` can publish all pages
+ :rtype: bool
+ """
return user.has_perm('cms.publish_pages')
|
{"golden_diff": "diff --git a/src/cms/rules.py b/src/cms/rules.py\n--- a/src/cms/rules.py\n+++ b/src/cms/rules.py\n@@ -1,3 +1,22 @@\n+\"\"\"\n+We use `django-rules <https://pypi.org/project/rules/>`_ to add custom permissions for specific pages.\n+\n+For a given user and page, the following permissions are added:\n+\n+* ``cms.edit_page`` if one of the following predicates return true:\n+\n+ * :func:`~cms.rules.can_edit_all_pages`\n+ * :func:`~cms.rules.is_page_editor`\n+ * :func:`~cms.rules.can_publish_all_pages`\n+ * :func:`~cms.rules.is_page_publisher`\n+\n+* ``cms.publish_page`` if one of the following predicates return true:\n+\n+ * :func:`~cms.rules.can_publish_all_pages`\n+ * :func:`~cms.rules.is_page_publisher`\n+\n+See the project's `README <https://github.com/dfunckt/django-rules/blob/master/README.rst>`_ to learn more.\n+\"\"\"\n from rules import add_perm, predicate\n \n \n@@ -5,12 +24,36 @@\n \n @predicate\n def is_page_editor(user, page):\n+ \"\"\"\n+ This predicate checks whether the given user is one of the editors of the given page.\n+\n+ :param user: The user who's permission should be checked\n+ :type user: ~django.contrib.auth.models.User\n+\n+ :param page: The requested page\n+ :type page: ~cms.models.pages.page.Page\n+\n+ :return: Whether or not ``user`` is an editor of ``page``\n+ :rtype: bool\n+ \"\"\"\n if not page:\n return False\n return user in page.editors.all()\n \n @predicate\n def is_page_publisher(user, page):\n+ \"\"\"\n+ This predicate checks whether the given user is one of the publishers of the given page.\n+\n+ :param user: The user who's permission should be checked\n+ :type user: ~django.contrib.auth.models.User\n+\n+ :param page: The requested page\n+ :type page: ~cms.models.pages.page.Page\n+\n+ :return: Whether or not ``user`` is a publisher of ``page``\n+ :rtype: bool\n+ \"\"\"\n if not page:\n return False\n return user in page.publishers.all()\n@@ -18,11 +61,35 @@\n @predicate\n # pylint: disable=unused-argument\n def can_edit_all_pages(user, page):\n+ \"\"\"\n+ This predicate checks whether the given user can edit all pages.\n+\n+ :param user: The user who's permission should be checked\n+ :type user: ~django.contrib.auth.models.User\n+\n+ :param page: Unused page parameter (the function signature must match the other predicates)\n+ :type page: ~cms.models.pages.page.Page\n+\n+ :return: Whether or not ``user`` can edit all pages\n+ :rtype: bool\n+ \"\"\"\n return user.has_perm('cms.edit_pages')\n \n @predicate\n # pylint: disable=unused-argument\n def can_publish_all_pages(user, page):\n+ \"\"\"\n+ This predicate checks whether the given user can publish all pages.\n+\n+ :param user: The user who's permission should be checked\n+ :type user: ~django.contrib.auth.models.User\n+\n+ :param page: Unused page parameter (the function signature must match the other predicates)\n+ :type page: ~cms.models.pages.page.Page\n+\n+ :return: Whether or not ``user`` can publish all pages\n+ :rtype: bool\n+ \"\"\"\n return user.has_perm('cms.publish_pages')\n", "issue": "Improve documentation of cms rules\nExplain the rules module and how it interacts with our permission management. Add docstrings of the following format:\r\n```\r\n\"\"\"\r\n[Summary]\r\n\r\n:param [ParamName]: [ParamDescription], defaults to [DefaultParamVal]\r\n:type [ParamName]: [ParamType](, optional)\r\n...\r\n:raises [ErrorType]: [ErrorDescription]\r\n...\r\n:return: [ReturnDescription]\r\n:rtype: [ReturnType]\r\n\"\"\"\r\n```\nImprove documentation of cms rules\nExplain the rules module and how it interacts with our permission management. Add docstrings of the following format:\r\n```\r\n\"\"\"\r\n[Summary]\r\n\r\n:param [ParamName]: [ParamDescription], defaults to [DefaultParamVal]\r\n:type [ParamName]: [ParamType](, optional)\r\n...\r\n:raises [ErrorType]: [ErrorDescription]\r\n...\r\n:return: [ReturnDescription]\r\n:rtype: [ReturnType]\r\n\"\"\"\r\n```\n", "before_files": [{"content": "from rules import add_perm, predicate\n\n\n# Predicates\n\n@predicate\ndef is_page_editor(user, page):\n if not page:\n return False\n return user in page.editors.all()\n\n@predicate\ndef is_page_publisher(user, page):\n if not page:\n return False\n return user in page.publishers.all()\n\n@predicate\n# pylint: disable=unused-argument\ndef can_edit_all_pages(user, page):\n return user.has_perm('cms.edit_pages')\n\n@predicate\n# pylint: disable=unused-argument\ndef can_publish_all_pages(user, page):\n return user.has_perm('cms.publish_pages')\n\n\n# Permissions\n\nadd_perm('cms.edit_page', can_edit_all_pages | is_page_editor | can_publish_all_pages | is_page_publisher)\nadd_perm('cms.publish_page', can_publish_all_pages | is_page_publisher)\n", "path": "src/cms/rules.py"}]}
| 956 | 808 |
gh_patches_debug_3675
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-center-index-8132
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[request] perfetto/v21.0
### Package Details
* Package Name/Version: **perfetto/v21.0**
* Changelog: **https://github.com/google/perfetto/releases/tag/v21.0**
The above mentioned version is newly released by the upstream project and not yet available as a recipe. PR follows
</issue>
<code>
[start of recipes/perfetto/all/conanfile.py]
1 from conans import ConanFile, CMake, tools
2 from conans.errors import ConanInvalidConfiguration
3
4 import os
5
6 required_conan_version = ">=1.33.0"
7
8
9 class PerfettoConan(ConanFile):
10 name = "perfetto"
11 license = "Apache-2.0"
12 homepage = "https://perfetto.dev"
13 url = "https://github.com/conan-io/conan-center-index"
14 description = "Performance instrumentation and tracing for Android, Linux and Chrome"
15 topics = ("linux", "profiling", "tracing")
16 settings = "os", "compiler", "build_type", "arch"
17 options = {
18 "shared": [True, False],
19 "fPIC": [True, False]
20 }
21 default_options = {
22 "shared": False,
23 "fPIC": True
24 }
25
26 exports_sources = ["CMakeLists.txt"]
27 generators = "cmake"
28
29 _cmake = None
30
31 @property
32 def _source_subfolder(self):
33 return "source_subfolder"
34
35 def config_options(self):
36 if self.settings.os == "Windows":
37 del self.options.fPIC
38
39 def configure(self):
40 if self.options.shared:
41 del self.options.fPIC
42
43 def validate(self):
44 if self.settings.compiler == "gcc" and tools.Version(self.settings.compiler.version) < 7:
45 raise ConanInvalidConfiguration ("perfetto requires gcc >= 7")
46 if self.settings.compiler.cppstd:
47 tools.check_min_cppstd(self, 11)
48
49 def source(self):
50 tools.get(**self.conan_data["sources"][self.version],
51 strip_root=True, destination=self._source_subfolder)
52
53 def _configure_cmake(self):
54 if self._cmake:
55 return self._cmake
56 self._cmake = CMake(self)
57 self._cmake.configure()
58 return self._cmake
59
60 def build(self):
61 cmake = self._configure_cmake()
62 cmake.build()
63
64 def package(self):
65 self.copy("LICENSE", src=self._source_subfolder, dst="licenses")
66 cmake = self._configure_cmake()
67 cmake.install()
68
69 def package_info(self):
70 self.cpp_info.libs = ["perfetto"]
71 self.cpp_info.names["pkgconfig"] = "perfetto"
72 if self.settings.os == "Linux":
73 self.cpp_info.system_libs.append("pthread")
74 if self.settings.os == "Windows":
75 self.cpp_info.system_libs.append("ws2_32")
76
77
[end of recipes/perfetto/all/conanfile.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/recipes/perfetto/all/conanfile.py b/recipes/perfetto/all/conanfile.py
--- a/recipes/perfetto/all/conanfile.py
+++ b/recipes/perfetto/all/conanfile.py
@@ -68,7 +68,6 @@
def package_info(self):
self.cpp_info.libs = ["perfetto"]
- self.cpp_info.names["pkgconfig"] = "perfetto"
if self.settings.os == "Linux":
self.cpp_info.system_libs.append("pthread")
if self.settings.os == "Windows":
|
{"golden_diff": "diff --git a/recipes/perfetto/all/conanfile.py b/recipes/perfetto/all/conanfile.py\n--- a/recipes/perfetto/all/conanfile.py\n+++ b/recipes/perfetto/all/conanfile.py\n@@ -68,7 +68,6 @@\n \n def package_info(self):\n self.cpp_info.libs = [\"perfetto\"]\n- self.cpp_info.names[\"pkgconfig\"] = \"perfetto\"\n if self.settings.os == \"Linux\":\n self.cpp_info.system_libs.append(\"pthread\")\n if self.settings.os == \"Windows\":\n", "issue": "[request] perfetto/v21.0\n### Package Details\r\n * Package Name/Version: **perfetto/v21.0**\r\n * Changelog: **https://github.com/google/perfetto/releases/tag/v21.0**\r\n\r\n\r\nThe above mentioned version is newly released by the upstream project and not yet available as a recipe. PR follows\r\n\n", "before_files": [{"content": "from conans import ConanFile, CMake, tools\nfrom conans.errors import ConanInvalidConfiguration\n\nimport os\n\nrequired_conan_version = \">=1.33.0\"\n\n\nclass PerfettoConan(ConanFile):\n name = \"perfetto\"\n license = \"Apache-2.0\"\n homepage = \"https://perfetto.dev\"\n url = \"https://github.com/conan-io/conan-center-index\"\n description = \"Performance instrumentation and tracing for Android, Linux and Chrome\"\n topics = (\"linux\", \"profiling\", \"tracing\")\n settings = \"os\", \"compiler\", \"build_type\", \"arch\"\n options = {\n \"shared\": [True, False],\n \"fPIC\": [True, False]\n }\n default_options = {\n \"shared\": False,\n \"fPIC\": True\n }\n\n exports_sources = [\"CMakeLists.txt\"]\n generators = \"cmake\"\n\n _cmake = None\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n\n def config_options(self):\n if self.settings.os == \"Windows\":\n del self.options.fPIC\n\n def configure(self):\n if self.options.shared:\n del self.options.fPIC\n\n def validate(self):\n if self.settings.compiler == \"gcc\" and tools.Version(self.settings.compiler.version) < 7:\n raise ConanInvalidConfiguration (\"perfetto requires gcc >= 7\")\n if self.settings.compiler.cppstd:\n tools.check_min_cppstd(self, 11)\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version],\n strip_root=True, destination=self._source_subfolder)\n\n def _configure_cmake(self):\n if self._cmake:\n return self._cmake\n self._cmake = CMake(self)\n self._cmake.configure()\n return self._cmake\n\n def build(self):\n cmake = self._configure_cmake()\n cmake.build()\n\n def package(self):\n self.copy(\"LICENSE\", src=self._source_subfolder, dst=\"licenses\")\n cmake = self._configure_cmake()\n cmake.install()\n\n def package_info(self):\n self.cpp_info.libs = [\"perfetto\"]\n self.cpp_info.names[\"pkgconfig\"] = \"perfetto\"\n if self.settings.os == \"Linux\":\n self.cpp_info.system_libs.append(\"pthread\")\n if self.settings.os == \"Windows\":\n self.cpp_info.system_libs.append(\"ws2_32\")\n\n", "path": "recipes/perfetto/all/conanfile.py"}]}
| 1,310 | 126 |
gh_patches_debug_15591
|
rasdani/github-patches
|
git_diff
|
plone__Products.CMFPlone-2714
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bug: `_smtp` is missing at SMTPMailer's __init__ patching what is introduced in zope.sendmail from version 4.1.0
### What I did:
I am working on internal Addon development (adding support for Plone 5.2) , sending mail notification one of the part functionalities. FYI: some how I forget to active MockMailhost.
When I run all my existing unittests and got unexpected errors :
```
File "/home/nazrul/.cache/buildout/eggs/plone.testing-7.0.0-py2.7.egg/plone/testing/zope.py", line 859, in testTearDown
transaction.abort()
File "/home/nazrul/.cache/buildout/eggs/transaction-2.4.0-py2.7.egg/transaction/_manager.py", line 255, in abort
return self.manager.abort()
File "/home/nazrul/.cache/buildout/eggs/transaction-2.4.0-py2.7.egg/transaction/_manager.py", line 136, in abort
return self.get().abort()
File "/home/nazrul/.cache/buildout/eggs/transaction-2.4.0-py2.7.egg/transaction/_transaction.py", line 529, in abort
reraise(t, v, tb)
File "/home/nazrul/.cache/buildout/eggs/transaction-2.4.0-py2.7.egg/transaction/_transaction.py", line 515, in abort
rm.abort(self)
File "/home/nazrul/.cache/buildout/eggs/zope.sendmail-4.2-py2.7.egg/zope/sendmail/delivery.py", line 57, in abort
self.onAbort()
File "/home/nazrul/.cache/buildout/eggs/zope.sendmail-4.2-py2.7.egg/zope/sendmail/mailer.py", line 78, in abort
if self.connection is None:
File "/home/nazrul/.cache/buildout/eggs/zope.sendmail-4.2-py2.7.egg/zope/sendmail/mailer.py", line 48, in <lambda>
return property(lambda self: getattr(self._smtp, name),
AttributeError: 'SMTPMailer' object has no attribute '_smtp'
```
All tests are passing for earlier version of Plone.
### What is my prediction:
After day long investigation, I found [SMTPMailer __init__ method is patched here](https://github.com/plone/Products.CMFPlone/blob/master/Products/CMFPlone/patches/sendmail.py#L39) , beside Also found that [zope.sendmail from version 4.1.0 the SMTPMailer's __init__](https://github.com/zopefoundation/zope.sendmail/blob/4.1.0/src/zope/sendmail/mailer.py#L45)
has been introduced a new attribute `_smtp` what is ignored during patching.
### How to reproduce:
This is only for Plone 5.2.x
1. disable Mock Mail
2. Try to send email from your tests code
3. Or try send mail from your production/testing server.
</issue>
<code>
[start of Products/CMFPlone/patches/sendmail.py]
1 # -*- coding: utf-8 -*-
2 from plone.registry.interfaces import IRegistry
3 from Products.CMFPlone.interfaces import IMailSchema
4 from transaction._transaction import Status
5 from zope.component import getUtility
6 from zope.sendmail.mailer import SMTPMailer
7
8 import logging
9 import transaction
10
11 log = logging.getLogger("MailDataManager")
12
13
14 # BBB remove when zope.sendmail 3.8.0 is released.
15 def catchAllExceptions(func):
16 def _catch(*args, **kwargs):
17 try:
18 return func(*args, **kwargs)
19 except Exception as e:
20 txn = transaction.get()
21 if txn.status == Status.ACTIVE:
22 # sent with immediate=True
23 raise
24 else:
25 # Avoid raising errors during tpc_finish as these could lead to
26 # inconsistent state
27 log.exception(e)
28
29 return _catch
30
31
32 def applyPatches():
33 from zope.sendmail.mailer import SMTPMailer
34 old_mailer = getattr(SMTPMailer, 'vote', None) is None
35 if old_mailer:
36 SMTPMailer.send = catchAllExceptions(SMTPMailer.send)
37
38
39 def new_init(
40 self,
41 hostname='localhost',
42 port=25,
43 username=None,
44 password=None,
45 no_tls=False,
46 force_tls=False):
47
48 registry = getUtility(IRegistry)
49 mail_settings = registry.forInterface(IMailSchema, prefix='plone')
50 self.hostname = mail_settings.smtp_host
51 self.port = mail_settings.smtp_port
52 self.username = mail_settings.smtp_userid
53 self.password = mail_settings.smtp_pass
54 self.force_tls = force_tls
55 self.no_tls = no_tls
56
57 SMTPMailer.__init__ = new_init
58
[end of Products/CMFPlone/patches/sendmail.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/Products/CMFPlone/patches/sendmail.py b/Products/CMFPlone/patches/sendmail.py
--- a/Products/CMFPlone/patches/sendmail.py
+++ b/Products/CMFPlone/patches/sendmail.py
@@ -3,11 +3,13 @@
from Products.CMFPlone.interfaces import IMailSchema
from transaction._transaction import Status
from zope.component import getUtility
+from zope.sendmail.mailer import _SMTPState
from zope.sendmail.mailer import SMTPMailer
import logging
import transaction
+
log = logging.getLogger("MailDataManager")
@@ -53,5 +55,7 @@
self.password = mail_settings.smtp_pass
self.force_tls = force_tls
self.no_tls = no_tls
+ self._smtp = _SMTPState()
+
SMTPMailer.__init__ = new_init
|
{"golden_diff": "diff --git a/Products/CMFPlone/patches/sendmail.py b/Products/CMFPlone/patches/sendmail.py\n--- a/Products/CMFPlone/patches/sendmail.py\n+++ b/Products/CMFPlone/patches/sendmail.py\n@@ -3,11 +3,13 @@\n from Products.CMFPlone.interfaces import IMailSchema\n from transaction._transaction import Status\n from zope.component import getUtility\n+from zope.sendmail.mailer import _SMTPState\n from zope.sendmail.mailer import SMTPMailer\n \n import logging\n import transaction\n \n+\n log = logging.getLogger(\"MailDataManager\")\n \n \n@@ -53,5 +55,7 @@\n self.password = mail_settings.smtp_pass\n self.force_tls = force_tls\n self.no_tls = no_tls\n+ self._smtp = _SMTPState()\n+\n \n SMTPMailer.__init__ = new_init\n", "issue": "Bug: `_smtp` is missing at SMTPMailer's __init__ patching what is introduced in zope.sendmail from version 4.1.0\n### What I did:\r\nI am working on internal Addon development (adding support for Plone 5.2) , sending mail notification one of the part functionalities. FYI: some how I forget to active MockMailhost.\r\nWhen I run all my existing unittests and got unexpected errors : \r\n\r\n```\r\nFile \"/home/nazrul/.cache/buildout/eggs/plone.testing-7.0.0-py2.7.egg/plone/testing/zope.py\", line 859, in testTearDown\r\n transaction.abort()\r\n File \"/home/nazrul/.cache/buildout/eggs/transaction-2.4.0-py2.7.egg/transaction/_manager.py\", line 255, in abort\r\n return self.manager.abort()\r\n File \"/home/nazrul/.cache/buildout/eggs/transaction-2.4.0-py2.7.egg/transaction/_manager.py\", line 136, in abort\r\n return self.get().abort()\r\n File \"/home/nazrul/.cache/buildout/eggs/transaction-2.4.0-py2.7.egg/transaction/_transaction.py\", line 529, in abort\r\n reraise(t, v, tb)\r\n File \"/home/nazrul/.cache/buildout/eggs/transaction-2.4.0-py2.7.egg/transaction/_transaction.py\", line 515, in abort\r\n rm.abort(self)\r\n File \"/home/nazrul/.cache/buildout/eggs/zope.sendmail-4.2-py2.7.egg/zope/sendmail/delivery.py\", line 57, in abort\r\n self.onAbort()\r\n File \"/home/nazrul/.cache/buildout/eggs/zope.sendmail-4.2-py2.7.egg/zope/sendmail/mailer.py\", line 78, in abort\r\n if self.connection is None:\r\n File \"/home/nazrul/.cache/buildout/eggs/zope.sendmail-4.2-py2.7.egg/zope/sendmail/mailer.py\", line 48, in <lambda>\r\n return property(lambda self: getattr(self._smtp, name),\r\nAttributeError: 'SMTPMailer' object has no attribute '_smtp'\r\n```\r\nAll tests are passing for earlier version of Plone.\r\n\r\n### What is my prediction: \r\nAfter day long investigation, I found [SMTPMailer __init__ method is patched here](https://github.com/plone/Products.CMFPlone/blob/master/Products/CMFPlone/patches/sendmail.py#L39) , beside Also found that [zope.sendmail from version 4.1.0 the SMTPMailer's __init__](https://github.com/zopefoundation/zope.sendmail/blob/4.1.0/src/zope/sendmail/mailer.py#L45)\r\nhas been introduced a new attribute `_smtp` what is ignored during patching.\r\n\r\n### How to reproduce:\r\n\r\nThis is only for Plone 5.2.x\r\n\r\n1. disable Mock Mail\r\n2. Try to send email from your tests code \r\n3. Or try send mail from your production/testing server.\r\n\r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom plone.registry.interfaces import IRegistry\nfrom Products.CMFPlone.interfaces import IMailSchema\nfrom transaction._transaction import Status\nfrom zope.component import getUtility\nfrom zope.sendmail.mailer import SMTPMailer\n\nimport logging\nimport transaction\n\nlog = logging.getLogger(\"MailDataManager\")\n\n\n# BBB remove when zope.sendmail 3.8.0 is released.\ndef catchAllExceptions(func):\n def _catch(*args, **kwargs):\n try:\n return func(*args, **kwargs)\n except Exception as e:\n txn = transaction.get()\n if txn.status == Status.ACTIVE:\n # sent with immediate=True\n raise\n else:\n # Avoid raising errors during tpc_finish as these could lead to\n # inconsistent state\n log.exception(e)\n\n return _catch\n\n\ndef applyPatches():\n from zope.sendmail.mailer import SMTPMailer\n old_mailer = getattr(SMTPMailer, 'vote', None) is None\n if old_mailer:\n SMTPMailer.send = catchAllExceptions(SMTPMailer.send)\n\n\ndef new_init(\n self,\n hostname='localhost',\n port=25,\n username=None,\n password=None,\n no_tls=False,\n force_tls=False):\n\n registry = getUtility(IRegistry)\n mail_settings = registry.forInterface(IMailSchema, prefix='plone')\n self.hostname = mail_settings.smtp_host\n self.port = mail_settings.smtp_port\n self.username = mail_settings.smtp_userid\n self.password = mail_settings.smtp_pass\n self.force_tls = force_tls\n self.no_tls = no_tls\n\nSMTPMailer.__init__ = new_init\n", "path": "Products/CMFPlone/patches/sendmail.py"}]}
| 1,748 | 198 |
gh_patches_debug_10806
|
rasdani/github-patches
|
git_diff
|
Kinto__kinto-850
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Return 400 if a group contains system.Everyone or a group URL
Unless I'm mistaken:
- We don't support groups for anonymous requests
- We don't support recursivity in groups definitions
So we should reject with `400` if such groups definitons are created
</issue>
<code>
[start of kinto/views/groups.py]
1 import colander
2
3 from kinto.core import resource, utils
4 from kinto.core.events import ResourceChanged, ACTIONS
5 from pyramid.events import subscriber
6
7
8 class GroupSchema(resource.ResourceSchema):
9 members = colander.SchemaNode(colander.Sequence(),
10 colander.SchemaNode(colander.String()))
11
12
13 @resource.register(name='group',
14 collection_path='/buckets/{{bucket_id}}/groups',
15 record_path='/buckets/{{bucket_id}}/groups/{{id}}')
16 class Group(resource.ShareableResource):
17 mapping = GroupSchema()
18
19 def get_parent_id(self, request):
20 bucket_id = request.matchdict['bucket_id']
21 parent_id = utils.instance_uri(request, 'bucket', id=bucket_id)
22 return parent_id
23
24
25 @subscriber(ResourceChanged,
26 for_resources=('group',),
27 for_actions=(ACTIONS.DELETE,))
28 def on_groups_deleted(event):
29 """Some groups were deleted, remove them from users principals.
30 """
31 permission_backend = event.request.registry.permission
32
33 for change in event.impacted_records:
34 group = change['old']
35 bucket_id = event.payload['bucket_id']
36 group_uri = utils.instance_uri(event.request, 'group',
37 bucket_id=bucket_id,
38 id=group['id'])
39
40 permission_backend.remove_principal(group_uri)
41
42
43 @subscriber(ResourceChanged,
44 for_resources=('group',),
45 for_actions=(ACTIONS.CREATE, ACTIONS.UPDATE))
46 def on_groups_changed(event):
47 """Some groups were changed, update users principals.
48 """
49 permission_backend = event.request.registry.permission
50
51 for change in event.impacted_records:
52 if 'old' in change:
53 existing_record_members = set(change['old'].get('members', []))
54 else:
55 existing_record_members = set()
56
57 group = change['new']
58 group_uri = '/buckets/{bucket_id}/groups/{id}'.format(id=group['id'],
59 **event.payload)
60 new_record_members = set(group.get('members', []))
61 new_members = new_record_members - existing_record_members
62 removed_members = existing_record_members - new_record_members
63
64 for member in new_members:
65 # Add the group to the member principal.
66 permission_backend.add_user_principal(member, group_uri)
67
68 for member in removed_members:
69 # Remove the group from the member principal.
70 permission_backend.remove_user_principal(member, group_uri)
71
[end of kinto/views/groups.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kinto/views/groups.py b/kinto/views/groups.py
--- a/kinto/views/groups.py
+++ b/kinto/views/groups.py
@@ -5,9 +5,15 @@
from pyramid.events import subscriber
+def validate_member(node, member):
+ if member.startswith('/buckets/') or member == 'system.Everyone':
+ raise colander.Invalid(node, "%r is not a valid user ID." % member)
+
+
class GroupSchema(resource.ResourceSchema):
members = colander.SchemaNode(colander.Sequence(),
- colander.SchemaNode(colander.String()))
+ colander.SchemaNode(colander.String(),
+ validator=validate_member))
@resource.register(name='group',
|
{"golden_diff": "diff --git a/kinto/views/groups.py b/kinto/views/groups.py\n--- a/kinto/views/groups.py\n+++ b/kinto/views/groups.py\n@@ -5,9 +5,15 @@\n from pyramid.events import subscriber\n \n \n+def validate_member(node, member):\n+ if member.startswith('/buckets/') or member == 'system.Everyone':\n+ raise colander.Invalid(node, \"%r is not a valid user ID.\" % member)\n+\n+\n class GroupSchema(resource.ResourceSchema):\n members = colander.SchemaNode(colander.Sequence(),\n- colander.SchemaNode(colander.String()))\n+ colander.SchemaNode(colander.String(),\n+ validator=validate_member))\n \n \n @resource.register(name='group',\n", "issue": "Return 400 if a group contains system.Everyone or a group URL\nUnless I'm mistaken:\n- We don't support groups for anonymous requests\n- We don't support recursivity in groups definitions\n\nSo we should reject with `400` if such groups definitons are created\n\n", "before_files": [{"content": "import colander\n\nfrom kinto.core import resource, utils\nfrom kinto.core.events import ResourceChanged, ACTIONS\nfrom pyramid.events import subscriber\n\n\nclass GroupSchema(resource.ResourceSchema):\n members = colander.SchemaNode(colander.Sequence(),\n colander.SchemaNode(colander.String()))\n\n\[email protected](name='group',\n collection_path='/buckets/{{bucket_id}}/groups',\n record_path='/buckets/{{bucket_id}}/groups/{{id}}')\nclass Group(resource.ShareableResource):\n mapping = GroupSchema()\n\n def get_parent_id(self, request):\n bucket_id = request.matchdict['bucket_id']\n parent_id = utils.instance_uri(request, 'bucket', id=bucket_id)\n return parent_id\n\n\n@subscriber(ResourceChanged,\n for_resources=('group',),\n for_actions=(ACTIONS.DELETE,))\ndef on_groups_deleted(event):\n \"\"\"Some groups were deleted, remove them from users principals.\n \"\"\"\n permission_backend = event.request.registry.permission\n\n for change in event.impacted_records:\n group = change['old']\n bucket_id = event.payload['bucket_id']\n group_uri = utils.instance_uri(event.request, 'group',\n bucket_id=bucket_id,\n id=group['id'])\n\n permission_backend.remove_principal(group_uri)\n\n\n@subscriber(ResourceChanged,\n for_resources=('group',),\n for_actions=(ACTIONS.CREATE, ACTIONS.UPDATE))\ndef on_groups_changed(event):\n \"\"\"Some groups were changed, update users principals.\n \"\"\"\n permission_backend = event.request.registry.permission\n\n for change in event.impacted_records:\n if 'old' in change:\n existing_record_members = set(change['old'].get('members', []))\n else:\n existing_record_members = set()\n\n group = change['new']\n group_uri = '/buckets/{bucket_id}/groups/{id}'.format(id=group['id'],\n **event.payload)\n new_record_members = set(group.get('members', []))\n new_members = new_record_members - existing_record_members\n removed_members = existing_record_members - new_record_members\n\n for member in new_members:\n # Add the group to the member principal.\n permission_backend.add_user_principal(member, group_uri)\n\n for member in removed_members:\n # Remove the group from the member principal.\n permission_backend.remove_user_principal(member, group_uri)\n", "path": "kinto/views/groups.py"}]}
| 1,225 | 151 |
gh_patches_debug_16119
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-center-index-549
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[package] make/4.2.1: not building for Linux Clang 9
The recipe for `make/4.2.1` does not build under Linux Clang 9.
After generating all the index packages for Clang 9, the ones for this library failed to compile. In this case it doesn't matter that much as this is packaging a tool to be used as a build requirement.
Related to #211
### Package and Environment Details (include every applicable attribute)
* Package Name/Version: **make/4.2.1**
* Operating System+version: **Linux Ubuntu 18.04**
* Compiler+version: **Clang 9**
* Conan version: **conan 1.21.0**
* Python version: **Python 3.7.4**
</issue>
<code>
[start of recipes/make/all/conanfile.py]
1 from conans import ConanFile, tools, AutoToolsBuildEnvironment
2 import os
3
4
5 class MakeConan(ConanFile):
6 name = "make"
7 description = "GNU Make is a tool which controls the generation of executables and other non-source files of a program from the program's source files"
8 topics = ("conan", "make", "build", "makefile")
9 url = "https://github.com/conan-io/conan-center-index"
10 homepage = "https://www.gnu.org/software/make/"
11 license = "GPL-3.0-or-later"
12 settings = "os_build", "arch_build", "compiler"
13 _source_subfolder = "source_subfolder"
14
15 def source(self):
16 tools.get(**self.conan_data["sources"][self.version])
17 extracted_dir = "make-" + self.version
18 os.rename(extracted_dir, self._source_subfolder)
19
20 def configure(self):
21 del self.settings.compiler.libcxx
22 del self.settings.compiler.cppstd
23
24 def build(self):
25 with tools.chdir(self._source_subfolder):
26 # README.W32
27 if self.settings.os_build == "Windows":
28 if self.settings.compiler == "Visual Studio":
29 command = "build_w32.bat --without-guile"
30 else:
31 command = "build_w32.bat --without-guile gcc"
32 else:
33 env_build = AutoToolsBuildEnvironment(self)
34 env_build.configure()
35 command = "./build.sh"
36 with tools.vcvars(self.settings) if self.settings.compiler == "Visual Studio" else tools.no_op():
37 self.run(command)
38
39 def package(self):
40 self.copy(pattern="COPYING", dst="licenses", src=self._source_subfolder)
41 self.copy(pattern="make", dst="bin", src=self._source_subfolder, keep_path=False)
42 self.copy(pattern="*gnumake.exe", dst="bin", src=self._source_subfolder, keep_path=False)
43
44 def package_info(self):
45 make = "gnumake.exe" if self.settings.os_build == "Windows" else "make"
46 make = os.path.join(self.package_folder, "bin", make)
47 self.output.info('Creating CONAN_MAKE_PROGRAM environment variable: %s' % make)
48 self.env_info.CONAN_MAKE_PROGRAM = make
49
50 def package_id(self):
51 del self.info.settings.compiler
52
[end of recipes/make/all/conanfile.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/recipes/make/all/conanfile.py b/recipes/make/all/conanfile.py
--- a/recipes/make/all/conanfile.py
+++ b/recipes/make/all/conanfile.py
@@ -10,6 +10,7 @@
homepage = "https://www.gnu.org/software/make/"
license = "GPL-3.0-or-later"
settings = "os_build", "arch_build", "compiler"
+ exports_sources = ["patches/*"]
_source_subfolder = "source_subfolder"
def source(self):
@@ -22,6 +23,9 @@
del self.settings.compiler.cppstd
def build(self):
+ for patch in self.conan_data["patches"][self.version]:
+ tools.patch(**patch)
+
with tools.chdir(self._source_subfolder):
# README.W32
if self.settings.os_build == "Windows":
|
{"golden_diff": "diff --git a/recipes/make/all/conanfile.py b/recipes/make/all/conanfile.py\n--- a/recipes/make/all/conanfile.py\n+++ b/recipes/make/all/conanfile.py\n@@ -10,6 +10,7 @@\n homepage = \"https://www.gnu.org/software/make/\"\n license = \"GPL-3.0-or-later\"\n settings = \"os_build\", \"arch_build\", \"compiler\"\n+ exports_sources = [\"patches/*\"]\n _source_subfolder = \"source_subfolder\"\n \n def source(self):\n@@ -22,6 +23,9 @@\n del self.settings.compiler.cppstd\n \n def build(self):\n+ for patch in self.conan_data[\"patches\"][self.version]:\n+ tools.patch(**patch)\n+\n with tools.chdir(self._source_subfolder):\n # README.W32\n if self.settings.os_build == \"Windows\":\n", "issue": "[package] make/4.2.1: not building for Linux Clang 9\nThe recipe for `make/4.2.1` does not build under Linux Clang 9.\r\n\r\nAfter generating all the index packages for Clang 9, the ones for this library failed to compile. In this case it doesn't matter that much as this is packaging a tool to be used as a build requirement.\r\n\r\nRelated to #211 \r\n\r\n### Package and Environment Details (include every applicable attribute)\r\n * Package Name/Version: **make/4.2.1**\r\n * Operating System+version: **Linux Ubuntu 18.04**\r\n * Compiler+version: **Clang 9**\r\n * Conan version: **conan 1.21.0**\r\n * Python version: **Python 3.7.4**\n", "before_files": [{"content": "from conans import ConanFile, tools, AutoToolsBuildEnvironment\nimport os\n\n\nclass MakeConan(ConanFile):\n name = \"make\"\n description = \"GNU Make is a tool which controls the generation of executables and other non-source files of a program from the program's source files\"\n topics = (\"conan\", \"make\", \"build\", \"makefile\")\n url = \"https://github.com/conan-io/conan-center-index\"\n homepage = \"https://www.gnu.org/software/make/\"\n license = \"GPL-3.0-or-later\"\n settings = \"os_build\", \"arch_build\", \"compiler\"\n _source_subfolder = \"source_subfolder\"\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n extracted_dir = \"make-\" + self.version\n os.rename(extracted_dir, self._source_subfolder)\n\n def configure(self):\n del self.settings.compiler.libcxx\n del self.settings.compiler.cppstd\n\n def build(self):\n with tools.chdir(self._source_subfolder):\n # README.W32\n if self.settings.os_build == \"Windows\":\n if self.settings.compiler == \"Visual Studio\":\n command = \"build_w32.bat --without-guile\"\n else:\n command = \"build_w32.bat --without-guile gcc\"\n else:\n env_build = AutoToolsBuildEnvironment(self)\n env_build.configure()\n command = \"./build.sh\"\n with tools.vcvars(self.settings) if self.settings.compiler == \"Visual Studio\" else tools.no_op():\n self.run(command)\n\n def package(self):\n self.copy(pattern=\"COPYING\", dst=\"licenses\", src=self._source_subfolder)\n self.copy(pattern=\"make\", dst=\"bin\", src=self._source_subfolder, keep_path=False)\n self.copy(pattern=\"*gnumake.exe\", dst=\"bin\", src=self._source_subfolder, keep_path=False)\n\n def package_info(self):\n make = \"gnumake.exe\" if self.settings.os_build == \"Windows\" else \"make\"\n make = os.path.join(self.package_folder, \"bin\", make)\n self.output.info('Creating CONAN_MAKE_PROGRAM environment variable: %s' % make)\n self.env_info.CONAN_MAKE_PROGRAM = make\n\n def package_id(self):\n del self.info.settings.compiler\n", "path": "recipes/make/all/conanfile.py"}]}
| 1,322 | 202 |
gh_patches_debug_8852
|
rasdani/github-patches
|
git_diff
|
pwndbg__pwndbg-363
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Broken `entry` command
### Description
The `entry` command pass arguments differently then the `run` command.
### Steps to reproduce
```
[dc@dc:pwndbg|dev *$%]$ gdb python
Loaded 113 commands. Type pwndbg [filter] for a list.
Reading symbols from python...(no debugging symbols found)...done.
pwndbg> set exception-verbose on
Set whether to print a full stacktracefor exceptions raised in Pwndbg commands to True
pwndbg> run -c "print(1); print(2)"
Starting program: /usr/bin/python -c "print(1); print(2)"
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/usr/lib/libthread_db.so.1".
1
2
[Inferior 1 (process 20590) exited normally]
pwndbg> entry -c "print(1); print(2)"
('-c', 'print(1); print(2)')
Running '%s' run -c print(1); print(2)
/bin/bash: -c: line 0: syntax error near unexpected token `('
/bin/bash: -c: line 0: `exec /usr/bin/python -c print(1); print(2)'
Traceback (most recent call last):
File "/home/dc/installed/pwndbg/pwndbg/commands/__init__.py", line 100, in __call__
return self.function(*args, **kwargs)
File "/home/dc/installed/pwndbg/pwndbg/commands/__init__.py", line 181, in _OnlyWithFile
return function(*a, **kw)
File "/home/dc/installed/pwndbg/pwndbg/commands/start.py", line 72, in entry
gdb.execute(run, from_tty=False)
gdb.error: During startup program exited with code 1.
If that is an issue, you can report it on https://github.com/pwndbg/pwndbg/issues
(Please don't forget to search if it hasn't been reported before)
PS: Pull requests are welcome
```
### My version
```
pwndbg> version
Gdb: GNU gdb (GDB) 8.0.1
Python: 3.6.3 (default, Oct 24 2017, 14:48:20) [GCC 7.2.0]
Pwndbg: 1.0.0 build: 5811010
```
</issue>
<code>
[start of pwndbg/commands/start.py]
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 """
4 Launches the target process after setting a breakpoint at a convenient
5 entry point.
6 """
7 from __future__ import absolute_import
8 from __future__ import division
9 from __future__ import print_function
10 from __future__ import unicode_literals
11
12 import gdb
13
14 import pwndbg.commands
15 import pwndbg.elf
16 import pwndbg.events
17 import pwndbg.symbol
18
19 break_on_first_instruction = False
20
21
22 @pwndbg.events.start
23 def on_start():
24 global break_on_first_instruction
25 if break_on_first_instruction:
26 spec = "*%#x" % (int(pwndbg.elf.entry()))
27 gdb.Breakpoint(spec, temporary=True)
28 break_on_first_instruction = False
29
30
31 @pwndbg.commands.Command
32 def start(*a):
33 """
34 Set a breakpoint at a convenient location in the binary,
35 generally 'main', 'init', or the entry point.
36 """
37 run = 'run ' + ' '.join(a)
38
39 symbols = ["main",
40 "_main",
41 "start",
42 "_start",
43 "init",
44 "_init"]
45
46 for symbol in symbols:
47 address = pwndbg.symbol.address(symbol)
48
49 if not address:
50 continue
51
52 b = gdb.Breakpoint(symbol, temporary=True)
53 gdb.execute(run, from_tty=False, to_string=True)
54 return
55
56 # Try a breakpoint at the binary entry
57 entry(*a)
58
59
60 @pwndbg.commands.Command
61 @pwndbg.commands.OnlyWithFile
62 def entry(*a):
63 """
64 Set a breakpoint at the first instruction executed in
65 the target binary.
66 """
67 global break_on_first_instruction
68 break_on_first_instruction = True
69 run = 'run ' + ' '.join(a)
70 gdb.execute(run, from_tty=False)
71
[end of pwndbg/commands/start.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pwndbg/commands/start.py b/pwndbg/commands/start.py
--- a/pwndbg/commands/start.py
+++ b/pwndbg/commands/start.py
@@ -9,6 +9,8 @@
from __future__ import print_function
from __future__ import unicode_literals
+import shlex
+
import gdb
import pwndbg.commands
@@ -66,5 +68,5 @@
"""
global break_on_first_instruction
break_on_first_instruction = True
- run = 'run ' + ' '.join(a)
+ run = 'run ' + ' '.join(map(shlex.quote, a))
gdb.execute(run, from_tty=False)
|
{"golden_diff": "diff --git a/pwndbg/commands/start.py b/pwndbg/commands/start.py\n--- a/pwndbg/commands/start.py\n+++ b/pwndbg/commands/start.py\n@@ -9,6 +9,8 @@\n from __future__ import print_function\n from __future__ import unicode_literals\n \n+import shlex\n+\n import gdb\n \n import pwndbg.commands\n@@ -66,5 +68,5 @@\n \"\"\"\n global break_on_first_instruction\n break_on_first_instruction = True\n- run = 'run ' + ' '.join(a)\n+ run = 'run ' + ' '.join(map(shlex.quote, a))\n gdb.execute(run, from_tty=False)\n", "issue": "Broken `entry` command\n### Description\r\n\r\nThe `entry` command pass arguments differently then the `run` command.\r\n\r\n### Steps to reproduce\r\n\r\n```\r\n[dc@dc:pwndbg|dev *$%]$ gdb python\r\nLoaded 113 commands. Type pwndbg [filter] for a list.\r\nReading symbols from python...(no debugging symbols found)...done.\r\npwndbg> set exception-verbose on\r\nSet whether to print a full stacktracefor exceptions raised in Pwndbg commands to True\r\npwndbg> run -c \"print(1); print(2)\"\r\nStarting program: /usr/bin/python -c \"print(1); print(2)\"\r\n[Thread debugging using libthread_db enabled]\r\nUsing host libthread_db library \"/usr/lib/libthread_db.so.1\".\r\n1\r\n2\r\n[Inferior 1 (process 20590) exited normally]\r\npwndbg> entry -c \"print(1); print(2)\"\r\n('-c', 'print(1); print(2)')\r\nRunning '%s' run -c print(1); print(2)\r\n/bin/bash: -c: line 0: syntax error near unexpected token `('\r\n/bin/bash: -c: line 0: `exec /usr/bin/python -c print(1); print(2)'\r\nTraceback (most recent call last):\r\n File \"/home/dc/installed/pwndbg/pwndbg/commands/__init__.py\", line 100, in __call__\r\n return self.function(*args, **kwargs)\r\n File \"/home/dc/installed/pwndbg/pwndbg/commands/__init__.py\", line 181, in _OnlyWithFile\r\n return function(*a, **kw)\r\n File \"/home/dc/installed/pwndbg/pwndbg/commands/start.py\", line 72, in entry\r\n gdb.execute(run, from_tty=False)\r\ngdb.error: During startup program exited with code 1.\r\n\r\nIf that is an issue, you can report it on https://github.com/pwndbg/pwndbg/issues\r\n(Please don't forget to search if it hasn't been reported before)\r\nPS: Pull requests are welcome\r\n```\r\n\r\n### My version\r\n\r\n```\r\npwndbg> version\r\nGdb: GNU gdb (GDB) 8.0.1\r\nPython: 3.6.3 (default, Oct 24 2017, 14:48:20) [GCC 7.2.0]\r\nPwndbg: 1.0.0 build: 5811010\r\n```\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"\nLaunches the target process after setting a breakpoint at a convenient\nentry point.\n\"\"\"\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\nfrom __future__ import unicode_literals\n\nimport gdb\n\nimport pwndbg.commands\nimport pwndbg.elf\nimport pwndbg.events\nimport pwndbg.symbol\n\nbreak_on_first_instruction = False\n\n\[email protected]\ndef on_start():\n global break_on_first_instruction\n if break_on_first_instruction:\n spec = \"*%#x\" % (int(pwndbg.elf.entry()))\n gdb.Breakpoint(spec, temporary=True)\n break_on_first_instruction = False\n\n\[email protected]\ndef start(*a):\n \"\"\"\n Set a breakpoint at a convenient location in the binary,\n generally 'main', 'init', or the entry point.\n \"\"\"\n run = 'run ' + ' '.join(a)\n\n symbols = [\"main\",\n \"_main\",\n \"start\",\n \"_start\",\n \"init\",\n \"_init\"]\n\n for symbol in symbols:\n address = pwndbg.symbol.address(symbol)\n\n if not address:\n continue\n\n b = gdb.Breakpoint(symbol, temporary=True)\n gdb.execute(run, from_tty=False, to_string=True)\n return\n\n # Try a breakpoint at the binary entry\n entry(*a)\n\n\[email protected]\[email protected]\ndef entry(*a):\n \"\"\"\n Set a breakpoint at the first instruction executed in\n the target binary.\n \"\"\"\n global break_on_first_instruction\n break_on_first_instruction = True\n run = 'run ' + ' '.join(a)\n gdb.execute(run, from_tty=False)\n", "path": "pwndbg/commands/start.py"}]}
| 1,630 | 152 |
gh_patches_debug_7911
|
rasdani/github-patches
|
git_diff
|
edgedb__edgedb-1946
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ISE when LIMIT/OFFSET correlated with query
```
sully> SELECT Object LIMIT len(<str>.id);
ERROR: InternalServerError: argument of LIMIT must not contain variables
```
```
sully> SELECT Object OFFSET len(<str>.id);
ERROR: InternalServerError: argument of OFFSET must not contain variables
```
Rejecting these is correct but we want a real error.
</issue>
<code>
[start of edb/edgeql/compiler/clauses.py]
1 #
2 # This source file is part of the EdgeDB open source project.
3 #
4 # Copyright 2008-present MagicStack Inc. and the EdgeDB authors.
5 #
6 # Licensed under the Apache License, Version 2.0 (the "License");
7 # you may not use this file except in compliance with the License.
8 # You may obtain a copy of the License at
9 #
10 # http://www.apache.org/licenses/LICENSE-2.0
11 #
12 # Unless required by applicable law or agreed to in writing, software
13 # distributed under the License is distributed on an "AS IS" BASIS,
14 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
15 # See the License for the specific language governing permissions and
16 # limitations under the License.
17 #
18
19
20 """EdgeQL compiler functions to process shared clauses."""
21
22
23 from __future__ import annotations
24
25 from typing import *
26
27 from edb.edgeql import ast as qlast
28 from edb.ir import ast as irast
29
30 from edb import errors
31
32 from . import context
33 from . import dispatch
34 from . import inference
35 from . import polyres
36 from . import schemactx
37 from . import setgen
38
39
40 def compile_where_clause(
41 ir_stmt: irast.FilteredStmt,
42 where: Optional[qlast.Base], *,
43 ctx: context.ContextLevel) -> None:
44
45 if where is None:
46 return
47
48 with ctx.newscope(fenced=True) as subctx:
49 subctx.path_scope.unnest_fence = True
50 ir_expr = dispatch.compile(where, ctx=subctx)
51 bool_t = ctx.env.get_track_schema_type('std::bool')
52 ir_set = setgen.scoped_set(ir_expr, typehint=bool_t, ctx=subctx)
53
54 ir_stmt.where = ir_set
55
56
57 def compile_orderby_clause(
58 sortexprs: Optional[Iterable[qlast.SortExpr]], *,
59 ctx: context.ContextLevel) -> List[irast.SortExpr]:
60
61 result: List[irast.SortExpr] = []
62 if not sortexprs:
63 return result
64
65 with ctx.new() as subctx:
66 for sortexpr in sortexprs:
67 with subctx.newscope(fenced=True) as exprctx:
68 exprctx.path_scope.unnest_fence = True
69 ir_sortexpr = dispatch.compile(sortexpr.path, ctx=exprctx)
70 ir_sortexpr = setgen.scoped_set(
71 ir_sortexpr, force_reassign=True, ctx=exprctx)
72 ir_sortexpr.context = sortexpr.context
73
74 # Check that the sortexpr type is actually orderable
75 # with either '>' or '<' based on the DESC or ASC sort
76 # order.
77 env = exprctx.env
78 sort_type = inference.infer_type(ir_sortexpr, env)
79 # Postgres by default treats ASC as using '<' and DESC
80 # as using '>'. We should do the same.
81 if sortexpr.direction == qlast.SortDesc:
82 op_name = '>'
83 else:
84 op_name = '<'
85 opers = env.schema.get_operators(
86 op_name, module_aliases=exprctx.modaliases)
87
88 # Verify that a comparison operator is defined for 2
89 # sort_type expressions.
90 matched = polyres.find_callable(
91 opers,
92 args=[(sort_type, ir_sortexpr), (sort_type, ir_sortexpr)],
93 kwargs={},
94 ctx=exprctx)
95 if len(matched) != 1:
96 sort_type_name = schemactx.get_material_type(
97 sort_type, ctx=ctx).get_displayname(env.schema)
98 if len(matched) == 0:
99 raise errors.QueryError(
100 f'type {sort_type_name!r} cannot be used in '
101 f'ORDER BY clause because ordering is not '
102 f'defined for it',
103 context=sortexpr.context)
104
105 elif len(matched) > 1:
106 raise errors.QueryError(
107 f'type {sort_type_name!r} cannot be used in '
108 f'ORDER BY clause because ordering is '
109 f'ambiguous for it',
110 context=sortexpr.context)
111
112 result.append(
113 irast.SortExpr(
114 expr=ir_sortexpr,
115 direction=sortexpr.direction,
116 nones_order=sortexpr.nones_order))
117
118 return result
119
120
121 def compile_limit_offset_clause(
122 expr: Optional[qlast.Base], *,
123 ctx: context.ContextLevel) -> Optional[irast.Set]:
124 if expr is None:
125 ir_set = None
126 else:
127 with ctx.newscope(fenced=True) as subctx:
128 ir_expr = dispatch.compile(expr, ctx=subctx)
129 int_t = ctx.env.get_track_schema_type('std::int64')
130 ir_set = setgen.scoped_set(
131 ir_expr, force_reassign=True, typehint=int_t, ctx=subctx)
132 ir_set.context = expr.context
133
134 return ir_set
135
[end of edb/edgeql/compiler/clauses.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/edb/edgeql/compiler/clauses.py b/edb/edgeql/compiler/clauses.py
--- a/edb/edgeql/compiler/clauses.py
+++ b/edb/edgeql/compiler/clauses.py
@@ -125,6 +125,10 @@
ir_set = None
else:
with ctx.newscope(fenced=True) as subctx:
+ # Clear out the partial_path_prefix, since we aren't in
+ # the scope of the select subject
+ subctx.partial_path_prefix = None
+
ir_expr = dispatch.compile(expr, ctx=subctx)
int_t = ctx.env.get_track_schema_type('std::int64')
ir_set = setgen.scoped_set(
|
{"golden_diff": "diff --git a/edb/edgeql/compiler/clauses.py b/edb/edgeql/compiler/clauses.py\n--- a/edb/edgeql/compiler/clauses.py\n+++ b/edb/edgeql/compiler/clauses.py\n@@ -125,6 +125,10 @@\n ir_set = None\n else:\n with ctx.newscope(fenced=True) as subctx:\n+ # Clear out the partial_path_prefix, since we aren't in\n+ # the scope of the select subject\n+ subctx.partial_path_prefix = None\n+\n ir_expr = dispatch.compile(expr, ctx=subctx)\n int_t = ctx.env.get_track_schema_type('std::int64')\n ir_set = setgen.scoped_set(\n", "issue": "ISE when LIMIT/OFFSET correlated with query\n```\r\nsully> SELECT Object LIMIT len(<str>.id);\r\nERROR: InternalServerError: argument of LIMIT must not contain variables\r\n```\r\n\r\n```\r\nsully> SELECT Object OFFSET len(<str>.id);\r\nERROR: InternalServerError: argument of OFFSET must not contain variables\r\n```\r\n\r\nRejecting these is correct but we want a real error.\r\n\n", "before_files": [{"content": "#\n# This source file is part of the EdgeDB open source project.\n#\n# Copyright 2008-present MagicStack Inc. and the EdgeDB authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\n\n\"\"\"EdgeQL compiler functions to process shared clauses.\"\"\"\n\n\nfrom __future__ import annotations\n\nfrom typing import *\n\nfrom edb.edgeql import ast as qlast\nfrom edb.ir import ast as irast\n\nfrom edb import errors\n\nfrom . import context\nfrom . import dispatch\nfrom . import inference\nfrom . import polyres\nfrom . import schemactx\nfrom . import setgen\n\n\ndef compile_where_clause(\n ir_stmt: irast.FilteredStmt,\n where: Optional[qlast.Base], *,\n ctx: context.ContextLevel) -> None:\n\n if where is None:\n return\n\n with ctx.newscope(fenced=True) as subctx:\n subctx.path_scope.unnest_fence = True\n ir_expr = dispatch.compile(where, ctx=subctx)\n bool_t = ctx.env.get_track_schema_type('std::bool')\n ir_set = setgen.scoped_set(ir_expr, typehint=bool_t, ctx=subctx)\n\n ir_stmt.where = ir_set\n\n\ndef compile_orderby_clause(\n sortexprs: Optional[Iterable[qlast.SortExpr]], *,\n ctx: context.ContextLevel) -> List[irast.SortExpr]:\n\n result: List[irast.SortExpr] = []\n if not sortexprs:\n return result\n\n with ctx.new() as subctx:\n for sortexpr in sortexprs:\n with subctx.newscope(fenced=True) as exprctx:\n exprctx.path_scope.unnest_fence = True\n ir_sortexpr = dispatch.compile(sortexpr.path, ctx=exprctx)\n ir_sortexpr = setgen.scoped_set(\n ir_sortexpr, force_reassign=True, ctx=exprctx)\n ir_sortexpr.context = sortexpr.context\n\n # Check that the sortexpr type is actually orderable\n # with either '>' or '<' based on the DESC or ASC sort\n # order.\n env = exprctx.env\n sort_type = inference.infer_type(ir_sortexpr, env)\n # Postgres by default treats ASC as using '<' and DESC\n # as using '>'. We should do the same.\n if sortexpr.direction == qlast.SortDesc:\n op_name = '>'\n else:\n op_name = '<'\n opers = env.schema.get_operators(\n op_name, module_aliases=exprctx.modaliases)\n\n # Verify that a comparison operator is defined for 2\n # sort_type expressions.\n matched = polyres.find_callable(\n opers,\n args=[(sort_type, ir_sortexpr), (sort_type, ir_sortexpr)],\n kwargs={},\n ctx=exprctx)\n if len(matched) != 1:\n sort_type_name = schemactx.get_material_type(\n sort_type, ctx=ctx).get_displayname(env.schema)\n if len(matched) == 0:\n raise errors.QueryError(\n f'type {sort_type_name!r} cannot be used in '\n f'ORDER BY clause because ordering is not '\n f'defined for it',\n context=sortexpr.context)\n\n elif len(matched) > 1:\n raise errors.QueryError(\n f'type {sort_type_name!r} cannot be used in '\n f'ORDER BY clause because ordering is '\n f'ambiguous for it',\n context=sortexpr.context)\n\n result.append(\n irast.SortExpr(\n expr=ir_sortexpr,\n direction=sortexpr.direction,\n nones_order=sortexpr.nones_order))\n\n return result\n\n\ndef compile_limit_offset_clause(\n expr: Optional[qlast.Base], *,\n ctx: context.ContextLevel) -> Optional[irast.Set]:\n if expr is None:\n ir_set = None\n else:\n with ctx.newscope(fenced=True) as subctx:\n ir_expr = dispatch.compile(expr, ctx=subctx)\n int_t = ctx.env.get_track_schema_type('std::int64')\n ir_set = setgen.scoped_set(\n ir_expr, force_reassign=True, typehint=int_t, ctx=subctx)\n ir_set.context = expr.context\n\n return ir_set\n", "path": "edb/edgeql/compiler/clauses.py"}]}
| 1,968 | 162 |
gh_patches_debug_30436
|
rasdani/github-patches
|
git_diff
|
uccser__cs-unplugged-463
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add sorting networks lessons
- [ ] Lesson 2 (8-10) - needs generated resources
- [ ] Lesson 1 (11-14)
- [ ] Lesson 2 (11-14)
</issue>
<code>
[start of csunplugged/resources/views/sorting_network_cards.py]
1 """Module for generating Sorting Network Cards resource."""
2
3 from random import sample
4 from PIL import Image, ImageDraw, ImageFont
5 from utils.retrieve_query_parameter import retrieve_query_parameter
6
7
8 def resource_image(request, resource):
9 """Create a image for Sorting Network Cards resource.
10
11 Args:
12 request: HTTP request object.
13 resource: Object of resource data.
14
15 Returns:
16 A list of Pillow image objects.
17 """
18 IMAGE_SIZE_X = 2000
19 IMAGE_SIZE_Y = 3000
20 LINE_COLOUR = "#000000"
21 LINE_WIDTH = 3
22 font_path = "static/fonts/PatrickHand-Regular.ttf"
23
24 # Retrieve parameters
25 parameter_options = valid_options()
26 card_type = retrieve_query_parameter(request, "type", parameter_options["type"])
27
28 # Create card outlines
29 card_outlines = Image.new("RGB", (IMAGE_SIZE_X, IMAGE_SIZE_Y), "#fff")
30 draw = ImageDraw.Draw(card_outlines)
31 for x_coord in range(0, IMAGE_SIZE_X, IMAGE_SIZE_X - LINE_WIDTH):
32 draw.line([(x_coord, 0), (x_coord, IMAGE_SIZE_Y)], fill=LINE_COLOUR, width=LINE_WIDTH)
33 for y_coord in range(0, IMAGE_SIZE_Y, int(IMAGE_SIZE_Y / 2 - LINE_WIDTH)):
34 draw.line([(0, y_coord), (IMAGE_SIZE_X, y_coord)], fill=LINE_COLOUR, width=LINE_WIDTH)
35
36 # Prepare text data
37 if card_type == "small_numbers":
38 font_size = 800
39 text = ["1", "2", "3", "4", "5", "6"]
40 elif card_type == "large_numbers":
41 font_size = 500
42 text = []
43 numbers = sample(range(1700000, 2100000), 6)
44 for number in numbers:
45 text.append("{:,}".format(number))
46 elif card_type == "fractions":
47 font_size = 900
48 font_path = "static/fonts/NotoSans-Regular.ttf"
49 text = [u"\u00bd", u"\u2153", u"\u2154", u"\u215c", u"\u00be", u"\u215d"]
50 else:
51 font_size = 300
52 text = [
53 "tahi",
54 "rua",
55 "toru",
56 "whā",
57 "rima",
58 "ono",
59 "whitu",
60 "waru",
61 "iwa",
62 "tekau",
63 "tekau mā tahi",
64 "tekau mā waru",
65 "tekau mā toru",
66 "tekau mā whā",
67 "rua tekau",
68 "rua tekau mā ono",
69 ]
70
71 font = ImageFont.truetype(font_path, font_size)
72 card_centers = [
73 (IMAGE_SIZE_X / 2, IMAGE_SIZE_Y / 4),
74 (IMAGE_SIZE_X / 2, (IMAGE_SIZE_Y / 4) * 3),
75 ]
76
77 # Add text to cards
78 images = []
79 for (text_number, text_string) in enumerate(text):
80 if text_number % 2 == 0:
81 page = card_outlines.copy()
82 draw = ImageDraw.Draw(page)
83 (x, y) = card_centers[0]
84 else:
85 (x, y) = card_centers[1]
86
87 text_width, text_height = draw.textsize(text_string, font=font)
88 coord_x = x - (text_width / 2)
89 coord_y = y - (text_height / 1.5)
90 draw.text(
91 (coord_x, coord_y),
92 text_string,
93 font=font,
94 fill="#000"
95 )
96 # If text on second card but not last page
97 if text_number % 2 == 1 and text_number != len(text) - 1:
98 images.append(page)
99 images.append(page)
100
101 return images
102
103
104 def subtitle(request, resource):
105 """Return the subtitle string of the resource.
106
107 Used after the resource name in the filename, and
108 also on the resource image.
109
110 Args:
111 request: HTTP request object
112 resource: Object of resource data.
113
114 Returns:
115 text for subtitle (string)
116 """
117 return "{} - {}".format(
118 retrieve_query_parameter(request, "type").replace("_", " "),
119 retrieve_query_parameter(request, "paper_size")
120 )
121
122
123 def valid_options():
124 """Provide dictionary of all valid parameters.
125
126 This excludes the header text parameter.
127
128 Returns:
129 All valid options (dict).
130 """
131 return {
132 "type": ["small_numbers", "large_numbers", "fractions", "maori_numbers"],
133 "paper_size": ["a4", "letter"],
134 }
135
[end of csunplugged/resources/views/sorting_network_cards.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/csunplugged/resources/views/sorting_network_cards.py b/csunplugged/resources/views/sorting_network_cards.py
--- a/csunplugged/resources/views/sorting_network_cards.py
+++ b/csunplugged/resources/views/sorting_network_cards.py
@@ -47,25 +47,24 @@
font_size = 900
font_path = "static/fonts/NotoSans-Regular.ttf"
text = [u"\u00bd", u"\u2153", u"\u2154", u"\u215c", u"\u00be", u"\u215d"]
- else:
+ elif card_type == "maori_numbers":
font_size = 300
text = [
- "tahi",
- "rua",
- "toru",
- "whā",
- "rima",
- "ono",
- "whitu",
- "waru",
- "iwa",
- "tekau",
- "tekau mā tahi",
- "tekau mā waru",
- "tekau mā toru",
- "tekau mā whā",
- "rua tekau",
- "rua tekau mā ono",
+ "tahi", "rua", "toru", "whā", "rima", "ono", "whitu", "waru",
+ "iwa", "tekau", "tekau mā tahi", "tekau mā waru", "tekau mā toru",
+ "tekau mā whā", "rua tekau", "rua tekau mā ono"
+ ]
+ elif card_type == "words":
+ font_size = 500
+ text = ["crocodile", "crochet", "kiwi", "weka", "kiwi", "kiwano"]
+ elif card_type == "letters":
+ font_size = 800
+ text = ["L", "O", "N", "K", "E", "D", "S", "P", "G", "B", "I", "Y"]
+ else:
+ font_size = 500
+ text = [
+ "whero", "kākāriki", "kiwikiwi", "karaka",
+ "kōwhai", "pango", "māwhero", "mā"
]
font = ImageFont.truetype(font_path, font_size)
@@ -129,6 +128,9 @@
All valid options (dict).
"""
return {
- "type": ["small_numbers", "large_numbers", "fractions", "maori_numbers"],
+ "type": [
+ "small_numbers", "large_numbers", "fractions", "maori_numbers",
+ "words", "letters", "maori_colours"
+ ],
"paper_size": ["a4", "letter"],
}
|
{"golden_diff": "diff --git a/csunplugged/resources/views/sorting_network_cards.py b/csunplugged/resources/views/sorting_network_cards.py\n--- a/csunplugged/resources/views/sorting_network_cards.py\n+++ b/csunplugged/resources/views/sorting_network_cards.py\n@@ -47,25 +47,24 @@\n font_size = 900\n font_path = \"static/fonts/NotoSans-Regular.ttf\"\n text = [u\"\\u00bd\", u\"\\u2153\", u\"\\u2154\", u\"\\u215c\", u\"\\u00be\", u\"\\u215d\"]\n- else:\n+ elif card_type == \"maori_numbers\":\n font_size = 300\n text = [\n- \"tahi\",\n- \"rua\",\n- \"toru\",\n- \"wh\u0101\",\n- \"rima\",\n- \"ono\",\n- \"whitu\",\n- \"waru\",\n- \"iwa\",\n- \"tekau\",\n- \"tekau m\u0101 tahi\",\n- \"tekau m\u0101 waru\",\n- \"tekau m\u0101 toru\",\n- \"tekau m\u0101 wh\u0101\",\n- \"rua tekau\",\n- \"rua tekau m\u0101 ono\",\n+ \"tahi\", \"rua\", \"toru\", \"wh\u0101\", \"rima\", \"ono\", \"whitu\", \"waru\",\n+ \"iwa\", \"tekau\", \"tekau m\u0101 tahi\", \"tekau m\u0101 waru\", \"tekau m\u0101 toru\",\n+ \"tekau m\u0101 wh\u0101\", \"rua tekau\", \"rua tekau m\u0101 ono\"\n+ ]\n+ elif card_type == \"words\":\n+ font_size = 500\n+ text = [\"crocodile\", \"crochet\", \"kiwi\", \"weka\", \"kiwi\", \"kiwano\"]\n+ elif card_type == \"letters\":\n+ font_size = 800\n+ text = [\"L\", \"O\", \"N\", \"K\", \"E\", \"D\", \"S\", \"P\", \"G\", \"B\", \"I\", \"Y\"]\n+ else:\n+ font_size = 500\n+ text = [\n+ \"whero\", \"k\u0101k\u0101riki\", \"kiwikiwi\", \"karaka\",\n+ \"k\u014dwhai\", \"pango\", \"m\u0101whero\", \"m\u0101\"\n ]\n \n font = ImageFont.truetype(font_path, font_size)\n@@ -129,6 +128,9 @@\n All valid options (dict).\n \"\"\"\n return {\n- \"type\": [\"small_numbers\", \"large_numbers\", \"fractions\", \"maori_numbers\"],\n+ \"type\": [\n+ \"small_numbers\", \"large_numbers\", \"fractions\", \"maori_numbers\",\n+ \"words\", \"letters\", \"maori_colours\"\n+ ],\n \"paper_size\": [\"a4\", \"letter\"],\n }\n", "issue": "Add sorting networks lessons\n- [ ] Lesson 2 (8-10) - needs generated resources\r\n- [ ] Lesson 1 (11-14)\r\n- [ ] Lesson 2 (11-14)\n", "before_files": [{"content": "\"\"\"Module for generating Sorting Network Cards resource.\"\"\"\n\nfrom random import sample\nfrom PIL import Image, ImageDraw, ImageFont\nfrom utils.retrieve_query_parameter import retrieve_query_parameter\n\n\ndef resource_image(request, resource):\n \"\"\"Create a image for Sorting Network Cards resource.\n\n Args:\n request: HTTP request object.\n resource: Object of resource data.\n\n Returns:\n A list of Pillow image objects.\n \"\"\"\n IMAGE_SIZE_X = 2000\n IMAGE_SIZE_Y = 3000\n LINE_COLOUR = \"#000000\"\n LINE_WIDTH = 3\n font_path = \"static/fonts/PatrickHand-Regular.ttf\"\n\n # Retrieve parameters\n parameter_options = valid_options()\n card_type = retrieve_query_parameter(request, \"type\", parameter_options[\"type\"])\n\n # Create card outlines\n card_outlines = Image.new(\"RGB\", (IMAGE_SIZE_X, IMAGE_SIZE_Y), \"#fff\")\n draw = ImageDraw.Draw(card_outlines)\n for x_coord in range(0, IMAGE_SIZE_X, IMAGE_SIZE_X - LINE_WIDTH):\n draw.line([(x_coord, 0), (x_coord, IMAGE_SIZE_Y)], fill=LINE_COLOUR, width=LINE_WIDTH)\n for y_coord in range(0, IMAGE_SIZE_Y, int(IMAGE_SIZE_Y / 2 - LINE_WIDTH)):\n draw.line([(0, y_coord), (IMAGE_SIZE_X, y_coord)], fill=LINE_COLOUR, width=LINE_WIDTH)\n\n # Prepare text data\n if card_type == \"small_numbers\":\n font_size = 800\n text = [\"1\", \"2\", \"3\", \"4\", \"5\", \"6\"]\n elif card_type == \"large_numbers\":\n font_size = 500\n text = []\n numbers = sample(range(1700000, 2100000), 6)\n for number in numbers:\n text.append(\"{:,}\".format(number))\n elif card_type == \"fractions\":\n font_size = 900\n font_path = \"static/fonts/NotoSans-Regular.ttf\"\n text = [u\"\\u00bd\", u\"\\u2153\", u\"\\u2154\", u\"\\u215c\", u\"\\u00be\", u\"\\u215d\"]\n else:\n font_size = 300\n text = [\n \"tahi\",\n \"rua\",\n \"toru\",\n \"wh\u0101\",\n \"rima\",\n \"ono\",\n \"whitu\",\n \"waru\",\n \"iwa\",\n \"tekau\",\n \"tekau m\u0101 tahi\",\n \"tekau m\u0101 waru\",\n \"tekau m\u0101 toru\",\n \"tekau m\u0101 wh\u0101\",\n \"rua tekau\",\n \"rua tekau m\u0101 ono\",\n ]\n\n font = ImageFont.truetype(font_path, font_size)\n card_centers = [\n (IMAGE_SIZE_X / 2, IMAGE_SIZE_Y / 4),\n (IMAGE_SIZE_X / 2, (IMAGE_SIZE_Y / 4) * 3),\n ]\n\n # Add text to cards\n images = []\n for (text_number, text_string) in enumerate(text):\n if text_number % 2 == 0:\n page = card_outlines.copy()\n draw = ImageDraw.Draw(page)\n (x, y) = card_centers[0]\n else:\n (x, y) = card_centers[1]\n\n text_width, text_height = draw.textsize(text_string, font=font)\n coord_x = x - (text_width / 2)\n coord_y = y - (text_height / 1.5)\n draw.text(\n (coord_x, coord_y),\n text_string,\n font=font,\n fill=\"#000\"\n )\n # If text on second card but not last page\n if text_number % 2 == 1 and text_number != len(text) - 1:\n images.append(page)\n images.append(page)\n\n return images\n\n\ndef subtitle(request, resource):\n \"\"\"Return the subtitle string of the resource.\n\n Used after the resource name in the filename, and\n also on the resource image.\n\n Args:\n request: HTTP request object\n resource: Object of resource data.\n\n Returns:\n text for subtitle (string)\n \"\"\"\n return \"{} - {}\".format(\n retrieve_query_parameter(request, \"type\").replace(\"_\", \" \"),\n retrieve_query_parameter(request, \"paper_size\")\n )\n\n\ndef valid_options():\n \"\"\"Provide dictionary of all valid parameters.\n\n This excludes the header text parameter.\n\n Returns:\n All valid options (dict).\n \"\"\"\n return {\n \"type\": [\"small_numbers\", \"large_numbers\", \"fractions\", \"maori_numbers\"],\n \"paper_size\": [\"a4\", \"letter\"],\n }\n", "path": "csunplugged/resources/views/sorting_network_cards.py"}]}
| 1,959 | 677 |
gh_patches_debug_11597
|
rasdani/github-patches
|
git_diff
|
fedora-infra__bodhi-4037
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Side tag updates are not automatically pushed to testing
When I create a side tag update for a stable Fedora, it sits in pending until I manually click "push to testing". This is inconsistent with regular updates and a tad confusing.
See also https://pagure.io/fedora-infrastructure/issue/8930
</issue>
<code>
[start of bodhi/server/consumers/signed.py]
1 # Copyright © 2016-2019 Red Hat, Inc.
2 #
3 # This file is part of Bodhi.
4 #
5 # This program is free software; you can redistribute it and/or
6 # modify it under the terms of the GNU General Public License
7 # as published by the Free Software Foundation; either version 2
8 # of the License, or (at your option) any later version.
9 #
10 # This program is distributed in the hope that it will be useful,
11 # but WITHOUT ANY WARRANTY; without even the implied warranty of
12 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
13 # GNU General Public License for more details.
14 #
15 # You should have received a copy of the GNU General Public License along with
16 # this program; if not, write to the Free Software Foundation, Inc., 51
17 # Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.
18 """
19 The "signed handler".
20
21 This module is responsible for marking builds as "signed" when they get moved
22 from the pending-signing to pending-updates-testing tag by RoboSignatory.
23 """
24
25 import logging
26
27 import fedora_messaging
28 from sqlalchemy import func
29
30 from bodhi.server.config import config
31 from bodhi.server.models import Build, UpdateStatus, TestGatingStatus
32 from bodhi.server.util import transactional_session_maker
33
34 log = logging.getLogger('bodhi')
35
36
37 class SignedHandler(object):
38 """
39 The Bodhi Signed Handler.
40
41 A fedora-messaging listener waiting for messages from koji about builds being tagged.
42 """
43
44 def __init__(self):
45 """Initialize the SignedHandler."""
46 self.db_factory = transactional_session_maker()
47
48 def __call__(self, message: fedora_messaging.api.Message):
49 """
50 Handle messages arriving with the configured topic.
51
52 This marks a build as signed if it is assigned to the pending testing release tag.
53
54 Example message format::
55 {
56 'body': {
57 'build_id': 442562,
58 'name': 'colord',
59 'tag_id': 214,
60 'instance': 's390',
61 'tag': 'f26-updates-testing-pending',
62 'user': 'sharkcz',
63 'version': '1.3.4',
64 'owner': 'sharkcz',
65 'release': '1.fc26'
66 },
67 }
68
69 The message can contain additional keys.
70
71 Duplicate messages: this method is idempotent.
72
73 Args:
74 message: The incoming message in the format described above.
75 """
76 message = message.body
77 build_nvr = '%(name)s-%(version)s-%(release)s' % message
78 tag = message['tag']
79
80 log.info("%s tagged into %s" % (build_nvr, tag))
81
82 with self.db_factory() as dbsession:
83 build = Build.get(build_nvr)
84 if not build:
85 log.info("Build was not submitted, skipping")
86 return
87
88 if not build.release:
89 log.info('Build is not assigned to release, skipping')
90 return
91
92 if build.update and build.update.from_tag:
93 koji_testing_tag = build.release.get_testing_side_tag(build.update.from_tag)
94 if tag != koji_testing_tag:
95 log.info("Tag is not testing side tag, skipping")
96 return
97 else:
98 if build.release.pending_testing_tag != tag:
99 log.info("Tag is not pending_testing tag, skipping")
100 return
101
102 if build.signed:
103 log.info("Build was already marked as signed (maybe a duplicate message)")
104 return
105
106 # This build was moved into the pending_testing tag for the applicable release, which
107 # is done by RoboSignatory to indicate that the build has been correctly signed and
108 # written out. Mark it as such.
109 log.info("Build has been signed, marking")
110 build.signed = True
111 dbsession.flush()
112 log.info("Build %s has been marked as signed" % build_nvr)
113
114 # If every build in update is signed change status to testing
115 if build.update \
116 and not build.update.release.composed_by_bodhi \
117 and build.update.signed:
118 log.info("Every build in update is signed, set status to testing")
119
120 build.update.status = UpdateStatus.testing
121 build.update.date_testing = func.current_timestamp()
122 build.update.request = None
123 build.update.pushed = True
124
125 if config.get("test_gating.required"):
126 log.debug('Test gating is required, marking the update as waiting on test '
127 'gating and updating it from Greenwave to get the real status.')
128 build.update.test_gating_status = TestGatingStatus.waiting
129 build.update.update_test_gating_status()
130
131 log.info(f"Update {build.update.display_name} status has been set to testing")
132
[end of bodhi/server/consumers/signed.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bodhi/server/consumers/signed.py b/bodhi/server/consumers/signed.py
--- a/bodhi/server/consumers/signed.py
+++ b/bodhi/server/consumers/signed.py
@@ -89,7 +89,9 @@
log.info('Build is not assigned to release, skipping')
return
- if build.update and build.update.from_tag:
+ if build.update \
+ and build.update.from_tag \
+ and not build.update.release.composed_by_bodhi:
koji_testing_tag = build.release.get_testing_side_tag(build.update.from_tag)
if tag != koji_testing_tag:
log.info("Tag is not testing side tag, skipping")
|
{"golden_diff": "diff --git a/bodhi/server/consumers/signed.py b/bodhi/server/consumers/signed.py\n--- a/bodhi/server/consumers/signed.py\n+++ b/bodhi/server/consumers/signed.py\n@@ -89,7 +89,9 @@\n log.info('Build is not assigned to release, skipping')\n return\n \n- if build.update and build.update.from_tag:\n+ if build.update \\\n+ and build.update.from_tag \\\n+ and not build.update.release.composed_by_bodhi:\n koji_testing_tag = build.release.get_testing_side_tag(build.update.from_tag)\n if tag != koji_testing_tag:\n log.info(\"Tag is not testing side tag, skipping\")\n", "issue": "Side tag updates are not automatically pushed to testing \nWhen I create a side tag update for a stable Fedora, it sits in pending until I manually click \"push to testing\". This is inconsistent with regular updates and a tad confusing.\r\n\r\nSee also https://pagure.io/fedora-infrastructure/issue/8930\n", "before_files": [{"content": "# Copyright \u00a9 2016-2019 Red Hat, Inc.\n#\n# This file is part of Bodhi.\n#\n# This program is free software; you can redistribute it and/or\n# modify it under the terms of the GNU General Public License\n# as published by the Free Software Foundation; either version 2\n# of the License, or (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.\n\"\"\"\nThe \"signed handler\".\n\nThis module is responsible for marking builds as \"signed\" when they get moved\nfrom the pending-signing to pending-updates-testing tag by RoboSignatory.\n\"\"\"\n\nimport logging\n\nimport fedora_messaging\nfrom sqlalchemy import func\n\nfrom bodhi.server.config import config\nfrom bodhi.server.models import Build, UpdateStatus, TestGatingStatus\nfrom bodhi.server.util import transactional_session_maker\n\nlog = logging.getLogger('bodhi')\n\n\nclass SignedHandler(object):\n \"\"\"\n The Bodhi Signed Handler.\n\n A fedora-messaging listener waiting for messages from koji about builds being tagged.\n \"\"\"\n\n def __init__(self):\n \"\"\"Initialize the SignedHandler.\"\"\"\n self.db_factory = transactional_session_maker()\n\n def __call__(self, message: fedora_messaging.api.Message):\n \"\"\"\n Handle messages arriving with the configured topic.\n\n This marks a build as signed if it is assigned to the pending testing release tag.\n\n Example message format::\n {\n 'body': {\n 'build_id': 442562,\n 'name': 'colord',\n 'tag_id': 214,\n 'instance': 's390',\n 'tag': 'f26-updates-testing-pending',\n 'user': 'sharkcz',\n 'version': '1.3.4',\n 'owner': 'sharkcz',\n 'release': '1.fc26'\n },\n }\n\n The message can contain additional keys.\n\n Duplicate messages: this method is idempotent.\n\n Args:\n message: The incoming message in the format described above.\n \"\"\"\n message = message.body\n build_nvr = '%(name)s-%(version)s-%(release)s' % message\n tag = message['tag']\n\n log.info(\"%s tagged into %s\" % (build_nvr, tag))\n\n with self.db_factory() as dbsession:\n build = Build.get(build_nvr)\n if not build:\n log.info(\"Build was not submitted, skipping\")\n return\n\n if not build.release:\n log.info('Build is not assigned to release, skipping')\n return\n\n if build.update and build.update.from_tag:\n koji_testing_tag = build.release.get_testing_side_tag(build.update.from_tag)\n if tag != koji_testing_tag:\n log.info(\"Tag is not testing side tag, skipping\")\n return\n else:\n if build.release.pending_testing_tag != tag:\n log.info(\"Tag is not pending_testing tag, skipping\")\n return\n\n if build.signed:\n log.info(\"Build was already marked as signed (maybe a duplicate message)\")\n return\n\n # This build was moved into the pending_testing tag for the applicable release, which\n # is done by RoboSignatory to indicate that the build has been correctly signed and\n # written out. Mark it as such.\n log.info(\"Build has been signed, marking\")\n build.signed = True\n dbsession.flush()\n log.info(\"Build %s has been marked as signed\" % build_nvr)\n\n # If every build in update is signed change status to testing\n if build.update \\\n and not build.update.release.composed_by_bodhi \\\n and build.update.signed:\n log.info(\"Every build in update is signed, set status to testing\")\n\n build.update.status = UpdateStatus.testing\n build.update.date_testing = func.current_timestamp()\n build.update.request = None\n build.update.pushed = True\n\n if config.get(\"test_gating.required\"):\n log.debug('Test gating is required, marking the update as waiting on test '\n 'gating and updating it from Greenwave to get the real status.')\n build.update.test_gating_status = TestGatingStatus.waiting\n build.update.update_test_gating_status()\n\n log.info(f\"Update {build.update.display_name} status has been set to testing\")\n", "path": "bodhi/server/consumers/signed.py"}]}
| 1,946 | 157 |
gh_patches_debug_22750
|
rasdani/github-patches
|
git_diff
|
mitmproxy__mitmproxy-4761
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Cannot inject websocket with binary or string content.
#### Problem Description
mitmproxy attempts to parse the injected websocket binary data as text, and replaces the binary data if it cannot be decoded into text, changing the injected websocket message. Also, when a string is given instead, there is error:
File "\mitmproxy\proxy\layers\websocket.py", line 230, in msg
data_str = data.decode(errors="replace")
AttributeError: 'str' object has no attribute 'decode'
#### Steps to reproduce the behavior:
1. from mitmproxy.ctx import master
2. master.commands.call("inject.websocket", flow, False, bytes([i for i in range(256)])) # No error, but message contents are changed
3. master.commands.call("inject.websocket", flow, False, "string") # AttributeError
#### System Information
Mitmproxy: 7.0.2
Python: 3.9.6
OpenSSL: OpenSSL 1.1.1k 25 Mar 2021
Platform: Windows-10-10.0.19043-SP0
</issue>
<code>
[start of examples/addons/websocket-inject-message.py]
1 """
2 Inject a WebSocket message into a running connection.
3
4 This example shows how to inject a WebSocket message into a running connection.
5 """
6 import asyncio
7
8 from mitmproxy import ctx, http
9
10
11 # Simple example: Inject a message as a response to an event
12
13 def websocket_message(flow: http.HTTPFlow):
14 assert flow.websocket is not None # make type checker happy
15 last_message = flow.websocket.messages[-1]
16 if b"secret" in last_message.content:
17 last_message.drop()
18 ctx.master.commands.call("inject.websocket", flow, last_message.from_client, "ssssssh")
19
20
21 # Complex example: Schedule a periodic timer
22
23 async def inject_async(flow: http.HTTPFlow):
24 msg = "hello from mitmproxy! "
25 assert flow.websocket is not None # make type checker happy
26 while flow.websocket.timestamp_end is None:
27 ctx.master.commands.call("inject.websocket", flow, True, msg)
28 await asyncio.sleep(1)
29 msg = msg[1:] + msg[:1]
30
31
32 def websocket_start(flow: http.HTTPFlow):
33 asyncio.create_task(inject_async(flow))
34
[end of examples/addons/websocket-inject-message.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/addons/websocket-inject-message.py b/examples/addons/websocket-inject-message.py
--- a/examples/addons/websocket-inject-message.py
+++ b/examples/addons/websocket-inject-message.py
@@ -13,9 +13,9 @@
def websocket_message(flow: http.HTTPFlow):
assert flow.websocket is not None # make type checker happy
last_message = flow.websocket.messages[-1]
- if b"secret" in last_message.content:
+ if last_message.is_text and "secret" in last_message.text:
last_message.drop()
- ctx.master.commands.call("inject.websocket", flow, last_message.from_client, "ssssssh")
+ ctx.master.commands.call("inject.websocket", flow, last_message.from_client, "ssssssh".encode())
# Complex example: Schedule a periodic timer
@@ -24,7 +24,7 @@
msg = "hello from mitmproxy! "
assert flow.websocket is not None # make type checker happy
while flow.websocket.timestamp_end is None:
- ctx.master.commands.call("inject.websocket", flow, True, msg)
+ ctx.master.commands.call("inject.websocket", flow, True, msg.encode())
await asyncio.sleep(1)
msg = msg[1:] + msg[:1]
|
{"golden_diff": "diff --git a/examples/addons/websocket-inject-message.py b/examples/addons/websocket-inject-message.py\n--- a/examples/addons/websocket-inject-message.py\n+++ b/examples/addons/websocket-inject-message.py\n@@ -13,9 +13,9 @@\n def websocket_message(flow: http.HTTPFlow):\n assert flow.websocket is not None # make type checker happy\n last_message = flow.websocket.messages[-1]\n- if b\"secret\" in last_message.content:\n+ if last_message.is_text and \"secret\" in last_message.text:\n last_message.drop()\n- ctx.master.commands.call(\"inject.websocket\", flow, last_message.from_client, \"ssssssh\")\n+ ctx.master.commands.call(\"inject.websocket\", flow, last_message.from_client, \"ssssssh\".encode())\n \n \n # Complex example: Schedule a periodic timer\n@@ -24,7 +24,7 @@\n msg = \"hello from mitmproxy! \"\n assert flow.websocket is not None # make type checker happy\n while flow.websocket.timestamp_end is None:\n- ctx.master.commands.call(\"inject.websocket\", flow, True, msg)\n+ ctx.master.commands.call(\"inject.websocket\", flow, True, msg.encode())\n await asyncio.sleep(1)\n msg = msg[1:] + msg[:1]\n", "issue": "Cannot inject websocket with binary or string content.\n#### Problem Description\r\nmitmproxy attempts to parse the injected websocket binary data as text, and replaces the binary data if it cannot be decoded into text, changing the injected websocket message. Also, when a string is given instead, there is error:\r\nFile \"\\mitmproxy\\proxy\\layers\\websocket.py\", line 230, in msg\r\n data_str = data.decode(errors=\"replace\")\r\nAttributeError: 'str' object has no attribute 'decode'\r\n\r\n#### Steps to reproduce the behavior:\r\n1. from mitmproxy.ctx import master\r\n2. master.commands.call(\"inject.websocket\", flow, False, bytes([i for i in range(256)])) # No error, but message contents are changed\r\n3. master.commands.call(\"inject.websocket\", flow, False, \"string\") # AttributeError\r\n\r\n#### System Information\r\nMitmproxy: 7.0.2\r\nPython: 3.9.6\r\nOpenSSL: OpenSSL 1.1.1k 25 Mar 2021\r\nPlatform: Windows-10-10.0.19043-SP0\r\n\n", "before_files": [{"content": "\"\"\"\nInject a WebSocket message into a running connection.\n\nThis example shows how to inject a WebSocket message into a running connection.\n\"\"\"\nimport asyncio\n\nfrom mitmproxy import ctx, http\n\n\n# Simple example: Inject a message as a response to an event\n\ndef websocket_message(flow: http.HTTPFlow):\n assert flow.websocket is not None # make type checker happy\n last_message = flow.websocket.messages[-1]\n if b\"secret\" in last_message.content:\n last_message.drop()\n ctx.master.commands.call(\"inject.websocket\", flow, last_message.from_client, \"ssssssh\")\n\n\n# Complex example: Schedule a periodic timer\n\nasync def inject_async(flow: http.HTTPFlow):\n msg = \"hello from mitmproxy! \"\n assert flow.websocket is not None # make type checker happy\n while flow.websocket.timestamp_end is None:\n ctx.master.commands.call(\"inject.websocket\", flow, True, msg)\n await asyncio.sleep(1)\n msg = msg[1:] + msg[:1]\n\n\ndef websocket_start(flow: http.HTTPFlow):\n asyncio.create_task(inject_async(flow))\n", "path": "examples/addons/websocket-inject-message.py"}]}
| 1,086 | 281 |
gh_patches_debug_385
|
rasdani/github-patches
|
git_diff
|
searx__searx-1477
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
New release?
Hi,
I'm the Debian maintainer of searx and we are still shipping version 0.14.0 of searx because there has not been a more recent release since February.
Unfortunately, we see a number of services that do not work anymore with 0.14.0 but which are fixed in git. Would it be possible to make a release soon?
The last commit to the repository was back in August. Is the project still alive? Debian plans to release its next stable version soon and we should not include searx if it's not maintained anymore.
Thanks!
cheers, josch
</issue>
<code>
[start of searx/version.py]
1 # -*- coding: utf-8 -*-
2 '''
3 searx is free software: you can redistribute it and/or modify
4 it under the terms of the GNU Affero General Public License as published by
5 the Free Software Foundation, either version 3 of the License, or
6 (at your option) any later version.
7
8 searx is distributed in the hope that it will be useful,
9 but WITHOUT ANY WARRANTY; without even the implied warranty of
10 MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
11 GNU Affero General Public License for more details.
12
13 You should have received a copy of the GNU Affero General Public License
14 along with searx. If not, see < http://www.gnu.org/licenses/ >.
15
16 (C) 2013- by Adam Tauber, <[email protected]>
17 '''
18
19 # version of searx
20 VERSION_MAJOR = 0
21 VERSION_MINOR = 14
22 VERSION_BUILD = 0
23
24 VERSION_STRING = "{0}.{1}.{2}".format(VERSION_MAJOR,
25 VERSION_MINOR,
26 VERSION_BUILD)
27
[end of searx/version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/searx/version.py b/searx/version.py
--- a/searx/version.py
+++ b/searx/version.py
@@ -18,7 +18,7 @@
# version of searx
VERSION_MAJOR = 0
-VERSION_MINOR = 14
+VERSION_MINOR = 15
VERSION_BUILD = 0
VERSION_STRING = "{0}.{1}.{2}".format(VERSION_MAJOR,
|
{"golden_diff": "diff --git a/searx/version.py b/searx/version.py\n--- a/searx/version.py\n+++ b/searx/version.py\n@@ -18,7 +18,7 @@\n \n # version of searx\n VERSION_MAJOR = 0\n-VERSION_MINOR = 14\n+VERSION_MINOR = 15\n VERSION_BUILD = 0\n \n VERSION_STRING = \"{0}.{1}.{2}\".format(VERSION_MAJOR,\n", "issue": "New release?\nHi,\r\n\r\nI'm the Debian maintainer of searx and we are still shipping version 0.14.0 of searx because there has not been a more recent release since February.\r\n\r\nUnfortunately, we see a number of services that do not work anymore with 0.14.0 but which are fixed in git. Would it be possible to make a release soon?\r\n\r\nThe last commit to the repository was back in August. Is the project still alive? Debian plans to release its next stable version soon and we should not include searx if it's not maintained anymore.\r\n\r\nThanks!\r\ncheers, josch\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n'''\nsearx is free software: you can redistribute it and/or modify\nit under the terms of the GNU Affero General Public License as published by\nthe Free Software Foundation, either version 3 of the License, or\n(at your option) any later version.\n\nsearx is distributed in the hope that it will be useful,\nbut WITHOUT ANY WARRANTY; without even the implied warranty of\nMERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\nGNU Affero General Public License for more details.\n\nYou should have received a copy of the GNU Affero General Public License\nalong with searx. If not, see < http://www.gnu.org/licenses/ >.\n\n(C) 2013- by Adam Tauber, <[email protected]>\n'''\n\n# version of searx\nVERSION_MAJOR = 0\nVERSION_MINOR = 14\nVERSION_BUILD = 0\n\nVERSION_STRING = \"{0}.{1}.{2}\".format(VERSION_MAJOR,\n VERSION_MINOR,\n VERSION_BUILD)\n", "path": "searx/version.py"}]}
| 934 | 96 |
gh_patches_debug_2628
|
rasdani/github-patches
|
git_diff
|
praw-dev__praw-1441
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
PRAW 6.5.1 and 7.0.0 require Python versions above 3.5.2
**Describe the bug**
At https://praw.readthedocs.io/en/latest/getting_started/installation.html, it says:
> PRAW supports Python 3.5+
3.5.2 seems to be insufficient for PRAW versions after 6.4.0. I *think* 3.5.3 is probably sufficient based on what I have read searching for information on this error message, but I am skipping that version on this particular system so I haven't confirmed.
**To Reproduce**
Steps to reproduce the behavior:
1. Upgrade PRAW to either version 6.5.1 or 7.0.0
2. Run a simple PRAW script
3. Get this error:
```
$ python3 ~/test.py
Traceback (most recent call last):
File "/home/myusername/test.py", line 5, in <module>
import praw
File "/home/myusername/.local/lib/python3.5/site-packages/praw/__init__.py", line 14, in <module>
from .reddit import Reddit # NOQA
File "/home/myusername/.local/lib/python3.5/site-packages/praw/reddit.py", line 50, in <module>
class Reddit:
File "/home/myusername/.local/lib/python3.5/site-packages/praw/reddit.py", line 128, in Reddit
requestor_kwargs: Dict[str, Any] = None,
File "/usr/lib/python3.5/typing.py", line 649, in __getitem__
return Union[arg, type(None)]
File "/usr/lib/python3.5/typing.py", line 552, in __getitem__
dict(self.__dict__), parameters, _root=True)
File "/usr/lib/python3.5/typing.py", line 512, in __new__
for t2 in all_params - {t1} if not isinstance(t2, TypeVar)):
File "/usr/lib/python3.5/typing.py", line 512, in <genexpr>
for t2 in all_params - {t1} if not isinstance(t2, TypeVar)):
File "/usr/lib/python3.5/typing.py", line 1077, in __subclasscheck__
if super().__subclasscheck__(cls):
File "/usr/lib/python3.5/abc.py", line 225, in __subclasscheck__
for scls in cls.__subclasses__():
TypeError: descriptor '__subclasses__' of 'type' object needs an argument
```
**Expected behavior**
Python 3.5.2 works fine with PRAW 6.4.0 and earlier.
**Code/Logs**
`import praw` will do the trick.
**System Info**
- OS: Linux
- Python: 3.5.2
- PRAW Version: 6.5.1 or 7.0.0
</issue>
<code>
[start of setup.py]
1 """praw setup.py"""
2
3 import re
4 from codecs import open
5 from os import path
6
7 from setuptools import find_packages, setup
8
9 PACKAGE_NAME = "praw"
10 HERE = path.abspath(path.dirname(__file__))
11 with open(path.join(HERE, "README.rst"), encoding="utf-8") as fp:
12 README = fp.read()
13 with open(path.join(HERE, PACKAGE_NAME, "const.py"), encoding="utf-8") as fp:
14 VERSION = re.search('__version__ = "([^"]+)"', fp.read()).group(1)
15
16 extras = {
17 "ci": ["coveralls"],
18 "dev": ["pre-commit"],
19 "lint": [
20 "black",
21 "flake8",
22 "pydocstyle",
23 "sphinx<3.0",
24 "sphinx_rtd_theme",
25 ],
26 "test": [
27 "betamax >=0.8, <0.9",
28 "betamax-matchers >=0.3.0, <0.5",
29 "pytest >=2.7.3",
30 ],
31 }
32 extras["dev"] += extras["lint"] + extras["test"]
33
34 setup(
35 name=PACKAGE_NAME,
36 author="Bryce Boe",
37 author_email="[email protected]",
38 python_requires=">=3.5",
39 classifiers=[
40 "Development Status :: 5 - Production/Stable",
41 "Environment :: Console",
42 "Intended Audience :: Developers",
43 "License :: OSI Approved :: BSD License",
44 "Natural Language :: English",
45 "Operating System :: OS Independent",
46 "Programming Language :: Python",
47 "Programming Language :: Python :: 3",
48 "Programming Language :: Python :: 3.5",
49 "Programming Language :: Python :: 3.6",
50 "Programming Language :: Python :: 3.7",
51 "Programming Language :: Python :: 3.8",
52 "Topic :: Utilities",
53 ],
54 description=(
55 "PRAW, an acronym for `Python Reddit API Wrapper`, is a "
56 "python package that allows for simple access to "
57 "reddit's API."
58 ),
59 extras_require=extras,
60 install_requires=[
61 "prawcore >=1.3.0, <2.0",
62 "update_checker >=0.16",
63 "websocket-client >=0.54.0",
64 ],
65 keywords="reddit api wrapper",
66 license="Simplified BSD License",
67 long_description=README,
68 package_data={
69 "": ["LICENSE.txt"],
70 PACKAGE_NAME: ["*.ini", "images/*.jpg"],
71 },
72 packages=find_packages(exclude=["tests", "tests.*", "tools", "tools.*"]),
73 url="https://praw.readthedocs.org/",
74 version=VERSION,
75 )
76
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -35,7 +35,7 @@
name=PACKAGE_NAME,
author="Bryce Boe",
author_email="[email protected]",
- python_requires=">=3.5",
+ python_requires=">3.5.3",
classifiers=[
"Development Status :: 5 - Production/Stable",
"Environment :: Console",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -35,7 +35,7 @@\n name=PACKAGE_NAME,\n author=\"Bryce Boe\",\n author_email=\"[email protected]\",\n- python_requires=\">=3.5\",\n+ python_requires=\">3.5.3\",\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Environment :: Console\",\n", "issue": "PRAW 6.5.1 and 7.0.0 require Python versions above 3.5.2\n**Describe the bug**\r\n\r\nAt https://praw.readthedocs.io/en/latest/getting_started/installation.html, it says:\r\n\r\n> PRAW supports Python 3.5+\r\n\r\n3.5.2 seems to be insufficient for PRAW versions after 6.4.0. I *think* 3.5.3 is probably sufficient based on what I have read searching for information on this error message, but I am skipping that version on this particular system so I haven't confirmed.\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Upgrade PRAW to either version 6.5.1 or 7.0.0\r\n\r\n2. Run a simple PRAW script\r\n\r\n3. Get this error:\r\n\r\n```\r\n$ python3 ~/test.py\r\nTraceback (most recent call last):\r\n File \"/home/myusername/test.py\", line 5, in <module>\r\n import praw\r\n File \"/home/myusername/.local/lib/python3.5/site-packages/praw/__init__.py\", line 14, in <module>\r\n from .reddit import Reddit # NOQA\r\n File \"/home/myusername/.local/lib/python3.5/site-packages/praw/reddit.py\", line 50, in <module>\r\n class Reddit:\r\n File \"/home/myusername/.local/lib/python3.5/site-packages/praw/reddit.py\", line 128, in Reddit\r\n requestor_kwargs: Dict[str, Any] = None,\r\n File \"/usr/lib/python3.5/typing.py\", line 649, in __getitem__\r\n return Union[arg, type(None)]\r\n File \"/usr/lib/python3.5/typing.py\", line 552, in __getitem__\r\n dict(self.__dict__), parameters, _root=True)\r\n File \"/usr/lib/python3.5/typing.py\", line 512, in __new__\r\n for t2 in all_params - {t1} if not isinstance(t2, TypeVar)):\r\n File \"/usr/lib/python3.5/typing.py\", line 512, in <genexpr>\r\n for t2 in all_params - {t1} if not isinstance(t2, TypeVar)):\r\n File \"/usr/lib/python3.5/typing.py\", line 1077, in __subclasscheck__\r\n if super().__subclasscheck__(cls):\r\n File \"/usr/lib/python3.5/abc.py\", line 225, in __subclasscheck__\r\n for scls in cls.__subclasses__():\r\nTypeError: descriptor '__subclasses__' of 'type' object needs an argument\r\n```\r\n\r\n**Expected behavior**\r\n\r\nPython 3.5.2 works fine with PRAW 6.4.0 and earlier.\r\n\r\n**Code/Logs**\r\n\r\n`import praw` will do the trick.\r\n\r\n**System Info**\r\n - OS: Linux\r\n - Python: 3.5.2\r\n - PRAW Version: 6.5.1 or 7.0.0\r\n\r\n\n", "before_files": [{"content": "\"\"\"praw setup.py\"\"\"\n\nimport re\nfrom codecs import open\nfrom os import path\n\nfrom setuptools import find_packages, setup\n\nPACKAGE_NAME = \"praw\"\nHERE = path.abspath(path.dirname(__file__))\nwith open(path.join(HERE, \"README.rst\"), encoding=\"utf-8\") as fp:\n README = fp.read()\nwith open(path.join(HERE, PACKAGE_NAME, \"const.py\"), encoding=\"utf-8\") as fp:\n VERSION = re.search('__version__ = \"([^\"]+)\"', fp.read()).group(1)\n\nextras = {\n \"ci\": [\"coveralls\"],\n \"dev\": [\"pre-commit\"],\n \"lint\": [\n \"black\",\n \"flake8\",\n \"pydocstyle\",\n \"sphinx<3.0\",\n \"sphinx_rtd_theme\",\n ],\n \"test\": [\n \"betamax >=0.8, <0.9\",\n \"betamax-matchers >=0.3.0, <0.5\",\n \"pytest >=2.7.3\",\n ],\n}\nextras[\"dev\"] += extras[\"lint\"] + extras[\"test\"]\n\nsetup(\n name=PACKAGE_NAME,\n author=\"Bryce Boe\",\n author_email=\"[email protected]\",\n python_requires=\">=3.5\",\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Environment :: Console\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: BSD License\",\n \"Natural Language :: English\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Topic :: Utilities\",\n ],\n description=(\n \"PRAW, an acronym for `Python Reddit API Wrapper`, is a \"\n \"python package that allows for simple access to \"\n \"reddit's API.\"\n ),\n extras_require=extras,\n install_requires=[\n \"prawcore >=1.3.0, <2.0\",\n \"update_checker >=0.16\",\n \"websocket-client >=0.54.0\",\n ],\n keywords=\"reddit api wrapper\",\n license=\"Simplified BSD License\",\n long_description=README,\n package_data={\n \"\": [\"LICENSE.txt\"],\n PACKAGE_NAME: [\"*.ini\", \"images/*.jpg\"],\n },\n packages=find_packages(exclude=[\"tests\", \"tests.*\", \"tools\", \"tools.*\"]),\n url=\"https://praw.readthedocs.org/\",\n version=VERSION,\n)\n", "path": "setup.py"}]}
| 1,911 | 102 |
gh_patches_debug_39983
|
rasdani/github-patches
|
git_diff
|
elastic__apm-agent-python-1613
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Remove py2 leftovers
This is an issue to track all of the py2 stuff we can remove once a sufficient waiting period after 6.0 has passed.
- [x] Remove `zerorpc` (py2 only)
- [x] Remove `compat.py`
- [x] Run `pyupgrade`?
Ref #928
</issue>
<code>
[start of elasticapm/contrib/zerorpc/__init__.py]
1 # BSD 3-Clause License
2 #
3 # Copyright (c) 2012, the Sentry Team, see AUTHORS for more details
4 # Copyright (c) 2019, Elasticsearch BV
5 # All rights reserved.
6 #
7 # Redistribution and use in source and binary forms, with or without
8 # modification, are permitted provided that the following conditions are met:
9 #
10 # * Redistributions of source code must retain the above copyright notice, this
11 # list of conditions and the following disclaimer.
12 #
13 # * Redistributions in binary form must reproduce the above copyright notice,
14 # this list of conditions and the following disclaimer in the documentation
15 # and/or other materials provided with the distribution.
16 #
17 # * Neither the name of the copyright holder nor the names of its
18 # contributors may be used to endorse or promote products derived from
19 # this software without specific prior written permission.
20 #
21 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
22 # AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
23 # IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
24 # DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
25 # FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
26 # DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
27 # SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
28 # CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
29 # OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
30
31
32 import inspect
33
34 from elasticapm.base import Client
35
36
37 class Middleware(object):
38 """ElasticAPM middleware for ZeroRPC.
39
40 >>> elasticapm = Middleware(service_name='..', secret_token='...')
41 >>> zerorpc.Context.get_instance().register_middleware(elasticapm)
42
43 Exceptions detected server-side in ZeroRPC will be submitted to the apm server (and
44 propagated to the client as well).
45 """
46
47 def __init__(self, hide_zerorpc_frames=True, client=None, **kwargs):
48 """Create a middleware object that can be injected in a ZeroRPC server.
49
50 - hide_zerorpc_frames: modify the exception stacktrace to remove the
51 internal zerorpc frames (True by default to make
52 the stacktrace as readable as possible);
53 - client: use an existing raven.Client object, otherwise one will be
54 instantiated from the keyword arguments.
55
56 """
57 self._elasticapm_client = client or Client(**kwargs)
58 self._hide_zerorpc_frames = hide_zerorpc_frames
59
60 def server_inspect_exception(self, req_event, rep_event, task_ctx, exc_info):
61 """Called when an exception has been raised in the code run by ZeroRPC"""
62
63 # Hide the zerorpc internal frames for readability, for a REQ/REP or
64 # REQ/STREAM server the frames to hide are:
65 # - core.ServerBase._async_task
66 # - core.Pattern*.process_call
67 # - core.DecoratorBase.__call__
68 #
69 # For a PUSH/PULL or PUB/SUB server the frame to hide is:
70 # - core.Puller._receiver
71 if self._hide_zerorpc_frames:
72 traceback = exc_info[2]
73 while traceback:
74 zerorpc_frame = traceback.tb_frame
75 zerorpc_frame.f_locals["__traceback_hide__"] = True
76 frame_info = inspect.getframeinfo(zerorpc_frame)
77 # Is there a better way than this (or looking up the filenames
78 # or hardcoding the number of frames to skip) to know when we
79 # are out of zerorpc?
80 if frame_info.function == "__call__" or frame_info.function == "_receiver":
81 break
82 traceback = traceback.tb_next
83
84 self._elasticapm_client.capture_exception(exc_info, extra=task_ctx, handled=False)
85
[end of elasticapm/contrib/zerorpc/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/elasticapm/contrib/zerorpc/__init__.py b/elasticapm/contrib/zerorpc/__init__.py
deleted file mode 100644
--- a/elasticapm/contrib/zerorpc/__init__.py
+++ /dev/null
@@ -1,84 +0,0 @@
-# BSD 3-Clause License
-#
-# Copyright (c) 2012, the Sentry Team, see AUTHORS for more details
-# Copyright (c) 2019, Elasticsearch BV
-# All rights reserved.
-#
-# Redistribution and use in source and binary forms, with or without
-# modification, are permitted provided that the following conditions are met:
-#
-# * Redistributions of source code must retain the above copyright notice, this
-# list of conditions and the following disclaimer.
-#
-# * Redistributions in binary form must reproduce the above copyright notice,
-# this list of conditions and the following disclaimer in the documentation
-# and/or other materials provided with the distribution.
-#
-# * Neither the name of the copyright holder nor the names of its
-# contributors may be used to endorse or promote products derived from
-# this software without specific prior written permission.
-#
-# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
-# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
-# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
-# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
-# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
-# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
-# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
-# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
-# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
-
-
-import inspect
-
-from elasticapm.base import Client
-
-
-class Middleware(object):
- """ElasticAPM middleware for ZeroRPC.
-
- >>> elasticapm = Middleware(service_name='..', secret_token='...')
- >>> zerorpc.Context.get_instance().register_middleware(elasticapm)
-
- Exceptions detected server-side in ZeroRPC will be submitted to the apm server (and
- propagated to the client as well).
- """
-
- def __init__(self, hide_zerorpc_frames=True, client=None, **kwargs):
- """Create a middleware object that can be injected in a ZeroRPC server.
-
- - hide_zerorpc_frames: modify the exception stacktrace to remove the
- internal zerorpc frames (True by default to make
- the stacktrace as readable as possible);
- - client: use an existing raven.Client object, otherwise one will be
- instantiated from the keyword arguments.
-
- """
- self._elasticapm_client = client or Client(**kwargs)
- self._hide_zerorpc_frames = hide_zerorpc_frames
-
- def server_inspect_exception(self, req_event, rep_event, task_ctx, exc_info):
- """Called when an exception has been raised in the code run by ZeroRPC"""
-
- # Hide the zerorpc internal frames for readability, for a REQ/REP or
- # REQ/STREAM server the frames to hide are:
- # - core.ServerBase._async_task
- # - core.Pattern*.process_call
- # - core.DecoratorBase.__call__
- #
- # For a PUSH/PULL or PUB/SUB server the frame to hide is:
- # - core.Puller._receiver
- if self._hide_zerorpc_frames:
- traceback = exc_info[2]
- while traceback:
- zerorpc_frame = traceback.tb_frame
- zerorpc_frame.f_locals["__traceback_hide__"] = True
- frame_info = inspect.getframeinfo(zerorpc_frame)
- # Is there a better way than this (or looking up the filenames
- # or hardcoding the number of frames to skip) to know when we
- # are out of zerorpc?
- if frame_info.function == "__call__" or frame_info.function == "_receiver":
- break
- traceback = traceback.tb_next
-
- self._elasticapm_client.capture_exception(exc_info, extra=task_ctx, handled=False)
|
{"golden_diff": "diff --git a/elasticapm/contrib/zerorpc/__init__.py b/elasticapm/contrib/zerorpc/__init__.py\ndeleted file mode 100644\n--- a/elasticapm/contrib/zerorpc/__init__.py\n+++ /dev/null\n@@ -1,84 +0,0 @@\n-# BSD 3-Clause License\n-#\n-# Copyright (c) 2012, the Sentry Team, see AUTHORS for more details\n-# Copyright (c) 2019, Elasticsearch BV\n-# All rights reserved.\n-#\n-# Redistribution and use in source and binary forms, with or without\n-# modification, are permitted provided that the following conditions are met:\n-#\n-# * Redistributions of source code must retain the above copyright notice, this\n-# list of conditions and the following disclaimer.\n-#\n-# * Redistributions in binary form must reproduce the above copyright notice,\n-# this list of conditions and the following disclaimer in the documentation\n-# and/or other materials provided with the distribution.\n-#\n-# * Neither the name of the copyright holder nor the names of its\n-# contributors may be used to endorse or promote products derived from\n-# this software without specific prior written permission.\n-#\n-# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n-# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n-# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n-# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n-# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n-# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n-# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n-# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n-# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n-\n-\n-import inspect\n-\n-from elasticapm.base import Client\n-\n-\n-class Middleware(object):\n- \"\"\"ElasticAPM middleware for ZeroRPC.\n-\n- >>> elasticapm = Middleware(service_name='..', secret_token='...')\n- >>> zerorpc.Context.get_instance().register_middleware(elasticapm)\n-\n- Exceptions detected server-side in ZeroRPC will be submitted to the apm server (and\n- propagated to the client as well).\n- \"\"\"\n-\n- def __init__(self, hide_zerorpc_frames=True, client=None, **kwargs):\n- \"\"\"Create a middleware object that can be injected in a ZeroRPC server.\n-\n- - hide_zerorpc_frames: modify the exception stacktrace to remove the\n- internal zerorpc frames (True by default to make\n- the stacktrace as readable as possible);\n- - client: use an existing raven.Client object, otherwise one will be\n- instantiated from the keyword arguments.\n-\n- \"\"\"\n- self._elasticapm_client = client or Client(**kwargs)\n- self._hide_zerorpc_frames = hide_zerorpc_frames\n-\n- def server_inspect_exception(self, req_event, rep_event, task_ctx, exc_info):\n- \"\"\"Called when an exception has been raised in the code run by ZeroRPC\"\"\"\n-\n- # Hide the zerorpc internal frames for readability, for a REQ/REP or\n- # REQ/STREAM server the frames to hide are:\n- # - core.ServerBase._async_task\n- # - core.Pattern*.process_call\n- # - core.DecoratorBase.__call__\n- #\n- # For a PUSH/PULL or PUB/SUB server the frame to hide is:\n- # - core.Puller._receiver\n- if self._hide_zerorpc_frames:\n- traceback = exc_info[2]\n- while traceback:\n- zerorpc_frame = traceback.tb_frame\n- zerorpc_frame.f_locals[\"__traceback_hide__\"] = True\n- frame_info = inspect.getframeinfo(zerorpc_frame)\n- # Is there a better way than this (or looking up the filenames\n- # or hardcoding the number of frames to skip) to know when we\n- # are out of zerorpc?\n- if frame_info.function == \"__call__\" or frame_info.function == \"_receiver\":\n- break\n- traceback = traceback.tb_next\n-\n- self._elasticapm_client.capture_exception(exc_info, extra=task_ctx, handled=False)\n", "issue": "Remove py2 leftovers\nThis is an issue to track all of the py2 stuff we can remove once a sufficient waiting period after 6.0 has passed.\r\n\r\n- [x] Remove `zerorpc` (py2 only)\r\n- [x] Remove `compat.py`\r\n- [x] Run `pyupgrade`?\r\n\r\nRef #928 \n", "before_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2012, the Sentry Team, see AUTHORS for more details\n# Copyright (c) 2019, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n\n\nimport inspect\n\nfrom elasticapm.base import Client\n\n\nclass Middleware(object):\n \"\"\"ElasticAPM middleware for ZeroRPC.\n\n >>> elasticapm = Middleware(service_name='..', secret_token='...')\n >>> zerorpc.Context.get_instance().register_middleware(elasticapm)\n\n Exceptions detected server-side in ZeroRPC will be submitted to the apm server (and\n propagated to the client as well).\n \"\"\"\n\n def __init__(self, hide_zerorpc_frames=True, client=None, **kwargs):\n \"\"\"Create a middleware object that can be injected in a ZeroRPC server.\n\n - hide_zerorpc_frames: modify the exception stacktrace to remove the\n internal zerorpc frames (True by default to make\n the stacktrace as readable as possible);\n - client: use an existing raven.Client object, otherwise one will be\n instantiated from the keyword arguments.\n\n \"\"\"\n self._elasticapm_client = client or Client(**kwargs)\n self._hide_zerorpc_frames = hide_zerorpc_frames\n\n def server_inspect_exception(self, req_event, rep_event, task_ctx, exc_info):\n \"\"\"Called when an exception has been raised in the code run by ZeroRPC\"\"\"\n\n # Hide the zerorpc internal frames for readability, for a REQ/REP or\n # REQ/STREAM server the frames to hide are:\n # - core.ServerBase._async_task\n # - core.Pattern*.process_call\n # - core.DecoratorBase.__call__\n #\n # For a PUSH/PULL or PUB/SUB server the frame to hide is:\n # - core.Puller._receiver\n if self._hide_zerorpc_frames:\n traceback = exc_info[2]\n while traceback:\n zerorpc_frame = traceback.tb_frame\n zerorpc_frame.f_locals[\"__traceback_hide__\"] = True\n frame_info = inspect.getframeinfo(zerorpc_frame)\n # Is there a better way than this (or looking up the filenames\n # or hardcoding the number of frames to skip) to know when we\n # are out of zerorpc?\n if frame_info.function == \"__call__\" or frame_info.function == \"_receiver\":\n break\n traceback = traceback.tb_next\n\n self._elasticapm_client.capture_exception(exc_info, extra=task_ctx, handled=False)\n", "path": "elasticapm/contrib/zerorpc/__init__.py"}]}
| 1,647 | 1,007 |
gh_patches_debug_24645
|
rasdani/github-patches
|
git_diff
|
getnikola__nikola-3455
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
reST doc directive: slugs with slashes in no longer work
At some point in the previous few versions, slugs with slashes in no longer work - links pointing to them have their slashes removed before the link is resolved, leading to an error like `"swowndata" slug doesn't exist` for a slug called `sw/owndata`. I can't find this being mentioned in the release notes or the other issues here, so I assume this was done by accident, is a bug, and should be fixed.
</issue>
<code>
[start of nikola/plugins/compile/rest/doc.py]
1 # -*- coding: utf-8 -*-
2
3 # Copyright © 2012-2020 Roberto Alsina and others.
4
5 # Permission is hereby granted, free of charge, to any
6 # person obtaining a copy of this software and associated
7 # documentation files (the "Software"), to deal in the
8 # Software without restriction, including without limitation
9 # the rights to use, copy, modify, merge, publish,
10 # distribute, sublicense, and/or sell copies of the
11 # Software, and to permit persons to whom the Software is
12 # furnished to do so, subject to the following conditions:
13 #
14 # The above copyright notice and this permission notice
15 # shall be included in all copies or substantial portions of
16 # the Software.
17 #
18 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY
19 # KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE
20 # WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR
21 # PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS
22 # OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR
23 # OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
24 # OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
25 # SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
26
27 """reST role for linking to other documents."""
28
29 from docutils import nodes
30 from docutils.parsers.rst import roles
31
32 from nikola.utils import split_explicit_title, LOGGER, slugify
33 from nikola.plugin_categories import RestExtension
34
35
36 class Plugin(RestExtension):
37 """Plugin for doc role."""
38
39 name = 'rest_doc'
40
41 def set_site(self, site):
42 """Set Nikola site."""
43 self.site = site
44 roles.register_canonical_role('doc', doc_role)
45 self.site.register_shortcode('doc', doc_shortcode)
46 doc_role.site = site
47 return super().set_site(site)
48
49
50 def _doc_link(rawtext, text, options={}, content=[]):
51 """Handle the doc role."""
52 # split link's text and post's slug in role content
53 has_explicit_title, title, slug = split_explicit_title(text)
54 if '#' in slug:
55 slug, fragment = slug.split('#', 1)
56 else:
57 fragment = None
58 slug = slugify(slug)
59 # check if the slug given is part of our blog posts/pages
60 twin_slugs = False
61 post = None
62 for p in doc_role.site.timeline:
63 if p.meta('slug') == slug:
64 if post is None:
65 post = p
66 else:
67 twin_slugs = True
68 break
69
70 try:
71 if post is None:
72 raise ValueError("No post with matching slug found.")
73 except ValueError:
74 return False, False, None, None, slug
75
76 if not has_explicit_title:
77 # use post's title as link's text
78 title = post.title()
79 permalink = post.permalink()
80 if fragment:
81 permalink += '#' + fragment
82
83 return True, twin_slugs, title, permalink, slug
84
85
86 def doc_role(name, rawtext, text, lineno, inliner, options={}, content=[]):
87 """Handle the doc role."""
88 success, twin_slugs, title, permalink, slug = _doc_link(rawtext, text, options, content)
89 if success:
90 if twin_slugs:
91 inliner.reporter.warning(
92 'More than one post with the same slug. Using "{0}"'.format(permalink))
93 LOGGER.warning(
94 'More than one post with the same slug. Using "{0}" for doc role'.format(permalink))
95 node = make_link_node(rawtext, title, permalink, options)
96 return [node], []
97 else:
98 msg = inliner.reporter.error(
99 '"{0}" slug doesn\'t exist.'.format(slug),
100 line=lineno)
101 prb = inliner.problematic(rawtext, rawtext, msg)
102 return [prb], [msg]
103
104
105 def doc_shortcode(*args, **kwargs):
106 """Implement the doc shortcode."""
107 text = kwargs['data']
108 success, twin_slugs, title, permalink, slug = _doc_link(text, text, LOGGER)
109 if success:
110 if twin_slugs:
111 LOGGER.warning(
112 'More than one post with the same slug. Using "{0}" for doc shortcode'.format(permalink))
113 return '<a href="{0}">{1}</a>'.format(permalink, title)
114 else:
115 LOGGER.error(
116 '"{0}" slug doesn\'t exist.'.format(slug))
117 return '<span class="error text-error" style="color: red;">Invalid link: {0}</span>'.format(text)
118
119
120 def make_link_node(rawtext, text, url, options):
121 """Make a reST link node."""
122 node = nodes.reference(rawtext, text, refuri=url, *options)
123 return node
124
[end of nikola/plugins/compile/rest/doc.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/nikola/plugins/compile/rest/doc.py b/nikola/plugins/compile/rest/doc.py
--- a/nikola/plugins/compile/rest/doc.py
+++ b/nikola/plugins/compile/rest/doc.py
@@ -47,16 +47,8 @@
return super().set_site(site)
-def _doc_link(rawtext, text, options={}, content=[]):
- """Handle the doc role."""
- # split link's text and post's slug in role content
- has_explicit_title, title, slug = split_explicit_title(text)
- if '#' in slug:
- slug, fragment = slug.split('#', 1)
- else:
- fragment = None
- slug = slugify(slug)
- # check if the slug given is part of our blog posts/pages
+def _find_post(slug):
+ """Find a post with the given slug in posts or pages."""
twin_slugs = False
post = None
for p in doc_role.site.timeline:
@@ -66,6 +58,23 @@
else:
twin_slugs = True
break
+ return post, twin_slugs
+
+
+def _doc_link(rawtext, text, options={}, content=[]):
+ """Handle the doc role."""
+ # split link's text and post's slug in role content
+ has_explicit_title, title, slug = split_explicit_title(text)
+ if '#' in slug:
+ slug, fragment = slug.split('#', 1)
+ else:
+ fragment = None
+
+ # Look for the unslugified input first, then try to slugify (Issue #3450)
+ post, twin_slugs = _find_post(slug)
+ if post is None:
+ slug = slugify(slug)
+ post, twin_slugs = _find_post(slug)
try:
if post is None:
|
{"golden_diff": "diff --git a/nikola/plugins/compile/rest/doc.py b/nikola/plugins/compile/rest/doc.py\n--- a/nikola/plugins/compile/rest/doc.py\n+++ b/nikola/plugins/compile/rest/doc.py\n@@ -47,16 +47,8 @@\n return super().set_site(site)\n \n \n-def _doc_link(rawtext, text, options={}, content=[]):\n- \"\"\"Handle the doc role.\"\"\"\n- # split link's text and post's slug in role content\n- has_explicit_title, title, slug = split_explicit_title(text)\n- if '#' in slug:\n- slug, fragment = slug.split('#', 1)\n- else:\n- fragment = None\n- slug = slugify(slug)\n- # check if the slug given is part of our blog posts/pages\n+def _find_post(slug):\n+ \"\"\"Find a post with the given slug in posts or pages.\"\"\"\n twin_slugs = False\n post = None\n for p in doc_role.site.timeline:\n@@ -66,6 +58,23 @@\n else:\n twin_slugs = True\n break\n+ return post, twin_slugs\n+\n+\n+def _doc_link(rawtext, text, options={}, content=[]):\n+ \"\"\"Handle the doc role.\"\"\"\n+ # split link's text and post's slug in role content\n+ has_explicit_title, title, slug = split_explicit_title(text)\n+ if '#' in slug:\n+ slug, fragment = slug.split('#', 1)\n+ else:\n+ fragment = None\n+\n+ # Look for the unslugified input first, then try to slugify (Issue #3450)\n+ post, twin_slugs = _find_post(slug)\n+ if post is None:\n+ slug = slugify(slug)\n+ post, twin_slugs = _find_post(slug)\n \n try:\n if post is None:\n", "issue": "reST doc directive: slugs with slashes in no longer work\nAt some point in the previous few versions, slugs with slashes in no longer work - links pointing to them have their slashes removed before the link is resolved, leading to an error like `\"swowndata\" slug doesn't exist` for a slug called `sw/owndata`. I can't find this being mentioned in the release notes or the other issues here, so I assume this was done by accident, is a bug, and should be fixed.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright \u00a9 2012-2020 Roberto Alsina and others.\n\n# Permission is hereby granted, free of charge, to any\n# person obtaining a copy of this software and associated\n# documentation files (the \"Software\"), to deal in the\n# Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the\n# Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice\n# shall be included in all copies or substantial portions of\n# the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY\n# KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE\n# WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR\n# PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS\n# OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\n# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR\n# OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\n\"\"\"reST role for linking to other documents.\"\"\"\n\nfrom docutils import nodes\nfrom docutils.parsers.rst import roles\n\nfrom nikola.utils import split_explicit_title, LOGGER, slugify\nfrom nikola.plugin_categories import RestExtension\n\n\nclass Plugin(RestExtension):\n \"\"\"Plugin for doc role.\"\"\"\n\n name = 'rest_doc'\n\n def set_site(self, site):\n \"\"\"Set Nikola site.\"\"\"\n self.site = site\n roles.register_canonical_role('doc', doc_role)\n self.site.register_shortcode('doc', doc_shortcode)\n doc_role.site = site\n return super().set_site(site)\n\n\ndef _doc_link(rawtext, text, options={}, content=[]):\n \"\"\"Handle the doc role.\"\"\"\n # split link's text and post's slug in role content\n has_explicit_title, title, slug = split_explicit_title(text)\n if '#' in slug:\n slug, fragment = slug.split('#', 1)\n else:\n fragment = None\n slug = slugify(slug)\n # check if the slug given is part of our blog posts/pages\n twin_slugs = False\n post = None\n for p in doc_role.site.timeline:\n if p.meta('slug') == slug:\n if post is None:\n post = p\n else:\n twin_slugs = True\n break\n\n try:\n if post is None:\n raise ValueError(\"No post with matching slug found.\")\n except ValueError:\n return False, False, None, None, slug\n\n if not has_explicit_title:\n # use post's title as link's text\n title = post.title()\n permalink = post.permalink()\n if fragment:\n permalink += '#' + fragment\n\n return True, twin_slugs, title, permalink, slug\n\n\ndef doc_role(name, rawtext, text, lineno, inliner, options={}, content=[]):\n \"\"\"Handle the doc role.\"\"\"\n success, twin_slugs, title, permalink, slug = _doc_link(rawtext, text, options, content)\n if success:\n if twin_slugs:\n inliner.reporter.warning(\n 'More than one post with the same slug. Using \"{0}\"'.format(permalink))\n LOGGER.warning(\n 'More than one post with the same slug. Using \"{0}\" for doc role'.format(permalink))\n node = make_link_node(rawtext, title, permalink, options)\n return [node], []\n else:\n msg = inliner.reporter.error(\n '\"{0}\" slug doesn\\'t exist.'.format(slug),\n line=lineno)\n prb = inliner.problematic(rawtext, rawtext, msg)\n return [prb], [msg]\n\n\ndef doc_shortcode(*args, **kwargs):\n \"\"\"Implement the doc shortcode.\"\"\"\n text = kwargs['data']\n success, twin_slugs, title, permalink, slug = _doc_link(text, text, LOGGER)\n if success:\n if twin_slugs:\n LOGGER.warning(\n 'More than one post with the same slug. Using \"{0}\" for doc shortcode'.format(permalink))\n return '<a href=\"{0}\">{1}</a>'.format(permalink, title)\n else:\n LOGGER.error(\n '\"{0}\" slug doesn\\'t exist.'.format(slug))\n return '<span class=\"error text-error\" style=\"color: red;\">Invalid link: {0}</span>'.format(text)\n\n\ndef make_link_node(rawtext, text, url, options):\n \"\"\"Make a reST link node.\"\"\"\n node = nodes.reference(rawtext, text, refuri=url, *options)\n return node\n", "path": "nikola/plugins/compile/rest/doc.py"}]}
| 1,946 | 421 |
gh_patches_debug_4308
|
rasdani/github-patches
|
git_diff
|
tiangolo__fastapi-320
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
eta on pydantic update to 0.28
really need your latest PR
it shoud solve recurring issues with sqlalchemy to pydantic mapping
thank you !
</issue>
<code>
[start of fastapi/utils.py]
1 import re
2 from typing import Any, Dict, List, Sequence, Set, Type
3
4 from fastapi import routing
5 from fastapi.openapi.constants import REF_PREFIX
6 from pydantic import BaseModel
7 from pydantic.fields import Field
8 from pydantic.schema import get_flat_models_from_fields, model_process_schema
9 from starlette.routing import BaseRoute
10
11
12 def get_flat_models_from_routes(
13 routes: Sequence[Type[BaseRoute]]
14 ) -> Set[Type[BaseModel]]:
15 body_fields_from_routes: List[Field] = []
16 responses_from_routes: List[Field] = []
17 for route in routes:
18 if getattr(route, "include_in_schema", None) and isinstance(
19 route, routing.APIRoute
20 ):
21 if route.body_field:
22 assert isinstance(
23 route.body_field, Field
24 ), "A request body must be a Pydantic Field"
25 body_fields_from_routes.append(route.body_field)
26 if route.response_field:
27 responses_from_routes.append(route.response_field)
28 if route.response_fields:
29 responses_from_routes.extend(route.response_fields.values())
30 flat_models = get_flat_models_from_fields(
31 body_fields_from_routes + responses_from_routes
32 )
33 return flat_models
34
35
36 def get_model_definitions(
37 *, flat_models: Set[Type[BaseModel]], model_name_map: Dict[Type[BaseModel], str]
38 ) -> Dict[str, Any]:
39 definitions: Dict[str, Dict] = {}
40 for model in flat_models:
41 m_schema, m_definitions = model_process_schema(
42 model, model_name_map=model_name_map, ref_prefix=REF_PREFIX
43 )
44 definitions.update(m_definitions)
45 model_name = model_name_map[model]
46 definitions[model_name] = m_schema
47 return definitions
48
49
50 def get_path_param_names(path: str) -> Set[str]:
51 return {item.strip("{}") for item in re.findall("{[^}]*}", path)}
52
[end of fastapi/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/fastapi/utils.py b/fastapi/utils.py
--- a/fastapi/utils.py
+++ b/fastapi/utils.py
@@ -28,7 +28,7 @@
if route.response_fields:
responses_from_routes.extend(route.response_fields.values())
flat_models = get_flat_models_from_fields(
- body_fields_from_routes + responses_from_routes
+ body_fields_from_routes + responses_from_routes, known_models=set()
)
return flat_models
|
{"golden_diff": "diff --git a/fastapi/utils.py b/fastapi/utils.py\n--- a/fastapi/utils.py\n+++ b/fastapi/utils.py\n@@ -28,7 +28,7 @@\n if route.response_fields:\n responses_from_routes.extend(route.response_fields.values())\n flat_models = get_flat_models_from_fields(\n- body_fields_from_routes + responses_from_routes\n+ body_fields_from_routes + responses_from_routes, known_models=set()\n )\n return flat_models\n", "issue": "eta on pydantic update to 0.28\nreally need your latest PR \r\nit shoud solve recurring issues with sqlalchemy to pydantic mapping\r\nthank you !\n", "before_files": [{"content": "import re\nfrom typing import Any, Dict, List, Sequence, Set, Type\n\nfrom fastapi import routing\nfrom fastapi.openapi.constants import REF_PREFIX\nfrom pydantic import BaseModel\nfrom pydantic.fields import Field\nfrom pydantic.schema import get_flat_models_from_fields, model_process_schema\nfrom starlette.routing import BaseRoute\n\n\ndef get_flat_models_from_routes(\n routes: Sequence[Type[BaseRoute]]\n) -> Set[Type[BaseModel]]:\n body_fields_from_routes: List[Field] = []\n responses_from_routes: List[Field] = []\n for route in routes:\n if getattr(route, \"include_in_schema\", None) and isinstance(\n route, routing.APIRoute\n ):\n if route.body_field:\n assert isinstance(\n route.body_field, Field\n ), \"A request body must be a Pydantic Field\"\n body_fields_from_routes.append(route.body_field)\n if route.response_field:\n responses_from_routes.append(route.response_field)\n if route.response_fields:\n responses_from_routes.extend(route.response_fields.values())\n flat_models = get_flat_models_from_fields(\n body_fields_from_routes + responses_from_routes\n )\n return flat_models\n\n\ndef get_model_definitions(\n *, flat_models: Set[Type[BaseModel]], model_name_map: Dict[Type[BaseModel], str]\n) -> Dict[str, Any]:\n definitions: Dict[str, Dict] = {}\n for model in flat_models:\n m_schema, m_definitions = model_process_schema(\n model, model_name_map=model_name_map, ref_prefix=REF_PREFIX\n )\n definitions.update(m_definitions)\n model_name = model_name_map[model]\n definitions[model_name] = m_schema\n return definitions\n\n\ndef get_path_param_names(path: str) -> Set[str]:\n return {item.strip(\"{}\") for item in re.findall(\"{[^}]*}\", path)}\n", "path": "fastapi/utils.py"}]}
| 1,065 | 100 |
gh_patches_debug_2391
|
rasdani/github-patches
|
git_diff
|
scrapy__scrapy-2929
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
LinkExtractor is not ignoring .m4v extension (video) by default
By chance I found out that LinkExtractor is not ignoring the video extension m4v in the same way it is ignoring other video formats.
https://en.wikipedia.org/wiki/M4V
</issue>
<code>
[start of scrapy/linkextractors/__init__.py]
1 """
2 scrapy.linkextractors
3
4 This package contains a collection of Link Extractors.
5
6 For more info see docs/topics/link-extractors.rst
7 """
8 import re
9
10 from six.moves.urllib.parse import urlparse
11 from parsel.csstranslator import HTMLTranslator
12 from w3lib.url import canonicalize_url
13
14 from scrapy.utils.misc import arg_to_iter
15 from scrapy.utils.url import (
16 url_is_from_any_domain, url_has_any_extension,
17 )
18
19
20 # common file extensions that are not followed if they occur in links
21 IGNORED_EXTENSIONS = [
22 # images
23 'mng', 'pct', 'bmp', 'gif', 'jpg', 'jpeg', 'png', 'pst', 'psp', 'tif',
24 'tiff', 'ai', 'drw', 'dxf', 'eps', 'ps', 'svg',
25
26 # audio
27 'mp3', 'wma', 'ogg', 'wav', 'ra', 'aac', 'mid', 'au', 'aiff',
28
29 # video
30 '3gp', 'asf', 'asx', 'avi', 'mov', 'mp4', 'mpg', 'qt', 'rm', 'swf', 'wmv',
31 'm4a',
32
33 # office suites
34 'xls', 'xlsx', 'ppt', 'pptx', 'pps', 'doc', 'docx', 'odt', 'ods', 'odg',
35 'odp',
36
37 # other
38 'css', 'pdf', 'exe', 'bin', 'rss', 'zip', 'rar',
39 ]
40
41
42 _re_type = type(re.compile("", 0))
43 _matches = lambda url, regexs: any(r.search(url) for r in regexs)
44 _is_valid_url = lambda url: url.split('://', 1)[0] in {'http', 'https', 'file'}
45
46
47 class FilteringLinkExtractor(object):
48
49 _csstranslator = HTMLTranslator()
50
51 def __init__(self, link_extractor, allow, deny, allow_domains, deny_domains,
52 restrict_xpaths, canonicalize, deny_extensions, restrict_css):
53
54 self.link_extractor = link_extractor
55
56 self.allow_res = [x if isinstance(x, _re_type) else re.compile(x)
57 for x in arg_to_iter(allow)]
58 self.deny_res = [x if isinstance(x, _re_type) else re.compile(x)
59 for x in arg_to_iter(deny)]
60
61 self.allow_domains = set(arg_to_iter(allow_domains))
62 self.deny_domains = set(arg_to_iter(deny_domains))
63
64 self.restrict_xpaths = tuple(arg_to_iter(restrict_xpaths))
65 self.restrict_xpaths += tuple(map(self._csstranslator.css_to_xpath,
66 arg_to_iter(restrict_css)))
67
68 self.canonicalize = canonicalize
69 if deny_extensions is None:
70 deny_extensions = IGNORED_EXTENSIONS
71 self.deny_extensions = {'.' + e for e in arg_to_iter(deny_extensions)}
72
73 def _link_allowed(self, link):
74 if not _is_valid_url(link.url):
75 return False
76 if self.allow_res and not _matches(link.url, self.allow_res):
77 return False
78 if self.deny_res and _matches(link.url, self.deny_res):
79 return False
80 parsed_url = urlparse(link.url)
81 if self.allow_domains and not url_is_from_any_domain(parsed_url, self.allow_domains):
82 return False
83 if self.deny_domains and url_is_from_any_domain(parsed_url, self.deny_domains):
84 return False
85 if self.deny_extensions and url_has_any_extension(parsed_url, self.deny_extensions):
86 return False
87 return True
88
89 def matches(self, url):
90
91 if self.allow_domains and not url_is_from_any_domain(url, self.allow_domains):
92 return False
93 if self.deny_domains and url_is_from_any_domain(url, self.deny_domains):
94 return False
95
96 allowed = (regex.search(url) for regex in self.allow_res) if self.allow_res else [True]
97 denied = (regex.search(url) for regex in self.deny_res) if self.deny_res else []
98 return any(allowed) and not any(denied)
99
100 def _process_links(self, links):
101 links = [x for x in links if self._link_allowed(x)]
102 if self.canonicalize:
103 for link in links:
104 link.url = canonicalize_url(link.url)
105 links = self.link_extractor._process_links(links)
106 return links
107
108 def _extract_links(self, *args, **kwargs):
109 return self.link_extractor._extract_links(*args, **kwargs)
110
111
112 # Top-level imports
113 from .lxmlhtml import LxmlLinkExtractor as LinkExtractor
114
[end of scrapy/linkextractors/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scrapy/linkextractors/__init__.py b/scrapy/linkextractors/__init__.py
--- a/scrapy/linkextractors/__init__.py
+++ b/scrapy/linkextractors/__init__.py
@@ -28,7 +28,7 @@
# video
'3gp', 'asf', 'asx', 'avi', 'mov', 'mp4', 'mpg', 'qt', 'rm', 'swf', 'wmv',
- 'm4a',
+ 'm4a', 'm4v',
# office suites
'xls', 'xlsx', 'ppt', 'pptx', 'pps', 'doc', 'docx', 'odt', 'ods', 'odg',
|
{"golden_diff": "diff --git a/scrapy/linkextractors/__init__.py b/scrapy/linkextractors/__init__.py\n--- a/scrapy/linkextractors/__init__.py\n+++ b/scrapy/linkextractors/__init__.py\n@@ -28,7 +28,7 @@\n \n # video\n '3gp', 'asf', 'asx', 'avi', 'mov', 'mp4', 'mpg', 'qt', 'rm', 'swf', 'wmv',\n- 'm4a',\n+ 'm4a', 'm4v',\n \n # office suites\n 'xls', 'xlsx', 'ppt', 'pptx', 'pps', 'doc', 'docx', 'odt', 'ods', 'odg',\n", "issue": "LinkExtractor is not ignoring .m4v extension (video) by default\nBy chance I found out that LinkExtractor is not ignoring the video extension m4v in the same way it is ignoring other video formats.\r\n\r\nhttps://en.wikipedia.org/wiki/M4V\r\n\n", "before_files": [{"content": "\"\"\"\nscrapy.linkextractors\n\nThis package contains a collection of Link Extractors.\n\nFor more info see docs/topics/link-extractors.rst\n\"\"\"\nimport re\n\nfrom six.moves.urllib.parse import urlparse\nfrom parsel.csstranslator import HTMLTranslator\nfrom w3lib.url import canonicalize_url\n\nfrom scrapy.utils.misc import arg_to_iter\nfrom scrapy.utils.url import (\n url_is_from_any_domain, url_has_any_extension,\n)\n\n\n# common file extensions that are not followed if they occur in links\nIGNORED_EXTENSIONS = [\n # images\n 'mng', 'pct', 'bmp', 'gif', 'jpg', 'jpeg', 'png', 'pst', 'psp', 'tif',\n 'tiff', 'ai', 'drw', 'dxf', 'eps', 'ps', 'svg',\n\n # audio\n 'mp3', 'wma', 'ogg', 'wav', 'ra', 'aac', 'mid', 'au', 'aiff',\n\n # video\n '3gp', 'asf', 'asx', 'avi', 'mov', 'mp4', 'mpg', 'qt', 'rm', 'swf', 'wmv',\n 'm4a',\n\n # office suites\n 'xls', 'xlsx', 'ppt', 'pptx', 'pps', 'doc', 'docx', 'odt', 'ods', 'odg',\n 'odp',\n\n # other\n 'css', 'pdf', 'exe', 'bin', 'rss', 'zip', 'rar',\n]\n\n\n_re_type = type(re.compile(\"\", 0))\n_matches = lambda url, regexs: any(r.search(url) for r in regexs)\n_is_valid_url = lambda url: url.split('://', 1)[0] in {'http', 'https', 'file'}\n\n\nclass FilteringLinkExtractor(object):\n\n _csstranslator = HTMLTranslator()\n\n def __init__(self, link_extractor, allow, deny, allow_domains, deny_domains,\n restrict_xpaths, canonicalize, deny_extensions, restrict_css):\n\n self.link_extractor = link_extractor\n\n self.allow_res = [x if isinstance(x, _re_type) else re.compile(x)\n for x in arg_to_iter(allow)]\n self.deny_res = [x if isinstance(x, _re_type) else re.compile(x)\n for x in arg_to_iter(deny)]\n\n self.allow_domains = set(arg_to_iter(allow_domains))\n self.deny_domains = set(arg_to_iter(deny_domains))\n\n self.restrict_xpaths = tuple(arg_to_iter(restrict_xpaths))\n self.restrict_xpaths += tuple(map(self._csstranslator.css_to_xpath,\n arg_to_iter(restrict_css)))\n\n self.canonicalize = canonicalize\n if deny_extensions is None:\n deny_extensions = IGNORED_EXTENSIONS\n self.deny_extensions = {'.' + e for e in arg_to_iter(deny_extensions)}\n\n def _link_allowed(self, link):\n if not _is_valid_url(link.url):\n return False\n if self.allow_res and not _matches(link.url, self.allow_res):\n return False\n if self.deny_res and _matches(link.url, self.deny_res):\n return False\n parsed_url = urlparse(link.url)\n if self.allow_domains and not url_is_from_any_domain(parsed_url, self.allow_domains):\n return False\n if self.deny_domains and url_is_from_any_domain(parsed_url, self.deny_domains):\n return False\n if self.deny_extensions and url_has_any_extension(parsed_url, self.deny_extensions):\n return False\n return True\n\n def matches(self, url):\n\n if self.allow_domains and not url_is_from_any_domain(url, self.allow_domains):\n return False\n if self.deny_domains and url_is_from_any_domain(url, self.deny_domains):\n return False\n\n allowed = (regex.search(url) for regex in self.allow_res) if self.allow_res else [True]\n denied = (regex.search(url) for regex in self.deny_res) if self.deny_res else []\n return any(allowed) and not any(denied)\n\n def _process_links(self, links):\n links = [x for x in links if self._link_allowed(x)]\n if self.canonicalize:\n for link in links:\n link.url = canonicalize_url(link.url)\n links = self.link_extractor._process_links(links)\n return links\n\n def _extract_links(self, *args, **kwargs):\n return self.link_extractor._extract_links(*args, **kwargs)\n\n\n# Top-level imports\nfrom .lxmlhtml import LxmlLinkExtractor as LinkExtractor\n", "path": "scrapy/linkextractors/__init__.py"}]}
| 1,849 | 167 |
gh_patches_debug_17330
|
rasdani/github-patches
|
git_diff
|
bornhack__bornhack-website-187
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
include iban/swift/bic info on custominvoice pdfs
include iban/swift/bic info on custominvoice pdfs
</issue>
<code>
[start of src/shop/invoiceworker.py]
1 from django.core.files import File
2 from utils.pdf import generate_pdf_letter
3 from shop.email import add_invoice_email, add_creditnote_email
4 from shop.models import Order, CustomOrder, Invoice, CreditNote
5 import logging
6 logging.basicConfig(level=logging.INFO)
7 logger = logging.getLogger('bornhack.%s' % __name__)
8
9
10 def do_work():
11 """
12 The invoice worker creates Invoice objects for shop orders and
13 for custom orders. It also generates PDF files for Invoice objects
14 that have no PDF. It also emails invoices for shop orders.
15 """
16
17 # check if we need to generate any invoices for shop orders
18 for order in Order.objects.filter(paid=True, invoice__isnull=True):
19 # generate invoice for this Order
20 Invoice.objects.create(order=order)
21 logger.info('Generated Invoice object for %s' % order)
22
23 # check if we need to generate any invoices for custom orders
24 for customorder in CustomOrder.objects.filter(invoice__isnull=True):
25 # generate invoice for this CustomOrder
26 Invoice.objects.create(customorder=customorder)
27 logger.info('Generated Invoice object for %s' % customorder)
28
29 # check if we need to generate any pdf invoices
30 for invoice in Invoice.objects.filter(pdf=''):
31 # generate the pdf
32 try:
33 if invoice.customorder:
34 template = 'pdf/custominvoice.html'
35 else:
36 template = 'pdf/invoice.html'
37 pdffile = generate_pdf_letter(
38 filename=invoice.filename,
39 template=template,
40 formatdict={
41 'invoice': invoice,
42 },
43 )
44 logger.info('Generated pdf for invoice %s' % invoice)
45 except Exception as E:
46 logger.exception('Unable to generate PDF file for invoice #%s. Error: %s' % (invoice.pk, E))
47 continue
48
49 # update invoice object with the file
50 invoice.pdf.save(invoice.filename, File(pdffile))
51 invoice.save()
52
53 # check if we need to send out any invoices (only for shop orders, and only where pdf has been generated)
54 for invoice in Invoice.objects.filter(order__isnull=False, sent_to_customer=False).exclude(pdf=''):
55 logger.info("found unmailed Invoice object: %s" % invoice)
56 # add email to the outgoing email queue
57 if add_invoice_email(invoice=invoice):
58 invoice.sent_to_customer = True
59 invoice.save()
60 logger.info('OK: Invoice email to {} added to queue.'.format(
61 invoice.order.user.email)
62 )
63 else:
64 logger.error('Unable to add email for invoice {} to {}'.format(
65 invoice.pk,
66 invoice.order.user.email
67 )
68 )
69
70 # check if we need to generate any pdf creditnotes?
71 for creditnote in CreditNote.objects.filter(pdf=''):
72 # generate the pdf
73 try:
74 pdffile = generate_pdf_letter(
75 filename=creditnote.filename,
76 template='pdf/creditnote.html',
77 formatdict={
78 'creditnote': creditnote,
79 },
80 )
81 logger.info('Generated pdf for creditnote %s' % creditnote)
82 except Exception as E:
83 logger.exception('Unable to generate PDF file for creditnote #%s. Error: %s' % (creditnote.pk, E))
84 continue
85
86 # update creditnote object with the file
87 creditnote.pdf.save(creditnote.filename, File(pdffile))
88 creditnote.save()
89
90 # check if we need to send out any creditnotes (only where pdf has been generated and only for creditnotes linked to a user)
91 for creditnote in CreditNote.objects.filter(sent_to_customer=False).exclude(pdf='').exclude(user=None):
92 # send the email
93 if add_creditnote_email(creditnote=creditnote):
94 logger.info('OK: Creditnote email to %s added' % creditnote.user.email)
95 creditnote.sent_to_customer = True
96 creditnote.save()
97 else:
98 logger.error('Unable to add creditnote email for creditnote %s to %s' % (creditnote.pk, creditnote.user.email))
99
100
[end of src/shop/invoiceworker.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/shop/invoiceworker.py b/src/shop/invoiceworker.py
--- a/src/shop/invoiceworker.py
+++ b/src/shop/invoiceworker.py
@@ -1,3 +1,4 @@
+from django.conf import settings
from django.core.files import File
from utils.pdf import generate_pdf_letter
from shop.email import add_invoice_email, add_creditnote_email
@@ -39,6 +40,11 @@
template=template,
formatdict={
'invoice': invoice,
+ 'bank': settings.BANKACCOUNT_BANK,
+ 'bank_iban': settings.BANKACCOUNT_IBAN,
+ 'bank_bic': settings.BANKACCOUNT_SWIFTBIC,
+ 'bank_dk_reg': settings.BANKACCOUNT_REG,
+ 'bank_dk_accno': settings.BANKACCOUNT_ACCOUNT,
},
)
logger.info('Generated pdf for invoice %s' % invoice)
|
{"golden_diff": "diff --git a/src/shop/invoiceworker.py b/src/shop/invoiceworker.py\n--- a/src/shop/invoiceworker.py\n+++ b/src/shop/invoiceworker.py\n@@ -1,3 +1,4 @@\n+from django.conf import settings\n from django.core.files import File\n from utils.pdf import generate_pdf_letter\n from shop.email import add_invoice_email, add_creditnote_email\n@@ -39,6 +40,11 @@\n template=template,\n formatdict={\n 'invoice': invoice,\n+ 'bank': settings.BANKACCOUNT_BANK,\n+ 'bank_iban': settings.BANKACCOUNT_IBAN,\n+ 'bank_bic': settings.BANKACCOUNT_SWIFTBIC,\n+ 'bank_dk_reg': settings.BANKACCOUNT_REG,\n+ 'bank_dk_accno': settings.BANKACCOUNT_ACCOUNT,\n },\n )\n logger.info('Generated pdf for invoice %s' % invoice)\n", "issue": "include iban/swift/bic info on custominvoice pdfs\n\ninclude iban/swift/bic info on custominvoice pdfs\n\n", "before_files": [{"content": "from django.core.files import File\nfrom utils.pdf import generate_pdf_letter\nfrom shop.email import add_invoice_email, add_creditnote_email\nfrom shop.models import Order, CustomOrder, Invoice, CreditNote\nimport logging\nlogging.basicConfig(level=logging.INFO)\nlogger = logging.getLogger('bornhack.%s' % __name__)\n\n\ndef do_work():\n \"\"\"\n The invoice worker creates Invoice objects for shop orders and\n for custom orders. It also generates PDF files for Invoice objects\n that have no PDF. It also emails invoices for shop orders.\n \"\"\"\n\n # check if we need to generate any invoices for shop orders\n for order in Order.objects.filter(paid=True, invoice__isnull=True):\n # generate invoice for this Order\n Invoice.objects.create(order=order)\n logger.info('Generated Invoice object for %s' % order)\n\n # check if we need to generate any invoices for custom orders\n for customorder in CustomOrder.objects.filter(invoice__isnull=True):\n # generate invoice for this CustomOrder\n Invoice.objects.create(customorder=customorder)\n logger.info('Generated Invoice object for %s' % customorder)\n\n # check if we need to generate any pdf invoices\n for invoice in Invoice.objects.filter(pdf=''):\n # generate the pdf\n try:\n if invoice.customorder:\n template = 'pdf/custominvoice.html'\n else:\n template = 'pdf/invoice.html'\n pdffile = generate_pdf_letter(\n filename=invoice.filename,\n template=template,\n formatdict={\n 'invoice': invoice,\n },\n )\n logger.info('Generated pdf for invoice %s' % invoice)\n except Exception as E:\n logger.exception('Unable to generate PDF file for invoice #%s. Error: %s' % (invoice.pk, E))\n continue\n\n # update invoice object with the file\n invoice.pdf.save(invoice.filename, File(pdffile))\n invoice.save()\n\n # check if we need to send out any invoices (only for shop orders, and only where pdf has been generated)\n for invoice in Invoice.objects.filter(order__isnull=False, sent_to_customer=False).exclude(pdf=''):\n logger.info(\"found unmailed Invoice object: %s\" % invoice)\n # add email to the outgoing email queue\n if add_invoice_email(invoice=invoice):\n invoice.sent_to_customer = True\n invoice.save()\n logger.info('OK: Invoice email to {} added to queue.'.format(\n invoice.order.user.email)\n )\n else:\n logger.error('Unable to add email for invoice {} to {}'.format(\n invoice.pk,\n invoice.order.user.email\n )\n )\n\n # check if we need to generate any pdf creditnotes?\n for creditnote in CreditNote.objects.filter(pdf=''):\n # generate the pdf\n try:\n pdffile = generate_pdf_letter(\n filename=creditnote.filename,\n template='pdf/creditnote.html',\n formatdict={\n 'creditnote': creditnote,\n },\n )\n logger.info('Generated pdf for creditnote %s' % creditnote)\n except Exception as E:\n logger.exception('Unable to generate PDF file for creditnote #%s. Error: %s' % (creditnote.pk, E))\n continue\n\n # update creditnote object with the file\n creditnote.pdf.save(creditnote.filename, File(pdffile))\n creditnote.save()\n\n # check if we need to send out any creditnotes (only where pdf has been generated and only for creditnotes linked to a user)\n for creditnote in CreditNote.objects.filter(sent_to_customer=False).exclude(pdf='').exclude(user=None):\n # send the email\n if add_creditnote_email(creditnote=creditnote):\n logger.info('OK: Creditnote email to %s added' % creditnote.user.email)\n creditnote.sent_to_customer = True\n creditnote.save()\n else:\n logger.error('Unable to add creditnote email for creditnote %s to %s' % (creditnote.pk, creditnote.user.email))\n\n", "path": "src/shop/invoiceworker.py"}]}
| 1,622 | 206 |
gh_patches_debug_10518
|
rasdani/github-patches
|
git_diff
|
Mailu__Mailu-1052
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Regular alpine base-image update
To receive current updates for upstream projects, security fixes and new features such as mentioned in #1049 , let’s upgrade the alpine baseimage to latest 3.10
</issue>
<code>
[start of core/postfix/start.py]
1 #!/usr/bin/python3
2
3 import os
4 import glob
5 import shutil
6 import multiprocessing
7 import logging as log
8 import sys
9 from mailustart import resolve, convert
10
11 from podop import run_server
12
13 log.basicConfig(stream=sys.stderr, level=os.environ.get("LOG_LEVEL", "WARNING"))
14
15 def start_podop():
16 os.setuid(100)
17 url = "http://" + os.environ["ADMIN_ADDRESS"] + "/internal/postfix/"
18 # TODO: Remove verbosity setting from Podop?
19 run_server(0, "postfix", "/tmp/podop.socket", [
20 ("transport", "url", url + "transport/§"),
21 ("alias", "url", url + "alias/§"),
22 ("domain", "url", url + "domain/§"),
23 ("mailbox", "url", url + "mailbox/§"),
24 ("senderaccess", "url", url + "sender/access/§"),
25 ("senderlogin", "url", url + "sender/login/§")
26 ])
27
28 # Actual startup script
29 os.environ["FRONT_ADDRESS"] = resolve(os.environ.get("FRONT_ADDRESS", "front"))
30 os.environ["ADMIN_ADDRESS"] = resolve(os.environ.get("ADMIN_ADDRESS", "admin"))
31 os.environ["HOST_ANTISPAM"] = resolve(os.environ.get("HOST_ANTISPAM", "antispam:11332"))
32 os.environ["HOST_LMTP"] = resolve(os.environ.get("HOST_LMTP", "imap:2525"))
33
34 for postfix_file in glob.glob("/conf/*.cf"):
35 convert(postfix_file, os.path.join("/etc/postfix", os.path.basename(postfix_file)))
36
37 if os.path.exists("/overrides/postfix.cf"):
38 for line in open("/overrides/postfix.cf").read().strip().split("\n"):
39 os.system('postconf -e "{}"'.format(line))
40
41 if os.path.exists("/overrides/postfix.master"):
42 for line in open("/overrides/postfix.master").read().strip().split("\n"):
43 os.system('postconf -Me "{}"'.format(line))
44
45 for map_file in glob.glob("/overrides/*.map"):
46 destination = os.path.join("/etc/postfix", os.path.basename(map_file))
47 shutil.copyfile(map_file, destination)
48 os.system("postmap {}".format(destination))
49 os.remove(destination)
50
51 if "RELAYUSER" in os.environ:
52 path = "/etc/postfix/sasl_passwd"
53 convert("/conf/sasl_passwd", path)
54 os.system("postmap {}".format(path))
55
56 convert("/conf/rsyslog.conf", "/etc/rsyslog.conf")
57
58 # Run Podop and Postfix
59 multiprocessing.Process(target=start_podop).start()
60 if os.path.exists("/var/run/rsyslogd.pid"):
61 os.remove("/var/run/rsyslogd.pid")
62 os.system("/usr/lib/postfix/post-install meta_directory=/etc/postfix create-missing")
63 os.system("/usr/lib/postfix/master &")
64 os.execv("/usr/sbin/rsyslogd", ["rsyslogd", "-n"])
65
[end of core/postfix/start.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/core/postfix/start.py b/core/postfix/start.py
--- a/core/postfix/start.py
+++ b/core/postfix/start.py
@@ -53,12 +53,7 @@
convert("/conf/sasl_passwd", path)
os.system("postmap {}".format(path))
-convert("/conf/rsyslog.conf", "/etc/rsyslog.conf")
-
# Run Podop and Postfix
multiprocessing.Process(target=start_podop).start()
-if os.path.exists("/var/run/rsyslogd.pid"):
- os.remove("/var/run/rsyslogd.pid")
-os.system("/usr/lib/postfix/post-install meta_directory=/etc/postfix create-missing")
-os.system("/usr/lib/postfix/master &")
-os.execv("/usr/sbin/rsyslogd", ["rsyslogd", "-n"])
+os.system("/usr/libexec/postfix/post-install meta_directory=/etc/postfix create-missing")
+os.system("postfix start-fg")
|
{"golden_diff": "diff --git a/core/postfix/start.py b/core/postfix/start.py\n--- a/core/postfix/start.py\n+++ b/core/postfix/start.py\n@@ -53,12 +53,7 @@\n convert(\"/conf/sasl_passwd\", path)\n os.system(\"postmap {}\".format(path))\n \n-convert(\"/conf/rsyslog.conf\", \"/etc/rsyslog.conf\")\n-\n # Run Podop and Postfix\n multiprocessing.Process(target=start_podop).start()\n-if os.path.exists(\"/var/run/rsyslogd.pid\"):\n- os.remove(\"/var/run/rsyslogd.pid\")\n-os.system(\"/usr/lib/postfix/post-install meta_directory=/etc/postfix create-missing\")\n-os.system(\"/usr/lib/postfix/master &\")\n-os.execv(\"/usr/sbin/rsyslogd\", [\"rsyslogd\", \"-n\"])\n+os.system(\"/usr/libexec/postfix/post-install meta_directory=/etc/postfix create-missing\")\n+os.system(\"postfix start-fg\")\n", "issue": "Regular alpine base-image update\nTo receive current updates for upstream projects, security fixes and new features such as mentioned in #1049 , let\u2019s upgrade the alpine baseimage to latest 3.10\n", "before_files": [{"content": "#!/usr/bin/python3\n\nimport os\nimport glob\nimport shutil\nimport multiprocessing\nimport logging as log\nimport sys\nfrom mailustart import resolve, convert\n\nfrom podop import run_server\n\nlog.basicConfig(stream=sys.stderr, level=os.environ.get(\"LOG_LEVEL\", \"WARNING\"))\n\ndef start_podop():\n os.setuid(100)\n url = \"http://\" + os.environ[\"ADMIN_ADDRESS\"] + \"/internal/postfix/\"\n # TODO: Remove verbosity setting from Podop?\n run_server(0, \"postfix\", \"/tmp/podop.socket\", [\n\t\t(\"transport\", \"url\", url + \"transport/\u00a7\"),\n\t\t(\"alias\", \"url\", url + \"alias/\u00a7\"),\n\t\t(\"domain\", \"url\", url + \"domain/\u00a7\"),\n (\"mailbox\", \"url\", url + \"mailbox/\u00a7\"),\n (\"senderaccess\", \"url\", url + \"sender/access/\u00a7\"),\n (\"senderlogin\", \"url\", url + \"sender/login/\u00a7\")\n ])\n\n# Actual startup script\nos.environ[\"FRONT_ADDRESS\"] = resolve(os.environ.get(\"FRONT_ADDRESS\", \"front\"))\nos.environ[\"ADMIN_ADDRESS\"] = resolve(os.environ.get(\"ADMIN_ADDRESS\", \"admin\"))\nos.environ[\"HOST_ANTISPAM\"] = resolve(os.environ.get(\"HOST_ANTISPAM\", \"antispam:11332\"))\nos.environ[\"HOST_LMTP\"] = resolve(os.environ.get(\"HOST_LMTP\", \"imap:2525\"))\n\nfor postfix_file in glob.glob(\"/conf/*.cf\"):\n convert(postfix_file, os.path.join(\"/etc/postfix\", os.path.basename(postfix_file)))\n\nif os.path.exists(\"/overrides/postfix.cf\"):\n for line in open(\"/overrides/postfix.cf\").read().strip().split(\"\\n\"):\n os.system('postconf -e \"{}\"'.format(line))\n\nif os.path.exists(\"/overrides/postfix.master\"):\n for line in open(\"/overrides/postfix.master\").read().strip().split(\"\\n\"):\n os.system('postconf -Me \"{}\"'.format(line))\n\nfor map_file in glob.glob(\"/overrides/*.map\"):\n destination = os.path.join(\"/etc/postfix\", os.path.basename(map_file))\n shutil.copyfile(map_file, destination)\n os.system(\"postmap {}\".format(destination))\n os.remove(destination)\n\nif \"RELAYUSER\" in os.environ:\n path = \"/etc/postfix/sasl_passwd\"\n convert(\"/conf/sasl_passwd\", path)\n os.system(\"postmap {}\".format(path))\n\nconvert(\"/conf/rsyslog.conf\", \"/etc/rsyslog.conf\")\n\n# Run Podop and Postfix\nmultiprocessing.Process(target=start_podop).start()\nif os.path.exists(\"/var/run/rsyslogd.pid\"):\n os.remove(\"/var/run/rsyslogd.pid\")\nos.system(\"/usr/lib/postfix/post-install meta_directory=/etc/postfix create-missing\")\nos.system(\"/usr/lib/postfix/master &\")\nos.execv(\"/usr/sbin/rsyslogd\", [\"rsyslogd\", \"-n\"])\n", "path": "core/postfix/start.py"}]}
| 1,347 | 207 |
gh_patches_debug_8478
|
rasdani/github-patches
|
git_diff
|
ocf__ocfweb-535
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
versioned caching is broken
On [this line](https://github.com/ocf/ocfweb/blob/e0ca5b9053abf4908fd6dd3ff344724e61c38b53/ocfweb/environment.py#L15) we use a marathon environment variable to determine the cache version. We need to change this to use a Kubernetes things, a la
https://kubernetes.io/docs/tasks/inject-data-application/environment-variable-expose-pod-information/.
</issue>
<code>
[start of ocfweb/environment.py]
1 """Introspection into the current environment."""
2 import os
3 from functools import lru_cache
4
5
6 @lru_cache()
7 def ocfweb_version():
8 """Return string representing ocfweb version.
9
10 In dev, returns 'dev'. In prod, returns a version
11 similar to '2015.12.06.02.25-gitb98c8cb6'.
12 """
13 # On Marathon, read it out of environ
14 try:
15 docker_image, tag = os.environ['MARATHON_APP_DOCKER_IMAGE'].split(':', 1)
16 return tag
17 except KeyError:
18 pass
19
20 # Otherwise, we must be in dev.
21 return 'dev'
22
[end of ocfweb/environment.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ocfweb/environment.py b/ocfweb/environment.py
--- a/ocfweb/environment.py
+++ b/ocfweb/environment.py
@@ -8,12 +8,11 @@
"""Return string representing ocfweb version.
In dev, returns 'dev'. In prod, returns a version
- similar to '2015.12.06.02.25-gitb98c8cb6'.
+ similar to '2019-08-20-T21-10-57-gite0ca5b9'.
"""
- # On Marathon, read it out of environ
+ # On Kubernetes, read it out of environ
try:
- docker_image, tag = os.environ['MARATHON_APP_DOCKER_IMAGE'].split(':', 1)
- return tag
+ return os.environ['OCFWEB_PROD_VERSION']
except KeyError:
pass
|
{"golden_diff": "diff --git a/ocfweb/environment.py b/ocfweb/environment.py\n--- a/ocfweb/environment.py\n+++ b/ocfweb/environment.py\n@@ -8,12 +8,11 @@\n \"\"\"Return string representing ocfweb version.\n \n In dev, returns 'dev'. In prod, returns a version\n- similar to '2015.12.06.02.25-gitb98c8cb6'.\n+ similar to '2019-08-20-T21-10-57-gite0ca5b9'.\n \"\"\"\n- # On Marathon, read it out of environ\n+ # On Kubernetes, read it out of environ\n try:\n- docker_image, tag = os.environ['MARATHON_APP_DOCKER_IMAGE'].split(':', 1)\n- return tag\n+ return os.environ['OCFWEB_PROD_VERSION']\n except KeyError:\n pass\n", "issue": "versioned caching is broken\nOn [this line](https://github.com/ocf/ocfweb/blob/e0ca5b9053abf4908fd6dd3ff344724e61c38b53/ocfweb/environment.py#L15) we use a marathon environment variable to determine the cache version. We need to change this to use a Kubernetes things, a la \r\nhttps://kubernetes.io/docs/tasks/inject-data-application/environment-variable-expose-pod-information/.\n", "before_files": [{"content": "\"\"\"Introspection into the current environment.\"\"\"\nimport os\nfrom functools import lru_cache\n\n\n@lru_cache()\ndef ocfweb_version():\n \"\"\"Return string representing ocfweb version.\n\n In dev, returns 'dev'. In prod, returns a version\n similar to '2015.12.06.02.25-gitb98c8cb6'.\n \"\"\"\n # On Marathon, read it out of environ\n try:\n docker_image, tag = os.environ['MARATHON_APP_DOCKER_IMAGE'].split(':', 1)\n return tag\n except KeyError:\n pass\n\n # Otherwise, we must be in dev.\n return 'dev'\n", "path": "ocfweb/environment.py"}]}
| 838 | 214 |
gh_patches_debug_6883
|
rasdani/github-patches
|
git_diff
|
shuup__shuup-1573
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Admin: Fix category name in category edit view
Do not show the category with hierarchy on breadcrumbs and title

</issue>
<code>
[start of shuup/admin/modules/categories/views/edit.py]
1 # -*- coding: utf-8 -*-
2 # This file is part of Shuup.
3 #
4 # Copyright (c) 2012-2018, Shuup Inc. All rights reserved.
5 #
6 # This source code is licensed under the OSL-3.0 license found in the
7 # LICENSE file in the root directory of this source tree.
8 from django.core.urlresolvers import reverse_lazy
9
10 from shuup.admin.form_part import FormPartsViewMixin, SaveFormPartsMixin
11 from shuup.admin.modules.categories.form_parts import (
12 CategoryBaseFormPart, CategoryProductFormPart
13 )
14 from shuup.admin.shop_provider import get_shop
15 from shuup.admin.toolbar import get_default_edit_toolbar
16 from shuup.admin.utils.tour import is_tour_complete
17 from shuup.admin.utils.views import CreateOrUpdateView
18 from shuup.core.models import Category
19
20
21 class CategoryEditView(SaveFormPartsMixin, FormPartsViewMixin, CreateOrUpdateView):
22 model = Category
23 template_name = "shuup/admin/categories/edit.jinja"
24 context_object_name = "category"
25 base_form_part_classes = [CategoryBaseFormPart, CategoryProductFormPart]
26 form_part_class_provide_key = "admin_category_form_part"
27
28 def get_toolbar(self):
29 save_form_id = self.get_save_form_id()
30 object = self.get_object()
31 delete_url = reverse_lazy("shuup_admin:category.delete", kwargs={"pk": object.pk}) if object.pk else None
32 return get_default_edit_toolbar(self, save_form_id, delete_url=delete_url)
33
34 def get_context_data(self, **kwargs):
35 context = super(CategoryEditView, self).get_context_data(**kwargs)
36 context["tour_key"] = "category"
37 context["tour_complete"] = is_tour_complete(get_shop(self.request), "category")
38 return context
39
40 def form_valid(self, form):
41 return self.save_form_parts(form)
42
43 def get_queryset(self):
44 return Category.objects.all_except_deleted(shop=get_shop(self.request))
45
[end of shuup/admin/modules/categories/views/edit.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/shuup/admin/modules/categories/views/edit.py b/shuup/admin/modules/categories/views/edit.py
--- a/shuup/admin/modules/categories/views/edit.py
+++ b/shuup/admin/modules/categories/views/edit.py
@@ -35,6 +35,9 @@
context = super(CategoryEditView, self).get_context_data(**kwargs)
context["tour_key"] = "category"
context["tour_complete"] = is_tour_complete(get_shop(self.request), "category")
+ if self.object.pk:
+ context["title"] = self.object.name
+
return context
def form_valid(self, form):
|
{"golden_diff": "diff --git a/shuup/admin/modules/categories/views/edit.py b/shuup/admin/modules/categories/views/edit.py\n--- a/shuup/admin/modules/categories/views/edit.py\n+++ b/shuup/admin/modules/categories/views/edit.py\n@@ -35,6 +35,9 @@\n context = super(CategoryEditView, self).get_context_data(**kwargs)\n context[\"tour_key\"] = \"category\"\n context[\"tour_complete\"] = is_tour_complete(get_shop(self.request), \"category\")\n+ if self.object.pk:\n+ context[\"title\"] = self.object.name\n+\n return context\n \n def form_valid(self, form):\n", "issue": "Admin: Fix category name in category edit view\nDo not show the category with hierarchy on breadcrumbs and title\r\n\r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# This file is part of Shuup.\n#\n# Copyright (c) 2012-2018, Shuup Inc. All rights reserved.\n#\n# This source code is licensed under the OSL-3.0 license found in the\n# LICENSE file in the root directory of this source tree.\nfrom django.core.urlresolvers import reverse_lazy\n\nfrom shuup.admin.form_part import FormPartsViewMixin, SaveFormPartsMixin\nfrom shuup.admin.modules.categories.form_parts import (\n CategoryBaseFormPart, CategoryProductFormPart\n)\nfrom shuup.admin.shop_provider import get_shop\nfrom shuup.admin.toolbar import get_default_edit_toolbar\nfrom shuup.admin.utils.tour import is_tour_complete\nfrom shuup.admin.utils.views import CreateOrUpdateView\nfrom shuup.core.models import Category\n\n\nclass CategoryEditView(SaveFormPartsMixin, FormPartsViewMixin, CreateOrUpdateView):\n model = Category\n template_name = \"shuup/admin/categories/edit.jinja\"\n context_object_name = \"category\"\n base_form_part_classes = [CategoryBaseFormPart, CategoryProductFormPart]\n form_part_class_provide_key = \"admin_category_form_part\"\n\n def get_toolbar(self):\n save_form_id = self.get_save_form_id()\n object = self.get_object()\n delete_url = reverse_lazy(\"shuup_admin:category.delete\", kwargs={\"pk\": object.pk}) if object.pk else None\n return get_default_edit_toolbar(self, save_form_id, delete_url=delete_url)\n\n def get_context_data(self, **kwargs):\n context = super(CategoryEditView, self).get_context_data(**kwargs)\n context[\"tour_key\"] = \"category\"\n context[\"tour_complete\"] = is_tour_complete(get_shop(self.request), \"category\")\n return context\n\n def form_valid(self, form):\n return self.save_form_parts(form)\n\n def get_queryset(self):\n return Category.objects.all_except_deleted(shop=get_shop(self.request))\n", "path": "shuup/admin/modules/categories/views/edit.py"}]}
| 1,144 | 137 |
gh_patches_debug_34446
|
rasdani/github-patches
|
git_diff
|
litestar-org__litestar-1255
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bug: Issue with reload
**Describe the bug**
When I start my app using starlite run -r I get the following error
INFO: Will watch for changes in these directories: ['/Users/alc/starlite-apps/starlite_test']
ERROR: [Errno 48] Address already in use
If I stop that and run it without -r it works, so I guess my port is not blocked
**To Reproduce**
Save this as `app.py`
```python
from starlite import get, Starlite
@get('/')
def route() -> str:
return 'Hello'
app = Starlite([route])
```
**Additional context**
@provinzkraut in discord help suggested a workaround using ` uvicorn <app file>:<application object> --reload` and also linked https://github.com/encode/uvicorn/issues/1045
</issue>
<code>
[start of starlite/cli/commands/core.py]
1 from __future__ import annotations
2
3 import inspect
4 import multiprocessing
5
6 import click
7 from click import command, option
8 from rich.tree import Tree
9
10 from starlite import Starlite
11 from starlite.cli.utils import StarliteCLIException, StarliteEnv, console, show_app_info
12 from starlite.routes import HTTPRoute, WebSocketRoute
13 from starlite.utils.helpers import unwrap_partial
14
15
16 @command(name="info")
17 def info_command(app: Starlite) -> None:
18 """Show information about the detected Starlite app."""
19
20 show_app_info(app)
21
22
23 @command(name="run")
24 @option("-r", "--reload", help="Reload server on changes", default=False, is_flag=True)
25 @option("-p", "--port", help="Serve under this port", type=int, default=8000, show_default=True)
26 @option(
27 "-wc",
28 "--web-concurrency",
29 help="The number of HTTP workers to launch",
30 type=click.IntRange(min=1, max=multiprocessing.cpu_count() + 1),
31 show_default=True,
32 default=1,
33 )
34 @option("--host", help="Server under this host", default="127.0.0.1", show_default=True)
35 @option("--debug", help="Run app in debug mode", is_flag=True)
36 def run_command(
37 reload: bool,
38 port: int,
39 web_concurrency: int,
40 host: str,
41 debug: bool,
42 env: StarliteEnv,
43 app: Starlite,
44 ) -> None:
45 """Run a Starlite app.
46
47 The app can be either passed as a module path in the form of <module name>.<submodule>:<app instance or factory>,
48 set as an environment variable STARLITE_APP with the same format or automatically discovered from one of these
49 canonical paths: app.py, asgi.py, application.py or app/__init__.py. When auto-discovering application factories,
50 functions with the name ``create_app`` are considered, or functions that are annotated as returning a ``Starlite``
51 instance.
52 """
53
54 try:
55 import uvicorn
56 except ImportError:
57 raise StarliteCLIException("Uvicorn needs to be installed to run an app") # pylint: disable=W0707
58
59 if debug or env.debug:
60 app.debug = True
61
62 show_app_info(app)
63
64 console.rule("[yellow]Starting server process", align="left")
65
66 uvicorn.run(
67 env.app_path,
68 reload=env.reload or reload,
69 host=env.host or host,
70 port=env.port or port,
71 workers=env.web_concurrency or web_concurrency,
72 factory=env.is_app_factory,
73 )
74
75
76 @command(name="routes")
77 def routes_command(app: Starlite) -> None: # pragma: no cover
78 """Display information about the application's routes."""
79
80 tree = Tree("", hide_root=True)
81
82 for route in sorted(app.routes, key=lambda r: r.path):
83 if isinstance(route, HTTPRoute):
84 branch = tree.add(f"[green]{route.path}[/green] (HTTP)")
85 for handler in route.route_handlers:
86 handler_info = [
87 f"[blue]{handler.name or handler.handler_name}[/blue]",
88 ]
89
90 if inspect.iscoroutinefunction(unwrap_partial(handler.fn.value)):
91 handler_info.append("[magenta]async[/magenta]")
92 else:
93 handler_info.append("[yellow]sync[/yellow]")
94
95 handler_info.append(f'[cyan]{", ".join(sorted(handler.http_methods))}[/cyan]')
96
97 if len(handler.paths) > 1:
98 for path in handler.paths:
99 branch.add(" ".join([f"[green]{path}[green]", *handler_info]))
100 else:
101 branch.add(" ".join(handler_info))
102
103 else:
104 if isinstance(route, WebSocketRoute):
105 route_type = "WS"
106 else:
107 route_type = "ASGI"
108 branch = tree.add(f"[green]{route.path}[/green] ({route_type})")
109 branch.add(f"[blue]{route.route_handler.name or route.route_handler.handler_name}[/blue]")
110
111 console.print(tree)
112
[end of starlite/cli/commands/core.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/starlite/cli/commands/core.py b/starlite/cli/commands/core.py
--- a/starlite/cli/commands/core.py
+++ b/starlite/cli/commands/core.py
@@ -2,17 +2,31 @@
import inspect
import multiprocessing
+import subprocess
+from typing import Any
import click
from click import command, option
from rich.tree import Tree
from starlite import Starlite
-from starlite.cli.utils import StarliteCLIException, StarliteEnv, console, show_app_info
+from starlite.cli.utils import StarliteEnv, console, show_app_info
from starlite.routes import HTTPRoute, WebSocketRoute
from starlite.utils.helpers import unwrap_partial
+def _convert_uvicorn_args(args: dict[str, Any]) -> list[str]:
+ process_args = []
+ for arg, value in args.items():
+ if isinstance(value, bool):
+ if value:
+ process_args.append(f"--{arg}")
+ else:
+ process_args.append(f"--{arg}={value}")
+
+ return process_args
+
+
@command(name="info")
def info_command(app: Starlite) -> None:
"""Show information about the detected Starlite app."""
@@ -51,11 +65,6 @@
instance.
"""
- try:
- import uvicorn
- except ImportError:
- raise StarliteCLIException("Uvicorn needs to be installed to run an app") # pylint: disable=W0707
-
if debug or env.debug:
app.debug = True
@@ -63,14 +72,18 @@
console.rule("[yellow]Starting server process", align="left")
- uvicorn.run(
- env.app_path,
- reload=env.reload or reload,
- host=env.host or host,
- port=env.port or port,
- workers=env.web_concurrency or web_concurrency,
- factory=env.is_app_factory,
- )
+ # invoke uvicorn in a subprocess to be able to use the --reload flag. see
+ # https://github.com/starlite-api/starlite/issues/1191 and https://github.com/encode/uvicorn/issues/1045
+
+ process_args = {
+ "reload": env.reload or reload,
+ "host": env.host or host,
+ "port": env.port or port,
+ "workers": env.web_concurrency or web_concurrency,
+ "factory": env.is_app_factory,
+ }
+
+ subprocess.run(["uvicorn", env.app_path, *_convert_uvicorn_args(process_args)], check=True)
@command(name="routes")
|
{"golden_diff": "diff --git a/starlite/cli/commands/core.py b/starlite/cli/commands/core.py\n--- a/starlite/cli/commands/core.py\n+++ b/starlite/cli/commands/core.py\n@@ -2,17 +2,31 @@\n \n import inspect\n import multiprocessing\n+import subprocess\n+from typing import Any\n \n import click\n from click import command, option\n from rich.tree import Tree\n \n from starlite import Starlite\n-from starlite.cli.utils import StarliteCLIException, StarliteEnv, console, show_app_info\n+from starlite.cli.utils import StarliteEnv, console, show_app_info\n from starlite.routes import HTTPRoute, WebSocketRoute\n from starlite.utils.helpers import unwrap_partial\n \n \n+def _convert_uvicorn_args(args: dict[str, Any]) -> list[str]:\n+ process_args = []\n+ for arg, value in args.items():\n+ if isinstance(value, bool):\n+ if value:\n+ process_args.append(f\"--{arg}\")\n+ else:\n+ process_args.append(f\"--{arg}={value}\")\n+\n+ return process_args\n+\n+\n @command(name=\"info\")\n def info_command(app: Starlite) -> None:\n \"\"\"Show information about the detected Starlite app.\"\"\"\n@@ -51,11 +65,6 @@\n instance.\n \"\"\"\n \n- try:\n- import uvicorn\n- except ImportError:\n- raise StarliteCLIException(\"Uvicorn needs to be installed to run an app\") # pylint: disable=W0707\n-\n if debug or env.debug:\n app.debug = True\n \n@@ -63,14 +72,18 @@\n \n console.rule(\"[yellow]Starting server process\", align=\"left\")\n \n- uvicorn.run(\n- env.app_path,\n- reload=env.reload or reload,\n- host=env.host or host,\n- port=env.port or port,\n- workers=env.web_concurrency or web_concurrency,\n- factory=env.is_app_factory,\n- )\n+ # invoke uvicorn in a subprocess to be able to use the --reload flag. see\n+ # https://github.com/starlite-api/starlite/issues/1191 and https://github.com/encode/uvicorn/issues/1045\n+\n+ process_args = {\n+ \"reload\": env.reload or reload,\n+ \"host\": env.host or host,\n+ \"port\": env.port or port,\n+ \"workers\": env.web_concurrency or web_concurrency,\n+ \"factory\": env.is_app_factory,\n+ }\n+\n+ subprocess.run([\"uvicorn\", env.app_path, *_convert_uvicorn_args(process_args)], check=True)\n \n \n @command(name=\"routes\")\n", "issue": "Bug: Issue with reload\n**Describe the bug**\r\nWhen I start my app using starlite run -r I get the following error\r\n\r\nINFO: Will watch for changes in these directories: ['/Users/alc/starlite-apps/starlite_test']\r\nERROR: [Errno 48] Address already in use\r\n\r\nIf I stop that and run it without -r it works, so I guess my port is not blocked\r\n\r\n**To Reproduce**\r\nSave this as `app.py`\r\n\r\n```python\r\nfrom starlite import get, Starlite\r\n\r\n@get('/')\r\ndef route() -> str:\r\n return 'Hello'\r\n\r\napp = Starlite([route])\r\n```\r\n\r\n**Additional context**\r\n@provinzkraut in discord help suggested a workaround using ` uvicorn <app file>:<application object> --reload` and also linked https://github.com/encode/uvicorn/issues/1045\r\n\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nimport inspect\nimport multiprocessing\n\nimport click\nfrom click import command, option\nfrom rich.tree import Tree\n\nfrom starlite import Starlite\nfrom starlite.cli.utils import StarliteCLIException, StarliteEnv, console, show_app_info\nfrom starlite.routes import HTTPRoute, WebSocketRoute\nfrom starlite.utils.helpers import unwrap_partial\n\n\n@command(name=\"info\")\ndef info_command(app: Starlite) -> None:\n \"\"\"Show information about the detected Starlite app.\"\"\"\n\n show_app_info(app)\n\n\n@command(name=\"run\")\n@option(\"-r\", \"--reload\", help=\"Reload server on changes\", default=False, is_flag=True)\n@option(\"-p\", \"--port\", help=\"Serve under this port\", type=int, default=8000, show_default=True)\n@option(\n \"-wc\",\n \"--web-concurrency\",\n help=\"The number of HTTP workers to launch\",\n type=click.IntRange(min=1, max=multiprocessing.cpu_count() + 1),\n show_default=True,\n default=1,\n)\n@option(\"--host\", help=\"Server under this host\", default=\"127.0.0.1\", show_default=True)\n@option(\"--debug\", help=\"Run app in debug mode\", is_flag=True)\ndef run_command(\n reload: bool,\n port: int,\n web_concurrency: int,\n host: str,\n debug: bool,\n env: StarliteEnv,\n app: Starlite,\n) -> None:\n \"\"\"Run a Starlite app.\n\n The app can be either passed as a module path in the form of <module name>.<submodule>:<app instance or factory>,\n set as an environment variable STARLITE_APP with the same format or automatically discovered from one of these\n canonical paths: app.py, asgi.py, application.py or app/__init__.py. When auto-discovering application factories,\n functions with the name ``create_app`` are considered, or functions that are annotated as returning a ``Starlite``\n instance.\n \"\"\"\n\n try:\n import uvicorn\n except ImportError:\n raise StarliteCLIException(\"Uvicorn needs to be installed to run an app\") # pylint: disable=W0707\n\n if debug or env.debug:\n app.debug = True\n\n show_app_info(app)\n\n console.rule(\"[yellow]Starting server process\", align=\"left\")\n\n uvicorn.run(\n env.app_path,\n reload=env.reload or reload,\n host=env.host or host,\n port=env.port or port,\n workers=env.web_concurrency or web_concurrency,\n factory=env.is_app_factory,\n )\n\n\n@command(name=\"routes\")\ndef routes_command(app: Starlite) -> None: # pragma: no cover\n \"\"\"Display information about the application's routes.\"\"\"\n\n tree = Tree(\"\", hide_root=True)\n\n for route in sorted(app.routes, key=lambda r: r.path):\n if isinstance(route, HTTPRoute):\n branch = tree.add(f\"[green]{route.path}[/green] (HTTP)\")\n for handler in route.route_handlers:\n handler_info = [\n f\"[blue]{handler.name or handler.handler_name}[/blue]\",\n ]\n\n if inspect.iscoroutinefunction(unwrap_partial(handler.fn.value)):\n handler_info.append(\"[magenta]async[/magenta]\")\n else:\n handler_info.append(\"[yellow]sync[/yellow]\")\n\n handler_info.append(f'[cyan]{\", \".join(sorted(handler.http_methods))}[/cyan]')\n\n if len(handler.paths) > 1:\n for path in handler.paths:\n branch.add(\" \".join([f\"[green]{path}[green]\", *handler_info]))\n else:\n branch.add(\" \".join(handler_info))\n\n else:\n if isinstance(route, WebSocketRoute):\n route_type = \"WS\"\n else:\n route_type = \"ASGI\"\n branch = tree.add(f\"[green]{route.path}[/green] ({route_type})\")\n branch.add(f\"[blue]{route.route_handler.name or route.route_handler.handler_name}[/blue]\")\n\n console.print(tree)\n", "path": "starlite/cli/commands/core.py"}]}
| 1,841 | 589 |
gh_patches_debug_38540
|
rasdani/github-patches
|
git_diff
|
adap__flower-458
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Improve docstring for `start_keras_client`
</issue>
<code>
[start of src/py/flwr/common/__init__.py]
1 # Copyright 2020 Adap GmbH. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ==============================================================================
15 """Flower utilities shared between server and client."""
16
17
18 from .parameter import bytes_to_ndarray as bytes_to_ndarray
19 from .parameter import ndarray_to_bytes as ndarray_to_bytes
20 from .parameter import parameters_to_weights as parameters_to_weights
21 from .parameter import weights_to_parameters as weights_to_parameters
22 from .typing import Disconnect as Disconnect
23 from .typing import EvaluateIns as EvaluateIns
24 from .typing import EvaluateRes as EvaluateRes
25 from .typing import FitIns as FitIns
26 from .typing import FitRes as FitRes
27 from .typing import Parameters as Parameters
28 from .typing import ParametersRes as ParametersRes
29 from .typing import Reconnect as Reconnect
30 from .typing import Weights as Weights
31
32 GRPC_MAX_MESSAGE_LENGTH: int = 536870912 # == 512 * 1024 * 1024
33
34 __all__ = [
35 "bytes_to_ndarray",
36 "Disconnect",
37 "EvaluateIns",
38 "EvaluateRes",
39 "FitIns",
40 "FitRes",
41 "GRPC_MAX_MESSAGE_LENGTH",
42 "ndarray_to_bytes",
43 "Parameters",
44 "parameters_to_weights",
45 "ParametersRes",
46 "Reconnect",
47 "Weights",
48 "weights_to_parameters",
49 ]
50
[end of src/py/flwr/common/__init__.py]
[start of src/py/flwr/client/app.py]
1 # Copyright 2020 Adap GmbH. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ==============================================================================
15 """Flower client app."""
16
17
18 import time
19 from logging import INFO
20
21 from flwr.common import GRPC_MAX_MESSAGE_LENGTH
22 from flwr.common.logger import log
23
24 from .client import Client
25 from .grpc_client.connection import insecure_grpc_connection
26 from .grpc_client.message_handler import handle
27 from .keras_client import KerasClient, KerasClientWrapper
28
29
30 def start_client(
31 server_address: str,
32 client: Client,
33 grpc_max_message_length: int = GRPC_MAX_MESSAGE_LENGTH,
34 ) -> None:
35 """Start a Flower Client which connects to a gRPC server."""
36 while True:
37 sleep_duration: int = 0
38 with insecure_grpc_connection(
39 server_address, max_message_length=grpc_max_message_length
40 ) as conn:
41 receive, send = conn
42 log(INFO, "Opened (insecure) gRPC connection")
43
44 while True:
45 server_message = receive()
46 client_message, sleep_duration, keep_going = handle(
47 client, server_message
48 )
49 send(client_message)
50 if not keep_going:
51 break
52 if sleep_duration == 0:
53 log(INFO, "Disconnect and shut down")
54 break
55 # Sleep and reconnect afterwards
56 log(
57 INFO,
58 "Disconnect, then re-establish connection after %s second(s)",
59 sleep_duration,
60 )
61 time.sleep(sleep_duration)
62
63
64 def start_keras_client(server_address: str, client: KerasClient) -> None:
65 """Start a Flower KerasClient which connects to a gRPC server."""
66
67 # Wrap the Keras client
68 flower_client = KerasClientWrapper(client)
69
70 # Start
71 start_client(server_address, flower_client)
72
[end of src/py/flwr/client/app.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/py/flwr/client/app.py b/src/py/flwr/client/app.py
--- a/src/py/flwr/client/app.py
+++ b/src/py/flwr/client/app.py
@@ -32,7 +32,25 @@
client: Client,
grpc_max_message_length: int = GRPC_MAX_MESSAGE_LENGTH,
) -> None:
- """Start a Flower Client which connects to a gRPC server."""
+ """Start a Flower Client which connects to a gRPC server.
+
+ Arguments:
+ server_address: str. The IPv6 address of the server. If the Flower
+ server runs on the same machine on port 8080, then `server_address`
+ would be `"[::]:8080"`.
+ client: flwr.client.Client. An implementation of the abstract base
+ class `flwr.client.Client`.
+ grpc_max_message_length: int (default: 536_870_912, this equals 512MB).
+ The maximum length of gRPC messages that can be exchanged with the
+ Flower server. The default should be sufficient for most models.
+ Users who train very large models might need to increase this
+ value. Note that the Flower server needs to started with the same
+ value (see `flwr.server.start_server`), otherwise it will not know
+ about the increased limit and block larger messages.
+
+ Returns:
+ None.
+ """
while True:
sleep_duration: int = 0
with insecure_grpc_connection(
@@ -61,11 +79,37 @@
time.sleep(sleep_duration)
-def start_keras_client(server_address: str, client: KerasClient) -> None:
- """Start a Flower KerasClient which connects to a gRPC server."""
+def start_keras_client(
+ server_address: str,
+ client: KerasClient,
+ grpc_max_message_length: int = GRPC_MAX_MESSAGE_LENGTH,
+) -> None:
+ """Start a Flower KerasClient which connects to a gRPC server.
+
+ Arguments:
+ server_address: str. The IPv6 address of the server. If the Flower
+ server runs on the same machine on port 8080, then `server_address`
+ would be `"[::]:8080"`.
+ client: flwr.client.KerasClient. An implementation of the abstract base
+ class `flwr.client.KerasClient`.
+ grpc_max_message_length: int (default: 536_870_912, this equals 512MB).
+ The maximum length of gRPC messages that can be exchanged with the
+ Flower server. The default should be sufficient for most models.
+ Users who train very large models might need to increase this
+ value. Note that the Flower server needs to started with the same
+ value (see `flwr.server.start_server`), otherwise it will not know
+ about the increased limit and block larger messages.
+
+ Returns:
+ None.
+ """
# Wrap the Keras client
flower_client = KerasClientWrapper(client)
# Start
- start_client(server_address, flower_client)
+ start_client(
+ server_address=server_address,
+ client=flower_client,
+ grpc_max_message_length=grpc_max_message_length,
+ )
diff --git a/src/py/flwr/common/__init__.py b/src/py/flwr/common/__init__.py
--- a/src/py/flwr/common/__init__.py
+++ b/src/py/flwr/common/__init__.py
@@ -29,7 +29,7 @@
from .typing import Reconnect as Reconnect
from .typing import Weights as Weights
-GRPC_MAX_MESSAGE_LENGTH: int = 536870912 # == 512 * 1024 * 1024
+GRPC_MAX_MESSAGE_LENGTH: int = 536_870_912 # == 512 * 1024 * 1024
__all__ = [
"bytes_to_ndarray",
|
{"golden_diff": "diff --git a/src/py/flwr/client/app.py b/src/py/flwr/client/app.py\n--- a/src/py/flwr/client/app.py\n+++ b/src/py/flwr/client/app.py\n@@ -32,7 +32,25 @@\n client: Client,\n grpc_max_message_length: int = GRPC_MAX_MESSAGE_LENGTH,\n ) -> None:\n- \"\"\"Start a Flower Client which connects to a gRPC server.\"\"\"\n+ \"\"\"Start a Flower Client which connects to a gRPC server.\n+\n+ Arguments:\n+ server_address: str. The IPv6 address of the server. If the Flower\n+ server runs on the same machine on port 8080, then `server_address`\n+ would be `\"[::]:8080\"`.\n+ client: flwr.client.Client. An implementation of the abstract base\n+ class `flwr.client.Client`.\n+ grpc_max_message_length: int (default: 536_870_912, this equals 512MB).\n+ The maximum length of gRPC messages that can be exchanged with the\n+ Flower server. The default should be sufficient for most models.\n+ Users who train very large models might need to increase this\n+ value. Note that the Flower server needs to started with the same\n+ value (see `flwr.server.start_server`), otherwise it will not know\n+ about the increased limit and block larger messages.\n+\n+ Returns:\n+ None.\n+ \"\"\"\n while True:\n sleep_duration: int = 0\n with insecure_grpc_connection(\n@@ -61,11 +79,37 @@\n time.sleep(sleep_duration)\n \n \n-def start_keras_client(server_address: str, client: KerasClient) -> None:\n- \"\"\"Start a Flower KerasClient which connects to a gRPC server.\"\"\"\n+def start_keras_client(\n+ server_address: str,\n+ client: KerasClient,\n+ grpc_max_message_length: int = GRPC_MAX_MESSAGE_LENGTH,\n+) -> None:\n+ \"\"\"Start a Flower KerasClient which connects to a gRPC server.\n+\n+ Arguments:\n+ server_address: str. The IPv6 address of the server. If the Flower\n+ server runs on the same machine on port 8080, then `server_address`\n+ would be `\"[::]:8080\"`.\n+ client: flwr.client.KerasClient. An implementation of the abstract base\n+ class `flwr.client.KerasClient`.\n+ grpc_max_message_length: int (default: 536_870_912, this equals 512MB).\n+ The maximum length of gRPC messages that can be exchanged with the\n+ Flower server. The default should be sufficient for most models.\n+ Users who train very large models might need to increase this\n+ value. Note that the Flower server needs to started with the same\n+ value (see `flwr.server.start_server`), otherwise it will not know\n+ about the increased limit and block larger messages.\n+\n+ Returns:\n+ None.\n+ \"\"\"\n \n # Wrap the Keras client\n flower_client = KerasClientWrapper(client)\n \n # Start\n- start_client(server_address, flower_client)\n+ start_client(\n+ server_address=server_address,\n+ client=flower_client,\n+ grpc_max_message_length=grpc_max_message_length,\n+ )\ndiff --git a/src/py/flwr/common/__init__.py b/src/py/flwr/common/__init__.py\n--- a/src/py/flwr/common/__init__.py\n+++ b/src/py/flwr/common/__init__.py\n@@ -29,7 +29,7 @@\n from .typing import Reconnect as Reconnect\n from .typing import Weights as Weights\n \n-GRPC_MAX_MESSAGE_LENGTH: int = 536870912 # == 512 * 1024 * 1024\n+GRPC_MAX_MESSAGE_LENGTH: int = 536_870_912 # == 512 * 1024 * 1024\n \n __all__ = [\n \"bytes_to_ndarray\",\n", "issue": "Improve docstring for `start_keras_client`\n\n", "before_files": [{"content": "# Copyright 2020 Adap GmbH. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"Flower utilities shared between server and client.\"\"\"\n\n\nfrom .parameter import bytes_to_ndarray as bytes_to_ndarray\nfrom .parameter import ndarray_to_bytes as ndarray_to_bytes\nfrom .parameter import parameters_to_weights as parameters_to_weights\nfrom .parameter import weights_to_parameters as weights_to_parameters\nfrom .typing import Disconnect as Disconnect\nfrom .typing import EvaluateIns as EvaluateIns\nfrom .typing import EvaluateRes as EvaluateRes\nfrom .typing import FitIns as FitIns\nfrom .typing import FitRes as FitRes\nfrom .typing import Parameters as Parameters\nfrom .typing import ParametersRes as ParametersRes\nfrom .typing import Reconnect as Reconnect\nfrom .typing import Weights as Weights\n\nGRPC_MAX_MESSAGE_LENGTH: int = 536870912 # == 512 * 1024 * 1024\n\n__all__ = [\n \"bytes_to_ndarray\",\n \"Disconnect\",\n \"EvaluateIns\",\n \"EvaluateRes\",\n \"FitIns\",\n \"FitRes\",\n \"GRPC_MAX_MESSAGE_LENGTH\",\n \"ndarray_to_bytes\",\n \"Parameters\",\n \"parameters_to_weights\",\n \"ParametersRes\",\n \"Reconnect\",\n \"Weights\",\n \"weights_to_parameters\",\n]\n", "path": "src/py/flwr/common/__init__.py"}, {"content": "# Copyright 2020 Adap GmbH. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"Flower client app.\"\"\"\n\n\nimport time\nfrom logging import INFO\n\nfrom flwr.common import GRPC_MAX_MESSAGE_LENGTH\nfrom flwr.common.logger import log\n\nfrom .client import Client\nfrom .grpc_client.connection import insecure_grpc_connection\nfrom .grpc_client.message_handler import handle\nfrom .keras_client import KerasClient, KerasClientWrapper\n\n\ndef start_client(\n server_address: str,\n client: Client,\n grpc_max_message_length: int = GRPC_MAX_MESSAGE_LENGTH,\n) -> None:\n \"\"\"Start a Flower Client which connects to a gRPC server.\"\"\"\n while True:\n sleep_duration: int = 0\n with insecure_grpc_connection(\n server_address, max_message_length=grpc_max_message_length\n ) as conn:\n receive, send = conn\n log(INFO, \"Opened (insecure) gRPC connection\")\n\n while True:\n server_message = receive()\n client_message, sleep_duration, keep_going = handle(\n client, server_message\n )\n send(client_message)\n if not keep_going:\n break\n if sleep_duration == 0:\n log(INFO, \"Disconnect and shut down\")\n break\n # Sleep and reconnect afterwards\n log(\n INFO,\n \"Disconnect, then re-establish connection after %s second(s)\",\n sleep_duration,\n )\n time.sleep(sleep_duration)\n\n\ndef start_keras_client(server_address: str, client: KerasClient) -> None:\n \"\"\"Start a Flower KerasClient which connects to a gRPC server.\"\"\"\n\n # Wrap the Keras client\n flower_client = KerasClientWrapper(client)\n\n # Start\n start_client(server_address, flower_client)\n", "path": "src/py/flwr/client/app.py"}]}
| 1,713 | 924 |
gh_patches_debug_6417
|
rasdani/github-patches
|
git_diff
|
kornia__kornia-694
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Broken link "InvDepthSmoothnessLoss"
## 📚 Documentation
In the documentation of this function https://kornia.readthedocs.io/en/latest/losses.html#kornia.losses.inverse_depth_smoothness_loss, the link is broken.
```See InvDepthSmoothnessLoss for details.```
The error is due to an incorrect name. The correct name should be `InverseDepthSmoothnessLoss`.
</issue>
<code>
[start of kornia/losses/depth_smooth.py]
1 import torch
2 import torch.nn as nn
3 import torch.nn.functional as F
4
5 # Based on
6 # https://github.com/tensorflow/models/blob/master/research/struct2depth/model.py#L625-L641
7
8
9 def _gradient_x(img: torch.Tensor) -> torch.Tensor:
10 assert len(img.shape) == 4, img.shape
11 return img[:, :, :, :-1] - img[:, :, :, 1:]
12
13
14 def _gradient_y(img: torch.Tensor) -> torch.Tensor:
15 assert len(img.shape) == 4, img.shape
16 return img[:, :, :-1, :] - img[:, :, 1:, :]
17
18
19 def inverse_depth_smoothness_loss(
20 idepth: torch.Tensor,
21 image: torch.Tensor) -> torch.Tensor:
22 r"""Computes image-aware inverse depth smoothness loss.
23
24 See :class:`~kornia.losses.InvDepthSmoothnessLoss` for details.
25 """
26 if not torch.is_tensor(idepth):
27 raise TypeError("Input idepth type is not a torch.Tensor. Got {}"
28 .format(type(idepth)))
29
30 if not torch.is_tensor(image):
31 raise TypeError("Input image type is not a torch.Tensor. Got {}"
32 .format(type(image)))
33
34 if not len(idepth.shape) == 4:
35 raise ValueError("Invalid idepth shape, we expect BxCxHxW. Got: {}"
36 .format(idepth.shape))
37
38 if not len(image.shape) == 4:
39 raise ValueError("Invalid image shape, we expect BxCxHxW. Got: {}"
40 .format(image.shape))
41
42 if not idepth.shape[-2:] == image.shape[-2:]:
43 raise ValueError("idepth and image shapes must be the same. Got: {} and {}"
44 .format(idepth.shape, image.shape))
45
46 if not idepth.device == image.device:
47 raise ValueError(
48 "idepth and image must be in the same device. Got: {} and {}" .format(
49 idepth.device, image.device))
50
51 if not idepth.dtype == image.dtype:
52 raise ValueError(
53 "idepth and image must be in the same dtype. Got: {} and {}" .format(
54 idepth.dtype, image.dtype))
55
56 # compute the gradients
57 idepth_dx: torch.Tensor = _gradient_x(idepth)
58 idepth_dy: torch.Tensor = _gradient_y(idepth)
59 image_dx: torch.Tensor = _gradient_x(image)
60 image_dy: torch.Tensor = _gradient_y(image)
61
62 # compute image weights
63 weights_x: torch.Tensor = torch.exp(
64 -torch.mean(torch.abs(image_dx), dim=1, keepdim=True))
65 weights_y: torch.Tensor = torch.exp(
66 -torch.mean(torch.abs(image_dy), dim=1, keepdim=True))
67
68 # apply image weights to depth
69 smoothness_x: torch.Tensor = torch.abs(idepth_dx * weights_x)
70 smoothness_y: torch.Tensor = torch.abs(idepth_dy * weights_y)
71 return torch.mean(smoothness_x) + torch.mean(smoothness_y)
72
73
74 class InverseDepthSmoothnessLoss(nn.Module):
75 r"""Criterion that computes image-aware inverse depth smoothness loss.
76
77 .. math::
78
79 \text{loss} = \left | \partial_x d_{ij} \right | e^{-\left \|
80 \partial_x I_{ij} \right \|} + \left |
81 \partial_y d_{ij} \right | e^{-\left \| \partial_y I_{ij} \right \|}
82
83
84 Shape:
85 - Inverse Depth: :math:`(N, 1, H, W)`
86 - Image: :math:`(N, 3, H, W)`
87 - Output: scalar
88
89 Examples::
90
91 >>> idepth = torch.rand(1, 1, 4, 5)
92 >>> image = torch.rand(1, 3, 4, 5)
93 >>> smooth = kornia.losses.DepthSmoothnessLoss()
94 >>> loss = smooth(idepth, image)
95 """
96
97 def __init__(self) -> None:
98 super(InverseDepthSmoothnessLoss, self).__init__()
99
100 def forward(self, idepth: torch.Tensor, image: torch.Tensor) -> torch.Tensor: # type:ignore
101 return inverse_depth_smoothness_loss(idepth, image)
102
[end of kornia/losses/depth_smooth.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kornia/losses/depth_smooth.py b/kornia/losses/depth_smooth.py
--- a/kornia/losses/depth_smooth.py
+++ b/kornia/losses/depth_smooth.py
@@ -21,7 +21,7 @@
image: torch.Tensor) -> torch.Tensor:
r"""Computes image-aware inverse depth smoothness loss.
- See :class:`~kornia.losses.InvDepthSmoothnessLoss` for details.
+ See :class:`~kornia.losses.InverseDepthSmoothnessLoss` for details.
"""
if not torch.is_tensor(idepth):
raise TypeError("Input idepth type is not a torch.Tensor. Got {}"
|
{"golden_diff": "diff --git a/kornia/losses/depth_smooth.py b/kornia/losses/depth_smooth.py\n--- a/kornia/losses/depth_smooth.py\n+++ b/kornia/losses/depth_smooth.py\n@@ -21,7 +21,7 @@\n image: torch.Tensor) -> torch.Tensor:\n r\"\"\"Computes image-aware inverse depth smoothness loss.\n \n- See :class:`~kornia.losses.InvDepthSmoothnessLoss` for details.\n+ See :class:`~kornia.losses.InverseDepthSmoothnessLoss` for details.\n \"\"\"\n if not torch.is_tensor(idepth):\n raise TypeError(\"Input idepth type is not a torch.Tensor. Got {}\"\n", "issue": "Broken link \"InvDepthSmoothnessLoss\"\n## \ud83d\udcda Documentation\r\n\r\nIn the documentation of this function https://kornia.readthedocs.io/en/latest/losses.html#kornia.losses.inverse_depth_smoothness_loss, the link is broken.\r\n\r\n```See InvDepthSmoothnessLoss for details.```\r\n\r\nThe error is due to an incorrect name. The correct name should be `InverseDepthSmoothnessLoss`.\r\n\r\n\n", "before_files": [{"content": "import torch\nimport torch.nn as nn\nimport torch.nn.functional as F\n\n# Based on\n# https://github.com/tensorflow/models/blob/master/research/struct2depth/model.py#L625-L641\n\n\ndef _gradient_x(img: torch.Tensor) -> torch.Tensor:\n assert len(img.shape) == 4, img.shape\n return img[:, :, :, :-1] - img[:, :, :, 1:]\n\n\ndef _gradient_y(img: torch.Tensor) -> torch.Tensor:\n assert len(img.shape) == 4, img.shape\n return img[:, :, :-1, :] - img[:, :, 1:, :]\n\n\ndef inverse_depth_smoothness_loss(\n idepth: torch.Tensor,\n image: torch.Tensor) -> torch.Tensor:\n r\"\"\"Computes image-aware inverse depth smoothness loss.\n\n See :class:`~kornia.losses.InvDepthSmoothnessLoss` for details.\n \"\"\"\n if not torch.is_tensor(idepth):\n raise TypeError(\"Input idepth type is not a torch.Tensor. Got {}\"\n .format(type(idepth)))\n\n if not torch.is_tensor(image):\n raise TypeError(\"Input image type is not a torch.Tensor. Got {}\"\n .format(type(image)))\n\n if not len(idepth.shape) == 4:\n raise ValueError(\"Invalid idepth shape, we expect BxCxHxW. Got: {}\"\n .format(idepth.shape))\n\n if not len(image.shape) == 4:\n raise ValueError(\"Invalid image shape, we expect BxCxHxW. Got: {}\"\n .format(image.shape))\n\n if not idepth.shape[-2:] == image.shape[-2:]:\n raise ValueError(\"idepth and image shapes must be the same. Got: {} and {}\"\n .format(idepth.shape, image.shape))\n\n if not idepth.device == image.device:\n raise ValueError(\n \"idepth and image must be in the same device. Got: {} and {}\" .format(\n idepth.device, image.device))\n\n if not idepth.dtype == image.dtype:\n raise ValueError(\n \"idepth and image must be in the same dtype. Got: {} and {}\" .format(\n idepth.dtype, image.dtype))\n\n # compute the gradients\n idepth_dx: torch.Tensor = _gradient_x(idepth)\n idepth_dy: torch.Tensor = _gradient_y(idepth)\n image_dx: torch.Tensor = _gradient_x(image)\n image_dy: torch.Tensor = _gradient_y(image)\n\n # compute image weights\n weights_x: torch.Tensor = torch.exp(\n -torch.mean(torch.abs(image_dx), dim=1, keepdim=True))\n weights_y: torch.Tensor = torch.exp(\n -torch.mean(torch.abs(image_dy), dim=1, keepdim=True))\n\n # apply image weights to depth\n smoothness_x: torch.Tensor = torch.abs(idepth_dx * weights_x)\n smoothness_y: torch.Tensor = torch.abs(idepth_dy * weights_y)\n return torch.mean(smoothness_x) + torch.mean(smoothness_y)\n\n\nclass InverseDepthSmoothnessLoss(nn.Module):\n r\"\"\"Criterion that computes image-aware inverse depth smoothness loss.\n\n .. math::\n\n \\text{loss} = \\left | \\partial_x d_{ij} \\right | e^{-\\left \\|\n \\partial_x I_{ij} \\right \\|} + \\left |\n \\partial_y d_{ij} \\right | e^{-\\left \\| \\partial_y I_{ij} \\right \\|}\n\n\n Shape:\n - Inverse Depth: :math:`(N, 1, H, W)`\n - Image: :math:`(N, 3, H, W)`\n - Output: scalar\n\n Examples::\n\n >>> idepth = torch.rand(1, 1, 4, 5)\n >>> image = torch.rand(1, 3, 4, 5)\n >>> smooth = kornia.losses.DepthSmoothnessLoss()\n >>> loss = smooth(idepth, image)\n \"\"\"\n\n def __init__(self) -> None:\n super(InverseDepthSmoothnessLoss, self).__init__()\n\n def forward(self, idepth: torch.Tensor, image: torch.Tensor) -> torch.Tensor: # type:ignore\n return inverse_depth_smoothness_loss(idepth, image)\n", "path": "kornia/losses/depth_smooth.py"}]}
| 1,785 | 159 |
gh_patches_debug_2038
|
rasdani/github-patches
|
git_diff
|
RedHatInsights__insights-core-1112
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
hostname parser doesn't handle sos_commands/general/hostname
sos_commands/general/hostname contains the hostname with a newline at the end, which results in a file with two lines. The hostname parser specifically checks for one line but doesn't gracefully handle the problem.
We can update the parser to handle this case and/or investigate whether proc/sys/kernel/hostname is a valid substitute to put in sos_archive.py instead.
</issue>
<code>
[start of insights/parsers/hostname.py]
1 """
2 hostname - command ``/bin/hostname``
3 ====================================
4
5 This parser simply reads the output of ``/bin/hostname``, which is the
6 configured fully qualified domain name of the client system. It then
7 splits it into ``hostname`` and ``domain`` and stores these as attributes,
8 along with the unmodified name in the ``fqdn`` attribute.
9
10 Examples:
11
12 >>> hostname = shared[Hostname]
13 >>> hostname.fqdn
14 'www.example.com'
15 >>> hostname.hostname
16 'www'
17 >>> hostname.domain
18 'example.com'
19
20 """
21
22 from .. import Parser, parser
23 from insights.specs import Specs
24
25
26 @parser(Specs.hostname)
27 class Hostname(Parser):
28 """Class for parsing ``hostname`` command output.
29
30 Attributes:
31 fqdn: The fully qualified domain name of the host. The same to
32 ``hostname`` when domain part is not set.
33 hostname: The hostname.
34 domain: The domain get from the fqdn.
35 """
36 def parse_content(self, content):
37 raw = None
38 if len(content) == 1:
39 raw = content[0].strip()
40 self.fqdn = raw
41 self.hostname = raw.split(".")[0] if raw else None
42 self.domain = ".".join(raw.split(".")[1:]) if raw else None
43
44 def __str__(self):
45 return "<hostname: {h}, domain: {d}>".format(h=self.hostname, d=self.domain)
46
[end of insights/parsers/hostname.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/insights/parsers/hostname.py b/insights/parsers/hostname.py
--- a/insights/parsers/hostname.py
+++ b/insights/parsers/hostname.py
@@ -34,6 +34,7 @@
domain: The domain get from the fqdn.
"""
def parse_content(self, content):
+ content = filter(None, content)
raw = None
if len(content) == 1:
raw = content[0].strip()
|
{"golden_diff": "diff --git a/insights/parsers/hostname.py b/insights/parsers/hostname.py\n--- a/insights/parsers/hostname.py\n+++ b/insights/parsers/hostname.py\n@@ -34,6 +34,7 @@\n domain: The domain get from the fqdn.\n \"\"\"\n def parse_content(self, content):\n+ content = filter(None, content)\n raw = None\n if len(content) == 1:\n raw = content[0].strip()\n", "issue": "hostname parser doesn't handle sos_commands/general/hostname\nsos_commands/general/hostname contains the hostname with a newline at the end, which results in a file with two lines. The hostname parser specifically checks for one line but doesn't gracefully handle the problem.\r\n\r\nWe can update the parser to handle this case and/or investigate whether proc/sys/kernel/hostname is a valid substitute to put in sos_archive.py instead.\n", "before_files": [{"content": "\"\"\"\nhostname - command ``/bin/hostname``\n====================================\n\nThis parser simply reads the output of ``/bin/hostname``, which is the\nconfigured fully qualified domain name of the client system. It then\nsplits it into ``hostname`` and ``domain`` and stores these as attributes,\nalong with the unmodified name in the ``fqdn`` attribute.\n\nExamples:\n\n >>> hostname = shared[Hostname]\n >>> hostname.fqdn\n 'www.example.com'\n >>> hostname.hostname\n 'www'\n >>> hostname.domain\n 'example.com'\n\n\"\"\"\n\nfrom .. import Parser, parser\nfrom insights.specs import Specs\n\n\n@parser(Specs.hostname)\nclass Hostname(Parser):\n \"\"\"Class for parsing ``hostname`` command output.\n\n Attributes:\n fqdn: The fully qualified domain name of the host. The same to\n ``hostname`` when domain part is not set.\n hostname: The hostname.\n domain: The domain get from the fqdn.\n \"\"\"\n def parse_content(self, content):\n raw = None\n if len(content) == 1:\n raw = content[0].strip()\n self.fqdn = raw\n self.hostname = raw.split(\".\")[0] if raw else None\n self.domain = \".\".join(raw.split(\".\")[1:]) if raw else None\n\n def __str__(self):\n return \"<hostname: {h}, domain: {d}>\".format(h=self.hostname, d=self.domain)\n", "path": "insights/parsers/hostname.py"}]}
| 1,017 | 110 |
gh_patches_debug_411
|
rasdani/github-patches
|
git_diff
|
ocf__ocfweb-48
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Have next 7 days in hours sidebar
This means all our normal hours are visible on a normal week.
</issue>
<code>
[start of ocfweb/main/home.py]
1 from datetime import date
2 from datetime import timedelta
3
4 from django.shortcuts import render_to_response
5 from django.template import RequestContext
6 from django.utils import timezone
7 from ocflib.lab.hours import get_hours
8 from ocflib.lab.staff_hours import get_staff_hours_soonest_first
9
10 from ocfweb.component.blog import get_blog_posts
11 from ocfweb.component.lab_status import get_lab_status
12
13
14 def home(request):
15 hours = [
16 get_hours(date.today() + timedelta(days=i)) for i in range(7)
17 ]
18
19 blog_posts = [
20 post for post
21 in get_blog_posts()
22 if timezone.now() - post.published < timedelta(days=365)
23 ][:2]
24
25 return render_to_response(
26 'home.html',
27 {
28 'fulltitle': 'Open Computing Facility at UC Berkeley',
29 'description': (
30 'The Open Computing Facility is an all-volunteer student '
31 'organization dedicated to free and open-source computing for all UC '
32 'Berkeley students.'''
33 ),
34 'staff_hours': get_staff_hours_soonest_first()[:2],
35 'hours': hours,
36 'today': hours[0],
37 'blog_posts': blog_posts,
38 'lab_status': get_lab_status(),
39 },
40 context_instance=RequestContext(request),
41 )
42
[end of ocfweb/main/home.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ocfweb/main/home.py b/ocfweb/main/home.py
--- a/ocfweb/main/home.py
+++ b/ocfweb/main/home.py
@@ -13,7 +13,7 @@
def home(request):
hours = [
- get_hours(date.today() + timedelta(days=i)) for i in range(7)
+ get_hours(date.today() + timedelta(days=i)) for i in range(5)
]
blog_posts = [
|
{"golden_diff": "diff --git a/ocfweb/main/home.py b/ocfweb/main/home.py\n--- a/ocfweb/main/home.py\n+++ b/ocfweb/main/home.py\n@@ -13,7 +13,7 @@\n \n def home(request):\n hours = [\n- get_hours(date.today() + timedelta(days=i)) for i in range(7)\n+ get_hours(date.today() + timedelta(days=i)) for i in range(5)\n ]\n \n blog_posts = [\n", "issue": "Have next 7 days in hours sidebar\nThis means all our normal hours are visible on a normal week.\n\n", "before_files": [{"content": "from datetime import date\nfrom datetime import timedelta\n\nfrom django.shortcuts import render_to_response\nfrom django.template import RequestContext\nfrom django.utils import timezone\nfrom ocflib.lab.hours import get_hours\nfrom ocflib.lab.staff_hours import get_staff_hours_soonest_first\n\nfrom ocfweb.component.blog import get_blog_posts\nfrom ocfweb.component.lab_status import get_lab_status\n\n\ndef home(request):\n hours = [\n get_hours(date.today() + timedelta(days=i)) for i in range(7)\n ]\n\n blog_posts = [\n post for post\n in get_blog_posts()\n if timezone.now() - post.published < timedelta(days=365)\n ][:2]\n\n return render_to_response(\n 'home.html',\n {\n 'fulltitle': 'Open Computing Facility at UC Berkeley',\n 'description': (\n 'The Open Computing Facility is an all-volunteer student '\n 'organization dedicated to free and open-source computing for all UC '\n 'Berkeley students.'''\n ),\n 'staff_hours': get_staff_hours_soonest_first()[:2],\n 'hours': hours,\n 'today': hours[0],\n 'blog_posts': blog_posts,\n 'lab_status': get_lab_status(),\n },\n context_instance=RequestContext(request),\n )\n", "path": "ocfweb/main/home.py"}]}
| 911 | 108 |
gh_patches_debug_34747
|
rasdani/github-patches
|
git_diff
|
Cloud-CV__EvalAI-1035
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add serializers for creating challenge using zip file.
</issue>
<code>
[start of apps/challenges/serializers.py]
1 from rest_framework import serializers
2
3 from hosts.serializers import ChallengeHostTeamSerializer
4
5 from .models import (
6 Challenge,
7 ChallengePhase,
8 ChallengePhaseSplit,
9 DatasetSplit,)
10
11
12 class ChallengeSerializer(serializers.ModelSerializer):
13
14 is_active = serializers.ReadOnlyField()
15
16 def __init__(self, *args, **kwargs):
17 super(ChallengeSerializer, self).__init__(*args, **kwargs)
18 context = kwargs.get('context')
19 if context and context.get('request').method != 'GET':
20 challenge_host_team = context.get('challenge_host_team')
21 kwargs['data']['creator'] = challenge_host_team.pk
22 else:
23 self.fields['creator'] = ChallengeHostTeamSerializer()
24
25 class Meta:
26 model = Challenge
27 fields = ('id', 'title', 'short_description', 'description', 'terms_and_conditions',
28 'submission_guidelines', 'evaluation_details',
29 'image', 'start_date', 'end_date', 'creator',
30 'published', 'enable_forum', 'anonymous_leaderboard', 'is_active',)
31
32
33 class ChallengePhaseSerializer(serializers.ModelSerializer):
34
35 is_active = serializers.ReadOnlyField()
36
37 def __init__(self, *args, **kwargs):
38 super(ChallengePhaseSerializer, self).__init__(*args, **kwargs)
39 context = kwargs.get('context')
40 if context:
41 challenge = context.get('challenge')
42 kwargs['data']['challenge'] = challenge.pk
43
44 class Meta:
45 model = ChallengePhase
46 fields = ('id', 'name', 'description', 'leaderboard_public', 'start_date',
47 'end_date', 'challenge', 'max_submissions_per_day', 'max_submissions',
48 'is_public', 'is_active', 'codename')
49
50
51 class DatasetSplitSerializer(serializers.ModelSerializer):
52
53 class Meta:
54 model = DatasetSplit
55 fields = '__all__'
56
57
58 class ChallengePhaseSplitSerializer(serializers.ModelSerializer):
59 """Serialize the ChallengePhaseSplits Model"""
60
61 dataset_split_name = serializers.SerializerMethodField()
62 challenge_phase_name = serializers.SerializerMethodField()
63
64 class Meta:
65 model = ChallengePhaseSplit
66 fields = '__all__'
67 fields = ('id', 'dataset_split', 'challenge_phase', 'challenge_phase_name', 'dataset_split_name', 'visibility')
68
69 def get_dataset_split_name(self, obj):
70 return obj.dataset_split.name
71
72 def get_challenge_phase_name(self, obj):
73 return obj.challenge_phase.name
74
[end of apps/challenges/serializers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/apps/challenges/serializers.py b/apps/challenges/serializers.py
--- a/apps/challenges/serializers.py
+++ b/apps/challenges/serializers.py
@@ -2,11 +2,12 @@
from hosts.serializers import ChallengeHostTeamSerializer
-from .models import (
- Challenge,
+from .models import (Challenge,
+ ChallengeConfiguration,
ChallengePhase,
ChallengePhaseSplit,
- DatasetSplit,)
+ DatasetSplit,
+ Leaderboard,)
class ChallengeSerializer(serializers.ModelSerializer):
@@ -63,7 +64,6 @@
class Meta:
model = ChallengePhaseSplit
- fields = '__all__'
fields = ('id', 'dataset_split', 'challenge_phase', 'challenge_phase_name', 'dataset_split_name', 'visibility')
def get_dataset_split_name(self, obj):
@@ -71,3 +71,48 @@
def get_challenge_phase_name(self, obj):
return obj.challenge_phase.name
+
+
+class ChallengeConfigSerializer(serializers.ModelSerializer):
+ """
+ Serialize the ChallengeConfiguration Model.
+ """
+ def __init__(self, *args, **kwargs):
+ super(ChallengeConfigSerializer, self).__init__(*args, **kwargs)
+ context = kwargs.get('context')
+ if context:
+ user = context.get('user')
+ kwargs['data']['user'] = user.pk
+
+ class Meta:
+ model = ChallengeConfiguration
+ fields = ('zip_configuration', 'user',)
+
+
+class LeaderboardSerializer(serializers.ModelSerializer):
+ """
+ Serialize the Leaderboard Model.
+ """
+ class Meta:
+ model = Leaderboard
+ fields = '__all__'
+
+
+class ZipChallengeSerializer(ChallengeSerializer):
+ """
+ Serializer used for creating challenge through zip file.
+ """
+ class Meta:
+ model = Challenge
+ fields = ('id', 'title', 'short_description', 'description', 'terms_and_conditions',
+ 'submission_guidelines', 'start_date', 'end_date', 'creator',
+ 'published', 'enable_forum', 'anonymous_leaderboard', 'is_active',)
+
+
+class ZipChallengePhaseSplitSerializer(serializers.ModelSerializer):
+ """
+ Serializer used for creating challenge phase split through zip file.
+ """
+ class Meta:
+ model = ChallengePhaseSplit
+ fields = '__all__'
|
{"golden_diff": "diff --git a/apps/challenges/serializers.py b/apps/challenges/serializers.py\n--- a/apps/challenges/serializers.py\n+++ b/apps/challenges/serializers.py\n@@ -2,11 +2,12 @@\n \n from hosts.serializers import ChallengeHostTeamSerializer\n \n-from .models import (\n- Challenge,\n+from .models import (Challenge,\n+ ChallengeConfiguration,\n ChallengePhase,\n ChallengePhaseSplit,\n- DatasetSplit,)\n+ DatasetSplit,\n+ Leaderboard,)\n \n \n class ChallengeSerializer(serializers.ModelSerializer):\n@@ -63,7 +64,6 @@\n \n class Meta:\n model = ChallengePhaseSplit\n- fields = '__all__'\n fields = ('id', 'dataset_split', 'challenge_phase', 'challenge_phase_name', 'dataset_split_name', 'visibility')\n \n def get_dataset_split_name(self, obj):\n@@ -71,3 +71,48 @@\n \n def get_challenge_phase_name(self, obj):\n return obj.challenge_phase.name\n+\n+\n+class ChallengeConfigSerializer(serializers.ModelSerializer):\n+ \"\"\"\n+ Serialize the ChallengeConfiguration Model.\n+ \"\"\"\n+ def __init__(self, *args, **kwargs):\n+ super(ChallengeConfigSerializer, self).__init__(*args, **kwargs)\n+ context = kwargs.get('context')\n+ if context:\n+ user = context.get('user')\n+ kwargs['data']['user'] = user.pk\n+\n+ class Meta:\n+ model = ChallengeConfiguration\n+ fields = ('zip_configuration', 'user',)\n+\n+\n+class LeaderboardSerializer(serializers.ModelSerializer):\n+ \"\"\"\n+ Serialize the Leaderboard Model.\n+ \"\"\"\n+ class Meta:\n+ model = Leaderboard\n+ fields = '__all__'\n+\n+\n+class ZipChallengeSerializer(ChallengeSerializer):\n+ \"\"\"\n+ Serializer used for creating challenge through zip file.\n+ \"\"\"\n+ class Meta:\n+ model = Challenge\n+ fields = ('id', 'title', 'short_description', 'description', 'terms_and_conditions',\n+ 'submission_guidelines', 'start_date', 'end_date', 'creator',\n+ 'published', 'enable_forum', 'anonymous_leaderboard', 'is_active',)\n+\n+\n+class ZipChallengePhaseSplitSerializer(serializers.ModelSerializer):\n+ \"\"\"\n+ Serializer used for creating challenge phase split through zip file.\n+ \"\"\"\n+ class Meta:\n+ model = ChallengePhaseSplit\n+ fields = '__all__'\n", "issue": "Add serializers for creating challenge using zip file.\n\n", "before_files": [{"content": "from rest_framework import serializers\n\nfrom hosts.serializers import ChallengeHostTeamSerializer\n\nfrom .models import (\n Challenge,\n ChallengePhase,\n ChallengePhaseSplit,\n DatasetSplit,)\n\n\nclass ChallengeSerializer(serializers.ModelSerializer):\n\n is_active = serializers.ReadOnlyField()\n\n def __init__(self, *args, **kwargs):\n super(ChallengeSerializer, self).__init__(*args, **kwargs)\n context = kwargs.get('context')\n if context and context.get('request').method != 'GET':\n challenge_host_team = context.get('challenge_host_team')\n kwargs['data']['creator'] = challenge_host_team.pk\n else:\n self.fields['creator'] = ChallengeHostTeamSerializer()\n\n class Meta:\n model = Challenge\n fields = ('id', 'title', 'short_description', 'description', 'terms_and_conditions',\n 'submission_guidelines', 'evaluation_details',\n 'image', 'start_date', 'end_date', 'creator',\n 'published', 'enable_forum', 'anonymous_leaderboard', 'is_active',)\n\n\nclass ChallengePhaseSerializer(serializers.ModelSerializer):\n\n is_active = serializers.ReadOnlyField()\n\n def __init__(self, *args, **kwargs):\n super(ChallengePhaseSerializer, self).__init__(*args, **kwargs)\n context = kwargs.get('context')\n if context:\n challenge = context.get('challenge')\n kwargs['data']['challenge'] = challenge.pk\n\n class Meta:\n model = ChallengePhase\n fields = ('id', 'name', 'description', 'leaderboard_public', 'start_date',\n 'end_date', 'challenge', 'max_submissions_per_day', 'max_submissions',\n 'is_public', 'is_active', 'codename')\n\n\nclass DatasetSplitSerializer(serializers.ModelSerializer):\n\n class Meta:\n model = DatasetSplit\n fields = '__all__'\n\n\nclass ChallengePhaseSplitSerializer(serializers.ModelSerializer):\n \"\"\"Serialize the ChallengePhaseSplits Model\"\"\"\n\n dataset_split_name = serializers.SerializerMethodField()\n challenge_phase_name = serializers.SerializerMethodField()\n\n class Meta:\n model = ChallengePhaseSplit\n fields = '__all__'\n fields = ('id', 'dataset_split', 'challenge_phase', 'challenge_phase_name', 'dataset_split_name', 'visibility')\n\n def get_dataset_split_name(self, obj):\n return obj.dataset_split.name\n\n def get_challenge_phase_name(self, obj):\n return obj.challenge_phase.name\n", "path": "apps/challenges/serializers.py"}]}
| 1,203 | 526 |
gh_patches_debug_9413
|
rasdani/github-patches
|
git_diff
|
cisagov__manage.get.gov-908
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Update Domain management permissions
### Issue Description
Domain management, specifically that of DNS specific information, should be reserved for approved domain requests. Currently, if an item is in the list of registered domains and the status of the associated domain request switches to something like Withdrawn/Investigating, then the user can still edit the domain information AND the domain still appears in Active domains
AC
1. In Active Domain Request table, do not show domain applications that are approved.
Suggestion: check to make sure when you change states on an application that the domain management page doesn't show when the status shouldn't allow it.
### Additional Context (optional)
see [slack thread](https://cisa-corp.slack.com/archives/C05BDEA3C11/p1689089565297719)
### Issue Links
may relate to #701
relates to: #818
_No response_
</issue>
<code>
[start of src/registrar/views/index.py]
1 from django.db.models import F
2 from django.shortcuts import render
3
4 from registrar.models import DomainApplication
5
6
7 def index(request):
8 """This page is available to anyone without logging in."""
9 context = {}
10 if request.user.is_authenticated:
11 applications = DomainApplication.objects.filter(creator=request.user)
12 context["domain_applications"] = applications
13
14 domains = request.user.permissions.values(
15 "role",
16 pk=F("domain__id"),
17 name=F("domain__name"),
18 created_time=F("domain__created_at"),
19 application_status=F("domain__domain_application__status"),
20 )
21 context["domains"] = domains
22 return render(request, "home.html", context)
23
[end of src/registrar/views/index.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/registrar/views/index.py b/src/registrar/views/index.py
--- a/src/registrar/views/index.py
+++ b/src/registrar/views/index.py
@@ -9,7 +9,10 @@
context = {}
if request.user.is_authenticated:
applications = DomainApplication.objects.filter(creator=request.user)
- context["domain_applications"] = applications
+ # Let's exclude the approved applications since our
+ # domain_applications context will be used to populate
+ # the active applications table
+ context["domain_applications"] = applications.exclude(status="approved")
domains = request.user.permissions.values(
"role",
|
{"golden_diff": "diff --git a/src/registrar/views/index.py b/src/registrar/views/index.py\n--- a/src/registrar/views/index.py\n+++ b/src/registrar/views/index.py\n@@ -9,7 +9,10 @@\n context = {}\n if request.user.is_authenticated:\n applications = DomainApplication.objects.filter(creator=request.user)\n- context[\"domain_applications\"] = applications\n+ # Let's exclude the approved applications since our\n+ # domain_applications context will be used to populate\n+ # the active applications table\n+ context[\"domain_applications\"] = applications.exclude(status=\"approved\")\n \n domains = request.user.permissions.values(\n \"role\",\n", "issue": "Update Domain management permissions \n### Issue Description\r\n\r\nDomain management, specifically that of DNS specific information, should be reserved for approved domain requests. Currently, if an item is in the list of registered domains and the status of the associated domain request switches to something like Withdrawn/Investigating, then the user can still edit the domain information AND the domain still appears in Active domains\r\n\r\nAC\r\n\r\n1. In Active Domain Request table, do not show domain applications that are approved. \r\n\r\n\r\nSuggestion: check to make sure when you change states on an application that the domain management page doesn't show when the status shouldn't allow it.\r\n\r\n\r\n### Additional Context (optional)\r\n\r\nsee [slack thread](https://cisa-corp.slack.com/archives/C05BDEA3C11/p1689089565297719)\r\n\r\n### Issue Links\r\nmay relate to #701 \r\nrelates to: #818 \r\n_No response_\n", "before_files": [{"content": "from django.db.models import F\nfrom django.shortcuts import render\n\nfrom registrar.models import DomainApplication\n\n\ndef index(request):\n \"\"\"This page is available to anyone without logging in.\"\"\"\n context = {}\n if request.user.is_authenticated:\n applications = DomainApplication.objects.filter(creator=request.user)\n context[\"domain_applications\"] = applications\n\n domains = request.user.permissions.values(\n \"role\",\n pk=F(\"domain__id\"),\n name=F(\"domain__name\"),\n created_time=F(\"domain__created_at\"),\n application_status=F(\"domain__domain_application__status\"),\n )\n context[\"domains\"] = domains\n return render(request, \"home.html\", context)\n", "path": "src/registrar/views/index.py"}]}
| 922 | 143 |
gh_patches_debug_2812
|
rasdani/github-patches
|
git_diff
|
comic__grand-challenge.org-827
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Update to Django 2.2
- [ ] Check that all Django apps support 2.2
</issue>
<code>
[start of app/grandchallenge/serving/views.py]
1 import os
2 import posixpath
3 import re
4
5 from django.conf import settings
6 from django.core.files import File
7 from django.core.files.storage import DefaultStorage
8 from django.http import Http404, HttpResponse
9 from django.shortcuts import get_object_or_404
10 from django.utils._os import safe_join
11 from rest_framework.authentication import TokenAuthentication
12 from rest_framework.exceptions import AuthenticationFailed
13
14 from grandchallenge.cases.models import Image
15 from grandchallenge.challenges.models import Challenge
16 from grandchallenge.core.storage import ProtectedS3Storage
17 from grandchallenge.evaluation.models import Submission
18 from grandchallenge.serving.api import serve_file
19 from grandchallenge.serving.permissions import (
20 can_access,
21 user_can_download_image,
22 user_can_download_submission,
23 )
24
25
26 def serve_fullpath(*, fullpath):
27 storage = DefaultStorage()
28
29 if not (os.path.abspath(fullpath) == fullpath) or not storage.exists(
30 fullpath
31 ):
32 raise Http404("File not found.")
33
34 try:
35 f = storage.open(fullpath, "rb")
36 file = File(f)
37 return serve_file(file, save_as=True)
38 except IOError:
39 raise Http404("File not found.")
40
41
42 def protected_storage_redirect(*, name):
43 # Get the storage with the internal redirect and auth. This will prepend
44 # settings.PROTECTED_S3_STORAGE_KWARGS['endpoint_url'] to the url
45 storage = ProtectedS3Storage(internal=True)
46
47 if not storage.exists(name=name):
48 raise Http404("File not found.")
49
50 url = storage.url(name=name)
51
52 # Now strip the endpoint_url
53 external_url = re.match(
54 f"^{settings.PROTECTED_S3_STORAGE_KWARGS['endpoint_url']}(.*)$", url
55 ).group(1)
56
57 response = HttpResponse()
58 response["X-Accel-Redirect"] = external_url
59
60 return response
61
62
63 def serve_folder(request, *, challenge_name=None, folder=None, path):
64 """
65 Serve static files in a folder.
66
67 If the file is in a challenge folder, then the subfolders of this challenge
68 will be checked for permissions, see `can_access`.
69
70 If the challenge_short_name is not set, then the folder must be set.
71 ALL FILES IN THIS FOLDER WILL BE AVAILABLE TO DOWNLOAD.
72 """
73 path = posixpath.normpath(path).lstrip("/")
74
75 if challenge_name:
76 if folder:
77 raise AttributeError("Only challenge_name or folder should be set")
78
79 challenge = get_object_or_404(
80 Challenge, short_name__iexact=challenge_name
81 )
82
83 document_root = safe_join(settings.MEDIA_ROOT, challenge.short_name)
84 fullpath = safe_join(document_root, path)
85 allowed = can_access(
86 request.user,
87 fullpath[len(document_root) :].lstrip("/"),
88 challenge=challenge,
89 )
90 elif folder:
91 document_root = safe_join(settings.MEDIA_ROOT, folder)
92 fullpath = safe_join(document_root, path)
93 allowed = True
94 else:
95 raise AttributeError("challenge_name or folder must be set")
96
97 if not allowed:
98 raise Http404("File not found.")
99
100 return serve_fullpath(fullpath=fullpath)
101
102
103 def serve_images(request, *, pk, path):
104 document_root = safe_join(f"/{settings.IMAGE_FILES_SUBDIRECTORY}", pk)
105 path = posixpath.normpath(path).lstrip("/")
106 name = safe_join(document_root, path)
107
108 try:
109 image = Image.objects.get(pk=pk)
110 except Image.DoesNotExist:
111 raise Http404("File not found.")
112
113 try:
114 user, _ = TokenAuthentication().authenticate(request)
115 except (AuthenticationFailed, TypeError):
116 user = request.user
117
118 if user_can_download_image(user=user, image=image):
119 return protected_storage_redirect(name=name)
120
121 raise Http404("File not found.")
122
123
124 def serve_submissions(request, *, submission_pk, **_):
125 try:
126 submission = Submission.objects.get(pk=submission_pk)
127 except Submission.DoesNotExist:
128 raise Http404("File not found.")
129
130 if user_can_download_submission(user=request.user, submission=submission):
131 return protected_storage_redirect(name=submission.file.name)
132
133 raise Http404("File not found.")
134
[end of app/grandchallenge/serving/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/app/grandchallenge/serving/views.py b/app/grandchallenge/serving/views.py
--- a/app/grandchallenge/serving/views.py
+++ b/app/grandchallenge/serving/views.py
@@ -101,7 +101,7 @@
def serve_images(request, *, pk, path):
- document_root = safe_join(f"/{settings.IMAGE_FILES_SUBDIRECTORY}", pk)
+ document_root = safe_join(f"/{settings.IMAGE_FILES_SUBDIRECTORY}", str(pk))
path = posixpath.normpath(path).lstrip("/")
name = safe_join(document_root, path)
|
{"golden_diff": "diff --git a/app/grandchallenge/serving/views.py b/app/grandchallenge/serving/views.py\n--- a/app/grandchallenge/serving/views.py\n+++ b/app/grandchallenge/serving/views.py\n@@ -101,7 +101,7 @@\n \n \n def serve_images(request, *, pk, path):\n- document_root = safe_join(f\"/{settings.IMAGE_FILES_SUBDIRECTORY}\", pk)\n+ document_root = safe_join(f\"/{settings.IMAGE_FILES_SUBDIRECTORY}\", str(pk))\n path = posixpath.normpath(path).lstrip(\"/\")\n name = safe_join(document_root, path)\n", "issue": "Update to Django 2.2\n- [ ] Check that all Django apps support 2.2\n", "before_files": [{"content": "import os\nimport posixpath\nimport re\n\nfrom django.conf import settings\nfrom django.core.files import File\nfrom django.core.files.storage import DefaultStorage\nfrom django.http import Http404, HttpResponse\nfrom django.shortcuts import get_object_or_404\nfrom django.utils._os import safe_join\nfrom rest_framework.authentication import TokenAuthentication\nfrom rest_framework.exceptions import AuthenticationFailed\n\nfrom grandchallenge.cases.models import Image\nfrom grandchallenge.challenges.models import Challenge\nfrom grandchallenge.core.storage import ProtectedS3Storage\nfrom grandchallenge.evaluation.models import Submission\nfrom grandchallenge.serving.api import serve_file\nfrom grandchallenge.serving.permissions import (\n can_access,\n user_can_download_image,\n user_can_download_submission,\n)\n\n\ndef serve_fullpath(*, fullpath):\n storage = DefaultStorage()\n\n if not (os.path.abspath(fullpath) == fullpath) or not storage.exists(\n fullpath\n ):\n raise Http404(\"File not found.\")\n\n try:\n f = storage.open(fullpath, \"rb\")\n file = File(f)\n return serve_file(file, save_as=True)\n except IOError:\n raise Http404(\"File not found.\")\n\n\ndef protected_storage_redirect(*, name):\n # Get the storage with the internal redirect and auth. This will prepend\n # settings.PROTECTED_S3_STORAGE_KWARGS['endpoint_url'] to the url\n storage = ProtectedS3Storage(internal=True)\n\n if not storage.exists(name=name):\n raise Http404(\"File not found.\")\n\n url = storage.url(name=name)\n\n # Now strip the endpoint_url\n external_url = re.match(\n f\"^{settings.PROTECTED_S3_STORAGE_KWARGS['endpoint_url']}(.*)$\", url\n ).group(1)\n\n response = HttpResponse()\n response[\"X-Accel-Redirect\"] = external_url\n\n return response\n\n\ndef serve_folder(request, *, challenge_name=None, folder=None, path):\n \"\"\"\n Serve static files in a folder.\n\n If the file is in a challenge folder, then the subfolders of this challenge\n will be checked for permissions, see `can_access`.\n\n If the challenge_short_name is not set, then the folder must be set.\n ALL FILES IN THIS FOLDER WILL BE AVAILABLE TO DOWNLOAD.\n \"\"\"\n path = posixpath.normpath(path).lstrip(\"/\")\n\n if challenge_name:\n if folder:\n raise AttributeError(\"Only challenge_name or folder should be set\")\n\n challenge = get_object_or_404(\n Challenge, short_name__iexact=challenge_name\n )\n\n document_root = safe_join(settings.MEDIA_ROOT, challenge.short_name)\n fullpath = safe_join(document_root, path)\n allowed = can_access(\n request.user,\n fullpath[len(document_root) :].lstrip(\"/\"),\n challenge=challenge,\n )\n elif folder:\n document_root = safe_join(settings.MEDIA_ROOT, folder)\n fullpath = safe_join(document_root, path)\n allowed = True\n else:\n raise AttributeError(\"challenge_name or folder must be set\")\n\n if not allowed:\n raise Http404(\"File not found.\")\n\n return serve_fullpath(fullpath=fullpath)\n\n\ndef serve_images(request, *, pk, path):\n document_root = safe_join(f\"/{settings.IMAGE_FILES_SUBDIRECTORY}\", pk)\n path = posixpath.normpath(path).lstrip(\"/\")\n name = safe_join(document_root, path)\n\n try:\n image = Image.objects.get(pk=pk)\n except Image.DoesNotExist:\n raise Http404(\"File not found.\")\n\n try:\n user, _ = TokenAuthentication().authenticate(request)\n except (AuthenticationFailed, TypeError):\n user = request.user\n\n if user_can_download_image(user=user, image=image):\n return protected_storage_redirect(name=name)\n\n raise Http404(\"File not found.\")\n\n\ndef serve_submissions(request, *, submission_pk, **_):\n try:\n submission = Submission.objects.get(pk=submission_pk)\n except Submission.DoesNotExist:\n raise Http404(\"File not found.\")\n\n if user_can_download_submission(user=request.user, submission=submission):\n return protected_storage_redirect(name=submission.file.name)\n\n raise Http404(\"File not found.\")\n", "path": "app/grandchallenge/serving/views.py"}]}
| 1,775 | 129 |
gh_patches_debug_11032
|
rasdani/github-patches
|
git_diff
|
spesmilo__electrum-1608
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
allow non-root installation on Linux
I want to install Electrum on my Ubuntu machine in my user's `$HOME` directory, i.e., not via `sudo`. If I run the command
```
pip install https://download.electrum.org/2.5.4/Electrum-2.5.4.tar.gz
```
I get an error when the installation tries to create a desktop shortcut:
```
copying electrum.desktop -> /usr/share/applications/
error: [Errno 13] Permission denied: '/usr/share/applications/electrum.desktop'
```
Maybe the installation script could `try` if this copy operation works, and try again at `$HOME/.local/share/applications` (or, better, `$XDG_DATA_HOME/applications`) in case it doesn't.
If you agree this would make sense and point me to the file where I would need to do this, I'd be happy to provide a PR.
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python2
2
3 # python setup.py sdist --format=zip,gztar
4
5 from setuptools import setup
6 import os
7 import sys
8 import platform
9 import imp
10
11 version = imp.load_source('version', 'lib/version.py')
12
13 if sys.version_info[:3] < (2, 7, 0):
14 sys.exit("Error: Electrum requires Python version >= 2.7.0...")
15
16 data_files = []
17
18 if platform.system() in ['Linux', 'FreeBSD', 'DragonFly']:
19 usr_share = os.path.join(sys.prefix, "share")
20 data_files += [
21 (os.path.join(usr_share, 'applications/'), ['electrum.desktop']),
22 (os.path.join(usr_share, 'pixmaps/'), ['icons/electrum.png'])
23 ]
24
25 setup(
26 name="Electrum",
27 version=version.ELECTRUM_VERSION,
28 install_requires=[
29 'slowaes>=0.1a1',
30 'ecdsa>=0.9',
31 'pbkdf2',
32 'requests',
33 'qrcode',
34 'protobuf',
35 'dnspython',
36 'jsonrpclib',
37 ],
38 packages=[
39 'electrum',
40 'electrum_gui',
41 'electrum_gui.qt',
42 'electrum_plugins',
43 'electrum_plugins.audio_modem',
44 'electrum_plugins.cosigner_pool',
45 'electrum_plugins.email_requests',
46 'electrum_plugins.exchange_rate',
47 'electrum_plugins.greenaddress_instant',
48 'electrum_plugins.keepkey',
49 'electrum_plugins.labels',
50 'electrum_plugins.ledger',
51 'electrum_plugins.plot',
52 'electrum_plugins.trezor',
53 'electrum_plugins.trustedcoin',
54 'electrum_plugins.virtualkeyboard',
55 ],
56 package_dir={
57 'electrum': 'lib',
58 'electrum_gui': 'gui',
59 'electrum_plugins': 'plugins',
60 },
61 package_data={
62 'electrum': [
63 'www/index.html',
64 'wordlist/*.txt',
65 'locale/*/LC_MESSAGES/electrum.mo',
66 ]
67 },
68 scripts=['electrum'],
69 data_files=data_files,
70 description="Lightweight Bitcoin Wallet",
71 author="Thomas Voegtlin",
72 author_email="[email protected]",
73 license="GNU GPLv3",
74 url="https://electrum.org",
75 long_description="""Lightweight Bitcoin Wallet"""
76 )
77
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
old mode 100644
new mode 100755
--- a/setup.py
+++ b/setup.py
@@ -17,6 +17,11 @@
if platform.system() in ['Linux', 'FreeBSD', 'DragonFly']:
usr_share = os.path.join(sys.prefix, "share")
+ if not os.access(usr_share, os.W_OK):
+ if 'XDG_DATA_HOME' in os.environ.keys():
+ usr_share = os.environ['$XDG_DATA_HOME']
+ else:
+ usr_share = os.path.expanduser('~/.local/share')
data_files += [
(os.path.join(usr_share, 'applications/'), ['electrum.desktop']),
(os.path.join(usr_share, 'pixmaps/'), ['icons/electrum.png'])
|
{"golden_diff": "diff --git a/setup.py b/setup.py\nold mode 100644\nnew mode 100755\n--- a/setup.py\n+++ b/setup.py\n@@ -17,6 +17,11 @@\n \n if platform.system() in ['Linux', 'FreeBSD', 'DragonFly']:\n usr_share = os.path.join(sys.prefix, \"share\")\n+ if not os.access(usr_share, os.W_OK):\n+ if 'XDG_DATA_HOME' in os.environ.keys():\n+ usr_share = os.environ['$XDG_DATA_HOME']\n+ else:\n+ usr_share = os.path.expanduser('~/.local/share')\n data_files += [\n (os.path.join(usr_share, 'applications/'), ['electrum.desktop']),\n (os.path.join(usr_share, 'pixmaps/'), ['icons/electrum.png'])\n", "issue": "allow non-root installation on Linux\nI want to install Electrum on my Ubuntu machine in my user's `$HOME` directory, i.e., not via `sudo`. If I run the command\n\n```\npip install https://download.electrum.org/2.5.4/Electrum-2.5.4.tar.gz\n```\n\nI get an error when the installation tries to create a desktop shortcut:\n\n```\ncopying electrum.desktop -> /usr/share/applications/\n\nerror: [Errno 13] Permission denied: '/usr/share/applications/electrum.desktop'\n```\n\nMaybe the installation script could `try` if this copy operation works, and try again at `$HOME/.local/share/applications` (or, better, `$XDG_DATA_HOME/applications`) in case it doesn't.\n\nIf you agree this would make sense and point me to the file where I would need to do this, I'd be happy to provide a PR.\n\n", "before_files": [{"content": "#!/usr/bin/env python2\n\n# python setup.py sdist --format=zip,gztar\n\nfrom setuptools import setup\nimport os\nimport sys\nimport platform\nimport imp\n\nversion = imp.load_source('version', 'lib/version.py')\n\nif sys.version_info[:3] < (2, 7, 0):\n sys.exit(\"Error: Electrum requires Python version >= 2.7.0...\")\n\ndata_files = []\n\nif platform.system() in ['Linux', 'FreeBSD', 'DragonFly']:\n usr_share = os.path.join(sys.prefix, \"share\")\n data_files += [\n (os.path.join(usr_share, 'applications/'), ['electrum.desktop']),\n (os.path.join(usr_share, 'pixmaps/'), ['icons/electrum.png'])\n ]\n\nsetup(\n name=\"Electrum\",\n version=version.ELECTRUM_VERSION,\n install_requires=[\n 'slowaes>=0.1a1',\n 'ecdsa>=0.9',\n 'pbkdf2',\n 'requests',\n 'qrcode',\n 'protobuf',\n 'dnspython',\n 'jsonrpclib',\n ],\n packages=[\n 'electrum',\n 'electrum_gui',\n 'electrum_gui.qt',\n 'electrum_plugins',\n 'electrum_plugins.audio_modem',\n 'electrum_plugins.cosigner_pool',\n 'electrum_plugins.email_requests',\n 'electrum_plugins.exchange_rate',\n 'electrum_plugins.greenaddress_instant',\n 'electrum_plugins.keepkey',\n 'electrum_plugins.labels',\n 'electrum_plugins.ledger',\n 'electrum_plugins.plot',\n 'electrum_plugins.trezor',\n 'electrum_plugins.trustedcoin',\n 'electrum_plugins.virtualkeyboard',\n ],\n package_dir={\n 'electrum': 'lib',\n 'electrum_gui': 'gui',\n 'electrum_plugins': 'plugins',\n },\n package_data={\n 'electrum': [\n 'www/index.html',\n 'wordlist/*.txt',\n 'locale/*/LC_MESSAGES/electrum.mo',\n ]\n },\n scripts=['electrum'],\n data_files=data_files,\n description=\"Lightweight Bitcoin Wallet\",\n author=\"Thomas Voegtlin\",\n author_email=\"[email protected]\",\n license=\"GNU GPLv3\",\n url=\"https://electrum.org\",\n long_description=\"\"\"Lightweight Bitcoin Wallet\"\"\"\n)\n", "path": "setup.py"}]}
| 1,391 | 188 |
gh_patches_debug_21674
|
rasdani/github-patches
|
git_diff
|
fedora-infra__bodhi-2007
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
bodhi-dequqe-stable dies if any update in the queue is no longer eligible to go stable
QuLogic from Freenode reported today that batched updates didn't go stable at 03:00 UTC like they should have. I confirmed that the cron job ran, but I didn't see any notes about its output. I then ran the command by hand and received this output:
```
[bowlofeggs@bodhi-backend01 ~][PROD]$ sudo -u apache /usr/bin/bodhi-dequeue-stable
No handlers could be found for logger "bodhi.server"
This update has not yet met the minimum testing requirements defined in the <a href="https://fedoraproject.org/wiki/Package_update_acceptance_criteria">Package Update Acceptance Criteria</a>
```
The [```dequeue_stable()```](https://github.com/fedora-infra/bodhi/blob/3.0.0/bodhi/server/scripts/dequeue_stable.py#L28-L46) function runs a large transaction with only a single try/except. It seems that some update in the queue no longer meets testing requirements (probably due to receiving a -1 karma after going to batched) and is raising an Exception when the tool attempts to mark it for stable. Since there is only one try/except handler, this causes the whole transaction to be rolled back.
It should be easy to fix this - we just need a try/except around each update.
Thanks to QuLogic from Freenode for reporting this issue to me.
</issue>
<code>
[start of bodhi/server/scripts/dequeue_stable.py]
1 # -*- coding: utf-8 -*-
2 # Copyright © 2017 Caleigh Runge-Hottman
3 #
4 # This file is part of Bodhi.
5 #
6 # This program is free software; you can redistribute it and/or
7 # modify it under the terms of the GNU General Public License
8 # as published by the Free Software Foundation; either version 2
9 # of the License, or (at your option) any later version.
10 #
11 # This program is distributed in the hope that it will be useful,
12 # but WITHOUT ANY WARRANTY; without even the implied warranty of
13 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
14 # GNU General Public License for more details.
15 #
16 # You should have received a copy of the GNU General Public License
17 # along with this program; if not, write to the Free Software
18 # Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.
19 """This script is responsible for moving all updates with a batched request to a stable request."""
20
21 import sys
22
23 import click
24
25 from bodhi.server import buildsys, config, models, Session, initialize_db
26
27
28 @click.command()
29 @click.version_option(message='%(version)s')
30 def dequeue_stable():
31 """Convert all batched requests to stable requests."""
32 initialize_db(config.config)
33 buildsys.setup_buildsystem(config.config)
34 db = Session()
35
36 try:
37 batched = db.query(models.Update).filter_by(request=models.UpdateRequest.batched).all()
38 for update in batched:
39 update.set_request(db, models.UpdateRequest.stable, u'bodhi')
40 db.commit()
41
42 except Exception as e:
43 print(str(e))
44 db.rollback()
45 Session.remove()
46 sys.exit(1)
47
[end of bodhi/server/scripts/dequeue_stable.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bodhi/server/scripts/dequeue_stable.py b/bodhi/server/scripts/dequeue_stable.py
--- a/bodhi/server/scripts/dequeue_stable.py
+++ b/bodhi/server/scripts/dequeue_stable.py
@@ -1,5 +1,5 @@
# -*- coding: utf-8 -*-
-# Copyright © 2017 Caleigh Runge-Hottman
+# Copyright © 2017 Caleigh Runge-Hottman and Red Hat, Inc.
#
# This file is part of Bodhi.
#
@@ -36,11 +36,17 @@
try:
batched = db.query(models.Update).filter_by(request=models.UpdateRequest.batched).all()
for update in batched:
- update.set_request(db, models.UpdateRequest.stable, u'bodhi')
- db.commit()
-
+ try:
+ update.set_request(db, models.UpdateRequest.stable, u'bodhi')
+ db.commit()
+ except Exception as e:
+ print('Unable to stabilize {}: {}'.format(update.alias, str(e)))
+ db.rollback()
+ msg = u"Bodhi is unable to request this update for stabilization: {}"
+ update.comment(db, msg.format(str(e)), author=u'bodhi')
+ db.commit()
except Exception as e:
print(str(e))
- db.rollback()
- Session.remove()
sys.exit(1)
+ finally:
+ Session.remove()
|
{"golden_diff": "diff --git a/bodhi/server/scripts/dequeue_stable.py b/bodhi/server/scripts/dequeue_stable.py\n--- a/bodhi/server/scripts/dequeue_stable.py\n+++ b/bodhi/server/scripts/dequeue_stable.py\n@@ -1,5 +1,5 @@\n # -*- coding: utf-8 -*-\n-# Copyright \u00a9 2017 Caleigh Runge-Hottman\n+# Copyright \u00a9 2017 Caleigh Runge-Hottman and Red Hat, Inc.\n #\n # This file is part of Bodhi.\n #\n@@ -36,11 +36,17 @@\n try:\n batched = db.query(models.Update).filter_by(request=models.UpdateRequest.batched).all()\n for update in batched:\n- update.set_request(db, models.UpdateRequest.stable, u'bodhi')\n- db.commit()\n-\n+ try:\n+ update.set_request(db, models.UpdateRequest.stable, u'bodhi')\n+ db.commit()\n+ except Exception as e:\n+ print('Unable to stabilize {}: {}'.format(update.alias, str(e)))\n+ db.rollback()\n+ msg = u\"Bodhi is unable to request this update for stabilization: {}\"\n+ update.comment(db, msg.format(str(e)), author=u'bodhi')\n+ db.commit()\n except Exception as e:\n print(str(e))\n- db.rollback()\n- Session.remove()\n sys.exit(1)\n+ finally:\n+ Session.remove()\n", "issue": "bodhi-dequqe-stable dies if any update in the queue is no longer eligible to go stable\nQuLogic from Freenode reported today that batched updates didn't go stable at 03:00 UTC like they should have. I confirmed that the cron job ran, but I didn't see any notes about its output. I then ran the command by hand and received this output:\r\n\r\n```\r\n[bowlofeggs@bodhi-backend01 ~][PROD]$ sudo -u apache /usr/bin/bodhi-dequeue-stable\r\nNo handlers could be found for logger \"bodhi.server\"\r\nThis update has not yet met the minimum testing requirements defined in the <a href=\"https://fedoraproject.org/wiki/Package_update_acceptance_criteria\">Package Update Acceptance Criteria</a>\r\n```\r\n\r\nThe [```dequeue_stable()```](https://github.com/fedora-infra/bodhi/blob/3.0.0/bodhi/server/scripts/dequeue_stable.py#L28-L46) function runs a large transaction with only a single try/except. It seems that some update in the queue no longer meets testing requirements (probably due to receiving a -1 karma after going to batched) and is raising an Exception when the tool attempts to mark it for stable. Since there is only one try/except handler, this causes the whole transaction to be rolled back.\r\n\r\nIt should be easy to fix this - we just need a try/except around each update.\r\n\r\nThanks to QuLogic from Freenode for reporting this issue to me.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright \u00a9 2017 Caleigh Runge-Hottman\n#\n# This file is part of Bodhi.\n#\n# This program is free software; you can redistribute it and/or\n# modify it under the terms of the GNU General Public License\n# as published by the Free Software Foundation; either version 2\n# of the License, or (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this program; if not, write to the Free Software\n# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.\n\"\"\"This script is responsible for moving all updates with a batched request to a stable request.\"\"\"\n\nimport sys\n\nimport click\n\nfrom bodhi.server import buildsys, config, models, Session, initialize_db\n\n\[email protected]()\[email protected]_option(message='%(version)s')\ndef dequeue_stable():\n \"\"\"Convert all batched requests to stable requests.\"\"\"\n initialize_db(config.config)\n buildsys.setup_buildsystem(config.config)\n db = Session()\n\n try:\n batched = db.query(models.Update).filter_by(request=models.UpdateRequest.batched).all()\n for update in batched:\n update.set_request(db, models.UpdateRequest.stable, u'bodhi')\n db.commit()\n\n except Exception as e:\n print(str(e))\n db.rollback()\n Session.remove()\n sys.exit(1)\n", "path": "bodhi/server/scripts/dequeue_stable.py"}]}
| 1,337 | 320 |
gh_patches_debug_57022
|
rasdani/github-patches
|
git_diff
|
astronomer__astro-sdk-1401
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Doc: Cross link to API reference page from Operators page
Currently there is no way to jump to Func/Operator definition from https://astro-sdk-python.readthedocs.io/en/stable/astro/sql/operators/get_value_list.html (and other operators listed on https://astro-sdk-python.readthedocs.io/en/stable/guides/operators.html) to their definition https://astro-sdk-python.readthedocs.io/en/stable/autoapi/index.html
We should cross-link them using https://www.sphinx-doc.org/en/master/usage/restructuredtext/domains.html#cross-referencing-syntax
</issue>
<code>
[start of python-sdk/src/astro/sql/__init__.py]
1 from airflow.configuration import conf
2 from airflow.decorators.base import get_unique_task_id
3 from airflow.models.xcom_arg import XComArg
4
5 from astro.sql.operators.append import AppendOperator, append
6 from astro.sql.operators.cleanup import CleanupOperator, cleanup
7 from astro.sql.operators.dataframe import DataframeOperator, dataframe
8 from astro.sql.operators.drop import DropTableOperator, drop_table
9 from astro.sql.operators.export_file import ExportFileOperator, export_file
10 from astro.sql.operators.load_file import LoadFileOperator, load_file
11 from astro.sql.operators.merge import MergeOperator, merge
12 from astro.sql.operators.raw_sql import RawSQLOperator, run_raw_sql
13 from astro.sql.operators.transform import TransformOperator, transform, transform_file
14 from astro.table import Metadata, Table
15
16 __all__ = [
17 "AppendOperator",
18 "append",
19 "CleanupOperator",
20 "cleanup",
21 "DataframeOperator",
22 "dataframe",
23 "DropTableOperator",
24 "drop_table",
25 "ExportFileOperator",
26 "export_file",
27 "LoadFileOperator",
28 "load_file",
29 "MergeOperator",
30 "merge",
31 "Metadata",
32 "run_raw_sql",
33 "Table",
34 "TransformOperator",
35 "transform_file",
36 "transform",
37 ]
38
39
40 def get_value_list(sql: str, conn_id: str, **kwargs) -> XComArg:
41 """
42 Execute a sql statement and return the result.
43 By default, the response size is less than equal to value of ``max_map_length`` conf.
44 You can call a callable handler to alter the response by default it call ``fetchall`` on database result set.
45
46
47 :param sql: sql query to execute.
48 If the sql query will return huge number of row then it can overload the XCOM.
49 also, If you are using output of this method to expand a task using dynamic task map then
50 it can create lots of parallel task. So it is advisable to limit your sql query statement.
51 :param conn_id: Airflow connection id. This connection id will be used to identify the database client
52 and connect with it at runtime
53 """
54 handler = kwargs.get("handler") or (lambda result_set: result_set.fetchall())
55 max_map_length = int(conf.get(section="core", key="max_map_length"))
56 op_kwargs = {
57 "handler": handler,
58 "response_limit": max_map_length,
59 }
60 task_id = kwargs.get("task_id") or get_unique_task_id(
61 "get_value_list", dag=kwargs.get("dag"), task_group=kwargs.get("task_group")
62 )
63 kwargs.update({"task_id": task_id})
64 return RawSQLOperator(
65 sql=sql, conn_id=conn_id, op_kwargs=op_kwargs, python_callable=(lambda *args: None), **kwargs
66 ).output
67
[end of python-sdk/src/astro/sql/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/python-sdk/src/astro/sql/__init__.py b/python-sdk/src/astro/sql/__init__.py
--- a/python-sdk/src/astro/sql/__init__.py
+++ b/python-sdk/src/astro/sql/__init__.py
@@ -24,6 +24,7 @@
"drop_table",
"ExportFileOperator",
"export_file",
+ "get_value_list",
"LoadFileOperator",
"load_file",
"MergeOperator",
|
{"golden_diff": "diff --git a/python-sdk/src/astro/sql/__init__.py b/python-sdk/src/astro/sql/__init__.py\n--- a/python-sdk/src/astro/sql/__init__.py\n+++ b/python-sdk/src/astro/sql/__init__.py\n@@ -24,6 +24,7 @@\n \"drop_table\",\n \"ExportFileOperator\",\n \"export_file\",\n+ \"get_value_list\",\n \"LoadFileOperator\",\n \"load_file\",\n \"MergeOperator\",\n", "issue": "Doc: Cross link to API reference page from Operators page\nCurrently there is no way to jump to Func/Operator definition from https://astro-sdk-python.readthedocs.io/en/stable/astro/sql/operators/get_value_list.html (and other operators listed on https://astro-sdk-python.readthedocs.io/en/stable/guides/operators.html) to their definition https://astro-sdk-python.readthedocs.io/en/stable/autoapi/index.html\r\n\r\nWe should cross-link them using https://www.sphinx-doc.org/en/master/usage/restructuredtext/domains.html#cross-referencing-syntax\n", "before_files": [{"content": "from airflow.configuration import conf\nfrom airflow.decorators.base import get_unique_task_id\nfrom airflow.models.xcom_arg import XComArg\n\nfrom astro.sql.operators.append import AppendOperator, append\nfrom astro.sql.operators.cleanup import CleanupOperator, cleanup\nfrom astro.sql.operators.dataframe import DataframeOperator, dataframe\nfrom astro.sql.operators.drop import DropTableOperator, drop_table\nfrom astro.sql.operators.export_file import ExportFileOperator, export_file\nfrom astro.sql.operators.load_file import LoadFileOperator, load_file\nfrom astro.sql.operators.merge import MergeOperator, merge\nfrom astro.sql.operators.raw_sql import RawSQLOperator, run_raw_sql\nfrom astro.sql.operators.transform import TransformOperator, transform, transform_file\nfrom astro.table import Metadata, Table\n\n__all__ = [\n \"AppendOperator\",\n \"append\",\n \"CleanupOperator\",\n \"cleanup\",\n \"DataframeOperator\",\n \"dataframe\",\n \"DropTableOperator\",\n \"drop_table\",\n \"ExportFileOperator\",\n \"export_file\",\n \"LoadFileOperator\",\n \"load_file\",\n \"MergeOperator\",\n \"merge\",\n \"Metadata\",\n \"run_raw_sql\",\n \"Table\",\n \"TransformOperator\",\n \"transform_file\",\n \"transform\",\n]\n\n\ndef get_value_list(sql: str, conn_id: str, **kwargs) -> XComArg:\n \"\"\"\n Execute a sql statement and return the result.\n By default, the response size is less than equal to value of ``max_map_length`` conf.\n You can call a callable handler to alter the response by default it call ``fetchall`` on database result set.\n\n\n :param sql: sql query to execute.\n If the sql query will return huge number of row then it can overload the XCOM.\n also, If you are using output of this method to expand a task using dynamic task map then\n it can create lots of parallel task. So it is advisable to limit your sql query statement.\n :param conn_id: Airflow connection id. This connection id will be used to identify the database client\n and connect with it at runtime\n \"\"\"\n handler = kwargs.get(\"handler\") or (lambda result_set: result_set.fetchall())\n max_map_length = int(conf.get(section=\"core\", key=\"max_map_length\"))\n op_kwargs = {\n \"handler\": handler,\n \"response_limit\": max_map_length,\n }\n task_id = kwargs.get(\"task_id\") or get_unique_task_id(\n \"get_value_list\", dag=kwargs.get(\"dag\"), task_group=kwargs.get(\"task_group\")\n )\n kwargs.update({\"task_id\": task_id})\n return RawSQLOperator(\n sql=sql, conn_id=conn_id, op_kwargs=op_kwargs, python_callable=(lambda *args: None), **kwargs\n ).output\n", "path": "python-sdk/src/astro/sql/__init__.py"}]}
| 1,391 | 104 |
gh_patches_debug_5063
|
rasdani/github-patches
|
git_diff
|
cltk__cltk-371
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Inconsistent case of data directory
[The latin module](https://github.com/cltk/cltk/blob/36b6fe7aa23a8c4f41ef694ddb64b4b02534146c/cltk/corpus/latin/__init__.py#L20) tries to load the latin library from "~/CLTK_DATA", which fails on a case-sensitive filesystem.
All other modules seem to use "~/cltk_data", so that should be standardized.
(It would probably be best if the path was factored out and also configurable, but fixing at least that one inconsistency lets me actually import stuff without errors.)
Inconsistent case of data directory
[The latin module](https://github.com/cltk/cltk/blob/36b6fe7aa23a8c4f41ef694ddb64b4b02534146c/cltk/corpus/latin/__init__.py#L20) tries to load the latin library from "~/CLTK_DATA", which fails on a case-sensitive filesystem.
All other modules seem to use "~/cltk_data", so that should be standardized.
(It would probably be best if the path was factored out and also configurable, but fixing at least that one inconsistency lets me actually import stuff without errors.)
</issue>
<code>
[start of cltk/corpus/latin/__init__.py]
1 # CLTK: Latin Corpus Readers
2
3 __author__ = 'Patrick J. Burns <[email protected]>'
4 __license__ = 'MIT License. See LICENSE.'
5
6 """
7 CLTK Latin corpus readers
8 """
9
10 import os.path
11 from nltk.corpus.reader.plaintext import PlaintextCorpusReader
12 from nltk.tokenize.punkt import PunktSentenceTokenizer, PunktParameters
13
14 from cltk.tokenize.sentence import TokenizeSentence
15 from cltk.tokenize.word import WordTokenizer
16
17 # Would like to have this search through a CLTK_DATA environment variable
18 # Better to use something like make_cltk_path in cltk.utils.file_operations?
19 home = os.path.expanduser('~')
20 cltk_path = os.path.join(home, 'CLTK_DATA')
21
22 word_tokenizer = WordTokenizer('latin')
23
24 if os.path.exists(cltk_path + 'latin/model/latin_models_cltk/tokenizers/sentence'):
25 sent_tokenizer = TokenizeSentence('latin')
26 else:
27 punkt_param = PunktParameters()
28 abbreviations = ['c', 'l', 'm', 'p', 'q', 't', 'ti', 'sex', 'a', 'd', 'cn', 'sp', "m'", 'ser', 'ap', 'n', 'v', 'k', 'mam', 'post', 'f', 'oct', 'opet', 'paul', 'pro', 'sert', 'st', 'sta', 'v', 'vol', 'vop']
29 punkt_param.abbrev_types = set(abbreviations)
30 sent_tokenizer = PunktSentenceTokenizer(punkt_param)
31
32 # Latin Library
33 try:
34 latinlibrary = PlaintextCorpusReader(cltk_path + '/latin/text/latin_text_latin_library',
35 '.*\.txt',
36 word_tokenizer=word_tokenizer,
37 sent_tokenizer=sent_tokenizer,
38 encoding='utf-8')
39 pass
40 except IOError as e:
41 print("Corpus not found. Please check that the Latin Library is installed in CLTK_DATA.")
42
[end of cltk/corpus/latin/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/cltk/corpus/latin/__init__.py b/cltk/corpus/latin/__init__.py
--- a/cltk/corpus/latin/__init__.py
+++ b/cltk/corpus/latin/__init__.py
@@ -17,7 +17,7 @@
# Would like to have this search through a CLTK_DATA environment variable
# Better to use something like make_cltk_path in cltk.utils.file_operations?
home = os.path.expanduser('~')
-cltk_path = os.path.join(home, 'CLTK_DATA')
+cltk_path = os.path.join(home, 'cltk_data')
word_tokenizer = WordTokenizer('latin')
|
{"golden_diff": "diff --git a/cltk/corpus/latin/__init__.py b/cltk/corpus/latin/__init__.py\n--- a/cltk/corpus/latin/__init__.py\n+++ b/cltk/corpus/latin/__init__.py\n@@ -17,7 +17,7 @@\n # Would like to have this search through a CLTK_DATA environment variable\n # Better to use something like make_cltk_path in cltk.utils.file_operations?\n home = os.path.expanduser('~')\n-cltk_path = os.path.join(home, 'CLTK_DATA')\n+cltk_path = os.path.join(home, 'cltk_data')\n \n word_tokenizer = WordTokenizer('latin')\n", "issue": "Inconsistent case of data directory\n[The latin module](https://github.com/cltk/cltk/blob/36b6fe7aa23a8c4f41ef694ddb64b4b02534146c/cltk/corpus/latin/__init__.py#L20) tries to load the latin library from \"~/CLTK_DATA\", which fails on a case-sensitive filesystem.\n\nAll other modules seem to use \"~/cltk_data\", so that should be standardized. \n\n(It would probably be best if the path was factored out and also configurable, but fixing at least that one inconsistency lets me actually import stuff without errors.)\n\nInconsistent case of data directory\n[The latin module](https://github.com/cltk/cltk/blob/36b6fe7aa23a8c4f41ef694ddb64b4b02534146c/cltk/corpus/latin/__init__.py#L20) tries to load the latin library from \"~/CLTK_DATA\", which fails on a case-sensitive filesystem.\n\nAll other modules seem to use \"~/cltk_data\", so that should be standardized. \n\n(It would probably be best if the path was factored out and also configurable, but fixing at least that one inconsistency lets me actually import stuff without errors.)\n\n", "before_files": [{"content": "# CLTK: Latin Corpus Readers\n\n__author__ = 'Patrick J. Burns <[email protected]>'\n__license__ = 'MIT License. See LICENSE.'\n\n\"\"\"\nCLTK Latin corpus readers\n\"\"\"\n\nimport os.path\nfrom nltk.corpus.reader.plaintext import PlaintextCorpusReader\nfrom nltk.tokenize.punkt import PunktSentenceTokenizer, PunktParameters\n\nfrom cltk.tokenize.sentence import TokenizeSentence\nfrom cltk.tokenize.word import WordTokenizer\n\n# Would like to have this search through a CLTK_DATA environment variable\n# Better to use something like make_cltk_path in cltk.utils.file_operations?\nhome = os.path.expanduser('~')\ncltk_path = os.path.join(home, 'CLTK_DATA')\n\nword_tokenizer = WordTokenizer('latin')\n\nif os.path.exists(cltk_path + 'latin/model/latin_models_cltk/tokenizers/sentence'):\n sent_tokenizer = TokenizeSentence('latin')\nelse:\n punkt_param = PunktParameters()\n abbreviations = ['c', 'l', 'm', 'p', 'q', 't', 'ti', 'sex', 'a', 'd', 'cn', 'sp', \"m'\", 'ser', 'ap', 'n', 'v', 'k', 'mam', 'post', 'f', 'oct', 'opet', 'paul', 'pro', 'sert', 'st', 'sta', 'v', 'vol', 'vop']\n punkt_param.abbrev_types = set(abbreviations)\n sent_tokenizer = PunktSentenceTokenizer(punkt_param)\n\n# Latin Library\ntry:\n latinlibrary = PlaintextCorpusReader(cltk_path + '/latin/text/latin_text_latin_library', \n '.*\\.txt',\n word_tokenizer=word_tokenizer, \n sent_tokenizer=sent_tokenizer, \n encoding='utf-8') \n pass\nexcept IOError as e:\n print(\"Corpus not found. Please check that the Latin Library is installed in CLTK_DATA.\")\n", "path": "cltk/corpus/latin/__init__.py"}]}
| 1,341 | 148 |
gh_patches_debug_35230
|
rasdani/github-patches
|
git_diff
|
ocadotechnology__aimmo-191
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Remove "staff required" for aimmo pages when URL viewing restrictions are merged
Will require https://github.com/ocadotechnology/codeforlife-deploy-appengine/pull/35
</issue>
<code>
[start of players/urls.py]
1 from django.conf.urls import url
2 from django.views.generic import TemplateView
3 from django.contrib.auth.decorators import login_required
4 from django.contrib.admin.views.decorators import staff_member_required
5
6 from players import views
7
8 urlpatterns = [
9 url(r'^$', staff_member_required(TemplateView.as_view(template_name='players/home.html')), name='aimmo/home'),
10
11 url(r'^program/$', staff_member_required(login_required(TemplateView.as_view(template_name='players/program.html'))), name='aimmo/program'),
12 url(r'^watch/$', staff_member_required(views.WatchView.as_view()), name='aimmo/watch'),
13 url(r'^statistics/$', staff_member_required(TemplateView.as_view(template_name='players/statistics.html')), name='aimmo/statistics'),
14
15 url(r'^api/code/$', staff_member_required(views.code), name='aimmo/code'),
16 url(r'^api/games/$', views.games, name='aimmo/games'),
17
18 url(r'^jsreverse/$', 'django_js_reverse.views.urls_js', name='aimmo/js_reverse'), # TODO: Pull request to make django_js_reverse.urls
19 ]
20
[end of players/urls.py]
[start of example_project/example_project/settings.py]
1 # -*- coding: utf-8 -*-
2 # Code for Life
3 #
4 # Copyright (C) 2015, Ocado Innovation Limited
5 #
6 # This program is free software: you can redistribute it and/or modify
7 # it under the terms of the GNU Affero General Public License as
8 # published by the Free Software Foundation, either version 3 of the
9 # License, or (at your option) any later version.
10 #
11 # This program is distributed in the hope that it will be useful,
12 # but WITHOUT ANY WARRANTY; without even the implied warranty of
13 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
14 # GNU Affero General Public License for more details.
15 #
16 # You should have received a copy of the GNU Affero General Public License
17 # along with this program. If not, see <http://www.gnu.org/licenses/>.
18 #
19 # ADDITIONAL TERMS – Section 7 GNU General Public Licence
20 #
21 # This licence does not grant any right, title or interest in any “Ocado” logos,
22 # trade names or the trademark “Ocado” or any other trademarks or domain names
23 # owned by Ocado Innovation Limited or the Ocado group of companies or any other
24 # distinctive brand features of “Ocado” as may be secured from time to time. You
25 # must not distribute any modification of this program using the trademark
26 # “Ocado” or claim any affiliation or association with Ocado or its employees.
27 #
28 # You are not authorised to use the name Ocado (or any of its trade names) or
29 # the names of any author or contributor in advertising or for publicity purposes
30 # pertaining to the distribution of this program, without the prior written
31 # authorisation of Ocado.
32 #
33 # Any propagation, distribution or conveyance of this program must include this
34 # copyright notice and these terms. You must not misrepresent the origins of this
35 # program; modified versions of the program must be marked as such and not
36 # identified as the original program.
37 """Django settings for example_project project."""
38 import os
39 import subprocess
40
41 DEBUG = True
42
43 DATABASES = {
44 'default': {
45 'ENGINE': 'django.db.backends.sqlite3', # Add 'postgresql_psycopg2', 'mysql', 'sqlite3' or 'oracle'.
46 'NAME': os.path.join(os.path.abspath(os.path.dirname(__file__)), 'db.sqlite3'), # Or path to database file if using sqlite3.
47 }
48 }
49
50 USE_I18N = True
51 USE_L10N = True
52
53 TIME_ZONE = 'Europe/London'
54 LANGUAGE_CODE = 'en-gb'
55 STATIC_ROOT = os.path.join(os.path.dirname(__file__), 'static')
56 STATIC_URL = '/static/'
57 SECRET_KEY = 'not-a-secret'
58
59 ROOT_URLCONF = 'django_autoconfig.autourlconf'
60
61 WSGI_APPLICATION = 'example_project.wsgi.application'
62
63 INSTALLED_APPS = (
64 'django.contrib.admin',
65 'players',
66 )
67
68 LOGGING = {
69 'version': 1,
70 'disable_existing_loggers': False,
71 'filters': {
72 'require_debug_false': {
73 '()': 'django.utils.log.RequireDebugFalse'
74 }
75 },
76 'handlers': {
77 'console': {
78 'level': 'DEBUG',
79 'class': 'logging.StreamHandler'
80 },
81 },
82 'loggers': {
83 'views': {
84 'handlers': ['console'],
85 'level': 'DEBUG'
86 },
87 }
88 }
89
90
91 def get_url(game):
92 if os.environ.get('AIMMO_MODE', '') == 'minikube':
93 output = subprocess.check_output(['./test-bin/minikube', 'service', 'game-%s' % game, '--url'])
94 return (output.strip(), '/game/%s/socket.io' % game)
95 else:
96 return ('http://localhost:5000', '/socket.io')
97
98 AIMMO_GAME_SERVER_LOCATION_FUNCTION = get_url
99
100 try:
101 from example_project.local_settings import * # pylint: disable=E0611
102 except ImportError:
103 pass
104
105 from django_autoconfig import autoconfig
106 autoconfig.configure_settings(globals())
107
[end of example_project/example_project/settings.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/example_project/example_project/settings.py b/example_project/example_project/settings.py
--- a/example_project/example_project/settings.py
+++ b/example_project/example_project/settings.py
@@ -62,6 +62,8 @@
INSTALLED_APPS = (
'django.contrib.admin',
+ 'django.contrib.auth',
+ 'django.contrib.contenttypes',
'players',
)
@@ -87,6 +89,16 @@
}
}
+LOGIN_URL = '/players/accounts/login/'
+
+MIDDLEWARE_CLASSES = [
+ 'django.contrib.sessions.middleware.SessionMiddleware',
+ 'django.middleware.locale.LocaleMiddleware',
+ 'django.middleware.common.CommonMiddleware',
+ 'django.middleware.csrf.CsrfViewMiddleware',
+ 'django.contrib.auth.middleware.AuthenticationMiddleware',
+ 'django.contrib.messages.middleware.MessageMiddleware',
+]
def get_url(game):
if os.environ.get('AIMMO_MODE', '') == 'minikube':
diff --git a/players/urls.py b/players/urls.py
--- a/players/urls.py
+++ b/players/urls.py
@@ -1,18 +1,19 @@
from django.conf.urls import url
from django.views.generic import TemplateView
+from django.contrib.auth import views as auth_views
from django.contrib.auth.decorators import login_required
-from django.contrib.admin.views.decorators import staff_member_required
from players import views
urlpatterns = [
- url(r'^$', staff_member_required(TemplateView.as_view(template_name='players/home.html')), name='aimmo/home'),
+ url(r'^$', TemplateView.as_view(template_name='players/home.html'), name='aimmo/home'),
- url(r'^program/$', staff_member_required(login_required(TemplateView.as_view(template_name='players/program.html'))), name='aimmo/program'),
- url(r'^watch/$', staff_member_required(views.WatchView.as_view()), name='aimmo/watch'),
- url(r'^statistics/$', staff_member_required(TemplateView.as_view(template_name='players/statistics.html')), name='aimmo/statistics'),
+ url(r'^program/$', login_required(TemplateView.as_view(template_name='players/program.html')), name='aimmo/program'),
+ url(r'^accounts/login/$', auth_views.login),
+ url(r'^watch/$', views.WatchView.as_view(), name='aimmo/watch'),
+ url(r'^statistics/$', TemplateView.as_view(template_name='players/statistics.html'), name='aimmo/statistics'),
- url(r'^api/code/$', staff_member_required(views.code), name='aimmo/code'),
+ url(r'^api/code/$', views.code, name='aimmo/code'),
url(r'^api/games/$', views.games, name='aimmo/games'),
url(r'^jsreverse/$', 'django_js_reverse.views.urls_js', name='aimmo/js_reverse'), # TODO: Pull request to make django_js_reverse.urls
|
{"golden_diff": "diff --git a/example_project/example_project/settings.py b/example_project/example_project/settings.py\n--- a/example_project/example_project/settings.py\n+++ b/example_project/example_project/settings.py\n@@ -62,6 +62,8 @@\n \n INSTALLED_APPS = (\n 'django.contrib.admin',\n+ 'django.contrib.auth',\n+ 'django.contrib.contenttypes',\n 'players',\n )\n \n@@ -87,6 +89,16 @@\n }\n }\n \n+LOGIN_URL = '/players/accounts/login/'\n+\n+MIDDLEWARE_CLASSES = [\n+ 'django.contrib.sessions.middleware.SessionMiddleware',\n+ 'django.middleware.locale.LocaleMiddleware',\n+ 'django.middleware.common.CommonMiddleware',\n+ 'django.middleware.csrf.CsrfViewMiddleware',\n+ 'django.contrib.auth.middleware.AuthenticationMiddleware',\n+ 'django.contrib.messages.middleware.MessageMiddleware',\n+]\n \n def get_url(game):\n if os.environ.get('AIMMO_MODE', '') == 'minikube':\ndiff --git a/players/urls.py b/players/urls.py\n--- a/players/urls.py\n+++ b/players/urls.py\n@@ -1,18 +1,19 @@\n from django.conf.urls import url\n from django.views.generic import TemplateView\n+from django.contrib.auth import views as auth_views\n from django.contrib.auth.decorators import login_required\n-from django.contrib.admin.views.decorators import staff_member_required\n \n from players import views\n \n urlpatterns = [\n- url(r'^$', staff_member_required(TemplateView.as_view(template_name='players/home.html')), name='aimmo/home'),\n+ url(r'^$', TemplateView.as_view(template_name='players/home.html'), name='aimmo/home'),\n \n- url(r'^program/$', staff_member_required(login_required(TemplateView.as_view(template_name='players/program.html'))), name='aimmo/program'),\n- url(r'^watch/$', staff_member_required(views.WatchView.as_view()), name='aimmo/watch'),\n- url(r'^statistics/$', staff_member_required(TemplateView.as_view(template_name='players/statistics.html')), name='aimmo/statistics'),\n+ url(r'^program/$', login_required(TemplateView.as_view(template_name='players/program.html')), name='aimmo/program'),\n+ url(r'^accounts/login/$', auth_views.login),\n+ url(r'^watch/$', views.WatchView.as_view(), name='aimmo/watch'),\n+ url(r'^statistics/$', TemplateView.as_view(template_name='players/statistics.html'), name='aimmo/statistics'),\n \n- url(r'^api/code/$', staff_member_required(views.code), name='aimmo/code'),\n+ url(r'^api/code/$', views.code, name='aimmo/code'),\n url(r'^api/games/$', views.games, name='aimmo/games'),\n \n url(r'^jsreverse/$', 'django_js_reverse.views.urls_js', name='aimmo/js_reverse'), # TODO: Pull request to make django_js_reverse.urls\n", "issue": "Remove \"staff required\" for aimmo pages when URL viewing restrictions are merged\nWill require https://github.com/ocadotechnology/codeforlife-deploy-appengine/pull/35\n", "before_files": [{"content": "from django.conf.urls import url\nfrom django.views.generic import TemplateView\nfrom django.contrib.auth.decorators import login_required\nfrom django.contrib.admin.views.decorators import staff_member_required\n\nfrom players import views\n\nurlpatterns = [\n url(r'^$', staff_member_required(TemplateView.as_view(template_name='players/home.html')), name='aimmo/home'),\n\n url(r'^program/$', staff_member_required(login_required(TemplateView.as_view(template_name='players/program.html'))), name='aimmo/program'),\n url(r'^watch/$', staff_member_required(views.WatchView.as_view()), name='aimmo/watch'),\n url(r'^statistics/$', staff_member_required(TemplateView.as_view(template_name='players/statistics.html')), name='aimmo/statistics'),\n\n url(r'^api/code/$', staff_member_required(views.code), name='aimmo/code'),\n url(r'^api/games/$', views.games, name='aimmo/games'),\n\n url(r'^jsreverse/$', 'django_js_reverse.views.urls_js', name='aimmo/js_reverse'), # TODO: Pull request to make django_js_reverse.urls\n]\n", "path": "players/urls.py"}, {"content": "# -*- coding: utf-8 -*-\n# Code for Life\n#\n# Copyright (C) 2015, Ocado Innovation Limited\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU Affero General Public License as\n# published by the Free Software Foundation, either version 3 of the\n# License, or (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU Affero General Public License for more details.\n#\n# You should have received a copy of the GNU Affero General Public License\n# along with this program. If not, see <http://www.gnu.org/licenses/>.\n#\n# ADDITIONAL TERMS \u2013 Section 7 GNU General Public Licence\n#\n# This licence does not grant any right, title or interest in any \u201cOcado\u201d logos,\n# trade names or the trademark \u201cOcado\u201d or any other trademarks or domain names\n# owned by Ocado Innovation Limited or the Ocado group of companies or any other\n# distinctive brand features of \u201cOcado\u201d as may be secured from time to time. You\n# must not distribute any modification of this program using the trademark\n# \u201cOcado\u201d or claim any affiliation or association with Ocado or its employees.\n#\n# You are not authorised to use the name Ocado (or any of its trade names) or\n# the names of any author or contributor in advertising or for publicity purposes\n# pertaining to the distribution of this program, without the prior written\n# authorisation of Ocado.\n#\n# Any propagation, distribution or conveyance of this program must include this\n# copyright notice and these terms. You must not misrepresent the origins of this\n# program; modified versions of the program must be marked as such and not\n# identified as the original program.\n\"\"\"Django settings for example_project project.\"\"\"\nimport os\nimport subprocess\n\nDEBUG = True\n\nDATABASES = {\n 'default': {\n 'ENGINE': 'django.db.backends.sqlite3', # Add 'postgresql_psycopg2', 'mysql', 'sqlite3' or 'oracle'.\n 'NAME': os.path.join(os.path.abspath(os.path.dirname(__file__)), 'db.sqlite3'), # Or path to database file if using sqlite3.\n }\n}\n\nUSE_I18N = True\nUSE_L10N = True\n\nTIME_ZONE = 'Europe/London'\nLANGUAGE_CODE = 'en-gb'\nSTATIC_ROOT = os.path.join(os.path.dirname(__file__), 'static')\nSTATIC_URL = '/static/'\nSECRET_KEY = 'not-a-secret'\n\nROOT_URLCONF = 'django_autoconfig.autourlconf'\n\nWSGI_APPLICATION = 'example_project.wsgi.application'\n\nINSTALLED_APPS = (\n 'django.contrib.admin',\n 'players',\n)\n\nLOGGING = {\n 'version': 1,\n 'disable_existing_loggers': False,\n 'filters': {\n 'require_debug_false': {\n '()': 'django.utils.log.RequireDebugFalse'\n }\n },\n 'handlers': {\n 'console': {\n 'level': 'DEBUG',\n 'class': 'logging.StreamHandler'\n },\n },\n 'loggers': {\n 'views': {\n 'handlers': ['console'],\n 'level': 'DEBUG'\n },\n }\n}\n\n\ndef get_url(game):\n if os.environ.get('AIMMO_MODE', '') == 'minikube':\n output = subprocess.check_output(['./test-bin/minikube', 'service', 'game-%s' % game, '--url'])\n return (output.strip(), '/game/%s/socket.io' % game)\n else:\n return ('http://localhost:5000', '/socket.io')\n\nAIMMO_GAME_SERVER_LOCATION_FUNCTION = get_url\n\ntry:\n from example_project.local_settings import * # pylint: disable=E0611\nexcept ImportError:\n pass\n\nfrom django_autoconfig import autoconfig\nautoconfig.configure_settings(globals())\n", "path": "example_project/example_project/settings.py"}]}
| 1,935 | 613 |
gh_patches_debug_18386
|
rasdani/github-patches
|
git_diff
|
liqd__a4-meinberlin-1168
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
On creating a plan, "Berlin" may be selected as district
"Berlin" is part of the dropdown in the vorhaben create and update form
@MagdaN should i add this issue to the whiteboard or taiga, too?
</issue>
<code>
[start of meinberlin/apps/plans/models.py]
1 from ckeditor.fields import RichTextField
2 from django.conf import settings
3 from django.core.urlresolvers import reverse
4 from django.db import models
5 from django.utils.translation import ugettext_lazy as _
6
7 from adhocracy4 import transforms
8 from adhocracy4.maps import fields as map_fields
9 from adhocracy4.models.base import UserGeneratedContentModel
10 from adhocracy4.projects import models as project_models
11 from meinberlin.apps.maps.models import MapPreset
12
13 STATUS_TODO = 0
14 STATUS_PLANNING = 1
15 STATUS_IMPLEMENTATION = 2
16 STATUS_DONE = 3
17 STATUS_STOPPED = 4
18
19 PARTICIPATION_NO = 0
20 PARTICIPATION_YES = 1
21 PARTICIPATION_UNDECIDED = 2
22
23
24 class Plan(UserGeneratedContentModel):
25 title = models.CharField(max_length=120, verbose_name=_('Title'))
26 organisation = models.ForeignKey(
27 settings.A4_ORGANISATIONS_MODEL,
28 on_delete=models.CASCADE)
29 project = models.ForeignKey(project_models.Project, blank=True, null=True)
30 point = map_fields.PointField(
31 verbose_name=_('Where can the plan be located on a map?'),
32 help_text=_('Click inside marked area on the map to set a marker. '
33 'Drag and drop the marker to change its place. '
34 'Alternatively you can use the search field to search '
35 'for an address.'))
36 point_label = models.CharField(
37 blank=True,
38 default='',
39 max_length=255,
40 verbose_name=_('Label of the location'),
41 help_text=_('This could be an address or the name of a landmark.'),
42 )
43 district = models.ForeignKey(
44 MapPreset,
45 limit_choices_to={'category__name': 'Berlin'})
46 contact = models.TextField(max_length=255, verbose_name=_('Contact'))
47 cost = models.PositiveIntegerField(blank=True, null=True,
48 verbose_name=_('Cost'))
49 description = RichTextField(verbose_name=_('Description'), blank=True)
50 category = models.CharField(max_length=255, verbose_name=_('Type of plan'))
51 status = models.SmallIntegerField(choices=(
52 (STATUS_TODO, _('Idea')),
53 (STATUS_PLANNING, _('Planning')),
54 (STATUS_IMPLEMENTATION, _('Implementation')),
55 (STATUS_DONE, _('Done')),
56 (STATUS_STOPPED, _('Stopped')),
57 ))
58 participation = models.SmallIntegerField(choices=(
59 (PARTICIPATION_YES, _('Yes')),
60 (PARTICIPATION_NO, _('No')),
61 (PARTICIPATION_UNDECIDED, _('Still undecided')),
62 ))
63
64 class Meta:
65 ordering = ['-created']
66
67 @property
68 def reference_number(self):
69 return '{:d}-{:05d}'.format(self.created.year, self.pk)
70
71 def __str__(self):
72 return self.title
73
74 def get_absolute_url(self):
75 return reverse('meinberlin_plans:plan-detail',
76 kwargs=dict(pk=self.pk, year=self.created.year))
77
78 def save(self, *args, **kwargs):
79 self.description = transforms.clean_html_field(self.description)
80 super().save(*args, **kwargs)
81
[end of meinberlin/apps/plans/models.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/meinberlin/apps/plans/models.py b/meinberlin/apps/plans/models.py
--- a/meinberlin/apps/plans/models.py
+++ b/meinberlin/apps/plans/models.py
@@ -2,6 +2,7 @@
from django.conf import settings
from django.core.urlresolvers import reverse
from django.db import models
+from django.db.models import Q
from django.utils.translation import ugettext_lazy as _
from adhocracy4 import transforms
@@ -42,7 +43,7 @@
)
district = models.ForeignKey(
MapPreset,
- limit_choices_to={'category__name': 'Berlin'})
+ limit_choices_to=Q(category__name='Berlin') & ~Q(name='Berlin'))
contact = models.TextField(max_length=255, verbose_name=_('Contact'))
cost = models.PositiveIntegerField(blank=True, null=True,
verbose_name=_('Cost'))
|
{"golden_diff": "diff --git a/meinberlin/apps/plans/models.py b/meinberlin/apps/plans/models.py\n--- a/meinberlin/apps/plans/models.py\n+++ b/meinberlin/apps/plans/models.py\n@@ -2,6 +2,7 @@\n from django.conf import settings\n from django.core.urlresolvers import reverse\n from django.db import models\n+from django.db.models import Q\n from django.utils.translation import ugettext_lazy as _\n \n from adhocracy4 import transforms\n@@ -42,7 +43,7 @@\n )\n district = models.ForeignKey(\n MapPreset,\n- limit_choices_to={'category__name': 'Berlin'})\n+ limit_choices_to=Q(category__name='Berlin') & ~Q(name='Berlin'))\n contact = models.TextField(max_length=255, verbose_name=_('Contact'))\n cost = models.PositiveIntegerField(blank=True, null=True,\n verbose_name=_('Cost'))\n", "issue": "On creating a plan, \"Berlin\" may be selected as district\n\"Berlin\" is part of the dropdown in the vorhaben create and update form\r\n\r\n@MagdaN should i add this issue to the whiteboard or taiga, too?\n", "before_files": [{"content": "from ckeditor.fields import RichTextField\nfrom django.conf import settings\nfrom django.core.urlresolvers import reverse\nfrom django.db import models\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom adhocracy4 import transforms\nfrom adhocracy4.maps import fields as map_fields\nfrom adhocracy4.models.base import UserGeneratedContentModel\nfrom adhocracy4.projects import models as project_models\nfrom meinberlin.apps.maps.models import MapPreset\n\nSTATUS_TODO = 0\nSTATUS_PLANNING = 1\nSTATUS_IMPLEMENTATION = 2\nSTATUS_DONE = 3\nSTATUS_STOPPED = 4\n\nPARTICIPATION_NO = 0\nPARTICIPATION_YES = 1\nPARTICIPATION_UNDECIDED = 2\n\n\nclass Plan(UserGeneratedContentModel):\n title = models.CharField(max_length=120, verbose_name=_('Title'))\n organisation = models.ForeignKey(\n settings.A4_ORGANISATIONS_MODEL,\n on_delete=models.CASCADE)\n project = models.ForeignKey(project_models.Project, blank=True, null=True)\n point = map_fields.PointField(\n verbose_name=_('Where can the plan be located on a map?'),\n help_text=_('Click inside marked area on the map to set a marker. '\n 'Drag and drop the marker to change its place. '\n 'Alternatively you can use the search field to search '\n 'for an address.'))\n point_label = models.CharField(\n blank=True,\n default='',\n max_length=255,\n verbose_name=_('Label of the location'),\n help_text=_('This could be an address or the name of a landmark.'),\n )\n district = models.ForeignKey(\n MapPreset,\n limit_choices_to={'category__name': 'Berlin'})\n contact = models.TextField(max_length=255, verbose_name=_('Contact'))\n cost = models.PositiveIntegerField(blank=True, null=True,\n verbose_name=_('Cost'))\n description = RichTextField(verbose_name=_('Description'), blank=True)\n category = models.CharField(max_length=255, verbose_name=_('Type of plan'))\n status = models.SmallIntegerField(choices=(\n (STATUS_TODO, _('Idea')),\n (STATUS_PLANNING, _('Planning')),\n (STATUS_IMPLEMENTATION, _('Implementation')),\n (STATUS_DONE, _('Done')),\n (STATUS_STOPPED, _('Stopped')),\n ))\n participation = models.SmallIntegerField(choices=(\n (PARTICIPATION_YES, _('Yes')),\n (PARTICIPATION_NO, _('No')),\n (PARTICIPATION_UNDECIDED, _('Still undecided')),\n ))\n\n class Meta:\n ordering = ['-created']\n\n @property\n def reference_number(self):\n return '{:d}-{:05d}'.format(self.created.year, self.pk)\n\n def __str__(self):\n return self.title\n\n def get_absolute_url(self):\n return reverse('meinberlin_plans:plan-detail',\n kwargs=dict(pk=self.pk, year=self.created.year))\n\n def save(self, *args, **kwargs):\n self.description = transforms.clean_html_field(self.description)\n super().save(*args, **kwargs)\n", "path": "meinberlin/apps/plans/models.py"}]}
| 1,403 | 200 |
gh_patches_debug_29253
|
rasdani/github-patches
|
git_diff
|
mars-project__mars-2957
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Submit query condition to remote node instead of fetch to local then query
<!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Is your feature request related to a problem? Please describe.**
Curently if ray fetcher gets objects with condition, it will fetch objects to local, then filter local objects with conditions. This will incur much objects transfer cost and high memory footsprint in local node.
**Describe the solution you'd like**
We should submit query to objects' node then fetch queried result instead.
</issue>
<code>
[start of mars/services/task/execution/ray/fetcher.py]
1 # Copyright 1999-2021 Alibaba Group Holding Ltd.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import asyncio
16 from collections import namedtuple
17 from typing import Dict, List
18 from ..api import Fetcher, register_fetcher_cls
19
20
21 _FetchInfo = namedtuple("FetchInfo", ["key", "object_ref", "conditions"])
22
23
24 @register_fetcher_cls
25 class RayFetcher(Fetcher):
26 name = "ray"
27 required_meta_keys = ("object_refs",)
28
29 def __init__(self, **kwargs):
30 self._fetch_info_list = []
31 self._no_conditions = True
32
33 async def append(self, chunk_key: str, chunk_meta: Dict, conditions: List = None):
34 if conditions is not None:
35 self._no_conditions = False
36 self._fetch_info_list.append(
37 _FetchInfo(chunk_key, chunk_meta["object_refs"][0], conditions)
38 )
39
40 async def get(self):
41 objects = await asyncio.gather(
42 *(info.object_ref for info in self._fetch_info_list)
43 )
44 if self._no_conditions:
45 return objects
46 results = []
47 for o, fetch_info in zip(objects, self._fetch_info_list):
48 if fetch_info.conditions is None:
49 results.append(o)
50 else:
51 try:
52 results.append(o.iloc[fetch_info.conditions])
53 except AttributeError:
54 results.append(o[fetch_info.conditions])
55 return results
56
[end of mars/services/task/execution/ray/fetcher.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mars/services/task/execution/ray/fetcher.py b/mars/services/task/execution/ray/fetcher.py
--- a/mars/services/task/execution/ray/fetcher.py
+++ b/mars/services/task/execution/ray/fetcher.py
@@ -15,9 +15,10 @@
import asyncio
from collections import namedtuple
from typing import Dict, List
+from .....utils import lazy_import
from ..api import Fetcher, register_fetcher_cls
-
+ray = lazy_import("ray")
_FetchInfo = namedtuple("FetchInfo", ["key", "object_ref", "conditions"])
@@ -38,18 +39,27 @@
)
async def get(self):
- objects = await asyncio.gather(
- *(info.object_ref for info in self._fetch_info_list)
- )
if self._no_conditions:
- return objects
- results = []
- for o, fetch_info in zip(objects, self._fetch_info_list):
+ return await asyncio.gather(
+ *(info.object_ref for info in self._fetch_info_list)
+ )
+ refs = [None] * len(self._fetch_info_list)
+ for index, fetch_info in enumerate(self._fetch_info_list):
if fetch_info.conditions is None:
- results.append(o)
+ refs[index] = fetch_info.object_ref
else:
- try:
- results.append(o.iloc[fetch_info.conditions])
- except AttributeError:
- results.append(o[fetch_info.conditions])
- return results
+ refs[index] = query_object_with_condition.remote(
+ fetch_info.object_ref, fetch_info.conditions
+ )
+ return await asyncio.gather(*refs)
+
+
+def query_object_with_condition(o, conditions):
+ try:
+ return o.iloc[conditions]
+ except AttributeError:
+ return o[conditions]
+
+
+if ray:
+ query_object_with_condition = ray.remote(query_object_with_condition)
|
{"golden_diff": "diff --git a/mars/services/task/execution/ray/fetcher.py b/mars/services/task/execution/ray/fetcher.py\n--- a/mars/services/task/execution/ray/fetcher.py\n+++ b/mars/services/task/execution/ray/fetcher.py\n@@ -15,9 +15,10 @@\n import asyncio\n from collections import namedtuple\n from typing import Dict, List\n+from .....utils import lazy_import\n from ..api import Fetcher, register_fetcher_cls\n \n-\n+ray = lazy_import(\"ray\")\n _FetchInfo = namedtuple(\"FetchInfo\", [\"key\", \"object_ref\", \"conditions\"])\n \n \n@@ -38,18 +39,27 @@\n )\n \n async def get(self):\n- objects = await asyncio.gather(\n- *(info.object_ref for info in self._fetch_info_list)\n- )\n if self._no_conditions:\n- return objects\n- results = []\n- for o, fetch_info in zip(objects, self._fetch_info_list):\n+ return await asyncio.gather(\n+ *(info.object_ref for info in self._fetch_info_list)\n+ )\n+ refs = [None] * len(self._fetch_info_list)\n+ for index, fetch_info in enumerate(self._fetch_info_list):\n if fetch_info.conditions is None:\n- results.append(o)\n+ refs[index] = fetch_info.object_ref\n else:\n- try:\n- results.append(o.iloc[fetch_info.conditions])\n- except AttributeError:\n- results.append(o[fetch_info.conditions])\n- return results\n+ refs[index] = query_object_with_condition.remote(\n+ fetch_info.object_ref, fetch_info.conditions\n+ )\n+ return await asyncio.gather(*refs)\n+\n+\n+def query_object_with_condition(o, conditions):\n+ try:\n+ return o.iloc[conditions]\n+ except AttributeError:\n+ return o[conditions]\n+\n+\n+if ray:\n+ query_object_with_condition = ray.remote(query_object_with_condition)\n", "issue": "Submit query condition to remote node instead of fetch to local then query\n<!--\r\nThank you for your contribution!\r\n\r\nPlease review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.\r\n-->\r\n\r\n**Is your feature request related to a problem? Please describe.**\r\nCurently if ray fetcher gets objects with condition, it will fetch objects to local, then filter local objects with conditions. This will incur much objects transfer cost and high memory footsprint in local node. \r\n\r\n**Describe the solution you'd like**\r\nWe should submit query to objects' node then fetch queried result instead. \r\n\r\n\n", "before_files": [{"content": "# Copyright 1999-2021 Alibaba Group Holding Ltd.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport asyncio\nfrom collections import namedtuple\nfrom typing import Dict, List\nfrom ..api import Fetcher, register_fetcher_cls\n\n\n_FetchInfo = namedtuple(\"FetchInfo\", [\"key\", \"object_ref\", \"conditions\"])\n\n\n@register_fetcher_cls\nclass RayFetcher(Fetcher):\n name = \"ray\"\n required_meta_keys = (\"object_refs\",)\n\n def __init__(self, **kwargs):\n self._fetch_info_list = []\n self._no_conditions = True\n\n async def append(self, chunk_key: str, chunk_meta: Dict, conditions: List = None):\n if conditions is not None:\n self._no_conditions = False\n self._fetch_info_list.append(\n _FetchInfo(chunk_key, chunk_meta[\"object_refs\"][0], conditions)\n )\n\n async def get(self):\n objects = await asyncio.gather(\n *(info.object_ref for info in self._fetch_info_list)\n )\n if self._no_conditions:\n return objects\n results = []\n for o, fetch_info in zip(objects, self._fetch_info_list):\n if fetch_info.conditions is None:\n results.append(o)\n else:\n try:\n results.append(o.iloc[fetch_info.conditions])\n except AttributeError:\n results.append(o[fetch_info.conditions])\n return results\n", "path": "mars/services/task/execution/ray/fetcher.py"}]}
| 1,201 | 433 |
gh_patches_debug_1383
|
rasdani/github-patches
|
git_diff
|
vega__altair-150
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
to_dict() not in Chart.__dir__
All in title.
</issue>
<code>
[start of altair/schema/baseobject.py]
1 import pandas as pd
2 import traitlets as T
3
4 from ..utils._py3k_compat import string_types
5
6 _attr_template = "Attribute not found: {0}. Valid keyword arguments for this class: {1}"
7
8
9 class BaseObject(T.HasTraits):
10
11 skip = []
12
13 def __init__(self, **kwargs):
14 all_traits = list(self.traits())
15 for k in kwargs:
16 if k not in all_traits:
17 raise KeyError(_attr_template.format(k, all_traits))
18 super(BaseObject, self).__init__(**kwargs)
19
20 @classmethod
21 def infer_keywords(cls, *args, **kwargs):
22 """Utility to initialize object from args and kwargs
23
24 Arguments are converted to keyword arguments by inferring the keyword
25 from their type.
26 Keyword arguments are converted to the correct Instance class
27 if required.
28 """
29 def get_class(trait):
30 # TODO: what do do with lists?
31 if isinstance(trait, T.Union):
32 for klass in map(get_class, trait.trait_types):
33 if klass:
34 return klass
35 elif isinstance(trait, T.Instance):
36 return trait.klass
37
38 traits = cls.class_traits()
39 classes = {n: get_class(t) for n, t in traits.items()}
40
41 # Turn all keyword arguments to the appropriate class
42 for name, arg in kwargs.items():
43 Trait = classes.get(name, None)
44 if Trait is not None and not isinstance(arg, Trait):
45 try:
46 kwargs[name] = Trait(arg)
47 except (TypeError, T.TraitError):
48 pass # errors will handled by traitlets below
49
50 # find forward/backward mapping among unique classes
51 name_to_trait = {}
52 while classes:
53 name, trait = classes.popitem()
54 if trait is None:
55 continue
56 if trait not in set.union(set(classes.values()),
57 set(name_to_trait.values())):
58 name_to_trait[name] = trait
59 trait_to_name = {t: n for n, t in name_to_trait.items()}
60
61 # Update all arguments
62 for arg in args:
63 name = trait_to_name.get(type(arg), None)
64 if name is None:
65 raise ValueError("{0}: Unable to infer argument name for {1}".format(cls, arg))
66 elif name in kwargs:
67 raise ValueError("{0}: {1} specified both by arg and kwarg".format(cls, name))
68 else:
69 kwargs[name] = arg
70 return kwargs
71
72 def update_traits(self, **kwargs):
73 for key, val in kwargs.items():
74 self.set_trait(key, val)
75 return self
76
77 def update_inferred_traits(self, *args, **kwargs):
78 kwargs = self.infer_keywords(*args, **kwargs)
79 return self.update_traits(**kwargs)
80
81 def update_subtraits(self, attrs, *args, **kwargs):
82 """Update sub-traits without overwriting other traits"""
83 if not (args or kwargs):
84 return self
85 if isinstance(attrs, string_types):
86 attrs = (attrs,)
87 if len(attrs) == 0:
88 self.update_inferred_traits(*args, **kwargs)
89 else:
90 attr = attrs[0]
91 if attr not in self.traits():
92 raise ValueError('{0} has no trait {1}'.format(self, attr))
93 trait = getattr(self, attr)
94 if trait is None:
95 trait = self.traits()[attr].klass()
96 setattr(self, attr, trait.update_subtraits(attrs[1:], *args, **kwargs))
97 return self
98
99 def __contains__(self, key):
100 try:
101 value = getattr(self, key)
102 except AttributeError:
103 return False
104
105 # comparison to None will break, so check DataFrame specifically
106 if isinstance(value, pd.DataFrame):
107 return True
108 elif value is not None:
109 if isinstance(value, (int, float, bool)):
110 return True
111 else:
112 return bool(value)
113 else:
114 return False
115
116 def __dir__(self):
117 """Customize tab completed attributes."""
118 return list(self.traits())
119
120 @classmethod
121 def from_dict(cls, dct):
122 """Instantiate the object from a valid JSON dictionary"""
123 from ..utils.visitors import FromDict
124 return FromDict().clsvisit(cls, dct)
125
126 def to_dict(self, data=True):
127 """Emit the JSON representation for this object as as dict."""
128 from ..utils.visitors import ToDict
129 self._finalize()
130 return ToDict().visit(self, data)
131
132 def _finalize(self, **kwargs):
133 """Finalize the object, and all contained objects, for export."""
134 def finalize_obj(obj):
135 if isinstance(obj, BaseObject):
136 obj._finalize(**kwargs)
137 elif isinstance(obj, list):
138 for item in obj:
139 finalize_obj(item)
140
141 for name in self.traits():
142 value = getattr(self, name)
143 finalize_obj(value)
144
[end of altair/schema/baseobject.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/altair/schema/baseobject.py b/altair/schema/baseobject.py
--- a/altair/schema/baseobject.py
+++ b/altair/schema/baseobject.py
@@ -115,7 +115,7 @@
def __dir__(self):
"""Customize tab completed attributes."""
- return list(self.traits())
+ return list(self.traits())+['to_dict', 'from_dict']
@classmethod
def from_dict(cls, dct):
|
{"golden_diff": "diff --git a/altair/schema/baseobject.py b/altair/schema/baseobject.py\n--- a/altair/schema/baseobject.py\n+++ b/altair/schema/baseobject.py\n@@ -115,7 +115,7 @@\n \n def __dir__(self):\n \"\"\"Customize tab completed attributes.\"\"\"\n- return list(self.traits())\n+ return list(self.traits())+['to_dict', 'from_dict']\n \n @classmethod\n def from_dict(cls, dct):\n", "issue": "to_dict() not in Chart.__dir__\nAll in title.\n\n", "before_files": [{"content": "import pandas as pd\nimport traitlets as T\n\nfrom ..utils._py3k_compat import string_types\n\n_attr_template = \"Attribute not found: {0}. Valid keyword arguments for this class: {1}\"\n\n\nclass BaseObject(T.HasTraits):\n\n skip = []\n\n def __init__(self, **kwargs):\n all_traits = list(self.traits())\n for k in kwargs:\n if k not in all_traits:\n raise KeyError(_attr_template.format(k, all_traits))\n super(BaseObject, self).__init__(**kwargs)\n\n @classmethod\n def infer_keywords(cls, *args, **kwargs):\n \"\"\"Utility to initialize object from args and kwargs\n\n Arguments are converted to keyword arguments by inferring the keyword\n from their type.\n Keyword arguments are converted to the correct Instance class\n if required.\n \"\"\"\n def get_class(trait):\n # TODO: what do do with lists?\n if isinstance(trait, T.Union):\n for klass in map(get_class, trait.trait_types):\n if klass:\n return klass\n elif isinstance(trait, T.Instance):\n return trait.klass\n\n traits = cls.class_traits()\n classes = {n: get_class(t) for n, t in traits.items()}\n\n # Turn all keyword arguments to the appropriate class\n for name, arg in kwargs.items():\n Trait = classes.get(name, None)\n if Trait is not None and not isinstance(arg, Trait):\n try:\n kwargs[name] = Trait(arg)\n except (TypeError, T.TraitError):\n pass # errors will handled by traitlets below\n\n # find forward/backward mapping among unique classes\n name_to_trait = {}\n while classes:\n name, trait = classes.popitem()\n if trait is None:\n continue\n if trait not in set.union(set(classes.values()),\n set(name_to_trait.values())):\n name_to_trait[name] = trait\n trait_to_name = {t: n for n, t in name_to_trait.items()}\n\n # Update all arguments\n for arg in args:\n name = trait_to_name.get(type(arg), None)\n if name is None:\n raise ValueError(\"{0}: Unable to infer argument name for {1}\".format(cls, arg))\n elif name in kwargs:\n raise ValueError(\"{0}: {1} specified both by arg and kwarg\".format(cls, name))\n else:\n kwargs[name] = arg\n return kwargs\n\n def update_traits(self, **kwargs):\n for key, val in kwargs.items():\n self.set_trait(key, val)\n return self\n\n def update_inferred_traits(self, *args, **kwargs):\n kwargs = self.infer_keywords(*args, **kwargs)\n return self.update_traits(**kwargs)\n\n def update_subtraits(self, attrs, *args, **kwargs):\n \"\"\"Update sub-traits without overwriting other traits\"\"\"\n if not (args or kwargs):\n return self\n if isinstance(attrs, string_types):\n attrs = (attrs,)\n if len(attrs) == 0:\n self.update_inferred_traits(*args, **kwargs)\n else:\n attr = attrs[0]\n if attr not in self.traits():\n raise ValueError('{0} has no trait {1}'.format(self, attr))\n trait = getattr(self, attr)\n if trait is None:\n trait = self.traits()[attr].klass()\n setattr(self, attr, trait.update_subtraits(attrs[1:], *args, **kwargs))\n return self\n\n def __contains__(self, key):\n try:\n value = getattr(self, key)\n except AttributeError:\n return False\n\n # comparison to None will break, so check DataFrame specifically\n if isinstance(value, pd.DataFrame):\n return True\n elif value is not None:\n if isinstance(value, (int, float, bool)):\n return True\n else:\n return bool(value)\n else:\n return False\n\n def __dir__(self):\n \"\"\"Customize tab completed attributes.\"\"\"\n return list(self.traits())\n\n @classmethod\n def from_dict(cls, dct):\n \"\"\"Instantiate the object from a valid JSON dictionary\"\"\"\n from ..utils.visitors import FromDict\n return FromDict().clsvisit(cls, dct)\n\n def to_dict(self, data=True):\n \"\"\"Emit the JSON representation for this object as as dict.\"\"\"\n from ..utils.visitors import ToDict\n self._finalize()\n return ToDict().visit(self, data)\n\n def _finalize(self, **kwargs):\n \"\"\"Finalize the object, and all contained objects, for export.\"\"\"\n def finalize_obj(obj):\n if isinstance(obj, BaseObject):\n obj._finalize(**kwargs)\n elif isinstance(obj, list):\n for item in obj:\n finalize_obj(item)\n\n for name in self.traits():\n value = getattr(self, name)\n finalize_obj(value)\n", "path": "altair/schema/baseobject.py"}]}
| 1,928 | 109 |
gh_patches_debug_435
|
rasdani/github-patches
|
git_diff
|
mitmproxy__mitmproxy-1864
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Missing documentation about unit testing inline scripts
At the company I work on we are developing some inline scripts to use internally.
We are struggling to create test for our scripts because the only code we found to test scripts are the ones at [/mitmproxy/mitmproxy/blob/v0.17/test/mitmproxy/test_examples.py](/mitmproxy/mitmproxy/blob/v0.17/test/mitmproxy/test_examples.py).
The examples are quite good but real documentation is missing for the ones who wants to unit test.
Is there another place where I can find better (maybe more advanced) test examples ?
</issue>
<code>
[start of mitmproxy/events.py]
1 from mitmproxy import controller
2 from mitmproxy import http
3 from mitmproxy import tcp
4 from mitmproxy import websocket
5
6 Events = frozenset([
7 "clientconnect",
8 "clientdisconnect",
9 "serverconnect",
10 "serverdisconnect",
11
12 "tcp_start",
13 "tcp_message",
14 "tcp_error",
15 "tcp_end",
16
17 "http_connect",
18 "request",
19 "requestheaders",
20 "response",
21 "responseheaders",
22 "error",
23
24 "intercept",
25 "resume",
26
27 "websocket_handshake",
28 "websocket_start",
29 "websocket_message",
30 "websocket_error",
31 "websocket_end",
32
33 "next_layer",
34
35 "configure",
36 "done",
37 "log",
38 "start",
39 "tick",
40 ])
41
42
43 def event_sequence(f):
44 if isinstance(f, http.HTTPFlow):
45 if f.request:
46 yield "requestheaders", f
47 yield "request", f
48 if f.response:
49 yield "responseheaders", f
50 yield "response", f
51 if f.error:
52 yield "error", f
53 elif isinstance(f, websocket.WebSocketFlow):
54 messages = f.messages
55 f.messages = []
56 f.reply = controller.DummyReply()
57 yield "websocket_start", f
58 while messages:
59 f.messages.append(messages.pop(0))
60 yield "websocket_message", f
61 if f.error:
62 yield "websocket_error", f
63 yield "websocket_end", f
64 elif isinstance(f, tcp.TCPFlow):
65 messages = f.messages
66 f.messages = []
67 f.reply = controller.DummyReply()
68 yield "tcp_start", f
69 while messages:
70 f.messages.append(messages.pop(0))
71 yield "tcp_message", f
72 if f.error:
73 yield "tcp_error", f
74 yield "tcp_end", f
75 else:
76 raise NotImplementedError
77
[end of mitmproxy/events.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mitmproxy/events.py b/mitmproxy/events.py
--- a/mitmproxy/events.py
+++ b/mitmproxy/events.py
@@ -21,9 +21,6 @@
"responseheaders",
"error",
- "intercept",
- "resume",
-
"websocket_handshake",
"websocket_start",
"websocket_message",
|
{"golden_diff": "diff --git a/mitmproxy/events.py b/mitmproxy/events.py\n--- a/mitmproxy/events.py\n+++ b/mitmproxy/events.py\n@@ -21,9 +21,6 @@\n \"responseheaders\",\n \"error\",\n \n- \"intercept\",\n- \"resume\",\n-\n \"websocket_handshake\",\n \"websocket_start\",\n \"websocket_message\",\n", "issue": "Missing documentation about unit testing inline scripts\nAt the company I work on we are developing some inline scripts to use internally.\n\nWe are struggling to create test for our scripts because the only code we found to test scripts are the ones at [/mitmproxy/mitmproxy/blob/v0.17/test/mitmproxy/test_examples.py](/mitmproxy/mitmproxy/blob/v0.17/test/mitmproxy/test_examples.py).\n\nThe examples are quite good but real documentation is missing for the ones who wants to unit test.\n\nIs there another place where I can find better (maybe more advanced) test examples ?\n\n", "before_files": [{"content": "from mitmproxy import controller\nfrom mitmproxy import http\nfrom mitmproxy import tcp\nfrom mitmproxy import websocket\n\nEvents = frozenset([\n \"clientconnect\",\n \"clientdisconnect\",\n \"serverconnect\",\n \"serverdisconnect\",\n\n \"tcp_start\",\n \"tcp_message\",\n \"tcp_error\",\n \"tcp_end\",\n\n \"http_connect\",\n \"request\",\n \"requestheaders\",\n \"response\",\n \"responseheaders\",\n \"error\",\n\n \"intercept\",\n \"resume\",\n\n \"websocket_handshake\",\n \"websocket_start\",\n \"websocket_message\",\n \"websocket_error\",\n \"websocket_end\",\n\n \"next_layer\",\n\n \"configure\",\n \"done\",\n \"log\",\n \"start\",\n \"tick\",\n])\n\n\ndef event_sequence(f):\n if isinstance(f, http.HTTPFlow):\n if f.request:\n yield \"requestheaders\", f\n yield \"request\", f\n if f.response:\n yield \"responseheaders\", f\n yield \"response\", f\n if f.error:\n yield \"error\", f\n elif isinstance(f, websocket.WebSocketFlow):\n messages = f.messages\n f.messages = []\n f.reply = controller.DummyReply()\n yield \"websocket_start\", f\n while messages:\n f.messages.append(messages.pop(0))\n yield \"websocket_message\", f\n if f.error:\n yield \"websocket_error\", f\n yield \"websocket_end\", f\n elif isinstance(f, tcp.TCPFlow):\n messages = f.messages\n f.messages = []\n f.reply = controller.DummyReply()\n yield \"tcp_start\", f\n while messages:\n f.messages.append(messages.pop(0))\n yield \"tcp_message\", f\n if f.error:\n yield \"tcp_error\", f\n yield \"tcp_end\", f\n else:\n raise NotImplementedError\n", "path": "mitmproxy/events.py"}]}
| 1,210 | 83 |
gh_patches_debug_4680
|
rasdani/github-patches
|
git_diff
|
zestedesavoir__zds-site-5936
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Espaces insécables dans le titre de mise en Une
**Description du bug**
Espace non insécable dans l'aperçu de mis en Une. Ce problème n'a pas pu être par #5292 car l'aperçu est généré par du JavaScript.
**Comment reproduire ?**
La liste des étapes qui permet de reproduire le bug :
1. Se connecter en tant qu'administrateur ;
2. Accéder à la page d'un contenu ;
3. Mettre ce contenu en Une ;
4. Mettre le titre suivant : « `Comment alerter les secours ?` ».
**Comportement attendu**
L'espace doit automatiquement être remplacé par un espace insécable, avant ou après les signes concernés.
</issue>
<code>
[start of zds/utils/templatetags/french_typography.py]
1 from django import template
2 from django.template.defaultfilters import stringfilter
3 from django.utils.safestring import mark_safe
4
5 register = template.Library()
6
7
8 @register.filter()
9 @stringfilter
10 def french_typography(str):
11 """
12 Replaces spaces with non-breaking-spaces or narrow non-breaking-spaces
13 before or after some symbols, according to French typography.
14
15 This filter is naive and should not be used on Markdown content.
16 """
17 return mark_safe(
18 # Narrow non-breaking space:  
19 str.replace(' ;', ' ;')
20 .replace(' ?', ' ?')
21 .replace(' !', ' !')
22 .replace(' %', ' %')
23 # Non-breaking space:
24 .replace('« ', '« ')
25 .replace(' »', ' »')
26 .replace(' :', ' :')
27 )
28
[end of zds/utils/templatetags/french_typography.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/zds/utils/templatetags/french_typography.py b/zds/utils/templatetags/french_typography.py
--- a/zds/utils/templatetags/french_typography.py
+++ b/zds/utils/templatetags/french_typography.py
@@ -13,6 +13,9 @@
before or after some symbols, according to French typography.
This filter is naive and should not be used on Markdown content.
+
+
+ Any change here should also be made in assets/js/featured-resource-preview.js
"""
return mark_safe(
# Narrow non-breaking space:  
|
{"golden_diff": "diff --git a/zds/utils/templatetags/french_typography.py b/zds/utils/templatetags/french_typography.py\n--- a/zds/utils/templatetags/french_typography.py\n+++ b/zds/utils/templatetags/french_typography.py\n@@ -13,6 +13,9 @@\n before or after some symbols, according to French typography.\n \n This filter is naive and should not be used on Markdown content.\n+\n+\n+ Any change here should also be made in assets/js/featured-resource-preview.js\n \"\"\"\n return mark_safe(\n # Narrow non-breaking space:  \n", "issue": "Espaces ins\u00e9cables dans le titre de mise en Une\n**Description du bug**\r\n\r\nEspace non ins\u00e9cable dans l'aper\u00e7u de mis en Une. Ce probl\u00e8me n'a pas pu \u00eatre par #5292 car l'aper\u00e7u est g\u00e9n\u00e9r\u00e9 par du JavaScript.\r\n\r\n**Comment reproduire ?**\r\n\r\nLa liste des \u00e9tapes qui permet de reproduire le bug :\r\n\r\n1. Se connecter en tant qu'administrateur\u00a0;\r\n2. Acc\u00e9der \u00e0 la page d'un contenu\u00a0;\r\n3. Mettre ce contenu en Une\u00a0;\r\n4. Mettre le titre suivant\u00a0: \u00ab\u00a0`Comment alerter les secours ?` \u00bb.\r\n\r\n**Comportement attendu**\r\n\r\nL'espace doit automatiquement \u00eatre remplac\u00e9 par un espace ins\u00e9cable, avant ou apr\u00e8s les signes concern\u00e9s.\n", "before_files": [{"content": "from django import template\nfrom django.template.defaultfilters import stringfilter\nfrom django.utils.safestring import mark_safe\n\nregister = template.Library()\n\n\[email protected]()\n@stringfilter\ndef french_typography(str):\n \"\"\"\n Replaces spaces with non-breaking-spaces or narrow non-breaking-spaces\n before or after some symbols, according to French typography.\n\n This filter is naive and should not be used on Markdown content.\n \"\"\"\n return mark_safe(\n # Narrow non-breaking space:  \n str.replace(' ;', ' ;')\n .replace(' ?', ' ?')\n .replace(' !', ' !')\n .replace(' %', ' %')\n # Non-breaking space: \n .replace('\u00ab ', '\u00ab ')\n .replace(' \u00bb', ' \u00bb')\n .replace(' :', ' :')\n )\n", "path": "zds/utils/templatetags/french_typography.py"}]}
| 982 | 144 |
gh_patches_debug_22737
|
rasdani/github-patches
|
git_diff
|
aio-libs__aiohttp-6144
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Switch http_parser to llhttp
Nodejs decide to move from their hard-coded C parser to this one.
https://github.com/nodejs/http-parser/pull/285#issuecomment-456025694
*Upd:*
proposed parser is https://llhttp.org
</issue>
<code>
[start of setup.py]
1 import os
2 import pathlib
3 import re
4 import sys
5
6 from setuptools import Extension, setup
7
8 if sys.version_info < (3, 7):
9 raise RuntimeError("aiohttp 4.x requires Python 3.7+")
10
11
12 NO_EXTENSIONS = bool(os.environ.get("AIOHTTP_NO_EXTENSIONS")) # type: bool
13 HERE = pathlib.Path(__file__).parent
14 IS_GIT_REPO = (HERE / ".git").exists()
15
16
17 if sys.implementation.name != "cpython":
18 NO_EXTENSIONS = True
19
20
21 if IS_GIT_REPO and not (HERE / "vendor/http-parser/README.md").exists():
22 print("Install submodules when building from git clone", file=sys.stderr)
23 print("Hint:", file=sys.stderr)
24 print(" git submodule update --init", file=sys.stderr)
25 sys.exit(2)
26
27
28 # NOTE: makefile cythonizes all Cython modules
29
30 extensions = [
31 Extension("aiohttp._websocket", ["aiohttp/_websocket.c"]),
32 Extension(
33 "aiohttp._http_parser",
34 [
35 "aiohttp/_http_parser.c",
36 "vendor/http-parser/http_parser.c",
37 "aiohttp/_find_header.c",
38 ],
39 define_macros=[("HTTP_PARSER_STRICT", 0)],
40 ),
41 Extension("aiohttp._helpers", ["aiohttp/_helpers.c"]),
42 Extension("aiohttp._http_writer", ["aiohttp/_http_writer.c"]),
43 ]
44
45
46 txt = (HERE / "aiohttp" / "__init__.py").read_text("utf-8")
47 try:
48 version = re.findall(r'^__version__ = "([^"]+)"\r?$', txt, re.M)[0]
49 except IndexError:
50 raise RuntimeError("Unable to determine version.")
51
52 install_requires = [
53 "charset-normalizer>=2.0,<3.0",
54 "multidict>=4.5,<7.0",
55 "async_timeout>=4.0a2,<5.0",
56 'asynctest==0.13.0; python_version<"3.8"',
57 "yarl>=1.0,<2.0",
58 "typing_extensions>=3.7.4",
59 "frozenlist>=1.1.1",
60 "aiosignal>=1.1.2",
61 ]
62
63
64 def read(f):
65 return (HERE / f).read_text("utf-8").strip()
66
67
68 args = dict(
69 name="aiohttp",
70 version=version,
71 description="Async http client/server framework (asyncio)",
72 long_description="\n\n".join((read("README.rst"), read("CHANGES.rst"))),
73 long_description_content_type="text/x-rst",
74 classifiers=[
75 "License :: OSI Approved :: Apache Software License",
76 "Intended Audience :: Developers",
77 "Programming Language :: Python",
78 "Programming Language :: Python :: 3",
79 "Programming Language :: Python :: 3.7",
80 "Programming Language :: Python :: 3.8",
81 "Programming Language :: Python :: 3.9",
82 "Programming Language :: Python :: 3.10",
83 "Development Status :: 5 - Production/Stable",
84 "Operating System :: POSIX",
85 "Operating System :: MacOS :: MacOS X",
86 "Operating System :: Microsoft :: Windows",
87 "Topic :: Internet :: WWW/HTTP",
88 "Framework :: AsyncIO",
89 ],
90 author="Nikolay Kim",
91 author_email="[email protected]",
92 maintainer=", ".join(
93 (
94 "Nikolay Kim <[email protected]>",
95 "Andrew Svetlov <[email protected]>",
96 )
97 ),
98 maintainer_email="[email protected]",
99 url="https://github.com/aio-libs/aiohttp",
100 project_urls={
101 "Chat: Gitter": "https://gitter.im/aio-libs/Lobby",
102 "CI: GitHub Actions": "https://github.com/aio-libs/aiohttp/actions?query=workflow%3ACI", # noqa
103 "Coverage: codecov": "https://codecov.io/github/aio-libs/aiohttp",
104 "Docs: Changelog": "https://docs.aiohttp.org/en/stable/changes.html",
105 "Docs: RTD": "https://docs.aiohttp.org",
106 "GitHub: issues": "https://github.com/aio-libs/aiohttp/issues",
107 "GitHub: repo": "https://github.com/aio-libs/aiohttp",
108 },
109 license="Apache 2",
110 packages=["aiohttp"],
111 python_requires=">=3.7",
112 install_requires=install_requires,
113 extras_require={
114 "speedups": [
115 "aiodns>=1.1",
116 "Brotli",
117 "cchardet",
118 ],
119 },
120 include_package_data=True,
121 )
122
123 if not NO_EXTENSIONS:
124 print("*********************")
125 print("* Accelerated build *")
126 print("*********************")
127 setup(ext_modules=extensions, **args)
128 else:
129 print("*********************")
130 print("* Pure Python build *")
131 print("*********************")
132 setup(**args)
133
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -18,7 +18,7 @@
NO_EXTENSIONS = True
-if IS_GIT_REPO and not (HERE / "vendor/http-parser/README.md").exists():
+if IS_GIT_REPO and not (HERE / "vendor/llhttp/README.md").exists():
print("Install submodules when building from git clone", file=sys.stderr)
print("Hint:", file=sys.stderr)
print(" git submodule update --init", file=sys.stderr)
@@ -33,10 +33,13 @@
"aiohttp._http_parser",
[
"aiohttp/_http_parser.c",
- "vendor/http-parser/http_parser.c",
"aiohttp/_find_header.c",
+ "vendor/llhttp/build/c/llhttp.c",
+ "vendor/llhttp/src/native/api.c",
+ "vendor/llhttp/src/native/http.c",
],
- define_macros=[("HTTP_PARSER_STRICT", 0)],
+ define_macros=[("LLHTTP_STRICT_MODE", 0)],
+ include_dirs=["vendor/llhttp/build"],
),
Extension("aiohttp._helpers", ["aiohttp/_helpers.c"]),
Extension("aiohttp._http_writer", ["aiohttp/_http_writer.c"]),
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -18,7 +18,7 @@\n NO_EXTENSIONS = True\n \n \n-if IS_GIT_REPO and not (HERE / \"vendor/http-parser/README.md\").exists():\n+if IS_GIT_REPO and not (HERE / \"vendor/llhttp/README.md\").exists():\n print(\"Install submodules when building from git clone\", file=sys.stderr)\n print(\"Hint:\", file=sys.stderr)\n print(\" git submodule update --init\", file=sys.stderr)\n@@ -33,10 +33,13 @@\n \"aiohttp._http_parser\",\n [\n \"aiohttp/_http_parser.c\",\n- \"vendor/http-parser/http_parser.c\",\n \"aiohttp/_find_header.c\",\n+ \"vendor/llhttp/build/c/llhttp.c\",\n+ \"vendor/llhttp/src/native/api.c\",\n+ \"vendor/llhttp/src/native/http.c\",\n ],\n- define_macros=[(\"HTTP_PARSER_STRICT\", 0)],\n+ define_macros=[(\"LLHTTP_STRICT_MODE\", 0)],\n+ include_dirs=[\"vendor/llhttp/build\"],\n ),\n Extension(\"aiohttp._helpers\", [\"aiohttp/_helpers.c\"]),\n Extension(\"aiohttp._http_writer\", [\"aiohttp/_http_writer.c\"]),\n", "issue": "Switch http_parser to llhttp\nNodejs decide to move from their hard-coded C parser to this one.\r\n\r\nhttps://github.com/nodejs/http-parser/pull/285#issuecomment-456025694\r\n\r\n*Upd:* \r\nproposed parser is https://llhttp.org\r\n\n", "before_files": [{"content": "import os\nimport pathlib\nimport re\nimport sys\n\nfrom setuptools import Extension, setup\n\nif sys.version_info < (3, 7):\n raise RuntimeError(\"aiohttp 4.x requires Python 3.7+\")\n\n\nNO_EXTENSIONS = bool(os.environ.get(\"AIOHTTP_NO_EXTENSIONS\")) # type: bool\nHERE = pathlib.Path(__file__).parent\nIS_GIT_REPO = (HERE / \".git\").exists()\n\n\nif sys.implementation.name != \"cpython\":\n NO_EXTENSIONS = True\n\n\nif IS_GIT_REPO and not (HERE / \"vendor/http-parser/README.md\").exists():\n print(\"Install submodules when building from git clone\", file=sys.stderr)\n print(\"Hint:\", file=sys.stderr)\n print(\" git submodule update --init\", file=sys.stderr)\n sys.exit(2)\n\n\n# NOTE: makefile cythonizes all Cython modules\n\nextensions = [\n Extension(\"aiohttp._websocket\", [\"aiohttp/_websocket.c\"]),\n Extension(\n \"aiohttp._http_parser\",\n [\n \"aiohttp/_http_parser.c\",\n \"vendor/http-parser/http_parser.c\",\n \"aiohttp/_find_header.c\",\n ],\n define_macros=[(\"HTTP_PARSER_STRICT\", 0)],\n ),\n Extension(\"aiohttp._helpers\", [\"aiohttp/_helpers.c\"]),\n Extension(\"aiohttp._http_writer\", [\"aiohttp/_http_writer.c\"]),\n]\n\n\ntxt = (HERE / \"aiohttp\" / \"__init__.py\").read_text(\"utf-8\")\ntry:\n version = re.findall(r'^__version__ = \"([^\"]+)\"\\r?$', txt, re.M)[0]\nexcept IndexError:\n raise RuntimeError(\"Unable to determine version.\")\n\ninstall_requires = [\n \"charset-normalizer>=2.0,<3.0\",\n \"multidict>=4.5,<7.0\",\n \"async_timeout>=4.0a2,<5.0\",\n 'asynctest==0.13.0; python_version<\"3.8\"',\n \"yarl>=1.0,<2.0\",\n \"typing_extensions>=3.7.4\",\n \"frozenlist>=1.1.1\",\n \"aiosignal>=1.1.2\",\n]\n\n\ndef read(f):\n return (HERE / f).read_text(\"utf-8\").strip()\n\n\nargs = dict(\n name=\"aiohttp\",\n version=version,\n description=\"Async http client/server framework (asyncio)\",\n long_description=\"\\n\\n\".join((read(\"README.rst\"), read(\"CHANGES.rst\"))),\n long_description_content_type=\"text/x-rst\",\n classifiers=[\n \"License :: OSI Approved :: Apache Software License\",\n \"Intended Audience :: Developers\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Development Status :: 5 - Production/Stable\",\n \"Operating System :: POSIX\",\n \"Operating System :: MacOS :: MacOS X\",\n \"Operating System :: Microsoft :: Windows\",\n \"Topic :: Internet :: WWW/HTTP\",\n \"Framework :: AsyncIO\",\n ],\n author=\"Nikolay Kim\",\n author_email=\"[email protected]\",\n maintainer=\", \".join(\n (\n \"Nikolay Kim <[email protected]>\",\n \"Andrew Svetlov <[email protected]>\",\n )\n ),\n maintainer_email=\"[email protected]\",\n url=\"https://github.com/aio-libs/aiohttp\",\n project_urls={\n \"Chat: Gitter\": \"https://gitter.im/aio-libs/Lobby\",\n \"CI: GitHub Actions\": \"https://github.com/aio-libs/aiohttp/actions?query=workflow%3ACI\", # noqa\n \"Coverage: codecov\": \"https://codecov.io/github/aio-libs/aiohttp\",\n \"Docs: Changelog\": \"https://docs.aiohttp.org/en/stable/changes.html\",\n \"Docs: RTD\": \"https://docs.aiohttp.org\",\n \"GitHub: issues\": \"https://github.com/aio-libs/aiohttp/issues\",\n \"GitHub: repo\": \"https://github.com/aio-libs/aiohttp\",\n },\n license=\"Apache 2\",\n packages=[\"aiohttp\"],\n python_requires=\">=3.7\",\n install_requires=install_requires,\n extras_require={\n \"speedups\": [\n \"aiodns>=1.1\",\n \"Brotli\",\n \"cchardet\",\n ],\n },\n include_package_data=True,\n)\n\nif not NO_EXTENSIONS:\n print(\"*********************\")\n print(\"* Accelerated build *\")\n print(\"*********************\")\n setup(ext_modules=extensions, **args)\nelse:\n print(\"*********************\")\n print(\"* Pure Python build *\")\n print(\"*********************\")\n setup(**args)\n", "path": "setup.py"}]}
| 2,003 | 294 |
gh_patches_debug_36882
|
rasdani/github-patches
|
git_diff
|
ipython__ipython-5963
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Problems when displaying multiple views of ContainerWidget.
`ContainerView.render` registers anonymous functions to `this.model.on('displayed')` . This is a problem because when rendering multiple views of the same widget container, multiple instances of this anonymous function get registered to this event.
PS: This is also related to #5958
</issue>
<code>
[start of IPython/html/widgets/widget_container.py]
1 """ContainerWidget class.
2
3 Represents a container that can be used to group other widgets.
4 """
5 #-----------------------------------------------------------------------------
6 # Copyright (c) 2013, the IPython Development Team.
7 #
8 # Distributed under the terms of the Modified BSD License.
9 #
10 # The full license is in the file COPYING.txt, distributed with this software.
11 #-----------------------------------------------------------------------------
12
13 #-----------------------------------------------------------------------------
14 # Imports
15 #-----------------------------------------------------------------------------
16 from .widget import DOMWidget
17 from IPython.utils.traitlets import Unicode, Tuple, TraitError
18
19 #-----------------------------------------------------------------------------
20 # Classes
21 #-----------------------------------------------------------------------------
22
23 class ContainerWidget(DOMWidget):
24 _view_name = Unicode('ContainerView', sync=True)
25
26 # Child widgets in the container.
27 # Using a tuple here to force reassignment to update the list.
28 # When a proper notifying-list trait exists, that is what should be used here.
29 children = Tuple()
30 _children = Tuple(sync=True)
31
32
33 def __init__(self, **kwargs):
34 super(ContainerWidget, self).__init__(**kwargs)
35 self.on_displayed(ContainerWidget._fire_children_displayed)
36
37 def _fire_children_displayed(self):
38 for child in self._children:
39 child._handle_displayed()
40
41 def _children_changed(self, name, old, new):
42 """Validate children list.
43
44 Makes sure only one instance of any given model can exist in the
45 children list.
46 An excellent post on uniqifiers is available at
47 http://www.peterbe.com/plog/uniqifiers-benchmark
48 which provides the inspiration for using this implementation. Below
49 I've implemented the `f5` algorithm using Python comprehensions."""
50 if new is not None:
51 seen = {}
52 def add_item(i):
53 seen[i.model_id] = True
54 return i
55 self._children = [add_item(i) for i in new if not i.model_id in seen]
56
57
58 class PopupWidget(ContainerWidget):
59 _view_name = Unicode('PopupView', sync=True)
60
61 description = Unicode(sync=True)
62 button_text = Unicode(sync=True)
63
[end of IPython/html/widgets/widget_container.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/IPython/html/widgets/widget_container.py b/IPython/html/widgets/widget_container.py
--- a/IPython/html/widgets/widget_container.py
+++ b/IPython/html/widgets/widget_container.py
@@ -2,58 +2,29 @@
Represents a container that can be used to group other widgets.
"""
-#-----------------------------------------------------------------------------
-# Copyright (c) 2013, the IPython Development Team.
-#
+
+# Copyright (c) IPython Development Team.
# Distributed under the terms of the Modified BSD License.
-#
-# The full license is in the file COPYING.txt, distributed with this software.
-#-----------------------------------------------------------------------------
-#-----------------------------------------------------------------------------
-# Imports
-#-----------------------------------------------------------------------------
from .widget import DOMWidget
from IPython.utils.traitlets import Unicode, Tuple, TraitError
-#-----------------------------------------------------------------------------
-# Classes
-#-----------------------------------------------------------------------------
-
class ContainerWidget(DOMWidget):
_view_name = Unicode('ContainerView', sync=True)
# Child widgets in the container.
# Using a tuple here to force reassignment to update the list.
# When a proper notifying-list trait exists, that is what should be used here.
- children = Tuple()
- _children = Tuple(sync=True)
-
+ children = Tuple(sync=True)
def __init__(self, **kwargs):
super(ContainerWidget, self).__init__(**kwargs)
self.on_displayed(ContainerWidget._fire_children_displayed)
def _fire_children_displayed(self):
- for child in self._children:
+ for child in self.children:
child._handle_displayed()
- def _children_changed(self, name, old, new):
- """Validate children list.
-
- Makes sure only one instance of any given model can exist in the
- children list.
- An excellent post on uniqifiers is available at
- http://www.peterbe.com/plog/uniqifiers-benchmark
- which provides the inspiration for using this implementation. Below
- I've implemented the `f5` algorithm using Python comprehensions."""
- if new is not None:
- seen = {}
- def add_item(i):
- seen[i.model_id] = True
- return i
- self._children = [add_item(i) for i in new if not i.model_id in seen]
-
class PopupWidget(ContainerWidget):
_view_name = Unicode('PopupView', sync=True)
|
{"golden_diff": "diff --git a/IPython/html/widgets/widget_container.py b/IPython/html/widgets/widget_container.py\n--- a/IPython/html/widgets/widget_container.py\n+++ b/IPython/html/widgets/widget_container.py\n@@ -2,58 +2,29 @@\n \n Represents a container that can be used to group other widgets.\n \"\"\"\n-#-----------------------------------------------------------------------------\n-# Copyright (c) 2013, the IPython Development Team.\n-#\n+\n+# Copyright (c) IPython Development Team.\n # Distributed under the terms of the Modified BSD License.\n-#\n-# The full license is in the file COPYING.txt, distributed with this software.\n-#-----------------------------------------------------------------------------\n \n-#-----------------------------------------------------------------------------\n-# Imports\n-#-----------------------------------------------------------------------------\n from .widget import DOMWidget\n from IPython.utils.traitlets import Unicode, Tuple, TraitError\n \n-#-----------------------------------------------------------------------------\n-# Classes\n-#-----------------------------------------------------------------------------\n-\n class ContainerWidget(DOMWidget):\n _view_name = Unicode('ContainerView', sync=True)\n \n # Child widgets in the container.\n # Using a tuple here to force reassignment to update the list.\n # When a proper notifying-list trait exists, that is what should be used here.\n- children = Tuple()\n- _children = Tuple(sync=True)\n-\n+ children = Tuple(sync=True)\n \n def __init__(self, **kwargs):\n super(ContainerWidget, self).__init__(**kwargs)\n self.on_displayed(ContainerWidget._fire_children_displayed)\n \n def _fire_children_displayed(self):\n- for child in self._children:\n+ for child in self.children:\n child._handle_displayed()\n \n- def _children_changed(self, name, old, new):\n- \"\"\"Validate children list.\n-\n- Makes sure only one instance of any given model can exist in the \n- children list.\n- An excellent post on uniqifiers is available at \n- http://www.peterbe.com/plog/uniqifiers-benchmark\n- which provides the inspiration for using this implementation. Below\n- I've implemented the `f5` algorithm using Python comprehensions.\"\"\"\n- if new is not None:\n- seen = {}\n- def add_item(i):\n- seen[i.model_id] = True\n- return i\n- self._children = [add_item(i) for i in new if not i.model_id in seen]\n-\n \n class PopupWidget(ContainerWidget):\n _view_name = Unicode('PopupView', sync=True)\n", "issue": "Problems when displaying multiple views of ContainerWidget. \n`ContainerView.render` registers anonymous functions to `this.model.on('displayed')` . This is a problem because when rendering multiple views of the same widget container, multiple instances of this anonymous function get registered to this event. \n\nPS: This is also related to #5958\n\n", "before_files": [{"content": "\"\"\"ContainerWidget class. \n\nRepresents a container that can be used to group other widgets.\n\"\"\"\n#-----------------------------------------------------------------------------\n# Copyright (c) 2013, the IPython Development Team.\n#\n# Distributed under the terms of the Modified BSD License.\n#\n# The full license is in the file COPYING.txt, distributed with this software.\n#-----------------------------------------------------------------------------\n\n#-----------------------------------------------------------------------------\n# Imports\n#-----------------------------------------------------------------------------\nfrom .widget import DOMWidget\nfrom IPython.utils.traitlets import Unicode, Tuple, TraitError\n\n#-----------------------------------------------------------------------------\n# Classes\n#-----------------------------------------------------------------------------\n\nclass ContainerWidget(DOMWidget):\n _view_name = Unicode('ContainerView', sync=True)\n\n # Child widgets in the container.\n # Using a tuple here to force reassignment to update the list.\n # When a proper notifying-list trait exists, that is what should be used here.\n children = Tuple()\n _children = Tuple(sync=True)\n\n\n def __init__(self, **kwargs):\n super(ContainerWidget, self).__init__(**kwargs)\n self.on_displayed(ContainerWidget._fire_children_displayed)\n\n def _fire_children_displayed(self):\n for child in self._children:\n child._handle_displayed()\n\n def _children_changed(self, name, old, new):\n \"\"\"Validate children list.\n\n Makes sure only one instance of any given model can exist in the \n children list.\n An excellent post on uniqifiers is available at \n http://www.peterbe.com/plog/uniqifiers-benchmark\n which provides the inspiration for using this implementation. Below\n I've implemented the `f5` algorithm using Python comprehensions.\"\"\"\n if new is not None:\n seen = {}\n def add_item(i):\n seen[i.model_id] = True\n return i\n self._children = [add_item(i) for i in new if not i.model_id in seen]\n\n\nclass PopupWidget(ContainerWidget):\n _view_name = Unicode('PopupView', sync=True)\n \n description = Unicode(sync=True)\n button_text = Unicode(sync=True)\n", "path": "IPython/html/widgets/widget_container.py"}]}
| 1,165 | 517 |
gh_patches_debug_2794
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-5468
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[CKV_DOCKER_7] Erroneous failed check when --platform flag is used in multistage Dockerfile
**Describe the issue**
In the `CKV_DOCKER_7` check, when the `--platform` flag is used in a multistage Dockerfile, the check fails erroneously for images that have been created within the current Dockerfile and thus no version pegging should be required.
**Examples**
The Dockerfile below is green
```
FROM golang:1.20-bullseye AS base
FROM base AS build
```
but as soon as a `--platform` flag is added, the check fails:
```
FROM --platform=$BUILDPLATFORM golang:1.20-bullseye AS base
FROM base AS build
```
**Version (please complete the following information):**
- Checkov Version 2.4.4
</issue>
<code>
[start of checkov/dockerfile/checks/ReferenceLatestTag.py]
1 from __future__ import annotations
2
3 import re
4 from typing import TYPE_CHECKING
5
6 from checkov.common.models.enums import CheckCategories, CheckResult
7 from checkov.dockerfile.base_dockerfile_check import BaseDockerfileCheck
8
9 if TYPE_CHECKING:
10 from dockerfile_parse.parser import _Instruction
11
12 MULTI_STAGE_PATTERN = re.compile(r"(\S+)\s+as\s+(\S+)", re.IGNORECASE)
13
14
15 class ReferenceLatestTag(BaseDockerfileCheck):
16 def __init__(self) -> None:
17 name = "Ensure the base image uses a non latest version tag"
18 id = "CKV_DOCKER_7"
19 supported_instructions = ("FROM",)
20 categories = (CheckCategories.CONVENTION,)
21 super().__init__(name=name, id=id, categories=categories, supported_instructions=supported_instructions)
22
23 def scan_resource_conf(self, conf: list[_Instruction]) -> tuple[CheckResult, list[_Instruction] | None]:
24 stages = []
25
26 for content in conf:
27 base_image = content["value"]
28 if " as " in base_image.lower():
29 # do an initial lookup before using the regex
30 multi_stage = re.match(MULTI_STAGE_PATTERN, base_image)
31 if multi_stage:
32 base_image = multi_stage[1]
33 stages.append(multi_stage[2])
34
35 if ":" not in base_image and base_image not in stages and base_image != "scratch":
36 return CheckResult.FAILED, [content]
37 elif base_image.endswith(":latest"):
38 return CheckResult.FAILED, [content]
39 return CheckResult.PASSED, [content]
40
41
42 check = ReferenceLatestTag()
43
[end of checkov/dockerfile/checks/ReferenceLatestTag.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/checkov/dockerfile/checks/ReferenceLatestTag.py b/checkov/dockerfile/checks/ReferenceLatestTag.py
--- a/checkov/dockerfile/checks/ReferenceLatestTag.py
+++ b/checkov/dockerfile/checks/ReferenceLatestTag.py
@@ -9,7 +9,7 @@
if TYPE_CHECKING:
from dockerfile_parse.parser import _Instruction
-MULTI_STAGE_PATTERN = re.compile(r"(\S+)\s+as\s+(\S+)", re.IGNORECASE)
+MULTI_STAGE_PATTERN = re.compile(r"(?:--platform=\S+\s+)?(\S+)\s+as\s+(\S+)", re.IGNORECASE)
class ReferenceLatestTag(BaseDockerfileCheck):
|
{"golden_diff": "diff --git a/checkov/dockerfile/checks/ReferenceLatestTag.py b/checkov/dockerfile/checks/ReferenceLatestTag.py\n--- a/checkov/dockerfile/checks/ReferenceLatestTag.py\n+++ b/checkov/dockerfile/checks/ReferenceLatestTag.py\n@@ -9,7 +9,7 @@\n if TYPE_CHECKING:\n from dockerfile_parse.parser import _Instruction\n \n-MULTI_STAGE_PATTERN = re.compile(r\"(\\S+)\\s+as\\s+(\\S+)\", re.IGNORECASE)\n+MULTI_STAGE_PATTERN = re.compile(r\"(?:--platform=\\S+\\s+)?(\\S+)\\s+as\\s+(\\S+)\", re.IGNORECASE)\n \n \n class ReferenceLatestTag(BaseDockerfileCheck):\n", "issue": "[CKV_DOCKER_7] Erroneous failed check when --platform flag is used in multistage Dockerfile\n**Describe the issue**\r\nIn the `CKV_DOCKER_7` check, when the `--platform` flag is used in a multistage Dockerfile, the check fails erroneously for images that have been created within the current Dockerfile and thus no version pegging should be required.\r\n\r\n**Examples**\r\nThe Dockerfile below is green\r\n\r\n```\r\nFROM golang:1.20-bullseye AS base\r\n\r\nFROM base AS build\r\n```\r\n\r\nbut as soon as a `--platform` flag is added, the check fails:\r\n\r\n```\r\nFROM --platform=$BUILDPLATFORM golang:1.20-bullseye AS base\r\n\r\nFROM base AS build\r\n```\r\n\r\n**Version (please complete the following information):**\r\n - Checkov Version 2.4.4\n", "before_files": [{"content": "from __future__ import annotations\n\nimport re\nfrom typing import TYPE_CHECKING\n\nfrom checkov.common.models.enums import CheckCategories, CheckResult\nfrom checkov.dockerfile.base_dockerfile_check import BaseDockerfileCheck\n\nif TYPE_CHECKING:\n from dockerfile_parse.parser import _Instruction\n\nMULTI_STAGE_PATTERN = re.compile(r\"(\\S+)\\s+as\\s+(\\S+)\", re.IGNORECASE)\n\n\nclass ReferenceLatestTag(BaseDockerfileCheck):\n def __init__(self) -> None:\n name = \"Ensure the base image uses a non latest version tag\"\n id = \"CKV_DOCKER_7\"\n supported_instructions = (\"FROM\",)\n categories = (CheckCategories.CONVENTION,)\n super().__init__(name=name, id=id, categories=categories, supported_instructions=supported_instructions)\n\n def scan_resource_conf(self, conf: list[_Instruction]) -> tuple[CheckResult, list[_Instruction] | None]:\n stages = []\n\n for content in conf:\n base_image = content[\"value\"]\n if \" as \" in base_image.lower():\n # do an initial lookup before using the regex\n multi_stage = re.match(MULTI_STAGE_PATTERN, base_image)\n if multi_stage:\n base_image = multi_stage[1]\n stages.append(multi_stage[2])\n\n if \":\" not in base_image and base_image not in stages and base_image != \"scratch\":\n return CheckResult.FAILED, [content]\n elif base_image.endswith(\":latest\"):\n return CheckResult.FAILED, [content]\n return CheckResult.PASSED, [content]\n\n\ncheck = ReferenceLatestTag()\n", "path": "checkov/dockerfile/checks/ReferenceLatestTag.py"}]}
| 1,166 | 152 |
gh_patches_debug_31303
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-3410
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Spider anytime_fitness is broken
During the global build at 2021-09-29-14-42-48, spider **anytime_fitness** failed with **0 features** and **0 errors**.
Here's [the log](https://data.alltheplaces.xyz/runs/2021-09-29-14-42-48/logs/anytime_fitness.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-09-29-14-42-48/output/anytime_fitness.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-09-29-14-42-48/output/anytime_fitness.geojson))
</issue>
<code>
[start of locations/spiders/anytime_fitness.py]
1 # -*- coding: utf-8 -*-
2 import scrapy
3 from locations.items import GeojsonPointItem
4 import json
5 import html
6
7
8 class AnytimeFitnessSpider(scrapy.Spider):
9 name = 'anytime_fitness'
10 item_attributes = { 'brand': "Anytime Fitness" }
11 allowed_domains = ['www.anytimefitness.com']
12
13 def start_requests(self):
14 url = 'https://www.anytimefitness.com/wp-content/uploads/gyms.json'
15 yield scrapy.Request(url, callback=self.parse)
16
17 def parse(self, response):
18 gyms = json.loads(response.body_as_unicode())
19
20 for gym in gyms:
21 yield GeojsonPointItem(
22 lat = gym['latitude'],
23 lon = gym['longitude'],
24 addr_full = ", ".join(filter(None, [gym['content']['address'], gym['content']['address2']])),
25 city = gym['content']['city'],
26 phone = gym['content']['phone'],
27 state = gym['content']['state_abbr'],
28 postcode = gym['content']['zip'],
29 ref = gym['content']['url'],
30 country = gym['content']['country'],
31 name = html.unescape(gym['content']['title']),
32 extras = {"number": gym['content']['number']}
33 )
34
[end of locations/spiders/anytime_fitness.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/locations/spiders/anytime_fitness.py b/locations/spiders/anytime_fitness.py
--- a/locations/spiders/anytime_fitness.py
+++ b/locations/spiders/anytime_fitness.py
@@ -7,27 +7,27 @@
class AnytimeFitnessSpider(scrapy.Spider):
name = 'anytime_fitness'
- item_attributes = { 'brand': "Anytime Fitness" }
+ item_attributes = {'brand': "Anytime Fitness", 'brand_wikidata': "Q4778364"}
allowed_domains = ['www.anytimefitness.com']
def start_requests(self):
- url = 'https://www.anytimefitness.com/wp-content/uploads/gyms.json'
+ url = 'https://www.anytimefitness.com/wp-content/uploads/locations.json'
yield scrapy.Request(url, callback=self.parse)
def parse(self, response):
- gyms = json.loads(response.body_as_unicode())
+ gyms = json.loads(response.text)
for gym in gyms:
yield GeojsonPointItem(
- lat = gym['latitude'],
- lon = gym['longitude'],
- addr_full = ", ".join(filter(None, [gym['content']['address'], gym['content']['address2']])),
- city = gym['content']['city'],
- phone = gym['content']['phone'],
- state = gym['content']['state_abbr'],
- postcode = gym['content']['zip'],
- ref = gym['content']['url'],
- country = gym['content']['country'],
- name = html.unescape(gym['content']['title']),
- extras = {"number": gym['content']['number']}
- )
+ lat=gym['latitude'],
+ lon=gym['longitude'],
+ addr_full=", ".join(filter(None, [gym['content']['address'], gym['content']['address2']])),
+ city=gym['content']['city'],
+ phone=gym['content']['phone'],
+ state=gym['content']['state_abbr'],
+ postcode=gym['content']['zip'],
+ ref=gym['content']['url'],
+ country=gym['content']['country'],
+ name=html.unescape(gym['content']['title']),
+ extras={"number": gym['content']['number']}
+ )
|
{"golden_diff": "diff --git a/locations/spiders/anytime_fitness.py b/locations/spiders/anytime_fitness.py\n--- a/locations/spiders/anytime_fitness.py\n+++ b/locations/spiders/anytime_fitness.py\n@@ -7,27 +7,27 @@\n \n class AnytimeFitnessSpider(scrapy.Spider):\n name = 'anytime_fitness'\n- item_attributes = { 'brand': \"Anytime Fitness\" }\n+ item_attributes = {'brand': \"Anytime Fitness\", 'brand_wikidata': \"Q4778364\"}\n allowed_domains = ['www.anytimefitness.com']\n \n def start_requests(self):\n- url = 'https://www.anytimefitness.com/wp-content/uploads/gyms.json'\n+ url = 'https://www.anytimefitness.com/wp-content/uploads/locations.json'\n yield scrapy.Request(url, callback=self.parse)\n \n def parse(self, response):\n- gyms = json.loads(response.body_as_unicode())\n+ gyms = json.loads(response.text)\n \n for gym in gyms:\n yield GeojsonPointItem(\n- lat = gym['latitude'],\n- lon = gym['longitude'],\n- addr_full = \", \".join(filter(None, [gym['content']['address'], gym['content']['address2']])),\n- city = gym['content']['city'],\n- phone = gym['content']['phone'],\n- state = gym['content']['state_abbr'],\n- postcode = gym['content']['zip'],\n- ref = gym['content']['url'],\n- country = gym['content']['country'],\n- name = html.unescape(gym['content']['title']),\n- extras = {\"number\": gym['content']['number']}\n- )\n+ lat=gym['latitude'],\n+ lon=gym['longitude'],\n+ addr_full=\", \".join(filter(None, [gym['content']['address'], gym['content']['address2']])),\n+ city=gym['content']['city'],\n+ phone=gym['content']['phone'],\n+ state=gym['content']['state_abbr'],\n+ postcode=gym['content']['zip'],\n+ ref=gym['content']['url'],\n+ country=gym['content']['country'],\n+ name=html.unescape(gym['content']['title']),\n+ extras={\"number\": gym['content']['number']}\n+ )\n", "issue": "Spider anytime_fitness is broken\nDuring the global build at 2021-09-29-14-42-48, spider **anytime_fitness** failed with **0 features** and **0 errors**.\n\nHere's [the log](https://data.alltheplaces.xyz/runs/2021-09-29-14-42-48/logs/anytime_fitness.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-09-29-14-42-48/output/anytime_fitness.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-09-29-14-42-48/output/anytime_fitness.geojson))\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nimport scrapy\nfrom locations.items import GeojsonPointItem\nimport json\nimport html\n\n\nclass AnytimeFitnessSpider(scrapy.Spider):\n name = 'anytime_fitness'\n item_attributes = { 'brand': \"Anytime Fitness\" }\n allowed_domains = ['www.anytimefitness.com']\n\n def start_requests(self):\n url = 'https://www.anytimefitness.com/wp-content/uploads/gyms.json'\n yield scrapy.Request(url, callback=self.parse)\n\n def parse(self, response):\n gyms = json.loads(response.body_as_unicode())\n\n for gym in gyms:\n yield GeojsonPointItem(\n lat = gym['latitude'],\n lon = gym['longitude'],\n addr_full = \", \".join(filter(None, [gym['content']['address'], gym['content']['address2']])),\n city = gym['content']['city'],\n phone = gym['content']['phone'],\n state = gym['content']['state_abbr'],\n postcode = gym['content']['zip'],\n ref = gym['content']['url'],\n country = gym['content']['country'],\n name = html.unescape(gym['content']['title']),\n extras = {\"number\": gym['content']['number']}\n )\n", "path": "locations/spiders/anytime_fitness.py"}]}
| 1,052 | 504 |
gh_patches_debug_29620
|
rasdani/github-patches
|
git_diff
|
ansible__ansible-modules-core-3251
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
apache2_module hangs with "WARNING: The following essential module will be disabled."
I have this code in my playbook:
```
- apache2_module: name={{item}} state=absent
with_items:
- autoindex
- negotiation
```
However someone decided that autoindex and negotiation both are "essential", so when I try to disable them I get this warning:
```
# a2dismod autoindex
WARNING: The following essential module will be disabled.
This might result in unexpected behavior and should NOT be done
unless you know exactly what you are doing!
autoindex
To continue type in the phrase 'Yes, do as I say!' or retry by passing '-f':
```
and expects me to actually type "Yes, do as I say!" (WTF?!?) if I don't provide "-f". The ansible module does not provide that -f parameter, so it locks up.
As weird as that is, I think there _at least_ should be a "force=true" option in apache2_module - or -f should be default.
(Not sure if that's true for all "a2dismod" instances because there is a suspiciously low amount of Google results (none). It is at least there for apache2 currently installed from dotdeb.org)
</issue>
<code>
[start of web_infrastructure/apache2_module.py]
1 #!/usr/bin/python
2 #coding: utf-8 -*-
3
4 # (c) 2013-2014, Christian Berendt <[email protected]>
5 #
6 # This module is free software: you can redistribute it and/or modify
7 # it under the terms of the GNU General Public License as published by
8 # the Free Software Foundation, either version 3 of the License, or
9 # (at your option) any later version.
10 #
11 # This software is distributed in the hope that it will be useful,
12 # but WITHOUT ANY WARRANTY; without even the implied warranty of
13 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
14 # GNU General Public License for more details.
15 #
16 # You should have received a copy of the GNU General Public License
17 # along with this software. If not, see <http://www.gnu.org/licenses/>.
18
19 DOCUMENTATION = '''
20 ---
21 module: apache2_module
22 version_added: 1.6
23 author: "Christian Berendt (@berendt)"
24 short_description: enables/disables a module of the Apache2 webserver
25 description:
26 - Enables or disables a specified module of the Apache2 webserver.
27 options:
28 name:
29 description:
30 - name of the module to enable/disable
31 required: true
32 state:
33 description:
34 - indicate the desired state of the resource
35 choices: ['present', 'absent']
36 default: present
37
38 requirements: ["a2enmod","a2dismod"]
39 '''
40
41 EXAMPLES = '''
42 # enables the Apache2 module "wsgi"
43 - apache2_module: state=present name=wsgi
44
45 # disables the Apache2 module "wsgi"
46 - apache2_module: state=absent name=wsgi
47 '''
48
49 import re
50
51 def _disable_module(module):
52 name = module.params['name']
53 a2dismod_binary = module.get_bin_path("a2dismod")
54 if a2dismod_binary is None:
55 module.fail_json(msg="a2dismod not found. Perhaps this system does not use a2dismod to manage apache")
56
57 result, stdout, stderr = module.run_command("%s %s" % (a2dismod_binary, name))
58
59 if re.match(r'.*\b' + name + r' already disabled', stdout, re.S|re.M):
60 module.exit_json(changed = False, result = "Success")
61 elif result != 0:
62 module.fail_json(msg="Failed to disable module %s: %s" % (name, stdout))
63 else:
64 module.exit_json(changed = True, result = "Disabled")
65
66 def _enable_module(module):
67 name = module.params['name']
68 a2enmod_binary = module.get_bin_path("a2enmod")
69 if a2enmod_binary is None:
70 module.fail_json(msg="a2enmod not found. Perhaps this system does not use a2enmod to manage apache")
71
72 result, stdout, stderr = module.run_command("%s %s" % (a2enmod_binary, name))
73
74 if re.match(r'.*\b' + name + r' already enabled', stdout, re.S|re.M):
75 module.exit_json(changed = False, result = "Success")
76 elif result != 0:
77 module.fail_json(msg="Failed to enable module %s: %s" % (name, stdout))
78 else:
79 module.exit_json(changed = True, result = "Enabled")
80
81 def main():
82 module = AnsibleModule(
83 argument_spec = dict(
84 name = dict(required=True),
85 state = dict(default='present', choices=['absent', 'present'])
86 ),
87 )
88
89 if module.params['state'] == 'present':
90 _enable_module(module)
91
92 if module.params['state'] == 'absent':
93 _disable_module(module)
94
95 # import module snippets
96 from ansible.module_utils.basic import *
97 if __name__ == '__main__':
98 main()
99
[end of web_infrastructure/apache2_module.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/web_infrastructure/apache2_module.py b/web_infrastructure/apache2_module.py
--- a/web_infrastructure/apache2_module.py
+++ b/web_infrastructure/apache2_module.py
@@ -29,6 +29,12 @@
description:
- name of the module to enable/disable
required: true
+ force:
+ description:
+ - force disabling of default modules and override Debian warnings
+ required: false
+ choices: ['yes', 'no']
+ default: no
state:
description:
- indicate the desired state of the resource
@@ -50,10 +56,14 @@
def _disable_module(module):
name = module.params['name']
+ force = module.params['force']
a2dismod_binary = module.get_bin_path("a2dismod")
if a2dismod_binary is None:
module.fail_json(msg="a2dismod not found. Perhaps this system does not use a2dismod to manage apache")
+ if force:
+ a2dismod_binary += ' -f'
+
result, stdout, stderr = module.run_command("%s %s" % (a2dismod_binary, name))
if re.match(r'.*\b' + name + r' already disabled', stdout, re.S|re.M):
@@ -82,6 +92,7 @@
module = AnsibleModule(
argument_spec = dict(
name = dict(required=True),
+ force = dict(required=False, type='bool', default=False),
state = dict(default='present', choices=['absent', 'present'])
),
)
|
{"golden_diff": "diff --git a/web_infrastructure/apache2_module.py b/web_infrastructure/apache2_module.py\n--- a/web_infrastructure/apache2_module.py\n+++ b/web_infrastructure/apache2_module.py\n@@ -29,6 +29,12 @@\n description:\n - name of the module to enable/disable\n required: true\n+ force:\n+ description:\n+ - force disabling of default modules and override Debian warnings\n+ required: false\n+ choices: ['yes', 'no']\n+ default: no\n state:\n description:\n - indicate the desired state of the resource\n@@ -50,10 +56,14 @@\n \n def _disable_module(module):\n name = module.params['name']\n+ force = module.params['force']\n a2dismod_binary = module.get_bin_path(\"a2dismod\")\n if a2dismod_binary is None:\n module.fail_json(msg=\"a2dismod not found. Perhaps this system does not use a2dismod to manage apache\")\n \n+ if force:\n+ a2dismod_binary += ' -f'\n+\n result, stdout, stderr = module.run_command(\"%s %s\" % (a2dismod_binary, name))\n \n if re.match(r'.*\\b' + name + r' already disabled', stdout, re.S|re.M):\n@@ -82,6 +92,7 @@\n module = AnsibleModule(\n argument_spec = dict(\n name = dict(required=True),\n+ force = dict(required=False, type='bool', default=False),\n state = dict(default='present', choices=['absent', 'present'])\n ),\n )\n", "issue": "apache2_module hangs with \"WARNING: The following essential module will be disabled.\"\nI have this code in my playbook:\n\n```\n- apache2_module: name={{item}} state=absent\n with_items:\n - autoindex\n - negotiation\n```\n\nHowever someone decided that autoindex and negotiation both are \"essential\", so when I try to disable them I get this warning:\n\n```\n# a2dismod autoindex\nWARNING: The following essential module will be disabled.\nThis might result in unexpected behavior and should NOT be done\nunless you know exactly what you are doing!\n autoindex\n\nTo continue type in the phrase 'Yes, do as I say!' or retry by passing '-f':\n```\n\nand expects me to actually type \"Yes, do as I say!\" (WTF?!?) if I don't provide \"-f\". The ansible module does not provide that -f parameter, so it locks up.\n\nAs weird as that is, I think there _at least_ should be a \"force=true\" option in apache2_module - or -f should be default.\n\n(Not sure if that's true for all \"a2dismod\" instances because there is a suspiciously low amount of Google results (none). It is at least there for apache2 currently installed from dotdeb.org)\n\n", "before_files": [{"content": "#!/usr/bin/python\n#coding: utf-8 -*-\n\n# (c) 2013-2014, Christian Berendt <[email protected]>\n#\n# This module is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This software is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this software. If not, see <http://www.gnu.org/licenses/>.\n\nDOCUMENTATION = '''\n---\nmodule: apache2_module\nversion_added: 1.6\nauthor: \"Christian Berendt (@berendt)\"\nshort_description: enables/disables a module of the Apache2 webserver\ndescription:\n - Enables or disables a specified module of the Apache2 webserver.\noptions:\n name:\n description:\n - name of the module to enable/disable\n required: true\n state:\n description:\n - indicate the desired state of the resource\n choices: ['present', 'absent']\n default: present\n\nrequirements: [\"a2enmod\",\"a2dismod\"]\n'''\n\nEXAMPLES = '''\n# enables the Apache2 module \"wsgi\"\n- apache2_module: state=present name=wsgi\n\n# disables the Apache2 module \"wsgi\"\n- apache2_module: state=absent name=wsgi\n'''\n\nimport re\n\ndef _disable_module(module):\n name = module.params['name']\n a2dismod_binary = module.get_bin_path(\"a2dismod\")\n if a2dismod_binary is None:\n module.fail_json(msg=\"a2dismod not found. Perhaps this system does not use a2dismod to manage apache\")\n\n result, stdout, stderr = module.run_command(\"%s %s\" % (a2dismod_binary, name))\n\n if re.match(r'.*\\b' + name + r' already disabled', stdout, re.S|re.M):\n module.exit_json(changed = False, result = \"Success\")\n elif result != 0:\n module.fail_json(msg=\"Failed to disable module %s: %s\" % (name, stdout))\n else:\n module.exit_json(changed = True, result = \"Disabled\")\n\ndef _enable_module(module):\n name = module.params['name']\n a2enmod_binary = module.get_bin_path(\"a2enmod\")\n if a2enmod_binary is None:\n module.fail_json(msg=\"a2enmod not found. Perhaps this system does not use a2enmod to manage apache\")\n\n result, stdout, stderr = module.run_command(\"%s %s\" % (a2enmod_binary, name))\n\n if re.match(r'.*\\b' + name + r' already enabled', stdout, re.S|re.M):\n module.exit_json(changed = False, result = \"Success\")\n elif result != 0:\n module.fail_json(msg=\"Failed to enable module %s: %s\" % (name, stdout))\n else:\n module.exit_json(changed = True, result = \"Enabled\")\n\ndef main():\n module = AnsibleModule(\n argument_spec = dict(\n name = dict(required=True),\n state = dict(default='present', choices=['absent', 'present'])\n ),\n )\n\n if module.params['state'] == 'present':\n _enable_module(module)\n\n if module.params['state'] == 'absent':\n _disable_module(module)\n\n# import module snippets\nfrom ansible.module_utils.basic import *\nif __name__ == '__main__':\n main()\n", "path": "web_infrastructure/apache2_module.py"}]}
| 1,850 | 369 |
gh_patches_debug_21796
|
rasdani/github-patches
|
git_diff
|
psychopy__psychopy-4625
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
404 errors on some of the page in the HELP menus
Version used
- psychopy: 2021.2.3
https://www.psychopy.org/builder/builder.html
https://www.psychopy.org/api/api.html
</issue>
<code>
[start of psychopy/app/urls.py]
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3
4 """A central location to store information about urls
5 """
6 urls = dict()
7
8 # links based on string names
9 urls['builder'] = "https://www.psychopy.org/builder/builder.html"
10 urls['builder.loops'] = "https://www.psychopy.org/builder/flow.html#loops"
11 # NB. builder components get their urls defined by the component code
12 # (so a custom component can have a url)
13
14 urls['downloads'] = "https://github.com/psychopy/psychopy/releases"
15 urls['changelog'] = "https://www.psychopy.org/changelog.html"
16
17 general = "https://www.psychopy.org/general/"
18 urls['prefs'] = general + "prefs.html"
19 urls['prefs.general'] = general + "prefs.html#general-settings"
20 urls['prefs.app'] = general + "prefs.html#application-settings"
21 urls['prefs.coder'] = general + "prefs.html#coder-settings"
22 urls['prefs.builder'] = general + "prefs.html#builder-settings"
23 urls['prefs.connections'] = general + "prefs.html#connection-settings"
24
25 # links keyed by wxIDs (e.g. menu item IDs)
26 urls['psychopyHome'] = "https://www.psychopy.org/"
27 urls['psychopyReference'] = "https://www.psychopy.org/api/api.html"
28 urls['coderTutorial'] = "https://www.psychopy.org/coder/tutorial1.html"
29 urls['builderHelp'] = urls['builder']
30 urls['builderDemos'] = "http://code.google.com/p/psychopy/downloads/list?can=2&q=demos"
31 urls['projsAbout'] = "https://www.psychopy.org/general/projects.html"
32
[end of psychopy/app/urls.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/psychopy/app/urls.py b/psychopy/app/urls.py
--- a/psychopy/app/urls.py
+++ b/psychopy/app/urls.py
@@ -6,7 +6,7 @@
urls = dict()
# links based on string names
-urls['builder'] = "https://www.psychopy.org/builder/builder.html"
+urls['builder'] = "https://www.psychopy.org/builder"
urls['builder.loops'] = "https://www.psychopy.org/builder/flow.html#loops"
# NB. builder components get their urls defined by the component code
# (so a custom component can have a url)
@@ -24,7 +24,7 @@
# links keyed by wxIDs (e.g. menu item IDs)
urls['psychopyHome'] = "https://www.psychopy.org/"
-urls['psychopyReference'] = "https://www.psychopy.org/api/api.html"
+urls['psychopyReference'] = "https://www.psychopy.org/api"
urls['coderTutorial'] = "https://www.psychopy.org/coder/tutorial1.html"
urls['builderHelp'] = urls['builder']
urls['builderDemos'] = "http://code.google.com/p/psychopy/downloads/list?can=2&q=demos"
|
{"golden_diff": "diff --git a/psychopy/app/urls.py b/psychopy/app/urls.py\n--- a/psychopy/app/urls.py\n+++ b/psychopy/app/urls.py\n@@ -6,7 +6,7 @@\n urls = dict()\n \n # links based on string names\n-urls['builder'] = \"https://www.psychopy.org/builder/builder.html\"\n+urls['builder'] = \"https://www.psychopy.org/builder\"\n urls['builder.loops'] = \"https://www.psychopy.org/builder/flow.html#loops\"\n # NB. builder components get their urls defined by the component code\n # (so a custom component can have a url)\n@@ -24,7 +24,7 @@\n \n # links keyed by wxIDs (e.g. menu item IDs)\n urls['psychopyHome'] = \"https://www.psychopy.org/\"\n-urls['psychopyReference'] = \"https://www.psychopy.org/api/api.html\"\n+urls['psychopyReference'] = \"https://www.psychopy.org/api\"\n urls['coderTutorial'] = \"https://www.psychopy.org/coder/tutorial1.html\"\n urls['builderHelp'] = urls['builder']\n urls['builderDemos'] = \"http://code.google.com/p/psychopy/downloads/list?can=2&q=demos\"\n", "issue": "404 errors on some of the page in the HELP menus\nVersion used\r\n- psychopy: 2021.2.3\r\n\r\nhttps://www.psychopy.org/builder/builder.html\r\nhttps://www.psychopy.org/api/api.html\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\"\"\"A central location to store information about urls\n\"\"\"\nurls = dict()\n\n# links based on string names\nurls['builder'] = \"https://www.psychopy.org/builder/builder.html\"\nurls['builder.loops'] = \"https://www.psychopy.org/builder/flow.html#loops\"\n# NB. builder components get their urls defined by the component code\n# (so a custom component can have a url)\n\nurls['downloads'] = \"https://github.com/psychopy/psychopy/releases\"\nurls['changelog'] = \"https://www.psychopy.org/changelog.html\"\n\ngeneral = \"https://www.psychopy.org/general/\"\nurls['prefs'] = general + \"prefs.html\"\nurls['prefs.general'] = general + \"prefs.html#general-settings\"\nurls['prefs.app'] = general + \"prefs.html#application-settings\"\nurls['prefs.coder'] = general + \"prefs.html#coder-settings\"\nurls['prefs.builder'] = general + \"prefs.html#builder-settings\"\nurls['prefs.connections'] = general + \"prefs.html#connection-settings\"\n\n# links keyed by wxIDs (e.g. menu item IDs)\nurls['psychopyHome'] = \"https://www.psychopy.org/\"\nurls['psychopyReference'] = \"https://www.psychopy.org/api/api.html\"\nurls['coderTutorial'] = \"https://www.psychopy.org/coder/tutorial1.html\"\nurls['builderHelp'] = urls['builder']\nurls['builderDemos'] = \"http://code.google.com/p/psychopy/downloads/list?can=2&q=demos\"\nurls['projsAbout'] = \"https://www.psychopy.org/general/projects.html\"\n", "path": "psychopy/app/urls.py"}]}
| 1,017 | 286 |
gh_patches_debug_36007
|
rasdani/github-patches
|
git_diff
|
arviz-devs__arviz-414
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
arviz-darkgrid not working in example from quickstart
This command is not being recognized.
I installed the program from github on Mac OS 10.13 using macports Python3.5
az.style.use('arviz-darkgrid')
</issue>
<code>
[start of setup.py]
1 import codecs
2 import shutil
3 import os
4 import re
5
6 import setuptools
7 from setuptools import setup, find_packages
8 from setuptools.command.install import install
9 from setuptools.command.develop import develop
10
11
12 PROJECT_ROOT = os.path.dirname(os.path.realpath(__file__))
13 REQUIREMENTS_FILE = os.path.join(PROJECT_ROOT, 'requirements.txt')
14 README_FILE = os.path.join(PROJECT_ROOT, 'README.md')
15 VERSION_FILE = os.path.join(PROJECT_ROOT, 'arviz', '__init__.py')
16
17
18 # Ensure matplotlib dependencies are available to copy
19 # styles over
20 setuptools.dist.Distribution().fetch_build_eggs(['matplotlib>=3.0'])
21
22 def get_requirements():
23 with codecs.open(REQUIREMENTS_FILE) as buff:
24 return buff.read().splitlines()
25
26
27 def get_long_description():
28 with codecs.open(README_FILE, 'rt') as buff:
29 return buff.read()
30
31
32 def copy_styles():
33 from matplotlib import get_configdir
34 sd = os.path.join(get_configdir(), "stylelib")
35 source = os.path.dirname(os.path.realpath(__file__))
36 lsd = os.path.join(source, 'arviz', 'plots', 'styles')
37 styles = [f for f in os.listdir(lsd)]
38 if not os.path.isdir(sd):
39 os.makedirs(sd)
40 for s in styles:
41 shutil.copy(os.path.join(lsd, s), os.path.join(sd, s))
42
43
44 class DevelopStyles(develop):
45 def run(self):
46 copy_styles()
47 develop.run(self)
48
49 class InstallStyles(install):
50 def run(self):
51 copy_styles()
52 install.run(self)
53
54 def get_version():
55 lines = open(VERSION_FILE, 'rt').readlines()
56 version_regex = r"^__version__ = ['\"]([^'\"]*)['\"]"
57 for line in lines:
58 mo = re.search(version_regex, line, re.M)
59 if mo:
60 return mo.group(1)
61 raise RuntimeError('Unable to find version in %s.' % (VERSION_FILE,))
62
63 setup(
64 name='arviz',
65 version=get_version(),
66 description='Exploratory analysis of Bayesian models',
67 author='ArviZ Developers',
68 url="http://github.com/arviz-devs/arviz",
69 packages=find_packages(),
70 install_requires=get_requirements(),
71 long_description=get_long_description(),
72 long_description_content_type='text/markdown',
73 include_package_data=True,
74 cmdclass={
75 'develop': DevelopStyles,
76 'install': InstallStyles,
77 },
78 )
79
[end of setup.py]
[start of arviz/__init__.py]
1 # pylint: disable=wildcard-import,invalid-name,wrong-import-position
2 """ArviZ is a library for exploratory analysis of Bayesian models."""
3 __version__ = "0.2.1"
4
5 import logging
6 from matplotlib.pyplot import style
7
8 # Configure logging before importing arviz internals
9 _log = logging.getLogger("arviz")
10
11 if not logging.root.handlers:
12 handler = logging.StreamHandler()
13 _log.setLevel(logging.INFO)
14 _log.addHandler(handler)
15
16 from .data import *
17 from .plots import *
18 from .stats import *
19
[end of arviz/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/arviz/__init__.py b/arviz/__init__.py
--- a/arviz/__init__.py
+++ b/arviz/__init__.py
@@ -2,9 +2,15 @@
"""ArviZ is a library for exploratory analysis of Bayesian models."""
__version__ = "0.2.1"
+import os
import logging
from matplotlib.pyplot import style
+# add ArviZ's styles to matplotlib's styles
+arviz_style_path = os.path.join(os.path.dirname(__file__), "plots", "styles")
+style.core.USER_LIBRARY_PATHS.append(arviz_style_path)
+style.core.reload_library()
+
# Configure logging before importing arviz internals
_log = logging.getLogger("arviz")
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -1,5 +1,4 @@
import codecs
-import shutil
import os
import re
@@ -15,10 +14,6 @@
VERSION_FILE = os.path.join(PROJECT_ROOT, 'arviz', '__init__.py')
-# Ensure matplotlib dependencies are available to copy
-# styles over
-setuptools.dist.Distribution().fetch_build_eggs(['matplotlib>=3.0'])
-
def get_requirements():
with codecs.open(REQUIREMENTS_FILE) as buff:
return buff.read().splitlines()
@@ -28,29 +23,6 @@
with codecs.open(README_FILE, 'rt') as buff:
return buff.read()
-
-def copy_styles():
- from matplotlib import get_configdir
- sd = os.path.join(get_configdir(), "stylelib")
- source = os.path.dirname(os.path.realpath(__file__))
- lsd = os.path.join(source, 'arviz', 'plots', 'styles')
- styles = [f for f in os.listdir(lsd)]
- if not os.path.isdir(sd):
- os.makedirs(sd)
- for s in styles:
- shutil.copy(os.path.join(lsd, s), os.path.join(sd, s))
-
-
-class DevelopStyles(develop):
- def run(self):
- copy_styles()
- develop.run(self)
-
-class InstallStyles(install):
- def run(self):
- copy_styles()
- install.run(self)
-
def get_version():
lines = open(VERSION_FILE, 'rt').readlines()
version_regex = r"^__version__ = ['\"]([^'\"]*)['\"]"
@@ -71,8 +43,4 @@
long_description=get_long_description(),
long_description_content_type='text/markdown',
include_package_data=True,
- cmdclass={
- 'develop': DevelopStyles,
- 'install': InstallStyles,
- },
)
|
{"golden_diff": "diff --git a/arviz/__init__.py b/arviz/__init__.py\n--- a/arviz/__init__.py\n+++ b/arviz/__init__.py\n@@ -2,9 +2,15 @@\n \"\"\"ArviZ is a library for exploratory analysis of Bayesian models.\"\"\"\n __version__ = \"0.2.1\"\n \n+import os\n import logging\n from matplotlib.pyplot import style\n \n+# add ArviZ's styles to matplotlib's styles\n+arviz_style_path = os.path.join(os.path.dirname(__file__), \"plots\", \"styles\")\n+style.core.USER_LIBRARY_PATHS.append(arviz_style_path)\n+style.core.reload_library()\n+\n # Configure logging before importing arviz internals\n _log = logging.getLogger(\"arviz\")\n \ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -1,5 +1,4 @@\n import codecs\n-import shutil\n import os\n import re\n \n@@ -15,10 +14,6 @@\n VERSION_FILE = os.path.join(PROJECT_ROOT, 'arviz', '__init__.py')\n \n \n-# Ensure matplotlib dependencies are available to copy\n-# styles over\n-setuptools.dist.Distribution().fetch_build_eggs(['matplotlib>=3.0'])\n-\n def get_requirements():\n with codecs.open(REQUIREMENTS_FILE) as buff:\n return buff.read().splitlines()\n@@ -28,29 +23,6 @@\n with codecs.open(README_FILE, 'rt') as buff:\n return buff.read()\n \n-\n-def copy_styles():\n- from matplotlib import get_configdir\n- sd = os.path.join(get_configdir(), \"stylelib\")\n- source = os.path.dirname(os.path.realpath(__file__))\n- lsd = os.path.join(source, 'arviz', 'plots', 'styles')\n- styles = [f for f in os.listdir(lsd)]\n- if not os.path.isdir(sd):\n- os.makedirs(sd)\n- for s in styles:\n- shutil.copy(os.path.join(lsd, s), os.path.join(sd, s))\n-\n-\n-class DevelopStyles(develop):\n- def run(self):\n- copy_styles()\n- develop.run(self)\n-\n-class InstallStyles(install):\n- def run(self):\n- copy_styles()\n- install.run(self)\n-\n def get_version():\n lines = open(VERSION_FILE, 'rt').readlines()\n version_regex = r\"^__version__ = ['\\\"]([^'\\\"]*)['\\\"]\"\n@@ -71,8 +43,4 @@\n long_description=get_long_description(),\n long_description_content_type='text/markdown',\n include_package_data=True,\n- cmdclass={\n- 'develop': DevelopStyles,\n- 'install': InstallStyles,\n- },\n )\n", "issue": "arviz-darkgrid not working in example from quickstart\nThis command is not being recognized.\r\nI installed the program from github on Mac OS 10.13 using macports Python3.5 \r\n\r\naz.style.use('arviz-darkgrid')\n", "before_files": [{"content": "import codecs\nimport shutil\nimport os\nimport re\n\nimport setuptools\nfrom setuptools import setup, find_packages\nfrom setuptools.command.install import install\nfrom setuptools.command.develop import develop\n\n\nPROJECT_ROOT = os.path.dirname(os.path.realpath(__file__))\nREQUIREMENTS_FILE = os.path.join(PROJECT_ROOT, 'requirements.txt')\nREADME_FILE = os.path.join(PROJECT_ROOT, 'README.md')\nVERSION_FILE = os.path.join(PROJECT_ROOT, 'arviz', '__init__.py')\n\n\n# Ensure matplotlib dependencies are available to copy\n# styles over\nsetuptools.dist.Distribution().fetch_build_eggs(['matplotlib>=3.0'])\n\ndef get_requirements():\n with codecs.open(REQUIREMENTS_FILE) as buff:\n return buff.read().splitlines()\n\n\ndef get_long_description():\n with codecs.open(README_FILE, 'rt') as buff:\n return buff.read()\n\n\ndef copy_styles():\n from matplotlib import get_configdir\n sd = os.path.join(get_configdir(), \"stylelib\")\n source = os.path.dirname(os.path.realpath(__file__))\n lsd = os.path.join(source, 'arviz', 'plots', 'styles')\n styles = [f for f in os.listdir(lsd)]\n if not os.path.isdir(sd):\n os.makedirs(sd)\n for s in styles:\n shutil.copy(os.path.join(lsd, s), os.path.join(sd, s))\n\n\nclass DevelopStyles(develop):\n def run(self):\n copy_styles()\n develop.run(self)\n\nclass InstallStyles(install):\n def run(self):\n copy_styles()\n install.run(self)\n\ndef get_version():\n lines = open(VERSION_FILE, 'rt').readlines()\n version_regex = r\"^__version__ = ['\\\"]([^'\\\"]*)['\\\"]\"\n for line in lines:\n mo = re.search(version_regex, line, re.M)\n if mo:\n return mo.group(1)\n raise RuntimeError('Unable to find version in %s.' % (VERSION_FILE,))\n\nsetup(\n name='arviz',\n version=get_version(),\n description='Exploratory analysis of Bayesian models',\n author='ArviZ Developers',\n url=\"http://github.com/arviz-devs/arviz\",\n packages=find_packages(),\n install_requires=get_requirements(),\n long_description=get_long_description(),\n long_description_content_type='text/markdown',\n include_package_data=True,\n cmdclass={\n 'develop': DevelopStyles,\n 'install': InstallStyles,\n },\n)\n", "path": "setup.py"}, {"content": "# pylint: disable=wildcard-import,invalid-name,wrong-import-position\n\"\"\"ArviZ is a library for exploratory analysis of Bayesian models.\"\"\"\n__version__ = \"0.2.1\"\n\nimport logging\nfrom matplotlib.pyplot import style\n\n# Configure logging before importing arviz internals\n_log = logging.getLogger(\"arviz\")\n\nif not logging.root.handlers:\n handler = logging.StreamHandler()\n _log.setLevel(logging.INFO)\n _log.addHandler(handler)\n\nfrom .data import *\nfrom .plots import *\nfrom .stats import *\n", "path": "arviz/__init__.py"}]}
| 1,414 | 589 |
gh_patches_debug_30651
|
rasdani/github-patches
|
git_diff
|
googleapis__google-cloud-python-8481
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Firestore: sync shim module with 'firestore_v1' package.
See https://github.com/googleapis/google-cloud-python/issues/7533#issuecomment-495917295 &ff.
</issue>
<code>
[start of firestore/google/cloud/firestore.py]
1 # Copyright 2017 Google LLC All rights reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Python idiomatic client for Google Cloud Firestore."""
16
17
18 from google.cloud.firestore_v1 import __version__
19 from google.cloud.firestore_v1 import Client
20 from google.cloud.firestore_v1 import CollectionReference
21 from google.cloud.firestore_v1 import DELETE_FIELD
22 from google.cloud.firestore_v1 import DocumentReference
23 from google.cloud.firestore_v1 import DocumentSnapshot
24 from google.cloud.firestore_v1 import enums
25 from google.cloud.firestore_v1 import ExistsOption
26 from google.cloud.firestore_v1 import GeoPoint
27 from google.cloud.firestore_v1 import LastUpdateOption
28 from google.cloud.firestore_v1 import Query
29 from google.cloud.firestore_v1 import ReadAfterWriteError
30 from google.cloud.firestore_v1 import SERVER_TIMESTAMP
31 from google.cloud.firestore_v1 import Transaction
32 from google.cloud.firestore_v1 import transactional
33 from google.cloud.firestore_v1 import types
34 from google.cloud.firestore_v1 import Watch
35 from google.cloud.firestore_v1 import WriteBatch
36 from google.cloud.firestore_v1 import WriteOption
37
38
39 __all__ = [
40 "__version__",
41 "Client",
42 "CollectionReference",
43 "DELETE_FIELD",
44 "DocumentReference",
45 "DocumentSnapshot",
46 "enums",
47 "ExistsOption",
48 "GeoPoint",
49 "LastUpdateOption",
50 "Query",
51 "ReadAfterWriteError",
52 "SERVER_TIMESTAMP",
53 "Transaction",
54 "transactional",
55 "types",
56 "Watch",
57 "WriteBatch",
58 "WriteOption",
59 ]
60
[end of firestore/google/cloud/firestore.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/firestore/google/cloud/firestore.py b/firestore/google/cloud/firestore.py
--- a/firestore/google/cloud/firestore.py
+++ b/firestore/google/cloud/firestore.py
@@ -16,6 +16,8 @@
from google.cloud.firestore_v1 import __version__
+from google.cloud.firestore_v1 import ArrayRemove
+from google.cloud.firestore_v1 import ArrayUnion
from google.cloud.firestore_v1 import Client
from google.cloud.firestore_v1 import CollectionReference
from google.cloud.firestore_v1 import DELETE_FIELD
@@ -24,7 +26,10 @@
from google.cloud.firestore_v1 import enums
from google.cloud.firestore_v1 import ExistsOption
from google.cloud.firestore_v1 import GeoPoint
+from google.cloud.firestore_v1 import Increment
from google.cloud.firestore_v1 import LastUpdateOption
+from google.cloud.firestore_v1 import Maximum
+from google.cloud.firestore_v1 import Minimum
from google.cloud.firestore_v1 import Query
from google.cloud.firestore_v1 import ReadAfterWriteError
from google.cloud.firestore_v1 import SERVER_TIMESTAMP
@@ -38,6 +43,8 @@
__all__ = [
"__version__",
+ "ArrayRemove",
+ "ArrayUnion",
"Client",
"CollectionReference",
"DELETE_FIELD",
@@ -46,7 +53,10 @@
"enums",
"ExistsOption",
"GeoPoint",
+ "Increment",
"LastUpdateOption",
+ "Maximum",
+ "Minimum",
"Query",
"ReadAfterWriteError",
"SERVER_TIMESTAMP",
|
{"golden_diff": "diff --git a/firestore/google/cloud/firestore.py b/firestore/google/cloud/firestore.py\n--- a/firestore/google/cloud/firestore.py\n+++ b/firestore/google/cloud/firestore.py\n@@ -16,6 +16,8 @@\n \n \n from google.cloud.firestore_v1 import __version__\n+from google.cloud.firestore_v1 import ArrayRemove\n+from google.cloud.firestore_v1 import ArrayUnion\n from google.cloud.firestore_v1 import Client\n from google.cloud.firestore_v1 import CollectionReference\n from google.cloud.firestore_v1 import DELETE_FIELD\n@@ -24,7 +26,10 @@\n from google.cloud.firestore_v1 import enums\n from google.cloud.firestore_v1 import ExistsOption\n from google.cloud.firestore_v1 import GeoPoint\n+from google.cloud.firestore_v1 import Increment\n from google.cloud.firestore_v1 import LastUpdateOption\n+from google.cloud.firestore_v1 import Maximum\n+from google.cloud.firestore_v1 import Minimum\n from google.cloud.firestore_v1 import Query\n from google.cloud.firestore_v1 import ReadAfterWriteError\n from google.cloud.firestore_v1 import SERVER_TIMESTAMP\n@@ -38,6 +43,8 @@\n \n __all__ = [\n \"__version__\",\n+ \"ArrayRemove\",\n+ \"ArrayUnion\",\n \"Client\",\n \"CollectionReference\",\n \"DELETE_FIELD\",\n@@ -46,7 +53,10 @@\n \"enums\",\n \"ExistsOption\",\n \"GeoPoint\",\n+ \"Increment\",\n \"LastUpdateOption\",\n+ \"Maximum\",\n+ \"Minimum\",\n \"Query\",\n \"ReadAfterWriteError\",\n \"SERVER_TIMESTAMP\",\n", "issue": "Firestore: sync shim module with 'firestore_v1' package.\nSee https://github.com/googleapis/google-cloud-python/issues/7533#issuecomment-495917295 &ff.\n", "before_files": [{"content": "# Copyright 2017 Google LLC All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Python idiomatic client for Google Cloud Firestore.\"\"\"\n\n\nfrom google.cloud.firestore_v1 import __version__\nfrom google.cloud.firestore_v1 import Client\nfrom google.cloud.firestore_v1 import CollectionReference\nfrom google.cloud.firestore_v1 import DELETE_FIELD\nfrom google.cloud.firestore_v1 import DocumentReference\nfrom google.cloud.firestore_v1 import DocumentSnapshot\nfrom google.cloud.firestore_v1 import enums\nfrom google.cloud.firestore_v1 import ExistsOption\nfrom google.cloud.firestore_v1 import GeoPoint\nfrom google.cloud.firestore_v1 import LastUpdateOption\nfrom google.cloud.firestore_v1 import Query\nfrom google.cloud.firestore_v1 import ReadAfterWriteError\nfrom google.cloud.firestore_v1 import SERVER_TIMESTAMP\nfrom google.cloud.firestore_v1 import Transaction\nfrom google.cloud.firestore_v1 import transactional\nfrom google.cloud.firestore_v1 import types\nfrom google.cloud.firestore_v1 import Watch\nfrom google.cloud.firestore_v1 import WriteBatch\nfrom google.cloud.firestore_v1 import WriteOption\n\n\n__all__ = [\n \"__version__\",\n \"Client\",\n \"CollectionReference\",\n \"DELETE_FIELD\",\n \"DocumentReference\",\n \"DocumentSnapshot\",\n \"enums\",\n \"ExistsOption\",\n \"GeoPoint\",\n \"LastUpdateOption\",\n \"Query\",\n \"ReadAfterWriteError\",\n \"SERVER_TIMESTAMP\",\n \"Transaction\",\n \"transactional\",\n \"types\",\n \"Watch\",\n \"WriteBatch\",\n \"WriteOption\",\n]\n", "path": "firestore/google/cloud/firestore.py"}]}
| 1,128 | 342 |
gh_patches_debug_20390
|
rasdani/github-patches
|
git_diff
|
buildbot__buildbot-1488
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
unicode literrals
based on irc discussion with @rjarry
</issue>
<code>
[start of master/buildbot/util/lineboundaries.py]
1 # This file is part of Buildbot. Buildbot is free software: you can
2 # redistribute it and/or modify it under the terms of the GNU General Public
3 # License as published by the Free Software Foundation, version 2.
4 #
5 # This program is distributed in the hope that it will be useful, but WITHOUT
6 # ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
7 # FOR A PARTICULAR PURPOSE. See the GNU General Public License for more
8 # details.
9 #
10 # You should have received a copy of the GNU General Public License along with
11 # this program; if not, write to the Free Software Foundation, Inc., 51
12 # Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
13 #
14 # Copyright Buildbot Team Members
15
16 from twisted.internet import defer
17
18
19 class LineBoundaryFinder(object):
20
21 __slots__ = ['partialLine', 'callback']
22
23 def __init__(self, callback):
24 self.partialLine = None
25 self.callback = callback
26
27 def append(self, text):
28 if self.partialLine:
29 text = self.partialLine + text
30 self.partialLine = None
31 if text:
32 if text[-1] != '\n':
33 i = text.rfind('\n')
34 if i >= 0:
35 i = i + 1
36 text, self.partialLine = text[:i], text[i:]
37 else:
38 self.partialLine = text
39 return defer.succeed(None)
40 return self.callback(text)
41
42 def flush(self):
43 if self.partialLine:
44 return self.append('\n')
45 else:
46 return defer.succeed(None)
47
[end of master/buildbot/util/lineboundaries.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/master/buildbot/util/lineboundaries.py b/master/buildbot/util/lineboundaries.py
--- a/master/buildbot/util/lineboundaries.py
+++ b/master/buildbot/util/lineboundaries.py
@@ -13,6 +13,8 @@
#
# Copyright Buildbot Team Members
+import re
+
from twisted.internet import defer
@@ -20,6 +22,10 @@
__slots__ = ['partialLine', 'callback']
+ # the lookahead here (`(?=.)`) ensures that `\r` doesn't match at the end
+ # of the buffer
+ newline_re = re.compile(r'(\r\n|\r(?=.)|\n)')
+
def __init__(self, callback):
self.partialLine = None
self.callback = callback
@@ -28,6 +34,7 @@
if self.partialLine:
text = self.partialLine + text
self.partialLine = None
+ text = self.newline_re.sub('\n', text)
if text:
if text[-1] != '\n':
i = text.rfind('\n')
|
{"golden_diff": "diff --git a/master/buildbot/util/lineboundaries.py b/master/buildbot/util/lineboundaries.py\n--- a/master/buildbot/util/lineboundaries.py\n+++ b/master/buildbot/util/lineboundaries.py\n@@ -13,6 +13,8 @@\n #\n # Copyright Buildbot Team Members\n \n+import re\n+\n from twisted.internet import defer\n \n \n@@ -20,6 +22,10 @@\n \n __slots__ = ['partialLine', 'callback']\n \n+ # the lookahead here (`(?=.)`) ensures that `\\r` doesn't match at the end\n+ # of the buffer\n+ newline_re = re.compile(r'(\\r\\n|\\r(?=.)|\\n)')\n+\n def __init__(self, callback):\n self.partialLine = None\n self.callback = callback\n@@ -28,6 +34,7 @@\n if self.partialLine:\n text = self.partialLine + text\n self.partialLine = None\n+ text = self.newline_re.sub('\\n', text)\n if text:\n if text[-1] != '\\n':\n i = text.rfind('\\n')\n", "issue": "unicode literrals\nbased on irc discussion with @rjarry \n", "before_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\nfrom twisted.internet import defer\n\n\nclass LineBoundaryFinder(object):\n\n __slots__ = ['partialLine', 'callback']\n\n def __init__(self, callback):\n self.partialLine = None\n self.callback = callback\n\n def append(self, text):\n if self.partialLine:\n text = self.partialLine + text\n self.partialLine = None\n if text:\n if text[-1] != '\\n':\n i = text.rfind('\\n')\n if i >= 0:\n i = i + 1\n text, self.partialLine = text[:i], text[i:]\n else:\n self.partialLine = text\n return defer.succeed(None)\n return self.callback(text)\n\n def flush(self):\n if self.partialLine:\n return self.append('\\n')\n else:\n return defer.succeed(None)\n", "path": "master/buildbot/util/lineboundaries.py"}]}
| 996 | 252 |
gh_patches_debug_7
|
rasdani/github-patches
|
git_diff
|
microsoft__Qcodes-4248
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Filename collision due to case-sensitivity in Keysight folder
When pulling the qcodes repository on Windows, there is a filename collision between the uppercase and lowercase Keysight folders.
The error message is as follows:
```bash
$ git clone https://github.com/QCoDeS/Qcodes.git
Cloning into 'Qcodes'...
remote: Enumerating objects: 1522, done.
remote: Counting objects: 100% (1522/1522), done.
remote: Compressing objects: 100% (655/655), done.
Receiving objects: 100% (112398/112398), 242.65 MiB | 2.58 MiB/s, done.
Resolving deltas: 100% (87395/87395), done.
warning: the following paths have collided (e.g. case-sensitive paths
on a case-insensitive filesystem) and only one from the same
colliding group is in the working tree:
'qcodes/instrument_drivers/Keysight/__init__.py'
'qcodes/instrument_drivers/keysight/__init__.py'
```
I propose we remove the lowercase keysight folder as it has now been deprecated for over 2 years.
### System
Windows/OSX and other OS's with case insensitive file systems.
</issue>
<code>
[start of qcodes/instrument_drivers/Keysight/__init__.py]
[end of qcodes/instrument_drivers/Keysight/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/qcodes/instrument_drivers/Keysight/__init__.py b/qcodes/instrument_drivers/Keysight/__init__.py
--- a/qcodes/instrument_drivers/Keysight/__init__.py
+++ b/qcodes/instrument_drivers/Keysight/__init__.py
@@ -0,0 +1 @@
+# Intentionally left blank
|
{"golden_diff": "diff --git a/qcodes/instrument_drivers/Keysight/__init__.py b/qcodes/instrument_drivers/Keysight/__init__.py\n--- a/qcodes/instrument_drivers/Keysight/__init__.py\n+++ b/qcodes/instrument_drivers/Keysight/__init__.py\n@@ -0,0 +1 @@\n+# Intentionally left blank\n", "issue": "Filename collision due to case-sensitivity in Keysight folder\nWhen pulling the qcodes repository on Windows, there is a filename collision between the uppercase and lowercase Keysight folders.\r\n\r\nThe error message is as follows:\r\n```bash\r\n$ git clone https://github.com/QCoDeS/Qcodes.git\r\nCloning into 'Qcodes'...\r\nremote: Enumerating objects: 1522, done.\r\nremote: Counting objects: 100% (1522/1522), done.\r\nremote: Compressing objects: 100% (655/655), done.\r\n\r\nReceiving objects: 100% (112398/112398), 242.65 MiB | 2.58 MiB/s, done.\r\nResolving deltas: 100% (87395/87395), done.\r\nwarning: the following paths have collided (e.g. case-sensitive paths\r\non a case-insensitive filesystem) and only one from the same\r\ncolliding group is in the working tree:\r\n\r\n 'qcodes/instrument_drivers/Keysight/__init__.py'\r\n 'qcodes/instrument_drivers/keysight/__init__.py'\r\n```\r\n\r\nI propose we remove the lowercase keysight folder as it has now been deprecated for over 2 years.\r\n\r\n### System\r\nWindows/OSX and other OS's with case insensitive file systems.\n", "before_files": [{"content": "", "path": "qcodes/instrument_drivers/Keysight/__init__.py"}]}
| 860 | 80 |
gh_patches_debug_9066
|
rasdani/github-patches
|
git_diff
|
pulp__pulpcore-3062
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
general_create performes one unnecessary db lookup
`Serializer.save()` returns the instance we want already. No need to fetch it again from the db.
</issue>
<code>
[start of pulpcore/app/tasks/base.py]
1 from django.db import transaction
2
3 from pulpcore.app.apps import get_plugin_config
4 from pulpcore.app.models import CreatedResource, PulpTemporaryFile
5 from pulpcore.app.files import PulpTemporaryUploadedFile
6 from pulpcore.plugin.models import MasterModel
7
8
9 def general_create_from_temp_file(app_label, serializer_name, temp_file_pk, *args, **kwargs):
10 """
11 Create a model instance from contents stored in a temporary file.
12
13 A task which executes this function takes the ownership of a temporary file and deletes it
14 afterwards. This function calls the function general_create() to create a model instance.
15 """
16 temp_file = PulpTemporaryFile.objects.get(pk=temp_file_pk)
17
18 data = kwargs.pop("data", {})
19 data["file"] = PulpTemporaryUploadedFile.from_file(temp_file.file)
20
21 general_create(app_label, serializer_name, data=data, *args, **kwargs)
22 temp_file.delete()
23
24
25 def general_create(app_label, serializer_name, *args, **kwargs):
26 """
27 Create a model instance.
28
29 Raises:
30 ValidationError: If the serializer is not valid
31
32 """
33 data = kwargs.pop("data", None)
34 context = kwargs.pop("context", {})
35 serializer_class = get_plugin_config(app_label).named_serializers[serializer_name]
36 serializer = serializer_class(data=data, context=context)
37 serializer.is_valid(raise_exception=True)
38 serializer.save()
39 instance = serializer_class.Meta.model.objects.get(pk=serializer.instance.pk).cast()
40 resource = CreatedResource(content_object=instance)
41 resource.save()
42
43
44 def general_update(instance_id, app_label, serializer_name, *args, **kwargs):
45 """
46 Update a model
47
48 The model instance is identified using the app_label, id, and serializer name. The serializer is
49 used to perform validation.
50
51 Args:
52 id (str): the id of the model
53 app_label (str): the Django app label of the plugin that provides the model
54 serializer_name (str): name of the serializer class for the model
55 data (dict): dictionary whose keys represent the fields of the model and their corresponding
56 values.
57 partial (bool): When true, only the fields specified in the data dictionary are updated.
58 When false, any fields missing from the data dictionary are assumed to be None and
59 their values are updated as such.
60
61 Raises:
62 :class:`rest_framework.exceptions.ValidationError`: When serializer instance can't be saved
63 due to validation error. This theoretically should never occur since validation is
64 performed before the task is dispatched.
65 """
66 data = kwargs.pop("data", None)
67 partial = kwargs.pop("partial", False)
68 serializer_class = get_plugin_config(app_label).named_serializers[serializer_name]
69 instance = serializer_class.Meta.model.objects.get(pk=instance_id).cast()
70 serializer = serializer_class(instance, data=data, partial=partial)
71 serializer.is_valid(raise_exception=True)
72 serializer.save()
73
74
75 def general_delete(instance_id, app_label, serializer_name):
76 """
77 Delete a model
78
79 The model instance is identified using the app_label, id, and serializer name.
80
81 Args:
82 id (str): the id of the model
83 app_label (str): the Django app label of the plugin that provides the model
84 serializer_name (str): name of the serializer class for the model
85 """
86 serializer_class = get_plugin_config(app_label).named_serializers[serializer_name]
87 instance = serializer_class.Meta.model.objects.get(pk=instance_id).cast()
88 instance.delete()
89
90
91 def general_multi_delete(instance_ids):
92 """
93 Delete a list of model instances in a transaction
94
95 The model instances are identified using the id, app_label, and serializer_name.
96
97 Args:
98 instance_ids (list): List of tupels of id, app_label, serializer_name
99 """
100 instances = []
101 for instance_id, app_label, serializer_name in instance_ids:
102 serializer_class = get_plugin_config(app_label).named_serializers[serializer_name]
103 instance = serializer_class.Meta.model.objects.get(pk=instance_id)
104 if isinstance(instance, MasterModel):
105 instance = instance.cast()
106 instances.append(instance)
107 with transaction.atomic():
108 for instance in instances:
109 instance.delete()
110
[end of pulpcore/app/tasks/base.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pulpcore/app/tasks/base.py b/pulpcore/app/tasks/base.py
--- a/pulpcore/app/tasks/base.py
+++ b/pulpcore/app/tasks/base.py
@@ -35,8 +35,7 @@
serializer_class = get_plugin_config(app_label).named_serializers[serializer_name]
serializer = serializer_class(data=data, context=context)
serializer.is_valid(raise_exception=True)
- serializer.save()
- instance = serializer_class.Meta.model.objects.get(pk=serializer.instance.pk).cast()
+ instance = serializer.save().cast()
resource = CreatedResource(content_object=instance)
resource.save()
|
{"golden_diff": "diff --git a/pulpcore/app/tasks/base.py b/pulpcore/app/tasks/base.py\n--- a/pulpcore/app/tasks/base.py\n+++ b/pulpcore/app/tasks/base.py\n@@ -35,8 +35,7 @@\n serializer_class = get_plugin_config(app_label).named_serializers[serializer_name]\n serializer = serializer_class(data=data, context=context)\n serializer.is_valid(raise_exception=True)\n- serializer.save()\n- instance = serializer_class.Meta.model.objects.get(pk=serializer.instance.pk).cast()\n+ instance = serializer.save().cast()\n resource = CreatedResource(content_object=instance)\n resource.save()\n", "issue": "general_create performes one unnecessary db lookup\n`Serializer.save()` returns the instance we want already. No need to fetch it again from the db.\n", "before_files": [{"content": "from django.db import transaction\n\nfrom pulpcore.app.apps import get_plugin_config\nfrom pulpcore.app.models import CreatedResource, PulpTemporaryFile\nfrom pulpcore.app.files import PulpTemporaryUploadedFile\nfrom pulpcore.plugin.models import MasterModel\n\n\ndef general_create_from_temp_file(app_label, serializer_name, temp_file_pk, *args, **kwargs):\n \"\"\"\n Create a model instance from contents stored in a temporary file.\n\n A task which executes this function takes the ownership of a temporary file and deletes it\n afterwards. This function calls the function general_create() to create a model instance.\n \"\"\"\n temp_file = PulpTemporaryFile.objects.get(pk=temp_file_pk)\n\n data = kwargs.pop(\"data\", {})\n data[\"file\"] = PulpTemporaryUploadedFile.from_file(temp_file.file)\n\n general_create(app_label, serializer_name, data=data, *args, **kwargs)\n temp_file.delete()\n\n\ndef general_create(app_label, serializer_name, *args, **kwargs):\n \"\"\"\n Create a model instance.\n\n Raises:\n ValidationError: If the serializer is not valid\n\n \"\"\"\n data = kwargs.pop(\"data\", None)\n context = kwargs.pop(\"context\", {})\n serializer_class = get_plugin_config(app_label).named_serializers[serializer_name]\n serializer = serializer_class(data=data, context=context)\n serializer.is_valid(raise_exception=True)\n serializer.save()\n instance = serializer_class.Meta.model.objects.get(pk=serializer.instance.pk).cast()\n resource = CreatedResource(content_object=instance)\n resource.save()\n\n\ndef general_update(instance_id, app_label, serializer_name, *args, **kwargs):\n \"\"\"\n Update a model\n\n The model instance is identified using the app_label, id, and serializer name. The serializer is\n used to perform validation.\n\n Args:\n id (str): the id of the model\n app_label (str): the Django app label of the plugin that provides the model\n serializer_name (str): name of the serializer class for the model\n data (dict): dictionary whose keys represent the fields of the model and their corresponding\n values.\n partial (bool): When true, only the fields specified in the data dictionary are updated.\n When false, any fields missing from the data dictionary are assumed to be None and\n their values are updated as such.\n\n Raises:\n :class:`rest_framework.exceptions.ValidationError`: When serializer instance can't be saved\n due to validation error. This theoretically should never occur since validation is\n performed before the task is dispatched.\n \"\"\"\n data = kwargs.pop(\"data\", None)\n partial = kwargs.pop(\"partial\", False)\n serializer_class = get_plugin_config(app_label).named_serializers[serializer_name]\n instance = serializer_class.Meta.model.objects.get(pk=instance_id).cast()\n serializer = serializer_class(instance, data=data, partial=partial)\n serializer.is_valid(raise_exception=True)\n serializer.save()\n\n\ndef general_delete(instance_id, app_label, serializer_name):\n \"\"\"\n Delete a model\n\n The model instance is identified using the app_label, id, and serializer name.\n\n Args:\n id (str): the id of the model\n app_label (str): the Django app label of the plugin that provides the model\n serializer_name (str): name of the serializer class for the model\n \"\"\"\n serializer_class = get_plugin_config(app_label).named_serializers[serializer_name]\n instance = serializer_class.Meta.model.objects.get(pk=instance_id).cast()\n instance.delete()\n\n\ndef general_multi_delete(instance_ids):\n \"\"\"\n Delete a list of model instances in a transaction\n\n The model instances are identified using the id, app_label, and serializer_name.\n\n Args:\n instance_ids (list): List of tupels of id, app_label, serializer_name\n \"\"\"\n instances = []\n for instance_id, app_label, serializer_name in instance_ids:\n serializer_class = get_plugin_config(app_label).named_serializers[serializer_name]\n instance = serializer_class.Meta.model.objects.get(pk=instance_id)\n if isinstance(instance, MasterModel):\n instance = instance.cast()\n instances.append(instance)\n with transaction.atomic():\n for instance in instances:\n instance.delete()\n", "path": "pulpcore/app/tasks/base.py"}]}
| 1,687 | 136 |
gh_patches_debug_17239
|
rasdani/github-patches
|
git_diff
|
OCA__server-tools-18
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bug] mass_editing - Search in ir.model.fields not working
I setup the mass_editing for res.partner then i go to:
Settings -> Technical -> Database Structure -> Fields
and go to the Filter with ('model_id','=',61) where 61 is the id of res.partner in res.model. By typ "res.partner" and select "Partner" from the suggestion.
Then i get the following error:
File "[..]/mass_editing/mass_editing.py", line 34, in search
model_domain += [('model_id', 'in', map(int, domain[2][1:-1].split(',')))]
TypeError: 'int' object has no attribute '**getitem**'
</issue>
<code>
[start of mass_editing/models/ir_model_fields.py]
1 # -*- coding: utf-8 -*-
2 ##############################################################################
3 #
4 # This module uses OpenERP, Open Source Management Solution Framework.
5 # Copyright (C):
6 # 2012-Today Serpent Consulting Services (<http://www.serpentcs.com>)
7 #
8 # This program is free software: you can redistribute it and/or modify
9 # it under the terms of the GNU General Public License as published by
10 # the Free Software Foundation, either version 3 of the License, or
11 # (at your option) any later version.
12 #
13 # This program is distributed in the hope that it will be useful,
14 # but WITHOUT ANY WARRANTY; without even the implied warranty of
15 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
16 # GNU General Public License for more details.
17 #
18 # You should have received a copy of the GNU General Public License
19 # along with this program. If not, see <http://www.gnu.org/licenses/>
20 #
21 ##############################################################################
22
23 from openerp.osv import orm
24
25
26 class IrModelFields(orm.Model):
27 _inherit = 'ir.model.fields'
28
29 def search(
30 self, cr, uid, args, offset=0, limit=0, order=None, context=None,
31 count=False):
32 model_domain = []
33 for domain in args:
34 if domain[0] == 'model_id' and domain[2]\
35 and type(domain[2]) != list:
36 model_domain += [(
37 'model_id', 'in', map(int, domain[2][1:-1].split(',')))]
38 else:
39 model_domain.append(domain)
40 return super(IrModelFields, self).search(
41 cr, uid, model_domain, offset=offset, limit=limit, order=order,
42 context=context, count=count)
43
[end of mass_editing/models/ir_model_fields.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mass_editing/models/ir_model_fields.py b/mass_editing/models/ir_model_fields.py
--- a/mass_editing/models/ir_model_fields.py
+++ b/mass_editing/models/ir_model_fields.py
@@ -31,12 +31,14 @@
count=False):
model_domain = []
for domain in args:
- if domain[0] == 'model_id' and domain[2]\
- and type(domain[2]) != list:
- model_domain += [(
- 'model_id', 'in', map(int, domain[2][1:-1].split(',')))]
+ if (len(domain) > 2 and domain[0] == 'model_id'
+ and isinstance(domain[2], basestring)):
+ model_domain += [
+ ('model_id', 'in', map(int, domain[2][1:-1].split(',')))
+ ]
else:
model_domain.append(domain)
return super(IrModelFields, self).search(
cr, uid, model_domain, offset=offset, limit=limit, order=order,
- context=context, count=count)
+ context=context, count=count
+ )
|
{"golden_diff": "diff --git a/mass_editing/models/ir_model_fields.py b/mass_editing/models/ir_model_fields.py\n--- a/mass_editing/models/ir_model_fields.py\n+++ b/mass_editing/models/ir_model_fields.py\n@@ -31,12 +31,14 @@\n count=False):\n model_domain = []\n for domain in args:\n- if domain[0] == 'model_id' and domain[2]\\\n- and type(domain[2]) != list:\n- model_domain += [(\n- 'model_id', 'in', map(int, domain[2][1:-1].split(',')))]\n+ if (len(domain) > 2 and domain[0] == 'model_id'\n+ and isinstance(domain[2], basestring)):\n+ model_domain += [\n+ ('model_id', 'in', map(int, domain[2][1:-1].split(',')))\n+ ]\n else:\n model_domain.append(domain)\n return super(IrModelFields, self).search(\n cr, uid, model_domain, offset=offset, limit=limit, order=order,\n- context=context, count=count)\n+ context=context, count=count\n+ )\n", "issue": "[Bug] mass_editing - Search in ir.model.fields not working\nI setup the mass_editing for res.partner then i go to:\nSettings -> Technical -> Database Structure -> Fields\nand go to the Filter with ('model_id','=',61) where 61 is the id of res.partner in res.model. By typ \"res.partner\" and select \"Partner\" from the suggestion.\n\nThen i get the following error:\nFile \"[..]/mass_editing/mass_editing.py\", line 34, in search\n model_domain += [('model_id', 'in', map(int, domain[2][1:-1].split(',')))]\nTypeError: 'int' object has no attribute '**getitem**'\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n##############################################################################\n#\n# This module uses OpenERP, Open Source Management Solution Framework.\n# Copyright (C):\n# 2012-Today Serpent Consulting Services (<http://www.serpentcs.com>)\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this program. If not, see <http://www.gnu.org/licenses/>\n#\n##############################################################################\n\nfrom openerp.osv import orm\n\n\nclass IrModelFields(orm.Model):\n _inherit = 'ir.model.fields'\n\n def search(\n self, cr, uid, args, offset=0, limit=0, order=None, context=None,\n count=False):\n model_domain = []\n for domain in args:\n if domain[0] == 'model_id' and domain[2]\\\n and type(domain[2]) != list:\n model_domain += [(\n 'model_id', 'in', map(int, domain[2][1:-1].split(',')))]\n else:\n model_domain.append(domain)\n return super(IrModelFields, self).search(\n cr, uid, model_domain, offset=offset, limit=limit, order=order,\n context=context, count=count)\n", "path": "mass_editing/models/ir_model_fields.py"}]}
| 1,151 | 265 |
gh_patches_debug_27276
|
rasdani/github-patches
|
git_diff
|
sql-machine-learning__elasticdl-1393
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[PS-1] RPC service `pull_variable` implementation
</issue>
<code>
[start of elasticdl/python/ps/servicer.py]
1 import threading
2
3 from google.protobuf import empty_pb2
4
5 from elasticdl.proto import elasticdl_pb2, elasticdl_pb2_grpc
6
7
8 class PserverServicer(elasticdl_pb2_grpc.PserverServicer):
9 """PS service implementation"""
10
11 def __init__(
12 self,
13 parameters,
14 grads_to_wait,
15 optimizer,
16 lr_staleness_modulation=False,
17 use_async=False,
18 ):
19 self._parameters = parameters
20 self._grads_to_wait = grads_to_wait
21 self._optimizer = optimizer
22 self._lr_staleness_modulation = lr_staleness_modulation
23 self._use_async = use_async
24 self._version = 0
25 self._lock = threading.Lock()
26
27 def pull_variable(self, request, _):
28 # TODO: implement this RPC service
29 return elasticdl_pb2.PullVariableResponse()
30
31 def pull_embedding_vector(self, request, _):
32 # TODO: implement this RPC service
33 return elasticdl_pb2.Tensor()
34
35 def push_model(self, request, _):
36 with self._lock:
37 self._parameters.init_from_model_pb(request)
38 return empty_pb2.Empty()
39
40 def push_gradient(self, request, _):
41 # TODO: implement this RPC service
42 return elasticdl_pb2.PushGradientResponse()
43
[end of elasticdl/python/ps/servicer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/elasticdl/python/ps/servicer.py b/elasticdl/python/ps/servicer.py
--- a/elasticdl/python/ps/servicer.py
+++ b/elasticdl/python/ps/servicer.py
@@ -3,6 +3,7 @@
from google.protobuf import empty_pb2
from elasticdl.proto import elasticdl_pb2, elasticdl_pb2_grpc
+from elasticdl.python.common.dtypes import dtype_numpy_to_tensor
class PserverServicer(elasticdl_pb2_grpc.PserverServicer):
@@ -25,8 +26,30 @@
self._lock = threading.Lock()
def pull_variable(self, request, _):
- # TODO: implement this RPC service
- return elasticdl_pb2.PullVariableResponse()
+ """
+ Response with all non-embedding parameters if initialized.
+ """
+ res = elasticdl_pb2.PullVariableResponse()
+ if not self._parameters.init_status:
+ res.model_init_status = False
+ return res
+
+ # Only sync-SGD needs lock
+ # TODO: use a read-write lock to support multiple concurrent reads
+ if not self._use_async:
+ self._lock.acquire()
+ res.model.version = self._parameters.version
+ for name, var in self._parameters.non_embedding_params.items():
+ tensor = res.model.param.add()
+ tensor.name = name
+ tensor.dim.extend(var.shape.as_list())
+ var_values = var.numpy()
+ tensor.content = var_values.tobytes()
+ tensor.dtype = dtype_numpy_to_tensor(var_values.dtype)
+ if not self._use_async:
+ self._lock.release()
+ res.model_init_status = True
+ return res
def pull_embedding_vector(self, request, _):
# TODO: implement this RPC service
|
{"golden_diff": "diff --git a/elasticdl/python/ps/servicer.py b/elasticdl/python/ps/servicer.py\n--- a/elasticdl/python/ps/servicer.py\n+++ b/elasticdl/python/ps/servicer.py\n@@ -3,6 +3,7 @@\n from google.protobuf import empty_pb2\n \n from elasticdl.proto import elasticdl_pb2, elasticdl_pb2_grpc\n+from elasticdl.python.common.dtypes import dtype_numpy_to_tensor\n \n \n class PserverServicer(elasticdl_pb2_grpc.PserverServicer):\n@@ -25,8 +26,30 @@\n self._lock = threading.Lock()\n \n def pull_variable(self, request, _):\n- # TODO: implement this RPC service\n- return elasticdl_pb2.PullVariableResponse()\n+ \"\"\"\n+ Response with all non-embedding parameters if initialized.\n+ \"\"\"\n+ res = elasticdl_pb2.PullVariableResponse()\n+ if not self._parameters.init_status:\n+ res.model_init_status = False\n+ return res\n+\n+ # Only sync-SGD needs lock\n+ # TODO: use a read-write lock to support multiple concurrent reads\n+ if not self._use_async:\n+ self._lock.acquire()\n+ res.model.version = self._parameters.version\n+ for name, var in self._parameters.non_embedding_params.items():\n+ tensor = res.model.param.add()\n+ tensor.name = name\n+ tensor.dim.extend(var.shape.as_list())\n+ var_values = var.numpy()\n+ tensor.content = var_values.tobytes()\n+ tensor.dtype = dtype_numpy_to_tensor(var_values.dtype)\n+ if not self._use_async:\n+ self._lock.release()\n+ res.model_init_status = True\n+ return res\n \n def pull_embedding_vector(self, request, _):\n # TODO: implement this RPC service\n", "issue": "[PS-1] RPC service `pull_variable` implementation\n\n", "before_files": [{"content": "import threading\n\nfrom google.protobuf import empty_pb2\n\nfrom elasticdl.proto import elasticdl_pb2, elasticdl_pb2_grpc\n\n\nclass PserverServicer(elasticdl_pb2_grpc.PserverServicer):\n \"\"\"PS service implementation\"\"\"\n\n def __init__(\n self,\n parameters,\n grads_to_wait,\n optimizer,\n lr_staleness_modulation=False,\n use_async=False,\n ):\n self._parameters = parameters\n self._grads_to_wait = grads_to_wait\n self._optimizer = optimizer\n self._lr_staleness_modulation = lr_staleness_modulation\n self._use_async = use_async\n self._version = 0\n self._lock = threading.Lock()\n\n def pull_variable(self, request, _):\n # TODO: implement this RPC service\n return elasticdl_pb2.PullVariableResponse()\n\n def pull_embedding_vector(self, request, _):\n # TODO: implement this RPC service\n return elasticdl_pb2.Tensor()\n\n def push_model(self, request, _):\n with self._lock:\n self._parameters.init_from_model_pb(request)\n return empty_pb2.Empty()\n\n def push_gradient(self, request, _):\n # TODO: implement this RPC service\n return elasticdl_pb2.PushGradientResponse()\n", "path": "elasticdl/python/ps/servicer.py"}]}
| 916 | 404 |
gh_patches_debug_26256
|
rasdani/github-patches
|
git_diff
|
koxudaxi__datamodel-code-generator-8
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Use `Optional` for nullable fields?
If a field is `nullable` (https://swagger.io/docs/specification/data-models/data-types/#null) use the `Optional` type hint (https://pydantic-docs.helpmanual.io/#pep-484-types)
</issue>
<code>
[start of datamodel_code_generator/__main__.py]
1 #! /usr/bin/env python
2
3 """
4 Main function.
5 """
6
7 import os
8 import sys
9 from argparse import ArgumentParser, FileType
10 from enum import IntEnum
11 from typing import Optional, Sequence
12
13 import argcomplete
14
15 from datamodel_code_generator.model import BaseModel, DataModelField
16 from datamodel_code_generator.parser.openapi import Parser
17
18
19 class Exit(IntEnum):
20 """Exit reasons."""
21
22 OK = 0
23 ERROR = 1
24
25
26 arg_parser = ArgumentParser()
27 arg_parser.add_argument("--input", help="Open API YAML file")
28 arg_parser.add_argument("--output", help="Output file", type=FileType("wt"), default=sys.stdout)
29
30
31 def main(args: Optional[Sequence[str]] = None) -> Exit:
32 """Main function."""
33
34 # add cli completion support
35 argcomplete.autocomplete(arg_parser)
36
37 if args is None:
38 args = sys.argv[1:]
39
40 args = arg_parser.parse_args(args)
41
42 input_filename = os.path.abspath(os.path.expanduser(args.input))
43 parser = Parser(BaseModel, DataModelField, filename=input_filename)
44 with args.output as file:
45 parser.parse(file)
46 print(parser.parse(), file=file)
47
48 return Exit.OK
49
50
51 if __name__ == "__main__":
52 sys.exit(main())
53
[end of datamodel_code_generator/__main__.py]
[start of datamodel_code_generator/parser/openapi.py]
1 from dataclasses import Field, dataclass
2 from typing import Dict, List, Optional, Set, Type, Union
3
4 from prance import BaseParser, ResolvingParser
5
6 from ..model import CustomRootType, DataModel, DataModelField
7 from ..model.base import TemplateBase
8
9
10 @dataclass
11 class DataType:
12 type_hint: str
13 format: Optional[str] = None
14 default: Optional[Field] = None
15
16
17 data_types: Dict[str, Dict[str, DataType]] = {
18 # https://docs.python.org/3.7/library/json.html#encoders-and-decoders
19 'integer':
20 {
21 'int32': DataType(type_hint='int'),
22 'int64': DataType(type_hint='int')
23 },
24 'number':
25 {
26 'float': DataType(type_hint='float'),
27 'double': DataType(type_hint='float')
28 },
29 'string':
30 {'default': DataType(type_hint='str'),
31 'byte': DataType(type_hint='str'),
32 'binary': DataType(type_hint='bytes')
33 },
34 # 'data': date,}, #As defined by full-date - RFC3339
35 'boolean': {'default': DataType(type_hint='bool')}
36 }
37
38
39 def get_data_type(_type, format =None) -> DataType:
40 _format: str = format or 'default'
41 return data_types[_type][_format]
42
43
44 def dump_templates(templates: Union[TemplateBase, List[TemplateBase]]) -> str:
45 if isinstance(templates, TemplateBase):
46 templates = [templates]
47 return '\n\n'.join(str(m) for m in templates)
48
49
50 class Parser:
51 def __init__(self, data_model_type: Type[DataModel], data_model_field_type: Type[DataModelField],
52 filename: str = "api.yaml"):
53 self.base_parser = BaseParser(filename, backend='openapi-spec-validator')
54 self.resolving_parser = ResolvingParser(filename, backend='openapi-spec-validator')
55
56 self.data_model_type: Type[DataModel] = data_model_type
57 self.data_model_field_type: Type[DataModelField] = data_model_field_type
58 self.models = []
59
60 def parse_object(self, name: str, obj: Dict) -> str:
61 requires: Set[str] = set(obj.get('required', []))
62 d_list: List[DataModelField] = []
63 for field_name, filed in obj['properties'].items():
64 # object
65 d_list.append(self.data_model_field_type(
66 name=field_name, type_hint=get_data_type(filed["type"],
67 filed.get("format")).type_hint,
68 required=field_name in requires))
69 return dump_templates(self.data_model_type(name, fields=d_list))
70
71 def parse_array(self, name: str, obj: Dict) -> str:
72 templates: List[TemplateBase] = []
73 # continue
74 if '$ref' in obj['items']:
75 _type: str = f"List[{obj['items']['$ref'].split('/')[-1]}]"
76 templates.append(CustomRootType(name, _type))
77 elif 'properties' in obj['items']:
78 self.parse_object(name[:-1], obj['items'])
79 templates.append(CustomRootType(name, f'List[{name[:-1]}]'))
80 return dump_templates(templates)
81
82 def parse(self) -> str:
83 parsed_objects: List[str] = []
84 for obj_name, obj in self.base_parser.specification['components']['schemas'].items():
85 if 'properties' in obj:
86 parsed_objects.append(self.parse_object(obj_name, obj))
87 elif 'items' in obj:
88 parsed_objects.append(self.parse_array(obj_name, obj))
89
90 return '\n\n\n'.join(parsed_objects)
91
[end of datamodel_code_generator/parser/openapi.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/datamodel_code_generator/__main__.py b/datamodel_code_generator/__main__.py
--- a/datamodel_code_generator/__main__.py
+++ b/datamodel_code_generator/__main__.py
@@ -7,6 +7,7 @@
import os
import sys
from argparse import ArgumentParser, FileType
+from datetime import datetime, timezone
from enum import IntEnum
from typing import Optional, Sequence
@@ -41,8 +42,20 @@
input_filename = os.path.abspath(os.path.expanduser(args.input))
parser = Parser(BaseModel, DataModelField, filename=input_filename)
+ timestamp = datetime.now(timezone.utc).replace(microsecond=0).isoformat()
+ header = f"""\
+# generated by datamodel-codegen:
+# filename: {os.path.split(input_filename)[1]}
+# timestamp: {timestamp}
+
+from typing import List, Optional
+
+from pydantic import BaseModel
+
+
+"""
with args.output as file:
- parser.parse(file)
+ print(header, file=file)
print(parser.parse(), file=file)
return Exit.OK
diff --git a/datamodel_code_generator/parser/openapi.py b/datamodel_code_generator/parser/openapi.py
--- a/datamodel_code_generator/parser/openapi.py
+++ b/datamodel_code_generator/parser/openapi.py
@@ -1,6 +1,6 @@
-from dataclasses import Field, dataclass
from typing import Dict, List, Optional, Set, Type, Union
+from dataclasses import Field, dataclass
from prance import BaseParser, ResolvingParser
from ..model import CustomRootType, DataModel, DataModelField
|
{"golden_diff": "diff --git a/datamodel_code_generator/__main__.py b/datamodel_code_generator/__main__.py\n--- a/datamodel_code_generator/__main__.py\n+++ b/datamodel_code_generator/__main__.py\n@@ -7,6 +7,7 @@\n import os\n import sys\n from argparse import ArgumentParser, FileType\n+from datetime import datetime, timezone\n from enum import IntEnum\n from typing import Optional, Sequence\n \n@@ -41,8 +42,20 @@\n \n input_filename = os.path.abspath(os.path.expanduser(args.input))\n parser = Parser(BaseModel, DataModelField, filename=input_filename)\n+ timestamp = datetime.now(timezone.utc).replace(microsecond=0).isoformat()\n+ header = f\"\"\"\\\n+# generated by datamodel-codegen:\n+# filename: {os.path.split(input_filename)[1]}\n+# timestamp: {timestamp}\n+\n+from typing import List, Optional\n+\n+from pydantic import BaseModel\n+\n+\n+\"\"\"\n with args.output as file:\n- parser.parse(file)\n+ print(header, file=file)\n print(parser.parse(), file=file)\n \n return Exit.OK\ndiff --git a/datamodel_code_generator/parser/openapi.py b/datamodel_code_generator/parser/openapi.py\n--- a/datamodel_code_generator/parser/openapi.py\n+++ b/datamodel_code_generator/parser/openapi.py\n@@ -1,6 +1,6 @@\n-from dataclasses import Field, dataclass\n from typing import Dict, List, Optional, Set, Type, Union\n \n+from dataclasses import Field, dataclass\n from prance import BaseParser, ResolvingParser\n \n from ..model import CustomRootType, DataModel, DataModelField\n", "issue": "Use `Optional` for nullable fields?\nIf a field is `nullable` (https://swagger.io/docs/specification/data-models/data-types/#null) use the `Optional` type hint (https://pydantic-docs.helpmanual.io/#pep-484-types)\n", "before_files": [{"content": "#! /usr/bin/env python\n\n\"\"\"\nMain function.\n\"\"\"\n\nimport os\nimport sys\nfrom argparse import ArgumentParser, FileType\nfrom enum import IntEnum\nfrom typing import Optional, Sequence\n\nimport argcomplete\n\nfrom datamodel_code_generator.model import BaseModel, DataModelField\nfrom datamodel_code_generator.parser.openapi import Parser\n\n\nclass Exit(IntEnum):\n \"\"\"Exit reasons.\"\"\"\n\n OK = 0\n ERROR = 1\n\n\narg_parser = ArgumentParser()\narg_parser.add_argument(\"--input\", help=\"Open API YAML file\")\narg_parser.add_argument(\"--output\", help=\"Output file\", type=FileType(\"wt\"), default=sys.stdout)\n\n\ndef main(args: Optional[Sequence[str]] = None) -> Exit:\n \"\"\"Main function.\"\"\"\n\n # add cli completion support\n argcomplete.autocomplete(arg_parser)\n\n if args is None:\n args = sys.argv[1:]\n\n args = arg_parser.parse_args(args)\n\n input_filename = os.path.abspath(os.path.expanduser(args.input))\n parser = Parser(BaseModel, DataModelField, filename=input_filename)\n with args.output as file:\n parser.parse(file)\n print(parser.parse(), file=file)\n\n return Exit.OK\n\n\nif __name__ == \"__main__\":\n sys.exit(main())\n", "path": "datamodel_code_generator/__main__.py"}, {"content": "from dataclasses import Field, dataclass\nfrom typing import Dict, List, Optional, Set, Type, Union\n\nfrom prance import BaseParser, ResolvingParser\n\nfrom ..model import CustomRootType, DataModel, DataModelField\nfrom ..model.base import TemplateBase\n\n\n@dataclass\nclass DataType:\n type_hint: str\n format: Optional[str] = None\n default: Optional[Field] = None\n\n\ndata_types: Dict[str, Dict[str, DataType]] = {\n # https://docs.python.org/3.7/library/json.html#encoders-and-decoders\n 'integer':\n {\n 'int32': DataType(type_hint='int'),\n 'int64': DataType(type_hint='int')\n },\n 'number':\n {\n 'float': DataType(type_hint='float'),\n 'double': DataType(type_hint='float')\n },\n 'string':\n {'default': DataType(type_hint='str'),\n 'byte': DataType(type_hint='str'),\n 'binary': DataType(type_hint='bytes')\n },\n # 'data': date,}, #As defined by full-date - RFC3339\n 'boolean': {'default': DataType(type_hint='bool')}\n}\n\n\ndef get_data_type(_type, format =None) -> DataType:\n _format: str = format or 'default'\n return data_types[_type][_format]\n\n\ndef dump_templates(templates: Union[TemplateBase, List[TemplateBase]]) -> str:\n if isinstance(templates, TemplateBase):\n templates = [templates]\n return '\\n\\n'.join(str(m) for m in templates)\n\n\nclass Parser:\n def __init__(self, data_model_type: Type[DataModel], data_model_field_type: Type[DataModelField],\n filename: str = \"api.yaml\"):\n self.base_parser = BaseParser(filename, backend='openapi-spec-validator')\n self.resolving_parser = ResolvingParser(filename, backend='openapi-spec-validator')\n\n self.data_model_type: Type[DataModel] = data_model_type\n self.data_model_field_type: Type[DataModelField] = data_model_field_type\n self.models = []\n\n def parse_object(self, name: str, obj: Dict) -> str:\n requires: Set[str] = set(obj.get('required', []))\n d_list: List[DataModelField] = []\n for field_name, filed in obj['properties'].items():\n # object\n d_list.append(self.data_model_field_type(\n name=field_name, type_hint=get_data_type(filed[\"type\"],\n filed.get(\"format\")).type_hint,\n required=field_name in requires))\n return dump_templates(self.data_model_type(name, fields=d_list))\n\n def parse_array(self, name: str, obj: Dict) -> str:\n templates: List[TemplateBase] = []\n # continue\n if '$ref' in obj['items']:\n _type: str = f\"List[{obj['items']['$ref'].split('/')[-1]}]\"\n templates.append(CustomRootType(name, _type))\n elif 'properties' in obj['items']:\n self.parse_object(name[:-1], obj['items'])\n templates.append(CustomRootType(name, f'List[{name[:-1]}]'))\n return dump_templates(templates)\n\n def parse(self) -> str:\n parsed_objects: List[str] = []\n for obj_name, obj in self.base_parser.specification['components']['schemas'].items():\n if 'properties' in obj:\n parsed_objects.append(self.parse_object(obj_name, obj))\n elif 'items' in obj:\n parsed_objects.append(self.parse_array(obj_name, obj))\n\n return '\\n\\n\\n'.join(parsed_objects)\n", "path": "datamodel_code_generator/parser/openapi.py"}]}
| 1,965 | 360 |
gh_patches_debug_39482
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-center-index-1773
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[package] date/2.4.1: header_only option
Please add a header_only option to 'date' recipe.
</issue>
<code>
[start of recipes/date/all/conanfile.py]
1 import os
2 from conans import ConanFile, CMake, tools
3
4
5 class DateConan(ConanFile):
6 name = "date"
7 url = "https://github.com/conan-io/conan-center-index"
8 homepage = "https://github.com/HowardHinnant/date"
9 description = "A date and time library based on the C++11/14/17 <chrono> header"
10 topics = ("date", "datetime", "timezone",
11 "calendar", "time", "iana-database")
12 license = "MIT"
13 exports_sources = ["patches/*", "CMakeLists.txt"]
14 settings = "os", "arch", "compiler", "build_type"
15 generators = "cmake",
16 options = {"shared": [True, False],
17 "fPIC": [True, False],
18 "use_system_tz_db": [True, False],
19 "use_tz_db_in_dot": [True, False]}
20 default_options = {"shared": False,
21 "fPIC": True,
22 "use_system_tz_db": False,
23 "use_tz_db_in_dot": False}
24
25 _cmake = None
26
27 @property
28 def _source_subfolder(self):
29 return "source_subfolder"
30 @property
31 def _build_subfolder(self):
32 return "build_subfolder"
33
34 def _configure_cmake(self):
35 if self._cmake:
36 return self._cmake
37 cmake = CMake(self)
38 cmake.definitions["ENABLE_DATE_TESTING"] = False
39 cmake.definitions["USE_SYSTEM_TZ_DB"] = self.options.use_system_tz_db
40 cmake.definitions["USE_TZ_DB_IN_DOT"] = self.options.use_tz_db_in_dot
41 cmake.configure()
42
43 self._cmake = cmake
44 return self._cmake
45
46 def config_options(self):
47 if self.settings.os == "Windows":
48 del self.options.fPIC
49
50 def configure(self):
51 if self.settings.compiler.cppstd:
52 tools.check_min_cppstd(self, "11")
53
54 def requirements(self):
55 if not self.options.use_system_tz_db:
56 self.requires("libcurl/7.69.1")
57
58 def source(self):
59 tools.get(**self.conan_data["sources"][self.version])
60 extracted_dir = self.name + "-" + self.version
61 os.rename(extracted_dir, self._source_subfolder)
62
63 def build(self):
64 for patch in self.conan_data["patches"][self.version]:
65 tools.patch(**patch)
66 cmake = self._configure_cmake()
67 cmake.build()
68
69 def package(self):
70 self.copy(pattern="LICENSE.txt", dst="licenses",
71 src=self._source_subfolder)
72 cmake = self._configure_cmake()
73 cmake.install()
74 tools.rmdir(os.path.join(self.package_folder, "lib", "cmake"))
75 tools.rmdir(os.path.join(self.package_folder, "CMake"))
76
77 def package_info(self):
78 self.cpp_info.libs = tools.collect_libs(self)
79 if self.settings.os == "Linux":
80 self.cpp_info.system_libs.append("pthread")
81
82 if self.options.use_system_tz_db and not self.settings.os == "Windows":
83 use_os_tzdb = 1
84 else:
85 use_os_tzdb = 0
86
87 defines = ["USE_OS_TZDB={}".format(use_os_tzdb)]
88 if self.settings.os == "Windows" and self.options.shared:
89 defines.append("DATE_USE_DLL=1")
90
91 self.cpp_info.defines.extend(defines)
92
[end of recipes/date/all/conanfile.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/recipes/date/all/conanfile.py b/recipes/date/all/conanfile.py
--- a/recipes/date/all/conanfile.py
+++ b/recipes/date/all/conanfile.py
@@ -15,10 +15,12 @@
generators = "cmake",
options = {"shared": [True, False],
"fPIC": [True, False],
+ "header_only": [True, False],
"use_system_tz_db": [True, False],
"use_tz_db_in_dot": [True, False]}
default_options = {"shared": False,
"fPIC": True,
+ "header_only": False,
"use_system_tz_db": False,
"use_tz_db_in_dot": False}
@@ -52,6 +54,8 @@
tools.check_min_cppstd(self, "11")
def requirements(self):
+ if self.options.header_only:
+ return
if not self.options.use_system_tz_db:
self.requires("libcurl/7.69.1")
@@ -63,18 +67,34 @@
def build(self):
for patch in self.conan_data["patches"][self.version]:
tools.patch(**patch)
+ if self.options.header_only:
+ self.output.info("Header only package, skipping build")
+ return
cmake = self._configure_cmake()
cmake.build()
def package(self):
self.copy(pattern="LICENSE.txt", dst="licenses",
src=self._source_subfolder)
+ if self.options.header_only:
+ src = os.path.join(self._source_subfolder, "include", "date")
+ dst = os.path.join("include", "date")
+ self.copy(pattern="date.h", dst=dst, src=src)
+ self.copy(pattern="tz.h", dst=dst, src=src)
+ self.copy(pattern="iso_week.h", dst=dst, src=src)
+ self.copy(pattern="julian.h", dst=dst, src=src)
+ self.copy(pattern="islamic.h", dst=dst, src=src)
+ return
+
cmake = self._configure_cmake()
cmake.install()
tools.rmdir(os.path.join(self.package_folder, "lib", "cmake"))
tools.rmdir(os.path.join(self.package_folder, "CMake"))
def package_info(self):
+ if self.options.header_only:
+ return
+
self.cpp_info.libs = tools.collect_libs(self)
if self.settings.os == "Linux":
self.cpp_info.system_libs.append("pthread")
@@ -89,3 +109,7 @@
defines.append("DATE_USE_DLL=1")
self.cpp_info.defines.extend(defines)
+
+ def package_id(self):
+ if self.options.header_only:
+ self.info.header_only()
|
{"golden_diff": "diff --git a/recipes/date/all/conanfile.py b/recipes/date/all/conanfile.py\n--- a/recipes/date/all/conanfile.py\n+++ b/recipes/date/all/conanfile.py\n@@ -15,10 +15,12 @@\n generators = \"cmake\",\n options = {\"shared\": [True, False],\n \"fPIC\": [True, False],\n+ \"header_only\": [True, False],\n \"use_system_tz_db\": [True, False],\n \"use_tz_db_in_dot\": [True, False]}\n default_options = {\"shared\": False,\n \"fPIC\": True,\n+ \"header_only\": False,\n \"use_system_tz_db\": False,\n \"use_tz_db_in_dot\": False}\n \n@@ -52,6 +54,8 @@\n tools.check_min_cppstd(self, \"11\")\n \n def requirements(self):\n+ if self.options.header_only:\n+ return\n if not self.options.use_system_tz_db:\n self.requires(\"libcurl/7.69.1\")\n \n@@ -63,18 +67,34 @@\n def build(self):\n for patch in self.conan_data[\"patches\"][self.version]:\n tools.patch(**patch)\n+ if self.options.header_only:\n+ self.output.info(\"Header only package, skipping build\")\n+ return\n cmake = self._configure_cmake()\n cmake.build()\n \n def package(self):\n self.copy(pattern=\"LICENSE.txt\", dst=\"licenses\",\n src=self._source_subfolder)\n+ if self.options.header_only:\n+ src = os.path.join(self._source_subfolder, \"include\", \"date\")\n+ dst = os.path.join(\"include\", \"date\")\n+ self.copy(pattern=\"date.h\", dst=dst, src=src)\n+ self.copy(pattern=\"tz.h\", dst=dst, src=src)\n+ self.copy(pattern=\"iso_week.h\", dst=dst, src=src)\n+ self.copy(pattern=\"julian.h\", dst=dst, src=src)\n+ self.copy(pattern=\"islamic.h\", dst=dst, src=src)\n+ return\n+\n cmake = self._configure_cmake()\n cmake.install()\n tools.rmdir(os.path.join(self.package_folder, \"lib\", \"cmake\"))\n tools.rmdir(os.path.join(self.package_folder, \"CMake\"))\n \n def package_info(self):\n+ if self.options.header_only:\n+ return\n+\n self.cpp_info.libs = tools.collect_libs(self)\n if self.settings.os == \"Linux\":\n self.cpp_info.system_libs.append(\"pthread\")\n@@ -89,3 +109,7 @@\n defines.append(\"DATE_USE_DLL=1\")\n \n self.cpp_info.defines.extend(defines)\n+\n+ def package_id(self):\n+ if self.options.header_only:\n+ self.info.header_only()\n", "issue": "[package] date/2.4.1: header_only option\nPlease add a header_only option to 'date' recipe.\n", "before_files": [{"content": "import os\nfrom conans import ConanFile, CMake, tools\n\n\nclass DateConan(ConanFile):\n name = \"date\"\n url = \"https://github.com/conan-io/conan-center-index\"\n homepage = \"https://github.com/HowardHinnant/date\"\n description = \"A date and time library based on the C++11/14/17 <chrono> header\"\n topics = (\"date\", \"datetime\", \"timezone\",\n \"calendar\", \"time\", \"iana-database\")\n license = \"MIT\"\n exports_sources = [\"patches/*\", \"CMakeLists.txt\"]\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n generators = \"cmake\",\n options = {\"shared\": [True, False],\n \"fPIC\": [True, False],\n \"use_system_tz_db\": [True, False],\n \"use_tz_db_in_dot\": [True, False]}\n default_options = {\"shared\": False,\n \"fPIC\": True,\n \"use_system_tz_db\": False,\n \"use_tz_db_in_dot\": False}\n\n _cmake = None\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n @property\n def _build_subfolder(self):\n return \"build_subfolder\"\n\n def _configure_cmake(self):\n if self._cmake:\n return self._cmake\n cmake = CMake(self)\n cmake.definitions[\"ENABLE_DATE_TESTING\"] = False\n cmake.definitions[\"USE_SYSTEM_TZ_DB\"] = self.options.use_system_tz_db\n cmake.definitions[\"USE_TZ_DB_IN_DOT\"] = self.options.use_tz_db_in_dot\n cmake.configure()\n\n self._cmake = cmake\n return self._cmake\n\n def config_options(self):\n if self.settings.os == \"Windows\":\n del self.options.fPIC\n\n def configure(self):\n if self.settings.compiler.cppstd:\n tools.check_min_cppstd(self, \"11\")\n\n def requirements(self):\n if not self.options.use_system_tz_db:\n self.requires(\"libcurl/7.69.1\")\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n extracted_dir = self.name + \"-\" + self.version\n os.rename(extracted_dir, self._source_subfolder)\n\n def build(self):\n for patch in self.conan_data[\"patches\"][self.version]:\n tools.patch(**patch)\n cmake = self._configure_cmake()\n cmake.build()\n\n def package(self):\n self.copy(pattern=\"LICENSE.txt\", dst=\"licenses\",\n src=self._source_subfolder)\n cmake = self._configure_cmake()\n cmake.install()\n tools.rmdir(os.path.join(self.package_folder, \"lib\", \"cmake\"))\n tools.rmdir(os.path.join(self.package_folder, \"CMake\"))\n\n def package_info(self):\n self.cpp_info.libs = tools.collect_libs(self)\n if self.settings.os == \"Linux\":\n self.cpp_info.system_libs.append(\"pthread\")\n\n if self.options.use_system_tz_db and not self.settings.os == \"Windows\":\n use_os_tzdb = 1\n else:\n use_os_tzdb = 0\n\n defines = [\"USE_OS_TZDB={}\".format(use_os_tzdb)]\n if self.settings.os == \"Windows\" and self.options.shared:\n defines.append(\"DATE_USE_DLL=1\")\n\n self.cpp_info.defines.extend(defines)\n", "path": "recipes/date/all/conanfile.py"}]}
| 1,507 | 631 |
gh_patches_debug_7814
|
rasdani/github-patches
|
git_diff
|
angr__angr-1703
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Unlink simprocedure missing errno behavior
<!--
*Disclaimer:
The angr suite is maintained by a small team of volunteers.
While we cannot guarantee any timeliness for fixes and enhancements, we will do our best.
For more real-time help with angr, from us and the community, join our [Slack.](http://angr.io/invite/)*
-->
---
**Is your feature request related to a problem? Please describe.**
The unlink() function/syscall can set a diverse range of errno values. The simprocedure version of unlink doesn't model any of them, which causes incorrect execution of programs that use this interface.
The problem I'm specifically having is distinguishing failure because an existing file can't be removed, and failure because there is no file to remove.
**Describe the solution you would like.**
Add relevant errno assignments to the simprocedure. I'm not sure if the simfs function gives enough data to decide which error to return on failure, so its return might need to be augmented, as well.
**Please include a sample of what *should* work if this feature is implemented.**
Currently, the marked branch in the following C code is unreachable:
```
int my_remove() {
if(remove("/foo/bar")) {
if(ERRNO == ENOENT) {
//UNREACHABLE D:
return 0
}
return 1
}
return 0
}
```
**Describe alternatives you have considered.**
Forcing the simfs remove() operation to succeed would make my problem go away, but it doesn't solve the general issue that code reading the errno values after a failure won't work properly.
**Additional context.**
<!--
Add any other context or screenshots about the feature request here.
-->
</issue>
<code>
[start of angr/procedures/linux_kernel/unlink.py]
1 import angr
2
3 ######################################
4 # unlink
5 ######################################
6
7 class unlink(angr.SimProcedure): #pylint:disable=W0622
8 #pylint:disable=arguments-differ
9
10 def run(self, path_addr):
11 # This is a dummy for now
12 strlen = angr.SIM_PROCEDURES['libc']['strlen']
13
14 p_strlen = self.inline_call(strlen, path_addr)
15 str_expr = self.state.memory.load(path_addr, p_strlen.max_null_index, endness='Iend_BE')
16 str_val = self.state.solver.eval(str_expr, cast_to=bytes)
17
18 if self.state.fs.delete(str_val):
19 return 0
20 else:
21 return -1
22
[end of angr/procedures/linux_kernel/unlink.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/angr/procedures/linux_kernel/unlink.py b/angr/procedures/linux_kernel/unlink.py
--- a/angr/procedures/linux_kernel/unlink.py
+++ b/angr/procedures/linux_kernel/unlink.py
@@ -15,6 +15,10 @@
str_expr = self.state.memory.load(path_addr, p_strlen.max_null_index, endness='Iend_BE')
str_val = self.state.solver.eval(str_expr, cast_to=bytes)
+ # Check if entity exists before attempting to unlink
+ if not self.state.fs.get(str_val):
+ return self.state.libc.ret_errno('ENOENT')
+
if self.state.fs.delete(str_val):
return 0
else:
|
{"golden_diff": "diff --git a/angr/procedures/linux_kernel/unlink.py b/angr/procedures/linux_kernel/unlink.py\n--- a/angr/procedures/linux_kernel/unlink.py\n+++ b/angr/procedures/linux_kernel/unlink.py\n@@ -15,6 +15,10 @@\n str_expr = self.state.memory.load(path_addr, p_strlen.max_null_index, endness='Iend_BE')\n str_val = self.state.solver.eval(str_expr, cast_to=bytes)\n \n+ # Check if entity exists before attempting to unlink\n+ if not self.state.fs.get(str_val):\n+ return self.state.libc.ret_errno('ENOENT')\n+\n if self.state.fs.delete(str_val):\n return 0\n else:\n", "issue": "Unlink simprocedure missing errno behavior\n<!--\r\n*Disclaimer:\r\nThe angr suite is maintained by a small team of volunteers.\r\nWhile we cannot guarantee any timeliness for fixes and enhancements, we will do our best.\r\nFor more real-time help with angr, from us and the community, join our [Slack.](http://angr.io/invite/)*\r\n-->\r\n\r\n---\r\n\r\n**Is your feature request related to a problem? Please describe.**\r\nThe unlink() function/syscall can set a diverse range of errno values. The simprocedure version of unlink doesn't model any of them, which causes incorrect execution of programs that use this interface.\r\n\r\nThe problem I'm specifically having is distinguishing failure because an existing file can't be removed, and failure because there is no file to remove.\r\n\r\n**Describe the solution you would like.**\r\nAdd relevant errno assignments to the simprocedure. I'm not sure if the simfs function gives enough data to decide which error to return on failure, so its return might need to be augmented, as well.\r\n\r\n**Please include a sample of what *should* work if this feature is implemented.**\r\nCurrently, the marked branch in the following C code is unreachable:\r\n\r\n```\r\nint my_remove() {\r\n if(remove(\"/foo/bar\")) {\r\n if(ERRNO == ENOENT) {\r\n //UNREACHABLE D:\r\n return 0\r\n }\r\n return 1\r\n }\r\n return 0\r\n}\r\n```\r\n\r\n**Describe alternatives you have considered.**\r\nForcing the simfs remove() operation to succeed would make my problem go away, but it doesn't solve the general issue that code reading the errno values after a failure won't work properly.\r\n\r\n**Additional context.**\r\n<!--\r\nAdd any other context or screenshots about the feature request here.\r\n-->\r\n\n", "before_files": [{"content": "import angr\n\n######################################\n# unlink\n######################################\n\nclass unlink(angr.SimProcedure): #pylint:disable=W0622\n #pylint:disable=arguments-differ\n\n def run(self, path_addr):\n # This is a dummy for now\n strlen = angr.SIM_PROCEDURES['libc']['strlen']\n\n p_strlen = self.inline_call(strlen, path_addr)\n str_expr = self.state.memory.load(path_addr, p_strlen.max_null_index, endness='Iend_BE')\n str_val = self.state.solver.eval(str_expr, cast_to=bytes)\n\n if self.state.fs.delete(str_val):\n return 0\n else:\n return -1\n", "path": "angr/procedures/linux_kernel/unlink.py"}]}
| 1,098 | 162 |
gh_patches_debug_38409
|
rasdani/github-patches
|
git_diff
|
litestar-org__litestar-447
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Enhancement: Support dictConfig in picologging
`picologging` will implement a `dictConfig` with the following PR: https://github.com/microsoft/picologging/issues/53
We should enhance our integration to call this method once it's officially released.
</issue>
<code>
[start of starlite/logging/__init__.py]
1 from logging import config
2 from typing import Any, Dict, List, Optional, Union
3
4 from pydantic import BaseModel
5 from typing_extensions import Literal
6
7 from starlite.logging.standard import QueueListenerHandler
8
9 __all__ = ["LoggingConfig", "QueueListenerHandler"]
10
11
12 class LoggingConfig(BaseModel):
13 """Convenience `pydantic` model for configuring logging.
14
15 For detailed instructions consult [standard library docs](https://docs.python.org/3/library/logging.config.html).
16 """
17
18 version: Literal[1] = 1
19 """The only valid value at present is 1."""
20 incremental: bool = False
21 """Whether the configuration is to be interpreted as incremental to the existing configuration. """
22 disable_existing_loggers: bool = False
23 """Whether any existing non-root loggers are to be disabled."""
24 filters: Optional[Dict[str, Dict[str, Any]]] = None
25 """A dict in which each key is a filter id and each value is a dict describing how to configure the corresponding Filter instance."""
26 propagate: bool = True
27 """If messages must propagate to handlers higher up the logger hierarchy from this logger."""
28 formatters: Dict[str, Dict[str, Any]] = {
29 "standard": {"format": "%(levelname)s - %(asctime)s - %(name)s - %(module)s - %(message)s"}
30 }
31 handlers: Dict[str, Dict[str, Any]] = {
32 "console": {
33 "class": "logging.StreamHandler",
34 "level": "DEBUG",
35 "formatter": "standard",
36 },
37 "queue_listener": {"class": "starlite.QueueListenerHandler", "handlers": ["cfg://handlers.console"]},
38 }
39 """A dict in which each key is a handler id and each value is a dict describing how to configure the corresponding Handler instance."""
40 loggers: Dict[str, Dict[str, Any]] = {
41 "starlite": {
42 "level": "INFO",
43 "handlers": ["queue_listener"],
44 },
45 }
46 """A dict in which each key is a logger name and each value is a dict describing how to configure the corresponding Logger instance."""
47 root: Dict[str, Union[Dict[str, Any], List[Any], str]] = {"handlers": ["queue_listener"], "level": "INFO"}
48 """This will be the configuration for the root logger. Processing of the configuration will be as for any logger,
49 except that the propagate setting will not be applicable."""
50
51 def configure(self) -> None:
52 """Configured logger with the given configuration."""
53 config.dictConfig(self.dict(exclude_none=True))
54
[end of starlite/logging/__init__.py]
[start of starlite/logging/picologging.py]
1 from queue import Queue
2 from typing import Any, List
3
4 from picologging.handlers import QueueHandler, QueueListener
5
6 from starlite.logging.standard import resolve_handlers
7
8
9 class QueueListenerHandler(QueueHandler): # type: ignore
10 def __init__(self, handlers: List[Any], respect_handler_level: bool = False, queue: Queue = Queue(-1)):
11 """Configures queue listener and handler to support non-blocking
12 logging configuration.
13
14 Requires `picologging`, install with:
15 ```shell
16 $ pip install starlite[picologging]
17 ```
18
19 Args:
20 handlers (list): list of handler names.
21 respect_handler_level (bool): A handler’s level is respected (compared with the level for the message) when
22 deciding whether to pass messages to that handler.
23 """
24 super().__init__(queue)
25 self.handlers = resolve_handlers(handlers)
26 self._listener: QueueListener = QueueListener(
27 self.queue, *self.handlers, respect_handler_level=respect_handler_level
28 )
29 self._listener.start()
30
[end of starlite/logging/picologging.py]
[start of starlite/logging/standard.py]
1 from logging.handlers import QueueHandler, QueueListener
2 from queue import Queue
3 from typing import Any, List
4
5
6 class QueueListenerHandler(QueueHandler):
7 """Configures queue listener and handler to support non-blocking logging
8 configuration."""
9
10 def __init__(self, handlers: List[Any], respect_handler_level: bool = False, queue: Queue = Queue(-1)):
11 """Configures queue listener and handler to support non-blocking
12 logging configuration.
13
14 Args:
15 handlers (list): list of handler names.
16 respect_handler_level (bool): A handler’s level is respected (compared with the level for the message) when
17 deciding whether to pass messages to that handler.
18 """
19 super().__init__(queue)
20 self.handlers = resolve_handlers(handlers)
21 self._listener: QueueListener = QueueListener(
22 self.queue, *self.handlers, respect_handler_level=respect_handler_level
23 )
24 self._listener.start()
25
26
27 def resolve_handlers(handlers: List[Any]) -> List[Any]:
28 """Converts list of string of handlers to the object of respective handler.
29
30 Indexing the list performs the evaluation of the object.
31 """
32 return [handlers[i] for i in range(len(handlers))]
33
[end of starlite/logging/standard.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/starlite/logging/__init__.py b/starlite/logging/__init__.py
--- a/starlite/logging/__init__.py
+++ b/starlite/logging/__init__.py
@@ -1,11 +1,16 @@
from logging import config
-from typing import Any, Dict, List, Optional, Union
+from typing import Any, Dict, Generator, Iterable, List, Optional, Union
from pydantic import BaseModel
from typing_extensions import Literal
from starlite.logging.standard import QueueListenerHandler
+try:
+ from picologging import config as picologging_config
+except ImportError:
+ picologging_config = None
+
__all__ = ["LoggingConfig", "QueueListenerHandler"]
@@ -49,5 +54,33 @@
except that the propagate setting will not be applicable."""
def configure(self) -> None:
- """Configured logger with the given configuration."""
+ """Configured logger with the given configuration.
+
+ If the logger class contains the word `picologging`, we try to
+ import and set the dictConfig
+ """
+ for logging_class in find_keys(self.handlers, "class"):
+ if "picologging" in logging_class and picologging_config:
+ picologging_config.dictConfig(self.dict(exclude_none=True))
+ break
config.dictConfig(self.dict(exclude_none=True))
+
+
+def find_keys(node: Union[List, Dict], key: str) -> Generator[Iterable, None, None]:
+ """Find Nested Keys with name
+ Search a dictionary for the presence of key
+ Args:
+ node (Union[List, Dict]): a dictionary to search
+ key (str): the dictionary key to find
+
+ Yields:
+ Generator[Iterable, None, None]: Value of dictionary key
+ """
+ if isinstance(node, list):
+ for list_entry in node:
+ yield from find_keys(list_entry, key)
+ elif isinstance(node, dict):
+ if key in node:
+ yield node[key]
+ for dict_entry in node.values():
+ yield from find_keys(dict_entry, key)
diff --git a/starlite/logging/picologging.py b/starlite/logging/picologging.py
--- a/starlite/logging/picologging.py
+++ b/starlite/logging/picologging.py
@@ -18,7 +18,7 @@
Args:
handlers (list): list of handler names.
- respect_handler_level (bool): A handler’s level is respected (compared with the level for the message) when
+ respect_handler_level (bool): A handler's level is respected (compared with the level for the message) when
deciding whether to pass messages to that handler.
"""
super().__init__(queue)
diff --git a/starlite/logging/standard.py b/starlite/logging/standard.py
--- a/starlite/logging/standard.py
+++ b/starlite/logging/standard.py
@@ -13,7 +13,7 @@
Args:
handlers (list): list of handler names.
- respect_handler_level (bool): A handler’s level is respected (compared with the level for the message) when
+ respect_handler_level (bool): A handler's level is respected (compared with the level for the message) when
deciding whether to pass messages to that handler.
"""
super().__init__(queue)
|
{"golden_diff": "diff --git a/starlite/logging/__init__.py b/starlite/logging/__init__.py\n--- a/starlite/logging/__init__.py\n+++ b/starlite/logging/__init__.py\n@@ -1,11 +1,16 @@\n from logging import config\n-from typing import Any, Dict, List, Optional, Union\n+from typing import Any, Dict, Generator, Iterable, List, Optional, Union\n \n from pydantic import BaseModel\n from typing_extensions import Literal\n \n from starlite.logging.standard import QueueListenerHandler\n \n+try:\n+ from picologging import config as picologging_config\n+except ImportError:\n+ picologging_config = None\n+\n __all__ = [\"LoggingConfig\", \"QueueListenerHandler\"]\n \n \n@@ -49,5 +54,33 @@\n except that the propagate setting will not be applicable.\"\"\"\n \n def configure(self) -> None:\n- \"\"\"Configured logger with the given configuration.\"\"\"\n+ \"\"\"Configured logger with the given configuration.\n+\n+ If the logger class contains the word `picologging`, we try to\n+ import and set the dictConfig\n+ \"\"\"\n+ for logging_class in find_keys(self.handlers, \"class\"):\n+ if \"picologging\" in logging_class and picologging_config:\n+ picologging_config.dictConfig(self.dict(exclude_none=True))\n+ break\n config.dictConfig(self.dict(exclude_none=True))\n+\n+\n+def find_keys(node: Union[List, Dict], key: str) -> Generator[Iterable, None, None]:\n+ \"\"\"Find Nested Keys with name\n+ Search a dictionary for the presence of key\n+ Args:\n+ node (Union[List, Dict]): a dictionary to search\n+ key (str): the dictionary key to find\n+\n+ Yields:\n+ Generator[Iterable, None, None]: Value of dictionary key\n+ \"\"\"\n+ if isinstance(node, list):\n+ for list_entry in node:\n+ yield from find_keys(list_entry, key)\n+ elif isinstance(node, dict):\n+ if key in node:\n+ yield node[key]\n+ for dict_entry in node.values():\n+ yield from find_keys(dict_entry, key)\ndiff --git a/starlite/logging/picologging.py b/starlite/logging/picologging.py\n--- a/starlite/logging/picologging.py\n+++ b/starlite/logging/picologging.py\n@@ -18,7 +18,7 @@\n \n Args:\n handlers (list): list of handler names.\n- respect_handler_level (bool): A handler\u2019s level is respected (compared with the level for the message) when\n+ respect_handler_level (bool): A handler's level is respected (compared with the level for the message) when\n deciding whether to pass messages to that handler.\n \"\"\"\n super().__init__(queue)\ndiff --git a/starlite/logging/standard.py b/starlite/logging/standard.py\n--- a/starlite/logging/standard.py\n+++ b/starlite/logging/standard.py\n@@ -13,7 +13,7 @@\n \n Args:\n handlers (list): list of handler names.\n- respect_handler_level (bool): A handler\u2019s level is respected (compared with the level for the message) when\n+ respect_handler_level (bool): A handler's level is respected (compared with the level for the message) when\n deciding whether to pass messages to that handler.\n \"\"\"\n super().__init__(queue)\n", "issue": "Enhancement: Support dictConfig in picologging\n`picologging` will implement a `dictConfig` with the following PR: https://github.com/microsoft/picologging/issues/53\r\n\r\nWe should enhance our integration to call this method once it's officially released.\r\n\n", "before_files": [{"content": "from logging import config\nfrom typing import Any, Dict, List, Optional, Union\n\nfrom pydantic import BaseModel\nfrom typing_extensions import Literal\n\nfrom starlite.logging.standard import QueueListenerHandler\n\n__all__ = [\"LoggingConfig\", \"QueueListenerHandler\"]\n\n\nclass LoggingConfig(BaseModel):\n \"\"\"Convenience `pydantic` model for configuring logging.\n\n For detailed instructions consult [standard library docs](https://docs.python.org/3/library/logging.config.html).\n \"\"\"\n\n version: Literal[1] = 1\n \"\"\"The only valid value at present is 1.\"\"\"\n incremental: bool = False\n \"\"\"Whether the configuration is to be interpreted as incremental to the existing configuration. \"\"\"\n disable_existing_loggers: bool = False\n \"\"\"Whether any existing non-root loggers are to be disabled.\"\"\"\n filters: Optional[Dict[str, Dict[str, Any]]] = None\n \"\"\"A dict in which each key is a filter id and each value is a dict describing how to configure the corresponding Filter instance.\"\"\"\n propagate: bool = True\n \"\"\"If messages must propagate to handlers higher up the logger hierarchy from this logger.\"\"\"\n formatters: Dict[str, Dict[str, Any]] = {\n \"standard\": {\"format\": \"%(levelname)s - %(asctime)s - %(name)s - %(module)s - %(message)s\"}\n }\n handlers: Dict[str, Dict[str, Any]] = {\n \"console\": {\n \"class\": \"logging.StreamHandler\",\n \"level\": \"DEBUG\",\n \"formatter\": \"standard\",\n },\n \"queue_listener\": {\"class\": \"starlite.QueueListenerHandler\", \"handlers\": [\"cfg://handlers.console\"]},\n }\n \"\"\"A dict in which each key is a handler id and each value is a dict describing how to configure the corresponding Handler instance.\"\"\"\n loggers: Dict[str, Dict[str, Any]] = {\n \"starlite\": {\n \"level\": \"INFO\",\n \"handlers\": [\"queue_listener\"],\n },\n }\n \"\"\"A dict in which each key is a logger name and each value is a dict describing how to configure the corresponding Logger instance.\"\"\"\n root: Dict[str, Union[Dict[str, Any], List[Any], str]] = {\"handlers\": [\"queue_listener\"], \"level\": \"INFO\"}\n \"\"\"This will be the configuration for the root logger. Processing of the configuration will be as for any logger,\n except that the propagate setting will not be applicable.\"\"\"\n\n def configure(self) -> None:\n \"\"\"Configured logger with the given configuration.\"\"\"\n config.dictConfig(self.dict(exclude_none=True))\n", "path": "starlite/logging/__init__.py"}, {"content": "from queue import Queue\nfrom typing import Any, List\n\nfrom picologging.handlers import QueueHandler, QueueListener\n\nfrom starlite.logging.standard import resolve_handlers\n\n\nclass QueueListenerHandler(QueueHandler): # type: ignore\n def __init__(self, handlers: List[Any], respect_handler_level: bool = False, queue: Queue = Queue(-1)):\n \"\"\"Configures queue listener and handler to support non-blocking\n logging configuration.\n\n Requires `picologging`, install with:\n ```shell\n $ pip install starlite[picologging]\n ```\n\n Args:\n handlers (list): list of handler names.\n respect_handler_level (bool): A handler\u2019s level is respected (compared with the level for the message) when\n deciding whether to pass messages to that handler.\n \"\"\"\n super().__init__(queue)\n self.handlers = resolve_handlers(handlers)\n self._listener: QueueListener = QueueListener(\n self.queue, *self.handlers, respect_handler_level=respect_handler_level\n )\n self._listener.start()\n", "path": "starlite/logging/picologging.py"}, {"content": "from logging.handlers import QueueHandler, QueueListener\nfrom queue import Queue\nfrom typing import Any, List\n\n\nclass QueueListenerHandler(QueueHandler):\n \"\"\"Configures queue listener and handler to support non-blocking logging\n configuration.\"\"\"\n\n def __init__(self, handlers: List[Any], respect_handler_level: bool = False, queue: Queue = Queue(-1)):\n \"\"\"Configures queue listener and handler to support non-blocking\n logging configuration.\n\n Args:\n handlers (list): list of handler names.\n respect_handler_level (bool): A handler\u2019s level is respected (compared with the level for the message) when\n deciding whether to pass messages to that handler.\n \"\"\"\n super().__init__(queue)\n self.handlers = resolve_handlers(handlers)\n self._listener: QueueListener = QueueListener(\n self.queue, *self.handlers, respect_handler_level=respect_handler_level\n )\n self._listener.start()\n\n\ndef resolve_handlers(handlers: List[Any]) -> List[Any]:\n \"\"\"Converts list of string of handlers to the object of respective handler.\n\n Indexing the list performs the evaluation of the object.\n \"\"\"\n return [handlers[i] for i in range(len(handlers))]\n", "path": "starlite/logging/standard.py"}]}
| 1,879 | 746 |
gh_patches_debug_61002
|
rasdani/github-patches
|
git_diff
|
ourownstory__neural_prophet-1254
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Static Trend does not follow required forecasting pattern
**Source Code:**
```
import pandas as pd
from neuralprophet import NeuralProphet, set_log_level, set_random_seed
set_log_level("ERROR")
data_location = "https://raw.githubusercontent.com/ourownstory/neuralprophet-data/main/datasets/"
file = "energy/SF_hospital_load.csv"
data_df = pd.read_csv(data_location + file)
m = NeuralProphet()
train_df, test_df = m.split_df(data_df, freq="H", valid_p=1.0 / 5)
quantile_lo, quantile_hi = 0.05, 0.95
quantiles = [quantile_lo, quantile_hi]
n_lags = 3 * 24
n_forecasts = 24
m = NeuralProphet(
growth="off",
yearly_seasonality=False,
weekly_seasonality=False,
daily_seasonality=False,
n_forecasts = n_forecasts,
n_lags=n_lags,
ar_reg=1,
learning_rate=0.01,
quantiles=quantiles,
)
random_seed = 0
set_random_seed(random_seed)
metrics = m.fit(train_df, freq="H")
forecast = m.predict(test_df)
```
**Error:**
```
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
Input In [1], in <cell line: 34>()
31 metrics = m.fit(train_df, freq="H")
32 metrics.tail(1)
---> 34 forecast = m.predict(test_df)
File ~.../neuralprophet/forecaster.py:940, in NeuralProphet.predict(self, df, decompose, raw)
938 fcst = fcst[:-1]
939 else:
--> 940 fcst = self._reshape_raw_predictions_to_forecst_df(df_i, predicted, components)
941 if periods_added[df_name] > 0:
942 fcst = fcst[: -periods_added[df_name]]
File ~.../neuralprophet/forecaster.py:3169, in NeuralProphet._reshape_raw_predictions_to_forecst_df(self, df, predicted, components)
3167 for j in range(len(self.config_train.quantiles)):
3168 forecast_0 = components[comp][0, :, j]
-> 3169 forecast_rest = components[comp][1:, self.n_forecasts - 1, j]
3170 yhat = np.concatenate(([np.NaN] * self.max_lags, forecast_0, forecast_rest))
3171 if j == 0: # temporary condition to add only the median component
3172 # add yhat into dataframe, using df_forecast indexing
IndexError: index 23 is out of bounds for axis 1 with size 1
```
Is it because I used the empty `m = NeuralProphet()` to split to data to train/test?
</issue>
<code>
[start of neuralprophet/components/trend/static.py]
1 from neuralprophet.components.trend import Trend
2
3
4 class StaticTrend(Trend):
5 def __init__(self, config, id_list, quantiles, num_trends_modelled, n_forecasts, device):
6 super().__init__(
7 config=config,
8 n_forecasts=n_forecasts,
9 num_trends_modelled=num_trends_modelled,
10 quantiles=quantiles,
11 id_list=id_list,
12 device=device,
13 )
14
15 def forward(self, t, meta):
16 """
17 Computes trend based on model configuration.
18
19 Parameters
20 ----------
21 t : torch.Tensor float
22 normalized time, dim: (batch, n_forecasts)
23 meta: dict
24 Metadata about the all the samples of the model input batch. Contains the following:
25 * ``df_name`` (list, str), time series ID corresponding to each sample of the input batch.
26 Returns
27 -------
28 torch.Tensor
29 Trend component, same dimensions as input t
30 """
31 return self.bias.unsqueeze(dim=0).repeat(t.shape[0], 1, 1)
32
33 @property
34 def get_trend_deltas(self):
35 pass
36
37 def add_regularization(self):
38 pass
39
[end of neuralprophet/components/trend/static.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/neuralprophet/components/trend/static.py b/neuralprophet/components/trend/static.py
--- a/neuralprophet/components/trend/static.py
+++ b/neuralprophet/components/trend/static.py
@@ -28,7 +28,7 @@
torch.Tensor
Trend component, same dimensions as input t
"""
- return self.bias.unsqueeze(dim=0).repeat(t.shape[0], 1, 1)
+ return self.bias.unsqueeze(dim=0).repeat(t.shape[0], self.n_forecasts, 1)
@property
def get_trend_deltas(self):
|
{"golden_diff": "diff --git a/neuralprophet/components/trend/static.py b/neuralprophet/components/trend/static.py\n--- a/neuralprophet/components/trend/static.py\n+++ b/neuralprophet/components/trend/static.py\n@@ -28,7 +28,7 @@\n torch.Tensor\n Trend component, same dimensions as input t\n \"\"\"\n- return self.bias.unsqueeze(dim=0).repeat(t.shape[0], 1, 1)\n+ return self.bias.unsqueeze(dim=0).repeat(t.shape[0], self.n_forecasts, 1)\n \n @property\n def get_trend_deltas(self):\n", "issue": "Static Trend does not follow required forecasting pattern\n**Source Code:**\r\n\r\n```\r\nimport pandas as pd\r\nfrom neuralprophet import NeuralProphet, set_log_level, set_random_seed\r\nset_log_level(\"ERROR\")\r\n\r\ndata_location = \"https://raw.githubusercontent.com/ourownstory/neuralprophet-data/main/datasets/\"\r\nfile = \"energy/SF_hospital_load.csv\"\r\ndata_df = pd.read_csv(data_location + file)\r\n\r\nm = NeuralProphet()\r\ntrain_df, test_df = m.split_df(data_df, freq=\"H\", valid_p=1.0 / 5)\r\n\r\nquantile_lo, quantile_hi = 0.05, 0.95\r\nquantiles = [quantile_lo, quantile_hi]\r\nn_lags = 3 * 24\r\nn_forecasts = 24\r\n\r\nm = NeuralProphet(\r\n growth=\"off\",\r\n yearly_seasonality=False,\r\n weekly_seasonality=False,\r\n daily_seasonality=False,\r\n n_forecasts = n_forecasts,\r\n n_lags=n_lags,\r\n ar_reg=1,\r\n learning_rate=0.01,\r\n quantiles=quantiles,\r\n)\r\n\r\nrandom_seed = 0\r\nset_random_seed(random_seed)\r\nmetrics = m.fit(train_df, freq=\"H\")\r\n\r\nforecast = m.predict(test_df)\r\n```\r\n\r\n**Error:**\r\n\r\n```\r\n---------------------------------------------------------------------------\r\nIndexError Traceback (most recent call last)\r\nInput In [1], in <cell line: 34>()\r\n 31 metrics = m.fit(train_df, freq=\"H\")\r\n 32 metrics.tail(1)\r\n---> 34 forecast = m.predict(test_df)\r\n\r\nFile ~.../neuralprophet/forecaster.py:940, in NeuralProphet.predict(self, df, decompose, raw)\r\n 938 fcst = fcst[:-1]\r\n 939 else:\r\n--> 940 fcst = self._reshape_raw_predictions_to_forecst_df(df_i, predicted, components)\r\n 941 if periods_added[df_name] > 0:\r\n 942 fcst = fcst[: -periods_added[df_name]]\r\n\r\nFile ~.../neuralprophet/forecaster.py:3169, in NeuralProphet._reshape_raw_predictions_to_forecst_df(self, df, predicted, components)\r\n 3167 for j in range(len(self.config_train.quantiles)):\r\n 3168 forecast_0 = components[comp][0, :, j]\r\n-> 3169 forecast_rest = components[comp][1:, self.n_forecasts - 1, j]\r\n 3170 yhat = np.concatenate(([np.NaN] * self.max_lags, forecast_0, forecast_rest))\r\n 3171 if j == 0: # temporary condition to add only the median component\r\n 3172 # add yhat into dataframe, using df_forecast indexing\r\n\r\nIndexError: index 23 is out of bounds for axis 1 with size 1\r\n```\r\n\r\nIs it because I used the empty `m = NeuralProphet()` to split to data to train/test?\n", "before_files": [{"content": "from neuralprophet.components.trend import Trend\n\n\nclass StaticTrend(Trend):\n def __init__(self, config, id_list, quantiles, num_trends_modelled, n_forecasts, device):\n super().__init__(\n config=config,\n n_forecasts=n_forecasts,\n num_trends_modelled=num_trends_modelled,\n quantiles=quantiles,\n id_list=id_list,\n device=device,\n )\n\n def forward(self, t, meta):\n \"\"\"\n Computes trend based on model configuration.\n\n Parameters\n ----------\n t : torch.Tensor float\n normalized time, dim: (batch, n_forecasts)\n meta: dict\n Metadata about the all the samples of the model input batch. Contains the following:\n * ``df_name`` (list, str), time series ID corresponding to each sample of the input batch.\n Returns\n -------\n torch.Tensor\n Trend component, same dimensions as input t\n \"\"\"\n return self.bias.unsqueeze(dim=0).repeat(t.shape[0], 1, 1)\n\n @property\n def get_trend_deltas(self):\n pass\n\n def add_regularization(self):\n pass\n", "path": "neuralprophet/components/trend/static.py"}]}
| 1,542 | 137 |
gh_patches_debug_10878
|
rasdani/github-patches
|
git_diff
|
open-mmlab__mmsegmentation-1463
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
STDC training on fp16: Input type (torch.cuda.FloatTensor) and weight type (torch.cuda.HalfTensor) should be the same
在stdc1_512x1024_80k_cityscapes.py中添加了
```
optimizer_config = dict(type='Fp16OptimizerHook', loss_scale='dynamic')
fp16 = dict()
```
后再次进行训练则出现了以下报错
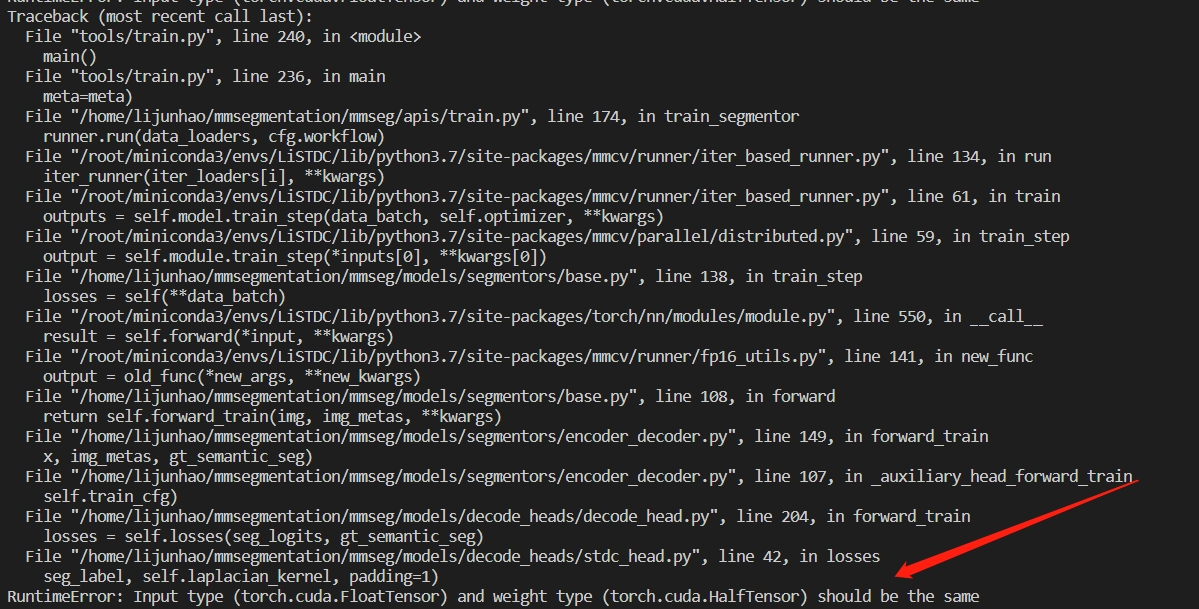
请问该如何修改
</issue>
<code>
[start of mmseg/models/decode_heads/stdc_head.py]
1 # Copyright (c) OpenMMLab. All rights reserved.
2 import torch
3 import torch.nn.functional as F
4
5 from ..builder import HEADS
6 from .fcn_head import FCNHead
7
8
9 @HEADS.register_module()
10 class STDCHead(FCNHead):
11 """This head is the implementation of `Rethinking BiSeNet For Real-time
12 Semantic Segmentation <https://arxiv.org/abs/2104.13188>`_.
13
14 Args:
15 boundary_threshold (float): The threshold of calculating boundary.
16 Default: 0.1.
17 """
18
19 def __init__(self, boundary_threshold=0.1, **kwargs):
20 super(STDCHead, self).__init__(**kwargs)
21 self.boundary_threshold = boundary_threshold
22 # Using register buffer to make laplacian kernel on the same
23 # device of `seg_label`.
24 self.register_buffer(
25 'laplacian_kernel',
26 torch.tensor([-1, -1, -1, -1, 8, -1, -1, -1, -1],
27 dtype=torch.float32,
28 requires_grad=False).reshape((1, 1, 3, 3)))
29 self.fusion_kernel = torch.nn.Parameter(
30 torch.tensor([[6. / 10], [3. / 10], [1. / 10]],
31 dtype=torch.float32).reshape(1, 3, 1, 1),
32 requires_grad=False)
33
34 def losses(self, seg_logit, seg_label):
35 """Compute Detail Aggregation Loss."""
36 # Note: The paper claims `fusion_kernel` is a trainable 1x1 conv
37 # parameters. However, it is a constant in original repo and other
38 # codebase because it would not be added into computation graph
39 # after threshold operation.
40 seg_label = seg_label.float()
41 boundary_targets = F.conv2d(
42 seg_label, self.laplacian_kernel, padding=1)
43 boundary_targets = boundary_targets.clamp(min=0)
44 boundary_targets[boundary_targets > self.boundary_threshold] = 1
45 boundary_targets[boundary_targets <= self.boundary_threshold] = 0
46
47 boundary_targets_x2 = F.conv2d(
48 seg_label, self.laplacian_kernel, stride=2, padding=1)
49 boundary_targets_x2 = boundary_targets_x2.clamp(min=0)
50
51 boundary_targets_x4 = F.conv2d(
52 seg_label, self.laplacian_kernel, stride=4, padding=1)
53 boundary_targets_x4 = boundary_targets_x4.clamp(min=0)
54
55 boundary_targets_x4_up = F.interpolate(
56 boundary_targets_x4, boundary_targets.shape[2:], mode='nearest')
57 boundary_targets_x2_up = F.interpolate(
58 boundary_targets_x2, boundary_targets.shape[2:], mode='nearest')
59
60 boundary_targets_x2_up[
61 boundary_targets_x2_up > self.boundary_threshold] = 1
62 boundary_targets_x2_up[
63 boundary_targets_x2_up <= self.boundary_threshold] = 0
64
65 boundary_targets_x4_up[
66 boundary_targets_x4_up > self.boundary_threshold] = 1
67 boundary_targets_x4_up[
68 boundary_targets_x4_up <= self.boundary_threshold] = 0
69
70 boudary_targets_pyramids = torch.stack(
71 (boundary_targets, boundary_targets_x2_up, boundary_targets_x4_up),
72 dim=1)
73
74 boudary_targets_pyramids = boudary_targets_pyramids.squeeze(2)
75 boudary_targets_pyramid = F.conv2d(boudary_targets_pyramids,
76 self.fusion_kernel)
77
78 boudary_targets_pyramid[
79 boudary_targets_pyramid > self.boundary_threshold] = 1
80 boudary_targets_pyramid[
81 boudary_targets_pyramid <= self.boundary_threshold] = 0
82
83 loss = super(STDCHead, self).losses(seg_logit,
84 boudary_targets_pyramid.long())
85 return loss
86
[end of mmseg/models/decode_heads/stdc_head.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mmseg/models/decode_heads/stdc_head.py b/mmseg/models/decode_heads/stdc_head.py
--- a/mmseg/models/decode_heads/stdc_head.py
+++ b/mmseg/models/decode_heads/stdc_head.py
@@ -37,7 +37,7 @@
# parameters. However, it is a constant in original repo and other
# codebase because it would not be added into computation graph
# after threshold operation.
- seg_label = seg_label.float()
+ seg_label = seg_label.to(self.laplacian_kernel)
boundary_targets = F.conv2d(
seg_label, self.laplacian_kernel, padding=1)
boundary_targets = boundary_targets.clamp(min=0)
|
{"golden_diff": "diff --git a/mmseg/models/decode_heads/stdc_head.py b/mmseg/models/decode_heads/stdc_head.py\n--- a/mmseg/models/decode_heads/stdc_head.py\n+++ b/mmseg/models/decode_heads/stdc_head.py\n@@ -37,7 +37,7 @@\n # parameters. However, it is a constant in original repo and other\n # codebase because it would not be added into computation graph\n # after threshold operation.\n- seg_label = seg_label.float()\n+ seg_label = seg_label.to(self.laplacian_kernel)\n boundary_targets = F.conv2d(\n seg_label, self.laplacian_kernel, padding=1)\n boundary_targets = boundary_targets.clamp(min=0)\n", "issue": "STDC training on fp16: Input type (torch.cuda.FloatTensor) and weight type (torch.cuda.HalfTensor) should be the same\n\u5728stdc1_512x1024_80k_cityscapes.py\u4e2d\u6dfb\u52a0\u4e86\r\n```\r\noptimizer_config = dict(type='Fp16OptimizerHook', loss_scale='dynamic')\r\nfp16 = dict()\r\n```\r\n\u540e\u518d\u6b21\u8fdb\u884c\u8bad\u7ec3\u5219\u51fa\u73b0\u4e86\u4ee5\u4e0b\u62a5\u9519\r\n\r\n\r\n\u8bf7\u95ee\u8be5\u5982\u4f55\u4fee\u6539\r\n\r\n\n", "before_files": [{"content": "# Copyright (c) OpenMMLab. All rights reserved.\nimport torch\nimport torch.nn.functional as F\n\nfrom ..builder import HEADS\nfrom .fcn_head import FCNHead\n\n\[email protected]_module()\nclass STDCHead(FCNHead):\n \"\"\"This head is the implementation of `Rethinking BiSeNet For Real-time\n Semantic Segmentation <https://arxiv.org/abs/2104.13188>`_.\n\n Args:\n boundary_threshold (float): The threshold of calculating boundary.\n Default: 0.1.\n \"\"\"\n\n def __init__(self, boundary_threshold=0.1, **kwargs):\n super(STDCHead, self).__init__(**kwargs)\n self.boundary_threshold = boundary_threshold\n # Using register buffer to make laplacian kernel on the same\n # device of `seg_label`.\n self.register_buffer(\n 'laplacian_kernel',\n torch.tensor([-1, -1, -1, -1, 8, -1, -1, -1, -1],\n dtype=torch.float32,\n requires_grad=False).reshape((1, 1, 3, 3)))\n self.fusion_kernel = torch.nn.Parameter(\n torch.tensor([[6. / 10], [3. / 10], [1. / 10]],\n dtype=torch.float32).reshape(1, 3, 1, 1),\n requires_grad=False)\n\n def losses(self, seg_logit, seg_label):\n \"\"\"Compute Detail Aggregation Loss.\"\"\"\n # Note: The paper claims `fusion_kernel` is a trainable 1x1 conv\n # parameters. However, it is a constant in original repo and other\n # codebase because it would not be added into computation graph\n # after threshold operation.\n seg_label = seg_label.float()\n boundary_targets = F.conv2d(\n seg_label, self.laplacian_kernel, padding=1)\n boundary_targets = boundary_targets.clamp(min=0)\n boundary_targets[boundary_targets > self.boundary_threshold] = 1\n boundary_targets[boundary_targets <= self.boundary_threshold] = 0\n\n boundary_targets_x2 = F.conv2d(\n seg_label, self.laplacian_kernel, stride=2, padding=1)\n boundary_targets_x2 = boundary_targets_x2.clamp(min=0)\n\n boundary_targets_x4 = F.conv2d(\n seg_label, self.laplacian_kernel, stride=4, padding=1)\n boundary_targets_x4 = boundary_targets_x4.clamp(min=0)\n\n boundary_targets_x4_up = F.interpolate(\n boundary_targets_x4, boundary_targets.shape[2:], mode='nearest')\n boundary_targets_x2_up = F.interpolate(\n boundary_targets_x2, boundary_targets.shape[2:], mode='nearest')\n\n boundary_targets_x2_up[\n boundary_targets_x2_up > self.boundary_threshold] = 1\n boundary_targets_x2_up[\n boundary_targets_x2_up <= self.boundary_threshold] = 0\n\n boundary_targets_x4_up[\n boundary_targets_x4_up > self.boundary_threshold] = 1\n boundary_targets_x4_up[\n boundary_targets_x4_up <= self.boundary_threshold] = 0\n\n boudary_targets_pyramids = torch.stack(\n (boundary_targets, boundary_targets_x2_up, boundary_targets_x4_up),\n dim=1)\n\n boudary_targets_pyramids = boudary_targets_pyramids.squeeze(2)\n boudary_targets_pyramid = F.conv2d(boudary_targets_pyramids,\n self.fusion_kernel)\n\n boudary_targets_pyramid[\n boudary_targets_pyramid > self.boundary_threshold] = 1\n boudary_targets_pyramid[\n boudary_targets_pyramid <= self.boundary_threshold] = 0\n\n loss = super(STDCHead, self).losses(seg_logit,\n boudary_targets_pyramid.long())\n return loss\n", "path": "mmseg/models/decode_heads/stdc_head.py"}]}
| 1,726 | 157 |
gh_patches_debug_31467
|
rasdani/github-patches
|
git_diff
|
pfnet__pytorch-pfn-extras-15
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bug in sequential repeat when the layer has no parameters
**problems Statement**
In `init` mode, the repeated layer will be reset. In `Pytorch`, we used `reset_parameters` function to reset the parameters of layers, as here:
https://github.com/pfnet/pytorch-pfn-extras/blob/92dad97e3a3eaafb9eb2b2b804266b5ef922e4c7/pytorch_pfn_extras/nn/modules/extended_sequential.py#L15
However, there are layers have no parameters nor `reset_parameters`, such as `torch.nn.ReLU`. An error is raised when the model contains such layer.
**Error Message**
```
pytorch_pfn_extras/nn/modules/extended_sequential.py:68: in repeat
model_list.append(self._copy_model(mode))
pytorch_pfn_extras/nn/modules/extended_sequential.py:27: in _copy_model
return _reset_parameters(copy.deepcopy(self))
pytorch_pfn_extras/nn/modules/extended_sequential.py:9: in _reset_parameters
_reset_parameters(submodel)
pytorch_pfn_extras/nn/modules/extended_sequential.py:17: in _reset_parameters
model.reset_parameters()
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = ReLU(), name = 'reset_parameters'
def __getattr__(self, name):
if '_parameters' in self.__dict__:
_parameters = self.__dict__['_parameters']
if name in _parameters:
return _parameters[name]
if '_buffers' in self.__dict__:
_buffers = self.__dict__['_buffers']
if name in _buffers:
return _buffers[name]
if '_modules' in self.__dict__:
modules = self.__dict__['_modules']
if name in modules:
return modules[name]
raise AttributeError("'{}' object has no attribute '{}'".format(
> type(self).__name__, name))
E AttributeError: 'ReLU' object has no attribute 'reset_parameters'
```
</issue>
<code>
[start of pytorch_pfn_extras/nn/modules/extended_sequential.py]
1 import torch
2 import copy
3
4
5 def _reset_parameters(model):
6 if isinstance(model, torch.nn.Sequential) or \
7 isinstance(model, torch.nn.ModuleList):
8 for submodel in model:
9 _reset_parameters(submodel)
10 elif isinstance(model, torch.nn.ModuleDict):
11 for submodel in model.values():
12 _reset_parameters(submodel)
13 else:
14 if isinstance(model, torch.nn.Module):
15 model.reset_parameters()
16 return model
17
18
19 class ExtendedSequential(torch.nn.Sequential):
20 """Sequential module with extended features from chainer.
21
22 """
23 def _copy_model(self, mode):
24 if mode == 'init':
25 return _reset_parameters(copy.deepcopy(self))
26 elif mode == 'copy':
27 return copy.deepcopy(self)
28 else:
29 # mode == share
30 return copy.copy(self)
31
32 def repeat(self, n_repeat: int, mode: 'str' = 'init'):
33 """Repeats this Sequential multiple times.
34
35 This method returns a :class:`~torch.nn.Sequential` object which has
36 original `Sequential` multiple times repeatedly. The ``mode``
37 argument means how to copy this sequential to repeat.
38
39 The functions is supposed to behave the same way as `repeat`
40 in `chainer`.
41
42 Args:
43 n_repeat (int): Number of times to repeat.
44 mode (str): It should be either ``init``, ``copy``, or ``share``.
45 ``init`` means parameters of each repeated element in the
46 returned :class:`~torch.nn.Sequential` will be re-initialized,
47 so that all elements have different initial parameters.
48 ``copy`` means that the parameters will not be re-initialized
49 but object itself will be deep-copied, so that all elements
50 have same initial parameters but can be changed independently.
51 ``share`` means all the elements which consist the resulting
52 :class:`~torch.nn.Sequential` object are same object because
53 they are shallow-copied, so that all parameters of elements
54 are shared with each other.
55 """
56 if n_repeat <= 0:
57 return ExtendedSequential()
58
59 if mode not in ['copy', 'share', 'init']:
60 raise ValueError(
61 'The \'mode\' argument should be either \'init\','
62 '\'copy\', or \'share\'. But {} was given.'.format(mode))
63
64 model_list = []
65 for _ in range(n_repeat):
66 model_list.append(self._copy_model(mode))
67 return ExtendedSequential(*model_list)
68
[end of pytorch_pfn_extras/nn/modules/extended_sequential.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pytorch_pfn_extras/nn/modules/extended_sequential.py b/pytorch_pfn_extras/nn/modules/extended_sequential.py
--- a/pytorch_pfn_extras/nn/modules/extended_sequential.py
+++ b/pytorch_pfn_extras/nn/modules/extended_sequential.py
@@ -1,5 +1,6 @@
import torch
import copy
+import warnings
def _reset_parameters(model):
@@ -11,8 +12,19 @@
for submodel in model.values():
_reset_parameters(submodel)
else:
- if isinstance(model, torch.nn.Module):
+ if hasattr(model, 'reset_parameters'):
model.reset_parameters()
+ elif hasattr(model, '_reset_parameters'):
+ model._reset_parameters()
+ else:
+ if (len(list(model.parameters())) != 0 or
+ len(list(model.buffers())) != 0):
+ warnings.warn('Cannot reset the parameters of module {}. '
+ 'Consider adding `reset_parameters` or '
+ '`_reset_parameters` '
+ 'functions to the module'.format(model),
+ UserWarning)
+
return model
@@ -39,6 +51,18 @@
The functions is supposed to behave the same way as `repeat`
in `chainer`.
+ When the mode is set to ``init``, the default value,
+ modules will be copied and reinitialized by calling
+ ``reset_parameters`` (or ``_reset_parameters``) method.
+
+ To repeat user-defined modules, which have parameters or buffers,
+ with mode=``init`` in this Sequential,
+ you need to implement the ``reset_parameters`` or ``_reset_parameters``
+ method to the module to reinitialize parameters
+ and (if necessary) buffers;
+ otherwise the initialization cannot be performed
+ and a warning message will be shown.
+
Args:
n_repeat (int): Number of times to repeat.
mode (str): It should be either ``init``, ``copy``, or ``share``.
|
{"golden_diff": "diff --git a/pytorch_pfn_extras/nn/modules/extended_sequential.py b/pytorch_pfn_extras/nn/modules/extended_sequential.py\n--- a/pytorch_pfn_extras/nn/modules/extended_sequential.py\n+++ b/pytorch_pfn_extras/nn/modules/extended_sequential.py\n@@ -1,5 +1,6 @@\n import torch\n import copy\n+import warnings\n \n \n def _reset_parameters(model):\n@@ -11,8 +12,19 @@\n for submodel in model.values():\n _reset_parameters(submodel)\n else:\n- if isinstance(model, torch.nn.Module):\n+ if hasattr(model, 'reset_parameters'):\n model.reset_parameters()\n+ elif hasattr(model, '_reset_parameters'):\n+ model._reset_parameters()\n+ else:\n+ if (len(list(model.parameters())) != 0 or\n+ len(list(model.buffers())) != 0):\n+ warnings.warn('Cannot reset the parameters of module {}. '\n+ 'Consider adding `reset_parameters` or '\n+ '`_reset_parameters` '\n+ 'functions to the module'.format(model),\n+ UserWarning)\n+\n return model\n \n \n@@ -39,6 +51,18 @@\n The functions is supposed to behave the same way as `repeat`\n in `chainer`.\n \n+ When the mode is set to ``init``, the default value,\n+ modules will be copied and reinitialized by calling\n+ ``reset_parameters`` (or ``_reset_parameters``) method.\n+\n+ To repeat user-defined modules, which have parameters or buffers,\n+ with mode=``init`` in this Sequential,\n+ you need to implement the ``reset_parameters`` or ``_reset_parameters``\n+ method to the module to reinitialize parameters\n+ and (if necessary) buffers;\n+ otherwise the initialization cannot be performed\n+ and a warning message will be shown.\n+\n Args:\n n_repeat (int): Number of times to repeat.\n mode (str): It should be either ``init``, ``copy``, or ``share``.\n", "issue": "Bug in sequential repeat when the layer has no parameters\n**problems Statement**\r\nIn `init` mode, the repeated layer will be reset. In `Pytorch`, we used `reset_parameters` function to reset the parameters of layers, as here:\r\nhttps://github.com/pfnet/pytorch-pfn-extras/blob/92dad97e3a3eaafb9eb2b2b804266b5ef922e4c7/pytorch_pfn_extras/nn/modules/extended_sequential.py#L15\r\n\r\nHowever, there are layers have no parameters nor `reset_parameters`, such as `torch.nn.ReLU`. An error is raised when the model contains such layer.\r\n\r\n**Error Message**\r\n```\r\npytorch_pfn_extras/nn/modules/extended_sequential.py:68: in repeat\r\n model_list.append(self._copy_model(mode))\r\npytorch_pfn_extras/nn/modules/extended_sequential.py:27: in _copy_model\r\n return _reset_parameters(copy.deepcopy(self))\r\npytorch_pfn_extras/nn/modules/extended_sequential.py:9: in _reset_parameters\r\n _reset_parameters(submodel)\r\npytorch_pfn_extras/nn/modules/extended_sequential.py:17: in _reset_parameters\r\n model.reset_parameters()\r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _\r\n\r\nself = ReLU(), name = 'reset_parameters'\r\n\r\n def __getattr__(self, name):\r\n if '_parameters' in self.__dict__:\r\n _parameters = self.__dict__['_parameters']\r\n if name in _parameters:\r\n return _parameters[name]\r\n if '_buffers' in self.__dict__:\r\n _buffers = self.__dict__['_buffers']\r\n if name in _buffers:\r\n return _buffers[name]\r\n if '_modules' in self.__dict__:\r\n modules = self.__dict__['_modules']\r\n if name in modules:\r\n return modules[name]\r\n raise AttributeError(\"'{}' object has no attribute '{}'\".format(\r\n> type(self).__name__, name))\r\nE AttributeError: 'ReLU' object has no attribute 'reset_parameters'\r\n```\n", "before_files": [{"content": "import torch\nimport copy\n\n\ndef _reset_parameters(model):\n if isinstance(model, torch.nn.Sequential) or \\\n isinstance(model, torch.nn.ModuleList):\n for submodel in model:\n _reset_parameters(submodel)\n elif isinstance(model, torch.nn.ModuleDict):\n for submodel in model.values():\n _reset_parameters(submodel)\n else:\n if isinstance(model, torch.nn.Module):\n model.reset_parameters()\n return model\n\n\nclass ExtendedSequential(torch.nn.Sequential):\n \"\"\"Sequential module with extended features from chainer.\n\n \"\"\"\n def _copy_model(self, mode):\n if mode == 'init':\n return _reset_parameters(copy.deepcopy(self))\n elif mode == 'copy':\n return copy.deepcopy(self)\n else:\n # mode == share\n return copy.copy(self)\n\n def repeat(self, n_repeat: int, mode: 'str' = 'init'):\n \"\"\"Repeats this Sequential multiple times.\n\n This method returns a :class:`~torch.nn.Sequential` object which has\n original `Sequential` multiple times repeatedly. The ``mode``\n argument means how to copy this sequential to repeat.\n\n The functions is supposed to behave the same way as `repeat`\n in `chainer`.\n\n Args:\n n_repeat (int): Number of times to repeat.\n mode (str): It should be either ``init``, ``copy``, or ``share``.\n ``init`` means parameters of each repeated element in the\n returned :class:`~torch.nn.Sequential` will be re-initialized,\n so that all elements have different initial parameters.\n ``copy`` means that the parameters will not be re-initialized\n but object itself will be deep-copied, so that all elements\n have same initial parameters but can be changed independently.\n ``share`` means all the elements which consist the resulting\n :class:`~torch.nn.Sequential` object are same object because\n they are shallow-copied, so that all parameters of elements\n are shared with each other.\n \"\"\"\n if n_repeat <= 0:\n return ExtendedSequential()\n\n if mode not in ['copy', 'share', 'init']:\n raise ValueError(\n 'The \\'mode\\' argument should be either \\'init\\','\n '\\'copy\\', or \\'share\\'. But {} was given.'.format(mode))\n\n model_list = []\n for _ in range(n_repeat):\n model_list.append(self._copy_model(mode))\n return ExtendedSequential(*model_list)\n", "path": "pytorch_pfn_extras/nn/modules/extended_sequential.py"}]}
| 1,752 | 449 |
gh_patches_debug_20459
|
rasdani/github-patches
|
git_diff
|
pytorch__text-1805
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Make TorchText installable from direct reference
In order to make `pip install https://github.com/pytorch/text` succeed
`setup.py` should have logic to initialize submodules
Add `check_submodules()` routine to setup.py to check if
'third_party/re2/CMakeLists.txt' is present on the filesystem and
attempt to initialize submodules if it is not
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 import distutils.command.clean
3 import io
4 import os
5 import shutil
6 import subprocess
7 from pathlib import Path
8
9 from build_tools import setup_helpers
10 from setuptools import find_packages, setup
11
12 ROOT_DIR = Path(__file__).parent.resolve()
13
14
15 def read(*names, **kwargs):
16 with io.open(ROOT_DIR.joinpath(*names), encoding=kwargs.get("encoding", "utf8")) as fp:
17 return fp.read()
18
19
20 def _get_version():
21 try:
22 cmd = ["git", "rev-parse", "HEAD"]
23 sha = subprocess.check_output(cmd, cwd=str(ROOT_DIR)).decode("ascii").strip()
24 except Exception:
25 sha = None
26
27 if "BUILD_VERSION" in os.environ:
28 version = os.environ["BUILD_VERSION"]
29 else:
30 with open(os.path.join(ROOT_DIR, "version.txt"), "r") as f:
31 version = f.readline().strip()
32 if sha is not None:
33 version += "+" + sha[:7]
34
35 if sha is None:
36 sha = "Unknown"
37 return version, sha
38
39
40 def _export_version(version, sha):
41 version_path = ROOT_DIR / "torchtext" / "version.py"
42 with open(version_path, "w") as fileobj:
43 fileobj.write("__version__ = '{}'\n".format(version))
44 fileobj.write("git_version = {}\n".format(repr(sha)))
45
46
47 VERSION, SHA = _get_version()
48 _export_version(VERSION, SHA)
49
50 print("-- Building version " + VERSION)
51
52 pytorch_package_version = os.getenv("PYTORCH_VERSION")
53
54 pytorch_package_dep = "torch"
55 if pytorch_package_version is not None:
56 pytorch_package_dep += "==" + pytorch_package_version
57
58
59 class clean(distutils.command.clean.clean):
60 def run(self):
61 # Run default behavior first
62 distutils.command.clean.clean.run(self)
63
64 # Remove torchtext extension
65 for path in (ROOT_DIR / "torchtext").glob("**/*.so"):
66 print(f"removing '{path}'")
67 path.unlink()
68 # Remove build directory
69 build_dirs = [
70 ROOT_DIR / "build",
71 ROOT_DIR / "third_party" / "build",
72 ]
73 for path in build_dirs:
74 if path.exists():
75 print(f"removing '{path}' (and everything under it)")
76 shutil.rmtree(str(path), ignore_errors=True)
77
78
79 setup_info = dict(
80 # Metadata
81 name="torchtext",
82 version=VERSION,
83 author="PyTorch core devs and James Bradbury",
84 author_email="[email protected]",
85 url="https://github.com/pytorch/text",
86 description="Text utilities and datasets for PyTorch",
87 long_description=read("README.rst"),
88 license="BSD",
89 install_requires=["tqdm", "requests", pytorch_package_dep, "numpy"],
90 python_requires=">=3.7",
91 classifiers=[
92 "Programming Language :: Python :: 3.7",
93 "Programming Language :: Python :: 3.8",
94 "Programming Language :: Python :: 3.9",
95 ],
96 # Package info
97 packages=find_packages(exclude=("test*", "build_tools*")),
98 zip_safe=False,
99 # Extension info
100 # If you are trying to use torchtext.so and see no registered op.
101 # See here: https://github.com/pytorch/vision/issues/2134"
102 ext_modules=setup_helpers.get_ext_modules(),
103 cmdclass={
104 "build_ext": setup_helpers.CMakeBuild,
105 "clean": clean,
106 },
107 )
108
109 setup(**setup_info)
110
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -4,6 +4,7 @@
import os
import shutil
import subprocess
+import sys
from pathlib import Path
from build_tools import setup_helpers
@@ -44,6 +45,18 @@
fileobj.write("git_version = {}\n".format(repr(sha)))
+def _init_submodule():
+ print(" --- Initializing submodules")
+ try:
+ subprocess.check_call(["git", "submodule", "init"])
+ subprocess.check_call(["git", "submodule", "update"])
+ except Exception:
+ print(" --- Submodule initalization failed")
+ print("Please run:\n\tgit submodule update --init --recursive")
+ sys.exit(1)
+ print(" --- Initialized submodule")
+
+
VERSION, SHA = _get_version()
_export_version(VERSION, SHA)
@@ -76,6 +89,7 @@
shutil.rmtree(str(path), ignore_errors=True)
+_init_submodule()
setup_info = dict(
# Metadata
name="torchtext",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -4,6 +4,7 @@\n import os\n import shutil\n import subprocess\n+import sys\n from pathlib import Path\n \n from build_tools import setup_helpers\n@@ -44,6 +45,18 @@\n fileobj.write(\"git_version = {}\\n\".format(repr(sha)))\n \n \n+def _init_submodule():\n+ print(\" --- Initializing submodules\")\n+ try:\n+ subprocess.check_call([\"git\", \"submodule\", \"init\"])\n+ subprocess.check_call([\"git\", \"submodule\", \"update\"])\n+ except Exception:\n+ print(\" --- Submodule initalization failed\")\n+ print(\"Please run:\\n\\tgit submodule update --init --recursive\")\n+ sys.exit(1)\n+ print(\" --- Initialized submodule\")\n+\n+\n VERSION, SHA = _get_version()\n _export_version(VERSION, SHA)\n \n@@ -76,6 +89,7 @@\n shutil.rmtree(str(path), ignore_errors=True)\n \n \n+_init_submodule()\n setup_info = dict(\n # Metadata\n name=\"torchtext\",\n", "issue": "Make TorchText installable from direct reference\nIn order to make `pip install https://github.com/pytorch/text` succeed\r\n`setup.py` should have logic to initialize submodules\r\n\r\nAdd `check_submodules()` routine to setup.py to check if\r\n'third_party/re2/CMakeLists.txt' is present on the filesystem and\r\nattempt to initialize submodules if it is not\n", "before_files": [{"content": "#!/usr/bin/env python\nimport distutils.command.clean\nimport io\nimport os\nimport shutil\nimport subprocess\nfrom pathlib import Path\n\nfrom build_tools import setup_helpers\nfrom setuptools import find_packages, setup\n\nROOT_DIR = Path(__file__).parent.resolve()\n\n\ndef read(*names, **kwargs):\n with io.open(ROOT_DIR.joinpath(*names), encoding=kwargs.get(\"encoding\", \"utf8\")) as fp:\n return fp.read()\n\n\ndef _get_version():\n try:\n cmd = [\"git\", \"rev-parse\", \"HEAD\"]\n sha = subprocess.check_output(cmd, cwd=str(ROOT_DIR)).decode(\"ascii\").strip()\n except Exception:\n sha = None\n\n if \"BUILD_VERSION\" in os.environ:\n version = os.environ[\"BUILD_VERSION\"]\n else:\n with open(os.path.join(ROOT_DIR, \"version.txt\"), \"r\") as f:\n version = f.readline().strip()\n if sha is not None:\n version += \"+\" + sha[:7]\n\n if sha is None:\n sha = \"Unknown\"\n return version, sha\n\n\ndef _export_version(version, sha):\n version_path = ROOT_DIR / \"torchtext\" / \"version.py\"\n with open(version_path, \"w\") as fileobj:\n fileobj.write(\"__version__ = '{}'\\n\".format(version))\n fileobj.write(\"git_version = {}\\n\".format(repr(sha)))\n\n\nVERSION, SHA = _get_version()\n_export_version(VERSION, SHA)\n\nprint(\"-- Building version \" + VERSION)\n\npytorch_package_version = os.getenv(\"PYTORCH_VERSION\")\n\npytorch_package_dep = \"torch\"\nif pytorch_package_version is not None:\n pytorch_package_dep += \"==\" + pytorch_package_version\n\n\nclass clean(distutils.command.clean.clean):\n def run(self):\n # Run default behavior first\n distutils.command.clean.clean.run(self)\n\n # Remove torchtext extension\n for path in (ROOT_DIR / \"torchtext\").glob(\"**/*.so\"):\n print(f\"removing '{path}'\")\n path.unlink()\n # Remove build directory\n build_dirs = [\n ROOT_DIR / \"build\",\n ROOT_DIR / \"third_party\" / \"build\",\n ]\n for path in build_dirs:\n if path.exists():\n print(f\"removing '{path}' (and everything under it)\")\n shutil.rmtree(str(path), ignore_errors=True)\n\n\nsetup_info = dict(\n # Metadata\n name=\"torchtext\",\n version=VERSION,\n author=\"PyTorch core devs and James Bradbury\",\n author_email=\"[email protected]\",\n url=\"https://github.com/pytorch/text\",\n description=\"Text utilities and datasets for PyTorch\",\n long_description=read(\"README.rst\"),\n license=\"BSD\",\n install_requires=[\"tqdm\", \"requests\", pytorch_package_dep, \"numpy\"],\n python_requires=\">=3.7\",\n classifiers=[\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n ],\n # Package info\n packages=find_packages(exclude=(\"test*\", \"build_tools*\")),\n zip_safe=False,\n # Extension info\n # If you are trying to use torchtext.so and see no registered op.\n # See here: https://github.com/pytorch/vision/issues/2134\"\n ext_modules=setup_helpers.get_ext_modules(),\n cmdclass={\n \"build_ext\": setup_helpers.CMakeBuild,\n \"clean\": clean,\n },\n)\n\nsetup(**setup_info)\n", "path": "setup.py"}]}
| 1,607 | 248 |
gh_patches_debug_36718
|
rasdani/github-patches
|
git_diff
|
prowler-cloud__prowler-2726
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bug]: Context name on conditions are case-insensitive
### Steps to Reproduce
As yo can see here https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_elements_condition.html, context name on conditions are case-insensitive. Some default aws policies are "AWS:xxxx" instead of "aws:xxxx", so prowler fails to detect it. Also can happen with manual policies, if someone put "aws:sourceaccount" inseat of "aws:SourceAccount". So is_account_only_allowed_in_condition must be case-insensitive to work.
I found it on SNS default policy, which look like this:
```
{
"Version": "2008-10-17",
"Id": "__default_policy_ID",
"Statement": [
{
"Sid": "__default_statement_ID",
"Effect": "Allow",
"Principal": {
"AWS": "*"
},
"Action": [
"SNS:GetTopicAttributes",
"SNS:SetTopicAttributes",
"SNS:AddPermission",
"SNS:RemovePermission",
"SNS:DeleteTopic",
"SNS:Subscribe",
"SNS:ListSubscriptionsByTopic",
"SNS:Publish",
"SNS:Receive"
],
"Resource": "arn:aws:sns:eu-west-1:XXXXXXXX:config-topic",
"Condition": {
"StringEquals": {
"AWS:SourceOwner": "XXXXXXXX"
}
}
}
]
}
```
### Expected behavior
It should pass when found a condition like "AWS:SourceOwner" with a valid value.
### Actual Result with Screenshots or Logs
It can't detect correctly the condition, so the test fails.
╭────────────┬───────────┬───────────┬────────────┬────────┬──────────┬───────╮
│ Provider │ Service │ Status │ Critical │ High │ Medium │ Low │
├────────────┼───────────┼───────────┼────────────┼────────┼──────────┼───────┤
│ aws │ sns │ FAIL (13) │ 0 │ 13 │ 0 │ 0 │
╰────────────┴───────────┴───────────┴────────────┴────────┴──────────┴───────╯
### How did you install Prowler?
Cloning the repository from github.com (git clone)
### Environment Resource
8. SNS
### OS used
5. Ubuntu
### Prowler version
Prowler 3.8.2
### Pip version
pip 23.2.1
### Context
_No response_
</issue>
<code>
[start of prowler/providers/aws/lib/policy_condition_parser/policy_condition_parser.py]
1 # lista de cuentas y te devuelva las válidas
2 def is_account_only_allowed_in_condition(
3 condition_statement: dict, source_account: str
4 ):
5 is_condition_valid = False
6 valid_condition_options = {
7 "StringEquals": [
8 "aws:SourceAccount",
9 "aws:SourceOwner",
10 "s3:ResourceAccount",
11 "aws:PrincipalAccount",
12 "aws:ResourceAccount",
13 ],
14 "StringLike": [
15 "aws:SourceAccount",
16 "aws:SourceOwner",
17 "aws:SourceArn",
18 "aws:PrincipalArn",
19 "aws:ResourceAccount",
20 "aws:PrincipalAccount",
21 ],
22 "ArnLike": ["aws:SourceArn", "aws:PrincipalArn"],
23 "ArnEquals": ["aws:SourceArn", "aws:PrincipalArn"],
24 }
25
26 for condition_operator, condition_operator_key in valid_condition_options.items():
27 if condition_operator in condition_statement:
28 for value in condition_operator_key:
29 if value in condition_statement[condition_operator]:
30 # values are a list
31 if isinstance(
32 condition_statement[condition_operator][value],
33 list,
34 ):
35 # if there is an arn/account without the source account -> we do not consider it safe
36 # here by default we assume is true and look for false entries
37 is_condition_valid = True
38 for item in condition_statement[condition_operator][value]:
39 if source_account not in item:
40 is_condition_valid = False
41 break
42
43 # value is a string
44 elif isinstance(
45 condition_statement[condition_operator][value],
46 str,
47 ):
48 if (
49 source_account
50 in condition_statement[condition_operator][value]
51 ):
52 is_condition_valid = True
53
54 return is_condition_valid
55
[end of prowler/providers/aws/lib/policy_condition_parser/policy_condition_parser.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/prowler/providers/aws/lib/policy_condition_parser/policy_condition_parser.py b/prowler/providers/aws/lib/policy_condition_parser/policy_condition_parser.py
--- a/prowler/providers/aws/lib/policy_condition_parser/policy_condition_parser.py
+++ b/prowler/providers/aws/lib/policy_condition_parser/policy_condition_parser.py
@@ -1,31 +1,52 @@
-# lista de cuentas y te devuelva las válidas
def is_account_only_allowed_in_condition(
condition_statement: dict, source_account: str
):
+ """
+ is_account_only_allowed_in_condition parses the IAM Condition policy block and returns True if the source_account passed as argument is within, False if not.
+
+ @param condition_statement: dict with an IAM Condition block, e.g.:
+ {
+ "StringLike": {
+ "AWS:SourceAccount": 111122223333
+ }
+ }
+
+ @param source_account: str with a 12-digit AWS Account number, e.g.: 111122223333
+ """
is_condition_valid = False
+
+ # The conditions must be defined in lowercase since the context key names are not case-sensitive.
+ # For example, including the aws:SourceAccount context key is equivalent to testing for AWS:SourceAccount
+ # https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_elements_condition.html
valid_condition_options = {
"StringEquals": [
- "aws:SourceAccount",
- "aws:SourceOwner",
- "s3:ResourceAccount",
- "aws:PrincipalAccount",
- "aws:ResourceAccount",
+ "aws:sourceaccount",
+ "aws:sourceowner",
+ "s3:resourceaccount",
+ "aws:principalaccount",
+ "aws:resourceaccount",
],
"StringLike": [
- "aws:SourceAccount",
- "aws:SourceOwner",
- "aws:SourceArn",
- "aws:PrincipalArn",
- "aws:ResourceAccount",
- "aws:PrincipalAccount",
+ "aws:sourceaccount",
+ "aws:sourceowner",
+ "aws:sourcearn",
+ "aws:principalarn",
+ "aws:resourceaccount",
+ "aws:principalaccount",
],
- "ArnLike": ["aws:SourceArn", "aws:PrincipalArn"],
- "ArnEquals": ["aws:SourceArn", "aws:PrincipalArn"],
+ "ArnLike": ["aws:sourcearn", "aws:principalarn"],
+ "ArnEquals": ["aws:sourcearn", "aws:principalarn"],
}
for condition_operator, condition_operator_key in valid_condition_options.items():
if condition_operator in condition_statement:
for value in condition_operator_key:
+ # We need to transform the condition_statement into lowercase
+ condition_statement[condition_operator] = {
+ k.lower(): v
+ for k, v in condition_statement[condition_operator].items()
+ }
+
if value in condition_statement[condition_operator]:
# values are a list
if isinstance(
|
{"golden_diff": "diff --git a/prowler/providers/aws/lib/policy_condition_parser/policy_condition_parser.py b/prowler/providers/aws/lib/policy_condition_parser/policy_condition_parser.py\n--- a/prowler/providers/aws/lib/policy_condition_parser/policy_condition_parser.py\n+++ b/prowler/providers/aws/lib/policy_condition_parser/policy_condition_parser.py\n@@ -1,31 +1,52 @@\n-# lista de cuentas y te devuelva las v\u00e1lidas\n def is_account_only_allowed_in_condition(\n condition_statement: dict, source_account: str\n ):\n+ \"\"\"\n+ is_account_only_allowed_in_condition parses the IAM Condition policy block and returns True if the source_account passed as argument is within, False if not.\n+\n+ @param condition_statement: dict with an IAM Condition block, e.g.:\n+ {\n+ \"StringLike\": {\n+ \"AWS:SourceAccount\": 111122223333\n+ }\n+ }\n+\n+ @param source_account: str with a 12-digit AWS Account number, e.g.: 111122223333\n+ \"\"\"\n is_condition_valid = False\n+\n+ # The conditions must be defined in lowercase since the context key names are not case-sensitive.\n+ # For example, including the aws:SourceAccount context key is equivalent to testing for AWS:SourceAccount\n+ # https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_elements_condition.html\n valid_condition_options = {\n \"StringEquals\": [\n- \"aws:SourceAccount\",\n- \"aws:SourceOwner\",\n- \"s3:ResourceAccount\",\n- \"aws:PrincipalAccount\",\n- \"aws:ResourceAccount\",\n+ \"aws:sourceaccount\",\n+ \"aws:sourceowner\",\n+ \"s3:resourceaccount\",\n+ \"aws:principalaccount\",\n+ \"aws:resourceaccount\",\n ],\n \"StringLike\": [\n- \"aws:SourceAccount\",\n- \"aws:SourceOwner\",\n- \"aws:SourceArn\",\n- \"aws:PrincipalArn\",\n- \"aws:ResourceAccount\",\n- \"aws:PrincipalAccount\",\n+ \"aws:sourceaccount\",\n+ \"aws:sourceowner\",\n+ \"aws:sourcearn\",\n+ \"aws:principalarn\",\n+ \"aws:resourceaccount\",\n+ \"aws:principalaccount\",\n ],\n- \"ArnLike\": [\"aws:SourceArn\", \"aws:PrincipalArn\"],\n- \"ArnEquals\": [\"aws:SourceArn\", \"aws:PrincipalArn\"],\n+ \"ArnLike\": [\"aws:sourcearn\", \"aws:principalarn\"],\n+ \"ArnEquals\": [\"aws:sourcearn\", \"aws:principalarn\"],\n }\n \n for condition_operator, condition_operator_key in valid_condition_options.items():\n if condition_operator in condition_statement:\n for value in condition_operator_key:\n+ # We need to transform the condition_statement into lowercase\n+ condition_statement[condition_operator] = {\n+ k.lower(): v\n+ for k, v in condition_statement[condition_operator].items()\n+ }\n+\n if value in condition_statement[condition_operator]:\n # values are a list\n if isinstance(\n", "issue": "[Bug]: Context name on conditions are case-insensitive\n### Steps to Reproduce\n\nAs yo can see here https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_elements_condition.html, context name on conditions are case-insensitive. Some default aws policies are \"AWS:xxxx\" instead of \"aws:xxxx\", so prowler fails to detect it. Also can happen with manual policies, if someone put \"aws:sourceaccount\" inseat of \"aws:SourceAccount\". So is_account_only_allowed_in_condition must be case-insensitive to work.\r\n\r\nI found it on SNS default policy, which look like this:\r\n\r\n```\r\n{\r\n \"Version\": \"2008-10-17\",\r\n \"Id\": \"__default_policy_ID\",\r\n \"Statement\": [\r\n {\r\n \"Sid\": \"__default_statement_ID\",\r\n \"Effect\": \"Allow\",\r\n \"Principal\": {\r\n \"AWS\": \"*\"\r\n },\r\n \"Action\": [\r\n \"SNS:GetTopicAttributes\",\r\n \"SNS:SetTopicAttributes\",\r\n \"SNS:AddPermission\",\r\n \"SNS:RemovePermission\",\r\n \"SNS:DeleteTopic\",\r\n \"SNS:Subscribe\",\r\n \"SNS:ListSubscriptionsByTopic\",\r\n \"SNS:Publish\",\r\n \"SNS:Receive\"\r\n ],\r\n \"Resource\": \"arn:aws:sns:eu-west-1:XXXXXXXX:config-topic\",\r\n \"Condition\": {\r\n \"StringEquals\": {\r\n \"AWS:SourceOwner\": \"XXXXXXXX\"\r\n }\r\n }\r\n }\r\n ]\r\n}\r\n```\r\n\r\n\n\n### Expected behavior\n\nIt should pass when found a condition like \"AWS:SourceOwner\" with a valid value. \n\n### Actual Result with Screenshots or Logs\n\nIt can't detect correctly the condition, so the test fails.\r\n\u256d\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u252c\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u252c\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u252c\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u252c\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u252c\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u252c\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u256e\r\n\u2502 Provider \u2502 Service \u2502 Status \u2502 Critical \u2502 High \u2502 Medium \u2502 Low \u2502\r\n\u251c\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u253c\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u253c\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u253c\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u253c\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u253c\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u253c\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2524\r\n\u2502 aws \u2502 sns \u2502 FAIL (13) \u2502 0 \u2502 13 \u2502 0 \u2502 0 \u2502\r\n\u2570\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2534\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2534\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2534\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2534\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2534\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2534\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u256f\n\n### How did you install Prowler?\n\nCloning the repository from github.com (git clone)\n\n### Environment Resource\n\n8. SNS\n\n### OS used\n\n5. Ubuntu\n\n### Prowler version\n\nProwler 3.8.2\n\n### Pip version\n\npip 23.2.1\n\n### Context\n\n_No response_\n", "before_files": [{"content": "# lista de cuentas y te devuelva las v\u00e1lidas\ndef is_account_only_allowed_in_condition(\n condition_statement: dict, source_account: str\n):\n is_condition_valid = False\n valid_condition_options = {\n \"StringEquals\": [\n \"aws:SourceAccount\",\n \"aws:SourceOwner\",\n \"s3:ResourceAccount\",\n \"aws:PrincipalAccount\",\n \"aws:ResourceAccount\",\n ],\n \"StringLike\": [\n \"aws:SourceAccount\",\n \"aws:SourceOwner\",\n \"aws:SourceArn\",\n \"aws:PrincipalArn\",\n \"aws:ResourceAccount\",\n \"aws:PrincipalAccount\",\n ],\n \"ArnLike\": [\"aws:SourceArn\", \"aws:PrincipalArn\"],\n \"ArnEquals\": [\"aws:SourceArn\", \"aws:PrincipalArn\"],\n }\n\n for condition_operator, condition_operator_key in valid_condition_options.items():\n if condition_operator in condition_statement:\n for value in condition_operator_key:\n if value in condition_statement[condition_operator]:\n # values are a list\n if isinstance(\n condition_statement[condition_operator][value],\n list,\n ):\n # if there is an arn/account without the source account -> we do not consider it safe\n # here by default we assume is true and look for false entries\n is_condition_valid = True\n for item in condition_statement[condition_operator][value]:\n if source_account not in item:\n is_condition_valid = False\n break\n\n # value is a string\n elif isinstance(\n condition_statement[condition_operator][value],\n str,\n ):\n if (\n source_account\n in condition_statement[condition_operator][value]\n ):\n is_condition_valid = True\n\n return is_condition_valid\n", "path": "prowler/providers/aws/lib/policy_condition_parser/policy_condition_parser.py"}]}
| 1,603 | 698 |
gh_patches_debug_28421
|
rasdani/github-patches
|
git_diff
|
plone__Products.CMFPlone-3015
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Plone does not redirect ajax calls
## BUG/PROBLEM REPORT (OR OTHER COMMON ISSUE)
### What I did:
1. Create a document with id "a"
2. Rename it to "b"
3. Run `curl -sI 'http://localhost:8080/Plone/a/@@getVocabulary' -H 'Authorization: Basic YOURB64' -H 'Accept: text/html'`: you will get a redirect (301) + some not useful text ignored by the browser
4. Run `curl -sI 'http://localhost:8080/Plone/a/@@getVocabulary' -H 'Authorization: Basic YOURB64' -H 'Accept: application/json'` you will get a not found json text (status 404)
Note that the two commands differ only for the `Accept` header.
### What I expect to happen:
I expect a 301 when I browse to http://localhost:8080/Plone/a/@@getVocabulary for both the values of the Accept header
</issue>
<code>
[start of Products/CMFPlone/browser/exceptions.py]
1 # -*- coding: utf-8 -*-
2 from AccessControl import getSecurityManager
3 from Products.Five import BrowserView
4 from Products.Five.browser.pagetemplatefile import ViewPageTemplateFile
5 from zExceptions.ExceptionFormatter import format_exception
6
7 import json
8 import sys
9
10
11 class ExceptionView(BrowserView):
12 basic_template = ViewPageTemplateFile('templates/basic_error_message.pt')
13
14 def is_manager(self):
15 return getSecurityManager().checkPermission(
16 'Manage portal', self.context)
17
18 def __call__(self):
19 exception = self.context
20 self.context = self.__parent__
21 request = self.request
22
23 error_type = exception.__class__.__name__
24 exc_type, value, traceback = sys.exc_info()
25 error_tb = ''.join(
26 format_exception(exc_type, value, traceback, as_html=False))
27 request.response.setStatus(exc_type)
28
29 # Indicate exception as JSON
30 if "text/html" not in request.getHeader('Accept', ''):
31 request.response.setHeader("Content-Type", "application/json")
32 return json.dumps({
33 'error_type': error_type,
34 })
35
36 # Render page with user-facing error notice
37 request.set('disable_border', True)
38 request.set('disable_plone.leftcolumn', True)
39 request.set('disable_plone.rightcolumn', True)
40
41 try:
42 return self.index(
43 error_type=error_type,
44 error_tb=error_tb)
45 except:
46 return self.basic_template(
47 error_type=error_type,
48 error_tb=error_tb)
49
[end of Products/CMFPlone/browser/exceptions.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/Products/CMFPlone/browser/exceptions.py b/Products/CMFPlone/browser/exceptions.py
--- a/Products/CMFPlone/browser/exceptions.py
+++ b/Products/CMFPlone/browser/exceptions.py
@@ -1,8 +1,10 @@
# -*- coding: utf-8 -*-
from AccessControl import getSecurityManager
+from plone.memoize.view import memoize
from Products.Five import BrowserView
from Products.Five.browser.pagetemplatefile import ViewPageTemplateFile
from zExceptions.ExceptionFormatter import format_exception
+from zope.component import getMultiAdapter
import json
import sys
@@ -15,12 +17,24 @@
return getSecurityManager().checkPermission(
'Manage portal', self.context)
+ @property
+ @memoize
+ def plone_redirector_view(self):
+ return getMultiAdapter(
+ (self.__parent__, self.request), name="plone_redirector_view"
+ )
+
def __call__(self):
exception = self.context
+ error_type = exception.__class__.__name__
+ if error_type == "NotFound" and self.plone_redirector_view.attempt_redirect():
+ # if a redirect is possible attempt_redirect returns True
+ # and sets the proper location header
+ return
+
self.context = self.__parent__
request = self.request
- error_type = exception.__class__.__name__
exc_type, value, traceback = sys.exc_info()
error_tb = ''.join(
format_exception(exc_type, value, traceback, as_html=False))
|
{"golden_diff": "diff --git a/Products/CMFPlone/browser/exceptions.py b/Products/CMFPlone/browser/exceptions.py\n--- a/Products/CMFPlone/browser/exceptions.py\n+++ b/Products/CMFPlone/browser/exceptions.py\n@@ -1,8 +1,10 @@\n # -*- coding: utf-8 -*-\n from AccessControl import getSecurityManager\n+from plone.memoize.view import memoize\n from Products.Five import BrowserView\n from Products.Five.browser.pagetemplatefile import ViewPageTemplateFile\n from zExceptions.ExceptionFormatter import format_exception\n+from zope.component import getMultiAdapter\n \n import json\n import sys\n@@ -15,12 +17,24 @@\n return getSecurityManager().checkPermission(\n 'Manage portal', self.context)\n \n+ @property\n+ @memoize\n+ def plone_redirector_view(self):\n+ return getMultiAdapter(\n+ (self.__parent__, self.request), name=\"plone_redirector_view\"\n+ )\n+\n def __call__(self):\n exception = self.context\n+ error_type = exception.__class__.__name__\n+ if error_type == \"NotFound\" and self.plone_redirector_view.attempt_redirect():\n+ # if a redirect is possible attempt_redirect returns True\n+ # and sets the proper location header\n+ return\n+\n self.context = self.__parent__\n request = self.request\n \n- error_type = exception.__class__.__name__\n exc_type, value, traceback = sys.exc_info()\n error_tb = ''.join(\n format_exception(exc_type, value, traceback, as_html=False))\n", "issue": "Plone does not redirect ajax calls\n## BUG/PROBLEM REPORT (OR OTHER COMMON ISSUE)\r\n\r\n### What I did:\r\n\r\n1. Create a document with id \"a\"\r\n2. Rename it to \"b\"\r\n3. Run `curl -sI 'http://localhost:8080/Plone/a/@@getVocabulary' -H 'Authorization: Basic YOURB64' -H 'Accept: text/html'`: you will get a redirect (301) + some not useful text ignored by the browser\r\n4. Run `curl -sI 'http://localhost:8080/Plone/a/@@getVocabulary' -H 'Authorization: Basic YOURB64' -H 'Accept: application/json'` you will get a not found json text (status 404)\r\n\r\nNote that the two commands differ only for the `Accept` header.\r\n\r\n### What I expect to happen:\r\n\r\nI expect a 301 when I browse to http://localhost:8080/Plone/a/@@getVocabulary for both the values of the Accept header\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom AccessControl import getSecurityManager\nfrom Products.Five import BrowserView\nfrom Products.Five.browser.pagetemplatefile import ViewPageTemplateFile\nfrom zExceptions.ExceptionFormatter import format_exception\n\nimport json\nimport sys\n\n\nclass ExceptionView(BrowserView):\n basic_template = ViewPageTemplateFile('templates/basic_error_message.pt')\n\n def is_manager(self):\n return getSecurityManager().checkPermission(\n 'Manage portal', self.context)\n\n def __call__(self):\n exception = self.context\n self.context = self.__parent__\n request = self.request\n\n error_type = exception.__class__.__name__\n exc_type, value, traceback = sys.exc_info()\n error_tb = ''.join(\n format_exception(exc_type, value, traceback, as_html=False))\n request.response.setStatus(exc_type)\n\n # Indicate exception as JSON\n if \"text/html\" not in request.getHeader('Accept', ''):\n request.response.setHeader(\"Content-Type\", \"application/json\")\n return json.dumps({\n 'error_type': error_type,\n })\n\n # Render page with user-facing error notice\n request.set('disable_border', True)\n request.set('disable_plone.leftcolumn', True)\n request.set('disable_plone.rightcolumn', True)\n\n try:\n return self.index(\n error_type=error_type,\n error_tb=error_tb)\n except:\n return self.basic_template(\n error_type=error_type,\n error_tb=error_tb)\n", "path": "Products/CMFPlone/browser/exceptions.py"}]}
| 1,193 | 355 |
gh_patches_debug_36768
|
rasdani/github-patches
|
git_diff
|
googleapis__python-bigquery-1309
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Python `bigquery_create_job` sample is inconsistent with other code samples
The https://github.com/googleapis/python-bigquery/blob/main/samples/create_job.py code sample appears here: https://cloud.google.com/bigquery/docs/running-jobs#running_jobs_using_client_libraries
This sample requires two improvements:
* [ ] That section is about any kind of job, not just queries. As such, it should use the [create_job](https://googleapis.dev/python/bigquery/latest/generated/google.cloud.bigquery.client.Client.html#google.cloud.bigquery.client.Client.create_job) method instead of the more specific `query` method. There should be comments that it is recommended to use the corresponding method for query/copy/load/extract.
* [ ] Remove `job_id_prefix` logic, as labels cover similar functionality and are recommended over custom job IDs.
* [ ] Move the sample to the `samples/snippets` directory. Needs to be done in 2 separate PRs so that the existing samples in the docs don't 404.
</issue>
<code>
[start of samples/create_job.py]
1 # Copyright 2019 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import typing
16
17 if typing.TYPE_CHECKING:
18 from google.cloud import bigquery
19
20
21 def create_job() -> "bigquery.QueryJob":
22
23 # [START bigquery_create_job]
24 from google.cloud import bigquery
25
26 # Construct a BigQuery client object.
27 client = bigquery.Client()
28
29 query_job = client.query(
30 "SELECT country_name from `bigquery-public-data.utility_us.country_code_iso`",
31 # Explicitly force job execution to be routed to a specific processing
32 # location.
33 location="US",
34 # Specify a job configuration to set optional job resource properties.
35 job_config=bigquery.QueryJobConfig(
36 labels={"example-label": "example-value"}, maximum_bytes_billed=1000000
37 ),
38 # The client libraries automatically generate a job ID. Override the
39 # generated ID with either the job_id_prefix or job_id parameters.
40 job_id_prefix="code_sample_",
41 ) # Make an API request.
42
43 print("Started job: {}".format(query_job.job_id))
44 # [END bigquery_create_job]
45 return query_job
46
[end of samples/create_job.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/samples/create_job.py b/samples/create_job.py
--- a/samples/create_job.py
+++ b/samples/create_job.py
@@ -13,12 +13,13 @@
# limitations under the License.
import typing
+from typing import Union
if typing.TYPE_CHECKING:
- from google.cloud import bigquery
+ from google.cloud.bigquery import LoadJob, CopyJob, ExtractJob, QueryJob
-def create_job() -> "bigquery.QueryJob":
+def create_job() -> "Union[LoadJob, CopyJob, ExtractJob, QueryJob]":
# [START bigquery_create_job]
from google.cloud import bigquery
@@ -26,20 +27,41 @@
# Construct a BigQuery client object.
client = bigquery.Client()
- query_job = client.query(
- "SELECT country_name from `bigquery-public-data.utility_us.country_code_iso`",
- # Explicitly force job execution to be routed to a specific processing
- # location.
- location="US",
- # Specify a job configuration to set optional job resource properties.
- job_config=bigquery.QueryJobConfig(
- labels={"example-label": "example-value"}, maximum_bytes_billed=1000000
- ),
- # The client libraries automatically generate a job ID. Override the
- # generated ID with either the job_id_prefix or job_id parameters.
- job_id_prefix="code_sample_",
+ query_job = client.create_job(
+ # Specify a job configuration, providing a query
+ # and/or optional job resource properties, as needed.
+ # The job instance can be a LoadJob, CopyJob, ExtractJob, QueryJob
+ # Here, we demonstrate a "query" job.
+ # References:
+ # https://googleapis.dev/python/bigquery/latest/generated/google.cloud.bigquery.client.Client.html#google.cloud.bigquery.client.Client.create_job
+ # https://cloud.google.com/bigquery/docs/reference/rest/v2/Job
+ #
+ # Example use cases for .create_job() include:
+ # * to retry failed jobs
+ # * to generate jobs with an experimental API property that hasn't
+ # been added to one of the manually written job configuration
+ # classes yet
+ #
+ # NOTE: unless it is necessary to create a job in this way, the
+ # preferred approach is to use one of the dedicated API calls:
+ # client.query()
+ # client.extract_table()
+ # client.copy_table()
+ # client.load_table_file(), client.load_table_from_dataframe(), etc
+ job_config={
+ "query": {
+ "query": """
+ SELECT country_name
+ FROM `bigquery-public-data.utility_us.country_code_iso`
+ LIMIT 5
+ """,
+ },
+ "labels": {"example-label": "example-value"},
+ "maximum_bytes_billed": 10000000,
+ }
) # Make an API request.
- print("Started job: {}".format(query_job.job_id))
+ print(f"Started job: {query_job.job_id}")
# [END bigquery_create_job]
+
return query_job
|
{"golden_diff": "diff --git a/samples/create_job.py b/samples/create_job.py\n--- a/samples/create_job.py\n+++ b/samples/create_job.py\n@@ -13,12 +13,13 @@\n # limitations under the License.\n \n import typing\n+from typing import Union\n \n if typing.TYPE_CHECKING:\n- from google.cloud import bigquery\n+ from google.cloud.bigquery import LoadJob, CopyJob, ExtractJob, QueryJob\n \n \n-def create_job() -> \"bigquery.QueryJob\":\n+def create_job() -> \"Union[LoadJob, CopyJob, ExtractJob, QueryJob]\":\n \n # [START bigquery_create_job]\n from google.cloud import bigquery\n@@ -26,20 +27,41 @@\n # Construct a BigQuery client object.\n client = bigquery.Client()\n \n- query_job = client.query(\n- \"SELECT country_name from `bigquery-public-data.utility_us.country_code_iso`\",\n- # Explicitly force job execution to be routed to a specific processing\n- # location.\n- location=\"US\",\n- # Specify a job configuration to set optional job resource properties.\n- job_config=bigquery.QueryJobConfig(\n- labels={\"example-label\": \"example-value\"}, maximum_bytes_billed=1000000\n- ),\n- # The client libraries automatically generate a job ID. Override the\n- # generated ID with either the job_id_prefix or job_id parameters.\n- job_id_prefix=\"code_sample_\",\n+ query_job = client.create_job(\n+ # Specify a job configuration, providing a query\n+ # and/or optional job resource properties, as needed.\n+ # The job instance can be a LoadJob, CopyJob, ExtractJob, QueryJob\n+ # Here, we demonstrate a \"query\" job.\n+ # References:\n+ # https://googleapis.dev/python/bigquery/latest/generated/google.cloud.bigquery.client.Client.html#google.cloud.bigquery.client.Client.create_job\n+ # https://cloud.google.com/bigquery/docs/reference/rest/v2/Job\n+ #\n+ # Example use cases for .create_job() include:\n+ # * to retry failed jobs\n+ # * to generate jobs with an experimental API property that hasn't\n+ # been added to one of the manually written job configuration\n+ # classes yet\n+ #\n+ # NOTE: unless it is necessary to create a job in this way, the\n+ # preferred approach is to use one of the dedicated API calls:\n+ # client.query()\n+ # client.extract_table()\n+ # client.copy_table()\n+ # client.load_table_file(), client.load_table_from_dataframe(), etc\n+ job_config={\n+ \"query\": {\n+ \"query\": \"\"\"\n+ SELECT country_name\n+ FROM `bigquery-public-data.utility_us.country_code_iso`\n+ LIMIT 5\n+ \"\"\",\n+ },\n+ \"labels\": {\"example-label\": \"example-value\"},\n+ \"maximum_bytes_billed\": 10000000,\n+ }\n ) # Make an API request.\n \n- print(\"Started job: {}\".format(query_job.job_id))\n+ print(f\"Started job: {query_job.job_id}\")\n # [END bigquery_create_job]\n+\n return query_job\n", "issue": "Python `bigquery_create_job` sample is inconsistent with other code samples\nThe https://github.com/googleapis/python-bigquery/blob/main/samples/create_job.py code sample appears here: https://cloud.google.com/bigquery/docs/running-jobs#running_jobs_using_client_libraries\r\n\r\nThis sample requires two improvements:\r\n\r\n* [ ] That section is about any kind of job, not just queries. As such, it should use the [create_job](https://googleapis.dev/python/bigquery/latest/generated/google.cloud.bigquery.client.Client.html#google.cloud.bigquery.client.Client.create_job) method instead of the more specific `query` method. There should be comments that it is recommended to use the corresponding method for query/copy/load/extract.\r\n* [ ] Remove `job_id_prefix` logic, as labels cover similar functionality and are recommended over custom job IDs.\r\n* [ ] Move the sample to the `samples/snippets` directory. Needs to be done in 2 separate PRs so that the existing samples in the docs don't 404.\n", "before_files": [{"content": "# Copyright 2019 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport typing\n\nif typing.TYPE_CHECKING:\n from google.cloud import bigquery\n\n\ndef create_job() -> \"bigquery.QueryJob\":\n\n # [START bigquery_create_job]\n from google.cloud import bigquery\n\n # Construct a BigQuery client object.\n client = bigquery.Client()\n\n query_job = client.query(\n \"SELECT country_name from `bigquery-public-data.utility_us.country_code_iso`\",\n # Explicitly force job execution to be routed to a specific processing\n # location.\n location=\"US\",\n # Specify a job configuration to set optional job resource properties.\n job_config=bigquery.QueryJobConfig(\n labels={\"example-label\": \"example-value\"}, maximum_bytes_billed=1000000\n ),\n # The client libraries automatically generate a job ID. Override the\n # generated ID with either the job_id_prefix or job_id parameters.\n job_id_prefix=\"code_sample_\",\n ) # Make an API request.\n\n print(\"Started job: {}\".format(query_job.job_id))\n # [END bigquery_create_job]\n return query_job\n", "path": "samples/create_job.py"}]}
| 1,200 | 730 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.