
content
stringlengths 228
999k
| pred_label
stringclasses 1
value | pred_score
float64 0.5
1
|
|---|---|---|
1. BassAceGold
OP BassAceGold Testicles
Member
Joined:
Aug 14, 2006
Messages:
495
Country:
Canada
So while I was trying to port a library to the DSTwo, the newest zlib, I have noticed that the official libraries for the DSTwo were missing a few file handling functions.
So basically this unofficial release adds basic unistd support (ds2_unistd.h) which contains the functions - close, lseek, write and read. Very basic fcntl support has been added as well (ds2_fcntl.h) which only contains the open function (fcntl function has yet to be completed).
zlib 1.5.2 has also been included and modified for use with the sdk as well. I have currently only tested gzip compression/decompression and it seems to work fine so far.
The updated library can be found here.
Newest library update (R2-2.2)
Margen67 likes this.
2. BassAceGold
OP BassAceGold Testicles
Member
Joined:
Aug 14, 2006
Messages:
495
Country:
Canada
Release 2!
Includes some various fixes such as:
-faster fopen times
-mkdir now works (may not have been a previous issue)
-makes the DS2's DMA copy features available
and a big one:
-More CPU clock levels!
The DMA and CPU features have been added to the folder libsrc/core and are just modifications of the files found in the
Supercard SDK 1.2 sources. This library features additions to the Supercard SDK 0.13 beta release which contains more audio buffers
and a working ds2_plug_exit() function that is broken in the official 1.2 sources.
**CPU CLOCK NOTES**
For the cpu clock levels, I've managed to get my Supercard to 456MHz (level 18). I haven't tested if it's stable and overclocking
results may differ on a per card basis. There is no guarantee that your card can achieve such results, but there is probably no
harm in trying. I also have not done any testing to the extent of heat output at such levels, and if it may be damaging to the surrounding
components or not.
New clock levels can be added, and current clock levels changed, by manipulating the pll_m_n array in the libsrc/core/ds2_cpuclock.c file
Regardless, use these levels at your own risk!
Perhaps I'll throw a program together for CPU testing so we can generate an average overclock that people can obtain on their cards.
Download Here
Margen67 likes this.
3. Nebuleon
Nebuleon MAH BOI/GURL
Member
Joined:
Dec 22, 2012
Messages:
900
Country:
Canada
Were there any meaningful changes between 0.13 and 1.2, and is your library based more on 0.13 or on 1.2?
Would you be open to adding C compilation flags from CATSFC into your program library if they make zlib go faster at level 9 when the CPU clock is constant?
I'll try out your modifications to the CPU and DMA in CATSFC and DS2Compress experimental branches after releasing CATSFC 1.25, and I'll report results here! :) In the meanwhile, if an overclocker becomes available, I'll test it out.
4. BassAceGold
OP BassAceGold Testicles
Member
Joined:
Aug 14, 2006
Messages:
495
Country:
Canada
The library is based on 0.13. As far as changes, I think 0.13 was an after thought, it fixed somethings from a previous release of the SDK but then they only released the source for that previous version of the SDK and labeled as 1.2 (probably based on the 0.12 sources). The DMA and CPU clock stuff was code taken from libds2b sources provided in the 1.2 release of the sdk.
What C flags are there to add?
5. Rydian
Rydian Resident Furvert™
Member
Joined:
Feb 4, 2010
Messages:
27,880
Country:
United States
Hahahaha, wow.
Man, this is tempting, but I don't have any replacements in case mine gets damaged (neither DSTwo or DS unit).
6. Nebuleon
Nebuleon MAH BOI/GURL
Member
Joined:
Dec 22, 2012
Messages:
900
Country:
Canada
From CATSFC:
Code:
CFLAGS := -mips32 -mno-abicalls -fno-pic -fno-builtin \
-fno-exceptions -ffunction-sections -mno-long-calls \
-msoft-float -G 4 \
-O3 -fomit-frame-pointer -fgcse-sm -fgcse-las -fgcse-after-reload \
-fweb -fpeel-loops
You could probably add everything that's after -O3, as well as -mno-long-calls. -mno-long-calls makes every function call into a jal instruction, instead of loading the address in 2 instructions then jumping to it with jalr.
-mno-long-calls:
Code:
jal <address of SomeZlibInternalFunction / 4>
-mlong-calls:
Code:
lui t5, <address of SomeZlibInternalFunction, upper 16 bits>
add t5, <address of SomeZlibInternalFunction, lower 16 bits>
jalr t5
GCSE and -fpeel-loops are for loops.
Indeed... that is also my case. However, 456 MHz should be pretty safe as far as overclocking standards go. I wouldn't trust anything over 550 MHz, though! Plus, BAG's DSTwo is still probably in good shape after the 456 MHz test, or he wouldn't be testing anymore and posting a big red warning sign instead ;)
7. Rydian
Rydian Resident Furvert™
Member
Joined:
Feb 4, 2010
Messages:
27,880
Country:
United States
I suppose, but I've got one of those limited-edition GBATemp DSTwo units, a little protective of it.
8. BassAceGold
OP BassAceGold Testicles
Member
Joined:
Aug 14, 2006
Messages:
495
Country:
Canada
The worst I find with overclocking is that the CPU will just stall if it doesn't work; it seem pretty resilient. I don't think the NDS slot can output enough power to overclock the cpu to a state where it could do harm.
Adding em now.
9. Nebuleon
Nebuleon MAH BOI/GURL
Member
Joined:
Dec 22, 2012
Messages:
900
Country:
Canada
Please pull from my CATSFC experimental branch: https://github.com/ShadauxCat/CATSFC/tree/experimental
and compare with master: https://github.com/ShadauxCat/CATSFC/tree/master
The experimental branch goes to /EXPSFC on your card, and it compiles to expsfc.plg, so you don't need to worry about overwriting constantly.
It looks like the ds2_setCPULevel function delays for an entire second before working, and the video is way choppier than usual at "CPU speed 5" (denoted as 396 MHz in /Options). Could it be that mdelay, udelay and getSysTime are all way slower?
10. Nebuleon
Nebuleon MAH BOI/GURL
Member
Joined:
Dec 22, 2012
Messages:
900
Country:
Canada
For the record, 438 MHz is decently stable, and 456 MHz is an instant freeze when exiting the menu, for my Supercard DSTwo.
11. BassAceGold
OP BassAceGold Testicles
Member
Joined:
Aug 14, 2006
Messages:
495
Country:
Canada
I had made a build of CATSFC with the new cpu level function, and a new build of BAGSFC with it. BAGSFC seemed to accept it much better than CATSFC does. In my own personal programs, I haven't had any issues with getSysTime being slower--if that were the case, I wouldn't be measuring better performance with the overclock.
Maybe mdelay and udelay are slower. I generally try to avoid using those as it is a waste of power, but if they are necessary for stability (because the SDK sucks like that), you could try using __dcache_writeback_all(); instead. This just makes sure all changes in the DS2's cpu cache are actually written back to the memory and not dropped, which has caused me quite a bit of problems before.
Ok, here is whats happening:
These features of the SDK regarding the hardware (cpu clocks and dma) aren't accessible by default, that is, they aren't supposed to be accessed by anyone since it was closed source to begin with. Any code from this portion can be accessed if you know the name of the function you want and can define an extern prototype for it. Through this way, you would be using the native functions already provided in the library (libds2b). However, since I have made changes and have not compiled these changes to the original library (libds2b, but they are "redefined" in libds2a), there are actually two versions of some code that can be accessed(native vs my changes).
The cpu functions happen to store some values in certain variables, which could not be accessed through the extern method since they are defined locally in the file. So these had to be copied/redefined into the new code. The udelay function depends on one of these variables, but since we are manipulating the copied version with ds2_setCPULevel, udelay operates incorrectly using the native version of said variable.
So to fix udelay/mdelay, we need to make our own variants of the functions that use the variable that is updated by my copy of the detect_clock() function. So basically, we just need to re-add them to the ds2_cpuclock file, and call the functions something else to avoid conflicts with the native code.
Code:
void udelayX(unsigned int usec)
{
unsigned int i = usec * (_iclk / 2000000);
__asm__ __volatile__ (
"\t.set noreorder\n"
"1:\n\t"
"bne\t%0, $0, 1b\n\t"
"addi\t%0, %0, -1\n\t"
".set reorder\n"
: "=r" (i)
: "0" (i)
);
}
void mdelayX(unsigned int msec)
{
int i;
for(i=0;i<msec;i++)
{
udelay(1000);
}
}
And then define those in a place where they can be found by the programmer to use in their programs.
I shall have a fixed version of the library up in a bit with these changes.
Alright, here is the update:
http://filetrip.net/dl?CCv0QSb7k8
The functions are now:
ds2_udelay(...) and
ds2_mdelay(...)
12. Nebuleon
Nebuleon MAH BOI/GURL
Member
Joined:
Dec 22, 2012
Messages:
900
Country:
Canada
Thanks; I'll deal with those later today or tomorrow. I'll also modify any remaining references to ds2_setCPUclocklevel, if any.
Can I assume that getSysTime() is correct, by the way?
edit: As for mdelay and udelay, I use them for ensuring that ds2_setBacklight doesn't crash (100 milliseconds does it) and formerly for synchronisation of frame times, but I believe some speed-syncing code in Snes9x itself was retrofitted to use mdelay somewhere.
(in 1.25 I call S9xProcessSound instead of udelay just in case I'm missing 11 milliseconds already, to avoid crackling)
However, I think the internal communication functions use udelay too. I'll need to look at that.
13. Nebuleon
Nebuleon MAH BOI/GURL
Member
Joined:
Dec 22, 2012
Messages:
900
Country:
Canada
Please pull again from my experimental branch: https://github.com/ShadauxCat/CATSFC/tree/experimental
Commit c6f98980230ace9efc950525eddf5efce417c4f3 isolates a crash/freeze in function fat_getDiskSpaceInfo.
* Compile, run, go into Options and observe that the emulator has frozen.
* Add -DDISABLE_FREE_SPACE to the Makefile's DEFS variable.
* Compile, run, go into Options and observe that the emulator continues working, with a placeholder ??? for card capacity.
The ds2_mdelay function works well, though! It's not uber-slow anymore.
14. Nebuleon
Nebuleon MAH BOI/GURL
Member
Joined:
Dec 22, 2012
Messages:
900
Country:
Canada
Addendum: Nope, it doesn't work so well. Starting at 420 MHz, and maybe lower, I touch the lower screen to return to the menu and it doesn't even get to setting the backlight, so there must be some kind of freeze, crash or infinite loop caused by overflow in ds2_setCPULevel(0) from level 15+.
15. BassAceGold
OP BassAceGold Testicles
Member
Joined:
Aug 14, 2006
Messages:
495
Country:
Canada
Honestly, that menu code is a mess, and the DSTwo is such an unstable system anyway, so I wouldn't put all these problems as simply a result of overclocking. The overclocking might just be expressing some problems you may eventually run into in the future.
However, it does suck that these problems even exist at all. For now I shall experiment with overclocking in my own programs for I have had some success with it myself.
16. Nebuleon
Nebuleon MAH BOI/GURL
Member
Joined:
Dec 22, 2012
Messages:
900
Country:
Canada
I fixed a load of crash bugs in the menu that were expressed in CATSFC 1.19 at 394 MHz (= 13); the previous menu was not set to NULL sometimes before calling choose_menu(&main_menu), so an inexistent end_function was called for it. Now those crashes shouldn't happen anymore.
But what I do is set the CPU clock back to 60 MHz (= 0) in menus. My rationale is that the user won't need to run a higher clock in the menu, waste every cycle anyway and thus waste battery life. At 394 MHz this is stable, at 408 MHz it appears to be stable so far, but at 420 MHz it runs up to 5 minutes before crashing.
Do you lower the CPU to 60 MHz sometimes in your programs?
17. BassAceGold
OP BassAceGold Testicles
Member
Joined:
Aug 14, 2006
Messages:
495
Country:
Canada
There are a few cpu levels on the lower frequencies that don't even work for me no matter what, so I try to keep the cpu on levels that do work. Those stable clocks usually don't cause any problems when switching between them. Can't say I've ever had luck with levels 0, 2, 5, and 7.
18. Nebuleon
Nebuleon MAH BOI/GURL
Member
Joined:
Dec 22, 2012
Messages:
900
Country:
Canada
In commit 0568880af3ce49ba60d699f3ceeb89a510823040 I made the emulator go to 120 MHz (= 1) instead of 60 MHz, and made it easier to change the "low" level used by the menu to save on power usage: everything is funneled through LowFrequencyCPU().
With that commit, 420 MHz (= 15) is stable on my cart, whereas it was not before.
438 MHz (= 16) crashes when touching the lower screen after a few minutes, and seems slower than 420 MHz;
444 MHz (= 17) crashes when touching the lower screen after a minute, or on its own at some point during emulation;
456 MHz (= 18) crashes before the first frame is emitted after exiting the menu.
Margen67 likes this.
19. Nebuleon
Nebuleon MAH BOI/GURL
Member
Joined:
Dec 22, 2012
Messages:
900
Country:
Canada
Alright, I'm still encountering roadblocks and glitches with the release 2 of this libds2a.a, such as waiting 1 entire second before clearing the menu screen (it's not after disabling the lower backlight this time) and odd glitches in DMA near the end of a rendered screen. I can't continue using this; if you want some code to chew on, though, feel free to make pull requests on the experimental branch.
Pull from experimental again and load Yoshi's Cookie or Chrono Trigger, and you might see partial text being rendered.
EDIT: DMA was bad because the last bytes to be written to the screen were still only in the data cache. Calling __dcache_writeback_all() before DMA fixed it.
Here's how the Yoshi's Cookie title screen looked without it:
yoshis-cookie-with-dma.png
20. BassAceGold
OP BassAceGold Testicles
Member
Joined:
Aug 14, 2006
Messages:
495
Country:
Canada
I'm curious now, do you still have issues with the newest release of this lib now that you have your sdk problems fixed? I just compiled your newest experimental build of CATSFC with it and haven't noticed any issues yet (apart from unstable clock speeds in the very upper end). I'll keep testing things and we'll see what happens.
Draft saved Draft deleted
Loading...
Hide similar threads Similar threads with keywords - unofficial, libds2a,
|
__label__pos
| 0.514153 |
Commit 409dfc83 authored by Nigel Kukard's avatar Nigel Kukard
Browse files
Merge branch 'closures' into 'master'
Closures
- Added Section 7.5. on Closures based on PSR-1
See merge request !14
parents 82417b3d 44968ba7
......@@ -400,6 +400,96 @@ switch ($expr) {
}
```
## 7.5. Closures
Closures MUST be declared with a space after the function keyword, and a space before and after the use keyword.
The opening brace MUST go on the same line, and the closing brace MUST go on the next line following the body.
There MUST NOT be a space after the opening parenthesis of the argument list or variable list,
and there MUST NOT be a space before the closing parenthesis of the argument list or variable list.
In the argument list and variable list, there MUST NOT be a space before each comma, and there MUST be one space after each comma.
Closure arguments with default values MUST go at the end of the argument list.
A closure declaration looks like the following. Note the placement of parentheses, commas, spaces, and braces:
<?php
$closureWithArgs = function ($arg1, $arg2) {
// body
};
$closureWithArgsAndVars = function ($arg1, $arg2) use ($var1, $var2) {
// body
};
Argument lists and variable lists MAY be split across multiple lines, where each subsequent line is indented once.
When doing so, the first item in the list MUST be on the next line, and there MUST be only one argument or variable per line.
When the ending list (whether or arguments or variables) is split across multiple lines, the closing parenthesis and opening
brace MUST be placed together on their own line with one space between them.
The following are examples of closures with and without argument lists and variable lists split across multiple lines.
Example...
```php
<?php
$longArgs_noVars = function (
$longArgument,
$longerArgument,
$muchLongerArgument
) {
// body
};
$noArgs_longVars = function () use (
$longVar1,
$longerVar2,
$muchLongerVar3
) {
// body
};
$longArgs_longVars = function (
$longArgument,
$longerArgument,
$muchLongerArgument
) use (
$longVar1,
$longerVar2,
$muchLongerVar3
) {
// body
};
$longArgs_shortVars = function (
$longArgument,
$longerArgument,
$muchLongerArgument
) use ($var1) {
// body
};
$shortArgs_longVars = function ($arg) use (
$longVar1,
$longerVar2,
$muchLongerVar3
) {
// body
};
```
Note that the formatting rules also apply when the closure is used directly in a function or method call as an argument.
Example...
```php
<?php
$foo->bar(
$arg1,
function ($arg2) use ($var1) {
// body
},
$arg3
);
```
## 8. HTML PHP Mixed
### 8.1. No indentation for php tags unless it's on 1 line
......
Markdown is supported
0% or .
You are about to add 0 people to the discussion. Proceed with caution.
Finish editing this message first!
Please register or to comment
|
__label__pos
| 0.980737 |
Q Write a query to display the name, job title and salary of employee who do not have manager.
Table :-
Answer :-
Select ename , job , sal from Empl
Where job <> "manager" ;
26 Comments
You can help us by Clicking on ads. ^_^
Please do not send spam comment : )
1. where is not equal sign?
ReplyDelete
2. Select ename , job , sal
from Empl
where mgr IS NULL;
ReplyDelete
Replies
1. Output is :-
AMIR, PRISIDENT, 5000.00
Delete
2. thank u a lot. needed that too
Delete
3. Is it correct?
Delete
3. manager pe quotes bhi hone chahiye..
ReplyDelete
4. Select ename , job , sal
from Empl
where mgr IS NULL;
Can't this be the answer to this question as MGR in table stands for manager only
ReplyDelete
Replies
1. He was asking for output not telling us answer.
Delete
5. select ename,job,sal from empl where job <>"manager";
ReplyDelete
6. where is not equal to sign
ReplyDelete
7. we can also write like this select ename,job,sal from empl where job not in manager
ReplyDelete
8. Why <> this symbol ?
ReplyDelete
9. )Increment the salary of all clerks by 25/-.
ReplyDelete
10. Wrong answer
It should be --> select ename, job, sal from Empl where mgr is Null;
ReplyDelete
11. bro but in paper we can write the syblol of not equal to right?
ReplyDelete
Post a Comment
You can help us by Clicking on ads. ^_^
Please do not send spam comment : )
Previous Post Next Post
|
__label__pos
| 0.999681 |
Laravel Nova is now available! Get your copy today!
Routing
Basic Routing
The most basic Laravel routes accept a URI and a Closure, providing a very simple and expressive method of defining routes:
Route::get('foo', function () {
return 'Hello World';
});
The Default Route Files
All Laravel routes are defined in your route files, which are located in the routes directory. These files are automatically loaded by the framework. The routes/web.php file defines routes that are for your web interface. These routes are assigned the web middleware group, which provides features like session state and CSRF protection. The routes in routes/api.php are stateless and are assigned the api middleware group.
For most applications, you will begin by defining routes in your routes/web.php file. The routes defined in routes/web.php may be accessed by entering the defined route's URL in your browser. For example, you may access the following route by navigating to http://your-app.dev/user in your browser:
Route::get('/user', '[email protected]');
Routes defined in the routes/api.php file are nested within a route group by the RouteServiceProvider. Within this group, the /api URI prefix is automatically applied so you do not need to manually apply it to every route in the file. You may modify the prefix and other route group options by modifying your RouteServiceProvider class.
Available Router Methods
The router allows you to register routes that respond to any HTTP verb:
Route::get($uri, $callback);
Route::post($uri, $callback);
Route::put($uri, $callback);
Route::patch($uri, $callback);
Route::delete($uri, $callback);
Route::options($uri, $callback);
Sometimes you may need to register a route that responds to multiple HTTP verbs. You may do so using the match method. Or, you may even register a route that responds to all HTTP verbs using the any method:
Route::match(['get', 'post'], '/', function () {
//
});
Route::any('foo', function () {
//
});
CSRF Protection
Any HTML forms pointing to POST, PUT, or DELETE routes that are defined in the web routes file should include a CSRF token field. Otherwise, the request will be rejected. You can read more about CSRF protection in the CSRF documentation:
<form method="POST" action="/profile">
{{ csrf_field() }}
...
</form>
Redirect Routes
If you are defining a route that redirects to another URI, you may use the Route::redirect method. This method provides a convenient shortcut so that you do not have to define a full route or controller for performing a simple redirect:
Route::redirect('/here', '/there', 301);
View Routes
If your route only needs to return a view, you may use the Route::view method. Like the redirect method, this method provides a simple shortcut so that you do not have to define a full route or controller. The view method accepts a URI as its first argument and a view name as its second argument. In addition, you may provide an array of data to pass to the view as an optional third argument:
Route::view('/welcome', 'welcome');
Route::view('/welcome', 'welcome', ['name' => 'Taylor']);
Route Parameters
Required Parameters
Of course, sometimes you will need to capture segments of the URI within your route. For example, you may need to capture a user's ID from the URL. You may do so by defining route parameters:
Route::get('user/{id}', function ($id) {
return 'User '.$id;
});
You may define as many route parameters as required by your route:
Route::get('posts/{post}/comments/{comment}', function ($postId, $commentId) {
//
});
Route parameters are always encased within {} braces and should consist of alphabetic characters, and may not contain a - character. Instead of using the - character, use an underscore (_). Route parameters are injected into route callbacks / controllers based on their order - the names of the callback / controller arguments do not matter.
Optional Parameters
Occasionally you may need to specify a route parameter, but make the presence of that route parameter optional. You may do so by placing a ? mark after the parameter name. Make sure to give the route's corresponding variable a default value:
Route::get('user/{name?}', function ($name = null) {
return $name;
});
Route::get('user/{name?}', function ($name = 'John') {
return $name;
});
Regular Expression Constraints
You may constrain the format of your route parameters using the where method on a route instance. The where method accepts the name of the parameter and a regular expression defining how the parameter should be constrained:
Route::get('user/{name}', function ($name) {
//
})->where('name', '[A-Za-z]+');
Route::get('user/{id}', function ($id) {
//
})->where('id', '[0-9]+');
Route::get('user/{id}/{name}', function ($id, $name) {
//
})->where(['id' => '[0-9]+', 'name' => '[a-z]+']);
Global Constraints
If you would like a route parameter to always be constrained by a given regular expression, you may use the pattern method. You should define these patterns in the boot method of your RouteServiceProvider:
/**
* Define your route model bindings, pattern filters, etc.
*
* @return void
*/
public function boot()
{
Route::pattern('id', '[0-9]+');
parent::boot();
}
Once the pattern has been defined, it is automatically applied to all routes using that parameter name:
Route::get('user/{id}', function ($id) {
// Only executed if {id} is numeric...
});
Named Routes
Named routes allow the convenient generation of URLs or redirects for specific routes. You may specify a name for a route by chaining the name method onto the route definition:
Route::get('user/profile', function () {
//
})->name('profile');
You may also specify route names for controller actions:
Route::get('user/profile', '[email protected]')->name('profile');
Generating URLs To Named Routes
Once you have assigned a name to a given route, you may use the route's name when generating URLs or redirects via the global route function:
// Generating URLs...
$url = route('profile');
// Generating Redirects...
return redirect()->route('profile');
If the named route defines parameters, you may pass the parameters as the second argument to the route function. The given parameters will automatically be inserted into the URL in their correct positions:
Route::get('user/{id}/profile', function ($id) {
//
})->name('profile');
$url = route('profile', ['id' => 1]);
Inspecting The Current Route
If you would like to determine if the current request was routed to a given named route, you may use the named method on a Route instance. For example, you may check the current route name from a route middleware:
/**
* Handle an incoming request.
*
* @param \Illuminate\Http\Request $request
* @param \Closure $next
* @return mixed
*/
public function handle($request, Closure $next)
{
if ($request->route()->named('profile')) {
//
}
return $next($request);
}
Route Groups
Route groups allow you to share route attributes, such as middleware or namespaces, across a large number of routes without needing to define those attributes on each individual route. Shared attributes are specified in an array format as the first parameter to the Route::group method.
Middleware
To assign middleware to all routes within a group, you may use the middleware method before defining the group. Middleware are executed in the order they are listed in the array:
Route::middleware(['first', 'second'])->group(function () {
Route::get('/', function () {
// Uses first & second Middleware
});
Route::get('user/profile', function () {
// Uses first & second Middleware
});
});
Namespaces
Another common use-case for route groups is assigning the same PHP namespace to a group of controllers using the namespace method:
Route::namespace('Admin')->group(function () {
// Controllers Within The "App\Http\Controllers\Admin" Namespace
});
Remember, by default, the RouteServiceProvider includes your route files within a namespace group, allowing you to register controller routes without specifying the full App\Http\Controllers namespace prefix. So, you only need to specify the portion of the namespace that comes after the base App\Http\Controllers namespace.
Sub-Domain Routing
Route groups may also be used to handle sub-domain routing. Sub-domains may be assigned route parameters just like route URIs, allowing you to capture a portion of the sub-domain for usage in your route or controller. The sub-domain may be specified by calling the domain method before defining the group:
Route::domain('{account}.myapp.com')->group(function () {
Route::get('user/{id}', function ($account, $id) {
//
});
});
Route Prefixes
The prefix method may be used to prefix each route in the group with a given URI. For example, you may want to prefix all route URIs within the group with admin:
Route::prefix('admin')->group(function () {
Route::get('users', function () {
// Matches The "/admin/users" URL
});
});
Route Name Prefixes
The name method may be used to prefix each route name in the group with a given string. For example, you may want to prefix all of the grouped route's names with admin. The given string is prefixed to the route name exactly as it is specified, so we will be sure to provide the trailing . character in the prefix:
Route::name('admin.')->group(function () {
Route::get('users', function () {
// Route assigned name "admin.users"...
});
});
Route Model Binding
When injecting a model ID to a route or controller action, you will often query to retrieve the model that corresponds to that ID. Laravel route model binding provides a convenient way to automatically inject the model instances directly into your routes. For example, instead of injecting a user's ID, you can inject the entire User model instance that matches the given ID.
Implicit Binding
Laravel automatically resolves Eloquent models defined in routes or controller actions whose type-hinted variable names match a route segment name. For example:
Route::get('api/users/{user}', function (App\User $user) {
return $user->email;
});
Since the $user variable is type-hinted as the App\User Eloquent model and the variable name matches the {user} URI segment, Laravel will automatically inject the model instance that has an ID matching the corresponding value from the request URI. If a matching model instance is not found in the database, a 404 HTTP response will automatically be generated.
Customizing The Key Name
If you would like model binding to use a database column other than id when retrieving a given model class, you may override the getRouteKeyName method on the Eloquent model:
/**
* Get the route key for the model.
*
* @return string
*/
public function getRouteKeyName()
{
return 'slug';
}
Explicit Binding
To register an explicit binding, use the router's model method to specify the class for a given parameter. You should define your explicit model bindings in the boot method of the RouteServiceProvider class:
public function boot()
{
parent::boot();
Route::model('user', App\User::class);
}
Next, define a route that contains a {user} parameter:
Route::get('profile/{user}', function ($user) {
//
});
Since we have bound all {user} parameters to the App\User model, a User instance will be injected into the route. So, for example, a request to profile/1 will inject the User instance from the database which has an ID of 1.
If a matching model instance is not found in the database, a 404 HTTP response will be automatically generated.
Customizing The Resolution Logic
If you wish to use your own resolution logic, you may use the Route::bind method. The Closure you pass to the bind method will receive the value of the URI segment and should return the instance of the class that should be injected into the route:
public function boot()
{
parent::boot();
Route::bind('user', function ($value) {
return App\User::where('name', $value)->first() ?? abort(404);
});
}
Form Method Spoofing
HTML forms do not support PUT, PATCH or DELETE actions. So, when defining PUT, PATCH or DELETE routes that are called from an HTML form, you will need to add a hidden _method field to the form. The value sent with the _method field will be used as the HTTP request method:
<form action="/foo/bar" method="POST">
<input type="hidden" name="_method" value="PUT">
<input type="hidden" name="_token" value="{{ csrf_token() }}">
</form>
You may use the method_field helper to generate the _method input:
{{ method_field('PUT') }}
Accessing The Current Route
You may use the current, currentRouteName, and currentRouteAction methods on the Route facade to access information about the route handling the incoming request:
$route = Route::current();
$name = Route::currentRouteName();
$action = Route::currentRouteAction();
Refer to the API documentation for both the underlying class of the Route facade and Route instance to review all accessible methods.
|
__label__pos
| 0.875907 |
Вход
Быстрая регистрация
Если вы у нас впервые: О проекте FAQ
1
Как доказать, что разность квадратов любых нечетных чисел делится на 8?
Никольский [5K] 10 месяцев назад
На БВ есть похожий вопрос.
Но там речь идет лишь о последовательных нечетных числах. Между тем, разность квадратов любых нечетных чисел делится на 8. Например, 7^2 - 3^2 = 49 - 9 = 40 = 5*8 . Вопрос, как это доказать в общем случае.
2
Как уже предлагалось, рассмотрим разность квадратов чисел 2n+1 и 2m+1. Преобразуя ((2n+1)-(2m+1))*((2n+1)-(2m+1)), получим 4*(n(n+1)-m(m+1)). То есть разность точно кратна четырём. А если рассмотреть содержимое скобок, то
совершенно очевидно, что произведения n(n+1) и m(m+1) - кратные двум числа, а значит, и их разность кратна двум. 2*4=8, всё.
автор вопроса выбрал этот ответ лучшим
2
В общем виде любое нечётное число можно записать в виде (2х+1), другое нечётное число записать в виде (2у+1). Тогда разность их квадратов (2х+1)^2-(2у+1)^2, распишем в виде [(2х+1)+(2у+1)]*[(2х+1)-(2у+1)]. Производим очевидные преобразования:
[(2х+1)+(2у+1)]*[(2х+1)-(2у+1)]=(2х+2у+2)*(2х-2у)=4*(х+у+1)*(х-у). Чтобы разность (2х+1)^2-(2у+1)^2 делилась на 8, достаточно, чтобы одно из чисел (х+у+1) или (х-у) было чётным.
Если х и у - одинаковой чётности (или оба чётные, или оба нечётные), то их разность - чётная.
Если х и у - разной чётности (одно из них чётное,а другое - нечётное, то их сумма - нечётная, а число (х+у+1) - чётное. Таким образом, теорема доказана.
1
Для общего доказательства нужно уйти в абстракцию, то бишь в алгебру. Вобщем виде любое нечетное число можно записать как (2n + 1). Другое нечетное число очевидно будет (2n + 3). Разность квадратов этих чисел по алгебраическому преобразованию есть произведение их суммы на их разность.
Поэтому имеем (2n + 1 + 2n + 3) * (2n + 1 - 2n - 3). После упрощения этого выражения получаем (4n + 4) * (-2) или еще проще (-2) * 4 * (n + 1),или совсем просто: (-8) * (n + 1). А из этого последнего выражения уже явно просматривается, что оно должно нацело делиться на 8.
Никольский [5K]
Вы предложили доказательство для двух последовательных нечетных чисел (2n + 1) и (2n + 3).
Но задача заключается в том, чтобы доказать это для ЛЮБЫХ нечетных чисел.
10 месяцев назад
Сыррожа [65.5K]
А что мешает второе число записать как (2m + 1)? Тогда после преобразований описанных в моем решении получим чуть более сложное выражение типа 8 * n * m * (n + m + 1). Отсюда тоже видно, что данное выражение должно делиться на 8. 10 месяцев назад
Никольский [5K]
Выражение вида 8 * n * m * (n + m + 1) там никак не может получиться. Наверное, у Вас какая-то описка. 10 месяцев назад
Сыррожа [65.5K]
Да вы правы. В чистом виде получаются только выражения типа 4 * (n - m) * (n + m + 1) - это если второе число записать как 2m + 1. Либо будет выражение типа 4 * (n + m) * (n - m + 1), если второе число записать как 2m - 1.
Но обратите внимание на сомножители (n - m) или (n + m). Если оба числа n и m - нечетные по условию, то их сумма или разность обязательно будет четной. А раз так то она будет кратной 2. Ну а 2 * 4 всегда кратно 8.
10 месяцев назад
комментировать
0
Запишем числа в виде 1) 4х+1(где х -0,1,..) и (4х+1) образует последовательность 1,5,9...и 2) 4у-1 (где у-1,2,3.. ) и образуется последовательность 3,7,11...Видим что эти последовательности охватывают все нечётные числа.Если нечётные числа равны, то разность их квадратов 0,на 8 делится.Доказывать нечего.В общем же случае получим 16x^2+8x+1-(16y^2-8y+1)=16(x^2-y^2)+8(x+y).Число 8 можно вынести за скобки.Вот и получается произведение двух сомножителей, один из которых 8.Значит и всё произведение делится на 8.Всё.
Никольский [5K]
Доказательство в принципе верное, но не полное.
Потому что если взять два числа вида (4х+1) и (4у+1), то разность их квадратов тоже будет кратна 8. То же самое с разностью квадратов (4х-1) и (4у-1). Вы же рассмотрели только разность квадратов (4х+1) и (4y-1).
10 месяцев назад
Евгений трохов [22.6K]
Да,верно подметили.Но сами понимаете что если произвести вычисления то результат такой же.1)16x^2-16y^2+8x-8y 2)16x^2-16y^2+8y-8x.Спасибо,что поправили. 10 месяцев назад
комментировать
Знаете ответ?
Есть интересный вопрос? Задайте его нашему сообществу, у нас наверняка найдется ответ!
Делитесь опытом и знаниями, зарабатывайте награды и репутацию, заводите новых интересных друзей!
Задавайте интересные вопросы, давайте качественные ответы и зарабатывайте деньги. Подробнее..
регистрация
OpenID
|
__label__pos
| 0.828434 |
Skip to content
Permalink
Branch: master
Find file Copy path
Find file Copy path
Fetching contributors…
Cannot retrieve contributors at this time
129 lines (76 sloc) 4.69 KB
C# Language Design Notes for Jun 25, 2018
Warning: These are raw notes, and still need to be cleaned up. Read at your own peril!
Agenda
1. Target-typed new-expressions
Target-typed new-expressions
Syntax
C c = new (...){ ... };
You can leave off either the constructor parameters (...) or initializer { ... } but not both, just as when the type is in.
Conversion
This will only work if a) we can determine a unique constructor for C through overload resolution, and b) the object/collection initializer binds appropriately.
But are these errors part of conversion or part of the expression itself? It doesn't matter in a simple example like this, but it matters in overload resolution.
Overload resolution
There are two philosophies we can take on what happens when a target-typed new-expression is passed to an overloaded method.
"late filter" approach
Don't try to weed out overload candidates that won't work with the new-expression, thus possibly causing an ambiguity down the line, or selecting a candidate that won't work. If we make it through, we will do a final check to bind the constructor and object initializer, and if we can't, we'll issue an error.
This reintroduces the notion of "conversion exists with errors" which we just removed in C# 7.3.
"early filter" approach
Consider arguments to constructor, as well as member names in object initializer, as part of applicability of a given overload. Could even consider conversions to members in object initializer. The question is how far to go.
Trade-off
The "early filter" approach is more likely to ultimately succeed - it weeds out things that will fail later before they get picked. It does mean that it relies more on the specifics of the chosen target type for overload resolution, so it is more vulnerable to changes to those specifics.
struct S1 { public int x; }
struct S2 {}
M(S1 s1);
M(S2 s2);
M(new () { x = 43 }); // ambiguous with late filter, resolved with early. What does the IDE show?
Adding constructors to the candidate types can break both models. Adding fields, properties, members called Add, implementing IEnumerable can all potentially break in the early filter model.
M2(Func<S1> f);
M2(Func<S2> f);
M2(() => new () { x = 43 });
S1 Foo() => new () { x = 43 };
Even if we did late filtering, this would probably work (i.e. the S2 overload would fail), because "conversion with error" would give an error in the lambda, which in itself rules out the overload.
We're having a hard time thinking of practical scenarios where the difference really matters. Only if we go to the "extremely early" position where the expression could contribute even to type inference. We've previously considered:
M<T>(C<T> c);
M(new C (...) { ... });
Where the type arguments to C could be left off and inferred from the new expression. This would take it a bit further and allow
M (new (...) {...});
In that same setup, contributing to type inference from the innards of an implicit new expression.
Conclusion
We are good with late checking for now. This does mean that we reintroduce the notion of conversion with errors.
Breaking change
As mentioned this introduces a new kind of breaking change in source code, where adding a constructor can influence overload resolution where a target-typed new expression is used in the call.
Unconstructible types
That said, we could define a set of types which can never be target types for new expressions. That is not subject to the same worries as the discussion above, where the innards of the new expression could potentially affect overload resolution. These are overloads where no implicit new expression could ever work.
Candidates for unconstructible types:
• Pointer types
• array types
• abstract classes
• interfaces
• enums
Tuples are constructible. You can use ValueTuple overloads. Delegates are constructible.
Nullable value types
Without special treatment, they would only allow the constructors of nullable itself. Not very useful. Should they instead drive constructors of the underlying type?
S? s = new (){}
Conclusion
Yes
Natural type
Target-typed new doesn't have a natural type. In the IDE experience we will drive completion and errors from the target type, offering constructor overloads and members (for object initializers) based on that.
Newde
Should we allow stand-alone new without any type, constructor arguments or initializers?
No. We don't allow new C either.
Dynamic
We don't allow new dynamic(), so we shouldn't allow new() with dynamic as a target type.
For constructor parameters that are dynamic there is no new/special problem.
You can’t perform that action at this time.
|
__label__pos
| 0.6181 |
Boost logo
Boost :
From: boost (boost_at_[hidden])
Date: 2001-03-28 18:31:01
Dear J. Walter and M. Koch & boost'ers,
I had a short look at your matrix classes.
Like many other I have also written
my own expression template library for matrices.
I had to do some linear algebra (eigenvalues,
eigen vectors, linear system of equation, on dense and sparse
matrices, dyadics vectors ... ).
One problem was to write a generic routine for diagonalitzation of
dense symmetric/hermitean matrices, e.g. HMatrix<T>
In my implementation I introduced a helper class which defines
some functions on the type T,
e.g.
double LA_Abs( const double& z)
{
return fabs(z);
}
double LA_HermiteanMul( const double& a, const double& b)
{
return a*b;
}
double LA_SquaredAbs( const complex<double>& a)
{
return a.real() * a.real() + a.imag() * a.imag();
}
double LA_HermiteanMul( const complex<double>& a, const complex<double>&
b)
// defined as ( a*b + b*a) /2
{
return a.real() * b.real() - a.imag() * b.imag();
}
Note that the return type of x = LA_SquaredAbs( const complex<double>& a) is
a double and not a complex number. This is nice if you have to calculate
sin(x) or atan(x) to calculate rotation matrices. LA_HermiteanMul was
important
in a few routines special to my problems.
In the same way I defined Hermitean Matrices in a way that
the Diagonal Elements for HMatrix< complex<double> > are
of type double. One has to be careful with
complex<double>& HMatrix::operator(i,j)
since this reference doesn't exist in my implementation,
as the diagonal elements are stored in a double* array.
But it works fine.
Same applies for the type of the eigen values,
which is also double for HMatrix< complex<double> >.
I would be interested in switching to boost and to do
some contributions to a matrix/linear algebra library
if Hermitean matrices will be supported.
Please note, that I even have to use more abtract classes as
complex numbers, e.g. small matrices which share the property
that the norm type and the eigen value type differ from the
matrix element type.
Best wishes,
Peter
Thanks for reading through this long mail
Boost list run by bdawes at acm.org, gregod at cs.rpi.edu, cpdaniel at pacbell.net, john at johnmaddock.co.uk
|
__label__pos
| 0.919683 |
Website Design Wizardry: Techniques for Stunning Visuals
Website Design
In the enchanting world of website design, where creativity meets functionality, the quest for stunning visuals is not just an ambition—it’s a necessity. Crafting a website is akin to painting on a digital canvas, where each stroke is a line of code and every color blend is a meticulous choice of theme and layout. The artistry involved in this process can transform the mundane into the magnificent, turning a simple online presence into a captivating digital experience. This article delves deep into the heart of website design wizardry, unveiling techniques that breathe life into visuals and engage users beyond the ordinary.
The Spellbinding Start: Understanding the Canvas
Before the first pixel is placed, the successful website designer must understand their canvas—the digital expanse where aesthetics meet user experience. This understanding isn’t merely about recognizing screen sizes or device types; it’s about appreciating the user’s journey from the moment they land on the page. Herein lies the first secret: designing for emotion and interaction, not just for looks.
Harmony of Elements: Balancing Act of Design
In the realm of website design, each element holds the potential to contribute to a story. From typography to color schemes, from layout to imagery, every choice is a thread in the fabric of the webpage. However, the true wizardry lies in the balance. A website swathed in vibrant colors may captivate the eye, but without the right contrast or whitespace, it can quickly become an overwhelming chaos.
Typography, in its own right, is a powerful spell in the designer’s arsenal. The right font does not merely convey information; it sets the tone, evokes emotion, and enhances readability. Pairing fonts and mastering hierarchy can transform text into a visual journey, guiding the user’s eye from headline to body text with seamless grace.
📰 Read More : The Benefits of Incorporating Video Content in Website Design
Magical Motifs: The Power of Branding in Website Design
Branding in website design transcends mere logos and taglines. It’s about weaving a consistent theme throughout the site, creating an atmosphere that resonates with the audience. This requires not just artistic flair but a deep understanding of the brand’s ethos and the message it seeks to convey. A well-branded website is a symphony of color, imagery, and text that speaks directly to the viewer’s heart, turning casual visitors into loyal patrons.
The Alchemy of Layouts: Crafting the User’s Journey
A well-structured layout is like a map to treasure; it guides the user through the website, from discovery to action, with intuitive ease. The clever use of grids, sections, and navigational elements can turn a confusing labyrinth into a clear path, leading the user naturally from one point to the next. Here, the wizardry lies in anticipation—predicting the user’s needs and designing a flow that feels as natural as a river running through the landscape.
Imagery and Icons: Windows to the World
In the digital realm, an image can be a portal—a window into the heart of the website. The strategic use of imagery and icons can elevate a website from plain to profound, creating a visual rhythm that complements the content. But beware the curse of overuse or irrelevance; every image must have a purpose, every icon a clear meaning. In this delicate dance, quality triumphs over quantity, and relevance is king.
Interactive Elements: The Spark of Engagement
The magic of website design often shines brightest in its interactive elements. Hover effects, scroll animations, and dynamic content can turn a static page into a living landscape, inviting the user to explore, discover, and engage. But as with all spells, caution is advised—overuse can lead to distraction or annoyance. The key is subtlety; the goal is to enhance the user experience, not overshadow the content.
📰 Read More : 6 Technologies That Will Impact the Future of Web Design
Testing and Feedback: The Crucible of Improvement
Even the most experienced wizards must test their spells. In website design, this means rigorous testing across devices and browsers, seeking feedback from real users, and being prepared to iterate. The journey of a website from launch to maturity is paved with feedback, analytics, and continuous improvement. The wise designer knows that a website is never truly finished but is a living entity, growing and evolving with its audience.
This inclusive approach extends to the choice of colors, fonts, and interactive elements, ensuring they are not just aesthetically pleasing but also readable and functional for people with various disabilities. The true wizardry in website design lies not in creating the most visually stunning site but in crafting experiences that are memorable, accessible, and impactful for everyone.
Furthermore, sustainability in website design is an emerging conversation, intertwining the magic of creativity with the responsibility of environmental stewardship. Designers are now considering the carbon footprint of their websites, optimizing images, and streamlining code to ensure that our digital creations tread lightly on the earth. This new dimension adds a layer of complexity and consciousness to the design process, challenging us to rethink our approaches and methodologies.
In embracing these challenges, website designers are not just artists and technicians; they are also visionaries and guardians of the digital realm. They hold the power to shape perceptions, influence decisions, and drive actions. With each project, they have the opportunity to forge connections, build communities, and create lasting impressions.
As we look to the future, the field of website design is poised for even greater innovations. Technologies like AI, VR, and AR are opening new frontiers for creativity and interaction, offering unprecedented ways to engage and mesmerize users. The role of the designer is evolving, merging traditional skills with new competencies, and continually adapting to the ever-changing digital landscape.
📰 Read More : How to Create a Comprehensive Business Website Design
In conclusion, website design is a form of modern-day wizardry, blending art, technology, and psychology to create digital experiences that move, engage, and inspire. It is a craft that demands not only creativity and technical skill but also empathy, insight, and a deep commitment to the user’s experience. As designers, our mission is to harness this power responsibly, crafting websites that not only dazzle the eyes but also touch the heart and ignite the mind. In this digital age, where every click and scroll tells a story, let us be the ones who write captivating tales, build bridges across cyberspace, and create magic that lingers long after the screen goes dark.
|
__label__pos
| 0.896263 |
Articles of mongodb
MongoDB:如何解决客户端上的DBRef?
我是mongodb的新手,很抱歉,如果这个问题是愚蠢的:我已经拉了一个文件,结构如下: { "_id" : ObjectId("575df70512a1aa0adbc2b496"), "name" : "something", "content" : { "product" : { "$ref" : "products", "$id" : ObjectId("575ded1012a1aa0adbc2b394"), "$db" : "mdb" }, "client" : { "$ref" : "clients", "$id" : ObjectId("575ded1012a1aa0adbc2b567"), "$db" : "mdb" } } 我指的是products和clients收集中的文档。 我读过,有可能在客户端解决这些DBRefs( https://stackoverflow.com/a/4067227/1114975 )。 我该怎么做呢? 我想避免查询这些对象并将它们embedded到文档中。 谢谢
Node.js模块从MongoDB数据库中获取数据
我想使用一个模块来获取和处理来自我的MongoDB数据库的数据。 (它应该生成一个代表我的Express.js网站的导航栏的对象) 我想到做这样的事情: var nav = { Home: "/" }; module.exports = function() { MongoClient.connect(process.env.MONGO_URL, function(err, db) { assert.equal(err, null); fetchData(db, function(articles, categories) { combine(articles, categories, function(sitemap) { // I got the data. What now? console.log("NAV: ", nav); }) }); }); }; var fetchData = function(db, callback) { db.collection('articles').find({}).toArray(function(err, result) { assert.equal(err); articles = result; […]
Expressjs +mongoose – 这个网页不可用?
为什么mongoose崩溃expressjs网站? 以下是我的代码: var express = require('express'); var mongoose = require('mongoose'); var app = express(); // Connect to mongodb mongoose.connect("mongodb://localhost/testdb", function(err) { if (err) throw err; console.log("Successfully connected to mongodb"); // Start the application after the database connection is ready app.listen(3000); console.log("Listening on port 3000"); }); // With Mongoose, everything is derived from a Schema. Let's […]
Javascript商店作为一个variables逗号分隔的string为mongoDB
我在MongoDB中使用nodeJS。 我试图查询数据库并添加populate像文档说: Story .findOne({ title: /timex/i }) .populate('_creator', 'name') 事情是,我需要使用'_creator', 'name'几次。 我怎样才能在我的文件开始存储这个,以便我可以多次使用它?
返回mongoDB中基于字段x的第一个字节x按ytypes分组的logging
如果我有以下json结构: [ { id: 1, type: "Drinks", isActive : "true", location: "QLD" }, { id: 2, type: "Drinks", isActive : "false", location: "NSW" }, { id: 3, type: "Drinks", isActive : "true" location: "QLD" }, { id: 3, type: "Drinks", isActive : "false" location: "QLD" }, { id: 3, type: "Drinks", isActive : "true" location: […]
Express / MongoDB – 数据库操作期间的意外行为
我有一个用户列表,我试图存储/更新到我的mongoDB数据库。 但是只有我列表中的最后一个元素被考虑在内,其他用户则不能进入thenfunction。 我是Nodejs的新手,这似乎是由于我不明白的同步行为。 var User = require('../to/path/user-service'); …. userList.forEach(function(user) { try { User.updateUser(user); } catch(err) { return console.error(err); } }); 用户服务 … var User = mongoose.model('User', userSchema); console.log(user.name); export.updateUser = function (user) { Issue.findOne({name: user.name}) .then((user) => { if(user) console.log(user.name + ' has been updated'); else console.log(user.name + ' has been created'); }).catch((err) => console.error(err)); […]
如何在Node中使用variables名创buildMongo Collection?
要将节点插入到Mongo Collection中,命令是 db.collection.insertOne({………}); 目前我收集的是用户input的string db.$$<VarCollectionName>.insertOne({……..]); 这样做会导致我的程序崩溃。 什么是正确的语法去做这个? 最终目标是每次用户使用我的方法时创build一个新的集合,并parsing一个文本文件。
MongoDB _id长度为25
我正尝试使用nodeJS从MongoDB中删除一个文档。 我的代码stream程如下:1.用户可以删除特定的学生。 因此,我把所有的学生文件从数据库中提取出来,存储在学生对象中。 3.用户可以使用提供的文本框过滤search,并可以select一个特定的学生,并可以删除。 请find下面的UI: HTML页面如下: <h2 align="center">Delete Student</h2> <div ng-controller="deleteStudentController"> <form ng-submit="deleteStudent()"> Student Name:<input type="text" letters-only ng-model="searchName"/><br> <div ng-repeat="student in students | filter:searchName" ng-show="searchName.length"> <input type="radio" ng-model="$parent.studentRadio" name="studentRadio" value="{{student._id}}"/>{{student | formatter}} </div> <input type="submit" value="Delete Student"/> {{output}} </form> </div> 与UI相关的angularJS控制器如下所示: mainApp.controller("deleteStudentController", function($scope,$http) { var resData = {}; $scope.student = {}; var urlGet = "/students/all"; […]
如何删除对象考虑到在Mongoose Node.js中的引用?
这是我的MongoDB架构: var partnerSchema = new mongoose.Schema({ name: String, products: [ { type: mongoose.Schema.Types.ObjectId, ref: 'Product' }] }); var productSchema = new mongoose.Schema({ name: String, campaign: [ { type: mongoose.Schema.Types.ObjectId, ref: 'Campaign' } ] }); var campaignSchema = new mongoose.Schema({ name: String, }); module.exports = { Partner: mongoose.model('Partner', partnerSchema), Product: mongoose.model('Product', productSchema), Campaign: mongoose.model('Campaign', campaignSchema) } […]
Node.js结合mongoose和Sails水线
我在Node.js上开发基于开源微软服务的项目。 问题描述 一些微服务是如此薄,只与MongoDB交互,所以我没有在那里使用Sails,并且首选直接使用Mongoose。 因此,我已经为我需要在mongo中坚持的每个对象实现了mongoose模式。 我还将在其他一些微服务中使用Sails.js,因此我将不得不实施Waterlinetypes的模式来保存和查询对象。 问题是模式的重复,我发现它是无用的。 我想到的解决scheme 我希望在所有的服务中使用一种types的模式。 现在有3个选项: 一个神奇的方法来连接模式(我不知道),并有两个世界同时工作(最不可能的select)。 为了在所有的微服务中使用Waterline,无论是否使用Sails.js,因此在系统中有1个模式types。 为了强制Sails.js使用mongoose适配器而不是Waterline,然后实现一些内部使用Mongoose的CRUD数据访问层(DAL),并在任何地方使用它来访问数据库。 因此,mongoose模式将贯穿整个系统。 但是后来我放弃了Waterline的封装function,如果将来我想改变DB,我会遇到麻烦。 我也可以在我的应用程序中妥协和重复模式,但这是最后的手段,因为我相信这个问题必须有一些解决scheme。
|
__label__pos
| 0.990592 |
Sunday, 25 January 2015
A tale of Hackers, Geniuses and Geeks
"The computer and the Internet are among the most important inventions of our era, but few people know who created them. They were not conjured up in a garret or garage by solo inventors suitable to be singled out on magazine covers or put into a pantheon with Edison, Bell, and Morse. Instead, most of the innovations of the digital age were done collaboratively."
This is how author Walter Isaacson introduces 'The Innovators', a fascinating tale of pioneers and entrepreneurs who are responsible for some of the most significant breakthroughs of the digital age.
The reason why I liked this book lies in Isaacson's ability to describe the lives of these visionaries in detail. He shows their profound passion and deep care for building great products that ultimately changed our lives. At the same time, the author likes to emphasise how their remarkable inventions were mostly the results of collaboration. Being able to work in teams made those inventors "even more creative."
"The tale of their teamwork is important because we don't often focus on how central that skill is to innovation."
From Ada, Countess of Lovelace to the Web
Isaacson begins with Ada Lovelace. The English mathematician and writer published her "Notes" on Babbage's Analytical Engine in 1843. Notes were recognised as the first algorithm carried out by a machine.
Over the years, Lovelace has been celebrated as a feminist icon as well as a computer pioneer. What stood out was her appreciation for poetical science, which the author likes to emphasise as a lasting lesson for innovating at all times.
"Ada's ability to appreciate the beauty of mathematics is a gift that eludes many people, including some who think of themselves as intellectual. She realized that math was a lovely language, one that describes the harmonies of the universe and can be poetic at times...She was able to understand the connections between poetry and analysis."
Many influential people who have made a big impact on our society often have gathered enemies or disagreements along the way. This applies to Ada Lovelace too. "She has also been ridiculed as delusional, flighty, and only a minor contributor," writes Isaacson.
However, the author perfectly captures the reason why Lovelace must be recognised in The Innovators:
"The reality is that Ada's contribution was both profound and inspirational. More than Babbage or any other person of her era, she was able to glimpse a future in which machines would become partners of human imagination...Her appreciation for poetical science led her to celebrate a proposed calculating machine that was dismissed by the scientific establishment of her day, and she perceived how the processing power of such a device could be used on any form of information. Thus did Ada, Countess of Lovelace, help sow the seeds of a digital age that would blossom a hundred years later."
Creativity
The author likes to remind us of a crucial element to the partnership between humans and machines: creativity.
"We humans can remain relevant in an era of cognitive computing because we are able to think different, something that an algorithm, almost by definition, can't master. We possess an imagination that, as Ada said, "bring together things, facts, ideas, conceptions in new, original, endless, ever-varying combinations." We discern patterns and appreciate their beauty. We weave information into narratives. We are storytelling as well as social animals."
Isaacson believes that arts and humanities should endeavor to appreciate the beauty of math and physics. And vice versa.
He encourages us to respect both the two worlds. But, more importantly he suggests understanding how they intersect. "The next phase of the Digital Revolution will bring even more new methods of marrying technology with the creative industries, such as media, fashion, music, entertainment, education, literature, and the arts."
New platforms and social networks are enabling fresh opportunities for individual imagination and collaborative creativity. It is through the interplay between technology and the arts that new forms of expression will eventaully emerge.
"This innovation will come from people who are able to link beauty to engineering, humanity to technology, and poetry to processors."
The human-machine partnership
The book encompasses all the major key players in computing, programming, electronic devices, microchips, video games, the Internet, the personal computers, software, online and the web.
It concludes by describing IBM's Watson and its Jeopardy!-playing computer, a good example of how people and machines can partner and get smarter together for the better of society.
Isaacson describes a project where Watson was used to work in partnership with doctors on cancer treatments.
"The Watson system was fed more than 2 million pages from medical journals and 600,000 pieces of clinical evidence, and could search up to 1.5 million patient records. When a doctor put in a patient's symptoms and vital information, the computer provided a list of recommendations ranked in order of its confidence."
But, as often happens with new technological developments, there was an initial resistance from physicians who were not happy to have a computer telling them what to do. It was mainly a problem of communication and language. The author writes, "in order to be useful, the IBM teams realized, the machine needed to interact with human doctors in a manner that made collaboration pleasant."
They decided to reprogram the system to come across as humble. After those iterations "doctors were delighted, saying that it felt like a conversation with a knowledgable colleague."
Innovation is a team game
Other key lessons can be drawn from Isaacson's book in addition to the power of creativity and the possibilities created by the human-machine partnerships just discussed.
The following ones are very close to the internal communicator's heart.
First and foremost, as the author puts it, "innovation comes from teams more often than from the lightbulb moments of lone geniuses." I like the example of Twitter that Isaacson uses to make the point.
The popular social network,
"was invented by a team of people who were collaborative but also quite contentious. When one of the cofounders, Jack Dorsey, started taking a lot of the credit in media interviews, another cofounder, Evan Williams, a serial entrepreneur who had previoulsy created Blogger, told him to chill out, according to Nick Bilton of the New York Times. "But, I invented Twitter," Dorsey said. "No, you didn't invent Twitter," Williams replied. "I didn't invent Twitter either. Neither did Biz [Stone, another cofounder]. People don't invent things on the Internet. They simply expand on an idea that already exists."
Within the Twitter story lies another useful lesson:
"The digital age may seem revolutionary, but it was based on expanding the ideas handed down from previous generations. The collaboration was not merely among contemporaries, but also between generations."
Two more lessons are worth acknowledging. One is that the most productive teams are made of people with a diverse range of specialities. The second one is that the physical closeness of team members can help to drive innovation.
The latter is interesting. It is often the subject of lively debates on the nature of our workplaces. The author observes that despite today's virtual tools, "now as in the past, physical proximity is beneficial. There is something special...about meetings in the flesh, which cannot be replicated digitally."
He uses the research facility Bell Laboratories as an example to illustrate his point:
"In its long corridors in suburban New Jersey, there were theoretical physicists, experimentalists, material scientists, engineers, a few business-men, and even some telephone-pole climbers with grease under their fingernails. Walter Brattain, an experimentalist, and John Bardeen, a theorist, shared a workspace, like a librettist and a composer sharing a piano bench, so they could perform a call-and response all day about how to make what became the first transitor."
Conclusions
"We talk so much about innovation these days that it has become a buzzword, drained of clear meaning."
Probably that is true. But, Isaacson doesn't fail to bring that meaning back reporting on how innovation is actually occuring in the real world.
If you want to find out how the most disruptive ideas have been concretely turned into realities, then 'The Innovators' is the book for you. The manual is full of pointers that communicators and leaders of any progressive organisation may use as a sort of inspiration. Plus, I would like to applaude the author's ability to write about technological developments in such a clear and simple way that even 'non techy' people can easily comprehend and much appreciate.
-----------------------------------------------------------------------------------
This article originally appeared on simply-communicate
|
__label__pos
| 0.513377 |
salivan salivan - 1 year ago 373
Javascript Question
can I use ul li instead of select dropdown and with jquery make it part of a form?
I went really long way trying to rewrite select to ul li and style it accordingly. But I'm getting really annoyed with the weight of code and minor annoyances on the way.
So I'm thinking to ditch the idea completely, and just use normal ul li menu and some kind of javascript to make it function like select (for form submission etc).
So is this possible? any example code you can give me?
My concerns is Cross browser compatibility.
Answer Source
Lovely idea. I just made one in the fiddle check it out here.
HTML
<ul>
<li class="init">[SELECT]</li>
<li data-value="value 1">Option 1</li>
<li data-value="value 2">Option 2</li>
<li data-value="value 3">Option 3</li>
</ul>
JAVASCRIPT
$("ul").on("click", ".init", function() {
$(this).closest("ul").children('li:not(.init)').toggle();
});
var allOptions = $("ul").children('li:not(.init)');
$("ul").on("click", "li:not(.init)", function() {
allOptions.removeClass('selected');
$(this).addClass('selected');
$("ul").children('.init').html($(this).html());
allOptions.toggle();
});
CSS
ul {
height: 30px;
width: 150px;
border: 1px #000 solid;
}
ul li { padding: 5px 10px; z-index: 2; }
ul li:not(.init) { float: left; width: 130px; display: none; background: #ddd; }
ul li:not(.init):hover, ul li.selected:not(.init) { background: #09f; }
li.init { cursor: pointer; }
a#submit { z-index: 1; }
|
__label__pos
| 0.98837 |
BookmarkSubscribeRSS Feed
sfo
Quartz | Level 8 sfo
Quartz | Level 8
Hi,
Is there a way I can color code the Y-axis data points used in proc gplot for example:
ID YData XData
101 10 10
101 20 20
101 30 30
102 10 40
102 20 50
102 30 60
I am using proc gplot YData * XData = ID and would like to color code each YData i.e. value 10 gets color blue, value 20 gets color red, value 30 gets color orange.
Also, all the data points for each ID should be connected using a black line.
4 REPLIES 4
DanH_sas
SAS Super FREQ
What version of SAS are you using?
sfo
Quartz | Level 8 sfo
Quartz | Level 8
I am using 9.2 and prefer to use Proc Gplot
Thanks
DanH_sas
SAS Super FREQ
See if this will work for you:
data test;
input ID YData XData;
cards;
101 10 10
101 20 20
101 30 30
102 10 40
102 20 50
102 30 60
;
run;
symbol1 i=join c=black v=none;
symbol2 i=join c=black v=none;
symbol3 i=none v=dot c=blue;
symbol4 i=none v=dot c=red;
symbol5 i=none v=dot c=orange;
proc gplot data=test;
plot ydata*xdata=id;
plot2 ydata*xdata=ydata;
run;
sfo
Quartz | Level 8 sfo
Quartz | Level 8
Thanks for the solution. It worked.
SAS INNOVATE 2024
Innovate_SAS_Blue.png
Registration is open! SAS is returning to Vegas for an AI and analytics experience like no other! Whether you're an executive, manager, end user or SAS partner, SAS Innovate is designed for everyone on your team. Register for just $495 by 12/31/2023.
If you are interested in speaking, there is still time to submit a session idea. More details are posted on the website.
Register now!
How to Concatenate Values
Learn how use the CAT functions in SAS to join values from multiple variables into a single value.
Find more tutorials on the SAS Users YouTube channel.
Get the $99 certification deal.jpg
Back in the Classroom!
Select SAS Training centers are offering in-person courses. View upcoming courses for:
View all other training opportunities.
Discussion stats
• 4 replies
• 1399 views
• 1 like
• 2 in conversation
|
__label__pos
| 0.519155 |
Does my design necessitate threading?
I’m developing a turn based strategy game. Right now, I have the standard core game loop provided jMonkey:
1. respond to input listeners
2. update which executes game logic
3. render graphics & sound
By design:
• Almost everything in the game has a logical representation & a ‘viz’ representation with any jMonkey related code.
• Most objects, including those responsible for step 2, are loaded at runtime from init files.
As a simplification, let’s say the game state requires the logic to evaluate a fireball - the logic would then determine the results of buffs, debuffs, determine chance to hit, damage, trigger reaction spells, etc. It updates the logical representation & queues up the corresponding graphics & sounds for the core loop & returns. Works fine.
Here’s the problem: let’s say I want ‘chance to hit’ to be a reflex based minigame rather than a percentage. This requires the inside of step 2 to reach back to the outer loop, initiate some stuff & wait for a response. Now step 2 is waiting for the outer loop to give a response & the outer loop is waiting for step 2 to finish.
It seems like threads are required to deal with this. The best I’ve come up with is:
• make step 2 its own thread, spawned by the outer loop
• when minigame code occurs, the logic thread makes calls to the game object to init the minigame
• the logic thread then waits, polling the minigame for a response
• the outer loop in turn does its thing, polling the logic thread & responding as needed
My questions are:
Is there a sane way to solve this situation without resorting to using threads?
If threads are required, is there a better way to solve the problem than what I’ve come up with?
Are there unknown unknowns I haven’t considered?
Yep. Make it event based instead of “outer and inner loops” or whatever. We don’t really know enough about your logic to go into much more detail than that.
There is always a way to do it without threads… and I’m not convinced threads are even the right way in this case.
3 Likes
The inner loop is the call to public void simpleUpdate(float tpf) & the outer loop is where jMonkey handles rendering, etc; are you suggesting I replace the call to simpleUpdate with events?
No. What purpose would that solve?
No, those are the same “loop”. I think you might be confused.
There are no inner and outer loops then. You may need to explain what you mean by “reflex based”.
You can use update from AppStates or controlUpdate from controls so you can remove a lot of logic from simpleUpdate in your application. You don’t need a thread for your solution.
I can give you an example of my personal approach:
let’s say you handle the essential in simpleUpdate so for step 2 of your problem:
• Initialize and attach an appState that will contain all logic you need for the minigame with a callback to your application (via variable or interface). And let simpleUpdate handle other stuff that does not require those steps.
• Let the app state handle everything of the minigame and use it’s own update method in case you need it and when done, call back to the main application.
• Once the callback is made, the application will detach the app state and continue to the next step.
This will not affect your performance when done right
I probably gave a poor descsription of the problem earlier. Essentially I have code at frame N that can’t proceeed until frame N+X has been rendered (where X > 0). While I’ve been mulling over this, I’ve noticed some other aspects of my design that need to be reconsidered & those may have a strong bearing on how I approach this particular part.
Thanks to @pspeed & @bloodwalker for weighing in on my design.
In all honesty, it sounds like you may simply need to rethink your design. If your code relies on things that haven’t happened yet, surely there are more intuitive ways of rewriting it? Without understanding the context it’s impossible to say. Your code can’t proceed until something happens later, but if that code is time sensitive (i.e input interaction or rendering), then any kind of threading will result in a delay in that action or event until whatever code it’s waiting on is done.
|
__label__pos
| 0.882238 |
Shafizadeh Shafizadeh - 2 years ago 54
SQL Question
Is leaving a field empty better or filling it with null?
I have a table that contains a column named
first_name
. It is not mandatory for users to fill it, and sometimes users leave it empty. Now I want to know: is it better to define
null
value as its default?
Answer Source
Consider the following table:
create table test1 (
id int not null,
first_name varchar(50), -- nullable
last_name varchar(50) -- also nullable
);
If first_name is not provided in your UI, you can choose to not insert data into that field by doing:
insert into test1 (id, last_name) values (123, 'Smith');
Or, you can choose to explicitly provide NULL for first_name like so:
insert into test1 (id, first_name, last_name) values (123, NULL, 'Smith');
-- you could also do like this below:
-- insert into test1 values (123, NULL, 'Smith');
-- I just like providing explicit fieldnames and values
Either way you choose, just stay consistent throughout your application. Your results will look the same:
+-----+------------+-----------+
| id | first_name | last_name |
+-----+------------+-----------+
| 123 | NULL | Smith |
| 123 | NULL | Smith |
+-----+------------+-----------+
So - to answer the real question: don't define an explicit null in your table creation.
When supplying '' or NULL, just make sure you are consistent. If some first_name are '' and some are NULL, your select statement would have to be:
select * from test1 where first_name is NULL or first_name is '';
That brings another point - what if user typed ' ' (4 spaces)? You would have to ensure that first_name meets certain criteria and trimmed version of first_name goes through validation before being entered in the database. If your database ends up with '', ' ', ' ' etc. you would have to constantly run:
select * from test1 where first_name is NULL or trim(first_name) = '';
--or--
--select * from test1 where first_name is NULL or length(trim(first_name)) = 0;
Consistency with NULL first_name will help querying with confidence.
Recommended from our users: Dynamic Network Monitoring from WhatsUp Gold from IPSwitch. Free Download
|
__label__pos
| 0.964954 |
Rui Carneiro Rui Carneiro - 1 year ago 91
CSS Question
Adjust table column width to content size
Form (with firebug highlight hover the td):
example
Label column CSS:
width: auto;
padding: 0;
margin: 0;
The problem:
Why my left columns have that invisible "padding-right"? It's not possible to shrink columns to fit their content?
--EDIT--
The problem was the table itself. I defined table with "width: 100%". Removed that and the problem is gone.
Answer Source
The problem was the table width. I had used width: 100% for the table. The table columns are adjusted automatically after removing the width tag.
Recommended from our users: Dynamic Network Monitoring from WhatsUp Gold from IPSwitch. Free Download
|
__label__pos
| 0.53879 |
THE WORLD'S LARGEST WEB DEVELOPER SITE
Python Tutorial
Python HOME Python Intro Python Get Started Python Syntax Python Comments Python Variables Python Data Types Python Numbers Python Casting Python Strings Python Booleans Python Operators Python Lists Python Tuples Python Sets Python Dictionaries Python If...Else Python While Loops Python For Loops Python Functions Python Lambda Python Arrays Python Classes/Objects Python Inheritance Python Iterators Python Scope Python Modules Python Dates Python Math Python JSON Python RegEx Python PIP Python Try...Except Python User Input Python String Formatting
File Handling
Python File Handling Python Read Files Python Write/Create Files Python Delete Files
Python NumPy
NumPy Intro NumPy Getting Started NumPy Creating Arrays NumPy Array Indexing NumPy Array Slicing NumPy Data Types NumPy Copy vs View NumPy Array Shape NumPy Array Reshape NumPy Array Iterating NumPy Array Join NumPy Array Split NumPy Array Search NumPy Array Sort NumPy Array Filter NumPy Random NumPy ufunc
Python SciPy
SciPy Intro SciPy Getting Started SciPy Constants SciPy Optimizers SciPy Sparse Data SciPy Graphs SciPy Spatial Data SciPy Matlab Arrays SciPy Interpolation SciPy Significance Tests
Machine Learning
Getting Started Mean Median Mode Standard Deviation Percentile Data Distribution Normal Data Distribution Scatter Plot Linear Regression Polynomial Regression Multiple Regression Scale Train/Test Decision Tree
Python MySQL
MySQL Get Started MySQL Create Database MySQL Create Table MySQL Insert MySQL Select MySQL Where MySQL Order By MySQL Delete MySQL Drop Table MySQL Update MySQL Limit MySQL Join
Python MongoDB
MongoDB Get Started MongoDB Create Database MongoDB Create Collection MongoDB Insert MongoDB Find MongoDB Query MongoDB Sort MongoDB Delete MongoDB Drop Collection MongoDB Update MongoDB Limit
Python Reference
Python Overview Python Built-in Functions Python String Methods Python List Methods Python Dictionary Methods Python Tuple Methods Python Set Methods Python File Methods Python Keywords Python Exceptions Python Glossary
Module Reference
Random Module Requests Module Statistics Module Math Module cMath Module
Python How To
Remove List Duplicates Reverse a String Add Two Numbers
Python Examples
Python Examples Python Compiler Python Exercises Python Quiz Python Certificate
Python Random Module
Python has a built-in module that you can use to make random numbers.
The random module has a set of methods:
Method Description
seed() Initialize the random number generator
getstate() Returns the current internal state of the random number generator
setstate() Restores the internal state of the random number generator
getrandbits() Returns a number representing the random bits
randrange() Returns a random number between the given range
randint() Returns a random number between the given range
choice() Returns a random element from the given sequence
choices() Returns a list with a random selection from the given sequence
shuffle() Takes a sequence and returns the sequence in a random order
sample() Returns a given sample of a sequence
random() Returns a random float number between 0 and 1
uniform() Returns a random float number between two given parameters
triangular() Returns a random float number between two given parameters, you can also set a mode parameter to specify the midpoint between the two other parameters
betavariate() Returns a random float number between 0 and 1 based on the Beta distribution (used in statistics)
expovariate() Returns a random float number based on the Exponential distribution (used in statistics)
gammavariate() Returns a random float number based on the Gamma distribution (used in statistics)
gauss() Returns a random float number based on the Gaussian distribution (used in probability theories)
lognormvariate() Returns a random float number based on a log-normal distribution (used in probability theories)
normalvariate() Returns a random float number based on the normal distribution (used in probability theories)
vonmisesvariate() Returns a random float number based on the von Mises distribution (used in directional statistics)
paretovariate() Returns a random float number based on the Pareto distribution (used in probability theories)
weibullvariate() Returns a random float number based on the Weibull distribution (used in statistics)
|
__label__pos
| 0.99965 |
• Xakac is a payload forwarder
Once upon a time I was need to configure a CI for a private github repo. Public CI providers such as Travis, CircleCI and other don’t provide free plans for private repos. Besides tests I wanted to run are not publicly available. So I decided to provision a Jenkins server inside corporate VPN. How to trigger a pipeline on PR? Github provides a webhooks mechanism. Generally speaking it’s a just HTTP request with some payload. And here we have a problem. How to pass a github webhook to the Jenkins which is not exposed to the Internet?
• 3
• 4
|
__label__pos
| 0.553073 |
Pixel Envy
Written by Nick Heer.
Microsoft Surface Allows People to Create
That’s the headline, and that’s Nick Bilton’s thesis in a nut, which he seems to think is revolutionary. What about the iPad, Nick?
The iPad, for all it’s glory, suffers from one very distinct flaw: It’s very difficult to use for creation.
I’ll bite. Why, Nick?
The keyboard on the screen, although pretty to look at, is abysmal for typing anything over 140 characters.
I’ve written 2000-word papers on it comfortably. But I’m weird like that. To each their own, and so forth.
Why else, Nick?
There isn’t a built-in pen for note-taking, either.
Are you kidding me?
|
__label__pos
| 0.998647 |
maths in english - Maths Langella
twenty-four is two times twelve. Twelve is two times six, and six is two times three. ... Here are the first prime numbers: 2 ; 3 ; 5 ; 7 ; 11 ; 13. Work out the prime ...
282KB taille 4 téléchargements 350 vues
DNL - Maths in English
Mme Langella - 4èmes
MATHS IN ENGLISH 5. Fifth sequence: "Prime factors" Get to : http://www.bbc.co.uk/schools/gcsebitesize/maths/ Choose "Number"
"Factors, powers and roots"
" Prime factors-foundation"
"activity".
The words marked with an asterisk* are translated in French at the bottom of the paragraph. Meet posh* prime* numbers, and find out why they are the hardest working aristocrats of the maths world.
Prime numbers are pretty* posh; they have just two factors: themselves and one. Here are the first few prime numbers we'd like you to meet.
What is drawn* on the numbers to show that they are "posh"? ................................................................................
One doesn't get in because it's not a prime number. It's so posh that it doesn't have any factors, apart from itself.
Why isn't 1 a prime number? ......................................................................................................................................... You could think of prime numbers as the aristocrats of the maths world. Except this lot don't mind working for a living*. In fact prime numbers are the building* blocks (or factors) of all other numbers. What are the prime numbers for the other numbers? ................................................................................................... Let's look at the prime factors of twenty-four. We begin by dividing by the lowest* prime number that will work. So twenty-four is two times twelve. Twelve is two times six, and six is two times three. This means that the prime factors of twenty-four are two, two, two and three!
When you want to find out the prime factors of 24, what is the first operation you do? ................................................ How can you write 6 as a multiplication between two prime numbers? .......................................................................... What are the prime factors of twenty-four? .....................................................................................................................
DNL - Maths in English
Mme Langella - 4èmes
Ok; now it's your chance to shine: work out the prime factors of thirty-six, and fill in the gaps!
And your answer is: 36 = ..... × ..... × ..... × ..... Vocabulary: posh : snob. N.B.: En français, le mot "snob" vient de la contraction de "sans noblesse". prime: premier pretty: joli, mais est parfois utilisé pour dire "assez". Par exemple, "pretty bad" signifie "assez mauvais". to draw (drew, drawn): dessiner. to work for a living: travailler pour gagner sa vie. to build: construire. lowest: le plus bas (ici, le plus petit). Exercise: Here are the first prime numbers: 2 ; 3 ; 5 ; 7 ; 11 ; 13 ; 17 ; 19 ... Work out the prime factors decomposition of the following numbers: 6=...................................................... 20=.................................................... 12 = .................................................. 50=.................................................... 60=.................................................... 120=.................................................. This decomposition can be used to simplify fractions. For example, as the decomposition of 40 is 40 = 2 × 2 × 2 × 5 , and the decomposition of 420 is 420 = 2 × 2 × 3 × 5 × 7 , we can simplify the fraction
40 as follows: 420
40 2× 2× 2×5 2 × 2 × 2× 5 2 2 = = = = . 420 2 × 2 × 3 × 5 × 7 2 × 2 × 3 × 5 × 7 3 × 7 21 And
2 40 is the irreducible (unsimplifiable) able) form of the fraction . 21 420
Do the same and find out the irreducible form of the following fractions (please write the calculations): calculations)
6 = ............................................. 20 90 = .................................................. 60 50 = ........................................... 120
XKCD.com
|
__label__pos
| 0.99461 |
LIDAR and Stereo Camera Calibration. Remap input topics
asked 2019-10-25 01:46:39 -0500
Astronaut gravatar image
updated 2019-10-25 01:53:39 -0500
Hi All
I have Quanergy LIDAR and PointGrey Grasshoppers RGB cameras that are connected as Master Slave and work as stereo Camera. I want to do Sensor Fusion of LIDAR and Cemeras and for that need to calibrate the LIDAR and Cameras. I have python code but is not working. I took the code from link text and modified to work for my sensors. So This package assumes that the bag file has at least the following topic names and message types by default, these can be modified in the launch scripts.
/sensors/camera/camera_info (sensor_msgs/CameraInfo)
/sensors/camera/image_color (sensor_msgs/Image)
/sensors/velodyne_points (sensor_msgs/PointCloud2)
In my case these are
/stereo/left/camera_info
/stereo/left/image_rect_color
/Sensor/points
Here are the scripts
'''
The main ROS node which handles the topics
Inputs:
camera_info - [str] - ROS sensor camera info topic
image_color - [str] - ROS sensor image topic
velodyne - [str] - ROS velodyne PCL2 topic
camera_lidar - [str] - ROS projected points image topic
Outputs: None
'''
def listener(camera_info, image_raw, points, camera_lidar=None):
# Start node
rospy.init_node('calibrate_camera_lidar', anonymous=True)
rospy.loginfo('Current PID: [%d]' % os.getpid())
rospy.loginfo('Projection mode: %s' % PROJECT_MODE)
rospy.loginfo('CameraInfo topic: %s' % camera_info)
rospy.loginfo('Image topic: %s' % image_raw)
rospy.loginfo('PointCloud2 topic: %s' % points)
rospy.loginfo('Output topic: %s' % camera_lidar)
# Subscribe to topics
info_sub = message_filters.Subscriber(camera_info, CameraInfo)
image_sub = message_filters.Subscriber(image_raw, Image)
Sensor_sub = message_filters.Subscriber(points, PointCloud2)
# Publish output topic
image_pub = None
if camera_lidar: image_pub = rospy.Publisher(camera_lidar, Image, queue_size=5)
# Synchronize the topics by time
ats = message_filters.ApproximateTimeSynchronizer(
[image_sub, info_sub, Sensor_sub], queue_size=5, slop=0.1)
ats.registerCallback(callback, image_pub)
# Keep python from exiting until this node is stopped
try:
rospy.spin()
except rospy.ROSInterruptException:
rospy.loginfo('Shutting down')
if __name__ == '__main__':
# Calibration mode, rosrun
if sys.argv[1] == '--calibrate':
camera_info = '/stereo/left/camera_info'
image_raw = '/stereo/left/image_raw'
points = '/Sensor/points'
camera_lidar = None
PROJECT_MODE = False
# Projection mode, run from launch file
else:
camera_info = rospy.get_param('camera_info_topic')
image_raw = rospy.get_param('image_color_topic')
points = rospy.get_param('points_topic')
camera_lidar = rospy.get_param('camera_lidar_topic')
PROJECT_MODE = bool(rospy.get_param('project_mode'))
# Start keyboard handler thread
if not PROJECT_MODE: start_keyboard_handler()
# Start subscriber
listener(camera_info, image_raw, points, camera_lidar)
and display lidar camera calibration
?xml version="1.0" encoding="UTF-8"?>
<launch>
<arg name="camera" default="/stereo/left" />
<!-- Play rosbag record -->
<include file="$(find lidar_camera_calibration)/launch/play_rosbag.launch">
<arg name="bagfile" value="2019-10-24-16-56-30.bag" />
</include>
<!-- Nodelet manager for this pipeline -->
<node
pkg="nodelet"
type="nodelet"
args="manager"
name="lidar_camera_manager"
output="screen" />
<node
pkg="image_proc"
type="image_proc"
name="image_proc_node1" />
<!-- Run image_proc/rectify nodelet -->
<node
pkg="nodelet"
type="nodelet"
name="rectify_color"
args="load image_proc/rectify lidar_camera_manager --no-bond" >
<!-- Remap input topics -->
<remap from="image_mono" to="$(arg camera)/image_rect_color" />
<remap from="camera_info" to="$(arg camera)/camera_info" />
<!-- Remap output topics -->
<remap from="image_rect" to="$(arg camera)/image_rect" />
</node>
<!-- Wire static transform from the world to velodyne frame -->
<node
pkg="tf2_ros"
type="static_transform_publisher"
name="world_velodyne_tf"
output="screen"
args="-0.0 -0 ...
(more)
edit retag flag offensive close merge delete
Comments
Can you tell what the exact problem is that you are having?
Choco93 gravatar image Choco93 ( 2019-10-25 07:53:58 -0500 )edit
when try to perform calibration using the matplotlib GUI to pick correspondences in the camera and the LiDAR frames wirh roslaunch lidar_camera_calibration play_rosbag.launch bagfile:=/path/to/file.bag and rosrun lidar_camera_calibration calibrate_camera_lidar.py --calibrate it doesnt open the GUI but it compile. So any help?
Astronaut gravatar image Astronaut ( 2019-10-26 05:00:34 -0500 )edit
|
__label__pos
| 0.710808 |
cancel
Showing results for
Show only | Search instead for
Did you mean:
About data collection specification of User actions
menda
Guide
Hi,
I have a question about data collection specification of User actions.
Our customers are using RUM.
They intend to set user action names to collect detailed user operations.
Does setting a default user action name have any effect on the application?
Also, depending on the following candidates, will the data collection method of user action change?
user-action-settings-st-cjp98919-dynatrace.png
- Loading <page> (OR XHR URL)
- User input
- Anchor (#part of URL)
I look forward to reply.
Best Regards,
Masahiko Enda
2 REPLIES 2
AlexanderSommer
Dynatrace Champion
Dynatrace Champion
User action naming has no impact on the overall application metrics, but of course can change the metric on the user action itself, if you use naming rules for group individual user actions to one user action as the aggregates are changing.
You can use the preview rules button to get a first impression how the naming will change
menda
Guide
Thank you for your reply.
I understand that the naming of user actions does not affect the metrics of the entire application.
I have an additional question.
Does the naming of user actions change the behavior of their applications or systems?(For example, web page may not be displayed due to JavaScript error etc.)
I look forward to reply.
Best Regards,
Masahiko Enda
Featured Posts
|
__label__pos
| 0.964186 |
Boost C++ Libraries
...one of the most highly regarded and expertly designed C++ library projects in the world. Herb Sutter and Andrei Alexandrescu, C++ Coding Standards
boost/date_time/posix_time/posix_time_config.hpp
#ifndef POSIX_TIME_CONFIG_HPP___
#define POSIX_TIME_CONFIG_HPP___
/* Copyright (c) 2002,2003,2005 CrystalClear Software, Inc.
* Use, modification and distribution is subject to the
* Boost Software License, Version 1.0. (See accompanying
* file LICENSE_1_0.txt or http://www.boost.org/LICENSE_1_0.txt)
* Author: Jeff Garland, Bart Garst
* $Date$
*/
#include <cstdlib> //for MCW 7.2 std::abs(long long)
#include <boost/limits.hpp>
#include <boost/cstdint.hpp>
#include <boost/config/no_tr1/cmath.hpp>
#include <boost/date_time/time_duration.hpp>
#include <boost/date_time/time_resolution_traits.hpp>
#include <boost/date_time/gregorian/gregorian_types.hpp>
#include <boost/date_time/wrapping_int.hpp>
#include <boost/date_time/compiler_config.hpp>
namespace boost {
namespace posix_time {
//Remove the following line if you want 64 bit millisecond resolution time
//#define BOOST_GDTL_POSIX_TIME_STD_CONFIG
#ifdef BOOST_DATE_TIME_POSIX_TIME_STD_CONFIG
// set up conditional test compilations
#define BOOST_DATE_TIME_HAS_MILLISECONDS
#define BOOST_DATE_TIME_HAS_MICROSECONDS
#define BOOST_DATE_TIME_HAS_NANOSECONDS
typedef date_time::time_resolution_traits<boost::date_time::time_resolution_traits_adapted64_impl, boost::date_time::nano,
1000000000, 9 > time_res_traits;
#else
// set up conditional test compilations
#define BOOST_DATE_TIME_HAS_MILLISECONDS
#define BOOST_DATE_TIME_HAS_MICROSECONDS
#undef BOOST_DATE_TIME_HAS_NANOSECONDS
typedef date_time::time_resolution_traits<
boost::date_time::time_resolution_traits_adapted64_impl, boost::date_time::micro,
1000000, 6 > time_res_traits;
// #undef BOOST_DATE_TIME_HAS_MILLISECONDS
// #undef BOOST_DATE_TIME_HAS_MICROSECONDS
// #undef BOOST_DATE_TIME_HAS_NANOSECONDS
// typedef date_time::time_resolution_traits<boost::int64_t, boost::date_time::tenth,
// 10, 0 > time_res_traits;
#endif
//! Base time duration type
/*! \ingroup time_basics
*/
class time_duration :
public date_time::time_duration<time_duration, time_res_traits>
{
public:
typedef time_res_traits rep_type;
typedef time_res_traits::day_type day_type;
typedef time_res_traits::hour_type hour_type;
typedef time_res_traits::min_type min_type;
typedef time_res_traits::sec_type sec_type;
typedef time_res_traits::fractional_seconds_type fractional_seconds_type;
typedef time_res_traits::tick_type tick_type;
typedef time_res_traits::impl_type impl_type;
time_duration(hour_type hour,
min_type min,
sec_type sec,
fractional_seconds_type fs=0) :
date_time::time_duration<time_duration, time_res_traits>(hour,min,sec,fs)
{}
time_duration() :
date_time::time_duration<time_duration, time_res_traits>(0,0,0)
{}
//! Construct from special_values
time_duration(boost::date_time::special_values sv) :
date_time::time_duration<time_duration, time_res_traits>(sv)
{}
//Give duration access to ticks constructor -- hide from users
friend class date_time::time_duration<time_duration, time_res_traits>;
protected:
explicit time_duration(impl_type tick_count) :
date_time::time_duration<time_duration, time_res_traits>(tick_count)
{}
};
#ifdef BOOST_DATE_TIME_POSIX_TIME_STD_CONFIG
//! Simple implementation for the time rep
struct simple_time_rep
{
typedef gregorian::date date_type;
typedef time_duration time_duration_type;
simple_time_rep(date_type d, time_duration_type tod) :
day(d),
time_of_day(tod)
{
// make sure we have sane values for date & time
if(!day.is_special() && !time_of_day.is_special()){
if(time_of_day >= time_duration_type(24,0,0)) {
while(time_of_day >= time_duration_type(24,0,0)) {
day += date_type::duration_type(1);
time_of_day -= time_duration_type(24,0,0);
}
}
else if(time_of_day.is_negative()) {
while(time_of_day.is_negative()) {
day -= date_type::duration_type(1);
time_of_day += time_duration_type(24,0,0);
}
}
}
}
date_type day;
time_duration_type time_of_day;
bool is_special()const
{
return(is_pos_infinity() || is_neg_infinity() || is_not_a_date_time());
}
bool is_pos_infinity()const
{
return(day.is_pos_infinity() || time_of_day.is_pos_infinity());
}
bool is_neg_infinity()const
{
return(day.is_neg_infinity() || time_of_day.is_neg_infinity());
}
bool is_not_a_date_time()const
{
return(day.is_not_a_date() || time_of_day.is_not_a_date_time());
}
};
class posix_time_system_config
{
public:
typedef simple_time_rep time_rep_type;
typedef gregorian::date date_type;
typedef gregorian::date_duration date_duration_type;
typedef time_duration time_duration_type;
typedef time_res_traits::tick_type int_type;
typedef time_res_traits resolution_traits;
#if (defined(BOOST_DATE_TIME_NO_MEMBER_INIT)) //help bad compilers
#else
BOOST_STATIC_CONSTANT(boost::int64_t, tick_per_second = 1000000000);
#endif
};
#else
class millisec_posix_time_system_config
{
public:
typedef boost::int64_t time_rep_type;
//typedef time_res_traits::tick_type time_rep_type;
typedef gregorian::date date_type;
typedef gregorian::date_duration date_duration_type;
typedef time_duration time_duration_type;
typedef time_res_traits::tick_type int_type;
typedef time_res_traits::impl_type impl_type;
typedef time_res_traits resolution_traits;
#if (defined(BOOST_DATE_TIME_NO_MEMBER_INIT)) //help bad compilers
#else
BOOST_STATIC_CONSTANT(boost::int64_t, tick_per_second = 1000000);
#endif
};
#endif
} }//namespace posix_time
#endif
|
__label__pos
| 0.969099 |
dcsimg
TODAY'S HEADLINES | ARTICLE ARCHIVE | FORUMS | TIP BANK
Browse DevX
Sign up for e-mail newsletters from DevX
Tip of the Day
Language: Microsoft Exchange
Expertise: Beginner
Jul 25, 2000
WEBINAR:
On-Demand
Building the Right Environment to Support AI, Machine Learning and Deep Learning
Limit Access to Free/Busy
Question:
Our CEO has three Personal Assistants who access his Mail and Calendar Items. He does not anyone else to be able to book a meeting directly. How can he gray out his Free/Busy when someone invites him to a meeting?
Answer:
I hope I understand your question. Basically what I would do is give the PA's adequate privileges to his calendar to review and edit it directly and then go to Tools | Options | Calendar Options | Free/Busy Options (on his machine) and set it to publish zero months of free/busy information to the server.
That should result in his free/busy info being unavailable to everybody, but the PA's will still be able to access and schedule things on his calendar.
DevX Pro
Thanks for your registration, follow us on our social networks to keep up-to-date
|
__label__pos
| 0.6017 |
2 Replies Latest reply: Sep 27, 2012 8:20 PM by litpuvn RSS
library referencing
litpuvn
Hi,
I am facing library referencing issue. I am using Netbeans 7.1.2; glassfish 3.1.2
My computer, i can use this API: FacesContext.getCurrentInstance().getMessageList()
But my friend's computer, also the same OS version; netbeans 7.1.2; glassfish 3.1.2
But he can't use that method because it is not found.
Do you see any problems that made my code compiled but the other isn't?
thanks,
|
__label__pos
| 0.743486 |
TabLayout 和ViewPager和Fragment的多页面滑动(主要实现一个水平的布局用来展示Tabs加上ViewPager实现联动效果)
主要实现一个类似于头条最上面的水平的布局,可以拉动如:
然后ViewPager主要负责实现展示LisyView条目, 代码如下 一步步开始:
首先导入依赖:
compile 'com.android.support:design:26.0.0-alpha1'
接下来就是布局:
<?xml version="1.0" encoding="utf-8"?>
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:orientation="vertical"
tools:context="daylx0911.day0913tablayoutviewpager.MainActivity">
<android.support.design.widget.TabLayout
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:id="@+id/tab"
app:tabGravity="center"
// 改变指示器下标的颜色
app:tabIndicatorColor="#ff0"
//改变整个TabLayout的颜色
android:background="#000"
//改变选中字体的颜色
app:tabSelectedTextColor="#ff0000"
//改变未选中字体的颜色
app:tabTextColor="#aaa"
//默认是fixed 固定的 标签很多时候会被挤压 不能滑动
//scrollable 可以滑动的
app:tabMode="scrollable"
//改变指示器下标的高度
app:tabIndicatorHeight="4dp"
/>
<android.support.v4.view.ViewPager
android:layout_width="match_parent"
android:layout_height="match_parent"
android:id="@+id/pager"
/>
</LinearLayout>
====================================================================
MainActivity代码如下:
public class MainActivity extends AppCompatActivity {
private TabLayout tab;
private ViewPager pa;
private List<String> list=new ArrayList<String>();
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
//查找控件
tab = (TabLayout) findViewById(R.id.tab);
pa = (ViewPager) findViewById(R.id.pager);
//tab的标题
list.add("头条");
list.add("社会");
list.add("国内");
list.add("国际");
list.add("娱乐");
list.add("体育");
list.add("军事");
list.add("科技");
list.add("财经");
list.add("时尚");
//tablayout和viewpager关联
tab.setupWithViewPager(pa);
//设置viewpager适配器
pa.setAdapter(new FragmentPagerAdapter(getSupportFragmentManager()) {
//重写这个方法,将设置每个Tab的标题
@Override
public CharSequence getPageTitle(int position) {
return list.get(position);
}
@Override
public Fragment getItem(int position) {
//一般我们在这个位置对比一下标题是什么,,,然后返回对应的fragment
//初始化fragment 对应position有多少,fragment有多少
NewFragment newFragment = new NewFragment();
Bundle bundle = new Bundle();
if (list.get(position).equals("头条")){
bundle.putString("name","top");
}else if (list.get(position).equals("社会")){
bundle.putString("name","shehui");
}else if (list.get(position).equals("国内")){
bundle.putString("name","guonei");
}else if (list.get(position).equals("国际")){
bundle.putString("name","guoji");
}else if (list.get(position).equals("娱乐")){
bundle.putString("name","yule");
}else if (list.get(position).equals("体育")){
bundle.putString("name","tiyu");
}else if (list.get(position).equals("军事")){
bundle.putString("name","junshi");
}else if (list.get(position).equals("科技")){
bundle.putString("name","keji");
}else if (list.get(position).equals("财经")){
bundle.putString("name","caijing");
}else if (list.get(position).equals("时尚")){
bundle.putString("name","shishang");
}
//给fragment 加bundle 数据
//activity与fragment 1.getset,2.接口回调,3.setArguments ,getAraguments
newFragment.setArguments(bundle);
return newFragment;
}
@Override
public int getCount() {
return list.size();
}
});
}
}
=========================================================================================
Fragment 类:
public class NewFragment extends Fragment {
private ListView list;
@Nullable
@Override
public View onCreateView(LayoutInflater inflater, @Nullable ViewGroup container, @Nullable Bundle savedInstanceState) {
//找到布局文件
View v = View.inflate(getActivity(), R.layout.listview, null);
//ListView控件
list = (ListView)v.findViewById(R.id.list);
return v;
}
@Override
public void onActivityCreated(@Nullable Bundle savedInstanceState) {
super.onActivityCreated(savedInstanceState);
Bundle bundle = getArguments();
//接收传递过来的值
String string = bundle.getString("name", "top");
//调用解析方法
Jiexi(string);
}
//解析方法
private void Jiexi(final String string) {
//使用异步
new AsyncTask<String,Integer,String>(){
@Override
protected String doInBackground(String... strings) {
String str="";
try {
URL url = new URL("http://v.juhe.cn/toutiao/index?type=" + string + "&key=597b4f9dcb50e051fd725a9ec54d6653");
HttpURLConnection conne= (HttpURLConnection) url.openConnection();
conne.setConnectTimeout(5000);
conne.setReadTimeout(5000);
int responseCode = conne.getResponseCode();
if (responseCode==200){
InputStream in = conne.getInputStream();
byte[] by=new byte[1024];
int len=0;
while ((len=in.read(by))!=-1){
str+=new String(by,0,len);
}
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return str;
}
@Override
protected void onPostExecute(String s) {
//Gson解析
Gson gson = new Gson();
User user = gson.fromJson(s, User.class);
List<User.ResultBean.DataBean> data = user.getResult().getData();
//listview适配器
Myadpader myadpader = new Myadpader(data, getActivity());
list.setAdapter(myadpader);
super.onPostExecute(s);
}
}.execute();
}
}
最后实现的效果:
这样写的好处是不需要写多个Fragment就可以实现多个不同的数据变化,只要滑动上面的Tab控件就可以变化数据
省的写好多继承Fragment的类
阅读更多
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_40090482/article/details/77970385
想对作者说点什么? 我来说一句
没有更多推荐了,返回首页
关闭
关闭
关闭
|
__label__pos
| 0.696355 |
JEE Main & Advanced Mathematics Linear Programming Question Bank Critical Thinking
• question_answer The maximum value of \[z=4x+3y\] subject to the constraints \[3x+2y\ge 160,\ 5x+2y\ge 200\], \[x+2y\ge 80\]; \[x,\ y\ge 0\] is [MP PET 1998]
A) 320
B) 300
C) 230
D) None of these
Correct Answer: D
Solution :
Obviously, it is unbounded. Therefore its maximum value does not exist.
adversite
You need to login to perform this action.
You will be redirected in 3 sec spinner
|
__label__pos
| 0.853094 |
We use cookies to give you the best experience on our website. If you continue to browse, then you agree to our privacy policy and cookie policy. Image for the cookie policy date
PdfWordWrapType.None disappears and PdfWordWrapType.WordOnly not working for text within a PdfGrid
Hey guys,
I was hoping to have word-wrapping removed for an aggregate row added to the last row of a PdfGrid, so that the sum would not wrap if it ended up being larger than the column. I tried setting the WordWrap property of the PdfStringFormat, unsure of whether it would clip or extend past the column. Instead the text disappeared!
Likewise the WordOnly setting appears to function the same as Word, which does not seem correct.
Is this a known issue? I'm currently working through the Syncfusion.Pdf.NETStandard library, version 16.3.0.29.
Also, can you let me know if the expected behavior will be clipping or text running past the boundries?
Thanks,
-Ricky
1 Reply
KC Karthikeyan Chandrasekar Syncfusion Team January 28, 2019 08:59 AM
Hi Ricky,
Please find the description for different WordWrap types in string format:
// Text wrapping between lines when formatting within a rectangle is disabled.
format.WordWrap = PdfWordWrapType.None;
//Text is wrapped by words. If there is a word that is longer than bounds' width, this word is wrapped by characters.
format.WordWrap = PdfWordWrapType.Word;
//Text is wrapped by words. If there is a word that is longer than bounds' width, it won't be wrapped at all
format.WordWrap = PdfWordWrapType.WordOnly;
// Text is wrapped by characters. In this case the word at the end of the text line can be split.
format.WordWrap = PdfWordWrapType.Character;
Note: By default the word wrap type for the string format in Grid is “Word” type.
We have tested different word wrap type in the PdfStringFormat and created sample PDF for each. Could you please confirm are you reporting this behavior.
Regards,
Karthikeyan
Loader.
Live Chat Icon For mobile
Up arrow icon
|
__label__pos
| 0.941775 |
/[escript]/trunk/doc/user/firststep.tex
ViewVC logotype
Diff of /trunk/doc/user/firststep.tex
Parent Directory Parent Directory | Revision Log Revision Log | View Patch Patch
revision 3277 by caltinay, Thu Oct 14 06:14:30 2010 UTC revision 3278 by caltinay, Fri Oct 15 02:00:45 2010 UTC
# Line 200 the right hand side $f$ of the PDE to co Line 200 the right hand side $f$ of the PDE to co
200 mypde = Poisson(mydomain) mypde = Poisson(mydomain)
201 mypde.setValue(f=1) mypde.setValue(f=1)
202 \end{python} \end{python}
203 We have not specified any boundary condition but the We have not specified any boundary condition but the \Poisson class implicitly
204 \Poisson class implicitly assumes homogeneous Neuman boundary conditions \index{Neumann assumes homogeneous Neuman boundary conditions\index{Neumann boundary condition!homogeneous} defined by \eqn{eq:FirstSteps.2}.
205 boundary condition!homogeneous} defined by \eqn{eq:FirstSteps.2}. With this boundary With this boundary condition the BVP\index{boundary value problem!BVP} we have
206 condition the BVP\index{boundary value problem!BVP} we have defined has no unique solution. In fact, with any solution $u$ defined has no unique solution.
207 and any constant $C$ the function $u+C$ becomes a solution as well. We have to add In fact, with any solution $u$ and any constant $C$ the function $u+C$ becomes
208 a Dirichlet boundary condition \index{Dirichlet boundary condition}. This is done a solution as well.
209 by defining a characteristic function \index{characteristic function} We have to add a Dirichlet boundary condition\index{Dirichlet boundary condition}.
210 which has positive values at locations $x=(x\hackscore{0},x\hackscore{1})$ where Dirichlet boundary condition is set This is done by defining a characteristic function\index{characteristic function}
211 and $0$ elsewhere. In our case of $\Gamma^D$ defined by \eqn{eq:FirstSteps.2c}, which has positive values at locations $x=(x\hackscore{0},x\hackscore{1})$
212 we need to construct a function \var{gammaD} which is positive for the cases $x\hackscore{0}=0$ or $x\hackscore{1}=0$. To get where Dirichlet boundary condition is set and $0$ elsewhere.
213 an object \var{x} which contains the coordinates of the nodes in the domain use In our case of $\Gamma^D$ defined by \eqn{eq:FirstSteps.2c}, we need to
214 construct a function \var{gammaD} which is positive for the cases $x\hackscore{0}=0$ or $x\hackscore{1}=0$.
215 To get an object \var{x} which contains the coordinates of the nodes in the domain use
216 \begin{python} \begin{python}
217 x=mydomain.getX() x=mydomain.getX()
218 \end{python} \end{python}
219 The method \method{getX} of the \Domain \var{mydomain} The method \method{getX} of the \Domain \var{mydomain} gives access to locations
220 gives access to locations in the domain defined by \var{mydomain}.
221 in the domain defined by \var{mydomain}. The object \var{x} is actually a \Data object which will be The object \var{x} is actually a \Data object which will be discussed in
222 discussed in \Chap{ESCRIPT CHAP} in more detail. What we need to know here is that \Chap{ESCRIPT CHAP} in more detail.
223 What we need to know here is that \var{x} has \Rank (number of dimensions) and
224 \var{x} has \Rank (number of dimensions) and a \Shape (list of dimensions) which can be viewed by a \Shape (list of dimensions) which can be viewed by calling the \method{getRank} and \method{getShape} methods:
calling the \method{getRank} and \method{getShape} methods:
225 \begin{python} \begin{python}
226 print "rank ",x.getRank(),", shape ",x.getShape() print "rank ",x.getRank(),", shape ",x.getShape()
227 \end{python} \end{python}
# Line 237 will print Line 238 will print
238 \begin{python} \begin{python}
239 Function space type: Finley_Nodes on FinleyMesh Function space type: Finley_Nodes on FinleyMesh
240 \end{python} \end{python}
241 which tells us that the coordinates are stored on the nodes of (rather than on points in the interior of) a \finley mesh. which tells us that the coordinates are stored on the nodes of (rather than on
242 To get the $x\hackscore{0}$ coordinates of the locations we use the points in the interior of) a \finley mesh.
243 statement To get the $x\hackscore{0}$ coordinates of the locations we use the statement
244 \begin{python} \begin{python}
245 x0=x[0] x0=x[0]
246 \end{python} \end{python}
247 Object \var{x0} Object \var{x0} is again a \Data object now with \Rank $0$ and \Shape $()$.
248 is again a \Data object now with \Rank $0$ and It inherits the \FunctionSpace from \var{x}:
\Shape $()$. It inherits the \FunctionSpace from \var{x}:
249 \begin{python} \begin{python}
250 print x0.getRank(),x0.getShape(),x0.getFunctionSpace() print x0.getRank(), x0.getShape(), x0.getFunctionSpace()
251 \end{python} \end{python}
252 will print will print
253 \begin{python} \begin{python}
254 0 () Function space type: Finley_Nodes on FinleyMesh 0 () Function space type: Finley_Nodes on FinleyMesh
255 \end{python} \end{python}
256 We can now construct a function \var{gammaD} which is only non-zero on the bottom and left edges We can now construct a function \var{gammaD} which is only non-zero on the
257 of the domain with bottom and left edges of the domain with
258 \begin{python} \begin{python}
259 from esys.escript import whereZero from esys.escript import whereZero
260 gammaD=whereZero(x[0])+whereZero(x[1]) gammaD=whereZero(x[0])+whereZero(x[1])
261 \end{python} \end{python}
262
263 \code{whereZero(x[0])} creates function which equals $1$ where \code{x[0]} is (almost) equal to zero \code{whereZero(x[0])} creates a function which equals $1$ where \code{x[0]} is (almost) equal to zero and $0$ elsewhere.
264 and $0$ elsewhere. Similarly, \code{whereZero(x[1])} creates a function which equals $1$ where \code{x[1]} is equal to zero and $0$ elsewhere.
265 Similarly, \code{whereZero(x[1])} creates function which equals $1$ where \code{x[1]} is The sum of the results of \code{whereZero(x[0])} and \code{whereZero(x[1])}
equal to zero and $0$ elsewhere.
The sum of the results of \code{whereZero(x[0])} and \code{whereZero(x[1])}
266 gives a function on the domain \var{mydomain} which is strictly positive where $x\hackscore{0}$ or $x\hackscore{1}$ is equal to zero. gives a function on the domain \var{mydomain} which is strictly positive where $x\hackscore{0}$ or $x\hackscore{1}$ is equal to zero.
267 Note that \var{gammaD} has the same \Rank, \Shape and \FunctionSpace like \var{x0} used to define it. So from Note that \var{gammaD} has the same \Rank, \Shape and \FunctionSpace like \var{x0} used to define it.
268 So from
269 \begin{python} \begin{python}
270 print gammaD.getRank(),gammaD.getShape(),gammaD.getFunctionSpace() print gammaD.getRank(), gammaD.getShape(), gammaD.getFunctionSpace()
271 \end{python} \end{python}
272 one gets one gets
273 \begin{python} \begin{python}
274 0 () Function space type: Finley_Nodes on FinleyMesh 0 () Function space type: Finley_Nodes on FinleyMesh
275 \end{python} \end{python}
276 An additional parameter \var{q} of the \code{setValue} method of the \Poisson class defines the An additional parameter \var{q} of the \code{setValue} method of the \Poisson
277 characteristic function \index{characteristic function} of the locations class defines the characteristic function\index{characteristic function} of
278 of the domain where homogeneous Dirichlet boundary condition \index{Dirichlet boundary condition!homogeneous} the locations of the domain where the homogeneous Dirichlet boundary condition\index{Dirichlet boundary condition!homogeneous} is set.
279 are set. The complete definition of our example is now: The complete definition of our example is now:
280 \begin{python} \begin{python}
281 from esys.linearPDEs import Poisson from esys.escript.linearPDEs import Poisson
282 x = mydomain.getX() x = mydomain.getX()
283 gammaD = whereZero(x[0])+whereZero(x[1]) gammaD = whereZero(x[0])+whereZero(x[1])
284 mypde = Poisson(domain=mydomain) mypde = Poisson(domain=mydomain)
285 mypde.setValue(f=1,q=gammaD) mypde.setValue(f=1,q=gammaD)
286 \end{python} \end{python}
287 The first statement imports the \Poisson class definition from the \linearPDEs module \escript package. The first statement imports the \Poisson class definition from the \linearPDEs module.
288 To get the solution of the Poisson equation defined by \var{mypde} we just have to call its To get the solution of the Poisson equation defined by \var{mypde} we just have to call its \method{getSolution} method.
\method{getSolution}.
289
290 Now we can write the script to solve our Poisson problem Now we can write the script to solve our Poisson problem
291 \begin{python} \begin{python}
# Line 304 Now we can write the script to solve our Line 302 Now we can write the script to solve our
302 mypde.setValue(f=1,q=gammaD) mypde.setValue(f=1,q=gammaD)
303 u = mypde.getSolution() u = mypde.getSolution()
304 \end{python} \end{python}
305 The question is what we do with the calculated solution \var{u}. Besides postprocessing, eg. calculating the gradient or the average value, which will be discussed later, plotting the solution is one one things you might want to do. \escript offers two ways to do this, both base on external modules or packages and so data need to converted The question is what we do with the calculated solution \var{u}.
306 to hand over the solution. The first option is using the \MATPLOTLIB module which allows plotting 2D results relatively quickly, see~\cite{matplotlib}. However, there are limitations when using this tool, eg. in problem size and when solving 3D problems. Therefore \escript provides a second options based on \VTK files which is especially Besides postprocessing, e.g. calculating the gradient or the average value, which will be discussed later, plotting the solution is one of the things you might want to do.
307 designed for large scale and 3D problem and which can be read by a variety of software packages such as \mayavi \cite{mayavi}, \VisIt~\cite{VisIt}. \escript offers two ways to do this, both based on external modules or packages and so data need to converted to hand over the solution.
308 The first option is using the \MATPLOTLIB module which allows plotting 2D results relatively quickly from within the Python script, see~\cite{matplotlib}.
309 However, there are limitations when using this tool, especially for large problems and when solving 3-dimensional problems.
310 Therefore, \escript provides functionality to export data as files which can subsequently be read by third-party software packages such as \mayavi\cite{mayavi} or \VisIt~\cite{VisIt}.
311
312 \subsection{Plotting Using \MATPLOTLIB} \subsection{Plotting Using \MATPLOTLIB}
313 The \MATPLOTLIB module provides a simple and easy to use way to visualize PDE solutions (or other \Data objects). The \MATPLOTLIB module provides a simple and easy-to-use way to visualize PDE solutions (or other \Data objects).
314 To hand over data from \escript to \MATPLOTLIB the values need to mapped onto a rectangular grid To hand over data from \escript to \MATPLOTLIB the values need to mapped onto
315 \footnote{Users of Debian 5(Lenny) please note: this example makes use of the \function{griddata} method in \module{matplotlib.mlab}. a rectangular grid\footnote{Users of Debian 5 (Lenny) please note: this example
316 makes use of the \function{griddata} method in \module{matplotlib.mlab}.
317 This method is not part of version 0.98.1 which is available with Lenny. This method is not part of version 0.98.1 which is available with Lenny.
318 If you wish to use contour plots, you may need to install a later version. If you wish to use contour plots, you may need to install a later version.
319 Users of Ubuntu 8.10 or later should be fine.}. We will make use Users of Ubuntu 8.10 or later should be fine.}. We will make use of the \numpy module.
of the \numpy module.
320
321 First we need to create a rectangular grid. We use the following statements: First we need to create a rectangular grid which is accomplished by the following statements:
322 \begin{python} \begin{python}
323 import numpy import numpy
324 x_grid = numpy.linspace(0.,1.,50) x_grid = numpy.linspace(0., 1., 50)
325 y_grid = numpy.linspace(0.,1.,50) y_grid = numpy.linspace(0., 1., 50)
326 \end{python} \end{python}
327 \var{x_grid} is an array defining the x coordinates of the grids while \var{x_grid} is an array defining the x coordinates of the grid while
328 \var{y_grid} defines the y coordinates of the grid. In this case we use $50$ points over the interval $[0,1]$ \var{y_grid} defines the y coordinates of the grid.
329 in both directions. In this case we use $50$ points over the interval $[0,1]$ in both directions.
330
331 Now the values created by \escript need to be interpolated to this grid. We will use the \MATPLOTLIB Now the values created by \escript need to be interpolated to this grid.
332 \function{mlab.griddata} function to do this. We can easily extract spatial coordinates as a \var{list} by We will use the \MATPLOTLIB \function{mlab.griddata} function to do this.
333 Spatial coordinates are easily extracted as a \var{list} by
334 \begin{python} \begin{python}
335 x=mydomain.getX()[0].toListOfTuples() x=mydomain.getX()[0].toListOfTuples()
336 y=mydomain.getX()[1].toListOfTuples() y=mydomain.getX()[1].toListOfTuples()
337 \end{python} \end{python}
338 In principle we can apply the same \member{toListOfTuples} method to extract the values from the In principle we can apply the same \member{toListOfTuples} method to extract the values from the PDE solution \var{u}.
339 PDE solution \var{u}. However, we have to make sure that the \Data object we extract the values from However, we have to make sure that the \Data object we extract the values from
340 uses the same \FunctionSpace as we have us when extracting \var{x} and \var{y}. We apply the uses the same \FunctionSpace as we have used when extracting \var{x} and \var{y}.
341 \function{interpolation} to \var{u} before extraction to achieve this: We apply the \function{interpolation} to \var{u} before extraction to achieve this:
342 \begin{python} \begin{python}
343 z=interpolate(u,mydomain.getX().getFunctionSpace()) z=interpolate(u, mydomain.getX().getFunctionSpace())
344 \end{python} \end{python}
345 The values in \var{z} are now the values at the points with the coordinates given by \var{x} and \var{y}. These The values in \var{z} are the values at the points with the coordinates given by \var{x} and \var{y}.
346 values are now interpolated to the grid defined by \var{x_grid} and \var{y_grid} by using These values are interpolated to the grid defined by \var{x_grid} and \var{y_grid} by using
347 \begin{python} \begin{python}
348 import matplotlib import matplotlib
349 z_grid = matplotlib.mlab.griddata(x,y,z,xi=x_grid,yi=y_grid ) z_grid = matplotlib.mlab.griddata(x, y, z, xi=x_grid, yi=y_grid)
350 \end{python} \end{python}
351 \var{z_grid} gives now the values of the PDE solution \var{u} at the grid. The values can be plotted now Now \var{z_grid} gives the values of the PDE solution \var{u} at the grid which can be plotted using \function{contourf}:
using the \function{contourf}:
352 \begin{python} \begin{python}
353 matplotlib.pyplot.contourf(x_grid, y_grid, z_grid, 5) matplotlib.pyplot.contourf(x_grid, y_grid, z_grid, 5)
354 matplotlib.pyplot.savefig("u.png") matplotlib.pyplot.savefig("u.png")
355 \end{python} \end{python}
356 Here we use $5$ contours. The last statement writes the plot to the file \file{u.png} in the PNG format. Alternatively, one can use Here we use 5 contours. The last statement writes the plot to the file \file{u.png} in the PNG format.
357 Alternatively, one can use
358 \begin{python} \begin{python}
359 matplotlib.pyplot.contourf(x_grid, y_grid, z_grid, 5) matplotlib.pyplot.contourf(x_grid, y_grid, z_grid, 5)
360 matplotlib.pyplot.show() matplotlib.pyplot.show()
361 \end{python} \end{python}
362 which gives an interactive browser window. which gives an interactive browser window.
363
364 \begin{figure} \begin{figure}
365 \centerline{\includegraphics[width=\figwidth]{figures/FirstStepResultMATPLOTLIB}} \centerline{\includegraphics[width=\figwidth]{figures/FirstStepResultMATPLOTLIB}}
366 \caption{Visualization of the Poisson Equation Solution for $f=1$ using \MATPLOTLIB.} \caption{Visualization of the Poisson Equation Solution for $f=1$ using \MATPLOTLIB}
367 \label{fig:FirstSteps.3b} \label{fig:FirstSteps.3b}
368 \end{figure} \end{figure}
369
370 Now we can write the script to solve our Poisson problem Now we can write the script to solve our Poisson problem
371 \begin{python} \begin{python}
372 from esys.escript import * from esys.escript import *
373 from esys.escript.linearPDEs import Poisson from esys.escript.linearPDEs import Poisson
374 from esys.finley import Rectangle from esys.finley import Rectangle
375 import numpy import numpy
376 import matplotlib import matplotlib
377 import pylab import pylab
378 # generate domain: # generate domain:
379 mydomain = Rectangle(l0=1.,l1=1.,n0=40, n1=20) mydomain = Rectangle(l0=1.,l1=1.,n0=40, n1=20)
380 # define characteristic function of Gamma^D # define characteristic function of Gamma^D
381 x = mydomain.getX() x = mydomain.getX()
382 gammaD = whereZero(x[0])+whereZero(x[1]) gammaD = whereZero(x[0])+whereZero(x[1])
383 # define PDE and get its solution u # define PDE and get its solution u
384 mypde = Poisson(domain=mydomain) mypde = Poisson(domain=mydomain)
385 mypde.setValue(f=1,q=gammaD) mypde.setValue(f=1,q=gammaD)
386 u = mypde.getSolution() u = mypde.getSolution()
387 # interpolate u to a matplotlib grid: # interpolate u to a matplotlib grid:
388 x_grid = numpy.linspace(0.,1.,50) x_grid = numpy.linspace(0.,1.,50)
389 y_grid = numpy.linspace(0.,1.,50) y_grid = numpy.linspace(0.,1.,50)
390 x=mydomain.getX()[0].toListOfTuples() x=mydomain.getX()[0].toListOfTuples()
391 y=mydomain.getX()[1].toListOfTuples() y=mydomain.getX()[1].toListOfTuples()
392 z=interpolate(u,mydomain.getX().getFunctionSpace()) z=interpolate(u,mydomain.getX().getFunctionSpace())
393 z_grid = matplotlib.mlab.griddata(x,y,z,xi=x_grid,yi=y_grid ) z_grid = matplotlib.mlab.griddata(x,y,z,xi=x_grid,yi=y_grid )
394 # interpolate u to a rectangular grid: # interpolate u to a rectangular grid:
395 matplotlib.pyplot.contourf(x_grid, y_grid, z_grid, 5) matplotlib.pyplot.contourf(x_grid, y_grid, z_grid, 5)
396 matplotlib.pyplot.savefig("u.png") matplotlib.pyplot.savefig("u.png")
397 \end{python} \end{python}
398 The entire code is available as \file{poisson\hackscore matplotlib.py} in the \ExampleDirectory. The entire code is available as \file{poisson\hackscore matplotlib.py} in the \ExampleDirectory.
399 You can run the script using the {\it escript} environment You can run the script using the {\it escript} environment
400 \begin{verbatim} \begin{verbatim}
401 run-escript poisson_matplotlib.py run-escript poisson_matplotlib.py
402 \end{verbatim} \end{verbatim}
403 This will create the \file{u.png}, see Figure~\fig{fig:FirstSteps.3b}. This will create the \file{u.png}, see \fig{fig:FirstSteps.3b}.
404 For details on the usage of the \MATPLOTLIB module we refer to the documentation~\cite{matplotlib}. For details on the usage of the \MATPLOTLIB module we refer to the documentation~\cite{matplotlib}.
405
406 As pointed out, \MATPLOTLIB is restricted to the two-dimensional case and As pointed out, \MATPLOTLIB is restricted to the two-dimensional case and
407 should be used for small problems only. It can not be used under \MPI as the \member{toListOfTuples} method is should be used for small problems only.
408 not safe under \MPI\footnote{The phrase 'safe under \MPI' means that a program will produce correct results when run on more than one processor under \MPI.}. It can not be used under \MPI as the \member{toListOfTuples} method is not
409 safe under \MPI\footnote{The phrase 'safe under \MPI' means that a program
410 will produce correct results when run on more than one processor under \MPI.}.
411
412 \begin{figure} \begin{figure}
413 \centerline{\includegraphics[width=\figwidth]{figures/FirstStepResult}} \centerline{\includegraphics[width=\figwidth]{figures/FirstStepResult}}
# Line 411 not safe under \MPI\footnote{The phrase Line 415 not safe under \MPI\footnote{The phrase
415 \label{fig:FirstSteps.3} \label{fig:FirstSteps.3}
416 \end{figure} \end{figure}
417
418 \subsection{Visualization using \VTK} \subsection{Visualization using export files}
419
420 As an alternative {\it escript} supports the usage of visualization tools which base on \VTK, eg. mayavi \cite{mayavi}, \VisIt~\cite{VisIt}. In this case the solution is written to a file in the \VTK format. This file the can read by the tool of choice. Using \VTK file is \MPI safe. As an alternative to \MATPLOTLIB, {\it escript} supports exporting data to
421 \VTK and \SILO files which can be read by visualization tools such as
422 mayavi\cite{mayavi} and \VisIt~\cite{VisIt}. This method is \MPI safe and
423 works with large 2D and 3D problems.
424
425 To write the solution \var{u} in Poisson problem to the file \file{u.xml} one need to add the line To write the solution \var{u} of the Poisson problem in the \VTK file format
426 to the file \file{u.vtu} one needs to add:
427 \begin{python} \begin{python}
428 saveVTK("u.xml",sol=u) saveVTK("u.vtu", sol=u)
429 \end{python} \end{python}
430 The solution \var{u} is now available in the \file{u.xml} tagged with the name "sol". This file can then be opened in a \VTK compatible visualization tool where the
431 solution is accessible by the name {\it sol}.
432
433 The Poisson problem script is now The Poisson problem script is now
434 \begin{python} \begin{python}
# Line 436 The Poisson problem script is now Line 445 The Poisson problem script is now
445 mypde.setValue(f=1,q=gammaD) mypde.setValue(f=1,q=gammaD)
446 u = mypde.getSolution() u = mypde.getSolution()
447 # write u to an external file # write u to an external file
448 saveVTK("u.xml",sol=u) saveVTK("u.vtu",sol=u)
449 \end{python} \end{python}
450 The entire code is available as \file{poisson\hackscore VTK.py} in the \ExampleDirectory. The entire code is available as \file{poisson\hackscore vtk.py} in the \ExampleDirectory.
451
452 You can run the script using the {\it escript} environment You can run the script using the {\it escript} environment and visualize the
453 and visualize the solution using \mayavi: solution using \mayavi:
454 \begin{verbatim} \begin{verbatim}
455 run-escript poisson_VTK.py run-escript poisson_VTK.py
456 mayavi2 -d u.xml -m SurfaceMap mayavi2 -d u.vtu -m SurfaceMap
457 \end{verbatim} \end{verbatim}
458 The result is shown in Figure~\fig{fig:FirstSteps.3}. The result is shown in \fig{fig:FirstSteps.3}.
459
Legend:
Removed from v.3277
changed lines
Added in v.3278
ViewVC Help
Powered by ViewVC 1.1.26
|
__label__pos
| 1 |
#!/usr/bin/perl -w -T # <@LICENSE> # Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to you under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at: # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # use strict; use warnings; # use bytes; use Errno qw(EBADF); use Getopt::Long; use Pod::Usage; use File::Spec; use POSIX qw(locale_h setsid sigprocmask _exit); POSIX::setlocale(LC_TIME,'C'); our ( $spamtest, %opt, $isspam, $forget, $messagecount, $learnedcount, $messagelimit, $progress, $total_messages, $init_results, $start_time, $synconly, $learnprob, @targets, $bayes_override_path ); my $PREFIX = '@@PREFIX@@'; # substituted at 'make' time my $DEF_RULES_DIR = '@@DEF_RULES_DIR@@'; # substituted at 'make' time my $LOCAL_RULES_DIR = '@@LOCAL_RULES_DIR@@'; # substituted at 'make' time use lib '@@INSTALLSITELIB@@'; # substituted at 'make' time BEGIN { # see comments in "spamassassin.raw" for doco my @bin = File::Spec->splitpath($0); my $bin = ($bin[0] ? File::Spec->catpath(@bin[0..1], '') : $bin[1]) || File::Spec->curdir; if (-e $bin.'/lib/Mail/SpamAssassin.pm' || !-e '@@INSTALLSITELIB@@/Mail/SpamAssassin.pm' ) { my $searchrelative; $searchrelative = 1; # disabled during "make install": REMOVEFORINST if ($searchrelative && $bin eq '../' && -e '../blib/lib/Mail/SpamAssassin.pm') { unshift ( @INC, '../blib/lib' ); } else { foreach ( qw(lib ../lib/site_perl ../lib/spamassassin ../share/spamassassin/lib)) { my $dir = File::Spec->catdir( $bin, split ( '/', $_ ) ); if ( -f File::Spec->catfile( $dir, "Mail", "SpamAssassin.pm" ) ) { unshift ( @INC, $dir ); last; } } } } } use Mail::SpamAssassin; use Mail::SpamAssassin::ArchiveIterator; use Mail::SpamAssassin::Message; use Mail::SpamAssassin::PerMsgLearner; use Mail::SpamAssassin::Util::Progress; use Mail::SpamAssassin::Logger; ########################################################################### $SIG{PIPE} = 'IGNORE'; # used to be CmdLearn::cmd_run() ... %opt = ( 'force-expire' => 0, 'use-ignores' => 0, 'nosync' => 0, 'quiet' => 0, 'cf' => [] ); Getopt::Long::Configure( qw(bundling no_getopt_compat permute no_auto_abbrev no_ignore_case) ); GetOptions( 'forget' => \$forget, 'ham|nonspam' => sub { $isspam = 0; }, 'spam' => sub { $isspam = 1; }, 'sync' => \$synconly, 'rebuild' => sub { $synconly = 1; warn "The --rebuild option has been deprecated. Please use --sync instead.\n" }, 'q|quiet' => \$opt{'quiet'}, 'username|u=s' => \$opt{'username'}, 'configpath|config-file|config-dir|c|C=s' => \$opt{'configpath'}, 'prefspath|prefs-file|p=s' => \$opt{'prefspath'}, 'siteconfigpath=s' => \$opt{'siteconfigpath'}, 'cf=s' => \@{$opt{'cf'}}, 'folders|f=s' => \$opt{'folders'}, 'force-expire|expire' => \$opt{'force-expire'}, 'local|L' => \$opt{'local'}, 'no-sync|nosync' => \$opt{'nosync'}, 'showdots' => \$opt{'showdots'}, 'progress' => \$opt{'progress'}, 'use-ignores' => \$opt{'use-ignores'}, 'no-rebuild|norebuild' => sub { $opt{'nosync'} = 1; warn "The --no-rebuild option has been deprecated. Please use --no-sync instead.\n" }, 'learnprob=f' => \$opt{'learnprob'}, 'randseed=i' => \$opt{'randseed'}, 'stopafter=i' => \$opt{'stopafter'}, 'max-size=i' => \$opt{'max-size'}, 'debug|debug-level|D:s' => \$opt{'debug'}, 'help|h|?' => \$opt{'help'}, 'version|V' => \$opt{'version'}, 'dump:s' => \$opt{'dump'}, 'import' => \$opt{'import'}, 'backup' => \$opt{'backup'}, 'clear' => \$opt{'clear'}, 'restore=s' => \$opt{'restore'}, 'dir' => sub { $opt{'old_format'} = 'dir'; }, 'file' => sub { $opt{'old_format'} = 'file'; }, 'mbox' => sub { $opt{'format'} = 'mbox'; }, 'mbx' => sub { $opt{'format'} = 'mbx'; }, 'single' => sub { $opt{'old_format'} = 'single'; }, 'db|dbpath=s' => \$bayes_override_path, 're|regexp=s' => \$opt{'regexp'}, '<>' => \&target, ) or usage( 0, "Unknown option!" ); if ( defined $opt{'help'} ) { usage( 0, "For more information read the manual page" ); } if ( defined $opt{'version'} ) { print "SpamAssassin version " . Mail::SpamAssassin::Version() . "\n"; exit 0; } # set debug areas, if any specified (only useful for command-line tools) if (defined $opt{'debug'}) { $opt{'debug'} ||= 'all'; } if ( $opt{'force-expire'} ) { $synconly = 1; } if ($opt{'showdots'} && $opt{'progress'}) { print "--showdots and --progress may not be used together, please select just one\n"; exit 0; } if ( !defined $isspam && !defined $synconly && !defined $forget && !defined $opt{'dump'} && !defined $opt{'import'} && !defined $opt{'clear'} && !defined $opt{'backup'} && !defined $opt{'restore'} && !defined $opt{'folders'} ) { usage( 0, "Please select either --spam, --ham, --folders, --forget, --sync, --import,\n--dump, --clear, --backup or --restore" ); } # We need to make sure the journal syncs pre-forget... if ( defined $forget && $opt{'nosync'} ) { $opt{'nosync'} = 0; warn "sa-learn warning: --forget requires read/write access to the database, and is incompatible with --no-sync\n"; } if ( defined $opt{'old_format'} ) { #Format specified in the 2.5x form of --dir, --file, --mbox, --mbx or --single. #Convert it to the new behavior: if ( $opt{'old_format'} eq 'single' ) { push ( @ARGV, '-' ); } } my $post_config = ''; # kluge to support old check_bayes_db operation # bug 3799: init() will go r/o with the configured DB, and then dbpath needs # to override. Just access the dbpath version via post_config_text. if ( defined $bayes_override_path ) { # Add a default prefix if the path is a directory if ( -d $bayes_override_path ) { $bayes_override_path = File::Spec->catfile( $bayes_override_path, 'bayes' ); } $post_config .= "bayes_path $bayes_override_path\n"; } # These options require bayes_scanner, which requires "use_bayes 1", but # that's not necessary for these commands. if (defined $opt{'dump'} || defined $opt{'import'} || defined $opt{'clear'} || defined $opt{'backup'} || defined $opt{'restore'}) { $post_config .= "use_bayes 1\n"; } $post_config .= join("\n", @{$opt{'cf'}})."\n"; # create the tester factory $spamtest = new Mail::SpamAssassin( { rules_filename => $opt{'configpath'}, site_rules_filename => $opt{'siteconfigpath'}, userprefs_filename => $opt{'prefspath'}, username => $opt{'username'}, debug => $opt{'debug'}, local_tests_only => $opt{'local'}, dont_copy_prefs => 1, PREFIX => $PREFIX, DEF_RULES_DIR => $DEF_RULES_DIR, LOCAL_RULES_DIR => $LOCAL_RULES_DIR, post_config_text => $post_config, } ); $spamtest->init(1); dbg("sa-learn: spamtest initialized"); # Bug 6228 hack: bridge the transition gap of moving Bayes.pm into a plugin; # To be resolved more cleanly!!! if ($spamtest->{bayes_scanner}) { foreach my $plugin ( @{ $spamtest->{plugins}->{plugins} } ) { if ($plugin->isa('Mail::SpamAssassin::Plugin::Bayes')) { # copy plugin's "store" object ref one level up! $spamtest->{bayes_scanner}->{store} = $plugin->{store}; } } } if (Mail::SpamAssassin::Util::am_running_on_windows()) { binmode(STDIN) or die "cannot set binmode on STDIN: $!"; # bug 4363 binmode(STDOUT) or die "cannot set binmode on STDOUT: $!"; } if ( defined $opt{'dump'} ) { my ( $magic, $toks ); if ( $opt{'dump'} eq 'all' || $opt{'dump'} eq '' ) { # show us all tokens! ( $magic, $toks ) = ( 1, 1 ); } elsif ( $opt{'dump'} eq 'magic' ) { # show us magic tokens only ( $magic, $toks ) = ( 1, 0 ); } elsif ( $opt{'dump'} eq 'data' ) { # show us data tokens only ( $magic, $toks ) = ( 0, 1 ); } else { # unknown option warn "Unknown dump option '" . $opt{'dump'} . "'\n"; $spamtest->finish_learner(); exit 1; } if (!$spamtest->dump_bayes_db( $magic, $toks, $opt{'regexp'}) ) { $spamtest->finish_learner(); die "ERROR: Bayes dump returned an error, please re-run with -D for more information\n"; } $spamtest->finish_learner(); # make sure we notice any write errors while flushing output buffer close STDOUT or die "error closing STDOUT: $!"; close STDIN or die "error closing STDIN: $!"; exit 0; } if ( defined $opt{'import'} ) { my $ret = $spamtest->{bayes_scanner}->{store}->perform_upgrade(); $spamtest->finish_learner(); # make sure we notice any write errors while flushing output buffer close STDOUT or die "error closing STDOUT: $!"; close STDIN or die "error closing STDIN: $!"; exit( !$ret ); } if (defined $opt{'clear'}) { unless ($spamtest->{bayes_scanner}->{store}->clear_database()) { $spamtest->finish_learner(); die "ERROR: Bayes clear returned an error, please re-run with -D for more information\n"; } $spamtest->finish_learner(); # make sure we notice any write errors while flushing output buffer close STDOUT or die "error closing STDOUT: $!"; close STDIN or die "error closing STDIN: $!"; exit 0; } if (defined $opt{'backup'}) { unless ($spamtest->{bayes_scanner}->{store}->backup_database()) { $spamtest->finish_learner(); die "ERROR: Bayes backup returned an error, please re-run with -D for more information\n"; } $spamtest->finish_learner(); # make sure we notice any write errors while flushing output buffer close STDOUT or die "error closing STDOUT: $!"; close STDIN or die "error closing STDIN: $!"; exit 0; } if (defined $opt{'restore'}) { my $filename = $opt{'restore'}; unless ($filename) { $spamtest->finish_learner(); die "ERROR: You must specify a filename to restore.\n"; } unless ($spamtest->{bayes_scanner}->{store}->restore_database($filename, $opt{'showdots'})) { $spamtest->finish_learner(); die "ERROR: Bayes restore returned an error, please re-run with -D for more information\n"; } $spamtest->finish_learner(); # make sure we notice any write errors while flushing output buffer close STDOUT or die "error closing STDOUT: $!"; close STDIN or die "error closing STDIN: $!"; exit 0; } if ( !$spamtest->{conf}->{use_bayes} ) { warn "ERROR: configuration specifies 'use_bayes 0', sa-learn disabled\n"; exit 1; } $spamtest->init_learner( { force_expire => $opt{'force-expire'}, learn_to_journal => $opt{'nosync'}, wait_for_lock => 1, caller_will_untie => 1 } ); $spamtest->{bayes_scanner}{use_ignores} = $opt{'use-ignores'}; if ($synconly) { $spamtest->rebuild_learner_caches( { verbose => !$opt{'quiet'}, showdots => $opt{'showdots'} } ); $spamtest->finish_learner(); # make sure we notice any write errors while flushing output buffer close STDOUT or die "error closing STDOUT: $!"; close STDIN or die "error closing STDIN: $!"; exit 0; } $messagelimit = $opt{'stopafter'}; $learnprob = $opt{'learnprob'}; if ( defined $opt{'randseed'} ) { srand( $opt{'randseed'} ); } # sync the journal first if we're going to go r/w so we make sure to # learn everything before doing anything else. # if ( !$opt{nosync} ) { $spamtest->rebuild_learner_caches(); } # what is the result of the run? will end up being the exit code. my $exit_status = 0; # run this lot in an eval block, so we can catch die's and clear # up the dbs. eval { $SIG{HUP} = \&killed; $SIG{INT} = \&killed; $SIG{TERM} = \&killed; if ( $opt{folders} ) { open( F, $opt{folders} ) or die "cannot open $opt{folders}: $!"; for ($!=0; ; $!=0) { chomp; next if /^\s*$/; if (/^(ham|spam):(\w*):(.*)/) { my $class = $1; my $format = $2 || "detect"; my $target = $3; push ( @targets, "$class:$format:$target" ); } else { target($_); } } defined $_ || $!==0 or $!==EBADF ? dbg("error reading from $opt{folders}: $!") : die "error reading from $opt{folders}: $!"; close(F) or die "error closing $opt{folders}: $!"; } ########################################################################### # Deal with the target listing, and STDIN -> tempfile my $tempfile; # will be defined if stdin -> tempfile push(@targets, @ARGV); @targets = ('-') unless @targets || $opt{folders}; for(my $elem = 0; $elem <= $#targets; $elem++) { # ArchiveIterator doesn't really like STDIN, so if "-" is specified # as a target, make it a temp file instead. if ( $targets[$elem] =~ /(?:^|:)-$/ ) { if (defined $tempfile) { # uh-oh, stdin specified multiple times? warn "skipping extra stdin target (".$targets[$elem].")\n"; splice @targets, $elem, 1; $elem--; # go back to this element again next; } else { my $handle; ( $tempfile, $handle ) = Mail::SpamAssassin::Util::secure_tmpfile(); binmode $handle or die "cannot set binmode on file $tempfile: $!"; # avoid slurping the whole file into memory, copy chunk by chunk my($inbuf,$nread); while ( $nread=sysread(STDIN,$inbuf,16384) ) { print {$handle} $inbuf or die "error writing to $tempfile: $!" } defined $nread or die "error reading from STDIN: $!"; close $handle or die "error closing $tempfile: $!"; # re-aim the targets at the tempfile instead of STDIN $targets[$elem] =~ s/-$/$tempfile/; } } # make sure the target list is in the normal AI format if ($targets[$elem] !~ /^[^:]*:[a-z]+:/) { my $item = splice @targets, $elem, 1; target($item); # add back to the list $elem--; # go back to this element again next; } } ########################################################################### my $iter = new Mail::SpamAssassin::ArchiveIterator( { # skip messages larger than max-size bytes, # 0 for no limit, undef defaults to 256 KB 'opt_max_size' => $opt{'max-size'}, 'opt_want_date' => 0, 'opt_from_regex' => $spamtest->{conf}->{mbox_format_from_regex}, } ); $iter->set_functions(\&wanted, \&result); $messagecount = 0; $learnedcount = 0; $init_results = 0; $start_time = time; # if exit_status isn't already set to non-zero, set it to the reverse of the # run result (0 is bad, 1+ is good -- the opposite of exit status codes) my $run_ok = eval { $exit_status ||= ! $iter->run(@targets); 1 }; print STDERR "\n" if ($opt{showdots}); $progress->final() if ($opt{progress} && $progress); my $phrase = defined $forget ? "Forgot" : "Learned"; print "$phrase tokens from $learnedcount message(s) ($messagecount message(s) examined)\n" if !$opt{'quiet'}; # If we needed to make a tempfile, go delete it. if (defined $tempfile) { unlink $tempfile or die "cannot unlink temporary file $tempfile: $!"; undef $tempfile; } if (!$run_ok && $@ !~ /HITLIMIT/) { die $@ } 1; } or do { my $eval_stat = $@ ne '' ? $@ : "errno=$!"; chomp $eval_stat; $spamtest->finish_learner(); die $eval_stat; }; $spamtest->finish_learner(); # make sure we notice any write errors while flushing output buffer close STDOUT or die "error closing STDOUT: $!"; close STDIN or die "error closing STDIN: $!"; exit $exit_status; ########################################################################### sub killed { $spamtest->finish_learner(); die "interrupted"; } sub target { my ($target) = @_; my $class = ( $isspam ? "spam" : "ham" ); my $format = ( defined( $opt{'format'} ) ? $opt{'format'} : "detect" ); push ( @targets, "$class:$format:$target" ); } ########################################################################### sub init_results { $init_results = 1; return unless $opt{'progress'}; $total_messages = $Mail::SpamAssassin::ArchiveIterator::MESSAGES; $progress = Mail::SpamAssassin::Util::Progress->new({total => $total_messages,}); } ########################################################################### sub result { my ($class, $result, $time) = @_; # don't open results files until we get here to avoid overwriting files &init_results if !$init_results; $progress->update($messagecount) if ($opt{progress} && $progress); } ########################################################################### sub wanted { my ( $class, $id, $time, $dataref ) = @_; my $spam = $class eq "s" ? 1 : 0; if ( defined($learnprob) ) { if ( int( rand( 1 / $learnprob ) ) != 0 ) { print STDERR '_' if ( $opt{showdots} ); return 1; } } if ( defined($messagelimit) && $learnedcount > $messagelimit ) { $progress->final() if ($opt{progress} && $progress); die 'HITLIMIT'; } $messagecount++; my $ma = $spamtest->parse($dataref); if ( $ma->get_header("X-Spam-Checker-Version") ) { my $new_ma = $spamtest->parse($spamtest->remove_spamassassin_markup($ma), 1); $ma->finish(); $ma = $new_ma; } my $status = $spamtest->learn( $ma, undef, $spam, $forget ); my $learned = $status->did_learn(); if ( !defined $learned ) { # undef=learning unavailable die "ERROR: the Bayes learn function returned an error, please re-run with -D for more information\n"; } elsif ( $learned == 1 ) { # 1=message was learned. 0=message wasn't learned $learnedcount++; } # Do cleanup ... $status->finish(); undef $status; $ma->finish(); undef $ma; print STDERR '.' if ( $opt{showdots} ); return 1; } ########################################################################### sub usage { my ( $verbose, $message ) = @_; my $ver = Mail::SpamAssassin::Version(); print "SpamAssassin version $ver\n"; pod2usage( -verbose => $verbose, -message => $message, -exitval => 64 ); } # --------------------------------------------------------------------------- =head1 NAME sa-learn - train SpamAssassin's Bayesian classifier =head1 SYNOPSIS B [options] [file]... B [options] --dump [ all | data | magic ] Options: --ham Learn messages as ham (non-spam) --spam Learn messages as spam --forget Forget a message --use-ignores Use bayes_ignore_from and bayes_ignore_to --sync Synchronize the database and the journal if needed --force-expire Force a database sync and expiry run --dbpath Allows commandline override (in bayes_path form) for where to read the Bayes DB from --dump [all|data|magic] Display the contents of the Bayes database Takes optional argument for what to display --regexp For dump only, specifies which tokens to dump based on a regular expression. -f file, --folders=file Read list of files/directories from file --dir Ignored; historical compatibility --file Ignored; historical compatibility --mbox Input sources are in mbox format --mbx Input sources are in mbx format --max-size Skip messages larger than b bytes; defaults to 256 KB, 0 implies no limit --showdots Show progress using dots --progress Show progress using progress bar --no-sync Skip synchronizing the database and journal after learning -L, --local Operate locally, no network accesses --import Migrate data from older version/non DB_File based databases --clear Wipe out existing database --backup Backup, to STDOUT, existing database --restore Restore a database from filename -u username, --username=username Override username taken from the runtime environment, used with SQL -C path, --configpath=path, --config-file=path Path to standard configuration dir -p prefs, --prefspath=file, --prefs-file=file Set user preferences file --siteconfigpath=path Path for site configs (default: @@PREFIX@@/etc/mail/spamassassin) --cf='config line' Additional line of configuration -D, --debug [area=n,...] Print debugging messages -V, --version Print version -h, --help Print usage message =head1 DESCRIPTION Given a typical selection of your incoming mail classified as spam or ham (non-spam), this tool will feed each mail to SpamAssassin, allowing it to 'learn' what signs are likely to mean spam, and which are likely to mean ham. Simply run this command once for each of your mail folders, and it will ''learn'' from the mail therein. Note that csh-style I in the mail folder names is supported; in other words, listing a folder name as C<*> will scan every folder that matches. See C for more details. If you are using mail boxes in format other than maildir you should use the B<--mbox> or B<--mbx> parameters. SpamAssassin remembers which mail messages it has learnt already, and will not re-learn those messages again, unless you use the B<--forget> option. Messages learnt as spam will have SpamAssassin markup removed, on the fly. If you make a mistake and scan a mail as ham when it is spam, or vice versa, simply rerun this command with the correct classification, and the mistake will be corrected. SpamAssassin will automatically 'forget' the previous indications. Users of C who wish to perform training remotely, over a network, should investigate the C switch. =head1 OPTIONS =over 4 =item B<--ham> Learn the input message(s) as ham. If you have previously learnt any of the messages as spam, SpamAssassin will forget them first, then re-learn them as ham. Alternatively, if you have previously learnt them as ham, it'll skip them this time around. If the messages have already been filtered through SpamAssassin, the learner will ignore any modifications SpamAssassin may have made. =item B<--spam> Learn the input message(s) as spam. If you have previously learnt any of the messages as ham, SpamAssassin will forget them first, then re-learn them as spam. Alternatively, if you have previously learnt them as spam, it'll skip them this time around. If the messages have already been filtered through SpamAssassin, the learner will ignore any modifications SpamAssassin may have made. =item B<--folders>=I, B<-f> I sa-learn will read in the list of folders from the specified file, one folder per line in the file. If the folder is prefixed with C or C, sa-learn will learn that folder appropriately, otherwise the folders will be assumed to be of the type specified by B<--ham> or B<--spam>. C above is optional, but is the same as the standard for ArchiveIterator: mbox, mbx, dir, file, or detect (the default if not specified). =item B<--mbox> sa-learn will read in the file(s) containing the emails to be learned, and will process them in mbox format (one or more emails per file). =item B<--mbx> sa-learn will read in the file(s) containing the emails to be learned, and will process them in mbx format (one or more emails per file). =item B<--use-ignores> Don't learn the message if a from address matches configuration file item C or a to address matches C. The option might be used when learning from a large file of messages from which the hammy spam messages or spammy ham messages have not been removed. =item B<--sync> Synchronize the journal and databases. Upon successfully syncing the database with the entries in the journal, the journal file is removed. =item B<--force-expire> Forces an expiry attempt, regardless of whether it may be necessary or not. Note: This doesn't mean any tokens will actually expire. Please see the EXPIRATION section below. Note: C<--force-expire> also causes the journal data to be synchronized into the Bayes databases. =item B<--forget> Forget a given message previously learnt. =item B<--dbpath> Allows a commandline override of the I configuration option. =item B<--dump> I
|
__label__pos
| 0.960239 |
Continue Statement in Python
Updated: May 18
The continue statement is used within a loop to skip the rest of the statements in the body of loop for the current iteration and jump to the start of the loop for next iteration. The break and continue statements are opposite each other which are used to change the flow of loop, break terminates the loop when a condition is got and continue leave out the current iteration.
Syntax:
continue
Flow diagram
Example:
program to display only odd numbers
for n in [10, 13, 9, 68, 4, 91, 54]:
if n%2 == 0:
continue
print(n)
Output:
13
9
91
|
__label__pos
| 0.582046 |
Click here
piconet
A network of devices connected in an ad hoc fashion using Bluetooth technology. A piconet is formed when at least two devices, such as a portable PC and a cellular phone, connect. A piconet can support up to eight devices. When a piconet is formed, one device acts as the master while the others act as slaves for the duration of the piconet connection. A piconet is sometimes called a PAN.
"Piconet" is a combination of the prefix "pico," meaning very small or one trillionth, and network.
Top Terms
Connect with Webopedia
• What is 250 GB Data Usage?
What is 250 GB (250 gigabytes) and why is this phrase so popular? Webopedia explains what the phrase 250 GB means in reference to data storage...
Read More »
Did You Know? Archive »
• Quick Reference Archive »
|
__label__pos
| 0.74299 |
Create a gist now
Instantly share code, notes, and snippets.
Complex numbers.
package com.czechscala.blank
class Complex(val r: Double, val i: Double) {
def this(coord: Tuple2[Double, Double]) = this(
coord._1 * Math.cos(coord._2),
coord._1 * Math.sin(coord._2)
)
def +(other: Complex) = new Complex(r + other.r, i + other.i)
def -(other: Complex) = new Complex(r - other.r, i - other.i)
def *(other: Complex) = new Complex(
r * other.r - i * other.i,
i * other.r + r * other.i
)
def /(other: Complex) = new Complex(
(r * other.r + i * other.i) / (other.r * other.r + other.i * other.i),
(i * other.r - r * other.i) / (other.r * other.r + other.i * other.i)
)
override def equals(obj: scala.Any) = obj match {
case that: Complex => Math.abs((r - that.r) / r) <= 0.001 && Math.abs((i - that.i) / i) <= 0.001
case _ => false
}
override def toString = {
val sign = if (i < 0) '-' else '+'
s"($r $sign ${Math.abs(i)}i)"
}
}
package com.czechscala.blank
import org.scalatest.FunSuite
class ComplexTest extends FunSuite {
trait ComplexTrait {
val c1 = new Complex(1, 2)
val c2 = new Complex(3, 4)
}
test("constructor") {
val comp = new Complex(1, 2)
assert(comp.r === 1)
assert(comp.i === 2)
}
test("simple adding") {
new ComplexTrait {
val c3 = new Complex(4, 6)
assert(c1 + c2 === c3)
}
}
test("simple subtraction") {
new ComplexTrait {
val c3 = new Complex(-2, -2)
assert(c1 - c2 === c3)
}
}
test("simple multiplication") {
new ComplexTrait {
val c3 = new Complex(-5, 10)
assert(c1 * c2 === c3)
}
}
test("simple division") {
new ComplexTrait {
val c3 = new Complex(0.44, 0.08)
assert(c1 / c2 === c3)
}
}
test("toString") {
new ComplexTrait {
assert(c1.toString === "(1.0 + 2.0i)")
assert(new Complex(-1, 2).toString === "(-1.0 + 2.0i)")
assert(new Complex(-1, -2).toString === "(-1.0 - 2.0i)")
}
}
test("equals") {
new ComplexTrait {
assert(c1 == new Complex(c1.r, c1.i))
assert(c1 != c2)
assert(c1 != new Object())
assert(c1 != true)
assert(new Complex(1.00001, 1.00004) == new Complex(1, 1))
}
}
test("construct with polar coordinates") {
val c = new Complex((5, 0.92729))
assert(c === new Complex(3, 4))
assert(c != new Complex(3, 40))
}
}
@v6ak
Mám tu dvě poznámky. K první doporučuji si něco najít o case classes, hodí se skoro všude. Druhá poznámka bude zajímavá až při řešení syntaxe typu 2+3.i.
1. Metoda equals by šla vyřešit pomocí case classes - začátek deklarace třídy by byl case class Complex(r: Double, i: Double) a dostali byste "zdarma" metodu equals plus další metody (např. hashCode, na které jste zapomněli).
2. Tady to zatím není moc vidět, ale pokud bychom chtěli umožnit zápis 3+2.i, museli bychom udělat dvě* implicitní konverze (řekněme realToComplex pro operace mezi reálnými a komplexními čísly a k tomu realComplexConversions pro výraz 2.i) hodilo by se přejmenovat field i na něco jiného. Jinak by asi vznikla nejednoznačnost u implicitních konverzí - 2.i by se mohlo vyhodnotit
a) buď jako realToComplex(2).i (tedy by se to snažilo zjistit imaginární složku z dvojky, která by samozřejmě byla nulová, tedy 0.0)
b) nebo jako realComplexConversions(2).i, což by mělo vrátit Complex(0, 2).
*) OK, zanedbávám, že reálné číslo může být vyjádřeno nejen typem Double, ale i Float nebo dokonce Int apod. Pro zjednodušení.
Sign up for free to join this conversation on GitHub. Already have an account? Sign in to comment
|
__label__pos
| 0.967531 |
Mariano Ravinale's Blog
Sharing Experiences
Asp.net MVC Simple CQRS part 3 – Command
leave a comment »
In this part we need to implement a mechanism that will change the state of our domain, this mechanism will be the CommandMessage.
this Command should delivery a message that will change the state of our domain, and our view should reflect that change.
after each commit or domain change, we should trigger a view update, for that reason I thaught that SignalR would be a good fit.
Example:
Command
public interface ICommand { }
public class DeleteAlbumCommand : ICommand
{
public int Id { get; set; }
}
This command is an action that will be triggered by the user in order to delete an Album
CommandProcessor
public class CommandProcessor : IProcessCommand
{
private readonly IWindsorContainer container;
public CommandProcessor(IWindsorContainer container)
{
this.container = container;
}
public void Execute(ICommand command)
{
dynamic handler = Assembly.GetExecutingAssembly()
.GetTypes()
.Where(t =>typeof(IHandleCommand<>)
.MakeGenericType(command.GetType()).IsAssignableFrom(t)
&& !t.IsAbstract
&& !t.IsInterface)
.Select(i => container.Resolve(i)).Single();
handler.Handle((dynamic)command);
}
}
Each command needs to be sent to the handler, for that we need a routing mechanism as well,
and that should be the resposability of the command processor.
Abstract CommandHandler:
public abstract class BaseCommandHandler<TCommand> : IHandleCommand<TCommand> where TCommand : ICommand
{
public ISessionFactory SessionFactory { get; set; }
public IConnectionManager ConnectionManager { get; set; }
protected ISession Session
{
get { return SessionFactory.GetCurrentSession(); }
}
#region Implementation of IHandleCommand<TCommand>
public abstract void Handle(TCommand command);
#endregion
}
The BaseCommandHandler will provide the basic infrastructure to handle any business logic
these handlers will cause a change of the states of our domain, each command is particular action
for that will cause a change and after this change we need to alert or syncronize all clients.
CommandHandler
public class DeleteAlbumCommandHandler : BaseCommandHandler<DeleteAlbumCommand>
{
public override void Handle(DeleteAlbumCommand command)
{
var entity = Session.Get<Core.Album>(command.Id);
Session.Delete(entity);
//client side method invocation (update the clients!)
ConnectionManager.GetClients<AlbumsHub>().Redraw();
}
}
The mechanism and resposability for synchronize all domain changes will be asigned to SignalR, after each change
SignalR will trigger the redraw event of the datatable plugin, this event will update all the data that is
being displaying in that moment.
Handlers Installer:
public class HandlersInstaller : IWindsorInstaller
{
public void Install(IWindsorContainer container, IConfigurationStore store)
{
var metadataProviderContributorsAssemblies = new[] { typeof (QueryProcessor).Assembly };
container.Register(AllTypes.From(metadataProviderContributorsAssemblies
.SelectMany(a => a.GetExportedTypes()))
.Where(t => t.Name.EndsWith("Handler") && t.IsAbstract == false)
.Configure(x => x.LifestyleSingleton())
);
container.Register(Component.For<IProcessQuery>()
.ImplementedBy<QueryProcessor>().LifeStyle.Singleton);
container.Register(Component.For<IProcessCommand>()
.ImplementedBy<CommandProcessor>().LifeStyle.Singleton);
}
}
An example of the registration of our components using Windsor Castle Container.
MvcInstaller:
public class MvcInstaller : IWindsorInstaller
{
public void Install(IWindsorContainer container, IConfigurationStore store)
{
container.Register(
AllTypes.FromAssemblyContaining<HomeController>()
.BasedOn<IController>()
.WithService.Self()
.Configure(cfg => cfg.LifestyleTransient()),
Component.For<IControllerFactory>().ImplementedBy<WindsorControllerFactory>(),
Component.For<IConnectionManager>().Instance(AspNetHost.DependencyResolver.Resolve<IConnectionManager>())
);
DependencyResolver.SetResolver(new WindsorDependencyResolver(container));
}
}
Remeber that be need to register the SignalR components here you have an example of how
to register the IConectionManager.
Asp.Net MVC Controller’s example:
public class AlbumsController : Controller
{
public IProcessCommand CommandProcessor { get; set; }
public ActionResult Index() { return View(); }
[HttpPost]
public void Delete(DeleteAlbumCommand command)
{
CommandProcessor.Execute(command);
}
}
In our Controller we need to inject the command Processor, and execute
the delete command that contains the id of the album the we need to delete.
SignalR in Album.js:
var Albums = (function ($) {
var public = {};
public.init = function (param) {
initSignalR();
initLayoutResources();
};
var initLayoutResources = function () {
$(".link").button();
$("#dialog").dialog({ autoOpen: false, modal: true });
$(".edit-link").createForm({ baseUrl: "Albums/Edit/" });
$(".details-link").createForm({ baseUrl: "Albums/Details/" });
$(".insert-link").createForm({ baseUrl: "Albums/Insert/" });
$(".delete-link").deleteAction({ baseUrl: "Albums/Delete/" });
};
var initSignalR = function () {
//Create SignalR object to get communicate with server
var hub = $.connection.AlbumsHub;
hub.Redraw = function () {
DataTable.reload();
};
// Start the connection
$.connection.hub.start();
};
return public;
} (jQuery));
Remember that we need to update the state of the clients after each command action that
triggered a domain change, for that we should initialize the SignalR comunication with the server and
declare the redraw function that will call the jQuery Datatable reload method in order to update all the data.
Download or Fork the project on GitHub
May the code be with you!.
Mariano Ravinale
Creative Commons License
Written by @mravinale
octubre 14, 2012 at 9:05 pm
Publicado en Asp.Net MVC
Tagged with ,
Asp.net MVC Simple CQRS part 2 – Edit form using jquery dialog
with 2 comments
The goal:
Reuse all Asp.net MVC Form client/server validations functionality using jquery dialog.
This feature will be useful for this post series and for building general crud applications, as well.
Example:
First, let’s create our model:
public class AlbumModel
{
[Display(Name = "Id")]
public int AlbumId { get; set; }
[Required]
public string Title { get; set; }
[HiddenInput(DisplayValue = false)]
[Display(Name = "Artists")]
public int ArtistId { get; set; }
public string ArtistName { get; set; }
public IEnumerable<SelectListItem> Artists { get; set; }
}
Now, we should create a partial view in order to render the Form
Edit.cshtml:
@model Chinook.Core.AlbumModel
@using (Html.BeginForm("Edit", "Albums",FormMethod.Post, new { id = "EditForm" }))
{
@Html.ValidationSummary(true)
<fieldset>
<legend>Edit Album - @Model.AlbumId</legend>
@Html.HiddenFor(model => model.AlbumId)
<div class="editor-label">
@Html.LabelFor(model => model.Title)
</div>
<div class="editor-field">
@Html.EditorFor(model => model.Title)
@Html.ValidationMessageFor(model => model.Title)
</div>
<div class="editor-label">
@Html.LabelFor(model => model.ArtistId)
</div>
<div class="editor-field">
@Html.DropDownListFor(model => model.ArtistId, Model.Artists, new { style = "width: 206px" })
@Html.ValidationMessageFor(model => model.ArtistId)
</div>
<p>
<input type="submit" value="Save" />
</p>
</fieldset>
}
<!--Lets add jquery validations for model Validations before submit-->
<script src="@Url.Content("~/Scripts/jquery.validate.min.js")" type="text/javascript"></script>
<script src="@Url.Content("~/Scripts/jquery.validate.unobtrusive.min.js")" type="text/javascript"></script>
<script type="text/javascript" charset="utf-8">
$(document).ready(function () {
$('#EditForm').ajaxForm({
beforeSubmit: function () {
return $('#EditForm').valid();
},
success: function () {
$('#dialog').dialog("close");
}
});
});
</script>
As you can see I’ve added jquery.validate.min.js and jquery.validate.unobtrusive.min.js this will executed when
the partial view is loaded after ajax call has been made.
A little peace of functionality must be writen first, two events:
before submit, verify all the fields are valid and
Success, when everything is ok close the dialog.
Album.js
$(function () {
Albums.init();
});
//Module Pattern: http://tinyurl.com/crdgdzn
var Albums = function () {
var initLayout = function () {
$(".edit-link").button();
$("#dialog").dialog({ autoOpen: false, modal: true });
};
var initEditForm = function () {
$(".edit-link").live('click', function (event) {
event.preventDefault();
$.ajax({
url: "Albums/Edit/1",
success: function (data) {
$("#dialog").html(data);
$("#dialog").dialog('open');
},
error: function () { alert("Sorry,error"); }
});
});
}
// Reveal public pointers to
// private functions and properties
return {
init: function () {
initLayout();
initEditForm();
}
};
} ();
Now in order to call the Form we need to add an ajax call, we should call to the server asking for the information and the html, and add this html to the div with the id “dialog”.
AlbumsController:
[HttpGet]
public ActionResult Edit(GetAlbumsByIdQuery query)
{
return PartialView("Edit", QueryProcessor.Execute(query));
}
When someone calls to this method we will return the partial view with the information retrieved from the database.
Index.cshtml
<div id="demo">
<div>
<a class="edit-link" href="">Edit Album</a>
</div>
<table id="example" class="display" >
<thead>
<tr>
<th>Id</th>
<th>Title</th>
<th>Artist Name</th>
</tr>
</thead>
<tbody></tbody>
</table>
<div id="dialog" title="Basic dialog"></div>
</div>
<script src="@Url.Content("~/Scripts/albums.js")" type="text/javascript"></script>
Finally the index page, here you can see the anchor that will be the trigger for the dialog call.
and the div that will be the container for the html form rendered.
in the next post, we’ll see how to render the data grid using http://datatables.net/ using ajax.
Download or Fork the project on GitHub
May the code be with you!.
Mariano Ravinale
Creative Commons License
Written by @mravinale
septiembre 23, 2012 at 9:04 pm
Publicado en Asp.Net MVC
Asp.net MVC Simple CQRS part 1 – Query
with 5 comments
Inspired by the Jeremy blog post crud its now cqrs or is it and
Gregory Young simple CQRS project: https://github.com/gregoryyoung/m-r
I’ve been working in a very simple insight for Asp.net MVC, in order to work comfortably in our business applications.
Quoting some words of Jeremy Likness: “CQRS provides what I think is a very valuable insight: that how you read and query data is probably very different from how you manage, update, and manipulate data. You don’t have to have a picture-perfect implementation of CQRS to take advantage of this concept”
image
The main Idea is to encapsulate our query and execute it using a processor, the processor wil be in charge to match each query to their handler in order to return the result from the data source.
Let’s take a look inside the code:
Query: Will define an unique query action with an expected result
public interface IQuery { }
public class GetAlbumsByIdQuery : IQuery
{
public int Id { get; set; }
}
QueryProcessor: Will be in charge to match each query to their handler (using reflection and with a little help of dynamics) returning the handler’s result from the datasource.
public class QueryProcessor : IProcessQuery
{
private readonly IWindsorContainer container;
public QueryProcessor(IWindsorContainer container)
{
this.container = container;
}
public TResult Execute(IQuery query)
{
dynamic handler = Assembly.GetExecutingAssembly()
.GetTypes()
.Where(t =>typeof(IHandleQuery)
.MakeGenericType(query.GetType(), typeof(TResult)).IsAssignableFrom(t)
&& !t.IsAbstract
&& !t.IsInterface)
.Select(i => container.Resolve(i)).Single();
return handler.Handle((dynamic)query);
}
}
Abstract QueryHandler: This abstract class will implement the base signature for each handler that we will create, in order to have NHibernate Infrastructure ready for our queries.
public abstract class BaseQueryHandler : IHandleQuery where TQuery : IQuery
{
public ISessionFactory SessionFactory { get; set; }
protected ISession Session
{
get { return SessionFactory.GetCurrentSession(); }
}
#region IQueryHandler Members
public abstract TResult Handle(TQuery query);
#endregion
}
QueryHandler: Given the query and the returning signature we will execute the query and map the entity to our view Model using Automapper
public class GetAlbumsByIdQueryHandler : BaseQueryHandler
{
public override AlbumModel Handle(GetAlbumsByIdQuery query)
{
var entity = Session.Get(query.Id);
return Mapper.Map(entity);
}
}
Windsor Installer:
public class HandlersInstaller : IWindsorInstaller
{
public void Install(IWindsorContainer container, IConfigurationStore store)
{
var metadataProviderContributorsAssemblies = new[] { typeof (QueryProcessor).Assembly };
container.Register(AllTypes.From(metadataProviderContributorsAssemblies
.SelectMany(a => a.GetExportedTypes()))
.Where(t => t.Name.EndsWith("Handler") && t.IsAbstract == false)
.Configure(x => x.LifestyleSingleton())
);
container.Register(Component.For<IProcessQuery>()
.ImplementedBy<QueryProcessor>().LifeStyle.Singleton);
container.Register(Component.For<IProcessCommand>()
.ImplementedBy<CommandProcessor>().LifeStyle.Singleton);
}
}
Asp.Net MVC Controller’s example:
public class AlbumsController : Controller
{
public IProcessQuery QueryProcessor { get; set; }
public ActionResult Index() { return View(); }
[HttpGet]
public ActionResult Details(GetAlbumsByIdQuery query)
{
return PartialView("Details", QueryProcessor.Execute(query));
}
}
Now executing our query we’ll get the result in order to fill our view.
In case you are wondering about how to Handle NHibernate Session in Asp.net Mvc, I would recommend take a look to this post:
http://nhforge.org/blogs/nhibernate/archive/2011/03/03/effective-nhibernate-session-management-for-web-apps.aspx
And of course read about mapping by code:
http://fabiomaulo.blogspot.com.ar/2011/04/nhibernate-32-mapping-by-code.html
Next post I’ll show the view, and command handling.
Download or Fork the project on GitHub
May the code be with you!.
Mariano Ravinale
Creative Commons License
Written by @mravinale
junio 20, 2012 at 5:48 pm
Publicado en Asp.Net MVC
Visual State Publisher
leave a comment »
The Idea is that when we do doubleClick over the list we’ll see the detail and again doing doubleClick we’ll see the list again.
In this proyect I’ve added some flavor doing some states animations, so in the viewmodel you may see this implementation:
private ICommand _showDetailCommand;
public ICommand ShowDetailCommand {
get {
if (_showDetailCommand == null) {
_showDetailCommand = new RelayCommand<string>(state =>
Publisher.VSM.Publish(state)
);
}
return _showDetailCommand;
}
}
private ICommand _showListCommand;
public ICommand ShowListCommand {
get {
if (_showListCommand == null) {
_showListCommand = new RelayCommand<string>(state =>
Publisher.VSM.Publish(state)
);
}
return _showListCommand;
}
}
For that we need to implement both commands as you can see and a event publisher implementation for each one, that what really is a Facade that encapsulates a Mediator Pattern implementation that in Mvvm Light is named as Messenger .
public static class VSM {
public static void Publish<T>(T message) where T : class {
Messenger.Default.Send<T>(message, typeof(VSM));
}
public static void Register<T>(object reference, Action<T> action) where T : class {
Messenger.Default.Register<T>(reference, typeof(VSM), action);
}
public static void UnRegister<T>(object reference) where T : class {
Messenger.Default.Unregister<T>(reference);
}
}
Ok, but how can I call the View?!??! because the VSM is there!!! there’s a couple solutions for that, but what I really like is to use a behavior, the code is quite reusable and we can attach to any control the code is quite simple:
public class VSMBehavior : Behavior<FrameworkElement> {
public VSMBehavior() { }
protected override void OnAttached() {
base.OnAttached();
Publisher.VSM.Register<string>(this, state =>
VisualStateManager.GoToState(AssociatedObject as Control, state, true)
);
}
protected override void OnDetaching() {
base.OnDetaching();
Publisher.VSM.UnRegister<string>(this);
}
}
In case you want to see other implementations your are free to see some of them VSM1, VSM2,
But one of the best implementations for MVVM VSM is here the Visual State Aggregator by Jeremy Likness. Based on the Event Agregator Pattern, but is very similar to the Mediator pattern and in Mvvm is already implemented, so I thaught to use it in a similar way.
Ok, but all this really works?
that would be my question if I was reading a post like this, for that reason I’ve made this short video showing the project working:
I really hope this article would be helpful and encorage you to use Ninject Di/Ioc and extensions with Mvvm Light,
Here you can download the project.
The project uses some Data sample provided by Blend, in some future post we can add some real services and some more animations.
Written by @mravinale
febrero 20, 2011 at 12:41 am
Publicado en Uncategorized
Working with MvvmLight and Ninject cool extensions
with one comment
Today I would like to share some cool stuff that you can do with MvvmLight and Ninject extensions,
Other objective of this article is to show how to implement in a very quick way(easy steps) the AOP IANPC Interception (actions to be executed before or after the execution of every call to a method in our code) provided by Ninject Extensions(DI/Ioc) applied in the implementation of the interface INotifyPropertyChange as a simple atribute.
in other words :
We are going to change this code:
public class SomeViewModel : ViewModelBase {
private ObservableCollection<Item> _listCollection;
public ObservableCollection<Item> ListCollection {
get {
return _listCollection;
}
set {
_listCollection = value;
OnPropertyChanged("ListCollection");
}
}
}
To this code:
public class SomeViewModel : AutoNotifyViewModelBase {
[NotifyOfChanges]
public virtual ObservableCollection<Item> ListCollection { get; set; }
}
A little of history and motivation first:
I’ve been doing some experiments with AOP, and then I saw a really nice article in code project about using Aspects applied to INotifyPropertyChanged (INPC), but I didn’t see a Ninject implementation so as always I’ve started to google about it.
What I saw was a gret article of Jonas Follesoe talking about using dynamic proxy for automatic INPC with Ninject I really recomend to read that post and download the project.
Reading article you can see that Ian Davis, the owner of interseption-extension for Ninject, contacted Jonas, and then he made his own adaptation of automatic INPC(IANPC) another great article
After couple week I had some free time and I wanted to see the source, of Ian davis project, and realised that the code of the IANPC was already inside, so I’ve started to make it work for share with you.
Let’s start to see the implementation:
First step is download the assemblies that we need:
Get Silverlight Ninject asemblies from GitHub.
Get Common Service locator from codeplex.
Ones that we finished to add all references to the project, let’s get to work!
In this example we are going to fill a List(Flick Behavior) with some mock items and add some effects.
Add a new Class named IocContainer.cs
image
Add the binding for each instance that you need in your project, as an example I’ve made some bindings for the main instance that I need to use:
public class IocContainer : NinjectModule {
public override void Load() {
this.Bind<ISampleDataSource>().To<SampleDataSource>();
//Services
this.Bind<IDataService>().To<MockItemsService>();
//Pages
this.Bind<MainPage>().ToSelf();
//ViewModels
this.Bind<MainViewModel>().ToSelf();
}
}
Add the Ioc Initialization into the app, Adding The Bootstrapper
public class Bootstrapper
{
private static IKernel Container { get; set; }
public static void Initialize()
{
Container = new StandardKernel(new DynamicProxy2Module(), new IocContainer());
ServiceLocator.SetLocatorProvider(() => new NinjectServiceLocator(Container));
}
public static void ShutDown()
{
Container.Dispose();
}
}
The normal implementation of this would be something like this:
var kernel = new StandardKernel(new IocContainer());
But we need to create proxies in order to do the Interception to our virtual members, that’s way we’ve added the new instance of DynamicProxy2Module, and way we need the reference to Castle.Core assembly.
Let’s do the last and important part of IANPC , the atribute NotifyOfChanges :)
[NotifyOfChanges]
public virtualObservableCollection<Item> ListCollection { get; set; }
But we need to implement the Interface IAutoNotifyPropertyChanged from Ninject.Extensions.Interseption in our view model otherwise it won’t work, but in MvvmLight we have a ViewModelBase with a diferent contract implementation instead to use OnPropertyChanged MvvmLight uses RaisePropertyChanged shit!!, I’ve been forced to create a new class, AutoNotifyViewModelBase that implements IAutoNotifyPropertyChanged and mvvm methods.
Implement the interface IAutoNotifyPropertyChanged in this case is already implmented in AutoNotifyViewModelBase .
public class MainViewModel : AutoNotifyViewModelBase {
[NotifyOfChanges]
public virtual ObservableCollection<Item> ListCollection { get; set; }
}
So far we have develop all things required to retrieve data from a service and fill our List Collection, we have the infrastructure using Ninject Ioc, and the interception IANPC Atributes cool right.
May the code be with you!
Mariano Ravinale.
Creative Commons License
This work is licensed under a Creative Commons Attribution 3.0 Unported License
Written by @mravinale
febrero 18, 2011 at 8:15 pm
Publicado en Silverlight
Flick Behavior – Using a SL Listbox control as you do on WP7
with 3 comments
Working with Windows Phone 7, I get used to handle the ListBox control using that flickering efect with my mouse, then I’ve started to seek on the web for some control in Silverlight that imitates the same behavior, and I’ve found the Sasha Barber’s web, who built a Creating A Scrollable Control Surface In WPF with a nice efect and a very cool way to do the maths and calculate the speed and distance.
So I’ve started to make it work in Silverlight as a user control, the first drop worked, but I made it using a ScrollViewer and ItemsControl, as this example:
<Grid x:Name=”LayoutRoot”>
<
ScrollViewer x:Name=”MyScrollViewer”Margin=”0″Background=”White”
HorizontalScrollBarVisibility="Disabled">
<ItemsControl x:Name="itemsControl"
MouseLeftButtonDown="itemsControl_MouseLeftButtonDown"
MouseLeftButtonUp="itemsControl_MouseLeftButtonUp"
MouseMove="itemsControl_MouseMove"
ItemTemplate="{StaticResource ItemTemplate}"
ItemsSource="{Binding DataSource, ElementName=userControl}" />
</ScrollViewer>
</Grid>
but I didn’t like it, because the listbox it is more popular, and it has already a ScrollViewer and the ItemsPresenter as a Template, but it was ok, so far I’ve learned that the key is handle the MouseLeftbuttonDown , MouseLeftButtonUp and Mousemove events, to do the Maths.
So now what I’ve got to do is create a behavior for the ListBox, navigate inside the template, and get attached to the events mentionated before.
yap,but how can I find the ItemsPresenter within the ListBox?,the answer would be with the findByType<T> method, inspired by the XamlQuery library, with some magic to make it portable ;)
protected IEnumerable<DependencyObject> FindByType<T>(DependencyObject control) where T : class {
var childrenCount = VisualTreeHelper.GetChildrenCount(control);
for (var index = 0; index < childrenCount; index++) {
var child = VisualTreeHelper.GetChild(control, index);
if (child is T) yield return child;
foreach (var desc inFindByType<T>(child)) {
if (desc is T) yield return desc;
}
}
}
And now let’s find the scrollViewer and the ItemsPresenter inside the ListBox.
MyScrollViewer = FindByType<ScrollViewer>(AssociatedObject).ToList().First() as ScrollViewer;
MyItemPresenter = FindByType<ItemsPresenter>(AssociatedObject).ToList().First() as ItemsPresenter;
Yea!, so far so good, now I’ve got the main controls for the LisBox, and now let’s try to do the same that I did with the user control. but the problem was that the MouseLeftButtonDown didn’t work beacuse the event was toked by it’s parent in this case Listbox for the SelectionChanged event so the trick is to add handlers:
MyItemPresenter.AddHandler(UIElement.MouseLeftButtonDownEvent,
new MouseButtonEventHandler(ItemPresenter_MouseLeftButtonDown), true);
MyItemPresenter.AddHandler(UIElement.MouseLeftButtonUpEvent,
new MouseButtonEventHandler(ItemPresenter_MouseLeftButtonUp), true);
Ok, now lets handle the events: first let’s track the mouse position, and calculate the desviation between the last point that it has been captured, and the current,so the follow event will be in charge of that:
private void AssociatedObject_MouseMove(object sender, MouseEventArgs e) {
if (IsMouseCaptured ) {
CurrentPoint = new Point(e.GetPosition(AssociatedObject).X,
e.GetPosition(AssociatedObject).Y);
var delta = new Point(ScrollStartPoint.X - CurrentPoint.X,
ScrollStartPoint.Y - CurrentPoint.Y);
ScrollTarget.X = ScrollStartOffset.X + delta.X / Speed;
ScrollTarget.Y = ScrollStartOffset.Y + delta.Y / Speed;
MyScrollViewer.ScrollToHorizontalOffset(ScrollTarget.X);
MyScrollViewer.ScrollToVerticalOffset(ScrollTarget.Y);
}
And now let’s take a look to the events in charge to do the capture of the mouse clicks and points:
private void ItemPresenter_MouseLeftButtonDown(object sender, MouseButtonEventArgs e) {
ScrollStartPoint = new Point(e.GetPosition(AssociatedObject).X,
e.GetPosition(AssociatedObject).Y);
ScrollStartOffset.X = MyScrollViewer.HorizontalOffset;
ScrollStartOffset.Y = MyScrollViewer.VerticalOffset;
IsMouseCaptured = !IsMouseCaptured;
}
private void ItemPresenter_MouseLeftButtonUp(object sender, MouseButtonEventArgs e) {
IsMouseCaptured = !IsMouseCaptured;
}
Take a look to this video Introducing the behavior.
if you are interested to see how it works take a look to this video
remember to visit Michael’s page for see how to create sample datasource http://geekswithblogs.net/mbcrump/archive/2010/09/03/easy-way-to-generate-sample-data-for-your-silverlight-4.aspx
you’re free to grab the code and see how it was built, whith this post I’ve tried to share with you the journey making this component, and I really hope, that you may find this control useful and you may improve it for your own needs.
See it in action and download In expression Blend Gallery!
may the code be with you.
Mariano Ravinale
Creative Commons License
This work is licensed under a Creative Commons Attribution 3.0 Unported License
Written by @mravinale
noviembre 14, 2010 at 2:40 am
Publicado en Silverlight
Mvvm Light project template for Windows Phone 7 RTM
with 2 comments
Today I would like to share a project template ready to build great windows phone 7 applications using Mvvm Light, first of all this this project template is an update that I made from the current Mvvm Light project hosted on codeplex: http://mvvmlight.codeplex.com/ my favorite toolkit to build Silverlight and Windows Phone 7 applications.
Besides to make it compatible for the current tools version, and support the Laurent Bugnion Project, I just added a very simple reactive extensions example, in order to make it ready to work with services in our model.
Download the file: MvvmLight WP7 RTM
remember to paste the .zip on project templates folder.
Example:
C:\Users\Mariano\Documents\Visual Studio 2010\Templates\ProjectTemplates\Silverlight for Window Phone\Mvvm
I hope this could be Helpful.
May the code be with you.
Mariano Ravinale.
Creative Commons License
This work is licensed under a Creative Commons Attribution 3.0 Unported License
Written by @mravinale
octubre 27, 2010 at 10:01 pm
Publicado en Windows Phone 7
Seguir
Recibe cada nueva publicación en tu buzón de correo electrónico.
|
__label__pos
| 0.55019 |
Considerations To Know About r programming homework help
They estimate the multivariate generalized linear blended styles (MGLMMs) making use of either common or adaptive Gaussian quadrature. The authors also compare two-amount fastened and random consequences linear styles. The appendices comprise extra information on quadrature, model estimation, and endogenous variables, in conjunction with SabreR commands and examples. In health-related and social science research, MGLMMs help disentangle state dependence from incidental parameters. Specializing in these complex facts Evaluation procedures, this book explains the statistical concept and modeling involved with longitudinal scientific studies. Several examples throughout the textual content illustrate the Investigation of serious-environment data sets. Routines, alternatives, and other product are offered with a supporting Internet site.
Crank out 2nd or 3D histograms and charts, scatter and line plots, contour and density plots, stream and vector fields, and graph and network diagrams
Making use of R for Statistics is a difficulty-Resolution primer for employing R to build your information, pose your problems and acquire solutions utilizing a wide array of statistical tests. The reserve walks you through R Fundamental principles and the way to use R to accomplish all kinds statistical functions. You'll navigate the R system, enter and import info, manipulate datasets, work out summary studies, produce statistical plots and customise their overall look, execute hypothesis checks such as the t-checks and analyses of variance, and Establish regression types.
`Master R in per day' supplies the reader with key programming skills by way of an illustrations-oriented approach and is particularly ideally suited to academics, researchers, mathematicians and engineers. The reserve assumes no prior understanding of Computer system programming and progressively covers each of the necessary techniques required to grow to be assured and proficient in using R inside of a working day.
A lot of the just lately reserved words begin with an underscore followed by a capital letter, due to the fact identifiers of that sort were previously reserved with the C common for use only by implementations. Considering the fact that present method supply code must not have already been working with these identifiers, it wouldn't be affected when C implementations started out supporting these extensions on the programming language.
Enumerated forms are probable With all the enum keyword. They aren't tagged, and are freely interconvertible with integers.
Working with R for Numerical Assessment in Science and Engineering offers a solid introduction to one of the most handy numerical techniques for scientific and engineering information Evaluation making use of R.
There are numerous publications which have been outstanding sources of information about particular person statistical tools (survival models, common linear designs, etc.), however the artwork of knowledge Investigation is about picking out and utilizing numerous equipment. While in the phrases of Chatfield “... learners normally know the complex particulars of regression one example is, although not essentially when and the way to apply it. This argues the need for a far better balance within the literature and in statistical educating amongst strategies and difficulty resolving techniques.
Find out about the distinction between declaring a variable, course or function--and defining it--and why it matters If you have issues compiling your code
Missing info variety a dilemma in each individual scientific willpower, however the procedures required to tackle them are difficult and sometimes lacking. One of the terrific ideas in statistical science---multiple imputation---fills gaps in the information with plausible values, the uncertainty of which happens to be coded in the info itself. What's more, it solves other challenges, a lot of which might be lacking details troubles in disguise. Versatile Imputation of Missing Data is supported by a lot of examples making use of real information taken from the author's broad knowledge of collaborative investigation, and offers a sensible information for managing missing data under the framework of several imputation.
Adopting R like a most important Software for phylogenetic analyses sease the workflow in biologists' details analyses, ensure greater scientific repeatability, and greatly enhance the exchange of Strategies and methodological developments.
A Modern Method of Regression with R concentrates on tools and strategies for developing regression designs making use of real-planet data and assessing their validity. When weaknesses within the product are identified, the subsequent stage is to address each of such weaknesses. A vital concept through the reserve is usually that it is sensible to base inferences or conclusions only on legitimate types. The regression output and plots that look all over the book are produced employing R. About the e-book Web page you will find the R code used in Each individual illustration while in the text. Additionally, you will locate SAS code and STATA code to create the equivalent output to the ebook website.
Cet ouvrage expose en détail l'une des méthodes statistiques les furthermore courantes : la régression. Il concilie théorie et apps, en insistant notamment sur l'analyse de données réelles avec le logiciel R. Les premiers chapitres sont consacrés à la régression linéaire basic et numerous, et expliquent les fondements de la méthode, tant au niveau des choix opérés que des hypothèses et de leur utilité. Puis ils développent les outils permettant de vérifier les hypothèses de base mises en œuvre par link la régression, et présentent les modèles d'analyse de la variance et covariance. Go well with l'analyse du choix de modèle en régression various. Les derniers chapitres présentent certaines extensions de la régression, comme la régression sous contraintes (ridge, lasso et lars), la régression sur composantes (PCR et PLS), et, enfin, introduisent à la régression non paramétrique (spline et noyau).
For the reason that code introduced while in the textual content almost always needs the usage of Earlier launched programming constructs, diligent learners also acquire simple programming talents in R. The book is intended for Innovative undergraduate and graduate pupils in almost any willpower, although the emphasis is on linguistics, psychology, and cognitive science. It's created for self-instruction, nonetheless it can be applied as being a textbook for a primary study course on figures. Before variations of the reserve are already Employed in undergraduate and graduate courses in Europe as well as the US.
Leave a Reply
Your email address will not be published. Required fields are marked *
|
__label__pos
| 0.803285 |
Jump to content
• Advertisement
Sign in to follow this
Chozo
Trouble with normal maps
This topic is 5045 days old which is more than the 365 day threshold we allow for new replies. Please post a new topic.
If you intended to correct an error in the post then please contact us.
Recommended Posts
I've run through this so many times I think I've created a block for myself. Right now I have this vertex shader (GLSL):
varying vec3 V, N;
void main(void)
{
// set the vertex position
gl_Position = gl_ModelViewProjectionMatrix * gl_Vertex;
// setup lighting
V = gl_ModelViewMatrix * gl_Vertex;
N = gl_NormalMatrix * gl_Normal;
// setup texturing
gl_TexCoord[0] = gl_MultiTexCoord0;
gl_TexCoord[1] = gl_MultiTexCoord1;
}
and this fragment shader:
uniform sampler2D detail, normalmap;
varying vec3 V, N;
void main(void)
{
vec3 normal = normalize(2.0 * texture2D(normalmap, gl_TexCoord[1]).xyz - 1.0);
vec3 L = normalize(gl_LightSource[0].position.xyz - V);
vec3 E = normalize(-V);
float diffuse = dot(normal, L);
vec3 R = normalize(2.0 * diffuse * normal - L);
// ambient
vec4 Iamb = gl_FrontLightProduct[0].ambient;
// diffuse
vec4 Idiff = gl_FrontLightProduct[0].diffuse * diffuse;
// specular
float specular = pow(max(dot(R, E), 0.0), gl_FrontMaterial.shininess);
vec4 Ispec = gl_FrontLightProduct[0].specular * specular;
// final color
vec4 tv = texture2D(detail, gl_TexCoord[0]);
gl_FragColor = tv * (gl_FrontLightModelProduct.sceneColor + Iamb + Idiff + Ispec);
}
But I'm getting an odd clipping effect of some kind. I think it's actually just light being applied in odd places, but it basically looks like if you had binoculars and moved them down and to the right, so you could only see the bottom left of what you're looking at, through a semi-circle. Hard to describe, I know, but that's basically it. I can grab a screenshot if that would help. I guess I'm just completely lost on how to use GLSL to make use of Doom3 style normal maps. I figured it'd just be a matter of doing a lookup in the texture to grab the normal, but that doesn't seem to be working. Thanks in advance for any help.
Share this post
Link to post
Share on other sites
Advertisement
for normalmapping youre not supplying enuf info, youve only got the normals there, u also need to supply per vertex the tangents + bitangents as well
Share this post
Link to post
Share on other sites
A screenshot would help.
Like Zedzeek said, you need to specify tangents and binormals per vertex. For my program I found that specifying both a tangent and binormal as a vertex attribute caused errors. I'm not sure if it was the naming or space issues, but the binormal data overwrote the normal data. So I simply pass the tangent as a vertex attribute then calculate the binormal in the vertex shader.
The other thing to do is make sure that all your tangents and binormals are consistent, ie., don't have one tangent pointing left, then on the next face it points right or something.
Oh, one more thing. It's minor, but casting from a vec4 to a vec3 is bad in a shader program. In fact, the compiler should be giving you warnings about that. So, try this just to be more correct:
varying vec3 V;
varying vec3 N;
varying vec3 T;//tangent
varying vec3 B;//binormal
attribute vec3 tangent;
void main(void)
{
// set the vertex position
gl_Position = gl_ModelViewProjectionMatrix * gl_Vertex;
// setup lighting
V = vec3(gl_ModelViewMatrix * gl_Vertex);
N = vec3(gl_NormalMatrix * gl_Normal);
T = tangent;
B = cross(T,N);
// setup texturing
gl_TexCoord[0] = gl_MultiTexCoord0;
gl_TexCoord[1] = gl_MultiTexCoord1;
}
Share this post
Link to post
Share on other sites
I'm looking at the simple bumpmap tutorial:
Quote:
float deltaT0=v0.texCoords.y-v1.texCoords.y;
float deltaT1=v2.texCoords.y-v1.texCoords.y;
sTangent=deltaT1*side0-deltaT0*side1;
sTangent.Normalize();
//Calculate t tangent
float deltaS0=v0.texCoords.x-v1.texCoords.x;
float deltaS1=v2.texCoords.x-v1.texCoords.x;
tTangent=deltaS1*side0-deltaS0*side1;
tTangent.Normalize();
Is it correct to say that v0.texCoords.y is the same as my u texture coordinate? Or is equivalent to the v. I'm seeing how to calculate the tangent/bitangent (I already calculate the normal, so I can throw that in with it). Is there a way that I can pass the per-vertex data into a GLSL program? I'm using VBOs so I'm not sure how to do the vertex attributes (haven't seen a tutorial for them anywhere).
Am I also correct in assuming that using GLSL means there's no need for the cube map? I'm not very clear about how that works into things so I don't see where it would be necessary.
Sorry for all the questions, I'd just like to know what's going on with these things. What I've read so far has it making a lot of sense, it's just the minor stuff I need filled in. Thanks again for the help.
Share this post
Link to post
Share on other sites
>>N = vec3(gl_NormalMatrix * gl_Normal);
T = tangent;<<
the tangent/bitangent needs to be orientated the same as the normal thus perhaps u need to do
T = vec3(gl_NormalMatrix * tangent);
>> Is there a way that I can pass the per-vertex data into a GLSL program?<<
u can use attributes (check the spec) works with VBO's also, another method ppl use is using texturecoordinates to pass data (this is what i do
eg
tangent = gl_MultiTexCoord1.xyz;
bitangent = gl_MultiTexCoord2.xyz;
normal = gl_MultiTexCoord3.xyz;
Share this post
Link to post
Share on other sites
Okay, I've got everything golden except that things still don't look quite right. This is how I get the tangent/binormal:
void MD5Triangle::calculate_normal_tangents()
{
const EnVector3<GLdouble> a(m_v2->position - m_v1->position), b(m_v3->position - m_v2->position);
m_normal = a ^ b;
m_normal.normalize();
float d0 = m_v1->texture_v - m_v2->texture_v;
float d1 = m_v3->texture_v - m_v2->texture_v;
m_tangent = d1*a - d0*b;
m_tangent.normalize();
d0 = m_v1->texture_u - m_v2->texture_u;
d1 = m_v3->texture_u - m_v2->texture_u;
m_binormal = d1*a - d0*b;
//m_binormal = m_tangent ^ m_normal;
m_binormal.normalize();
}
This is my vertex shader:
attribute vec3 tangent, binormal;
varying vec3 V, L;
void main(void)
{
// set the vertex position
gl_Position = gl_ModelViewProjectionMatrix * gl_Vertex;
// get the vertex in eye space
V = vec3(gl_ModelViewMatrix * gl_Vertex);
// get the light position in object space
// then the vector from it to the vertex
L = normalize((gl_ModelViewMatrixInverse * gl_LightSource[0].position).xyz - gl_Vertex);
// create the tangent matrix
mat3 tbm;
tbm[0] = tangent;
tbm[1] = binormal;
tbm[2] = gl_Normal;
// put the light vector into tangent space
L = L * tbm;
// setup texturing
gl_TexCoord[0] = gl_MultiTexCoord0;
gl_TexCoord[1] = gl_MultiTexCoord1;
}
And my fragment shader:
uniform sampler2D detail, normalmap;
varying vec3 V, L;
void main(void)
{
// get the normal
vec3 normal = normalize(2.0 * texture2D(normalmap, vec2(gl_TexCoord[1])).xyz - 1.0);
// get the eye vector
vec3 E = normalize(-V);
// get the diffuse value
float diffuse = dot(normal, L);
// get the reflection vector
vec3 R = normalize(2.0 * diffuse * normal - L);
// ambient color
vec4 Iamb = gl_FrontLightProduct[0].ambient;
// diffuse color
vec4 Idiff = gl_FrontLightProduct[0].diffuse * diffuse;
// get the specular amount
float specular = pow(max(dot(R, E), 0.0), gl_FrontMaterial.shininess);
// specular color
vec4 Ispec = gl_FrontLightProduct[0].specular * specular;
// final color
vec4 tv = texture2D(detail, vec2(gl_TexCoord[0]));
gl_FragColor = tv * (gl_FrontLightModelProduct.sceneColor + Iamb + Idiff + Ispec);
}
I thought I understood how this would work, so I'm a bit confused about why it doesn't. Hopefully it's something obvious. Thanks for taking a look at it.
Share this post
Link to post
Share on other sites
Okay, after some simplifying, I think it's working. Here's what I'm going:
vert:
attribute vec4 tangent, bitangent;
varying vec3 L;
void main(void)
{
// set the vertex position
gl_Position = gl_ModelViewProjectionMatrix * gl_Vertex;
// create the tangent matrix
mat4 tbn;
tbn[0] = tangent;
tbn[1] = bitangent;
tbn[2].xyz = gl_Normal;
tbn[3] = (0, 0, 0, 1);
// get the light position in object space
vec4 PO = gl_ModelViewMatrixInverse * gl_LightSource[0].position;
// then the vector from it to the vertex
vec4 LV = normalize(PO - gl_Vertex);
// put the light vector into tangent space
L = vec3(tbn * LV);
// setup texturing
gl_TexCoord[0] = gl_MultiTexCoord0;
gl_TexCoord[1] = gl_MultiTexCoord1;
}
frag:
uniform sampler2D detail, normalmap;
varying vec3 L;
void main(void)
{
// get the normal
vec3 normal = normalize(2.0 * texture2D(normalmap, vec2(gl_TexCoord[1])).xyz - 1.0);
// final color
vec4 tv = texture2D(detail, vec2(gl_TexCoord[0]));
gl_FragColor = tv * (max(dot(normal, L), 0.0) * gl_FrontLightProduct[0].diffuse);
}
My problem now is that I want the light to be directional, not positional. I'm not exactly sure what modifications are necessary for that (all the tutorials deal with positional lights rather than directional). Is there an easy way to do that conversion?
Share this post
Link to post
Share on other sites
think about it, a direction light is just like a positional light BUT it remains in the same position WRT the vertex, thus it doesnt matter what the vertex has done (moved rotated, the offset to the light remains the same)
u need to look at these lines (directional lights have a 0.0 w component)
// get the light position in object space
vec4 PO = gl_ModelViewMatrixInverse * gl_LightSource[0].position;
// then the vector from it to the vertex
vec4 LV = normalize(PO - gl_Vertex);
Share this post
Link to post
Share on other sites
So what's going on here then? This is what it looks like right now (with a directional light at 0.0, 0.0, 1.0):
Screenshot 1
Screenshot 2
This is what it looks like if I don't use my shader:
Screenshot 3
Screenshot 4
The light is way brighter than I intended and it looks like it cuts off a lot earlier than the GL version. The params I'm using to create it are:
Quote:
position 0.0 0.0 1.0
ambient 0.0 0.0 0.0 1.0
diffuse 1.0 1.0 1.0 1.0
specular 1.0 1.0 1.0 1.0
Those are the only things I'm setting on the light. It also doesn't even look like the normal map is doing with it should be doing. There's no more detail on the models than there are without using normal maps.
Share this post
Link to post
Share on other sites
the first two are done using normalmapping right?
if thats the case then its not working,
first thing to do is disable ALL texturing (extra details confuse the issue)
in the fragment shader use this
float diffuse = dot( L, vec3(0.0,0.0,1.0) );
gl_FragColor = vec4( diffuse,diffuse,diffuse,1.0 );
thus u dont sample any textures at all.
i think the problem is that the normals/bitangents/tangents aint correct. to check the normal first use this in the fragment shader
float diffuse = dot( vec3(1.0,0.0,0.0), normal );
gl_FragColor = vec4( diffuse,diffuse,diffuse,1.0 );
// normal u get from the vertex shader
Share this post
Link to post
Share on other sites
Sign in to follow this
• Advertisement
×
Important Information
By using GameDev.net, you agree to our community Guidelines, Terms of Use, and Privacy Policy.
We are the game development community.
Whether you are an indie, hobbyist, AAA developer, or just trying to learn, GameDev.net is the place for you to learn, share, and connect with the games industry. Learn more About Us or sign up!
Sign me up!
|
__label__pos
| 0.810886 |
Area of Triangle Shaded Region
In summary, the determinant area formula can be used to find the area of a triangle if the given points are known.
• #1
mathland
33
0
Hello everyone. I am having trouble finding the area of the shaded region using the determinant area formula. I know where to plug in the numbers into the formula. My problem here is finding the needed points in the form (x, y) from the given picture for question 21.
Screenshot_20210115-185039_Drive.jpg
Mathematics news on Phys.org
• #2
Please only post one question per thread.
For the second problem what graphing utilities do have access to? (Assuming they don't want you to find one on the internet.)
-Dan
• #3
problem 21
let point B = (0,0)
A = (-10,25)
C = (18,5)
area of the triangle is half the area of the parallelogram formed by adjacent sides BC and BA which may be found using the cross product of two vectors ...
area = $\dfrac{1}{2}(\vec{BC} \times \vec{BA}) =
\dfrac{1}{2}\begin{vmatrix}
\vec{i} &\vec{j} & \vec{k}\\
18 & 5 & 0\\
-10 & 25 & 0
\end{vmatrix}=
\dfrac{1}{2}\begin{vmatrix}
18 & 5\\
-10 &25
\end{vmatrix}$
Last edited by a moderator:
• #4
topsquark said:
Please only post one question per thread.
For the second problem what graphing utilities do have access to? (Assuming they don't want you to find one on the internet.)
-Dan
I don't need help with 22. I just need the set up for 21.
• #5
skeeter said:
problem 21
let point B = (0,0)
A = (-10,25)
C = (18,5)
area of the triangle is half the area of the parallelogram formed by adjacent sides BC and BA which may be found using the cross product of two vectors ...
area = $\dfrac{1}{2}(\vec{BC} \times \vec{BA}) =
\dfrac{1}{2}\begin{vmatrix}
\vec{i} &\vec{j} & \vec{k}\\
18 & 5 & 0\\
-10 & 25 & 0
\end{vmatrix}=
\dfrac{1}{2}\begin{vmatrix}
18 & 5\\
-10 &25
\end{vmatrix}$
Can you tell me how you came up with the elements of the determinant?
• #6
Beer soaked ramblings follow.
mathland said:
Hello everyone. I am having trouble finding the area of the shaded region using the determinant area formula. I know where to plug in the numbers into the formula. My problem here is finding the needed points in the form (x, y) from the given picture for question 21.
View attachment 10940
Duplicate post from MHF by gufeliz (aka https://mathhelpboards.com/members/harpazo.8631/) that was deleted and who was subsequently banned by topsquark.
You really ought to read your book's relevant section before diving into the exercises.
And you should do it when you're fesh and full of energy; preferably after you've rested and slept (and presumably had some nourishment with coffee shortly afterwards) so that you can maximize your mental energy into understanding and applying what you've been reading and not when "my brain is tired and I am physically exhausted" as you like to embellish it. Regardless of how passionate you are about math, you can't work/study and concentrate as hard at the end of a study session (in your case, the end of a working day) as at the beginning.
mathland said:
I don't need help with 22. I just need the set up for 21.
Fourteen years of Precalculus review should have given you some insight on how to set up your problems on your own. How can you ever hope to fish on your own if you keep asking others to throw the net for you so you can just pull it up without knowing what made others throw the net the way they did.
Alternatively,
Vertices: (0, 25), (10, 0), (28, 5)
Area = $
\dfrac{1}{2}\begin{vmatrix}
\ 0& 25&1\\
10 & 0 & 1\\
28 & 5 & 1
\end{vmatrix}$
https://www.physicsforums.com/attachments/311846._xfImport
The area should be clear to you from this diagram.
If it's not then you really have a big problem.
Last edited:
Related to Area of Triangle Shaded Region
What is the formula for finding the area of a triangle?
The formula for finding the area of a triangle is A = 1/2 * b * h, where A represents the area, b represents the base, and h represents the height of the triangle.
How do I find the area of a shaded region in a triangle?
To find the area of a shaded region in a triangle, you first need to find the area of the entire triangle using the formula A = 1/2 * b * h. Then, you can subtract the area of any non-shaded regions from the total area to find the area of the shaded region.
Can the area of a shaded region be negative?
No, the area of a shaded region cannot be negative. The area of a triangle is always a positive value, so even if the shaded region is smaller than the non-shaded region, the area will still be a positive value.
Do I need to know the measurements of all sides of the triangle to find the area of a shaded region?
No, you do not need to know the measurements of all sides of the triangle to find the area of a shaded region. As long as you know the base and height of the triangle, you can use the formula A = 1/2 * b * h to find the area.
Can I use the same formula to find the area of any triangle?
Yes, the formula A = 1/2 * b * h can be used to find the area of any triangle, regardless of its shape or size. This formula is a universal method for finding the area of a triangle.
Similar threads
Replies
1
Views
910
• General Math
Replies
1
Views
1K
• General Math
Replies
2
Views
1K
Replies
2
Views
2K
Replies
1
Views
2K
• General Math
Replies
1
Views
726
• General Math
Replies
1
Views
989
Replies
1
Views
857
Replies
4
Views
1K
Back
Top
|
__label__pos
| 0.995953 |
Versions
Description
The purpose of this app is to allow adding dynamic conditions to relations between objects. How is this useful? ------------------- Let's say you develop an application that will present content to user based on various conditions. Gamification comes to mind. Let's say you want to set the conditions on a per-user or per-group basis. For example girls get happy hours on Saturday and boys get them on Thursdays. Hardcoding that would be a bit harsh if you tend to change your mind frequently. Requirements ------------ Django >= 1.4 Usage ----- After installing the package and adding 'clausula' to INSTALLED_APPS you should define some abstract conditions you'd like to use. Do this by creating a file `conditions.py` in your app. Then you need to import `clauses` registry, define your conditions and register them. Example `conditions.py`:: def day_of_week_clause(obj, *args, **kwargs): import datetime weekday = datetime.date.today().weekday() if weekday == int(obj.param): return True return False clauses.register(day_of_week_clause, "checks day of week") Each condition is a function that fullows these rules: * it takes one mandatory argument: an `object` (a :class:`Condition` instance) * it silently accepts any number of optional arguments (*args, **kwargs) * it returns a boolean value `clauses.register` accepts two arguments: a callable and a string representation that will be displayed in Admin. The `object` is guaranteed to have a `param` attribute which holds a string which can be used to compute returned boolean value. There can also be some relations available as :class:`Condition` is a subclass of :class:`django.db.models.Model`. Feel free to experiment and find some hackish uses for this package.
Repository
https://github.com/dekoza/django-clausula.git
Project Slug
django-clausula
Last Built
No builds yet
Maintainers
Home Page
https://github.com/dekoza/django-clausula
Badge
Tags
clause, condition, django
Short URLs
django-clausula.readthedocs.io
django-clausula.rtfd.io
Default Version
latest
'latest' Version
master
|
__label__pos
| 0.923587 |
JQuery Modal Dialog opens with button selected
I have a dialog created like this:
<div id="choose_product" title="Choose a Product" style="display:none;">
<button id="sel_1">Prod. 1</button>
<button id="sel_2">Prod. 2</button>
</div>
with JS:
$('#choose_product').dialog({
autoOpen: true,
show: "blind",
hide: "explode",
modal: true,
buttons: {
Cancel: function(){
$(this).dialog("close");
}
}
});
When the dialog box opens, the Prod 1 button is selected (highlighted) by default, I don't know why. You can see this on the JSFiddle . When you press RUN, you can see that the button is Prod. 1
selected by default. Does anyone know why this is happening? Is there something I am doing wrong?
Thank!
** Edit **
In my application, I actually use $('#choose_product').dialog("open");
to open a dialog. if you use $('#choose_product :button').blur();
immediately after this, no buttons will be selected by default. Little work but seems to work.
See the updated fiddle .
+3
source to share
1 answer
My guess is that when you give the type "modal" to the jQuery UI dialog, it will automatically focus the first button. Also, the reason it's not designed correctly is because you haven't added css to your fiddle.
Edit: After looking more closely, I found this question which confirms what I said above.
+1
source
All Articles
|
__label__pos
| 0.963228 |
Telegram account purchase:telegram profile pic(Rewrite Request Please provide the original title for me to rewrite it.)
Telegram Profile Pic: A Reflection of Identity and Expression
Introduction:
In the digital era, social media platforms have become an essential part of our lives, enabling us to connect with others, share our thoughts and experiences, and express our identities. Telegram, a popular messaging app, offers users the ability to communicate via text, voice, and images. One significant aspect of Telegram is the profile picture, which users can choose to represent themselves. In this article, we will explore the significance of a Telegram profile pic as a reflection of identity and expression.
The Art of Choosing a Profile Picture:
When joining Telegram, users are prompted to select a profile picture. This seemingly simple act carries more weight than one might think. The profile picture serves as the visual representation of oneself, allowing others to form impressions of who we are based on that single image. It is an opportunity for users to showcase their personality, interests, and creativity.
telegram profile pic(Rewrite Request Please provide the original title for me to rewrite it.)
Customizing Identity:
Your Telegram profile picture is a gateway for self-expressionMatch account purchase. Some users choose to showcase their physical appearance, uploading a photo that captures their unique features and characteristics. This allows friends, family, and acquaintances to easily recognize them within the digital realm. It fosters a sense of familiarity and connection, especially when physically meeting someone for the first time after establishing contact online.
Others prefer to utilize symbols, objects, or abstract imagery to represent their identity. These profile pictures can be seen as an artistic extension of oneself, offering a glimpse into the person’s interests, beliefs, or aspirations. For instance, a nature enthusiast may opt for a profile picture of a tranquil landscape, while an avid reader might choose an image of their favorite book. These symbols can serve as conversation starters, encouraging others to connect and engage in meaningful discussions.Zalo account purchase
Maintaining Anonymity:
While many users choose to display their true identity in their profile pictures, others prefer to maintain a level of anonymity. This choice may be driven by personal reasons, such as concerns about privacy or security. Some individuals, for instance, might have professional careers that require them to separate their personal and online personas. In such cases, a profile picture that obscures the user’s face or uses an abstract image can provide a sense of security and control over their online presence.
The Psychology of Profile Pictures:
The selection of a profile picture is not merely an aesthetic choice; it is deeply intertwined with the psychology of self-presentation. The image we choose to represent ourselves on Telegram can reveal insights into our personalities, desires, and emotions. Psychologists suggest that profile pictures often reflect how we want others to perceive us. It is a deliberate representation that allows us to present ourselves in a certain light, controlling the narrative others might construct about us.
Impressions and Judgments:
Whether consciously or subconsciously, people often form impressions and make judgments based on profile pictures. Studies have shown that certain images can lead to biased perceptions and assumptions. For example, an individual with a professional headshot might be perceived as more competent or reliable than someone with a casual snapshot. Similarly, profile pictures displaying happiness or positive emotions can influence others to perceive the user as friendly and approachable.
Conclusion:
The Telegram profile picture is a powerful tool for self-expression and representation. It allows users to reflect their identities, interests, and beliefs, while also presenting themselves in a controlled manner to others. Whether users choose to display their true identity or cultivate a level of anonymity, the profile picture is an opportunity to communicate who we are and what we stand for. As we navigate the digital sphere, let us remember the significance of these visual representations, recognizing the impact they can have on our online interactions and relationships.
WhatsApp account purchase
Telegram Profile Pic: A Reflection of Identity and Expression Introduction: In the digital era, social media platforms have become an essential part of our lives, enabling us to connect with others, share our thoughts and experiences, and express our identities. Telegram, a popular messaging app, offers users the ability to communicate via text, voice, and…
|
__label__pos
| 0.9853 |
search-engine-algorithm
What Are The Main Search Engine Algorithms? (7 algorithm )
One thing that comes up in SEO is the search engine algorithm, which essentially shows the behavior of the Google search engine. Google’s algorithms or SEO algorithms
make this search engine more brilliant day by day, and in simpler terms, these algorithms identify errors and points awarded to sites.
Optimizing your site according to search engine algorithm is better for your SEO to succeed. Stay with us in this article to fully explain Google algorithms.
Google Algorithms – what are SEO algorithms?
In this article, we intend to give you information about Google’s algorithms. If you are aware of the goals and behind the scenes of this search engine’s performance, you can determine your site’s strategies more accurately and plan for its optimization. Stay with us to get detailed information about search engine algorithm.
What is the purpose of Google?
The most used and popular search engine among users is Google, which provides many features to users. The goal of this search engine is simple: “providing the best and most relevant answers to users in the shortest possible time.” algorithms need to be designed and modified continuously.
How does google’s algorithm work
Search engine algorithm are a set of instructions to achieve a specific goal. Likewise, search engine algorithm are guidelines for analyzing websites and improving the results that can be presented to users.
Algorithms serve two primary purposes:
1. Identifying low-quality and spam sites and reducing their rank
2. Identifying valuable and useful sites and increasing their ranking
Get to know search Engine Algorithm better
Search engine algorithm are divided into two categories. The main algorithms are part of the central core of the Google search engine, and Google’s side algorithms are used to identify low-quality sites and improve search results.
This article will introduce some essential search engine algorithm and how many google algorithms are there.
• Google Panda Algorithm
Google-Panda-Algorithm
The Google Panda algorithm was created to evaluate the quality of web page content and gives each page a quality score, which is used as one of the ranking factors. The first version of the Panda algorithm was introduced on February 23, 2011. And the next day, Google explained it by publishing a blog post.
According to that post, Panda’s algorithm significantly improved at the time as it influenced 11.8% of search results.
Google created search engine algorithm to reduce the ranking of sites whose content is not helpful and valuable for the user or copied from other websites. And on the other hand, it improves the ranking of sites with high-quality and helpful content. google panda effects on page seo. so check the on page seo checklist
The things that this algorithm checks are:
• Duplicate content
• Content copied or aggregated from other websites
• Short or sparse content
• User-generated spam
• Keyword overuse
• Poor user experience (UX)
Optimization for pandas algorithm
Check the site for duplicate content: This is one of the most common triggers for the Panda algorithm. Therefore, we recommend checking the site’s content regularly to ensure no such problem. If you cannot remove duplicate pages for valid reasons, use 301 redirect or canonical tag. Another solution is to block those pages with a txt file or noindex metatag.
Check the content for duplicates: Another driver of the Panda algorithm is external duplicate content or copied from other websites.
Avoid creating pages with little content: This means pages whose content includes few words and a lot of advertisements and links and gives little information to the user. Of course, it is essential to note that the number of appropriate words for each content depends on the purpose of that page and the keyword intended for it.
Check your site for excessive use of keywords: Over-optimizing a page for a keyword reduces the quality and readability of the content.
Fix the detected problems and items as soon as possible: it is better to improve the problems until this algorithm is sensitive on your site and checks the pages.
• Google Penguin Algorithm
Google-Penguin-Algorithm
Google created The Penguin anti-spam algorithm to identify and reduce the ranking of sites that have created links in unnatural ways. Since the end of 2016, this search engine algorithm has become part of Google’s core algorithm because it runs in real-time. Violating sites are detected and penalized faster, reducing recovery time.
The things that this algorithm checks are:
• Backlinks from low-quality and spam sites
• Backlinks from sites created for link building (PBN)
• Backlinks from sites with unrelated content
• Paid links
• Links with anchor text are over-optimized
Of course, you should note that this search engine algorithm also examines web pages in terms of keyword stuffing.
Optimization for Penguin algorithm
Always keep an eye on your site’s link growth: Google will never penalize a site for having one or two spam links, but having many non-original backlinks can be problematic.
Get rid of harmful links: Ideally, you should ask the web admins of the link-building sites to remove your spam links. If the webmasters do not respond or the number of harmful links is high, you can use the Google Disavow tool. Disavowing links means that you tell Google to ignore these links when evaluating the site’s links.
• Google Hummingbird Algorithm
Google-Hummingbird-Algorithm
The HummingBird algorithm interprets search queries (significantly larger and conversational queries).This search engine algorithm is high-speed and accurate. It recognizes synonyms of words to some extent and helps Google provide results closer to what the user wants (and not necessarily including the keyword of the search term).
Although the keyword of the search term is critical, Hummingbird can provide better and more relevant results to the user with the help of Google’s knowledge graph (The Knowledge Graph) and semantic search. In fact, by using this search engine algorithm, instead of listing the results containing the keyword, Google shows the results that are semantically close to the search term in the SERP results.
The things that this algorithm checks are:
• Targeting a keyword
• Overuse of keywords
Optimization for the hummingbird algorithm
Broaden your keyword research: Given the performance of Hummingbird, it’s a good idea to focus on related searches, synonyms, and terms to diversify your content rather than relying on short and specific keywords.
Know the language of your audience: A great way is to use tools to identify your keywords, such as brand names, competitors, industry terms, etc., on social networks and a larger scale, on the web, and check how your audience is talking about them.
Instead of trying to match keywords perfectly, consider the concepts: unnatural phrases are still used in website content, especially in titles and meta descriptions, but as search engines grow in natural language processing, this can become a problem.
Do not use robots to create a content:
If you are one of this category and you use language like robot language for the content of your site pages, please stop! Using keywords in the title and description is very important, but ensure that the content’s author looks like a human, not a robot! Improving the title and meta description will undoubtedly attract users and, as a result, increase the site’s click rate.
Use standard markup (Schema): Schema is a series of data and instructions added to the website code to mark the content and specify the essential parts. In this way, Google will have a better understanding of the page’s content.
• Google Pigeon Algorithm
Google-Pigeon-Algorithm
It must have happened to you to look for the nearest store, hospital, restaurant. Since Google’s goal is to provide the best results to users and to satisfy them as much as possible, it has presented the Pigeon algorithm.
This search engine algorithm attempts to personalize search results by examining the user’s search term and providing the best and closest results if the user’s location is involved or related to a local business. The Pigeon algorithm uses location and distance as crucial factors in ranking results and significantly impacts Local Seo.
The things that this algorithm examines are:
• Poorly optimized pages
• Improper setup of Google My Business page
• Name, address, phone number (NAP) mismatch
• Lack of documentation in local directories (if necessary)
Optimization for pigeon algorithm
Register your business information in Google Map: The pigeon algorithm has more integrated the search engine and Google map. One of the crucial factors for ranking and displaying your site based on location is Google’s correct understanding of your business location.
On the other hand, in this way, users can express their opinions about your business, which is one of the critical and influential factors in local SEO.
Be careful that your name, address, and phone number (NAP) list on the site: Google will look at the website you have linked to through the information recorded in the Google map, and if matched, the name, address, and phone number. You have done your work correctly.
Register your site in local directories: Directory sites list businesses in different regions and cities. These sites have grown significantly with the advent of the pigeon algorithm.
• Google’s Mobilegeddon Algorithm
Google's-Mobilegeddon-Algorithm
The number of people using mobile phones for internet searches is increasing yearly. According to published statistics, 52.2% of a website’s traffic belongs to mobile devices, and, naturally, Google pays special attention to mobile users.
The Mobilegeddon algorithm, or the purpose of checking whether web pages are optimized for ranking on mobile devices and are so-called mobile friendly, was created.
Pages that are not optimized for mobile will suffer a drop in rank. This search engine algorithm does not affect desktop searches.
The critical point here is that Mobilegeddon is a page-level algorithm, meaning that one website page may rank well and others may not.
This algorithm considers the following:
• No mobile version of the page
• Improper configuration of page appearance
• Illegal content
• Use the plugin
Optimization for Mobilegeddon algorithm
The design of your site should be reactive or responsive: make sure your site is displayed correctly on all types of screens.
Use Google’s Mobile-Friendly Test Tool: You must meet Google’s mobile-friendly criteria to rank well in mobile search results.
Get help from site speed testing tools: One of the most important factors for mobile users is page loading speed.
• Google’s RankBrain Algorithm
Google's-RankBrain-Algorithm
The RankBrain algorithm is a machine learning system that helps Google understand the meaning of a search term to provide better and more relevant results.
This search engine algorithm is like the hummingbird algorithm but more advanced. Like humans, the RankBrain algorithm learns over time from the experiences it acquires and performs better. According to search engine algorithm, this search engine algorithm is the third most important and influential factor in ranking sites.
So just as it has a query processing component, it also has a ranking component. The noteworthy point is that this search engine algorithm can probably summarize a page’s content and evaluate the relevance of search results.
The RankBrain algorithm relies on traditional SEO factors such as links, on-page optimization, etc., but it also pays attention to other factors specific to each query. Identifies the relevant factors of the indexed and relevant pages and ranks the SERP results.
The things that the RankBrain algorithm checks are:
• Absence of specific communication factors in each query
• Poor user experience (UX)
Optimization for RankBrain algorithm
Improve user experience: RankBrain’s algorithm is constantly analyzing user behavior so that it can change accordingly. Use user experience factors in Google Analytics, such as click rate (CTR), bounce rate, and session duration.
Research regarding competitors’ performance: One of the tasks of the RankBrain algorithm is to identify the characteristics of web pages related to any specific query and use them to rank in the search results.
Those features can be anything that has a positive impact on the user experience. For example, pages that have more content and attractive elements are more successful. Although there is no list of these features, you can get good results by reviewing and analyzing the standard features of competitors.
• Google’s Blind Mouse Algorithm
Google's-Blind-Mouse-Algorithm
Google created The blind mouse (Possum) algorithm to provide more quality and relevant results to the user based on the user’s location and the business’s physical address. This search engine algorithm collects recent changes in Google’s local ranking filter.
With the help of the Possum algorithm, Google offers more mixed results depending on the searcher’s location and the search term. In fact, the closer you are to a business in terms of location, the more likely it is to show up in local results.
The critical point is that this search engine algorithm also boosted businesses outside the city limits. In the past, the problem with local SEO was that businesses outside the city limits, even when they were active on keywords containing the city name, would still not appear in the city search results. After the blind mouse algorithm, many of these businesses significantly improved their local rankings.
In addition, businesses with the same address as other businesses in the same field will suffer a drop in Google results. In the past, google filtered them based on their phone number or similar website domain.
For example, consider a physical therapy center with a separate work profile registered for the center and each of the three physical therapists. These profiles are all linked to the same site and have the same contact number.
One or two would appear in local search results, and it would filter out the rest. With the blind mouse algorithm, many businesses were filtered due to having the same address and workgroup.
The things that the blind mouse algorithm examines are:
• Having the same physical address as a business in the same industry
• Competitors whose business location is closer to the user
Optimization for blind mouse algorithm
Track ranking based on a specific geographic location: the location you search is very effective in ranking.
Make a list of local keywords: The blind mouse algorithm will provide different search results for relatively similar keywords.
Summary Of Google Algorithms
search engine algorithm
Google algorithms are constantly changing and improving. This article introduced some important search engine algorithm and ways to optimize them. Now we know that the Panda algorithm focuses on the quality of the content. Penguin’s algorithm fights against illegal linking.
With the help of the hummingbird algorithm and semantic search, Google provides better and more relevant results to users. Pigeon and blind mouse algorithms consider the user and business location as a ranking factor and provide the closest and best results.
The Mobilegeddon algorithm examines sites based on whether they are compatible with mobile devices. The RankBrain algorithm is constantly learning and growing by analyzing user behavior with the help of artificial intelligence.
Each of these search engine algorithms helps Google in a way to achieve its goal of “providing the best answer to users.” Thank you for being with Digiwaremarketing until the end of this article.
Be sure to pay attention to Google’s algorithms when optimizing
One of the ways to succeed in SEO is to pay attention to search engine algorithm when optimizing your site. Try to consider algorithms as much as you can when optimizing. As discussed in the article What is SEO, SEO methods are very different, but you should use logical and moral methods.
You should use methods to avoid Google errors. search engine algorithm detect most errors. Try to get as many points as possible from Google’s algorithms to improve your site’s ranking on the SERP pages. We suggest you read technical SEO articles and the impact of link building in SEO for better optimization of your site.
What do you think about search engine algorithm? To what extent do you pay attention to SEO algorithms
when optimizing? Share your thoughts with us below this post.
Leave a Comment
Shopping Basket
|
__label__pos
| 0.623252 |
6 years, 7 months ago.
is there only one UDP socket per thread ?
Hi there,
we have a mbed project where we listen to 3 different UDP sockets. So our main.cpp includes these libraries to get there
1. include "EthernetInterface.h"
2. include "NetworkAPI/buffer.hpp"
3. include "NetworkAPI/ip/address.hpp"
4. include "NetworkAPI/udp/socket.hpp"
Each socket (since we'd like to receive data) is wrapped inside a thread, using osThreadCreate(...) and everything worked so far.
Now, we are in a situation where socket #3 receives something from a client and needs to reply, so I use the same socket, modify the endpoint (set the port) and send a reply. This works also well.
But our protocol requires, that we frequently notify the client that just talked to us via socket #3 and so we tried to use the same socket we opened and used in socket-thread-#3. It seems that the socket only works, when called from this thread #3 context.
Next we tried to open a second socket #3b and use this one to reply only. Even the socket.open() failed.
Also when I tried to use a global socket, declared as static on the main level, the open() failed.
Because we need to do some real-time things, we use the RtosTimer to execute a routine and we were not able to send anything via the socket #3 from this routine.
It seems to us, that we can have only one socket per thread and only this thread may use it.
Since we do RTOS and multithreading, is there something we need to be aware of ? I know a similar behaviour from java, but I never seen it in C/C++.
Would the correct way, to have one more communication thread, and we need to create a message queue or pipeline or something to feed messages from other threads into this one ?
any comments appreciated thanks for your help, Matthias
1 Answer
5 years, 9 months ago.
Hi Matthias,
Did you come up with an answer to your question? I'm about to deal with a similar scenario.
Regards David G
|
__label__pos
| 0.942053 |
Software Development & Community Engineering
Get the full picture in our final information to DevOps. Software testing detects and solves technical points within the software program supply code and assesses the overall usability, performance, security and compatibility of the product to make sure it meets its requirements. Functional requirements establish what the software ought to do. They embody technical details, knowledge manipulation and processing, calculations or some other particular operate that specifies what an utility goals to accomplish.
technology, computer, software
As ICAI methods mature, digital actors can present personae to work together with participants in a VE system. The need to build detailed three-dimensional geometric models arises in computer-aided design , in mainstream laptop graphics, and in various other fields. Geometric modeling is an active area of educational and industrial research in its own right, and a wide range of business modeling methods is out there. Despite the wealth of accessible tools, modeling is generally considered an onerous task.
Necessities
System software communicates with and coordinates hardware so that the essential capabilities of computers are usable, whereas software software helps customers carry out specific duties on their computer systems. After laptop software engineers and systems analysts design software program applications, the programmer converts that design into a logical collection of directions that the computer can observe. The programmer codes these directions in any of a quantity of programming languages, depending on the need. The most common languages are C++ and Python.
Students learn to research, design, and develop solutions to business issues via the use of technology. The Server Administrationprogram is targeted on related enterprise server operating systems configuration, management, and safety. The program focuses on current and related server administration concepts including network security concepts/best-practices and trade certification preparation.
Ontario Colleges Providing Pc Software Programs
The program will incorporate the competencies of industry-recognized certification exams. In common, the extra technical software is, the extra likely it could be patented. For example, a software product could be granted a patent if it creates a new type of database structure or enhances the overall performance and function of a pc. To preserve software quality as soon as it is deployed, builders must continuously adapt it to fulfill new customer requirements and handle problems clients establish. This contains enhancing functionality, fixing bugs and adjusting software code to prevent points.
technology, computer, software
A system which takes data from any of several sources and places it on a single line or sends it to a single destination. A check protection standards which requires enough take a look at instances such that each one potential combinations of situation outcomes in each decision, and all factors of entry, are invoked no much less than once. Contrast with department coverage, condition protection, choice protection, path protection, statement coverage. A practical unit that modulates and demodulates indicators.
Degree Completion: Honours Bachelor Of Utilized Computer Science Mobile Computing
First, a unified central representation could also be employed that captures all of the geometric, floor, and physical properties wanted for physical simulation and rendering functions. In principle, strategies similar to finite component modeling might be used as the premise for representing these properties and for physical simulation and rendering functions. The former strategy is architecturally essentially the most elegant and avoids issues of maintaining correct spatial and temporal correlation between the RSR processes for every modality.
|
__label__pos
| 0.722996 |
PDA
View Full Version : sql database update in vb.net
markdlv77
12-04-2007, 01:57 AM
I am writing a vb.net and sql database program and can't figure out how to update the actual database. The 'dataset' is updated in a millisecond and I can view that just fine in my datagrid, but then when I restart the program.. the actual database was never updated and I'm starting all over. Any help would be great! God bless
peace,
mark
markdlv77
12-04-2007, 02:41 AM
I found on the microsoft website this code to perform the task I'm attempting:
' Modify the following code to correctly connect to your SQL Server.
sConnectionString = "Password=jC13942;User ID=budget;" & _
"Initial Catalog=BudgetDB;" & _
"Data Source=(local)"
Dim objConn As New SqlConnection(sConnectionString)
objConn.Open()
' Create an instance of a DataAdapter.
Dim daTransactions As New SqlDataAdapter("SELECT * FROM transactions", objConn)
' Create an instance of a DataSet, and retrieve data from the Authors table.
Dim dsBudgetDB As New DataSet("BudgetDB")
daTransactions.FillSchema(dsBudgetDB, SchemaType.Source, "transactions")
daTransactions.Fill(dsBudgetDB, "transactions")
'subtract textbox amount from appropriate category and report to 'database'
If TitheRdo.Checked = True Then
'Form1.TitheSpent = Double.Parse((Double.Parse(Form1.TitheSpent)) + (Double.Parse(TextBox1.Text)))
'Form1.Trans(Form1.TransCtr) = "Tithe Spent: $" + TextBox1.Text
'Form1.TransCtr += 1
'TransactionsTableAdapter1.Insert(Trans1.ctr,"Tithe",Date.Today,Double.Parse(TextBox1.Text),'check',0)
' Create a new instance of a DataTable.
Dim tblTransactions As DataTable
tblTransactions = dsBudgetDB.Tables("transactions")
Dim drCurrent As DataRow
' Obtain a new DataRow object from the DataTable.
drCurrent = tblTransactions.NewRow()
' Set the DataRow field values as necessary.
drCurrent("transID") = Form1.TransCtr
drCurrent("category") = "Tithe"
drCurrent("date") = Date.Today
drCurrent("amount") = Double.Parse(TextBox1.Text)
drCurrent("currency") = "check"
drCurrent("cleared") = 0
'Pass that new object into the Add method of the DataTable.Rows collection.
tblTransactions.Rows.Add(drCurrent)
MsgBox("Add was successful.")
I get an exception every time saying that the default settings for sql server don't allow remote connections.. but I've already adjusted that in the sql server surface area configuration. Any ideas?
|
__label__pos
| 0.591053 |
『面试的底气』—— 设计模式之单例模式
· 阅读 1384
定义
单例模式,保证一个类仅有一个实例,并提供一个访问它的全局访问点。
自己的理解
通常我们可以让一个全局变量使得一个对象被访问,但它不能防止实例化多个对象。一个最好的办法就是,让类自身负责保持它的唯一实例,且这个类保证没有其他实例可以被创建,并且它可以提供一个访问该实例的方法。
实现单例模式
要实现一个简单的单例模式并不复杂,无非是用一个变量来缓存一个类实例化生成的对象,然后用这个变量来判断一个类是否已经实例化过。如何变量有值,则在下一次要获取该类的实例化生成的对象时,直接返回这个变量(之前实例化生成的对象)。
var Singleton = function(name) {
this.name = name;
this.instance = null;
};
Singleton.prototype.init = function() {
//...初始化
};
Singleton.getInstance = function(name) {
if (!this.instance) {
this.instance = new Singleton(name);
this.instance.init();
}
return this.instance;
};
var a = Singleton.getInstance('a');
var b = Singleton.getInstance('b');
console.log(a === b); // true
正常来说一个类每次实例化生成的对象是不同的,在上述代码中分别使用Singleton.getInstance获取Singleton类实例化生成的对象并赋值给对象a和对象b,执行console.log(a === b)打印出true,说明上述代码实现单例模式成功。
或不把实例化生成的对象挂载到类的属性上也可以实现,代码如下所示:
var Sington = function( name ){
this.name = name;
};
Singleton.prototype.init = function() {
//...初始化
};
Singleton.getInstance = (function(){
var instance = null;
return function( name ){
if ( !instance ){
instance = new Singleton( name );
instance.init();
}
return instance;
}
})();
变量instance用来缓存类实例化生成的对象,用自执行匿名函数创建了一个闭包,把变量instance存储在闭包中,每次执行Singleton.getInstance时就可以用变量instance来判断Singleton类是否已经实例化过。
透明的单例模式
上述实现单例模式的方法中有一个问题,就是增加了这个类的“不透明性”,Singleton类的使用者必须知道这是一个单例类,跟以往通过new XXX的方式来实例化类,这里要使用Singleton.getInstance来实例类。故要换一种方法来实现透明的单例模式。
const Singleton = (function() {
let instance;
const Singleton = function(name) {
if (instance) {
return instance;
}
this.name = name;
this.init();
return instance = this;
};
Singleton.prototype.init = function() {
//...初始化
};
return Singleton;
})();
const a = new Singleton('a');
const b = new Singleton('b');
console.log(a === b); // true
以上代码中,Singleton类的构造函数是一个自执行的匿名函数,会构成一个闭包,可以把判断类是否实例化过的和缓存类实例化生成的对象的变量instance缓存起来,最后在返回真正的Singleton类构造方法。那么就可以使用new Singleton来实例化Singleton类。
必须遵循设计模式的原则
上述代码还不够完美,有两点:
• Singleton类的真正的构造函数放在自执行的匿名函数中返回,有点奇怪。
• Singleton类的构造函数中违背了设计模式的单一职责原则,做了二件事情,创建类实例化生成的对象和执行初始化init方法,保证了只能实例化一次。
实现任何设计模式都要遵循设计模式的原则,要把“创建类实例化生成的对象和执行初始化init方法”和“保证了只能实例化一次”这两个职责分隔开来。下面用代理实现单例模式。
const Singleton = function (name) {
this.name = name;
this.init();
}
Singleton.prototype.init = function () {
//...初始化
};
const PropxSingleton = (function () {
var instance;
return function (name) {
if (!instance) {
instance = new Singleton(name);
}
return instance;
}
})();
var a = new PropxSingleton('a');
var b = new PropxSingleton('b');
console.log(a === b);//true
以上用代理类propxSingleton实现了Singleton类的单例模式,而Singleton类仍旧是一个普通的类,不影响在其它地方的使用。
然后以上代码还不够完美,假如要给另外一个类实现单例模式,得去修改代理类propxSingleton的代码,不符合设计模式中的开放-封闭原则,得封装一个获取不同类的代理类propxSingletongetPropxSingleton方法。
const Singleton = function (name) {
this.name = name;
this.init();
}
Singleton.prototype.init = function () {
//...初始化
};
const getPropxSingleton = function (customClass) {
return (function () {
var instance;
return function (name) {
if (!instance) {
instance = new customClass(name);
}
return instance;
}
})()
};
const PropxSingleton = getPropxSingleton(Singleton);
var a = new PropxSingleton('a');
var b = new PropxSingleton('b');
console.log(a === b); //true
用ES6来实现一个单例模式
以上都是用ES5实现的单例模式,现在都是使用ES6了,故用ES6来实现一个单例模式。
class Singleton {
constructor(name) {
this.name = name;
this.init();
}
init() {
//...初始化
}
}
const getPropxSingleton = function (customClass) {
let instance = null;
return class {
constructor() {
if (instance) return instance;
return instance = new customClass(...arguments)
}
}
};
const PropxSingleton = getPropxSingleton(Singleton);
var a = new PropxSingleton('a');
var b = new PropxSingleton('b');
console.log(a === b); //true
分类:
前端
分类:
前端
收藏成功!
已添加到「」, 点击更改
|
__label__pos
| 0.999111 |
Why do we need alt-text for Text Frames in InDesign CS5.5?
Last week I wrote about the supercool Object Export Options, and how you can apply Alt-Text to different objects.
I had several people asking me why on earth do we need Alt-text for text frames? It’s already text, isn’t it? So I asked the product team, and this is what I learned.
Rasterize Text Frames to preserve styles, effects, and fonts
Rasterize Text Frames to preserve styles, effects, and fonts
Imagine a text frame for display type like a headline, with a bevel-emboss and drop shadow effect. In order to preserve this appearance in an HTML and EPUB export, you will need to apply custom image conversion settings (Object > Object Export Options > EPUB & HTML). In InDesign, it is still a text frame, but the resulting “image” in HTML/EPUB would need to have Alt-Text applied to describe the text that is rasterized in the export process.
You could also use it if you want to rasterize some text because you want to keep the styling/font intact. For example, a font which ePub is incapable of rendering which may be part of a logo, caption or larger design. In these cases it makes sense to first rasterize that text, and then apply some Alt-Text so when the ePub or HTML is “read aloud” then it can actually read out some text to go with what is now a raster.
Can you think of something else? Share it with us, post a comment below.
Bookmark and Share
, , , ,
1. #1 by Michelle on May 19, 2011 - 11:32 pm
This comment isn’t even about the blog! I have searched everywhere on the site to just send an email to ask a question! There is no way to just ask a question by sending an email to Adobe?!
• #2 by Vikrant on May 20, 2011 - 11:15 am
Hi Michelle,
You can use various official channels to get in touch with Adobe. Most of them are listed here: http://www.adobe.com/aboutadobe/contact.html. All communication is filtered, and sent to the most appropriate person.
We also actively follow activity on our blogs, forums etc, so if you post a question there, the person most qualified to answer will usually respond.
For example, if you have a question about InDesign or Illustrator, you can post your question here, and if am unqualified to answer your question, I’ll try and get the most appropriate person to answer.
(will not be published)
two − = 0
|
__label__pos
| 0.923585 |
Tag Archives: AWS CodeBuild
Using AWS DevOps Tools to model and provision AWS Glue workflows
Post Syndicated from Nuatu Tseggai original https://aws.amazon.com/blogs/devops/provision-codepipeline-glue-workflows/
This post provides a step-by-step guide on how to model and provision AWS Glue workflows utilizing a DevOps principle known as infrastructure as code (IaC) that emphasizes the use of templates, source control, and automation. The cloud resources in this solution are defined within AWS CloudFormation templates and provisioned with automation features provided by AWS CodePipeline and AWS CodeBuild. These AWS DevOps tools are flexible, interchangeable, and well suited for automating the deployment of AWS Glue workflows into different environments such as dev, test, and production, which typically reside in separate AWS accounts and Regions.
AWS Glue workflows allow you to manage dependencies between multiple components that interoperate within an end-to-end ETL data pipeline by grouping together a set of related jobs, crawlers, and triggers into one logical run unit. Many customers using AWS Glue workflows start by defining the pipeline using the AWS Management Console and then move on to monitoring and troubleshooting using either the console, AWS APIs, or the AWS Command Line Interface (AWS CLI).
Solution overview
The solution uses COVID-19 datasets. For more information on these datasets, see the public data lake for analysis of COVID-19 data, which contains a centralized repository of freely available and up-to-date curated datasets made available by the AWS Data Lake team.
Because the primary focus of this solution showcases how to model and provision AWS Glue workflows using AWS CloudFormation and CodePipeline, we don’t spend much time describing intricate transform capabilities that can be performed in AWS Glue jobs. As shown in the Python scripts, the business logic is optimized for readability and extensibility so you can easily home in on the functions that aggregate data based on monthly and quarterly time periods.
The ETL pipeline reads the source COVID-19 datasets directly and writes only the aggregated data to your S3 bucket.
The solution exposes the datasets in the following tables:
Table NameDescriptionDataset locationProvider
countrycodeLookup table for country codess3://covid19-lake/static-datasets/csv/countrycode/Rearc
countypopulationLookup table for the population of each countys3://covid19-lake/static-datasets/csv/CountyPopulation/Rearc
state_abvLookup table for US state abbreviationss3://covid19-lake/static-datasets/json/state-abv/Rearc
rearc_covid_19_nyt_data_in_usa_us_countiesData on COVID-19 cases at US county levels3://covid19-lake/rearc-covid-19-nyt-data-in-usa/csv/us-counties/Rearc
rearc_covid_19_nyt_data_in_usa_us_statesData on COVID-19 cases at US state levels3://covid19-lake/rearc-covid-19-nyt-data-in-usa/csv/us-states/Rearc
rearc_covid_19_testing_data_states_dailyData on COVID-19 cases at US state levels3://covid19-lake/rearc-covid-19-testing-data/csv/states_daily/Rearc
rearc_covid_19_testing_data_us_dailyUS total test daily trends3://covid19-lake/rearc-covid-19-testing-data/csv/us_daily/Rearc
rearc_covid_19_testing_data_us_total_latestUS total testss3://covid19-lake/rearc-covid-19-testing-data/csv/us-total-latest/Rearc
rearc_covid_19_world_cases_deaths_testingWorld total testss3://covid19-lake/rearc-covid-19-world-cases-deaths-testing/Rearc
rearc_usa_hospital_bedsHospital beds and their utilization in the USs3://covid19-lake/rearc-usa-hospital-beds/Rearc
world_cases_deaths_aggregatesMonthly and quarterly aggregate of the worlds3://<your-S3-bucket-name>/covid19/world-cases-deaths-aggregates/Aggregate
Prerequisites
This post assumes you have the following:
• Access to an AWS account
• The AWS CLI (optional)
• Permissions to create a CloudFormation stack
• Permissions to create AWS resources, such as AWS Identity and Access Management (IAM) roles, Amazon Simple Storage Service (Amazon S3) buckets, and various other resources
• General familiarity with AWS Glue resources (triggers, crawlers, and jobs)
Architecture
The CloudFormation template glue-workflow-stack.yml defines all the AWS Glue resources shown in the following diagram.
architecture diagram showing ETL process
Figure: AWS Glue workflow architecture diagram
Modeling the AWS Glue workflow using AWS CloudFormation
Let’s start by exploring the template used to model the AWS Glue workflow: glue-workflow-stack.yml
We focus on two resources in the following snippet:
• AWS::Glue::Workflow
• AWS::Glue::Trigger
From a logical perspective, a workflow contains one or more triggers that are responsible for invoking crawlers and jobs. Building a workflow starts with defining the crawlers and jobs as resources within the template and then associating it with triggers.
Defining the workflow
This is where the definition of the workflow starts. In the following snippet, we specify the type as AWS::Glue::Workflow and the property Name as a reference to the parameter GlueWorkflowName.
Parameters:
GlueWorkflowName:
Type: String
Description: Glue workflow that tracks all triggers, jobs, crawlers as a single entity
Default: Covid_19
Resources:
Covid19Workflow:
Type: AWS::Glue::Workflow
Properties:
Description: Glue workflow that tracks specified triggers, jobs, and crawlers as a single entity
Name: !Ref GlueWorkflowName
Defining the triggers
This is where we define each trigger and associate it with the workflow. In the following snippet, we specify the property WorkflowName on each trigger as a reference to the logical ID Covid19Workflow.
These triggers allow us to create a chain of dependent jobs and crawlers as specified by the properties Actions and Predicate.
The trigger t_Start utilizes a type of SCHEDULED, which means that it starts at a defined time (in our case, one time a day at 8:00 AM UTC). Every time it runs, it starts the job with the logical ID Covid19WorkflowStarted.
The trigger t_GroupA utilizes a type of CONDITIONAL, which means that it starts when the resources specified within the property Predicate have reached a specific state (when the list of Conditions specified equals SUCCEEDED). Every time t_GroupA runs, it starts the crawlers with the logical ID’s CountyPopulation and Countrycode, per the Actions property containing a list of actions.
TriggerJobCovid19WorkflowStart:
Type: AWS::Glue::Trigger
Properties:
Name: t_Start
Type: SCHEDULED
Schedule: cron(0 8 * * ? *) # Runs once a day at 8 AM UTC
StartOnCreation: true
WorkflowName: !Ref GlueWorkflowName
Actions:
- JobName: !Ref Covid19WorkflowStarted
TriggerCrawlersGroupA:
Type: AWS::Glue::Trigger
Properties:
Name: t_GroupA
Type: CONDITIONAL
StartOnCreation: true
WorkflowName: !Ref GlueWorkflowName
Actions:
- CrawlerName: !Ref CountyPopulation
- CrawlerName: !Ref Countrycode
Predicate:
Conditions:
- JobName: !Ref Covid19WorkflowStarted
LogicalOperator: EQUALS
State: SUCCEEDED
Provisioning the AWS Glue workflow using CodePipeline
Now let’s explore the template used to provision the CodePipeline resources: codepipeline-stack.yml
This template defines an S3 bucket that is used as the source action for the pipeline. Any time source code is uploaded to a specified bucket, AWS CloudTrail logs the event, which is detected by an Amazon CloudWatch Events rule configured to start running the pipeline in CodePipeline. The pipeline orchestrates CodeBuild to get the source code and provision the workflow.
For more information on any of the available source actions that you can use with CodePipeline, such as Amazon S3, AWS CodeCommit, Amazon Elastic Container Registry (Amazon ECR), GitHub, GitHub Enterprise Server, GitHub Enterprise Cloud, or Bitbucket, see Start a pipeline execution in CodePipeline.
We start by deploying the stack that sets up the CodePipeline resources. This stack can be deployed in any Region where CodePipeline and AWS Glue are available. For more information, see AWS Regional Services.
Cloning the GitHub repo
Clone the GitHub repo with the following command:
$ git clone https://github.com/aws-samples/provision-codepipeline-glue-workflows.git
Deploying the CodePipeline stack
Deploy the CodePipeline stack with the following command:
$ aws cloudformation deploy \
--stack-name codepipeline-covid19 \
--template-file cloudformation/codepipeline-stack.yml \
--capabilities CAPABILITY_NAMED_IAM \
--no-fail-on-empty-changeset \
--region <AWS_REGION>
When the deployment is complete, you can view the pipeline that was provisioned on the CodePipeline console.
CodePipeline console showing the deploy pipeline in failed state
Figure: CodePipeline console
The preceding screenshot shows that the pipeline failed. This is because we haven’t uploaded the source code yet.
In the following steps, we zip and upload the source code, which triggers another (successful) run of the pipeline.
Zipping the source code
Zip the source code containing Glue scripts, CloudFormation templates, and Buildspecs file with the following command:
$ zip -r source.zip . -x images/\* *.history* *.git* *.DS_Store*
You can omit *.DS_Store* from the preceding command if you are not a Mac user.
Uploading the source code
Upload the source code with the following command:
$ aws s3 cp source.zip s3://covid19-codepipeline-source-<AWS_ACCOUNT_ID>-<AWS_REGION>
Make sure to provide your account ID and Region in the preceding command. For example, if your AWS account ID is 111111111111 and you’re using Region us-west-2, use the following command:
$ aws s3 cp source.zip s3://covid19-codepipeline-source-111111111111-us-west-2
Now that the source code has been uploaded, view the pipeline again to see it in action.
CodePipeline console showing the deploy pipeline in success state
Figure: CodePipeline console displaying stage “Deploy” in-progress
Choose Details within the Deploy stage to see the build logs.
CodeBuild console displaying build logs
Figure: CodeBuild console displaying build logs
To modify any of the commands that run within the Deploy stage, feel free to modify: deploy-glue-workflow-stack.yml
Try uploading the source code a few more times. Each time it’s uploaded, CodePipeline starts and runs another deploy of the workflow stack. If nothing has changed in the source code, AWS CloudFormation automatically determines that the stack is already up to date. If something has changed in the source code, AWS CloudFormation automatically determines that the stack needs to be updated and proceeds to run the change set.
Viewing the provisioned workflow, triggers, jobs, and crawlers
To view your workflows on the AWS Glue console, in the navigation pane, under ETL, choose Workflows.
Glue console showing workflows
Figure: Navigate to Workflows
To view your triggers, in the navigation pane, under ETL, choose Triggers.
Glue console showing triggers
Figure: Navigate to Triggers
To view your crawlers, under Data Catalog, choose Crawlers.
Glue console showing crawlers
Figure: Navigate to Crawlers
To view your jobs, under ETL, choose Jobs.
Glue console showing jobs
Figure: Navigate to Jobs
Running the workflow
The workflow runs automatically at 8:00 AM UTC. To start the workflow manually, you can use either the AWS CLI or the AWS Glue console.
To start the workflow with the AWS CLI, enter the following command:
$ aws glue start-workflow-run – name Covid_19 – region <AWS_REGION>
To start the workflow on the AWS Glue console, on the Workflows page, select your workflow and choose Run on the Actions menu.
Glue console run workflow
Figure: AWS Glue console start workflow run
To view the run details of the workflow, choose the workflow on the AWS Glue console and choose View run details on the History tab.
Glue console view run details of a workflow
Figure: View run details
The following screenshot shows a visual representation of the workflow as a graph with your run details.
Glue console showing visual representation of the workflow as a graph.
Figure: AWS Glue console displaying details of successful workflow run
Cleaning up
To avoid additional charges, delete the stack created by the CloudFormation template and the contents of the buckets you created.
1. Delete the contents of the covid19-dataset bucket with the following command:
$ aws s3 rm s3://covid19-dataset-<AWS_ACCOUNT_ID>-<AWS_REGION> – recursive
2. Delete your workflow stack with the following command:
$ aws cloudformation delete-stack – stack-name glue-covid19 – region <AWS_REGION>
To delete the contents of the covid19-codepipeline-source bucket, it’s simplest to use the Amazon S3 console because it makes it easy to delete multiple versions of the object at once.
3. Navigate to the S3 bucket named covid19-codepipeline-source-<AWS_ACCOUNT_ID>- <AWS_REGION>.
4. Choose List versions.
5. Select all the files to delete.
6. Choose Delete and follow the prompts to permanently delete all the objects.
S3 console delete all object versions
Figure: AWS S3 console delete all object versions
7. Delete the contents of the covid19-codepipeline-artifacts bucket:
$ aws s3 rm s3://covid19-codepipeline-artifacts-<AWS_ACCOUNT_ID>-<AWS-REGION> – recursive
8. Delete the contents of the covid19-cloudtrail-logs bucket:
$ aws s3 rm s3://covid19-cloudtrail-logs-<AWS_ACCOUNT_ID>-<AWS-REGION> – recursive
9. Delete the pipeline stack:
$ aws cloudformation delete-stack – stack-name codepipeline-covid19 – region <AWS-REGION>
Conclusion
In this post, we stepped through how to use AWS DevOps tooling to model and provision an AWS Glue workflow that orchestrates an end-to-end ETL pipeline on a real-world dataset.
You can download the source code and template from this Github repository and adapt it as you see fit for your data pipeline use cases. Feel free to leave comments letting us know about the architectures you build for your environment. To learn more about building ETL pipelines with AWS Glue, see the AWS Glue Developer Guide and the AWS Data Analytics learning path.
About the Authors
Nuatu Tseggai
Nuatu Tseggai is a Cloud Infrastructure Architect at Amazon Web Services. He enjoys working with customers to design and build event-driven distributed systems that span multiple services.
Suvojit Dasgupta
Suvojit Dasgupta is a Sr. Customer Data Architect at Amazon Web Services. He works with customers to design and build complex data solutions on AWS.
Building end-to-end AWS DevSecOps CI/CD pipeline with open source SCA, SAST and DAST tools
Post Syndicated from Srinivas Manepalli original https://aws.amazon.com/blogs/devops/building-end-to-end-aws-devsecops-ci-cd-pipeline-with-open-source-sca-sast-and-dast-tools/
DevOps is a combination of cultural philosophies, practices, and tools that combine software development with information technology operations. These combined practices enable companies to deliver new application features and improved services to customers at a higher velocity. DevSecOps takes this a step further, integrating security into DevOps. With DevSecOps, you can deliver secure and compliant application changes rapidly while running operations consistently with automation.
Having a complete DevSecOps pipeline is critical to building a successful software factory, which includes continuous integration (CI), continuous delivery and deployment (CD), continuous testing, continuous logging and monitoring, auditing and governance, and operations. Identifying the vulnerabilities during the initial stages of the software development process can significantly help reduce the overall cost of developing application changes, but doing it in an automated fashion can accelerate the delivery of these changes as well.
To identify security vulnerabilities at various stages, organizations can integrate various tools and services (cloud and third-party) into their DevSecOps pipelines. Integrating various tools and aggregating the vulnerability findings can be a challenge to do from scratch. AWS has the services and tools necessary to accelerate this objective and provides the flexibility to build DevSecOps pipelines with easy integrations of AWS cloud native and third-party tools. AWS also provides services to aggregate security findings.
In this post, we provide a DevSecOps pipeline reference architecture on AWS that covers the afore-mentioned practices, including SCA (Software Composite Analysis), SAST (Static Application Security Testing), DAST (Dynamic Application Security Testing), and aggregation of vulnerability findings into a single pane of glass. Additionally, this post addresses the concepts of security of the pipeline and security in the pipeline.
You can deploy this pipeline in either the AWS GovCloud Region (US) or standard AWS Regions. As of this writing, all listed AWS services are available in AWS GovCloud (US) and authorized for FedRAMP High workloads within the Region, with the exception of AWS CodePipeline and AWS Security Hub, which are in the Region and currently under the JAB Review to be authorized shortly for FedRAMP High as well.
Services and tools
In this section, we discuss the various AWS services and third-party tools used in this solution.
CI/CD services
For CI/CD, we use the following AWS services:
• AWS CodeBuild – A fully managed continuous integration service that compiles source code, runs tests, and produces software packages that are ready to deploy.
• AWS CodeCommit – A fully managed source control service that hosts secure Git-based repositories.
• AWS CodeDeploy – A fully managed deployment service that automates software deployments to a variety of compute services such as Amazon Elastic Compute Cloud (Amazon EC2), AWS Fargate, AWS Lambda, and your on-premises servers.
• AWS CodePipeline – A fully managed continuous delivery service that helps you automate your release pipelines for fast and reliable application and infrastructure updates.
• AWS Lambda – A service that lets you run code without provisioning or managing servers. You pay only for the compute time you consume.
• Amazon Simple Notification Service – Amazon SNS is a fully managed messaging service for both application-to-application (A2A) and application-to-person (A2P) communication.
• Amazon Simple Storage Service – Amazon S3 is storage for the internet. You can use Amazon S3 to store and retrieve any amount of data at any time, from anywhere on the web.
• AWS Systems Manager Parameter Store – Parameter Store gives you visibility and control of your infrastructure on AWS.
Continuous testing tools
The following are open-source scanning tools that are integrated in the pipeline for the purposes of this post, but you could integrate other tools that meet your specific requirements. You can use the static code review tool Amazon CodeGuru for static analysis, but at the time of this writing, it’s not yet available in GovCloud and currently supports Java and Python (available in preview).
• OWASP Dependency-Check – A Software Composition Analysis (SCA) tool that attempts to detect publicly disclosed vulnerabilities contained within a project’s dependencies.
• SonarQube (SAST) – Catches bugs and vulnerabilities in your app, with thousands of automated Static Code Analysis rules.
• PHPStan (SAST) – Focuses on finding errors in your code without actually running it. It catches whole classes of bugs even before you write tests for the code.
• OWASP Zap (DAST) – Helps you automatically find security vulnerabilities in your web applications while you’re developing and testing your applications.
Continuous logging and monitoring services
The following are AWS services for continuous logging and monitoring:
Auditing and governance services
The following are AWS auditing and governance services:
• AWS CloudTrail – Enables governance, compliance, operational auditing, and risk auditing of your AWS account.
• AWS Identity and Access Management – Enables you to manage access to AWS services and resources securely. With IAM, you can create and manage AWS users and groups, and use permissions to allow and deny their access to AWS resources.
• AWS Config – Allows you to assess, audit, and evaluate the configurations of your AWS resources.
Operations services
The following are AWS operations services:
• AWS Security Hub – Gives you a comprehensive view of your security alerts and security posture across your AWS accounts. This post uses Security Hub to aggregate all the vulnerability findings as a single pane of glass.
• AWS CloudFormation – Gives you an easy way to model a collection of related AWS and third-party resources, provision them quickly and consistently, and manage them throughout their lifecycles, by treating infrastructure as code.
• AWS Systems Manager Parameter Store – Provides secure, hierarchical storage for configuration data management and secrets management. You can store data such as passwords, database strings, Amazon Machine Image (AMI) IDs, and license codes as parameter values.
• AWS Elastic Beanstalk – An easy-to-use service for deploying and scaling web applications and services developed with Java, .NET, PHP, Node.js, Python, Ruby, Go, and Docker on familiar servers such as Apache, Nginx, Passenger, and IIS. This post uses Elastic Beanstalk to deploy LAMP stack with WordPress and Amazon Aurora MySQL. Although we use Elastic Beanstalk for this post, you could configure the pipeline to deploy to various other environments on AWS or elsewhere as needed.
Pipeline architecture
The following diagram shows the architecture of the solution.
AWS DevSecOps CICD pipeline architecture
AWS DevSecOps CICD pipeline architecture
The main steps are as follows:
1. When a user commits the code to a CodeCommit repository, a CloudWatch event is generated which, triggers CodePipeline.
2. CodeBuild packages the build and uploads the artifacts to an S3 bucket. CodeBuild retrieves the authentication information (for example, scanning tool tokens) from Parameter Store to initiate the scanning. As a best practice, it is recommended to utilize Artifact repositories like AWS CodeArtifact to store the artifacts, instead of S3. For simplicity of the workshop, we will continue to use S3.
3. CodeBuild scans the code with an SCA tool (OWASP Dependency-Check) and SAST tool (SonarQube or PHPStan; in the provided CloudFormation template, you can pick one of these tools during the deployment, but CodeBuild is fully enabled for a bring your own tool approach).
4. If there are any vulnerabilities either from SCA analysis or SAST analysis, CodeBuild invokes the Lambda function. The function parses the results into AWS Security Finding Format (ASFF) and posts it to Security Hub. Security Hub helps aggregate and view all the vulnerability findings in one place as a single pane of glass. The Lambda function also uploads the scanning results to an S3 bucket.
5. If there are no vulnerabilities, CodeDeploy deploys the code to the staging Elastic Beanstalk environment.
6. After the deployment succeeds, CodeBuild triggers the DAST scanning with the OWASP ZAP tool (again, this is fully enabled for a bring your own tool approach).
7. If there are any vulnerabilities, CodeBuild invokes the Lambda function, which parses the results into ASFF and posts it to Security Hub. The function also uploads the scanning results to an S3 bucket (similar to step 4).
8. If there are no vulnerabilities, the approval stage is triggered, and an email is sent to the approver for action.
9. After approval, CodeDeploy deploys the code to the production Elastic Beanstalk environment.
10. During the pipeline run, CloudWatch Events captures the build state changes and sends email notifications to subscribed users through SNS notifications.
11. CloudTrail tracks the API calls and send notifications on critical events on the pipeline and CodeBuild projects, such as UpdatePipeline, DeletePipeline, CreateProject, and DeleteProject, for auditing purposes.
12. AWS Config tracks all the configuration changes of AWS services. The following AWS Config rules are added in this pipeline as security best practices:
13. CODEBUILD_PROJECT_ENVVAR_AWSCRED_CHECK – Checks whether the project contains environment variables AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY. The rule is NON_COMPLIANT when the project environment variables contains plaintext credentials.
14. CLOUD_TRAIL_LOG_FILE_VALIDATION_ENABLED – Checks whether CloudTrail creates a signed digest file with logs. AWS recommends that the file validation be enabled on all trails. The rule is noncompliant if the validation is not enabled.
Security of the pipeline is implemented by using IAM roles and S3 bucket policies to restrict access to pipeline resources. Pipeline data at rest and in transit is protected using encryption and SSL secure transport. We use Parameter Store to store sensitive information such as API tokens and passwords. To be fully compliant with frameworks such as FedRAMP, other things may be required, such as MFA.
Security in the pipeline is implemented by performing the SCA, SAST and DAST security checks. Alternatively, the pipeline can utilize IAST (Interactive Application Security Testing) techniques that would combine SAST and DAST stages.
As a best practice, encryption should be enabled for the code and artifacts, whether at rest or transit.
In the next section, we explain how to deploy and run the pipeline CloudFormation template used for this example. Refer to the provided service links to learn more about each of the services in the pipeline. If utilizing CloudFormation templates to deploy infrastructure using pipelines, we recommend using linting tools like cfn-nag to scan CloudFormation templates for security vulnerabilities.
Prerequisites
Before getting started, make sure you have the following prerequisites:
Deploying the pipeline
To deploy the pipeline, complete the following steps: Download the CloudFormation template and pipeline code from GitHub repo.
1. Log in to your AWS account if you have not done so already.
2. On the CloudFormation console, choose Create Stack.
3. Choose the CloudFormation pipeline template.
4. Choose Next.
5. Provide the stack parameters:
• Under Code, provide code details, such as repository name and the branch to trigger the pipeline.
• Under SAST, choose the SAST tool (SonarQube or PHPStan) for code analysis, enter the API token and the SAST tool URL. You can skip SonarQube details if using PHPStan as the SAST tool.
• Under DAST, choose the DAST tool (OWASP Zap) for dynamic testing and enter the API token, DAST tool URL, and the application URL to run the scan.
• Under Lambda functions, enter the Lambda function S3 bucket name, filename, and the handler name.
• Under STG Elastic Beanstalk Environment and PRD Elastic Beanstalk Environment, enter the Elastic Beanstalk environment and application details for staging and production to which this pipeline deploys the application code.
• Under General, enter the email addresses to receive notifications for approvals and pipeline status changes.
CF Deploymenet - Passing parameter values
CloudFormation deployment - Passing parameter values
CloudFormation template deployment
After the pipeline is deployed, confirm the subscription by choosing the provided link in the email to receive the notifications.
The provided CloudFormation template in this post is formatted for AWS GovCloud. If you’re setting this up in a standard Region, you have to adjust the partition name in the CloudFormation template. For example, change ARN values from arn:aws-us-gov to arn:aws.
Running the pipeline
To trigger the pipeline, commit changes to your application repository files. That generates a CloudWatch event and triggers the pipeline. CodeBuild scans the code and if there are any vulnerabilities, it invokes the Lambda function to parse and post the results to Security Hub.
When posting the vulnerability finding information to Security Hub, we need to provide a vulnerability severity level. Based on the provided severity value, Security Hub assigns the label as follows. Adjust the severity levels in your code based on your organization’s requirements.
• 0 – INFORMATIONAL
• 1–39 – LOW
• 40– 69 – MEDIUM
• 70–89 – HIGH
• 90–100 – CRITICAL
The following screenshot shows the progression of your pipeline.
CodePipeline stages
CodePipeline stages
SCA and SAST scanning
In our architecture, CodeBuild trigger the SCA and SAST scanning in parallel. In this section, we discuss scanning with OWASP Dependency-Check, SonarQube, and PHPStan.
Scanning with OWASP Dependency-Check (SCA)
The following is the code snippet from the Lambda function, where the SCA analysis results are parsed and posted to Security Hub. Based on the results, the equivalent Security Hub severity level (normalized_severity) is assigned.
Lambda code snippet for OWASP Dependency-check
Lambda code snippet for OWASP Dependency-check
You can see the results in Security Hub, as in the following screenshot.
SecurityHub report from OWASP Dependency-check scanning
SecurityHub report from OWASP Dependency-check scanning
Scanning with SonarQube (SAST)
The following is the code snippet from the Lambda function, where the SonarQube code analysis results are parsed and posted to Security Hub. Based on SonarQube results, the equivalent Security Hub severity level (normalized_severity) is assigned.
Lambda code snippet for SonarQube
Lambda code snippet for SonarQube
The following screenshot shows the results in Security Hub.
SecurityHub report from SonarQube scanning
SecurityHub report from SonarQube scanning
Scanning with PHPStan (SAST)
The following is the code snippet from the Lambda function, where the PHPStan code analysis results are parsed and posted to Security Hub.
Lambda code snippet for PHPStan
Lambda code snippet for PHPStan
The following screenshot shows the results in Security Hub.
SecurityHub report from PHPStan scanning
SecurityHub report from PHPStan scanning
DAST scanning
In our architecture, CodeBuild triggers DAST scanning and the DAST tool.
If there are no vulnerabilities in the SAST scan, the pipeline proceeds to the manual approval stage and an email is sent to the approver. The approver can review and approve or reject the deployment. If approved, the pipeline moves to next stage and deploys the application to the provided Elastic Beanstalk environment.
Scanning with OWASP Zap
After deployment is successful, CodeBuild initiates the DAST scanning. When scanning is complete, if there are any vulnerabilities, it invokes the Lambda function similar to SAST analysis. The function parses and posts the results to Security Hub. The following is the code snippet of the Lambda function.
Lambda code snippet for OWASP-Zap
Lambda code snippet for OWASP-Zap
The following screenshot shows the results in Security Hub.
SecurityHub report from OWASP-Zap scanning
SecurityHub report from OWASP-Zap scanning
Aggregation of vulnerability findings in Security Hub provides opportunities to automate the remediation. For example, based on the vulnerability finding, you can trigger a Lambda function to take the needed remediation action. This also reduces the burden on operations and security teams because they can now address the vulnerabilities from a single pane of glass instead of logging into multiple tool dashboards.
Conclusion
In this post, I presented a DevSecOps pipeline that includes CI/CD, continuous testing, continuous logging and monitoring, auditing and governance, and operations. I demonstrated how to integrate various open-source scanning tools, such as SonarQube, PHPStan, and OWASP Zap for SAST and DAST analysis. I explained how to aggregate vulnerability findings in Security Hub as a single pane of glass. This post also talked about how to implement security of the pipeline and in the pipeline using AWS cloud native services. Finally, I provided the DevSecOps pipeline as code using AWS CloudFormation. For additional information on AWS DevOps services and to get started, see AWS DevOps and DevOps Blog.
Srinivas Manepalli is a DevSecOps Solutions Architect in the U.S. Fed SI SA team at Amazon Web Services (AWS). He is passionate about helping customers, building and architecting DevSecOps and highly available software systems. Outside of work, he enjoys spending time with family, nature and good food.
How FactSet automates thousands of AWS accounts at scale
Post Syndicated from Amit Borulkar original https://aws.amazon.com/blogs/devops/factset-automation-at-scale/
This post is by FactSet’s Cloud Infrastructure team, Gaurav Jain, Nathan Goodman, Geoff Wang, Daniel Cordes, Sunu Joseph, and AWS Solution Architects Amit Borulkar and Tarik Makota. In their own words, “FactSet creates flexible, open data and software solutions for tens of thousands of investment professionals around the world, which provides instant access to financial data and analytics that investors use to make crucial decisions. At FactSet, we are always working to improve the value that our products provide.”
At FactSet, our operational goal to use the AWS Cloud is to have high developer velocity alongside enterprise governance. Assigning AWS accounts per project enables the agility and isolation boundary needed by each of the project teams to innovate faster. As existing workloads are migrated and new workloads are developed in the cloud, we realized that we were operating close to thousands of AWS accounts. To have a consistent and repeatable experience for diverse project teams, we automated the AWS account creation process, various service control policies (SCP) and AWS Identity and Access Management (IAM) policies and roles associated with the accounts, and enforced policies for ongoing configuration across the accounts. This post covers our automation workflows to enable governance for thousands of AWS accounts.
AWS account creation workflow
To empower our project teams to operate in the AWS Cloud in an agile manner, we developed a platform that enables AWS account creation with the default configuration customized to meet FactSet’s governance policies. These AWS accounts are provisioned with defaults such as a virtual private cloud (VPC), subnets, routing tables, IAM roles, SCP policies, add-ons for monitoring and load-balancing, and FactSet-specific governance. Developers and project team members can request a micro account for their product via this platform’s website, or do so programmatically using an API or wrap-around custom Terraform modules. The following screenshot shows a portion of the web interface that allows developers to request an AWS account.
FactSet service catalog
Continue reading How FactSet automates thousands of AWS accounts at scale
Automate thousands of mainframe tests on AWS with the Micro Focus Enterprise Suite
Post Syndicated from Kevin Yung original https://aws.amazon.com/blogs/devops/automate-mainframe-tests-on-aws-with-micro-focus/
Micro Focus – AWS Advanced Technology Parnter, they are a global infrastructure software company with 40 years of experience in delivering and supporting enterprise software.
We have seen mainframe customers often encounter scalability constraints, and they can’t support their development and test workforce to the scale required to support business requirements. These constraints can lead to delays, reduce product or feature releases, and make them unable to respond to market requirements. Furthermore, limits in capacity and scale often affect the quality of changes deployed, and are linked to unplanned or unexpected downtime in products or services.
The conventional approach to address these constraints is to scale up, meaning to increase MIPS/MSU capacity of the mainframe hardware available for development and testing. The cost of this approach, however, is excessively high, and to ensure time to market, you may reject this approach at the expense of quality and functionality. If you’re wrestling with these challenges, this post is written specifically for you.
To accompany this post, we developed an AWS prescriptive guidance (APG) pattern for developer instances and CI/CD pipelines: Mainframe Modernization: DevOps on AWS with Micro Focus.
Overview of solution
In the APG, we introduce DevOps automation and AWS CI/CD architecture to support mainframe application development. Our solution enables you to embrace both Test Driven Development (TDD) and Behavior Driven Development (BDD). Mainframe developers and testers can automate the tests in CI/CD pipelines so they’re repeatable and scalable. To speed up automated mainframe application tests, the solution uses team pipelines to run functional and integration tests frequently, and uses systems test pipelines to run comprehensive regression tests on demand. For more information about the pipelines, see Mainframe Modernization: DevOps on AWS with Micro Focus.
In this post, we focus on how to automate and scale mainframe application tests in AWS. We show you how to use AWS services and Micro Focus products to automate mainframe application tests with best practices. The solution can scale your mainframe application CI/CD pipeline to run thousands of tests in AWS within minutes, and you only pay a fraction of your current on-premises cost.
The following diagram illustrates the solution architecture.
Mainframe DevOps On AWS Architecture Overview, on the left is the conventional mainframe development environment, on the left is the CI/CD pipelines for mainframe tests in AWS
Figure: Mainframe DevOps On AWS Architecture Overview
Best practices
Before we get into the details of the solution, let’s recap the following mainframe application testing best practices:
• Create a “test first” culture by writing tests for mainframe application code changes
• Automate preparing and running tests in the CI/CD pipelines
• Provide fast and quality feedback to project management throughout the SDLC
• Assess and increase test coverage
• Scale your test’s capacity and speed in line with your project schedule and requirements
Automated smoke test
In this architecture, mainframe developers can automate running functional smoke tests for new changes. This testing phase typically “smokes out” regression of core and critical business functions. You can achieve these tests using tools such as py3270 with x3270 or Robot Framework Mainframe 3270 Library.
The following code shows a feature test written in Behave and test step using py3270:
# home_loan_calculator.feature
Feature: calculate home loan monthly repayment
the bankdemo application provides a monthly home loan repayment caculator
User need to input into transaction of home loan amount, interest rate and how many years of the loan maturity.
User will be provided an output of home loan monthly repayment amount
Scenario Outline: As a customer I want to calculate my monthly home loan repayment via a transaction
Given home loan amount is <amount>, interest rate is <interest rate> and maturity date is <maturity date in months> months
When the transaction is submitted to the home loan calculator
Then it shall show the monthly repayment of <monthly repayment>
Examples: Homeloan
| amount | interest rate | maturity date in months | monthly repayment |
| 1000000 | 3.29 | 300 | $4894.31 |
# home_loan_calculator_steps.py
import sys, os
from py3270 import Emulator
from behave import *
@given("home loan amount is {amount}, interest rate is {rate} and maturity date is {maturity_date} months")
def step_impl(context, amount, rate, maturity_date):
context.home_loan_amount = amount
context.interest_rate = rate
context.maturity_date_in_months = maturity_date
@when("the transaction is submitted to the home loan calculator")
def step_impl(context):
# Setup connection parameters
tn3270_host = os.getenv('TN3270_HOST')
tn3270_port = os.getenv('TN3270_PORT')
# Setup TN3270 connection
em = Emulator(visible=False, timeout=120)
em.connect(tn3270_host + ':' + tn3270_port)
em.wait_for_field()
# Screen login
em.fill_field(10, 44, 'b0001', 5)
em.send_enter()
# Input screen fields for home loan calculator
em.wait_for_field()
em.fill_field(8, 46, context.home_loan_amount, 7)
em.fill_field(10, 46, context.interest_rate, 7)
em.fill_field(12, 46, context.maturity_date_in_months, 7)
em.send_enter()
em.wait_for_field()
# collect monthly replayment output from screen
context.monthly_repayment = em.string_get(14, 46, 9)
em.terminate()
@then("it shall show the monthly repayment of {amount}")
def step_impl(context, amount):
print("expected amount is " + amount.strip() + ", and the result from screen is " + context.monthly_repayment.strip())
assert amount.strip() == context.monthly_repayment.strip()
To run this functional test in Micro Focus Enterprise Test Server (ETS), we use AWS CodeBuild.
We first need to build an Enterprise Test Server Docker image and push it to an Amazon Elastic Container Registry (Amazon ECR) registry. For instructions, see Using Enterprise Test Server with Docker.
Next, we create a CodeBuild project and uses the Enterprise Test Server Docker image in its configuration.
The following is an example AWS CloudFormation code snippet of a CodeBuild project that uses Windows Container and Enterprise Test Server:
BddTestBankDemoStage:
Type: AWS::CodeBuild::Project
Properties:
Name: !Sub '${AWS::StackName}BddTestBankDemo'
LogsConfig:
CloudWatchLogs:
Status: ENABLED
Artifacts:
Type: CODEPIPELINE
EncryptionDisabled: true
Environment:
ComputeType: BUILD_GENERAL1_LARGE
Image: !Sub "${EnterpriseTestServerDockerImage}:latest"
ImagePullCredentialsType: SERVICE_ROLE
Type: WINDOWS_SERVER_2019_CONTAINER
ServiceRole: !Ref CodeBuildRole
Source:
Type: CODEPIPELINE
BuildSpec: bdd-test-bankdemo-buildspec.yaml
In the CodeBuild project, we need to create a buildspec to orchestrate the commands for preparing the Micro Focus Enterprise Test Server CICS environment and issue the test command. In the buildspec, we define the location for CodeBuild to look for test reports and upload them into the CodeBuild report group. The following buildspec code uses custom scripts DeployES.ps1 and StartAndWait.ps1 to start your CICS region, and runs Python Behave BDD tests:
version: 0.2
phases:
build:
commands:
- |
# Run Command to start Enterprise Test Server
CD C:\
.\DeployES.ps1
.\StartAndWait.ps1
py -m pip install behave
Write-Host "waiting for server to be ready ..."
do {
Write-Host "..."
sleep 3
} until(Test-NetConnection 127.0.0.1 -Port 9270 | ? { $_.TcpTestSucceeded } )
CD C:\tests\features
MD C:\tests\reports
$Env:Path += ";c:\wc3270"
$address=(Get-NetIPAddress -AddressFamily Ipv4 | where { $_.IPAddress -Match "172\.*" })
$Env:TN3270_HOST = $address.IPAddress
$Env:TN3270_PORT = "9270"
behave.exe – color – junit – junit-directory C:\tests\reports
reports:
bankdemo-bdd-test-report:
files:
- '**/*'
base-directory: "C:\\tests\\reports"
In the smoke test, the team may run both unit tests and functional tests. Ideally, these tests are better to run in parallel to speed up the pipeline. In AWS CodePipeline, we can set up a stage to run multiple steps in parallel. In our example, the pipeline runs both BDD tests and Robot Framework (RPA) tests.
The following CloudFormation code snippet runs two different tests. You use the same RunOrder value to indicate the actions run in parallel.
#...
- Name: Tests
Actions:
- Name: RunBDDTest
ActionTypeId:
Category: Build
Owner: AWS
Provider: CodeBuild
Version: 1
Configuration:
ProjectName: !Ref BddTestBankDemoStage
PrimarySource: Config
InputArtifacts:
- Name: DemoBin
- Name: Config
RunOrder: 1
- Name: RunRbTest
ActionTypeId:
Category: Build
Owner: AWS
Provider: CodeBuild
Version: 1
Configuration:
ProjectName : !Ref RpaTestBankDemoStage
PrimarySource: Config
InputArtifacts:
- Name: DemoBin
- Name: Config
RunOrder: 1
#...
The following screenshot shows the example actions on the CodePipeline console that use the preceding code.
Screenshot of CodePipeine parallel execution tests using a same run order value
Figure – Screenshot of CodePipeine parallel execution tests
Both DBB and RPA tests produce jUnit format reports, which CodeBuild can ingest and show on the CodeBuild console. This is a great way for project management and business users to track the quality trend of an application. The following screenshot shows the CodeBuild report generated from the BDD tests.
CodeBuild report generated from the BDD tests showing 100% pass rate
Figure – CodeBuild report generated from the BDD tests
Automated regression tests
After you test the changes in the project team pipeline, you can automatically promote them to another stream with other team members’ changes for further testing. The scope of this testing stream is significantly more comprehensive, with a greater number and wider range of tests and higher volume of test data. The changes promoted to this stream by each team member are tested in this environment at the end of each day throughout the life of the project. This provides a high-quality delivery to production, with new code and changes to existing code tested together with hundreds or thousands of tests.
In enterprise architecture, it’s commonplace to see an application client consuming web services APIs exposed from a mainframe CICS application. One approach to do regression tests for mainframe applications is to use Micro Focus Verastream Host Integrator (VHI) to record and capture 3270 data stream processing and encapsulate these 3270 data streams as business functions, which in turn are packaged as web services. When these web services are available, they can be consumed by a test automation product, which in our environment is Micro Focus UFT One. This uses the Verastream server as the orchestration engine that translates the web service requests into 3270 data streams that integrate with the mainframe CICS application. The application is deployed in Micro Focus Enterprise Test Server.
The following diagram shows the end-to-end testing components.
Regression Test the end-to-end testing components using ECS Container for Exterprise Test Server, Verastream Host Integrator and UFT One Container, all integration points are using Elastic Network Load Balancer
Figure – Regression Test Infrastructure end-to-end Setup
To ensure we have the coverage required for large mainframe applications, we sometimes need to run thousands of tests against very large production volumes of test data. We want the tests to run faster and complete as soon as possible so we reduce AWS costs—we only pay for the infrastructure when consuming resources for the life of the test environment when provisioning and running tests.
Therefore, the design of the test environment needs to scale out. The batch feature in CodeBuild allows you to run tests in batches and in parallel rather than serially. Furthermore, our solution needs to minimize interference between batches, a failure in one batch doesn’t affect another running in parallel. The following diagram depicts the high-level design, with each batch build running in its own independent infrastructure. Each infrastructure is launched as part of test preparation, and then torn down in the post-test phase.
Regression Tests in CodeBuoild Project setup to use batch mode, three batches running in independent infrastructure with containers
Figure – Regression Tests in CodeBuoild Project setup to use batch mode
Building and deploying regression test components
Following the design of the parallel regression test environment, let’s look at how we build each component and how they are deployed. The followings steps to build our regression tests use a working backward approach, starting from deployment in the Enterprise Test Server:
1. Create a batch build in CodeBuild.
2. Deploy to Enterprise Test Server.
3. Deploy the VHI model.
4. Deploy UFT One Tests.
5. Integrate UFT One into CodeBuild and CodePipeline and test the application.
Creating a batch build in CodeBuild
We update two components to enable a batch build. First, in the CodePipeline CloudFormation resource, we set BatchEnabled to be true for the test stage. The UFT One test preparation stage uses the CloudFormation template to create the test infrastructure. The following code is an example of the AWS CloudFormation snippet with batch build enabled:
#...
- Name: SystemsTest
Actions:
- Name: Uft-Tests
ActionTypeId:
Category: Build
Owner: AWS
Provider: CodeBuild
Version: 1
Configuration:
ProjectName : !Ref UftTestBankDemoProject
PrimarySource: Config
BatchEnabled: true
CombineArtifacts: true
InputArtifacts:
- Name: Config
- Name: DemoSrc
OutputArtifacts:
- Name: TestReport
RunOrder: 1
#...
Second, in the buildspec configuration of the test stage, we provide a build matrix setting. We use the custom environment variable TEST_BATCH_NUMBER to indicate which set of tests runs in each batch. See the following code:
version: 0.2
batch:
fast-fail: true
build-matrix:
static:
ignore-failure: false
dynamic:
env:
variables:
TEST_BATCH_NUMBER:
- 1
- 2
- 3
phases:
pre_build:
commands:
#...
After setting up the batch build, CodeBuild creates multiple batches when the build starts. The following screenshot shows the batches on the CodeBuild console.
Regression tests Codebuild project ran in batch mode, three batches ran in prallel successfully
Figure – Regression tests Codebuild project ran in batch mode
Deploying to Enterprise Test Server
ETS is the transaction engine that processes all the online (and batch) requests that are initiated through external clients, such as 3270 terminals, web services, and websphere MQ. This engine provides support for various mainframe subsystems, such as CICS, IMS TM and JES, as well as code-level support for COBOL and PL/I. The following screenshot shows the Enterprise Test Server administration page.
Enterprise Server Administrator window showing configuration for CICS
Figure – Enterprise Server Administrator window
In this mainframe application testing use case, the regression tests are CICS transactions, initiated from 3270 requests (encapsulated in a web service). For more information about Enterprise Test Server, see the Enterprise Test Server and Micro Focus websites.
In the regression pipeline, after the stage of mainframe artifact compiling, we bake in the artifact into an ETS Docker container and upload the image to an Amazon ECR repository. This way, we have an immutable artifact for all the tests.
During each batch’s test preparation stage, a CloudFormation stack is deployed to create an Amazon ECS service on Windows EC2. The stack uses a Network Load Balancer as an integration point for the VHI’s integration.
The following code is an example of the CloudFormation snippet to create an Amazon ECS service using an Enterprise Test Server Docker image:
#...
EtsService:
DependsOn:
- EtsTaskDefinition
- EtsContainerSecurityGroup
- EtsLoadBalancerListener
Properties:
Cluster: !Ref 'WindowsEcsClusterArn'
DesiredCount: 1
LoadBalancers:
-
ContainerName: !Sub "ets-${AWS::StackName}"
ContainerPort: 9270
TargetGroupArn: !Ref EtsPort9270TargetGroup
HealthCheckGracePeriodSeconds: 300
TaskDefinition: !Ref 'EtsTaskDefinition'
Type: "AWS::ECS::Service"
EtsTaskDefinition:
Properties:
ContainerDefinitions:
-
Image: !Sub "${AWS::AccountId}.dkr.ecr.us-east-1.amazonaws.com/systems-test/ets:latest"
LogConfiguration:
LogDriver: awslogs
Options:
awslogs-group: !Ref 'SystemsTestLogGroup'
awslogs-region: !Ref 'AWS::Region'
awslogs-stream-prefix: ets
Name: !Sub "ets-${AWS::StackName}"
cpu: 4096
memory: 8192
PortMappings:
-
ContainerPort: 9270
EntryPoint:
- "powershell.exe"
Command:
- '-F'
- .\StartAndWait.ps1
- 'bankdemo'
- C:\bankdemo\
- 'wait'
Family: systems-test-ets
Type: "AWS::ECS::TaskDefinition"
#...
Deploying the VHI model
In this architecture, the VHI is a bridge between mainframe and clients.
We use the VHI designer to capture the 3270 data streams and encapsulate the relevant data streams into a business function. We can then deliver this function as a web service that can be consumed by a test management solution, such as Micro Focus UFT One.
The following screenshot shows the setup for getCheckingDetails in VHI. Along with this procedure we can also see other procedures (eg calcCostLoan) defined that get generated as a web service. The properties associated with this procedure are available on this screen to allow for the defining of the mapping of the fields between the associated 3270 screens and exposed web service.
example of VHI designer to capture the 3270 data streams and encapsulate the relevant data streams into a business function getCheckingDetails
Figure – Setup for getCheckingDetails in VHI
The following screenshot shows the editor for this procedure and is initiated by the selection of the Procedure Editor. This screen presents the 3270 screens that are involved in the business function that will be generated as a web service.
VHI designer Procedure Editor shows the procedure
Figure – VHI designer Procedure Editor shows the procedure
After you define the required functional web services in VHI designer, the resultant model is saved and deployed into a VHI Docker image. We use this image and the associated model (from VHI designer) in the pipeline outlined in this post.
For more information about VHI, see the VHI website.
The pipeline contains two steps to deploy a VHI service. First, it installs and sets up the VHI models into a VHI Docker image, and it’s pushed into Amazon ECR. Second, a CloudFormation stack is deployed to create an Amazon ECS Fargate service, which uses the latest built Docker image. In AWS CloudFormation, the VHI ECS task definition defines an environment variable for the ETS Network Load Balancer’s DNS name. Therefore, the VHI can bootstrap and point to an ETS service. In the VHI stack, it uses a Network Load Balancer as an integration point for UFT One test integration.
The following code is an example of a ECS Task Definition CloudFormation snippet that creates a VHI service in Amazon ECS Fargate and integrates it with an ETS server:
#...
VhiTaskDefinition:
DependsOn:
- EtsService
Type: AWS::ECS::TaskDefinition
Properties:
Family: systems-test-vhi
NetworkMode: awsvpc
RequiresCompatibilities:
- FARGATE
ExecutionRoleArn: !Ref FargateEcsTaskExecutionRoleArn
Cpu: 2048
Memory: 4096
ContainerDefinitions:
- Cpu: 2048
Name: !Sub "vhi-${AWS::StackName}"
Memory: 4096
Environment:
- Name: esHostName
Value: !GetAtt EtsInternalLoadBalancer.DNSName
- Name: esPort
Value: 9270
Image: !Ref "${AWS::AccountId}.dkr.ecr.us-east-1.amazonaws.com/systems-test/vhi:latest"
PortMappings:
- ContainerPort: 9680
LogConfiguration:
LogDriver: awslogs
Options:
awslogs-group: !Ref 'SystemsTestLogGroup'
awslogs-region: !Ref 'AWS::Region'
awslogs-stream-prefix: vhi
#...
Deploying UFT One Tests
UFT One is a test client that uses each of the web services created by the VHI designer to orchestrate running each of the associated business functions. Parameter data is supplied to each function, and validations are configured against the data returned. Multiple test suites are configured with different business functions with the associated data.
The following screenshot shows the test suite API_Bankdemo3, which is used in this regression test process.
the screenshot shows the test suite API_Bankdemo3 in UFT One test setup console, the API setup for getCheckingDetails
Figure – API_Bankdemo3 in UFT One Test Editor Console
For more information, see the UFT One website.
Integrating UFT One and testing the application
The last step is to integrate UFT One into CodeBuild and CodePipeline to test our mainframe application. First, we set up CodeBuild to use a UFT One container. The Docker image is available in Docker Hub. Then we author our buildspec. The buildspec has the following three phrases:
• Setting up a UFT One license and deploying the test infrastructure
• Starting the UFT One test suite to run regression tests
• Tearing down the test infrastructure after tests are complete
The following code is an example of a buildspec snippet in the pre_build stage. The snippet shows the command to activate the UFT One license:
version: 0.2
batch:
# . . .
phases:
pre_build:
commands:
- |
# Activate License
$process = Start-Process -NoNewWindow -RedirectStandardOutput LicenseInstall.log -Wait -File 'C:\Program Files (x86)\Micro Focus\Unified Functional Testing\bin\HP.UFT.LicenseInstall.exe' -ArgumentList @('concurrent', 10600, 1, ${env:AUTOPASS_LICENSE_SERVER})
Get-Content -Path LicenseInstall.log
if (Select-String -Path LicenseInstall.log -Pattern 'The installation was successful.' -Quiet) {
Write-Host 'Licensed Successfully'
} else {
Write-Host 'License Failed'
exit 1
}
#...
The following command in the buildspec deploys the test infrastructure using the AWS Command Line Interface (AWS CLI)
aws cloudformation deploy – stack-name $stack_name `
--template-file cicd-pipeline/systems-test-pipeline/systems-test-service.yaml `
--parameter-overrides EcsCluster=$cluster_arn `
--capabilities CAPABILITY_IAM
Because ETS and VHI are both deployed with a load balancer, the build detects when the load balancers become healthy before starting the tests. The following AWS CLI commands detect the load balancer’s target group health:
$vhi_health_state = (aws elbv2 describe-target-health – target-group-arn $vhi_target_group_arn – query 'TargetHealthDescriptions[0].TargetHealth.State' – output text)
$ets_health_state = (aws elbv2 describe-target-health – target-group-arn $ets_target_group_arn – query 'TargetHealthDescriptions[0].TargetHealth.State' – output text)
When the targets are healthy, the build moves into the build stage, and it uses the UFT One command line to start the tests. See the following code:
$process = Start-Process -Wait -NoNewWindow -RedirectStandardOutput UFTBatchRunnerCMD.log `
-FilePath "C:\Program Files (x86)\Micro Focus\Unified Functional Testing\bin\UFTBatchRunnerCMD.exe" `
-ArgumentList @("-source", "${env:CODEBUILD_SRC_DIR_DemoSrc}\bankdemo\tests\API_Bankdemo\API_Bankdemo${env:TEST_BATCH_NUMBER}")
The next release of Micro Focus UFT One (November or December 2020) will provide an exit status to indicate a test’s success or failure.
When the tests are complete, the post_build stage tears down the test infrastructure. The following AWS CLI command tears down the CloudFormation stack:
#...
post_build:
finally:
- |
Write-Host "Clean up ETS, VHI Stack"
#...
aws cloudformation delete-stack – stack-name $stack_name
aws cloudformation wait stack-delete-complete – stack-name $stack_name
At the end of the build, the buildspec is set up to upload UFT One test reports as an artifact into Amazon Simple Storage Service (Amazon S3). The following screenshot is the example of a test report in HTML format generated by UFT One in CodeBuild and CodePipeline.
UFT One HTML report shows regression testresult and test detals
Figure – UFT One HTML report
A new release of Micro Focus UFT One will provide test report formats supported by CodeBuild test report groups.
Conclusion
In this post, we introduced the solution to use Micro Focus Enterprise Suite, Micro Focus UFT One, Micro Focus VHI, AWS developer tools, and Amazon ECS containers to automate provisioning and running mainframe application tests in AWS at scale.
The on-demand model allows you to create the same test capacity infrastructure in minutes at a fraction of your current on-premises mainframe cost. It also significantly increases your testing and delivery capacity to increase quality and reduce production downtime.
A demo of the solution is available in AWS Partner Micro Focus website AWS Mainframe CI/CD Enterprise Solution. If you’re interested in modernizing your mainframe applications, please visit Micro Focus and contact AWS mainframe business development at [email protected].
References
Micro Focus
Peter Woods
Peter Woods
Peter has been with Micro Focus for almost 30 years, in a variety of roles and geographies including Technical Support, Channel Sales, Product Management, Strategic Alliances Management and Pre-Sales, primarily based in Europe but for the last four years in Australia and New Zealand. In his current role as Pre-Sales Manager, Peter is charged with driving and supporting sales activity within the Application Modernization and Connectivity team, based in Melbourne.
Leo Ervin
Leo Ervin
Leo Ervin is a Senior Solutions Architect working with Micro Focus Enterprise Solutions working with the ANZ team. After completing a Mathematics degree Leo started as a PL/1 programming with a local insurance company. The next step in Leo’s career involved consulting work in PL/1 and COBOL before he joined a start-up company as a technical director and partner. This company became the first distributor of Micro Focus software in the ANZ region in 1986. Leo’s involvement with Micro Focus technology has continued from this distributorship through to today with his current focus on cloud strategies for both DevOps and re-platform implementations.
Kevin Yung
Kevin Yung
Kevin is a Senior Modernization Architect in AWS Professional Services Global Mainframe and Midrange Modernization (GM3) team. Kevin currently is focusing on leading and delivering mainframe and midrange applications modernization for large enterprise customers.
Creating multi-architecture Docker images to support Graviton2 using AWS CodeBuild and AWS CodePipeline
Post Syndicated from Tyler Lynch original https://aws.amazon.com/blogs/devops/creating-multi-architecture-docker-images-to-support-graviton2-using-aws-codebuild-and-aws-codepipeline/
This post provides a clear path for customers who are evaluating and adopting Graviton2 instance types for performance improvements and cost-optimization.
Graviton2 processors are custom designed by AWS using 64-bit Arm Neoverse N1 cores. They power the T4g*, M6g*, R6g*, and C6g* Amazon Elastic Compute Cloud (Amazon EC2) instance types and offer up to 40% better price performance over the current generation of x86-based instances in a variety of workloads, such as high-performance computing, application servers, media transcoding, in-memory caching, gaming, and more.
More and more customers want to make the move to Graviton2 to take advantage of these performance optimizations while saving money.
During the transition process, a great benefit AWS provides is the ability to perform native builds for each architecture, instead of attempting to cross-compile on homogenous hardware. This has the benefit of decreasing build time as well as reducing complexity and cost to set up.
To see this benefit in action, we look at how to build a CI/CD pipeline using AWS CodePipeline and AWS CodeBuild that can build multi-architecture Docker images in parallel to aid you in evaluating and migrating to Graviton2.
Solution overview
With CodePipeline and CodeBuild, we can automate the creation of architecture-specific Docker images, which can be pushed to Amazon Elastic Container Registry (Amazon ECR). The following diagram illustrates this architecture.
Solution overview architectural diagram
The steps in this process are as follows:
1. Create a sample Node.js application and associated Dockerfile.
2. Create the buildspec files that contain the commands that CodeBuild runs.
3. Create three CodeBuild projects to automate each of the following steps:
• CodeBuild for x86 – Creates a x86 Docker image and pushes to Amazon ECR.
• CodeBuild for arm64 – Creates a Arm64 Docker image and pushes to Amazon ECR.
• CodeBuild for manifest list – Creates a Docker manifest list, annotates the list, and pushes to Amazon ECR.
4. Automate the orchestration of these projects with CodePipeline.
Prerequisites
The prerequisites for this solution are as follows:
• The correct AWS Identity and Access Management (IAM) role permissions for your account allowing for the creation of the CodePipeline pipeline, CodeBuild projects, and Amazon ECR repositories
• An Amazon ECR repository named multi-arch-test
• A source control service such as AWS CodeCommit or GitHub that CodeBuild and CodePipeline can interact with
• The source code repository initialized and cloned locally
Creating a sample Node.js application and associated Dockerfile
For this post, we create a sample “Hello World” application that self-reports the processor architecture. We work in the local folder that is cloned from our source repository as specified in the prerequisites.
1. In your preferred text editor, add a new file with the following Node.js code:
# Hello World sample app.
const http = require('http');
const port = 3000;
const server = http.createServer((req, res) => {
res.statusCode = 200;
res.setHeader('Content-Type', 'text/plain');
res.end(`Hello World. This processor architecture is ${process.arch}`);
});
server.listen(port, () => {
console.log(`Server running on processor architecture ${process.arch}`);
});
1. Save the file in the root of your source repository and name it app.js.
2. Commit the changes to Git and push the changes to our source repository. See the following code:
git add .
git commit -m "Adding Node.js sample application."
git push
We also need to create a sample Dockerfile that instructs the docker build command how to build the Docker images. We use the default Node.js image tag for version 14.
1. In a text editor, add a new file with the following code:
# Sample nodejs application
FROM node:14
WORKDIR /usr/src/app
COPY package*.json app.js ./
RUN npm install
EXPOSE 3000
CMD ["node", "app.js"]
1. Save the file in the root of the source repository and name it Dockerfile. Make sure it is Dockerfile with no extension.
2. Commit the changes to Git and push the changes to our source repository:
git add .
git commit -m "Adding Dockerfile to host the Node.js sample application."
git push
Creating a build specification file for your application
It’s time to create and add a buildspec file to our source repository. We want to use a single buildspec.yml file for building, tagging, and pushing the Docker images to Amazon ECR for both target native architectures, x86, and Arm64. We use CodeBuild to inject environment variables, some of which need to be changed for each architecture (such as image tag and image architecture).
A buildspec is a collection of build commands and related settings, in YAML format, that CodeBuild uses to run a build. For more information, see Build specification reference for CodeBuild.
The buildspec we add instructs CodeBuild to do the following:
• install phase – Update the yum package manager
• pre_build phase – Sign in to Amazon ECR using the IAM role assumed by CodeBuild
• build phase – Build the Docker image using the Docker CLI and tag the newly created Docker image
• post_build phase – Push the Docker image to our Amazon ECR repository
We first need to add the buildspec.yml file to our source repository.
1. In a text editor, add a new file with the following build specification:
version: 0.2
phases:
install:
commands:
- yum update -y
pre_build:
commands:
- echo Logging in to Amazon ECR...
- $(aws ecr get-login – no-include-email – region $AWS_DEFAULT_REGION)
build:
commands:
- echo Build started on `date`
- echo Building the Docker image...
- docker build -t $IMAGE_REPO_NAME:$IMAGE_TAG .
- docker tag $IMAGE_REPO_NAME:$IMAGE_TAG $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME:$IMAGE_TAG
post_build:
commands:
- echo Build completed on `date`
- echo Pushing the Docker image...
- docker push $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME:$IMAGE_TAG
1. Save the file in the root of the repository and name it buildspec.yml.
Because we specify environment variables in the CodeBuild project, we don’t need to hard code any values in the buildspec file.
1. Commit the changes to Git and push the changes to our source repository:
git add .
git commit -m "Adding CodeBuild buildspec.yml file."
git push
Creating a build specification file for your manifest list creation
Next we create a buildspec file that instructs CodeBuild to create a Docker manifest list, and associate that manifest list with the Docker images that the buildspec file builds.
A manifest list is a list of image layers that is created by specifying one or more (ideally more than one) image names. You can then use it in the same way as an image name in docker pull and docker run commands, for example. For more information, see manifest create.
As of this writing, manifest creation is an experimental feature of the Docker command line interface (CLI).
Experimental features provide early access to future product functionality. These features are intended only for testing and feedback because they may change between releases without warning or be removed entirely from a future release. Experimental features must not be used in production environments. For more information, Experimental features.
When creating the CodeBuild project for manifest list creation, we specify a buildspec file name override as buildspec-manifest.yml. This buildspec instructs CodeBuild to do the following:
• install phase – Update the yum package manager
• pre_build phase – Sign in to Amazon ECR using the IAM role assumed by CodeBuild
• build phase – Perform three actions:
• Set environment variable to enable Docker experimental features for the CLI
• Create the Docker manifest list using the Docker CLI
• Annotate the manifest list to add the architecture-specific Docker image references
• post_build phase – Push the Docker image to our Amazon ECR repository and use docker manifest inspect to echo out the contents of the manifest list from Amazon ECR
We first need to add the buildspec-manifest.yml file to our source repository.
1. In a text editor, add a new file with the following build specification:
version: 0.2
# Based on the Docker documentation, must include the DOCKER_CLI_EXPERIMENTAL environment variable
# https://docs.docker.com/engine/reference/commandline/manifest/
phases:
install:
commands:
- yum update -y
pre_build:
commands:
- echo Logging in to Amazon ECR...
- $(aws ecr get-login – no-include-email – region $AWS_DEFAULT_REGION)
build:
commands:
- echo Build started on `date`
- echo Building the Docker manifest...
- export DOCKER_CLI_EXPERIMENTAL=enabled
- docker manifest create $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME:latest-arm64v8 $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME:latest-amd64
- docker manifest annotate – arch arm64 $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME:latest-arm64v8
- docker manifest annotate – arch amd64 $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME:latest-amd64
post_build:
commands:
- echo Build completed on `date`
- echo Pushing the Docker image...
- docker manifest push $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME
- docker manifest inspect $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME
1. Save the file in the root of the repository and name it buildspec-manifest.yml.
2. Commit the changes to Git and push the changes to our source repository:
git add .
git commit -m "Adding CodeBuild buildspec-manifest.yml file."
git push
Setting up your CodeBuild projects
Now we have created a single buildspec.yml file for building, tagging, and pushing the Docker images to Amazon ECR for both target native architectures: x86 and Arm64. This file is shared by two of the three CodeBuild projects that we create. We use CodeBuild to inject environment variables, some of which need to be changed for each architecture (such as image tag and image architecture). We also want to use the single Docker file, regardless of the architecture. We also need to ensure any third-party libraries are present and compiled correctly for the target architecture.
For more information about third-party libraries and software versions that have been optimized for Arm, see the Getting started with AWS Graviton GitHub repo.
We use the same environment variable names for the CodeBuild projects, but each project has specific values, as detailed in the following table. You need to modify these values to your numeric AWS account ID, the AWS Region where your Amazon ECR registry endpoint is located, and your Amazon ECR repository name. The instructions for adding the environment variables in the CodeBuild projects are in the following sections.
Environment Variablex86 Project valuesArm64 Project valuesmanifest Project values
1AWS_DEFAULT_REGIONus-east-1us-east-1us-east-1
2AWS_ACCOUNT_ID111111111111111111111111111111111111
3IMAGE_REPO_NAMEmulti-arch-testmulti-arch-testmulti-arch-test
4IMAGE_TAGlatest-amd64latest-arm64v8latest
The image we use in this post uses architecture-specific tags with the term latest. This is for demonstration purposes only; it’s best to tag the images with an explicit version or another meaningful reference.
CodeBuild for x86
We start with creating a new CodeBuild project for x86 on the CodeBuild console.
CodeBuild looks for a file named buildspec.yml by default, unless overridden. For these first two CodeBuild projects, we rely on that default and don’t specify the buildspec name.
1. On the CodeBuild console, choose Create build project.
2. For Project name, enter a unique project name for your build project, such as node-x86.
3. To add tags, add them under Additional Configuration.
4. Choose a Source provider (for this post, we choose GitHub).
5. For Environment image, choose Managed image.
6. Select Amazon Linux 2.
7. For Runtime(s), choose Standard.
8. For Image, choose aws/codebuild/amazonlinux2-x86_64-standard:3.0.
This is a x86 build image.
1. Select Privileged.
2. For Service role, choose New service role.
3. Enter a name for the new role (one is created for you), such as CodeBuildServiceRole-nodeproject.
We reuse this same service role for the other CodeBuild projects associated with this project.
1. Expand Additional configurations and move to the Environment variables
2. Create the following Environment variables:
NameValueType
1AWS_DEFAULT_REGIONus-east-1Plaintext
2AWS_ACCOUNT_ID111111111111Plaintext
3IMAGE_REPO_NAMEmulti-arch-testPlaintext
4IMAGE_TAGlatest-amd64Plaintext
1. Choose Create build project.
Attaching the IAM policy
Now that we have created the CodeBuild project, we need to adjust the new service role that was just created and attach an IAM policy so that it can interact with the Amazon ECR API.
1. On the CodeBuild console, choose the node-x86 project
2. Choose the Build details
3. Under Service role, choose the link that looks like arn:aws:iam::111111111111:role/service-role/CodeBuildServiceRole-nodeproject.
A new browser tab should open.
1. Choose Attach policies.
2. In the Search field, enter AmazonEC2ContainerRegistryPowerUser.
3. Select AmazonEC2ContainerRegistryPowerUser.
4. Choose Attach policy.
CodeBuild for arm64
Now we move on to creating a new (second) CodeBuild project for Arm64.
1. On the CodeBuild console, choose Create build project.
2. For Project name, enter a unique project name, such as node-arm64.
3. If you want to add tags, add them under Additional Configuration.
4. Choose a Source provider (for this post, choose GitHub).
5. For Environment image, choose Managed image.
6. Select Amazon Linux 2.
7. For Runtime(s), choose Standard.
8. For Image, choose aws/codebuild/amazonlinux2-aarch64-standard:2.0.
This is an Arm build image and is different from the image selected in the previous CodeBuild project.
1. Select Privileged.
2. For Service role, choose Existing service role.
3. Choose CodeBuildServiceRole-nodeproject.
4. Select Allow AWS CodeBuild to modify this service role so it can be used with this build project.
5. Expand Additional configurations and move to the Environment variables
6. Create the following Environment variables:
NameValueType
1AWS_DEFAULT_REGIONus-east-1Plaintext
2AWS_ACCOUNT_ID111111111111Plaintext
3IMAGE_REPO_NAMEmulti-arch-testPlaintext
4IMAGE_TAGlatest-arm64v8Plaintext
1. Choose Create build project.
CodeBuild for manifest list
For the last CodeBuild project, we create a Docker manifest list, associating that manifest list with the Docker images that the preceding projects create, and pushing the manifest list to ECR. This project uses the buildspec-manifest.yml file created earlier.
1. On the CodeBuild console, choose Create build project.
2. For Project name, enter a unique project name for your build project, such as node-manifest.
3. If you want to add tags, add them under Additional Configuration.
4. Choose a Source provider (for this post, choose GitHub).
5. For Environment image, choose Managed image.
6. Select Amazon Linux 2.
7. For Runtime(s), choose Standard.
8. For Image, choose aws/codebuild/amazonlinux2-x86_64-standard:3.0.
This is a x86 build image.
1. Select Privileged.
2. For Service role, choose Existing service role.
3. Choose CodeBuildServiceRole-nodeproject.
4. Select Allow AWS CodeBuild to modify this service role so it can be used with this build project.
5. Expand Additional configurations and move to the Environment variables
6. Create the following Environment variables:
NameValueType
1AWS_DEFAULT_REGIONus-east-1Plaintext
2AWS_ACCOUNT_ID111111111111Plaintext
3IMAGE_REPO_NAMEmulti-arch-testPlaintext
4IMAGE_TAGlatestPlaintext
1. For Buildspec name – optional, enter buildspec-manifest.yml to override the default.
2. Choose Create build project.
Setting up CodePipeline
Now we can move on to creating a pipeline to orchestrate the builds and manifest creation.
1. On the CodePipeline console, choose Create pipeline.
2. For Pipeline name, enter a unique name for your pipeline, such as node-multi-architecture.
3. For Service role, choose New service role.
4. Enter a name for the new role (one is created for you). For this post, we use the generated role name CodePipelineServiceRole-nodeproject.
5. Select Allow AWS CodePipeline to create a service role so it can be used with this new pipeline.
6. Choose Next.
7. Choose a Source provider (for this post, choose GitHub).
8. If you don’t have any existing Connections to GitHub, select Connect to GitHub and follow the wizard.
9. Choose your Branch name (for this post, I choose main, but your branch might be different).
10. For Output artifact format, choose CodePipeline default.
11. Choose Next.
You should now be on the Add build stage page.
1. For Build provider, choose AWS CodeBuild.
2. Verify the Region is your Region of choice (for this post, I use US East (N. Virginia)).
3. For Project name, choose node-x86.
4. For Build type, select Single build.
5. Choose Next.
You should now be on the Add deploy stage page.
1. Choose Skip deploy stage.
A pop-up appears that reads Your pipeline will not include a deployment stage. Are you sure you want to skip this stage?
1. Choose Skip.
2. Choose Create pipeline.
CodePipeline immediately attempts to run a build. You can let it continue without worry if it fails. We are only part of the way done with the setup.
Adding an additional build step
We need to add the additional build step for the Arm CodeBuild project in the Build stage.
1. On the CodePipeline console, choose node-multi-architecture pipeline
2. Choose Edit to start editing the pipeline stages.
You should now be on the Editing: node-multi-architecture page.
1. For the Build stage, choose Edit stage.
2. Choose + Add action.
Editing node-multi-architecture
1. For Action name, enter Build-arm64.
2. For Action provider, choose AWS CodeBuild.
3. Verify your Region is correct.
4. For Input artifacts, select SourceArtifact.
5. For Project name, choose node-arm64.
6. For Build type, select Single build.
7. Choose Done.
8. Choose Save.
A pop-up appears that reads Saving your changes cannot be undone. If the pipeline is running when you save your changes, that execution will not complete.
1. Choose Save.
Updating the first build action name
This step is optional. The CodePipeline wizard doesn’t allow you to enter your Build action name during creation, but you can update the Build stage’s first build action to have consistent naming.
1. Choose Edit to start editing the pipeline stages.
2. Choose the Edit icon.
3. For Action name, enter Build-x86.
4. Choose Done.
5. Choose Save.
A pop-up appears that says Saving your changes cannot be undone. If the pipeline is running when you save your changes, that execution will not complete.
1. Choose Save.
Adding the project
Now we add the CodeBuild project for manifest creation and publishing.
1. On the CodePipeline console, choose node-multi-architecture pipeline.
2. Choose Edit to start editing the pipeline stages.
3. Choose +Add stage below the Build
4. Set the Stage name to Manifest
5. Choose +Add action group.
6. For Action name, enter Create-manifest.
7. For Action provider, choose AWS CodeBuild.
8. Verify your Region is correct.
9. For Input artifacts, select SourceArtifact.
10. For Project name, choose node-manifest.
11. For Build type, select Single build.
12. Choose Done.
13. Choose Save.
A pop-up appears that reads Saving your changes cannot be undone. If the pipeline is running when you save your changes, that execution will not complete.
1. Choose Save.
Testing the pipeline
Now let’s verify everything works as planned.
1. In the pipeline details page, choose Release change.
This runs the pipeline in stages. The process should take a few minutes to complete. The pipeline should show each stage as Succeeded.
Pipeline visualization
Now we want to inspect the output of the Create-manifest action that runs the CodeBuild project for manifest creation.
1. Choose Details in the Create-manifest
This opens the CodeBuild pipeline.
1. Under Build logs, we should see the output from the manifest inspect command we ran as the last step in the buildspec-manifest.yml See the following sample log:
[Container] 2020/10/07 16:47:39 Running command docker manifest inspect $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME
{
"schemaVersion": 2,
"mediaType": "application/vnd.docker.distribution.manifest.list.v2+json",
"manifests": [
{
"mediaType": "application/vnd.docker.distribution.manifest.v2+json",
"size": 1369,
"digest": "sha256:238c2762212ff5d7e0b5474f23d500f2f1a9c851cdd3e7ef0f662efac508cd04",
"platform": {
"architecture": "amd64",
"os": "linux"
}
},
{
"mediaType": "application/vnd.docker.distribution.manifest.v2+json",
"size": 1369,
"digest": "sha256:0cc9e96921d5565bdf13274e0f356a139a31d10e95de9ad3d5774a31b8871b05",
"platform": {
"architecture": "arm64",
"os": "linux"
}
}
]
}
Cleaning up
To avoid incurring future charges, clean up the resources created as part of this post.
1. On the CodePipeline console, choose the pipeline node-multi-architecture.
2. Choose Delete pipeline.
3. When prompted, enter delete.
4. Choose Delete.
5. On the CodeBuild console, choose the Build project node-x86.
6. Choose Delete build project.
7. When prompted, enter delete.
8. Choose Delete.
9. Repeat the deletion process for Build projects node-arm64 and node-manifest.
Next we delete the Docker images we created and pushed to Amazon ECR. Be careful to not delete a repository that is being used for other images.
1. On the Amazon ECR console, choose the repository multi-arch-test.
You should see a list of Docker images.
1. Select latest, latest-arm64v8, and latest-amd64.
2. Choose Delete.
3. When prompted, enter delete.
4. Choose Delete.
Finally, we remove the IAM roles that we created.
1. On the IAM console, choose Roles.
2. In the search box, enter CodePipelineServiceRole-nodeproject.
3. Select the role and choose Delete role.
4. When prompted, choose Yes, delete.
5. Repeat these steps for the role CodeBuildServiceRole-nodeproject.
Conclusion
To summarize, we successfully created a pipeline to create multi-architecture Docker images for both x86 and arm64. We referenced them via annotation in a Docker manifest list and stored them in Amazon ECR. The Docker images were based on a single Docker file that uses environment variables as parameters to allow for Docker file reuse.
For more information about these services, see the following:
About the Authors
Tyler Lynch photo
Tyler Lynch
Tyler Lynch is a Sr. Solutions Architect focusing on EdTech at AWS.
Alistair McLean photo
Alistair McLean
Alistair is a Principal Solutions Architect focused on State and Local Government and K12 customers at AWS.
Automating deployments to Raspberry Pi devices using AWS CodePipeline
Post Syndicated from Ahmed ElHaw original https://aws.amazon.com/blogs/devops/automating-deployments-to-raspberry-pi-devices-using-aws-codepipeline/
Managing applications deployments on Raspberry Pi can be cumbersome, especially in headless mode and at scale when placing the devices outdoors and out of reach such as in home automation projects, in the yard (for motion detection) or on the roof (as a humidity and temperature sensor). In these use cases, you have to remotely connect via secure shell to administer the device.
It can be complicated to keep physically connecting when you need a monitor, keyboard, and mouse. Alternatively, you can connect via SSH in your home local network, provided your client workstation is also on the same private network.
In this post, we discuss using Raspberry Pi as a headless server with minimal-to-zero direct interaction by using AWS CodePipeline. We examine two use cases:
• Managing and automating operational tasks of the Raspberry Pi, running Raspbian OS or any other Linux distribution. For more information about this configuration, see Manage Raspberry Pi devices using AWS Systems Manager.
• Automating deployments to one or more Raspberry Pi device in headless mode (in which you don’t use a monitor or keyboard to run your device). If you use headless mode but still need to do some wireless setup, you can enable wireless networking and SSH when creating an image.
Solution overview
Our solution uses the following services:
We use CodePipeline to manage continuous integration and deployment to Raspberry Pi running Ubuntu Server 18 for ARM. As of this writing, CodeDeploy agents are supported on Windows OS, Red Hat, and Ubuntu.
For this use case, we use the image ubuntu-18.04.4-preinstalled-server-arm64+raspi3.img.
To close the loop, you edit your code or commit new revisions from your PC or Amazon Elastic Compute Cloud (Amazon EC2) to trigger the pipeline to deploy to Pi. The following diagram illustrates the architecture of our automated pipeline.
Solution Overview architectural diagram
Setting up a Raspberry Pi device
To set up a CodeDeploy agent on a Raspberry Pi device, the device should be running an Ubuntu Server 18 for ARM, which is supported by the Raspberry Pi processor architecture and the CodeDeploy agent, and it should be connected to the internet. You will need a keyboard and a monitor for the initial setup.
Follow these instructions for your initial setup:
1. Download the Ubuntu image.
Pick the image based on your Raspberry Pi model. For this use case, we use Raspberry Pi 4 with Ubuntu 18.04.4 LTS.
1. Burn the Ubuntu image to your microSD using a disk imager software (or other reliable tool). For instructions, see Create an Ubuntu Image for a Raspberry Pi on Windows.
2. Configure WiFi on the Ubuntu server.
After booting from the newly flashed microSD, you can configure the OS.
1. To enable DHCP, enter the following YAML (or create the yaml file if it doesn’t exist) to /etc/netplan/wireless.yaml:
network:
version: 2
wifis:
wlan0:
dhcp4: yes
dhcp6: no
access-points:
"<your network ESSID>":
password: "<your wifi password>"
Replace the variables <your network ESSID> and <your wifi password> with your wireless network SSID and password, respectively.
1. Run the netplan by entering the following command:
[email protected]:~$ sudo netplan try
Installing CodeDeploy and registering Raspberry Pi as an on-premises instance
When the Raspberry Pi is connected to the internet, you’re ready to install the AWS Command Line Interface (AWS CLI) and the CodeDeploy agent to manage automated deployments through CodeDeploy.
To register an on-premises instance, you must use an AWS Identity and Access Management (IAM) identity to authenticate your requests. You can choose from the following options for the IAM identity and registration method you use:
• An IAM user ARN. This is best for registering a single on-premises instance.
• An IAM role to authenticate requests with periodically refreshed temporary credentials generated with the AWS Security Token Service (AWS STS). This is best for registering a large number of on-premises instances.
For this post, we use the first option and create an IAM user and register a single Raspberry Pi. You can use this procedure for a handful of devices. Make sure you limit the privileges of the IAM user to what you need to achieve; a scoped-down IAM policy is given in the documentation instructions. For more information, see Use the register command (IAM user ARN) to register an on-premises instance.
1. Install the AWS CLI on Raspberry Pi with the following code:
[email protected]:~$ sudo apt install awscli
1. Configure the AWS CLI and enter your newly created IAM access key, secret access key, and Region (for example, eu-west-1):
[email protected]:~$ sudo aws configure
AWS Access Key ID [None]: <IAM Access Key>
AWS Secret Access Key [None]: <Secret Access Key>
Default region name [None]: <AWS Region>
Default output format [None]: Leave default, press Enter.
1. Now that the AWS CLI running on the Raspberry Pi has access to CodeDeploy API operations, you can register the device as an on-premises instance:
[email protected]:~$ sudo aws deploy register – instance-name rpi4UbuntuServer – iam-user-arn arn:aws:iam::<AWS_ACCOUNT_ID>:user/Rpi – tags Key=Name,Value=Rpi4 – region eu-west-1
Registering the on-premises instance... DONE
Adding tags to the on-premises instance... DONE
Tags allow you to assign metadata to your AWS resources. Each tag is a simple label consisting of a customer-defined key and an optional value that can make it easier to manage, search for, and filter resources by purpose, owner, environment, or other criteria.
When working with on-premises instances with CodeDeploy, tags are mandatory to select the instances for deployment. For this post, we tag the first device with Key=Name,Value=Rpi4. Generally speaking, it’s good practice to use tags on all applicable resources.
You should see something like the following screenshot on the CodeDeploy console.
CodeDeploy console
Or from the CLI, you should see the following output:
[email protected]:~$ sudo aws deploy list-on-premises-instances
{
"instanceNames": [
"rpi4UbuntuServer"
]
}
1. Install the CodeDeploy agent:
[email protected]:~$ sudo aws deploy install – override-config – config-file /etc/codedeploy-agent/conf/codedeploy.onpremises.yml – region eu-west-1
If the preceding command fails due to dependencies, you can get the CodeDeploy package and install it manually:
[email protected]:~$ sudo apt-get install ruby
[email protected]:~$ sudo wget https://aws-codedeploy-us-west-2.s3.amazonaws.com/latest/install
--2020-03-28 18:58:15-- https://aws-codedeploy-us-west-2.s3.amazonaws.com/latest/install
Resolving aws-codedeploy-us-west-2.s3.amazonaws.com (aws-codedeploy-us-west-2.s3.amazonaws.com)... 52.218.249.82
Connecting to aws-codedeploy-us-west-2.s3.amazonaws.com (aws-codedeploy-us-west-2.s3.amazonaws.com)|52.218.249.82|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 13819 (13K) []
Saving to: ‘install’
install 100%[====================================================================>] 13.50K – .-KB/s in 0.003s
2020-03-28 18:58:16 (3.81 MB/s) - ‘install’ saved [13819/13819]
[email protected]:~$ sudo chmod +x ./install
[email protected]:~$ sudo ./install auto
Check the service status with the following code:
[email protected]:~$ sudo service codedeploy-agent status
codedeploy-agent.service - LSB: AWS CodeDeploy Host Agent
Loaded: loaded (/etc/init.d/codedeploy-agent; generated)
Active: active (running) since Sat 2020-08-15 14:18:22 +03; 17s ago
Docs: man:systemd-sysv-generator(8)
Tasks: 3 (limit: 4441)
CGroup: /system.slice/codedeploy-agent.service
└─4243 codedeploy-agent: master 4243
Start the service (if not started automatically):
[email protected]:~$ sudo service codedeploy-agent start
Congratulations! Now that the CodeDeploy agent is installed and the Raspberry Pi is registered as an on-premises instance, CodeDeploy can deploy your application build to the device.
Creating your source stage
You’re now ready to create your source stage.
1. On the CodeCommit console, under Source, choose Repositories.
2. Choose Create repository.
For instructions on connecting your repository from your local workstation, see Setup for HTTPS users using Git credentials.
CodeCommit repo
1. In the root directory of the repository, you should include an AppSpec file for an EC2/On-Premises deployment, where the filename must be yml for a YAML-based file. The file name is case-sensitive.
AppSpec file
The following example code is from the appspec.yml file:
version: 0.0
os: linux
files:
- source: /
destination: /home/ubuntu/AQI/
hooks:
BeforeInstall:
- location: scripts/testGPIO.sh
timeout: 60
runas: root
AfterInstall:
- location: scripts/testSensors.sh
timeout: 300
runas: root
ApplicationStart:
- location: startpublishdht11toshadow.sh
- location: startpublishnovatoshadow.sh
timeout: 300
runas: root
The files section defines the files to copy from the repository to the destination path on the Raspberry Pi.
The hooks section runs one time per deployment to an instance. If an event hook isn’t present, no operation runs for that event. This section is required only if you’re running scripts as part of the deployment. It’s useful to implement some basic testing before and after installation of your application revisions. For more information about hooks, see AppSpec ‘hooks’ section for an EC2/On-Premises deployment.
Creating your deploy stage
To create your deploy stage, complete the following steps:
1. On the CodeDeploy console, choose Applications.
2. Create your application and deployment group.
1. For Deployment type, select In-place.
Deployment group
1. For Environment configuration, select On-premises instances.
2. Add the tags you registered the instance with in the previous step (for this post, we add the key-value pair Name=RPI4.
on-premises tags
Creating your pipeline
You’re now ready to create your pipeline.
1. On the CodePipeline console, choose Pipelines.
2. Choose Create pipeline.
3. For Pipeline name, enter a descriptive name.
4. For Service role¸ select New service role.
5. For Role name, enter your service role name.
6. Leave the advanced settings at their default.
7. Choose Next.
Pipeline settings
1. For Source provider, choose AWS CodeCommit
2. For Repository name, choose the repository you created earlier.
3. For Branch name, enter your repository branch name.
4. For Change detection options, select Amazon CloudWatch Events.
5. Choose Next.
Source stage
As an optional step, you can add a build stage, depending on whether your application is built with an interpreted language like Python or a compiled one like .NET C#. CodeBuild creates a fully managed build server on your behalf that runs the build commands using the buildspec.yml in the source code root directory.
1. For Deploy provider, choose AWS CodeDeploy.
2. For Region, choose your Region.
3. For Application name, choose your application.
4. For Deployment group, choose your deployment group.
5. Choose Next.
Deploy stage
1. Review your settings and create your pipeline.
Cleaning up
If you no longer plan to deploy to your Raspberry PI and want remove the CodeDeploy agent from your device, you can clean up with the following steps.
Uninstalling the agent
Automatically uninstall the CodeDeploy agent and remove the configuration file from an on-premises instance with the following code:
[email protected]:~$ sudo aws deploy uninstall
(Reading database ... 238749 files and directories currently installed.)
Removing codedeploy-agent (1.0-1.1597) ...
Processing triggers for systemd (237-3ubuntu10.39) ...
Processing triggers for ureadahead (0.100.0-21) ...
Uninstalling the AWS CodeDeploy Agent... DONE
Deleting the on-premises instance configuration... DONE
The uninstall command does the following:
1. Stops the running CodeDeploy agent on the on-premises instance.
2. Uninstalls the CodeDeploy agent from the on-premises instance.
3. Removes the configuration file from the on-premises instance. (For Ubuntu Server and RHEL, this is /etc/codedeploy-agent/conf/codedeploy.onpremises.yml. For Windows Server, this is C:\ProgramData\Amazon\CodeDeploy\conf.onpremises.yml.)
De-registering the on-premises instance
This step is only supported using the AWS CLI. To de-register your instance, enter the following code:
[email protected]:~$ sudo aws deploy deregister – instance-name rpi4UbuntuServer – region eu-west-1
Retrieving on-premises instance information... DONE
IamUserArn: arn:aws:iam::XXXXXXXXXXXX:user/Rpi
Tags: Key=Name,Value=Rpi4
Removing tags from the on-premises instance... DONE
Deregistering the on-premises instance... DONE
Deleting the IAM user policies... DONE
Deleting the IAM user access keys... DONE
Deleting the IAM user (Rpi)... DONE
Optionally, delete your application from CodeDeploy, and your repository from CodeCommit and CodePipeline from the respective service consoles.
Conclusion
You’re now ready to automate your deployments to your Raspberry Pi or any on-premises supported operating system. Automated deployments and source code version control frees up more time in developing your applications. Continuous deployment helps with the automation and version tracking of your scripts and applications deployed on the device.
For more information about IoT projects created using a Raspberry Pi, see my Air Pollution demo and Kid Monitor demo.
About the author
Ahmed ElHaw is a Sr. Solutions Architect at Amazon Web Services (AWS) with background in telecom, web development and design, and is passionate about spatial computing and AWS serverless technologies. He enjoys providing technical guidance to customers, helping them architect and build solutions that make the best use of AWS. Outside of work he enjoys spending time with his kids and playing video games.
Building a cross-account CI/CD pipeline for single-tenant SaaS solutions
Post Syndicated from Rafael Ramos original https://aws.amazon.com/blogs/devops/cross-account-ci-cd-pipeline-single-tenant-saas/
With the increasing demand from enterprise customers for a pay-as-you-go consumption model, more and more independent software vendors (ISVs) are shifting their business model towards software as a service (SaaS). Usually this kind of solution is architected using a multi-tenant model. It means that the infrastructure resources and applications are shared across multiple customers, with mechanisms in place to isolate their environments from each other. However, you may not want or can’t afford to share resources for security or compliance reasons, so you need a single-tenant environment.
To achieve this higher level of segregation across the tenants, it’s recommended to isolate the environments on the AWS account level. This strategy brings benefits, such as no network overlapping, no account limits sharing, and simplified usage tracking and billing, but it comes with challenges from an operational standpoint. Whereas multi-tenant solutions require management of a single shared production environment, single-tenant installations consist of dedicated production environments for each customer, without any shared resources across the tenants. When the number of tenants starts to grow, delivering new features at a rapid pace becomes harder to accomplish, because each new version needs to be manually deployed on each tenant environment.
This post describes how to automate this deployment process to deliver software quickly, securely, and less error-prone for each existing tenant. I demonstrate all the steps to build and configure a CI/CD pipeline using AWS CodeCommit, AWS CodePipeline, AWS CodeBuild, and AWS CloudFormation. For each new version, the pipeline automatically deploys the same application version on the multiple tenant AWS accounts.
There are different caveats to build such cross-account CI/CD pipelines on AWS. Because of that, I use AWS Command Line Interface (AWS CLI) to manually go through the process and demonstrate in detail the various configuration aspects you have to handle, such as artifact encryption, cross-account permission granting, and pipeline actions.
Single-tenancy vs. multi-tenancy
One of the first aspects to consider when architecting your SaaS solution is its tenancy model. Each brings their own benefits and architectural challenges. On multi-tenant installations, each customer shares the same set of resources, including databases and applications. With this mode, you can use the servers’ capacity more efficiently, which generally leads to significant cost-saving opportunities. On the other hand, you have to carefully secure your solution to prevent a customer from accessing sensitive data from another. Designing for high availability becomes even more critical on multi-tenant workloads, because more customers are affected in the event of downtime.
Because the environments are by definition isolated from each other, single-tenant solutions are simpler to design when it comes to security, networking isolation, and data segregation. Likewise, you can customize the applications per customer, and have different versions for specific tenants. You also have the advantage of eliminating the noisy-neighbor effect, and can plan the infrastructure for the customer’s scalability requirements. As a drawback, in comparison with multi-tenant, the single-tenant model is operationally more complex because you have more servers and applications to maintain.
Which tenancy model to choose depends ultimately on whether you can meet your customer needs. They might have specific governance requirements, be bound to a certain industry regulation, or have compliance criteria that influences which model they can choose. For more information about modeling your SaaS solutions, see SaaS on AWS.
Solution overview
To demonstrate this solution, I consider a fictitious single-tenant ISV with two customers: Unicorn and Gnome. It uses one central account where the tools reside (Tooling account), and two other accounts, each representing a tenant (Unicorn and Gnome accounts). As depicted in the following architecture diagram, when a developer pushes code changes to CodeCommit, Amazon CloudWatch Events triggers the CodePipeline CI/CD pipeline, which automatically deploys a new version on each tenant’s AWS account. It ensures that the fictitious ISV doesn’t have the operational burden to manually re-deploy the same version for each end-customers.
Architecture diagram of a CI/CD pipeline for single-tenant SaaS solutions
For illustration purposes, the sample application I use in this post is an AWS Lambda function that returns a simple JSON object when invoked.
Prerequisites
Before getting started, you must have the following prerequisites:
Setting up the Git repository
Your first step is to set up your Git repository.
1. Create a CodeCommit repository to host the source code.
The CI/CD pipeline is automatically triggered every time new code is pushed to that repository.
1. Make sure Git is configured to use IAM credentials to access AWS CodeCommit via HTTP by running the following command from the terminal:
git config – global credential.helper '!aws codecommit credential-helper [email protected]'
git config – global credential.UseHttpPath true
1. Clone the newly created repository locally, and add two files in the root folder: index.js and application.yaml.
The first file is the JavaScript code for the Lambda function that represents the sample application. For our use case, the function returns a JSON response object with statusCode: 200 and the body Hello!\n. See the following code:
exports.handler = async (event) => {
const response = {
statusCode: 200,
body: `Hello!\n`,
};
return response;
};
The second file is where the infrastructure is defined using AWS CloudFormation. The sample application consists of a Lambda function, and we use AWS Serverless Application Model (AWS SAM) to simplify the resources creation. See the following code:
AWSTemplateFormatVersion: '2010-09-09'
Transform: 'AWS::Serverless-2016-10-31'
Description: Sample Application.
Parameters:
S3Bucket:
Type: String
S3Key:
Type: String
ApplicationName:
Type: String
Resources:
SampleApplication:
Type: 'AWS::Serverless::Function'
Properties:
FunctionName: !Ref ApplicationName
Handler: index.handler
Runtime: nodejs12.x
CodeUri:
Bucket: !Ref S3Bucket
Key: !Ref S3Key
Description: Hello Lambda.
MemorySize: 128
Timeout: 10
1. Push both files to the remote Git repository.
Creating the artifact store encryption key
By default, CodePipeline uses server-side encryption with an AWS Key Management Service (AWS KMS) managed customer master key (CMK) to encrypt the release artifacts. Because the Unicorn and Gnome accounts need to decrypt those release artifacts, you need to create a customer managed CMK in the Tooling account.
From the terminal, run the following command to create the artifact encryption key:
aws kms create-key – region <YOUR_REGION>
This command returns a JSON object with the key ARN property if run successfully. Its format is similar to arn:aws:kms:<YOUR_REGION>:<TOOLING_ACCOUNT_ID>:key/<KEY_ID>. Record this value to use in the following steps.
The encryption key has been created manually for educational purposes only, but it’s considered a best practice to have it as part of the Infrastructure as Code (IaC) bundle.
Creating an Amazon S3 artifact store and configuring a bucket policy
Our use case uses Amazon Simple Storage Service (Amazon S3) as artifact store. Every release artifact is encrypted and stored as an object in an S3 bucket that lives in the Tooling account.
To create and configure the artifact store, follow these steps in the Tooling account:
1. From the terminal, create an S3 bucket and give it a unique name:
aws s3api create-bucket \
– bucket <BUCKET_UNIQUE_NAME> \
– region <YOUR_REGION> \
– create-bucket-configuration LocationConstraint=<YOUR_REGION>
1. Configure the bucket to use the customer managed CMK created in the previous step. This makes sure the objects stored in this bucket are encrypted using that key, replacing <KEY_ARN> with the ARN property from the previous step:
aws s3api put-bucket-encryption \
– bucket <BUCKET_UNIQUE_NAME> \
– server-side-encryption-configuration \
'{
"Rules": [
{
"ApplyServerSideEncryptionByDefault": {
"SSEAlgorithm": "aws:kms",
"KMSMasterKeyID": "<KEY_ARN>"
}
}
]
}'
1. The artifacts stored in the bucket need to be accessed from the Unicorn and Gnome Configure the bucket policies to allow cross-account access:
aws s3api put-bucket-policy \
– bucket <BUCKET_UNIQUE_NAME> \
– policy \
'{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"s3:GetBucket*",
"s3:List*"
],
"Effect": "Allow",
"Principal": {
"AWS": [
"arn:aws:iam::<UNICORN_ACCOUNT_ID>:root",
"arn:aws:iam::<GNOME_ACCOUNT_ID>:root"
]
},
"Resource": [
"arn:aws:s3:::<BUCKET_UNIQUE_NAME>"
]
},
{
"Action": [
"s3:GetObject*"
],
"Effect": "Allow",
"Principal": {
"AWS": [
"arn:aws:iam::<UNICORN_ACCOUNT_ID>:root",
"arn:aws:iam::<GNOME_ACCOUNT_ID>:root"
]
},
"Resource": [
"arn:aws:s3:::<BUCKET_UNIQUE_NAME>/CrossAccountPipeline/*"
]
}
]
}'
This S3 bucket has been created manually for educational purposes only, but it’s considered a best practice to have it as part of the IaC bundle.
Creating a cross-account IAM role in each tenant account
Following the security best practice of granting least privilege, each action declared on CodePipeline should have its own IAM role. For this use case, the pipeline needs to perform changes in the Unicorn and Gnome accounts from the Tooling account, so you need to create a cross-account IAM role in each tenant account.
Repeat the following steps for each tenant account to allow CodePipeline to assume role in those accounts:
1. Configure a named CLI profile for the tenant account to allow running commands using the correct access keys.
2. Create an IAM role that can be assumed from another AWS account, replacing <TENANT_PROFILE_NAME> with the profile name you defined in the previous step:
aws iam create-role \
– role-name CodePipelineCrossAccountRole \
– profile <TENANT_PROFILE_NAME> \
– assume-role-policy-document \
'{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::<TOOLING_ACCOUNT_ID>:root"
},
"Action": "sts:AssumeRole"
}
]
}'
1. Create an IAM policy that grants access to the artifact store S3 bucket and to the artifact encryption key:
aws iam create-policy \
– policy-name CodePipelineCrossAccountArtifactReadPolicy \
– profile <TENANT_PROFILE_NAME> \
– policy-document \
'{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"s3:GetBucket*",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::<BUCKET_UNIQUE_NAME>"
],
"Effect": "Allow"
},
{
"Action": [
"s3:GetObject*",
"s3:Put*"
],
"Resource": [
"arn:aws:s3:::<BUCKET_UNIQUE_NAME>/CrossAccountPipeline/*"
],
"Effect": "Allow"
},
{
"Action": [
"kms:DescribeKey",
"kms:GenerateDataKey*",
"kms:Encrypt",
"kms:ReEncrypt*",
"kms:Decrypt"
],
"Resource": "<KEY_ARN>",
"Effect": "Allow"
}
]
}'
1. Attach the CodePipelineCrossAccountArtifactReadPolicy IAM policy to the CodePipelineCrossAccountRole IAM role:
aws iam attach-role-policy \
– profile <TENANT_PROFILE_NAME> \
– role-name CodePipelineCrossAccountRole \
– policy-arn arn:aws:iam::<TENANT_ACCOUNT_ID>:policy/CodePipelineCrossAccountArtifactReadPolicy
1. Create an IAM policy that allows to pass the IAM role CloudFormationDeploymentRole to CloudFormation and to perform CloudFormation actions on the application Stack:
aws iam create-policy \
– policy-name CodePipelineCrossAccountCfnPolicy \
– profile <TENANT_PROFILE_NAME> \
– policy-document \
'{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"iam:PassRole"
],
"Resource": "arn:aws:iam::<TENANT_ACCOUNT_ID>:role/CloudFormationDeploymentRole",
"Effect": "Allow"
},
{
"Action": [
"cloudformation:*"
],
"Resource": "arn:aws:cloudformation:<YOUR_REGION>:<TENANT_ACCOUNT_ID>:stack/SampleApplication*/*",
"Effect": "Allow"
}
]
}'
1. Attach the CodePipelineCrossAccountCfnPolicy IAM policy to the CodePipelineCrossAccountRole IAM role:
aws iam attach-role-policy \
– profile <TENANT_PROFILE_NAME> \
– role-name CodePipelineCrossAccountRole \
– policy-arn arn:aws:iam::<TENANT_ACCOUNT_ID>:policy/CodePipelineCrossAccountCfnPolicy
Additional configuration is needed in the Tooling account to allow access, which you complete later on.
Creating a deployment IAM role in each tenant account
After CodePipeline assumes the CodePipelineCrossAccountRole IAM role into the tenant account, it triggers AWS CloudFormation to provision the infrastructure based on the template defined in the application.yaml file. For that, AWS CloudFormation needs to assume an IAM role that grants privileges to create resources into the tenant AWS account.
Repeat the following steps for each tenant account to allow AWS CloudFormation to create resources in those accounts:
1. Create an IAM role that can be assumed by AWS CloudFormation:
aws iam create-role \
– role-name CloudFormationDeploymentRole \
– profile <TENANT_PROFILE_NAME> \
– assume-role-policy-document \
'{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "cloudformation.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}'
1. Create an IAM policy that grants permissions to create AWS resources:
aws iam create-policy \
– policy-name CloudFormationDeploymentPolicy \
– profile <TENANT_PROFILE_NAME> \
– policy-document \
'{
"Version": "2012-10-17",
"Statement": [
{
"Action": "iam:PassRole",
"Resource": "arn:aws:iam::<TENANT_ACCOUNT_ID>:role/*",
"Effect": "Allow"
},
{
"Action": [
"iam:GetRole",
"iam:CreateRole",
"iam:DeleteRole",
"iam:AttachRolePolicy",
"iam:DetachRolePolicy"
],
"Resource": "arn:aws:iam::<TENANT_ACCOUNT_ID>:role/*",
"Effect": "Allow"
},
{
"Action": "lambda:*",
"Resource": "*",
"Effect": "Allow"
},
{
"Action": "codedeploy:*",
"Resource": "*",
"Effect": "Allow"
},
{
"Action": [
"s3:GetObject*",
"s3:GetBucket*",
"s3:List*"
],
"Resource": [
"arn:aws:s3:::<BUCKET_UNIQUE_NAME>",
"arn:aws:s3:::<BUCKET_UNIQUE_NAME>/*"
],
"Effect": "Allow"
},
{
"Action": [
"kms:Decrypt",
"kms:DescribeKey"
],
"Resource": "<KEY_ARN>",
"Effect": "Allow"
},
{
"Action": [
"cloudformation:CreateStack",
"cloudformation:DescribeStack*",
"cloudformation:GetStackPolicy",
"cloudformation:GetTemplate*",
"cloudformation:SetStackPolicy",
"cloudformation:UpdateStack",
"cloudformation:ValidateTemplate"
],
"Resource": "arn:aws:cloudformation:<YOUR_REGION>:<TENANT_ACCOUNT_ID>:stack/SampleApplication*/*",
"Effect": "Allow"
},
{
"Action": [
"cloudformation:CreateChangeSet"
],
"Resource": "arn:aws:cloudformation:<YOUR_REGION>:aws:transform/Serverless-2016-10-31",
"Effect": "Allow"
}
]
}'
The granted permissions in this IAM policy depend on the resources your application needs to be provisioned. Because the application in our use case consists of a simple Lambda function, the IAM policy only needs permissions over Lambda. The other permissions declared are to access and decrypt the Lambda code from the artifact store, use AWS CodeDeploy to deploy the function, and create and attach the Lambda execution role.
1. Attach the IAM policy to the IAM role:
aws iam attach-role-policy \
– profile <TENANT_PROFILE_NAME> \
– role-name CloudFormationDeploymentRole \
– policy-arn arn:aws:iam::<TENANT_ACCOUNT_ID>:policy/CloudFormationDeploymentPolicy
Configuring an artifact store encryption key
Even though the IAM roles created in the tenant accounts declare permissions to use the CMK encryption key, that’s not enough to have access to the key. To access the key, you must update the CMK key policy.
From the terminal, run the following command to attach the new policy:
aws kms put-key-policy \
– key-id <KEY_ARN> \
– policy-name default \
– region <YOUR_REGION> \
– policy \
'{
"Id": "TenantAccountAccess",
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Enable IAM User Permissions",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::<TOOLING_ACCOUNT_ID>:root"
},
"Action": "kms:*",
"Resource": "*"
},
{
"Effect": "Allow",
"Principal": {
"AWS": [
"arn:aws:iam::<GNOME_ACCOUNT_ID>:role/CloudFormationDeploymentRole",
"arn:aws:iam::<GNOME_ACCOUNT_ID>:role/CodePipelineCrossAccountRole",
"arn:aws:iam::<UNICORN_ACCOUNT_ID>:role/CloudFormationDeploymentRole",
"arn:aws:iam::<UNICORN_ACCOUNT_ID>:role/CodePipelineCrossAccountRole"
]
},
"Action": [
"kms:Decrypt",
"kms:DescribeKey"
],
"Resource": "*"
}
]
}'
Provisioning the CI/CD pipeline
Each CodePipeline workflow consists of two or more stages, which are composed by a series of parallel or serial actions. For our use case, the pipeline is made up of four stages:
• Source – Declares CodeCommit as the source control for the application code.
• Build – Using CodeBuild, it installs the dependencies and builds deployable artifacts. In this use case, the sample application is too simple and this stage is used for illustration purposes.
• Deploy_Dev – Deploys the sample application on a sandbox environment. At this point, the deployable artifacts generated at the Build stage are used to create a CloudFormation stack and deploy the Lambda function.
• Deploy_Prod – Similar to Deploy_Dev, at this stage the sample application is deployed on the tenant production environments. For that, it contains two actions (one per tenant) that are run in parallel. CodePipeline uses CodePipelineCrossAccountRole to assume a role on the tenant account, and from there, CloudFormationDeploymentRole is used to effectively deploy the application.
To provision your resources, complete the following steps from the terminal:
1. Download the CloudFormation pipeline template:
curl -LO https://cross-account-ci-cd-pipeline-single-tenant-saas.s3.amazonaws.com/pipeline.yaml
1. Deploy the CloudFormation stack using the pipeline template:
aws cloudformation deploy \
– template-file pipeline.yaml \
– region <YOUR_REGION> \
– stack-name <YOUR_PIPELINE_STACK_NAME> \
– capabilities CAPABILITY_IAM \
– parameter-overrides \
ArtifactBucketName=<BUCKET_UNIQUE_NAME> \
ArtifactEncryptionKeyArn=<KMS_KEY_ARN> \
UnicornAccountId=<UNICORN_TENANT_ACCOUNT_ID> \
GnomeAccountId=<GNOME_TENANT_ACCOUNT_ID> \
SampleApplicationRepositoryName=<YOUR_CODECOMMIT_REPOSITORY_NAME> \
RepositoryBranch=<YOUR_CODECOMMIT_MAIN_BRANCH>
This is the list of the required parameters to deploy the template:
• ArtifactBucketName – The name of the S3 bucket where the deployment artifacts are to be stored.
• ArtifactEncryptionKeyArn – The ARN of the customer managed CMK to be used as artifact encryption key.
• UnicornAccountId – The AWS account ID for the first tenant (Unicorn) where the application is to be deployed.
• GnomeAccountId – The AWS account ID for the second tenant (Gnome) where the application is to be deployed.
• SampleApplicationRepositoryName – The name of the CodeCommit repository where source changes are detected.
• RepositoryBranch – The name of the CodeCommit branch where source changes are detected. The default value is master in case no value is provided.
1. Wait for AWS CloudFormation to create the resources.
When stack creation is complete, the pipeline starts automatically.
For each existing tenant, an action is declared within the Deploy_Prod stage. The following code is a snippet of how these actions are configured to deploy the application on a different account:
RoleArn: !Sub arn:aws:iam::${UnicornAccountId}:role/CodePipelineCrossAccountRole
Configuration:
ActionMode: CREATE_UPDATE
Capabilities: CAPABILITY_IAM,CAPABILITY_AUTO_EXPAND
StackName: !Sub SampleApplication-unicorn-stack-${AWS::Region}
RoleArn: !Sub arn:aws:iam::${UnicornAccountId}:role/CloudFormationDeploymentRole
TemplatePath: CodeCommitSource::application.yaml
ParameterOverrides: !Sub |
{
"ApplicationName": "SampleApplication-Unicorn",
"S3Bucket": { "Fn::GetArtifactAtt" : [ "ApplicationBuildOutput", "BucketName" ] },
"S3Key": { "Fn::GetArtifactAtt" : [ "ApplicationBuildOutput", "ObjectKey" ] }
}
The code declares two IAM roles. The first one is the IAM role assumed by the CodePipeline action to access the tenant AWS account, whereas the second is the IAM role used by AWS CloudFormation to create AWS resources in the tenant AWS account. The ParameterOverrides configuration declares where the release artifact is located. The S3 bucket and key are in the Tooling account and encrypted using the customer managed CMK. That’s why it was necessary to grant access from external accounts using a bucket and KMS policies.
Besides the CI/CD pipeline itself, this CloudFormation template declares IAM roles that are used by the pipeline and its actions. The main IAM role is named CrossAccountPipelineRole, which is used by the CodePipeline service. It contains permissions to assume the action roles. See the following code:
{
"Action": "sts:AssumeRole",
"Effect": "Allow",
"Resource": [
"arn:aws:iam::<TOOLING_ACCOUNT_ID>:role/<PipelineSourceActionRole>",
"arn:aws:iam::<TOOLING_ACCOUNT_ID>:role/<PipelineApplicationBuildActionRole>",
"arn:aws:iam::<TOOLING_ACCOUNT_ID>:role/<PipelineDeployDevActionRole>",
"arn:aws:iam::<UNICORN_ACCOUNT_ID>:role/CodePipelineCrossAccountRole",
"arn:aws:iam::<GNOME_ACCOUNT_ID>:role/CodePipelineCrossAccountRole"
]
}
When you have more tenant accounts, you must add additional roles to the list.
After CodePipeline runs successfully, test the sample application by invoking the Lambda function on each tenant account:
aws lambda invoke – function-name SampleApplication – profile <TENANT_PROFILE_NAME> – region <YOUR_REGION> out
The output should be:
{
"StatusCode": 200,
"ExecutedVersion": "$LATEST"
}
Cleaning up
Follow these steps to delete the components and avoid future incurring charges:
1. Delete the production application stack from each tenant account:
aws cloudformation delete-stack – profile <TENANT_PROFILE_NAME> – region <YOUR_REGION> – stack-name SampleApplication-<TENANT_NAME>-stack-<YOUR_REGION>
1. Delete the dev application stack from the Tooling account:
aws cloudformation delete-stack – region <YOUR_REGION> – stack-name SampleApplication-dev-stack-<YOUR_REGION>
1. Delete the pipeline stack from the Tooling account:
aws cloudformation delete-stack – region <YOUR_REGION> – stack-name <YOUR_PIPELINE_STACK_NAME>
1. Delete the customer managed CMK from the Tooling account:
aws kms schedule-key-deletion – region <YOUR_REGION> – key-id <KEY_ARN>
1. Delete the S3 bucket from the Tooling account:
aws s3 rb s3://<BUCKET_UNIQUE_NAME> – force
1. Optionally, delete the IAM roles and policies you created in the tenant accounts
Conclusion
This post demonstrated what it takes to build a CI/CD pipeline for single-tenant SaaS solutions isolated on the AWS account level. It covered how to grant cross-account access to artifact stores on Amazon S3 and artifact encryption keys on AWS KMS using policies and IAM roles. This approach is less error-prone because it avoids human errors when manually deploying the exact same application for multiple tenants.
For this use case, we performed most of the steps manually to better illustrate all the steps and components involved. For even more automation, consider using the AWS Cloud Development Kit (AWS CDK) and its pipeline construct to create your CI/CD pipeline and have everything as code. Moreover, for production scenarios, consider having integration tests as part of the pipeline.
Rafael Ramos
Rafael Ramos
Rafael is a Solutions Architect at AWS, where he helps ISVs on their journey to the cloud. He spent over 13 years working as a software developer, and is passionate about DevOps and serverless. Outside of work, he enjoys playing tabletop RPG, cooking and running marathons.
Complete CI/CD with AWS CodeCommit, AWS CodeBuild, AWS CodeDeploy, and AWS CodePipeline
Post Syndicated from Nitin Verma original https://aws.amazon.com/blogs/devops/complete-ci-cd-with-aws-codecommit-aws-codebuild-aws-codedeploy-and-aws-codepipeline/
Many organizations have been shifting to DevOps practices, which is the combination of cultural philosophies, practices, and tools that increases your organization’s ability to deliver applications and services at high velocity; for example, evolving and improving products at a faster pace than organizations using traditional software development and infrastructure management processes.
DevOps-Feedback-Flow
An integral part of DevOps is adopting the culture of continuous integration and continuous delivery/deployment (CI/CD), where a commit or change to code passes through various automated stage gates, all the way from building and testing to deploying applications, from development to production environments.
This post uses the AWS suite of CI/CD services to compile, build, and install a version-controlled Java application onto a set of Amazon Elastic Compute Cloud (Amazon EC2) Linux instances via a fully automated and secure pipeline. The goal is to promote a code commit or change to pass through various automated stage gates all the way from development to production environments, across AWS accounts.
AWS services
This solution uses the following AWS services:
• AWS CodeCommit – A fully-managed source control service that hosts secure Git-based repositories. CodeCommit makes it easy for teams to collaborate on code in a secure and highly scalable ecosystem. This solution uses CodeCommit to create a repository to store the application and deployment codes.
• AWS CodeBuild – A fully managed continuous integration service that compiles source code, runs tests, and produces software packages that are ready to deploy, on a dynamically created build server. This solution uses CodeBuild to build and test the code, which we deploy later.
• AWS CodeDeploy – A fully managed deployment service that automates software deployments to a variety of compute services such as Amazon EC2, AWS Fargate, AWS Lambda, and your on-premises servers. This solution uses CodeDeploy to deploy the code or application onto a set of EC2 instances running CodeDeploy agents.
• AWS CodePipeline – A fully managed continuous delivery service that helps you automate your release pipelines for fast and reliable application and infrastructure updates. This solution uses CodePipeline to create an end-to-end pipeline that fetches the application code from CodeCommit, builds and tests using CodeBuild, and finally deploys using CodeDeploy.
• AWS CloudWatch Events – An AWS CloudWatch Events rule is created to trigger the CodePipeline on a Git commit to the CodeCommit repository.
• Amazon Simple Storage Service (Amazon S3) – An object storage service that offers industry-leading scalability, data availability, security, and performance. This solution uses an S3 bucket to store the build and deployment artifacts created during the pipeline run.
• AWS Key Management Service (AWS KMS) – AWS KMS makes it easy for you to create and manage cryptographic keys and control their use across a wide range of AWS services and in your applications. This solution uses AWS KMS to make sure that the build and deployment artifacts stored on the S3 bucket are encrypted at rest.
Overview of solution
This solution uses two separate AWS accounts: a dev account (111111111111) and a prod account (222222222222) in Region us-east-1.
We use the dev account to deploy and set up the CI/CD pipeline, along with the source code repo. It also builds and tests the code locally and performs a test deploy.
The prod account is any other account where the application is required to be deployed from the pipeline in the dev account.
In summary, the solution has the following workflow:
• A change or commit to the code in the CodeCommit application repository triggers CodePipeline with the help of a CloudWatch event.
• The pipeline downloads the code from the CodeCommit repository, initiates the Build and Test action using CodeBuild, and securely saves the built artifact on the S3 bucket.
• If the preceding step is successful, the pipeline triggers the Deploy in Dev action using CodeDeploy and deploys the app in dev account.
• If successful, the pipeline triggers the Deploy in Prod action using CodeDeploy and deploys the app in the prod account.
The following diagram illustrates the workflow:
cicd-overall-flow
Failsafe deployments
This example of CodeDeploy uses the IN_PLACE type of deployment. However, to minimize the downtime, CodeDeploy inherently supports multiple deployment strategies. This example makes use of following features: rolling deployments and automatic rollback.
CodeDeploy provides the following three predefined deployment configurations, to minimize the impact during application upgrades:
• CodeDeployDefault.OneAtATime – Deploys the application revision to only one instance at a time
• CodeDeployDefault.HalfAtATime – Deploys to up to half of the instances at a time (with fractions rounded down)
• CodeDeployDefault.AllAtOnce – Attempts to deploy an application revision to as many instances as possible at once
For OneAtATime and HalfAtATime, CodeDeploy monitors and evaluates instance health during the deployment and only proceeds to the next instance or next half if the previous deployment is healthy. For more information, see Working with deployment configurations in CodeDeploy.
You can also configure a deployment group or deployment to automatically roll back when a deployment fails or when a monitoring threshold you specify is met. In this case, the last known good version of an application revision is automatically redeployed after a failure with the new application version.
How CodePipeline in the dev account deploys apps in the prod account
In this post, the deployment pipeline using CodePipeline is set up in the dev account, but it has permissions to deploy the application in the prod account. We create a special cross-account role in the prod account, which has the following:
• Permission to use fetch artifacts (app) rom Amazon S3 and deploy it locally in the account using CodeDeploy
• Trust with the dev account where the pipeline runs
CodePipeline in the dev account assumes this cross-account role in the prod account to deploy the app.
Do I need multiple accounts?
If you answer “yes” to any of the following questions you should consider creating more AWS accounts:
• Does your business require administrative isolation between workloads? Administrative isolation by account is the most straightforward way to grant independent administrative groups different levels of administrative control over AWS resources based on workload, development lifecycle, business unit (BU), or data sensitivity.
• Does your business require limited visibility and discoverability of workloads? Accounts provide a natural boundary for visibility and discoverability. Workloads cannot be accessed or viewed unless an administrator of the account enables access to users managed in another account.
• Does your business require isolation to minimize blast radius? Separate accounts help define boundaries and provide natural blast-radius isolation to limit the impact of a critical event such as a security breach, an unavailable AWS Region or Availability Zone, account suspensions, and so on.
• Does your business require a particular workload to operate within AWS service limits without impacting the limits of another workload? You can use AWS account service limits to impose restrictions on a business unit, development team, or project. For example, if you create an AWS account for a project group, you can limit the number of Amazon Elastic Compute Cloud (Amazon EC2) or high performance computing (HPC) instances that can be launched by the account.
• Does your business require strong isolation of recovery or auditing data? If regulatory requirements require you to control access and visibility to auditing data, you can isolate the data in an account separate from the one where you run your workloads (for example, by writing AWS CloudTrail logs to a different account).
Prerequisites
For this walkthrough, you should complete the following prerequisites:
1. Have access to at least two AWS accounts. For this post, the dev and prod accounts are in us-east-1. You can search and replace the Region and account IDs in all the steps and sample AWS Identity and Access Management (IAM) policies in this post.
2. Ensure you have EC2 Linux instances with the CodeDeploy agent installed in all the accounts or VPCs where the sample Java application is to be installed (dev and prod accounts).
• To manually create EC2 instances with CodeDeploy agent, refer Create an Amazon EC2 instance for CodeDeploy (AWS CLI or Amazon EC2 console). Keep in mind the following:
• CodeDeploy uses EC2 instance tags to identify instances to use to deploy the application, so it’s important to set tags appropriately. For this post, we use the tag name Application with the value MyWebApp to identify instances where the sample app is installed.
• Make sure to use an EC2 instance profile (AWS Service Role for EC2 instance) with permissions to read the S3 bucket containing artifacts built by CodeBuild. Refer to the IAM role cicd_ec2_instance_profile in the table Roles-1 below for the set of permissions required. You must update this role later with the actual KMS key and S3 bucket name created as part of the deployment process.
• To create EC2 Linux instances via AWS Cloudformation, download and launch the AWS CloudFormation template from the GitHub repo: cicd-ec2-instance-with-codedeploy.json
• This deploys an EC2 instance with AWS CodeDeploy agent.
• Inputs required:
• AMI : Enter name of the Linux AMI in your region. (This template has been tested with latest Amazon Linux 2 AMI)
• Ec2SshKeyPairName: Name of an existing SSH KeyPair
• Ec2IamInstanceProfile: Name of an existing EC2 instance profile. Note: Use the permissions in the template cicd_ec2_instance_profile_policy.json to create the policy for this EC2 Instance Profile role. You must update this role later with the actual KMS key and S3 bucket name created as part of the deployment process.
• Update the EC2 instance Tags per your need.
3. Ensure required IAM permissions. Have an IAM user with an IAM Group or Role that has the following access levels or permissions:
AWS Service / Components Access LevelAccountsComments
AWS CodeCommitFull (admin)DevUse AWS managed policy AWSCodeCommitFullAccess.
AWS CodePipelineFull (admin)DevUse AWS managed policy AWSCodePipelineFullAccess.
AWS CodeBuildFull (admin)DevUse AWS managed policy AWSCodeBuildAdminAccess.
AWS CodeDeployFull (admin)All
Use AWS managed policy
AWSCodeDeployFullAccess.
Create S3 bucket and bucket policiesFull (admin)DevIAM policies can be restricted to specific bucket.
Create KMS key and policiesFull (admin)DevIAM policies can be restricted to specific KMS key.
AWS CloudFormationFull (admin)Dev
Use AWS managed policy
AWSCloudFormationFullAccess.
Create and pass IAM rolesFull (admin)AllAbility to create IAM roles and policies can be restricted to specific IAM roles or actions. Also, an admin team with IAM privileges could create all the required roles. Refer to the IAM table Roles-1 below.
AWS Management Console and AWS CLIAs per IAM User permissionsAllTo access suite of Code services.
4. Create Git credentials for CodeCommit in the pipeline account (dev account). AWS allows you to either use Git credentials or associate SSH public keys with your IAM user. For this post, use Git credentials associated with your IAM user (created in the previous step). For instructions on creating a Git user, see Create Git credentials for HTTPS connections to CodeCommit. Download and save the Git credentials to use later for deploying the application.
5. Create all AWS IAM roles as per the following tables (Roles-1). Make sure to update the following references in all the given IAM roles and policies:
• Replace the sample dev account (111111111111) and prod account (222222222222) with actual account IDs
• Replace the S3 bucket mywebapp-codepipeline-bucket-us-east-1-111111111111 with your preferred bucket name.
• Replace the KMS key ID key/82215457-e360-47fc-87dc-a04681c91ce1 with your KMS key ID.
Table: Roles-1
ServiceIAM Role TypeAccountIAM Role Name (used for this post)IAM Role Policy (required for this post)IAM Role Permissions
AWS CodePipelineService roleDev (111111111111)
cicd_codepipeline_service_role
Select Another AWS Account and use this account as the account ID to create the role.
Later update the trust as follows:
“Principal”: {“Service”: “codepipeline.amazonaws.com”},
Use the permissions in the template cicd_codepipeline_service_policy.json to create the policy for this role.This CodePipeline service role has appropriate permissions to the following services in a local account:
• Manage CodeCommit repos
• Initiate build via CodeBuild
• Create deployments via CodeDeploy
• Assume cross-account CodeDeploy role in prod account to deploy the application
AWS CodePipelineIAM roleDev (111111111111)
cicd_codepipeline_trigger_cwe_role
Select Another AWS Account and use this account as the account ID to create the role.
Later update the trust as follows:
“Principal”: {“Service”: “events.amazonaws.com”},
Use the permissions in the template cicd_codepipeline_trigger_cwe_policy.json to create the policy for this role.CodePipeline uses this role to set a CloudWatch event to trigger the pipeline when there is a change or commit made to the code repository.
AWS CodePipelineIAM roleProd (222222222222)
cicd_codepipeline_cross_ac_role
Choose Another AWS Account and use the dev account as the trusted account ID to create the role.
Use the permissions in the template cicd_codepipeline_cross_ac_policy.json to create the policy for this role.This role is created in the prod account and has permissions to use CodeDeploy and fetch from Amazon S3. The role is assumed by CodePipeline from the dev account to deploy the app in the prod account. Make sure to set up trust with the dev account for this IAM role on the Trust relationships tab.
AWS CodeBuildService roleDev (111111111111)
cicd_codebuild_service_role
Choose CodeBuild as the use case to create the role.
Use the permissions in the template cicd_codebuild_service_policy.json to create the policy for this role.This CodeBuild service role has appropriate permissions to:
• The S3 bucket to store artefacts
• Stream logs to CloudWatch Logs
• Pull code from CodeCommit
• Get the SSM parameter for CodeBuild
• Miscellaneous Amazon EC2 permissions
AWS CodeDeployService roleDev (111111111111) and Prod (222222222222)
cicd_codedeploy_service_role
Choose CodeDeploy as the use case to create the role.
Use the built-in AWS managed policy AWSCodeDeployRole for this role.This CodeDeploy service role has appropriate permissions to:
• Miscellaneous Amazon EC2 Auto Scaling
• Miscellaneous Amazon EC2
• Publish Amazon SNS topic
• AWS CloudWatch metrics
• Elastic Load Balancing
EC2 InstanceService role for EC2 instance profileDev (111111111111) and Prod (222222222222)
cicd_ec2_instance_profile
Choose EC2 as the use case to create the role.
Use the permissions in the template cicd_ec2_instance_profile_policy.json to create the policy for this role.
This is set as the EC2 instance profile for the EC2 instances where the app is deployed. It has appropriate permissions to fetch artefacts from Amazon S3 and decrypt contents using the KMS key.
You must update this role later with the actual KMS key and S3 bucket name created as part of the deployment process.
Setting up the prod account
To set up the prod account, complete the following steps:
1. Download and launch the AWS CloudFormation template from the GitHub repo: cicd-codedeploy-prod.json
• This deploys the CodeDeploy app and deployment group.
• Make sure that you already have a set of EC2 Linux instances with the CodeDeploy agent installed in all the accounts where the sample Java application is to be installed (dev and prod accounts). If not, refer back to the Prerequisites section.
2. Update the existing EC2 IAM instance profile (cicd_ec2_instance_profile):
• Replace the S3 bucket name mywebapp-codepipeline-bucket-us-east-1-111111111111 with your S3 bucket name (the one used for the CodePipelineArtifactS3Bucket variable when you launched the CloudFormation template in the dev account).
• Replace the KMS key ARN arn:aws:kms:us-east-1:111111111111:key/82215457-e360-47fc-87dc-a04681c91ce1 with your KMS key ARN (the one created as part of the CloudFormation template launch in the dev account).
Setting up the dev account
To set up your dev account, complete the following steps:
1. Download and launch the CloudFormation template from the GitHub repo: cicd-aws-code-suite-dev.json
The stack deploys the following services in the dev account:
• CodeCommit repository
• CodePipeline
• CodeBuild environment
• CodeDeploy app and deployment group
• CloudWatch event rule
• KMS key (used to encrypt the S3 bucket)
• S3 bucket and bucket policy
2. Use following values as inputs to the CloudFormation template. You should have created all the existing resources and roles beforehand as part of the prerequisites.
KeyExample ValueComments
CodeCommitWebAppRepoMyWebAppRepoName of the new CodeCommit repository for your web app.
CodeCommitMainBranchNamemasterMain branch name on your CodeCommit repository. Default is master (which is pushed to the prod environment).
CodeBuildProjectNameMyCBWebAppProjectName of the new CodeBuild environment.
CodeBuildServiceRolearn:aws:iam::111111111111:role/cicd_codebuild_service_roleARN of an existing IAM service role to be associated with CodeBuild to build web app code.
CodeDeployAppMyCDWebAppName of the new CodeDeploy app to be created for your web app. We assume that the CodeDeploy app name is the same in all accounts where deployment needs to occur (in this case, the prod account).
CodeDeployGroupDevMyCICD-Deployment-Group-DevName of the new CodeDeploy deployment group to be created in the dev account.
CodeDeployGroupProdMyCICD-Deployment-Group-ProdName of the existing CodeDeploy deployment group in prod account. Created as part of the prod account setup.
CodeDeployGroupTagKey
ApplicationName of the tag key that CodeDeploy uses to identify the existing EC2 fleet for the deployment group to use.
CodeDeployGroupTagValue
MyWebAppValue of the tag that CodeDeploy uses to identify the existing EC2 fleet for the deployment group to use.
CodeDeployConfigNameCodeDeployDefault.OneAtATime
Desired Code Deploy config name. Valid options are:
CodeDeployDefault.OneAtATime
CodeDeployDefault.HalfAtATime
CodeDeployDefault.AllAtOnce
For more information, see Deployment configurations on an EC2/on-premises compute platform.
CodeDeployServiceRolearn:aws:iam::111111111111:role/cicd_codedeploy_service_role
ARN of an existing IAM service role to be associated with CodeDeploy to deploy web app.
CodePipelineNameMyWebAppPipelineName of the new CodePipeline to be created for your web app.
CodePipelineArtifactS3Bucketmywebapp-codepipeline-bucket-us-east-1-111111111111Name of the new S3 bucket to be created where artifacts for the pipeline are stored for this web app.
CodePipelineServiceRolearn:aws:iam::111111111111:role/cicd_codepipeline_service_roleARN of an existing IAM service role to be associated with CodePipeline to deploy web app.
CodePipelineCWEventTriggerRolearn:aws:iam::111111111111:role/cicd_codepipeline_trigger_cwe_roleARN of an existing IAM role used to trigger the pipeline you named earlier upon a code push to the CodeCommit repository.
CodeDeployRoleXAProdarn:aws:iam::222222222222:role/cicd_codepipeline_cross_ac_roleARN of an existing IAM role in the cross-account for CodePipeline to assume to deploy the app.
It should take 5–10 minutes for the CloudFormation stack to complete. When the stack is complete, you can see that CodePipeline has built the pipeline (MyWebAppPipeline) with the CodeCommit repository and CodeBuild environment, along with actions for CodeDeploy in local (dev) and cross-account (prod). CodePipeline should be in a failed state because your CodeCommit repository is empty initially.
3. Update the existing Amazon EC2 IAM instance profile (cicd_ec2_instance_profile):
• Replace the S3 bucket name mywebapp-codepipeline-bucket-us-east-1-111111111111 with your S3 bucket name (the one used for the CodePipelineArtifactS3Bucket parameter when launching the CloudFormation template in the dev account).
• Replace the KMS key ARN arn:aws:kms:us-east-1:111111111111:key/82215457-e360-47fc-87dc-a04681c91ce1 with your KMS key ARN (the one created as part of the CloudFormation template launch in the dev account).
Deploying the application
You’re now ready to deploy the application via your desktop or PC.
1. Assuming you have the required HTTPS Git credentials for CodeCommit as part of the prerequisites, clone the CodeCommit repo that was created earlier as part of the dev account setup. Obtain the name of the CodeCommit repo to clone, from the CodeCommit console. Enter the Git user name and password when prompted. For example:
$ git clone https://git-codecommit.us-east-1.amazonaws.com/v1/repos/MyWebAppRepo my-web-app-repo
Cloning into 'my-web-app-repo'...
Username for 'https://git-codecommit.us-east-1.amazonaws.com/v1/repos/MyWebAppRepo': xxxx
Password for 'https://[email protected]/v1/repos/MyWebAppRepo': xxxx
2. Download the MyWebAppRepo.zip file containing a sample Java application, CodeBuild configuration to build the app, and CodeDeploy config file to deploy the app.
3. Copy and unzip the file into the my-web-app-repo Git repository folder created earlier.
4. Assuming this is the sample app to be deployed, commit these changes to the Git repo. For example:
$ cd my-web-app-repo
$ git add -A
$ git commit -m "initial commit"
$ git push
For more information, see Tutorial: Create a simple pipeline (CodeCommit repository).
After you commit the code, the CodePipeline will be triggered and all the stages and your application should be built, tested, and deployed all the way to the production environment!
The following screenshot shows the entire pipeline and its latest run:
Troubleshooting
To troubleshoot any service-related issues, see the following:
Cleaning up
To avoid incurring future charges or to remove any unwanted resources, delete the following:
• EC2 instance used to deploy the application
• CloudFormation template to remove all AWS resources created through this post
• IAM users or roles
Conclusion
Using this solution, you can easily set up and manage an entire CI/CD pipeline in AWS accounts using the native AWS suite of CI/CD services, where a commit or change to code passes through various automated stage gates all the way from building and testing to deploying applications, from development to production environments.
FAQs
In this section, we answer some frequently asked questions:
1. Can I expand this deployment to more than two accounts?
• Yes. You can deploy a pipeline in a tooling account and use dev, non-prod, and prod accounts to deploy code on EC2 instances via CodeDeploy. Changes are required to the templates and policies accordingly.
2. Can I ensure the application isn’t automatically deployed in the prod account via CodePipeline and needs manual approval?
3. Can I use a CodeDeploy group with an Auto Scaling group?
• Yes. Minor changes required to the CodeDeploy group creation process. Refer to the following Solution Variations section for more information.
4. Can I use this pattern for EC2 Windows instances?
Solution variations
In this section, we provide a few variations to our solution:
Author bio
author-pic
Nitin Verma
Nitin is currently a Sr. Cloud Architect in the AWS Managed Services(AMS). He has many years of experience with DevOps-related tools and technologies. Speak to your AWS Managed Services representative to deploy this solution in AMS!
Why Deployment Requirements are Important When Making Architectural Choices
Post Syndicated from Yusuf Mayet original https://aws.amazon.com/blogs/architecture/why-deployment-requirements-are-important-when-making-architectural-choices/
Introduction
Too often, architects fall into the trap of thinking the architecture of an application is restricted to just the runtime part of the architecture. By doing this we focus on only a single customer (such as the application’s users and how they interact with the system) and we forget about other important customers like developers and DevOps teams. This means that requirements regarding deployment ease, deployment frequency, and observability are delegated to the back burner during design time and tacked on after the runtime architecture is built. This leads to increased costs and reduced ability to innovate.
In this post, I discuss the importance of key non-functional requirements, and how they can and should influence the target architecture at design time.
Architectural patterns
When building and designing new applications, we usually start by looking at the functional requirements, which will define the functionality and objective of the application. These are all the things that the users of the application expect, such as shopping online, searching for products, and ordering. We also consider aspects such as usability to ensure a great user experience (UX).
We then consider the non-functional requirements, the so-called “ilities,” which typically include requirements regarding scalability, availability, latency, etc. These are constraints around the functional requirements, like response times for placing orders or searching for products, which will define the expected latency of the system.
These requirements—both functional and non-functional together—dictate the architectural pattern we choose to build the application. These patterns include Multi-tierevent-driven architecturemicroservices, and others, and each one has benefits and limitations. For example, a microservices architecture allows for a system where services can be deployed and scaled independently, but this also introduces complexity around service discovery.
Aligning the architecture to technical users’ requirements
Amazon is a customer-obsessed organization, so it’s important for us to first identify who the main customers are at each point so that we can meet their needs. The customers of the functional requirements are the application users, so we need to ensure the application meets their needs. For the most part, we will ensure that the desired product features are supported by the architecture.
But who are the users of the architecture? Not the applications’ users—they don’t care if it’s monolithic or microservices based, as long as they can shop and search for products. The main customers of the architecture are the technical teams: the developers, architects, and operations teams that build and support the application. We need to work backwards from the customers’ needs (in this case the technical team), and make sure that the architecture meets their requirements. We have therefore identified three non-functional requirements that are important to consider when designing an architecture that can equally meet the needs of the technical users:
1. Deployability: Flow and agility to consistently deploy new features
2. Observability: feedback about the state of the application
3. Disposability: throwing away resources and provision new ones quickly
Together these form part of the Developer Experience (DX), which is focused on providing developers with APIs, documentation, and other technologies to make it easy to understand and use. This will ensure that we design for Day 2 operations in mind.
Deployability: Flow
There are many reasons that organizations embark on digital transformation journeys, which usually involve moving to the cloud and adopting DevOps. According to Stephen Orban, GM of AWS Data Exchange, in his book Ahead in the Cloud, faster product development is often a key motivator, meaning the most important non-functional requirement is achieving flow, the speed at which you can consistently deploy new applications, respond to competitors, and test and roll out new features. As well, the architecture needs to be designed upfront to support deployability. If the architectural pattern is a monolithic application, this will hamper the developers’ ability to quickly roll out new features to production. So we need to choose and design the architecture to support easy and automated deployments. Results from years of research prove that leaders use DevOps to achieve high levels of throughput:
Graphic - Using DevOps to achieve high levels of throughput
Decisions on the pace and frequency of deployments will dictate whether to use rolling, blue/green, or canary deployment methodologies. This will then inform the architectural pattern chosen for the application.
Using AWS, in order to achieve flow of deployability, we will use services such as AWS CodePipelineAWS CodeBuildAWS CodeDeploy and AWS CodeStar.
Observability: feedback
Once you have achieved a rapid and repeatable flow of features into production, you need a constant feedback loop of logs and metrics in order to detect and avoid problems. Observability is a property of the architecture that will allow us to better understand the application across the delivery pipeline and into production. This requires that we design the architecture to ensure that health reports are generated to analyze and spot trends. This includes error rates and stats from each stage of the development process, how many commits were made, build duration, and frequency of deployments. This not only allows us to measure code characteristics such as test coverage, but also developer productivity.
On AWS, we can leverage Amazon CloudWatch to gather and search through logs and metrics, AWS X-Ray for tracing, and Amazon QuickSight as an analytics tool to measure CI/CD metrics.
Disposability: automation
In his book, Cloud Strategy: A Decision-based Approach to a Successful Cloud Journey, Gregor Hohpe, Enterprise Strategist at AWS, notes that cloud and automation add a new “-ility”: disposability, which is the ability to set up and dispose of new servers in an automated and pain-free manner. Having immutable, disposable infrastructure greatly enhances your ability to achieve high levels of deployability and flow, especially when used in a CI/CD pipeline, which can create new resources and kill off the old ones.
At AWS, we can achieve disposability with serverless using AWS Lambda, or with containers running on Amazon Elastic Container Service (ECS) or Amazon Elastic Kubernetes Service (EKS), or using AWS Auto Scaling with Amazon Elastic Compute Cloud (EC2).
Three different views of the architecture
Once we have designed an architecture that caters for deployability, observability, and disposability, it exposes three lenses across which we can view the architecture:
3 views of the architecture
1. Build lens: the focus of this part of the architecture is on achieving deployability, with the objective to give the developers an easy-to-use, automated platform that builds, tests, and pushes their code into the different environments, in a repeatable way. Developers can push code changes more reliably and frequently, and the operations team can see greater stability because environments have standard configurations and rollback procedures are automated
2. Runtime lens: the focus is on the users of the application and on maximizing their experience by making the application responsive and highly available.
3. Operate lens: the focus is on achieving observability for the DevOps teams, allowing them to have complete visibility into each part of the architecture.
Summary
When building and designing new applications, the functional requirements (such as UX) are usually the primary drivers for choosing and defining the architecture to support those requirements. In this post I have discussed how DX characteristics like deployability, observability, and disposability are not just operational concerns that get tacked on after the architecture is chosen. Rather, they should be as important as the functional requirements when choosing the architectural pattern. This ensures that the architecture can support the needs of both the developers and users, increasing quality and our ability to innovate.
How Pushly Media used AWS to pivot and quickly spin up a StartUp
Post Syndicated from Eddie Moser original https://aws.amazon.com/blogs/devops/how-pushly-media-used-aws-to-pivot-and-quickly-spin-up-a-startup/
This is a guest post from Pushly. In their own words, “Pushly provides a scalable, easy-to-use platform designed to deliver targeted and timely content via web push notifications across all modern desktop browsers and Android devices.”
Introduction
As a software engineer at Pushly, I’m part of a team of developers responsible for building our SaaS platform.
Our customers are content publishers spanning the news, ecommerce, and food industries, with the primary goal of increasing page views and paid subscriptions, ultimately resulting in increased revenue.
Pushly’s platform is designed to integrate seamlessly into a publisher’s workflow and enables advanced features such as customizable opt-in flow management, behavioral targeting, and real-time reporting and campaign delivery analytics.
As developers, we face various challenges to make all this work seamlessly. That’s why we turned to Amazon Web Services (AWS). In this post, I explain why and how we use AWS to enable the Pushly user experience.
At Pushly, my primary focus areas are developer and platform user experience. On the developer side, I’m responsible for building and maintaining easy-to-use APIs and a web SDK. On the UX side, I’m responsible for building a user-friendly and stable platform interface.
The CI/CD process
We’re a cloud native company and have gone all in with AWS.
AWS CodePipeline lets us automate the software release process and release new features to our users faster. Rapid delivery is key here, and CodePipeline lets us automate our build, test, and release process so we can quickly and easily test each code change and fail fast if needed. CodePipeline is vital to ensuring the quality of our code by running each change through a staging and release process.
One of our use cases is continuous reiteration deployment. We foster an environment where developers can fully function in their own mindset while adhering to our company’s standards and the architecture within AWS.
We deploy code multiple times per day and rely on AWS services to run through all checks and make sure everything is packaged uniformly. We want to fully test in a staging environment before moving to a customer-facing production environment.
The development and staging environments
Our development environment allows developers to securely pull down applications as needed and access the required services in a development AWS account. After an application is tested and is ready for staging, the application is deployed to our staging environment—a smaller reproduction of our production environment—so we can test how the changes work together. This flow allows us to see how the changes run within the entire Pushly ecosystem in a secure environment without pushing to production.
When testing is complete, a pull request is created for stakeholder review and to merge the changes to production branches. We use AWS CodeBuild, CodePipeline, and a suite of in-house tools to ensure that the application has been thoroughly tested to our standards before being deployed to our production AWS account.
Here is a high level diagram of the environment described above:
Diagram showing at a high level the Pushly environment.Ease of development
Ease of development was—and is—key. AWS provides the tools that allow us to quickly iterate and adapt to ever-changing customer needs. The infrastructure as code (IaC) approach of AWS CloudFormation allows us to quickly and simply define our infrastructure in an easily reproducible manner and rapidly create and modify environments at scale. This has given us the confidence to take on new challenges without concern over infrastructure builds impacting the final product or causing delays in development.
The Pushly team
Although Pushly’s developers all have the skill-set to work on both front-end-facing and back-end-facing projects, primary responsibilities are split between front-end and back-end developers. Developers that primarily focus on front-end projects concentrate on public-facing projects and internal management systems. The back-end team focuses on the underlying architecture, delivery systems, and the ecosystem as a whole. Together, we create and maintain a product that allows you to segment and target your audiences, which ensures relevant delivery of your content via web push notifications.
Early on we ran all services entirely off of AWS Lambda. This allowed us to develop new features quickly in an elastic, cost efficient way. As our applications have matured, we’ve identified some services that would benefit from an always on environment and moved them to AWS Elastic Beanstalk. The capability to quickly iterate and move from service to service is a credit to AWS, because it allows us to customize and tailor our services across multiple AWS offerings.
Elastic Beanstalk has been the fastest and simplest way for us to deploy this suite of services on AWS; their blue/green deployments allow us to maintain minimal downtime during deployments. We can easily configure deployment environments with capacity provisioning, load balancing, autoscaling, and application health monitoring.
The business side
We had several business drivers behind choosing AWS: we wanted to make it easier to meet customer demands and continually scale as much as needed without worrying about the impact on development or on our customers.
Using AWS services allowed us to build our platform from inception to our initial beta offering in fewer than 2 months! AWS made it happen with tools for infrastructure deployment on top of the software deployment. Specifically, IaC allowed us to tailor our infrastructure to our specific needs and be confident that it’s always going to work.
On the infrastructure side, we knew that we wanted to have a staging environment that truly mirrored the production environment, rather than managing two entirely disparate systems. We could provide different sets of mappings based on accounts and use the templates across multiple environments. This functionality allows us to use the exact same code we use in our current production environment and easily spin up additional environments in 2 hours.
The need for speed
It took a very short time to get our project up and running, which included rewriting different pieces of the infrastructure in some places and completely starting from scratch in others.
One of the new services that we adopted is AWS CodeArtifact. It lets us have fully customized private artifact stores in the cloud. We can keep our in-house libraries within our current AWS accounts instead of relying on third-party services.
CodeBuild lets us compile source code, run test suites, and produce software packages that are ready to deploy while only having to pay for the runtime we use. With CodeBuild, you don’t need to provision, manage, and scale your own build servers, which saves us time.
The new tools that AWS is releasing are going to even further streamline our processes. We’re interested in the impact that CodeArtifact will have on our ability to share libraries in Pushly and with other business units.
Cost savings is key
What are we saving by choosing AWS? A lot. AWS lets us scale while keeping costs at a minimum. This was, and continues to be, a major determining factor when choosing a cloud provider.
By using Lambda and designing applications with horizontal scale in mind, we have scaled from processing millions of requests per day to hundreds of millions, with very little change to the underlying infrastructure. Due to the nature of our offering, our traffic patterns are unpredictable. Lambda allows us to process these requests elastically and avoid over-provisioning. As a result, we can increase our throughput tenfold at any time, pay for the few minutes of extra compute generated by a sudden burst of traffic, and scale back down in seconds.
In addition to helping us process these requests, AWS has been instrumental in helping us manage an ever-growing data warehouse of clickstream data. With Amazon Kinesis Data Firehose, we automatically convert all incoming events to Parquet and store them in Amazon Simple Storage Service (Amazon S3), which we can query directly using Amazon Athena within minutes of being received. This has once again allowed us to scale our near-real-time data reporting to a degree that would have otherwise required a significant investment of time and resources.
As we look ahead, one thing we’re interested in is Lambda custom stacks, part of AWS’s Lambda-backed custom resources. Amazon supports many languages, so we can run almost every language we need. If we want to switch to a language that AWS doesn’t support by default, they still provide a way for us to customize a solution. All we have to focus on is the code we’re writing!
The importance of speed for us and our customers is one of our highest priorities. Think of a news publisher in the middle of a briefing who wants to get the story out before any of the competition and is relying on Pushly—our confidence in our ability to deliver on this need comes from AWS services enabling our code to perform to its fullest potential.
Another way AWS has met our needs was in the ease of using Amazon ElastiCache, a fully managed in-memory data store and cache service. Although we try to be as horizontal thinking as possible, some services just can’t scale with the immediate elasticity we need to handle a sudden burst of requests. We avoid duplicate lookups for the same resources with ElastiCache. ElastiCache allows us to process requests quicker and protects our infrastructure from being overwhelmed.
In addition to caching, ElastiCache is a great tool for job locking. By locking messages by their ID as soon as they are received, we can use the near-unlimited throughput of Amazon Simple Queue Service (Amazon SQS) in a massively parallel environment without worrying that messages are processed more than once.
The heart of our offering is in the segmentation of subscribers. We allow building complex queries in our dashboard that calculate reach in real time and are available to use immediately after creation. These queries are often never-before-seen and may contain custom properties provided by our clients, operate on complex data types, and include geospatial conditions. No matter the size of the audience, we see consistent sub-second query times when calculating reach. We can provide this to our clients using Amazon Elasticsearch Service (Amazon ES) as the backbone to our subscriber store.
Summary
AWS has countless positives, but one key theme that we continue to see is overall ease of use, which enables us to rapidly iterate. That’s why we rely on so many different AWS services—Amazon API Gateway with Lambda integration, Elastic Beanstalk, Amazon Relational Database Service (Amazon RDS), ElastiCache, and many more.
We feel very secure about our future working with AWS and our continued ability to improve, integrate, and provide a quality service. The AWS team has been extremely supportive. If we run into something that we need to adjust outside of the standard parameters, or that requires help from the AWS specialists, we can reach out and get feedback from subject matter experts quickly. The all-around capabilities of AWS and its teams have helped Pushly get where we are, and we’ll continue to rely on them for the foreseeable future.
Integrating AWS CloudFormation security tests with AWS Security Hub and AWS CodeBuild reports
Post Syndicated from Vesselin Tzvetkov original https://aws.amazon.com/blogs/security/integrating-aws-cloudformation-security-tests-with-aws-security-hub-and-aws-codebuild-reports/
The concept of infrastructure as code, by using pipelines for continuous integration and delivery, is fundamental for the development of cloud infrastructure. Including code quality and vulnerability scans in the pipeline is essential for the security of this infrastructure as code. In one of our previous posts, How to build a CI/CD pipeline for container vulnerability scanning with Trivy and AWS Security Hub, you learned how to scan containers to efficiently identify Common Vulnerabilities and Exposures (CVEs) and work with your developers to address them.
In this post, we’ll continue this topic, and also introduce a method for integrating open source tools that find potentially insecure patterns in your AWS CloudFormation templates with both AWS Security Hub and AWS CodeBuild reports. We’ll be using Stelligent’s open source tool CFN-Nag. We also show you how you can extend the solution to use AWS CloudFormation Guard (currently in preview).
One reason to use this integration is that it gives both security and development teams visibility into potential security risks, and resources that are insecure or non-compliant to your company policy, before they’re deployed.
Solution benefit and deliverables
In this solution, we provide you with a ready-to-use template for performing scanning of your AWS CloudFormation templates by using CFN-Nag. This tool has more than 140 predefined patterns, such as AWS Identity and Access Management (IAM) rules that are too permissive (wildcards), security group rules that are too permissive (wildcards), access logs that aren’t enabled, or encryption that isn’t enabled. You can additionally define your own rules to match your company policy as described in the section later in this post, by using custom profiles and exceptions, and suppressing false positives.
Our solution enables you to do the following:
• Integrate CFN-Nag in a CodeBuild project, scanning the infrastructure code for more than 140 possible insecure patterns, and classifying them as warnings or a failing test.
• Learn how to integrate AWS CloudFormation Guard (CFN-Guard). You need to define your scanning rules in this case.
• Generate CodeBuild reports, so that developers can easily identify failed security tests. In our sample, the build process fails if any critical findings are identified.
• Import to Security Hub the aggregated finding per code branch, so that security professionals can easily spot vulnerable code in repositories and branches. For every branch, we import one aggregated finding.
• Store the original scan report in an Amazon Simple Storage Service (Amazon S3) bucket for auditing purposes.
Note: in this solution, the AWS CloudFormation scanning tools won’t scan your application code that is running at AWS Lambda functions, Amazon Elastic Container Service (Amazon ECS), or Amazon Elastic Compute Cloud (Amazon EC2) instances.
Architecture
Figure 1 shows the architecture of the solution. The main steps are as follows:
1. Your pipeline is triggered when new code is pushed to CodeCommit (which isn’t part of the template) to start a new build.
2. The build process scans the AWS CloudFormation templates by using the cfn_nag_scan or cfn-guard command as defined by the build job.
3. A Lambda function is invoked, and the scan report is sent to it.
4. The scan report is published in an S3 bucket via the Lambda function.
5. The Lambda function aggregates the findings report per repository and git branch and imports the report to Security Hub. The Lambda function also suppresses any previous findings related to this current repo and branch. The severity of the finding is calculated by the number of findings and a weight coefficient that depends on whether the finding is designated as warning or critical.
6. Finally, the Lambda function generates the CodeBuild test report in JUnit format and returns it to CodeBuild. This report only includes information about any failed tests.
7. CodeBuild creates a new test report from the new findings under the SecurityReports test group.
Figure 1: Solution architecture
Figure 1: Solution architecture
Walkthrough
To get started, you need to set up the sample solution that scans one of your repositories by using CFN-Nag or CFN-Guard.
To set up the sample solution
1. Log in to your AWS account if you haven’t done so already. Choose Launch Stack to launch the AWS CloudFormation console with the prepopulated AWS CloudFormation demo template. Choose Next.
Select the Launch Stack button to launch the templateAdditionally, you can find the latest code on GitHub.
2. Fill in the stack parameters as shown in Figure 2:
• CodeCommitBranch: The name of the branch to be monitored, for example refs/heads/master.
• CodeCommitUrl: The clone URL of the CodeCommit repo that you want to monitor. It must be in the same Region as the stack being launched.
• TemplateFolder: The folder in your repo that contains the AWS CloudFormation templates.
• Weight coefficient for failing: The weight coefficient for a failing violation in the template.
• Weight coefficient for warning: The weight coefficient for a warning in the template.
• Security tool: The static analysis tool that is used to analyze the templates (CFN-Nag or CFN-Guard).
• Fail build: Whether to fail the build when security findings are detected.
• S3 bucket with sources: This bucket contains all sources, such as the Lambda function and templates. You can keep the default text if you’re not customizing the sources.
• Prefix for S3 bucket with sources: The prefix for all objects. You can keep the default if you’re not customizing the sources.
Figure 2: AWS CloudFormation stack
Figure 2: AWS CloudFormation stack
View the scan results
After you execute the CodeBuild project, you can view the results in three different ways depending on your preferences: CodeBuild report, Security Hub, or the original CFN-Nag or CFN-Guard report.
CodeBuild report
In the AWS Management Console, go to CodeBuild and choose Report Groups. You can find the report you are interested in under SecurityReports. Both failures and warnings are represented as failed tests and are prefixed with W(Warning) or F(Failure), respectively, as shown in Figure 3. Successful tests aren’t part of the report because they aren’t provided by CFN-Nag reports.
Figure 3: AWS CodeBuild report
Figure 3: AWS CodeBuild report
In the CodeBuild navigation menu, under Report groups, you can see an aggregated view of all scans. There you can see a historical view of the pass rate of your tests, as shown in Figure 4.
Figure 4: AWS CodeBuild Group
Figure 4: AWS CodeBuild Group
Security Hub findings
In the AWS Management Console, go to Security Hub and select the Findings view. The aggregated finding per branch has the title CFN scan repo:name:branch with Company Personal and Product Default. The name and branch are placeholders for the repo and branch name. There is one active finding per repo and branch. All previous reports for this repo and branch are suppressed, so that by default you see only the last ones. If necessary, you can see the previous reports by removing the selection filter in the Security Hub finding console. Figure 5 shows an example of the Security Hub findings.
Figure 5: Security Hub findings
Figure 5: Security Hub findings
Original scan report
Lastly, you can find the original scan report in the S3 bucket aws-sec-build-reports-hash. You can also find a reference to this object in the associated Security Hub finding source URL. The S3 object key is constructed as follows.
cfn-nag-report/repo:source_repository/branch:branch_short/cfn-nag-createdAt.json
where source_repository is the name of the repository, branch_short is the name of the branch, and createdAt is the report date.
The following screen capture shows a sample view of the content.
Figure 6: CFN_NAG report sample
Figure 6: CFN_NAG report sample
Security Hub severity and weight coefficients
The Lambda function aggregates CFN-Nag findings to one Security Hub finding per branch and repo. We consider that in this way you get the best visibility without losing orientation in too many findings if you have a large code base.
The Security Hub finding severity is calculated as follows:
• CFN-Nag critical findings are weighted (multiplied) by 20 and the warnings by 1.
• The sum of all CFN-Nag findings multiplied by their weighted coefficient results in the severity of the Security Hub finding.
The severity label or normalized severity (from 0 to 100) (see AWS Security Finding Format (ASFF) for more information) is calculated from the summed severity. We implemented the following convention:
• If the severity is more than 100 points, the label is set as CRITICAL (100).
• If the severity is lower than 100, the normalized severity and label are mapped as described in AWS Security Finding Format (ASFF).
Your company might have a different way to calculate the severity. If you want to adjust the weight coefficients, change the stack parameter. If you want to adjust the mapping of the CFN-Nag findings to Security hub severity, then you’ll need to adapt the Lambda’s calculateSeverity Python function.
Using custom profiles and exceptions, and suppressing false positives
You can customize CFN-Nag to use a certain rule set by including the specific list of rules to apply (called a profile) within the repository. Customizing rule sets is useful because developers or applications might have different security considerations or risk profiles in specific applications. Additionally the operator might prefer to exclude rules that are prone to introducing false positives.
To add a custom profile, you can modify the cfn_nag_scan command specified in the CodeBuild buildspec.yml file. Use the –profile-path command argument to point to the file that contains the list of rules to use, as shown in the following code sample.
cfn_nag_scan – fail-on-warnings –profile-path .cfn_nag.profile – input-path ${TemplateFolder} -o json > ./report/cfn_nag.out.json
Where .cfn_nag.profile file contains one rule identifier per line:
F2
F3
F5
W11
You can find the full list of available rules using cfn_nag_rules command.
You can also choose instead to use a global deny list of rules, or directly suppress findings per resource by using Metadata tags in each AWS CloudFormation resource. For more information, see the CFN-Nag GitHub repository.
Integrating with AWS CloudFormation Guard
The integration with AWS CloudFormation Guard (CFN-Guard) follows the same architecture pattern as CFN-Nag. The ImportToSecurityHub Lambda function can process both CFN-Nag and CFN-Guard results to import to Security Hub and generate a CodeBuild report.
To deploy the CFN-Guard tool
1. In the AWS Management Console, go to CloudFormation, and then choose Update the previous stack deployed.
2. Choose Next, and then change the SecurityTool parameter to cfn-guard.
3. Continue to navigate through the console and deploy the stack.
This creates a new buildspec.yml file that uses the cfn-guard command line interface (CLI) to scan all AWS CloudFormation templates in the source repository. The scans use an example rule set found in the CFN-Guard repository.
You can choose to generate the rule set for the AWS CloudFormation templates that are required by the scanning engine and add the rule set to your repository as described on the GitHub page for AWS CloudFormation Guard. The rule set must reflect your company security policy. This can be one set for all templates, or dependent on the security profile of the application.
You can use your own rule set by modifying the cfn-guard –rule_path parameter to point to a file from within your repository, as follows.
cfn-guard – rule_set .cfn_guard.ruleset – template "$template" > ./report/template_report
Troubleshooting
If the build report fails, you can find the CloudBuild run logs in the CodeBuild Build history. The build will fail if critical security findings are detected in the templates.
Additionally, the Lambda function execution logs can be found in the CloudWatch Log group aws/lambda/ImportToSecurityHub.
Summary
In this post, you learned how to scan the AWS CloudFormation templates for resources that are potentially insecure or not compliant to your company policy in a CodeBuild project, import the findings to Security Hub, and generate CodeBuild test reports. Integrating this solution to your pipelines can help multiple teams within your organization detect potential security risks in your infrastructure code before its deployed to your AWS environments. If you would like to extend the solution further and need support, contact AWS professional services or an Amazon Partner Network (APN) Partner. If you have technical questions, please use the AWS Security Hub or AWS CodeBuild forums.
If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security how-to content, news, and feature announcements? Follow us on Twitter.
Author
Vesselin Tzvetkov
Vesselin is senior security consultant at AWS Professional Services and is passionate about security architecture and engineering innovative solutions. Outside of technology, he likes classical music, philosophy, and sports. He holds a Ph.D. in security from TU-Darmstadt and a M.S. in electrical engineering from Bochum University in Germany.
Author
Joaquin Manuel Rinaudo
Joaquin is a Senior Security Consultant with AWS Professional Services. He is passionate about building solutions that help developers improve their software quality. Prior to AWS, he worked across multiple domains in the security industry, from mobile security to cloud and compliance related topics. In his free time, Joaquin enjoys spending time with family and reading science-fiction novels.
Reducing Docker image build time on AWS CodeBuild using an external cache
Post Syndicated from Camillo Anania original https://aws.amazon.com/blogs/devops/reducing-docker-image-build-time-on-aws-codebuild-using-an-external-cache/
With the proliferation of containerized solutions to simplify creating, deploying, and running applications, coupled with the use of automation CI/CD pipelines that continuously rebuild, test, and deploy such applications when new changes are committed, it’s important that your CI/CD pipelines run as quickly as possible, enabling you to get early feedback and allowing for faster releases.
AWS CodeBuild supports local caching, which makes it possible to persist intermediate build artifacts, like a Docker layer cache, locally on the build host and reuse them in subsequent runs. The CodeBuild local cache is maintained on the host at best effort, so it’s possible several of your build runs don’t hit the cache as frequently as you would like.
A typical Docker image is built from several intermediate layers that are constructed during the initial image build process on a host. These intermediate layers are reused if found valid in any subsequent image rebuild; doing so speeds up the build process considerably because the Docker engine doesn’t need to rebuild the whole image if the layers in the cache are still valid.
This post shows how to implement a simple, effective, and durable external Docker layer cache for CodeBuild to significantly reduce image build runtime.
Solution overview
The following diagram illustrates the high-level architecture of this solution. We describe implementing each stage in more detail in the following paragraphs.
CodeBuildExternalCacheDiagram
In a modern software engineering approach built around CI/CD practices, whenever specific events happen, such as an application code change is merged, you need to rebuild, test, and eventually deploy the application. Assuming the application is containerized with Docker, the build process entails rebuilding one or multiple Docker images. The environment for this rebuild is on CodeBuild, which is a fully managed build service in the cloud. CodeBuild spins up a new environment to accommodate build requests and runs a sequence of actions defined in its build specification.
Because each CodeBuild instance is an independent environment, build artifacts can’t be persisted in the host indefinitely. The native CodeBuild local caching feature allows you to persist a cache for a limited time so that immediate subsequent builds can benefit from it. Native local caching is performed at best effort and can’t be relied on when multiple builds are triggered at different times. This solution describes using an external persistent cache that you can reuse across builds and is valid at any time.
After the first build of a Docker image is complete, the image is tagged and pushed to Amazon Elastic Container Registry (Amazon ECR). In each subsequent build, the image is pulled from Amazon ECR and the Docker build process is forced to use it as cache for its next build iteration of the image. Finally, the newly produced image is pushed back to Amazon ECR.
In the following paragraphs, we explain the solution and walk you through an example implementation. The solution rebuilds the publicly available Amazon Linux 2 Standard 3.0 image, which is an optimized image that you can use with CodeBuild.
Creating a policy and service role
The first step is to create an AWS Identity and Access Management (IAM) policy and service role for CodeBuild with the minimum set of permissions to perform the job.
1. On the IAM console, choose Policies.
2. Choose Create policy.
3. Provide the following policy in JSON format:
CodeBuild Docker Cache Policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"ecr:GetAuthorizationToken",
"ecr:BatchCheckLayerAvailability",
"ecr:GetDownloadUrlForLayer",
"ecr:GetRepositoryPolicy",
"ecr:DescribeRepositories",
"ecr:ListImages",
"ecr:DescribeImages",
"ecr:BatchGetImage",
"ecr:ListTagsForResource",
"ecr:DescribeImageScanFindings",
"ecr:InitiateLayerUpload",
"ecr:UploadLayerPart",
"ecr:CompleteLayerUpload",
"ecr:PutImage"
],
"Resource": "*"
}
]
}
4. In the Review policy section, enter a name (for example, CodeBuildDockerCachePolicy).
5. Choose Create policy.
6. Choose Roles on the navigation pane.
7. Choose Create role.
8. Keep AWS service as the type of role and choose CodeBuild from the list of services.
9. Choose Next.
10. Search for and add the policy you created.
11. Review the role and enter a name (for example, CodeBuildDockerCacheRole).
12. Choose Create role.
Creating an Amazon ECR repository
In this step, we create an Amazon ECR repository to store the built Docker images.
1. On the Amazon ECR console, choose Create repository.
2. Enter a name (for example, amazon_linux_codebuild_image).
3. Choose Create repository.
Configuring a CodeBuild project
You now configure the CodeBuild project that builds the Docker image and configures its cache to speed up the process.
1. On the CodeBuild console, choose Create build project.
2. Enter a name (for example, SampleDockerCacheProject).
3. For Source provider, choose GitHub.
4. For Repository, select Public repository.
5. For Repository URL, enter https://github.com/aws/aws-codebuild-docker-images.
CodeBuildGitHubSourceConfiguration
6. In the Environment section, for Environment image, select Managed image.
7. For Operating system, choose Amazon Linux 2.
8. For Runtime(s), choose Standard.
9. For Image, enter aws/codebuild/amazonlinux2-x86_64-standard:3.0.
10. For Image version, choose Always use the latest image for this runtime version.
11. For Environment type, choose Linux.
12. For Privileged, select Enable this flag if you want to build Docker images or want your builds to get elevated privileges.
13. For Service role, select Existing service role.
14. For Role ARN, enter the ARN for the service role you created (CodeBuildDockerCachePolicy).
15. Select Allow AWS CodeBuild to modify this service so it can be used with this build project.
CodeBuildEnvironmentConfiguration
16. In the Buildspec section, select Insert build commands.
17. Choose Switch to editor.
18. Enter the following build specification (substitute account-ID and region).
version: 0.2
env:
variables:
CONTAINER_REPOSITORY_URL: account-ID.dkr.ecr.region.amazonaws.com/amazon_linux_codebuild_image
TAG_NAME: latest
phases:
install:
runtime-versions:
docker: 19
pre_build:
commands:
- $(aws ecr get-login – no-include-email)
- docker pull $CONTAINER_REPOSITORY_URL:$TAG_NAME || true
build:
commands:
- cd ./al2/x86_64/standard/1.0
- docker build – cache-from $CONTAINER_REPOSITORY_URL:$TAG_NAME – tag
$CONTAINER_REPOSITORY_URL:$TAG_NAME .
post_build:
commands:
- docker push $CONTAINER_REPOSITORY_URL
19. Choose Create the project.
The provided build specification instructs CodeBuild to do the following:
• Use the Docker 19 runtime to run the build. The following process doesn’t work reliably with Docker versions lower than 19.
• Authenticate with Amazon ECR and pull the image you want to rebuild if it exists (on the first run, this image doesn’t exist).
• Run the image rebuild, forcing Docker to consider as cache the image pulled at the previous step using the –cache-from parameter.
• When the image rebuild is complete, push it to Amazon ECR.
Testing the solution
The solution is fully configured, so we can proceed to evaluate its behavior.
For the first run, we record a runtime of approximately 39 minutes. The build doesn’t use any cache and the docker pull in the pre-build stage fails to find the image we indicate, as expected (the || true statement at the end of the command line guarantees that the CodeBuild instance doesn’t stop because the docker pull failed).
The second run pulls the previously built image before starting the rebuild and completes in approximately 6 minutes, most of which is spent downloading the image from Amazon ECR (which is almost 5 GB).
We trigger another run after simulating a change halfway through the Dockerfile (addition of an echo command to the statement at line 291 of the Dockerfile). Docker still reuses the layers in the cache until the point of the changed statement and then rebuilds from scratch the remaining layers described in the Dockerfile. The runtime was approximately 31 minutes; the overhead of downloading the whole image first partially offsets the advantages of using it as cache.
It’s relevant to note the image size in this use case is considerably large; on average, projects deal with smaller images that introduce less overhead. Furthermore, the previous run had the built-in CodeBuild feature to cache Docker layers at best effort disabled; enabling it provides further efficiency because the docker pull specified in the pre-build stage doesn’t have to download the image if the one available locally matches the one on Amazon ECR.
Cleaning up
When you’re finished testing, you should un-provision the following resources to avoid incurring further charges and keep the account clean from unused resources:
• The amazon_linux_codebuild_image Amazon ECR repository and its images;
• The SampleDockerCacheProject CodeBuild project;
• The CodeBuildDockerCachePolicy policy and the CodeBuildDockerCacheRole role.
Conclusion
In this post, we reviewed a simple and effective solution to implement a durable external cache for Docker on CodeBuild. The solution provides significant improvements in the execution time of the Docker build process on CodeBuild and is general enough to accommodate the majority of use cases, including multi-stage builds.
The approach works in synergy with the built-in CodeBuild feature of caching Docker layers at best effort, and we recommend using it for further improvements. Shorter build processes translate to lower compute costs, and overall determine a shorter development lifecycle for features released faster and at a lower cost.
About the Author
Camillo Anania is a Global DevOps Consultant with AWS Professional Services, London, UK.
James Jacob is a Global DevOps Consultant with AWS Professional Services, London, UK.
Scalable agile development practices based on AWS CodeCommit
Post Syndicated from Mengxin Zhu original https://aws.amazon.com/blogs/devops/scalable-agile-development-practices-based-on-aws-codecommit/
Development teams use agile development processes based on Git services extensively. AWS provides AWS CodeCommit, a managed, Git protocol-based, secure, and highly available code service. The capabilities of CodeCommit combined with other developer tools, like AWS CodeBuild and AWS CodePipeline, make it easy to manage collaborative, scalable development process with fine-grained permissions and on-demand resources.
You can manage user roles with different AWS Identity and Access Management (IAM) policies in the code repository of CodeCommit. You can build your collaborative development process with pull requests and approval rules. The process described in this post only requires you to manage the developers’ role, without forking the source repository for individual developers. CodeCommit pull requests can integrate numerous code analysis services as approvers to improve code quality and mitigate security vulnerabilities, such as SonarQube static scanning and the ML-based code analysis service Amazon CodeGuru Reviewer.
The CodeCommit-based agile development process described in this post has the following characteristics:
• Control permissions of the CodeCommit repository via IAM.
• Any code repository has at least two user roles:
• Development collaborator – Participates in the development of the project.
• Repository owner – Has code review permission and partial management permissions of the repository. The repository owner is also the collaborator of the repository.
• Both development collaborator and owner have read permissions of the repository and can pull code to local disk via the Git-supported protocols.
• The development collaborator can push new code to branches with a specific prefix, for example, features/ or bugs/. Multiple collaborators can work on a particular branch for one pull request. Collaborators can create new pull requests to request merging code into the main branch, such as the mainline branch.
• The repository owner has permission to review pull requests with approval voting and merge pull requests.
• Directly pushing code to the main branch of repository is denied.
• Development workflow. This includes the following:
• Creating an approval template rule of CodeCommit that requires at least two approvals from the sanity checking build of the pull request and repository owner. The workflow also applies the approval rule to require mandatory approvals for pull requests of the repository.
• The creation and update of source branch events of pull requests via Amazon EventBridge triggers a sanity checking build of CodeBuild to compile, test, and analyze the pull request code. If all checks pass, the pull request gets an approval voting from the sanity checking build.
• Watching the main branch of the repository triggers a continuous integration for any commit. You can continuously publish artifacts of your project to the artifact repository or integrate the latest version of the service to your business system.
This agile development process can use AWS CloudFormation and AWS Cloud Development Kit (AWS CDK) to orchestrate AWS resources with the best practice of infrastructure as code. You can manage hundreds of repositories in your organization and automatically provision new repositories and related DevOps resources from AWS after the pull request of your IaC as a new application is approved. This makes sure that you’re managing the code repository and DevOps resources in a secure and compliant way. You can use it as a reference solution for your organization to manage large-scale R&D resources.
Solution overview
In the following use case, you’re working on a Java-based project AWS Toolkit for JetBrains. This application has developers that can submit code via pull requests. Each pull request is automatically checked and validated by CodeBuild builds. The owners of the project can review the pull request and merge it to the main branch. The code submitted to the main branch triggers the continuous integration to build the project artifacts.
The following diagram illustrates the components built in this post and their role in the DevOps process.
architecture diagram
Prerequisites
For this walkthrough, you should meet the following prerequisites:
Preparing the code
Clone the sample code from the Github repo with your preferred Git client or IDE and view branch aws-toolkit-jetbrains, or download the sample code directly and unzip it into an empty folder.
Initializing the environment
Open the terminal or command prompt of your operating system, enter the directory where the sample code is located, enter the following code to initialize the environment, and install the dependency packages:
npm run init
Deploying application
After successfully initializing the AWS CDK environment and installing the dependencies of the sample application, enter the following code to deploy the application:
npm run deploy
Because the application creates the IAM roles and policies, AWS CDK requires you to confirm security-related changes before deploying it. You see the following outputs from the command line.
deploy stack
Enter y to confirm the security changes, and AWS CDK begins to deploy the application. After a few minutes, you see output similar to the following code, indicating that the application stack has been successfully deployed in your AWS account:
✅ CodecommitDevopsModelStack
Outputs:
CodecommitDevopsModelStack.Repo1AdminRoleOutput = arn:aws:iam::012345678912:role/codecommitmodel/CodecommitDevopsModelStack-Repo1AdminRole0648F018-OQGKZPM6T0HP
CodecommitDevopsModelStack.Repo1CollaboratorRoleOutput = arn:aws:iam::012345678912:role/codecommitmodel/CodecommitDevopsModelStac-Repo1CollaboratorRole1EB-15KURO7Z9VNOY
Stack ARN:
arn:aws:cloudformation:ap-southeast-1:012345678912:stack/CodecommitDevopsModelStack/5ecd1c50-b56b-11ea-8061-020de04cec9a
As shown in the preceding code, the output of successful deployment indicates that the ARN of two IAM roles were created on behalf of the owner and development collaborator of the source code repository.
Checking deployment results
After successfully deploying the app, you can sign in to the CodeCommit console and browse repositories. The following screenshot shows three repositories.
created repos
For this post, we use three repositories to demonstrate configuring the different access permissions for different teams in your organization. As shown in the following screenshot, the repository CodeCommitDevopsModelStack-MyApp1 is tagged to grant permissions to the specific team abc.
repository tags
The IAM roles for the owner and development collaborator only have access to the code repository with the following tags combination:
{
'app': 'my-app-1',
'team': 'abc',
}
Configuring CodeCommit repository access on behalf of owner and collaborator
Next, you configure the current user to simulate the owner and development collaborator via IAM’s AssumeRole.
Edit the AWS CLI profile file with your preferred text editor and add the following configuration lines:
[profile codecommit-repo1-owner]
role_arn = <the ARN of owner role after successfully deploying sample app>
source_profile = default
region = ap-southeast-1
cli_pager=
[profile codecommit-repo1-collaborator]
role_arn = <the ARN of collaborator role after successfully deploying sample app>
source_profile = default
region = ap-southeast-1
cli_pager=
Replace the role_arn in the owner and collaborator sections with the corresponding output after successfully deploying the sample app.
If the AWS CLI isn’t using the default profile, replace the value of source_profile with the profile name you’re currently using.
Make the region consistent with the value configured in source_profile. For example, this post uses ap-southeast-1.
After saving the modification of the profile, you can test this configuration from the command line. See the following code:
export AWS_DEFAULT_PROFILE=codecommit-repo1-owner # assume owner role of repository
aws sts get-caller-identity # get current user identity, you should see output like below,
{
"UserId": "AROAQP3VLCVWYYTPJL2GW:botocore-session-1587717914",
"Account": "0123456789xx",
"Arn": "arn:aws:sts::0123456789xx:assumed-role/CodecommitDevopsModelStack-Repo1AdminRole0648F018-1SNXR23P4XVYZ/botocore-session-1587717914"
}
aws codecommit list-repositories # list of all repositories of AWS CodeCommit in configured region
{
"repositories": [
{
"repositoryName": "CodecommitDevopsModelStack-MyApp1",
"repositoryId": "208dd6d1-ade4-4633-a2a3-fe1a9a8f3d1c "
},
{
"repositoryName": "CodecommitDevopsModelStack-MyApp2",
"repositoryId": "44421652-d12e-413e-85e3-e0db894ab018"
},
{
"repositoryName": "CodecommitDevopsModelStack-MyApp3",
"repositoryId": "8d146b34-f659-4b17-98d8-85ebaa07283c"
}
]
}
aws codecommit get-repository – repository-name CodecommitDevopsModelStack-MyApp1 # get detail information of repository name ends with MyApp1
{
"repositoryMetadata": {
"accountId": "0123456789xx",
"repositoryId": "208dd6d1-ade4-4633-a2a3-fe1a9a8f3d1c",
"repositoryName": "CodecommitDevopsModelStack-MyApp1",
"repositoryDescription": "Repo for App1.",
"lastModifiedDate": "2020-06-24T00:06:24.734000+08:00",
"creationDate": "2020-06-24T00:06:24.734000+08:00",
"cloneUrlHttp": "https://git-codecommit.ap-southeast-1.amazonaws.com/v1/repos/CodecommitDevopsModelStack-MyApp1",
"cloneUrlSsh": "ssh://git-codecommit.ap-southeast-1.amazonaws.com/v1/repos/CodecommitDevopsModelStack-MyApp1",
"Arn": "arn:aws:codecommit:ap-southeast-1:0123456789xx:CodecommitDevopsModelStack-MyApp1"
}
}
aws codecommit get-repository – repository-name CodecommitDevopsModelStack-MyApp2 # try to get detail information of repository MyApp2 that does not have accessing permission by the role
An error occurred (AccessDeniedException) when calling the GetRepository operation: User: arn:aws:sts::0123456789xx:assumed-role/CodecommitDevopsModelStack-Repo1AdminRole0648F018-OQGKZPM6T0HP/botocore-session-1593325146 is not authorized to perform: codecommit:GetRepository on resource: arn:aws:codecommit:ap-southeast-1:0123456789xx:CodecommitDevopsModelStack-MyApp2
You can also grant IAM policies starting with CodecommitDevopsmodelStack-CodecommitCollaborationModel to existing IAM users for the corresponding owner or collaborator permissions.
Initializing the repository
The new code repository CodecommitdevopsmodelStack-MyApp1 is an empty Git repository without any commit. You can use the AWS Toolkit for JetBrains project as the existing local codebase and push the code to the repository hosted by CodeCommit.
Enter the following code from the command line:
export AWS_DEFAULT_PROFILE=codecommit-repo1-owner # assume owner role of repository
git clone https://github.com/aws/aws-toolkit-jetbrains.git # clone aws-toolkit-jetbrains to local as existing codebase
cd aws-toolkit-jetbrains
git remote add codecommit codecommit::ap-southeast-1://CodecommitDevopsModelStack-MyApp1 # add CodeCommit hosted repo as new remote named as codecommit. Follow the doc set up AWS CodeCommit with git-remote-codecommit, or use remote url of repository via https/ssh protocol
git push codecommit master:init # push existing codebase to a temporary branch named 'init'
aws codecommit create-branch – repository-name CodecommitDevopsModelStack-MyApp1 – branch-name master – commit-id `git rev-parse master` # create new branch 'master'
aws codecommit update-default-branch – repository-name CodecommitDevopsModelStack-MyApp1 – default-branch-name master # set branch 'master' as main branch of repository
aws codecommit delete-branch – repository-name CodecommitDevopsModelStack-MyApp1 – branch-name init # clean up 'init' branch
Agile development practices
For this use case, you act as the collaborator of the repository implementing a new feature for aws-toolkit-jetbrains, then follow the development process to submit your code changes to the main branch.
Enter the following code from the command line:
export AWS_DEFAULT_PROFILE=codecommit-repo1-collaborator # assume collaborator role of repository
# add/modify/delete source files for your new feature
git commit -m 'This is my new feature.' -a
git push codecommit HEAD:refs/heads/features/my-feature # push code to new branch with prefix /features/
aws codecommit create-pull-request – title 'My feature "Short Description".' – description 'Detail description of feature request' – targets repositoryName=CodecommitDevopsModelStack-MyApp1,sourceReference=features/my-feature,destinationReference=master # create pull request for new feature
The preceding code submits the changes of the new feature to a branch with the prefix features/ and creates a pull request to merge the change into the main branch.
On the CodeCommit console, you can see that a pull request called My feature "Short Description". created by the development collaborator has passed the sanity checking build of the pull request and gets an approval voting (it takes about 15 minutes to complete the checking build in this project).
PR build result
The owner of the repository also needs to review the pull request with one approval at least, then they can merge the repository to the main branch. The pull request on the CodeCommit console supports several code review features, such as change comparison, in-line comments, and code discussions. For more information, see Using AWS CodeCommit Pull Requests to request code reviews and discuss code. The following screenshot shows the review tool on the CodeCommit console, on the Changes tab.
CodeReview Tool
The following screenshot shows the approval details of the pull request, on the Approvals tab.
Approvals tab
When browsing the continuous integration deployment project after merging the pull request, you can see that a new continuous integration build has been triggered by the event of merging the pull request to the main branch.
Deployment build
Cleaning up
When you’re finished exploring this use case and discovering the deployed resources, the last step is to clean up your account. The following code deletes all the resources you created:
npm run cleanup
Summary
This post discussed agile development practices based on CodeCommit, including implementation mechanisms and practice processes, and demonstrated how to collaborate in development under those processes. AWS powers the code that manages the code repository itself and the DevOps processes built around it in the example application. You can use the IaC capability of AWS and apply those practices in your organization to build compliant and secure R&D processes.
Automated CI/CD pipeline for .NET Core Lambda functions using AWS extensions for dotnet CLI
Post Syndicated from Sundar Narasiman original https://aws.amazon.com/blogs/devops/automated-ci-cd-pipeline-for-net-core-lambda-functions-using-aws-extensions-for-dotnet-cli/
The trend of building AWS Serverless applications using AWS Lambda is increasing at an ever-rapid pace. Common use cases for AWS Lambda include data processing, real-time file processing, and extract, transform, and load (ETL) for data processing, web backends, internet of things (IoT) backends, and mobile backends. Lambda natively supports languages such as Java, Go, PowerShell, Node.js, C#, Python, and Ruby. It also provides a Runtime API that allows you to use any additional programming languages to author your functions.
.NET framework occupies a significant footprint in the technology landscape of enterprises. Nowadays, enterprise customers are modernizing .NET framework applications to .NET Core using AWS Serverless (Lambda). In this journey, you break down a large monolith service into multiple smaller independent and autonomous microservices using.NET Core Lambda functions
When you have several microservices running in production, a change management strategy is key for business agility and time-to-market changes. The change management of .NET Core Lambda functions translates to how well you implement an automated CI/CD pipeline using AWS CodePipeline. In this post, you see two approaches for implementing CI/CD for .NET Core Lambda functions: creating a pipeline with either two or three stages.
Creating a pipeline with two stages
In this approach, you define the pipeline in CodePipeline with two stages: AWS CodeCommit and AWS CodeBuild. CodeCommit is the fully-managed source control repository that stores the source code for .NET Core Lambda functions. It triggers CodeBuild when a new code change is published. CodeBuild defines a compute environment for the build process. It builds the .NET Core Lambda function and creates a deployment package (.zip). Finally, CodeBuild uses AWS extensions for Dotnet CLI to deploy the Lambda packages (.zip) to the Lambda environment. The following diagram illustrates this architecture.
CodePipeline with CodeBuild and CodeCommit stages.
CodePipeline with CodeBuild and CodeCommit stages.
Creating a pipeline with three stages
In this approach, you define the pipeline with three stages: CodeCommit, CodeBuild, and AWS CodeDeploy.
CodeCommit stores the source code for .NET Core Lambda functions and triggers CodeBuild when a new code change is published. CodeBuild defines a compute environment for the build process and builds the .NET Core Lambda function. Then CodeBuild invokes the CodeDeploy stage. CodeDeploy uses AWS CloudFormation templates to deploy the Lambda function to the Lambda environment. The following diagram illustrates this architecture.
CodePipeline with CodeCommit, CodeBuild and CodeDeploy stages.
CodePipeline with CodeCommit, CodeBuild and CodeDeploy stages.
Solution Overview
In this post, you learn how to implement an automated CI/CD pipeline using the first approach: CodePipeline with CodeCommit and CodeBuild stages. The CodeBuild stage in this approach implements the build and deploy functionalities. The high-level steps are as follows:
1. Create the CodeCommit repository.
2. Create a Lambda execution role.
3. Create a Lambda project with .NET Core CLI.
4. Change the Lambda project configuration.
5. Create a buildspec file.
6. Commit changes to the CodeCommit repository.
7. Create your CI/CD pipeline.
8. Complete and verify pipeline creation.
For the source code and buildspec file, see the GitHub repo.
Prerequisites
Before you get started, you need the following prerequisites:
Creating a CodeCommit repository
You first need a CodeCommit repository to store the Lambda project source code.
1. In the Repository settings section, for Repository name, enter a name for your repository.
2. Choose Create.
Name a repository
3. Initialize this repository with a markdown file (readme.md). You need this markdown file to create documentation about the repository.
4. Set up an AWS Identity and Access Management (IAM) credential to CodeCommit. Alternatively, you can set up SSH-based access. For instructions, see Setup for HTTPS users using Git credentials and Setup steps for SSH connections to AWS CodeCommit repositories on Linux, MacOS, or Unix. You need this to work with the CodeCommit repository from the development environment.
5. Clone the CodeCommit repository to a local folder.
Proceed to the next step to create an IAM role for Lambda execution.
Creating a Lambda execution role
Every Lambda function needs an IAM role for execution. Create an IAM role for Lambda execution with the appropriate IAM policy, if it doesn’t exist already. You’re now ready to create a Lambda function project using .NET Core Command Line Interface (CLI).
Creating a Lambda function project
You have multiple options for creating .NET Core Lambda function projects, such as using Visual Studio 2019, Visual Studio Code, and .NET Core CLI. In this post, you use .NET Core CLI.
By default, .NET Core CLI doesn’t support Lambda projects. You need the Amazon.Lambda.Templates nuget package to create your project.
1. Install the nuget package Amazon.Lambda.Templates to have all the Amazon Lambda project templates in the development environment. See the following CLI Command.
dotnet new -i Amazon.Lambda.Templates::*
2. Verify the installation with the following CLI Command.
dotnet new
You should see the following output reflecting the presence of various Lambda templates in the development environment. You also need to install AWS extensions for Dotnet Lambda CLI to deploy and invoke Lambda functions from the terminal or command prompt.dotnet cli command listing lambda project templates
3. To install the extensions, enter the following CLI Commands.
dotnet tool install -g Amazon.Lambda.Tools
dotnet tool update -g Amazon.Lambda.Tools
You’re now ready to create a Lambda function project in the development environment.
4. Navigate to the root of the cloned CodeCommit repository (which you created in the previous step).
5. Create the Lambda function by entering the following CLI Command.
dotnet new lambda.EmptyFunction – name Dotnetlambda4 – profile default – region us-east-1
After you create your Lambda function project, you need to make some configuration changes.
Changing the Lambda function project configuration
When you create a .NET Core Lambda function project, it adds the configuration file aws-lambda-tools-defaults.json at the root of the project directory. This file holds the various configuration parameters for Lambda execution. You want to make sure that the function role is set to the IAM role you created earlier, and that the profile is set to default.
The updated aws-lambda-tools-defaults.json file should look like the following code:
{
"Information": [
"This file provides default values for the deployment wizard inside Visual Studio and the AWS Lambda commands added to the .NET Core CLI.",
"To learn more about the Lambda commands with the .NET Core CLI execute the following command at the command line in the project root directory.",
"dotnet lambda help",
"All the command line options for the Lambda command can be specified in this file."
],
"profile": "default",
"region": "us-east-1",
"configuration": "Release",
"framework": "netcoreapp3.1",
"function-runtime": "dotnetcore3.1",
"function-memory-size": 256,
"function-timeout": 30,
"function-handler": "Dotnetlambda4::Dotnetlambda4.Function::FunctionHandler",
"function-role": "arn:aws:iam::awsaccountnumber:role/testlambdarole"
}
After you update your project configuration, you’re ready to create the buildspec.yml file.
Creating a buildspec file
As a prerequisite to configuring the CodeCommit stage, you created a Lambda function project. For the CodeBuild stage, you need to create a buildspec file.
Create a buildspec.yml file with the following definition and save it at the root of the CodeCommit directory:
version: 0.2
env:
variables:
DOTNET_ROOT: /root/.dotnet
secrets-manager:
AWS_ACCESS_KEY_ID_PARAM: CodeBuild:AWS_ACCESS_KEY_ID
AWS_SECRET_ACCESS_KEY_PARAM: CodeBuild:AWS_SECRET_ACCESS_KEY
phases:
install:
runtime-versions:
dotnet: 3.1
pre_build:
commands:
- echo Restore started on `date`
- export PATH="$PATH:/root/.dotnet/tools"
- pip install – upgrade awscli
- aws configure set profile $Profile
- aws configure set region $Region
- aws configure set aws_access_key_id $AWS_ACCESS_KEY_ID_PARAM
- aws configure set aws_secret_access_key $AWS_SECRET_ACCESS_KEY_PARAM
- cd Dotnetlambda4
- cd src
- cd Dotnetlambda4
- dotnet clean
- dotnet restore
build:
commands:
- echo Build started on `date`
- dotnet new -i Amazon.Lambda.Templates::*
- dotnet tool install -g Amazon.Lambda.Tools
- dotnet tool update -g Amazon.Lambda.Tools
- dotnet lambda deploy-function "Dotnetlambda4" – function-role "arn:aws:iam::yourawsaccount:role/youriamroleforlambda" – region "us-east-1"
You’re now ready to commit your changes to the CodeCommit repository.
Committing changes to the CodeCommit repository
To push changes to your CodeCommit repository, enter the following git commands.
git add – all
git commit –a –m “Initial Comment”
git push
After you commit the changes, you can create your CI/CD pipeline using CodePipeline.
Creating a CI/CD pipeline
To create your pipeline with a CodeCommit and CodeBuild stage, complete the following steps:
1. In the Pipeline settings section, for Pipeline name, enter a name.
2. For Service role, select New service role.
3. For Role name, use the auto-generated name.
4. Select Allow AWS CodePipeline to create a service role so it can be used with this new pipeline.
5. Choose Next.Choose Pipeline settings
6. In the Source section, for Source provider, choose AWS CodeCommit.
7. For Repository name, choose your repository.
8. For Branch name, choose your branch.
9. For Change detection options, select Amazon CloudWatch Events.
10. Choose Next.Populating the Source stage
11. In the Build section, for Build provider, choose AWS CodeBuild.Populating the CodeBuild stage
12. For Environment image, choose Managed image.
13. For Operating system, choose Ubuntu.
14. For Image, choose aws/codebuild/standard:4.0.
15. For Image version, choose Always use the latest image for this runtime versionSelecting Codebuild runtime
16. CodeBuild needs to assume an IAM service role to get the required privileges for successful build operation.Create a new service role for the CodeBuild project.Selecting the Service role
17. Attach the following IAM policy to the role:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "SecretManagerRead",
"Effect": "Allow",
"Action": [
"secretsmanager:GetRandomPassword",
"secretsmanager:GetResourcePolicy",
"secretsmanager:UntagResource",
"secretsmanager:GetSecretValue",
"secretsmanager:DescribeSecret",
"secretsmanager:ListSecretVersionIds",
"secretsmanager:ListSecrets",
"secretsmanager:TagResource"
],
"Resource": "*"
}
]
}
18. You now need to define the compute and environment variables for CodeBuild. For Compute, select your preferred compute.
19. For Environment variables, enter two variables. For Region, enter your preferred Region. For Profile, Enter Value as default. Selecting CodeBuild env optionsThis allows the environment to use the default AWS profile in the build process.
20. To set up an AWS profile, the CodeBuild environment needs AccessKeyId and SecretAccessKey. As a best practice, configure AccessKeyId and SecretAccessKey as secrets in AWS Secrets Manager and reference it in buildspec.yml. On the Secrets Manager console, choose Store a new secret.
21. For Select secret type, select Other type of secrets.Selecting secret types
22. Configure secrets AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY.Configuring secrets
23. For the encryption key, choose DefaultEncryptionKey.
24. Choose Next.
25. For Secret name, enter CodeBuild.Secret name
26. Leave the rest of selections as default and choose Store.Commented code
27. In the Add deploy stage section, choose Skip deploy stage.Add Deploy stage
Completing and verifying your pipeline
After you save your pipeline, push the code changes of the Lambda function from the local repository to the remote CodeCommit repository.
After a few seconds, you should see the activation of the CodeCommit stage and transition to CodeBuild stage. Pipeline creation can take up to a few minutes.
CodePipeline
You can verity your pipeline on the CodePipeline console. This should deploy the Lambda function changes to the Lambda environment.
Cleaning up
If you no longer need the following resources, delete them to avoid incurring further charges:
• CodeCommit repository
• CodePipeline project
• CodeBuild project
• IAM role for Lambda execution
• Lambda function
Conclusion
In this post, you implemented an automated CI/CD for .NET Core Lambda functions using two stages of CodePipeline: CodeCommit and CodeBuild. You can apply this solution to your own use cases.
About the author
Sundararajan Narasiman works as Senior Partner Solutions Architect with Amazon Web Services.
ICYMI: Serverless Q2 2020
Post Syndicated from Moheeb Zara original https://aws.amazon.com/blogs/compute/icymi-serverless-q2-2020/
Welcome to the 10th edition of the AWS Serverless ICYMI (in case you missed it) quarterly recap. Every quarter, we share all of the most recent product launches, feature enhancements, blog posts, webinars, Twitch live streams, and other interesting things that you might have missed!
In case you missed our last ICYMI, checkout what happened last quarter here.
AWS Lambda
AWS Lambda functions can now mount an Amazon Elastic File System (EFS). EFS is a scalable and elastic NFS file system storing data within and across multiple Availability Zones (AZ) for high availability and durability. In this way, you can use a familiar file system interface to store and share data across all concurrent execution environments of one, or more, Lambda functions. EFS supports full file system access semantics, such as strong consistency and file locking.
Using different EFS access points, each Lambda function can access different paths in a file system, or use different file system permissions. You can share the same EFS file system with Amazon EC2 instances, containerized applications using Amazon ECS and AWS Fargate, and on-premises servers.
Learn how to create an Amazon EFS-mounted Lambda function using the AWS Serverless Application Model in Sessions With SAM Episode 10.
With our recent launch of .NET Core 3.1 AWS Lambda runtime, we’ve also released version 2.0.0 of the PowerShell module AWSLambdaPSCore. The new version now supports PowerShell 7.
Amazon EventBridge
At AWS re:Invent 2019, we introduced a preview of Amazon EventBridge schema registry and discovery. This is a way to store the structure of the events (the schema) in a central location. It can simplify using events in your code by generating the code to process them for Java, Python, and TypeScript. In April, we announced general availability of EventBridge Schema Registry.
We also added support for resource policies. Resource policies allow sharing of schema repository across different AWS accounts and organizations. In this way, developers on different teams can search for and use any schema that another team has added to the shared registry.
Ben Smith, AWS Serverless Developer Advocate, published a guide on how to capture user events and monitor user behavior using the Amazon EventBridge partner integration with Auth0. This enables better insight into your application to help deliver a more customized experience for your users.
AWS Step Functions
In May, we launched a new AWS Step Functions service integration with AWS CodeBuild. CodeBuild is a fully managed continuous integration service that compiles source code, runs tests, and produces packages that are ready for deployment. Now, during the execution of a state machine, you can start or stop a build, get build report summaries, and delete past build executions records.
With the new AWS CodePipeline support to invoke Step Functions you can customize your delivery pipeline with choices, external validations, or parallel tasks. Each of those tasks can now call CodeBuild to create a custom build following specific requirements. Learn how to build a continuous integration workflow with Step Functions and AWS CodeBuild.
Rob Sutter, AWS Serverless Developer Advocate, has published a video series on Step Functions. We’ve compiled a playlist on YouTube to help you on your serverless journey.
AWS Amplify
The AWS Amplify Framework announced in April that they have rearchitected the Amplify UI component library to enable JavaScript developers to easily add authentication scenarios to their web apps. The authentication components include numerous improvements over previous versions. These include the ability to automatically sign in users after sign-up confirmation, better customization, and improved accessibility.
Amplify also announced the availability of Amplify Framework iOS and Amplify Framework Android libraries and tools. These help mobile application developers to easily build secure and scalable cloud-powered applications. Previously, mobile developers relied on a combination of tools and SDKS along with the Amplify CLI to create and manage a backend.
These new native libraries are oriented around use-cases, such as authentication, data storage and access, machine learning predictions etc. They provide a declarative interface that enables you to programmatically apply best practices with abstractions.
A mono-repository is a repository that contains more than one logical project, each in its own repository. Monorepo support is now available for the AWS Amplify Console, allowing developers to connect Amplify Console to a sub-folder in your mono-repository. Learn how to set up continuous deployment and hosting on a monorepo with the Amplify Console.
Amazon Keyspaces (for Apache Cassandra)
Amazon Managed Apache Cassandra Service (MCS) is now generally available under the new name: Amazon Keyspaces (for Apache Cassandra). Amazon Keyspaces is built on Apache Cassandra and can be used as a fully managed serverless database. Your applications can read and write data from Amazon Keyspaces using your existing Cassandra Query Language (CQL) code, with little or no changes. Danilo Poccia explains how to use Amazon Keyspace with API Gateway and Lambda in this launch post.
AWS Glue
In April we extended AWS Glue jobs, based on Apache Spark, to run continuously and consume data from streaming platforms such as Amazon Kinesis Data Streams and Apache Kafka (including the fully-managed Amazon MSK). Learn how to manage a serverless extract, transform, load (ETL) pipeline with Glue in this guide by Danilo Poccia.
Serverless posts
Our team is always working to build and write content to help our customers better understand all our serverless offerings. Here is a list of the latest published to the AWS Compute Blog this quarter.
Introducing the new serverless LAMP stack
Ben Smith, AWS Serverless Developer Advocate, introduces the Serverless LAMP stack. He explains how to use serverless technologies with PHP. Learn about the available tools, frameworks and strategies to build serverless applications, and why now is the right time to start.
Building a location-based, scalable, serverless web app
James Beswick, AWS Serverless Developer Advocate, walks through building a location-based, scalable, serverless web app. Ask Around Me is an example project that allows users to ask questions within a geofence to create an engaging community driven experience.
Building well-architected serverless applications
Julian Wood, AWS Serverless Developer Advocate, published two blog series on building well-architected serverless applications. Learn how to better understand application health and lifecycle management.
Device hacking with serverless
Go beyond the browser with these creative and physical projects. Moheeb Zara, AWS Serverless Developer Advocate, published several serverless powered device hacks, all using off the shelf parts.
April
May
June
Tech Talks and events
We hold AWS Online Tech Talks covering serverless topics throughout the year. You can find these in the serverless section of the AWS Online Tech Talks page. We also regularly join in on podcasts, and record short videos you can find to learn in quick bite-sized chunks.
Here are the highlights from Q2.
Innovator Island Workshop
Learn how to build a complete serverless web application for a popular theme park called Innovator Island. James Beswick created a video series to walk you through this popular workshop at your own pace.
Serverless First Function
In May, we held a new virtual event series, the Serverless-First Function, to help you and your organization get the most out of the cloud. The first event, on May 21, included sessions from Amazon CTO, Dr. Werner Vogels, and VP of Serverless at AWS, David Richardson. The second event, May 28, was packed with sessions with our AWS Serverless Developer Advocate team. Catch up on the AWS Twitch channel.
Live streams
The AWS Serverless Developer Advocate team hosts several weekly livestreams on the AWS Twitch channel covering a wide range of topics. You can catch up on all our past content, including workshops, on the AWS Serverless YouTube channel.
Eric Johnson hosts “Sessions with SAM” every Thursday at 10AM PST. Each week, Eric shows how to use SAM to solve different serverless challenges. He explains how to use SAM templates to build powerful serverless applications. Catch up on the last few episodes.
James Beswick, AWS Serverless Developer Advocate, has compiled a round-up of all his content from Q2. He has plenty of videos ranging from beginner to advanced topics.
AWS Serverless Heroes
We’re pleased to welcome Kyuhyun Byun and Serkan Özal to the growing list of AWS Serverless Heroes. The AWS Hero program is a selection of worldwide experts that have been recognized for their positive impact within the community. They share helpful knowledge and organize events and user groups. They’re also contributors to numerous open-source projects in and around serverless technologies.
Still looking for more?
The Serverless landing page has much more information. The Lambda resources page contains case studies, webinars, whitepapers, customer stories, reference architectures, and even more getting started tutorials.
Follow the AWS Serverless team on our new LinkedIn page we share all the latest news and events. You can also follow all of us on Twitter to see latest news, follow conversations, and interact with the team.
Chris Munns: @chrismunns
Eric Johnson: @edjgeek
James Beswick: @jbesw
Moheeb Zara: @virgilvox
Ben Smith: @benjamin_l_s
Rob Sutter: @rts_rob
Julian Wood: @julian_wood
Serverless Architecture for a Web Scraping Solution
Post Syndicated from Dzidas Martinaitis original https://aws.amazon.com/blogs/architecture/serverless-architecture-for-a-web-scraping-solution/
If you are interested in serverless architecture, you may have read many contradictory articles and wonder if serverless architectures are cost effective or expensive. I would like to clear the air around the issue of effectiveness through an analysis of a web scraping solution. The use case is fairly simple: at certain times during the day, I want to run a Python script and scrape a website. The execution of the script takes less than 15 minutes. This is an important consideration, which we will come back to later. The project can be considered as a standard extract, transform, load process without a user interface and can be packed into a self-containing function or a library.
Subsequently, we need an environment to execute the script. We have at least two options to consider: on-premises (such as on your local machine, a Raspberry Pi server at home, a virtual machine in a data center, and so on) or you can deploy it to the cloud. At first glance, the former option may feel more appealing — you have the infrastructure available free of charge, why not to use it? The main concern of an on-premises hosted solution is the reliability — can you assure its availability in case of a power outage or a hardware or network failure? Additionally, does your local infrastructure support continuous integration and continuous deployment (CI/CD) tools to eliminate any manual intervention? With these two constraints in mind, I will continue the analysis of the solutions in the cloud rather than on-premises.
Let’s start with the pricing of three cloud-based scenarios and go into details below.
Pricing table of three cloud-based scenarios
*The AWS Lambda free usage tier includes 1M free requests per month and 400,000 GB-seconds of compute time per month. Review AWS Lambda pricing.
Option #1
The first option, an instance of a virtual machine in AWS (called Amazon Elastic Cloud Compute or EC2), is the most primitive one. However, it definitely does not resemble any serverless architecture, so let’s consider it as a reference point or a baseline. This option is similar to an on-premises solution giving you full control of the instance, but you would need to manually spin an instance, install your environment, set up a scheduler to execute your script at a specific time, and keep it on for 24×7. And don’t forget the security (setting up a VPC, route tables, etc.). Additionally, you will need to monitor the health of the instance and maybe run manual updates.
Option #2
The second option is to containerize the solution and deploy it on Amazon Elastic Container Service (ECS). The biggest advantage to this is platform independence. Having a Docker file (a text document that contains all the commands you could call on the command line to assemble an image) with a copy of your environment and the script enables you to reuse the solution locally—on the AWS platform, or somewhere else. A huge advantage to running it on AWS is that you can integrate with other services, such as AWS CodeCommit, AWS CodeBuild, AWS Batch, etc. You can also benefit from discounted compute resources such as Amazon EC2 Spot instances.
Architecture of CloudWatch, Batch, ECR
The architecture, seen in the diagram above, consists of Amazon CloudWatch, AWS Batch, and Amazon Elastic Container Registry (ECR). CloudWatch allows you to create a trigger (such as starting a job when a code update is committed to a code repository) or a scheduled event (such as executing a script every hour). We want the latter: executing a job based on a schedule. When triggered, AWS Batch will fetch a pre-built Docker image from Amazon ECR and execute it in a predefined environment. AWS Batch is a free-of-charge service and allows you to configure the environment and resources needed for a task execution. It relies on ECS, which manages resources at the execution time. You pay only for the compute resources consumed during the execution of a task.
You may wonder where the pre-built Docker image came from. It was pulled from Amazon ECR, and now you have two options to store your Docker image there:
• You can build a Docker image locally and upload it to Amazon ECR.
• You just commit few configuration files (such as Dockerfile, buildspec.yml, etc.) to AWS CodeCommit (a code repository) and build the Docker image on the AWS platform.This option, shown in the image below, allows you to build a full CI/CD pipeline. After updating a script file locally and committing the changes to a code repository on AWS CodeCommit, a CloudWatch event is triggered and AWS CodeBuild builds a new Docker image and commits it to Amazon ECR. When a scheduler starts a new task, it fetches the new image with your updated script file. If you feel like exploring further or you want actually implement this approach please take a look at the example of the project on GitHub.
CodeCommit. CodeBuild, ECR
Option #3
The third option is based on AWS Lambda, which allows you to build a very lean infrastructure on demand, scales continuously, and has generous monthly free tier. The major constraint of Lambda is that the execution time is capped at 15 minutes. If you have a task running longer than 15 minutes, you need to split it into subtasks and run them in parallel, or you can fall back to Option #2.
By default, Lambda gives you access to standard libraries (such as the Python Standard Library). In addition, you can build your own package to support the execution of your function or use Lambda Layers to gain access to external libraries or even external Linux based programs.
Lambda Layer
You can access AWS Lambda via the web console to create a new function, update your Lambda code, or execute it. However, if you go beyond the “Hello World” functionality, you may realize that online development is not sustainable. For example, if you want to access external libraries from your function, you need to archive them locally, upload to Amazon Simple Storage Service (Amazon S3), and link it to your Lambda function.
One way to automate Lambda function development is to use AWS Cloud Development Kit (AWS CDK), which is an open source software development framework to model and provision your cloud application resources using familiar programming languages. Initially, the setup and learning might feel strenuous; however the benefits are worth of it. To give you an example, please take a look at this Python class on GitHub, which creates a Lambda function, a CloudWatch event, IAM policies, and Lambda layers.
In a summary, the AWS CDK allows you to have infrastructure as code, and all changes will be stored in a code repository. For a deployment, AWS CDK builds an AWS CloudFormation template, which is a standard way to model infrastructure on AWS. Additionally, AWS Serverless Application Model (SAM) allows you to test and debug your serverless code locally, meaning that you can indeed create a continuous integration.
See an example of a Lambda-based web scraper on GitHub.
Conclusion
In this blog post, we reviewed two serverless architectures for a web scraper on AWS cloud. Additionally, we have explored the ways to implement a CI/CD pipeline in order to avoid any future manual interventions.
Building well-architected serverless applications: Approaching application lifecycle management – part 3
Post Syndicated from Julian Wood original https://aws.amazon.com/blogs/compute/building-well-architected-serverless-applications-approaching-application-lifecycle-management-part-3/
This series of blog posts uses the AWS Well-Architected Tool with the Serverless Lens to help customers build and operate applications using best practices. In each post, I address the nine serverless-specific questions identified by the Serverless Lens along with the recommended best practices. See the Introduction post for a table of contents and explanation of the example application.
Question OPS2: How do you approach application lifecycle management?
This post continues part 2 of this Operational Excellence question where I look at deploying to multiple stages using temporary environments, and rollout deployments. In part 1, I cover using infrastructure as code with version control to deploy applications in a repeatable manner.
Good practice: Use configuration management
Use environment variables and configuration management systems to make and track configuration changes. These systems reduce errors caused by manual processes, reduce the level of effort to deploy changes, and help isolate configuration from business logic.
Environment variables are suited for infrequently changing configuration options such as logging levels, and database connection strings. Configuration management systems are for dynamic configuration that might change frequently or contain sensitive data such as secrets.
Environment variables
The serverless airline example used in this series uses AWS Amplify Console environment variables to store application-wide settings.
For example, the Stripe payment keys for all branches, and names for individual branches, are visible within the Amplify Console in the Environment variables section.
AWS Amplify environment variables
AWS Amplify environment variables
AWS Lambda environment variables are set up as part of the function configuration stored using the AWS Serverless Application Model (AWS SAM).
For example, the airline booking ReserveBooking AWS SAM template sets global environment variables including the LOG_LEVEL with the following code.
Globals:
Function:
Environment:
Variables:
LOG_LEVEL: INFO
This is visible in the AWS Lambda console within the function configuration.
AWS Lambda environment variables in console
AWS Lambda environment variables in console
See the AWS Documentation for more information on using AWS Lambda environment variables and also how to store sensitive data. Amazon API Gateway can also pass stage-specific metadata to Lambda functions.
Dynamic configuration
Dynamic configuration is also stored in configuration management systems to specify external values and is unique to each environment. This configuration may include values such as an Amazon Simple Notification Service (Amazon SNS) topic, Lambda function name, or external API credentials. AWS System Manager Parameter Store, AWS Secrets Manager, and AWS AppConfig have native integrations with AWS CloudFormation to store dynamic configuration. For more information, see the examples for referencing dynamic configuration from within AWS CloudFormation.
For the serverless airline application, dynamic configuration is stored in AWS Systems Manager Parameter Store. During CloudFormation stack deployment, a number of parameters are stored in Systems Manager. For example, in the booking service AWS SAM template, the booking SNS topic ARN is stored.
BookingTopicParameter:
Type: "AWS::SSM::Parameter"
Properties:
Name: !Sub /${Stage}/service/booking/messaging/bookingTopic
Description: Booking SNS Topic ARN
Type: String
Value: !Ref BookingTopic
View the stored SNS topic value by navigating to the Parameter Store console, and search for BookingTopic.
Finding Systems Manager Parameter Store values
Finding Systems Manager Parameter Store values
Select the Parameter name and see the Amazon SNS ARN.
Viewing SNS topic value
Viewing SNS topic value
The loyalty service then references this value within another stack.
When the Amplify Console Makefile deploys the loyalty service, it retrieves this value for the booking service from Parameter Store, and references it as a parameter-override. The deployment is also parametrized with the $${AWS_BRANCH} environment variable if there are multiple environments within the same AWS account and Region.
sam deploy \
--parameter-overrides \
BookingSNSTopic=/$${AWS_BRANCH}/service/booking/messaging/bookingTopic
Environment variables and configuration management systems help with managing application configuration.
Improvement plan summary
1. Use environment variables for configuration options that change infrequently such as logging levels, and database connection strings.
2. Use a configuration management system for dynamic configuration that might change frequently or contain sensitive data such as secrets.
Best practice: Use CI/CD including automated testing across separate accounts
Continuous integration/delivery/deployment is one of the cornerstones of cloud application development and a vital part of a DevOps initiative.
Explanation of CI/CD stages
Explanation of CI/CD stages
Building CI/CD pipelines increases software delivery quality and feedback time for detecting and resolving errors. I cover how to deploy multiple stages in isolated environments and accounts, which helps with creating separate testing CI/CD pipelines in part 2. As the serverless airline example is using AWS Amplify Console, this comes with a built-in CI/CD pipeline.
Automate the build, deployment, testing, and rollback of the workload using KPI and operational alerts. This eases troubleshooting, enables faster remediation and feedback time, and enables automatic and manual rollback/roll-forward should an alert trigger.
I cover metrics, KPIs, and operational alerts in this series in the Application Health part 1, and part 2 posts. I cover rollout deployments with traffic shifting based on metrics in this question’s part 2.
CI/CD pipelines should include integration, and end-to-end tests. I cover local unit testing for Lambda and API Gateway in part 2.
Add an optional testing stage to Amplify Console to catch regressions before pushing code to production. Use the test step to run any test commands at build time using any testing framework of your choice. Amplify Console has deeper integration with the Cypress test suite that allows you to generate a UI report for your tests. Here is an example to set up end-to-end tests with Cypress.
Cypress testing example
Cypress testing example
There are a number of AWS and third-party solutions to host code and create CI/CD pipelines for serverless applications.
AWS Code Suite
AWS Code Suite
For more information on how to use the AWS Code* services together, see the detailed Quick Start deployment guide Serverless CI/CD for the Enterprise on AWS.
All these AWS services have a number of integrations with third-party products so you can integrate your serverless applications with your existing tools. For example, CodeBuild can build from GitHub and Atlassian Bitbucket repositories. CodeDeploy integrates with a number of developer tools and configuration management systems. CodePipeline has a number of pre-built integrations to use existing tools for your serverless applications. For more information specifically on using CircleCI for serverless applications, see Simplifying Serverless CI/CD with CircleCI and the AWS Serverless Application Model.
Improvement plan summary
1. Use a continuous integration/continuous deployment (CI/CD) pipeline solution that deploys multiple stages in isolated environments/accounts.
2. Automate testing including but not limited to unit, integration, and end-to-end tests.
3. Favor rollout deployments over all-at-once deployments for more resilience, and gradually learn what metrics best determine your workload’s health to appropriately alert on.
4. Use a deployment system that supports traffic shifting as part of your pipeline, and rollback/roll-forward traffic to previous versions if an alert is triggered.
Good practice: Review function runtime deprecation policy
Lambda functions created using AWS provided runtimes follow official long-term support deprecation policies. Third-party provided runtime deprecation policy may differ from official long-term support. Review your runtime deprecation policy and have a mechanism to report on runtimes that, if deprecated, may affect your workload to operate as intended.
Review the AWS Lambda runtime policy support page to understand the deprecation schedule for your runtime.
AWS Health provides ongoing visibility into the state of your AWS resources, services, and accounts. Use the AWS Personal Health Dashboard for a personalized view and automate custom notifications to communication channels other than your AWS Account email.
Use AWS Config to report on AWS Lambda function runtimes that might be near their deprecation. Run compliance and operational checks with AWS Config for Lambda functions.
If you are unable to migrate to newer runtimes within the deprecation schedule, use AWS Lambda custom runtimes as an interim solution.
Improvement plan summary
1. Identify and report runtimes that might deprecate and their support policy.
Conclusion
Introducing application lifecycle management improves the development, deployment, and management of serverless applications. In part 1, I cover using infrastructure as code with version control to deploy applications in a repeatable manner. This reduces errors caused by manual processes and gives you more confidence your application works as expected. In part 2, I cover prototyping new features using temporary environments, and rollout deployments to gradually shift traffic to new application code.
In this post I cover configuration management, CI/CD for serverless applications, and managing function runtime deprecation.
In an upcoming post, I will cover the first Security question from the Well-Architected Serverless Lens – Controlling access to serverless APIs.
Fine-grained Continuous Delivery With CodePipeline and AWS Step Functions
Post Syndicated from Richard H Boyd original https://aws.amazon.com/blogs/devops/new-fine-grained-continuous-delivery-with-codepipeline-and-aws-stepfunctions/
Automating your software release process is an important step in adopting DevOps best practices. AWS CodePipeline is a fully managed continuous delivery service that helps you automate your release pipelines for fast and reliable application and infrastructure updates. CodePipeline was modeled after the way that the retail website Amazon.com automated software releases, and many early decisions for CodePipeline were based on the lessons learned from operating a web application at that scale.
However, while most cross-cutting best practices apply to most releases, there are also business specific requirements that are driven by domain or regulatory requirements. CodePipeline attempts to strike a balance between enforcing best practices out-of-the-box and offering enough flexibility to cover as many use-cases as possible.
To support use cases requiring fine-grained customization, we are launching today a new AWS CodePipeline action type for starting an AWS Step Functions state machine execution. Previously, accomplishing such a workflow required you to create custom integrations that marshaled data between CodePipeline and Step Functions. However, you can now start either a Standard or Express Step Functions state machine during the execution of a pipeline.
With this integration, you can do the following:
· Conditionally run an Amazon SageMaker hyper-parameter tuning job
· Write and read values from Amazon DynamoDB, as an atomic transaction, to use in later stages of the pipeline
· Run an Amazon Elastic Container Service (Amazon ECS) task until some arbitrary condition is satisfied, such as performing integration or load testing
Example Application Overview
In the following use case, you’re working on a machine learning application. This application contains both a machine learning model that your research team maintains and an inference engine that your engineering team maintains. When a new version of either the model or the engine is released, you want to release it as quickly as possible if the latency is reduced and the accuracy improves. If the latency becomes too high, you want the engineering team to review the results and decide on the approval status. If the accuracy drops below some threshold, you want the research team to review the results and decide on the approval status.
This example will assume that a CodePipeline already exists and is configured to use a CodeCommit repository as the source and builds an AWS CodeBuild project in the build stage.
The following diagram illustrates the components built in this post and how they connect to existing infrastructure.
Architecture Diagram for CodePipline Step Functions integration
First, create a Lambda function that uses Amazon Simple Email Service (Amazon SES) to email either the research or engineering team with the results and the opportunity for them to review it. See the following code:
import json
import os
import boto3
import base64
def lambda_handler(event, context):
email_contents = """
<html>
<body>
<p><a href="{url_base}/{token}/success">PASS</a></p>
<p><a href="{url_base}/{token}/fail">FAIL</a></p>
</body>
</html>
"""
callback_base = os.environ['URL']
token = base64.b64encode(bytes(event["token"], "utf-8")).decode("utf-8")
formatted_email = email_contents.format(url_base=callback_base, token=token)
ses_client = boto3.client('ses')
ses_client.send_email(
Source='[email protected]',
Destination={
'ToAddresses': [event["team_alias"]]
},
Message={
'Subject': {
'Data': 'PLEASE REVIEW',
'Charset': 'UTF-8'
},
'Body': {
'Text': {
'Data': formatted_email,
'Charset': 'UTF-8'
},
'Html': {
'Data': formatted_email,
'Charset': 'UTF-8'
}
}
},
ReplyToAddresses=[
'[email protected]',
]
)
return {}
To set up the Step Functions state machine to orchestrate the approval, use AWS CloudFormation with the following template. The Lambda function you just created is stored in the email_sender/app directory. See the following code:
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Resources:
NotifierFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: email_sender/
Handler: app.lambda_handler
Runtime: python3.7
Timeout: 30
Environment:
Variables:
URL: !Sub "https://${TaskTokenApi}.execute-api.${AWS::Region}.amazonaws.com/Prod"
Policies:
- Statement:
- Sid: SendEmail
Effect: Allow
Action:
- ses:SendEmail
Resource: '*'
MyStepFunctionsStateMachine:
Type: AWS::StepFunctions::StateMachine
Properties:
RoleArn: !GetAtt SFnRole.Arn
DefinitionString: !Sub |
{
"Comment": "A Hello World example of the Amazon States Language using Pass states",
"StartAt": "ChoiceState",
"States": {
"ChoiceState": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.accuracypct",
"NumericLessThan": 96,
"Next": "ResearchApproval"
},
{
"Variable": "$.latencyMs",
"NumericGreaterThan": 80,
"Next": "EngineeringApproval"
}
],
"Default": "SuccessState"
},
"EngineeringApproval": {
"Type":"Task",
"Resource":"arn:aws:states:::lambda:invoke.waitForTaskToken",
"Parameters":{
"FunctionName":"${NotifierFunction.Arn}",
"Payload":{
"latency.$":"$.latencyMs",
"team_alias":"[email protected]",
"token.$":"$$.Task.Token"
}
},
"Catch": [ {
"ErrorEquals": ["HandledError"],
"Next": "FailState"
} ],
"Next": "SuccessState"
},
"ResearchApproval": {
"Type":"Task",
"Resource":"arn:aws:states:::lambda:invoke.waitForTaskToken",
"Parameters":{
"FunctionName":"${NotifierFunction.Arn}",
"Payload":{
"accuracy.$":"$.accuracypct",
"team_alias":"[email protected]",
"token.$":"$$.Task.Token"
}
},
"Catch": [ {
"ErrorEquals": ["HandledError"],
"Next": "FailState"
} ],
"Next": "SuccessState"
},
"FailState": {
"Type": "Fail",
"Cause": "Invalid response.",
"Error": "Failed Approval"
},
"SuccessState": {
"Type": "Succeed"
}
}
}
TaskTokenApi:
Type: AWS::ApiGateway::RestApi
Properties:
Description: String
Name: TokenHandler
SuccessResource:
Type: AWS::ApiGateway::Resource
Properties:
ParentId: !Ref TokenResource
PathPart: "success"
RestApiId: !Ref TaskTokenApi
FailResource:
Type: AWS::ApiGateway::Resource
Properties:
ParentId: !Ref TokenResource
PathPart: "fail"
RestApiId: !Ref TaskTokenApi
TokenResource:
Type: AWS::ApiGateway::Resource
Properties:
ParentId: !GetAtt TaskTokenApi.RootResourceId
PathPart: "{token}"
RestApiId: !Ref TaskTokenApi
SuccessMethod:
Type: AWS::ApiGateway::Method
Properties:
HttpMethod: GET
ResourceId: !Ref SuccessResource
RestApiId: !Ref TaskTokenApi
AuthorizationType: NONE
MethodResponses:
- ResponseParameters:
method.response.header.Access-Control-Allow-Origin: true
StatusCode: 200
Integration:
IntegrationHttpMethod: POST
Type: AWS
Credentials: !GetAtt APIGWRole.Arn
Uri: !Sub "arn:aws:apigateway:${AWS::Region}:states:action/SendTaskSuccess"
IntegrationResponses:
- StatusCode: 200
ResponseTemplates:
application/json: |
{}
- StatusCode: 400
ResponseTemplates:
application/json: |
{"uhoh": "Spaghetti O's"}
RequestTemplates:
application/json: |
#set($token=$input.params('token'))
{
"taskToken": "$util.base64Decode($token)",
"output": "{}"
}
PassthroughBehavior: NEVER
IntegrationResponses:
- StatusCode: 200
OperationName: "TokenResponseSuccess"
FailMethod:
Type: AWS::ApiGateway::Method
Properties:
HttpMethod: GET
ResourceId: !Ref FailResource
RestApiId: !Ref TaskTokenApi
AuthorizationType: NONE
MethodResponses:
- ResponseParameters:
method.response.header.Access-Control-Allow-Origin: true
StatusCode: 200
Integration:
IntegrationHttpMethod: POST
Type: AWS
Credentials: !GetAtt APIGWRole.Arn
Uri: !Sub "arn:aws:apigateway:${AWS::Region}:states:action/SendTaskFailure"
IntegrationResponses:
- StatusCode: 200
ResponseTemplates:
application/json: |
{}
- StatusCode: 400
ResponseTemplates:
application/json: |
{"uhoh": "Spaghetti O's"}
RequestTemplates:
application/json: |
#set($token=$input.params('token'))
{
"cause": "Failed Manual Approval",
"error": "HandledError",
"output": "{}",
"taskToken": "$util.base64Decode($token)"
}
PassthroughBehavior: NEVER
IntegrationResponses:
- StatusCode: 200
OperationName: "TokenResponseFail"
APIDeployment:
Type: AWS::ApiGateway::Deployment
DependsOn:
- FailMethod
- SuccessMethod
Properties:
Description: "Prod Stage"
RestApiId:
Ref: TaskTokenApi
StageName: Prod
APIGWRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: "Allow"
Principal:
Service:
- "apigateway.amazonaws.com"
Action:
- "sts:AssumeRole"
Path: "/"
Policies:
- PolicyName: root
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action:
- 'states:SendTaskSuccess'
- 'states:SendTaskFailure'
Resource: '*'
SFnRole:
Type: "AWS::IAM::Role"
Properties:
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: "Allow"
Principal:
Service:
- "states.amazonaws.com"
Action:
- "sts:AssumeRole"
Path: "/"
Policies:
- PolicyName: root
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action:
- 'lambda:InvokeFunction'
Resource: !GetAtt NotifierFunction.Arn
After you create the CloudFormation stack, you have a state machine, an Amazon API Gateway REST API, a Lambda function, and the roles each resource needs.
Your pipeline invokes the state machine with the load test results, which contain the accuracy and latency statistics. It decides which, if either, team to notify of the results. If the results are positive, it returns a success status without notifying either team. If a team needs to be notified, the Step Functions asynchronously invokes the Lambda function and passes in the relevant metric and the team’s email address. The Lambda function renders an email with links to the pass/fail response so the team can choose the Pass or Fail link in the email to respond to the review. You use the REST API to capture the response and send it to Step Functions to continue the state machine execution.
The following diagram illustrates the visual workflow of the approval process within the Step Functions state machine.
StepFunctions StateMachine for approving code changes
After you create your state machine, Lambda function, and REST API, return to CodePipeline console and add the Step Functions integration to your existing release pipeline. Complete the following steps:
1. On the CodePipeline console, choose Pipelines.
2. Choose your release pipeline.CodePipeline before adding StepFunction integration
3. Choose Edit.CodePipeline Edit View
4. Under the Edit:Build section, choose Add stage.
5. Name your stage Release-Approval.
6. Choose Save.
You return to the edit view and can see the new stage at the end of your pipeline.CodePipeline Edit View with new stage
7. In the Edit:Release-Approval section, choose Add action group.
8. Add the Step Functions StateMachine invocation Action to the action group. Use the following settings:
1. For Action name, enter CheckForRequiredApprovals.
2. For Action provider, choose AWS Step Functions.
3. For Region, choose the Region where your state machine is located (this post uses US West (Oregon)).
4. For Input artifacts, enter BuildOutput (the name you gave the output artifacts in the build stage).
5. For State machine ARN, choose the state machine you just created.
6. For Input type¸ choose File path. (This parameter tells CodePipeline to take the contents of a file and use it as the input for the state machine execution.)
7. For Input, enter results.json (where you store the results of your load test in the build stage of the pipeline).
8. For Variable namespace, enter StepFunctions. (This parameter tells CodePipeline to store the state machine ARN and execution ARN for this event in a variable namespace named StepFunctions. )
9. For Output artifacts, enter ApprovalArtifacts. (This parameter tells CodePipeline to store the results of this execution in an artifact called ApprovalArtifacts. )Edit Action Configuration
9. Choose Done.
You return to the edit view of the pipeline.
CodePipeline Edit Configuration
10. Choose Save.
11. Choose Release change.
When the pipeline execution reaches the approval stage, it invokes the Step Functions state machine with the results emitted from your build stage. This post hard-codes the load-test results to force an engineering approval by increasing the latency (latencyMs) above the threshold defined in the CloudFormation template (80ms). See the following code:
{
"accuracypct": 100,
"latencyMs": 225
}
When the state machine checks the latency and sees that it’s above 80 milliseconds, it invokes the Lambda function with the engineering email address. The engineering team receives a review request email similar to the following screenshot.
review email
If you choose PASS, you send a request to the API Gateway REST API with the Step Functions task token for the current execution, which passes the token to Step Functions with the SendTaskSuccess command. When you return to your pipeline, you can see that the approval was processed and your change is ready for production.
Approved code change with stepfunction integration
Cleaning Up
When the engineering and research teams devise a solution that no longer mixes performance information from both teams into a single application, you can remove this integration by deleting the CloudFormation stack that you created and deleting the new CodePipeline stage that you added.
Conclusion
For more information about CodePipeline Actions and the Step Functions integration, see Working with Actions in CodePipeline.
Building a CI/CD pipeline for multi-region deployment with AWS CodePipeline
Post Syndicated from Akash Kumar original https://aws.amazon.com/blogs/devops/building-a-ci-cd-pipeline-for-multi-region-deployment-with-aws-codepipeline/
This post discusses the benefits of and how to build an AWS CI/CD pipeline in AWS CodePipeline for multi-region deployment. The CI/CD pipeline triggers on application code changes pushed to your AWS CodeCommit repository. This automatically feeds into AWS CodeBuild for static and security analysis of the CloudFormation template. Another CodeBuild instance builds the application to generate an AMI image as output. AWS Lambda then copies the AMI image to other Regions. Finally, AWS CloudFormation cross-region actions are triggered and provision the instance into target Regions based on AMI image.
The solution is based on using a single pipeline with cross-region actions, which helps in provisioning resources in the current Region and other Regions. This solution also helps manage the complete CI/CD pipeline at one place in one Region and helps as a single point for monitoring and deployment changes. This incurs less cost because a single pipeline can deploy the application into multiple Regions.
As a security best practice, the solution also incorporates static and security analysis using cfn-lint and cfn-nag. You use these tools to scan CloudFormation templates for security vulnerabilities.
The following diagram illustrates the solution architecture.
Multi region AWS CodePipeline architecture
Multi region AWS CodePipeline architecture
Prerequisites
Before getting started, you must complete the following prerequisites:
• Create a repository in CodeCommit and provide access to your user
• Copy the sample source code from GitHub under your repository
• Create an Amazon S3 bucket in the current Region and each target Region for your artifact store
Creating a pipeline with AWS CloudFormation
You use a CloudFormation template for your CI/CD pipeline, which can perform the following actions:
1. Use CodeCommit repository as source code repository
2. Static code analysis on the CloudFormation template to check against the resource specification and block provisioning if this check fails
3. Security code analysis on the CloudFormation template to check against secure infrastructure rules and block provisioning if this check fails
4. Compilation and unit test of application code to generate an AMI image
5. Copy the AMI image into target Regions for deployment
6. Deploy into multiple Regions using the CloudFormation template; for example, us-east-1, us-east-2, and ap-south-1
You use a sample web application to run through your pipeline, which requires Java and Apache Maven for compilation and testing. Additionally, it uses Tomcat 8 for deployment.
The following table summarizes the resources that the CloudFormation template creates.
Resource NameTypeObjective
CloudFormationServiceRoleAWS::IAM::RoleService role for AWS CloudFormation
CodeBuildServiceRoleAWS::IAM::RoleService role for CodeBuild
CodePipelineServiceRoleAWS::IAM::RoleService role for CodePipeline
LambdaServiceRoleAWS::IAM::RoleService role for Lambda function
SecurityCodeAnalysisServiceRoleAWS::IAM::RoleService role for security analysis of provisioning CloudFormation template
StaticCodeAnalysisServiceRoleAWS::IAM::RoleService role for static analysis of provisioning CloudFormation template
StaticCodeAnalysisProjectAWS::CodeBuild::ProjectCodeBuild for static analysis of provisioning CloudFormation template
SecurityCodeAnalysisProjectAWS::CodeBuild::ProjectCodeBuild for security analysis of provisioning CloudFormation template
CodeBuildProjectAWS::CodeBuild::ProjectCodeBuild for compilation, testing, and AMI creation
CopyImageAWS::Lambda::FunctionPython Lambda function for copying AMI images into other Regions
AppPipelineAWS::CodePipeline::PipelineCodePipeline for CI/CD
To start creating your pipeline, complete the following steps:
• Launch the CloudFormation stack with the following link:
Launch button for CloudFormation
Launch button for CloudFormation
• Choose Next.
• For Specify details, provide the following values:
ParameterDescription
Stack nameName of your stack
OtherRegion1Input the target Region 1 (other than current Region) for deployment
OtherRegion2Input the target Region 2 (other than current Region) for deployment
RepositoryBranchBranch name of repository
RepositoryNameRepository name of the project
S3BucketNameInput the S3 bucket name for artifact store
S3BucketNameForOtherRegion1Create a bucket in target Region 1 and specify the name for artifact store
S3BucketNameForOtherRegion2Create a bucket in target Region 2 and specify the name for artifact store
Choose Next.
• On the Review page, select I acknowledge that this template might cause AWS CloudFormation to create IAM resources.
• Choose Create.
• Wait for the CloudFormation stack status to change to CREATE_COMPLETE (this takes approximately 5–7 minutes).
When the stack is complete, your pipeline should be ready and running in the current Region.
• To validate the pipeline, check the images and EC2 instances running into the target Regions and also refer the AWS CodePipeline Execution summary as below.
AWS CodePipeline Execution Summary
AWS CodePipeline Execution Summary
We will walk you through the following steps for creating a multi-region deployment pipeline:
1. Using CodeCommit as your source code repository
The deployment workflow starts by placing the application code on the CodeCommit repository. When you add or update the source code in CodeCommit, the action generates a CloudWatch event, which triggers the pipeline to run.
2. Static code analysis of CloudFormation template to provision AWS resources
Historically, AWS CloudFormation linting was limited to the ValidateTemplate action in the service API. This action tells you if your template is well-formed JSON or YAML, but doesn’t help validate the actual resources you’ve defined.
You can use a linter such as the cfn-lint tool for static code analysis to improve your AWS CloudFormation development cycle. The tool validates the provisioning CloudFormation template properties and their values (mappings, joins, splits, conditions, and nesting those functions inside each other) against the resource specification. This can cover the most common of the underlying service constraints and help encode some best practices.
The following rules cover underlying service constraints:
• E2530 – Checks that Lambda functions have correctly configured memory sizes
• E3025 – Checks that your RDS instances use correct instance types for the database engine
• W2001 – Checks that each parameter is used at least once
You can also add this step as a pre-commit hook for your GIT repository if you are using CodeCommit or GitHub.
You provision a CodeBuild project for static code analysis as the first step in CodePipeline after source. This helps in early detection of any linter issues.
3. Security code analysis of CloudFormation template to provision AWS resources
You can use Stelligent’s cfn_nag tool to perform additional validation of your template resources for security. The cfn-nag tool looks for patterns in CloudFormation templates that may indicate insecure infrastructure provisioning and validates against AWS best practices. For example:
• IAM rules that are too permissive (wildcards)
• Security group rules that are too permissive (wildcards)
• Access logs that aren’t enabled
• Encryption that isn’t enabled
• Password literals
You provision a CodeBuild project for security code analysis as the second step in CodePipeline. This helps detect any insecure infrastructure provisioning issues.
4. Compiling and testing application code and generating an AMI image
Because you use a Java-based application for this walkthrough, you use Amazon Corretto as your JVM. Corretto is a no-cost, multi-platform, production-ready distribution of the Open Java Development Kit (OpenJDK). Corretto comes with long-term support that includes performance enhancements and security fixes.
You also use Apache Maven as a build automation tool to build the sample application, and the HashiCorp Packer tool to generate an AMI image for the application.
You provision a CodeBuild project for compilation, unit testing, AMI generation, and storing the AMI ImageId in the Parameter Store, which the CloudFormation template uses as the next step of the pipeline.
5. Copying the AMI image into target Regions
You use a Lambda function to copy the AMI image into target Regions so the CloudFormation template can use it to provision instances into that Region as the next step of the pipeline. It also writes the target Region AMI ImageId into the target Region’s Parameter Store.
6. Deploying into multiple Regions with the CloudFormation template
You use the CloudFormation template as a cross-region action to provision AWS resources into a target Region. CloudFormation uses Parameter Store’s ImageId as reference and provisions the instances into the target Region.
Cleaning up
To avoid additional charges, you should delete the following AWS resources after you validate the pipeline:
• The cross-region CloudFormation stack in the target and current Regions
• The main CloudFormation stack in the current Region
• The AMI you created in the target and current Regions
• The Parameter Store AMI_VERSION in the target and current Regions
Conclusion
You have now created a multi-region deployment pipeline in CodePipeline without having to worry about the mechanics of creating and copying AMI images across Regions. CodePipeline abstracts the creating and copying of the images in the background in each Region. You can now upload new source code changes to the CodeCommit repository in the primary Region, and changes deploy automatically to other Regions. Cross-region actions are very powerful and are not limited to deploy actions. You can also use them with build and test actions.
|
__label__pos
| 0.658839 |
The Art of Extracting Hidden Treasures: Mastering the World of Web Scraping
The Art of Extracting Hidden Treasures: Mastering the World of Web Scraping
Web scraping has become a valuable skill in the ever-expanding world of data-driven decision making. By harnessing the power of web data, businesses have the opportunity to uncover hidden treasures, gaining insights that can provide a significant advantage in their respective industries. At "Scraping Pros," we are experts in the art of web scraping, transforming raw web data into valuable resources that fuel success.
In this article, we will delve into the intricacies of web scraping, exploring its potential to unlock a wealth of information that can guide businesses towards smarter decision making. Whether you’re looking to analyze market trends, gather competitive intelligence, or simply extract data for research purposes, web scraping is a powerful tool that can deliver the answers you seek.
Join us as we navigate through the world of web scraping, uncovering the techniques, challenges, and best practices that can help you become a master in this thriving field. With our expert guidance, you’ll gain the skills necessary to wield web data as a business advantage, revolutionizing the way you make data-driven decisions and ultimately propelling your success to new heights. Let’s embark on this journey of extracting hidden treasures together!
Why Web Scraping is Essential for Data-driven Decision Making
In today’s data-driven world, acquiring accurate and up-to-date information is crucial for making informed decisions. This is where web scraping comes into play. Web scraping, also known as web data extraction or screen scraping, is the process of extracting data from websites, transforming it into a structured format, and then analyzing it for valuable insights.
With the exponential growth of the internet and the vast amount of data available online, manual data collection becomes impractical and time-consuming. Web scraping offers an efficient and automated solution to gather data from various online sources. By retrieving data from websites, businesses can harness the power of big data to drive their decision-making processes.
One of the key reasons why web scraping is essential for data-driven decision making is the ability to access real-time data. The internet is constantly evolving, and information on websites gets updated regularly. Web scraping allows organizations to stay up-to-date with the latest market trends, competitor activity, product pricing, and customer sentiment. By having access to real-time data, businesses can make timely and accurate decisions that give them a competitive edge.
Another benefit of web scraping is the ability to aggregate data from multiple sources. Websites often contain valuable data that is scattered across different pages or even different websites. Web scraping allows businesses to consolidate this data and analyze it holistically. By combining information from various sources, organizations can gain comprehensive insights that are not possible with isolated data sets.
Web scraping also enables businesses to monitor and track changes in data over time. By scraping data at regular intervals, organizations can identify trends, patterns, and anomalies in their industry or market. This enables them to make proactive decisions, adapt their strategies, and capitalize on emerging opportunities.
In conclusion, web scraping plays a vital role in data-driven decision making. It empowers businesses to access real-time data, aggregate information from multiple sources, and monitor changes over time. By mastering the art of web scraping, businesses can transform web data into a valuable asset and leverage it to fuel their success.
The Benefits of Scraping Pros in Transforming Web Data
In today’s data-driven world, the importance of web data cannot be overstated. It holds valuable insights that can give businesses a competitive edge and fuel informed decision making. Web scraping is the key to unlocking this wealth of information, and when it comes to harnessing its power, Scraping Pros is the team you can rely on.
Web Scraping Company
With their expertise in web scraping, Scraping Pros is able to transform raw web data into a powerful asset for your business. By utilizing advanced scraping techniques, they can extract relevant information from multiple websites and compile it into a comprehensive and easily accessible format. This means you can save valuable time and effort by having all the data you need at your fingertips.
One of the main benefits of working with Scraping Pros is their ability to provide tailored solutions to meet your specific needs. Whether you require data for market research, competitor analysis, or any other business intelligence purposes, they can customize their scraping methods to ensure you get the exact information you’re looking for. This level of flexibility makes them an invaluable partner in your quest for data-driven success.
Furthermore, Scraping Pros understands the importance of data quality and accuracy. They employ rigorous quality control measures to ensure the information you receive is reliable and up-to-date. This attention to detail allows you to make informed decisions based on accurate data, giving you a significant advantage in the marketplace.
In summary, web scraping is a powerful tool for unlocking the hidden treasures of web data. With Scraping Pros as your trusted partner, you can harness the benefits of web scraping to propel your business forward. Their expertise, tailored solutions, and commitment to data quality make them an invaluable asset in transforming raw web data into a valuable business advantage.
Mastering the Techniques of Web Scraping for Business Success
Web scraping has emerged as a powerful tool for businesses to extract valuable data from the vast realm of the internet. With the ability to gather specific information swiftly and efficiently, web scraping has become an essential skill for those seeking to gain a competitive edge. By mastering the techniques of web scraping, businesses can unlock hidden treasures buried within the web data and harness it as a pivotal asset for data-driven decision making.
One of the primary techniques in web scraping is identifying and selecting the relevant data sources. It involves understanding the structure and organization of websites, recognizing patterns, and pinpointing the specific information that will drive business success. Through meticulous analysis and exploration, businesses can uncover hidden gems of data that provide valuable insights and give them a leg up in the market.
A crucial aspect of mastering web scraping is utilizing appropriate tools and technologies. There is a myriad of web scraping tools available, each with its own strengths and weaknesses. By selecting the right tool for the task at hand, businesses can enhance their scraping capabilities and extract web data effectively and efficiently. Whether it’s utilizing ready-made scraping software or developing custom scraping scripts, having a solid understanding of the available tools is an essential step towards achieving success in web scraping.
Lastly, mastering the techniques of web scraping requires continuous learning and adaptation. The internet is a dynamic environment, with websites frequently changing their structure and data formats. To stay ahead of the game, businesses must adapt their scraping techniques to accommodate these changes. By continuously honing their skills, keeping up with industry trends, and adopting innovative scraping strategies, businesses can conquer the challenges of web scraping and transform web data into a valuable asset for informed decision making and overall success.
In conclusion, web scraping presents an opportunity for businesses to extract hidden treasures from the vast ocean of web data. By mastering the techniques of web scraping, businesses can gain access to valuable insights that can propel their data-driven decision making and ultimately lead to success in the competitive landscape. Through understanding data sources, utilizing appropriate tools, and embracing continuous learning, businesses can harness the power of web scraping and uncover the hidden gems that lie within the vast expanse of the internet.
|
__label__pos
| 0.968161 |
Business
Allintext:username filetype:log
Welcome to our weblog publish on the interesting global of log documents! If you are interested by know-how how web sites feature backstage, then you definitely’ve come to the proper area. Today, we will be delving into the mysterious realm of log files and uncovering their significance for website owners and directors.
From protection worries to quality practices for coping with log files, we will cowl all of it. So snatch a cup of coffee, take a seat returned, and prepare to get to the bottom of the secrets and techniques hidden within those reputedly ordinary logs. Let’s dive in!
Understanding the Search Query
When you kind a search query right into a search engine, have you ever questioned how it knows exactly what you’re searching out? This is wherein expertise the search question will become essential. Search engines like Google use complex algorithms to research and interpret the words and phrases on your seek string.
By the usage of the advanced method called “allintext:username filetype:log,” you could slim down your search outcomes to particular log files that incorporate records related to usernames. This may be incredibly useful if you’re attempting to find unique person hobby or troubleshoot troubles on your website.
The “allintext” operator ensures that all the phrases to your query are gift within the textual content of the log report, even as “filetype:log” tells the search engine to only display results which can be log documents. By combining these operators, you may refine your searches and store time with the aid of getting more specific outcomes.
Understanding the way to nicely shape your search queries can substantially enhance your ability to locate applicable facts inside log files. It’s critical to be aware that one of a kind styles of logs may additionally require exceptional syntaxes or key phrases, so it is constantly beneficial to make yourself familiar with diverse operators to be had for refining searches.
With this expertise handy, cross in advance and harness the power of unique searching through log files! You’ll be amazed at how seamlessly they offer insights into person conduct and help find hidden gems of records. So subsequent time you embark on a quest for information buried deep inside the ones logs, recall – learning the artwork of crafting effective search queries will take you one step nearer in the direction of unlocking treasured insights approximately your website.
What is a Log File?
In the arena of web sites, log documents play a essential function in retaining tune of sports and occasions. But what precisely is a log file? Simply put, it is like a journal that records all the actions achieved in your internet site. It captures information about who accessed your web page, after they did it, and what unique pages or resources they interacted with.
Log documents are normally stored in plain text format and can be accessed with the aid of every body with the right permissions. They include treasured information together with IP addresses, consumer marketers, referring URLs, HTTP status codes, and greater. This information allows website proprietors analyze site visitors patterns and identify potential problems or security threats.
The content of log files can range depending on the server configuration and software getting used. Common types encompass get admission to logs (tracking requests made to the server), mistakes logs (recording any encountered errors), and security logs (monitoring suspicious activities).
Having access to log documents allows webmasters to advantage insights into user behavior, improve performance optimization efforts, troubleshoot troubles quick, stumble on malicious activities or assaults early on.
Understanding log files is essential for powerful internet site control and cybersecurity practices. By leveraging their electricity successfully while also prioritizing security features around them – you’ll be nicely-geared up to ensure easy operations on your on line presence! So live tuned for our subsequent weblog phase in which we will dive deeper into why log files are important for web sites!
Importance of Log Files for Websites
Log documents are an imperative part of website control and optimization. They offer treasured insights into how users interact with your website online, what pages they visit, and the movements they take. These logs report every request made for your server, capturing information consisting of IP addresses, timestamps, person marketers, and standing codes.
One of the key advantages of log files is their ability to help you recognize how search engines like google crawl your website online. By analyzing those logs, you may identify any crawling issues or mistakes that may be preventing sure pages from being indexed. This facts allows you to optimize your internet site’s structure and improve its visibility in seek engine results.
Log files also play a vital function in figuring out capacity security threats or assaults to your website. By monitoring log records for suspicious interest or unauthorized get admission to attempts, you can quick reply to protect your website online and its visitors’ sensitive facts.
Furthermore, log documents help in troubleshooting technical problems by using providing targeted mistakes messages and diagnostic facts. Whether it’s figuring out broken links or resolving server mistakes, gaining access to this facts simplifies the debugging procedure and guarantees a easy person experience.
In addition to their importance for everyday website management responsibilities like SEO auditing and safety monitoring; log documents also are essential for validating advertising and marketing campaigns. By tracking referral URLs from various sources along with social media platforms or electronic mail newsletters; you may determine which channels are driving visitors and conversions correctly; permitting you to allocate assets more efficaciously.
Overall; knowledge the importance of log documents is crucial for any internet site proprietor or administrator seeking better overall performance; improved security measures; enhanced user reports; focused advertising and marketing efforts; quicker difficulty resolution timescales among different advantages!
Risks Associated with Log Files
Log documents play a important function inside the functioning of web sites and offer treasured insights into user conduct, website overall performance, and protection problems. However, like another element of era, log documents also include their truthful share of risks.
One important chance related to log files is the capability for unauthorized get admission to. If someone profits get entry to in your log documents, they can extract sensitive records approximately your website’s infrastructure and probably exploit any vulnerabilities they find out.
Another risk is that log documents can end up pretty big and difficult to manage through the years. This not only consumes garage space however also makes it tougher to identify vital records in the logs while wanted.
Additionally, previous or misconfigured logging settings can create protection vulnerabilities. For instance, if touchy information inclusive of usernames or passwords are being logged with out right safety measures in location, it can reveal this statistics to malicious actors.
Furthermore, fallacious managing of log files may also violate privacy policies consisting of GDPR or HIPAA. It’s vital to ensure compliance at the same time as coping with and storing logs containing personally identifiable information (PII) or other sensitive statistics.
If log documents aren’t nicely monitored or reviewed frequently, essential events would possibly pass not noted. This consists of protection breaches or uncommon patterns that might suggest an ongoing assault in your website.
Given those dangers related to log file control and security practices have to be carried out to mitigate them efficaciously. In the subsequent segment we can talk some excellent practices for securing log documents.
How to Secure Log Files
Securing log files is vital for keeping the privacy and integrity of your internet site’s facts. By enforcing effective safety features, you can prevent unauthorized get admission to to sensitive facts and shield in opposition to capacity breaches or assaults.
One critical step in securing log files is to restriction access to simplest legal individuals or structures. This can be performed through putting in place proper consumer permissions and ensuring that simplest depended on users have the essential privileges to view or regulate these documents.
In addition, it is essential to often monitor and evaluation log document pastime. Keeping a near eye on any suspicious activities or unusual patterns can assist discover ability safety threats early on. Implementing automatic tracking equipment can streamline this system and offer real-time alerts for any anomalies detected inside the log documents.
Encrypting log documents adds a further layer of protection by means of encoding the statistics inside them. This ensures that even supposing a person gains get admission to to the logs, they won’t be able to decipher their contents without the encryption key.
Regularly backing up log files is every other essential aspect of securing them. In case of a gadget failure or information loss, having backups effortlessly available will allow you to restore your logs speedy and successfully.
Keeping all software and systems used for logging up to date with the modern day safety patches is crucial. Regularly updating those additives guarantees that any vulnerabilities are addressed directly, minimizing the chance of exploitation.
By following these first-rate practices for securing log documents, you may considerably beautify your internet site’s normal protection posture even as safeguarding treasured facts from potential threats or breaches.
Best Practices for Managing Log Files
When it involves managing log files, there are some best practices which can assist make certain the smooth operation of your website. Here are some suggestions to maintain in mind:
1. Regularly assessment and analyze your log documents: By often reviewing your log files, you may advantage valuable insights into the overall performance and security of your website. Look for any uncommon activity or errors that could imply ability issues.
2. Use filtering and segmentation strategies: Log documents can incorporate a widespread amount of statistics, so it’s critical to use filtering and segmentation techniques to cognizance at the most relevant data. This will make it less difficult to identify styles or traits that could impact your internet site’s performance.
3. Keep backups of your log documents: It’s critical to have backups of your log documents in case they get corrupted or accidentally deleted. Consider enforcing an automated backup system to ensure you constantly have get right of entry to to this critical information.
Four. Set up indicators for vital occasions: Configure signals for vital activities along with server errors or security breaches that can be logged within the record. This way, you may be notified immediately if any main troubles arise.
Five. Limit get right of entry to to log documents: Restrict get admission to to log files best to legal personnel who want them for evaluation or troubleshooting functions. Implement right person authentication mechanisms and take into account encrypting touchy logs for added protection.
By following those quality practices, you could correctly control your log documents and optimize the overall performance and safety of your website.
Conclusion
In cutting-edge digital age, log documents play a vital function in information and optimizing website performance. By analyzing these precious data of person hobby, webmasters can gain insights into how traffic have interaction with their web page, pick out mistakes or problems, and make knowledgeable decisions to decorate the user revel in.
However, it’s far vital to observe that log documents also pose sure risks if now not handled nicely. From ability protection breaches to privacy issues, there are various elements that need cautious attention while coping with log files. Implementing strong safety features and adhering to exceptional practices can assist mitigate these dangers and make certain the integrity of your internet site’s statistics.
Remember constantly to hold your log files secure by using proscribing get entry to handiest to authorized personnel. Regularly monitor and analyze them for any suspicious activities or anomalies that may indicate unauthorized access attempts or cyber threats.
Furthermore, following pleasant practices together with setting up computerized log rotation schedules, imposing strong passwords for record get right of entry to, and engaging in ordinary backups will make contributions appreciably to preserving the fitness and efficiency of your website’s logs.
In end (without specifying), harnessing the strength of log files is an critical a part of powerful internet site management. By know-how their cause, significance, capacity dangers concerned,and enforcing proper security features along side pleasant practices you’ll be capable maximize their blessings even as safeguarding sensitive facts from undesirable intrusions or misuse.
Related Articles
Leave a Reply
Your email address will not be published. Required fields are marked *
Back to top button
|
__label__pos
| 0.628004 |
Technology
React Native Vs Flutter – Which One is Better?
React is a framework developed by Facebook, and it has an architecture that uses a declarative syntax. Flutter is a newbie in the computer development world. Like React Native, it develops cross-platform apps and makes them look stylish and nice. User interface, development time, and performance are the key features that distinguish both frameworks from each other. In this article, you’ll know about the main differences between Flutter and React Native and what benefits might bring to you, working as a react native developer
What are the benefits of working with React Native
The key benefits of using React Native are knowledge of iOS and Android platforms for building an app and creation of native components for them. Also, React Native supports the PhoneGap library that contains a wrapper that supports user interfaces with CSS, HTML, and JavaScript. It helps developers compile these programming codes to the device’s machine language. In general, the use of the same code, open-source, time reduction of creating an app are the main advantages that React Native can bring to you. Do you dream about building a mobile product without any problems? If you do so, React Native is a good option for you! Its community is open for every developer who wants to learn it. With React Native, you’ll learn how to fix bugs and improve technical features for a mobile app at ease. The use of the same code is effective for mobile developers because it allows them to use it on different platforms. Time reduction is also important for app creation, and React Native has a code that you can reuse again. So all these mentioned features prove the fact why more and more IT companies decide to use this platform.
What is Flutter?
Flutter is free of charge and an open framework that uses iOS and Android platforms. Similar to React Native, it has the same code base that allows developers to build a mobile app simply. Flutter has been around the IT community since 2015 once Google created it, but the buzz about its advantages has emerged only recently. It uses Dart, a simple computer language, for building mobile apps. Widgets and their creation are the main ideas for Flutter. With this feature, it’s possible to create structural and stylistic elements as menus and buttons. The advantages of Flutter are high performance and productivity, fast development, and compatibility with diverse OS versions.
Similarities between Flutter and React Native
The similar traits of Flutter and React Native are cross-platform, same code, and openness. The opportunity to use Android and iOS for building a mobile app and make it stylish. Both Flutter and React Native have native components that make a product intuitive and stylish. The support of various programming languages like JavaScript, CSS, and HTML is the other common characteristic for both platforms. Additionally, the open community of developers is available for those who work with Flutter and React Native.
Differences between React Native and Flutter
The distinctive aspects of React Native and Flutter are the performance, development time, and user interface. So let’s mention them step-by-step. Flutter works flawlessly when it comes to user interface components in contrast to React Native. We know that time is important for product development, and React Native beats Flutter in this feature. It takes more time to build an app with Flutter than with React Native. Despite this drawback, Flutter has a high performance in creating a mobile product. Its native components out beat React Native in the tech domain. So both frameworks have their advantages and disadvantages for building a mobile app, and it’s up to you what you want to choose.
Leave a Response
Edward Cullens
I am Edward Cullens passionate of internet stuff such as blogging, affiliate marketing and most important, I like to trade domain and website. If you are inside digital marketing, let's connect us for future opportunities I am currently working at Techlipz.com.
Subscribe To TechLipz Newsletter
Subscribe to TechLipz email newsletter today to receive updates on the latest news, tutorials and special offers!
Thanks for signing up. You must confirm your email address before we can send you. Please check your email and follow the instructions.
We respect your privacy. Your information is safe and will never be shared.
Don't miss out. Subscribe today.
×
×
WordPress Popup Plugin
|
__label__pos
| 0.860675 |
Content-type: text/html Man page of mlib_GraphicsDrawTriangleSet
mlib_GraphicsDrawTriangleSet
Section: mediaLib Library Functions (3MLIB)
Updated: 2 Mar 2007
Index Return to Main Contents
NAME
mlib_GraphicsDrawTriangleSet, mlib_GraphicsDrawTriangleSet_8, mlib_GraphicsDrawTriangleSet_32, mlib_GraphicsDrawTriangleSet_X_8, mlib_GraphicsDrawTriangleSet_X_32, mlib_GraphicsDrawTriangleSet_A_8, mlib_GraphicsDrawTriangleSet_A_32, mlib_GraphicsDrawTriangleSet_B_8, mlib_GraphicsDrawTriangleSet_B_32, mlib_GraphicsDrawTriangleSet_G_8, mlib_GraphicsDrawTriangleSet_G_32, mlib_GraphicsDrawTriangleSet_Z_8, mlib_GraphicsDrawTriangleSet_Z_32, mlib_GraphicsDrawTriangleSet_AB_8, mlib_GraphicsDrawTriangleSet_AB_32, mlib_GraphicsDrawTriangleSet_ABG_8, mlib_GraphicsDrawTriangleSet_ABG_32, mlib_GraphicsDrawTriangleSet_ABGZ_8, mlib_GraphicsDrawTriangleSet_ABGZ_32, mlib_GraphicsDrawTriangleSet_ABZ_8, mlib_GraphicsDrawTriangleSet_ABZ_32, mlib_GraphicsDrawTriangleSet_AG_8, mlib_GraphicsDrawTriangleSet_AG_32, mlib_GraphicsDrawTriangleSet_AGZ_8, mlib_GraphicsDrawTriangleSet_AGZ_32, mlib_GraphicsDrawTriangleSet_AZ_8, mlib_GraphicsDrawTriangleSet_AZ_32, mlib_GraphicsDrawTriangleSet_BG_8, mlib_GraphicsDrawTriangleSet_BG_32, mlib_GraphicsDrawTriangleSet_BGZ_8, mlib_GraphicsDrawTriangleSet_BGZ_32, mlib_GraphicsDrawTriangleSet_BZ_8, mlib_GraphicsDrawTriangleSet_BZ_32, mlib_GraphicsDrawTriangleSet_GZ_8, mlib_GraphicsDrawTriangleSet_GZ_32 - draw triangle set where each member can have different vertices
SYNOPSIS
cc [ flag... ] file... -lmlib [ library... ]
#include <mlib.h>
mlib_status mlib_GraphicsDrawTriangleSet_8(mlib_image *buffer,
const mlib_s16 *x, const mlib_s16 *y, mlib_s32 npoints, mlib_s32 c);
mlib_status mlib_GraphicsDrawTriangleSet_32(mlib_image *buffer,
const mlib_s16 *x, const mlib_s16 *y, mlib_s32 npoints, mlib_s32 c);
mlib_status mlib_GraphicsDrawTriangleSet_X_8(mlib_image *buffer,
const mlib_s16 *x, const mlib_s16 *y, mlib_s32 npoints, mlib_s32 c,
mlib_s32 c2);
mlib_status mlib_GraphicsDrawTriangleSet_X_32(mlib_image *buffer,
const mlib_s16 *x, const mlib_s16 *y, mlib_s32 npoints, mlib_s32 c,
mlib_s32 c2);
mlib_status mlib_GraphicsDrawTriangleSet_A_8(mlib_image *buffer,
const mlib_s16 *x, const mlib_s16 *y, mlib_s32 npoints, mlib_s32 c);
mlib_status mlib_GraphicsDrawTriangleSet_A_32(mlib_image *buffer,
const mlib_s16 *x, const mlib_s16 *y, mlib_s32 npoints, mlib_s32 c);
mlib_status mlib_GraphicsDrawTriangleSet_B_8(mlib_image *buffer,
const mlib_s16 *x, const mlib_s16 *y, mlib_s32 npoints, mlib_s32 c,
mlib_s32 a);
mlib_status mlib_GraphicsDrawTriangleSet_B_32(mlib_image *buffer,
const mlib_s16 *x, const mlib_s16 *y, mlib_s32 npoints, mlib_s32 c,
mlib_s32 a);
mlib_status mlib_GraphicsDrawTriangleSet_G_8(mlib_image *buffer,
const mlib_s16 *x, const mlib_s16 *y, mlib_s32 npoints,
const mlib_s32 *c);
mlib_status mlib_GraphicsDrawTriangleSet_G_32(mlib_image *buffer,
const mlib_s16 *x, const mlib_s16 *y, mlib_s32 npoints,
const mlib_s32 *c);
mlib_status mlib_GraphicsDrawTriangleSet_Z_8(mlib_image *buffer,
mlib_image *zbuffer, const mlib_s16 *x, const mlib_s16 *y,
const mlib_s16 *z, mlib_s32 npoints, mlib_s32 c);
mlib_status mlib_GraphicsDrawTriangleSet_Z_32(mlib_image *buffer,
mlib_image *zbuffer, const mlib_s16 *x, const mlib_s16 *y,
const mlib_s16 *z, mlib_s32 npoints, mlib_s32 c);
mlib_status mlib_GraphicsDrawTriangleSet_AB_8(mlib_image *buffer,
const mlib_s16 *x, const mlib_s16 *y, mlib_s32 npoints, mlib_s32 c,
mlib_s32 a);
mlib_status mlib_GraphicsDrawTriangleSet_AB_32(mlib_image *buffer,
const mlib_s16 *x, const mlib_s16 *y, mlib_s32 npoints, mlib_s32 c,
mlib_s32 a);
mlib_status mlib_GraphicsDrawTriangleSet_ABG_8(mlib_image *buffer,
const mlib_s16 *x, const mlib_s16 *y, mlib_s32 npoints,
const mlib_s32 *c, mlib_s32 a);
mlib_status mlib_GraphicsDrawTriangleSet_ABG_32(mlib_image *buffer,
const mlib_s16 *x, const mlib_s16 *y, mlib_s32 npoints,
const mlib_s32 *c, mlib_s32 a);
mlib_status mlib_GraphicsDrawTriangleSet_ABGZ_8(mlib_image *buffer,
mlib_image *zbuffer, const mlib_s16 *x, const mlib_s16 *y,
const mlib_s16 *z, mlib_s32 npoints, const mlib_s32 *c, mlib_s32 a);
mlib_status mlib_GraphicsDrawTriangleSet_ABGZ_32(mlib_image *buffer,
mlib_image *zbuffer, const mlib_s16 *x, const mlib_s16 *y,
const mlib_s16 *z, mlib_s32 npoints, const mlib_s32 *c, mlib_s32 a);
mlib_status mlib_GraphicsDrawTriangleSet_ABZ_8(mlib_image *buffer,
mlib_image *zbuffer, const mlib_s16 *x, const mlib_s16 *y,
const mlib_s16 *z, mlib_s32 npoints, mlib_s32 c, mlib_s32 a);
mlib_status mlib_GraphicsDrawTriangleSet_ABZ_32(mlib_image *buffer,
mlib_image *zbuffer, const mlib_s16 *x, const mlib_s16 *y,
const mlib_s16 *z, mlib_s32 npoints, mlib_s32 c, mlib_s32 a);
mlib_status mlib_GraphicsDrawTriangleSet_AG_8(mlib_image *buffer,
const mlib_s16 *x, const mlib_s16 *y, mlib_s32 npoints,
const mlib_s32 *c);
mlib_status mlib_GraphicsDrawTriangleSet_AG_32(mlib_image *buffer,
const mlib_s16 *x, const mlib_s16 *y, mlib_s32 npoints,
const mlib_s32 *c);
mlib_status mlib_GraphicsDrawTriangleSet_AGZ_8(mlib_image *buffer,
mlib_image *zbuffer, const mlib_s16 *x, const mlib_s16 *y,
const mlib_s16 *z, mlib_s32 npoints, const mlib_s32 *c);
mlib_status mlib_GraphicsDrawTriangleSet_AGZ_32(mlib_image *buffer,
mlib_image *zbuffer, const mlib_s16 *x, const mlib_s16 *y,
const mlib_s16 *z, mlib_s32 npoints, const mlib_s32 *c);
mlib_status mlib_GraphicsDrawTriangleSet_AZ_8(mlib_image *buffer,
mlib_image *zbuffer, const mlib_s16 *x, const mlib_s16 *y,
const mlib_s16 *z, mlib_s32 npoints, mlib_s32 c);
mlib_status mlib_GraphicsDrawTriangleSet_AZ_32(mlib_image *buffer,
mlib_image *zbuffer, const mlib_s16 *x, const mlib_s16 *y,
const mlib_s16 *z,mlib_s32 npoints, mlib_s32 c);
mlib_status mlib_GraphicsDrawTriangleSet_BG_8(mlib_image *buffer,
const mlib_s16 *x, const mlib_s16 *y, mlib_s32 npoints,
const mlib_s32 *c, mlib_s32 a);
mlib_status mlib_GraphicsDrawTriangleSet_BG_32(mlib_image *buffer,
const mlib_s16 *x, const mlib_s16 *y, mlib_s32 npoints,
const mlib_s32 *c, mlib_s32 a);
mlib_status mlib_GraphicsDrawTriangleSet_BGZ_8(mlib_image *buffer,
mlib_image *zbuffer, const mlib_s16 *x, const mlib_s16 *y,
const mlib_s16 *z, mlib_s32 npoints, const mlib_s32 *c, mlib_s32 a);
mlib_status mlib_GraphicsDrawTriangleSet_BGZ_32(mlib_image *buffer,
mlib_image *zbuffer, const mlib_s16 *x, const mlib_s16 *y,
const mlib_s16 *z, mlib_s32 npoints, const mlib_s32 *c, mlib_s32 a);
mlib_status mlib_GraphicsDrawTriangleSet_BZ_8(mlib_image *buffer,
mlib_image *zbuffer, const mlib_s16 *x, const mlib_s16 *y,
const mlib_s16 *z, mlib_s32 npoints, mlib_s32 c, mlib_s32 a);
mlib_status mlib_GraphicsDrawTriangleSet_BZ_32(mlib_image *buffer,
mlib_image *zbuffer, const mlib_s16 *x, const mlib_s16 *y,
const mlib_s16 *z, mlib_s32 npoints, mlib_s32 c, mlib_s32 a);
mlib_status mlib_GraphicsDrawTriangleSet_GZ_8(mlib_image *buffer,
mlib_image *zbuffer, const mlib_s16 *x, const mlib_s16 *y,
const mlib_s16 *z, mlib_s32 npoints, const mlib_s32 *c);
mlib_status mlib_GraphicsDrawTriangleSet_GZ_32(mlib_image *buffer,
mlib_image *zbuffer, const mlib_s16 *x, const mlib_s16 *y,
const mlib_s16 *z, mlib_s32 npoints, const mlib_s32 *c);
DESCRIPTION
Each of the mlib_GraphicsDrawTriangleSet_*() functions draws a set of triangles with vertices at {(x1,y1), (x2,y2), (x3,y3)}, {(x4,y4), (x5,y5), (x6,y6)}, ..., and {(xn-2,yn-2), (xn-1,yn-1), (xn,yn)}.
Each of the mlib_GraphicsDrawTriangleSet_X_*() functions draws a set of triangles in Xor mode as follows:
data[x,y] ^= c ^ c2
Each of the mlib_GraphicsDrawTriangleSet_A_*() functions draws a set of triangles with antialiasing.
Each of the mlib_GraphicsDrawTriangleSet_B_*() functions draws a set of triangles with alpha blending as follows:
data[x,y] = (data[x,y] * (255 - a) + c * a) / 255
Each of the mlib_GraphicsDrawTriangleSet_G_*() functions draws a set of triangles with Gouraud shading.
Each of the mlib_GraphicsDrawTriangleSet_Z_*() functions draws a set of triangles with Z buffering.
Each of the other functions draws a set of triangles with a combination of two or more features like antialiasing (A), alpha blending (B), Gouraud shading (G), and Z buffering (Z).
PARAMETERS
Each of the functions takes some of the following arguments:
buffer
Pointer to the image into which the function is drawing.
zbuffer
Pointer to the image that holds the Z buffer.
x
Pointer to array of X coordinates of the points.
y
Pointer to array of Y coordinates of the points.
z
Pointer to array of Z coordinates of the points.
npoints
Number of points in the arrays. npoints must be a multiple of 3.
c
Color used in the drawing, or pointer to array of colors of the points in the case of Gouraud shading.
c2
Alternation color.
a
Alpha value for blending. 0 ≤ a ≤ 255.
RETURN VALUES
Each of the functions returns MLIB_SUCCESS if successful. Otherwise it returns MLIB_FAILURE.
ATTRIBUTES
See attributes(5) for descriptions of the following attributes:
ATTRIBUTE TYPEATTRIBUTE VALUE
Interface StabilityCommitted
MT-Level
SEE ALSO
mlib_GraphicsDrawTriangle(3MLIB), mlib_GraphicsDrawTriangleFanSet(3MLIB), mlib_GraphicsDrawTriangleStripSet(3MLIB), attributes(5)
Index
NAME
SYNOPSIS
DESCRIPTION
PARAMETERS
RETURN VALUES
ATTRIBUTES
SEE ALSO
This document was created by man2html, using the manual pages.
Time: 02:37:54 GMT, October 02, 2010
|
__label__pos
| 0.982547 |
Search results
Focus the double clicked column in JavaScript Grid control
27 Jul 2021 / 2 minutes to read
You can focus the double clicked column edit form an through an recordDoubleClick event. With the help of this event you can focus the double clicked column in inline edit mode.
Source
Preview
index.ts
index.html
Copied to clipboard
import { Grid, Page, Edit, Toolbar } from '@syncfusion/ej2-grids';
import { data } from './datasource.ts';
Grid.Inject(Page, Toolbar, Edit);
let grid: Grid = new Grid({
dataSource: data,
allowPaging: true,
editSettings: { allowEditing: true, allowAdding: true, allowDeleting: true,
mode: "Normal"
},
recordDoubleClick: recordDoubleClick,
actionComplete: actionComplete,
columns: [
{ field: 'OrderID', isPrimaryKey: true, headerText: 'Order ID', textAlign: 'Right', width: 120, type: 'number' },
{ field: 'CustomerID', width: 140, headerText: 'Customer ID', type: 'string' },
{ field: 'Freight', headerText: 'Freight', editType: "numericedit", textAlign: 'Right', width: 120, format: 'C2' },
{ field: 'OrderDate', headerText: 'Order Date', textAlign: 'Right', width: 140, editType: "datetimepickeredit",
format: { type: "dateTime", format: "M/d/y hh:mm a" }, },
{ field: "ShipCountry", headerText: "Ship Country", editType: "dropdownedit", width: 150, edit: { params: { popupHeight: "300px" } }
}
],
height: 220
});
grid.appendTo('#Grid');
var fieldName;
function recordDoubleClick(e) {
var clickedColumnIndex = e.cell.getAttribute("aria-colindex");
fieldName = this.columnModel[parseInt(clickedColumnIndex)].field;
}
function actionComplete(e) {
if (e.requestType === "beginEdit") {
// focus the column
e.form.elements[grid.element.getAttribute("id") + fieldName].focus();
}
}
Copied to clipboard
<!DOCTYPE html>
<html lang="en">
<head>
<title>EJ2 Grid</title>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<meta name="description" content="Typescript Grid Control" />
<meta name="author" content="Syncfusion" />
<link href="index.css" rel="stylesheet" />
<link href="//cdn.syncfusion.com/ej2/ej2-base/styles/material.css" rel="stylesheet" />
<link href="//cdn.syncfusion.com/ej2/ej2-grids/styles/material.css" rel="stylesheet" />
<link href="//cdn.syncfusion.com/ej2/ej2-buttons/styles/material.css" rel="stylesheet" />
<link href="//cdn.syncfusion.com/ej2/ej2-popups/styles/material.css" rel="stylesheet" />
<link href="//cdn.syncfusion.com/ej2/ej2-navigations/styles/material.css" rel="stylesheet" />
<link href="//cdn.syncfusion.com/ej2/ej2-dropdowns/styles/material.css" rel="stylesheet" />
<link href="//cdn.syncfusion.com/ej2/ej2-lists/styles/material.css" rel="stylesheet" />
<link href="//cdn.syncfusion.com/ej2/ej2-inputs/styles/material.css" rel="stylesheet" />
<link href="//cdn.syncfusion.com/ej2/ej2-calendars/styles/material.css" rel="stylesheet" />
<link href="//cdn.syncfusion.com/ej2/ej2-splitbuttons/styles/material.css" rel="stylesheet" />
<script src="https://cdnjs.cloudflare.com/ajax/libs/systemjs/0.19.38/system.js"></script>
<script src="systemjs.config.js"></script>
</head>
<body>
<div id='loader'>Loading....</div>
<div id='container'>
<div id='Grid'></div>
</div>
</body>
</html>
|
__label__pos
| 0.92382 |
Jannah Theme License is not validated, Go to the theme options page to validate the license, You need a single license for each domain name.
Fixes
Easily Fix Windows could not Automatically Detect this Network’s Proxy Settings Error
If you have been getting the “Windows could not automatically detect this network’s proxy settings” Error on your computer, you don’t need to worry because we have compiled this guide to address this issue. Basically, we started to experiment with different troubleshooting methods and came to conclude the most effective ones in this guide.
windows could not automatically detect this network's proxy settings
Windows could not automatically detect this network’s proxy settings
In addition to that, we also pinpointed the reasons due to which the error might be seen on your computer and have also listed them below. Make sure to implement these fixes on your computer one by one until one of them fixes the error message for you.
What Causes the Windows could not Automatically Detect This Network’s Proxy Settings Error?
After studying this issue in detail, we came to conclude that the following have to be the most important reasons due to which the error message is triggered.
• Network Adapter Issue: It is possible in some cases that the network adapter that has been installed on the computer got glitched and due to that, the error message is being triggered. Therefore, we suggest that you try to update, restart or reinstall this adapter in an attempt to fix the “Windows could not automatically detect this network’s proxy settings” issue as we have mentioned below.
• VPN Connection: In certain cases, the VPN connection that you have connected to might be preventing the automatic detection of the Network’s Proxy settings. Therefore, you can try to temporarily disconnect from the VPN and check to see if the issue is fixed in that way.
• Firewall/Antivirus: Sometimes the Firewall or the Antivirus installed on your computer might prevent the proper functioning of some other services on the computer and this might prevent the automatic detection of network proxy settings.
• Problem with DNS and IP Address Detection: If the IP Address and the DNS Server address have both been configured to be automatically detected, you might get this error on your computer. Therefore, we strongly suggest that you try to set a static value for these as we have done below in order to be able to Automatically detect the network’s proxy settings.
Now that we have taken you through most of the reasons behind the occurrence of this issue, we can finally start implementing the solutions.
Before you Start:
1. Restart your Computer: Sometimes, a simple restart to the computer might fix this issue completely. Therefore, click on the “Windows” icon at the bottom left side and click on the “Power” icon. Press “Shift” on your keyboard and click on the “Shutdown” button to completely shut down the computer. After that, start it back up and check to see if you are able to fix this issue.
Shutdown the Computer
Shutdown the Computer
2. Restart your Internet Router: Press the “Power” button on your internet router to turn it off and unplug its power adapter from the wall. After that, make sure to press and hold the “Power” button for a while to get rid of any leftover electricity. Start the router back up and check to see if doing so has fixed the “Windows could not Automatically Detect This Network’s Proxy Settings” Error.
Fixing the Windows could not Automatically Detect This Network’s Proxy Settings Error:
Method 1: Configure Automatic Detection of Network Settings
1. From your keyboard, press the “Window + I” keys to launch into the settings.
2. Here, click on the “Network & Internet” option and then click on the “Proxy” option from the left side.
3. Clicking on the "Automatically Detect Settings" option
Clicking on the “Automatically Detect Settings” option
Make sure that the “Automatically Detect Settings” option has been enabled.
4. Check to see if doing so fixes the “Windows could not Automatically Detect This Network’s Proxy Settings” issue.
Method 2: Troubleshoot Network Adapter
1. Press the “Window + I” keys simultaneously to launch into the Settings panel.
2. From the panel, click on the “Update & Security” option and then select the “Troubleshoot” button from the left side.
To show the option that is to be selected
Clicking on “Update and Security”
3. After doing so, click on the “Additional troubleshooters” button and then select the “Network Adapter” button.
4. After that, click on the “Run the Troubleshooter” button to start the troubleshooting of the network adapter.
Run the troubleshooter
Run the troubleshooter
5. Follow through with the on-screen instructions to complete the troubleshooting process and check to see if the Windows could not Automatically Detect This Network’s Proxy Settings issue is fixed.
Method 3: Configure Automatic Obtaining of IP and DNS Address
1. Press the “Windows + I” keys to launch into settings and click on the “Network and Internet” button.
2. Click on the “Status” option and from the right side, click on the “Change Adapter Options” button.
Change adapter options
Change adapter options
3. Right-click on the “Wi-Fi” network that you are connected to and click on the “Properties” option.
4. Double-click on the “Internet Protocol Version 4 (IPV4)” option and make sure to check the “Obtain an IP Address Automatically” and the “Obtain DNS Server Address Automatically“.
5. After doing this, make sure to save your changes and restart the computer.
6. Check to see if doing so fixes the “Windows could not Automatically Detect this Network’s Proxy Settings” error.
Method 4: Update Network Driver
1. Press “Windows + R” keys on your keyboard to launch into the Run prompt and type in “devmgmt.msc” and press “Enter” to launch into the device manager.
Typing devmgmt.msc in the Run prompt
Typing devmgmt.msc in the Run prompt
2. From here, the list of drivers installed on your computer will be shown, make sure to expand the “Network Adapter” list and right-click on the installed driver and select the “Update Driver” option.
3. From the next screen, make sure to select the “Search Automatically for updated driver software” option.
Search automatically for updated driver
Search automatically for updated driver
4. Check to see if doing so has fixed the Windows could not Automatically Detect This Network’s Proxy Settings error.
Method 5: Rollback Network Driver
1. Press “Windows + R” keys on your keyboard to launch into the Run prompt and type in “devmgmt.msc” and press “Enter” to launch into the device manager.
2. From here, the list of drivers installed on your computer will be shown, make sure to expand the “Network Adapter” list and double-click on the installed drivers.
3. Click on the “Driver” option and from there, click on the “Roll Back Driver” option.
Rollback Driver
Rollback Driver
4. After doing so, make sure to save your changes and fix the Windows could not Automatically Detect This Network’s Proxy Settings error.
Method 6: Reset Network Configurations
1. Press “Windows + R” to launch into the Run prompt, type in “cmd” and press “Shift + Ctrl + Enter” to launch with admin permissions.
2. After this, type in the following commands and press “Enter” to execute them.
netsh int ip reset resetlog.txt
netsh winsock reset
Netsh int ip reset
ipconfig /release
ipconfig /renew
ipconfig /flushdns
DISM /Online /Cleanup-Image /RestoreHealth
1. After executing these commands, make sure to restart your computer and check to see if the issue is fixed on your computer.
Method 7: Disable firewall
1. Press “Windows + I” to launch into the Windows settings and from there, click on the “Update and Security” option.
2. After this, click on the “Windows Security” option from the left side and then click on the “Firewall & Network Protection” option.
Choose Windows Security Option
Choose Windows Security Option
3. Now, click on the Domain, Private and Public options one by one and make sure to turn off the “Microsoft Defender Firewall” toggle one by one.
Turning Microsoft Defender OFF for Private Network to fix Windows could not Automatically Detect This Network's Proxy Settings
Turning Microsoft Defender OFF for Private Network
4. After this, make sure to restart your computer and check to see if the issue is fixed.
Method 8: Disable VPN
1. Press “Windows + I” to open the settings and click on the “Network and Internet” option.
2. From the left side, click on the “VPN” option, and, make sure to disable and turn “OFF” any VPN connection running on your computer.
Turning VPN OFF to fix Windows could not Automatically Detect This Network's Proxy Settings
Turning VPN OFF
3. If you are running a third-party VPN connection software, make sure that you have “Disabled” it as well.
4. Check to see if by doing so, you have managed to fix the Windows could not Automatically Detect This Network’s Proxy Settings error.
Method 9: Disable Real-Time Protection
1. Press “Windows + I” to launch into the Windows settings and from there, click on the “Update and Security” option.
2. After this, click on the “Windows Security” option from the left side and then click on the “Virus and Threat Protection” option.
Virus and Threat Protection
Virus and Threat Protection
3. After doing so, click on the “Manage Settings” option under the “Virus and Threat Protection” heading.
4. From here, make sure that you disable the “Real-Time Protection” toggle and then exit out of the Window.
5. Check to see if doing so helps you in fixing the issue and if it doesn’t, make sure to turn the protection back on because it shouldn’t be disabled for too long.
Method 10: Scan with Malwarebytes
1. Download the Malwarebytes Software on your computer and run the executable.
2. After running the downloaded executable, make sure to follow the on-screen instructions to install it on your computer.
3. After installing, make sure to launch the software and run a scan.
Run Scan
Run a Threat Scan
4. Check to see if the scan finds anything of concern and remove it from the computer.
Method 11: Perform a System Restore
1. Press “Windows + R” to open Run, type in “rstrui.exe” and press “Enter” to launch into the restore window.
2. After this, click on “Next” and then select “Choose a different restore point” or the “Show More Restore Points” option.
Clicking on the "Show more Restore Points"
Clicking on the “Show more Restore Points”
3. This will list all the different restore points that are available on your computer.
4. Make sure to select one and then follow through with the on-screen instructions to reset your computer.
5. Check to see if doing so fixes the Windows could not Automatically Detect This Network’s Proxy Settings error.
Method 12: Reset Network Settings
1. Press “Windows + I” to open settings, click on the “Network and Internet” option, and from the left side, click on the “Status” button.
Network and Internet
Network and Internet
2. In here, make sure that you click on the “Network Reset” option and then select the “Reset Now” button.
3. After the reset process has been finished, check to see if you are able to fix the issue.
Method 13: Restart Network Adapter
1. Press “Windows + R” to launch the Run prompt, type in “ncpa.cpl” and press “Enter” to launch into the network control panel.
Typing in "ncpa.cpl"
Typing in “ncpa.cpl”
2. Here, right-click on the Wi-Fi connection that you are using and select the “Disable” option.
3. Wait for at least 1 minute and then right-click on the disabled connection and select the “Enable” button to start the Wi-Fi connection back up.
Method 14: Run SFC Scan
1. Press “Windows + R” to launch into the Run prompt, type in “cmd” and then press “Shift + Ctrl + Enter” to launch in admin mode.
Typing in cmd
Typing in cmd
2. Type in the following command and press “Enter” to execute it on your computer.
sfc /scannow
3. Wait for the scan to be completed and check to see if you are able to fix this issue.
Method 15: Uninstall Antivirus Program
1. Press “Windows + R” to open the run prompt.
2. Type in “appwiz.cpl” and press “Enter” to launch into the application wizard.
Typing in "Appwiz.cpl" in the Run box.
Typing in “Appwiz.cpl” in the Run box.
3. From here, make sure to find the Antivirus program that you have installed on your computer and right-click on it.
4. Click on the “Uninstall” button to remove the software from your computer and check to see if the Windows could not Automatically Detect This Network’s Proxy Settings error is fixed.
Method 16: Reset Internet Settings
1. Press “Windows + R” to open the Run prompt.
2. Type in “inetcpl.cpl” and press “Enter” to open the internet explorer window.
Typing "inetcpl.cpl" to fix windows could not automatically detect this network's proxy settings
Typing “inetcpl.cpl”
3. In here, click on the “Advanced” tab from the top and select the “Reset” option under the “Reset Internet Explorer Settings” window.
4. After completing this step, check to see if you have been able to fix the error message on your computer.
Method 17: Disable Proxy Server
1. Press “Windows + R” to open the Run prompt.
2. Type in “inetcpl.cpl” and press “Enter” to open the internet explorer window.
3. From the top, click on the “Connections” tab and then select the “LAN Settings” option.
4. Once in here, make sure that you have the “Use a Proxy Server for your LAN” option unchecked.
Disable the proxy servers to fix windows could not automatically detect this network's proxy settings
Disable the proxy servers
5. Click on “OK” and then verify if the Windows could not Automatically Detect This Network’s Proxy Settings message has been fixed.
Method 18: Reconfigure Services
1. Press “Windows + R” to launch into the Run prompt, type in “cmd” and then press “Shift + Ctrl + Enter” to launch in admin mode.
2. Type in the following commands one by one and press “Enter” to execute them on your computer.
sc config Wlansvc start= demand
sc config dot3svc start= demand
sc config Dhcp start= auto
1. After this step has been completed, restart your device and check to see if you have been able to fix this error message.
Method 19: Use Static DNS and IP Address
1. Press the “Windows + I” keys to launch into settings and click on the “Network and Internet” button.
2. Click on the “Status” option and from the right side, click on the “Change Adapter Options” button.
3. Right-click on the “Wi-Fi” network that you are connected to and click on the “Properties” option.
4. Double-click on the “Internet Protocol Version 4 (IPV4)” option and make sure to check the “Use the Following DNS Address” option.
Internet Protocol Version 4 (TCP/IPv4)
Internet Protocol Version 4 (TCP/IPv4)
5. Type in the following DNS Addresses as the Primary and the Secondary DNS Addresses respectively.
8.8.8.8
8.8.4.4
6. Click on “Apply” and then on “OK” and exit out of the window.
7. Check to see if doing so has fixed the issue on your computer.
8. If it hasn’t, press “Windows + R“, type in “cmd” and press “Shift + CTRL + Enter“.
9. After that, run the “ipconfig” command inside cmd and note down the IPV4 Address, Default Gateway, and Subnet mask that has been listed.
ipconfig/all to fix windows could not automatically detect this network's proxy settings
ipconfig/all
10. From here, make sure that you repeat up to the 4th step and check the “Use the Following IP Address” option, and type in the values that we noted down previously.
11. Check to see if you are able to fix the Windows could not Automatically Detect This Network’s Proxy Settings error.
Method 20: Enable custom 3D Support
1. From the System Tray at the bottom right side of your desktop, click on the “Riva Tuner Statistics Server“.
2. Once the app launches, make sure to turn on the “Custom 3D Support” option.
3. Check to see if the issue has been resolved.
Method 21: Perform Clean Reinstall of Windows
1. First of all, download the Media Creation Tool on your computer from the official Microsoft Website.
2. After downloading, run the executable and install it on your computer.
Create installation media (USB flash drive, DVD, or ISO file for another PC to fix windows could not automatically detect this network's proxy settings
Create installation media (USB flash drive, DVD, or ISO file for another PC
3. Launch the installed ISO file and from there, follow the on-screen instructions to install Windows.
4. Make sure to delete the present files on all previous hard drives for a completely new installation.
5. Check to see if doing so fixes the issue.
If the error message still occurs, we suggest that you Contact Us for further troubleshooting.
Alan Adams
Alan is a hardcore tech enthusiast that lives and breathes tech. When he is not indulged in playing the latest video games, he helps users with technical problems that they might run into. Alan is a Computer Science Graduate with a Masters in Data Science.
Back to top button
|
__label__pos
| 0.745617 |
Sign messages
Prompt users to sign a message to prove they control an address or authorize an in-app action.
The ability for a user to sign a cryptographic message to prove ownership of a particular address is a key feature provided by Stacks Connect.
In this guide, you will learn how to:
1. Prompt users to sign a message.
2. Verify the signature.
3. Process and handle the results.
Setup and installation
Using your preferred package manager, setup and install a new project with the following packages:
• @stacks/network: Used to interact with the Stacks blockchain network.
• @stacks/encryption: Used to sign and verify messages.
• @stacks/connect: Used to authenticate users and broadcast the transactions.
npm install @stacks/network @stacks/encryption @stacks/connect
Initiate a session
Users must authenticate to an app before you request message signing. Users can install an authenticator like the Leather wallet.
If you haven't already, refer to the authentication guide before proceeding to integrate the following message signing capabilities.
To prompt users to log in, use the showConnect function from the @stacks/connect package:
import { AppConfig, UserSession, showConnect } from '@stacks/connect';
const appConfig = new AppConfig(['store_write', 'publish_data']);
const userSession = new UserSession({ appConfig });
function authenticate() {
showConnect({
appDetails: {
name: 'My App',
icon: window.location.origin + '/my-app-logo.svg',
},
redirectTo: '/',
onFinish: () => {
let userData = userSession.loadUserData();
},
userSession: userSession,
});
}
Prompt users to sign a message
Call the openSignatureRequestPopup function provided by the @stacks/connect package to trigger the display of the message signing prompt:
import { openSignatureRequestPopup } from '@stacks/connect';
import { StacksTestnet } from '@stacks/network';
const message = 'Hello World';
openSignatureRequestPopup({
message,
network: new StacksTestnet(), // for mainnet, `new StacksMainnet()`
appDetails: {
name: 'My App',
icon: window.location.origin + '/my-app-logo.svg',
},
onFinish(data) {
console.log('Signature of the message', data.signature);
console.log('Use public key:', data.publicKey);
},
});
All of the methods included on this page accept a network option. By default, Connect uses a testnet network option. You can import a network configuration from the @stacks/network package:
import { StacksTestnet, StacksMainnet } from '@stacks/network';
const testnet = new StacksTestnet();
const mainnet = new StacksMainnet();
// use this in your messe signing method:
openSignatureRequestPopup({
network: mainnet,
// other relevant options
});
Several parameters are available for calling openSignatureRequestPopup:
interface SignatureRequestOptions {
message: string;
onFinish?: (data: SignatureData) => void;
onCancel?: (data: SignatureData) => void;
appDetails: {
name: string;
icon: string;
};
authOrigin?: string;
stxAddress?: string;
userSession?: UserSession;
}
Getting the signed message back after completion
The openSignatureRequestPopup method from @stacks/connect allows you to specify an onFinish callback. This callback will be triggered after the user has successfully signed the message.
You can get the signature of the message via the arguments passed to onFinish. Your callback will be fired with a single data argument:
const onFinish = (data: SignatureData) => {
const { signature, publicKey } = data;
console.log('Signature', signature);
console.log('PublicKey', publicKey);
};
export interface SignatureData {
/* Hex encoded DER signature */
signature: string;
/* Hex encoded private string taken from privateKey */
publicKey: string;
}
How to verify a signature
When you verify a signature, you're confirming that the message was indeed created by the claimed sender and that it hasn't been altered since it was signed. To do this, use the verifyMessageSignatureRsv function from the @stacks/encryption package:
import type { SignatureData } from '@stacks/connect';
import { verifyMessageSignatureRsv } from '@stacks/encryption';
const message = 'Hello World';
openSignatureRequestPopup({
message,
network: new StacksTestnet(),
appDetails: {
name: 'My App',
icon: window.location.origin + '/my-app-logo.svg',
},
onFinish(data: SignatureData) {
const { signature, publicKey } = data;
const verified = verifyMessageSignatureRsv({ message, publicKey, signature });
if (verified) {
/* your logic here */
}
},
});
Next steps
|
__label__pos
| 0.953711 |
Multilingual RPC
img
Cross-language call
With the wide-scale application of microservice scenarios, multi-language scenarios are becoming more and more common, and developers are more willing to use more suitable languages to implement different modules of a complex system. For example, use C to write gateways, use Go to write K8S resource operators, and use Java to write business applications. Languages and scenarios are not bound. Enterprises can often choose the appropriate language by combining their own technology stack and the expertise of developers.
In multilingual scenarios, the ability to call across languages is very important.
Cross-language capability is essentially the capability provided by [Network Protocol]. How to conveniently allow users to use the required network protocols, develop for appropriate cross-language scenarios, and enjoy the service governance capabilities of the Dubbo ecosystem are the concerns of the Dubbo-go service framework.
Cross Ecology
The Dubbo-go service framework provides cross-ecology capabilities. Developers can use Dubbo-go and its ecology project to build HTTP/front-end services, Dubbo/Spring applications , The connection between gRPC ecological applications.
Last modified January 2, 2023: Enhance Dubbogo docs (#1800) (71c8e722740)
|
__label__pos
| 0.651053 |
blob: 5224ee5b392d07f06ea963c0a0910f66a6bff263 [file] [log] [blame]
/*
* test module to check whether the TSC-based delay routine continues
* to work properly after cpufreq transitions. Needs ACPI to work
* properly.
*
* Based partly on the Power Management Timer (PMTMR) code to be found
* in arch/i386/kernel/timers/timer_pm.c on recent 2.6. kernels, especially
* code written by John Stultz. The read_pmtmr function was copied verbatim
* from that file.
*
* (C) 2004 Dominik Brodowski
*
* To use:
* 1.) pass clock=tsc to the kernel on your bootloader
* 2.) modprobe this module (it'll fail)
* 3.) change CPU frequency
* 4.) modprobe this module again
* 5.) if the third value, "diff_pmtmr", changes between 2. and 4., the
* TSC-based delay routine on the Linux kernel does not correctly
* handle the cpufreq transition. Please report this to
* [email protected]
*/
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/init.h>
#include <linux/delay.h>
#include <linux/acpi.h>
#include <asm/io.h>
static int pm_tmr_ioport = 0;
/*helper function to safely read acpi pm timesource*/
static u32 read_pmtmr(void)
{
u32 v1=0,v2=0,v3=0;
/* It has been reported that because of various broken
* chipsets (ICH4, PIIX4 and PIIX4E) where the ACPI PM time
* source is not latched, so you must read it multiple
* times to insure a safe value is read.
*/
do {
v1 = inl(pm_tmr_ioport);
v2 = inl(pm_tmr_ioport);
v3 = inl(pm_tmr_ioport);
} while ((v1 > v2 && v1 < v3) || (v2 > v3 && v2 < v1)
|| (v3 > v1 && v3 < v2));
/* mask the output to 24 bits */
return (v2 & 0xFFFFFF);
}
static int __init cpufreq_test_tsc(void)
{
u32 now, then, diff;
u64 now_tsc, then_tsc, diff_tsc;
int i;
/* the following code snipped is copied from arch/x86/kernel/acpi/boot.c
of Linux v2.6.25. */
/* detect the location of the ACPI PM Timer */
if (acpi_gbl_FADT.header.revision >= FADT2_REVISION_ID) {
/* FADT rev. 2 */
if (acpi_gbl_FADT.xpm_timer_block.space_id !=
ACPI_ADR_SPACE_SYSTEM_IO)
return 0;
pm_tmr_ioport = acpi_gbl_FADT.xpm_timer_block.address;
/*
* "X" fields are optional extensions to the original V1.0
* fields, so we must selectively expand V1.0 fields if the
* corresponding X field is zero.
*/
if (!pm_tmr_ioport)
pm_tmr_ioport = acpi_gbl_FADT.pm_timer_block;
} else {
/* FADT rev. 1 */
pm_tmr_ioport = acpi_gbl_FADT.pm_timer_block;
}
printk(KERN_DEBUG "start--> \n");
then = read_pmtmr();
rdtscll(then_tsc);
for (i=0;i<20;i++) {
mdelay(100);
now = read_pmtmr();
rdtscll(now_tsc);
diff = (now - then) & 0xFFFFFF;
diff_tsc = now_tsc - then_tsc;
printk(KERN_DEBUG "t1: %08u t2: %08u diff_pmtmr: %08u diff_tsc: %016llu\n", then, now, diff, diff_tsc);
then = now;
then_tsc = now_tsc;
}
printk(KERN_DEBUG "<-- end \n");
return -ENODEV;
}
static void __exit cpufreq_none(void)
{
return;
}
module_init(cpufreq_test_tsc)
module_exit(cpufreq_none)
MODULE_AUTHOR("Dominik Brodowski");
MODULE_DESCRIPTION("Verify the TSC cpufreq notifier working correctly -- needs ACPI-enabled system");
MODULE_LICENSE ("GPL");
|
__label__pos
| 0.892495 |
Personalize Your iPhone with Name Calling Ringtone
P
Your iPhone is more than just a device; it’s an extension of your personality. One way to make it truly yours is by personalizing your ringtone. While you can choose from a range of default ringtones, creating a name calling ringtone adds a unique touch that reflects your individuality.
In this guide, we’ll explore why personalizing your iPhone ringtone is a great idea and provide step-by-step instructions for creating custom name calling ringtones. We’ll also delve into customization options, contact-specific ringtones, troubleshooting, and why this small tweak can make a big difference.
Iphone Name Calling Ringtone 1
Why Personalizing Your iPhone Ringtone is a Great Idea
Personalizing your ringtone offers several advantages:
• Distinctive Identity: A personalized ringtone helps you stand out in a crowd. When your phone rings, you’ll know it’s yours, even in a noisy environment.
• Emotional Connection: Hearing a loved one’s name when they call adds a personal touch and enhances the emotional connection.
• Effortless Recognition: Custom ringtones for specific contacts allow you to identify callers without looking at your phone.
• Fun and Creativity: Creating custom ringtones is a fun way to express your creativity and add a touch of humor or sentimentality to your device.
Steps to Create a Name Calling Ringtone on Your iPhone
Iphone Name Calling Ringtone 2
Follow these steps to create a name calling ringtone:
1. Choose a Voice Recording: Open the Voice Memos app on your iPhone and record the name or phrase you want as your ringtone.
2. Trim the Recording: Trim the recording to the desired length, typically no longer than 30 seconds.
3. Save the Recording: Save the trimmed recording with a clear and recognizable name.
4. Transfer to GarageBand: If you don’t have GarageBand installed, download it from the App Store. Import the voice recording into GarageBand.
5. Edit in GarageBand: In GarageBand, you can further edit the recording, add effects, and adjust the volume.
6. Export as Ringtone: Once you’re satisfied, export the edited recording as a ringtone. GarageBand will save it in the “Tones” section of your iPhone’s settings.
Customization Options and Settings for Unique Ringtones
When creating custom ringtones, explore various customization options:
• Sound Effects: Experiment with sound effects, pitch adjustments, and speed alterations to create unique tones.
• Music Integration: Combine music with the name calling recording to create a personalized melody.
• Vibrations: Set custom vibrations to complement your ringtone. This adds a tactile dimension to caller identification.
How to Assign Personalized Ringtones to Specific Contacts
Iphone Name Calling Ringtone 3
After creating your name calling ringtone, assign it to specific contacts:
1. Open Contacts: Go to your Contacts app and select the person you want to customize.
2. Edit Contact: Tap “Edit” in the upper-right corner.
3. Ringtone: Scroll down to “Ringtone” and tap it. Choose your custom ringtone from the list.
4. Save: Tap “Done” to save your changes.
Now, when that contact calls, your personalized ringtone will play.
Troubleshooting Common Issues with Ringtone Customization
If you encounter issues with your custom ringtone:
• Check File Format: Ensure your ringtone is in the correct format (M4R).
• Length: Keep your ringtone under 30 seconds in length.
• Syncing: If the ringtone doesn’t appear on your iPhone, sync it via iTunes on your computer.
Personalizing your iPhone with name calling ringtones is a creative and fun way to make your device uniquely yours. It adds a personal touch to your communication experience and helps you identify callers with ease.
By following the steps outlined in this guide, you can create custom ringtones that reflect your individuality and enhance your iPhone’s functionality. So go ahead, have some fun, and let your iPhone speak your name in your own voice.
About the author
Satria Bijaksana
Recent News
Popular Topics
Media Partner
Save
|
__label__pos
| 0.532808 |
Reply to post:
No more IP addresses for countries that shut down internet access
Anonymous Coward
Anonymous Coward
> Part of the rules allows them to revoke the whole block back
Oh right, and then what.
Are they going to prevent the ISP from originating the route? Are they going to use RPKI to stop the route propagating?
Either way, they're doing exactly what the plan was supposed to avoid: disconnecting the country from the Internet. So that seems pretty counter-productive to me.
Basically this is using IPv4 scarcity as a political lever, which I guess is an opportunity to encourage IPv6 deployment. After all, your initial v6 allocation is likely to last you many years if you deploy it wisely. So this makes you less beholden to the whim of registries as you expand.
Corrupt countries leading the way in IPv6 - who'd have thunk it?
Besides, who's judge and jury in the registry, making these political judgements? Having seen how ICANN have behaved over the last few years, maybe a tinpot dictator is preferable.
POST COMMENT House rules
Not a member of The Register? Create a new account here.
• Enter your comment
• Add an icon
Anonymous cowards cannot choose their icon
Biting the hand that feeds IT © 1998–2019
|
__label__pos
| 0.927423 |
{ "cells": [ { "cell_type": "markdown", "metadata": {}, "source": [ "# Introduction\n", "\n", "PIn previous Notebooks, we saw how to create an asymmetrical key (using RSA) and a symmetrical one (using Elliptical Curve Diffie-Hellman protocol). Now we will assume that we have the key between Alice and Bob and we will check how to encrypt / decrypt a file.\n", "\n", "According to the NIST, there is 2 algorithm considered as safe (Publication and Block Cipher Techniques) which are AES and Triple DES. This is the one we will use in this exercice.\n", "\n", "# Principle\n", "\n", "In encryption / decryption, the principle is to take a piece of code (fixed and determined by the key length and the algorithm used), encrypt it and do it for every block. This is mainly what I did in the notebook regarding RSA by taking the value of each character.\n", "\n", "## Padding\n", "\n", "However, what happen with the last block. there is few chances that it has exaclty the size of the block. As a result, we have to apply some padding which have to be known. It exists several ones explained in Wikipedia. Based on some other videos I saw, I applied here the ANSI X9.23.\n", "\n", "## Mode Operation\n", "\n", "On what I did on the notebook regarding RSA is not recommended because 2 identical input block will have 2 identical output block. It's the case with \"l\" letter in \"Hello\". However on this exemple, our block is far too small (it was just for learning purposes) but the result is still valid. It exist several alternative well explained also on Wikipedia. In this notebook, we will use CBC and CTR modes which are the 2 block cipher modes recommended by Niels Ferguson and Bruce Schneier (2 experts in cryptography). NIST also recommand them in the publication presented previously.\n", "\n", "Now we have everythin explained, let's do some practical test with AES / Triple DES using those 2 modes and the padding ANSI X9.23\n", "\n", "# Implementation\n", "\n", "Unfortunately, at this stage, it's still too complicated for me to implement those algorithms. As a reuslt I'll use a library called cryptography" ] }, { "cell_type": "code", "execution_count": 2, "metadata": {}, "outputs": [], "source": [ "import os\n", "import re\n", "import random\n", "import hashlib\n", "\n", "import cryptography\n", "import lorem\n", "\n", "from cryptography.hazmat.primitives.ciphers import Cipher, algorithms, modes\n", "from cryptography.hazmat.backends import default_backend" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "## AES (CBC)\n", "\n", "let's create random keys to start. For this algorithm we need a 32 bit key as encryption key (but also another key commnly called IV which is used as a starting point for the Mode Operation). This key cqn be publicly transfered. It's just to avoid having repeating clock of encrypted message used by attacker to decypher it. This keyt must be 16 bit long." ] }, { "cell_type": "code", "execution_count": 3, "metadata": {}, "outputs": [], "source": [ "letter = \"0123456789ABCDEF\"\n", "random.seed(42)\n", "key = \"\".join([random.choice(letter) for i in range(32)])\n", "key = bytes(key, 'utf-8')\n", "\n", "iv = \"\".join([random.choice(letter) for i in range(16)])\n", "iv = bytes(iv, 'utf-8')" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "the module os also provides a generator easy to use :" ] }, { "cell_type": "code", "execution_count": 66, "metadata": {}, "outputs": [], "source": [ "# key = os.urandom(32)\n", "# iv = os.urandom(16)" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Let's now declare the encryption/decryption algorithm and the mode (the padding will be done manually)" ] }, { "cell_type": "code", "execution_count": 4, "metadata": {}, "outputs": [], "source": [ "algo = algorithms.AES(key)" ] }, { "cell_type": "code", "execution_count": 5, "metadata": {}, "outputs": [], "source": [ "mode = modes.CBC(iv)" ] }, { "cell_type": "code", "execution_count": 6, "metadata": {}, "outputs": [], "source": [ "cipher = Cipher(algorithms.AES(key), modes.CBC(iv), backend=default_backend())" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "For the exercice, let's create a text file with lorem text." ] }, { "cell_type": "code", "execution_count": 70, "metadata": {}, "outputs": [], "source": [ "# with open(\"lorem.txt\", \"w\") as f:\n", "# for i in range(20):\n", "# f.write(lorem.paragraph())" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "now we can create a new file and write each cyphered block in" ] }, { "cell_type": "code", "execution_count": 71, "metadata": {}, "outputs": [ { "data": { "text/plain": [ "b''" ] }, "execution_count": 71, "metadata": {}, "output_type": "execute_result" } ], "source": [ "encryptor = cipher.encryptor()\n", "with open(\"encoded_CBC.txt\", \"wb\") as f_out, open(\"lorem.txt\", \"rb\") as f_in:\n", " while True:\n", " b = f_in.read(64)\n", " if not b:\n", " break\n", "\n", "# ANSI X9.23\n", " if len(b) < 64:\n", " padding_size = 64-len(b)\n", " padding_str = \"0\"*(padding_size-2) + \"{:02d}\".format(padding_size)\n", " b += bytes(padding_str, 'utf-8')\n", " ct = encryptor.update(b)\n", " f_out.write(ct)\n", "encryptor.finalize()" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "This new file can be decrypted with the same principle" ] }, { "cell_type": "code", "execution_count": 72, "metadata": {}, "outputs": [ { "data": { "text/plain": [ "b''" ] }, "execution_count": 72, "metadata": {}, "output_type": "execute_result" } ], "source": [ "decryptor = cipher.decryptor()\n", "with open(\"decoded_CBC.txt\", \"w\") as f_out, open(\"encoded_CBC.txt\", \"rb\") as f_in:\n", " while True:\n", " b = f_in.read(64)\n", " if not b:\n", " break\n", " ct = decryptor.update(b)\n", " ct=ct.decode(\"utf-8\")\n", "\n", "# ANSI X9.23\n", " if ct[-2:].isnumeric():\n", " padding_size = int(ct[-2:])\n", " if ct[-padding_size:-2] == \"0\"*(padding_size-2):\n", " ct = ct[:-padding_size]\n", " \n", " f_out.write(ct)\n", "decryptor.finalize()" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "To check that both files (initial and final) are identical, let's look at the hash of both files." ] }, { "cell_type": "code", "execution_count": 7, "metadata": {}, "outputs": [], "source": [ "def get_md5(path_file):\n", " hash_md5 = hashlib.md5()\n", " with open(path_file, \"rb\") as f:\n", " for chunk in iter(lambda: f.read(4096), b\"\"):\n", " hash_md5.update(chunk)\n", " return hash_md5.hexdigest()" ] }, { "cell_type": "code", "execution_count": 8, "metadata": {}, "outputs": [ { "data": { "text/plain": [ "'438b07c6a2bb6625b75947ce43e81510'" ] }, "execution_count": 8, "metadata": {}, "output_type": "execute_result" } ], "source": [ "get_md5(\"decoded_CBC.txt\")" ] }, { "cell_type": "code", "execution_count": 9, "metadata": {}, "outputs": [ { "data": { "text/plain": [ "'438b07c6a2bb6625b75947ce43e81510'" ] }, "execution_count": 9, "metadata": {}, "output_type": "execute_result" } ], "source": [ "get_md5(\"lorem.txt\")" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "## AES (CTR)\n", "\n", "Let's do the same but twith the Mode Operation (CTR) using the same keys" ] }, { "cell_type": "code", "execution_count": 14, "metadata": {}, "outputs": [], "source": [ "algo = algorithms.AES(key)\n", "mode = modes.CTR(iv)\n", "cipher = Cipher(algorithms.AES(key), modes.CTR(iv), backend=default_backend())" ] }, { "cell_type": "code", "execution_count": 15, "metadata": {}, "outputs": [ { "data": { "text/plain": [ "b''" ] }, "execution_count": 15, "metadata": {}, "output_type": "execute_result" } ], "source": [ "encryptor = cipher.encryptor()\n", "with open(\"encoded_CTR.txt\", \"wb\") as f_out, open(\"lorem.txt\", \"rb\") as f_in:\n", " while True:\n", " b = f_in.read(64)\n", " if not b:\n", " break\n", "\n", "# ANSI X9.23\n", " if len(b) < 64:\n", " padding_size = 64-len(b)\n", " padding_str = \"0\"*(padding_size-2) + \"{:02d}\".format(padding_size)\n", " b += bytes(padding_str, 'utf-8')\n", " ct = encryptor.update(b)\n", " f_out.write(ct)\n", "encryptor.finalize()" ] }, { "cell_type": "code", "execution_count": 16, "metadata": {}, "outputs": [ { "data": { "text/plain": [ "b''" ] }, "execution_count": 16, "metadata": {}, "output_type": "execute_result" } ], "source": [ "decryptor = cipher.decryptor()\n", "with open(\"decoded_CTR.txt\", \"w\") as f_out, open(\"encoded_CTR.txt\", \"rb\") as f_in:\n", " while True:\n", " b = f_in.read(64)\n", " if not b:\n", " break\n", " ct = decryptor.update(b)\n", " ct=ct.decode(\"utf-8\")\n", "\n", "# ANSI X9.23\n", " if ct[-2:].isnumeric():\n", " padding_size = int(ct[-2:])\n", " if ct[-padding_size:-2] == \"0\"*(padding_size-2):\n", " ct = ct[:-padding_size]\n", " \n", " f_out.write(ct)\n", "decryptor.finalize()" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "let's have a look at the hash of this new decrypted file." ] }, { "cell_type": "code", "execution_count": 17, "metadata": {}, "outputs": [ { "data": { "text/plain": [ "'438b07c6a2bb6625b75947ce43e81510'" ] }, "execution_count": 17, "metadata": {}, "output_type": "execute_result" } ], "source": [ "get_md5(\"decoded_CTR.txt\")" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "it's the same so everythin gis fine. We can also compare both encrypted file isn term of hash. We will see that even if they have the same key, the cfile will have different hash\n" ] }, { "cell_type": "code", "execution_count": 18, "metadata": {}, "outputs": [ { "data": { "text/plain": [ "'3751b303a9228b590473aaac8a425d0f'" ] }, "execution_count": 18, "metadata": {}, "output_type": "execute_result" } ], "source": [ "get_md5(\"encoded_CBC.txt\")" ] }, { "cell_type": "code", "execution_count": 82, "metadata": {}, "outputs": [ { "data": { "text/plain": [ "'953f03bb3701383e47d570d5f3c2412c'" ] }, "execution_count": 82, "metadata": {}, "output_type": "execute_result" } ], "source": [ "get_md5(\"encoded_CTR.txt\")" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Perfect ! Let's not do the same with Triple DES in CBC\n", "\n", "## Triple DES (CBC)\n", "\n", "This model requires a 24 bits key. Let's create new one." ] }, { "cell_type": "code", "execution_count": 19, "metadata": {}, "outputs": [], "source": [ "letter = \"0123456789ABCDEF\"\n", "random.seed(42)\n", "key = \"\".join([random.choice(letter) for i in range(24)])\n", "key = bytes(key, 'utf-8')\n", "\n", "iv = \"\".join([random.choice(letter) for i in range(16)])\n", "iv = bytes(iv, 'utf-8')" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "All the rest is similar" ] }, { "cell_type": "code", "execution_count": 21, "metadata": {}, "outputs": [], "source": [ "algo = algorithms.TripleDES(key)\n", "mode = modes.CBC(iv)\n", "cipher = Cipher(algorithms.AES(key), modes.CBC(iv), backend=default_backend())" ] }, { "cell_type": "code", "execution_count": 22, "metadata": {}, "outputs": [ { "data": { "text/plain": [ "b''" ] }, "execution_count": 22, "metadata": {}, "output_type": "execute_result" } ], "source": [ "encryptor = cipher.encryptor()\n", "with open(\"encoded.txt\", \"wb\") as f_out, open(\"lorem.txt\", \"rb\") as f_in:\n", " while True:\n", " b = f_in.read(64)\n", " if not b:\n", " break\n", "\n", "# ANSI X9.23\n", " if len(b) < 64:\n", " padding_size = 64-len(b)\n", " padding_str = \"0\"*(padding_size-2) + \"{:02d}\".format(padding_size)\n", " b += bytes(padding_str, 'utf-8')\n", " ct = encryptor.update(b)\n", " f_out.write(ct)\n", "encryptor.finalize()" ] }, { "cell_type": "code", "execution_count": 23, "metadata": {}, "outputs": [ { "data": { "text/plain": [ "b''" ] }, "execution_count": 23, "metadata": {}, "output_type": "execute_result" } ], "source": [ "decryptor = cipher.decryptor()\n", "with open(\"decoded.txt\", \"w\") as f_out, open(\"encoded.txt\", \"rb\") as f_in:\n", " while True:\n", " b = f_in.read(64)\n", " if not b:\n", " break\n", " ct = decryptor.update(b)\n", " ct=ct.decode(\"utf-8\")\n", "\n", "# ANSI X9.23\n", " if ct[-2:].isnumeric():\n", " padding_size = int(ct[-2:])\n", " if ct[-padding_size:-2] == \"0\"*(padding_size-2):\n", " ct = ct[:-padding_size]\n", " \n", " f_out.write(ct)\n", "decryptor.finalize()" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "And once more, we can look at hashes. the final file has the same hash as the initial one." ] }, { "cell_type": "code", "execution_count": 88, "metadata": {}, "outputs": [ { "data": { "text/plain": [ "'438b07c6a2bb6625b75947ce43e81510'" ] }, "execution_count": 88, "metadata": {}, "output_type": "execute_result" } ], "source": [ "get_md5(\"decoded.txt\")" ] }, { "cell_type": "code", "execution_count": 89, "metadata": {}, "outputs": [ { "data": { "text/plain": [ "'5e1d256a8b3d21a050ef32de02cfadf9'" ] }, "execution_count": 89, "metadata": {}, "output_type": "execute_result" } ], "source": [ "get_md5(\"encoded.txt\")" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "# Conclusion\n", "\n", "In this notebook, we saw the next block in the encryption algorithm. We now know :\n", "- how to generate a key\n", "- how to encrypt / decrypt messages with a symmetrical key\n", " - Using different Operation Modes\n", " - Using different Padding System\n", " - Using different Algorithms\n", "\n", "The only remaining point was partially discussed in the first Notebook regarding encryption / decryption with asymmetrical key. This was discussed in the first notebook and all the rest from this notebook remain true. We have to take longer block and apply some padding. The Operation Mode can also be applied. \n", "\n", "That means we are done for now on this domain. I bought a book about it and if there is some other interesting topics, I'll go thru on new Notebooks." ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [] } ], "metadata": { "kernelspec": { "display_name": "Python 3", "language": "python", "name": "python3" }, "language_info": { "codemirror_mode": { "name": "ipython", "version": 3 }, "file_extension": ".py", "mimetype": "text/x-python", "name": "python", "nbconvert_exporter": "python", "pygments_lexer": "ipython3", "version": "3.6.3" }, "toc": { "base_numbering": 1, "nav_menu": {}, "number_sections": true, "sideBar": true, "skip_h1_title": false, "title_cell": "Table of Contents", "title_sidebar": "Contents", "toc_cell": false, "toc_position": {}, "toc_section_display": true, "toc_window_display": false }, "varInspector": { "cols": { "lenName": 16, "lenType": 16, "lenVar": 40 }, "kernels_config": { "python": { "delete_cmd_postfix": "", "delete_cmd_prefix": "del ", "library": "var_list.py", "varRefreshCmd": "print(var_dic_list())" }, "r": { "delete_cmd_postfix": ") ", "delete_cmd_prefix": "rm(", "library": "var_list.r", "varRefreshCmd": "cat(var_dic_list()) " } }, "types_to_exclude": [ "module", "function", "builtin_function_or_method", "instance", "_Feature" ], "window_display": false } }, "nbformat": 4, "nbformat_minor": 2 }
|
__label__pos
| 0.993966 |
странициране добавка
vankata
Registered
$page=(int)$_GET['page'];
if($page == NULL || $page <= 0)
{
$page = 1;
}
$pp = 10;
$start = ($page*$pp) - $pp;
$query = run_q("SELECT * FROM `home`.`ip`");
$broi = mysql_numrows($query);
$total = ceil($broi/$pp);
$sql=run_q("SELECT * FROM `home`.`ip` ORDER BY time DESC LIMIT $start,$pp ");
$prev = $page - 1;
$next = $page + 1;
if($page == 1) {
echo "";
}
else
{
echo "<a href='?page=$prev'>Предишна</a>";
}
if($page >= $total) {
echo "";
}
else
{
echo "<a href='?page=$next'>Следваща</a>";
}
така ми излизат само линкове за
Предишна & Следваща..
как да си направя заявката да излиза
Страници: 1 2 3 4 5 6 7
Код:
<?php
echo "<table align='center' class='lesson'>";
include_once ("blocks/bd.php");
$table = "p_e_bylgaria";
if(!isset($_GET['page'])){ $page = 1; } else { $page = $_GET['page']; }
echo "<center><br>";
$max_results = 5;
$from = (($page * $max_results) - $max_results);
$i="0";
$nared="3";
$result = mysql_query ("SELECT * FROM $table ORDER BY id DESC LIMIT $from, $max_results",$db) or die ("<p>Не може да се свърже с базата данни</p>");
while ($myrow = mysql_fetch_array ($result))
{
$id = $myrow[id];
$title = $myrow[title];
$days = $myrow[days];
$dates = $myrow[dates];
$price = $myrow[price];
$author = $myrow[author];
$description = $myrow[description];
$poster = $myrow[poster];
$i++;
}
$zapis = mysql_num_rows($result);
$width=ceil(100/$nared);
if($zapis != 0) {
do { printf ("
<td class='lesson_title' valign=\'top\' width=\''.$width.'%\'>
<p class='lesson_name'><a href='vij_bg.php?id=%s'><img class='mini_poster' align='left' src=\"./images/$myrow[poster]\"></a><a href='vij_bg.php?id=%s' >%s</a></p>
<p class='lesson_adds'>Дни: <font color='#53a961'>%s</font></p>
<p class='lesson_adds'>Дати: <font color='#FF0000'>%s</font></p>
<p class='lesson_adds'>Цена: <font color='#53a961'>%s</font></p>
<p class='lesson_adds'>Автор: <font color='#8AA3E1'>%s</font></p></td>
</tr>
<tr>
<td colspan='2'><p>%s</p></td>", $myrow["id"], $myrow["id"], $myrow["title"],$myrow["days"], $myrow["dates"], $myrow["price"],$myrow["author"],$myrow["description"], $myrow["poster"] );
if ($i==$nared)
{
echo "</tr>
<tr>";
$i=0;
}
}
while ($myrow = mysql_fetch_array ($result));
}
echo "<p class='paging'>";
// стоп
$total_results = mysql_result(mysql_query("SELECT COUNT(*) as Num FROM $table"),0);
$total_pages = ceil($total_results / $max_results);
if($page > 1){
$prev = ($page - 1);
echo "<a href=\"".$_SERVER['PHP_SELF']."?page=$prev\" class=\"paging\">Предишна</a> ";
}
for($i = 1; $i <= $total_pages; $i++){
if(($page) == $i){
echo "<b>$i</b> ";
} else {
echo "<a href=\"".$_SERVER['PHP_SELF']."?page=$i\">$i</a> ";
}
}
if($page < $total_pages){
$next = ($page + 1);
echo "<a href=\"".$_SERVER['PHP_SELF']."?page=$next\" class=\"paging\">Следваща</a>";
echo "</p><br>";
}
echo "</table>";
?>
Аз исползвам нещо лесно да ми добавя нещо в страницата когато отворя някаф си линк
Код:
<?
if($_GET['Нещо'] == 'Нещо2'){
echo "<br><center><b>Текст</b></center><br>";
}
?>
и то излиза http://localhost/index.php?Нещо?=Нещо2
доста ми помага на мен специално :)
Горе
|
__label__pos
| 0.99636 |
days
-6
-2
hours
-1
-2
minutes
-5
-9
seconds
-4
-8
search
Fly high with this Eclipse cloud development platform
Eclipse Dirigible
Yordan Pavlov
MicroProfile
© Shutterstock / Sadovski
Eclipse Dirigible is an open source cloud development platform, providing the right toolset to build, run, and operate business applications in the cloud. In this article, Yordan Pavlov goes over how developers can build and run applications in enterprise JavaScript.
Eclipse Dirigible is an open source cloud development platform, part of the Eclipse Foundation and the top-level Eclipse Cloud Development project. The ultimate goal of the platform is to provide software developers with the right toolset for building, running, and operating business applications in the cloud. To achieve this goal, Dirigible provides both independent Design Time and Runtime components.
Mission
Nowadays, providing a full-stack application development platform is not enough. Building and running on top of it has to be fast and smooth! Having that in mind, slow and cumbersome “Build”“CI”, and “Deployment” processes have a direct impact on development productivity. In this line of thought, it isn’t hard to imagine that the Java development model for web applications doesn’t fit in the cloud world.
Luckily, one of the strongest advantages of Dirigible comes at hand – the In-System Development model. Right from the early days of Dirigible, it was clear that it is going to be the platform for Business Applications Development in the cloud and not just another general purpose IDE in the browser. The reason for that decision is pretty simple – “One size doesn’t fit all”! Making a choice between providing “In-System Development” in the cloud and adding support for a new language (Java, C#, PHP, …), is really easy. The new language doesn’t really add much to the uniqueness and usability of the platform, as the In-System development model does!
Architecture
The goal of the In-System development model is to ultimately change the state of the system while it’s up and running, without affecting the overall performance and without service degradation. You can easily think of several such systems like Programmable Microcontrollers, Relational Database Management Systems, ABAP. As mentioned earlier, Dirigible provides a suitable design time and runtime for that, so let’s talk a little bit about the architecture. The Dirigible stack is pretty simple:
Eclipse Dirigible
The building blocks are:
• Application Server (provided)
• Runtime (built-in)
• Engine(s) – (Rhino/Nashorn/V8)
• Repository – (fs/database)
• Design Time (built-in)
• Web IDE (workspace/database/git/… perspective)
• Applications (developed)
• Application (database/rest/ui)
• Application (indexing/messaging/job)
• Application (extensionpoint/extension)
Enterprise JavaScript
The language of choice in the Dirigible business application platform is JavaScript! But why JavaScript? Why not Java? Is it mature enough, is it scalable, can it satisfy the business application needs? The answer is: It sure does! The code that is being written is similar to Java. The developers can write their business logic in a synchronous fashion and can leverage a large set of Enterprise JavaScript APIs. For heavy loads, the Dirigible stack performs better than the NodeJS due to multithreading of the underlying JVM and the application server, and using the same V8 engine underneath.
Examples
Request/Response API
var response = require('http/v3/response');
response.println("Hello World!");
response.flush();
response.close();
Database API
var database = require('db/v3/database');
var response = require('http/v3/response');
var connection = database.getConnection();
try {
var statement = connection.prepareStatement("select * from MY_TABLE where MY_PATH like ?");
var i = 0;
statement.setString(++i, "%");
var resultSet = statement.executeQuery();
while (resultSet.next()) {
response.println("[path]: " + resultSet.getString("MY_PATH"));
}
resultSet.close();
statement.close();
} catch(e) {
console.trace(e);
response.println(e.message);
} finally {
connection.close();
}
response.flush();
response.close();
The provided Enterprise JavaScript APIs leverage some of the mature Java specifications and de facto standards (e.g. JDBC, Servlet, CMIS, ActiveMQ, File System, Streams, etc.). Eliminating the build process (due to the lack of compilation) and at the same time exposing proven frameworks (that does the heavy lifting), results in having the perfect environment for in-system development of business applications, with close to “Zero Turn-Around-Time”. In conclusion, the Dirigible platform is really tailored to the needs of Business Application Developers.
Getting Started
• Download
• Get the latest release here.
• The latest master branch can be found at GitHub
• Download the latest Tomcat 8.x here.
NOTE: You can use the try out instance, that is available at http://dirigible.eclipse.org and skip through the Develop section
• Start
• Put the ROOT.war into the ${tomcat-dir}/webapps directory
• Execute ./catalina.sh start from the ${tomcat-dir}/bin directory
• Login
• Develop
• Project
1. Create a project
1. Click + -> ProjectEclipse Dirigible
• Database table
1. Generate a Database Table
• Right-click New > Generate > Database table
Eclipse Dirigible
2. Edit the students.table definition
{
"name": "Students",
"type": "TABLE",
"columns": [{
"name": "ID",
"type": "INTEGER",
"primaryKey": "true"
}, {
"name": "FIRST_NAME",
"type": "VARCHAR",
"length": "50"
}, {
"name": "LAST_NAME",
"type": "VARCHAR",
"length": "50"
}, {
"name": "AGE",
"type": "INTEGER"
}]
}
3. Publish
• Right-click the project and select Publish
NOTE: The auto publish function is enabled by default
1. Explore
• The database scheme can be explored from the Database perspective
• Click Window > Open Perspective > Database
• Insert some sample data
insert into students values(1, 'John', 'Doe', 25)
insert into students values(2, 'Jane', 'Doe', 23)Note: The perspectives are available also from the side menu
REST service
1. Generate a Hello World service
• Right-click New > Generate > Hello World
2. Edit the students.js service
var database = require('db/v3/database');
var response = require('http/v3/response');
var students = listStudents();
response.println(students);
response.flush();
response.close();
function listStudents() {
let students = [];
var connection = database.getConnection();
try {
var statement = connection.prepareStatement("select * from STUDENTS");
var resultSet = statement.executeQuery();
while (resultSet.next()) {
students.push({
'id': resultSet.getInt('ID'),
'firstName': resultSet.getString('FIRST_NAME'),
'lastName': resultSet.getString('LAST_NAME'),
'age': resultSet.getInt('AGE')
});
}
resultSet.close();
statement.close();
} catch(e) {
console.error(e);
response.println(e.message);
} finally {
connection.close();
}
return students;
}
3. Explore
• The student.js service is accessible through the Preview vie
NOTE: All backend services are up and running after save/publish, due to the In-System Development
Create a UI
• Generate a HTML5 (AngularJS) page
• Right-click New > Generate > HTML5 (AngularJS)
• Edit the page
<!DOCTYPE html>
<html lang="en" ng-app="page">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta name="description" content="">
<meta name="author" content="">
<link type="text/css" rel="stylesheet" href="/services/v3/core/theme/bootstrap.min.css">
<link type="text/css" rel="stylesheet" href="/services/v3/web/resources/font-awesome-4.7.0/css/font-awesome.min.css">
<script type="text/javascript" src="/services/v3/web/resources/angular/1.4.7/angular.min.js"></script>
<script type="text/javascript" src="/services/v3/web/resources/angular/1.4.7/angular-resource.min.js"></script>
</head>
<body ng-controller="PageController">
<div>
<div class="page-header">
<h1>Students</h1>
</div>
<div class="container">
<table class="table table-hover">
<thead>
<th>Id</th>
<th>First Name</th>
<th>Last Name</th>
<th>Age</th>
</thead>
<tbody>
<tr ng-repeat="student in students">
<td>{{student.id}}</td>
<td>{{student.firstName}}</td>
<td>{{student.lastName}}</td>
<td>{{student.age}}</td>
</tr>
</tbody>
</table>
</div>
</div>
<script type="text/javascript">
angular.module('page', []);
angular.module('page').controller('PageController', function ($scope, $http) {
$http.get('../../js/university/students.js')
.success(function(data) {
$scope.students = data;
});
});
</script>
</body>
</html>
“What’s next?”
The In-System Development model provides the business application developers with the right toolset for rapid application development. By leveraging a few built-in templates and the Enterprise JavaScript API, whole vertical scenarios can be set up in several minutes. With the close to Zero Turn-Around-Time, changes in the backend can be made and applied on the fly, through an elegant Web IDE. The perfect fit for your digital transformation!
The goal of the Dirigible platform is clear – ease the developers as much as possible and let them concentrate on the development of critical business logic.
So, what’s next? Can I provide my own set of templates? Can I expose a new Enterprise JavaScript API? Can I provide a new perspective/view? Can I build my own Dirigible stack? Can it be integrated with the services of my cloud provider?
To all these questions, the answer is simple: Yes, you can do it!
Resources
Enjoy!
eclipseorb_color
This post was originally published in the February 2018 issue of the Eclipse Newsletter: Boot & Build Eclipse Projects
For more information and articles check out the Eclipse Newsletter.
Author
Yordan Pavlov
Yordan Pavlov is an experienced Software Developer with a demonstrated history of working in the computer software industry. He is skilled in Java EE, Cloud Computing, SAP Hana Cloud Platform and Agile Methodologies. Project lead & committer in the Eclipse Dirigible open-source project. Strong engineering professional with a Master’s Degree focused in Computer Science from Technical University Sofia.
Leave a Reply
Be the First to Comment!
avatar
400
Subscribe
Notify of
|
__label__pos
| 0.855022 |
Categories
Versions
You are viewing the RapidMiner Studio documentation for version 9.9 - Check here for latest version
Loop Attribute Subsets (RapidMiner Studio Core)
Synopsis
This operator iterates over its subprocess for all possible combinations of regular attributes in the input ExampleSet. Optionally, the minimum and maximum number of attributes in a combination can be specified by the user.
Description
The Loop Attribute Subsets operator is a nested operator i.e. it has a subprocess. The subprocess of the Loop Attribute Subsets operator executes n number of times, where n is the number of possible combinations of the regular attributes in the given ExampleSet. The user can specify the minimum and maximum number of attributes in a combination through the respective parameters; in this case the value of n will change accordingly. So, if an ExampleSet has three regular attributes say a, b and c. Then this operator will execute 7 times; once for each attribute combination. The combinations will be {a},{b},{c},{a,b},{a,c},{b,c} and {a,b,c}. Please study the attached Example Process for more information.
This operator can be useful in combination with the Log operator and, for example, a performance evaluation operator. In contrast to the brute force feature selection, which performs a similar task, this iterative approach needs much less memory and can be performed on larger data sets.
Input
• example set (Data Table)
This input port expects an ExampleSet. It is the output of the Retrieve operator in the attached Example Process. The output of other operators can also be used as input.
Output
• example set (Data Table)
The ExampleSet that was given as input is delivered through this port without any modifications.
Parameters
• use_exact_numberIf this parameter is set to true, then the subprocess will be executed only for combinations of a specified length i.e. specified number of attributes. The length of combinations is specified by the exact number of attributes parameter. Range: boolean
• exact_number_of_attributesThis parameter determines the exact number of attributes to be used for the combinations. Range: integer
• min_number_of_attributesThis parameter determines the minimum number of attributes to be used for the combinations. Range: integer
• limit_max_numberIf this parameter is set to true, then the subprocess will be executed only for combinations that have less than or equal to m number of attributes; where m is specified by the max number of attributes parameter. Range: boolean
• max_number_of_attributesThis parameter determines the maximum number of attributes to be used for the combinations. Range: integer
Tutorial Processes
Introduction to the Loop Attribute Subsets operator
The 'Golf' data set is loaded using the Retrieve operator. A breakpoint is inserted here so that you can have a look at the ExampleSet before the application of the Loop Attribute Subsets operator. You can see that the ExampleSet has four regular attributes. The Loop Attribute Subsets operator is applied on this ExampleSet with default values of all parameters. As no limit is applied on the minimum and maximum number of attributes in a combination, the subprocess of this operator will execute for all possible combinations of the four regular attributes. Have a look at the subprocess of the Loop Attribute Subsets operator. The Log operator is applied there to store the names of attributes of each iteration in the Log table. Execute the process and shift to the Results Workspace. Check the Table View of the Log results. You will see the names of attributes of each iteration. As there were 4 attributes there are 15 possible non-null combinations.
|
__label__pos
| 0.965557 |
Sign up ×
TeX - LaTeX Stack Exchange is a question and answer site for users of TeX, LaTeX, ConTeXt, and related typesetting systems. It's 100% free, no registration required.
I want to move the following remark environment, which nicely splits over pages :), towards the left so that it is not centered anymore. I have been unsuccessfully trying for a while: would you please have suggestions? Thanks. I was thinking of embedding it in a second environment with the required properties?
\documentclass[fleqn,10pt]{book}
\usepackage{kpfonts}
\usepackage{xcolor}
\usepackage[top=7cm,left=5cm,right=5cm,bottom=7cm,a4paper]{geometry}
\usepackage{lipsum}
\usepackage{framed}
\renewcommand*\FrameCommand{\fcolorbox{red!10}{red!10}}%
\newenvironment{rem}[1][]{%
\MakeFramed{\advance\hsize-10em \FrameRestore}%
\noindent\textsc{#1}%
\small%
\begin{list}{}{%
\setlength{\leftmargin}{0.04\textwidth}%
\setlength{\rightmargin}{0.01\textwidth}%
}%
\item[]%
}{%
\hfill$\square$%
\end{list}\endMakeFramed}
\begin{document}
\lipsum[4]
\lipsum[4]
\lipsum[4]
\lipsum[5]
\begin{rem}[Latin]
some random text some random text some random text some random text some random
text some random text some random text some random text some random text some
random text some random text some random text some random text some random text some
random text some random
\end{rem}
\lipsum[4]
\end{document}
share|improve this question
I can't see anything obvious from looking through the package source. I suggest asking on c.t.t.; Donald Arseneau often answers questions there and he's the best person to ask. – Will Robertson Oct 3 '10 at 6:50
ok. thanks for the suggestion – pluton Oct 3 '10 at 7:05
1 Answer 1
up vote 2 down vote accepted
Would
\renewcommand*\FrameCommand{\hskip-2cm\fcolorbox{red!10}{red!10}}%
not do it?
share|improve this answer
correct. Very nice ! – pluton Oct 3 '10 at 15:36
Your Answer
discard
By posting your answer, you agree to the privacy policy and terms of service.
Not the answer you're looking for? Browse other questions tagged or ask your own question.
|
__label__pos
| 0.999864 |
How to use 2 graphics cards at the same time
Last Updated: Feb 15, 2024 by
If you’re a gamer or a video editor, you know the importance of having a powerful graphics card. But what if you could double that power by using two graphics cards at the same time? This is possible through a process called GPU scaling, and in this article, we’ll discuss how to use multiple graphics cards simultaneously and the compatibility requirements for this setup.
What is GPU Scaling?
GPU scaling, also known as CrossFire (for AMD) or SLI (for NVIDIA), is a technology that allows you to use multiple graphics cards in tandem to improve performance. This is achieved by splitting the workload between the two cards, allowing for faster rendering and smoother gameplay. However, not all graphics cards are compatible with this technology, so it’s important to do your research before attempting to use multiple cards.
Graphics Card Compatibility
The first step in using two graphics cards at the same time is to ensure that they are compatible with each other. Both cards must be from the same manufacturer (AMD or NVIDIA) and have the same GPU model. Additionally, they must have the same amount of VRAM and be from the same series (e.g. both GTX 1080). It’s also important to note that not all games and applications support GPU scaling, so it’s best to check compatibility before attempting to use this setup.
Installing the Graphics Cards
Once you have confirmed compatibility, the next step is to physically install the graphics cards into your computer. This may require additional power cables and a compatible motherboard with enough PCIe slots. It’s important to follow the manufacturer’s instructions for installation and to properly ground yourself to avoid any damage to the cards.
Enabling GPU Scaling
After the cards are installed, you’ll need to enable GPU scaling in your computer’s settings. For AMD cards, this can be done through the Radeon Settings software, while NVIDIA users can use the NVIDIA Control Panel. Once enabled, you may need to restart your computer for the changes to take effect.
Testing and Troubleshooting
To ensure that your setup is working properly, you can run a benchmark test or play a graphics-intensive game. If everything is working correctly, you should see a significant improvement in performance. However, if you encounter any issues, such as crashes or artifacts, you may need to troubleshoot your setup. This could involve updating drivers, adjusting settings, or even replacing one of the graphics cards.
Conclusion
Using two graphics cards at the same time can greatly improve your computer’s performance, but it’s important to make sure that your cards are compatible and that you follow the proper installation and setup process. With the right hardware and software, you can take your gaming or video editing to the next level. Have you tried using multiple graphics cards? Let us know in the comments.
Gulrukh Ch
About the Author: Gulrukh Ch
Gulrukh Chaudhary, an accomplished digital marketer and technology writer with a passion for exploring the frontiers of innovation. Armed with a Master's degree in Information Technology, Gulrukh seamlessly blends her technical prowess with her creative flair, resulting in captivating insights into the world of emerging technologies. Discover more about her on her LinkedIn profile.
|
__label__pos
| 0.801407 |
What is the DNS Changer Malware?
On November 8th 2011, the Estonian police, the FBI, and the NASA-OIG arrested seven men in Operation Ghost Click. This group of people operated under the company name Rove Digital, and distributed viruses that changes the DNS settings of victims. The Estonian court found their guilt not proven, but one member later plead guilty in the USA, and was sentenced to seven and a quarter years in prison. This malware was known under the names of DNS changer, Alureon, TDSS, TidServ and TDL4.
What does the DNS Changer Malware do?
The DNS changer malware pointed the victims DNS configuration to their own malicious DNS servers in Estonia, Chicago, and New York. This caused DNS lookup queries to be directed to malicious DNS servers, and in turn allowed the group to re-route internet traffic to malicious web servers. These web servers then served to replace the links in search results, and replace ads on popular websites. At the time, DNS wasn't as secure as it is today, making this attack quite effective.
On March 12th 2012, the FBI announced that, under a court order, the ISC (Internet Systems Consortium) was operating a replacement DNS service for the Rove Digital network. This will allow affected networks time to identify infected hosts, and avoid sudden disruption of services to victim machines. These servers were to be shut off on July 9th 2012.
How Can I Protect Myself?
If you were affected by this DNS Changer, then your DNS configuration has changed. You can make sure your operating system has the latest security patches, and update your configured DNS servers in its operating system. However, this malware is no longer being distributed, and many popular sites are now defended against this type of attack. So the chances of this still affecting you are very small.
|
__label__pos
| 0.993108 |
3
What's the difference between en0 and eth0?
In my CentOS 6 VM, there is list of network-scripts:
[root@localhost /]# ls /etc/sysconfig/network-scripts/
ifcfg-en0 ifdown-ipv6 ifup ifup-plip ifup-wireless
ifcfg-eth0 ifdown-isdn ifup-aliases ifup-plusb init.ipv6-global
ifcfg-lo ifdown-post ifup-bnep ifup-post net.hotplug
ifdown ifdown-ppp ifup-eth ifup-ppp network-functions
ifdown-bnep ifdown-routes ifup-ippp ifup-routes network-functions-ipv6
ifdown-eth ifdown-sit ifup-ipv6 ifup-sit
ifdown-ippp ifdown-tunnel ifup-isdn ifup-tunnel
you see there are ifcfg-en0 and ifcfg-eth0, does it have any difference between them? the ifcfg-eth0 I have used(configured data in it), now I want to add a more IP address, which file I can configured?
EDIT-01
The enoX and the ethX is not related to my post, mine is enX.
3
• 1
Similar on Super User: What is the difference between eth1 and eno1? – user56041 Sep 26 '18 at 4:43
• Check the output of ifconfig -a or ip link show to see which interface name you have and use it. – muru Sep 26 '18 at 5:26
• ethtool -i en0 and ethtool -i eth0 might provide useful information too (the PCI device ID and the name of the driver responsible for the NIC). – telcoM Sep 26 '18 at 8:06
1
I see your edit, but the comment is correct... It is the same mechanism referenced.
It's the concept of biosdevnames / consistent device naming.
In RHEL6/CentOS 6 there was an attempt to work around this via a special udev rule:
/etc/udev/rules.d/70-persistent-net.rules
Within that file you will see a mapping (by mac address) attempting to provide consistent names, but not in the way mentioned in the consistent device naming article linked above.
The most common case I experienced this was when users would clone a VM. This would change the mac address of the VM and then that UDEV rule would present the new mac address as a new device, effectively locking the old device in as eth0.
To determine the file you should use, check the name mapped in /etc/udev/rules.d/70-persistent-net.rules by the mac address of the VMs network adapter. Using that file, you can map it to anything you like. Once you know the name, use the corresponding file in /etc/sysconfig/network-scripts.
After UDEV rule changes, reload them with:
sudo udevadm control -R
After that you can manually trigger processing of the rules with:
sudo udevadm trigger
In the long run you should clear any unwanted rules from /etc/udev/rules.d/70-persistent-net.rules.
0
en0 and eth0 is the name of interfaces name in your server, if you execute ifconfig you can see the number of interfaces available in your server.
you can rename interfaces from /etc/udev/rules.d/70-persistent.rules file
2
Not the answer you're looking for? Browse other questions tagged or ask your own question.
|
__label__pos
| 0.910795 |
Python List Comprehension
title: List Comprehension
List Comprehension
List Comprehension is a way of looping through a list to produce a new list based on some conditions. It can be confusing at first but once you are acclimated to the syntax it is very powerful and quick.
The first step in learning how to use list comprehension is to look at the traditional way of looping through a list. The following is a simple example that returns a new list of even numbers.
# Example list for demonstration some_list = [1, 2, 5, 7, 8, 10] # Empty list that will be populated with a loop even_list = [] for number in some_list: if number % 2 == 0: even_list.append(number) # even_list now equals [2, 8, 10]
First a list is created with some numbers. You then create an empty list that will hold your results from the loop. In the loop you check to see if each number is divisible by 2 and if so you add it the the even_list. This took 5 lines of code not including comments and white space which isn’t much in this example.
Now for the list comprehension example.
# Example list for demonstration some_list = [1, 2, 5, 7, 8, 10] # List Comprehension even_list = [number for number in some_list if number % 2 == 0] # even_list now equals [2, 8, 10]
Another example, with the same two steps:
The following will create a list of numbers that correspond to the numbers in my_starting_list multiplied by 7.
my_starting_list = [1, 2, 3, 4, 5, 6, 7, 8] my_new_list = [] for item in my_starting_list: my_new_list.append(item * 7)
When this code is run, the final value of my_new_list is:
[7, 14, 21, 28, 35, 42, 49, 56]
A developer using list comprehension could achieve the same result using the following list comprehension, which results in the same my_new_list.
my_starting_list = [1, 2, 3, 4, 5, 6, 7, 8] my_new_list = [item * 7 for item in my_starting_list]
A simple formula to write in a list comprehension way is:
my_list = [{operation with input n} for n in {python iterable}]
Replace {operation with input n} with however you want to change the item returned from the iterable. The above example uses n * 7 but the operation can be as simple or as complex as necessary.
Replace {python iterable} with any iterable. Sequence types will be most common. A list was used in the above example, but tuples and ranges are also common.
List comprehension adds an element from an existing list to a new list if some condition is met. It is neater, but is also much faster in most cases. In some cases, list comprehension may hinder readability, so the devloper must weigh their options when choosing to use list comprehension.
Examples of List Comprehension with Conditionals
The flow of control in list comprehensions can be controlled using conditionals. For example:
only_even_list = [i for i in range(13) if i%2==0]
This is equivalent to the following loop:
only_even_list = list() for i in range(13): if i%2 == 0: only_even_list.append(i)
List comprehension can also contain nested if conditions. Consider the following loop:
divisible = list() for i in range(50): if i%2 == 0: if i%3 == 0: divisible.append(i)
Using list comprehension this can be written as:
divisible = [i for i in range(50) if i%2==0 if i%3==0]
If-Else statement can also be used along with list comprehension.
list_1 = [i if i%2==0 else i*-1 for i in range(10)]
More Information:
Python Data Structures – Lists
Python For Loops
Python Lists
Python For Beginners – List Comprehensions
This article needs improvement. You can help improve this article. You can also write similar articles and help the community.
|
__label__pos
| 0.994588 |
API ReferenceIntegrationsKnowledge Base
1. Create the Authorization Transaction
You can create an authorization transaction:
1.1. Using Razorpay APIs🔗
To create an authorization transaction using Razorpay APIs, you need to:
1. Create a Customer.
2. Create an Order.
3. Create Authorization Payment using Razorpay APIs.
1.1.1. Create a Customer🔗
Razorpay links recurring tokens to customers via a unique identifier. This unique identifier for the customer is generated using the Customer API.
You can create customers with basic details such as email and contact and use them for various Razorpay offerings. Learn more about Razorpay Customers.
You can create a customer using the below endpoint.
/customers
Once a customer is created, you can create an order for the authorization of the payment.
Request Parameters🔗
name mandatory
string The customer's name. For example, Gaurav Kumar.
email mandatory
string The customer's email address. For example, [email protected].
contact mandatory
string The customer's phone number. For example, 9876543210.
fail_existing optional
string If a customer with the same details already exists, the request throws an exception by default. You can pass an additional parameter fail_existing to get the details of the existing customer in the response. Possible values:
• 0 - fetch details of existing customer
• 1 - throw the exception error (default)
notes optional
object Key-value pair that can be used to store additional information about the entity. Maximum 15 key-value pairs, 256 characters (maximum) each. For example, "note_key": "Beam me up Scotty”.
1.1.2. Create an Order🔗
The Orders API allows you to create a unique Razorpay order_id, for example, order_1Aa00000000001, that would be tied to the authorization transaction. To learn more about Razorpay Orders, refer to our detailed Order documentation.
Use the below endpoint to create an order.
/orders
You can create a payment against the order_id once it is generated.
Authorization transaction + auto-charge first payment:
You can register a customer's mandate AND charge them the first recurring payment as part of the same transaction. Refer to the Emandate section under Registration and Charge First Payment Together for more information.
Request Parameters🔗
amount mandatory
integer Amount in currency subunits. For emandate, the amount has to be 0.
currency mandatory
string The 3-letter ISO currency code for the payment. Currently, we only support INR.
method mandatory
string The authorization method. In this case the value will be emandate.
customer_id mandatory
string The unique identifier of the customer, who is to be charged. For example, cust_D0cs04OIpPPU1F.
receipt optional
string. A user-entered unique identifier for the order. For example, rcptid #1. This parameter should be mapped to the order_id sent by Razorpay.
notesoptional
object Key-value pair that can be used to store additional information about the entity. Maximum 15 key-value pairs, 256 characters (maximum) each. For example, "note_key": "Beam me up Scotty”.
token
Details related to the authorization such as max amount and bank account information.
auth_type optional
string Possible values:
• netbanking
• debitcard
• aadhaar
max_amount optional
integer The maximum amount, in paise, that a customer can be charged in one transaction. The value can range from 500 - 100000000. Defaults to 9999900 (₹99,999).
expire_at optional
integer The timestamp, in Unix format, till when you can use the token (authorization on the payment method) to charge the customer subsequent payments. Defaults to 10 years for emandate. The value can range from the current date to 31-12-2099 (4102444799).
notesoptional
object Key-value pair that can be used to store additional information about the entity. Maximum 15 key-value pairs, 256 characters (maximum) each. For example, "note_key": "Beam me up Scotty”.
bank_account
Customer's bank account details that should be pre-filled on the checkout.
account_number optional
string Customer's bank account number.
account_type optional
string Customer's bank account type. Possible values:
• savings (default value)
• current
ifsc_code optional
string Customer's bank IFSC. For example UTIB0000001.
beneficiary_name optional
string Customer's name. For example, Gaurav Kumar.
notesoptional
object. Key-value pair that can be used to store additional information about the entity. Maximum 15 key-value pairs, 256 characters (maximum) each. For example, "note_key": "Beam me up Scotty”.
Authorization transaction + auto-charge first payment:
You can register a customer's mandate AND charge them the first recurring payment as part of the same transaction. Refer to the Emandate section under Registration and Charge First Payment Together for more information.
1.1.3. Create an Authorization Payment🔗
Handler Function vs Callback URL:
• Handler Function:
When you use the handler function, the response object of the successful payment (razorpay_payment_id, razorpay_order_id and razorpay_signature) is submitted to the Checkout Form. You need to collect these and send them to your server.
• Callback URL:
When you use a Callback URL, the response object of the successful payment (razorpay_payment_id, razorpay_order_id and razorpay_signature) is submitted to the Callback URL.
Additional Checkout Fields🔗
The following additional parameters must be sent along with the existing checkout options as part of the authorization transaction.
customer_id mandatory
string Unique identifier of the customer created in the first step.
order_id mandatory
string Unique identifier of the order created in the second step.
recurring mandatory
integer. In this case, the value has to be 1.
1.2. Using a Registration Link🔗
Registration Links are an alternate way of creating an authorization transaction. If you create a registration link, you need not create a customer or an order.
When you create a registration link, an invoice is automatically issued to the customer. The customer can use the invoice to make the Authorization Payment.
Learn how to create Registration Links using the Razorpay Dashboard.
Note:
You can use Webhooks to get notifications about successful payments against a registration link.
A registration link must always have an amount (in Paise) that the customer will be charged when making the authorization payment. In the case of emandate, the order amount must be 0.
Use the below endpoint to create a registration link for recurring payments.
/subscription_registration/auth_links
Request Parameters🔗
customer
Details of the customer to whom the registration link will be sent.
name mandatory
string. Customer's name.
email mandatory
string. Customer's email address.
contactmandatory
string. Customer's phone number.
type mandatory
string. In this case, the value is link.
currency mandatory
string. The 3-letter ISO currency code for the payment. Currently, only INR is supported.
amount mandatory
integer. The payment amount in the smallest currency sub-unit.
description mandatory
string. A description that appears on the hosted page. For example, 12:30 p.m. Thali meals (Gaurav Kumar).
subscription_registration
Details of the authorization payment.
method mandatory
string The authorization method. In this case, it will be emandate.
auth_type optional
string Possible values:
• netbanking
• debitcard
• aadhaar
max_amount optional
integer The maximum amount, in paise, that a customer can be charged in one transaction. The value can range from 500 - 99999900. Defaults to 9999900 (₹99,999).
expire_at optional
integer The timestamp, in Unix format, till when you can use the token (authorization on the payment method) to charge the customer subsequent payments. Defaults to 10 years for emandate. The value can range from the current date to 31-12-2099 (4101580799).
bank_account
The customer's bank account details.
beneficiary_name optional
string Name on the bank account. For example Gaurav Kumar.
account_number optional
integer Customer's bank account number. For example 11214311215411.
account_type optional
string Customer's bank account type. Possible values:
• savings (default)
• current
ifsc_code optional
string Customer's bank IFSC. For example HDFC0000001.
sms_notify optional
boolean Indicates if SMS notifications are to be sent by Razorpay. Can have the following values:
• 0 - Notifications are not sent by Razorpay.
• 1 - Notifications are sent by Razorpay(default value).
email_notify optional
boolean Indicates if email notifications are to be sent by Razorpay. Can have the following values:
• 0 - Notifications are not sent by Razorpay.
• 1 - Notifications are sent by Razorpay (default value).
expire_by optional
integer The timestamp, in Unix, till when the registration link should be available to the customer to make the authorization transaction.
receipt optional
string A unique identifier entered by you for the order. For example, Receipt No. 1. This parameter should be mapped to the order_id sent by Razorpay.
notes optional
object This is a key-value pair that can be used to store additional information about the entity. Maximum 15 key-value pairs, 256 characters (maximum) each. For example, "note_key": "Beam me up Scotty”.
1.2.2. Send/Resend Notifications🔗
Use the below endpoint to send/resend notifications with the short URL to the customer.
/invoices/:id/notify_by/:medium
Allowed values for medium path parameter is sms and email
Path Parameters🔗
idmandatory
string The unique identifier of the invoice linked to the registration link for which you want to send the notification. For example, inv_1Aa00000000001.
medium mandatory
string How you want to resend the notification. Possible values are
• sms
• email
Use the below endpoint to cancel a registration link.
/invoices/:id/cancel
Note
You can only cancel registration link that is in the issued state.
Path Parameter🔗
id mandatory
string The unique identifier for the invoice linked to the registration link that you want to cancel. For example, inv_1Aa00000000001.
×
|
__label__pos
| 0.514177 |
Changes between Version 4 and Version 5 of ContribAuthImprovements
Ignore:
Timestamp:
03/22/2012 08:37:50 PM (6 years ago)
Author:
Alex Ogier
Comment:
added solution 2a (a USER_MODEL setting independent of auth.User)
Legend:
Unmodified
Added
Removed
Modified
• ContribAuthImprovements
v4 v5
102102 * Has unpredictable failure modes if a third-party app assumes that User has a certain attribute or property which the project-provided User model doesn't support (or supports in a way different to the core auth.User model).
103103
104== Solution 2a: `USER_MODEL` setting ==
105
106Similar to solution 2. Specify a User model via a setting, but don't mount it at django.contrib.auth.User.
107
108=== Implementation ===
109
110Introduce an `USER_MODEL` setting (not necessarily related to `AUTH` at all) that defaults to `"auth.User"`.
111
112Here is a branch of django trunk that implements the basic idea:
113
114 * https://github.com/ogier/django/tree/auth-mixins Also refactors !auth.User into authentication, permissions and profile mixins
115
116=== Advantages ===
117
118 * Allows any user model, potentially independent of contrib.auth entirely.
119 * Existing projects require no migration (though distributable apps might become outdated if they don't respect the setting).
120 * Apps can explicitly signal their support of this new setting by using it and not referring to django.contrib.auth.User. For example, foreign key fields can be specified as `models.ForeignKey(settings.USER_MODEL)`.
121 * Doesn't have the circular dependency issue of solutions 1 and 2.
122
123Optionally:
124
125 * Split off as much of !auth.User into orthogonal mixins that can be reused.
126 * Modify !auth.User to inherit these mixins. Care must be taken to ensure that the database expression of the new User model is identical to the old User model, to ensure backwards compatibility.
127 * Unrelated and third-party apps can indicate that they depend on various orthogonal mixins. For example, contrib.admin can specify that it works with !auth.User out of the box, and with any model implementing !PermissionsMixin if you supply your own login forms.
128
129Exposing pieces of !auth.User as mixins is optional, and potentially advantageous for any solution that allows you to define your own user models, such as solution 2.
130
131=== Problems ===
132
133 * Doesn't address the !EmailField length problem for existing users. We could address this by having a User model (reflecting current field lengths) and a new !SimpleUser (that reflects better defaults); then use global_settings and project template settings to define which User is the default for new vs existing projects.
134 * Doesn't solve the analogous problem for any other project.
135
104136== Solution 3: Leverage App Refactor ==
105137
Back to Top
|
__label__pos
| 0.646064 |
Evolution of Artificial Intelligence: From Turing to Deep Learning
Artificial Intelligence (AI) mimics human intelligence through learning and problem-solving. It evolved from early rule-based systems to machine and deep learning, enabling applications in healthcare, finance, transportation, and entertainment. Despite ethical and technical challenges, AI’s potential to transform various sectors, enhance decision-making, and improve efficiencies is significant.
The New iPad Pro 13”: What People Are Saying!
The new iPad Pro 13″ impresses with its advanced features, including a Liquid Retina XDR display, M2 chip, and high-quality camera system. Praised for its design, performance, and versatile professional use, it excels in creative fields. Despite its high price, it is highly regarded for its technological innovation and seamless Apple ecosystem integration.
Choosing the Right Microsoft Windows: Editions and Specialized Versions
Microsoft Windows has continuously evolved since its inception, catering to various user needs. Windows XP and Vista laid foundational features, while Windows 7 and 8/8.1 enhanced efficiency and functionality. Windows 10, known for its broad compatibility and regular updates, meets diverse professional and personal needs. Windows 11, with aesthetic and performance improvements, targets modern hardware and advanced users. Choosing between Home and Pro editions hinges on the need for advanced security and management features. Specialized versions like Education and Enterprise offer tailored functionalities for educational and corporate environments.
MacOS vs. Windows: A Comprehensive Comparison
a close up of a keyboard
The ongoing debate between MacOS and Windows hinges on their evolving features and dedicated user bases. MacOS, known for its user-friendly design and creative software, suits professionals like designers and developers. Windows excels in versatility, hardware compatibility, and gaming, appealing to a wider audience. Choosing between them depends on individual needs and preferences.
Which Version of Windows Makes You Smile? Share Your Rig Below!
Img 2281
Operating systems are crucial to tech interactions, with Windows OS being particularly significant. Its evolution, from Windows XP to Windows 11, has consistently focused on innovation and user needs. Windows 7 is a favorite for its stability and compatibility, while newer versions like Windows 10 and 11 introduce advanced features. Personal preference and hardware compatibility guide users in selecting the right OS.
Choosing the Best Email Provider for Your Needs: A Comprehensive Guide
person holding black iphone 5
Choosing an email provider is crucial for effective communication. Providers like Gmail, Outlook, Yahoo Mail, Apple Mail, and ProtonMail offer different features tailored to various needs including security, storage, and integration with other tools. Evaluating these aspects in light of personal or professional requirements can guide users towards optimal decisions.
Optimizing Internet Speed: How Quality Routers Enhance Performance
person running on road street cliff during golden hour
Routers are crucial for managing and directing data traffic between devices and the internet, ensuring efficient communication. High-quality routers enhance speed, range, security, and support multiple devices, making them essential for modern households and businesses. Investing in a good router offers long-term cost-efficiency, robust network performance, improved security, and future-proofing capabilities.
The Everlasting Relevance of Computers in Modern Society
black computer keyboard showing keyboard
Computers remain indispensable as they continually adapt to technological advancements, playing critical roles in sectors like healthcare, finance, education, and entertainment. Advances in AI, quantum computing, IoT, and hardware ensure their ongoing relevance. They facilitate daily operations, enhance productivity, and drive innovation, making them irreplaceable in modern society.
Computer Repair vs. Replacement: Cost, Performance, and Environmental Impact
a desk with two laptops and a keyboard on it
In today’s tech-driven world, deciding whether to repair or replace a malfunctioning or outdated computer involves assessing factors such as cost, performance, personal needs, and environmental impact. Repairs can be more economical and sustainable but may not deliver the enhanced functionality of new models. Professional advice can help make an informed choice.
Essential Software: Unveiling the Top 100 Programs for Everyday Use
Img 2235
Software programs have become essential in our digital lives, evolving to meet diverse needs. This blog post examines the top 100 programs commonly found on computers, covering productivity, communication, creative, security, web browsers, and entertainment software. Criteria for selection include user ratings, download statistics, and overall impact. Future trends suggest a move towards AI, cybersecurity, and cloud-based applications. Users are invited to share their favorite programs and experiences.
Maximize PC Lifespan: Essential Maintenance Tips for Efficiency
person using MacBook Pro
Maintaining your personal computer involves routine tasks that improve performance and extend its lifespan. Regularly cleaning hardware, updating software, managing files, optimizing startup processes, and running antivirus scans are crucial. Backing up data and performing advanced maintenance like hardware upgrades and system diagnostics ensure your computer operates smoothly and efficiently, akin to its initial state.
Maximizing Efficiency: The Necessity of Upgrading in a Rapidly Evolving Technological Landscape
a phone with a stethoscope on top of it
The necessity of upgrading products like phones and office equipment is driven by the rapid pace of technological advancements. Upgrading enhances performance, security, and user experience, while also contributing to cost savings and environmental sustainability through improved energy efficiency. Staying updated with new technology ensures optimal productivity and compliance with security standards.
Optimizing Performance: Leveraging the Power of Regular Updates
black laptop computer turned on on brown wooden table
Software updates are essential for maintaining the health, privacy, security, and efficiency of digital devices. Regularly updating operating systems and applications helps provide new features, bug fixes, and critical security patches that protect against cyber threats. Failure to update can result in degraded performance and increased vulnerability to attack, emphasizing the need for timely updates.
Telstra, Optus, and Vodafone: Network, Plans, and Coverage Comparison
person holding Android tablet computer
Choosing the right phone carrier is essential for connectivity and cost management. This guide reviews three major Australian carriers: Telstra, Optus, and Vodafone. Telstra offers extensive rural coverage but is pricier. Optus provides a balance of coverage and affordability with entertainment perks. Vodafone excels in urban areas with competitive pricing and international roaming options.
Custom PC Building Guide: Cost Savings, Customization, and Learning
Image 5
Building your own computer offers cost savings, customization, and a valuable learning experience. Key steps include selecting the right CPU, motherboard, RAM, and storage options, as well as assembling these components. Initial setup involves BIOS configuration and OS installation. Proper driver installation and stress testing ensure optimal performance and system stability.
The Devastating Impact of Spam and Scams on Individuals and Businesses
teal LED panel
Spam refers to unsolicited bulk messages, often inappropriate or irrelevant, mainly for promotions. Scams aim to deceive individuals into revealing personal information or money, with phishing and lottery scams being common examples. The emotional and financial impacts are severe for both individuals and businesses. Vigilance, education, and utilizing security tools are essential for protection.
Apple’s AI Innovations: Transforming User Experiences
a hand holding a cell phone
In recent years, Apple has made significant advancements in AI, aiming to seamlessly integrate it into everyday experiences. Apple’s AI initiatives span from improving Siri’s natural language processing to enhancing camera features with Smart HDR and Night Mode. AI-driven health monitoring and fitness tracking on Apple Watch also underscore its commitment to personal wellness.
Computer Diagnostics: A Comprehensive Guide for Efficient Troubleshooting
desktop monitor beside computer tower on inside room
Computer diagnostics entails identifying and solving computer issues to maintain efficiency. A systematic approach using diagnostic tools addresses hardware failures, software glitches, and network issues. Tools and cheat sheets help users troubleshoot common problems like slow performance, crashes, overheating, and unusual noises. Recognizing hardware versus software issues and utilizing built-in and third-party tools, as well as maintaining regular preventative measures, ensures optimal computer performance, though professional help may be needed for complex problems.
Custom Computer Building Guide: Hardware, Software, and Assembly
Image 25
Building your own computer offers significant benefits including customization, performance optimization, and educational value. Essential components are the CPU, GPU, motherboard, RAM, storage drives, PSU, cooling systems, and case. The process also involves installing an operating system, necessary drivers, and additional tools for efficient assembly. This guide and checklist ensure a successful build.
Drones for Aerial Photography: Versatility and Accessibility
black DJI Mavi quadcopter near body of water
Drones have revolutionized aerial photography by providing accessible, high-quality aerial views previously limited to expensive methods. Modern drones feature advanced cameras and user-friendly technology such as GPS, stabilization, and automated flight modes. Their affordability has made them popular among hobbyists and professionals, offering unique perspectives across various industries including real estate, agriculture, and conservation.
Maximizing Efficiency and Security: Unveiling the Best Computer Technology Tools
monitor showing Java programming
Modern computer technology tools have evolved from basic programs to sophisticated software that enhances productivity, security, and user experience. This blog post reviews the top ten computer tools, covering advanced antivirus software, cloud storage solutions, VPN services, productivity suites, graphic design software, project management tools, and programming environments. These tools cater to diverse user needs, providing free and paid options to improve efficiency and overall digital experience. The future trends highlight increasing reliance on cloud solutions, AI integration, cybersecurity advancements, and IoT device integration.
Internet Security, Here’s what you need to know.
Image 11
As digital reliance grows in 2024, robust antivirus and internet security become essential due to increasing cyber threats like malware, ransomware, and phishing. Key criteria for selecting such software include protection efficiency, minimal system impact, user-friendly interfaces, additional features, customer support, and fair pricing. Top contenders offer specific strengths, from advanced customization to multi-device protection.
Harnessing the Full Potential of Technology: A Comprehensive Guide to Entering the Tech World
Image 49
Technology is transforming diverse sectors like healthcare, education, communication, and entertainment by driving innovation and efficiency. To thrive, individuals must align their goals with industry trends, acquire fundamental tech skills, and gain hands-on experience through projects and internships. Staying informed and engaging with tech communities is essential for continuous growth and adaptability.
Should I Use AI in My Business? Why and What Type?
Artificial Intelligence (AI) is transforming industries by enhancing efficiency, accuracy, and customer satisfaction. This post explores the benefits of integrating AI, like cost reduction and improved decision-making, alongside challenges such as investment costs and data privacy. Discussing AI technologies, use-cases across sectors, implementation steps, and future trends, it provides a comprehensive guide for businesses considering AI adoption.
The Ultimate Guide to Computer Maintenance: 10 Steps to Tune Your Computer and 5 Free Tools to Try
Regular computer maintenance enhances performance and extends the lifespan of your device. Key tasks include disk cleanup, defragmentation, software updates, managing startup programs, and scanning for malware. Additional steps like optimizing browser and visual settings, regular data backups, cleaning hardware, and timely restarts can significantly improve system efficiency. Use free tools for assistance.
The Evolution of Facebook Marketplace: A New Era for Local E-Commerce
Facebook Marketplace, launched in 2016, rapidly became a key player in local e-commerce, leveraging its massive user base for seamless, integrated transactions. Despite its popularity and community-focused approach, it lacks a formal payment system and faces issues with scams and insufficient customer support. Privacy concerns and the potential for sustainability make it a double-edged platform that could evolve with better security and eco-conscious practices. Nevertheless, it poses a unique, flexible option for peer-to-peer buying and selling with room for future growth and improvement.
|
__label__pos
| 0.872408 |
Slickplan
Slickplan Help Content Planner Adding Content
How do I add labels to content blocks?
How do I add labels to content blocks
You can add labels to any content blocks. Labels help you to signify your content, making your projects more legible not only for you, but for your contributors as well.
To add labels to your content blocks:
1. Open the content dashboard from the toolbar and click on the selected page, or navigate directly from the sitemap by clicking the content icon on a selected page.
Screen_Shot_2020-11-13_at_1_52_05_PM.jpg
2. Click on Add label above the content block.
Screen_Shot_2020-10-28_at_1_29_22_PM.jpg
3. In the modal window, enter a short description and confirm that by clicking Confirm.
Screen_Shot_2020-11-13_at_1.39.04_PM.jpg
|
__label__pos
| 0.899063 |
how to mine ethereum fast as possoible
Last Updated on April 18, 2022 by
How to Mine Ethereum: Step by Step Guide Updated for 2022
How to Mine Ethereum: Step by Step Guide Updated for 2022
Mining Ethereum in a pool is the simplest and quickest way to get started. In pool mining, you join forces with other individuals. All the miners joining a pool agree that if one of them solves the cryptographic puzzles, rewards will be split among them according to the hashpower provided.May 10, 2022
How to mine Ethereum: A beginner's guide to ETH mining
How to mine Ethereum: A beginner's guide to ETH mining
The most straightforward way to mine ETH is by joining one of many Ethereum mining pools like SparkPool, Nanopool, F2Pool and many others. These allow miners to …
How to mine Ethereum: A step-by-step guide – Business Insider
How to mine Ethereum: A step-by-step guide – Business Insider
Step 1: Pick your mining approach · Step 2: Open a crypto wallet · Step 3: Choose your hardware and software · Step 4: Choose a mining pool · Step 5 …
Guide On How To Mine Ethereum, Staking, Mining Pools
Guide On How To Mine Ethereum, Staking, Mining Pools
Answer: The first step is to select the method of mining – pool, solo, or cloud. Then create an Ethereum wallet address, which you will use to …
How to Mine Ethereum: Step by Step Process to Start Mining
How to Mine Ethereum: Step by Step Process to Start Mining
How to mine Ethereum in 5 min – Medium
How to mine Ethereum in 5 min – Medium
What’s more, is that it doesn’t seem this bubble is going anywhere, anytime soon. As you can see in the graph below, the total market cap of cryptocurrencies …
The Ultimate Beginner's Guide to Mining Ethereum in 7 Steps …
The Ultimate Beginner's Guide to Mining Ethereum in 7 Steps …
A single laptop or PC usually doesn’t have enough processing power to consistently and safely solve the hash problem and mine Ethereum on its own. Indeed, …
Beginner's Guide to Ethereum mining – 99Bitcoins
Beginner's Guide to Ethereum mining – 99Bitcoins
Open the Ethereum wallet and generate a new account and contract based wallet. This wallet will contain the payout address to which you’ll receive mining …
How to Mine Ethereum: NiceHash, Mining Pools, Best Settings
How to Mine Ethereum: NiceHash, Mining Pools, Best Settings
The easiest is to use the new QuickMiner, which is a web interface to a basic mining solution. You download the QuickMiner software, run that, …
The Quick Guide to Mining Ethereum – MakeUseOf
The Quick Guide to Mining Ethereum – MakeUseOf
To mine any cryptocurrency, you need the correct hardware. In the case of mining Ethereum, GPUs (graphics cards) are your best bet for optimum …
How fast can I mine 1 Ethereum?
Q #2) How long does it take to mine 1 Ethereum? Answer: It takes around 7.5 days to mine Ethereum as of September 13, 2021, at the hash rate or hashing power of 500 mh/s with an NVIDIA GTX 3090 that hashes at around 500MH/s.
Can you mine 1 Ethereum a day?
If you created a mining rig with a 100MH/s hash rate, for example, it would take an estimated 403 days to mine 1 ETH – or its equivalent – according to CoinWarz. Even a whopping 2000MH/s, or 2 GH/s, farm would take around 20 days to mine 1 ETH. Of course, most Ethereum miners don't set out to mine 1 ETH.
What is the cheapest way to mine Ethereum?
GPU Mining: This is probably the most popular method of mining cryptocurrencies. Miners use one or several graphics processing units to mine Ethereum. It's both relatively cheap and efficient to build a mining rig comprising of GPUs.
Can a beginner mine Ethereum?
Getting started with Ethereum Mining is pretty easy. All you need is a Graphics Processing Unit (GPU) and you can start generating Ether.
What is the easiest crypto to mine?
Monero
Answer: Monero is the easiest cryptocurrency to mine now because it can be mined via browser extensions and free software over websites. It is even mined via crypto jacking. The mining code can also easily be incorporated into apps and websites to facilitate mining.
How many Ethereum are left to mine?
Currently, there are infinitely many Ethereum left to mine. If Ethereum remains inflationary or becomes deflationary is still uncertain. Let's look at the numbers. By January 2022, according to the figures, a total of 9M+ ETH had been staked.
How long does it take to mine 1 shiba inu?
You can mine 100,000 SHIB in one week (worth $5 as of this writing), but the next day, that same amount of SHIB could be worth $1. Here are some other concerns you should keep in mind: Increased wear-and-tear on your hardware.
Can I mine Ethereum using my phone?
Yes, it does work. It is possible to mine bitcoin with an android device even if you might have numerous reasons to stay away from it. Also, using a mobile phone to mine crypto coins isn't close to the way the traditional mining software or hardware works.
Is crypto mining still worth it in 2022?
The price of Bitcoin mining equipment is a major factor in profitability. The prices of top and mid-tier application-specific integrated circuit (ASIC) miners, the specialized chips made for Bitcoin mining, are reportedly down roughly 70% from their all-time highs in 2022 when units sold for around $10,000 to $18,000.
Can I mine Shiba Inu?
To get started on mining SHIB, you'll need a Shiba Inu wallet — this will collect all your SHIB rewards once you've reached your payout threshold. I recommend Coinbase Wallet (opens in new tab) (on Android and iOS).
Can I mine Ethereum on my phone?
Yes, it does work. It is possible to mine bitcoin with an android device even if you might have numerous reasons to stay away from it. Also, using a mobile phone to mine crypto coins isn't close to the way the traditional mining software or hardware works.
Is Ethereum mining going away?
“The Merge,” a long-anticipated update to the Ethereum network, will end the practice of Ethereum mining. After numerous delays, the Merge, previously referred to as “Ethereum 2.0,” appears likely to take place by the end of the year.
What is the most profitable crypto to mine?
10 BEST Cryptocurrency to Mine with GPU [Most Profitable]
• Comparison of the Most Profitable Coins to Mine.
• #1) Vertcoin.
• #2) Bitcoin.
• #3) Monero.
• #4) Ravencoin.
• #5) Haven Protocol (XHV)
• #6) Ethereum Classic (ETC)
• #7) Bitcoin Gold.
Can I mine ethereum for free?
Ethereum cloud mining can either be free or paid. You hire the mining devices at a certain cost that can be billed once, monthly, or yearly in the paid plan. On the other hand, you don't have to pay any money to access the mining services in a free plan.
What coin is worth mining?
Comparison of the Most Profitable Coins to Mine
Cryptocurrency Rewards per block Our rating
Bitcoin 2.5 BTC 4.7/5
Monero 4.99 XMR 4.6/5
Ravencoin 5,000 RVNs 4.5/5
Haven Protocol 5.0906 XHVs. 4.55/5
•Aug 7, 2022
Which crypto is easiest to mine?
Monero
Answer: Monero is the easiest cryptocurrency to mine now because it can be mined via browser extensions and free software over websites. It is even mined via crypto jacking. The mining code can also easily be incorporated into apps and websites to facilitate mining.
How much can a crypto miner make in a day?
27, the estimated daily profit for an Ethereum miner using a single GPU was $4.59. For Feathercoin, by way of comparison, miners were estimated to lose $0.58 per day. Obviously, to generate a significant amount of profit, you'd need to host a large number of GPUs using these calculations.
How can I get free ethereum?
2:224:07How To Earn Free Ethereum – YouTubeYouTube
Is mining still profitable 2022?
Bitcoin Mining Companies As the profitability of Bitcoin mining dropped in 2022, top crypto miners' share prices have also fallen. Fortunately, Canaccord Genuity analyst Joseph Vafi says the most efficient Bitcoin miners are still turning a significant profit on their rigs.
How can I get ETH without buying?
2:024:07How To Earn Free Ethereum – YouTubeYouTube
|
__label__pos
| 0.716617 |
Scripting Blog
A place to learn about PowerShell and share stories of automation
Hey, Scripting Guy! How Can I Prevent Office Excel From Turning My Imported Numbers Into Dates?
Hey, Scripting Guy! I have a CSV file, and every time I open that file in Office Excel my numbers get converted to dates. How can I import numbers as numbers?-- JR Hey, JR. You know, just yesterday the Scripting Guy who writes this column learned about Yelo, an interesting little company based in New York City. So what does Yelo do? Well, ...
Hey, Scripting Guy! How Can I Change the Value and Color of a Spreadsheet Cell Based on the Sum of Other Cells in That Spreadsheet?
Hey, Scripting Guy! I’m new to Excel, and I was wondering how to change the color of a cell if specific requirements are met. I have a spreadsheet that has three columns of numbers; I’d like to add the numbers in each row and, if they total 100, set the text of a fourth column to “Yes” and color that cell green. If the numbers don...
Hey, Scripting Guy! How Can I Import a Fixed-Width Data File into Microsoft Excel?
Hey, Scripting Guy! How can I import a fixed-width data file into Microsoft Excel?-- RS Hey, RS. This column is being written on a Friday morning, and so far it’s been a very weird morning at that. For one thing, it’s not raining and – if you look closely – you can even see the sun. (It’s been awhile, but we’d recognize the sun ...
Hey, Scripting Guy! How Can I Separate The Month From the Year in a Date String Like 122007?
Hey, Scripting Guy! I have a column of data in Microsoft Excel that is formatted as MYYYY (12008 = January 2008) and MMYYYY (122007 = December 2007). I need to split these values into month and year, but I can’t figure out how to do that. Any suggestions?-- DW Hey, DW. Well, it’s finally beginning to warm up here in Scripting Land, ...
Hey, Scripting Guy! How Can I Cut a Row From One Office Excel Spreadsheet and Paste That Row Into Another Spreadsheet?
Hey, Scripting Guy! How can I cut a row from an Office Excel spreadsheet and paste it into the first unused row in another Excel spreadsheet?-- NC Hey, NC. We apologize if today’s column feels a little damp; as it turns out, those of us in the Seattle area are experiencing another one of the Puget Sound’s … delightful … shifts in ...
Feedback usabilla icon
|
__label__pos
| 0.951607 |
\hypertarget{overwritemergeconfiguration_8hpp}{}\section{overwritemergeconfiguration.\+hpp File Reference} \label{overwritemergeconfiguration_8hpp}\index{overwritemergeconfiguration.hpp@{overwritemergeconfiguration.hpp}} A configuration for a simple automerge and guaranteed conflict resolution by one side. {\ttfamily \#include $<$merging/automergeconfiguration.\+hpp$>$}\newline Include dependency graph for overwritemergeconfiguration.\+hpp\+: \nopagebreak \begin{figure}[H] \begin{center} \leavevmode \includegraphics[width=350pt]{overwritemergeconfiguration_8hpp__incl} \end{center} \end{figure} This graph shows which files directly or indirectly include this file\+: \nopagebreak \begin{figure}[H] \begin{center} \leavevmode \includegraphics[width=260pt]{overwritemergeconfiguration_8hpp__dep__incl} \end{center} \end{figure} \subsection*{Namespaces} \begin{DoxyCompactItemize} \item \mbox{\hyperlink{namespacekdb}{kdb}} \begin{DoxyCompactList}\small\item\em This is the main namespace for the C++ binding and libraries. \end{DoxyCompactList}\item \mbox{\hyperlink{namespacekdb_1_1tools}{kdb\+::tools}} \begin{DoxyCompactList}\small\item\em This namespace is for the libtool library. \end{DoxyCompactList}\end{DoxyCompactItemize} \subsection{Detailed Description} A configuration for a simple automerge and guaranteed conflict resolution by one side. \begin{DoxyCopyright}{Copyright} B\+SD License (see L\+I\+C\+E\+N\+S\+E.\+md or \href{https://www.libelektra.org}{\texttt{ https\+://www.\+libelektra.\+org}}) \end{DoxyCopyright}
|
__label__pos
| 1 |
Click here to Skip to main content
Click here to Skip to main content
Accessing CVS Repository with C#
, 24 Nov 2004
Rate this:
Please Sign up or sign in to vote.
An article on accessing a CVS repositry using C#.
Sample Image
Introduction
Most of my development projects are Visual Studio .NET projects that are stored in CVS repositories running on a Linux machine. Additionally, we use a third party bug tracking software that runs on Windows 2000 to track bug fixes/customer problems, etc. For auditing reasons, I needed to develop a program that would tie together the history of files changed in the CVS repository between different version tags with problem tracking records in the bug tracking system. To do this, I needed an easy way to access the history data in the CVS repository. In doing so, I created a simple and extensible class for accessing the CVS repository directly from a C# class.
I am not going to cover the part about accessing the bug tracking software. That software stores its information in an ODBC compliant database. That portion of the problem was neither unique nor interesting.
Accessing the CVS Repository: Setup
I do not want to go into great details on how to set up CVS. Suffice it to say that we use WinCVS on the Windows Client machines with SSH server authentication. By using this combination, not only can we access the CVS repository through WinCVS, but we can also access it from the command prompt.
The code
To start, I created a central class called CVSCommand. That class executes an arbitrary CVS command via a command line process. Additionally, it starts a secondary thread that monitors the console output of the CVS command and places it into a buffer for processing. Though you can issue CVS commands directly by using this class, I derived specific CVS command classes from CVSCommand.
To execute a command, the CVSCommand or derived class must know a few things. It must know the CVS Root, the RSH (remote shell) command, and the Working Directory for the command execution. There are property variables created to store this information. For example, to execute an arbitrary command using the CVSCommand class:
// Generic CVS command
CVSCommand cmd = new CVSCommand("log MainForm.cs");
cmd.CvsRoot = "[email protected]:/home/cvs";
cmd.CvsRsh = "c:/Program Files/GNU/SSHCVS/ssh.exe"
cmd.WorkingDirectory = @"c:\cvs repository\application 1\";
// Execute the command
cmd.Start();
cmd.WaitDone();
// Output the command response
Console.WriteLine(cmd.Output);
Using the CVSGetFileHistory Class
Though you can issue any CVS command using the CVSCommand class, the parsing of the response is still required. For my application, I created a simple derived class called CVSGetFileHistory. That command uses all the built in functionality of the base class to execute the CVS command, but adds special parsing code to parse the CVS response in a familiar and easy to use format. Additionally, the constructor allows you to specify the file you want the history of. For example, the above code can be changed to use the CVSGetFileHistory class as follows:
// CVS History File command
CVSGetFileHistory cmd = new CVSGetFileHistory("MainForm.cs");
cmd.CvsRoot = "[email protected]:/home/cvs";
cmd.CvsRsh = "c:/Program Files/GNU/SSHCVS/ssh.exe"
cmd.WorkingDirectory = @"c:\cvs repository\application 1\";
// Execute the command
cmd.Start();
cmd.WaitDone();
// Print out the results
foreach (CVSHistoryItem hi in cmd.History)
{
Console.WriteLine("File: {0}", hi.File);
Console.WriteLine("Revision: {0}",hi.Revision);
Console.WriteLine("Date: {0}", hi.Date);
Console.WriteLine("Author: {0}", hi.Author);
Console.WriteLine("Description: {0}", hi.Description);
}
A Closer Look at CVSCommand
The CVS Command is a rather simple class. As previously stated, its main function is to execute an arbitrary CVS command via a command line process. To do so, it uses the System.Diagnostics.Process class. However, it must also ensure that certain environment variables used by CVS are defined. After it starts the process, it also starts a background thread that monitors the console output of the process and appends it to a buffer. The method Start() is where all of this is handled:
public void Start()
{
// Do not allow if already running
if (this.Running == true)
return;
ProcessStartInfo i = new ProcessStartInfo("cvs", command);
i.UseShellExecute = false;
if (this.CvsRoot.Length != 0)
i.EnvironmentVariables.Add("CVSROOT", this.CvsRoot);
if (this.CvsRsh.Length != 0)
i.EnvironmentVariables.Add("CVS_RSH", this.CvsRsh);
if (this.WorkingDirectory.Length != 0)
i.WorkingDirectory = this.WorkingDirectory;
i.RedirectStandardOutput = true;
i.CreateNoWindow = true;
p = Process.Start(i);
monitor = new Thread(new System.Threading.ThreadStart(MonitorMain));
monitor.Start();
}
Once the command is started, the Running property can be checked to see if the command is still executing or the WaitDone() method can be called to wait until the process is completed.
The background monitoring thread is rather simple. The code simply reads the StandardOutput property of the process and appends the results to the buffer. Furthermore, it monitors the Running property of the class to determine when it can stop execution.
Deriving a new Class
Deriving a new class is not difficult. All you really need to do is provide a constructor that accepts the proper information for the command and parsing functions to parse the command response. For example, the CVSGetFileHistory constructor looks like this:
public CVSGetFileHistory(string file) : base("log "+file)
{
}
It also has several properties that act as parsing functions for the Output of the CVSCommand class. For example, when a cvs log function is executed on the command line, this is output to the console:
C:\MCS\APPLIC~1\NM90>cvs log AssemblyInfo.cs
RCS file: /home/cvs/MCS/Applications/NM90/AssemblyInfo.cs,v
Working file: AssemblyInfo.cs
head: 1.61
branch:
locks: strict
access list:
symbolic names:
NM90_Version_2_3_Build_52: 1.57
NM90_Version_2_3_Build_50: 1.56
NM90_Version_2_3_Build_14: 1.41
NM90_Version_2_2_Build_44: 1.22
NM90_Version_2_2_Build_42: 1.21
NM90_Version_2_2_Build_40: 1.20
NM90_Version_2_2_Build_32: 1.15
NM90_Version_2_2_Build_28: 1.12
NM100_Version_2_2_Build_6: 1.5
keyword substitution: kv
total revisions: 61; selected revisions: 61
description:
----------------------------
revision 1.61
date: 2004/11/22 13:50:06; author: cnelson; state: Exp; lines: +1 -1
PRN:302
----------------------------
revision 1.60
date: 2004/11/16 21:04:21; author: cnelson; state: Exp; lines: +1 -1
PRN:310
----------------------------
...
To make this more useable from a programming perspective, the derived class needs to parse this information and present it in a way that can be easily used. For example, CVSGetFileHistory parses all the revision text listed above and places it into a container class called CVSHistoryItemList which is exposed as the History property variable. In doing so, the following can be easily done:
// Execute the command
cmd.Start();
cmd.WaitDone();
// Print out the results
foreach (CVSHistoryItem hi in cmd.History)
{
Console.WriteLine("File: {0}", hi.File);
Console.WriteLine("Revision: {0}",hi.Revision);
Console.WriteLine("Date: {0}", hi.Date);
Console.WriteLine("Author: {0}", hi.Author);
Console.WriteLine("Description: {0}", hi.Description);
}
Additional Notes
In closing, this basic class does what I needed it to do, no more and no less. Additional error trapping certainly could be added with not too much difficulty. Additional commands could also be implemented, as well.
History
• November 22, 2004 - Initial posting.
License
This article has no explicit license attached to it but may contain usage terms in the article text or the download files themselves. If in doubt please contact the author via the discussion board below.
A list of licenses authors might use can be found here
Share
About the Author
Jay Nelson
Web Developer
United States United States
I have been developing software professionaly since 1991 writing software in Automation and Manufacturing environments. For 14 years I worked for companies that built custom robotic automated equipment for the semiconductor, telecommunications, and other industies. Presently, I work for a medical device manufacturer developing applications for the compact framework.
My undergraduate degrees are in Mathematics and Philosopy. My graduate degree is in Management Information Systems. I am MCSD certified in Visual C++ 6.0 and MCSD.NET certified in C#.
I enjoy triathlons and reading.
Comments and Discussions
Generaldoesn't support :ext protocol Pinmembercvsclient20-Jan-05 23:04
General General News News Suggestion Suggestion Question Question Bug Bug Answer Answer Joke Joke Rant Rant Admin Admin
Use Ctrl+Left/Right to switch messages, Ctrl+Up/Down to switch threads, Ctrl+Shift+Left/Right to switch pages.
| Advertise | Privacy | Mobile
Web02 | 2.8.141022.2 | Last Updated 25 Nov 2004
Article Copyright 2004 by Jay Nelson
Everything else Copyright © CodeProject, 1999-2014
Terms of Service
Layout: fixed | fluid
|
__label__pos
| 0.81186 |
Skip to content
• Thomas Miedema's avatar
Don't drop last char of file if -osuf contains dot · 48db13d2
Thomas Miedema authored
Given:
* `file = "foo.a.b"`
* `osuf = ".a.b"` -- Note the initial dot.
* `new_osuf = "c"`
Before (bad, the last character of the filename is dropped):
`dropTail (length osuf + 1) file <.> new_osuf == "fo.c"`
After (good):
`stripExtension osuf file <.> new_osuf` == "foo.c"
This regression was introduced in commit c489af73 (#5554). That commit
fixed a similar but different bug, and care has been taken to not
reintroduce it (using the the newly introduced
`System.Filepath.stripExtension`).
Given:
* `file = "foo.a.b"`
* `osuf = "a.b"`
* `new_osuf = "c"`
Before c489af73 (bad, the full suffix should get replaced):
`replaceExtension file new_osuf == "foo.a.c"`
After c489af73 (good):
`dropTail (length osuf + 1) file <.> new_osuf == "foo.c"`
After this commit (still good):
`stripExtension osuf file <.> new_osuf == "foo.c"`
Reviewed by: bgamari
Differential Revision: https://phabricator.haskell.org/D1692
GHC Trac Issues: #9760
48db13d2
|
__label__pos
| 0.917173 |
Software
How Can You Save Costing While Developing Cross-Platform Applications?
Today, there is an increase in the popularity of cross-platform applications. Most business houses are switching to these apps to create an application that can run on multiple platforms. They have enormous advantages that cannot be denied. However, the most compelling feature of cross-platform applications is their cost-effectiveness. Business houses hire a cross-platform app development company to design apps that can run on various platforms like Android, iOS, and Windows.
In this article, readers will be introduced to some vital features of cross-platform applications that help to cut down the overall cost. Companies looking forward to launching their apps should go through these features carefully for extracting the maximum benefits.
Codebase is Reusable
Earlier, app developers had to write a separate codebase for creating applications for different platforms. But cross-platform apps have changed the entire process with the approach of reusable code. These apps have the same codebase, and they can run on various platforms effortlessly. Developers can retain almost 80% of the entire codebase and make minor changes to it for running it on separate operating systems. However, native apps do not offer this advantage as they need to be coded from scratch for all platforms. Therefore, cross-platform applications save time and money for app developers.
Easy to Test
The assessment process of cross-platform apps is more comfortable than native apps. Developers have to use separate tools for testing native apps which is a very hectic process. However, cross-platform apps reduce the tasks of developers and testers effectively. The developing tools used for these apps are integrated with testing features that allow assessing them effortlessly. One can test them in the development process and save a lot of time. Moreover, app developers can perform the task of testers which is an imperative cost-effective feature of these applications.
The requirement of Less Resource
Native applications consume more resources than cross-platform applications. Business houses need to hire separate app development teams to create applications for Android, iOS, and Windows. However, cross-platform apps can be developed by one cross-platform app development company. That helps businesses in saving a lot of money that they would have to invest in separate app designing teams. Similarly, cross-platform apps use the same codebase for multiple operating systems. It is another major factor that reduces the consumption of excessive resources while creating an application.
Lower Maintenance Charges
Cross-platform applications attract lower maintenance charges making them more budget-friendly. Companies have to maintain one version of an app for various platforms, which means they will have to update the single version and save cost on maintaining numerous versions. It will directly affect the maintenance cost the company has to pay to the app developer. It can do with a lower maintenance charge which will enable it to maintain a steady budget.
Single Security System
Applications contain a lot of confidential user data, and thus, they should be given the utmost protection. Companies owning apps for various platforms need to invest a fair amount of money in their security systems. Native apps have a separate codebase, and so, their security systems need to be different as well. However, cross-platform apps score higher in this section, as owners can implement a single security system for maintaining apps on various platforms. It reduces the overall cost of maintaining multiple apps for different operating systems.
Offline Mode
Most apps are designed in a way that users can operate even without an active internet connection. It is called the offline mode of an app. In the case of the native app, the implementation of the offline operation model has to be done separately and incurs a lot of added charges. However, cross-platform apps include the offline model in their packages. Therefore, companies can save on their app development expenses as the online and offline operation models come in a single pack.
Helping in Reaching Out to More Customers
Cross-platforms apps have more significant reach than native apps, and this fact is undeniable. Businesses opting for native applications often pick one platform and leave aside the others. This cuts down on their reach as each operating system has a vast user base across the world. Companies should not dare to let go of the opportunity of grabbing potential customers on various platforms. Therefore, they should prefer designing cross-platform apps that can help to attract more traffic by spending less.
Numerous App Development Frameworks Available
App developers get numerous choices of cross-platform frameworks that already exist in the market. Some of them have top-notch features and are a favorite of application designers. These frameworks help to develop apps faster and without consuming more resources. They have component libraries that allow designing the interface effortlessly. Moreover, app developers can complete their task within a short time with these frameworks and cut down the expenses of businesses.
Integration into the Cloud System
Nowadays, cloud integration is an essential aspect that app developers need to address. Most applications are connected to the cloud for availing of a massive data storage system. Unlike native apps, developers can integrate cross-platform apps easily into the cloud system. It is a significant advantage of these apps that cater to the requirements of businesses. Cross-platform apps are universally compatible, and they help in saving money through seamless cloud integration.
New App Development Technology in the Block
The process of developing cross-platform applications attracts less charge as compared to native apps. It is because cross-platform apps are new in the market, and many developers are working on it. They might offer lower price quotes to clients to gain their confidence and create the right image. Moreover, app developers can develop fantastic apps for multiple platforms using the same codebase, which enables them to work on a lower charge. Therefore, businesses can get the maximum benefits by choosing this technology without spending much for the same.
Yields Fruitful Results Faster
Cross-platform apps take less preparation time, and thus, businesses can establish them faster. Developers can create apps for more than one platform to launch them quickly. That will help to reach out to a vast client base within a short span and increase the rate of conversion. Cross-platform apps are also straightforward to promote, which benefits companies. They can expect positive outcomes in less time and get high returns.
Increased Application Scalability
In today’s modern world, businesses look for highly scalable applications. Application scalability is the term used to denote the ability of an app to grow with time. Scalable apps can handle more RPM or requests per minute, which is a vital feature. Cross-platform applications are more scalable than native apps. These apps are designed on an uncomplicated codebase that is easy to scale. Companies can expect to receive an application that is scalable on both development and business aspects. These apps are cost-effective, and thus, scaling them becomes more convenient.
Bottom Line
All the features mentioned in this article contribute to increasing the budget-friendliness of an app. They help in reducing the overall expense of developing an application that can run on more than one platform seamlessly. Today, a cross-platform app development company is the first choice of maximum business looking forward to launching apps. The primary reason for this shift in preference is the cost-effectiveness of cross-platform apps that helps companies in saving a lot of money. Besides money, these applications also save time and yield faster returns on investments.
Contributed by https://theninehertz.com/
A post by neerajsharma (1 Posts)
neerajsharma is author at LeraBlog. The author's views are entirely their own and may not reflect the views and opinions of LeraBlog staff.
|
__label__pos
| 0.712626 |
Omar HossamEldin Omar HossamEldin - 9 months ago 56
Swift Question
UIImageView overlaps UILabel on next ViewController Open
I have a parent ViewController which opens a second one.
Second ViewController contains a grid view like in the image.
Correct Image
When I go back and enter same screen again I found layout changed to this
Wrong Image
Here in the second image, the UIImage overlaps the label.
Here is my InterfaceBuilder Settings
enter image description here
I change the size and EdgeInsets using following code
func collectionView(_ collectionView: UICollectionView, layout: UICollectionViewLayout, sizeForItemAtIndexPath: IndexPath) -> CGSize {
let width = collectionView.frame.size.width/2 - 8*2
if let cell = collectionView.cellForItem(at: sizeForItemAtIndexPath) {
return CGSize(width: width, height: cell.frame.height)
} else {
return CGSize(width: width, height: 104)
}
}
func collectionView(_ collectionView: UICollectionView, layout: UICollectionViewLayout, insetForSectionAtIndex : NSInteger) -> UIEdgeInsets {
return UIEdgeInsets(top: 8, left: 8, bottom: 8, right: 8);
}
Why do the first time only the layout is correct and after that the layout changes, Any Clues?
Edit1:
Here is a screen shot for 3d Debugging
3d debugging first open
3d debugging second launch
Answer Source
Try to give aspect ratio constraint from UILabel to image. Hit and then run. But before this make sure you did not want a static height for you imageView. If you want to the height of imageView to not be increase or decrease device wise then instead of aspect ratio just give a static height constraint to imageView. Your problem will be solve.
|
__label__pos
| 0.839377 |
How to fix a ‘Object of class WP_Error could not be converted to string’ error in WordPress
If you see a blank page while trying to log in to your WordPress site, check your web server’s error logs. You may get the following error:
stderr: PHP Catchable fatal error: Object of class WP_Error
could not be converted to string in
/var/[PATH TO YOUR DOCUMENT ROOT]/wp-includes/default-constants.php on line 139
Note that the line number may be different depending on your version of WordPress but the code generating the error is as follows:
function wp_plugin_directory_constants() {
if ( !defined('WP_CONTENT_URL') )
define( 'WP_CONTENT_URL', get_option('siteurl') . '/wp-content');
Do not be tempted to debug by editing the code as it’s not the source of the error. Your problem will very likely be that the siteurl option value in your WordPress database does not contain a valid entry. In this case, the error message is telling you that get_option() receives a WP_Error object rather than a string that it’s expecting.
To fix this:
1. First check the siteurl option to verify that the value is indeed incorrect. Run the following SQL:
SELECT * FROM `wp_options` WHERE option_name = 'siteurl';
You will likely find a serialized array containing a WP_Error object.
2. Correct the option value by setting it with your domain’s URL:
UPDATE wp_options SET option_value = '[YOUR URL]' WHERE option_name = 'siteurl';
I’m not sure what overwrites the siteurl option value. Most likely there is a misbehaving plugin installed or malware has infected your installation. Be sure to run a scan on your server.
Scroll to Top
|
__label__pos
| 0.993575 |
Android Studio入门指南
发布时间: 2024-01-31 21:52:38 阅读量: 19 订阅数: 11
# 1. 认识Android Studio ## 1.1 什么是Android Studio Android Studio是由谷歌推出的官方集成开发环境(IDE),专门用于Android应用程序的开发。它基于JetBrains的IntelliJ IDEA开发,提供了丰富的功能和工具,为开发者提供了一个高效、便捷的开发环境。 ## 1.2 Android Studio的功能和特点 Android Studio集成了丰富的工具和功能,包括代码编辑器、调试器、性能分析工具、布局编辑器等。它还支持快速的应用程序构建、调试和发布,并且与Android设备和模拟器紧密集成。 ## 1.3 Android Studio的发展历史 Android Studio首次发布于2013年,取代了Eclipse作为官方推荐的Android开发工具。自发布以来,Android Studio不断更新和改进,不仅增加了新的功能,还改善了性能和稳定性。其稳定版本和预览版本的发布频率很高,以满足开发者对于新功能和改进的需求。 # 2. 安装和配置Android Studio ### 2.1 下载Android Studio 在开始使用Android Studio之前,首先需要从官方网站下载Android Studio的安装包。以下是下载Android Studio的步骤: 1. 打开浏览器并访问[Android Studio官方网站](https://developer.android.com/studio)。 2. 在网页上找到并点击下载按钮,下载Android Studio的最新版本。 3. 根据你的操作系统选择相应的下载版本(Windows、Mac或Linux)。 4. 下载完成后,可以继续进行安装步骤。 ### 2.2 安装Android Studio 下载完成Android Studio的安装包后,接下来进行安装。以下是安装Android Studio的步骤: 1. 运行下载的安装包文件,打开安装向导。 2. 按照向导的指示,选择安装位置和组件(可根据需要进行自定义)。 3. 点击"Next"继续进行安装。 4. 随后,你将看到一些关于Android Studio的可选配置项,如设置桌面快捷方式、创建启动菜单项等。 5. 完成安装过程后,Android Studio将自动启动。 ### 2.3 配置Android Studio的基本设置 在完成Android Studio的安装后,还需要进行一些基本的配置。以下是配置Android Studio的基本设置的步骤: 1. 首次启动Android Studio时,会提示你选择导入设置或创建新的设置。如果是第一次使用Android Studio,建议选择创建新的设置。 2. 在后续的设置中,你可以选择配置Android Studio的UI主题、字体大小、编程语言等。 3. 可以选择安装和配置Android SDK,以便进行Android应用程序开发。 完成上述配置后,你已经成功配置了Android Studio的基本设置。现在,你可以开始创建和开发Android应用程序了。 在下一章节中,我们将介绍如何掌握Android Studio的界面。 # 3. 掌握Android Studio的界面 在本章中,我们将深入了解Android Studio的主要界面,包括工具栏、菜单栏、编辑器窗口和文件目录结构。掌握Android Studio的界面是开发Android应用程序的基础,也是提高工作效率的关键。 #### 3.1 了解Android Studio的主要界面 Android Studio的主要界面分为以下几个部分: - **菜单栏**:提供了各种菜单选项,包括文件操作、项目构建、运行调试等功能。 - **工具栏**:包含常用的操作按钮,如运行应用程序、调试、同步项目等。 - **编辑器窗口**:用于编辑和查看代码文件、布局文件等。 - **项目窗口**:显示项目的文件和目录结构。 - **版本控制窗口**:用于管理项目的版本控制操作。 #### 3.2 工具栏和菜单栏的功能 工具栏和菜单栏中包含了丰富的功能和操作选项,如: - **运行应用程序**:通过工具栏的运行按钮可以启动应用程序在模拟器或真机上运行。 - **调试应用程序**:调试按钮可以启动应用程序的调试模式,进行断点调试等操作。 - **同步项目**:同步按钮可以将项目和Gradle进行同步,更新依赖项和构建项目。 - **菜单栏的各类菜单选项**:如文件、编辑、视图、导航、代码、分析等,提供了丰富的功能操作选项。 #### 3.3 编辑器窗口和文件目录结构 在Android Studio中,编辑器窗口用于编辑和查看代码文件,包括Java文件、XML布局文件等。同时,项目窗口则显示了项目的文件和目录结构,方便开发者进行文件的查找和管理。 以上就是Android Studio界面的基本介绍,接下来我们将深入学习如何使用这些界面来开发Android应用程序。 # 4. 创建和运行Android应用程序 在这一章中,我们将学习如何在Android Studio中创建和运行一个简单的Android应用程序。我们会了解如何创建新的项目,编写代码,并在模拟器或真机上进行应用程序的运行和调试。 #### 4.1 创建新的Android项目 在Android Studio中,创建一个新的Android项目非常简单。首先,打开Android Studio,然后按照以下步骤进行操作: 1. 在欢迎页面点击 "Start a new Android Studio project",或者在菜单栏中选择 "File" -> "New" -> "New Project"。 2. 在弹出的对话框中,填写应用程序的名称、包名、保存位置等信息。可以选择使用空白Activity或其他模板作为起点。 3. 按照向导一步步进行设置,包括选择最低的Android SDK版本、配置项目的名称和位置等。 #### 4.2 编写和调试Android应用程序 一旦项目创建完成,我们就可以开始在Android Studio中编写和调试我们的应用程序了。在项目中的 "app" 目录下,可以找到 "java" 和 "res" 等子目录,用于存放Java代码和资源文件。 在 "java" 目录下找到应用程序的入口Activity文件,通常是一个以 "MainActivity" 命名的Java类。在这个类中,我们可以编写应用程序的逻辑代码,比如UI界面的控制、事件处理等。 同时,Android Studio提供了强大的调试工具,可以帮助开发者定位和解决应用程序中的问题。通过设置断点、观察变量、以及查看日志信息,开发者可以方便地进行调试和测试。 #### 4.3 在模拟器或真机上运行应用程序 在编写和调试完成后,我们可以在模拟器或真实的Android设备上运行我们的应用程序。在Android Studio的工具栏中,可以找到 "Run" 按钮,点击后可以选择目标设备进行应用程序的运行。 对于模拟器,Android Studio提供了内置的模拟器工具,支持选择不同的Android版本和设备型号进行模拟。而对于真机设备,我们可以通过USB连接设备并启用调试模式,然后就可以直接在真机上进行应用程序的测试和调试了。 通过以上步骤,我们可以在Android Studio中创建、编写和调试Android应用程序,并在模拟器或真机上进行运行测试。这为开发者提供了一个高效、便捷的开发环境,有助于快速开发出高质量的Android应用程序。 # 5. Android Studio中的常用工具和技巧 本章将介绍Android Studio中的一些常用工具和技巧,帮助开发者更高效地使用Android Studio进行应用程序开发。 #### 5.1 调试工具的使用 在Android Studio中,提供了丰富的调试工具,方便开发者进行应用程序的调试和排错。其中常用的调试工具包括: - 断点调试:通过在代码中设置断点,可以在断点处暂停应用程序的执行,以便查看变量的值、调用栈等信息,来进行调试和分析问题。 - 日志输出:Android Studio提供了Logcat窗口,开发者可以在代码中使用Log类输出调试信息,通过Logcat窗口查看应用程序的日志输出。 - 监视器:通过监视器窗口,可以实时查看应用程序的内存使用情况、CPU占用率等信息,帮助开发者进行性能优化和内存管理。 以下是一个使用断点调试的示例: ```java public class MainActivity extends AppCompatActivity { private static final String TAG = "MainActivity"; @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); int result = addNumbers(4, 5); Log.d(TAG, "The result is: " + result); } private int addNumbers(int a, int b) { int sum = a + b; return sum; } } ``` 通过在addNumbers方法的第一行设置断点,在调试模式下运行应用程序,可以在断点处暂停执行,查看sum变量的值。 #### 5.2 布局编辑器和资源管理器 Android Studio提供了强大的布局编辑器和资源管理器,方便开发者进行界面设计和资源管理。 布局编辑器可以帮助开发者直观地设计应用程序的界面,调整控件的位置、大小、颜色等属性,快速生成布局文件。 资源管理器可以管理应用程序的资源文件,包括图片、字符串、颜色等,方便开发者进行资源的添加、删除和修改。 以下是一个使用布局编辑器和资源管理器的示例: ```xml <LinearLayout xmlns:android="http://schemas.android.com/apk/res/android" android:layout_width="match_parent" android:layout_height="match_parent" android:orientation="vertical"> <ImageView android:id="@+id/imageView" android:layout_width="wrap_content" android:layout_height="wrap_content" android:src="@drawable/image" /> <TextView android:id="@+id/textView" android:layout_width="wrap_content" android:layout_height="wrap_content" android:text="@string/hello" /> </LinearLayout> ``` 在布局编辑器中,可以直接拖拽ImageView和TextView控件到适当位置,通过资源管理器可以添加名为"image"的图片资源和名为"hello"的字符串资源。 #### 5.3 版本控制和项目管理 Android Studio集成了流行的版本控制工具Git,方便开发者进行代码的管理和版本控制。 通过Android Studio的版本控制功能,可以进行代码的提交、更新、分支管理等操作,方便团队协作和代码的维护。 同时,Android Studio还提供了项目管理工具,可以方便地管理和组织应用程序的文件结构,包括添加新的文件、重命名文件、移动文件等操作。 总结: 本章介绍了Android Studio中的常用工具和技巧,包括调试工具的使用、布局编辑器和资源管理器的功能,以及版本控制和项目管理工具的使用。开发者可以掌握这些工具和技巧,提高开发效率和代码质量。 # 6. 进阶Android Studio开发技巧 在这一章中,我们将探索一些进阶的Android Studio开发技巧,以帮助你更好地开发Android应用程序。 ### 6.1 性能优化和内存管理 在大型Android应用程序中,性能和内存管理是非常重要的。在本节中,我们将介绍一些常用的性能优化和内存管理技巧。 #### 6.1.1 使用内存分析器 Android Studio提供了内存分析器工具,用于检测和解决内存泄漏和内存消耗过多的问题。你可以使用内存分析器来查看应用程序的内存使用情况,并找出可能导致性能问题的对象和引用。 下面是使用内存分析器的步骤: 1. 启动你的应用程序,并选择一个设备或模拟器。 2. 在Android Studio的工具栏中,点击"Profile"按钮。 3. 选择"Memory"选项卡,并点击"Start Recording"按钮开始记录内存使用情况。 4. 与你的应用程序进行一些操作,例如点击按钮或切换页面。 5. 点击"Stop Recording"按钮停止记录,并查看内存分析报告。 通过分析内存分析报告,你可以找出可能导致内存泄漏或内存消耗过多的问题,并采取相应的优化措施。 #### 6.1.2 使用性能监视器 Android Studio还提供了性能监视器工具,用于检测应用程序的性能瓶颈。你可以使用性能监视器来分析应用程序的CPU使用情况、内存分配情况、方法执行时间等关键指标。 使用性能监视器的步骤如下: 1. 启动你的应用程序,并选择一个设备或模拟器。 2. 在Android Studio的工具栏中,点击"Profile"按钮。 3. 选择"CPU"选项卡,并点击"Start Recording"按钮开始记录CPU使用情况。 4. 与你的应用程序进行一些操作,例如点击按钮或切换页面。 5. 点击"Stop Recording"按钮停止记录,并查看性能监视器报告。 通过分析性能监视器报告,你可以找出应用程序的性能瓶颈,并进行优化。 ### 6.2 代码重构和自动化测试 在开发过程中,代码重构和自动化测试是非常重要的环节。在本节中,我们将介绍一些Android Studio中的工具和技巧,以帮助你更好地进行代码重构和自动化测试。 #### 6.2.1 使用重构工具 Android Studio提供了强大的重构工具,可以帮助你快速、安全地进行代码重构。以下是一些常用的重构操作: - 重命名变量、方法、类等标识符 - 提取方法、内联方法 - 移动类、字段等 你可以使用快捷键或通过右键菜单访问这些重构操作。重构工具将自动更新你的代码,并确保重构的结果是正确的。 #### 6.2.2 编写自动化测试 自动化测试是保证代码质量的重要手段之一。在Android Studio中,你可以使用JUnit和AndroidJUnit等测试框架编写自动化测试。 以下是编写自动化测试的步骤: 1. 在测试目录中创建一个新的测试类。 2. 在测试类中编写测试方法,并使用断言来验证代码的行为是否符合预期。 3. 在Android Studio的工具栏中,点击"Run"按钮运行测试。 4. 查看测试结果,确保所有测试用例都通过了。 通过编写自动化测试,你可以及早发现和修复潜在的问题,保证应用程序的稳定性和可靠性。 ### 6.3 使用插件和扩展功能 Android Studio支持各种插件和扩展功能,可以扩展其默认的功能和工具。在本节中,我们将介绍一些常用的插件和扩展功能。 #### 6.3.1 使用插件 Android Studio的插件生态系统非常丰富,你可以根据自己的需求选择适合的插件来增强和定制开发环境。以下是一些常用的插件: - ButterKnife:简化Android布局和视图的绑定操作。 - GsonFormat:根据JSON数据自动生成Java实体类。 - FindBugs:静态代码分析工具,帮助检测可能的bug和错误。 你可以通过Android Studio的插件管理器来安装和管理插件。 #### 6.3.2 扩展功能 除了插件外,Android Studio还提供了一些扩展功能,可以通过配置文件来开启或关闭。以下是一些常用的扩展功能: - Lint检查:静态代码分析工具,帮助检测潜在的问题和错误。 - ProGuard代码混淆:帮助保护你的应用程序的源代码不被反编译。 - 数据绑定:使用简洁的语法将布局和数据绑定在一起。 你可以通过Android Studio的设置界面来配置这些扩展功能。 以上是关于Android Studio入门指南的第六章节的内容,希望对你有帮助。
相关推荐
陆鲁
资深技术专家
超过10年工作经验的资深技术专家,曾在多家知名大型互联网公司担任重要职位。任职期间,参与并主导了多个重要的移动应用项目。
专栏简介
《App Creator - Android移动应用开发基础与应用》是一本以Android为平台的移动应用开发基础指南。该专栏涵盖了Android移动应用开发的全方位知识,包括Java基础知识在Android开发中的应用、Android Studio入门指南、XML布局设计与Android界面开发、Android中的用户界面控件和交互、Android中的资源管理和多媒体应用、Android中的数据存储与文件操作、Android中的网络通信与数据交互、Android中的线程与异步任务、Android中的权限管理与安全开发、Android中的地理位置和地图应用、Android中的传感器与设备硬件交互、Android中的通知与消息推送、Android中的自定义控件与界面优化、Android中的混合开发与Webview应用、Android中的测试与调试技巧等主题。无论您是初学者还是有一定经验的开发者,该专栏都能为您提供宝贵的学习资源和实践指导,帮助您掌握Android移动应用开发的核心技术和最佳实践。
最低0.47元/天 解锁专栏
15个月+AI工具集
百万级 高质量VIP文章无限畅学
千万级 优质资源任意下载
C知道 免费提问 ( 生成式Al产品 )
最新推荐
【YOLO目标检测中的异常目标检测技术研究】: 研究YOLO目标检测中的异常目标检测技术
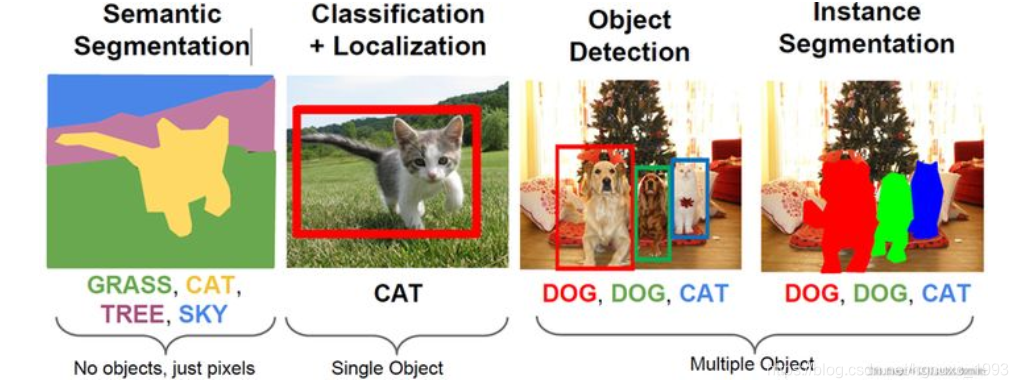 # 1. 介绍YOLO目标检测 目标检测是计算机视觉中的重要任务,而YOLO(You Only Look Once)算
【Transformer模型的未来发展趋势与展望】: 展望Transformer模型的未来发展趋势
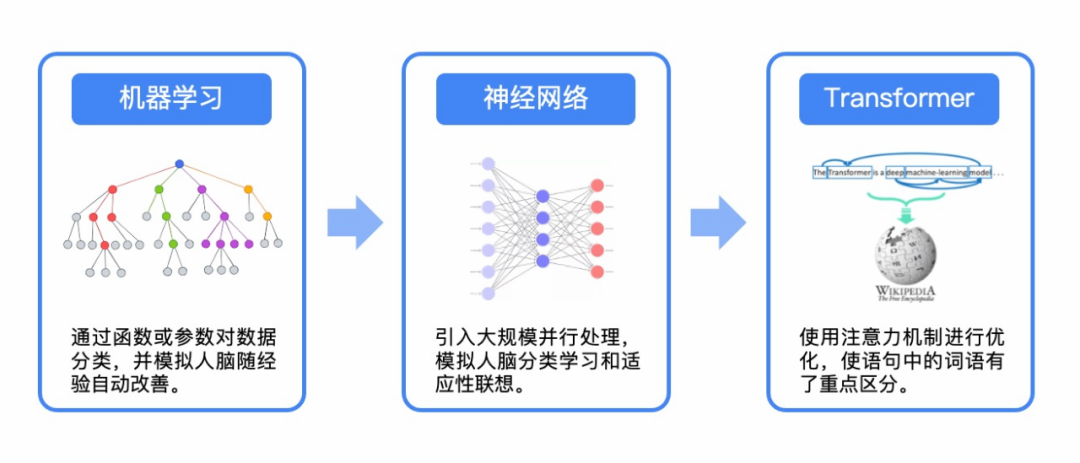 # 1. Transformer模型简介 Transformer 模型是一种基于注意力机制的深度学习模型,由 Vaswani 等人于 2017 年提出。相较于传统的循环神经网络和卷积神经网络,Transformer 在处理序列数据时表现出色。其核心理念是利用自注意力机制实现对不同位置的注意力集中,实现并行计算,因此被广泛应用于自然语言
【协助解决涉密信息扩散模型中的安全性问题】: 协助解决涉密信息扩散模型中的安全性问题
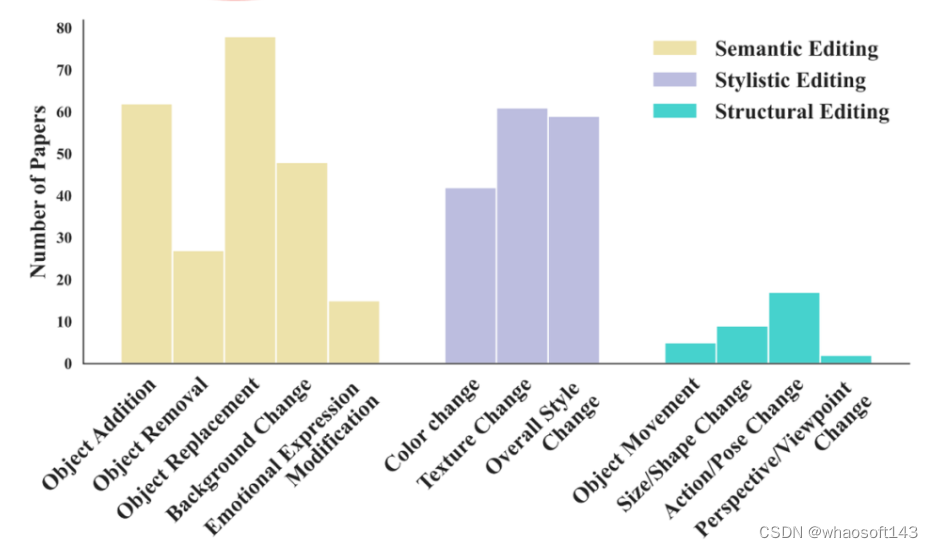 # 1. 了解涉密信息扩散模型 在当今信息时代,涉密信息扩散模型的安全性问题日益突出。了解这一模型的运作原理以及潜在的安全风险至关重要。通过深入研究涉密信息扩散模型,我们可以更好地认识到其中的安全挑战,并寻找解决这些问题的有效途径。本章将为您详细介绍涉密信息扩散模型的基本概念,帮助您全面了解该模型的运行机制及安全性问题的根源。 # 2. 安全性问题分析与剖
【探讨自注意力机制的跨领域应用前景】: 探讨自注意力机制在不同领域的跨领域应用前景
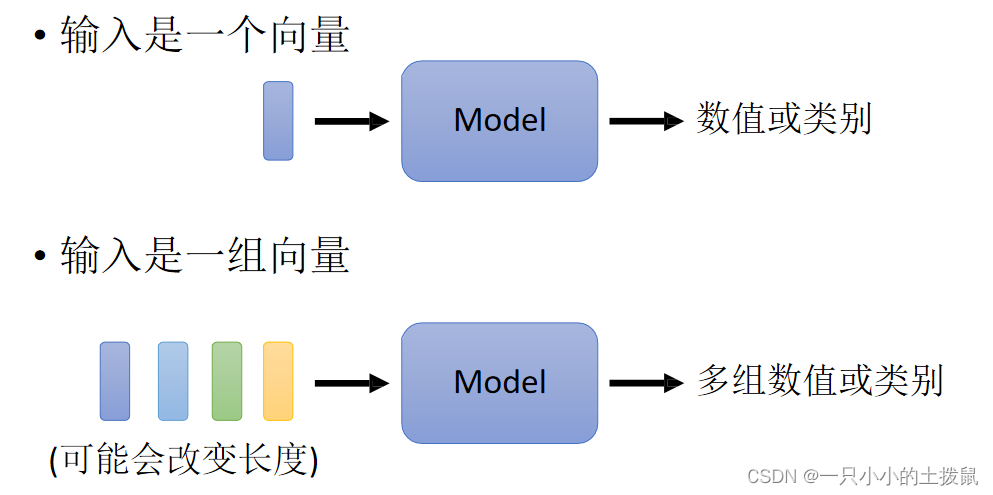 # 1. 自注意力机制简介 自注意力机制是一种可以在不同位置之间建立关联的机制,广泛运用于各种人工智能领域。在神经网络中,自注意力机制允许模型在进行预测时,将不同位置的信息进行关联,从而更好地捕捉长距离依赖关系。通过赋予每个输入信号不同的注意权重,自注意力机制可以有效地对输入进行加权汇聚,从而实现更高效的信息提取和表示学习。 自注意力机制的简单原理包括查询、键和值的计算,
【高级数据可视化技巧】: 动态图表与报告生成
# 1. 认识高级数据可视化技巧 在当今信息爆炸的时代,数据可视化已经成为了信息传达和决策分析的重要工具。学习高级数据可视化技巧,不仅可以让我们的数据更具表现力和吸引力,还可以提升我们在工作中的效率和成果。通过本章的学习,我们将深入了解数据可视化的概念、工作流程以及实际应用场景,从而为我们的数据分析工作提供更多可能性。 在高级数据可视化技巧的学习过程中,首先要明确数据可视化的目标以及选择合适的技巧来实现这些目标。无论是制作动态图表、定制报告生成工具还是实现实时监控,都需要根据需求和场景灵活运用各种技巧和工具。只有深入了解数据可视化的目标和调用技巧,才能在实践中更好地应用这些技术,为数据带来
【掌握利用diffusion模型进行市场趋势预测】: 掌握利用diffusion模型进行市场趋势预测
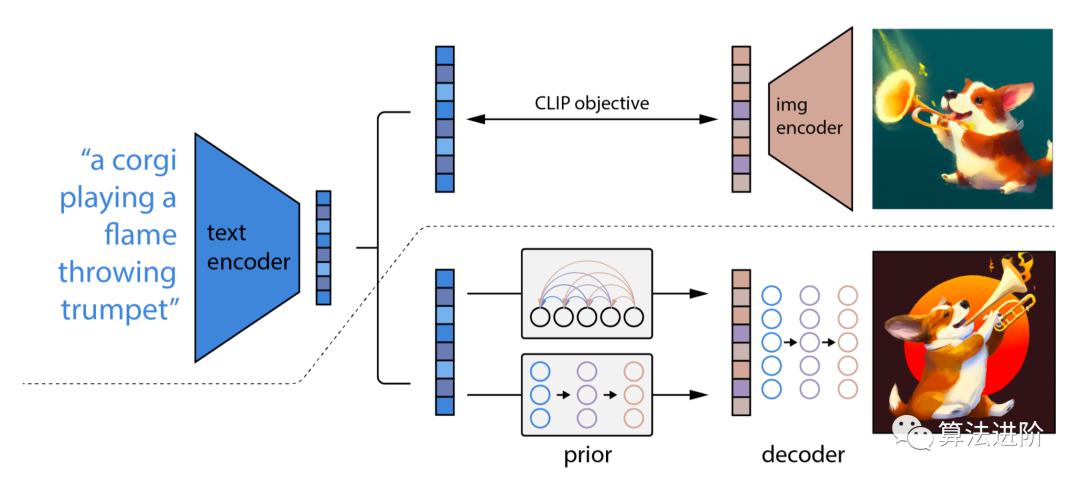 # 1. 介绍Diffusion模型 Diffusion模型是一种用于市场趋势预测的重要工具,通过模拟信息在人群中的传播过程来预测未来的市场走势。这种模型基于信息传播的原理,可以帮助分析市场中的趋势和风险,为决策提供科学依据。在现代的金融、制造和医疗领域,Diffusion模型都发挥着重要作用,成为数据分析和预测的利器。深入了解Di
【BP与递归神经网络对决】: 区别与应用场景全面解析
 # 1. 认识BP神经网络与递归神经网络 在深入研究神经网络之前,了解BP神经网络和递归神经网络的基本概念非常重要。BP神经网络是一种前馈神经网络,通过反向传播算法进行训练。递归神经网络则是一种具有记忆特性的网络结构,能够处理序列数据的特点。它们在机器学习和人工智能领域有着广泛的应用和重要性。通过学习它们的原理与应用场景,我们可以更好地理解神经网络的本质和作用。 神经网络作为模拟人脑神经元连接的数学模
【未来人脸识别技术发展趋势及前景展望】: 展望未来人脸识别技术的发展趋势和前景
# 1. 人脸识别技术的历史背景 人脸识别技术作为一种生物特征识别技术,在过去几十年取得了长足的进步。早期的人脸识别技术主要基于几何学模型和传统的图像处理技术,其识别准确率有限,易受到光照、姿态等因素的影响。随着计算机视觉和深度学习技术的发展,人脸识别技术迎来了快速的发展时期。从简单的人脸检测到复杂的人脸特征提取和匹配,人脸识别技术在安防、金融、医疗等领域得到了广泛应用。未来,随着人工智能和生物识别技术的结合,人脸识别技术将呈现更广阔的发展前景。 # 2. 人脸识别技术基本原理 人脸识别技术作为一种生物特征识别技术,基于人脸的独特特征进行身份验证和识别。在本章中,我们将深入探讨人脸识别技
【整合多种注意力机制模块的复合模型设计与实现方法详解】: 详细介绍整合多种注意力机制模块的复合模型的设计与实现方法
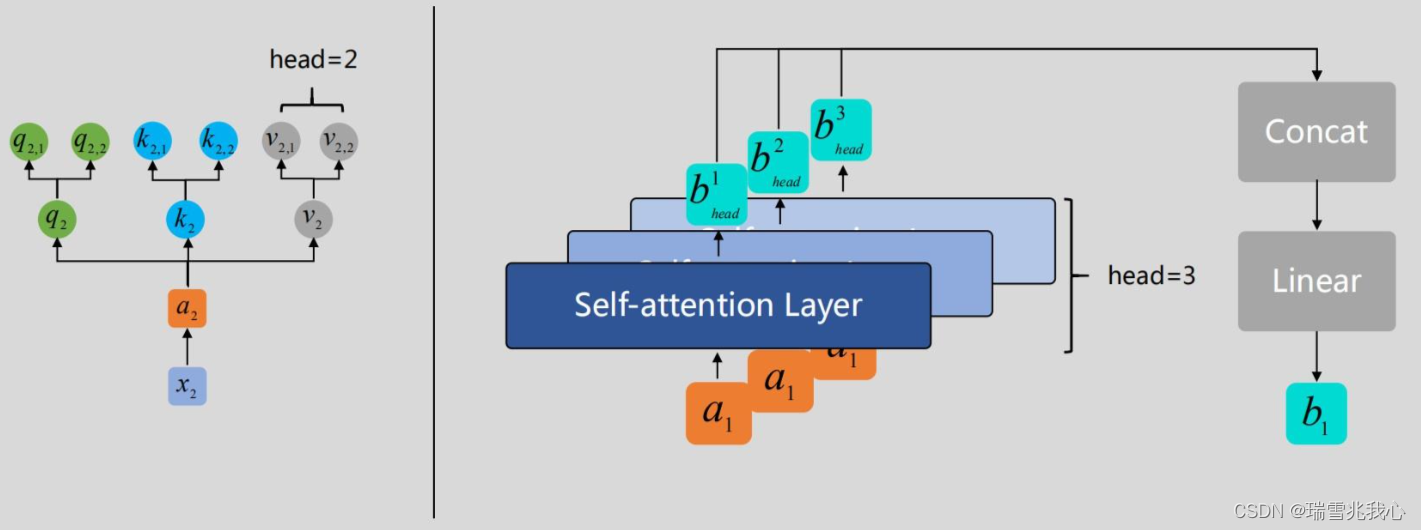 # 1. 注意力机制模块概述 在深度学习领域,注意力机制作为一种关键的技术,被广泛运用于各种模型中,以提升模型性能和精度。注意力机制的设计灵感来源于人类的视觉注意力,其核心思想是模拟人类在处理信息时所具有的关注重点和优先级,使得模型能够专注于重要的部分。通过对输入的不同部分赋予不同的注意权重,模型可以有针对性地处理信息,实现更加
【未来发展趋势下的车牌识别技术展望和发展方向】: 展望未来发展趋势下的车牌识别技术和发展方向
 # 1. 车牌识别技术简介 车牌识别技术是一种通过计算机视觉和深度学习技术,实现对车牌字符信息的自动识别的技术。随着人工智能技术的飞速发展,车牌识别技术在智能交通、安防监控、物流管理等领域得到了广泛应用。通过车牌识别技术,可以实现车辆识别、违章监测、智能停车管理等功能,极大地提升了城市管理和交通运输效率。本章将从基本原理、相关算法和技术应用等方面介绍
|
__label__pos
| 0.558412 |
Part 3: Migrating Gatsby Pages to TypeScript
By Ilyas Assainov / In Gatsby, TypeScript / December 28, 2019
P
In the previous part, we successfully converted Gatsby API modules to TypeScript.
In the post, we will finally dive into migrating pages. This example is universal for any Gatsby page, template or a child component, so for the theory we will only focus on the home page.
As always, you can find the final repository in this starter: gatsby-extensive-starter-typescript.
First, let’s start off by renaming the home page file from index.js to index.tsx. TSX extension is necessary if you’re using TSX syntax, otherwise TypeScript will take XML brackets as a type cast and throw an error.
index.tsx
...importing modules
import { IPageProps } from '../types/page-props';
class BlogIndex extends React.Component<IPageQuery & IPageProps> {
render(): JSX.Element {
const { data } = this.props;
const siteTitle = data.site.siteMetadata.title;
const posts = data.allMarkdownRemark.edges;
return (
<Layout location={this.props.location} title={siteTitle}>
<SEO title="All posts" />
<Bio />
{posts.map(({ node }) => {
const title = node.frontmatter.title || node.fields.slug;
return (
<article key={node.fields.slug}>
<header>
<h3
style={{
marginBottom: rhythm(1 / 4),
}}
>
<Link style={{ boxShadow: `none` }} to={node.fields.slug}>
{title}
</Link>
</h3>
<small>{node.frontmatter.date}</small>
</header>
<section>
<p
dangerouslySetInnerHTML={{
__html: node.frontmatter.description || node.excerpt,
}}
/>
</section>
</article>
);
})}
</Layout>
);
}
}
export default BlogIndex;
interface IPageQuery {
data: {
site: {
siteMetadata: {
title: string;
};
};
allMarkdownRemark: {
edges: IEdge[];
};
};
}
interface IEdge {
node: {
excerpt: string;
fields: {
slug: string;
};
frontmatter: {
date: string;
title: string;
description: string;
};
};
}
export const pageQuery = graphql`
query {
site {
siteMetadata {
title
}
}
allMarkdownRemark(sort: { fields: [frontmatter___date], order: DESC }) {
edges {
node {
excerpt
fields {
slug
}
frontmatter {
date(formatString: "MMMM DD, YYYY")
title
description
}
}
}
}
}
`;
As you can see at first, the page is a regular React class component, so there is nothing new here. Gatsby passes location prop to all generated pages. IPageProps is an interface with that location prop, which is passed to all pages by @reach/router.
page-props.ts
import { WindowLocation } from '@reach/router';
export interface IPageProps {
location: WindowLocation;
}
IQueryProps is an interface for the graphql query.
Maybe you already noticed: our interface has the exact same structure as the graphql query. Woudn’t it be nice if we could take advantage of that? We will come back later to this point.
For now let’s fix one important issue.
Validating GraphQL query result with TypeScript
I left a mistake on purpose in the code snippet above: graphql result interface does not have any optional (nullable) types, but what happens if the data from the query is not available? Because the data might be coming from CMS, you shouldn’t rely on it - you need to always validate it. This is where the whole power of TypeScript comes in!
What happens if the data from the query is not available? Because the data might be coming from CMS, you shouldn’t rely on it - you need to always validate it.
First, you need to make sure you setup TypeScript compiler to enable strict or strictNullChecks modes (strict mode already includes strictNullChecks). Once you enable it, specify all props in the query as optional:
index.tsx
interface IPageQuery {
data: {
site?: {
siteMetadata?: {
title?: string;
};
};
allMarkdownRemark?: {
edges?: IEdge[];
};
};
}
interface IEdge {
node?: {
excerpt?: string;
fields?: {
slug?: string;
};
frontmatter?: {
date?: string;
title?: string;
description?: string;
};
};
}
Now the compiler will always complain until you provide a default value to the prop. The reason is the compiler wants to ensure we don’t get a runtime error in case any of the properties is null:
terminal
TypeError: Cannot read property 'title' of undefined
So, let’s provide a default value in case our prop is empty:
index.tsx
...
// other imports
import { DeepPropertyAccess } from '../utils/deep-property-access';
...
// inside render() method
const siteTitle = DeepPropertyAccess.get(data, 'site', 'siteMetadata', 'title') || 'My site';
...
You can now safely use siteTitle in your React component without having to worry about runtime errors. The DeepPropertyAccess.get() method provides type inference and intellisense support for the object data. To learn more about different ways to accomplish the same, check out this 5-min read: Accessing Deep Properties in TypeScript.
Reducing typescript boilerplate code
Now that our code is compiling, we can look into the problem with reduntant interfaces for graphql query result. Remember? When we define an interface for a graphql query result, we write something like this…
index.tsx
interface IPageQuery {
data: {
site?: {
siteMetadata?: {
title?: string;
};
};
};
}
… For our query that looks like:
index.tsx
query HomePageQuery {
site {
siteMetadata {
title
}
}
}
Can you see it? It’s the exact same structure.
Luckily, as always, there is a handy plugin to generate interfaces on the fly: gatsby-plugin-codegen. Let’s install it and see how it works:
terminal
npm i -D gatsby-plugin-codegen
Include it in gatsby-config.ts:
gatsby-config.ts
plugins: [
// other plugins
{
resolve: 'gatsby-plugin-codegen',
options: {},
},
],
Start the development server:
gatsby-config.ts
npm start
And observe the magic:
generated-graphql-types
The plugin has automatically generated interfaces for all graphql queries, and put them in the same directory as a component in the generated folder:
HomePageQuery.d.ts
export interface HomePageQuery_site_siteMetadata {
__typename: "SiteSiteMetadata";
title: string | null;
}
export interface HomePageQuery_site {
__typename: "Site";
siteMetadata: HomePageQuery_site_siteMetadata | null;
}
// other interfaces
And that’s all to it. Simple, yet powerful!
Note: If __generated__ folder was not generated, try to save any of the files having GraphQL queries.
Note: If you have an error as below, make sure you name all of your queries.
terminal
Change detected, generating types...
error file /Users/ilyas/Desktop/TypeScript/extensive.one/src/pages/index.tsx
ERROR
Error while generating types: Apollo does not support anonymous operations
The plugin will also generate schema.json and apollo.config.js configuration files in the root of the project. You can learn more and tweak many plugin options available on the plugin’s page.
Now that we automatically generate graphql response interfaces, all we need to do is import the interface into the page:
index.tsx
import { HomePageQuery } from './__generated__/HomePageQuery';
interface IPageQuery {
data: HomePageQuery;
}
class BlogIndex extends React.Component<IPageQuery & IPageProps> {
// body
In this tutorial, we mainly learned two things:
1. All graphql props should be validated with the help of deep property access helper.
2. Graphql response interface generation can be automated with the help of the plugin.
Although the process was simple, we as developers can now be more productive and sleep better.
I hope you liked the article. In the next part, we will dive deeper into building robust Gatsby apps by introducing unit and end-to-end tests. As always, the focus will be on the developer productivity and quality.
Stay in touch!
Get notified about new articles without spam!
Ilyas Assainov
Ilyas Assainov
Ilyas is a full stack developer specializing in extensible JavaScript solutions. In this blog, he shares his daily challenges and solutions.
extensive.one © 2020 - by Ilyas Assainov
|
__label__pos
| 0.926069 |
Proposed features/transit
From OpenStreetMap Wiki
< Proposed features(Redirected from Key:transit)
Jump to navigation Jump to search
How a lane continues in the next road segment
Status: Abandoned (inactive)
Proposed by: imagic
Tagging: transit=continue/fork/join_with_left/join_with_right/new_on_left/new_on_right/end/leave
Applies to: wayrelation
Definition: Specify how a lane continues in the next road segment, i.e. if and where it forks/joins
Rendered as: Some renderers (e.g. included in navigation devices) may show the lanes at very high zoom level
Drafted on: 2015-01-13
This proposal introduces the key and relation transit which allows to specify how a lane continues in the next road segment, i.e. if and where it forks/joins. It is intended to be used together with the suffixes :lanes, :forward or :backward.
Original idea from hurdygurdyman and others.
Due to fundamental design issues using this tag on ways was described as a horrible tagging scheme by iD, Vespucci and JOSM developers, see https://lists.openstreetmap.org/pipermail/tagging/2018-June/037082.html and https://lists.openstreetmap.org/pipermail/tagging/2018-June/037105.html and https://josm.openstreetmap.de/ticket/11054 and they refused to support it.
Short overview - TL;DR
This proposal introduces one new key transit=* with eight possible values which can be used either as a tag directly on an OSM way or within a relation with type=transit. The key can be used to specify how the lanes of two immediately adjacent OSM ways connect to each other.
While the key may only be used in simple situations (like one-ways or if the road they refer to, carries the same name or reference), the relation can be used in every situation.
Rationale
This tagging scheme is intended to provide the information how the lanes of different road segments connect to each other. A key as well as a relation is proposed, both with the same syntax:
As the connection between different road segments always refers to two OSM ways (the "from-way" and the "to-way"), the key transit=* is ambiguous as soon as more than two ways connect at one node. The reason for introducing the key transit=* nonetheless is the higher expected acceptance within the community. In many situations the data consumer is able to determine the correct to-way based on some simple rules (as explained below). If we allow the mapper to specify the lane connection in such a situation as a tag instead of a relation, it would not be necessary to switch back and forth from simple tags (e.g. turn:lanes=*) to a relation, when all the mapper does all the time is mapping lanes.
The proposed key compared to the proposed relation moves a little burden from the mappers to the consumers. It needs more processing of the data and it can not be used in all situations. But in many situation this key should be sufficient and it allows a more continuous, uninterrupted mapping process and therefore we can expect higher acceptance in the community.
Tagging
The key transit=* supports the following values:
Value Lane change
continue The lane doesn't fork/join/etc., but simply continues.
fork The lane forks to two lanes, whereby both following lanes are accessible without lane change.
new_on_left
Left of that lane a new lane appears; to access the new lane, one has to change to that lane.
This value does not provide information about the current lane and should be combined with another appropriate value. If it is not combined with any value besides new_on_right, it should be assumed that it is combined with continue, i.e. for example continue|continue;new_on_left and continue|new_on_left are equivalent.
new_on_right
Right of that lane a new lane appears; to access the new lane, one has to change to that lane.
This value does not provide information about the current lane and should be combined with another appropriate value. If it is not combined with any value besides new_on_left, it should be assumed that it is combined with continue, i.e. for example continue|continue;new_on_right and continue|new_on_right are equivalent.
join_with_left This lane joins with the lane to the left of the current road segment, whereby the joined lane is reachable without lane change from both lanes. This value must not be used on the leftmost lane.
join_with_right This lane joins with the lane to the right of the current road segment, whereby the joined lane is reachable without lane change from both lanes. This value must not be used on the rightmost lane.
end The lane ends.
leave This lane separates from this road, i.e. it leaves.
The values fork, new_on_left and new_on_right may be extended by :number in order to provide the number of lanes the way forks to resp. the number of new lanes. For examples transit=fork:3 means that the single lane of an oneway forks into three lanes.
Combination of values
Only the values new_on_left and new_on_right (and their variants with an arbitrary number of lanes) may be combined with other values using the usual semi-colon syntax, e.g. transit=new_on_left;continue;new_on_right means that the single lane of an oneway is connected to the middle lane of three lanes in the the to-way. Other combinations are invalid as well as combinations of new_on_left resp. new_on_right with their variants with an arbitrary number of lanes.
Suffixes
The key transit=* may be combined with the usual suffixes, mostly :lanes, :forward and :backward. See the section "See also" for further reference.
Determining the correct values
Lane Link - Consider only two roads.png
When determining the correct values, only consider those two road segments the tag/relation refers to and completely ignore others, but you have to consider all lanes of both road segments. In the example on the right we only consider the left from-way and ignore the right way. Therefore we get the tag transit:lanes=continue|new_on_right, which can be read as: the first lane continues and at the right side of the second lane another one emerges, i.e. in the following road segment we have three lanes.
If we would consider both from-ways in the example to the right, we might be tempted to specify transit:lanes=continue|join_with_right, which is incorrect as the lanes that join are from different road segments. If we only considers the left from-way, we do not see any lanes joining and therefore will determine the correct values.
Used as tag on ways
The key transit=* is added to the from-way (as defined above), usually with appropriate suffixes. The value of the key specifies how a lane forks or joins directly at the transition to the to-way.
The tag must not be used if the from-way contains lanes used by traffic going in both directions. In such case the relation has to be used.
Note: If the key is used together with the suffix :backward (i.e. either as transit:backward=* or transit:lanes:backward=*) on an OSM way it describes the transition in reverse direction, i.e. in the opposite direction of the OSM way. In such case the to-way for transit:backward=* is different from the to-way for transit:forward=*.
Rules for determining the relevant OSM ways
As soon as more than two OSM ways connect, the key transit=* is ambiguous. If the mapper decides against the use of the relation in such situation, the consumer needs to determine the to-way, which the tags refer to. This should be done according to the following rules in the given order:
1. Identical value of the key ref=*
2. Identical value of the key name=*
3. Identical value of the key highway=*
If after the application of those rules, the to-way can still not be determined unambiguous, it shall be assumed that the to-way is the one with the smallest angle to the from-way.
The use of the key transit=* should be limited to simple situations. Generally, in more complex situations with multiple OSM ways meeting at one node, the use of the relation should be preferred.
Used as relation
In situations where it is not possible for data consumers to determine the correct to-way of the tag, the relation can be used. The relation requires exactly two members: the from-way with role "from" and the to-way with role "to", whereas one end of both ways must be connected to each other. Note: Further members are strictly forbidden, especially so called via-nodes or -ways as known from other relations.
The following tags have to be specified for the relation:
Tag M/O¹ Description
type=transit M Identifies as transit-relation.
transit=* M This key uses the same values as describe above. It may be used with the usual suffixes :lanes, :forward or :backward. It is possible to add this key twice, once with suffix :forward and once with suffix :backward. For sake of readability it is strongly recommended to use the suffix :forward if :backward is also used.
through_route=yes/no O This tag can be used to specify if this direction is the "main route" or if you would have to "turn" to follow that direction. This problem of determining the correct "main route" is a well-known problem of routing (so called bifurcation).
¹ M=Mandatory, O=Optional
Note: If the key is used together with the suffix :backward (i.e. either as transit:backward=* or transit:lanes:backward=*) within the relation it describes the transition in reverse direction, i.e. from the to-way back to the from-way. This is different to the use of the key directly on OSM ways! Therefore the use of the suffix :backward is not recommend within the relation.
When to use and when not
The transit key/relation is not intended to be used for all connections of road segments. It should only be used on connections which are not obvious and where it is not possible for data consumers to determine the lane connections otherwise. It is recommend that every data consumers supports at least the following and therefore mappers may not provide transit-information in the following cases:
• the number of lanes is unchanged
• the number of lanes changes, but on both related OSM ways the key placement=* is either specified (except with the value transition) or is unnecessary, because the OSM way is drawn in the middle of the carriageway
• in case of a left-turn, all lanes leading left are marked with one, unique value *_left of the key turn=* and only one possibility to turn left exists
• in case of a right-turn, all lanes leading right are marked with one, unique value *_right of the key turn=* and only one possibility to turn right exists
Examples
If not stated otherwise, the following is assumed in the examples:
• Right-hand traffic
• the direction of the OSM way (green line) is upwards
Using the key
# Description Image Tags on from/to way
1 A one-way road with two lanes, where a third lane starts at the right side. Lane Link Example 1.png To way
lanes=3
turn:lanes=none|through|right
placement=right_of:1
From way
lanes=2
turn:lanes=none|through;right
transit:lanes=continue|new_on_right
Note: the second value (i.e. new_on_right) in this example is the short form of continue;new_on_right.
2 A one-way road with two lanes, where the rightmost lane forks into two lanes. Lane Link FAQ 1.png To way
lanes=3
turn:lanes=none|through|right
placement=right_of:1
From way
lanes=2
turn:lanes=none|through;right
transit:lanes=continue|fork
3 A one-way road with two lanes, where a third lane starts at the left side. Lane Link Example 2.png To way
lanes=3
turn:lanes=left|through|none
placement=right_of:2
From way
lanes=2
turn:lanes=left;through|none
transit:lanes=new_on_left|continue
4 A road with one to three lanes in each direction. In forward direction the road starts with one lane and a deceleration lane is then added on the right side. In backward direction the road starts with two lanes and a third lane is added on the left side for overtaking because of the steep slope of the road. Lane Link Example 3.png To way
lanes:forward=2
lanes:backward=2
turn:lanes:forward=none|slight_right
transit:lanes:backward=new_on_left|continue
From way
lanes:forward=1
lanes:backward=3
placement:forward=left_of:1
hgv:lanes:backward=no|yes|yes
transit:forward=new_on_right
5 A one-way road that leads to a Y-shaped junction. Although the road to the right after the junction has the same reference as the road before the junction, the "main direction" of the road (i.e. what a human would call "follow the road") is left. Lane Link Example 4.png This can not be specified with this tag. You need to use the relation, because it is not possible to determine the correct "following" road segment and without relation you are losing the information about the main direction of the road.
6 Two one-way roads join, whereas the lanes of these roads simply continue and do not join. Lane Link Example 5.png To way
lanes=4
From way
Tags of the road to the left:
lanes=2
placement:end=right_of:2
No transit tag necessary
Tags of the road to the right:
lanes=2
placement:end=left_of:1
No transit tag necessary
7 The two middle lanes of an one-way road with four lanes join. Lane Link Example 10.png To way
lanes=3
placement=transition
From way
lanes=4
transit:lanes=continue|join_with_right|join_with_left|continue
8 Two one-way roads join, whereas the inner lane of them joins. Lane Link Example 6.png To way
lanes=3
width:lanes:start=2|4|2
width:lanes:end=2|2|2
From way
Tags of the road to the left:
lanes=2
placement:end=right_of:2
transit:lanes=continue|new_on_right
Tags of the road to the right:
lanes=2
placement:end=left_of:1
transit:lanes=new_on_left|continue
Note: Do not use join_with_* in this case, because the lanes that join are on different road segments.
9a An acceleration lane on a motorway. The lane ends and it is necessary to change to a different lane. Lane Link Example 7.png To way
lanes=2
From way
lanes=3
placement=right_of:1
turn:lanes=none|none|merge_to_left
transit:lanes=continue|continue|end
9b The same as before, but now it is not necessary to change the lane. Lane Link Example 7b.png To way
lanes=2
From way
lanes=3
placement=right_of:1
turn:lanes=none|none|merge_to_left
transit:lanes=continue|join_with_right|join_with_left
10 A one-way road with three lanes, whereas the leftmost lane leaves this road. Lane Link Example 8.png To way
Tags of the road to the left:
lanes=1
placement=transition
Tags of the road to the right:
lanes=2
From way
lanes=3
placement=right_of:2
turn:lanes=left|through|none
transit:lanes=leave|continue|continue
11 All OSM ways lead to the centre of the junction, whereas lanes in forward direction are in dark grey and lanes in backward direction in light grey. This examples is very complex and can only be solved with the relation (see below), as it is impossible for the data consumer to determine the correct OSM way the tags refer to. Lane Link Example 9.png Way A
oneway=yes
ref=A1
turn:lanes=left|through|right
placement=right_of:1
Way B
lanes=2
ref=B2
name=Upway Road
Way C
lanes=2
ref=L1234
Way D
lanes=4
ref=B2
name=Somewhere Street
lanes:forward=2
lanes:backward=2
turn:lanes:forward=none|right
Note: Be cautious when tagging two-way roads. The values ending with _left and _right are viewed in the direction of the OSM-way unless they are used in conjunction with the :backward suffix. Therefore it is strongly recommend to always use the :forward/:backward suffix on two-way roads.
Using the relation
# Description Image Tags on from/to way Relation(s)
A A one-way road that leads to a Y-shaped junction. Although the road to the right after the junction has the same reference as the road before the junction, the "main direction" of the road (i.e. what a human would call "follow the road") is left. Lane Link Example 4.png To way Left Right
Tags of the road to the left:
lanes=2
ref=A1
Tags of the road to the right:
lanes=2
ref=B2
type=transit
transit:lanes=continue|continue
through_route=yes
type=transit
transit:lanes=leave|fork
From way
lanes=2
ref=B2
turn:lanes=none|right
B1 All OSM ways lead to the centre of the junction, whereas lanes in forward direction are in dark grey and lanes in backward direction in light grey. Lane Link Example 9.png Way A A -> C B -> D
oneway=yes
ref=A1
turn:lanes=left|through|right
placement=right_of:1
type=transit
transit:lanes=leave|continue|leave
type=transit
transit=new_on_right
Way B
lanes=2
ref=B2
name=Upway Road
Way C C -> D D -> B
lanes=2
ref=L1234
type=transit
transit=new_on_right
type=transit
transit:lanes=continue|leave
Alternative to relation B -> D:
type=transit
transit:lanes:forward=continue|leave
transit:backward=new_on_right
Way D
lanes=4
ref=B2
name=Somewhere Street
lanes:forward=2
lanes:backward=2
turn:lanes:forward=none|right
B2 Same as above but now for left-hand traffic. Lane Link Example 9 left.png Way A A -> C B -> D
oneway=yes
ref=A1
turn:lanes=left|through|right
placement=right_of:2
type=transit
transit:lanes=leave|continue|leave
type=transit
transit=new_on_left
Way B
lanes=2
ref=B2
name=Upway Road
Way C C -> D D -> B
lanes=2
ref=L1234
type=transit
transit=new_on_right
type=transit
transit:lanes=continue|leave
Alternative to relation B -> D:
type=transit
transit:lanes:forward=continue|leave
transit:backward=new_on_left
Way D
lanes=4
ref=B2
name=Somewhere Street
lanes:forward=2
lanes:backward=2
turn:lanes:forward=none|right
Common questions
Why not only use a relation for this?
Please read the section Rationale again, especially the paragraph starting with "The proposed key compared to the proposed relation moves a little burden".
What variants of the transit key are possible
The transit key uses common and established suffixes like :forward and :backward and of course :lanes. Possible variants include:
• transit
• transit:forward
• transit:backward
• transit:lanes
• transit:lanes:forward
• transit:lanes:backward
What about left-hand traffic?
Everything works the same.
Are bicycle lanes covered?
Yes. As explained in the proposal of the lanes suffix, contrary to the key lanes=*, the lane-dependent values of tags ending on :lanes cover all lanes, independent of the kind of traffic they are designated to.
How are lanes connected, that allow driving in both directions
Both Ways Example 1.jpeg
They are considered in both directions, as if they were lanes in that direction. In the example to the right the red marked way contains three lanes: one backward, one in the middle for both directions and one forward.
When one wants to specify the lane connections from the way below the red way up to the red way, one may use transit:lanes:forward=continue|continue although the red way has only one forward lane, but the lane in the middle is treated as if it was a forward lane.
Important note: If the from-way contains lanes for both driving directions, the tag must not be used. One has to use the relation if the from-way contains lanes for both driving directions.
How do I specify that some lane connection is only permitted for buses/taxi/bicycles?
With some access tags or the turning restriction relation, but not with this tagging scheme. This scheme specifies how the lanes are linked on the ground. It does not provide any access or turning restrictions as there are already established concepts for these.
In some rare situations we would need lane-based turning restrictions. But to provide such information the turning restriction relation should be extended by the well-known :lanes concept, so that all turning restrictions are kept in one place. For example if one has to turn right if driving on the third lane, one could specify this with the tag restriction:lanes=||only_right_turn within a restriction relation.
How does key/relation transit compare to the key turn?
These are two completely different concepts.
• The key turn=* specifies for one road segment the indicated direction in which a way or a lane will lead
• The key and relation transit=* specifies how the lanes of two adjacent road segments connect to each other.
Wouldn't be merge_with_XXX be better instead of join_with_XXX?
The values merge_to_XXX are in use with the key turn=*, where they refer to the traffic that has to merge with the traffic of a different lane. Using very similar values with the key transit=* might lead to some irritations and mistakes as the meaning would be quite different.
Current usage
transit:lanes=*
transit:lanes:forward=*
transit:lanes:backward=*
transit=*
transit:forward=*
transit:backward=*
Comments
Please use the Discussion page for this.
Related keys
See also
Guideline for data consumers
This section provides a guideline how to determine lane connections between two road segments dependent on the available information, and how to render individual lanes.
This section is work in progress!
Determining lane connections
In this section the following special terms will be used:
• Connecting Node means each node, that is part of more than one relevant OSM way.
• All OSM ways that are connected to a Connecting Node, shall be called Connected Ways.
• Entering Way in relation to a specific Connecting Node means a Connected Way, that allows driving up to that Connecting Node. Exit Way in relation to a specific Connecting Node means a Connected Way, that allows driving away from that Connecting Node. Note: a single Connected Way might be an Entering Way and Exit Way at the same time.
• Connection means a specific pair of Entering Way and Exit Way and From Way means the Entering Way and To Way means the Exit Way of such Connection. For a Reverse Connection of a Connection the To Way and From Way are exchanged. Note: a Reverse Connection may not exist, e.g. if the From Way of a Connection is a Entering Way but not also an Exit Way, no Reverse Connection for the respective Connection exits.
• In relation to the connection of a specific pair of Entering Way and Exit Way, Left Turn, Right Turn resp. Straight On means that that specific connection (in the specific direction from Entering Way to Exit Way!) should be considered a left turn, right turn resp. straight on, as specified below.
• The rules given in this section provide the lane connections for all Connected Ways for one single Connecting Node.
Furthermore the following is assumed:
• Only consider relevant OSM ways, e.g. those road classes given in the table below.
• Treat all OSM ways as being split at the Connecting Node, i.e. if the connecting node is not an end-node of an OSM way, treat such OSM way as two separate OSM ways ending in the connecting node. Immediately connect all the lanes of its two parts one-on-one and make sure not to try to determine the lane connections in the further processing!
• For the determination of angles between OSM ways, only consider the Connecting Node and the first adjacent node of each OSM way.
• Pay attention to to possible endless loops and treat them as data errors, especially when processing join_with_left or join_with_right.
• Pay close attention to the meaning of the :forward and :backward suffix when used together with the tag or relation:
• The suffix :backward will result in the same from-way but in a different to-way, when used in the transit tag.
• The suffix :backward will result in the from- and to-way replaced by each other, when used in the relation.
• If not stated otherwise, in every situation only one driving direction is considered. Pay attention to lanes for both driving directions!
• If after processing all possible Connections some lane connection have not been determined, treat this as data error.
Preparation:
• For all Connected Ways, determine the number of lanes separately for both driving directions as follows:
• Number of lane-dependent values of all relevant key with suffix :lanes. Such number has to be identical for all keys relating to one driving direction. If the number is not identical, it shall be considered a data error. As fall-back strategy 1) use that number, that occurs most frequently resp. 2) use the lowest of those numbers if 1) is not unique.
• The value of the key lanes=* resp. its relevant subkey.
• Assume the number of lanes depending on the type of road as specified in the table below.
• Pay close attention to lanes for both driving directions! Example: lanes:forward=1 + lanes:backward=1 + lanes:both_ways=1 results in two lanes in each direction.
• Verify all lane-dependent values of transit tags or relation: if a value only contains new_on_left and/or new_on_right, treat it as if continue is also present.
• Determine to which Exit Way the tag transit of a given Entering Way refers.
• If the OSM way is directed to the Connecting Node, do not consider transit tags with the suffix :backward.
• If the OSM way is directed away from the Connecting Node, only consider transit tags with the suffix :backward.
• Select all Exit Ways and then remove those that do not fit the following rules in the given order. After each rule verify if exactly one Exit Way is left over. If so, the tag transit refers to that Exit Way.
• The value of ref=* of the Exit Way is identical to the value of ref=* of the Entering Way.
• The value of name=* of the Exit Way is identical to the value of name=* of the Entering Way.
• The value of highway=* of the Exit Way is identical to the value of highway=* of the Entering Way.
• If no result was achieved after those rules, the tag transit shall refer to that Exit Way, for which the angle to the Entering Way is smallest. If this is still ambiguous use that way of the remaining Entering Ways, that carries the smallest OSM ID.
• Determine for all possible Connections of all Entering Ways that have turn indications specified via turn=*, if if they should be considered a Turn Left, Turn Right or Straight On. To do so, process all possible Connections of one Entering Way and then proceed to the next Entering Way. Verify for all possible Connections of one Entering Way the first of the following rules, then verify for all Connections that have not yet been identified the second rule, and so on. Rules are:
• If the respective To Way is the only Exit Way, the Connection is a Straight On.
• If the respective To Way is a highway=motorway, the Connection is a Straight On.
• If a turning restriction is specified for this Connection and if restriction is:
• *_left_turn, consider the Connection a Left Turn and a potential Reverse Connection a Right Turn
• *_right_turn, consider the Connection a Right Turn and a potential Reverse Connection a Left turn
• *_u_turn, (TODO: fix this) if right-hand traffic, consider the Connection a Left Turn and a potential Reverse Connection a Right Turn, otherwise consider the Connection a Right Turn and a potential Reverse Connection a Left Turn
• *_straight_on, consider the Connection/Reverse Connection a Straight On
• TODO: Bei getrennt gemappten Fahrtrichtungen, schlägt das fehl: If up to now no Straight On has been identified: If the respective To Way is the only Exit Way that has the same reference as the From Way, the respective Connection/Reverse Connection is a Straight On. If a common reference can not be found: if the respective To Way is the only Exit Way that has the same name as the From Way, the respective Connection/Reverse Connection is a Straight On. If a common name can also not be found: if the From Way has the highest road class and the To Way is the only Exit Way that has the same road class, the respective Connection/Reverse Connection is a Straight On. (This is one single rule)
• For all further rules: determine the angle between the From Way and the To Way of all (i.e. also already identified) Connections of the current Entering Way.
• If up to now no Straight On has been identified: if the smallest angle of all unidentified Connections is between -20° and +20°, that respective Connection and its Reverse Connection is a Straight On.
• If at least one Straight On has been identified: if the angle of a Connection is below the smallest angle of all Straight Ons, that Connection is a Left Turn and its Reverse Connection is a Right Turn. (In simple words: if the To Way is left of the leftmost Straight On)
• If at least one Straight On has been identified: if the angle of a Connection is above the highest angle of all Straight Ons, that Connection is a Right Turn and its Reverse Connection is a Left Turn. (In simple words: if the To Way is right of the rightmost Straight On)
• If more than one Straight On has been identified: if the angle of a Connection is below the smallest angle and above the highest angle of all Straight Ons, treat this as data error and consider the Connection/Reverse Connection a Straight On. (In simple words: if this Connection is between the leftmost and rightmost Straight On)
• Finally: If the angle of the Connection is below 0°, the Connection is a Left Turn and a potential Reverse Connection a Right Turn, otherwise the Connection is a Right Turn and a potential Reverse Connection a Left Turn.
TODO: u-turn
Determining lane connections:
• Collect all Connected Ways for the given Connecting Node
• First - the easy part - process all Connections, for which transit information (via tags or relations for the relevant direction!) is available. Connections may be processed in random order.
• Process one lane after the other of the From Way from left to right and connect it to zero, one or more ways of the To Way, as specified below. After connecting lanes skip to the following lane in the From Way resp. To Way, if not mentioned otherwise. If multiple values are given for on lane, process the value new_on_left first and new_on_right last.
• continue: connect this lane to the next lane of the To Way.
• fork: connect this lane to the next two lanes of the To Way.
• fork:number: connect this lane to the given number of lanes of the To Way.
• new_on_left: skip one lane in the To Way (i.e. it is not connected to the From Way). This value always must be the first value of a lane to be processed.
• new_on_left:number: skip the given number of lanes in the To Way (i.e. they are not connected to the From Way). This value always must be the first value of a lane to be processed.
• new_on_right: skip one lane in the To Way (i.e. it is not connected to the From Way). This value always must be the last value of a lane to be processed.
• new_on_right:number: skip the given number of lanes in the To Way (i.e. they are not connected to the From Way). This value always must be the last value of a lane to be processed.
• join_with_left: connect this lane to the next lane in the To Way. If this is the value of the leftmost lane of the From Way, additionally treat it as data error.
• join_with_right: connect this lane to the next lane in the To Way, but do not skip to the next lane in the To Way. If this is the value of the rightmost lane of the From Way, additionally treat it as data error.
• end: skip to the next lane of the From Way, but do not skip to the next lane in the To Way.
• leave: skip to the next lane of the From Way, but do not skip to the next lane in the To Way.
• All the following rules represent some kind of "guessing-strategy", because all other tags and relations only provide hints regarding lane connectivity but not a precise specification. Also this strategy is based on the previous determination (i.e. guessing) of Straight On, Left Turn and Right Turn, which may or may not be correct. Different consumers might use different strategies.
• From now on only connect lanes with identical designation, e.g. if a lane is designated to bicycles (i.e. bicycle:lanes=...|designated|...) only connect it to a lane, that is also designated to bicycles. It might be a good idea to process lanes with different designation separately.
• Second process those Connections, for which transit information (via tags or relations for the relevant direction!) is not available and which are Straight On.
• If the number of lanes in the To Way compared to the number of lanes in the From Way is
• identical: connect all lanes one on one.
• lower: based on the (assumed or explicitly specified placement-values, determine an appropriate lane offset and connect adjacent lanes (see section below). Treat unconnected lanes of the From Way as ending.
• higher: based on the (assumed or explicitly specified placement-values, determine an appropriate lane offset and connect adjacent lanes (see section below). Treat unconnected lanes of the To Way as new, beginning lanes.
• After connecting the lanes of a Straight On, check if the lanes in the To Way have the same turning indications as in the From Way. If so, ignore those turning indications in the From Way from now on (especially when processing a Left/Right Turn connection). Pay attention to multiple turning indications on one lane: if e.g. a lane in the From Way has the indication through;right and in the To Way only through, then treat the indication in the From Way from now on as only right.
• Third process all Entering Ways, for which up to now not all possible Connections have been fully determined. Note: Differently to before one Connection is now not completely processed and all lanes are linked. Instead one or more lanes of one Entering Way are connected to one or more Exit Ways, i.e. multiple Connections are processed at a time.
• If for the leftmost lane of the Entering Way a turning indication with *left is specified (note: some turning indications may have been removed while processing Straight On connections):
• Determine the number of variations of *left in the turning indications of all lanes, e.g. two, if "sharp_left" and "left" is present, or one if only "slight_left" is present. If this number compared to the number of all possible Left Turns (with or without transit information!) is:
• equal to or greater than: connect those lanes of the Entering Way, which use the leftmost variation, to the Exit Way of the leftmost Left Turn, the lanes with the next variation to the Exit Way of the next Left Turn, and so on, until the last Left Turn. Ignore lanes with surplus variations.
• If the lanes of the Connection from the current Entering Way to the current Exit Way have already been determined in a previous step, skip the current variation and Left Turn!
• If the number of lanes of the current turn variation compared to the number of lanes in the Exit Way is:
• equal to or less than: connect the lanes in right-to-left (left-hand traffic: left-to-right) order.
• greater than (right-hand traffic): connect the lanes in left-to-right order and connect all surplus lanes of the Entering Way to the rightmost lane. Treat this as data error.
• greater than (left-hand traffic): connect the lanes in right-to-left order and connect all surplus lanes of the Entering Way to the leftmost lane. Treat this as data error.
• less than: Identical to the case "equal to or greater than", but connect the lanes of the last variation to the lanes of all remaining Left Turns.
• If for the leftmost lane of the Entering Way a turning indication with *left is not specified, connect only the leftmost lane of the Entering Way to the rightmost (left-hand traffic: leftmost) lane of the Exit Way of all Left Turns.
• If for the rightmost lane of the Entering Way a turning indication with *right is specified (note: some turning indications may have been removed while processing Straight On connections):
• Determine the number of variations of *right in the turning indications of all lanes, e.g. two, if "sharp_right" and "right" is present, or one if only "slight_right" is present. If this number compared to the number of all possible Right Turns (with or without transit information!) is:
• equal to or greater than: connect those lanes of the Entering Way, which use the rightmost variation, to the Exit Way of the rightmost Right Turn, the lanes with the next variation to the Exit Way of the next Right Turn, and so on, until the last Right Turn. Ignore lanes with surplus variations.
• If the lanes of the Connection from the current Entering Way to the current Exit Way have already been determined in a previous step, skip the current variation and Right Turn!
• If the number of lanes of the current turn variation compared to the number of lanes in the Exit Way is:
• equal to or less than: connect the lanes in right-to-left (left-hand traffic: left-to-right) order.
• greater than (right-hand traffic): connect the lanes in right-to-left order and connect all surplus lanes of the Entering Way to the leftmost lane. Treat this as data error.
• greater than (left-hand traffic): connect the lanes in left-to-right order and connect all surplus lanes of the Entering Way to the rightmost lane. Treat this as data error.
• less than: Identical to the case "equal to or greater than", but connect the lanes of the last variation to the lanes of all remaining Right Turns.
• If for the rightmost lane of the Entering Way a turning indication with *right is not specified, connect only the rightmost lane of the Entering Way to the rightmost (left-hand traffic: leftmost) lane of the Exit Way of all Right Turns.
Note regarding new_on_left and new_on_right: in such case, the "new" lane is not directly connected to the from-way, but it can be reached by changing the lane (if allowed). Pay attention to this when building a routing graph. For routing (but not for rendering) it may be possible to treat those values identical to fork.
Road classes and assumed number of lanes
The following table lists relevant road classes ordered by priority and the assumed number of lanes, if not specified explicitly.
Road class
(ordered)
Assumed # lanes
two way
Assumed # lanes
one way
highway=motorway
highway=trunk
4 2
highway=primary
highway=secondary
highway=tertiary
highway=unclassified
highway=residential
highway=motorway_link
highway=primary_link
highway=secondary_link
highway=tertiary_link
2 1
highway=service
highway=track
highway=path
highway=living_street
highway=road
highway=cycleway
1 1
Determining adjacent lanes based on the placement key
Variable Meaning
f The number of forward lanes.
b The number of backward lanes.
c The number of centre lanes, i.e. lanes between forward and backward lanes, which are specified using the suffix :both_ways.
Tag¹ Right-hand
traffic
Left-hand
traffic
placement=left_of:x
placement:forward=left_of:x
x x - f - 1
placement=right_of:x
placement:forward=right_of:x
x + 1 x - f
placement=middle_of:x
placement:forward=middle_of:x
x + 0.5 x - f - 0.5
placement:backward=left_of:x 2 - x - c b + c - x + 1
placement:backward=right_of:x 1 - x - c b + c - x
placement:backward=middle_of:x 1.5 - x - c b + c - x + 0.5
placement:both_ways=left_of:x x - c x - 1
placement:both_ways=right_of:x x - c - 1 x
placement:both_ways=middle_of:x x - c - 0.5 x - 0.5
¹ The mentioned tags may carry an additional :start or :end suffix. Make sure to use the correct tag, i.e. the one relating to the connecting node of both OSM ways.
Rules:
• Determine for both OSM ways an offset as described in the table above. Following o1 means the offset of the From Way and o2 means the offset of the To Way.
• In case the direction of both OSM ways is not identical, treat one OSM way as if it would be reversed and adjust its offset as follows: oX = c - oX. Note: the following rules assume that one OSM way ends ad the connecting node and the other one starts there.
• From Way means the OSM way ending in the connecting node and To Way the one starting in the connecting node.
• Determine the index i as: i = 1 + max( o1 - o2 , 0 ). If necessary, round down to the nearest integer and treat this as data error. (TODO: better strategy?)
• The i-th forward lane of the From Way (viewed from left to right, starting with 1) now connects to the leftmost forward lane of the To Way; continue to the right until you reach the rightmost forward lane of either the From Way or To Way. Note: if i is greater than the number of forward lanes in the From Way, no forward lanes are connected between the From Way and To Way. This is usually a data error. In such a situation routing applications might connect the rightmost forward lane of the From Way to the leftmost forward lane of the To Way.
• The i-th backward lane of the To Way (viewed from left to right, starting with 1) now connects to the leftmost backward lane of the From Way; continue to the right until you reach the rightmost backward lane of either the From Way or To Way. Note: if i is greater than the number of backward lanes in the To Way, no backward lanes are connected between the From Way and To Way. This is usually a data error. In such a situation routing applications might connect the rightmost backward lane of the To Way to the leftmost backward lane of the From Way.
• The i-th centre lane of the From Way (viewed from left to right, starting with 1) now connects to the leftmost centre lane of the To Way; continue to the right until you reach the rightmost centre lane of either the From Way or To Way. Note: if i is greater than the number of centre lanes in the From Way, no centre lanes are connected between the From Way and To Way. This is usually a data error. In such a situation routing applications might connect the rightmost centre lane of the From Way to the leftmost forward lane of the To Way.
TODO: left-hand traffic
Examples
Only number of lanes available
Number of lanes and placement of OSM way available
Number of lanes and turn indications available
Transit key or relation
TODO: mixed example with tag, relation and no transit
Rendering lanes
...
|
__label__pos
| 0.874424 |
Find file History
Fetching latest commit…
Cannot retrieve the latest commit at this time.
..
Failed to load latest commit information.
project
readme
src/main
README.md
README.md
Estimating Pi with Akka
4 Mar 2011
This example demonstrates the simplicity in using Akka to scale up a basic distributable task: estimating the value of Pi. It was created with Scala 2.8.1, Akka 1.0, and SBT 0.7.4. To try it out, run the following:
> sbt update run
To change the number of workers, add or remove Worker actors from the workers list in the run method.
Pi is estimated by summing elements in an infinite series derived from the following equation:
Pi equation
The evaluation of each element in the the series can be carried out independently, then combined with one another at the end, making this a perfect problem for distributed computing.
This algorithm splits the series into finite lists of elements, each of which is evaluated by a worker then given to an accumulator to keep track of the total sum.
A worker is implemented as an Akka Actor.
class Worker extends Actor {
def receive = {
case range: Range => self.reply((for (k <- range) yield (4 * math.pow(-1, k) / (2 * k + 1))).sum)
}
}
A Worker iterates over a Range of k, evaluating each kth element in the series. The sum of the results is sent as a message to the accumulator.
The accumulator is implemented as an Akka Actor.
class Accumulator(iterations: Int) extends Actor {
var count: Int = _
var pi: Double = _
var start: Long = _
def receive = {
case result: Double =>
pi += result;
count += 1;
if (count == iterations) Actor.registry.shutdownAll
}
override def preStart = {
start = System.currentTimeMillis
}
override def postStop = {
println("\n>>> result: " + pi)
println(">>> run time: " + (System.currentTimeMillis - start) + " ms\n")
}
}
The Accumulator listens for results from Workers, keeping a running sum of each. It measures its run time with preStart and postStop, and stops all actors once it has received the expected number of worker replies.
A simple runner is used to manage the actors and distribute the work to the workers.
object Runner {
def main(args: Array[String]) = run(10000, 10000)
def run(iterations: Int, length: Int) = {
implicit val accumulator = Option(Actor.actorOf(new Accumulator(iterations)).start)
val workers = loadBalancerActor(new CyclicIterator(List(
Actor.actorOf[Worker].start,
Actor.actorOf[Worker].start
)))
for (x <- 0 until iterations) workers ! ((x * length) to ((x + 1) * length - 1))
}
}
The Runner has a main method which starts an Accumulator and a list of Workers, then sends 10,000 ranges to the workers in a round robin fashion using a CyclicIterator.
My laptop has two CPU cores, both of which are running in powersave mode as I write this on an airplane. Following are the results of computing 10,000 lists of 10,000 elements with one, two, four, and eight workers. Pi was estimated each time to be 3.1415926435897883.
# Actors Run Time (ms)
1 35,268
2 21,063
4 20,919
8 20,730
This code has a few limitations which would need to be addressed if this were to form the basis for a serious attempt at distributed computing. The workers could be remote actors instead of local actors, allowing the work to be scaled out. Waiting for the workers to finish by counting the results recieved by the accumulator is not a good idea, since it is vulnerable to crashed or delayed workers.
|
__label__pos
| 0.988546 |
Identifies a servlet bean input parameter; or defines a page parameter.
<dsp:param name="sbparam-namesbparam-value />
<dsp:param name="pgparam-namepgparam-value />
Attributes
name (servlet bean)
Identifies an input parameter that is defined for the current servlet bean. For information on input parameters for specific servlet beans, see Appendix B, ATG Servlet Beans.
name (page parameter)
Defines a page parameter that is accessible to the current JSP and embedded child pages. For more information, see Page Parameters.
sbparam-value
Specifies the input parameter’s value in one of the following ways:
bean="prop-spec"
Sets the parameter to the specified property, where prop-spec includes the Nucleus path, component name, and property name. For example:
<dsp:param name="repository"
bean="/atg/dynamo/droplet/PossibleValues.repository/>
param="pName"
Sets the parameter to the value of the page parameter pName. For example:
<dsp:param name="propertyName" param="element.repositoryId"/>
value="value"
Sets the parameter to a static value. For example:
<dsp:param name="sortProperties" value="date"/>
The parameter value specification can also include a tag converter such as Date or Nullable. For more information, see Tag Converters.
pgparam-value
Specifies the page parameter’s value in one of the following ways:
beanvalue="prop-spec"
Sets the parameter to a property value, where prop-spec includes a Nucleus path, component name, and property name. For example:
beanvalue="FreshmanScience.name"
paramvalue="pName"
Sets the parameter from the page parameter pName. For example:
paramvalue="name"
value="value"
Sets the parameter to a static value. For example:
value="Bartleby Scrivener
Copyright © 1997, 2012 Oracle and/or its affiliates. All rights reserved. Legal Notices
|
__label__pos
| 0.816891 |
The 5 Most Common Ways That Ransomware Spreads
In the past few years, ransomware has become one of the biggest cyber security threats that organisations face. It was the second-leading cause of cyber attacks in 2021, according to research by IT Governance, with more than 400 publicly disclosed incidents being reported.
The nature of ransomware means that it is more disruptive than other forms of cyber attack. The malware worms through the victim’s system rapidly, and business operations are brought to a halt while the organisation decides how to deal with the situation.
But how exactly does ransomware spread through an organisation? We answer that question in this blog, as we look at the five most common ways that a ransomware infection begins.
What is ransomware?
Ransomware is a type of malware that encrypts computer files, locking the owner out of their systems.
Once this happens, the ransomware will display a message demanding that the victim make a payment to regain access to their files.
Many ransomware victims feel obliged to pay up, because it’s the quickest and least expensive way to get up and running again.
However, experts generally urge organisations not to negotiate, because ransom payments help fuel the cyber crime industry. There is also no guarantee that paying the ransom will mean the criminals release the files.
See also:
How does ransomware spread?
For a ransomware attack to begin, the attackers must find a way to plant the malware on an organisation’s systems. There are countless ways they can do this, but they will typically use one of the following five methods.
1. Email attachments
Phishing emails are the most common delivery method for ransomware. Scammers send messages that appear to be from a legitimate organisation and prompt the recipient to open an attachment.
The messages often take the form of a business correspondence, with the attached file seemingly related to a work topic. Emails also often masquerade as invoices, with the recipient being instructed that they have been billed for something.
These are just a few examples. Phishing emails can take any form, and the attachment can appear as a Word document, Excel spreadsheet, PDF or ZIP file.
However, in every instance, the attachment contains a malicious payload that is downloaded as soon as the recipient opens the file.
The ransomware might be deployed immediately, but in other situations the scammers wait days or even months to instigate the attack.
2. Malicious URLs
Phishing emails present another threat in the form of malicious URLs. Instead of downloading an attachment, the message prompts the recipient to follow a hyperlink.
These scams follow the same pattern that we’ve described above, with the attackers posing as a legitimate organisation.
The only difference is that malicious URL attacks are more likely to pose as a private organisation such as PayPal, Netflix or Microsoft. They might state, for example, that there is a problem with the user’s account and instruct them to log on to address the issue.
The message will contain a link that appears to direct the recipient to a login page but which is in fact a mock-up of the legitimate site. When the user provides their username and password, they are inadvertently handing over this information to the attackers, who can then use the compromised account to launch a ransomware attack.
In some cases, simply following the link is enough to trigger the ransomware to download on a device. This is particularly the case for people using older versions of operating systems or browsers, because they don’t have the same protections in place to prevent malware from executing automatically.
3. Remote desktop protocol
RDP (remote desktop protocol) is a way for one computer to connect to another virtually. It’s often used when an employee seeks IT support and the team isn’t nearby to look at the problem in person.
The expert takes control of the computer using remote access software, which allows them to control another device using their own keyboard and mouse.
If a cyber criminal was able to gain remote access to someone’s computer, they could plant ransomware. There are two ways they can do this. The first is by finding system vulnerabilities that enable the attacker to create their own remote access.
By default, RDP receives connection requests through port 3389. Cyber criminals can use port-scanners to scour the Internet for devices with exposed ports.
Once they’ve found a target, they might try to gain access by exploiting a security vulnerability or conducting a brute-force attack to crack the machine’s login credentials.
Alternatively, they can trick people into handing over remote access by conducting a social engineering attack. One of the most popular techniques is to create a pop-up spam message in an Internet browser that claims that the individual’s computer is infected with malware.
The window is designed to trick people who aren’t tech-savvy and cannot differentiate between an Internet window and an alert sent by their antivirus software.
The scammer’s message will contain a phoneline that users are prompted to call to receive support. Those who call the number are directed to a fake support centre and someone claiming to help fix the issue.
They will request remote access to the device to perform a bogus vulnerability scan, which will detect the apparent virus. The scammer will then download a piece of software that appears to fix the issue, but it is in fact malware.
The malicious software might be ransomware itself or a keylogger that tracks everything that a user types on their machine, such as passwords or other sensitive information.
With those details, the attacker can gain extended access to the victim’s account. This helps them conduct further scams before finally unleashing a ransomware strain on the device.
4. Pirated software
Illegitimate software was once the single-most common way that malware was spread.
Individuals who downloaded cracked software believed they were getting a bargain by not having to pay for the legitimate service, but they soon learned that the software was laced with malware.
Part of the problem is that unlicensed software doesn’t receive updates from the developer, which means that it will contain an increasing number of vulnerabilities that a cyber criminal can exploit.
Pirate sites that enable individuals to download songs and films provide another way for malware to spread. As with malicious email attachments, the files might have been injected with a malicious executable that enables attackers to surreptitiously infect the user’s device.
The threat of ransomware attacks via pirated software has decreased in recent years as the popularity of the services have waned. It is increasingly easy and affordable to stream content legitimately, reducing the popularity of pirate sites.
However, for people who still use these services, there remains a serious risk of infection.
5. Removeable devices
Organisations are highly susceptible to malware that enters their systems via removeable devices such as USB sticks. Unlike when transferring files over email, there is no threat detection system that can warn users of a security risk.
With removeable devices, individuals can simply plug them into their computer and copy over files. It only takes one infected document to compromise an organisation’s systems.
Cyber criminals often exploit this weakness by leaving infected USB sticks in public. The goal is for someone to find the device and be curious enough to plug it into their computer to see what’s stored on it.
Organisations are equally liable to fall victim if an employee uses a removeable device for both their personal and work computers. They might inadvertently download malware while doing personal activities, and that malicious code will execute when it is plugged into another computer.
How to prevent ransomware attacks
All of the techniques we’ve listed here have one thing in common: they are, to some extent, the result of human error.
Ransomware is often considered an IT problem, because cyber criminals exploit system weaknesses to plant malware. But in most cases, the first step of the process is to leverage a vulnerability introduced by the individual.
The success of phishing emails relies on individuals fooling for the bait and downloading a malicious attachment or clicking a bogus link.
RDP attacks are only possible if people fall for scams or employees fail to properly configure their networks, and infections via pirated software and removeable devices occur because people don’t understand the threat using untrusted sources.
The key to protecting your organisation from ransomware is therefore to educate employees on the threats they face and the steps they can take to stay safe.
IT Governance’s Ransomware Staff Awareness E-learning Course contains the materials and tools you need to get started.
This online course provides a comprehensive introduction to ransomware in just 30 minutes. It’s designed for all employees, and covers:
• The threats posed by a ransomware attack;
• The main forms a ransomware attack can take and how they work; and
• Actions that individuals and organisations can take to help protect against ransomware.
Author
• Luke Irwin
Luke Irwin is a writer for IT Governance. He has a master’s degree in Critical Theory and Cultural Studies, specialising in aesthetics and technology..
|
__label__pos
| 0.616459 |
Exercise - Add a dev container to an existing project
Completed
When you're setting up the dev container for a project, you'll need to add a container configuration to that project first. A container configuration sets up your environment in Visual Studio Code.
In this exercise, you'll add a dev container and open the Products Dashboard project in the container.
Add a dev container
1. Return to VS Code and the project you cloned earlier
2. Press F1 to open the Command Palette.
3. Type add dev container and select Dev Containers: Add Development Container Configuration Files.
4. Select the following options:
Option Value
Select a container configuration definition Python 3
Python version 3.10
Install Node.js none
Add Features Select "OK"
A Dev Container configuration will be added to your project. Visual Studio Code will notify you that you can now open the project in a container. For now, dismiss this notification.
Inspect configuration files
1. Notice that a new folder called '.devcontainer' has been added to the project.
2. Expand that folder and notice that it contains both a Dockerfile and a devcontainer.json file.
Open the project in a container
1. Press F1 to open the Command Palette.
2. Type reopen in container.
3. Select Dev Containers: Reopen in Container from the list of available options.
The container will begin building. The initial build might take a few minutes because a new image has to be pulled down and built on your machine. After the container has been built the first time, later builds will be much faster.
View the Remote Indicator
When the container build is complete, you can see that you're connected to the container by examining the Remote Indicator. You should also now see your project files loaded in VS Code.
• Examine the Remote Indicator by viewing the bottom left-hand corner of VS Code. Notice that it now says, "Dev Container: Python 3".
Remote indicator with text that says dev container python 3
Important
You may see notifications about Pylance or improving performance on Windows. You can safely dismiss any notifications that you see in VS Code. You won't need to do those things.
Inspect the container
1. Press Ctrl + ` to open the integrated terminal in Visual Studio Code if it isn't already open.
2. Notice that the terminal prompt might look different than your normal terminal prompt.
VS Code integrated terminal prompt
3. Run the following command to ensure that Python is installed:
python --version
The terminal's output should be the version of Python being used in the container.
Install project dependencies
• Run the following command in the terminal to install the Flask dependencies that you need to run the project:
pip3 install --user -r requirements.txt
Run the project
1. Enter the following command in the terminal to start the project:
python app.py
2. Open the project in a browser by navigating to http://127.0.0.1:5000.
Screenshot of the Python Products Dashboard application.
Great work! You have a Python web application with Flask running on your machine, and you might not know what those things even are. That's OK! You don't have to. The container takes care of setting up the entire environment.
In the next section, you'll learn how to use the "devcontainer.json" file to automate the dependency install, and customize VS Code for this Python project.
|
__label__pos
| 0.637106 |
Get one quick Python tip each week Weekly Python advice: one quick Python tip every week
What is a class?
Series: Classes
Trey Hunner smiling in a t-shirt against a yellow wall
Trey Hunner
3 min. read 5 min. video Python 3.7—3.11
Share
Copied to clipboard.
Python Morsels
Watch as video
04:34
Classes are for coupling state and functionality. You've got some data and some actions you'd like to perform on that data. You want to bundle those two concepts together. That's what a class is for in Python.
Defining a class
We define a class by using the class keyword. That's how we start a class definition:
class Product:
def __init__(self, name, cost, price):
self.name = name
self.cost = cost
self.price = price
def profit_margin(self):
return self.price - self.cost
This is similar to how you define a function by using the def keyword.
Once we've defined a class, we can call it. Calling a class is a little bit different than calling a function. When you call a function, you get the return value of the function. When you call a class, you get an object whose type is that class:
>>> from product import Product
>>> duck = Product(name="rubber duck", cost=1, price=5)
>>> duck
<product.Product object at 0x7f584c643310>
>>> type(duck)
<class 'product.Product'>
The words type and the word class are basically interchangeable in Python. The type of something is its class.
Strange object-oriented terminology
The object-oriented Python world has a lot of redundant and overlapping terminology.
Here are three different ways to say the same thing:
1. When you call the Product class, you are instantiating a new Product instance.
2. Also, when you call the Product class, you are constructing a new Product object.
3. And, when you call the Product class, you are making a Product.
So, a Product instance, a Product object, and just a Product, all mean the same thing; that is an object whose type (whose class) is Product.
Working with Python objects
Once you've made an instance of a class (an object whose type is that class) there are two main things that you can do with that object:
1. You can get the data that's stored within that instance
2. You can perform actions on that instance
We have a Product object here, that we are pointing to with the duck variable (see figure below). So, the duck variable points to a Product instance, or a Product object.
Attributes: variables that live on class instances
We can access the data that's stored on this Product instance by looking up its attributes.
You can access an attribute by taking a reference to the Product object, putting a . after it, and then putting the name of the attribute. Here are the name, cost, and price attributes:
>>> duck.name
'rubber duck'
>>> duck.cost
1
>>> duck.price
5
You can think of an attribute as kind of like a variable name that lives specifically on one object, specifically on a Product instance in this case.
These attributes would be different for different Product instances. So, if we had a Product object named "stuffed unicorn", it would have different attributes on it.
So that's how we access the data that's on a class instance.
Methods: functions that live on classes
What about performing actions on a class?
You can perform actions on a class by using methods. A method is basically a function that lives on a class and specifically operates on instances of that class.
To use our profit_margin method, we can look up the profit_margin attribute on a Product instance and put parentheses after it to call it:
>>> duck.profit_margin()
4
The profit_margin method accessed the name and price attributes on our Product instance and subtracted them to get 4.
Methods tend to either access data from a class instance (as we're doing here) or change the data in a class instance.
Summary
So, classes in Python take data and functionality and couple them together.
When you call a class, the thing you get back is an instance of that class. Once you've got that instance, you can get the data through attributes. If you'd like to perform actions on that class instance, you can do that by calling methods on that class instance.
Also the phrase "instance of class Product" means the same thing as "an object whose type is Product".
Series: Classes
Classes are a way to bundle functionality and state together. The terms "type" and "class" are interchangeable: list, dict, tuple, int, str, set, and bool are all classes.
You'll certainly use quite a few classes in Python (remember types are classes) but you may not need to create your own often.
To track your progress on this Python Morsels topic trail, sign in or sign up.
0%
Concepts Beyond Intro to Python
Intro to Python courses often skip over some fundamental Python concepts.
Sign up below and I'll share ideas new Pythonistas often overlook.
Python Morsels
Watch as video
04:34
|
__label__pos
| 0.95454 |
OurBigBook
Allows to link to headers with the \H file argument, e.g.:
= My header
Check out this amazing file: <path/to/myfile.txt>{file}
== path/to/myfile.txt
Some live demos follow:
\x[file_demo]{file}
which renders as:
\x[file_demo/file_demo_subdir]{file}
which renders as:
\x[file_demo/file_demo_subdir/hello_world.js]{file}
which renders as:
\x[file_demo/my.bin]{file}
which renders as:
\x[Tank_man_standing_in_front_of_some_tanks.jpg]{file}
which renders as:
\x[https://www.youtube.com/watch?v=YeFzeNAHEhU]{file}
which renders as:
Ancestors
1. \x arguments
2. Cross reference
3. Macro
4. OurBigBook Markup
5. OurBigBook Project
|
__label__pos
| 0.99839 |
Skip to content
Instantly share code, notes, and snippets.
Avatar
David Zmick dpzmick
View GitHub Profile
View threaded.c
#define _GNU_SOURCE
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <sys/stat.h>
#include <time.h>
#include <unistd.h>
#include <stdint.h>
#include <pthread.h>
View sad_ch_perf.py
N = 1000
# make two scripts to pass to clickhouse client to demonstrate sadness with
# materialized columns
with open('create.sql', 'w') as f:
f.write("DROP DATABASE IF EXISTS test;")
f.write("CREATE DATABASE test;")
# --- fast table as a baseline
View p1.py
# simple error correcting code
# assume that data is transmitted over a channel which
# sometimes corrupts the data stream
#
# for example, if we sent the bits 10110011
# we might receive 10110010 on the other side
#
# Consider a channel which has a 1% chance of incorrectly transmitting each bit
# that is sent.
# Additionally, assume messages we send contain 100 bits.
View rs-cpp.org
Understanding Pin for C and C++ developers
My initial impression of Pin was that it said “hey there’s something sitting at this memory location. Feel free to use it, even though, in this context, the compiler can’t lexically prove that it is actually still there.” My understanding of Pin was roughly that it was a backdoor through the lifetime system.
Opening up the documentation, the page starts with a discussion about Unpin. Unpin is weird. Basically, Unpin says “yeah I know this
@dpzmick
dpzmick / rb_move_semantics.cpp
Created Nov 10, 2019
possibly incorrect ring buffer move semantics explanation
View rb_move_semantics.cpp
#include <array>
#include <iostream>
#include <stdexcept>
template <typename T, size_t N>
struct ring_buffer {
std::array<T, N+1> entries;
T* head = entries.data(); // pop from here
T* tail = head+1; // push to here, one past the end
@dpzmick
dpzmick / 0_test.c
Last active Oct 10, 2019
get wrecked clang
View 0_test.c
#include <stdlib.h>
int test() {
int *x = NULL;
int y = rand();
int z = rand();
int v = 4;
if (z == 8) x = &v;
View quadtree.c
#include <assert.h>
#include <stdbool.h>
#include <stddef.h>
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <x86intrin.h>
/*
@dpzmick
dpzmick / topsort.cpp
Last active Oct 6, 2017
fragile topological sort in c++ templates
View topsort.cpp
#include <cstddef>
#include <iostream>
#include <sstream>
#include <type_traits>
struct nil { };
template <typename H, class T>
struct cons
{
View views.cpp
#include <cstddef>
#include <iostream>
#include <type_traits>
struct nil { };
template <typename H, class T>
struct cons
{
using head = H;
View apply.cpp
#include <tuple>
#include <iostream>
class LoudCopy
{
public:
LoudCopy() { }
LoudCopy(const LoudCopy&) = delete;
LoudCopy(LoudCopy&&) {}
};
|
__label__pos
| 0.981281 |
Developer
Create XML with MySQL and PHP
PHP is a popular scripting environment that allows you to work with XML. Get an introduction to using open source tools such as PHP and MySQL to manipulate XML.
XML has emerged as a standard for data exchange. Java and .NET both include inherent XML support, but developers outside of these environments need not worry about being left out. PHP is a popular scripting environment that also allows you to work with XML.
In this article, I'll introduce you to using open source tools like PHP and MySQL to manipulate XML. I'll execute a MySQL query and format the data into well-formed XML. Finally, I'll explain how to write XML to a file and examine the system setup before diving into the code.
To use the code I've included in this article, you must have PHP and MySQL running, and you need to know your MySQL host name, username, and password to fully use the samples. The sample MySQL database has the format shown in Figure A. Let’s look at how to connect to the sample database with PHP.
Figure A
Establishing a database connection with PHP
The following sample PHP script connects to the database and executes a query:
<?php
$db_name = "xrandomusa_4";
$connection = mysql_connect("MySQL.somewhere.com", "username", "password") or die("Could not connect.");
$table_name = 'pages';
Querying MySQL
With the connection made, you must establish the current database using the MySQL connection. The following code handles this task:
$db = mysql_select_db($dbName, $link);
Now, write a SQL statement to select all rows in $table_name.
$query = "select * from " . $table_name;
If necessary, you can add attributes later. For now, execute the query like so:
$result = mysql_query($query, $connection) or die("Could not complete database query");
$num = mysql_num_rows($result);
For reference, you can view all MySQL functions via the PHP.net Web site.
Build and write the XML
At this point, you're ready to create a new XML document. There are many ways to approach it, but I think the approach used in Listing A suffices for most purposes:
Here’s a breakdown of what’s happening. Variable num represents the presence of row data from your query, measurable using MySQL’s mysql_num_rows function. This leads us into your procedural output of the XML. Variable $file contains a pointer to the file object produced when PHP successfully reads the file system in search of results.xml. If results.xml is found, your PHP file object, named file, is created and made writeable. Now you can print the contents of a variable to it, which is what you’ll do because your directory permissions are set up to allow PHP to do this.
Keep in mind that for security reasons, this is a dumb thing to do in real-world Web applications. To make sure your implementation of the concepts covered in this article are secure, you should provide a full path to a directory containing the files you wish to open for writing, and make sure it’s in a directory above your Web root.
Next, PHP's mysql_fetch_array function converts the query variable $result to an array, and loops through its keys. If pageTitle was among the columns returned in the query, for each row returned, some XML-formatted text is written to string variable $_xml.
Note that the operator ".=", which is being used to append the XML-formatted strings as values, is read from $row. When the loop is finished, the root XML node is printed to variable $_xml, and the whole variable is written to file.xml using PHP’s fwrite function.
At this point, a link appears on the screen. Make sure this link points to the path of your XML file, or you won’t be able to see the formatted XML produced by PHP from your MySQL query.
Additional resources
Check out these links to learn more about the technologies used in this article:
A test drive
You can easily test the code by running it in a browser. If all goes well, you will see a new file in your directory called results.xml. This is the XML file created with the PHP. It should look like this:
<?xml version="1.0" encoding="UTF-8" ?>
<site>
<page title="Page One">
<file>http://www.yoursite.com/pageOne</file>
</page>
<page title="Page Two">
<file>http://www.yoursite.com/pageTwo</file>
</page>
</site>
Only the start of something bigger
The resulting code from this article would be useful as an include file in the context of a larger application. It is a tried-and-true technique for creating and updating XML documents, but it's not the only solution: There are other technologies that extend PHP—PEAR, for instance—that present some exciting alternatives.
Editor's Picks
Free Newsletters, In your Inbox
|
__label__pos
| 0.565404 |
2010年8月29日日曜日
いまどきCUIでマインスイーパ For Linux
あまりにも暇なのでLinux環境でCUIのマインスイーパ作ってみたw
まだUI部分だけの未完成品だけど、完成したら更に100行ぐらい増えるかも。
// MineSweeper
// Author:Imoimo
// Maked At:2010/08/29
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
#include <termios.h> //Linux系環境依存
#include <unistd.h> //Linux系環境依存
#define STAGE_X 20
#define STAGE_Y 10
#define SCREEN_X (STAGE_X + 2)
#define SCREEN_Y (STAGE_Y + 2)
#define STAGE_ARRAY (STAGE_X * STAGE_Y)
#define BOMB_NUM 10
#define KEY_SPACE 0x20
#define KEY_ENTER 0x0A
#define KEY_LM 'm'
#define KEY_UM 'M'
#define KEY_UP 0x41
#define KEY_DOWN 0x42
#define KEY_LEFT 0x44
#define KEY_RIGHT 0x43
#define KEY_LE 'e'
#define KEY_UE 'E'
#define ESC_CLEAR "\x1b[2J\x1b[0;0H"
#define ESC_NORMAL "\x1b[0m"
#define ESC_REVERSE "\x1b[7m"
#define TITLE_STR "-MineSweeper-"
#define MAX_STR_BUF 256
#define POLL_DELAY 16667
#define HELP_STR "[HELP]Arrow=MoveCursor,M=Mark,Space=Flag,Enter=OpenCell."
// キャラクタコード
enum eCharCode{
CHR_OPEN,
CHR_1,
CHR_2,
CHR_3,
CHR_4,
CHR_5,
CHR_6,
CHR_7,
CHR_8,
CHR_FLAG,
CHR_MARK,
CHR_BOMB,
CHR_CLOSE,
CHR_CORNER,
CHR_H_BORDER,
CHR_V_BORDER,
};
// ゲームモード
enum eGameMode{ GAME_INIT,GAME_CLEAR,GAME_BODY,GAME_OVER,GAME_EXIT };
// ターミナルパラメータ格納用(Linux依存)
static struct termios TOrigin;
// 表示キャラクタ配列
const char Chars[] = {
'_','1','2','3','4','5','6','7','8','P','X','*','#','+','-','|'
};
// 表示顔文字配列(笑
const char *Faces[] = {"(--)","(^^)","(@@)","(xx)"};
// 色々とグローバル変数。
int Stage[STAGE_ARRAY];
int Bombs[BOMB_NUM];
int X;
int Y;
int TimeCount;
int HitBombs;
int FlagNum;
int FaceCode;
// 範囲内のランダム値を返す。
int getRandom(int min,int max){
srand(time(NULL));
return min + (int)(rand() * (max - min + 1.0) / (1.0 + RAND_MAX));
}
// 2次元座標から一次元配列の添字に変換する。
int getIndex(int x,int y){
return x + y * STAGE_X;
}
// ステージ初期化。
void initStage(void){
int i;
for(i=0;i<STAGE_ARRAY;i++) Stage[i] = CHR_CLOSE;
for(i=0;i<BOMB_NUM;i++){
Bombs[i] = 0;
}
}
// 地雷配置。
void setBomb(int x,int y){
int i;
for(i=0;i<BOMB_NUM;i++){
int bi,ind = getIndex(x,y);
bi = getRandom(0,STAGE_ARRAY);
if(bi == ind){
i--;
continue;
}
Bombs[i] = bi;
}
}
// ゲーム初期化。
int initGame(void){
X = STAGE_X / 2;
Y = STAGE_Y / 2;
TimeCount = 0;
HitBombs = 0;
FaceCode = GAME_BODY;
FlagNum = BOMB_NUM;
initStage();
return GAME_BODY;
}
// 文字列をフィールドの中央に表示する。
void drawCenter(const char *c){
int len = strlen(c);
int i,pad = (SCREEN_X - len) / 2;
char cPads[SCREEN_X],cBuf[MAX_STR_BUF];
strcpy(cBuf,c);
for(i=0;i<SCREEN_X;i++) cPads[i] = ' ';
if((pad + len) > SCREEN_X){
cBuf[SCREEN_X - pad] = '\0';
}
strcpy(cPads + pad,cBuf);
puts(cPads);
}
// ステージを描画。
void drawStage(void){
int x,y;
for(y=0;y<STAGE_Y;y++){
putchar(Chars[CHR_V_BORDER]);
for(x=0;x<STAGE_X;x++){
if((x == X)&&(y == Y)) printf(ESC_REVERSE);
putchar(Chars[Stage[getIndex(x,y)]]);
printf(ESC_NORMAL);
}
putchar(Chars[CHR_V_BORDER]);
putchar('\n');
}
}
// 画面全体を描画。
void drawScreen(void){
int i;
printf(ESC_CLEAR);
drawCenter(TITLE_STR);
drawCenter(Faces[FaceCode]);
for(i=0;i<SCREEN_X;i++){
if((i == 0)||(i == STAGE_X + 1)) putchar(Chars[CHR_CORNER]);
else putchar(Chars[CHR_H_BORDER]);
}
putchar('\n');
drawStage();
for(i=0;i<SCREEN_X;i++){
if((i == 0)||(i == SCREEN_X - 1)) putchar(Chars[CHR_CORNER]);
else putchar(Chars[CHR_H_BORDER]);
}
putchar('\n');
printf("Time: %04d Secs\n",TimeCount);
printf("Flag: %03d/%03d\n",FlagNum,BOMB_NUM);
printf("Hit Bombs: %03d/%03d\n",HitBombs,BOMB_NUM);
}
// keybd()関数の代替:初期化
void begin_getch(void){
struct termios t;
tcgetattr(0, &t);
TOrigin = t;
t.c_lflag &= ~(ICANON | ECHO);
t.c_cc[VMIN] = 0;
t.c_cc[VTIME] = 0;
tcsetattr(0, TCSANOW, &t);
}
// keybd()関数の代替:後始末
void end_getch(void) {
tcsetattr(0, TCSADRAIN, &TOrigin);
}
// keybd()関数の代替:本体。
char getch(void){
char c;
begin_getch();
while(1) {
usleep(POLL_DELAY);
if (read(0, &c, 1) != 0) break;
}
end_getch();
return c;
}
// キー入力処理
int inputMethod(void){
char c = getch();
switch(c){
case KEY_SPACE:
if((Stage[getIndex(X,Y)] == CHR_CLOSE)&&(FlagNum > 0)){
Stage[getIndex(X,Y)] = CHR_FLAG;
FlagNum--;
}else if(Stage[getIndex(X,Y)] == CHR_FLAG){
Stage[getIndex(X,Y)] = CHR_CLOSE;
FlagNum++;
}
break;
case KEY_ENTER:
if(Stage[getIndex(X,Y)] == CHR_CLOSE){
Stage[getIndex(X,Y)] = CHR_OPEN;
}
break;
case KEY_LM:
case KEY_UM:
if(Stage[getIndex(X,Y)] == CHR_CLOSE){
Stage[getIndex(X,Y)] = CHR_MARK;
}else if(Stage[getIndex(X,Y)] == CHR_MARK){
Stage[getIndex(X,Y)] = CHR_CLOSE;
}
break;
case KEY_UP:
if(Y > 0) Y--;
break;
case KEY_DOWN:
if(Y < STAGE_Y - 1) Y++;
break;
case KEY_LEFT:
if(X > 0) X--;
break;
case KEY_RIGHT:
if(X < STAGE_X - 1) X++;
break;
case KEY_LE:
case KEY_UE:
return 1;
break;
default:
puts(HELP_STR);
getch();
break;
}
return 0;
}
// ゲーム更新処理
int updateGame(void){
return 0;
}
// ゲームメインループ
int gameBody(void){
drawScreen();
if(inputMethod()) return GAME_EXIT;
if(updateGame()) return GAME_OVER;
return GAME_BODY;
}
// ゲームクリアループ
int gameClear(void){
return GAME_EXIT;
}
// ゲームオーバーループ
int gameOver(void){
return GAME_EXIT;
}
// エントリポイント。
int main(void){
int gm = GAME_INIT;
int (*f[])(void) = {initGame,gameClear,gameBody,gameOver};
while(gm != GAME_EXIT) gm = f[gm]();
return 0;
}
2010年8月28日土曜日
C言語でリスト構造その2。
前回のソースを改変し、配列的な使い方ができるようにしました。
まあだいたいこんなイメージだと思います。
ちなみにgccで動作確認済みです。おそらくVC++でも動くと思います。
// リスト構造を配列っぽく使えるようにする。
// ついでに要素の削除、挿入処理も追加してみる。
// 基本実装のおさらいが主旨なので、例外処理はなるべく省略したよ!
#include <stdio.h>
#include <stdlib.h>
// リスト要素の構造体定義。
typedef struct s_list{
int index;
int value;
struct s_list *next;
struct s_list *prev;
}LIST;
// 構造体LIST型のグローバルポインタ変数を宣言。
LIST *ls_ptr;
// グローバル変数追加:リストの先頭アドレス
LIST *ls_start;
// リスト構造の使用準備(更新)
void initList(){
if(ls_start != NULL) return; //追加:すでにリストが作成されている場合は何もしない!
ls_ptr = malloc(sizeof(LIST));
ls_start = ls_ptr; // 追加:リストの先頭ポインタを保存
ls_ptr->next = NULL;
ls_ptr->prev = NULL;
ls_ptr->value = 0;
ls_ptr->index = 0;
}
// インデックスの最大値を返す。
int getMaxIndex(){
LIST *lp = ls_start;
while(lp->next != NULL){
lp = lp->next;
}
return lp->index + 1;
}
// インデックスからリスト要素のポインタを返す。
// 見つからない場合はNULLが返る。
LIST* getPointerFromIndex(int index){
LIST *lp = ls_start;
while((lp != NULL)&&(lp->index != index)){
lp = lp->next;
}
return lp;
}
// 使われていない最小インデックス番号を返す。
// 使われていないインデックスがなければ、最大インデックス+1を返す。
int getFreeIndex(){
LIST *lp = ls_start;
int i;
for(i=0;lp != NULL;i++){
if(lp->index != i) return i;
lp = lp->next;
}
return i+1;
}
// インデックスから要素を取り出す。
int getItemValue(int index){
LIST *lp = getPointerFromIndex(index);
if(lp == NULL) return 0;
return lp->value;
}
// 指定インデックス番号を削除する。
// index=0(開始ポインタ)を削除しようとした場合は何もしない。
LIST* deleteItem(int index){
LIST *lp = getPointerFromIndex(index);
if(lp->prev == NULL) goto EXIT_HANDLER;
lp->prev->next = lp->next;
lp->next->prev = lp->prev;
free(lp);
EXIT_HANDLER:
return lp->next->prev;
}
// 指定インデックスの次に要素を挿入する。
// (インデックスは使用されていない最小の値とする)
LIST* insertItem(int index,int value){
LIST *lp = getPointerFromIndex(index);
LIST *new_ptr = malloc(sizeof(LIST));
new_ptr->next = lp->next;
new_ptr->prev = lp;
new_ptr->index = getFreeIndex();
new_ptr->value = value;
lp->next = new_ptr;
return new_ptr;
}
// リストを一括削除する。
// ※free(NULL)は何もしないことが保証されているよ。
void deleteList(){
LIST *lp = ls_start;
while(lp != NULL){
LIST *next = lp->next;
free(lp);
lp = next;
}
ls_ptr = NULL;
ls_start = NULL;
}
// リスト構造の末尾に要素を追加する。
int pushList(int val){
LIST *prev;
ls_ptr->next = malloc(sizeof(LIST));
prev = ls_ptr;
ls_ptr = ls_ptr->next;
ls_ptr->next = NULL;
ls_ptr->prev = prev;
ls_ptr->index = prev->index + 1;
ls_ptr->value = val;
return ls_ptr->index;
}
// リスト構造の末尾から要素を取り出す(取り出された要素は削除される)。
int popList(void){
int val = ls_ptr->value;
if(ls_ptr->prev == NULL) goto EXIT_HANDLER;
ls_ptr = ls_ptr->prev;
free(ls_ptr->next);
ls_ptr->next = NULL;
EXIT_HANDLER:
return val;
}
// 現在のリストインデックスを取得。
int listIndex(){
return ls_ptr->index;
}
// リスト要素の終端をチェックし、要素がない場合はリスト構造を破棄する。
int checkEndOfList(){
if(ls_ptr->prev == NULL){
free(ls_ptr);
ls_ptr = NULL;
return 0;
}
return 1;
}
// エントリポイント
int main(int argc,char **argv){
int i,max;
initList();
pushList(1);
pushList(2);
pushList(5);
pushList(7);
pushList(8);
pushList(9);
pushList(100);
max = getMaxIndex();
for(i=0;i < max;i++){
printf("要素番号 %d : 値 %d\n",i,getItemValue(i));
}
return 0;
}
※追記:かなりバグがあったのでだいぶ修正しましたwww
2010年8月25日水曜日
C言語でリスト構造のおさらい。
リハビリを兼ねてC言語でリスト構造のおさらいをしてみました。
正確にはスタックの動作をするリスト構造というべきでしょうか。
これにリストを先頭からスキャンする処理を追加すると、配列的な使い方もできるようになります。
ちなみに、自作テトリスのリプレイ機能は基本的にこのようなリスト構造を使用しています。
// リスト構造(データコンテナ)をC言語で実装してみる。
#include <stdio.h>
#include <stdlib.h>
// リスト要素の構造体定義。
typedef struct s_list{
int index;
int value;
struct s_list *next;
struct s_list *prev;
}LIST;
// 構造体LIST型のグローバルポインタ変数を宣言。
LIST *ls_ptr;
// リスト構造の使用準備
void initList(){
ls_ptr = malloc(sizeof(LIST));
ls_ptr->next = NULL;
ls_ptr->prev = NULL;
ls_ptr->value = 0;
ls_ptr->index = 0;
}
// リスト構造の末尾に要素を追加する。
int pushList(int val){
LIST *prev;
ls_ptr->next = malloc(sizeof(LIST));
prev = ls_ptr;
ls_ptr = ls_ptr->next;
ls_ptr->next = NULL;
ls_ptr->prev = prev;
ls_ptr->index = prev->index + 1;
ls_ptr->value = val;
return ls_ptr->index;
}
// リスト構造の末尾から要素を取り出す(取り出された要素は削除される)。
int popList(void){
int val = ls_ptr->value;
if(ls_ptr->prev == NULL) goto EXIT_HANDLER;
ls_ptr = ls_ptr->prev;
free(ls_ptr->next);
ls_ptr->next = NULL;
EXIT_HANDLER:
return val;
}
// 現在のリストインデックスを取得。
int listIndex(){
return ls_ptr->index;
}
// リスト要素の終端をチェックし、要素がない場合はリスト構造を破棄する。
int checkEndOfList(){
if(ls_ptr->prev == NULL){
free(ls_ptr);
ls_ptr = NULL;
return 0;
}
return 1;
}
// エントリポイント
int main(int argc,char **argv){
initList();
pushList(1);
pushList(2);
pushList(5);
pushList(7);
pushList(8);
pushList(9);
pushList(100);
while(checkEndOfList()){
printf("要素番号 %d : 値 %d\n",listIndex(),popList());
}
return 0;
}
実行イメージ
2010年8月7日土曜日
CVS構築メモ。
ソース管理ツールCVSの構築手順をメモっておく。
eclipseをCVSクライアントとして使用することを想定しています。
★Windows環境
• CVSNT-SJIS版を今回は使用。
• インストーラですべて標準設定でセットアップ。
• CVS接続用のユーザ(通常ユーザでOK)を作成。
• CVSのルートパスとなるフォルダを作成。(例:C:¥CVSHOME)
• 環境変数を設定。[CVSROOT=(CVSルートパス)]
• 必要であればインストールしたCVSのパスを通しておく。(例:C:¥Program Files¥cvsnt¥)
• [スタート]→[設定]→[コントロールパネル]→[CVS for NT]を開く。
• CVSサービス及びロックサービスが動いている場合は止めておく。
• [リポジトリ]タブを選択し、CVSROOTに設定したパスを登録する。
• [詳細]タブを選択し、[Unix CVSであるふりをする]にチェックし、他のチェックは外す。
• [サービスの状態]タブに戻り、サービスを再起動する。
• コマンドプロンプトを開き、[cvs init]を実行、リポジトリを初期化する。
• 続けてユーザとパスワードを追加する。[例:cvs passwd -r (CVS用Windowsユーザ) -a (追加するユーザ名)]
• 必要であれば2401ー2402のTCPポートを開けておく。
★Ubuntu(Linux)環境
• SynapticでCVSとxinetdをインストール。
• [/etc/xinetd.d/]フォルダ配下に[cvspserver]ファイルを作成※1
• CVS用システムユーザを作成し、そのユーザでログイン。(例:sudo adduser cvs)
• CVSのルートパスとなるフォルダを作成。(例:/home/cvs/cvshome)
• [cvs -d (CVSルートパス) init]を実行し、リポジトリを初期化する。
• (CVSルートパス)/CVSROOTに移動し、[htpasswd -c passwd (追加するユーザ名)]を実行し、パスワードを登録する。
• CVSユーザからログオフする。
※1 /etc/xinetd.d/cvspserverの内容(テキストファイル)
------------------------------------------------
service cvspserver
{
disable =no
port =2401
socket_type =stream
protocol =tcp
wait =no
user =root
passenv =PATH
server =/usr/bin/cvs
env =HOME=(CVSルートパス)
server_args =-f --allow-root=(CVSルートパス) pserver
}
------------------------------------------------
以上でサーバ側の設定はOK。だと思う。
2010年8月3日火曜日
Android開発近況。
やればやるほど面白くなってきましたAndroid SDK。
今日はこんなコードを書いてみました。
適当にゴチャッと書いたので汚いのは許してね。
ちなみにこのコードはボタンを押すとテキストボックスに入力された
URLでブラウザを開くだけのものですw
package com.imoimo.intent_test;
import android.app.Activity;
import android.app.AlertDialog;
import android.os.Bundle;
import android.content.Intent;
import android.net.Uri;
import android.view.View;
import android.view.View.OnClickListener;
import android.widget.LinearLayout;
import android.widget.EditText;
import android.widget.Button;
import android.text.SpannableStringBuilder;
public class Form1 extends Activity implements OnClickListener{
EditText et;
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.main);
LinearLayout ll = new LinearLayout(this);
ll.setOrientation(LinearLayout.VERTICAL);
setContentView(ll);
et = new EditText(this);
et.setText("http://imoimo2010.blogspot.com/");
ll.addView(et);
Button bt = new Button(this);
bt.setText("ブラウザ起動");
bt.setOnClickListener(this);
ll.addView(bt);
}
public void onClick(View v){
SpannableStringBuilder sb = (SpannableStringBuilder)et.getText();
openBrowser(sb.toString());
}
public void openBrowser(String uri){
try{
Intent i = new Intent(Intent.ACTION_VIEW,Uri.parse(uri));
startActivity(i);
}catch(Exception e){
viewDialog("エラー","ブラウザの起動に失敗しました。");
}
}
public void viewDialog(CharSequence title,CharSequence msg){
AlertDialog.Builder dlg;
dlg = new AlertDialog.Builder(this);
dlg.setTitle(title);
dlg.setMessage(msg);
dlg.setPositiveButton("閉じる", null);
dlg.show();
}
}
|
__label__pos
| 0.807726 |
ハンバーガーメニューの作り方【jQuery】
この記事では,ハンバーガーメニューの作り方について紹介します.
ハンバーガーメニューと言っても,ハンバーガー屋のメニューのことではありません.
と〜げ
webサイトの幅を狭めると,ヘッダーのメニューが消えて,ハンバーガーのように三本線が現れて,これをクリックするとメニューが表示されるやつです.
↓↓↓↓↓↓↓↓↓↓↓
では,上のようなハンバーガーメニューを作っていきます.
と〜げ
すべてのファイル(html,css, jsファイル)に関しては,最後に貼っておきます.必要に応じてコピペしてください.
ハンバーガーメニューの作り方
See the Pen
GLvVad
by Yoshitaka (@YOSHITAKA3)
on CodePen.
ポイント
• PC幅のときは,ハンバーガー3本線(class=”humberger-wrap)は非表示
SP(スマホ)幅のときは,ハンバーガ3本線(class=”humberger-wrap)を表示,ヘッダーメニュ(nav)ーを非表示させます.
• jQueryで,ハンバーガー3本線(.hunmberger-wrap)をクリックすると,ハンバーガ3本線(class=”humberger-wrap)と,ヘッダー(header)にopenedというクラスを追加する
• ハンバーガー3本線をクリックしたときopenedクラスを利用して,cssで,3本線の変化やメニューの形を整える.
htmlファイル
<!doctype html>
cssファイル
* {
box-sizing: border-box;
margin:0;
padding:0;
}
body {
font-size: .9375rem;
font-weight: 400;
line-height: 1.67;
overflow: hidden;
letter-spacing: .05em;
color: #333;
background: #fff;
}
a {
cursor: pointer;
text-decoration: none;
color: #000;
}
ol, ul {
list-style:none;
}
/*--header--*/
header {
font-size: 15px;
font-size: .9375rem;
position: fixed;
top: 0;
left: 0;
width: 100%;
height: 60px;
letter-spacing: .05em;
background:#f1f1f1;
}
header .inner {
display: flex;
width: 100%;
height: 60px;
flex-flow: row wrap;
justify-content: center;
}
/*ハンバーガー3本線を非表示*/
header .humberger-wrap {
display:none;
}
header nav {
position:relative;
}
header nav, header ul {
display:flex;
}
header nav li {
cursor:pointer;
}
header nav a {
line-height:60px;
display:block;
height:60px;
padding:0 30px;
}
@media screen and (max-width:901px) {
/*3本線の表示*/
header .humberger-wrap {
display:block;
}
/*3本線の位置*/
header .humberger-wrap {
position: absolute;
top: 0;
right: 20px;
width: 40px;
height: 100%;
cursor: pointer;
}
/*humberger-border1,2,3の線*/
header .humberger-wrap [class*=humberger-border] {
position: absolute;
width: 40px;
height: 2px;
transition: .4s all ease;
transform-origin: center center;
background: #333;
}
/*1本目の線*/
header .humberger-wrap .humberger-border-1 {
top:20px;
right:0;
}
/*2本目の線*/
header .humberger-wrap .humberger-border-2 {
top:30px;
right:0;
}
/*3本目の線*/
header .humberger-wrap .humberger-border-3 {
top:40px;
right:0;
}
/*開閉ボタンopen時の横線1本目*/
header .humberger-wrap.opened .humberger-border-1 {
top: 30px;
transform: rotate(45deg);
}
/*開閉ボタンopen時の横線2本目*/
header .humberger-wrap.opened .humberger-border-2 {
top: 30px;
transform: rotate(-45deg);
}
/*開閉ボタンopen時の横線3本目*/
header .humberger-wrap.opened .humberger-border-3 {
top: 30px;
transform: rotate(-45deg);
opacity:0;
}
/*メニューを非表示*/
header nav {
display:none;
}
/*open時に一番上のヘッダーの背景色を変化*/
header.opened {
background: #fff;
}
header.opened nav {
display: block;
min-height: 100vh;
opacity: 1;
top:60px;
}
header nav ul.header-navigation {
flex-flow: column nowrap;
}
header nav ul.header-navigation li a {
display: block;
height: auto;
margin: 0;
padding: 10px 0;
}
}
javascriptファイル
$(function(){
$(".humberger-wrap").on("click",function(){
$(".humberger-wrap").toggleClass("opened");
$("header").toggleClass("opened");
});
$(".header-navigation > a").on("click",function(){
$(".humberger-wrap").removeClass("opened");
$("header").removeClass("opened");
})
});
コメントを残す
メールアドレスが公開されることはありません。 * が付いている欄は必須項目です
|
__label__pos
| 0.508891 |
/[pcre]/code/trunk/pcre_compile.c
ViewVC logotype
Contents of /code/trunk/pcre_compile.c
Parent Directory Parent Directory | Revision Log Revision Log
Revision 282 - (show annotations)
Fri Dec 7 19:32:32 2007 UTC (7 years, 7 months ago) by ph10
File MIME type: text/plain
File size: 195559 byte(s)
Error occurred while calculating annotation data.
Fix non-diagnosis of (?=a)(?R) (positive lookaheads not skipped when checking
for an empty match).
1 /*************************************************
2 * Perl-Compatible Regular Expressions *
3 *************************************************/
4
5 /* PCRE is a library of functions to support regular expressions whose syntax
6 and semantics are as close as possible to those of the Perl 5 language.
7
8 Written by Philip Hazel
9 Copyright (c) 1997-2007 University of Cambridge
10
11 -----------------------------------------------------------------------------
12 Redistribution and use in source and binary forms, with or without
13 modification, are permitted provided that the following conditions are met:
14
15 * Redistributions of source code must retain the above copyright notice,
16 this list of conditions and the following disclaimer.
17
18 * Redistributions in binary form must reproduce the above copyright
19 notice, this list of conditions and the following disclaimer in the
20 documentation and/or other materials provided with the distribution.
21
22 * Neither the name of the University of Cambridge nor the names of its
23 contributors may be used to endorse or promote products derived from
24 this software without specific prior written permission.
25
26 THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
27 AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
28 IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
29 ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE
30 LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR
31 CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF
32 SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS
33 INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN
34 CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE)
35 ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE
36 POSSIBILITY OF SUCH DAMAGE.
37 -----------------------------------------------------------------------------
38 */
39
40
41 /* This module contains the external function pcre_compile(), along with
42 supporting internal functions that are not used by other modules. */
43
44
45 #ifdef HAVE_CONFIG_H
46 #include "config.h"
47 #endif
48
49 #define NLBLOCK cd /* Block containing newline information */
50 #define PSSTART start_pattern /* Field containing processed string start */
51 #define PSEND end_pattern /* Field containing processed string end */
52
53 #include "pcre_internal.h"
54
55
56 /* When DEBUG is defined, we need the pcre_printint() function, which is also
57 used by pcretest. DEBUG is not defined when building a production library. */
58
59 #ifdef DEBUG
60 #include "pcre_printint.src"
61 #endif
62
63
64 /* Macro for setting individual bits in class bitmaps. */
65
66 #define SETBIT(a,b) a[b/8] |= (1 << (b%8))
67
68 /* Maximum length value to check against when making sure that the integer that
69 holds the compiled pattern length does not overflow. We make it a bit less than
70 INT_MAX to allow for adding in group terminating bytes, so that we don't have
71 to check them every time. */
72
73 #define OFLOW_MAX (INT_MAX - 20)
74
75
76 /*************************************************
77 * Code parameters and static tables *
78 *************************************************/
79
80 /* This value specifies the size of stack workspace that is used during the
81 first pre-compile phase that determines how much memory is required. The regex
82 is partly compiled into this space, but the compiled parts are discarded as
83 soon as they can be, so that hopefully there will never be an overrun. The code
84 does, however, check for an overrun. The largest amount I've seen used is 218,
85 so this number is very generous.
86
87 The same workspace is used during the second, actual compile phase for
88 remembering forward references to groups so that they can be filled in at the
89 end. Each entry in this list occupies LINK_SIZE bytes, so even when LINK_SIZE
90 is 4 there is plenty of room. */
91
92 #define COMPILE_WORK_SIZE (4096)
93
94
95 /* Table for handling escaped characters in the range '0'-'z'. Positive returns
96 are simple data values; negative values are for special things like \d and so
97 on. Zero means further processing is needed (for things like \x), or the escape
98 is invalid. */
99
100 #ifndef EBCDIC /* This is the "normal" table for ASCII systems */
101 static const short int escapes[] = {
102 0, 0, 0, 0, 0, 0, 0, 0, /* 0 - 7 */
103 0, 0, ':', ';', '<', '=', '>', '?', /* 8 - ? */
104 '@', -ESC_A, -ESC_B, -ESC_C, -ESC_D, -ESC_E, 0, -ESC_G, /* @ - G */
105 -ESC_H, 0, 0, -ESC_K, 0, 0, 0, 0, /* H - O */
106 -ESC_P, -ESC_Q, -ESC_R, -ESC_S, 0, 0, -ESC_V, -ESC_W, /* P - W */
107 -ESC_X, 0, -ESC_Z, '[', '\\', ']', '^', '_', /* X - _ */
108 '`', 7, -ESC_b, 0, -ESC_d, ESC_e, ESC_f, 0, /* ` - g */
109 -ESC_h, 0, 0, -ESC_k, 0, 0, ESC_n, 0, /* h - o */
110 -ESC_p, 0, ESC_r, -ESC_s, ESC_tee, 0, -ESC_v, -ESC_w, /* p - w */
111 0, 0, -ESC_z /* x - z */
112 };
113
114 #else /* This is the "abnormal" table for EBCDIC systems */
115 static const short int escapes[] = {
116 /* 48 */ 0, 0, 0, '.', '<', '(', '+', '|',
117 /* 50 */ '&', 0, 0, 0, 0, 0, 0, 0,
118 /* 58 */ 0, 0, '!', '$', '*', ')', ';', '~',
119 /* 60 */ '-', '/', 0, 0, 0, 0, 0, 0,
120 /* 68 */ 0, 0, '|', ',', '%', '_', '>', '?',
121 /* 70 */ 0, 0, 0, 0, 0, 0, 0, 0,
122 /* 78 */ 0, '`', ':', '#', '@', '\'', '=', '"',
123 /* 80 */ 0, 7, -ESC_b, 0, -ESC_d, ESC_e, ESC_f, 0,
124 /* 88 */-ESC_h, 0, 0, '{', 0, 0, 0, 0,
125 /* 90 */ 0, 0, -ESC_k, 'l', 0, ESC_n, 0, -ESC_p,
126 /* 98 */ 0, ESC_r, 0, '}', 0, 0, 0, 0,
127 /* A0 */ 0, '~', -ESC_s, ESC_tee, 0,-ESC_v, -ESC_w, 0,
128 /* A8 */ 0,-ESC_z, 0, 0, 0, '[', 0, 0,
129 /* B0 */ 0, 0, 0, 0, 0, 0, 0, 0,
130 /* B8 */ 0, 0, 0, 0, 0, ']', '=', '-',
131 /* C0 */ '{',-ESC_A, -ESC_B, -ESC_C, -ESC_D,-ESC_E, 0, -ESC_G,
132 /* C8 */-ESC_H, 0, 0, 0, 0, 0, 0, 0,
133 /* D0 */ '}', 0, -ESC_K, 0, 0, 0, 0, -ESC_P,
134 /* D8 */-ESC_Q,-ESC_R, 0, 0, 0, 0, 0, 0,
135 /* E0 */ '\\', 0, -ESC_S, 0, 0,-ESC_V, -ESC_W, -ESC_X,
136 /* E8 */ 0,-ESC_Z, 0, 0, 0, 0, 0, 0,
137 /* F0 */ 0, 0, 0, 0, 0, 0, 0, 0,
138 /* F8 */ 0, 0, 0, 0, 0, 0, 0, 0
139 };
140 #endif
141
142
143 /* Table of special "verbs" like (*PRUNE). This is a short table, so it is
144 searched linearly. Put all the names into a single string, in order to reduce
145 the number of relocations when a shared library is dynamically linked. */
146
147 typedef struct verbitem {
148 int len;
149 int op;
150 } verbitem;
151
152 static const char verbnames[] =
153 "ACCEPT\0"
154 "COMMIT\0"
155 "F\0"
156 "FAIL\0"
157 "PRUNE\0"
158 "SKIP\0"
159 "THEN";
160
161 static verbitem verbs[] = {
162 { 6, OP_ACCEPT },
163 { 6, OP_COMMIT },
164 { 1, OP_FAIL },
165 { 4, OP_FAIL },
166 { 5, OP_PRUNE },
167 { 4, OP_SKIP },
168 { 4, OP_THEN }
169 };
170
171 static int verbcount = sizeof(verbs)/sizeof(verbitem);
172
173
174 /* Tables of names of POSIX character classes and their lengths. The names are
175 now all in a single string, to reduce the number of relocations when a shared
176 library is dynamically loaded. The list of lengths is terminated by a zero
177 length entry. The first three must be alpha, lower, upper, as this is assumed
178 for handling case independence. */
179
180 static const char posix_names[] =
181 "alpha\0" "lower\0" "upper\0" "alnum\0" "ascii\0" "blank\0"
182 "cntrl\0" "digit\0" "graph\0" "print\0" "punct\0" "space\0"
183 "word\0" "xdigit";
184
185 static const uschar posix_name_lengths[] = {
186 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 4, 6, 0 };
187
188 /* Table of class bit maps for each POSIX class. Each class is formed from a
189 base map, with an optional addition or removal of another map. Then, for some
190 classes, there is some additional tweaking: for [:blank:] the vertical space
191 characters are removed, and for [:alpha:] and [:alnum:] the underscore
192 character is removed. The triples in the table consist of the base map offset,
193 second map offset or -1 if no second map, and a non-negative value for map
194 addition or a negative value for map subtraction (if there are two maps). The
195 absolute value of the third field has these meanings: 0 => no tweaking, 1 =>
196 remove vertical space characters, 2 => remove underscore. */
197
198 static const int posix_class_maps[] = {
199 cbit_word, cbit_digit, -2, /* alpha */
200 cbit_lower, -1, 0, /* lower */
201 cbit_upper, -1, 0, /* upper */
202 cbit_word, -1, 2, /* alnum - word without underscore */
203 cbit_print, cbit_cntrl, 0, /* ascii */
204 cbit_space, -1, 1, /* blank - a GNU extension */
205 cbit_cntrl, -1, 0, /* cntrl */
206 cbit_digit, -1, 0, /* digit */
207 cbit_graph, -1, 0, /* graph */
208 cbit_print, -1, 0, /* print */
209 cbit_punct, -1, 0, /* punct */
210 cbit_space, -1, 0, /* space */
211 cbit_word, -1, 0, /* word - a Perl extension */
212 cbit_xdigit,-1, 0 /* xdigit */
213 };
214
215
216 #define STRING(a) # a
217 #define XSTRING(s) STRING(s)
218
219 /* The texts of compile-time error messages. These are "char *" because they
220 are passed to the outside world. Do not ever re-use any error number, because
221 they are documented. Always add a new error instead. Messages marked DEAD below
222 are no longer used. This used to be a table of strings, but in order to reduce
223 the number of relocations needed when a shared library is loaded dynamically,
224 it is now one long string. We cannot use a table of offsets, because the
225 lengths of inserts such as XSTRING(MAX_NAME_SIZE) are not known. Instead, we
226 simply count through to the one we want - this isn't a performance issue
227 because these strings are used only when there is a compilation error. */
228
229 static const char error_texts[] =
230 "no error\0"
231 "\\ at end of pattern\0"
232 "\\c at end of pattern\0"
233 "unrecognized character follows \\\0"
234 "numbers out of order in {} quantifier\0"
235 /* 5 */
236 "number too big in {} quantifier\0"
237 "missing terminating ] for character class\0"
238 "invalid escape sequence in character class\0"
239 "range out of order in character class\0"
240 "nothing to repeat\0"
241 /* 10 */
242 "operand of unlimited repeat could match the empty string\0" /** DEAD **/
243 "internal error: unexpected repeat\0"
244 "unrecognized character after (? or (?-\0"
245 "POSIX named classes are supported only within a class\0"
246 "missing )\0"
247 /* 15 */
248 "reference to non-existent subpattern\0"
249 "erroffset passed as NULL\0"
250 "unknown option bit(s) set\0"
251 "missing ) after comment\0"
252 "parentheses nested too deeply\0" /** DEAD **/
253 /* 20 */
254 "regular expression is too large\0"
255 "failed to get memory\0"
256 "unmatched parentheses\0"
257 "internal error: code overflow\0"
258 "unrecognized character after (?<\0"
259 /* 25 */
260 "lookbehind assertion is not fixed length\0"
261 "malformed number or name after (?(\0"
262 "conditional group contains more than two branches\0"
263 "assertion expected after (?(\0"
264 "(?R or (?[+-]digits must be followed by )\0"
265 /* 30 */
266 "unknown POSIX class name\0"
267 "POSIX collating elements are not supported\0"
268 "this version of PCRE is not compiled with PCRE_UTF8 support\0"
269 "spare error\0" /** DEAD **/
270 "character value in \\x{...} sequence is too large\0"
271 /* 35 */
272 "invalid condition (?(0)\0"
273 "\\C not allowed in lookbehind assertion\0"
274 "PCRE does not support \\L, \\l, \\N, \\U, or \\u\0"
275 "number after (?C is > 255\0"
276 "closing ) for (?C expected\0"
277 /* 40 */
278 "recursive call could loop indefinitely\0"
279 "unrecognized character after (?P\0"
280 "syntax error in subpattern name (missing terminator)\0"
281 "two named subpatterns have the same name\0"
282 "invalid UTF-8 string\0"
283 /* 45 */
284 "support for \\P, \\p, and \\X has not been compiled\0"
285 "malformed \\P or \\p sequence\0"
286 "unknown property name after \\P or \\p\0"
287 "subpattern name is too long (maximum " XSTRING(MAX_NAME_SIZE) " characters)\0"
288 "too many named subpatterns (maximum " XSTRING(MAX_NAME_COUNT) ")\0"
289 /* 50 */
290 "repeated subpattern is too long\0" /** DEAD **/
291 "octal value is greater than \\377 (not in UTF-8 mode)\0"
292 "internal error: overran compiling workspace\0"
293 "internal error: previously-checked referenced subpattern not found\0"
294 "DEFINE group contains more than one branch\0"
295 /* 55 */
296 "repeating a DEFINE group is not allowed\0"
297 "inconsistent NEWLINE options\0"
298 "\\g is not followed by a braced name or an optionally braced non-zero number\0"
299 "(?+ or (?- or (?(+ or (?(- must be followed by a non-zero number\0"
300 "(*VERB) with an argument is not supported\0"
301 /* 60 */
302 "(*VERB) not recognized\0"
303 "number is too big\0"
304 "subpattern name expected\0"
305 "digit expected after (?+";
306
307
308 /* Table to identify digits and hex digits. This is used when compiling
309 patterns. Note that the tables in chartables are dependent on the locale, and
310 may mark arbitrary characters as digits - but the PCRE compiling code expects
311 to handle only 0-9, a-z, and A-Z as digits when compiling. That is why we have
312 a private table here. It costs 256 bytes, but it is a lot faster than doing
313 character value tests (at least in some simple cases I timed), and in some
314 applications one wants PCRE to compile efficiently as well as match
315 efficiently.
316
317 For convenience, we use the same bit definitions as in chartables:
318
319 0x04 decimal digit
320 0x08 hexadecimal digit
321
322 Then we can use ctype_digit and ctype_xdigit in the code. */
323
324 #ifndef EBCDIC /* This is the "normal" case, for ASCII systems */
325 static const unsigned char digitab[] =
326 {
327 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 0- 7 */
328 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 8- 15 */
329 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 16- 23 */
330 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 24- 31 */
331 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* - ' */
332 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* ( - / */
333 0x0c,0x0c,0x0c,0x0c,0x0c,0x0c,0x0c,0x0c, /* 0 - 7 */
334 0x0c,0x0c,0x00,0x00,0x00,0x00,0x00,0x00, /* 8 - ? */
335 0x00,0x08,0x08,0x08,0x08,0x08,0x08,0x00, /* @ - G */
336 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* H - O */
337 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* P - W */
338 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* X - _ */
339 0x00,0x08,0x08,0x08,0x08,0x08,0x08,0x00, /* ` - g */
340 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* h - o */
341 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* p - w */
342 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* x -127 */
343 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 128-135 */
344 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 136-143 */
345 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 144-151 */
346 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 152-159 */
347 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 160-167 */
348 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 168-175 */
349 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 176-183 */
350 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 184-191 */
351 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 192-199 */
352 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 200-207 */
353 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 208-215 */
354 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 216-223 */
355 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 224-231 */
356 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 232-239 */
357 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 240-247 */
358 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00};/* 248-255 */
359
360 #else /* This is the "abnormal" case, for EBCDIC systems */
361 static const unsigned char digitab[] =
362 {
363 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 0- 7 0 */
364 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 8- 15 */
365 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 16- 23 10 */
366 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 24- 31 */
367 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 32- 39 20 */
368 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 40- 47 */
369 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 48- 55 30 */
370 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 56- 63 */
371 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* - 71 40 */
372 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 72- | */
373 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* & - 87 50 */
374 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 88- 95 */
375 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* - -103 60 */
376 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 104- ? */
377 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 112-119 70 */
378 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 120- " */
379 0x00,0x08,0x08,0x08,0x08,0x08,0x08,0x00, /* 128- g 80 */
380 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* h -143 */
381 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 144- p 90 */
382 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* q -159 */
383 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 160- x A0 */
384 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* y -175 */
385 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* ^ -183 B0 */
386 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 184-191 */
387 0x00,0x08,0x08,0x08,0x08,0x08,0x08,0x00, /* { - G C0 */
388 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* H -207 */
389 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* } - P D0 */
390 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* Q -223 */
391 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* \ - X E0 */
392 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* Y -239 */
393 0x0c,0x0c,0x0c,0x0c,0x0c,0x0c,0x0c,0x0c, /* 0 - 7 F0 */
394 0x0c,0x0c,0x00,0x00,0x00,0x00,0x00,0x00};/* 8 -255 */
395
396 static const unsigned char ebcdic_chartab[] = { /* chartable partial dup */
397 0x80,0x00,0x00,0x00,0x00,0x01,0x00,0x00, /* 0- 7 */
398 0x00,0x00,0x00,0x00,0x01,0x01,0x00,0x00, /* 8- 15 */
399 0x00,0x00,0x00,0x00,0x00,0x01,0x00,0x00, /* 16- 23 */
400 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 24- 31 */
401 0x00,0x00,0x00,0x00,0x00,0x01,0x00,0x00, /* 32- 39 */
402 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 40- 47 */
403 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 48- 55 */
404 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 56- 63 */
405 0x01,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* - 71 */
406 0x00,0x00,0x00,0x80,0x00,0x80,0x80,0x80, /* 72- | */
407 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* & - 87 */
408 0x00,0x00,0x00,0x80,0x80,0x80,0x00,0x00, /* 88- 95 */
409 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* - -103 */
410 0x00,0x00,0x00,0x00,0x00,0x10,0x00,0x80, /* 104- ? */
411 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 112-119 */
412 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* 120- " */
413 0x00,0x1a,0x1a,0x1a,0x1a,0x1a,0x1a,0x12, /* 128- g */
414 0x12,0x12,0x00,0x00,0x00,0x00,0x00,0x00, /* h -143 */
415 0x00,0x12,0x12,0x12,0x12,0x12,0x12,0x12, /* 144- p */
416 0x12,0x12,0x00,0x00,0x00,0x00,0x00,0x00, /* q -159 */
417 0x00,0x00,0x12,0x12,0x12,0x12,0x12,0x12, /* 160- x */
418 0x12,0x12,0x00,0x00,0x00,0x00,0x00,0x00, /* y -175 */
419 0x80,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /* ^ -183 */
420 0x00,0x00,0x80,0x00,0x00,0x00,0x00,0x00, /* 184-191 */
421 0x80,0x1a,0x1a,0x1a,0x1a,0x1a,0x1a,0x12, /* { - G */
422 0x12,0x12,0x00,0x00,0x00,0x00,0x00,0x00, /* H -207 */
423 0x00,0x12,0x12,0x12,0x12,0x12,0x12,0x12, /* } - P */
424 0x12,0x12,0x00,0x00,0x00,0x00,0x00,0x00, /* Q -223 */
425 0x00,0x00,0x12,0x12,0x12,0x12,0x12,0x12, /* \ - X */
426 0x12,0x12,0x00,0x00,0x00,0x00,0x00,0x00, /* Y -239 */
427 0x1c,0x1c,0x1c,0x1c,0x1c,0x1c,0x1c,0x1c, /* 0 - 7 */
428 0x1c,0x1c,0x00,0x00,0x00,0x00,0x00,0x00};/* 8 -255 */
429 #endif
430
431
432 /* Definition to allow mutual recursion */
433
434 static BOOL
435 compile_regex(int, int, uschar **, const uschar **, int *, BOOL, BOOL, int,
436 int *, int *, branch_chain *, compile_data *, int *);
437
438
439
440 /*************************************************
441 * Find an error text *
442 *************************************************/
443
444 /* The error texts are now all in one long string, to save on relocations. As
445 some of the text is of unknown length, we can't use a table of offsets.
446 Instead, just count through the strings. This is not a performance issue
447 because it happens only when there has been a compilation error.
448
449 Argument: the error number
450 Returns: pointer to the error string
451 */
452
453 static const char *
454 find_error_text(int n)
455 {
456 const char *s = error_texts;
457 for (; n > 0; n--) while (*s++ != 0);
458 return s;
459 }
460
461
462 /*************************************************
463 * Handle escapes *
464 *************************************************/
465
466 /* This function is called when a \ has been encountered. It either returns a
467 positive value for a simple escape such as \n, or a negative value which
468 encodes one of the more complicated things such as \d. A backreference to group
469 n is returned as -(ESC_REF + n); ESC_REF is the highest ESC_xxx macro. When
470 UTF-8 is enabled, a positive value greater than 255 may be returned. On entry,
471 ptr is pointing at the \. On exit, it is on the final character of the escape
472 sequence.
473
474 Arguments:
475 ptrptr points to the pattern position pointer
476 errorcodeptr points to the errorcode variable
477 bracount number of previous extracting brackets
478 options the options bits
479 isclass TRUE if inside a character class
480
481 Returns: zero or positive => a data character
482 negative => a special escape sequence
483 on error, errorcodeptr is set
484 */
485
486 static int
487 check_escape(const uschar **ptrptr, int *errorcodeptr, int bracount,
488 int options, BOOL isclass)
489 {
490 BOOL utf8 = (options & PCRE_UTF8) != 0;
491 const uschar *ptr = *ptrptr + 1;
492 int c, i;
493
494 GETCHARINCTEST(c, ptr); /* Get character value, increment pointer */
495 ptr--; /* Set pointer back to the last byte */
496
497 /* If backslash is at the end of the pattern, it's an error. */
498
499 if (c == 0) *errorcodeptr = ERR1;
500
501 /* Non-alphanumerics are literals. For digits or letters, do an initial lookup
502 in a table. A non-zero result is something that can be returned immediately.
503 Otherwise further processing may be required. */
504
505 #ifndef EBCDIC /* ASCII coding */
506 else if (c < '0' || c > 'z') {} /* Not alphanumeric */
507 else if ((i = escapes[c - '0']) != 0) c = i;
508
509 #else /* EBCDIC coding */
510 else if (c < 'a' || (ebcdic_chartab[c] & 0x0E) == 0) {} /* Not alphanumeric */
511 else if ((i = escapes[c - 0x48]) != 0) c = i;
512 #endif
513
514 /* Escapes that need further processing, or are illegal. */
515
516 else
517 {
518 const uschar *oldptr;
519 BOOL braced, negated;
520
521 switch (c)
522 {
523 /* A number of Perl escapes are not handled by PCRE. We give an explicit
524 error. */
525
526 case 'l':
527 case 'L':
528 case 'N':
529 case 'u':
530 case 'U':
531 *errorcodeptr = ERR37;
532 break;
533
534 /* \g must be followed by a number, either plain or braced. If positive, it
535 is an absolute backreference. If negative, it is a relative backreference.
536 This is a Perl 5.10 feature. Perl 5.10 also supports \g{name} as a
537 reference to a named group. This is part of Perl's movement towards a
538 unified syntax for back references. As this is synonymous with \k{name}, we
539 fudge it up by pretending it really was \k. */
540
541 case 'g':
542 if (ptr[1] == '{')
543 {
544 const uschar *p;
545 for (p = ptr+2; *p != 0 && *p != '}'; p++)
546 if (*p != '-' && (digitab[*p] & ctype_digit) == 0) break;
547 if (*p != 0 && *p != '}')
548 {
549 c = -ESC_k;
550 break;
551 }
552 braced = TRUE;
553 ptr++;
554 }
555 else braced = FALSE;
556
557 if (ptr[1] == '-')
558 {
559 negated = TRUE;
560 ptr++;
561 }
562 else negated = FALSE;
563
564 c = 0;
565 while ((digitab[ptr[1]] & ctype_digit) != 0)
566 c = c * 10 + *(++ptr) - '0';
567
568 if (c < 0)
569 {
570 *errorcodeptr = ERR61;
571 break;
572 }
573
574 if (c == 0 || (braced && *(++ptr) != '}'))
575 {
576 *errorcodeptr = ERR57;
577 break;
578 }
579
580 if (negated)
581 {
582 if (c > bracount)
583 {
584 *errorcodeptr = ERR15;
585 break;
586 }
587 c = bracount - (c - 1);
588 }
589
590 c = -(ESC_REF + c);
591 break;
592
593 /* The handling of escape sequences consisting of a string of digits
594 starting with one that is not zero is not straightforward. By experiment,
595 the way Perl works seems to be as follows:
596
597 Outside a character class, the digits are read as a decimal number. If the
598 number is less than 10, or if there are that many previous extracting
599 left brackets, then it is a back reference. Otherwise, up to three octal
600 digits are read to form an escaped byte. Thus \123 is likely to be octal
601 123 (cf \0123, which is octal 012 followed by the literal 3). If the octal
602 value is greater than 377, the least significant 8 bits are taken. Inside a
603 character class, \ followed by a digit is always an octal number. */
604
605 case '1': case '2': case '3': case '4': case '5':
606 case '6': case '7': case '8': case '9':
607
608 if (!isclass)
609 {
610 oldptr = ptr;
611 c -= '0';
612 while ((digitab[ptr[1]] & ctype_digit) != 0)
613 c = c * 10 + *(++ptr) - '0';
614 if (c < 0)
615 {
616 *errorcodeptr = ERR61;
617 break;
618 }
619 if (c < 10 || c <= bracount)
620 {
621 c = -(ESC_REF + c);
622 break;
623 }
624 ptr = oldptr; /* Put the pointer back and fall through */
625 }
626
627 /* Handle an octal number following \. If the first digit is 8 or 9, Perl
628 generates a binary zero byte and treats the digit as a following literal.
629 Thus we have to pull back the pointer by one. */
630
631 if ((c = *ptr) >= '8')
632 {
633 ptr--;
634 c = 0;
635 break;
636 }
637
638 /* \0 always starts an octal number, but we may drop through to here with a
639 larger first octal digit. The original code used just to take the least
640 significant 8 bits of octal numbers (I think this is what early Perls used
641 to do). Nowadays we allow for larger numbers in UTF-8 mode, but no more
642 than 3 octal digits. */
643
644 case '0':
645 c -= '0';
646 while(i++ < 2 && ptr[1] >= '0' && ptr[1] <= '7')
647 c = c * 8 + *(++ptr) - '0';
648 if (!utf8 && c > 255) *errorcodeptr = ERR51;
649 break;
650
651 /* \x is complicated. \x{ddd} is a character number which can be greater
652 than 0xff in utf8 mode, but only if the ddd are hex digits. If not, { is
653 treated as a data character. */
654
655 case 'x':
656 if (ptr[1] == '{')
657 {
658 const uschar *pt = ptr + 2;
659 int count = 0;
660
661 c = 0;
662 while ((digitab[*pt] & ctype_xdigit) != 0)
663 {
664 register int cc = *pt++;
665 if (c == 0 && cc == '0') continue; /* Leading zeroes */
666 count++;
667
668 #ifndef EBCDIC /* ASCII coding */
669 if (cc >= 'a') cc -= 32; /* Convert to upper case */
670 c = (c << 4) + cc - ((cc < 'A')? '0' : ('A' - 10));
671 #else /* EBCDIC coding */
672 if (cc >= 'a' && cc <= 'z') cc += 64; /* Convert to upper case */
673 c = (c << 4) + cc - ((cc >= '0')? '0' : ('A' - 10));
674 #endif
675 }
676
677 if (*pt == '}')
678 {
679 if (c < 0 || count > (utf8? 8 : 2)) *errorcodeptr = ERR34;
680 ptr = pt;
681 break;
682 }
683
684 /* If the sequence of hex digits does not end with '}', then we don't
685 recognize this construct; fall through to the normal \x handling. */
686 }
687
688 /* Read just a single-byte hex-defined char */
689
690 c = 0;
691 while (i++ < 2 && (digitab[ptr[1]] & ctype_xdigit) != 0)
692 {
693 int cc; /* Some compilers don't like ++ */
694 cc = *(++ptr); /* in initializers */
695 #ifndef EBCDIC /* ASCII coding */
696 if (cc >= 'a') cc -= 32; /* Convert to upper case */
697 c = c * 16 + cc - ((cc < 'A')? '0' : ('A' - 10));
698 #else /* EBCDIC coding */
699 if (cc <= 'z') cc += 64; /* Convert to upper case */
700 c = c * 16 + cc - ((cc >= '0')? '0' : ('A' - 10));
701 #endif
702 }
703 break;
704
705 /* For \c, a following letter is upper-cased; then the 0x40 bit is flipped.
706 This coding is ASCII-specific, but then the whole concept of \cx is
707 ASCII-specific. (However, an EBCDIC equivalent has now been added.) */
708
709 case 'c':
710 c = *(++ptr);
711 if (c == 0)
712 {
713 *errorcodeptr = ERR2;
714 break;
715 }
716
717 #ifndef EBCDIC /* ASCII coding */
718 if (c >= 'a' && c <= 'z') c -= 32;
719 c ^= 0x40;
720 #else /* EBCDIC coding */
721 if (c >= 'a' && c <= 'z') c += 64;
722 c ^= 0xC0;
723 #endif
724 break;
725
726 /* PCRE_EXTRA enables extensions to Perl in the matter of escapes. Any
727 other alphanumeric following \ is an error if PCRE_EXTRA was set;
728 otherwise, for Perl compatibility, it is a literal. This code looks a bit
729 odd, but there used to be some cases other than the default, and there may
730 be again in future, so I haven't "optimized" it. */
731
732 default:
733 if ((options & PCRE_EXTRA) != 0) switch(c)
734 {
735 default:
736 *errorcodeptr = ERR3;
737 break;
738 }
739 break;
740 }
741 }
742
743 *ptrptr = ptr;
744 return c;
745 }
746
747
748
749 #ifdef SUPPORT_UCP
750 /*************************************************
751 * Handle \P and \p *
752 *************************************************/
753
754 /* This function is called after \P or \p has been encountered, provided that
755 PCRE is compiled with support for Unicode properties. On entry, ptrptr is
756 pointing at the P or p. On exit, it is pointing at the final character of the
757 escape sequence.
758
759 Argument:
760 ptrptr points to the pattern position pointer
761 negptr points to a boolean that is set TRUE for negation else FALSE
762 dptr points to an int that is set to the detailed property value
763 errorcodeptr points to the error code variable
764
765 Returns: type value from ucp_type_table, or -1 for an invalid type
766 */
767
768 static int
769 get_ucp(const uschar **ptrptr, BOOL *negptr, int *dptr, int *errorcodeptr)
770 {
771 int c, i, bot, top;
772 const uschar *ptr = *ptrptr;
773 char name[32];
774
775 c = *(++ptr);
776 if (c == 0) goto ERROR_RETURN;
777
778 *negptr = FALSE;
779
780 /* \P or \p can be followed by a name in {}, optionally preceded by ^ for
781 negation. */
782
783 if (c == '{')
784 {
785 if (ptr[1] == '^')
786 {
787 *negptr = TRUE;
788 ptr++;
789 }
790 for (i = 0; i < (int)sizeof(name) - 1; i++)
791 {
792 c = *(++ptr);
793 if (c == 0) goto ERROR_RETURN;
794 if (c == '}') break;
795 name[i] = c;
796 }
797 if (c !='}') goto ERROR_RETURN;
798 name[i] = 0;
799 }
800
801 /* Otherwise there is just one following character */
802
803 else
804 {
805 name[0] = c;
806 name[1] = 0;
807 }
808
809 *ptrptr = ptr;
810
811 /* Search for a recognized property name using binary chop */
812
813 bot = 0;
814 top = _pcre_utt_size;
815
816 while (bot < top)
817 {
818 i = (bot + top) >> 1;
819 c = strcmp(name, _pcre_utt_names + _pcre_utt[i].name_offset);
820 if (c == 0)
821 {
822 *dptr = _pcre_utt[i].value;
823 return _pcre_utt[i].type;
824 }
825 if (c > 0) bot = i + 1; else top = i;
826 }
827
828 *errorcodeptr = ERR47;
829 *ptrptr = ptr;
830 return -1;
831
832 ERROR_RETURN:
833 *errorcodeptr = ERR46;
834 *ptrptr = ptr;
835 return -1;
836 }
837 #endif
838
839
840
841
842 /*************************************************
843 * Check for counted repeat *
844 *************************************************/
845
846 /* This function is called when a '{' is encountered in a place where it might
847 start a quantifier. It looks ahead to see if it really is a quantifier or not.
848 It is only a quantifier if it is one of the forms {ddd} {ddd,} or {ddd,ddd}
849 where the ddds are digits.
850
851 Arguments:
852 p pointer to the first char after '{'
853
854 Returns: TRUE or FALSE
855 */
856
857 static BOOL
858 is_counted_repeat(const uschar *p)
859 {
860 if ((digitab[*p++] & ctype_digit) == 0) return FALSE;
861 while ((digitab[*p] & ctype_digit) != 0) p++;
862 if (*p == '}') return TRUE;
863
864 if (*p++ != ',') return FALSE;
865 if (*p == '}') return TRUE;
866
867 if ((digitab[*p++] & ctype_digit) == 0) return FALSE;
868 while ((digitab[*p] & ctype_digit) != 0) p++;
869
870 return (*p == '}');
871 }
872
873
874
875 /*************************************************
876 * Read repeat counts *
877 *************************************************/
878
879 /* Read an item of the form {n,m} and return the values. This is called only
880 after is_counted_repeat() has confirmed that a repeat-count quantifier exists,
881 so the syntax is guaranteed to be correct, but we need to check the values.
882
883 Arguments:
884 p pointer to first char after '{'
885 minp pointer to int for min
886 maxp pointer to int for max
887 returned as -1 if no max
888 errorcodeptr points to error code variable
889
890 Returns: pointer to '}' on success;
891 current ptr on error, with errorcodeptr set non-zero
892 */
893
894 static const uschar *
895 read_repeat_counts(const uschar *p, int *minp, int *maxp, int *errorcodeptr)
896 {
897 int min = 0;
898 int max = -1;
899
900 /* Read the minimum value and do a paranoid check: a negative value indicates
901 an integer overflow. */
902
903 while ((digitab[*p] & ctype_digit) != 0) min = min * 10 + *p++ - '0';
904 if (min < 0 || min > 65535)
905 {
906 *errorcodeptr = ERR5;
907 return p;
908 }
909
910 /* Read the maximum value if there is one, and again do a paranoid on its size.
911 Also, max must not be less than min. */
912
913 if (*p == '}') max = min; else
914 {
915 if (*(++p) != '}')
916 {
917 max = 0;
918 while((digitab[*p] & ctype_digit) != 0) max = max * 10 + *p++ - '0';
919 if (max < 0 || max > 65535)
920 {
921 *errorcodeptr = ERR5;
922 return p;
923 }
924 if (max < min)
925 {
926 *errorcodeptr = ERR4;
927 return p;
928 }
929 }
930 }
931
932 /* Fill in the required variables, and pass back the pointer to the terminating
933 '}'. */
934
935 *minp = min;
936 *maxp = max;
937 return p;
938 }
939
940
941
942 /*************************************************
943 * Find forward referenced subpattern *
944 *************************************************/
945
946 /* This function scans along a pattern's text looking for capturing
947 subpatterns, and counting them. If it finds a named pattern that matches the
948 name it is given, it returns its number. Alternatively, if the name is NULL, it
949 returns when it reaches a given numbered subpattern. This is used for forward
950 references to subpatterns. We know that if (?P< is encountered, the name will
951 be terminated by '>' because that is checked in the first pass.
952
953 Arguments:
954 ptr current position in the pattern
955 count current count of capturing parens so far encountered
956 name name to seek, or NULL if seeking a numbered subpattern
957 lorn name length, or subpattern number if name is NULL
958 xmode TRUE if we are in /x mode
959
960 Returns: the number of the named subpattern, or -1 if not found
961 */
962
963 static int
964 find_parens(const uschar *ptr, int count, const uschar *name, int lorn,
965 BOOL xmode)
966 {
967 const uschar *thisname;
968
969 for (; *ptr != 0; ptr++)
970 {
971 int term;
972
973 /* Skip over backslashed characters and also entire \Q...\E */
974
975 if (*ptr == '\\')
976 {
977 if (*(++ptr) == 0) return -1;
978 if (*ptr == 'Q') for (;;)
979 {
980 while (*(++ptr) != 0 && *ptr != '\\');
981 if (*ptr == 0) return -1;
982 if (*(++ptr) == 'E') break;
983 }
984 continue;
985 }
986
987 /* Skip over character classes */
988
989 if (*ptr == '[')
990 {
991 while (*(++ptr) != ']')
992 {
993 if (*ptr == 0) return -1;
994 if (*ptr == '\\')
995 {
996 if (*(++ptr) == 0) return -1;
997 if (*ptr == 'Q') for (;;)
998 {
999 while (*(++ptr) != 0 && *ptr != '\\');
1000 if (*ptr == 0) return -1;
1001 if (*(++ptr) == 'E') break;
1002 }
1003 continue;
1004 }
1005 }
1006 continue;
1007 }
1008
1009 /* Skip comments in /x mode */
1010
1011 if (xmode && *ptr == '#')
1012 {
1013 while (*(++ptr) != 0 && *ptr != '\n');
1014 if (*ptr == 0) return -1;
1015 continue;
1016 }
1017
1018 /* An opening parens must now be a real metacharacter */
1019
1020 if (*ptr != '(') continue;
1021 if (ptr[1] != '?' && ptr[1] != '*')
1022 {
1023 count++;
1024 if (name == NULL && count == lorn) return count;
1025 continue;
1026 }
1027
1028 ptr += 2;
1029 if (*ptr == 'P') ptr++; /* Allow optional P */
1030
1031 /* We have to disambiguate (?<! and (?<= from (?<name> */
1032
1033 if ((*ptr != '<' || ptr[1] == '!' || ptr[1] == '=') &&
1034 *ptr != '\'')
1035 continue;
1036
1037 count++;
1038
1039 if (name == NULL && count == lorn) return count;
1040 term = *ptr++;
1041 if (term == '<') term = '>';
1042 thisname = ptr;
1043 while (*ptr != term) ptr++;
1044 if (name != NULL && lorn == ptr - thisname &&
1045 strncmp((const char *)name, (const char *)thisname, lorn) == 0)
1046 return count;
1047 }
1048
1049 return -1;
1050 }
1051
1052
1053
1054 /*************************************************
1055 * Find first significant op code *
1056 *************************************************/
1057
1058 /* This is called by several functions that scan a compiled expression looking
1059 for a fixed first character, or an anchoring op code etc. It skips over things
1060 that do not influence this. For some calls, a change of option is important.
1061 For some calls, it makes sense to skip negative forward and all backward
1062 assertions, and also the \b assertion; for others it does not.
1063
1064 Arguments:
1065 code pointer to the start of the group
1066 options pointer to external options
1067 optbit the option bit whose changing is significant, or
1068 zero if none are
1069 skipassert TRUE if certain assertions are to be skipped
1070
1071 Returns: pointer to the first significant opcode
1072 */
1073
1074 static const uschar*
1075 first_significant_code(const uschar *code, int *options, int optbit,
1076 BOOL skipassert)
1077 {
1078 for (;;)
1079 {
1080 switch ((int)*code)
1081 {
1082 case OP_OPT:
1083 if (optbit > 0 && ((int)code[1] & optbit) != (*options & optbit))
1084 *options = (int)code[1];
1085 code += 2;
1086 break;
1087
1088 case OP_ASSERT_NOT:
1089 case OP_ASSERTBACK:
1090 case OP_ASSERTBACK_NOT:
1091 if (!skipassert) return code;
1092 do code += GET(code, 1); while (*code == OP_ALT);
1093 code += _pcre_OP_lengths[*code];
1094 break;
1095
1096 case OP_WORD_BOUNDARY:
1097 case OP_NOT_WORD_BOUNDARY:
1098 if (!skipassert) return code;
1099 /* Fall through */
1100
1101 case OP_CALLOUT:
1102 case OP_CREF:
1103 case OP_RREF:
1104 case OP_DEF:
1105 code += _pcre_OP_lengths[*code];
1106 break;
1107
1108 default:
1109 return code;
1110 }
1111 }
1112 /* Control never reaches here */
1113 }
1114
1115
1116
1117
1118 /*************************************************
1119 * Find the fixed length of a pattern *
1120 *************************************************/
1121
1122 /* Scan a pattern and compute the fixed length of subject that will match it,
1123 if the length is fixed. This is needed for dealing with backward assertions.
1124 In UTF8 mode, the result is in characters rather than bytes.
1125
1126 Arguments:
1127 code points to the start of the pattern (the bracket)
1128 options the compiling options
1129
1130 Returns: the fixed length, or -1 if there is no fixed length,
1131 or -2 if \C was encountered
1132 */
1133
1134 static int
1135 find_fixedlength(uschar *code, int options)
1136 {
1137 int length = -1;
1138
1139 register int branchlength = 0;
1140 register uschar *cc = code + 1 + LINK_SIZE;
1141
1142 /* Scan along the opcodes for this branch. If we get to the end of the
1143 branch, check the length against that of the other branches. */
1144
1145 for (;;)
1146 {
1147 int d;
1148 register int op = *cc;
1149 switch (op)
1150 {
1151 case OP_CBRA:
1152 case OP_BRA:
1153 case OP_ONCE:
1154 case OP_COND:
1155 d = find_fixedlength(cc + ((op == OP_CBRA)? 2:0), options);
1156 if (d < 0) return d;
1157 branchlength += d;
1158 do cc += GET(cc, 1); while (*cc == OP_ALT);
1159 cc += 1 + LINK_SIZE;
1160 break;
1161
1162 /* Reached end of a branch; if it's a ket it is the end of a nested
1163 call. If it's ALT it is an alternation in a nested call. If it is
1164 END it's the end of the outer call. All can be handled by the same code. */
1165
1166 case OP_ALT:
1167 case OP_KET:
1168 case OP_KETRMAX:
1169 case OP_KETRMIN:
1170 case OP_END:
1171 if (length < 0) length = branchlength;
1172 else if (length != branchlength) return -1;
1173 if (*cc != OP_ALT) return length;
1174 cc += 1 + LINK_SIZE;
1175 branchlength = 0;
1176 break;
1177
1178 /* Skip over assertive subpatterns */
1179
1180 case OP_ASSERT:
1181 case OP_ASSERT_NOT:
1182 case OP_ASSERTBACK:
1183 case OP_ASSERTBACK_NOT:
1184 do cc += GET(cc, 1); while (*cc == OP_ALT);
1185 /* Fall through */
1186
1187 /* Skip over things that don't match chars */
1188
1189 case OP_REVERSE:
1190 case OP_CREF:
1191 case OP_RREF:
1192 case OP_DEF:
1193 case OP_OPT:
1194 case OP_CALLOUT:
1195 case OP_SOD:
1196 case OP_SOM:
1197 case OP_EOD:
1198 case OP_EODN:
1199 case OP_CIRC:
1200 case OP_DOLL:
1201 case OP_NOT_WORD_BOUNDARY:
1202 case OP_WORD_BOUNDARY:
1203 cc += _pcre_OP_lengths[*cc];
1204 break;
1205
1206 /* Handle literal characters */
1207
1208 case OP_CHAR:
1209 case OP_CHARNC:
1210 case OP_NOT:
1211 branchlength++;
1212 cc += 2;
1213 #ifdef SUPPORT_UTF8
1214 if ((options & PCRE_UTF8) != 0)
1215 {
1216 while ((*cc & 0xc0) == 0x80) cc++;
1217 }
1218 #endif
1219 break;
1220
1221 /* Handle exact repetitions. The count is already in characters, but we
1222 need to skip over a multibyte character in UTF8 mode. */
1223
1224 case OP_EXACT:
1225 branchlength += GET2(cc,1);
1226 cc += 4;
1227 #ifdef SUPPORT_UTF8
1228 if ((options & PCRE_UTF8) != 0)
1229 {
1230 while((*cc & 0x80) == 0x80) cc++;
1231 }
1232 #endif
1233 break;
1234
1235 case OP_TYPEEXACT:
1236 branchlength += GET2(cc,1);
1237 if (cc[3] == OP_PROP || cc[3] == OP_NOTPROP) cc += 2;
1238 cc += 4;
1239 break;
1240
1241 /* Handle single-char matchers */
1242
1243 case OP_PROP:
1244 case OP_NOTPROP:
1245 cc += 2;
1246 /* Fall through */
1247
1248 case OP_NOT_DIGIT:
1249 case OP_DIGIT:
1250 case OP_NOT_WHITESPACE:
1251 case OP_WHITESPACE:
1252 case OP_NOT_WORDCHAR:
1253 case OP_WORDCHAR:
1254 case OP_ANY:
1255 branchlength++;
1256 cc++;
1257 break;
1258
1259 /* The single-byte matcher isn't allowed */
1260
1261 case OP_ANYBYTE:
1262 return -2;
1263
1264 /* Check a class for variable quantification */
1265
1266 #ifdef SUPPORT_UTF8
1267 case OP_XCLASS:
1268 cc += GET(cc, 1) - 33;
1269 /* Fall through */
1270 #endif
1271
1272 case OP_CLASS:
1273 case OP_NCLASS:
1274 cc += 33;
1275
1276 switch (*cc)
1277 {
1278 case OP_CRSTAR:
1279 case OP_CRMINSTAR:
1280 case OP_CRQUERY:
1281 case OP_CRMINQUERY:
1282 return -1;
1283
1284 case OP_CRRANGE:
1285 case OP_CRMINRANGE:
1286 if (GET2(cc,1) != GET2(cc,3)) return -1;
1287 branchlength += GET2(cc,1);
1288 cc += 5;
1289 break;
1290
1291 default:
1292 branchlength++;
1293 }
1294 break;
1295
1296 /* Anything else is variable length */
1297
1298 default:
1299 return -1;
1300 }
1301 }
1302 /* Control never gets here */
1303 }
1304
1305
1306
1307
1308 /*************************************************
1309 * Scan compiled regex for numbered bracket *
1310 *************************************************/
1311
1312 /* This little function scans through a compiled pattern until it finds a
1313 capturing bracket with the given number.
1314
1315 Arguments:
1316 code points to start of expression
1317 utf8 TRUE in UTF-8 mode
1318 number the required bracket number
1319
1320 Returns: pointer to the opcode for the bracket, or NULL if not found
1321 */
1322
1323 static const uschar *
1324 find_bracket(const uschar *code, BOOL utf8, int number)
1325 {
1326 for (;;)
1327 {
1328 register int c = *code;
1329 if (c == OP_END) return NULL;
1330
1331 /* XCLASS is used for classes that cannot be represented just by a bit
1332 map. This includes negated single high-valued characters. The length in
1333 the table is zero; the actual length is stored in the compiled code. */
1334
1335 if (c == OP_XCLASS) code += GET(code, 1);
1336
1337 /* Handle capturing bracket */
1338
1339 else if (c == OP_CBRA)
1340 {
1341 int n = GET2(code, 1+LINK_SIZE);
1342 if (n == number) return (uschar *)code;
1343 code += _pcre_OP_lengths[c];
1344 }
1345
1346 /* Otherwise, we can get the item's length from the table, except that for
1347 repeated character types, we have to test for \p and \P, which have an extra
1348 two bytes of parameters. */
1349
1350 else
1351 {
1352 switch(c)
1353 {
1354 case OP_TYPESTAR:
1355 case OP_TYPEMINSTAR:
1356 case OP_TYPEPLUS:
1357 case OP_TYPEMINPLUS:
1358 case OP_TYPEQUERY:
1359 case OP_TYPEMINQUERY:
1360 case OP_TYPEPOSSTAR:
1361 case OP_TYPEPOSPLUS:
1362 case OP_TYPEPOSQUERY:
1363 if (code[1] == OP_PROP || code[1] == OP_NOTPROP) code += 2;
1364 break;
1365
1366 case OP_TYPEUPTO:
1367 case OP_TYPEMINUPTO:
1368 case OP_TYPEEXACT:
1369 case OP_TYPEPOSUPTO:
1370 if (code[3] == OP_PROP || code[3] == OP_NOTPROP) code += 2;
1371 break;
1372 }
1373
1374 /* Add in the fixed length from the table */
1375
1376 code += _pcre_OP_lengths[c];
1377
1378 /* In UTF-8 mode, opcodes that are followed by a character may be followed by
1379 a multi-byte character. The length in the table is a minimum, so we have to
1380 arrange to skip the extra bytes. */
1381
1382 #ifdef SUPPORT_UTF8
1383 if (utf8) switch(c)
1384 {
1385 case OP_CHAR:
1386 case OP_CHARNC:
1387 case OP_EXACT:
1388 case OP_UPTO:
1389 case OP_MINUPTO:
1390 case OP_POSUPTO:
1391 case OP_STAR:
1392 case OP_MINSTAR:
1393 case OP_POSSTAR:
1394 case OP_PLUS:
1395 case OP_MINPLUS:
1396 case OP_POSPLUS:
1397 case OP_QUERY:
1398 case OP_MINQUERY:
1399 case OP_POSQUERY:
1400 if (code[-1] >= 0xc0) code += _pcre_utf8_table4[code[-1] & 0x3f];
1401 break;
1402 }
1403 #endif
1404 }
1405 }
1406 }
1407
1408
1409
1410 /*************************************************
1411 * Scan compiled regex for recursion reference *
1412 *************************************************/
1413
1414 /* This little function scans through a compiled pattern until it finds an
1415 instance of OP_RECURSE.
1416
1417 Arguments:
1418 code points to start of expression
1419 utf8 TRUE in UTF-8 mode
1420
1421 Returns: pointer to the opcode for OP_RECURSE, or NULL if not found
1422 */
1423
1424 static const uschar *
1425 find_recurse(const uschar *code, BOOL utf8)
1426 {
1427 for (;;)
1428 {
1429 register int c = *code;
1430 if (c == OP_END) return NULL;
1431 if (c == OP_RECURSE) return code;
1432
1433 /* XCLASS is used for classes that cannot be represented just by a bit
1434 map. This includes negated single high-valued characters. The length in
1435 the table is zero; the actual length is stored in the compiled code. */
1436
1437 if (c == OP_XCLASS) code += GET(code, 1);
1438
1439 /* Otherwise, we can get the item's length from the table, except that for
1440 repeated character types, we have to test for \p and \P, which have an extra
1441 two bytes of parameters. */
1442
1443 else
1444 {
1445 switch(c)
1446 {
1447 case OP_TYPESTAR:
1448 case OP_TYPEMINSTAR:
1449 case OP_TYPEPLUS:
1450 case OP_TYPEMINPLUS:
1451 case OP_TYPEQUERY:
1452 case OP_TYPEMINQUERY:
1453 case OP_TYPEPOSSTAR:
1454 case OP_TYPEPOSPLUS:
1455 case OP_TYPEPOSQUERY:
1456 if (code[1] == OP_PROP || code[1] == OP_NOTPROP) code += 2;
1457 break;
1458
1459 case OP_TYPEPOSUPTO:
1460 case OP_TYPEUPTO:
1461 case OP_TYPEMINUPTO:
1462 case OP_TYPEEXACT:
1463 if (code[3] == OP_PROP || code[3] == OP_NOTPROP) code += 2;
1464 break;
1465 }
1466
1467 /* Add in the fixed length from the table */
1468
1469 code += _pcre_OP_lengths[c];
1470
1471 /* In UTF-8 mode, opcodes that are followed by a character may be followed
1472 by a multi-byte character. The length in the table is a minimum, so we have
1473 to arrange to skip the extra bytes. */
1474
1475 #ifdef SUPPORT_UTF8
1476 if (utf8) switch(c)
1477 {
1478 case OP_CHAR:
1479 case OP_CHARNC:
1480 case OP_EXACT:
1481 case OP_UPTO:
1482 case OP_MINUPTO:
1483 case OP_POSUPTO:
1484 case OP_STAR:
1485 case OP_MINSTAR:
1486 case OP_POSSTAR:
1487 case OP_PLUS:
1488 case OP_MINPLUS:
1489 case OP_POSPLUS:
1490 case OP_QUERY:
1491 case OP_MINQUERY:
1492 case OP_POSQUERY:
1493 if (code[-1] >= 0xc0) code += _pcre_utf8_table4[code[-1] & 0x3f];
1494 break;
1495 }
1496 #endif
1497 }
1498 }
1499 }
1500
1501
1502
1503 /*************************************************
1504 * Scan compiled branch for non-emptiness *
1505 *************************************************/
1506
1507 /* This function scans through a branch of a compiled pattern to see whether it
1508 can match the empty string or not. It is called from could_be_empty()
1509 below and from compile_branch() when checking for an unlimited repeat of a
1510 group that can match nothing. Note that first_significant_code() skips over
1511 backward and negative forward assertions when its final argument is TRUE. If we
1512 hit an unclosed bracket, we return "empty" - this means we've struck an inner
1513 bracket whose current branch will already have been scanned.
1514
1515 Arguments:
1516 code points to start of search
1517 endcode points to where to stop
1518 utf8 TRUE if in UTF8 mode
1519
1520 Returns: TRUE if what is matched could be empty
1521 */
1522
1523 static BOOL
1524 could_be_empty_branch(const uschar *code, const uschar *endcode, BOOL utf8)
1525 {
1526 register int c;
1527 for (code = first_significant_code(code + _pcre_OP_lengths[*code], NULL, 0, TRUE);
1528 code < endcode;
1529 code = first_significant_code(code + _pcre_OP_lengths[c], NULL, 0, TRUE))
1530 {
1531 const uschar *ccode;
1532
1533 c = *code;
1534
1535 /* Skip over forward assertions; the other assertions are skipped by
1536 first_significant_code() with a TRUE final argument. */
1537
1538 if (c == OP_ASSERT)
1539 {
1540 do code += GET(code, 1); while (*code == OP_ALT);
1541 c = *code;
1542 continue;
1543 }
1544
1545 /* Groups with zero repeats can of course be empty; skip them. */
1546
1547 if (c == OP_BRAZERO || c == OP_BRAMINZERO)
1548 {
1549 code += _pcre_OP_lengths[c];
1550 do code += GET(code, 1); while (*code == OP_ALT);
1551 c = *code;
1552 continue;
1553 }
1554
1555 /* For other groups, scan the branches. */
1556
1557 if (c == OP_BRA || c == OP_CBRA || c == OP_ONCE || c == OP_COND)
1558 {
1559 BOOL empty_branch;
1560 if (GET(code, 1) == 0) return TRUE; /* Hit unclosed bracket */
1561
1562 /* Scan a closed bracket */
1563
1564 empty_branch = FALSE;
1565 do
1566 {
1567 if (!empty_branch && could_be_empty_branch(code, endcode, utf8))
1568 empty_branch = TRUE;
1569 code += GET(code, 1);
1570 }
1571 while (*code == OP_ALT);
1572 if (!empty_branch) return FALSE; /* All branches are non-empty */
1573 c = *code;
1574 continue;
1575 }
1576
1577 /* Handle the other opcodes */
1578
1579 switch (c)
1580 {
1581 /* Check for quantifiers after a class. XCLASS is used for classes that
1582 cannot be represented just by a bit map. This includes negated single
1583 high-valued characters. The length in _pcre_OP_lengths[] is zero; the
1584 actual length is stored in the compiled code, so we must update "code"
1585 here. */
1586
1587 #ifdef SUPPORT_UTF8
1588 case OP_XCLASS:
1589 ccode = code += GET(code, 1);
1590 goto CHECK_CLASS_REPEAT;
1591 #endif
1592
1593 case OP_CLASS:
1594 case OP_NCLASS:
1595 ccode = code + 33;
1596
1597 #ifdef SUPPORT_UTF8
1598 CHECK_CLASS_REPEAT:
1599 #endif
1600
1601 switch (*ccode)
1602 {
1603 case OP_CRSTAR: /* These could be empty; continue */
1604 case OP_CRMINSTAR:
1605 case OP_CRQUERY:
1606 case OP_CRMINQUERY:
1607 break;
1608
1609 default: /* Non-repeat => class must match */
1610 case OP_CRPLUS: /* These repeats aren't empty */
1611 case OP_CRMINPLUS:
1612 return FALSE;
1613
1614 case OP_CRRANGE:
1615 case OP_CRMINRANGE:
1616 if (GET2(ccode, 1) > 0) return FALSE; /* Minimum > 0 */
1617 break;
1618 }
1619 break;
1620
1621 /* Opcodes that must match a character */
1622
1623 case OP_PROP:
1624 case OP_NOTPROP:
1625 case OP_EXTUNI:
1626 case OP_NOT_DIGIT:
1627 case OP_DIGIT:
1628 case OP_NOT_WHITESPACE:
1629 case OP_WHITESPACE:
1630 case OP_NOT_WORDCHAR:
1631 case OP_WORDCHAR:
1632 case OP_ANY:
1633 case OP_ANYBYTE:
1634 case OP_CHAR:
1635 case OP_CHARNC:
1636 case OP_NOT:
1637 case OP_PLUS:
1638 case OP_MINPLUS:
1639 case OP_POSPLUS:
1640 case OP_EXACT:
1641 case OP_NOTPLUS:
1642 case OP_NOTMINPLUS:
1643 case OP_NOTPOSPLUS:
1644 case OP_NOTEXACT:
1645 case OP_TYPEPLUS:
1646 case OP_TYPEMINPLUS:
1647 case OP_TYPEPOSPLUS:
1648 case OP_TYPEEXACT:
1649 return FALSE;
1650
1651 /* These are going to continue, as they may be empty, but we have to
1652 fudge the length for the \p and \P cases. */
1653
1654 case OP_TYPESTAR:
1655 case OP_TYPEMINSTAR:
1656 case OP_TYPEPOSSTAR:
1657 case OP_TYPEQUERY:
1658 case OP_TYPEMINQUERY:
1659 case OP_TYPEPOSQUERY:
1660 if (code[1] == OP_PROP || code[1] == OP_NOTPROP) code += 2;
1661 break;
1662
1663 /* Same for these */
1664
1665 case OP_TYPEUPTO:
1666 case OP_TYPEMINUPTO:
1667 case OP_TYPEPOSUPTO:
1668 if (code[3] == OP_PROP || code[3] == OP_NOTPROP) code += 2;
1669 break;
1670
1671 /* End of branch */
1672
1673 case OP_KET:
1674 case OP_KETRMAX:
1675 case OP_KETRMIN:
1676 case OP_ALT:
1677 return TRUE;
1678
1679 /* In UTF-8 mode, STAR, MINSTAR, POSSTAR, QUERY, MINQUERY, POSQUERY, UPTO,
1680 MINUPTO, and POSUPTO may be followed by a multibyte character */
1681
1682 #ifdef SUPPORT_UTF8
1683 case OP_STAR:
1684 case OP_MINSTAR:
1685 case OP_POSSTAR:
1686 case OP_QUERY:
1687 case OP_MINQUERY:
1688 case OP_POSQUERY:
1689 case OP_UPTO:
1690 case OP_MINUPTO:
1691 case OP_POSUPTO:
1692 if (utf8) while ((code[2] & 0xc0) == 0x80) code++;
1693 break;
1694 #endif
1695 }
1696 }
1697
1698 return TRUE;
1699 }
1700
1701
1702
1703 /*************************************************
1704 * Scan compiled regex for non-emptiness *
1705 *************************************************/
1706
1707 /* This function is called to check for left recursive calls. We want to check
1708 the current branch of the current pattern to see if it could match the empty
1709 string. If it could, we must look outwards for branches at other levels,
1710 stopping when we pass beyond the bracket which is the subject of the recursion.
1711
1712 Arguments:
1713 code points to start of the recursion
1714 endcode points to where to stop (current RECURSE item)
1715 bcptr points to the chain of current (unclosed) branch starts
1716 utf8 TRUE if in UTF-8 mode
1717
1718 Returns: TRUE if what is matched could be empty
1719 */
1720
1721 static BOOL
1722 could_be_empty(const uschar *code, const uschar *endcode, branch_chain *bcptr,
1723 BOOL utf8)
1724 {
1725 while (bcptr != NULL && bcptr->current >= code)
1726 {
1727 if (!could_be_empty_branch(bcptr->current, endcode, utf8)) return FALSE;
1728 bcptr = bcptr->outer;
1729 }
1730 return TRUE;
1731 }
1732
1733
1734
1735 /*************************************************
1736 * Check for POSIX class syntax *
1737 *************************************************/
1738
1739 /* This function is called when the sequence "[:" or "[." or "[=" is
1740 encountered in a character class. It checks whether this is followed by an
1741 optional ^ and then a sequence of letters, terminated by a matching ":]" or
1742 ".]" or "=]".
1743
1744 Argument:
1745 ptr pointer to the initial [
1746 endptr where to return the end pointer
1747 cd pointer to compile data
1748
1749 Returns: TRUE or FALSE
1750 */
1751
1752 static BOOL
1753 check_posix_syntax(const uschar *ptr, const uschar **endptr, compile_data *cd)
1754 {
1755 int terminator; /* Don't combine these lines; the Solaris cc */
1756 terminator = *(++ptr); /* compiler warns about "non-constant" initializer. */
1757 if (*(++ptr) == '^') ptr++;
1758 while ((cd->ctypes[*ptr] & ctype_letter) != 0) ptr++;
1759 if (*ptr == terminator && ptr[1] == ']')
1760 {
1761 *endptr = ptr;
1762 return TRUE;
1763 }
1764 return FALSE;
1765 }
1766
1767
1768
1769
1770 /*************************************************
1771 * Check POSIX class name *
1772 *************************************************/
1773
1774 /* This function is called to check the name given in a POSIX-style class entry
1775 such as [:alnum:].
1776
1777 Arguments:
1778 ptr points to the first letter
1779 len the length of the name
1780
1781 Returns: a value representing the name, or -1 if unknown
1782 */
1783
1784 static int
1785 check_posix_name(const uschar *ptr, int len)
1786 {
1787 const char *pn = posix_names;
1788 register int yield = 0;
1789 while (posix_name_lengths[yield] != 0)
1790 {
1791 if (len == posix_name_lengths[yield] &&
1792 strncmp((const char *)ptr, pn, len) == 0) return yield;
1793 pn += posix_name_lengths[yield] + 1;
1794 yield++;
1795 }
1796 return -1;
1797 }
1798
1799
1800 /*************************************************
1801 * Adjust OP_RECURSE items in repeated group *
1802 *************************************************/
1803
1804 /* OP_RECURSE items contain an offset from the start of the regex to the group
1805 that is referenced. This means that groups can be replicated for fixed
1806 repetition simply by copying (because the recursion is allowed to refer to
1807 earlier groups that are outside the current group). However, when a group is
1808 optional (i.e. the minimum quantifier is zero), OP_BRAZERO is inserted before
1809 it, after it has been compiled. This means that any OP_RECURSE items within it
1810 that refer to the group itself or any contained groups have to have their
1811 offsets adjusted. That one of the jobs of this function. Before it is called,
1812 the partially compiled regex must be temporarily terminated with OP_END.
1813
1814 This function has been extended with the possibility of forward references for
1815 recursions and subroutine calls. It must also check the list of such references
1816 for the group we are dealing with. If it finds that one of the recursions in
1817 the current group is on this list, it adjusts the offset in the list, not the
1818 value in the reference (which is a group number).
1819
1820 Arguments:
1821 group points to the start of the group
1822 adjust the amount by which the group is to be moved
1823 utf8 TRUE in UTF-8 mode
1824 cd contains pointers to tables etc.
1825 save_hwm the hwm forward reference pointer at the start of the group
1826
1827 Returns: nothing
1828 */
1829
1830 static void
1831 adjust_recurse(uschar *group, int adjust, BOOL utf8, compile_data *cd,
1832 uschar *save_hwm)
1833 {
1834 uschar *ptr = group;
1835
1836 while ((ptr = (uschar *)find_recurse(ptr, utf8)) != NULL)
1837 {
1838 int offset;
1839 uschar *hc;
1840
1841 /* See if this recursion is on the forward reference list. If so, adjust the
1842 reference. */
1843
1844 for (hc = save_hwm; hc < cd->hwm; hc += LINK_SIZE)
1845 {
1846 offset = GET(hc, 0);
1847 if (cd->start_code + offset == ptr + 1)
1848 {
1849 PUT(hc, 0, offset + adjust);
1850 break;
1851 }
1852 }
1853
1854 /* Otherwise, adjust the recursion offset if it's after the start of this
1855 group. */
1856
1857 if (hc >= cd->hwm)
1858 {
1859 offset = GET(ptr, 1);
1860 if (cd->start_code + offset >= group) PUT(ptr, 1, offset + adjust);
1861 }
1862
1863 ptr += 1 + LINK_SIZE;
1864 }
1865 }
1866
1867
1868
1869 /*************************************************
1870 * Insert an automatic callout point *
1871 *************************************************/
1872
1873 /* This function is called when the PCRE_AUTO_CALLOUT option is set, to insert
1874 callout points before each pattern item.
1875
1876 Arguments:
1877 code current code pointer
1878 ptr current pattern pointer
1879 cd pointers to tables etc
1880
1881 Returns: new code pointer
1882 */
1883
1884 static uschar *
1885 auto_callout(uschar *code, const uschar *ptr, compile_data *cd)
1886 {
1887 *code++ = OP_CALLOUT;
1888 *code++ = 255;
1889 PUT(code, 0, ptr - cd->start_pattern); /* Pattern offset */
1890 PUT(code, LINK_SIZE, 0); /* Default length */
1891 return code + 2*LINK_SIZE;
1892 }
1893
1894
1895
1896 /*************************************************
1897 * Complete a callout item *
1898 *************************************************/
1899
1900 /* A callout item contains the length of the next item in the pattern, which
1901 we can't fill in till after we have reached the relevant point. This is used
1902 for both automatic and manual callouts.
1903
1904 Arguments:
1905 previous_callout points to previous callout item
1906 ptr current pattern pointer
1907 cd pointers to tables etc
1908
1909 Returns: nothing
1910 */
1911
1912 static void
1913 complete_callout(uschar *previous_callout, const uschar *ptr, compile_data *cd)
1914 {
1915 int length = ptr - cd->start_pattern - GET(previous_callout, 2);
1916 PUT(previous_callout, 2 + LINK_SIZE, length);
1917 }
1918
1919
1920
1921 #ifdef SUPPORT_UCP
1922 /*************************************************
1923 * Get othercase range *
1924 *************************************************/
1925
1926 /* This function is passed the start and end of a class range, in UTF-8 mode
1927 with UCP support. It searches up the characters, looking for internal ranges of
1928 characters in the "other" case. Each call returns the next one, updating the
1929 start address.
1930
1931 Arguments:
1932 cptr points to starting character value; updated
1933 d end value
1934 ocptr where to put start of othercase range
1935 odptr where to put end of othercase range
1936
1937 Yield: TRUE when range returned; FALSE when no more
1938 */
1939
1940 static BOOL
1941 get_othercase_range(unsigned int *cptr, unsigned int d, unsigned int *ocptr,
1942 unsigned int *odptr)
1943 {
1944 unsigned int c, othercase, next;
1945
1946 for (c = *cptr; c <= d; c++)
1947 { if ((othercase = _pcre_ucp_othercase(c)) != NOTACHAR) break; }
1948
1949 if (c > d) return FALSE;
1950
1951 *ocptr = othercase;
1952 next = othercase + 1;
1953
1954 for (++c; c <= d; c++)
1955 {
1956 if (_pcre_ucp_othercase(c) != next) break;
1957 next++;
1958 }
1959
1960 *odptr = next - 1;
1961 *cptr = c;
1962
1963 return TRUE;
1964 }
1965 #endif /* SUPPORT_UCP */
1966
1967
1968
1969 /*************************************************
1970 * Check if auto-possessifying is possible *
1971 *************************************************/
1972
1973 /* This function is called for unlimited repeats of certain items, to see
1974 whether the next thing could possibly match the repeated item. If not, it makes
1975 sense to automatically possessify the repeated item.
1976
1977 Arguments:
1978 op_code the repeated op code
1979 this data for this item, depends on the opcode
1980 utf8 TRUE in UTF-8 mode
1981 utf8_char used for utf8 character bytes, NULL if not relevant
1982 ptr next character in pattern
1983 options options bits
1984 cd contains pointers to tables etc.
1985
1986 Returns: TRUE if possessifying is wanted
1987 */
1988
1989 static BOOL
1990 check_auto_possessive(int op_code, int item, BOOL utf8, uschar *utf8_char,
1991 const uschar *ptr, int options, compile_data *cd)
1992 {
1993 int next;
1994
1995 /* Skip whitespace and comments in extended mode */
1996
1997 if ((options & PCRE_EXTENDED) != 0)
1998 {
1999 for (;;)
2000 {
2001 while ((cd->ctypes[*ptr] & ctype_space) != 0) ptr++;
2002 if (*ptr == '#')
2003 {
2004 while (*(++ptr) != 0)
2005 if (IS_NEWLINE(ptr)) { ptr += cd->nllen; break; }
2006 }
2007 else break;
2008 }
2009 }
2010
2011 /* If the next item is one that we can handle, get its value. A non-negative
2012 value is a character, a negative value is an escape value. */
2013
2014 if (*ptr == '\\')
2015 {
2016 int temperrorcode = 0;
2017 next = check_escape(&ptr, &temperrorcode, cd->bracount, options, FALSE);
2018 if (temperrorcode != 0) return FALSE;
2019 ptr++; /* Point after the escape sequence */
2020 }
2021
2022 else if ((cd->ctypes[*ptr] & ctype_meta) == 0)
2023 {
2024 #ifdef SUPPORT_UTF8
2025 if (utf8) { GETCHARINC(next, ptr); } else
2026 #endif
2027 next = *ptr++;
2028 }
2029
2030 else return FALSE;
2031
2032 /* Skip whitespace and comments in extended mode */
2033
2034 if ((options & PCRE_EXTENDED) != 0)
2035 {
2036 for (;;)
2037 {
2038 while ((cd->ctypes[*ptr] & ctype_space) != 0) ptr++;
2039 if (*ptr == '#')
2040 {
2041 while (*(++ptr) != 0)
2042 if (IS_NEWLINE(ptr)) { ptr += cd->nllen; break; }
2043 }
2044 else break;
2045 }
2046 }
2047
2048 /* If the next thing is itself optional, we have to give up. */
2049
2050 if (*ptr == '*' || *ptr == '?' || strncmp((char *)ptr, "{0,", 3) == 0)
2051 return FALSE;
2052
2053 /* Now compare the next item with the previous opcode. If the previous is a
2054 positive single character match, "item" either contains the character or, if
2055 "item" is greater than 127 in utf8 mode, the character's bytes are in
2056 utf8_char. */
2057
2058
2059 /* Handle cases when the next item is a character. */
2060
2061 if (next >= 0) switch(op_code)
2062 {
2063 case OP_CHAR:
2064 #ifdef SUPPORT_UTF8
2065 if (utf8 && item > 127) { GETCHAR(item, utf8_char); }
2066 #endif
2067 return item != next;
2068
2069 /* For CHARNC (caseless character) we must check the other case. If we have
2070 Unicode property support, we can use it to test the other case of
2071 high-valued characters. */
2072
2073 case OP_CHARNC:
2074 #ifdef SUPPORT_UTF8
2075 if (utf8 && item > 127) { GETCHAR(item, utf8_char); }
2076 #endif
2077 if (item == next) return FALSE;
2078 #ifdef SUPPORT_UTF8
2079 if (utf8)
2080 {
2081 unsigned int othercase;
2082 if (next < 128) othercase = cd->fcc[next]; else
2083 #ifdef SUPPORT_UCP
2084 othercase = _pcre_ucp_othercase((unsigned int)next);
2085 #else
2086 othercase = NOTACHAR;
2087 #endif
2088 return (unsigned int)item != othercase;
2089 }
2090 else
2091 #endif /* SUPPORT_UTF8 */
2092 return (item != cd->fcc[next]); /* Non-UTF-8 mode */
2093
2094 /* For OP_NOT, "item" must be a single-byte character. */
2095
2096 case OP_NOT:
2097 if (next < 0) return FALSE; /* Not a character */
2098 if (item == next) return TRUE;
2099 if ((options & PCRE_CASELESS) == 0) return FALSE;
2100 #ifdef SUPPORT_UTF8
2101 if (utf8)
2102 {
2103 unsigned int othercase;
2104 if (next < 128) othercase = cd->fcc[next]; else
2105 #ifdef SUPPORT_UCP
2106 othercase = _pcre_ucp_othercase(next);
2107 #else
2108 othercase = NOTACHAR;
2109 #endif
2110 return (unsigned int)item == othercase;
2111 }
2112 else
2113 #endif /* SUPPORT_UTF8 */
2114 return (item == cd->fcc[next]); /* Non-UTF-8 mode */
2115
2116 case OP_DIGIT:
2117 return next > 127 || (cd->ctypes[next] & ctype_digit) == 0;
2118
2119 case OP_NOT_DIGIT:
2120 return next <= 127 && (cd->ctypes[next] & ctype_digit) != 0;
2121
2122 case OP_WHITESPACE:
2123 return next > 127 || (cd->ctypes[next] & ctype_space) == 0;
2124
2125 case OP_NOT_WHITESPACE:
2126 return next <= 127 && (cd->ctypes[next] & ctype_space) != 0;
2127
2128 case OP_WORDCHAR:
2129 return next > 127 || (cd->ctypes[next] & ctype_word) == 0;
2130
2131 case OP_NOT_WORDCHAR:
2132 return next <= 127 && (cd->ctypes[next] & ctype_word) != 0;
2133
2134 case OP_HSPACE:
2135 case OP_NOT_HSPACE:
2136 switch(next)
2137 {
2138 case 0x09:
2139 case 0x20:
2140 case 0xa0:
2141 case 0x1680:
2142 case 0x180e:
2143 case 0x2000:
2144 case 0x2001:
2145 case 0x2002:
2146 case 0x2003:
2147 case 0x2004:
2148 case 0x2005:
2149 case 0x2006:
2150 case 0x2007:
2151 case 0x2008:
2152 case 0x2009:
2153 case 0x200A:
2154 case 0x202f:
2155 case 0x205f:
2156 case 0x3000:
2157 return op_code != OP_HSPACE;
2158 default:
2159 return op_code == OP_HSPACE;
2160 }
2161
2162 case OP_VSPACE:
2163 case OP_NOT_VSPACE:
2164 switch(next)
2165 {
2166 case 0x0a:
2167 case 0x0b:
2168 case 0x0c:
2169 case 0x0d:
2170 case 0x85:
2171 case 0x2028:
2172 case 0x2029:
2173 return op_code != OP_VSPACE;
2174 default:
2175 return op_code == OP_VSPACE;
2176 }
2177
2178 default:
2179 return FALSE;
2180 }
2181
2182
2183 /* Handle the case when the next item is \d, \s, etc. */
2184
2185 switch(op_code)
2186 {
2187 case OP_CHAR:
2188 case OP_CHARNC:
2189 #ifdef SUPPORT_UTF8
2190 if (utf8 && item > 127) { GETCHAR(item, utf8_char); }
2191 #endif
2192 switch(-next)
2193 {
2194 case ESC_d:
2195 return item > 127 || (cd->ctypes[item] & ctype_digit) == 0;
2196
2197 case ESC_D:
2198 return item <= 127 && (cd->ctypes[item] & ctype_digit) != 0;
2199
2200 case ESC_s:
2201 return item > 127 || (cd->ctypes[item] & ctype_space) == 0;
2202
2203 case ESC_S:
2204 return item <= 127 && (cd->ctypes[item] & ctype_space) != 0;
2205
2206 case ESC_w:
2207 return item > 127 || (cd->ctypes[item] & ctype_word) == 0;
2208
2209 case ESC_W:
2210 return item <= 127 && (cd->ctypes[item] & ctype_word) != 0;
2211
2212 case ESC_h:
2213 case ESC_H:
2214 switch(item)
2215 {
2216 case 0x09:
2217 case 0x20:
2218 case 0xa0:
2219 case 0x1680:
2220 case 0x180e:
2221 case 0x2000:
2222 case 0x2001:
2223 case 0x2002:
2224 case 0x2003:
2225 case 0x2004:
2226 case 0x2005:
2227 case 0x2006:
2228 case 0x2007:
2229 case 0x2008:
2230 case 0x2009:
2231 case 0x200A:
2232 case 0x202f:
2233 case 0x205f:
2234 case 0x3000:
2235 return -next != ESC_h;
2236 default:
2237 return -next == ESC_h;
2238 }
2239
2240 case ESC_v:
2241 case ESC_V:
2242 switch(item)
2243 {
2244 case 0x0a:
2245 case 0x0b:
2246 case 0x0c:
2247 case 0x0d:
2248 case 0x85:
2249 case 0x2028:
2250 case 0x2029:
2251 return -next != ESC_v;
2252 default:
2253 return -next == ESC_v;
2254 }
2255
2256 default:
2257 return FALSE;
2258 }
2259
2260 case OP_DIGIT:
2261 return next == -ESC_D || next == -ESC_s || next == -ESC_W ||
2262 next == -ESC_h || next == -ESC_v;
2263
2264 case OP_NOT_DIGIT:
2265 return next == -ESC_d;
2266
2267 case OP_WHITESPACE:
2268 return next == -ESC_S || next == -ESC_d || next == -ESC_w;
2269
2270 case OP_NOT_WHITESPACE:
2271 return next == -ESC_s || next == -ESC_h || next == -ESC_v;
2272
2273 case OP_HSPACE:
2274 return next == -ESC_S || next == -ESC_H || next == -ESC_d || next == -ESC_w;
2275
2276 case OP_NOT_HSPACE:
2277 return next == -ESC_h;
2278
2279 /* Can't have \S in here because VT matches \S (Perl anomaly) */
2280 case OP_VSPACE:
2281 return next == -ESC_V || next == -ESC_d || next == -ESC_w;
2282
2283 case OP_NOT_VSPACE:
2284 return next == -ESC_v;
2285
2286 case OP_WORDCHAR:
2287 return next == -ESC_W || next == -ESC_s || next == -ESC_h || next == -ESC_v;
2288
2289 case OP_NOT_WORDCHAR:
2290 return next == -ESC_w || next == -ESC_d;
2291
2292 default:
2293 return FALSE;
2294 }
2295
2296 /* Control does not reach here */
2297 }
2298
2299
2300
2301 /*************************************************
2302 * Compile one branch *
2303 *************************************************/
2304
2305 /* Scan the pattern, compiling it into the a vector. If the options are
2306 changed during the branch, the pointer is used to change the external options
2307 bits. This function is used during the pre-compile phase when we are trying
2308 to find out the amount of memory needed, as well as during the real compile
2309 phase. The value of lengthptr distinguishes the two phases.
2310
2311 Arguments:
2312 optionsptr pointer to the option bits
2313 codeptr points to the pointer to the current code point
2314 ptrptr points to the current pattern pointer
2315 errorcodeptr points to error code variable
2316 firstbyteptr set to initial literal character, or < 0 (REQ_UNSET, REQ_NONE)
2317 reqbyteptr set to the last literal character required, else < 0
2318 bcptr points to current branch chain
2319 cd contains pointers to tables etc.
2320 lengthptr NULL during the real compile phase
2321 points to length accumulator during pre-compile phase
2322
2323 Returns: TRUE on success
2324 FALSE, with *errorcodeptr set non-zero on error
2325 */
2326
2327 static BOOL
2328 compile_branch(int *optionsptr, uschar **codeptr, const uschar **ptrptr,
2329 int *errorcodeptr, int *firstbyteptr, int *reqbyteptr, branch_chain *bcptr,
2330 compile_data *cd, int *lengthptr)
2331 {
2332 int repeat_type, op_type;
2333 int repeat_min = 0, repeat_max = 0; /* To please picky compilers */
2334 int bravalue = 0;
2335 int greedy_default, greedy_non_default;
2336 int firstbyte, reqbyte;
2337 int zeroreqbyte, zerofirstbyte;
2338 int req_caseopt, reqvary, tempreqvary;
2339 int options = *optionsptr;
2340 int after_manual_callout = 0;
2341 int length_prevgroup = 0;
2342 register int c;
2343 register uschar *code = *codeptr;
2344 uschar *last_code = code;
2345 uschar *orig_code = code;
2346 uschar *tempcode;
2347 BOOL inescq = FALSE;
2348 BOOL groupsetfirstbyte = FALSE;
2349 const uschar *ptr = *ptrptr;
2350 const uschar *tempptr;
2351 uschar *previous = NULL;
2352 uschar *previous_callout = NULL;
2353 uschar *save_hwm = NULL;
2354 uschar classbits[32];
2355
2356 #ifdef SUPPORT_UTF8
2357 BOOL class_utf8;
2358 BOOL utf8 = (options & PCRE_UTF8) != 0;
2359 uschar *class_utf8data;
2360 uschar utf8_char[6];
2361 #else
2362 BOOL utf8 = FALSE;
2363 uschar *utf8_char = NULL;
2364 #endif
2365
2366 #ifdef DEBUG
2367 if (lengthptr != NULL) DPRINTF((">> start branch\n"));
2368 #endif
2369
2370 /* Set up the default and non-default settings for greediness */
2371
2372 greedy_default = ((options & PCRE_UNGREEDY) != 0);
2373 greedy_non_default = greedy_default ^ 1;
2374
2375 /* Initialize no first byte, no required byte. REQ_UNSET means "no char
2376 matching encountered yet". It gets changed to REQ_NONE if we hit something that
2377 matches a non-fixed char first char; reqbyte just remains unset if we never
2378 find one.
2379
2380 When we hit a repeat whose minimum is zero, we may have to adjust these values
2381 to take the zero repeat into account. This is implemented by setting them to
2382 zerofirstbyte and zeroreqbyte when such a repeat is encountered. The individual
2383 item types that can be repeated set these backoff variables appropriately. */
2384
2385 firstbyte = reqbyte = zerofirstbyte = zeroreqbyte = REQ_UNSET;
2386
2387 /* The variable req_caseopt contains either the REQ_CASELESS value or zero,
2388 according to the current setting of the caseless flag. REQ_CASELESS is a bit
2389 value > 255. It is added into the firstbyte or reqbyte variables to record the
2390 case status of the value. This is used only for ASCII characters. */
2391
2392 req_caseopt = ((options & PCRE_CASELESS) != 0)? REQ_CASELESS : 0;
2393
2394 /* Switch on next character until the end of the branch */
2395
2396 for (;; ptr++)
2397 {
2398 BOOL negate_class;
2399 BOOL should_flip_negation;
2400 BOOL possessive_quantifier;
2401 BOOL is_quantifier;
2402 BOOL is_recurse;
2403 BOOL reset_bracount;
2404 int class_charcount;
2405 int class_lastchar;
2406 int newoptions;
2407 int recno;
2408 int refsign;
2409 int skipbytes;
2410 int subreqbyte;
2411 int subfirstbyte;
2412 int terminator;
2413 int mclength;
2414 uschar mcbuffer[8];
2415
2416 /* Get next byte in the pattern */
2417
2418 c = *ptr;
2419
2420 /* If we are in the pre-compile phase, accumulate the length used for the
2421 previous cycle of this loop. */
2422
2423 if (lengthptr != NULL)
2424 {
2425 #ifdef DEBUG
2426 if (code > cd->hwm) cd->hwm = code; /* High water info */
2427 #endif
2428 if (code > cd->start_workspace + COMPILE_WORK_SIZE) /* Check for overrun */
2429 {
2430 *errorcodeptr = ERR52;
2431 goto FAILED;
2432 }
2433
2434 /* There is at least one situation where code goes backwards: this is the
2435 case of a zero quantifier after a class (e.g. [ab]{0}). At compile time,
2436 the class is simply eliminated. However, it is created first, so we have to
2437 allow memory for it. Therefore, don't ever reduce the length at this point.
2438 */
2439
2440 if (code < last_code) code = last_code;
2441
2442 /* Paranoid check for integer overflow */
2443
2444 if (OFLOW_MAX - *lengthptr < code - last_code)
2445 {
2446 *errorcodeptr = ERR20;
2447 goto FAILED;
2448 }
2449
2450 *lengthptr += code - last_code;
2451 DPRINTF(("length=%d added %d c=%c\n", *lengthptr, code - last_code, c));
2452
2453 /* If "previous" is set and it is not at the start of the work space, move
2454 it back to there, in order to avoid filling up the work space. Otherwise,
2455 if "previous" is NULL, reset the current code pointer to the start. */
2456
2457 if (previous != NULL)
2458 {
2459 if (previous > orig_code)
2460 {
2461 memmove(orig_code, previous, code - previous);
2462 code -= previous - orig_code;
2463 previous = orig_code;
2464 }
2465 }
2466 else code = orig_code;
2467
2468 /* Remember where this code item starts so we can pick up the length
2469 next time round. */
2470
2471 last_code = code;
2472 }
2473
2474 /* In the real compile phase, just check the workspace used by the forward
2475 reference list. */
2476
2477 else if (cd->hwm > cd->start_workspace + COMPILE_WORK_SIZE)
2478 {
2479 *errorcodeptr = ERR52;
2480 goto FAILED;
2481 }
2482
2483 /* If in \Q...\E, check for the end; if not, we have a literal */
2484
2485 if (inescq && c != 0)
2486 {
2487 if (c == '\\' && ptr[1] == 'E')
2488 {
2489 inescq = FALSE;
2490 ptr++;
2491 continue;
2492 }
2493 else
2494 {
2495 if (previous_callout != NULL)
2496 {
2497 if (lengthptr == NULL) /* Don't attempt in pre-compile phase */
2498 complete_callout(previous_callout, ptr, cd);
2499 previous_callout = NULL;
2500 }
2501 if ((options & PCRE_AUTO_CALLOUT) != 0)
2502 {
2503 previous_callout = code;
2504 code = auto_callout(code, ptr, cd);
2505 }
2506 goto NORMAL_CHAR;
2507 }
2508 }
2509
2510 /* Fill in length of a previous callout, except when the next thing is
2511 a quantifier. */
2512
2513 is_quantifier = c == '*' || c == '+' || c == '?' ||
2514 (c == '{' && is_counted_repeat(ptr+1));
2515
2516 if (!is_quantifier && previous_callout != NULL &&
2517 after_manual_callout-- <= 0)
2518 {
2519 if (lengthptr == NULL) /* Don't attempt in pre-compile phase */
2520 complete_callout(previous_callout, ptr, cd);
2521 previous_callout = NULL;
2522 }
2523
2524 /* In extended mode, skip white space and comments */
2525
2526 if ((options & PCRE_EXTENDED) != 0)
2527 {
2528 if ((cd->ctypes[c] & ctype_space) != 0) continue;
2529 if (c == '#')
2530 {
2531 while (*(++ptr) != 0)
2532 {
2533 if (IS_NEWLINE(ptr)) { ptr += cd->nllen - 1; break; }
2534 }
2535 if (*ptr != 0) continue;
2536
2537 /* Else fall through to handle end of string */
2538 c = 0;
2539 }
2540 }
2541
2542 /* No auto callout for quantifiers. */
2543
2544 if ((options & PCRE_AUTO_CALLOUT) != 0 && !is_quantifier)
2545 {
2546 previous_callout = code;
2547 code = auto_callout(code, ptr, cd);
2548 }
2549
2550 switch(c)
2551 {
2552 /* ===================================================================*/
2553 case 0: /* The branch terminates at string end */
2554 case '|': /* or | or ) */
2555 case ')':
2556 *firstbyteptr = firstbyte;
2557 *reqbyteptr = reqbyte;
2558 *codeptr = code;
2559 *ptrptr = ptr;
2560 if (lengthptr != NULL)
2561 {
2562 if (OFLOW_MAX - *lengthptr < code - last_code)
2563 {
2564 *errorcodeptr = ERR20;
2565 goto FAILED;
2566 }
2567 *lengthptr += code - last_code; /* To include callout length */
2568 DPRINTF((">> end branch\n"));
2569 }
2570 return TRUE;
2571
2572
2573 /* ===================================================================*/
2574 /* Handle single-character metacharacters. In multiline mode, ^ disables
2575 the setting of any following char as a first character. */
2576
2577 case '^':
2578 if ((options & PCRE_MULTILINE) != 0)
2579 {
2580 if (firstbyte == REQ_UNSET) firstbyte = REQ_NONE;
2581 }
2582 previous = NULL;
2583 *code++ = OP_CIRC;
2584 break;
2585
2586 case '$':
2587 previous = NULL;
2588 *code++ = OP_DOLL;
2589 break;
2590
2591 /* There can never be a first char if '.' is first, whatever happens about
2592 repeats. The value of reqbyte doesn't change either. */
2593
2594 case '.':
2595 if (firstbyte == REQ_UNSET) firstbyte = REQ_NONE;
2596 zerofirstbyte = firstbyte;
2597 zeroreqbyte = reqbyte;
2598 previous = code;
2599 *code++ = OP_ANY;
2600 break;
2601
2602
2603 /* ===================================================================*/
2604 /* Character classes. If the included characters are all < 256, we build a
2605 32-byte bitmap of the permitted characters, except in the special case
2606 where there is only one such character. For negated classes, we build the
2607 map as usual, then invert it at the end. However, we use a different opcode
2608 so that data characters > 255 can be handled correctly.
2609
2610 If the class contains characters outside the 0-255 range, a different
2611 opcode is compiled. It may optionally have a bit map for characters < 256,
2612 but those above are are explicitly listed afterwards. A flag byte tells
2613 whether the bitmap is present, and whether this is a negated class or not.
2614 */
2615
2616 case '[':
2617 previous = code;
2618
2619 /* PCRE supports POSIX class stuff inside a class. Perl gives an error if
2620 they are encountered at the top level, so we'll do that too. */
2621
2622 if ((ptr[1] == ':' || ptr[1] == '.' || ptr[1] == '=') &&
2623 check_posix_syntax(ptr, &tempptr, cd))
2624 {
2625 *errorcodeptr = (ptr[1] == ':')? ERR13 : ERR31;
2626 goto FAILED;
2627 }
2628
2629 /* If the first character is '^', set the negation flag and skip it. Also,
2630 if the first few characters (either before or after ^) are \Q\E or \E we
2631 skip them too. This makes for compatibility with Perl. */
2632
2633 negate_class = FALSE;
2634 for (;;)
2635 {
2636 c = *(++ptr);
2637 if (c == '\\')
2638 {
2639 if (ptr[1] == 'E') ptr++;
2640 else if (strncmp((const char *)ptr+1, "Q\\E", 3) == 0) ptr += 3;
2641 else break;
2642 }
2643 else if (!negate_class && c == '^')
2644 negate_class = TRUE;
2645 else break;
2646 }
2647
2648 /* If a class contains a negative special such as \S, we need to flip the
2649 negation flag at the end, so that support for characters > 255 works
2650 correctly (they are all included in the class). */
2651
2652 should_flip_negation = FALSE;
2653
2654 /* Keep a count of chars with values < 256 so that we can optimize the case
2655 of just a single character (as long as it's < 256). However, For higher
2656 valued UTF-8 characters, we don't yet do any optimization. */
2657
2658 class_charcount = 0;
2659 class_lastchar = -1;
2660
2661 /* Initialize the 32-char bit map to all zeros. We build the map in a
2662 temporary bit of memory, in case the class contains only 1 character (less
2663 than 256), because in that case the compiled code doesn't use the bit map.
2664 */
2665
2666 memset(classbits, 0, 32 * sizeof(uschar));
2667
2668 #ifdef SUPPORT_UTF8
2669 class_utf8 = FALSE; /* No chars >= 256 */
2670 class_utf8data = code + LINK_SIZE + 2; /* For UTF-8 items */
2671 #endif
2672
2673 /* Process characters until ] is reached. By writing this as a "do" it
2674 means that an initial ] is taken as a data character. At the start of the
2675 loop, c contains the first byte of the character. */
2676
2677 if (c != 0) do
2678 {
2679 const uschar *oldptr;
2680
2681 #ifdef SUPPORT_UTF8
2682 if (utf8 && c > 127)
2683 { /* Braces are required because the */
2684 GETCHARLEN(c, ptr, ptr); /* macro generates multiple statements */
2685 }
2686 #endif
2687
2688 /* Inside \Q...\E everything is literal except \E */
2689
2690 if (inescq)
2691 {
2692 if (c == '\\' && ptr[1] == 'E') /* If we are at \E */
2693 {
2694 inescq = FALSE; /* Reset literal state */
2695 ptr++; /* Skip the 'E' */
2696 continue; /* Carry on with next */
2697 }
2698 goto CHECK_RANGE; /* Could be range if \E follows */
2699 }
2700
2701 /* Handle POSIX class names. Perl allows a negation extension of the
2702 form [:^name:]. A square bracket that doesn't match the syntax is
2703 treated as a literal. We also recognize the POSIX constructions
2704 [.ch.] and [=ch=] ("collating elements") and fault them, as Perl
2705 5.6 and 5.8 do. */
2706
2707 if (c == '[' &&
2708 (ptr[1] == ':' || ptr[1] == '.' || ptr[1] == '=') &&
2709 check_posix_syntax(ptr, &tempptr, cd))
2710 {
2711 BOOL local_negate = FALSE;
2712 int posix_class, taboffset, tabopt;
2713 register const uschar *cbits = cd->cbits;
2714 uschar pbits[32];
2715
2716 if (ptr[1] != ':')
2717 {
2718 *errorcodeptr = ERR31;
2719 goto FAILED;
2720 }
2721
2722 ptr += 2;
2723 if (*ptr == '^')
2724 {
2725 local_negate = TRUE;
2726 should_flip_negation = TRUE; /* Note negative special */
2727 ptr++;
2728 }
2729
2730 posix_class = check_posix_name(ptr, tempptr - ptr);
2731 if (posix_class < 0)
2732 {
2733 *errorcodeptr = ERR30;
2734 goto FAILED;
2735 }
2736
2737 /* If matching is caseless, upper and lower are converted to
2738 alpha. This relies on the fact that the class table starts with
2739 alpha, lower, upper as the first 3 entries. */
2740
2741 if ((options & PCRE_CASELESS) != 0 && posix_class <= 2)
2742 posix_class = 0;
2743
2744 /* We build the bit map for the POSIX class in a chunk of local store
2745 because we may be adding and subtracting from it, and we don't want to
2746 subtract bits that may be in the main map already. At the end we or the
2747 result into the bit map that is being built. */
2748
2749 posix_class *= 3;
2750
2751 /* Copy in the first table (always present) */
2752
2753 memcpy(pbits, cbits + posix_class_maps[posix_class],
2754 32 * sizeof(uschar));
2755
2756 /* If there is a second table, add or remove it as required. */
2757
2758 taboffset = posix_class_maps[posix_class + 1];
2759 tabopt = posix_class_maps[posix_class + 2];
2760
2761 if (taboffset >= 0)
2762 {
2763 if (tabopt >= 0)
2764 for (c = 0; c < 32; c++) pbits[c] |= cbits[c + taboffset];
2765 else
2766 for (c = 0; c < 32; c++) pbits[c] &= ~cbits[c + taboffset];
2767 }
2768
2769 /* Not see if we need to remove any special characters. An option
2770 value of 1 removes vertical space and 2 removes underscore. */
2771
2772 if (tabopt < 0) tabopt = -tabopt;
2773 if (tabopt == 1) pbits[1] &= ~0x3c;
2774 else if (tabopt == 2) pbits[11] &= 0x7f;
2775
2776 /* Add the POSIX table or its complement into the main table that is
2777 being built and we are done. */
2778
2779 if (local_negate)
2780 for (c = 0; c < 32; c++) classbits[c] |= ~pbits[c];
2781 else
2782 for (c = 0; c < 32; c++) classbits[c] |= pbits[c];
2783
2784 ptr = tempptr + 1;
2785 class_charcount = 10; /* Set > 1; assumes more than 1 per class */
2786 continue; /* End of POSIX syntax handling */
2787 }
2788
2789 /* Backslash may introduce a single character, or it may introduce one
2790 of the specials, which just set a flag. The sequence \b is a special
2791 case. Inside a class (and only there) it is treated as backspace.
2792 Elsewhere it marks a word boundary. Other escapes have preset maps ready
2793 to 'or' into the one we are building. We assume they have more than one
2794 character in them, so set class_charcount bigger than one. */
2795
2796 if (c == '\\')
2797 {
2798 c = check_escape(&ptr, errorcodeptr, cd->bracount, options, TRUE);
2799 if (*errorcodeptr != 0) goto FAILED;
2800
2801 if (-c == ESC_b) c = '\b'; /* \b is backspace in a class */
2802 else if (-c == ESC_X) c = 'X'; /* \X is literal X in a class */
2803 else if (-c == ESC_R) c = 'R'; /* \R is literal R in a class */
2804 else if (-c == ESC_Q) /* Handle start of quoted string */
2805 {
2806 if (ptr[1] == '\\' && ptr[2] == 'E')
2807 {
2808 ptr += 2; /* avoid empty string */
2809 }
2810 else inescq = TRUE;
2811 continue;
2812 }
2813 else if (-c == ESC_E) continue; /* Ignore orphan \E */
2814
2815 if (c < 0)
2816 {
2817 register const uschar *cbits = cd->cbits;
2818 class_charcount += 2; /* Greater than 1 is what matters */
2819
2820 /* Save time by not doing this in the pre-compile phase. */
2821
2822 if (lengthptr == NULL) switch (-c)
2823 {
2824 case ESC_d:
2825 for (c = 0; c < 32; c++) classbits[c] |= cbits[c+cbit_digit];
2826 continue;
2827
2828 case ESC_D:
2829 should_flip_negation = TRUE;
2830 for (c = 0; c < 32; c++) classbits[c] |= ~cbits[c+cbit_digit];
2831 continue;
2832
2833 case ESC_w:
2834 for (c = 0; c < 32; c++) classbits[c] |= cbits[c+cbit_word];
2835 continue;
2836
2837 case ESC_W:
2838 should_flip_negation = TRUE;
2839 for (c = 0; c < 32; c++) classbits[c] |= ~cbits[c+cbit_word];
2840 continue;
2841
2842 case ESC_s:
2843 for (c = 0; c < 32; c++) classbits[c] |= cbits[c+cbit_space];
2844 classbits[1] &= ~0x08; /* Perl 5.004 onwards omits VT from \s */
2845 continue;
2846
2847 case ESC_S:
2848 should_flip_negation = TRUE;
2849 for (c = 0; c < 32; c++) classbits[c] |= ~cbits[c+cbit_space];
2850 classbits[1] |= 0x08; /* Perl 5.004 onwards omits VT from \s */
2851 continue;
2852
2853 default: /* Not recognized; fall through */
2854 break; /* Need "default" setting to stop compiler warning. */
2855 }
2856
2857 /* In the pre-compile phase, just do the recognition. */
2858
2859 else if (c == -ESC_d || c == -ESC_D || c == -ESC_w ||
2860 c == -ESC_W || c == -ESC_s || c == -ESC_S) continue;
2861
2862 /* We need to deal with \H, \h, \V, and \v in both phases because
2863 they use extra memory. */
2864
2865 if (-c == ESC_h)
2866 {
2867 SETBIT(classbits, 0x09); /* VT */
2868 SETBIT(classbits, 0x20); /* SPACE */
2869 SETBIT(classbits, 0xa0); /* NSBP */
2870 #ifdef SUPPORT_UTF8
2871 if (utf8)
2872 {
2873 class_utf8 = TRUE;
2874 *class_utf8data++ = XCL_SINGLE;
2875 class_utf8data += _pcre_ord2utf8(0x1680, class_utf8data);
2876 *class_utf8data++ = XCL_SINGLE;
2877 class_utf8data += _pcre_ord2utf8(0x180e, class_utf8data);
2878 *class_utf8data++ = XCL_RANGE;
2879 class_utf8data += _pcre_ord2utf8(0x2000, class_utf8data);
2880 class_utf8data += _pcre_ord2utf8(0x200A, class_utf8data);
2881 *class_utf8data++ = XCL_SINGLE;
2882 class_utf8data += _pcre_ord2utf8(0x202f, class_utf8data);
2883 *class_utf8data++ = XCL_SINGLE;
2884 class_utf8data += _pcre_ord2utf8(0x205f, class_utf8data);
2885 *class_utf8data++ = XCL_SINGLE;
2886 class_utf8data += _pcre_ord2utf8(0x3000, class_utf8data);
2887 }
2888 #endif
2889 continue;
2890 }
2891
2892 if (-c == ESC_H)
2893 {
2894 for (c = 0; c < 32; c++)
2895 {
2896 int x = 0xff;
2897 switch (c)
2898 {
2899 case 0x09/8: x ^= 1 << (0x09%8); break;
2900 case 0x20/8: x ^= 1 << (0x20%8); break;
2901 case 0xa0/8: x ^= 1 << (0xa0%8); break;
2902 default: break;
2903 }
2904 classbits[c] |= x;
2905 }
2906
2907 #ifdef SUPPORT_UTF8
2908 if (utf8)
2909 {
2910 class_utf8 = TRUE;
2911 *class_utf8data++ = XCL_RANGE;
2912 class_utf8data += _pcre_ord2utf8(0x0100, class_utf8data);
2913 class_utf8data += _pcre_ord2utf8(0x167f, class_utf8data);
2914 *class_utf8data++ = XCL_RANGE;
2915 class_utf8data += _pcre_ord2utf8(0x1681, class_utf8data);
2916 class_utf8data += _pcre_ord2utf8(0x180d, class_utf8data);
2917 *class_utf8data++ = XCL_RANGE;
2918 class_utf8data += _pcre_ord2utf8(0x180f, class_utf8data);
2919 class_utf8data += _pcre_ord2utf8(0x1fff, class_utf8data);
2920 *class_utf8data++ = XCL_RANGE;
2921 class_utf8data += _pcre_ord2utf8(0x200B, class_utf8data);
2922 class_utf8data += _pcre_ord2utf8(0x202e, class_utf8data);
2923 *class_utf8data++ = XCL_RANGE;
2924 class_utf8data += _pcre_ord2utf8(0x2030, class_utf8data);
2925 class_utf8data += _pcre_ord2utf8(0x205e, class_utf8data);
2926 *class_utf8data++ = XCL_RANGE;
2927 class_utf8data += _pcre_ord2utf8(0x2060, class_utf8data);
2928 class_utf8data += _pcre_ord2utf8(0x2fff, class_utf8data);
2929 *class_utf8data++ = XCL_RANGE;
2930 class_utf8data += _pcre_ord2utf8(0x3001, class_utf8data);
2931 class_utf8data += _pcre_ord2utf8(0x7fffffff, class_utf8data);
2932 }
2933 #endif
2934 continue;
2935 }
2936
2937 if (-c == ESC_v)
2938 {
2939 SETBIT(classbits, 0x0a); /* LF */
2940 SETBIT(classbits, 0x0b); /* VT */
2941 SETBIT(classbits, 0x0c); /* FF */
2942 SETBIT(classbits, 0x0d); /* CR */
2943 SETBIT(classbits, 0x85); /* NEL */
2944 #ifdef SUPPORT_UTF8
2945 if (utf8)
2946 {
2947 class_utf8 = TRUE;
2948 *class_utf8data++ = XCL_RANGE;
2949 class_utf8data += _pcre_ord2utf8(0x2028, class_utf8data);
2950 class_utf8data += _pcre_ord2utf8(0x2029, class_utf8data);
2951 }
2952 #endif
2953 continue;
2954 }
2955
2956 if (-c == ESC_V)
2957 {
2958 for (c = 0; c < 32; c++)
2959 {
2960 int x = 0xff;
2961 switch (c)
2962 {
2963 case 0x0a/8: x ^= 1 << (0x0a%8);
2964 x ^= 1 << (0x0b%8);
2965 x ^= 1 << (0x0c%8);
2966 x ^= 1 << (0x0d%8);
2967 break;
2968 case 0x85/8: x ^= 1 << (0x85%8); break;
2969 default: break;
2970 }
2971 classbits[c] |= x;
2972 }
2973
2974 #ifdef SUPPORT_UTF8
2975 if (utf8)
2976 {
2977 class_utf8 = TRUE;
2978 *class_utf8data++ = XCL_RANGE;
2979 class_utf8data += _pcre_ord2utf8(0x0100, class_utf8data);
2980 class_utf8data += _pcre_ord2utf8(0x2027, class_utf8data);
2981 *class_utf8data++ = XCL_RANGE;
2982 class_utf8data += _pcre_ord2utf8(0x2029, class_utf8data);
2983 class_utf8data += _pcre_ord2utf8(0x7fffffff, class_utf8data);
2984 }
2985 #endif
2986 continue;
2987 }
2988
2989 /* We need to deal with \P and \p in both phases. */
2990
2991 #ifdef SUPPORT_UCP
2992 if (-c == ESC_p || -c == ESC_P)
2993 {
2994 BOOL negated;
2995 int pdata;
2996 int ptype = get_ucp(&ptr, &negated, &pdata, errorcodeptr);
2997 if (ptype < 0) goto FAILED;
2998 class_utf8 = TRUE;
2999 *class_utf8data++ = ((-c == ESC_p) != negated)?
3000 XCL_PROP : XCL_NOTPROP;
3001 *class_utf8data++ = ptype;
3002 *class_utf8data++ = pdata;
3003 class_charcount -= 2; /* Not a < 256 character */
3004 continue;
3005 }
3006 #endif
3007 /* Unrecognized escapes are faulted if PCRE is running in its
3008 strict mode. By default, for compatibility with Perl, they are
3009 treated as literals. */
3010
3011 if ((options & PCRE_EXTRA) != 0)
3012 {
3013 *errorcodeptr = ERR7;
3014 goto FAILED;
3015 }
3016
3017 class_charcount -= 2; /* Undo the default count from above */
3018 c = *ptr; /* Get the final character and fall through */
3019 }
3020
3021 /* Fall through if we have a single character (c >= 0). This may be
3022 greater than 256 in UTF-8 mode. */
3023
3024 } /* End of backslash handling */
3025
3026 /* A single character may be followed by '-' to form a range. However,
3027 Perl does not permit ']' to be the end of the range. A '-' character
3028 at the end is treated as a literal. Perl ignores orphaned \E sequences
3029 entirely. The code for handling \Q and \E is messy. */
3030
3031 CHECK_RANGE:
3032 while (ptr[1] == '\\' && ptr[2] == 'E')
3033 {
3034 inescq = FALSE;
3035 ptr += 2;
3036 }
3037
3038 oldptr = ptr;
3039
3040 /* Remember \r or \n */
3041
3042 if (c == '\r' || c == '\n') cd->external_flags |= PCRE_HASCRORLF;
3043
3044 /* Check for range */
3045
3046 if (!inescq && ptr[1] == '-')
3047 {
3048 int d;
3049 ptr += 2;
3050 while (*ptr == '\\' && ptr[1] == 'E') ptr += 2;
3051
3052 /* If we hit \Q (not followed by \E) at this point, go into escaped
3053 mode. */
3054
3055 while (*ptr == '\\' && ptr[1] == 'Q')
3056 {
3057 ptr += 2;
3058 if (*ptr == '\\' && ptr[1] == 'E') { ptr += 2; continue; }
3059 inescq = TRUE;
3060 break;
3061 }
3062
3063 if (*ptr == 0 || (!inescq && *ptr == ']'))
3064 {
3065 ptr = oldptr;
3066 goto LONE_SINGLE_CHARACTER;
3067 }
3068
3069 #ifdef SUPPORT_UTF8
3070 if (utf8)
3071 { /* Braces are required because the */
3072 GETCHARLEN(d, ptr, ptr); /* macro generates multiple statements */
3073 }
3074 else
3075 #endif
3076 d = *ptr; /* Not UTF-8 mode */
3077
3078 /* The second part of a range can be a single-character escape, but
3079 not any of the other escapes. Perl 5.6 treats a hyphen as a literal
3080 in such circumstances. */
3081
3082 if (!inescq && d == '\\')
3083 {
3084 d = check_escape(&ptr, errorcodeptr, cd->bracount, options, TRUE);
3085 if (*errorcodeptr != 0) goto FAILED;
3086
3087 /* \b is backspace; \X is literal X; \R is literal R; any other
3088 special means the '-' was literal */
3089
3090 if (d < 0)
3091 {
3092 if (d == -ESC_b) d = '\b';
3093 else if (d == -ESC_X) d = 'X';
3094 else if (d == -ESC_R) d = 'R'; else
3095 {
3096 ptr = oldptr;
3097 goto LONE_SINGLE_CHARACTER; /* A few lines below */
3098 }
3099 }
3100 }
3101
3102 /* Check that the two values are in the correct order. Optimize
3103 one-character ranges */
3104
3105 if (d < c)
3106 {
3107 *errorcodeptr = ERR8;
3108 goto FAILED;
3109 }
3110
3111 if (d == c) goto LONE_SINGLE_CHARACTER; /* A few lines below */
3112
3113 /* Remember \r or \n */
3114
3115 if (d == '\r' || d == '\n') cd->external_flags |= PCRE_HASCRORLF;
3116
3117 /* In UTF-8 mode, if the upper limit is > 255, or > 127 for caseless
3118 matching, we have to use an XCLASS with extra data items. Caseless
3119 matching for characters > 127 is available only if UCP support is
3120 available. */
3121
3122 #ifdef SUPPORT_UTF8
3123 if (utf8 && (d > 255 || ((options & PCRE_CASELESS) != 0 && d > 127)))
3124 {
3125 class_utf8 = TRUE;
3126
3127 /* With UCP support, we can find the other case equivalents of
3128 the relevant characters. There may be several ranges. Optimize how
3129 they fit with the basic range. */
3130
3131 #ifdef SUPPORT_UCP
3132 if ((options & PCRE_CASELESS) != 0)
3133 {
3134 unsigned int occ, ocd;
3135 unsigned int cc = c;
3136 unsigned int origd = d;
3137 while (get_othercase_range(&cc, origd, &occ, &ocd))
3138 {
3139 if (occ >= (unsigned int)c &&
3140 ocd <= (unsigned int)d)
3141 continue; /* Skip embedded ranges */
3142
3143 if (occ < (unsigned int)c &&
3144 ocd >= (unsigned int)c - 1) /* Extend the basic range */
3145 { /* if there is overlap, */
3146 c = occ; /* noting that if occ < c */
3147 continue; /* we can't have ocd > d */
3148 } /* because a subrange is */
3149 if (ocd > (unsigned int)d &&
3150 occ <= (unsigned int)d + 1) /* always shorter than */
3151 { /* the basic range. */
3152 d = ocd;
3153 continue;
3154 }
3155
3156 if (occ == ocd)
3157 {
3158 *class_utf8data++ = XCL_SINGLE;
3159 }
3160 else
3161 {
3162 *class_utf8data++ = XCL_RANGE;
3163 class_utf8data += _pcre_ord2utf8(occ, class_utf8data);
3164 }
3165 class_utf8data += _pcre_ord2utf8(ocd, class_utf8data);
3166 }
3167 }
3168 #endif /* SUPPORT_UCP */
3169
3170 /* Now record the original range, possibly modified for UCP caseless
3171 overlapping ranges. */
3172
3173 *class_utf8data++ = XCL_RANGE;
3174 class_utf8data += _pcre_ord2utf8(c, class_utf8data);
3175 class_utf8data += _pcre_ord2utf8(d, class_utf8data);
3176
3177 /* With UCP support, we are done. Without UCP support, there is no
3178 caseless matching for UTF-8 characters > 127; we can use the bit map
3179 for the smaller ones. */
3180
3181 #ifdef SUPPORT_UCP
3182 continue; /* With next character in the class */
3183 #else
3184 if ((options & PCRE_CASELESS) == 0 || c > 127) continue;
3185
3186 /* Adjust upper limit and fall through to set up the map */
3187
3188 d = 127;
3189
3190 #endif /* SUPPORT_UCP */
3191 }
3192 #endif /* SUPPORT_UTF8 */
3193
3194 /* We use the bit map for all cases when not in UTF-8 mode; else
3195 ranges that lie entirely within 0-127 when there is UCP support; else
3196 for partial ranges without UCP support. */
3197
3198 class_charcount += d - c + 1;
3199 class_lastchar = d;
3200
3201 /* We can save a bit of time by skipping this in the pre-compile. */
3202
3203 if (lengthptr == NULL) for (; c <= d; c++)
3204 {
3205 classbits[c/8] |= (1 << (c&7));
3206 if ((options & PCRE_CASELESS) != 0)
3207 {
3208 int uc = cd->fcc[c]; /* flip case */
3209 classbits[uc/8] |= (1 << (uc&7));
3210 }
3211 }
3212
3213 continue; /* Go get the next char in the class */
3214 }
3215
3216 /* Handle a lone single character - we can get here for a normal
3217 non-escape char, or after \ that introduces a single character or for an
3218 apparent range that isn't. */
3219
3220 LONE_SINGLE_CHARACTER:
3221
3222 /* Handle a character that cannot go in the bit map */
3223
3224 #ifdef SUPPORT_UTF8
3225 if (utf8 && (c > 255 || ((options & PCRE_CASELESS) != 0 && c > 127)))
3226 {
3227 class_utf8 = TRUE;
3228 *class_utf8data++ = XCL_SINGLE;
3229 class_utf8data += _pcre_ord2utf8(c, class_utf8data);
3230
3231 #ifdef SUPPORT_UCP
3232 if ((options & PCRE_CASELESS) != 0)
3233 {
3234 unsigned int othercase;
3235 if ((othercase = _pcre_ucp_othercase(c)) != NOTACHAR)
3236 {
3237 *class_utf8data++ = XCL_SINGLE;
3238 class_utf8data += _pcre_ord2utf8(othercase, class_utf8data);
3239 }
3240 }
3241 #endif /* SUPPORT_UCP */
3242
3243 }
3244 else
3245 #endif /* SUPPORT_UTF8 */
3246
3247 /* Handle a single-byte character */
3248 {
3249 classbits[c/8] |= (1 << (c&7));
3250 if ((options & PCRE_CASELESS) != 0)
3251 {
3252 c = cd->fcc[c]; /* flip case */
3253 classbits[c/8] |= (1 << (c&7));
3254 }
3255 class_charcount++;
3256 class_lastchar = c;
3257 }
3258 }
3259
3260 /* Loop until ']' reached. This "while" is the end of the "do" above. */
3261
3262 while ((c = *(++ptr)) != 0 && (c != ']' || inescq));
3263
3264 if (c == 0) /* Missing terminating ']' */
3265 {
3266 *errorcodeptr = ERR6;
3267 goto FAILED;
3268 }
3269
3270
3271 /* This code has been disabled because it would mean that \s counts as
3272 an explicit \r or \n reference, and that's not really what is wanted. Now
3273 we set the flag only if there is a literal "\r" or "\n" in the class. */
3274
3275 #if 0
3276 /* Remember whether \r or \n are in this class */
3277
3278 if (negate_class)
3279 {
3280 if ((classbits[1] & 0x24) != 0x24) cd->external_flags |= PCRE_HASCRORLF;
3281 }
3282 else
3283 {
3284 if ((classbits[1] & 0x24) != 0) cd->external_flags |= PCRE_HASCRORLF;
3285 }
3286 #endif
3287
3288
3289 /* If class_charcount is 1, we saw precisely one character whose value is
3290 less than 256. As long as there were no characters >= 128 and there was no
3291 use of \p or \P, in other words, no use of any XCLASS features, we can
3292 optimize.
3293
3294 In UTF-8 mode, we can optimize the negative case only if there were no
3295 characters >= 128 because OP_NOT and the related opcodes like OP_NOTSTAR
3296 operate on single-bytes only. This is an historical hangover. Maybe one day
3297 we can tidy these opcodes to handle multi-byte characters.
3298
3299 The optimization throws away the bit map. We turn the item into a
3300 1-character OP_CHAR[NC] if it's positive, or OP_NOT if it's negative. Note
3301 that OP_NOT does not support multibyte characters. In the positive case, it
3302 can cause firstbyte to be set. Otherwise, there can be no first char if
3303 this item is first, whatever repeat count may follow. In the case of
3304 reqbyte, save the previous value for reinstating. */
3305
3306 #ifdef SUPPORT_UTF8
3307 if (class_charcount == 1 && !class_utf8 &&
3308 (!utf8 || !negate_class || class_lastchar < 128))
3309 #else
3310 if (class_charcount == 1)
3311 #endif
3312 {
3313 zeroreqbyte = reqbyte;
3314
3315 /* The OP_NOT opcode works on one-byte characters only. */
3316
3317 if (negate_class)
3318 {
3319 if (firstbyte == REQ_UNSET) firstbyte = REQ_NONE;
3320 zerofirstbyte = firstbyte;
3321 *code++ = OP_NOT;
3322 *code++ = class_lastchar;
3323 break;
3324 }
3325
3326 /* For a single, positive character, get the value into mcbuffer, and
3327 then we can handle this with the normal one-character code. */
3328
3329 #ifdef SUPPORT_UTF8
3330 if (utf8 && class_lastchar > 127)
3331 mclength = _pcre_ord2utf8(class_lastchar, mcbuffer);
3332 else
3333 #endif
3334 {
3335 mcbuffer[0] = class_lastchar;
3336 mclength = 1;
3337 }
3338 goto ONE_CHAR;
3339 } /* End of 1-char optimization */
3340
3341 /* The general case - not the one-char optimization. If this is the first
3342 thing in the branch, there can be no first char setting, whatever the
3343 repeat count. Any reqbyte setting must remain unchanged after any kind of
3344 repeat. */
3345
3346 if (firstbyte == REQ_UNSET) firstbyte = REQ_NONE;
3347 zerofirstbyte = firstbyte;
3348 zeroreqbyte = reqbyte;
3349
3350 /* If there are characters with values > 255, we have to compile an
3351 extended class, with its own opcode, unless there was a negated special
3352 such as \S in the class, because in that case all characters > 255 are in
3353 the class, so any that were explicitly given as well can be ignored. If
3354 (when there are explicit characters > 255 that must be listed) there are no
3355 characters < 256, we can omit the bitmap in the actual compiled code. */
3356
3357 #ifdef SUPPORT_UTF8
3358 if (class_utf8 && !should_flip_negation)
3359 {
3360 *class_utf8data++ = XCL_END; /* Marks the end of extra data */
3361 *code++ = OP_XCLASS;
3362 code += LINK_SIZE;
3363 *code = negate_class? XCL_NOT : 0;
3364
3365 /* If the map is required, move up the extra data to make room for it;
3366 otherwise just move the code pointer to the end of the extra data. */
3367
3368 if (class_charcount > 0)
3369 {
3370 *code++ |= XCL_MAP;
3371 memmove(code + 32, code, class_utf8data - code);
3372 memcpy(code, classbits, 32);
3373 code = class_utf8data + 32;
3374 }
3375 else code = class_utf8data;
3376
3377 /* Now fill in the complete length of the item */
3378
3379 PUT(previous, 1, code - previous);
3380 break; /* End of class handling */
3381 }
3382 #endif
3383
3384 /* If there are no characters > 255, set the opcode to OP_CLASS or
3385 OP_NCLASS, depending on whether the whole class was negated and whether
3386 there were negative specials such as \S in the class. Then copy the 32-byte
3387 map into the code vector, negating it if necessary. */
3388
3389 *code++ = (negate_class == should_flip_negation) ? OP_CLASS : OP_NCLASS;
3390 if (negate_class)
3391 {
3392 if (lengthptr == NULL) /* Save time in the pre-compile phase */
3393 for (c = 0; c < 32; c++) code[c] = ~classbits[c];
3394 }
3395 else
3396 {
3397 memcpy(code, classbits, 32);
3398 }
3399 code += 32;
3400 break;
3401
3402
3403 /* ===================================================================*/
3404 /* Various kinds of repeat; '{' is not necessarily a quantifier, but this
3405 has been tested above. */
3406
3407 case '{':
3408 if (!is_quantifier) goto NORMAL_CHAR;
3409 ptr = read_repeat_counts(ptr+1, &repeat_min, &repeat_max, errorcodeptr);
3410 if (*errorcodeptr != 0) goto FAILED;
3411 goto REPEAT;
3412
3413 case '*':
3414 repeat_min = 0;
3415 repeat_max = -1;
3416 goto REPEAT;
3417
3418 case '+':
3419 repeat_min = 1;
3420 repeat_max = -1;
3421 goto REPEAT;
3422
3423 case '?':
3424 repeat_min = 0;
3425 repeat_max = 1;
3426
3427 REPEAT:
3428 if (previous == NULL)
3429 {
3430 *errorcodeptr = ERR9;
3431 goto FAILED;
3432 }
3433
3434 if (repeat_min == 0)
3435 {
3436 firstbyte = zerofirstbyte; /* Adjust for zero repeat */
3437 reqbyte = zeroreqbyte; /* Ditto */
3438 }
3439
3440 /* Remember whether this is a variable length repeat */
3441
3442 reqvary = (repeat_min == repeat_max)? 0 : REQ_VARY;
3443
3444 op_type = 0; /* Default single-char op codes */
3445 possessive_quantifier = FALSE; /* Default not possessive quantifier */
3446
3447 /* Save start of previous item, in case we have to move it up to make space
3448 for an inserted OP_ONCE for the additional '+' extension. */
3449
3450 tempcode = previous;
3451
3452 /* If the next character is '+', we have a possessive quantifier. This
3453 implies greediness, whatever the setting of the PCRE_UNGREEDY option.
3454 If the next character is '?' this is a minimizing repeat, by default,
3455 but if PCRE_UNGREEDY is set, it works the other way round. We change the
3456 repeat type to the non-default. */
3457
3458 if (ptr[1] == '+')
3459 {
3460 repeat_type = 0; /* Force greedy */
3461 possessive_quantifier = TRUE;
3462 ptr++;
3463 }
3464 else if (ptr[1] == '?')
3465 {
3466 repeat_type = greedy_non_default;
3467 ptr++;
3468 }
3469 else repeat_type = greedy_default;
3470
3471 /* If previous was a character match, abolish the item and generate a
3472 repeat item instead. If a char item has a minumum of more than one, ensure
3473 that it is set in reqbyte - it might not be if a sequence such as x{3} is
3474 the first thing in a branch because the x will have gone into firstbyte
3475 instead. */
3476
3477 if (*previous == OP_CHAR || *previous == OP_CHARNC)
3478 {
3479 /* Deal with UTF-8 characters that take up more than one byte. It's
3480 easier to write this out separately than try to macrify it. Use c to
3481 hold the length of the character in bytes, plus 0x80 to flag that it's a
3482 length rather than a small character. */
3483
3484 #ifdef SUPPORT_UTF8
3485 if (utf8 && (code[-1] & 0x80) != 0)
3486 {
3487 uschar *lastchar = code - 1;
3488 while((*lastchar & 0xc0) == 0x80) lastchar--;
3489 c = code - lastchar; /* Length of UTF-8 character */
3490 memcpy(utf8_char, lastchar, c); /* Save the char */
3491 c |= 0x80; /* Flag c as a length */
3492 }
3493 else
3494 #endif
3495
3496 /* Handle the case of a single byte - either with no UTF8 support, or
3497 with UTF-8 disabled, or for a UTF-8 character < 128. */
3498
3499 {
3500 c = code[-1];
3501 if (repeat_min > 1) reqbyte = c | req_caseopt | cd->req_varyopt;
3502 }
3503
3504 /* If the repetition is unlimited, it pays to see if the next thing on
3505 the line is something that cannot possibly match this character. If so,
3506 automatically possessifying this item gains some performance in the case
3507 where the match fails. */
3508
3509 if (!possessive_quantifier &&
3510 repeat_max < 0 &&
3511 check_auto_possessive(*previous, c, utf8, utf8_char, ptr + 1,
3512 options, cd))
3513 {
3514 repeat_type = 0; /* Force greedy */
3515 possessive_quantifier = TRUE;
3516 }
3517
3518 goto OUTPUT_SINGLE_REPEAT; /* Code shared with single character types */
3519 }
3520
3521 /* If previous was a single negated character ([^a] or similar), we use
3522 one of the special opcodes, replacing it. The code is shared with single-
3523 character repeats by setting opt_type to add a suitable offset into
3524 repeat_type. We can also test for auto-possessification. OP_NOT is
3525 currently used only for single-byte chars. */
3526
3527 else if (*previous == OP_NOT)
3528 {
3529 op_type = OP_NOTSTAR - OP_STAR; /* Use "not" opcodes */
3530 c = previous[1];
3531 if (!possessive_quantifier &&
3532 repeat_max < 0 &&
3533 check_auto_possessive(OP_NOT, c, utf8, NULL, ptr + 1, options, cd))
3534 {
3535 repeat_type = 0; /* Force greedy */
3536 possessive_quantifier = TRUE;
3537 }
3538 goto OUTPUT_SINGLE_REPEAT;
3539 }
3540
3541 /* If previous was a character type match (\d or similar), abolish it and
3542 create a suitable repeat item. The code is shared with single-character
3543 repeats by setting op_type to add a suitable offset into repeat_type. Note
3544 the the Unicode property types will be present only when SUPPORT_UCP is
3545 defined, but we don't wrap the little bits of code here because it just
3546 makes it horribly messy. */
3547
3548 else if (*previous < OP_EODN)
3549 {
3550 uschar *oldcode;
3551 int prop_type, prop_value;
3552 op_type = OP_TYPESTAR - OP_STAR; /* Use type opcodes */
3553 c = *previous;
3554
3555 if (!possessive_quantifier &&
3556 repeat_max < 0 &&
3557 check_auto_possessive(c, 0, utf8, NULL, ptr + 1, options, cd))
3558 {
3559 repeat_type = 0; /* Force greedy */
3560 possessive_quantifier = TRUE;
3561 }
3562
3563 OUTPUT_SINGLE_REPEAT:
3564 if (*previous == OP_PROP || *previous == OP_NOTPROP)
3565 {
3566 prop_type = previous[1];
3567 prop_value = previous[2];
3568 }
3569 else prop_type = prop_value = -1;
3570
3571 oldcode = code;
3572 code = previous; /* Usually overwrite previous item */
3573
3574 /* If the maximum is zero then the minimum must also be zero; Perl allows
3575 this case, so we do too - by simply omitting the item altogether. */
3576
3577 if (repeat_max == 0) goto END_REPEAT;
3578
3579 /* All real repeats make it impossible to handle partial matching (maybe
3580 one day we will be able to remove this restriction). */
3581
3582 if (repeat_max != 1) cd->external_flags |= PCRE_NOPARTIAL;
3583
3584 /* Combine the op_type with the repeat_type */
3585
3586 repeat_type += op_type;
3587
3588 /* A minimum of zero is handled either as the special case * or ?, or as
3589 an UPTO, with the maximum given. */
3590
3591 if (repeat_min == 0)
3592 {
3593 if (repeat_max == -1) *code++ = OP_STAR + repeat_type;
3594 else if (repeat_max == 1) *code++ = OP_QUERY + repeat_type;
3595 else
3596 {
3597 *code++ = OP_UPTO + repeat_type;
3598 PUT2INC(code, 0, repeat_max);
3599 }
3600 }
3601
3602 /* A repeat minimum of 1 is optimized into some special cases. If the
3603 maximum is unlimited, we use OP_PLUS. Otherwise, the original item is
3604 left in place and, if the maximum is greater than 1, we use OP_UPTO with
3605 one less than the maximum. */
3606
3607 else if (repeat_min == 1)
3608 {
3609 if (repeat_max == -1)
3610 *code++ = OP_PLUS + repeat_type;
3611 else
3612 {
3613 code = oldcode; /* leave previous item in place */
3614 if (repeat_max == 1) goto END_REPEAT;
3615 *code++ = OP_UPTO + repeat_type;
3616 PUT2INC(code, 0, repeat_max - 1);
3617 }
3618 }
3619
3620 /* The case {n,n} is just an EXACT, while the general case {n,m} is
3621 handled as an EXACT followed by an UPTO. */
3622
3623 else
3624 {
3625 *code++ = OP_EXACT + op_type; /* NB EXACT doesn't have repeat_type */
3626 PUT2INC(code, 0, repeat_min);
3627
3628 /* If the maximum is unlimited, insert an OP_STAR. Before doing so,
3629 we have to insert the character for the previous code. For a repeated
3630 Unicode property match, there are two extra bytes that define the
3631 required property. In UTF-8 mode, long characters have their length in
3632 c, with the 0x80 bit as a flag. */
3633
3634 if (repeat_max < 0)
3635 {
3636 #ifdef SUPPORT_UTF8
3637 if (utf8 && c >= 128)
3638 {
3639 memcpy(code, utf8_char, c & 7);
3640 code += c & 7;
3641 }
3642 else
3643 #endif
3644 {
3645 *code++ = c;
3646 if (prop_type >= 0)
3647 {
3648 *code++ = prop_type;
3649 *code++ = prop_value;
3650 }
3651 }
3652 *code++ = OP_STAR + repeat_type;
3653 }
3654
3655 /* Else insert an UPTO if the max is greater than the min, again
3656 preceded by the character, for the previously inserted code. If the
3657 UPTO is just for 1 instance, we can use QUERY instead. */
3658
3659 else if (repeat_max != repeat_min)
3660 {
3661 #ifdef SUPPORT_UTF8
3662 if (utf8 && c >= 128)
3663 {
3664 memcpy(code, utf8_char, c & 7);
3665 code += c & 7;
3666 }
3667 else
3668 #endif
3669 *code++ = c;
3670 if (prop_type >= 0)
3671 {
3672 *code++ = prop_type;
3673 *code++ = prop_value;
3674 }
3675 repeat_max -= repeat_min;
3676
3677 if (repeat_max == 1)
3678 {
3679 *code++ = OP_QUERY + repeat_type;
3680 }
3681 else
3682 {
3683 *code++ = OP_UPTO + repeat_type;
3684 PUT2INC(code, 0, repeat_max);
3685 }
3686 }
3687 }
3688
3689 /* The character or character type itself comes last in all cases. */
3690
3691 #ifdef SUPPORT_UTF8
3692 if (utf8 && c >= 128)
3693 {
3694 memcpy(code, utf8_char, c & 7);
3695 code += c & 7;
3696 }
3697 else
3698 #endif
3699 *code++ = c;
3700
3701 /* For a repeated Unicode property match, there are two extra bytes that
3702 define the required property. */
3703
3704 #ifdef SUPPORT_UCP
3705 if (prop_type >= 0)
3706 {
3707 *code++ = prop_type;
3708 *code++ = prop_value;
3709 }
3710 #endif
3711 }
3712
3713 /* If previous was a character class or a back reference, we put the repeat
3714 stuff after it, but just skip the item if the repeat was {0,0}. */
3715
3716 else if (*previous == OP_CLASS ||
3717 *previous == OP_NCLASS ||
3718 #ifdef SUPPORT_UTF8
3719 *previous == OP_XCLASS ||
3720 #endif
3721 *previous == OP_REF)
3722 {
3723 if (repeat_max == 0)
3724 {
3725 code = previous;
3726 goto END_REPEAT;
3727 }
3728
3729 /* All real repeats make it impossible to handle partial matching (maybe
3730 one day we will be able to remove this restriction). */
3731
3732 if (repeat_max != 1) cd->external_flags |= PCRE_NOPARTIAL;
3733
3734 if (repeat_min == 0 && repeat_max == -1)
3735 *code++ = OP_CRSTAR + repeat_type;
3736 else if (repeat_min == 1 && repeat_max == -1)
3737 *code++ = OP_CRPLUS + repeat_type;
3738 else if (repeat_min == 0 && repeat_max == 1)
3739 *code++ = OP_CRQUERY + repeat_type;
3740 else
3741 {
3742 *code++ = OP_CRRANGE + repeat_type;
3743 PUT2INC(code, 0, repeat_min);
3744 if (repeat_max == -1) repeat_max = 0; /* 2-byte encoding for max */
3745 PUT2INC(code, 0, repeat_max);
3746 }
3747 }
3748
3749 /* If previous was a bracket group, we may have to replicate it in certain
3750 cases. */
3751
3752 else if (*previous == OP_BRA || *previous == OP_CBRA ||
3753 *previous == OP_ONCE || *previous == OP_COND)
3754 {
3755 register int i;
3756 int ketoffset = 0;
3757 int len = code - previous;
3758 uschar *bralink = NULL;
3759
3760 /* Repeating a DEFINE group is pointless */
3761
3762 if (*previous == OP_COND && previous[LINK_SIZE+1] == OP_DEF)
3763 {
3764 *errorcodeptr = ERR55;
3765 goto FAILED;
3766 }
3767
3768 /* If the maximum repeat count is unlimited, find the end of the bracket
3769 by scanning through from the start, and compute the offset back to it
3770 from the current code pointer. There may be an OP_OPT setting following
3771 the final KET, so we can't find the end just by going back from the code
3772 pointer. */
3773
3774 if (repeat_max == -1)
3775 {
3776 register uschar *ket = previous;
3777 do ket += GET(ket, 1); while (*ket != OP_KET);
3778 ketoffset = code - ket;
3779 }
3780
3781 /* The case of a zero minimum is special because of the need to stick
3782 OP_BRAZERO in front of it, and because the group appears once in the
3783 data, whereas in other cases it appears the minimum number of times. For
3784 this reason, it is simplest to treat this case separately, as otherwise
3785 the code gets far too messy. There are several special subcases when the
3786 minimum is zero. */
3787
3788 if (repeat_min == 0)
3789 {
3790 /* If the maximum is also zero, we just omit the group from the output
3791 altogether. */
3792
3793 if (repeat_max == 0)
3794 {
3795 code = previous;
3796 goto END_REPEAT;
3797 }
3798
3799 /* If the maximum is 1 or unlimited, we just have to stick in the
3800 BRAZERO and do no more at this point. However, we do need to adjust
3801 any OP_RECURSE calls inside the group that refer to the group itself or
3802 any internal or forward referenced group, because the offset is from
3803 the start of the whole regex. Temporarily terminate the pattern while
3804 doing this. */
3805
3806 if (repeat_max <= 1)
3807 {
3808 *code = OP_END;
3809 adjust_recurse(previous, 1, utf8, cd, save_hwm);
3810 memmove(previous+1, previous, len);
3811 code++;
3812 *previous++ = OP_BRAZERO + repeat_type;
3813 }
3814
3815 /* If the maximum is greater than 1 and limited, we have to replicate
3816 in a nested fashion, sticking OP_BRAZERO before each set of brackets.
3817 The first one has to be handled carefully because it's the original
3818 copy, which has to be moved up. The remainder can be handled by code
3819 that is common with the non-zero minimum case below. We have to
3820 adjust the value or repeat_max, since one less copy is required. Once
3821 again, we may have to adjust any OP_RECURSE calls inside the group. */
3822
3823 else
3824 {
3825 int offset;
3826 *code = OP_END;
3827 adjust_recurse(previous, 2 + LINK_SIZE, utf8, cd, save_hwm);
3828 memmove(previous + 2 + LINK_SIZE, previous, len);
3829 code += 2 + LINK_SIZE;
3830 *previous++ = OP_BRAZERO + repeat_type;
3831 *previous++ = OP_BRA;
3832
3833 /* We chain together the bracket offset fields that have to be
3834 filled in later when the ends of the brackets are reached. */
3835
3836 offset = (bralink == NULL)? 0 : previous - bralink;
3837 bralink = previous;
3838 PUTINC(previous, 0, offset);
3839 }
3840
3841 repeat_max--;
3842 }
3843
3844 /* If the minimum is greater than zero, replicate the group as many
3845 times as necessary, and adjust the maximum to the number of subsequent
3846 copies that we need. If we set a first char from the group, and didn't
3847 set a required char, copy the latter from the former. If there are any
3848 forward reference subroutine calls in the group, there will be entries on
3849 the workspace list; replicate these with an appropriate increment. */
3850
3851 else
3852 {
3853 if (repeat_min > 1)
3854 {
3855 /* In the pre-compile phase, we don't actually do the replication. We
3856 just adjust the length as if we had. Do some paranoid checks for
3857 potential integer overflow. */
3858
3859 if (lengthptr != NULL)
3860 {
3861 int delta = (repeat_min - 1)*length_prevgroup;
3862 if ((double)(repeat_min - 1)*(double)length_prevgroup >
3863 (double)INT_MAX ||
3864 OFLOW_MAX - *lengthptr < delta)
3865 {
3866 *errorcodeptr = ERR20;
3867 goto FAILED;
3868 }
3869 *lengthptr += delta;
3870 }
3871
3872 /* This is compiling for real */
3873
3874 else
3875 {
3876 if (groupsetfirstbyte && reqbyte < 0) reqbyte = firstbyte;
3877 for (i = 1; i < repeat_min; i++)
3878 {
3879 uschar *hc;
3880 uschar *this_hwm = cd->hwm;
3881 memcpy(code, previous, len);
3882 for (hc = save_hwm; hc < this_hwm; hc += LINK_SIZE)
3883 {
3884 PUT(cd->hwm, 0, GET(hc, 0) + len);
3885 cd->hwm += LINK_SIZE;
3886 }
3887 save_hwm = this_hwm;
3888 code += len;
3889 }
3890 }
3891 }
3892
3893 if (repeat_max > 0) repeat_max -= repeat_min;
3894 }
3895
3896 /* This code is common to both the zero and non-zero minimum cases. If
3897 the maximum is limited, it replicates the group in a nested fashion,
3898 remembering the bracket starts on a stack. In the case of a zero minimum,
3899 the first one was set up above. In all cases the repeat_max now specifies
3900 the number of additional copies needed. Again, we must remember to
3901 replicate entries on the forward reference list. */
3902
3903 if (repeat_max >= 0)
3904 {
3905 /* In the pre-compile phase, we don't actually do the replication. We
3906 just adjust the length as if we had. For each repetition we must add 1
3907 to the length for BRAZERO and for all but the last repetition we must
3908 add 2 + 2*LINKSIZE to allow for the nesting that occurs. Do some
3909 paranoid checks to avoid integer overflow. */
3910
3911 if (lengthptr != NULL && repeat_max > 0)
3912 {
3913 int delta = repeat_max * (length_prevgroup + 1 + 2 + 2*LINK_SIZE) -
3914 2 - 2*LINK_SIZE; /* Last one doesn't nest */
3915 if ((double)repeat_max *
3916 (double)(length_prevgroup + 1 + 2 + 2*LINK_SIZE)
3917 > (double)INT_MAX ||
3918 OFLOW_MAX - *lengthptr < delta)
3919 {
3920 *errorcodeptr = ERR20;
3921 goto FAILED;
3922 }
3923 *lengthptr += delta;
3924 }
3925
3926 /* This is compiling for real */
3927
3928 else for (i = repeat_max - 1; i >= 0; i--)
3929 {
3930 uschar *hc;
3931 uschar *this_hwm = cd->hwm;
3932
3933 *code++ = OP_BRAZERO + repeat_type;
3934
3935 /* All but the final copy start a new nesting, maintaining the
3936 chain of brackets outstanding. */
3937
3938 if (i != 0)
3939 {
3940 int offset;
3941 *code++ = OP_BRA;
3942 offset = (bralink == NULL)? 0 : code - bralink;
3943 bralink = code;
3944 PUTINC(code, 0, offset);
3945 }
3946
3947 memcpy(code, previous, len);
3948 for (hc = save_hwm; hc < this_hwm; hc += LINK_SIZE)
3949 {
3950 PUT(cd->hwm, 0, GET(hc, 0) + len + ((i != 0)? 2+LINK_SIZE : 1));
3951 cd->hwm += LINK_SIZE;
3952 }
3953 save_hwm = this_hwm;
3954 code += len;
3955 }
3956
3957 /* Now chain through the pending brackets, and fill in their length
3958 fields (which are holding the chain links pro tem). */
3959
3960 while (bralink != NULL)
3961 {
3962 int oldlinkoffset;
3963 int offset = code - bralink + 1;
3964 uschar *bra = code - offset;
3965 oldlinkoffset = GET(bra, 1);
3966 bralink = (oldlinkoffset == 0)? NULL : bralink - oldlinkoffset;
3967 *code++ = OP_KET;
3968 PUTINC(code, 0, offset);
3969 PUT(bra, 1, offset);
3970 }
3971 }
3972
3973 /* If the maximum is unlimited, set a repeater in the final copy. We
3974 can't just offset backwards from the current code point, because we
3975 don't know if there's been an options resetting after the ket. The
3976 correct offset was computed above.
3977
3978 Then, when we are doing the actual compile phase, check to see whether
3979 this group is a non-atomic one that could match an empty string. If so,
3980 convert the initial operator to the S form (e.g. OP_BRA -> OP_SBRA) so
3981 that runtime checking can be done. [This check is also applied to
3982 atomic groups at runtime, but in a different way.] */
3983
3984 else
3985 {
3986 uschar *ketcode = code - ketoffset;
3987 uschar *bracode = ketcode - GET(ketcode, 1);
3988 *ketcode = OP_KETRMAX + repeat_type;
3989 if (lengthptr == NULL && *bracode != OP_ONCE)
3990 {
3991 uschar *scode = bracode;
3992 do
3993 {
3994 if (could_be_empty_branch(scode, ketcode, utf8))
3995 {
3996 *bracode += OP_SBRA - OP_BRA;
3997 break;
3998 }
3999 scode += GET(scode, 1);
4000 }
4001 while (*scode == OP_ALT);
4002 }
4003 }
4004 }
4005
4006 /* Else there's some kind of shambles */
4007
4008 else
4009 {
4010 *errorcodeptr = ERR11;
4011 goto FAILED;
4012 }
4013
4014 /* If the character following a repeat is '+', or if certain optimization
4015 tests above succeeded, possessive_quantifier is TRUE. For some of the
4016 simpler opcodes, there is an special alternative opcode for this. For
4017 anything else, we wrap the entire repeated item inside OP_ONCE brackets.
4018 The '+' notation is just syntactic sugar, taken from Sun's Java package,
4019 but the special opcodes can optimize it a bit. The repeated item starts at
4020 tempcode, not at previous, which might be the first part of a string whose
4021 (former) last char we repeated.
4022
4023 Possessifying an 'exact' quantifier has no effect, so we can ignore it. But
4024 an 'upto' may follow. We skip over an 'exact' item, and then test the
4025 length of what remains before proceeding. */
4026
4027 if (possessive_quantifier)
4028 {
4029 int len;
4030 if (*tempcode == OP_EXACT || *tempcode == OP_TYPEEXACT ||
4031 *tempcode == OP_NOTEXACT)
4032 tempcode += _pcre_OP_lengths[*tempcode];
4033 len = code - tempcode;
4034 if (len > 0) switch (*tempcode)
4035 {
4036 case OP_STAR: *tempcode = OP_POSSTAR; break;
4037 case OP_PLUS: *tempcode = OP_POSPLUS; break;
4038 case OP_QUERY: *tempcode = OP_POSQUERY; break;
4039 case OP_UPTO: *tempcode = OP_POSUPTO; break;
4040
4041 case OP_TYPESTAR: *tempcode = OP_TYPEPOSSTAR; break;
4042 case OP_TYPEPLUS: *tempcode = OP_TYPEPOSPLUS; break;
4043 case OP_TYPEQUERY: *tempcode = OP_TYPEPOSQUERY; break;
4044 case OP_TYPEUPTO: *tempcode = OP_TYPEPOSUPTO; break;
4045
4046 case OP_NOTSTAR: *tempcode = OP_NOTPOSSTAR; break;
4047 case OP_NOTPLUS: *tempcode = OP_NOTPOSPLUS; break;
4048 case OP_NOTQUERY: *tempcode = OP_NOTPOSQUERY; break;
4049 case OP_NOTUPTO: *tempcode = OP_NOTPOSUPTO; break;
4050
4051 default:
4052 memmove(tempcode + 1+LINK_SIZE, tempcode, len);
4053 code += 1 + LINK_SIZE;
4054 len += 1 + LINK_SIZE;
4055 tempcode[0] = OP_ONCE;
4056 *code++ = OP_KET;
4057 PUTINC(code, 0, len);
4058 PUT(tempcode, 1, len);
4059 break;
4060 }
4061 }
4062
4063 /* In all case we no longer have a previous item. We also set the
4064 "follows varying string" flag for subsequently encountered reqbytes if
4065 it isn't already set and we have just passed a varying length item. */
4066
4067 END_REPEAT:
4068 previous = NULL;
4069 cd->req_varyopt |= reqvary;
4070 break;
4071
4072
4073 /* ===================================================================*/
4074 /* Start of nested parenthesized sub-expression, or comment or lookahead or
4075 lookbehind or option setting or condition or all the other extended
4076 parenthesis forms. */
4077
4078 case '(':
4079 newoptions = options;
4080 skipbytes = 0;
4081 bravalue = OP_CBRA;
4082 save_hwm = cd->hwm;
4083 reset_bracount = FALSE;
4084
4085 /* First deal with various "verbs" that can be introduced by '*'. */
4086
4087 if (*(++ptr) == '*' && (cd->ctypes[ptr[1]] & ctype_letter) != 0)
4088 {
4089 int i, namelen;
4090 const char *vn = verbnames;
4091 const uschar *name = ++ptr;
4092 previous = NULL;
4093 while ((cd->ctypes[*++ptr] & ctype_letter) != 0);
4094 if (*ptr == ':')
4095 {
4096 *errorcodeptr = ERR59; /* Not supported */
4097 goto FAILED;
4098 }
4099 if (*ptr != ')')
4100 {
4101 *errorcodeptr = ERR60;
4102 goto FAILED;
4103 }
4104 namelen = ptr - name;
4105 for (i = 0; i < verbcount; i++)
4106 {
4107 if (namelen == verbs[i].len &&
4108 strncmp((char *)name, vn, namelen) == 0)
4109 {
4110 *code = verbs[i].op;
4111 if (*code++ == OP_ACCEPT) cd->had_accept = TRUE;
4112 break;
4113 }
4114 vn += verbs[i].len + 1;
4115 }
4116 if (i < verbcount) continue;
4117 *errorcodeptr = ERR60;
4118 goto FAILED;
4119 }
4120
4121 /* Deal with the extended parentheses; all are introduced by '?', and the
4122 appearance of any of them means that this is not a capturing group. */
4123
4124 else if (*ptr == '?')
4125 {
4126 int i, set, unset, namelen;
4127 int *optset;
4128 const uschar *name;
4129 uschar *slot;
4130
4131 switch (*(++ptr))
4132 {
4133 case '#': /* Comment; skip to ket */
4134 ptr++;
4135 while (*ptr != 0 && *ptr != ')') ptr++;
4136 if (*ptr == 0)
4137 {
4138 *errorcodeptr = ERR18;
4139 goto FAILED;
4140 }
4141 continue;
4142
4143
4144 /* ------------------------------------------------------------ */
4145 case '|': /* Reset capture count for each branch */
4146 reset_bracount = TRUE;
4147 /* Fall through */
4148
4149 /* ------------------------------------------------------------ */
4150 case ':': /* Non-capturing bracket */
4151 bravalue = OP_BRA;
4152 ptr++;
4153 break;
4154
4155
4156 /* ------------------------------------------------------------ */
4157 case '(':
4158 bravalue = OP_COND; /* Conditional group */
4159
4160 /* A condition can be an assertion, a number (referring to a numbered
4161 group), a name (referring to a named group), or 'R', referring to
4162 recursion. R<digits> and R&name are also permitted for recursion tests.
4163
4164 There are several syntaxes for testing a named group: (?(name)) is used
4165 by Python; Perl 5.10 onwards uses (?(<name>) or (?('name')).
4166
4167 There are two unfortunate ambiguities, caused by history. (a) 'R' can
4168 be the recursive thing or the name 'R' (and similarly for 'R' followed
4169 by digits), and (b) a number could be a name that consists of digits.
4170 In both cases, we look for a name first; if not found, we try the other
4171 cases. */
4172
4173 /* For conditions that are assertions, check the syntax, and then exit
4174 the switch. This will take control down to where bracketed groups,
4175 including assertions, are processed. */
4176
4177 if (ptr[1] == '?' && (ptr[2] == '=' || ptr[2] == '!' || ptr[2] == '<'))
4178 break;
4179
4180 /* Most other conditions use OP_CREF (a couple change to OP_RREF
4181 below), and all need to skip 3 bytes at the start of the group. */
4182
4183 code[1+LINK_SIZE] = OP_CREF;
4184 skipbytes = 3;
4185 refsign = -1;
4186
4187 /* Check for a test for recursion in a named group. */
4188
4189 if (ptr[1] == 'R' && ptr[2] == '&')
4190 {
4191 terminator = -1;
4192 ptr += 2;
4193 code[1+LINK_SIZE] = OP_RREF; /* Change the type of test */
4194 }
4195
4196 /* Check for a test for a named group's having been set, using the Perl
4197 syntax (?(<name>) or (?('name') */
4198
4199 else if (ptr[1] == '<')
4200 {
4201 terminator = '>';
4202 ptr++;
4203 }
4204 else if (ptr[1] == '\'')
4205 {
4206 terminator = '\'';
4207 ptr++;
4208 }
4209 else
4210 {
4211 terminator = 0;
4212 if (ptr[1] == '-' || ptr[1] == '+') refsign = *(++ptr);
4213 }
4214
4215 /* We now expect to read a name; any thing else is an error */
4216
4217 if ((cd->ctypes[ptr[1]] & ctype_word) == 0)
4218 {
4219 ptr += 1; /* To get the right offset */
4220 *errorcodeptr = ERR28;
4221 goto FAILED;
4222 }
4223
4224 /* Read the name, but also get it as a number if it's all digits */
4225
4226 recno = 0;
4227 name = ++ptr;
4228 while ((cd->ctypes[*ptr] & ctype_word) != 0)
4229 {
4230 if (recno >= 0)
4231 recno = ((digitab[*ptr] & ctype_digit) != 0)?
4232 recno * 10 + *ptr - '0' : -1;
4233 ptr++;
4234 }
4235 namelen = ptr - name;
4236
4237 if ((terminator > 0 && *ptr++ != terminator) || *ptr++ != ')')
4238 {
4239 ptr--; /* Error offset */
4240 *errorcodeptr = ERR26;
4241 goto FAILED;
4242 }
4243
4244 /* Do no further checking in the pre-compile phase. */
4245
4246 if (lengthptr != NULL) break;
4247
4248 /* In the real compile we do the work of looking for the actual
4249 reference. If the string started with "+" or "-" we require the rest to
4250 be digits, in which case recno will be set. */
4251
4252 if (refsign > 0)
4253 {
4254 if (recno <= 0)
4255 {
4256 *errorcodeptr = ERR58;
4257 goto FAILED;
4258 }
4259 recno = (refsign == '-')?
4260 cd->bracount - recno + 1 : recno +cd->bracount;
4261 if (recno <= 0 || recno > cd->final_bracount)
4262 {
4263 *errorcodeptr = ERR15;
4264 goto FAILED;
4265 }
4266 PUT2(code, 2+LINK_SIZE, recno);
4267 break;
4268 }
4269
4270 /* Otherwise (did not start with "+" or "-"), start by looking for the
4271 name. */
4272
4273 slot = cd->name_table;
4274 for (i = 0; i < cd->names_found; i++)
4275 {
4276 if (strncmp((char *)name, (char *)slot+2, namelen) == 0) break;
4277 slot += cd->name_entry_size;
4278 }
4279
4280 /* Found a previous named subpattern */
4281
4282 if (i < cd->names_found)
4283 {
4284 recno = GET2(slot, 0);
4285 PUT2(code, 2+LINK_SIZE, recno);
4286 }
4287
4288 /* Search the pattern for a forward reference */
4289
4290 else if ((i = find_parens(ptr, cd->bracount, name, namelen,
4291 (options & PCRE_EXTENDED) != 0)) > 0)
4292 {
4293 PUT2(code, 2+LINK_SIZE, i);
4294 }
4295
4296 /* If terminator == 0 it means that the name followed directly after
4297 the opening parenthesis [e.g. (?(abc)...] and in this case there are
4298 some further alternatives to try. For the cases where terminator != 0
4299 [things like (?(<name>... or (?('name')... or (?(R&name)... ] we have
4300 now checked all the possibilities, so give an error. */
4301
4302 else if (terminator != 0)
4303 {
4304 *errorcodeptr = ERR15;
4305 goto FAILED;
4306 }
4307
4308 /* Check for (?(R) for recursion. Allow digits after R to specify a
4309 specific group number. */
4310
4311 else if (*name == 'R')
4312 {
4313 recno = 0;
4314 for (i = 1; i < namelen; i++)
4315 {
4316 if ((digitab[name[i]] & ctype_digit) == 0)
4317 {
4318 *errorcodeptr = ERR15;
4319 goto FAILED;
4320 }
4321 recno = recno * 10 + name[i] - '0';
4322 }
4323 if (recno == 0) recno = RREF_ANY;
4324 code[1+LINK_SIZE] = OP_RREF; /* Change test type */
4325 PUT2(code, 2+LINK_SIZE, recno);
4326 }
4327
4328 /* Similarly, check for the (?(DEFINE) "condition", which is always
4329 false. */
4330
4331 else if (namelen == 6 && strncmp((char *)name, "DEFINE", 6) == 0)
4332 {
4333 code[1+LINK_SIZE] = OP_DEF;
4334 skipbytes = 1;
4335 }
4336
4337 /* Check for the "name" actually being a subpattern number. We are
4338 in the second pass here, so final_bracount is set. */
4339
4340 else if (recno > 0 && recno <= cd->final_bracount)
4341 {
4342 PUT2(code, 2+LINK_SIZE, recno);
4343 }
4344
4345 /* Either an unidentified subpattern, or a reference to (?(0) */
4346
4347 else
4348 {
4349 *errorcodeptr = (recno == 0)? ERR35: ERR15;
4350 goto FAILED;
4351 }
4352 break;
4353
4354
4355 /* ------------------------------------------------------------ */
4356 case '=': /* Positive lookahead */
4357 bravalue = OP_ASSERT;
4358 ptr++;
4359 break;
4360
4361
4362 /* ------------------------------------------------------------ */
4363 case '!': /* Negative lookahead */
4364 ptr++;
4365 if (*ptr == ')') /* Optimize (?!) */
4366 {
4367 *code++ = OP_FAIL;
4368 previous = NULL;
4369 continue;
4370 }
4371 bravalue = OP_ASSERT_NOT;
4372 break;
4373
4374
4375 /* ------------------------------------------------------------ */
4376 case '<': /* Lookbehind or named define */
4377 switch (ptr[1])
4378 {
4379 case '=': /* Positive lookbehind */
4380 bravalue = OP_ASSERTBACK;
4381 ptr += 2;
4382 break;
4383
4384 case '!': /* Negative lookbehind */
4385 bravalue = OP_ASSERTBACK_NOT;
4386 ptr += 2;
4387 break;
4388
4389 default: /* Could be name define, else bad */
4390 if ((cd->ctypes[ptr[1]] & ctype_word) != 0) goto DEFINE_NAME;
4391 ptr++; /* Correct offset for error */
4392 *errorcodeptr = ERR24;
4393 goto FAILED;
4394 }
4395 break;
4396
4397
4398 /* ------------------------------------------------------------ */
4399 case '>': /* One-time brackets */
4400 bravalue = OP_ONCE;
4401 ptr++;
4402 break;
4403
4404
4405 /* ------------------------------------------------------------ */
4406 case 'C': /* Callout - may be followed by digits; */
4407 previous_callout = code; /* Save for later completion */
4408 after_manual_callout = 1; /* Skip one item before completing */
4409 *code++ = OP_CALLOUT;
4410 {
4411 int n = 0;
4412 while ((digitab[*(++ptr)] & ctype_digit) != 0)
4413 n = n * 10 + *ptr - '0';
4414 if (*ptr != ')')
4415 {
4416 *errorcodeptr = ERR39;
4417 goto FAILED;
4418 }
4419 if (n > 255)
4420 {
4421 *errorcodeptr = ERR38;
4422 goto FAILED;
4423 }
4424 *code++ = n;
4425 PUT(code, 0, ptr - cd->start_pattern + 1); /* Pattern offset */
4426 PUT(code, LINK_SIZE, 0); /* Default length */
4427 code += 2 * LINK_SIZE;
4428 }
4429 previous = NULL;
4430 continue;
4431
4432
4433 /* ------------------------------------------------------------ */
4434 case 'P': /* Python-style named subpattern handling */
4435 if (*(++ptr) == '=' || *ptr == '>') /* Reference or recursion */
4436 {
4437 is_recurse = *ptr == '>';
4438 terminator = ')';
4439 goto NAMED_REF_OR_RECURSE;
4440 }
4441 else if (*ptr != '<') /* Test for Python-style definition */
4442 {
4443 *errorcodeptr = ERR41;
4444 goto FAILED;
4445 }
4446 /* Fall through to handle (?P< as (?< is handled */
4447
4448
4449 /* ------------------------------------------------------------ */
4450 DEFINE_NAME: /* Come here from (?< handling */
4451 case '\'':
4452 {
4453 terminator = (*ptr == '<')? '>' : '\'';
4454 name = ++ptr;
4455
4456 while ((cd->ctypes[*ptr] & ctype_word) != 0) ptr++;
4457 namelen = ptr - name;
4458
4459 /* In the pre-compile phase, just do a syntax check. */
4460
4461 if (lengthptr != NULL)
4462 {
4463 if (*ptr != terminator)
4464 {
4465 *errorcodeptr = ERR42;
4466 goto FAILED;
4467 }
4468 if (cd->names_found >= MAX_NAME_COUNT)
4469 {
4470 *errorcodeptr = ERR49;
4471 goto FAILED;
4472 }
4473 if (namelen + 3 > cd->name_entry_size)
4474 {
4475 cd->name_entry_size = namelen + 3;
4476 if (namelen > MAX_NAME_SIZE)
4477 {
4478 *errorcodeptr = ERR48;
4479 goto FAILED;
4480 }
4481 }
4482 }
4483
4484 /* In the real compile, create the entry in the table */
4485
4486 else
4487 {
4488 slot = cd->name_table;
4489 for (i = 0; i < cd->names_found; i++)
4490 {
4491 int crc = memcmp(name, slot+2, namelen);
4492 if (crc == 0)
4493 {
4494 if (slot[2+namelen] == 0)
4495 {
4496 if ((options & PCRE_DUPNAMES) == 0)
4497 {
4498 *errorcodeptr = ERR43;
4499 goto FAILED;
4500 }
4501 }
4502 else crc = -1; /* Current name is substring */
4503 }
4504 if (crc < 0)
4505 {
4506 memmove(slot + cd->name_entry_size, slot,
4507 (cd->names_found - i) * cd->name_entry_size);
4508 break;
4509 }
4510 slot += cd->name_entry_size;
4511 }
4512
4513 PUT2(slot, 0, cd->bracount + 1);
4514 memcpy(slot + 2, name, namelen);
4515 slot[2+namelen] = 0;
4516 }
4517 }
4518
4519 /* In both cases, count the number of names we've encountered. */
4520
4521 ptr++; /* Move past > or ' */
4522 cd->names_found++;
4523 goto NUMBERED_GROUP;
4524
4525
4526 /* ------------------------------------------------------------ */
4527 case '&': /* Perl recursion/subroutine syntax */
4528 terminator = ')';
4529 is_recurse = TRUE;
4530 /* Fall through */
4531
4532 /* We come here from the Python syntax above that handles both
4533 references (?P=name) and recursion (?P>name), as well as falling
4534 through from the Perl recursion syntax (?&name). We also come here from
4535 the Perl \k<name> or \k'name' back reference syntax and the \k{name}
4536 .NET syntax. */
4537
4538 NAMED_REF_OR_RECURSE:
4539 name = ++ptr;
4540 while ((cd->ctypes[*ptr] & ctype_word) != 0) ptr++;
4541 namelen = ptr - name;
4542
4543 /* In the pre-compile phase, do a syntax check and set a dummy
4544 reference number. */
4545
4546 if (lengthptr != NULL)
4547 {
4548 if (namelen == 0)
4549 {
4550 *errorcodeptr = ERR62;
4551 goto FAILED;
4552 }
4553 if (*ptr != terminator)
4554 {
4555 *errorcodeptr = ERR42;
4556 goto FAILED;
4557 }
4558 if (namelen > MAX_NAME_SIZE)
4559 {
4560 *errorcodeptr = ERR48;
4561 goto FAILED;
4562 }
4563 recno = 0;
4564 }
4565
4566 /* In the real compile, seek the name in the table. We check the name
4567 first, and then check that we have reached the end of the name in the
4568 table. That way, if the name that is longer than any in the table,
4569 the comparison will fail without reading beyond the table entry. */
4570
4571 else
4572 {
4573 slot = cd->name_table;
4574 for (i = 0; i < cd->names_found; i++)
4575 {
4576 if (strncmp((char *)name, (char *)slot+2, namelen) == 0 &&
4577 slot[2+namelen] == 0)
4578 break;
4579 slot += cd->name_entry_size;
4580 }
4581
4582 if (i < cd->names_found) /* Back reference */
4583 {
4584 recno = GET2(slot, 0);
4585 }
4586 else if ((recno = /* Forward back reference */
4587 find_parens(ptr, cd->bracount, name, namelen,
4588 (options & PCRE_EXTENDED) != 0)) <= 0)
4589 {
4590 *errorcodeptr = ERR15;
4591 goto FAILED;
4592 }
4593 }
4594
4595 /* In both phases, we can now go to the code than handles numerical
4596 recursion or backreferences. */
4597
4598 if (is_recurse) goto HANDLE_RECURSION;
4599 else goto HANDLE_REFERENCE;
4600
4601
4602 /* ------------------------------------------------------------ */
4603 case 'R': /* Recursion */
4604 ptr++; /* Same as (?0) */
4605 /* Fall through */
4606
4607
4608 /* ------------------------------------------------------------ */
4609 case '-': case '+':
4610 case '0': case '1': case '2': case '3': case '4': /* Recursion or */
4611 case '5': case '6': case '7': case '8': case '9': /* subroutine */
4612 {
4613 const uschar *called;
4614
4615 if ((refsign = *ptr) == '+')
4616 {
4617 ptr++;
4618 if ((digitab[*ptr] & ctype_digit) == 0)
4619 {
4620 *errorcodeptr = ERR63;
4621 goto FAILED;
4622 }
4623 }
4624 else if (refsign == '-')
4625 {
4626 if ((digitab[ptr[1]] & ctype_digit) == 0)
4627 goto OTHER_CHAR_AFTER_QUERY;
4628 ptr++;
4629 }
4630
4631 recno = 0;
4632 while((digitab[*ptr] & ctype_digit) != 0)
4633 recno = recno * 10 + *ptr++ - '0';
4634
4635 if (*ptr != ')')
4636 {
4637 *errorcodeptr = ERR29;
4638 goto FAILED;
4639 }
4640
4641 if (refsign == '-')
4642 {
4643 if (recno == 0)
4644 {
4645 *errorcodeptr = ERR58;
4646 goto FAILED;
4647 }
4648 recno = cd->bracount - recno + 1;
4649 if (recno <= 0)
4650 {
4651 *errorcodeptr = ERR15;
4652 goto FAILED;
4653 }
4654 }
4655 else if (refsign == '+')
4656 {
4657 if (recno == 0)
4658 {
4659 *errorcodeptr = ERR58;
4660 goto FAILED;
4661 }
4662 recno += cd->bracount;
4663 }
4664
4665 /* Come here from code above that handles a named recursion */
4666
4667 HANDLE_RECURSION:
4668
4669 previous = code;
4670 called = cd->start_code;
4671
4672 /* When we are actually compiling, find the bracket that is being
4673 referenced. Temporarily end the regex in case it doesn't exist before
4674 this point. If we end up with a forward reference, first check that
4675 the bracket does occur later so we can give the error (and position)
4676 now. Then remember this forward reference in the workspace so it can
4677 be filled in at the end. */
4678
4679 if (lengthptr == NULL)
4680 {
4681 *code = OP_END;
4682 if (recno != 0) called = find_bracket(cd->start_code, utf8, recno);
4683
4684 /* Forward reference */
4685
4686 if (called == NULL)
4687 {
4688 if (find_parens(ptr, cd->bracount, NULL, recno,
4689 (options & PCRE_EXTENDED) != 0) < 0)
4690 {
4691 *errorcodeptr = ERR15;
4692 goto FAILED;
4693 }
4694 called = cd->start_code + recno;
4695 PUTINC(cd->hwm, 0, code + 2 + LINK_SIZE - cd->start_code);
4696 }
4697
4698 /* If not a forward reference, and the subpattern is still open,
4699 this is a recursive call. We check to see if this is a left
4700 recursion that could loop for ever, and diagnose that case. */
4701
4702 else if (GET(called, 1) == 0 &&
4703 could_be_empty(called, code, bcptr, utf8))
4704 {
4705 *errorcodeptr = ERR40;
4706 goto FAILED;
4707 }
4708 }
4709
4710 /* Insert the recursion/subroutine item, automatically wrapped inside
4711 "once" brackets. Set up a "previous group" length so that a
4712 subsequent quantifier will work. */
4713
4714 *code = OP_ONCE;
4715 PUT(code, 1, 2 + 2*LINK_SIZE);
4716 code += 1 + LINK_SIZE;
4717
4718 *code = OP_RECURSE;
4719 PUT(code, 1, called - cd->start_code);
4720 code += 1 + LINK_SIZE;
4721
4722 *code = OP_KET;
4723 PUT(code, 1, 2 + 2*LINK_SIZE);
4724 code += 1 + LINK_SIZE;
4725
4726 length_prevgroup = 3 + 3*LINK_SIZE;
4727 }
4728
4729 /* Can't determine a first byte now */
4730
4731 if (firstbyte == REQ_UNSET) firstbyte = REQ_NONE;
4732 continue;
4733
4734
4735 /* ------------------------------------------------------------ */
4736 default: /* Other characters: check option setting */
4737 OTHER_CHAR_AFTER_QUERY:
4738 set = unset = 0;
4739 optset = &set;
4740
4741 while (*ptr != ')' && *ptr != ':')
4742 {
4743 switch (*ptr++)
4744 {
4745 case '-': optset = &unset; break;
4746
4747 case 'J': /* Record that it changed in the external options */
4748 *optset |= PCRE_DUPNAMES;
4749 cd->external_flags |= PCRE_JCHANGED;
4750 break;
4751
4752 case 'i': *optset |= PCRE_CASELESS; break;
4753 case 'm': *optset |= PCRE_MULTILINE; break;
4754 case 's': *optset |= PCRE_DOTALL; break;
4755 case 'x': *optset |= PCRE_EXTENDED; break;
4756 case 'U': *optset |= PCRE_UNGREEDY; break;
4757 case 'X': *optset |= PCRE_EXTRA; break;
4758
4759 default: *errorcodeptr = ERR12;
4760 ptr--; /* Correct the offset */
4761 goto FAILED;
4762 }
4763 }
4764
4765 /* Set up the changed option bits, but don't change anything yet. */
4766
4767 newoptions = (options | set) & (~unset);
4768
4769 /* If the options ended with ')' this is not the start of a nested
4770 group with option changes, so the options change at this level. If this
4771 item is right at the start of the pattern, the options can be
4772 abstracted and made external in the pre-compile phase, and ignored in
4773 the compile phase. This can be helpful when matching -- for instance in
4774 caseless checking of required bytes.
4775
4776 If the code pointer is not (cd->start_code + 1 + LINK_SIZE), we are
4777 definitely *not* at the start of the pattern because something has been
4778 compiled. In the pre-compile phase, however, the code pointer can have
4779 that value after the start, because it gets reset as code is discarded
4780 during the pre-compile. However, this can happen only at top level - if
4781 we are within parentheses, the starting BRA will still be present. At
4782 any parenthesis level, the length value can be used to test if anything
4783 has been compiled at that level. Thus, a test for both these conditions
4784 is necessary to ensure we correctly detect the start of the pattern in
4785 both phases.
4786
4787 If we are not at the pattern start, compile code to change the ims
4788 options if this setting actually changes any of them. We also pass the
4789 new setting back so that it can be put at the start of any following
4790 branches, and when this group ends (if we are in a group), a resetting
4791 item can be compiled. */
4792
4793 if (*ptr == ')')
4794 {
4795 if (code == cd->start_code + 1 + LINK_SIZE &&
4796 (lengthptr == NULL || *lengthptr == 2 + 2*LINK_SIZE))
4797 {
4798 cd->external_options = newoptions;
4799 options = newoptions;
4800 }
4801 else
4802 {
4803 if ((options & PCRE_IMS) != (newoptions & PCRE_IMS))
4804 {
4805 *code++ = OP_OPT;
4806 *code++ = newoptions & PCRE_IMS;
4807 }
4808
4809 /* Change options at this level, and pass them back for use
4810 in subsequent branches. Reset the greedy defaults and the case
4811 value for firstbyte and reqbyte. */
4812
4813 *optionsptr = options = newoptions;
4814 greedy_default = ((newoptions & PCRE_UNGREEDY) != 0);
4815 greedy_non_default = greedy_default ^ 1;
4816 req_caseopt = ((options & PCRE_CASELESS) != 0)? REQ_CASELESS : 0;
4817 }
4818
4819 previous = NULL; /* This item can't be repeated */
4820 continue; /* It is complete */
4821 }
4822
4823 /* If the options ended with ':' we are heading into a nested group
4824 with possible change of options. Such groups are non-capturing and are
4825 not assertions of any kind. All we need to do is skip over the ':';
4826 the newoptions value is handled below. */
4827
4828 bravalue = OP_BRA;
4829 ptr++;
4830 } /* End of switch for character following (? */
4831 } /* End of (? handling */
4832
4833 /* Opening parenthesis not followed by '?'. If PCRE_NO_AUTO_CAPTURE is set,
4834 all unadorned brackets become non-capturing and behave like (?:...)
4835 brackets. */
4836
4837 else if ((options & PCRE_NO_AUTO_CAPTURE) != 0)
4838 {
4839 bravalue = OP_BRA;
4840 }
4841
4842 /* Else we have a capturing group. */
4843
4844 else
4845 {
4846 NUMBERED_GROUP:
4847 cd->bracount += 1;
4848 PUT2(code, 1+LINK_SIZE, cd->bracount);
4849 skipbytes = 2;
4850 }
4851
4852 /* Process nested bracketed regex. Assertions may not be repeated, but
4853 other kinds can be. All their opcodes are >= OP_ONCE. We copy code into a
4854 non-register variable in order to be able to pass its address because some
4855 compilers complain otherwise. Pass in a new setting for the ims options if
4856 they have changed. */
4857
4858 previous = (bravalue >= OP_ONCE)? code : NULL;
4859 *code = bravalue;
4860 tempcode = code;
4861 tempreqvary = cd->req_varyopt; /* Save value before bracket */
4862 length_prevgroup = 0; /* Initialize for pre-compile phase */
4863
4864 if (!compile_regex(
4865 newoptions, /* The complete new option state */
4866 options & PCRE_IMS, /* The previous ims option state */
4867 &tempcode, /* Where to put code (updated) */
4868 &ptr, /* Input pointer (updated) */
4869 errorcodeptr, /* Where to put an error message */
4870 (bravalue == OP_ASSERTBACK ||
4871 bravalue == OP_ASSERTBACK_NOT), /* TRUE if back assert */
4872 reset_bracount, /* True if (?| group */
4873 skipbytes, /* Skip over bracket number */
4874 &subfirstbyte, /* For possible first char */
4875 &subreqbyte, /* For possible last char */
4876 bcptr, /* Current branch chain */
4877 cd, /* Tables block */
4878 (lengthptr == NULL)? NULL : /* Actual compile phase */
4879 &length_prevgroup /* Pre-compile phase */
4880 ))
4881 goto FAILED;
4882
4883 /* At the end of compiling, code is still pointing to the start of the
4884 group, while tempcode has been updated to point past the end of the group
4885 and any option resetting that may follow it. The pattern pointer (ptr)
4886 is on the bracket. */
4887
4888 /* If this is a conditional bracket, check that there are no more than
4889 two branches in the group, or just one if it's a DEFINE group. We do this
4890 in the real compile phase, not in the pre-pass, where the whole group may
4891 not be available. */
4892
4893 if (bravalue == OP_COND && lengthptr == NULL)
4894 {
4895 uschar *tc = code;
4896 int condcount = 0;
4897
4898 do {
4899 condcount++;
4900 tc += GET(tc,1);
4901 }
4902 while (*tc != OP_KET);
4903
4904 /* A DEFINE group is never obeyed inline (the "condition" is always
4905 false). It must have only one branch. */
4906
4907 if (code[LINK_SIZE+1] == OP_DEF)
4908 {
4909 if (condcount > 1)
4910 {
4911 *errorcodeptr = ERR54;
4912 goto FAILED;
4913 }
4914 bravalue = OP_DEF; /* Just a flag to suppress char handling below */
4915 }
4916
4917 /* A "normal" conditional group. If there is just one branch, we must not
4918 make use of its firstbyte or reqbyte, because this is equivalent to an
4919 empty second branch. */
4920
4921 else
4922 {
4923 if (condcount > 2)
4924 {
4925 *errorcodeptr = ERR27;
4926 goto FAILED;
4927 }
4928 if (condcount == 1) subfirstbyte = subreqbyte = REQ_NONE;
4929 }
4930 }
4931
4932 /* Error if hit end of pattern */
4933
4934 if (*ptr != ')')
4935 {
4936 *errorcodeptr = ERR14;
4937 goto FAILED;
4938 }
4939
4940 /* In the pre-compile phase, update the length by the length of the group,
4941 less the brackets at either end. Then reduce the compiled code to just a
4942 set of non-capturing brackets so that it doesn't use much memory if it is
4943 duplicated by a quantifier.*/
4944
4945 if (lengthptr != NULL)
4946 {
4947 if (OFLOW_MAX - *lengthptr < length_prevgroup - 2 - 2*LINK_SIZE)
4948 {
4949 *errorcodeptr = ERR20;
4950 goto FAILED;
4951 }
4952 *lengthptr += length_prevgroup - 2 - 2*LINK_SIZE;
4953 *code++ = OP_BRA;
4954 PUTINC(code, 0, 1 + LINK_SIZE);
4955 *code++ = OP_KET;
4956 PUTINC(code, 0, 1 + LINK_SIZE);
4957 break; /* No need to waste time with special character handling */
4958 }
4959
4960 /* Otherwise update the main code pointer to the end of the group. */
4961
4962 code = tempcode;
4963
4964 /* For a DEFINE group, required and first character settings are not
4965 relevant. */
4966
4967 if (bravalue == OP_DEF) break;
4968
4969 /* Handle updating of the required and first characters for other types of
4970 group. Update for normal brackets of all kinds, and conditions with two
4971 branches (see code above). If the bracket is followed by a quantifier with
4972 zero repeat, we have to back off. Hence the definition of zeroreqbyte and
4973 zerofirstbyte outside the main loop so that they can be accessed for the
4974 back off. */
4975
4976 zeroreqbyte = reqbyte;
4977 zerofirstbyte = firstbyte;
4978 groupsetfirstbyte = FALSE;
4979
4980 if (bravalue >= OP_ONCE)
4981 {
4982 /* If we have not yet set a firstbyte in this branch, take it from the
4983 subpattern, remembering that it was set here so that a repeat of more
4984 than one can replicate it as reqbyte if necessary. If the subpattern has
4985 no firstbyte, set "none" for the whole branch. In both cases, a zero
4986 repeat forces firstbyte to "none". */
4987
4988 if (firstbyte == REQ_UNSET)
4989 {
4990 if (subfirstbyte >= 0)
4991 {
4992 firstbyte = subfirstbyte;
4993 groupsetfirstbyte = TRUE;
4994 }
4995 else firstbyte = REQ_NONE;
4996 zerofirstbyte = REQ_NONE;
4997 }
4998
4999 /* If firstbyte was previously set, convert the subpattern's firstbyte
5000 into reqbyte if there wasn't one, using the vary flag that was in
5001 existence beforehand. */
5002
5003 else if (subfirstbyte >= 0 && subreqbyte < 0)
5004 subreqbyte = subfirstbyte | tempreqvary;
5005
5006 /* If the subpattern set a required byte (or set a first byte that isn't
5007 really the first byte - see above), set it. */
5008
5009 if (subreqbyte >= 0) reqbyte = subreqbyte;
5010 }
5011
5012 /* For a forward assertion, we take the reqbyte, if set. This can be
5013 helpful if the pattern that follows the assertion doesn't set a different
5014 char. For example, it's useful for /(?=abcde).+/. We can't set firstbyte
5015 for an assertion, however because it leads to incorrect effect for patterns
5016 such as /(?=a)a.+/ when the "real" "a" would then become a reqbyte instead
5017 of a firstbyte. This is overcome by a scan at the end if there's no
5018 firstbyte, looking for an asserted first char. */
5019
5020 else if (bravalue == OP_ASSERT && subreqbyte >= 0) reqbyte = subreqbyte;
5021 break; /* End of processing '(' */
5022
5023
5024 /* ===================================================================*/
5025 /* Handle metasequences introduced by \. For ones like \d, the ESC_ values
5026 are arranged to be the negation of the corresponding OP_values. For the
5027 back references, the values are ESC_REF plus the reference number. Only
5028 back references and those types that consume a character may be repeated.
5029 We can test for values between ESC_b and ESC_Z for the latter; this may
5030 have to change if any new ones are ever created. */
5031
5032 case '\\':
5033 tempptr = ptr;
5034 c = check_escape(&ptr, errorcodeptr, cd->bracount, options, FALSE);
5035 if (*errorcodeptr != 0) goto FAILED;
5036
5037 if (c < 0)
5038 {
5039 if (-c == ESC_Q) /* Handle start of quoted string */
5040 {
5041 if (ptr[1] == '\\' && ptr[2] == 'E') ptr += 2; /* avoid empty string */
5042 else inescq = TRUE;
5043 continue;
5044 }
5045
5046 if (-c == ESC_E) continue; /* Perl ignores an orphan \E */
5047
5048 /* For metasequences that actually match a character, we disable the
5049 setting of a first character if it hasn't already been set. */
5050
5051 if (firstbyte == REQ_UNSET && -c > ESC_b && -c < ESC_Z)
5052 firstbyte = REQ_NONE;
5053
5054 /* Set values to reset to if this is followed by a zero repeat. */
5055
5056 zerofirstbyte = firstbyte;
5057 zeroreqbyte = reqbyte;
5058
5059 /* \k<name> or \k'name' is a back reference by name (Perl syntax).
5060 We also support \k{name} (.NET syntax) */
5061
5062 if (-c == ESC_k && (ptr[1] == '<' || ptr[1] == '\'' || ptr[1] == '{'))
5063 {
5064 is_recurse = FALSE;
5065 terminator = (*(++ptr) == '<')? '>' : (*ptr == '\'')? '\'' : '}';
5066 goto NAMED_REF_OR_RECURSE;
5067 }
5068
5069 /* Back references are handled specially; must disable firstbyte if
5070 not set to cope with cases like (?=(\w+))\1: which would otherwise set
5071 ':' later. */
5072
5073 if (-c >= ESC_REF)
5074 {
5075 recno = -c - ESC_REF;
5076
5077 HANDLE_REFERENCE: /* Come here from named backref handling */
5078 if (firstbyte == REQ_UNSET) firstbyte = REQ_NONE;
5079 previous = code;
5080 *code++ = OP_REF;
5081 PUT2INC(code, 0, recno);
5082 cd->backref_map |= (recno < 32)? (1 << recno) : 1;
5083 if (recno > cd->top_backref) cd->top_backref = recno;
5084 }
5085
5086 /* So are Unicode property matches, if supported. */
5087
5088 #ifdef SUPPORT_UCP
5089 else if (-c == ESC_P || -c == ESC_p)
5090 {
5091 BOOL negated;
5092 int pdata;
5093 int ptype = get_ucp(&ptr, &negated, &pdata, errorcodeptr);
5094 if (ptype < 0) goto FAILED;
5095 previous = code;
5096 *code++ = ((-c == ESC_p) != negated)? OP_PROP : OP_NOTPROP;
5097 *code++ = ptype;
5098 *code++ = pdata;
5099 }
5100 #else
5101
5102 /* If Unicode properties are not supported, \X, \P, and \p are not
5103 allowed. */
5104
5105 else if (-c == ESC_X || -c == ESC_P || -c == ESC_p)
5106 {
5107 *errorcodeptr = ERR45;
5108 goto FAILED;
5109 }
5110 #endif
5111
5112 /* For the rest (including \X when Unicode properties are supported), we
5113 can obtain the OP value by negating the escape value. */
5114
5115 else
5116 {
5117 previous = (-c > ESC_b && -c < ESC_Z)? code : NULL;
5118 *code++ = -c;
5119 }
5120 continue;
5121 }
5122
5123 /* We have a data character whose value is in c. In UTF-8 mode it may have
5124 a value > 127. We set its representation in the length/buffer, and then
5125 handle it as a data character. */
5126
5127 #ifdef SUPPORT_UTF8
5128 if (utf8 && c > 127)
5129 mclength = _pcre_ord2utf8(c, mcbuffer);
5130 else
5131 #endif
5132
5133 {
5134 mcbuffer[0] = c;
5135 mclength = 1;
5136 }
5137 goto ONE_CHAR;
5138
5139
5140 /* ===================================================================*/
5141 /* Handle a literal character. It is guaranteed not to be whitespace or #
5142 when the extended flag is set. If we are in UTF-8 mode, it may be a
5143 multi-byte literal character. */
5144
5145 default:
5146 NORMAL_CHAR:
5147 mclength = 1;
5148 mcbuffer[0] = c;
5149
5150 #ifdef SUPPORT_UTF8
5151 if (utf8 && c >= 0xc0)
5152 {
5153 while ((ptr[1] & 0xc0) == 0x80)
5154 mcbuffer[mclength++] = *(++ptr);
5155 }
5156 #endif
5157
5158 /* At this point we have the character's bytes in mcbuffer, and the length
5159 in mclength. When not in UTF-8 mode, the length is always 1. */
5160
5161 ONE_CHAR:
5162 previous = code;
5163 *code++ = ((options & PCRE_CASELESS) != 0)? OP_CHARNC : OP_CHAR;
5164 for (c = 0; c < mclength; c++) *code++ = mcbuffer[c];
5165
5166 /* Remember if \r or \n were seen */
5167
5168 if (mcbuffer[0] == '\r' || mcbuffer[0] == '\n')
5169 cd->external_flags |= PCRE_HASCRORLF;
5170
5171 /* Set the first and required bytes appropriately. If no previous first
5172 byte, set it from this character, but revert to none on a zero repeat.
5173 Otherwise, leave the firstbyte value alone, and don't change it on a zero
5174 repeat. */
5175
5176 if (firstbyte == REQ_UNSET)
5177 {
5178 zerofirstbyte = REQ_NONE;
5179 zeroreqbyte = reqbyte;
5180
5181 /* If the character is more than one byte long, we can set firstbyte
5182 only if it is not to be matched caselessly. */
5183
5184 if (mclength == 1 || req_caseopt == 0)
5185 {
5186 firstbyte = mcbuffer[0] | req_caseopt;
5187 if (mclength != 1) reqbyte = code[-1] | cd->req_varyopt;
5188 }
5189 else firstbyte = reqbyte = REQ_NONE;
5190 }
5191
5192 /* firstbyte was previously set; we can set reqbyte only the length is
5193 1 or the matching is caseful. */
5194
5195 else
5196 {
5197 zerofirstbyte = firstbyte;
5198 zeroreqbyte = reqbyte;
5199 if (mclength == 1 || req_caseopt == 0)
5200 reqbyte = code[-1] | req_caseopt | cd->req_varyopt;
5201 }
5202
5203 break; /* End of literal character handling */
5204 }
5205 } /* end of big loop */
5206
5207
5208 /* Control never reaches here by falling through, only by a goto for all the
5209 error states. Pass back the position in the pattern so that it can be displayed
5210 to the user for diagnosing the error. */
5211
5212 FAILED:
5213 *ptrptr = ptr;
5214 return FALSE;
5215 }
5216
5217
5218
5219
5220 /*************************************************
5221 * Compile sequence of alternatives *
5222 *************************************************/
5223
5224 /* On entry, ptr is pointing past the bracket character, but on return it
5225 points to the closing bracket, or vertical bar, or end of string. The code
5226 variable is pointing at the byte into which the BRA operator has been stored.
5227 If the ims options are changed at the start (for a (?ims: group) or during any
5228 branch, we need to insert an OP_OPT item at the start of every following branch
5229 to ensure they get set correctly at run time, and also pass the new options
5230 into every subsequent branch compile.
5231
5232 This function is used during the pre-compile phase when we are trying to find
5233 out the amount of memory needed, as well as during the real compile phase. The
5234 value of lengthptr distinguishes the two phases.
5235
5236 Arguments:
5237 options option bits, including any changes for this subpattern
5238 oldims previous settings of ims option bits
5239 codeptr -> the address of the current code pointer
5240 ptrptr -> the address of the current pattern pointer
5241 errorcodeptr -> pointer to error code variable
5242 lookbehind TRUE if this is a lookbehind assertion
5243 reset_bracount TRUE to reset the count for each branch
5244 skipbytes skip this many bytes at start (for brackets and OP_COND)
5245 firstbyteptr place to put the first required character, or a negative number
5246 reqbyteptr place to put the last required character, or a negative number
5247 bcptr pointer to the chain of currently open branches
5248 cd points to the data block with tables pointers etc.
5249 lengthptr NULL during the real compile phase
5250 points to length accumulator during pre-compile phase
5251
5252 Returns: TRUE on success
5253 */
5254
5255 static BOOL
5256 compile_regex(int options, int oldims, uschar **codeptr, const uschar **ptrptr,
5257 int *errorcodeptr, BOOL lookbehind, BOOL reset_bracount, int skipbytes,
5258 int *firstbyteptr, int *reqbyteptr, branch_chain *bcptr, compile_data *cd,
5259 int *lengthptr)
5260 {
5261 const uschar *ptr = *ptrptr;
5262 uschar *code = *codeptr;
5263 uschar *last_branch = code;
5264 uschar *start_bracket = code;
5265 uschar *reverse_count = NULL;
5266 int firstbyte, reqbyte;
5267 int branchfirstbyte, branchreqbyte;
5268 int length;
5269 int orig_bracount;
5270 int max_bracount;
5271 branch_chain bc;
5272
5273 bc.outer = bcptr;
5274 bc.current = code;
5275
5276 firstbyte = reqbyte = REQ_UNSET;
5277
5278 /* Accumulate the length for use in the pre-compile phase. Start with the
5279 length of the BRA and KET and any extra bytes that are required at the
5280 beginning. We accumulate in a local variable to save frequent testing of
5281 lenthptr for NULL. We cannot do this by looking at the value of code at the
5282 start and end of each alternative, because compiled items are discarded during
5283 the pre-compile phase so that the work space is not exceeded. */
5284
5285 length = 2 + 2*LINK_SIZE + skipbytes;
5286
5287 /* WARNING: If the above line is changed for any reason, you must also change
5288 the code that abstracts option settings at the start of the pattern and makes
5289 them global. It tests the value of length for (2 + 2*LINK_SIZE) in the
5290 pre-compile phase to find out whether anything has yet been compiled or not. */
5291
5292 /* Offset is set zero to mark that this bracket is still open */
5293
5294 PUT(code, 1, 0);
5295 code += 1 + LINK_SIZE + skipbytes;
5296
5297 /* Loop for each alternative branch */
5298
5299 orig_bracount = max_bracount = cd->bracount;
5300 for (;;)
5301 {
5302 /* For a (?| group, reset the capturing bracket count so that each branch
5303 uses the same numbers. */
5304
5305 if (reset_bracount) cd->bracount = orig_bracount;
5306
5307 /* Handle a change of ims options at the start of the branch */
5308
5309 if ((options & PCRE_IMS) != oldims)
5310 {
5311 *code++ = OP_OPT;
5312 *code++ = options & PCRE_IMS;
5313 length += 2;
5314 }
5315
5316 /* Set up dummy OP_REVERSE if lookbehind assertion */
5317
5318 if (lookbehind)
5319 {
5320 *code++ = OP_REVERSE;
5321 reverse_count = code;
5322 PUTINC(code, 0, 0);
5323 length += 1 + LINK_SIZE;
5324 }
5325
5326 /* Now compile the branch; in the pre-compile phase its length gets added
5327 into the length. */
5328
5329 if (!compile_branch(&options, &code, &ptr, errorcodeptr, &branchfirstbyte,
5330 &branchreqbyte, &bc, cd, (lengthptr == NULL)? NULL : &length))
5331 {
5332 *ptrptr = ptr;
5333 return FALSE;
5334 }
5335
5336 /* Keep the highest bracket count in case (?| was used and some branch
5337 has fewer than the rest. */
5338
5339 if (cd->bracount > max_bracount) max_bracount = cd->bracount;
5340
5341 /* In the real compile phase, there is some post-processing to be done. */
5342
5343 if (lengthptr == NULL)
5344 {
5345 /* If this is the first branch, the firstbyte and reqbyte values for the
5346 branch become the values for the regex. */
5347
5348 if (*last_branch != OP_ALT)
5349 {
5350 firstbyte = branchfirstbyte;
5351 reqbyte = branchreqbyte;
5352 }
5353
5354 /* If this is not the first branch, the first char and reqbyte have to
5355 match the values from all the previous branches, except that if the
5356 previous value for reqbyte didn't have REQ_VARY set, it can still match,
5357 and we set REQ_VARY for the regex. */
5358
5359 else
5360 {
5361 /* If we previously had a firstbyte, but it doesn't match the new branch,
5362 we have to abandon the firstbyte for the regex, but if there was
5363 previously no reqbyte, it takes on the value of the old firstbyte. */
5364
5365 if (firstbyte >= 0 && firstbyte != branchfirstbyte)
5366 {
5367 if (reqbyte < 0) reqbyte = firstbyte;
5368 firstbyte = REQ_NONE;
5369 }
5370
5371 /* If we (now or from before) have no firstbyte, a firstbyte from the
5372 branch becomes a reqbyte if there isn't a branch reqbyte. */
5373
5374 if (firstbyte < 0 && branchfirstbyte >= 0 && branchreqbyte < 0)
5375 branchreqbyte = branchfirstbyte;
5376
5377 /* Now ensure that the reqbytes match */
5378
5379 if ((reqbyte & ~REQ_VARY) != (branchreqbyte & ~REQ_VARY))
5380 reqbyte = REQ_NONE;
5381 else reqbyte |= branchreqbyte; /* To "or" REQ_VARY */
5382 }
5383
5384 /* If lookbehind, check that this branch matches a fixed-length string, and
5385 put the length into the OP_REVERSE item. Temporarily mark the end of the
5386 branch with OP_END. */
5387
5388 if (lookbehind)
5389 {
5390 int fixed_length;
5391 *code = OP_END;
5392 fixed_length = find_fixedlength(last_branch, options);
5393 DPRINTF(("fixed length = %d\n", fixed_length));
5394 if (fixed_length < 0)
5395 {
5396 *errorcodeptr = (fixed_length == -2)? ERR36 : ERR25;
5397 *ptrptr = ptr;
5398 return FALSE;
5399 }
5400 PUT(reverse_count, 0, fixed_length);
5401 }
5402 }
5403
5404 /* Reached end of expression, either ')' or end of pattern. In the real
5405 compile phase, go back through the alternative branches and reverse the chain
5406 of offsets, with the field in the BRA item now becoming an offset to the
5407 first alternative. If there are no alternatives, it points to the end of the
5408 group. The length in the terminating ket is always the length of the whole
5409 bracketed item. If any of the ims options were changed inside the group,
5410 compile a resetting op-code following, except at the very end of the pattern.
5411 Return leaving the pointer at the terminating char. */
5412
5413 if (*ptr != '|')
5414 {
5415 if (lengthptr == NULL)
5416 {
5417 int branch_length = code - last_branch;
5418 do
5419 {
5420 int prev_length = GET(last_branch, 1);
5421 PUT(last_branch, 1, branch_length);
5422 branch_length = prev_length;
5423 last_branch -= branch_length;
5424 }
5425 while (branch_length > 0);
5426 }
5427
5428 /* Fill in the ket */
5429
5430 *code = OP_KET;
5431 PUT(code, 1, code - start_bracket);
5432 code += 1 + LINK_SIZE;
5433
5434 /* Resetting option if needed */
5435
5436 if ((options & PCRE_IMS) != oldims && *ptr == ')')
5437 {
5438 *code++ = OP_OPT;
5439 *code++ = oldims;
5440 length += 2;
5441 }
5442
5443 /* Retain the highest bracket number, in case resetting was used. */
5444
5445 cd->bracount = max_bracount;
5446
5447 /* Set values to pass back */
5448
5449 *codeptr = code;
5450 *ptrptr = ptr;
5451 *firstbyteptr = firstbyte;
5452 *reqbyteptr = reqbyte;
5453 if (lengthptr != NULL)
5454 {
5455 if (OFLOW_MAX - *lengthptr < length)
5456 {
5457 *errorcodeptr = ERR20;
5458 return FALSE;
5459 }
5460 *lengthptr += length;
5461 }
5462 return TRUE;
5463 }
5464
5465 /* Another branch follows. In the pre-compile phase, we can move the code
5466 pointer back to where it was for the start of the first branch. (That is,
5467 pretend that each branch is the only one.)
5468
5469 In the real compile phase, insert an ALT node. Its length field points back
5470 to the previous branch while the bracket remains open. At the end the chain
5471 is reversed. It's done like this so that the start of the bracket has a
5472 zero offset until it is closed, making it possible to detect recursion. */
5473
5474 if (lengthptr != NULL)
5475 {
5476 code = *codeptr + 1 + LINK_SIZE + skipbytes;
5477 length += 1 + LINK_SIZE;
5478 }
5479 else
5480 {
5481 *code = OP_ALT;
5482 PUT(code, 1, code - last_branch);
5483 bc.current = last_branch = code;
5484 code += 1 + LINK_SIZE;
5485 }
5486
5487 ptr++;
5488 }
5489 /* Control never reaches here */
5490 }
5491
5492
5493
5494
5495 /*************************************************
5496 * Check for anchored expression *
5497 *************************************************/
5498
5499 /* Try to find out if this is an anchored regular expression. Consider each
5500 alternative branch. If they all start with OP_SOD or OP_CIRC, or with a bracket
5501 all of whose alternatives start with OP_SOD or OP_CIRC (recurse ad lib), then
5502 it's anchored. However, if this is a multiline pattern, then only OP_SOD
5503 counts, since OP_CIRC can match in the middle.
5504
5505 We can also consider a regex to be anchored if OP_SOM starts all its branches.
5506 This is the code for \G, which means "match at start of match position, taking
5507 into account the match offset".
5508
5509 A branch is also implicitly anchored if it starts with .* and DOTALL is set,
5510 because that will try the rest of the pattern at all possible matching points,
5511 so there is no point trying again.... er ....
5512
5513 .... except when the .* appears inside capturing parentheses, and there is a
5514 subsequent back reference to those parentheses. We haven't enough information
5515 to catch that case precisely.
5516
5517 At first, the best we could do was to detect when .* was in capturing brackets
5518 and the highest back reference was greater than or equal to that level.
5519 However, by keeping a bitmap of the first 31 back references, we can catch some
5520 of the more common cases more precisely.
5521
5522 Arguments:
5523 code points to start of expression (the bracket)
5524 options points to the options setting
5525 bracket_map a bitmap of which brackets we are inside while testing; this
5526 handles up to substring 31; after that we just have to take
5527 the less precise approach
5528 backref_map the back reference bitmap
5529
5530 Returns: TRUE or FALSE
5531 */
5532
5533 static BOOL
5534 is_anchored(register const uschar *code, int *options, unsigned int bracket_map,
5535 unsigned int backref_map)
5536 {
5537 do {
5538 const uschar *scode = first_significant_code(code + _pcre_OP_lengths[*code],
5539 options, PCRE_MULTILINE, FALSE);
5540 register int op = *scode;
5541
5542 /* Non-capturing brackets */
5543
5544 if (op == OP_BRA)
5545 {
5546 if (!is_anchored(scode, options, bracket_map, backref_map)) return FALSE;
5547 }
5548
5549 /* Capturing brackets */
5550
5551 else if (op == OP_CBRA)
5552 {
5553 int n = GET2(scode, 1+LINK_SIZE);
5554 int new_map = bracket_map | ((n < 32)? (1 << n) : 1);
5555 if (!is_anchored(scode, options, new_map, backref_map)) return FALSE;
5556 }
5557
5558 /* Other brackets */
5559
5560 else if (op == OP_ASSERT || op == OP_ONCE || op == OP_COND)
5561 {
5562 if (!is_anchored(scode, options, bracket_map, backref_map)) return FALSE;
5563 }
5564
5565 /* .* is not anchored unless DOTALL is set and it isn't in brackets that
5566 are or may be referenced. */
5567
5568 else if ((op == OP_TYPESTAR || op == OP_TYPEMINSTAR ||
5569 op == OP_TYPEPOSSTAR) &&
5570 (*options & PCRE_DOTALL) != 0)
5571 {
5572 if (scode[1] != OP_ANY || (bracket_map & backref_map) != 0) return FALSE;
5573 }
5574
5575 /* Check for explicit anchoring */
5576
5577 else if (op != OP_SOD && op != OP_SOM &&
5578 ((*options & PCRE_MULTILINE) != 0 || op != OP_CIRC))
5579 return FALSE;
5580 code += GET(code, 1);
5581 }
5582 while (*code == OP_ALT); /* Loop for each alternative */
5583 return TRUE;
5584 }
5585
5586
5587
5588 /*************************************************
5589 * Check for starting with ^ or .* *
5590 *************************************************/
5591
5592 /* This is called to find out if every branch starts with ^ or .* so that
5593 "first char" processing can be done to speed things up in multiline
5594 matching and for non-DOTALL patterns that start with .* (which must start at
5595 the beginning or after \n). As in the case of is_anchored() (see above), we
5596 have to take account of back references to capturing brackets that contain .*
5597 because in that case we can't make the assumption.
5598
5599 Arguments:
5600 code points to start of expression (the bracket)
5601 bracket_map a bitmap of which brackets we are inside while testing; this
5602 handles up to substring 31; after that we just have to take
5603 the less precise approach
5604 backref_map the back reference bitmap
5605
5606 Returns: TRUE or FALSE
5607 */
5608
5609 static BOOL
5610 is_startline(const uschar *code, unsigned int bracket_map,
5611 unsigned int backref_map)
5612 {
5613 do {
5614 const uschar *scode = first_significant_code(code + _pcre_OP_lengths[*code],
5615 NULL, 0, FALSE);
5616 register int op = *scode;
5617
5618 /* Non-capturing brackets */
5619
5620 if (op == OP_BRA)
5621 {
5622 if (!is_startline(scode, bracket_map, backref_map)) return FALSE;
5623 }
5624
5625 /* Capturing brackets */
5626
5627 else if (op == OP_CBRA)
5628 {
5629 int n = GET2(scode, 1+LINK_SIZE);
5630 int new_map = bracket_map | ((n < 32)? (1 << n) : 1);
5631 if (!is_startline(scode, new_map, backref_map)) return FALSE;
5632 }
5633
5634 /* Other brackets */
5635
5636 else if (op == OP_ASSERT || op == OP_ONCE || op == OP_COND)
5637 { if (!is_startline(scode, bracket_map, backref_map)) return FALSE; }
5638
5639 /* .* means "start at start or after \n" if it isn't in brackets that
5640 may be referenced. */
5641
5642 else if (op == OP_TYPESTAR || op == OP_TYPEMINSTAR || op == OP_TYPEPOSSTAR)
5643 {
5644 if (scode[1] != OP_ANY || (bracket_map & backref_map) != 0) return FALSE;
5645 }
5646
5647 /* Check for explicit circumflex */
5648
5649 else if (op != OP_CIRC) return FALSE;
5650
5651 /* Move on to the next alternative */
5652
5653 code += GET(code, 1);
5654 }
5655 while (*code == OP_ALT); /* Loop for each alternative */
5656 return TRUE;
5657 }
5658
5659
5660
5661 /*************************************************
5662 * Check for asserted fixed first char *
5663 *************************************************/
5664
5665 /* During compilation, the "first char" settings from forward assertions are
5666 discarded, because they can cause conflicts with actual literals that follow.
5667 However, if we end up without a first char setting for an unanchored pattern,
5668 it is worth scanning the regex to see if there is an initial asserted first
5669 char. If all branches start with the same asserted char, or with a bracket all
5670 of whose alternatives start with the same asserted char (recurse ad lib), then
5671 we return that char, otherwise -1.
5672
5673 Arguments:
5674 code points to start of expression (the bracket)
5675 options pointer to the options (used to check casing changes)
5676 inassert TRUE if in an assertion
5677
5678 Returns: -1 or the fixed first char
5679 */
5680
5681 static int
5682 find_firstassertedchar(const uschar *code, int *options, BOOL inassert)
5683 {
5684 register int c = -1;
5685 do {
5686 int d;
5687 const uschar *scode =
5688 first_significant_code(code + 1+LINK_SIZE, options, PCRE_CASELESS, TRUE);
5689 register int op = *scode;
5690
5691 switch(op)
5692 {
5693 default:
5694 return -1;
5695
5696 case OP_BRA:
5697 case OP_CBRA:
5698 case OP_ASSERT:
5699 case OP_ONCE:
5700 case OP_COND:
5701 if ((d = find_firstassertedchar(scode, options, op == OP_ASSERT)) < 0)
5702 return -1;
5703 if (c < 0) c = d; else if (c != d) return -1;
5704 break;
5705
5706 case OP_EXACT: /* Fall through */
5707 scode += 2;
5708
5709 case OP_CHAR:
5710 case OP_CHARNC:
5711 case OP_PLUS:
5712 case OP_MINPLUS:
5713 case OP_POSPLUS:
5714 if (!inassert) return -1;
5715 if (c < 0)
5716 {
5717 c = scode[1];
5718 if ((*options & PCRE_CASELESS) != 0) c |= REQ_CASELESS;
5719 }
5720 else if (c != scode[1]) return -1;
5721 break;
5722 }
5723
5724 code += GET(code, 1);
5725 }
5726 while (*code == OP_ALT);
5727 return c;
5728 }
5729
5730
5731
5732 /*************************************************
5733 * Compile a Regular Expression *
5734 *************************************************/
5735
5736 /* This function takes a string and returns a pointer to a block of store
5737 holding a compiled version of the expression. The original API for this
5738 function had no error code return variable; it is retained for backwards
5739 compatibility. The new function is given a new name.
5740
5741 Arguments:
5742 pattern the regular expression
5743 options various option bits
5744 errorcodeptr pointer to error code variable (pcre_compile2() only)
5745 can be NULL if you don't want a code value
5746 errorptr pointer to pointer to error text
5747 erroroffset ptr offset in pattern where error was detected
5748 tables pointer to character tables or NULL
5749
5750 Returns: pointer to compiled data block, or NULL on error,
5751 with errorptr and erroroffset set
5752 */
5753
5754 PCRE_EXP_DEFN pcre *
5755 pcre_compile(const char *pattern, int options, const char **errorptr,
5756 int *erroroffset, const unsigned char *tables)
5757 {
5758 return pcre_compile2(pattern, options, NULL, errorptr, erroroffset, tables);
5759 }
5760
5761
5762 PCRE_EXP_DEFN pcre *
5763 pcre_compile2(const char *pattern, int options, int *errorcodeptr,
5764 const char **errorptr, int *erroroffset, const unsigned char *tables)
5765 {
5766 real_pcre *re;
5767 int length = 1; /* For final END opcode */
5768 int firstbyte, reqbyte, newline;
5769 int errorcode = 0;
5770 int skipatstart = 0;
5771 #ifdef SUPPORT_UTF8
5772 BOOL utf8;
5773 #endif
5774 size_t size;
5775 uschar *code;
5776 const uschar *codestart;
5777 const uschar *ptr;
5778 compile_data compile_block;
5779 compile_data *cd = &compile_block;
5780
5781 /* This space is used for "compiling" into during the first phase, when we are
5782 computing the amount of memory that is needed. Compiled items are thrown away
5783 as soon as possible, so that a fairly large buffer should be sufficient for
5784 this purpose. The same space is used in the second phase for remembering where
5785 to fill in forward references to subpatterns. */
5786
5787 uschar cworkspace[COMPILE_WORK_SIZE];
5788
5789
5790 /* Set this early so that early errors get offset 0. */
5791
5792 ptr = (const uschar *)pattern;
5793
5794 /* We can't pass back an error message if errorptr is NULL; I guess the best we
5795 can do is just return NULL, but we can set a code value if there is a code
5796 pointer. */
5797
5798 if (errorptr == NULL)
5799 {
5800 if (errorcodeptr != NULL) *errorcodeptr = 99;
5801 return NULL;
5802 }
5803
5804 *errorptr = NULL;
5805 if (errorcodeptr != NULL) *errorcodeptr = ERR0;
5806
5807 /* However, we can give a message for this error */
5808
5809 if (erroroffset == NULL)
5810 {
5811 errorcode = ERR16;
5812 goto PCRE_EARLY_ERROR_RETURN2;
5813 }
5814
5815 *erroroffset = 0;
5816
5817 /* Can't support UTF8 unless PCRE has been compiled to include the code. */
5818
5819 #ifdef SUPPORT_UTF8
5820 utf8 = (options & PCRE_UTF8) != 0;
5821 if (utf8 && (options & PCRE_NO_UTF8_CHECK) == 0 &&
5822 (*erroroffset = _pcre_valid_utf8((uschar *)pattern, -1)) >= 0)
5823 {
5824 errorcode = ERR44;
5825 goto PCRE_EARLY_ERROR_RETURN2;
5826 }
5827 #else
5828 if ((options & PCRE_UTF8) != 0)
5829 {
5830 errorcode = ERR32;
5831 goto PCRE_EARLY_ERROR_RETURN;
5832 }
5833 #endif
5834
5835 if ((options & ~PUBLIC_OPTIONS) != 0)
5836 {
5837 errorcode = ERR17;
5838 goto PCRE_EARLY_ERROR_RETURN;
5839 }
5840
5841 /* Set up pointers to the individual character tables */
5842
5843 if (tables == NULL) tables = _pcre_default_tables;
5844 cd->lcc = tables + lcc_offset;
5845 cd->fcc = tables + fcc_offset;
5846 cd->cbits = tables + cbits_offset;
5847 cd->ctypes = tables + ctypes_offset;
5848
5849 /* Check for global one-time settings at the start of the pattern, and remember
5850 the offset for later. */
5851
5852 while (ptr[skipatstart] == '(' && ptr[skipatstart+1] == '*')
5853 {
5854 int newnl = 0;
5855 int newbsr = 0;
5856
5857 if (strncmp((char *)(ptr+skipatstart+2), "CR)", 3) == 0)
5858 { skipatstart += 5; newnl = PCRE_NEWLINE_CR; }
5859 else if (strncmp((char *)(ptr+skipatstart+2), "LF)", 3) == 0)
5860 { skipatstart += 5; newnl = PCRE_NEWLINE_LF; }
5861 else if (strncmp((char *)(ptr+skipatstart+2), "CRLF)", 5) == 0)
5862 { skipatstart += 7; newnl = PCRE_NEWLINE_CR + PCRE_NEWLINE_LF; }
5863 else if (strncmp((char *)(ptr+skipatstart+2), "ANY)", 4) == 0)
5864 { skipatstart += 6; newnl = PCRE_NEWLINE_ANY; }
5865 else if (strncmp((char *)(ptr+skipatstart+2), "ANYCRLF)", 8) == 0)
5866 { skipatstart += 10; newnl = PCRE_NEWLINE_ANYCRLF; }
5867
5868 else if (strncmp((char *)(ptr+skipatstart+2), "BSR_ANYCRLF)", 12) == 0)
5869 { skipatstart += 14; newbsr = PCRE_BSR_ANYCRLF; }
5870 else if (strncmp((char *)(ptr+skipatstart+2), "BSR_UNICODE)", 12) == 0)
5871 { skipatstart += 14; newbsr = PCRE_BSR_UNICODE; }
5872
5873 if (newnl != 0)
5874 options = (options & ~PCRE_NEWLINE_BITS) | newnl;
5875 else if (newbsr != 0)
5876 options = (options & ~(PCRE_BSR_ANYCRLF|PCRE_BSR_UNICODE)) | newbsr;
5877 else break;
5878 }
5879
5880 /* Check validity of \R options. */
5881
5882 switch (options & (PCRE_BSR_ANYCRLF|PCRE_BSR_UNICODE))
5883 {
5884 case 0:
5885 case PCRE_BSR_ANYCRLF:
5886 case PCRE_BSR_UNICODE:
5887 break;
5888 default: errorcode = ERR56; goto PCRE_EARLY_ERROR_RETURN;
5889 }
5890
5891 /* Handle different types of newline. The three bits give seven cases. The
5892 current code allows for fixed one- or two-byte sequences, plus "any" and
5893 "anycrlf". */
5894
5895 switch (options & PCRE_NEWLINE_BITS)
5896 {
5897 case 0: newline = NEWLINE; break; /* Build-time default */
5898 case PCRE_NEWLINE_CR: newline = '\r'; break;
5899 case PCRE_NEWLINE_LF: newline = '\n'; break;
5900 case PCRE_NEWLINE_CR+
5901 PCRE_NEWLINE_LF: newline = ('\r' << 8) | '\n'; break;
5902 case PCRE_NEWLINE_ANY: newline = -1; break;
5903 case PCRE_NEWLINE_ANYCRLF: newline = -2; break;
5904 default: errorcode = ERR56; goto PCRE_EARLY_ERROR_RETURN;
5905 }
5906
5907 if (newline == -2)
5908 {
5909 cd->nltype = NLTYPE_ANYCRLF;
5910 }
5911 else if (newline < 0)
5912 {
5913 cd->nltype = NLTYPE_ANY;
5914 }
5915 else
5916 {
5917 cd->nltype = NLTYPE_FIXED;
5918 if (newline > 255)
5919 {
5920 cd->nllen = 2;
5921 cd->nl[0] = (newline >> 8) & 255;
5922 cd->nl[1] = newline & 255;
5923 }
5924 else
5925 {
5926 cd->nllen = 1;
5927 cd->nl[0] = newline;
5928 }
5929 }
5930
5931 /* Maximum back reference and backref bitmap. The bitmap records up to 31 back
5932 references to help in deciding whether (.*) can be treated as anchored or not.
5933 */
5934
5935 cd->top_backref = 0;
5936 cd->backref_map = 0;
5937
5938 /* Reflect pattern for debugging output */
5939
5940 DPRINTF(("------------------------------------------------------------------\n"));
5941 DPRINTF(("%s\n", pattern));
5942
5943 /* Pretend to compile the pattern while actually just accumulating the length
5944 of memory required. This behaviour is triggered by passing a non-NULL final
5945 argument to compile_regex(). We pass a block of workspace (cworkspace) for it
5946 to compile parts of the pattern into; the compiled code is discarded when it is
5947 no longer needed, so hopefully this workspace will never overflow, though there
5948 is a test for its doing so. */
5949
5950 cd->bracount = cd->final_bracount = 0;
5951 cd->names_found = 0;
5952 cd->name_entry_size = 0;
5953 cd->name_table = NULL;
5954 cd->start_workspace = cworkspace;
5955 cd->start_code = cworkspace;
5956 cd->hwm = cworkspace;
5957 cd->start_pattern = (const uschar *)pattern;
5958 cd->end_pattern = (const uschar *)(pattern + strlen(pattern));
5959 cd->req_varyopt = 0;
5960 cd->external_options = options;
5961 cd->external_flags = 0;
5962
5963 /* Now do the pre-compile. On error, errorcode will be set non-zero, so we
5964 don't need to look at the result of the function here. The initial options have
5965 been put into the cd block so that they can be changed if an option setting is
5966 found within the regex right at the beginning. Bringing initial option settings
5967 outside can help speed up starting point checks. */
5968
5969 ptr += skipatstart;
5970 code = cworkspace;
5971 *code = OP_BRA;
5972 (void)compile_regex(cd->external_options, cd->external_options & PCRE_IMS,
5973 &code, &ptr, &errorcode, FALSE, FALSE, 0, &firstbyte, &reqbyte, NULL, cd,
5974 &length);
5975 if (errorcode != 0) goto PCRE_EARLY_ERROR_RETURN;
5976
5977 DPRINTF(("end pre-compile: length=%d workspace=%d\n", length,
5978 cd->hwm - cworkspace));
5979
5980 if (length > MAX_PATTERN_SIZE)
5981 {
5982 errorcode = ERR20;
5983 goto PCRE_EARLY_ERROR_RETURN;
5984 }
5985
5986 /* Compute the size of data block needed and get it, either from malloc or
5987 externally provided function. Integer overflow should no longer be possible
5988 because nowadays we limit the maximum value of cd->names_found and
5989 cd->name_entry_size. */
5990
5991 size = length + sizeof(real_pcre) + cd->names_found * (cd->name_entry_size + 3);
5992 re = (real_pcre *)(pcre_malloc)(size);
5993
5994 if (re == NULL)
5995 {
5996 errorcode = ERR21;
5997 goto PCRE_EARLY_ERROR_RETURN;
5998 }
5999
6000 /* Put in the magic number, and save the sizes, initial options, internal
6001 flags, and character table pointer. NULL is used for the default character
6002 tables. The nullpad field is at the end; it's there to help in the case when a
6003 regex compiled on a system with 4-byte pointers is run on another with 8-byte
6004 pointers. */
6005
6006 re->magic_number = MAGIC_NUMBER;
6007 re->size = size;
6008 re->options = cd->external_options;
6009 re->flags = cd->external_flags;
6010 re->dummy1 = 0;
6011 re->first_byte = 0;
6012 re->req_byte = 0;
6013 re->name_table_offset = sizeof(real_pcre);
6014 re->name_entry_size = cd->name_entry_size;
6015 re->name_count = cd->names_found;
6016 re->ref_count = 0;
6017 re->tables = (tables == _pcre_default_tables)? NULL : tables;
6018 re->nullpad = NULL;
6019
6020 /* The starting points of the name/number translation table and of the code are
6021 passed around in the compile data block. The start/end pattern and initial
6022 options are already set from the pre-compile phase, as is the name_entry_size
6023 field. Reset the bracket count and the names_found field. Also reset the hwm
6024 field; this time it's used for remembering forward references to subpatterns.
6025 */
6026
6027 cd->final_bracount = cd->bracount; /* Save for checking forward references */
6028 cd->bracount = 0;
6029 cd->names_found = 0;
6030 cd->name_table = (uschar *)re + re->name_table_offset;
6031 codestart = cd->name_table + re->name_entry_size * re->name_count;
6032 cd->start_code = codestart;
6033 cd->hwm = cworkspace;
6034 cd->req_varyopt = 0;
6035 cd->had_accept = FALSE;
6036
6037 /* Set up a starting, non-extracting bracket, then compile the expression. On
6038 error, errorcode will be set non-zero, so we don't need to look at the result
6039 of the function here. */
6040
6041 ptr = (const uschar *)pattern + skipatstart;
6042 code = (uschar *)codestart;
6043 *code = OP_BRA;
6044 (void)compile_regex(re->options, re->options & PCRE_IMS, &code, &ptr,
6045 &errorcode, FALSE, FALSE, 0, &firstbyte, &reqbyte, NULL, cd, NULL);
6046 re->top_bracket = cd->bracount;
6047 re->top_backref = cd->top_backref;
6048 re->flags = cd->external_flags;
6049
6050 if (cd->had_accept) reqbyte = -1; /* Must disable after (*ACCEPT) */
6051
6052 /* If not reached end of pattern on success, there's an excess bracket. */
6053
6054 if (errorcode == 0 && *ptr != 0) errorcode = ERR22;
6055
6056 /* Fill in the terminating state and check for disastrous overflow, but
6057 if debugging, leave the test till after things are printed out. */
6058
6059 *code++ = OP_END;
6060
6061 #ifndef DEBUG
6062 if (code - codestart > length) errorcode = ERR23;
6063 #endif
6064
6065 /* Fill in any forward references that are required. */
6066
6067 while (errorcode == 0 && cd->hwm > cworkspace)
6068 {
6069 int offset, recno;
6070 const uschar *groupptr;
6071 cd->hwm -= LINK_SIZE;
6072 offset = GET(cd->hwm, 0);
6073 recno = GET(codestart, offset);
6074 groupptr = find_bracket(codestart, (re->options & PCRE_UTF8) != 0, recno);
6075 if (groupptr == NULL) errorcode = ERR53;
6076 else PUT(((uschar *)codestart), offset, groupptr - codestart);
6077 }
6078
6079 /* Give an error if there's back reference to a non-existent capturing
6080 subpattern. */
6081
6082 if (errorcode == 0 && re->top_backref > re->top_bracket) errorcode = ERR15;
6083
6084 /* Failed to compile, or error while post-processing */
6085
6086 if (errorcode != 0)
6087 {
6088 (pcre_free)(re);
6089 PCRE_EARLY_ERROR_RETURN:
6090 *erroroffset = ptr - (const uschar *)pattern;
6091 PCRE_EARLY_ERROR_RETURN2:
6092 *errorptr = find_error_text(errorcode);
6093 if (errorcodeptr != NULL) *errorcodeptr = errorcode;
6094 return NULL;
6095 }
6096
6097 /* If the anchored option was not passed, set the flag if we can determine that
6098 the pattern is anchored by virtue of ^ characters or \A or anything else (such
6099 as starting with .* when DOTALL is set).
6100
6101 Otherwise, if we know what the first byte has to be, save it, because that
6102 speeds up unanchored matches no end. If not, see if we can set the
6103 PCRE_STARTLINE flag. This is helpful for multiline matches when all branches
6104 start with ^. and also when all branches start with .* for non-DOTALL matches.
6105 */
6106
6107 if ((re->options & PCRE_ANCHORED) == 0)
6108 {
6109 int temp_options = re->options; /* May get changed during these scans */
6110 if (is_anchored(codestart, &temp_options, 0, cd->backref_map))
6111 re->options |= PCRE_ANCHORED;
6112 else
6113 {
6114 if (firstbyte < 0)
6115 firstbyte = find_firstassertedchar(codestart, &temp_options, FALSE);
6116 if (firstbyte >= 0) /* Remove caseless flag for non-caseable chars */
6117 {
6118 int ch = firstbyte & 255;
6119 re->first_byte = ((firstbyte & REQ_CASELESS) != 0 &&
6120 cd->fcc[ch] == ch)? ch : firstbyte;
6121 re->flags |= PCRE_FIRSTSET;
6122 }
6123 else if (is_startline(codestart, 0, cd->backref_map))
6124 re->flags |= PCRE_STARTLINE;
6125 }
6126 }
6127
6128 /* For an anchored pattern, we use the "required byte" only if it follows a
6129 variable length item in the regex. Remove the caseless flag for non-caseable
6130 bytes. */
6131
6132 if (reqbyte >= 0 &&
6133 ((re->options & PCRE_ANCHORED) == 0 || (reqbyte & REQ_VARY) != 0))
6134 {
6135 int ch = reqbyte & 255;
6136 re->req_byte = ((reqbyte & REQ_CASELESS) != 0 &&
6137 cd->fcc[ch] == ch)? (reqbyte & ~REQ_CASELESS) : reqbyte;
6138 re->flags |= PCRE_REQCHSET;
6139 }
6140
6141 /* Print out the compiled data if debugging is enabled. This is never the
6142 case when building a production library. */
6143
6144 #ifdef DEBUG
6145
6146 printf("Length = %d top_bracket = %d top_backref = %d\n",
6147 length, re->top_bracket, re->top_backref);
6148
6149 printf("Options=%08x\n", re->options);
6150
6151 if ((re->flags & PCRE_FIRSTSET) != 0)
6152 {
6153 int ch = re->first_byte & 255;
6154 const char *caseless = ((re->first_byte & REQ_CASELESS) == 0)?
6155 "" : " (caseless)";
6156 if (isprint(ch)) printf("First char = %c%s\n", ch, caseless);
6157 else printf("First char = \\x%02x%s\n", ch, caseless);
6158 }
6159
6160 if ((re->flags & PCRE_REQCHSET) != 0)
6161 {
6162 int ch = re->req_byte & 255;
6163 const char *caseless = ((re->req_byte & REQ_CASELESS) == 0)?
6164 "" : " (caseless)";
6165 if (isprint(ch)) printf("Req char = %c%s\n", ch, caseless);
6166 else printf("Req char = \\x%02x%s\n", ch, caseless);
6167 }
6168
6169 pcre_printint(re, stdout, TRUE);
6170
6171 /* This check is done here in the debugging case so that the code that
6172 was compiled can be seen. */
6173
6174 if (code - codestart > length)
6175 {
6176 (pcre_free)(re);
6177 *errorptr = find_error_text(ERR23);
6178 *erroroffset = ptr - (uschar *)pattern;
6179 if (errorcodeptr != NULL) *errorcodeptr = ERR23;
6180 return NULL;
6181 }
6182 #endif /* DEBUG */
6183
6184 return (pcre *)re;
6185 }
6186
6187 /* End of pcre_compile.c */
Properties
Name Value
svn:eol-style native
svn:keywords "Author Date Id Revision Url"
ViewVC Help
Powered by ViewVC 1.1.5
|
__label__pos
| 0.950598 |
xor tile optimization
Hello, thank you for the great tool!
I've been running through an issue where I'm trying to optimize an xor script used for huge layouts using TilingProcessor I used the script in the documentation and it is really fast, but I was wondering how I could output these layers into a new gds file (I added a loop that gets all layers from the 2 layouts and queues them to do the xor). I tried using this function and then doing a simple layout.write("output.gds") after the loop but it ends up with an empty layout.
Any suggestions on how to write the output one by one? maybe from inside the queue script itself?
Comments
• edited August 15
@marwaneltoukhy The script inside the tiling processor should not write anything. In order to receive something on the output, you need to call the "_output" function inside the script.
The TilingProcessor description gives an example.
Maybe this discussion is easier if you paste code.
Matthias
• @Matthias The code for xor:
# set up input a
a = source($a, $top_cell)
lay_a = a.layout
# set up input b
b = source($b, $top_cell)
lay_b = b.layout
o = RBA::Layout::new
cell = o.create_cell($top_cell.to_s)
cell_ind = cell.cell_index()
# collect all common layers
layers = {}
[ a.layout, b.layout ].each do |ly|
ly.layer_indices.each do |li|
i = ly.get_info(li)
layers[i.to_s] = i
end
end
tp = RBA::TilingProcessor::new
tp.tile_size(500, 500)
tp.threads = $thr.to_i
tp.dbu = layout.dbu
layers.keys.sort.each do |l|
i = layers[l]
tp.input("a1", lay_a, lay_a.top_cell().cell_index, i )
tp.input("a2", lay_b, lay_b.top_cell().cell_index, i )
tp.output("o1", o, cell_ind, i)
tp.queue("_output(o1, a1 ^ a2)")
end
tp.execute("XOR")
o.write("output.gds")
• edited August 23
@marwaneltoukhy The script is basically correct, but it's a bit weird: are you trying to use DRC or is that a basic Ruby API script?
When I rewrite it to Ruby, the script looks like this:
# set up input a
a = source($a, $top_cell)
lay_a = a.layout
# set up input b
b = source($b, $top_cell)
lay_b = b.layout
o = RBA::Layout::new
cell = o.create_cell($top_cell.to_s)
cell_ind = cell.cell_index()
# collect all common layers
layers = {}
[ a.layout, b.layout ].each do |ly|
ly.layer_indices.each do |li|
i = ly.get_info(li)
layers[i.to_s] = i
end
end
tp = RBA::TilingProcessor::new
tp.tile_size(500, 500)
tp.threads = $thr.to_i
tp.dbu = layout.dbu
layers.keys.sort.each do |l|
i = layers[l]
tp.input("a1", lay_a, lay_a.top_cell().cell_index, i )
tp.input("a2", lay_b, lay_b.top_cell().cell_index, i )
tp.output("o1", o, cell_ind, i)
tp.queue("_output(o1, a1 ^ a2)")
end
tp.execute("XOR")
o.write("output.gds")
And for me it seems to work.
Inside DRC you don't need to implement the tiling yourself. DRC wraps it for you. Just say:
# set up input a
a = source($a, $top_cell)
# set up input b
b = source($b, $top_cell)
# set up the output
target("output.gds")
# enable tiling with 4 cores:
tiles(500.0)
threads(4)
# collect all common layers
layers = {}
[ a.layout, b.layout ].each do |ly|
ly.layer_indices.each do |li|
i = ly.get_info(li)
(a.input(i) ^ b.input(i)).output(i)
end
end
Matthias
• @Matthias Thanks for your clarification, but the o.write("output.gds") in the first script actually doesn't output anything in the output.gds file
• @marwaneltoukhy No, sorry, I just confirmed that the Ruby script I showed works (I added the missing '#' at the beginning).
But maybe your input files are identical? In this case the XOR output is empty. That's how XOR says the files are the same.
Matthias
Sign In or Register to comment.
|
__label__pos
| 0.980672 |
Was this page helpful?
Your feedback about this content is important. Let us know what you think.
Additional feedback?
1500 characters remaining
Using WMI Windows PowerShell Cmdlets to Manage the BITS Compact Server
Using WMI Windows PowerShell Cmdlets to Manage the BITS Compact Server
Windows PowerShell provides a simple mechanism to connect to Windows Management Instrumentation (WMI) on a remote computer and manage the Background Intelligent Transfer Service (BITS) Compact Server. The BITS Compact Server is an optional server component that must be installed separately. For information about installing the Compact Server, see the BITS Compact Server documentation.
1. Connect to the BITS provider.
$cred = Get-Credential
$bcs = Get-WmiObject -Namespace "root\Microsoft\BITS" -Class "BITSCompactServerUrlGroup" `
-List -ComputerName Server1 -Credential $cred
The Get-Credential cmdlet requests the user's credentials to connect to the remote computer and assigns the credentials to the $cred object.
The objects returned by the Get-WmiObject cmdlet are assigned to the $bcs variable. In the preceding example, the Get-WmiObject cmdlet retrieves the BITSCompactServerUrlGroup class in the root\Microsoft\BITS namespace of Server1. Static methods exposed by the BITSCompactServerUrlGroup class can be called on the $bcs object. For more information about BITS remote management, see BITS provider and BITS provider classes.
Note The grave-accent character (`) is used to indicate a line break.
2. Create a URL group on the server.
$URLGroup = "http://Server1:80/testurlgroup"
$bcs.CreateUrlGroup($URLGroup)
The "http://Server1:80/testurlgroup" URL prefix string is assigned to the $URLGroup variable. The $URLGroup variable is passed to the CreateUrlGroup method, which creates the URL group on Server1.
You can specify a different URL group. The URL group must conform to a valid URL prefix string. For more information about URL prefixes, see UrlPrefix Strings.
3. Host a file on the URL group.
$bcsObj = Get-WmiObject -Namespace "root\Microsoft\BITS" -Class "BITSCompactServerUrlGroup" -filter ("UrlGroup='" + $URLGroup + "'") -ComputerName Server1 -Credential $cred
$bcsObj.CreateURL("url.txt", "c:\\temp\\1.txt", "") -ComputerName Server1 -Credential $cred
The BITSCompactServerUrlGroup instance returned by the Get-WmiObject cmdlet is assigned to the $bcsObj variable. The CreateUrl method is called for the $bcsObj with the "url.txt" URL suffix, the "c:\\temp\\1.txt" source path for the file, and an empty security descriptor string as parameters. The "url.txt" suffix is added to the URL group prefix. Clients can download the file from the following address: http://Server1:80/testurlgroup/url.txt.
4. Clean up the URL and the URL group.
$bcsObj.Delete()
The system.object Delete method deletes the $bcsObj object.
Related topics
BITS Compact Server
BITS provider
BITS provider classes
Get-Credential
Get-WmiObject
Community Additions
ADD
Show:
© 2015 Microsoft
|
__label__pos
| 0.973626 |
View logs for a container or service
Estimated reading time: 2 minutes
The docker logs command shows information logged by a running container. The docker service logs command shows information logged by all containers participating in a service. The information that is logged and the format of the log depends almost entirely on the container’s endpoint command.
By default, docker logs or docker service logs shows the command’s output just as it would appear if you ran the command interactively in a terminal. UNIX and Linux commands typically open three I/O streams when they run, called STDIN, STDOUT, and STDERR. STDIN is the command’s input stream, which may include input from the keyboard or input from another command. STDOUT is usually a command’s normal output, and STDERR is typically used to output error messages. By default, docker logs shows the command’s STDOUT and STDERR. To read more about I/O and Linux, see the Linux Documentation Project article on I/O redirection.
In some cases, docker logs may not show useful information unless you take additional steps.
• If you use a logging driver which sends logs to a file, an external host, a database, or another logging back-end, and have “dual logging” disabled, docker logs may not show useful information.
• If your image runs a non-interactive process such as a web server or a database, that application may send its output to log files instead of STDOUT and STDERR.
In the first case, your logs are processed in other ways and you may choose not to use docker logs. In the second case, the official nginx image shows one workaround, and the official Apache httpd image shows another.
The official nginx image creates a symbolic link from /var/log/nginx/access.log to /dev/stdout, and creates another symbolic link from /var/log/nginx/error.log to /dev/stderr, overwriting the log files and causing logs to be sent to the relevant special device instead. See the Dockerfile.
The official httpd driver changes the httpd application’s configuration to write its normal output directly to /proc/self/fd/1 (which is STDOUT) and its errors to /proc/self/fd/2 (which is STDERR). See the Dockerfile.
Next steps
docker, logging
|
__label__pos
| 0.555164 |
ADO.NET
ADO.NET Projects
ADO.NET Project 1
ADO.NET Examples
Examples
Handling DataAdapter Events
Previous Home Next
DataAdapter supports only two events:
OnRowUpdating and OnRowUpdated.
These two events occur on either side of the actual dataset update, providing fine control of the process.
1. OnRowUpdating Event
2. The OnRowUpdating event is raised after the Update method has set the parameter values of the command to be executed but before the command is executed.The event handler for this event receives an argument whose properties provide essential information about the command that is about to be executed.
The class of the event arguments is defined by the Data Provider, so it will be either OleDbRowUpdatingEventArgs or SqlRowUpdatingEventArgs if one of the .NET Framework Data Providers is used.
RowUpdatingEventArgs Properties:
Command: The Data Command to be executed.
Errors: The errors generated by the .NET Data Provider
Row: The DataReader to be updated
StatementType: The type of Command tobe executed.The possiblevalues are Select, Insert Delete, and Update
Status: The UpdateStatus of the Command
TableMapping: The DataTableMap ping used by the update
3. OnRowUpdated Event
The OnRowUpdated event is raised after the Update method executes the appropriate command against the data source. The event handler for this event is either passed an SqlRowUpdatedEventArgs or an OleDbRowUpdatedEventArgs argument, depending on the Data Provider.
Example:
// Assumes that connection is a valid SqlConnection object.
SqlDataAdapter sda = new SqlDataAdapter(
"SELECT EmpID, EmpName FROM Emp", connection);
// Add handlers.
sda.RowUpdating += new SqlRowUpdatingEventHandler(OnRowUpdating);
sda.RowUpdated += new SqlRowUpdatedEventHandler(OnRowUpdated);
// Set DataAdapter command properties, fill DataSet, modify DataSet.
sda.Update(ds, "Emp");
// Remove handlers.
sda.RowUpdating -= new SqlRowUpdatingEventHandler(OnRowUpdating);
sda.RowUpdated -= new SqlRowUpdatedEventHandler(OnRowUpdated);
protected static void OnRowUpdating(
object sender, SqlRowUpdatingEventArgs args)
{
if (args.StatementType == StatementType.Delete)
{
System.IO.TextWriter tw = System.IO.File.AppendText("Deletes.log");
tw.WriteLine(
"{0}: Customer {1} Deleted.", DateTime.Now,
args.Row["EmpID", DataRowVersion.Original]);
tw.Close();
}
}
protected static void OnRowUpdated(
object sender, SqlRowUpdatedEventArgs args)
{
if (args.Status == UpdateStatus.ErrorsOccurred)
{
args.Row.RowError = args.Errors.Message;
args.Status = UpdateStatus.SkipCurrentRow;
}
}
Previous Home Next
>
|
__label__pos
| 0.839315 |
If you're seeing this message, it means we're having trouble loading external resources on our website.
If you're behind a web filter, please make sure that the domains *.kastatic.org and *.kasandbox.org are unblocked.
Main content
Reasoning with systems of equations
When we perform operations on a system of equations, some operations produce an equivalent system, while others don't necessarily produce an equivalent system. When we're solving a system of equations, we need to use operations that guarantee equivalence. Created by Sal Khan.
Want to join the conversation?
• piceratops ultimate style avatar for user JamesBlagg Read Bio
At couldn't he have multiplied by negative one to cancel out they and then x would be positive, same with the answer at the end?
2x+y=8
x+y=5
2x+y=8
-x-y=-5
x=3
I thought that would be so much easier.
(14 votes)
Default Khan Academy avatar avatar for user
• orange juice squid orange style avatar for user matt crichton
My sense is, that Sal is trying to teach us to do “mathematical reasoning” (at ) with a little bit tricky stuff--meaning at he says “…not super mathematically rigorous…” which to me, means doing it this particular way shows that you know how to work with algebra and systems that much better. I think the key for this method is to know and be comfortable with substituting x and y for a single number (where 2x + y is substituted for 8). It’s usually totally up to you how “deep” you want to go with the math.
(9 votes)
• blobby green style avatar for user Khaled Fadl
I don't understand anything from this video :D
(7 votes)
Default Khan Academy avatar avatar for user
• scuttlebug blue style avatar for user The Travelling Twit
Can someone please explain this clearer?
(4 votes)
Default Khan Academy avatar avatar for user
• orange juice squid orange style avatar for user matt crichton
I think the key is at , to watch and listen a few times, as Sal explains what he is going to use instead of the 8 on the left side of the equation in the upper right hand corner. Instead of the 8, he uses the 2x + y. I think this is to show us another way, and also to “play” with the algebra, because I think he is attempting to teach us some “reasoning” skills in the short amount of time this video allows.
(4 votes)
• blobby green style avatar for user Humming Birb
What does 'system' in systems of equations mean? is it like a set??... Please help me!
(4 votes)
Default Khan Academy avatar avatar for user
• starky seed style avatar for user Soerenna Farhoudi
Could someone help me with a problem about airplane seats? The following info is given:
"For every 13 seats in economy class there are 5 seats in business class"
my immediate intuition is to write this as 13e = 5b but this is wrong. Instead it was supposed to be 5e = 13b or e/13 = b/5. Somehow I keep making this mistake and was wondering if someone can shed light on why the latter makes more sense! Thank you in advance
(1 vote)
Default Khan Academy avatar avatar for user
• duskpin sapling style avatar for user mitul
I like to think about this as a ratio it really helps me so the ratio of business seats to economy seats is 5 to 13 (I used 5 to 13 as the ratio symbol shows the time in the video for example ). So, for every 5 business seats there are 13 economy seats. So we can make a equation where b = business seats and e = economy seats. So we can form the equation (e/13)*5 = b.
(e/13)=(b/5)
So now you can cross multiply and you get 5e = 13b
we can make sure that this equation (e/13)*5 = b works so let's say there are 39 economy seats so (39/13)*5 = b, so now we can say that b = 3*5, and that is b = 15. Now to double check the equation (39/13)*5 = 15
5 to 13, 10 to 26, 15 to 39 are all equal.
(5 votes)
• male robot hal style avatar for user Noor
Ok, so this is a bit of a big concept to grasp. Can someone just clarify whether or not I am doing it correctly?
So I think that if you add the equations in any system you will end up with the right answer?
Like this?
2x + y = 8
-2x - 2y = -10
2x + (-2x) = 0
y + (-2y) = -y
8 + (-10) = -2
We are left with -y = -2 or y = 2. Does this apply to all systems, and is it really that simple to find the answer or am I skipping a step?
Any help would be appreciated
- Your fellow Khan-Academy User
(2 votes)
Default Khan Academy avatar avatar for user
• blobby green style avatar for user snowychristmas1202
In the practice for this video (Resoning with systems of equations) there are sometimes answers like:
A: Replace one equation with the sum/difference of both equations
B: Replace only the left-hand side of one equation with the sum/difference of the left-hand sides of both equations
I'm confused on what's the difference between the two, and what is the "left-side of one equation"
-Thanks (:
(2 votes)
Default Khan Academy avatar avatar for user
• mr pink green style avatar for user David Severin
lets say you have 3x + 2y = 12. 3x+2y is left hand side and 12 is right hand side. Then if 4x + y = 15, you have a system of equations. A says to add (7x + 3y = 27 ) or subtract (1st - 2nd gives -x - y = -3 and 2nd-1st gives x+y=3) equations, B says add or subtract left side only to get something like 7x + 3y = 12 or 7x+3y = 15 depending on which equation you start with, hopefully this answer looks incorrect because you could get two different answers.
(2 votes)
• female robot grace style avatar for user sarra
that was journey!
(2 votes)
Default Khan Academy avatar avatar for user
• aqualine ultimate style avatar for user Simum
What is a system?
(1 vote)
Default Khan Academy avatar avatar for user
• leafers ultimate style avatar for user Ruth
At the part where he adds the two equations in the system together (), would the resulting system still be equivalent to the others if he had rewritten the first equation as the result from adding them together instead of the second?
2x + y = 8
-y = -2
(the way he did it, leaving the first equation the way it was and replacing the second equation with the sum of the two)
vs
-y = -2
2x -2y = -10
(a system of equations that I think is equivalent because the only change is that the second equation is left alone and the first equation is replaced with the sum of the two equations)
(2 votes)
Default Khan Academy avatar avatar for user
• piceratops ultimate style avatar for user ZY
In theory, yes. You can definitely choose whichever equation to keep. (I think Sal chose to keep the first equation because it's easier to work with.)
However, I want to point out that in the last equation, you skipped the negative sign (-) at the beginning, which I think is why Jaakko Mäkinen thought that you were doing something wrong.
(1 vote)
Video transcript
- [Sal] In a previous video, we talk about the notion of equivalence with equations. And equivalence is just this notion that there's different ways of writing what our equivalent statements in algebra. And I can give some simple examples. I could say two x equals 10, or I could say x equals five. These are equivalent equations. Why are they? Because an x satisfies one of them if and only if it satisfies the other. And you can verify that in both cases, x equals five is the only x that satisfies both. Another set of equivalent equations, you could have two x is equal to eight and x equals four. These two are equivalent equations. An x satisfies one if and only if it satisfies the other. In this video, we're going to extend our knowledge of equivalence to thinking about equivalent systems. And really, in your past when you were solving systems of equations, you were doing operations assuming equivalence, but you might not have just been thinking about it that way. So let's give ourselves a system. So let's say this system tells us that there's some x y pair where two times that x plus that y is equal to eight, and that x plus that y is equal to five. Now we can have an equivalent system if we replace either of these equations with an equivalent version. So for example, many of you when you look to try to solve this, you might say well, if this was a negative two x here, maybe I could eventually add the left side. And we'll talk about why that is an equivalence preserving operation. But in order to get a negative two out here, you'd have to multiply this entire equation times negative two. And so if you did that, if you multiplied both sides of this times negative two, times negative two, what you're going to get is negative two x minus two y is equal to negative 10. This equation and this equation are equivalent. Why? Because any x y pair that satisfies one of them will satisfy the other, or an x y pair satisfies one if and only if it satisfies the other. And so if I now think about the system, the system where I've rewritten this second equation and my first equation is the same, this is an equivalent system to our first system. So these, any x y pair, if an x y pair satisfies one of these systems, it's going to satisfy the other and vice versa. Now the next interesting thing that you might realize, and if you were just trying to solve this, and this isn't an introductory video in solving systems, so I'm assuming some familiarity with it, you've probably seen solving by elimination where you say okay, look, if I can somehow add these, the left side to the left side and the right side to the right side, these x's will quote cancel out and then I'll just be left with y's. And we've done this before. You can kind of think you're trying to solve for y. But in this video, I want to think about why you end up with an equivalent system if you were to do that. And one way to think about it is what I'm going to do to create an equivalent system here is I am going to keep my first equation, two x plus y is equal to eight. But then I'm gonna take my second equation and add the same thing to both sides. We know if you add or subtract the same thing to both sides of an equation, you get an equivalent equation. So I'm gonna do that over here. But it's gonna be a little bit interesting. So if you had negative two x minus two y is equal to negative 10, and what I want to do is I want to add eight to both sides. So I could do it like this. I could add eight to both sides. But remember, our system is saying that both of these statements are true, that two x plus y is equal to eight and negative two x minus two y is equal to negative 10. So instead of adding explicitly eight to both sides, I could add something that's equivalent to eight to both sides. And I know something that is equivalent to eight based on this first equation. I could add eight, and I could do eight on the left hand side, or I could just add two x plus y. So two x plus y. Now I really want you, you might want to pause your video and say okay, how can I do this? Why is Sal saying that I'm adding the same thing to both sides? Because remember, when we're taking a system, we're assuming that both of these need to be true. An x y pair satisfies one equation if and only if, only if, if and only if it satisfies the other. So here, we know that x, two x plus y needs to be equal to eight. So if I'm adding two x plus y to the left and I'm adding eight to the right, I'm really just adding eight to both sides, which is equivalence preserving. And when you do that, you get, these negative two x and two x cancels out, you get negative y is equal to negative two. And so I can rewrite that second equation as negative y is equal to negative two. And I know what you're thinking. You're like wait, but I'm used to solving systems of equations. I'm used to just adding these two together and then I just have this one equation. And really, that's not super mathematically rigorous because the other equation is still there. It's still a constraint. Oftentimes, you solve for one and then you quote substitute back in. But really, the both equations are there the whole time. You're just rewriting them in equivalent ways. So once again, this system, this system, and this system are all equivalent. Any x y pair that satisfies one will satisfy all of them, and vice versa. And once again, we can continue to rewrite this in equivalent ways. That second equation, I can multiply both sides by negative one. That's equivalence preserving. And if I did that, then I get, I haven't changed my top equation, two x plus y is equal to eight. And on the second one, if I multiply both sides by negative one, I get y is equal to two. Once again, these are all equivalent systems. I know I'm, I sound very repetitive in this. But now, I can do another thing to make this, to keep the equivalence but get a clearer idea of what that x y pair is. If we know that y is equal to two and we know that that's true in both equations, remember, it is an and here. We're assuming there's x y, some x y pair that satisfies both. Two x plus y needs to be equal to eight and y is equal to two. Well that means up here where we see a y, we can write an equivalent system where instead of writing a y there, we could write a two because we know that y is equal to two. And so we can rewrite that top equation by substituting a two for y. So we could rewrite that as two x plus two is equal to eight and y is equal to two. So this is an and right over there. It's implicitly there. And of course, we can keep going from there. I'll scroll down a little bit. I could write another equivalent system to this by doing equivalence preserving operations on that top equation. What if I subtracted two from both sides of that top equation? It's still going to be an equivalent equation. And so I could rewrite it as, if I subtract two from both sides, I'm gonna get two x is equal to six. And then that second equation hasn't changed. Y is equal to two. So there's some x y pair that if it satisfies one, it satisfies the other, and vice versa. This system is equivalent to every system that I've written so far in this chain of operations, so to speak, and then of course, this top equation, an equivalence preserving operation is to divide both sides by a non, the same nonzero value. And in this case, I could divide both sides by two. And then I would get, if I divide the top by two, I would get x equals three, and y is equal to two. And once again, this is a different way of thinking about it. All I'm doing is rewriting the same system in an equivalent way that just gets us a little bit clearer as to what that x y pair actually is. In the past, you might've just, you know, just assumed that you can add both sides of an equation or do this type of elimination or do some type of substitution to just quote figure out the x and y. But really, you're rewriting the system. You're rewriting the constraints of the system in equivalent ways to make it more explicit what that x y pair is that satisfies both equations in the system.
|
__label__pos
| 0.980652 |
PHPCon Poland 2024
add a note
User Contributed Notes 2 notes
up
6
dulao5 at gmail dot com
17 years ago
mb_ereg_search & subpatterns
use loop:
<?php
$str
= "中国abc + abc ?!?!字符# china string";
$reg = "\w+";
mb_regex_encoding("UTF-8");
mb_ereg_search_init($str, $reg);
$r = mb_ereg_search();
if(!
$r)
{
echo
"null\n";
}
else
{
$r = mb_ereg_search_getregs(); //get first result
do
{
var_dump($r[0]);
$r = mb_ereg_search_regs();//get next result
}
while(
$r);
}
?>
up
0
Christian
2 years ago
A 'match_all' helper function based on dulao's answer. Someone might find it useful...
<?php
function mb_ereg_match_all($pattern, $subject, &$matches, $options = '', $setOrder = false, $offset = 0) {
if (!
mb_ereg_search_init($subject, $pattern, $options)) {
return
false;
}
if (
$offset != 0 && !mb_ereg_search_setpos($offset)) {
return
false;
}
$matches = [];
if (!
mb_ereg_search()) {
return
0;
}
$regs = mb_ereg_search_getregs();
$count = 0;
do {
$count++;
if (
$setOrder) {
foreach (
$regs as $key => $val) {
$matches[$key][] = $val;
}
} else {
$matches[] = $regs;
}
$regs = mb_ereg_search_regs();
}
while(
$regs);
return
$count;
}
?>
To Top
|
__label__pos
| 0.999727 |
How to solve | x + 2 | + 16 = 14 ?
Bapilievolia0o0
Bapilievolia0o0
Answered question
2023-02-21
How to solve | x + 2 | + 16 = 14 ?
Answer & Explanation
ice0ver13zdi8
ice0ver13zdi8
Beginner2023-02-22Added 3 answers
To begin, take 16 away from either side of the equation.
| x + 2 | + 16 - 16 = 14 - 16
| x + 2 | + 0 = - 2
| x + 2 | = - 2
By definition of the absolute value function the result of the function will always be greater than or equal to 0 . This means that there is no answer to this issue, or the solution set is empty - x = { }
Do you have a similar question?
Recalculate according to your conditions!
Ask your question.
Get an expert answer.
Let our experts help you. Answer in as fast as 15 minutes.
Didn't find what you were looking for?
|
__label__pos
| 1 |
Couple of Questions About Classes
This is a discussion on Couple of Questions About Classes within the C++ Programming forums, part of the General Programming Boards category; Hi, I'm working through the book C++ Without Fear, and I'm trying to better understand some stuff in one of ...
1. #1
Registered User
Join Date
Sep 2007
Posts
127
Couple of Questions About Classes
Hi,
I'm working through the book C++ Without Fear, and I'm trying to better understand some stuff in one of the examples. Basically, I have a couple of questions that relate to the following [modified] example code from the book:
1. Lines 24-26 (marked by [Q1 relevant] in the code). If line 26 is commented out, when main runs, it will display c correctly as a series of spaces. But why should this be necessary?
In the book, Brian Overland says that you can use a line like "operator int() {return atoi(ptr);}" to convert an object's type "whenever such a conversion would supply the only way to legally evaluate an expression".
I don't understand why it makes a difference in this case. The variable c is just a series of spaces. Why should the program decide to activate the operator conversion function?
2. Line 53-4 (marked by [Q2 relevant] in the code). If I uncomment line 54, the program crashes when it's run. How come?
Code:
#include <iostream>
#include <string.h>
#include <stdlib.h>
using namespace std;
class String
{
private:
char *ptr;
public:
String();
String(int n);
String(const char *s);
String(const String &src);
~String();
String& operator=(const String &src)
{cpy(src.ptr); return *this;}
String& operator=(const char *s)
{ cpy(s); return *this;}
int operator==(const String &other);
operator char*() {return ptr;}
// [Q1 relevant] If the following line is commented out, c displays correctly in main.
operator int() {return atoi(ptr);}
void cpy(const char *s);
};
int main()
{
String a("3");
cout << a << endl;
String c(3);
cout << "This is c: [" << c << "]";
return 0;
}
// ------------------------
// STRING CLASS FUNCTIONS
String::String()
{
ptr = new char[1];
ptr[0] = '\0';
}
String::String(int n) {
// [Q2 relevant] If the following line is uncommented, the program crashes.
// delete [] ptr;
int i;
ptr = new char[n + 1];
for (i = 0; i < n; i++)
ptr[i] = ' ';
ptr[i] = '\0';
}
String::String(const char *s)
{
int n = strlen(s);
ptr = new char[n + 1];
strcpy(ptr, s);
}
String::String(const String &src)
{
int n = strlen(src.ptr);
ptr = new char[n + 1];
strcpy(ptr, src.ptr);
}
String::~String()
{
delete [] ptr;
}
int String:: operator==(const String &other)
{
return (strcmp(ptr, other.ptr) == 0);
}
// cpy -- Copy string function
//
void String::cpy(const char *s)
{
delete [] ptr;
int n = strlen(s);
ptr = new char[n + 1];
strcpy(ptr, s);
}
Thanks for your help.
Last edited by bengreenwood; 05-20-2009 at 11:38 AM.
2. #2
Registered User hk_mp5kpdw's Avatar
Join Date
Jan 2002
Location
Northern Virginia/Washington DC Metropolitan Area
Posts
3,788
Quote Originally Posted by bengreenwood
2. Line 53-4 (marked by [Q2 relevant] in the code). If I uncomment line 54, the program crashes when it's run. How come?
Code:
String::String(int n) {
// [Q2 relevant] If the following line is uncommented, the program crashes.
// delete [] ptr;
That's because ptr hasn't been initialized to point anywhere yet (and you should not attempt a delete on an uninitialized pointer). Since this is a constructor, a delete is pointless, but if you really wanted it there for some purpose, you could get things working with that line uncommented if you first initialized ptr to 0 (perhaps in the initializer list):
Code:
String::String(int n) : ptr(0) {
delete [] ptr;
Last edited by hk_mp5kpdw; 05-20-2009 at 12:32 PM.
"Owners of dogs will have noticed that, if you provide them with food and water and shelter and affection, they will think you are god. Whereas owners of cats are compelled to realize that, if you provide them with food and water and shelter and affection, they draw the conclusion that they are gods."
-Christopher Hitchens
3. #3
Registered User
Join Date
Sep 2007
Posts
127
Thanks.
4. #4
The larch
Join Date
May 2006
Posts
3,573
// [Q1 relevant] If the following line is commented out, c displays correctly in main.
If the following line is not commented out I get a compile error. The class itself doesn't overload operator<<, but there are two equally good conversions to choose from when you try to output it.
Conversion operators themselves are somewhat problematic. They make it harder to trace what is going on in the code - are there any implicit conversions? - and they can make unexpected and otherwise wrong code compilable. There is a reason std::string provides a method called c_str to get a constant char*, and not operator const char*.
An example of how conversion operator makes code compilable where it might not be desired. Streams provide operator void*, so they can be tested in boolean contexts, but this also makes this code acceptable:
Code:
#include <iostream>
int main()
{
std::cout << std::cout; //outputs address of cout, e.g 0x4463c4
}
(This may be not desirable, since it allows attempts to cout for example a stringstream - perhaps expecting it to output the contents of the stringstream, which won't happen.)
I might be wrong.
Thank you, anon. You sure know how to recognize different types of trees from quite a long way away.
Quoted more than 1000 times (I hope).
Popular pages Recent additions subscribe to a feed
Similar Threads
1. Couple of questions about XOR linked lists...
By klawson88 in forum C Programming
Replies: 5
Last Post: 04-19-2009, 04:55 PM
2. a couple of questions about System.String
By Elkvis in forum C# Programming
Replies: 5
Last Post: 02-17-2009, 01:48 PM
3. A couple of Basic questions
By ozumsafa in forum C Programming
Replies: 8
Last Post: 09-26-2007, 04:06 PM
4. Couple of Questions
By toonlover in forum Windows Programming
Replies: 10
Last Post: 07-14-2006, 01:04 AM
5. A couple questions
By punkrockguy318 in forum Tech Board
Replies: 4
Last Post: 01-12-2004, 09:52 PM
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
|
__label__pos
| 0.951701 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.