
repo_id
stringclasses 208
values | file_path
stringlengths 31
190
| content
stringlengths 1
2.65M
| __index_level_0__
int64 0
0
|
|---|---|---|---|
qxf2_public_repos/cars-api
|
qxf2_public_repos/cars-api/terraform/carsapi.tf
|
provider "aws" {
region = var.aws_region
profile = var.profile
}
// Generate a secure private TLS key
resource "tls_private_key" "carsapiprivate" {
algorithm = "RSA"
rsa_bits = 4096
}
resource "aws_key_pair" "deployer" {
key_name = var.key_name
public_key = tls_private_key.carsapiprivate.public_key_openssh
provisioner "local-exec" {
command = <<-EOT
echo '${tls_private_key.carsapiprivate.private_key_pem}' > "${var.private_key_path}/${var.key_name}.pem"
chmod 400 "${var.private_key_path}/${var.key_name}.pem"
EOT
}
}
locals {
# Create the contents of the carsapi service file using the template
carsapi_service_content = templatefile("${path.module}/carsapi.service.tpl", {
home_directory = "/home/ubuntu"
})
# Create the contents of the NGINX configuration file using the template
nginx_conf_content = templatefile("${path.module}/nginx.conf.tpl", {})
}
resource "aws_instance" "carsapp_server" {
ami = data.aws_ami.ubuntu.id
instance_type = "t2.micro"
key_name = aws_key_pair.deployer.key_name
vpc_security_group_ids = [aws_security_group.carsapp_sg.id]
user_data = <<-EOF
#!/bin/bash
export HOME="/home/ubuntu"
export DEBIAN_FRONTEND=noninteractive
# Variables for file paths
SERVICE_FILE="/etc/systemd/system/carsapi.service"
NGINX_CONF="/etc/nginx/sites-available/carsapi"
# Create code directory and clone repo
su - ubuntu -c "mkdir -p $HOME/code"
su - ubuntu -c "cd $HOME/code && git clone https://github.com/qxf2/cars-api.git"
# System Update & Package Installation as root
apt-get update
apt-get install -y software-properties-common
add-apt-repository -y universe
apt-get update
apt-get -y upgrade
apt-get install -y python3-pip python3-dev build-essential libssl-dev libffi-dev python3-setuptools nginx python3-venv
# Install Certbot Nginx package
apt-get install -y python3-certbot-nginx
# Setup virtual environment and install dependencies
su - ubuntu -c "cd \$HOME/code && python3 -m venv venv-carsapi"
# Activate virtual environment and install dependencies
su - ubuntu -c "source \$HOME/code/venv-carsapi/bin/activate && pip install -r \$HOME/code/cars-api/requirements.txt && pip install gunicorn"
# Generate systemd service file from template provided by local variable
echo "${local.carsapi_service_content}" > $SERVICE_FILE
# Reload daemon and start service
sudo systemctl daemon-reload
sudo systemctl start carsapi.service
sudo systemctl enable carsapi.service
# Generate NGINX configuration file from template provided by local variable
echo "${local.nginx_conf_content}" > $NGINX_CONF
# Link and reload NGINX
sudo ln -s /etc/nginx/sites-available/carsapi /etc/nginx/sites-enabled
sudo rm /etc/nginx/sites-enabled/default
sudo nginx -t
sudo systemctl reload nginx
# Configure certbot for SSL/TLS certificate installation
sudo certbot --nginx --non-interactive --agree-tos -m [email protected] -d cars-app.qxf2.com -d www.cars-app.qxf2.com --redirect
EOF
tags = {
Name = "carsapi"
}
}
// EBS Volume
resource "aws_ebs_volume" "carsapp_volume" {
availability_zone = aws_instance.carsapp_server.availability_zone
size = 8
type = "gp2"
tags = {
Name = "carsapi"
}
}
// Attach the volume to the server
resource "aws_volume_attachment" "ebs_attach" {
device_name = "/dev/sdh"
volume_id = aws_ebs_volume.carsapp_volume.id
instance_id = aws_instance.carsapp_server.id
}
# deleting the private key when terminating the instance.
resource "null_resource" "delete_key" {
triggers = {
key_path = "${var.private_key_path}/${var.key_name}.pem"
}
provisioner "local-exec" {
when = destroy
command = "rm -f ${self.triggers.key_path}"
on_failure = continue // This allows the destroy provisioner to not fail even if the file doesn't exist.
}
depends_on = [ aws_key_pair.deployer ]
}
| 0
|
qxf2_public_repos/cars-api
|
qxf2_public_repos/cars-api/terraform/variables.tf
|
/*
terraform/variables.tf
Modify default values of variables as needed for aws_region, profile, keyname*/
variable "aws_region" {
default = "us-east-1"
description = "The AWS region to create resources in"
type = string
}
variable "profile" {
default = "personal"
type = string
}
variable "key_name" {
description = "The EC2 Key Pair name"
default = "carsapi-key-pair"
type = string
}
# to declare private key path
variable "private_key_path" {
default = "/tmp"
type = string
description = "Path to the PEM private key file"
}
variable "home_directory" {
default = "/home/ubuntu"
type = string
description = "Path to the home directory"
}
| 0
|
qxf2_public_repos/cars-api
|
qxf2_public_repos/cars-api/terraform/ami-datasource.tf
|
data "aws_ami" "ubuntu" {
most_recent = true
filter {
name = "name"
values = ["ubuntu/images/hvm-ssd/ubuntu-jammy-22.04-amd64-server-*"]
}
filter {
name = "virtualization-type"
values = ["hvm"]
}
owners = ["099720109477"] # Canonical
}
| 0
|
qxf2_public_repos/cars-api
|
qxf2_public_repos/cars-api/templates/index.html
|
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Cars API</title>
<link href="//maxcdn.bootstrapcdn.com/bootstrap/4.1.3/css/bootstrap.min.css" rel="stylesheet">
<link href="//netdna.bootstrapcdn.com/font-awesome/4.0.3/css/font-awesome.css" rel="stylesheet">
<script src="//maxcdn.bootstrapcdn.com/bootstrap/4.1.3/js/bootstrap.min.js"></script>
<script src="//cdnjs.cloudflare.com/ajax/libs/jquery/3.2.1/jquery.min.js"></script>
<style>
.thin-text {
font-family: Abel, Arial, sans-serif;
font-weight: lighter;
}
.white-text {
color: #ffffff;
}
.top-space {
margin-top: 25px;
}
p {
line-height: 2.0;
}
.grey-text {
color: #808080;
}
.endpoint {
color: #c7254e;
}
.cmdline {
color: #c7254e;;
}
.question {
color: #F00000;;
}
</style>
<link href="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/9.12.0/styles/agate.min.css" rel="stylesheet">
<script src="//cdnjs.cloudflare.com/ajax/libs/highlight.js/9.12.0/highlight.min.js"></script>
<script>hljs.initHighlightingOnLoad();</script>
</head>
<body>
<div class=container>
<div class="row">
<div class="col-md-10 offset-md-1 top-space">
<h1 class="thin-text text-center">Practice API automation</h1>
<br>
<p class="text-justify">This REST application written in Python was built to help testers learn to write API automation. The application has endpoints for you to practice automating GET, POST, PUT and DELETE methods. We have also included permissioning and authentication too. This web application was developed by <a href="https://www.qxf2.com/?utm_source=carsapi&utm_medium=click&utm_campaign=From%20carspai">Qxf2 Services</a>.<br><br><strong>Note:</strong> You can look at the username/password combinations in the <strong>user_list</strong> variable in <a href="https://github.com/qxf2/cars-api/blob/master/cars_app.py">this file</a>.</p>
<br>
<br>
<h2 class="thin-text">Setup</h2>
<p class="text-justify">We recommend you get setup with this application locally as it is a good opportunity for you to get some practice setting up a simple Flask application. It's easy and takes less than 15-minutes for absolute beginners to get setup. So, don't worry!
<ol type="1">
<li>In your terminal prompt, <span class="cmdline">pip install flask</span></li>
<li>If you know git, <span class="cmdline">git clone https://github.com/qxf2/cars-api.git</span></li>
<li>If you don't know git, copy the contents of <a href="https://github.com/qxf2/cars-api/blob/master/cars_app.py">this file</a> and save it (anywhere) as <span class="cmdline">cars_app.py</span></li>
<li>In your terminal prompt, <span class="cmdline">cd directory_that_has_cars_app_py</span></li>
<li>In your terminal prompt, <span class="cmdline">python cars_app.py</span></li>
</ol>
If everything goes right, you should see an output similar to the following image:
<img src="/static/img/cars_api_started.png">
</p>
<br>
<br>
<h2 class="thin-text">API endpoints and examples</h2>
<p class="text-justify">This section lists the API endpoints present. It also lists the call you would make with Python's requests library. To follow along, please run <span class="cmdline">python cars_app.py</span> in one terminal prompt. Then, in a new terminal prompt, pull up your Python interpreter (by typing <span class="cmdline">python</span>) and <span class="cmdline">import requests</span>. Then, follow along by running the commands below in your Python interpreter.</p>
<h4 class="thin-text">1. GET</h4>
<br>
a) <strong class="thin-text endpoint"> /cars</strong>: Get a list of cars
<pre>
<code class="python">
response = requests.get(url='http://127.0.0.1:5000/cars',auth=(username,password))
</code>
</pre>
b) <strong class="thin-text endpoint"> /users</strong>: Get the list of users
<pre>
<code class="python">
response = requests.get(url='http://127.0.0.1:5000/users',auth=(username,password))
</code>
</pre>
c) <strong class="thin-text endpoint">
/cars/filter/<%car_type%> </strong>: Get the list of users
<pre>
<code class="python">
response = requests.get(url='http://127.0.0.1:5000/cars/filter/hatchback',auth=(username,password))
</code>
</pre>
d) <strong class="thin-text endpoint"> /register </strong>: Get registered cars
<pre>
<code class="python">
response = requests.get(url='http://127.0.0.1:5000/register',auth=(username,password))
</code>
</pre>
e) <strong class="thin-text endpoint"> /cars/<%name%> </strong>: Get cars by name
<pre>
<code class="python">
response = requests.get(url='http://127.0.0.1:5000/cars/Swift',auth=(username,password))
</code>
</pre>
<br>
<h4 class="thin-text">2. POST</h4>
<br>
a) <strong class="thin-text endpoint"> /cars/add</strong>: Add new cars
<pre>
<code class="python">
response = requests.post(url='http://127.0.0.1:5000/cars/add',json={'name':'figo','brand':'Ford','price_range':'2-3lacs','car_type':'hatchback'},auth=(username,password))
</code>
</pre>
🤔 How do you verify that your post did change data on the server? One effective way is to keep track of the cars that were present before you added a new car. And then look at the cars that are present after you added a new car. So try:
<pre>
<code class="python">
#Cars present before you add a new car
response = requests.get(url='http://127.0.0.1:5000/cars',auth=(username,password))
cars_before_add = response.json()
print(f'Cars present before adding a new car: {cars_before_add}')
#Make the POST to add a new car
response = requests.post(url='http://127.0.0.1:5000/cars/add',json={'name':'figo','brand':'Ford','price_range':'2-3lacs','car_type':'hatchback'},auth=(username,password))
#Cars present after you added a new car
response = requests.get(url='http://127.0.0.1:5000/cars',auth=(username,password))
cars_after_add = response.json()
print(f'Cars present after adding a new car: {cars_after_add}')
</code>
</pre>
😲 ... the cars present before you added a new car and the cars present after you added a new car seem identical! What happened?
<br>
<br>
💡 Maybe the Cars App is using sessions? So each request is treated as a new session and the POST does not affect the next GET. Luckily for us, Python's <span class="cmdline">requests</span> module makes it easy to create a session. You simply have to try:
<pre>
<code class="python">
#Create a session
my_session = requests.Session()
#⭐ KEY CHANGE: Now use my_session.blah() wherever you were using requests.blah()
#Cars present before you add a new car
response = my_session.get(url='http://127.0.0.1:5000/cars',auth=(username,password))
cars_before_add = response.json()
print(f'Cars present before adding a new car: {cars_before_add}')
#Make the POST to add a new car
response = my_session.post(url='http://127.0.0.1:5000/cars/add',json={'name':'figo','brand':'Ford','price_range':'2-3lacs','car_type':'hatchback'},auth=(username,password))
#Cars present after you added a new car
response = my_session.get(url='http://127.0.0.1:5000/cars',auth=(username,password))
cars_after_add = response.json()
print(f'Cars present after adding a new car: {cars_after_add}')
</code>
</pre>
😎 Now, you see that the car you have added did indeed get added! From now on, it is recommended you start using a session to interact with the app. This is especially true if you are going to be performing actions that change data (a.k.a non-idempotent actions) of the application.
<br>
<br>
b) <strong class="thin-text endpoint"> /register/car</strong>: Register a car
<pre>
<code class="python">
response = requests.post(url='http://127.0.0.1:5000/register/car',params={'car_name':'figo','brand':'Ford'},json={'customer_name': 'Unai Emery','city': 'London'},auth=(username,password))
</code>
</pre>
<span class="question">Question: How do you verify that the registration happened correctly?</span>
<br>
<br>
<h4 class="thin-text">3. PUT</h4>
<br>
a) <strong class="thin-text endpoint"> /cars/update/<%name%></strong>: Update a car
<pre>
<code class="python">
esponse = requests.post(url='http://127.0.0.1:5000/cars/add',json={'name':'figo','brand':'Ford','price_range':'2-3lacs','car_type':'hatchback'},auth=(username,password))
</code>
</pre>
<br>
<h4 class="thin-text">4. DELETE</h4>
<br>
a) <strong class="thin-text endpoint">/cars/remove/<%name%></strong>: Delete a car
<pre>
<code class="python">
response = requests.delete(url='http://127.0.0.1:5000/register/cars/remove/City',auth=(username,password))
</code>
</pre>
b) <strong class="thin-text endpoint"> /register/car/delete</strong>: Delete first entry in car registration list
<pre>
<code class="python">
response = requests.delete(url='http://127.0.0.1:5000/register/car/delete',auth=(username,password))
</code>
</pre>
</div>
</div>
</div>
</body>
</html>
| 0
|
qxf2_public_repos
|
qxf2_public_repos/weather-shopper-app-apk/LICENSE
|
MIT License
Copyright (c) 2024 rohandudam
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
| 0
|
qxf2_public_repos
|
qxf2_public_repos/weather-shopper-app-apk/README.md
|
# Weather Shopper App Apk
Weather Shopper App is developed by [Qxf2 Services](https://www.qxf2.com/?utm_source=weather-shopper-android-app&utm_medium=click&utm_campaign=From%20Github) for practical learning of Appium and programming language. This repository holds the APK file of the Weather Shopper App.
You can download weather Shopper app on your device from Google Playstore also. Checkout [here](https://play.google.com/store/apps/details?id=com.qxf2.weathershopper)
To know more about this app, look at our blog [here](https://qxf2.com/blog/weather-shopper-learn-appium/)
| 0
|
qxf2_public_repos
|
qxf2_public_repos/context-based-qa-rag/explore_rag.py
|
"""
A context-based question answering script that reads the context from a dataset
and answers questions based on it
"""
import os
import torch
from datasets import load_dataset
from transformers import DPRContextEncoder, \
DPRContextEncoderTokenizer, \
RagTokenizer, \
RagRetriever, \
RagSequenceForGeneration, \
logging
torch.set_grad_enabled(False)
# Suppress Warnings
logging.set_verbosity_error()
# Initialize context encoder & decoder model
ctx_encoder = DPRContextEncoder.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base")
ctx_tokenizer = DPRContextEncoderTokenizer.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base")
dataset_name = "rony/soccer-dialogues"
localfile_name = dataset_name.split('/')[-1]
# load 100 rows from the dataset
ds = load_dataset(dataset_name, split='train[:100]')
def transforms(examples):
"""
Transform dataset to be passed
as an input to the RAG model
"""
inputs = {}
inputs['text'] = examples['text'].replace('_',' ')
inputs['embeddings'] = ctx_encoder(**ctx_tokenizer(inputs['text'], return_tensors="pt"))[0][0].numpy()
inputs['title'] = 'soccer'
return inputs
ds = ds.map(transforms)
# Add faiss index to the dataset, it is needed for DPR
ds.add_faiss_index(column='embeddings')
# Initialize retriever and model
rag_model = "facebook/rag-sequence-nq"
tokenizer = RagTokenizer.from_pretrained(rag_model)
retriever = RagRetriever.from_pretrained(rag_model, indexed_dataset=ds)
model = RagSequenceForGeneration.from_pretrained(rag_model, retriever=retriever)
# Generate output for questions
question = "How old is Granit Xhaka"
input_dict = tokenizer(question, return_tensors="pt")
generated = model.generate(input_ids=input_dict["input_ids"], max_new_tokens=50)
print(f"{question}?")
print(tokenizer.batch_decode(generated, skip_special_tokens=True)[0])
| 0
|
qxf2_public_repos
|
qxf2_public_repos/context-based-qa-rag/LICENSE
|
MIT License
Copyright (c) 2023 shivahari
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
| 0
|
qxf2_public_repos
|
qxf2_public_repos/context-based-qa-rag/requirements.txt
|
torch==2.0.1
torchvision==0.15.2
transformers==4.30.2
datasets==2.13.1
faiss-cpu==1.7.4
| 0
|
qxf2_public_repos
|
qxf2_public_repos/context-based-qa-rag/README.md
|
# context-based-qa-rag
Context-based Question Answering using RAG
| 0
|
qxf2_public_repos
|
qxf2_public_repos/qxf2-employees/run.py
|
from employees.employee_app import app
#----START OF SCRIPT
if __name__=='__main__':
app.run()
| 0
|
qxf2_public_repos
|
qxf2_public_repos/qxf2-employees/requirements.txt
|
SQLAlchemy==1.3.20
graphene-sqlalchemy==2.3.0
Flask==1.1.2
Flask-GraphQL==2.0.1
flask-graphql-auth==1.3.2
PyJWT==1.7.0
| 0
|
qxf2_public_repos
|
qxf2_public_repos/qxf2-employees/README.md
|
# Employee Database
This repo is a GraphQL implementation of a single table (employees) using Flask and Graphene. The app has authentication (JWT) and exposes the web based graphiQL editor too. Qxf2 uses this app to practice writing tests, learning to make graphQL queries and as a starting point to understanding the relationship between schemas and the exposed queries.
### Setup
0. Clone this repo
1. Setup a virtual environment (Python 3.7 or higher) and activate it `virtualenv -p python3.8 venv-employee-database`
2. `pip install -r requirements.txt`
3. Setup some fake data with `sqlite3 data/employee_database.sqlite3`
> .mode csv
> .import data/dummy_data.csv employee
> select * from employee; #You should see a couple of rows
> .quit
4. Update `employees/secret.py` with any secret string you want to use
5. Add a new file called `employees/allowed_users.py` and the following lines:
>USERS = {'A_USERNAME_YOU_SELECT':'A_PASSWORD_YOU_SET', 'ANOTHER_USERNAME':'ANOTHER_PASSWORD'}
5. Start your server with `python run.py`
### Usage
1. Visit `http://localhost:5000/graphql` in your browser
2. Try the following query:
```
mutation {
auth(password: "A_PASSWORD_YOU_SET", username: "A_USERNAME_YOU_SELECT") {
accessToken
refreshToken
}
}
```
3. If all goes well, step 2 will return an acessToken in the field - copy it
4. Use a browser plugin to modify your header. Add a `Authorization` key and set it to `Bearer accessToken` where `accessToken` is the token you copied in step 3.
5. Now try the 3 different queries allowed:
5a. Query all the employees
```
query findAllEmployees{
allEmployees{
edges{
node{
email
employeeId
dateJoined
isActive
blogAuthorName
}
}
}
}
```
5b. Query by employee email
```
query FindEmployeeByEmail($email: String = "[email protected]") {
findEmployee(email: $email) {
githubId
blogAuthorName
phone
skypeId
}
}
```
5c. Query by employee Skype id
```
query FindEmployeeBySkype($skype_id: String = "emmanuel.lasker.qxf2") {
findEmployee(skypeId: $skype_id) {
email
blogAuthorName
phone
}
}
```
6. If all goes well, you should be seeing data returned. The dummy database currently has two employees populated - WIlhelm Steinitz and Emmanuel Lasker.
| 0
|
qxf2_public_repos/qxf2-employees
|
qxf2_public_repos/qxf2-employees/data/dummy_data.csv
|
email,firstname,lastname,employee_id,skype_id,blog_author_name,phone,github_id,aws_id,trello_id,date_joined,employment_type,is_active
[email protected],Wilhelm,Steinitz,WorldChamp001,wilihelm.steinitz.qxf2,user1,188621894,steinitz_qxf2,123456789,steinitzqxf21,01-Feb-86,full,Y
[email protected],Emmanuel,Lasker,WorldChamp002,emmanuel.lasker.qxf2,user2,189421921,lasker_qxf2,223456789,laskerqxf21,01-Mar-94,full,Y
| 0
|
qxf2_public_repos/qxf2-employees
|
qxf2_public_repos/qxf2-employees/employees/employee_app.py
|
"""
Flask app that exposes the GraphQL interface
"""
from flask import Flask
from flask_graphql_auth import (
AuthInfoField,
GraphQLAuth,
get_jwt_identity,
get_raw_jwt,
create_access_token,
create_refresh_token,
query_jwt_required,
mutation_jwt_refresh_token_required,
mutation_jwt_required,
)
from flask_graphql import GraphQLView
from employees.models import db_session
from employees.schema import schema
import employees.secret as SECRET
app = Flask(__name__)
app.config["JWT_SECRET_KEY"] = SECRET.JWT_SECRET_KEY
app.config["REFRESH_EXP_LENGTH"] = 30
app.config["ACCESS_EXP_LENGTH"] = 10
auth = GraphQLAuth(app)
app.debug = True
app.add_url_rule(
'/graphql',
view_func=GraphQLView.as_view(
'graphql',
schema=schema,
graphiql=True
)
)
@app.teardown_appcontext
def shutdown_session(exception=None):
db_session.remove()
if __name__ == '__main__':
app.run()
| 0
|
qxf2_public_repos/qxf2-employees
|
qxf2_public_repos/qxf2-employees/employees/models.py
|
"""
Models for the employee app
"""
from sqlalchemy import *
from sqlalchemy.orm import scoped_session, sessionmaker, relationship, backref
from sqlalchemy.ext.declarative import declarative_base
engine = create_engine('sqlite:///data/employee_database.sqlite3', convert_unicode=True)
db_session = scoped_session(sessionmaker(autocommit=False, autoflush=False,\
bind=engine))
Base = declarative_base()
Base.query = db_session.query_property()
class Employee(Base):
__tablename__ = 'employee'
email = Column(String, primary_key=True)
firstname = Column(String)
lastname = Column(String)
employee_id = Column(String)
skype_id = Column(String)
blog_author_name = Column(String)
phone = Column(String)
github_id = Column(String)
aws_id = Column(String)
trello_id = Column(String)
date_joined = Column(String)
employment_type = Column(String)
is_active = Column(String)
| 0
|
qxf2_public_repos/qxf2-employees
|
qxf2_public_repos/qxf2-employees/employees/secret.py
|
JWT_SECRET_KEY="FILL_THIS_OUT_PLEASE"
| 0
|
qxf2_public_repos/qxf2-employees
|
qxf2_public_repos/qxf2-employees/employees/schema.py
|
"""
This script ties the database model to the GraphQL schema
"""
import graphene
from graphene import relay
from graphene_sqlalchemy import SQLAlchemyObjectType, SQLAlchemyConnectionField
from flask_graphql_auth import (
create_access_token,
query_header_jwt_required,
create_refresh_token)
from employees.models import db_session, Employee as EmployeeModel
import employees.allowed_users as allowed
class Employee(SQLAlchemyObjectType):
class Meta:
model = EmployeeModel
interfaces = (relay.Node, )
class AuthMutation(graphene.Mutation):
class Arguments(object):
username = graphene.String()
password = graphene.String()
access_token = graphene.String()
refresh_token = graphene.String()
@classmethod
def mutate(cls, _, info, username, password):
if username in allowed.USERS.keys() and password == allowed.USERS[username]:
return AuthMutation(
access_token=create_access_token(username),
refresh_token=create_refresh_token(username),
)
else:
return {}
class Mutation(graphene.ObjectType):
auth = AuthMutation.Field()
class Query(graphene.ObjectType):
node = relay.Node.Field()
all_employees = SQLAlchemyConnectionField(Employee.connection)
employee = relay.Node.Field(Employee)
find_employee = graphene.Field(lambda: Employee, email=graphene.String(), skype_id=graphene.String())
@query_header_jwt_required
def resolve_all_employees(self, info, **kwargs):
"Return all the employees"
query = Employee.get_query(info)
return query.all()
@query_header_jwt_required
def resolve_find_employee(self, info, **kwargs):
query = Employee.get_query(info)
email = kwargs.get('email', None)
if email:
result = query.filter(EmployeeModel.email == email).first()
skype_id = kwargs.get('skype_id', None)
if skype_id:
result = query.filter(EmployeeModel.skype_id == skype_id).first()
return result
schema = graphene.Schema(query=Query, mutation=Mutation)
| 0
|
qxf2_public_repos
|
qxf2_public_repos/flask-tutorial-demo/LICENSE
|
MIT License
Copyright (c) 2018
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
| 0
|
qxf2_public_repos
|
qxf2_public_repos/flask-tutorial-demo/mybio.py
|
"""
Flask app to host my simple bio
Habit: Develop -> test locally -> commit -> push to remote -> deploy to prod -> test on prod === 30 minutes
"""
from flask import Flask
app = Flask(__name__)
@app.route("/")
def index_page():
"The search page"
return "<html><h1>Under construction</h1>Hello, I'm arun.<html>"
#----START OF SCRIPT
if __name__=='__main__':
app.run(host='0.0.0.0',port=6464)
| 0
|
qxf2_public_repos
|
qxf2_public_repos/flask-tutorial-demo/README.md
|
# flask-tutorial-demo
This tutorial was used to give a one-hour live demo on writing a web application with Flask.
| 0
|
qxf2_public_repos
|
qxf2_public_repos/py_isolid/LICENSE
|
MIT License
Copyright (c) 2019
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
| 0
|
qxf2_public_repos
|
qxf2_public_repos/py_isolid/README.md
|
# py_isolid
This is a Python module to work with Inrupt's Solid.
| 0
|
qxf2_public_repos
|
qxf2_public_repos/delta-lake-trello/LICENSE
|
MIT License
Copyright (c) 2023 sravantit25
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
| 0
|
qxf2_public_repos
|
qxf2_public_repos/delta-lake-trello/requirements.txt
|
delta-spark==2.1.1
deltalake==0.6.4
pydelta==1.7.0
pyspark==3.3.1
requests
pandas
loguru
| 0
|
qxf2_public_repos
|
qxf2_public_repos/delta-lake-trello/README.md
|
## Delta Lake implementation for Qxf2's Trello data
### Background
Delta lake is an open-source storage framework that brings reliability to data lakes by ensuring ACID transactions, scalable metadata handling and much more. It thereby enables building a Lakehouse architecure on top of existing data lakes. The Lakehouse follows a multi-layered approach to store data called medallion architecture.
* Bronze layer - Contains raw state of the data. Can be combination of streaming and batch transactions
* Silver layer - Represents a cleaned and conformed version of data that can be used for downstream analytics
* Gold layer - highly refined and aggregated data serving specific use-case
### Data pipeline using Delta Lake tables
We have implemented the medallion architecture by using Delta Lake tables to store and analyse our Trello data.
* Bronze Delta Lake tables (Ingestion) - The raw data of all the cards of Trello boards and the Trello board members is ingested into these tables
* Silver Delta Lake tables (Refinement) - The data from the Bronze tables is refined to pick required columns, join with the members lookup delta table and add board info
* Gold Delta Lake tables (Aggregation) - Built based on specific use case. Eg: One of the tables consist of all the cards that are in doing list have no activity for specified number of days
### Storage and workloads
Currently the Delta Lake tables reside on local Linux system (an EC2 instance). Cron jobs are scheduled to load the data into the Delta Lake tables.
The ingestion and refinement run daily. And the aggregation on demand
### Tests
### Enchancements
- Improvise the data fetch for bronze delta tables
- Move the delta tables to data lake - AWS S3
- Visualization for the Gold Delta lake tables data
| 0
|
qxf2_public_repos/delta-lake-trello
|
qxf2_public_repos/delta-lake-trello/config/delta_table_conf.py
|
"""
Contains the paths of the delta tables
"""
cards_bronze_table_path = '/home/ubuntu/lakehouse_project/data_tables/bronze_cards_table'
members_bronze_table_path = '/home/ubuntu/lakehouse_project/data_tables/bronze_members_table'
cards_silver_table_path = '/home/ubuntu/lakehouse_project/data_tables/silver_cards_table'
noactive_cards_gold_path = '/home/ubuntu/lakehouse_project/data_tables/gold_noactive_cards_table'
cards_unique_silver_table_path = '/home/ubuntu/lakehouse_project/data_tables/silver_unique_cards_table'
sravanti_cards_gold_path = '/home/ubuntu/lakehouse_project/data_tables/sravanti_cards_gold_table'
akkul_cards_gold_path = '/home/ubuntu/lakehouse_project/data_tables/akkul_cards_gold_table'
avinash_cards_gold_path = '/home/ubuntu/lakehouse_project/data_tables/avinash_cards_gold_table'
archana_cards_gold_path = '/home/ubuntu/lakehouse_project/data_tables/archana_cards_gold_table'
ajitava_cards_gold_path = '/home/ubuntu/lakehouse_project/data_tables/ajitava_cards_gold_table'
drishya_cards_gold_path = '/home/ubuntu/lakehouse_project/data_tables/drishya_cards_gold_table'
indira_cards_gold_path = '/home/ubuntu/lakehouse_project/data_tables/indira_cards_gold_table'
mohan_cards_gold_path = '/home/ubuntu/lakehouse_project/data_tables/mohan_cards_gold_table'
preedhi_cards_gold_path = '/home/ubuntu/lakehouse_project/data_tables/preedhi_cards_gold_table'
raghava_cards_gold_path = '/home/ubuntu/lakehouse_project/data_tables/raghava_cards_gold_table'
raji_cards_gold_path = '/home/ubuntu/lakehouse_project/data_tables/raji_cards_gold_table'
rohan_cards_gold_path = '/home/ubuntu/lakehouse_project/data_tables/rohan_cards_gold_table'
shiva_cards_gold_path = '/home/ubuntu/lakehouse_project/data_tables/shiva_cards_gold_table'
| 0
|
qxf2_public_repos/delta-lake-trello
|
qxf2_public_repos/delta-lake-trello/config/trello_conf.py
|
"""
Contains the Trello configuration details
"""
import os
TRELLO_API_KEY = os.environ["TRELLO_API_KEY"]
TRELLO_API_SECRET= os.environ["TRELLO_API_SECRET"]
TRELLO_TOKEN = os.environ["TRELLO_TOKEN"]
| 0
|
qxf2_public_repos/delta-lake-trello
|
qxf2_public_repos/delta-lake-trello/config/skype_conf.py
|
"""
Contains Skype configuration details
"""
import os
SKYPE_CHANNEL = os.environ["SKYPE_CHANNEL"]
SKYPE_URL= os.environ["SKYPE_API_KEY"]
SKYPE_API_KEY = os.environ["SKYPE_API_KEY"]
| 0
|
qxf2_public_repos/delta-lake-trello
|
qxf2_public_repos/delta-lake-trello/operations/bronze_layer_operations.py
|
"""
This script contains the functions that help in ingestion operations
* Fetching the raw trello cards data
* Fetching the raw trello members data
"""
import os
import sys
import json
from loguru import logger
from delta import *
from delta.tables import DeltaTable
# add project root to sys path
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from config import delta_table_conf as dc
from helpers import trello_functions as tf
def ingest_raw_cards_data_bronze(spark, spark_context, board_id, board_name):
"""
Fetch raw cards data of a trello board and save it into a Delta Lake Bronze table
:param spark: Spark session
:param spark_context:
:param board_id: Trello board id
:param board_name: Trello board name
:return none
"""
path = dc.cards_bronze_table_path
try:
all_cards = tf.get_all_cards(board_id)
logger.success(
f"Fetched all the cards of the board {board_id}, {board_name}")
deltaTable = DeltaTable.forPath(spark, path)
for each_card in all_cards:
card_obj = tf.fetch_card_details(each_card)
jsonRDD = spark_context.parallelize([json.dumps(card_obj)])
data_df = spark.read.json(jsonRDD, multiLine=True)
data_df = data_df.select("id", "closed", "dateLastActivity", "due", "idBoard",
"idList", "desc", "idMembers", "name", "shortLink", "shortUrl", "url")
deltaTable.alias("target").merge(
source=data_df.alias("source"),
condition="target.id = source.id").whenMatchedUpdateAll().whenNotMatchedInsertAll().execute()
logger.success(
f'Successfully added the cards data to delta bronze table for the board {board_id}, {board_name}')
except Exception as error:
logger.exception(
f'Exception while ingesting cards data for the board {board_id}, {board_name}')
raise error
def ingest_raw_members_data_bronze(spark, spark_context, board_id, board_name):
"""
Fetch raw members data of a trello board and save it into a Delta Lake Bronze table
data ingested only for the following selected columns:
id, fullName, initials, membersType, url, username, status, email, idOrganizations
:param board_id: Trello board id
:param board_name: Trello board name
:return none
"""
path = dc.members_bronze_table_path
try:
all_members = tf.get_all_members(board_id)
logger.success(
f'Fetched all the members of the board {board_id}, {board_name}')
deltaTable = DeltaTable.forPath(spark, path)
for each_mem in all_members:
mem_obj = tf.fetch_member_details(each_mem)
jsonRDD = spark_context.parallelize([json.dumps(mem_obj)])
data_df = spark.read.json(jsonRDD, multiLine=True)
# Select only the required columns
data_df = data_df.select("id", "fullName", "initials", "memberType",
"url", "username", "status", "email", "idOrganizations")
deltaTable.alias("target").merge(
source=data_df.alias("source"),
condition="target.id = source.id").whenMatchedUpdateAll().whenNotMatchedInsertAll().execute()
logger.success(
f'Successfully added the members data to delta bronze table for the board {board_id}, {board_name}')
except Exception as error:
logger.exception(
f'Exception while ingesting members data for the board {board_id}, {board_name}')
raise error
| 0
|
qxf2_public_repos/delta-lake-trello
|
qxf2_public_repos/delta-lake-trello/operations/silver_layer_operations.py
|
"""
This script contains the functions that help in refinement operations
"""
import os
import sys
from loguru import logger
from delta.tables import DeltaTable
from pyspark.sql.functions import col, date_format, lit, row_number
from pyspark.sql.window import Window
# add project root to sys path
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from config import delta_table_conf as dc
def refine_current_board_cards_silver(spark, board_id, board_name):
"""
Refine cards data of a trello board and save it into a Delta Lake Silver table
:param board_id: Trello board id
:return none
"""
path = dc.cards_silver_table_path
try:
# Fetch raw cards data from bronze delta table that have been recently added
raw_cards_data = spark.read.format(
"delta").load(dc.cards_bronze_table_path)
logger.info(f'Fetched the raw cards data')
raw_mem_data = spark.read.format(
"delta").load(dc.members_bronze_table_path)
logger.info(f'Fetched the raw members data')
# Filter data based on current sprint board
refined_cards_data = raw_cards_data.filter(
raw_cards_data.idBoard == board_id)
# Create temporary views for members and cards data to run sql queries
refined_cards_data.createOrReplaceTempView("trello_cards")
raw_mem_data.createOrReplaceTempView("trello_members")
refined_cards_data = spark.sql("select tc.*, array_join(collect_list(tm.fullName), ', ') as card_members from trello_cards tc \
left outer join trello_members tm where array_contains (tc.idMembers, tm.id) \
group by tc.id, tc.closed, tc.dateLastActivity, tc.due, tc.idBoard, tc.idList, \
tc.idMembers, tc.name, tc.desc, tc.shortLink, tc.shortUrl, tc.url")
# Change the format of dateLastActivity for readability
refined_cards_data = refined_cards_data.withColumn(
'LastUpdated', date_format('dateLastActivity', "dd-MM-yyyy"))
# Add board_name to the list of columns
refined_cards_data = refined_cards_data.withColumn(
'board_name', lit(board_name))
logger.info(
"Completed refining the data, writing cleaned and conformed data as a Silver table in Delta Lake")
deltaTable = DeltaTable.forPath(spark, path)
deltaTable.alias("target").merge(
source=refined_cards_data.alias("source"),
condition="target.id = source.id").whenMatchedUpdateAll().whenNotMatchedInsertAll().execute()
logger.success(
f'\n Refined data and created cards Silver Delta Table successfully for board {board_id} {board_name}')
except Exception as error:
logger.exception(
f'Exception while creating Silver Delta Table for board {board_id} {board_name}')
raise error
def get_unique_cards_silver(spark):
"""
Remove the duplicate cards of silver table and save it into a Delta Lake Silver table
:param spark: Spark session object
"""
unique_cards_path = dc.cards_unique_silver_table_path
try:
# Fetch refined cards data from Silver table
refined_cards_data = spark.read.format(
"delta").load(dc.cards_silver_table_path)
logger.info(f'Fetched the refined silver cards data')
#Remove duplicate cards (Cards that might have been worked across various trello boards,
#the one with latest timestamp is picked)
win = Window.partitionBy("name").orderBy(col("dateLastActivity").desc())
deduplicated_cards = refined_cards_data.withColumn(
"row", row_number().over(win)).filter(col("row") == 1).drop("row")
logger.info(
"Completed deduplicating the data, writing it as a Silver table in Delta Lake")
#Write it to another Delta Lake Silver table
deduplicated_cards.write.format('delta').mode(
"overwrite").option("mergeSchema", 'true').save(unique_cards_path)
logger.info("Completed writing the data to Silver table")
except Exception as error:
logger.exception(
f'Exception while creating Silver Delta Table')
raise error
| 0
|
qxf2_public_repos/delta-lake-trello
|
qxf2_public_repos/delta-lake-trello/jobs/rohan_cards_gold.py
|
"""
This script will:
- fetch all cards from silver unique cards table,
- filter data for specific user over specified time frame and
- save it to user Delta Lake Gold table
"""
import os
import sys
from datetime import datetime
import argparse
from loguru import logger
from pyspark.sql.functions import col
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from helpers import spark_helper as sh
from config import delta_table_conf as dc
def get_user_cards_and_save_to_gold_table(start_date, end_date, user_name):
"""
Fetch the user specific data for specified period and save it at specified gold table
"""
logger.info("Starting the job to fetch the user cards worked for specified time period")
try:
# Set the gold table path
path = dc.rohan_cards_gold_path
# Get SparkSession and Context
spark, context = sh.start_spark()
# Convert the start_date and end_date argument
start_date = datetime.strptime(start_date, '%Y-%m-%d')
end_date = datetime.strptime(end_date, '%Y-%m-%d')
# Fetch the cards data from the unique cards silver table
unique_silver_cards_data = spark.read.format("delta").load(dc.cards_unique_silver_table_path)
logger.info(f'Fetched the cards data from unique silver cards table')
# Filter user card data for specified time period
filtered_users_unique_cards_data = unique_silver_cards_data.filter(col("card_members").contains(user_name)
& (col("dateLastActivity") >= start_date) & (col("dateLastActivity") <= end_date))
# Select columns
filtered_users_unique_cards_data = filtered_users_unique_cards_data.select("id", "name", "LastUpdated", "board_name", "card_members")
# Write the data to Delta Lake Gold table
filtered_users_unique_cards_data.write.format('delta').mode("overwrite").option("mergeSchema", 'true').save(path)
logger.success(
f'Saved {user_name} cards data to path: {path}')
except Exception as error:
logger.exception(
f'Exception while fetching data for the user: {user_name}')
raise error
# ---START OF SCRIPT----
if __name__ == "__main__":
PARSER = argparse.ArgumentParser(description='Create Individual gold card table')
PARSER.add_argument('--start_date', metavar='Please pass date in YYYY-MM-DD format', required=True,
help='Start date for filtering tickets')
PARSER.add_argument('--end_date', metavar='Please pass date in YYYY-MM-DD format', required=True,
help='End date for filtering tickets')
ARGS = PARSER.parse_args()
get_user_cards_and_save_to_gold_table(ARGS.start_date, ARGS.end_date, user_name="rohandudam")
| 0
|
qxf2_public_repos/delta-lake-trello
|
qxf2_public_repos/delta-lake-trello/jobs/archana_gold_card.py
|
"""
Script to
- fetch all the cards that a member has worked on within the given duration
- save this data to the member's Delta Lake Gold table
"""
import os
import sys
from datetime import datetime
import argparse
from loguru import logger
from pyspark.sql.functions import col
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from helpers import spark_helper as sh
from config import delta_table_conf as dc
def store_member_cards_data_gold(member_cards_data, delta_table_path = dc.archana_cards_gold_path):
"""
Store the member's cards data for the passed duration, into a Delta Lake Gold table
:param member_cads_data: PySpark SQL DataFrame
:param delta_table_path: str
:return: none
"""
try:
# Write the data to members Delta Lake Gold table
member_cards_data.write.format('delta').mode(
"overwrite").option("mergeSchema", 'true').save(delta_table_path)
logger.success(
'\n Saved members cards data for the passed duration')
logger.info(
f'Saved members cards data for the passed duration to {delta_table_path} table')
except Exception as error:
logger.exception(
'Exception while fetching cards data for the passed duration')
raise error
def get_member_cards(start_date, end_date, member_name = "Archana"):
"""
Fetch member's Trello cards data for the passed duration
:param start_date: str
:param end_date: str
:param member_name: str
:return: PySpark SQL DataFrame
"""
try:
# Initiation
spark, _ = sh.start_spark()
# Fetch the cards data from the unique cards silver delta table into a spark dataframe
unique_cards_data = spark.read.format(
"delta").load(dc.cards_unique_silver_table_path)
logger.info('Fetched the unique cards data from silver table')
# Extract that particular member cards
member_cards_data = unique_cards_data.where(col("card_members").contains(member_name))
logger.info('Extracted cards mapped with the members name')
# Retrieve member cards that fall within the duration passed
start_date = datetime.strptime(start_date, "%Y-%m-%d")
end_date = datetime.strptime(end_date, "%Y-%m-%d")
member_duration_cards = member_cards_data.where(
(col('dateLastActivity') >= start_date) &
(col('dateLastActivity') <= end_date))
logger.info('Filtered member cards within the passed duration')
# Select the required columns
member_duration_cards = member_duration_cards.select(
"id", "name", "card_members", "LastUpdated", "board_name")
logger.info('Extracted required fields from the data to be stored')
return member_duration_cards
except Exception as error:
logger.exception(
'Exception while fetching members cards data')
raise error
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='Pass duration to create member gold delta table')
parser.add_argument('--start_date', metavar='string', required=True,
help='start date in %Y-%m-%d format eg: 2020-04-01')
parser.add_argument('--end_date', metavar='string', required=True,
help='end date in %Y-%m-%d format eg: 2020-04-01')
args = parser.parse_args()
# By defaults runs for <Archana>. Pass member name to run for different member.
cards_data = get_member_cards(args.start_date, args.end_date)
# By default stores results into <archana_gold_table>.
# Pass appropriate file path for different member.
store_member_cards_data_gold(cards_data)
| 0
|
qxf2_public_repos/delta-lake-trello
|
qxf2_public_repos/delta-lake-trello/jobs/raghava_nelbo_trello_to_gold.py
|
"""
This script will fetch all the cards of a Trello board according to the defined criteria:
This script fetches all the Trello cards that I have worked on over a period of time
and place it in a Gold delta table
This script is scheduled to run twice a week
"""
import os
import sys
from datetime import datetime, timedelta
import argparse
from loguru import logger
from pyspark.sql.functions import col
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from helpers import spark_helper as sh
from config import delta_table_conf as dc
def get_member_cards(start_date,end_date):
"""
Fetch all the cards data between provided date range and
save it into a Delta Lake Gold table
:param spark: Spark session
:return none
"""
path = dc.raghava_cards_gold_path
try:
spark, context = sh.start_spark()
# Fetch the cards data from the refined cards silver delta table
refined_cards_data = spark.read.format(
"delta").load(dc.cards_unique_silver_table_path)
logger.info(f'Fetched the refined cards data from silver table')
# trim date using datetime
start_date = datetime.strptime(start_date,'%Y-%m-%d')
end_date = datetime.strptime(end_date,'%Y-%m-%d')
# filter the data based on name, start date and end date
filtered_data = refined_cards_data.filter(col("card_members").contains("raghava.nelabhotla") & (col("dateLastActivity") >= start_date) & (col("dateLastActivity") <= end_date))
#Select the required columns
member_cards_data = filtered_data.select(
"id", "name", "card_members", "LastUpdated", "board_name")
#Write the data to Delta Lake Gold table
member_cards_data.write.format('delta').mode(
"overwrite").option("mergeSchema", 'true').save(path)
logger.success(
f'\n Saved raghava cards data to {path}')
logger.info(
f'Saved raghava cards data for boardto {path} table')
except Exception as error:
logger.exception(
f'Exception while fetching cards for')
raise error
# --------START OF SCRIPT
if __name__ == "__main__":
PARSER = argparse.ArgumentParser(description='Create gold delta table')
PARSER.add_argument('--start_date', metavar='starting date', required=True,
help='start date')
PARSER.add_argument('--end_date', metavar='end date', required=True,
help='end date')
ARGS = PARSER.parse_args()
get_member_cards(ARGS.start_date, ARGS.end_date)
| 0
|
qxf2_public_repos/delta-lake-trello
|
qxf2_public_repos/delta-lake-trello/jobs/mohan_gold_data.py
|
"""
This script will fetch all the cards from silver unique cards table and
- filter the table for specific user
- filter data for specific timeframe passed in the script
- save it to user Delta Lake Gold table
"""
import os
import sys
from datetime import datetime, timedelta
import argparse
from loguru import logger
from pyspark.sql.functions import col, from_utc_timestamp, to_date
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from helpers import spark_helper as sh, common_functions as cf, trello_functions as tf
from config import delta_table_conf as dc
def get_user_cards(spark, start_date, end_date):
"""
Fetch all the cards data for the given user within the given date range
and save it into a Delta Lake Gold table
:param spark: Spark session
:param start_date: start date
:param end_date: end date
:return none
"""
path = dc.mohan_cards_gold_path
try:
# Fetch the cards data from the refined cards silver delta table
refined_cards_data = spark.read.format(
"delta").load(dc.cards_unique_silver_table_path)
logger.info(
f'Fetched refined card data from silver delta table')
# Convert from_date to a datetime object
start_date = datetime.strptime(start_date, '%Y-%m-%d')
# Convert "dateLastActivity" column to date format
refined_cards_data = refined_cards_data.withColumn("dateLastActivity", to_date(from_utc_timestamp("dateLastActivity", "UTC")))
# Filter the DataFrame for the given user and date range
filtered_cards_data = refined_cards_data.filter(col("card_members").contains('Mohan Kumar') & (col("dateLastActivity") >= start_date) & (col("dateLastActivity") <= end_date))
logger.info(f'Fetched user card data within the date range')
#Select the required columns
filtered_cards_data = filtered_cards_data.select(
"id", "name", "LastUpdated", "board_name")
#Write the data to Delta Lake Gold table
filtered_cards_data.write.format('delta').mode(
"overwrite").option("mergeSchema", 'true').save(path)
logger.success(
f'\n Saved user card data for the given data range')
logger.info(
f'Saved user card data to {path} table')
except Exception as error:
logger.exception(
f'Exception while fetching cards data')
raise error
def perform_user_cards_aggregation_to_gold(start_date, end_date):
"""
Run the steps to get all the data of cards within the provided dates and place it Delta Lake Gold table
"""
logger.info("Starting the job to fetch all the cards for the given dates")
try:
# Get SparkSession and SparkContext
spark, context = sh.start_spark()
# Fetch all cards for the given date range
get_user_cards(spark, start_date, end_date)
logger.success('Completed get user cards by date range job')
except Exception as error:
logger.exception(
f'Failure in job to fetch user card data between the dates {start_date} - {end_date}')
raise error
# --------START OF SCRIPT
if __name__ == "__main__":
PARSER = argparse.ArgumentParser(description='Create gold delta table')
PARSER.add_argument('--start_date', type=str, required=True, help='Start date in the format YYYY-MM-DD')
PARSER.add_argument('--end_date', type=str, required=True, help='End date in the format YYYY-MM-DD')
ARGS = PARSER.parse_args()
perform_user_cards_aggregation_to_gold(ARGS.start_date, ARGS.end_date)
| 0
|
qxf2_public_repos/delta-lake-trello
|
qxf2_public_repos/delta-lake-trello/jobs/akkul_cards_gold.py
|
"""
This script will fetch all the cards from silver unique cards table and
- filter the table for specific user
- filter data for specific timeframe passed in the script
- save it to user Delta Lake Gold table
"""
import os
import sys
from datetime import datetime, timedelta
import argparse
from loguru import logger
from pyspark.sql.functions import col, from_utc_timestamp, to_date
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from helpers import spark_helper as sh
from config import delta_table_conf as dc
def get_user_cards(spark, start_date, end_date):
"""
Fetch all the cards data for the given user within the given date range
and save it into a Delta Lake Gold table
:param spark: Spark session
:param start_date: start date
:param end_date: end date
:return none
"""
path = dc.akkul_cards_gold_path
try:
# Fetch the cards data from the refined cards silver delta table
refined_cards_data = spark.read.format(
"delta").load(dc.cards_unique_silver_table_path)
logger.info(
f'Fetched refined card data from silver delta table')
# Convert from_date to a datetime object
start_date = datetime.strptime(start_date, '%Y-%m-%d')
# Convert "dateLastActivity" column to date format
refined_cards_data = refined_cards_data.withColumn("dateLastActivity", to_date(from_utc_timestamp("dateLastActivity", "UTC")))
# Filter the DataFrame for the given user and date range
filtered_cards_data = refined_cards_data.filter((col("card_members").like("%akkul%")) & (col("dateLastActivity") >= start_date) & (col("dateLastActivity") <= end_date))
logger.info(f'Fetched user card data within the date range')
#Select the required columns
filtered_cards_data = filtered_cards_data.select(
"id", "name", "LastUpdated", "board_name", "card_members")
#Write the data to Delta Lake Gold table
filtered_cards_data.write.format('delta').mode(
"overwrite").option("mergeSchema", 'true').save(path)
logger.success(
f'\n Saved user card data for the given data range')
logger.info(
f'Saved user card data to {path} table')
except Exception as error:
logger.exception(
f'Exception while fetching cards data')
raise error
def perform_user_cards_aggregation_to_gold(start_date, end_date):
"""
Run the steps to get all the data of cards within the provided dates and place it Delta Lake Gold table
"""
logger.info("Starting the job to fetch all the cards for the given dates")
try:
# Get SparkSession and SparkContext
spark, context = sh.start_spark()
# Fetch all cards for the given date range
get_user_cards(spark, start_date, end_date)
logger.success('Completed get user cards by date range job')
except Exception as error:
logger.exception(
f'Failure in job to fetch user card data between the dates {start_date} - {end_date}')
raise error
# --------START OF SCRIPT
if __name__ == "__main__":
PARSER = argparse.ArgumentParser(description='Create gold delta table')
PARSER.add_argument('--start_date', type=str, required=True, help='Start date in the format YYYY-MM-DD')
PARSER.add_argument('--end_date', type=str, required=True, help='End date in the format YYYY-MM-DD')
ARGS = PARSER.parse_args()
perform_user_cards_aggregation_to_gold(ARGS.start_date, ARGS.end_date)
| 0
|
qxf2_public_repos/delta-lake-trello
|
qxf2_public_repos/delta-lake-trello/jobs/shiva_cards_gold.py
|
"""
What does the script do:
- Get all the cards a member has worked on
- Filter the cars based on start & end date CLI params passed
- Create a Gold table with the filtered cards
"""
import argparse
from enum import Enum
from datetime import datetime
import os
import sys
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from loguru import logger
from pyspark.sql.functions import col
from helpers import spark_helper
from config import delta_table_conf as conf
class Member(Enum):
Shiva = "shivahari p"
class SilverTable(Enum):
All = conf.cards_unique_silver_table_path
class GoldTable(Enum):
Shiva = conf.shiva_cards_gold_path
class TrelloCardProperties(Enum):
ID = "id"
NAME = "name"
MEMBERS = "card_members"
LASTUPDATED = "LastUpdated"
BOARDNAME = "board_name"
class Aggregator():
"Create Gold Delta Lake tables based on specific use case"
def __init__(self, member:str, silver_table:str, gold_table:str, start_date:datetime=None, end_date:datetime=None):
self.logger = logger
self.spark, _ = spark_helper.start_spark()
self.member = member
self.gold_table = gold_table
self.silver_table = silver_table
self.start_date = start_date
self.end_date = end_date
@property
def member(self):
return self._member
@member.setter
def member(self, value):
self.logger.info(f"Setting {value} as member")
self._member = value
@property
def gold_table(self):
return self._gold_table
@gold_table.setter
def gold_table(self, value):
self.logger.info(f"Setting {value} as Output Gold table location for {self.member}")
self._gold_table = value
@property
def silver_table(self):
return self._silver_table
@silver_table.setter
def silver_table(self, value):
self.logger.info(f"Setting {value} as Input Silver table location for {self.member}")
self._silver_table = value
@property
def start_date(self):
return self._start_date
@start_date.setter
def start_date(self, value):
if value:
self.logger.info(f"Setting {value} as start_date")
self._start_date = datetime.strptime(value, "%Y-%m-%d")
else:
self._start_date = None
self.logger.warning(f"Start date is passed as None")
@property
def end_date(self):
return self._end_date
@end_date.setter
def end_date(self, value):
if value:
self.logger.info(f"Setting {value} as end_date")
self._end_date = datetime.strptime(value, "%Y-%m-%d")
else:
self._end_date = None
self.logger.warning(f"End date is passed as None")
def get_cards(self):
"""
Get all cards based on:
:self.member: Member contributed to the Trello card
:self.start_date: Date from which the member started contributing
:self.edn_date: Date until which the member contributed
return:
:cards: Trello cards Data Frame
"""
try:
self.logger.info(f"Gettings cards for member {self.member}")
cards = self.spark.read.format("delta").load(self.silver_table)
cards = cards.where(col("card_members").contains(self.member))
if cards:
self.logger.success(f"Successfully fetched cards for {self.member}")
else:
raise f"Unable to fetch cards for {self.member}"
if self.start_date and self.end_date:
cards = cards.where((col("dateLastActivity") >= self.start_date) & (col("dateLastActivity") <= self.end_date))
# Filter the columns based on TrellCardProperties
if cards:
cards = cards.select([field.value for field in TrelloCardProperties])
return cards
except Exception as err:
self.logger.error(f"Unable to get cards due to {err}")
def build_gold_table(self, cards):
"""
Create a Gold table
param:
:cards: Trello cards Data Frame
"""
try:
cards.write.format("delta").mode("overwrite").option("mergeSchema","true").save(self.gold_table)
self.logger.success(f"Successfully created Gold table for {self.member}")
except Exception as err:
self.logger.error(f"Unable to create Gold table due ti {err}")
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Pass start & end date to create member gold delta table")
parser.add_argument("--start_date",
metavar="string",
default=None,
help="start date in %Y-%m-%d format eg: 2021-12-31")
parser.add_argument("--end_date",
metavar="string",
default=None,
help="end date in %Y-%m-%d format eg: 2022-12-31")
args = parser.parse_args()
aggregator = Aggregator(member = Member.Shiva.value,
silver_table=SilverTable.All.value,
gold_table=GoldTable.Shiva.value,
start_date=args.start_date,
end_date=args.end_date)
cards = aggregator.get_cards()
aggregator.build_gold_table(cards)
| 0
|
qxf2_public_repos/delta-lake-trello
|
qxf2_public_repos/delta-lake-trello/jobs/refine_unique_cards_silver.py
|
"""
This job will run the steps which will deduplicate the refined cards data and place them
in a Delta Lake Silver table
"""
import os
import sys
from loguru import logger
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from operations import silver_layer_operations as sl
from helpers import spark_helper as sh
def remove_duplicate_cards_refinement_to_silver():
"""
Run the steps to perform deduplication of cards data and place it Delta Lake Silver table
"""
logger.info("Starting the cards refinement job")
try:
# Get SparkSession
spark, spark_context = sh.start_spark()
# Extract raw cards data
sl.get_unique_cards_silver(spark)
logger.success('Completed the cards refinement job')
except Exception as error:
logger.exception(
f'Failure in job to refine cards data')
raise error
# --------START OF SCRIPT
if __name__ == "__main__":
remove_duplicate_cards_refinement_to_silver()
| 0
|
qxf2_public_repos/delta-lake-trello
|
qxf2_public_repos/delta-lake-trello/jobs/avinash_cards_gold.py
|
"""
This script will fetch all the cards from silver unique cards table and
- filter the table for specific user
- filter data for specific timeframe passed in the script
- save it to user Delta Lake Gold table
"""
import os
import sys
from datetime import datetime
import argparse
from loguru import logger
from pyspark.sql.functions import col
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from helpers import spark_helper as sh
from config import delta_table_conf as dc
def get_user_activity_cards(from_date, to_date, path, user_name):
"""
Fetch all the cards that Avinash has worked within the provided timeframe
"""
logger.info("Starting the job to fetch cards worked by user for provided time frame")
try:
# Get SparkSession and SparkContext
spark, context = sh.start_spark()
# Fetch the cards data from the unique cards silver table
refined_unique_cards_data = spark.read.format(
"delta").load(dc.cards_unique_silver_table_path)
logger.info(f'Fetched the unique cards data from silver unique cards table')
# Convert the from_date and to_date argument passed to a datetime function
from_date = datetime.strptime(from_date, '%Y-%m-%d')
to_date = datetime.strptime(to_date, '%Y-%m-%d')
# Filter card data for avinash and for date range provided
filtered_unique_cards_data = refined_unique_cards_data.filter(col("card_members").contains(user_name) & (col("dateLastActivity") >= from_date) & (col("dateLastActivity") <= to_date))
# Select the required columns
filtered_unique_cards_data = filtered_unique_cards_data.select(
"id", "name", "LastUpdated", "board_name","card_members")
# Write the data to Delta Lake Gold table
filtered_unique_cards_data.write.format('delta').mode(
"overwrite").option("mergeSchema", 'true').save(path)
logger.success(
f'\n Saved Avinash cards data to path: {path}')
logger.info(
f'Saved Avinash cards data to path: {path}')
except Exception as error:
logger.exception(
f'Exception while fetching data for the user')
raise error
# --------START OF SCRIPT
if __name__ == "__main__":
PARSER = argparse.ArgumentParser(description='Fetch Individual card details')
PARSER.add_argument('--from_date', metavar='date in YYYY-MM-DD format', required=True,
help='Start date from which you need the tickets you worked')
PARSER.add_argument('--to_date', metavar='date in YYYY-MM-DD format', required=True,
help='End date to which you need the tickets you worked')
ARGS = PARSER.parse_args()
path = dc.avinash_cards_gold_path
get_user_activity_cards(ARGS.from_date, ARGS.to_date, path, user_name="avinash")
| 0
|
qxf2_public_repos/delta-lake-trello
|
qxf2_public_repos/delta-lake-trello/jobs/sravanti_cards_gold.py
|
"""
This script will fetch all the cards that have a particular person as the member.
It can be queried based on date
"""
import os
import sys
from datetime import datetime as dt
import argparse
from loguru import logger
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from config import delta_table_conf as dc
from helpers import spark_helper as sh
def get_memeber_cards(spark,from_date,to_date):
"""
Fetch all the cards data of a particular trello board member, queried based on date range
and save it into a Delta Lake Gold table
:param spark: Spark session
:param from_date: Start date
:param to_date: End date
:return none
"""
path = dc.sravanti_cards_gold_path
try:
# Fetch the cards data from the refined unique cards silver delta table
refined_unique_cards_data = spark.read.format(
"delta").load(dc.cards_unique_silver_table_path)
logger.info(f'Fetched the refined unique cards data from silver table')
#Filter by member name
aggregate_cards_data = refined_unique_cards_data.filter(
'card_members LIKE "%Sravanti%"')
#Filter by dates
aggregate_cards_data = aggregate_cards_data.filter(aggregate_cards_data.dateLastActivity >
dt.strptime(from_date, '%Y-%m-%d')).filter(aggregate_cards_data.dateLastActivity <
dt.strptime(to_date, '%Y-%m-%d'))
#Select the required columns
aggregate_cards_data = aggregate_cards_data.select("id", "name","LastUpdated", "board_name", "card_members")
#Write to Delta Lake Gold table
aggregate_cards_data.write.format('delta').mode(
"overwrite").option("mergeSchema", 'true').save(path)
logger.success(f'Saved cards in the gold table in {path}')
except Exception as error:
logger.exception(
f'Exception while fetching member cards data')
raise error
def perform_member_data_aggregation_to_gold(from_date,to_date):
"""
Run the steps to get member aggregated data
and place it in Delta Lake Gold table
"""
logger.info("Starting the job to fetch aggregated member data")
try:
# Get SparkSession and SparkContext
spark, context = sh.start_spark()
# Fetch cards that have no activity from past 7 days
get_memeber_cards(spark, from_date, to_date)
logger.success('Completed the job')
except Exception as error:
logger.exception(
f'Failure in job to fetch aggregated member data')
raise error
# --------START OF SCRIPT
if __name__ == "__main__":
PARSER = argparse.ArgumentParser(description='Create gold delta table for member cards')
PARSER.add_argument('--from_date', metavar='date', required=True,
help='from date; should be in the format YYYY-MM-DD (Eg:2023-01-02)')
PARSER.add_argument('--to_date', metavar='date', required=True,
help='to_date date; should be in the format YYYY-MM-DD (Eg:2023-02-02)')
ARGS = PARSER.parse_args()
perform_member_data_aggregation_to_gold(ARGS.from_date, ARGS.to_date)
| 0
|
qxf2_public_repos/delta-lake-trello
|
qxf2_public_repos/delta-lake-trello/jobs/ingest_cards_bronze.py
|
"""
This job will run the steps which will extract raw cards data of a trello board and place them
in a Delta Lake Bronze table
It is scheduled to run daily
"""
import os
import sys
from loguru import logger
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from operations import bronze_layer_operations as bl
from helpers import common_functions as cf, spark_helper as sh
def perform_cards_ingestion_to_bronze():
"""
Run the steps to extract raw cards data and place it Delta Lake Bronze table
"""
# logger.add(lc.cards_bronze_table_path)
logger.info("Starting the cards ingestion job")
try:
# Get SparkSession
spark, spark_context = sh.start_spark()
# Get current sprint board info
board_id, board_name = cf.get_current_sprint_board()
logger.info(
f'Fetched current sprint board info for {board_id} {board_name}')
# Extract raw cards data
bl.ingest_raw_cards_data_bronze(
spark, spark_context, board_id, board_name)
logger.info(
f'Extraction of raw cards data completed for board {board_id} {board_name}')
logger.success("Completed the cards ingestion job")
except Exception as error:
logger.exception(
f'Failure in job to fetch raw cards data for board {board_id} {board_name}')
raise error
# --------START OF SCRIPT
if __name__ == "__main__":
perform_cards_ingestion_to_bronze()
| 0
|
qxf2_public_repos/delta-lake-trello
|
qxf2_public_repos/delta-lake-trello/jobs/ajitava_cards_gold.py
|
"""
This script will fetch all the cards of a trello board that according to the below criteria:
- Get the data for a defined data range
Save the data to Delta Lake Gold table
This script is scheduled to run twice a week
"""
import os
import sys
from datetime import datetime, timedelta
import argparse
from loguru import logger
from pyspark.sql.functions import col
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from helpers import spark_helper as sh
from config import delta_table_conf as dc
def get_cards(spark, start_date, end_date):
"""
Fetch all the cards data of a user within the mentioned date range
:param spark: Spark session
:param start_date: Start date
:param end_date: End date
:return none
"""
path = dc.ajitava_cards_gold_path
try:
# Fetch the cards data from the refined cards silver delta table
refined_cards_data = spark.read.format(
"delta").load(dc.cards_unique_silver_table_path)
logger.info(f'Fetched the refined cards data from silver table')
#Fetch the data based on user
user_card_data = refined_cards_data.filter((col("card_members").like("%Ajitava%")))
logger.info(f'Got the user cards based on specific user')
# Get the dates
start_date = datetime.strptime(start_date, "%d-%m-%Y")
end_date = datetime.strptime(end_date, "%d-%m-%Y")
#Fetch the data based on specified duration
user_date_cards = user_card_data.where((col('dateLastActivity') >= start_date) & (col('dateLastActivity') <= end_date))
logger.info(f'Fetched user cards for specific duration')
#Select the required columns
user_date_cards = user_date_cards.select(
"id", "name", "card_members", "LastUpdated", "board_name")
#Write the data to Delta Lake Gold table
user_date_cards.write.format('delta').mode(
"overwrite").option("mergeSchema", 'true').save(path)
logger.success(
f'\n Saved user data for specified duration')
logger.info(
f'Saved user data to {path} table')
except Exception as error:
logger.exception(
f'Exception while fetching user data')
raise error
def perform_user_cards_aggregation_to_gold(start_date,end_date):
"""
Run the steps to get all the data of cards for the users
and place it Delta Lake Gold table
"""
logger.info("Starting the job to fetch user cards")
try:
# Get SparkSession and SparkContext
spark, context = sh.start_spark()
# Fetch cards for specified duration
get_cards(spark, start_date, end_date)
logger.success('Completed fetching data for the specified duration')
except Exception as error:
logger.exception(
f'Failure in job to fetch user cards data')
raise error
# --------START OF SCRIPT
if __name__ == "__main__":
PARSER = argparse.ArgumentParser(description='Create gold delta table')
PARSER.add_argument('--start_date', metavar='string', required=True,
help='Start in date format of MM-DD-YYYY')
PARSER.add_argument('--end_date', metavar='string', required=True,
help='End in date format of MM-DD-YYYY')
ARGS = PARSER.parse_args()
perform_user_cards_aggregation_to_gold(ARGS.start_date,ARGS.end_date)
| 0
|
qxf2_public_repos/delta-lake-trello
|
qxf2_public_repos/delta-lake-trello/jobs/indira_gold_table.py
|
"""
This script will fetch all the cards for the given user according to the below criteria:
- get the date within the given date range
- save the data to Delta Lake Gold table
- This script is scheduled to run twice a week
"""
import os
import sys
from datetime import datetime, timedelta
import argparse
from loguru import logger
from pyspark.sql.functions import col, from_utc_timestamp, to_date
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from helpers import spark_helper as sh
from config import delta_table_conf as dc
def get_user_cards(spark, start_date, end_date):
"""
Fetch all the cards data for the given user within the given date range
and save it into a Delta Lake Gold table
:param spark: Spark session
:param start_date: start date
:param end_date: end date
:return none
"""
path = dc.indira_cards_gold_path
try:
# Fetch the cards data from the refined cards silver delta table
refined_cards_data = spark.read.format(
"delta").load(dc.cards_unique_silver_table_path)
logger.info(
f'Fetched refined card data from silver delta table')
# Convert start_date to a datetime object
start_date = datetime.strptime(start_date, '%Y-%m-%d')
# Convert end_date to a datetime object
end_date = datetime.strptime(end_date, '%Y-%m-%d')
# Filter the DataFrame for the given user and date range
filtered_cards_data = refined_cards_data.filter((col("card_members").like("%Indiranellutla%")) & (col("dateLastActivity") >= start_date) & (col("dateLastActivity") <= end_date))
logger.info(f'Fetched user card data within the date range')
#Select the required columns
filtered_cards_data = filtered_cards_data.select(
"id", "name", "LastUpdated", "board_name")
#Write the data to Delta Lake Gold table
filtered_cards_data.write.format('delta').mode(
"overwrite").option("mergeSchema", 'true').save(path)
logger.success(
f'\n Saved user card data for the given data range')
logger.info(
f'Saved user card data to {path} table')
except Exception as error:
logger.exception(
f'Exception while fetching cards data')
raise error
def perform_user_cards_aggregation_to_gold(start_date, end_date):
"""
Run the steps to get all the data of cards within the provided dates and place it Delta Lake Gold table
"""
logger.info("Starting the job to fetch all the cards for the given dates")
try:
# Get SparkSession and SparkContext
spark, context = sh.start_spark()
# Fetch all cards for the given date range
get_user_cards(spark, start_date, end_date)
logger.success('Completed get user cards by date range job')
except Exception as error:
logger.exception(
f'Failure in job to fetch user card data between the dates {start_date} - {end_date}')
raise error
# --------START OF SCRIPT
if __name__ == "__main__":
PARSER = argparse.ArgumentParser(description='Create gold delta table')
PARSER.add_argument('--start_date', type=str, required=True, help='Start date in the format YYYY-MM-DD')
PARSER.add_argument('--end_date', type=str, required=True, help='End date in the format YYYY-MM-DD')
ARGS = PARSER.parse_args()
perform_user_cards_aggregation_to_gold(ARGS.start_date, ARGS.end_date)
| 0
|
qxf2_public_repos/delta-lake-trello
|
qxf2_public_repos/delta-lake-trello/jobs/noactivity_cards_gold.py
|
"""
This script will fetch all the cards of a trello board that according to the below criteria:
- present in doing list
- does not have any activity from past specified days
Save the data to Delta Lake Gold table
This script is scheduled to run twice a week
"""
import os
import sys
from datetime import datetime, timedelta
import argparse
from loguru import logger
from pyspark.sql.functions import col
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from helpers import spark_helper as sh, common_functions as cf, trello_functions as tf
from config import delta_table_conf as dc
def get_noactivity_cards(spark, board_id, board_name, no_of_days):
"""
Fetch all the cards data of a trello board that are in doing list and
not active from past specified days and save it into a Delta Lake Gold table
:param spark: Spark session
:param board_id: trello board id
:param board_name: trello board name
:param no_of_days: number of days the cards are not active
:return none
"""
path = dc.noactive_cards_gold_path
try:
# Fetch the cards data from the refined cards silver delta table
refined_cards_data = spark.read.format(
"delta").load(dc.cards_silver_table_path)
logger.info(f'Fetched the refined cards data from silver table')
# Get the cards from the doing list
doing_list_id = tf.extract_list_id(board_id, "doing")
refined_doing_cards_data = refined_cards_data.where(
col("idList") == doing_list_id)
# Fetch all cards that are not active from provided number of days
noactive_doing_cards = refined_doing_cards_data.where(
col('dateLastActivity') < datetime.now() - timedelta(days=no_of_days))
logger.info('Fetched all the doing cards that have no activity')
#Select the required columns
noactive_doing_cards = noactive_doing_cards.select(
"id", "name", "card_members", "LastUpdated", "board_name")
#Write the data to Delta Lake Gold table
noactive_doing_cards.write.format('delta').mode(
"overwrite").option("mergeSchema", 'true').save(path)
logger.success(
f'\n Saved no activity doing cards data for board {board_id} {board_name}')
logger.info(
f'Saved no activity doing cards data for board {board_id} {board_name} to {path} table')
except Exception as error:
logger.exception(
f'Exception while fetching no activity doing cards for {board_id} {board_name}')
raise error
def perform_noactive_cards_aggregation_to_gold(no_of_days):
"""
Run the steps to get all the data of cards that
are not active and place it Delta Lake Gold table
"""
logger.info("Starting the job to fetch no activity cards")
try:
# Get SparkSession and SparkContext
spark, context = sh.start_spark()
# Get current sprint board info
board_id, board_name = cf.get_current_sprint_board()
logger.info(
f'Fetched current sprint board info for {board_id} {board_name}')
# Fetch cards that have no activity from past 7 days
get_noactivity_cards(spark, board_id, board_name, no_of_days)
logger.success('Completed the no activity cards job')
except Exception as error:
logger.exception(
f'Failure in job to fetch noactivity cards data for board {board_id} {board_name}')
raise error
# --------START OF SCRIPT
if __name__ == "__main__":
PARSER = argparse.ArgumentParser(description='Create gold delta table')
PARSER.add_argument('--days', metavar='number', required=True,
help='Number of days')
ARGS = PARSER.parse_args()
perform_noactive_cards_aggregation_to_gold(int(ARGS.days))
| 0
|
qxf2_public_repos/delta-lake-trello
|
qxf2_public_repos/delta-lake-trello/jobs/ingest_members_bronze.py
|
"""
This job will run the steps which will extract raw members data of a trello board and place them
in a Delta Lake Bronze table
It is run once
"""
import os
import sys
from loguru import logger
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from operations import bronze_layer_operations as bl
from helpers import common_functions as cf, spark_helper as sh
def perform_members_ingestion_to_bronze():
"""
Run the steps to extract raw members data and place it Delta Lake Bronze table
"""
logger.info("Starting the members ingestion job")
try:
# Get SparkSession
spark, spark_context = sh.start_spark()
# Get current sprint board info
board_id, board_name = cf.get_current_sprint_board()
logger.info(
f'Fetched current sprint board info for {board_id} {board_name}')
# Extract raw members data
bl.ingest_raw_members_data_bronze(
spark, spark_context, board_id, board_name)
logger.info(
f'Ingestion of raw members data completed for board {board_id} {board_name}')
logger.success('Completed the members ingestion job')
except Exception as error:
logger.exception(
f'Failure in job to fetch raw members data for board {board_id} {board_name}')
raise error
# --------START OF SCRIPT
if __name__ == "__main__":
perform_members_ingestion_to_bronze()
| 0
|
qxf2_public_repos/delta-lake-trello
|
qxf2_public_repos/delta-lake-trello/jobs/refine_current_doing_cards_silver.py
|
"""
This job will run the steps which will refine cards data of a trello board and place them
in a Delta Lake Silver table
It is scheduled to run
"""
import os
import sys
from loguru import logger
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from operations import silver_layer_operations as sl
from helpers import common_functions as cf, spark_helper as sh
def perform_cards_refinement_to_silver():
"""
Run the steps to perform refinement of cards data and place it Delta Lake Silver table
"""
logger.info("Starting the cards refinement job")
try:
# Get SparkSession
spark, spark_context = sh.start_spark()
# Get current sprint board info
board_id, board_name = cf.get_current_sprint_board()
logger.info(
f'Fetched current sprint board info for {board_id} {board_name}')
# Extract raw cards data
sl.refine_current_board_cards_silver(spark, board_id, board_name)
logger.info(
f'Refinement of cards data completed for board {board_id} {board_name}')
logger.success('Completed the cards refinement job')
except Exception as error:
logger.exception(
f'Failure in job to refine cards data for board {board_id} {board_name}')
raise error
# --------START OF SCRIPT
if __name__ == "__main__":
perform_cards_refinement_to_silver()
| 0
|
qxf2_public_repos/delta-lake-trello
|
qxf2_public_repos/delta-lake-trello/jobs/preedhi_cards_duration_gold.py
|
"""
Script to
- fetch all the cards that a member has worked on within the given duration
- save this data to the member's Delta Lake Gold table
"""
import os
import sys
from datetime import datetime
import argparse
from loguru import logger
from pyspark.sql.functions import col
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from helpers import spark_helper as sh
from config import delta_table_conf as dc
def store_member_cards_data_gold(member_cards_data, delta_table_path = dc.preedhi_cards_gold_path):
"""
Store the member's cards data for the passed duration, into a Delta Lake Gold table
:param member_cads_data: PySpark SQL DataFrame
:param delta_table_path: str
:return: none
"""
try:
# Write the data to members Delta Lake Gold table
member_cards_data.write.format('delta').mode(
"overwrite").option("mergeSchema", 'true').save(delta_table_path)
logger.success(
'\n Saved members cards data for the passed duration')
logger.info(
f'Saved members cards data for the passed duration to {delta_table_path} table')
except Exception as error:
logger.exception(
'Exception while fetching cards data for the passed duration')
raise error
def get_member_cards(start_date, end_date, member_name = "Preedhi Vivek"):
"""
Fetch member's Trello cards data for the passed duration
:param start_date: str
:param end_date: str
:param member_name: str
:return: PySpark SQL DataFrame
"""
try:
# Initiation
spark, _ = sh.start_spark()
# Fetch the cards data from the unique cards silver delta table into a spark dataframe
unique_cards_data = spark.read.format(
"delta").load(dc.cards_unique_silver_table_path)
logger.info('Fetched the unique cards data from silver table')
# Extract that particular member cards
member_cards_data = unique_cards_data.where(col("card_members").contains(member_name))
logger.info('Extracted cards mapped with the members name')
# Retrieve member cards that fall within the duration passed
start_date = datetime.strptime(start_date, "%Y-%m-%d")
end_date = datetime.strptime(end_date, "%Y-%m-%d")
member_duration_cards = member_cards_data.where(
(col('dateLastActivity') >= start_date) &
(col('dateLastActivity') <= end_date))
logger.info('Filtered member cards within the passed duration')
# Select the required columns
member_duration_cards = member_duration_cards.select(
"id", "name", "card_members", "LastUpdated", "board_name")
logger.info('Extracted required fields from the data to be stored')
return member_duration_cards
except Exception as error:
logger.exception(
'Exception while fetching members cards data')
raise error
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='Pass duration to create member gold delta table')
parser.add_argument('--start_date', metavar='string', required=True,
help='start date in %Y-%m-%d format eg: 2020-04-01')
parser.add_argument('--end_date', metavar='string', required=True,
help='end date in %Y-%m-%d format eg: 2020-04-01')
args = parser.parse_args()
# By defaults runs for <Preedhi Vivek>. Pass member name to run for different member.
cards_data = get_member_cards(args.start_date, args.end_date)
# By default stores results into <preedhi_gold_table>.
# Pass appropriate file path for different member.
store_member_cards_data_gold(cards_data)
| 0
|
qxf2_public_repos/delta-lake-trello
|
qxf2_public_repos/delta-lake-trello/jobs/drishya_cards_gold.py
|
"""
This script will fetch all the cards of a trello board that according to the below criteria:
- present with in timeframe
- Fetch data for Drishya as username
Save the data to Delta Lake Gold table
"""
import os
import sys
from datetime import datetime, timedelta
import argparse
from loguru import logger
from pyspark.sql.functions import col
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from helpers import spark_helper as sh
from config import delta_table_conf as dc
def get_user_activity_cards(spark, start_date, end_date, nameofuser):
"""
Fetch all the cards data of a trello board for the user and specified days and save it into a Delta Lake Gold table
:param spark: Spark session
:param start_date: trello fetching details start date
:param end_date: trello fetching details end date
:param nameofuser: the name of user that needs to filter/fetch
:return none
"""
path = dc.drishya_cards_gold_path
try:
# Fetch the cards data from the refined cards silver delta table
refined_cards_data = spark.read.format(
"delta").load(dc.cards_unique_silver_table_path)
logger.info(f'Fetched the refined cards data from silver table')
# Convert dates to a datetime object
start_date = datetime.strptime(start_date, '%Y-%m-%d')
end_date = datetime.strptime(end_date, '%Y-%m-%d')
# Fetch all cards that are for the user within the specified dates
user_cards = refined_cards_data.filter((col("card_members").contains(nameofuser)) & (col("dateLastActivity") >= start_date) & (col("dateLastActivity") <= end_date))
#Select the required columns
user_only_cards = user_cards.select(
"id", "name","card_members", "LastUpdated", "board_name")
#Write the data to Delta Lake Gold table
user_only_cards.write.format('delta').mode(
"overwrite").option("mergeSchema", 'true').save(path)
logger.success(
f'\n Saved activity cards data for user {nameofuser}.')
logger.info(
f'Saved activity cards data for user {nameofuser} to {path} table')
except Exception as error:
logger.exception(
f'Exception while fetching no cards for {nameofuser}')
raise error
def fetch_drishya_aggregation_to_gold(start_date, end_date,name_user):
"""
Run the steps to get all the data of cards that
are with name drishya and place it Delta Lake Gold table
"""
logger.info(f'Starting the job to fetch {name_user} activity cards')
try:
# Get SparkSession and SparkContext
spark, context = sh.start_spark()
logger.info(
f'Fetched info for {start_date} between {end_date}')
# Fetch cards that required for the user within the specified dates
get_user_activity_cards(spark, start_date, end_date, name_user)
logger.success(f'Completed the {name_user} activity cards job')
except Exception as error:
logger.exception(
f'Failure in job to fetch {name_user} cards data for board')
raise error
# --------START OF SCRIPT
if __name__ == "__main__":
PARSER = argparse.ArgumentParser(description='Create gold delta table for User')
PARSER.add_argument('--start_date',type=str,required=True,help="Start Date format YYYY-MM-DD")
PARSER.add_argument('--end_date',type=str,required=True,help="Start Date format YYYY-MM-DD")
ARGS = PARSER.parse_args()
fetch_drishya_aggregation_to_gold(ARGS.start_date,ARGS.end_date,name_user="Drishya")
| 0
|
qxf2_public_repos/delta-lake-trello
|
qxf2_public_repos/delta-lake-trello/jobs/rg_trello_cards_gold.py
|
"""
This script will fetch all the trello cards of Raji Gali
Save the data to Delta Lake Gold table raji_cards_gold
"""
import os
import sys
from datetime import datetime, timedelta
import argparse
from loguru import logger
from pyspark.sql.functions import *
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from helpers import spark_helper as sh, common_functions as cf, trello_functions as tf
from config import delta_table_conf as dc
def user_cards_to_gold(startDate,endDate,user="rajigali"):
"""
Run the steps to get all the data of cards that
belongs to user and place it Delta Lake Gold table
"""
logger.info("Starting the job to fetch user cards")
try:
# Get SparkSession and SparkContext
spark, context = sh.start_spark()
path = dc.raji_cards_gold_path
startDate = datetime.strptime(startDate, '%Y-%m-%d')
endDate = datetime.strptime(endDate, '%Y-%m-%d')
# Fetch the cards data from the refined cards silver delta table
refined_cards_data = spark.read.format(
"delta").load(dc.cards_unique_silver_table_path)
logger.info(f'Fetched the refined cards data from silver table')
#convert trello last activity date format is in UTC to python date time
refined_cards_data = refined_cards_data.withColumn("dateLastActivity", to_date(from_utc_timestamp("dateLastActivity", "UTC")))
# Apply the filters for the start date , end date & the member to fetch
user_cards_data = refined_cards_data.filter((col("card_members").like(f"%{user}%")) & \
(col("dateLastActivity") >= startDate) & (col("dateLastActivity") <= endDate)) \
.select("id", "name", "LastUpdated", "board_name")
#Write the data to Delta Lake Gold table
user_cards_data.write.format('delta').mode("overwrite").option("mergeSchema", 'true').save(path)
logger.success(f'Completed fetching and saving given user={user} activity cards')
except Exception as error:
logger.exception(
f'Failure in job to fetch the member cards data')
raise error
# --------START OF SCRIPT
if __name__ == "__main__":
PARSER = argparse.ArgumentParser(description='Create gold delta table for the member: Raji Gali')
PARSER.add_argument('--startDate',metavar=str,required=True,help="Start Date %Y-%m-%d")
PARSER.add_argument('--endDate',metavar=str,required=True,help="End Date %Y-%m-%d")
ARGS = PARSER.parse_args()
user_cards_to_gold(ARGS.startDate,ARGS.endDate,"rajigali")
| 0
|
qxf2_public_repos/delta-lake-trello
|
qxf2_public_repos/delta-lake-trello/helpers/trello_functions.py
|
"""
Module containing helper functions for use with Trello
"""
from trello import TrelloClient
from config import trello_conf as tc
def get_trello_client():
"""
return trello_client object
:return trello_client: Trello client object
"""
try:
trello_client = TrelloClient(
api_key=tc.TRELLO_API_KEY,
api_secret=tc.TRELLO_API_SECRET,
token=tc.TRELLO_TOKEN
)
except Exception:
raise Exception('Unable to create Trello client')
return trello_client
def get_boards_list():
"""
Get the list of all boards
:return list of boards
"""
try:
client = get_trello_client()
all_boards = client.list_boards()
#log.warn('Got the list of all boards')
except Exception as error:
raise Exception('Unable to get list of boards') from error
return all_boards
def get_board(board_id):
"""
Get board object
:param board_id: board_id
:return board: board object
"""
try:
client = get_trello_client()
board = client.get_board(board_id)
except Exception as error:
raise Exception('Unable to create board object') from error
return board
def get_list_details(board_id):
"""
Get list from board
:param board_id: id of the board
:return list_details: list dict
"""
try:
client = get_trello_client()
json_obj = client.fetch_json(
'/boards/' + board_id + '/lists',
query_params={'cards': 'none'})
except Exception as error:
raise Exception('Unable to fetch list details') from error
return json_obj
def extract_list_id(board_id, list_name):
"""
Extracts the id of the list from list details json object
:param board_id: id of the board
:param list_name: the name of the list
:return list_id: id extracted from list details object
"""
try:
list_details = get_list_details(board_id)
extracted_list_details = list_details['id' == list_name]
list_id = extracted_list_details['id']
#log.info('Extracted list id')
except Exception as error:
raise Exception('Unable to extract list id') from error
return list_id
def get_all_cards(board_id):
"""
Fetches all cards of given board
:param board_id: id of the board
:return all_cards: all the cards of the board
"""
try:
board = get_board(board_id)
all_cards = board.get_cards()
#log.info('Fetched details of all cards of the board')
except Exception as error:
raise Exception('Unable to fetch all cards') from error
return all_cards
def get_all_members(board_id):
"""
Fetches all members of given board
:param board_id: id of the board
:return all_members: all the members of the board
"""
try:
board = get_board(board_id)
all_members = board.get_members()
except Exception as error:
raise Exception('Unable to fetch all members') from error
return all_members
def get_board_name(board_id):
"""
Fetches the name of the board based on id
:param board_id: id of the board
:return board_name: name of the board
"""
try:
board = get_board(board_id)
board_name = board.name
except Exception as error:
raise Exception('Unable to fetch name of the board') from error
return board_name
def fetch_member_details(mem_id):
"""
Fetches all members details of given board
:param mem_id: id of the member
:return member details json
"""
try:
client = get_trello_client()
json_obj = client.fetch_json(
'/members/' + mem_id.id, query_params={'badges': False}
)
except Exception as error:
raise Exception('Unable to fetch details of member') from error
return json_obj
def fetch_card_details(card_id):
"""
Fetch all attributes for the card
:param card_id: id of the card
:return card details json
"""
try:
client = get_trello_client()
json_obj = client.fetch_json(
'/cards/' + card_id.id,
query_params={'badges': False}
)
except Exception as error:
raise Exception('Unable to fetch details of card') from error
return json_obj
| 0
|
qxf2_public_repos/delta-lake-trello
|
qxf2_public_repos/delta-lake-trello/helpers/common_functions.py
|
"""
This module contains common functions
"""
import re
import datetime
import sys
import os
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
import helpers.trello_functions as tf
def clean_board_date(date: str):
"""
Cleans up date format in the sprint board name
"""
if date is None:
return date
months = ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun',
'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec']
date_arr = date.split("-")
day = date_arr[0]
extracted_month = date_arr[1]
if len(date_arr) < 3:
year = date[-4:]
else:
year = date_arr[2]
for month in months:
if extracted_month.lower().startswith(month.lower()):
return day + "-" + month + "-" + year
return None
def get_current_sprint_board():
"""
Gets the board id of the current sprint
:return board id: id of the current sprint board
:return board_name: name of the current sprint board
"""
date_board_map = {}
date_list = []
try:
all_boards = tf.get_boards_list()
for board in all_boards:
arr = re.findall(r"\((.*?)\)", board.name)
if len(arr) > 0:
date = arr[0]
cleaned_date = clean_board_date(date)
if cleaned_date is None:
continue
date_list.append(cleaned_date)
date_board_map[cleaned_date] = board
sorted(date_list, key=lambda x: datetime.datetime.strptime(x, '%d-%b-%Y'))
current_board_id = date_board_map[date_list[-1]].id
current_board_name = date_board_map[date_list[-1]].name
except Exception as error:
raise Exception('Unable to get list of boards') from error
return current_board_id, current_board_name
| 0
|
qxf2_public_repos/delta-lake-trello
|
qxf2_public_repos/delta-lake-trello/helpers/skype_sender.py
|
"""
This script is used to send message to provided Skype channel
"""
import os
import sys
import requests
from loguru import logger
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from config import skype_conf as sc
def post_message_on_skype(message):
"""
Posts a message on the set Skype channel
:param message: text
"""
try:
headers = {"Content-Type": "application/json"}
payload = {
"msg": message,
"channel": sc.SKYPE_CHANNEL,
"API_KEY": sc.SKYPE_API_KEY,
}
response = requests.post(
url=sc.SKYPE_URL,
json=payload,
headers=headers,
)
if response.status_code == 200:
logger.info(f"Successfully sent the Skype message - {message}")
else:
logger.info("Failed to send Skype message", level="error")
except Exception as err:
raise Exception(f"Unable to post message to Skype channel, due to {err}")
| 0
|
qxf2_public_repos/delta-lake-trello
|
qxf2_public_repos/delta-lake-trello/helpers/spark_helper.py
|
"""
Module containing helper functions for use with Apache Spark
"""
import pyspark
from pyspark.sql import SparkSession
from delta import *
def start_spark(app_name='trello_delta_app'):
"""
Start a Spark session
:param app_name: Name of Spark app
:return: Spark session object
"""
# get Spark session factory
builder = pyspark.sql.SparkSession.builder.appName(app_name) \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")\
.config("spark.jars.packages", "io.delta:delta-core_2.12:1.1.0")\
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")\
.config("spark.databricks.delta.schema.autoMerge.enabled", "true")\
.config("spark.ui.showConsoleProgress", "false")
spark = configure_spark_with_delta_pip(builder).getOrCreate()
spark_context = spark.sparkContext
return spark, spark_context
| 0
|
qxf2_public_repos
|
qxf2_public_repos/the-bored-qa/LICENSE
|
MIT License
Copyright (c) 2020 qxf2
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
| 0
|
qxf2_public_repos
|
qxf2_public_repos/the-bored-qa/requirements.txt
|
Flask==1.1.2
| 0
|
qxf2_public_repos
|
qxf2_public_repos/the-bored-qa/README.md
|
# the-bored-qa
A site that shows a random question or situation that make the QA __think__ for themselves and serve as good starting points for discussion and deeper exploration.
I'd like a site that throws up challenges that make testers think deeper about testing. So imagine something like a site that QA can visit with exactly one button called 'Surprise Me' that throws up a random question or situation that make the QA __think__ for themselves or serve as good starting points for discussion and deeper exploration.
I don't really care if the user 'solves' the problem as much as they think, then Google and see what other people do. If it leads to discussion within a team, then great!
__Setup__
This is a super-standard Flask app. Create a virtual environment, install the requirements, then `python run.py` to start the application.
__Example questions__
a) How do you test a screen sharing functionality of Google Hangouts
a1) manually? (which OSes to cover? which browsers?)
a2) as part of CI?
b) QA leads, what separates a Jr QA Eng with a Sr QA Eng?
c) How do you counter the 'automate everything' mentality?
d) What kind of bugs do you expect with the browser's 'History' function?
__Use cases__
1. I'm hoping QA teams everywhere can use a tool like this to conduct a group discussion type of session within their companies.
2. We can use this during our interviews
3. We can use this for our training too. This is an easy way to generate content that is unique and interesting for QA engineers.
4. We can use this for our pairing exercises as well
__Background__
A while ago, @rajigali pointed out that we rarely talk about testing or even encourage exercises around testing. We are one derivative away from testing in that we work a lot with code that will eventually be used to test. But we are not attacking testing directly.
This bias shows in many ways and affects our hiring, interviewing and sense of accomplishment within Qxf2. While there are multiple genuine reasons for this bias, it has been nagging me that we never directly focus on testing. This is our first attempt at a tool to solve this problem.
| 0
|
qxf2_public_repos
|
qxf2_public_repos/the-bored-qa/application.py
|
"""
This file starts the bored QA web application
"""
from the_bored_qa import app as application
#----START OF SCRIPT
if __name__ == "__main__":
application.run()
| 0
|
qxf2_public_repos/the-bored-qa
|
qxf2_public_repos/the-bored-qa/the_bored_qa/__init__.py
|
"""
The bored QA app starts here!
"""
from flask import Flask
app = Flask(__name__)
from the_bored_qa import views
| 0
|
qxf2_public_repos/the-bored-qa
|
qxf2_public_repos/the-bored-qa/the_bored_qa/views.py
|
"""
The Bored QA
"""
import json
import os
import random
from flask import render_template, request
from the_bored_qa import app
#import open_questions
#import explain_me
#import architecture_diagrams
#Where are the data files stored?
CURR_PATH = os.path.dirname(os.path.abspath(__file__))
DATA_PATH = os.path.join(CURR_PATH, 'static', 'data')
def get_challenges_metadata():
"Return the contents of the file holding challenges metadata"
challenges_metadata = []
challenges_metadata_src = os.path.join(DATA_PATH, 'challenge_metadata.json')
with open(challenges_metadata_src) as file_handle:
data = json.load(file_handle)
challenges_metadata = data["challenges_meta"]
return challenges_metadata
def get_template(challenge_type):
"Return the template to use based on challenge type"
template_name = 'error.html'
challenges_metadata = get_challenges_metadata()
for challenge_meta in challenges_metadata:
if challenge_meta.get('type', '') == challenge_type.lower():
template_name = challenge_meta.get('template', 'error.html')
break
return template_name
def get_datafile(challenge_type):
"Return the template to use based on challenge type"
datafile = None
challenges_metadata = get_challenges_metadata()
for challenge_meta in challenges_metadata:
if challenge_meta.get('type', '') == challenge_type.lower():
datafile = challenge_meta.get('data', None)
break
return datafile
def read_questions(datafile):
"Return all the situtational questions"
questions = []
questions_src = os.path.join(DATA_PATH, datafile)
with open(questions_src) as file_handle:
data = json.load(file_handle)
questions = data["challenges"]
return questions
def get_challenges(challenge_type=None):
"Get a list of all available challenges"
challenges = []
if challenge_type is None:
#Collect challenges of all types
challenges_metadata = get_challenges_metadata()
for challenge_meta in challenges_metadata:
challenges += read_questions(challenge_meta['data'])
else:
datafile = get_datafile(challenge_type)
if datafile is not None:
challenges += read_questions(datafile)
return challenges
def get_next_question(challenge_type=None):
"Pick a question"
challenges = get_challenges(challenge_type)
challenge = random.choice(challenges)
challenge_template = get_template(challenge.get('type', ''))
return render_template(challenge_template, challenge=challenge, endpoint=challenge_type)
@app.route("/", methods=['GET', 'POST'])
def read_json():
"Read json or other questions files"
if request.method == 'POST':
return get_next_question()
return render_template("index.html")
@app.route("/error")
def error_screen():
"Display the error screen when something goes wrong"
return render_template("error.html")
@app.route("/what")
def what():
"What is this site?"
return render_template("what.html")
@app.route("/why")
def why():
"Why did we make this site"
return render_template("why.html")
@app.route("/how")
def how():
"How to use this site"
return render_template("how.html")
@app.route("/faq")
def faq():
"FAQs"
return render_template("faq.html")
#----START OF SCRIPT
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000, debug=True)
| 0
|
qxf2_public_repos/the-bored-qa/the_bored_qa/static
|
qxf2_public_repos/the-bored-qa/the_bored_qa/static/css/bored_qa_styles.css
|
/* Src: https://github.com/pure-css/pure/blob/master/site/static/layouts/marketing/styles.css*/
* {
-webkit-box-sizing: border-box;
-moz-box-sizing: border-box;
box-sizing: border-box;
}
/*
* -- BASE STYLES --
* Most of these are inherited from Base, but I want to change a few.
*/
body {
line-height: 1.7em;
color: #7f8c8d;
font-size: 13px;
}
h1,
h2,
h3,
h4,
h5,
h6,
label {
color: #34495e;
}
.pure-img-responsive {
max-width: 100%;
height: auto;
}
/*
* -- LAYOUT STYLES --
* These are some useful classes which I will need
*/
.l-box {
padding: 1em;
}
.l-box-lrg {
padding: 2em;
border-bottom: 1px solid rgba(0,0,0,0.1);
}
.is-center {
text-align: center;
}
/*
* -- PURE FORM STYLES --
* Style the form inputs and labels
*/
.pure-form label {
margin: 1em 0 0;
font-weight: bold;
font-size: 100%;
}
.pure-form input[type] {
border: 2px solid #ddd;
box-shadow: none;
font-size: 100%;
width: 100%;
margin-bottom: 1em;
}
/*
* -- PURE BUTTON STYLES --
* I want my pure-button elements to look a little different
*/
.pure-button {
background-color: #1f8dd6;
color: white;
padding: 0.5em 2em;
border-radius: 5px;
}
a.pure-button-primary {
background: white;
color: #1f8dd6;
border-radius: 5px;
font-size: 120%;
}
.button-index {
color: white;
background: #880000;
border-radius: 4px;
text-shadow: 0 1px 1px rgba(0, 0, 0, 0.2);
}
/*
* -- MENU STYLES --
* I want to customize how my .pure-menu looks at the top of the page
*/
.home-menu {
padding: 0.5em;
text-align: center;
box-shadow: 0 1px 1px rgba(0,0,0, 0.10);
}
.home-menu {
background: #2d3e50;
}
.pure-menu.pure-menu-fixed {
/* Fixed menus normally have a border at the bottom. */
border-bottom: none;
/* I need a higher z-index here because of the scroll-over effect. */
z-index: 4;
}
.home-menu .pure-menu-heading {
color: white;
font-weight: 400;
font-size: 120%;
}
.home-menu .pure-menu-selected a {
color: white;
}
.home-menu a {
color: #6FBEF3;
}
.home-menu li a:hover,
.home-menu li a:focus {
background: none;
border: none;
color: #AECFE5;
}
a.challenge-metadata {
font-size: 70%;
color: #888888;
}
.copyright {
font-size: 70%;
color: #888888;
}
a.copyright {
color: #888888;
}
/*
* -- SPLASH STYLES --
* This is the blue top section that appears on the page.
*/
.splash-container {
/*background: #1f8dd6;*/
z-index: 1;
overflow: hidden;
/* The following styles are required for the "scroll-over" effect */
width: 100%;
height: 93%;
top: 0;
left: 0;
position: fixed !important;
}
.splash {
/* absolute center .splash within .splash-container */
width: 80%;
height: 50%;
margin: auto;
position: absolute;
top: 100px; left: 0; bottom: 0; right: 0;
text-align: center;
text-transform: uppercase;
}
.img-splash {
/* absolute center .splash within .splash-container */
width: 80%;
height: 80%;
margin: auto;
position: absolute;
top: 30px; left: 0; bottom: 0; right: 0;
text-align: center;
text-transform: uppercase;
}
.block-diagram-img{
max-width: 95%;
max-height: 100%;
}
/* This is the main heading that appears on the blue section */
.splash-head {
font-size: 20px;
font-weight: bold;
color: #880000;
/*border: 3px solid #440000;*/
padding: 1em 1.6em;
font-weight: 100;
border-radius: 5px;
line-height: 1em;
}
/* This is the subheading that appears on the blue section */
.splash-subhead {
color: #880000;
letter-spacing: 0.05em;
opacity: 0.8;
}
/*
* -- CONTENT STYLES --
* This represents the content area (everything below the blue section)
*/
.content-wrapper {
/* These styles are required for the "scroll-over" effect */
position: absolute;
top: 87%;
width: 100%;
min-height: 12%;
z-index: 2;
background: white;
}
/* Instructions */
p.instructions {
font-size: 90%;
color: #666666;
text-transform: none;
text-align: justify;
}
p.normal-text{
color: black;
text-align: justify;
text-transform: none;
}
/* We want to give the content area some more padding */
.content {
padding: 1em 1em 3em;
}
/* This is the class used for the main content headers (<h2>) */
.content-head {
font-weight: 400;
text-transform: uppercase;
letter-spacing: 0.1em;
margin: 2em 0 1em;
}
.explain-me-head {
font-weight: 400;
color: #c7254e;
text-transform: none;
letter-spacing: 0.1em;
margin: 2em 0 1em;
}
/* This is a modifier class used when the content-head is inside a ribbon */
.content-head-ribbon {
color: white;
}
/* This is the class used for the content sub-headers (<h3>) */
.content-subhead {
color: #1f8dd6;
}
.content-subhead i {
margin-right: 7px;
}
/* This is the class used for the dark-background areas. */
.ribbon {
background: #2d3e50;
color: #aaa;
}
/* This is the class used for the footer */
.footer {
background: #111;
position: absolute;
bottom: 0;
width: 100%;
}
.footer a {
color: #AAAAAA;
}
.footer li a:hover,
.footer li a:focus {
background: none;
border: none;
color: #AECFE5;
}
/*
* -- TABLET (AND UP) MEDIA QUERIES --
* On tablets and other medium-sized devices, we want to customize some
* of the mobile styles.
*/
@media (min-width: 48em) {
/* We increase the body font size */
body {
font-size: 16px;
}
/* We can align the menu header to the left, but float the
menu items to the right. */
.home-menu {
text-align: left;
}
.home-menu ul {
float: right;
}
/* We increase the height of the splash-container */
/* .splash-container {
height: 500px;
}*/
/* We decrease the width of the .splash, since we have more width
to work with */
.splash {
width: 50%;
height: 50%;
}
.splash-head {
font-size: 250%;
}
/* We remove the border-separator assigned to .l-box-lrg */
.l-box-lrg {
border: none;
}
}
/*
* -- DESKTOP (AND UP) MEDIA QUERIES --
* On desktops and other large devices, we want to over-ride some
* of the mobile and tablet styles.
*/
@media (min-width: 78em) {
/* We increase the header font size even more */
.splash-head {
font-size: 300%;
}
}
| 0
|
qxf2_public_repos/the-bored-qa/the_bored_qa/static
|
qxf2_public_repos/the-bored-qa/the_bored_qa/static/css/style.css
|
body {
background-color: white;
background-size:cover;
}
.questions{
position: absolute;
left: 10%;
top: 40%;
}
.block {
display: block;
width: 20%;
border: none;
background-color: #4CAF50;
color: white;
padding: 14px 28px;
font-size: 20px;
cursor: pointer;
text-align: center;
margin: 100px 0px;
position: absolute;
left: 40%;
top: 50%;
}
.block:hover {
background-color: #ddd;
color: black;
}
.fit-image{
width: 100%;
object-fit: cover;
}
| 0
|
qxf2_public_repos/the-bored-qa/the_bored_qa/static
|
qxf2_public_repos/the-bored-qa/the_bored_qa/static/js/bored_qa.js
|
function toggleInstructions(id) {
var div = document.getElementById(id);
div.style.display = div.style.display == "none" ? "block" : "none";
}
| 0
|
qxf2_public_repos/the-bored-qa/the_bored_qa/static
|
qxf2_public_repos/the-bored-qa/the_bored_qa/static/data/block_diagrams.json
|
{
"challenges": [
{
"name": "real time monitoring and debugging",
"image_url": "https://drive.google.com/uc?id=1zrjxYfzxXShJL_7rEyQsdu5vfUTR_MLQ&export=download",
"src": "https://bytes.swiggy.com/architecture-and-design-principles-behind-the-swiggys-delivery-partners-app-4db1d87a048a",
"type": "block-diagram"
},
{
"name": "celery queue",
"image_url": "https://drive.google.com/uc?id=1XKhlgLisXHwI74BkpE_KgVEpaXovfS_p&export=download",
"src": "https://cloud.google.com/blog/products/data-analytics/scale-your-composer-environment-together-your-business",
"type": "block-diagram"
},
{
"name": "real time historical logs",
"image_url": "https://drive.google.com/uc?id=1sXlNSw6L2FBbCoAfmC4tmbAXrrFo63DY&export=download",
"src": "https://bytes.swiggy.com/architecture-and-design-principles-behind-the-swiggys-delivery-partners-app-4db1d87a048a",
"type": "block-diagram"
},
{
"name": "poor network scenarios",
"image_url": "https://drive.google.com/uc?id=1RjVPch1nOVSKuq3bstp50ZfTjJJNdxA3&export=download",
"src": "https://bytes.swiggy.com/architecture-and-design-principles-behind-the-swiggys-delivery-partners-app-4db1d87a048a",
"type": "block-diagram"
},
{
"name": "aws lamda",
"image_url": "https://drive.google.com/uc?id=1EAN2HP4qaf0iYipaibG4URdIb9FJp3gf&export=download",
"src": "https://aws.amazon.com/blogs/architecture/architecting-a-low-cost-web-content-publishing-system/",
"type": "block-diagram"
},
{
"name": "order management",
"image_url": "https://drive.google.com/uc?id=1Lw5NRYvKE6feosrls4P7lr1nlgoyf-_l&export=download",
"src": "https://bytes.swiggy.com/architecture-and-design-principles-behind-the-swiggys-delivery-partners-app-4db1d87a048a",
"type": "block-diagram"
},
{
"name": "reddis twitter",
"image_url": "https://drive.google.com/uc?id=1u2eTu1bij3u-3szwfAT4Ubg4Pm5-vd4R&export=download",
"src": "https://medium.com/@narengowda/system-design-for-twitter-e737284afc95",
"type": "block-diagram"
},
{
"name": "swiggy data flow",
"image_url": "https://drive.google.com/uc?id=1gNxTg2pFJAYy9AmG-hFqmpxwVbHZ8UfQ&export=download",
"src": "https://bytes.swiggy.com/architecture-and-design-principles-behind-the-swiggys-delivery-partners-app-4db1d87a048a",
"type": "block-diagram"
},
{
"name": "swiggy partners",
"image_url": "https://drive.google.com/uc?id=1O8q19or1i778mYvoHPpFqhQN19UD83Ib&export=download",
"src": "https://bytes.swiggy.com/architecture-and-design-principles-behind-the-swiggys-delivery-partners-app-4db1d87a048a",
"type": "block-diagram"
},
{
"name": "twitter system design",
"image_url": "https://drive.google.com/uc?id=1PdPV4NIL7ELn1Ojr9NuNecxLCqoX_qfB&export=download",
"src": "https://medium.com/@narengowda/system-design-for-twitter-e737284afc95",
"type": "block-diagram"
}
]
}
| 0
|
qxf2_public_repos/the-bored-qa/the_bored_qa/static
|
qxf2_public_repos/the-bored-qa/the_bored_qa/static/data/open_questions.json
|
{
"challenges": [{
"type": "open-question",
"question": "How do you test the emoticons are displayed across different platforms correctly?",
"example_apps": [
"Skype",
"Slack",
"MS Teams"
]
},
{
"type": "open-question",
"question": "How do I test recording?",
"example_apps": [
"GoogleHangouts",
"MS Teams"
]
},
{
"type": "open-question",
"question": "How do you test 'block user' functionality in a chat app?",
"example_apps": [
"Skype",
"Slack"
]
},
{
"type": "open-question",
"question": "Does the recording pick up the background noise from one of the participant?",
"example_apps": [
"GoogleHangouts",
"MS Team"
]
},
{
"type": "open-question",
"question": "How do you test a video call application temporarily disables video for someone who has high latency?",
"example_apps": [
"GoogleHangouts",
"MS Team"
]
},
{
"type": "open-question",
"question": "How does a word processing application hande mulitple people editing the same line at the same time?",
"example_apps": [
"Google Docs",
"MS Office"
]
},
{
"type": "open-question",
"question": "How does a CI/CD tool handle a queue of events that trigger a test?",
"example_apps": [
"Jenkins",
"Circle CI"
]
},
{
"type": "open-question",
"question": "How do you check the plugin's compatibility for a platform that changes frequently?",
"example_apps": [
"Chrome",
"Firefox",
"Jenkins"
]
},
{
"type": "open-question",
"question": "How do you test if the search returns the right results on chat platforms?",
"example_apps": [
"Skype",
"Slack",
"MS Teams"
]
},
{
"type": "open-question",
"question": "How does the video chat application knows there is latency in a connection?",
"example_apps": [
"Skype",
"Slack",
"MS Teams"
]
},
{
"type": "open-question",
"question": "How are the messages ordered in a group chat? messages first sent to the application server are listed first? messages received at the server are listed first?",
"example_apps": [
"Skype",
"Slack",
"MS Teams"
]
},
{
"type": "open-question",
"question": "I liked the utility future bug predictor and usage of machine learning in predicting bugs. How do you test the feature of predicting the bugs such as there will be 5 bugs in next release?",
"example_apps": [
"Atlassian"
]
},
{
"type": "open-question",
"question": "@linkedin, I like the feature views of your post, to know how many views you have received, I was wondering how do you test the integration of this feature with external sources such blogs, tweeter etc..?",
"example_apps": [
"Linkedin"
]
},
{
"type": "open-question",
"question": "How do you test calendar events sent to people across different time zones?",
"example_apps": [
"Google",
"Outlook"
]
},
{
"type": "open-question",
"question": "IDEs support multiple languages. How do you test for each one of them?",
"example_apps": [
"VS Code",
"Notepad",
"SublimeText"
]
},
{
"type": "open-question",
"question": "Social media apps provide many face filters and lenses. How do we go about testing these?",
"example_apps": [
"Snapchat",
"Instagram",
"Facebook"
]
},
{
"type": "open-question",
"question": "How does one test the smart draw features like eraser and the limit of branching in mindmaps feature, in remote whiteboards?",
"example_apps": [
"Miro"
]
},
{
"type": "open-question",
"question": "I regularly use #GoogleMeet.Recently I have used the Turn-on Captions feature How to see its ability to capture some of the things as words even though we spell out letters e.g my company name QxF2. As a tester, I am wondering how do we test this feature with complex and variety of inputs ?",
"example_apps": [
"GoogleMeet"
]
},
{
"type": "open-question",
"question": "When you create overview videos, how do you know to pick the relevant photos (For example, it ignores document images, blurred images etc.)",
"example_apps": [
"Google Photos"
]
},
{
"type": "open-question",
"question": "#Whatsapp, I wonder how do you test data sync between web and mobile app for the same account and to what accuracy can it be synced ?",
"example_apps": [
"Whatsapp",
"Facebook"
]
},
{
"type": "open-question",
"question": "How do you test a feature in which the way VR controller handles the sensors and differentiates movement, speed.",
"example_apps": [
"Oculus Rift"
]
},
{
"type": "open-question",
"question": "How do you test that the suggested videos are relevant. Can it be done in an automated way?",
"example_apps": [
"YouTube"
]
},
{
"type": "open-question",
"question": "How do you test the words when pronunciation is different for other regions?",
"example_apps": [
"Google",
"Google voice search"
]
},
{
"type": "open-question",
"question": "how do you track sleep? what is the technology you are using?",
"example_apps": [
"Fitbit"
]
},
{
"type": "open-question",
"question": "Google Earth has so many features. How do you test view/zoom location/image feature ?",
"example_apps": [
"Google Earth"
]
}
]
}
| 0
|
qxf2_public_repos/the-bored-qa/the_bored_qa/static
|
qxf2_public_repos/the-bored-qa/the_bored_qa/static/data/situational_questions.json
|
{
"challenges": [
{
"question": "Can Regression testing be fully automated?",
"src": "https://www.reddit.com/r/softwaretesting/comments/f8r3ic/regression_testing_can_never_be_fully_automated/",
"type": "situational-question"
},
{
"question": "Where do our flaky tests come from?",
"src": "https://www.reddit.com/r/softwaretesting/comments/68vvzk/where_do_our_flaky_tests_come_from_google_testing/",
"type": "situational-question"
},
{
"question": "What to do when you let a major bug pass?",
"src": "https://www.reddit.com/r/softwaretesting/comments/cnjode/what_to_do_when_you_let_a_major_bug_pass/",
"type": "situational-question"
},
{
"question": "What is a good comeback to 'We should have found this earlier'?",
"src": "https://www.reddit.com/r/softwaretesting/comments/4wv5dz/what_is_a_good_comeback_to_we_should_have_found/",
"type": "situational-question"
},
{
"question": "Joining A Startup As The First QA",
"src": "https://www.reddit.com/r/softwaretesting/comments/btjfiw/joining_a_startup_as_the_first_qa/",
"type": "situational-question"
},
{
"question": "How implementing test automation can improve development speed?",
"src": "https://www.reddit.com/r/softwaretesting/comments/aq8gv2/how_implementing_test_automation_can_improve/",
"type": "situational-question"
},
{
"question": "What makes a GREAT QA team?",
"src": "https://www.reddit.com/r/softwaretesting/comments/du9ps7/what_makes_a_great_qa_team/",
"type": "situational-question"
},
{
"question": "How to test AI models?",
"src": "https://www.reddit.com/r/softwaretesting/comments/84ciff/how_to_test_ai_models_an_introduction_guide_for_qa/",
"type": "situational-question"
},
{
"question": "How do you keep up to date with software dev changes outside QA?",
"src": "https://www.reddit.com/r/softwaretesting/comments/7zo8ux/how_do_you_keep_up_to_date_with_software_dev/",
"type": "situational-question"
},
{
"question": "This is 4pm on second to last day of the sprint when everyone decides to finally move their tickets to QA...",
"src": "https://www.reddit.com/r/QualityAssurance/comments/dobq1v/this_is_4pm_on_second_to_last_day_of_the_sprint/",
"type": "situational-question"
},
{
"question": "Who is the Boss: Tester or Developer?",
"src": "https://www.reddit.com/r/QualityAssurance/comments/c3a1a2/who_is_the_boss_tester_or_developer/",
"type": "situational-question"
},
{
"question": "Also why we QA?",
"src": "https://www.reddit.com/r/QualityAssurance/comments/b9ezfo/also_why_we_qa/",
"type": "situational-question"
},
{
"question": "When a PM tells you that Quality Assurance is not needed",
"src": "https://www.reddit.com/r/QualityAssurance/comments/6r4hfw/when_a_pm_tells_you_that_quality_assurance_is_not/",
"type": "situational-question"
},
{
"question": "QAs (in small teams) that have to do both automation and manual testing : how do you manage?",
"src": "https://www.reddit.com/r/QualityAssurance/comments/9yepwj/qas_in_small_teams_that_have_to_do_both/",
"type": "situational-question"
}
]
}
| 0
|
qxf2_public_repos/the-bored-qa/the_bored_qa/static
|
qxf2_public_repos/the-bored-qa/the_bored_qa/static/data/challenge_metadata.json
|
{
"challenges_meta": [
{
"type": "situational-question",
"template": "situational-questions.html",
"data": "situational_questions.json"
},
{
"type": "explain-me",
"template": "explain-me.html",
"data": "explain_me.json"
},
{
"type": "block-diagram",
"template": "block-diagrams.html",
"data": "block_diagrams.json"
},
{
"type": "open-question",
"template": "open-questions.html",
"data": "open_questions.json"
},
{
"type": "bug",
"template": "bugs.html",
"data": "bugs.json"
}
]
}
| 0
|
qxf2_public_repos/the-bored-qa/the_bored_qa/static
|
qxf2_public_repos/the-bored-qa/the_bored_qa/static/data/bugs.json
|
{
"challenges": [
{
"type": "bug",
"src": "https://github.com/notepad-plus-plus/notepad-plus-plus/issues/7995",
"description": "Notepad++ crashes when trying 'replace in files'"
},
{
"type": "bug",
"src": "https://issues.jenkins-ci.org/browse/JENKINS-61171?jql=project%20%3D%20JENKINS%20AND%20component%20%3D%20jiratestresultreporter-plugin",
"description": "The JiraTestReporter plugin stopped working"
},
{
"type": "bug",
"src": "https://discuss.circleci.com/t/cache-paths-changed-in-2-1/34596",
"description": "CircleCI cache path doesn't work when using ~"
},
{
"type": "bug",
"src": "https://github.com/sharkdp/bat/issues/858",
"description": "Git Bash not reading system clipboard"
},
{
"type": "bug",
"src": "https://bugs.mysql.com/bug.php?id=98516",
"description": "MySQL Workbench blurs result grid during horizontal scrolling"
},
{
"type": "bug",
"src": "https://support.google.com/docs/thread/3847705?hl=en",
"description": "The comment button goes missing in Google Docs "
},
{
"type": "bug",
"src": "https://support.google.com/drive/thread/9186304?hl=en",
"description": "Deleting trash doesn't work on Google Drive"
},
{
"type": "bug",
"src": "https://support.google.com/hangouts/thread/10473772?hl=en",
"description": "Mic and audio stop working abruptly during a Hangout call"
},
{
"type": "bug",
"src": "https://github.com/microsoft/vscode/issues/92126",
"description": "Debug view is sometimes not working in VS Code"
}
]
}
| 0
|
qxf2_public_repos/the-bored-qa/the_bored_qa/static
|
qxf2_public_repos/the-bored-qa/the_bored_qa/static/data/explain_me.json
|
{
"challenges": [
{
"type": "explain-me",
"question": "pip install --upgrade robotframework-seleniumlibrary",
"src": "https://github.com/robotframework/SeleniumLibrary",
"answer": "Install Python-specific modules and use --upgrade to upgrade the existing python specific module"
},
{
"type": "explain-me",
"question": "sudo pip install -r requirements.txt",
"src": "https://github.com/qxf2/qxf2-page-object-model",
"answer": "Install pre-requisite libraries/dependencies"
},
{
"type": "explain-me",
"question": "git submodule sync",
"src": "https://git-scm.com/book/en/v2/Git-Tools-Submodules",
"answer": "Apply the remote repo's configuration to your local submodule repos. Make the child repo follow the parent repo. It is similar to master/slave"
},
{
"type": "explain-me",
"question": "source path to python exe location/scripts/activate",
"src": "https://gist.github.com/simonw/4835a22c79a8d3c29dd155c716b19e16",
"answer": "Activating python virtualenv"
},
{
"type": "explain-me",
"question": "sudo apt-get update && sudo apt-get upgrade && sudo apt-get install",
"src": "https://github.com/M4cs/BabySploit",
"answer": "These are the common commands in Linux to install and upgrade packages."
},
{
"type": "explain-me",
"question": "python -m http.server {port}",
"src": "https://github.com/IBM/ibm.github.io",
"answer": "To run the tests on the desired port or to test changes locally."
},
{
"type": "explain-me",
"question": "docker-compose up --build",
"src": "https://github.com/PokeAPI/pokeapi",
"answer": "To start the process in detached mode and specify the -d switch to start in detached mode."
},
{
"type": "explain-me",
"question": "curl -L https://git.io/rustlings | bash",
"src": "https://github.com/rust-lang/rustlings",
"answer": "To install the package to the default path"
},
{
"type": "explain-me",
"question": "xvfb-run --server-args='-screen 0 1024x768x24' python test_script.py",
"src": "https://github.com/joyzoursky/docker-python-chromedriver",
"answer": "To run the script in a headless display screen with the given dimensions."
},
{
"type": "explain-me",
"question": "ssh -i /Users/yaroslav/.ncluster/ncluster5-yaroslav-316880547378-us-east-1.pem -o StrictHostKeyChecking=no [email protected] a",
"src": "https://github.com/joyzoursky/docker-python-chromedriver",
"answer": "Ssh/Login into a Ubuntu instance using a .pem file(trust chain with user identification) where host key is not being checked for login purposes."
}
]
}
| 0
|
qxf2_public_repos/the-bored-qa/the_bored_qa
|
qxf2_public_repos/the-bored-qa/the_bored_qa/templates/why.html
|
{% extends "base.html" %} {% block content %}
<div class="splash-container">
<div class="splash">
<h2 class="content-head">Why did we build this?</h2>
<p class="normal-text">A while ago, my colleague <a href="https://www.linkedin.com/in/rajigali/">Raji Gali</a> pointed out that we rarely talk about testing or even encourage exercises around testing. We are one derivative away from testing in that we talk a lot with code/tools that will eventually be used to test. But we are not talking about testing directly.</p>
<p class="normal-text">This bias shows in many ways and affects our hiring, interviewing and sense of accomplishment within <a href="https://qxf2.com/?utm_source=what&utm_medium=click&utm_campaign=The%20Bored%20QA">Qxf2</a>. While there are multiple genuine reasons for this bias, it has been nagging me that we never directly focus on testing. This is our first attempt at a tool to solve this problem.</p>
{% include 'copyright.html' %}
</div>
</div>
{% endblock %}
| 0
|
qxf2_public_repos/the-bored-qa/the_bored_qa
|
qxf2_public_repos/the-bored-qa/the_bored_qa/templates/copyright.html
|
<div class="is-center">
<span class="copyright">©</span> <a href="https://qxf2.com/?utm_source=footer&utm_medium=click&utm_campaign=The%20Bored%20QA" class="copyright">Qxf2
Services</a> <span class="copyright">2020</span>
<!-- -
<script>document.write(new Date().getFullYear())</script>-->
</div>
| 0
|
qxf2_public_repos/the-bored-qa/the_bored_qa
|
qxf2_public_repos/the-bored-qa/the_bored_qa/templates/index.html
|
{% extends "base.html" %} {% block content %}
<div class="splash-container">
<div class="splash">
<h1 class="splash-head">Spin, tester. Spin!</h1>
<p class="splash-subhead">
Challenges to trigger thought, discussion and exploration
</p>
{% include 'challenge_button.html' %}
{% include 'copyright.html' %}
</div>
</div>
{% endblock %}
| 0
|
qxf2_public_repos/the-bored-qa/the_bored_qa
|
qxf2_public_repos/the-bored-qa/the_bored_qa/templates/base.html
|
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta name="description" content="The bored QA">
<title>The bored QA</title>
<link rel='icon' href='/static/img/favicon.ico' type='image/x-icon'/ >
<link rel="stylesheet" href="https://unpkg.com/[email protected]/build/pure-min.css"
integrity="sha384-cg6SkqEOCV1NbJoCu11+bm0NvBRc8IYLRGXkmNrqUBfTjmMYwNKPWBTIKyw9mHNJ" crossorigin="anonymous">
<link rel="stylesheet" href="https://netdna.bootstrapcdn.com/font-awesome/4.0.3/css/font-awesome.css">
<link rel="stylesheet" href="/static/css/bored_qa_styles.css">
<script type="text/javascript" src="/static/js/bored_qa.js"></script>
<!-- Global site tag (gtag.js) - Google Analytics -->
<script async src="https://www.googletagmanager.com/gtag/js?id=UA-38578610-9"></script>
<script>
window.dataLayer = window.dataLayer || [];
function gtag() { dataLayer.push(arguments); }
gtag('js', new Date());
gtag('config', 'UA-38578610-9');
</script>
</head>
<body>
<div class="header">
<div class="home-menu pure-menu pure-menu-horizontal pure-menu-fixed">
<a class="pure-menu-heading" href="/">The bored QA</a>
<ul class="pure-menu-list">
<li class="pure-menu-item pure-menu-selected"><a href="/" class="pure-menu-link">Home</a></li>
<li class="pure-menu-item"><a href="/what" class="pure-menu-link">What?</a></li>
<li class="pure-menu-item"><a href="/why" class="pure-menu-link">Why?</a></li>
<li class="pure-menu-item"><a href="/how" class="pure-menu-link">How to?</a></li>
<li class="pure-menu-item"><a href="/faq" class="pure-menu-link">FAQ</a></li>
</ul>
</div>
</div>
{% block content %}{% endblock %}
</body>
</html>
| 0
|
qxf2_public_repos/the-bored-qa/the_bored_qa
|
qxf2_public_repos/the-bored-qa/the_bored_qa/templates/explain-me.html
|
{% extends "base.html" %} {% block content %}
<div class="splash-container">
<div class="splash">
<p class="challenge-metadata">Explain this command in English</p>
<h2 class="explain-me-head">{{ challenge.question }}</h2>
<span>
<a class="challenge-metadata" href="{{ challenge.src }}">Source</a>
</span>
<span> </span>
<span>
<a class="challenge-metadata" onclick="toggleInstructions('instructions')" href="#">What am I expected to do?</a>
</span>
<div id="instructions" style="display: none;">
<p class="instructions">Explain the command in plain English. How skill is this useful to a tester? We noticed that testers (especially me!) run into all sorts of setup issues when we start a new project. We usually ask for help but we ask for help poorly because we lack the vocabulary to describe what command we ran and what error we faced. Unless we had already established credibility in the eyes of the helper, the person helping us begins doubting our technical capabilities. This exercise is to help testers verbalize technical commands better. As an added bonus, you will be developing a crucial skill in mentoring junior testers! If you find this exercise boring, simply hit the 'Challenge Me' button to do to try a new challenge.</p>
</div>
{% include 'challenge_button.html' %}
{% include 'copyright.html' %}
</div>
</div>
{% endblock %}
| 0
|
qxf2_public_repos/the-bored-qa/the_bored_qa
|
qxf2_public_repos/the-bored-qa/the_bored_qa/templates/how.html
|
{% extends "base.html" %} {% block content %}
<div class="splash-container">
<div class="splash">
<h2 class="content-head">How to use this site?</h2>
<p class="normal-text">Visit this site when you are bored. Click on the 'Challenge me!' button. Every challenge comes with a 'what am I expected to do?' link that will tell you what to do. Try your best to think about the challenge. Feel free to Google and follow your curiousity wherever it takes you! The required endpoint is not that you solve the challenge but that you think and learn. Try to involve your team-mates too!</p>
<p class="normal-text">Do NOT go about clicking on 'Challenge Me!' without actually spending time on each challenge. It's OK (actually preferable) if you do not agree with the challenge/premise shown. Try to think about the challenge presented</p>
<p class="normal-text">Do NOT ask yourself "what is the use of learning this?" - that's a lousy question that has a high probability of blocking learning opportunities. Think of this as <a href="https://fs.blog/2012/07/what-is-deliberate-practice/">deliberate practice</a> and do the exercises.</p>
{% include 'copyright.html' %}
</div>
</div>
{% endblock %}
| 0
|
qxf2_public_repos/the-bored-qa/the_bored_qa
|
qxf2_public_repos/the-bored-qa/the_bored_qa/templates/open-questions.html
|
{% extends "base.html" %} {% block content %}
<div class="splash-container">
<div class="splash">
<p class="challenge-metadata">The curious cat</p>
<h2 class="content-head">{{ challenge.question }}</h2>
<p class="challenge-metadata">Example applications: {{ challenge.example_apps }}</p>
<span>
<a class="challenge-metadata" onclick="toggleInstructions('instructions')" href="#">What am I expected to do?</a>
</span>
<div id="instructions" style="display: none;">
<p class="instructions">Think about the question being asked. Then, Google around for solutions. Why do we have this class of exercise? To expand our horizons and remain curious. We use so many software applications through the day. But we rarely stop to wonder how the different features are being tested. We rarely pause to think about how we would go about testing these features. By doing this exercise, hopefully, you will be a bit more curious and your explorations will lead you to new lands! If you find this exercise boring, simply hit the 'Challenge Me' button to do to try a new challenge.</p>
</div>
{% include 'challenge_button.html' %}
{% include 'copyright.html' %}
</div>
</div>
{% endblock %}
| 0
|
qxf2_public_repos/the-bored-qa/the_bored_qa
|
qxf2_public_repos/the-bored-qa/the_bored_qa/templates/bugs.html
|
{% extends "base.html" %} {% block content %}
<div class="splash-container">
<div class="splash">
<p class="challenge-metadata">Everyone has bugs</p>
<h2 class="content-head"><a href="{{ challenge.src}}">{{ challenge.description }}</a></h2>
<span>
<a class="challenge-metadata" onclick="toggleInstructions('instructions')" href="#">What am I expected to
do?</a>
</span>
<div id="instructions" style="display: none;">
<p class="instructions">We are showing you a bug report filed against a world class software application that millions of people use. Read through the bug report and think of why it happened, how you might have caught the issue and if you can get any new testing ideas. If you find this exercise boring, simply hit the 'Challenge Me' button to do to try a new challenge. </p>
</div>
{% include 'challenge_button.html' %}
{% include 'copyright.html' %}
</div>
</div>
{% endblock %}
| 0
|
qxf2_public_repos/the-bored-qa/the_bored_qa
|
qxf2_public_repos/the-bored-qa/the_bored_qa/templates/situational-questions.html
|
{% extends "base.html" %} {% block content %}
<div class="splash-container">
<div class="splash">
<p class="challenge-metadata">From the Internet</p>
<h2 class="content-head">{{ challenge.question }}</h2>
<span>
<a class="challenge-metadata" href="{{ challenge.src }}">Source</a>
</span>
<span> </span>
<span>
<a class="challenge-metadata" onclick="toggleInstructions('instructions')" href="#">What am I expected to do?</a>
</span>
<div id="instructions" style="display: none;">
<p class="instructions">We are showing you a question from popular software testing forums/feeds online. We give this class of exercise to help you better organize your arguments and solutions while also sparking interesting conversations with your QA colleagues. Think about the questions on your own and/or discuss it with your colleagues. The goal is not arrive at an answer or even agree with the premise of the question. Our hope, instead, is that you practice verbalizing your ideas and disagreements. When you are done thinking/discussing, click on the source link and read the discussion there. Pay attention to the words being used and the variety of view points presented. If you find this exercise boring, simply hit the 'Challenge Me' button to do to try a new challenge.</p>
</div>
{% include 'challenge_button.html' %}
{% include 'copyright.html' %}
</div>
</div>
{% endblock %}
| 0
|
qxf2_public_repos/the-bored-qa/the_bored_qa
|
qxf2_public_repos/the-bored-qa/the_bored_qa/templates/challenge_button.html
|
<form action='/' method="post">
<p>
<button class="pure-button button-index" type="submit">Challenge me!</button>
</p>
</form>
| 0
|
qxf2_public_repos/the-bored-qa/the_bored_qa
|
qxf2_public_repos/the-bored-qa/the_bored_qa/templates/block-diagrams.html
|
{% extends "base.html" %} {% block content %}
<div class="splash-container">
<div class="img-splash">
<div class="pure-g">
<div class="pure-u-2-3">
<img class="block-diagram-img" src="{{ challenge.image_url }}"></img>
</div>
<div class="pure-u-1-3">
<h2 class="content-head">
👈 What's going on in this image?</h2>
<span>
<a class="challenge-metadata" href="{{ challenge.src }}">Source</a>
</span>
<span> </span>
<span>
<a class="challenge-metadata" onclick="toggleInstructions('instructions')" href="#">What am
I expected to
do?</a>
</span>
<div id="instructions" style="display: none;">
<p class="instructions">Think about what is being communicated in the block diagram. Do not
spend more than
5-minutes. Think about how you would start thinking about testing what is represented in
the diagram
above. Then read the article in the source to check your understanding. Why is being
able to grok
technical diagrams important to testers? Because it lets us participate early and at a
higher level of
abstraction also. As testers, we seem to be good at participating in highly detailed
oriented
discussions. But we should try to participate in imagining the evolution of the product
and the
architectural trade-offs being made. If
you find this exercise boring, simply hit the 'Challenge Me' button to do to try a new
challenge.</p>
</div>
{% include 'challenge_button.html' %}
{% include 'copyright.html' %}
</div>
</div>
</div>
</div>
{% endblock %}
| 0
|
qxf2_public_repos/the-bored-qa/the_bored_qa
|
qxf2_public_repos/the-bored-qa/the_bored_qa/templates/what.html
|
{% extends "base.html" %} {% block content %}
<div class="splash-container">
<div class="splash">
<h2 class="content-head">What is this site?</h2>
<p class="normal-text">This is a site meant for software testers. The site throws a random challenge that makes the tester think. We hope the challenges trigger conversations about testing with your colleagues and serve as a starting point for deeper discussions and fun explorations.</p>
<p class="normal-text">The challenges chosen are based on <a href="https://qxf2.com/?utm_source=what&utm_medium=click&utm_campaign=The%20Bored%20QA">Qxf2's</a> experience in hiring and training testers. We do not provide any answers. We just want the tester to think and discuss the challenges with their colleagues.</p>
{% include 'copyright.html' %}
</div>
</div>
{% endblock %}
| 0
|
qxf2_public_repos/the-bored-qa/the_bored_qa
|
qxf2_public_repos/the-bored-qa/the_bored_qa/templates/error.html
|
{% extends "base.html" %} {% block content %}
<div class="splash-container">
<div class="splash">
<h1 class="splash-head">🤦 Uh oh! </h1>
<p class="splash-subhead">
We handled your last request poorly. Please try again.
</p>
{% include 'challenge_button.html' %}
{% include 'copyright.html' %}
</div>
</div>
{% endblock %}
| 0
|
qxf2_public_repos/the-bored-qa/the_bored_qa
|
qxf2_public_repos/the-bored-qa/the_bored_qa/templates/faq.html
|
{% extends "base.html" %} {% block content %}
<div class="splash-container">
<div class="img-splash">
<h2 class="content-head">FAQ</h2>
<p class="normal-text"><strong>1. Can I see all the questions in one place?</strong></p>
<p class="normal-text">Ans. No. Not as of Jul-2020. We do plan to expose the questions once we have a set that we are happy with.</p>
<p class="normal-text"><strong>2. Can I challenges of only one type?</strong></p>
<p class="normal-text">Ans. No. Not as of Jul-2020. You are welcome to develop this feature for us! The GitHub repo associated with this project is <a href="https://github.com/qxf2/the-bored-qa">here</a>.</p>
<p class="normal-text"><strong>3. Where can I see the answers?</strong></p>
<p class="normal-text">Ans. Nowhere. We don't provide answers. These are not challenges in the traditional sense. Treat them as random starting points for thinking, exploring and having conversations about testing.</p>
<p class="normal-text"><strong>4. How can I contribute ideas or challenges?</strong></p>
<p class="normal-text">Ans. You can raise issue on <a href="https://github.com/qxf2/the-bored-qa">GitHub repo</a> or email me (Arun) directly at <strong>[email protected]</strong>.</p>
{% include 'copyright.html' %}
</div>
</div>
{% endblock %}
| 0
|
qxf2_public_repos
|
qxf2_public_repos/qxf2-page-object-model/bandit.yml
|
# Skip flagging assert statement inclusion in test during Codacy check
assert_used:
skips: ['*/test_*.py']
| 0
|
qxf2_public_repos
|
qxf2_public_repos/qxf2-page-object-model/conftest.py
|
"""
Pytest configuration and shared fixtures
This module contains the common pytest fixtures, hooks, and utility functions
used throughout the test suite. These fixtures help to set up test dependencies
such as browser configurations, base URLs, and
external services (e.g., BrowserStack, SauceLabs, TestRail, Report Portal, etc).
"""
import os
import sys
import glob
import shutil
import pytest
from loguru import logger
from dotenv import load_dotenv
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
from conf import browser_os_name_conf # pylint: disable=import-error wrong-import-position
from conf import base_url_conf # pylint: disable=import-error wrong-import-position
from endpoints.api_player import APIPlayer # pylint: disable=import-error wrong-import-position
from page_objects.PageFactory import PageFactory # pylint: disable=import-error wrong-import-position
from utils import interactive_mode # pylint: disable=import-error wrong-import-position
from core_helpers.custom_pytest_plugins import CustomTerminalReporter # pylint: disable=import-error wrong-import-position
from core_helpers.logging_objects import Logging_Objects # pylint: disable=import-error wrong-import-position
load_dotenv()
@pytest.fixture
def test_obj(base_url, browser, browser_version, os_version, os_name, remote_flag, # pylint: disable=redefined-outer-name too-many-arguments too-many-locals
testrail_flag, tesults_flag, test_run_id, remote_project_name, remote_build_name, # pylint: disable=redefined-outer-name
testname, reportportal_service, interactivemode_flag, highlighter_flag, testreporter): # pylint: disable=redefined-outer-name
"Return an instance of Base Page that knows about the third party integrations"
try:
if interactivemode_flag.lower() == "y":
default_flag = interactive_mode.set_default_flag_gui(browser, browser_version,
os_version, os_name, remote_flag, testrail_flag, tesults_flag)
if default_flag is False:
browser,browser_version,remote_flag,os_name,os_version,testrail_flag,tesults_flag =\
interactive_mode.ask_questions_gui(browser,browser_version,os_version,os_name,
remote_flag,testrail_flag,tesults_flag)
test_obj = PageFactory.get_page_object("Zero",base_url=base_url) # pylint: disable=redefined-outer-name
test_obj.set_calling_module(testname)
#Setup and register a driver
test_obj.register_driver(remote_flag, os_name, os_version, browser, browser_version,
remote_project_name, remote_build_name, testname)
#Set highlighter
if highlighter_flag.lower()=='y':
test_obj.turn_on_highlight()
#Setup TestRail reporting
if testrail_flag.lower()=='y':
if test_run_id is None:
test_obj.write("\n\nTestRail Integration Exception:"\
" It looks like you are trying to use TestRail Integration without"\
" providing test run id. \nPlease provide a valid test run id along"\
" with test run command using --test_run_id and try again."\
" for eg: pytest --testrail_flag Y --test_run_id 100\n", level='critical')
testrail_flag = 'N'
if test_run_id is not None:
test_obj.register_testrail()
test_obj.set_test_run_id(test_run_id)
if tesults_flag.lower()=='y':
test_obj.register_tesults()
if reportportal_service:
test_obj.set_rp_logger(reportportal_service)
yield test_obj
# Collect the failed scenarios, these scenarios will be printed as table \
# by the pytest's custom testreporter
if test_obj.failed_scenarios:
testreporter.failed_scenarios[testname] = test_obj.failed_scenarios
if os.getenv('REMOTE_BROWSER_PLATFORM') == 'LT' and remote_flag.lower() == 'y':
if test_obj.pass_counter == test_obj.result_counter:
test_obj.execute_javascript("lambda-status=passed")
else:
test_obj.execute_javascript("lambda-status=failed")
elif os.getenv('REMOTE_BROWSER_PLATFORM') == 'BS' and remote_flag.lower() == 'y':
#Upload test logs to BrowserStack
response = upload_test_logs_to_browserstack(test_obj.log_name,test_obj.session_url)
if isinstance(response, dict) and "error" in response:
# Handle the error response returned as a dictionary
test_obj.write(f"Error: {response['error']}",level='error')
if "details" in response:
test_obj.write(f"Details: {response['details']}",level='error')
test_obj.write("Failed to upload log file to BrowserStack",level='error')
else:
# Handle the case where the response is assumed to be a response object
if response.status_code == 200:
test_obj.write("Log file uploaded to BrowserStack session successfully.",
level='success')
else:
test_obj.write(f"Failed to upload log file. Status code:{response.status_code}",
level='error')
test_obj.write(response.text,level='error')
#Update test run status to respective BrowserStack session
if test_obj.pass_counter == test_obj.result_counter:
test_obj.write("Test Status: PASS",level='success')
result_flag = test_obj.execute_javascript("""browserstack_executor:
{"action": "setSessionStatus",
"arguments": {"status":"passed", "reason": "All test cases passed"}}""")
test_obj.conditional_write(result_flag,
positive="Successfully set BrowserStack Test Session Status to PASS",
negative="Failed to set Browserstack session status to PASS")
else:
test_obj.write("Test Status: FAILED",level='error')
result_flag = test_obj.execute_javascript("""browserstack_executor:
{"action": "setSessionStatus","arguments": {"status":"failed",
"reason": "Test failed. Look at terminal logs for more details"}}""")
test_obj.conditional_write(result_flag,
positive="Successfully set BrowserStack Test Session Status to FAILED",
negative="Failed to set Browserstack session status to FAILED")
test_obj.write("*************************")
else:
test_obj.wait(3)
#Teardown
test_obj.teardown()
except Exception as e: # pylint: disable=broad-exception-caught
print(Logging_Objects.color_text(f"Exception when trying to run test:{__file__}","red"))
print(Logging_Objects.color_text(f"Python says:{str(e)}","red"))
if os.getenv('REMOTE_BROWSER_PLATFORM') == 'LT' and remote_flag.lower() == 'y':
test_obj.execute_javascript("lambda-status=error")
elif os.getenv('REMOTE_BROWSER_PLATFORM') == 'BS' and remote_flag.lower() == 'y':
test_obj.execute_javascript("""browserstack_executor: {"action": "setSessionStatus",
"arguments": {"status":"failed", "reason": "Exception occured"}}""")
if browser.lower() == "edge":
print(Logging_Objects.color_text("Selenium Manager requires administrator permissions"\
" to install Microsoft Edge in Windows automatically."))
@pytest.fixture
def test_mobile_obj(mobile_os_name, mobile_os_version, device_name, app_package, app_activity, # pylint: disable=redefined-outer-name too-many-arguments too-many-locals
remote_flag, device_flag, testrail_flag, tesults_flag, test_run_id, app_name, # pylint: disable=redefined-outer-name
app_path, appium_version, interactivemode_flag, testname, remote_project_name, # pylint: disable=redefined-outer-name
remote_build_name, orientation, testreporter): # pylint: disable=redefined-outer-name
"Return an instance of Base Page that knows about the third party integrations"
try:
if interactivemode_flag.lower()=="y":
mobile_os_name, mobile_os_version, device_name, app_package, app_activity, \
remote_flag, device_flag, testrail_flag, tesults_flag, app_name, app_path= \
interactive_mode.ask_questions_mobile(mobile_os_name, mobile_os_version, device_name,
app_package, app_activity, remote_flag, device_flag, testrail_flag,
tesults_flag, app_name, app_path, orientation)
test_mobile_obj = PageFactory.get_page_object("Zero mobile") # pylint: disable=redefined-outer-name
test_mobile_obj.set_calling_module(testname)
#Setup and register a driver
test_mobile_obj.register_driver(mobile_os_name, mobile_os_version, device_name,
app_package, app_activity, remote_flag, device_flag, app_name,
app_path, ud_id,org_id, signing_id, no_reset_flag, appium_version,
remote_project_name, remote_build_name, orientation)
#3. Setup TestRail reporting
if testrail_flag.lower()=='y':
if test_run_id is None:
test_mobile_obj.write("\n\nTestRail Integration Exception: "\
"It looks like you are trying to use TestRail Integration "\
"without providing test run id. \nPlease provide a valid test run id "\
"along with test run command using --test_run_id and try again."\
" for eg: pytest --testrail_flag Y --test_run_id 100\n",level='critical')
testrail_flag = 'N'
if test_run_id is not None:
test_mobile_obj.register_testrail()
test_mobile_obj.set_test_run_id(test_run_id)
if tesults_flag.lower()=='y':
test_mobile_obj.register_tesults()
yield test_mobile_obj
# Collect the failed scenarios, these scenarios will be printed as table \
# by the pytest's custom testreporter
if test_mobile_obj.failed_scenarios:
testreporter.failed_scenarios[testname] = test_mobile_obj.failed_scenarios
if os.getenv('REMOTE_BROWSER_PLATFORM') == 'BS' and remote_flag.lower() == 'y':
response = upload_test_logs_to_browserstack(test_mobile_obj.log_name,
test_mobile_obj.session_url,
appium_test = True)
if isinstance(response, dict) and "error" in response:
# Handle the error response returned as a dictionary
test_mobile_obj.write(f"Error: {response['error']}",level='error')
if "details" in response:
test_mobile_obj.write(f"Details: {response['details']}",level='error')
test_mobile_obj.write("Failed to upload log file to BrowserStack",level='error')
else:
# Handle the case where the response is assumed to be a response object
if response.status_code == 200:
test_mobile_obj.write("Log file uploaded to BrowserStack session successfully.",
level='success')
else:
test_mobile_obj.write("Failed to upload log file. "\
f"Status code: {response.status_code}",level='error')
test_mobile_obj.write(response.text,level='error')
#Update test run status to respective BrowserStack session
if test_mobile_obj.pass_counter == test_mobile_obj.result_counter:
test_mobile_obj.write("Test Status: PASS",level='success')
result_flag = test_mobile_obj.execute_javascript("""browserstack_executor:
{"action": "setSessionStatus", "arguments": {"status":"passed",
"reason": "All test cases passed"}}""")
test_mobile_obj.conditional_write(result_flag,
positive="Successfully set BrowserStack Test Session Status to PASS",
negative="Failed to set Browserstack session status to PASS")
else:
test_mobile_obj.write("Test Status: FAILED",level='error')
result_flag = test_mobile_obj.execute_javascript("""browserstack_executor:
{"action": "setSessionStatus", "arguments": {"status":"failed",
"reason": "Test failed. Look at terminal logs for more details"}}""")
test_mobile_obj.conditional_write(result_flag,
positive="Successfully set BrowserStack Test Session Status to FAILED",
negative="Failed to set Browserstack session status to FAILED")
test_mobile_obj.write("*************************")
#Teardown
test_mobile_obj.wait(3)
test_mobile_obj.teardown()
except Exception as e: # pylint: disable=broad-exception-caught
print(Logging_Objects.color_text(f"Exception when trying to run test:{__file__}","red"))
print(Logging_Objects.color_text(f"Python says:{str(e)}","red"))
if os.getenv('REMOTE_BROWSER_PLATFORM') == 'BS' and remote_flag.lower() == 'y':
test_mobile_obj.execute_javascript("""browserstack_executor:
{"action": "setSessionStatus", "arguments":
{"status":"failed", "reason": "Exception occured"}}""")
@pytest.fixture
def test_api_obj(interactivemode_flag, testname, api_url): # pylint: disable=redefined-outer-name
"Return an instance of Base Page that knows about the third party integrations"
log_file = testname + '.log'
try:
if interactivemode_flag.lower()=='y':
api_url = interactive_mode.ask_questions_api(api_url)
test_api_obj = APIPlayer(api_url, # pylint: disable=redefined-outer-name
log_file_path=log_file)
else:
test_api_obj = APIPlayer(url=api_url,
log_file_path=log_file)
yield test_api_obj
except Exception as e: # pylint: disable=broad-exception-caught
print(Logging_Objects.color_text(f"Exception when trying to run test:{__file__}","red"))
print(Logging_Objects.color_text(f"Python says:{str(e)}","red"))
def upload_test_logs_to_browserstack(log_name, session_url, appium_test = False):
"Upload log file to provided BrowserStack session"
try:
from integrations.cross_browsers.BrowserStack_Library import BrowserStack_Library # pylint: disable=import-error,import-outside-toplevel
# Initialize BrowserStack object
browserstack_obj = BrowserStack_Library()
# Build log file path
log_file_dir = os.path.abspath(os.path.join(os.path.dirname(__file__),'log'))
log_file = log_file_dir + os.sep + 'temp_' + log_name
# Check if the log file exists
if not os.path.isfile(log_file):
raise FileNotFoundError(f"Log file '{log_file}' not found.")
# Extract session ID from the provided session URL
session_id = browserstack_obj.extract_session_id(session_url)
if not session_id:
raise ValueError(f"Invalid session URL provided: '{session_url}'")
# Upload the log file to BrowserStack
response = browserstack_obj.upload_terminal_logs(log_file,session_id,appium_test)
return response
except ImportError as e:
return {"error": "Failed to import BrowserStack_Library.", "details": str(e)}
except FileNotFoundError as e:
return {"error": "Log file not found.", "details": str(e)}
except ValueError as e:
return {"error": "Invalid session URL.", "details": str(e)}
except Exception as e: # pylint: disable=broad-exception-caught
# Handle any other unexpected exceptions
return {"error": "An unexpected error occurred while uploading logs"\
" to BrowserStack.", "details": str(e)}
@pytest.fixture
def testname(request):
"pytest fixture for testname"
name_of_test = request.node.name
name_of_test = name_of_test.split('[')[0]
return name_of_test
@pytest.fixture
def testreporter(request):
"pytest summary reporter"
return request.config.pluginmanager.get_plugin("terminalreporter")
@pytest.fixture
def browser(request):
"pytest fixture for browser"
return request.config.getoption("--browser")
@pytest.fixture
def base_url(request):
"pytest fixture for base url"
return request.config.getoption("--app_url")
@pytest.fixture
def api_url(request):
"pytest fixture for base url"
return request.config.getoption("--api_url")
@pytest.fixture
def test_run_id(request):
"pytest fixture for test run id"
return request.config.getoption("--test_run_id")
@pytest.fixture
def testrail_flag(request):
"pytest fixture for test rail flag"
return request.config.getoption("--testrail_flag")
@pytest.fixture
def remote_flag(request):
"pytest fixture for browserstack/sauce flag"
return request.config.getoption("--remote_flag")
@pytest.fixture
def highlighter_flag(request):
"pytest fixture for element highlighter flag"
return request.config.getoption("--highlighter_flag")
@pytest.fixture
def browser_version(request):
"pytest fixture for browser version"
return request.config.getoption("--ver")
@pytest.fixture
def os_name(request):
"pytest fixture for os_name"
return request.config.getoption("--os_name")
@pytest.fixture
def os_version(request):
"pytest fixture for os version"
return request.config.getoption("--os_version")
@pytest.fixture
def remote_project_name(request):
"pytest fixture for browserStack project name"
return request.config.getoption("--remote_project_name")
@pytest.fixture
def remote_build_name(request):
"pytest fixture for browserStack build name"
return request.config.getoption("--remote_build_name")
@pytest.fixture
def slack_flag(request):
"pytest fixture for sending reports on slack"
return request.config.getoption("--slack_flag")
@pytest.fixture
def tesults_flag(request):
"pytest fixture for sending results to tesults"
return request.config.getoption("--tesults")
@pytest.fixture
def mobile_os_name(request):
"pytest fixture for mobile os name"
return request.config.getoption("--mobile_os_name")
@pytest.fixture
def mobile_os_version(request):
"pytest fixture for mobile os version"
return request.config.getoption("--mobile_os_version")
@pytest.fixture
def device_name(request):
"pytest fixture for device name"
return request.config.getoption("--device_name")
@pytest.fixture
def app_package(request):
"pytest fixture for app package"
return request.config.getoption("--app_package")
@pytest.fixture
def app_activity(request):
"pytest fixture for app activity"
return request.config.getoption("--app_activity")
@pytest.fixture
def device_flag(request):
"pytest fixture for device flag"
return request.config.getoption("--device_flag")
@pytest.fixture
def email_pytest_report(request):
"pytest fixture for device flag"
return request.config.getoption("--email_pytest_report")
@pytest.fixture
def app_name(request):
"pytest fixture for app name"
return request.config.getoption("--app_name")
@pytest.fixture
def ud_id(request):
"pytest fixture for iOS udid"
return request.config.getoption("--ud_id")
@pytest.fixture
def org_id(request):
"pytest fixture for iOS team id"
return request.config.getoption("--org_id")
@pytest.fixture
def signing_id(request):
"pytest fixture for iOS signing id"
return request.config.getoption("--signing_id")
@pytest.fixture
def appium_version(request):
"pytest fixture for app name"
return request.config.getoption("--appium_version")
@pytest.fixture
def no_reset_flag(request):
"pytest fixture for no_reset_flag"
return request.config.getoption("--no_reset_flag")
@pytest.fixture
def app_path(request):
"pytest fixture for app path"
return request.config.getoption("--app_path")
@pytest.fixture
def interactivemode_flag(request):
"pytest fixture for questionary module"
return request.config.getoption("--interactive_mode_flag")
@pytest.fixture
def reportportal_service(request):
"pytest service fixture for reportportal"
try:
reportportal_pytest_service = None
if request.config.getoption("--reportportal"):
reportportal_pytest_service = request.node.config.py_test_service
except Exception as e: # pylint: disable=broad-exception-caught
print(Logging_Objects.color_text(f"Exception when trying to run test:{__file__}","red"))
print(Logging_Objects.color_text(f"Python says:{str(e)}","red"))
solution = "It looks like you are trying to use report portal to run your test."\
"\nPlease make sure you have updated .env with the right credentials."
print(Logging_Objects.color_text(f"\nSOLUTION: {solution}\n", "green"))
return reportportal_pytest_service
@pytest.fixture
def summary_flag(request):
"pytest fixture for generating summary using LLM"
return request.config.getoption("--summary")
@pytest.fixture
def orientation(request):
"pytest fixture for device orientation"
return request.config.getoption("--orientation")
def pytest_sessionstart(session):
"""
Perform cleanup at the start of the test session.
Delete the consolidated log file and temporary log files if present.
"""
if not hasattr(session.config, "workerinput"): # Executes during the main session only
source_directory = "log"
log_file_name = "temp_*.log"
consolidated_log_file = os.path.join(source_directory, "consolidated_log.txt")
# Delete the consolidated log file
if os.path.exists(consolidated_log_file):
try:
os.remove(consolidated_log_file)
except OSError as error:
print(Logging_Objects.color_text(
f"Error removing existing consolidated log file: {error}"))
# Delete all temporary log files if present
for temp_log_file in glob.glob(os.path.join(source_directory, log_file_name)):
try:
os.remove(temp_log_file)
except OSError as error:
print(Logging_Objects.color_text(f"Error removing temporary log file: {error}"))
def pytest_sessionfinish(session):
"""
Called after the entire test session finishes.
The temporary log files are consolidated into a single log file
and later deleted.
"""
if not hasattr(session.config, "workerinput"): # Executes during the main session only
source_directory = "log"
log_file_name = "temp_*.log"
consolidated_log_file = os.path.join(source_directory, "consolidated_log.txt")
#Detach all handlers from the logger inorder to release the file handle
#which can be used for deleting the temp files later
logger.remove(None)
#Consolidate the temporary log files into the consolidated log file
try:
with open(consolidated_log_file, "a", encoding="utf-8") as final_log:
for file_name in glob.glob(os.path.join(source_directory, log_file_name)):
source_file = None
try:
with open(file_name, "r", encoding="utf-8") as source_file:
shutil.copyfileobj(source_file, final_log)
os.remove(file_name)
except FileNotFoundError as error:
print(Logging_Objects.color_text(f"Temporary log file not found: {error}"))
except Exception as error: # pylint: disable=broad-exception-caught
print(Logging_Objects.color_text(
f"Error processing the temporary log file: {error}"))
except OSError as error:
print(Logging_Objects.color_text(f"Error processing consolidated log file: {error}"))
@pytest.hookimpl(trylast=True)
def pytest_configure(config):
"Sets the launch name based on the marker selected."
browser = config.getoption("browser") # pylint: disable=redefined-outer-name
version = config.getoption("browser_version")
os_name = config.getoption("os_name") # pylint: disable=redefined-outer-name
os_version = config.getoption("os_version") # pylint: disable=redefined-outer-name
# Check if version is specified without a browser
if version and not browser:
raise ValueError("You have specified a browser version without setting a browser." \
"Please use the --browser option to specify the browser.")
if os_version and not os_name:
raise ValueError("You have specified an OS version without setting an OS." \
"Please use the --os_name option to specify the OS.")
default_os_versions = browser_os_name_conf.default_os_versions
# Set default versions for browsers that don't have versions specified
if browser and not version:
version = ["latest"] * len(browser)
if os_name and not os_version:
for os_entry in os_name:
if os_entry.lower() in default_os_versions:
os_version.append(default_os_versions[os_entry.lower()])
else:
raise ValueError(f"No default version available for browser '{os_entry}'."\
" Please specify a version using --ver.")
# Assign back the modified version list to config (in case it was updated)
config.option.browser_version = version
global if_reportportal # pylint: disable=global-variable-undefined
if_reportportal =config.getoption('--reportportal')
# Unregister the old terminalreporter plugin
# Register the custom terminalreporter plugin
if config.pluginmanager.has_plugin("terminalreporter"):
old_reporter = config.pluginmanager.get_plugin("terminalreporter")
config.pluginmanager.unregister(old_reporter, "terminalreporter")
reporter = CustomTerminalReporter(config)
config.pluginmanager.register(reporter, "terminalreporter")
try:
config._inicache["rp_api_key"] = os.getenv('report_portal_api_key') # pylint: disable=protected-access
config._inicache["rp_endpoint"]= os.getenv('report_portal_endpoint') # pylint: disable=protected-access
config._inicache["rp_project"]= os.getenv('report_portal_project') # pylint: disable=protected-access
config._inicache["rp_launch"]= os.getenv('report_portal_launch') # pylint: disable=protected-access
except Exception as e: # pylint: disable=broad-exception-caught
print(Logging_Objects.color_text(f"Exception when trying to run test:{__file__}","red"))
print(Logging_Objects.color_text(f"Python says:{str(e)}","red"))
#Registering custom markers to supress warnings
config.addinivalue_line("markers", "GUI: mark a test as part of the GUI regression suite.")
config.addinivalue_line("markers", "API: mark a test as part of the GUI regression suite.")
config.addinivalue_line("markers", "MOBILE: mark a test as part of the GUI regression suite.")
def pytest_terminal_summary(terminalreporter):
"add additional section in terminal summary reporting."
try:
if not hasattr(terminalreporter.config, 'workerinput'):
if terminalreporter.config.getoption("--slack_flag").lower() == 'y':
from integrations.reporting_channels import post_test_reports_to_slack # pylint: disable=import-error,import-outside-toplevel
post_test_reports_to_slack.post_reports_to_slack()
if terminalreporter.config.getoption("--email_pytest_report").lower() == 'y':
from integrations.reporting_channels.email_pytest_report import EmailPytestReport # pylint: disable=import-error,import-outside-toplevel
#Initialize the Email_Pytest_Report object
email_obj = EmailPytestReport()
# Send html formatted email body message with pytest report as an attachment
email_obj.send_test_report_email(html_body_flag=True,attachment_flag=True,
report_file_path='default')
if terminalreporter.config.getoption("--tesults").lower() == 'y':
from integrations.reporting_tools import Tesults # pylint: disable=import-error,import-outside-toplevel
Tesults.post_results_to_tesults()
if terminalreporter.config.getoption("--summary").lower() == 'y':
from utils import gpt_summary_generator # pylint: disable=import-error,import-outside-toplevel
gpt_summary_generator.generate_gpt_summary()
except Exception as e: # pylint: disable=broad-exception-caught
print(Logging_Objects.color_text(f"Exception when trying to run test:{__file__}","red"))
print(Logging_Objects.color_text(f"Python says:{str(e)}","red"))
solution = "It looks like you are trying to use email pytest report to run your test." \
"\nPlease make sure you have updated .env with the right credentials ."
print(Logging_Objects.color_text(f"\nSOLUTION: {solution}\n","green"))
def pytest_generate_tests(metafunc):
"test generator function to run tests across different parameters"
try:
if 'browser' in metafunc.fixturenames:
if metafunc.config.getoption("--remote_flag").lower() == 'y':
if metafunc.config.getoption("--browser") == ["all"]:
metafunc.parametrize("browser,browser_version,os_name,os_version",
browser_os_name_conf.cross_browser_cross_platform_config)
elif not metafunc.config.getoption("--browser") or \
not metafunc.config.getoption("--ver") or \
not metafunc.config.getoption("--os_name") or \
not metafunc.config.getoption("--os_version"):
print("Feedback: Missing command-line arguments." \
" Falling back to default values.")
# Use default values from the default list if not provided
default_config_list = browser_os_name_conf.default_config_list
config_list = []
if not metafunc.config.getoption("--browser"):
config_list.append(default_config_list[0][0])
else:
config_list.append(metafunc.config.getoption("--browser")[0])
if not metafunc.config.getoption("--ver"):
config_list.append(default_config_list[0][1])
else:
config_list.append(metafunc.config.getoption("--ver")[0])
if not metafunc.config.getoption("--os_name"):
config_list.append(default_config_list[0][2])
else:
config_list.append(metafunc.config.getoption("--os_name")[0])
if not metafunc.config.getoption("--os_version"):
config_list.append(default_config_list[0][3])
else:
config_list.append(metafunc.config.getoption("--os_version")[0])
metafunc.parametrize("browser, browser_version, os_name, os_version",
[tuple(config_list)])
else:
config_list = [(metafunc.config.getoption("--browser")[0],
metafunc.config.getoption("--ver")[0],
metafunc.config.getoption("--os_name")[0],
metafunc.config.getoption("--os_version")[0])]
metafunc.parametrize("browser,browser_version,os_name,os_version",
config_list)
if metafunc.config.getoption("--remote_flag").lower() !='y':
if metafunc.config.getoption("--browser") == ["all"]:
metafunc.config.option.browser = browser_os_name_conf.local_browsers
metafunc.parametrize("browser", metafunc.config.option.browser)
elif metafunc.config.getoption("--browser") == [] and metafunc.config.getoption("--ver") == []:
metafunc.parametrize("browser",browser_os_name_conf.default_browser)
elif metafunc.config.getoption("--browser") != [] and metafunc.config.getoption("--ver") == []:
config_list_local = [(metafunc.config.getoption("--browser")[0])]
metafunc.parametrize("browser", config_list_local)
elif metafunc.config.getoption("--browser") == [] and metafunc.config.getoption("--ver") != []:
config_list_local = [(browser_os_name_conf.default_browser[0], metafunc.config.getoption("--ver")[0])]
metafunc.parametrize("browser, browser_version", config_list_local)
else:
config_list_local = [(metafunc.config.getoption("--browser")[0], metafunc.config.getoption("--ver")[0])]
metafunc.parametrize("browser, browser_version", config_list_local)
except Exception as e: # pylint: disable=broad-exception-caught
print(Logging_Objects.color_text(f"Exception when trying to run test:{__file__}","red"))
print(Logging_Objects.color_text(f"Python says:{str(e)}","red"))
def pytest_addoption(parser):
"Method to add the option to ini."
try:
parser.addoption("--browser",
dest="browser",
action="append",
default=[],
help="Browser. Valid options are firefox, Edge and chrome")
parser.addoption("--app_url",
dest="url",
default=base_url_conf.ui_base_url,
help="The url of the application")
parser.addoption("--api_url",
dest="api_url",
default=base_url_conf.api_base_url,
help="The url of the api")
parser.addoption("--testrail_flag",
dest="testrail_flag",
default='N',
help="Y or N. 'Y' if you want to report to TestRail")
parser.addoption("--test_run_id",
dest="test_run_id",
default=None,
help="The test run id in TestRail")
parser.addoption("--remote_flag",
dest="remote_flag",
default="N",
help="Run the test in Browserstack/Sauce Lab: Y or N")
parser.addoption("--os_version",
dest="os_version",
action="append",
help="The operating system: xp, 7",
default=[])
parser.addoption("--ver",
dest="browser_version",
action="append",
help="The version of the browser: a whole number",
default=[])
parser.addoption("--os_name",
dest="os_name",
action="append",
help="The operating system: Windows 7, Linux",
default=[])
parser.addoption("--remote_project_name",
dest="remote_project_name",
help="The project name if its run in BrowserStack",
default=None)
parser.addoption("--remote_build_name",
dest="remote_build_name",
help="The build name if its run in BrowserStack",
default=None)
parser.addoption("--slack_flag",
dest="slack_flag",
default="N",
help="Post the test report on slack channel: Y or N")
parser.addoption("--mobile_os_name",
dest="mobile_os_name",
help="Enter operating system of mobile. Ex: Android, iOS",
default="Android")
parser.addoption("--mobile_os_version",
dest="mobile_os_version",
help="Enter version of operating system of mobile: 11.0",
default="11.0")
parser.addoption("--device_name",
dest="device_name",
help="Enter device name. Ex: Emulator, physical device name",
default="Samsung Galaxy S21")
parser.addoption("--app_package",
dest="app_package",
help="Enter name of app package. Ex: com.dudam.rohan.bitcoininfo",
default="com.qxf2.weathershopper")
parser.addoption("--app_activity",
dest="app_activity",
help="Enter name of app activity. Ex: .MainActivity",
default=".MainActivity")
parser.addoption("--device_flag",
dest="device_flag",
help="Enter Y or N. 'Y' if you want to run the test on device." \
"'N' if you want to run the test on emulator.",
default="N")
parser.addoption("--email_pytest_report",
dest="email_pytest_report",
help="Email pytest report: Y or N",
default="N")
parser.addoption("--tesults",
dest="tesults_flag",
default='N',
help="Y or N. 'Y' if you want to report results with Tesults")
parser.addoption("--app_name",
dest="app_name",
help="Enter application name to be uploaded." \
"Ex:Bitcoin Info_com.dudam.rohan.bitcoininfo.apk",
default="app-release-v1.2.apk")
parser.addoption("--ud_id",
dest="ud_id",
help="Enter your iOS device UDID which is required" \
"to run appium test in iOS device",
default=None)
parser.addoption("--org_id",
dest="org_id",
help="Enter your iOS Team ID which is required" \
"to run appium test in iOS device",
default=None)
parser.addoption("--signing_id",
dest="signing_id",
help="Enter your iOS app signing id which is required" \
"to run appium test in iOS device",
default="iPhone Developer")
parser.addoption("--no_reset_flag",
dest="no_reset_flag",
help="Pass false if you want to reset app eveytime you run app",
default="true")
parser.addoption("--app_path",
dest="app_path",
help="Enter app path")
parser.addoption("--appium_version",
dest="appium_version",
help="The appium version if its run in BrowserStack",
default="2.4.1")
parser.addoption("--interactive_mode_flag",
dest="questionary",
default="n",
help="set the questionary flag")
parser.addoption("--summary",
dest="summary",
default="n",
help="Generate pytest results summary using LLM (GPT): y or n")
parser.addoption("--orientation",
dest="orientation",
default=None,
help="Enter LANDSCAPE to change device orientation to landscape")
parser.addoption("--highlighter_flag",
dest="highlighter_flag",
default='N',
help="Y or N. 'Y' if you want turn on element highlighter")
except Exception as e: # pylint: disable=broad-exception-caught
print(Logging_Objects.color_text(f"Exception when trying to run test:{__file__}","red"))
print(Logging_Objects.color_text(f"Python says:{str(e)}","red"))
| 0
|
qxf2_public_repos
|
qxf2_public_repos/qxf2-page-object-model/pytest.ini
|
[pytest]
addopts = -v -s -rsxX --continue-on-collection-errors --tb=short --ignore=utils/Test_Rail.py --ignore=tests/test_boilerplate.py --ignore=utils/Test_Runner_Class.py -p no:cacheprovider
norecursedirs = .svn _build tmp* log .vscode .git
markers =
GUI: mark a test as part of the GUI regression suite
API: mark a test as part of the API regression suite
MOBILE: mark a test as part of the MOBILE regression suite
ACCESSIBILITY: mark a test as part of the ACCESSIBILITY suite
junit_family=xunit2
| 0
|
qxf2_public_repos
|
qxf2_public_repos/qxf2-page-object-model/LICENSE
|
MIT License
Copyright (c) 2016 Qxf2
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
| 0
|
qxf2_public_repos
|
qxf2_public_repos/qxf2-page-object-model/requirements.txt
|
requests==2.32.0
reportportal-client==5.5.4
pytest==8.1.1
selenium==4.12.0
python_dotenv==0.16.0
Appium_Python_Client==3.2.0
pytest-xdist>=1.31
pytest-html>=3.0.0
pytest-rerunfailures>=9.1.1
pytest_reportportal==5.4.0
pillow>=6.2.0
tesults==1.2.1
boto3==1.33.0
loguru
imageio
questionary>=1.9.0
clear-screen>=0.1.14
prompt-toolkit==2.0.10
axe_selenium_python==2.1.6
pytest-snapshot==0.9.0
beautifulsoup4>=4.12.3
openai==1.12.0
pytesseract==0.3.10
pytest-asyncio==0.23.7
prettytable==3.10.2
setuptools>=75.1.0; python_version >= '3.12'
openapi3-parser==1.1.17
jinja2==3.1.5
deepdiff>=8.1.1
| 0
|
qxf2_public_repos
|
qxf2_public_repos/qxf2-page-object-model/Dockerfile
|
# Pull ubuntu 22.04 base image
FROM ubuntu:22.04
LABEL maintainer="Qxf2 Services"
ENV DISPLAY=:20
# Essential tools and xvfb
RUN apt-get update && apt-get install -y \
software-properties-common \
unzip \
wget \
bzip2 \
xvfb \
x11vnc \
fluxbox \
xterm
# Install Google Chrome and dependencies
RUN wget -qO /tmp/google.pub https://dl-ssl.google.com/linux/linux_signing_key.pub \
&& apt-key add /tmp/google.pub \
&& rm /tmp/google.pub \
&& echo 'deb http://dl.google.com/linux/chrome/deb/ stable main' > /etc/apt/sources.list.d/google.list \
&& mkdir -p /usr/share/desktop-directories \
&& apt-get -y update \
&& apt-get install -y google-chrome-stable \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
# Disable the SUID sandbox so that Chrome can launch without being in a privileged container
RUN dpkg-divert --add --rename --divert /opt/google/chrome/google-chrome.real /opt/google/chrome/google-chrome \
&& printf "#!/bin/bash\nexec /opt/google/chrome/google-chrome.real --no-sandbox --disable-setuid-sandbox \"\$@\"" > /opt/google/chrome/google-chrome \
&& chmod 755 /opt/google/chrome/google-chrome
# Install Chrome Driver (latest version)
RUN CHROME_VER=$(google-chrome --version | grep -oP "Google Chrome \K[\d.]+") \
&& echo "Chrome version: $CHROME_VER" \
&& wget --no-verbose -O /tmp/chromedriver-linux64.zip "https://storage.googleapis.com/chrome-for-testing-public/${CHROME_VER}/linux64/chromedriver-linux64.zip" \
&& rm -rf /opt/selenium/chromedriver \
&& mkdir -p /opt/selenium \
&& unzip /tmp/chromedriver-linux64.zip -d /opt/selenium \
&& rm /tmp/chromedriver-linux64.zip \
&& mv /opt/selenium/chromedriver-linux64/chromedriver /usr/bin/chromedriver \
&& chmod 755 /usr/bin/chromedriver
ARG FIREFOX_VERSION=latest
RUN FIREFOX_DOWNLOAD_URL="$(if [ "$FIREFOX_VERSION" = "latest" ]; then echo "https://download.mozilla.org/?product=firefox-"$FIREFOX_VERSION"-ssl&os=linux64&lang=en-US"; else echo "https://download-installer.cdn.mozilla.net/pub/firefox/releases/"$FIREFOX_VERSION"/linux-x86_64/en-US/firefox-"$FIREFOX_VERSION".tar.bz2"; fi)" \
&& echo "Firefox download URL: $FIREFOX_DOWNLOAD_URL" \
&& apt-get -qqy update \
&& apt-get -qqy --no-install-recommends install firefox \
&& apt-get -y install libdbus-glib-1-2 \
&& rm -rf /var/lib/apt/lists/* /var/cache/apt/* \
&& wget --no-verbose -O /tmp/firefox.tar.bz2 "$FIREFOX_DOWNLOAD_URL" \
&& apt-get -y purge firefox \
&& rm -rf /opt/firefox \
&& tar -C /opt -xjf /tmp/firefox.tar.bz2 \
&& rm /tmp/firefox.tar.bz2 \
&& mv /opt/firefox /opt/firefox-"$FIREFOX_VERSION" \
&& ln -fs /opt/firefox-"$FIREFOX_VERSION"/firefox /usr/bin/firefox \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
# Download and install the latest Geckodriver binary
RUN GECKODRIVER_VERSION=$(wget -qO- 'https://api.github.com/repos/mozilla/geckodriver/releases/latest' | grep '"tag_name":' | sed -E 's/.*"v([^"]+)".*/\1/') \
&& wget --no-verbose -O /tmp/geckodriver.tar.gz "https://github.com/mozilla/geckodriver/releases/download/v${GECKODRIVER_VERSION}/geckodriver-v${GECKODRIVER_VERSION}-linux64.tar.gz" \
&& tar -xzf /tmp/geckodriver.tar.gz -C /tmp \
&& mv /tmp/geckodriver /usr/bin/geckodriver \
&& rm /tmp/geckodriver.tar.gz
# Python 3.10 and Python Pip
RUN apt-get update && apt-get install -y \
python3.10 \
python3-setuptools=59.6.0-1.2ubuntu0.22.04.1 \
python3-pip=22.0.2+dfsg-1ubuntu0.4 \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
# Creating a new directory
RUN mkdir /shell_script
# Copying shell script to directory
COPY entrypoint.sh /shell_script
# Setting the working directory
WORKDIR /shell_script
# Setting the entry point
ENTRYPOINT ["/bin/bash", "/shell_script/entrypoint.sh"]
# Setting the default command to be run in the container
CMD ["sh", "-c", "Xvfb :20 -screen 0 1366x768x16 & x11vnc -passwd password -display :20 -N -forever"]
| 0
|
qxf2_public_repos
|
qxf2_public_repos/qxf2-page-object-model/env_remote
|
#Set REMOTE_BROWSER_PLATFROM TO BS TO RUN ON BROWSERSTACK else
#SET REMOTE_BROWSER_PLATFORM TO SL TO RUN ON SAUCELABS
#SET REMOTE_BROWSER_PLATFORM TO LT TO RUN ON LAMBDATEST
REMOTE_BROWSER_PLATFORM = "BS"
REMOTE_USERNAME = "Enter your username"
REMOTE_ACCESS_KEY = "Enter your access key"
| 0
|
qxf2_public_repos
|
qxf2_public_repos/qxf2-page-object-model/env_conf
|
# Tesults Configuration
tesults_target_token_default = ""
#TestRail url and credentials
testrail_url = "Add your testrail url"
testrail_user = 'TESTRAIL_USERNAME'
testrail_password = 'TESTRAIL_PASSWORD'
#Details needed for the Gmail
#Fill out the email details over here
imaphost ="imap.gmail.com" #Add imap hostname of your email client
app_username ='USERNAME'
#Login has to use the app password because of Gmail security configuration
# 1. Setup 2 factor authentication
# 2. Follow the 2 factor authentication setup wizard to enable an app password
#Src: https://support.google.com/accounts/answer/185839?hl=en
#Src: https://support.google.com/mail/answer/185833?hl=en
app_password = 'APP_PASSWORD'
#Details for sending pytest report
smtp_ssl_host = 'smtp.gmail.com' # Add smtp ssl host of your email client
smtp_ssl_port = 465 # Add smtp ssl port number of your email client
sender = '[email protected]' #Add senders email address here
targets = ['[email protected]','[email protected]'] # Add recipients email address in a list
#REPORT PORTAL
report_portal_api_key = "Enter your report portal api key here"
report_portal_endpoint = "Enter your endpoint here"
report_portal_project = "Enter your Project here"
report_portal_launch = "Enter your project launch here"
#Slack channel incoming webhook
#To generate incoming webhook url ref: https://qxf2.com/blog/post-pytest-test-results-on-slack/
slack_incoming_webhook_url = "Add Slack incomming webhook url here"
# To generate pytest_report.log file add ">pytest_report.log" at end of py.test command
# for e.g. pytest -k example_form --slack_flag y -v > log/pytest_report.log
| 0
|
qxf2_public_repos
|
qxf2_public_repos/qxf2-page-object-model/Readme.md
|



[](https://circleci.com/gh/qxf2/qxf2-page-object-model)
[](https://automate.browserstack.com/public-build/cVVDdmxnTmpNL3FEeS9FUWY2S2M2Q0xLRFJoTFhVV0RUNlJRS292Sm9WWT0tLWxuS2dGeWhmK0M3SUt2d1hOR0F2TXc9PQ==--f6f4c1765a8d4d5250966b5ee1397a93da38a7a3)





--------
A Pythonic Selenium, Appium and API test automation framework
--------
You can use this test automation framework to write
1. __Selenium__ and Python automation scripts to test web applications
2. __Appium__ and Python scripts for __mobile automation__ (Android and iOS)
3. __API automation__ scripts to test endpoints of your web/mobile applications
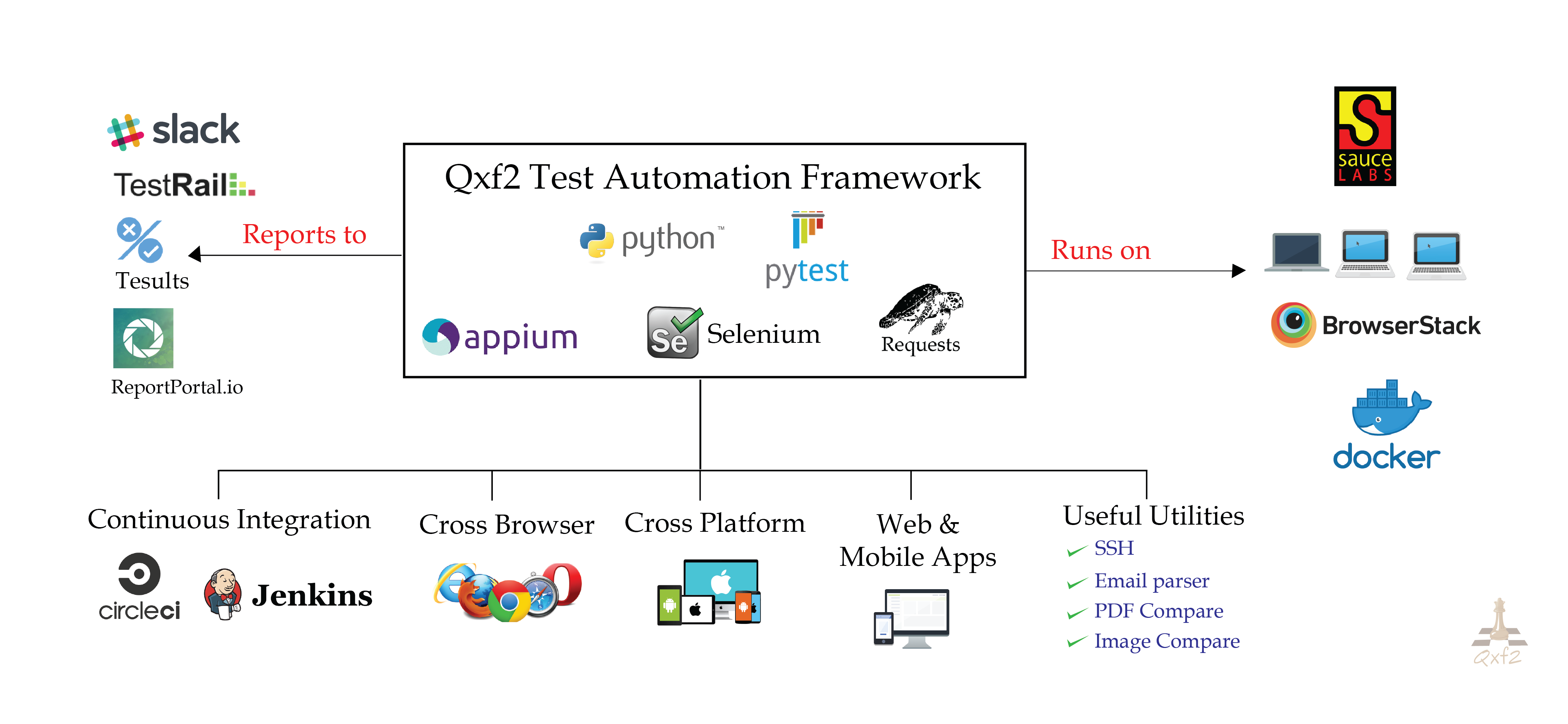
This GUI and API test automation framework is developed and maintained by [Qxf2 Services](https://qxf2.com). This framework is written in __Python__ and is based on the __Page Object Model__ - a design pattern that makes it easy to maintain and develop robust tests. We have also included our __API test automation framework__ based on the player-interface pattern in this repository. You can now write your API tests along with your Selenium and Appium tests.
We've implemented some version of this framework at several [clients](https://qxf2.com/clients). In all cases, this framework helped us write automated tests within the first week of our engagement. We hope you find this framework useful too!
Looking for ways to automate your __UI__ and __API__ tests quickly and effectively? You've come to the right place. By harnessing __AI__ and __code auto-generation__ capabilities, we've developed solutions that significantly decrease the time needed to create a fully functional test suite. For further information, please refer to the following links.
* [Qxf2's Gen AI test automation service](https://qxf2.com/qait)
* [Qxf2's API test automation service](https://qxf2.com/api-tests-autogenerate.html)
------
Setup
------
The setup for our open-sourced Python test automation framework is fairly simple. We have documented the setup instructions in detail so even beginners can get started.
The setup has four parts:
1. [Prerequisites](https://github.com/qxf2/qxf2-page-object-model/wiki/Setup#1-Prerequisites)
2. [Setup for GUI/Selenium automation](https://github.com/qxf2/qxf2-page-object-model/wiki/Setup#2-setup-for-guiselenium-automation)
3. [Setup for Mobile/Appium automation](https://github.com/qxf2/qxf2-page-object-model/wiki/Setup#3-setup-for-mobileappium-automation)
4. [Setup for API automation](https://github.com/qxf2/qxf2-page-object-model/wiki/Setup#4-setup-for-api-automation)
Above links redirects to our github wiki pages.
__Optional steps__ for integrating with third-party tools:
* [Integrate our Python test automation framework with Testrail](https://github.com/qxf2/qxf2-page-object-model/wiki/Integration-with-TestRail-using-Python)
* [Integration with ReportPortal](https://github.com/qxf2/qxf2-page-object-model/wiki/Integration-with-ReportPortal)
* [Integrate our Python GUI/web automation framework with BrowserStack ](https://github.com/qxf2/qxf2-page-object-model/wiki/Integration-with-Cloud-Services#browserstack)
* [Integrate our Python Selenium automation framework with Sauce Labs ](https://github.com/qxf2/qxf2-page-object-model/wiki/Integration-with-Cloud-Services#sauce-labs)
* [Integrate our Python GUI/web automation framework with LambdaTest](https://github.com/qxf2/qxf2-page-object-model/wiki/Integration-with-Cloud-Services#lambdatest)
* [Run Python integration tests on Jenkins ](https://github.com/qxf2/qxf2-page-object-model/wiki/Integration-with-CI-Tools#jenkins)
* [Run Python integration tests on CircleCI ](https://github.com/qxf2/qxf2-page-object-model/wiki/Integration-with-CI-Tools#circleci)
* [Post Python automation test results on Slack ](https://github.com/qxf2/qxf2-page-object-model/wiki/Integration-with-Slack)
* [Email pytest report with Gmail](https://github.com/qxf2/qxf2-page-object-model/wiki/Email-pytest-report-with-Gmail)
-------------------
Repository details
-------------------
Directory structure of our current Templates
```
./
|_ conf: For all configurations files
|_ core_helpers: Contains our web app and mobile app helpers and DriverFactory
|_ endpoints: Contains our Base Mechanize, different End Points, API Player, API Interface
|_ integrations: Contains cross-browsers (BrowserStack, SauceLabs, Lambdatest), reporting tools (TestRail, Tesults) and reporting channel integrations (Slack, Gmail)
|_ log: Log files for all tests
|_ page_objects: Contains our PageFactory, different Page Objects examples
|_ screenshots: For screenshots
|_ tests: Put your tests here
|_ utils: All utility modules (ssh_util, compare csv, compare images, Base Logger, etc) are kept in this folder
|_ conftest.py: Configuration file to add different fixtures used in py.test
|_ .env and .env.remote: For credential details. Refer env_conf and env_remote file and rename it to .env and .env_conf.
```
For more details about the structure, refer our wiki page [here](https://github.com/qxf2/qxf2-page-object-model/wiki/Repository-details)
---------------------------
COMMANDS FOR RUNNING TESTS
---------------------------
### a) General Command
`python -m pytest [options]`
### Options
- **`--app_url`**
*Runs against a specific URL.*
**Example:**
`python -m pytest --app_url http://YOUR_localhost_URL`
This will run against your local instance.
- **`--remote_flag`**
*Runs tests on Browserstack/LambdaTest/Sauce Labs.*
**Example:**
`python -m pytest -s --remote_flag Y --app_url https://qxf2.com`
- **`--browser all`**
*Runs the tests against multiple browsers.*
**Example:**
`python -m pytest --browser all`
This will run each test against the list of browsers specified in the `conf/browser_os_name_conf.py` file (e.g., Firefox and Chrome).
- **`--ver / --os_name / --os_version`**
*Runs against different browser versions, OS platform and OS versions.*
**Example:**
`python -m pytest --ver 120 --os_name windows --os_version 11 --remote_flag y`
This will run each test with default browser (chrome) and provided combination (browser version 120 windows 11)
- **`-h`**
*Displays help for more options.*
**Example:**
`python -m pytest -h`
- **`-k`**
*Runs tests matching the given substring expression.*
**Example:**
`python -m pytest -k table`
This will trigger tests that match the pattern, such as `test_example_table.py`.
- **`--slack_flag`**
*Posts pytest reports on the Slack channel.*
**Example:**
`python -m pytest --slack_flag Y -v > log/pytest_report.log`
This will send the pytest-report on configued slack channel at the end of test run.
- **`-n`**
*Runs tests in parallel.*
**Example:**
`python -m pytest -n 3 -v`
This will run three tests in parallel.
- **`--tesults`**
*Reports test results to Tesults.*
**Example:**
`python -m pytest tests/test_example_form.py --tesults Y`
- **`--interactive_mode_flag`**
*Runs the tests interactively.*
**Example:**
`python -m pytest tests/test_example_form.py --interactive_mode_flag Y`
This option allows the user to pick the desired configuration to run the test from a menu displayed.
**Note:** If you wish to run the test in interactive mode on Git Bash for Windows, set your bash alias by adding the following command to `.bashrc`:
`alias python='winpty python.exe'`
- **`--summary`**
*Summarizes the pytest results in an HTML report.*
**Example:**
`python -m pytest -k example_table --summary y`
**Note:** You need to provide your `OPENAI_API_KEY` using `export OPENAI_API_KEY=<your-key>`.
### b) Specific Commands
- **Standalone Test**
`python -m pytest tests/test_example_form.py`
- **Run Against Specific Browser**
`python -m pytest tests/test_example_form.py --browser Chrome`
- **API Test**
`python -m pytest tests/test_api_example.py`
**Note:** Ensure the sample `cars-api` is available at `qxf2/cars-api` repository before running the API test.
- **Mobile Test Run on Browserstack/Sauce Labs**
`python -m pytest tests/test_mobile_bitcoin_price --mobile_os_version <android version> --device_name <simulator> --app_path <.apk location on local> --remote_flag Y`
**Note:** For running tests on Browserstack/Sauce Labs, update the Browser_Plaform, Username and AccessKey in `.env.remote` from your Browserstack/Sauce Labs account. Refer our wiki page for more details: [Integrate our Python Selenium automation framework with Cloud Services ](https://github.com/qxf2/qxf2-page-object-model/wiki/Integration-with-Cloud-Services)
- **Run Test along with Tesults**
`python -m pytest tests/test_example_form.py --tesults Y`
**Note:** For running the test along with Tesults, update the .env file with target_token and run the above command. Refer env_conf file for configuration.
- **Run Tests along with ReportPortal**
`python -m pytest -k example --reportportal`
**Note:** For running the test along with ReportPortal, update the .env file with ReportPortal credential details and run the above command. Refer our wiki page for more details: [Integration with ReportPortal](https://github.com/qxf2/qxf2-page-object-model/wiki/Integration-with-ReportPortal)
- **Run Tests along with TestRail**
`python -m pytest -k example --testrail_flag Y --test_run_id <testrail run id>`
**Note:** For running the test along with TestRail, update the .env file with TestRail credential details and run the above command. Refer our wiki page for more details: [Integrate our Python test automation framework with Testrail](https://github.com/qxf2/qxf2-page-object-model/wiki/Integration-with-TestRail-using-Python)
- **Post test results on Slack**
`pytest -k example_form --slack_flag y -v > log/pytest_report.log`
**Note:** For setup and other details, refer our wiki page: [Post Python automation test results on Slack ](https://github.com/qxf2/qxf2-page-object-model/wiki/Integration-with-Slack)
- **Email pytest report with Gmail**
`pytest -s -v --email_pytest_report y --html=log/pytest_report.html`
**Note:** For setup and other details, refer our wiki page: [Email pytest report with Gmail](https://github.com/qxf2/qxf2-page-object-model/wiki/Email-pytest-report-with-Gmail)
--------
ISSUES?
--------
a) If Python complains about an "Import" exception, please 'pip3 install $module_name'
b) If you don't have drivers set up for the web browsers, you will see a helpful error from Selenium telling you where to go and get them
c) If your are using firefox 47 and above, you need to set up Geckodriver. Refer following link for setup: https://qxf2.com/blog/selenium-geckodriver-issue/
d) On Ubuntu, you may run into an issue installing the cryptography module. You need to `sudo apt-get install libssl-dev` and then run `sudo pip install -r requirements.txt`
e) The Edge in Windows can not be downloaded automatically to the local cache (~/.cache/selenium) by Selenium Manager as it requires administrative access. When Edge is attempted to installed with Selenium Manager it will through ``edge can only be installed in Windows with administrator permissions.``
-----------
Continuous Integration and Support
-----------
This project uses:
<a href="https://www.browserstack.com/"><img src="http://www.browserstack.com/images/layout/browserstack-logo-600x315.png" width="150" height="100" hspace="10"></a>
<a href="https://circleci.com/"><img src="https://github.com/circleci/media/blob/master/logo/build/horizontal_dark.1.png?raw=true" width="150" height="100" hspace="10"></a>
1. [BrowserStack](https://www.browserstack.com) for testing our web and mobile based tests on cloud across different platform and browsers.
2. [CircleCI](https://circleci.com/) for continuous integration.
-----------
NEED HELP?
-----------
Struggling to get your GUI automation going? You can hire Qxf2 Services to help. Contact us at [email protected]
| 0
|
qxf2_public_repos
|
qxf2_public_repos/qxf2-page-object-model/CONTRIBUTING.md
|
Contributing Guidelines
--------
Your contributions are always welcome! There are a number of ways you can contribute. These guidelines instruct how to submit issues and contribute code or documentation to [Qxf2 Automation Framework](https://github.com/qxf2/qxf2-page-object-model).
Reporting bugs
--------
This section guides you through submitting a bug report for Qxf2. Before submitting a new issue, it is always a good idea to check if the same bug or enhancement is already reported. If it is, please add your comments to the existing issue instead of creating a new one.
Bugs are tracked as [GitHub issues](https://github.com/qxf2/qxf2-page-object-model/issues). After you've determined which repository your bug is related to, create an issue on that repository and provide the following information:
* __Use a clear and descriptive title__ for the issue to identify the problem
* __Explain the steps to reproduce__ so that others can understand it and and preferably also reproduce it
* __Provide snippets to demonstrate the steps__ which you might think is causing the bug
* Expected result
* Actual results
* Environment details: Operating system and its version, packages installed
Enhancement requests
--------
Enhancement suggestions are tracked as [GitHub issues](https://github.com/qxf2/qxf2-page-object-model/issues). Enhancements can be anything including completely new features and minor improvements to existing functionality. After you've determined which repository your enhancement suggestion is related to, create an issue on that repository and provide the following information:
* __Use a clear and descriptive title__ for the issue to identify the suggestion.
* __Provide a step-by-step description__ of the suggested enhancement in as many details as possible.
* __Provide specific examples__ to demonstrate the steps.
* __Describe the current behavior__ and __describe which behavior you expected to see instead__ and why.
* __Include screenshots or animated GIF's__ which help you demonstrate the steps or point out the part of framework which the suggestion is related to.
* __Explain how and why this enhancement__ would be useful
* __Specify the name and version of the OS__ you're using.
* __Specify the browser version__ you're using.
* __Describe the new feature and use cases__ for it in as much detail as possible
Code Contributions
--------
This part of the document will guide you through the contribution process. If you have fixed a bug or implemented an enhancement, you can contribute your changes via GitHub's Pull requests. If this is your first time contributing to a project via GitHub follow below guidelines
Here is the basic workflow:
1) Fork the Qxf2 repo. You can do this via the GitHub website. By doing this, you will have a local copy of the qxf2 repo under your Github account.
2) Clone the Qxf2 repo to your local machine
3) Create a feature branch and start hacking
4) Commit the changes on that branch
5) Push your change to your repo
6) Bug fixes and features should have tests. Before you submit your pull request make sure you pass all the tests.
7) Use the github UI to open a PR
8) When code review is complete, a committer will take your PR and merge it on our master branch.
| 0
|
qxf2_public_repos
|
qxf2_public_repos/qxf2-page-object-model/tox.ini
|
[tox]
skipsdist = true
[testenv]
#Setting the dependency file
deps = -r{toxinidir}/requirements.txt
#used to not trigger the “not installed in virtualenv” warning message
whitelist_externals=*
#setting the environment
setenv= app_path= {toxinidir}/weather-shopper-app-apk/app/
#Command to run the test
commands = python -m pytest -s -v --app_path {env:app_path} --remote_flag Y -n 3 --remote_project_name Qxf2_Selenium_POM --remote_build_name Selenium_Tutorial --junitxml=test-reports/junit.xml --tb=native --ignore=tests/test_mobile_bitcoin_price.py
| 0
|
qxf2_public_repos
|
qxf2_public_repos/qxf2-page-object-model/entrypoint.sh
|
#!/bin/bash
export DISPLAY=:20
Xvfb :20 -screen 0 1366x768x16 &
# Start x11vnc
x11vnc -passwd TestVNC -display :20 -N -forever &
# Run CMD command
exec "$@"
| 0
|
qxf2_public_repos
|
qxf2_public_repos/qxf2-page-object-model/env_ssh_conf
|
#Server credential details needed for ssh
HOST = 'Enter your host details here'
USERNAME = 'USERNAME'
PASSWORD = 'PASSWORD'
PORT = 22
TIMEOUT = 10
#.pem file details
PKEY = 'Enter your key filename here'
#Sample commands to execute(Add your commands here)
COMMANDS = ['ls;mkdir sample']
#Sample file locations to upload and download
UPLOADREMOTEFILEPATH = '/etc/example/filename.txt'
UPLOADLOCALFILEPATH = 'home/filename.txt'
DOWNLOADREMOTEFILEPATH = '/etc/sample/data.txt'
DOWNLOADLOCALFILEPATH = 'home/data.txt'
| 0
|
qxf2_public_repos/qxf2-page-object-model
|
qxf2_public_repos/qxf2-page-object-model/endpoints/registration_api_endpoints.py
|
"""
API endpoint abstraction for /registration endpoint
"""
from .base_api import BaseAPI
class RegistrationAPIEndpoints(BaseAPI):
"Class for registration endpoints"
def registration_url(self,suffix=''):
"""Append API end point to base URL"""
return self.base_url+'/register/'+suffix
def register_car(self,url_params,json,headers):
"register car "
url = self.registration_url('car?')+url_params
json_response = self.post(url,params=url_params,json=json,headers=headers)
return {
'url':url,
'response':json_response.json()
}
def get_registered_cars(self,headers):
"gets registered cars"
url = self.registration_url('')
json_response = self.get(url,headers=headers)
return {
'url':url,
'response':json_response.json()
}
def delete_registered_car(self,headers):
"deletes registered car"
url = self.registration_url('car/delete/')
json_response = self.delete(url,headers)
return {
'url':url,
'response':json_response.json()
}
# Async methods
async def get_registered_cars_async(self,headers):
"Get registered cars"
url = self.registration_url('')
response = await self.async_get(url,headers=headers)
return response
| 0
|
qxf2_public_repos/qxf2-page-object-model
|
qxf2_public_repos/qxf2-page-object-model/endpoints/api_player.py
|
# pylint: disable=line-too-long
"""
API_Player class does the following:
a) serves as an interface between the test and API_Interface
b) contains several useful wrappers around commonly used combination of actions
c) maintains the test context/state
"""
from base64 import b64encode
import logging
import urllib.parse
from .api_interface import APIInterface
from utils.results import Results
class APIPlayer(Results):
"The class that maintains the test context/state"
def __init__(self, url, log_file_path=None):
"Constructor"
super().__init__(level=logging.DEBUG, log_file_path=log_file_path)
self.api_obj = APIInterface(url=url)
def set_auth_details(self, username, password):
"encode auth details"
user = username
b64login = b64encode(bytes(f"{user}:{password}","utf-8"))
return b64login.decode('utf-8')
def set_header_details(self, auth_details=None):
"make header details"
if auth_details != '' and auth_details is not None:
headers = {'Authorization': f"Basic {auth_details}"}
else:
headers = {'content-type': 'application/json'}
return headers
def get_cars(self, auth_details=None):
"get available cars "
result_flag = False
headers = self.set_header_details(auth_details)
json_response = self.api_obj.get_cars(headers=headers)
json_response = json_response['response']
if json_response["successful"]:
result_flag = True
self.write(msg=f"Fetched cars list: {json_response}")
self.conditional_write(result_flag,
positive="Successfully fetched cars",
negative="Could not fetch cars")
return json_response
def get_car(self, car_name, brand, auth_details=None):
"gets a given car details"
result_flag = False
url_params = {'car_name': car_name, 'brand': brand}
url_params_encoded = urllib.parse.urlencode(url_params)
headers = self.set_header_details(auth_details)
json_response = self.api_obj.get_car(url_params=url_params_encoded,
headers=headers)
response = json_response['response']
if response["successful"]:
result_flag = True
self.write(msg=f"Fetched car details of : {car_name} {response}")
return result_flag
def add_car(self, car_details, auth_details=None):
"adds a new car"
result_flag = False
data = car_details
headers = self.set_header_details(auth_details)
json_response = self.api_obj.add_car(data=data,
headers=headers)
if json_response["response"]["successful"]:
result_flag = True
return result_flag
def register_car(self, car_name, brand, auth_details=None):
"register car"
result_flag = False
# pylint: disable=import-outside-toplevel
from conf import api_example_conf as conf
url_params = {'car_name': car_name, 'brand': brand}
url_params_encoded = urllib.parse.urlencode(url_params)
customer_details = conf.customer_details
data = customer_details
headers = self.set_header_details(auth_details)
json_response = self.api_obj.register_car(url_params=url_params_encoded,
json=data,
headers=headers)
response = json_response['response']
if response["registered_car"]["successful"]:
result_flag = True
return result_flag
def update_car(self, car_details, car_name='figo', auth_details=None):
"updates a car"
result_flag = False
data = {'name': car_details['name'],
'brand': car_details['brand'],
'price_range': car_details['price_range'],
'car_type': car_details['car_type']}
headers = self.set_header_details(auth_details)
json_response = self.api_obj.update_car(car_name,
json=data,
headers=headers)
json_response = json_response['response']
if json_response["response"]["successful"]:
result_flag = True
return result_flag
def remove_car(self, car_name, auth_details=None):
"deletes a car entry"
result_flag = False
headers = self.set_header_details(auth_details)
json_response = self.api_obj.remove_car(car_name,
headers=headers)
if json_response["response"]["successful"]:
result_flag = True
return result_flag
def get_registered_cars(self, auth_details=None):
"gets registered cars"
result_flag = False
headers = self.set_header_details(auth_details)
json_response = self.api_obj.get_registered_cars(headers=headers)
response = json_response['response']
if response["successful"]:
result_flag = True
self.write(msg=f"Fetched registered cars list: {json_response}")
self.conditional_write(result_flag,
positive='Successfully fetched registered cars list',
negative='Could not fetch registered cars list')
return response
def delete_registered_car(self, auth_details=None):
"deletes registered car"
result_flag = False
headers = self.set_header_details(auth_details)
json_response = self.api_obj.delete_registered_car(headers=headers)
if json_response["response"]["successful"]:
result_flag = True
self.conditional_write(result_flag,
positive='Successfully deleted registered cars',
negative='Could not delete registered car')
def get_car_count(self,auth_details=None):
"Verify car count at the start"
self.write('\n*****Verifying car count******')
car_count = self.get_cars(auth_details)
car_count = len(car_count['cars_list'])
return car_count
def get_regi_car_count(self,auth_details=None):
"Verify registered car count"
car_count_registered = self.get_registered_cars(auth_details)
car_count_registered = len(car_count_registered['registered'])
return car_count_registered
def verify_car_count(self, expected_count, auth_details=None):
"Verify car count"
result_flag = False
self.write('\n*****Verifying car count******')
car_count = self.get_cars(auth_details)
car_count = len(car_count['cars_list'])
if car_count == expected_count:
result_flag = True
return result_flag
def verify_registration_count(self, expected_count, auth_details=None):
"Verify registered car count"
result_flag = False
self.write('\n******Verifying registered car count********')
car_count = self.get_registered_cars(auth_details)
car_count = len(car_count['registered'])
if car_count == expected_count:
result_flag = True
return result_flag
def get_user_list(self, auth_details=None):
"get user list"
headers = self.set_header_details(auth_details)
try:
result = self.api_obj.get_user_list(headers=headers)
self.write(f"Request & Response: {result}")
except (TypeError, AttributeError) as e:
raise e
return {'user_list': result['user_list'], 'response_code': result['response']}
def check_validation_error(self, auth_details=None):
"verify validatin error 403"
result = self.get_user_list(auth_details)
response_code = result['response_code']
result_flag = False
msg = ''
if response_code == 403:
msg = "403 FORBIDDEN: Authentication successful but no access for non admin users"
elif response_code == 200:
result_flag = True
msg = "successful authentication and access permission"
elif response_code == 401:
msg = "401 UNAUTHORIZED: Authenticate with proper credentials OR Require Basic Authentication"
elif response_code == 404:
msg = "404 NOT FOUND: URL not found"
else:
msg = "unknown reason"
return {'result_flag': result_flag, 'msg': msg}
# Async methods
async def async_get_cars(self, auth_details=None):
"get available cars asynchronously"
result_flag = False
headers = self.set_header_details(auth_details)
result = await self.api_obj.get_cars_async(headers)
if result.status_code == 200:
result_flag = True
return result_flag
async def async_get_car(self, car_name, brand, auth_details=None):
"gets a given car details"
result_flag = False
url_params = {'car_name': car_name, 'brand': brand}
url_params_encoded = urllib.parse.urlencode(url_params)
headers = self.set_header_details(auth_details)
response = await self.api_obj.get_car_async(url_params=url_params_encoded,
headers=headers)
if response.status_code == 200:
result_flag = True
return result_flag
async def async_add_car(self, car_details, auth_details=None):
"adds a new car"
result_flag = False
data = car_details
headers = self.set_header_details(auth_details)
response = await self.api_obj.add_car_async(data=data,
headers=headers)
if response.status_code == 200:
result_flag = True
return result_flag
async def async_get_registered_cars(self, auth_details=None):
"get registered cars"
result_flag = False
headers = self.set_header_details(auth_details)
response = await self.api_obj.get_registered_cars_async(headers=headers)
if response.status_code == 200:
result_flag = True
return result_flag
| 0
|
qxf2_public_repos/qxf2-page-object-model
|
qxf2_public_repos/qxf2-page-object-model/endpoints/base_api.py
|
"""
A wrapper around Requests to make Restful API calls
"""
import asyncio
import requests
from requests.exceptions import HTTPError, RequestException
class BaseAPI:
"Main base class for Requests based scripts"
session_object = requests.Session()
base_url = None
def make_request(self,
method,
url,
headers=None,
auth=None,
params=None,
data=None,
json=None):
"Generic method to make HTTP request"
headers = headers if headers else {}
try:
response = self.session_object.request(method=method,
url=url,
headers=headers,
auth=auth,
params=params,
data=data,
json=json)
response.raise_for_status()
except HTTPError as http_err:
print(f"{method} request failed: {http_err}")
except ConnectionError:
print(f"\033[1;31mFailed to connect to {url}. Check if the API server is up.\033[1;m")
except RequestException as err:
print(f"\033[1;31mAn error occurred: {err}\033[1;m")
return response
def get(self, url, headers=None):
"Get request"
headers = headers if headers else {}
try:
response = self.session_object.get(url=url, headers=headers)
response.raise_for_status()
except HTTPError as http_err:
print(f"GET request failed: {http_err}")
except ConnectionError:
print(f"\033[1;31mFailed to connect to {url}. Check if the API server is up.\033[1;m")
except RequestException as err:
print(f"\033[1;31mAn error occurred: {err}\033[1;m")
return response
# pylint: disable=too-many-arguments
def post(self, url,params=None, data=None,json=None,headers=None):
"Post request"
headers = headers if headers else {}
try:
response = self.session_object.post(url,
params=params,
data=data,
json=json,
headers=headers)
response.raise_for_status()
except HTTPError as http_err:
print(f"POST request failed: {http_err}")
except ConnectionError:
print(f"\033[1;31mFailed to connect to {url}. Check if the API server is up.\033[1;m")
except RequestException as err:
print(f"\033[1;31mAn error occurred: {err}\033[1;m")
return response
def delete(self, url,headers=None):
"Delete request"
headers = headers if headers else {}
try:
response = self.session_object.delete(url, headers=headers)
response.raise_for_status()
except HTTPError as http_err:
print(f"DELETE request failed: {http_err}")
except ConnectionError:
print(f"\033[1;31mFailed to connect to {url}. Check if the API server is up.\033[1;m")
except RequestException as err:
print(f"\033[1;31mAn error occurred: {err}\033[1;m")
return response
def put(self,url,json=None, headers=None):
"Put request"
headers = headers if headers else {}
try:
response = self.session_object.put(url, json=json, headers=headers)
response.raise_for_status()
except HTTPError as http_err:
print(f"PUT request failed: {http_err}")
except ConnectionError:
print(f"\033[1;31mFailed to connect to {url}. Check if the API server is up.\033[1;m")
except RequestException as err:
print(f"\033[1;31mAn error occurred: {err}\033[1;m")
return response
async def async_get(self, url, headers=None):
"Run the blocking GET method in a thread"
headers = headers if headers else {}
response = await asyncio.to_thread(self.get, url, headers)
return response
# pylint: disable=too-many-arguments
async def async_post(self,
url,
params=None,
data=None,
json=None,
headers=None):
"Run the blocking POST method in a thread"
headers = headers if headers else {}
response = await asyncio.to_thread(self.post,
url,
params,
data,
json,
headers)
return response
async def async_delete(self, url, headers=None):
"Run the blocking DELETE method in a thread"
headers = headers if headers else {}
response = await asyncio.to_thread(self.delete, url, headers)
return response
async def async_put(self, url, json=None, headers=None):
"Run the blocking PUT method in a thread"
headers = headers if headers else {}
response = await asyncio.to_thread(self.put, url, json, headers)
return response
| 0
|
qxf2_public_repos/qxf2-page-object-model
|
qxf2_public_repos/qxf2-page-object-model/endpoints/user_api_endpoints.py
|
"""
API endpoints for Registration
"""
from .base_api import BaseAPI
class UserAPIEndpoints(BaseAPI):
"Class for user endpoints"
def user_url(self,suffix=''):
"""Append API end point to base URL"""
return self.base_url+'/users'+suffix
def get_user_list(self,headers):
"get users list"
try:
url = self.user_url('')
json_response = self.get(url,headers=headers)
except Exception as err: # pylint: disable=broad-exception-caught
print(f"Python says: {err}")
json_response = None
return {
'url':url,
'response':json_response.status_code,
'user_list':json_response.json()
}
| 0
|
qxf2_public_repos/qxf2-page-object-model
|
qxf2_public_repos/qxf2-page-object-model/endpoints/api_interface.py
|
"""
A composed Interface for all the Endpoint abstraction objects:
* Cars API Endpoints
* Registration API Endpoints
* User API Endpoints
The APIPlayer Object interacts only to the Interface to access the Endpoint
"""
from .cars_api_endpoints import CarsAPIEndpoints
from .registration_api_endpoints import RegistrationAPIEndpoints
from .user_api_endpoints import UserAPIEndpoints
class APIInterface(CarsAPIEndpoints, RegistrationAPIEndpoints, UserAPIEndpoints):
"A composed interface for the API objects"
def __init__(self, url):
"Initialize the Interface"
self.base_url = url
| 0
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.